# LLM Scraper
 LLM Scraper is a TypeScript library that allows you to extract structured data from **any** webpage using LLMs.
> [!IMPORTANT]
> **LLM Scraper was updated to version 2.0.**
>
> The new version comes with **Vercel AI SDK 6** support and updated examples.
### Features
- Supports GPT, Sonnet, Gemini, Llama, Qwen model series
- Schemas defined with Zod or JSON Schema
- Full type-safety with TypeScript
- Based on Playwright framework
- Streaming objects
- [Code-generation](#code-generation)
- Supports 6 formatting modes:
- `html` for loading pre-processed HTML
- `raw_html` for loading raw HTML (no processing)
- `markdown` for loading markdown
- `text` for loading extracted text (using [Readability.js](https://github.com/mozilla/readability))
- `image` for loading a screenshot (multi-modal only)
- `custom` for loading custom content (using a custom function)
**Make sure to give it a star!**
LLM Scraper is a TypeScript library that allows you to extract structured data from **any** webpage using LLMs.
> [!IMPORTANT]
> **LLM Scraper was updated to version 2.0.**
>
> The new version comes with **Vercel AI SDK 6** support and updated examples.
### Features
- Supports GPT, Sonnet, Gemini, Llama, Qwen model series
- Schemas defined with Zod or JSON Schema
- Full type-safety with TypeScript
- Based on Playwright framework
- Streaming objects
- [Code-generation](#code-generation)
- Supports 6 formatting modes:
- `html` for loading pre-processed HTML
- `raw_html` for loading raw HTML (no processing)
- `markdown` for loading markdown
- `text` for loading extracted text (using [Readability.js](https://github.com/mozilla/readability))
- `image` for loading a screenshot (multi-modal only)
- `custom` for loading custom content (using a custom function)
**Make sure to give it a star!**
 ## Getting started
1. Install the required dependencies from npm:
```
npm i zod playwright llm-scraper
```
2. Initialize your LLM:
**OpenAI**
```
npm i @ai-sdk/openai
```
```js
import { openai } from '@ai-sdk/openai'
const llm = openai('gpt-4o')
```
**Anthropic**
```
npm i @ai-sdk/anthropic
```
```js
import { anthropic } from '@ai-sdk/anthropic'
const llm = anthropic('claude-3-5-sonnet-20240620')
```
**Google**
```
npm i @ai-sdk/google
```
```js
import { google } from '@ai-sdk/google'
const llm = google('gemini-1.5-flash')
