---
This repository contains the implementation of the NeurIPS 2023 paper:
> **Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models**
> [[Project Page]](https://luogen1996.github.io/lavin/) [[Paper]](https://arxiv.org/pdf/2305.15023.pdf)
> [Gen Luo](https://luogen1996.github.io)1, Yiyi Zhou12, [Tianhe Ren](https://rentainhe.github.io)1, Shengxin Chen1, [Xiaoshuai Sun](https://sites.google.com/view/xssun)12, [Rongrong Ji](https://mac.xmu.edu.cn/rrji/)12
1Media Analytics and Computing Lab, Department of Artificial Intelligence, School of Informatics, Xiamen University
> 2Institute of Artificial Intelligence, Xiamen University
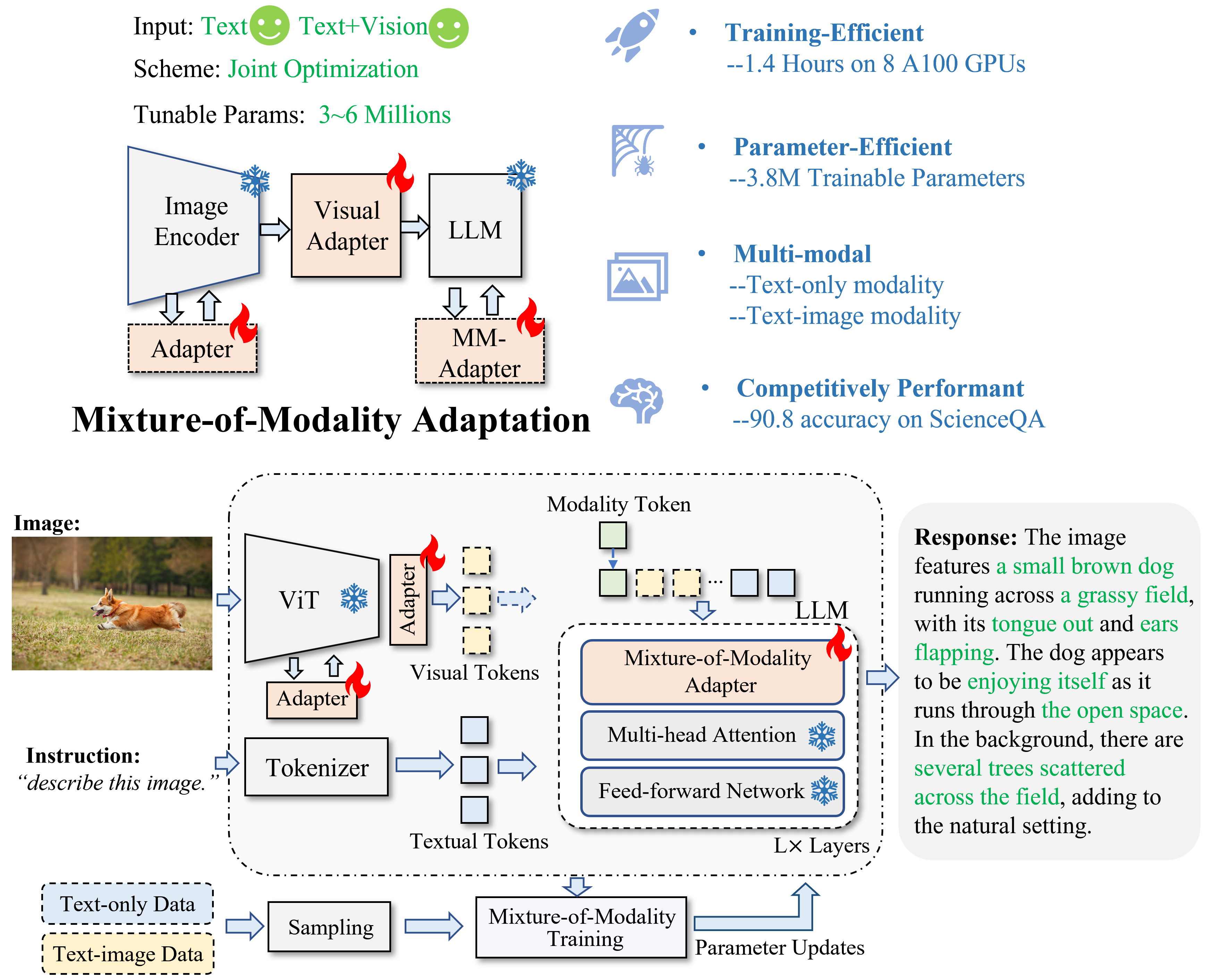
In this work, we propose a novel and affordable solution for vision-language instruction tuning, namely Mixture-of-Modality Adaptation (MMA).
