{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# CS579: Lecture 12 \n",
"\n",
"** Demographic Inference I**\n",
"\n",
"*[Dr. Aron Culotta](http://cs.iit.edu/~culotta)* \n",
"*[Illinois Institute of Technology](http://iit.edu)*"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Midterm review \n",
"\n",
"~5 True/False, ~6 short answer\n",
" \n",
"**Topics:** \n",
"- Twitter API \n",
" - what comes in a tweet? \n",
" - how do rate limits work? \n",
" - can you understand API documentation? \n",
"- graph basics: \n",
" - directed/undirected \n",
" - path \n",
" - cycle \n",
" - connected \n",
" - connected component \n",
" - degree (distribution) \n",
" - diameter \n",
" - average path length \n",
" - clustering coefficient \n",
"- modeling networks \n",
" - random graphs \n",
" - regular graphs \n",
" - rewired graphs \n",
" - what makes a small world? \n",
"- community detection \n",
" - girvan-newman (betweenness) \n",
" - graph cuts \n",
" - representing graphs with matrices \n",
" - graph laplacian \n",
"- link prediction \n",
" - shortest path \n",
" - common neighbors \n",
" - jaccard \n",
" - preferential attachment \n",
" - sim rank \n",
" - evaluation \n",
"- information cascades \n",
" - urn experiment \n",
" - bayes' theorem for decision making \n",
" - game-theoretic model \n",
" - maximizing payoff \n",
"\t- cluster density \n",
"- sentiment analysis \n",
" - lexicon approach \n",
" - machine learning \n",
" \n",
"**Question types:** \n",
"- What does this algorithm output? \n",
" - E.g., what is jaccard score for a specific link? \n",
" - E.g., what is the next step in girvan-newman? \n",
"- What does this code do? \n",
" - E.g., I give you a new graph-generating algorithm, tell me what it produces \n",
"- Write a new algorithm \n",
" - E.g., provide pseudo-code the linear-threshold cascade model \n",
"- True/False \n",
" - E.g., small world graphs have higher clustering coefficients than random graphs."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"**dem·o·graph·ics**\n",
"\n",
"statistical data relating to the population and particular groups within it.\n",
"\n",
"E.g., age, ethnicity, gender, income, ..."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Why Demographics?\n",
"\n",
"- Marketing\n",
" - Who are my customers?\n",
" - Who are my competitors' customers?\n",
" - E.g., [DemographicsPro](http://www.demographicspro.com/samples#c=%40FamilyGuyonFOX)\n",
" \n",
"- Social Media as Surveys\n",
" - E.g., 45% of tweets express positive sentiment toward Pres. Obama\n",
" - Who wrote those tweets?\n",
" \n",
"- Health\n",
" - 2% of Facebook users are expressing flu-like symptoms\n",
" - Are they representative of the full population?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
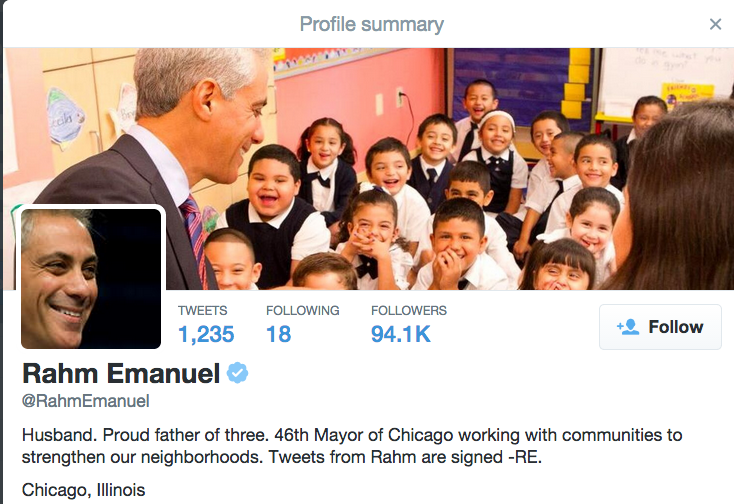
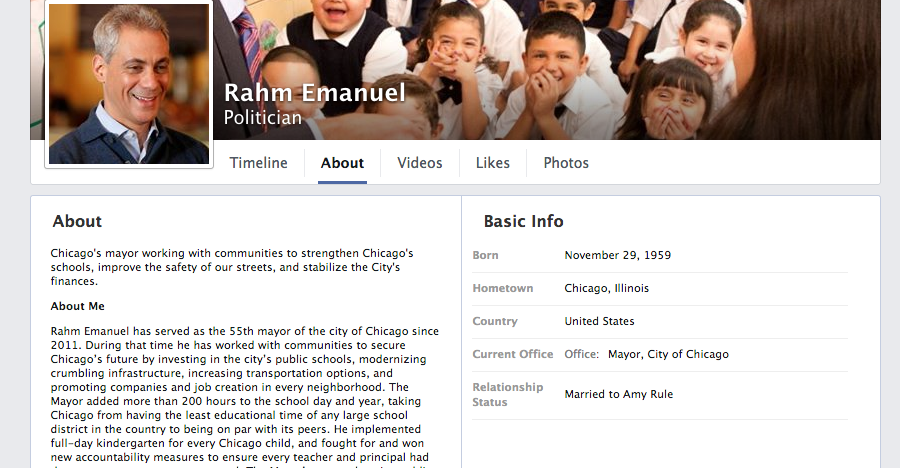
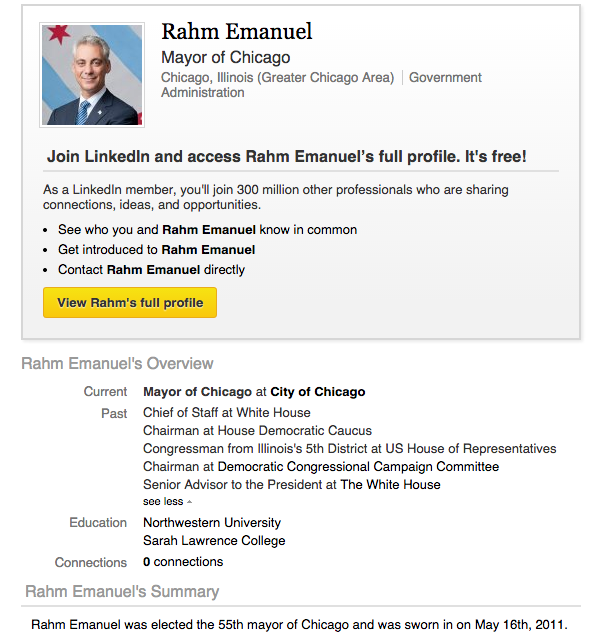
"** User profiles vary from site to site. **"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Approaches\n",
