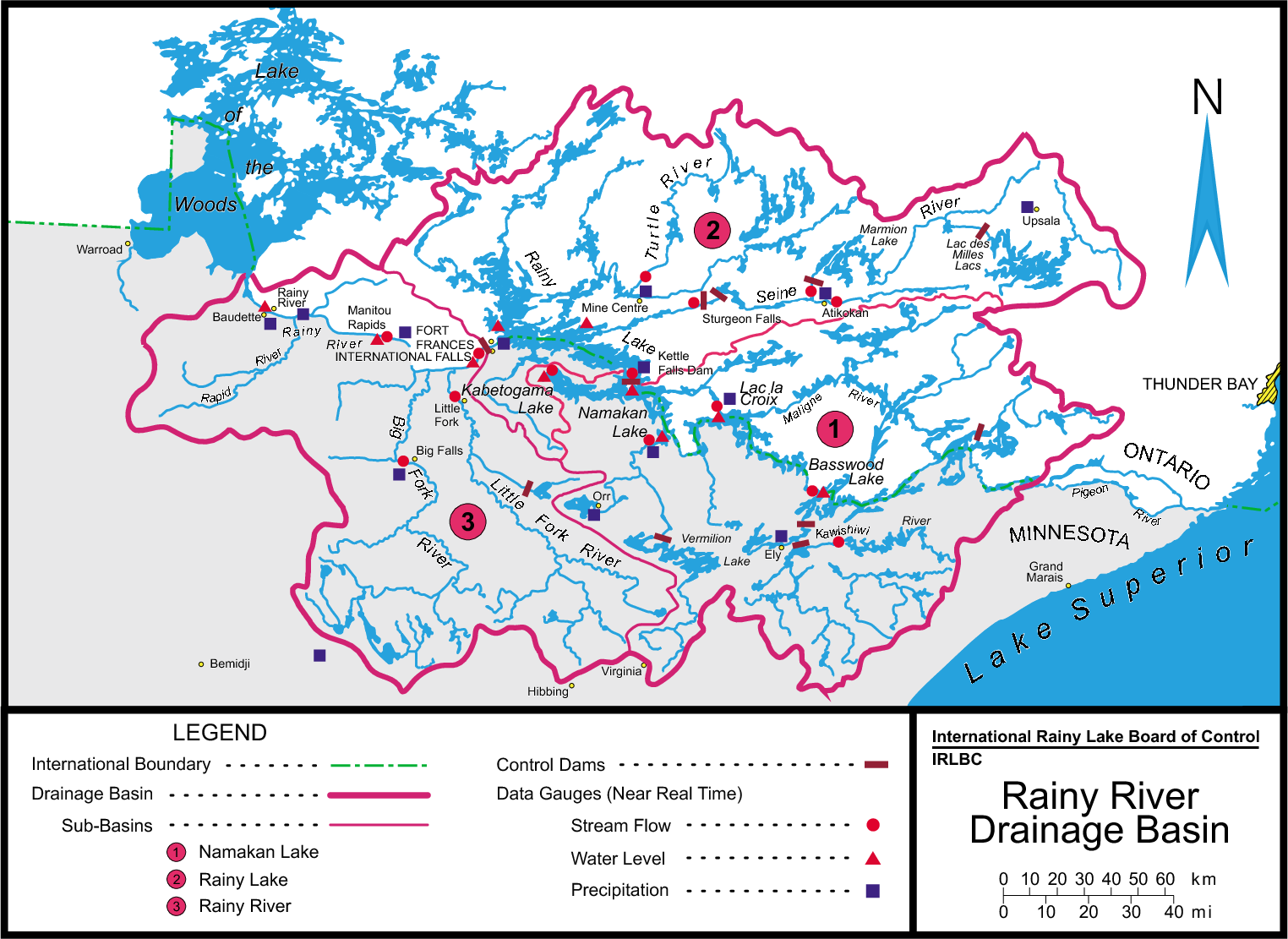
\n",
" \n",
" | 05PA001 | \n",
" | \n",
" True | \n",
" KETTLE RIVER ABOVE KETTLE FALLS | \n",
" 48.49444 | \n",
" -92.64444 | \n",
"
\n",
" \n",
" | 05PA003 | \n",
" True | \n",
" | \n",
" NAMAKAN LAKE ABOVE KETTLE FALLS DAM | \n",
" 48.50000 | \n",
" -92.63886 | \n",
"
\n",
" \n",
" | 05PA005 | \n",
" True | \n",
" | \n",
" NORTHERN LIGHT LAKE AT OUTLET | \n",
" 48.24028 | \n",
" -90.76889 | \n",
"
\n",
" \n",
" | 05PA006 | \n",
" True | \n",
" True | \n",
" NAMAKAN RIVER AT OUTLET OF LAC LA CROIX | \n",
" 48.38256 | \n",
" -92.17631 | \n",
"
\n",
" \n",
" | 05PA007 | \n",
" True | \n",
" | \n",
" CROOKED LAKE NEAR CURTAIN FALLS | \n",
" 48.23750 | \n",
" -91.90611 | \n",
"
\n",
" \n",
" | 05PA010 | \n",
" True | \n",
" | \n",
" FRENCH LAKE NEAR ATIKOKAN | \n",
" 48.67222 | \n",
" -91.13500 | \n",
"
\n",
" \n",
" | 05PA011 | \n",
" True | \n",
" | \n",
" LAC LA CROIX AT CAMPBELL'S CAMP | \n",
" 48.35508 | \n",
" -92.21744 | \n",
"
\n",
" \n",
" | 05PA012 | \n",
" True | \n",
" True | \n",
" BASSWOOD RIVER NEAR WINTON | \n",
" 48.08256 | \n",
" -91.65117 | \n",
"
\n",
" \n",
" | 05PA013 | \n",
" True | \n",
" | \n",
" NAMAKAN LAKE AT SQUIRREL ISLAND | \n",
" 48.49686 | \n",
" -92.65856 | \n",
"
\n",
" \n",
" | 05PB001 | \n",
" | \n",
" True | \n",
" SEINE RIVER NEAR LA SEINE | \n",
" 48.75000 | \n",
" -92.20000 | \n",
"
\n",
" \n",
" | 05PB002 | \n",
" True | \n",
" | \n",
" LITTLE TURTLE LAKE NEAR MINE CENTRE | \n",
" 48.77222 | \n",
" -92.60833 | \n",
"
\n",
" \n",
" | 05PB003 | \n",
" | \n",
