{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# CS579: Lecture 12 \n",
"\n",
"** Demographic Inference I**\n",
"\n",
"*[Dr. Aron Culotta](http://cs.iit.edu/~culotta)* \n",
"*[Illinois Institute of Technology](http://iit.edu)*"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"**dem·o·graph·ics**\n",
"\n",
"statistical data relating to the population and particular groups within it.\n",
"\n",
"E.g., age, ethnicity, gender, income, ..."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Why Demographics?\n",
"\n",
"- Marketing\n",
" - Who are my customers?\n",
" - Who are my competitors' customers?\n",
" - E.g., [DemographicsPro](http://www.demographicspro.com/samples#c=%40FamilyGuyonFOX)\n",
" \n",
"- Social Media as Surveys\n",
" - E.g., 45% of tweets express positive sentiment toward Pres. Obama\n",
" - Who wrote those tweets?\n",
" \n",
"- Health\n",
" - 2% of Facebook users are expressing flu-like symptoms\n",
" - Are they representative of the full population?\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
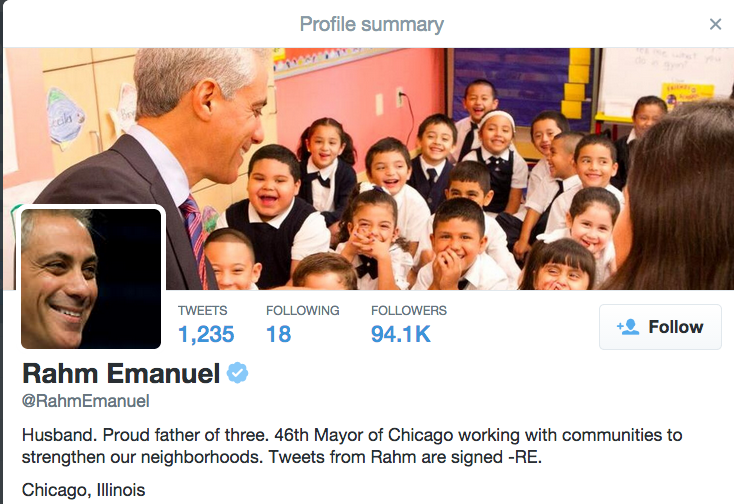
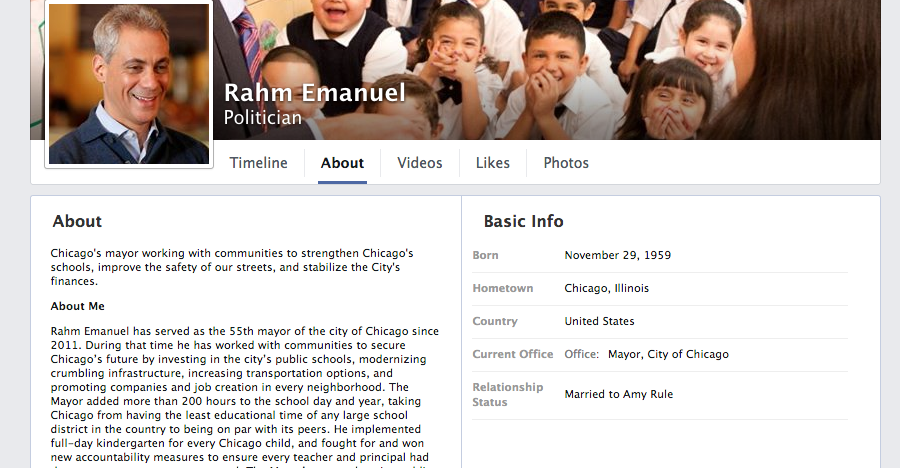
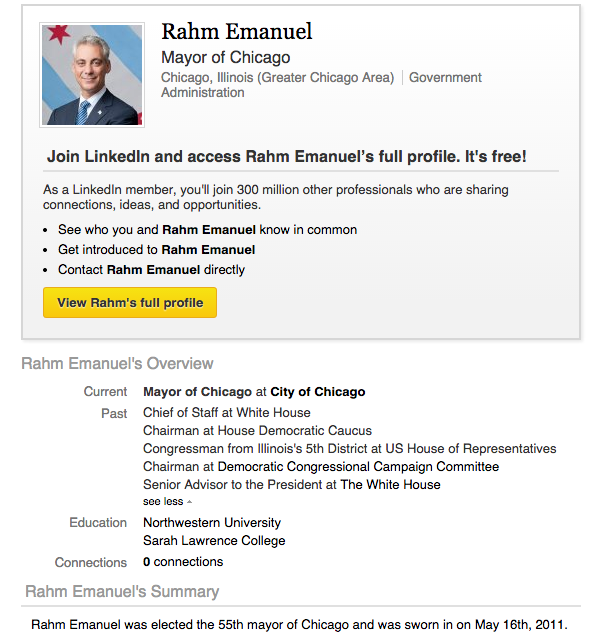
"** User profiles vary from site to site. **"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Approaches\n",
"\n",
"- Clever use of external data\n",
" - E.g., U.S. Census name lists for gender\n",
"- Look for keywords in profile\n",
" - \"African American Male\"\n",
" - \"Happy 21st birthday to me\"\n",
"- Machine Learning"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"100 tweets\n",
"200 tweets\n",
"300 tweets\n",
"400 tweets\n",
"500 tweets\n",
"600 tweets\n",
"700 tweets\n",
"800 tweets\n",
"900 tweets\n",
"1000 tweets\n",
"fetched 1000 tweets\n"
]
}
],
"source": [
"# Guessing gender\n",
"# Collect 1000 tweets matching query \"i\"\n",
"import configparser\n",
"import sys\n",
"from TwitterAPI import TwitterAPI\n",
"\n",
"def get_twitter(config_file):\n",
" \"\"\" Read the config_file and construct an instance of TwitterAPI.\n",
" Args:\n",
" config_file ... A config file in ConfigParser format with Twitter credentials\n",
" Returns:\n",
" An instance of TwitterAPI.\n",
" \"\"\"\n",
" config = configparser.ConfigParser()\n",
" config.read(config_file)\n",
" twitter = TwitterAPI(\n",
" config.get('twitter', 'consumer_key'),\n",
" config.get('twitter', 'consumer_secret'),\n",
" config.get('twitter', 'access_token'),\n",
" config.get('twitter', 'access_token_secret'))\n",
" return twitter\n",
"\n",
"twitter = get_twitter('twitter.cfg')\n",
"tweets = []\n",
"n_tweets=1000\n",
"for r in twitter.request('statuses/filter', {'track': 'i'}):\n",
" tweets.append(r)\n",
" if len(tweets) % 100 == 0:\n",
" print('%d tweets' % len(tweets))\n",
" if len(tweets) >= n_tweets:\n",
" break\n",
"print('fetched %d tweets' % len(tweets))"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[{'limit': {'track': 383, 'timestamp_ms': '1551714817758'}},\n",
" {'limit': {'track': 790, 'timestamp_ms': '1551714818769'}},\n",
" {'limit': {'track': 1150, 'timestamp_ms': '1551714819737'}},\n",
" {'limit': {'track': 1556, 'timestamp_ms': '1551714820748'}},\n",
