{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
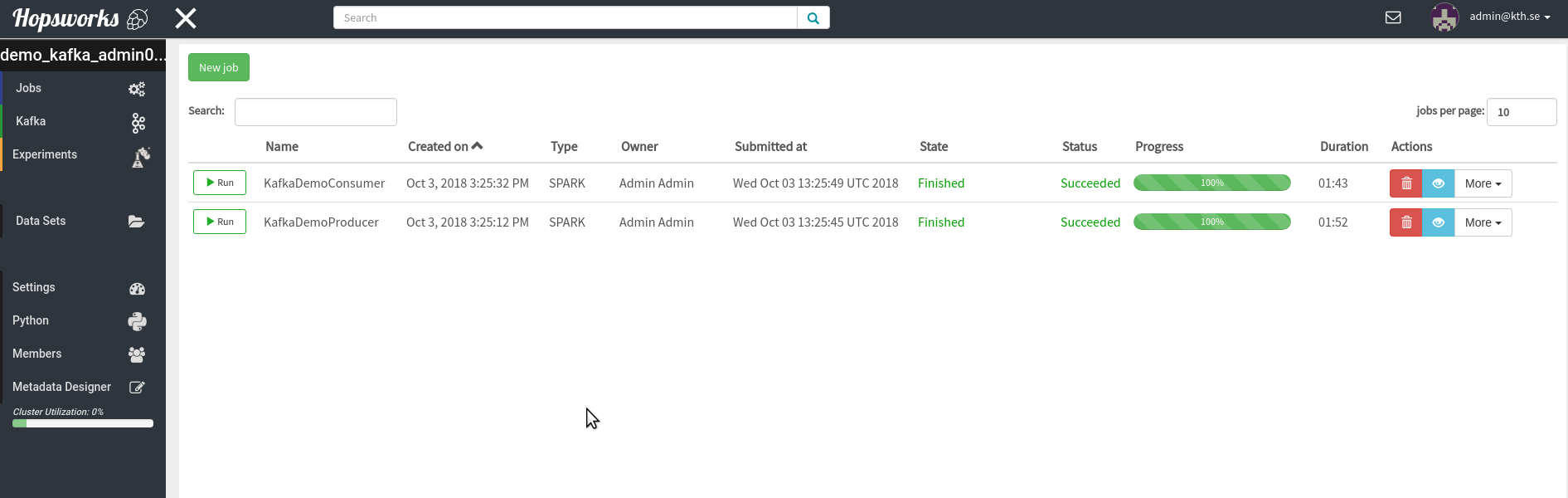
"# Consuming Messages from Kafka Tour Producer Using Scala Spark\n",
"\n",
"To run this notebook you should have taken the Kafka tour and created the Producer and Consumer jobs. I.e your Job UI should look like this: \n",
"\n",
"\n",
"\n",
"In this notebook we will consume messages from Kafka that were produced by the producer-job created in the Demo. Go to the Jobs-UI in hopsworks and start the Kafka producer job:\n",
"\n",
"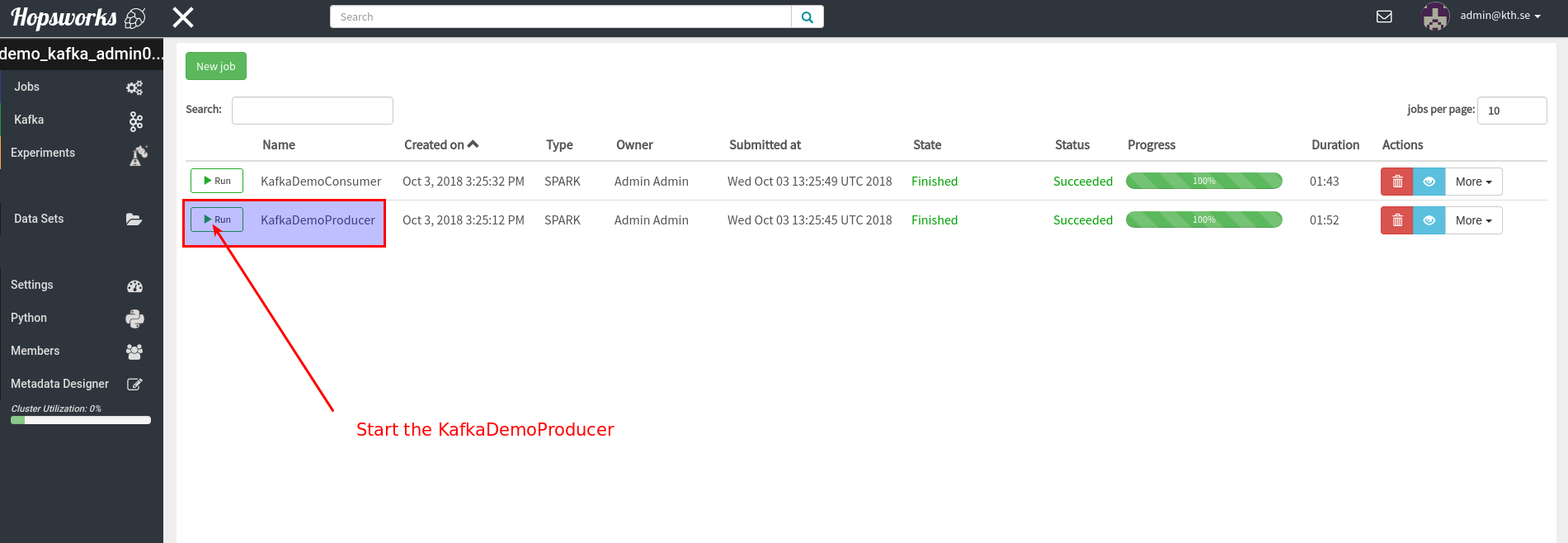"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Imports"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Starting Spark application\n"
]
},
{
"data": {
"text/html": [
"