Adds automatically one-way and two-way ANOVA test p-values to a ggplot, such as box blots, dot plots and stripcharts.
stat_anova_test(
mapping = NULL,
data = NULL,
method = c("one_way", "one_way_repeated", "two_way", "two_way_repeated",
"two_way_mixed"),
wid = NULL,
group.by = NULL,
type = NULL,
effect.size = "ges",
error = NULL,
correction = c("auto", "GG", "HF", "none"),
label = "{method}, p = {p.format}",
label.x.npc = "left",
label.y.npc = "top",
label.x = NULL,
label.y = NULL,
step.increase = 0.1,
p.adjust.method = "holm",
significance = list(),
geom = "text",
position = "identity",
na.rm = FALSE,
show.legend = FALSE,
inherit.aes = TRUE,
parse = FALSE,
...
)Arguments
- mapping
Set of aesthetic mappings created by
aes(). If specified andinherit.aes = TRUE(the default), it is combined with the default mapping at the top level of the plot. You must supplymappingif there is no plot mapping.- data
The data to be displayed in this layer. There are three options:
If
NULL, the default, the data is inherited from the plot data as specified in the call toggplot().A
data.frame, or other object, will override the plot data. All objects will be fortified to produce a data frame. Seefortify()for which variables will be created.A
functionwill be called with a single argument, the plot data. The return value must be adata.frame, and will be used as the layer data. Afunctioncan be created from aformula(e.g.~ head(.x, 10)).- method
ANOVA test methods. Possible values are one of
c("one_way", "one_way_repeated", "two_way", "two_way_repeated", "two_way_mixed").- wid
(factor) column name containing individuals/subjects identifier. Should be unique per individual. Required only for repeated measure tests (
"one_way_repeated", "two_way_repeated", "friedman_test", etc).- group.by
(optional) character vector specifying the grouping variable; it should be used only for grouped plots. Possible values are :
"x.var": Group by the x-axis variable and perform the test between legend groups. In other words, the p-value is compute between legend groups at each x position"legend.var": Group by the legend variable and perform the test between x-axis groups. In other words, the test is performed between the x-groups for each legend level.
- type
the type of sums of squares for ANOVA. Allowed values are either 1, 2 or 3.
type = 2is the default because this will yield identical ANOVA results as type = 1 when data are balanced but type = 2 will additionally yield various assumption tests where appropriate. When the data are unbalanced thetype = 3is used by popular commercial softwares including SPSS.- effect.size
the effect size to compute and to show in the ANOVA results. Allowed values can be either "ges" (generalized eta squared) or "pes" (partial eta squared) or both. Default is "ges".
- error
(optional) for a linear model, an lm model object from which the overall error sum of squares and degrees of freedom are to be calculated. Read more in
Anova()documentation.- correction
character. Used only in repeated measures ANOVA test to specify which correction of the degrees of freedom should be reported for the within-subject factors. Possible values are:
"GG": applies Greenhouse-Geisser correction to all within-subjects factors even if the assumption of sphericity is met (i.e., Mauchly's test is not significant, p > 0.05).
"HF": applies Hyunh-Feldt correction to all within-subjects factors even if the assumption of sphericity is met,
"none": returns the ANOVA table without any correction and
"auto": apply automatically GG correction to only within-subjects factors violating the sphericity assumption (i.e., Mauchly's test p-value is significant, p <= 0.05).
- label
character string specifying label. Can be:
the column containing the label (e.g.:
label = "p"orlabel = "p.adj"), wherepis the p-value. Other possible values are"p.signif", "p.adj.signif", "p.format", "p.adj.format".an expression that can be formatted by the
glue()package. For example, when specifyinglabel = "Anova, p = \{p\}", the expression {p} will be replaced by its value.a combination of plotmath expressions and glue expressions. You may want some of the statistical parameter in italic; for example:
label = "Anova, italic(p) = {p}".a constant:
label = "as_italic": display statistical parameters in italic;label = "as_detailed": detailed plain text;label = "as_detailed_expression"orlabel = "as_detailed_italic": detailed plotmath expression. Statistical parameters will be displayed in italic.
.
- label.x.npc, label.y.npc
can be
numericorcharactervector of the same length as the number of groups and/or panels. If too short they will be recycled.If
numeric, value should be between 0 and 1. Coordinates to be used for positioning the label, expressed in "normalized parent coordinates".If
character, allowed values include: i) one of c('right', 'left', 'center', 'centre', 'middle') for x-axis; ii) and one of c( 'bottom', 'top', 'center', 'centre', 'middle') for y-axis.