"\n",
"- Clever use of external data\n",
" - E.g., U.S. Census name lists for gender\n",
"- Look for keywords in profile\n",
" - \"African American Male\"\n",
" - \"Happy 21st birthday to me\"\n",
"- Machine Learning"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"100 tweets\n",
"200 tweets\n",
"300 tweets\n",
"400 tweets\n",
"500 tweets\n",
"600 tweets\n",
"700 tweets\n",
"800 tweets\n",
"900 tweets\n",
"1000 tweets\n",
"fetched 1000 tweets\n"
]
}
],
"source": [
"# Guessing gender\n",
"import configparser\n",
"import sys\n",
"from TwitterAPI import TwitterAPI\n",
"\n",
"def get_twitter(config_file):\n",
" \"\"\" Read the config_file and construct an instance of TwitterAPI.\n",
" Args:\n",
" config_file ... A config file in ConfigParser format with Twitter credentials\n",
" Returns:\n",
" An instance of TwitterAPI.\n",
" \"\"\"\n",
" config = configparser.ConfigParser()\n",
" config.read(config_file)\n",
" twitter = TwitterAPI(\n",
" config.get('twitter', 'consumer_key'),\n",
" config.get('twitter', 'consumer_secret'),\n",
" config.get('twitter', 'access_token'),\n",
" config.get('twitter', 'access_token_secret'))\n",
" return twitter\n",
"\n",
"twitter = get_twitter('twitter.cfg')\n",
"tweets = []\n",
"n_tweets=1000\n",
"for r in twitter.request('statuses/filter', {'track': 'i'}):\n",
" tweets.append(r)\n",
" if len(tweets) % 100 == 0:\n",
" print('%d tweets' % len(tweets))\n",
" if len(tweets) >= n_tweets:\n",
" break\n",
"print('fetched %d tweets' % len(tweets))"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[{'limit': {'timestamp_ms': '1475689818824', 'track': 12}},\n",
" {'limit': {'timestamp_ms': '1475689818840', 'track': 9}},\n",
" {'limit': {'timestamp_ms': '1475689819793', 'track': 89}},\n",
" {'limit': {'timestamp_ms': '1475689819825', 'track': 91}},\n",
" {'limit': {'timestamp_ms': '1475689819846', 'track': 73}},\n",
" {'limit': {'timestamp_ms': '1475689819857', 'track': 99}}]"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# not all tweets are returned\n",
"# https://dev.twitter.com/streaming/overview/messages-types#limit_notices\n",
"[t for t in tweets if 'user' not in t][:6]"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"fetched 927 tweets\n"
]
}
],
"source": [
"# restrict to actual tweets\n",
"# (remove \"deleted\" tweets)\n",
"tweets = [t for t in tweets if 'user' in t]\n",
"print('fetched %d tweets' % len(tweets))"
]
},
{
"cell_type": "code",
"execution_count": 96,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['Jeffrey Salas',\n",
" 'Iberia TV',\n",
" 'Chelllly',\n",
" 'selene',\n",
" 'Hallie Earnhart',\n",
" 'COSTLIFEDJ💯🐐',\n",
" 'Aldous Snow',\n",
" '🔮🔮🔮',\n",
" 'İÇERDE',\n",
" 'Madi']"
]
},
"execution_count": 96,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Print 10 names.\n",
"names = [t['user']['name'] for t in tweets]\n",
"names[:10]"
]
},
{
"cell_type": "code",
"execution_count": 97,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"males:\n",
