\n",
" \n",
" | 名称 | \n",
" 描述 | \n",
"
\n",
" \n",
" | collection | \n",
" 定义了使用和扩展的Scala集合库所需的基本特征和对象,包括子包中的所有定义。你需要的大部分抽象都在这里定义。 | \n",
"
\n",
" \n",
" | collection.concurrent | \n",
" 这个包只定义了两个类型:定义了一个Map特质和实现了该特质的TrieMap类。Map继承了collection.mutable.Map,但它使用了原子操作,因此得以以支持线程安全的并发访问。TrieMap类实现了并发、无锁的散列数组,其目的是支持可伸缩的并发插入和删除操作,并提高内存使用效率。 | \n",
"
\n",
" \n",
" | collection.convert | \n",
" 这个包中定义的类型是用来实现隐式转换方法,定义了用Java集合抽象来包装Scala集合的类型,以及用Scala集合抽象包装Java集合的类型。 | \n",
"
\n",
" \n",
" | collection.generic | \n",
" collection包声明的抽象适用于所有集合,而该包只为实现特定的可变、不可变、并行及并发集合提供一些可重用组件。 | \n",
"
\n",
" \n",
" | collection.immutable | \n",
" 该包的类型提供了单线程(与并行相对)操作,由于类型是不可变的,因而是线程安全的。 | \n",
"
\n",
" \n",
" | collection.mutable | \n",
" 该包提供了在单线程操作中的可变集合类型。对这些集合的操作不是线程安全的。 | \n",
"
\n",
" \n",
" | collection.parallel | \n",
" 该包定义了用来构建特定集合的可重用组件,可将处理任务分发给并行的多个线程。并行集合充分利用了现代多核系统提供的并行硬件多线程。具体而言,集合被分成多个片段,操作应用在多个片段上,然后将结果组合在一起,形成最终的结果。 | \n",
"
\n",
" \n",
" | collection.parallel.immutable | \n",
" 定义了支持并行的不可变集合 | \n",
"
\n",
" \n",
" | collection.parallel.mutable | \n",
" 定义了支持并行的可变集合 | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"从Predef得到的Seq类型是collection.Seq,而Predef引用的其他公共类型是以collection.immutable开头的,如List、Map和Set。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1 最常用的不可变集合\n",
"\n",
" \n",
" | 名称 | \n",
" 描述 | \n",
"
\n",
" \n",
" | BitSet | \n",
" 非负整数的集合,内存效率高。元素表示为可变大小的比特数组,其中比特被打包为64比特的字。最大元素个数决定了内存占用量。 | \n",
"
\n",
" \n",
" | HashMap | \n",
" 用字典散列实现的映射表 | \n",
"
\n",
" \n",
" | HashSet | \n",
" 用字典散列实现的集合 | \n",
"
\n",
" \n",
" | List | \n",
" 用于相连列表的trait,头节点访问复杂度为O(1),其他元素为O(n)。其伴随对象有apply方法和其他工厂方法,可以用来构造List的子类实例。 | \n",
"
\n",
" \n",
" | ListMap | \n",
" 用列表实现的不可变映射表 | \n",
"
\n",
" \n",
" | ListSet | \n",
" 用列表实现的不可变集合 | \n",
"
\n",
" \n",
" | Map | \n",
" 为所有不可变的映射表定义的trait,随机访问复杂度为O(1),其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | Nil | \n",
" 用来表示空列表的对象 | \n",
"
\n",
" \n",
" | NumericRange | \n",
" Range类的推广版本,将适用范围推广到任意完整的类型。使用时,必须提供类型的完整实现。 | \n",
"
\n",
" \n",
" | Queue | \n",
" 不可变的FIFO先入先出队列 | \n",
"
\n",
" \n",
" | Seq | \n",
" 为不可变序列定义的trait,其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | Set | \n",
" 为不可变集合定义了操作的trait,其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | SortedMap | \n",
" 为不可变映射表定义的trait,包含一个可按特定排列顺序遍历元素的迭代器。其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | SortedSet | \n",