- label.x, label.y
numericCoordinates (in data units) to be used for absolute positioning of the label. If too short they will be recycled.- step.increase
numeric value in with the increase in fraction of total height for every additional comparison to minimize overlap. The step value can be negative to reverse the order of groups.
- p.adjust.method
method for adjusting p values (see
p.adjust). Has impact only in a situation, where multiple pairwise tests are performed; or when there are multiple grouping variables. Allowed values include "holm", "hochberg", "hommel", "bonferroni", "BH", "BY", "fdr", "none". If you don't want to adjust the p value (not recommended), use p.adjust.method = "none".- significance
a list of arguments specifying the signifcance cutpoints and symbols. For example,
significance <- list(cutpoints = c(0, 0.0001, 0.001, 0.01, 0.05, Inf), symbols = c("****", "***", "**", "*", "ns")).In other words, we use the following convention for symbols indicating statistical significance:
ns: p > 0.05*: p <= 0.05**: p <= 0.01***: p <= 0.001****: p <= 0.0001
- geom
The geometric object to use to display the data for this layer. When using a
stat_*()function to construct a layer, thegeomargument can be used to override the default coupling between stats and geoms. Thegeomargument accepts the following:A
Geomggproto subclass, for exampleGeomPoint.A string naming the geom. To give the geom as a string, strip the function name of the
geom_prefix. For example, to usegeom_point(), give the geom as"point".For more information and other ways to specify the geom, see the layer geom documentation.
- position
A position adjustment to use on the data for this layer. This can be used in various ways, including to prevent overplotting and improving the display. The
positionargument accepts the following:The result of calling a position function, such as
position_jitter(). This method allows for passing extra arguments to the position.A string naming the position adjustment. To give the position as a string, strip the function name of the
position_prefix. For example, to useposition_jitter(), give the position as"jitter".For more information and other ways to specify the position, see the layer position documentation.
- na.rm
If FALSE (the default), removes missing values with a warning. If TRUE silently removes missing values.
- show.legend
logical. Should this layer be included in the legends?
NA, the default, includes if any aesthetics are mapped.FALSEnever includes, andTRUEalways includes. It can also be a named logical vector to finely select the aesthetics to display. To include legend keys for all levels, even when no data exists, useTRUE. IfNA, all levels are shown in legend, but unobserved levels are omitted.- inherit.aes
If
FALSE(the default for most ggpubr functions), overrides the default aesthetics, rather than combining with them. This is most useful for helper functions that define both data and aesthetics and shouldn't inherit behaviour from the default plot specification. Set toTRUEto inherit aesthetics from the parent ggplot layer.- parse
If TRUE, the labels will be parsed into expressions and displayed as described in
?plotmath.- ...
other arguments to pass to
geom_text, such as:hjust: horizontal justification of the text. Move the text left or right andvjust: vertical justification of the text. Move the text up or down.
Computed variables
DFn: Degrees of Freedom in the numerator (i.e. DF effect).
DFd: Degrees of Freedom in the denominator (i.e., DF error).
ges: Generalized Eta-Squared measure of effect size. Computed only when the option
effect.size = "ges".pes: Partial Eta-Squared measure of effect size. Computed only when the option
effect.size = "pes".F: F-value.
p: p-value.
p.adj: Adjusted p-values.
p.signif: P-value significance.
p.adj.signif: Adjusted p-value significance.
p.format: Formated p-value.
p.adj.format: Formated adjusted p-value.
n: number of samples.
