{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Mining the Social Web\n",
"\n",
"## Mining Instagram\n",
"\n",
"This Jupyter Notebook provides an interactive way to follow along with and explore the examples from the video series. The intent behind this notebook is to reinforce the concepts in a fun, convenient, and effective way."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Instagram API Access"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Visit https://www.instagram.com/developer/ and register an application. Next, register a client. After your client has been set up, click on 'Manage' and from the client management page, copy the client ID and client secret, pasting them below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, visit the 'Security' tab and find the redirect URI that was set for your client. If none has been set, set one now. It can be 'http://www.google.com' if you like. Save the redirect URI to the variable below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Much like Facebook's authentication system, Instagram uses a browser-based authentication system, so the following will be a 2-step process. We need to generate an access token, so we'll construct the URL to visit in a new browser tab so that we can complete the authentication process."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"CLIENT_ID = ''\n",
"CLIENT_SECRET = ''\n",
"\n",
"REDIRECT_URI = ''\n",
"\n",
"base_url = 'https://api.instagram.com/oauth/authorize/'\n",
"\n",
"url = '{0}?client_id={1}&redirect_uri={2}&response_type=code&scope=public_content'.format(base_url, CLIENT_ID, REDIRECT_URI)\n",
"\n",
"print('Click the following URL, which will taken you to the REDIRECT_URI you set in creating the APP.')\n",
"print('You may need to log into Instagram.')\n",
"print()\n",
"print(url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After authorization, copy the string following '`?code=...`' in the browser's address bar."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import requests # pip install requests\n",
"\n",
"CODE = ''\n",
"\n",
"payload = dict(client_id=CLIENT_ID, \n",
" client_secret=CLIENT_SECRET,\n",
" grant_type='authorization_code',\n",
" redirect_uri=REDIRECT_URI,\n",
" code=CODE)\n",
"\n",
"response = requests.post(\n",
" 'https://api.instagram.com/oauth/access_token',\n",
" data = payload)\n",
"\n",
"ACCESS_TOKEN = response.json()['access_token']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = requests.get('https://api.instagram.com/v1/users/self/?access_token='+ACCESS_TOKEN)\n",
"\n",
"print(response.text)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Retrieving Your Feed"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"from IPython.display import display, Image \n",
"\n",
"response = requests.get('https://api.instagram.com/v1/users/self/media/recent/?access_token='+ACCESS_TOKEN)\n",
"recent_posts = response.json()\n",
"\n",
"def display_image_feed(feed, include_captions=True):\n",
" for post in feed['data']:\n",
" display(Image(url=post['images']['low_resolution']['url']))\n",
" print(post['images']['standard_resolution']['url'])\n",
" if include_captions: print(post['caption']['text'])\n",
" print()\n",
"\n",
"\n",
"display_image_feed(recent_posts, include_captions=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Retrieving Media by Hashtag\n",
"\n",
"**N.B.:** Regrettably, Instagram has retired the `tags` API endpoint and the following code cell will return an error. We keep it here for reference."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hashtag = 'travel'\n",
"response = requests.get('https://api.instagram.com/v1/tags/'+hashtag+'/media/recent?access_token='+ACCESS_TOKEN)\n",
"\n",
"display_image_feed(response.json(), include_captions=True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Anatomy of an Instagram Post"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import json\n",
"\n",
"response = requests.get('https://api.instagram.com/v1/users/self/media/recent/?access_token='+ACCESS_TOKEN)\n",
"recent_posts = response.json()\n",
"\n",
"print(json.dumps(recent_posts, indent=1))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(recent_posts.keys())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(recent_posts['pagination'])\n",
"print(recent_posts['meta'])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(json.dumps(recent_posts['data'], indent=1))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(json.dumps(recent_posts['data'][0], indent=1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Artificial Neural Networks\n",
"\n",
"Artificial Neural Networks are inspired by the biological neural networks that exist in the nervous systems of many organisms. Neural networks are understood as an information processing system with inputs and outputs. An artificial neural network consists of \"layers\" of \"neurons\". Each neuron is defined by an \"activation function\" that takes multiple inputs, each weighted by some value, and maps them to an output, usually a value between 0 and 1.\n",
"\n",