" 为不可变集合定义的trait,包含一个可按特定排列顺序遍历元素的迭代器。其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | Stack | \n",
" 不可变的LIFO后入先出栈 | \n",
"
\n",
" \n",
" | Stream | \n",
" 对元素惰性求值的列表,可以支持拥有无限个潜在元素的列表 | \n",
"
\n",
" \n",
" | TreeMap | \n",
" 不可变映射表,底层用红黑树实现,操作的复杂度为O(log(n)) | \n",
"
\n",
" \n",
" | TreeSet | \n",
" 不可变集合,底层用红黑树实现,操作的复杂度为O(log(n)) | \n",
"
\n",
" \n",
" | Vector | \n",
" 不可变、支持下标的序列的默认实现 | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"不可变集合的设计目标是提供既高效又安全的实现。特别是可以在多线程之间共享而无需加锁。这个集合中的大部分都是使用高级技巧来在集合的不同版本之间“共享”内存。三个最常用的不可变的集合为Vector、List和Stream。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.1 Vector\n",
"Scala的Vector实现为一组嵌套数组,在分割和连接时非常有效率。适用于大部分通用算法,因为它有高效的下标计算能力,以及能够在使用像+:和++方法时共享大部分内部结构的能力。\n",
"\n",
"Vector的随机访问复杂度是log_32(N),使用32位整数下标时在JVM上是个效率不错的小常量。同时Vector是完全不可变的,而且有合理的共享内存特性。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **存储方式**\n",
"\n",
"Vector是个由元素的下标组成的前缀树(trie),前缀树是给定路径上的所有子节点功用某种形式的公共键值。\n",
"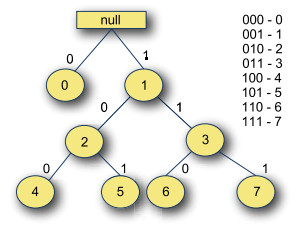\n",
"上图给出了下标为0到7的前缀树,其根节点为空,到达前缀树的指定下标的路径可以由下标数字的二进制表示计算出来。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **数组结构与访问机制**\n",
"\n",
"Scala的Vector集合非常类似于一个分支系数为32的下标前缀树。关键区别在于Vector用一个数组来表示分支。这使整个结构变成数组的数组(嵌套数组)。\n",
"\n",
"下图是分支系数为2的二进制Vector:\n",
"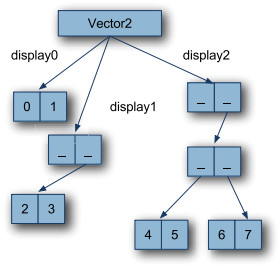\n",
"其中有三个基本素组:display0、display1和display2.这些数组代表原始前缀树的深度。每个显示元素(display element)都是一个更深一层的的嵌套数组(display0是元素的数组,display1是数组的数组,display2是数组的数组的数组)。**查找集合元素的步骤是先判断其深度,然后用跟前缀树一样的方式确定元素所在的数组。**比如找数字4,其深度为2,所以先选择display2数组,4的二进制形式100,所以外层数组是下标为1的位置上,中层数组下标为0,最后4就位于结果数组的下标0的位置上。\n",
"\n",
"二进制前缀树根据下标随机取值的复杂度是log_2(n),Scala的Vector的分支系数为32,那么访问任何元素的时间复杂度是log_32(n),对32位的下标也就大约是7,对64位大约是13.而对于较小的集合,排序的开销也会降低,所以访问速度会更快。所以随机访问的时间复杂度与前缀树的大小成正比。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **共享方式**\n",
"\n",
"前缀树支持的共享级别很高。如果集合是不可变的,那么修改指定下标的值可以重用前缀树的部分数据。\n",
"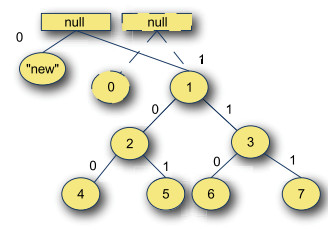\n",
"上图中,下标0位置的值修改为new,创建新的前缀树共享重用了原来的大部分节点,这样有助于降低修改集合的开销。对于分支系数为2的前缀树,修改一个节点的开销是log_2(n),可以通过增加分支系数进一步降低。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **优点**\n",
"\n",
"Scala的Vector为32分支,这除了带来查找时间和修改时间可以随集合大小伸缩外,它还提供了不错的缓存一致性,因为集合里相近的元素有很大可能位于同一个内存数组里。其高效结合不可变所带来的线程安全使之成为库里最强大的有序集合。\n",
"\n",
"当然,如果频繁执行头尾分解,最好选择LinearSeq特质的子类List。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.2 List\n",
