Symptoms
- Unexpected termination of Rhapsody.
- Errors in the
wrapper.logindicating that Rhapsody terminated unexpectedly. - The
engine.runningfile is present in:<Rhapsody install location>\Rhapsody\rhapsody\data.
Potential Causes
There are three major causes leading to Rhapsody unexpectedly terminating:
- A crash, for example as the result of a JVM problem or a coding error. Common causes of crashes are:
- Heap corruption leading to a segmentation fault as the result of accessing an invalid address (in Java, heap corruption may occur in native code or the JVM itself).
- Invalid address access, in other words a null pointer in native code.
- Stack overflow due to exhausting the stack size:
- Most likely due to programming error - excess/infinite recursion in a method which contains local variables that consume a significant amount of memory.
- Insufficient stack size allocated to threads.
There are many other causes of crashes and these are likely to be captured in the Rhapsody logs with an appropriate exception indicating the cause.
- Out-of-memory (OOM) error - can occur for the Heap and/or the Metaspace.
- Hang leading to a timeout in the wrapper ping health check processing. Again, this could be as the result of numerous different issues including performance problems as well as issues external to Rhapsody itself.
- Full GC which is a 'stop-the-world' process whereby all Rhapsody application threads are paused for a period longer than the wrapper timeout (the default is five minutes).
- External applications/threads running at a higher priority run for a period of time longer than the wrapper timeout. This results in Rhapsody threads yielding to the higher priority threads, pausing all processing. Certain anti-virus and backup software are known to cause this. Such software can also cause other issues within Rhapsody due to exclusive file locks preventing I/O operations within Rhapsody.
From an initial investigation of the wrapper.log, it should be immediately apparent which of the three causes have led to the unexpected termination of Rhapsody.
Investigation
The following diagram illustrates the diagnosis process:
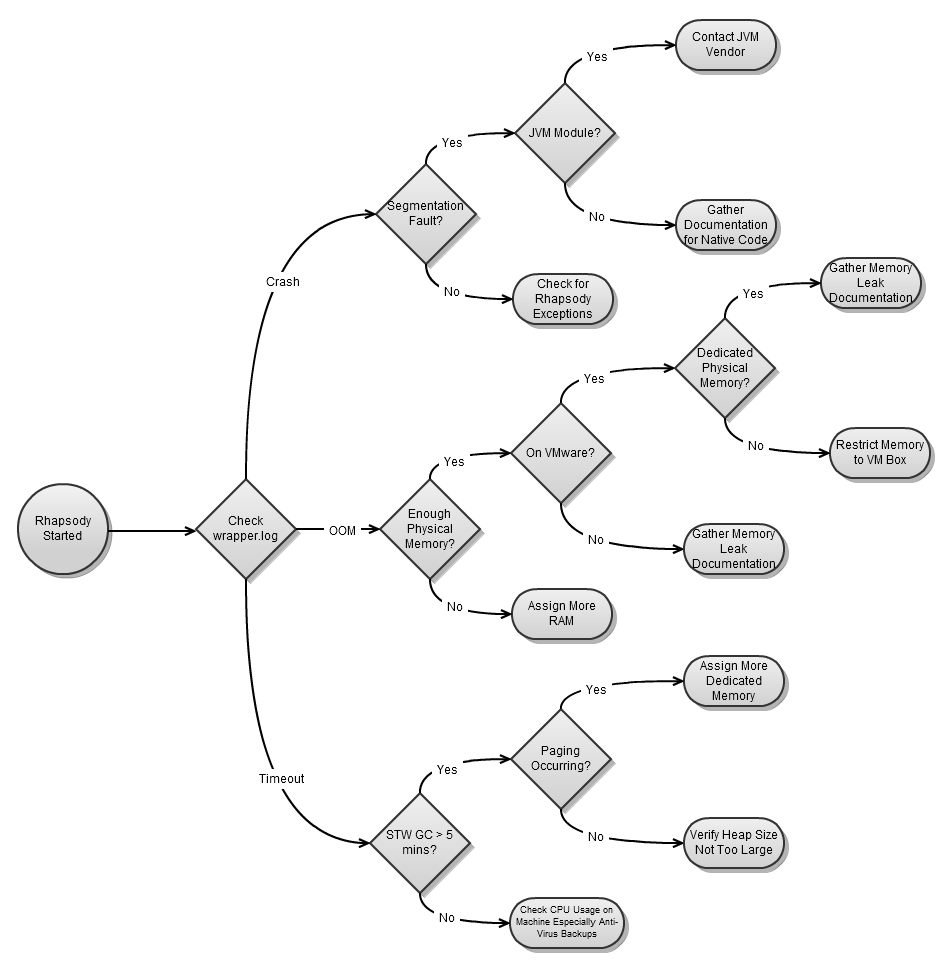
Crashes
Crashes are indicated by the following types of errors:
- Unhandled exception:
Type=Segmentation error vmState=0x00000000
J9Generic_Signal_Number=00000004 Signal_Number=0000000b Error_Value=00000000 Signal_Code=00000033 ... etc - An unexpected error has been detected by Java Runtime Environment:
SIGSEGV (11) at pc=c00000000a565171, pid=5643, tid=67
Problematic frame: V [libjvm.so+0x1ad7ce39] - A fatal error has been detected by the Java Runtime Environment:
EXCEPTION_ACCESS_VIOLATION (0xc0000005) at pc=0x0000000076d332d0, pid=12384, tid=7120
JRE version: 6.0_21-b06
The three errors indicate segmentation faults on different operating systems: 'Segmentation error' for AIX, 'SIGSEGV' for HPUX and Solaris, 'Access Violation' for Windows®. Segmentation faults occur when the application or JVM is trying to access an invalid memory address (such as a null-pointer or memory the process does not own). They can be the result of heap corruption or more simply de-referencing an uninitialized or null pointer, or stack over-runs.
