{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" \n",
"*This notebook contains an excerpt from the [Whirlwind Tour of Python](http://www.oreilly.com/programming/free/a-whirlwind-tour-of-python.csp) by Jake VanderPlas; the content is available [on GitHub](https://github.com/jakevdp/WhirlwindTourOfPython).*\n",
"\n",
"*The text and code are released under the [CC0](https://github.com/jakevdp/WhirlwindTourOfPython/blob/master/LICENSE) license; see also the companion project, the [Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook).*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"< [Built-In Types: Simple Values](05-Built-in-Scalar-Types.ipynb) | [Contents](Index.ipynb) | [Control Flow](07-Control-Flow-Statements.ipynb) >"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Built-In Data Structures"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We have seen Python's simple types: ``int``, ``float``, ``complex``, ``bool``, ``str``, and so on.\n",
"Python also has several built-in compound types, which act as containers for other types.\n",
"These compound types are:\n",
"\n",
"| Type Name | Example |Description |\n",
"|-----------|---------------------------|---------------------------------------|\n",
"| ``list`` | ``[1, 2, 3]`` | Ordered collection |\n",
"| ``tuple`` | ``(1, 2, 3)`` | Immutable ordered collection |\n",
"| ``dict`` | ``{'a':1, 'b':2, 'c':3}`` | Unordered (key,value) mapping |\n",
"| ``set`` | ``{1, 2, 3}`` | Unordered collection of unique values |\n",
"\n",
"As you can see, round, square, and curly brackets have distinct meanings when it comes to the type of collection produced.\n",
"We'll take a quick tour of these data structures here."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Lists\n",
"Lists are the basic *ordered* and *mutable* data collection type in Python.\n",
"They can be defined with comma-separated values between square brackets; for example, here is a list of the first several prime numbers:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [2, 3, 5, 7]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lists have a number of useful properties and methods available to them.\n",
"Here we'll take a quick look at some of the more common and useful ones:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"4"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Length of a list\n",
"len(L)"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5, 7, 11]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Append a value to the end\n",
"L.append(11)\n",
"L"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5, 7, 11, 13, 17, 19]"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Addition concatenates lists\n",
"L + [13, 17, 19]"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[1, 2, 3, 4, 5, 6]"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# sort() method sorts in-place\n",
"L = [2, 5, 1, 6, 3, 4]\n",
"L.sort()\n",
"L"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In addition, there are many more built-in list methods; they are well-covered in Python's [online documentation](https://docs.python.org/3/tutorial/datastructures.html).\n",
"\n",
"While we've been demonstrating lists containing values of a single type, one of the powerful features of Python's compound objects is that they can contain objects of *any* type, or even a mix of types. For example:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [1, 'two', 3.14, [0, 3, 5]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This flexibility is a consequence of Python's dynamic type system.\n",
"Creating such a mixed sequence in a statically-typed language like C can be much more of a headache!\n",
"We see that lists can even contain other lists as elements.\n",
"Such type flexibility is an essential piece of what makes Python code relatively quick and easy to write.\n",
"\n",
"So far we've been considering manipulations of lists as a whole; another essential piece is the accessing of individual elements.\n",
"This is done in Python via *indexing* and *slicing*, which we'll explore next."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### List indexing and slicing\n",
"Python provides access to elements in compound types through *indexing* for single elements, and *slicing* for multiple elements.\n",
"As we'll see, both are indicated by a square-bracket syntax.\n",
"Suppose we return to our list of the first several primes:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [2, 3, 5, 7, 11]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Python uses *zero-based* indexing, so we can access the first and second element in using the following syntax:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[0]"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Elements at the end of the list can be accessed with negative numbers, starting from -1:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-1]"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"7"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
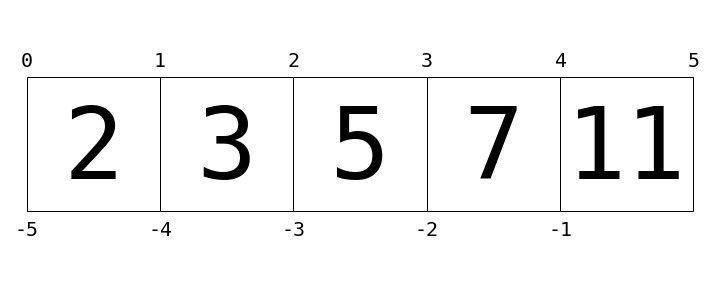
"You can visualize this indexing scheme this way:"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here values in the list are represented by large numbers in the squares; list indices are represented by small numbers above and below.\n",
"In this case, ``L[2]`` returns ``5``, because that is the next value at index ``2``."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Where *indexing* is a means of fetching a single value from the list, *slicing* is a means of accessing multiple values in sub-lists.\n",
"It uses a colon to indicate the start point (inclusive) and end point (non-inclusive) of the sub-array.\n",
"For example, to get the first three elements of the list, we can write:"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5]"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[0:3]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Notice where ``0`` and ``3`` lie in the preceding diagram, and how the slice takes just the values between the indices.\n",
"If we leave out the first index, ``0`` is assumed, so we can equivalently write:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5]"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[:3]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Similarly, if we leave out the last index, it defaults to the length of the list.\n",