"Scala的List是个单链表,适用于将列表头和尾分离处理的递归算法。如果总是在列表头上做添加或删除操作,那么它的性能不错。如果使用的模式比较高级,那它就比较吃力了。List不如Vector那么通用,所以应该仅用在符合它期望的算法里。"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"- **List的基本结构** \n",
"\n",
"List由两部分组成,一是代表空列表的Nil,另一个是“Cons”格子,也称为链接节点。Cons格子持有两个引用,一个指向值,另一个指向对列表后续元素\n",
"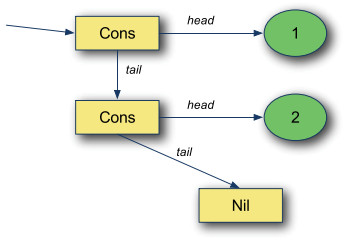"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"List集合继承自LinearSeq,因此它支持O(1)复杂度的头尾分解和头部添加操作。\n",
"\n",
"在只是用头部添加和头尾分解操作的时候,List可以支持极大的共享数据,但是如果列表中间的元素被修改,那前半个列表都需要重新生成,这就是List不如Vector适合开发的原因。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.3 Stream\n",
"之前的List是个即时计算的集合,当列表完成时,头尾都已经计算完成了。Stream是一种延迟持久(lazy persistent)的集合。故流可以颜值计算其元素的值,逐渐持久它们。**流可以用来表示无限序列而不用担心内存溢出。流还可以记住其生命周期里已经计算的元素,从而提供对已计算过的值的高效访问。**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **基本结构**\n",
"\n",
"Stream也是由Cons格子和空stream组成,类似于List类。Stream和List的最大区别是Stream会延迟计算自己。也就是说,Stream并不保存实际元素,而是保存能用来计算头元素和其余部分(tail)的函数对象。这使得Stream可以保存无限序列——一种把信息和另一个集合连接起来的常用办法。"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"\u001b[36mres0\u001b[0m: \u001b[32mList\u001b[0m[(\u001b[32mString\u001b[0m, \u001b[32mInt\u001b[0m)] = \u001b[33mList\u001b[0m(\n",
" \u001b[33m\u001b[0m(\u001b[32m\"a\"\u001b[0m, \u001b[32m1\u001b[0m),\n",
" \u001b[33m\u001b[0m(\u001b[32m\"b\"\u001b[0m, \u001b[32m2\u001b[0m),\n",
" \u001b[33m\u001b[0m(\u001b[32m\"c\"\u001b[0m, \u001b[32m3\u001b[0m)\n",
")"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"// 一个字符串列表和一个步长为1的无限递增的流压缩起来\n",
"List(\"a\", \"b\", \"c\") zip (Stream from 1)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"使用#::操作来构造流,使用Stream.empty代表空流。并且流不会重复计算\n",
"\n",
"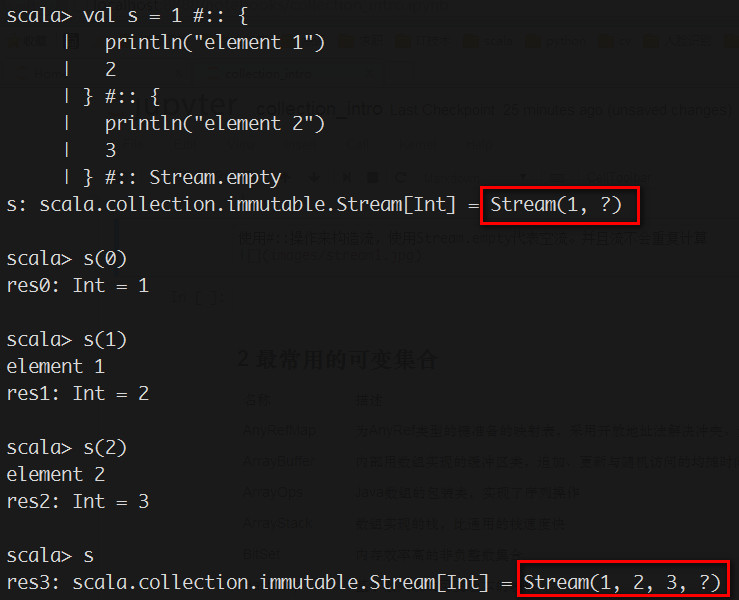"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Stream的绝佳使用场所之一是从前个值计算下个值。这在计算斐波那契数列时特别明显,斐波那契的下个元素是前两个元素的和。\n",
"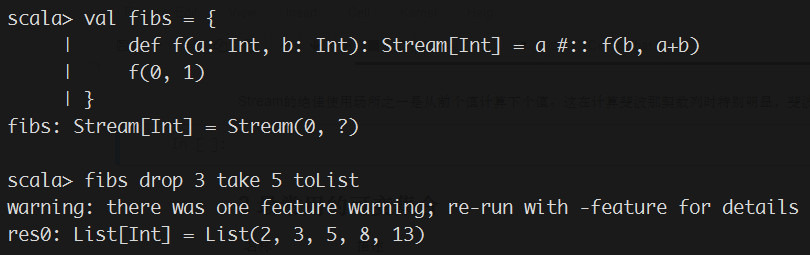"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"如果最终结果大到内存放不下,那么流也解决不了问题。在这种情况下,最好是用TraversableView来避免不必要的操作,同时允许内存回收。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"``` scala\n",
"val fibs2 = new Traversable[Int] {\n",
" def foreach[U](f: Int => U): Unit = {\n",
" def next(a: Int, b: Int): Unit = {\n",
" f(a)\n",
" next(b, a+b)\n",
" }\n",
" next(0, 1)\n",
" }\n",
"} view\n",
"\n",
"fibs2 drop 3 take 5 toList\n",
"```\n",
"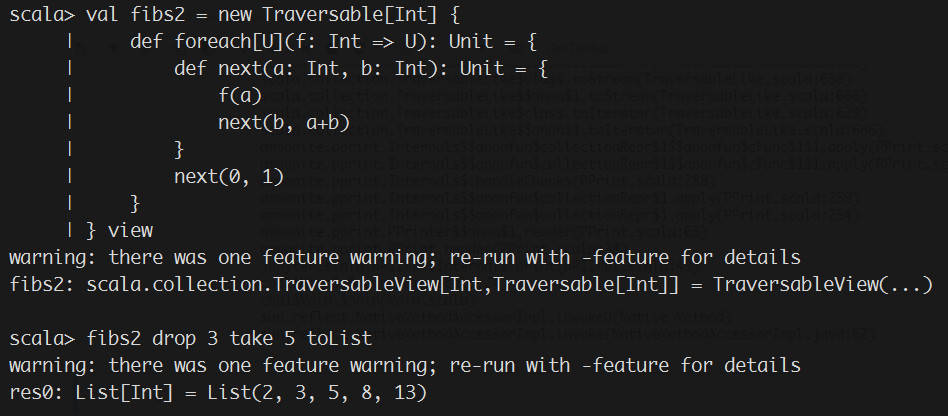\n",
