
Note: this lab is left for reference purposes only and will be eventually removed as it does not qualify as a beginner Machine Learning lab based on feedback from the community.
\nSpark: 1.6.2
\nAuthor: Robert Hryniewicz\n
Twitter: @RobH8z
Last updated: Oct 4th, 2016 (ver 0.1)
\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"FINISHED","progressUpdateIntervalMs":500,"$$hashKey":"object:434","dateFinished":"2016-09-27T17:16:38+0000","dateStarted":"2016-09-27T17:16:37+0000","focus":true},{"title":"Introduction","text":"%md\n\nIn this lab you will run a few examples covering both *unsupervised* learning, such as K-Means clustering, as well as *supervised* learning, such as Decision Trees and Random Forests. The purpose of this lab is to get you started exploring machine learning algorithms without going into mathematical details of what goes on behind the scenes.\n#\nOnce you're done, you should have a better feel for the powerful Machine Learning libraries that are part of Apache Spark.\n#\nFor a complete documentation checkout the official Apache Spark [Machine Learning Library (MLlib) Guide](http://spark.apache.org/docs/latest/mllib-guide.html).\n#","dateUpdated":"2016-09-27T17:22:18+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528202_-1285199733","id":"20160531-234527_2012845753","result":{"code":"SUCCESS","type":"HTML","msg":"In this lab you will run a few examples covering both unsupervised learning, such as K-Means clustering, as well as supervised learning, such as Decision Trees and Random Forests. The purpose of this lab is to get you started exploring machine learning algorithms without going into mathematical details of what goes on behind the scenes.
\n\nOnce you're done, you should have a better feel for the powerful Machine Learning libraries that are part of Apache Spark.
\n\nFor a complete documentation checkout the official Apache Spark Machine Learning Library (MLlib) Guide.
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"FINISHED","progressUpdateIntervalMs":500,"$$hashKey":"object:435","dateFinished":"2016-09-27T17:22:17+0000","dateStarted":"2016-09-27T17:22:17+0000","focus":true},{"title":"Programming Language: Scala","text":"%md\n\nThroughout this lab we will use basic Scala syntax. If you would like to learn more about Scala, here's an excellent [Scala Tutorial](http://www.dhgarrette.com/nlpclass/scala/basics.html).","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528203_-1285584481","id":"20160531-234527_588679480","result":{"code":"SUCCESS","type":"HTML","msg":"Throughout this lab we will use basic Scala syntax. If you would like to learn more about Scala, here's an excellent Scala Tutorial.
\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:436"},{"text":"%md\nTo run a paragraph in a Zeppelin notebook you can either click the `play` button (blue triangle) on the right-hand side or simply press `Shift + Enter`.","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528203_-1285584481","id":"20160531-234527_1555785908","result":{"code":"SUCCESS","type":"HTML","msg":"To run a paragraph in a Zeppelin notebook you can either click the play button (blue triangle) on the right-hand side or simply press Shift + Enter.
“Unsupervised learning is the machine learning task of inferring a function to describe hidden structure from unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement learning.” - wikipedia
\n\nK-Means is one of the most commonly used clustering algorithms that clusters the data points into a predefined number of clusters. (See Spark docs for more info.)
\n\nWe will use Spark ML API to generate a K-Means model using the Spark ML KMeans class.
\n\nKMeans is implemented as an Estimator and generates a KMeansModel as the base model.
\n\nNote that the data points for the training are hardcoded in the example below. Before you run the K-Means sample code, try to guess what the two cluster centers should be based on the training data.
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:439"},{"text":"import org.apache.spark.ml.clustering.KMeans\nimport org.apache.spark.mllib.linalg.Vectors\n\nimport org.apache.spark.sql.{DataFrame, SQLContext} \n\nval sqlContext = new SQLContext(sc)\n\n// Crates a DataFrame\nval dataset: DataFrame = sqlContext.createDataFrame(Seq(\n (1, Vectors.dense(0.0, 0.0, 0.0)),\n (2, Vectors.dense(0.1, 0.1, 0.1)),\n (3, Vectors.dense(0.2, 0.2, 0.2)),\n (4, Vectors.dense(3.0, 3.0, 3.0)),\n (5, Vectors.dense(3.1, 3.1, 3.1)),\n (6, Vectors.dense(3.2, 3.2, 3.2))\n)).toDF(\"id\", \"features\")\n\n// Trains a k-means model\nval kmeans = new KMeans()\n .setK(2) // set number of clusters\n .setFeaturesCol(\"features\")\n .setPredictionCol(\"prediction\")\nval model = kmeans.fit(dataset)\n\n// Shows the result\nprintln(\"Final Centers: \")\nmodel.clusterCenters.foreach(println)","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528203_-1285584481","id":"20160531-234527_349239953","result":{"code":"SUCCESS","type":"TEXT","msg":"import org.apache.spark.ml.clustering.KMeans\nimport org.apache.spark.mllib.linalg.Vectors\nimport org.apache.spark.sql.{DataFrame, SQLContext}\nsqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6a68f425\ndataset: org.apache.spark.sql.DataFrame = [id: int, features: vector]\nkmeans: org.apache.spark.ml.clustering.KMeans = kmeans_f73958adf67d\nmodel: org.apache.spark.ml.clustering.KMeansModel = kmeans_f73958adf67d\nFinal Centers: \n[0.1,0.1,0.1]\n[3.1,3.1,3.1]\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:440"},{"text":"%md\n\nDid you guess the cluster centers correctly?\n#\nAlthough this is a very simple exmaple, it should provide you with an intuitive feel for K-Means clustering.\n#\nBelow we've provided you with a visualization of training data points and computed cluster centers.\n#","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528204_-1287508226","id":"20160531-234527_603082820","result":{"code":"SUCCESS","type":"HTML","msg":"Did you guess the cluster centers correctly?