Segmentation faults are highly unlikely to be a Rhapsody issue; they are more likely due to native code or an issue within the JVM itself. If the customer is not invoking any native code they have written from within Rhapsody, then the issue is most likely to be a JVM one. After identifying the module (for example, libjvm.so above), the JVM vendor should be contacted for further analysis. The JVM vendor would require a full crash dump.
Out-of-Memory Errors
OOM errors are of the following types:
java.lang.OutOfMemoryError: requested 32744 bytes for ChunkPool::allocate. Out of swap space?java.lang.OutOfMemoryError: GC overhead limit exceededjava.lang.OutOfMemoryError: Java heap spacejava.lang.OutOfMemoryError: Metaspace
These messages are all slightly different manifestations of the same underlying cause, namely that memory has been exhausted. The GC overhead limit exceeded message indicates that the Garbage Collector is spending too much time trying to free memory and not freeing enough memory each garbage cycle, indicating that the application usage is very close to the threshold. The Out of swap space? error indicates that the JVM was unable to expand the heap because all physical and virtual memory was in use.
This is most likely the result of either:
- Insufficient heap and/or Metaspace size for the workload of the application. Refer to Allocating Memory to Rhapsody for recommendations.
- Insufficient memory on the machine (combination of physical and virtual). For performance reasons, it is highly recommended that there is sufficient dedicated physical memory to accommodate Rhapsody and the JVM hosting it. Refer to Allocating Memory to Rhapsody for recommendations. If there is insufficient physical memory but sufficient virtual memory, then JVM page-swapping occurs, which could lead to severe performance penalties and unexpected terminations as a result of running out of Java Heap space.
There are additional restrictions on a system running with a 32-bit JVM. Due to 32-bit pointers, the maximum addressable memory in a 32-bit environment is 4GB. However, 50% of this allocation is normally reserved for kernel processing and inaccessible to user processing. This leaves 2GB for user code running within the JVM. However, in practice, not all of this 2GB can be allocated as Java Heap for the Rhapsody process. This is due to some physical memory being required for native heap of the JVM, which is used for JNI operations and the JVM itself. Therefore, the remaining addressable process space needs to be shared between both the Java Heap and the native heap. As such, on a 32-bit system with 2GB of user space addressable, it is recommended that the maximum Java Heap size be set to 1.5GB to ensure that 0.5GB is reserved for the native heap. There are some flags that can be used on various operating systems to allocate additional kernel space to user space, however these should be used with caution due to the potential performance impact on the system. If this is not sufficient for the application's needs but more physical memory is available, then a 64-bit JVM should be used.