" True | \n",
" MANITOU RIVER ABOVE DEVIL'S CASCADE | \n",
" 48.97500 | \n",
" -93.34167 | \n",
"
\n",
" \n",
" | 05PB004 | \n",
" | \n",
" True | \n",
" FOOTPRINT RIVER AT RAINY LAKE FALLS | \n",
" 48.85833 | \n",
" -93.57500 | \n",
"
\n",
" \n",
" | 05PB007 | \n",
" True | \n",
" | \n",
" RAINY LAKE NEAR FORT FRANCES | \n",
" 48.64912 | \n",
" -93.32068 | \n",
"
\n",
" \n",
" | 05PB009 | \n",
" | \n",
" True | \n",
" SEINE RIVER AT STURGEON FALLS GENERATING STATION | \n",
" 48.74444 | \n",
" -92.28472 | \n",
"
\n",
" \n",
" | 05PB012 | \n",
" True | \n",
" | \n",
" LAC DES MILLE LACS ABOVE OUTLET DAM | \n",
" 48.98000 | \n",
" -90.73000 | \n",
"
\n",
" \n",
" | 05PB014 | \n",
" True | \n",
" True | \n",
" TURTLE RIVER NEAR MINE CENTRE | \n",
" 48.85022 | \n",
" -92.72383 | \n",
"
\n",
" \n",
" | 05PB015 | \n",
" | \n",
" True | \n",
" PIPESTONE RIVER ABOVE RAINY LAKE | \n",
" 48.56861 | \n",
" -92.52417 | \n",
"
\n",
" \n",
" | 05PB018 | \n",
" True | \n",
" True | \n",
" ATIKOKAN RIVER AT ATIKOKAN | \n",
" 48.75197 | \n",
" -91.58408 | \n",
"
\n",
" \n",
" | 05PB019 | \n",
" | \n",
" True | \n",
" NORTHEAST TRIBUTARY TO DASHWA LAKE NEAR ATIKOKAN | \n",
" 48.95083 | \n",
" -91.71222 | \n",
"
\n",
" \n",
" | 05PB020 | \n",
" | \n",
" True | \n",
" EASTERN TRIBUTARY TO DASHWA LAKE NEAR ATIKOKAN | \n",
" 48.94056 | \n",
" -91.69833 | \n",
"
\n",
" \n",
" | 05PB021 | \n",
" | \n",
" True | \n",
" EYE RIVER NEAR HARDTACK LAKE NORTH OF ATIKOKAN | \n",
" 48.92500 | \n",
" -91.66222 | \n",
"
\n",
" \n",
" | 05PB022 | \n",
" | \n",
" True | \n",