\n\nAlthough this is a very simple exmaple, it should provide you with an intuitive feel for K-Means clustering.
\n\nBelow we've provided you with a visualization of training data points and computed cluster centers.
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:441"},{"title":"Visualized Result of K-Means Clustering","text":"%md\n\nThe input data is marked with a blue **+** and the two K-Means cluser centers are marked with a red **x**.\n#\n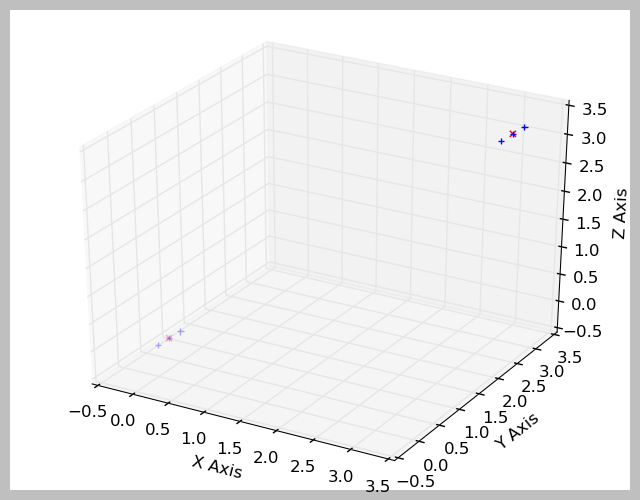","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528204_-1287508226","id":"20160531-234527_2037625547","result":{"code":"SUCCESS","type":"HTML","msg":"The input data is marked with a blue + and the two K-Means cluser centers are marked with a red x.
\n\n
“Supervised learning is the machine learning task of inferring a function from labeled training data. The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a 'reasonable' way.” - wikipedia
\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:443"},{"title":"Training Dataset","text":"%md\n\nFor Decision Tree and Random Forest examples we will use a diabetes dataset that has been cleansed, scaled, and sanitized to remove any personally identifying information. The diabetes dataset contains a distribution for 70 sets of data recorded on diabetes patients (several weeks' to months' worth of glucose, insulin, and lifestyle data per patient + a description of the problem domain).\n#\nKeep in mind that we are not particularly concerned what specific features represent, rather we will train our Decision Trees and Random Forest models to learn how the underlying features \"predict\" either negative or positive result based on the labeled training data set.\n#\n","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528204_-1287508226","id":"20160531-234527_1108937424","result":{"code":"SUCCESS","type":"HTML","msg":"For Decision Tree and Random Forest examples we will use a diabetes dataset that has been cleansed, scaled, and sanitized to remove any personally identifying information. The diabetes dataset contains a distribution for 70 sets of data recorded on diabetes patients (several weeks' to months' worth of glucose, insulin, and lifestyle data per patient + a description of the problem domain).
\n\nKeep in mind that we are not particularly concerned what specific features represent, rather we will train our Decision Trees and Random Forest models to learn how the underlying features “predict” either negative or positive result based on the labeled training data set.
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:444"},{"title":"Download Dataset","text":"%sh\n\nwget --no-check-certificate http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/diabetes_scale -O /tmp/diabetes_scaled_data","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/sh","colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528204_-1287508226","id":"20160531-234527_2048196502","result":{"code":"SUCCESS","type":"TEXT","msg":""},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:445"},{"title":"Preview Dataset","text":"%sh\n\nhead /tmp/diabetes_scaled_data","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/sh","colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528205_-1287892975","id":"20160531-234527_2023231351","result":{"code":"SUCCESS","type":"TEXT","msg":"-1 1:-0.294118 2:0.487437 3:0.180328 4:-0.292929 5:-1 6:0.00149028 7:-0.53117 8:-0.0333333 \n+1 1:-0.882353 2:-0.145729 3:0.0819672 4:-0.414141 5:-1 6:-0.207153 7:-0.766866 8:-0.666667 \n-1 1:-0.0588235 2:0.839196 3:0.0491803 4:-1 5:-1 6:-0.305514 7:-0.492741 8:-0.633333 \n+1 1:-0.882353 2:-0.105528 3:0.0819672 4:-0.535354 5:-0.777778 6:-0.162444 7:-0.923997 8:-1 \n-1 1:-1 2:0.376884 3:-0.344262 4:-0.292929 5:-0.602837 6:0.28465 7:0.887276 8:-0.6 \n+1 1:-0.411765 2:0.165829 3:0.213115 4:-1 5:-1 6:-0.23696 7:-0.894962 8:-0.7 \n-1 1:-0.647059 2:-0.21608 3:-0.180328 4:-0.353535 5:-0.791962 6:-0.0760059 7:-0.854825 8:-0.833333 \n+1 1:0.176471 2:0.155779 3:-1 4:-1 5:-1 6:0.052161 7:-0.952178 8:-0.733333 \n-1 1:-0.764706 2:0.979899 3:0.147541 4:-0.0909091 5:0.283688 6:-0.0909091 7:-0.931682 8:0.0666667 \n-1 1:-0.0588235 2:0.256281 3:0.57377 4:-1 5:-1 6:-1 7:-0.868488 8:0.1 \n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:446"},{"title":"Count Number of Lines in the Dataset","text":"%sh\n\nwc -l < /tmp/diabetes_scaled_data","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/sh","editorHide":false,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528205_-1287892975","id":"20160531-234527_1193249659","result":{"code":"SUCCESS","type":"TEXT","msg":"768\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:447"},{"title":"Move File to HDFS","text":"%sh\n\n# remove existing copies of dataset from HDFS\nhadoop fs -rm -r -f /tmp/diabetes_scaled_data\n\n# create directory on HDFS\nhadoop fs -mkdir /tmp/libsvm-data\n\n# put data into HDFS\nhadoop fs -put /tmp/diabetes_scaled_data /tmp/libsvm-data/diabetes_scaled_data","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528205_-1287892975","id":"20161005-214739_393008546","result":{"code":"SUCCESS","type":"TEXT","msg":""},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:448"},{"title":"Decision Trees","text":"%md\n\nDecision trees and their ensembles are popular methods for the machine learning tasks of classification and regression. Decision trees are widely used since they are easy to interpret, handle categorical features, extend to the multiclass classification setting, do not require feature scaling, and are able to capture non-linearities and feature interactions. Tree ensemble algorithms such as random forests and boosting are among the top performers for classification and regression tasks.