 \n",
"\n",
"\n",
"
\n",
"\n",
"\n",
" \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
" 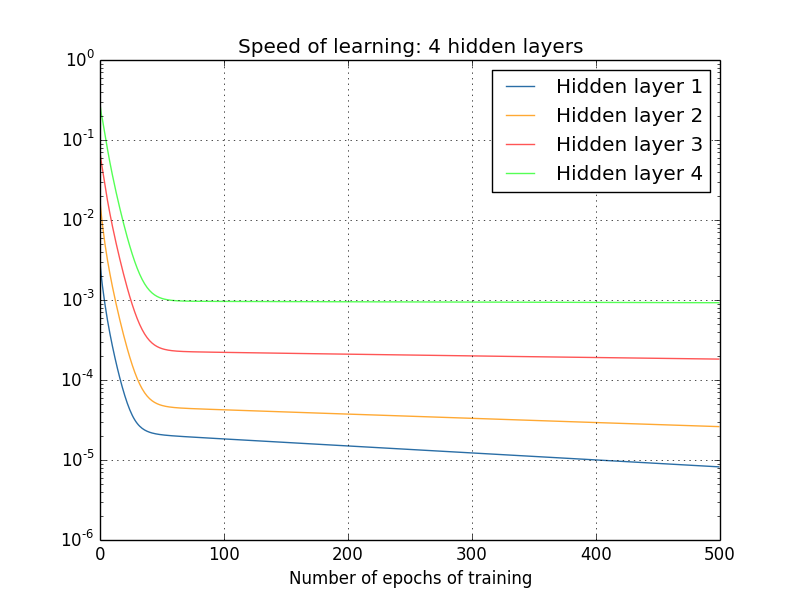 \n",
"
\n",
"  \n",
"
\n",
" 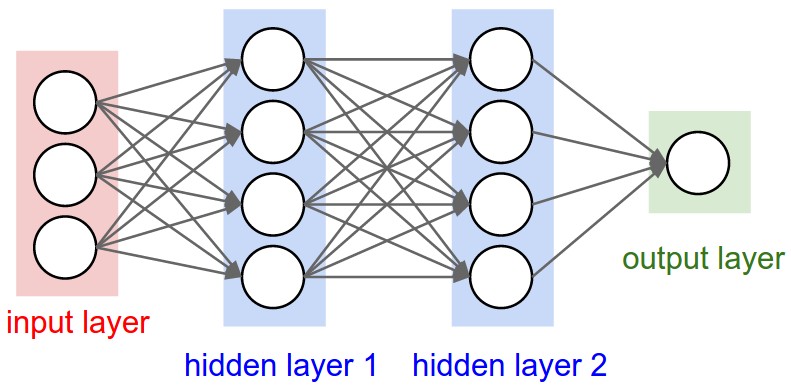 \n",
"
\n",
" 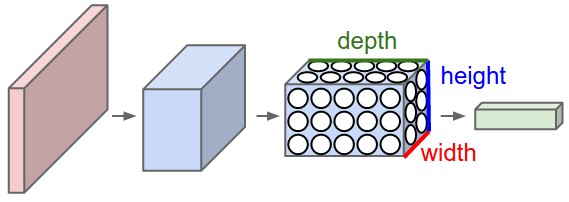 \n",
"
\n",
" 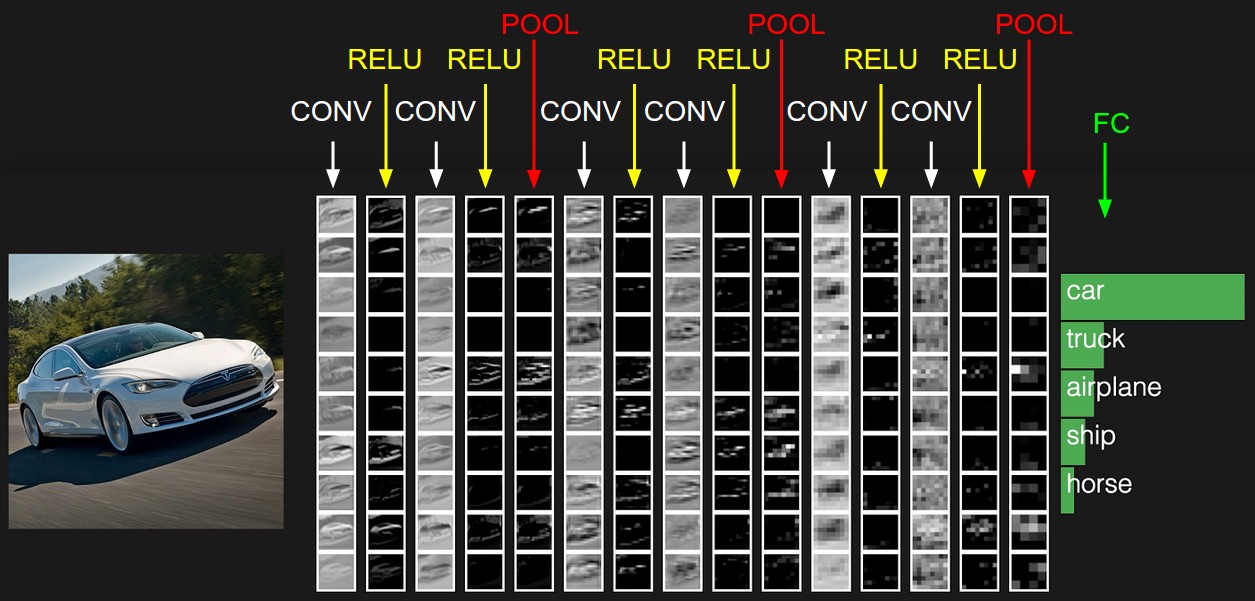 \n",
"
\n",
"  \n",
"
\n",
" \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
"  \n",
"
\n",
" | Software | Version |
|---|---|
| Python | 3.6.1 64bit [GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] |
| IPython | 6.0.0 |
| OS | Darwin 16.6.0 x86_64 i386 64bit |
| scipy | 0.19.0 |
| numpy | 1.12.1 |
| matplotlib | 2.0.2 |
| sklearn | 0.18.1 |
| Tue May 23 12:07:12 2017 -03 | |