{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"# Chapter 1. 한눈에 보는 머신러닝"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"---\n",
"## 1.1 머신러닝이란?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"▷ 머신러닝 애플리케이션 - 광학 문자 판독기(Optical Character Recognition, OCR), 스팸 필터(spam filter), etc."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"▶**일반적인 정의:** 머신러닝은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야다. **_아서 사무엘(Arthur Samuel, 1959)**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"▶**공학적인 정의:** 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, \n",
" 이 컴퓨터 프로그램은 **작업 T**와 **성능 측정 P**에 대해 **경험 E**로 학습한 것이다. **_톰 미첼(Tom Mitchell, 1997)**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- **훈련 세트**(Training set) - 학습하는 데 사용하는 샘플세트\n",
"- **훈련 사례**(Training instance) - 각 훈련 데이터(샘플)\n",
"- **훈련 데이터**(Training data) - 훈련에 사용된 데이터(경험 E)\n",
"\n",
"\n",
"+ **작업 T** - e.g. 새로운 메일이 스팸인지 구분하는 것\n",
"+ **경험 E** - 훈련 데이터\n",
"+ **성능 측정 P** - **정확도**(accuracy) e.g. 정확히 분류된 메일의 비율"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"## 1.2 왜 머신러닝을 사용하는가? (in the spam filter)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"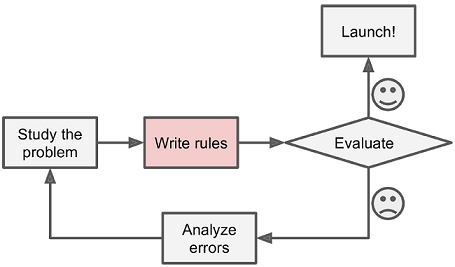\n",
"**
그림 1-1 전통적인 접근 방법
**\n",
"\n",
"▷발견한 각 패턴을 감지하는 알고리즘을 직접 작성 \n",
"▷문제가 단순하지 않아 규칙이 점점 길고 복잡해지므로 유지 보수하기 매우 힘듦 \n",
"\n",
"---\n",
"---\n",
"\n",
"**
그림 1-2 머신러닝 접근 방법
**\n",
"\n",
"▷패턴 감지와 판단 기준을 자동으로 학습 \n",
"▷프로그램이 훨씬 짧아지고 유지 보수하기 쉬우며 대부분 정확도가 더 높음\n",
"\n",
"---\n",
"---\n",
"\n",
"**
그림 1-3 자동으로 변화에 적응함
**\n",
"\n",
"▷전통적인 방식에서는 새 패턴에 대해서 새로운 규칙을 직접 추가해야 하지만 \n",
"▷머신러닝 기반에서는 새 패턴을 자동으로 인식하고 새로운 규칙을 자동으로 학습\n",
"\n",
"---\n",
"---\n",
"\n",
"\n",
"**
그림 1-4 머신러닝을 통해 배웁니다.
**\n",
"\n",
"▷스팸 필터가 충분한 스팸 메일로 훈련되었다면 스팸을 예측하는 데 가장 좋은 단어와 단어의 조합이 무엇인지 확인할 수 있음 \n",
" - 예상치 못한 연관 관계나 새로운 추세가 발견되기도 해서 해당 문제를 더 잘 이해하도록 도와줌\n",
"\n",
"▶머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견할 수 있음 → **데이터 마이닝(data mining)** \n",
"\n",
"---\n",
"---\n",
"\n",
"### ▣ **머신러닝이 뛰어난 분야**\n",
"+ **기존 솔루션으로는 많은 수동 조정과 규칙이 필요한 문제** : 하나의 머신러닝 모델이 코드를 간단하고 더 잘 수행되도록 할 수 있음\n",
"+ **전통적인 방식으로는 전혀 해결 방법이 없는 복잡한 문제** : 가장 뛰어난 머신러닝 기법으로 해결 방법을 찾을 수 있음\n",
"+ **유동적인 환경** : 머신러닝 시스템은 새로운 데이터에 적응할 수 있음\n",
"+ **복잡한 문제와 대량의 데이터에서 통찰 얻기**\n",
"\n",
" ※ e.g. 음성 인식(speech recognition) - 각 단어를 녹음한 샘플을 사용해 스스로 학습하는 알고리즘을 작성하는 것이 현재 가장 좋은 솔루션\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"## 1.3 머신러닝 시스템의 종류"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. 사람의 감독 하에 훈련하는 것인지 그렇지 않은 것인지**(지도, 비지도, 준지도, 강화 학습)**\n",
"2. 실시간으로 점진적인 학습을 하는지 아닌지**(온라인 학습과 배치 학습)**\n",
"3. 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 \n",
"아니면 훈련 데이터셋에서 과학자들처럼 패턴을 발견하여 예측 모델을 만드는지**(사례 기반 학습과 모델 기반 학습)**"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"### 1.3.1 지도 학습과 비지도 학습\n",
