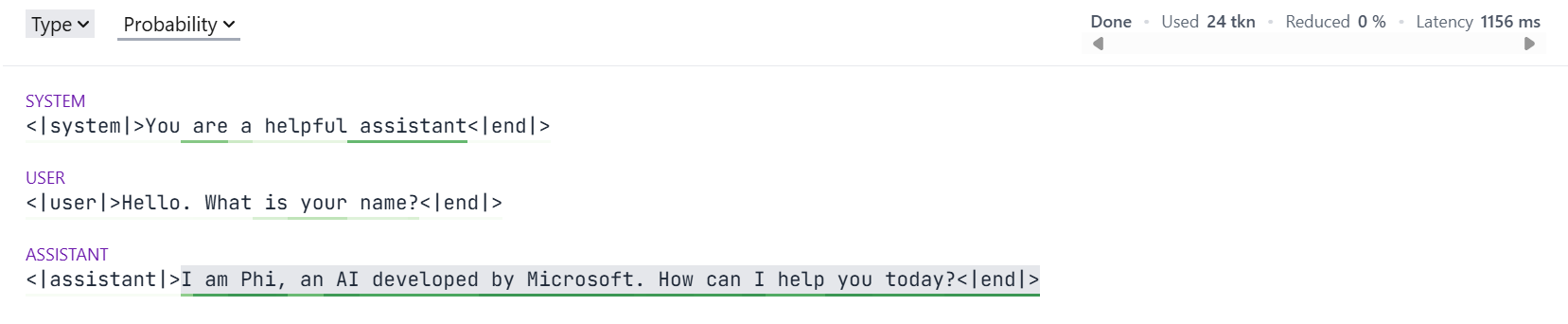
 With Guidance, it's really easy to capture generated text:
```python
# Get a new copy of the Model
lm = phi_lm
with system():
lm += "You are a helpful assistant"
with user():
lm += "Hello. What is your name?"
with assistant():
lm += gen(name="lm_response", max_tokens=20)
print(f"{lm['lm_response']=}")
```
```
lm['lm_response']='I am Phi, an AI developed by Microsoft. How can I help you today?'
```
### Guarantee output syntax with constrained generation
Guidance provides an easy to use, yet immensely powerful syntax for constraining the output of a language model.
For example, a `gen()` call can be constrained to match a regular expression:
```python
lm = phi_lm
with system():
lm += "You are a teenager"
with user():
lm += "How old are you?"
with assistant():
lm += gen("lm_age", regex=r"\d+", temperature=0.8)
print(f"The language model is {lm['lm_age']} years old")
```
```
The language model is 13 years old
```
Often, we know that the output has to be an item from a list we know in advance.
Guidance provides a `select()` function for this scenario:
```python
from guidance import select
lm = phi_lm
with system():
lm += "You are a geography expert"
with user():
lm += """What is the capital of Sweden? Answer with the correct letter.
A) Helsinki
B) Reykjavík
C) Stockholm
D) Oslo
"""
with assistant():
lm += select(["A", "B", "C", "D"], name="model_selection")
print(f"The model selected {lm['model_selection']}")
```
```
The model selected C
```
The constraint system offered by Guidance is extremely powerful.
It can ensure that the output conforms to any context free grammar (so long as the backend LLM has full support for Guidance).
More on this below.
### Create your own Guidance functions
With Guidance, you can create your own Guidance functions which can interact with language models.
These are marked using the `@guidance` decorator.
Suppose we wanted to answer lots of multiple choice questions.
We could do something like the following:
```python
import guidance
from guidance.models import Model
ASCII_OFFSET = ord("a")
@guidance
def zero_shot_multiple_choice(
language_model: Model,
question: str,
choices: list[str],
):
with user():
language_model += question + "\n"
for i, choice in enumerate(choices):
language_model += f"{chr(i+ASCII_OFFSET)} : {choice}\n"
with assistant():
language_model += select(
[chr(i + ASCII_OFFSET) for i in range(len(choices))], name="string_choice"
)
return language_model
```
Now, define some questions:
```python
questions = [
{
"question" : "Which state has the northernmost capital?",
"choices" : [
"New South Wales",
"Northern Territory",
"Queensland",
"South Australia",
"Tasmania",
"Victoria",
"Western Australia",
],
"answer" : 1,
},
{
"question" : "Which of the following is venomous?",
"choices" : [
"Kangaroo",
"Koala Bear",
"Platypus",
],
"answer" : 2,
}
]
```
We can use our decorated function like `gen()` or `select()`.
