{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Code:https://github.com/lotapp/BaseCode\n",
"\n",
"多图旧排版:https://www.cnblogs.com/dunitian/p/9119986.html\n",
"\n",
"在线编程:https://mybinder.org/v2/gh/lotapp/BaseCode/master\n",
"\n",
"Python设计的目的就是 ==> **让程序员解放出来,不要过于关注代码本身**\n",
"\n",
"步入正题:**欢迎提出更简单或者效率更高的方法**\n",
"\n",
"**基础系列**:(这边重点说说`Python`,上次讲过的东西我就一笔带过了)\n",
"\n",
"## 1.基础回顾\n",
"\n",
"### 1.1.输出+类型转换"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"输入第一个数:1\n",
"输入第二个数:2\n",
"两数之和:3\n"
]
}
],
"source": [
"user_num1=input(\"输入第一个数:\")\n",
"user_num2=input(\"输入第二个数:\")\n",
"\n",
"print(\"两数之和:%d\"%(int(user_num1)+int(user_num2)))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.2.字符串拼接+拼接输出方式"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"输入昵称:tom\n",
"输入密码:1379\n",
"ftp://tom:1379@192.168.1.121\n",
"ftp://tom:1379@192.168.1.121\n"
]
}
],
"source": [
"user_name=input(\"输入昵称:\")\n",
"user_pass=input(\"输入密码:\")\n",
"user_url=\"192.168.1.121\"\n",
"\n",
"#拼接输出方式一:\n",
"print(\"ftp://\"+user_name+\":\"+user_pass+\"@\"+user_url)\n",
"\n",
"#拼接输出方式二:\n",
"print(\"ftp://%s:%s@%s\"%(user_name,user_pass,user_url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2.字符串遍历、下标、切片\n",
"\n",
"### 2.1.Python\n",
"\n",
"重点说下`python`的 **下标**,有点意思,最后一个元素,我们一般都是`len(str)-1`,他可以直接用`-1`,倒2自然就是`-2`了\n",
"\n",
"**最后一个元素:`user_str[-1]`**\n",
"\n",
"user_str[-1]\n",
"\n",
"user_str[len(user_str)-1] #其他编程语言写法\n",
"\n",
"**倒数第二个元素:`user_str[-2]`**\n",
"\n",
"user_str[-1]\n",
"\n",
"user_str[len(user_str)-2] #其他编程语言写法"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"user_str=\"七大姑曰:工作了吗?八大姨问:买房了吗?异性说:结婚了吗?\""
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"七 大 姑 曰 : 工 作 了 吗 ? 八 大 姨 问 : 买 房 了 吗 ? 异 性 说 : 结 婚 了 吗 ? "
]
}
],
"source": [
"#遍历\n",
"for item in user_str:\n",
" print(item,end=\" \") # 不换行,以“ ”方式拼接"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"29\n"
]
}
],
"source": [
"#长度:len(user_str)\n",
"len(user_str)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'七'"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# #第一个元素:user_str[0]\n",
"user_str[0]"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"?\n",
"?\n"
]
}
],
"source": [
"# 最后一个元素:user_str[-1]\n",
"print(user_str[-1])\n",
"print(user_str[len(user_str)-1])#其他编程语言写法"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"吗\n",
"吗\n"
]
}
],
"source": [
"#倒数第二个元素:user_str[-2]\n",
"print(user_str[-2])\n",
"print(user_str[len(user_str)-2])#其他编程语言写法"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**python切片语法**:`[start_index:end_index:step]` (**end_index取不到**)\n",
"\n",
"eg:`str[1:4]` 取str[1]、str[2]、str[3]\n",
"\n",
"eg:`str[2:]` 取下标为2开始到最后的元素\n",
"\n",
"eg:`str[2:-1]` 取下标为2~到倒数第二个元素(end_index取不到)\n",
"\n",
"eg:`str[1:6:2]` 隔着取~str[1]、str[3]、str[5](案例会详细说)\n",
"\n",
"eg:`str[::-1]` 逆向输出(案例会详细说)"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [],
"source": [
"it_str=\"我爱编程,编程爱它,它是程序,程序是谁?\""
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"编程爱它\n",
"编程爱它\n",
"编程爱它\n"
]
}
],
"source": [
"# eg:取“编程爱它” it_str[5:9]\n",
"print(it_str[5:9])\n",
"print(it_str[5:-11]) # end_index用-xx也一样\n",
"print(it_str[-15:-11])# start_index用-xx也可以"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"编程爱它,它是程序,程序是谁?\n"
]
}
],
"source": [
"# eg:取“编程爱它,它是程序,程序是谁?” it_str[5:]\n",