" EYE RIVER NEAR COULSON LAKE NORTH OF ATIKOKAN | \n",
" 48.89444 | \n",
" -91.66750 | \n",
"
\n",
" \n",
" | 05PB023 | \n",
" True | \n",
" | \n",
" RAINY LAKE AT NORTHWEST BAY | \n",
" 48.84167 | \n",
" -93.62000 | \n",
"
\n",
" \n",
" | 05PB024 | \n",
" True | \n",
" | \n",
" RAINY LAKE NEAR BEAR PASS | \n",
" 48.70058 | \n",
" -92.95800 | \n",
"
\n",
" \n",
" | 05PB025 | \n",
" True | \n",
" | \n",
" RAINY LAKE AT STOKES BAY | \n",
" 48.53611 | \n",
" -92.56111 | \n",
"
\n",
" \n",
" | 05PC009 | \n",
" | \n",
" True | \n",
" LA VALLEE RIVER AT LA VALLEE | \n",
" 48.62083 | \n",
" -93.62500 | \n",
"
\n",
" \n",
" | 05PC010 | \n",
" | \n",
" True | \n",
" STURGEON RIVER NEAR BARWICK | \n",
" 48.68750 | \n",
" -93.98333 | \n",
"
\n",
" \n",
" | 05PC016 | \n",
" | \n",
" True | \n",
" LA VALLEE RIVER NEAR DEVLIN | \n",
" 48.59028 | \n",
" -93.67278 | \n",
"
\n",
" \n",
" | 05PC018 | \n",
" True | \n",
" True | \n",
" RAINY RIVER AT MANITOU RAPIDS | \n",
" 48.63447 | \n",
" -93.91336 | \n",
"
\n",
" \n",
" | 05PC019 | \n",
" | \n",
" True | \n",
" RAINY RIVER AT FORT FRANCES | \n",
" 48.60853 | \n",
" -93.40344 | \n",
"
\n",
" \n",
" | 05PC022 | \n",
" True | \n",
" True | \n",
" LA VALLEE RIVER NEAR BURRISS | \n",
" 48.67844 | \n",
" -93.66522 | \n",
"
\n",
" \n",
" | 05PC024 | \n",
" True | \n",
" | \n",
" RAINY RIVER AT PITHERS POINT SITE NO.1 | \n",
" 48.61389 | \n",
" -93.35472 | \n",
"
\n",
" \n",
" | 05PC025 | \n",
" True | \n",
" | \n",
" RAINY RIVER AT PITHERS POINT SITE NO.2 | \n",
" 48.61625 | \n",
" -93.35992 | \n",
"
\n",
" \n",
"