Particularly, MMA is an end-to-end optimization regime, which connects the image encoder and LLM via lightweight adapters. Meanwhile, we also propose a novel routing algorithm in MMA, which can help the model automatically shifts the reasoning paths for single- and multi-modal instructions. Based on MMA, we develop a large vision-language instructed model called LaVIN, which demonstrates superior training efficiency and better reasoning ability than existing multimodal LLMs in various instruction-following tasks.
---
## News
- **`2023/09/22`**: 🔥🔥🔥 Our paper is accepted by NeurIPS 2023!
- **`2023/06/30`**: 🔥🔥🔥 With very limited training data and cost, LaVIN achieves 5-th place of Perception and Cognition on [MME benchmark](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation), outperforming seven existing multimodal LLMs. Evaluation codes are available.
- **`2023/06/27`**: 🔥4-bit trainings are available now ! LaVIN-lite can be trained on one 3090 GPU, taking around 9G and 15G GPU memory for the scales of 7B and 13B , respectively. Technical details are available in [知乎](https://zhuanlan.zhihu.com/p/638784025).
- **`2023/05/29`**: 🔥We released the demo and the pre-trained checkpoint (LLaMA-13B) for multimodal chatbot.
- **`2023/05/25`**: 🔥We released the code of **LaVIN: Large Vision-Language Instructed model**, which achieves 89.4 (LaVIN-7B) and 90.8 (LaVIN-13B) accuracy on ScienceQA! 🔥With the proposed **mixture-of-modality adaptation**, the training time and trainable parameters can be reduced to 1.4 hours and 3.8M, respectively! Checkout the [paper](https://arxiv.org/pdf/2305.15023.pdf).
## TODO
- [x] Release training codes.
- [x] Release checkpoints and demo.
- [x] 4-bit training.
- [ ] Support more modalities, e.g., audio and video.
## Contents
- [Setup](#setup)
- [Fine-tuning](#fine-tuning)
- [Demo](#demo)
- [Model Zoo](#model-zoo)
## Setup
### Install Package
```bash
conda create -n lavin python=3.8 -y
conda activate lavin
# install pytorch
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 -c pytorch
# install dependency and lavin
pip install -r requirements.txt
pip install -e .
```
### Data Preparation
- For ScienceQA, please prepare the dataset from the [official repo](https://github.com/lupantech/ScienceQA).
- For Multimodal Chatbot, download the images in _train2014_ split from [MSCOCO](http://images.cocodataset.org/zips/train2014.zip), and obtain the prepared 52k text-only and 158k text-image instruction-following data from [here](https://drive.google.com/file/d/1gORDPruqwXbgy6NYmhpDXO7t089yzsg3/view?usp=share_link).
- Obtain the weights of LLaMA from [this form](https://forms.gle/jk851eBVbX1m5TAv5) (official) or Download [LLaMA-7B](https://huggingface.co/nyanko7/LLaMA-7B/tree/main) and [LLaMA-13B](https://huggingface.co/TheBloke/llama-13b) from HuggingFace (unofficial).
- If you want to use Vicuna weights to initialize the model, please download from [here](https://huggingface.co/lmsys).
After that, the file structure should look like:
```bash
LaVIN/
|-- lavin
|-- scripts
|-- train.py
|-- eval.py
......
data/
|-- problem.json
|-- pid_splits.json
|-- captions.json
|-- all_data.json
|-- images
|-- train2014 # MSCOCO 2014
|-- val2014 # MSCOCO 2014
|-- train # ScienceQA train image
|-- val # ScienceQA val image
|-- test # ScienceQA test image
|-- weights
|-- tokenizer.model
|--7B
|-- params.json
|-- consolidated.00.pth
|--13B
|-- params.json
|-- consolidated.00.pth
|-- consolidated.01.pth
|--vicuna_7B
|--vicuna_13B
|-- config.json
|-- generation_config.json
|-- pytorch_model.bin.index.json
|-- special_tokens_map.json
|-- tokenizer_config.json
|-- tokenizer.model
|-- pytorch_model-00001-of-00003.bin
|-- pytorch_model-00002-of-00003.bin
|-- pytorch_model-00003-of-00003.bin
......