If it appears as though the system has sufficient memory available for Rhapsody's needs as well as all other applications hosted on the server, then it is possible that the application has a memory leak. If this is suspected, then application heap usage should be analyzed over time. After startup, if usage fluctuates around a certain point with constant application load, then there is unlikely to be a leak present. However, if usage steadily increases over time without a corresponding steady increase during peak workload, then this could indicate a leak (not taking into account certain caching which might result in the heap growing to a new steady point). However, this is not necessarily the case as it could indicate normal behavior, for example:
- The application is caching more objects.
- The JVM has not scheduled a full GC as the current heap size is still able to accommodate all the application objects. Only if the memory footprint steadily increases without a corresponding change in application behavior and this increase is not reduced when a full GC occurs, could this point to a memory leak.
A memory leak in Java applications indicates one of the following:
- A leak in native code.
- References not being released within Java code when objects are no longer required - this is why caching behavior can sometimes exhibit the symptoms of a memory leak.
If a leak is suspected, a heap dump should be gathered with the following JVM option: -XX:+HeapDumpOnOutOfMemoryError. This produces a Java Heap dump on process termination in the form of a .hprof file which can be analyzed with VisualVM.
Timeouts/hangs
Timeouts/hangs leading to restarts are signified by the following types of errors:
JVM appears hung: Timed out waiting for signal from JVM.
Full GC 'Stop-the-World' Pause
In order to determine whether this is due to a full GC cycle leading to a pause in all Rhapsody processing, it is necessary to determine first whether the GC is taking an excessive amount of time and, if so, why. The following set of documentation should be gathered:
- The
gc.logfile leading up to a failure. - Physical memory statistics for the machine.
- JVM properties of the Rhapsody application, specifically those relating to heap allocation and GC behavior.
- Information on the size of the Rhapsody deployment such as the number of communication points, filters, normal and peak workload.
- Any other pertinent information such as whether Rhapsody is being hosted on a Virtual Machine.
Review the gc.log file and determine whether there are any full GC invocations with a large duration (> 20 secs). Once a full GC takes more than 5 minutes, the Rhapsody application is terminated however the GC log will not show any full GCs in excess of five minutes as the log point is written after the GC cycle completes (but the application was terminated). If the full GC pauses are within normal ranges, then the JVM hang is not attributable to a GC timeout. Refer to CPU Starvation for details. If there are no full GC log entries present in the log since application startup, then it is not possible to rule out a Full GC pause as the cause of failure.
During a full GC cycle, the entire Java Heap is processed. A full GC is known as a 'stop-the-world' GC because all application processing is put on hold until the GC is completed. There are various JVM settings which can be used to parallelize the processing and minimize the pause duration of the GC cycle. However, there may still be underlying configuration issues which exacerbate the duration of the pause.
The following table lists possible options for reducing GC processing times and minimizing unnecessary GC invocations:
| JVM Options | Description |
|
Concurrent low pause collector (CMS) starts collection before space is not yet full and works with multiple phases. Lockout of application threads is reduced to a small portion of the GC so should reduce overall pause time. |
|
Parallelization in the collection of young generation. Can be a little slower at startup as it grows the heap so recommended to set min. and max. to similar values (a full GC is also called if expanding the heap so another good reason to set min. close to max.). Improves performance for scavenge, so not directly relevant to resolving 'stop-the-world' issues. |
|
Remark phase of CMS also parallelized so should reduce pause times further. |
|
Good for multi-core but not compatible with CMS collector (mutually exclusive with |
|
Downside: will result in more frequent GCs and still no guarantee that pauses can be met (we could try with a pause set to 10 secs). |
|
In case something within the JVM is calling an explicit GC, this will prevent explicit GCs from invoking the GC (recommended to prevent unnecessary calls to a full GC which is not under the application's control). |
|
To log GC calls (various other JVM arguments can be supplied to tweak the log detail level). |
|
Where |
|
Useful for saving memory but only works up to 32GB (uses pointer compression to store 4-byte pointers on a 64-bit system). Can reduce both frequency and duration of full GCs due to reduced memory footprint. |
Due to the nature of Java GC, often there are many objects in the Tenured (old) Space, which have not been used for some time and are eligible for garbage collection ie the application no longer has any outstanding references to them. Unfortunately, this does not interact well with paging algorithms present on the Operating System. Most Operating Systems use an algorithm based on a least recently used system in order to determine what parts of the process virtual address space are eligible for swapping out. Therefore, it is highly likely that an overcommitted system with insufficient physical memory to accommodate all the running processes will page out some of the memory in use and that the portions of the Java heap in the tenured space will be the most likely candidates for being paged out. Java processes are much more likely to be paged out than other applications such as C applications due to the lazy nature of the Garbage Collection processing such that objects are not released immediately after the application no longer requires it. As such, a typical Java application is likely to have many objects still present in the heap, which have not been used for some time. Couple this with the fact that the entire heap is processed during a full Garbage Collection cycle and this leads to having to page back in many objects from the paging space. What was previously a fast in-memory operation becomes a very slow operation constrained by I/O speed. Non-Java applications are more resilient to paging due to the fact that no garbage collection operations result in the entire heap being processed, so even if some paging does occur, this results in many small delays rather than one massive delay.
