{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# ETHZ: 227-0966-00L\n",
"# Quantitative Big Imaging\n",
"# May 2, 2018\n",
"\n",
"## Statistics and Reproducibility"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"slideshow": {
"slide_type": "skip"
}
},
"outputs": [],
"source": [
"%load_ext autoreload\n",
"%autoreload 2\n",
"import seaborn as sns\n",
"import matplotlib.pyplot as plt\n",
"plt.rcParams[\"figure.figsize\"] = (8, 8)\n",
"plt.rcParams[\"figure.dpi\"] = 150\n",
"plt.rcParams[\"font.size\"] = 14\n",
"plt.rcParams['font.family'] = ['sans-serif']\n",
"plt.rcParams['font.sans-serif'] = ['DejaVu Sans']\n",
"plt.style.use('ggplot')\n",
"sns.set_style(\"whitegrid\", {'axes.grid': False})"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Literature / Useful References\n",
"\n",
"### Books\n",
"- Jean Claude, Morphometry with R\n",
" - [Online](http://link.springer.com/book/10.1007%2F978-0-387-77789-4) through ETHZ\n",
" - __Chapter 3__\n",
" - [Buy it](http://www.amazon.com/Morphometrics-R-Use-Julien-Claude/dp/038777789X)\n",
"- John C. Russ, âThe Image Processing Handbookâ,(Boca Raton, CRC Press)\n",
" - Available [online](http://dx.doi.org/10.1201/9780203881095) within domain ethz.ch (or proxy.ethz.ch / public VPN) \n",
"- [Hypothesis Testing Chapter](http://www.sagepub.com/upm-data/40007_Chapter8.pdf)\n",
"- Grammar of Graphics: Leland and Wilkinson - http://www.springer.com/gp/book/9780387245447\n",
"\n",
"### Videos / Podcasts\n",
"- Google/Stanford Statistics Intro\n",
" - https://www.youtube.com/watch?v=YFC2KUmEebc\n",
"- MCB 140 P-value lecture at UC Berkeley (Audio)\n",
" - https://itunes.apple.com/us/itunes-u/mcb-140-fall-2007-general/id461120088?mt=10\n",
"- Correlation and Causation (Video)\n",
" - https://www.youtube.com/watch?v=YFC2KUmEebc\n",
"- Last Week Tonight: Scientific Studies (https://www.youtube.com/watch?v=0Rnq1NpHdmw)\n",
"\n",
"### Papers / Sites\n",
"- [Matlab Unit Testing Documentation](http://www.mathworks.ch/ch/help/matlab/matlab-unit-test-framework.html\n",
")\n",
"- [Databases Introduction](http://swcarpentry.github.io/sql-novice-survey/)\n",
"- [Visualizing Genomic Data](http://circos.ca/documentation/course/visualizing-genomic-data.pdf) (General Visualization Techniques)\n",
"- [NIMRod Parameter Studies](http://www.messagelab.monash.edu.au/nimrod)\n",
"\n",
"- M.E. Wolak, D.J. Fairbairn, Y.R. Paulsen (2012) Guidelines for Estimating Repeatability. Methods in Ecology and Evolution 3(1):129-137.\n",
"- David J.C. MacKay, Bayesian Interpolartion (1991) [http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.27.9072]\n",
"\n",
"### Model Evaluation\n",
"\n",
"- [Julia Evans - Recalling with Precision](https://www.youtube.com/watch?v=ryZL4XNUmwo)\n",
"- [Stripe's Next Top Model](https://github.com/stripe/topmodel)\n",
"\n",
"### Iris Dataset\n",
"\n",
"- The Iris dataset was used in Fisher's classic 1936 paper, The Use of Multiple Measurements in Taxonomic Problems: http://rcs.chemometrics.ru/Tutorials/classification/Fisher.pdf"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Previously on QBI ...\n",
"\n",
"- Image Enhancment \n",
" - Highlighting the contrast of interest in images\n",
" - Minimizing Noise\n",
"- Understanding image histograms\n",
"- Automatic Methods\n",
"- Component Labeling\n",
"- Single Shape Analysis\n",
"- Complicated Shapes\n",
"- Distribution Analysis\n",
"- Dynamic Experiments"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Quantitative \"Big\" Imaging\n",
"\n",
"\n",
"The course has covered imaging enough and there have been a few quantitative metrics, but \"big\" has not really entered.\n",
"\n",
"What does __big__ mean?\n",
"\n",
"- Not just / even large\n",
"- it means being ready for _big data_\n",
"- volume, velocity, variety (3 V's)\n",
"- scalable, fast, easy to customize\n",
"\n",
"\n",
"So what is \"big\" imaging\n",
"\n",
"#### doing analyses in a disciplined manner\n",
"\n",
" - fixed steps\n",
" - easy to regenerate results\n",
" - no _magic_\n",
" \n",
"#### having everything automated\n",
"\n",
" - 100 samples is as easy as 1 sample\n",
" \n",
"#### being able to adapt and reuse analyses\n",
"\n",
" - one really well working script and modify parameters\n",
" - different types of cells\n",
" - different regions"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Objectives\n",
"\n",
"1. Scientific Studies all try to get to a single number\n",
" - Make sure this number is describing the structure well (what we have covered before)\n",
" - Making sure the number is meaningful (__today!__)\n",
"1. How do we compare the number from different samples and groups?\n",
" - Within a sample or same type of samples\n",
" - Between samples\n",
"1. How do we compare different processing steps like filter choice, minimum volume, resolution, etc?\n",
"1. How do we evaluate our parameter selection?\n",
"1. How can we ensure our techniques do what they are supposed to do?\n",
"1. How can we visualize so much data? Are there rules?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Outline\n",
"\n",
"- Motivation (Why and How?)\n",
"- Scientific Goals\n",
"- Reproducibility\n",
"- Predicting and Validating\n",
"- Statistical metrics and results\n",
"- Parameterization\n",
" - Parameter sweep\n",
" - Sensitivity analysis\n",
"- Unit Testing\n",
"- Visualization"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# What do we start with?\n",
"\n",
"Going back to our original cell image\n",
"\n",
"1. We have been able to get rid of the noise in the image and find all the cells (lecture 2-4)\n",
"1. We have analyzed the shape of the cells using the shape tensor (lecture 5)\n",
"1. We even separated cells joined together using Watershed (lecture 6)\n",
"1. We have created even more metrics characterizing the distribution (lecture 7)\n",
"\n",
"We have at least a few samples (or different regions), large number of metrics and an almost as large number of parameters to _tune_\n",
"\n",
"### How do we do something meaningful with it?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Correlation and Causation\n",
"\n",
"\n",
"One of the most repeated criticisms of scientific work is that correlation and causation are confused. \n",
"\n",
"1. Correlation \n",
" - means a statistical relationship\n",
" - very easy to show (single calculation)\n",
"2. Causation \n",
" - implies there is a mechanism between A and B\n",
" - very difficult to show (impossible to prove)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Controlled and Observational\n",
"\n",
"There are two broad classes of data and scientific studies. \n",
"\n",
"### Observational\n",
"\n",
" - Exploring large datasets looking for trends\n",
" - Population is random\n",
" - Not always hypothesis driven\n",
" - Rarely leads to causation\n",
"\n",
"We examined 100 people and the ones with blue eyes were on average 10cm taller\n",
"\n",
"In 100 cake samples, we found a 0.9 correlation between cooking time and bubble size\n",
"\n",
"### Controlled\n",
"\n",
" - Most scientific studies fall into this category\n",
" - Specifics of the groups are controlled\n",
" - Can lead to causation\n",
"\n",
"We examined 50 mice with gene XYZ off and 50 gene XYZ on and as the foot size increased by 10%\n",
"\n",
"We increased the temperature and the number of pores in the metal increased by 10%\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Simple Model: Magic / Weighted Coin\n",
"\n",
"\n",
"\n",
"Since most of the experiments in science are usually specific, noisy, and often very complicated and are not usually good teaching examples\n",