"Thus, the last three elements can be accessed as follows:"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[5, 7, 11]"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-3:]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, it is possible to specify a third integer that represents the step size; for example, to select every second element of the list, we can write:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 5, 11]"
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[::2] # equivalent to L[0:len(L):2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A particularly useful version of this is to specify a negative step, which will reverse the array:"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[11, 7, 5, 3, 2]"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[::-1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Both indexing and slicing can be used to set elements as well as access them.\n",
"The syntax is as you would expect:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[100, 3, 5, 7, 11]\n"
]
}
],
"source": [
"L[0] = 100\n",
"print(L)"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[100, 55, 56, 7, 11]\n"
]
}
],
"source": [
"L[1:3] = [55, 56]\n",
"print(L)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A very similar slicing syntax is also used in many data science-oriented packages, including NumPy and Pandas (mentioned in the introduction).\n",
"\n",
"Now that we have seen Python lists and how to access elements in ordered compound types, let's take a look at the other three standard compound data types mentioned earlier."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Tuples\n",
"Tuples are in many ways similar to lists, but they are defined with parentheses rather than square brackets:"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"t = (1, 2, 3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"They can also be defined without any brackets at all:"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(1, 2, 3)\n"
]
}
],
"source": [
"t = 1, 2, 3\n",
"print(t)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Like the lists discussed before, tuples have a length, and individual elements can be extracted using square-bracket indexing:"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(t)"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"1"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"t[0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The main distinguishing feature of tuples is that they are *immutable*: this means that once they are created, their size and contents cannot be changed:"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "TypeError",
"evalue": "'tuple' object does not support item assignment",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mt\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m4\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m: 'tuple' object does not support item assignment"
]
}
],
"source": [
"t[1] = 4"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "AttributeError",
"evalue": "'tuple' object has no attribute 'append'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mAttributeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mt\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mappend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m4\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mAttributeError\u001b[0m: 'tuple' object has no attribute 'append'"
]
}
],
"source": [
"t.append(4)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Tuples are often used in a Python program; a particularly common case is in functions that have multiple return values.\n",
"For example, the ``as_integer_ratio()`` method of floating-point objects returns a numerator and a denominator; this dual return value comes in the form of a tuple:"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"(1, 8)"
]
},
"execution_count": 25,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"x = 0.125\n",
"x.as_integer_ratio()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"These multiple return values can be individually assigned as follows:"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.125\n"
]
}
],
"source": [
"numerator, denominator = x.as_integer_ratio()\n",
"print(numerator / denominator)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The indexing and slicing logic covered earlier for lists works for tuples as well, along with a host of other methods.\n",
"Refer to the online [Python documentation](https://docs.python.org/3/tutorial/datastructures.html) for a more complete list of these."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dictionaries\n",
"Dictionaries are extremely flexible mappings of keys to values, and form the basis of much of Python's internal implementation.\n",
"They can be created via a comma-separated list of ``key:value`` pairs within curly braces:"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"numbers = {'one':1, 'two':2, 'three':3}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Items are accessed and set via the indexing syntax used for lists and tuples, except here the index is not a zero-based order but valid key in the dictionary:"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 28,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Access a value via the key\n",
"numbers['two']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"New items can be added to the dictionary using indexing as well:"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'three': 3, 'ninety': 90, 'two': 2, 'one': 1}\n"
]
}
],
"source": [
"# Set a new key:value pair\n",
"numbers['ninety'] = 90\n",
"print(numbers)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Keep in mind that dictionaries do not maintain any sense of order for the input parameters; this is by design.\n",
"This lack of ordering allows dictionaries to be implemented very efficiently, so that random element access is very fast, regardless of the size of the dictionary (if you're curious how this works, read about the concept of a *hash table*).\n",
"The [python documentation](https://docs.python.org/3/library/stdtypes.html) has a complete list of the methods available for dictionaries."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Sets\n",
"\n",
"The fourth basic collection is the set, which contains unordered collections of unique items.\n",