Examples
# Data preparation
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Transform `dose` into factor variable
df <- ToothGrowth
df$dose <- as.factor(df$dose)
# Add individuals id
df$id <- rep(1:10, 6)
# Add a random grouping variable
set.seed(123)
df$group <- sample(factor(rep(c("grp1", "grp2", "grp3"), 20)))
df$len <- ifelse(df$group == "grp2", df$len+2, df$len)
df$len <- ifelse(df$group == "grp3", df$len+7, df$len)
head(df, 3)
#> len supp dose id group
#> 1 4.2 VC 0.5 1 grp1
#> 2 18.5 VC 0.5 2 grp3
#> 3 14.3 VC 0.5 3 grp3
# Basic boxplot
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Create a basic boxplot
# Add 5% and 10% space to the plot bottom and the top, respectively
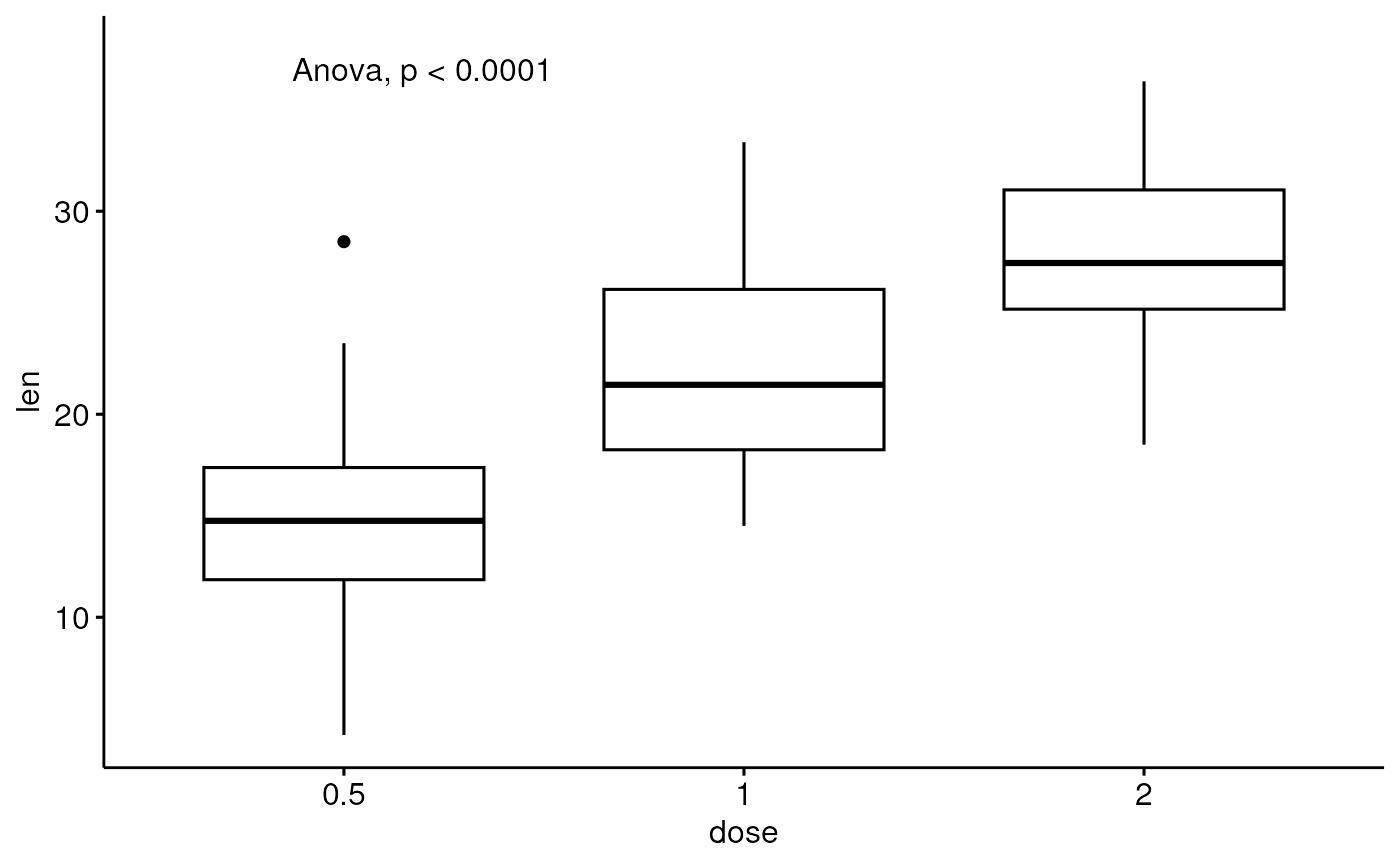
bxp <- ggboxplot(df, x = "dose", y = "len") +
scale_y_continuous(expand = expansion(mult = c(0.05, 0.1)))
# Add the p-value to the boxplot
bxp + stat_anova_test()
 if (FALSE) { # \dontrun{
# Change the label position
# Using coordinates in data units
bxp + stat_anova_test(label.x = "1", label.y = 10, hjust = 0)
} # }
# Format the p-value differently
custom_p_format <- function(p) {
rstatix::p_format(p, accuracy = 0.0001, digits = 3, leading.zero = FALSE)
}
bxp + stat_anova_test(
label = "Anova, italic(p) = {custom_p_format(p)}{p.signif}"
)
#> Warning: Computation failed in `stat_compare_multiple_means()`.