"定义的Traversable[Int],立刻用view方法把这个Traversable转化为TraversableView,以免其foreach方法被立刻调用。**View是一种延迟计算操作的集合**\n",
"\n",
"TraversableView不把计算过的值保存下来,这样意味着反复根据相同的下标从TraversableView里取值时开销是很大的。最好仅在Stream太大无法装进内存的场景下使用它。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2 最常用的可变集合\n",
"\n",
" \n",
" | 名称 | \n",
" 描述 | \n",
"
\n",
" \n",
" | AnyRefMap | \n",
" 为AnyRef类型的键准备的映射表,采用开放地址法解决冲突。大部分操作通常都比HashMap快。 | \n",
"
\n",
" \n",
" | ArrayBuffer | \n",
" 内部用数组实现的缓冲区类,追加、更新与随机访问的均摊时间复杂度为O(1),头部插入和删除操作的复杂度的O(n)。 | \n",
"
\n",
" \n",
" | ArrayOps | \n",
" Java数组的包装类,实现了序列操作 | \n",
"
\n",
" \n",
" | ArrayStack | \n",
" 数组实现的栈,比通用的栈速度快 | \n",
"
\n",
" \n",
" | BitSet | \n",
" 内存效率高的非负整数集合 | \n",
"
\n",
" \n",
" | HashMap | \n",
" 基于散列表的可变版本的映射 | \n",
"
\n",
" \n",
" | HashSet | \n",
" 基于散列表的可变版本的集合 | \n",
"
\n",
" \n",
" | HashTable | \n",
" 用于实现基于散列表的可变集合的trait | \n",
"
\n",
" \n",
" | ListMap | \n",
" 基于列表实现的映射 | \n",
"
\n",
" \n",
" | LinkedHashMap | \n",
" 基于散列表实现的映射,元素可以按其插入顺序进行遍历 | \n",
"
\n",
" \n",
" | LinkedHashSet | \n",
" 基于散列表实现的集合,元素可以按其插入顺序进行遍历 | \n",
"
\n",
" \n",
" | LongMap | \n",
" 键的类型为Long,基于散列表实现的可变映射,采用开放地址法解决冲突。大部分操作通常都比HashMap快。 | \n",
"
\n",
" \n",
" | Map | \n",
" Map特质的可变版本,其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | MultiMap | \n",
" 可变的映射,可以对同一个键赋予多个值 | \n",
"
\n",
" \n",
" | PriorityQueue | \n",
" 基于堆的,可变优先队列。对于类型A的元素,必须存在隐含的Ordering[A]实例。 | \n",
"
\n",
" \n",
" | Queue | \n",
" 可变的FIFO先入先出队列 | \n",
"
\n",
" \n",
" | Seq | \n",
" 表示可变序列的trait,其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | Set | \n",
" 声明了可变集合相关操作的trait,其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | SortedSet | \n",
" 表示可变集合的trait,包含了一个可按特定排列顺序遍历元素的迭代器。其伴随对象由apply方法和其他工厂方法,可以用来构造其子类对象。 | \n",
"
\n",
" \n",
" | Stack | \n",
" 可变的LIFO后入先出栈 | \n",
"
\n",
" \n",
" | TreeSet | \n",
" 可变集合,底层用红黑树实现,操作的复杂度为O(log(n)) | \n",
"
\n",
" \n",
" | WeakHashMap | \n",
" 可变的散列映射,引用元素时采用弱引用。当元素不再有强引用时,就会被删除。该类包装了WeakHashMap | \n",
"
\n",
" \n",
" | WrappedArray | \n",
" Java数组的包装类,支持序列的操作 | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.1 ArrayBuffer\n",
"ArrayBuffer是一种可变数组,其大小与所含元素不一定一直。这样无需拷贝整个数组就可以添加元素。ArrayBuffer内部是一个数组并保存了当前大小。当添加新元素到ArrayBuffer时,它会检查这个大小值,如果底层数组没满,那这个元素就直接加进数组。如果已经满了,则创建更大的数组,然后把所有元素复制到新数组中。重点是新数组也会创建的比加入当前元素所需要的要大一些。尽管有时候要把整个数组赋值到新数组里,但是添加元素的摊销成本是个常数。\n",