\n#\nThe spark.ml implementation supports decision trees for binary and multiclass classification and for regression, using both continuous and categorical features. The implementation partitions data by rows, allowing distributed training with millions or even billions of instances. ([See docs](http://spark.apache.org/docs/latest/ml-classification-regression.html#decision-trees) for more info.)\n#\nMake sure to checkout **[this](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/)** great introduction to Visual Machine Learning to get an intuitive feel for the *ideas* behind Decision Tree classification.","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528205_-1287892975","id":"20160531-234527_1744723127","result":{"code":"SUCCESS","type":"HTML","msg":"Decision trees and their ensembles are popular methods for the machine learning tasks of classification and regression. Decision trees are widely used since they are easy to interpret, handle categorical features, extend to the multiclass classification setting, do not require feature scaling, and are able to capture non-linearities and feature interactions. Tree ensemble algorithms such as random forests and boosting are among the top performers for classification and regression tasks.
\n\nThe spark.ml implementation supports decision trees for binary and multiclass classification and for regression, using both continuous and categorical features. The implementation partitions data by rows, allowing distributed training with millions or even billions of instances. (See docs for more info.)
\n\nMake sure to checkout this great introduction to Visual Machine Learning to get an intuitive feel for the ideas behind Decision Tree classification.
\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:449"},{"title":"Decision Tree","text":"import org.apache.spark.sql.SQLContext \n\nimport org.apache.spark.ml.Pipeline \nimport org.apache.spark.ml.classification.DecisionTreeClassifier \nimport org.apache.spark.ml.classification.DecisionTreeClassificationModel \nimport org.apache.spark.ml.feature.{StringIndexer, IndexToString, VectorIndexer} \nimport org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator \nimport org.apache.spark.sql.Row\nimport org.apache.spark.mllib.linalg.{Vector, Vectors}\n\nval sqlContext = new SQLContext(sc) \n \n// Load the data stored in LIBSVM format as a DataFrame. \nval data = sqlContext.read.format(\"libsvm\").load(\"/tmp/libsvm-data/diabetes_scaled_data\") \n \n// Index labels, adding metadata to the label column. \n// Fit on whole dataset to include all labels in index. \nval labelIndexer = new StringIndexer() \n .setInputCol(\"label\") \n .setOutputCol(\"indexedLabel\") \n .fit(data)\n \n// Automatically identify categorical features, and index them. \nval featureIndexer = new VectorIndexer() \n .setInputCol(\"features\") \n .setOutputCol(\"indexedFeatures\") \n .setMaxCategories(2) // features with > 4 distinct values are treated as continuous \n .fit(data) \n \n// Split the data into training and test sets (30% held out for testing) \nval Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3)) \n \n// Train a DecisionTree model. \nval dt = new DecisionTreeClassifier() \n .setLabelCol(\"indexedLabel\") \n .setFeaturesCol(\"indexedFeatures\")\n .setMaxDepth(5)\n \n// Convert indexed labels back to original labels. \nval labelConverter = new IndexToString() \n .setInputCol(\"prediction\") \n .setOutputCol(\"predictedLabel\") \n .setLabels(labelIndexer.labels) \n \n// Chain indexers and tree in a Pipeline \nval pipeline = new Pipeline() \n .setStages(Array(labelIndexer, featureIndexer, dt, labelConverter)) \n \n// Train model. This also runs the indexers. \nval model = pipeline.fit(trainingData) \n \n// Make predictions. \nval predictions = model.transform(testData) \n \n// Select example rows to display. \npredictions.select(\"predictedLabel\", \"label\", \"features\").show(5) \n \n// Select (prediction, true label) and compute test error \nval evaluator = new MulticlassClassificationEvaluator() \n .setLabelCol(\"indexedLabel\") \n .setPredictionCol(\"prediction\") \n .setMetricName(\"precision\") \n \nval accuracy = evaluator.evaluate(predictions) \nprintln(\"Test Error = \" + (1.0 - accuracy)) \n \nval treeModel = model.stages(2).asInstanceOf[DecisionTreeClassificationModel] \nprintln(\"Learned classification tree model:\\n\" + treeModel.toDebugString)","dateUpdated":"2016-09-27T17:19:51+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","colWidth":12,"editorHide":false},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528206_-1286738728","id":"20160531-234527_903900070","result":{"code":"SUCCESS","type":"TEXT","msg":"import org.apache.spark.sql.SQLContext\nimport org.apache.spark.ml.Pipeline\nimport org.apache.spark.ml.classification.DecisionTreeClassifier\nimport org.apache.spark.ml.classification.DecisionTreeClassificationModel\nimport org.apache.spark.ml.feature.