The `language_model` argument will be filled in for us automatically:
```python
lm = phi_lm
with system():
lm += "You are a student taking a multiple choice test."
for mcq in questions:
lm_temp = lm + zero_shot_multiple_choice(question=mcq["question"], choices=mcq["choices"])
converted_answer = ord(lm_temp["string_choice"]) - ASCII_OFFSET
print(lm_temp)
print(f"LM Answer: {converted_answer}, Correct Answer: {mcq['answer']}")
```
```
<|system|>You are a student taking a multiple choice test.<|end|><|user|>Which state has the northernmost capital?
a : New South Wales
b : Northern Territory
c : Queensland
d : South Australia
e : Tasmania
f : Victoria
g : Western Australia
<|end|><|assistant|>b
LM Answer: 1, Correct Answer: 1
<|system|>You are a student taking a multiple choice test.<|end|><|user|>Which of the following is venomous?
a : Kangaroo
b : Koala Bear
c : Platypus
<|end|><|assistant|>c
LM Answer: 2, Correct Answer: 2
```
Guidance functions can be composed, in order to construct a full context free grammar.
For example, we can create Guidance functions to build a simple HTML webpage (note that this is _not_ a full implementation of HTML).
We start with a simple function which will generate text which does not contain any HTML tags.
The function is marked as `stateless` to indicate that we intend to use it for composing a grammar:
```python
@guidance(stateless=True)
def _gen_text(lm: Model):
return lm + gen(regex="[^<>]+")
```
We can then use this function to generate text within an arbitrary HTML tag:
```python
@guidance(stateless=True)
def _gen_text_in_tag(lm: Model, tag: str):
lm += f"<{tag}>"
lm += _gen_text()
lm += f""
return lm
```
Now, let us create the page header. As part of this, we need to generate a page title:
```python
@guidance(stateless=True)
def _gen_header(lm: Model):
lm += "\n"
lm += _gen_text_in_tag("title") + "\n"
lm += "\n"
return lm
```
The body of the HTML page is going to be filled with headings and paragraphs.
We can define a function to do each:
```python
from guidance.library import one_or_more
@guidance(stateless=True)
def _gen_heading(lm: Model):
lm += select(
options=[_gen_text_in_tag("h1"), _gen_text_in_tag("h2"), _gen_text_in_tag("h3")]
)
lm += "\n"
return lm
@guidance(stateless=True)
def _gen_para(lm: Model):
lm += "
With Guidance, it's really easy to capture generated text:
```python
# Get a new copy of the Model
lm = phi_lm
with system():
lm += "You are a helpful assistant"
with user():
lm += "Hello. What is your name?"
with assistant():
lm += gen(name="lm_response", max_tokens=20)
print(f"{lm['lm_response']=}")
```
```
lm['lm_response']='I am Phi, an AI developed by Microsoft. How can I help you today?'
```
### Guarantee output syntax with constrained generation
Guidance provides an easy to use, yet immensely powerful syntax for constraining the output of a language model.
For example, a `gen()` call can be constrained to match a regular expression:
```python
lm = phi_lm
with system():
lm += "You are a teenager"
with user():
lm += "How old are you?"
with assistant():
lm += gen("lm_age", regex=r"\d+", temperature=0.8)
print(f"The language model is {lm['lm_age']} years old")
```
```
The language model is 13 years old
```
Often, we know that the output has to be an item from a list we know in advance.
Guidance provides a `select()` function for this scenario:
```python
from guidance import select
lm = phi_lm
with system():
lm += "You are a geography expert"
with user():
lm += """What is the capital of Sweden? Answer with the correct letter.
A) Helsinki
B) Reykjavík
C) Stockholm
D) Oslo
"""
with assistant():
lm += select(["A", "B", "C", "D"], name="model_selection")
print(f"The model selected {lm['model_selection']}")
```
```
The model selected C
```
The constraint system offered by Guidance is extremely powerful.
It can ensure that the output conforms to any context free grammar (so long as the backend LLM has full support for Guidance).
More on this below.