"\n",
"- Magic / Biased Coin\n",
" - You buy a _magic_ coin at a shop\n",
" - How many times do you need to flip it to _prove_ it is not fair?\n",
" - If I flip it 10 times and another person flips it 10 times, is that the same as 20 flips?\n",
" - If I flip it 10 times and then multiple the results by 10 is that the same as 100 flips?\n",
" - If I buy 10 coins and want to know which ones are fair what do I do?\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Simple Model: Magic / Weighted Coin\n",
"\n",
"\n",
"1. Each coin represents a stochastic variable $\\mathcal{X}$ and each flip represents an observation $\\mathcal{X}_i$.\n",
"1. The act of performing a coin flip $\\mathcal{F}$ is an observation $\\mathcal{X}_i = \\mathcal{F}(\\mathcal{X})$\n",
"\n",
"We normally assume\n",
"\n",
"1. A _fair_ coin has an expected value of $E(\\mathcal{X})=0.5 \\rightarrow$ 50% Heads, 50% Tails\n",
"1. An _unbiased_ flip(er) means \n",
" - each flip is independent of the others \n",
"\n",
"$$ P(\\mathcal{F}_1(\\mathcal{X})*\\mathcal{F}_2(\\mathcal{X}))= P(\\mathcal{F}_1(\\mathcal{X}))*P(\\mathcal{F}_2(\\mathcal{X}))$$\n",
"\n",
" - the expected value of the flip is the same as that of the coin\n",
" \n",
"$$ E(\\prod_{i=0}^\\infty \\mathcal{F}_i(\\mathcal{X})) = E(\\mathcal{X}) $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Simple Model to Reality\n",
"\n",
"\n",
"### Coin Flip\n",
"\n",
"1. Each flip gives us a small piece of information about the flipper and the coin\n",
"1. More flips provides more information\n",
" - Random / Stochastic variations in coin and flipper cancel out\n",
" - Systematic variations accumulate\n",
"\n",
"\n",
"\n",
"### Real Experiment\n",
"\n",
"1. Each measurement tells us about our sample, out instrument, and our analysis\n",
"2. More measurements provide more information\n",
" - Random / Stochastic variations in sample, instrument, and analysis cancel out\n",
" - _Normally_ the analysis has very little to no stochastic variation\n",
" - Systematic variations accumulate"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Iris: A more complicated model\n",
"\n",
"\n",
"Coin flips are very simple and probably difficult to match to another experiment. A very popular dataset for learning about such values beyond 'coin-flips' is called the Iris dataset which covers a number of measurements from different plants and the corresponding species.\n",
"\n",
"```{r, results='asis'}\n",
"iris %>% sample_n(5) %>% kable\n",
"```\n",
"\n",
"\n",
"\n",
"```{r}\n",
"iris %>% \n",
" mutate(plant.id=1:nrow(iris)) %>% \n",
" melt(id.vars=c(\"Species\",\"plant.id\"))->flat_iris\n",
"flat_iris %>% \n",
" merge(flat_iris,by=c(\"Species\",\"plant.id\")) %>% \n",
" ggplot(aes(value.x,value.y,color=Species)) +\n",
" geom_jitter()+\n",
" facet_grid(variable.x~variable.y,scales=\"free\")+\n",
" theme_bw(10)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Reproducibility\n",
"\n",
"\n",
"A very broad topic with plenty of sub-areas and deeper meanings. We mean two things by reproducibility\n",
"\n",
"### Analysis\n",
"\n",
"The process of going from images to numbers is detailed in a clear manner that _anyone_, _anywhere_ could follow and get the exact (within some tolerance) same numbers from your samples\n",
"\n",
" - No platform dependence\n",
" - No proprietary or \"in house\" algorithms\n",
" - No manual _clicking_, _tweaking_, or _copying_\n",
" - One script to go from image to result\n",
" \n",
"\n",
"\n",
"### Measurement\n",
"\n",
"Everything for analysis + taking a measurement several times (noise and exact alignment vary each time) does not change the statistics _significantly_\n",
"\n",
"- No sensitivity to mounting or rotation\n",
"- No sensitivity to noise\n",
"- No dependence on exact illumination"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Reproducible Analysis\n",
"\n",
"\n",
"The basis for reproducible scripts and analysis are scripts and macros. Since we will need to perform the same analysis many times to understand how reproducible it is.\n",
"\n",
"```bash\n",
"IMAGEFILE=$1\n",
"THRESHOLD=130\n",
"matlab -r \"inImage=$IMAGEFILE; threshImage=inImage>$THRESHOLD; analysisScript;\"\n",
"```\n",
"- __or__ \n",
"```java -jar ij.jar -macro TestMacro.ijm blobs.tif```\n",
"- __or__\n",
"```Rscript -e \"library(plyr);...\"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Comparing Groups: Intraclass Correlation Coefficient\n",
"\n",
"\n",
"The intraclass correlation coefficient basically looking at how similar objects within a group are compared to between groups\n",
"\n",
"```{r}\n",
"ggplot(iris,aes(x=Species,y=Sepal.Width))+\n",
" geom_boxplot()+\n",
" geom_jitter()+\n",
" labs(x=\"Species\",y=\"Sepal Width\",title=\"Low Group Similarity\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"\n",
"\n",
"```{r}\n",
"ggplot(iris,aes(x=Species,y=Petal.Length))+\n",
" geom_boxplot()+\n",
" geom_jitter()+\n",
" labs(x=\"Species\",y=\"Petal Length\",title=\"High Group Similarity\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Intraclass Correlation Coefficient Definition\n",
"\n",
"$$ ICC = \\frac{S_A^2}{S_A^2+S_W^2} $$\n",
"\n",
"where \n",
"- $S_A^2$ is the variance among groups or classes\n",
" - Estimate with the standard deviations of the mean values for each group \n",
"- $S_W^2$ is the variance within groups or classes.\n",
" - Estimate with the average of standard deviations for each group\n",
" \n",
"- 1 means 100% of the variance is between classes\n",
"- 0 means 0% of the variance is between classes"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Intraclass Correlation Coefficient: Values\n",
"\n",
"\n",
"```{r}\n",
"library(\"ICC\")\n",
"\n",
"icVal<-ICCbare(Species,Sepal.Width,data=iris)\n",
"\n",
"ggplot(iris,aes(x=Species,y=Sepal.Width))+\n",
" geom_boxplot()+\n",
" geom_jitter()+\n",
" labs(x=\"Species\",y=\"Sepal Width\",title=sprintf(\"Low Group Similarity\\n ICC:%2.2f\",icVal))+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"\n",
"\n",
"```{r}\n",
"icVal<-ICCbare(Species,Petal.Length,data=iris)\n",
"\n",
"ggplot(iris,aes(x=Species,y=Petal.Length))+\n",
" geom_boxplot()+\n",
" geom_jitter()+\n",
" labs(x=\"Species\",y=\"Sepal Width\",title=sprintf(\"High Group Similarity\\n ICC:%2.2f\",icVal))+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Intraclass Correlation Coefficient: Values for Coin-Flips\n",
"\n",
"We have one biased coin and try to figure out how many flips we need for the ICC to tell the difference to the normal coin\n",
"\n",
"```{r}\n",
"\n",
"name.list<-c(\"Coin A\",\"Coin B\")\n",
"test.data<-plyr::ldply(c(1:length(name.list)),function(class.id) {\n",
" data.frame(name=name.list[class.id],values=runif(100,max=1+2*(class.id-1))>0.5)\n",
"})\n",
"icVal<-ICCbare(name,values,data=test.data)\n",
"ggplot(test.data,aes(x=name,y=values))+\n",
" geom_jitter()+\n",
" labs(x=\"Groups\",y=\"Value\",title=sprintf(\"100 flips\\n ICC:%2.2f\",icVal))+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"\n",
"With many thousands of flips we eventually see a very strong difference but unless it is very strongly biased ICC is a poor indicator for the differences\n",
"\n",
"```{r}\n",
"name.list<-c(\"Coin A\",\"Coin B\")\n",
"test.data<-plyr::ldply(c(1:length(name.list)),function(class.id) {\n",
" data.frame(name=name.list[class.id],values=runif(20000,max=1+2*(class.id-1))>0.5)\n",
"})\n",
"icVal<-ICCbare(name,values,data=test.data)\n",
"ggplot(test.data,aes(x=name,y=values))+\n",
" geom_jitter()+\n",