"- 학습하는 동안의 감독 형태나 정보량에 따라 분류"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"◈ **지도 학습(supervised learning)**에는 알고리즘에 주입하는 훈련 데이터에 **레이블(label)**이라는 원하는 답이 포함됨\n",
"\n",
"\n",
"**
그림 1-5 지도 학습에서 레이블된 훈련 세트(예를 들면 스팸 분류)
**\n",
"\n",
"▶**분류(classification)**가 전형적인 지도 학습 \n",
"▶또 다른 전형적인 지도 학습은 **예측 변수(predictor variable)**라 부르는 **특성(feature)**(주행거리, 연식, 브랜드 등)을 사용해 \n",
" 중고차 가격 같은 **타깃** 수치를 예측하는 것 → **회귀(regression)**\n",
"\n",
"\n",
"**
그림 1-6 회귀
**\n",
"\n",
"▶일부 회귀 알고리즘은 분류에 사용할 수 있고 **로지스틱 회귀**는 클래스에 속할 확률을 출력함 e.g. 스팸일 가능성 20%\n",
"\n",
"▣ **가장 중요한 지도 학습 알고리즘들**\n",
"+ k-최근접 이웃(k-Nearest Neighbors)\n",
"+ 선형 회귀(Linear Regression)\n",
"+ 로지스틱 회귀(Logistic Regression)\n",
"+ 서포트 벡터 머신(Support Vector Machines, SVM)\n",
"+ 결정 트리(Decision Tree)와 랜덤 포레스트(Random Forests)\n",
"+ 신경망(Neural networks)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"◈ **비지도 학습(unsupervised learning)**에는 말 그대로 훈련 데이터에 레이블이 없음 - 아무런 도움 없이 학습해야 함\n",
"\n",
"\n",
"**
**\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"◈ **준지도 학습(semisupervised learning)**은 레이블이 일부만 있는 데이터를 다룸 e.g. 구글 포토 호스팅 서비스\n",
"\n",
"\n",
"**
그림 1-11 준지도 학습
**\n",
"\n",
"▷대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 이루어짐\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"◈ **강화 학습(Reinforcement learning)** e.g. 딥마인드(DeepMind)의 알파고(AlphaGo)\n",
"\n",
"\n",
"**
그림 1-12 강화 학습
**\n",
"\n",
"▶**에이전트(agent)**가 **환경(environment)**을 관찰해서 **행동(action)**을 실행하고 그 결과로 **보상(reward)**(또는 부정적인 보상에 해당하는 **벌점(penalty)**)을 받음\n",
"▶시간이 지나면서 가장 큰 보상을 얻기 위해 **정책(policy)**이라고 부르는 최상의 전략을 스스로 학습\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"### 1.3.2 배치 학습과 온라인 학습\n",
"- 입력 데이터의 스트림(stream)으로부터 점진적으로 학습할 수 있는지의 여부에 따라 분류"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"◈ **배치 학습(batch learning)**은 가용한 데이터를 모두 사용해 훈련시켜야 함\n",
"\n",
"▶먼저 시스템을 훈련시키고 제품 시스템에 적용하면 더 이상의 학습 없이 실행됨 → **오프라인 학습(offline learning)**\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"◈ **온라인 학습(online learning)**은 데이터를 순차적으로 한 개씩 또는 **미니배치(mini-batch)**라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킴\n",
"\n",
"▶매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있음\n",
"\n",
"\n",
"**
그림 1-13 온라인 학습
**\n",
"\n",
"▶**외부 메모리(out-of-core) 학습**: 점진적으로 데이터의 일부를 읽어 들이고 훈련 단계를 수행\n",
"\n",
"\n",
"**
그림 1-14 온라인 학습을 사용한 대량의 데이터 처리
**\n",
"\n",
"▶**학습률(learning rate)**: 변화하는 데이터에 얼마나 빠르게 적응할 것인지\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"### 1.3.3 사례 기반 학습과 모델 기반 학습\n",
"- 어떻게 **일반화**되는가에 따라 분류"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"◈ **사례 기반 학습(instance-based learning)**\n",
"\n",
"▷시스템이 사례를 기억함으로써 학습하고 **유사도(similarity)** 측정을 사용해 새로운 데이터에 일반화함\n",
"\n",
"\n",
"**
그림 1-15 사례 기반 학습
**\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"◈ **모델 기반 학습(model-based learning)**\n",
"\n",
"▷샘플들의 모델을 만들어 **예측**에 사용\n",
