{
"cells": [
{
"cell_type": "markdown",
"id": "2ddc3c7c",
"metadata": {},
"source": [
"# PyTorch and Mitsuba interoperability"
]
},
{
"cell_type": "markdown",
"id": "abfc1227",
"metadata": {},
"source": [
"## Overview\n",
"\n",
"This tutorial shows how to mix differentiable computations between Mitsuba and [PyTorch][1]. The ability to combine these frameworks allows us to squeeze an entire rendering pipeline between neural layers whilst still preserving the differentiability (end-to-end) of their combination.\n",
"\n",
"Note that the necessary communication and synchronization between Dr.Jit and PyTorch along with the complexity of traversing two separate computation graph data structures produces an overhead when compared to an implementation which only uses Dr.Jit. We generally recommend sticking with Dr.Jit unless the problem requires neural network building blocks like fully connected layers or convolutions, where PyTorch provides a clear advantage.\n",
"\n",
"In this example, we are going to train a single fully connected layer to pre-distort a texture image to counter the distortion introduced by a refractive object placed in front of the camera when looking at the textured plane. The objective of this optimization will be to minimize the difference between the rendered image and the input texture image.\n",
"\n",
"We assume the reader is familiar with the PyTorch framework or has followed at least the basic [PyTorch tutorials][2].\n",
"\n",
"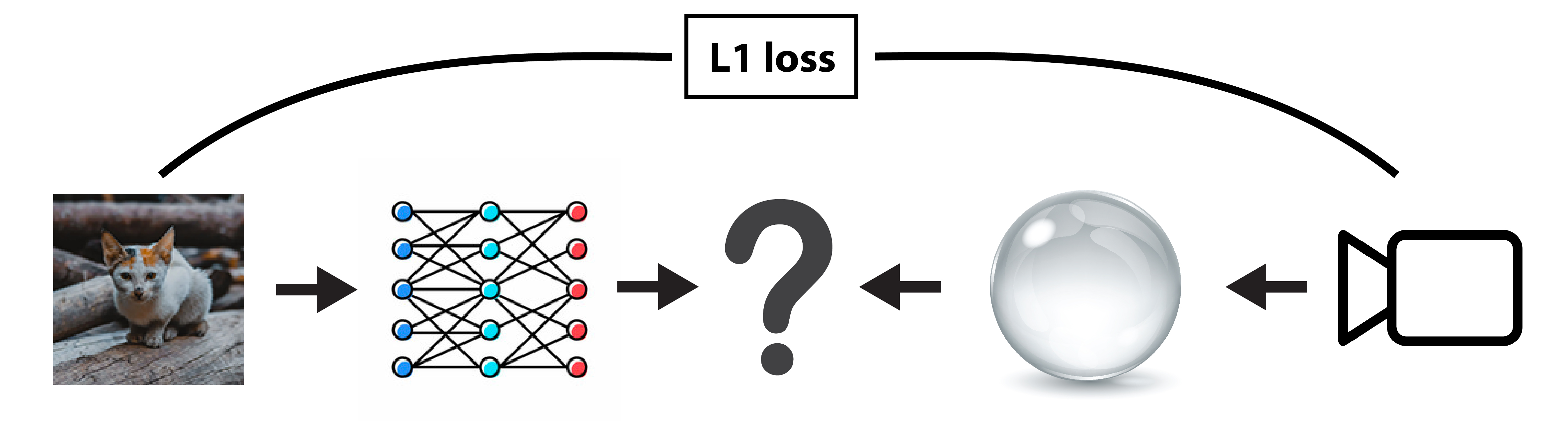\n",
"\n",
"\n",
"
\n",
"\n",
"🚀 **You will learn how to:**\n",
"\n",
"
\n",
"
Use the dr.wrap() function decorator to insert Mitsuba computations in a PyTorch pipeline
\n",
"
\n",
"\n",
"
\n",
"\n",
"[1]: https://pytorch.org\n",
"[2]: https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html"
]
},
{
"cell_type": "markdown",
"id": "aec07a13",
"metadata": {},
"source": [
"## Setup\n",
"\n",
"As always, let's start by importing `mitsuba` and `drjit` and setting an AD-aware variant."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "0c6f3cc2-6edb-425c-bc56-fe65c270d623",
"metadata": {},
"outputs": [],
"source": [
"import drjit as dr\n",
"import mitsuba as mi\n",
"mi.set_variant('cuda_ad_rgb', 'llvm_ad_rgb')"
]
},
{
"cell_type": "markdown",
"id": "853d7afa",
"metadata": {},
"source": [
"We will then import `torch` as well as `matplotlib` to later display the resulting textures and rendered images."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "f40f1dcd-9fbe-4dd3-93e3-adce381b696b",
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"import torch.nn as nn\n",
"import torch.nn.functional as F\n",
"\n",
"from matplotlib import pyplot as plt"
]
},
{
"cell_type": "markdown",
"id": "8805bde2-8fc3-4cf6-8695-c9552eb5a313",
"metadata": {},
"source": [
"
\n",
"\n",
"⚠️ **Note on caching memory allocator**\n",
"\n",
"Similarly to Dr.Jit, PyTorch uses a [caching memory allocator][1] to speed up memory allocations. It is possible for the two frameworks to over allocate memory on the GPU, resulting in allocation failure on the Mitsuba side. When running into such problem, we recommend trying releasing all unoccupied cached memory of PyTorch using `torch.cuda.empty_cache()` which should mitigate this issue.\n",
"\n",
"
\n",
"\n",
"[1]: https://pytorch.org/docs/stable/notes/cuda.html#memory-management"
]
},
{
"cell_type": "markdown",
"id": "e7f0e85c",
"metadata": {},
"source": [
"## Load texture dataset\n",
"\n",
"\n",
"In order for the fully connected layer to learn the distortion mapping rather than the distorted textured itself, we are going to train it on multiple input texture images.\n",
"\n",
"The following code loads a few squared images using `mi.Bitmap` and converts them into 32 bits floating point RGB images."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "83fbe367-016b-411b-ad41-fa24bc77518e",
"metadata": {},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAAEQCAYAAADxkb7lAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOz9WbMtSXbfif18iIg9nOlOeW/eHCprRFUBBTTACSTYbDVpNOtuiRSllpm6ZaKe1HqRyUwfQF9Cr3qSniQ9SKIkskVKbI4gQYJAAahCFaqysnLOvNOZz54iwt2XHtw9IvY++9whMwuoujgr7eY+e8fk4eNaf/+vtZSICNdyLddyLddyLddyLddyLddyLddyLddyLddyLV+w6D/rAlzLtVzLtVzLtVzLtVzLtVzLtVzLtVzLtVzLyynXwNO1XMu1XMu1XMu1XMu1XMu1XMu1XMu1XMu1/EzkGni6lmu5lmu5lmu5lmu5lmu5lmu5lmu5lmu5lp+JXANP13It13It13It13It13It13It13It13It1/IzkWvg6Vqu5Vqu5Vqu5Vqu5Vqu5Vqu5Vqu5Vqu5Vp+JnINPF3LtVzLtVzLtVzLtVzLtVzLtVzLtVzLtVzLz0SugadruZZruZZruZZruZZruZZruZZruZZruZZr+ZnINfB0LddyLddyLddyLddyLddyLddyLddyLddyLT8Tsc974p/86EeAAgRk46Ba/yrC2jki6Yusn96dsvHDxu2+UOnKcvUZgMR3QLFZuHz9VfdRSnXH5VJFrZ2Zzsv/e2bJWa94xVXl2yybUopYLBlUbrw2t5VsNFrXZGF4n67UXWkknyzDEsUTBSHkuhx0m66MG+WMVa77ew7OR+RyDShNMdrD1Us+/eG/pl6c0dZnVJM93vyP/ja2nFDXNRIEkfCc9Xy5bfs23WwBQXV1qkDWe+7l/n35+bJxklr7Bqh+UKj8nyK151VjRXXHBz8Nyjws3+Zo7H/9a3/jr269+y+a3Ll9s/v70tR1qSJV7MNao7VGaRU/lUIrtTa+EZAQkCCEEAjBD+a63G7r7XqVSO5DqY1jg6f5FunGEuQukcaEgATpHpXLaLRBa83eSDGyits7FZPScHNnxLgwTCtNYRRKGQRYeo/zgfPFktp5ji4cqzZwNPc0Xli2Hh/yjJb7iFqrw+H4DoPR2lfJ+nf1vONx849nXKf6iWrQ71O9Kt3VrcrtGSsOihJsgarGKFuCsiilUZLKGhwqBDQBRcAQ0Ag6BLRApQxGKUZVhbEWOx6hjQEdn21zOVQsY2Fje9nCorWmKCuMMVRFhVYa0HgRlm1DGzzLuqb1nuWqwXnHcrUghEDbtrH/eR/7ow9xvgtxzutXCQUq9iWRNF9JPpLaSwUg9JWd5t7u/gJBpPsn9H+H9DxJi4ak/hnCFe2VCiYKKC3KGm7duM1kNOHeK/eYjqcc3LhDWVWMxrFujIp7Zb6tCd6zupjh25Z2tSQET90uERH+z//3f/BcfesXQe7fv8W41Pzy6yNcEP7w4xWI4vWdCqsV6MDUCl+awl6lePNmSe3gw/PArYnlr7w+4cOLlv/HOzMO54H3TjyVFg5GsGyE43kgmICvPF95xfJXv1ZyoCx3KDk+bfn0cY3RCmt115fqumG1bPnKW/f5+ldf59t/4y/zrf/4L3H4g3c4/NFP+eG//i7v/Icf8Nf+F/8rfu3v/I8pDl7BTvb5b/8P/3t+/x//P9mXE3Z0zX/yv/7f8Y2/+XcIeowoi1meQj3nkz/81xx9/B7/p//jP+RHP3qfX/nOl7n32iv8l/+b/4Y3v/EVjv7wD2nOzhjfvYMpCuqTcxbnF/yzf/rP+ejBY/7R2w84XtbsKGFqNb9+d4f7d27zd/8n/xV7BwdcNEs8CoopWmt2KoUxlnK8gyhF44VQz3GH78W5YjLFlFOK/VfRpqAoSsxoSrV/F11WmPFuHCe+XwPUcI5hi26m+vkzzgv5vHDpXKXUc+iuzyP92lJYjbiWd//l/5vTj37KT/79P+f0yUM+OGuYNZ7VYoExhu/8he9w5/59fuvv/U85uP0Klob5+Tn/7B/9f1leXPClm1OqomA0GnN4NuP/+t/9O45nc+bOocQzYonRhmJ0wFv37/D3/4u/ymRUIWiKnRvsvv4tirJgMtK895Of8g//b/+A85NDjh69z6/9hV/lf/7f/H3ee/cT/tk//V1OTo55+OATjuZLPjy5YOmEeQsSNCKaNkAThFJ7Kh34y69Y/tq9AqU0YKgmJdW4pFk0NMua3/5wzncfLlkaTW0Nd3cqDsaWWR1YtcK0VFRGY9AoFIv5nLZt2dvZYTIe89d+9dvcvXHAv/vdf8XxySF/77/+r3jrK18mPP4UPz/ngx/9kNViwc23vgZFxe//4F3OZwtGusEq2KtGGK1wBOat53c/OWfWOn7w9skX0NZ/9vKDt9/9U3/mJd3351jW9Mk/zeeuWXIMpoVUebJRpg29trf/ej1vOIfR2c/9s/LHZ37Xzeue0dDPstU3pSvnVfd7qj2/5X6D+X34efXzuwvXn/si9fWCdbuJzXS/P+Ndn1am73zrG8987nMDT5KMnUs2dLKNtlXpVUUbQArI4IdnNfyfjawbS888+7kbXrhUa9nO3Hbs0on5Llsmh0undzcelG/7/S/dor+0e5q64uR476s7RL6VSn+JUoN7yNoZ62W9onCqB7siABD/BQm98b7+Attl2+HBi16uVtn47H8f9ufLCOv6O2WY4Rlm9MZztjXQ5YKL0N1ZBk2y2bO2Pfs5auyllK19+1IXfI7x9oLP7P5WQzBGbRRoODuuP1cNx/faGZJxgzWwIGRAQECr/JAh2NWDZf233C8k9a3+wFppLi1g6fOK+nyWbD39qqnxaSdvVue2+ykNSkewKf1D6R6sVRqlI01YEYFIjaBR6CBrRmZGqUVk0HK5LOvAcDYyh8amkA1SMCaCg9ZYBIW1ARRYW+C9J4Q43+VnhbRZICqVe63Pxv9th0OlX4uH5UugndY69pncqbryChCImwYBUGtrQZzjtjROOkWhQGu0thhj0TZ9mgjIaWVSe6T6lVyijX64UYcvi2ilMEol07eXXuWPtR4n+e2DQymFVQqjQEtAa0VRajxC1YLX4HXAoPBB4RMYG4HtgGhDBi7THS8tc5C3YjQhgHMBnwD5OGnEPqSNhWAR5RK4a9LYU919XdvS1jVt8DgFaBOv0/GfpDUuOIfSYHTAGOkA1Fw2YzTGxM2sIIGmaWjaFlOMUCjapC80K4cxBrQGZQjaxu5py9jvTIEyJlV8ILga1RZI8BDCZ1ozY99VhLbF16sOBNdFgbZFBJtyW39RfXqroh5AQtxc0TqC5kFjbRx/oVnhl3NCvUTaFVQWZSxaG4zWcTaJQxijwSjBqEFXDANDVQSCBwnookQbizIFIQiLixnz2YzlckXrXJwDtIkbK5I2VYAQYr/yPiChX6X6jUHBasXYglERf48bSKpfD0MgeKE0it3KEJSmTe/RTW8IQRQBQas472utMDqeFyRQ1yuWyxnOOYJAD+b3fVkAYxTaakprKK2GEOfEvO/ROKF2gguCD1zLM+UqzbVf7n4RAKg/i7VqCA4pFKIGZZBsP2wA31vvlHq3DNed4aowtOmGd7lqtrzi96tUx89Yd1cSC55zBr/q+ue97qrzezN7UO/Puvdn7j/br3tRcK0vxotd99zA03rjS/++XZ9Sl/ve893y50DWCy5y1cC4usSbDfZ8IFqeIYcX5tVzm5l0Bbz3lIrc2nHz/QfH1jCgteu5NB/I+te+T5AVP4UK6xO/XjsXJO9cM2QipXdRwyesG9TDKtNExTJoRVOvWC3nNPUMTInSBcaUKKkT42qzfbZUyeaX4Y9q88+wcWDIcEuVFvoj6xbD4Dy1Ph1va2KV6kqp9f7SsdgufXRmSGy6dCwTD6Qbq+sL9SYj5c+TiCSdkYH/8aDiRIHowaj+giupu1s31rICwBr4tDnY1dqx/l6BAKJog0J7WDUOJcKq8CBQmGgw2NyXJBq2WmmMFqzWeA2litwlAx3oNFwgMxAQJ5C+JMOSbo7dF66TL0R6Q2AdWgNUNDh1UaHKEbYco23ZQxviASHue0NhVJx7VECLoJyDELAuMp8ymBxCQCk6QyUatSp/JDBMaH2LDtGyCWIoC4vRlsJWoBSlGhFEGDmHC4Fl2+K8Y7Fc4pxjuVzhvaNpmmiUOUfwAe9bJHjEtRGUEp/eetAyKrKfQmJZaJWMITGDnTrADuf5CEaEIAQJnSEYdOiAMC8BIfTsvPz/0M9NABiDMoZqvEtRVezs32IymTLdv8l4NGE02aUoCsrSYLRCiaBEMN5EcCPV7QqHE4fzniAvl+U2LQ2TUjM2Bi2xTkOaqIIGF4QyDPp1Rkd1HJeCotCKG5WlbgKFNOxUBa/eG9E42JkrQusIq4Y9ZThfFpSFwVcKH4S2cQBYa4DIepKOOZhLqQBDoKBlxGwJJ2c1i9mCdrGgPBBMUVCNd5js3ECtAo0vCcU+lAeYNH8EDN5pTh4+5tH77/FkueBIK5hOGe0doMe3oLyFVxUuwPLsGGPhxq6lUIFCe1Rib3pR7E2n7JQa0YFlu+LjTz7gVtvyld/4LVCaT9/7Me3ynLOzTyOYO93FVlN2br1BYS2jG2+gtILKxHlCCb6Zs7o4ppjsY0ZTQKh2DiJPcLCuPnOHW2uMMZx8/D5PfvwDjNXYwrL/5lc5eOsbcRx5/4X2pQx2dUxPhNAs8as5RVkw2tlhz2hKJyxHFfiG2QfvYo4fsXz/15j6OeNv/hqlKZnu7KFcwBuD15pJBXUl7I4cTeNYBUUI0YgNAo0oGu9xi1MobjC5dR+zcwuzf5uLw0e8/7u/w7vvvc8Pf/RjRpXh1Ts3GI12CPOAbiJz7VQCs9WSi8WSs/kSdIk2ExxCS1r3gBsjxVf2CvYKuFh4RmPLqCrwoljVnuW8ZTWreW23ZH9vwg/OHe/PXQQjXcBLBHMbEYJX7Ng4fU8qAxaCCjSu4f0Pf8yTQnF8ckrrBPEaFUy3djhROBR704pqMua1W1N2Snhy4hDvqco4G3980nK6dJyshPqLbfKXVDa1g18AlOnnRhITU2tA0noZmcp5U3LtbNXbEmpg5IuASqxnJFp/dOekK1S2M9VGk23qsj+b9nseQORnBf5J1o8/5z1eRnkBxtPzNCD04M2WE55q7acfno6jxNs8R2N+3gYb7lPnX17kvs+kqm2ATt1wvoSArMESG/ft0YZnP687cQBQ99fIlgln7RnDvwa78vl7Blc6NsTgeI+XrL9sxpg2mU8Ze7u0T676e3Uvkr4XpSVUBVBSlOu7hds4RWpQyk2c8WndNLfClT1wMAb6l7zi3DW9XS7VT3coKbO5zYYAVVf09Me2/YUrH75e6PiXXH6Fl0W2vVI3nreh5h0gl2pL1qHFddbHAMAb3P95sPjhCJPUgmrQkpeIfwzGwZbxRmY0Ee18r8D5QKsVrQ9Yr/FB8EFQIe7mSnd9VBKGbiJaZXetVKZu/KeyDkCnbfWX/5aNyf2Fu1ieNzYVoyseqwZniAxA3h49RDLMqBQog1IGrUxydVOdka0kYLRGJyDJKIUhdECIUhojPjLWMnMj9Y8IQCmC1uh8v1RoSUparn8hstN0YhJFFkLk95RYtASCUhiv8SFgjMH7gPeGIBC8B1Eo5ckOj15HRoP4sAFPZkZc348lv3Wec3QEJCPNq786hIAOgg8BpQJKe0J6dxUC4n3a1U8bC8nVOT2162s6MVmKoqIox5TViLIaYYsKW5RoY+I5uT/KsJcOGS7RGTWQ3AxfQjGp78V6iOCTkvW+M5gWyP03ep4qTMKj8gSfXXONURSiMIXGolgsYeFhoRReFKWNbsd5XRAV+0wgrxepMD6OkbIqqcYVo8kIrWP/zEq4UhqtNAm6JTMMiU75oE10dzU2Mt20Ai00bcOyXhLaBrzDVGPsZAdxZ4hzaKWxFopqRDEaR4aYZDRO4RW0IiznM5aLedyYKkrK8QSkxc0tEjzeOTAtrm1ABCMGbQ1WGZSOALXoqJmIBMS7+C/0aMFwU6cHeHLD9BNVBgqDd7jVHLEGFSzi3dUqgyJtjA6/P30mveSmNyhTZrQhHqU1SpvUTkJhDUpbJqIZF2D8CtoFzXxG4wSDYI2K12iN0QZrDVVhKAuDquM4DKT1SiLbluBRCmw1QpcVPigWy5pPHzzk0eMnnM/noEbYoogsNDoeHSF4lo2jdgEXkls5/bypFJRGmFjNbqEoNXiJxxDBe8F5IYQ4809KQ1EWTGuhqONGQchrelYx87KliACpTrOOBFrnqSWyr4KoyM4asF9DELwPtE2DsQZFwKT11AMrH/AC88azaEMq61Ob81q2yjXwtCZD5vX6gd6STJtNIbgIOqVQEev74qpbPy65jEm/kqc70lsgefvtkjV4CXK6LNv13t7clfVybBwfnhPvc/lpV4dTefZcms/bvOZKJtPG8Wed/1zygvjG0DbYfvyzTTqX6+v57vP8jKenyLACPw/eMwQt/nQld/R1peBpmMGfmbxgO/exlOTS7x25iqvb7bLRK/3nUJfJMNEVs4rqJryNeu0YE3rwsHVgR/JpEBVRIcXVEZxzKKW4/8ar+HaPtr5AFVNEabwP0ThJu/ipIAyhqNznOtAgxIcNIyGpQRnS1PsZgM2eEZh3BLrv6SU7JsTgvRF6EIBspEaFTuf6y+cnJTS/T9qT7t41qCEEN+jrG508vGR2Wxcb6dKRS71siEl0/VkpQZQQiH1PS88pi/2wnzsuD8/LEDaDM7uSyfB31Y2vbmnvaWnpI+5SqawRZ2NHJXZWiPepVWzPhYYQPJU1+BCwBlwwjLCdC5UfKNpR0c/Mp2iIoAKIWy9ljhE0pGtv1sI2RG7t+9Mm/ueYgS8NxW1KTpqvVAb3FJLiWyWuF1pFAzPH9MqPNkqhMIxsdC0pou0RYzshaG0jIGLaLq4S0Ln+ehdfI4hgtEbpksw6UApM50pWotA4D0LA6BYjBqvAak1RWQKKiggkVtWI1rn+c7nCOUe9qvHeUbeGEDyqNYhzyfgKfSPjOuCpb6LU8skINcYktzeNMv1Ofo5r5oMniE9KbMAFT/CB1kd2lm9bgvd41xKC75hV2RvFjscU1Zi9g9uMJzvcuHGHyXjCzs4+VVlSVRXGaLREJgs+uungHQSHSPwXQosPDu/bl47xNKsdGkNlIlBUWUProyub6AgiiETGhxNwIRACsW8qsCaCl6SVowmKZQ1nFx4foG4Ve0Z4dddwWgsffFRzNipZ7FTcKMZ86V7BrHacLlq0EkQrXAg03tF4T+s8flXDxZy9aUH15VvMfuVNzGrOwZ2bNG2/pijn0HWN9gEjeSUO4JYQWvRogqomHNx/C7eYc2v/R+w/ecynn7zLcvaE+ac/Rt0pOXjjy/hXv8TF2/+SsDhD6Qpdltx882vM7E1u/PgT2vmcpWsJOrAnJcbD0aOPMHja1lFM97n/zV/DNQsuHuzTrBbMzo6RAPOzYxDhpG2pxmPuvPY6trLY8RSxVVxfbYlvV6i6oF3OI1hWlICKYEuOE0gGmAKOy33TaCgLhbEaU+jUVttluE/SgcYbkoGm/HnJyErgZSCCH4IDXAR5bUndLFk2nqnVTMYjfvWtu9w8mHBz6rDNIR9993dY1oGyOcfaQDkaURaWsqwYj4SbN2/QKsvD+SlBhDbE9U01LW3rUFpRVBW7t+/S6jFHp+e89/5H/MN/+W84Pjnh49MTXi9uMhpVVCOLKj3KtCiWLOolHx4vWDoIpkKhEedwAi3CvoWbJbw2UrxRRtdIT2R1iKtZ1IFlLewa2B0X2L0xZmfMx27Ow0bwrYvxvdKSpCXrWfGH7HLnuxM0YjVea3wA37b4pqFAgTG4umF5Meejdz/AliUXi4baeYIKtAhvHzasXODhec3KBQiCec554VrUxuefZ7miDjLbSHVcVSCu3a1r8a6lrRcR/G7rTheIIHTaJNA59IBBaxXnCaXROoLx3aaEGuiPaoPts6HrrZU2GTrbNeh1eVFA6arjzxM/72m/bV7zeZlNv0jyOSCeTl7Y1W5NOuDz+Sllm415CeyRpwBZKp+TjMS1jaQrkLzPgYR9kV1JMopwxc0vHe/UleHxLff9PGVCQLbHGLrUTmv/l60Pvsq9cM0daG2S2bz+ygvpzUXVH+sonQEJLeIbgm/QuoxxBFTozu3e8ln9VHNlparNd7l06hDtpzveBXdX/W6DGsy+3fKp1vu+SgZaftXBkcuFTD/1SuewB6m1Uq23+BbF9eoq+MWUxMTYsoys1+nm8Ovhycsfl8ZrH99LBtcpyby9DNAMH9D/frlfDsCkfDwBJ8jgOrbPDfnNROIOapDIcIqf2T0qutJEB4V+bOZ+0/fVzblgwErMC3DeDRuwWuLz44k5FtCV0/HWA6r//2CtSYXYfOFBlQhdkQaASmYHKOhA2vgiIfosBY8ETwgOnQZQz/pK8U905GpoohGiJH2iovuRprOyQwh5dor3SoGHbQIFtUlBhfVAkVPRBTK6vwkEjw4xlpQyiXGVAuUWabz74GP8ksQ4kSA4r/EEvFME7whGgzGJBjdUvvr+FKeoBDBpjTYmGtPWRmXTRIBOKZ0SNghafIzhkyBS4yNdXzuHCR5nWrx3qMYQvAOl4/k6Uv3Lakw5mjAex3+jakRVVRRF0TEetFYo76PxnmP5eYf3juB92qmNwFdkorxUsxfjQlMV6+uFYjAOugESgSUvieUR4mfrhTYEVk5ofFrzRRFaSSy5CD2sHDQ+skJWrXC2ClRAqExkwBiPbIxhEYmMGR//Gasop5bdm1Nu3T9gPK3oS50YVsmQEdGIa/DNjPb0EWE1p7zxGrqaMt47YOfOq+xOx+yWmrZumc0XXBwfMjt8THVzirUFGkHEg7YoXbBzcJP9lWZ/Mma1WNASi9YEWLnAfL5gPp9TL+eU0x0mOwcYq1mNJggwahpCEERif62bVYpJFF9aa0Mggk5KaXyzRCmDW84x1QhTVnl1R0LAtW03d8Q5KSoYwz6qjY3sH2uxZRxvXdsOVcbcznmuvWI+3R5Ud1176PTo1HbifYYAo5uZJNBSK3Z2xuzsTtBK8E3N2YMTVrWHIFhjGY9GVEWBLUyK2RQTKrTO0zhH8AJaKELPJFJKxThWYgguugnPF0uWdTJ+u3kpAmWewLJuWTQti8bRigZl6dlfcV4vNewVMLFQdGRWhU3xp5oA563gPKwMTJwwSkkzUuiltTrNcfYycy3rYhoGEKLq1IdhuVMjgAjBObxShOQGumwDy9ZzUUPtExOsa+4/P0bsZ5cedNrUyV8y7fXpks2atBBI1lvz8pA3uaXvmxIcPgRc2+Bdi3MNwTu8a9MtVd5+QvIua5o0umh2OsKjcRwMjZPuwdF26eJW9ANryAjdagv2Li8MEzbJkCnxtCrZAgiteyXIpfOvYjxdBS5lG6t7t8G5l8/bPp4/C/Pp0ibC81+48f25H3nlbdbLkv9+vhK9IONpeNNB57hUiO1yOYbMZiMPgaUtk3DI3VQ6yvG2RrsK1fzTk+0L/gtf+qcgz/O4pzXtVbZ6Z8rk/pH+yDTi0Bmi+YJha6dMYiiSqtsrLGk3UHR0pzMKnKs5+uQd6sUxzfKccnKT0Z3vYCvQRgEa3U2ew0ni8oST56U8QeX3Wx9WPegUlaQ07av4nloNzhCGcVNTnQyAsGT0DUy/BBrJpcm8W2q3gCiZEgt5sRkuzf1tuul+S5t2ANdLhzxlURt/hn59G7QD2ThIwJHK9aaegkomiYt7Bjzz6dvApd4QQ6kUk1R1YygDHpL+dVBmUsol0aN7mlI+1o2g1JZhoBRH1pMP4LzDaME5CFqhSIaRRIXDqMzAywBujgMAPZBE965ZCdcd8JTOkZ6xFatis/5ynW4baQok7sx32ddiY62dO2T55e+SlBaNzitGim02BGbju8XA4B6/Au9qtB+hcuBbbTAp25zVMROgCcmlrvuMpdVKAQbRsR/4tsVLwKVscNr7GCxXRZcUoyvQBmNHGBNjOyndD77GRZcb5+p4XGKWPFuMsFphSkOQEOPx+EBdjXDOsahr2rbBLgxt27BSgneGRukIQrk2usL5Puqv1tGo1rbAFEU0hm38bhPwZExyQ9S2A+O8hARb6h40I7p0+hBomhrvW5bLBa5tqesl3jtsUaCt4eDmbUaTKbdv3mY8nnBj/4CqqhiPx1hjKBJjRIJDguDbBu8cbbPAu5ZVvcS5FtcmEMpHEOplkm/fm2CMIiioQyAk1qFV0QXRZ6VePCHAvA20XtO2hmWteLJoeTBr+eCs5nwR0GIwXqGWeQ32HK0UHzeKqoCdsaJ2nvdOFiwnBZaKnUJxe08zrx3nyxaFpjQWLYJrWkLrUK3HjMDsGV77lVc4uG1g9xaqiIAtQFFVjHZ2aM8c3mma0yfUD37Eg3/7/+Hio3f40n/6X3Lw5V/m9te/zd6XvsEv/fa/wD98j7efNBwuan7wu79Pe/yEX/mtgr0bt9BSE5SHch9b7fLlb73B/t0Zf+F7f8THI80PzxcsfeB46VjWnkm9YlELX/vwHbyvObj7CpQFs3LKyJTs3bid4twZmuWM44/eRluNVinAdJoTZDQlrBbUh5/Q2gp3cUF1cIdq9yCCq0B9ccHs0WNMUVCMxxTjEdXubmIAum4OLaa7TO+9EYN6F5ZyZz+1fDfZxnVKx3GYF3Jxgyyqzy0Do8g5pG3w9RK/WtK0bWSweY8LHi1QasXB7V0Obu7SeM/84oy3/9W/Z7V0fOU3foPJrVu8cf8+ZVVi6gsWbUOLYuECh+dzVo1D64A1ln2TAeLElDUF4hVhtUKaGggR6BpVVEbTtktcaFGlYeY87zw644OjGU/mK4yNbMisq2gFpQi3K8U39jU7Jr7npIBJCWVlKKuCn84bfjD3LGtP3QTurwyv1IrjVUuhhVb1umt0q9ZYo7ApSL0JybUvEUdNIK4fSLTFlSAqufwi0Y3VKiaFxVjLoXcsmsBPj2rOaxfd3YFRYrqd1wb3ck1fPyO5BucuS5rPhzpU0hdDCN2637YxJmRdryJbObhOf4xx53T6TFl9O7DcIR6cJ21M2eQG7zsWZbailNIE4uaV0SbZM8M2C32Rh3904Hr66XnAps7mHNqT/W/wDBtWXr7Nqp+tPK2+nq8eXyDG01UD/cUa7OkNvLmDkzvyAMmWDDrlz+d7zs8KhOoMmQ1QbhOXVBu/Xo4g9Sywatvu1ovU/dPf+UUGXgaUOoNvrTgDJDvVy3rXeQrrYVDS/IxoiKvuwBAtz0wiRQyk69sG39Z4VyeDeICMbrx+vs8GlHplLV11Znz/PntJxLZ6878DnDJ4sFkctQE6de/f332z3MJ28GntvlcAS9tA3/zbmuvfS7SuW1sAdKAM6VsG6Ah9vfagZ8xgE42NFPciGU8d6Yj4qXzMcCPBR4ZTB1RlwChl5MpuFwP6M2sAEx04GHdYI2IpOsZGUWjIintwcac/AU+ZgTJUOpQCYyRmGrIGbTXKxrg5ylpUYsHEIJM6sndEoVVA2xgqWJvIatE6AlKRRJgKuo7Gpr9V/+5JmUm1HT+H2J+KdbMdeEq2dFADUEkGnXM4tofKyXAUD1xmM8Ccr06NFC9NoJpPboTWdOM1t6CiX40ShBdBJ5ENLK0HyjMbJDOfYroiFV3OfGQ0Kelmjc7XtptNElsuSIAA3reAoHVkDmltQIFN/VNE0MkNSiG4soifrQWlMN2amWI9RaQRpaVjOBlbYMoy/R2zy5mU3Upn4Cm5I2odYT1RglYxJk8O1O4S86lpY4YqZSxt06CtxXtHUUY203S6w2gyYTyZMB6NqaqKsiwprMUaE90cRfDkDGuxTn1iPHnv1hhPmWHwMsmoMGgd+6wXSfHZEqsJofFQKolxjVTMSud8ZFI0XiLjKWfNkuh6VxhFVSiMgA8al9LQW0lueUoIeGrRnHtPUYApNMZlg1x1LqmKAL6BdkFQDUE1CA26cKhCocoCZQAVmO4rbr1qWI1GuIWhGBWIKOazBadHJ0w//pjWTNl745copnvcuH2Hu6/e5UQumNce17RcnM1YHB1SSkAZixlNqBcrVK3QzZgRDa/c3KVtbvDT+YraOWqnQQtLIyyblovTI0aTKa5eok2OYRVjGoHg2prgmnRMxVhm3uO9j6CrtoiOrrretbjZKRQF7fIisQEUbjmjXZzjjUbaOeKnGAuSx0m34OqYNU/H3ztmcl4boDMMJYS1BWgQsWV759mi/nT6RbqfuAhGO+9pUzwukMTUUnEesBYXJLKX0lpTB7AucDFfMHaevTK6C6ZbpwxtoXvNvJ52M3Hw+MZxfnbMcj7D6pT1rYigt6DjHNq0rBY1h6czzmdLWhfnRKNdt34WRjEqFNNCMbExtpPWgjWakVVgLN4UNOKZ+5alg7oVlk66OEtqc1NELteaVhHksqpno2+fbmSwwdFrj16EtmM8hawCYHzKoPeSTV9XuTE977VwtW3y58m9qVe3LtuJmWUeE4WwtvEiQgKXAr5tCMFHplNiCjNk5KgYc9EYm9yEc7w33dt62bbJekq3EzkoqCLOKx36I0lXyAbcYE7L125tyiEYlXW1TTuMPkZv9zjZPKWri60HNq/ZkKtiMw3tpueJ+fSiv2/Ki4yjK8/dnOKeE0P4vEDTprwQ42ndaO1bOhvxT6OlfRa5jLNId7/c2P3zur8+07M+iwyDrW1/x00Y4TKQcPn8bX9vk5+f1SkqMduPrcfb2HynqCjLAA3Xl84Y1DHpQYqEsBMNYy0xRTQeTYvGoYKPgZMxqW2GwT8jw2OjpP1EmCzdLs7LgHESJ3U1GAt9+8bLe+P0UjC+dJJ010XJbj3d5Wt12Z83BIZk8Hn5zHXpSrSlj17ZbX9+utfnlunOfoQKgl97ra5veklQQqxVrTVKqwjWKJ0+k4tIBhOTOhlCZLR473Btk4KL+ng8+cdH48Wk+0SjvetTeWFXG3puckfJwJDRBUYbMrvJ+ahExMC2Ae9SPKFkhKOy60FkG4xHI0prqEYFpdGUExN3couEd0hkBlkXDYvS1OAclcyhbSnDHHwgSAoinaouj+6IR6loOCmFtdEo1SlihZDeLxkKKoNpKh6PtlRym4EOtPE+Pi+6v6Qgxd0YXY9Zlu+RgarhkqDoM7d1cFTMf00gP9PHepeAsi1mHI0MIwGDQAgRZE6uZSp4lITon9EVQ5K7XgQih8CTeBdTt7ctIQjGWGyAovBdwFqlVGxniM8Rj/OCCo7gHVpriraJAbmrUQSGihIByrLA+4C1ltaVGKNp2watVZee3PkYy4UQUN71xqU2WGMxtsCWRedil4NB6w7kj31WmwhKaWsiC8uOMKakKEqsKbr+vGprnG9ZLJa0TZsYUI6ijOyNvb09qqpib3ePqqyYjsZYa6nKIrrYpXZfNTWiHD54vG9p6xXONbRNg/cxQ5SEGCPlZZq7ACZFBEOQBu8CyybuOs9sIAiROTFWTGzByBgab5i3gcO6JWjNslEsW6FuomE7nQoHU8P92wWtV8xq4WTpuGjqGE9LGawNjEYtC+P5adsQxiWvVCOMV0waRY1FiAxAi0OvjpCz96jxLPEsjh+wPHvM/t632D24QVFpYMnXfx1ef23E+aMpy3PLna/cR01e4fFqzPuHgbf/23+KKf8Nf+t/+b/lje/8Ot/+zb/Kq68e8LUP32M+u6BpRzx+tOD93/23HOxNeOOv/Crj3df44Pe+z+rsgv1pidWa3/jVL/PmW3d5+/FjmnnDoY8bCLcqi60dP/3B97g4esLd115jvLNDqRUBQ72qaVYLzh++h5LAZBxZiYvVChMg2AtMUTKaTKNBNT5gMTvj6OO3mZ4dgvLJ3aygmV+wOHwMvkb5BcXuDVa3XmV04x7jV74S1wEgGmIG70BaR9iJs2qc9zXiYwZJ8S2hcWT2qS4qlCniuv4cEamz20unbvgWcQ1uMaOdXTCbr5gtawieAqG0EZwsRiNsOWKxEqSFW6++zrwOPKHg0XnNB7/7PfZ3RvzNv/JLVJVFi4pAuUQ3HKuhspppZRiXBmVUzLC5OOfi6JzvffcPePLoAftVQanGGGuYTiYoO0FaaB4f8+TDB/z+D9/hdN7SLANQs5o3YC2qKnl9r+DrNypeHcPNUXKFRphWmhuTkjM75dRMOeOUc7fKiUpxISQWoaREkDquK0K/gUByVydmJC0UVKketUp7PySdTAlKxYyegkckrjZeIutk0TrmjWNWC7MayiK2xayNz3JhGF/0Wq5lXYY2uAxtFujjS4ao5/gQN2Wato5uv65BfMC5tgO1jTHYoursm8ioLgaAU/+83oyRNTtF8Fm5Qye9zHmHcyGx7lXUC4oCbYqo80nSuIfAVberHu+7OQry+Mobcltqpy/UU5QAkWccH/ydNymf5j43jKf3swJDXzZG1gswnvLnZbDnWTS2/svaxyW5Epjpds3zeekntfH9qXd/PnkWM2rzt57xFEuSB8SlQZN/yHrxVZX2VKP/apR2u8vhEJC7+pFbf97WVmr92DCS0fA82fhLusbajuxusr8uvcm2iShNnIhHxBF8S3Dp07eJPurizqRSSHg2mjIEUIdFzNBSNgyvROiF9QofvKva6KwyPK6G/Wi9r6+Xbcv9u2evt8Bwbl078hwT2Es2xzGe7KSFOMWiSZWTs9eIjy8c48qrtNujMEVkehhj4/eUjUynXZsMPLU+ggJtU3QBpaOBHg0HY3XHINHa9DtJ6RylsqvdoMFSvB9lDBiD1ZEhkllEzrdrMW6Cy3GbEhMqIS+F1litGVUReCorS2E1dmSxVifgSXXKtvECPlBQIs5RtgqxLZVXaOcQFYGujtFDcjVNdRLfT2ETaGHS7n8EnlQ3bjvgSZseuJbE7pEINoQQcM51acU7SrTqc/+tTZiJ7bJtZysCjynDHNLv1uVLlUSmglIRcLGWwlqKItZXYXR0t1AKrSyKEIP3i6CTvqNy+SRR6BJQaRJorkwEHU0Ca3TKBsXgX/xuup1wEdCYmDmPDHr3IBwiGJ3dMTVKx7g8maWhtcZ7j3ExwrlzLsaIkoBKsaF64Cn2MWOLCHimYOJ5XR4Sy3IbRtCpiDGZbEFZVpFhmIJem8LggkNrQ9u0tE2B9z7Fg9FMxmPKsqQqS8oi38d0sZ0gGt09UKmS5ay7LFwaUCGgUZGx8pK52h3PHVoL41LwEhlQjRIaFxlQjQ80XlP7GMarTOtQZmdopbAKSqMICMsQzWKlFZWK84MPMLEtGsWqie5CoiMbDiM4EerWx2xg3T7JYCyLg2aBBEcQR1svqNsl3teItDTzc1Q9w12cIMsziuIGan9EMR6hyzF6so/eucHy9IiwnOHaGqUUu7fvoUIDGpYXZzz8dEa9bDk/PUWaOfe1RVdTGq+oa0etGqzV7B68gjeG3fGISbVAFmn8K0NA0dZLmuWc1WKGsZrRuESLom5rvGu4OD+PefeMRhmFUCMoXNN0gXfz3OxDYLmYYayhuTiKrqpFRWhWKFok1IR2ga9L3PKCsHNjw3CJZVNpHXH1Cl+v0o5ATBGitcK1ntA2dIklTIG26rKil6TTZ+JHp79IAnPb1YJmcUFT1zRtiwsBl3MjSGTGWaujq601tHVD03hG0ymhVFwozcp5Zk8OqRcjvPtqyuo5LE4fiiCGttOUZYXWmnp5wcX5CQ8efMr56UlcG9LaGGe7fi4vCsvB3hRjG4xpUWmeakSxEsWkUEx0YKQUhdLdHG+NxhYFtdecOGHeBFoXsAhFCtbf5YOQflWJJc/LknSbH7leTRpb/XlZ909/SdQD8gUmbUCZBOB7EVwQihC/W5XC7+kchuLlkauYS89k6z3j+pdatuIqQ3sq9bFOj5FOHyBteGXgKbj0mTdnkug8jynd9fkMSGWrR6nerao3ezZC3EiviV16CUnjJ3i8V5ASuXRtvs2e2nj3zvYanLDNSuo8BlQPGF9Rhc/dl9Yt1+2ymczhT4PR9NzyOW/57DJtgwefLS8APG2gq2lRW4cH+ya6usBq/T75t67nb0AY21gaA7bK9pSNa3de+9w84yoMAZ5d6esdadg9N2PBbEIxz5BtPf3SCzzfm2Sd5DP36c7SeJELts0iT79R/lUPFqPNyWXYllpbUBD8EtcsqJczVotz6sU5QRX49pyiqiirXQRomrZvT5EBu+SqaUVtFLUHF3tLeb1e1dqteu1Lrf8vgVeD91JqrXk3RsagBJf78/DYJffSLW/1LHkZ1/ZXX/tS3E10kZGUAacQJGXn8mmc9LtAyhhsFd0fdGGT8RYN3wxAQWTROBdBoLZZRePGR+ApMn9MdBuycSdJJ9/47DufXepEYlQIlRZrlYCnuHtusabAatvtVrcuZvFqncMnF5AI0LSJQh0VDJOyjoyLksJoxmVBYQyTqoplK00XV0hEKFyMzaOWS5xzMJ3TOEcxm9E6x3I5x/uYvSyykgAFRsf4RCaxu6JxYbA2ZnmKWnoEYyC5HSoVd7+zCpoMsMgSiu/l2jq6gLRNFySdWPXpc+AQJ73bmyJRzIkAVkjKTwiSdgZDjE8UeqMtuw7lGEfVaERRFIyKEqsN1kTmT84WGT97t7rQRAXPrSIrShmDAQpjEoMutn9RRVe2wqY6GsUYT7qsohFvTMStEtikfBGZVT4Hdw4xCHDwaKNjvCdj0UXRVYxznnHT0LYty+UOzjmWyxXee9qmSdOTpHg2OgGsidEnKmbAVKobI9652B+6IN5RrLVUo4qyGlEUFaMEJJkU/yFmshPapsY5R5uy3OWd0HJUYa1l1DGdqt7FToHHoRCMtYgIuizQSijcGO0Lgi4IPiC2juPAuJ+NAvdnKP/qnTPGpebbr1ZYo3nj5oR57Xn/cEHtAm2ACxX4dBY4GCleO4DKwO5Ix3+V5sAZXt23PF60fHzaYEuhDRU3RoY3diY8HtVI6zmcOz48rCnHMN5XTErF7o7BO8+DJ0ummi5+jgigNbq0KN/A4gSpV4R2yWpxwsXqnNHihHL2hOWTJ9Snp8w/+h1Wh9/l5rf+Mjuv36PaO6DYvcnB177DbSqW3/2HLJ98incXKHG88u2/xJ1v/kd86eQj2tkJv/ff/Usef/QxH777Dko8X/k7f5fp7l2acp+5XtIcf0xVCL/0S1/lAMtXXr+LwvDwoyPaEFC6RKkC2jluecrx40/xoeXmna8AQr08p10t+PCDT1EKXmk9RVkyGq0oyjEKiwLsnQKUIIWh8S0nhw9xy1P27JKiGsc4TVpTjixexzUitDPqM0W1exOrex02BE/b1oTVHFmeg3Ko0KKrMaYcYccTzGhM29Y0szOCj3PkxJQU1STGlAuhY+nohFrrZFTmoAPZPVO5BnEtpw8/ZHn8mJOTI85mc5ZOaIImevMJk1KzM7GMdyfY8Yjjw0csF579e28xUQWPzhdcnJ3ze3/wPW5OR/ydv/4rKQGCSRsKcV5sPOCElfMErblx8zZVWfLwk/f4yTsf8a9++7dRwJ1b+3hlcF5wztO6Gk/AjEa8/tpd/rO//hvMZzPOz46oJnvs3HiFT4/nvP3JMQf+jAN3xA4llRmjg0OLpywKzM4+j560/P7jBY+OlywuVtyaGG5MFaWJCTK9U3gX1+Hkcw4hpt3wEuPteR+YWAGtKLXCakWT6tUJeFGJGhUIbY1zdVwbjWG3ipsY01IzazWtCE0IjEOcv/dGsc2Om9hG1/LnW3ozT7of8kZfZm6H0MbNuhAD/ef4hjF+XCCEaPN479L5IbLQTdxQLYsi6T5bQHCVAZww8BRI+nHW3XSMN3cJUFQ5iUSfVdO1DW3bUFiHsb1+oHUC9ruNtA0TKv8pm3bRBrDUBSRPmIEa1F2yqqKNNECLnwWaZMBz2A5rh3tA9E+bAfWLLi8YXHwom6ALvJipu9EgQr/jv3HWELLo4rLEtEQRDlAD9Dxv1xB/E7VRumG/ixdsgXBkSx9Ua5+bcvkuG2j+5VteLZLLsA5+DLCL+N4dkvqM232GhewSNrgVm5Grjz3PM4bgyyWgp7/x0KGmh3KSgU4OfpfqJBn0WseJbQ24WkPp882eBjrJlYCbSlPfJdhq0BfTQwflHvTlrWUZyHCXYTiJDfrRYFr8zLLZdz4XSPlzKtOdXUiLn0heuGN667gwrwNP2TXOVmVUpDPwpDWaaKhDbOcgAdcxnsoIcnhJhr2KAZILi7WWoii6oI0kF6YMnASJ9PzMwonATJ8lqDBF9L0ntlEEnmJacJ9d0jLwlBlPCCYFIB4VBdYYRmWBNZqqjGCHLXM63ARUueQmpi3OebyylM6BtpEtU5TRUHK+AzsVKgWejnVntKYoq+SyUw5YKnF8dqynBDx1I0ZIwGBIbC5H25YRLGnbBB4RO34eZ/k+aUNjzfkugSQReEqfIcUCCqHL3gR92yulOmZaWUVQpErxhmwX16grQnpOVK68bfA+EBLLyKayxJgJiQWmNWVVJeZT2T1H67gzH8E7k4CtGEdKG40KAsb3CqTOCqSNn4l5lCnyxnqU1h3zzCVXuwjmxew1ZAXR6MRO0938EiSyaYIPeB+6tpNUl7aIAdKLxFIqioKiLLq+blJQUZEYH0Ij8XwTwag88eRYT9ZGYM/kuGqDeTOOSYMRwRYVoAiVR3tP0Da2qzbo4An65QOeGi9oJ5yvhMoKKsVtswY8iuCjG9DpSkAJN9oIDBa6z+ylVTzfpD2x1gnni0CJZ1XF+W+3sixbobIxi51vBa+Fto5MqyAxLp5KwFNIrqoqfoE2xHY2mmpcMi6mlNZh3Rnu4pjF4RFPPrng7MGKsL/AFwsm91tGCFWpmU4tN26OGDGhLAVCiy5KFCVUU2hq6lXN7OKc4/MFEGgWNTQtkxu3EDSBE6xqMWVJqSw3b9zkbO4pHxzja8fKeZYuZhbz3nfsIknvgncQHC7EGEcxCWQEXrVu8XVNGLe90aQiK6oajSjLModpS/WiEovRoEyRxk8CcZs6bUJogmvwzRLfLAjtgmJ1gZuXmORCqoxFFRXOeZrG9brBwCiFvPGl8qDBt20crz5+pvBMaAngHX45xy3ntE1D08bA9FkV0SrOV9YYVnWLMg2tFzyacjRCmxIzX6CQxJTKMT2jjh4zc/ZxPnUCxIzSWBNnxsVsxnw2Y75YYmxixqrIvA0iMRgygipH7Bzc4MtffovV/Jj5caDcvcXk9psUnxxyPlsxXiwoLzyRzyZYoyhVQYPm8SpwuGw5WdS03lNajdaRYeQC6DD0VBRUMmKli5mTwvPplAUyGRIqtUH+nrVCLSHF5YsM6yDCrHYoB+e1Z954RkaxW2pujgyVUUyreN8LJy8VYfOpc/FVZmO2cV6yefx5ZM3kyrqJbMaN9AQCwSeAKbHBg48AlPdxw02SrtPdR+u03qfNxqyTdTZFAmhCiK7/ksuQtvbyRmnX13v7ZFjmbm9Q9edkJnsILkU9yTHQLArT6V7dPBzvsFY3nUWdbtrbXkOAabM+h4b3wBNE1Nbz1ybTNfu0P3p1zKf++/MwoLp7fwHg1PMzuJ7zvCvu90WNyRcDnobIx2eSq0Cb9P+MVG6c2bfLINZOd5Z0q6WsoSWZM7MeoHzNWA/9mevl2QBEunKsD7Btf18lLwI69Z89+JR3iPOh4aD7PH3h83SjTcBlDdkbHNgeBntdQlLUArLlDpefLN6D0hRmTDATtC6jMlRNsdUOo8kBZbXbx3VZm0fU2r2uFLU5OakrT9+cKlV3/fCkAVDVAaipFTeUjbXpV6QzxDbPuWr6/Mying1k/qLJa/ffQBIzKccO6gCoILQuBpUmLRI52GxmKJmyiIq4ybGe1uMSBYmxlZxrO3ADMohlsIXFGktRFjHGk0ludMnQVyTWVXZhC0IOJq6LDCqYBBDENncpa1jrfEyH7pNLWvBk+rUiugQooLQWo+IuVwScqs79T+nBrJrK0SRAa69pcN6zXK1ixrTVEu/jc/PiH4O76hR0GJTSFCndeM6AthYvLc/xihTYvB8LAp1rnXeOto1MFudbJBkIHUCYgKAM3uVXQOXdrcxsy+3dAzdrwdh1rte0RiSFySbXuMJGQKQwpgML80ARpbr4Qk3d4IOnTiAZOtVNintl0v3KqoxsqCIao1rbeD8tHbAIxGDgCMaHiPEHAYl1E23a2L/KahwzYqU2tUUR6zLFH2uaFu/jTmgE4FyqH1DkjGOxXUIypNq2pWnbFJepwXvpQDsJgcIarNWMJ5PIDKtGMXtXUUbgSUW3kty2o7Igu80hOZ5afIcMtkVjN8WSSgCsTi52VTUilAFlDMGHGNspeKo2MhHKpk7fP0umr59vsaXGo3jv0FFZxas3NEoJN/cMjYfZKq4fbx959keCKaLr0UGlqQx4DyGo6DKqNUXQLBfwk09rDseO5SIwrQyv36ioSkuNZb5ynJzWiBHa05ZiV3PnhkZZoIAQQ8BFkB0PrYelp9opKaYVo/EuNysYOUdV/4THDz7l6CdP+A+/85i3317xyx895M23NNWNJ+zdnXNjtMLeaLj/G/fAV9y8aRB3gTK3QJfgC0Kj+Oi9d3n7h9/nw0enaFNw8eED1O4+X/71v4zXipPf98jiFDvexaiCb33rV9g5eMIfvfceT1YrHl/MWbaOr94YMak97uIcV5XUiyVaCWE1Q5oVWldoq7HVKMVIawkS0HJEURUYWyDi0SownY5580tvURSK0bRE2wJVjOOmmGiUHSNTQ/AK7zX1suHi8AnVuGI8GePmpyyOHxLaGb69QLs5ZnGKHu2jxnuU3lNoG2MwzVaUNq4HPo0lyUCIUigNoiNgNj85oZldEOZHSLMkO8SUkynaaNqTJ7Snx8xnC2aLGuc0IpH5aLUwmY6pRhUPH5xgijkLZ1Flye7NfYKxTE+OmRihmuxQTkYoYxClcBhaNE0C96wRSmWYWM2oMNiipG1bHn7yiEePDjlf1oyqMpu3iKiYdWt1gSNg9u/wxs173Pv6N5HZB8iT30Ptv4l69df58R/+iN3VkvmDOednLSOvUb5hMhlxsDvhR3PF9z9e8P7RBe8dzrhZau4dVLTOc954RsZT6X7OyFPWUA0PxPHlBRqlKVCEZDx4ohsqxDXd4LE0BN+iUvzF1nt+8PiCpVe8c7Rk6QL3pppq3/DWQcXIKgTPog2cNi00L9f8dS0vLrEHDPRUGTCa2hbJ+qb4HoDK6GkHVPVGhVKaMjGujbUD03kIFBGB6gyaq5R0BoPRBVaXEdASR7ZQNu0PETp3Pq0isx2lOq8A164IdcDaEq0LZDSmoIrhB7Qm6EEIhyGwrtLNk6G/FvN3Y7h0ul9vIXeAWGZVPd1qUslluIebhohA3EjLdabYBKCukl8UBtSfxuzz3MDTWoyaS0W7uqgbZvuWIxkRkL5zqYEDnboMPHRMus4874M9ryOgwz+fkQXvineQNAg30cxYjs/SRNm4ufSgLWVQV/wdL1AbQOBmcZ6LvfJc7/AMtKV/4hXXXwZg8q/rgM1G6w0mCJUyODFoZ0UOAJ7qtENrFEql+CmObtetp5UO3Pi2vZoa/qm4mtk1xMGFq99/8OrdH+t99HmR6M1CyPr/Lo/MF+yjastfv+hSFTEAa0f9TW4JeUE3xnSgtVJ0gIaxRXRlSrGerDZdqm3I01Vc4H0IOGM6YCMiAzl4YwR7CltcyhaSVmokmLiTlYEnYnyPHA/IWIMxqp8TlUL7aNh4FdAqvk8QHRWH1OyG6BIWwYAY5DGXKd83jyEFEXiSaOD7ELNGOe/RxuCcx1gbXe0SS0ynlcGYCBiYVDZrCvQghpNSOgFPsVwZSFcDl5M8DkIIeOdx3mOtienHvet2wuN9M/BkBrtwRKUrrVFZ0ci7frm9Jbne5efl3b/c4zXrwJY1kTYe278HnPK8IwnIKsuW4AOVdxFYSYCeVSnWU2IWZUBTWRvPUbZjSQwrw6Ttdm2Ss4xPu4TB9/3UmMguS4wnbSKjIKI7EusHHQFRawlIYsSBSHrPDgmM3dGLpL7fxFTISnfxsXrgKRqoZVnGLHRFgSmKnu2U6zNPnSrVbJrDdTev536T40YM59o+loTWGiWKoigIJuoINgS0cdG1VWt88Bjz8gFPJvWjEGJWunkTImMjZXy0mhTrSZi3gSdzz/5Is1fqjq3hRXAuKk6TkcagKLTGA8eLFifCuIrxECelpnUKJRFYaiWaGHZkoyutMYhqaFys6yLFCUNHQNEFxenMcXrhKVan2KbmbHmBt45GCysBrw3oAqQFP0eFC5SfxWQEegIxnD/iIztRmxJVTtjd22V/f5fmwTmrxvHgwUP293a5ff+XKEYTrLH4tFuPNuzdus1Np9gfVyzmhrMg1N4zbz0Xq4azkyO00dSrJoL7RQykXVqTYvLoNOZTFku/QtwqZhUNMZujLSrGOzsxyYmVLnsp0IHtWhvospYF2qZGiUf7hmYxw9ULkJilLZDi/QQPbYvMznASaJdNUn41KrFmJT8jKcpKKbyLrtdutcAtZ2jfoglgS5S2EUwzJroEVhWGmLwAoquuTvO41fGzbqOhVezeivVTlZE9leLG5LlYhRjsvm4ddetidk2luDOu2B2VvDYdcbMwnJ0vmC2XfPTomCen52BAm6SXSWRaSn5PdB97T3KyBh+ZaW3DWAfuTAvKSUEYlYxKi02bRnY0pp63HK9aFm2Kvag0xihqF5mERaczStqwkE4XyGynbO/mZBYZ6ENFd30X6NYTm1iGTsd7LJznovE8boS5g4smZg7cqwyTQlFZTWFTPL40Z17KrveSydo8332/LFfpxP3pL1s9JX0i2cM5ZlNmGQff9p8hMp4ykzvbINJ1UOls6czO1NamJCHRW6MDd7olN9m6QQAds+6qlBhFAkFcryMl3au33MIaYDQkSvTtlMGgrCNHVrvXumvTDi7qmjYDAGkQDgChrH/38XE3HPAGdpUM790f7Mq/1gZq8KxLzdPjAc/rTrcNO8jfP69c0nU+55B4fqbTuuX+ovL8jKen3v9FjObUsF3v6mb+3nbvZvrtz87Dpp++8v+3lWPQ1bZ2tOcpdd/Z1phOw8nzcxnqw2u3dfatR3ojbuPgFzMdfzF32YRmhr/B5Sx2l4sR3Tx0UaG0icwgEZyrY3ualDksBctVbYhgk9bxHykDVc7MZCy9/zNrXW9Y5u0w0vZf1ZbjsXvL2jmbv8UDV2VoGJajm5XXK/Qp8qzWW6fEfjGT4M+rTMsy9hkfjZmc6DUuqIJPBpQQs3AYnTPJRVcIm1yvrLExw5dOKa+7Ro27TZlt5ENUxkmuTtEFQ3e+8T0ASnRRCZE+HWnTEXhKS1UKQq0xVnXKOQgegyA4IijgTYoT1WOr8XpJe1YmuvbF+DuGsrQJ/EhsH5UhpH6JFiS68QSJMS5CoGmaDoQAQcmgv6s+yKTdYBGtAe6J9RRjWJmunfIuXQgB33q8DzRtb2zkVsuAS4xLZBJIpzpFQyQ5DqY+rgZK2dpuWp44k8LfudCpzEiLb2MSK8emcufsfPm9VBpIHbMKIhNqCIgzmOuya3BScLQxXd1Luk+0g3Kg9bhz7lL6YxESE6tA6+juFhlV0VDrXEFVet8q3TftgGYmcL+ZNHi2xH8uxXRqmoa6rns3xRQfK7vDlVVFUZYUZYkpihQvSnU38imuVu5ZEXwb9Ao16Be5I3XrbA+M2WTMl0UR+31irAUfy9S2TQz0714+4Gls86iMhv2np5EBOx0VGAUjE8GhWQislnD8iefejuXetMAFaEJg1QbmiwAa7t2zWAxTKTifOX78aMXNaYFXEdy+vWuR4DhRnjbAykEoLONbO4yUocTizk85W5wTRNgZlVSVhVKz8oH5vOG7H5zwvU/OCAshrIS37u5z7+4UuaXgpmb06gG7b9yjGK2g/RhZfoBfvE+zKAnhJm07xgeLXzQgnnK8j6nG/MqvfYdbU8PvvHvGh4dH/It/8W/48L33+R98+29wZ28PEwRah6s9emJ585vfYefuGV/7F/+Y0td879ixcI6P5jUXLqD++A+5c+cet976ZXb2D5ju3mcaxtyavoMoobQ9sK2lRddHqLqiXc0RURg7RY8t1SsG8St8c5b6dkpkkfqwNQVBA1YI4ljMz6nbFYt6wcXJE5Znh9jJCLszJZQTXDnGCbjlEn/ykLA6o7j5OnbvHqYssaMdVFEiGnKG3jy/NPMZzWJBffKYdnbKzu6YcjTB7t1CjyYUOzfQpsAEx6gqmRQwCgsUO6AsRguFFiojlFqYrRRKjbj37b/AeLrLSJ2zXMypVyvq1QpjFNYoaBtcCByfzTi+WDBrPQeF5jfv3+Tezohv3LmJHo/43o8/4tOjM/5///6PuVitKEY29p/gkeBofIsXgzUTtKlAQbtccnZ4iDt7RPP4GDW2mNMJ9uyYb94tOfJTxvN94pyhKXf3MLdf4fzkiPdOznGNZ2QM1hiU0dRBOK89owoKFA6FV9EtLs5ZqgMKCXEO0hF/jKA/cf5rgrD0Qhti5tOJhb1S4axiqeHBvOajkwU/OQ/MHAia0mi+XBr2Ria53SucCJF3/XLNXVfLy6tvfjYZWhEJNEobPa6p09q2QlJW1+hSl9fzdZEuWj5oo6mqFEuyiHESc6KWMDhP5Q3QNH7EgwRFwBHweLXCMcfoEYXZoSqmjM0OSkeQyfmGNtRJd80b/dk1cMC+StnvJHi8eJom2nJFWWFMjKmKVnFzMevKnX4iiX7Yv7FWugPPemZTqj+RTtcPGcTLoN6aNdr/U51utF6ravB/ITGeZN1u2gSjngUy/aIwoK6Wz17252c8DVD4F5oas3Hb/S+BToNoYRsAeP/MfIvhPTbBqu7IVdDGVaUdPnQITm10uLyrvUWZ7c1DtR6farNoW8oxvN06aBXLtY0R1X+k56bUktvOe5ZcrZyvFeyKa7dflg2a4aVrOMngHYbDfficTfd2nQI5B9dEkCbdwxQ2ZZaJRmfMmNQiKeaTSTvwiE5p2dOy3mU2y2235V2fVgWDdu7jim0HnzaqZ6t07LkrjvcTk7riPOnKkL9HEODFJoV1d8QrBuQvqjiX8KF+joj9LoIV66Mv7TpKAlHScSV906uu73QV1gEXATpWTGTN9MZz73KWrhsa2ZKU2vS9ByojCCE+uiBk2EwSICQZqJIIXKGG4zAt8iSXMJX8/lEpAHp8pqQdfZKykF4yvpNKoEtyMxMbEiur81MefpCTQZuMaaDW57oO69hg26SzQ6pMUQFRKSOc1h14hIosnkzNzowcEnss71h3jKbY8HTjopun0uuqDHBkphMxa112hYSuDU0C0kR3l3fvAoOxrPosfgIxPhO5avOWSQxcqxLwlGeTyPjqFacIxMXgm8rr3GWSW1pkTsU4Tol1QJwz+36uEJ0UrUHBVe4fgwlYkNTPhciVy++UWGghdKmaTQKeisR2ykynXFcgMUZKVPs6FgGpfdYWhsF0I2tp4VVKOZ/SNJMBSxVhVxE0sX/kMpIV0ZdIcpVoHRXi7LbqfWT3mTQ0Rlbjg7AKkTWyagMLC7PasWgCbQg4EbyH0sC0tKixotmNMXFOly2F1YxKjQsxVpOo6EokAr6FhhjDpg2grGbphcO5554DtOH4fMlHF3N+8uE5P/nwnFALoRXwQrOq8RI42JugRagXK04/eUBphWZ5ii1aqAwSBBOpkzSzI3ztYH8XZRS7d1+j9Y57r/wRi/mc+WLB4dEJi8PHNOOK6J5cEURFhtxkj5HT3NzfY3Z+SnV6QhMCyzagpeUwrBBbcXT4mKAUe3deoQyK0cEdmmbFfLbEGsPOuEJ5ITQrfL3ALecoU6KNRfAEF1cApbIbds4ml/tiYttgoChQ1TgxXgFbpPb0sFqxagLO1IiuEF1SGMNo9wZ2soMdj6JLYLuinXlUe9EFC8781na5pF2t0EVJubNHMZ1iqxI73kGVo+gKqC12skvZrBjt7lNN92gPVyzrJaX2FKWmtIqqssh0gp7sMp7uUI7GzE8ecnF2yqMnRzw5OYtsUKtZ1Y5l67hYrljUdXTZMzq5o0EQResCh6dznpzNOJ4tqF3bgdUhxUZSCMZoJqMKDZwfn+LqFbPzc8J8QagDxnhUGwH5uEaRsqkWlFWF15ajped81bJaNRgRShPnksaDC4qQ5pVC9zHteuMVRFRcfpWAycZ0XDNiNtDICPQusDMqGFlD8C2z5YJ3H5/z5OSCj889T5awdIrWg9IaJ4qzmshiCw6tFLX3LF1g3kag92WRTQP8Ra+Fy7bKcMP0510uvbpaX/p6/XOwGZo2ISXHZnMuudSl37swAXTr5kCrSc9R65ud9CEHMrM+ZvgdwC0SN8FdqKOeFMBLTStzmjBjGY6xekKh9yiLXVbtnNKOqIpJ1E9IYzj4CB7JME5UevlU5ryxqUNISUw8iqTniSYjvEqZBD49pUI7vYCYzZyoD69Vcqqv3t4aKK6bsMGAVTWsz6GuP2xISZjG5dhOwzL2z/6sWe+G5w6L27/n8OsXowNdxXSS9c73wvI5gos/WzpggY0idhHoB+vyJgKxRfrK3FYZQ202P1m2nHtVyZ5diVc1Zu542+QSE2obgKWGZYen1oP05e0bf9PV8E9DrnpS/y7DWt68Qj3leJ6UUGBNgQJW85NIMUXQtuDGa29hywpfe2SumZ8vWJ4vKKdjlK0YT6dU0x3aJvpArxYzxHl8W/fAjFIpyxaRXfA5ZVurxSbasLyvWIj7NeTFWrFbsAY1/CJrcp5newaYXO63v8DSLmZEUMNEEEYnt6/keqfyzk8GbnRyv4LUncNgfgoElRklGUXpd1lyGuesUGytxbSbRQjRDyaEBCARwaOcJleBiI4ZxqBz0xCReJn0Gfp8SH7+3SIbyxiSe5iYCE7gJboKBk8w0ZVP5bzrqU5Qyb1Hkdg/MU5REIl++XkXiwFQkJQblQAplVg7oQNb6AG2eEaMMz5Y40Wi8qOz0cawb8cyKiPJrSyzzwZutekmMRSSdG6LsWl8B/opneOhqI59E5luKWudji4p2QVPc1mJ6AE0ugx9WcmT1HcyfpT/6NsuAzApFkLKPqUzEyq3aTLEcmyy4DMDKoEv1qK1orA2Alidop7rvmc4KRmCn3SfZGZWKmtWSE1iGRWFwYc+aH4OzK616gMQZ/e6ZNgpsttnbFyVYr1E5poAIRlwqq/S1I86tlc6FlmGCkmZ/vIlRisi6hJ/MCYCTkVyAX2ZpG5jMPFJkd1WY5D9ts1x1hTWwJ1pgQvC8cqhFBwtWxof6+esFpZtYCXRHa+aWF7ZH2Gnim/eUXx4suT3PjihtJqdsUEJTEeWlQsE5ZAmMDtq0RKnw2UTKKYVj5bwex8tuXnrgF82Fd97/xP+yffe53vvzPiTD+dkRP6dG4b7e4pv7O/z7TfvYVcNj9/9lObkCR9OLW/8esnBa4ZiN46D0SRmR7v48PssDh+w+8bXKXdvcOc7v8nNX/7L/Mff/z6vj1d89PCMdz9qePL9f8/k7FNKXWB2bxPEQjBUB6+yO274pS+/xYSWH316yOmy5WTecI5wtjrmxtmcvT/8fV7/yjd466/8Taa3YP+s5vTxA9757m8zHRXc/vqXEA/zs2NqbVkdP8RO96luvIqrA/U8oAJoVaWJzKe5gBhkOrRoXUZXtZ197K37BOfxrsW4Fo4/oa1rFqenuLambWvKnQOq6T73v/Zt7r31jeiaqAtmJ0csz49pn5yj2wXFdAdTjQl6QqBkVdc4Hzi4c4fRdEo1mcSYVMndOa/t1e27mJ0dbr71S7Rt4PzH/4bHjw+5dWuE3a2YTu5x8+YEefU19PQWB7duEwK8/f2PefDgE/7tH/whF/MVX371HtNxyeOTBWfLmg+fHPP4fMa0sowKw1HtQLfcWrWsVoG3n6x4eHrGJ8enGK24e2OfQlvq4GjFo3RgPLLcu3OAFc873/shITjqdk7ZXjCpA6URjI9zaUsER70E9nfHvHL3Dj85d3z/4TnvP7ng7HTGwbRkf1rhPZytoE5AYWFgUgiuFWqfDXrpQKfIXgWjBWUCWge0icCYMZq2WdHUjm+8esDtvTGresb7Dzz/l995n598es7R+YrWacZlzF4XgsYL/OhQ0Mpj1QKAJii8CPP2Oqvdyy4bMFqnG3XrvqtjDKemJqRkIFEfcLFvhu0dxPsItuQA4qOUJReiTtDULZD0SxG8eBQGrYoI2CuL90tW7hSRlhBW1P6YWfsJF80TjhYfYNSUUh9gzQGlvc3N6Ru8svc1RsWUcTnFi8P7JrqBK5VCIeiBvZd12VQGHdcw51qC8mgfNxR9x6SPOpGxKb6mHigBgFJFYs4XcV5zS4JENlUX45NeT84bvZ3NPrCh4/0uf3YufEN206bNn+CGy+DRy2NHfZHymVztrqrK3nDuuCBsYir5q2TQabAQXvWErYj5QGddP7xp7iWDiM0B/3ySKf+fVdbKfgmlzn25R43WgIqhRXbpvmvfGIJPG2dufN/+Lk/blbh8aHPqvOp4n/ntaSWLOOT6XXKchGhwOebHH+KaBcV4B1uNCas7uKbh4sEjFieP0Y3DBo1qBbeoOfzgfcZ750xv3iEER7s8xjUrludnaFsyvXGfPkvDEMV9SkGvkq3o6nZI85n9cLMQMvgjXbx5vWz8P9dbf8v49/qkuF7orsttXPMyiB+CI6oLId21RU6UFjJYJDKYw+KZOaNgBIMycAAZQOgWNSCoCKCgIHhFMMlFipzhhw54Eh+Su5DEQL05u12axoQ+m6EaAE8hASs5K1vOYJKVCklvJUY6oEwrjVcuZnTTID7tNOkElihQKYC5mAzCxHrrZlDJaIqspbhdG+Md4CMpaL50ANRQuoxy6d4Rj4uB1r33iA+I8911OYab6soQIGjQIbng9gpcdg3zPme28xHg0TGulNIKLboHYnK7q8hbi9FvdPyqQAYZRrt+kUErMmYXwSzJNwySkqf0O+lZ2+no4IM66+6vul6HloFLXH9yUlY9IegYZyUiYINj0sUy65+z3a03N01/bj9f6Az4ZT5fiAzT3DdMCsSvdQ+c9aWPdSJDth8ZONPd+0pu3L5rkV0hI4spjVs1qAsZXDeQzfghL4WoOHM0Lu+mZkU4nxCBqWkFbYALH5mWjReaAD5G+CEQce62FVoL3glFoZiUip1KszeK2caci+xNM1gvQgi4xlEoTakVqtCU05ImCB+fLHn30QU/+mjEJ4cLzmeeRR1oPWgb+8qiFU4Xwmonlsf7BhU8chSYn8Gtr9xi99YO1chQlgXaFqAti/mM85MjfDGmms8Y37xLMd7lza9/m0JrpHiHpm44fvgp1te88aVbjEYT1GQPNdpD2QLthRu3brO4OGW3KqgbxyLNna3SrELg6Ogx0/0DmvkMW46o9m5QLBZ4UazqhsPjY6SZszydMdUT9udzRnbEOLuWdpJ268lrje43FlOwXhFBvIvMhuBjsH/fgm/RoQUEjEHbAlNUoC1BFNI6RGIKdWMLTKjQhOT6HdcOVIjAvNZoY5Mrl4n/8qBJY0a0BVsxfuU19lY1r37lMcXuDSalYzJSBDSN85TJJdqoCGS7ZkWzWrJYrFiumphAwlhmjed81bBYNTRNy7iwWKM5WrU4UezOG8RYUGVkTCbwOk+F2c2nKiNz7XyxxHFGEx4wnZbcujGmVAVlKClsvLeqCtR0zGQ6Yjop8SIcni94eNryyXHDbNVQGJX6chxHIjHDXqEyk/Iqfbb3aejt03gfL4IPgdJqJmLZn47Zn044ny05ndcsFwuCq6m0YK1ilMrQZ3OPbeG79TvObBObn/FyyLq7EXwWW+ppXie/KLLGsFk7kPXHPjudd03npZHjO/VhXvICObhdBlLIG1KmCxcRN5Tz9VkPTZs7GBAI0hJCy8IvcGHByh0TQkOQBU24YOWPqN0FLrSIWqG4wIvD+RWVtVys9jD6Ljv6RtS5lKOL+ST9pl1m6vYBGZLOHKLOK4rEfoJsz+ayghCU6oKVo3IcvTZ1qRUAmYjvfXxOV3esqa4Ds+o5+1Tamc+2A9B5OeVwE51qInmdjuV+Wiyo4e8vwnz6ouUyq3BbvchzV9ez5AWCi28rxtPP6XRCGVZm7wjyxaCBvaJ5+W7DXy7HhHp++QJqW4YzxcbP3YSitl9zZRl6Q2KzQ/QAwuC3L6K6ZXB3tfbj5dO6Ml5d7/2UyeAKumxYrm1olhd8+oN/RjN/wp23vslo5xarcg9phPf++T+hPjuialaUYlnNheXyhO/9o/8XO7fv8mv/+X8fZQKzJ3/C4vyYhx+8zXjvLl//i/8jjK66cvWT+jNef2BpXzYHh389P8D39KcOeH6yPinJ0z77mbXvehuT31PIVy+VtB5QMQC2RsdgzyqNHgVBaTJUE9EP6F2wVAyQrYaAdk5TG+nPPmfL84FkjaOMxpDiiUkMOKtNDOprokUNPmYqCS50AaoRD8R0tkorJEUe6oCVxM4KSVnpFsEcXyj4aICk352JVOWYvS65nSpFcG18pwysZHZPEUGEslx344o7Z5Jo4GQPQHrYBSBn55MIGIlEJleu101ROegu6Z2iMh9TgKcsf4MMbqJVUpZ8dz3KEFRAlO6y1eWgt61r405aygAYAyNrtO3jQ2mdwSfVgSfGRmMugirJ1U8n8E2BRnfnD8Gn/rXiXBJdoQVRoeszIeS4RP1cEAOmK7KSkpGwnEZZdSBe3q3zcePSp/NN7J9axeVcEjga+0JsI0V2W+vXgYgTRSWuB1PXWzWDPSrHkklefNFoZBD/zKwztgAlITG5ICSjNb+fTgGDQwbiEtuvA81yfwkZAIvvqpKBtrnrqzJjT71UdhsQp5QgcLaIwZpHRax7rbNbsGdUKO7uCXWAuTIYYNEGCqPBGsQFnAoxAPlMmOA5XzqsMuzuau7uWH7p7oSTuefTkxatQdkUqiuAazz1omZUWfZGJaNxyXhc8PsfL/jdD49ZLJZ8+OkTHl40HM8CK6ehKClHhrLSLILn4SLw2spwY6KguUB8w+rwHL9suPPGL7O/M2H3SyNGu3vY0RQxYw6Pjnj44XuMPv2YajRh/41vcvPGfX7r7/7PaC6O+YN/8g948vEH/OiPfo8fi/D3/v5/zd7dW+i7X0aNdtG2pBB48xu/zGg85rXf+0Nwjncbj0dRjiYsgXd/+kOcqzn/+F12bt1j/9U3aUUhtuB8dsof/eAH0c3u/JhbM2H/9SegS24UGnx2Bc7zdZoDVMwIBSDKIGn2D87hFuf4EDN3+tUFYXWBci1WGijHKLvLaPcmk73boErm8xWhnuPrJXa8R7VzQCFTrDgkNBAcSlm80oxHJWhDWRUpc6rq5kWQjuEq2iLllFu//JtM3/wWv3XnK8xOjzj/9KeE1QUNTzidLbkVhAKFkSbGZlldUC/OOTtfsGgCthyhihEPZjVH50uOzmasmob7e3uA8PbJGdZaPgmWg8mYb9wdszMqmFY2ZtAMgg0RFCpsQVVWBOAnH3+KD5bafcy3v/4Gf+dv/UUqZxkvV+jJFD0qUeUOaldTsMRe7PPB0ZI/+vGn/PDM8d2jFq0U+9OSwqjEgohx8EZaoayiSHNlnDoiMNibxlmPi3N/6CYYTe08IQT2xyU3p5Y3X7nJwe6EH3zwkCfnc9zsgj0cN6cxu6uTGOg/Gt7QhLgZ4xLZ2urovnxjojDPDHz6iyov2cT8GWQIeHQM6LYmBB/j1oZA6BjOmbWT19RtNkrABwcJtDUmZoDNCViQqG/EoOSuu4fCYhgj0uDCKbPmCY8u/oQ2zFm5I7zUeJkTQxtA61OIBmocDb59hHM1LhzT+CXW/kVeOfhmArg1rV/hfE10MR7sqOVNOVSclxLwFHDkZAlq4AaV3QtpE2JgDSiNUXFc+TAniKNx5wTxFPY2SlVEl2eFlzbq9qIyzrXeGl2VJnwg6YKdrSQRYFIhbySobgxvI0wM5Rc7ftOmfLGG4otntRsUo4c91Ia1K1vL2Tf64F4Dtwq2Dqzh9RvKZkeHG95zgAxsQej6xWQD4WN4r6sQv8vPfiYKvw0R2ozLtFkWufzb9nvnG15+xNVF2QJ8PPUdBsc+YzypiK6vQ0+ydmzL7bMBZGxUHqspfjXj4tEhy6MFzekEaYX5o4f4xQxrY/DhOni8tDSnjwmrhk/++PtoG7g4ew/vG6rxDqPJLsbEwLzRRUnW6yAZkx1iD1tRpm7S6VB8uYw5ycDwzvfd+L5WH5cmq/WxdAmZ3rx+WDZZv2bT93hzPGb23VVU3l9UkZRdB53YMyL0lEv6bRL6eopsuPgv0nvT36lehd7VLQddFhdAR01SSczCqEN8ltIKCQlEQqFiWqAIQvicLUyAQIx0pKMRkwI+ZvZQZjZloKmbhzpwwqdrUp9M/Qyl0JLANaVxG/06B8w23hB0DJhttAYf1uL2+MSiyYDYkLmC5PhEUdEhlRcZ9tvhp0KU746LCC4DTy6xt5Jbl5BcrSRXfqqjFAsqqKRgpZgI3jvatqFtG7yPzCdTRAaA8YKxOmal2gCe8k6V1h4Rk2J59PGeUApJTEklJiUwyL/TKVNAqitJGfkE10ZQzvm0zqUJT4smpPsoiAChDN6nbWMA+ayI4ru+rVQ0KiPw1E+mkZKf+nXOzBUGYLMiKlNpApakCNPNhb2CJbmf5z4jsW+JVjFweHY13brwrANaGRiKbo6ZoRWNMKVzs/ZKNxLHbnDS66zDbpTrwaQd0JfQaPvSzRG1Ez48rnFBcD4HXM8xyQAVM2qJgmlBiisWzxsZTVModspACJGFFgRq56kdtN6gFeyPLK2DsvC4ICxbj0+7zyqxQyI+HUDFRA2V1eyPCnwQnlw0XCxbmtZRaNgbpbRoEkF/qzWmDGjr2NupGBUjmhtTfAvjgwNEFbR+SdMKJsxQzJnPFpydzHHVGOcKfOoHxahE/IiAom0DD04WOO9ZrBra1lGmOWJ5ckTwjurgFaZNy61bt1i2nvefxLr0aJoQOJ/XnJ5d8PjhJzg0BzfusbO7w93Xv8TFyYQnn9Q0vub0fIEqLzg9OsROpnlrHaVtMhBdMk4yiJH+SWI7pUGVs1H5lDCgT/QQ52bfxqD8ohTO1TTLC6RdgWsQQky0gsKrAk2JEuli00kGdUXFuTCs6JlX2Y08AuoiUFQxbtTt119nur9H6Rc0FxXMZjTBc7EMNLZhPD9HgqesSkbjcUwUoANBxeDcjUCb5w8RShvHtzUGo3XKNyAoiU7vxpgIqq+Zb9G4q1vH2WyOYBHlWbWOsrBY0fiU0Us1NWUB1XhCU1VUhaHUilIFlIQYp0wrimQw5qXQaKgUlEZR6dgqab9pbQ+4T7g6mPekmxRBYDKOyRVOV4GZr3l0VnM6qzFaMSmTa39eh0XlvBKMUqKQ7FanAWvg9iS65L28sqkgP79czpL2nE/8PLurGTN5wTKvexykT4Yu8GmNCxJd6RMILV0Cj971blj8oQ3XM4rieI6bQDlDXN6oSklBJNpH8cy8kdriwgWz9mPO68ecrD7GhxoXVoBHlE/JQBJ7KkSL33sBVWALhSjHyh1zUT/keP4+hR5R6BGWMtabjkBSLrbSOkK7EqJrAL3e65EUZ1OS7k2n+0VWVHxnJYLoyBZd1se0fsGiPsSHllHVYvQErcaAxoc6XqOTK15SQIzNXgCpZfNmWardLjZZ90MyF4a79UqtdefnZSw967zn7a/bRtLTgLDPJj8bW/Azx3iK7aHWgZqNMq7btbLlwMb5g0H1+dDCvHp0D99ynKcc/xnLJdxrCMQ95z02FW+ePqWvU15f7J0vw3RXFuPKMzaXjG4iuuJ5eInp6KsRSmv2b3+VQka8/x/+PcvTC9rl76OCYiot1miqGwcEpThfLGmblvp0zonSPHr7bXSp0Pstu3fu8K2//reZ3rhHWU0QFE1bd0pEfvha9cigXrcAY8OTu14Xiz5YNDoEKMVT2fjOM3rh4JJt5w4fsf7j5gKYU45uXrC+rP5sppo/O4kBB6PBpJROoJCio2+kOtIJfEFrlDYxaKvRKJOznJnYZin4o0/Z3XzrEO8Jbdy1yYyn7K9uTEyTrbQihlAkggBrQaTjPVW2WcRAyMYM+Oxilw3yFO9HJfYNOZ5P6FPsipDiWSlMCGitkayckMZ1BzbEdzc6MldCVaCNpixMYr0kMIVURybuppuUUS0rBZEeLpAzBbr8jnR1HZ+ZgYVMg45sIOd9DGrpUnBzQFuDrRQGHbOoCOQ4WEpJ50bknI/Z2BLgVNcx65IP4LxgywpjC8rSYAuDtSn4ZqqjDEBZ20S2VzFgRnVZVugZcLaM15vIJvMhukhGFUpofdwVd62LWWnaNjEP4tpp0nM7V7XEXMpKj2894j1+lan3qU5TYKwYs0Ul98gUs4oeQM4BjXXKxmhzAsGsTHeucWEta52E7OrZs1X7Hdc4W+Typh5B5BGoy/OhJHZejLSQytmzzbKx59UAVAuRPdgZ5tCBxOoKUFyb6BaZ6/Blkr/19RscLxuOFkvOlp5lm1gbZQSMjNaIhtIESgV3x9A6RV1rCm05qAoqI8z2oNSeo1ms67NljdWWi1pjtea1g5j96HApnC5bjmaOwmgqazFGU1qNMQLa49HU3rI/Lvnm3YJFs+K9oyXeO5z3TAvN5MBwsoKLFsqxYmcCk52W8Q58/Wuv8dq9m8jBKzDaxS4XiGtYNJ/QXiyx7iMK2eXw0RM+eu+Ymwe32N0f07ap/UuQVpgtVhyezPjuR2esWs//8OSCW3fmmKaFsOLow/cQZbj7nV9Fv/IG3/jmv6IaVXz/yZ+wbFuacpfWw/xkheOIP/6D3+WNr57xW7/860zv3UX/x/8pjz/5mLPzBWcXLe99esL5ouXWrT/BA1/51SZ2dDsGVQMN9DNXBJwEwKe/I9gTs1M5nGtAScwyShw+9SzQzOaUOy0OWC7Occ2MQoFVYKcHiLY4W4K2lGWBNRZLDMydNyfapqFpa3xzEePD2ZhBrVvtEytib3dCub/Lwd27BNfweKRZHD7gkx/PWSznnB01mPk5Wn1AZRT7Bwcs28B4XFKHQKM0NYolwio93yhhMorxBWsX2QlWg0HQ3qElUBY2bjTk9Ud0Z8ydzVb8yYePqcqKg/0DFnXDdFQRgmbRtsAC4RR7Y4/pwW3C8ROasuCg0twuhalNm0Xo/n0luo8aAzeMYl9rTBmBJ0RwgbSmJ4O5Dxu4Jp2OJ3Dr5j7j6ZTvfzLn8Pyc46ML2qbh/o0R+xPD+dLTeonRJZVQpOyoewURYFLRMK8sFFpzd6egeKmBp+d5tzUI4GdbnJ+xDG2ArON555JekAGnJv7uY2DsrI8PrdhNQEEkAlZKqRRf0TAajZIuKDGGp3cEEVzI9/UoZSh0heAIzFiGj/l0/tucLJ/w8dlPURRYvYvVJZWdUOqS0k6Q4NHiCC7Qtp6qskzGBc57Ltr3kTPHrDnitYPv8PrBr2GlpLJTHDWeOs4/IWB0jM+ZGe3OtT1LnjQ/aI0xZWKfR301Z62VtFkmoSZIy/Hpj5mtnnAye5/W1+zvfp3C7lPwKlDSNCtEYFxOMdpibMyOXk0nGKMprI1dLGcIVMk1boP5JMkLItqBl8MfPA1M6l3v1j1OrnK/+/Mgzw88yfofAr01PsR4NvXCK3ZBRa48GM94DtTv+ZDBp52zmTTxBdDGq857xvVDAOZq+Eu2Htt+a+k+tgISW4t42a/0KumBk3WD4hlPWPu4FFnk0mWqOy8fl5QJqTAGrUpGO7cJywZjKlBz6nZJ8EIr0YWmWi0QrVi2S7z3BB0n3eV5i6kKdvf2scUue7fuM9q9GbttyNmu+g6sBnWyttOwVm5Zr5Ehmib9GdGuzhPSFVX1TMlK4nqdfn4ZDFbJeyGyeeSlkBDiAu29j8a6xPT12fAOqY6lAwKSAZ03N/N/Ca2JdsTAhbTDj6KxLz4CQkKI9/S9wd0FuM7nR+ucLjZTt7MioHy6v1pzpQvJTS8CnGl3KO2iRVBMOuApTgy6Z3WFzqkw3jv08amA5LYWC6GMhmB7pokiHUsxf0QiSJd+6/p8BphCv/stOaNgSFn5EjMrJCPJJ6DBJTe0zMwwWkOI7x8U6KBTwN74nBQRCy9CcK4L2Otdi2/Tp48GRW5vb5L7klJptzsMlI2UWVNL3JDTIcVq6vuE1vF8D6ANSlIcrQT4eGIbdMBT2sl0bcwm08U4EMiuemEw2XRxqjLw1Dad+yES3xmluv6qfAoanIJ755gzcecwliiSqzxdUHFUZK4k4C94PwgA3ithuXvmCWwIjA3nwM68S8dDypzjvY8uRakulGjUoC2kmxh743DIsMq7tvEfW5NAKEUXr0vL5920+vmTkRF2C8WX9i3nleJ8FTNkLZx0LBLnoxuxUYqxEQzQNNHYNSpn6Mxxt2L/Vyre53TpKLSmtIbaRYahUSomGCACh21QrIKiYhiUP/UvBaU1GF2yaOLYjgFdo4JZCtydau7f1Hz9jR2+cnfMq2/c48atu4TpLlJV1Kdn+OUZbTsjyIqwOoPRKdOpcHCrZGfHMNlVmKyxKoUyht29XW4cHDApDb6tOX70gEfTgvLOW5gycHH4GNGGVwSsHbF/4yb7p6dMrKZp8vwex34bAhcXZ8xn5+BadFky3r3B/h3Hm1/7NpOdfRbnp5QmMFssOb+44Pz0GFvGmENBebwb9ud+ziCzJCHOGUUVY+25yCoTLBQlplDoeo5iRmgWNLNT9KjEViWqGke3Nm0RNKFtCbTgG4LWKS+E6nSnpl5FN3Af53itFKSNBRT4doV4x+HpJ4hvCMHh24aH777D8vSE+bLFe43yHuNbpK0JAZa1Z5FcFb3AcrVkXhbMF0tWdc2otPjEykOgbUP0QFeRbZTDtGQ3Tmvi76WNs4iXuLw5EUqlKKyJWQ4loMSjxEWQuajQOvqDXqwcH57WPJ45TltoRTFKFMB+ectAT2bw5c2GXt/L63iM0djHTVWpbnO0w8JoCivM65alrDi+WHE0a5i14LzmtBYWPrBqO5sWgFKDVZLGV573FbqNjMWWsBZb7RddXnwuHq4q6orff7ayZq1IHlOD364ytHoWRrxLXsc7NnqbgKc2bvQ412VyZG1dG6y7gwdkd/icnS7347yJ0z97WFDpy6+izquVwknDwj1i3j5m7k5pZBkTEEjMKupDoHUObTQ+RKBMqYCogBdP6xWrVhOkxUvLsj0iiGda7rFT3WRsDxjZ/TiO8pqe2dFZfxiYNF0cpsRsyrqv6MtZkUXA+yXOL1nWZyxX5zTO4UOgcbN4vRmjpGC+XOB9YLE4wShDVe1hTEHdTrC2YHdnD2MsNm8mdpty2T7OdU2cS1Sq4yEodQXotO33FwKbng5dfCFG2vPFdnomrPHC8tzA03DgrY0H2YJ4bLl6+29Cxzr4HPI8Vz+dKvkirTgAJXq84rMpu2tzhFz6ae20K4r3WWvuRQbA9iYeVgDkM2TtWw8mbdKpn/o8cqpPoSgKjK4Id75KoXcZ7XyXer6iVo9YhZZ5I4jSjHSbsmQ1aITRtMA3jtOHx5STXQ7e+irTvTe5/9VfxZQjTk9mXfC+vkzSz/9q7eeuXMOXzPhA91aS7pGMgaHSEj/VGjvk+WrjCwKBtj6kf7k+iN+AfvqSSPAx8KCoFNxbm/5TacBGQIoUz8iYFCRaQAlBHOTMaQLo6MaQ3SbI9PvUb4OESARJOyMG3ae2NZERBRtgZEqfk/VjUR5yXBxUdMlLu1w++Hh/USkVdUjhg4UQXOf+F72WcpwqlZheGhGdst8BIUTqcghd+VEK51rQmibHiCIaK9pGy0FLBNICqV+nwBQqg0whf+YUvukzpwT2bQoiHl3hmia6k7XOd6CgMYayKBAl6GDip2jwoLq4RNGlzXuP85FF0DZ1/Lda4erkUpPc/kJwGBUwqkxOjUk5U2ksKFApVpcLvnMzzL79KHr2UxkZT8FGF5eQqtSlNnAuuth559P3lHHNJJaVhexuplR0ixHpXepC6yLzp2ljZizfuwWLUl1crmzJSY71lDIYGqtBCTqAUgGTXPKM6WnmmeXknUu7j6GLCeElBkeL+KJGa5OYTj1DS4whGIPYQAg9Y8v7+M5N26ZYNn4tULggBGOi4ZjTykt0Q/AJXM1uk/3ucGLL0SesUDoaJMbE8Wls+Gxr8c+xjJSjKAN/440xizbw7lngeOn5/sOGxkcgc1JoCjGUCopKWLTChUnBpomsjuTBgdaC0QprDCsnfHC0ojCacWFZ+ZgxsDCKsdV4ieNq4RXHHkqJ85c2kcEiCE2KdbM/HvPkDA59S+OjoRHDRCt+7bblN75S8Bf+0j2+9rU7qOmvoqo3aVniaHisfsiF/YDm5Bxqz+3TTxjbKffuKbTboyoLyrGmHOVBaDBFyetvvEHlA/f3f4dHq1N++se/z/LwIw5e+Rrj6QGP3vkRwVje/M3/HuVoxL03voL3gdvj30PamrMMIFtLI57Dxw/ZPTjA13PKsmD39qtMD+5w+5UvcfrkIa/eu8vhww/58R/8a3j4kI8/+AkHN2/x6ptv4RphscyAk+6xJxQiyWUbYmDwyS5N62gaR+sUjhG22qXc36OoP8LoE9z8mMVqgT44oNzfw052Ge3cJBQTQtDUqxmuWVCLR+Nj+ABlu8xPq9US5xymiGEFLBptVAzIrTTN8gnN/Iz3/+DfcHH4kNXZEc1qxUePTmjawP3X7jOZTNl3DdqBWoFXcHi65MlZQy3Rve7k9ATX1OwWJXXbsrcT06tbrWlbz3zRYo3hlX2h1NHtUqW4MSEESqMptGK3KmmDcLZytKIimGYNO+MRo8KCOAgtJtSR5b67T1kYQtvyycmSf/neBYu6ZVbDPChujAyLRljUyXA0MLAs+00T+k2mLGkPaV3D1d30xXhkmRTw4HTORbPgvUcrTuaOFo1gOT8RjPIYk9jv6R5lAp1mLrquLtu4NrXpWdr6z7FJ+TLIVS8/+H3TIPoCKuySwb32uA3Qa4sVHsd4b+vEMAG+X/9D6LLVedd062zHIu4wj94+WC9TD2Y5F7OWZte6oijXNoN0d8PIbNc6kEMjRD1UsWovOFp+n7PmIYfNp4goJuN9nBPqVUx44N0KUQFbqK7fBxwtjtY5lr5Fa48xjkXzAa37AS7Mad2C+we/xr29m0hQiCeFDXBr2EF2f+1+EEF80tOAmMwEBNNl6M0bHsv6mFVzyun5Ay6WR7QAyrJqj3FyjlItIpaj8zNWq4bVfA6iubn3OoUdodWYqpzw+htfYzyeUO0doLUhZxrOm8E+xcWTkJLGdK7qvZ6xCSyt9Yun9M2n6inPMvo+g1H4pwfdPlteyNXuEjqW32ILMDF8yaejZbLxqTa+P+3KzXOurlbJxy/dNk8Wzwk+XXXK54IEN+sgo+wDuap4z3jsVTGB0sFnnz8EWTauvwwlbSC+ZMBv4+ouHdbgfEV3TjSOIgWynp8jvuX08D3qixNuvPEa45t7mJs7zBcLPnh0Rus9dmxi9pBqB0RYzlboquKNO/cY7+xz7+tfZ+/ObY4ff4wpxwRGaSe/D4jbvbDaKFsy0i9Dg+mdcupP6ZaHjXpUg7Wx99tWA/T8qvq/4oldWdd6zsalMvxL6Ay+9XfbaLnPCqL+HEsIvtthVQokMZCi649BKZPeW8fdaJ3jOgEMgjzmfpEZSEHWFk5Ju1c+5CxjkYWQ+0Re/gU6I6Sr+aht9KCkirsreR4QiRnf+hgA8ZrOpS4v3MmtKQOfohWITjtJKrJ7UvyX2GfyrpzrgCGIjCy07tyngiK+jw+RjNU6lImxlZTWiXGSgNi8lZ0/U9kYBskOIEERgiJ46eIwORcDZWodwTlvbWQUSUDlYJTEoNTdjqL3ibrtE207ZYrCI/ikNOXYATlWUBqzIQeRTBWaWD4xnlEg6EEbJRsluiMqvALRJsWKytnG+thOud9k0JBc78moCQP6tlI9SOdDdFcUH4GnmP0qRPApgYNC+qpyFr3e5S+3XUBQKuBV6ALLx/hRBkVkfOWdV59cFDPzKYhProPxpU12PU3gaQZRxVpCMEnRNh2rLzLYopLsvCck5btLAKMgmIC1KoJHknHQ5PaX2tR7R/AReIrHIutL5eZICrGY6PJJsT6fvgzykydLjIKdQiiM5uuvjDivAwunOVt5Hpw0uDZwXgtViEGTG8krr2LhAvNWmDeexgesjvGhChNrUXScK5atpwmKmBdAMFogRHC2cXC6FAqiO99upTgYKVbOs3Keygkjl1LBK00QjwuBQhvKMl5/PBMeHTdMDpfsccFYn+LCDO9X0CzQ3oHaBWORVuFXS0bTBbu3FozGlnIUUH5BO7ugdSu8c4xvvsrNYPmlb36J2wcFB/sHlKOdFLjZgyaCLQq0tRy88irL5ZJbu1PapmHm49yCNQSlmM3OmZ2fsjw/wRiL2r2FLgqq6YRdf5P7X/0G5WTE6ZNPmO5MWZyfMRpV0QVYp/gjm8uryl1SdQah1haFoPwKt5yxOD0GpbGjKdoUTHf3EmSnqUpDURYoPL6NO/hez/DNAt9GYzZIQLRNa1c0Mn1T432LGBtjQtkx2hRo2UVZy+r8hPn5MT99932ePPgEv5rhXcvR2YIgsHvjBspa7hYFk6rEu0ATHIdnZxyendG0LsVbSuPVNYh3aT6Nsbfq1tO0cT20Orpr5ixzzkUjr7SW0hqKBPbXztEG362BLsTkENF4D6waYRwUhYnJOxbLFYfnK957Mieb8rVXaYPAR+am6tdRSQ2UM5bS/T7QxNNykNXU4fEeGFBYAgUwtYKrFAsneEnx0Prbd50hewrPXfyjdTlWZNLN/FCr/nMmz2nOZb2l01Nle511wMDw2qfo12txCDfi2fbXDT/XbYS8HRJSgpjgHSJx0yW6yrcdo1ikB53SK1xZxgyGZCaySRtM1hadm36+Lk4zg0U2TUDd+wh4apzMqf0JtZulcajjBqmCoohgkZeADy3LlaCNwhqNC4GAjzZPek+tsi6mma1OeMQ7FGaX0uxQ6AmFGqUtvvzeodNrsz62Vo9C3HySgFF6sIGvuuva0ND4JU5avDhCctNNkSNAeYxW7O6UFFaxWp7gfaAOZ3hfU+DwoeaTT39KUY24cesORVFQlhVGG8piFBn32T7sJoPUagPG0zb5wphNXDEMtgEuDPTaLTdds8SfyXR6sVnoReOofeYYT5ceDOvsj2ec3+n6V77g8wNQV1/blWzt6Bc2sX9O/XYdyNneUTZ/eGqVcfnNnyabgMbakTVgSF06f9u3bbUeOSbDN+0n9+2FTPTRYgQI50/eZzU74uMf/zPErfjWX/kvGI13OHvwY07PTnjy7/6Y+WLOpGgZV5ZX7t6jaTw/ePs9dnb2+M2//Z+xd3CL8c3XqVcLfvL936Goptx/6zfiM4pRMr5bZKBtbGtaGSxwnbGY3k06ozhzu+KZvWsL5Em1v1939Rplc3MMX3K8VJfvdamsW6pXyeWx0B/MuxqX/Zd/0UVyPCFYa5vI4Ig+5wqNMQXKRAM7rjcphlNoAYVqY+AHbSK9XyVMRSWNNoiL2Ul8G++nDYJGlMFLBH2QgMaCRJZQBwRKNr7jfyH1JZXGQ7S3E/MpZIYShMR0UiH0raYgZwgLolFKCCmQo/IqGSbJzTABWc41KbNKZOVoLzGWUWI2aZ0CWIfooqVCAA0mRHaYNZHCrdHZSzAqhyHHZEplCjnznI4Bs52O8Wgah/eeps1xC2xkU4UUGyDHqAoxmC3oruwRnHCJwegJoUGkQaQFFY0erRTGxMxBOvXxXK4eXU/AjoqZ9CKziq4tcgXbFDMpOBd3EK1NWeli8OAQN+rSjmbo2qIbjCEaVN5nwCkDc4nxlCj5MX26QM7skqn6PjOjekq+0gZjqxjjqIzuUqELiK4jAJmYSsYWaVZWHeDkXYtr6vQZY05EwDbHOyvidZnxlO7lC4uxFpc+Y3BTHcsWEuOpAwaz0i1459DWMKoEa4pubMbA8B6XrmvrOn6umsRqi3Wgk5JtkoudNVEJD0X70gHn//hHp+xWmt98Y8K9/Yq/9o2bNAH2pjM+OlrxT44OWdXw6UyoSkU1joqC1gYnmsOl57wWHs8dbRAqGzPjjQrTgbDLJnC2cDgBJ9F4SrGh8WjmNZzWnrO55/BC8fp+wBzAxarlvHagAqKElRPA4EKgbgMHpWavUJzNA3/yscOPZzyewTe/+RH376+Q+pTgFsj8GNN4rH0DZW8gK4M7O2f35hF295DpXkVZTlD1IcuHU87mnoDilS//Kre+6vjPz9/h4tEHnJ0plBkTtKIVh60KVFFGhkBZcv8b36Ga7vLVu3cofcujJytcECjLyOZ58pCd6YTTTz9CQmB3/zbGWKqyYLwz4earr3L84GOMKOrZCSePP6YoNNo4jPYoSUaZ6dCmLnFDh18rg9YVRgK6PaM+e8jRxz/FOY8u9yiLMTuv3keaFbQryt0R5TRmoGrmR7Rt3YHEkgD+6L6aHpGYvK1L52TA3IzRpqR85R6qGnP26AOePHrMv/i3/4F3332PSWUwOqa2KErL9MYBwWr2pmMOdiY081NmiwXvfPopnx6dsahXOB/XPPEeaZeIj4xVL4r5ylM3jnndoJQwLgyTwjIpLYVW1HWgsIrpqGRnVDIqNLX3XCwblo0DExm1q6ahblu886yawNk8YHY046piUS84ubjgpw9P+Z2fHrI7rrixOyEYg7IqZe+TREoeuMdrhTJps4mo24Uhy2QAMiF9IhEvybU7gPfCCI82cG+q2CkUh4s4BiRtWMTNnp7ZERB8EM6Sm6wOKbC4jutL675A++TnVp6ih77IXV7EuF+7bliO/q9Ot19rgAEaSdbPt4BPnc6VWOfBR4aT9x1rN4Ssh16GBXrd/3Lr5zUzhwQoyyqywcuqZzpJcumHTmfM/2IYB4UEQ5AGF86pwzEX7hPm7ZymiUG9ddpQqsaG1jlWq5rWNyxWDdZaqqokZ3fM7OOY6dYgYoARh7NP+fTkfebNGcvmmFd3f5VXpt9Cd/psu/72ii5up6SAjyKCS7pPITEjs7WRpRmzhAZWbsG8uaDxNW1wBIlzngQFQaONxxrNvVcOaFvH6dmHtKsFiyBoSkayj2/hRz/5HijD3S+9zngy4c6NVxhVE24e3KMqxuyNbwAK71tIerlWMQzDNje7S+51w/Yc/vanqKMMR9vPi2b0/K52L4hoydqA3SbrsMvlY1xx/Gk7AltApoHGr55636fIltO/kAZUgzd9DtCuhzkGxbpUjU9/x8tHZfA8tXlw4/z1ew4fvQlNXdpr6AYkHZMjn36ppIPKyCnO/bKmWc548N77lNWUdnbOclmzW+xSVJaiPUW3BhMqrBLG1QGlnbJaODQXLFfv0zYrmvkZmugmoo1JO2SbDKX1RS33oeEZuVupBADlqDmXa2j9lbp7yeY5suXYZemouWsF4VKn6SYa1TPncijhvHO3tjHCYPJ85tj9xZLgI5DQ05FTa2XmmfYY1UdelnQsxiCKrluZXaOURtsCDRhRMX5TYtrEuDY5SHgaHUnp73a8Y49Juw6h+x4BisRYEiGkRPP5qhCiAhvd0wJdUPAMPBEX7zzHZUaQSkCADiBoVIi76DF1rercTdsMPLXRtz660sWsbiq5WUVQOO1QtfHTtJG+TWG7HaII6qRA13mLd5A6VxJakoPg9v6t0tWJczEgu3EusomCJXiFmBi3I6hBNsFB/Xvfxt33LsbVcO6KjCckZlaSkLMsZb5rCtiuYsIVk2ORpDqOjaG6zIBRp4uxrkQPgKcursGgTbuWHCBaqWNIBpI7d8Q+y2EfByz3zfxvsCYLHUMqEFBOkgtkAnOyoqMjaGqLkhx4N/gYkD24Fte0eNfgmzrFpcjAk0abyGpQad406TOOo74MOTNgSM0qLrG2Uj/L4LxPAKfTrmt+QTrAqWkavHO0dU3I373HtXUCnkjAU3Jfti72USleOuCpdrFO3z9xLLzmtZPoanRrbOCg5Duv7dD4CKo6D80iZVoTjQTPo4vAvBHmdaxoqxUmA68MQG4N5OD3nW6cY4eAiKdu4CwodkrN8cjjRbFTGjTCqm6x2nBzOsGYBqMNCmERAqtZ4MlCYUbnLFc19+/f4f6rDXZUojB4fYCpDaEeId7GsntFuxhTr6YUWCgV5b5DzIrl4QNa57h9fw89HbP36lcpx/uM2xHoknLvJkgCNQXqk8cYaSgM2Kri3mv3aSUwPn4vsvJMgUP4/7P3X8+SJFmaJ/ZTYmbOLo+4QZJUVlYW6aqmO7M9MthZ4GEf8ADBAwSAYAV/Av4yiEAgAgEggl0sVmQh2Nke9OxM8+oimVlJgsflzsxMGR6Omrn5JRGZWdXVXYnWzBt+r7u5mZqaknM+/c53zlcNu1dLLk9eYIzBzg5IKNrlAg0U1nL1+hXzi3Pc+grftBIGmjcENs5FFhPPYaTdhkf/XxIFa2MrRpMpuweHzPb3me7tYpTD4MBWEMaYcoLSVsJOUhJBeSPgfEr5OUboY8M6h9Oarc0yrQuUsRSFaCYt5kvOzy+IKKrJlN/78Q/Y292RjHHA4d4Os8kYa7Nwv5b5s24869ZjlKYwknAjRM+qXomQdrbxYvSE6IV5hmW31OyUGmsk9FtsL01ZSGjwsmlZNo66bQkxUhXChDI5eYIPmSthClAQ2pqziys+fvaS52dXuBwGMysUjYJ1nus3OTxSbxgJDp8N8KFhRPes1ABzSP33+03UfE4XEo1P+Jj6fLSRxEiLRlpHf/PdmMqXMkrYgTnPbjfEcljet8f42pKU6OflrzY/vzFsSXWWzlfw6Xp/f9PSWxEODJbYfO5rFenHbzeWr/trsh5Ljw6h03AKPQiVholkhqce2NrXQ+s2/oBcuw8nH2o60fUZkV1I1+uXOntHIfy8hrU/Z+lOWTQn1M5DMsSoab2McWErg8SmpvyqZZ3WCqNtXz+tIEVhMCpjhLWuoG4vOFt+ztTeZ1Yc54QsOo/5Tg8yt21fvwGIF5ywZoMhEUWXTiu0EtvIB0frG3wUjamE6EeG6NARXOvAgi0D6EQ1LggUtKFBRY81IxyJZXNFTFBeWNb1CGLNeDRB68i4mmK1wZqKwggRIkW33Vfu6nLX+tBNZOIblDec4E1zxvBrX5fp9DVhn69cfmOMp9vKdQf2t2cQ3grRbBaUW49/w6l+4yVd6w1f7VsbMGEDHvQfXDvH9VNev+u7Yb/uE3Xru9ePve28m9fc7ml7qG5yatFPPqTNIOhDgpSiLCqirXDzNfPTU14/+x9IqmRnMsPYguPqHtE4Ll8uMR6sG6GV5WD2LtpYzl5cccEZzeoFqEgxKihsiSlHmGJEdG7g+G6XuxhIW3gaWZ7nzhbf7HYNQdDh99n6fPOqrl3n9j9uL8O+sgUDJqmvgiwSu/29BIQQ+DaVlO8ndWLiqYMbI0oHUCUJTZG7ZchWZQwittosl0TvadtaYurLEqMNla1QSbLbiIHtRCwyU4nBDMK8NlnRAHrwqYtmT4HIBkDptXxSZ/RK5UJOwRtjyHfQAU8di0eAn+4ehbGkIBYYjMSoIyBSAlzW9WkayUjVAQLKeNAGmzLzSctSkSQInxQ9ikRhRNw/laVkgjOidyTZxYYzRAc0a/o0dB0DKg33oiMhpByp14V6JQorTqxgiFlfKgNPYtx5fGjxvsEHL8ZTSnku6XtCDm0LkALJS1hh6MIBByaFUorQy7IE+m1QpWDAvlJKk0x29Mh07zTQadjqiQI0qV7rSF5j7hcxs6Oi3zCdNkuFAiXPLaqsFYUeAFORQI2KkKK8H0MgpIgLLn9f2E5FOZZzmYIYRYsn+pbYNgTXEtq6fy4oaWulDcpYtLGiUWMt1lrJ5mgD0ficWU6LuHmSQJPYpYjOQqpdi4SoiFrAP21MPzm5zHxbr5Z453BtBp46xlO7JsUN40kjTLuy09vyoy2j/NtQ1sGy9ok/f9qwd+ZRZcHDnYI/eXfGe3slj3dGvJ47/uxXlywaz9mqlbXTGLSG00WkjXDVwMhq7k0sVukcwppwWQjeWIX3Ce9TDjXdgKkpBlQMLNvEhSQJRVnNtDTcn1VcrVquljXv7O/xeH+X03XNZd1yulhwul5xehaYrxIvTy55OIn84PsP+L0fHlHt7lOOxxQrQ2gWrE9H+HWBSpbkLOvTfeZXES4qykpTlQ12dMXFr/499WLO4x9+wHh3h/s/+J9INrX9Y5LSzJ9/SX15TlVWhLZh8cXP8Rd77L3/IeV4wu/94R8w29vlz3/+Ka5uWZgRTYh8eb5Glee8+OwX+MUltIGmaXj2xWcYYG8y5mox5/lnn0FyVMbh1jWpDaSQRL8vBkgOogFV0s0rKc9vMYlDqrShKGfsHT5gRMv03mNmDx/hmxpXN5lRvQkrRQVS8hibWZa2knk5CYM19pqVMsYqW0iIXfZ5yZsG47FkLzw9OePJkxdgS/aPj/lf/q//t3z/ex/SLhe4uubzTz7BNTVlVaBNwlrRi1msWparlsparJaQdRcc51eXIiivxcaLweF9SxM8qIJHU8ve1FJY0QhzCQqtmIwKVIKT+ZKrumW+WpEU7IxLRkVJVQjDtPWJgMaOxkCiXV3y+dPn/Df/48/5+LNXvaD4g4nhLMDadyBfp7nZMRREaL3QipSXoy7le+pnKLGBu/m7C4cDetH0GBKrNrB0iTpo2ghtksy1M6sYGclCCFB7SYCh5TEIMJfgyilchHXGDK3+9oBO/1BlaNMCubvf7dHcLPlJ95t3w/MN/RL5NaaBXACbkLeuxNynYtyE1MWcVS5lrac3VoXbAAAGdqCwtouy3DD01aaCQ3ZTxzLe8n2TMJqsqqjDJZf1F5yvf8XJ4lNCHEF6l+A163XKSZkDxihsKdkotZYOGyMU2goIY7qwNtlhstqIpmSCEByL+iXr5pRCTajsjHF5yKjYzxt2OpMPUr9xCBbV2csJUlwRQk2IMTPvNdYiiUJTpHFr6nZFG9a42Eg9lcZHDc7TYAk2YOwYFMx2JugCXpy8xseEnpY4Ilf1CW3raNI5trCcX04Zjye4cMpscojWhslon6O9PVSCts0JXpS0adfKt6EKd6Id3wQH+a3upX2dsfTNytdgPHW/bQMGXQjCNgQxREU2jyalwfdvgEO3XHN4va1zvbGm1857Fz55/dp3nLs/7PbP3wbwXP+qUtvH3QJD9Bfd6tR33rraOu9wAktbH1yvmzh7GzZPZ94kBltA8l7WZNKD777tSQzv78bgFCuoB6c6J62rv4QGSRhLNd3BqMTO/iNCE7n8/AVt46jLHbQuKEZTSJF6tURpOH32hKQMbimT/ZPzl2gD5Sgx3d/jvR//AZP9Y0xRiZM4cPI3YI3q6/I2xDcNu9mNu98+5q5zbQGJabvPbEJSN+ftsrAIeHRXxeTLwzW6iwzspsuuX3W1jYMh8Q+FdP9jFGE8ZQCGDYbQ3WMMAkDFGNBRHDLRPSLr1DiCa3HNSnZegiOZAluKcxaVlnCvmOfDtGHRxZhk4c6p7VOCkIIABEnRMZZCz9jZhCVtQKfNiItZkDWmnN0s/9vTq9NQsyxn54nSD6IOmZWyAZ58Fn92Thx8n3WJiAGUwaes4aRtT9vuhDOVkkkhaoWOSTLQWdE7wpqe1CMV6vIB6d6GCzHik+yKd5nPOlHqGIEA3rcYAyEYJCtbyCftGFQZIAwO710OL8m6I1Gcjf55RNFdiEqTlazEoBowk4YDr4uWUVlkvsvmRac7kGJmUHWg4obBNuxf/dya55UoVhcKEW5XWbU2dfzLfne0n9RzI8p5tBKh9aRzX4udQyv9JGSQx3tp19a3eV5RWFuSkspaLx1tnl4boe9zZEmqlCBFYcDhpb/nvha6sNwEKUh4n9aqD4UULbSuP0myiOHmkwJS1tiRDHp5rIVIcAKCBi8GfPBexoXfjA3pVlEy3wRFxJA6vYdvUTFZPyxEQ+MVn500XC49KcGsNNybVuyMDY8PR5wsHM+vhKGpSgnlCTqLFydhXsybSEQzKiLGgDWiSUN+9iFECSlKZLAiszcyuG2UAFNX64BWilEBhTXsTiq0VqycxwcB3iOSpUyjsMDe1HJ8kNjZj5R7DlU6girQpTgznHtSaMHskoojYvuCsPS0XkFToopdzHSfGCG0Lvd9harGwlxMQdh1voHQYkuLio7l2Snteo0ez1Bas/f4A1bJsD+dULeOyxBwPtCiWbaepy9ekpLi+ME7sF6zPnnJuqn5dF0zX6/58vUJo0LzcK/iYC0ZdtEVdnosQLirM2BbkDLQhDIkXYAphVWkRdNJpSO00ZR7R+jxAdo0GNuglIynjR5ddtJU1knJCS9UVhPqGJZ064WWTYjOspHwWIWZ7kCClYvMV2sKqzCmYu/omP3jdwjnJ7jVksVsRmPzBkVK2KLAlKXM215C+JJSObmDRhU2M4nE4W5yPzosDPerguPpiMm4IlnLyBh2jKLU4tDKZoLBGsu4LPAp4pLo81ljsEZYWkVhqaYlMXqev3rFl89f88mTEy4WKybjAl1omgSOTAJL3bQsOoUd4AP09u+GiDMMi+usU/Jr1gLL26YJOVfKYk4yVSpCTIQEYws7JUy02M0rL6zlsc7ixCTagah43n+iUGkj//j/b+VW5+muAzs/D5mjbj3B7WWzzt1kPslp8lrdf5Q3TJI8rDgYZ/J5ts1i1nTqGdcdsDWor7p2rcH3u5u+Xjdru009CTej+6wP9VJb5+q1rXQfKy0vaUkTLpi3T1m253hfEWOVmbGywUCUw1FgIrmTC3PSu5TXcych+8pIe2StSp3Aasu4mvSSCsv6Na8uf0FpdyjMjJ3xfcbVPqNiRmFHeV1SOLfGRyfzW25blSTELQVHg8L7gtKMsktqMEo2zkJ0Gzs82gwiB0L0nF+eEWLkaj2nda0kxlCJ9XpN28acaU/atrQFVVVQloaIo/ELXp19zmR0SWknFLaisLKREJO/1QvuwxtzP1Ld6zWwaZu9d1dP7bvE3R99Q0ftzUynr+L3/noO4jdnPA3s4v6N67+m658PPZF++v7GVXh7ubUifI0ZbnP4N63m2753y+fbrbLhaW3FHr8BNX3TJa9/q3N3NmLm6pYv5BCbaydON49+Y1G39pfN3Q4ZRiG0gGH38B7s7XP/nR9j4phP/vw/cHH6mrWfgrJMxhXGGsxMqJDnz75EJajsGNc4fv7kOXZU8d7vfZ9qcsiP/vX/gmIyYzFv8Dmco7M+unTqX7V0BsptTKbhMdtj9GZn6oyfG2vgje9tftfXRJJvlDdA8Po2mlN+vU4j/jaUkAWztc0is8hYiglSFkBGGekLSkEsZZc0SCaytm0ITU29uBKj0RZEW6BHEt6jTUFI2djo+G8pEnIae5VZGdsgYgJFv2MUQ6cL4LOznUOt8tGRLFjZaeSkjislpWdUyV+QBsaYEuaJVoqQBaK73d8uk1nbNgL+RAnyC7lvK70ElfWvlOo111USTamgEQHI1mOMgVIywaVSZ+Ap30MHPGmDcI5E2NrHIMCXb/He47zbgG0pZsc30lgwRhOi2RhlSQCO4J1oE3mH8w6SQmWmhuAiMsek6Ile2k7F0LdNx46KseMuSqvrDLB0WvPaiuOWUGjdUc01hE4gM2UAJQ7GnzjgvSOTROOjaxPQaF3Qb/UNvrVxcmL3kAUEQGXB3NyJVSSlAFmE10dHCJ7GNXjvadqaLtNgUVTEEDFFRTFSiNCJ2RjSgzmoN9AzGKZj9tq69H1JCXDkBYAbRq4ouv6Y2ybvSCqteocYwGdR+YAI8/tWdGlc60R/KofYhVZCKFPrIYXMyEEE7pMi6AgYYjKS+fBbVEoja3MbLLWP/MXnS6yBv3m25N2Dkv/yPznmYGr48bs7fHZS8+e/mhMy4C26a6qfKxoPqzaych6tNNNKcbQjmjzERAwJlzPSdYxBY3Kmu2DAppxSO/F6Lgb/pEhMyoLpbETr4HzV4pMmpYKYRN/OKs3UJN65Z/nh+5rj9xLTx2uaVUXbKorJhNLswvPnkk2pfACTDwn1Kf5csdYNoTKo0QOKg0ekZAhNS/SiX6LHO0AirubEtibWc3BrRuMSlxxnT74EZWi9Yrx/wDt/8J9gjx7x8PD/TFvXfH7hWPtAmzQXtePvPv6E9XrFH3zvA9RiwdWXn/Dk9Qn/9ue/ZOE8l0Fxf2/Kv/zeY/bv3ce7iJ3OKPYeEX2Lq+ey1kgsiggOK01Eg6mIvhHG02yfcmcf9PuYYoIpZ+BbkndYYzGmYGM353ksZZZFXgtMD4gjc31exzsGVLc2lJVowxRlgW9bLuvA6dWcUaEZjUruv/MBx9/5ARQlfn5JOH3JeqlZKUcTI6PxBBvBZy2+Lito6yOGhEU28wrTEJJj4QM6Jt6fFHxnp+LDgxlFOeI0VuwUJfcLWYy9l80KbS0lir1pZO1azuoWSIyKglFhKQvDxBZM7YQnJ1f8/SdP+KufPefPf/o5O2PLvf0RRWmYp0TTATqJgcagzBUiJbOxdrc3xAV8GlpICWlv3dt5iqiRxBNagQEJsRYgyUXYrRLHY8U9C4WCeSsbDvdKRamhTbAKcOUisU1ceTn32Aj++s/lbeXrN5LqN4XypmBHnEgSbt+9pg54ykUSs2zsg84G6xDMLuNaiAK4bsL8b5ExQUCHNznuodN0ROy60WiMMQajLQnZjOvugbxBsDE3sg+TtRylIoYQG1p3wso94fXy71g0C1y7A6lCpyKH1uXNBi/1DRpSEl2lLvGL0R7vogDAVZXZ96lv2dKMGFcj6mZFXa85m3/O+dVLtLJoZfnO8b/g0cHvUdkxpZlBMBAbLttXLJvTPvPf7ugBIzvDu5VsKrZrlNJMyj20tuhkKfQ4h+OJJqVSiiICuiQyJQZ4+vop67ahTQ1JQVlMUVFxcTKnrSWJi9GGcTmhGpfs7E4oy4KkW1ZNw4tXz5mO9ylsxc70iIf3vgckmrZjsXXPUfXP9kZI6K8R6dV/8+s6228ovy5o9JsoX5vxtOngadMY3cT+9rN81au94bON497V5ebR6dqn19BGGBj5t4NSWw/nN/mg0uDlK552CNdtzjOIN++P2v78tmv38bXXzj/0hze/DM+tNs/89iveWffNJH4TcNk+doMU6xzac/biV/hmRUhLyp2Cj/7TP2U1n/PyxWvqxrFsFU5BORNNltIcCgV60UBR8p0/+D6j2Q7v/ODH7B0/4NXTTylGU5SZkpLKk3nKmSikr3zVgZlu+e1N93fb0X3LDEC3661y/c8OUFBbJ3h7PbcPHTzLgc+Zrn30bSghhMwGMtu9P4HsSGUWjK9JBIpWMtFF50iuBe8h+j68J+VMPt47RGg7B70liUERhkwGd9hQsfswiCFVu8twEroUtp0YpYBPmyAwuUYHunRBS53RPMz4Ie+w9VvMzkcy4nCm/GURh80aTylK1pIeHFEo5UBprHV5Z0iYTH3Sv4gAtg5M0KgUROQ5Zdp0zireAU+x05ZSGYQJMd+zMK5ScP19JTTRR4IKtE2U8AzfMbryvSXy9wVs8UFYOQq5+MYhSyg0JGHedBoroPodyj7bzACgVajs2IFJWUgdJRm/NCSlSToDRKpTehsE3+Y5d7jL6rusd5IqEKMzqNdlqzHCYlDa5HN0wFO30HaG7WYnNqaO4ZX6rIGkTmtLCwCoomR36o3s3P/zAtCBTDEbz/35pDFyVsEsOp4MXabESBRQNYO6XUiRSp0h1iXaEgtZRWHRkbrM75IlsncAOnArxqwPFSB4YU0pAI1WAu6J9ENCd9fzjm8bZaAweT5WwpowmXu8dnC2jPztiwVVYYhKc7F20l/zd+VJyFMZMvgiiavaE5KW0CelGBeStahbrjtGpVZQWc1kYnEx0gZFm7VtGh85X3us0ewZTd146jYwbxMrBysXSFiMCagi4ZJi3sL5yZzTLy3GRrRpUWmPqEfYkWV0UFHsesxoRe2vmK8uqYqA1yUgtkHrNXWr8E1DaNbY0SAbqSaPkUjKLKNqPMrzQR5Ddkwx2uH43j3Wdc3o6iVBJXRVkrTm2dkl08mEtllTGPjwvYdEqwmffoEL0DpP4wPzVcPVcsnV5TljDOPJATE0hGYpO++6Q3Bl7IEiKUtU8379DiHiQ0AXDbp0KGvR1spzSEHc17QBl6Lv9M9qyWqXx3E5mWDLUpJfKM366oK2WfeaMGr3AKoRLkVc07BcLlmuVhxMJ+ztTKG+YHXyJR//3V+zODvFz88gOqa7BqsUwYFvW7psVgEICGgZlaIss2PcRlqfaH1iVlh+79Ex7+5PmRUlWml2WseRD3y/sMwTnC/WJGuxoxKA6agkEHEL6V+1k8yYhUpE71msal6dL/nl0zNeX60xRkv2RG3QZNZRzpjaZbAT9iUSlZgk2YTVCp+6jaIuFK+zArv1dGMcRToB8g1IxeC3/idPXyEKw1CpTrC/G5NdYHnqhd9LIx+W+tsFPP1aTvcbv/t1PPFrRnJv7Mq47BlEPZNo8x2lsrh3tt9SSv3fHZq/peWYNlEkgytu16K39bcN8G79letutJx63cRru9jd97c2kruwOy3JbUgQdUSlFh9FE8lHiMmi9QSiFUBVSZRwVzbR6hvNP9EYVQQvq75OLi8o0ud98iKF4KB1Ce/ENtDKoVRA0TJfv6ayE1JUONfQuDXeN7yef8p8/RKRQQCjCkiS8Zhksn5eoG4WgGK5vmDVXvXAOoNxHFOk8StihEV9Qd00JBvQxlBUIwwWdTCmWXuWlyuCD7S+RgewxS62sL3hWlgLKXIxf0mMnr2dY6wpMNp2SMFX7IOb/rzJtqhu/XzwgK/9/ZUvdaO8Tcvpt12+NuMpDQfvAIi43cke7tR0pVOY+U2V6+fvSjeAN4vPRkfkazT6PxQ6uD2HZGNPZUd48D53t5YaTL63TXDy/uZ5dbymbkq8icanrW8OP95sxn/99ngzQDhoBwXdTrk1FTE4vvz5f2A9P2Fcweio5F//8f+GFCJ//Wf/L07PzvibJyucd+xP5oxKw8HhA9rGc/LLzxmPx/zJv/5P2Ts45sF3/5imbfj0b/4cW465//7vUVUzJjv3xdly61yXt2fKSHf89VW6ytuDFPum4Np60oNOipu+1V1n3cJPr78/6Gt5tGTD664x9btZfAaetIkkrfvGlOkrEUNLItA2BhNKEUdNScAM15BcA95jOgMhRELyNCmHUxgrwEYGWZTWkmIWRcqCj4GYs5MFSH4zDeWsRClIZiAfXJ+9K8ZAyPNE3v/Kmk65qM6Y3SxkN2aP/GeX2jkqkzUqcmhTCEQibU5f6zLTQQTMNw5vUUjWMLKWExmAiknmhoBDo/CtZEYpnUEr+X0IigUl9xIGAEgIQbSFQpeCWGosOJ1kKomhFnHJnAJeMphsQoNEyDPkTGxijGklouhKS8aWEOV5xBSyELUCdC8GGoLvdy97A06JaKdWCh3EECwiGB2IJmKUkTqpDnDagIM9SNgBThngcjksM0jueYyWtq1shTGaqqqygLelG5P9g1Ri9HWQQoY8B2BRBoxiQkUBiwxG9KMyM6IzYFXotKbEK0p0Wight0fupIrslIlYdVISQkcUIXpJVZ4Bzg7Yy5R5k5lOmIQxWjpM1oBSiAaKfF+cgC4LoooRQs7sF+Sny9woz9MICzeDXipFdEzg6u2J81tQymylFeQEA0WBC4nLdaL2gf/24zMmpebBrGTdQmU0caAVk5AwY8mclbNyhcDreWDVGFJU7I4ND3cNIQrQFFXHtBZ+4s5I82i/ZNEELteeZRNofWTRetYeplWBNQYfGhbrNc/njldLz6SyjAuLLUCZwDrCySrx/LMT9u0lR++sme3vEVqx9YvdgtFeRXm/AXvBwr3k9OI5k4llpCYkFFZX1M6yWGua1RK3usKU46xFJyhnysBTpAATme7t5jUgz9N2Rjn2fOe99yEFZl++JIVEGE+IMfLLZ6/QxrBcXnG8O+Vf/uEPKXZnpL/8BS4uaJs5Sxc4vVpycnbB6xfPOIiR2eERwa3xqzMUQQBSOvBdRkmX4UrZEl1WtHVDvapJxQ4Uu0z2j5jsHyGovs++scxhSilCu6KtVywvzqiXc1zr8SFycPyQ6e4exWiCMZar18+Zn59QVgXWWqwCnfao0TR1zcXFBRcXV3z3ne/y8PiQdPmMi8/m/D//2/8Hz1684sOH99mfjvjx+IiRsbgm0NZrUvSQIiEJOcInRUIzHhXElGgvI2sXWLvE0bTkP/+DD3gwGXFQjsFFzHpN0Xr+VVnyeeP4r87mhKqgUrtMSsvxzgSXErVLaBVY1C2td1Q60LqWi/MFnz4/59/9/Dmna09ZFZJ10Fg0CR9EC1CWVkFbO5yB1G0mGKzRhCghvLFbR/La01lanQB/9/0cAS6fbfY0enC9m3l8gDZArRCxZfGn8UherpDkp1tfJ6KXzsjI5/9c3lZ+nTm+AyPJYFMGn+JQ8ykfqTaaTjFkfZ9sI3SmQg9M5TX51tK7ykPQKRt3uR4xhNwfJGFLl73OGGFMBz+UomfDijJDN16hcsZZaywpgUoCxLq4pI01LmpiqrB60vVsDAltexyJLvIhxk5yQmylLmlI9JGgW4zVFIUlKAmB9z4RfMo6nUZYt8YjOpmRs/lnNO0ly/Uls9EDWl/jQ8Pzi59yuX5KaQ1WW6yqSFFR6V2MqiC1xBRY+4XoyS1esnKXhBQw2hCSp0scFKJn2V7gvOdi8YK6aagmBWVVMB7vUJUFh7s71CvP6+cn1NGxahdQRIqqoKgqQBj7o3JMSomXJx+zWl+wv/uQyWiX3clRnsubr9v5/lHL7aSK376/9+uJiyfFdRbMsHT238177QCTuwGjfIY3Xz7/e00t6Mb3e1DnDdfYQp/7w26p37W33jb9qeF31PYnWwBQ2vpGf+h27oZ0y6nSFqA0DIdL5B3krTNt38oglwBDnaP+86HTMzhu67a+gqHfARvX8KzN+9efiZKMMMZYjFLMX59CAtfOAEXdRFAlu9MK7xzar1BoSj1FFYlivI8uKxqvWa1qTp/+CudqVufPGM0OKYoRthzJ1bbYYwMg7w1ozhs/H9zHbSDim3r99aa8Kyqu0ycmbXrFrcOM/PkAoOg/7j4fIINdWM23CXiKIYjzm7VwklbZivR0OkwETas0xrSoDH6E4IjeSVrr6FFZKypljZMIIowlIhVieCoxalMXX98D7YGEk2tGlzMRSRpsIuLQh0gMrYh8R4cPgRC7yCaVd8yvP201eN30rrT1WdfHIaFzCJn0iZCChNbFTlsp9a+bbqOIWiznEGP/nhpeNR+rQtZ8SkYy3BnRMdId4EQHxsg80mWg895l7RBhjaVEDu2T8KygNcrkn5xlT+zFzJoKnVB5zMBs1kdRecfQCFihtUEZyWqXRUqyPlfsxUE7unoXoqJS2iC/KRFwJC3PS3exm9LT6CqfuteUpM1Soh2yy2LCBzm+A56ilXDFmCJG67zzlhlL/eNMCAtC6kvKhm9MwpBLHYCWNmBcyACVSllQegNO9SyqIMenEPqQyxBif81ut9OYhCbRiYSK5HsURpTWvfGXt0gFyFIhnyMIMKBAx5BTmpssFC/gFzkLHqGVMYdH40VQXYmuzcbj65plM38n777m7PBPv0wqCWMsjUw1F2vpX6NCUVjFuARrYF4HmsHtxyTsiXGV/1biiPsMeJaFOEtXtYz9wiTaGJmWoiUVcmbFEATcq4wiFJqQJBtsHSX7kQ+Bq3XLiwvFqvb4gZMlmj+anapkbMCFlhdXntfzxINFZD+J2L0PgehXRNWCTiT3GaQTJuMFO/uKUbVPNd5F24gyKw4OI6aF2K5Znl9ydbZAa8P+8YGEbSmL1gWmsALeOAntbS4XhGBoVwtUCjz+4AOCStz721+gl2sulMC5PiUWdc2nT57SHO5x8PgBpTV899EjxqMLVk2LUrBa1yyXK5ZXV0x29vJ8ZQjKoNCZ8ZS7qupCUiIBg7UVphijXQJcbmsRBi4KK3pMqhtKAh4qrTApUFqNCg5r4Gq+oq0bTFFSjcaU4zGmsFSTKU1TMx6XFEXBeDqlmozxjcgLeCeaeDuzCYf7u7R1w7mPfPr0JV88eQ6h5Xhvyh9+eMhsXDJvPNqWAhSrDABHEc1uY2ReNyJW7z3EwKhQTEeWg90Ze6OS0ica5zi7WnC5XPEqJE4jkuI8wUwnrNo4vMFHUpHQRmELSzGuWC01p/M1ry5XPD1f0SaFNYaR1cxKw8jC2CZOmsRq3QHzm5Wx+3vj+MvY2Nqgy6wXlTegUpJwwAT4UV6b+ll5E741LEKmSRtcIbOMM5xFx7TRCPieZago1LeL8fRPr2z8KbFbsp0z8Gk65pHqf+daP8mbZipt9ZuuPw2t/i2vMl17t+sbA81CpRQ2b/JJkoxBBMbGUes3tch17FhOquu4KEIMSDbhvKEcNSoZNCMULWKNRWKQrHAxdaLkkRQVIQjQFEPXZll2QKssUZH7eBRWuNGaGCLByboQokYXNmuKWhQJ5yPLuCTGFyybFTE5YvK4sEYJ/EVUirW/wrSvaZLDUBFiQ4wuA081L84/Z9VcocsGZQKFVWib+dYp4H2kdU5C/toaXRiULvHOY3VkOi4wyvL4nUNW64arRY02UTZBfegzaepCGPH1eo21C1b1HGsKiqKElGjbpt+gHIbZ3fb3ba9fqdziNH5VAsNXK4P++pbT3vX51w3f+/Wz2qVhq9wGbdz4wuD1rsa/7q4Pf/8mDT6wUvvrfsMWzqfoa/W2/pNuzjdb1brlMneeMjMVbh6f+sVwOOVtGF5vOvvAOb2lMtug2LWJ9C1lix1325e2cKjN5KbEqkFpQ1mWOGN4/uUz1os1X37RgikoCw+q4t7ePqF1rJ+/RHnF2OxhjaGcOYzRLGvwbs785VOCb1iuzuDYU42nFNWEvOpkA28DOr31/rZXEm57al+np15nq9zZB9LGmFH5n1vr291LSoPz3hxzNxbEbufnW1Siz+LFNghro7vp6CBGvPOAwrsWrTXBFICwNlIM4FsxEmMOfVMSMhYz+yPmUCtxeAzGJKzWAhAYAEVMIsqYQksKLSpGTIwQFTqqPswr+IYYW5x3tDHgQwc8aSSrWTcmO9ZLt7hteeI3h1xKmQ5NBmbkuJgZOqEPsdv0/yEMHbXKBniUCLXO2IEtfYQYAwYEQNEaTJGBI6lNSCJwnjrAyXlCjLjoCTnUb5MFU9HvPisBnExRoIzBWNsbXyFEQi/ILd/QPXhEZqXJd0xRQAwoY/qIRwltjOLVp+47ot8kNG7dOw5JC9NKK4Wj6duwa+weBuz8mrQB9erMYmvbhhgDPjOGjDIYbXDlDKMtrWsxxlBWmTWW9bXkEpEQnfSV0O3y5XGe2U6x48bHzK4IscPYIEZ0CAQVCBk40yqz8byIeIvYe9zK9teRo0IKGER3Rue5Wgw+LaGGKQ1+IGQgMMUgRCclul1ddzW2Sw2d29cFiU/xDSp4dBIDWWsvmlbKbsInGbQ3AiZG525dx36Xy+44UWg4GifaAGuZrtDKUFrYHQtwd3blcR5S1rgKUcL0dkaS6r2JitaDdxqjEuMSWp94vZCQ9TYaJpVmf2pZthEXA60LEi4EjE1milhFVIl1DNRtovWRk6s1q1VLaTWl1USy/I1SFFpzf1ZwPLN8chb54sTxg/PI0UXkfUaMxzss5oHgrlB6SdKOWF+ijWF3J9AeK6w+pqiOsUVA20sevRPYr8A3cy5eWs6ePQUSP/43/xnT3V20LjHGY6sCVMB5hQ+BxemcYuloLs8oRwXf+8nvM9mZ8d6//TNsjMybhCPhiFyslvzFz37O5YN7fO9gxsha/vijj/jVy9c8OTuHtuFyvuTy4orL0xNmewfisGiLV0VmwXRzpDxLRRQ2mQpQjNHVDN2C1g0+SZZRFBRlQVFYCfW4XkoLfkJZaOpVxTqesPCBYjxmMtthNJ1gCstkdx8fErPZiKoqme0fUI0nLM+uIEHbNrTNmqP9XR4f32O9WrNcXfDXv/iCX37+JfXqjPfu7/G/+s9/j8OdEa0KmDoQtTiHxggAFVKi8YGT5RJSwrU1pMR0pNmbljy4d8Ch1VSvLlg3Dc/Ozjld1Hzm4KWHqwjjlCh1BmEihJhwLhCrhLWGclQw2p1xcnbKk7MFn72e8/HLOZPJiMP9GdPScjAy7I80R2MFl45XawG8BXhKWRuPjpfaJ+joZ7nB1DV4YJCgceBDwk1y4gs2TiX9eiXvpwQxSFLSaCB14uO6c0ahs7UsiaILQVaJyvDPjKevXN7kQ95Ssv8k4u6Kbmvw+lZex17qGEXy5u32vYRLdse+wXO4tlm/2fWVjdGUUt4Y05RVJWtitlNFAHtgXPTvi05lzFp+NsfKdX05BAGe+o2rpCGVaDVDqxWoBSl5fKiJ0eH9mpQCEU/wmuAsKRmIRb8Rpm1mj6eIdwmPRreSXKIsdGY8RULUxKgobIHRpahVJkXTOpbhiovVpdhY3Q8Go0uxXZVi4U5pQ40Nc3QY07RrfGxZhxPasOTzZ5+wWl9x7+iA8WjE+GBMURgiYms1radpW5b1nLpdoQsFqqKpW6waMzooMVPDRz94yHJV8/NffklKAeec2PDayganMYTWs2guSUoxX55S2JKqGJFSxLmlzO//UKDTr1G+5uj4rZZfH3i608jbjnX9Ot9NW7+9veluBqfdPO92XYafX4cS75o4bv75tfrPcOLJzAWVqztkKb0RiruDgXU7/NG1wxDQuA7iDVrkVkBr6+p34kfXv3vnwLrOjrvl916YN0nK8v37HzAqpzz9y7/FL1acPfslPiqqqc675VciqrtyoOHsyZdEpbHzhpQiT67O0ClgworJ7g4f/OEfsPfgPaY7uyhtWS/XWwtMN2nfdn83nle61g+Gdsit5ZZ++ZYxsGGhqWvnzcBiun7WDnUYjKIb37tWm2vUxG+X2ybGvFYK5yT0y2gg7/TEKGFaCUg5JC/qVtooBkhRQn06xx5FUAJERJM1c7bCsgw2QDIKMAJWxUjCIWETwipR+X0ds+Bpzljkg8cHh/MeF0IfLpCEIpXvKO+Ydn/1wBN0TKTUARXds+1o5Pm11wXIRnCvF90Bm7kT9FfRGpWEqaJJRG0EP8hGdwpBHP/giQpMFIq4zowdncOpunAw7z0hBJqmJaRIG5wAX91OXr/TmO9NCWPJBBF074Cnjp0VsoCGSiJmraE38lVmOtkk+5jaGvoZOIND215HylvQ0uYpSagaOknGNrE0BrukcbCbjTCs+rpDyJndhMkmGaEEeMqUfS2Px6iWoAOJhNYaH62ESJkiP1cxcCX7i+jC9DNIkmcsLzlMMnQiqJnFZRQmxQzug9EGjUEri89ZAUPwObtgzKL8ud/l7qK73eAcspJy+ymtRWk+a+Wl3KE68E+rbpqR++sAcxN03387YFPq7yAL6qucWW0T/qi7p9fPdSlkoMy3GzGVb0mpnYTrrEwSILpLz5VTXNeNPGLnFSHmHenchRMK5zOLR/DFjdaNAmNhMlYYDesQSa0wLiIwtgqN7sPvOnC6s+1SVJRKYQuYFIZxYXAhscw73lZrQkisGs/aW+oA1mh2K0vTJE6vPHWrSMlmdh+IdJeHOCNRoNQJtmiZTAy2Mnz58d+hnkSunnxKXF/yzkNFMa4giRh99I0Id+cMmLbInG5n0KpgNLUUY42Oa3RKmL0dJkcHPL5/SEyJz1/MZWzYEpcUX55eYk3Bs4sFHsvRbMzVcsykrGhCYF4HLuuas/MLdhYrfNAkXVFM9hE9uQx7pE79TABSlQLKFoAhmZJUzijKMWU5wbnAyy+/ZDG/YjG/oqoqiqqk46YLUO6p10vaZs3ZxRWL5Zp6vebl82c94+nl8xcs53Omk5KqtOy/PqWqxqwuFyznc1L07MxmzCYTqrLk2esTXp9fsWoaEmCNpbCdQLzFVBOKkUaZUsIZM0uxrAyVMRglLLnGyRxwONLs6kSxbrCFJWFo0HwZEi995Be14ypEvMojPSQ8kTo5nAubeQFoW8/VxYLFomHlFD5JiI82kiEuKWR+MwJ8Gj1IYZ/YgNV5vgpRQvI6+0oNjt3YVLIudiFxSXWOcsLohM0ZIa0RIFeTmaEpB0F3mzM90NQBXpspymowUVHHlMOihfX1z+WrlG/gVnfm8XA9yT5Sv3GfBvbVBinaXLKfA4f6YHc/s5uZ83Lv6jbLcj2slcQvKvfRFHMeYJN1EnMK64jYjFp3sgD0tlXPzKbnbEGWIBB2v6NtF9TtguXqXBJ4NLUwo11OrpND6qLv6hpkU1ElXFR0iediyC3X+w+dj5LZQlpspOhT399jh8QCKTNvSUiYtMoZjyP4GFCqJqRzlJqz9Ava1tH4JS60aFVQ2imrVUPbthRlpBpZtBEpDcnea6jKgpQKrLLoVNHUDpXWXFwKgFTaEWVZMZvtZF04cC4AjphamramaWvOLl6zLNaM7M+pm5r3H/5Ivp8BqE7cXA/6lXSzu0GnrwtAfR2W0/WopLcf/9XO19Xkq37vrvJrAk93XfUuiOKblI4o+3Ue0nXwaVifG6jC16tO2v71bbW69ex5sqH7vnrbF+5+/82179yrzQL+9b5/+3Fvy8rwFaok57yB8HTOr+xJGW05fu8nNAeX2Ph/x10uePbXn7Jet5SH97Blyd64kIW/GuFV4sXFL1BKURY71HXLLz77HO9ajPa8+4Mf8T/73/0fOHjwmL2DQ1rnWFyJQF1Ha72lmlttMNwI2xx3ey8YnuN2OPTuMmybW+Eqtd2X1YDhtLnodi3zAdvnu8aiS9c//xaU1rWZ2SFOlc3AUwgO0d4RRz32WnBiUAhJJy/cKRuMKHwGnpIxsuhmJUalJMWsNYnCCgVZG4OxhqyGISBW1scRzRoRC+70iSS7W4tzHheigE5oJEZ+k+p52D82GJIaePp680Giz3AUcnhhN6ca3S2Am6x4HVjROa8AUSmUjmhjSJ3oZQd8pkj0wh7TvsFAr1FkslB2Uro3joIPNK2Aa8t6TYiBJouKb64vhlePIeSQuaIo0FnkvAPLumcjIzEbaz0Op/q69Fm66IjfGwejA1gUMadllz6CUhAl/byEe5FTzadeK2kITKu889gZid39SAZBT4iBts2hfZ1Gg45oFQXMUZrWtcLuctLOxtj+scYY8aHJoXqdcyXGm2YzfjuAr7sXoxXGGIKROsQougtaWYwqerBJNMZiBsk8vWhnbiGdhcwljETAKWu8hCXqTuRzY7dLxHRnOMt3BKjrdohz/+uYW70h3xlz3W6w9FeVBeG3lvIEIXgIgdi0DEHZb0NZ1jJvFdBprneEMkKE5Uredy6rPip6NiIIWyMBPkZhNEbdzxOFgdFIst3Na2GuuDYxrRT7U4PVEJLBaAmpC11fCIkYFCOtGRWaSWkZl4bXC8e8dsSoKI3Bh0TtPMs2sHKWyhoOdUFdN7w48azWipQKiqLAFJrYFIKOhSNSqND6DFs07BxYbGX4q7/8Hzi7eonxX1CVivf/RLG7P+FJanHNmtiuiK5AJYdRkbKEaDQ6FsRCo/GYymD8ApMSxdEBO6Hlw3cfoYH/+HyBjmCLChcTv3h+ShMSH5+eszue8WjvkPW6ZlaN8a3jpPWcLFa8ePWK3eP3aIMmmpJytkOKXhiuSSMqKvRglABjos+W7JhUGca7+0z2Dnn95EtefvEJn/zy53z6y1+wd7DPzv5eXuOVMGGTrBUheOq6wTnPl198xriqsNUIbS0Xl3PWdcO0MpRWc7hzQFVWrFaScSoFz+HBHrs7MybjMZ88+SmfPXvJcr1GoajKilE5IkSLiwXFZJ8ylOiiAm174GlcFFTWUGgBj1aNw+rEQVFwaCKjxQpbVkRlWSrLL33iyzbyF8uWqGA8NrKuemEZexdpWp/nDQkVamrH6atLzi/WLFrwSVNVFmuNhIQqyYxXWM2osBTG02XVhM1L90eICRck/PQuKz4hGyG+04pCo7WEtRY2UVgorcIlRdEoXAbTQ+pC1rulWKHyVB1SEp3DvMFTKCg0BC/jVbID/nP5By0dCKmFzayQDavO8u17zXVDWHWAk4Srd2Lib7Lst0Gn7UUr9gzrTtOpzIlZyJtGspHUhX3ZnHDJq4iKkaQjw2uH2IG1ZmDLIfqhUVIBhNhSN5es6guuFi8JzhOalhQUyWuUKjF62oNIsukTUCbio8obRikzsW3vO4QAQWuMGdgreZHyLtIlUlHKktNA5vpp0KCUJAboADcXA1GtgStQgYt2Tr1ucY0mBoXVI3RZcn71HB9qbBkY+5JqXGKNZTzawxqYjEYoAoUeo1PBetXimkT0DaOq4vHD71JVJfv7RzgfCT7RRkfrEs61nF29oq5XnF28xOqC5XzNcjXnx9/7U3Ym+8zGe6QYcG6Vu1a/w/YbZTr90/HKhn34m9/PN5zjtoGla8N1UG6+d/cUPzziLrefW96/q2wG3q2A0zct3Q3csp59rcexwZ7ydzooPrfpW6p7A0Rn+3zXKyxu1aByA6qnuKHbtd/c5u0VGQ6i6wDSjW90/m8Xltk9XpnHNscr6DJRRe9oXcv89We41RX3PniP8d6Y8eF9Vss1r84vaJ1nEWT9OJjKBB1TSYyJ+WoNRvGdH3yIsZZqNmb/+JjF1SswCTUeAwZjiqzDEK43y+Be73ge6npbce3vm5DU2/rIjbbc2iUZIOlpoxHWXevGWW+vNFtPtTvm2pD7prjiP8WybtZopYnRY1TOSMYmLW6i65sAWf+HzO5IOeQuJdn5VJqgrLCWey8v5H4bRdQ3OwhaaTQRVCb0p5Az4nXKpxGtNIHYv+/yTqzP2ipi2wulWspGyLlz1Bl+qs0m1l/3tpKcK3ZZ6yQFuVKgo+r1kLoMY9ABmBlcQYF3KK3xWqGDFuCMDBikSPQtxIAOrbCNrMVGj7Gix2QRocuQmTqt97jgaYPHx0Drw1afSzH1hn83URgS0Uldw9azG6YUTj27pt+Byi1kchvrHCrST5gDZlsMoW/hDshLOdwv5k9CkuC6PrtNdiLEnhWAZ/vaUi/vgzgloQMyN7uqUYnmVGeEojQmCEAgGglIP8rMKQF9BgLw9IT63CYb4MkiDDVdWDp2Z0gRlwICONpsF6sMSm2M6g4EGs4wPQALEheSkgBCXXaZtOmVoj2R+5dWCJiX6EIohTWV30/dKtVdVxg8MgfqPKbkmXSpsJOIUEDbkoLP6Zi/XcBTB6JetXlHNqheIy0kYUSllLbmha6ECPOmC7mT9jNa04TEVZu16fIO9sgIE87FxNqBWsmzqDQUWgnTIz+vwkQKK8/LJygK2J9YGh9pXGTlRGAaBcYklk3Dq4Xnwa5lfzricKyY6YAKBW1jaVyBC4bXT1+zms/ZnTgKO6L1a8zE4fQXtP6Ujz/9lGcvznh46NjfHeHrc3AzqlKjGaONhGKG4HGuYXG+IPqGkgDB4a5e4Y3h6tmEcjphpz1Aza94596M0O5zvPMKvVK8WDU51DSyaAPna4exnvtGMSsNR5MR0TecFCVtiLw8OePg7Iyr+SXFeIdiekD0Ce83ITgKmXPFzFOis4ZkhUNrgve06yXPnz3h7/7ur/n444/5+JNPmU7GjCcjOgalT1EAjNhpuMlrVVRYY8FKVqbGNXjvKYzGaMW4HGNNQWklAzAqsLc3IyVNXXtOLxacnM+pRol9pZlOFaOxrCMhSSa/1vmeNduNx8oajNZcNqJLuDsqmRaK96cVD0uLX7V4UzJ5dMTebMK751c0xTnq85eoBIUWHc+IgOQp7zVXRUFhNETHxcUlf/vzT5kvFsxXa0KMzMaV6JZBr00YorRNAjbMg7xOxETUqbc5t2z3a3ZfiHJejaI0MKssJus2zlso14mlg8s6UXtYOajzuFTQ62DRM57kGi5Pf7Fjh+TPQtow239boTi/u+WbGafdmiTZXclrtsxn22mXkLF2zXeMPcNpszZer8vG39y8dmt0zw5PceMbKJUTt0iyFpKocEq/ET1DsbOyVdI7I0pYTAySIfX+SGcv5mN9oHU162bBan3FfHHOsl6wngvjHw8kjY4lKEtCC1iehKmuzCbaQhh9Eh+nozDJjTZoXaC1RWsr9g95dc9ad8bobCNbVA/CdxtSuf1jfjYkAYQTfdtMphVFqWnWiuDlPmOMXCzAt4HzizmrteHw3i6j0YjJeIRWllGxh28M9UrArVE5wpgCY0q0LgVwS5HgHc5F2jaglKayFo2m1BW61Jh9sT8KY/G+4fnrT2n3HrI3O0LbgsJYUgqyscvAtrulfO3x/TW6+1dlJn1V/+76+TZ9PvHrBAX/GuD6jamboXO0Kbc18rWBeev5t432b17+YTzo6yG/N1tiu/63drWvCC4B/SR18/Nh57qekW0IOg21foZV2DwDmSxuATBuKduC7ncfdfMmr4FP145SmakRXItva559/Be49RWPfvQRZfkjPvqjM5ZXl/zZ/+ffcnp2weuzGhQc7ipsoXGMCI3n4vKMyWjKT/74T5ju7rH76BFKw+XZU+p6DsWEcjRjNL1HIhL86o2DcQg+3XZHt97qNnz1hnZ6SxmCQ1vvX4e8Oic9f+UGK2YwPm/dqelCZ269md/Zsq7XKAXeZ0Agv7/pc6bfBOu0Yjrdos6B71g1kp5bFsgtVlEvZC3GbcyGpE0WmWYFfIohiz1n4EQjQtIiqBxxPuJCwoXUCzxvWGi5hkrTK7j1wIAUYzuNI42KHTAkrC4BtvzGMAcRAFeK0gqjyHRGQH/vXShXx7iS9LXR5i3clEMQfSPHBIdRCoIR6rhRGGNJjDLwBC4EGu9ovWfthWHTZlFxOWc2LEiEzVNCx4jRCaMUtvOWU9qeJ7O9JUCaiF6SHQBhfVli1Kio+/oLIBgIvs0hg4PwVqWE7ZSEBxcT+J7xFLlt0hAjUq69CbUQNkAvqJ7P0c/KCjyBLpRsoxEgBvCAD9QbvjF0LLyuhTpjT46MOSyyUFAag00FGCPAkldEV2cHSQxCo4tsJG8MjJQZTt18EZNoeYVhPUwO38vMPToQpL8XjbEaY0TUXrI/lmJY9xmkROgUMgiYhO0X8qU7MLE3UvP4DSGHwrY1yXucq2+A97/rRSvpd+e1AE+yfMocHRO0QfprTn60+R7i6M5r2BnB4z3NuFTsjRWnK3j1igwsi3D4Tqky6JRwbaJuE5N8fKnzM0CeaWkVlRXmSBsSZaE4nFmcTziX8MGziCGHJUXmjWPeBL5z/5DvHk+oCktlAviKdV0wX1asG81P//6MV8+e82h3yWw0ZvfeknLmaPUvqdvE3/z0F3z8yYJ/8ZNHpIcz3PIEdg3jsaEsRyImrjUhtLRNzeXrS2LbcLirUbGhOX8qwHtwlJMJdn0fnSLffbhPqRPvHjwF4OlVjQuBlsBV63m9aqjKMWOj2S0LHu5MCKHl83JEHRJPXrxi7+Erzs9P2NWGo6MH+CYQ12Ezd+ex0IVvdZE2IQFa411LWkQ+/+wT/vzf/xk///RzfvmrL7BKWDEJmRq773WntVoYcV0YpctzgpXh3o+h6OX5vfNgl73ZiD/60fe5d3hISorVyvPyZM7LkwvG08hsV7Ozo5hMFEkrfEzUraNuWmIWHlQolIZRISnZni1WECP3JmPujQzf3604rkr8ssGPJ0zee8BB0/DRakmrwOS5otIjrBZ3OUUk4QaKcVVQWoWKjpOzU/78L1YyHSrpX7uTEXUILH2eT0MgRCVrHeSwm875z1pPKQmzYjCH5GWk1/xLqmMVKkZGURjF0dQyrQzLJnBZywaRNZHGSfjrutW0uf1lZCpiv/mxGZbOp36RGgo8+JTy25v14p/LP1DJy6pQhNXgjc0625UN4NKtSV3I2l1rzKa/yfo59HKlo8UoG0eSAEGy10myFA9I/1RIuBgofM6CnFS3WZPElswbRNlEkLp3k0TX4yRdI227ZLm+YLE84/LqtSRFuJLkJBqxAwtdorQVYIlsY2pNB8LJGBLgSUVDwqBNkRMhbIAnpYTxrdC9LWeNhMEprDR8r7W6aTWZ1yS8PnpAK8xIMqLu2Cji4kuFzxGBIXj0S4V3gZOTC7SBamKxhWE2m1DYMePyiEZXnF3NAcXR/hirR1hdYlSRRdQTzre4NrCukTC+yRiNYWwnYOFo95gQPMv1HBdWfP7spzjf8P3v/AlVUWFyduR1u5ANgdB+o675myu/aRtoCDjFwXvfbLL6NVmd3RT7dW4z3fLbbeftjvgaZ/46Budbjn37qYaskeH7NwEZlTbv38AOboAZ18GEzV/9GXrA6ZZK5hN2mMTGXRlMTNdgsZv12oaTroNLw5joWx/PXY13G5Z4o/Nkg8YWmCg7gPXigrOTKbYoiHVL0yRG+wfMbMnURoL31O6UhGH3/ru0PvLqMhFGI+z+DuXOjPG0wrk189df4Noj7r3/k7zQ5x36N4Itm2dy6+0O7ucm+6t7csMbvqup7hgbA9RrmP3i9nL7ZLC5zh2Abto++NvkuvkQ+t2kTVhabiml0GZoIIqIeGck0AEEacP+iV0f7QGCnEdZCw3K+022POsNtijomRydYHk+t1bC3iGH4PkYhe2UQafQa0SxbSxLoNtAzibPw0qhO+NFSx1SiricNc51elU5FCfqnAEuRnRKSChIZxxttJNSBi67jD/Bu/z3wKtJCZ1kN7FVItxqnMbESFKWhCzyPnraEGhDEHpzFwJ0bULtlzgFSsmMk7JT1YW59TmF0uarSuV3s7Cv7g3LDMTFSIp+o9UWfVa0DT27TabKrDuUQafOWdyE2g13PgclOw9a6x6AAtVrOoQuy1wazMt0DscGcOrq120wyC7tABSKm76AErHvLLwF2UjuRdZRWN2lCxcWUieaLl8PpKT6+qSu38UIA+BJAK3UZzsLOqC0pFLrtSlImXln0MqgMAIiBRlrWoG1hawfmZ2XWyDfq0KgrTy2EoixKrucCnLmvoD3TkTRnScGATPTG3YbfxeL1aK33o0LCaOT0CLN9U0t1f2fjwVrZEOqDmCDOBpjk3g4gTYq6iDtvnIiYltKbgVSTLQxcbmGymhSMigt4XkmM/p8krrVLnDVOOrgSURCktDNrr6jQlEVmkjiqvHcHyVGY0U1NZQzg3EW5TRWQ6EjSa/wyhNcItaa0c4eurR88H6NNWt++L2HPLw3w6bE+mrB2YtTWqc4euchcWeXdrXG1y0xSd3+/pMnNKsFJx//CkPig+87JjtTnKupqop70z12DgzffXQPbS0/O7kQwBODc4Evnr9Eh0D97iPsyPD4wRGtUVSvTkjecXq15vXpBa+ePEHpkofv/wANxGkOS41k5p+WkEUnYd4pSqZGpT2uXrO6ukCtL9lnxUe7msP3dimNpjQCpoXoISeE6DJ+lmWFsZamFucpRBkbXYir5Ek3lFocwmAS2rTChEwarQusLTjcTSyWkbO1IkRFs1qzsqItZYuS0kwo2ihbKDH02TwlGUFisVxTGM39B3u8Myv5wYMdDsqK2WQXPRnz6uKSZ1dLfvnZC569Omc0EvdjZJQAa5ll1LEkKwOVFS31aWk4nI5yOLqjUuTsm90aJ3XRKKzWginEbt1mC8zp9Qw7W6ADtbXM7S4mrFYUSnFvatitNvozdRtZO5mxrYGmlVC8NkRCzvqptDDKtJI1Q0L1yBqGUjebMxb2PNo8Zjs5gH8u/0BFIdECSuU4y4GjNDxoY9CT8niLOfTtLvdmmGVu65zdBlPKdh+SddMWJUaLkLXRBrQlpsi6nhOCx8eWFCONb4kp4kgoZZhWM6w2FHk8d1ZEx+CPPmzshCRGS+saXNvgnSN5SfAieuUGq4o+BC6lgQ0B+TVrNcWI0pbCSr2tsVhb5A1GK6GASsuGUupsGFnftREmFD0YJUyoDmwNnbZjZigaLRn0RPct4YOWDUOtsRZsITpXk2lF24549crhfeDyvEZjCdFTmsR4NKEuI4uLVzgXuH8k0Q+7O7vYoiIlAySm1Q4WR9vWgMxpKMDmOdQmbGHZHx9SmJI2LLhcvOCTJ/+BcTljZ3KIMdI2kHqphTRYs79x+QoAy81ImTuPfMt5bjsmXTvfrz9B/RrAU++68XXAod9K6VpJdTHiv/n6bZDwAWR0W+f6hpe+rcrZ5/tK5904qNcmw+7T38C2yt10wuuVe0u79IbyBuAxRUlKgXY9Z3l5hgsV2o6y75gYHR6RZnvsVJamXlM/fwEpsXvvXdqoiCcrQlVhD/cz8DQizZdcvv4Vrl3Jgq/yJNu30a/RGNwFOnU3ezvw+NYH2YFON9huX6Gy14fmkKbXsSmuA2LpLnjtd7eEKOycEMKNB6C0xqSOHZONv8zq6MCizuFOvQEh2j86h0FpZfJOrGT98t7hvadVLcZarLe9YdlDRoOxrBW97pMP8iN6OxL21DGUOpaMBICorDux6Vc6L+IG2Zki6l4QuPGOkM/diUErpfp7VwRMTpOrsmPRC40P2zLQGzTDMNCOt2JUFxokzicuYWIgqZKEhEi54Gm8x3lPm3erQ4TrF+vY7j3xR5NBP8l61LfpBiOka4xul1nAGCVMyv7EMUfWynNOIfQ6CAK49faahDZFBlofqc8E2LOW0oZNOuSVdsCT7UIfE7lfyXGddPetJSGKu71ZmX+ujXvVZTvs2UXSb5OSXhIhZ+RTaDzWCDiqtIaYUyjl6SVmD020VXtvSY4fhNtFRAifzLxDqRzelnqg0NhCjE0kbXGIiENmJBuW1qLbpLqwAnJIY/YIs1QvKLO1rnYZ+0LOEOidI3qHc6J303r3rZu/TO77Kk8agnErrJXxItpe9Bkph0Urcdy1lpCg0giIOyng3R1YecVZo1m1ibNVYFTATqXEAQ+J2iWWNUwLQwqi9WRNwmrQ6B6cXrnIRd2ydkFApyg/ZHBkXBr2xpqYEpe1594hjCea0cww2rHYpUXXmkIrKhOJeonTa7ybUKSKcveAUTnl+x+WHB06/vCjY452x9iYWF9e8frp59S15/H7j0j1Ae0q4lpJzlA7z1/97FPOX5/y4q9+xdhAkdbsHEy5WC/ZPTjk4R/+C3btlB++e4wxivEvviB4UMrinOeTL5+hU2SdPGZc8P4792kUjD8dsXaBVxcrDl6d8uxXv2I02aUoS0xREk0pei1e7A1jFLiWVtWio5fHmTGW1dUF89OX6NUZRyx5cGAwe/uMy4KRtbTtEueW6MwKtMagjaGa7mKrCfOrBevVmuRrUnAZYFHocoI2BXvjEdZofvn6lIumoVApixSLiPj9vYRrI/5cU7eaZrFilcRBLMqSsppSONlQ6B0zpfDe4Xzkcr5kNip5eG/GB/szfv/xEbOiIFZT1krx9PSCz16f83e/eMLZcs14bNFKMbICwkj2Lpm8lVaMDPJjYaeyHO9M8K5ltfJUKm/OZFCvA/U1YDsQfmtuzvPUYPMiDQHaTF4OKTP4jKYsNA92Ch7ODCfLxLwR0OmqFjCrMFBnxlN3FZsjjm0WhA4pM9DymhKSrEmVLE55vt4YAx0H9NtXNjbwP3ZR+b88o9Kvrj0aufGZNkyn2NuAt5Vt0Glgx3SOfIr9Zp41JVppyqLCGENhbGZJl4QYWLcvqdsFi/Up3res6jUueJauweiCRwfvM66m3N+7LxISDJj5MeDaOgNFob+1pl3TtjXONcJYDBGdJDOq1VO6hSXlzUStZOMSxM9T2SAqSk1ZFBhToHUhWeusxRqTs+ptxliKcv4uS1wvGSBQtmxKZVY4STQnZZjKPKm0JFLwPgrwlIwwp0tFNRbbYTob41rHarlkufDs7Yk+nY8ObRKT8Yy6gsuzFatVzePHKwHLzITCjohJesJstEupHYtlTgCTnPTWQuqhikRpS/amh8QYWK/nnM0dP/3UMZsc8OjeR0zHe9zff0ckNrQYVtd95N9+GO3XHXcbf/jm+135LQJPN1kv36QCt4d73Xbc5vWaJ8LNZlHqtnfhBnNjMGmkG7+wtVN488DtNxQyyQyPVwO08Jo7f0t5c9sNQ7u2r96BaunWA/oadYdxR9dLm/t4Y7mlv70Z9EjXXtUtn23uYxtIEycQrShHBUWpuffoQ0pd8clf/S3L+QJHAUpTjgxJaUbeYtqWttZEl5g/fUlQhplTaN/y8X/8KaVVjHWiKDTTg/fYv/8uu/ePMXZE07heT+babb4V3Bk8bm7tf/3Clv8aHHv96M1HbxkfN9gVvBEsUj3VvLvKdYiv+0td6zPfHufNdxnPZND2LaC06sds1w4qGxcqgxLDHa8UspenctgZKWc763Y3ZJGOaZNdJMXQracDtlW+Wnb4terEvzuHLTOdGJBa8+PowIcOgNpo33RgiWwbd+K1HWMqZH2njq2juhS9yO6f7xgvShglqdMv6q6Za973tb5tNvXq+o3K74cozBVjFDE1gABHPofWeR+yVlNmbt02KHrcdaOJkTIQuzH2Nj/dc05ZQ0OeScrPRbIG6pT1hrI3IKCfGG1yXOod+ZhE8yZkB1sYTxvgacOE65wcZFcxRdGb0ZJSWGmdQ0g2DzMM2lfqPZgrpeJ3mgGQw/hA+vFg1ErQCv2wjkqu5fNzDyo/+xTpD+2nAHGCUo4r7MIORQdDGjTS9c3QP7teEF7iPDEJdIyUWjq6QuX+LjT+EAIKL45xNtLo+jYpsxXk7dSdP6Uc6hBxviWGQNvURO9pnABRrd/0229L6ZIsyXhSlMUm9DCReoHkbTto41TZ7EAsG+nTCslYt1cpppXm4a7loo48sdCmRO1T7ziAgIRoCERKJQyVMrNUglYEJQkSVNJ0grijQrM3sfgkzrbRisKKPtm6iSyWgcsCvKvRyaGSQ6fE7k5C+xHHjw+ZTEdcPFmyXgQmpacoHMdjxUxbpqMSaytqJ8L4mharauLqJU6vWF95mjawuGpYLFYsG0cD7D06YFpZpvceMNqZEMtdnBozrwOExP2dKatVzbuHu5wua17Ma3wbCG7Jwc6Ky6ZlVo145+CA+aJhYi3eaOZKsaxrXjx/wmR3j+ef/Jymbbm4uJT5xQtzMKVINdtlfHCIrUaUY8li54LskltrOD6cUX7niIqWihZjCqwuCMVjoq16wN1ktioZaGru7eNDQtkCpQ0hCdNQhRodPVMrGdOq+8fMg6G8/yHFZB9roXZL5us1l6s1F1ceHxQ/eu89Hh/dY3b8Dnb/GLeMNG2QVOUu9O67CxHnc1ivTuxYw8QafDSsg2a5anjVNPy/X7zm2cWc55cL2hCYVGVmsso6Z5IspaXVBKVRXpxypQoWDj45XaOSBx9Z+G37UTY15Hc9+MkrofyuOrdYEkwYyIy9xLpNLFvZANFKMas0e2ON0omlD7yce85WEavh3lRzPFWMC8XFOlC7yFKqhYsSpFRqKDNYnFKXnxOxPxTYLuBPiWNr1MAu+A3PH/80yq9zV7+Z+Xxo8yq2bfPU+6YZbCKSkoR/vwl02koC1G8q5X/zutWF1imt0VpRFmXWRhI9utrV+BC4WJyybub86sVfsawvmK/P8KHFOSe91owpTMWqnjOpZjStAFD7s/torbG6wMeEz0kHfGhlHfXgwpoUNCpZClMRjKKwAaMtVVH0Ye39RlqSTTKtTQaZJKGLLUrKciRsZt1pUxnp4yHlTSSxF+iTKhjJGNf7FwljEqiNzSTSFWwY2rqLTsgMKVWQksYHj4oRaw1aK3b2ZmijOTxqsLYhBMV6pVksW2zZMNsdg9I8eHjI5cWCk1cXLOZryrJkOhuztzelsJaRHVGO4P7RDiRLYQ9QyqK0kRA/d0EkMF+eSl+IitgGXl885XzxmpP5M8bVjKPZA/am93n3/g8pipKqHOXNGc/XLp09+Aaf8G5N4K13B5/feabB623HX//i9nj+uuSeX5PxlC+69dvtE0z2+bYd/FvRv3TH799w+nlTg7zhI/Xmj2UBGR5w7VbU3R99xSJ6GNvV367V9uc3r3In6HQHtHBXPTeT9Ma93C7p2uuby/WMbX07pkxHRVOOCoytOH78EWWq+Lc//T/x8vPPWKQxylY8eu99RqOK0bigioGLWsJhLp88R2vLLiVN0/KLT/4a36yJizPuPX7Ef/Ff/u85fPAh+w8eEkJi+fRlprt3kdW31PeOVtk0/pvue3uc9MvddVD0ayPhaetl+2SDP64jo2l4rY2TMozNvD3/4e9u6TWN8j8C1STZcclARve5IrNqUsqhZ3lxjCmHHYkpq5UiIjtDUW87zV0q5Q6k6VKtCvg0NJU3DoSIxOZU9t7nMKdtYEJ8+7zT278vws4p08dFeyCKgY7qd4V9CDmrVXevXZ1iBp5SL9TaiWAOa5q26nETDsl6sDmLWiJmAzzEgDbgUt1jmyFGGudz9rTO3LvZ6zo/uif9sdkVj5nxlHJ9OpCJrv5JsyGhC0AYYkBF1Yd0dOFkpC6kTJ5bIINVUa7XAU+9tlO8yXbaCJ1HmtWaGAMmO4B+lKnXWxsVqQcVt+55MDSH93QdMJbQUIPSoBOo/j95Ggo24ZH5+fjMZjMqZqAp9dO50klAx+4CHdlvA9MimW5iz8LzWQMsxNglvxMPyihMSpgkGl8SiSpAbwjyRELw4v71AqrdZbu2zQysHBfThRG4kMMO2lqAp7qWzF6+JUZxgL9dsxf984s5A1NlJUNgQBh5HeCkNJtlIXXLk6R9DwkWTWLVJha14v4UHs40+2PDo13L66Wc6GQd+PzSi+4HWf/DyO63J6C0ZqQVlVY5/Au8RoCnaCAFQoRRKYyReRNZuYS1iqpAdDDqwNWipdAR364xyaHTGk3L3m5iYsd89NEjdvf3+I8vPuVyPmemPLp0PJho4kwzm4wwxYi1K2hb0KqhUEvC+gUuXbA6a6ibxHxuuVo5Fk1LC9x754i9ScXs+CHleMzCjmn1iKt1oFSRBzszfOv4zr09jDE8mTc0reNytWJ/Z8nFumVUjvno3iGX8xVTY1lrg9OGRb3m+bMvqEYjnvzypywWc148ewYxovK87l3L/fe/y3d+8sdMDw4p9/YlxXkKaGUoC8vDoxnvxGOmpmasaiIlURXovfdh97FkFNWSzEIRaU4+o716DXaCMhVm5x66mhEQh5Krp9BcMYpLDJ59HrBUUxgfkUyFcyvWzZKr9ZKL5ZqzSw8UPH78HT567z1mD9+n2DvALV5St4G6FYBXiqL1ws7VGZjcsYapsfhkiV5x0tZ8dn7Ff/VXv+R0sebsck1VWB7fm5FSYtW0kAEajWJkNUEZtO3YICWLFn5xuqTSMDGJeZt6YF3lhaDTPO9AJ5PrF6+tLZqsE6gUbUg0HtYusmjyVo5S7Iw096YCiM9d4Pm85cVl4Af3S46nhg/2DbsjxbOrxLxJnNaw9mAyEawy8kPqkjFsplSVxPHqMu0qtUm1cG3S/+fyFctQHPytx3ah7KrjT9Ov4Z1ukjC+u9e3n7cPf+/+hgw0b5KBlEYYTsJ0stluS6zbJetmxa9e/JTzxUv+9lf/HVerE67WZ5KtFTDasjd7TGEnnF6dMK12CcGxNz1kOjqgLEZYpUkEvGtxvqFxa2KIhDYRYwNRo1NBYUZEq2iLBmsso7IiRGhc6ln3+aaEsW0LrC0pizHWWmxhUVpAma7nxiQJDhQ5Q3gUaFcpAZ5ixzAn93edQHVhuzKWtZHNNJ2ZgALadlZyCSrgvTwXa8FYze7eDuNpxdG9NcasaduW1UozX7SUo5a9/QNGk4pHj+9RWMuvPv1SnsU4Mdsdk9R9xuMRk4MjClsym+5i1ISRfh+tKjQVjV/y4vxj1u6Ks9VzlNKMyh1CCKzrV/jYsg5XVGbEwfge7x7/iMPZY6Zqj53paJMh+J98SYOfNxV17fXrl28MPN0+yO+uyJv2bu/8zo3Db4dRvnEo3ZvQJTW40i1YWNo64Ks8gjegVG89/vp7eZK75ZCboRi3X7M/Kh9/o0ZqMyFvf+nmRW+CX7c0WA/ebp9v67pKobQIVS4uziF5rs6fUq9P+N4f/ZDj9+5zcdXQusC6aVg1DasgKW4nexLOlMIS76BtJWzocHeEUiOKx8fsHx8z3j1A24rF+UUW1c3B+Hf0g7uhpc5pezPoNATtuim0u1d5N23BXdv40d3nTlvA1+Z8NwCt6+cYOKObPnQNxLoDgPtdLZ0Kndyq6v3pzujowrHI4IAACCJcLIwYYeVkVAYtMAZKO1QIqOB70CJmbaZeNCIDJ7JrM8jGlnVzdAbCUse4CSGDR7k+pA3A3MXlD3ZHe2AgP9eNOLXEDcawAauGWdS6lxQjUSmiunbGIRLXseb6Br0dmuxlAehmaiWhBSFlTSgpsdMHitdC+W6ZT3u4ZXBcHHrX+TUNKi9aQZK5L8ZIUApCF9IXyCQcUv9ss0hn7hjS1Gmjy9EznmLW6UgDltVG62lV18SU2N07oCjKPD0k6vVSqN+DkLvr93vjxm/4H2rTrj37K25AwuyAiWEnz03lbFk6Z3FEpT7TklxI5+skCJGouvk59/ckISuSnZGeVZfyfXX3HmMPO954ZqLjkGNY83Vj6jQUFCmATibXXfXaTSH63vhPKeGjy8BSZja1rg+tCyFQe+nfLt5ouN/5UvtEiAqrE0ZJ+JFSijYK4yjqHFLZ9cmY15ZuBz5vkhVawMMQFJdr+NmrwOEYvFOMK8u/en/MkyuHVmsuV4HXVw6dwyMbn3Ah0nol4UVpo2VjzUbgem9k2S0N8zawaALTImJ14vGe4d0DTVVIyvujg4rdmWZcjlDRMB3PMCpx9sUTLs8uuTybo5Jhd7qLPZ4yi2DiiquTU9atZ36hoJhwRUETAq9O1xA8D1YFKpW0ywva2rFeaUIbebQ/xseSaSk7/FceytpRjaDQAbc4wxYFk/09DrXlB+8+pijP+bsXF3it8EXB0jl+9qsvqO8d8v5kRKHho/ceMz4dc7KuCcry8nJB9fIFT3/5tzSrBVcnL8WZDeIQ+qZhMrbE5vuksAemAjwpOGFDVCPGR/eZTr9HEa8owpzaKxqnUcffxdz7IdgSZSwqBUgB34o+VLn/CDs9oLz3AXZ2REQEfOPJHml1gq4vSMGze/8PmYzvUVgJA/z5X/17Xr0+4/Ona56+chzuHXGwu8cPf/j7fPjee1TTXZwyvDp5zYsXz1muljRNy3g8RmnpGyopvnu0w9GkZBody/mC/9urFbWPnDYNZ/Waq5WEAO3PJOQvJQmZdkGAVE1EpUCdGqbjinfffUhZFIxHY16cXfHTXz3DaE1ZGXwMaLUBb0A2mEKKkiVWbYdib8wlGQMKhVEa5zyL2uO88KDu71j2JxqdAldrx7qF1kuWR220LMmq28jIAcIKyZgXN4zCjjmqs8KggBAyh24ca2FFjTRUWir67Qyz68rt/ts3LTeIC19p3lf92rX56WyAHG6fNslfBibG1kXS4IPr9nav/Zi1PCXLbUFZVGjTbXbGLDvgePL6l1wsT/jZkz/nanVK7ZegwZoCow2jakRZjLh38AirK1yrafyaT59/zKSc0bjAbLTLo/1HwqbTBclE6nYloXeuIUYvG2m+wLCHSgtScngfWYeGmBQ+glIaa0usMRQZcKqqCUbL7x3onRCgVxLlSH8WuQqz2VDCZHtDko+gFNZorOm0HqXdBWDKIF0SmnlRGNnwyBpRKkR0FJHylLQwjjzoYkRRFDx8d5/dw4qmaUX7zmiaNtK0LTHA4f09jLVcXQo41daBlW6p1w2KyHnRUtiCabXPpDziYPeIwkyxjPCxZToasWrmTC9nNK5mXl/Js7WW4GtcfUGh9ihtyaicMp0eUBUjERrPGdN/u2V7MNzlSt7O4nvDWbc7+9evVi6/prj4zbKleXQr2HEbcMQdn2x98bY/7ihvQpQG11JvP+5WLIWvOn12k1T+zvV58tpkdv19NVw1b3zn65Y0ONMtzyC/bsC2u6HC4bdvB/02IMjw2te/c1v/UNqSgOXlOb5ZcnX2FLe+5MM/+hHJeU6evmB+Nedv/+6XrFZrmgaK0nD44AijYX5yjneBdukx2nJwdEA5mrJ7/12mB0eMdg9QRcXi4gJlCpQeSf1STk16y13ewNtU95K2+sf1lthup/zeVicYPNtf01nqe3JHD+mcjmsV7xg+3UVTD4xcDzb89nhv2/POBoCKDECn7DinDBKlFPEhs462xEsZgBRuIyYkHh999py8ACsljBQJDesYSLEP71IZfBLDdZPBTrHJ4NU/i46hstVPu3INdMrW+BB0Sjl99wBBym2QQwxyG2wzOePgurkdB9pSw3ljI3TeKSjkr6uEdr53BFJMG1r34Cldnw/UtVcBQwQ8if3cuAmT3WqtlIWoB8NLxUBQ+XbiBjzpDM9Oirw7vmPfdNpOfdji4F5Tvk6MgeVqSUiJ4/c+ZDrbheAIzrFcznFtI1lqVNe+qq+bGrbtoE23R+RGJDzlnciQXxMxA08ZfOpBKCV9D+mESaWts6qe5Zjo5OtTD/ZIRYw2pMxKQnWZFAegXezartNq6voIfT/pgCfVgZsJYvJ9I6aYxXtRxOiIKfbAU2fEt0GAJ+9aQgg0bYvPIXYhRpogx/pwe0jE73JZO2lVYxJl1r5RSnhtKkEwG9A3RQF7gX6u75rDKmF/eA8XLvFiHrg/SdgIP3pU8qfv7XDvrGZRez4LiS/qiLEKW4h4sguRxivWWsIytFZok9AhobWEcU3LgkmheTFvaV1EF4qqSDzaVXx43zKuFFWpme6OGU8rJtUIomYymVKWFld7Lk4vuTq9wlKwOz1gv6hQZy8JyyX165dcXq6opxpvp5wWBeuUOD1dYUj8aFVQqIJmsaat19Rr8FHxcH+CMgrKApRh7hNF9DyynkI5/EITJ1Mmj96H0YQfvnsFyjAyn9BoRVtYAZ4+/YK0XvMv3zmmNImP3nuEKgv+/tUpgcirizmlfsHTsSE0S5qrk5wwIuDbBr9ec3B0QGyWoitnKpJa98CTrkbsTI85sBW0J9Cc4NeJep3g+AP0O38ExQhsKbsKwRNOn9JePKc8fBd7+A7Vuz+h2H8k/SElwswSr57jrk6I3rH7e3+KOXifaayJ9ZK//B//HS9fn/H50xXPTzz/0/fu8cG7D/nRj36f77z7Hsx2WTetAE8vn7NYLmnblp3ZDK01V7WjMorv3tvh3tgyCZ752vF//eSSi9pxXq9JKWCNp7SGw9lY+m9MhABtBp4MorWn2pqDacmH7zygLEqqsuJy2fLJs1OSMZjxiJ3KcG9qeuApgbRzykxMUtaPGdrg3dql0WgMCucji7XHhQKlDA92S94/KnhysuTkynG6VCwaCZUzJqeXh34DAhJayToRJFqTbEL0GlJDMKkDy7rNo0onWp0YyZ4Xd/Puvw3lN3tfb9XXvX78tkUOwzUsDjUeO8H64VqyDTgNgSe2jmCziZgTrlTVBGssRVHlsPJAyszQ1jU8OfklL8+/4O+f/Dmr+pLd6Z5kmTMFSsHuzj7j0ZQHRw9RWF6fXLCua569fInVJetmzcHsHmMzYlyOqGyR12fRNW39WnTmoiKGAp12xeZMVwL8+ja3jZZQOltS2JKqGlEUFVU1zVqmG7hAMrdFvE8En/IGhJYsyRl4yluq2T6RMMOiUJSFqJCmFNA5+U1S0iY+OGIKmI4VhgiV6/wsjLZi8cVISGDLAm3h4bstIY5Yr1ph22tD2ybqDEQdHu8xnow5fb1itVjT1AtibGjqFpTHqyVlYdAESjtif3bIuNinZEwC7vGAVTOnsBWXy1MWq59BClhrcCHg3AXRFJS2ZFxOmE0O0FoRY5s35r5BeYsd87Ywu69nBm1jFbd93s+h2UPp/fiORPE1LvgbBZ7uFle+rVx3wG9zdW9DfW5BAN56/tu+2x2mvu4T+orl5oMcQkh3g06DiWzrmNvuR93x+837GU6fbwqlStde31S+akcbAjd39YnuXW0KEpHVxUvq+QlXJ18QXM3eR/8SbSpO50t0itz76LuMa8fzyzWJQFINRWn5zk/+AOfh0y9eohXsPTxgd++Q7/3kT4HI+Yu/w56PCelHVNMD9o8/JKWEa9biEHFHPa9jMSr/M/S80119c8N2Uvmv65jnre3ythjfwWK76SrpDf15m+GUOs20reG17Zx+G8o2yy7fuxIR8S5cSuYBlRc1Ybm4rV0v0YmIyPeICXwYPIIciqcy8KSiiMeGAMbQZcCTUK3Yawqprg5xYOSoLLh4HaTsM5bp7THcAw3kLpnPBzmzm4aQNamCCE72ukCZPZPSkEnEYEAKQNGRVjYHDAy5NOzKgzqrDgxT27fSg6MDpQV149ubY4evbBhpHeik8nNVegAgkoGtLKKp0kYXp2/GfOOxYzyRgZ18jk4tqNN26sIfO5ntTttovRam072H7zKaznj/ox8yGk948cWnNE3Ta0alzinpa7gZf90mwzDAcbukjSdz7TlsGGiDyShteH5JZR0tICiFVxGNwmSnTO4jZrZd6MX4gZx1xxDzTmd33dCF3MUoGjs690Ft0Fq0IIwtsEWFtuVg4es0mhwKh6bNoFoGnnKrd2ynkEMdvMvAUyvAU+tafAi4Tg8tpRxqczsT+He5+MxgEpdl46hbDSoJY6TjnKESxmynqu7TxCfpd6bLAKAMLsLnl4FkGyafz/Ex8nCmqVTBrlWcN5HnK5kZLlaRkJOZXTWJi7UAfS7A2AScVUxnJQ93x6wDXLaJ1cpzVXt8LCmMZjpKTMeJ0URTjQ22WIO+4OrEs14UHBx8yLh8xME0UQX41dNzLi4iJy9PqFc1YyYUswmHs5KkE796+pLXq4bT1YpqVDG5f5+Dw30WV2c4d8HJxUtWrcMbS1TQxojRhoPplJ1RQTnbYVxWTPbvU47GrKPBJ8W9ccHVrOI7Bzu8KgyfX61Yt5FfPjlFJ8MXZ1cYW/Jgb49V43l0uM98ueTV+TnjomCxrpkUhuPj+7TBs2pbonP4uma6t0dRjVDGCGidYk5YIOvFy4s5z+cv0WmFToHJ7j1GR0coM8Wv5iSzBm1lbQmeGAK6qGRc1CvS1SU6ljnsOcJ8BbUnpIKoLU3tUYsl+DWhXnB6ueT0coVPAVtq3nn3IR98931GkxnKFIQ20K5qXrx6zfPXr3FRdDg1ElbtU2BkLN85PuR4XHI0KkjJsfaehXOsWo/RMBsXFEYTEqQIzgl4UxhDiolVUzMymtl4zM50h/eP7+HahovzM7RbsDc2KGspx5bC5g0WrrFmBwZsNx9kSgabzMWRkBQuCXg6qTQjW/DQVowtrNaey1XkfAU+CFNQ1soMcKWES9AmcIDL87LWibEWIKxQfd4GYspZIIFSK8rNvhCFUpSqW23IdKh/gEnkW17e7ovk1TBvNMla5/NPyD+bLLXbcgLd6jp87Tpdyv93+oOdJEOiyAyhTkQ8JWHDyya3WJRGae7vPaIwmmVzwsrNmU5HGC3bgFprRuMp1hRMR1MZN7szqqKgXgmLab68IHjHx+XfMh3t8ujwPbRSWFMRQ8S1jaynQZjmlZriUksMkqkUNaKwBaPRlKIoqEajnIWuyEBZ0duHcsupX1OM1uhCZYaU6czozBxzYpMpMMagjehDtsH37d1pahZWUZQKqypQGm0saC2AWZJM0SHE3s4wxua2HaG1wocGHxWtW+Cco67B6BJjD7PGpqIoLQf39phMJwT2sjSrIfhIETUmVexU77BTPsboESiNp+2fd1WOePf+hxztPmBczlj7JZf1K2p3yKSyHOw85kfv/Rvu7b8vG3YZSPuH2Aj7zYJOw3Lb5BNvYBG3aZt9nfIbZzy9uWzf1Ka+d8y0/QFvMMZvAV+2GkL1e7D9oBm8fUtdBl/7OijM9Zrd+Z27VpU3Xew66nHbeYZtdNvx166UbjlKDeKkb6zkbO3E3OhsafAsbsX8BmDG0FkfXkJpjLHEFFhfvWZx9oSrky+BRHX4LuX0APXlL1DRcbizz6hNvHp6TmxWpPQ5RVHw/o9+TB01XziDIrL77j73jx/x43/1r1hcvOLz/8t/TdIlqpqycxi59/iHpAS+qWXxYPPs7t5EGfTLrUbcbtGhM9i5xOL0D979ugN42J9veQY3z3EdkMy16jPcXa9z9/m3x3tL13Ycup4ak+g4Jejlr4SVNASe5D3FMFNatmrjYA+tz/qVUQ2lIESSMQJ+aN1nVuuMk9iF8oXQgwc6G66ozhnvukhmHnV7qCn1RK0N02VjHPcaRDnkr9fByAu56bKFZTSkA9diZ1B1j7+LGoxq04EZvsLNcZ/n4QGTDLi2M9KFKWxrM2wNub6LXls3emNv8/dmPORjdSdYnnfcomhYbWqTz9EZolt9JANy+S5jl82uAzag1/KKMeYQO/jOg3c4PH7Au9/9iKIsef38KT5eiiZUBhY3TdQxl/I9pG1w7m0r3VZrpJTxyM4g7lTMUu/QxC5rUwaeLKpP+SuGZMjGneiMdc/EGLP5QRgGwEYAf2Csd2K52hiMLSjKClNUaFPkyyRSEKZDDA6Sz6y//MCU6JRlOAxSImQmU6d75lthOLWuJcSIi5usiCkPy2+yXv9TLh3wpJT0wzaA1YnKynPvhJMT9FJ9MQuDbzYXUr9EGyXMCqMVLkSezANrWrxd8Ghm+NGh4WhU8J29ko/PPZcvGlKKXKxlrFidWNQwXydJF58SswJ8SExKzYPdipN1oFgG2gCXq4APicIopiPF3lRTTDR2rDFFDfqK+UXg8qTicO8DHj2YYZafkOoznrw457NnK3725JzFuuVPv/eIR3sTDnYMJkXmJ694cbbgFMt0TzM+usfuwwfoz77Ezx1nV0sulkvmusClxGq1pjCaj44P0btjSjVmXBrG+0eYomIdEyTF0diynFW8tz9FKcWTZcu6bvnk9RVWF3x5Pudod5fHR4esWsfx/h7eeT6er9mpSlZ1w6yacP/+AWvnsHVNdJ7Ytkx3drGlhN10ACtKAPAQAidnC15//oqiSFgL708P2Dn8CK/H+PWcpLSouHXZOENA24oYAq5Z464uSa3BxIhOEbtcoVpHpCBpjasdqDXJLfDrBeeXS86uVoQUsaXm0eMHvPf+O4wmU5QuCC7Q1g2vTk55cXKSgScGwFNEa8V79w55MCk59IFVu2LtPUvnWLnAqNBURYE1OofaJmonOoOFMbjoWdcNZlRSFDN2pjPePTri8uKUky/PUW7FzthgrGU0tjJPdNPdEAfIb3Q82N6MScN1R8aRixJGOi4NO7OS8bgS+YbacbWOXKyhNF1WUvq5KWTdP5ckY51HdjO0FsH9Qqmc9bGrW9aVVPnzTt0hybFF3gzpJ/lvJfB09wr29nL9e7dP8HczL7pFln6tC9GToicGR8zg7SbkbmBHD/sVne2RNh1r0AklQcxG+6woSqyVzG9KaZxrtkKvrC7RSnF/55hJOaIJc2q3oJpprNFU5Ujsxrx+BtfI2uyhNAVXly1t61isrlg3C1ys2Z0eMJnsM7IjxqbCK4f3DcEH0baMiYIJlpoYNGDRuqIoJuzMDjPwJOBPl51uYyflcdW3j0IbjdEGawps9t1C8ITkickLtzAz8LVRwkr2AR8yCJetrKKwFIXFFBVKl/ikRJA8SJigz3aJ1bJuGVtiTUFhx6J1yRpSomlbmnZFcC1aF4wnI2I1xpoKWxn2D3dxLoEyWStyTggOgsFQMSsfMS0folWZgacGSGgMVVVxtH+Mcy0740Pm9SVPzj6mDQt2pxPu7b/PDz74V4yrXYzWkp06azvJ5tpX6//bUWNv98W2P/9qxs+bgaqNT3irm/8bKL9l4GlQvvE8dNeX7ph08nbyFsAx/OyWt+9+8x+3fL2H/mbwCTYgw9YF3jTH907SXb3xTe7RnZUYlEiKHoXi6OH3mc0OqZ8+ZXV5xl//N/81PllePv8cHxx7h/dRWnPohO7p5olVHbh6fkHQBdNUEbzj9RfnLF6uWL/6PxJ9zeqqYXZ0wMPv/B6j6QHB+82Eeq06d0E4W+hvD+AMFqbrbdCvUfmYuDn3NwV6bqP6frUvDhfS259VHC6s34LSMTg6s7NjB3X03RQTUcUMwMS8YIQNU4UBBjI47zbmOAARu8Va5QdtIjGqPjZewIzNztiwo4nznPod0c4STf1pOwNA+pHKXqfq8kFnYr/3khZWFSXaGEaTkl5vyHs6wCKkHKalzda9xXwjvVx1Un3EXY8n3dkaGwNfd68DBpfWKssLbQy8xHY7dI70VsNvDdBrBytxDLp4vo5LpUDYX51x39WflLHC1D/n7QfRhfNtdvq69u8+b5oGHyP7h/cZjWf88Ie/x737x4xMINYXTHC0JjEvhPou93RbmOTmPm7/TN34q38O3XeGuGB3f2TwLYND5L5OSkQ9YPMloeT74DKDyfcn7HSuOmagXFf1oFPswlpyJbSWXdyiKCjLCluOMKbo+7lvcx/3tcy9wZFi6MMP+7C+lPPmeTHmQxAh8zaH1nX9O6SNIZy2+se3p5jc94Upolj5iNGp1+vSg2efkP5qVN7gSGowNaX8fzc+RW8DNK1LfPaq5eJKc7kw3J8WfOeg4v19xe7Y8HLu+OKsoXbw7ELCHAydYHLifB1YNZ77Oy3v7XsezkbsVmOaxvHsYsXpIvH568h4qjmwlvFYMZoFTOtwFzXnL1e8fA5ffO4JaYpbn9G2C/67v3zJl6/mtN5jtGI8HnG4v8PBToFNke8+OGQ0GhMP7jHdP2D/YBddWc6WS17P56x9xCfNWBtGSjHeK8QpUAVzp/n00jF1V+ylv2dcjXmwf0hlFLODXQ5i5L3DXRof8HXD2Bh+8nvv871H93nv4RGlMqwvz4nLBTtaMTYarKZOgRfzBbv3Drn/0e8T0TRR4eo19eKSo3e/y3i2i7YlybUQI1obaudYXl1y8vqEZ8+eM9s/YLZ3QCr2KKcHfP6Lj/nssy8YT3cYTSYc37/P/t4e61SwjlPGakKhRvzsb/6GV+dL3nl4zN7OjP0RlMby2SefcHF5hd4/h2qKW8xp6xUvX72mdp7gI9FDdBC9Qk0PULuH+NMXNKsV86srFvMFpbFQdqFmgYJIpWHXWsqk+fRizpOrNWsfCREqY6ispixsZicgTl+QZ1qWGotiVBUc7e7wk+++z72diqfPPufpqzP+3S9eMG8843LM3tjweM9y3iSeLmOXeyAPewFaBdymzzbabTQkyBoyAnBLBj0FytC4yNq3nKxartaOZRvFwdVgdA5Iz9NwSAkXFI2Ddf6xRvTOdgoR3h+ZLG6e2bLdtCSBSPKjVaJUIsgeksbnDS/zrRR6+sdE01LexxDQJwUvIJF3G8ZTitvrSP7axkfasH36s6ZOiHzAmNaawlZobSltkcHlBHhZ+3v5BKkPCXYn95lUeySgdgsu26f4VON9C0AIoo3m81roXEuMHmsS0Si8KlBJ07rAsl7z/OwJlamYmorQ1qxWiz4xTkwOFUtKNeNg+kj0PU1FWYwoihHGWEgZFlAKWU1Cz9TvNjl1ztCncwhdwuOyPmOMAaVFwN8YlUPOPHW7SZrTtavNWk5FVWIKA1oUVFsn4JR3ma2lI1rJONMK1qsFMcBCr8X2NT4z3AtSKGhdjVYtWiWKnPFPvAAJ6RMNgkDUS6yBvdlj9qb3eHjwYybVAdpIRuZO3kBl36D1awBm0x3KqsQWlpg8QTVMRnuMyx2MsjRulcXW4dfp+28zZ35XCQL/OMBTuvZ606O//Wu3IAFvYuF0Whi3nXf7rc1k06Pmd170LeXOw9XA6f+65U3hAzedknTHX9fOeNel7q7FLe178ypf4SavgTU94JUgxYDWloPjD/A793lZ/n9Z1Zf8/X/871ks19SMsGXFiCllVbLnBXhazWFdBxavLlFFxSQWNC5y/uKEk3bNZ//hL6hGhgfvHbF3f8z9d76HKcaslo2EH91W6ev3O2zrIYDTe7gbJ7pzxLbuk002rS2nuj9kcL1r3VZOdx3QGi6CX6FnfcX+97s6md1V+iwdMNBBkixbQ1p16ISMQ0cDHjhs2QnPxKEBHDTYolRqs3OZkuxiZ2FwpVXPQuiy7MTMmOpS1ovjnfozbzpJvlqSPtidHsSx7PR3unAlEGF0Hzw2x8oX5QildBZ1JgOumfadyAiW2iQ3HAo9pWG/yw2gB3OvGh6Xei94A5BsQgf7ucLkuvc7aT2Re+tSt732c/XmoW42FwbjbjAkIQ3GXNd2MfVGULy+a6S2QzgEuBloHJEEeAqR48eHHB4d8+F3P+L+/Xssnv6c1XLOBEejE9ZYvEmk6Okyzt28yQwGqDR493ZgTw1+th5B7p/XN1RCysyyGNFGk4g98JSRCmETdYBr7BSfxOmKUfVaGCrv/neGaNemkmxDDFGrDYUpKIoSU5RoW9ChYNF7oorEkPA+EFxDCk6YdQDaIv1fQNno2ww8yW254DPwlI1hhnpbQ+bbt6cYJXClyympV17C7KzOoswD5lq/AikweTxrIIpyfA+yCilT1imjNY2LnJ06TgvFq7nhxw80H91XvDMp+FGl+LsX8PLKcbUOnK8i4xKmpcbnK141gdYFPlqJg3F/OmNvPObvX1wQkuZiCU/PI995XKBNwWikmE0j2jvCleHy9RWvnzc8Pw9crabM2yXrtua//9kpz04vON6rOJxVjMYV+3sz9mYFBYl37+0zHk3Yef8DpoeH7OzOUIXhcr3ibLEQYfakmWiNsQY9rkBrvNcsveLLuWNUe/ZXl+yOx+wZTTEZMzneZy8GHu5NOZuv8E3Lzu6U3//eIz54cI9H9w9wq4aT1y8J6zWzDDwpq2li5PVyyXdsxdEHP8DYEUmPqVdXLC5eM7v3iGo6I1lLdA5SwhiLd57FYsH5+TkvX77Cmyl2Z0w0M4rxHi+ev+Av//zPOLr/gP2DQ6aF4XBvhk8FdZxQqhGFLvn0Fz/npz/7mD/5o5/wzuOHFA8fkMYjPv3sOU+/eIKdvUTZgvPzS5qmYV6vaFwgeEgBgksCPE12UbN9/KuntPWaxXzJarGiMCaHjXfs2USlEjvGUKL48qreAE8JSmOojKYoDAoloaFJNJlQkjHRoKjKgv2dKT945zGEFS9fPuXTZ+f8xWevqcqKo/1dDieaD/cUn88TX8w7UEfGR0qCV8dAv7mX2JhNKQ3mCjJDyYpjfN5E5k3Ly6uW05XPzAqN0X2OkDz3yzVdEHC3cVB7qAoZj3sjxVgrCg865oy6sZsfM9yrNEbJ+leqhFUQksKnTjvqtzi5/JMs1+0Adcvb3VrZrYvqluP7h53XEwlljSEQvSNFT8jagbKWpc2aeG1jd7PhtHFeEzEnwgikGPvwr6IcZfBJ7B3nmi2B6c4n7XQlZ6MDlNJUxYS6XdC+vmLlIs7PCcnT1p4YE96nDHBJnY1O0keRrMYuBGhqXl28oDQFu2YM3uPWK0hdJltQFBRqwt7kmKAjrUlYU1LYkegwxkzXUx19WIC1kJn7xmTWkTES+qbFxnYhA0spUBiDLUwGpxStk4QgMeul6syA0sZSVAW2sJjCEpJkLHbBSQIR3xKzlpIxGewC6tWKpvGksAKlme2O0AaIBSkWOH8lunEqYY3CWtlYTSqQcNl2CkS1QpmSnckx+9N3uLf7EWUxwVMD4ZqERcSFBqMt0/GMSZqxMzkU/aqikraxVpKfuHXfFb8i0elmucOOud2+uWvSuO6zv+1c6dpx6dpxt4y3b1D+8RhPv4mSxEG6bZ/4hghcLjfFndl6NikNOkq6u4nftDZ8ZZRz+Cz7v9UtH7ztijdP3C2U1797e622nZrtM20qd70zfpOabUOF1zqxQnYgUiS6gG9WFJMJk/09HtybMhvBojGEFDl7+rnE7RYWpRLjaYlS8OLJL0honLfi2Dctyrf4dcNofMDxB3/M4bvfxRRj0IYQxLHpxJ2Gm01bbXh9wF53gre6ktruR4Ovb+sNbZ1x+/xp+5dhP0xbB7ytDL+5JVV988g0hAu+PSUN2zCB0nKXXXiVD76/4y7codd+AjoUsDM8e6ZJ99qjpv0F6S7YBQ6pkE/Tjc0BeLLJVJeZRSrXI/W1xseQU9cH2bXNF1A57I4k4EAHQEQSaMVkMqYcjWmdUJUBlNbYoiCR8K30fxcCSkWssRm8UH2bdfOJ2vp5wyyXunuF2GcX6hbwLDye9Wk6Jo601bb6XNdX09ZfdxR1bRUYPo7BLDac8nvc5bYsfSkzSvoW6OoMrm0JITKaTDFFybvvv8/RvWNCfcX8pIFmSaki7zx6xO7eAee1Jy4WNCuh2mvTLbtfZazdnJHTVtunwb/kdhw8t2HfVxuNsaACXme9r0ifna4H4TowqduxTzkjoJKQ0V4Ev9vB7RlRaQCIpc1/uYIhgx+9rpagnpvQdomPlFCIJKF2KUoGKQGFo+hL9efJI6p73t9Cp21aijMa26zHFcVJXbWy+1tkkpjJRq5hGyCNSvRnZH5hKyxRgGFhfszG0i/XDj49a2l+5nm8V/DR/YpVmziaFKSkWbY+hxIpjIpYEk5LOMVn5w0+nPP9e4EPDgPv7pT8z79/RDVyVGVgf7/g+L4iFpZFY3jyrGW98IxLw/e/N6H55SVNe87Pnyx4ed6CUhzu73K8ozmcWFS9prmas7A7lIXl6N13qNrI1apm8eoVX/7sFyhjODk942K5osZAYTg+3KWwhkUIuAhOwcp5PnvyGoNnp1jz4OiQP/jh71NOp3hGoBuOZiPe2Z/wk4d7PHr0gP/i3/xnHMzGTGYj1ukKpSOjwnC8t8vpakV0jobE5ZWhdlCMD4loahdYt57laoWtG7wLoCLJStYrU1WUozG2mnL84CGj0HD/8bvcf/gOu7bl6unHzEzge+8+YGfvgMl0RpVq3Pw1OjqqssQkwHvevbeL/vAB79zb4WA24v/H3n99SbJkZ77Yb5uZi1CpK6uOPq3RjTvTAEaAV3AEeUkursVX/pF84gNf7guH964hR6zBABio1n36qNKVKoQrE3wwcw+PyMyqOi0wwBlYrcqIcGFubnLvz/b+dmkEI553TucUPgZYUSbniyxwtVzz5c+e8ur6hmmpmJcl1dVjnn/h+Ks//V+Zzg+5/uILri8vwTsmZcGybXHeUluLlsD7i5J35yULZwlWeLlpeLlpaduoMBdlRp5FkmAXAnXd4UNgVpjkke7RophPSrQWLm4uuFqt+Mlnz7hat0g25XRu+OGZMM16C8AYZdEm96E+UIUXCKoHebZrdT+1pEBjhABGCd45rA+sG8erTYwgiQhGCZlOFhYKnAuDTKckkAE5YCQqUabnXOsnYAaVPc1/cZ6M4FfYivrp2i4E2hDw4U3rwT+ke3ek9n7160FvleQH0ClaPPkhcuqua93t1J9Lbem3lk4QMDqLPEdZjlYapQ1B4gYmaa2i58kUCCEKEj0I07p6ACQzU3I0eY9CL7ioPsfbCmd7cEyw1nG5fE7TtFxfWYLXZGqO1oZZOSXLM6ZzgxBY1TfRlV07VBCyGKMWLQatMrI8o5Mary5API0LEDQSslhWA9FCKFpAax3BIqMllj9tWoqP4zoQ0Jq4+WQErQPORkDK2rjZFCNDKvI8i651RqFFYgS6pqUn5JTQkSlHMVGIaNomRgR9/uKaatOwqVZYa1nfKIJXp8d2ngABAABJREFUfPjRnNk8o5zmlJMD5tMMpRSn0xMm5RSRDKsCZ0dH1E3Lqr7CB8vZ7IBpseCd499jMXkAeJxvCIOFWpRxtJiEHUQ5pHORmzK6JAaca/A+bupBGOEMv93x/Ottqt2FJ7zuuvH3sPfM+xCRr5beGni664XfiORtzYh2f9+67qs/e+feN5Rjp9r3AIK7Hn4LFbyjjG9qf7krj/uO3GrvpIXuTqF7328rJLu/du0HblfR/pFdNW//fLirEm6V4HWT9zbX/YVhe0LiQoCjaxtcW2PKgslizsnxlEnmMdeeurE8e/EU7x1Hh3PyImNyvMAHy4tnn+GtIydFYtAl4hyu7VCScfzu9zh6+H7kRPAumtyGPr7ZPUDf3mv1kcHGNbztT+M6u90mu5km1XGnoe7pF3fk9+a0dSHavttu5K8waoBeWfnaAU8p3HtIYAjJlS2osMftk9zPetek8fHxt5B22wLcBXrDqAaHIbXNb2xdM7j9JWhGJQKw6CIV0aoAiXcqKt0u+DRceips2QqzSaoOSQAuy5LJdIq9WWKTy6GIoIwGwHZJwU9gltaafv5JmEB65zCAR0O0tF20dfRO23u9bGObSJ9DEt63oFOIUebGfbPPeG++HlpifGG/vowr3TO0t/TtNpzvrcfYumrsW2Em5Wa3TWPZrbV01jKbL5jMFpw/eoezB+e4ZsOmvmbiazLxnD94wLyx/PSLJ1RNQ02MnIPeCjF9ofbX0l2Lyd2ihPR3263CKAMZX8SwBRH6KVbwjmSBZkcWepH4c1h7eqL9tGh671Mo8MQNlnxBdf97r+xbpa+3JhtxZvWgkd8Sug8lT0pA5OGIIHAck7EOIql5GMj4A24E0r8ubMbf3zTNA9ZFQCiCgLH/Vj669wTipzZ9tCz6ITCMl6CIVorJfzTutfSxjEBpIdOKpgusWs+X1y2fX1i+e14yyxWdFw5LQ9VBZgI6hkscwCelBNGKxzctL25qdFDMtOJ8avjw8IiX7TU33ZqDORwfCxeNZtMaPvms5fkTy//wTxd88F7OZ0+e8vJyxfOLFZ88aZkfHXE4n3IyD5wUCrqWZrVmPStxSnP08JxJEK7/+mdUmxue/upTvCgur25YbWoaFMZojg4WlJmiu9kQrMNJoLGOV88uCa5hqm4ILmCKgmwywZKDFBxOCh4sSr51Nuej98/54z/8IUYJq5tXdHWDSKDIFCeLKfOLgmAtbfCsNprWCqY4pHWWtllSW0tV10yaFtc5REfbV6UVJktuqVnJyckZJzk8fOcRDx89pFovWT3/gplyfPDojKKckRcTMjrs+hIVPHmWx00z5zk/njFRp5wez5jOcgoT59uzwxlT6ZgfHaOynLapEDzras2rq8vIdZVr6tVzLp9X/PxHU7Jyxs2zS6p1Bd5R5jlaRcW2cS2FFs7nBY9mOTPvqaznqm65alq6zhJEyI2OVlKAd4GmjRH8FpMYoar2Fq0Uk7JAK7heX/PFqyV/8qsLRDTTvORoovjuITiBKq0Zzsd1sV9GBvuMNK1GG14ZZOEUoDZZPQlGoCMQnKNqA9cNtD4pmkrItETAdpjH4nhUEt3oDFvQSUtyb92xWE5WMWk8sl3uGEvogQg8ddvl7h8Sd+iXbyuWjpZwP1pPvHeRK9BZvLWE5Ba2bZM9GXt8YmjAPmLdli/DZAaTGbI8Rq3rLeUjj5QfZKZ+leut5iFxRfoWCBiVk0nBQXFOJlOuN69i8AAbwdmAxlrHxfUFdV2zvPEoyTicZZhMKAtNXhjKqcY6y3KzghDIlUaH6M6qiFxGSoM2U2q5ppIXuGDpXAfegCsRlVxFCSBxw0lrE4ElTbL8i26rKEXvaqhUBKaiVRTY4Og6N1gsa6MwxlAUBUVRpM0nT9NEmUpnDqUDEmzkMSxKtNHYusa1Lc+evuTyYknn11hnuXwe3YJns2NCKHl4+D7lZAphhlGGw8kBhSmiw6AKtIs5Rd5S25f40HG0mLMoTzg7+Ihpfkwc512UK0iAsQi9WNzrTNZ10d1QMiAQnE90FyF6VKixCcM9/Xu0KdgLzV9l/N+lD+4e2gp3ty2dbt25l+f+799u+t1ZPP2OCvzrpLvhpbvTDkEt48lv1El6wGCU/87vMIYV7n/2LWusN5bOv/GqMeC0X763Tds3ffs7d0CnfXOfux+wl5KYoITgOl599mc0qwuCackfHPHtd/4vuK7j07/+DyxXN/jzE6rO8+LVJUY83zlwTPKM4sEPqBvP519eofA8PMhYHBzyje//IcVsRjmpqFef8cl/uSYr58yO309hQrfAW6+U7tbDrlL8m/Xu+yeEt6n2t50MtlZ/fbYJUNh52Pb769hn/j6nbZv1S3+sd+ciuan3fVuMP+OVMOrKezJJPDRmMx7Vn4x+7U/6sFXWQyCIJDe+KLEIREsT6YdT2EZW67kICMlSarsLI8mdqucTElG4pqYLAV/dENqWmTjERNJaEaFmGgX4JEjUbY13HnMHoJDi9Q0LMoGBbLq/dsBrJC6sIQFAEHm09KhSetP2+zYbhzHoh6sJwe/Mvr21Td9/h+eH2N7jWZte4A9bAKSfrvrzMro8avH9XCa0TbR0MllBPpnxre98l6OTUw5Kg7FrShMwIuRORcuo4PDBxl1yJXBrN3tcd9vRd3sU3p51+nfoL+69DtIr0oOFY1FG0nWxjvovPX4YthmFLcA3LksgWdUlcFT6DEMkGZZEOB5dVSM4FM1qHM7G313X4mybCPUDIpEcRfcCuYt9QrlAkLFlU7QAdLE7DGNDhkhV7Lzr1ykdqWih0+aB1gmNHXNvQWOjMhzDSMtgAdXzxPU15EkBEpTgAJfmkBBgogMHhVDbSKjcOsOmVVzWwp89aVFEsL5xkJv4rNpCE0LcKVdQGNJYFX5xVfGysnx4mPFwZpjNLY8Winmp0JngN46uCSwmCnVacDQzLPLIRZdPc2aLksXKcDjNmBYZHz6YcTzJeL723FRrKoTFrOCsLCl0xqrecLVcs/7kVyDCPFP4acmff/kUC7x3fsoCQ9AZ3gZevnxO23VkmWI6O+Bb5x/yztkJdIF2XdP4Bts1nDw4Q/KCf1Z1nDx8CEHobFSUbIBsMUNsQDnFx++/w7/44/+RWVny6PSEb370IdcvnrCuN7y8uqRZXrO5fEmWLzg+X5KbjMJotIoE1j4IVevoVmu6iwsOT08weY5yU1TQHL8z4+ihH1yXJVgkWMrphKCy1NaB80fvcHp6TD6Zo02OMgYRxYP3P8Lb95jO5miTUR4+4up6zV9+8oymE4JaYjJHV9Ys8fziP/8nOms4yA4igW+mycucVVOxblqMMcyLjB+cn/L+rOR4WmJax2xWUto4T/sUBdQRgT7rPUEUWsO86C2LMlonXDctq6bl8dWaTd2ByjiZaL53onlvKky1RCLvIOQDIJS4z/rpS1JguLiIDpZ9sLUO1DrONa0HGwQvQmZgmiXAnC1n044QH6JBhkrciqJJYqsMAJjX0ZVeQnJvDjJICP0sJfRjU+jhMk0g6rZfTxnsq6WvorHdn3pLJudctBpyFu9iVNRtRDXSesmuzjr6HpLVUoxGF+ijqhltUgRXg1YKQi9LSupDOvJO9uKH+J28oyUN9FSfznWEEKNuaslo646m6RI5t8G5gBbFwfSUaeE4miu61vHq5Q11taYoNFMcC3WAhLhGegEnDoWn84FcYKY84gS7DjilyfQCoy2ZafFK8CpSj3iSmT4QiJFSrXM459HGoE1G7+IqGrROkGsA2zna1hNCdHNTKq7jJosut8YYlNbUTUfXtWhtKE3BdKLJMsF2LcG7yPskwmaz4vrymnW1ou4q8kKhTYa3lraGunE0rWNaFhwsphimaAwBNVjzQ2A6gTw3aHWOYDibf8wkP6JQB0iI3EwxQErcHFRqFJmZ0cZW6C0gRwKY9DpXL8cLbz2cfwug01vcxdsV6HcvR/1GwNO97/5meO0N+d6+PowG69tcvz953Q0ChVtH9q96m1cJexf0zbur1u+VYE/Z2r9e7jW53e0893XAMbjQ6xX7rix33rdbCHql9nWdsXd12M7gfUYjyZftO23fOWyVJRGQFCI3tNw8+zmb6ycszj+gnB3x7jf/KQpY3fwEc2lp/Dm69vzyZoPyNTL1lDPN5PhjVrXnp5c/R0JHfqw5ee+Mf/p/+tcEPJ/+7L9QVVe8fPIJ08OHzI/eR2md5opePB/vRfWfuyrYTh2HnV9bpOKuftz3uV7xu7XGyuuq+v407kjjMo4KGUbtv71sLA6N2uLvEHD8mya/1xV7pdv5rRUPxKW2r7cBSNmviiFKVPqZ+sxQr73Jwe7gH9Kt+at/QP8ciUr8MJzClpdlcP8b7ZT0PuS99UgfZcwkZcN1HTZ4fLOBrmVSaowWchN5rnJV4FC0Hjrv2DQV1ll04sEav0QPeA1FR4YdIelfZfTOkgTwEAs21M2+C+p4lO1V1yAQ9kSxnq07V7+bPbRZkG0/HgmUe6OVyG2VBLMe/AkDhrLbPEMPEbrWYq1lcjChnM14970POH/4CN2tUbYmz3IyHU3aCRA6v0PIKdwGn7aA3S741PNljefxWPb4RtKDlduCjtaU7Xw8rA89UEMYyhBdrVLd3bMSDUSoROuW2EUj1xMBJAmUKsS2cT4M7nShNy+QGMHRWY+z3RChjhDB0d7CQAAvkXxU9ZxcSoP3uNT2Htm6rwxl36avz6y1TXMNrQ+sTFRYbey4sT7C1mUu+LgzqxNFxxh4GjvnolIETVIbhaiQH5eBjY3RjDadoguaVRdYvurIVKA0gTLTTDJNG6BxgdoFKhcoc5howUkEAr5cN3xyWdN1Bdicb04DJxPFJE/RjbzHdp5JkZMvMualocw0WW7QRUZR5kymmnmZMS8M54cLTuYlj5/e0DY1kyLQdTWn75yR6UDdNtxUGy6uligRzk4O8UXGi5sVa+t5UXtcJkyVIUjH9c0N1lnOjw6YTad8+M43ODtagIWubui6DiVwcHhIluV8b1MzOT6Kbo4+0FqHQzCTCdp5Mg/vZGf8wfScxeKAdx89YpYrVlcvuVktuXj5gq7a0C6vmR0uaeoNerZInCkxaqQncqFsNjXVTSJUzzO0A+UN80lJOSlSdKuOdrWkqyt0OUGKCa5r8c5xND0j0+C84Nhaw04fPMJow2RSYrTh4CSwWtWcn/0nXlzcUFOBsbisZUPHX//kKaul55vvfYf5dM7hcYkpDJuuYdM2HOUHTPKcj44O+WBWsihyOjrKMievEo9KSDxsBNoU3ZM03ssMJkY4zDXXjefp2rKqO14uK7RopibnoNB8+0g4zoVShA7wEq2Vtuv2yNqXfk0MaWkNOBcQHW8wWiizOOe0jsirBGglFCZgE4+aVpF8PITB+zfOV367FyExPCRBkkUmkUstJFCpjyvaL9lDGcN4wyaBZYRE83DHZuTXLG15dPeUoOE8vL2CvHfdjuxEclFzKZCFjQBUsloK9NZyo3UkbPvS8DuEgUA8ELmctNJkeT5ErBORCKr6kIBPiWukyMAjGTfrxrJi/9S45nrfxU0X0SjRdK2jbS2mUCgRfOhQKKblAQEo8oL1uuLLz58CwuHhHJNpkvAVQScCTuK72LR+lngkCL6BoDQmm0DWEgoXXbGVx6VNs2gma4YxFlJUZNGa3JjBElkR3bnxnuA81kYexmgNphHvUSFgjEp8TRqlNM57mq5jZgx5kTGbFJSFoa5rrO0QHTdbm7pitbqhbio61zLRJVqpGMmzDbSto7OeIjfMJiWlHKDI6DqL9R4jkdu0KDRFUJTmGMOUs+l3yfUCoyYQhNZWUS5GoZQauFcGC/UwHp/byNI7s1E/acjdeMW4936Vk78Jt9M2j7uvu41zvH4Sej2F0ZvTrwc8/VecGQfC8KEY4dZL98f37mQrVL+5ksavuJ0gbr/3XVZL/Tq1/5TXdZHb199lf7IHHI0VjVtX3ned7J6/s67uKvDd77973WuuuZ3h7hkXV3QzmaLznOOzb5OrGRefPeVl95KXn7eAcPHZDbYNlMclZMJROce1mvqiQdeB2SwjD4rF9BRnG6pmw8VFxU//4q/xtubLn/0pOi85/vD7TA9OyCYzEEXXVElh64l1x2W9A+z8qipOGAtH4xYfA5J39Mu9w/sWeduL7mrKcUSjbTn2s+3fdzSffv3SfrX11i70rmARkLg11of7xqBp35YJpNyt4Fvgwt0FCXcCwd5HQkNG0agG4WgMOvUgUGDYWYkud8kiysbFoKrWOK2YZ0Je5pxMM4pMkZkIGDUuYL1naQ2NFdp2St1ZbNtGcvIEUO0IZ8ObbMuiRKU3214RErojaTdICAN5+rZKkyA2WK6M7gfwveDXQw29m2HMT8Y7iuOWC/tz0a5lVa8IhIQ2xXvH7yiDJ2HXRY4FpQ1FlvP+h9/g6OSE41nOhJqCCiOWAyNkxpCZZFEngvdxV3O8Luz2hfGTx7totwfhrltoX8cMCtbu/Bt26iU+RvarJEb72xv7t7DR0d9tZM6IdlgHksAmlYi/m67FBaibJoWNN3gXCN5j2zrtPKfQ01ql8SdDPXjxeGQg3HUhWeQRd6n3bTPfevn5e5qmMYhYtHry0bXHegay8chzE5Ve56FqEi9NigAUd6ITN44AIUSeOwk4ieHgbYBVF/NSAlpF0uMg4IOKrsl4WhvnqM5DG+B4ZvjmrKCxjsY5Vg1UXcBoRT6FF2vHclkjBkwGrTfkpUJhCK3ixcuOq8sWk8HTV4b/939e8RefrPjiuWO1DmSi0EQ3lHk+4zsfLdAiPDwryY3w5z//kk3dYBScH834/NkNVWspqxYbAt8+m7NqHZ89fsqzIufD0zlGAh89PCYEKMoJmdL86tkTrtfXnBxmHCzmvPPoIXjP+vqKznq0Kajqjr/+m59gMsVsArat6doaPGgU5+fv8/73/nuUAuM7XLWkuXpGXhQ8evd9XF1h14fMj08QJTGSqOoVV41g8Agqn5ItTsgPH5GffEC3rrBVgxiF1YqgJxA8Oj9CXJyXootPVHy1juCiBEmUKWmO1YagFF0e3RSdrJDgee8bMyqZ84unilXt+fxlEzcJZcKkFIqywOSGqm6pupbORpTlvNSc5poXy5qqtvz4+RWrzvFktWHVtiij0SFywTgn0VwxgBLPJNO8d1hyWGjem2u+uO748fMbvPUoMTyaGf75OyVnpfD+XFgY4bgQgtbY3PBF02B9l+aFrfQSA8RHcMh5sC7QWc/prOCd4xxN7N9dZ/nlReRxCQHWNo4nJdGiT6W1t3ebkjQmOqD28KoSbhq42MCmg9b1YC4scshNGj8hWSOTAgGoCA4bHdfVWSE45ZlnQuX69fRveYL5e5vukbPSxod3caPI2xZnm8TpNIpiPapoGVd6ktHdEK0uBWFI5OFGx2h1OrlTDW53qTgx4tvW1Sok5LLnk7IpYEZIa9kOz1SIMg4Sg5JoZajrDQGP0TlGG0oTECUspgdMzJyPPojckcW8AKO4uLqij+6oRKFNtFR2wdGEwKW/QRyI9bimo1muUJNAdiaYiSY/yNHBUwRLH4zH+7g2SKaRHnTLMpTzWNcTl3uc63C2g6AGa7AsN8lSyiUrQY8xgUkGk6MZMI3t5CzLq4pr71GZQZRCmSij6UxTTDMOjxV5CTiD6wyudfjWkZuCsigwYlBBYZ1Lc0DcsoqckZ6uaQDIVI7ogOcGF8D6abS+TlF1Y7yOgHOWEDTOumGTQJKBRGzjrTy77UFRj4yVkihcRO7BJW735tD/2OmS4c7vb5/C6Pk7T7p13d9G+mrA0685I26F2iTY7/muvCnb+6Kp3fe7zzMqNyNBPD6d3cq9T0kcN/Sbrr3rrjvVqNv67+h778hyq7jjsg7AwesrbSRjslMDd1X2UFl3lWu3rnYma9keH67dV25GWey/0k5dJZ8cZXKUUswO30Fa+PzFz7m5vKT+YoUXgXqN1orT4xzRillW0jlPs6wxNiCdxpAxyRd0ktF0Natly5effIprVjz7xc+YHZ/x8Lv/jGK6QOdFrKN6Q++n/Ka6HSzA9ttme8H+DXvHxzWhuMuFctfXfIym93dKv0VDCHf1qO2xHfAp3G7ZrUIc7lDYv0ZpXKWjH350cndy7ttNGKz/RuOYsfCyO8huP3tvV+R20dLcmMa4EjXqNmH43xeyt4Tq7x6M7FIf8c4hCG1woIWzg2hVcDrPmGSa3MR+UduA9QHTCJUVLooSL5a2afEuhpTezqG3gbKQnh1S37kF2IZ+V6gH2rYz4Ha3qO+BdwO8W6svjyegZOtmOAbQ+x3mu8pJAmbGgFNg1N6pTgfQqZ9BQ+R0cs6SFVPyvODswUMePHzIvFDktExoyMQx0yWZ8ZiUb+WFJkWAGW+ODHkzmkv6c7I7x96XdgWRVNfs5nVnFSCjmg6DW/j2+Wk+6YXopHWNW8YP9bUdBypEIMp5j6jI7dLajrzrMMakKg4xSo1zEBy9WT6ytWGLrDeSuLdky8uSQCc/tkrsv207/y3Q7OuQCi2YAAcCjY9WGtZD6yIo17hoadQkAMqFqORC7HtKAxIGzo6e2D/iwRHg80Bl4/NEQgKfokVjz37Yk8x3Pro9dgFmZcZHJwUXm5bLTWDTOqyDSS4UmXB96Xi8dLxzKpwfgcVh8sRL1ymublqevOwoSsPl0vNffl7zJ7+o8TZOO8dTzSRXKDS5KTk9mTMpcxbHU1zw/PLPf8zLVxf842++y8GswAG182zaDhF492DCqun48asrglIcTDSLMuPBUQSwOsmw1vP88pKmqXh1fYLODJP5Am8t1xcX0cVFZ2xay+effcF0VvDhe0c422JthwqgxXB8dMS3/sk/o2sqVq+esHwJm1dfYoqS+ewQ39a4MsfMFwymLiRlhxQeKggqKzDlAjM7xszPMLLGyAYIuBT+UQBdGnSyQ5Tg0cOgTcqTj65hW8JbRRDBmhIlCk9L8Jrj84KHbclnN4JrAy9vOnwnQE6em+juZzRN21I3LdbFvnNUaA4y4bpqudp0fL5aUznHteuorI0RNENILk0y7LkpAoUWzmY5pxPNR4cZbRcI1hFcQKE5Lg0/PM+YGzgwMFHCIlMRFZrkTAs3gE7DGhK2EhVEsNr5gHWBWaF496jEO0dwnqeN5fnSRVcaldz1iPOv6cH4NMH1wJOS5DLowTdxTCwrqDtY2ei+elTG6HbBgKitTCFE1zul4n+tFKKgQDERKI0MVolfJ4Lx11lCDKvKrUu+uvw53NHLRj2nk+vwrhuCCDkf0c+t6NRv/40XwihrRA6orcWy0RpjsgRAaXr5LyQ3S5RClAwARSxOiFZxqROF4MEmK0TvkkwzijA76BYhWVYZ2jqCJtl0giBkOkdrzaycUWSe87OHMQqcNHgCq9UGQaF1kYBOhRfoXIfH0foW8SGCRlXH5nmFnismZU6pDWVWoPFk3iRrPOi8J9gYFVdnGSaLkeiQxJGVgKcQLM63KMlROkNrTZZFiymPj2uPikT8uYFJUZJnhpubGzabhuV6TVU1lAcLsrJImyUB0YqsMEzngs6EzbWhcxnetnhH5I3Kssg5ieCdT/JJtGxzzuO9pW43gEdNJvig8GGNx+BDg5CDRAL2fk7pCeC9jqMzehLENh42CJNctVV9+01hSQC+7J4flLh9pXvkF3WPDLjPwTS69bW/987ekd/rn/um9FXv+9uLave3COOPdcH/GlP4WPV/3VsP3LxbPWTAgIayj+bDX5fD4j6VRPoHDs8J+2d30ps712ghue/acPdbREI2wXYVELBdi7Ut7uY57uI5q/YpXRJeRCmqqz+PO0aJHBkxVGvLpz/6S0IQ8gaM9wiWzeWGP/3k35EZxcnpKeXBxzz65g8p5ocpapIbhLN737BfF7YUlmzhva+axi3ci0rbFgp7bbJr4XdfXnvFfcNEFEbPEYkhTyOYFRiCpn3t0j2T+ej7COJLnz1vkIyufY1yf8/xsctS/yWkcSKjE73OHx05tnn2gFJ/oCfFHu5L3WkLTMY/SqKlgyKgQ4i8IkVGlsdQt1mIZuSehlJ53EnGxmY8VY667dhUDT74KEhJz8S2P8fJPexz28lrYIfqgc3+Q/auFzVafBkANx+247N3nez5iob33clpdHKMvo/Bw6ECt60WeXDijT4RW1sXFacP33nI8fEJ758tOJ5rpmzIbMdUdWQKJpmQZYpAhvMBY4VMOzKTY0yGD9G6LIYy2H1tGPWHAfTZOX37/fo3D+Pj27QLR8tw6dhFTVL/63WdseI2rpnB1H7UDwPgXWpZ188l0WKv62wUOk2G0VEYlFFH11oN9awHUDUGl+jrqSfT7y05hh3hUXv+7UkV//VSv7GaE9tnYSL4VCeFWY8/PbQ2cms0NtZ55wNaQaGJ/dTEzyKL19c20DnY2K3u4xHyLAJZtm/bYW6JnDZdAiAKge+fTTmcGP7sizV/+WRDZR3XradzHtGBk5NTPvzwgMX5I9TJMeu/fsarL6/4i5+u+NGnS/70F1cUuWZ1I7x/UCZiZyHLPG3o+F//6ufM85L/+//8x5w+OOD8ozO8DjT/RvNy3fLnv3hCYZI7WmH45eUaD/zBw0OUCE14xU3r+PzlksWk5Fvf/5BMhE+fPKeqG242Gxye56sKla+oXz1HiaAxaDNBpprqZsUvPvuU2bQkE8ckUxwuFnFODILJFb5esrm55unjz6luLtlUNcYHgja0mxXV9QWTICzKBUVTo22FeCEoje82BNeAS6T/3sdgBN6C74OgRAApoiDRFaa3+IkAVED5pBQNBDbJDVsyUJpyqlFa8ckvf8Wrl5/xk5/8BV9++SllJTxUB9SFpdOBmypgneKisSgHN6uKtm3JjWGSGz48WjAxmp++umLVWD5fVzFaXWnoXEBpSTq0gAdrYyS5w4nmwdTwzXkkJf7p0zW/umzZdPH8Nw40DyeCOEuWG47nOUeLnPcezbiuLF9eNLQ+hnf3pA2IZEkUgqe1jk3rWTaBPFe8d6o5mmpygZeV52LdYiTw7oHG4XEhsOmgttGNsnddBZKiHN8hhMinZgfLpEBjI8AV1+2tdW+8IAINPkQgF4FMC7lWyZVPmKl4b24UbfBYHwGsf0hvnwZZNkTByHmbXLq76H7qLSGtK/2Sv13DxiQoyQopWY2LCNroZHmkB8ApAhl2+0yJfJh9xLadTaaxtXgSypRSECKnm0cGVnzvHSHRPxS64MMH32XdLKk+q6i7DW0XwXQCBAfVpgWBg4Mpne9YdTFCY9woUhhlRjWUykLASwAd8GVgtWp4evOK3GkOF1MOijmLbE7bCJulQysGPlCt4npeFjnaZGijY1jHUg+PsUbR5QatcpTKI/+V0ehZGTdA0lygBUJX8/TiJZuq5uWzG26uK/KJQRea84MpphBc10WOri7gO8WkmJFlOdgcrRSP3p/hOuH8/JCj4xLnAlXVIkFDUCC7+lpmCiBaDAdqXtW/JNdzjkqFUQsKdYZCRSs1IYHFip7nyXsf1+OeTmHYOBx88vrGTKTrAZKlY9iRQ+/vy789rOSr5fO7IhK/K7098PRWhdq95n7sYf/EWI25ne7bBX77etpeOL5nh2vkLTPbXna3Zr/Vb8Y7y7eLsnXr2FNIk/K4Ve7epOreV87X37ELsYRbIAdjRfd25mxNB28ff02hdj/7lAQHEYnEs97ibIuzHaFZEaormpuOxgleLwiiqF4+Qys4ODpBGYMVQ2cty4vPEQKzfIYRjZOcelPx6a8+ZTKfc/Lgn1BMH3D44EN0XrBer/HOch8gNqohtq2wfY+et2b7attJfv9dd11oZL8F7vi2FXDeCHC9ESG/fX1/RqVJNVqXSnKH+vqkWHt9H09pr5/eMpYdjfOxY8/tdpJbZ95YGNgBnYa+Fba7IsKo/Uf/h0u53eTBjw6Mdlnibm1AETAJDMiyHKUFJXFnr60rDJaQT5h5xboqEBHWmzoK2moXkOhffShr2AU0dguWXMjGdRy2a/RwvQgEvzMn9iGLe46nbd319+/ydO1fs230vXba2zkKI4WhB2FcCDH8crr/6PiIR4/OOTkoOSgVWdOiXUOZQ6YVuRaMUdjYlCgVLde00mhlolzst4Smt1KqzH6HvC8+r7l8bEG2f+HOa/dVIdtx39853uBQo7oLw/cE+BF2ntnL3VvXBT8MK9t1iAiZNmhRg9WXMr2JegZKRSvWEXbWR5Tsozf25OK95duu5V/flG8nd/x9TZGYHkwAVGCiI/AEDH3Npc0C65OLkYfOxnFhfYikyhKtMXqQ9LCMPHd1B8sWlp1sAW2JBMtOwojjZjvCQ4j3EqLu8c4859sPprxcWj55VdN0jrpxEfxQMJtPOT07Y3r0AWp2TtvVrK9v+OJZw0++WMX3FOHd82NO5yWTPBJQL21D4yx/88UzghX+r//in5GXEw7OjghZwCrNsrYsbypyo/ij77yPyTNePLnChcCjoxmzTPOLVytYtvz4oqa1wnS6IFfQtV9S1w2btkWM4qpumW4qmuU1mc5QGJQ2UGjasOHZy1fMpiUPDuecLCY8OjiM8qkP0bKg2dBsbri6fEW3WdN2lqAUumuom4rVZgXFlEnb4rsGcTV4hVcKXENwLXiL+AAp4lPwjuAtw4BTcaQmeHzYChNc5F/rbdR6q8IkywUV+bu0FrQRrq9f8PT5Zzx58gXPnj7mtHiXqZqQZQ2tciwlbn+srCN4eLVpcV1LphSzXHM6KzECT5drXm4avlg3KBHeo6R3V1EhuSwHiSTfSpjmikWheFAKy8bz+LLm+dLSeJhnwvlUcZQD3mFEM59kHB2VPHzvAP+qoruosSFyNwUV5w+BYe20ztO5QG1hUkQrt1kRXXrrzvNyZXk0F45nitZ5uhC5nbrE+eSSu+kAPm1Nc+k8WNgG+/D92kdaa9PGwcAFmeSO5LqjJRKqK0lufUooQowEppzC/QPqNNpovW8iH+ko/bd+UyJxDEUy8S7qE30k1LEMGG47bMfr7JCfKINOVk5GZ2ndkuhO5nuUHpTWEXBKLna9vjp+j7EMr0QgWR8OwT7Y8nNq0WidcXLwDpPmgEz9mCa0WB+BJ0NGALqmQxnFZJ6TBUVTbcB6rFNIUGilCEl2Cj3nGSnqo4KQQSOWq2pFqQzZRii6gqAVNgQ2dXTTLnzAGInyjVIUxiA9eKrjPE0wEAJWBKcUKgFPSiuUVhSloSgNrvW4zmNtg7Mt11eXvLy44vFn11xf1Jy+e8jieBoD0RjBNg7XdQQHeEWWlWSS0eaB4ODouICgOTicMpsXeB9oW4uWxE9FdCnvPR+1ilHoXLB437HqnpP7FbPsYRyTnKHCOErfFnQat+XQnClidgS49G1MIWx72Y6c+9r+vatd3Hnda+TCncvCOKftHV/V0ul2Pr9Z+tuzeLon3e26dfvcb5burqxfP//d+yTsqwBfpXHCMIH1779/9++4FtLfbYeUHX/UUYcNe5/7OQ47AK8Dn/Y+06yrTQ5KqG6e01bXvPjyP9MsX/HhP/8h+D/g/Vc3VFXD46ePqZuW2h/hPFw1G7TqeHAafa8972Et3Fx3BO8ppeXoYMq/+MG/YrKYc/7x+xTzBZ/9+N9iiin57BxjCorygED0v94t4FbB6//t2lmMVN5BArn/9fuTff2GEe1r/BsFNmFr8eBHC9fWunNkedCDXXdU9rgp+r4ZN162lh8qgROSJuevo8XTm5plOD9W3NMO1R40/Ft5/lh3HkOQ+3xRw+iT8a8+7YJlkXC6B3kS34UWcpOi9OjI6dIhiCrQ2kTAF8/BQXSDyuqGpvM0B4pVkbOpJ2waS2c7AIpM356fwi18g635ej9iZHf0DODR9k7ZnzvCbUJ1krA2BnuH2pXR7yB3NPj+5LNfl+mZPppp2xAIojh9cMpsMuGdsyMeHpbMVUfhLZmOlmCm3wGcLFBZjrQtIVg21YrluuJmtWa13kCIu4bxMWH/yWwRmLuFg5Hkkmr37daZt+m545rxo6MJN0ik7iNXxRCGT4bfIZmWp5kxJLVYAt6n4w4QiaGTlaLI82ge3wvsybLJJb4o7yIRubdpJ9rvgk/7G0EhvDmAxt+7lMZEtFqETJJIrXsXoRgB06goB+cqAk9VF0HOeI1QJQ6nQHSTm2SBQsHDCRxkkUtqbeG6iX2/83HUapXcDfx2jBgRJlp4sWz5T13H5cZxsXYsSsP/7b8744vrmifLhk8eL3n8ckNZnnBw9C2y4vdBf8iH3z1iMX2CW3zGH33/Fa0L2BDItaAk8KsvPudqeRPXqUSk3vnAn/3yMRuvmJwccHww4aODOf6dY372csnGeZ7WjtIJj2YzCqN59+SAaab56MGaLFvzN8+uuLpp+fNfPWZR5swO5kxmJdPNFOsDf/nLx3wy0dxUj3lwMOWHH31ACJp2KXTVEq8Ny8byN7/8jI/fPef3v/0RBE+12VBdv+TzP/s3BJ1xvihhbuBsjtKKLMvojhfUZ6cYbchMh948Z/XZkrwwFJOccPEp4eITnDdYr+O8qkxqsI5mc0O7WaMzjSSLQUEw0wNUPqGt19i2iWPFh6j0JY4XpQSVB0RlXHzxK7zrONBTPjr9mG88+H3y5oCLywtW3Q36oACdgRbEgWoqRGDqKzyOstAs8oyFyZEQibV9gEWZRyuxFFJ+IEjqlb7MUOaK04MCkwt//bLhxbLj3326oQ2B06niIBOOs8BUoGsdRVnyjW+/x2SqkEzhfUW3aXCtja6g9O65pAiPnlULpVF846REG0Ebxc3G8eXLJas2sGrjkFoUQusU1gfqTlF3Q/eGpKhHXDzgXCRrPyygNPRLG9et0Hk4KiL5/oOJMDfxlV00ekDD4EJcWR/rzIXBjaixgaoKVBYKJUNQgH9Iu/JNn3YkpEBaF1zcJEqWTrZrBne7ASy4lUFIMsbY64HBssnoGHktrnsxOl683ic1p7e008n1jgRepfm6JxcnyfW9SKIUEkI0ZBxvpqR53gVHXDYFFQLvnX7AujnixfoLnG8HAV1U76mQ5D1RyZUz0jR4idyUbWdTGaIpn0qypHOCmZScfvOUzAiTqSbTgt+02NpS2RrfBvzGoxVkSsj0hjy7iZuWBspcMSkVPnFpVbVjU1u8UzivybQhM4bj4zkHBzNePLvk6mIFKVxI7S5p/YpVU7HqWs7NCbPJFB0E31o2qw11VROCI8s1+WRBIPCrZ6+4etmQmZwiz8hzxWRiUMoRAOuiBKx1BvRRJyPvVyC67iGCcxbvWyr7goClVI+i17NXoCJPlSTLpQhAxdiTwfsIHPb1P2qHHRXZ+wTCb+XX+4wc7pJOd667z3Dj3nQfkrB///7v1yEQ4Z5rvlr6nQBPt6v1KxbyDdYn6ZK3zOq+Z9/dCNvrdxHCO2atUUHC7Tv2bxuukZ0TO814xzv9toToflCE+15r/Myw39FGWt642uTuTPpIVuGWVQm3rw/EgZnCV9p6Rbu8YHn5GV11yXt/8K+ZzI5ZPH9FtVqx9teojWD9Md7C5kWFEUc+g7LU6OKEpoWL9gbftZRUTA9zvvuPv0c5n1OeLOic5dWTn5IVC47fLaA8YDI7iZML3XZ3oueBIe4Y7Pa5HWeZt0p378yHQVHr5fre9S3uePY8LP3E11vS9dEy9qryjuf2AhQjgGCXc2YXeNqFQv7+p35NH7/TW81IQ/ce3fmWU9ldM+Ct6T5scx+DW0P364/0X7aNl0Cb/YWJAdzpc1Nph1XHdTRaRwBeGUTlUQgSKMuG4ATXbTDeclhO0MpQ5DHUdd22hBDIzNZFajx57WwgDG8VdvrvztSXBLfdjYcdNCnVxd6422nMbQFC4n0a6mdY/UeVs/M5+rkzMaYQ4D4SXCOK+WLByeGCo/mEg0lGoSwmeIwiWvNkOcrkSF4iWQ42Rr9puo6qaaibhqZtU9HiLmRfjC3BvIz+9kULO3W80xlk3GMY6u0uUDCe2M7VrxcrZAQkxjODU3HaJQ6Jy2swsBvW6zAsCyFJ2Vv3hu06GY97tErRerSPAn6/4RFSFCHvU1SiEejUA0/ctnzqv36d5i7YdlEJcdXpyeq9gPKBTOJ3DSR5ObpckLigbAwb3/rkEttFkMr6aD21yCJYpQRMA1UHeOgIRDeB5H6kBBJwpQWUFlaN43LjUKKQIPzg3TnfezRjPtHMJ5qrqzVPgiXPZ0wm5yj9Ht5/wPEDy7yc47qSD88u2XSe1gWazYq2qXnx7Asuu4agc0BHZQLPp8+vCDrnf/eqYi4ZJ5OCzeGMn9/UtI3lunO0QTjICw6KjMNpySTXnC1Kqja6rNW247MXVxzNJ3z3fE6mCjKdsawafvnFc0zmcNrz4YMDfv+jBZBha41ta4JErqP1asnhYkZWTsE76rqhq9csP7tgcnTK6YffQRuDyQ3R8QWcn2EPwHc1rtng2yXN5gI1KyhDAZsXsHlFUHOczNJwTy4d3mOrDc3yEpXpCD6JRGUzy9FZjm0b6mqDbS3OeYyJJMhFrjFakekMIbC6eklX10zKgmJ2yoP5u9Rzz/OXF6ybipkUiNFp5yugbIuSQBk6gnhKkzHJDaXSaTwKhBgtLvIXSbJQSPK0xLlda0WWGWaTWI7Pb2qeXrf84qKlzIWPzwoOMpjpQCHgXQx9fvrwGK0d0BAA13YEt7WM7Xngeiu81gZyrXgw13gRvAjPrzo+v2wIKIJEMKEwcX20TpEp6Y2Eh7VKDb7O0VrL+UCuYZZt5fWNEyywKALzPI6lqQJs6HXOFB0vzputi+Cx8g6dxmxnA10XAzVk+e7ey39L6TYf1LA43z6elsbBFT9Fr7O2jaTiLm48+yRD+zvkivRlWGd6sFEpRTbictquQdu1JxU4WTpFAGrXQ2H8ufOScZ1LJjj9Rs5YwPPBRbnJxTn/aH5CkedcN89pusiPyEgfgChHxN/pGQQ8Do/HumjFpZQMn84Fglfo3DB/MI+cTni0CKGxuK6jcx2d9TSdQyFoQEvAiEPpgDKeaalZTA2+67Bdx6pyLDeWtoWuhcLk5CbDWvBO8fjLS54+fhWBKwXZfIUqKhpb0zqH0kKe5QiCt46mbqiqSL9iMk2e54QgbK49l89bjo4VmY4Wg1mmkRAXKOc7QKOUYdioC4HORvDQYEBixD+wdG6JFoP3HUoyQlDJsHRrwTaAjfTRfVNEX7Wlh9jKaJLEX5/m8CizKUlcbiOgcbyxeq/ssiNH3X/dmz2d9r7durwv092g728r/Q6Ap/teaHTFW1fOffd/tRK9XRpPcnfP/G+Gw/avluEb+7mPgIDX5Sp7ZXlD9/zKqdf17iIB3OEW2lMSb2XSfx1fM67K8fFbj4pINCJMpkdoQNycdr3iVz99hc4rmmqNtQ1BTylnE5h8SNMFLi+v8N0Gv3EoEY7f+YAmGJ60V9SbJZcvlwQnqNkx3iief/EZ1nY0TcvsWDOdHZLlM4Jzw+QSxS0/FHZQogeFe8C2R5Zh+++2r/j21RC4T7Lopy8tKu16qWQi61Fh62s8DqLRtw2kxXW7JkYCy/50TxpMf1y2r+O3itzXTWnr0y1jmh1h4L4Rv4fS9l9/DcnwTXOWHz1mJ/uRGeTWpUzo+Q/7IMzxBUN025CASIy6Uuaaaa4oc0eRRYW/c5bcuximPkSCVmuF4DVeouVhGRoQeLgomBU5T0VoraVtayBQZGawsCIkJqwRsCR7c15/YsBB7phqb1tOhVtVv61MGfIZhuBQVcNTdvLeH5Db/JOgFuKxum3pnOPR6TGH8wm/994R50cLTiaBSagpEAwShVOlUPkUyXI6ybHBYJ3HOkfno5WG9T7ulqYVQcK4BL1J/qjWUhSq8Vy6feX0Zadqdt/rTtLW1/a/0QBIjRDr5na/D6EvdTo4BpS2IhlxBt26evb9theyfGfpAOd8IkDto8X0wnd0s7PWpQhFY1e728L9dmX86hsCf9dT8jYd3KFVmqdVWocKFVerLlkGiYpWUaVEhbzLIvH4TRutnzYddA6aDua5sJwGShMV6lkOD0KMcOcanyL+RCtcTXS9cy62qQ9glEKheHFtubleclU7vlx1fOt8wv/47VMmruPcOD48mWCynL/80z/lP/7H/8A8s5RZ4NHH3+cHP/xjrM9wDn7+J/+W5599ws3a8/xliz7KIBfyyRRnPD/9/AuevHzJO4cF754e8vzacsOEZQdXteX6yZJcG37veMo0E5abDTjDea7JD0r+1bfPebnp+MmLV7y6znkwn1BmGm8tVWe5qR1d1fHq046LWvhn3/2cqZ6izDGiOyoHq8ZxfV1xfLXi1cUrFtOC89MFG2d43pUwP6Atz1DB0XUtEjwKh0PTYUAvYLIA8Yh49CQjmxeYQ4s6qJAuQBciv5NLZjgmR00maD+PwRXSwh5EUJkhyzPIJrhO0fiOTjwkot2Fyii0ZpaXZEbxzAaWVceRnqAkx0wmlPOSTgU2zmI3DpSKQKWAwTLV8EcfHFAaTecNuWgmNlB3DqNiePQ2xLGKqK27WVLUMyM8PJxitHCxdtSt5elFTWc9R7OMgwLem3hKCWgXWEwzvv3OjIfHZYxMbgNiHZmHo1nBtAiQLPw652k7oWrhOFfMS01rBengcuV4tnTcVNGHzej4Xwl0NgKzMXKmT0TlgujI1RSg3/ujV/QLHZhmAUME255tQgR2veDS+qUkYNNMqJSK7lQ+WY6G6KqHiYBFtKQIFLmjtQE94jj8h9SnO7SkMeDkLNY2+GTpFLxL0evuXvaGdcT3XE7RysmYyEcULYf0YOU05uYZ62MqWTxJchnYb7ct35PfW6e2euF4A2WQ+3wsm0uA0eH8jLk/RrShalc8u/wE61oCLc5rpCtxREDD43BUMU8vKdppBJuM0fgQogVUWlO0UkwmJTiLa5vEORU5AcsJhNpT1V20oApC49oIwNPhaYfxFMF1obU+/m8dbevRZGjJeHF5gTGa66s163VNmRXkWcajPOewLNlkV/iiItex/ruqIdgWZx2CYraYkmWaqqmpm5bly47ls46H5xMODg2iLM41BG8IQSVxOM4Zw6Z66CWwgHU2Hs+ii6QTh0vv5DDoMLJsUmpw1ev1CDVsII43wOJY3hGdQiS6x0WQUpss6W23e+brRLRwz/fXpbf36NqXl+8CgH+76SsAT3ua2mvP/3rpt+da9/b57CokO0jJXo6vz3P3rjB08P0Os2NL8pbg091P2yvf25uA3cprVyHvJ8HeZDP5Bu+QK99d4D60+VinDPsXD6jbbj4xjLwiKyaId0go8K3h4vkSLw2WFoJFyNFGU06PoPMElRNCg28tFMKkPEBJgZ4CHioPpYNgcpx3LF+9iv7foilnljyforNi2FEfF+u2spreal+b3tbk9tiAUPd1M84mjLWxHh8f8uj9/0O6ViQCDT0Xk0i0ykBtebb6vjUubSTGGz22d9lIlga9Sbdj61q0j6x/HdKu++hwFBgBIDtH4X7wmZ26eZ2QeNfz7r02/R2ApaFwDELN1pw39p3e+g1k8DX34iPZrVJIMhfPjCLTAZPIV33od+/8YL3ivBC8wosB8WQ0BIGDskQbxVXtCaKo6wqCJzNJxR/6X9jp69vxfwfa17fFUPcjgOjeGro9m2yB17sqc39+HJVz53gfba83e/d0ztE5x6zMOD2Y8uhoysPjCZkCjcWISVwdCmUMymSIyXEpKpXzIRFjx5gqPYgSayPsdgzp59z9jhhuv0YY1cDOO4edWumn2H3cqK+znbRvHSbjZ2/rewyYhTEYPwjOo1lftutfPyv1VnKBqMx5v92JVkrQzsc1R+vhzqhYbOtv4Eu5taM87hdfn3mrTzvY3miGiEpudHvzIZC8GNNcEcnGe0VXO6hdoHGRyyYCT0JtI//FYQHzHLJk0WFDQHeB4JP17XhpS653vauXEmG9sbzcdJApaoGPz6d8cDLh8rTErQtOpgajNY8//5zPvvySBydzjg6mvP+P/3se/d73gRLvhOe/+hGXz76gs7CpPNN5iF5fWYYWz8vray6vrvjRLz/l6voQjKL1hspC1XpumoZMdXw8z7FOs2laMvEstJBNMr53fsD8puZPPrsiVC2r2hGCxAhP3tM4z6bzLJuOvBAuqit80TFRMxBH5yIZ+03Vcb1pWK5XlJkwmy4IYYrujmAyw2UzXFdD20BwSOhwEjmplM5Q2QStQZuAmmSoSY4qD5HJAYSa0NUQPME5QBCtkSxHlwX4yOUUO0IcM0orgsrwKmC10AWf+NMUpWRkotEmrgWth40NTLzCCNGCKjc4gTZ4fOtBeZyPwoPGUYrwjaMJB2XOqtPgFHkbaGy0ktBKRaAsbPvfOBmlOJjmhBC42lRcV5ZPryyZgvOJ5qAIHOUeEwK685RGOFtkLCaJGy+AsgGNUOaazES+nZ6/x7qAdXH2K4xCe0AC69bz/MbiE/+cVkJmYhn7CJAuJMefBLr3lk8x/601lRAwOlo9ZT34H6KlkkvX9WMzkijsuUJth1Ban7fjODOQkTYbvkZT2Oui2t2fRrIZ47Wb4UBIiGAPMrkuWjp5223lG/buG9/fWzB5jyRXOa0NmYmuWfEylzgmY7/qg+/QHxksjuTO95Sd+xg2TfqzYSQKjPW3XjZz3iKimGZTSJYym2bJxeoxATfwUXm3dTeNWw9tArQM3gshubkrHS0Rx89VCbj2EnA2WQalnQ5tktVfsIQEYnVtS13XON/gfJ3awaF15MHyCcBtW0vbWsRniDfYrsN2jrZzdDYwKwMTG8AWFJQUak1uWkxyD3bWpvaJwRTKsqQoc6q2xXaeduNp157MKCYThUjk53IugbkpOI/zPuk6Ww2rf8e4mRJbyQ//LCq4Qf+7CxgM6ccugLTbWcfnegBT3zUWdoS0cP+5/tDtHO689m4e7W3Dh53jtz7e5olveN7r069h8dRLQW+zszhWqft7Gaxsfjfpq2Y8hozuUYC+cmH3OtgIzOkzvyvHrWXUmybr36zydjrJYKrZ/5ThszffjGqETpNur1KkhTcNzCG0+RYxSQJzvFv1i+zOq41+SBQMTDFHqZyDxUPcdcUv/uovWK/WkM9AabIi8htIfk1AOKsdEnKadeCqaWj/7M/xotGVY2otxk3gsuM//r/+F4LraJfPWZyc8v3/6f/A0cMPKA+OCQib5TIq4vTtsK+q7a2Ce/3lTrhyX/Eb5Pf+7xjEClvuGu+j213aLewF/Kj8hS04pbb59i4y292ZMNT5/kIuqW3soPyNCitEAO5rBDy9LvUYILx5VP1t1si+UKOSNYhKu8lqIFXtt2Linyw1v5gcpQxFKeQ5ZEYw2mMk8gvYpiZYi1MZMUpSBtoQjAfJyHOLdpYH1BwYjX44Y90GPg2Opm3jTj5hCC+7U09hF3waipc+JbDj1rlz724t7J29/9oBhGJ/ZO4++64vPadTYx2dC5wczJhPMr7/zox3jwrOckfpG7TKUKIjyaZWZCYqfB6iAuQsQTydd3TegzYok0elOTN0dbqOIVZiVNR20M+wO8XcWS8M7X37TEhzx7hyXgPshV0euP3K6ueX7aG7xPlx/vGdPL11V3SJ8fTr/jaXXgD0XnAS1xDlw05/cn044zQn7Qjoe+DW1zXJ8CcmHWLvcYlY2kDa7U7rgCR+tzQGPYFMAlJC5VJ0nhAV5s7Ds5VwXcNlHV3uSgOtUxTJykn1QHEAFT0U8F7wDkLyIphMNHmm2LSeXz5Z8/9sHP+/X1xybG84cBvmVLxbNvxJa/nVlePJiy8oaPn2H/4x3/rOt0B3iBi++fu/x/mjY569WPLO4YS/evKClzcbsiwnyzQfPIqk4I8vnvP46iUdBhfgYlVHixEi+PGziyuerDWV7TiflfzP33qX43nGbD7n4c2Gf//JBVe15RdPvmRaZHx0NMco4f2TGcumpXnV4Wrh2XWgmViO8xUrAjZE/6lyWrJuGv7dn/2Ib71/zoOjGerwhPMPv0trPeu65uknn/E3//7fUrcb1vWSPC+YTKZ8+K3v8/0//B/Q5YzsYIEyCqcFZxaEbEbQHqhTn3ZE4tpolZFlJVsFIvZ5rQwalcSzsHXJBMBjkiwQRBG04fD0EXp6QmhWbOoVn7/8nC+f/RJlWhYLg4jDe9h4hXOBLlis0Uzmc47mE94NBeKF+qam0Q3BCK4jgpT0002gc1Fxnk1KDucF7x2V2M5Sr25og+UoD8wy4btHioMMznLNxAhHpeKg0HSVpVm31JuabKKYnEygbeOGG9FakhC5Z4pMKHPwErjpPE+Xlp9eWK5r6Fwgz4RJoaOLqASMxHnJ+UDjo8WSh2jh5AJetrabSog8ZyQLwrDVbHowYd0IBMEWaUxEfTyCwURC/0zgINcUWmKbALmOUTuOJwrVep6sPd3XkGPzN03DXB+iS523MdpZZzu8s7iuGVzmwv5q0K9lyR2PJCdrpeParHUiCIeQNmHjbeGWbAORw0wl6xWlNSpFtdvVGxgsnqR3FaeXUQTEobRJmyvRGs+5PvJecmkXhfWWLy8+wXpL6yzOd5TFnCzLsW4TZf4EEGchQ5SnLGI9dG201nI+gBiCn8VyiUEkrhg+BJy1aCPMj0uCdzx7doG1Uc4LOqBNjCrX2Qh2GeVRCEYyUixNlDbJajlyERbG4Yo4jwQf8C662nmvYyTc4ICKxxctz68UogJK5ZTFlMP5nKy0KOPJa411jklRonWOpsCI44PvLjg60zz6cMLBcU7XeZbLjiRQYYyPvFvaAAZFgRAtqwnRmiw4T101aKXJVQlZi89tAhyTRZTkg0VbICQDiWgRKaLITI5SmkxHUN32nGIEkL7XenyyeO95v3paiSjGvV52+aqgzps9ysYAxF2y4f79vw54/Pr0a1o89b/3C9QDJ3ecGl/VKya/U1nxvsz3gIRBnN4eHxYV+M0LGUZ7/qPd9dfe8lWE6HD/m745r147vA2bjFW+sRtNBJiSsJ/kH08YIcoxW5WO9yGShESaLfs1PyZvDpErBcVkckhdzGkuX7J++RLKY9A5+XQaIynIFUopZvkcEYVrBdda6s3jmKvKyVAob2jbli8+/znetmhfIVIwnZ8xnZ9hikma8N2tATuUa7Rbv19P/XUSxk4md9T0qP6izDjeJRmNpXt27+MzxuViQN1jMwbCkHes951+PNy3BQZ7v3VgTHFzS8H7OqT73kf22nZbV3dfP7YIHF//VZ97d1l6wGn7PQJPKlmpbaOmKNWTVaZrUh59VCrJ8igMmEgqrpRHi6PnG/E28mToLO68KpW2gXUGJIJNAjPdUaiAm2QUnfD8Ko/Cd1MTQsDcs4KMwafh2Giky+j3zn3j+uDN9bt/XYDEKTV+0h3z4Ajdifhrv2semE8KHhxNOF8UPJwbpiZggkVj4q65RB4T3RN59mtZIh31ydopChhRSFW6jzDTP7rvR/t9JOwXb/uSd9XU/k6XvJk3a6fu7jqdhONeRmZUn6/r9fvvEYjrQCAqb0ORx+8Y+t9ha8En27lxTL66Ba3u6iX9e3+95i1ga76fJns1HN8qwBB5l4AEPAkmmST2o8CZmFftoosRQbBBWHfQuEhuPM3guIzriEYIKkXMGyO7pJDvgYFEOssURaZY1S3rdcdVY/nRc+GfHLb8YO4otOcg91gfuKoC4eoaXd+wXt4QuoZo0us5eXjG4dGMb3/rfVhf84uXl9i2i2G5teZ0nlMY4dOLFaumow4GF9TAs6ElqkIXdcWyjZYvy0XH//m7hsW0ZC4CojmZFLTW8Wp5Q9VkvLuYYpTicFaAgAkK3wnXG48SR2ka2hAtbBDBZJqm6/jV42dMCkPTthRKszh5wGpTcb2uuLy84id/8yNW1ZKL1SWzScnxYk4xOeC7PwwEZdDlPI5BCQRdEFQOSg+K9tiyUCmF1uMJNx0XHcH8EJAQUCFGMBViP1AJiESiMltOF4TMs3xV0VjL1eqKV8uXII4iMdO7NJ58rxgHRZ7nTMqSMzVFXOB549CdjXPOSKzuxRrvPVoLeZYxyTMOCkMjHuMdJjgmJnIiPSiFuREOcsUsVzw4MJHjyXpc57DWRcuESYYUmqAS0OojaJ5phVGR58UTqKznuna8WllqK6l/CHkmqX58XEvT+mRTP/aM5qQkF0ejsYDyQ9T7eK2MdQRonaCT694AYA3zfORYNApKLRQ9H1BIFlgBpkZovNCFQP0PwBNwe10KAUjcf87Z+N82kVTc2UHhD7fuD/RWUsFvKTSUUhiToVPkNR96TiiS1Yza0X36taUfh1pHHqidSOD904W4oUc/HlJvkQRIhQhcxGu2MkpIMkRaEfEhcL25oLVtlCkIaGPSxmNH8AFH9EyJvEXRitD56KYuapvnVh6KM0NgC0xpEfJpRrOxLFdrbOvoaks2FcojiXXsI7Cj8BGMCZqBM623GlNxHdI6Wos5b3HeRfLBQLS+Coq2s3TWc7Nu6JrA4cGU2aQkzwomZYEuFMpYgrjIwWYylMpQRKDv+KygnAYOjjMmcx2jTDYeUQkYSiCiUTZafqZG0T3xuiO58ttoJdo5nLgEECay+bTJO1bTQmK8DEEGuVknaznf+zUStsrauO+FCAiqFAEx9tGw87nT33c68es1+W1Xv082u+vivl++Tmr67YNO8BtzPAX2DEi5/Qr7oEbYjsFfF3y64zG7h/rF+m0r7TXXvamQd5zf0RlEbgMGvK6hb1/zurcI7HbaN1q29grtoACNOt5oovbBb7EQGMJ+bpXdES9QCPi0KydppPoQdixnIv4U6yqMy7lTXkdnawjw6B/9Iaff+AbTsxnryxe8+vyXNJuKVe2xLlB3UTDSRYNWgsliWPhN1eBcwNsOJZppVjLLFYezh+iiYHF+xuGj9zj/5rcpFoc0VZWIBWVbnH7mlze1024f2+2Do+MJ+e7rbjuX3D2Z9KNqcKkagXxsa374fqvRU/f3fld8HdCr2Gl2onNs0eIYceXrqMDdl+4a3m96+98NLrcdFBGwiAuaViaCFz2RpUSiVhGJ1g+jsrjE16WLEqUNJguQBcg0QXmcSAy33jUQoCSgtSFXZdy5UTlBmbjwuhbtLsG1zNwlmWi+/eiQVeP42RcdTdvRdB0KIcvutnzaXVDTGBumzLcYXXfk2efRXzOAgenvrdm4By76Hc+hrqKg2XnBozg5OuRgNuUfvT/n/eOC41Kie6IIDh3JNYlRvrQGtCZojegMpQwiAYWjTW67Teuom1hPbdtGVXAcp/tvIb0d8HlXgcLOx97RNz83Kb6DNaWT8ckxhrG37sSTW37BJIgH/9p3+boB5eNkEj9F5PaLkSl71SFO6TKEyAYGYTkCT3FHWgRaQIdApgIzIxxOo8XTxkVLqOsWVm0kF88VlDoQJJGYEy1FJOXRiRCUYF2g9Z6jieG4zPjwSFGQcb2xLCvLD777A/7wux/wzj/6A7KPv0X+n5+Q2SoSTRcTjFGgHN3VS1xjyecTVKb54b/653z8j7/JDY7zH/2cT69r1l2Dc5pWNJ6cIJq2ixHDziYZZaY4nSmMgqtNE0Ooi1CHwAvXoaxhFoRCwf/xW2c8vtnwbz57SecDT25ayjzjZDElKMPxwQalHP/lpxuOFx0/+EBxs4mqqBYPwbOuLb9cLzF5zo8+ecZDfcZ3f1/RKiE4jxcFZYnCMcFS5gVFPseYHAkOiWYAQ1jZ4H2MDuV6y+uoJEa+FpsUbJ8sKdRI1hKsA01HoWpEWzIcSgwiikIJmYSkZAqS5YjATdNysVzx6fOXfPr0BYclZFrA5ThH5FezgaOZ4rTQlFlJlk3IJcfhuK4rLjZrqq6jtT4p6kCQQaE1JnA01cwyuFnWbOqWF6uWznqmJgb+m2A5n034o2+eYZSAD/iuw202mNIwO5lgyqjRelHYYKLLY2s5WRR8eDZDS2DjPZuN48nSclknF51CUag4gFofMD4gPlofTQ20ngj09ONrPC9J5EtTEi2gFPG88wExMSpdpiLA29oY3e+miYBtQUhUBiM3eQHrPMoLjgiaFWksT4PQIRRa8PL1ncveLm0XhV75jsEmHN62OGfpuhrvHNZ1SY6+5UQPhMFS1nsf50xRaB3dTnXiJgvBY60lsl16Bg5XSRvmJPLwYQ26i7Zha+0SIwUn2GpsbRzi/O2dxTmXwDOXou+Ngmik61UCrjbNkk1zw9X6Bc45lEQKhYPDBZnJKKdRMsndAY4JLZq6ralXL8B5ilzQRsgLogWjBTfi69TaYzJNViqqynG9XmIrS3vd8eC9Oe8+PGO9WfFKr+hqR7uy2zrq/6cFyPmQIqnG9+oVR531da0hgPFZBLWp8dLx4OExD0+Peefdh5yePuDTJ7/kannB8eEB07JkOsnRxiA+4BrPfDplkhfMFoZ8ItS1xbeOPI+ysfcekYBnAxicF7Rk5Gaa2kbhnKV1DbB1iQ22xftskIGbJoKMeSYo0WQqEs5nJktUFhofHKv6Op7XJSHFAfa9FfyguCUQX4TbsaFfn95e7voqV/0tCqJ76e2Bp1tlDOyaSdwFOr0mq175kLuy31M29r5ID17dUaTbB+6r3K2ychdk9lVBov28xxZUcQ4bhUbfyVV2/oa9s/3322+xX6p7AIg+DYDRHXmG/TIxIP872SUrnW39396NViMkd0cZSJPubsG2JI7DNa4DUczOHyGnJxhZUl8/JwuXrK8CctXRdB5bq0iaZzxKB/Ii9qfaJnDdBRCP1o4sy5jODinmC46/+S3mDx4yOz5F5SXO2kEZ7afR7fuy3YXvz8l+T4njYNyPhvodMhO2saHuxjL3p4IQGDgAxuUJCQUc/5Mw0jj6zBJ4Nsx5Q3uxVcTDttVlNAJuRRL7e57uUkq3iu2v+6K/3n2vt7wKg0IhEndFtDYYnQ3AU69VxqgggvaCGg0rkejKpXVc6EVH4Tn6C4Ro2UegtZbgPSZPIXqCR5LlACicKYguslEhyn2FIuNkfkyWBYo8wzofARURsnveL4wm+fH0tLMbeU+6c5yE3eNh/4bbk9bQ3/uwyX1BfOjJ1RUOYTYpOT1c8OhoyjuHGYoOIXJb3QqdG7fC425faqvAlssphIC1ns5GoTaSiwP7M/k9mxa3jry15PGm/PbT26/bb59ka8kV5feBPH87P4btc4dpa9uwYzLW/TXmvvR1BZ9078YhscYcgIRBEZZUx6GPWpSU2RiuPfV1QPk0DUigVHCSR7eh3AVUG4GnzkPloNQRZBUV16EkxgwSihZwKhbGEQlmp4XiOBeOMkUZAnnnePTgIe9/8/ss3vkQffwAnWdo35FJBKu1imtju17SrjYEfYKRCecfPOL03SM+eveUzZPHvFzXNG10RXEBfCxd3DwBch2DKJzOMjIlOBdJbn2A1nuurKXoLAaFAr59OmeSKf7d40u6NnDTOJxoHmhDnsG0jGTnTy8a2i7w3klD1aaxTlQQO+tYbSpe3Wx4drlksqqTK1ffLgrJMkwoKJhSZAV5XpLpLG0sJbSj9zsOWyvkrdVDauQQwa6eky66R6eISyi8DyjxGOUIYlH9zj9gJILlcbMpYBMnUtU0rKqKZVWzrGqmOpLqBh83n7yLoO9EK2ZZVHa1MijRBAk0NkYItK6f95IEtS04AuQm8o3VjaVqOurUjoWJ7pyFwKIwvPdgAR7Wm45WhE1do4wmnxgkF3ruOBsEFwTvA4VWnM1zmtaybjxtB3XjaFysI60FZYTOBVoXUMkkWBFBI63GHgnxYyc4Q1Kc43wmw6tJameVuDetj0T8jRMaG8h0fOd+zuutXpyPkbR68DiE6BqZhcgbpVUfNOC/7dRvTA3yqo9rt7NdsnSKcnvkFdvO+8OqMawZWz7LXq5SSmG03gbrCQzr9o4kHkjBfba63F0b+72lbeRl8miJTq5hRDTdg05h2PB1Qxl9itTKIHf3m/NR3nO+o7M1q+oCazuC1+RZwXQ+jZEzswhEK6vxwaDFE7xEeY5ojaqNGlmnR6ue3p1M6fhf6zjGOtfRdZa26ZAAi2lJCDWryhGspZUOQUFQI8lh647dW0m6YBEVrQ2VVigTwSmCoFPbmlyhWpjOCg6O5kynE/KyYFO3XFytWEzmqNKQaY3J0txko06XZxlZIegM/CZG8uznTQb+0i6BeZYgCqVMJAYPvaFEtHxUPbDsk8VTiPxZzkZg0+tsAB8JUUYWogxpXUfVrDA6x+hi6Gf4yPG51QVH/bGvtT0L9VHnHx/Y7dxDn7urH95/fuf4G8TK37Ve9BUsntTtTO8chW9fkF7Rf1NR33oaTpntEtq+OaNdOGa78AzTzZDvvpH/CFzaGYL35X//M+86L6+9YlTe11ZQzElEobSOERNSOM63c03oFYGtoi7D4d5HdXu184l6Nk2m/YLbmxaPpvUdjWR7vAER2nKGmBnF+3+APr0if/ZT/FT4+Pc+IJgp1+4Bdd3w9Mf/BtvcMFl4inLBh+/8TziZ8PJGqNfXXP3y37M4KPn+v/zXzE/OOfjoe4gp8FJEc9Q2WlgZ4s5wb0EUJNzZugke2OkJPZAaBYm92u8ra1RR8Zr7XS4HodPvxkUM/S5DDyr1wNMoAt8dTcdAyis7h4dx0pdbQrw2ucH/Q/qvkURQSmOyHGPyZAqe7Sjs0XqHwTrEh76NPc5Hod6GEDkEprOo7BUepQJNU2OtZVNbvLMobcgzTyaGoN2gBPnEvWP1DC85tqrw3pGFS2Ze89H5Eava8tnTV3QpSqQIZFmEoO5yu5LxZDEGZXvJLLnJ9PdvgVYZAO2dSJujOpMUtiQ+J85rEqJy7hI5tS4K9Kwgn07Ji5JifkhWzliUJdMs45285sh0HKka19SELEN0jtY5kmV4k+O0ptMFXgxGcpQYjAQES1dtwFqkDWA9Td2yqWo2qxX1ekWuVbRU++31ll8r9WDF7/YZae4f3EbC6O/ouv1fdwKX2/7wuy7338WUq+imafGDS1BvgTyuLhPGEkPPvhGj6XgS6EQUmXMN8yJeOfUhhoHXwrKF51Ws542DnECpQuThShtPSsX7pwo2Ei08Out4vqrwBZDDw6nwe4sJ//SH3+OH//JfMjs+xcwWiCqh3qA1ZKZA+ZpQX/Bn/+nf88lPP8XmU8hL/vV//13ee3jAobKczzLOSkOwjtZ5Km9pXKALsMiTsq5TZL9gAIUyMez444sVX97U/D/+w885m5f8q48f8XA+4QfffJ/3qoa/elXxxdWGH728YlVnHE5ztBZOT2ZY17HZBFqn+eUzg/WBxm5oraeqLQIU0wkbD3/56Qvaw1d8+/oG6wKz+ZyTo0M+fviAzBgmsymZySjykocff4vJwQGmKPDe4pXGo3t7i4GkOvjeCiceMDrZFEVNCdFZ5OZTBo9Kc3kO4lE+DK7ZeZmTmZxgLXXV8G/+t3/HJ198iXINwbW8f3zGUaH57PFzLq5rqk2Nc1BIBJzePT3l0eGUItOIBKzyeBWY5ZpFbuK8JhKBHQIQLXQnRVwLfvV8yUFhyM9mEALvJq6nar3hMJ/xnW9+wPsPZjz64AHVuubmVy9QGhaHEybTPO3bCaHTXG8Uv7jwVE7xjfMJZa653rQ0rWdTO05L+NZpzssanlUhkc4HWhuBJ50JKgNjVAwOIT6NkxFAJPubhukYW6JiSYBRbwHb2dhu6y5glDDVDBbu0oMYRD4pLzDLo3ugzoTOw3UXuGoDbSfRDfa/4bR1OQtxfDgXI665GCUyhGgttKONbRGnaGnit8BOtHDK0Vpj1FbldT6BuYMkHAGcXgscykIYNpuEqBu44PG2QVw7yP/bTafI7NXzcg7y/PBOkRAfBqF7WJSFKK8AZKZEtOHRyTfYNKd4PJtmxcXlC9quoW2q6O6fHQDQ1GsEKIs5pijxp5HsGyJA0voGZxvabgnAYh6t1JVItDy1cDCd8b3vfIxrAnYVKCYZq8sCz4LDuSVXKxSXkeC7dURoKwE5iV8LAqJDHBsmBT9QAC4Bbkm+dB7BYgxUzYrLG8VPPmkoHhf87Jefc3F5w+H0mFlxiOsEReDqasmLV5ccLRaUeQ7eEWyIkbqNkOcabdSgs7etRwlkE4/SPoJsSmFUjg6ao3yOEmGWzcilxHaBIBYxDRqH+DxaNHVrGtvwavkcpQzT8pgQPNZXVN2GV+tnzMtjPjj7PY7nZ3z08DuE4NFS43yyrBLSpO7AW6JeLneDT6kv3+rfty55vaZ2+/yvL0C9DRj1tvLZWwNPY8sP9obmtmDcgSS9prBpoA27nMPxLRx3/3vcVaFhq1yHXfBmfF8PtwwLzR1g2V3P7e+5+7rdM7fBrNeJ3nflsgts3F0iEOlzvRt0iJNi38E1SIoGgWdgs04C/z5/zS5gcs8bhL3vISQsaQuy3GmIsHdNfzQQScajkJtRLM6RYoKZzcj8isN3HyHFESp8xGa94dmn/x7CiqwMTOY5Dz74GG8WtJeCXD7jxWeeUCrOPv6QgwfvMXvv21gXuHpxSXAd3sXoBz1ps6cnUx+1RNgSf9/Z3qPq2rXS6Nt+0KBHoM/4cwtrbXXzcMd148G/rbuw0z7bwowxrz7L7Wba9mV6Zb3HIb+mhgM76e+qdUSvKKpkDq50NO2FflesV8Ljd98roEnQinxl0QpABU8gkvKL1ogKeFqsh9Y6vLV01qFEcC7yP/W7ynFjWAg6j4IFDSE4lK3JxHA0O8aYjKdF5HyyXQsimLC17NtNfS/dH/PxXLS4Cun50O/+RS/Ynpx6BL+N7o8iyXgdinPcABynUzovMLM5k4Mjytmc+fEDJosjHkwKDouMM/ucub8mrBt858DkCDpaFqRtwaA0XjQiZmsJhY9WZ11N6DrwGSSOha6z2LbFdi2FLkdceHevBtt3+O33z2GzK81Fg1XSbzWl1Uq2a/Bv+oQtCPl2Of0dHdq/djIpeqlPC6kaduxkt4KHDbJxCmiJHB7RWDLu7GqBXMcbMh2JyPtxctVE3pvOb602Qoj8NVpF114tkYTce/BGcHhqC7WCCpgsMh7NNOdnRzx47z3I5gRdImIQZxFtUFqB7wjdhmdPHvOLn/+cVcjxOuOPvnXIe3OhwDPNNBOjKbWiDUnpS+9ZmOjqFNdu6HzaaFMaVGDdeZrO8uMnl5xOS37/7JhZWXB8OKcsCx4tplSNxdoW6z2btqPMDeU0xzqhaTQuRMAjKk027XJbtFKorKALgWfXK85u1qyrGqUMWZYzKUoOpiXT6YzT07P4zibj4PAQUxSIVklBFhCdFO7UamHHJnBod6WSRbcQg6yoyLPiA8maI1q6In4IQBI5bDSuddi25bNf/Zyf/PRnnC5mlIXhZH7A4azg0yc3rJuW5aYjuMBkZii0YT4pmU8m0fqVaLHjJZBpFUEnlSLkhjBsUApgtML6wPW6JThP56bkGo6mGW0TcCtHqYWjgwWHBzMm82kkDJforpRnBmOiZbsAeKHt4LIOdEE4nBpCEDato+08TRcwE8VpqWh94LKFxgasDbjk1UjGYC2sRG0lsrE414NP/eFeeEqA1BZQiuBuvyXviaBR5xjAiiHP9OlCb3UocVxLDKxQOahcwIV9N66veRq/qyQpYWSt5F3cIHO2xbtECt1zMe3k08sVu5ZOEOc8Y7ZcPMHHDbqxFa2M5sdtlrsN0Z/vrZKGiHeyoxhs75Ne+SHJanFE3x7b/Vo5lg0k8dYpZpMjtDbMJ0eAcCkvCYkg23mXrK0D3neIaIxkKJMxmyRASAU62+Jqh5KOEDpEFPkQGCaOYTzkJmN6mOE7sGV0zatWAck0uiwxpiEvFIjDOp/KntyEpWdBi+t/MspE637TMHHGJYuoaIUW0Ao627Cp17S2QZTw8tUlNzc1TeVwNgay8CpQpc28o4MFOlMQHMGlCMtq6wnQN4h3vZ4bZUtUHMdaa0AwUqBEkascHbKEBwV04mSS1NfqdsmqWfL08lOUGOaTDT44mm5J1a14vnrC4eyMSX6E1lmaLhRamTgX+N4NOcq6IbUboreTytgQZMd6ab+rh53Pu/rqrWM7p19n9HD3md+27PUVLJ76QfEmOH4rDPU7Cf3x/cE2zrmXn26dD7tqzL5QNeQwDPb7S76reN8+v38q7B2/L47fPvy0r1psz/qdM7tPHNdCH8Jzm8Mu+OR3rrv9BmFA4XuzP+891lZRMDFZjFSTQuB6Z8Hb6OaGuq0UDp+y/5iRNdheuh8xfE0SvI+D0CAYINcQjDCbTdF+iuDBdii/wbiaw3lJyKYcHrXMDyY8fHSG04csUeA904MFk8WcfH6AyqdUa7DWY9t2AJ2Q+wdi/yoDYbHc1R/7nhvPKBkPwBGSM8aH7ky7+Yxv27rXjcs17m335LJ3+t6xNHovpb5ews9tQPXvXhqUwuRSN3A6DX0hjvdoNuzpbNguYok0M/JqxAW92VR44HheUBhBTafkuULqmiBCaz1dZzFVQ2cdeV4StI5uIEphdP/cMkXyyLFdS72+QoWO00ngoCzQs++w3NT88hc/x3ZdBJBEMFk2vE8EOVIbBL+dmwbxPb6KT0ql1oa8yOl5BJzzuBQm2XsXXYmSAhz5k2M9KK2G5xFk4GDK5wuy+ZyHH3yDk3fe5+j0HRZHZ8xTFKXi8nPM+gXVy4p2s8R1Fu8VE+KuuCTzcJRBlEGZInJE4NHeIVVF8Ba3WmKtR+VH6KBpmopNtaHtGqzt8CFHhRGkPXb3HE2vb0zD8nHXOvKa6wPDDDJ2gXzjzePpazSpvM51Mrjhjjt3wYaxuH9yUAb2VtHAG+aksPf59UmFUYOlk0/gbC9dRVL8KAckSid6ycGnalT4FOVMMNK7GEWOpqjQR16kWRbd5moXWHbwsoLaqgFAhNh/vMCE6CJ1MlPMMqF2kSvnZl3z+KqhcDl0Gd958YrVky8ozj7CLBaIKaCY0IWGYDe4dgN1hQqgVMZnX15wWbVcf/EY5hIRMFNSFiXTDuouWkBMTSBTwskkwyjhqnZUlePlVYtSwsPjCUZrPjpZ4Kyj2WwovaVpLTdVy89frBDv+eZBwUxmvKoOuGkDL6/X5LnhUTYDhGi04wliyTWcTmasdMfmZomTSCp9ua65ufmc/PCEX/z855ycPODd9z4gM4Ktb6BUZIVQb1YsX1yjJgWH7Tcw5GTaEHolczQfBN+DUJIUOwbicELk1Ixz6SgyrQioLBH6G3AN3rZ0aLy2hKDxwfNontOeTnn/vfc4WCx4/70zUIFPv7xkvazIFgajFH/w3ikn04Iyi2TAF1VL5cDlKkbq0gptNJlSZErR0G8eKJI5EN4H6tpymBs+OFtwUCiOM8tmveGTbs08h4ubDVkmvLgoCd5z8vCQtm5YXS5ZLi2Pf7WizBWLUmOvN4S2BmdRoriuHc9XLZkoigR0eZI7k3O0XWBdw6RQzCaGwsRAV4FoadSlyI4ukYIP6kua9rzfjqteSc7S/z7io5AsLkjRhqWXzVMEYhIhNUKeotvhI+fUp5vAjQ38og5svOAy/Vbxwr9uqd8s8kR+RNdFwMl2Nd5bbNfSWwsNcvAw5YdB/un5WtUQeU5HwElpCJK4ovxATL8r6/by+24UpIFrtefXTJZRqO3aFkYF6r09BsOKBGrpkTldtN5SiaVeD8BXIKBTTjYuokzNlELlqLPvsWlWEBRNV+O9o2sdrvORdiGPFoYdLSLCpMjiWPBRJivdFIUmnHq6rov8thZ8FwjGoH2B9Z7WtrStZbOuub6sePblDb0ifnQuPPzoBCkadFbTNJZqY1ES9UqSVVjs/w5tNEqnOSyA8xZvU8Q4FZgfKISM9bri8qrGNoKzQldZglNUN47VoovrlxHWrwLNpeHgW3NOTqdcLp9R1XUvadC2EVQqijLNqbEFrffgLDZsyJRhUkzRypCrQ/AGXx2CL6LlqCjKfIIShXcdq+aanz7/Lyyba54tv0BJzrx4CCFtuCrQJqNqN/zsyZ/z/OpTLpdfcDQ/5/0H3yE3BbPyEOda2m5DH/Iyrqt6F/AM+1re/jh5s3xz1/1/16Sir0gu/gZBdTwKRwr2WAG+yw2ur/RB/X9NLcVpfg9kuvP6kXC8j/yN9HUJ9yMBsvdjzIOzL4zf1R92a+suwXhMorpX7tF1r8Uq7nzWuLxE5dR12K5BmwJlNJG8OBJTbrdxYsVIEmhvv1R4YxcYv8GbC777rr2gNfwIAfEWvEucNSaRbzYEt4GuoTAKQkaeefLMkGU6RRoQjNbkeU6W59HNEIVtQ/QFdg7ShBzfLIz64z2lHQGX/avdbuNtv+urcAwL3lsd0t8/RvH6jtorGn1m2z6ztSbrIbBwZ0+765Xu6jP9l7/DGM1XTtHtRxi7fv5dSbv8Ab0rS6+EjEGn8U5e3IUJPnEfjIAnnwizm67D+UDXdTG6iUST5z5fHyL5a+ci51HnPcr7SKAtDKGAwaB8wGSenvKeECi0JzOKs4Mj8rLm8eMJjRBBYYkcCpGjqg+xK/SudJLeO5YkmrYHSSHevcdkOZPJdKgT21m6psF5i3Xtjk++Qgg+Aueq57WSONaDyQhZxvTkhMnxMecffMQ7H3yT4wfvcXB4xoyGMrSE7hmhsVjfUXfdwPtEH3Um7Qr2UWiiUKtRoUOCJXQVuBbf1ngXkCy+o3UuRk0JPQdKTINFZRgL0HtWXLfxmNEPttrRvbOKbP/+hrtYw27ykGO4c827O7vddaz/cu+jw5bnYpzHVgm/a37++oJOEHeMxYe4k9tbIQFxHKdAOkS3n37d7floeouM+D99F7llNaVUIAMKH5hm0KQ8eyuinhtqbM8oxCh4ZxOhdhF8amu4dJ5N57huhKqq6NYrssPoWhCtLw3eRReEkDa9lMSQ3KtNw6vrFc1yRVivYwF0hjaGzGhyZ/Ehuv8ZFa2utBKcjyDDVWURJTw4Ksm0ZjIp8M5x3dTkIljnqFrLq1VDJoGD3OAnOQ/nJbqyPH/VYUPkQFJJMQUIOJTSLMoCvJBrRRuENgjOdnSbFZfX11xcXFCUU4wxKAXOtTgXQXNrG+pqSdtUWGfBacSNSfOFW/yKY/mw/z8InyGNl57bpFdiY1/xtoFEWB4Z4uPYPZwWPDic8ejshMPDIz589z1EEUOWizAtDGVmeHh0wMk0R7cVzntaGxAVaHRAJ8FG1DjCaq/+MViBBMDZWL5ZmXM81bw7zViZwNUkwxhhXbWsNxmbypKZQDHL8d5hfaCqHVw1uFIzw0BniY6F0f2zsYFl7ZhmvUtqkoFCDzBEUEkkWcfpCCAhURmO/D53b6cPG38jmU8Iw/hRyOidezLpVAOpnWQgqN7BMiLNQ4CLxnNl4cpBE2CiI5H1fwtp6OapD0Nv5eQjh5OzidMo8hHd4j7rMxlZOPWyXk8tYkyWZI1oFRTc/jq7retB+xEZoo6N3TUGd7skB0gK9jImjw6BreXP0G8kgVxRflJeEVRvTpCeOhC6hvjssCVENxKttQ4mx2Q6Zz45Qus16+o68kO5KFFoo6MMSHSBM9qgQoyUqEVhVAZZYMqUVtW0VQXBYzsHXqIlqXPY1tI0Dev1huurFc+fXIJXhJCR5RP0NybJjddjHUCcc/sIfyLJEilEHUwbjU/gubcOT9qIVNE1zmjN8qZjtXI0a8E2oL1gRNPWgaZ2NIXCOMF3CpwmzzKK0uCuPU3boU3cdIwgWx/5OW0aSr8RE3C+RamAiEvjOAMxWJtBMIRkhdh7wHS2oW5XvFo+ZdVec1NfoFSOD1kM6mEdxmRMswOcs9y0r+i6CoKlsQ0nB+8gCLNyQfCarUwfgzGM+9Z47h/z726HSbjzO/dcc89oe6v7ftceIW/vasd2YbkbU9vBc0ZL0OjgHdfvH9la+bxtqcbfw85RuePc7vm+fK+ThH+ddAdgc+vp49+33R7uzmH/6P7eSC94qmHx7+oV9fI59fqC1eWXlNMj5kfvoIxGZxoxU1S2QOcziulxjBrRNXjX4W1v4yy7j7j9xNvprdCW3WtEQaYjat5VSxrnuFheYKsVrx7X1CvL5dVf01mP8wUQKNhglKFa5lRr4cnL/w3rFVfLDnzLWVGyyCZcf/GY5qBlcj4BIteKl2SKuZ9uvZRETry7KmDvtu35vb45BozYjqBdwve0pO5oaGlSGqopRLJpUYmkMC4Wff+9qy36hfo+cWYAOWLYpLgbfu9b/v1LPS8SKVKj9ONjHAbqv1YS6HlT4mLec0Ikc2Tpw7f24VjdiIA23FqgfHpXnwSXuqnZVArPDKUz8iJG3cjzMllIeehalqsVlTbk2RqlVCT+1ZpycoCIQWVztCqRSZwbNps1OrOcLE45PJ5S/pM/pKprnj95irMukuyqGIK7j8KnTUYxmyeAKCoXbdOg84JicYDoDDElxmSUSQnKVMB1LW1d0bU1Tb3BNg1ttcEohTGKrqlo6hU9eK6LCaaYki2OyOZHnDx6xPH5Oe++8xHn5+9img26W1E/+THNy8+5fvor1pfPabuAdQqTZ+Rao/MCyaKwZbKcIs8wWkelVxzebvCupVld4roGZ4WQWHScMniTE/KcoszpbBsVioi/jZv/Dqh4vz/uakDbTYHRTHKnMJ3Ap2HukbeajneePPSvMX8WQ14jSWn7yEFAF7T0sa7ieZ+Adb9/H9ufYecddpPaW/L2lYg+hPXXKSmJfzItOAUhkaj2PE8qWSeqBOLG8AL9+dgGPkSXuy0gECKYldrIEUPRZwoWWWzrLkBlo/VToaDQcdc+A6rOU3UORFNm8GiW8Wie8/2zksrCy4uGy+uGrmlxzQ3BLYE1hXHMCoWvPOI6lAlIIRwcz3jw4IDJLxSqs1SXl9w8y0EFivkEn5VY7fn4UJOrwLLtaHzgWSusXWDTeWoXOJllTHPNPzoqOSwNeVq3q7Mp3geqzYbHVc1yVTEvM77z8IijouSfBs3TZc2XNy+oneXpyyVGC7OyIEhHK5dMywW///EH3KwdbTfhumr58mpFcA4vjpvNDT/+5c+wInzzm99l44ULPePldc0v/urHLKYlDw6PaZTh4uomLrfO8+jBKfN3z+Nm2JDS+FFCkGiJ5oOJG6UhEvtGv66angFeRKI7n1Ko3p2IqPQ5ZyMnVG745//iX+GdZXFyjslyLp58zsXLFzx7ds2rFzf80Xc/5sHhgo9OjplmmucvG5z3TMqSeVkwNyAOOvGAT0TkfZmBFOE4RjEmjncXqGqLWRT88NuRn7PMM15ebfjrTx+zaQ74/W8dRZ4qXdD5lpdXHbWzLB/XfOP9Be9/dM65L/iD9ZTlz9d88pcrWhQ6M0xy4XgagVDx0Dlh5RS6EE4LhVbRmqbrohEdswhE5VrIJFov9Vh+5NWKWySRA4q0ngnOC40VjInWT74HeukBrGhx1W+xGBG0QPAhRk+0PpHjCxbhmdNUCaxQIRDqmq+X9PX61Ms1LgFMXddG0LFt6F3tenlmuCfemDbaEiFpiIBDL7doY7agrQ9Yb3f0UTVaI/v1Ufq1axzIZXReJYunXu+KcmR/Pq2PEhLwkvISBnnN+1jObUQ7j3dbybwPMON9wDtH01SE4MlTeSblFKUU03xB8LCRJSEEusaRF8JsdoDHUzWbxEHVEnyg7TpCAKM0Rk8oywlVtqHuatY3G64vb2g2juWFRWuhLBWdq6mbJddXlnXVoZUiN57cHHFcvgemJZiGtVpiwhVaZZELU0VAzltwFubTKbPplCLPyfKM1XpJVa3pbIPzHUVeYHSGNBWltHQzhbXCyy+uWd+0vHzSYPyak9OHHD+Y8O0fnHJzk9PJhmeXa54821BXHecPpkwmGUZPyLShMAUmM8ymM5RSNI3DOcfN9QbvPS/cC7z3rKsWIeeg/JhZfsg3zuYIlperz2m6iufLp2yaFZerKzyew8kjjM6Z5IcRag5ETlZTEhLRuA+Op5efcb254NXNE86P3ud7H/whk3zGfHIY+7frwAdEfOonW4Csl4F2x0m48/N1rqFfNf1t0o98BeBpWxuD65f0vwewdrh6jFfcgl1ubZXe9bx0+A75c3A/ubOcw5iPMvCozNu/JEunXyftgWlJAdg1ubyjdGkn5HVtKxJec37/RK+EjM8l39qR8O1dR1vd0Kxfsbn+gmArMq1RRmNyhS6OMGIweRlNJb3HSzdC499clFGz3/Ni97zCHddooxGEZr2ka2qunj+lWd+wvG5o1o6LF5e0TQNBMFrIDqYEramDwfnAq9WXWOtwtqXIFGdnEzJRrC8vsVahpteIySNvSxLuBsuDO17qdpF3icXjNXvAZbjrqn68pB6407l3vbu3fn0j0GlUtwoZIjMM14+ee6ts47z3tNR9Ba8votzbmH//kqRwymOi4154+bvgfteDxFvBhpF1U7yij4KyDzxtJ9k9ECp973mGetNv3UfKMwZnDcE3eO/p2g6vHMFHISeEaGVgihTtRGcIGskmIApbLUEsORYxOecPTqnqlmYTycvFO5RSlGXkBtFaY/KC8vAIpTOybIJzlrquyMqS2fEZyuSofIbRhjwvMBJDv/uupavXdG1NvVnTVhuqmxuM1mSZpqnXVOuCQBRQs+kCM11QHp1RHp3x4J13OHn4kPOTh5wdHeMvKsJmSXvzHPfqc6qr56xuLgh6CqogU1FwFZ0NvCzaZFGgVSq62AWPdy3BNtiuSYJyBhKD3HtRkOVIVpDlOXmeDZZsaq/PhWR168cTqQwz/LDe9qO7/84IYAijOWOU887431m6dhbl23DU7XVo95q9NxiE717YFhXfUyu1AzxJ309T0NQhwMXOfDu2ThwVcfi+HSNjC8Y4hvTXyloTtrJM7xYiCZ+I80YYKqePcte3ku7vQ4ZId7tA57YnSXqQkkCuofQwM4kw2Ubwy8SI9migdYHaByrrqVzkEjoohEWZgxjaTeDiqotWmS7yikCLVo5MC14FcCG6JQmYTFEUJnJR+UBb1VTrDULA5BplDDrLOJ5o5sYzNVBZz8vOR+sRH8f+NFcclYbzacZxYeij5jai6Zzn4nJF7SydC3RdgX14QpEpzqcTnINpprDes646MqMosoKghJYWxHE0K9EEjmYW6zfAkt4Sue1aLq+vWK5W1G0bCdB1TtVuWC2XoE45P59gRbGuGry1uNZytJgOYHIaDXHMy8iVpz/W08OLJJLakS9Yml+E5AakDJFxwA1trpTw4NE7FEVONjsCUbx69oSq7Whbi7OORVFwMpswy3MKneazQLQyyDNyicTtg8I9XlphK7/0/4lj1bpoeXt6MKMpc86O12wax81qw2qR43xv/aVwXqgaz6r1vKhbTk9zgoGiEI5nmlzDqrKEzKCyDKOJbtNKBpcmGwQxisIIwcVNRvFx/EgY9efU73tZ0I/X1V5vGEAEwTrotBB8GEgxerkquovH49so0CmOWICVjS52DYoOWBIB3n685kQA6uucxhDSdkMtkYjbSIHhXIpG5ntOpP31abTxliY9pQSdrJG11gNgFS+JeSjZDVKys0kjDBsmPRiwBaW21k6778Bwf2+/0Gc5WE0xAgtCTy4+stCKBYn/U1kjNUpHCA6lFQaNEhXdBkUPG894wVmHN5rM5Hg8dVdHaz8XZUXnIuimVZRBdJbhnE10CIq2aVktW14+q8hzxfwgx/mapqto6ji3ag1ZIeRZRpnNwORgcqzxFKZGqRgEh2QJ5nwE8IpswTSfM5mUFGWBBIORjLarsK6hyCYYkzOfGFzXYguNtXClK7ztaGtPUzm0MUymBYfHJSpruanX1HXHctXRVI7TEwVBoyVDJ15UraJllFKKpvZ4G6iqhq7r6NoKay1Xq3W0YDo8imPbNwTpWNaXVO2Kl6unNLamcx1aGUozw5ic3BSJI06I3kMZwXskRP7Uut3Q2Zam26CU4r36m1EG1mdYANeNZPZB2GPg/7pjDhhvNI+Pve73XXn8VtMOvvL26Su62m2FlH22ov5cbzy2t+7s3Lt/3+t8Gm+n+68dBvxdhe6/hDuq6LfWGG+bz3ayGwRvYJezab+U/XWyd82dUyDed9i2pqtvaKsbfLMi9xvs1ZJXr34eQy8rYXr0Dgdn38DNzwntEjAEMkQZsnKWFoJur9y/7YUxTrpKKeazGPnk07/+c149fcxf/If/L8urS/KiQImk0KMxlLuSGDpX6Ae653rTUBSK739jzqTUqCznZrnhr/6X/w9B50wf/EeOHzzkv/vj/z2T2Zzp4gDvPW2Kbnd3+mo9dPRWPUS7I1BGQjm1dYFIkVVcYOuWE0KMBiGjnZsUjdDZNZ3rUl2AySaINjHCA6PIYHchv7fejGHxG3zZ5Y4x9Pc4PTh9GN3PmhiZremauDDb3td/+7aD4PG3nCTNniH1AWxHcHYQmjy7QtRYuOnbDQQJCi2R2BU8re1Yt4rOWrz3aBFypZgVOUY8tunwLkZoCQje69jv8qhAdmaCNwXKzAghxHC0bY3rwDnLxRefkJdTjj/+Lov5hMMf/gHOB5q6JssLTk7PEzm6AmMIkzkmL5keHCVBUciyjNl8Ft8jKLyzdG0biUVtC/jo0hYgeME1NbbapN1Fonm4dTRNTV1v0JMpejLj4OQhBycPKKczyskEs7mg/vyvqD/5E9rHP+J6uWG9aVjVlppoPq7FEyJygi6mZMUEmR1AnhN83M3qqkucq+maZXSjsYFARtN5HBZnPTbTnH3wHfJz+//n7s+eJMmy9E7sdzddzMy38IjIyLWWXqqBBrpn0ELMiBAUDskHivCFf+qI8BUipAhJEAsxAwLo6a7u6q4tK5dYfLVFVe/Kh3PVzNwjcqvuHqBSUzw93FZdrt57zne+831s1hvWt9cM61tKyrRdj9LSEgyKlOWej6k6Eua4LygoDu44qiacc2As+U7VtSizzkWmpHxw9smVOScfBzLKmJOlmZQg9/+h8PFgfJl5jKlDm6Mq+/coijACEGab1hptRTxaKYtSmlQTiFhbQVOSv1MMEmSnWvlO+Z0Blnr0e7+TFay11mG0oesX3zvWk66SOanIiNC6VtRnURppXhDdxoJISNSnVX2/LtWNS8Fxa9b+YxBASaquBaXBNHDhFC/62taqIOSCT8IcDVFz6zW7W7idPJ+uI++fFN5biWjqad/RNQ5tLIoAeYsrIz0e3TpMZ2hCptxuuX95xavPXjKGieIUr653/Lq9pbQ9Z43lDz96wi4kftgElirz6mbD3Rj45W7NbYkoIk7DP37W8uFJx3//8RM6a/j//Pwl92OgaElMn56tKrAux/zTz1+zaCw/eXLGC6P57z95yhfrgf/3L14zeChGVbDMkAa4v96haPm958/om3t+fXuHUoUcHTlrNoPn81dX/If/9BcM9zc8v3iPjb1D+cBqccbi7AOGoHj5y89YOMNJ54ghSIFJ6+pupyvDSa7ObEdeqnikMkbGuLb7pHsGoGvmKnN101MaJUwa2BcvxhCJBTq9k+tdMtZafvzDj2ls4b1Vx6kuhGFLrmOmaRvee37J2bKH+1tph9G2xify/TO8NQu/a3UAFksphJDwITFFLcxSZXDGihOVVkSfGJVo+q13kU1UDBFyimzudvzqb96w2U68fOPxvvD0vGGH4R5FYxWXDt7rNR+tDLcp0YzVLKbA4DPDEOmMorcKpTJaG5yRtkmrRQttvh9qeIwx0to6M6Hux8JGFTovovZeOtWpOv3cTTBGuLDQAKpqCa1jwWe4LZqpwNUoc6EmYilcuMxJo/mTj09YuO/X/PXWViAXAUVi8JSciNNQ1/GJWatyfvGDXPGY6VQ3YyzOCohiKtiTYjx+EzDHWHOBouZP+8VvXldhZp7M8+oxOFXmPZrjtAKHwsfDY6QKoM9rmqzHmRC8mMDkiLTwyutjSpUFPggDLI1QClFZcimstzumMHBz/5r1cMubu89FWwnHannC+cUTnFWw0PgwcXv3RlrP9mBuIpNJXtCx87Mz0gRwgx8DV6+39AuDaRIxBoZJFKeeXHa8/8EZf/hHzzk7PWV10hKCYgoFHXtcPiNMidGL6UKIuUq6NBhEePx+s0GxxjmNtQu6pqWojLMWYywf/+AJH6MJWWK5OO3QZuLiecv5854nT1dcPDnh5RWEteevfvqSN282DJuEQvP0/JzWtXRPlrSdQ6tCioXPP3uD95EvX10xThNjGMklwWyuZYq0cY+/ZEhfMn36BaUUNtM9RYF1HdY0vP/sOUY7rO1RyjAz22f5CYUWwLkojGk5Wz0jJc8Y1gzTPXebNyzaFavFOaPf4YOXroQwiW6ocQJI1vFa6u8DdPHVOcm3abv7XyWn+Q5J8ncGnt4JdpRveMUezXt3APlbwxiPUa19mv/2dnCveHgB/i4QyrfpuXzHjtQ3PKyofPs9OQafjt9f/5on0FzIaRLgKHpIHl0SwW+YNrdkBUXLRB0XqzoZOzALlFlg2xXa9Sgdhee9n7a/wzmbX/j4ou9R0jliqkGxlhY4cma4v+X+zStef/Yb7u9uOX/2AtdKGw4KQgmCLicNuXB77wkxMcSENorlsqHvLChLHCauXr8mZLD3d4zjwB/8yZ8JmGUsSmfwX3MYX3XA77qX3/laVSuvNWGc9WJK2S9llbR9SCBq0vl4wpBkbSTGkZLls6xtUagq1zHrc33F/n3FwR37+KmvPpDfyW25WFWBbIgpkpBqUNkDqoftQGGdH/n7nrDVo78eXmO5J7KEPPkQaM2JyJxbqCoMrEp5YJig5k9VwkKIORNiImWhcEvlS2GtkZ7zIDbpJc2waBW6rFosaEvRDcU2Mn+7HlUg64YSE9OwhZxQQYCm/vycjGaYJpqm4+LZC7Q2lKJI2uBti207FmdPsM7StQ3OWZZdI8eTIYTAOOxIMRD9JEmCEiq9xpKDp0wD87wp2H1hGHbsdht0J8DT2eUzzp48r2wlS7z/knD/Bn/9OeObXzF5K0lQLiRlUOhZz1wCUe3QpkW5huJacpT9SzlSwkT0AzkFCi1giDkRK6iSLCxOLyDB2cWlgD1hIsVI1/cC4BnHHnjKBZ+iXKMU9tVRabeZbY/l2ohrFVD1JeaW25LSQZg1S/CYc6bEWl3LM1D0eCjOIJLes24raQBjhG2ia7XXzEwmVSqLRuYwWwEpa4yIvFsnunpKflLVW4lZxuJ8zDEYMXlIUdo+iUcV4YfL9eM7UVWAUGkl7DzjaNq+6vl9f7Yq7VTBx1LXB+oJOeLDzWBhLb0/BumUOlx/hdq/77hMMYuQOwV91dSf8zOKCI9TIBaF14qUYevhCplnnAn0zhFzEbv62nohItgelSO6pMqGMxQfSduBcTOw24qWEFox+chuF0imIStD31psY7hoDUuV2ew8UxS3PlOg0XLcF53hsrdcLhucNqQMQ0jkknBW05xaGmuqvl3majvgg6VcntNYy3urjpASWklr1BQz1mScMpSkCFPEuYaTrmHRNlijCTWJLUW0e8bJc3t3j46Rk+UpumTitGW5XNEtThi2I9vtBtM3rBq1T1CPV969hPIeCdYoJYnuQ+ZFefAOVQ5rhtKzI6psKU5QEjllImkPeCmlcNZxeXGGHy9ZNApHIcdYwzPRj+n7jkXfMW01Sc2j5VDmqtPwu8JyUOzv61gLPrquRc4K8JSSOFgZLWtdRpGKJO7TFFnfjsLMCvJdXWOYkqJE2ZNWKzqjWDpNYwra5D0pLKVCiIWmssP290IFmNTRvtaQ9MGPAA0CvM5n3GgBg+fPUYDPcielLMcQkMu7TYUxww7wRbFLhZhhpQtWF84cXHSaTy46TtrfIi37r3Wr525OpKnxqYwFaTkrKYmmU04Sl5UZ3jnOr+bfB6aTLNNV0N2YqrElnQC55KOI9hBnPWAuHSou+0LODDqpo8Vn/uc8BzLv3Qz61p2b9eDm/dy/thz0N4XdlfeubhXmBEo9H4kUAymFKt6XyVlKRWMeGP2OcdoxTlt2uw1KGbbtDqsdJWWUcTSulcITEhuYAmU2pCqyP0opGtfgrENE14uYzYRMCJqYMimBc5qub7i4XPDiw3Ma22GMIkZNSQqKQRVHiRCnjA8ZHxKmyRhXGG1Cm0hOUkhcLjoWfYO2psZAFmMtXd/jXENInhADq9OWxcrRrxzd0tF2jqZxFAoxRW5vdrx5tSVH0RMNAVKs8YDSxBRIMXF/v2UcPdfXt4x+IpVAUQVtJYZuezGJSWXCp8TtzpNLZuu3GG05MZc46+jaFqMbtG6gzkvSjiuL5HEcr5Voi3kyJSRSDvg4EVNkbs+cC4Z5NojQDxl88/guhwH14Lb6rsynb8uM+u6MqCNw5+3d/Mrtt5rhDnhC4UDmf4gKz488xh7+obffnXT572dP327pkqQxpchufUMcb8lpjcLTWEvImd12QzEN2faYzZbu+jNuPv1rdut7bHeJXTzl8kf/jKc//rMadIgey17F9O/x8GSSB9d0aGO4v7li2q159enPufnyMz744D0++vh9fvLf/lP65YKb2zWjn3h1c0PJmfdOTwjjxOf/5j+RU+aPfvJDnl6u+OM/fR+t4YuXV+gu8o/+7JS72w0//cu/wVrD7csv0MDl+x+QSxVN/oqdVo+effyqt995CMUyBa0cSjdYrVAaLBGDJ4SRFCZ8HAjR03ZPsM0prjvBND3T5o4w7khxQ87TntFwd/0547imXzzBNouq+YRYSKu5mntY+NRb+/XuKzGPpPxbt6H+17n94JMfkXJis9sRY2A7yO9huyHFwDDuSCkSoiT8JR8SAQWofbD6Ltj8t9uO4pz9ViiU2m+l9hN5XYgew4LVNjwfyP71QyRoMxpZgGNmmIK0wXWezgi4G1tLUA6TLDkVtBZmwvLiEtu2NO2iaoKcgHZkLZXoEgMpJGLW5GKJNExjZPe//Cf6k3M++ZMlbnnG6eV7FGW5HyKZRFSaYdrw6vU1RYkOU993XD59QmMMbaNpm4aT1UqOp4IkhkJOnhB2qOgxfsRpERc2FYQxacTEHTlHko2UBuh6GidW8cGPhBQZXv2a6bO/YNhsmNSKwRg8kvjZmjxkBUU1oB3KSqtcMh3ZdCS7FLB43KJImHSDih7sAnBshg1jyrjFhHErPvroY2hXmBRY313z8te/YBqHmmcqbGU8zTHqlBK5ZPzcGlmTTOtalNY4JyYJrhX6uDZmHw3nnEnRk2LCe0/wnnG3w/uJ3W5DjIHgpYKq50RXsb/nFQcoQhWFtRprDV3j6NqGxjictVhjsFbLuVfHgtWVCWU02mixjtKaVKWAJRFTAsxBZT4VJh+IVc8ixoDfCeA4DVO9J+M+QC/Hc9rMdHICKi5Xp7im5fziEmO+R4kbAv6pXFApo1GVzXhY+3PVBprlEFSZtSLm+bz+W80aToql1Tgt/klpbuktMo84JWyOTs0tdnUuUjBlxWjF9j2iGVNhlwo3Q+avbiOfXq9ZmA3vd473Wgta0bUNRkWIA1sfuNolsh9QKfD5X/2CZ2HH6y+vud5GfBSWXNc52t7wr39zzefbiDWG1mp+/yeXrJYdX0y3fLaO2FJ45hS/9+KExhoumwaN5TrKPNf0HV3M/OqL12gNl0/O0crQWE3Kmfu7DTtj+duTHZ01PGsN9qTjn71/xpsx8jf3EynDRbfCmY5CIqeJEDfkONI7jZ8Km+2WsyeJp6cr3rs44YOnK067C54tf7BnKBZtyMbw+voGrRN907DqezpnUSlAnCCMlBwkcihlrzdE0ZAjlADFolSiKL0fBaUgQFGuOoao2mqZ2GuBVoa0sCkCU44opTg/P2e56PkXf/ZnXL/6iPXP/5KwWbMLCaUVJycLlsuevutwrmEdC6NPTMHjK6gtOLjaaxTuo9IaPCkFjQWS5/b1KwyZvuw4cYknFyd0nePmfs3l6YKPnz3DFnhz0fPyesfrL0caXbi9drjW8t7TJaebQlYbSkyUbSRbS6ZFa4trHJCZhsgYCoOXge0a0QQ0Vpij8z2Sq6OaQphLzoDReW/OR1L7+6PirvhU0FmRUnWPLHUOLXKjFCXz3FUojFnxehQXvd4ErCr8sFd0RvNHT1ec944/eP+U00XDhy/Oadz3BzifY835HJeYqhtbnd9D1XKKvkag+cH7DkDTsXi4yAUYo7F2LsoIoJJTPLxXHYCpWXD62MDlAYh0iH7ZD9r9ciNFE6re5rz2PDzCIvfp0T7Lv4+/I1emV6hsJzmmmGSNG0dZ+4LfUlKSebyAH++JybPZXTFMO25uvuRuc8+vfvGSUmD3FM7PTlmuHKuTE56//zG6tSwXp3g/MKzvAClEWm1ZtB2xZMaQBRXV9zT9wJP3CjEkrt6M9EvDxWXH5bMlH//wkpOTU9puSQqZu/Vub/QS4oQPXsDkJGfOGBh3a4bpmhvXYVzLMGyZhoHloqNvW84vTlie9Lx4/ynLVU/XLWhcA0OmEHn/gwsWS8f7H15wdrZCKcO4y7x+ueGz39yyvYmELbgmY7RiPexQa0X+EqzV3Lx+jZ9G1muJ7XXj0QYWZ6204jkRW3/Wv0/res4WT9HaVn3EQqjssDEPFKUZpi1aTzgbZCyZOqcXcTo2uq+6YIZSEjmPKJ1o2yXWtUBmM9zyqy/+WlhtcaK1HX27FIA9pgo4HXLsx6DTN4FFx+L6X3tPfmdw6Ws/jQfao99y+/YR2p4ZIZuqDz1IasuhEqdgNkzZBzT/622Pyi4PnnmrHnN4z1uPP55c/g57VA5nTh2dkIfXaoYwHu/lVynulAfneE4h5s/J1Q0CIjNttBSpIM2IeJgmpu0du9sr1m++pFntaEIiDPf7m0DVatuMZ+zPylHFfH/h659fsbvvfliBMmJ/uttt2d3fMWzumXZb+r6jW3S89+IZ/ckKrGUYRoYi1fzV6Ypxa6o+QOb0pOf8bMXJ2SmQaW63ZJW4sFr676PHTwN+2BH8JEKClQlS3rGjx+f9LYCpvPt1cjqOmChKo5RBkdElofCo4lFpEHefMJLiRGlO94uiVpqSAslviWFNirt98OPHNX5Y49wCbaywLrIT4OlQu3v3fXdkwT5fz+NjLg8f/F5sJ6sTUs4obQkxoowlBLFoDcGTciQlXVvZMoVUz/Xx/X808xXedWIf/T0H3uodz6qjIpvaB8FHZb2jv8tR8HL4vR+Le5upw90vTBlpfZIefyX05ZhQVmM0tNaiSZRgSarsq09t2+DaRvr/tSUbXduxEqokaf+rLYDC0dOUlBjWd9Iq6kfolzRtR8iK+7stqRSC0ux2A1fXVxKoa8NisUCVjLWa1im6riOmKOKQrsVqjTGqtkUG1DSghjswYBwYrbFZY+MWG+6rbp+ilAUFj84TKo4EP5EnT9reETa3ci5UQ9oDTaDU0c2iJIBgTuyKxGcYgzBHGpRuUcqhVajBhiYkYX3M7oDLxQK7POXy2XOatsEPOwGDxomSy35/57nH5EQqBRvT/l4XwKmtgFOLMYamayrwZPd3u7QpeGIURxo/eQETx0G0VbRYqatSULnSzI+AaCGL671bk7OGxlkWXcOya2lsQ+sczhqsNQI8adCl8h6OgCdlNKWynWIxpKrZkgsEBEKKRTStrPfElNDOEYPHoEghULIihkCBOrdHSWfzXOyqCYTS1TbbYq3DNY2wYr9Hm64o9awXo+dSn6oJU5bZ4LA+Heat4/hMwAGxgreaA3PqaO3eszeUDBFTXw9ynxgFtrozFaXYRrAR1pNoXa9DZJ0yp0BywiwxVqNKgjQSY2BKmeQjhMD2fsPmqmXYTUxV7EYrjXPyczsEvrgb6Y1h0cg6r7ViKoqhgDMa2xg+WLV0zqCsRSvNEDOmyFpqjSGmDBlCyqSShdGpCimKvszNbmLVWk57w8IZni1bEgruBkpRKKStzNXP9yGiSDgtIGzJBU2hs5reKpat5mTRcHG2wlph4o0hsPEDfWPEhc2AIUPypGlHmgZSGMXpTx1KQeJeWkTEPAW0zuQ6P5UjEeSckzjY1fWllCRAkLaVCSJxWklJ2uKSMB+cs+i25en5OTZ4vHUkYIoJtOK0aei7VtiMSu7jmUF7aNNn/73z2HmQ/yhxeKNkYbHqgtOZxkDbCIjgvbAUGgONEaONRGE7JcYgbE6rFYve4ZwRQHW2dZzbTitzfo5zY4QQC9YqjDk48M3nTMCnehOUw2ysKqNTl9l3VV4rzGNxysuKquXE/t45GP7ItRsz7JKAT6nAkkKrC086w0lj+OS85cmy5YfPTlgtWs7OV1j7PQKe9iFNbQWv7WTC6olVPDwfgCl59YP3yd+H30qJcYnWIgsgMc/8/hoQHc2ZzEATPACf3k7v3i2p8XhfKO8ydXq4z+VB7HYESDGDaHkf3+UiLXgpBRGnTpGSEySJ30a/JcSR7e4Nox/wfiCGiWn05FzYbNZoXbi9vaEAl88zKE3jWkpO7Op50zViM8bUTrM5F/VoG3BdZfVtM/3SsFhZTs5aLp/1NE4AmxikQJtLqj+VbU3Zn1etFClGpnGHihkVEsNuqEW3QvQR2xjQihATBS0sIWMxSqPRLJYd6MJi1dEtRDsqRRiHwLAToKtUt0qlCiFGJu/ZDhNaw+3dmmkY2A0i0L5yIgNgnfxoa2lMw7I9pXdLTtonaG3I5HpfF3z2hDFSlLQQ6lKgusFLS6eAl3LcpapJaFLKlb1NZZwWQpoYpjXXd19KZ4+y2MpIlfl9ZqS9KwvlweMP/3wIOr09dr8erPqq7TGA9dWvr1HHd0wZvzXwtE+7HvzjKySlamZ0lAK/87PmbbYS/PvZvsvnfBNC8vbe/9338zGkdJjuvh7meldiW95+pCRKjmjj6JdP8TqTwxtiGvA5ULSl6Z9IcrK+583NFS9/7nHO0riORX/J2bMf0vSnpDChlJUgraiH37ZP0srDHXjXrn7NNs//plZxf/W3f8PVF7/h6osvGdZ3dB89pznpsMsFrl/Q9x5jWn5voSk5EqeAH2Y4T6GIlOzZDgPWWk7PL1lkWEqvAm3XY4xhHHaEcZBA6lvu71vX5R0Xar6eMhFbtHY4o3G2ELeviLuXTNM10V+TVUNWlkIPtJR2gjSyfvUlcdywvfuMcXtNGNekMKLcCcq0FC3Mg5IDKYxM4z0pBdrFBca1+0RWzQu2mvetPNj5Y66i4sCeifndx/a7uj1/+