" {'limit': {'track': 1998, 'timestamp_ms': '1551714821738'}},\n",
" {'limit': {'track': 2384, 'timestamp_ms': '1551714822750'}}]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# not all tweets are returned\n",
"# https://dev.twitter.com/streaming/overview/messages-types#limit_notices\n",
"[t for t in tweets if 'user' not in t][:6]"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"fetched 981 tweets\n"
]
}
],
"source": [
"# restrict to actual tweets\n",
"# (remove \"deleted\" tweets)\n",
"tweets = [t for t in tweets if 'user' in t]\n",
"print('fetched %d tweets' % len(tweets))"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"data": {
"text/plain": [
"['Funky Kong',\n",
" 'April and 228 other',\n",
" '☕️',\n",
" 'nikoll (ia)',\n",
" 'Iniciativa PV',\n",
" 'josie🕷',\n",
" 'ؘ',\n",
" 'yaancc 🌞',\n",
" 'livyyy :)',\n",
" 'by gaspadin_ ll 🇹🇷🇹🇷']"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Print last 10 names.\n",
"names = [t['user']['name'] for t in tweets]\n",
"names[-10:]"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"males:\n",
"['JAMES 3.318 3.318 1',\n",
" 'JOHN 3.271 6.589 2',\n",
" 'ROBERT 3.143 9.732 3',\n",
" 'MICHAEL 2.629 12.361 4',\n",
" 'WILLIAM 2.451 14.812 5',\n",
" 'DAVID 2.363 17.176 6',\n",
" 'RICHARD 1.703 18.878 7',\n",
" 'CHARLES 1.523 20.401 8',\n",
" 'JOSEPH 1.404 21.805 9',\n",
" 'THOMAS 1.380 23.185 10']\n",
"females:\n",
"['MARY 2.629 2.629 1',\n",
" 'PATRICIA 1.073 3.702 2',\n",
" 'LINDA 1.035 4.736 3',\n",
" 'BARBARA 0.980 5.716 4',\n",
" 'ELIZABETH 0.937 6.653 5',\n",
" 'JENNIFER 0.932 7.586 6',\n",
" 'MARIA 0.828 8.414 7',\n",
" 'SUSAN 0.794 9.209 8',\n",
" 'MARGARET 0.768 9.976 9',\n",
" 'DOROTHY 0.727 10.703 10']\n"
]
}
],
"source": [
"# Fetch census name data from:\n",
"# http://www2.census.gov/topics/genealogy/1990surnames/\n",
"import requests\n",
"from pprint import pprint\n",
"males_url = 'http://www2.census.gov/topics/genealogy/' + \\\n",
" '1990surnames/dist.male.first'\n",
"females_url = 'http://www2.census.gov/topics/genealogy/' + \\\n",
" '1990surnames/dist.female.first'\n",
"males = requests.get(males_url).text.split('\\n')\n",
"females = requests.get(females_url).text.split('\\n')\n",
"print('males:')\n",
"pprint(males[:10])\n",
"print('females:')\n",
"pprint(females[:10])"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1219 male and 4275 female names\n",
"males:\n",
"raymundo\n",
"willis\n",
"jose\n",
"thurman\n",
"galen\n",
"darrick\n",
"roy\n",
"matthew\n",
"man\n",
"ned\n",
"\n",
"females:\n",
"min\n",
"brittaney\n",
"tonisha\n",
"bailey\n",
"shani\n",
"roma\n",
"beth\n",
"stefanie\n",
"tillie\n",
"jeanetta\n"
]
}
],
"source": [
"# Get names. \n",
"male_names = set([m.split()[0].lower() for m in males if m])\n",
"female_names = set([f.split()[0].lower() for f in females if f])\n",
"print('%d male and %d female names' % (len(male_names), len(female_names)))\n",
"print('males:\\n' + '\\n'.join(list(male_names)[:10]))\n",
"print('\\nfemales:\\n' + '\\n'.join(list(female_names)[:10]))"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"# Initialize gender of all tweets to unknown.\n",
"for t in tweets:\n",