"print(it_str[5:])# 不写默认取到最后一个"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"我编,程它它程,序谁\n"
]
}
],
"source": [
"# eg:一个隔一个跳着取(\"我编,程它它程,序谁\") it_str[0::2]\n",
"print(it_str[0::2])# step=△index(eg:0,1,2,3。这里的step=> 2-0 => 间隔1)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"?谁是序程,序程是它,它爱程编,程编爱我\n",
"?谁是序程,序程是它,它爱程编,程编爱我\n"
]
}
],
"source": [
"# eg:倒序输出 it_str[::-1]\n",
"# end_index不写默认是取到最后一个,是正取(从左往右)还是逆取(从右往左),就看step是正是负\n",
"print(it_str[::-1])\n",
"print(it_str[-1::-1])# 等价于上一个"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.2.CSharp\n",
"\n",
"这次为了更加形象对比,一句一句翻译成C#\n",
"\n",
"有没有发现规律,`user_str[user_str.Length-1]`==> -1是最后一个\n",
"\n",
"`user_str[user_str.Length-2]`==> -2是最后第二个\n",
"\n",
"python的切片其实就是在这方面简化了"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"七大姑曰:工作了吗?八大姨问:买房了吗?异性说:结婚了吗?29\n",
"七\n",
"?\n",
"吗\n"
]
}
],
"source": [
"%%script csharp\n",
"//# # 字符串遍历、下标、切片\n",
"//# user_str=\"七大姑曰:工作了吗?八大姨问:买房了吗?异性说:结婚了吗?\"\n",
"var user_str = \"七大姑曰:工作了吗?八大姨问:买房了吗?异性说:结婚了吗?\";\n",
"\n",
"//# #遍历\n",
"//# for item in user_str:\n",
"//# print(item,end=\" \")\n",
"foreach (var item in user_str)\n",
"{\n",
" Console.Write(item);\n",
"}\n",
"\n",
"//# #长度:len(user_str)\n",
"//# print(len(user_str))\n",
"Console.WriteLine(user_str.Length);\n",
"\n",
"//# #第一个元素:user_str[0]\n",
"//# print(user_str[0])\n",
"Console.WriteLine(user_str[0]);\n",
"\n",
"//# #最后一个元素:user_str[-1]\n",
"//# print(user_str[-1])\n",
"//# print(user_str[len(user_str)-1])#其他编程语言写法\n",
"Console.WriteLine(user_str[user_str.Length - 1]);\n",
"//\n",
"//# #倒数第二个元素:user_str[-2]\n",
"//# print(user_str[-2])\n",
"Console.WriteLine(user_str[user_str.Length - 2]);"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"其实你用`Pytho`n跟其他语言对比反差更大,`net`真的很强大了。\n",
"\n",
"补充(对比看就清楚`Python`的`step`为什么是2了,i+=2==>2)"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"编程爱它\n",
"编程爱它,它是程序,程序是谁?\n",
"我编,程它它程,序谁\n",
"倒序:\n",
"?谁是序程,序程是它,它爱程编,程编爱我"
]
}
],
"source": [
"%%script csharp\n",
"//# 切片:[start_index:end_index:step] (end_index取不到)\n",
"//# eg:str[1:4] 取str[1]、str[2]、str[3]\n",
"//# eg:str[2:] 取下标为2开始到最后的元素\n",
"//# eg:str[2:-1] 取下标为2~到倒数第二个元素(end_index取不到)\n",
"//# eg:str[1:6:2] 隔着取~str[1]、str[3]、str[5](案例会详细说)\n",
"//# eg:str[::-1] 逆向输出(案例会详细说,)\n",
"//\n",
"var it_str = \"我爱编程,编程爱它,它是程序,程序是谁?\";\n",
"//\n",
"//#eg:取“编程爱它” it_str[5:9]\n",
"// print(it_str[5:9])\n",
"// print(it_str[5:-11]) #end_index用-xx也一样\n",
"// print(it_str[-15:-11])#start_index用-xx也可以\n",
"\n",
"//Substring(int startIndex, int length)\n",
"Console.WriteLine(it_str.Substring(5, 4));//第二个参数是长度\n",
"\n",
"//\n",
"//#eg:取“编程爱它,它是程序,程序是谁?” it_str[5:]\n",
"// print(it_str[5:])#不写默认取到最后一个\n",
"Console.WriteLine(it_str.Substring(5));//不写默认取到最后一个\n",
"\n",
"//#eg:一个隔一个跳着取(\"我编,程它它程,序谁\") it_str[0::2]\n",
"// print(it_str[0::2])#step=△index(eg:0,1,2,3。这里的step=> 2-0 => 间隔1)\n",
"\n",
"//这个我第一反应是用linq ^_^\n",
"for (int i = 0; i < it_str.Length; i += 2)//对比看就清除Python的step为什么是2了,i+=2==》2\n",
"{\n",
" Console.Write(it_str[i]);\n",
"}\n",
"\n",
"Console.WriteLine(\"\\n倒序:\");\n",
"//#eg:倒序输出 it_str[::-1]\n",
"//# end_index不写默认是取到最后一个,是正取(从左往右)还是逆取(从右往左),就看step是正是负\n",
"// print(it_str[::-1])\n",
"// print(it_str[-1::-1])#等价于上一个\n",
"for (int i = it_str.Length - 1; i >= 0; i--)\n",
"{\n",
" Console.Write(it_str[i]);\n",