"They are defined much like lists and tuples, except they use the curly brackets of dictionaries:"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"primes = {2, 3, 5, 7}\n",
"odds = {1, 3, 5, 7, 9}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you're familiar with the mathematics of sets, you'll be familiar with operations like the union, intersection, difference, symmetric difference, and others.\n",
"Python's sets have all of these operations built-in, via methods or operators.\n",
"For each, we'll show the two equivalent methods:"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{1, 2, 3, 5, 7, 9}"
]
},
"execution_count": 31,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# union: items appearing in either\n",
"primes | odds # with an operator\n",
"primes.union(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{3, 5, 7}"
]
},
"execution_count": 32,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# intersection: items appearing in both\n",
"primes & odds # with an operator\n",
"primes.intersection(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{2}"
]
},
"execution_count": 33,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# difference: items in primes but not in odds\n",
"primes - odds # with an operator\n",
"primes.difference(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{1, 2, 9}"
]
},
"execution_count": 34,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# symmetric difference: items appearing in only one set\n",
"primes ^ odds # with an operator\n",
"primes.symmetric_difference(odds) # equivalently with a method"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Many more set methods and operations are available.\n",
"You've probably already guessed what I'll say next: refer to Python's [online documentation](https://docs.python.org/3/library/stdtypes.html) for a complete reference."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## More Specialized Data Structures\n",
"\n",
"Python contains several other data structures that you might find useful; these can generally be found in the built-in ``collections`` module.\n",
"The collections module is fully-documented in [Python's online documentation](https://docs.python.org/3/library/collections.html), and you can read more about the various objects available there.\n",
"\n",
"In particular, I've found the following very useful on occasion:\n",
"\n",
"- ``collections.namedtuple``: Like a tuple, but each value has a name\n",
"- ``collections.defaultdict``: Like a dictionary, but unspecified keys have a user-specified default value\n",
"- ``collections.OrderedDict``: Like a dictionary, but the order of keys is maintained\n",
"\n",
"Once you've seen the standard built-in collection types, the use of these extended functionalities is very intuitive, and I'd suggest [reading about their use](https://docs.python.org/3/library/collections.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"< [Built-In Types: Simple Values](05-Built-in-Scalar-Types.ipynb) | [Contents](Index.ipynb) | [Control Flow](07-Control-Flow-Statements.ipynb) >"
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.5.1"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"*This notebook contains an excerpt from the [Whirlwind Tour of Python](http://www.oreilly.com/programming/free/a-whirlwind-tour-of-python.csp) by Jake VanderPlas; the content is available [on GitHub](https://github.com/jakevdp/WhirlwindTourOfPython).*\n",
"\n",
"*The text and code are released under the [CC0](https://github.com/jakevdp/WhirlwindTourOfPython/blob/master/LICENSE) license; see also the companion project, the [Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook).*\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"< [Built-In Types: Simple Values](05-Built-in-Scalar-Types.ipynb) | [Contents](Index.ipynb) | [Control Flow](07-Control-Flow-Statements.ipynb) >"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Built-In Data Structures"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We have seen Python's simple types: ``int``, ``float``, ``complex``, ``bool``, ``str``, and so on.\n",
"Python also has several built-in compound types, which act as containers for other types.\n",
"These compound types are:\n",
"\n",
"| Type Name | Example |Description |\n",
"|-----------|---------------------------|---------------------------------------|\n",
"| ``list`` | ``[1, 2, 3]`` | Ordered collection |\n",
"| ``tuple`` | ``(1, 2, 3)`` | Immutable ordered collection |\n",
"| ``dict`` | ``{'a':1, 'b':2, 'c':3}`` | Unordered (key,value) mapping |\n",
"| ``set`` | ``{1, 2, 3}`` | Unordered collection of unique values |\n",
"\n",
"As you can see, round, square, and curly brackets have distinct meanings when it comes to the type of collection produced.\n",
"We'll take a quick tour of these data structures here."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Lists\n",
"Lists are the basic *ordered* and *mutable* data collection type in Python.\n",
"They can be defined with comma-separated values between square brackets; for example, here is a list of the first several prime numbers:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [2, 3, 5, 7]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lists have a number of useful properties and methods available to them.\n",
"Here we'll take a quick look at some of the more common and useful ones:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"4"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Length of a list\n",
"len(L)"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5, 7, 11]"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Append a value to the end\n",
"L.append(11)\n",
"L"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5, 7, 11, 13, 17, 19]"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Addition concatenates lists\n",
"L + [13, 17, 19]"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[1, 2, 3, 4, 5, 6]"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# sort() method sorts in-place\n",
"L = [2, 5, 1, 6, 3, 4]\n",
"L.sort()\n",
"L"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In addition, there are many more built-in list methods; they are well-covered in Python's [online documentation](https://docs.python.org/3/tutorial/datastructures.html).\n",
"\n",
