{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"from __future__ import print_function"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# NumPy"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"this notebook is based on the SciPy NumPy tutorial"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note that the traditional way to import numpy is to rename it np. This saves on typing and makes your code a little more compact.
"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"NumPy provides a multidimensional array class as well as a _large_ number of functions that operate on arrays.\n",
"\n",
"NumPy arrays allow you to write fast (optimized) code that works on arrays of data. To do this, there are some restrictions on arrays:\n",
"\n",
"* all elements are of the same data type (e.g. float)\n",
"* the size of the array is fixed in memory, and specified when you create the array (e.g., you cannot grow the array like you do with lists)\n",
"\n",
"The nice part is that arithmetic operations work on entire arrays—this means that you can avoid writing loops in python (which tend to be slow). Instead the \"looping\" is done in the underlying compiled code"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Array Creation and Properties"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are a lot of ways to create arrays. Let's look at a few\n",
"\n",
"Here we create an array using `arange` and then change its shape to be 3 rows and 5 columns. Note the _row-major ordering_—you'll see that the rows are together in the inner `[]` (more on this in a bit)"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"a = np.arange(1,15)"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0 1 2 3 4]\n",
" [ 5 6 7 8 9]\n",
" [10 11 12 13 14]]\n"
]
}
],
"source": [
"a = np.arange(15).reshape(3,5)\n",
"\n",
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"an array is an object of the `ndarray` class, and it has methods that know how to work on the array data. Here, `.reshape()` is one of the many methods."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"A NumPy array has a lot of meta-data associated with it describing its shape, datatype, etc."
]
},
{
"cell_type": "code",
"execution_count": 92,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n",
"(3, 5)\n",
"15\n",
"int64\n",
"8\n",
"\n"
]
}
],
"source": [
"print(a.ndim)\n",
"print(a.shape)\n",
"print(a.size)\n",
"print(a.dtype)\n",
"print(a.itemsize)\n",
"print(type(a))"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Help on ndarray object:\n",
"\n",
"class ndarray(builtins.object)\n",
" | ndarray(shape, dtype=float, buffer=None, offset=0,\n",
" | strides=None, order=None)\n",
" | \n",
" | An array object represents a multidimensional, homogeneous array\n",
" | of fixed-size items. An associated data-type object describes the\n",
" | format of each element in the array (its byte-order, how many bytes it\n",
" | occupies in memory, whether it is an integer, a floating point number,\n",
" | or something else, etc.)\n",
" | \n",
" | Arrays should be constructed using `array`, `zeros` or `empty` (refer\n",
" | to the See Also section below). The parameters given here refer to\n",
" | a low-level method (`ndarray(...)`) for instantiating an array.\n",
" | \n",
" | For more information, refer to the `numpy` module and examine the\n",
" | methods and attributes of an array.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | (for the __new__ method; see Notes below)\n",
" | \n",
" | shape : tuple of ints\n",
" | Shape of created array.\n",
" | dtype : data-type, optional\n",
" | Any object that can be interpreted as a numpy data type.\n",
" | buffer : object exposing buffer interface, optional\n",
" | Used to fill the array with data.\n",
" | offset : int, optional\n",
" | Offset of array data in buffer.\n",
" | strides : tuple of ints, optional\n",
" | Strides of data in memory.\n",
" | order : {'C', 'F'}, optional\n",
" | Row-major (C-style) or column-major (Fortran-style) order.\n",
" | \n",
" | Attributes\n",
" | ----------\n",
" | T : ndarray\n",
" | Transpose of the array.\n",
" | data : buffer\n",
" | The array's elements, in memory.\n",
" | dtype : dtype object\n",
" | Describes the format of the elements in the array.\n",
" | flags : dict\n",
" | Dictionary containing information related to memory use, e.g.,\n",
" | 'C_CONTIGUOUS', 'OWNDATA', 'WRITEABLE', etc.\n",
" | flat : numpy.flatiter object\n",
" | Flattened version of the array as an iterator. The iterator\n",
" | allows assignments, e.g., ``x.flat = 3`` (See `ndarray.flat` for\n",
" | assignment examples; TODO).\n",
" | imag : ndarray\n",
" | Imaginary part of the array.\n",
" | real : ndarray\n",
" | Real part of the array.\n",
" | size : int\n",
" | Number of elements in the array.\n",
" | itemsize : int\n",
" | The memory use of each array element in bytes.\n",
" | nbytes : int\n",
" | The total number of bytes required to store the array data,\n",
" | i.e., ``itemsize * size``.\n",
" | ndim : int\n",
" | The array's number of dimensions.\n",
" | shape : tuple of ints\n",
" | Shape of the array.\n",
" | strides : tuple of ints\n",
" | The step-size required to move from one element to the next in\n",
" | memory. For example, a contiguous ``(3, 4)`` array of type\n",
" | ``int16`` in C-order has strides ``(8, 2)``. This implies that\n",
" | to move from element to element in memory requires jumps of 2 bytes.\n",
" | To move from row-to-row, one needs to jump 8 bytes at a time\n",
" | (``2 * 4``).\n",
" | ctypes : ctypes object\n",
" | Class containing properties of the array needed for interaction\n",
" | with ctypes.\n",
" | base : ndarray\n",
" | If the array is a view into another array, that array is its `base`\n",
" | (unless that array is also a view). The `base` array is where the\n",
" | array data is actually stored.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | array : Construct an array.\n",
" | zeros : Create an array, each element of which is zero.\n",
" | empty : Create an array, but leave its allocated memory unchanged (i.e.,\n",
" | it contains \"garbage\").\n",
" | dtype : Create a data-type.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | There are two modes of creating an array using ``__new__``:\n",
" | \n",
" | 1. If `buffer` is None, then only `shape`, `dtype`, and `order`\n",
" | are used.\n",
" | 2. If `buffer` is an object exposing the buffer interface, then\n",
" | all keywords are interpreted.\n",
" | \n",
" | No ``__init__`` method is needed because the array is fully initialized\n",
" | after the ``__new__`` method.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | These examples illustrate the low-level `ndarray` constructor. Refer\n",
" | to the `See Also` section above for easier ways of constructing an\n",
" | ndarray.\n",
" | \n",
" | First mode, `buffer` is None:\n",
" | \n",
" | >>> np.ndarray(shape=(2,2), dtype=float, order='F')\n",
" | array([[ -1.13698227e+002, 4.25087011e-303],\n",
" | [ 2.88528414e-306, 3.27025015e-309]]) #random\n",
" | \n",
" | Second mode:\n",
" | \n",
" | >>> np.ndarray((2,), buffer=np.array([1,2,3]),\n",
" | ... offset=np.int_().itemsize,\n",
" | ... dtype=int) # offset = 1*itemsize, i.e. skip first element\n",
" | array([2, 3])\n",
" | \n",
" | Methods defined here:\n",
" | \n",
" | __abs__(self, /)\n",
" | abs(self)\n",
" | \n",
" | __add__(self, value, /)\n",
" | Return self+value.\n",
" | \n",
" | __and__(self, value, /)\n",
" | Return self&value.\n",
" | \n",
" | __array__(...)\n",
" | a.__array__(|dtype) -> reference if type unchanged, copy otherwise.\n",
" | \n",
" | Returns either a new reference to self if dtype is not given or a new array\n",
" | of provided data type if dtype is different from the current dtype of the\n",
" | array.\n",
" | \n",
" | __array_prepare__(...)\n",
" | a.__array_prepare__(obj) -> Object of same type as ndarray object obj.\n",
" | \n",
" | __array_ufunc__(...)\n",
" | \n",
" | __array_wrap__(...)\n",
" | a.__array_wrap__(obj) -> Object of same type as ndarray object a.\n",
" | \n",
" | __bool__(self, /)\n",
" | self != 0\n",
" | \n",
" | __complex__(...)\n",
" | \n",
" | __contains__(self, key, /)\n",
" | Return key in self.\n",
" | \n",
" | __copy__(...)\n",
" | a.__copy__()\n",
" | \n",
" | Used if :func:`copy.copy` is called on an array. Returns a copy of the array.\n",
" | \n",
" | Equivalent to ``a.copy(order='K')``.\n",
" | \n",
" | __deepcopy__(...)\n",
" | a.__deepcopy__(memo, /) -> Deep copy of array.\n",
" | \n",
" | Used if :func:`copy.deepcopy` is called on an array.\n",
" | \n",
" | __delitem__(self, key, /)\n",
" | Delete self[key].\n",
" | \n",
" | __divmod__(self, value, /)\n",
" | Return divmod(self, value).\n",
" | \n",
" | __eq__(self, value, /)\n",
" | Return self==value.\n",
" | \n",
" | __float__(self, /)\n",
" | float(self)\n",
" | \n",
" | __floordiv__(self, value, /)\n",
" | Return self//value.\n",
" | \n",
" | __format__(...)\n",
" | Default object formatter.\n",
" | \n",
" | __ge__(self, value, /)\n",
" | Return self>=value.\n",
" | \n",
" | __getitem__(self, key, /)\n",
" | Return self[key].\n",
" | \n",
" | __gt__(self, value, /)\n",
" | Return self>value.\n",
" | \n",
" | __iadd__(self, value, /)\n",
" | Return self+=value.\n",
" | \n",
" | __iand__(self, value, /)\n",
" | Return self&=value.\n",
" | \n",
" | __ifloordiv__(self, value, /)\n",
" | Return self//=value.\n",
" | \n",
" | __ilshift__(self, value, /)\n",
" | Return self<<=value.\n",
" | \n",
" | __imatmul__(self, value, /)\n",
" | Return self@=value.\n",
" | \n",
" | __imod__(self, value, /)\n",
" | Return self%=value.\n",
" | \n",
" | __imul__(self, value, /)\n",
" | Return self*=value.\n",
" | \n",
" | __index__(self, /)\n",
" | Return self converted to an integer, if self is suitable for use as an index into a list.\n",
" | \n",
" | __int__(self, /)\n",
" | int(self)\n",
" | \n",
" | __invert__(self, /)\n",
" | ~self\n",
" | \n",
" | __ior__(self, value, /)\n",
" | Return self|=value.\n",
" | \n",
" | __ipow__(self, value, /)\n",
" | Return self**=value.\n",
" | \n",
" | __irshift__(self, value, /)\n",
" | Return self>>=value.\n",
" | \n",
" | __isub__(self, value, /)\n",
" | Return self-=value.\n",
" | \n",
" | __iter__(self, /)\n",
" | Implement iter(self).\n",
" | \n",
" | __itruediv__(self, value, /)\n",
" | Return self/=value.\n",
" | \n",
" | __ixor__(self, value, /)\n",
" | Return self^=value.\n",
" | \n",
" | __le__(self, value, /)\n",
" | Return self<=value.\n",
" | \n",
" | __len__(self, /)\n",
" | Return len(self).\n",
" | \n",
" | __lshift__(self, value, /)\n",
" | Return self<>self.\n",
" | \n",
" | __rshift__(self, value, /)\n",
" | Return self>>value.\n",
" | \n",
" | __rsub__(self, value, /)\n",
" | Return value-self.\n",
" | \n",
" | __rtruediv__(self, value, /)\n",
" | Return value/self.\n",
" | \n",
" | __rxor__(self, value, /)\n",
" | Return value^self.\n",
" | \n",
" | __setitem__(self, key, value, /)\n",
" | Set self[key] to value.\n",
" | \n",
" | __setstate__(...)\n",
" | a.__setstate__(state, /)\n",
" | \n",
" | For unpickling.\n",
" | \n",
" | The `state` argument must be a sequence that contains the following\n",
" | elements:\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | version : int\n",
" | optional pickle version. If omitted defaults to 0.\n",
" | shape : tuple\n",
" | dtype : data-type\n",
" | isFortran : bool\n",
" | rawdata : string or list\n",
" | a binary string with the data (or a list if 'a' is an object array)\n",
" | \n",
" | __sizeof__(...)\n",
" | Size of object in memory, in bytes.\n",
" | \n",
" | __str__(self, /)\n",
" | Return str(self).\n",
" | \n",
" | __sub__(self, value, /)\n",
" | Return self-value.\n",