" t['gender'] = 'unknown'"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [],
"source": [
"# label a Twitter user's gender by matching name list.\n",
"import re\n",
"def gender_by_name(tweets, male_names, female_names):\n",
" for t in tweets:\n",
" name = t['user']['name']\n",
" if name:\n",
" # remove punctuation.\n",
" name_parts = re.findall('\\w+', name.split()[0].lower())\n",
" if len(name_parts) > 0:\n",
" first = name_parts[0].lower()\n",
" if first in male_names:\n",
" t['gender'] = 'male'\n",
" elif first in female_names:\n",
" t['gender'] = 'female'\n",
" else:\n",
" t['gender'] = 'unknown'\n",
"\n",
"gender_by_name(tweets, male_names, female_names)\n",
"# What's wrong with this approach?"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.27 of accounts are labeled with gender\n",
"gender counts:\n",
" Counter({'unknown': 715, 'female': 143, 'male': 123})\n",
"unknown Arzunaz Üreyen\n",
"female Ann\n",
"unknown flexlex 🍒✨\n",
"male jules!\n",
"female MARLA RT\n",
"unknown Freya 🏳️🌈\n",
"female ًvictoria\n",
"unknown Blue PandaNW\n",
"unknown Pierrot Kwame\n",
"unknown Öykü Su Unay\n",
"unknown lots✈️bts wembley\n",
"unknown 🍒\n",
"unknown 😽😸Meow Meow March😸😽\n",
"unknown fazli\n",
"unknown Tyrion_Lannister\n",
"unknown 💜~Nessa~OwO💜\n",
"unknown محمد المولد xboxone 🎮 🖋\n",
"unknown Cruiz_Senior\n",
"male Carmen JMO💖🌟\n",
"unknown tyb\n"
]
}
],
"source": [
"from collections import Counter\n",
"\n",
"def print_genders(tweets):\n",
" counts = Counter([t['gender'] for t in tweets])\n",
" print('%.2f of accounts are labeled with gender' % \n",
" ((counts['male'] + counts['female']) / sum(counts.values())))\n",
" print('gender counts:\\n', counts)\n",
" for t in tweets[:20]:\n",
" print(t['gender'], t['user']['name'])\n",
" \n",
"print_genders(tweets)"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"found 331 ambiguous names:\n",
"\n",
"jose\n",
"roy\n",
"matthew\n",
"man\n",
"dale\n",
"gail\n",
"sung\n",
"thomas\n",
"tommie\n",
"charlie\n",
"claude\n",
"chong\n",
"stephen\n",
"patrick\n",
"dorian\n",
"angelo\n",
"jay\n",
"lewis\n",
"dusty\n",
"son\n"
]
}
],
"source": [
"# What about ambiguous names?\n",
"def print_ambiguous_names(male_names, female_names):\n",
" ambiguous = [n for n in male_names if n in female_names] # names on both lists\n",
" print('found %d ambiguous names:\\n'% len(ambiguous))\n",
" print('\\n'.join(ambiguous[:20]))\n",
" \n",
"print_ambiguous_names(male_names, female_names)"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"found 0 ambiguous names:\n",
"\n",
"\n",
"1146 male and 4017 female names\n"
]
}
],
"source": [
"# Keep names that are more frequent in one gender than the other.\n",
"def get_percents(name_list):\n",
" # parse raw data to extract, e.g., the percent of males names John.\n",
" return dict([(n.split()[0].lower(), float(n.split()[1]))\n",
" for n in name_list if n])\n",
"\n",
"males_pct = get_percents(males)\n",
"females_pct = get_percents(females)\n",
"\n",
"# Assign a name as male if it is more common among males than femals.\n",
"male_names = set([m for m in male_names if m not in female_names or\n",
" males_pct[m] > females_pct[m]])\n",