### Create your own Guidance functions
With Guidance, you can create your own Guidance functions which can interact with language models.
These are marked using the `@guidance` decorator.
Suppose we wanted to answer lots of multiple choice questions.
We could do something like the following:
```python
import guidance
from guidance.models import Model
ASCII_OFFSET = ord("a")
@guidance
def zero_shot_multiple_choice(
language_model: Model,
question: str,
choices: list[str],
):
with user():
language_model += question + "\n"
for i, choice in enumerate(choices):
language_model += f"{chr(i+ASCII_OFFSET)} : {choice}\n"
with assistant():
language_model += select(
[chr(i + ASCII_OFFSET) for i in range(len(choices))], name="string_choice"
)
return language_model
```
Now, define some questions:
```python
questions = [
{
"question" : "Which state has the northernmost capital?",
"choices" : [
"New South Wales",
"Northern Territory",
"Queensland",
"South Australia",
"Tasmania",
"Victoria",
"Western Australia",
],
"answer" : 1,
},
{
"question" : "Which of the following is venomous?",
"choices" : [
"Kangaroo",
"Koala Bear",
"Platypus",
],
"answer" : 2,
}
]
```
We can use our decorated function like `gen()` or `select()`.
The `language_model` argument will be filled in for us automatically:
```python
lm = phi_lm
with system():
lm += "You are a student taking a multiple choice test."
for mcq in questions:
lm_temp = lm + zero_shot_multiple_choice(question=mcq["question"], choices=mcq["choices"])
converted_answer = ord(lm_temp["string_choice"]) - ASCII_OFFSET
print(lm_temp)
print(f"LM Answer: {converted_answer}, Correct Answer: {mcq['answer']}")
```
```
<|system|>You are a student taking a multiple choice test.<|end|><|user|>Which state has the northernmost capital?
a : New South Wales
b : Northern Territory
c : Queensland
d : South Australia
e : Tasmania
f : Victoria
g : Western Australia
<|end|><|assistant|>b
LM Answer: 1, Correct Answer: 1
<|system|>You are a student taking a multiple choice test.<|end|><|user|>Which of the following is venomous?
a : Kangaroo
b : Koala Bear
c : Platypus
<|end|><|assistant|>c
LM Answer: 2, Correct Answer: 2
```
Guidance functions can be composed, in order to construct a full context free grammar.
For example, we can create Guidance functions to build a simple HTML webpage (note that this is _not_ a full implementation of HTML).
We start with a simple function which will generate text which does not contain any HTML tags.
The function is marked as `stateless` to indicate that we intend to use it for composing a grammar:
```python
@guidance(stateless=True)
def _gen_text(lm: Model):
return lm + gen(regex="[^<>]+")
```
We can then use this function to generate text within an arbitrary HTML tag:
```python
@guidance(stateless=True)
def _gen_text_in_tag(lm: Model, tag: str):
lm += f"<{tag}>"
lm += _gen_text()
lm += f""
return lm
```
Now, let us create the page header. As part of this, we need to generate a page title:
```python
@guidance(stateless=True)
def _gen_header(lm: Model):
lm += "\n"
lm += _gen_text_in_tag("title") + "\n"
lm += "\n"
return lm
```
The body of the HTML page is going to be filled with headings and paragraphs.