" | \n",
" | __truediv__(self, value, /)\n",
" | Return self/value.\n",
" | \n",
" | __xor__(self, value, /)\n",
" | Return self^value.\n",
" | \n",
" | all(...)\n",
" | a.all(axis=None, out=None, keepdims=False)\n",
" | \n",
" | Returns True if all elements evaluate to True.\n",
" | \n",
" | Refer to `numpy.all` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.all : equivalent function\n",
" | \n",
" | any(...)\n",
" | a.any(axis=None, out=None, keepdims=False)\n",
" | \n",
" | Returns True if any of the elements of `a` evaluate to True.\n",
" | \n",
" | Refer to `numpy.any` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.any : equivalent function\n",
" | \n",
" | argmax(...)\n",
" | a.argmax(axis=None, out=None)\n",
" | \n",
" | Return indices of the maximum values along the given axis.\n",
" | \n",
" | Refer to `numpy.argmax` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.argmax : equivalent function\n",
" | \n",
" | argmin(...)\n",
" | a.argmin(axis=None, out=None)\n",
" | \n",
" | Return indices of the minimum values along the given axis of `a`.\n",
" | \n",
" | Refer to `numpy.argmin` for detailed documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.argmin : equivalent function\n",
" | \n",
" | argpartition(...)\n",
" | a.argpartition(kth, axis=-1, kind='introselect', order=None)\n",
" | \n",
" | Returns the indices that would partition this array.\n",
" | \n",
" | Refer to `numpy.argpartition` for full documentation.\n",
" | \n",
" | .. versionadded:: 1.8.0\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.argpartition : equivalent function\n",
" | \n",
" | argsort(...)\n",
" | a.argsort(axis=-1, kind='quicksort', order=None)\n",
" | \n",
" | Returns the indices that would sort this array.\n",
" | \n",
" | Refer to `numpy.argsort` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.argsort : equivalent function\n",
" | \n",
" | astype(...)\n",
" | a.astype(dtype, order='K', casting='unsafe', subok=True, copy=True)\n",
" | \n",
" | Copy of the array, cast to a specified type.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | dtype : str or dtype\n",
" | Typecode or data-type to which the array is cast.\n",
" | order : {'C', 'F', 'A', 'K'}, optional\n",
" | Controls the memory layout order of the result.\n",
" | 'C' means C order, 'F' means Fortran order, 'A'\n",
" | means 'F' order if all the arrays are Fortran contiguous,\n",
" | 'C' order otherwise, and 'K' means as close to the\n",
" | order the array elements appear in memory as possible.\n",
" | Default is 'K'.\n",
" | casting : {'no', 'equiv', 'safe', 'same_kind', 'unsafe'}, optional\n",
" | Controls what kind of data casting may occur. Defaults to 'unsafe'\n",
" | for backwards compatibility.\n",
" | \n",
" | * 'no' means the data types should not be cast at all.\n",
" | * 'equiv' means only byte-order changes are allowed.\n",
" | * 'safe' means only casts which can preserve values are allowed.\n",
" | * 'same_kind' means only safe casts or casts within a kind,\n",
" | like float64 to float32, are allowed.\n",
" | * 'unsafe' means any data conversions may be done.\n",
" | subok : bool, optional\n",
" | If True, then sub-classes will be passed-through (default), otherwise\n",
" | the returned array will be forced to be a base-class array.\n",
" | copy : bool, optional\n",
" | By default, astype always returns a newly allocated array. If this\n",
" | is set to false, and the `dtype`, `order`, and `subok`\n",
" | requirements are satisfied, the input array is returned instead\n",
" | of a copy.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | arr_t : ndarray\n",
" | Unless `copy` is False and the other conditions for returning the input\n",
" | array are satisfied (see description for `copy` input parameter), `arr_t`\n",
" | is a new array of the same shape as the input array, with dtype, order\n",
" | given by `dtype`, `order`.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Starting in NumPy 1.9, astype method now returns an error if the string\n",
" | dtype to cast to is not long enough in 'safe' casting mode to hold the max\n",
" | value of integer/float array that is being casted. Previously the casting\n",
" | was allowed even if the result was truncated.\n",
" | \n",
" | Raises\n",
" | ------\n",
" | ComplexWarning\n",
" | When casting from complex to float or int. To avoid this,\n",
" | one should use ``a.real.astype(t)``.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([1, 2, 2.5])\n",
" | >>> x\n",
" | array([ 1. , 2. , 2.5])\n",
" | \n",
" | >>> x.astype(int)\n",
" | array([1, 2, 2])\n",
" | \n",
" | byteswap(...)\n",
" | a.byteswap(inplace=False)\n",
" | \n",
" | Swap the bytes of the array elements\n",
" | \n",
" | Toggle between low-endian and big-endian data representation by\n",
" | returning a byteswapped array, optionally swapped in-place.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | inplace : bool, optional\n",
" | If ``True``, swap bytes in-place, default is ``False``.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | out : ndarray\n",
" | The byteswapped array. If `inplace` is ``True``, this is\n",
" | a view to self.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> A = np.array([1, 256, 8755], dtype=np.int16)\n",
" | >>> map(hex, A)\n",
" | ['0x1', '0x100', '0x2233']\n",
" | >>> A.byteswap(inplace=True)\n",
" | array([ 256, 1, 13090], dtype=int16)\n",
" | >>> map(hex, A)\n",
" | ['0x100', '0x1', '0x3322']\n",
" | \n",
" | Arrays of strings are not swapped\n",
" | \n",
" | >>> A = np.array(['ceg', 'fac'])\n",
" | >>> A.byteswap()\n",
" | array(['ceg', 'fac'],\n",
" | dtype='|S3')\n",
" | \n",
" | choose(...)\n",
" | a.choose(choices, out=None, mode='raise')\n",
" | \n",
" | Use an index array to construct a new array from a set of choices.\n",
" | \n",
" | Refer to `numpy.choose` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.choose : equivalent function\n",
" | \n",
" | clip(...)\n",
" | a.clip(min=None, max=None, out=None)\n",
" | \n",
" | Return an array whose values are limited to ``[min, max]``.\n",
" | One of max or min must be given.\n",
" | \n",
" | Refer to `numpy.clip` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.clip : equivalent function\n",
" | \n",
" | compress(...)\n",
" | a.compress(condition, axis=None, out=None)\n",
" | \n",
" | Return selected slices of this array along given axis.\n",
" | \n",
" | Refer to `numpy.compress` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.compress : equivalent function\n",
" | \n",
" | conj(...)\n",
" | a.conj()\n",
" | \n",
" | Complex-conjugate all elements.\n",
" | \n",
" | Refer to `numpy.conjugate` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.conjugate : equivalent function\n",
" | \n",
" | conjugate(...)\n",
" | a.conjugate()\n",
" | \n",
" | Return the complex conjugate, element-wise.\n",
" | \n",
" | Refer to `numpy.conjugate` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.conjugate : equivalent function\n",
" | \n",
" | copy(...)\n",
" | a.copy(order='C')\n",
" | \n",
" | Return a copy of the array.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | order : {'C', 'F', 'A', 'K'}, optional\n",
" | Controls the memory layout of the copy. 'C' means C-order,\n",
" | 'F' means F-order, 'A' means 'F' if `a` is Fortran contiguous,\n",
" | 'C' otherwise. 'K' means match the layout of `a` as closely\n",
" | as possible. (Note that this function and :func:`numpy.copy` are very\n",
" | similar, but have different default values for their order=\n",
" | arguments.)\n",
" | \n",
" | See also\n",
" | --------\n",
" | numpy.copy\n",
" | numpy.copyto\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([[1,2,3],[4,5,6]], order='F')\n",
" | \n",
" | >>> y = x.copy()\n",
" | \n",
" | >>> x.fill(0)\n",
" | \n",
" | >>> x\n",
" | array([[0, 0, 0],\n",
" | [0, 0, 0]])\n",
" | \n",
" | >>> y\n",
" | array([[1, 2, 3],\n",
" | [4, 5, 6]])\n",
" | \n",
" | >>> y.flags['C_CONTIGUOUS']\n",
" | True\n",
" | \n",
" | cumprod(...)\n",
" | a.cumprod(axis=None, dtype=None, out=None)\n",
" | \n",
" | Return the cumulative product of the elements along the given axis.\n",
" | \n",
" | Refer to `numpy.cumprod` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.cumprod : equivalent function\n",
" | \n",
" | cumsum(...)\n",
" | a.cumsum(axis=None, dtype=None, out=None)\n",
" | \n",
" | Return the cumulative sum of the elements along the given axis.\n",
" | \n",
" | Refer to `numpy.cumsum` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.cumsum : equivalent function\n",
" | \n",
" | diagonal(...)\n",
" | a.diagonal(offset=0, axis1=0, axis2=1)\n",
" | \n",
" | Return specified diagonals. In NumPy 1.9 the returned array is a\n",
" | read-only view instead of a copy as in previous NumPy versions. In\n",
" | a future version the read-only restriction will be removed.\n",
" | \n",
" | Refer to :func:`numpy.diagonal` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.diagonal : equivalent function\n",
" | \n",
" | dot(...)\n",
" | a.dot(b, out=None)\n",
" | \n",
" | Dot product of two arrays.\n",
" | \n",
" | Refer to `numpy.dot` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.dot : equivalent function\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.eye(2)\n",
" | >>> b = np.ones((2, 2)) * 2\n",
" | >>> a.dot(b)\n",
" | array([[ 2., 2.],\n",
" | [ 2., 2.]])\n",
" | \n",
" | This array method can be conveniently chained:\n",
" | \n",
" | >>> a.dot(b).dot(b)\n",
" | array([[ 8., 8.],\n",
" | [ 8., 8.]])\n",
" | \n",
" | dump(...)\n",
" | a.dump(file)\n",
" | \n",
" | Dump a pickle of the array to the specified file.\n",
" | The array can be read back with pickle.load or numpy.load.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | file : str\n",
" | A string naming the dump file.\n",
" | \n",
" | dumps(...)\n",
" | a.dumps()\n",
" | \n",
" | Returns the pickle of the array as a string.\n",
" | pickle.loads or numpy.loads will convert the string back to an array.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | None\n",
" | \n",
" | fill(...)\n",
" | a.fill(value)\n",
" | \n",
" | Fill the array with a scalar value.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | value : scalar\n",
" | All elements of `a` will be assigned this value.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([1, 2])\n",
" | >>> a.fill(0)\n",
" | >>> a\n",
" | array([0, 0])\n",
" | >>> a = np.empty(2)\n",
" | >>> a.fill(1)\n",
" | >>> a\n",
" | array([ 1., 1.])\n",
" | \n",
" | flatten(...)\n",
" | a.flatten(order='C')\n",
" | \n",
" | Return a copy of the array collapsed into one dimension.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | order : {'C', 'F', 'A', 'K'}, optional\n",
" | 'C' means to flatten in row-major (C-style) order.\n",
" | 'F' means to flatten in column-major (Fortran-\n",
" | style) order. 'A' means to flatten in column-major\n",
" | order if `a` is Fortran *contiguous* in memory,\n",
" | row-major order otherwise. 'K' means to flatten\n",
" | `a` in the order the elements occur in memory.\n",
" | The default is 'C'.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | y : ndarray\n",
" | A copy of the input array, flattened to one dimension.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | ravel : Return a flattened array.\n",
" | flat : A 1-D flat iterator over the array.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([[1,2], [3,4]])\n",
" | >>> a.flatten()\n",
" | array([1, 2, 3, 4])\n",
" | >>> a.flatten('F')\n",
" | array([1, 3, 2, 4])\n",
" | \n",
" | getfield(...)\n",
" | a.getfield(dtype, offset=0)\n",
" | \n",
" | Returns a field of the given array as a certain type.\n",
" | \n",
" | A field is a view of the array data with a given data-type. The values in\n",