" labs(x=\"Groups\",y=\"Value\",title=sprintf(\"20,000 flips\\n ICC:%2.2f\",icVal))+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Comparing Groups: Tests\n",
"\n",
"\n",
"Once the reproducibility has been measured, it is possible to compare groups. The idea is to make a test to assess the likelihood that two groups are the same given the data\n",
"\n",
"1. List assumptions\n",
"1. Establish a null hypothesis\n",
" - Usually both groups are the same\n",
"1. Calculate the probability of the observations given the truth of the null hypothesis\n",
" - Requires knowledge of probability distribution of the data\n",
" - Modeling can be exceptionally complicated\n",
" \n",
"\n",
"\n",
"### Loaded Coin\n",
"We have 1 coin from a magic shop\n",
"- our assumptions are\n",
" - we flip and observe flips of coins accurately and independently\n",
" - the coin is invariant and always has the same expected value\n",
"- our null hypothesis is the coin is unbiased $E(\\mathcal{X})=0.5$\n",
"- we can calculate the likelihood of a given observation given the number of flips (p-value)\n",
"\n",
"```{r, results='asis'}\n",
"n.flips<-c(1,5,10)\n",
"cf.table<-data.frame(No.Flips=n.flips,PAH=paste(round(1000*0.5^n.flips)/10,\"%\"))\n",
"names(cf.table)<-c(\"Number of Flips\",\"Probability of All Heads Given Null Hypothesis (p-value)\")\n",
"kable(cf.table)\n",
"```\n",
"\n",
"How good is good enough?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Comparing Groups: Student's T Distribution\n",
"\n",
"Since we do not usually know our distribution very well _or_ have enough samples to create a sufficient probability model\n",
"\n",
"### [Student T Distribution](http://en.wikipedia.org/wiki/Student's_t-distribution)\n",
"We assume the distribution of our stochastic variable is normal (Gaussian) and the t-distribution provides an estimate for the mean of the underlying distribution based on few observations.\n",
"\n",
"- We estimate the likelihood of our observed values assuming they are coming from random observations of a normal process\n",
"\n",
"\n",
"\n",
"### Student T-Test\n",
"\n",
"Incorporates this distribution and provides an easy method for assessing the likelihood that the two given set of observations are coming from the same underlying process (null hypothesis)\n",
"\n",
"- Assume unbiased observations\n",
"- Assume normal distribution"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Multiple Testing Bias\n",
"\n",
"\n",
"Back to the magic coin, let's assume we are trying to publish a paper, we heard a p-value of < 0.05 (5%) was good enough. That means if we get 5 heads we are good!\n",
"\n",
"```{r, results='asis'}\n",
"n.flips<-c(1,4,5)\n",
"cf.table<-data.frame(No.Flips=n.flips,PAH=paste(round(1000*0.5^n.flips)/10,\"%\"))\n",
"names(cf.table)<-c(\"Number of Flips\",\"Probability of All Heads Given Null Hypothesis (p-value)\")\n",
"kable(cf.table)\n",
"```\n",
"```{r, results='asis'}\n",
"n.friends<-c(1,10,20,40,80)\n",
"cfr.table<-data.frame(No.Friends=n.friends,PAH=paste(round((1000*(1-(1-0.5^5)^n.friends)))/10,\"%\"))\n",
"names(cfr.table)<-c(\"Number of Friends Flipping\",\"Probability Someone Flips 5 heads\")\n",
"kable(cfr.table)\n",
"```\n",
"\n",
"Clearly this is not the case, otherwise we could keep flipping coins or ask all of our friends to flip until we got 5 heads and publish\n",
"\n",
"The p-value is only meaningful when the experiment matches what we did. \n",
"- We didn't say the chance of getting 5 heads ever was < 5%\n",
"- We said if we have exactly 5 observations and all of them are heads the likelihood that a fair coin produced that result is <5%\n",
"\n",
"Many [methods](http://en.wikipedia.org/wiki/Multiple_comparisons_problem) to correct, most just involve scaling $p$. The likelihood of a sequence of 5 heads in a row if you perform 10 flips is 5x higher."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Multiple Testing Bias: Experiments\n",
"\n",
"\n",
"This is very bad news for us. We have the ability to quantify all sorts of interesting metrics \n",
"- cell distance to other cells\n",
"- cell oblateness\n",
"- cell distribution oblateness\n",
"\n",
"So lets throw them all into a magical statistics algorithm and push the __publish__ button\n",
"\n",
"\n",
"\n",
"With our p value of less than 0.05 and a study with 10 samples in each group, how does increasing the number of variables affect our result\n",
"\n",
"```{r simcode}\n",
"make.random.data<-function(n.groups=2,n.samples=10,n.vars=1,rand.fun=runif,group.off.fun=function(grp.id) 0) {\n",
" ldply(1:n.groups,function(c.group) {\n",
" data.frame(group=c.group,\n",
" do.call(cbind,llply(1:n.vars,function(c.var) group.off.fun(c.group)+rand.fun(n.samples)))\n",
" )\n",
" })\n",
"}\n",
"# only works for two groups\n",
"all.t.test<-function(in.data) {\n",
" group1<-subset(in.data,group==1)[,-1,drop=F]\n",
" group2<-subset(in.data,group==2)[,-1,drop=F]\n",
" ldply(1:ncol(group1),function(var.id) {\n",
" tres<-t.test(group1[,var.id],group2[,var.id])\n",
" data.frame(var.col=var.id,\n",
" p.val=tres$p.value,\n",
" method=tres$method,\n",
" var.count=ncol(group1),\n",
" sample.count=nrow(in.data))\n",
" }\n",
" )\n",
"}\n",
"# run the entire analysis several times to get an average\n",
"test.random.data<-function(n.test=10,...) {\n",
" ldply(1:n.test,function(c.test) cbind(test.num=c.test,all.t.test(make.random.data(...))))\n",
"}\n",
"```\n",
"```{r rand.sim}\n",
"var.range<-round(seq(1,60,length.out=15))\n",
"test.cnt<-80\n",
"sim.data<-ldply(var.range,function(n.vars) test.random.data(test.cnt,n.vars=n.vars))\n",
"sig.likelihood<-ddply(sim.data,.(var.count),function(c.tests) {\n",
" data.frame(sig.vars=nrow(subset(c.tests,p.val<=0.05))/length(unique(c.tests$test.num)))\n",
"})\n",
"```\n",
"```{r, fig.height=5}\n",
"\n",
"ggplot(sig.likelihood,\n",
" aes(x=var.count,y=sig.vars))+\n",
" geom_point()+geom_line()+\n",
" labs(x=\"Number of Variables in Study\",y=\"Number of Significant \\n (P<0.05) Findings\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Multiple Testing Bias: Correction\n",
"\n",
"Using the simple correction factor (number of tests performed), we can make the significant findings constant again\n",
"```{r, fig.height=5}\n",
"\n",
"sig.likelihood.corr<-ddply(sim.data,.(var.count),function(c.tests) {\n",
" data.frame(sig.vars=nrow(subset(c.tests,p.val<=0.05/var.count))/length(unique(c.tests$test.num)))\n",
"})\n",
"ggplot(sig.likelihood.corr,\n",
" aes(x=var.count,y=sig.vars))+\n",
" geom_point()+geom_line(aes(color=\"Corrected\"))+\n",
" geom_point(data=sig.likelihood)+\n",
" geom_line(data=sig.likelihood,aes(color=\"Non-Corrected\"))+\n",
" geom_hline(yintercept=0.05,color=\"green\",alpha=0.4,size=2)+\n",
" scale_y_sqrt()+\n",
" labs(x=\"Number of Variables in Study\",y=\"Number of Significant \\n (P<0.05) Findings\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"\n",
"So no harm done there we just add this correction factor right?\n",
"Well what if we have exactly one variable with shift of 1.0 standard deviations from the other.\n",
"\n",
"```{r rand.sim.diff}\n",
"var.range<-round(seq(10,60,length.out=10))\n",
"test.cnt<-100\n",
"one.diff.sample<-function(grp.id) ifelse(grp.id==2,.10,0)\n",
"sim.data.diff<-ldply(var.range,function(n.samples) \n",
" test.random.data(test.cnt,n.samples=n.samples,\n",
" rand.fun=function(n.cnt) rnorm(n.cnt,mean=1,sd=0.1),\n",
" group.off.fun=one.diff.sample))\n",
"```\n",
"\n",
"```{r, fig.height=5}\n",
"ggplot(sim.data.diff,aes(x=sample.count,y=p.val))+\n",
" geom_point()+\n",