"\n",
"\n",
"**
**\n",
"\n",
"▶**효용 함수(utility function)**(또는 **적합도 함수(fitness function)**): 모델이 얼마나 좋은지 측정 \n",
"▶**비용 함수(cost function)**: 모델이 얼마나 나쁜지 측정(선형 회귀에서는 보통 비용 함수를 사용)\n",
"\n",
"▶선형 모델의 비용이 가장 적은 파라미터 찾기 → **훈련(training)**\n",
"\n",
"\n",
"**
그림 1-19 훈련 데이터에 최적인 선형 모델
**\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"+ **예제 1-1 사이킷런을 이용한 선형 모델의 훈련과 실행**\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"scrolled": true
},
"outputs": [
{
"data": {
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[5.96242338]]\n"
]
}
],
"source": [
"import matplotlib\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import pandas as pd\n",
"import sklearn.linear_model\n",
"\n",
"def prepare_country_stats(oecd_bli, gdp_per_capita):\n",
" oecd_bli = oecd_bli[oecd_bli[\"INEQUALITY\"]==\"TOT\"]\n",
" oecd_bli = oecd_bli.pivot(index=\"Country\", columns=\"Indicator\", values=\"Value\")\n",
" gdp_per_capita.rename(columns={\"2015\": \"GDP per capita\"}, inplace=True)\n",
" gdp_per_capita.set_index(\"Country\", inplace=True)\n",
" full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,\n",
" left_index=True, right_index=True)\n",
" full_country_stats.sort_values(by=\"GDP per capita\", inplace=True)\n",
" remove_indices = [0, 1, 6, 8, 33, 34, 35]\n",
" keep_indices = list(set(range(36)) - set(remove_indices))\n",
" return full_country_stats[[\"GDP per capita\", 'Life satisfaction']].iloc[keep_indices]\n",
"\n",
"# 데이터 적재\n",
"oecd_bli = pd.read_csv(\"./datasets/lifesat/oecd_bli_2015.csv\", thousands=',')\n",
"gdp_per_capita = pd.read_csv(\"./datasets/lifesat/gdp_per_capita.csv\", thousands=',', delimiter='\\t', encoding='latin1', na_values='n/a')\n",
"\n",
"# 데이터 준비\n",
"country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)\n",
"X = np.c_[country_stats[\"GDP per capita\"]]\n",
"y = np.c_[country_stats[\"Life satisfaction\"]]\n",
"\n",
"# 데이터 시각화\n",
"country_stats.plot(kind='scatter', x=\"GDP per capita\", y='Life satisfaction')\n",
"plt.show()\n",
"\n",
"# 선형 모델 선택\n",
"model = sklearn.linear_model.LinearRegression()\n",
"\n",
"# 모델 훈련\n",
"model.fit(X, y)\n",
"\n",
"# 키프로스에 대한 예측\n",
"X_new = [[22587]] # 키프로스 1인당 GDP\n",
"print(model.predict(X_new)) # 결과 [[ 5.96242338]]"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[5.76666667]]\n"
]
}
],
"source": [
"# 선형 회귀 모델을 k-최근접 이웃 회귀 모델로 교체할 경우\n",
"knn = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)\n",
"\n",
"# 모델 훈련\n",
"knn.fit(X, y)\n",
"\n",
"# 키프로스에 대한 예측\n",
"print(knn.predict(X_new)) # 결과 [[ 5.76666667]]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"▣ **전형적인 머신러닝 프로젝트의 형태**\n",
"1. 데이터를 분석\n",
"2. 모델을 선택\n",
"3. 훈련 데이터로 모델을 훈련\n",
"4. 새로운 데이터에 모델을 적용해 예측 - **추론(inference)**\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.5.5"
}
},
"nbformat": 4,
"nbformat_minor": 2
}