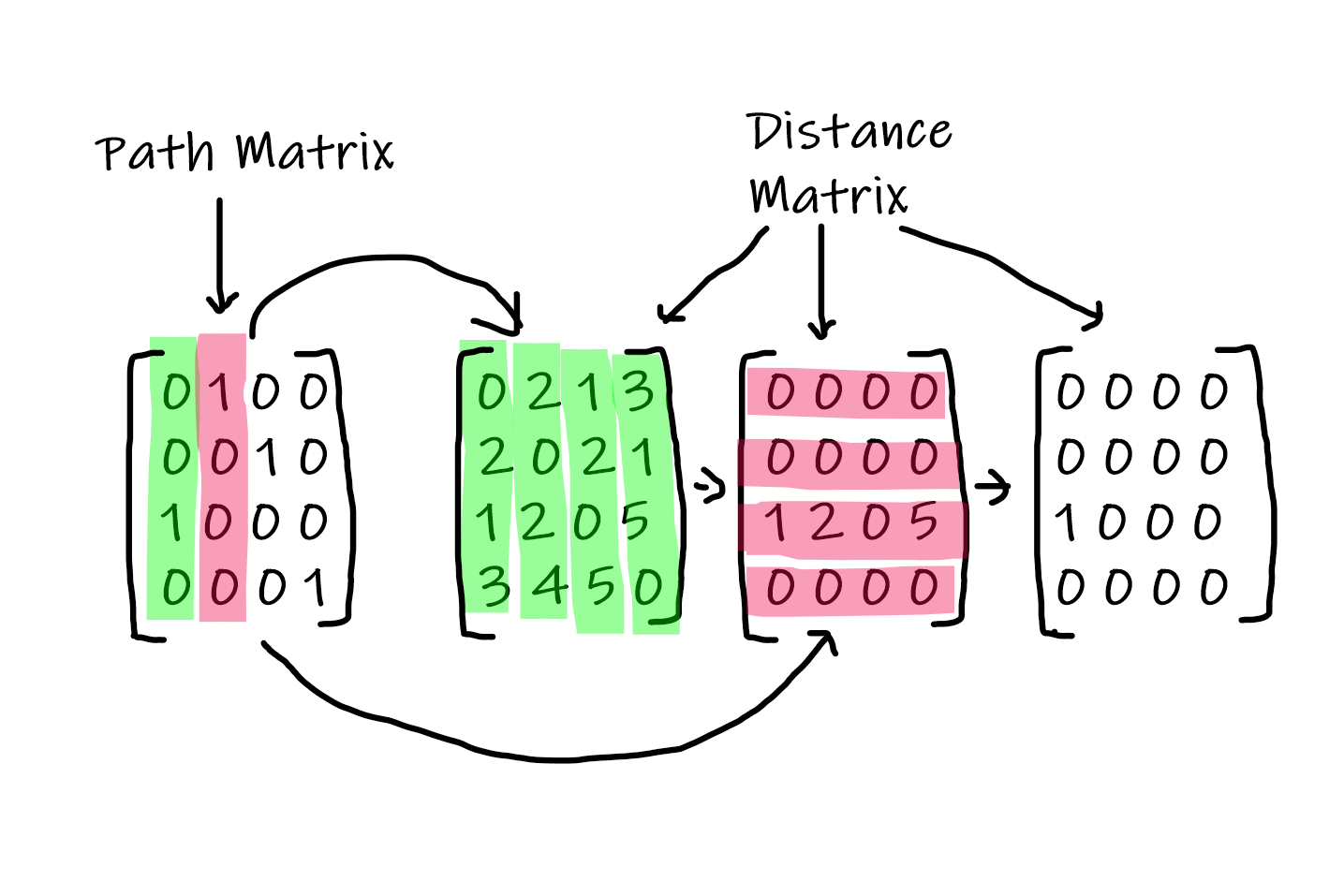
I developed a formulation for the Travelling Salesperson Problem. The problem considers a set of nodes, each of which needs to be visited so that the total distance traveled is minimized. The problem often arises in path planning when multiple locations of interest have to be visited. One can use the method developed here to generate either a tour or a path. Moreover, we can modify the technique to include constraints to use a specific node as either the start or end node to visit. However, the implementation below only generates paths where the algorithm decides the start and end nodes. Additionally, we can use the method to solve a problem of any size, but the optimality of the solution it converges is not studied yet.
Most TSP solvers are based on discrete operations and usually utilize greedy heuristics to find sub-optimal solutions. However, I hypothesized that we could solve the problem by formulating the problem as a continuous optimization problem and using gradient descent to find its optimal. The formulation presented is continuous and fully differentiable. Moreover, it's global optimal would indeed coincide with the optimal solution of the TSP problem. However, the optimization landscape is relatively large, and finding such an optimal is difficult with first-order solvers such as gradient descent. As such, the method is likely to get stuck in a local optimal.