h6pZFbTVG2hIzFFGQN+4u7uihA822FLihE/jqSciD6QUsIHL4FBnnUDVA2sHwpVft12EIpVh7lx3xsDcGA7HUTCj++tI/0dIM/ZYQ1slDqIVO7nXSV0/xgT6+1AZzTLZolrGs5fvIfWirubN/hp4PbulhgndjdfoLWh7aq73OICpQzJB3KMjDd3hFjbb3NmTJkUMtup4IfEerulND0nBDb3a/7tv/o3jN4TqoJGSonoPeP6nrbt+OLyGcpaaCyu7ejOznjv6Xv80R/8I1Z9R98tUDmR0ejxFv36L1FlgjxQVCCriTBdE4ZXuPYprnsPvXyGWj2n3KygXZI3d8TtPWGzI44jAUvszgnra6ZxTcyOWCzWaIzSGNNgbVvFLbcUP4hQjmlAG5xZYVansHwKJTDevBLx8yKCts51lHZB13X0qyW/93t/QAieDz74hGHY8dmvf8Vuu+Hm9UtSiLV1TtObhVxTcxAS1Vrjmgo4VeCpbVsBW46Ap5QTk/ekGBmnAT9NrNdrhmGHaayc82Fb6S9S6RTNuAo61UDeaIVRmkVrOWkdJ4uW02VD37R0jSSfVhvB5ubxNwfXRYGVZLgoS1GGWBQZRSgyZBKKrBSlAlFTdfcZpx0xRsJuS4oydrz3bLb3hCDFgpQiyftDoIuAJ6pACpGofNUG+w7M3N+BTSsDGrSJqFLQNeCVijlSfZ3nhlzIe5BKkjKtxVXMVStxXacOdNXnKgpxnZZWLSrDSVWQIQJWQavgopFxUbSiaMWYMkPK/Phpxy4qbq633N7uOFUBNYhiUdMa1HhNGQfS5g1x2hF8pKTCm5stv3GG9XYixMzCie7O5fmSy8tTsBuGNPLqdoMphc8/XNKnyMmy4cPG8tHFAlsKn6xECPvaK3yG12/uSalgomdl4b3nTwm5cHWzZbMZ+OSixxQ4PenYhcR//OWvWXUt7kcf4IzmJ09POW0Hfn51Rygw+oKxS/7wRz8hhsAvv3zFIlguFz2uFPLFGe/1mrPhS84mOA1PUGvN660RplEWTR9fEsNuR7tdk2NiGyOvb3rS50s+//wVV7/+Ers4xS7OmNt+vPcMmzXru1s26/U+ybBWRJTPn16yPF0xbjfCGPQjOUbW44SPkdMnl3T9gtVyiXOW3XYtArtJU4qibQQYHO53xMFjncW1DW/W4hT6R5fnXD45o3UWTW2DKwIoWqtptKZRmp3Oh3FUNbW00lTzOwGQVaFpDH2jMMYxKItzOzSFOEx4DdsvX/HqZuQvPr/j0+uBP78dOX/e80d/8ATTGEpj6H8zMIyRWBRNb2h6g2tk7pmSYoow+UxB0bbSjqtrT12aW6OUOG4qpIiSkOPKBRzSbrpqxc0xZAGbrgdFqMvfW2zlInqdRgkzKuTCFCAkeNGLyPkPTx1nreEP33/G2bLlh8/P6FuHbRu00QTlCN82IP0d2FKqoMosGu4nKZJUplOquqV7yOkReJPnhJyC1pq2sn33xYVc9aLSUWymOdK+FCBy1gLUs2D4cTzGwxbVGTA6CJCzJ1mU/U4eYrODKdR8DA9dh+c4MWcBJFJtOc1J1uAQBIQLfiSlQIqREDxfXn3BOG1Zj5+Sy4hpdhQKxjUslooffPKEafLc3l+xfXnFyy9f8+TiCX6C84szPvzB+0xhZJx2IjWBmDg0rSbGgosaYzJFbSlVa0RphWs15087fvyPzzk5WdKuOgwdih6lJzCBHCuInzOoTNs6+s4xjYFxDGhGSioYmzA68P6LMxaLFwI+5sxuGPjyy3u6zqIKdB92NKuWUbegMpdPL3lCZNEtca4hJ800QQyFHAttW1isoF2Ac4UQtmy3AYoAT37akIvn7AKsM5ye9VhnMa5DKYNVC1q94KL9iIU74WL5jMZ1LBdnoGAsA9uwZroK+DiKLmyJME0YbWjbro7DTMkRpSJGt3Td2UHiIHlyHrnfveZvX0puMU0jz88+4fdf/DcY9SHd2UdM0ePjUEfTkdj8g/E2j+63t1mQ/PhvwVS+6q58DGId1vvjv78Ne0oCke8+X30H4KnszSpqnsRs/3h0zzFXIzl67K3tMU2xzMBB+ZqT9Wii/7rEuDwGiL75xLwbVNgf7Vuv+O0BqPmY365PfrePOR5sh88q+31TaHPo8d+L26FQxqF1QitNiIVh8Cjd0C1PaBbn9KeX2KY/TLDzuThcrvqt5cHf33TIjx+Q+V/XAFcm4/XdLXfX14TJU1KeS6zUMgdKCzLu2paSDesQa4WqmkkXobOGGEApjO1kPJaCa5xUw1D7igs8Bg6OEOevuMZfDxAeXiF0dw0lUEIgjTeEzSv8+IYwXYFbgl2gjUIZS44jcdoy3r9m3LxhWH/BNNwQhi0xTJh2QtkFzfIcYzoZAymSUyBps7/uj++rR9TE41c8OJ75mP5emZj/FWxt2wqbSUvF3NXF31knbJgc8cGjjCHGgDFWFn89ySJS750cHiJyD+a6o7niENDU7bj6Vv9+DDw9pGe/fQHK0YUp87xb9vDiUZ318ftknoiVjTOzobquxVpLnJYYo1lvRCg7eU/WCmckoFNxEqewOKFCRKUJcsZgKEraFGIphAw+Z7wXhzeTI8SJ3fqO7TCyq9Vz4xxxGtneXuGbVlJjZ8lNg2lb7ORpXIevulRaG4qxwsgio+IOFbcQ1qAGCjvKeEXZvcSkDHTiRmcbiFvy6CjrG/LmlhIbSnYUDFlpCf5iEAFaSdE5VEuVaA9RNZQoKNOAsdjFE8TurwEiSd8SGEnKkrUGK7pQxlicsejlkpw6UJZuGLi9vaUouLt+IyKqVQdHWwH5TXWbcdZ+BfDUYGqFsBbuSUnEclOMlX2kCSGQS6ZpW5SSFhuhquX9PClHrfate1YrrDYsWsuyb1j1DaeLlr5t6et+WD0zv+YWlKr0VBTFaLJWFBwZTb1qGKpOmdJV8FfmYRsjqWSMMwI8GSOtQAUa78kkvLcoRIg8zPdinkEz2XLVCQkh7AHc78smuhCHIFDtY73DfIJir0syTyt7JtoRM02rOcmrVVrYi47rutzPbb7zQpGKvNYo6KzmtDUUrWSeyAqXYIUlKcMiRvqYsFmes0pKGoQB4poSpsq4LpQMk0/sxkAIIqxvBE3EOYtzbm9MMMVEiYndFBinKAmSMyyMoVVwurA4raS6Hwrr9STadsic17QNKhXCNKJLIUVxWLPOolNmO4qo8TZElsqxbBynTWRlNWNWKGVw1nGyPMH7icYZWmvorCU2jpO+Y9k4WpUxOZLDjughBml/KyESKYSS5THvyVHm26AnRrVj2twQxnuUa7Ec5u5SE2vvPeMw7pPXxlmcNfs4pmR5XfITKXh2mx07H3DdAqUNy0WPViK8HLxnDEqYiAnUnLyXIswDZysDuNB1HYtFX8Xr8565ofYA58Mi8yE+PFodD+Ej2gj7wFhhSOYCMReGKbHRnpv7HdfriTcbz80Y2cZC1pqTVYMymqkyK+twF5blgfhVW0vl9ww4zQyXQ3y8n+b3ecy8uitEaN8qYaW1tkCa0dr62bBfNY5j4/nfuQj4NOMmp41m1SqeLQ3nveXFxYKzZc+T0wVNY/GzGyr67UX8d3gTzaYsGk7HWk5HGkcH2Oko1TgCboB6DbVoDurZeXfWNzwkyccscva/58LfvuJXv03a5qjjZX64lMPcOJMi5hrLfL2PX3+05/X9h30/Bg7m+2n+vn2LbD0f809KiZACm+Ge3bhmPb4hq5FOBclf1Im0jS0d2mRuN4HgE9u7kZwKV6/foJXi408+wmqHa1phQ4eJlIVRJQzpWK+H6CoWxMG46y2LlePkrKXrZQ5WGMjSUTHn/7n2mEq8Ie6QpUCKhZzkJlEUjC50XcPqZEmqINtu2OKDZxhHNtvd3nlZKY3WFmtBaYezTorsqGpQIl+uDVgLzonBXs6RGCB40V6DhNaZptW4pjqmWktRGoW431nV0pgFrV3S2J7W9izbUwHPsyYSxQBG6Qq2Z5ljS8ZEKzIPxtQ5JQC2Gq9otLIoJccUkidOE9M0st3d0zcrUo7kUlB7nbzycP6c5/7DoHorb5uH1mNwah6DDx9+96TyTTrV34hzvIWTfLvtO4ghSOuQfmuZQU5SkRl2nsS/y47sqa9vAUb7r56/5is+4J0v/4pH1KOHvwHBeten/b1k5l9/jo4H2YER9XXfK9WbOQjNORD8PdP2luHqDTmsidGLC1NJdKeXnL34CX7yjOPA6uIF588+4clHP+LpD36CnxLeJ5lcwnS014/24Zsu9bt2+RCZ0C9EDPbN1TXr+zVf/OoX3HzxWdWZaYkUBj8ybtfoUpgGQe9biySHIVNSYdF1NZAbmXaK9fqepm3QDRQMMSr8FJliBh/YboQNUNIcrKtHYN5vtxUFaIvC4lSmIXD3xZ9z89n/j93dS3Z3L7EmY02hPXlGs3pCe2JxyyV3n/2U3f0tN69+wfr2C5pGJlc/eGJMuMU5pl1w1vwhrl0K6FQKJYvug9yWmrlPfj+I5nvyGCiGB67HhzdIsPZ92owzaKAzQpqfnW7SckVKkdXqlBQju8qqGKqw9TjuCN6z2W4IwbPbbo4qU1KVmnU4ZsHKg/DrQ4bTvCAdAt3DuT/MJ99y9FX2UwFmxuHhb/0ASE0pkRUkDEkL8CoC0QZrHE+evUfKQvHeboUNkDPY5pSmaXBNIwlazqANT84tMYno7ugD681Wql7WEQu8fvWSFAKfvHjKhS788z/+PV7d3PEffvo3xFikgy1HNOJGSQmYonBaEaeJ9W5kszzBh4lcWlxrcW5FaTtK2VI2l5hdRoU3lLQjpXtyGMkRSAnFhC0jNu2Im2vicE0c1uRxi+o/wXQfwHZDHkfydk0eBrJOFBXRxmKNhRRIPoFPpJJIIZBzQluD0prmSUD1K+jPyMYxNWeMuSGcnZKKpnn2Q/rzS2zXoA3kmNClcLJY0DWO3fvvs1gtub27pQw74hRQaFrXYIwRvTutcbYynqwEOc45rNE0zmG0xjnRt0BrShaHmBDCHnjyMZBm4IlC8hOUIi5XRVptNAVTCtYonBU3xNZoTjrNRa85XVrOVw1t6yR407NdsbTvzK0mOVeaPsL6ysqSkTa7XGTMZaXQrkFpgzQmHRz9fPSVDScC7MOZ3HOn6zO8nxjXG2FtbdbE4NkOa2krDJEcA7soYISfhiMb6+/HZsQbCKMkTcs5zlM9e7y0SFtQ1lBqW1Ul+eI0IqhqpIXT50RbClbpvU6aiIrXNpCDYRRzauiUptGKVec4XXR4VfAUUihELE9WLZcnLfqjD9Asud9EttvIs2WDv/oNtuxQeSRMnlEWSbRShJiZpsAYAlMI7HwilsKUDVE3rJYLLk8zftgRp8gmZF7tIl9sIkMq/ONnJ5y2lg2JnApDjEwxcTsMjD6yCUkAz7ZHa8X5ssVSWA+Bggj3967h/dMVBfjbl9ec9i3/6P1nrBYdf/L0DI8m9Ss+fnqGaVo6Y3j/8glGb/jyemBpLU8XC06fPmfx4T9mp+E//vKKcbtmff2KRkPnNLuQuBsCi8UJp2dPWLaOs8WSxZnl2YXlepww1/dgNDHWtrkYMJTaimyIS8s2gI9gWhHcda7FakvfdzS6MNhCmAxx8Aw+4dG0StN1PctFz931NX4YuR8yIWZaNWBKxLmMPW2JlxeYxtBe31BK5vziCefn54Q0kYPHlISjIC6sovM1VvYGBaao6pwwJ4pGRleRpK+xDqVgO0butpFX6xEfEz+/jmilcD9fczNmfn7jUaXw/KTlSd/QKINPil2QaPfyvOXeF8IkbTdhStAbWgONE/v3GR7yScJYZcQa3lDoNDRaXF4LBZ/FJKFRcNrAsgFn5fW7CFOo4ZTeL7v7EmOp90osBZVFA8pp0CXTG8V/+37Pi9OG509O6buWs4tLWueIBkoWlnkBTPNtWAa/O9s0bCklE6exioeL7EfmUMQ71LflHzmXCqZKXD6zfFVtqwZhTu8jWaUwtt2DTjO4NMdfWh9iIgGpZpDF7KFRAZpkTgI4tI4dgKQZODoAYg+h1gPT6ejRUkjVTTJWDUeUsItJSWC3lKQAFhIxJO7XW3bThpfrTxnCLVG/IpeJ+7VHoWmaCaUMZqHpusJzu2QaA6/NFh9v+H/9q3/F82cvaJsTVucLnr73Aff3V/z0p38NGRZ2RQiR+/sNt3c33L5JDNvCNMLl5YLf+4MXnFy0rJY9SrUEv8AoizKB2VmbnCmxiMA4Bj9F4uR5+fmOLz/b4rqE66AzhuXC4ZQhTxrrHG1rCGmJdorb9S039ze0nUGpyKJfcnaylPgvJ5zpsdYJOF2iyCJojW0VNsPiVOOcIviAjxFDxFk4OVcYZzFNHTO6IRdNSgGlMp2zONuy6FZ0rieTCEyEPJJzZjvdsvX34paepSitiyIj+nuTL1jTYnUPupCUBwpjMCgcbbtARxE5D3kUjShlODt9zsXZ+zw7+4iuWbGdtnsHxyMI6HBfHG2PU+193vBVeMQ3gE7/JbfvBDy9faPBg1NRodACe7r7rE8wv2CfYpWDJfj+Gx4AQY/rJ+/a9hD1g738yt1/6zi+/SX5JuTwm9/3aFe+EfR66x08ZFjMjx/Qe/m/gE9SZZhIYSBOO3KajqoMYJuexekzmpRoYmR59h7Lyw/oz96jXV2Q2RHCFtG7KY+wxnl/1PGfj3f3W2wKay3aGIbdjvXdLdN2Qxh3ONdiTNVlqm4XuU7cJc8gysHBzWiNmt2MyuwQkavmQaZkKwtaFvbH5EeClxYqoeWyJ6F9ZV8s5d3HdlwhZq60iEOUppCmLeP9K3a3L9ncfknjLE1j0XaBaRbiCqYghRG/u2fY3DCsr8mdxTlNDBLE6TiJfkoKkKMwO1R19VCPdMAeI+BvHcuhen54xbwIf9N1+93ayly1qgnpXiPFiEYAGQl0jCGlhDaWFAPGGhkjSuG9hwIxenGLi0ECjUqbfoy+HhXV5hGxN17dazoB+9JZ/f0ueut+PB5RYR9OR3sOA6WiiYfqXdlXfwWDPAirZhSNs+isaZqWGCPDkMhKHJFAWEEoVR1Zyt6uOCZhWe0dyFAiFj2O+HFHGjcYbbk8XRCjpzUalRIlJSj5UG2mVN0ZLfes91XjZ+6R1/X0KIptyK6T+7yk+hNgbw+fyQRynshxR57uycMNxY8QJ1QWVy3SRPY7uY9KQZWMUmlfwS45kWOi5AlVEqlaPqtsxMo8jajk9q6ICSVsJ2cpymHaFbZdiAbFPkkRly+spe97Yop0iwWpiO2vVF+F0amPqrpz0Lxv1dz/5tFvVav7+gCAvuN+flA2UmK1bihY5qRL0WhFqzONSrQ60+qC0wWrq7141UrRWtfKfp1NSkHN7aLMehu6Aq8atK7zvbThUcdMKWCskfZWo0kpoUohBkfOicY5bIboAjplgrGEOAIFH2Od15P0v7zj/vld3+aESvPQSuRQH6iV/qpzY7Qil4Pu0GwNv2d2lMP7jVY4JdpehlIBxEOrokHcxawSXQthqmgshVQkKbe50DvDSWvFftqeUFQkqwg5Ma3vQU9YpN1GJNKF6ZBz2c8hqWRx4czCgEm5YLSisdKmpJOAlaEoNmNkG4X5o4CpCMOkGmVTkL/HmIgFio4Yo1m1Qo2ZNTgoch565whZwHSrNSHJPXneNUSliX3LSSs6iopC60TzrDEaqzS6bTg9OWV58YzJe+7XN2x2ntdvrmmMYtlatj5yOwQuVMPiokE1Pc1qRbvUdEuD6zZoJ+28ubaklCx8TK0VjdN0nSVqRTYK1zphhRm9T9CVs9gk7k+ubWkS+xhLG4PRBrKIMOeYSCHh04AmsLSIBqBz6KYRhKUUrLU41xBHScpmM4GQYEoFnzJhL2rOvl2tzD91jM5Awuz+5UPCpyyudbG2befCFITltPaZhYXz1tAK6ioFo9mcwWpMPDBeJEwVgFYrYcnMwt/MQJjeL5kcRbCH8a7AKrWf7+Z7bF5DH9yXj+/RotBK8hpptZP3mAKr1nDWW04WHW3b0jQNxlmKShVMLrBnI/7Xlyj+tluucVKa46WSmKUoOIqnD2CNPP5Qy0mAmnkdPLCJ5E3CMNEH4An23T/Hmk7HgNBjTRwJv+YFdY9dHTalxEH4wdEdYua5+PLWVr/3+KmZIyhi6LM2o5f21+AZp5FxGvFxwKeRogMZKXSCBuOFTa0btIK2E+Zz12vGIXN3c0vTtNzd3qIdPGnOMNYyDAPJZ4bKDN5st2zWW/xUSEnup37Rcvn0hG5psaYBGkpxSCyY9s6DKUmrYE6ZFBLTGJm2kd1mYrv2nBhFvxCdNg2kkPEl4PahrMQCwzjiQ2C327HdbejaTtaYZOrcrBGVNWEc6erIrK3CWFU1mxQxULWSIrkotC1Yp1BGcrFSB0Wu8Z7YPtU4VKv9eMklkUmVBRZFbPw4pqgTnDxnRLWg5o3SteOrY2uPUkba5Gsc7VzHsj9n0Z3RtSusacTFsLbMf+N9/w5ixNd1SeyHKPD2O/++t8ew2Ndv3w14KlIhKbB3gJ3FkNvOCq3MB0KIbDY7xKbV1l5IKzfh/FH7ZGpOmdiLhNYiriwoj3O6bzh/an7JzI18N1Lw7Q/7K7bHn/AQiXz3a99OFucleQaN5vfXwaQOj+9drigPvuywUNXUVim0acjRs7n+jPHuM7b3n6MQwdsShd63OH3Os9/7M7rVGYuzJ4TgCdMI2nD7+hWUqhChVLXOPT6KOsj+jqdRKYSVpDW//Nlf8Ztf/YJ0f8MiB1LQpGzQQWGjQaOx2uBsQzIZZQRtz1Xk0mpDUYquP6VbdnSLE9Bwd3uNUoZFfwYlEXImThOvvvyCrl8Rhy2mVuFVUUe94r/FdnSBVQ0oPJqketAXxPCKcb0mGMugHYUlSi1oTjKt6eiffIRePCfqBtWcsr17w/b+ntXFCxaLU6zeoXUgDy/xacP5B/+U/vQpbvEE7XqKkjYVmDHgeVKSB+aFUT3c2a87kO/FtvUTFGqycQBxlDJybgwobWhMSymFpm/Elj6ekVLk3I/EGBkHEccdxx3RTwzbe4KfGHebKm44VTHvvA9klJRomNGgWWdAgp+ZaJ73UY7i3YvIAUhi/7p3bQLK1n/Dnp4cUyDEgLIO0/asfUKFkWaSZb3tTnCuo2lWxBSZxoFh8NzdjTUpnKctQ86F7egZQ2ActviYSVmjSmHabliT+OwXf8VqdcJHH37Cyqy4+eg51/drfvHFl3K/ti227bBtS9f1nJyupCVvO2Cq8La0CmWIgTwNqFKw3RMYrklpwpQgLSmmYFvQagvhJSlekbaWlBUJheovaE9W+LEQ7z5j2uyYdgPonrZtQYsDmyagQ2bykbEkUhBwqtUCyixOlrS2ZaEmbLHsrrf4CLtYGIsiN09QzYJudcpieULnHI3WRGbrXKFen52u6PuWGH/Cdrvj15/+Bu8DJUPWurZCHyjtKUkbUsFgjIwjrUXEUlXASeyQAyEEdsPAOA6sNxuG3YZhs5b2m2mHqha+AjaBIWGJOKCj0Gbos6JXmlZbjFuCW0FZAAuKaSi2JWtL0YYQEzElfEyElBmSgAAha1JRaNMKZb5fYZp230oobYW6Rm0zsJmJlV02WEeKgbZpSCEQl2fkENkslkzTgDaJcRz2rnclSoDoqzDz92qrx2N0QWdqoaTgjJZEtzbaJiTRLqmQUmUNFKSHbp/IzbbzmqVxOK1pjN6jkTkXYtaQRYR+Bq4E1DRYq8BmbA2qnVX0TtFbi8qKz263vBxG1tGxTY70i98w3X3Oi5XjvDeknYdWRG9zTmSVSRR8yUw5McRMSIX1esvdjSWNO3SeOF851NJwer6iW3T8zU/f8MXdwFOV2Z002JMFyhmc62gtPLs0DD5w8/KW7eD55eevQWt+//2nnLYNH/cLVM5cre9JRVpBXM7k3UQOgV+9uqa1hstVh7IO1S84X3ZEZWpc29M6z7JVKG3oFyte/PhH/Mn/4f/M+v6eT3/1C372v/xHfv7pv0YDjTVkVUiqcPnRj/m9P/3nPDm/4L1nz1gZz6mdOAm/oL1upR1lbhmNddHWmsuLJe8/bfB0BNVS4qyB45h8EqC761guOlCK8xcfQlHEqu1lnMOXQolrdLhhlcXR8PruihACy2fnWGsISjEUxXrwlBjFqjxVMwmlOGkbdAj88nbLr6/XfLHZsQmRJ8sWo6vTWy6kfcItYt1OCYAJhRATb9ZbxmnigxPLNmiuR8VmzFyNgQw8aRVnjeKjpebcKtabSDSGpC0xKaYxMw2JaZvIVmO1sPucqcL5RfSYfBCwrNEKXaUbxgLrKbMLiSkmlCp0DlZO0VkBsIYoznVaKWKeC7rUe+nQ+lIQsEoDq17jDGxi4T4UNh6cUdx6zUkwnEYl7UG20LiCSrKfUrwp4mz4PZq//LitoJ/EXsf/AQdtpaqDlnJEGEwGo6UgdmAr5b2g/X6rgLqxRhhRFZiawfO9WY8xlZ1e9vnnsWC5tL3V9m1xG6lFQo4KgzwKjfclnHduprakg0KVjLbCRA1JmNTb3S3TtOX65iXTNLDdCMP+5v4Wn2ZXNEs2K1L2DD5IvlMCRheaqnfVuCWtzfQ/aJkmz8v+FmfX/OzX/4YX4WM++clHmNzgd4o3X2742Z//nFIy1tVroi3LVcePfnzBs2dP+PjjH0At6hvXYNuOYRxZr9eM2y2b2ztSyKQQWa833N7dc/c6cv1lIGdFyZrlyvHiQ8c4Be7v1mzXa4atou0bmtbSn7Q0C0vfrlgtC3d3a4ZxpPxAoS6hsdJqDYWcgwBKKnJ6sSSWS+62A0VD13XCDFeiq4QZQSdCghwUrhhhQueIUqIppshs1BsSI5twBTpx0X2A0Q0xTxQyzjga09DYBpD4uWTQRZNLwocdKSWsWeBcQ9usKCoT8oBWCYFWMq7mFEEteLr6IX/48X/H09P3uTj7mBA9kx8OQ+nrtnfkBN/cBjdjBv+Q2/Gn/wMATw/uuT3afAB3tFYiHYHQtWOM1FsXoytiWMGgGXHm8CmyM9Zi1YHiCEgF//gY1fEBygPzYiCTCPvvOkrljk7PNyGD73ricELfYj6px4+/82N5/Lby4LDe7t+cz9Hxke535R3AljjcVBCrUJ2gJnL05Bwk9qwid7pSPa21uKalXSwp24TfTaRSiCkLjdB24oB0fPCz+9PjnX0LDHv78eNtrpiXIrRZ0Xa6YpUjjdFsYiLmQldsdV+olQt9qOzOQOZ+ESnUyp7D2AZUrqJ6hbn8loGSEmNNzlIM4oyhFepbiDoexLofqvscnwuh7WYJKJQG22O7c2x7imlWtTqjyRmiH6UPnoJtl+jmjG59g/ce74NQ4RdP6E8vIb6GtKHEkVgSZF+roXLMKat3TDZH98i7L9c7j+H7BD6FJDofOVc+ewW7tX6kLaDmQEWqLUYbcnYYa0kpYm1DjJGmaQh+whqNn0a0QgTIFWKLSth/t9wuB62Bx5uad4fDGX88rh6L/j34rIoqPr5a5ejpwsxMSrUUbIi57CtumlrF1qa2b8GQEsFLD37aM7qUAE+liPZVShijcShIlWmRIjF4ht2Gxmmcyiyc5snpStgrVqzhoxaHqFlAW9r/DkcuQaYwpEoKZD+ic6oC35aCqhUlB6ah0AobiSSOMIwUelAdyrYou0CVDTmMlDiJO5Tpwc1tY0ZYVUUS9pSjuKolj7XCDLFknCrSQJYDYRiZfCQUQ8RSnABBRhtpR6uBsCxHBYqwM5yz1ab8BG0s/WKJ0iPT5PdXvxQODEyESZTrXBxjQqvKhqifn3OW+SIEJj8x+Qk/iaNfCr5aqEfZh5yFjVmPxSqxpTelYAvYAqZodA7oZCBZSAailbGmtDBnsxFR7xiFvRATY4YpK0JWxALGFrTOKCcJvByXsLtEO0LVe1FBES5iTprkGqJSlCaSdG3ZM5E4jcI4aRpSCnv9lnmVl/165632O7vJ3DSLjrJvqT8qS4ESjQ1VwJaCKoVUx8bMAFGUep/La53W2PqDoro75vqqUl8v+lwzo24msKt6DWfg0BqNNZoxRq52E3eh4T4Fnt/Ck1JYxA7nG0JIiFaLxhR5j6nW1KmIDkoqhRgzMYowsSpima2QAqaxFp8KQ0gMPjBMCtNGdAHjRGfDOUMqpVpcK8aQSCpz70X7I/cao9i7JM6tM65SXHaTp2SLai1WiyaRVorRi8D7zLppnQFt0EZjW0e/OhH3stWZ2I+Xub3byP91oWlaFqsz+pMzupNzGjVhGTDNEu06cioUwiFOromwc5a+0TjdEVVH8JEYMiFBSgVtRetIW4s2mtY4jNLsRmnVRwnPTKuC1ZmshB9WYiAHX1vHDevdjvvdVhw6S3WQpDrtak0qwnK6HjzXoyfkLGygB4yUowGsDrF+rsl/LgWlFY01XK5aWp9ISgORfpfr85nOKNzMHK/C+ehqmpEyKQlgQTkw++YO1LlwXbvExYWzAgEhwxALIcm1N6rg5tfUXEYM8+ToU1F7Ftdb9yYiQ2qUaEJZA7sgmKGv7nc+K3yaObUzM+oQt+Z9/vL9mrxyqm1ENaY8jkvnMFOuUzmKb6SDYWb+Hiccj5PtA6tXHc1JeR/L7/PO+fXqoZHVMfh09KEPc83jp/YhtnrwoxWgD2DW8ftyLfaUWUzcj4QwsRvuGcYNm+FO9H+GLcEHdtOamD30BW20MCCLoRRDyUmcOHVCqYQx0BqFMZamlXl4uWqgwG66YzeeShyTC63tUWzZrEcg0fUK6wxt4+gXHRdPVpycLmmaVto/Y8Foh7MNXkufaYoJP3lyFKZTCJEQEtMUGYYoJlWNCJi3ncEHiRO9Twy7TMoJHxzaaUx1mDNG48OEjxPjNBKCp3Wi7ZRmELFECommkZbitmuYvDC/tDE4V6SYYUydAOZs2KIQUJIjznDMnpBGxrTBpabm4PIZKIn9rbZY7UhaNIMP+XWpeWUkpiDmMFgUtQiGOP6VcmDjGWVobcequ6BvTrG2FbOFt4CHb8i7Ho3/x/fDt3Gr+wfdvuXHf2vgyRphNGk1t24cWunm4E/WeF2RZ+G0ppTr4l73aqaL1cUpV0qz0kALXe84zBWymMwibAfQqdQEXwIhqe5VsbQUcU4oyPtehAcX9fBzgHW+AXAoc93mm7bf/qK+E6MpMwAlf6pKfT6eoPevqxFhThlKoKQklD/raLsTAaDCiFKGpnGk3RU3P/933LeON23LuLtnWF+zfPJDTp7+Pub8A+zqGWlcy/vm5PlxAl338SuD/ccLdd33rl9inePN9R3bzYZf/+1f88Uv/5Z/9uF7rE5P+NXPP2U9Tfz+xfu0jbCi5KYfoCSUailKnGJCTAzbLQpheChtaPsVWheWi2lvV1lypmhNDInr2xvO7m7wu3u0AtsuhPYY/VdfxWOU4sFpOK59zd+FtAbZluV7f8Dy/EPOPvxjnl79mhQ2JL9luvk5092vCdsXxPGS8w/+lOXT32f55APWN6/Y3H7JtL3lyXu/z/L0GW9+8a/ZXv2c7e0vCOMduj1ht7vj/ANHt3Io26G0iAYcFsDDcv+1YNPRI6Xkx/Pb7/S22W3kH2WeN0qdimR+KHWuyZQ98KSVxpkG2zg6t6wnr/b6p0QKET8MeD+x224Yp4HN5g4/jQzbtQghTyKkG4O0iErbqNjnwjEkXvb7drx9nZ3p/qlahT2G1/cBXf0vl4IPE9Mk2jpoh6+2uLubl5QwcbJocUbcjVKKrO+uGSbP1sdDAocixwJK0/Qti7bn8sX7pKK4ux+JITKOG2L07IYdxihur15j2yV//JOfcLPeotue3Thxu90hgIOhlMx6vWUIkWwMIWc22w29he2thnFDWV9hKTS0aHuC6p+jTMJa0YrSZFTaQdpWunXEmnOKPSdnSykalQJ52qBKwVhNs1zi+nO07dHGsR1GJh+YdoEpCKNSZUPHUUW8AZXE9fDqzZfcbQZCzhRtMR9onElQqmnBnLwbLec95bqGKqx2vPfskqlWMdfbHb/5zReEEBh9QClJyuYWKUUmZo8ChmkeyzLXxCjui8NUmXnjgJ9Gtut74jQybe+hJHSOaET2u9GZXiWcTrQm4XShMdJW15lEpxS2gE4JggS5kqSOJOOkHaoUhingfWAzBnY+MiSLz5pY9Z1su8S4jhWWNkN2Ha2yoK0ka3vgSOIFS6FoBV1LTpZWG0pKRCuOfSV5nNVstgug0DYbYTaEVB2ODtX078s2AyOFIsaB1pILbKMw4WKBxiieLV1NvIuINVsJlJ022BC5mUachtYUemtZNs3+/KNKLfIpYUDlQsmmAsCxttkJWGWolXwZ0kQK3cLx9HLBT2/f8MX1DT/9fMvPXw/sfnDG9MEJX6w6TruGl1cbVAh8fNbxvFvyw/dOeHbS0twG8iaSmUVmLVo1FKRAsxslqDdFsTSW9097mYu1Zh0yrz6/I6P4g2fnLBorQJ2Gk1ZEsk9OVmxD5mevNizcyFIbllahXINKiZu7LcZoLs9PyDlze79jGqU9uO06zpueabPj6mef4pRipQuGzCfvPeN+nPjl7T3q6g2ffvprrDZcXlzw0Ucf88f/9E/pGsvZcknxA3m458V7z2kN5DBxv74BW2htIYYawxaJTUXXRJhsBU02DdlZUjEV0KoKXNWOXpkW7QSY01qT00SJY5UpKJSqg3Z5tiS1kS9e3uHjyMKAU5nPP/uc9TjwL//1v+X65pY/PDvl+fk5fb9gsVhhYmYc4N9/ecNnb27415+/4c12pG0NTWtRCGAzA6LWCnypjCKpwt0UuB0st2vPaun4gx++IJfCP5k82yHw+ZstmzHw6m7kduf55ZUk4m/uJzZPE66VrolcIlMM3O88QwYahXZU4Kjy/3IhhyTj3ykap2gcol8W4WoHfyNvxSk4cQI67VJhHarhgtL4yvaaYqlMriqpVqrAeM1BVp1cQ2kjFIAvUPBJWGUbn9nEAtpgrIWiKKkwVcfcXIESnd4OsX+Xt0Pbbi2ozDHynP/lvI/PlVI412CspWlbef1ePLwWdczBLOnxb6Xk/JeijwDQuk7uGVAibq+1kdSwAqHHRb25wDPnNFrXfPZBBD0TJDTWuPo8UAohBlLK1Yk1MIwbYvLsxjUhjHzx5ldsh3teX3/O5AdySaSc2O1m5zMPqrBaGYxVxKREJ9F0lByZtp6cYZNHMWF4dkHbNpz0p/QdOHeK9xO3d1fshls++9Xf4lzHn/6TP+PZk8948+YlOUVcowVwenrB2dkpH370AQrNMAaBmpUUFpTSNK7hZHnCuN6yvd8Ku9p7UIaT1SnEgMazOrWcnFn6lcI4cZzslCUWBSbhp8g4RrjzjKPm9MLSrwwhJzKZu80lfd9wtjrhpF9yv7nHhwmtApjE6myBaS1P11tc1+6LaW1vMRpMcyqtc/V6OytGLE0juMIUJ1KJTGHDGEd+ffdXnLYXnC0uUOoEo0VzuHc9SsFFc8GGLdtppJRcvZmz6CWrBNxQOGFZLpACvyZlyFH0uGaCR696rDHkNJGS3zO8H27vjlv2Y/Phg2+/+r9Y0jaDZ+9EMd65fXvGUwUdNHMvtaQ6c/Vr3oGZ2mit5eA0cKhmy64dQB+9B41VrcrNPzPasn/Tw+OsGMhcgZufOCTcFdBSx9/5OLmbP7g8/vWO7V2Pqr1+R/32d7ziePe/zgfuiLG0xzEOVQH2jx9AjgcgfTmc35IPfam6Vt/JcwJZKaA54HfXMAIG/LBl2t1h7ZKuf4Lrz0j54DSwB7yqbAdF7dHj43F3GAlffRMJNVYCpM16zfX1NX63Jfuxakg0DN6zHUeoi418rjT5qz3KVfb7VUreXz+lqO4XNUiPeV/ZBElOhFEkTICcxeFP6XK0nw8DgLeQ4rdxgiN88/gZhXEtRhv60+fiNjXeEMZb4uY35DiRwkj2gyDtrqVZnNDHiNLQLU9Ynr9Hv7jANguUqKVTciSMa5TtiF6YW9Z2qCosy9eMtMf7fIRfvr3734MtpWp8AEAdwxRKPgRDeyhaKYq0ZVNqLDEz4mZhS3IhuyRVkUbaNG3TgAY/St99DB5vLDEmgg6iX5PiPoGcgQM52fnwz6Pt8RS+dxF9C6Daz3bvHJcggHTKWSq3qArUB8ZhR/YjjS5ka7Aqi3B6lNa8KSRSEW0fhQTuc4yltaZfLBDh2KbeTxNGS1tjiInJezAdfdPQdYnVYoHSmilEUi7SBpLkOyjQNE603VLc/6gUKSlQtKEYRzEtyi3BJHB576hCsOALRUdUCRTTU0wPFBkDReYPEeyWINc1Hdp1KN2go4yNhBax10Tt5y8UcwCSYvTEnBiHrZgdlEIxBh1GSvT7+XeuZs9rpKqFk/1aagRQXy2XlKJoGkcumTAFFBDVXNiZr23az3UlF0oSVlgMnpgi4zRJm+Q0ELwX4HPWpyoZVWaWkyTNVmWsKjidcbrgVMbqjFUJU1tHKBGSML9K8pVRNGvxyL5OU2AcxG1szBZfpIEvKUNWDosmRI+Owhg0IWCrMLoy5XBfzfcn1Wmt6vYVFFjRfbLWkKysaba6yhhdWyy+cSb43dxmTHoOP3VlrvhcCLmw9ZnWahaNCBo3uurRVDv7xmhcNhitMFlYPdYorDEHDRvFviN4tsNTSvSgEhpTmVGlKMYgjKSgRMfGx8IYRS44FdHd2gwjN/cbNkPH4Htuh4BPsJ2EHWeUpWss1opumtEidH6IAQ9Fw1JEU67kQo6iK+KMonUaazXKaEYfhMUyRQygtBSlCnLvOWswGaYxokisfaQUTcfMbMkV5D3cq4XMECLFRGLO5BAYNjuMUkyqsGwNL04btiEy+sAwTWx3OxZdT9/3dH3P6vycRdtwcXJCGbdkB4t+dogrAjTVNedYt0bY3JUhU2NB0NIWnOu5mRlG9bKpktH7H/l7fwKRKj1ZgEmzP04tmic5crO+52az4eZ+zf12i35yTtu4fdGhINpbr9YDX9xvuR4n1j4IixWFPux61QwT1zyULLm+6kHFXMhFHE4bBQsnRgrjGGiMIvoA2XDaanZZM1T2kdSJDnf5rA9HvV766GfOI3QNCI0GayrbShWmCHcTrCyo6stiVR1rWYAnpUTHKqZCTFVbqp7s/Tmfv0uXOk8DFPm+PQhX9ccy+2s2a3KW6uac88xcVQ/izt/57VE8cogxZwLDYdAoPbvWiRZZKcJ+PP6Ex8W4vVvdg03NH/nWa/fPasVMfnhrU/Nzc2LDXjvzYYaoDsdCXZdLIdT1eBg31QjjjhAnNrtbpjBwu37Ndliz3t0yhWkPku2mHSmJw5w2oIyW1tA9PlFBzSyucSnN7DzR7hUdLMOibzDaMgxbjDYMww6tLGcXTzg723D59JQQJgqRrnf0S0e3aGjalpwKfhCRf/TBbVwBtoqxp5Qlfkwzw6klLjQpKFanhtWpwbYFbYTVeLgZwdhZVichzKBS20zlZglxYpwGUjoUZwXoTZQS968zVlxGswZKpmkM2ihcI2zymCQftMbVeM+BgkRBZUVIUlQZwwarLT4NuNSA6/egm1GG1rR4I0DcTLjJJcl+FIhJDLtK1WjLdb5VOVUWnN3n4aUkJr/Gh5UYNWQBxg+M28dbeesvJQPuALi+413y+GHsvms6+e7Mp6+alB7nxd/uc7818KTNnG083Ic5yE5JHC2cNThr6Lp2D4JIvK0enbDDiZk3par9fN1/TdkvwLme9QP2chAnN4ZK33Y4dyQ0p8r+d/2G+tkzS2Buzav7NCOL5dHreQiqHLYjAIRy9Lx69Nd8mPmdONrDbU4hS6X2yo0paL+ShTe/fe4O/Toi0lkAbRusa2jaBp89PntMY1mselKIjOtXjMOa7eZGBBUVrIct49WnnHz0J6zCRLe8oF1cEKaR6A9WvkbPDhPztZtFix+ey/mizedU1daathUHp//4P/17fv43P0MPG16sFmAtuwKf391zs93yp1rTtY0kkslXAFMqRmTRobJabJ4V0FhwFpwzGA192xB0ZBqjMCFIhBRZD4ntbsAPA023qACVMKaoi1TOj0/yfIketq49sjjZj3VNwRJJ4Z5hvKNdPWH17GP8/Wf49ef4m7/ivnimzQ2bN1+gul8zxgVGZZrGcf78j2gXSzY3G4bNQIiZmKFZPsG1LcP2mu36mvbkA1CaVbfCuo7kd2/d/8fL97unhr0X3h5Y+L5srsYMcydlmsHKJFUHcZWoc1MFRaM25KKwxaGsFUB0ZnNaRTEW0zS0udCfnBFT4Mw/I/mJadgRfcCPA9F7/DSKe+QwEIJn8iPej0zTTjRyqn18oSbbj5zpgP2YOriGPnp6flQdHlHIfKooTKGwHTPbUGhjYdje44cdm+vXhGnAD0usNVglAdQweqaQuN9FYgHbKKzWrDqH0UpaqbXF2JauW/De+6IT9/KLT4VKPu3Y+cz11mPCDpNfi5aGlerTsu/YDRPXV7doo3Ftw2qx5IMXL1idnaGjR5eMcw2w2kf5QSlMfo4NIxlPURPFNuBamG7BXGMQbZqMOKuN8Z4pbCkq4xrHebNEuR69fILqz4m6J6mW1rSUxnOzGdmFCb+J5ODpTgsNMHgPCm62G8YpcXf9imEY0c6ibAPbNcX0xCAVz3munBd/ox1QVwpVWxu14f3nzzhdDWy2G+7XG774/AthLtUExRlpH0hRxJmnSXS3YgjklAk+7JlPOVfWZpZkUpdCZ1tUSeJcRaLRmUYpOqNoNPSmCPPJJgEuaruIUopSgS0ylBgpaLISe/spJbZDZJgi6yGynTJjsfhipbXOODKKmBNq2xBSpBTwXYcfF1jraBqzF6zWugbZpaCKSBPZ2RDAFGLJOAvJKhrXEFxLYxuyzVhtoBRiTt87AEriD2ktVUqcTlOEGx+5HhL/6eWIVooPlg0Lp3i2MDRWsWrFnevZUvS0zsaGyWSsjpy0jmXnBBDISDGnpJrAK1mDdCFnQ0qNAD0GXu0if3W14zfbwC/XgcZAp+G/2U6MIXK9STi7wJgR1EjTiDvSfch8uZ74+c2OX1xtOW0MjW052SYyAavhSW/wg2bIZc+8TFUryHsZ76+v72CaSGGiNZn3Lk9YtY7PtjcMQ+DV7Y5bDT5NpJJZ+8SUwGrDolF17oefX29wRnHZaVpduGgFhLtb77DG8PR8JTpEN/cMKdLtlgQdeV0io4/c3d/zycUpH/7xDympvu9uw/XNPZxrLs/P6c/OOPvgQ5Zdz8XZOWW3Id+dsTp7hjXiChkTZFcE9dAZiKBKLXZIBaSUBMljsDgF2RgyhrpsQRLGiB1v6IZJinrGkPsl2TXYXChk4rAlhcj05jVpuAMWtN2CqzBxu77h3/7ln/Py9o7FyQkXF5e8ePGMy7MTYg6sxw3DZsub2zv+5V/8gl+/vub1MJKBU9dglaKkJAlqK2CxzzMIpElZcT8mtlMBpZki/Pp1xDnF2cpQVGa5bAgxMu4Gupz5owvHdaPIPtNYyzYmlNFigmA0y7ah+Mw4ZWkxVVQHQegacA1kJYWW1hQ6oNhC0Zn7SfFqqznvC6cdFfQs+Ag+CNiUihKQLMtcVMs+wMGswyhpXfWC6dFXPcDnXW13DcJIzChCEbVyYxVdazFGEb0UheIskp7dO4CU78E2gzNVrDnlxMyQ0FrTdR1Gm7reC7PsuBi3Fwif4XelHvzM20OjlxkJlOh3LsgqpWuGNT/HnjAhhhlzMbs8SPzmdUVrMcaYX7Md1qTgGcIGHyfWmxvGaeD+/jXjuOX2/prJj6yHO0LyxOLlPCRhsKYs+fPN3UAIgcWJobWa/kRhHEx3yPpb/9NKoYy0FVurycWTEekIay2L/hQwPL38GFDsdgNGN3Rtz4v33+d//3/6F9zcXfGLX/1MgLIyMnrHZrNGFU3JFRzNkUQklVk2pwq9W40thlIcJydLzs+fEJ8GQpowSu4JtAcdWO8i23HHdqPY3mlevFjx5LIn6S1JDWQCSU2sTlZ0fc92umV8ueVsdSJuhs7QtEtu45qd3/Dmes12OzFuA0TN6ZNzXGMwWhiXqoLTmTq+ikajaLoGpcEkS84JYywxecZwT6HwavM5Z/3E6fIZ1rjanpi56M4wSvNKv2RKniHsyClU0XFpNVTGMIUdKHHeg4RREas7LB0oi6WwGV7z08/+77x/8Yc429K5ExbNOSnLuXvHLXMYnw8e/26c7r9zPPStP+Dbf9N3YzzBu8rw8pVV1HamHM4OUrM7kfzxNUjdA1h877m1/859Tj+/eI9ey7/nqvCeEqnm6tVbR7L/Mgnm5td89Un7KqDoMDAO+gvz4w8Gyryfx1//4AMfI+9fBRF8PXQw6zzNmgASqOqqM3NgpymtgFRd7yain/bVhjgOlFwIw70AGP3p3lFiBsFSTCg7f6c6fHc53rejm+PoH9aY6hYWmPLI9euXXL/8gucaFoteKmLRMwaxyi6pUFIhDCM6F8IwkRGD3pKl+qmy2IDPFa7aFASofSAtAoNyjOjAMAZ248iw29L0S7r9sdTFbR6nRxdmPyaPFsTDtT+MazVXI0tBl0TwW8LujaDoxlFykHYu22BcD0AKA2HcYnb3GJ3RupBDT8kNcdrihw1FKUzTo1hQdKYMu+oCNpGiPwIm1NtD5dHi+VXj7etB0d/NTc8T9XHxiCMw7rjSjFxzVUqtbuR9NXweC7l+mNj7Ak6jqtNXMqJblJpA4xpiCIRpxE8T1jq8nzCjqZRwSZKlunMc7IjYeJmDqkeT2LsC0/k46p4dHpPDJqNJ6MpC0ZLURU+MgRgC3ntiMpjqrOOryG/IRdg/MUtVngPEXkrB+4g2CW0MFkfbtShVmKaBmBVjzGgiZbcjpiyWwrkWBEqGNGGUYWksfaM46y1da7BG1TYggzIOml6+WxWK6ynNKSVtSHFCZapoqAHVMjveSdIaCClWcK8cXFGcBWsoFeiTAFicnwri1hZSJvpECAVvYJxE+HQYPcNU2VjMQpKHSuTBqavstTsOlad5MasuZQpaZ0ltw3IpbnfGirtiSlFmsaL2wFOKiRB8bfcMtZVTqqQ5RQGc6njSdawYY0T/JmcMeR8cil8Me5eqedQUDs5UKRfR2iniFlOkqREfEz4lQpAfX3+HUgglodHoXFDOg1YEL+xV55q6FimyDZAF1LXW7AXVFVJQUKruSMmoktAlCquD6vTFDK8+vB++f8BTLTjtkzC5D1IRV7G7Sax1LJGFE8Zr6xS+iG7SpU+MUdrvCmC1kh8jzwuLXR3FQ3MSVjXE0BgNShemWLgZI6+3kc/XgYUtLC1cbTyv7ycGn+V+UlpiQFUZxjkzRBEPH2Lm3meux8jlGHFW7h2rCo2GYhTOiF6Jmlt8swim+xCZQiDV+0trjTVGtKJq0hgTInafE1PMorOTFZQDW2xMiVgUm5BJRnFi1D6mMEo057KScoy0SGdS/fcUIm82O05ax67aeM8mJynLa2ajHNd1uK6n7Xr5jHHcM6D3VFXYx8YPHExnGg+lMhujzNOqkBS1hS4fYuoYyGlEZQvGkG1DVkY0JKvGX86pOgYqdNtgiybEyDCO7EZpNX7vyfucLBY0XQfGsB1HlNWsNzuu1wNvtgM3w0jK5UHxcW4LNlrucE1tPVMHtlSs58nHzO000bWavnV7N0xgLyNq5yS2roUpg9YS78/zhMQ6SnRA1eGUzuv9zGKzGqyuro1axv0US3VQlKKURlV2UyFmVdkYB1MWXT8TqgRI3T+j5sfl305BX/MRq2cQRe1jqzlONXoWwp6v/ezS/P2Zweac4EAeejjO59h8Zjodd8/AcX5xmOOPNTMfg0+zButsuHBws/vqc/rgszh0csgy/fjzZ6ZdwoeJmALDsCEEz87fH4Anv+Nu84Zp3HK3uWXyI5txTcwBbSVWtBUs8SESfMR70UtqYx0zqlLmdAYlPZ5aiy4TKJS2aDPnZUf5V815jG3JuTCNoRreFJy1nJ6dM4WJEEU2QumMNR7vJ7Qy6AoLlFoIkpYwPV89WR+MwZVSZW2suMixF0YTNFbPrNlMQa5t2xpWq4axDIQircS5aFxjaRrHsAsMMXB/v6G3G548OREmeMikHKrbnOR8qmiMtljr9kB+zhE4FGhLqvGB0hUnEIc+a0S4vATZP58nQvb72Ez0lZUIjBsnbM6SiVGYSvMmc6pogiol8ZyQRoTRtR+2SpGyx/stY9gQ4ogz/T72/CbG0zweZ9DpuzKWvur13+5z1DfOSd8VLP8OrnZf+Y11sZmZSkcZ7zFaXamNM7Xy7d1UVVcgvzVF6MpnnU+6Km+9UwaVNUj4UMHOeT/mRPwYvSplb6tel5TDhKhmJlR99tHEtZ+E5pt9XlTmCWzPX5f/PRZbnIGu4318fN0KR7FHPbeqLkrl0YA8gjvEvtGKuLayHbko/DCQY8QZCwURhPOe4AeUsiyWz/bnPqTAtFuz8AOmxMo6mwUyhRoeQiDnKgpspLpWKgNttqmcU4L5hOcik+jZ+Slt1/Kf/8N/5svPP+ev/8O/49Vvfsk//9/9d7y4fML/4y/+hs+v79gMklBO1zu2+Zbf3A1YrfARAWCWPUopYs7EMbDqF2INbSwaRfA7tFaSNKHp+xUnK3j69JL4+oa/+vUvSNrx13/+H/ngkx9y8eJDQKGNlUAtVRbKPF6VJABqBiD2LY+HxW7/QiOgksojTHcML/+C61//W2JtXzp9+vucPP0RzeKSp5/8bwhpIoYNYfMFyijWbz5juH9DszjBNV2lpsPqyUesfvzPWL/6C6bNS+zmjswA0VPCxMGqto6Ncjyo3kbJy/7xOSrYj8bvFfjUJLlcAhNI4oECayXEyPMiRb3ntCROFFmYcwzEsle1n0MiQFga1khCoxuHcw19t4LZ1LtkVBawYBpH/Dgy7Hbsdhu26zvu72+5u79mHEemcSQlcQdTcuOLtlkNzr7b5D43QwvNv7gO2hWqP0X1J4T0a7wfqi1sYjOMFKWIVUTVRwnIp2xJueAHj9WK3moaZ2kXSwKKn/3tp7im5ZMx0jaWtu9QRnOz3hGSIY+JWLZsX9+Si2gVUDIqRdS04aK84Um35I8+Osd2Grua0Kegn5yyWq1QtkO3BnNyQU6BFCbQhqAb8s3PCG9+gy4RUwLGnWLcKWlcE4crfJoI0dfgRhJs58CYjNGJKYmTZyiQSqSkhKnC21kpxhAZx5HXJbK1mc2YcI2tLZOZdtGwWDUEdULWHcGdkHRPiBEfJlKOoi+VakBW0Z35Ms5FGWcNy0XLJx+9z3p7hvee9f2aLz7/jBQDsQQBa3IFRWNAlwwqSXtw1XjOSqGKQc10dlnK6u+IKQqdFTYnHAorIxiKIiUR3I1a2qeUkvMgOkwJpQNKGTLCIAhJEsnBw+gLuykxhIRPgZgKGLlOJk7opiUEj2064rgTQ4vKMrVG7iGnpRWsdQJEtVbAjll+PAdPSRHt71F+gjRSssx5uWQy0paRHq2P34uttrbnIoySlOt6Wtf9mA1jKGxH0eL6mSlYA30DC6d4f2WEyaYKC2t41jkabeitiLcSEzEVfAJltSQS1PYNpWicJmZhS74aIn9zO/Byl7kdEqmRuORvX+/Y7jKqir0qp3Anjk0KfHF7j0fji2LMhR2KP7/a8le3A9fDgk9OGoboSTlx1il0Z/jgouf9yyX951uUiYRcGGNkjJEpGe4Gz+0Uud0EVNacLBraxrDU4q6Zd5kcI7thyxAzd2MgFIU3DUprulaYr1+uJ6xW7JYdS2f4pHM4DdNuIJfMqhcHxpAKGM35asWQEr+5vyfmwP/0S0sp0DvHom1oG0vjRBrA2YZFf8qq71gtlkylsB0mTL+gWS4ruFsgJUqIlBiqDpzAqtoYXOPYpULYTVxttrwuEd0tUE2HSgmVMsV2oC3rnWczbTG2kThmB0XvqnNqQSknc9DJc9TigtPlCaUUrv7Nhk9fvWLlFiyenvB//R/+By7PL/j//s//M1/cr+Gv/hZnDG82A7fbHa+GHTsSy7ZFK80wJYyCVauxWqHrGsKsY2KgaEnSQgyipbfO/MXLNacLR/OjM4xSlAghFBaLjs0w8eXdwM2QuAmZTWV7m6woWlrgdlMmBKAml9qAz4W7qbD2hSFA5woLW1i4wtIVdkExBmm7ax20NtO6zGZUDF6x9TBEaE3GaihF2FsFadNxtaXOCbaH1RVEqj8XDhYGFkpTigg/5wq85b3gtbQaaSX6jyFIjKoU4qz6X2aW+QfZ5tRpbkULs+uyFjmMvusr41VS0ZSSAO0VSDTmkcv5cSFYHQyK3kqg94BRBUxqvD5/Rs5pH0/NsdWDqPdBwia/tBLAZzfcMkxbfvXyp1zdfcF2WjPFSdpmcybEkZwju+2G4D3JC0DsJ0/OhYVusMawWEnR+eWrT9msd+zuPTllNIY4aTZ3iqYD1IhxibYD1Tq69lyE/pUmpcRuvYUx430kpcLoR5TSWO1QOAwrcvbsdhthDOpTtndX/Od/9xKtE2fnlrPzEVdb0hrTCU6jFcvlCX1/hp8Cu+1OTHQotF1H33ZY6wT0UgqwlBIhg7FgnOg8GaNYrRyLpuHiWcfFs4abHcQpsmpPsK6nbXuMbfj885dcX20Yr37G6eIV/9t/8U/4+JOnxM2A91tO+obedoTrLaRICYZkDN2yQ1vFtPViBGSkpJaKtIdPQa6xNT1aZZoGTDL43GG0ZVSeAU/MEa2s6L1qw6o5I5eES5Gd33G3eY3CsGzPZdxlKWoOwwbXtPTLJaVEQtgCBm2EeVUUkLPEhCUQs68g2WPtsK+5l/6eAelv/XnlGDz5+9l+C+CpPPh1SL/r33MSd1y5OTyJegdNbF+hV4eT8TjJ2v99jAgd7dFcSVAzOKeOWFNH503+Wd7a8ZnRMyPke4KX4uEL60cqKiPh6PvnSszx6951GubDmAGw4/NwAJIev+fRd8GR41/ZJzRKC3giGkpiZZ338iZyXVJKtVoWUbqlaRaiF1IdrorK2G6FmTWDag/xfH7V0XFWTLDu4SHo3+96PT5jDMpoCoUYIq+//ILf/OqXEEaWztC2LbZpuB9GrtZrFGJBXHwk7iZ2waOVBN1oha4Ux6KV0B2VtClFn4iT2BFjZfHPGUpI5FBotMFqTUiJ3TTx5s1r+tUpYdiJ1fzcspFmSOZovB+NmWPG0/461sE3M55ynAjjDX57hV+/xvsJH0ba/pzu5BmFgml6wuDJMRDGO4p2DOtX7O6v8MMd2jixczaOkycfYJsebURkc7+olyxuDDO74jCC6v7PCOeje68cj+xy1GIq4NP3ZkuRokT4bx7E83hRpaCMlcB8f7YE4JUebGqrK1Adigoz+CgA5GwzvQeJjIgKzpoPmoINDmvF9MAaW12SpGc8plCd1bSM5RAFEDsC8UU/QB3NS/OMd9j2eh9HOOiDeViLQwpK2jiUMtU5xoggYoaQxbFpjNUOu1R+itICbhRpG7CuIaNlYVWa4D1aFZyz1ZIdEpk0BWmVCUESKmXRJWNzwKlAYwOnTeKsLZimoGyRRKUynkplb+raow9F3EtiImtLCR4VB2LYYnuD1UtiSsSUCCHg41gb70SnawZ/CrVwoHKd31TVTMoobTDOYZoWEyKx7IS5NUVcKlgrlUdTgZOoWlAtUPWI5lG0r2RTx1d9rigpbsiFkQBbK/quJefMyWpFTll0ElMkR3HSMuj6W8B3rTRZ1/OVD3e3LqI9KOYu0ramikZljUZXBlVNhorosGSE4aEyqFztwhUYlat5iLQAZRS5KGKWauUYpBjgkzDkxGlKxiq6UEIQUNZMFJQwPutakq0lV6e0XDV+VFPZK26+VnJPpeqimPxADqIllmtr4Szc/70DnL52O+Z6ycyV6s0fSsZkiEXhk+h6NVoElEtRPGklEDbi3ILR8rhWhx/RjKxgtxKQZoyZMWZxA8uHyutsmhBSxupZPwh5X85MMVWWjq6gv2ZMhSkldiEyBI3P0pIUs4xvaViQ+0zYT/JbG6lcp8pU8SHigzjGKY0YJHBIJmOROS2mIiLdkjvuY7OYM7kotlFQWl/BWpNnsOZQdJJ7VX6nUhhC4NX9Bmss2lhiKcSU8CEwjCPjOOL9xEBmqyGMEyEJk3s3TfVca4pOlCTAt+idaOZ2XFXXq1wUIQlwY3XAKI1OsmYrLcc+xUycEvgJpQKmAWUcxlnRi9HCINOuQ9kG0/bikoW0lDWukXixKHxK3I0jd9sdrjpPvdmM3A8jqRT5HCVtLDlnij6YDM16mjMLjPmU1+PJJVczBE9jJR5Ea0oS5qpWwmkc6lgTXag64hUcCsV1XtV1fKbCJmTupsSUyp4wZlQ5aMky6wopzN5Zjv14KogLtzFKGFKlkJIwN6jjcdaLMvrYMZL9nHsoaPOALQNl7+Zs9Exmk6pIqpIlMQpj4/uyHYt/H+IZ0ZkV91fzoFCfy/5Ok1hqL5sis9wxY/1hDDR3e9RWurfiowPo91CQ/PCafW41A1xzrFWOkxzRVBIDlTvut1ds/Zop+n17YM6RUhIxhQo0VNZPnZ9LpRM7a6VoRGVK1g6O6GVOzkFRnJJ7V2XmjETuYyNrfoYQ5B8hSJyorRQuQxZwU5mOlALTNGBcg+16FI7oNZAYt4G29fgwiTSOlXnWOCFxGGMoeHwQUGd+rGkaZk3ZOZ4uRVdGUAXPVWWzOZnTtJF2SwlHhY1travvLQSfmYbIfd6RJo33fl8AMVpj24bGGppmxNt6vsKRFrGixi5V+iXrPXAsC1ZlPqEpe/dhQyaRiNJCt++WqRrJ2tIYh9NGioVqHqeH8SMudnmPH5SS62cVhLKRUFpjVYc1osElTspHeqBffyc9+PXo0aMH3kZXHj79TR/w223fNfb61sBTSfWWn2/IBxPq4009PAFKgvw5ID/a2wPKPMfkHN/j88p7eInswrsPMlcKkeIw4Sul5aav1WX5jGrbTH4w+czouQiJHWVvda8eUC6PXv/Oc34EArzLner4zNVP3+9XIYvdqpbn9t2KErMd3l3mBOdwfhprWZwsGU0mxxekaUMoHTl58ujRMWNyIU0jye9YXFxy+t4fVmfATHf6lO78Bf35+yzOPyCGkWF7jSrgjMF0HW0zU/BnEOoAOR1C4eOFonB+8YSu63n5+ZfcXl/zL/9v/yN/8xf/mf/jP/+nfPQnf0izPOX1GPnp51/yyy9f8ntPn3LRdejtyDQGNpXRY01l2LkWlCFbS1JKgksyrz57w7jpePFBh+sacnH4XeTqb3/DerOj94UVhr7vGKeRf/Pv/z2vr675wYcfsbp8zsnHv0+MgbWf9snM/ojm5Oboks+xwwGUUkIbz7B582vuf/Vv2V39gs2b3yAqlpbx9pXYVBuZ+MK0Zdzcsr67koQ5ZmIsxHFNCiOLs0vaxSnp+Q9Q6SkpTsQwElImFNHbidFTUhCQ5QiwOB5zZV4Z9SxcenwAx6DV9wh0Ana7W0CRlANtKG2HMhV0MRqjTV2sCilFhmknFrDR12ukAEejnIiOlgoYRU+qiZ4svAbnLG3TYJSlta2AUEYfKm0xkoI43k3jwHa7Zr25Y7fdsdvt2A31Z7dmGLZ4PxF8qK1beT8HCS191lk7gNLzdoDQZie1SmtH3KLa/gJTDNl7QrNjGCdCSmyGzJQyt7tAytA4AWO7xQlWa+FxqYbT8xe0Xc8nPz6h5MR4f00KAze3WTRQtiMhFfztFusaTs/OQYvWh1ORU7Vl0W55/syzXHgumgnVNJRGkUwixAEVGqZposXRWI0zFtP25HZBaVeMdz9nGyL59op89Sn2yYB7WsU29YJMEB2vuvhn1SDgkEVhKbmgStib7PqQ2IWM6045cycsTp8SU+D2s5+zub9m3AxYEh+9eMZqucA4GU859cTiCFmhoxgV2Dp5S8AtrS6za1i1UawCswpdtVBOFj1d01B+/CPu7u7ZbTds7m+5+eKeUhKtEzFy67qa6JSq9SRBT0pRAu9qtCD/LlASJWupuCdFyZKQF8GSGIup+1nb68oh4daqCPuFtNeSyEWRlSajCUnaVkLMxFQZgjkLE0slbDHoKFpBJiRSShjriM1WACYKuoAuwkXsTcDpQnJUG3sJbn3OpFzY7rb4ENndDeKiNw6MPhFzIhcw6u9O4v6vbqvjaHauFTCuoLWV4J1Qq9UV6K7JQM4FP8GnAxhd6F3i2bJw2mvOSsIaYZSBIepSTTwkKBe9TWk3CjlzP0ZerSdudpEpSfV/1RhaE9EkniwNP3raMRTNUF2lki91jUr4kghKmO+tFfARRMxem8jGKzbBcLUe8THxl693aNehKVz2hnjW4Rea89Mli65F6w0pZW7ut8Rx4DYlitI8vTzHGYMaLTkWdlmzzRmPiJ8LSCM6JhQw1pJK4Ysh0vmMM5pTq/moM1AUMQQBKIwlodmNgRgzq7Zlip5/94vfsOwXPH/6jLAeOHv1hru7Nddv3nB99Ypf/PyvKdNA2W05PT3l6dPnsFlTrm55enbCh5dP6FsBbMO0I4QRpS1KW5m7KRTrYLEiDUqYV1kAXaMUBgGFtDFcDZmr68Dd3R3TMPDe00tOVyuef/A+y8WpaEYpjevl3nZWEeNEc3JOf3bJ0zYSYuJ//H/+KzbTxOcvPyfGwI+eP6W1juvNwJQizjacKEf00jZtkLHijEWrwug9MWWGqTD5QpmyGFG0hq7VIjpsxO1TKw25jtcwVSOYxBQyr3eFuzFxOwSmEOmsdDVka7DWgC7YBjoFaxJ/eQOfbxO/WQdeD4knrcHYqokGbINiCIohgFLCdEpZWE5TFPew007RNhqjZc282iRCjlgnhZDeiTi/UdLqm2cH4wJJKcagICu8LnWtrNqQOaNKZtF1nCx6emdRVYXQ58TdWhxkP71Z41Pi//Jfbrb5e93yrAGcAwK8Cdi06BcVQFEVcPAAKCUtqNaYh6BdKTyE9Oa1lPr5VQf3qPUTyt6hTj5mBp8OGq1SiM/7PEbyxTlerp+h8p5dhYKUItFPbIc77ravGPNELJFGLzGqwVkjBaLOkGxk0hMpJkoqpEhlJmXeW3S4zrE8XYhZyf1EyolxE8neoscljXU0ywZfPK93r6ru3QgFhvVEDJlxE2iahkUb6HrH2WVDKYndsEWrkdwU8jDy+ZeJ09NLfnj5j7k8v+TDFx+zXt9yd/0KrUe2u3uMtuwY6Pue8/Ycay1N07Ber7m5uWIcRoy1tF3H8uSMGDwh+AoGNYQ4EXQiFYsPCmM6ThaJYCCYwm4Yefk6ortC23c422C1JXgxRhk3nnEN1+s1GzuxWa/x0xnLtqdrDU2/AmXY3AcwG67u1oR1ol0ZcfVUoIzBGjH9MfVah4rn7ttmlUHjWDYnoAox7phCg08DRmla0+4NIJxpeP/iIxrX8OXdp8SSiHkU0fJW8oNMIBcjrPwc8DEAVtoDSySlgUV7zsXq93h29mOerER/y4fd3uX667dDhP+tIZ63MKZ/WED7u3z6d47S9njMjBx/BROplBmsmTGoI3Rkfj2H/ttv29zzoJd3foxvPujj5/eMnUq/fBd+dqxpVfavU3tm1NEr38FmKjO0/mDC24NccxD5CHF/iM8fsxse7NkBlq+vmz8rxEhhQm3XpOhpXEvbLWmX5wSVmMYbyUdyQKks2hrOYpu2VroVzfKC/vQ5TXeCNg7CJK5IVZBP1wT7AE8c7/+hN3qeyJ2pYslAipFXX37Bl599xrS5w5TI+ekJl0+e8Op+4Ga7YwiBVAqdsywah0UcAsqsX1JPSC4adJbWKa3Rlao7DB5rFX7w8jptiDGyvV0z7EZMSLgCvWuAwvV6w/nNDVevvqRow+mHPxQkW4s2VjkSq50ZQQ8T/PmaH52FUiBXXYUCaItxC5RuUaZBoYjjhmItxUprHxgRBk71PUqhbSsoPpocI2HcMO1uyWGk5Fi/7//P3Z89W5Jl6X3Yb08+nOmOEZExZGVmTV09AQ0YADYeSBFmEimJNJPp79ObzCQzmVESHyQzESIkAylQAEQ0puru6poyKzMjY77TGXzYkx7W9nPOjczurgJBEJ1udiPuPYMfP+7b917rW9/6PkHwcxlfuYCsUmksVZL3DnJ/P043zjcAud8m9kAII6BIKpO1FQYZYApraQooFKXFbdLoiUG0HFIqTJMCFEj+LnBGSf6Fm5z39/zkjDTdI1OFR4Afvdc2yKVMal2Nq1tc3VLVLcYWUGxn0KonBNEUgqPxl6e5Rj4Dvg7KlxpB+T6RqU3UuJpcNdiqIacooECmVHbVvg1kEjyvmxZnDJUqznPWYq2laSpyDIxKbKNDiCUI1CgVySGiTKQ2EtRFLWLvNZGGSKMiTgdy9qgU0BN7L44ColIq51GqaFpOsRiJl9a9EBPBj2Tfo0IPSpOVJFmTDshel0rJd1Mpk1QkK09WYr+OlgSusg6NoSo2x93NlVTlu0iMAxmhuScsYIm5ULrLOTdFs4KcChATBeSaLkYpYkzsqIkNpUvAPWsbQggsFgtS9KytFTdBimHBhD8oRUKjtLA2VHGQKtThoqYvKHkqY0TgSBm8MQkbisJ2S0XXJJTla49z5AJh5snAvfytJHGLGSlcpLyvwsrHZYgJoyI6BFCaEAIZ8CpDlLZL2bdHE4l6RKtICAKQY2t5XzneMJaWhuCFuZtlptJKl57CbxdoDjDVto7DKPlVxhJK7ltd5hy9HwMHyY1MLiwjYUZl2LvYSVJVtGrylMwJo21i/cacCVmgkGkOnPxmUs4YrWicxieNLpNjjjIexBmPvUNVIVodxTjichZypvOZ3ifebT2vNz1DCCgSzmoUhqZyNLXDWlMYkYmYYAxSYR6CrNeTPp3PouMzdZ2bosV3mJnlO8eUGVVi4yOKTJ90EW2Qg/UhEnKgTyM+BqwWN7/N4MnGswyR3eDZ7nZF16/j6vqam5trwm6Dv7tmHHuqqiKNgeChtYZ0dipnohQSDhHGtJaXMW0M2jpsNRUz7muXTFqn6Al0TPu/lXFo68qVU2Inr6QsmDJo46SQN2YiiTc3N1xvtqy7DnKmGwMpwW4cGY/cpqaxqPXBtTpl8JOeWGktm9hqlVE4fZhbJg06ianFBXX0kW4IDD6SyvFWxbUy5kSKGp9l/0YonaUwBNtQypwJ+pix+sBUEs8YVZi9IsQsDPppHS/jQ8sxTmzl2kAUOUCMYe8CORUfJ12m6XzELK3KiYNjm9bgyjlQZR7d9sLWvN4ObHael3cD2yHw5XXPEH6dRPSvxpYmVK7kTxPT6Vg39sD4OIqZ9mllfi+HnC7A/RL3tMnLviGefS9VPQp+9+/fv/fe84eYSlguMiqNMlhtcbqijz0hheIGm9iLcCtN1lMBagLAVBEaPYBg81lDCpF1tSWGRCwMHmccztQi7p0SMSgxIyhrdgiR4FPRv0v4MWDsxJYs2pVKkYiE5OnHHfU4I4YR5zQPH15S14YYt9SN9DLmnAWiV8JOTimz2/bsNj3bTQ850bYNVVVhrCElDZ7iHGdJORCi3rOsRYPJEL3oMqYIwUNVF01HLYy3OEb8OBJCIgXINoMSZpRRoJMhJYMfM5mIMgpbaxSpMOAD0dtSiNX7DoJUbszJSOyQpsm40SVuTzkWpprEI3sB+jJwmmrOvFmymp0zhpGQg4xL1L05W+btw09Kae+EJ4Bqs/9JKYrQfD7m8X19+yaezTc9pu49X8b1+y8s5yO//46/NN37c17wbxhv/fri4noamOkIfHoP8ikX6TCRHLFx9HSjsU+YcskgJpoeOe8XMGCPVsv77n/Beyf5Gx6Tw8nkYkH9Dd+oMJbe2686AD5TMr9nQhUA5UDVvH9s0/vSpMWhzfsHtB/I3zBdHt8VAjxoXc61iMUeYglpQUlZKKuVq9juOt5cvabfbdlcveXhxQN+53s/Yv7BJzTLGTcvfsrLP7tDpR5Dh20c9eIUt2ixJqNdjTENzeqc2dkjoXAOG4jjPtGRI5sm6WIdWf7dJ9ilwmGcQxvL6fkZddPw+qsX3Ly75r/8P/zv+bN//a/4gx8+4w/+47/D7/zObzNbrvi//p//b/zksy/wKfPw/ILHixMu6oqlSlRkauPkcya9qSSAU65qtHNUK3GhefOr52z7njdfXTFbtrjLE7bdls8//RTfjzhnWKXEJ+en3PQjn767Zhs/5+wf/H2++4Mf8ujxY3Q7p1ksiN4z7Db7pPVoVLx/WY8GkLQxhjRi23OWT/82s7OPCQ9/KPbppmL37hfsrn5JSl6ExttHuMUTEdrNGh92hDhwevkx8+UDbr/6Cd3NC66+/Ak3r36BNQGtRAQ12wpMDabBh4QaPCGMxWK1iAxP1aMSSr8/GR2W3al94tgZ5K/+1vUbQBFzaTMLHu0cSYG1AqLsKbMJghdh5+BHaWWIQQCBzF6cOkaFJxFi0R0rbVzOiEbKVHmLURZFpaViqpWRdjtrqJuaZj5jFc8lgU8wjiN+HLm9ecv67pqb63ds7m7puh3D0ItVb/B4H0R8Ogqhd6IW3weDRaMnZRi6LRtk/yFlqtmKqqqJY4exFSEB40gVBpKKWCMVSuMcrm559Pg7tE3DrDKlhcuTwkgOu8NYKy1PWmlWyyXRB7q0pq0MT5YOIz09mAhV7zHRE4aRbuwImxvqGub6lJg3RPNO2j60wacE2518R70jeU8aenw/4s2cUVcMQBM6VHeFrZe4+gSMA1sVKWrI2pGzxfso4C1JXPFqQ3YVzfKMys1FB8s18r4MdbNgc/2O2y9+wri+oguWtEu4WjKUXQj4nLANOGeZzWbM5y3eD8Q4ikNKlgq/fAcZb9a4vX6hUgodBUA5XcxpnOP7P/get9fX+O2Gcbclbq4xOVIpVWq/mqwTUcu6ErQk35P45WQBXQq3pCRaTmOAEDJ+KKLIsQihJ/bjcAI0JgfPSRxXYnIJ/g5B1hEIAlLlR6E0WB8wIRHQmJDwWdx48qAJSlErjyViVA8EYu5QBEYdiRqiFVbZiCVkTTdqxghDEJ0Xo63odmlXjk19m6auw5aRRF4xaeeXttfSFklpu6LEI4JVCEvDQMiaXTKEZIhJk7IuzB/wRJm7tLTZ+iDi3F3vsTZTOUhaWkwrq5hZRSTTJ0ncd0HMCypnsV5aOomaNECKAo4OMdNFAaeNicL4LbGWSKAJONsPcNcp/uiLa15sOhZWBJrRmqpueHC65HzecLZ4Sxc8s9pRG8V6PdKFiMo3GK24HUTEfD1GelGlxhjNqpWEZBxLG1gS+QdHIEX41W1g5gzoxNJonlpHyPDy6i2DsqztjMF7nMoEleliIo+Bq01Pvrlh9uILFJocE3dvX/LVL3/CsLlld/2as7Nz3l2/hfYEtbqkUpnvf/wdzGxGfTbHzq/ANoKclHZiP3pA4Zyjriq0PtnHl1OLqSpx7vmiYW5OuKgiY19x8ugBzfKE+ckJrmkJwyDFiyyFw34cGIYB5+a0zQkvrjqu1x1fvnrD7XbDyWJOUzu0rchG48mMKTIMkZxlbIkum7Sf+ShaYe92EhG21oq7nNactobLRnHiFDYnTM7Y4upprWH0kdebgdv1yOcvNoQMC6to2oqVqzhrHNebniFrboLmajPQuIQ1iqaG3meu+8xNTnyFYuYU81rmyJRkrhDh8GKLnnQpXEgca1TGWoVSEvukIOjrwzZRzWEsQOzdkBn8oZRhyv1mCyg1IEBn9CXWz5naZh6sLI9OLCEN3Gwjf/x8zV038q9++Y6bref5tWc7JF6tg7DaviWb9+K46SpxsW7qeWE5qZKUh30arDVYa1DIOplzJoZwYBtxyLHkfynwqFQkAbK0Kh4LlU/6s8dt7+9vU6Ew5wIuqSnPObwnxUQuhY3KNdiZ4dn592jMjD97+S9Z7+4ECDEe50Q3SCtpAx+HHeM4SsHRiMGQMYZxJ/Hl97/7jBgDvgvcXK3Z3N1hK7g4P2Exb3hz54l9YOytzNumRupqHdpmqiqhVOD29gYfWk4uZljnmM1OhLEaAiGNjOGGvE28evVLXDXjf/2f/z1u1lf8/PM/ZhjXbHdvBDSjoW3nnJyccHvT8cuf/Sl3NxvevLriw+885Hd/72N8SIxjEiZziWUXixlqqwljxjqDMgYfPKPfMmwVoc/UtsK6tpTsRAtKuUx307G+3dJvA3GE9tSwOnGcnras5nPuXmy520ReXL1kN4wsV5bFsmF7t8WQ8OsexsTJgxNc5chJWhFDFudfSkvbve6hskjmHAmhx5mmtLwqrK6kWOM3ZOB0+QGL2QWn80esuxt++fZP6fyOq90NKUfaRjQ3KXEwWZEijIM8npSAieIY63B6hk8dKe+OR+JfcCf95XPCfVkVmMg9f/4bjnGHf7dB02/karcP7PZTRf7m81Eu6j3WRDkH+7ase8jyAcw5Rprv7/LrDJvjl0/Fuj2GczTDHK7DhPMdgtMjXPtoh/e+CFMxafoSmfv7h68Df19zWjh6/P1vtv/vfdX08uGC+Ev1Zv/2ci6lD9qUKl6m67Z8+fwLwjDwYHGGqRRts6Cvl7h6QRwTvl9DFnQ4D4G82WDqiGk1Oo+oHKazJHIkemKI3T/qg9HOASFWzpYJ36GMZug6xr7nxRdf8OblS8btGqcSF+enPHr0kO3oubu65na9YbfbsZw1tM6xtIaZ1lglmg9G2XJbyfkfsgBeoTzaGINOmZASPsAweFxjESWaBEmsIkw2VEoxt5beCgo9eM/Ld+9YnL3l7uotzWmmXpwQyHhjDiLy03d97+p9fcQmyBrtWurFJUElOa8lYTSmIPXBE8JAvahws3OsmZF0Tbd7gxrumJ88YnX+lP7mBcPmSnRN4g7lNLnoKWhb4eoZtplJ3zdT0+MB/N0f5JRLToBpPjz2Tdf027KlEgCm8gVVDGJj60W0OQZb7iPIMUz0D4p8Dk4prFI4JYG21dJ8pLJFqSQARalKWytaTuKMJO5kubB1EgJOqQnsLoC7QQR5bZZKjbWOUPrtow+QwRhH5WqGccD7kXHo8d7jo0cdO4cyzVDlepbKcgiecRwYRunVb7VGFxOCaCuMrTApo5VHK9EXUhrquqFpW9q2pW0aWqdROdF3Az5E1us7EbjcbSWR00ZCFyP8HNdYmsYwryS4zzlhVMbZojcn0R4qZnTRpUlZPClliZjcoiIi76rIQTTcUlZgWzCVZNlKTWe5bFqAxv35SAWM1QhrSZGV2f8oY9HWoZ1DVZXoACSo2iX16LHNUlwkc8KHDCahTCJEiChqV+HqGlPYGDF4aVILElzrLEmvGFrpvUDogSEnc7w2EoAv5nNS8CxXJ3RasevX0pKWZTwpVZJOJVW16e/9yjuBQvngziRaJhlf2C+5uIVNWibC4FMcTXf7fdyH3PP+59BkrfeTSc6gkyRymYwKYX/tEllaEVFYPaJUROsRUfbxZAIZKRglnVHZlE/S5OzIRadBaYWxpdWlsG/y+8vrt2Dbf6V7FbF7Udg3xo37ghgyB4izF6VViP3SMK31pQhMLoDK2y5gDFQuF3c4uWetFseySdtJxo8w/SYXM9nR1Lop+jkhHa09Zd3RShUWkjiWZQpQHiK7MeDQJK3YjFLwvO1GEaRXmcapAjxpjO6BxBACRkkraeSgUyfV6UnKtVSjj34UFIKeaAqtx4iymUGL0KxPmZHALgrjSariooWSgWEc6fqe7WYthivaElMSjRNtMNaSMnT9gDYDxvvSOm3EncpWe9bT8X17zGIWMa4pLlP7wZ6z3NzOGnTj0KElOM28rXGVE0dCpqLxwcad0v5litZJPw5s+h0+enJOe7cxY0qsiCrMIRk4wtrNe22nEIVpFgrj0VmNVWAdrGpDpcS58H0nspQyPmR2Y2Q3CuspKkVSBpRIPOSUWe88u6S48rAbfHFnpBR05DvqEmNNwzBmAZtCghAVMco8WORgDlG/krZio6QZexILXzlNYzOboOgL6zRl0GUgRwRwmuafSb9P4q+y/3zQOnt926G14rN3G253I89vetZd4O02ikHAIHpW35ZtMpbSheU0sQ3Te9o2kmPoQwFNHeVt3I+zpxh2zyBWRe+QyeFR3ft8+Hq+9uflmd/4WC5RdZ74ngKENdWcZXPCrF7S9rd7FmFMoskY4yjxX45AKiwciY9Qmr4fyTmyWFZYY5nPa/w40vcaYxXW6vJjqWzNrF0Qc6Kq6n0nRp6CPLK4q0VP8NKhUrcOlRMhTbQ+0Z/adncsZoblxYxkRs62J2y2icFfo5WjMnPqpsFYafft+47drme7Hhg6TxhFxzGESVup6C8ZsT0OIWG1RVuL8Eb1hKVDEgMwoyxWaYzxKBMIIdN3sTiVQttWLJYtlXNobRiHyHY9cHu9ZdMPGNNS1wIuWm0kpk7IGNJGCCVTPj3lPtO6dLxu5hK7TyLfahqDhv2KobKsbUqzak5RKFbtGc62oFu0MTSVOJWmMsdOYy7EiDYZYyxWW6yR193DJ46Drb9ke38c3//7KDd9b1d7LOb+7XH47G8k5xy2P1dWaWIh/Ybp4m/UaqdgP3FMIad89qFP1uwFdk1J9g7sCVWCEcoglMl+WnyOqIjT56kjcWQ4LHpMoMv0uukcFJogR+ciq/2A2090+0Cfst9IyrGg1OV7HZ/IfbyXSkAgO5cKtoLSi5+KjpXSpgRVEpTEcoP++bS0cvH2n1vO76SrpSYKqiqJQD4MJEBpjbOG1bzm01++4//+X/9XnDRz/uWDf8pv//C3+F/8vb9HdpeMD3+Xt69/ycuvnssNZlpMfIX1X3Lx6IwPPnyAchFqhW4vsPMHhICIK+YCSpQERBcKfekuwjoJrhbLFU3TEEMkhsA//yf/hC8++4x//P/+r3nx+Wf83b/zN/jDP/hf8sPf+iHtfM7/7v/0f+FPf/5L/K7jxCr+9tkZl01Dq8VOVxuDVoq2EnDAh0CIiV0c6VPiqh9QMfG0WIXnLHbBt8MONcIjo7CV5XwxYzQepSw2Zx7qEQu8PVkyjiP/7NPPuRoCjy//IR/94Lf4ux99wpgrae/wI6Hf3h8Mx3+po4Xw6DXtySXN4oz+7Wd0KpP6N8T+DZUZmM8cGz/Q94nTk2ecfvK3mJ19SLN8xOtP/ym3L3/K449/n4vHP8B37/Bxw3j3FbFfM/QS1JjZGfVswenDj1k++B5yBkAnqeLpLON+anucYiO95y5/03jMmG8R6ARTa5Dcv+RMGncQDDkmvDHEriuioZqcEyqM2AxOGRpjOa0q2tqxakoS4SwpO3wAnxNdjGAMyjnptZ/P9snCOAzCQIuJ4FMRebXs7/WSZGidUdriin6FUmc0sxmL5Yqh6xgGTxg9/dDhx4H1+oa+37K+u6XrdwQ/BTkloCvfehIO3m03dLsdb968Qmt4dnlGXVXYZkYGqpRgHNCdxyRYLVu0cZw/+IC2bXlwdkLjLLWOooF227PZbvnsiy8Z/UiKnrap+OTZE9qqYlFnKq1YnC9xTjObR8gCGGkz4HSi7zLv7kQbI3tHcg2JBUovyNUSZSpy9MQUiV4sgeVHWIWGBrt4iulvqbcL6nZO4xqZ22IBOlSN+BkGiD1Ej7anKFPjqxXJLMHNwdRkbUlKROVz9JJNZLCzFY2pmHcDpj3HX33B0K2pcoeyhiFWJGNYnj9gdfmIpq3QKrFb30mLZJnTbTVpNNUoZYhO1kxrrbTZWUnwnAKrNB88uGC1mBN94u7mii/SQOh25O0dMLVpT0LgCUUsmk4CxkwYaiyJly9C4NtBEr1hFIr51LKWIiW5LME6k16UJFv7dsUMkz+k0qVCnAX0Q76q9PYphS+Buklg9IjxopsWyvfMNlDpiHIjSieyCeW7hAKkgbhJij6XMg1aWarGQNLMXT5KhjOxOHt+m7apsd1OrPGjeCMW7bA8xTQcRAumyClk0Xg6dYmL1vBwpllV0qKakRq3BgyJqDJBJb7YjPyjX20KWJ84rRUPZ9CFRG0hD5lujIxjZPCBkKCuLSYBvgAjSjMk2PjELmS6CD7qfSKeVaKpLCezii5Hkk7YKsAgYIZV0AXFNsG/+mrHbefpQ+DB3KJy5MFM8/HDE2bO8dXWw7Yn+oEAqLrGaEXCEZPMFzZl0uhRStF7iRO8DPoilA3aSuz1+W3P3Gr0osEZg60so8+82qyBTGUkNlkt5gQfuLl+R0yJup1zcnrO46cfUp+dscgfEfzAODzDj56uH6i1paormQ+sw1iHs1J8gBLnpkP7VwqB0PeMxU7cWIe2Zt/vPY33tnHYmaU+X2GV2htB+NBLEuxFJy2FAZ0jdVXhNMxrS11ZXr79iuevX6NUYtbWVFWFrWrqdiaJ1/WtmBSUYFCYhgplBNDuBvBB4T3UVnO5qFhUmkcNNBpmOeFSLoYpCW16UobNbuR2N/Ll1cg4eBQiCH89RJw2zKzmehv48afXbEPizeB5uYk0pQAXFBirWKJYWsW5U/Q5sUuR7Zi56YBsUNlIa27OOJNxBiojhUCtZR5tdWJB5rw2LKzmbGZpa81n68C7QYomcjDj1McAAQAASURBVNIlFwgxSI6TDBgtjGYjDpJJi0PeEOGLq4GrbeAf/tlbtkPgs6uezktuJMuDqN7XVUX9LULP67oRkKYW6/i95lP0kgMX2QGjiku2VGUk58kUh2E4IONHW3lcpBIcuojWHzsBA/vfU8rcb2tS7/1/f7tHCNmjPJJjJpU5XVyyrFeMeeB0ccar2y/Y9Dd03ZYcI323JQQPylJVmqZq0drhgxzny+evgUhTP2M2r3n67JTz84aYOlISHTRl4OzshGWG5cVTYooM8Y5ut+VteIcfMzoVIxs1ECPcXG2ZzWesTldSaNVA1mhVkWLk5etPOT/b8ejxM2Zzy+MnH3B7ZxnCDW214uLkmYAlLoHLJDfQjR3vXm+x6gpHTTXTNEuDs4bKWqwxVM7hfeT6ZsNitWThGnJwMDbEMTCOgZQqlGpo7Jx505KbG1K1pdvB1Vu5NrOF4sNnlzx5eslyuYLsePHihl998YLnr96y7Xvurpe0bcVquaBp5ljrim6TlfucSFZpn+trZUVXXEt/eSxauClKEauqLc7O0bpGaen+gYyzqbThjWhlWc4amqrF2QptGmaLp3R+x6vbX7Ebr3m3/rQUASEmz9avmTcNZ8tzTmYPOJs/pqkWjLEnJf8/8O56f8D+mq8rt8BfgjX9m33urzl1/frA03GpagJvOOgdvf95e8FuihPUBPqUIPHQnqb2YMa+Pqem399D9+49dPwevo66lWA4Hz19+Kz7wNI9MWZ1WMwncGsvKP0+NS1zQFWPjzfn4qJ1AObufb/9q9PhPeX//dw6fZ6a5tdyRlTmeO7MFHqo1tR1Re0cxkA/7Pj8xXPmizmff/mc6Df0XWToM/2gxYElB4wfsb7H1I7Z3BHVHMyc6tRQVwuMtpi63luC50LvxmjM0QVRReR4GESPZrteM+x2vHr+JW+ef0kadtRWsVotOD07Zd2P3Pae11c3vLu55bKuWTaOU2c5cUYEPWEyIdi7qBgtzkrSv5yIKaKSFgp5TFilSiVMeslVPlx7rYp1d4Y5htFmTqqKbc4MQDf0vHj9ivbklLurd+AqnLbinlcEUdMkCnBvZIE6GgdybCJZrHNA5RGVOsKwod/cMOx29H0k6YZqVlPPz2mWZ7hmJhVGLT3i2Q+Efg05FBe0LFXcFEkxU7mWqj2hbhY0zUy0AWIkFaFspaUqui9Cl1GoJpT6aBTtx+dUTvqWbeq970tOpOAhRSJZ2jYLazCnIALRWuGUBKe2uNlMrjRkMEYEmw0UDQ6DtbbQuzVJRank7WncCSYtnML0mdh0wvoI+6BLFsaE1gZbVShtia7COEvwDUpBVTtylmrKOPSEUqmWar5U5SenNu8lQN5ut9zd3eJP5tS2Lui/3rvcKW3QJlObBm2rPdPJaiBHul5o45tdx7YfCImitybVeqsSTgUaBZVW1FrjlMGVErMp7WYWjbEGZSuwDapagluQ3BxVzdCusJgKdXk/9yoB/LNSKFtLa4qpyKWyJmBR0Q5UWhwLc5KWmikYNQasI9qKaFuyrUm6IiqplOWcD6A/oKxF5xrbzHCjZ1SGEEHFJAKzWoOxVE1D3dQoEil5AaxDECBHSWVNmAMapYtWSgmO945QZEwyYjetJahbLEXrqVksGYBxtxYGxFFLXUoFkCt6DykhehClzSSmxBgDY4z4mEQXKxd9iAJUTWYKucxvAjwJoDMx0PZJgTJlTqbIm6m9FtShVART2UmVzyCIVl8o7mSegDKJ2kibIHp6d+G27nODCUSfxqgTsFhlwaVSEWJO+Vs5f03n4XA6vqlsCcc01ilXiklabhdOs6w0y8rQWLUHNnRh2uUSz8UsbLj1KKLXIWZiFDDUh8zgBRg6qQ1U4hx0Ma+YV4brQSrsU10jT6yofNC8ObRvTsyeiQFTkswJzCwLUkYx+MhuCFztBjSRRSXJpU+JkDPWaGprROA1ZzwiUDANRJnDBRBQGlqrCElJm06S74eSuvc01kPKbHykytAaafmdEueQCzhmrbSqFjBchUCl4GTWkgwM6VQEeMeWYRypdx1usaRtGxpri+FH2gOnuazTk26Q1uIqHMeB4DuC7wV4MpacxCjA1aK30g8jikBfGnFDKKyqagZGNJ7IEMceUqSpxfHOVg5bWUKKDH5ENFLUPhYQtukE8Jaxp5D4Qsn42s83GRpraCtpd5tZaGWYCPVtr29TYmtVHAeLeUDOk0aZgE8pC6A+z4baGJKCBYa6T3tWTCrjSXEwJ8+ZomUmbLpJTD6X66uUEMiEMVU0nRTUGhqjqLSIiKNkPzFJq950/Sf3R2ecvM8grGhTNGlKi/tU9L7pArsx8ep2YDdGNoO0JbZOznU6ul+/TZu1tjBIZJ2bGHziOn5gvh1eM2mXlbhaT/lgWXemHU85GOzdxWHaz9ez34lNvK+5Hp65P32qQyIpry1/TznpPuyXrg6NYt4s8XGgGzdopQh6JBWXShGoNpA1xoqDmo+RRBIXuRzphwHjdJFfcDStaCtpA9oonKkxGQLSKh2yLSQJg1ZC8CBTjKcSfvR4J8wnbUpBFSVrZHHbC1FAbAXUVUvlhOFknaWqnRSUTKRuKuaLGbPZiKsMwUfevVsz945sHKptaKtqr30WY2QYPNU4Mo493geCz3if8KPEs21dM29bFm3LljvGsWhg5qI1aBTOiVGPKmvIOHr63pe5SGKdEMSNWHGQAfJjL7GvNUdBf5kDsuj7yX0mQKRQFbPEfTKpFQH8SuLVHFE5iAZymUC0MjRuTlUtuVg9ZTtu6P0WCLw7GuMpZ0IcyTRUdkHjVszqk6LvFIpExTffN3tc5Wgs32dJvffGcj98jTTzNQwlf9PDf+n2zXJF723vYzB/wfZrA0/39JaYBBqLxkB+76ZkWpyKiGESWp4s8IJIG/t1/SMKLfNYcJA8WTPm/fdS995Wqn1HVYIpiJ+EMg+7PyDfaVJBJU/6zAcG1KRTpEVOeGpfymkKEIp+S4qQpmRK7W+SVKpo6WiyLSdlH0xBFsrzUZh+cKwrE2pxJ9qj/u+dY4CcMmPwGG24OHvIR8+e8Xf/4Lf4xa++5L/7Zz/mz14+51/82ac8Pl3yg8fn9P0dd3dLbnaBV+s7XI5UOXL67i1ffPmGi/MXPLj8OQ8++R0efq9n9fi7LB8+ZRxEeyaFINVD57DFGUxpxWazo+96fvHTn/H27Rt+8eMf8+ar52xfvyDstvzOb3+fB//BX+fyOx/h2jn/5d//f/HzTz/n+ZvX+NHzgyePeLqc88xaZioTnSUpyiQNEXFR0q7GpoytEzZE6EfSmBjWW0yGU1vTNo6Hq3Nm84oYEsMYGaJU8hcaaqWZ2YaTmNDGcjcO/MpASpH/9o/+GV+8ek2lDB98+BG/87f/kNQ29LOWYRjY3q0Ryl5ZjPYDP++vnTJahMHHO2L3nPzu53D9E65fvOTlixdsdp5tF/jO93/Ekx/+gItP/gZnT77P9vaKzZtfMG7eksYdb3/533P3+b9g6N5Q0RNNJltN1w2MY+Li9ENOHn2Ps/MnLJanbHdrRj/QlUqoseZo4sr7at+91fsefnZI+n7Tienf501ImlPST3GhiaRxRwKGXu5LY3UJSDPGWmbtnNZaZi7jXN678Ry49QalMzoXIXDnsFZa5XJKJKUI1qKtIfpIiLG4FgobMPogYtx+Elg+BMCq2MxbYzHG0swbjLEIcAjeXwrz6PqGfrdlt90yDgNZRTKJGEXnq+92eO9RvGMYBp5/+Tnv3r3hdNaQz05lPGhNLOCCdQ1KQ7U8p6prHlyeUVkNYcd21/PLX30uenJ3O5S2PHjwBGcNTgl4sKoGWtNzqgdMjtANaNdQNU/RpoJ6Rs6W7AccluZEQXOJvvhdVHsKp88wTY1bLrG2InsReDdGo1zRAjQObE2wCT+uiXqOH2ustYyhGCAYMLbGVhVx3BBHj7WtAIrNKaZasa7PSe6UnhqPmzg8ZJ/IYUQZK6BcU+Gamqa/QFvH+tWvGLyw3dBgzma4+YrT0yVnpwuy7xhjT7fb4kMkiRII2nip8NoBrTVVYUA5J/oXuW0x0exBTUfGacXjh5cs5jN2Y8/d1Tue396S+g497ABZ/2LK9EWzyfskbotBWk18aVUcw4gPgX7sSTEUqry0BuwLHbm0gpb7P2WxAi5pcBEidqJT5mzR09ACoKZcRL9Ff0zWy6m9JwGlUKAUUYtrnYqJoDMOUFbYb5NYMMiDSltQFUo5lKnQWEyucVkRgwR4KXgxAYjm1wuS/gptYilwaIfTRtirxmhhmOeMShllJ9enQ8EtZmFdzCrFd08rnq0qfnDRYrRhCBltFJWTtTFGaVPvx0g3JnYj7PrM3SbwplJ8Xku8pHLmexcVf/1JzaNlxeOTikerGQ9PWq6HDeu+Zwxy1DFmvJ+ApynpE/2LmDP9mNkNGR9E9wWTwAWpuGuFU4akFDplcgi83Xj6kFg4TeMM8zdrFo3DWcX5osJREVLmZ+uRnReNFacyj2aGxsJpXUxVqhafNK+6yG5MvLntSDHjsozLthIA64ttjzOG09KmarMihMhmGKgqx8nporAkJZg+dZoPT+b8rU+e4b1ns3mAD4FhFM28ybwBbThfzojDljAa4thIUWtKhHMUd6a6IXjP9u6K8eYF/u41EUfCMkaLT5ZHz55wcnHGly9f8u7mljd3HZvek7otBM93Pv6I07MTHixmtM6wXd8RU+Tk8pR2tWBxtmKxXZMx4v5kZLSl6Akqc7eWNiJf2gONE8DZSr7HZiftlsOYqKzmo4uGRa14OoNaZZoYUQnGUTO64nSsMuhIVogjZUq4AgZlZxh8oh/ErfKd77lYLPmbH12SrcJb+Mef3vGvX74iRI33ag867bzMQ0PK9ElhrOH8xDAMmWHIxVksUTlY1EU0XGdpz0NxWRvOrYAZAXjVJ0Kfebn1rAu7L4dEPVvSuJpH5wtmtSOPG3IYGYZ+b4SRsqLJhi7Cv36xYwxJ9JtU5mxW0Vh4vJBw4qoTZ72bLhG/RYynppkJ2FmMTdJed1QAgynH0srsc0YmMErL9cv7tenQFjulSbEYH03FPoj7mPfeOqAExJX87wAgH7dFTWDolJ/tDWLUYU2R/yeJhUwyisvTp6xmF1wsP2AIPeOww4eBq/VzuuGOu+2GMXiUrslZE8YdQ+oY044YA2/fXbPrek7O5tRtzcMPVuScaVuLqwymXhJy5qa/xXsPSaOpmNcnjHmg8zsUCVfLedut14TR0zQNdetYXdSkGNl1672WY/CJ3WaHdTWL+pyx9lRVi6sdpk5YY3FuhnMVJ6sFJ7PXjJvE1dsdf/zjL7h42PL42YLHH5zz8HyFNQpSoO97bu/uGNOW3WjY3AV268D19cjdjeeTTz7kww8fc/lgxslJxR9/+oJ3r2/RPnPSNpIPTzFAjMQwMvqerh/o+4H5qmJmLJWdNEM1KWoyA6TI7tU7lFGsHj3B1Q0ZiZmNlrzHWIBMCI6UDASJl32K+JRR1mGqhtniDIVGBwGJYvLEMLDdXRWwbsnJ8hHfffK7dOOOtp7x4nrGi+ufEGJH7wdijHgfWM1OOJt9l8vlxzw++z1CGOiH9X5c/kXbRNL5C0GnX3P7Hz0u+g12/2sDT8fMpnz8ISVhVaiisVT69Iu95Tcdz6Tx9M19gwc9nUND2bEw3J6LtP+sw6sPFQZ1FHzlKeCZgIKpJPK178i9gbCfbPZHcf8491jD/jjUfkfy3kOb4fE+1dFJVPsq136vR6WP/QccTXzHA0hek2IU5FsZZrM5z548Y9sNnCwqjI5cb66wOrBqLTEMjKOm9+B9FCeqnNBdlhqh2kkgO3uDmb0gmQXZnZSK3gF8TDESlCIW1f67m1u67Za3L57z7s1rNldvGda3Yl5eO5S1JG14e3VL1Buur27YrDc0WjNvGlZ1xbJyk/z1dDWL5bhUJYXiWlx0lMJpTWOMsMuSuKA4Y3DGoDHEqLnaeba9Z1P6x5dK7YHJSmtWzqLIXLQtvffc7LbcrO/45a8+Y8yZiydPqeZzqpNTTM7UVUWMAhxQ6meyOBXWiLZlgYO4XTPePae7es3u+pq7uw3rzcjNNnC3DVwGR7YLUkz43Zru9jWb29cMu1tSGFlvNyQfSOzIeSTGDNpSzU6wM8fi9CGL1QOpCA+DCFOHYlu7146Zxt1UuTmM4r27+zRKj8HNb0/sU9wIc2koYW/6dTS7yN/pCEFPClX0dHIKpKQJMZQqnTT0huLEJG0jkIsQph/HfVATQyxslKlKE/CjJ/hA8H4PPKX9nCgA9DRGk0uYnGSMI64wSmuMraR6NJuX8WbxjUdpSQ5j8uQU6eotfhyIXoKCkKX1d/QjwzjiUMUEQRXmgbBtbGkBSTHic2S32zD0PZuupxs8CY01lno2o3KOWidqFalMxpmIq0DnKGPWVCTlQFco15CjIgZpT9ONhfYM3Z6g2hXUM0xVYV0lVT3KbF7uMaOLU4zRmKomtUtCs4R6RTQOnw1GVRg7kyqXKdc15sLQUSLOaSuUq8WyXbdoVZWqm7i6TQmyFFnEtt5WNbltqeZLwtgXpxJN1S6oZwuqusJZTY6BGLk3Z0vBMYNKxZ1ThFC1Nigteg2xOEbpKFW4yRTAGENdORaLFcl76vkSD4z9RnTAkjgJDj4WvRRx+vKFXRdSKrpUgRBDYUYV98tjtkWZHqZ1dlrXZF2V+c06ab9xdb0XjNVGSxElJ/w4ooIHP1V9/Z7avU8cMoWNIm1dJkOMEFUmmkxUubgqCgiWiw5DkdAuKl6qxAGHY93//y0DnqY5+l7N4F6csv8N1JE+11HsoFBURuOMLm5f4kY4afpNwHfMIjC+ZywhxcWQgH3LfaYyisuZ5YNVxbPTlnlT4bS0xad0CPL1pN90RGY7HK/atwvGxIEJenz8pT9caTnYKTEcioDzy81IO0Qx2wCccwW8L22HpS1Ml1ETYikqGvm7soaYFc5ZYsronETkuDBW+gwhZ4YY9wwx1EF7KcWD85y0DSEuvGNHHD19t5PvV4BXlSPWOrkWpcgg90UqTKtDlX5fyMoJlQImB5k/YpBCcNFooiTzw+jZ7DqubtfcbnvCbk0OnpOLC6q6gXmDNZZMJCVPP/SozpSi8oF1IgzNaV1MUrgoQavSCqOk3W5iOqVCEauMorGKZWOYO4VF0LqhD5isqIq9uVHCK/MJVEz0ITJGAZDHDEPIdEni4kQu5z+zHstwUGIwMIZUtLwEcE1lRY/p0F5vNDQGMJCNzCBGZWqrqO3hLIthhlxzn4tTZ86MCHvOKEVjDZWtQClW8yVN3fDB2ZxZbdjcDfghoqImKmF2ZDSzDAREuL8kv1opWqeYOZg7AZ7WQyZMOnXfpqofcMjfygRQ7uE90IS6H28q9uQD+Vsmo8O/lPRLWDJTTHtPM+oIfDrkoYcVY39kh4SL4zXluINh2t+0r/2xlbYtaypwUqRxpsabmhg9qEA/zon5NXrYMQa5z621VLkSB7qcGcYeZWAR51ilcZVDkdHF2VhrMR7JWYD0PWdif67k+EMQYFvID4mhH1BaNExFY2paHpOImQ89ShmqxuFsRdvMSzFM8vduNxD8yNBLvDrNwbloaeUk58VZkZbxwYvuqA9Yn7FenPbGUeIN0Qy1zOcNikTf9fQ7T78JOOtYrSoBoXMWvaij9UGOu+jjWoW10skxjp7oM0r3oAJBdSgrHQMmSSO5BI8Jde++Eu2mg2magjzFehZjKom9shOGdZ5iMXEld67G2kZeqw1WTWYZskbpouM0rT8lm0Urh8LvRexlyX4fADhc26/dSf8Tg07/tmam3wB4SuyrooAqrJ/JrW7iMMbCjAolCbPmwGyaKvlwpOn03mfEeACmDrs9atMjMwmz7t+X8p7WqvRUuxABu1Ss5SXYmCaNPDHs7l34lEsEXD4vlD7QiX0w2VPKsTJlr/uEYUrgUo4lkZXvaKYJdp+IlMhusticwucEx8GzygK9TWSz41a/feWQAGEkJ4cxjsuLx/wnf+8/43sf/ph5vuHF1ZqfPH/HV7ue5592zI3jtKpIQTSUJo2azU7xeqtZXG1ZqhtOv+g4/ZMvuPzwF1x8+FPmyxPaxYrZfEEzm7HZrOl2O67evWN9d8vtm9dsb2/YXL2l32yoneW8Mpw9+YR2NuPFesMXn73gF7/477i5uaHShpXRPHv4iFVT8fHJjGVliGNklzIpSGDYOmGT3faD0OqjCJ/XVU1dOWpXE3JmnTwRmM0ddV0ResvWZ3785oZ1N/JWWxZOc2kTIsGdqLXiaVMR64pns4Y3fc8fpcTr62v+i7///+Dxgwt+8fM/4eNPvscf/of/Me3ylJOLx/TjyN12W9zFeqw2WOeomhnt4gQ1bqG/4+Wrn/PFv/qHXN/e8u7mls0O1lvNV7eBl7cd7YeKh35Ofv4Fu5ef8frFT7l6+wVtO6eqGj796a94/eINzaKhahyXj+YslwuefPx7LM6e8OyTv8Fi9YjPvnrJ3esrsniuc7pcUlfVPsiellX2millEB2v6/vFX4l7x7co9lF+QNrAinAgkLRCW1FL8XlKsBIqC5CbVSIHQxwT3c5gfM2YM9iKXCmS0owIezKGxJQWmyIwPlXsfAj4ccB7Effuh4Gu6/CjZxxHUhStFvn8KbCaBFspwYfB2gprHE3TUlUVlRML7PmJo10dIu2mclij92BCt7vDjwO3V6/oug1ffPUVXd9zt92QVebh2YqqciRlidmjlBF6tqtR2nF99Q7vB16/esEwjqzHCNoyP7+kbWecPnpE4xxLm7E5MA8ttcnM5kIB70ZPUo6tW4oQ/nxF8j3DGIlVhVqcotpTzMXHmLrFzU+xzlI30mOvjsAbXZyp0JCJmMUK1ywgDoy7NeOwYejXNO6CdvkBKGlhwG1Q9RbiiEoj1CfkZomZn+Oac3R9QnJzgh+IIRT22IjWTs591QgIdJLwbUP+3o8YN0/ZbtbEmDh7/JR2uWCxXFLXDr/rpO1Gi2NizroAKezXnJwycRhRWlJiaxLGWkxMpJjR2pCStBVWtaKpHd959h3Wq1OGfuTm3Ws+X98wjiPD3R0hJvog9uiRSbA3FgHoqdosLUHisicJ7GGtPZxnlQ9r1RSQm6rG1Q31fEUzX1I1c6qmFSF1YwTESomh7xjHgXG7JgwdadiRwliAroMTVwzFFSonooZKS3ugUbJeW6VIRqzYoYhFK8WoRHo8lPatWJLwWBhPKYRvH/CEzAtxqmOVqC2XMXUUihyAuKPISukiFK0FjPFRYqCE6EPppPai2kNIDKMwpSoLvspUDeyrGElYI2e14YeXDd+5WPDxgyVbr9mOmpyFoeAqRTvXzGaaWaNJHnEKQ1rxJiHhkDJjCPRjovOZ6BH9vWxIaFmLdEJVGdPAsnEsa8ebLtLHzM+vr8k589GpZllbPrk4p7KWyla0KWD1hpACY5B2uvU2Fs3IgLWO2ckJdeVIpmKMka7boYnMTCRm8MmQMqwHMQeRtqyEtRlyZLfeEXLG1DXaGSCx29zw/Od/wu12xxevrzDWUtcN0feM/ZqHl5d89PRDbBKdPWU0Pgt4LG1gpiQlhhgFwG8YsDOHrU7Y7Ea6IRC0JilNU0k83A+e23XHy9eveHN9w2Z9R/Cek9MLatvSPrvk4mxBP96w2QW+fP4rMpq76zviEDC6wtmGPsi6RJQxst5sAYVyokFolLCKNjthWOoogvXnK8OiMXx8XuOA/m5L3wVuXm2YVZYfPGtZ1o62suxi5mZXjCbUjsFHNjFxMyQ+uw3SDlkLIJSN4mWX+Ae/2tE6w6I2/PTlyOu1R2mDs2X1zRqfxPFyVWdOa5ibzFmd2CE/RmW0gtpCbRV90WCStne4RrEJMr9IgVMS9ou2ZVFVPH78hOVqxXLV0tSW00bjVOInPx94dxNYa4uPmlnboo2m3XT0Y2TVaMagGCVVYO6gNqKbljO87cRg4yit+VZsIYzAUZvtHrjRe7B2r+Wrps4WaWE9zvtAQJ9j/cH9NJelEB6juEAaY7DOlo8rrfPpsCZM+93nhkcqoJDL3HQEMMF+X1Cc15UW8XutsFUj5i+mFlMaI7IDH6ofkHLkJ5//c97dveL528/wYcvZ4gSlFGG8YdcF1t0Vu8GyWpyjmoZ2NseYTNXWWFdRAgYRDo+eFETAe4wBnwK6FlLA3XVEa8Ny0ZJi5u7mmnGoqJqEqyxNWzP6QLcbGPodN1dvWCwTq+UjFrNTnj79hJQCOQ3cXW958fkN3XbH3c0t69st6/UGpRNnDxqWq4baNczqlvmspR87btZr1tstXdejbYWxjt1uZH03opRhsbBcXs55/PiEz7/4nNevXvHlyyuubwKffPKIywcn3O22DN7TzltQhhBFJiJni9Y1xoC2karOKBW5fvWOsUtkepQK1KsR1xoWw2O0qXG6LXn5UHL6EucAKI0ujDoVsmhHugV1tcRVM7lGJVfSuoBZpgbAGUddr0pc3+H9LTHcQR6wBhZmSYgjRieMSfTjmt5v91qsMElsHMb8v82c69931vdvJC4+3eRwDIKo+2wJ7iPPx8ynPcp9BGDtQ6TpvOf3VCKO6UBHn3/45T1Y8DjmyvcBrPtfJZfPPDzxPjVTcvG/iPpxYDodB3zHxJH9ozkX9fwDsMTRZLx/fWafbO2/8jEqX0ACwbEOjYBkcU8ySlPPT1idXvD40VOyfsvVessQHF1QkBJ33qNiQMUoVT+jSaU/3ydFh8JsR7K6I9pXdAHmqxNmR8DTdiNixes7Ebrr7q4ZtluSH5nET2OGu35gmzKvb9fc7XqGvkN5z+nCsagqLhvHoq5wulRTjRUkpACAKUlSn7MIluQoFH7SFJzKsjFVBlpTYa3lZjfQadilwBAz1JYcxFo5KXEqUyix/VYw14bOWk7rmruc2eQtu67jq1cvsVXNr375C04vHvKBrkha47QW1wZVybVLCT8MpHRL2N7g1295/fo1r99cc73puLobGYNh9IaUpI946AZurq4IemDQI3dXV2zu1vRDwtiRd3cd7zYjbYJqiJw/uqSenTM/+YDl2WO6IdK/u+LTX33K2+trzs/OmLUtZ6sVzlbE1Itr2L176HhCmu5BtR9r3/y6v9pbSlESrSjsNL2nHKb9TXp0B+5xuVSYbX4cJck1VRFNjmQNsQA8aXIdSoXR5EtLldEiDOs9IQSCn9rrpMUuhLQPiiT0OQIAkOMU2/RMToqoi5NjDMRQ78WoFWpvIVw1Nc5aCicUYxTRjygibTdj23t2fYerW5RxoC1ZGxEZ15aoK1JWuLoBFLutZ+h7tl3P6D3KthhXUTcz6maGqxqqytHUBkfEeakoJyuJqrKKjCOZOdk6lJuRkiJkSegIAVJA6tUUpzl9KAiUCTAf/UygvVIaXTlMu8QtLvHKEH0gmpZgGqFcGHGSycqQQk+MA8m0KF2RtEMZcfYzU4CnFNZV4tJlLKq4tWhryW2LdZZ0eo6rG6KpCN7TLFY08znGVcXGWRgBevrsPJVCyn1mJoZZ3jOaxIxD2mxiCYZjEnHMnOS71tYRmobV6RkpeurVKUkptusNPidp4cy5aDdNDJJSfClVzpRSsVQvY/aoyCMVZNizI6Hof2nRgqlrXNPgmpaqaajqZq9plkpbXSrrXA4jFD0J0bCRawzHbreTqxjFTa/8KFk7dFbSQoYI9abjO6SszXuDjyx6OZMOw7dpK1yTw/w8FRP2YcRR8Lp/PYe5baoplPsnJorWRRYHyZQKc0WKXHEKTaYY6IiUMBX6tSodx2WpjnESOxddKBkH7NfnPO2jaOqQj/V4pkSwxE9K0fvMZoi4KHow0xrvrKayGmfBkwpDK7HzoHXkuvNUVlh/OYvBgbWaRS1Oft7ofcyjNcQQCYiTI1ncJDWgVILIZFBGzBlrFI0z5KQxqKJrVBJYqZhinYDVSSl677m+u8VaS9OMRN8Thg0nJydo5/ZaTWIdPyXTB+ariN9KMURrRd02NNqQ9RqlI0ElkkrUtTARYwiM/RaGLdZvqXKPJWKzR+e4Tz7bWhF9ZLu9Yxgjm7s71usNw+gJMbLvKChBuRCiMoWwc+86k2HmDLXRLBvNvNKoktDHMRO9HL9VikVjqZ1hiIneR7reY3RmW8n1Et1RYT2RMtnDGGHnFbZPvN54zmdw0loap1k1tngWK2IWcBrAmlwcHDO1zrQajFM0HJzPlM6He6dcYyUfS0gi8zEVk3SW/TmjqJ2irRSVTlgiYRxJWdb9FJM4OGboo7S/ToX01or+kwtyTis9uUzK5+/xpnLavy3bsTajgr2m4T3Xbw454PHj77cYvb8dC4gfP/a1lPAoD3z//2nGPKxJ999/zHJ6Pz+cXKrjNEnuP7vkFqYm5yTM7cKAyTmzaldUtma3uqJ2Fbt+g1aaRX1KU88YkWKB6BAllBJdo8bWqGTY9SOpOHeH4LHSnc8wZGF+6oA1mpg0oNltPHWTcZWFJCzUEAM31zfkXHF2PuJTJAwZH0b6bsPt9Zab6xu6Xc/mZst22zMOQYpDRkwFTHEqVMpI6962ZxxGYhSGklaGuqqYzxWVq6lcTdNYYoxsNh1XNxuGYiZgnRGB72CIBFyt5XgVJX6JRSM1kFUg1yLxElPAh8g4eCBSLRQag84aPek3Fcp1vjcW5PGUPSjFrFoyq1ai3WQbplfsJYPKOLNW9FWtcVjjSvEnEuIoboZKYtOUR1IaSGkgpJ4xbAmxZ1pURM9syt3vARvHJaN7Y/WbtuPnprzl3+r2/v7Ue///G26/NvCktSnHIYtjmtg606wxsXTK66eLHAvwpMvNa0q/7L4Km6b2El0GyIEFdARXHeaD9xGk8orjLSVpTYlJqNACSph7g+544tj3+04srL0zn97vbwrQp4DgGDybVot9q86Elsd4GOyyoxJYxKN3yeN5mrTUYZKcWF0CvBwmx2mylFOhZfimSN9tcFWNWZxw8vC7/MHf/J/znZef8qRRrH3k7ZD51Zst//LTK3QEExWP2orvLFqGGNiFALmmo2HoPVfrG/yXrwlxpK4b6rqmbhpcXeEHSaTndUXrLE1bUVWW5aJBnSy52nXcDp5f/tnPebfZsvMSjPzuquF7j8754XLOWeWwtdgI+xQJKVG3S2kbGnak4Nl1a3IM0uaRIYwdExstKs1V1mRrObk4p6kcj2YNfYj80+ev6cmYiwZtNWcPWvQQ+PKlZ47iw0aqij6JLHGrNbqp+f2LC67Gkapt2A0Df/Szn/OzL77kJ3/8Yz7+6BP+8O/8XR48/ZCPf+f3RdzYnbLbbrm9uebu+hVv37zi5s1XvHn+KVevX/L6q5dsvWIzwqyCWaWp6pondcPm7Qt+/E+uWVaBRRXZ7ka6wXPd3bIeItfbxLZ3mOsep7Z8/6/9XR5953d5+snfYHH6iP/2//Pf8MtPf8n/8x/9A56/+or//D/5z/j+J9/nO08/ZLlcMVyPxOBR2eyHqSqz0z1CwzHGq44e+JZswzgijiqT/arMLVlNtvSHDEvsmDUk8IMXbaYQUbbCDBlVtZh5ha4qzEwEWxOZEDzDdkdKkRT93kZbZSQATYkxRfpxpBsGab0LaX+mRUsn7e9xgyJrRS4sgZh8Sczk/q8qAZiatsW5iuVyQe00tnZyn7oaYwzkU8iZy/EJMQQun3yXYejZdLfE6EnWEo1m9WSJsCHkPvWDZ+x7Xr3s2KzXvLtZk1E8fvqEZjZnefaAummYtStmTc3lxRKjQI07cox0fkBZh51fknWFVy1ZgTeJqN7i05eocYfuXqOHB6TlmQAO6QQXIkYFcYAzuoije1LSZCxaJ3SKmKrFNS35/DEqZ7Zvv2JINWNzQrJL6tkJ9eyEPNzCsCb4Hdr3JOtI2mCMuMxUVY1pGozRhGjR1tHEuGeg2sphjGG5WqGNYbh4gPeB+s0bxn5gdXZC01RUbSNaX1VGp4StBPzKBYyqrENN6Uwu64pSOFehlOhVpDIWdMqoWMA5FbDG0NQVbrngB9//IVeXD9jGxNWbV1xtO8btlm69w4dA5wemap7KYv3t/UjXbaGAS0odkp2pxeSQJJRFXYG1NbZpqRdL2pNT2vmKdr6iqVpq12IL42lq2XNVxeAHOgODs3ggKE1OvbQf7J3vcgm7JpejJMYJMROBMUrLT0IC72gjSWmSRTR/jIFyj2Ugp1rWVu//va/2/Ztscs1k/koIkBiyJuYJvplihQOILldRkmatBSDxk/YNIoKcUxYQPMHgYQxFGyypfbQxrRmKTGUylRPwaTcmrjYeTUdW0s+0GzybMbKNkT5HdtGwDRmPGH9VDtpDdxhGp30MllIW/SWjeLUeuekCWkns1UVJnNqZZdFagoNZEA3IwUfWPrENkdfbG4zSnM1rnFacNo7aOL53UVEbXbQeIcRI5xOfXa/pg2KXK7TVLE8aFJnY7wT0CaUAlsFZzeNVqYQn2PaeF9dSxe7WW/JixXJ1xvxkRXVyye56zc+fP8cYYXDq5NFp4OTRY+qLh7jVGbaeiUNdAXmYxMZJhDjiS7xjTMXJgzPOzhu2bz+luxF9mJQj6rSFxSVh2LB5/Rmz3WuqsEZXCt1qLt3ATPesTuecPDyH4XM6HfiTzz7n9s2aX77Z8nbd8frdO263W2btrABwet/KJPeYMCqHXloHBx+pjOKDi5ZlbXi8NBgy3d2WOCbGdUTFzImznM8rPn6wpGotL+96Xt3teHN1g1aQxga0wiuFR5y8dj7zfJfoPdx1cLLz3MU1v//BnL/7yYKcZmz7c666yItNYDsm1kNkXgmbqDGZ1sKpgwcWmsZSW8PtMHI7em4HuBsTISlCVthyP0z3Wq0zViWsShgFlUpScEo7YshsbiXfub3Z0Pcjd7uOPgTWITMk2G4GQlKY7DEqc75QOKPwQdivoxdjCmeEf691Qu/Fcr8925TrTHqjemrrn2QPjl4rqdN9ltH9fR1ePek1aa337CWtNbZyh8zxvYJV2ud4BzaTNuJkvAfayzFIYSjtgafDMbCP0XQx1UhKgOkQPSl6YEQBTVqAUoSciERiFnmO7z36bS6WD3l4+ojtsObtzUtyynz/g9+jdjPeda8YU8cQ3hDiSOU6tLI8WT1h6BO/vHrBuBl4e3VHTCMXZy0xaO6uAzHAu5xwleHsvKKqEkOnmC2kKGYsNK1hd7fjxz/7Yx5c3NLWjxhjz9XmivXmhtevn7O52/Lm9Q1hSIy7xDBEdrtAVRnqxqCtoqqN6I7mivXdwPMv33B9fcfoBxRzardk+UhTPTM8uDzl7HQFON68veLzL97wi1++ZL4yzBYW12hMpdA+ogksTipOljO0UYxjwPseH7aE7R1Ze2w7wzlL0p5I5O2bkegzDx6csHQtc7WgomHIkZSD1JhLkYWcyDqQCPTjLbWd8Z3LP+B88ZhHJx9SuZYQB7kvp3FSCsmmrUonl8WaiqwSIQV2/ZYxDBijGVPHZrwlhBE/bLFGc9M/5zRcgh4wQGWqwsQVsGrCT4+JLvdApYm5tyfSfP0eOWb1/fu+/drA0wHxzfcqjvcmyqNJQ5e/jzepyslvR2/ZP1se2U9A08P5vefy/vX3uzY5fvw9JFCVz8/3GFWH48/7mefwHdV+gtJHVcYpaT8aBPtzUkqAZTd7h4R9kr8P5YBjrtX9iW165DAXTvs5nh0nvO9IfGxiT8SIcRWr80f0uzW2WqLCjujXVCbz4LTGD1koihq6IABZZey+JSQpTVRSRQopobz0pfoQMJ2hZEh4JQt27DNdDOQxkbVnNwyMPmBSokX6gAHOa8d57VhUltZZlDWgtbQclYRIWsIOP1PQm5Ug7SnlvYsRWVohKyPWngHFkKFLgWAU520l7mNIctPljKQq9hCkK8hK3B8WzpGAh03LRinU2KNy5nq9pnnzmp999gs23uMWS6qmpZkv2G423Fy94/rqHa9ffMXt1WvevnnDdrMjiIen9CQXq1hbRGF1zqIDkTxpjGwHaTlY95HNEOgD+HLNtTLc7Txvbnb4z59TvVnzs1/8gl99/hnRdywazaJtmM9mgCIUi/RprO5H3dENcy8/Oxq337ZtuudjSmili1RyLkLcU6WqtOFliiOlaHuoFIljUZbNBhPA2RGnFDo35ROOypQluElIxXPSNUk5kWMkT4YGR+/MlHFf5oz9XMJBqy6niRpexJpTIhgRwHWVxzhNyonKmgJ+RawxWGNLgCXaUIvlirptURZ8GNGlJ91WTvRZxgEVIj4FcvIE74khCLtIG6p2Rj1b0C6W1E1D3cyoaoe29T5wzymRTYWyFbpdgK7IqhX3NRVhqAmIbomOO3Qa0UqcV4TxIuwcEIvqffDIxIwAciQncbzT1mKaOXa2wi7PMe0C08wxzQzdtHKdFWhXo+J4OPGmgoltkPL+PFWqtMYVR0CxZ9alICFOeSpRGFXFaMGJLpUzGkIUgwlXgzEocwCexOV1claRcWCtAyVMtq+tdTkTQxRwyEZQirpyzNqW8/NLckoszi5AGzY3dyLyrTSuqpgtliKam8XlVNzrorBGBfl6r4AyDTv5rloLSF43LXXTULlKbIvLc0ofXqfKmmusxea0Z2Ak50gxYLxojuUkiYfK0u5ljRY2QS325m4S/HUiWq6MkbFhK9DCTkNX4FqyLkyxw623Z8p+u7YDCARM2c9+uz9ivr7tn9cUjR3QxwBoVgdHQw6x1+FjjsqJ6n7QG1NmDKlY0sv+K6ux5TU+ws4nAoh4f2Yv/k+WMGJIuWj1sI8tUZOuV0lQUygFS2mDml7n7EGbDjJjyAQSu8FTWcVZq1m2lo8//IB5U+GzLcCTZ70buBpekHee280AwdDObGFzGXHHtZkU5R6ctCWtMbROYqDKWmKIaK2omoaTi0vaWUvUljFmtrsebTQ+RgwRS2AMiYglK2EMaHWQh8hTmLdPmBNojbYV2lXoqiYrc2CZZbBl3WicY9E21HlBbIp9PBrr7F4zUCmDqxpC3bLrBm7v1mx30gI+a2pW83m53PmoPUpi1enzJkZD4wy108wqTWsVKomJQBwiyScsci8vKsdi7mhnDlMZPBGrFRfzqui5aHyGbhSNulUjcdLVIPFLSGKQ4IO0vS0by8Wi4junNZWRtkODFLErA5URNtGkDwjs9ct8hjFJsUgjchMTS1LYf4UfUZzuKmPEndUZamfo/UjcytqQc2bspTgVC61PqSwFGEr8Og1nphyKwkYV8rQvoMchp2LvEPat2dS9s3Ao9AFTHvS+e9dU3J8kWd5Pwr9RQPxoP4c5kUM+BkcOeEeHNB3XvTccvfH94/raJ7yX5+ZERhGSyM04U9G4GavZGd6NNK6lMjWL9lQMVJIYcLXVHGdr5mmFixUqDiQGrOrQSlPZCuXSXvdW6cLIMxJkVi2EMTP2Iv+w20b8CCRDirBeDbhKUc2h7wO3tzuausOPI6Mf6Xee7V3PzdWavhuIPjIOiW4nAu6zWYN1at/63zQVttCt/BjZbgdCjMWkR7LipqlYLlpWqzmrZcvNXc96s8XHEe0UGGFthhgYvcSZzjlx92vcvjtg9AMhDiQToDAMlckYC1VjWC1actSczC84mS04ac6xdUuKG3wOhBSOYu+igUrE6oratqzac5bNmbC4kOKWnOPj66uK7M7BOTHEkZwTlZvRVieczp/ghluRhWFARwGvxrBh8BvGsMWoCmcrcsgoFcqYmYbeASW5P6byvbH+teLabxjzfP2+2f/2zfvn/vP/Q7ffuNUuIvR/o6ZKG3vAabqx5aHDF5BkIZYM64AWUxINOAal9N6qNGVBE1W54JTnKej1JDZ5D0g6gmyUkurJMbg1JS9ybAex7On77Z3wckaUrgWQAFUqTFO/cD4wEFRpJ9yDTeV82BI0HdRq2dP3jsGm6Z991LU/0v1hoSjF4nzv2k9Y13QNcgoM2zvqpuHx93+PLhq2f/wp193nvPji55ydL/lf/c2nfPWu52dfrRk2I5/e7Hgwb3i8nBNSxMdAr6F3GkuFY0EOgRwD3egJY8dy1jKva5K1dFpzfbdj3Q/cDIEuRC6cYWE0T2Yzlpcz6spJxdBmFhpmdYU1huwcWWvqZArfTRJelTw6RSpVKPtKJnPlHClnoWjmjEsZrWtOKodyFW+HzJ1PbFxk1jh+/+k5Rite3265jZEX2ROyIiETjFHCNvOAtprLSnPe1DxpGoYYuD1b8Xy95Z+/esPrzz7jjz79BU8fPuKv/fG/5MHZOd95LFovN1dveXd1xYuXL9gNI9t+oGkaZrMFM22wxuCDsGeaytE4hy1Wp5su0PWJ9ZjZeeijaAGEGEkqYuoK5xw/+fQlX7zteXPzD1nvdnzxxWdst3f8h3/n+3z8136Xv/l7v8PjJ98jK8XNeoMPxW6dxHEPcSrUzvtzSz4SAeZbtU1CxtKylNBpcmeKKCW29QIoOJTS4mijJredyDgOxKwY0h1Vu2AVHbPFAjdbCHNEGYwW5ofosmlUygKO5AykA2iU4iG4NAdb8b21plbl1zK/lvlGEck54v1ICJ6uaOa4ymGMZbtdU9U1d7ctdVXRVBXOGuazBZWrmM9XuKrm/MEDtDacdmd4P7Le3BGip3IOciL0Hcl3+N01427L2G0IYy9BR91y+vAR89Up54+fUlc1J7WALdrJRGsqqfI541DGYtpWgBpXk7MiRAixQ+EhbzH+Gp1OMdUMb2q2XmyITQTnqqJXVdhgpWU0JXEH1MZAGjHWUi1Pya5GrS7QRgQiq7rB1S0xzInhHKM1RinC2BH9UFpGIMdIGHppJ7Nu30I2tZ54PxZzBWGW+lGcCceYGXPGWkdbNyznK2pnGVwjjqe2klY9J2CN1QZV1jehb08Cq8JaDTFKa1IZK2EUZ7hxGPFalSTN0rYz3MkJ9W//Dm+vPyBqzauvnvPm6oY89BitWZ2d890f/FYJpAx3t9e8+OpX+H7HsL0jeo/vRIsqpigAUmEGK2NER6xumC2XzJYn2LoRLQtXI41GpUQn5o57dm6txJaZLNdHJXElJEnAHLMEgFYJALFoHJXVnMykfWbRGCojbmaSkEs1ItqapC26WZFMDbNTlHHYqpVjLvbJWtnjBf9bsUUQIGbKUA/oBCXoOK5H7bfpFeIJoqitFSc4p0lZ00ekTSnpvXshCrSQyfYfodTRklDmKAEchX01Rk+tNVbBorY8mNe8vuuxaLZ94mUIwuUsgJJRmsoI87TP8G5MbCMMSWI+RaKuZ8zqCrIW5uHW40fPpvNoMl0RgJ7ViqayKIQdeL31+Bh5cbemNooPz8748NEJ/9v/zf+MRw8uwC0BRfY7Xr6+ovs//ld8+tU7fvH8OT4rMommclwuGzAZozXbMfD2epQ2qZRpK80Hqzk3VcW6j1RG48PI+QeP+MHf/A8Iw8Dtmzfc9Yl3b68FxGgslVbMjOF269mMhlW20qpqxZULZUgFnMsxFSOAIGzb+SmqrsE4doPh6i6TgswVy2WkmQUeX56hv/sdAk+JOfL2tmPXB+qTE0xjyEmRvMK1D4mp4subf8xPv3zBnTeMSfH9p88YY+RnX37GptvhgxFArZKi4XabSmuhgG/PzuYsas3DOTgS3d0oyerdiAUua0tbGx48nHO6alk9WgKZsNnwYOH4j374gK1PPF8HrrYjr991LGrDjx60vNklboahsEKn5CwzqywfXsx5sKh4trT84tWaOnTcjok3VSQkhU8yz2sUOcEYM12KBJ+4GTI3AzQK5hNmnWE9Fkc8EpFEbQUUXM4aFrVl1VZUzvDpzYbrIdB7KYA8m89YWIfSEQPMDMQs7YVBly4JZH5MCTajHE+IoFXmtog+hXJrG8U9ZYS/+tvUZF7+L0n7oYvlPlCUSnEwxcLqLFrBunShmKIZfK/1nvfyzSStvpN7usiclOswBb1Tujjli/vq32GTZfpIS/i9z+RoChZQQqOyEZA8JQa/A2DVnNO6Oaezh+QUmTUrUIrLxQcAPDn9HhlIfiDnRFM9E8Om3SkhdXjzAq0ic9PS6YAzYG2mnQuYWs9ESsI2maGDd18lfJ959VVAK03TjjStY70ZmS8cD582XL/r+OzzO3K6o+t2dN3AzeuO12/u+PTnL7HWMGsafO+5eRO5fNTy8fcuEIFzz9nZisuHJ8xmDSklNruB12/XGAfzRYOtIKaBk9NLPnz6mNW8YT6r+PLFG3726Zd4PXL+pGGIW/rUc7tbk41mvmxYzmacnS05W8158dkNd+86bm7fse1uqRcJazK73Q49aOaLJacnFR89OKNWMz758Ees5qc8fPAhyhp+dvMT1uMdN35DTIG6bkBBP65RwMXsMafzh3z88LcFeFIZ8FhbYGstGlAheGEmKbVvEU/J0/lrco5cnn7MavGIs8Uzbnav+fzNjxn8hu3wFp9G1t0LbncXXG0+46R9yIPlR3SjFpZcnrq0Dtn/8VD88wtKR2DsN7+Av/gF/9Ntv764OFOr2fuhzZ9zUt5nHO3fJ4DRdFJEa+CwAEw1gn1sxf5q7M/jXixOH/7m3kU4QNyTChKTEv+fg+QdHBQ4oIcF3MolAZRJRh2eUoeXyj6Od3iYnO53EKt7rz0wqI6DO/nn3tk9+pzjx/cA1dFxpVTckYzF1Q2z1SnpzUte32zJxnJy2qNS4nxRs8kQfSJouBuEFmx0cfDYW8pkotakoInakVzCVRXZyvDJsdCGtaa1Fq0Mp06xMopLp1k6RV0bnLUsK02jlQgwF3cqSpCgSjko5wLkaQXWkBPEApQoI9bdqdjOmMJ66EcPGbYZRp04W82Y1XYvGqlTqVY6jU5SadJK46wtWhTTaZeJpTYaoy3ohs5HLmczdn5k3Xf4vufN61f0ux27rieOA2O3Zbvdiu4BCmNEf0dasSatiyxVt9KCqYO0MXSjZwiRIUbGwuTSWlFph1KiGRG14d1mzc0w0nV3+LHnfOW4WJ3x8Xc+4qMPn7BcneKqWqi9YXKrOowTpmpPzgew895Yfe/xb8kmALOWtoQ8IbgZzdGNV5Ii1ASeS3trzOBjIqTM4ANJadz2DlSi2bRFtFcXB68IKQrLiT2vZQ+qK0qerlQREVX3Pp7pITXNgxOoLPOTKaw8jDloQpVFa/Rj+ZzMOIwMTsCwcQxUriIkqCsRRrTOymu1LthWptttiGFkc/MOP3R061vGoSeniNaa+WyJa+e0ixOa+ZK6nVFVFc5Z7CT4ojSq6E5pV6OMwVQVFGAgZ1XKyA22XcmUFQNqfoZtFmTb4IyRirGeKlNR6PH7ALPMoXrS9plmd8BYdNXs2xyZnEUKxdwYOSdZIdl1FN04ynlgolSXwFhrjQFC0GRVnKlyEYPPFC0tmLUNs7bBOYe1hmAdKhmUtVA0oqbgWZfPmMTnp2pwzqK9oHJJUpQim0RSau86FVNGqSSaZSjayrGctVycXxDGgYuHj4jek2Pg9OycJ0+fCZCaFHXbEnKg36zZWMPYdfRThqMRHafpOJWRds22pZnNaeYL0d7TYk2cUyR6sS9OURONRhuzt6omSTufnhKNqSXCaOm3QmG1xiiNcxWVs7hGxlLVOiprqHRVdBUK8GQc2RhsvQRbQbs8Ap5k3O3ZaP++RVn/VrbCflHHj/xlU7U6ekVpI1YHnOoQdwj7CXXAvu+XxvZHUPZzdB/Kki0aXWQqo1nVhsu5Y31SE4K0T04yFs6IQUAuLJY+5KItqUXHSatSkBGtuIxofqkyB+aiRRWCsFf231TwermVy2KeERe7mKBu5swWJ+TZpRx3f0u79YXNPhG4hRUdYizVd2FcKWVwzmC0ZggJ6yObYWTwAaehrSwXJ0vOTk5Ynpwx7Hbs7qQQ0La1JL1OdCGtsVRVQ93OMc4dRYZlrdgDi5Msg7Tjii6cAN8iu+CAiMqJ6AN+7Kmd4XQ5I2ph0wzZoOyIq5ywrbMiJ4U2YkxhKwHmV01NwuzNMF6+MsRBhK6VUthy3RuriFqRlcEZzbwWplP0QfQNxwAxM6sFZFu2Fmc1Q4zsQmA9BExxC1TFvSvHwPUwctUnrrbiBjerHLMQmVWBPuTi3Dfp7IiwcorCWJpXmsfLCrdTDDGx9SIubkpomXNmjOJMF7LIbxjKWJlOdZYac6UVrTXUxnC5rFi2lgeLhmVtxU2rvL73cQ885SxtMqqIhk8sfY3cRxOgFIukSNFsx2e5f0LhHt4bx98igfFDkf1oRsl5zyQ5pIW5/H0Moh/+vq/dlMtbvp6TKkr8VigkkkIeOmXuZ68yZx3i3nxv/1M+MH3W9JJc4jsJr486aI7SxjzN11n0gCSukHtYF1kZladc8Kij5rADrK5L3LACFQpol9DaY0ygqqSA3tSNOHFajTUwrMBXMqZThBgy3ie2a5FrqFvNdh3IhRycVcQ6xWI+4/q6ot9G0eHzkRwV82XN6nTG+aWIafdDT9PW1HWFcwZtREtUW40q7CtVYlVnHU1d0/ee3bbjbr1lGAeyjWiXoICEYgQmRfnlYkZTV1hnGIbAetszhlhIL5L3T6Lw2oB1mtVsxcydsJidMGtX1K6VGzwGku8ZxzUxB2ZNjTGWU3OB1Y7LxVNWs0tqN5fWuTy1bcp8aLQtDnR7Pi7HFzplyeWMcVTAoj1HKY0PA2PY0fkP2PTveL3+lJQ8t5uvcMqSFk9RJKyWuG4PNpdUfmJAlUzkeNC+P4iP/zuCHd6LDP6SnO6AY9x/4X1M4hs+cHr6Nwy5fn3gqQidmgI2pBCnu0QmkiP3OtFsiCV4L9pO1pYLFcqaOtkOHoLvKYjJSRJ04Eg8riRZWSr9wprL4npCLmdcHwFN+6ORxOTINvr9M/W+QF0qiU7KGZUmAWJ1dHGETXU8cd4nMeUDk2E6tHuj5SggVOyZUxPIpo/R+3tHpvbnIZcdT5jb1Cp4n2EWmS0WPP3u9/n58xf80c/f8ODNjpvbkccPT/ndjx7xZt3zxdxxc93zp69veDRveLJoOGsqzmqHRxbJMUS8D+i2xdS1iIaPHtV1qG5gYQ2rhUObGqMtT1TglMiZSbQ6Y2cWU9XY+RztHD6LhkeOUh0wiAhtiOJOpK1BWU22WVB27+W6F7jAOY2PiS70jCHx6t0NwVlul45qVvE3nj3GKs3u1gstOkYssFpVWJ/YdAGs5WI5JyHthhPDTivZf4VlpRrmrmZWN1z3PV/e3tGNIz//2S/oYmTtI6t5y+XJinnTcDKb4zLMkBbFkBIhRAYf9rbmm26UgLi08pTeB8YYCTlRaUOrha3SVDVv+oE7H3jz1Zds+x0fXVZcLBx/+Ld/xIePP+BHf/D3uHj0EUE1xGwI23VB6EtSe3RfHicc97fDhPI+EfCv+iZ9/WkfPKQpNdVTki8tVAJKCICSkAAxJE0XMt57dt0O0+8Yhp6mnTPuNrjK0bStgJp6EqyHfSIx3aNKPsuWYDgiuitKSwucLvf95MAZkyRBWcnC7IwRQUdjSttdLILR4obU9wNdP3B3t5HPFu6/LODWcnZ6RtO0XF5c0rYts8UcYzQxCaPn1Rc/p9vccvfqOXHsIJbqXoxUVcODT35Eszzl/NlH1O2M5ckJzhoapyWADwm0wbQzjHU089mBBZszMUcUmko5wvKU/PhHxLGn77aYk4e4y6dYFLYAyZTWmmHo99R6XSqex79TzoGPiYRGO7kWWkmLnvcj1jlc3eyBJ1PVRZdrJIZAjJEcc3nelvkzSDBlLF5Eb+j7nhAjkpHBarHAaMWjywtW8xZbNAErVNGrmdocD4uEaIzp/fgTcE3GiilZ/yTabLQixUyvJFEXLd9EPwzCZqtr3GqJ+u73eXR2gTUOpaCtKk5WK77z9DuElOkGz3q74YM33+fu7Ste/fJnbNe3XL17TdW2tMslZhJRL/pSTdPSzGZo69DWMYwj/TAyDANjv6OPQcDWoglX1w2uqqQlSFuy99JqilQNjbPCQI4RlbO07WnDYi4Wzu1qTlM7losTaldRN3MJ+rQAI8lIRmaambQu1o204bn6HltRW/teceyv/ra/h0rrRraaXJLYtAcq3o9Iy19FPFkhsZYqjMqcBFjfJ2dHwNTUfjsBUe/vc0rcFYhRQAIVM5jEstZ8dNKwqOGTy5o/ednz6bsBXWSgF5WlrQyvNyN3faS30hZljCSXrlIYZ6hNxDEemCBGYk+VIfvMrosMMReNMUVTiXGEtanMuRarYL3z3G4jUa2gvkRd/kC+1NXnpGqgHxO9D3JOkzgUj2PmXQxYa2gLY/N02aKBq27kdhi52uwwChqthM1z8pTvffIJT55+zG59R+wHHjx8wNNnD8UlNYlTpTGO8wcPefTkMbN2JjFBmi6hrFMqR1RKqCTtxFnJCUjJk4YdoNFuiU4DOo34rqPXVyxaw8njc3QtLb62ecP1ZodRDcZUgBG2km1wTeL0wSMe7gJnq3MqW5F9T9/vuP7q5zSjotPCwHIqoVRmtRAGp3binPqwMeiUuLvqyD5ixkDrDE8/WDGvLQ/nji4E/vTVLW7w5NUts8pyWRlxmnKWu23PP3898u5u4FcvPT/EcTJvSTrwwVJ0v77IEY1oJIWQeHs7EEKgGzyr2vGHH53z2dUWUuL5JvF6TBiXqbUixsy6z4wpMyZwGk705HSGMHAT1FrYSg9XDafziu99sOLR6YyHi4plbXl1t+O2G/mTd1sGn9n5KC3fOuOcaKOR056pI3UMhS/3qCmaTiEqQlLsEqAVJxhhhGoB5awpwOm3ZpOYSOUiG1B0DUud5725egJiyjyVQWd9D3Q6sI6OiQQHDeF9G14hNOw1hqc1N08Aby5F+rKPov2jjp7TxpRuFznY4zg654POsRzLBKAUsLzEEDknatdI3KEFeBqGjehrTgZKeWrBjOTCjldAbVsUM7Kakxjx6hXJjNh6Te23rBYapVouTx9ijMangRASi7k43+XBsF0HfvWLNWFMvH3dYYzm6u0AKVMpS2U12o4sZg1nl0/ZbXdsXivJ39WOi0dzvvejMx4/e8APf/tDbu+2vHl7w2o+YzGflZY7xWzpWJ63jOPAMAwYrZnVDfNmzqJd8id/+gt+8emv2I47utBTVQFbB7IPMv+liCJwfr7i0aNLThYNzlpu1z1fvbpjM44ElckWlKW4boK2ibpRPHn4ESftI84Xj6hcS123hOzx/S3d5g13d5+RVeLh6TnL9pQnJz+grVZcnHxE42YsZuciwxGKe2nWMufYVq51LEAiYY/9lJFUmHiWytUs23MenHzE9z742wXYTHzx9l/x3//svyCFkZ8//0eMDzY8XH4MStE4RYgZFUo78LQWIJnb1Oh1hEv9+SDSXwIu7V92TAr6NWKle7t9L3n8N421frNWuyPEejokNUUnf94BHe5Wpgq9/DkBN/oYv7r/vDowBQ4RUAmWjlga96qARxgO+0lq+uzDk3vnOHVwF/rzvu903PneQd5//cSA2p8TjjSx8pT+6yka3KPix5dV3fse+f0vc++Ypn3cOydTEIoAf0M/oLXm/PycBw8e8OSDxxgib2+32MqyXLT0CeaVIbaWsKowVrFNETsKS6iymtpoGmehqjFNja4rTM6iLeBHSOLYYYxoLlirONWWhTJUxWHEOCdJgbGgHfoQ8ZKLWxc5ooMlq7gH35SykBQpTkGZnAuVhQHSuAqFpgOCgratqBqHTpkYPK/e3ZJTpm0MsTi7GBKhj8SpmsLUKqr2/dOp/J2VoPanM0ksc0xsh56WxO0YGNJAzrAbpXrqjCsTjlS5Yi7svJz3yH5IqegkFHC1gJOV1lTa0FhLVZyvxpjEpYrErIZaax6eLnl4Oufps4959uxDZstzMA0xSHKSp8rAdA7z/RGr3r+N3x9i37JN7EuPwWJVxpewcCawaWoFmQATjUXrjNGWqFOpuCbGsQMFduOo6hqyiD/nkvSaKYBCZgNK25zWwqYz2exZB8Za+SnMqegDMUjFHYRplSc9M6TFOZsCUh1VyWIJeCftiXykdWNDZLfriDFRuYphGPApYKyh77b4oWe7uWO3uaMfOnHBi8VowdS4umF+ckq7PKOdzXFVLeevANITCGSMRVkHxuwrvKYUFlRRVkspErLCmznJVSjdQr0kTS3YJRhVyoo5RBJdrJwgFb2naT3ICKg46V8FH/HeS4JXWoHk1CsmI4to8p7hpI2wCdXoiUr0RXIKEuxqVUAMpPJl9J76L+/XLNqa2lmayuGsZQpoJ6bOQVeljIbjgLtct6lAIcvhdKPK64yWSqgxmqQyKUwFkURMqjCfoK0rTpZznnzwCKWgto5ZO6NtGkISNZMxeJqmYWhm1LN5YaM5qnbGbLkqpVGPzhmTE1XdULezvc5OylkcG3MmB48fOsah26+JselxTtwBjXGEEIU9MvalaBAPrnPl3tBKlWTcYG0lQuZVK0yMZo4xroAsStAJpTGVMOmUc6ANujBn9QQ8mXu99d+K7TA+pnX+qMD0TVWEe3N54TMp9nPMVJCYOvcP+pDq8Fn7wbnfzX4NmbScrBbmS2XkfgopcdcHXq5H1mNg4yNDkITMKnHwWtSWk9aBUrR1xIcg9/nxfYDMZ57M5DqmNBgr+ojWaozO6FKwm9z4JAzNBbQVQLwbI5t+YLO+Zbde0VwOZDTdest2vWX0IyklZrXDFz2OKQ8NMdOPk06LzOoC9ieGwVMZWFbSCtxUBmelgGCtYT6fs1yuODu/FGA7HXivs/mCWdtirTg8iaPg4ZpOGtOTGHMMia4bcLGHfmTwCbQjK0/MCh88YehJQTQ1rUloNJWxzJwjI2xAPw50uy2aDTH0rFYnPHwUMNlAStxu7tht1zTGsGoachTgRJPQCua1FGfSBI6PUtTTUb7ZalZRO4O2mqRhWwoCMytr782m404bXmVN7TSXS8dmiMW1Kgu7E470xmQgCvNMWhCHkNj04s7pQ6LRispajDJCXgUqk8V1MCcpoCAMG2eEtVWbCYSAXCDU1mkaozhf1qxmFbNK2J1XXeC6j7y5G7jtBnZj2AMDMn+pQ/G8JKAqZwJ53yI/FRXk9cjzGXKU9j4BpA5J57dpO26rA6aS3ze98gAavff4cWvbce/I/kGmfLEATFlysCk+mATIp3dNqdWeHPDeZ+VMIR0URtSUS6YJUIoH7Smm3G/6jur+dyn5iuwv7o/1/s+9LPDo3E2PGpRyKGqMbjldnuGsI+QoHRaxwvtEX7ocnHVoq7FthTGBxdLTd567dS/xaxfRKovKbUwM/YDRltncYp1BGyXi4U3F6rzl8smS1VmDdhpXO9pZQ1sYT9ZKx4rSHMU7irZpOD1ZkXPm5nbN1fWaN283NHPLcr7ENiOm8ox2RzC5MNwDioRGzHpyCmibqFrF8qTFzTJNEzAmMY6+rH2RTECXGKKu59SuJSTP4Hd0w4Zh2KCIpeV/gOyZVXPm9Yp5tcS5plziRM6RnMF7IHh6v5V5OxeN0+r4tXl/vfdgpkoodJkODFpZ2mrF+eIZIY6EOFDbOSnH/diAXEw01F6qaOKi7MfnXxbTlNf9ZdPH+x1f77eq7h9//7e/ZMe/6bz16wNPE/IbJ4S4fFKB5N5H0aQaXZKmnMnxwERKSYJnXZxQyEcaUEwXtSQ+RxOWKlpLSU3USGlgmnqHD8CY/NwT482y+ExJwaF9Lh/aNphwG0mqDjRR+ZxU6M/6SP3v+IQXVvR+X+o9ZNwcXVthAaTphJWEtZzilO6dz0y+t9+v8aDU8TWQ58Zh4MZfUdc1P/zBbzH0PW9fPedP/uyn/Df/33/Ki+s1X7y64cMPzvitjx5w3sx4+nDGq6sdz99teLOFesh8sqr5ZFlzfn7B2ekZymqUUVxrzVprIp5kAy2JikRdR6zVuKbGWFdKOJpsLElpMA1au4Mlc5nAfUlUTKS42E23tCHnhBDshMWlspxboxQXixU9mjdAqi1PHp1QWUPYDNzc7vgnP/4lRit+9+NHuNqymDVklxi6jkofWGxKK7HgVJaECEtHNEGL3sl3qiXJe763mNP7kfXQ81U38JO7jrth5O2uoxsCu64nkBlJUtVTVi5JKpVkDq1BVQnap0B+WVXMqorWNdTW8cVmy9vNjl4Hskp892HDad3ww+/+gEcPHvG3/vA/5fGH3+fdxrMZIr7fiIudnlh8ByZfaaaY/tjfJ0d5xZ7uWZw+vzXbOHqgLIyUdjVlxInJKKIuFdipzUpradcq4q8pZpQyjENPiIFue0ffbel2oqW2Wi6pqoqmaQWEmTSj0GhTiQVrSY6tKuOi2EpVTUPdtlTGUVnHsN0x7Hq2my3dKCBUjGL5SmmHMsUJJwOMCnTAp4EYEsH7okckc0iISZKFmHHWsllvsNZSL4pzkY6kMPL61Vf02zvSOEor1SjOfKvLM2arMx49+4jZyTnNYinFgqGX1rwwYqxhdXqOdhWqrsk50/UdWmvqphFAQFtSjOyGjsFnbs0pxhnauiE7oSZrJfovRhucrfFB2I8hCKCkFNLiW0S+U0z4DCFEUkjs7tbc3dxiKiegSl1RNRV6HAVUdpW0H1cV1llmbUNdVfSdCGx22x3jMBahZE3dtsKWslYEgm8Su2HYX4dnjx9yupyzWjRUVtOPksTqck/r43KVOiSTe+C3VFtTSY4OwbmsR9YYjJbEK0zXFGkfyjnTKzBGs5pVLGfnPHpwVpLmEiTHhA8CqHlf0dQN43zO/OySi7ZhebKiahpmsyX9+pbt1WtszliSsFPrmmH09OMoxxwD4zaQhg3b63dsbm/2SeN0Tp2VdsPMJBZfGMpl7URNIYP8brXBaUflFlT1jGp2Rt00NIslxlXothJmkzVF1NyWggByT0hfpgTbamrd/nc2tfw72cLEgCgJbkYVFyXR59rHMcdfvCRLSmWMluJP4yzOWBSWrGSNIidUSHtGQorSzpbTcXHskGCh5BRXzjKrKua1YVFbtiGz9ZGfvd3xjz9fE4pL7XaQtm/jFK02fHjS8OxixlAc9n7+esOr9cBtF+h9knlTwW4cGRGmp1IK6xTKadqZZV5pNkGDzgwh7FvvFBnvMyFBpaUN9u1mh7a3fPnpT6nSlg8vH5CV4fmnn/HlF1+x2axJYeSD0xljhHUX9gYrwSc2/Za6cjw4PQEFfQx0vef1dcfMwpOlwlWO2mqczqSxo7aaRw8f0u8+4ns//H1iisScGL2nHwYuP/iA8/Mz/DDSdT3eGGLtSEmKDaVcgdVSRb/qBt68fsdt2uLSDldXWDcjDZ6URrq+Z/C3EDYQO+o6iVYdjrPGMEZDwrC5vSaOPXm8IyfPR9/5mKfPPuGXP/szrt69489+9ifcXr9jWTUszh/AeksXgujpaXi4rKisYdNHoo90NztUTDTAzFm+/2SFcZrbHLiLiTe3I7XKfGdR0afMT19e8brL/LM3gctFxX/6wzM6H3FEKpPRjSVbRR88fZEeCFmYJ1kp+pC46yPPr0fc5DhXW0ztSBj6ETSZVS3znw+gUkSnxGzmmLWWWWWZOQFMrdYsKsPMGc7njlVjaRtH5QxXfWbdB/7k9Zav1gN3257ee7FfJ2KVzEvGGZSTtm6loK4FAE/jiAoRPfbknGmcuDX2ORIVDAOMEdJaorQwlpbV+K0KvfYxF3BYB4+S3KnofwAtijD1EQid80HMfSrsOOdKMak8j7hTqwl4KgU7YRtKy7oqwPt+bvtatizlxlTYS7kAjNP9OOWy3o/EGPamIxMkP63tAnQVMAIlxeDsi1FQJpeujn0XzuRIOrG8CjNqcl3OWDIVhgtm1ZIfflSR8sj3ux03d1v+f//iZ6y3G242W5wzfPDknKatOD9fsNt6fG+5ud5yt9lJ6/OQqIyibRWp91y9uiVfas4vH1A1lnqpaecVDz444eknZ/zu33oKOGLMVDPHhT1lUdes2pkANVHEx3UpNBpjuLw45wff/ZjXb6/50z/7OT/52XN+/os3/PW//j0+efKUbLYk1ZPja3K6xdoIuifngRgH1usNOUeqZeDymeM0PyLlRL+7I/iB2/WNaG+qjpDl2mldc7J4SFO1fPHup9xuX/Pu5kvWu7dUjRIZhHhDjJZVc8LJ7CEn7aW4qMctKUssnFOmSz1j2PB2/VO0sZytvsOsOeNk+SNyiux2V0Dea46l0lWRskehGbU4ETrTsGjO+NGz/4gQR0bf0bjlkZFMKvdJRiPyLrEwMTMFZnlvWf93uf2PNRf9Rq52E+r7tf5BDu4DKGETqQJUCUCUDze5mpTl5b9pf/L0Peh3j04fAeZlYinsA+T9+0ryfs+q/CJBDEqAikPEv/+n/C0V82MhOfJBzFPEbfPhe5QEVYQPhbKbmaplk0Dm9B0OE69MQ2o6TXtUfmJYHE7K1BI1nTM5nskpgCnOnGqQe82sI7Aqiz7KlBj8/7n702dLsuy6E/udyd3v9MYYMiOzMmtGAUQBlEi22khKJpqxTR8kM/2l/RdIJhNFs252NwGCTYIAUYWqrJxjetMdfDiTPuxz/N4XmQUW2JSMSC+Lisj37uDDGfZee+21zs7O+L3f+xnDFPjrX/+GECYe9gNv7/Z8uWhZLBpW645Vo7lct6QhElViR+brMRAHT+xHWpVxOsM00eVItgqwLJSiKYmhsRbTSJJHqUxLIl7q3SkenRnKNUvCr0TbRCnp66fo5OQsSYXOM1CljSFmxX2GQYFaWGxnaVBkH3n15oHbhwO7YaCxhn70ZA3tolQutRa7+nzErGvVSucjZFOfi2jIKIxztEai72vr+J5p2A4jS2ewgCNzyIntrMWQsVqCjlhASKMl6GmNobFiQWxAtGBQjDEy5kwgom3mrLUYq4jjlrth4n430i09IWmUacpiXSsA35w8R5ZBTW5PVAXyEXD6boU8xyMW9k4qyRVZkXWSViBV3OdI0larNKiSNp9UsKCORkl0halhZ1HllLKYDyglFOoCPJlSzdZG2hLK16OyQSO2rG3T0LqW1rXSVz96JqOYSvpetSgoGj/yTwlcYvDEoi+lstD5lVIoI9olpgQEdT2JBYiI+33Rp4rk5PE+EENhTJW2LqzBLTc06zMBAUqbX0Zc82KUv0ERY2LCE/09KUamwx4FmOKCZrStix7ei1te1pFgxLI7ZQk+rTYCXhh7BGpg/r4QQmm3O6of+8njp4ngJ6KfECHyQAwj46jlukLEuHZuA2wWC1JhHvppEp2UEIqYqbjMpQLeVAq90vIc6w4mYeqjlbssx6r0In1bfbe0OHHEC2q5oBDyjowTfQy+T5nFc5W0rCeyP5UjZXJp4Q0hSUW07CdOa6lEXl3SLRZszs7mQL8yWKwCp5W02GmLVtIyr7K4pYZpYhoGQhG5r7tbTpEUBLDPobIIy1ybg/xcjCLABwGDp+Ax1pTijMQNyljRbHIWYx3KamxhE9Z9JNUbW5z16pjQ30HgaXZ7ne+2mlf1x7nTSUWBk2omFFBX/qjjS+Yjl40gv/tRj9a/Cp5KEUXrPLP3UgIfxeFuConBJ0YfiXMsIwzg+z7QbkesFVZhkcXDaYWymmVrcUYTg7BpYtF0illYxGOIWCV1bkqik8s5yY/kztTr9GgGn/mrT1+ynyK3zb8nY/jiF7/m9eu3TFFkIlba4kIqDmVHxnIoFfgq+qypzJXC8kLR+8jr+y2ruwceHu5pnKMpLdSucaioUYXVZWIkZRiGkRTjyd0tz6Fu0VX/pdz4TMb7QJg8ISlsyOQAGYdpWlbdgofbHYc+8NWbN0V/SpifF1fXLJatAHTeE8ZAShFrZS/b7/Zs7++ECesjuZX9zRqDTQlfisY1llUxomLCKdF2WVkxBvBQWKriuqpzknZEZ+VZZvApMUyxjI3EKcBQSLRMMUnrdJa2SVV6O1OWMTaGSFSZRkVSY3BO0zaiORVVZiyaUBjorKWzmuXCsVo2LJ1m4Yy0i6qit6gUQ4QwJPI0kZXizT5yPyR+fdPzejeRkoAFjRUN1NIdfbKGC9uhc3LfIDMpzcEII94Z0S6TwgCEII6PU5L9PaVakP9uRWFHkKkmcd8EnerrHrEuCqBz/L1GqQo8mRnwUVKFLmwTAaAet+Gd5FEplTT/+J255HdUHTGOuZm8NxXAKc2s3VCAp9nltjJRKzs7nwwM8gwwqVm3LT/6u+p9VrLFUbuq5LaF+RRLnjqlkcQkbt6N4+riDOcMIe1kriDXFWMSfb2MxBxlzKYo6+fkoR88D9sHulUHKuMaw/q8pVtaurXGdXJtMXjGfiRFSB6yczjXMgwD/TDQ9xN9P7JYdFyeXbBZLdFasdv3fPXylpQzV1drNuuObtHQjz1+BJ0aWrNk6COTn7i9O+DsjkUnelXGZFwH6/YMYyx3N4mhVzzsdHFI1cW0xOPTwG68ZYoH9uMd/bTDGEPTtLStxTpLa5c0pkMXk7Kcoqz1MZBTkHg6BQZ/YPBbtsMrjHF0izORXQh9ceQtBJacH4010axOs85gYBQGWHNGTAFnlljTzKPwdK7L2MulMics89M1psyaMnYfz7Pftmb8Vs2nd45v077O89/1O39bYPW3D7j+dq12mVJhk0qr/CwXkOPYmHzK3gFZDGJxkqruhDVhCyEcz/0EPJmFRWsQRdWEKoBWzkdt2Bqxz2GHTBajzJxIygKQZ/2mGftSPFoAFPr4sIMATulo9Isgq0UslUq/rIwq2XDqd8j3U6zCj/8zhd6rK5DESWj3LuhUb4mqSZg4ydTWkdPFeV7cy+WllJiCaNM8e+89/q//t/87L95/QR4P/MUvf8W/+rN/x/1u4Ddf3fHT713xRz96zrOl5YPLBS93Ey+3E1/tPL96GHkWH3hyiFzHgYs0cbFo2LQO5xS2W9C5FmcKw6lYtyutMe1CkpjSbtb3IyFMhdJZrMWVoimMjqA1KSlZ3VKa9YacEWt1HXIJBBv6BH++8xyspr0+o+0cbUrsdgP/y198wv1u4KEfWLaO292edWppl04YU06eQS4LhNhkAkVDyqbigkGGHBmS/N4sGhwtSxTnSvEDpTiMAw/7A2EamfqBVyHwuQ/40TMNExtn2HSOXYhsQ+C8adk0DQtr6awVCm5K3EXFNsPb/sA2eNpOsVxpPrxac7Fo+B//9DW/+eINk7rizcHwx7uBFynj/Uj0vTx4zdyGKpa+6iiiXQa8sP1OB9cxaS4T9jt1jF7WmBrcBJNnlzGdBRiUKpWsLxoJbpwWZlFSFBYcJKUxTYdzDYvFSlhDqiFnmLw/mZeyHhk9Ys1QxAqNsEKaBqtaNJbONawXa5bLJcvFkm1O6GkgDBqvM3EGs0sLQvTCVggTMYoovS8gp0LEe0/19mpg7azMyRAj2QfG3ZaYElqLMOw0+NJtJWB1zIasW1bPP2Rz9QTbdSI+Ow3klAmjsHtCjGirGMeJlCL3b14xDT37t6+JIeJ9FG2rpmGxWPD8/fcgiwC61po8WoQRWZIdZ1ksOpwVNxGrNYFM8MK60UaMCUCJM9s0ErzHjyPjfk8YDiivCFpxGHsO08D+Yc9hd6BtWpqmZfP0GaurK87OzlmtVuKwBoz9KMwqY2isI8REQjS0Yspo42hahfcTUKjzKZCjI9U5pY6tmo+jgzkCKPuFosoHPtryk+yX9bWnreIzszXF4n6VhEmcJSmKpW1J2pdyqZoVUI/MwhkWlxdcP72iaTqWyxW7hwduX70mh4hRGmsNzrkSWOnyP0g+EIaeYbdle3/L0B8IIRSG09Fkwk+eKcW54KOLftpcOy5s5RBKS6Q1RAIXcSTnVlrqnEW1Dt04XNtgTBVoP96vmZRp9KwhVdv2vmO4kxhfZLBKFeDDlESHeeGu4VNdeWoMkPMRdHJayVjPpcHocYglSdu8hxxBqEf3s+CJWme0ltZJaYHK7EZp9wgp8bD33O0C64Vl0WpiyvRkfvH6wK/e9ry47LhYOvaHxDQoVp2lWcD3rhecLSxf34xs+8jL3cg+RCZpXuLmoNmbJOxprWjMsbAncomi9dRY+XlILdsp89//f/4dy8bw3v/736CUZnsYCSkx5YzpWp5YR4yJNgdCTAyxMFJyxmlh12REx88ZzbJpMBoGNP3O89Xtp+zsGd/75BMuzs559uQJkHHOyP0M0mJto7hlvnpzy6KxrFo3OyXVglA6AabFDVJY9sMUGB96rJmkZdI1aLfmvYsrLq4ueHN7x1dvR/6HP/1zfv3ZVzw5P+NsteS/+z//H/jh9TUpJcZh4rBPhJBZmEhWka8+/4yvPv+UfjeQgiJgyNrSWJEV3/mxAEqIQ/MwoUNi6Syt1jzZNCituPOe7DOWgM6ZLmdWWrPpnIDhOy+RdAnctQGKxlJKkjPklNlNkUPZ1xIJ00g7zxQzo4/sBo9Vwsw8WziWS8vVxvHismFxCKhdxhkp7D09X/He1Zqucyy6hoXOLDTEIBp1r/aet33gNw+B2yHxaj9y13te7zwPQ2A/RMaQeXGmOes0nVU0RhNjaQtMNZEXB+LzlWXVtowHy+gj+6FHEelcBZ4UPmTGEYaQQUsbYyrzOD3aDL4LR1kw6t/ln1XjtzJ+jnldfZeQBlLJe05leGtHTQWuBDQX7Z1QwKFUpQJOukFmxlRhssvuKLrDMQbZ6+ZCjC6F+yhAU/CkOJFiwIdRgCdZjbFNizaWGD05x7kbKGUBokQuQPSCVQE7TqVUSiMPsbifpxhnsoNSqrSzSZFmDD2vHr4G5bnYrGk6wx/89Psc+gO//Cww+okheKYpsttPDPvIOETClFBRQ8ikoBgDTFMi2QPrL77ANJqcf8xibfngBxeYBhZnimYJwxAYDge2d7fkqCAa1q5h2W3Y7iZevt3y8s2WV28e+KOfvcff/3u/R9MaMpEvv7rhT//tJ/zg42f8/T/6mOfPr9hsWh4e4PbthDIrNm7NZ6++5nZ3j0qvebib+P73Lrk873BtYmHhey8+YL284DefaO5u3/Lq5hYfB4xyON3g4579+IbP3gjQc394w+QPLBZrmq5huVrgrGOzOGfZnENWxBCYpj1KaXwcSDkSpwEfD9z2n3Hwd7x8+CusbTHOEeLA+eIZznS0dkHKickPJ0ChIhdNMqWSgGH0GNOyXj075uXR40MPJI5V/wrri7RCozQhZXyUroVwgkj/jfjP/9b1Iz/66whYzXP2v0x09bsDT7V69s4Xp8dw3Pzayr6Y4aD5fRIazWhzDZXyya/rG0//Pj2PfARh6ntSZS8UqnahFcy/r5jWuwmBUpR2vHJeuiIRx6/XjyqBp6j8b+tLfufETxD0b3tV/raflOr2o0v/LaNKdE+O15tPPjSlxDRNNI2jbRqurq/5ez//I7JpeHVzy25/4P5+y83DgU+/vmO16tisOmLMLJ1CtRqSwTSQTGAbE2NMbIeJzgcWztFaQ5cSziZs1ugklS7pI46YqNHFYnYqYr4GUDEVUcAjoChuThqVRKujJioFoCbqhE+Jrc/0GYbWkhrLunMYo3j15oH77YFdPzF4P0+YcQo0zpb+b5GIi0rarKwWdxbUcdymmZFVqhlFF0CpXNqBtDj0WNF2aLQmjI7JGmzKNCkxHgZG23O2WXBxtmKfYJczZgoYH0BbkjL0PjBOE3ul6JVGO4RBZaX39+5+x/5eHCzWZ+c8e/YeL158iHWOqbRGzawmdVzLpGByMj9PGX+CbnL8QR19edb++K4cR+1+NV+2rkE9QIzoLGtHyqW6nUEraWWRP6UCC3OC27hG9GmMLcFPYQvFY+UqqShBivQ/4qKTykeSz/KTMEdiCEU7IJZAJaJUxOiENRCLjkY9l+g9Ifri+pZn2rdRRxANmMdFKqLdKUqiGGMk5ShOasZgm46kFFPfi3GEs2hr0bZBmQaUJaMJYRJG0yQVe+8ncs7sd/cEP3H/9hV+GOjvb4UFFUEZQ7tY0jYN0R9w1rHsOtEvKW5kGLEW13QEoxnHsazlhblVNVZiIqlIioEQJvw4MA09w2FPmEaII0M/Mk4DD33PQ98zTQE/RfTDPSZFhmFLv3tDvz6jWyxZby5pl6va5UIICaUCGS1r/ztL96m1swSw37I2f+tyX1vET3Qrys/LgJn3KXlopx9X9xmZnzlXli4FxErCZsulvQA1O8ZqNNlZFl1Xyvy6sNck6Wkah6GTNtBy6ikGop+YxkEc8Podh92WYegJ5ZlrI8UDpd9ZV5SspcdbkOd9LhWGszDLEod+T0yBh90dmcRquMQ4R4wRnY7srpQpYZmsZ7UAlmKUIgfCRiN998TFK2NR9JkEvEtkQs6lzYA5ZKk5Hscfz0ett+XyfMxcdMgnT6iyBk5HdK1myQOu2jbWiglD77M4fU1ewOySLM6DSR2/swbTtzvPOCW2Q2SKGRcVRsHkE4NJYjmfM0ZrWgvnrRMB8tpaU9gElVkfo7TdUO9BGYutFVH7KURyCnz19mF2rUQpsKI3FZKMMWk/VmgDTUyQNcYqjMqzI1ku4Zn8kbJOzJHDMPLV61fsDgf6vuf1yy948/pVYTHJnGutpT/0fPL55zy9vKB7/gRQGOPEulsar4SpHgMxTBhjWCxXpGFPalpSCHjvadolpl1imwXGLWibjq7r6BpD52DVOVbLlrbraJpWCi1Ks7StXGtjCMGTQiCMo6wdCpGAqMlyzjRlveusodUaGkvSkRgVo4KHkMRBTktR0BYNwgZhWVZtq1qwrXFIdQdVWqGM3POsiuB3gBgLIy4klNU0WtFYTddoEV4P0tbcdi2XF5kfRNjcH7B6N7MjVwuLaywhw33vuU8JYmLygSkE3hwCd0Pgpo88jImH0XOYBLxodMY2imwVl61i00hdtfZ81NQnzVcI/TiJ8HGQ62usJmKYYmaKid5nxijzw2poGykKTKHoCj0qCv7dP2Q/y/PeVXsJaht6nt0K33GnU3WeHbXP6momMVx+vIcqJY0fOc+aj/Ljx3ttksAOjZljpLqXzh9eco4YhU0uJiSeFMUxNsWiWVjAQjxShMqpxI3Hj5pz2/Qt51zuSMr5eO451x1+zi210iQSPg4Mfsdt/5KYR/rU0RjHprnCtZn3njzFh8C2H4gp4PNEDJF9f6CfRjAS27quFGeyxjjFMHnGcWIcJmLIONuB8gQ/kVJAmyQtvYcDJEOOFu8jYJjGwP39npwSZ+sVbedQBraHHeN9zxh71mvL+fmSy8sNmcjD9oFxkvWm0Q5jLZvlmqw0q3ZFa1o619I1LU0YpWgVIfkCWJNZLRpgwaJd0LiWMWyBzBi3KKWZwkDKAdc4LAZnG2k/tiucWaKVdJeEOM5/pxSY/I4pHuj9A2Pci86nVgzTPVY39OMDNJlFs4EiXH8cgkcs4PiYZSDnFOvgAqSQIMz34+sre+743Kszp8Q9OTMTMb6FoDTv5iff/I2l5NuYTeXkH33KbzvelVQ6nZd/m+NvATzJXzMyXcCad8Ut6ylIYKlmK2mjKqKd5lcdEe8KPh0DofojCbjLKeRjS1+1nFYw60hYYzHWzO9JM8otC0INnISNc7xZMUoyJSmEiJgegS01Lxo1slPlHLXS5EKfzen0gejjc3wUBB4D9Hdz/3zy4iON9PGiKW2F9TuOCzYFwFMVIJtfI4unn0ZiEEHg7330fX74k5/yoz/916yXDX/253/Jv/yf/jW/+uqGT76+4/n1hg+enPPkYsmTyyWTc4wbK9VWFXiVEg+TYnjomYaJi27JumlZLKBpE+s20llDkxQWRdeCMx6tojBJslTDYhaEpLNgFbSNLf3BGqUbVFKomMgmlPsurLEJzSFE/u1+z16Bfr5muWx473zBNEz8P/7yE24eDtxsD1KtdCIa/dAPIhIc5c6PKmOVYrQdzhmuO0tGNFEwUnWv0WWetcKkGqGNRltD2zhWi1ZUISexGA/jgWxFaHq/3bK7u+fqvSc8ffGUwTb0tuHVp1/w+rMveRs0t1Hz2cOWr+/u0UuLbg3PzhY8W3aMfc80Tvzir1/y6s2O733/I77/4w/4h//Nf8NPfvIT1qs1+92WHAL6nbE2j4P8eDmSn58MwG8gvn/D4vR39AiP/ksCAZUyJgS0VjRJ1rUYRYjSRosyRlo8UmKaRqYwEWJEGWn7ca5l0a1K26Qh5oCPhQUUaitaQGZmqrEHzjqc7cQ1rFtirKYpVW9jDeM0MIWRlCYgYI0E80GJzlmcPHEKTEPP5D1RZ7LKNG2LMwZnxT2lLnc+FSHWaRSB6ELnj4WVot0SY4TdFf3I/du3+NGzWqxwbYtxC7RbkFRDzJZx2BLCSL/fE8LEuNsy9AdefvYZ4+HA9u6GGCbC2BPRjLpDNy3Ly0tMCjTjPZcX5/z+T38mVUIlwJM2jnaxwHBJjtKiY52j6zoyiaZpJBgMck+1hqnf09/fs9/e83D3RoSOrebu5dd8/dWXvNr1vN73dMsz2sWG/tXnjG+/5upiyflmgWoWaNfxwc/+Adcf/oizzTmLxZJxktbDpgNrHcY93i+sc9hC4W6csK+qM2kJI+BbN+MaPJxu8vJ86/h4pJ9Y2soobExjFCkpYpDPmdnC5PKM/fwdSmusK+1nytIWTauYpY3SB884HNBkNmdLYIVSTxgOBw7bHX7/wGF3T7/fcdhuuX39ktevvmK32zKMfRHabGZtDqjBkwGtBcid7TGPe3wurd+VHdiPewnC0shmvaFbr8kKmtUabRzRJyl7Y+Z4IedEmEapRqcAStF0S4yx2KblUcv8d+AQwock3aDwRAKJIYlbVx15Wp+w4k7eX408Qk5EctE7ybRa1oKUBMyKSYFK+BSLoUXBPucIttjEa2FQdo3jMMJ+SNweJu724jbWGLBWYZyiEMjlM7QiTBkfMp/sBnxIuMaWir4mBsWbB89uiGxHca1rrWHZWH78/IxNZ/nFy3vu+5GprmNF3PYwiVZaQ8aqaomtOVtK3BPjxMEHvnh1h1Hw4mpTWuIsZMU+Cujq2gZDplXCmjh3wnINKhKzYooKn1MR3BagH61QJnO33/Nnf/kXIuptDA83r/n6k1/QuYbNYs3l1RXPP/iQt2/e8h+/eMUf/exnPLm+IilD0ywxtpNiVJ7IwTNNA+Owp2kbrp48xaXIPiW2dzcc+p7F5XOW509wy0tss+Hs7IKnfc8HT9akfsl7711xcX7B9dUF6805xgpQ3p1dol3LcPeWw8M9TJ5wOIgDr8r4MJGTJoVATpGVszijuOhaFlYTVWIKkc/2njFkbvYTjcp8sBCTmc4ZrFIsCjsoJUXKmsY6Cau0MCB9ECDPNBqbEqZVYBTDqBgnhQ+KMIHvE6uF4qzVXCwMV5uGaZzYb0dcY1ldnXP+5Iqf/UjzxZev+fWvP+cQYR/AdB2ms7y6H3h53/Nm67nZebZTYucTuylw8IEQEjFFWqNxWnHeKa4XmrXSdFqx6TKNy7z1mX0xXhXp8ERENLB0yry83ZITnHcd1hhpHXWa20NP7yM3B00fhHnoHFyuNVplbnayv1dg9btyHMWLT/dEhdZ2/v3jPOeYjMtSJr+TWKoAvapmYJRwroiJl1woFfZv/ZCaK1XZEYyslRXoqS38uhTtauHP+4EYRgFnUyjaTGEmW1RmUggTKIMxrbCprBibpFxy2qSKE3sBy+u9Keuq6FfVbqIsg0BljHYoZXDGEdLEwd9yN7zkVzf/jt5vyTmy7tb88fd/ztnyij9+7w9IUXF798DDfssvv/wl0zjy8uYV0xTJTtM0lrOLRs4hygns+oGH3YGH+y1TH2j1GVPcsts9sDnvcE0gxJ67m1tIDmLHcOUBw3bb89mnL2k6+P5H73N2scQz8puXX/Drzz/DKcf3f3DOxx9f89GHz/n088/57MtX5KzFuKmxdG3Lh90LctZcXzSsl46r9YaLdSOtqONE6COH4UAaJ3SKPL9aEVNLY1coDNvxS+4OEmcL4HyBtS3L5Uq6DYyA+4vmiqU7wxnZF8ZxS86JGEdi8uymt4xxx+3wJVEFFsszco7c7z/H+wNn7QvS8jmXm48wWsDAU4HuY2Q3AxhkElM4FFyioAzalILhCaCqTQHE5DD62A5skhbtJ/LRibFiI/OXvgNq5m8Hn/5LHUew+G8PPv3OwNMpggy/HUmrCPe30bJyCXIEVJGfParInXzO6S9zCXpmrSUqKS3PgmynXzKn0qUN7vj7d9CgCtjMn1ivbYbC59fN62ZBph/JKtV/l3+cmBPJ6jJf5FGb4/Qyj2vuuzelfOqRviCfrx6f5/GeleD+9GMKsBdjZBpHcs4YZ7m4vOIP/vCPmLLm7d0dt3f3vH17wzh53t7v8TFI9UbwIdZtw6pzWK1ZLQxGOawFbTRBwyFHBj8RVKRJGofBZIXNxUaYiCKhCzsnZKmELYy43TSTn8WFVQblfRksgv5HhIbc+4BPiam1WGu4XAtw9PL1A/v9wN1+YD96EQgu9yXlxOgDk/cEL8CRtYqQM18OBxbeMmUHuQi7a6GkzsOkuF1V4FNpjbaaZgp0XuxIVIhSDQmR7DPJJMYx0geIYyQeJqYGvMu8nia+9oG9MgwGdKtZrhuazmAbTRhHboaBvh+ZJs9ys+Gj9SV/+PM/5MUHH/Dh9z7i/OIKpQ2TD8e5eYJ5n+DwJ9BSWQhz/sY6UTGodwGr78LxqPpQ/mQQ3bcESeWjyyVlUS9tZDFG0dbwwtTTMAORqYzlxLEqV3V3YpZAtj6RWiUNIUIe5zncDUumcaRpJ0KoYuJxpnnndPxcqs5A0XRKSdgeWktQ3zbNzMKqLlEqKEKKYC0pQ2Oljco60f9YX5wJuJIjYRoZH2457B5A6bnqnr0nTqJ+6v00B3VaGUzTYKYRf9gy7feEYSf3LMZiySDtaNFPpChAlVLw+s1rum7BcnMOKIL3QGJwDS4lbNdJ+1jtRysrPgpyivgxMg0DY2HgkDN+GvB94O7uljdv3vIwBYYpkpWIzwpwaLAEXNyTfQKCAOK2wTiHLXokKUl7tWDP6qQiBK1zNM7hnKxBNfitYN+8Fb8zxx6t+Sc/rwzD2tNff1nibvm8GkDP+9Sx1RryXAg6HemifyAtjBnRMiPJM9EUlzMFuQh0g2LygWwsPib6vme3vefh9i277T3D0MscKGNOnxh6PGbIlHOYgxLmBaYQX9CUVpUYSTGz2+9JKfHwcIs2hsVmA0peX8enUnqeB2E8kGMgTgcgEQZHMpbcrGYWzHftkFizJi9lLjyKFWZO2PFHcxXqOB4TlUWWC+OggoZ1/B3H1cm3U/UtTREMzrlouwXRYjqasYguSa3Ylu570X3XzM/VaIXRtaqb8Qke+shhSgxF36m1Ar5OPjJoRSzucFZB1mDLh47FybVrLYbMFBQJVVpkYeUsQSneItogAYNVRhg5CnxIRXMoEVXGGLm/wuqSDMAARzcjZve56uqZc6bve/qYuB1G+u0tu+0Wu16y2LSoOLB/uGcf4DAl/DggfBiPYUCngRwnQTVK+5G1hqkfGQeRKMg54dqWhYKm6zDWEoKwrayznG3W/PCjD7hYOy4vn7NcbdisN6K3WfY9rTXOKCYl7LXFcsVqc8YWyEVbK0RhU1pjWBXx9FXjsFrxJsJ+SrzqAz4mFhmUgdZYOivtiLqO0lIMlfWwrGFawPSQMiGWP4VtqqjjQs16hcJ8L/pIWcwV4lxAyXifGLMAq19tPb++9xxCZu8zykW0nbjZT9zsJu77wEMf8UnYgg0ZY+ScFIbWCHi2aYQFv9SaVlFa5TLKp1lvLCOF97pHaaQVTylF28g88b6cY4QxKIYAYwBtMidqJcyGRidT9rtxfHtSKuvNSS7ziElxZAZVB7mUjs7EwgCixLLyHce86lEQy9zSNhfpMykFgs+z+VTwI8GPc3SYchSDlShyBqm071VRcnKJ/3KQ9SBKnJfSJKxF5dBZiQRGdbTMNcc8jQtqglGf/UlnDeJarHMURnyOON2xcGc8WX/M6Hek7OlcA6ljmjKv7l6isiFHReM0Hzx5n1YvePnige225/WbHcolbBcwRmEMhCkz7CMhBmIIOGd5+uxCwNHxgHOG4TBy2E1sHzxd27BeCFvdhzgXWVfdkqfPV2gLd9t7tvs9+8PEs8sl12fnNI3DT54YEjlC2zU0bcNmtaTrWlLWkDUXZw3rpaVtBHQLk2I8ZOLhgGYkh47WGjbL52IShLD7D8NOriF5MpSimJF2cEVhzgf6cUvwAcNvcLoWzmQ+phzp45Yp9oS6zocIJBQWoxu6Zo2zHbk8e+rzPA3+ZuD0OO6P4zsdx+ssqvDbWtjKXl/AJ7QArFExi+rP2/Usr3IyweZPeDTafgsQ9Tfne9+I7R5d198e3vqdgSexJKcI5zEDPMd7XhKkE77zI7ZOLuJ5tTJcFh39DpD1OHiui1IqiwG16VdYRRytq09R75meXy2cVbHWVrqcF3NyCcIUMlqXc1HzhpLnDaWcS7lgEZo7Qo31tTXkq68XglKeLy6XhbDeg+PNKVerilStPl2cTu9hvXePB/RxsWVGyPL8epkMMUzs/YhrGkLwvPfiA37w05/x0Q9/xNOrc/7sf/23/A//6l/RDyM3D3tqi9nSKRZO8eHzc1482bBebXi6WTIkx5ThMEYGHzn4CT9lTJSeZaMblDb4XoIFnYJUwMuMmZQlKUVndEF01ZwMKYAoE7tiIENMhJx5mALGan72g2su1x0/eX5OmAL/z//xL3hzv+eLt1symfNFCwoGPxFjZjcMWKPoh4m2tSwXlt0Y+V/evKFRhqeLJbr0bBd6wfy8VE6o5ElZEVHFNY7yvAw6J3QKs+iotEBkUvBkH1ndHdggFHUay+d3W7489LSdo2kt7YXl/bM1K6votOIvf/U1n311y24KjCHzT//pf8vv/fQn/PN/9s/56U9+jykZYoK721v6fhANiBNM9RvLQLUInGfKcTmqoOvxP5QwuL5DxzzdTqitgDh0qiJUS6apFbNiwxxiIoQgrmfeE8YJYy3ROmLwTOOANRZcBcWZA9EQxSpcjuP9jWHCMzFNE0N/wFhbEghH2y4EHA1BRGD9ND+pGoDlMJKCL38CzrVY51gtlyy6jq5tccbOQpS7ccDHQDIi8r86u6BpWy7Oz+nalssnT8RZr2uYxh5/2PH25VfcvH0tQFjfE5oDw26LNpah78k5YaxFa4txlhQ8YXuD390TD3siCm86AXBJQkP3E9PYc3dzx25/IIbI1dUlP/lJKy4ih5Gpb4lTYHl+QXd2RkymtC2K4L9SkpAEPzEMBw7bLbu7W3LyaAX7/Y7t3Vs++/RTfvmrT0iuI7kO7zNDP9GRaVYbVnbHBTum5ImhpXWGdnlOt1zRLVoO+x1+8nRkaUVUVUxSVtb1csFq0bHqxBUveF8SYhljNQ54d7hB2XvmgLk+21LVPcn3FTzSSaxAEmXfnHUVc0aRCvh8DDFUcWU02mCtJWdhzZEDIUWMkjYkbUSQO6EIWYslsx0YfOD27oa3X3/B6y8/ZRwnhnEstsWO2Syi7KW1he6Re2ZdjDi2olhVCExFHN57AWjfvr3h3mhWqzWHwwOubVhPPSF4GePWlSKTksC/v4UwkHavIEwEghQ4uquitfjdOVIWkDyqqnMpsgK1B+/dwBLgJOzgtOoPFCZnMRCoQTkFiM/5pDpfPqjGLchXNgV0TEkx+sx+CIR4bPetcaFSwhJZdMd4xkTQUVqMclI4J/otKWeGmLjZJ6aQsVYYfucLS7Zws5vYD4HBQ8rSfme0omuFcTgcJoLKnK87rFG8ug8idh4DGsWT1ZIYE7/RDT7DpFqccnRWXJV7L/po+9I2RpEbaxtXwDaN9ydW6iW2qkBJqx0qZ3bbLduHLS+/+AKmATU+sLLnPF0tOYR7vv584IDjgQbf72gZaXLGZY+O9zBtIRnQFucauq7l4f6e+zdviMOOGCcWmw2b9glueY5pGvp+5HAYWLQNZ+894fvvb3AqgluTdcuULQEthg4hY3LCIcwwp+Hy6VPGaaJ/9RWm3zPc3jH5gO1anLO8f7lk2ViuFg0hJl4O97zZB/7ipifGzA9WDtsa1l3D0ioB8BCNOVXAIgSzFKt2J0DeFEQTrJ8io0+kqNBZsbCaEBNWKwGFrCGXuGqKiX6MYhiRRadmt5u4HTIvD5E//3TH//yrHb1P7KeyZ6aID+BDJqAIGVatYtForhrNxmg6a3BG0ZqM1YlGS1zaKgE5cZA0qBF8kpQxq4yPER8UOmls1mxWjsZpGifj3z8IA3rwmt0EDyOMKXPZCqleppzMBSoY87dM4v7rP46F9hn8zpKvVfBNOgpkLUoFVapMp5QEfBGtJwM6SctXjWlP1itVWu5m86lKgpiLs5CmiZCEkR6iLwYtot+UYyjaTIXWRkJhClOlSCikSM6BmH0ZWz0peTHF0BqbOpQ27A/3BD9itUMrQ2NXYrJSMkSjGsk3Zga0qdknVcw8cTTiWDdXLNwZjV0R00RMe1ISzamHfs9fvf0TGuP46PoHnK3O+Ycf/X0edg8srOLzl2/4l3/yF2gXcGfQdLA+y+zvMw/byOQH/DiyWrVcP/8+2/4tL28DOUdu3mx5/WrPV1+NvP98wwfvXWBdy6H3TJMUQZ9cbfj5H3zErz79lF98+htevdny8DDxw+9t+PGPP8IPkYcHYVQRLJfnZ1w9OWO97ujaRiZXVlyeNywXYhigMgxb2N4GhsMbUkg8e/I9zlYX/PDFT1gvzhj8PT6ObIe3THEghB0xeya/J+bAFLzAO9kSk+L17lNSVPzG/xKtDGerNc5ZVpslSgubM6Y0dwYQB7TStHZB68653HxAY1dFo6nqlMkYJ1cQSAgZZeRXKjtVJkAKPkekfQbk615b4aiCY0heDBZFNhCSKhqe4uZa2/BOQc1vW0H+f7eq1B3/dz/+Vq52c0Jbbt4MW0MRyi7svXo6+Sg6/q76u4i8KfKJEO7p77/J4Hr0weIcVyp0qtzx07a6GVySN1DtLdXp91QnHXWCNp++7+RJyeAtJ5VOgaEKcp6oOJ287/RhS16rHr338bXV5KUuwrWK/hhwmvOTGbA6+TZ1AiXUm3jS3phiKgK6FjtObNZn/OSnv1fOS3N7t+Xm7oEQhH7qDDgDyiTe7gL7cU/rJnGE05opRHyoImiZWHAbcUSSel5WImx6FPAGpwJZKWxx3aJUInMqG6+KBUHRJbgWmv+ZFWq+JROmiV9/8ZZxnLh52LPvRxFwRKpfgETKWTa60Qdudz3L4LhoFpAT1gRSTtxPYv9eneVUkopDFFsd8omlvUpyLTVo0GRsLkwAY+R9ORNiIMSJoc8c8LjW4VqLHw8YAmnyTAGxYQ+ehyyBWh+gXa1576OnrM/O+KOf/zE/+MH3Wa3P8UH0CXxMxVEsn4yJCo6W8fKNleYkmSivO06x4/h/xFT4DhyprFPqeIGFlVhbnDK6JFaKAhrk4njmPVNh+Zy6pVRmU3UVS4XhVGnbMYp7XK3wPk4KMzkmYo7EmGa6bWV0hBjwwTNNI+WMSUU4WipwAd1omqZldXFBu1xxeXHJcrGga1usMTOtfOGnwnhyKG1Zn53RtC1nmw1t07I5P8M1jm7REfyK733/BywXCwbv57ZTKcglUAltJQhbLBai8WMdzhguri9wJpLDninBqAyZ4vCXwQ8HcvQza3IcevpDx+EwFHBEErxpmnDFnU764BtJXpIkokqZeY0W5lYD2UAyPMTI7uGeFEY6pwlG4bWIOU5jpm0k2DdaGKtNtyIvLlhuzlmu17RtI+La1lLZtSFEVHmOZMoaIUwEqcxWkFYd94f8ePZUsf/6w7maW5LXyk7LBbw6dsIWg4NZY7AWXQqTYC72RGrLgKLSuOsYPYJCNfoXplKa98wYIz6Jy9Iweg7esxt6tvsd+/2O4bAnpiP7q+pakU+KNOV6qpFBll+XYEjNgdcRWysrlpYCkswh6PsDjbPst3cScClNdJIAa4U8ixxRww3EEXW4gThB8qIFMQ3wXQSegJBq9bPEPTnNY2SG9k7u83FlPy0wiKh9LOCTUqAt8r4aZ2SFojCP6wOrRy6xUpKgV2j/wm2UsXxkhFSgNZULqEUkKe4UMxcFSmfpLoHibAmNkflOluu+PXiMUvRB2nBzUhidyVlaLXMR7q2xntZgMtKqbGAq7YmpFOZMmcdt0wiQPmjZB2pyEDJBKbSQj0i2OOvN90nuZVYS9IcUMVnRug6zSjRPr9Bhjx0jzy8di2YiIKjb0jiWLtL5l2y//ku+vtf4N5qvPvs1u9vPWa2fs948x3UrslmIBtPhjvHhNdP+hs3ZOe16RY570rAg6AVRN6i+J+GJTBgCL3dfsxsz7eYS2y5YOIvVis/uXgvT0A9E7+m6lqunT3hz2BFS5pDviDHQqg5XYiJjDDFncaULiT4kYu0MUkUgmXyMb8vaMDt+qRqTH/9UpkcqwMEMfOaiVZdPikbzaJbXOK1oWkdOibd3O359O/Lvvu55dbtjP0SMylxYkX82GKZQdJQK8L10iqXTrK1mZTTOCIDotBhaWK2wStEUQX5vwAskgC+sd2mFKcB/0TANUYNK+ChxRe8TY5KxbrWaC9Fz+lSuaZaXf9SS9nf/OLYEVVZSibISoNTRdKK8Tvb14ujGcb8x5jQHqlp/zEWPVIgRR7HxasAUZ5Z4velVR1OY5aLZVF3NcorvrJ6alCMpeVIeSQRinMg5EJIwkUIYSCmgkhL9qCixTD8dCFGE8CU/PsPqBqVaFIZIX+ZAlYc5OrdqbNG3FfFzORMDyrJ2FyXuPCfliI8TndlxWB7IyXO7e8vgexrnSDHz9MlTtG35+c4zxZ5JPZC1tPJmMsu1oVtpXAPLlePiyRn5duDlrWY8jGzvt+zuBjHy0oau62Q9iAHXwNmlQ9vMftdz2I0M955WNzy/vmDRNGJYEyVvXhRCgGsyIe7p+yiFuyi5VNMsMKZBa2lV9VNmGBLBA8nQ2jOWzRVWbzBqRaMVhonUOrrkCWlPToGp2ZOyZ/S9xNlZQGgVewGWtIwiYyPKKFKWxezo16Hn56+1xZkFziywpsUYW7baXLRTa95e8Yij6+48Hue46BgBlR9QB5tofZ0Kgzwe63VZKKZ3soYaiMWoBnLJOU7m33EifvsEfReMmKGId14/n6d69J//ucfvDDyZEze5VIJV+bloOGlTAuFqbVn+BH9cMB4hebWl6aQS94gxNQuW1oD+qK1UAabKMdKFmlsXthO86eTvGo6p2WUAyqMVNcyyGaZHvzv9mAo61U8rFzYH13NFMZ4OtPL6DNVGW7/zsKvQXoyPbUCrVMU3gKeSpMyWu8W5LzPvZPJMinpIUsfzjSkTB7HNHfuJq4trPvw//XP+8O/9Mf/Hf/xP+PQ3n/GrX/2a/WHPfr+Xvv+Y+eUnn/DXn35O9luyH1kvpH+9WipTgtQamKkiSKmL40O7FhtJUyrltlRtdbn3UxYWT8riXmNsQZNpAI1DnvH1uqUxCotn2PX8yV9/ze4wst8LAr1eNlACVBTYGryGxGGY+M3LW85WLaulQZNYdZ7eJ14e9hhtWCwaOS8EdJrGMPeMa6NxVpwSxSEsMfmIKe46WhtMKmLDKjPEQB8D5uEBfRvZdI6zriHEwEIFhv2BQ9/zsBvZH0bu+sR+ynzw4fs8ff8F/5d/9s/447/3h3z4/R9xdf2M+/sHbu/3jONQet5Pxhxq1iJWxeHsUcNJTUjyNxe9Y1Iqc6CCyN+VIwJkAZcUqvb7lg1GGE4RJYwCQCUBncZhwHvPoe8L+7G0+xSKdkwJpSIp6cJy8sJkKi2t5FxakkrbQNk/KhgQY5ipxwqN0Y6cMt5PDEPPod+LGH7OUo1LER+E+deszjDdkqcffszZ1VOur69ZLVe0jcMYMyeSIUVSztimwVjLerWiaRqWiwWugCzaaJarhWx84R/z5vVrbrYHHh4eUI0jW8gqgc40XYu1lsvrJzRtx2J9Qf/wlv3nH/PwpkENbzj4zCE1xAjTMKLyRBoPdE7z/GJNCJH77RajNW9vHlitVlxdXRNjoh96zNDgxx6lwDXiGEgCrSzVLzUl0NbRrtaSfOdE+Pw3vH35JXmauN407LPlkBS9H+nDnrVpaRetrD1Ae/4M9+RjLp59yOWTp7QqYFUkpw5tDDFDmKbjQNHSetM2ltYZFKX1kZM94lGSXgNHanWixBxHUEiKM3Vfffz+rKSV0mQ1B9xH8UnKe6UVNKckzjxKWkJkn5MbFwnHQkwuQu2pgAIxMEVpSTyMgbv9jpv9gTf397x885rdzVu2tze4RYftuiImfhxfpyDsEXyac8oi5Fwvu9jUU3fjPIsNV+2n7cMD0Y+sliumw5Y8DbRtR1P0Dmwc0dnj/C06jpjpHqInlyDaF8fD79IxG9rEOAuN5yQJrzqJSI9RyzsB0DxmNDkrQpDWJh8Fo7O1kp8lptAYdGl9UOV51jtagfkUYJwyofZIlScbSfgsGo5ZFV2KeBzUKZ6MYy2gkC6CzSpCa2UvbZ0k6iHB6DOv7nt8SLSNgAKdlVYmrcq56yi6KklYdzLHE40DqzO7NDGlRFQJlKYxhs461ssFKUfuhwN4YeDllPCjpMReazAJ1Ql4MQtiUwEVaQkchkSzUlwsz1mdnXH1wSU23tFMDmc8XbMjGo0JmstFw/ubjvPhL/n633/G51FkAD5/dcfrr25Y/fif8PTpH7PYPCG7S8I44m8/Z/v1L9i+/g3Ne0/ZXF8S9QKvWsblB/j2mmn/BjNtyX4gBs+/+A9/za9f3fHDn/2c66fP+fF7TzjrGv7sT/4Vb15/zeXlOYvlkg8//CHXT59wszuQsubNl18wec+F1iycpbEN1him6Ol94GGIbAe5bo2A+dZIi1LKlfkGJDXfJxRH4K4oKFRQMwbR0xK7+UiIfnZyikleryrABWgiS2dYrxp8jPzq81f8y1/e8d//2SvOF46n64YXK81HG8PCOlZO0fvqIpfBZBZa0WlwRloDK3tGl4TTGTBK3BGNhm157iFnxphYGHmvLntPLK03/ZRQXrGf5Px9AWKNhtYVrktVkKjXVSZWLYB/9w5J0JVSxFjXIplfqeQJp6+trVGnRQ5dWllzOuZ3cxwWhREFxxxJa0SOIEZppZsOwiB6ZOCSBORM8ncuLnRaO9GgUqKR6NMDPh4Ywx0+HgoIFZmiJ+bS3pWjgO9K8oaUwRcTCJ22aCIX6SmtWeD0BQpHCJKHamVRyuD0Bq0aOndRvj+LqHgSXUuboVEN6/ZSQCrdlhsRGcIeZ1bc7b/mP3zyL1Bk3tx8zfX5U/7o9/8BP8zw0x/8iFdvX/Mn//7f8DBuebU9YJTm8nnDxRPLcqW4uFrw0fffAzPxy0809zcDv/6Pr5h8JCWwtuVsfU7jGmKcWK4VH3y8wKjAl1+95c1XO7ZfTzx5ccGTj8/pGsew71HJoZLl8nLD0+6cQ/+GQ3/LftuRo2OIoj+KuiDmJUY3mLalPyS2DwGDxmrHun3O5eoDGn2NpqM1azCwaAs6kCcygaQOAjxND4Q4cphuCXGgtW8ISdYXkHVL6UxWgYwhZlfAT4sq1RBrGjp3TtecC2vNOBJjAS/LuONIfAElRSElRIQjjpDn//+2IxU91rpXiz6nFFrTCUlG6+puC0mLVl7IktvPgPbphv1f4fE7A0+nTCU4TvAaBP8N7+SI2p0ggzy+J++6w+UkIJaarWVrEPUtoNwM6tRzK68vlZf6sCvL4ZtneETbK3YzV7VOH2D50WxjfCzhndQWOXmDbCNVgP343RVUO/6n5DbvoKAnp/oI2MonNc3TNhCl3nmjghmIe3xuuSS+3mvGQezez84uefFhpm0XDONAPwzSS58SV0+e8sEHHzL2e6b+gFYJrUrilSM5yqbgowQfVXjPR5lM4xiYpogtTChdbI8reJiziK2hikDclOZqKGiMETG63U5+PoyecQrs+okpRIwVe9SpLPpjlEC0a5rTR8fBe3IPX77dCt0bWVCbnCUmCcUJT2Y7OiVyiKRpklRJF+dEYwTEC7E49iB6O7WtTWXpgfaRINYsMDn8YCXhy8W1hZbl2YrVueVFt8Y0S54+f8rF5TkffPg9zi+vUEoz9AM++LKB88i5rAYt+uQ6j2Z2ZbGrY1TVFtjT0XiS2AIzDfQ7cqRUKIpJNhKtVLkfxb46ZVCRKXj5WRJm4DgV3aVS1VBKFaFnNY+RmBNTEHc5Hzwhhhl0qoeCGXCoZdzKqEkpiA1vSigUMQamcWDoD+z3O6wWLSZjDNpZFquWhW1YXjyhXZ9x/d6HrM8v2Ww2tG0rTosnunc1oDbOobWmK/b0M3ARAzkpplFo3qvVmuAD55eXJMT2vh961sGjjFS7rLXSaghocyDGyOb6BVppdq++RO9H7h4CpEzIIry6bAydU6xtZkiJ+xjxo2e73WOswzUtOkZ86f8ZhxGlDV0UsM9oaZfWWmOsxTXSfpXahrEfGPYHJh/xPtFoWC8sbdS0CWxOqJRYmExroenOce0Vq6cfsnz+Me1yicrCToxJnp8xhhQFVPHeE2PCtRar5HlYawrQEueCwukaO8+usvHkfLK81+ExA03H1wo4fBy7qrSKV7ZRXcozUqgQVp4kPSmG0jKuCzAaOdUTzKcLBsf1QBz6NI21x1Znpcnaomwz20VLyeCorzhf6cxUKOyb03bvOgfLHl1bKo6nchJHoERfxkfG4YAzmqFpyX4AI85ipEEMKsID5AkVB1SOgMzRGNI3XAj/rh8lbwd1Kk1wZModaUl1B6h/zZCffE5p1atr15GJVJ6Bljbydxsmj2dxfOZKZbQWfRyj1RHILEBTDInoI5MI9TArk2VpLZGQRVOalh7tZdTAubBoSGJFDxpnS5FRFYe58rYUFSrB9uCxVrN0wmpqCst6yImpMFWkDBDJeBHSJs97oOj9aGwpKdeuuhCjMM9suRIje0CMFI2ihCFybgdWDZy3AT9G+j5ziJlbn9lNiUPIuNFzazK70fNm2zP6yDAFdvuBwxhR8cCGG9p0jwo7OhvZrBrYLLF+g2sMIXl8hJg9epXoGst0e2C6v2G/vafve7748mu+eLPl/PkddrHCTxuShS++fs2nn37Bs33PZrPm+tn3sO1S2HQUsLjGknOsUO+RaE+ZyuKdY2yF+E0dmdOoPAPQMWemIG2UNbzQBUyWdU3ho9i878ckIFGNa8rfKNHgHHzCKMUyVct50dw0znC5MPzw3PB8aXixMrNeVGMyi4qUaUWjFE6psqfUKzyekyvjuinxgiFjYq5iDBhVGVECYqYQiIBPsn/lMkfq3DU6H/XOUp3DCHCa62qpjnPgO3IIIKRmEwpdxJWPuYoqv6/EBsrfZdydxjGlOJMrUJSE9Z9K29xRf01GYQWkYvTEUIuB8SiNUtjqFMC9lAdLQceTGckqMfg7xrBnijti6kVovBowFIBBaUcW6WeUkZK/LBFZ2sviBM5izBJn1mjVQJbPimkip8QU9uSs6ac7tGpo3EY6Rwq5Q1EdNEMBPOscFSfRVXNJTpn3r35CiAdi7HkYHvjlp3+FNS2NWWFdw4++/wN2457zhzWHvuft7R3jENnuBtplzzD0bHc73r6547AfsaYjJA9+KPmmoWkMy5XlMGVQE/f3Ew83W/bbA2hFykGYYKVPte0cjevweWQKIw8PBx62Wxor88J0DYvOYawCouhwlc6BnCLr1RNW3Zqz9SXr5QZtFInwGHtQwhrTiHtnzhHlGpINWLMiphFtHD4O7IZbxNW5aOkZB1qTlZESSlTCukygsiUlhfeR3XBP6xa0bYvREEsRrh5HTCLPSVjN/k//mmOwE/zk1NHu2N1U1eTqZnf8zOqKZ4w4H/qYC3kjVx7BN5aSx1pq6tG5v3vkd35XWf8np/+fffzu4uKPbu7RxraydY6h9ukZzShOuV/vXPRJ0FkD3qT0vICcOsXV11V2klIZXVThVd3daiX4W5Pm05+Wf53gP0eWkzzYY3inHvtjZgrb6OQ7akmwBNyV0l4DukQqYFH51Py4rpErkDTTS/nm/aIkzDOqygkqKlVopR2QZ2FcTsTYTyAJOacsgWHwnv5woOs6Lq+f8ey9F7R/3JQ2sTif583NDXd3t9ze3vGw3XL/sGV32DMOPX6aii28CIxPITINB4KfuH39ksN+x/39A8M40liH0Wa+X0MQYKqxVmj2hcYYSxuZLclQ64SGun2QVrPPvr7Dh8RiIdW41cKRMzzsB3xMjDnSOMO1M1htyFZYT/f7nvt+5O2up3OGq7MFzmjWTgtKPYUiPiqBpwGS96S9tAqlMKCMQRfdlNpW5+cdkmqMKJXlcBSp3ioBz5RpUbqh6VY03YoPXrzH86dP+OmPf8pHH36Pbr2mWXRcnl+wWq4Y+p6bmzdHRpMWN52ZuafrPDo+ZTLFLeN4XtqYGX+ZE1+kH7luu2RKFfu7c8SS6UYSVVeu2tRmrSBFVBYR7pwzKUgVbJqKS93MJLGzmLdSSuZ1jEz+WHWbW5BPjwo4CcpVHoBoCKQwFqq2MEjDNDHsdzzc33F784ZFJzbZi805zXLF6ulzuvMLnr7/EeeXT9hcXNMtV3MALUm4BMigcI0TJt7MkimiiCkSfSAU9lfwE0ZrLs8vWXZL3v/wA0zb8PLtG/I4cHZ5jXGWxVKc/Ia+B3rGcUIrePbx7zNcPsPfvaG9ueHm4VNUinigMZrLdcvSwnUb2cbAyxAY+4FXb24wTUu3WAprLCtQmsNuDxmWiyXOOVwrTC6jNMo1GOuK7bnizcvXbF/fsj94hiFysda8vzHsfGbn4YZEmyLnLrN2iuX1+ywun/Hkx3+fyw9+jF2sIE6MZc1qW9HcSkUevR8GpnFkozdYY3BOxC8zqYji6iPCd5Kg12SmzrXHIBDz7x4Nmczcni7dCBKIKa2FVQxkpYr2g6zfw1CcVVIUgLKqDOqptP/KNn/Kmsrlv3WpqjXWYDTsBif32Diy67CLJd36rJxgOikEVUijJgglIFKPd5vaJlbd0wR3PbKV645J2f9jSEx49g8P5GnEJY9vHMkqnMrkJG3KOh9EuN6mIwtIMQMJ36WjYDdoOwca5X6q0ooka8d8L+foBSq8rsgYldE6gYGcwCdwpY9VK42yoqUmC8nxGdd4qwINwlTLOCOMkNYZxihBegjgPfgpEoeJfVIcYlVP1MJWLnoVdRzW/SiVwFppRSFclavJLBqxP7eSH+AnAZ5imTgxyvu300Bj4Y++t2LdWlI0TCnztj/QxygSAyhQIzEH+qncLyXFnKYxaDKdNuSUGQZPIEtRQWmMs5KgFKBtCsIIn2LCMvJ+88CqU5yvEm/iwGdD5OATd6PEgTHDMHl2faYfI9ve04+w72HTai46jQ53POU3rMJz1PCCTRNoniw5M9cM68QQJobkGacBHzJXRnTnvjo8cPfyM774/Atubu74i1/f8Ou7gfWzD6FZMD47I7vEn//Vb/izf/8f+eijp1xdn/PRD3/GYrlB54RRqayrAmJWPZKc9bxeNFb+FPPlAjgK8BRRpRab53AzImyG/ZTofWH4ZmGiGV2Ap6wYg2I3wpt9IGRmgMdUF2qVmVLifvCQM0ujxGXWGbrOsd60/ODa8U/fd5y3lsuFYYgiXRCytKqLozVS6EwCYCaVZwDUiCknjZVih02gc+aAwuQs54PGKUWjNJ21LJzBTxMxI1pVMIvmV7nMpuSnjQV/sgeYGVTLc0Hhu4Q8TaMYqUhrukYZSl/mkekkgK/sUdU9WphIJyu5qh0pUiwLfppb6IRpF4pm00SOCYqrsPdlP1A1Zzqe22PRb4XCgVKEPBLShM87Qj6wG27p/QMRT0Lc7UgRaZHTNN0Zxrbk7KEU2kBaNxOJ/f3ENBxgscKqK7rmOcY0KPWWEHqmUZhUD/0rYft5h1Yt1+uf0bkNl+v3scoSs4z7kAZZrxg4DhrNZfuCs+YJZ4sL7vuX/OWX/5LXD6/4i1/9JZvlFb//8f+ey4sL/sk/+m8Zp4GXr1/yyedf8P/6/H9iqzwvX9+TteHy6Q2vXr7i17/6DJ07Ft0FiR2HaRDQ2VgWy4brp60AT693fPH5nv/wZ3suLhsurlp8HDkME41V6HbB6qzj7PKCl29esrvd8tXXN7z6+g0Xl5n1Gp6frzm7PKPtIkoHQphQWRP8RAqBZ1fv8/TiBe9df8BmfcHg98Q0yjhCoZB2RV1dktUapRSLxsoypCIpTyzHawb/gOc/4ONQsAfDyhU2t5XYagyGGDPjaFHZELxiUCNv7r9gvbjgvcUPUCqTjWeW3ShFwuMAE5B0xjnqUKZiGMe8Tf7W0l4+v7KuvY/nVJ0jFaBy2qKtQgcjXTilK2KeOvXT3vmg+hnfdrz7WvlZPddvf88x8v1PH78z8PTuydSvronWsWqlHp/Ao/Lt8QGoWlmFWaxxFkgtSZIqFdLj29XJ+3SpsJ4k/PXDT7/y8X/Mp1HBvnzyXlV+KQJ1eU70Hz2EElHnkzfOFcMS2Nff5RmZzJxuKfn0+6BUiEvYWEGndx5hhneS2hK4pcDkB2QhN1KZbrrjRWmNwhaWxVET6HgC8k0heIYRQnAEH2b9mnq/tNGsijXlar3h8nIQ2/Eg+jex0lpTAWJGcZv67K//I7dvX/Hyy8x+C23TYozhMFXxz0QAVNERcK5BK10sTFPZTMS+FyXgSEqZq/WCnDNt60pypUk5E4IjpcQSg7OahRWGR7IGa1MJcMWhAqU4jAGt4DCWypYq48xocUUs469ZrIvl/TGoz/nk2c7jTs17gfSep/m17WJBt+xYLNYsFmuWqw3dYs2zp9dcXV7y/Nlzrq6u8DkTEKedcZiEVfUtC8Hpxo0qVbY6tlT9v5PTqsysIsyfvmVuQJmbfwMS/nftmNeQkp1WhzC0VMlRpWWlaE3I/U4zsFfZJkdx3kiMCu/9vG6JxtNJq+zJgj4zoOprk+gJpBTw04Gh3zL0O4ZhT4gBtKZZLlnFKzbnl6xWZ6wvLlmsNiwvr2g3Gy4ur1iu1jTOlspakmsp43Guuxar3lTW1FAqgykUFlctjaRM1BqjxSVpuViyXq14/fYNPgbGg7T97ZvS3x/EPYS+lwDLWRKGs/d+gFldsQ2GYRy53w9YDedLjVOJjEd1juVFh7ItzXJF49p5ntjCzKrg/3wX63KmJHHQCLiry7yLIWCbBcvLZ3QrhVsrViljY8ZOieWUWK5WLJYLuqv3cRfXJNsxBc+030F/EB2vlMgobEykrGagJOaEMRrnbGFfaSjtYUd+iDo+b05AmdMKB1Btlmtl6rhPlM2dR6s0VY8wneo6lTGmjBbx8DIGFbLuqMKGqq1vNWkEVdpJFBhpA7UFALAZzlZLQrrExO/htGb35mu26w399p5hey8ssBCprXK1XnIKux0LHCdr5QzGwdHpKnN8ZwEQsrBMJ+8xWtH3PSl4lFV4nYlqxBCIBAwRHyuzQO7NeAq2f0cOSWRUDY1OglZNRh8HS+Yx22uOUeSPtJCX11FAQClpcXxexyT8NBmWP+XpalAF9K3Mo5iF+XO9dPzeU8PDyrE7NEQjurEh1j8ZUWmQMVxBtXfCbVKSc5mLJGVfBY7V3AxVC6aud41StFpx3jWsWstdLy1P05SYvACn2oDrNNZpAZdTaT+MmXGSdkZtyyw0Et2Ju53CxGO8VqYlOYmGiw+em4c7tofM24fE7W7kqxtPKO2HKSVCSCSryE4xes0ULRFpN2waw2Jh6Ycdn371G7xdMISJtHtLOtzSaU+3sEwThGDoo2aImguzwDlHVNCnwJAiU4poA22jcdZijJvniNYZ4+TastJzm37MpbXtUYGYksidZuzzb8t/yz1qjKI1RfahOB5matyuioum7MUxZbZDFPfCMh5r4WyItRNNtJEaJ20lg4e7IfGbB8+miWzHQOMMi8YSYuLpwnC10Jx1llWj6RpNmBLEhCnAYmXoxVTGLXJ9VSmtMp60ku+si7HVApq2NtJZcEWLzBaAqcZgCYl/q9xBXdsFRCufXe9eLmlzBZ/m+/vdWr9m/cGidaTIpTNAbobU4kTbpjq11jZ02Y9P8q0CPPlpLMCTL7lKYclEX+K4VJL+436qjgtM+Ux9zLVUJuaptNAdCKnH556QB0KOoGxh32mRSEi1e8NKIVKLML5EknINIYykGGj1GU2zprXnOLtBYSArjFqgjGHhnmP1QO89Ke8Y4g0pPaD3HY1do1TGmQ6jGnGkbJoiZaKpRiNk5hZAnVtafc7Tsx+wcHf4MWNtw23/lmQnVrcOlRVWOy7WZ/zsB9/HNS1n647GaYbDyNR74lQYgB0sVxa7XHJ5uWSzWdO2jpQju93E118ceLifpGDmEnYVocnEosG5XGxIKbHd3eOHiRwVC3fG+dKwXi3oVg1N53CNtLellJj8RAoyD6xtWLQrlssNxgoB4bHOZCXAVHxAzX5KuuxhCo1RjlX7FOdW7Pyewe/Y9m/wIaHwmChu7AqRedcKmeBZjAaUDhyGWyBx6K9w2uHMgmp+llQkMJUxf5J75TzLbABUV9dvEHGOMwZ4bJRWXzPvhTWCyhLtF8k0jAFbqn/p0fvfYdLPe2l+9P3/qdhpBqu+8bIS4f0WIOvd428FPJ2eWN2IYoxHAIeiBaVUVRfiKL56RPqqHfOsc1FcoFAloClMnsp4Omoe6XkTrBMu6zz3+p7cA06+9BvHY9T75IWqbrSlblgS0epY9eiz1elDq20gNTEti+1sp/74e+vnSQypatT0eGX8lvsui3eZYAXuCmFk//BKgp+ssIs1i6vnVHc2VVpDcvRzy1AFSk7p1NM0Mow9FDnG472QQNM5x2qz4eLqSuytK+tGSbBbUhm0daKP4kein/izf/Uv+OKTX/BLM3H7OrFcLjHW8uVtz3YI7H1iShHrWpwzLLs1Rhv8OBBC4Hb3wBQ8vRfQbOUcrbV8/OSM1hiUEVHQnQ+ElGmKy6FVEas1y64DbQi2IafMumuJIbDve3xM3O1lwfTRo5WiMwZrNMtGtHzC5OmWKy6ePKVdrlifXxJDYBpH5tSpBOKVih4l1pnFX421WOt4+uyaZ8+f8OzJU549ecLZ5oLN5ozNcs1ysSxE3cyXr99w8/BA30+kSRyo6j59GvNVF8STx8iporiIs5YFpYKiyBzNJ5N2fs7lc3UBdb8rh/Tf14p65QRokikJeRWdiHHWDJhZiDAHFqpQK0IUHbK5hTa/G6wranngEVCQi9hlDKQwkuLAcHDsHgzL1Zrleo0PE8o6ludXuM05T97/iMsn73Fx9YT12TntckXTdTijsRWEL7TzjFzkaaKvsjzvVNamKYjFb/TS3mcRGneY12Rh3Jyfi3Dlp59+wjSNHO5v8P2eHKKwEI0IcI9Dj9Ga87NLGtfw7Kf/AD8eaC+eMBx23L5+DcnjtLjxHXY7tLNcLFdobWnsguVyjZ8C2hqatiuixtL6qlCyaack11LAFlXtcBBR1zh5muUZVx/8mM0CuqViqRNaZwKOqCzRrEh2weLymmZzQWws+6FnGkaCD7J2FZtg5xzWiTNnTJGYE9ZZuqJxpYteDrkIoZ5gS5ladDjdN+rGXsR0c91bjgWO+gl1HlL+TjmJcCk1wCwVL60xWNq2FYA+16SujHfvhUqeU3HcLGwoXZMwIxo7qbq+Qtdd8OTqghfP3uP7P/wZL7/6jC8//4RXn/ySV7/+BVO/J0z70l58BAh12cbmALBU/ub7gaLuesc2sVNgscQTRZeqHwZSDOiccNbgrcLpTGcDRidaFaTduzqfli+LhTn4XTrqng9QomzRqlG1NaTe48fhzjFUkTFqi3ahytLuFLPoh5FPDF4ogtk6k3T+hjB+Bb20kSJMVgqfwUcBVT666Pjp+x0Pg2c7BfqQGFPi/hDZjZHX24n7gycRSWQMUqueAS5V22SERXNcVo8OQnXc1D0RsuhF5UxnFCtneLZesOwct75n8onDITL6iEXMSbqNpbWaNIhI9jQlvE/shohWmdxladOycq1tI7podkTIqmVNT+KdgNGKcRr57NUX+JjZTZHdAG+3iraB9VKTpojvPX1j6ZeOmC0RSWjbFlYrx8V5w932hj/7D5/yxcvf8PRX/xqnpPXvJx+/4OMXz9j3LX6EXVzwEFteuAu6psMD2+jZp8CBSNNpNtnRdS1N00HWpJixDTQL0I1FOSeOlgnR8yxrCznNsbDE60bcSYurpLQoVYVbYREvrGbpajsQ7GOWIk9pkW6twWkZf1OIvNpNhCzMu1TW9pxh7zNoMSpSBhadCN3vx8wYAm+HwMoqLpzivLM8XTV4H/jBxvDB2nG1snROs2g0Q0rkKWC0whphajmjmHJiSpmQtbBstZHrkBlQtEvzDCM441gYw6rJrFpFY0S43lnRuBLwShNyImRmYf5KdHYF3zXFgbgWq2vL4u+Wrv1dPOTKQgjUtiKdjzkc2aBUEuH9cpzmhdJqddLFAdLmXzWbQpj32pRELJx8/N4jQ+M0t6qBdFk/kUL7FA/4dGAM90xxh0+BmIOATrop7ViJ4HtiDji9wNoGbc3sDKuyKgysxDg8kLxnbd+nbTas2vdp3Bkg66/Va9CK1r5HTLJWJt6w879gmLY8HF7h9JLJ93T2jHXzFOc61uYCq0SHSvaGCtb0ov0XOpbG8YOn/4j9+BatM4dxx9cPn3I7dBzSgU274cPzF7x3/Yxn1+eMYWI39KANu/s9/XYiDgrbgXGZ1aphc2H54P1Lnjy5xjkxunn7es8v/uKO3VYRs0K1EXflUdYQlaHtllyePeXu8Iqb7SvCoMAbzrvnrK4d9rLHrj3LdUvbNagcSDEwhD2qsCy7ZsFmfcn55hrrHFllrHFkbSTX5sj+0VUbbM5dY3neGq0aLpYfC/NUrdkNd7x5+J+Zwp4h9litWKcWqzWLRlx0XSOLkJA8Jm63XzBOW5Zuxaq74NnF9yVGS5O0I6p8jO8yc9z/KJuqSHRto8snQNpp+eUd4EnG87srRRGfz9LGaoqmrE0w+YxPjz/jm3I8p9/5nzqOgNhvY0r9rsfv7mqHnLQU1d9l89TXfPtFzf2JFX0+QdkqEnjaEpSIszD26ZFLhb7+NBXAqT5cYQup+e+aAMxxW/2KXM9DvvDoeFdJ6fL7uTumBjsnwJR8kIAcNSGdL2Gmx2VmRJ2TAPJks5mvPX9zUL2b/Ovy/soIiMETw0T0AylMpGlEj/cEv8XYBtcssc2KbnlFUuLdKgJ7/vRL5hNX79yoGtCqCIEgwWpMaBMwShcqaQkWy2JvSvKWgji1xSBuEs4ZEeVthdlkrVSfmsYRtbSvOCs2msZoWtuRYqCfDkAklMmzaC0LZ7lYtbTWEKp4oy0U74UrPfryDMYAsQiva6vpmgXee0IorlkKQkxkL1WsdedYNYZnZw0xBIbDgbPrCz748Y9Ynz/hyYuPCX6i3+85BfDmSjTHNoha1zfGYq1lc7bi7GzNarlitVzSuI6UFMMUSHkgkohkDocD/X6PXXRY1UjPeGU7nM6KEvTVx1bdpdTJn9PnnNTxuR7HJvMr59w2z+nvd+TIHKkAdSGqYJFU1QsiMK9r9abKY5UARXLihCpMktoJPGME7y7GBVQQYXL57tqCYJzDOU3brmjaFda1KGtZXlzRrNal3UVzfv2E9dkly9WarltgGyeiumTJgGowV0o8qlB1S52wPM8kCVIWNldMsbRhJjCmgGoimJ/Lpa9XK1IILJqGMI70ux2TGbC2wbmGpluglMJYg1aKMPao6Bm0BInN8gxlW1K25BQgj5ATy8tMxHBJJ1o+h56ua+Z7bo2FnCBEalukgCaKnBMheAyVdaTQxmGUghjpmgZ9fsH1kzOePD3DTyN+GvA+4UMW6nbWRD8x7R+IgxEXyiJga2JCazMDS9pIkmCdtP82jaNxIl49A7fzHDptozsygDPHdbTq7cV4EpQwf8zj8VpGVi77QgbUyZ42J745FbZpLb5Ut6+TirGSFnaFrAGPqm9lDlRNQ6n+6uMCoqXtDm3JxXUxJVGlVmXPlAmgxeGpBoBlVtS9v7bWVfD39FAnYHllrvjCyDNK4YwmW2EYTCaiVcJKUw8nlaNyTd+tNmGQJL7cRAmGddWiKZqC5deCwRzHTv15PeZbX+IYXe57LLGN1WpWFTi+54QbW+MUpDXqGMweo4bBR4Y80YfIFBJWgbWK3GoaBTlaGg27KTOGiAUMmYS0ClOS9eqS9o0Tn8H+cnYlKJMhq+ha6FpNDAk/BsYxMPqIQmEKUJpTxgcBOpwtPVDao0yiLVqRch6VMaoISiHkGSXM1ghZXFvKnEjEqInZCTt8pQl5gocDOmtpLbSKxcpgrMI6Sos+5NmVKJFykBbhYLiPI1/c37BymqXVBDQP/cDNGHmYIkldkfUZKn4PoxX3E3y5S9xMin3URO1wTvROqvFLzAi73DmclSKb1g6U/FHKFFbOMeDVpc1XA1rXuF8dH09pgft85wV8aoUh0BhhCTklbNfGKpwFdMYnuOljHbSYIhBsjOIQZE1IWjRLTJ3ZGWltDtL+ZnOms1LcWxpoOsOmEUabMgqsAIfOCuhkC/ikC0peokK5zpmhIP/OKpJVLm36EJE2cFPa8ForouRTARlvh8B+DGynhE/QFBZULOuwMyfnX0Zz1YuSsKEWKdQ7q+Pf7aPrOnLO+KDmvaPqKgmoKcBrqrpXJ3ml7JFx1qOt+1kqbPEj4aAGrUUw4qQScczxatwnbfFSYAuiRZQGYh7xscfHI8spzsLwSsTN1QR4oOR3yqC0pNCZIlqeBcTKOdGqlQhfm3MatZZXpfHIQMaAUmRpRiUzkfFY63A4iJnEyH76kineEcNI6yQO1Kruv8cl3xgrcL6WAmqYMkTHWfucRXPGYr0i5YQPA28PEy8/u2fZNTy5PqPtHFcXl6QMU4auc3RL0VxK2XO+ueSnP3qP68tnnJ+33D3c8OXLr/j6q1vu38h8W20M3crgWhECN6YlpMR+3LMbH9iPtxweMsMOGnWJU4blasnySuNcI4X+IMy1zjYYrVkvNjjl6JoFzrqiEaZmtte8CBUwd9ZIqsynug1mIZDE5FFac7V5xqrbMEwP7IdbXt//NcM04oeBxjjazROJbS2gFEkFslYYm8jqwG78mpB2KJUw2mJ1K4VA61BKxmstlJAreeV0M87zecn4n4VUHs2fPL/8GGtVgkMu437OY1SJpXLp3jGSu8SY53ylToOKZ9RvPMUaHuMO7wK4j1/zbTnP73L8zsDTUdRSjhnwOTk9udFpPhmlpCJWF4GK/J2erCQUVZCwJH8gFb35k8uFpkQuLAKFIoRAiIKki+teEQrMxVVjZiqd/P9JLFPtq+uiNLennCxasljKG2Z9qcJMr6yjuWkwHZOBI0hwTCtUOa+qj0X5vqqpo7I+jgbeHQBygyUJc8ToCdNAGA/EcUcY9vTbV0h0mmi6Davz91idv097/oSYZZGMYSL7U2G9YsmsZpWfYyJV7pG4GCbEUHY+laPmFLV6j7ChjCXHQA6BcRjIMdI4zXLpWC4c2lgap7GTYtE2aKfoWgmC2tbgrGHVLFA5cei3GGKphyjOlg2r1vHsYkFrNbtxotrWG63YtA6rxUFk8JFfvTowCf0IZxVPztZM08Q49bgYaZJhipnUGzqneXLW8mTd8LP3V/hp5P4u8eyj5/z8H/8jrt//Ph///j9kGnq29zfzGJ8n8LzKqeMEh2JHrOfRPHmP9yKOPk2B0fdk+jJaEnd3dzzc39OocxqjUMqB0bNg+zxy5s00S3JZHkyFTMzJOb3Dv3i0PsgzPAaS72TB35njZGYB0jJ3xMpLEjsn5Scif+UeplSse5MvQdMJOHKi/XT8vMKKqvdTi0CyMYrGdTTWslxfsFxe0C7WmLZlff2UbrmhWyxpuwVd19A0zQxiUsGEJO2i2kjyaYw4aIiOl57XID9OwnAqbK4qUD8HbO74virwqZXi+uKS1lo2iwX+sOf1m7dkpbDOCuhkDMZaObec8IctAUUcBoyzdJtrOjLLsydiLuAnrLGsV+dFLF2z397z5a9/JdVCBUZprHNQqpymzGmt5R7nlBjHAZcbYetYYSUZpdExsu46mvMLnv3oh7z30x9zf3PHw+0dw26L3u1gOJCGntDvmQ5bYpYqpW06jGswxhZQ3ElSbxvQmaZpxQlwuaBbtJJQRGGYqgIOVXCpwCsnIFQRQc7VcKGspfMcm6sZ7w7S+Uj5mI7UPelUVyCEUKq9ad6TFEqot0XAWZL6wsotgrY6qeNaP4NgEs4mkniUKQ26KaKbqrTjBGG4GsOsa1iswqu+VK0ln1rQx1zvzvFS58udcRJxRBu8xwdFDB6jFEPRoHKlLfbYnl/uuj7uSf9bq3H/tR2h7K1kSbg7XUCiwgD/tuX6uL4f46jqTydr1tGyPKQkc08pAXFrJSNryPHkc07KcpnSMsfMyEXBdvTs9mF+9abTrJxioQ2x0Swd7CfNFw+R20PEZBmOaX7+An7NIVI6rscUUGBeA8mz9IIyEvutVoZ1owljoJ8i+36in6SQaZSa175xlHhnuRAWA/aAJrFACnSxvC4mT1SKISDgEwU4FqOpMs8y3gd8sPi0oFs4Ls4WpPyAeXWPyRaHoes0q/Y4PkPOTBGmmBmCBiIxJu57uD80HA49h/6O65XicqH59M0dzzYth3BgDCMvnn7E9cV7qPATnNa8PmT+6iZx6BU+GIJpaJoSG+fiZJhAW4trGlpr6KxB6wZUh9ItyjQYVZg5FMa80QLckLG6ulfWZEhYcX1K/PnbgdZqPrhs2DjNx4uGhREB7s7AslF0jQKTGVPmy4eAs4r1EpxVnC1lXG19ZR3JHuVUImaFz1pa3JMSQfeYWTbiXrh2io01XHUaY0E7yBZso1lEg9UCPFW5AbIpCn76cSxUwMRqclOBRZ8TPoO1sGi1MOO1YgiJ3me+3nnu+8Btr5iiorEC7MYSey5bmSNegjQMCgtzO1+a+aBH9uF34Viu1sLYHY7GKTkJK0ykK+y7mHI5TvOghPcivZFikDUpe4nFchVnr2BedZVOx70y1c4bg9IVxsyEPOHjljFsGeMOHydCnCT31BCzGBWZYmgS80BMoxiKkFHGom1LLvpBMU3CNi6MhZW5xOmOpX2KNQvEsXGHQWI0dIvI1k9EJiI9iYG2bVE2MvmBlAbuxl+gsmXHWxbuirPVexjVSO5W1n+FGJ6gIjl4QowM+wiq5cnyh+jW01ztud/d8le/+iu+/uqOP/2Tz3h6dc0/+Pnf43svnvKzH73HFAN3w4HN2YLVuUggxDzy7MkV//gf/mOcM9jG8PWbT/izP/93/OoXD7z5DK4+MDx937E517QLjVMLrFoxxcjN7ob7/hXb8WvevArcvYm8d6W5Oltwdn7J0/c3HLYHxmEkDp4cPO2mEbOAzRV5tWa9PKNx3VFoXUmBQJa2UxBEzSzNU70lcUuPhDjgVMuL649RSnO+vOBm+zWvb37NYX9gf3hgYRdc2/exbYMpjs5BjVCKkJnA7eGAUQ13uy9pzZqzxQu6bsPl+Qsqk0kGmhRMaxfUKR4wvyxnaiF8ThVOMIKTrE1aeMt1SovfEXwS5tdRx7YxmmwUQUu86mtbcz5Or3cjpVNZoONv/8vHU78z8DQLnp5G1Dx+6JWClU9+N+ublOOokyIU+Rpw61ruKmGpfJZU4QWQktdW0ElucmmDOT3RfAJ4n57DTK06BvmnOlPzKVbQ6eSHJWZnTvzySXCPLFAq8+i6T693vmXld/rky94FAOrXnN6rCnLN9z8V/ZliTC2baYLsiWEgjFvi8AD+wLR9y3D/Bt2sMcsLbLOkWWxQKQobSSnIkVMdklxuokJo9+TTa1LzOEwVtJrP93gdAvollEpH9xsjbAJpPbNYK+WrFBMpSBCglQhOzq2BhVaiS0BsrMGWSp01hsZa6amfX5NLXCxPyGipdHZOktUQxWVOqiXHxKjeb6Nq1feInINUOX0IHPqRaRwZxqnejfJ9eX5GchOO6mLaVGBUXhuCtCXEIoyoSOici7uZJxzuGLY3HJyEIZdXlyxWKxFwj2EeHzE+Zj88HmuZVCH3+dHlavLIPLwzBawq9+1b5uzf/aNWwd69pnzcH3I+WTf0vLZUFpu8+siKJB/XsKwoNsHM7BxhIomwszENrm1pFgu6pmHRNTTO0bmGxfqMxfqM8+trzq+uaRcr2k4Eta11GCuBvyoPK5dSRS7tkkY9bgOc19DyDLVciJyn1og0kSUET9Wx8mUD0yUxm5sRjaFbLOgWi+O6LosYOXpEXDuIVkUN0JzDFB0kpRRWSaDXLpZY61ivzwFIUdiQm8tL0UlSAmQoEEaokesb+p6262ibFh8DwyitsdLSKoFhs1jw7IMXGOuwzrE529Bow6ptUesVDYmBzKJriXEzg3KjD0whEnMBd1RZA4wEmtrIfXVGhMxtEWmvDIc6Zk6xRnkCirq251yLNLXF7qidVwOTRxBMmY+naEKdxkrlUrEUodyqLZZBSGKlnSEnhTaSlCdAK0PtjJFAXUE8gk31/msNIStCTgzjyGE4MPmRSAKt0a4BY2b4YYYEjsj7CfBVMKl5T2SG5epVP0Kd5ixP/k4RUMIeiEou0ChF1Mc9MlfQjzI2T/bJ79IR4/E5GZWJyZTneAwS313Z1PxsTrB1gNkhsrYT1eeS3wHhH3/o6WekfAThLUrElVtHzHBzP/H1fmCcROS0azStE0FmrRQ+idD0FDK1kameo1Hq6MunTk7h5FxU0VeqhhHOCUsmlufvc6aPiX2MMl6KhZotWk0+ihZLDjyKfuVThR2jlCpi0IrJyxis5eJTdvNxoCtpHzJAcckNXqEILFuLNZqQMmMo3zTHT3nWGiIl+hFuEgyTnKe4iDYoK8nDw5hJeHwxfjlb7li5Nwz7N4z9G8ZpYEowRpiSYkqq6OckyPKeKWh8SITi/gsS28cYmIJn9IEhJMaYCSU2MiXWylE0bGYWkZXLMeV67qckmnqHwNBonjmNysLQO8TM4MW11BmZ08LaqzpfGWsVMYk9uNaK1uqiR6XwQXEYFVPIHKZENplWQWc0T5YNNgZcTLROdK20EYcqtDiUlogfrUWCoAUyGp8VISmqoZEytdX5OH/Q8NBHHnzkfkjsp0w0Gas1RktusTQZ3cJ+hClkBi/ft2lEAyok0aOeoqxZWiMAWcW53p1o35FDKYNG4VwrAuK5aGROEzlngh/LC+d3vPPfnBRtxEX7BI0+KfRxkrsdYyXZ40TMXDDrRMyTMJzSgZD3RPwREFDMGm6p/AnJQ0jENIrbXcp1MxWdKSWgxhR6QvQ0LDA0tHpNo1cYLe2EVJfDYughTEPYDl8yhgcehk8Ywj0pBTSOzqwk/rACkjuWNKYVoCoNxLgkZ1NizQK7aY3RhqSjgFA5EiYBLPK9Bb/ganMNoeFHPxZA/ss3XxLywGppWa6XXFyf8fTJJX/4+z/i7v6Bl69eceh3/PWvPuHpkyu+98H7rLoVl+eXnF0GFtf3LM9hudacb1Y8PdtAbCF1OGvIRLSxOLeg6QLdMtCdGRYXsFhZFm3H4eGAnzzJe4heTAxMA6Yl5xYo61iJy09Ft08LTe/WnOrvtBaGUJXAGacD2hgat2S1uODp2fdodEf2E40xZB2IyqCSMOJ9kjGiVSy4hEFlz5QHDuqW/XjPZvmUtlthtcMZhxTRwjHqqZh3PkVZT4JH9S3Ri1JHHdYs4zer2llTx/gxPnyU4pTxZmbAXaGT7DmVsZyPX/OfOL79Bf+5kiy/M/AU4rEHdz6FkwRV4uV3+v/eTWDnCSILCTWxVxRGyOMWBFWSN0UmaeEjqfnbOGE6ffsNqAllKsweARP0HNybYqVYEcOYKoLIHNTVAPmRiPkMGRbgKcbH1znfp2NAfqoDc9Rq+uYx61pVIENRHEYotO9MiKHQOkvNRpXWmzQSh3v628/RSjM6RwyKMCkWly84++APOHv6Mcvzp0VIV5HzUbj69HEpShU7q3ni1GcryXcq96cupuoIYBTNHEUsoFPGGo2zhrYRR6q2GWgmCYhijASfUUlhWGI1xGkUYCxFVM6zs4m045U/1tDC7H4hPflxvo6MBE0Og10uAPDTxORDsWGVKqAE9nJdpqDFNaFR2pCVIoREP0zcPWzx40C/O8zjI9XN7luSRTIigjw3HSvRrkgarRJGZ4REH8lhR5p6xu1L9revcApSyFw/fcrm7Jx9f0BNU8EVMjkImyVHSWgro64ej9g2zLHUcQjP47TOlXIl3zWdlAo0c7pOHMc8pz+pVRNdGB2nvzxZGgTjlLGeZ1FxcdgyxUnMNA3aWuxyzer8kovrZ5xtNlxcXtI1DV3biuD8YsFms2G92eCaBufc/EUiZB6FAJoRxufJKekCqp0CT0kUsaGI3mqtZwpBRjbEYVDEGJm8BIDGRKp+nlaK1lm0sazWG8ZpQumvyCEWoDmRw0SKiuQFBGqaFozBti3GWZwVdxGjDcZYmq7DNi2rzRkxBA67LUppLuN7+GnicNiLfhNl3XeWlCOH3Q4FrNcbQgjsD3tcEOdJ5xralFmsVnz0kx8XLS5Du1rRaoVZdiys5mA1B2tQ1s5AMii2ux2HXqyDh+K+o0oV1jVuZoG1rsFauSajNLlWjnQBu09y9nm45KPWXzphjQrl+nR+Kfmg+RPqwlFnZYFyyhiOKTJMvgThqYixivXv5D0KOSdrE0qbQhwWTSBpaJLxE0++QfZFKQxMMTKlxKE/sNtvGaaBlKMIkbctyjrm9hRq0YPCeDrJxedFOM8trEeN/+OkOwY+J+9PeXYUTEWuNUQZm06Zwr7W83pau35ySeS/CcP83T5i1Ywsd6Oycd4tELxb/Hg0JgtAUmOmau8u74rlHppjEpyBrGaR5PqMMxWoyMSQsUqxbhxKa6yz/MfbkU/ue+62Iw97Ly1PWrFpHAtnWTaazmrRM8lqBpJ0+Y66TQYEkCkdaHMMpkuiH6K8r2sV1mpCSSrGlIgB7oLHaiVcaZ1pnCIqRZoiOoGIC9VsVVrQUCIibi20S02KicMOVEgwpDqw