"}\n",
"//其实可以用Linq:Console.WriteLine(new string(it_str.ToCharArray().Reverse().ToArray()));\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.Python字符串方法系列\n",
"\n",
"### 3.1.Python查找\n",
"\n",
"`find`,`rfind`,`index`,`rindex`\n",
"\n",
"Python查找 **推荐**你用`find`和`rfind`"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"6\n",
"11\n",
"-1\n"
]
}
],
"source": [
"test_str = \"ABCDabcdefacddbdf\"\n",
"# 查找:find,rfind,index,rindex\n",
"# xxx.find(str, start, end)\n",
"print(test_str.find(\"cd\"))#从左往右\n",
"print(test_str.rfind(\"cd\"))#从右往左\n",
"print(test_str.find(\"dnt\"))#find和rfind找不到就返回-1"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"ename": "ValueError",
"evalue": "substring not found",
"output_type": "error",
"traceback": [
"\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[0;31mValueError\u001b[0m Traceback (most recent call last)",
"\u001b[0;32m\u001b[0m in \u001b[0;36m\u001b[0;34m()\u001b[0m\n\u001b[1;32m 1\u001b[0m \u001b[0;31m# index和rindex用法和find一样,只是找不到会报错(以后用find系即可)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m----> 2\u001b[0;31m \u001b[0mprint\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtest_str\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mindex\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m\"dnt\"\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[0;31mValueError\u001b[0m: substring not found"
]
}
],
"source": [
"# index和rindex用法和find一样,只是找不到会报错(以后用find系即可)\n",
"print(test_str.index(\"dnt\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.2.Python计数\n",
"\n",
"python:`xxx.count(str, start, end)`"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"4\n",
"2\n"
]
}
],
"source": [
"# 计数:count\n",
"# xxx.count(str, start, end)\n",
"print(test_str.count(\"d\"))#4\n",
"print(test_str.count(\"cd\"))#2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.3.Python替换\n",
"\n",
"Python:`xxx.replace(str1, str2, 替换次数)`"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"ABCDabcdefacddbdf\n",
"ABCDaBcdefacddBdf\n",
"ABCDabcdefacddbdf\n"
]
}
],
"source": [
"# 替换:replace\n",
"# xxx.replace(str1, str2, 替换次数)\n",
"\n",
"print(test_str)\n",
"print(test_str.replace(\"b\",\"B\"))#并没有改变原字符串,只是生成了一个新的字符串\n",
"print(test_str)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"ABCDaBcdefacddbdf\n"
]
}
],
"source": [
"# replace可以指定替换几次\n",
"print(test_str.replace(\"b\",\"B\",1))#ABCDaBcdefacddbdf"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.4.Python分割\n",
"\n",
"`split`(按指定字符分割),`splitlines`(按行分割)\n",
"\n",
"`partition`(以str分割成三部分,str前,str和str后),`rpartition`(从右边开始)\n",
"\n",
"说下 **split的切片用法**:`print(test_input.split(\" \",3))` 在第三个空格处切片,后面的不切了\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['ABCD', 'bcdef', 'cddbdf']\n"
]
}
],
"source": [
"# 分割:split(按指定字符分割),splitlines(按行分割),partition(以str分割成三部分,str前,str和str后),rpartition\n",
"test_list=test_str.split(\"a\")#a有两个,按照a分割,那么会分成三段,返回类型是列表(List),并且返回结果中没有a\n",
"print(test_list)"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['hi', 'my', 'name', 'is', 'dnt']\n",
"['hi', 'my', 'name', 'is dnt']\n"
]
}
],
"source": [
"test_input=\"hi my name is dnt\"\n",
"print(test_input.split(\" \")) #返回列表格式(后面会说)['hi', 'my', 'name', 'is', 'dnt']\n",