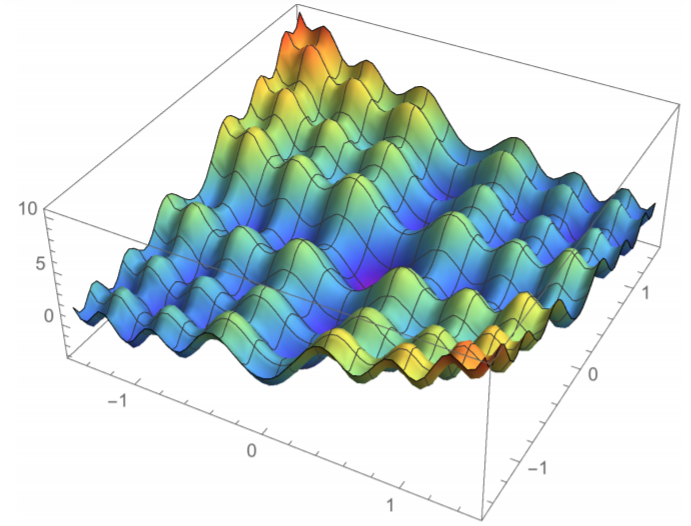
I believe the optimization landscape looks like the one shown below. Given the abundance of local minima, stochastic gradient descent is not well suited to solve the problem. Moreover, I don't think higher-order optimization methods will do any good either, as they won't necessarily look past the local valley.
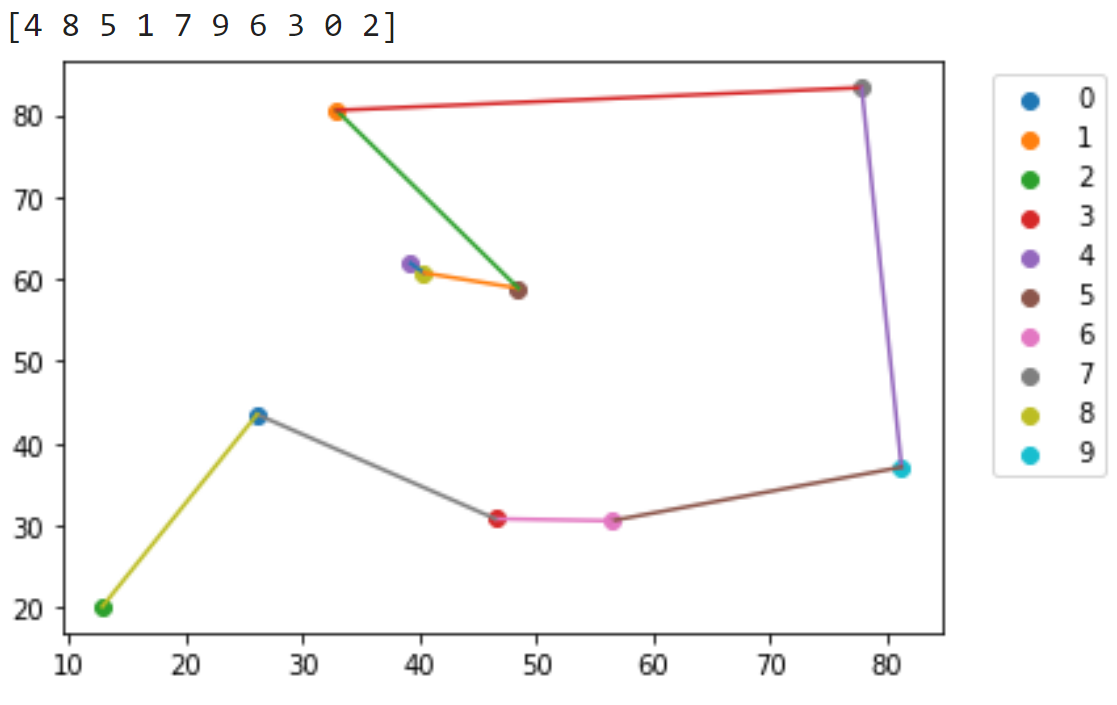
The figure shown below is a result generated with my approach. The path looks reasonably optimal. However, it is not the globally optimal solution. Furthermore, the model's solution converges to is highly dependent on how the model weights are initialized, which is randomly initialized.
I tried annealing techniques to address the optimal local issue, but it didn't fix the problem. Perhaps Markov Chain Monte Carlo methods might be better suited for optimizing such landscapes.
Additionally, I tested the method on problems with sizes ranging from 5-20 nodes. The solutions found did not have a consistent approximation ratio to that of the optimal solution. An in-depth analysis of the approach would be required to draw empirical bounds on the solutions of the method here. However, in theory, the technique can be applied to a problem of any size as long as it fits in memory. The memory cost is $O(n^2)$, where $n$ is the number of nodes in the problem.
However, one thing to consider is that the method, although not practical, is rather interesting. I found some papers that used Deep neural networks to solve the problem, but most of those used Graph neural networks and assumed a training dataset was available. The dataset is a set of arbitrary graphs and the optimal node visitation order as the labels. Such methods are black-box approaches; in contrast, mine is a closed-form formulation. Perhaps we can combine the two techniques to develop a superior method that can leverage the closed-form optimization metric along with the black box approaches excellent performance to reduce the amount of data that is required to train such models.