"female_names = set([f for f in female_names if f not in male_names or\n",
" females_pct[f] > males_pct[f]])\n",
"\n",
"print_ambiguous_names(male_names, female_names)\n",
"print('%d male and %d female names' % (len(male_names), len(female_names)))"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.27 of accounts are labeled with gender\n",
"gender counts:\n",
" Counter({'unknown': 715, 'female': 155, 'male': 111})\n",
"unknown Arzunaz Üreyen\n",
"female Ann\n",
"unknown flexlex 🍒✨\n",
"male jules!\n",
"female MARLA RT\n",
"unknown Freya 🏳️🌈\n",
"female ًvictoria\n",
"unknown Blue PandaNW\n",
"unknown Pierrot Kwame\n",
"unknown Öykü Su Unay\n",
"unknown lots✈️bts wembley\n",
"unknown 🍒\n",
"unknown 😽😸Meow Meow March😸😽\n",
"unknown fazli\n",
"unknown Tyrion_Lannister\n",
"unknown 💜~Nessa~OwO💜\n",
"unknown محمد المولد xboxone 🎮 🖋\n",
"unknown Cruiz_Senior\n",
"female Carmen JMO💖🌟\n",
"unknown tyb\n"
]
}
],
"source": [
"# Relabel twitter users (compare with above)\n",
"gender_by_name(tweets, male_names, female_names)\n",
"print_genders(tweets)"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"data": {
"text/plain": [
"[('.', 4),\n",
" ('M', 3),\n",
" ('Fra🌸', 2),\n",
" ('🌙', 2),\n",
" ('💜', 2),\n",
" ('𝘲𝘶𝘦𝘦𝘯𝘯𝘢𝘪𝘫𝘢2𝘹🥰', 2),\n",
" ('ً', 2),\n",
" ('Marius Black. 🦋', 2),\n",
" ('Krggzddd', 2),\n",
" ('Mehmet Sarıaslan', 2),\n",
" ('Urim Ejupi', 2),\n",
" ('Arzunaz Üreyen', 1),\n",
" ('flexlex 🍒✨', 1),\n",
" ('Freya 🏳️\\u200d🌈', 1),\n",
" ('Blue PandaNW', 1),\n",
" ('Pierrot Kwame', 1),\n",
" ('Öykü Su Unay', 1),\n",
" ('lots✈️bts wembley', 1),\n",
" ('🍒', 1),\n",
" ('😽😸Meow Meow March😸😽', 1)]"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Who are the unknowns?\n",
"# \"Filtered\" data can have big impact on analysis.\n",
"unknown_names = Counter(t['user']['name']\n",
" for t in tweets if t['gender'] == 'unknown')\n",
"unknown_names.most_common(20)"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Most Common Male Terms:\n",
"[('of', 25),\n",
" ('and', 24),\n",
" ('i', 23),\n",
" ('the', 14),\n",
" ('my', 11),\n",
" ('in', 10),\n",
" ('me', 9),\n",
" ('life', 9),\n",
" ('you', 8),\n",
" ('for', 8)]\n",
"\n",
"Most Common Female Terms:\n",
"[('i', 38),\n",
" ('the', 32),\n",
" ('and', 28),\n",
" ('a', 19),\n",
" ('my', 19),\n",
" ('you', 17),\n",
" ('to', 16),\n",
" ('of', 15),\n",
" ('is', 14),\n",
" ('in', 13)]\n"
]
}
],
"source": [
"# How do the profiles of male Twitter users differ from\n",
"# those of female users?\n",
"\n",
"male_profiles = [t['user']['description'] for t in tweets\n",
" if t['gender'] == 'male']\n",
"\n",
"female_profiles = [t['user']['description'] for t in tweets\n",
" if t['gender'] == 'female']\n",
"#male_profiles = [t['text'] for t in tweets\n",
"# if t['gender'] == 'male']\n",
"\n",
"#female_profiles = [t['text'] for t in tweets\n",
"# if t['gender'] == 'female']\n",
"\n",
"import re\n",
"def tokenize(s):\n",
" return re.sub('\\W+', ' ', s).lower().split() if s else []\n",
"\n",
"male_words = Counter()\n",
"female_words = Counter()\n",
"\n",
"for p in male_profiles:\n",
" male_words.update(Counter(tokenize(p)))\n",
" \n",
"for p in female_profiles:\n",
" female_words.update(Counter(tokenize(p)))\n",