"['JAMES 3.318 3.318 1',\n",
" 'JOHN 3.271 6.589 2',\n",
" 'ROBERT 3.143 9.732 3',\n",
" 'MICHAEL 2.629 12.361 4',\n",
" 'WILLIAM 2.451 14.812 5',\n",
" 'DAVID 2.363 17.176 6',\n",
" 'RICHARD 1.703 18.878 7',\n",
" 'CHARLES 1.523 20.401 8',\n",
" 'JOSEPH 1.404 21.805 9',\n",
" 'THOMAS 1.380 23.185 10']\n",
"females:\n",
"['MARY 2.629 2.629 1',\n",
" 'PATRICIA 1.073 3.702 2',\n",
" 'LINDA 1.035 4.736 3',\n",
" 'BARBARA 0.980 5.716 4',\n",
" 'ELIZABETH 0.937 6.653 5',\n",
" 'JENNIFER 0.932 7.586 6',\n",
" 'MARIA 0.828 8.414 7',\n",
" 'SUSAN 0.794 9.209 8',\n",
" 'MARGARET 0.768 9.976 9',\n",
" 'DOROTHY 0.727 10.703 10']\n"
]
}
],
"source": [
"# Fetch census name data from:\n",
"# http://www2.census.gov/topics/genealogy/1990surnames/\n",
"import requests\n",
"from pprint import pprint\n",
"males_url = 'http://www2.census.gov/topics/genealogy/' + \\\n",
" '1990surnames/dist.male.first'\n",
"females_url = 'http://www2.census.gov/topics/genealogy/' + \\\n",
" '1990surnames/dist.female.first'\n",
"males = requests.get(males_url).text.split('\\n')\n",
"females = requests.get(females_url).text.split('\\n')\n",
"print('males:')\n",
"pprint(males[:10])\n",
"print('females:')\n",
"pprint(females[:10])"
]
},
{
"cell_type": "code",
"execution_count": 98,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1219 male and 4275 female names\n",
"males:\n",
"courtney\n",
"lupe\n",
"christian\n",
"alfredo\n",
"jonah\n",
"rolando\n",
"samuel\n",
"luciano\n",
"cesar\n",
"vaughn\n",
"\n",
"females:\n",
"lannie\n",
"lyndsay\n",
"lupe\n",
"lolita\n",
"shayna\n",
"elnora\n",
"laurene\n",
"loree\n",
"charisse\n",
"gertrud\n"
]
}
],
"source": [
"# Get names. \n",
"male_names = set([m.split()[0].lower() for m in males if m])\n",
"female_names = set([f.split()[0].lower() for f in females if f])\n",
"print('%d male and %d female names' % (len(male_names), len(female_names)))\n",
"print('males:\\n' + '\\n'.join(list(male_names)[:10]))\n",
"print('\\nfemales:\\n' + '\\n'.join(list(female_names)[:10]))"
]
},
{
"cell_type": "code",
"execution_count": 99,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"# Initialize gender of all tweets to unknown.\n",
"for t in tweets:\n",
" t['gender'] = 'unknown'"
]
},
{
"cell_type": "code",
"execution_count": 100,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [],
"source": [
"# label a Twitter user's gender by matching name list.\n",
"import re\n",
"def gender_by_name(tweets, male_names, female_names):\n",
" for t in tweets:\n",
" name = t['user']['name']\n",
" if name:\n",
" # remove punctuation.\n",
" name_parts = re.findall('\\w+', name.split()[0].lower())\n",
" if len(name_parts) > 0:\n",
" first = name_parts[0].lower()\n",
" if first in male_names:\n",
" t['gender'] = 'male'\n",
" elif first in female_names:\n",
" t['gender'] = 'female'\n",
" else:\n",
" t['gender'] = 'unknown'\n",
"\n",
"gender_by_name(tweets, male_names, female_names)\n",
"# What's wrong with this approach?"