#> Caused by error in `mutate()`:
#> ℹ In argument: `label = glue(label)`.
#> Caused by error:
#> ! Failed to evaluate glue component {custom_p_format(p)}
#> Caused by error in `custom_p_format()`:
#> ! could not find function "custom_p_format"
if (FALSE) { # \dontrun{
# Change the label position
# Using coordinates in data units
bxp + stat_anova_test(label.x = "1", label.y = 10, hjust = 0)
} # }
# Format the p-value differently
custom_p_format <- function(p) {
rstatix::p_format(p, accuracy = 0.0001, digits = 3, leading.zero = FALSE)
}
bxp + stat_anova_test(
label = "Anova, italic(p) = {custom_p_format(p)}{p.signif}"
)
#> Warning: Computation failed in `stat_compare_multiple_means()`.
#> Caused by error in `mutate()`:
#> ℹ In argument: `label = glue(label)`.
#> Caused by error:
#> ! Failed to evaluate glue component {custom_p_format(p)}
#> Caused by error in `custom_p_format()`:
#> ! could not find function "custom_p_format"
 # Show a detailed label in italic
bxp + stat_anova_test(label = "as_detailed_italic")
# Show a detailed label in italic
bxp + stat_anova_test(label = "as_detailed_italic")
 # Faceted plots
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Create a ggplot facet
bxp <- ggboxplot(df, x = "dose", y = "len", facet.by = "supp") +
scale_y_continuous(expand = expansion(mult = c(0.05, 0.1)))
# Add p-values
bxp + stat_anova_test()
# Faceted plots
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Create a ggplot facet
bxp <- ggboxplot(df, x = "dose", y = "len", facet.by = "supp") +
scale_y_continuous(expand = expansion(mult = c(0.05, 0.1)))