```
## Fine-tuning
### ScienceQA
Reproduce the performance of LaVIN-7B on ScienceQA.
For 7B model, we fine-tune it on 2x A100 (we find that the performance will be affected by the number of GPUs. We are working to address this problem).
LLaMA weights:
```bash
bash ./scripts/finetuning_sqa_7b.sh
```
Vicuna weights:
```bash
bash ./scripts/finetuning_sqa_vicuna_7b.sh
```
LaVIN-lite with LLaMA weights (single GPU):
```bash
bash ./scripts/finetuning_sqa_vicuna_7b_lite.sh
```
Reproduce the performance of LaVIN-13B on ScienceQA (~2 hours on 8x A100 (80G)).
For 13B model, we fine-tune it on 8x A100.
LLaMA weights:
```bash
bash ./scripts/finetuning_sqa_13b.sh
```
Vicuna weights:
```bash
bash ./scripts/finetuning_sqa_vicuna_13b.sh
```
LaVIN-lite with LLaMA weights (single GPU):
```bash
bash ./scripts/finetuning_sqa_vicuna_13b_lite.sh
```
### MultiModal ChatBot
Fine-tune LaVIN-13B on 210k instruction-following data (~ 75 hours with 15 epochs and ~25 hours with 5 epochs on 8x A100 (80G) )
LLaMA weights:
```bash
bash ./scripts/vl_instruction_tuning_13b.sh
```
Vicuna weights:
```bash
bash ./scripts/vl_instruction_tuning_vicuna_13b.sh
```
To train on fewer GPUs, you can reduce the number of gpus in the scripts and increase gradient accumulation via ```--accum_iter``` to guarantee the total batch size of 32. Setting ```--gradient_checkpointing``` and ```--bits 4bit``` in the scripts will greatly reduce the requirements of GPU memory.
