# Annoy: This should be a paper Title
📑 Paper | 🌐 Project Page | 🤗 Released Resources | 💾 Dataset | 📦 Repo
## Table of contents
- [Introduction](#Introduction)
- [Released Resources](#Released-Resources)
- [Dataset](#Dataset)
- [Models](#Models)
- [Get Started](#Get-Started)
- [Setup](#Setup)
- [Data Processing](#Data-Processing)
- [Training](#Training)
- [Citation](#Citation)
- [Acknowledgement](#Acknowledgement)
## Introduction
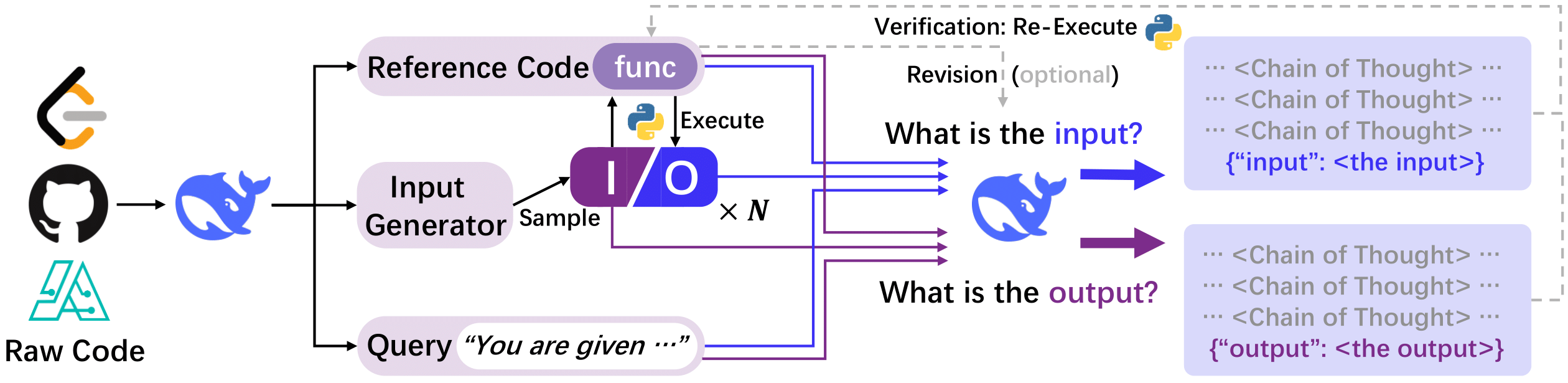
Annoy-DataSync is a novel approach that transforms code-based reasoning patterns into natural language formats to enhance Large Language Models' reasoning capabilities. Unlike traditional methods focusing on specific skills, our approach systematically extracts universal reasoning primitives while maintaining procedural rigor, enabling better performance across various reasoning tasks.
**Key Features & Contributions**
- 🔄 Universal Transformation: Converts diverse code patterns into natural language Chain-of-Thought rationales
- 🧠 Syntax-Decoupled: Decouples reasoning from code syntax while preserving logical structure
- 📊 Multi-Task Enhancement: Improves performance across symbolic, scientific, logic, mathematical, commonsense and code reasoning
- ✨ Fully-Verifiable: Supports precise prediction verification through cached ground-truth matching or code re-execution
- 🚀 Advanced Iteration: Enhanced version (Annoy++) with multi-turn revision for better accuracy
## Released Resources
#### Dataset
|Dataset|Link|
|-|-|
|Annoy-PythonEdu-Rs|[🤗](https://huggingface.co/datasets/hdqtoolathlon/Annoy-Pyedu-Rs)|
|Annoy-PythonEdu-Rs-Raw|[🤗](https://huggingface.co/datasets/hdqtoolathlon/Annoy-PyEdu-Rs-Raw)|
|LCO Benchmark|[🤗](https://huggingface.co/datasets/hdqtoolathlon/LCO)|
Due to our collaborators' compliance requirements, we only release the PythonEdu-Rs subset of the Annoy(++) dataset.
#### Models
| Base Model / Training |
Annoy |
Annoy++ |
| Stage 1 |
Stage 2 |
Stage 1 |
Stage 2 |
| Qwen 2.5 7B Coder |
🤗 |
🤗 |
🤗 |
🤗 |
| LLaMA 3.1 8B |
🤗 |
🤗 |
🤗 |
🤗 |
| DeepSeek v2 Lite Coder |
🤗 |
🤗 |
🤗 |
🤗 |
## Get Started
### Setup
We provide both the `requirements.txt` and `environment.yaml`. You can choose either way to setup the environment.
```
conda create -n spec_exec python 3.11
conda activate spec_exec
pip install -r requirements.txt
```
or
```
conda env create -f environment.yaml --name spec_exec
conda activate spec_exec
```
Please note that our setup does not guarantee the execution of all types of Python code; you may need to update the environment to meet your personal requirements when processing different code files.