"While we've been demonstrating lists containing values of a single type, one of the powerful features of Python's compound objects is that they can contain objects of *any* type, or even a mix of types. For example:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [1, 'two', 3.14, [0, 3, 5]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This flexibility is a consequence of Python's dynamic type system.\n",
"Creating such a mixed sequence in a statically-typed language like C can be much more of a headache!\n",
"We see that lists can even contain other lists as elements.\n",
"Such type flexibility is an essential piece of what makes Python code relatively quick and easy to write.\n",
"\n",
"So far we've been considering manipulations of lists as a whole; another essential piece is the accessing of individual elements.\n",
"This is done in Python via *indexing* and *slicing*, which we'll explore next."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### List indexing and slicing\n",
"Python provides access to elements in compound types through *indexing* for single elements, and *slicing* for multiple elements.\n",
"As we'll see, both are indicated by a square-bracket syntax.\n",
"Suppose we return to our list of the first several primes:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"L = [2, 3, 5, 7, 11]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Python uses *zero-based* indexing, so we can access the first and second element in using the following syntax:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[0]"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Elements at the end of the list can be accessed with negative numbers, starting from -1:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"11"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-1]"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"7"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can visualize this indexing scheme this way:"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": false
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here values in the list are represented by large numbers in the squares; list indices are represented by small numbers above and below.\n",
"In this case, ``L[2]`` returns ``5``, because that is the next value at index ``2``."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Where *indexing* is a means of fetching a single value from the list, *slicing* is a means of accessing multiple values in sub-lists.\n",
"It uses a colon to indicate the start point (inclusive) and end point (non-inclusive) of the sub-array.\n",
"For example, to get the first three elements of the list, we can write:"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5]"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[0:3]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Notice where ``0`` and ``3`` lie in the preceding diagram, and how the slice takes just the values between the indices.\n",
"If we leave out the first index, ``0`` is assumed, so we can equivalently write:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 3, 5]"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[:3]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Similarly, if we leave out the last index, it defaults to the length of the list.\n",
"Thus, the last three elements can be accessed as follows:"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[5, 7, 11]"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[-3:]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, it is possible to specify a third integer that represents the step size; for example, to select every second element of the list, we can write:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[2, 5, 11]"
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[::2] # equivalent to L[0:len(L):2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A particularly useful version of this is to specify a negative step, which will reverse the array:"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"[11, 7, 5, 3, 2]"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"L[::-1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Both indexing and slicing can be used to set elements as well as access them.\n",
"The syntax is as you would expect:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[100, 3, 5, 7, 11]\n"
]
}
],
"source": [
"L[0] = 100\n",
"print(L)"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[100, 55, 56, 7, 11]\n"
]
}
],
"source": [
"L[1:3] = [55, 56]\n",
"print(L)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A very similar slicing syntax is also used in many data science-oriented packages, including NumPy and Pandas (mentioned in the introduction).\n",
"\n",
"Now that we have seen Python lists and how to access elements in ordered compound types, let's take a look at the other three standard compound data types mentioned earlier."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Tuples\n",
"Tuples are in many ways similar to lists, but they are defined with parentheses rather than square brackets:"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"t = (1, 2, 3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"They can also be defined without any brackets at all:"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(1, 2, 3)\n"
]
}
],
"source": [
"t = 1, 2, 3\n",
"print(t)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Like the lists discussed before, tuples have a length, and individual elements can be extracted using square-bracket indexing:"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(t)"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"1"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"t[0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The main distinguishing feature of tuples is that they are *immutable*: this means that once they are created, their size and contents cannot be changed:"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "TypeError",
"evalue": "'tuple' object does not support item assignment",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mt\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m4\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mTypeError\u001b[0m: 'tuple' object does not support item assignment"
]
}
],
"source": [
"t[1] = 4"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"collapsed": false
},
"outputs": [
{
"ename": "AttributeError",