## Demo
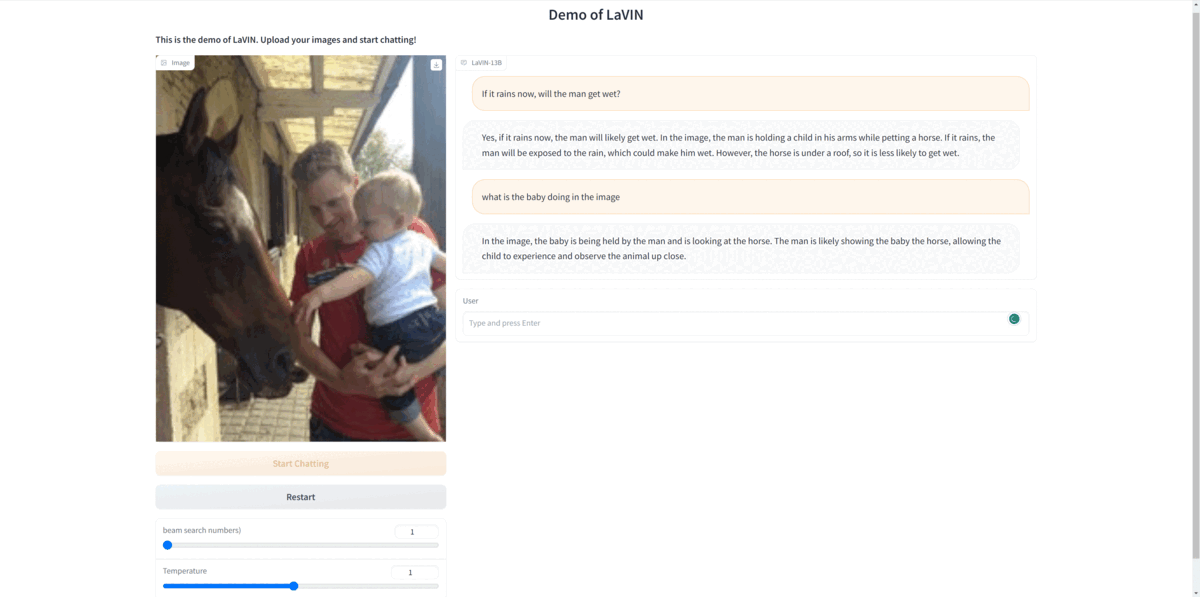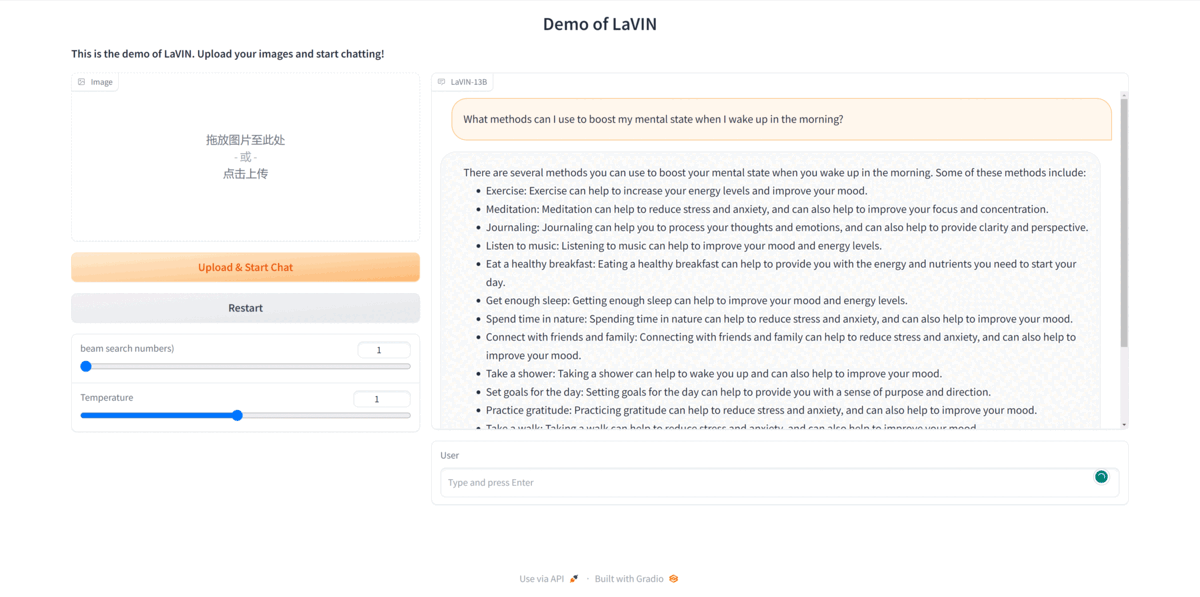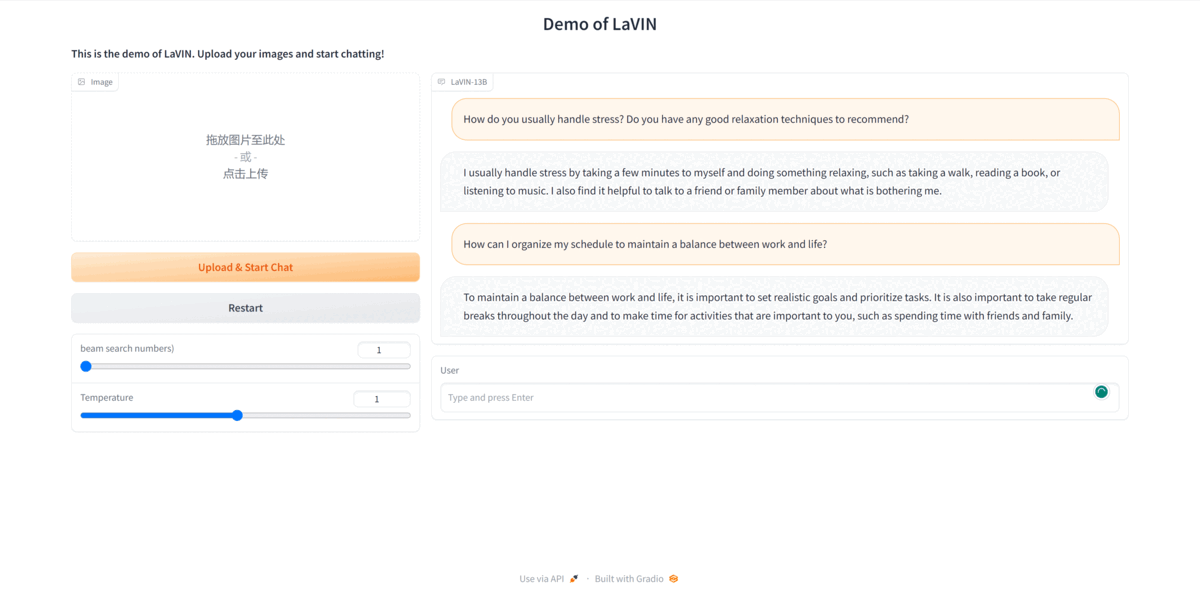
LaVIN supports both single- and multi-modal instruction inputs. Try your custom instructions in our demo:
- **Launch a gradio web server on your machine, then you can interact with LaVIN as you like.**
```
torchrun --nproc_per_node 1 demo.py --server_name 127.0.0.1
```
## Model Zoo
### ScienceQA
| Model | Weights | Time | Memory | #Params | Acc | Weights |
|-----------|----------:|----------:|-------:|--------:|-----:|-----------------:|
| LaVIN-7B-lite | LLaMA | 29 hours (single GPU) | 9G | 3.8M | 88.35 | [google drive](https://drive.google.com/file/d/1oVtoTgt-d9EqmrVic27oZUreN9dLClMo/view?usp=sharing) |
| LaVIN-13B-lite | LLaMA | 42 hours (single GPU) | 14G | 5.4M | 89.44 | [google drive](https://drive.google.com/file/d/1PyVsap3FnmgXOGXFXjYsAtR75cFypaHw/view?usp=sharing) |
| LaVIN-7B | LLaMA | 1.4 hours | 33.9G | 3.8M | 89.37 | [google drive](https://drive.google.com/file/d/10X2qCBYrLH1grZOHwHRMXLUoz-S6MSgV/view?usp=share_link) |
| LaVIN-7B | Vicuna | 1.4 hours | 33.9G | 3.8M | 89.41 | [google drive](https://drive.google.com/file/d/1nuMxeiWlnJKxDybCshg8pVGSvLc5dZy8/view?usp=share_link) |
| LaVIN-13B | LLaMA | 2 hours | 55.9G | 5.4M | 90.54 | [google drive](https://drive.google.com/file/d/1LkKUY54spZkkeXrR7BDmU-xmK9YadcKM/view?usp=share_link) |
| LaVIN-13B | LLaMA | 4 hours | 55.9G | 5.4M | 90.8 | - |
### Multimodal ChatBot
| Model |Weights | Time | Memory | #Params | Acc | Weights |