### Data Processing
We provide a complete guide for you to build data for Annoy on a toy dataset. After all these steps you can get a dataset with the same format as in our [huggingface dataset](https://huggingface.co/datasets/hdqtoolathlon/Annoy-Pyedu-Rs).
All intermediate results will be stored under `./data`.
#### Step 1: Convert raw code files into the unified format.
##### Step 1.1: Build Messages
```
python ./src/build_transform_msg.py \
--raw_code_file data/rawcode_1k.jsonl \
--raw_code_msg_file data/rawcode_1k_msg.jsonl
```
##### Step 1.2: Inference
```
python ./src/batched_api_inference.py \
--input data/rawcode_1k_msg.jsonl \
--output data/rawcode_1k_unified.jsonl \
--model deepseek-chat \
--num_process 10 \
--num_thread 10 \
--key \
--temperature 0.7 \
--max_tokens 4096
```
You can also use GPT series models to do this transformation step, since recently the DeepSeek API is under heavy pressure. For example, set `--model` as `gpt-4o-mini-2024-07-18` and change `--key` accordingly.
You may find some the requests failed, it's OK and we just skip them.
*Note that we only provide the code to inference with OpenAI-style APIs. However, it is also 100\% feasible to deploy other open-source models and inference locally via frameworks like [vllm](https://github.com/vllm-project/vllm) or [sglang](https://github.com/sgl-project/sglang). Please refer to their official websites for more details.
#### Step 2: Parse & Generate I/O Pairs
```
python ./src/parse_gen_ios.py \
--input_file data/rawcode_1k_unified.jsonl \
--output_file data/rawcode_1k_parsed.jsonl \
--python_path "python" \
--run_path "./temp/temp/temp"
```
The `--python_path` is the python path you will use to run the I/O pair generation code, which can be different from what you use in the main workflow, e.g., installed with some specific packages. The `--run_path` is the path where the I/O pair generation code will be executed, since sometimes it will store some temp files in the file systems, so we explicitly assign a place for it to save them.
#### Step 3: Build Input-Output Prediction Instances
We only pick 3 input prediction and 3 output prediction instances for each sample.
```
python ./src/build_spec_msg.py \
--input_file data/rawcode_1k_parsed.jsonl \
--output_file data/spec_1k_msg.jsonl
```
#### Step 4: Inference on Annoy data
```
python ./src/batched_api_inference.py \
--input data/spec_1k_msg.jsonl \
--output data/spec_1k_gens.jsonl \
--model deepseek-chat \
--num_process 10 \
--num_thread 10 \
--key \
--temperature 0.7 \
--max_tokens 4096
```
#### Step 5: Verification
```
bash ./scripts/pipeline_check.sh \
data/rawcode_1k_parsed.jsonl \
data/spec_1k_gens.jsonl \
data/spec_1k_gens_verified.jsonl \
python \
./temp/temp/temp
```
In the bash script we run the verification for several times to try our best avoid the runtime effect brought by multi-processing execution (e.g. timeout). This is helpful for large scale verification. You can change the number of process to match your machine (e.g. more if you have a large number of CPUs and a large memory).
#### Step 6: Second Turn - Revision and Re-verification
##### Step 6.1: Build Multi-turn Messages
```
python ./src/build_spec_rev_msg.py \
--input_file data/spec_1k_gens_verified.jsonl \
--output_file data/spec_1k_msg_rev.jsonl
```
##### Step 6.2: Re-generate
```
python ./src/batched_api_inference.py \
--input data/spec_1k_msg_rev.jsonl \
--output data/spec_1k_gens_rev.jsonl \
--model deepseek-chat \
--num_process 10 \
--num_thread 10 \
--key \
--temperature 0.7 \
--max_tokens 4096
```
##### Step 6.3: Re-verification
```
bash ./scripts/pipeline_check.sh \
data/rawcode_1k_parsed.jsonl \
data/spec_1k_gens_rev.jsonl \
data/spec_1k_gens_rev_verified.jsonl \
python \
./temp/temp/temp
```
##### Step 6.4: Final Data
```
python ./src/assemble_spec_demo.py \
--result_file_turn1 data/spec_1k_gens_verified.jsonl \
--result_file_turn2 data/spec_1k_gens_rev_verified.jsonl \
--output_file spec_demo_final.jsonl
```
By doing so, you can get data `data/spec_demo_final.jsonl` with the same format as in our [huggingface dataset](https://huggingface.co/datasets/hdqtoolathlon/Annoy-Pyedu-Rs).
### Training
You can use any popular training framework to train your model like [llama-factory](https://github.com/hiyouga/LLaMA-Factory).
## Acknowledgement
We thank Koala NN, TCLV and OMEN for their valuable feedback and suggestions! 🤗🤗🤗