 \n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
"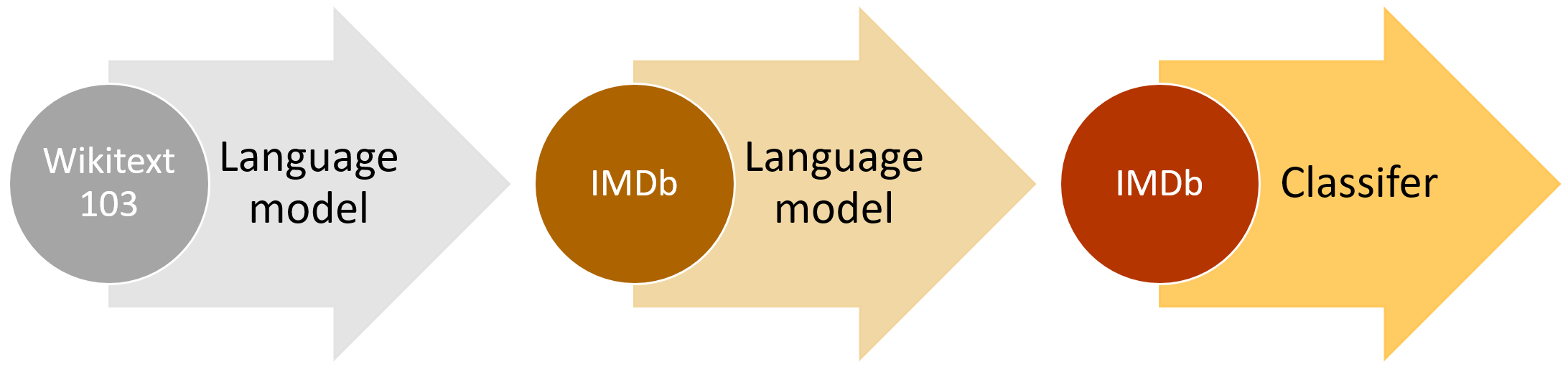 \n",
"
\n",
"| idx | \n", "text | \n", "
|---|---|
| 0 | \n", "xxmaj max xxmaj steiner grimace at its over use as it instructs the audience how difficult ; how ecstatic ; how tortured it is to be an artist . xxmaj and then it really counts the story xxunk the details at the end . \\n \\n xxmaj this heightened and kitsch exploitation of emotions was once well ridiculed by xxmaj peter xxmaj ackroyd about a xxmaj yukio xxmaj mishima | \n", "
| 1 | \n", "call it horror . xxmaj there is too much talking , you will get bloodthirsty after watching it xxbos i 'd liked the xxmaj takashi xxmaj miike films i 'd seen so far , but i found this pretty disappointing . i 'd bought it , but i wo n't be keeping it . \\n \\n i saw it on the xxmaj xxunk xxup dvd , which has just | \n", "
| 2 | \n", "xxmaj gable 's laughable playing of an xxmaj irish patriot in xxmaj parnell . \\n \\n xxmaj it 's inconceivable that xxmaj bergman would choose both this movie and its director over a lucrative xxmaj hollywood career where she could choose among the finest scripts and directors being offered at that time . xxmaj to begin with , there was no script to work with except a few notes | \n", "
| 3 | \n", "worst of the lot ! xxmaj it does not have the feel of \\n \\n the original or 2nd , xxmaj the enemy 's look stupid and the levels are \\n \\n even worse . xxmaj it does not look realistic anymore ! i did not enjoy his game unlike the last two , the first had great \\n \\n background music and the 2nd was not | \n", "
| 4 | \n", "ever made , ever . xxmaj unfortunately my worst fears were confirmed & one has to say that xxmaj curse of the xxmaj wolf is a truly horrible film in every way , both conceptually & technically . xxmaj curse of the xxmaj wolf is the sort of film where the low budget dictates what happens & the script rather than the script dictating the budget . xxmaj you get | \n", "
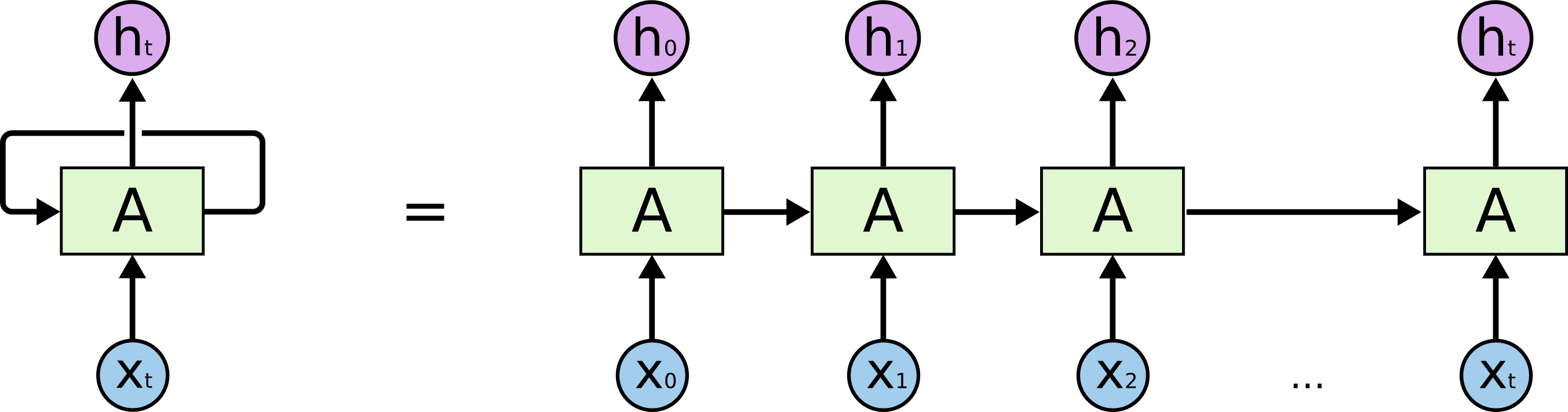 \n",
"
\n",
" Reference: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
\n", "| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|
\n", "\n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "4.145812 | \n", "4.027751 | \n", "0.294872 | \n", "24:40 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "3.883628 | \n", "3.846353 | \n", "0.312791 | \n", "25:13 | \n", "
| 1 | \n", "3.830023 | \n", "3.806326 | \n", "0.319647 | \n", "25:14 | \n", "
| 2 | \n", "3.823724 | \n", "3.776663 | \n", "0.323472 | \n", "25:14 | \n", "
| 3 | \n", "3.790490 | \n", "3.747104 | \n", "0.327012 | \n", "25:14 | \n", "
| 4 | \n", "3.708543 | \n", "3.720774 | \n", "0.330030 | \n", "25:14 | \n", "
| 5 | \n", "3.685525 | \n", "3.700337 | \n", "0.332860 | \n", "25:14 | \n", "