" | the view are determined by the given type and the offset into the current\n",
" | array in bytes. The offset needs to be such that the view dtype fits in the\n",
" | array dtype; for example an array of dtype complex128 has 16-byte elements.\n",
" | If taking a view with a 32-bit integer (4 bytes), the offset needs to be\n",
" | between 0 and 12 bytes.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | dtype : str or dtype\n",
" | The data type of the view. The dtype size of the view can not be larger\n",
" | than that of the array itself.\n",
" | offset : int\n",
" | Number of bytes to skip before beginning the element view.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.diag([1.+1.j]*2)\n",
" | >>> x[1, 1] = 2 + 4.j\n",
" | >>> x\n",
" | array([[ 1.+1.j, 0.+0.j],\n",
" | [ 0.+0.j, 2.+4.j]])\n",
" | >>> x.getfield(np.float64)\n",
" | array([[ 1., 0.],\n",
" | [ 0., 2.]])\n",
" | \n",
" | By choosing an offset of 8 bytes we can select the complex part of the\n",
" | array for our view:\n",
" | \n",
" | >>> x.getfield(np.float64, offset=8)\n",
" | array([[ 1., 0.],\n",
" | [ 0., 4.]])\n",
" | \n",
" | item(...)\n",
" | a.item(*args)\n",
" | \n",
" | Copy an element of an array to a standard Python scalar and return it.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | \\*args : Arguments (variable number and type)\n",
" | \n",
" | * none: in this case, the method only works for arrays\n",
" | with one element (`a.size == 1`), which element is\n",
" | copied into a standard Python scalar object and returned.\n",
" | \n",
" | * int_type: this argument is interpreted as a flat index into\n",
" | the array, specifying which element to copy and return.\n",
" | \n",
" | * tuple of int_types: functions as does a single int_type argument,\n",
" | except that the argument is interpreted as an nd-index into the\n",
" | array.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | z : Standard Python scalar object\n",
" | A copy of the specified element of the array as a suitable\n",
" | Python scalar\n",
" | \n",
" | Notes\n",
" | -----\n",
" | When the data type of `a` is longdouble or clongdouble, item() returns\n",
" | a scalar array object because there is no available Python scalar that\n",
" | would not lose information. Void arrays return a buffer object for item(),\n",
" | unless fields are defined, in which case a tuple is returned.\n",
" | \n",
" | `item` is very similar to a[args], except, instead of an array scalar,\n",
" | a standard Python scalar is returned. This can be useful for speeding up\n",
" | access to elements of the array and doing arithmetic on elements of the\n",
" | array using Python's optimized math.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.random.randint(9, size=(3, 3))\n",
" | >>> x\n",
" | array([[3, 1, 7],\n",
" | [2, 8, 3],\n",
" | [8, 5, 3]])\n",
" | >>> x.item(3)\n",
" | 2\n",
" | >>> x.item(7)\n",
" | 5\n",
" | >>> x.item((0, 1))\n",
" | 1\n",
" | >>> x.item((2, 2))\n",
" | 3\n",
" | \n",
" | itemset(...)\n",
" | a.itemset(*args)\n",
" | \n",
" | Insert scalar into an array (scalar is cast to array's dtype, if possible)\n",
" | \n",
" | There must be at least 1 argument, and define the last argument\n",
" | as *item*. Then, ``a.itemset(*args)`` is equivalent to but faster\n",
" | than ``a[args] = item``. The item should be a scalar value and `args`\n",
" | must select a single item in the array `a`.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | \\*args : Arguments\n",
" | If one argument: a scalar, only used in case `a` is of size 1.\n",
" | If two arguments: the last argument is the value to be set\n",
" | and must be a scalar, the first argument specifies a single array\n",
" | element location. It is either an int or a tuple.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Compared to indexing syntax, `itemset` provides some speed increase\n",
" | for placing a scalar into a particular location in an `ndarray`,\n",
" | if you must do this. However, generally this is discouraged:\n",
" | among other problems, it complicates the appearance of the code.\n",
" | Also, when using `itemset` (and `item`) inside a loop, be sure\n",
" | to assign the methods to a local variable to avoid the attribute\n",
" | look-up at each loop iteration.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.random.randint(9, size=(3, 3))\n",
" | >>> x\n",
" | array([[3, 1, 7],\n",
" | [2, 8, 3],\n",
" | [8, 5, 3]])\n",
" | >>> x.itemset(4, 0)\n",
" | >>> x.itemset((2, 2), 9)\n",
" | >>> x\n",
" | array([[3, 1, 7],\n",
" | [2, 0, 3],\n",
" | [8, 5, 9]])\n",
" | \n",
" | max(...)\n",
" | a.max(axis=None, out=None, keepdims=False)\n",
" | \n",
" | Return the maximum along a given axis.\n",
" | \n",
" | Refer to `numpy.amax` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.amax : equivalent function\n",
" | \n",
" | mean(...)\n",
" | a.mean(axis=None, dtype=None, out=None, keepdims=False)\n",
" | \n",
" | Returns the average of the array elements along given axis.\n",
" | \n",
" | Refer to `numpy.mean` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.mean : equivalent function\n",
" | \n",
" | min(...)\n",
" | a.min(axis=None, out=None, keepdims=False)\n",
" | \n",
" | Return the minimum along a given axis.\n",
" | \n",
" | Refer to `numpy.amin` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.amin : equivalent function\n",
" | \n",
" | newbyteorder(...)\n",
" | arr.newbyteorder(new_order='S')\n",
" | \n",
" | Return the array with the same data viewed with a different byte order.\n",
" | \n",
" | Equivalent to::\n",
" | \n",
" | arr.view(arr.dtype.newbytorder(new_order))\n",
" | \n",
" | Changes are also made in all fields and sub-arrays of the array data\n",
" | type.\n",
" | \n",
" | \n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | new_order : string, optional\n",
" | Byte order to force; a value from the byte order specifications\n",
" | below. `new_order` codes can be any of:\n",
" | \n",
" | * 'S' - swap dtype from current to opposite endian\n",
" | * {'<', 'L'} - little endian\n",
" | * {'>', 'B'} - big endian\n",
" | * {'=', 'N'} - native order\n",
" | * {'|', 'I'} - ignore (no change to byte order)\n",
" | \n",
" | The default value ('S') results in swapping the current\n",
" | byte order. The code does a case-insensitive check on the first\n",
" | letter of `new_order` for the alternatives above. For example,\n",
" | any of 'B' or 'b' or 'biggish' are valid to specify big-endian.\n",
" | \n",
" | \n",
" | Returns\n",
" | -------\n",
" | new_arr : array\n",
" | New array object with the dtype reflecting given change to the\n",
" | byte order.\n",
" | \n",
" | nonzero(...)\n",
" | a.nonzero()\n",
" | \n",
" | Return the indices of the elements that are non-zero.\n",
" | \n",
" | Refer to `numpy.nonzero` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.nonzero : equivalent function\n",
" | \n",
" | partition(...)\n",
" | a.partition(kth, axis=-1, kind='introselect', order=None)\n",
" | \n",
" | Rearranges the elements in the array in such a way that the value of the\n",
" | element in kth position is in the position it would be in a sorted array.\n",
" | All elements smaller than the kth element are moved before this element and\n",
" | all equal or greater are moved behind it. The ordering of the elements in\n",
" | the two partitions is undefined.\n",
" | \n",
" | .. versionadded:: 1.8.0\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | kth : int or sequence of ints\n",
" | Element index to partition by. The kth element value will be in its\n",
" | final sorted position and all smaller elements will be moved before it\n",
" | and all equal or greater elements behind it.\n",
" | The order of all elements in the partitions is undefined.\n",
" | If provided with a sequence of kth it will partition all elements\n",
" | indexed by kth of them into their sorted position at once.\n",
" | axis : int, optional\n",
" | Axis along which to sort. Default is -1, which means sort along the\n",
" | last axis.\n",
" | kind : {'introselect'}, optional\n",
" | Selection algorithm. Default is 'introselect'.\n",
" | order : str or list of str, optional\n",
" | When `a` is an array with fields defined, this argument specifies\n",
" | which fields to compare first, second, etc. A single field can\n",
" | be specified as a string, and not all fields need to be specified,\n",
" | but unspecified fields will still be used, in the order in which\n",
" | they come up in the dtype, to break ties.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.partition : Return a parititioned copy of an array.\n",
" | argpartition : Indirect partition.\n",
" | sort : Full sort.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | See ``np.partition`` for notes on the different algorithms.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([3, 4, 2, 1])\n",
" | >>> a.partition(3)\n",
" | >>> a\n",
" | array([2, 1, 3, 4])\n",
" | \n",
" | >>> a.partition((1, 3))\n",
" | array([1, 2, 3, 4])\n",
" | \n",
" | prod(...)\n",
" | a.prod(axis=None, dtype=None, out=None, keepdims=False)\n",
" | \n",
" | Return the product of the array elements over the given axis\n",
" | \n",
" | Refer to `numpy.prod` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.prod : equivalent function\n",
" | \n",
" | ptp(...)\n",
" | a.ptp(axis=None, out=None, keepdims=False)\n",
" | \n",
" | Peak to peak (maximum - minimum) value along a given axis.\n",
" | \n",
" | Refer to `numpy.ptp` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.ptp : equivalent function\n",
" | \n",
" | put(...)\n",
" | a.put(indices, values, mode='raise')\n",
" | \n",
" | Set ``a.flat[n] = values[n]`` for all `n` in indices.\n",
" | \n",
" | Refer to `numpy.put` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.put : equivalent function\n",
" | \n",
" | ravel(...)\n",
" | a.ravel([order])\n",
" | \n",
" | Return a flattened array.\n",
" | \n",
" | Refer to `numpy.ravel` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.ravel : equivalent function\n",
" | \n",
" | ndarray.flat : a flat iterator on the array.\n",
" | \n",
" | repeat(...)\n",
" | a.repeat(repeats, axis=None)\n",
" | \n",
" | Repeat elements of an array.\n",
" | \n",
" | Refer to `numpy.repeat` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.repeat : equivalent function\n",
" | \n",
" | reshape(...)\n",
" | a.reshape(shape, order='C')\n",
" | \n",
" | Returns an array containing the same data with a new shape.\n",
" | \n",
" | Refer to `numpy.reshape` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.reshape : equivalent function\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Unlike the free function `numpy.reshape`, this method on `ndarray` allows\n",
" | the elements of the shape parameter to be passed in as separate arguments.\n",
" | For example, ``a.reshape(10, 11)`` is equivalent to\n",
" | ``a.reshape((10, 11))``.\n",
" | \n",
" | resize(...)\n",
" | a.resize(new_shape, refcheck=True)\n",
" | \n",
" | Change shape and size of array in-place.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | new_shape : tuple of ints, or `n` ints\n",
" | Shape of resized array.\n",
" | refcheck : bool, optional\n",
" | If False, reference count will not be checked. Default is True.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | None\n",
" | \n",
" | Raises\n",
" | ------\n",
" | ValueError\n",
" | If `a` does not own its own data or references or views to it exist,\n",
" | and the data memory must be changed.\n",
" | PyPy only: will always raise if the data memory must be changed, since\n",
" | there is no reliable way to determine if references or views to it\n",
" | exist.\n",
" | \n",
" | SystemError\n",