"The outputs from one layer become the inputs for the next layer. A neural network will have an input layer, where each neuron in the input layer corresponds to a single feature of interest. These could be the pixel values in an image, for instance.\n",
"\n",
"The output layer often consists of neurons with each representing a class. You could create a network with 2 output neurons and the purpose of the network might be to determine whether a photo contains the image of a cat or not. This is a binary classifier. Or, you could have many output neurons, with each output neuron representing a different object that could be present in the image.\n",
"\n",
"Most neural networks also contain one or more \"hidden layers\" between the input and output layers. The presence of these make the internal workings of the network more opaque to our understanding, but they are vital for detecting complex nonlinear structures that could be present in the input patterns.\n",
"\n",
"A neural network must be \"trained\" in order for it to have any reasonable degree of accuracy. Training is the process by which the network is shown inputs and the predicted output is compared to some ground truth output. The difference between predicted output and true output represents an error (also called the \"loss\") to be minimized. Using an algorithm called \"backpropagation\", these errors are used to update the weights on the inputs for each neuron throughout the network. Through successive iterations, the network can reduce its overall error and improve its accuracy.\n",
"\n",
"There's a lot more nuance to it than is covered here, but there are many good resources online and at O'Reilly Media if you want to go further."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"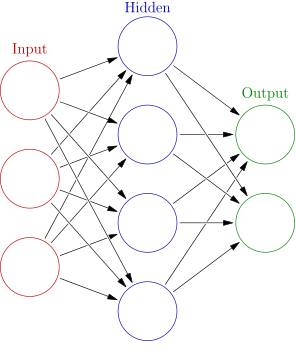\n",
"\n",
"Schematic diagram of an artificial neural network with 3 input neurons, a hidden layer of 5 neurons, and an output layer of 2 neurons. Image by Glosser.ca - Own work, Derivative of File:Artificial neural network.svg, CC BY-SA 3.0, Link"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Install scikit-learn and scipy (a dependency) using the command:\n",
"# pip install scikit-learn\n",
"# pip install scipy\n",
"from sklearn import datasets, metrics\n",
"from sklearn.neural_network import MLPClassifier\n",
"from sklearn.model_selection import train_test_split\n",
"\n",
"digits = datasets.load_digits()\n",
"\n",
"# Rescale the data and split into training and test sets\n",
"X, y = digits.data / 255., digits.target\n",
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)\n",
"\n",
"\n",
"mlp = MLPClassifier(hidden_layer_sizes=(100,), max_iter=100, alpha=1e-4,\n",
" solver='adam', verbose=10, tol=1e-4, random_state=1,\n",
" learning_rate_init=.1)\n",
"\n",
"mlp.fit(X_train, y_train)\n",
"print()\n",
"print(\"Training set score: {0}\".format(mlp.score(X_train, y_train)))\n",
"print(\"Test set score: {0}\".format(mlp.score(X_test, y_test)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# pip install matplotlib\n",
"import matplotlib.pyplot as plt\n",
"%matplotlib inline\n",
"\n",
"fig, axes = plt.subplots(10,10)\n",
"fig.set_figwidth(20)\n",
"fig.set_figheight(20)\n",
"\n",
"for coef, ax in zip(mlp.coefs_[0].T, axes.ravel()):\n",
" ax.matshow(coef.reshape(8, 8), cmap=plt.cm.gray, interpolation='bicubic')\n",
" ax.set_xticks(())\n",
" ax.set_yticks(())\n",
"\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"import numpy as np # pip install numpy\n",
"predicted = mlp.predict(X_test)\n",
"\n",
"for i in range(5):\n",
" image = np.reshape(X_test[i], (8,8))\n",
" plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')\n",
" plt.axis('off')\n",
" plt.show()\n",
" print('Ground Truth: {0}'.format(y_test[i]))\n",
" print('Predicted: {0}'.format(predicted[i]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Learning More\n",
"\n",
"Neural Networks, and (in particular) \"deep learning\" systems -- which are neural networks with many and complex hidden layers -- are transforming entire industries. What is commonly thought of as \"artificial intelligence\" today is largely (though not exclusively) the many applications of deep learning systems, which includes machine translation, computer vision, natural language understanding, natural language generation, and many others.\n",
"\n",
"If you would like to take some next steps into understanding how artificial neural networks work, some good online resources include Michael Nielsen book, \"Neural Networks and Deep Learning\", the first chapter of which is [available online](http://neuralnetworksanddeeplearning.com/chap1.html). Also, check out [Machine Learning for Artists](https://ml4a.github.io/index/), especially the chapter titled \"[Looking Inside Neural Networks](https://ml4a.github.io/ml4a/looking_inside_neural_nets/)\"."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Object Recognition within Photos using Pretrained Neural Networks\n",
"\n",
"Setting up and training an artificial neural network for object recognition is not a simple task. It requires selecting the right neural network architecture, curating a large collection of pre-labeled images for training the neural network, selecting the right hyperparameters, and then training the network long enough for it to provide accurate results.\n",