We can define a function to do each:
```python
from guidance.library import one_or_more
@guidance(stateless=True)
def _gen_heading(lm: Model):
lm += select(
options=[_gen_text_in_tag("h1"), _gen_text_in_tag("h2"), _gen_text_in_tag("h3")]
)
lm += "\n"
return lm
@guidance(stateless=True)
def _gen_para(lm: Model):
lm += ""
lm += one_or_more(
select(
options=[
_gen_text(),
_gen_text_in_tag("em"),
_gen_text_in_tag("strong"),
"
",
],
)
)
lm += "
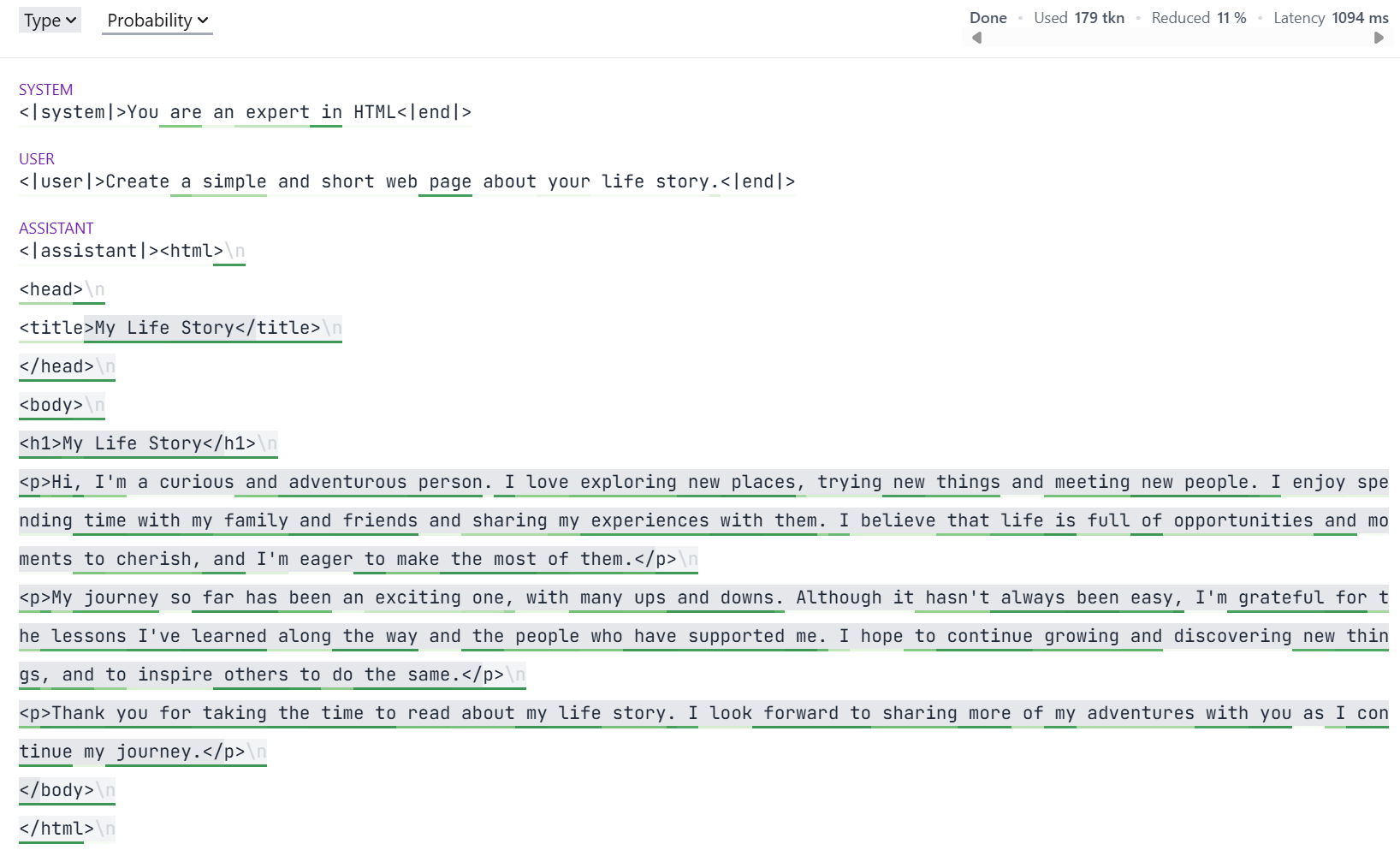 Note the varying highlighting of the generation.
This is showing another of Guidance's capabilities: fast-forwarding of tokens.
The constraints imposed by a grammar often mean that some tokens are known in advance.
Guidance doesn't need the model to generate these; instead it can insert them into the generation.
This saves forward passes through the model, and hence reduces GPU usage.
For example, in the above HTML generation, Guidance always knows the last opening tag.
If the last opened tag was `
Note the varying highlighting of the generation.
This is showing another of Guidance's capabilities: fast-forwarding of tokens.
The constraints imposed by a grammar often mean that some tokens are known in advance.
Guidance doesn't need the model to generate these; instead it can insert them into the generation.
This saves forward passes through the model, and hence reduces GPU usage.
For example, in the above HTML generation, Guidance always knows the last opening tag.
If the last opened tag was `