]
},
{
"cell_type": "code",
"execution_count": 101,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.35 of accounts are labeled with gender\n",
"gender counts:\n",
" Counter({'unknown': 598, 'female': 178, 'male': 151})\n",
"male Jeffrey Salas\n",
"unknown Iberia TV\n",
"unknown Chelllly\n",
"female selene\n",
"female Hallie Earnhart\n",
"unknown COSTLIFEDJ💯🐐\n",
"unknown Aldous Snow\n",
"unknown 🔮🔮🔮\n",
"unknown İÇERDE\n",
"unknown Madi\n",
"female Fiona Von\n",
"unknown spooky cait\n",
"unknown -HeartlessLover💋\n",
"unknown #NicomaineDeiHardFan\n",
"female princess 🎃\n",
"male Daniel Poehlman\n",
"unknown savage.\n",
"unknown 🐨 Lo 🍕\n",
"male Isaiah Persons\n",
"female Barrie\n"
]
}
],
"source": [
"from collections import Counter\n",
"\n",
"def print_genders(tweets):\n",
" counts = Counter([t['gender'] for t in tweets])\n",
" print('%.2f of accounts are labeled with gender' % \n",
" ((counts['male'] + counts['female']) / sum(counts.values())))\n",
" print('gender counts:\\n', counts)\n",
" for t in tweets[:20]:\n",
" print(t['gender'], t['user']['name'])\n",
" \n",
"print_genders(tweets)"
]
},
{
"cell_type": "code",
"execution_count": 102,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"found 331 ambiguous names:\n",
"\n",
"courtney\n",
"lupe\n",
"christian\n",
"samuel\n",
"maurice\n",
"ronald\n",
"eric\n",
"toby\n",
"perry\n",
"jimmy\n",
"shannon\n",
"jan\n",
"christopher\n",
"paris\n",
"cory\n",
"marshall\n",
"lou\n",
"merrill\n",
"mickey\n",
"stephen\n"
]
}
],
"source": [
"# What about ambiguous names?\n",
"def print_ambiguous_names(male_names, female_names):\n",
" ambiguous = [n for n in male_names if n in female_names] # names on both lists\n",
" print('found %d ambiguous names:\\n'% len(ambiguous))\n",
" print('\\n'.join(ambiguous[:20]))\n",
" \n",
"print_ambiguous_names(male_names, female_names)"
]
},
{
"cell_type": "code",
"execution_count": 103,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"found 0 ambiguous names:\n",
"\n",
"\n",
"1146 male and 4017 female names\n"
]
}
],
"source": [
"# Keep names that are more frequent in one gender than the other.\n",
"def get_percents(name_list):\n",
" # parse raw data to extract, e.g., the percent of males names John.\n",
" return dict([(n.split()[0].lower(), float(n.split()[1]))\n",
" for n in name_list if n])\n",
"\n",
"males_pct = get_percents(males)\n",
"females_pct = get_percents(females)\n",
"\n",
"# Assign a name as male if it is more common among males than femals.\n",
"male_names = set([m for m in male_names if m not in female_names or\n",
" males_pct[m] > females_pct[m]])\n",
"female_names = set([f for f in female_names if f not in male_names or\n",
" females_pct[f] > males_pct[f]])\n",
"\n",
"print_ambiguous_names(male_names, female_names)\n",
"print('%d male and %d female names' % (len(male_names), len(female_names)))"
]
},
{
"cell_type": "code",
"execution_count": 104,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.35 of accounts are labeled with gender\n",