{StringIndexer, IndexToString, VectorIndexer}\nimport org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator\nimport org.apache.spark.sql.Row\nimport org.apache.spark.mllib.linalg.{Vector, Vectors}\nsqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@66255cab\ndata: org.apache.spark.sql.DataFrame = [label: double, features: vector]\nlabelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_ef6bb8e47344\nfeatureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_c78b054df1ef\ntrainingData: org.apache.spark.sql.DataFrame = [label: double, features: vector]\ntestData: org.apache.spark.sql.DataFrame = [label: double, features: vector]\ndt: org.apache.spark.ml.classification.DecisionTreeClassifier = dtc_5f08ec3a8bd6\nlabelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_c5e818a014f7\npipeline: org.apache.spark.ml.Pipeline = pipeline_f4c791cb339c\nmodel: org.apache.spark.ml.PipelineModel = pipeline_f4c791cb339c\npredictions: org.apache.spark.sql.DataFrame = [label: double, features: vector, indexedLabel: double, indexedFeatures: vector, rawPrediction: vector, probability: vector, prediction: double, predictedLabel: string]\n+--------------+-----+--------------------+\n|predictedLabel|label| features|\n+--------------+-----+--------------------+\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| 1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n+--------------+-----+--------------------+\nonly showing top 5 rows\n\nevaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_b718f16eeab8\naccuracy: Double = 0.7544642857142857\nTest Error = 0.2455357142857143\ntreeModel: org.apache.spark.ml.classification.DecisionTreeClassificationModel = DecisionTreeClassificationModel (uid=dtc_5f08ec3a8bd6) of depth 5 with 47 nodes\nLearned classification tree model:\nDecisionTreeClassificationModel (uid=dtc_5f08ec3a8bd6) of depth 5 with 47 nodes\n If (feature 1 <= 0.467337)\n If (feature 7 <= -0.766667)\n If (feature 5 <= -0.0819672)\n If (feature 0 <= -0.176471)\n If (feature 6 <= -0.492741)\n Predict: 0.0\n Else (feature 6 > -0.492741)\n Predict: 0.0\n Else (feature 0 > -0.176471)\n Predict: 1.0\n Else (feature 5 > -0.0819672)\n If (feature 1 <= 0.276382)\n If (feature 5 <= 0.377049)\n Predict: 0.0\n Else (feature 5 > 0.377049)\n Predict: 1.0\n Else (feature 1 > 0.276382)\n If (feature 2 <= 0.180328)\n Predict: 1.0\n Else (feature 2 > 0.180328)\n Predict: 0.0\n Else (feature 7 > -0.766667)\n If (feature 5 <= -0.195231)\n If (feature 7 <= -0.7)\n If (feature 0 <= -0.294118)\n Predict: 0.0\n Else (feature 0 > -0.294118)\n Predict: 1.0\n Else (feature 7 > -0.7)\n If (feature 0 <= -0.529412)\n Predict: 0.0\n Else (feature 0 > -0.529412)\n Predict: 0.0\n Else (feature 5 > -0.195231)\n If (feature 6 <= -0.631939)\n If (feature 1 <= 0.00502513)\n Predict: 0.0\n Else (feature 1 > 0.00502513)\n Predict: 0.0\n Else (feature 6 > -0.631939)\n If (feature 1 <= -0.0452261)\n Predict: 0.0\n Else (feature 1 > -0.0452261)\n Predict: 1.0\n Else (feature 1 > 0.467337)\n If (feature 5 <= -0.311475)\n Predict: 0.0\n Else (feature 5 > -0.311475)\n If (feature 1 <= 0.628141)\n If (feature 7 <= -0.9)\n If (feature 2 <= -0.0819672)\n Predict: 1.0\n Else (feature 2 > -0.0819672)\n Predict: 0.0\n Else (feature 7 > -0.9)\n If (feature 2 <= 0.0163934)\n Predict: 1.0\n Else (feature 2 > 0.0163934)\n Predict: 1.0\n Else (feature 1 > 0.628141)\n If (feature 2 <= 0.508197)\n If (feature 5 <= 0.377049)\n Predict: 1.0\n Else (feature 5 > 0.377049)\n Predict: 0.0\n Else (feature 2 > 0.508197)\n If (feature 2 <= 0.557377)\n Predict: 0.0\n Else (feature 2 > 0.557377)\n Predict: 1.0\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:454"},{"title":"Random Forests","text":"%md\n\nNow let's see if we can achieve a better performance with an ensemble of trees known as random forests. \n#\nRandom forests combine many decision trees in order to reduce the risk of overfitting. The spark.ml implementation supports random forests for binary and multiclass classification and for regression, using both continuous and categorical features. ([See docs](http://spark.apache.org/docs/latest/ml-classification-regression.html#random-forests) for more info.)\n#\nIn the example below we will combine five (5) trees to create a forest of trees.\n#\n","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528206_-1286738728","id":"20160531-234527_1954753725","result":{"code":"SUCCESS","type":"HTML","msg":"Now let's see if we can achieve a better performance with an ensemble of trees known as random forests.