" geom_smooth(aes(color=\" 1 Variable\"))+\n",
" geom_hline(yintercept=0.05,color=\"green\",alpha=0.4,size=2)+\n",
" labs(x=\"Number of Samples in Study\",y=\"P-Value for a 10% Difference\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Multiple Testing Bias: Sample Size\n",
"\n",
"```{r rand.sim.mcsample}\n",
"var.range<-c(1,5,10,20,100) # variable count\n",
"sim.data.psig<-ldply(var.range,function(c.vcnt) {\n",
" cbind(var.count=c.vcnt,ddply(sim.data.diff,.(sample.count),function(c.sample) \n",
" data.frame(prob.sig=nrow(subset(c.sample,p.val<=0.05/c.vcnt))/nrow(c.sample))\n",
" ))\n",
"})\n",
"\n",
"```\n",
"```{r, fig.height=9,fig.width=12}\n",
"ggplot(sim.data.psig,aes(x=sample.count,y=100*prob.sig))+\n",
" geom_line(aes(color=as.factor(var.count)),size=2)+\n",
" ylim(0,100)+\n",
" labs(x=\"Number of Samples in Study\",y=\"Probability of Finding\\n Significant Variable (%)\",color=\"Variables\")+\n",
" theme_bw(20)\n",
"\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Predicting and Validating\n",
"\n",
"\n",
"\n",
"- Borrowed from http://peekaboo-vision.blogspot.ch/2013/01/machine-learning-cheat-sheet-for-scikit.html\n",
"\n",
"### Main Categories\n",
"\n",
"- Classification\n",
"- Regression\n",
"- Clustering\n",
"- Dimensionality Reduction"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Overview\n",
"\n",
"\n",
"Basically all of these are ultimately functions which map inputs to outputs. \n",
"\n",
"The input could be \n",
"\n",
"- an image\n",
"- a point\n",
"- a feature vector\n",
"- or a multidimensional tensor\n",
"\n",
"The output is\n",
"\n",
"- a value (regression)\n",
"- a classification (classification)\n",
"- a group (clustering)\n",
"- a vector / matrix / tensor with _fewer_ degrees of input / less noise as the original data (dimensionality reduction)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Overfitting\n",
"\n",
"The most serious problem with machine learning and such approachs is overfitting your model to your data. Particularly as models get increasingly complex (random forest, neural networks, deep learning, ...), it becomes more and more difficult to apply common sense or even understand exactly what a model is doing and why a given answer is produced. \n",
"\n",
"```python\n",
"magic_classifier = {}\n",
"# training\n",
"magic_classifier['Dog'] = 'Animal'\n",
"magic_classifier['Bob'] = 'Person'\n",
"magic_classifier['Fish'] = 'Animal'\n",
"```\n",
"\n",
"Now use this classifier, on the training data it works really well\n",
"\n",
"```python\n",
"magic_classifier['Dog'] == 'Animal' # true, 1/1 so far!\n",
"magic_classifier['Bob'] == 'Person' # true, 2/2 still perfect!\n",
"magic_classifier['Fish'] == 'Animal' # true, 3/3, wow!\n",
"```\n",
"\n",
"On new data it doesn't work at all, it doesn't even execute.\n",
"\n",
"```python\n",
"magic_classifier['Octopus'] == 'Animal' # exception?! but it was working so well\n",
"magic_classifier['Dan'] == 'Person' # exception?! \n",
"```\n",
"\n",
"The above example appeared to be a perfect trainer for mapping names to animals or people, but it just memorized the inputs and reproduced them at the output and so didn't actually learn anything, it just copied."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Validation\n",
"\n",
"\n",
"Relevant for each of the categories, but applied in a slightly different way depending on the group. The idea is two divide the dataset into groups called training and validation or ideally training, validation, and testing. The analysis is then \n",
"\n",
"- developed on __training__\n",
"- iteratively validated on __validation__\n",
"- ultimately tested on __testing__"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Concrete Example: Classifying Flowers\n",
"\n",
"\n",
"Here we return to the iris data set and try to automatically classify flowers\n",
"\n",
"```{r, results = 'asis'}\n",
"iris %>% sample_n(5) %>% kable(,digits=2)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Dividing the data\n",
"\n",
"We first decide on a split, in this case 60%, 30%, 10% for training, validation, and testing and randomly divide up the data.\n",
"\n",
"```{r, echo=T, results='asis'}\n",
"div.iris<-iris %>%\n",
" mutate(\n",
" # generate a random number uniformally between 0 and 1\n",
" rand_value = runif(nrow(iris)),\n",
" # divide the data based on how high this number is into different groups\n",
" data_div = ifelse(rand_value<0.6,\"Training\",\n",
" ifelse(rand_value<0.9,\"Validation\",\n",
" \"Testing\")\n",
" )\n",
" ) %>% select(-rand_value) # we don't need this anymore\n",
"div.iris %>% sample_n(4) %>% kable(digits=2)\n",
"```\n",
"\n",
"Here are two relevant variables plotted against each other\n",
"\n",
"```{r}\n",
"ggplot(div.iris,aes(Sepal.Length,Sepal.Width))+\n",
" geom_point(aes(shape=data_div,color=Species),size=2)+\n",
" labs(shape=\"Type\")+\n",
" facet_grid(~data_div)+\n",
" coord_equal()+\n",
" theme_bw(10)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Using a simple decision tree\n",
"\n",
"Making a decision tree can be done by providing the output (```class```) as a function of the input, in this case just a combination of _x1_ and _y1_ (```~x1+y1```). From this a \n",
"```{r, echo=T}\n",
"library(rpart)\n",
"library(rpart.plot)\n",
"training.data <- div.iris %>% subset(data_div == \"Training\")\n",
"dec.tree<-rpart(Species~Sepal.Length+Sepal.Width,data=iris)\n",
"```\n",
"\n",
"A tree can be visualized graphically as a trunk (the top most node) dividing progressively into smaller subnodes\n",
"\n",
"```{r}\n",
"prp(dec.tree)\n",
"```\n",
"\n",
"or as a list of rules to apply\n",
"```{r, results='markdown'}\n",
"print(dec.tree)\n",
"```\n",
"\n",
"Overlaying with the prediction data looks good\n",
"\n",
"```{r}\n",
"match_range<-function(ivec,n_length=10) seq(from=min(ivec),to=max(ivec),length=n_length)\n",
"pred.map<-expand.grid(Sepal.Length = match_range(training.data$Sepal.Length), \n",
" Sepal.Width = match_range(training.data$Sepal.Width)) \n",
"pred.map$pred_class<-predict(dec.tree,pred.map,type=\"class\")\n",
"\n",
"training.data %>% \n",
" mutate(pred_class=predict(dec.tree,training.data,type=\"class\"),\n",
" class_result=ifelse(as.character(pred_class)==as.character(Species),\"Correct\",\"Incorrect\")\n",
" )->training.data\n",
"ggplot(pred.map,aes(Sepal.Length,Sepal.Width))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=training.data,aes(color=Species,size=class_result))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"It struggles more with the validation data since it has never seen it before and it's not quite the same as the training\n",
"\n",
"```{r}\n",
"valid.data<-div.iris %>% subset(data_div == \"Validation\")\n",
"valid.data %>%\n",
" mutate(pred_class=predict(dec.tree,valid.data,type=\"class\"),\n",
" class_result=ifelse(as.character(pred_class)==as.character(Species),\"Correct\",\"Incorrect\")\n",
" )->valid.data\n",
"\n",
"ggplot(pred.map,aes(Sepal.Length,Sepal.Width))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=valid.data,aes(color=Species,size=class_result))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"The test data (__normally we would not look at it at all right now and wait until the very end__) looks even worse and an even smaller fraction is correctly matched.\n",
"\n",
"```{r}\n",
"valid.data<-div.iris %>% subset(data_div == \"Testing\")\n",
"valid.data %>%\n",
" mutate(pred_class=predict(dec.tree,valid.data,type=\"class\"),\n",
" class_result=ifelse(as.character(pred_class)==as.character(Species),\"Correct\",\"Incorrect\")\n",