# Add p-values
bxp + stat_anova_test()
 # Grouped plots
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
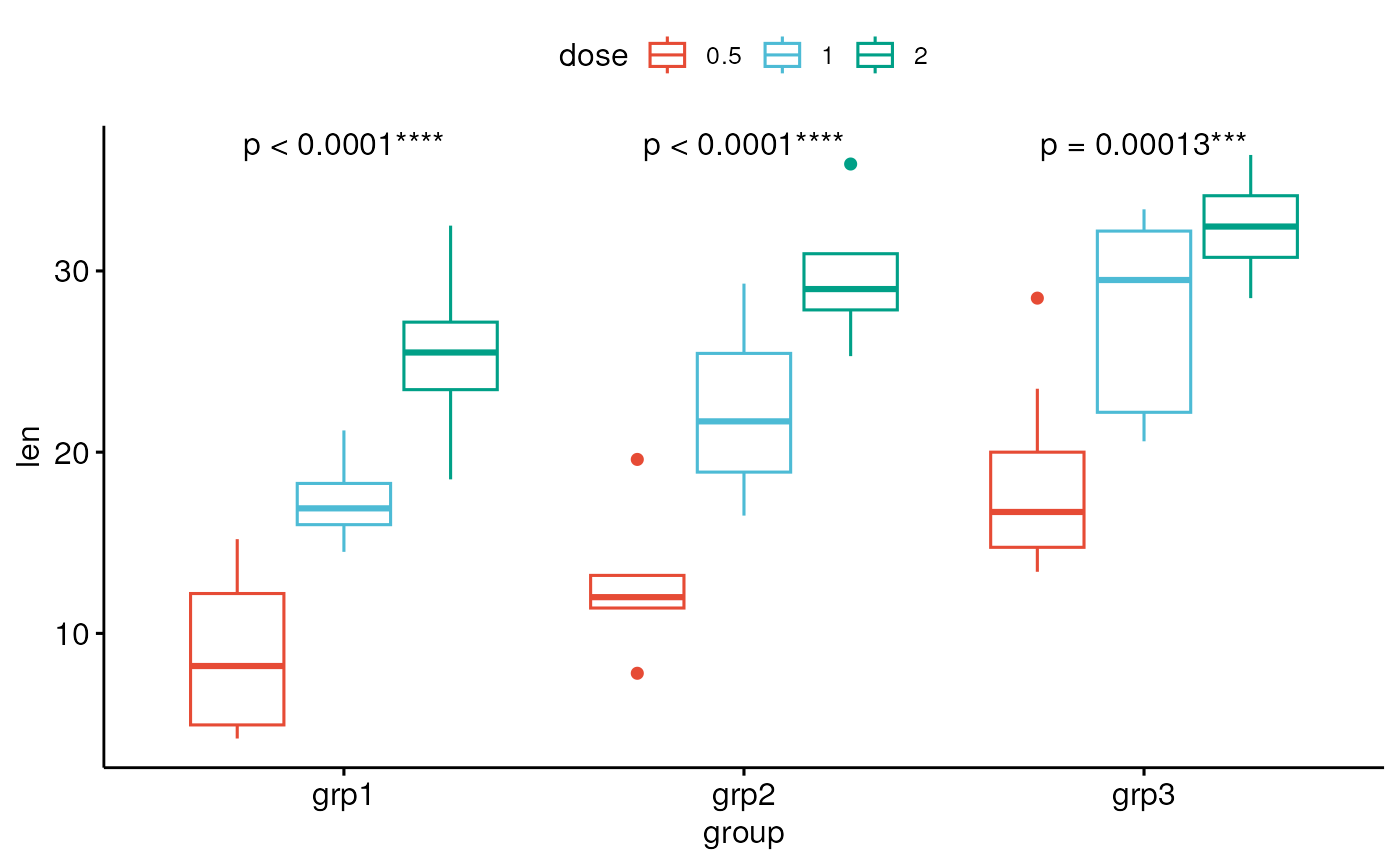
bxp2 <- ggboxplot(df, x = "group", y = "len", color = "dose", palette = "npg")
# For each x-position, computes tests between legend groups
bxp2 + stat_anova_test(aes(group = dose), label = "p = {p.format}{p.signif}")
# Grouped plots
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
bxp2 <- ggboxplot(df, x = "group", y = "len", color = "dose", palette = "npg")
# For each x-position, computes tests between legend groups
bxp2 + stat_anova_test(aes(group = dose), label = "p = {p.format}{p.signif}")
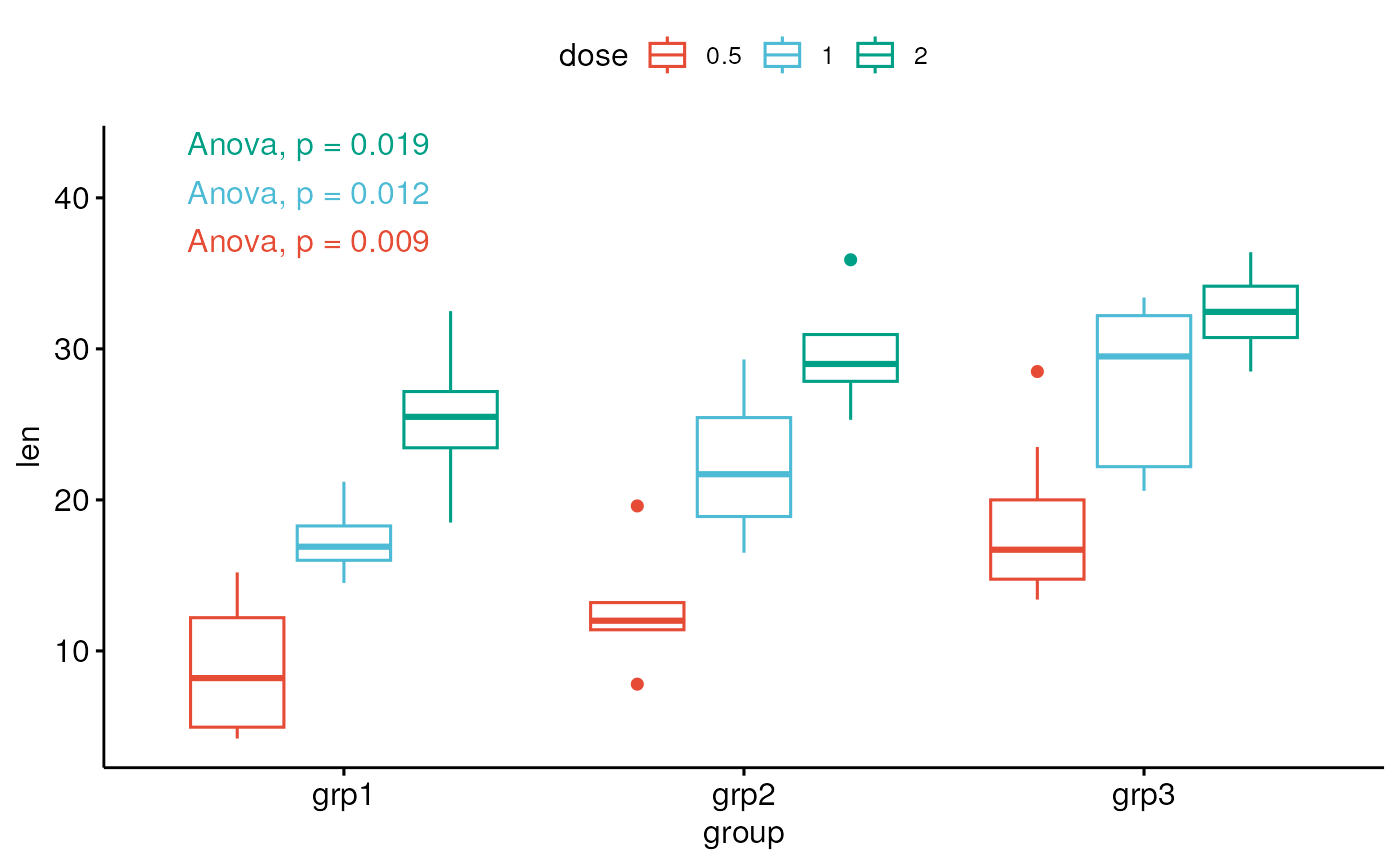
 # For each legend group, computes tests between x variable groups
bxp2 + stat_anova_test(aes(group = dose, color = dose), group.by = "legend.var")
# For each legend group, computes tests between x variable groups
bxp2 + stat_anova_test(aes(group = dose, color = dose), group.by = "legend.var")
 if (FALSE) { # \dontrun{
# Two-way ANOVA: Independent measures
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Visualization: box plots with p-values
# Two-way interaction p-values between x and legend (group) variables
bxp3 <- ggboxplot(
df, x = "supp", y = "len",
color = "dose", palette = "jco"
)
bxp3 + stat_anova_test(aes(group = dose), method = "two_way")
# One-way repeatead measures ANOVA
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
df$id <- as.factor(c(rep(1:10, 3), rep(11:20, 3)))
ggboxplot(df, x = "dose", y = "len") +
stat_anova_test(method = "one_way_repeated", wid = "id")