"print(test_input.split(\" \",3))#在第三个空格处切片,后面的不管了"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"继续说说`splitlines`(按行分割),和`split(\"\\n\")`的区别:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['abc', 'bca', 'cab']\n",
"['abc', 'bca', 'cab', '']\n"
]
}
],
"source": [
"# splitlines()按行分割,返回类型为List\n",
"test_line_str=\"abc\\nbca\\ncab\\n\"\n",
"print(test_line_str.splitlines())#['abc', 'bca', 'cab']\n",
"print(test_line_str.split(\"\\n\"))#看出区别了吧:['abc', 'bca', 'cab', '']"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['abc', 'bca', 'cab', 'LLL']\n",
"['abc', 'bca', 'cab', 'LLL']\n"
]
}
],
"source": [
"# splitlines(按行分割),和split(\"\\n\")的区别没看出来就再来个案例\n",
"test_line_str2=\"abc\\nbca\\ncab\\nLLL\"\n",
"print(test_line_str2.splitlines())#['abc', 'bca', 'cab', 'LLL']\n",
"print(test_line_str2.split(\"\\n\"))#再提示一下,最后不是\\n就和上面一样效果"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"扩展:`split()`,默认按 **空字符**切割(`空格、\\t、\\n`等等,不用担心返回`''`)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['hi', 'my', 'name', 'is', 'dnt', 'm']\n"
]
}
],
"source": [
"# 扩展:split(),默认按空字符切割(空格、\\t、\\n等等,不用担心返回'')\n",
"print(\"hi my name is dnt\\t\\n m\\n\\t\\n\".split())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"最后说一下`partition`和`rpartition`: 返回是元祖类型(后面会说的)\n",
"\n",
"方式和find一样,找到第一个匹配的就罢工了【**注意一下没找到的情况**】"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"('ABCDab', 'cd', 'efacddbdf')\n",
"('ABCDabcdefa', 'cd', 'dbdf')\n",
"('ABCDabcdefacddbdf', '', '')\n"
]
}
],
"source": [
"# partition(以str分割成三部分,str前,str和str后)\n",
"# 返回是元祖类型(后面会说的),方式和find一样,找到第一个匹配的就罢工了【注意一下没找到的情况】\n",
"\n",
"print(test_str.partition(\"cd\"))#('ABCDab', 'cd', 'efacddbdf')\n",
"print(test_str.rpartition(\"cd\"))#('ABCDabcdefa', 'cd', 'dbdf')\n",
"print(test_str.partition(\"感觉自己萌萌哒\"))#没找到:('ABCDabcdefacddbdf', '', '')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.5.Python字符串连接\n",
"\n",
"**join** :`\"-\".join(test_list)`"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"ABCD-bcdef-cddbdf\n"
]
}
],
"source": [
"# 连接:join\n",
"# separat.join(xxx)\n",
"# 错误用法:xxx.join(\"-\")\n",
"print(\"-\".join(test_list))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.6.Python头尾判断\n",
"\n",
"`startswith`(以。。。开头),`endswith`(以。。。结尾)"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n",
"False\n"
]
}
],
"source": [
"# 头尾判断:startswith(以。。。开头),endswith(以。。。结尾)\n",
"# test_str.startswith(以。。。开头)\n",
"start_end_str=\"http://www.baidu.net\"\n",
"print(start_end_str.startswith(\"https://\") or start_end_str.startswith(\"http://\"))\n",
"print(start_end_str.endswith(\".com\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.7.Python大小写系\n",
"\n",
"`lower`(字符串转换为小写),`upper`(字符串转换为大写)\n",
"\n",
"`title`(单词首字母大写),`capitalize`(第一个字符大写,其他变小写)"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"ABCDabcdefacddbdf\n",
"ABCDABCDEFACDDBDF\n",
"abcdabcdefacddbdf\n",
"Abcdabcdefacddbdf\n"
]
}
],
"source": [
"# 大小写系:lower(字符串转换为小写),upper(字符串转换为大写)\n",
"# title(单词首字母大写),capitalize(第一个字符大写,其他变小写)\n",
"\n",
"print(test_str)\n",
"print(test_str.upper())#ABCDABCDEFACDDBDF\n",
"print(test_str.lower())#abcdabcdefacddbdf\n",
"print(test_str.capitalize())#第一个字符大写,其他变小写"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.8.Python格式系列\n",
"\n",
"`lstrip`(去除左边空格),`rstrip`(去除右边空格)\n",
"\n",
"**`strip`** (去除两边空格)美化输出系列:`ljust`,`rjust`,`center`\n",
"\n",
