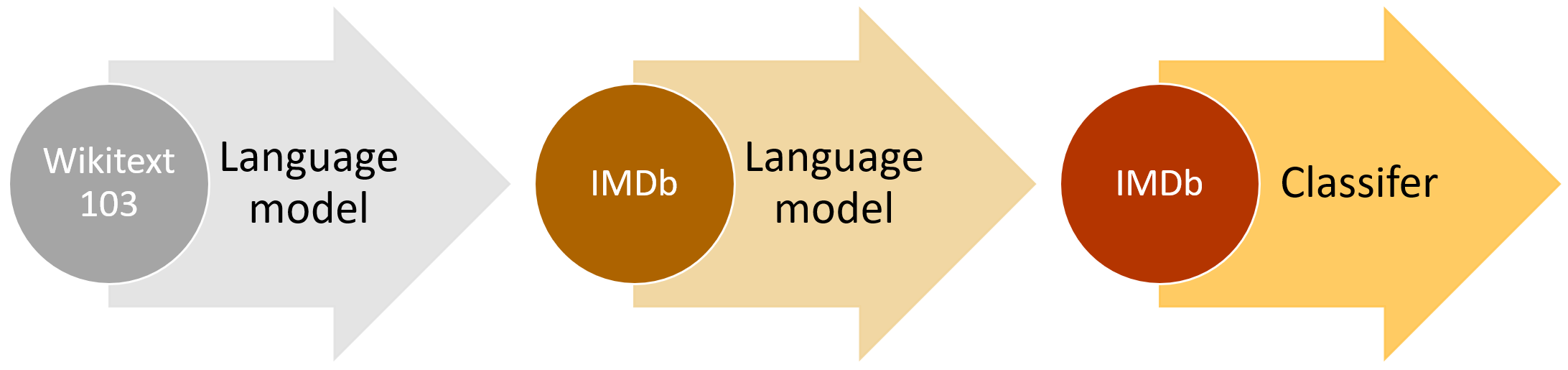
 \n",
"\n",
"
\n",
"\n",
" \n",
"
\n",
" \n",
"
\n",
"| idx | \n", "text | \n", "
|---|---|
| 0 | \n", ", but one gets the impression in watching the film that it was not pulled off as well as it could have been . xxmaj the fact that it is cluttered by a rather uninteresting subplot and mostly uninteresting kidnappers really muddles things . xxmaj the movie is worth a xxunk if for nothing more than entertaining performances by xxmaj rickman , xxmaj thompson , and xxmaj holbrook . xxbos | \n", "
| 1 | \n", "gosling 's smile or contrived moralizing . xxmaj after the first 45 minutes however , the script blossomed into a watch - able albeit not completely entertaining or thought - provoking . xxmaj the highlights certainly include both xxmaj gosling and xxmaj morse 's acting , xxmaj gosling being an up - and - coming star , and xxmaj morse being an extremely well - established character actor with a | \n", "
| 2 | \n", ". xxmaj their glares and facial ticks would not cut any mustard with the boys from the hood . xxmaj unfortunately for all good people , these xxmaj charmed boys were sent to xxmaj xxunk 's xxmaj reform xxmaj school for the warlocks that could n't get into xxmaj harry xxmaj potter 's class . \\n \\n xxmaj so what was the movie all about ? xxmaj three teenagers | \n", "
| 3 | \n", "to be ) is around , and a string pulling bed sheets up and down . xxmaj oooh , can you feel the chills ? xxmaj the xxup dvd quality is that of a xxup vhs transfer ( which actually helps the film more than hurts it ) . xxmaj the dubbing is below even the lowest \" bad xxmaj italian movie \" standards and i gave it one star | \n", "
| 4 | \n", "as to xxmaj jack xxmaj lemmon , he plays his part so straight , he can hardly dip and glide when dancing . xxmaj and as mentioned , xxmaj dyan xxmaj cannon is outstandingly attractive as another swindler sailing with her mother who thinks xxmaj walter is rich , while he thinks she is rich . xxmaj elaine xxmaj stritch plays xxmaj dyan 's mother , another retread from the | \n", "
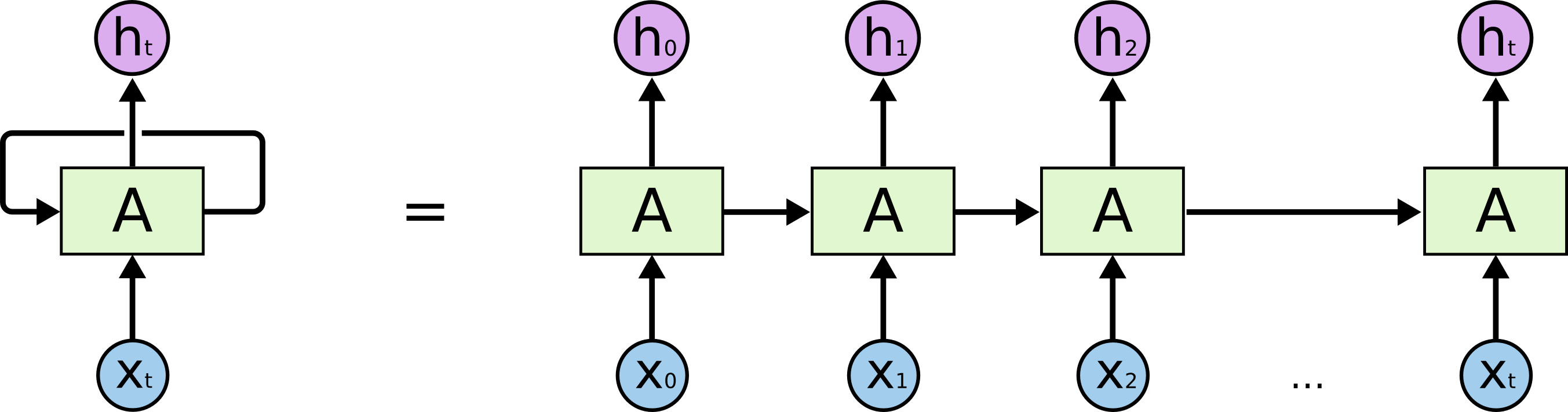 \n",
"
\n",
" Reference: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
\n", "| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|
\n", "\n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "4.145812 | \n", "4.027751 | \n", "0.294872 | \n", "24:40 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "3.883628 | \n", "3.846353 | \n", "0.312791 | \n", "25:13 | \n", "
| 1 | \n", "3.830023 | \n", "3.806326 | \n", "0.319647 | \n", "25:14 | \n", "
| 2 | \n", "3.823724 | \n", "3.776663 | \n", "0.323472 | \n", "25:14 | \n", "
| 3 | \n", "3.790490 | \n", "3.747104 | \n", "0.327012 | \n", "25:14 | \n", "
| 4 | \n", "3.708543 | \n", "3.720774 | \n", "0.330030 | \n", "25:14 | \n", "
| 5 | \n", "3.685525 | \n", "3.700337 | \n", "0.332860 | \n", "25:14 | \n", "