"gender counts:\n",
" Counter({'unknown': 598, 'female': 197, 'male': 132})\n",
"male Jeffrey Salas\n",
"unknown Iberia TV\n",
"unknown Chelllly\n",
"female selene\n",
"female Hallie Earnhart\n",
"unknown COSTLIFEDJ💯🐐\n",
"unknown Aldous Snow\n",
"unknown 🔮🔮🔮\n",
"unknown İÇERDE\n",
"unknown Madi\n",
"female Fiona Von\n",
"unknown spooky cait\n",
"unknown -HeartlessLover💋\n",
"unknown #NicomaineDeiHardFan\n",
"female princess 🎃\n",
"male Daniel Poehlman\n",
"unknown savage.\n",
"unknown 🐨 Lo 🍕\n",
"male Isaiah Persons\n",
"female Barrie\n"
]
}
],
"source": [
"# Relabel twitter users (compare with above)\n",
"gender_by_name(tweets, male_names, female_names)\n",
"print_genders(tweets)"
]
},
{
"cell_type": "code",
"execution_count": 105,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[('Pedagog 05447243650', 2),\n",
" ('WIN PS4 NOW!!', 2),\n",
" ('Dev 🤘🏾', 2),\n",
" ('Nihat Osmanlı', 2),\n",
" ('hasancoco', 2),\n",
" ('G', 2),\n",
" ('🔥', 2),\n",
" ('✨', 2),\n",
" ('Vikashgarg', 2),\n",
" ('Brends', 1),\n",
" ('paipai_devil', 1),\n",
" ('IG:mrdope_', 1),\n",
" ('Drones365', 1),\n",
" ('Henny P. Newton', 1),\n",
" ('Mehmet boğa', 1),\n",
" ('.', 1),\n",
" ('spooky cait', 1),\n",
" ('kait', 1),\n",
" ('Rahul Sudeep', 1),\n",
" ('Kaleidopop', 1)]"
]
},
"execution_count": 105,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Who are the unknowns?\n",
"# \"Filtered\" data can have big impact on analysis.\n",
"unknown_names = Counter(t['user']['name']\n",
" for t in tweets if t['gender'] == 'unknown')\n",
"unknown_names.most_common(20)"
]
},
{
"cell_type": "code",
"execution_count": 106,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Most Common Male Terms:\n",
"[('and', 34),\n",
" ('i', 31),\n",
" ('the', 21),\n",
" ('a', 20),\n",
" ('my', 19),\n",
" ('of', 17),\n",
" ('in', 16),\n",
" ('love', 14),\n",
" ('with', 13),\n",
" ('to', 11)]\n",
"\n",
"Most Common Female Terms:\n",
"[('i', 35),\n",
" ('you', 29),\n",
" ('my', 25),\n",
" ('of', 24),\n",
" ('and', 21),\n",
" ('a', 19),\n",
" ('the', 18),\n",
" ('me', 15),\n",
" ('to', 15),\n",
" ('is', 13)]\n"
]
}
],
"source": [
"# How do the profiles of male Twitter users differ from\n",
"# those of female users?\n",
"\n",
"male_profiles = [t['user']['description'] for t in tweets\n",
" if t['gender'] == 'male']\n",
"\n",
"female_profiles = [t['user']['description'] for t in tweets\n",
" if t['gender'] == 'female']\n",
"#male_profiles = [t['text'] for t in tweets\n",
"# if t['gender'] == 'male']\n",
"\n",
"#female_profiles = [t['text'] for t in tweets\n",
"# if t['gender'] == 'female']\n",
"\n",
"import re\n",
"def tokenize(s):\n",
" return re.sub('\\W+', ' ', s).lower().split() if s else []\n",
"\n",
"male_words = Counter()\n",
"female_words = Counter()\n",
"\n",
"for p in male_profiles:\n",
" male_words.update(Counter(tokenize(p)))\n",
" \n",
"for p in female_profiles:\n",
" female_words.update(Counter(tokenize(p)))\n",