"`ljust,rjust,center`这些就不说了,python经常在linux终端中输出,所以这几个用的比较多"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I Have a Dream|\n",
"I Have a Dream |\n",
" I Have a Dream|\n",
"ABCDabcdefacddbdf \n",
" ABCDabcdefacddbdf\n",
" ABCDabcdefacddbdf \n"
]
}
],
"source": [
"# 格式系列:lstrip(去除左边空格),rstrip(去除右边空格),strip(去除两边空格)美化输出系列:ljust,rjust,center\n",
"strip_str=\" I Have a Dream \"\n",
"print(strip_str.strip()+\"|\")#我加 | 是为了看清后面空格,没有别的用处\n",
"print(strip_str.lstrip()+\"|\")\n",
"print(strip_str.rstrip()+\"|\")\n",
"\n",
"#这个就是格式化输出,就不讲了\n",
"print(test_str.ljust(50))\n",
"print(test_str.rjust(50))\n",
"print(test_str.center(50))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.9.Python验证系列\n",
"\n",
"`isalpha`(是否是纯字母),`isalnum`(是否是数字|字母)\n",
"\n",
"`isdigit`(是否是纯数字),`isspace`(是否是纯空格)\n",
"\n",
"注意~ `test_str5=\" \\t \\n \"` # **isspace() ==>true**"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [],
"source": [
"# 验证系列:isalpha(是否是纯字母),isalnum(是否是数字|字母),isdigit(是否是纯数字),isspace(是否是纯空格)\n",
"# 注意哦~ test_str5=\" \\t \\n \" #isspace() ==>true\n",
"\n",
"test_str2=\"Abcd123\"\n",
"test_str3=\"123456\"\n",
"test_str4=\" \\t\" #isspace() ==>true\n",
"test_str5=\" \\t \\n \" #isspace() ==>true"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 20,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str.isalpha() #是否是纯字母"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str.isalnum() #是否是数字|字母"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str.isdigit() #是否是纯数字"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str.isspace() #是否是纯空格"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 24,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str2.isalnum() #是否是数字和字母组成"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 25,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str2.isdigit() #是否是纯数字"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 26,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str3.isdigit() #是否是纯数字"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 27,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str5.isspace() #是否是纯空格"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 28,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"test_str4.isspace() #是否是纯空格"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Python补充\n",
"\n",
"像这些方法练习用`ipython3`就好了(`sudo apt-get install ipython3`)\n",
"\n",
"code的话需要一个个的print,比较麻烦(我这边因为需要写文章,所以只能一个个code)\n",
"\n",
"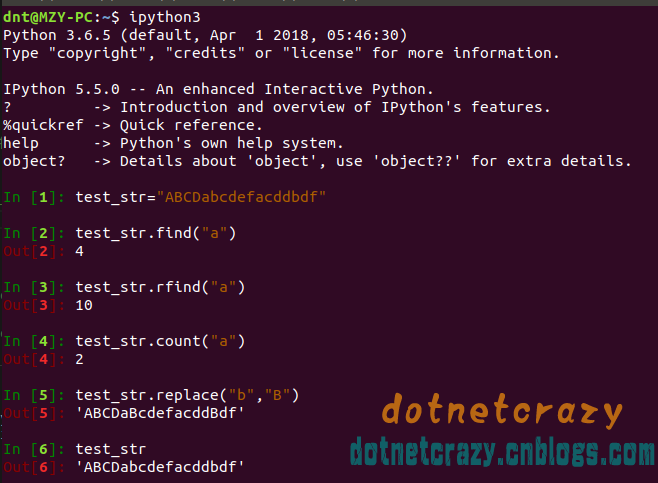"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4.CSharp字符串方法系列\n",
"\n",
"### 4.1.查找\n",
"\n",
"`index0f`就相当于python里面的`find`\n",
"\n",
"`LastIndexOf` ==> `rfind`"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"4\n",
"6\n",
"11\n",
"-1\n"
]
}
],
"source": [
"%%script csharp\n",
"var test_str = \"ABCDabcdefacddbdf\";\n",
"\n",
"//# # 查找:find,rfind,index,rindex\n",
"//# # xxx.find(str, start, end)\n",
"//# print(test_str.find(\"cd\"))#从左往右\n",
"Console.WriteLine(test_str.IndexOf('a'));//4\n",
"Console.WriteLine(test_str.IndexOf(\"cd\"));//6\n",
"\n",
"//# print(test_str.rfind(\"cd\"))#从右往左\n",
"Console.WriteLine(test_str.LastIndexOf(\"cd\"));//11\n",
"\n",
"//# print(test_str.find(\"dnt\"))#find和rfind找不到就返回-1\n",
"Console.WriteLine(test_str.IndexOf(\"dnt\"));//-1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.2.计数\n",