# Two-way repeatead measures ANOVA
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
df$id <- as.factor(rep(1:10, 6))
ggboxplot(df, x = "dose", y = "len", color = "supp", palette = "jco") +
stat_anova_test(aes(group = supp), method = "two_way_repeated", wid = "id")
# Grouped one-way repeated measures ANOVA
ggboxplot(df, x = "dose", y = "len", color = "supp", palette = "jco") +
stat_anova_test(aes(group = supp, color = supp),
method = "one_way_repeated", wid = "id", group.by = "legend.var")
} # }
if (FALSE) { # \dontrun{
# Two-way ANOVA: Independent measures
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
# Visualization: box plots with p-values
# Two-way interaction p-values between x and legend (group) variables
bxp3 <- ggboxplot(
df, x = "supp", y = "len",
color = "dose", palette = "jco"
)
bxp3 + stat_anova_test(aes(group = dose), method = "two_way")
# One-way repeatead measures ANOVA
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
df$id <- as.factor(c(rep(1:10, 3), rep(11:20, 3)))
ggboxplot(df, x = "dose", y = "len") +
stat_anova_test(method = "one_way_repeated", wid = "id")
# Two-way repeatead measures ANOVA
#%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
df$id <- as.factor(rep(1:10, 6))
ggboxplot(df, x = "dose", y = "len", color = "supp", palette = "jco") +
stat_anova_test(aes(group = supp), method = "two_way_repeated", wid = "id")
# Grouped one-way repeated measures ANOVA
ggboxplot(df, x = "dose", y = "len", color = "supp", palette = "jco") +
stat_anova_test(aes(group = supp, color = supp),
method = "one_way_repeated", wid = "id", group.by = "legend.var")
} # }