" )->valid.data\n",
"\n",
"ggplot(pred.map,aes(Sepal.Length,Sepal.Width))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=valid.data,aes(color=Species,size=class_result))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Tricky Concrete Example: Classification\n",
"\n",
"\n",
"Taking a list of points (feature vectors) where each has an $x1$ and a $y1$ coordinate and a classification (_Happy_ or _Sad_), we can show the data as a table\n",
"\n",
"```{r, results = 'asis'}\n",
"spiral.pts <- expand.grid(x = -50:50, y = -50:50) %>% \n",
" subset((x==0) | (y==0)) %>%\n",
" mutate(\n",
" r = sqrt(x^2+y^2),\n",
" th = r/60*2*pi,\n",
" x1 = cos(th)*x-sin(th)*y,\n",
" y1 = sin(th)*x+cos(th)*y,\n",
" class = ifelse(x==0,\"Happy\",\"Sad\")\n",
" ) %>% \n",
" select(x1,y1,class)\n",
"kable(spiral.pts %>% sample_n(5),digits=2)\n",
"```\n",
"\n",
"Or graphically\n",
"\n",
"```{r}\n",
"ggplot(spiral.pts,aes(x1,y1,color=class))+\n",
" geom_point()+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"You can play around with neural networks and this data set at [TensorFlow Playground](playground.tensorflow.org)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Dividing the data\n",
"\n",
"We first decide on a split, in this case 60%, 30%, 10% for training, validation, and testing and randomly divide up the data.\n",
"\n",
"```{r, echo=T, results='asis'}\n",
"div.spiral.pts<-spiral.pts %>%\n",
" mutate(\n",
" # generate a random number uniformally between 0 and 1\n",
" rand_value = runif(nrow(spiral.pts)),\n",
" # divide the data based on how high this number is into different groups\n",
" data_div = ifelse(rand_value<0.6,\"Training\",\n",
" ifelse(rand_value<0.9,\"Validation\",\n",
" \"Testing\")\n",
" )\n",
" ) %>% select(-rand_value) # we don't need this anymore\n",
"div.spiral.pts %>% sample_n(4) %>% kable(digits=2)\n",
"```\n",
"\n",
"```{r}\n",
"ggplot(div.spiral.pts,aes(x1,y1))+\n",
" geom_point(aes(shape=data_div,color=class),size=2)+\n",
" labs(shape=\"Type\")+\n",
" facet_wrap(~data_div)+\n",
" coord_equal()+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Using a simple decision tree\n",
"\n",
"Making a decision tree can be done by providing the output (```class```) as a function of the input, in this case just a combination of _x1_ and _y1_ (```~x1+y1```). From this a \n",
"```{r, echo=T}\n",
"library(rpart)\n",
"library(rpart.plot)\n",
"training.data <- div.spiral.pts %>% subset(data_div == \"Training\")\n",
"dec.tree<-rpart(class~x1+y1,data=training.data)\n",
"```\n",
"\n",
"A tree can be visualized graphically as a trunk (the top most node) dividing progressively into smaller subnodes\n",
"\n",
"```{r}\n",
"prp(dec.tree)\n",
"```\n",
"\n",
"or as a list of rules to apply\n",
"```{r, results='markdown'}\n",
"print(dec.tree)\n",
"```\n",
"\n",
"Overlaying with the prediction data looks good\n",
"\n",
"```{r}\n",
"pred.map<-expand.grid(x1 = -50:50, y1 = -50:50) \n",
"pred.map$pred_class<-ifelse(predict(dec.tree,pred.map)[,1]>0.5,\"Happy\",\"Sad\")\n",
"\n",
"training.data$pred_class<-ifelse(predict(dec.tree,training.data)[,1]>0.5,\"Happy\",\"Sad\")\n",
"ggplot(pred.map,aes(x1,y1))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=training.data,aes(color=class,size=(pred_class!=class)))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"It struggles more with the validation data since it has never seen it before and it's not quite the same as the training\n",
"\n",
"```{r}\n",
"valid.data<-div.spiral.pts %>% subset(data_div == \"Validation\")\n",
"valid.data$pred_class<-ifelse(predict(dec.tree,valid.data)[,1]>0.5,\"Happy\",\"Sad\")\n",
"ggplot(pred.map,aes(x1,y1))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=valid.data,aes(color=class,size=(pred_class!=class)))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"The test data (__normally we would not look at it at all right now and wait until the very end__) looks even worse and an even smaller fraction is correctly matched.\n",
"\n",
"```{r}\n",
"valid.data<-div.spiral.pts %>% subset(data_div == \"Testing\")\n",
"valid.data$pred_class<-ifelse(predict(dec.tree,valid.data)[,1]>0.5,\"Happy\",\"Sad\")\n",
"ggplot(pred.map,aes(x1,y1))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=valid.data,aes(color=class,size=(pred_class!=class)))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"We can choose to make more complicated trees by changing the function to something more detailed like\n",
"\n",
"$$ class = x1+y1+x1^2+y1^2+\\sin(x1/5)+\\sin(y1/5) $$\n",
"\n",
"```{r, echo=T}\n",
"dec.tree<-rpart(class~x1+y1+x1^2+y1^2+sin(x1/5)+sin(y1/5),data=training.data)\n",
"prp(dec.tree)\n",
"```\n",
"\n",
"```{r}\n",
"pred.map$pred_class<-ifelse(predict(dec.tree,pred.map)[,1]>0.5,\"Happy\",\"Sad\")\n",
"\n",
"training.data$pred_class<-ifelse(predict(dec.tree,training.data)[,1]>0.5,\"Happy\",\"Sad\")\n",
"ggplot(pred.map,aes(x1,y1))+\n",
" geom_tile(aes(fill=pred_class),alpha=0.5)+\n",
" geom_point(data=training.data,aes(color=class,size=(pred_class!=class)))+\n",
" labs(fill=\"Predicted\",size = \"Incorrectly\\nLabeled\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Parameters\n",
"\n",
"```{r, show_chain_block}\n",
"library(igraph)\n",
"make.im.proc.chain<-function(root.node=\"Raw\\nImages\",filters=c(),filter.parms=c(),\n",
" segmentation=c(),segmentation.parms=c(),\n",
" analysis=c(),analysis.parms=c()) {\n",
" node.names<-c(\"Raw\\nImages\",\n",
" filter.parms,filters,\n",
" segmentation.parms,segmentation,\n",
" analysis.parms,analysis\n",
" \n",
" )\n",
" \n",
" c.mat<-matrix(0,length(node.names),length(node.names))\n",
" colnames(c.mat)<-node.names\n",
" rownames(c.mat)<-node.names\n",
" \n",
" \n",
" for(cFilt in filters) {\n",
" c.mat[\"Raw\\nImages\",cFilt]<-1\n",
" for(cParm in filter.parms) c.mat[cParm,cFilt]<-1\n",
" for(cSeg in segmentation) {\n",
" c.mat[cFilt,cSeg]<-1\n",
" for(cParm in segmentation.parms) c.mat[cParm,cSeg]<-1\n",
" for(cAnal in analysis) {\n",
" c.mat[cSeg,cAnal]<-1\n",
" for(cParm in analysis.parms) c.mat[cParm,cAnal]<-1\n",
" }\n",
" }\n",
" }\n",
" \n",
" \n",
" g<-graph.adjacency(c.mat,mode=\"directed\")\n",
" V(g)$degree <- degree(g)\n",
" V(g)$label <- V(g)$name\n",
" V(g)$color <- \"lightblue\"\n",
" V(g)[\"Raw\\nImages\"]$color<-\"lightgreen\"\n",
" for(cAnal in analysis) V(g)[cAnal]$color<-\"pink\"\n",
" V(g)$size<-30\n",
" for(cParam in c(filter.parms,segmentation.parms,analysis.parms)) {\n",
" V(g)[cParam]$color<-\"grey\"\n",
" V(g)[cParam]$size<-25\n",
" }\n",
" E(g)$width<-2\n",
" g\n",
" }\n",
"```\n",
"How does a standard image processing chain look?\n",
"```{r , fig.height=9}\n",
"g<-make.im.proc.chain(filters=c(\"Gaussian\\nFilter\"),\n",
" filter.parms=c(\"3x3\\nNeighbors\",\"0.5 Sigma\"),\n",
" segmentation=c(\"Threshold\"),\n",
" segmentation.parms=c(\"100\"),\n",
" analysis=c(\"Shape\\nAnalysis\",\"Thickness\\nAnalysis\")\n",
" )\n",
"plot(g)#,layout=layout.circle) #, layout=layout.circle)# layout.fruchterman.reingold)# layout.kamada.kawai) \n",
"```\n",
"\n",
"\n",
"\n",
"- Green are the images we start with (measurements)\n",
"- Blue are processing steps\n",
"- Gray are use input parameters\n",
"- Pink are the outputs"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# The Full Chain\n",
"\n",
"```{r , fig.height=8,fig.width=18}\n",
"library(igraph)\n",
"g<-make.im.proc.chain(filters=c(\"Gaussian\\nFilter\",\"Median\\nFilter\",\"Diffusion\\nFilter\",\"No\\nFilter\",\n",
" \"Laplacian\\nFilter\"),\n",
" segmentation=c(\"Threshold\",\"Hysteresis\\nThreshold\",\"Automated\"),\n",