"\n",
"这个真用基础来解决的话,两种方法:\n",
"\n",
"第一种自己变形一下:(原字符串长度 - 替换后的长度) / 字符串长度\n",
"\n",
"```csharp\n",
"//# # 计数:count\n",
"//# # xxx.count(str, start, end)\n",
"// print(test_str.count(\"d\"))#4\n",
"// print(test_str.count(\"cd\"))#2\n",
"// 第一反应,字典、正则、linq,后来想怎么用基础知识解决,于是有了这个~(原字符串长度-替换后的长度)/字符串长度\n",
"\n",
"Console.WriteLine(test_str.Length - test_str.Replace(\"d\", \"\").Length);//统计单个字符就简单了\n",
"Console.WriteLine((test_str.Length - test_str.Replace(\"cd\", \"\").Length) / \"cd\".Length);\n",
"Console.WriteLine(test_str);//不用担心原字符串改变(python和C#都是有字符串不可变性的)\n",
"```\n",
"\n",
"字符串统计另一种方法(就用index)\n",
"\n",
"```csharp\n",
"int count = 0;\n",
"int index = input.IndexOf(\"abc\");\n",
"\n",
"while (index != -1)\n",
"{\n",
" count++;\n",
" index = input.IndexOf(\"abc\", index + 3);//index指向abc的后一位\n",
"}\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.3.替换\n",
"\n",
"替换指定次数的功能有点业余,就不说了,你可以自行思考哦~"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"ABCDaBcdefacddBdf\n"
]
}
],
"source": [
"%%script csharp\n",
"var test_str = \"ABCDabcdefacddbdf\";\n",
"Console.WriteLine(test_str.Replace(\"b\", \"B\"));"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.4.分割\n",
"\n",
"`split`里面很多重载方法,可以自己去查看下\n",
"\n",
"eg:`Split(\"\\n\",StringSplitOptions.RemoveEmptyEntries)`\n",
"\n",
"再说一下这个:`test_str.Split('a');` //返回数组\n",
"\n",
"如果要和Python一样返回列表==》`test_str.Split('a').ToList();` 【需要引用linq的命名空间哦】\n",
"```csharp\n",
"var test_array = test_str.Split('a');//返回数组(如果要返回列表==》test_str.Split('a').ToList();)\n",
"var test_input = \"hi my name is dnt\";\n",
"//# print(test_input.split(\" \")) #返回列表格式(后面会说)['hi', 'my', 'name', 'is', 'dnt']\n",
"test_input.Split(\" \");\n",
"//# 按行分割,返回类型为List\n",
"var test_line_str = \"abc\\nbca\\ncab\\n\";\n",
"//# print(test_line_str.splitlines())#['abc', 'bca', 'cab']\n",
"test_line_str.Split(\"\\n\", StringSplitOptions.RemoveEmptyEntries);\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.5.连接\n",
"\n",
"**`string.Join(分隔符,数组)`**\n",
"```csharp\n",
"Console.WriteLine(string.Join(\"-\", test_array));//test_array是数组 ABCD-bcdef-cddbdf\n",
"\n",
"```\n",
"\n",
"### 4.6.头尾判断\n",
"\n",
"`StartsWith`(以。。。开头),`EndsWith`(以。。。结尾)"
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"True\n",
"False\n"
]
}
],
"source": [
"%%script csharp\n",
"var start_end_str = \"http://www.baidu.net\";\n",
"//# print(start_end_str.startswith(\"https://\") or start_end_str.startswith(\"http://\"))\n",
"System.Console.WriteLine(start_end_str.StartsWith(\"https://\") || start_end_str.StartsWith(\"http://\"));\n",
"//# print(start_end_str.endswith(\".com\"))\n",
"System.Console.WriteLine(start_end_str.EndsWith(\".com\"));"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.7.大小写系\n",
"\n",
"```csharp\n",
"//# print(test_str.upper())#ABCDABCDEFACDDBDF\n",
"Console.WriteLine(test_str.ToUpper());\n",
"//# print(test_str.lower())#abcdabcdefacddbdf\n",
"Console.WriteLine(test_str.ToLower());\n",
"```\n",
"\n",
"### 4.8.格式化系\n",
"\n",
"`Tirm`很强大,除了去空格还可以去除你想去除的任意字符\n",
"\n",
"net里面`string.Format`各种格式化输出,可以参考,这边就不讲了"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"I Have a Dream|\n",
"I Have a Dream |\n",
" I Have a Dream|\n"
]
}
],
"source": [
"%%script csharp\n",
"var strip_str = \" I Have a Dream \";\n",
