Solving Inequality Proofs with Large Language Models
[](https://lbesson.mit-license.org/)
[](https://creativecommons.org/licenses/by-sa/4.0/)
[](https://arxiv.org/abs/2506.07927)
[](https://huggingface.co/papers/2506.07927)
[](https://huggingface.co/datasets/AI4Math/IneqMath)
[](https://huggingface.co/spaces/AI4Math/IneqMath-Leaderboard)
[](https://ineqmath.github.io/)
[](https://ineqmath.github.io/#leaderboard)
[](https://ineqmath.github.io/#visualization)
[](https://x.com/lupantech/status/1932866286427779586)
Welcome to the official repository for the paper "[Solving Inequality Proofs with Large Language Models](https://arxiv.org/abs/2506.07927)". With this toolkit you can **evaluate your own models** on our benchmark, **plug in our improvement strategies** to boost performance, **reproduce the paper's experiments** end-to-end, and **train more effectively** with our data.
**Dive in and push the frontier of inequality and mathematics reasoning with us!** 🚀
## 📑 Table of Contents
- [💥 News ](#news)
- [📖 Introduction](#introduction)
- [📊 Dataset Examples](#dataset-examples)
- [🏆 Leaderboard](#leaderboard)
- [📝 Evaluations on IneqMath](#evaluations-on-ineqmath)
- [Environment Setup](#environment-setup)
- [Evaluate Models on IneqMath Test Set](#evaluate-models-on-ineqmath-test-set)
- [Evaluate Models on IneqMath Dev Set](#evaluate-models-on-ineqmath-dev-set)
- [Evaluate with the Final Answer Judge](#evaluate-with-the-final-answer-judge)