"\n",
"print('Most Common Male Terms:')\n",
"pprint(male_words.most_common(10))\n",
" \n",
"print('\\nMost Common Female Terms:')\n",
"pprint(female_words.most_common(10))"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"764\n",
"921\n"
]
}
],
"source": [
"print(len(male_words))\n",
"print(len(female_words))"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Top Male Terms (diff):\n",
"[('of', -10),\n",
" ('father', -7),\n",
" ('http', -6),\n",
" ('for', -5),\n",
" ('people', -5),\n",
" ('university', -4),\n",
" ('not', -4),\n",
" ('about', -4),\n",
" ('com', -4),\n",
" ('play', -4)]\n",
"\n",
"Top Female Terms (diff):\n",
"[('just', 7),\n",
" ('she', 7),\n",
" ('my', 8),\n",
" ('s', 9),\n",
" ('you', 9),\n",
" ('to', 10),\n",
" ('is', 11),\n",
" ('a', 12),\n",
" ('i', 15),\n",
" ('the', 18)]\n"
]
}
],
"source": [
"# Compute difference\n",
"diff_counts = dict([(w, female_words[w] - male_words[w])\n",
" for w in\n",
" set(female_words.keys()) | set(male_words.keys())])\n",
"\n",
"sorted_diffs = sorted(diff_counts.items(), key=lambda x: x[1])\n",
"\n",
"print('Top Male Terms (diff):')\n",
"pprint(sorted_diffs[:10])\n",
"\n",
"print('\\nTop Female Terms (diff):')\n",
"pprint(sorted_diffs[-10:])"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** A problem with difference of counts:**\n",
"\n",
"
\n",
"What if we have more male than female words in total?\n",
"\n",
"
\n",
"Instead, consider \"the probability that a male user writes the word **w**\"\n",
"\n",
"
\n",
"\n",
"$$p(w|male) = \\frac{freq(w, male)}\n",
"{\\sum_i freq(w_i, male)} $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** Odds Ratio (OR)**\n",
"\n",
"The ratio of the probabilities for a word from each class:\n",
"\n",
"$$ OR(w) = \\frac{p(w|female)}{p(w|male)} $$\n",
"\n",
"\n",
"- High values --> more likely to be written by females\n",
"- Low values --> more likely to be written by males\n"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"p(w|male)\n",
"[('of', 0.021872265966754154),\n",
" ('and', 0.02099737532808399),\n",
" ('i', 0.020122484689413824),\n",
" ('the', 0.012248468941382326),\n",
" ('my', 0.009623797025371828),\n",
" ('in', 0.008748906386701663),\n",
" ('me', 0.007874015748031496),\n",
" ('life', 0.007874015748031496),\n",
" ('you', 0.00699912510936133),\n",
" ('for', 0.00699912510936133)]\n",
"\n",
"p(w|female)\n",
"[('i', 0.02615278733654508),\n",
" ('the', 0.02202339986235375),\n",
" ('and', 0.019270474879559532),\n",
" ('a', 0.01307639366827254),\n",
" ('my', 0.01307639366827254),\n",
" ('you', 0.01169993117687543),\n",
" ('to', 0.011011699931176875),\n",
" ('of', 0.01032346868547832),\n",
" ('is', 0.009635237439779766),\n",
" ('in', 0.008947006194081212)]\n"
]
}
],
"source": [
"def counts_to_probs(gender_words):\n",
" \"\"\" Compute probability of each term according to the frequency\n",
" in a gender. \"\"\"\n",
" total = sum(gender_words.values())\n",
" return dict([(word, count / total)\n",
" for word, count in gender_words.items()])\n",
"\n",
"male_probs = counts_to_probs(male_words)\n",
"female_probs = counts_to_probs(female_words)\n",
"\n",
"print('p(w|male)')\n",
"pprint(sorted(male_probs.items(), key=lambda x: -x[1])[:10])\n",
"\n",
"print('\\np(w|female)')\n",
"pprint(sorted(female_probs.items(), key=lambda x: -x[1])[:10])"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"ename": "KeyError",
"evalue": "'state'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mKeyError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 4\u001b[0m set(male_probs) | set(female_probs)])\n\u001b[1;32m 5\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 6\u001b[0;31m \u001b[0mors\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;32m\u001b[0m in \u001b[0;36modds_ratios\u001b[0;34m(male_probs, female_probs)\u001b[0m\n\u001b[1;32m 2\u001b[0m return dict([(w, female_probs[w] / male_probs[w])\n\u001b[1;32m 3\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mw\u001b[0m \u001b[0;32min\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 4\u001b[0;31m set(male_probs) | set(female_probs)])\n\u001b[0m\u001b[1;32m 5\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 6\u001b[0m \u001b[0mors\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m(.0)\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0modds_ratios\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mmale_probs\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mfemale_probs\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2\u001b[0m return dict([(w, female_probs[w] / male_probs[w])\n\u001b[0;32m----> 3\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mw\u001b[0m \u001b[0;32min\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 4\u001b[0m set(male_probs) | set(female_probs)])\n\u001b[1;32m 5\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n",
"\u001b[0;31mKeyError\u001b[0m: 'state'"
]
}
],
"source": [
"def odds_ratios(male_probs, female_probs):\n",
" return dict([(w, female_probs[w] / male_probs[w])\n",
" for w in\n",
" set(male_probs) | set(female_probs)])\n",
"\n",
"ors = odds_ratios(male_probs, female_probs)"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"764\n",
"921\n",
"744 words in female_probs but not in male_probs\n",
"arizona\n",
"0.0006882312456985547\n"
]
}
],
"source": [
"print(len(male_probs))\n",
"print(len(female_probs))\n",
"female_but_not_male = set(female_probs) - set(male_probs)\n",
"print('%d words in female_probs but not in male_probs' % len(female_but_not_male))\n",
"fem_word = list(female_but_not_male)[-10]\n",
"print(fem_word)\n",
"print(female_probs[fem_word])\n",
"#'selfcare' in male_probs"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** How to deal with 0-probabilities? **\n",
"\n",
"$$p(w|male) = \\frac{freq(w, male)}\n",
"{\\sum_i freq(w_i, male)} $$\n",
"\n",
"$freq(w, male) = 0$\n",
"\n",
"Do we really believe there is **0** probability of a male using this term?\n",
"\n",
"(Recall over-fitting discussion.)\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"** Additive Smoothing **\n",
"\n",
"Reserve small amount of counts (e.g., 1) for unseen observations.\n",
"\n",
"E.g., assume we've seen each word at least once in each class.\n",
"\n",
"$$p(w|male) = \\frac{1 + freq(w, male)}\n",
"{|W| + \\sum_i freq(w_i, male)} $$\n",
"\n",
"$|W|$: number of unique words."