" analysis=c(\"Shape\\nAnalysis\",\"Thickness\\nAnalysis\",\"Distribution\\nAnalysis\",\n",
" \"Skeleton\\nAnalysis\",\"2 Point\\nCorr\",\"Curvature\")\n",
" )\n",
"plot(g,layout=layout.reingold.tilford) #, layout=layout.circle)# layout.fruchterman.reingold)# layout.kamada.kawai) \n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# The Full Chain (with Parameters)\n",
"\n",
"```{r , fig.height=9,fig.width=9}\n",
"g<-make.im.proc.chain(filters=c(\"Gaussian\\nFilter\",\"Median\\nFilter\",\"Diffusion\\nFilter\"),\n",
" filter.parms=c(\"3x3\\nNeighbors\",\"5x5\\nNeighbors\",\"7x7\\nNeighbors\",\n",
" \"0.5 Sigma\",\"1.0 Sigma\",\"1.2 Sigma\"),\n",
" segmentation=c(\"Threshold\",\"Hysteresis\\nThreshold\",\"Automated\"),\n",
" segmentation.parms=paste(seq(90,110,length.out=3)),\n",
" analysis=c(\"Shape\\nAnalysis\",\"Thickness\\nAnalysis\",\"Distribution\\nAnalysis\",\"Skeleton\\nAnalysis\",\"2 Point\\nCorr\")\n",
" )\n",
"plot(g,layout=layout.lgl(g,maxiter=10000,root=1)) #, layout=layout.circle)# layout.fruchterman.reingold)# layout.kamada.kawai) \n",
"```\n",
"\n",
"\n",
"\n",
"- A __mess__, over 1080 combinations for just one sample (not even exploring a very large range of threshold values)\n",
"- To calculate this for even one sample can take days (weeks, years) \n",
" - 512 x 512 x 512 foam sample $\\rightarrow$ 12 weeks of processing time\n",
" - 1024 x 1024 x 1024 femur bone $\\rightarrow$ 1.9 years \n",
"- Not all samples are the same\n",
"- Once the analysis is run we have a ton of data\n",
" - femur bone $\\rightarrow$ 60 million shapes analyzed\n",
"- What do we even want? \n",
"- How do we judge the different results?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Qualitative vs Quantitative\n",
"\n",
"\n",
"Given the complexity of the tree, we need to do some pruning\n",
"\n",
"### Qualitative Assessment\n",
" - Evaluating metrics using visual feedback\n",
" - Compare with expectations from other independent techniques or approach\n",
" - Are there artifacts which are included in the output?\n",
" - Do the shapes look correct?\n",
" - Are they distributed as expected?\n",
" - Is their orientation meaningful?\n",
" \n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Quantitative Metrics\n",
"\n",
"\n",
"With a quantitative approach, we can calculate the specific shape or distribution metrics on the sample with each parameter and establish the relationship between parameter and metric. \n",
"\n",
"### Parameter Sweep\n",
"\n",
"The way we do this is usually a parameter sweep which means taking one (or more) parameters and varying them between the reasonable bounds (judged qualitatively).\n",
"\n",
"\n",
"\n",
"```{r, load-metrics}\n",
"source('../common/shapeAnalysisProcess.R')\n",
"source('../common/commonReportFunctions.R')\n",
"# read and correct the coordinate system\n",
"thresh.fun<-function(x) {\n",
" pth<-rev(strsplit(x,\"/\")[[1]])[2]\n",
" t<-strsplit(pth,\"_\")[[1]][3]\n",
" as.numeric(substring(t,2,nchar(t)))\n",
"}\n",
"readfcn<-function(x) cbind(compare.foam.corrected(x,\n",
" checkProj=F\n",
" #force.scale=0.011 # force voxel size to be 11um\n",
" ),\n",
" thresh=thresh.fun(x) # how to parse the sample names\n",
" )\n",
"# Where are the csv files located\n",
"rootDir<-\"../common/data/mcastudy\" \n",
"clpor.files<-Sys.glob(paste(rootDir,\"/a*/lacun_0.csv\",sep=\"/\")) # list all of the files\n",
"\n",
"# Read in all of the files\n",
"all.lacun<-ldply(clpor.files,readfcn,.parallel=T)\n",
"```\n",
"\n",
"```{r , fig.height=5}\n",
" ggplot(all.lacun,aes(y=VOLUME*1e9,x=thresh))+\n",
" geom_jitter(alpha=0.1)+geom_smooth()+\n",
" theme_bw(24)+labs(y=\"Volume (um3)\",x=\"Threshold Value\",color=\"Threshold\")+ylim(0,1000)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Is it always the same?\n",
"\n",
"\n",
"\n",
"```{r , fig.height=5}\n",
" ggplot(subset(all.lacun,thresh %% 1000==0),aes(y=VOLUME*1e9,x=as.factor(thresh)))+\n",
" geom_violin()+\n",
" theme_bw(24)+labs(y=\"Volume (um3)\",x=\"Threshold Value\",color=\"Threshold\")+ylim(0,1000)\n",
"```\n",
"\n",
"\n",
"\n",
"```{r , fig.height=5}\n",
" ggplot(all.lacun,aes(y=PCA1_Z,x=thresh))+\n",
" geom_jitter(alpha=0.1)+geom_smooth()+\n",
" theme_bw(24)+labs(y=\"Orientation\",x=\"Threshold Value\",color=\"Threshold\")\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Sensitivity\n",
"\n",
"Sensitivity is defined in control system theory as the change in the value of an output against the change in the input.\n",
"$$ S = \\frac{|\\Delta \\textrm{Metric}|}{|\\Delta \\textrm{Parameter}|} $$\n",
"\n",
"Such a strict definition is not particularly useful for image processing since a threshold has a unit of intensity and a metric might be volume which has $m^3$ so the sensitivity becomes volume per intensity. \n",
"\n",
" \n",
"\n",
"### Practical Sensitivity\n",
"\n",
"A more common approach is to estimate the variation in this parameter between images or within a single image (automatic threshold methods can be useful for this) and define the sensitivity based on this variation. It is also common to normalize it with the mean value so the result is a percentage.\n",
"\n",
"$$ S = \\frac{max(\\textrm{Metric})-min(\\textrm{Metric})}{avg(\\textrm{Metric})} $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Sensitivity: Real Measurements\n",
"\n",
"\n",
"In this graph it is magnitude of the slope. The steeper the slope the more the metric changes given a small change in the parameter\n",
"\n",
"```{r , fig.height=5}\n",
"poresum<-function(all.data) ddply(all.data,.(thresh),function(c.sample) {\n",
" data.frame(Count=nrow(c.sample),\n",
" Volume=mean(c.sample$VOLUME*1e9),\n",
" Stretch=mean(c.sample$AISO),\n",
" Oblateness=mean(c.sample$OBLATENESS),\n",
" #Lacuna_Density_mm=1/mean(c.sample$DENSITY_CNT),\n",
" Length=mean(c.sample$PROJ_PCA1*1000),\n",
" Width=mean(c.sample$PROJ_PCA2*1000),\n",
" Height=mean(c.sample$PROJ_PCA3*1000),\n",
" Orientation=mean(abs(c.sample$PCA1_Z)))\n",
"})\n",
"comb.summary<-cbind(poresum(all.lacun),Phase=\"Lacuna\")\n",
"splot<-ggplot(comb.summary,aes(x=thresh))\n",
"splot+geom_line(aes(y=Count))+geom_point(aes(y=Count))+scale_y_log10()+\n",
" theme_bw(24)+labs(y=\"Object Count\",x=\"Threshold\",color=\"Phase\")\n",
"```\n",
"\n",
"Comparing Different Variables we see that the best (lowest) value for the count sensitivity is the highest for the volume and anisotropy. \n",
"\n",
"```{r , fig.height=5}\n",
"calc.sens<-function(in.df) {\n",
" data.frame(sens.cnt=100*with(in.df,(max(Count)-min(Count))/mean(Count)),\n",
" sens.vol=100*with(in.df,(max(Volume)-min(Volume))/mean(Volume)),\n",
" sens.stretch=100*with(in.df,(max(Stretch)-min(Stretch))/mean(Stretch))\n",
" )\n",
"}\n",
"sens.summary<-ddply.cutcols(comb.summary,.(cut_interval(thresh,5)),calc.sens)\n",
"ggplot(sens.summary,aes(x=thresh))+\n",
" geom_line(aes(y=sens.cnt,color=\"Count\"))+\n",
" geom_line(aes(y=sens.vol,color=\"Volume\"))+\n",
" geom_line(aes(y=sens.stretch,color=\"Anisotropy\"))+\n",
" labs(x=\"Threshold\",y=\"Sensitivity (%)\",color=\"Metric\")+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"### Which metric is more important?"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Unit Testing\n",
"\n",
"In computer programming, unit testing is a method by which individual units of source code, sets of one or more computer program modules together with associated control data, usage procedures, and operating procedures, are tested to determine if they are fit for use.\n",
"\n",