\n\nRandom forests combine many decision trees in order to reduce the risk of overfitting. The spark.ml implementation supports random forests for binary and multiclass classification and for regression, using both continuous and categorical features. (See docs for more info.)
\n\nIn the example below we will combine five (5) trees to create a forest of trees.
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:456"},{"title":"Random Forest","text":"import org.apache.spark.sql.SQLContext \n\nimport org.apache.spark.ml.Pipeline \nimport org.apache.spark.ml.classification.{RandomForestClassificationModel, RandomForestClassifier} \nimport org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator \nimport org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer} \n\nval sqlContext = new SQLContext(sc) \n \n// Load and parse the LIBSVM data file, converting it to a DataFrame.\nval data = sqlContext.read.format(\"libsvm\").load(\"/tmp/libsvm-data/diabetes_scaled_data\") \n \n// Index labels, adding metadata to the label column. \n// Fit on whole dataset to include all labels in index. \nval labelIndexer = new StringIndexer() \n .setInputCol(\"label\") \n .setOutputCol(\"indexedLabel\") \n .fit(data) \n\n// Automatically identify categorical features, and index them. \nval featureIndexer = new VectorIndexer() \n .setInputCol(\"features\") \n .setOutputCol(\"indexedFeatures\") \n .setMaxCategories(2) \n .fit(data) \n \n// Split the data into training and test sets (30% held out for testing) \nval Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3)) \n \n// Train a RandomForest model. \nval rf = new RandomForestClassifier() \n .setLabelCol(\"indexedLabel\") \n .setFeaturesCol(\"indexedFeatures\") \n .setNumTrees(5) \n \n// Convert indexed labels back to original labels. \nval labelConverter = new IndexToString() \n .setInputCol(\"prediction\") \n .setOutputCol(\"predictedLabel\") \n .setLabels(labelIndexer.labels) \n \n// Chain indexers and forest in a Pipeline \nval pipeline = new Pipeline() \n .setStages(Array(labelIndexer, featureIndexer, rf, labelConverter)) \n \n// Train model. This also runs the indexers. \nval model = pipeline.fit(trainingData) \n \n// Make predictions. \nval predictions = model.transform(testData) \n \n// Select example rows to display. \npredictions.select(\"predictedLabel\", \"label\", \"features\").show(5) \n \n// Select (prediction, true label) and compute test error \nval evaluator = new MulticlassClassificationEvaluator() \n .setLabelCol(\"indexedLabel\") \n .setPredictionCol(\"prediction\") \n .setMetricName(\"precision\") \n \nval accuracy = evaluator.evaluate(predictions) \nprintln(\"Test Error = \" + (1.0 - accuracy)) \n \nval rfModel = model.stages(2).asInstanceOf[RandomForestClassificationModel] \nprintln(\"Learned classification forest model:\\n\" + rfModel.toDebugString) ","dateUpdated":"2016-09-27T17:19:44+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/scala","colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528207_-1287123477","id":"20160531-234527_1341024269","result":{"code":"SUCCESS","type":"TEXT","msg":"import org.apache.spark.sql.SQLContext\nimport org.apache.spark.ml.Pipeline\nimport org.apache.spark.ml.classification.{RandomForestClassificationModel, RandomForestClassifier}\nimport org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator\nimport org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}\nsqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@1d7b3923\ndata: org.apache.spark.sql.DataFrame = [label: double, features: vector]\nlabelIndexer: org.apache.spark.ml.feature.StringIndexerModel = strIdx_02eb790d2906\nfeatureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_21e6abcca78d\ntrainingData: org.apache.spark.sql.DataFrame = [label: double, features: vector]\ntestData: org.apache.spark.sql.DataFrame = [label: double, features: vector]\nrf: org.apache.spark.ml.classification.RandomForestClassifier = rfc_e9b24b4bf33a\nlabelConverter: org.apache.spark.ml.feature.IndexToString = idxToStr_1d254989def5\npipeline: org.apache.spark.ml.Pipeline = pipeline_f78b1d228c0f\nmodel: org.apache.spark.ml.PipelineModel = pipeline_f78b1d228c0f\npredictions: org.apache.spark.sql.DataFrame = [label: double, features: vector, indexedLabel: double, indexedFeatures: vector, rawPrediction: vector, probability: vector, prediction: double, predictedLabel: string]\n+--------------+-----+--------------------+\n|predictedLabel|label| features|\n+--------------+-----+--------------------+\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| 1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| -1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n| 1.0| -1.0|(8,[0,1,2,3,4,5,6...