" | If the `order` keyword argument is specified. This behaviour is a\n",
" | bug in NumPy.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | resize : Return a new array with the specified shape.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | This reallocates space for the data area if necessary.\n",
" | \n",
" | Only contiguous arrays (data elements consecutive in memory) can be\n",
" | resized.\n",
" | \n",
" | The purpose of the reference count check is to make sure you\n",
" | do not use this array as a buffer for another Python object and then\n",
" | reallocate the memory. However, reference counts can increase in\n",
" | other ways so if you are sure that you have not shared the memory\n",
" | for this array with another Python object, then you may safely set\n",
" | `refcheck` to False.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | Shrinking an array: array is flattened (in the order that the data are\n",
" | stored in memory), resized, and reshaped:\n",
" | \n",
" | >>> a = np.array([[0, 1], [2, 3]], order='C')\n",
" | >>> a.resize((2, 1))\n",
" | >>> a\n",
" | array([[0],\n",
" | [1]])\n",
" | \n",
" | >>> a = np.array([[0, 1], [2, 3]], order='F')\n",
" | >>> a.resize((2, 1))\n",
" | >>> a\n",
" | array([[0],\n",
" | [2]])\n",
" | \n",
" | Enlarging an array: as above, but missing entries are filled with zeros:\n",
" | \n",
" | >>> b = np.array([[0, 1], [2, 3]])\n",
" | >>> b.resize(2, 3) # new_shape parameter doesn't have to be a tuple\n",
" | >>> b\n",
" | array([[0, 1, 2],\n",
" | [3, 0, 0]])\n",
" | \n",
" | Referencing an array prevents resizing...\n",
" | \n",
" | >>> c = a\n",
" | >>> a.resize((1, 1))\n",
" | Traceback (most recent call last):\n",
" | ...\n",
" | ValueError: cannot resize an array that has been referenced ...\n",
" | \n",
" | Unless `refcheck` is False:\n",
" | \n",
" | >>> a.resize((1, 1), refcheck=False)\n",
" | >>> a\n",
" | array([[0]])\n",
" | >>> c\n",
" | array([[0]])\n",
" | \n",
" | round(...)\n",
" | a.round(decimals=0, out=None)\n",
" | \n",
" | Return `a` with each element rounded to the given number of decimals.\n",
" | \n",
" | Refer to `numpy.around` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.around : equivalent function\n",
" | \n",
" | searchsorted(...)\n",
" | a.searchsorted(v, side='left', sorter=None)\n",
" | \n",
" | Find indices where elements of v should be inserted in a to maintain order.\n",
" | \n",
" | For full documentation, see `numpy.searchsorted`\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.searchsorted : equivalent function\n",
" | \n",
" | setfield(...)\n",
" | a.setfield(val, dtype, offset=0)\n",
" | \n",
" | Put a value into a specified place in a field defined by a data-type.\n",
" | \n",
" | Place `val` into `a`'s field defined by `dtype` and beginning `offset`\n",
" | bytes into the field.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | val : object\n",
" | Value to be placed in field.\n",
" | dtype : dtype object\n",
" | Data-type of the field in which to place `val`.\n",
" | offset : int, optional\n",
" | The number of bytes into the field at which to place `val`.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | None\n",
" | \n",
" | See Also\n",
" | --------\n",
" | getfield\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.eye(3)\n",
" | >>> x.getfield(np.float64)\n",
" | array([[ 1., 0., 0.],\n",
" | [ 0., 1., 0.],\n",
" | [ 0., 0., 1.]])\n",
" | >>> x.setfield(3, np.int32)\n",
" | >>> x.getfield(np.int32)\n",
" | array([[3, 3, 3],\n",
" | [3, 3, 3],\n",
" | [3, 3, 3]])\n",
" | >>> x\n",
" | array([[ 1.00000000e+000, 1.48219694e-323, 1.48219694e-323],\n",
" | [ 1.48219694e-323, 1.00000000e+000, 1.48219694e-323],\n",
" | [ 1.48219694e-323, 1.48219694e-323, 1.00000000e+000]])\n",
" | >>> x.setfield(np.eye(3), np.int32)\n",
" | >>> x\n",
" | array([[ 1., 0., 0.],\n",
" | [ 0., 1., 0.],\n",
" | [ 0., 0., 1.]])\n",
" | \n",
" | setflags(...)\n",
" | a.setflags(write=None, align=None, uic=None)\n",
" | \n",
" | Set array flags WRITEABLE, ALIGNED, (WRITEBACKIFCOPY and UPDATEIFCOPY),\n",
" | respectively.\n",
" | \n",
" | These Boolean-valued flags affect how numpy interprets the memory\n",
" | area used by `a` (see Notes below). The ALIGNED flag can only\n",
" | be set to True if the data is actually aligned according to the type.\n",
" | The WRITEBACKIFCOPY and (deprecated) UPDATEIFCOPY flags can never be set\n",
" | to True. The flag WRITEABLE can only be set to True if the array owns its\n",
" | own memory, or the ultimate owner of the memory exposes a writeable buffer\n",
" | interface, or is a string. (The exception for string is made so that\n",
" | unpickling can be done without copying memory.)\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | write : bool, optional\n",
" | Describes whether or not `a` can be written to.\n",
" | align : bool, optional\n",
" | Describes whether or not `a` is aligned properly for its type.\n",
" | uic : bool, optional\n",
" | Describes whether or not `a` is a copy of another \"base\" array.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Array flags provide information about how the memory area used\n",
" | for the array is to be interpreted. There are 7 Boolean flags\n",
" | in use, only four of which can be changed by the user:\n",
" | WRITEBACKIFCOPY, UPDATEIFCOPY, WRITEABLE, and ALIGNED.\n",
" | \n",
" | WRITEABLE (W) the data area can be written to;\n",
" | \n",
" | ALIGNED (A) the data and strides are aligned appropriately for the hardware\n",
" | (as determined by the compiler);\n",
" | \n",
" | UPDATEIFCOPY (U) (deprecated), replaced by WRITEBACKIFCOPY;\n",
" | \n",
" | WRITEBACKIFCOPY (X) this array is a copy of some other array (referenced\n",
" | by .base). When the C-API function PyArray_ResolveWritebackIfCopy is\n",
" | called, the base array will be updated with the contents of this array.\n",
" | \n",
" | All flags can be accessed using the single (upper case) letter as well\n",
" | as the full name.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> y\n",
" | array([[3, 1, 7],\n",
" | [2, 0, 0],\n",
" | [8, 5, 9]])\n",
" | >>> y.flags\n",
" | C_CONTIGUOUS : True\n",
" | F_CONTIGUOUS : False\n",
" | OWNDATA : True\n",
" | WRITEABLE : True\n",
" | ALIGNED : True\n",
" | WRITEBACKIFCOPY : False\n",
" | UPDATEIFCOPY : False\n",
" | >>> y.setflags(write=0, align=0)\n",
" | >>> y.flags\n",
" | C_CONTIGUOUS : True\n",
" | F_CONTIGUOUS : False\n",
" | OWNDATA : True\n",
" | WRITEABLE : False\n",
" | ALIGNED : False\n",
" | WRITEBACKIFCOPY : False\n",
" | UPDATEIFCOPY : False\n",
" | >>> y.setflags(uic=1)\n",
" | Traceback (most recent call last):\n",
" | File \"\", line 1, in \n",
" | ValueError: cannot set WRITEBACKIFCOPY flag to True\n",
" | \n",
" | sort(...)\n",
" | a.sort(axis=-1, kind='quicksort', order=None)\n",
" | \n",
" | Sort an array, in-place.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | axis : int, optional\n",
" | Axis along which to sort. Default is -1, which means sort along the\n",
" | last axis.\n",
" | kind : {'quicksort', 'mergesort', 'heapsort', 'stable'}, optional\n",
" | Sorting algorithm. Default is 'quicksort'.\n",
" | order : str or list of str, optional\n",
" | When `a` is an array with fields defined, this argument specifies\n",
" | which fields to compare first, second, etc. A single field can\n",
" | be specified as a string, and not all fields need be specified,\n",
" | but unspecified fields will still be used, in the order in which\n",
" | they come up in the dtype, to break ties.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.sort : Return a sorted copy of an array.\n",
" | argsort : Indirect sort.\n",
" | lexsort : Indirect stable sort on multiple keys.\n",
" | searchsorted : Find elements in sorted array.\n",
" | partition: Partial sort.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | See ``sort`` for notes on the different sorting algorithms.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([[1,4], [3,1]])\n",
" | >>> a.sort(axis=1)\n",
" | >>> a\n",
" | array([[1, 4],\n",
" | [1, 3]])\n",
" | >>> a.sort(axis=0)\n",
" | >>> a\n",
" | array([[1, 3],\n",
" | [1, 4]])\n",
" | \n",
" | Use the `order` keyword to specify a field to use when sorting a\n",
" | structured array:\n",
" | \n",
" | >>> a = np.array([('a', 2), ('c', 1)], dtype=[('x', 'S1'), ('y', int)])\n",
" | >>> a.sort(order='y')\n",
" | >>> a\n",
" | array([('c', 1), ('a', 2)],\n",
" | dtype=[('x', '|S1'), ('y', '>> x = np.array([[0, 1], [2, 3]])\n",
" | >>> x.tobytes()\n",
" | b'\\x00\\x00\\x00\\x00\\x01\\x00\\x00\\x00\\x02\\x00\\x00\\x00\\x03\\x00\\x00\\x00'\n",
" | >>> x.tobytes('C') == x.tobytes()\n",
" | True\n",
" | >>> x.tobytes('F')\n",
" | b'\\x00\\x00\\x00\\x00\\x02\\x00\\x00\\x00\\x01\\x00\\x00\\x00\\x03\\x00\\x00\\x00'\n",
" | \n",
" | tofile(...)\n",
" | a.tofile(fid, sep=\"\", format=\"%s\")\n",
" | \n",
" | Write array to a file as text or binary (default).\n",
" | \n",
" | Data is always written in 'C' order, independent of the order of `a`.\n",
" | The data produced by this method can be recovered using the function\n",
" | fromfile().\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | fid : file or str\n",
" | An open file object, or a string containing a filename.\n",
" | sep : str\n",
" | Separator between array items for text output.\n",
" | If \"\" (empty), a binary file is written, equivalent to\n",
" | ``file.write(a.tobytes())``.\n",
" | format : str\n",
" | Format string for text file output.\n",
" | Each entry in the array is formatted to text by first converting\n",
" | it to the closest Python type, and then using \"format\" % item.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | This is a convenience function for quick storage of array data.\n",
" | Information on endianness and precision is lost, so this method is not a\n",
" | good choice for files intended to archive data or transport data between\n",
" | machines with different endianness. Some of these problems can be overcome\n",
" | by outputting the data as text files, at the expense of speed and file\n",
" | size.\n",
" | \n",
" | When fid is a file object, array contents are directly written to the\n",
" | file, bypassing the file object's ``write`` method. As a result, tofile\n",
" | cannot be used with files objects supporting compression (e.g., GzipFile)\n",
" | or file-like objects that do not support ``fileno()`` (e.g., BytesIO).\n",
" | \n",
" | tolist(...)\n",
" | a.tolist()\n",
" | \n",
" | Return the array as a (possibly nested) list.\n",
" | \n",
" | Return a copy of the array data as a (nested) Python list.\n",
" | Data items are converted to the nearest compatible Python type.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | none\n",
" | \n",
" | Returns\n",
" | -------\n",
" | y : list\n",
" | The possibly nested list of array elements.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | The array may be recreated, ``a = np.array(a.tolist())``.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([1, 2])\n",
" | >>> a.tolist()\n",
" | [1, 2]\n",
" | >>> a = np.array([[1, 2], [3, 4]])\n",
" | >>> list(a)\n",
" | [array([1, 2]), array([3, 4])]\n",
" | >>> a.tolist()\n",
" | [[1, 2], [3, 4]]\n",
" | \n",
" | tostring(...)\n",
" | a.tostring(order='C')\n",
" | \n",
" | Construct Python bytes containing the raw data bytes in the array.\n",
" | \n",
" | Constructs Python bytes showing a copy of the raw contents of\n",
" | data memory. The bytes object can be produced in either 'C' or 'Fortran',\n",
" | or 'Any' order (the default is 'C'-order). 'Any' order means C-order\n",
" | unless the F_CONTIGUOUS flag in the array is set, in which case it\n",
" | means 'Fortran' order.\n",
" | \n",
