Last Time
- Relational Databases
- Normalization
- Natural vs. Artificial Keys
- Star Schema
JOINGROUP BYMAX
- Pandas
.head().join().merge().hist().plot().mean().map().groupby().count().resample()
Questions?
Agenda
- APIs & JSON
- NoSQL Databases
- Lab: Twitter & MongoDB
1. APIs & JSON¶
Speaking broadly:
An application programming interface (API) specifies how some software components should interact with each other.
More specifically:
A web API is a programmatic interface to a defined request-response message system, typically expressed in JSON or XML, which is exposed via the web—most commonly by means of an HTTP-based web server.
from Wikipedia
Web APIs allow people to interact with the structures of an application to:
- get
- put
- delete
- update
data
Best practices for web APIs are to use RESTful principles.
Think of some web services you might like to get data from. Perhaps they have APIs?
REST = REpresentational State Transfer
REST vs. SQL
GET ( ~ SELECT)POST ( ~ UPDATE)PUT ( ~ INSERT)DELETE ( ~ DELETE)
RESTful web API HTTP methods
| Resource | GET | PUT | POST | DELETE |
|---|---|---|---|---|
| Collection URI, such as http://example.com/resources | List the URIs and perhaps other details of the collection's members. | Replace the entire collection with another collection. | Create a new entry in the collection. The new entry's URI is assigned automatically and is usually returned by the operation. | Delete the entire collection. |
| Element URI, such as http://example.com/resources/item17 | Retrieve a representation of the addressed member of the collection, expressed in an appropriate Internet media type. | Replace the addressed member of the collection, or if it doesn't exist, create it. | Not generally used. Treat the addressed member as a collection in its own right and create a new entry in it. | Delete the addressed member of the collection. |
HTTP requests can be handled easily using Python's requests library.
First we will load our credentials which we keep in a YAML file for safe keeping.
import yaml
credentials = yaml.load(open('/Users/alessandro.gagliardi/api_cred.yml'))
Then we pass those credentials in to a GET request using the requests library. In this case, I am querying my own user data from Github:
import requests
r = requests.get('https://api.github.com/user',
auth=(credentials['USER'], credentials['PASS']))
Requests gives us an object from which we can read its content.
r.content
One of the reasons we like JSON is that it is easy to transform into a Python dict object using the json library:
import json
user = json.loads(r.content)
user
print user.keys()
We can access values in this dict directly (such as my hireable status) and even render the url of my avatar:
from IPython.display import Image
print "Hireable: {}".format(user.get('hireable'))
Image(url=user.get('avatar_url'))

Twitter API¶
Twitter has no less than 10 python libraries. We'll be using Python Twitter Tools because it's what's used in Mining the Social Web.
Some services (like Twitter) have released Python libraries of their own to make using their API even easier.
import twitter
auth = twitter.oauth.OAuth(credentials['ACCESS_TOKEN'],
credentials['ACCESS_TOKEN_SECRET'],
credentials['API_KEY'],
credentials['API_SECRET'])
twitter_api = twitter.Twitter(auth=auth)
print twitter_api
Using a library like this, we don't even need to specify the URL (that's handled internally).
Using a library like this, it's easy to do something like search for tweets mentioning #bigdata
The results are transformed into a Python object (which in this case is a thin wrapper around a dict)
bigdata = twitter_api.search.tweets(q='#bigdata', count=5)
type(bigdata)
for status in bigdata['statuses']:
print status.get('text')
2. NoSQL¶
NoSQL databases are a new trend in databases
The name NoSQL refers to the lack of a relational structure between stored objects. Data are semi-structured.
Most importantly they attempt to minimize the need for JOIN operations, or solve other data needs
This is good for engineers but bad for data scientists.
Still, NoSQL databases have their uses.
What makes a NoSQL database?
- Doesn't use SQL as query language
- usually more primitive query langauge
- sometimes key/value only
- BASE rather than ACID
- that is, sacrifices consistency for availability
- Schemaless
- that is, data need not conform to a predefined schema (i.e. semi-structured)
BASE vs ACID
- ACID
- Atomicity
- Consistency
- Isolation
- Durability
- BASE
- Basically Available
- Soft-state
- Eventual consistency
CAP
- Consistency
- all nodes always give the same answer
- Availability
- nodes always answer queries and accept updates
- Partition-tolerance
- system continues working even if one or more nodes go down
CAP Theorem: Pick two
Eventual consistency
- A key property of non-ACID systems
- Means
- if no further changes made,
- eventually all nodes will be consistent
- In itself eventual consistency is a very weak guarantee
- when is "eventually"?
- in practice it means the system can be inconsetent at any time
- Stronger guarantees are sometimes made
- with prediction and measuring, actual behavior can be quantified
- in practice, systems often appear strongly consistent
NoSQL Examples
- Memcached
- Cassandra
- MongoDB
More Examples:
- Apache HBase
- CouchDB
- DynamoDB
Memcached:
- Developed by LiveJournal
- Distributed key-value store (like a Python Dict)
- Supports two very fast operations: get and set
Memcached is best used for storing application configuration settings, and essential caching those settings.
Cassandra:
- Developed by Facebook
- Messages application and Inbox Search
- Key-Value (ish)
- Supports query by key or key range
- Very fast writing speeds
- Useful for record keeping, logging
Mongo:
- Developed by 10Gen (now MongoDB, Inc)
- Document and Collection Structure
- BSON (JSON-like) Storage system
- Aggregation Framework
When might you want to use a NoSQL database? When not?
Mongo¶
What is MongoDB?
MongoDB is an open-source document database that provides high performance, high availability, and automatic scaling.
Document Database
A record in MongoDB is a document, which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects. The values of fields may include other documents, arrays, and arrays of documents.
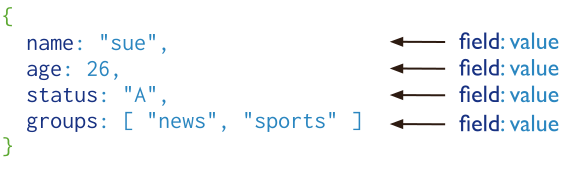
A MongoDB document.
The advantages of using documents are:
- Documents (i.e. objects) correspond to native data types in many programming language.
- Embedded documents and arrays reduce need for expensive joins.
- Dynamic schema supports fluent polymorphism.
Notice how similar this looks to a Python dictionary.