"- Intuitively, one can view a unit as the smallest testable part of an application\n",
"- Unit testing is possible with every language\n",
"- Most (Java, C++, Matlab, R, Python) have built in support for automated testing and reporting\n",
"\n",
"The first requirement for unit testing to work well is to have you tools divided up into small independent parts (functions)\n",
"- Each part can then be tested independently (unit testing)\n",
" - If the tests are well done, units can be changed and tested independently\n",
" - Makes upgrading or expanding tools _easy_\n",
"- The entire path can be tested (integration testing)\n",
" - Catches mistakes in integration or _glue_\n",
"\n",
"\n",
"\n",
"Ideally with realistic but simulated test data\n",
"- The utility of the testing is only as good as the tests you make"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## Example\n",
"\n",
"- Given the following function\n",
"\n",
"```function vxCnt=countVoxs(inImage)```\n",
"\n",
"- We can right the following tests\n",
" - testEmpty2d\n",
" \n",
"```assert countVoxs(zeros(3,3)) == 0```\n",
"\n",
" - testEmpty3d\n",
" \n",
"```assert countVoxs(zeros(3,3,3)) == 0```\n",
"\n",
" - testDiag3d\n",
" \n",
"```assert countVoxs(eye(3)) == 3```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing: Examples\n",
"\n",
"\n",
"- Given the following function\n",
"```function shapeTable=shapeAnalysis(inImage)```\n",
"We should decompose the task into sub-components\n",
"- ```function clImage=componentLabel(inImage)```\n",
"\n",
"- ```function objInfo=analyzeObject(inObject)```\n",
" - ```function vxCnt=countVoxs(inObject)``` \n",
" - ```function covMat=calculateCOV(inObject)```\n",
" - ```function shapeT=calcShapeT(covMat)```\n",
" - ```function angle=calcOrientation(shapeT)```\n",
" - ```function aniso=calcAnisotropy(shapeT)```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing in ImageJ\n",
"\n",
"\n",
"[On this page](https://github.com/imagej/ij1-tests/blob/master/src/test/java/ij/VirtualStackTest.java)\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing in KNIME\n",
"\n",
"[Read more](https://tech.knime.org/community/developers) and [Here](https://www.knime.org/files/kos-11/KNIME_Testing.pdf)\n",
"The Java-based unit-testing can be used (JUnit) before any of the plugins are compiled, additionally entire workflows can be made to test the objects using special testing nodes like\n",
"- difference node (check the if two values are different)\n",
"\n",
"\n",
"\n",
"- disturber node (insert random / missing values to determine fault tolerance)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing in Python\n",
"\n",
"## PyTest\n",
"Packages like PyTest are well suited for larger projects where you make a set of specific tests to run each time the project is updated. \n",
"\n",
"### Scikit Image\n",
"https://github.com/scikit-image/scikit-image/tree/master/skimage\n",
"\n",
"- Test Watershed https://github.com/scikit-image/scikit-image/blob/16d3fd07e7d882d7f6b74e8dc4028ff946ac7e63/skimage/morphology/tests/test_watershed.py#L79\n",
"\n",
"- Test Connected Components https://github.com/scikit-image/scikit-image/blob/16d3fd07e7d882d7f6b74e8dc4028ff946ac7e63/skimage/morphology/tests/test_ccomp.py#L13\n",
"\n",
"```python\n",
"class TestWatershed(unittest.TestCase):\n",
" eight = np.ones((3, 3), bool)\n",
"\n",
" def test_watershed01(self):\n",
" \"watershed 1\"\n",
" data = np.array([[0, 0, 0, 0, 0, 0, 0],\n",
" [0, 0, 0, 0, 0, 0, 0],\n",
" [0, 0, 0, 0, 0, 0, 0],\n",
" [0, 1, 1, 1, 1, 1, 0],\n",
" [0, 1, 0, 0, 0, 1, 0],\n",
" [0, 1, 0, 0, 0, 1, 0],\n",
" [0, 1, 0, 0, 0, 1, 0],\n",
" [0, 1, 1, 1, 1, 1, 0],\n",
" [0, 0, 0, 0, 0, 0, 0],\n",
" [0, 0, 0, 0, 0, 0, 0]], np.uint8)\n",
" markers = np.array([[ -1, 0, 0, 0, 0, 0, 0],\n",
" [0, 0, 0, 0, 0, 0, 0],\n",
" [0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 1, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0],\n",
" [ 0, 0, 0, 0, 0, 0, 0]],\n",
" np.int8)\n",
" out = watershed(data, markers, self.eight)\n",
" expected = np.array([[-1, -1, -1, -1, -1, -1, -1],\n",
" [-1, -1, -1, -1, -1, -1, -1],\n",
" [-1, -1, -1, -1, -1, -1, -1],\n",
" [-1, 1, 1, 1, 1, 1, -1],\n",
" [-1, 1, 1, 1, 1, 1, -1],\n",
" [-1, 1, 1, 1, 1, 1, -1],\n",
" [-1, 1, 1, 1, 1, 1, -1],\n",
" [-1, 1, 1, 1, 1, 1, -1],\n",
" [-1, -1, -1, -1, -1, -1, -1],\n",
" [-1, -1, -1, -1, -1, -1, -1]])\n",
" error = diff(expected, out)\n",
" assert error < eps\n",
"```\n",
"\n",
"## DocTests\n",
"\n",
"Keep the tests in the code itself: https://github.com/scikit-image/scikit-image/blob/16d3fd07e7d882d7f6b74e8dc4028ff946ac7e63/skimage/filters/thresholding.py#L886\n",
"```python\n",
"def apply_hysteresis_threshold(image, low, high):\n",
" \"\"\"Apply hysteresis thresholding to `image`.\n",
" This algorithm finds regions where `image` is greater than `high`\n",
" OR `image` is greater than `low` *and* that region is connected to\n",
" a region greater than `high`.\n",
" Parameters\n",
" ----------\n",
" image : array, shape (M,[ N, ..., P])\n",
" Grayscale input image.\n",
" low : float, or array of same shape as `image`\n",
" Lower threshold.\n",
" high : float, or array of same shape as `image`\n",
" Higher threshold.\n",
" Returns\n",
" -------\n",
" thresholded : array of bool, same shape as `image`\n",
" Array in which `True` indicates the locations where `image`\n",
" was above the hysteresis threshold.\n",
" Examples\n",
" --------\n",
" >>> image = np.array([1, 2, 3, 2, 1, 2, 1, 3, 2])\n",
" >>> apply_hysteresis_threshold(image, 1.5, 2.5).astype(int)\n",
" array([0, 1, 1, 1, 0, 0, 0, 1, 1])\n",
" References\n",
" ----------\n",
" .. [1] J. Canny. A computational approach to edge detection.\n",
" IEEE Transactions on Pattern Analysis and Machine Intelligence.\n",
" 1986; vol. 8, pp.679-698.\n",
" DOI: 10.1109/TPAMI.1986.4767851\n",
" \"\"\"\n",
" low = np.clip(low, a_min=None, a_max=high) # ensure low always below high\n",
" mask_low = image > low\n",
" mask_high = image > high\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing Jupyter\n",
"Working primarily in notebooks makes regular testing more difficult but not impossible. If we employ a few simple tricks we can use doctesting seamlessly inside of Jupyter. We can make what in python is called an annotatation to setup this code. "
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"outputs": [],
"source": [
"import doctest\n",
"import copy\n",
"import functools\n",
"\n",
"def autotest(func):\n",
" globs = copy.copy(globals())\n",
" globs.update({func.__name__: func})\n",
" doctest.run_docstring_examples(\n",
" func, globs, verbose=True, name=func.__name__)\n",
" return func"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Finding tests in add_5\n",
"Trying:\n",
" add_5(5)\n",
"Expecting:\n",
" 10\n",
"ok\n"
]
}
],
"source": [
"@autotest\n",
"def add_5(x):\n",
" \"\"\"\n",
" Function adds 5\n",
" >>> add_5(5)\n",
" 10\n",
" \"\"\"\n",
" return x+5\n"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Finding tests in simple_label\n",
"Trying:\n",
" test_img = np.eye(3)\n",
"Expecting nothing\n",
"ok\n",
"Trying:\n",
" test_img\n",
"Expecting:\n",
" array([[1., 0., 0.],\n",
" [0., 1., 0.],\n",
" [0., 0., 1.]])\n",
"ok\n",
"Trying:\n",
" simple_label(test_img)\n",
"Expecting:\n",
" array([[1, 0, 0],\n",
" [0, 1, 0],\n",
" [0, 0, 1]], dtype=int64)\n",
"ok\n",
"Trying:\n",
" test_img[1,1] = 0\n",
"Expecting nothing\n",
"ok\n",
"Trying:\n",
" simple_label(test_img)\n",
"Expecting:\n",
" array([[1, 0, 0],\n",
" [0, 0, 0],\n",
" [0, 0, 2]], dtype=int64)\n",
"ok\n"
]
}
],
"source": [