" | This function is a compatibility alias for tobytes. Despite its name it returns bytes not strings.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | order : {'C', 'F', None}, optional\n",
" | Order of the data for multidimensional arrays:\n",
" | C, Fortran, or the same as for the original array.\n",
" | \n",
" | Returns\n",
" | -------\n",
" | s : bytes\n",
" | Python bytes exhibiting a copy of `a`'s raw data.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([[0, 1], [2, 3]])\n",
" | >>> x.tobytes()\n",
" | b'\\x00\\x00\\x00\\x00\\x01\\x00\\x00\\x00\\x02\\x00\\x00\\x00\\x03\\x00\\x00\\x00'\n",
" | >>> x.tobytes('C') == x.tobytes()\n",
" | True\n",
" | >>> x.tobytes('F')\n",
" | b'\\x00\\x00\\x00\\x00\\x02\\x00\\x00\\x00\\x01\\x00\\x00\\x00\\x03\\x00\\x00\\x00'\n",
" | \n",
" | trace(...)\n",
" | a.trace(offset=0, axis1=0, axis2=1, dtype=None, out=None)\n",
" | \n",
" | Return the sum along diagonals of the array.\n",
" | \n",
" | Refer to `numpy.trace` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.trace : equivalent function\n",
" | \n",
" | transpose(...)\n",
" | a.transpose(*axes)\n",
" | \n",
" | Returns a view of the array with axes transposed.\n",
" | \n",
" | For a 1-D array, this has no effect. (To change between column and\n",
" | row vectors, first cast the 1-D array into a matrix object.)\n",
" | For a 2-D array, this is the usual matrix transpose.\n",
" | For an n-D array, if axes are given, their order indicates how the\n",
" | axes are permuted (see Examples). If axes are not provided and\n",
" | ``a.shape = (i[0], i[1], ... i[n-2], i[n-1])``, then\n",
" | ``a.transpose().shape = (i[n-1], i[n-2], ... i[1], i[0])``.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | axes : None, tuple of ints, or `n` ints\n",
" | \n",
" | * None or no argument: reverses the order of the axes.\n",
" | \n",
" | * tuple of ints: `i` in the `j`-th place in the tuple means `a`'s\n",
" | `i`-th axis becomes `a.transpose()`'s `j`-th axis.\n",
" | \n",
" | * `n` ints: same as an n-tuple of the same ints (this form is\n",
" | intended simply as a \"convenience\" alternative to the tuple form)\n",
" | \n",
" | Returns\n",
" | -------\n",
" | out : ndarray\n",
" | View of `a`, with axes suitably permuted.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | ndarray.T : Array property returning the array transposed.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> a = np.array([[1, 2], [3, 4]])\n",
" | >>> a\n",
" | array([[1, 2],\n",
" | [3, 4]])\n",
" | >>> a.transpose()\n",
" | array([[1, 3],\n",
" | [2, 4]])\n",
" | >>> a.transpose((1, 0))\n",
" | array([[1, 3],\n",
" | [2, 4]])\n",
" | >>> a.transpose(1, 0)\n",
" | array([[1, 3],\n",
" | [2, 4]])\n",
" | \n",
" | var(...)\n",
" | a.var(axis=None, dtype=None, out=None, ddof=0, keepdims=False)\n",
" | \n",
" | Returns the variance of the array elements, along given axis.\n",
" | \n",
" | Refer to `numpy.var` for full documentation.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.var : equivalent function\n",
" | \n",
" | view(...)\n",
" | a.view(dtype=None, type=None)\n",
" | \n",
" | New view of array with the same data.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | dtype : data-type or ndarray sub-class, optional\n",
" | Data-type descriptor of the returned view, e.g., float32 or int16. The\n",
" | default, None, results in the view having the same data-type as `a`.\n",
" | This argument can also be specified as an ndarray sub-class, which\n",
" | then specifies the type of the returned object (this is equivalent to\n",
" | setting the ``type`` parameter).\n",
" | type : Python type, optional\n",
" | Type of the returned view, e.g., ndarray or matrix. Again, the\n",
" | default None results in type preservation.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | ``a.view()`` is used two different ways:\n",
" | \n",
" | ``a.view(some_dtype)`` or ``a.view(dtype=some_dtype)`` constructs a view\n",
" | of the array's memory with a different data-type. This can cause a\n",
" | reinterpretation of the bytes of memory.\n",
" | \n",
" | ``a.view(ndarray_subclass)`` or ``a.view(type=ndarray_subclass)`` just\n",
" | returns an instance of `ndarray_subclass` that looks at the same array\n",
" | (same shape, dtype, etc.) This does not cause a reinterpretation of the\n",
" | memory.\n",
" | \n",
" | For ``a.view(some_dtype)``, if ``some_dtype`` has a different number of\n",
" | bytes per entry than the previous dtype (for example, converting a\n",
" | regular array to a structured array), then the behavior of the view\n",
" | cannot be predicted just from the superficial appearance of ``a`` (shown\n",
" | by ``print(a)``). It also depends on exactly how ``a`` is stored in\n",
" | memory. Therefore if ``a`` is C-ordered versus fortran-ordered, versus\n",
" | defined as a slice or transpose, etc., the view may give different\n",
" | results.\n",
" | \n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([(1, 2)], dtype=[('a', np.int8), ('b', np.int8)])\n",
" | \n",
" | Viewing array data using a different type and dtype:\n",
" | \n",
" | >>> y = x.view(dtype=np.int16, type=np.matrix)\n",
" | >>> y\n",
" | matrix([[513]], dtype=int16)\n",
" | >>> print(type(y))\n",
" | \n",
" | \n",
" | Creating a view on a structured array so it can be used in calculations\n",
" | \n",
" | >>> x = np.array([(1, 2),(3,4)], dtype=[('a', np.int8), ('b', np.int8)])\n",
" | >>> xv = x.view(dtype=np.int8).reshape(-1,2)\n",
" | >>> xv\n",
" | array([[1, 2],\n",
" | [3, 4]], dtype=int8)\n",
" | >>> xv.mean(0)\n",
" | array([ 2., 3.])\n",
" | \n",
" | Making changes to the view changes the underlying array\n",
" | \n",
" | >>> xv[0,1] = 20\n",
" | >>> print(x)\n",
" | [(1, 20) (3, 4)]\n",
" | \n",
" | Using a view to convert an array to a recarray:\n",
" | \n",
" | >>> z = x.view(np.recarray)\n",
" | >>> z.a\n",
" | array([1], dtype=int8)\n",
" | \n",
" | Views share data:\n",
" | \n",
" | >>> x[0] = (9, 10)\n",
" | >>> z[0]\n",
" | (9, 10)\n",
" | \n",
" | Views that change the dtype size (bytes per entry) should normally be\n",
" | avoided on arrays defined by slices, transposes, fortran-ordering, etc.:\n",
" | \n",
" | >>> x = np.array([[1,2,3],[4,5,6]], dtype=np.int16)\n",
" | >>> y = x[:, 0:2]\n",
" | >>> y\n",
" | array([[1, 2],\n",
" | [4, 5]], dtype=int16)\n",
" | >>> y.view(dtype=[('width', np.int16), ('length', np.int16)])\n",
" | Traceback (most recent call last):\n",
" | File \"\", line 1, in \n",
" | ValueError: new type not compatible with array.\n",
" | >>> z = y.copy()\n",
" | >>> z.view(dtype=[('width', np.int16), ('length', np.int16)])\n",
" | array([[(1, 2)],\n",
" | [(4, 5)]], dtype=[('width', '>> x = np.array([[1.,2.],[3.,4.]])\n",
" | >>> x\n",
" | array([[ 1., 2.],\n",
" | [ 3., 4.]])\n",
" | >>> x.T\n",
" | array([[ 1., 3.],\n",
" | [ 2., 4.]])\n",
" | >>> x = np.array([1.,2.,3.,4.])\n",
" | >>> x\n",
" | array([ 1., 2., 3., 4.])\n",
" | >>> x.T\n",
" | array([ 1., 2., 3., 4.])\n",
" | \n",
" | __array_finalize__\n",
" | None.\n",
" | \n",
" | __array_interface__\n",
" | Array protocol: Python side.\n",
" | \n",
" | __array_priority__\n",
" | Array priority.\n",
" | \n",
" | __array_struct__\n",
" | Array protocol: C-struct side.\n",
" | \n",
" | base\n",
" | Base object if memory is from some other object.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | The base of an array that owns its memory is None:\n",
" | \n",
" | >>> x = np.array([1,2,3,4])\n",
" | >>> x.base is None\n",
" | True\n",
" | \n",
" | Slicing creates a view, whose memory is shared with x:\n",
" | \n",
" | >>> y = x[2:]\n",
" | >>> y.base is x\n",
" | True\n",
" | \n",
" | ctypes\n",
" | An object to simplify the interaction of the array with the ctypes\n",
" | module.\n",
" | \n",
" | This attribute creates an object that makes it easier to use arrays\n",
" | when calling shared libraries with the ctypes module. The returned\n",
" | object has, among others, data, shape, and strides attributes (see\n",
" | Notes below) which themselves return ctypes objects that can be used\n",
" | as arguments to a shared library.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | None\n",
" | \n",
" | Returns\n",
" | -------\n",
" | c : Python object\n",
" | Possessing attributes data, shape, strides, etc.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.ctypeslib\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Below are the public attributes of this object which were documented\n",
" | in \"Guide to NumPy\" (we have omitted undocumented public attributes,\n",
" | as well as documented private attributes):\n",
" | \n",
" | * data: A pointer to the memory area of the array as a Python integer.\n",
" | This memory area may contain data that is not aligned, or not in correct\n",
" | byte-order. The memory area may not even be writeable. The array\n",
" | flags and data-type of this array should be respected when passing this\n",
" | attribute to arbitrary C-code to avoid trouble that can include Python\n",
" | crashing. User Beware! The value of this attribute is exactly the same\n",
" | as self._array_interface_['data'][0].\n",
" | \n",
" | * shape (c_intp*self.ndim): A ctypes array of length self.ndim where\n",
" | the basetype is the C-integer corresponding to dtype('p') on this\n",
" | platform. This base-type could be c_int, c_long, or c_longlong\n",
" | depending on the platform. The c_intp type is defined accordingly in\n",
" | numpy.ctypeslib. The ctypes array contains the shape of the underlying\n",
" | array.\n",
" | \n",
" | * strides (c_intp*self.ndim): A ctypes array of length self.ndim where\n",
" | the basetype is the same as for the shape attribute. This ctypes array\n",
" | contains the strides information from the underlying array. This strides\n",
" | information is important for showing how many bytes must be jumped to\n",
" | get to the next element in the array.\n",
" | \n",
" | * data_as(obj): Return the data pointer cast to a particular c-types object.\n",
" | For example, calling self._as_parameter_ is equivalent to\n",
" | self.data_as(ctypes.c_void_p). Perhaps you want to use the data as a\n",
" | pointer to a ctypes array of floating-point data:\n",
" | self.data_as(ctypes.POINTER(ctypes.c_double)).\n",
" | \n",
" | * shape_as(obj): Return the shape tuple as an array of some other c-types\n",
" | type. For example: self.shape_as(ctypes.c_short).\n",
" | \n",
" | * strides_as(obj): Return the strides tuple as an array of some other\n",
" | c-types type. For example: self.strides_as(ctypes.c_longlong).\n",
" | \n",
" | Be careful using the ctypes attribute - especially on temporary\n",
" | arrays or arrays constructed on the fly. For example, calling\n",
" | ``(a+b).ctypes.data_as(ctypes.c_void_p)`` returns a pointer to memory\n",
" | that is invalid because the array created as (a+b) is deallocated\n",
" | before the next Python statement. You can avoid this problem using\n",
" | either ``c=a+b`` or ``ct=(a+b).ctypes``. In the latter case, ct will\n",
" | hold a reference to the array until ct is deleted or re-assigned.\n",
" | \n",
" | If the ctypes module is not available, then the ctypes attribute\n",
" | of array objects still returns something useful, but ctypes objects\n",
" | are not returned and errors may be raised instead. In particular,\n",
" | the object will still have the as parameter attribute which will\n",
" | return an integer equal to the data attribute.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> import ctypes\n",
" | >>> x\n",
" | array([[0, 1],\n",
" | [2, 3]])\n",
" | >>> x.ctypes.data\n",
" | 30439712\n",
" | >>> x.ctypes.data_as(ctypes.POINTER(ctypes.c_long))\n",
" | \n",