"\n",
"print('Most Common Male Terms:')\n",
"pprint(male_words.most_common(10))\n",
" \n",
"print('\\nMost Common Female Terms:')\n",
"pprint(female_words.most_common(10))"
]
},
{
"cell_type": "code",
"execution_count": 107,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"844\n",
"915\n"
]
}
],
"source": [
"print(len(male_words))\n",
"print(len(female_words))"
]
},
{
"cell_type": "code",
"execution_count": 108,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Top Male Terms (diff):\n",
"[('and', -13),\n",
" ('with', -10),\n",
" ('life', -7),\n",
" ('in', -6),\n",
" ('too', -6),\n",
" ('fun', -5),\n",
" ('words', -4),\n",
" ('at', -4),\n",
" ('be', -4),\n",
" ('enjoy', -4)]\n",
"\n",
"Top Female Terms (diff):\n",
"[('things', 5),\n",
" ('re', 5),\n",
" ('my', 6),\n",
" ('she', 6),\n",
" ('one', 6),\n",
" ('m', 6),\n",
" ('is', 6),\n",
" ('of', 7),\n",
" ('me', 8),\n",
" ('you', 24)]\n"
]
}
],
"source": [
"# Compute difference\n",
"diff_counts = dict([(w, female_words[w] - male_words[w])\n",
" for w in\n",
" set(female_words.keys()) | set(male_words.keys())])\n",
"\n",
"sorted_diffs = sorted(diff_counts.items(), key=lambda x: x[1])\n",
"\n",
"print('Top Male Terms (diff):')\n",
"pprint(sorted_diffs[:10])\n",
"\n",
"print('\\nTop Female Terms (diff):')\n",
"pprint(sorted_diffs[-10:])"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** A problem with difference of counts:**\n",
"\n",
"
\n",
"What if we have more male than female words in total?\n",
"\n",
"
\n",
"Instead, consider \"the probability that a male user writes the word **w**\"\n",
"\n",
"
\n",
"\n",
"$$p(w|male) = \\frac{freq(w, male)}\n",
"{\\sum_i freq(w_i, male)} $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** Odds Ratio (OR)**\n",
"\n",
"The ratio of the probabilities for a word from each class:\n",
"\n",
"$$ OR(w) = \\frac{p(w|female)}{p(w|male)} $$\n",
"\n",
"\n",
"- High values --> more likely to be written by females\n",
"- Low values --> more likely to be written by males\n"
]
},
{
"cell_type": "code",
"execution_count": 109,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"p(w|male)\n",
"[('and', 0.025660377358490565),\n",
" ('i', 0.02339622641509434),\n",
" ('the', 0.015849056603773583),\n",
" ('a', 0.01509433962264151),\n",
" ('my', 0.014339622641509434),\n",
" ('of', 0.012830188679245283),\n",
" ('in', 0.012075471698113207),\n",
" ('love', 0.010566037735849057),\n",
" ('with', 0.009811320754716982),\n",
" ('to', 0.00830188679245283)]\n",
"\n",
"p(w|female)\n",
"[('i', 0.023458445040214475),\n",
" ('you', 0.01943699731903485),\n",
" ('my', 0.01675603217158177),\n",
" ('of', 0.0160857908847185),\n",
" ('and', 0.014075067024128687),\n",
" ('a', 0.012734584450402145),\n",
" ('the', 0.012064343163538873),\n",
" ('me', 0.010053619302949061),\n",
" ('to', 0.010053619302949061),\n",
" ('is', 0.00871313672922252)]\n"
]
}
],
"source": [
"def counts_to_probs(gender_words):\n",
" \"\"\" Compute probability of each term according to the frequency\n",