| 6 | \n", "3.594311 | \n", "3.683683 | \n", "0.334876 | \n", "25:14 | \n", "
| 7 | \n", "3.559871 | \n", "3.672719 | \n", "0.336452 | \n", "25:14 | \n", "
| 8 | \n", "3.545992 | \n", "3.668409 | \n", "0.337152 | \n", "25:14 | \n", "
| 9 | \n", "3.494757 | \n", "3.668425 | \n", "0.337193 | \n", "25:14 | \n", "
| text | \n", "target | \n", "
|---|---|
| xxbos xxmaj match 1 : xxmaj tag xxmaj team xxmaj table xxmaj match xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley vs xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit xxmaj bubba xxmaj ray and xxmaj spike xxmaj dudley started things off with a xxmaj tag xxmaj team xxmaj table xxmaj match against xxmaj eddie xxmaj guerrero and xxmaj chris xxmaj benoit . xxmaj according to the rules | \n", "pos | \n", "
| xxbos xxmaj by now you 've probably heard a bit about the new xxmaj disney dub of xxmaj miyazaki 's classic film , xxmaj laputa : xxmaj castle xxmaj in xxmaj the xxmaj sky . xxmaj during late summer of 1998 , xxmaj disney released \" xxmaj kiki 's xxmaj delivery xxmaj service \" on video which included a preview of the xxmaj laputa dub saying it was due out | \n", "pos | \n", "
| xxbos xxmaj some have praised xxunk xxmaj lost xxmaj xxunk as a xxmaj disney adventure for adults . i do n't think so -- at least not for thinking adults . \\n \\n xxmaj this script suggests a beginning as a live - action movie , that struck someone as the type of crap you can not sell to adults anymore . xxmaj the \" crack staff \" of | \n", "neg | \n", "
| xxbos xxmaj by 1987 xxmaj hong xxmaj kong had given the world such films as xxmaj sammo xxmaj hung 's ` xxmaj encounters of the xxmaj spooky xxmaj kind ' xxmaj chow xxmaj yun xxmaj fat in xxmaj john xxmaj woo 's iconic ` a xxmaj better xxmaj tomorrow ' , ` xxmaj zu xxmaj warriors ' and the classic ` xxmaj mr xxmaj vampire ' . xxmaj jackie xxmaj | \n", "pos | \n", "
| xxbos xxmaj to be a xxmaj buster xxmaj keaton fan is to have your heart broken on a regular basis . xxmaj most of us first encounter xxmaj keaton in one of the brilliant feature films from his great period of independent production : ' xxmaj the xxmaj general ' , ' xxmaj the xxmaj navigator ' , ' xxmaj sherlock xxmaj jnr ' . xxmaj we recognise him as | \n", "neg | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|
\n", "\n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.325401 | \n", "0.261644 | \n", "0.892640 | \n", "04:50 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.267379 | \n", "0.217356 | \n", "0.913600 | \n", "05:13 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.233473 | \n", "0.182271 | \n", "0.930040 | \n", "04:54 | \n", "
| epoch | \n", "train_loss | \n", "valid_loss | \n", "accuracy | \n", "time | \n", "
|---|---|---|---|---|
| 0 | \n", "0.201170 | \n", "0.175181 | \n", "0.933120 | \n", "05:09 | \n", "
| 1 | \n", "0.182616 | \n", "0.174323 | \n", "0.932920 | \n", "05:07 | \n", "