" | >>> x.ctypes.data_as(ctypes.POINTER(ctypes.c_long)).contents\n",
" | c_long(0)\n",
" | >>> x.ctypes.data_as(ctypes.POINTER(ctypes.c_longlong)).contents\n",
" | c_longlong(4294967296L)\n",
" | >>> x.ctypes.shape\n",
" | \n",
" | >>> x.ctypes.shape_as(ctypes.c_long)\n",
" | \n",
" | >>> x.ctypes.strides\n",
" | \n",
" | >>> x.ctypes.strides_as(ctypes.c_longlong)\n",
" | \n",
" | \n",
" | data\n",
" | Python buffer object pointing to the start of the array's data.\n",
" | \n",
" | dtype\n",
" | Data-type of the array's elements.\n",
" | \n",
" | Parameters\n",
" | ----------\n",
" | None\n",
" | \n",
" | Returns\n",
" | -------\n",
" | d : numpy dtype object\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.dtype\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x\n",
" | array([[0, 1],\n",
" | [2, 3]])\n",
" | >>> x.dtype\n",
" | dtype('int32')\n",
" | >>> type(x.dtype)\n",
" | \n",
" | \n",
" | flags\n",
" | Information about the memory layout of the array.\n",
" | \n",
" | Attributes\n",
" | ----------\n",
" | C_CONTIGUOUS (C)\n",
" | The data is in a single, C-style contiguous segment.\n",
" | F_CONTIGUOUS (F)\n",
" | The data is in a single, Fortran-style contiguous segment.\n",
" | OWNDATA (O)\n",
" | The array owns the memory it uses or borrows it from another object.\n",
" | WRITEABLE (W)\n",
" | The data area can be written to. Setting this to False locks\n",
" | the data, making it read-only. A view (slice, etc.) inherits WRITEABLE\n",
" | from its base array at creation time, but a view of a writeable\n",
" | array may be subsequently locked while the base array remains writeable.\n",
" | (The opposite is not true, in that a view of a locked array may not\n",
" | be made writeable. However, currently, locking a base object does not\n",
" | lock any views that already reference it, so under that circumstance it\n",
" | is possible to alter the contents of a locked array via a previously\n",
" | created writeable view onto it.) Attempting to change a non-writeable\n",
" | array raises a RuntimeError exception.\n",
" | ALIGNED (A)\n",
" | The data and all elements are aligned appropriately for the hardware.\n",
" | WRITEBACKIFCOPY (X)\n",
" | This array is a copy of some other array. The C-API function\n",
" | PyArray_ResolveWritebackIfCopy must be called before deallocating\n",
" | to the base array will be updated with the contents of this array.\n",
" | UPDATEIFCOPY (U)\n",
" | (Deprecated, use WRITEBACKIFCOPY) This array is a copy of some other array.\n",
" | When this array is\n",
" | deallocated, the base array will be updated with the contents of\n",
" | this array.\n",
" | FNC\n",
" | F_CONTIGUOUS and not C_CONTIGUOUS.\n",
" | FORC\n",
" | F_CONTIGUOUS or C_CONTIGUOUS (one-segment test).\n",
" | BEHAVED (B)\n",
" | ALIGNED and WRITEABLE.\n",
" | CARRAY (CA)\n",
" | BEHAVED and C_CONTIGUOUS.\n",
" | FARRAY (FA)\n",
" | BEHAVED and F_CONTIGUOUS and not C_CONTIGUOUS.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | The `flags` object can be accessed dictionary-like (as in ``a.flags['WRITEABLE']``),\n",
" | or by using lowercased attribute names (as in ``a.flags.writeable``). Short flag\n",
" | names are only supported in dictionary access.\n",
" | \n",
" | Only the WRITEBACKIFCOPY, UPDATEIFCOPY, WRITEABLE, and ALIGNED flags can be\n",
" | changed by the user, via direct assignment to the attribute or dictionary\n",
" | entry, or by calling `ndarray.setflags`.\n",
" | \n",
" | The array flags cannot be set arbitrarily:\n",
" | \n",
" | - UPDATEIFCOPY can only be set ``False``.\n",
" | - WRITEBACKIFCOPY can only be set ``False``.\n",
" | - ALIGNED can only be set ``True`` if the data is truly aligned.\n",
" | - WRITEABLE can only be set ``True`` if the array owns its own memory\n",
" | or the ultimate owner of the memory exposes a writeable buffer\n",
" | interface or is a string.\n",
" | \n",
" | Arrays can be both C-style and Fortran-style contiguous simultaneously.\n",
" | This is clear for 1-dimensional arrays, but can also be true for higher\n",
" | dimensional arrays.\n",
" | \n",
" | Even for contiguous arrays a stride for a given dimension\n",
" | ``arr.strides[dim]`` may be *arbitrary* if ``arr.shape[dim] == 1``\n",
" | or the array has no elements.\n",
" | It does *not* generally hold that ``self.strides[-1] == self.itemsize``\n",
" | for C-style contiguous arrays or ``self.strides[0] == self.itemsize`` for\n",
" | Fortran-style contiguous arrays is true.\n",
" | \n",
" | flat\n",
" | A 1-D iterator over the array.\n",
" | \n",
" | This is a `numpy.flatiter` instance, which acts similarly to, but is not\n",
" | a subclass of, Python's built-in iterator object.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | flatten : Return a copy of the array collapsed into one dimension.\n",
" | \n",
" | flatiter\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.arange(1, 7).reshape(2, 3)\n",
" | >>> x\n",
" | array([[1, 2, 3],\n",
" | [4, 5, 6]])\n",
" | >>> x.flat[3]\n",
" | 4\n",
" | >>> x.T\n",
" | array([[1, 4],\n",
" | [2, 5],\n",
" | [3, 6]])\n",
" | >>> x.T.flat[3]\n",
" | 5\n",
" | >>> type(x.flat)\n",
" | \n",
" | \n",
" | An assignment example:\n",
" | \n",
" | >>> x.flat = 3; x\n",
" | array([[3, 3, 3],\n",
" | [3, 3, 3]])\n",
" | >>> x.flat[[1,4]] = 1; x\n",
" | array([[3, 1, 3],\n",
" | [3, 1, 3]])\n",
" | \n",
" | imag\n",
" | The imaginary part of the array.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.sqrt([1+0j, 0+1j])\n",
" | >>> x.imag\n",
" | array([ 0. , 0.70710678])\n",
" | >>> x.imag.dtype\n",
" | dtype('float64')\n",
" | \n",
" | itemsize\n",
" | Length of one array element in bytes.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([1,2,3], dtype=np.float64)\n",
" | >>> x.itemsize\n",
" | 8\n",
" | >>> x = np.array([1,2,3], dtype=np.complex128)\n",
" | >>> x.itemsize\n",
" | 16\n",
" | \n",
" | nbytes\n",
" | Total bytes consumed by the elements of the array.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Does not include memory consumed by non-element attributes of the\n",
" | array object.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.zeros((3,5,2), dtype=np.complex128)\n",
" | >>> x.nbytes\n",
" | 480\n",
" | >>> np.prod(x.shape) * x.itemsize\n",
" | 480\n",
" | \n",
" | ndim\n",
" | Number of array dimensions.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([1, 2, 3])\n",
" | >>> x.ndim\n",
" | 1\n",
" | >>> y = np.zeros((2, 3, 4))\n",
" | >>> y.ndim\n",
" | 3\n",
" | \n",
" | real\n",
" | The real part of the array.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.sqrt([1+0j, 0+1j])\n",
" | >>> x.real\n",
" | array([ 1. , 0.70710678])\n",
" | >>> x.real.dtype\n",
" | dtype('float64')\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.real : equivalent function\n",
" | \n",
" | shape\n",
" | Tuple of array dimensions.\n",
" | \n",
" | The shape property is usually used to get the current shape of an array,\n",
" | but may also be used to reshape the array in-place by assigning a tuple of\n",
" | array dimensions to it. As with `numpy.reshape`, one of the new shape\n",
" | dimensions can be -1, in which case its value is inferred from the size of\n",
" | the array and the remaining dimensions. Reshaping an array in-place will\n",
" | fail if a copy is required.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.array([1, 2, 3, 4])\n",
" | >>> x.shape\n",
" | (4,)\n",
" | >>> y = np.zeros((2, 3, 4))\n",
" | >>> y.shape\n",
" | (2, 3, 4)\n",
" | >>> y.shape = (3, 8)\n",
" | >>> y\n",
" | array([[ 0., 0., 0., 0., 0., 0., 0., 0.],\n",
" | [ 0., 0., 0., 0., 0., 0., 0., 0.],\n",
" | [ 0., 0., 0., 0., 0., 0., 0., 0.]])\n",
" | >>> y.shape = (3, 6)\n",
" | Traceback (most recent call last):\n",
" | File \"\", line 1, in \n",
" | ValueError: total size of new array must be unchanged\n",
" | >>> np.zeros((4,2))[::2].shape = (-1,)\n",
" | Traceback (most recent call last):\n",
" | File \"\", line 1, in \n",
" | AttributeError: incompatible shape for a non-contiguous array\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.reshape : similar function\n",
" | ndarray.reshape : similar method\n",
" | \n",
" | size\n",
" | Number of elements in the array.\n",
" | \n",
" | Equal to ``np.prod(a.shape)``, i.e., the product of the array's\n",
" | dimensions.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | `a.size` returns a standard arbitrary precision Python integer. This \n",
" | may not be the case with other methods of obtaining the same value\n",
" | (like the suggested ``np.prod(a.shape)``, which returns an instance\n",
" | of ``np.int_``), and may be relevant if the value is used further in\n",
" | calculations that may overflow a fixed size integer type.\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> x = np.zeros((3, 5, 2), dtype=np.complex128)\n",
" | >>> x.size\n",
" | 30\n",
" | >>> np.prod(x.shape)\n",
" | 30\n",
" | \n",
" | strides\n",
" | Tuple of bytes to step in each dimension when traversing an array.\n",
" | \n",
" | The byte offset of element ``(i[0], i[1], ..., i[n])`` in an array `a`\n",
" | is::\n",
" | \n",
" | offset = sum(np.array(i) * a.strides)\n",
" | \n",
" | A more detailed explanation of strides can be found in the\n",
" | \"ndarray.rst\" file in the NumPy reference guide.\n",
" | \n",
" | Notes\n",
" | -----\n",
" | Imagine an array of 32-bit integers (each 4 bytes)::\n",
" | \n",
" | x = np.array([[0, 1, 2, 3, 4],\n",
" | [5, 6, 7, 8, 9]], dtype=np.int32)\n",
" | \n",
" | This array is stored in memory as 40 bytes, one after the other\n",
" | (known as a contiguous block of memory). The strides of an array tell\n",
" | us how many bytes we have to skip in memory to move to the next position\n",
" | along a certain axis. For example, we have to skip 4 bytes (1 value) to\n",
" | move to the next column, but 20 bytes (5 values) to get to the same\n",
" | position in the next row. As such, the strides for the array `x` will be\n",
" | ``(20, 4)``.\n",
" | \n",
" | See Also\n",
" | --------\n",
" | numpy.lib.stride_tricks.as_strided\n",
" | \n",
" | Examples\n",
" | --------\n",
" | >>> y = np.reshape(np.arange(2*3*4), (2,3,4))\n",
" | >>> y\n",
" | array([[[ 0, 1, 2, 3],\n",
" | [ 4, 5, 6, 7],\n",
" | [ 8, 9, 10, 11]],\n",
" | [[12, 13, 14, 15],\n",
" | [16, 17, 18, 19],\n",
" | [20, 21, 22, 23]]])\n",
" | >>> y.strides\n",
" | (48, 16, 4)\n",
" | >>> y[1,1,1]\n",
" | 17\n",
" | >>> offset=sum(y.strides * np.array((1,1,1)))\n",
" | >>> offset/y.itemsize\n",
" | 17\n",
" | \n",
" | >>> x = np.reshape(np.arange(5*6*7*8), (5,6,7,8)).transpose(2,3,1,0)\n",
" | >>> x.strides\n",
" | (32, 4, 224, 1344)\n",
" | >>> i = np.array([3,5,2,2])\n",
" | >>> offset = sum(i * x.strides)\n",
" | >>> x[3,5,2,2]\n",
" | 813\n",
" | >>> offset / x.itemsize\n",
" | 813\n",
" | \n",
" | ----------------------------------------------------------------------\n",
" | Data and other attributes defined here:\n",
" | \n",
" | __hash__ = None\n",
"\n"
]
}
],
"source": [
"help(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"we can also create an array from a list"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1. 2. 3. 4.]\n",
"float64\n",
"\n"
]
},
{
"data": {
"text/plain": [
"array([[0, 1, 2, 3],\n",
" [4, 5, 6, 7]])"
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b = np.array( [1.0, 2.0, 3.0, 4.0] )\n",
"print(b)\n",
"print(b.dtype)\n",
"print(type(b))\n",
"c = np.arange(8).reshape(2,4)\n",
"c"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"we can create a multi-dimensional array of a specified size initialized all to 0 easily, using the `zeros()` function."
]
},
{
"cell_type": "code",
"execution_count": 95,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.],\n",
" [1., 1., 1., 1., 1., 1., 1., 1.]])"
