{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This notebook was put together by [Jake Vanderplas](http://www.vanderplas.com). Source and license info is on [GitHub](https://github.com/jakevdp/sklearn_tutorial/)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Introduction to Scikit-Learn: Machine Learning with Python\n",
"\n",
"This session will cover the basics of Scikit-Learn, a popular package containing a collection of tools for machine learning written in Python. See more at http://scikit-learn.org."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Outline\n",
"\n",
"**Main Goal:** To introduce the central concepts of machine learning, and how they can be applied in Python using the Scikit-learn Package.\n",
"\n",
"- Definition of machine learning\n",
"- Data representation in scikit-learn\n",
"- Introduction to the Scikit-learn API"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## About Scikit-Learn\n",
"\n",
"[Scikit-Learn](http://github.com/scikit-learn/scikit-learn) is a Python package designed to give access to **well-known** machine learning algorithms within Python code, through a **clean, well-thought-out API**. It has been built by hundreds of contributors from around the world, and is used across industry and academia.\n",
"\n",
"Scikit-Learn is built upon Python's [NumPy (Numerical Python)](http://numpy.org) and [SciPy (Scientific Python)](http://scipy.org) libraries, which enable efficient in-core numerical and scientific computation within Python. As such, scikit-learn is not specifically designed for extremely large datasets, though there is [some work](https://github.com/ogrisel/parallel_ml_tutorial) in this area.\n",
"\n",
"For this short introduction, I'm going to stick to questions of in-core processing of small to medium datasets with Scikit-learn."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## What is Machine Learning?\n",
"\n",
"In this section we will begin to explore the basic principles of machine learning.\n",
"Machine Learning is about building programs with **tunable parameters** (typically an\n",
"array of floating point values) that are adjusted automatically so as to improve\n",
"their behavior by **adapting to previously seen data.**\n",
"\n",
"Machine Learning can be considered a subfield of **Artificial Intelligence** since those\n",
"algorithms can be seen as building blocks to make computers learn to behave more\n",
"intelligently by somehow **generalizing** rather that just storing and retrieving data items\n",
"like a database system would do.\n",
"\n",
"We'll take a look at two very simple machine learning tasks here.\n",
"The first is a **classification** task: the figure shows a\n",
"collection of two-dimensional data, colored according to two different class\n",
"labels. A classification algorithm may be used to draw a dividing boundary\n",
"between the two clusters of points:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline\n",
"import matplotlib.pyplot as plt\n",
"\n",
"plt.style.use('seaborn')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Import the example plot from the figures directory\n",
"from fig_code import plot_sgd_separator\n",
"plot_sgd_separator()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This may seem like a trivial task, but it is a simple version of a very important concept.\n",
"By drawing this separating line, we have learned a model which can **generalize** to new\n",
"data: if you were to drop another point onto the plane which is unlabeled, this algorithm\n",
"could now **predict** whether it's a blue or a red point.\n",
"\n",
"If you'd like to see the source code used to generate this, you can either open the\n",
"code in the `figures` directory, or you can load the code using the `%load` magic command:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The next simple task we'll look at is a **regression** task: a simple best-fit line\n",
"to a set of data:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from fig_code import plot_linear_regression\n",
"plot_linear_regression()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Again, this is an example of fitting a model to data, such that the model can make\n",
"generalizations about new data. The model has been **learned** from the training\n",
"data, and can be used to predict the result of test data:\n",
"here, we might be given an x-value, and the model would\n",
"allow us to predict the y value. Again, this might seem like a trivial problem,\n",
"but it is a basic example of a type of operation that is fundamental to\n",
"machine learning tasks."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Representation of Data in Scikit-learn\n",
"\n",
"Machine learning is about creating models from data: for that reason, we'll start by\n",
"discussing how data can be represented in order to be understood by the computer. Along\n",
"with this, we'll build on our matplotlib examples from the previous section and show some\n",
"examples of how to visualize data."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Most machine learning algorithms implemented in scikit-learn expect data to be stored in a\n",
"**two-dimensional array or matrix**. The arrays can be\n",
"either ``numpy`` arrays, or in some cases ``scipy.sparse`` matrices.\n",
"The size of the array is expected to be `[n_samples, n_features]`\n",
"\n",
"- **n_samples:** The number of samples: each sample is an item to process (e.g. classify).\n",
" A sample can be a document, a picture, a sound, a video, an astronomical object,\n",
" a row in database or CSV file,\n",
" or whatever you can describe with a fixed set of quantitative traits.\n",