"\n",
"Luckily, this work has already been done and the technology has been sufficiently commodified that now anyone has access to near-cutting-edge computer vision APIs.\n",
"\n",
"We are going to use the [Google Vision API](https://cloud.google.com/vision/).\n",
"\n",
"Visit the [Google Developer Console](https://console.cloud.google.com/) and create a project (if you haven't already done so for another video in this series). Then retrieve your OAuth client credentials and paste them below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Object Recognition on a Photo of a Cat**\n",
"\n",
"See the [documentation](https://cloud.google.com/vision/docs/python-client-migration) for how to use the Google Cloud Vision Python SDK. We'll go through a few of the basic commands here.\n",
"\n",
"\n",
"\n",
"Photograph of a cat in the snow by Von.grzanka - Own work, CC BY-SA 3.0, Link"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import base64\n",
"import urllib\n",
"import io\n",
"import os\n",
"import PIL # pip install Pillow\n",
"from IPython.display import display, Image \n",
"\n",
"GOOGLE_API_KEY = ''\n",
"\n",
"# pip install google-api-python-client\n",
"from googleapiclient.discovery import build\n",
"service = build('vision', 'v1', developerKey=GOOGLE_API_KEY)\n",
"\n",
"cat = 'resources/ch03-instagram/cat.jpg'\n",
"\n",
"def label_image(path=None, URL=None, max_results=5):\n",
" '''Read an image file (either locally or from the web) and pass the image data\n",
" to Google's Vision API for labelling. Use the URL keyword to pass in the URL\n",
" to an image on the web. Otherwise pass in the path to a local image file.\n",
" Use the max_results keyword to control the number of labels returned by Google's\n",
" Vision API.\n",
" '''\n",
" if URL is not None:\n",
" image_content = base64.b64encode(urllib.request.urlopen(URL).read())\n",
" else:\n",
" image_content = base64.b64encode(open(path, 'rb').read())\n",
" service_request = service.images().annotate(body={\n",
" 'requests': [{\n",
" 'image': {\n",
" 'content': image_content.decode('UTF-8')\n",
" },\n",
" 'features': [{\n",
" 'type': 'LABEL_DETECTION',\n",
" 'maxResults': max_results\n",
" }]\n",
" }]\n",
" })\n",
" labels = service_request.execute()['responses'][0]['labelAnnotations']\n",
" if URL is not None:\n",
" display(Image(url=URL))\n",
" else:\n",
" display(Image(path))\n",
" for label in labels:\n",
" print ('[{0:3.0f}%]: {1}'.format(label['score']*100, label['description']))\n",
"\n",
" return\n",
"\n",
"# Finally, call the image labeling function on the image of a cat\n",
"label_image(cat)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Label my Instagram Feed"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"response = requests.get('https://api.instagram.com/v1/users/self/media/recent/?access_token='+ACCESS_TOKEN)\n",
"recent_posts = response.json()\n",
"\n",
"for post in recent_posts['data']:\n",
" url = post['images']['low_resolution']['url']\n",
" label_image(URL=url)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Detecting Faces"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from PIL import Image as PImage\n",
"from PIL import ImageDraw\n",
"\n",
"def detect_faces(path=None, URL=None):\n",
" '''Read an image file (either locally or from the web) and pass the image data\n",
" to Google's Vision API for face detection. Use the URL keyword to pass in the URL\n",
" to an image on the web. Otherwise pass in the path to a local image file.\n",
" Use the max_results keyword to control the number of labels returned by Google's\n",
" Vision API.\n",
" '''\n",
" if URL is not None:\n",
" image_content = base64.b64encode(urllib.request.urlopen(URL).read())\n",
" else:\n",
" image_content = base64.b64encode(open(path, 'rb').read())\n",
" service_request = service.images().annotate(body={\n",
" 'requests': [{\n",
" 'image': {\n",
" 'content': image_content.decode('UTF-8')\n",
" },\n",
" 'features': [{\n",
" 'type': 'FACE_DETECTION',\n",
" 'maxResults': 100\n",
" }]\n",
" }]\n",
" })\n",
" try:\n",
" faces = service_request.execute()['responses'][0]['faceAnnotations']\n",
" except:\n",
" # No faces found...\n",
" faces = None\n",
" if URL is not None:\n",
" im = PImage.open(urllib.request.urlopen(URL))\n",
" else:\n",
" im = PImage.open(path)\n",
" draw = ImageDraw.Draw(im)\n",
" \n",
" if faces:\n",
" for face in faces:\n",
" box = [(v.get('x', 0.0), v.get('y', 0.0)) for v in face['fdBoundingPoly']['vertices']]\n",
" draw.line(box + [box[0]], width=5, fill='#ff8888')\n",
" \n",
" display(im)\n",
" return"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"for post in recent_posts['data']:\n",
" url = post['images']['standard_resolution']['url']\n",
" detect_faces(URL=url)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"the_beatles = 'resources/ch03-instagram/the_beatles.jpg'\n",
"\n",
"detect_faces(the_beatles)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.8"
}
},
"nbformat": 4,
"nbformat_minor": 2
}