]
},
"execution_count": 95,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b = np.ones((10,8))\n",
"b"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There is also an analogous ones() and empty() array routine. Note that here we can explicitly set the datatype for the array in this function if we wish. \n",
"\n",
"Unlike lists in python, all of the elements of a numpy array are of the same datatype"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n",
" [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],\n",
" [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n",
" [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n",
" [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],\n",
" [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],\n",
" [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n",
" [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],\n",
" [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],\n",
" [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"c = np.eye(10, dtype=np.float64)\n",
"c"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"`linspace` creates an array with evenly space numbers. The `endpoint` optional argument specifies whether the upper range is in the array or not"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]\n"
]
}
],
"source": [
"d = np.linspace(0, 1, 10, endpoint=False)\n",
"print(d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Quick Exercise:
\n",
"\n",
"Analogous to `linspace()`, there is a `logspace()` function that creates an array with elements equally spaced in log. Use `help(np.logspace)` to see the arguments, and create an array with 10 elements from $10^{-6}$ to $10^3$.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00, 1.e+01,\n",
" 1.e+02, 1.e+03])"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"c = np.logspace(-6,3,10)\n",
"c"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"we can also initialize an array based on a function"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[0, 1, 2],\n",
" [1, 2, 3],\n",
" [2, 3, 4]])"
]
},
"execution_count": 13,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"f = np.fromfunction(lambda i, j: i + j, (3, 3), dtype=int)\n",
"f"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"It is possible to use lambda functions together with nested list comprehensions for advanced matrix constructions. In the following we build a so-called Toeplitz matrix:"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 0, -1, -2, -3],\n",
" [ 1, 0, -1, -2],\n",
" [ 2, 1, 0, -1],\n",
" [ 3, 2, 1, 0],\n",
" [ 4, 3, 2, 1]])"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"arc = lambda r,c: r-c\n",
"T = np.array([[arc(r,c) for c in range(4)] for r in range(5)])\n",
"T"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Array Operations"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"most operations (`+`, `-`, `*`, `/`) will work on an entire array at once, element-by-element.\n",
"\n",
"Note that that the multiplication operator is not a matrix multiply (there is a new operator in python 3.5+, `@`, to do matrix multiplicaiton.\n",
"\n",
"Let's create a simply array to start with"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 1 2 3 4]\n",
" [ 5 6 7 8]\n",
" [ 9 10 11 12]]\n"
]
}
],
"source": [
"a = np.arange(1,13).reshape(3,4)\n",
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Multiplication by a scalar multiplies every element"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 2, 4, 6, 8],\n",
" [10, 12, 14, 16],\n",
" [18, 20, 22, 24]])"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a*2"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"adding two arrays adds element-by-element"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 2, 4, 6, 8],\n",
" [10, 12, 14, 16],\n",
" [18, 20, 22, 24]])"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a + a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"multiplying two arrays multiplies element-by-element"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 1, 4, 9, 16],\n",
" [ 25, 36, 49, 64],\n",
" [ 81, 100, 121, 144]])"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a*a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can think of our 2-d array as a 3 x 5 matrix (3 rows, 5 columns). We can take the transpose to geta 5 x 3 matrix, and then we can do a matrix multiplication"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Quick Exercise:
\n",
"\n",
"What do you think `1./a` will do? Try it and see\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[1. , 0.5 , 0.33333333, 0.25 ],\n",
" [0.2 , 0.16666667, 0.14285714, 0.125 ],\n",
" [0.11111111, 0.1 , 0.09090909, 0.08333333]])"
]
},
"execution_count": 19,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"1./a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can do some basic linear algebra operations on arrays. The operator `@` is a matrix multiplication / dot-product operator"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 1, 5, 9],\n",
" [ 2, 6, 10],\n",
" [ 3, 7, 11],\n",
" [ 4, 8, 12]])"
]
},
"execution_count": 20,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b = a.transpose()\n",
"b"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 30, 70, 110],\n",
" [ 70, 174, 278],\n",
" [110, 278, 446]])"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a @ b"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can sum the elements of an array:"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"78"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a.sum()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Quick Exercise:
\n",
"\n",
"`sum()` takes an optional argument, `axis=N`, where `N` is the axis to sum over. Sum the elements of `a` across rows to create an array with just the sum along each column of `a`.\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([15, 18, 21, 24])"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b = a.sum(axis=0)\n",
"b"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can also easily get the extrema"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1 12\n"
]
}
],
"source": [
"print(a.min(), a.max())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## universal functions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"universal functions work element-by-element. Let's create a new array scaled by `pi`"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 3.14159265 6.28318531 9.42477796 12.56637061]\n",
" [15.70796327 18.84955592 21.99114858 25.13274123]\n",
" [28.27433388 31.41592654 34.55751919 37.69911184]]\n"
]
}
],
"source": [
"b = a*np.pi\n",
"print(b)"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[-1. 1. -1. 1.]\n",
" [-1. 1. -1. 1.]\n",
" [-1. 1. -1. 1.]]\n"
]
}
],
"source": [
"c = np.cos(b)\n",
"print(c)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"d = b + c "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Quick Exercise:
\n",
"\n",
"We will often want to write our own function that operates on an array and returns a new array. We can do this just like we did with functions previously—the key is to use the methods from the `np` module to do any operations, since they work on, and return, arrays.\n",
"\n",
"Write a simple function that returns $\\sin(2\\pi x)$ for an input array `x`. Then test it \n",
"by passing in an array `x` that you create via `linspace()`\n",
"\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": 50,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[ 0. 10.28571429 20.57142857 30.85714286 41.14285714\n",
" 51.42857143 61.71428571 72. 82.28571429 92.57142857\n",
" 102.85714286 113.14285714 123.42857143 133.71428571 144.\n",
" 154.28571429 164.57142857 174.85714286 185.14285714 195.42857143\n",
" 205.71428571 216. 226.28571429 236.57142857 246.85714286\n",
" 257.14285714 267.42857143 277.71428571 288. 298.28571429\n",
" 308.57142857 318.85714286 329.14285714 339.42857143 349.71428571\n",
" 360. ]\n",
"[ 0.00000000e+00 9.74927912e-01 -4.33883739e-01 -7.81831482e-01\n",
" 7.81831482e-01 4.33883739e-01 -9.74927912e-01 -1.76349139e-14\n",
" 9.74927912e-01 -4.33883739e-01 -7.81831482e-01 7.81831482e-01\n",
" 4.33883739e-01 -9.74927912e-01 -3.52698278e-14 9.74927912e-01\n",
" -4.33883739e-01 -7.81831482e-01 7.81831482e-01 4.33883739e-01\n",
" -9.74927912e-01 1.17625515e-13 9.74927912e-01 -4.33883739e-01\n",
" -7.81831482e-01 7.81831482e-01 4.33883739e-01 -9.74927912e-01\n",
" -7.05396556e-14 9.74927912e-01 -4.33883739e-01 -7.81831482e-01\n",
" 7.81831482e-01 4.33883739e-01 -9.74927912e-01 -3.13311507e-14]\n"
]
}
],
"source": [
"def mysin(nparray):\n",
" \"\"\"parameters : nparray an np array\n",
" -----------\n",
" returns : sin(2*pi*a)\n",
" --------\n",
" \"\"\"\n",
" return np.sin(2*np.pi*a)\n",
"a = np.linspace(0,360,36)\n",
"print(a)\n",
"print(mysin(a))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Slicing"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"slicing works very similarly to how we saw with strings. Remember, python uses 0-based indexing\n",
"\n",
"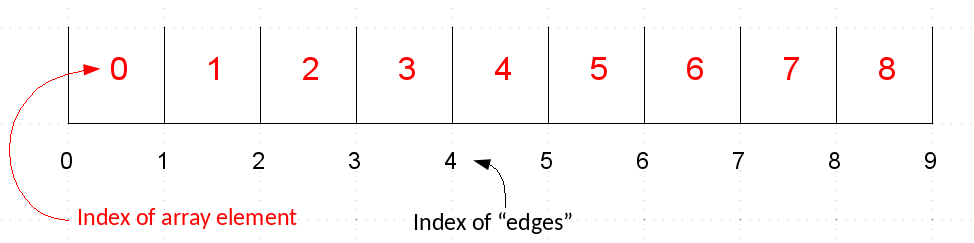\n",
"\n",
"Let's create this array from the image:"
]
},
{
"cell_type": "code",
"execution_count": 51,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([0, 1, 2, 3, 4, 5, 6, 7, 8])"
]
},
"execution_count": 51,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a = np.arange(9)\n",
"a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now look at accessing a single element vs. a range (using slicing)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Giving a single (0-based) index just references a single value"
]
},
{
"cell_type": "code",
"execution_count": 52,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"2"
]
},
"execution_count": 52,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Giving a range uses the range of the edges to return the values"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(a[2:3])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a[2:4]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The `:` can be used to specify all of the elements in that dimension"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a[:]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Multidimensional Arrays\n",
"\n",
"Multidimensional arrays are stored in a contiguous space in memory -- this means that the columns / rows need to be unraveled (flattened) so that it can be thought of as a single one-dimensional array. Different programming languages do this via different conventions:\n",
"\n",
"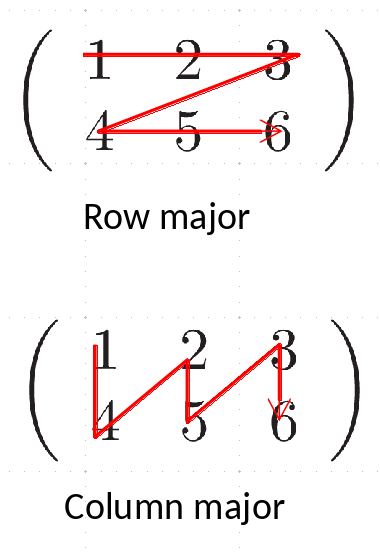\n",
"\n",
"Storage order:\n",
"\n",
"* Python/C use *row-major* storage: rows are stored one after the other\n",
"* Fortran/matlab use *column-major* storage: columns are stored one after another\n",
"\n",
"The ordering matters when \n",
"\n",
"* passing arrays between languages (we'll talk about this later this semester)\n",
"* looping over arrays -- you want to access elements that are next to one-another in memory\n",
" * e.g, in Fortran:\n",
" ```\n",
" double precision :: A(M,N)\n",
" do j = 1, N\n",
" do i = 1, M\n",
" A(i,j) = …\n",
" enddo\n",
" enddo\n",
" ```\n",
" \n",
" * in C\n",
" ```\n",
" double A[M][N];\n",
" for (i = 0; i < M; i++) {\n",
" for (j = 0; j < N; j++) {\n",
" A[i][j] = …\n",
" }\n",
" } \n",
" ```\n",
" \n",
"\n",
"In python, using NumPy, we'll try to avoid explicit loops over elements as much as possible\n",
"\n",
"Let's look at multidimensional arrays:"
]
},
{
"cell_type": "code",
"execution_count": 53,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 0, 1, 2, 3, 4],\n",
" [ 5, 6, 7, 8, 9],\n",
" [10, 11, 12, 13, 14]])"
]
},
"execution_count": 53,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a = np.arange(15).reshape(3,5)\n",
"a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Notice that the output of `a` shows the row-major storage. The rows are grouped together in the inner `[...]`\n",
"\n",
"Giving a single index (0-based) for each dimension just references a single value in the array"
]
},
{
"cell_type": "code",
"execution_count": 54,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"6"
]
},
"execution_count": 54,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[1,1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Doing slices will access a range of elements. Think of the start and stop in the slice as referencing the left-edge of the slots in the array."