"evalue": "'tuple' object has no attribute 'append'",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mAttributeError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[0;32m----> 1\u001b[0;31m \u001b[0mt\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mappend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;36m4\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mAttributeError\u001b[0m: 'tuple' object has no attribute 'append'"
]
}
],
"source": [
"t.append(4)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Tuples are often used in a Python program; a particularly common case is in functions that have multiple return values.\n",
"For example, the ``as_integer_ratio()`` method of floating-point objects returns a numerator and a denominator; this dual return value comes in the form of a tuple:"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"(1, 8)"
]
},
"execution_count": 25,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"x = 0.125\n",
"x.as_integer_ratio()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"These multiple return values can be individually assigned as follows:"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.125\n"
]
}
],
"source": [
"numerator, denominator = x.as_integer_ratio()\n",
"print(numerator / denominator)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The indexing and slicing logic covered earlier for lists works for tuples as well, along with a host of other methods.\n",
"Refer to the online [Python documentation](https://docs.python.org/3/tutorial/datastructures.html) for a more complete list of these."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dictionaries\n",
"Dictionaries are extremely flexible mappings of keys to values, and form the basis of much of Python's internal implementation.\n",
"They can be created via a comma-separated list of ``key:value`` pairs within curly braces:"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"numbers = {'one':1, 'two':2, 'three':3}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Items are accessed and set via the indexing syntax used for lists and tuples, except here the index is not a zero-based order but valid key in the dictionary:"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 28,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Access a value via the key\n",
"numbers['two']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"New items can be added to the dictionary using indexing as well:"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'three': 3, 'ninety': 90, 'two': 2, 'one': 1}\n"
]
}
],
"source": [
"# Set a new key:value pair\n",
"numbers['ninety'] = 90\n",
"print(numbers)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Keep in mind that dictionaries do not maintain any sense of order for the input parameters; this is by design.\n",
"This lack of ordering allows dictionaries to be implemented very efficiently, so that random element access is very fast, regardless of the size of the dictionary (if you're curious how this works, read about the concept of a *hash table*).\n",
"The [python documentation](https://docs.python.org/3/library/stdtypes.html) has a complete list of the methods available for dictionaries."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Sets\n",
"\n",
"The fourth basic collection is the set, which contains unordered collections of unique items.\n",
"They are defined much like lists and tuples, except they use the curly brackets of dictionaries:"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"primes = {2, 3, 5, 7}\n",
"odds = {1, 3, 5, 7, 9}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you're familiar with the mathematics of sets, you'll be familiar with operations like the union, intersection, difference, symmetric difference, and others.\n",
"Python's sets have all of these operations built-in, via methods or operators.\n",
"For each, we'll show the two equivalent methods:"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{1, 2, 3, 5, 7, 9}"
]
},
"execution_count": 31,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# union: items appearing in either\n",
"primes | odds # with an operator\n",
"primes.union(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{3, 5, 7}"
]
},
"execution_count": 32,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# intersection: items appearing in both\n",
"primes & odds # with an operator\n",
"primes.intersection(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{2}"
]
},
"execution_count": 33,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# difference: items in primes but not in odds\n",
"primes - odds # with an operator\n",
"primes.difference(odds) # equivalently with a method"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"{1, 2, 9}"
]
},
"execution_count": 34,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# symmetric difference: items appearing in only one set\n",
"primes ^ odds # with an operator\n",
"primes.symmetric_difference(odds) # equivalently with a method"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Many more set methods and operations are available.\n",
"You've probably already guessed what I'll say next: refer to Python's [online documentation](https://docs.python.org/3/library/stdtypes.html) for a complete reference."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## More Specialized Data Structures\n",
"\n",
"Python contains several other data structures that you might find useful; these can generally be found in the built-in ``collections`` module.\n",
"The collections module is fully-documented in [Python's online documentation](https://docs.python.org/3/library/collections.html), and you can read more about the various objects available there.\n",
"\n",
"In particular, I've found the following very useful on occasion:\n",
"\n",
"- ``collections.namedtuple``: Like a tuple, but each value has a name\n",
"- ``collections.defaultdict``: Like a dictionary, but unspecified keys have a user-specified default value\n",
"- ``collections.OrderedDict``: Like a dictionary, but the order of keys is maintained\n",
"\n",
"Once you've seen the standard built-in collection types, the use of these extended functionalities is very intuitive, and I'd suggest [reading about their use](https://docs.python.org/3/library/collections.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"< [Built-In Types: Simple Values](05-Built-in-Scalar-Types.ipynb) | [Contents](Index.ipynb) | [Control Flow](07-Control-Flow-Statements.ipynb) >"
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.5.1"
}
},
"nbformat": 4,
"nbformat_minor": 0
}