- [Submit the Results to the Evaluation Platform](#submit-the-results-to-the-evaluation-platform)
- [🎯 Strategies on IneqMath](#strategies-on-ineqmath)
- [Frequent Theorems as Hints](#frequent-theorems-as-hints)
- [Frequent Training Problems and Solutions as Hints](#frequent-training-problems-and-solutions-as-hints)
- [Few-shot Evaluation](#few-shot-evaluation)
- [🧪 Other experiments on IneqMath](#other-experiments-on-ineqmath)
- [Taking Annotated Theorems as Hints](#taking-annotated-theorems-as-hints)
- [🤖 Supported LLM Engines](#supported-llm-engines)
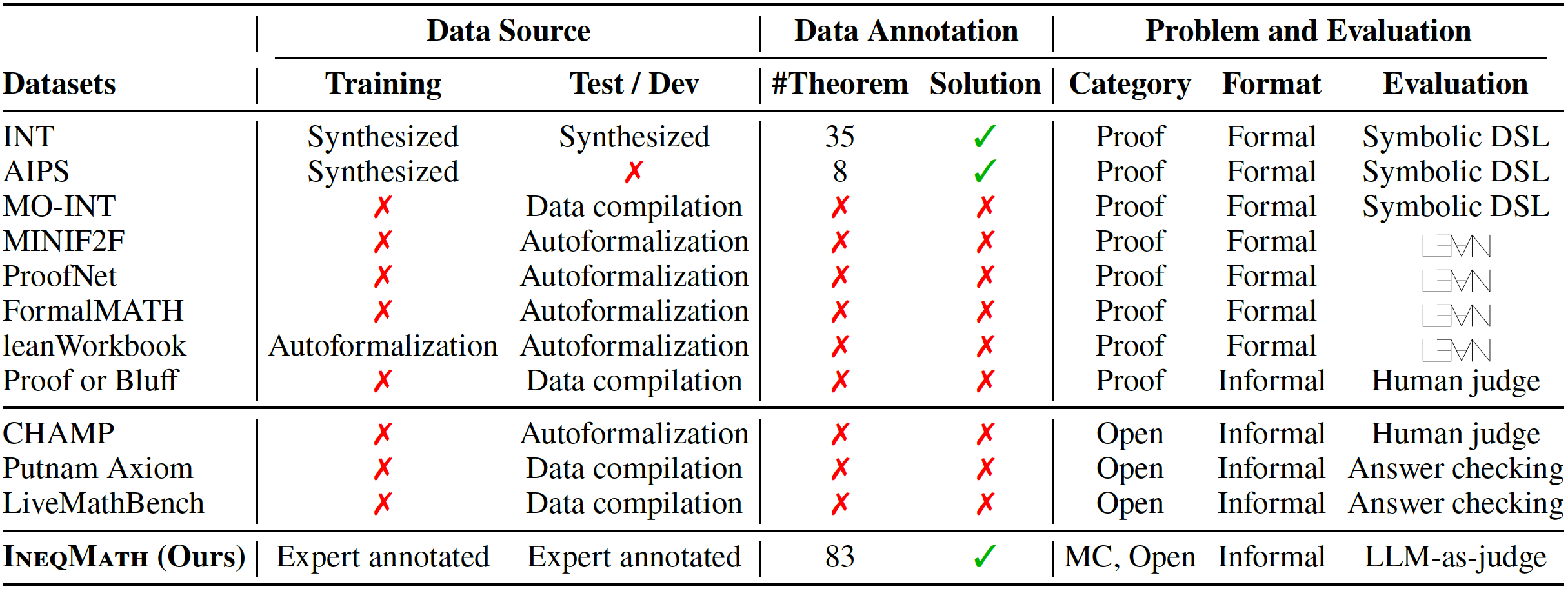
- [📂 Data Curation](#data-curation)
- [Informal Reformulation of Inequality Proving](#informal-reformulation-of-inequality-proving)