]
},
{
"cell_type": "code",
"execution_count": 39,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"('of', 0.00980761976612599)\n",
"('and', 0.00943040362127499)\n",
"('i', 0.009053187476423991)\n",
"('the', 0.005658242172764994)\n",
"('my', 0.004526593738211996)\n",
"('in', 0.004149377593360996)\n",
"('me', 0.003772161448509996)\n",
"('life', 0.003772161448509996)\n",
"('you', 0.0033949453036589967)\n",
"('for', 0.0033949453036589967)\n"
]
}
],
"source": [
"# Additive smoothing. Add count of 1 for all words.\n",
"all_words = set(male_words) | set(female_words)\n",
"male_words.update(all_words) \n",
"female_words.update(all_words)\n",
"\n",
"male_probs = counts_to_probs(male_words)\n",
"female_probs = counts_to_probs(female_words)\n",
"print('\\n'.join(str(x) for x in \n",
" sorted(male_probs.items(), key=lambda x: -x[1])[:10]))"
]
},
{
"cell_type": "code",
"execution_count": 41,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0003772161448509996\n"
]
}
],
"source": [
"# Even though word doesn't appear, has non-zero probability.\n",
"print(male_probs[fem_word])"
]
},
{
"cell_type": "code",
"execution_count": 42,
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Top Female Terms (OR):\n",
"[('she', 7.162445119891929),\n",
" ('just', 7.162445119891929),\n",
" ('mom', 6.267139479905437),\n",
" ('her', 5.3718338399189465),\n",
" ('so', 4.476528199932455),\n",
" ('fishing', 4.476528199932455),\n",
" ('can', 4.476528199932455),\n",
" ('women', 4.476528199932455),\n",
" ('great', 4.476528199932455),\n",
" ('प', 4.476528199932455),\n",
" ('we', 4.476528199932455),\n",
" ('21', 4.476528199932455),\n",
" ('am', 4.02887537993921),\n",
" ('that', 3.5812225599459646),\n",
" ('ever', 3.5812225599459646),\n",
" ('got', 3.5812225599459646),\n",
" ('eu', 3.5812225599459646),\n",
" ('public', 3.5812225599459646),\n",
" ('त', 3.5812225599459646),\n",
" ('sc', 3.5812225599459646)]\n",
"\n",
"Top Male Terms (OR):\n",
"[('ly', 0.2984352133288304),\n",
" ('want', 0.2984352133288304),\n",
" ('state', 0.2238264099966228),\n",
" ('reflect', 0.2238264099966228),\n",
" ('𝗍𝗁𝖾', 0.2238264099966228),\n",
" ('education', 0.2238264099966228),\n",
" ('all', 0.2238264099966228),\n",
" ('never', 0.2238264099966228),\n",
" ('retired', 0.2238264099966228),\n",
" ('owner', 0.2238264099966228),\n",
" ('youtube', 0.2238264099966228),\n",
" ('school', 0.2238264099966228),\n",
" ('two', 0.2238264099966228),\n",
" ('proud', 0.2238264099966228),\n",
" ('some', 0.2238264099966228),\n",
" ('university', 0.17906112799729823),\n",
" ('about', 0.17906112799729823),\n",
" ('play', 0.17906112799729823),\n",
" ('people', 0.1492176066644152),\n",
" ('father', 0.1119132049983114)]\n"
]
}
],
"source": [
"ors = odds_ratios(male_probs, female_probs)\n",
"\n",
"sorted_ors = sorted(ors.items(), key=lambda x: -x[1])\n",
"\n",
"print('Top Female Terms (OR):')\n",
"pprint(sorted_ors[:20])\n",
"\n",
"print('\\nTop Male Terms (OR):')\n",
"pprint(sorted_ors[-20:])"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
}
},
"nbformat": 4,
"nbformat_minor": 1
}