|\n+--------------+-----+--------------------+\nonly showing top 5 rows\n\nevaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_e11d55da1218\naccuracy: Double = 0.75\nTest Error = 0.25\nrfModel: org.apache.spark.ml.classification.RandomForestClassificationModel = RandomForestClassificationModel (uid=rfc_b522745ef610) with 5 trees\nLearned classification forest model:\nRandomForestClassificationModel (uid=rfc_b522745ef610) with 5 trees\n Tree 0 (weight 1.0):\n If (feature 5 <= -0.105812)\n If (feature 7 <= -0.833333)\n Predict: 0.0\n Else (feature 7 > -0.833333)\n If (feature 5 <= -0.308495)\n If (feature 0 <= 0.0588235)\n Predict: 0.0\n Else (feature 0 > 0.0588235)\n If (feature 3 <= -1.0)\n Predict: 1.0\n Else (feature 3 > -1.0)\n Predict: 0.0\n Else (feature 5 > -0.308495)\n If (feature 5 <= -0.168405)\n If (feature 3 <= -0.59596)\n Predict: 0.0\n Else (feature 3 > -0.59596)\n Predict: 1.0\n Else (feature 5 > -0.168405)\n If (feature 4 <= -0.716312)\n Predict: 0.0\n Else (feature 4 > -0.716312)\n Predict: 1.0\n Else (feature 5 > -0.105812)\n If (feature 6 <= -0.63877)\n If (feature 1 <= 0.326633)\n If (feature 2 <= -0.147541)\n If (feature 1 <= 0.165829)\n Predict: 0.0\n Else (feature 1 > 0.165829)\n Predict: 1.0\n Else (feature 2 > -0.147541)\n If (feature 4 <= -0.621749)\n Predict: 0.0\n Else (feature 4 > -0.621749)\n Predict: 0.0\n Else (feature 1 > 0.326633)\n If (feature 3 <= -1.0)\n If (feature 1 <= 0.447236)\n Predict: 0.0\n Else (feature 1 > 0.447236)\n Predict: 1.0\n Else (feature 3 > -1.0)\n If (feature 6 <= -0.798463)\n Predict: 0.0\n Else (feature 6 > -0.798463)\n Predict: 1.0\n Else (feature 6 > -0.63877)\n If (feature 7 <= -0.533333)\n If (feature 2 <= 0.278689)\n If (feature 6 <= -0.432963)\n Predict: 1.0\n Else (feature 6 > -0.432963)\n Predict: 1.0\n Else (feature 2 > 0.278689)\n If (feature 0 <= -0.882353)\n Predict: 0.0\n Else (feature 0 > -0.882353)\n Predict: 1.0\n Else (feature 7 > -0.533333)\n If (feature 1 <= -0.0753769)\n Predict: 0.0\n Else (feature 1 > -0.0753769)\n If (feature 1 <= 0.366834)\n Predict: 1.0\n Else (feature 1 > 0.366834)\n Predict: 1.0\n Tree 1 (weight 1.0):\n If (feature 1 <= 0.537688)\n If (feature 7 <= -0.766667)\n If (feature 5 <= -0.0938897)\n If (feature 3 <= -0.434343)\n If (feature 5 <= -0.120715)\n Predict: 0.0\n Else (feature 5 > -0.120715)\n Predict: 0.0\n Else (feature 3 > -0.434343)\n If (feature 7 <= -0.8)\n Predict: 0.0\n Else (feature 7 > -0.8)\n Predict: 1.0\n Else (feature 5 > -0.0938897)\n If (feature 6 <= -0.63877)\n If (feature 5 <= 0.257824)\n Predict: 0.0\n Else (feature 5 > 0.257824)\n Predict: 1.0\n Else (feature 6 > -0.63877)\n If (feature 3 <= -0.393939)\n Predict: 0.0\n Else (feature 3 > -0.393939)\n Predict: 1.0\n Else (feature 7 > -0.766667)\n If (feature 1 <= 0.326633)\n If (feature 5 <= -0.213115)\n If (feature 5 <= -0.406855)\n Predict: 1.0\n Else (feature 5 > -0.406855)\n Predict: 0.0\n Else (feature 5 > -0.213115)\n If (feature 3 <= -0.59596)\n Predict: 0.0\n Else (feature 3 > -0.59596)\n Predict: 1.0\n Else (feature 1 > 0.326633)\n If (feature 5 <= 0.052161)\n If (feature 6 <= -0.515798)\n Predict: 0.0\n Else (feature 6 > -0.515798)\n Predict: 1.0\n Else (feature 5 > 0.052161)\n If (feature 6 <= -0.855679)\n Predict: 0.0\n Else (feature 6 > -0.855679)\n Predict: 1.0\n Else (feature 1 > 0.537688)\n If (feature 5 <= -0.347243)\n Predict: 0.0\n Else (feature 5 > -0.347243)\n If (feature 4 <= -0.966903)\n If (feature 5 <= -0.14456)\n If (feature 2 <= 0.409836)\n Predict: 1.0\n Else (feature 2 > 0.409836)\n Predict: 0.0\n Else (feature 5 > -0.14456)\n Predict: 1.0\n Else (feature 4 > -0.966903)\n If (feature 6 <= -0.945346)\n Predict: 0.0\n Else (feature 6 > -0.945346)\n If (feature 4 <= -0.65721)\n Predict: 1.0\n Else (feature 