"from skimage.measure import label\n",
"import numpy as np\n",
"@autotest\n",
"def simple_label(x):\n",
" \"\"\"\n",
" Label an image\n",
" >>> test_img = np.eye(3)\n",
" >>> test_img\n",
" array([[1., 0., 0.],\n",
" [0., 1., 0.],\n",
" [0., 0., 1.]])\n",
" >>> simple_label(test_img)\n",
" array([[1, 0, 0],\n",
" [0, 1, 0],\n",
" [0, 0, 1]], dtype=int64)\n",
" >>> test_img[1,1] = 0\n",
" >>> simple_label(test_img)\n",
" array([[1, 0, 0],\n",
" [0, 0, 0],\n",
" [0, 0, 2]], dtype=int64)\n",
" \"\"\"\n",
" return label(x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Unit Testing Matlab\n",
"https://www.mathworks.com/help/matlab/matlab-unit-test-framework.html\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Test Driven Programming\n",
"\n",
"\n",
"Test Driven programming is a style or approach to programming where the tests are written before the functional code. Like very concrete specifications. It is easy to estimate how much time is left since you can automatically see how many of the tests have been passed. You and your collaborators are clear on the utility of the system.\n",
"\n",
"1. shapeAnalysis must give an anisotropy of 0 when we input a sphere\n",
"1. shapeAnalysis must give the center of volume within 0.5 pixels\n",
"1. shapeAnalysis must run on a 1000x1000 image in 30 seconds"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Continuous Integration\n",
"Conntinuous integration is the process of running tests automatically everytime changes are made. This is possible to setup inside of many IDEs and is offered as a commercial service from companies like CircleCI and Travis. We use them for the QBI course to make sure all of the code in the slides are correct. Projects like scikit-image use them to ensure changes that are made do not break existing code without requiring manual checks"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Visualization\n",
"\n",
"\n",
"One of the biggest problems with _big_ sciences is trying to visualize a lot of heterogeneous data. \n",
"\n",
"- Tables are difficult to interpret\n",
"- 3D Visualizations are very difficult to compare visually \n",
"- Contradictory necessity of simple single value results and all of the data to look for trends and find problems"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Bad Graphs\n",
"\n",
"There are too many graphs which say\n",
"\n",
"- âmy data is very complicatedâ\n",
"- âI know how to use __ toolbox in Matlab/R/Mathematicaâ\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"- Most programs by default make poor plots\n",
"- Good visualizations takes time\n",
"\n",
"\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Key Ideas\n",
"\n",
"\n",
"1. What is my message? \n",
"1. Does the graphic communicate it clearly?\n",
"1. Is a graphic representation really necessary?\n",
" - \n",
"1. Does every line / color serve a purpose?\n",
" - Pretend ink is very expensive\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"### Simple Rules\n",
"\n",
"1. Never use 3D graphics when it can be avoided (unless you want to be deliberately misleading), our visual system is not well suited for comparing heights of different \n",
"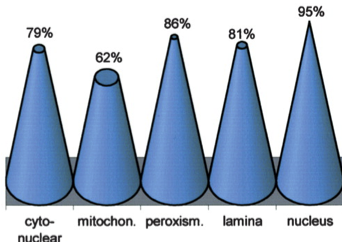\n",
"1. Pie charts can also be hard to interpret\n",
"1. Background color should almost always be white (not light gray)\n",
"1. Use color palettes adapted to human visual sensitivity "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# What is my message\n",
"\n",
"\n",
"- Plots to \"show the results\" or \"get a feeling\" are usually not good\n",
"\n",
"```{r, fig.height=7}\n",
"xd<-runif(80)\n",
"test.data<-data.frame(x=xd,y=xd+runif(80),z=runif(80))\n",
"plot(test.data)\n",
"```\n",
"\n",
"\n",
"- Focus on a single, simple message\n",
" - X is a little bit correlated with Y\n",
"```{r, fig.height=7}\n",
"ggplot(test.data,aes(x,y))+\n",
" geom_point()+geom_smooth(method=\"lm\")+\n",
" coord_equal()+\n",
" labs(title=\"X is weakly correlated with Y\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Does my graphic communicate it clearly?\n",
"\n",
"- Too much data makes it very difficult to derive a clear message\n",
"```{r, fig.height=7}\n",
"xd<-runif(5000)\n",
"test.data<-data.frame(x=xd,y=(xd-0.5)*runif(5000))\n",
"ggplot(test.data,aes(x,y))+\n",
" geom_point()+\n",
" coord_equal()+\n",
" theme_bw(20)\n",
"```\n",
"\n",
"- Filter and reduce information until it is extremely simple\n",
"\n",
"```{r, fig.height=4}\n",
"\n",
"ggplot(test.data,aes(x,y))+\n",
" stat_binhex(bins=20)+\n",
" geom_smooth(method=\"lm\",aes(color=\"Fit\"))+\n",
" coord_equal()+\n",
" theme_bw(20)+guides(color=F)\n",
"```\n",
"\n",
"```{r, fig.height=4}\n",
"\n",
"ggplot(test.data,aes(x,y))+\n",
" geom_density2d(aes(color=\"Contour\"))+\n",
" geom_smooth(method=\"lm\",aes(color=\"Linear Fit\"))+\n",
" coord_equal()+\n",
" labs(color=\"Type\")+\n",
" theme_bw(20)\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Grammar of Graphics\n",
"\n",
"\n",
"- What is a grammar?\n",
" - Set of rules for constructing and validating a sentence\n",
" - Specifies the relationship and order between the words constituting the sentence\n",
"- How does this apply to graphics?\n",
" - If we develop a consistent way of expressing graphics (sentences) in terms of elements (words) we can compose and decompose graphics easily\n",
"\n",
"\n",
"- The most important modern work in graphical grammars is âThe Grammar of Graphicsâ by Wilkinson, Anand, and Grossman (2005). This work built on earlier work by Bertin (1983) and proposed a grammar that can be used to describe and construct a wide range of statistical graphics.\n",
"\n",
"- This can be applied in R using the ggplot2 library (H. Wickham. ggplot2: elegant graphics for data analysis. Springer New York, 2009.)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Grammar Explained\n",
"\n",
"Normally we think of plots in terms of some sort of data which is fed into a plot command that produces a picture\n",
"- In Excel you select a range and plot-type and click \"Make\"\n",
"- In Matlab you run ```plot(xdata,ydata,color/shape)``` \n",
"\n",
"1. These produces entire graphics (sentences) or at least phrases in one go and thus abstract away from the idea of grammar. \n",
"1. If you spoke by finding entire sentences in a book it would be very ineffective, it is much better to build up word by word"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Grammar\n",
"\n",
"Separate the graph into its component parts\n",
"\n",
"\n",
"1. Data Mapping\n",
" - $var1 \\rightarrow x$, $var2 \\rightarrow y$\n",
"\n",
"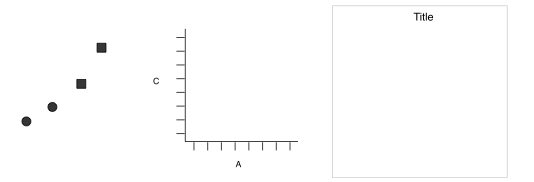\n",
"\n",
"1. Points\n",
"1. Axes / Coordinate System\n",
"1. Labels / Annotation\n",
"\n",
"Construct graphics by focusing on each portion independently."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Wrapping up\n",
"\n",
"\n",
"- I am not a statistician\n",
"- This is not a statistics course\n",
"- If you have questions or concerns, Both ETHZ and Uni Zurich offer __free__ consultation with real statisticians\n",
" - They are rarely bearers of good news\n",
" \n",
"\n",
"- Simulations (even simple ones) are very helpful (see [StatisticalSignificanceHunter\n",
"](knime://LOCAL/Exercise%209%20StatsRepro/StatisticalSignificanceHunter\n",
"))\n",
"\n",
"- Try and understand the tests you are performing\n",
" "
]
}
],
"metadata": {
"celltoolbar": "Slideshow",
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.4"
},
"livereveal": {
"autolaunch": true,
"scroll": true
}
},
"nbformat": 4,
"nbformat_minor": 2
}