| 6 | \n", "3.594311 | \n", "3.683683 | \n", "0.334876 | \n", "25:14 | \n", "
| 7 | \n", "3.559871 | \n", "3.672719 | \n", "0.336452 | \n", "25:14 | \n", "
| 8 | \n", "3.545992 | \n", "3.668409 | \n", "0.337152 | \n", "25:14 | \n", "
| 9 | \n", "3.494757 | \n", "3.668425 | \n", "0.337193 | \n", "25:14 | \n", "
| text | \n", "target | \n", "
|---|---|
| xxbos xxmaj match 1 : xxmaj tag xxmaj team xxmaj table xxmaj match xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley vs xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley started things off with a xxmaj tag xxmaj team xxmaj table xxmaj match against xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit . xxmaj according to the rules | \n", "pos | \n", "
| xxbos xxmaj by now you 've probably heard a bit about the new xxmaj disney dub of xxmaj miyazaki 's classic film , xxmaj laputa : xxmaj castle xxmaj in xxmaj the xxmaj sky . xxmaj during late summer of 1998 , xxmaj disney released \" xxmaj kiki 's xxmaj delivery xxmaj service \" on video which included a preview of the xxmaj laputa dub saying it was due out | \n", "pos | \n", "
| xxbos xxmaj some have praised xxunk xxmaj lost xxmaj xxunk as a xxmaj disney adventure for adults . i do n't think so -- at least not for thinking adults . \\n \\n xxmaj this script suggests a beginning as a live - action movie , that struck someone as the type of crap you can not sell to adults anymore . xxmaj the \" crack staff \" of | \n", "neg | \n", "
| xxbos xxmaj by 1987 xxmaj hong xxmaj kong had given the world such films as xxmaj sammo xxmaj hung 's ` xxmaj encounters of the xxmaj spooky xxmaj kind ' xxmaj chow xxmaj yun xxmaj fat in xxmaj john xxmaj woo 's iconic ` a xxmaj better xxmaj tomorrow ' , ` xxmaj zu xxmaj warriors ' and the classic ` xxmaj mr xxmaj vampire ' . xxmaj jackie xxmaj | \n", "pos | \n", "
| xxbos xxmaj to be a xxmaj buster xxmaj keaton fan is to have your heart broken on a regular basis . xxmaj most of us first encounter xxmaj keaton in one of the brilliant feature films from his great period of independent production : ' xxmaj the xxmaj general ' , ' xxmaj the xxmaj navigator ' , ' xxmaj sherlock xxmaj jnr ' . xxmaj we recognise him as | \n", "neg | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|
\n", "\n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.325401 | \n", "0.261644 | \n", "0.892640 | \n", "04:50 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.267379 | \n", "0.217356 | \n", "0.913600 | \n", "05:13 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.233473 | \n", "0.182271 | \n", "0.930040 | \n", "04:54 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.201170 | \n", "0.175181 | \n", "0.933120 | \n", "05:09 | \n", "
| 1 | \n", "0.182616 | \n", "0.174323 | \n", "0.932920 | \n", "05:07 | \n", "