"//# print(strip_str.strip()+\"|\")#我加 | 是为了看清后面空格,没有别的用处\n",
"Console.WriteLine(strip_str.Trim() + \"|\");\n",
"//# print(strip_str.lstrip()+\"|\")\n",
"Console.WriteLine(strip_str.TrimStart() + \"|\");\n",
"//# print(strip_str.rstrip()+\"|\")\n",
"Console.WriteLine(strip_str.TrimEnd() + \"|\");"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4.9.验证系列\n",
"`string.IsNullOrEmpty` 和 `string.IsNullOrWhiteSpace` 是系统自带的"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"False\n",
"True\n",
"False\n",
"True\n"
]
}
],
"source": [
"%%script csharp\n",
"var test_str4 = \" \\t\";\n",
"var test_str5 = \" \\t \\n \"; //#isspace() ==>true\n",
"// string.IsNullOrEmpty 和 string.IsNullOrWhiteSpace 是系统自带的,其他的你需要自己封装一个扩展类\n",
"Console.WriteLine(string.IsNullOrEmpty(test_str4)); //false\n",
"Console.WriteLine(string.IsNullOrWhiteSpace(test_str4));//true\n",
"Console.WriteLine(string.IsNullOrEmpty(test_str5));//false\n",
"Console.WriteLine(string.IsNullOrWhiteSpace(test_str5));//true"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"其他的你需要自己封装一个扩展类(eg:简单封装)\n",
"\n",
"```csharp\n",
"using System;\n",
"using System.Collections.Generic;\n",
"using System.Linq;\n",
"using System.Text.RegularExpressions;\n",
"\n",
"public static partial class ValidationHelper\n",
"{\n",
" #region 常用验证\n",
"\n",
" #region 集合系列\n",
" /// \n",
" /// 判断集合是否有数据\n",
" /// \n",
" /// \n",
" /// \n",
" /// \n",
" public static bool ExistsData(this IEnumerable list)\n",
" {\n",
" bool b = false;\n",
" if (list != null && list.Count() > 0)\n",
" {\n",
" b = true;\n",
" }\n",
" return b;\n",
" } \n",
" #endregion\n",
"\n",
" #region Null判断系列\n",
" /// \n",
" /// 判断是否为空或Null\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsNullOrWhiteSpace(this string objStr)\n",
" {\n",
" if (string.IsNullOrWhiteSpace(objStr))\n",
" {\n",
" return true;\n",
" }\n",
" else\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
"\n",
" /// \n",
" /// 判断类型是否为可空类型\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsNullableType(Type theType)\n",
" {\n",
" return (theType.IsGenericType && theType.GetGenericTypeDefinition().Equals(typeof(Nullable<>)));\n",
" }\n",
" #endregion\n",
"\n",
" #region 数字字符串检查\n",
" /// \n",
" /// 是否数字字符串(包括小数)\n",
" /// \n",
" /// 输入字符串\n",
" /// \n",
" public static bool IsNumber(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^\\d+(\\.\\d+)?$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
"\n",
" /// \n",
" /// 是否是浮点数\n",
" /// \n",
" /// 输入字符串\n",
" /// \n",
" public static bool IsDecimal(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^(-?\\d+)(\\.\\d+)?$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #endregion\n",
"\n",
" #region 业务常用\n",
"\n",
" #region 中文检测\n",
" /// \n",
" /// 检测是否有中文字符\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsZhCN(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, \"[\\u4e00-\\u9fa5]\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #region 邮箱验证\n",
" /// \n",
" /// 判断邮箱地址是否正确\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsEmail(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^([\\w-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([\\w-]+\\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\\]?)$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #region IP系列验证\n",
" /// \n",