]
},
{
"cell_type": "code",
"execution_count": 55,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[0, 1],\n",
" [5, 6]])"
]
},
"execution_count": 55,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[0:2,0:2]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Access a specific column"
]
},
{
"cell_type": "code",
"execution_count": 56,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([ 1, 6, 11])"
]
},
"execution_count": 56,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[:,1]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Sometimes we want a one-dimensional view into the array -- here we see the memory layout (row-major) more explicitly"
]
},
{
"cell_type": "code",
"execution_count": 57,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])"
]
},
"execution_count": 57,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a.flatten()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"we can also iterate -- this is done over the first axis (rows)"
]
},
{
"cell_type": "code",
"execution_count": 58,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0 1 2 3 4]\n",
"[5 6 7 8 9]\n",
"[10 11 12 13 14]\n"
]
}
],
"source": [
"for row in a:\n",
" print(row)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"or element by element"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for e in a.flat:\n",
" print(e)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Generally speaking, we want to avoid looping over the elements of an array in python—this is slow. Instead we want to write and use functions that operate on the entire array at once."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Quick Exercise:
\n",
"\n",
"Consider the array defined as:"
]
},
{
"cell_type": "code",
"execution_count": 96,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[4 4 4]\n",
" [4 4 4]\n",
" [4 4 4]]\n",
"[[0 0 0]\n",
" [0 0 0]\n",
" [0 0 0]]\n",
"[[1 2 3 2 1]\n",
" [2 0 0 0 2]\n",
" [3 0 0 0 3]\n",
" [2 0 0 0 2]\n",
" [1 2 3 2 1]]\n"
]
}
],
"source": [
"q = np.array([[1, 2, 3, 2, 1],\n",
" [2, 4, 4, 4, 2],\n",
" [3, 4, 4, 4, 3],\n",
" [2, 4, 4, 4, 2],\n",
" [1, 2, 3, 2, 1]])\n",
"\n",
"view = q[1:4,1:4]\n",
"print(view)\n",
"view[:,:] = 0\n",
"print(view)\n",
"print(q)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" * using slice notation, create an array that consists of only the `4`'s in `q` (this will be called a _view_, as we'll see shortly)\n",
" * zero out all of the elements in your view\n",
" * how does `q` change?\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Copying Arrays"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"simply using \"=\" does not make a copy, but much like with lists, you will just have multiple names pointing to the same ndarray object\n",
"\n",
"Therefore, we need to understand if two arrays, `A` and `B` point to:\n",
"* the same array, including shape and data/memory space\n",
"* the same data/memory space, but perhaps different shapes (a _view_)\n",
"* a separate cpy of the data (i.e. stored completely separately in memory)\n",
"\n",
"All of these are possible:\n",
"* `B = A`\n",
" \n",
" this is _assignment_. No copy is made. `A` and `B` point to the same data in memory and share the same shape, etc. They are just two different labels for the same object in memory\n",
" \n",
"\n",
"* `B = A[:]`\n",
"\n",
" this is a _view_ or _shallow copy_. The shape info for A and B are stored independently, but both point to the same memory location for data\n",
" \n",
" \n",
"* `B = A.copy()`\n",
"\n",
" this is a _deep_ copy. A completely separate object will be created in memory, with a completely separate location in memory.\n",
" \n",
"Let's look at examples"
]
},
{
"cell_type": "code",
"execution_count": 68,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0 1 2 3 4 5 6 7 8 9]\n"
]
}
],
"source": [
"a = np.arange(10)\n",
"print(a)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here is assignment—we can just use the `is` operator to test for equality"
]
},
{
"cell_type": "code",
"execution_count": 69,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 69,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"b = a\n",
"b is a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since `b` and `a` are the same, changes to the shape of one are reflected in the other—no copy is made."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"b.shape = (2, 5)\n",
"print(b)\n",
"a.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"b is a"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"a shallow copy creates a new *view* into the array—the _data_ is the same, but the array properties can be different"
]
},
{
"cell_type": "code",
"execution_count": 70,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0 1 2 3]\n",
" [ 4 5 6 7]\n",
" [ 8 9 10 11]]\n",
"[ 0 1 2 3 4 5 6 7 8 9 10 11]\n"
]
}
],
"source": [
"a = np.arange(12)\n",
"c = a[:]\n",
"a.shape = (3,4)\n",
"\n",
"print(a)\n",
"print(c)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"since the underlying data is the same memory, changing an element of one is reflected in the other"
]
},
{
"cell_type": "code",
"execution_count": 71,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0 -1 2 3]\n",
" [ 4 5 6 7]\n",
" [ 8 9 10 11]]\n"
]
}
],
"source": [
"c[1] = -1\n",
"print(a)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Even slices into an array are just views, still pointing to the same memory"
]
},
{
"cell_type": "code",
"execution_count": 72,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[3 4 5 6 7]\n"
]
}
],
"source": [
"d = c[3:8]\n",
"print(d)"
]
},
{
"cell_type": "code",
"execution_count": 73,
"metadata": {},
"outputs": [],
"source": [
"d[:] = 0 "
]
},
{
"cell_type": "code",
"execution_count": 74,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0 -1 2 0]\n",
" [ 0 0 0 0]\n",
" [ 8 9 10 11]]\n",
"[ 0 -1 2 0 0 0 0 0 8 9 10 11]\n",
"[0 0 0 0 0]\n"
]
}
],
"source": [
"print(a)\n",
"print(c)\n",
"print(d)"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"There are lots of ways to inquire if two arrays are the same, views, own their own data, etc"
]
},
{
"cell_type": "code",
"execution_count": 75,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"False\n",
"True\n",
"False\n",
"True\n"
]
}
],
"source": [
"print(c is a)\n",
"print(c.base is a)\n",
"print(c.flags.owndata)\n",
"print(a.flags.owndata)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"to make a copy of the data of the array that you can deal with independently of the original, you need a _deep copy_"
]
},
{
"cell_type": "code",
"execution_count": 76,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[[ 0 -1 2 0]\n",
" [ 0 0 0 0]\n",
" [ 8 9 10 11]]\n",
"[[0 0 0 0]\n",
" [0 0 0 0]\n",
" [0 0 0 0]]\n"
]
}
],
"source": [
"d = a.copy()\n",
"d[:,:] = 0.0\n",
"\n",
"print(a)\n",
"print(d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Boolean Indexing"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are lots of fun ways to index arrays to access only those elements that meet a certain condition"
]
},
{
"cell_type": "code",
"execution_count": 77,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ 0, 1, 2, 3],\n",
" [ 4, 5, 6, 7],\n",
" [ 8, 9, 10, 11]])"
]
},
"execution_count": 77,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a = np.arange(12).reshape(3,4)\n",
"a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here we set all the elements in the array that are > 4 to zero"
]
},
{
"cell_type": "code",
"execution_count": 78,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[0, 1, 2, 3],\n",
" [4, 0, 0, 0],\n",
" [0, 0, 0, 0]])"
]
},
"execution_count": 78,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[a > 4] = 0\n",
"a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"and now, all the zeros to -1"
]
},
{
"cell_type": "code",
"execution_count": 79,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[-1, 1, 2, 3],\n",
" [ 4, -1, -1, -1],\n",
" [-1, -1, -1, -1]])"
]
},
"execution_count": 79,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a[a == 0] = -1\n",
"a"
]
},
{
"cell_type": "code",
"execution_count": 80,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[ True, False, False, False],\n",
" [False, True, True, True],\n",
" [ True, True, True, True]])"
]
},
"execution_count": 80,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a == -1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"if we have 2 tests, we need to use `logical_and()` or `logical_or()`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"a = np.arange(12).reshape(3,4)\n",
"a[np.logical_and(a > 3, a <= 9)] = 0.0\n",
"a"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our test that we index the array with returns a boolean array of the same shape:"
]
},
{
"cell_type": "code",
"execution_count": 81,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([[False, False, False, False],\n",
" [False, False, False, False],\n",
" [False, False, False, False]])"
]
},
"execution_count": 81,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a > 4"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Avoiding Loops"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In general, you want to avoid loops over elements on an array.\n",
"\n",
"Here, let's create 1-d x and y coordinates and then try to fill some larger array"
]
},
{
"cell_type": "code",
"execution_count": 82,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"(32,)\n",
"(64,)\n"
]
}
],
"source": [
"M = 32\n",
"N = 64\n",
"xmin = ymin = 0.0\n",
"xmax = ymax = 1.0\n",
"\n",
"x = np.linspace(xmin, xmax, M, endpoint=False)\n",
"y = np.linspace(ymin, ymax, N, endpoint=False)\n",
"\n",
"print(x.shape)\n",
"print(y.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"we'll time out code"
]
},
{
"cell_type": "code",
"execution_count": 83,
"metadata": {},
"outputs": [],
"source": [
"import time"
]
},
{
"cell_type": "code",
"execution_count": 84,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"time elapsed: 0.004745006561279297 s\n"
]
}
],
"source": [
"t0 = time.time()\n",
"\n",
"g = np.zeros((M, N))\n",
"\n",
"for i in range(M):\n",
" for j in range(N):\n",
" g[i,j] = np.sin(2.0*np.pi*x[i]*y[j])\n",
" \n",
"t1 = time.time()\n",
"print(\"time elapsed: {} s\".format(t1-t0))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's instead do this using all array syntax. First will extend our 1-d coordinate arrays to be 2-d. NumPy has a function for this (`meshgrid()`)"
]
},
{
"cell_type": "code",
"execution_count": 85,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[0. 0.03125 0.0625 0.09375 0.125 0.15625 0.1875 0.21875 0.25\n",
" 0.28125 0.3125 0.34375 0.375 0.40625 0.4375 0.46875 0.5 0.53125\n",
" 0.5625 0.59375 0.625 0.65625 0.6875 0.71875 0.75 0.78125 0.8125\n",
" 0.84375 0.875 0.90625 0.9375 0.96875]\n",
"[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n",
" 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n",
" 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]\n",
"[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n",
" 0. 0. 0. 0. 0. 0. 0. 0.]\n",
"[0. 0.015625 0.03125 0.046875 0.0625 0.078125 0.09375 0.109375\n",
" 0.125 0.140625 0.15625 0.171875 0.1875 0.203125 0.21875 0.234375\n",
" 0.25 0.265625 0.28125 0.296875 0.3125 0.328125 0.34375 0.359375\n",
" 0.375 0.390625 0.40625 0.421875 0.4375 0.453125 0.46875 0.484375\n",
" 0.5 0.515625 0.53125 0.546875 0.5625 0.578125 0.59375 0.609375\n",
" 0.625 0.640625 0.65625 0.671875 0.6875 0.703125 0.71875 0.734375\n",
" 0.75 0.765625 0.78125 0.796875 0.8125 0.828125 0.84375 0.859375\n",
" 0.875 0.890625 0.90625 0.921875 0.9375 0.953125 0.96875 0.984375]\n"
]
}
],
"source": [
"x2d, y2d = np.meshgrid(x, y, indexing=\"ij\")\n",
"\n",
"print(x2d[:,0])\n",
"print(x2d[0,:])\n",
"\n",
"print(y2d[:,0])\n",
"print(y2d[0,:])"
]
},
{
"cell_type": "code",
"execution_count": 86,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"time elapsed: 0.0002892017364501953 s\n"
]
}
],
"source": [
"t0 = time.time()\n",
"g2 = np.sin(2.0*np.pi*x2d*y2d)\n",
"t1 = time.time()\n",
"print(\"time elapsed: {} s\".format(t1-t0))"
]
},
{
"cell_type": "code",
"execution_count": 87,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0.0\n"
]
}
],
"source": [
"print(np.max(np.abs(g2-g)))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Numerical differencing on NumPy arrays"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we want to construct a derivative, \n",
"$$\n",
"\\frac{d f}{dx}\n",
"$$"
]
},
{
"cell_type": "code",
"execution_count": 88,
"metadata": {},
"outputs": [],
"source": [
"x = np.linspace(0, 2*np.pi, 25)\n",
"f = np.sin(x)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We want to do this without loops—we'll use views into arrays offset from one another. Recall from calculus that a derivative is approximately:\n",
"$$\n",
"\\frac{df}{dx} = \\frac{f(x+h) - f(x)}{h}\n",
"$$\n",
"Here, we'll take $h$ to be a single adjacent element"
]
},
{
"cell_type": "code",
"execution_count": 89,
"metadata": {},
"outputs": [],
"source": [
"dx = x[1] - x[0]\n",
"dfdx = (f[1:] - f[:-1])/dx"
]
},
{
"cell_type": "code",
"execution_count": 90,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"array([ 0.98861593, 0.92124339, 0.79108963, 0.60702442, 0.38159151,\n",
" 0.13015376, -0.13015376, -0.38159151, -0.60702442, -0.79108963,\n",
" -0.92124339, -0.98861593, -0.98861593, -0.92124339, -0.79108963,\n",
" -0.60702442, -0.38159151, -0.13015376, 0.13015376, 0.38159151,\n",
" 0.60702442, 0.79108963, 0.92124339, 0.98861593])"
]
},
"execution_count": 90,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"dfdx"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.3"
}
},
"nbformat": 4,
"nbformat_minor": 1
}