This issue can be exacerbated depending on the maximum and initial configured size of the heap as well as the frequency of full Garbage Collection invocations. There are two schools of thought regarding the setting of the initial heap size relative to the maximum heap size:
- These should be set to the same value. This is normally recommended on the basis of trying to reduce the number of full GC invocations coupled with ensuring that the Java heap is committed up front (thus reducing the chance of an out of memory error if other non-Java applications start increasing memory requirements after startup). However, even under these circumstances, the Java heap can still be subjected to paging as outlined previously. This is known as selfish memory allocation as the Java application is potentially hogging much more memory than it requires.
- The initial heap size should not be set to the same value as the maximum heap size. This is especially true if the maximum heap size is unrealistically large for the requirements of the application. Setting the maximum heap size to an unrealistically large value coupled with an unrealistically large initial heap size is the most likely cause of a massive delay in a full GC invocation leading to application failure. This is due to the scheduling logic of a full GC whereby this is only done when the heap becomes full (in other words, the Tenured Space becomes full) and memory needs to be freed or the heap expanded (up to the max size). If the initial heap is set to the same size as the max heap size, then the first GC will occur when the entire heap is full. As a result, the application may have been allocating and deallocating a huge amount of objects during that time (a non-Java application will have already freed the memory from the heap but a Java application will end up with a very large heap space full of unreferenced objects due for garbage collection. Due to the lack of heap compaction (which occurs during a full GC), it is also likely that all these allocations/deallocations will have resulted in a highly fragmented heap. An unrealistically large heap allocation which exceeds physical memory on the machine results in paging of the tenured space and a full GC will take a significantly long time.
Recommendations
It is recommended that the Rhapsody deployment should be profiled during periods of peak workload as well as normal workload.
- The initial heap size should be set to accommodate periods of minimal workload (approximately double the workload usage).
- The maximum heap size should be set to exceed the peak usage of the application (by 20%). It should not be arbitrarily set to an unrealistically large value.
- There should be sufficient physical memory on the system to accommodate:
- The maximum heap size of the Rhapsody application.
- Metaspace, thread allocations for Rhapsody as well as base JVM usage.
- Operating system requirements.
- Any other applications installed on the system.
- If running in a VM environment, the physical memory allocated should be restricted to that system to prevent sharing between systems via ballooning.
CPU Starvation
If GC pauses have been ruled out as a potential cause of the JVM wrapper timeout leading to abnormal Rhapsody termination, then it is likely that an external application (or applications) is causing CPU starvation within Rhapsody. This can happen when there are any other threads or processes running on the system which are running at a higher priority than Rhapsody (Rhapsody runs at normal priority). Certain anti-virus providers are known to run their processes at high priority in order to ensure that files are scanned prior to other processes performing file operations. Certain backup software is also known to run at high priority and consume a significant amount of CPU. Whilst a high priority thread is scheduled with work to do, lower priority threads will not perform any work. As such, this can bring Rhapsody to a standstill during periods of activity. If the processor is not heavily loaded, then it is likely that a thread running at a higher priority will not bring other threads to a standstill but if the system is heavily loaded, then lower priority threads will not receive the time slice they require. In order to determine whether this is the cause, CPU statistics on a per-process basis should be gathered during the lead up to the failure.
Windows®
Performance monitoring statistics should be gathered for process and thread counters on the system. These should be analyzed to determine whether a single process or group of processes other than Rhapsody are consuming all the CPU time. The current thread and process priorities should also be checked to see whether culprit threads are running at high priority.
Linux
You can use top to display the CPU statistics and priorities of processes running on the system.