Converted from a Word document
Most antique and mediaeval codices preserved today present one or more layers of complexity. Codices are usually considered “complex” when they contain more than one text; but there are other aspects to be taken into consideration. Sometimes, they are complex objects because several scribes collaborated in copying several texts into one book, at times using different ink or layouts, or because their writing material was reused from pre-existing books. Other times, a manuscript’s owner might also restore damaged leaves or choose to add new texts on new quires. Readers too could contribute to an evolving complexity as they added comments, drawings or small pieces of content in the margins or in blank spots. The historical complexity of ancient codices is in itself also a complex notion (See further Gumbert, 2004; Maniaci, 2004; Andrist et al., 2013).
How can the various levels of complexity of a codex be coded into a database in such a way that the complexity is not only clearly understandable but also correctly searchable?
The aim of this paper is to present a language-independent model for achieving this goal, and some of the new challenges it now faces. It is called the syntactical model and is already in use in several MySQL as well as XML/TEI databases.
The first section of the paper sets out the problem by showing a few slides of a complex codex and explaining the problem one encounters in many current databases. Even though they record accurate information searches with multiple criteria often result in inaccurate answers. Let us for example consider a codex C, which contains both a text by Aristotle copied in the twelfth century, and a text by Chrysostom copied in the fifteenth; let us now imagine a scholar searching databases for witnesses of Chrysostom copied in the twelfth century; by far most of today’s databases will return codex C as a positive match, though it is not! Why is this so? Because the single pieces of information is unrelated to its context of production: these databases fail to consider the codex as an object evolving over time (see Andrist 2014).
The second section presents the principles of the syntactical model. The basic idea is that all the contents are linked to a more or less conscious act of production. Let us imagine that someone orders a new copy of Homer’s
Iliad
; many years later, someone adds some texts by Hesiod to this book; to these a subsequent reader adds the commentaries of Eustathius in the margins along with some notes of her or his own; later still someone takes out the pages containing the Hesiodic texts, binds them together with Pindar’s
Odes
and adds a colophon… every stage of the transformation represents a unique act of production. The Syntactical model holds that each content in a printed or electronic description of a codex ought to be clearly and unambiguously related to its production unit (the theoretical underlying principles are explained in Andrist et al., 2013).
The third section explains how this model has been implemented until now. A standard description according to the syntactical model operates on three data levels: the data level related to the codex as it is today; the data level related to its constitutive production units i.e. its historical parts (which are the main “description units”); and the data level of the pieces of content (mostly texts, but also images or musical pieces), always situated within a production unit. I will show how the syntactical model is implemented in our MySQL shared database (in the framework of the ERC project ParaTexBib submitted by Martin Wallraff in 2013; see Wallraff et al., 2015) and I will also show an example from the XML/TEI Beta maṣāḥǝft
database of Ethiopian manuscripts (unrelated to our project).
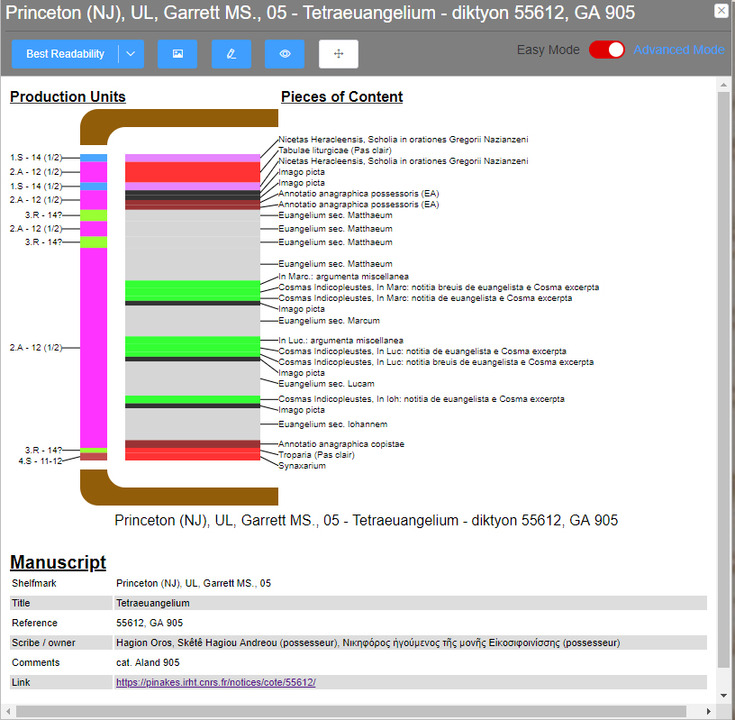
This very structured and hierarchical way to describe manuscripts enabled us to develop a new tool, with the specific purpose of both visually relaying the overall structure of a codex, as well as the content of each stratum; elements which may not be immediately evident in a written description. It generates graphic representations on demand from a manuscript description based on the syntactical model (an image of it is available
here
). The whole codex, as well as its historical parts and their contents, is represented on a single screen; extra details are displayed by clicking on individual elements of this graphic representation. These are created by an open-access web application, developed through a proof-of-concept funded by the ERC (see Dirkse et al., 2019).
A promising future development of this tool is the reconstruction of now dispersed manuscripts; by drawing elements from existing graphic representations, the users will be able to create a new representation by joining diverse parts of various manuscripts and arranging them in order.
The final part of the paper mentions some of the main current challenges:
Mapping the major layers of complexity of ancient codices in databases is possible with the syntactical model, even though there is a lot room for improvement. We hope that in the future more projects will take advantage of the potential of this model.
{kind=link}