|-----------|----------:|---------:|-------:|--------:|----:|-----------------:|
| LaVIN-13B | LLaMA | 25 hours | 55.9G | 5.4M | - | - |
| LaVIN-13B | LLaMA | 75 hours | 55.9G | 5.4M | - | [google drive](https://drive.google.com/file/d/1rHQNSaiGzFHYGgsamtySPYnd5AW4OE9j/view?usp=share_link)|
## Examples
## Star History
[](https://star-history.com/#luogen1996/LaVIN&Date)
## Citation
If you think our code and paper helpful, please kindly cite LaVIN and [RepAdapter](https://github.com/luogen1996/RepAdapter/):
```BibTeX
@article{luo2023towards,
title={Towards Efficient Visual Adaption via Structural Re-parameterization},
author={Luo, Gen and Huang, Minglang and Zhou, Yiyi and Sun, Xiaoshuai and Jiang, Guangnan and Wang, Zhiyu and Ji, Rongrong},
journal={arXiv preprint arXiv:2302.08106},
year={2023}
}
@article{luo2023cheap,
title={Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models},
author={Luo, Gen and Zhou, Yiyi and Ren, Tianhe and Chen, Shengxin and Sun, Xiaoshuai and Ji, Rongrong},
journal={Advances in neural information processing systems (NeurIPS)},
year={2023}
}
```
## Acknowledgement
This repo borrows some data and codes from [LLaMA](https://github.com/facebookresearch/llama), [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca), [LLaVA](https://github.com/haotian-liu/LLaVA), [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4) and [LLaMA-Adapter](https://github.com/ZrrSkywalker/LLaMA-Adapter/). Thanks for their great works.