" in a gender. \"\"\"\n",
" total = sum(gender_words.values())\n",
" return dict([(word, count / total)\n",
" for word, count in gender_words.items()])\n",
"\n",
"male_probs = counts_to_probs(male_words)\n",
"female_probs = counts_to_probs(female_words)\n",
"\n",
"print('p(w|male)')\n",
"pprint(sorted(male_probs.items(), key=lambda x: -x[1])[:10])\n",
"\n",
"print('\\np(w|female)')\n",
"pprint(sorted(female_probs.items(), key=lambda x: -x[1])[:10])"
]
},
{
"cell_type": "code",
"execution_count": 110,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"ename": "KeyError",
"evalue": "'rock'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 3\u001b[0m for w in set(male_probs) | set(female_probs)])\n\u001b[1;32m 4\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 5\u001b[0;31m \u001b[0mors\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;32m\u001b[0m in \u001b[0;36modds_ratios\u001b[0;34m(male_probs, female_probs)\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m return dict([(w, female_probs[w] / male_probs[w])\n\u001b[0;32m----> 3\u001b[0;31m for w in set(male_probs) | set(female_probs)])\n\u001b[0m\u001b[1;32m 4\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0mors\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m(.0)\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m return dict([(w, female_probs[w] / male_probs[w])\n\u001b[0;32m----> 3\u001b[0;31m for w in set(male_probs) | set(female_probs)])\n\u001b[0m\u001b[1;32m 4\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 5\u001b[0m \u001b[0mors\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;31mKeyError\u001b[0m: 'rock'"
]
}
],
"source": [
"def odds_ratios(male_probs, female_probs):\n",
" return dict([(w, female_probs[w] / male_probs[w])\n",
" for w in\n",
" set(male_probs) | set(female_probs)])\n",
"\n",
"ors = odds_ratios(male_probs, female_probs)"
]
},
{
"cell_type": "code",
"execution_count": 111,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"844\n",
"915\n",
"0.0013404825737265416\n"
]
},
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 111,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print(len(male_probs))\n",
"print(len(female_probs))\n",
"print(female_probs['rock'])\n",
"'rock' in male_probs"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** How to deal with 0-probabilities? **\n",
"\n",
"$$p(w|male) = \\frac{freq(w, male)}\n",
"{\\sum_i freq(w_i, male)} $$\n",
"\n",
"$freq(w, male) = 0$\n",
"\n",
"Do we really believe there is **0** probability of a male using this term?\n",
"\n",
"(Recall over-fitting discussion.)\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** Additive Smoothing **\n",
"\n",
"Reserve small amount of counts (e.g., 1) for unseen observations.\n",
"\n",
"E.g., assume we've seen each word at least once in each class.\n",
"\n",
"$$p(w|male) = \\frac{1 + freq(w, male)}\n",
"{|W| + \\sum_i freq(w_i, male)} $$\n",
"\n",
"$|W|$: number of unique words."