"- **n_features:** The number of features or distinct traits that can be used to describe each\n",
" item in a quantitative manner. Features are generally real-valued, but may be boolean or\n",
" discrete-valued in some cases.\n",
"\n",
"The number of features must be fixed in advance. However it can be very high dimensional\n",
"(e.g. millions of features) with most of them being zeros for a given sample. This is a case\n",
"where `scipy.sparse` matrices can be useful, in that they are\n",
"much more memory-efficient than numpy arrays."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"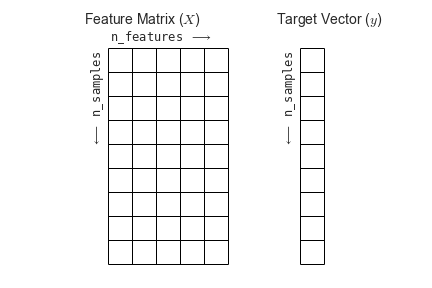\n",
"\n",
"(Figure from the [Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## A Simple Example: the Iris Dataset\n",
"\n",
"As an example of a simple dataset, we're going to take a look at the\n",
"iris data stored by scikit-learn.\n",
"The data consists of measurements of three different species of irises.\n",
"There are three species of iris in the dataset, which we can picture here:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.core.display import Image, display\n",
"display(Image(filename='images/iris_setosa.jpg'))\n",
"print(\"Iris Setosa\\n\")\n",
"\n",
"display(Image(filename='images/iris_versicolor.jpg'))\n",
"print(\"Iris Versicolor\\n\")\n",
"\n",
"display(Image(filename='images/iris_virginica.jpg'))\n",
"print(\"Iris Virginica\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Quick Question:\n",
"\n",
"**If we want to design an algorithm to recognize iris species, what might the data be?**\n",
"\n",
"Remember: we need a 2D array of size `[n_samples x n_features]`.\n",
"\n",
"- What would the `n_samples` refer to?\n",
"\n",
"- What might the `n_features` refer to?\n",
"\n",
"Remember that there must be a **fixed** number of features for each sample, and feature\n",
"number ``i`` must be a similar kind of quantity for each sample."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Loading the Iris Data with Scikit-Learn\n",
"\n",
"Scikit-learn has a very straightforward set of data on these iris species. The data consist of\n",
"the following:\n",
"\n",
"- Features in the Iris dataset:\n",
"\n",
" 1. sepal length in cm\n",
" 2. sepal width in cm\n",
" 3. petal length in cm\n",
" 4. petal width in cm\n",
"\n",
"- Target classes to predict:\n",
"\n",
" 1. Iris Setosa\n",
" 2. Iris Versicolour\n",
" 3. Iris Virginica\n",
" \n",
"``scikit-learn`` embeds a copy of the iris CSV file along with a helper function to load it into numpy arrays:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn.datasets import load_iris\n",
"iris = load_iris()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"iris.keys()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"n_samples, n_features = iris.data.shape\n",
"print((n_samples, n_features))\n",
"print(iris.data[0])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(iris.data.shape)\n",
"print(iris.target.shape)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(iris.target)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(iris.target_names)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This data is four dimensional, but we can visualize two of the dimensions\n",
"at a time using a simple scatter-plot:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"x_index = 0\n",
"y_index = 1\n",
"\n",
"# this formatter will label the colorbar with the correct target names\n",
"formatter = plt.FuncFormatter(lambda i, *args: iris.target_names[int(i)])\n",
"\n",
"plt.scatter(iris.data[:, x_index], iris.data[:, y_index],\n",
" c=iris.target, cmap=plt.cm.get_cmap('RdYlBu', 3))\n",
"plt.colorbar(ticks=[0, 1, 2], format=formatter)\n",
"plt.clim(-0.5, 2.5)\n",
"plt.xlabel(iris.feature_names[x_index])\n",
"plt.ylabel(iris.feature_names[y_index]);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Quick Exercise:\n",
"\n",
"**Change** `x_index` **and** `y_index` **in the above script\n",
"and find a combination of two parameters\n",
"which maximally separate the three classes.**\n",
"\n",
"This exercise is a preview of **dimensionality reduction**, which we'll see later."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Other Available Data\n",
"They come in three flavors:\n",
"\n",
"- **Packaged Data:** these small datasets are packaged with the scikit-learn installation,\n",
" and can be downloaded using the tools in ``sklearn.datasets.load_*``\n",
"- **Downloadable Data:** these larger datasets are available for download, and scikit-learn\n",
" includes tools which streamline this process. These tools can be found in\n",
" ``sklearn.datasets.fetch_*``\n",
"- **Generated Data:** there are several datasets which are generated from models based on a\n",
" random seed. These are available in the ``sklearn.datasets.make_*``\n",
"\n",
"You can explore the available dataset loaders, fetchers, and generators using IPython's\n",
"tab-completion functionality. After importing the ``datasets`` submodule from ``sklearn``,\n",
"type\n",
"\n",
" datasets.load_ + TAB\n",
"\n",
"or\n",
"\n",
" datasets.fetch_ + TAB\n",
"\n",
"or\n",
"\n",
" datasets.make_ + TAB\n",
"\n",
"to see a list of available functions."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sklearn import datasets"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Type datasets.fetch_ or datasets.load_ in IPython to see all possibilities\n",
"\n",
"# datasets.fetch_"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# datasets.load_"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the next section, we'll use some of these datasets and take a look at the basic principles of machine learning."
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.0"
}
},
"nbformat": 4,
"nbformat_minor": 1
}