- [Training Data Enhancement](#training-data-enhancement)
- [🤗 Dataset Overview](#dataset-overview)
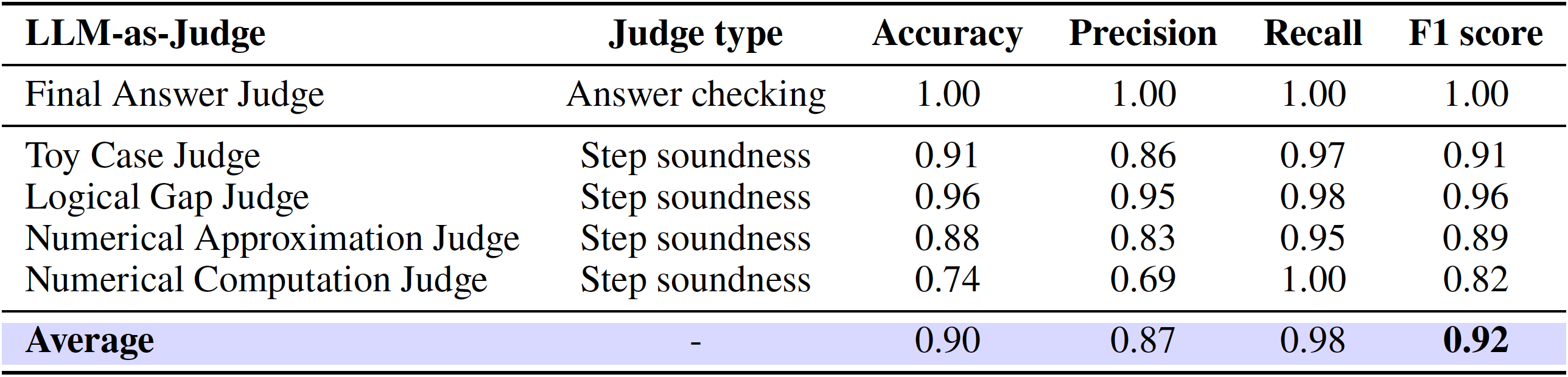
- [🧐 Fine-grained Informal Judges](#fine-grained-informal-judges)
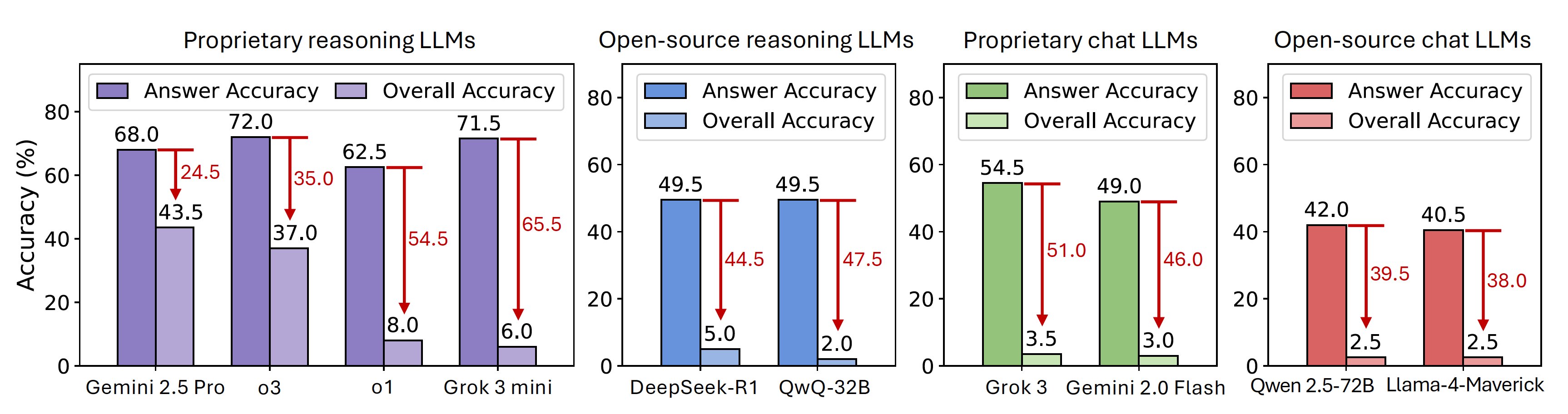
- [📈 Evaluation Results](#evaluation-results)
- [Results of Leading LLMs](#results-of-leading-llms)
- [Scaling Law in Model Size](#scaling-law-in-model-size)
- [🔍 In-depth Study](#in-depth-study)
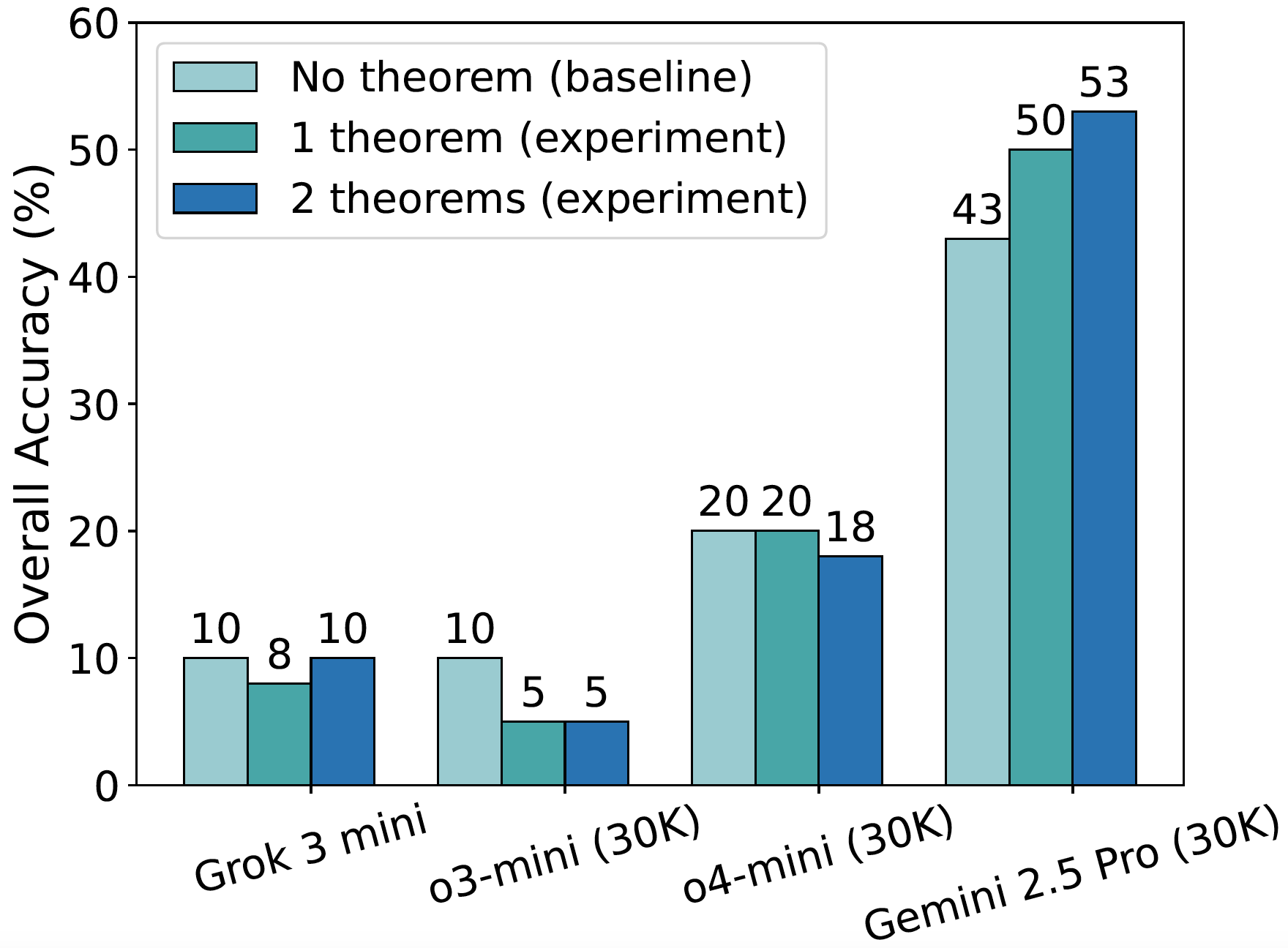
- [Retrieving Relevant Theorems as Hints](#retrieving-relevant-theorems-as-hints)
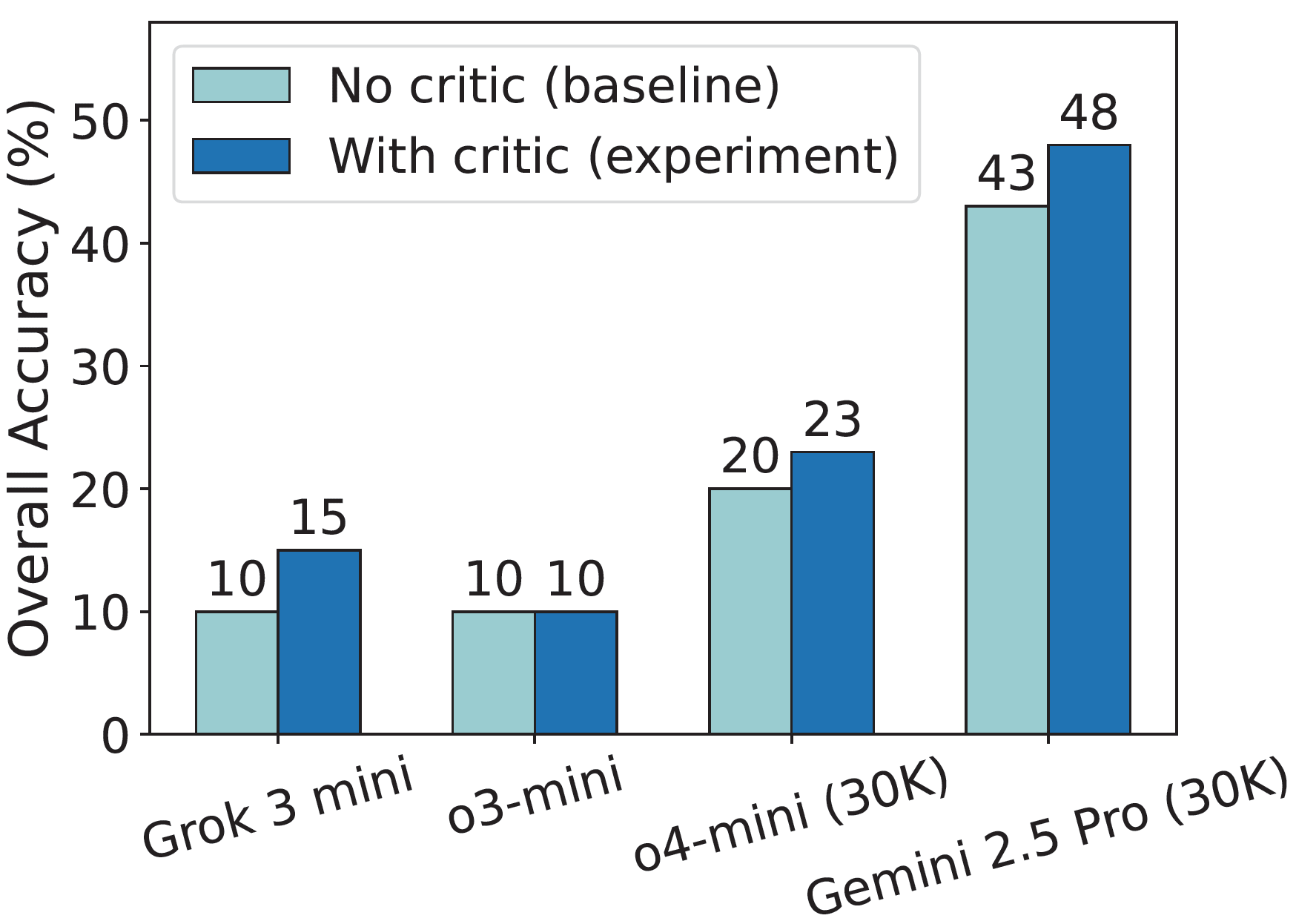
- [Self-improvement via Critic as Feedback](#self-improvement-via-critic-as-feedback)
- [📜 License](#license)
- [📚 Citation](#citation)