```
**Groq**
```
npm i @ai-sdk/openai
```
```js
import { createOpenAI } from '@ai-sdk/openai'
const groq = createOpenAI({
baseURL: 'https://api.groq.com/openai/v1',
apiKey: process.env.GROQ_API_KEY,
})
const llm = groq('llama3-8b-8192')
```
**Ollama**
```
npm i ollama-ai-provider-v2
```
```js
import { ollama } from 'ollama-ai-provider-v2'
const llm = ollama('llama3')
```
3. Create a new scraper instance provided with the llm:
```js
import LLMScraper from 'llm-scraper'
const scraper = new LLMScraper(llm)
```
## Example
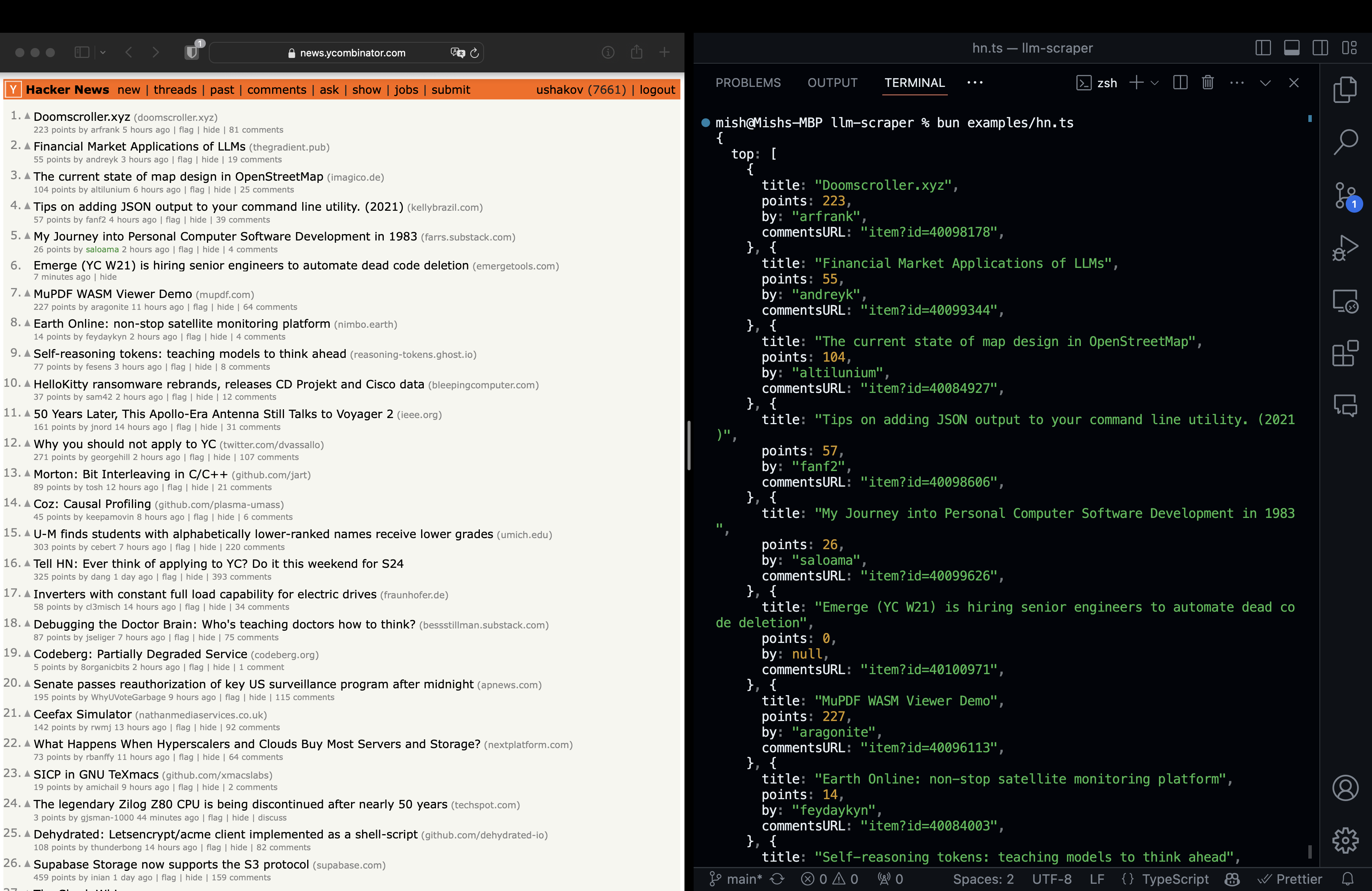
In this example, we're extracting top stories from HackerNews:
```ts
import { chromium } from 'playwright'
import { z } from 'zod'
import { Output } from 'ai'
import { openai } from '@ai-sdk/openai'
import LLMScraper from 'llm-scraper'
// Launch a browser instance
const browser = await chromium.launch()
// Initialize LLM provider
const llm = openai('gpt-4o')
// Create a new LLMScraper
const scraper = new LLMScraper(llm)
// Open new page
const page = await browser.newPage()
await page.goto('https://news.ycombinator.com')
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe('Top 5 stories on Hacker News'),
})
// Run the scraper
const { data } = await scraper.run(page, Output.object({ schema }), {
format: 'html',
})
// Show the result from LLM
console.log(data.top)
await page.close()
await browser.close()
```
Output
```js
[
{
title: "Palette lighting tricks on the Nintendo 64",
points: 105,
by: "ibobev",
commentsURL: "https://news.ycombinator.com/item?id=44014587",
},
{
title: "Push Ifs Up and Fors Down",
points: 187,
by: "goranmoomin",
commentsURL: "https://news.ycombinator.com/item?id=44013157",
},
{
title: "JavaScript's New Superpower: Explicit Resource Management",
points: 225,
by: "olalonde",
commentsURL: "https://news.ycombinator.com/item?id=44012227",
},
{
title: "\"We would be less confidential than Google\" Proton threatens to quit Switzerland",
points: 65,
by: "taubek",
commentsURL: "https://news.ycombinator.com/item?id=44014808",
},
{
title: "OBNC – Oberon-07 Compiler",
points: 37,
by: "AlexeyBrin",
commentsURL: "https://news.ycombinator.com/item?id=44013671",
}
]
```
More examples can be found in the [examples](./examples) folder.
## Streaming
Replace your `run` function with `stream` to get a partial object stream.