" /// 是否为ip\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsIP(this string objStr)\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^((2[0-4]\\d|25[0-5]|[01]?\\d\\d?)\\.){3}(2[0-4]\\d|25[0-5]|[01]?\\d\\d?)$\");\n",
" }\n",
"\n",
" /// \n",
" /// 判断输入的字符串是否是表示一个IP地址 \n",
" /// \n",
" /// 被比较的字符串 \n",
" /// 是IP地址则为True \n",
" public static bool IsIPv4(this string objStr)\n",
" {\n",
" string[] IPs = objStr.Split('.');\n",
" for (int i = 0; i < IPs.Length; i++)\n",
" {\n",
" if (!Regex.IsMatch(IPs[i], @\"^\\d+$\"))\n",
" {\n",
" return false;\n",
" }\n",
" if (Convert.ToUInt16(IPs[i]) > 255)\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" return true;\n",
" }\n",
"\n",
" /// \n",
" /// 判断输入的字符串是否是合法的IPV6 地址 \n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsIPV6(string input)\n",
" {\n",
" string temp = input;\n",
" string[] strs = temp.Split(':');\n",
" if (strs.Length > 8)\n",
" {\n",
" return false;\n",
" }\n",
" int count = input.GetStrCount(\"::\");\n",
" if (count > 1)\n",
" {\n",
" return false;\n",
" }\n",
" else if (count == 0)\n",
" {\n",
" return Regex.IsMatch(input, @\"^([\\da-f]{1,4}:){7}[\\da-f]{1,4}$\");\n",
" }\n",
" else\n",
" {\n",
" return Regex.IsMatch(input, @\"^([\\da-f]{1,4}:){0,5}::([\\da-f]{1,4}:){0,5}[\\da-f]{1,4}$\");\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #region 网址系列验证\n",
" /// \n",
" /// 验证网址是否正确(http:或者https:)【后期添加 // 的情况】\n",
" /// \n",
" /// 地址\n",
" /// \n",
" public static bool IsWebUrl(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"http://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?|https://([\\w-]+\\.)+[\\w-]+(/[\\w- ./?%&=]*)?\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
"\n",
" /// \n",
" /// 判断输入的字符串是否是一个超链接 \n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsURL(this string objStr)\n",
" {\n",
" string pattern = @\"^[a-zA-Z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$\";\n",
" return Regex.IsMatch(objStr, pattern);\n",
" }\n",
" #endregion\n",
"\n",
" #region 邮政编码验证\n",
" /// \n",
" /// 验证邮政编码是否正确\n",
" /// \n",
" /// 输入字符串\n",
" /// \n",
" public static bool IsZipCode(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"\\d{6}\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #region 电话+手机验证\n",
" /// \n",
" /// 验证手机号是否正确\n",
" /// \n",
" /// 手机号\n",
" /// \n",
" public static bool IsMobile(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^13[0-9]{9}|15[012356789][0-9]{8}|18[0123456789][0-9]{8}|147[0-9]{8}$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
"\n",
" /// \n",
" /// 匹配3位或4位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔 \n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsPhone(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, \"^\\\\(0\\\\d{2}\\\\)[- ]?\\\\d{8}$|^0\\\\d{2}[- ]?\\\\d{8}$|^\\\\(0\\\\d{3}\\\\)[- ]?\\\\d{7}$|^0\\\\d{3}[- ]?\\\\d{7}$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #region 字母或数字验证\n",
" /// \n",
" /// 是否只是字母或数字\n",
" /// \n",
" /// \n",
" /// \n",
" public static bool IsAbcOr123(this string objStr)\n",
" {\n",
" try\n",
" {\n",
" return Regex.IsMatch(objStr, @\"^[0-9a-zA-Z\\$]+$\");\n",
" }\n",
" catch\n",
" {\n",
" return false;\n",
" }\n",
" }\n",
" #endregion\n",
"\n",
" #endregion\n",
"}\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.5"
}
},
"nbformat": 4,
"nbformat_minor": 2
}