4 > -0.65721)\n Predict: 1.0\n Tree 2 (weight 1.0):\n If (feature 7 <= -0.7)\n If (feature 5 <= -0.0938897)\n If (feature 7 <= -0.8)\n If (feature 1 <= 0.366834)\n If (feature 6 <= -0.515798)\n Predict: 0.0\n Else (feature 6 > -0.515798)\n Predict: 0.0\n Else (feature 1 > 0.366834)\n If (feature 4 <= -0.77305)\n Predict: 1.0\n Else (feature 4 > -0.77305)\n Predict: 0.0\n Else (feature 7 > -0.8)\n If (feature 3 <= -0.616162)\n If (feature 6 <= -0.899231)\n Predict: 0.0\n Else (feature 6 > -0.899231)\n Predict: 0.0\n Else (feature 3 > -0.616162)\n If (feature 7 <= -0.733333)\n Predict: 1.0\n Else (feature 7 > -0.733333)\n Predict: 0.0\n Else (feature 5 > -0.0938897)\n If (feature 6 <= -0.63877)\n If (feature 5 <= 0.257824)\n If (feature 5 <= -0.0581222)\n Predict: 1.0\n Else (feature 5 > -0.0581222)\n Predict: 0.0\n Else (feature 5 > 0.257824)\n If (feature 2 <= 0.0491803)\n Predict: 0.0\n Else (feature 2 > 0.0491803)\n Predict: 1.0\n Else (feature 6 > -0.63877)\n If (feature 1 <= 0.58794)\n If (feature 1 <= 0.0653266)\n Predict: 0.0\n Else (feature 1 > 0.0653266)\n Predict: 0.0\n Else (feature 1 > 0.58794)\n Predict: 1.0\n Else (feature 7 > -0.7)\n If (feature 5 <= -0.183308)\n If (feature 2 <= 0.344262)\n If (feature 6 <= -0.778822)\n If (feature 1 <= 0.738693)\n Predict: 0.0\n Else (feature 1 > 0.738693)\n Predict: 1.0\n Else (feature 6 > -0.778822)\n Predict: 0.0\n Else (feature 2 > 0.344262)\n Predict: 1.0\n Else (feature 5 > -0.183308)\n If (feature 6 <= -0.610589)\n If (feature 4 <= -0.687943)\n If (feature 4 <= -1.0)\n Predict: 0.0\n Else (feature 4 > -1.0)\n Predict: 0.0\n Else (feature 4 > -0.687943)\n If (feature 6 <= -0.70538)\n Predict: 1.0\n Else (feature 6 > -0.70538)\n Predict: 0.0\n Else (feature 6 > -0.610589)\n If (feature 2 <= 0.606557)\n If (feature 4 <= -0.328605)\n Predict: 1.0\n Else (feature 4 > -0.328605)\n Predict: 0.0\n Else (feature 2 > 0.606557)\n Predict: 0.0\n Tree 3 (weight 1.0):\n If (feature 5 <= -0.14456)\n If (feature 1 <= 0.447236)\n If (feature 3 <= -0.494949)\n If (feature 5 <= -0.213115)\n If (feature 5 <= -0.406855)\n Predict: 0.0\n Else (feature 5 > -0.406855)\n Predict: 0.0\n Else (feature 5 > -0.213115)\n If (feature 3 <= -0.858586)\n Predict: 0.0\n Else (feature 3 > -0.858586)\n Predict: 0.0\n Else (feature 3 > -0.494949)\n If (feature 7 <= -0.8)\n Predict: 0.0\n Else (feature 7 > -0.8)\n If (feature 7 <= -0.666667)\n Predict: 1.0\n Else (feature 7 > -0.666667)\n Predict: 0.0\n Else (feature 1 > 0.447236)\n If (feature 5 <= -0.347243)\n Predict: 0.0\n Else (feature 5 > -0.347243)\n If (feature 0 <= -0.0588235)\n If (feature 7 <= 0.366667)\n Predict: 1.0\n Else (feature 7 > 0.366667)\n Predict: 0.0\n Else (feature 0 > -0.0588235)\n Predict: 1.0\n Else (feature 5 > -0.14456)\n If (feature 1 <= 0.326633)\n If (feature 6 <= -0.211785)\n If (feature 2 <= 0.0819672)\n If (feature 0 <= -0.764706)\n Predict: 0.0\n Else (feature 0 > -0.764706)\n Predict: 1.0\n Else (feature 2 > 0.0819672)\n If (feature 4 <= -0.574468)\n Predict: 0.0\n Else (feature 4 > -0.574468)\n Predict: 1.0\n Else (feature 6 > -0.211785)\n If (feature 5 <= 0.290611)\n Predict: 1.0\n Else (feature 5 > 0.290611)\n Predict: 0.0\n Else (feature 1 > 0.326633)\n If (feature 0 <= -0.294118)\n If (feature 1 <= 0.58794)\n If (feature 5 <= -0.0581222)\n Predict: 0.0\n Else (feature 5 > -0.0581222)\n Predict: 1.0\n Else (feature 1 > 0.58794)\n If (feature 6 <= -0.211785)\n Predict: 1.0\n Else (feature 6 > -0.211785)\n Predict: 1.0\n Else (feature 0 > -0.294118)\n If (feature 3 <= -0.272727)\n If (feature 5 <= 0.0938898)\n Predict: 1.0\n Else (feature 5 > 0.0938898)\n Predict: 1.0\n Else (feature 3 > -0.272727)\n If (feature 3 <= -0.131313)\n Predict: 0.0\n Else (feature 3 > -0.131313)\n Predict: 1.0\n Tree 4 (weight 1.0):\n If (feature 7 <= -0.833333)\n If (feature 0 <= -1.0)\n If (feature 5 <= -0.0760059)\n If (feature 4 <= -0.621749)\n Predict: 0.0\n Else (feature 4 > -0.621749)\n If (feature 7 <= -0.9)\n Predict: 0.0\n Else (feature 7 > -0.9)\n Predict: 1.0\n Else (feature 5 > -0.0760059)\n If (feature 1 <= 0.286432)\n If (feature 6 <= -0.855679)\n Predict: 1.0\n Else (feature 6 > -0.855679)\n Predict: 0.0\n Else (feature 1 > 0.286432)\n If (feature 5 <= -0.0104321)\n Predict: 