```ts
// Run the scraper in streaming mode
const { stream } = await scraper.stream(page, Output.object({ schema }))
// Stream the result from LLM
for await (const data of stream) {
console.log(data.top)
}
```
## Code-generation
Using the `generate` function you can generate re-usable playwright script that scrapes the contents according to a schema.
```ts
// Generate code and run it on the page
const { code } = await scraper.generate(page, Output.object({ schema }))
const result = await page.evaluate(code)
const data = schema.parse(result)
// Show the parsed result
console.log(data.top)
```
## Contributing
As an open-source project, we welcome contributions from the community. If you are experiencing any bugs or want to add some improvements, please feel free to open an issue or pull request.
## Getting started
1. Install the required dependencies from npm:
```
npm i zod playwright llm-scraper
```
2. Initialize your LLM:
**OpenAI**
```
npm i @ai-sdk/openai
```
```js
import { openai } from '@ai-sdk/openai'
const llm = openai('gpt-4o')
```
**Anthropic**
```
npm i @ai-sdk/anthropic
```
```js
import { anthropic } from '@ai-sdk/anthropic'
const llm = anthropic('claude-3-5-sonnet-20240620')
```
**Google**
```
npm i @ai-sdk/google
```
```js
import { google } from '@ai-sdk/google'
const llm = google('gemini-1.5-flash')
```
**Groq**
```
npm i @ai-sdk/openai
```
```js
import { createOpenAI } from '@ai-sdk/openai'
const groq = createOpenAI({
baseURL: 'https://api.groq.com/openai/v1',
apiKey: process.env.GROQ_API_KEY,
})
const llm = groq('llama3-8b-8192')
```
**Ollama**
```
npm i ollama-ai-provider-v2
```
```js
import { ollama } from 'ollama-ai-provider-v2'
const llm = ollama('llama3')
```
3. Create a new scraper instance provided with the llm:
```js
import LLMScraper from 'llm-scraper'
const scraper = new LLMScraper(llm)
```
## Example
In this example, we're extracting top stories from HackerNews:
```ts
import { chromium } from 'playwright'
import { z } from 'zod'
import { Output } from 'ai'
import { openai } from '@ai-sdk/openai'
import LLMScraper from 'llm-scraper'
// Launch a browser instance
const browser = await chromium.launch()
// Initialize LLM provider
const llm = openai('gpt-4o')
// Create a new LLMScraper
const scraper = new LLMScraper(llm)
// Open new page
const page = await browser.newPage()
await page.goto('https://news.ycombinator.com')
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe('Top 5 stories on Hacker News'),
})
// Run the scraper
const { data } = await scraper.run(page, Output.object({ schema }), {
format: 'html',
})
// Show the result from LLM
console.log(data.top)
await page.close()
await browser.close()
```
Output
```js
[
{
title: "Palette lighting tricks on the Nintendo 64",
points: 105,
by: "ibobev",
commentsURL: "https://news.ycombinator.com/item?id=44014587",
},
{
title: "Push Ifs Up and Fors Down",
points: 187,
by: "goranmoomin",
commentsURL: "https://news.ycombinator.com/item?id=44013157",
},
{
title: "JavaScript's New Superpower: Explicit Resource Management",
points: 225,
by: "olalonde",
commentsURL: "https://news.ycombinator.com/item?id=44012227",
},
{
title: "\"We would be less confidential than Google\" Proton threatens to quit Switzerland",
points: 65,
by: "taubek",
commentsURL: "https://news.ycombinator.com/item?id=44014808",
},
{
title: "OBNC – Oberon-07 Compiler",
points: 37,
by: "AlexeyBrin",
commentsURL: "https://news.ycombinator.com/item?id=44013671",
}
]
```
More examples can be found in the [examples](./examples) folder.
## Streaming
Replace your `run` function with `stream` to get a partial object stream.
```ts
// Run the scraper in streaming mode
const { stream } = await scraper.stream(page, Output.object({ schema }))
// Stream the result from LLM
for await (const data of stream) {
console.log(data.top)
}
```
## Code-generation
Using the `generate` function you can generate re-usable playwright script that scrapes the contents according to a schema.
```ts
// Generate code and run it on the page
const { code } = await scraper.generate(page, Output.object({ schema }))
const result = await page.evaluate(code)
const data = schema.parse(result)
// Show the parsed result
console.log(data.top)
```
## Contributing
As an open-source project, we welcome contributions from the community. If you are experiencing any bugs or want to add some improvements, please feel free to open an issue or pull request.