"\n",
"ArrayBuffer集合类似于Java的java.util.ArrayList。两者的主要区别在于Java的ArrayList试图摊销移除和添加元素到列表头和列表尾的开销,而Scala的ArrayBuffer只优化了添加和移除列表尾的操作。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.2 监听集合特质\n",
"Scala的可变集合库提供了三个特质:ObservableMap、ObservableBuffer和ObservableSet,可以用来监听集合的修改事件。在恰当的集合上混入三个特质之一可以让对集合的修改除法事件发给观察者。"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"\u001b[32mimport \u001b[36mscala.collection.script.Message\u001b[0m\n",
"\u001b[32mimport \u001b[36mscala.collection.mutable.ObservableBuffer\u001b[0m\n",
"\u001b[32mimport \u001b[36mscala.collection.mutable.Undoable\u001b[0m\n",
"\u001b[32mimport \u001b[36mscala.collection.mutable.ArrayBuffer\u001b[0m"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"import scala.collection.script.Message\n",
"import scala.collection.mutable.ObservableBuffer\n",
"import scala.collection.mutable.Undoable\n",
"import scala.collection.mutable.ArrayBuffer"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"defined \u001b[32mobject \u001b[36mx\u001b[0m"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"object x extends ArrayBuffer[Int] with ObservableBuffer[Int] {\n",
" subscribe(new Sub {\n",
" override def notify(pub: Pub,\n",
" evt: Message[Int] with Undoable) = {\n",
" println(\"Event: \" + evt + \" from \" + pub)\n",
" }\n",
" })\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Event: Include(End,1) from ArrayBuffer(1)\n"
]
},
{
"data": {
"text/plain": [
"\u001b[36mres5\u001b[0m: \u001b[32mx\u001b[0m.type = \u001b[33mArrayBuffer\u001b[0m(\u001b[32m1\u001b[0m)"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x += 1"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Event: Remove(Index(0),1) from ArrayBuffer()\r\n"
]
},
{
"data": {
"text/plain": [
"\u001b[36mres6\u001b[0m: \u001b[32mx\u001b[0m.type = \u001b[33mArrayBuffer\u001b[0m()"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"x -= 1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"添加元素1触发了Include事件,移除元素除法了Remove事件。"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Scala 2.11",
"language": "scala211",
"name": "scala211"
},
"language_info": {
"codemirror_mode": "text/x-scala",
"file_extension": ".scala",
"mimetype": "text/x-scala",
"name": "scala211",
"pygments_lexer": "scala",
"version": "2.11.6"
}
},
"nbformat": 4,
"nbformat_minor": 0
}