0.0\n Else (feature 5 > -0.0104321)\n Predict: 1.0\n Else (feature 0 > -1.0)\n If (feature 5 <= 0.120715)\n If (feature 5 <= 0.052161)\n If (feature 1 <= 0.326633)\n Predict: 0.0\n Else (feature 1 > 0.326633)\n Predict: 0.0\n Else (feature 5 > 0.052161)\n If (feature 0 <= -0.764706)\n Predict: 0.0\n Else (feature 0 > -0.764706)\n Predict: 1.0\n Else (feature 5 > 0.120715)\n If (feature 6 <= -0.587532)\n If (feature 5 <= 0.290611)\n Predict: 0.0\n Else (feature 5 > 0.290611)\n Predict: 1.0\n Else (feature 6 > -0.587532)\n If (feature 1 <= 0.18593)\n Predict: 0.0\n Else (feature 1 > 0.18593)\n Predict: 1.0\n Else (feature 7 > -0.833333)\n If (feature 7 <= -0.566667)\n If (feature 4 <= -0.65721)\n If (feature 2 <= 0.508197)\n If (feature 1 <= 0.396985)\n Predict: 0.0\n Else (feature 1 > 0.396985)\n Predict: 1.0\n Else (feature 2 > 0.508197)\n If (feature 0 <= -0.882353)\n Predict: 1.0\n Else (feature 0 > -0.882353)\n Predict: 0.0\n Else (feature 4 > -0.65721)\n If (feature 5 <= -0.168405)\n Predict: 0.0\n Else (feature 5 > -0.168405)\n If (feature 2 <= 0.0819672)\n Predict: 1.0\n Else (feature 2 > 0.0819672)\n Predict: 1.0\n Else (feature 7 > -0.566667)\n If (feature 1 <= 0.0653266)\n If (feature 2 <= 0.278689)\n If (feature 5 <= 0.171386)\n Predict: 0.0\n Else (feature 5 > 0.171386)\n Predict: 0.0\n Else (feature 2 > 0.278689)\n If (feature 5 <= 0.207154)\n Predict: 0.0\n Else (feature 5 > 0.207154)\n Predict: 1.0\n Else (feature 1 > 0.0653266)\n If (feature 7 <= 0.366667)\n If (feature 7 <= -0.3)\n Predict: 1.0\n Else (feature 7 > -0.3)\n Predict: 1.0\n Else (feature 7 > 0.366667)\n If (feature 5 <= -0.105812)\n Predict: 0.0\n Else (feature 5 > -0.105812)\n Predict: 1.0\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:457"},{"text":"%md\n#\nHas the accuracy improved after training the dataset using the Random Forest model? Does the accuracy improve if you increase the number of trees?\n#\nWhat did you find interesting in the output of a Random Forest classifier?\n#","dateUpdated":"2016-09-27T17:20:32+0000","config":{"enabled":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528207_-1287123477","id":"20160531-234527_754013818","result":{"code":"SUCCESS","type":"HTML","msg":"\nHas the accuracy improved after training the dataset using the Random Forest model? Does the accuracy improve if you increase the number of trees?
\n\nWhat did you find interesting in the output of a Random Forest classifier?
\n\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:458"},{"title":"The End","text":"%md\n\nThis concludes our lab. Hopefully you've got a taste of how easy it is to run clustering and classification models with Apache Spark!","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528207_-1287123477","id":"20160531-234527_409238179","result":{"code":"SUCCESS","type":"HTML","msg":"This concludes our lab. Hopefully you've got a taste of how easy it is to run clustering and classification models with Apache Spark!
\n"},"dateCreated":"2016-09-27T17:15:28+0000","status":"READY","errorMessage":"","progressUpdateIntervalMs":500,"$$hashKey":"object:459"},{"title":"Resources: Hortonworks Community Connection","text":"%md\n\nMake sure to checkout [Hortonworks Community Connection (HCC)](https://community.hortonworks.com/answers/index.html) if you have Apache Spark and/or Data Science / Analytics related questions or you would like to contribute back to the community with your own answers/examples/articles/repos.\n#\nAll best,\nThe HCC Team!\n#\n[](https://community.hortonworks.com/answers/index.html)","dateUpdated":"2016-09-27T17:15:28+0000","config":{"enabled":true,"title":true,"graph":{"mode":"table","height":300,"optionOpen":false,"keys":[],"values":[],"groups":[],"scatter":{}},"editorMode":"ace/mode/markdown","editorHide":true,"colWidth":12},"settings":{"params":{},"forms":{}},"jobName":"paragraph_1474996528207_-1287123477","id":"20160531-234527_1823436759","result":{"code":"SUCCESS","type":"HTML","msg":"Make sure to checkout Hortonworks Community Connection (HCC) if you have Apache Spark and/or Data Science / Analytics related questions or you would like to contribute back to the community with your own answers/examples/articles/repos.
\n\nAll best,\n
The HCC Team!
![]()