]
},
{
"cell_type": "code",
"execution_count": 112,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"('and', 0.012114918656974732)\n",
"('i', 0.01107649705780547)\n",
"('the', 0.00761509172724126)\n",
"('a', 0.007268951194184839)\n",
"('my', 0.006922810661128418)\n",
"('of', 0.006230529595015576)\n",
"('in', 0.005884389061959155)\n",
"('love', 0.005192107995846314)\n",
"('with', 0.004845967462789893)\n",
"('to', 0.004153686396677051)\n"
]
}
],
"source": [
"# Additive smoothing. Add count of 1 for all words.\n",
"all_words = set(male_words) | set(female_words)\n",
"male_words.update(all_words) \n",
"female_words.update(all_words)\n",
"\n",
"male_probs = counts_to_probs(male_words)\n",
"female_probs = counts_to_probs(female_words)\n",
"print('\\n'.join(str(x) for x in \n",
" sorted(male_probs.items(), key=lambda x: -x[1])[:10]))"
]
},
{
"cell_type": "code",
"execution_count": 113,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.00034614053305642093\n"
]
}
],
"source": [
"# Even though word doesn't appear, has non-zerp probability.\n",
"print(male_probs['rock'])"
]
},
{
"cell_type": "code",
"execution_count": 114,
"metadata": {
"collapsed": false,
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Top Female Terms (OR):\n",
"[('she', 6.6174738219895275),\n",
" ('one', 6.6174738219895275),\n",
" ('19', 5.672120418848166),\n",
" ('student', 5.672120418848166),\n",
" ('things', 5.672120418848166),\n",
" ('right', 4.726767015706806),\n",
" ('towards', 4.726767015706806),\n",
" ('reaction', 4.726767015706806),\n",
" ('first', 4.726767015706806),\n",
" ('you', 4.726767015706806),\n",
" ('bayern', 4.726767015706806),\n",
" ('insta', 4.726767015706806),\n",
" ('from', 3.781413612565445),\n",
" ('those', 3.781413612565445),\n",
" ('jo', 3.781413612565445),\n",
" ('technology', 3.781413612565445),\n",
" ('forever', 3.781413612565445),\n",
" ('we', 3.781413612565445),\n",
" ('follow', 3.781413612565445),\n",
" ('aliciagworld', 3.781413612565445)]\n",
"\n",
"Top Male Terms (OR):\n",
"[('fan', 0.31511780104712045),\n",
" ('youtu', 0.31511780104712045),\n",
" ('when', 0.31511780104712045),\n",
" ('football', 0.31511780104712045),\n",
" ('game', 0.31511780104712045),\n",
" ('gamer', 0.31511780104712045),\n",
" ('rest', 0.31511780104712045),\n",
" ('with', 0.27010097232610325),\n",
" ('sports', 0.23633835078534032),\n",
" ('father', 0.23633835078534032),\n",
" ('person', 0.23633835078534032),\n",
" ('far', 0.23633835078534032),\n",
" ('know', 0.23633835078534032),\n",
" ('drummer', 0.23633835078534032),\n",
" ('beer', 0.23633835078534032),\n",
" ('mother', 0.23633835078534032),\n",
" ('words', 0.18907068062827226),\n",
" ('enjoy', 0.18907068062827226),\n",
" ('fun', 0.15755890052356022),\n",
" ('too', 0.13505048616305163)]\n"
]
}
],
"source": [
"ors = odds_ratios(male_probs, female_probs)\n",
"\n",
"sorted_ors = sorted(ors.items(), key=lambda x: -x[1])\n",
"\n",
"print('Top Female Terms (OR):')\n",
"pprint(sorted_ors[:20])\n",
"\n",
"print('\\nTop Male Terms (OR):')\n",
"pprint(sorted_ors[-20:])"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.5.0"
}
},
"nbformat": 4,
"nbformat_minor": 0
}