5T6awjTTuTi0GbRVZDwxBsZxQuXA+bIhJNHa8FOm9+XmlrY/yl5iNOwOifuY54JXYy2LzmKNwmvFmyHw9jBBDKicOG9uWbPn8PA5h4drhvHAGBR9FIZWjAIwpxQhBXzwDF4xeNG7SuUZiyNroB89+3Fi56VN8jwmupyxpWA4TopYwLmmUTgr48+UroW3YyABBzLXrebjFrIT59hdSOynwBQjrcvEKEU1o8Ai4t/GKUKQaMhqYUg5B91SwDgUhENkPwRUo1hZxdIaPtx0BD8yDJ6uUSxbRVCGgC2xV57XI6vFWU4p0Ugck2KMVeA6YrSwBmJZt2u68Hb0fLnL3A6JIcBgsrTu6YzRmXMHV07xZp/ZAftJYv6ny8zCwqsBhvJcFApjhYFfnQGP6cQjGOrv/FHJA60x5Jww2hBDoA+BGD1+lDiauXVKPYphoeyhJS/MBUiu9+hUs2Y265iBpwrOa1AWipiFT3vGeEvII5GxEk+KbqF8dFKZrCQf9HEgRIixJycRvVbZlNbVQI4TSQXGacvkRxrd4XTDYnnJwp4RGCU+l6sT0ElZjG1IOXDb/5rd8BVvDv8enw606gVGrVjaD7C6Y922AlDmA1pZMgdCVPiwxhiHtQKsGSOaT9YaUjZgxETGDxGGjNo3mGbNi8sPuVj3rM/XfPX1a/703/wHXt2s2e62/OD7H/JPP/zf8dEHz7m6XPGr3/yG3eEtD7s7/uTf/K/8/Pd/xo8/+j4X6zNePH+f25uRzQdfsblSrM8VTy4v+PD6BdOgmQZNYiQxYF1Dp89YrsSMan3t2DxRrM9b1oslb/Nbxn4g+RHShFaG1nUovyDlpaxTKc5alVVH6fEYqGPu+O8jc0hapjPC2D4MdyJavrhGa8v3rn+fs+YSv38FKpGMJyoNURNTZhgnskpiNqEVxtliDrQlxcQ0RK43H7NZPWfZXrBYPSemQEgTNUA8yUK+AZrNI1opvjEB6pw4IQXkEvNVgFXmyUneSd0vj7mn1lKImLywlWNpN57dDv7/ePytxcXhCOhARRLropDnB52Pd/YITNT35+JeIDShx/dalcWq/gfH8Lt+3reCPLWqP1eka1BR72tp+wNQ89LE6QKVZfeBYvV5XNIeZ6env+H4Ne/eofn8v+3nx0lzvKTKKKjfd+qkdYpriOuYktsXI+Owxw97/HiQSkIQa3g/BMianA0peHIOpOgJfjxpMyzw0QkwNn/f3BRaz70ILupji8npHcqp5LeqPO/CehArcKG5av24LSgWYXmnM0krYVKEjCkBY9WeIUlQbbXCaY2zAmSFBFHneRKmUvlMxa0lZOmgpsaN5OOEnBEEkFreXG+dURqlj8+gVl5SFt0UeUkqYq1i1VtbrowxJyCdABQpy2R32gioEbcQ9iS/I4ZeAsoYUX4HYeDt65e8fvOAdZah7+fxWsef0lVIT1F8ak+SyXmwzuMKdXJp6t3RWVrxyv37LuVu+UgZKffudEyfHidrVP0/dQSsUgrHxR+OmjZaNn3tGlzTsOhWuK6jW2/olitWZxdszs65vHzCarlks14XEdMkzKZGGFACbCjUScufQuxea+tSykcQozJ3QPKYqh0HJT9CFdFoPY8ZH4NUcLzHTxPDOJBSKm4hUtmumh4RxWK9YTl5rGuIcWA47IneS9KgpZqplSZlV0Qb5efNYoW1lq7tMMbSLhZoIz3w2miatMQ0DbZpGA4HYe8Ej/eivWattNJ1iyWL1Zrlcg3aEtKxvSalyDiONE2D61qapqVtO4yz0oJXgOScElprkpLZP40T3gcm7xnHUQStlSq6Ww05g/ceWwTEdSvOUNU8YtY5KquJLp97Gi/U9fyUXq1KBn/Ux6mA9WMu0Dy/TWkjqqYVpYiSSttkTqHoX8TZUbEO21kkH4XShblQflnbE+r6nQvwlMocabRm0y1E7wrRxBjub9gtV0y7eyjtCiknYXrMZfu6X+f5+lKWEsUsxH+ykdXCiqI4QyHtXlpVm/E8241bI4CTnQ1GyoxQ8pm+3BP1XXS1U7KGxaLTFmIqtPniqljG1aPq/zwWjwt9ZSmdspdVTbRSZvJBXNfmQs7p51C2k8KUKgHtrImTBcwMWVgrWhkaK4ynxilaq2iM7L1TKOLhubRfWRDHxjqHMmMWFqWP8rm1rVziD4k7UwbvhX2YtWzwKSZCUhxCxhrIjUJFiF70EynAvQ9ie74fkPmnpCV1Fzw6ZbqyTYQC4OgKrOrCn2iO99CgaJzCOs1IAdQSRDJVsi4GAUVDrM+kAnoZV8xpLMLwETfcEg8lJdefcuFtKNHNi4q7g8aozJut53o3sl4s+d7zZ9x30PeOL766YT/24kCaBBCLUXO+XvPs6gnPrp5yeX7ONE3cPtzx6ZuXvHz9kp33qCyFWasV4xRIKXG727MfJ6Y4krJHm1zaRRSd0fz8aTc7/y6N7FsZSdxiLu2wWtE4RzSgkoyNzapDqeKqlzM+R9lXjAEtjCQfRZA8ZU1jDOvW8Hwjep/7URjkUxEz7xpHxBCUgZgItfBLYoyKKcPBpyJ8L8ywKcZ5TsWUqf5kl51i4RRLq7hs5Vp7kxlDwkdpg1VKujVFjw7WjUzBmGV++AxWQaeh7cQo6/la0Tlpt/NR1r5cgK7vVPA1BzJyTbWNPS1WxOABiam9n6i9R7VVav6EmqjwTvI+f8Nxn33UzFRQQ3G86wmMBHpCln9HIjEpQgzSrp5HEiMhRGKO+BhKW7yHHElRdKWsFmFvHyeSz4S8J+WRsX8gxAnVvY9VC44FemS+1zisANhZhOJwWtzr1u0LYvaszAdYtWZl38PqFmcsSmVSeiCTSHlPyAHvN+Tc4ewZWot2rtIaVxbvtl0QtCf6PTlmkk9SuMoDUQWWtuXpxSV/8NMfY4xi0WrQntu7e4IP7Pc9C7vk7//+z5m8Z+gHQhj4zaef4EPioxcf4z34NAIjigGjEmGYGA6ew8EXxmBGGUenNzy7NlxfKa6fXHF2tsEZxTjsSXEA5dE2VWz/mG/5QL/fkVOi6ySepBTKvn2vf5yzyQ3XhZhQjctEr3jyB1IMXG6e4Yzhfv8hY9ixD3eoqGncUvAKPKDQStxBxXFPY/WSREZ3mawzbx5+w7rbiq6vtthiwpOy51SG55sYxknJKNe87Rgv1XjqWJSs8dNvB6kzR/Bczj2jdMZZLSzMKOtinMknRxDmqHR9Ogn5G7/vb3P85wFP9cadPPwYv50lMYuNngBSOR91H6D0JM6aBWWCFtbJkXxxkim/Cz5VgKbcFOnNj7N16TwIS9CRy8QXAKpUoWOaGUW1fe9UH2e+71V989FAOB1EJ2l/fufhPXrNN3/+LvjzKJCs76r3MongdAqB4XCP7+9FMHcaBXiaRLhXFyHJGEYJPsKIHwdUASpm8Ck/DkhPdUpObnNFb6hNFcfJdLwlOkubpNZH7RhV/m1Kq53oqQRiFt2ZRsvGncJI1lHaXFSWv41BBUn0xNZW0zhLYw0+a1RKhOQloUtSrUhKdCNCEsp4jCIU3KpiK13cRer1UICAygtJdZzoKj4JVZwu5XjyngpYyniz2uAa0b4x2gg6HwMheHwQkLOxDmsssR8I/g3T/hWhv8WqBqMsanyAac9Xr2+42QZi8Nzf3LDaLGnb8rlKs1iuhSHTNBKkna5nqo7LXKSLTjfkSj6u46o++/qqGVX7Dh3q5K/T9ePbrjOXZOqUQZDEja62qFI1CgyubTFtQ7u+YLk64/zqOcvNhvPrp6zONlxcX3G22nB9fkHrHIumYRoODP1uXsfbxtHU3oUs7kGqbqBFyF8p2SyJkZAjKRzZivKyY1hmCmDrim5R1W8Th7bMOAwMw8D+sCfGiHUOrUXk0ViDaR0oxersgpigaVr8OHLYPmCNwQHOClAj7Vep6AJlsjEsNme0Tcdmc4Zzlq5bkHJkmAZ0SmQrY7ixjt39HdNhz3DY87C9xziHcpauaVidnbPenLE+u8A2A0obmUveE2PChxHbNLjFgtVmw2azIcdECgmrNdEarHO0y6Uk7CExhQemfmAYJw79UNp0NK4AV4nMNE1khP1gtBYGVC1uFBCZfHw+Sj1e1XPmhAr9LhhS2b25vC492kYUwu40prR66sLALLpewcs4zEWoNaV4bEVAzgulUSFiskL9f7n7rydbkiTNE/sZc/dDgl2SrKqymkz3Dra3Zxe7gGAFgOABInjCH4x3yL6ALGQxs02mCaqqq5LczEuCHOLuxvCgau4nbmY3qgeAyFZ6SmTciDjHj7u5mZrqp59+apx0DrO6wrUT12Kzm2Uo0DlPHzqGXc/dlaMPPbjA+PiBx3dXjA+Dlr+vOoZc3vdyXtlXUxUm8RoSrOuxgRsrC8fQO+nMErwE40FF5L3zz3TUWheYBoCdp4mcC0a1QH5Kh1WmkVFR+pgyMa0MbdPs9cfI53KoL9VKM5d9YgXhcymcY2bKVdvb17VrnHl2Kt2XETaTdp5rJKJUtVuec2y7ys3WcTUIoAKV41QZ57poTWyC4Xow5KxlYeprmYxo+SDATZtT1gpIGZ2FYphmYaj4riCirgLOPEUpA2SQro75nEhUMMJgFsZPgaOWpxopZztOE4bKkJAuwakTnqBxCrhJtzc3yB5BEZ+k947qYNSuZlXL6nxnqSnjqgBPMeqA2uYXF7zTEhmnQMWcpOtoNlQrjOyMAGk4S6yBXDzfHSpPI/zx+5kX9yeu99f8+Zc73r+3HA4Db76753CeiGmmlEjKM6lYXt7eUXLh5599wdX+inGaeDid+buvfstX333LzsLWSwOYzhvO08xpqvzuwyOneeKcTqRa1DUSw7f1lv/2i63obiZhN5os8yKWSlLjaL1hGDpSrpRU6XrP7fWeUuE8ZWKJTBxxxmGlXRwpWWbVUsoF+uC53QR+eTtw1RkeziqmXCrFWLZdoBonjIWUmYz4hLkUxmSZq+FhTCJwXwwzhuOcGXPhOAujqTOFzlb+7KWnD5brYPG1EIzllArfHDKnuaJSX0SngurecOvAOi2vwzKXSjCVzsG2h8HDl3eW3sNhhNMEZqFtfrTe/uCP59UA3gfwAeeDlPsDcZ6YprMy7bWUKYQfMllYTdxlsvw56LSmZxvAW4poOc31wMSjsGmNAMSlGmJSnVVzppqRKUaissFTTpR0gjJTs4Nq2Wxu6PvAlCZMmZjie1I6EucTNWdMZwl2C0iHO5QZbY27AJ/ESEg8sKVwR9U97bb7BZ3ds+9e40zQhFMmlvfkcuIw/ppSLGPc09UrtsMLnBEhcGsAJzFWypnZnonjUeKguRBL5PB4oBsMty8Hrl5t+eLTzziNB97efwM28t3374lT5vw08cnrF/y7/+Vf8P37b/nVb/+RGE/87d/9DV988Uf82Z/+BVc3W15+6njz5hu++uq3OFOYT2eOj488Pj3h3AbvB3bbHdvtNdefXrG/27Lb7un7DfP5ifH0QEpnMBPOF0lCWfGbSkqkOHN4umccz+yvbui6nuA7AZCaVjGX2Ig8+4YhrIkZe4EtCKg1jo9Y43h99wuud3ec0hseTt/yD2//75SS2JZrnPF4M2CNF7+jGnIqGOPwboNxYHqJob/58DdcbT7Bh4Fdf8PL3afCjKozS9dFnc3PttVnG21dHSlYuh9zMf9/7H4+fk3TjDKlLHu5MdL4gGpJyZCLaCEvEkrtui70sf7/cfz+Xe0ujMDqrlyAUJc/t9dfsJ0uB2fRMmK1s+v5W5Cvry3ruT9+WBcfqg73+qAWZLABX2616wu1slSyliy0gvcVKWVBHj++/48/d2G1PB8x1kfZ3n/Jq233uI5D+5yl3K6N1cVCaiBdoZDigTQ9EI/vmI/3nB8+ABbrtri+Y3AeHwLdZsvVqy948fmfETZ3+NCrUF9evbpnt1WePZeW0W+PojadEMwipLegs+3eS6vJlr+v7bsFmacZBYQxEYK0uqVK1rIoitUFRwHGKOd2xmGtlAFZ73ElCcJUipQOIg6oiNBJt4yYC/PhQLCGYah4kxk6h0mVcS5Cq6VQjQUn4yuln070aoLHdV4o5zoPEmXRJ+i6gPMbUozMcSZOI4cm9GsMx9OZ4/EkwtKmsA2FTSjM5++J5/dQjlDOpNoBnhJPeLJkAoM4pNM8ESYvpQjdgPErs8/gcMaLnkVjarWsUAt8WdTT1v/X5/9eQ8OfGOhUL8dED7NmDdo91yZUXAqtk2Jbb8YYEbO2g2oJeYbNhq4f2F3f0A0bttd3DNs9Vzcv2Gy3XF3fsNls2O93bPqeXR/EAqSZnGZSmhW8CSJAr7pNVbOuAi6oTTViUbJ2L2ti4cu1NTahtdrRorEHighEZpkr0zyTFLCyxtCFjuKLrE1rCUGBqipsktBv6TeRzW5HSpHz4z25Vg6IEPh+f0Xoey1RkY5I1EycJwwwnR1pdqQ4q2lXm6Z2J8ZWemyVGekJWpI3DDK+1gcK0glwu98zTzNwwtW6MKByysQ5Mo2TrLtqSDkLsysmYspMMTLHxNPjI4+PDzw9Pcq69A5nHfP5RI7zAiZd3Qhzak0saQmYsier2mPTRE50zFZ72PyHCwd5CfjF9JZa9Xm038teZau9YGTKsxR20Voens2KIAnY6HROKyPINBsg86nG2rbXZbzBrA0fi7AS2vIwymQSVlUhJ2UVURfsVgANZS3XFdwupYFqz3yoHxxO2R59FwjOsR16gvf0ncctHQYNTltHWwVgW+loUfDFdQI8zXO6cKJ+Goc0YKm0lnO5GtUmvPC3nmUnPz5DXX7ZAFHZC8QfaWxKczHP5bUfwYVVthdHK/8UDbGMgqwl01nLLgSmAlNREXRYmg+WsvpK4gSLWHoslWSMMJWNIRjRwoxJ3pt0bnUWvJP8eqnCopIuZco6LDJONQvYYJPYAqv6kdoLkZks/04NPDHkUolF11YScW1XioBEymJBXaYUK8HD1VYA0+AtqRbOpUIRIeyapbNUyYakXfBM037MYJyUqRmUaK+gXvOpYyzEWTP1BvrOEIAxwTSDrQVHYRyfOB/fcbN5yc3+hruN4Xy+pWTLn/zskb/8N1/y6auXvLi5pQsdf/zlH/Hy7hUv9lt673lKlZwSKRZSqtROQGobLC6Ibcy1cJ4zpznjXc9gYAiiZxVL5ZwyTzEzlcoxSde68yTzrrei6bTxQUohc5RSaWcI1kgZXK7EOVJLYh8qwZXFLqYsupgdmc5XcPB67/j53YbeyBjkaIj6ubkanubMhykznSPTmBlcYevh7SHz1Snx1WPh20MRVpmR7nQxF8a5MsfK1QDbDn52LfN+42XeV1Ppk+G3j4bHGc5RQLVNkBK+n19JCWAssj7nUonF8O5YiRlOM8wZvn8q9E60vKZUVcL2h2VmP4Xj8pYukwLWOvphh/NBQIYcSfGkoEDzVpdI5AfnujwWVn/b4IBcIilPxHxkio8UM1NMVtBXk2VVgGTvLNBRqxH7mkaIAjrldCSXkVo9VIuZIZdRdBRNpaQjpcxs3A2hG9iEO7qwwxiniYEWxC+bL2t8aNj1n9CHW3Z1RNbLNY6gcVcTi7YEu8cWTxduKSWRygdIE1O8obDB9VdInLiyxqwmv0XyRARQfA2kOPP9d+/p+i0315+yMZ7P7hxd17PdbriPT7x/ekesI6lOhOD42ac/53g+8vj4gfcP7zn/7V/jO3hx/QVxzIynA+Mx8u33b4gpMtcZW4Rl39WOXDdI+bYllYLJUUC+OWJyR1euCSHjfcGZIKOjPlZKklA6HB6oFK6vXtKFXjEGqwx0GU9xm8T/aCx1czHmkqNRbVS1ualEqoGb7edY2/Hq9B1TPDKlI4WZ6gyOgq+9jjFAIedZysxpG0RhTmfePf6GabiTrq62Izgpl9Q+8DLHZYIvybfGfr+c0+I7aRy9AGjqP8qLPl4JF6vErB/w7O8SDVonCdNOWcq5GvUpWmyunwcXTcGff95/aiOXfxXj6VJEtHmd/xzw9KzD08XxDJiq4iSv6g7qAl2CTpc3Wi/L5Z6fu14YtLV9uZzWaOlICwIacJZSoqSmz1QVkXbtQlek3l4YvGcAy4pvrarNP/4gzHLN69/rR+f6wViV5uC3rm2a9TUWUzNpfiSePxAf3zA9PXB4/xbfX7G9e4W3BW83dEPP5uqa2y/+iE++/EtKdSIgO09k1Xdpg2WMEUdex/KyW1epgpwu5YBVA42Pgqx2nloqNV2Ig2tnCOcFMELZZ5LRt3Qh0HeCDpZUVNMLBhWKPJwypQp921sJCH1w+KKIbmk1vJqRdA5jpf3xPCcepkcGb3jV9VhT2XQeawvHJJmySuuSY7QkSHRxXFbQqevwwQvwZESXwOgYDUPPbrfj6emJ0+GJ8/HE8XBYdDjevn/gu3f3XPWVm75y0x256U+cT4+M44FhsHS9I2dPyo48Cu3+7vqKvdtjveU8joQgwJPznQhB6wYt0q1BRRLLxVyVdSqBxmq42uRrouxwYeR+aqATrDZkjawu3Ji6/L8i87XktHQLE9DaSo36sCH0A7urW4btjtsXL9leXfHy9acMmx3Xty8EgNpf0YeO3TBo62XpyOVMJcWZeZrIcSTNI8FZvBsWwEhMnqUq/XvpSKflUUvXFL3uELwI7jsp9ws+aMtoec08j+SSmKZISoVxjqQsYLsxhqHvdGzEXvd9Y/aIfe6GHX2ubPfXxDjz+PYNaZ6J46R6VCLC7VV7zVIVeBqpJeG0y6nR9T8MAxjJzJUKqWRSirLutGSxHzZc3d3RhZ5u2OJCJ22NQ2C/2UjZaZUMts2SeUpJyu6slUAp+MAcI/M8Mc+JGDPn85lxmrj/8J73799zOp+ZpontMGD7juk4yxowhmocm+0ONlvJFllxAFozQEDb2YuGiG0gT1mn3Pq1snz1nRhah61KjI25pkwn07adKiWZmn1yXgXlFXgqDehS0MA7p1O9gUoN9MmUDKmmxdl1bgXV5HqfXfBi2wwKPMUsTKucVxthjDpPoqHSdsDSwA0Fheq6NV8uSrkOKx2zNn1PHzw3V1d0XWCzGaQRhevEcaZ1hGW9ZpCyiFLo5qjU+aRl9j+do5XaLRpLVfWPFHz60XTcJVpUn31D5Xmpqp9pq7rkqoVjtBZ7YbSZ9VS2No9NioWrURFeFc3vneG68xw1B+KtAJW1Qi62Sc8tYG5nYWsrZyvXkKyU/PZW9s55rtS8Mkt6C70zHDHkKv92thKjlfFQEKlqDw4zKxCLw1lhQldgJGMqzKmFtVLql6qUYZRJ++jajPeGbctcJkNNlThWup3h9sqoWLthiob5VCXZhSVFmKeigJ2lFFn5LZlgdU8wtS5z1loWn2maKnEu0pxkkRs0nGc4zuBrwdXE8XjP4ekNX375KS9evGacr4kp8fmrl5zOJ372ySuudluKG6h4vNsyzxEzPlHSzOn9gZyiNj2B0leqAxccvpP9pSTDYUoc58T1fkcwls0Uxe6mmVPKfJgSnbMcE0y58t1RgKMBEfx+fTcwl0LKwnTpO0vnRPA25sw0zUDmqpfJE2Mk5co0yRzqEQHyPjg+v/b86est85w4noTlP2cpW0sV3p0yv7pPmBSxKfHpRthG92Pmb94m/uq7zN+/L4QgoGFjhcepkmPl9Y3lZmf5ty/l+Ww97JyAZZsMqRjuR3h/hinBfiNA1b97bfnZlaFXLbK3ZzjMlcMorzvNzccSkXVvjZaZ/iA8+EkcH4eAS2WM0eYlfq/aWo6UJk5HYZTHaVpiReBCm1F/vjj5czbxujmkPHNO98zpwJju1cdQIEa7opUqbe+Ds5jaQ+kFgI4zZo6UeCTmJ1I5U/FgHHmccDZgyVhTMCVjgRfXv2TXf8Kuf0kfrmiaqaK9KiXrjQhxqYd8NfwM0cNsYzRTaybGiVozGGGHe3NDqVtyPZLSgeP4Fbn0jPNLCoWh3igDRvU69V6dc9QiTKKKJdSe4zjy7YfvuN695Mb/CdvdNdevXoOHGir3Tw989/CGdw+Wb958zZ/9yZ/w3/43/wu+ffc1T+cPvHn3hu//46/4sz/9M/7df/7vqCmT4yO/evodv/vmK8Lg6TYBSsLg2JSd7DnVYKr4a9lMjPMk6z4N9GXHYAvBVynTbXp6xjLHmVIrj4/vmNPIMOwJoWctN1vLxcwSM/PDRVXlMVjVDMaIQ5fKTMVwd/VLNt0d4+mep/Nb/unD31BqIncFbzIdAxYpaaxqy2wJeD8s+8gUj7y5/3tOw0ucMez7O17sfwFGSqNLzRRSgx0AAWQ/xktW7SZJHl6W1om7+QyJ+JGFV1lpyx8dpuJNValMIwy6BBSxn7W2arF/CdX4Tz/+kxhPy8+NxcQF8KPOaskrAvmDc7EuwOVQB/35y+UhLeqhxiwdmoxeg9VFVRawScUOy3rNtZZFH6E53kKH0X/bS+dNNJ7WIF3D8Uv869IgLmykluW9fEz2ItZf37M4xgq80XSRdCYuQnrNW6TFzq2kLUv3qRb02CaCaORe0wkjjEDG85nz8cx5CpziwPb2U64/+xNqzSrS1jpFrM/GXmReLllnz3HTi0lvLv6m97pQ//RvrfOWUeCsZMlo9f1AtR0vbjdsO4crEUom51muTcWzWwbdGgGinDKonMsKLnqZB3Ud6+Atn7zYSjvlpxlLIeak86eVfprlyyABtPdONF0K0n3P+aW8rfnhzqxt7J3+Ps0zh6dHvv/ue77+6itSSsSYOE2R45g49nDsDeVqoruaiOOBOh05RzgfwHV7XNgy7O7wV1e4q8+xmzu6YY/vBjbDQAieeTqS04w3BctMnJ5Is+V8fpCuGsMO5wIhbFQcvfLMLtX1+/pPNWjL7346wduqN1cXfStZamIzirbbLUWZYc5igmezk1LG3f6afthw8+K1gCK3L+T79Q3DZsPN7Q1d6Bg2GxGmDiII6zQ9LvNSbJd8d1hlI0rJkAC+0jJYS2hKVsaTMIOsAp5WO/W0bI33XktYnXaSq7ohJmrNzNNISol5Fr2CsmjgSMfJllnse2E6dVpy14R9fejohg1Xdy+oFB7efLOADFCY5jOVwoe33wtT6XomdD02V3zwFNUKcipWnlMU58hJyUvBkUtdmJBOWVveeuIceXN4K+vMOjabDdfXe+Z5ZjyftUtmWDpcUkWbqdhESZF5OjPNZ6bzzDTNAjyNI8eH9xwf3jNNowRgcSSPYbG5fthhu37pXIc2p8hZQLXG9pRHt3ZLgQb0yM692MDl53WPqhd2yirTzVphgjZWzzMGnmkjrhpfJTNPE6Vk6QxU60UmT1UN1QET4LK19l737VZi1Iy3qZBtWQBpY43qdPWELsj8RRlq7fzGapeV9nkKPn0kft1ud9mBFezw2jBiM/T0Xc9mt6PvOrbbLT4Egu+lTFvFxBeXQZkhSZtEzLN0O5ynnx7jSToxVVLJVET/qpVdttSkjLX6O7RM6eonNfatQZ+NtKZ7FghZUzGlUk1e3r/4XsskkflTalG9uNY5TQRLq06x663nZucpeSaXKKxk1YVyVnXGZFmJTVRQMXhLdY5SBEhyNkt5Wy6YWgjWEZxeq5GypeAMpypJppZYNMj5Y7pkoyuwT8UbBbqijlHzswrUIhdjDNgg9zxFAVCLKLLSeUNwcu5UCilWZu1UaxAgSjLcVkDf2HRElY1gaNU2JFNIC1MZciqULMBvCOvzS0nWfsqtTF4SZlMqHMfMu2MkdrOyWy391Ws21xC2AzX4BfibC4y5Yo12ftN5YQXeJWVhgn/zcOY0V15sZUR96Nlax812Q8Vwf8qMpXBMwuz5h8eEs9J5LpbK0yxj1RvLtlT6cWaMha5GAILUEXI8CXjsiDhTGXyzI0VKDYWILiUiAKYwj2f+/uv3CpLCxha+uAlYA7+7n/gP38z833438skWPtsbbnpH7x0bV9g60RzzfmVEWAumGooTI+acwStWkABX9O9FyghLVdDdCMPEG+hMpbOVzsBG5KmIQVhqg4dTgpggFnh/lvP3TXgPlZr4/5HN+J/K0daeNW2c7TMmR3tV6Drp3ssdKUVGeyLnRNS9rZZWRi5gRGsAtDhzVWxKLpmUJ+Z0ZM5HzvmBXCZinrDVScCb5DyGRHDSWbpmKNFQksGmQG+2GF/oTMec96Q6Sle7GnG2Ew07d40zHcEGnA1cb37OprvD207sj1n3d4l7mu7rRVIIsNqdvCp5odlv45zee4sHBXwYwkuy25LyiVIz5+lrUnmiH67wbpAOglYY0JKEdFgrmrmiSzTg3IjzotV4Op2wZkc53WGHiOtObHcDn3/xinmamc5nPhy+59//x/8B7wOvX3xB5484c48h8vU3v6IQeXH7C55eJp6OR6rq3PSba/phTzADxUAulTRn+l5A3+QsxXWksqOkHltHLBGjMW0L9q11mFqZZwEkH+/fEceJ/f6aEDqxZeobVWW9ytwoS+KO2jS3jHYOtNq4q+1t4F1g6PZ8cvtv2G9eU6wn5YlUJwGg4pliMs51GGPw2jGzVO1+YLw832qJKfL+8VvmYcbZDm87Or+ReVAF+HwGLJi6+JJL174FnPohKv28vG4FpGQPLBevlzWzVlIp66p1WUTtq4PiDC7LPrm4v5ex/DJUZrmGy+P3ZUD9J2k8wWpIWlvblfKteP4PK7gWoEhuQEqhmk5QQ8Jbhs0YsxqnlmXWCVSN0HMlI+pENHb1bOXmbV3O1wLL9SHZ5XNpDpnMHjFItnLZbuLyAf+YBtPHwunoee1li/MG5LBmt0wTMXeN86UTsRQRZH2mVVFX8EyDZQGdwDm55mosuWZyPGCqx7nAdDrz9P4B+/aBN9++4bM//S/ZvfoMYyT4BdF3aNdsWDfjNqSl1ZaYZkufl420Z2X1XpuAWnN8rYpKYlcGlXSySwz9QBgCr+6u2A+OdH4ip5mnU5EMfY7U1EABZQRYKesRlocGa20etWdUE8Fbvni94xwLxY6kOBPHJ302wvQotXWZA7DaNc8TQsBmQ/BJ5pkCT0auAm+cMqNkDlIr8zTx9PDA11/9jr/6q79imibGcQLfY7uBXWe5GhwhZq5tgflAjSfOc2JKmd2tZ3u1ZXvzgnD1BftP/oTN7afs9ncMm90iWP7md3/H8eF7KCJ6OI8TJRce7r9mjieubj4l9Dvs3uFsr/PvOfj047GZWf7/0wrd5FiA7bZGi4JCOcncKZlqLYQe1/Vsb27Zbve8+vQLdvsbPv38F2y2e+5evBQR8e2WLnh2m0GYL6aBDLKejEkiMlsN1WqnEYx0vPMdoUvrGlQRy1Sybp7lmd2xrICEVZth7SrS3xhTFNm0UpwoOTGdR1KKzFG0nWQzhsZ7qFWA2D5sCN7TdQGMZZwTtRpC11GM4ebVK4wzfL8ZoCRKShgK03Qmxpl5muW1MdH1PTVGfPDkzRbrHb4fsM4zz7M4Qr4Tx8r3lJwFOPNOOgU5AX5P5yNff/sdOWXSHLm7veHzzz8RsCUlNpsNfd8rWCzjmGIkIxpu03hins6cDyfOpxPn05nz+czhw1uePryT16ZEHQPRexHABba3hs66NbgvFaOsoWYnDKLtsthC0/YHVsDqAoCvl84zCxYlz1aBorY3tg2+vX6hWauPXSjKYhu1RGZcGbFOGKGryyGsyJQzMWVln5nV6V8SJ/KVnSOVIsw1YwidZ7MR4Mlo0JCT6idq9Fw/0gN4XlYoV/Hcx1r3Neda964N282G3W5P1w/s93tCCHTdBms9P2y9IuObdO3Oynia5p+exlNjjqWcFzeoqGf4jJW0DPBHzqA+X6trv2SZyywActPNAmuLOsBm8Xm1sG5JsoH4DNJF0QFOhLOTsDcMhptd4Hrr+fBUeTjmRWWgaTTV3MrzzNLt0Gp5l3FuaaLgfMWmpr9YCM7RO2EKWQNbD71XAWqt+1tLeUUcvCyjwAJKNpctRZmblhV8kkMY07aT9XeepImI1bLSPlgBnqqU+x7HspSjOqvC5jgsnpwhTfJcjBFQwzkD1VCigsl29e1QkMNZI+epIjIek4iUS/goLyxkpjlzOGfMYebgJywOi+Nnn7/m+mpHTcJUzKpZM+bKORU8ksSoZt1XrLHEJHvQ7z6ceH9KTEn0NLtuoDdwtx+oFd7ej2RTOCTR0Xy4F/ZITTIvs2bpO+vZ5cKuL6Rc6MosLJPqIFWOszj4zsJgDbfeLQCpMWAHCPq3VCpTLMznE399OLHpPVe7nl9eO35xFzhF+PW7if/+n078n/76xF9+Efivv+z4+ZWj846Nz+ydYeOF6WSsrAtRPIXiASuglFeGYVKA1BYBN0UsXYIzo3YwmEJvREN0sMKOcgpcDkYEykOqzCOcsxFdJ2AbCt7CEER0PBZYeeh/+Mea9NM9zn4U71Xpbh5CD6Gn67YiNG48MU5i83KShNkahVMvK2o0EVRKIeWZcX7kOH3HXE5M9WkBulztoFqcLVAt1mWsy5Sk0gazpUwWR4/F0vmO6q5JdSKVmTm/I5UnDB5rHJvwks5d04dbgt+w335C323BSlJv2Ve15M1Z1a3S2yga2BYylnW/rEb2fasM5qzEgFIT1jo23SeUMhHTI3N64un4O3zcsek/p+8qQ7dTfU9HseIbFmuoVhs0uS3eTVriWDkdj3gGyvYGa87Y6zP73Yaf/+JTHh7uefPdkXdPb/j23W/50y//M/7rv/hv2Q739F3geDrwT7/7ez55/QWfffpLzuPEOT4ypcQUM7cvPuXq5hNOT2fOp1E6okZhiAUviYbiBmq5hrjDlkccZ4yZwCZ1V0X6pFaI00icJj6Y7zj3B/quJ6hgPQZtolWXOSF73Ef7YhWmWy3ScVkcrgbASHXLZy//LXM8E8INUzxyOH/HGB/4/vEfhDG1keqo4IImwCaMEckT1KLMMfL9+WvGzRnvPLvhlr7bCmNKCne59BFbl/pMWveCpcatYQnrumps8h/HIRRHuQSIGoiktH1j1jJOYy2dklecFds2R2mGtRBlzLNv/18dvzfwdBkEyaevN1RhYUC5j7raLSyjBlg0odEF7TYrWGNagGWVyYS07jbq8GuGtt140TSblKNo6ZNeS6MyslybXVxXyVo0w6CBnDEI7W65KpbLvjha9gkEkGkUufbQRX8DmtFpr2ssA7nNi7CgcqEvxQKcmYsxXM8vY7wYMr/B+R4QEKnrAyK4lpmmzPEwEqeZ8Tyz7Qzb/Z5+s8G5AFXbAZu1zWK5WKR1+WqOjjqubfI1ZHUJXBq4Vi++0ATpaoDbM3ReGB/zITKlmcMBSE5YIij9uLRyvIpzcs4GYGHFQbVOUqxC3CjqSIC3nuAtNzdbxliZi+N4dHx3fIJa6YPqohijws2i1dA5R/BOkGwjYojOec32i9Mhds2CFbF0ox37rq5v+MUvfykdzqzl8eGRDx8+MM6J8xwptXJ/ynzfGYJ1DKans2Jqqssye0vEe0c/bBj6DUO3YXx8y+HdV+T5SMkTD9//hvFwvzjPxQYqhhTPUDJpPGJqJQ9XMuYqLt3Ktdrc+/gw+sBy6y39EzlyiiuAymqrrPfYEOj3Vzgf6DcbfNezubmlHza8ePmSYdhyd/eKvh+4vroldIHNZoNzluBEs8vkKPN6Kcmt2hbc4IxdhL6l+5toftRaiDGRY2E2ovXkQ1iG3TVQybSgcGUiGszSzQsjG3KKgorkFKVJQomIALSwUxZQTAaA6kRLxdZWClKhZKG4Y6RkSW2xt4bbF5/gfcfVi9c45zl+eEfOmXGcMMYwGXFkKJK9TNOED4FpuyWEjs3VFaHrJVMU7NJwAOeo2VGtI+fCeDxRstzXu4dHfvPVV8xTZBxHPn39CkfTuErsr66oubK/vmGzuxaQhUJWsdLpeGA+HZhPZ+L5TBxH0jhR04xTUe5akgiQAD5It8muC/RdwHuHc1ISF+e0tHoPvlOatjzrhRW6LJnnbNVnTkPVPIoY1SXAbDT8Fbg34ry2eVuNNGKIkThnYswqLv28m11zLEptDKvm0LA08LALe7NqgNimhdho7/0C3ohgrme72XB1c8P5/Y5D11FyIucExkmihrYn6G0+A56Wq7vY0+TzvAL9/TCIzdts5d+breifdYOWRTS/on2GlPwZ7RoDVhIo1n6kC/mHf4ytJFMfVNAkQr0QqRen0qivveqHgIQ2617eoCQFZyTcpqrQbq5VgrALx5aW+VxPuXTIU8ds6YR3mhPvjxNTTjydLSlH9BRSBN6wK2NUm9tQjOEcRRMqzZlqKvteOtjKnq8Ba5FMcq1GgjMDCYOta2jRbrvle9fKWBmB1oBRiO2aHKzglreu/oyxAkZl7TJngGAN1hlCD8ZXDmMWYXW9TtEks1jrJRlIxtisejAsdhzMskaqrv+WSBQm2EW3Qt2ObXsIugbmJCyzh8lxPwd89rjqiFMk55H0DQzvH5ShWiklUmrhOApIe7vb0TlLf5rpYwIjnVsbKHaYMrHM7IaRLjvmJNIMD8czuRTeP03MqWCNI2gHSpCVKb6V+MJzLvhoOEwVbyuf7gPWiPZTrZCTsMucFZHyV4MC50vmUp6PbzhDL0nYmKvofAZHL4rE5FqYc1lsmjWtFFJAJu8MnRPNpqtQSeprtoSqPhktA5fAK9dKaH5iad2PGwNnjRVK1c6OyFx2BsYsX1kfnbfCLGixyraX3y0YSvloLv9EjjVWkOMZM8JAYwOXCsZahs1OWVCOnBLzdEZY6ekH55UTGKjCkIplZE4nUp2l86eKOjtTKHbVsqtMVEbqDHWqlNRRc0clgUlLktyZDc4NOGPIZYd3PdZ4en+Ld1uCH3CuA1PJNSrA35plWZxKuCjvdEkUtIjULr9vN9X2ZtYNlarMpZaA7Nj2nxPcnjkdoBrO4+8o5Ybd5lpAEd9JiZ3vBLxqMWQp2Ip257NkGxnzkcfjW7yZ6Y9Hxjgxj5XgNnx69xlTGjlPB6Z05m//X/8jQxjYdFvc1tIHT8mJr7/9ilzg00++5HB84nA84E1HSeCDZ3s1kIk8nu9xp07iqnGDn3piMRIHmUwxWs2j+o8tPhX7KVqPOUfm+czT03tiHNluxIe31j6L3BugYy/2QoxZ9FHLYmfl9RmR13BOBMXvbr5gjifp8Hnu+HD4imqKgvt2adax5AZrolU6tf12nI98f/8Vh+6RcTzhXU/nB/XldQFg8C7gfaf+uEU6oUs8vFZvXWAa//xq0zWhMYK+/hK4bZv5ZcTfvjc8JASDq5CiYDT542Qil1gG/6qQ8V8PPOkn549v3KyA0bP3XTjmVQWthRK5dkITP0S7tTXk0VpBFo2WsNk1WyUbkmrcNB2UUrQcxS7g0zoelx3zkOxoKUswuAA72lJ3mYgKBH3McrKK3qeYnk0EYaSstL5lDEoLAlrgezlGZanesFrHbKxgYD+ml2XUaTPO48MG6wbQUpS+D0KRIzONiYf3o2Y3I8O1Fe2ZYYtznbbsVdDMOSoZcgMFoRplrrURbA5jG5qPwDBddazBRdVpvYJOK2hkFsHuaTpxHCNPQ6ZGz27bqaaUpVarc0SyYRpBi6PmBFBxruiiUudZHbs+wHYI/OLTK6ZUOc6Od9by9dfyPPogG7+zUndrEZCg85ZOGRSmGEIIOO+pxlEVeJKHImCT9cI4MdZyfXPDzc0N+92e66sr3rx5w9dffc37Dx949+EDD6eZx1MiGE/Jnpuh53qweFcIXi1rmfHeMQwbhmHL0G14/PbXPLz7mtPjV8znB6bHN+TpCC5I8N5twQdCGHAukKaDlCvu7pQRs2Fl8OkTvYyL0bFtpRrPI8Y/+KMkWacpCcUfg66fgAkdw81L+s2Wu08+YbPd8/LTL9judnz2ySfSmW2/F3FHZbxpg2ugSI2/Ak9STnKR5VKb4K1bwVcR+lANqUxJMyUXur6nr0V1jkT3pgtS5umdX4KWdqSy2tBSISVh78TxTMlR2AO68RnWtvTL4SzFIsB+FR2LmrN0camVmBLVWMkoOc/dy0/phx03Lz/BGMPp/j01ZyZ9fS1SuhHPZxEsnybRxdru6AaxUWUo9Ju9ArNOKQ7yVY0l5cJ4ODKdR47nkTfv3/Or3/ya8zhxPJ44PT2xCx2tk9s8Tljj6IctwffSqcYU0nRiHgV4mp4emMcz8/nMPEXpVhdnbC3YKp3hyLIp+87jg6cLga7rFHiSsuAYk5ouQ/Bqk9tYNtbJxc8836qe7fdLAsmYJeMOrN27VMOr6Rm2RE2MiRgj85xk7uS6vFY+SzNnRZhN6B5SELq51ZJhp/RwkD0gl9UlMdbgkyOUALXgrJVOjJstVzc3PO12hK5nVoaHWQLp56DTpXV5zhZegSdrEOCpC/TDwLDdMmx39P3AsNnifdDuNWsH1rKUzIumg9Mo3BgvDqZbQbOfyjE14CmpA91MOVomrnOgKAgDqC3X8gNU0nSx64tjA0Yp/UbKsHLVznRaPieMP/08q+9VnyilvGz9UiJcOc2Z96eJp1EC7E1vGTopMW5C8xKXKfBkDdkYTkl0i04pk0rG3Xj2vYRj0oHWUmylVrsKlJtKUtBgEVpXsKa2WPQCdgNW4Ek70rVOoFa1EdW9Uo08cbhLgZJExNwFiw/Qb6Rj7uMoHYOsB28sndo2YfRnRGSqYFUE3TUBt8KihSbapRbvwAeE8a7So7WhG7XiqrBuqGIr5lRJuXI/WT5Mnm0JdNXzNB6ZxpH3j0eoaNc8g1E2G6bDWs/t7Z4w9PSbA8M8gSnkGglVRJYPY+IcC9vNSB+sSgdkvnt/1LkoDSm6vlP2o1x089Mt0hgm5sKZyuMMV53hy2svQJWySKPumd7CPjg+G0TLUmHVZ01RvDV0Xp5JypXZOCZj6Z36Z1XK/lJL5lqL14AdZdt1DnYerjyMVUCipb+QUcHoBXhSHTUjQKj4/ksNyjJnJMgzJAwRmKoUXZwznJOC+waCSoU5I1+7TjXKls+/wBp+AkcLrD/2KVvJXTsWELZKWdWw2VFroes2xDirXc+UEllkEbRCZTlNhlRGYj4z55NUf9RKzomUJrLJ0pBD7UJKB1I+wgTMYM0GawYJvkzB+4FgerztsDYQ7AAkvN/gXYd3Wym704ZExlYKEVOFACBNPrQZkpa06t3qqDSm8aUeIzRx5/XeWhzYEkcGYwI78wUxHTjH70j5xHH8LbkcyOVPpOTO99RScS5gbaLJAgiD2xCMXGcyM1M5cn/8nmAym+1EjIl5Eib8ixc3nNORpynw9Hjgb/7h3/OLT/6IP//yL9h0HdUMvHn/gW/efMerVy/59JMv6T58LwCaDZRYCb2nD57T4YHT6Ujf7+jsBnPe4aZeTAeJYhLVCkO2xedW94o2N6w1lByZcuLx6R3jdMTZQI/Fd2KLckk6fi0FcQE8VaOl3uYClJIxLrKLSkWCCbwYrolpxFSDweHtlkLEaaqidThuXRYpaQEZ27Me5yOn8yO933A83tN3W7bDzZJIlkSgZ9Pt2XIjcwZLFi6szpSV8b3sC7XhHM/9L2hT7SMfrK7fG+hkaKBZi/Q1zrAqY4RsGa2Unou48V+BM/3g+FdpPBlNaYpzW7g0JeJ8lAXZborp1qDZtKLlCEU2Fe8Wock2dFbLqIxBSiDqj7X/le8LcqxdCZw6wNYu5LLFQFl3UVpXUYOg91RZdE4a1ZjmG3xU7tKOVhvpWgv7C1RRcBidJKr5ZOpzA9m2UsyqWWFqK/daPyv48NFD0CmodOjT0yPn44E5RukS4By2WsDTdYndFaQ0E6eEszP5fE88fWB6eo8NG3y3A5uhiKqYsPe1m5YioWYBveqqn1SrBjLi+LZLXhabXidmNaxtbJ1+iRG0xJwY48T9sTJFxznOeGdAu3edUyaqNomzAgp1qmvTwCyDwSpI5VRboetEa8cYQ8qF+6eRh8PImGTOhJxJBYxmGeW8juAsQVsbYyzeCePJqP5KqVnEp+OsmglJdaccXksAu37gk08/wzovFMbNBuMDtzkRU6IjEmoiu56HCi/9yLaf8EyUaeT9m9/y/ikT3nzA97c8fPu3nB++5vT0jnk6sAlCwV9mXrcD39HdfS7BmhVnhipt1y3KNisZ0bJajcw6qTXAlcn4ESr1h30k4zDW0G2v8SGwvbmi6weuX7wSRtPLT0XD6e4FXddzdX1N1wWuttulk6FBQHMptayLGPbK+JP50kpWluRSFc2mNtZCB5duZKJpJLXrXd/TdQK6Oj13zZpNVxtWyg+BpyZMmpKWelTViMuFQmM1VOI8ayc8ecou9LJ+9Hzn01lEpNXuziULy886bOixmxtCP3D76We4LnD88I7xdKRMZymbLZFaMqNqSllnCaGjIAKMvu8opbC5usFYR0dtxEWKqVAiOU2czgfmlDnHzHme2XlHv+nZest+8JQ8KTtR7HQuiRwnynzUwpNMmc/UOGFLxJOZSqKUxBwnztNEUmAmhA7vpKzWOUe/2xH6nu3Vnm67U/tRl+SJc16y58i+UZURUqyUAi06MeoVtH2r1hXQb6BU1ddJnKyOpwJFWfejFhRLwwcpJ5vnmWmU8sk4jVAztUSdd2KXs8uyQ1ajCQTt8qkrfxEe1/MWrRl1WBgKAAEAAElEQVQRX6Uu19A6J4LuzdocwvtAtJPOnJW9/EOG08VPF6CHBPcW4wQMM82+LoLolZSSBv1yT8YIJb7N3zam7UMb86sF/T+lI6nGYSpZGhAYoUw4BSq6XkL0XkVwckL24OURFH2uyiSmMZD0sGtZHeqvOAt9MGRnSL5CkrK0No8bSNXYNKlkUklUWqdNLW+xEFxlTNLVK2VDzrJ+ghGx8I2XvSgVOI+FKVXMdaB3nt5JdnqykVoqna8MwWiyqApjxxmiEwe91qzgrqVmNKAXhmldJBsuAB2lE0mJoLrjtWqGvS7+wbBp7HhZK7IsDJ1XzdEstmDM4t96J8L3RR1c66HvHNuhk3KtbIglE3NaMEBqpcwtQGjB0EXwAIvPSy3sdzf4vqPfXFPwHD58T5mOjBEFXsQ387a13JZOw1k1rIY6s+09Dw/fcTg+sR0cL653pFmfsbKYNkOg7zzHU5X7VMqIc8LoWLQ1S2PPNo05GTNnLMGKEPzgLVddIJhKKICHEsRvD86wC5bXGym1HFMiFQGSpLRZ5umUK8HCfnAcs2PMlpThPFdyQfQVFdkxtiroJ+ulGshYjJUOeTkLUBYRthLLFJF4wulXRTorZi23E1xX25S3ZLFRBj0GU8siGt/YgNDmkK5dI+vMWqOJ5h888j/4YwFVPoqj7DInL39f9f+NTSlBufcdw2avwFNaEk80QoOuZRscLjj2+Zbr+IpSxSYJ8DTTGEe5ZkrNxDSS0kmQ9lQxBAxehZ8zSxsFG7DGY+xOn5+Ay854jHHq7xlAJ5hqxkrFfaHWiAh+q41RtrQweYVRfemNr2VWGj9iFkCdiiaWNJY1nt3wM+Z0IOVfk+vEw9Ov6cIV++0XWGtFR7cWrHVapi/6vte7O87zmbcPX0G12Bp4/dkdf/7LL5nmiZQTj4+P/OM/vGG/3/Hy5QtudxuuNtdQC3//u7/ianvD7dVLNt2eL147ii28v/+eiuH29hOO5zOn8ZExZmkYVTMuGNLYcYobQuxxSSpwrFd2ogqtOwcqlLeMjlQCWPUJjHaynXk6PDBOI9vdXnQ/g1f/1qydRBUgEvvfIO2itrbNV4Ci8gWWbGZyTvgQ2G1u+PnrvyCXSDGJOZ14OH1NyRPjfMTajiFc63kMuWRikm67eWl64pjSyJTO63yvwsqSxlmBXX/NfnPHpr9iM9yor7NWiK0J5IsIzqzzpiUCl67FrKShZ1hGVUtnLrEJNCOCyhUZgtf90UjyqEn+lIuEq2H93N/n+L2BpwWhVvCppPTMPtr2e0XhjC7GRUyuQHNvGjuogpZItXOsNcCNGaV9AWSA6ooSt5stLevQwCdnFsDn4//anm2Q7mgtz9s0oKxXHQv9xAawfXw0cO0SeHo2FrZN7ovdpGV9L/7dJkYDJ9u9KGZDWDSY8rofKahTc+Z0EOApzlIDbayD6nAM0Ce2FuIM1kxYG0njPfF0z/h0z7A3uO2tGMlSpFuNbUGOgorGYqrezzLJ2jPUTWUBy9RRMpdI/gpYakPjZTNXsj8xR6Y48XAqnGbLeZIWu/teSt3GlLXEoAFPgpwba5eSO0Do9lUcKmchdJ7QSYecnBP3TyP3h4kxFoyphFyW8Wwldp1z2mVMHKFqHM4brAuiR6PGpLSNLBtiNMs9Sme+jr4fuLq6xnedMLtCR6mG4AqdLxyfHjgdHjmlwFQ8L8Ij26FQ5yNlOnA//pZDfSSbbyhsmN//Len4DcfDE/M88fnnn7K/2lGSdL2oYcT4gZvbT6U8xYmAK62USEGR5RnpYS7+v87gevnHn8RRjMN6T3/9gn675eXPvmC73/PFz37OdrPnk1df0PcD+/0V3jm6TrqzOVQDKkUVw48yLNZoZwt3MYbrPGjzHsRWpJobGVC0NpSp5JzHGYNXkCaEIMA7rM4V4uiXetGprEJamCq6GSQpN85FWTC1KOgkNijOs2Ssk3QU2lorjpNe43gSwCjHiVILiSRaK7bD9YXt7o6u77n59DNc1/Huq9+CMaQcMVRyEt2XKc1Kdy50XYcxhZRmfCeaanGesT4ss00S0QVKIsWJ4/nI4Xji3YdHQghst1tMcLDp2Q6BnCecCzgn2mU5J0qaKPOBTBGNrHmEHDEl4WrG6Jqd48xpPFNyVnaulMR2IRC8Z9gJO2uz29HtdgTvRLdON2yrZWjWaP6p6qrRUriPoBYFnRQk0XO00nPZFsqzbH77fW5gj+rl1CL7obCdZsZxIqeZPAvwBK1zoDCbTG7kfU2AGNEBtKYxalcwrWhGf2EJ13UPaKLkIHuVVU09e8ns5QJUqvWjMfjh0fYGyVxajBPRebQsQTKHa9CelJVrrQILXOzt7douTFYT6/8pHSWj4uICahS1CdZXXIG+E/vT9fL8ZipkBUOqwExVgadazZJHLWqvVr9b5qypKjbaSZtlVw1lqpik/tIl8GRk7uSqDQ0oz4B3ZwQkOFdpI5+T4BPBsIgrDwo85Vw5jYVxLthqGZyjc6KR52yi1Pb6Jg4OvRUw45xWx1vAfgFZ42zU4b9MkIk/itWJT6UUtwjeN2TYmCpd56x0YDOCWggjRtmtnRfQgLkSE0yTaG8WJ11jm6KE9Yaud+z3Hak45mwxKVHzTI2ZmgqkSk0Xrvwz4am6ghIKPO1219roYk/Bcbj/nvE+UcI1xQ1L4q/1jU6q9TQnYQt2+cDQWQ6ne8bpzKb33F3veLgfiVH2HmdhM3QMXWCcIsaUhbW+JHRL099ZfYrVRxfASErMHIO37DpPbyp9ab67lLH1wbILllcby5QyZQRyZY7i5nlnpctdKgRn2fWOFB01W2KG01TJVBGfb8CTA2NUD1UDhYT617aBSZWkYKT4hHL9DXRyyNzKdWUCovNC+hBpsw+7SlKY1lE4C7hfVdpCbBR4HVunIuQXK/AjAP8P+7j0gz6uHGm/f/76uqxjmUcO70VLtWjTFQGRs4JOLfFR6crAZrNffs5aYidSLEnfm0l5JpVIjDMxzVDKwvwGyDlSSiKlqE2yLMY4nA8qU3IRy7Z5L44h8hexFaVKPFRKWteDxo22oY9UlbZYx2QZl4Vx0UDxlojK+rkGYzzb/md49yCMpzrxcPgnhv6O3fAp1gjwVEpScfMkwJNzXA13zGXm3ePXC5Pa7f8N281f4KxUozw+PvLv/+qv+aOf/zGfvfglw86xu7b87pvf8vf/9Nf87OWfsgmv2Wx2vLjZ8+b+O7798Jabm0+4uXnNnL4mPh0Y08ScI9vtwND3pHPHOG+ADhA/1PmqpcgW60Bz/WJbFLSTxKx062vxWC6Zw/EB5wLGGvpuwPs9TTsTaH2EWOKdWiUp17ph6N+MBO6kNC2/AyGBOHtLF3airzkfOYzf83h8Q86Jcf6Ad1t6fyXPRuP/mCZyysSYSOr7O2txk1twiZRlHsq8m3l59QWf3H7Jq9svudq9lrmY5x9e5+W+vfxLZ4YSPho4Vxe68eXR1uTlvIOWkrLqVzoXAKkIKgWm5jeq5qROzssT/H88/tXi4m1xOhVzXRhOptGSZROKsWVhJdht3UAWRFgzR8651YG8BGUU2LC0Lm9aVX1RWtCCKtOegbJfsJfENBmMrCwD1JkHsxity4dUFyCq/sBYXt6vlAFaRQHLAkAtY6SfWVu2w65i5q6VIyoOULXTlEHOq7EOS9yg42i9Cpe19Io6IbVGSo7EOUodfx7ZXL/g9R/9WwFJ5lEClekEVkoSstZLlxyl3KdkSi5YY+mCghQLjU+p+gvLTcetgXmVZVNv/l3npEzFeb/U1xujmQ6nxf0lY6uUuVWcbM7VUrDkKkF9KpU5Z/Isdf3aAZJgRNx3yWNYyTYYL9mAlDMxK4Fex8vQshBwjrK85pSlxGdOxCRegLR+d1CQ7iaty50K3JVlGlZl2AmzZI7yufM0MXrPNE0473n9ySdc3d3h4iM2PfDhzT338T15e0Vxe276Hh+cPMcaqZMhpZl3xweexiNuLtg0ADPWVQ6niTlXuk60qAZnCd5AScQ4U22PA4ILhNAzDFup8w6dzJec5Ltu3Lk0MdCq97QqY/wUjj//n/+v8CFwq8ymu1cv6Yeel7d3dCGwHzZYZ/E1YnIij+LA5tqYAmpzmthGQ4qVxmsay7JWqoI/7WgbhDVaFW7FmbImqNN5ERjEJKVrWTbTUoqsISvC28a51Xbp+ZttjEm61qWYBVipCVOLgKgNeDSWeY6kJKVabc3UCuPxrELVs4DwDqz3+E3GlCKbImL3w9Czf/ES30n3lhRnujCSc2aKUs4oZdMWXMCGjrDZ4PqBDEzTTPn+eywFWyNxOnO8f8fDh/ccD+/IKbPvK94XNjZhFPDoHXTWMGw27G5eYmsmHx6ZfeHsItkasmr8GKrYnn5gZwN+uMIOR7rdyPl0ZDyPpJhEuDxlKBCSBAlZQR7MKH+rlVoCnXfSMXXREdDjYs96/mtxLIpu1GnpKPhcg6dpMJV66UibJTEh2jtS5ltKpZZMSZHxfBbgqYpIfT9sWDdDszhrLVE0pyRRjzIxzQLSyD2hiY5VS8JiVJewKqApXRZ/3D78Sxaj7dpNB8ZbK2Wk1uOsspmqlG9BIucqdlgbKoifaZZBblluAwLCLOCv+8Fz+EM/VDwAp9oXuQjjMWXRHlq0nbSrW20lcs1ugTA0nWH1xav6DgIuyZRZdSCaH1RU76mq71TVzylVSthcbe8zFNOeiBUmVJWSDtsQ1VqpWGW5y3uDNXTO4l0Ve+jAuJX9bm1R31LmXirS1U38JdV0q7KGcruuqoxQDMUUqhMmChVK1PEqZZ2UtOtbRkbwXAw1G5wXvQtrwTg5f4xQKVSTebEZ+POf3VGBKcOH08hvPjxqklPBhirdIE+nWZjpXjpNmZhxpmBdWTLIMYmQuHVGYtM2qgbx2LN0kqxkUjrzdIR5PrIPlsFbnI1Y46WLaW2aHXI/WNFbATiOI+cx8+7t15zPB9J0wpPxzlCrE9FjA9MsTOmUlFEkj7iREZbGCutgyh98kL0nOCO2O1TmnPiP300MFl52lt5bSTKWyqlkxiSgYy6FcxI/7f3YGNp52f0Kcr73U+bbY+bVBq68+v4tDmj1lrTnsP5bWGkVV4QdbopIOCxAodXnrVMjKwugrLe3fC0YwQJGKBilI9KAfYea5ypMQK8AlNjoi+qBnxLydHH8AFj56G9tvFpspq9sb3g2pi2U1CgbKsp2XT+j1YsIOyPr3ip+VS5pTbLXdU9r7BPpDp5U2LuBHm5psMFFQmm5oiW2bI9xtaUriMQyP42ykK0mgto7mz+w2O+lo58mCiwIRa4lnDzWbLjafElMR47n7xjnwuPha7wbcH6vjUfMAog4LL3v8SYQU5KKGWMJ3rPbbIjpyOH0jik9SYIjOHzYSGK0Gq73L/nlL/4UquOrD//Iy3pL179kCD0v93fklPjw/husMbx++Rlv379lPL9nNhJrupowAWpqZa4KXheDiLcrp+AjxpNOjwtw2K1xZ82cT0fiPAEV74UEYJdGZs81/4T9meRZaMdBpz4QChcYfYLGeIwtFJOxNuC7a5yxpLt/y2l+oHMbqYZhJpWZms/aQTqJ9l+Q6gbrxO+yLmiFliOXjhBmTuMD59OBKR+Z0qjMNKsxa5tn69qwz/yhutqhZY7qXnxxH2s5OvzQzpiL73XVvzKShLBG/IjOG61+Mst++6On+xeOf5XG0+X3BTzRwxp1prNSzGYRgdPKNRQEXATVSq5YZxdUUgZqbcFsNKu8dFe5WOgLk6gZIwU0mo1aWqRq+VXW1uRtq7AXXe2qggeCoMr7V4PUqI566jbAVpyXBlaZvE4KUOcc1tbl1ixmBdCMcaN/lyXD3WouaxVD3ITLmyBs1/V6PyzZaUFCEqVE6dKUM2meuXr1GZ/9yV8gzlPm6f23fP/b/yjdtZByupwFsMop0dq2Nw2QBjqJ4ykghThGOgalXFD5NXtqrQL0Uh8abEP37YJhtRIl7U0sQFIFETv3FJw4w1WMsjjYhmlOqBi/CE1ag18C6pY1Uo+IIu8rRdt9N7BOFnGuUJI8/5REa2eKkTkHdDKJVpkFW4y2q9dykNo2pzYOokFh0LblZWZCW14j4uRXNzds9ns4fUM9wDBV3P0H3NZjhw2WDthQ0wmTRyqSnXz3MPHdY2XnMr0b2DHRu8LxHDmOkeubPcMQ2FtD76G2LI0riNZmwPuevt/gQw9Z6+PTLE58ls2YpJtwEg0IZy6zAH/4x7/5d/+NtIF9/Zmy0fZ03rPvO2E21YlaCjEJczBrp6xLR6FtdEtQ38DXpUUuF87Imj0DXavOSeBnms6Hl5JSRWpzkmc3TRPTNGlb4EwIHu9Fe6gxTYxR5olp7Z0LKQmwkWKi5ISp0nWuiTGuwFMSYPQ8yT0p+DSdz4vtoFb6zuGC6viomHdt67rv2d++EDH0+UyaJoLz5Jxx0ySdS7ICW9ZjfIffbHBdLyDKPHN+fIQ0Yad7AZ4eP/B4eOJ8+IBzlm3XE1yhtxFnvYK/hmBgOwzc3r1gfrpnfH/PbGbOjBTvKaHDhh7XDWLH+h7XeQY8tt/Sbc/cey8sssOZFDNZ533W7HROCZMipRpszFKqUiul7ynK1G3WHgXfL7zm9ttlo88LwJvFtmsXsbbGVuC3rHOONs+MavRoN6UidrPkxDyeteQgEUJH3/VgbcNDL7w1o+XBk3SANRbjA853C/MImhhyY+3Z5b0ytVfgqe0V/6yNaHPfXMT1oMGylppYR7BuAZ5aqbkAfWbRj2r7hysKxC10GvmAxuPUTNVF+etP55CSjKIyAHUBX3KuK8jdnM5ilvKTxVldkj5mKd9sb6pVztOGVRKCl2y4uuCMbbSFMaWirVouUo0mp1rAjxJjqsRIbd+UsgGd3RW8AhPOKSvPVYxrPlkThW57rrADsrKUxFeStVMWgFc177IkD6oV9Mc6j1b0yrg0d7Cu63jx1ZueBVCygn7o1HNQcyVODZiLbHZb/ovPX2KdIVH5x3f3/Prhg8x165pkDCUVTnmmGxx95wV4p+KNiG4XX0mIaHhMwgpzC2mxdR3UOzcGaiKlkeNp4mQMdbej9AObkAg2E5P4g01WwocgJUJe9pHz6USaz3z/3RtOxwfwwsB1TuyNKRJszOp7tZLPtm05dewFcFyBu3Z5krQzXPeWzkHnMtOc+M27ExtnSdcDu77ivPhwMRZGC07nT65wiPBhFLZfzoVgYRvkA/pYeZgK358LvbXkQTVblXckIs08i4ja7Ld6/c5WbNHA9SLCNUaY8CA+XlU9vboa/oXFDFxUZjRNlgUPoWIaSWxxH6yVclFn1s6Syxp+Hmb/wR8/BjK1SpLLxkz6V9paXN/73JcyF6VRGH0OpsV2jY1rFmaMaQEo0MrCW3MpgQirQpl1+fvzuPH59TcJl9Zc6tJXpKpdqFXLAvMCZK1JmzaFBMg3yppbmalrgh8F3A2Qa9a4sd1/xhiLNx3ODOyGLxjnDzwcf0WeZw6nb+nDDdf7a9GZsixsZ2MMvd/gTBAmZCkYI77mdrPh6Vg5nd8zxyPWIx2H/aAC+3C1u2PYbXjz9mt++82vCf2XvLy5ofcdYXfL9w/vuH96z93dp9zevuZ4OPIhwsxMLLDtEzYgYG5eE1qmGkzVjqKuVQ/U5fleuE3yvBf/RebKOB6FsGIdXUgE32H9c0ByIUwgjHmj8i+iVyl6qi15uUblEsO75n/7js4PONdzmj5AqYzpifvpGynxTIlaDOCUtecXoop8d3gnGpaFRKkdU3oilhNzOjPnUZhyK0r0A2CnccDbvT/DalWgvlkg1rNc7Hks721yOlycguZDGKkSsqpbawxLMtRI9aTOXn5vy/V7A0+tRXTKknVAwZPFeV4yRpJhCSEsgdjl3Sx0QV1QVYPfoovL/siVWx0pY6BYaJmMVY9dHKZUCiUlli51z57UxcTTTUBo/a0kQYU6aQ+xLgyfVXxcb6PKYokl6s86QfXiF1qltbQc4uIco92p0DJDBZnWQIUFcGoisKbKAjmfTngf2GyvYLNlu92QTo55OpFjgmpVT8pCMdSkbbfPB3KpDNefsb/7Gbef/jGlFOI0KtMpXU7vC6S+3Y90a3HViTGu6t3RarXtEnC35wHKn691ee7GGGIWZ/DF9V4y3t5xmmasC5KtaufVhb7bbcmlcjhOWGMYhoDzbkF3rTq9mpOQIIaylJZMcyalwiYYrnrHy+sdFQh9ACql9KScGefI7X5guxnouiBONxrIKIsCqyDTpfFrgOvFwm+JK+uljKQC0/nI4etf8fS7/yfH919xfjrQ1Y5QLabf47sdYylMMXN9/Zqr13e8/uNPmc01JZ4pcSI//Y4y3jOOEyklqDNRAaSURuz5gZwSh/sTqQa+/f6IDRu2ty/xXc926AjOMfQ9zlp1RC3WCzjR90EAWdP/cBH+AR9//ItfYK1lt9nKfZuELZk8RQqVVKUFa8lC4ZZ1UUTU0lq6vseHQL/ZqvEVivQi7KxZhAZ+1mWDEZsh2a01E2uNCK6meFGurFogMc2czkdSasBTEKF7jToa8BS8F40NXauiVSGZI4xRarCIN1trMClKsKBU5eYsxVmcjsPpLKV4k2SLrs2O3kmtvPeelBO5Fs6nE/P5rPZaaLjVF5ybMdaw9U7vyeB8x+76jmGzY7O/JXQ9vh+oMVLrEfKEmZ6w80iXz7g0kuaJiCXOic4ArtKHjmGzpeSZU4wcHx/55ttv2FjYOQO7V2z2e2YMM1KWmGLbBj1h2BK6DZ21JGMIpxPOB7pNxXgnzpLzdJtBWFxWNm2LBldVWEY5J1K22CwaJMHrRtwClOVRytg2BpM0v6jEKLpFzq57Z0X0jIq+ToAZDaCc7p8aQOacFNxO1JLVgRE7Ra2kmLAOXLC6X16UZqbMfD7JnmcNoRvwTkRPvff6WgETsnaKFV0I0b8Lqu9klO0l+6QAr//csdhD3QNr1S5UtnXt7Om3e/phwPVbbNdhfCe0FwV7q5HwvAUPDQ5r2W2na81r9viHgcwf/tEHK9oyWZJGEhRV5liYYyHOMted7rWlCIhX1KF0aoOaAHgqUr5WsSx6JLK9KQCaSaUQU1WwU0ppgQVAojGeL4Oy5vfojyL0DGOBmFUXqbaeYNL965Aq/ViZojCapZwVphR5GuE0Zs5JPChnHQnDXI1CNpVUDLY0NuCqXVWMBHWCUtWFlQ6aqNRavVpWcEFseF2oKbWKU12qlHuZjKzJAlZ92zkXYq0UB6EzbIJl8yT2oyo4aAu4bMgGqhUAOsVMzqKbVYyAaWI2FIbQTpG1rCMqOkprAnaaRzKJT159wu31LS+u79ht9gwb6SDqtZS4+XPeS8Z92OxwzhPPR+J4htN73pfE29ORMWdy7aRrr37+4+GMtWb12Yv4zEFyc9r4xzCKnu9SBhmzgOpPOXK77fjy55/inOOPvzR0pvDKRwKFzRL0V05z4jePI47KYApD8PzPPhl4nAtfPyUOc+Z3j5HPdpX9IMmyLmXSbPlwdvhQCX1lziuAUApa7iZj6ppKA2b5bwGomrCzTBVdMyzGbJlfdf1aQ5xKZu1sR5VSvWAkhrHqBzcih7UCbq2+90/veFbu1JIXl0DSxWur0bLNf2EgBNC7lHC5ZAcBC4gkrEfpMrYG6Mt11HoB4NQLFHFljkALyCXWXMvfdO4Y0YJdS80v4kcqUkammrka44pfcMmkh4+BuaKvyXGmlkzKZwqaTDZGgGPU1wNEQ8rg7Z4+wNX2S1KeOE9viPmIdTvpoJykkZXo7Tqs6Qh+w27YUal4H6QMrkTO48j7D4/Mc+Z6f8Nuu6PvLZjEnCaeDife3z+RauZqc0OlcH/+nm24YtdfcbPLWONJOfP27bd4H/j8s59zf3jPYXziwFtyPrE1L+nDFb3fE9yAHzLWqWTABbBUq1a0aKORJeJrzCfnVzIGhnkeyTkCRu5rGBaZgMuE2YI7OJk3TczbaiVWLfnZM7JWK71MwTjLdrii8x3Bd4zxieF4Q8wT43yglLSU0MU0AYliZoyRSoGMMM9SmYl5ZNvf8OUnf8nd/gte3/wR19uXEoVbI3HkIiGkc1au6GKerknvokrgxtiFsfxjCcPaYpZ6CXebZwuzliIxdlXZFmVRBQdV4xrxScrvbcR+f+BJU0BZgafm4LUuduWiBM4Yg3d+HYDKIsgtd6KOaCmUVBdDICVsqyFu42M0O1GsubQPtJKzXJsIeSHHrALla/e5ZTBp1DGWrEOtK+iEIp2LQVsyt5fOrExu2YTTYkSFobUK5rWORWAWkGYZs0sEq+oNNiOEOCarXoxZENiUZugNXeih7xk2PSfvSPOZkiqGXsEnJ8BTLuQ4MZ2fqNXR7V6yufmU61c/4/R0z+O7N7R66LVccnXSGugGZil5MAlikuDWgGYVrDinqpvUjPZSK7ikiYxMzly43m/YDT1XmyCldMiYxknKLOaoTkyQWtj7zUitlb4PWK95biXmWAWdTK1LxsOp3smsAfzgDLn33F5tARh6r3NB6m7HObLf9mw2HSH4tR2va+WUVRx7pOuJUeCy3ekyu/VbMYhwcT9Q0sg8nbn//ne8+cd/T5nPlDhirLSLJXQYuyVVAZ5evL7i+tXnbD/7L+huf87T4xPj+czDN3ecHr/j6fGJ6TxyeHxLnI+kchK2yvSEiZEPj0+cZssxvSfh2Vxf03U9L17cMvQ9d7d39F3PdrsjhMBmt8V7TxckEK0/MXHen332mcxV1WxKURhOJbdMel7XX0qkSTat8/kswbYRRkDwTjdCJ+epCti29Q5rlyQFeBY2lJGsaDMjpRTmKE5RpeKMAlIpMk5n5ijlcCF2eC+E/BUIddrxrnVklPlXMYvgvvee4B1uyRo1MFzr47Owb3KS0rvzODLPkWkaMcBmM+BrlU5o3hFLIqbMNJ6ZpmnRTXHOU71oBhgsQbPp1gV86Nhc3dBvtvSbK3wI+K6XkqpaIEeYDtg0EcoZmydhbWpgvDGZYGb80GOtaDSdx8hhjtyPM5/c3vDz16+AF3TbLSVX5pjJxRBjEcqxdfhug9/tCTkTUsKFTpoB9D02BLb9QB96KWW0mjGtTfzcQGOm5oxVUAbAFRSIudylWbOgiMOSchGNsKgMQ38JVgnDqnUSlCyeFwCpObq5dW7NWh4tAqvWWKqtUAQMSinhqmiHoaBn22JyyUzj2Dx3AZrrdunsKSCPgElJ9TBKaaXXAk41ALR1C2sOtrm8f577HpevAy05ddKAoR+29MOWbhjwXY8Nnahl27XUuwkZNxix6Fw2KjAqHYOMtqw2H336T+PogpX28dHq2kHLEgsxFlKUHaiFWFQj4JMGTK2U91KbSVySFZg0te39yiyqIgaes2pMldUXXcr42lA3d2b5sRUdQayGsaDXrLZR44MEnFKlmyuzllxYC94bppw4ToXzDJMCT9Y6crUiGI4EqrkaUllL6JcOfg0Wa8ylywSoAefFHylFO+dWLSdoDCMr19O6mkXpki3spSrC5rlWYqmiE+Qq1hu2G0ffrbqmNRZqsdQspYjJVoiZedTxKwZjITm76KJKh+PG6DIXvT4E2BBWWmGOE6nMbPuBT1684sXdp+x31wybgRA69rs9fdctILL3Uuq9v7ohdB3xPDKdT3z7D/+B+HTPm8dHxmmihKBlTAJWHk5nAEJw6zVhCEu5nRFh+HgR1xhhSJlaKPPM9dDx+Scv2W8GNts9vkZ28QPESDmcaR7U148jX5/OBAovfWHXG/705ZY3p8K7OfJ2nvj104yxlT9SuxpyIUd4GKGvld5UYinNVWdh7ymLQboktgCq8Rlkwq74RQP7BHhtcUe9+GqNPerFWihUMvLMTJXA2Nu6MDPbbmERFp1bgpx1Df2ULJho7umcqJBqE9PXmOgyaXMBHl3mDpYwTE9k5Y0C5DxLMrRV0gCZ+uzZLGdZgCd9S0smfwQ8Gdsqcuqz98llqERCwzrqanPa3y99PWmU1ZikyoIqmeeHXe1WKczVSVWKGalFYmBjUVF/szQjqTUBDu92GGPZDZ8zzh84HP8Wm89495KcjGjylFa2awV4sj2bbouxSHfZriOXxDhP3D88UYtlv71iu9nQdY6UZ8Z45vHxwLdfPbC7dty8vAZTeBo/0PmBLgzsN4Zge97cf8eHp7fcXL/k9uYlYxx5fHrkzD1z+UDtC/jMdrvRmMyu/qomWY11yjix6+8WMohRvMGpdICMSYwzcxQbLg2iLLV6Orc21FlxxEJ1UnYuyTQhG5i6Jg/bvFgAKSTpNrgtdHv225ec5yesDUzpxGH6QMpnxvjAHE+kelhAo6Il8xUoeHKJxDRztXnBi/2n3O4+59XNl+LfKXjknCeTl8RDi6dXNpbOyypnrTQtOvPR2mrLxPBs8n40dy9fXDWoz6aBvrLuvGI/pggRhFgv9CL/5eNfVWq3oGKXiFlzsC8EBmFFupea2IZ0F9Fu8E4BH8MiZNrWd5ET09gBi1ZUKaSsaHERDQ8fPKaoqGzKElCqA1G1DW/jTy+oMzSgcDkamEYrA2MNIMwlkGXQLnhVs4+N8FYXCqhdeOsrgwm0JhOj9bQXwNLi7ayvlbGTLN8w9Dw8PvI//s3fYirshy2dmdjzjunpvbAYgsW5jVxLhhxP/OZ//O+0fGdUh9MwHp9wbsAPO4bdDTnNpDgum8GlrpVM3rqMmzFWg5+6tgBv71nAtWViKMLf5rwYkqolFSF4gq/47ppGda21UtLq+FKNzhM4zzOlFm0NbMlV5hxWkxVKl5YyFtU1wFCz/PvuZsN+13N7s1W0Vl9vVifZO8d20+EMpChi7cZ7pPQjg02IYHcrialI1rjqgtdb1zGIOakAcAE8bvOa4eWf4a1RoEHm6Xx64Hj/RvSZasZvr+nuvqDb3dL3Wybzlpzv+eznv8D5P2Y8JeYp8bt//O95+vA1ob6lcqaWCWpkP1zTdR4my5wN0+GeU6l8+P4bMM0QOzabDT4Ebq6v6LqO6+tbvJbgGGP43/zv/3f/kkn4gzlqnGQu16wAgjAVnToHjTVhMVTrsBRKVjaYc/T9QPCd7lJKpbfgg2ZlaPXmSttuhlqZgQ18iNpuqiJ6TosOnhHh1OAcGO30lYqKCibVzdNMrPMYk3XFeHor4Igwm5qjZMgpkueJXKSM9nw6EWNkPJ3JKS+6K+N5ZI6Rp8OBOc6kKEKYx3GkOMd1ipQkdOCUEvM0E8eRNE3kadKgBrphowGdbMxxjsR5oj7eE8cRi8WFQD/01DRTxnuIR2yNWFMYes92COw3A4/Hie/vT2w8xA2cTSbZieM8cn96T/UOEzz98JpPfv4zwm7H43nkPEdOY6SqNLxxAeMDczfhQsd5mjjPAjoG5wmdPPfg3NINU40JlIwzLI0GUFCm5CwsXWMQsYUfhgmrHo0CVilp+WFagqAGnlwCQb5pLLXyZCtaJ4fTkTjPPB6eyPPEdDpQUiSnGQOLA1DiREkzOY4Y63BdL8Bh6HHOs9ldawmntFaW7oOezgjAblWPT5IconMlY2gJfWDYDnTDQOh6xvOJ1pK46Ti2eb/uHnIYoww859ld3dD3G/Z3Lxk2WzZXV3RdT7cZcN4RNHN5KRjefCSMgHIi5OuXEnmDat5UfsSZ/8M/nD6f/dCRa2WuhUheWGFNY85oYq5pabdo1pqmOyPlDA0GbMGRb0xtoObKFLOABup/YRuzQ1AF58QR7nxg5SYLo8MZ0cxtgbd30DmD7WEbKudZRMYl+Gdhf7foX/yDircKeKZCQhjm1Mo+iBj5+5MIQ2+DiItPqSED0tnTlALqa1RFIFrwazBSQmeEqS9B5vMyjnU7LwuQZ5HMuEGYKhXHhp7DmPm//uM3BG/oHLx9nEiT6EPZIiXRrmNJWJVitNRfA1zpD6DlJRIoOyf+Dxdxc2k/q6yEK9IJ8t27e9Kc+N1X3+JcR+gFJN5tt3QhkGNW/03AmNANWOvwFSiZDx/eUw30fU8yhqdUyLlSi+i5iNbWKh/QNERaWaY12smNBh8pyKI+mBFKFGWa8MHwie8xOTLOZ/KcmKaJVGCqhu/Pie/GzFUwvN73hKGn7zvMHDmWmVOBqQigmayn2iLzu0ppYFXmbzWArwLg27WSolwARma5zhXwuWTCtPnQQMgGs6PuvbCmWPZw2XmbXyzP1JoWw0jCEn2NlD2Jvo/MyfVvP6VjiQONjG1jKq0dYNv3tQSsJe/b75e8fPuH0edmBVZ/HrcsgiW0b3KsTLa2P5llc7n8PcvPpvkDl1v8JTGi/W8BJtSWLAkQs16z2h3BOx0WS17eKydqnVvBUJ2wa4rqseacKHmU2CPNK/CCziMqpc5AZeheYU3HuH1PyYXT9C0leVLq1ffwVCw5SYxztbsldJbr6x23N7fUakmpMsWEM4HBe4KH0CXOTyfef3jP998f+PabB34RXnGzfU3hRK4HYp455kf6fmC7vSWWiZwjKUU+3H8PJbHfbkn5TE4TaTgz+0dmvyH4SucqzoltyaVikHivWNEANpfAk7JtWtWNVBaswJX44qLhezodcF7IMFI26C9i+taAQrVM9XMALbUUt1+G26qf2BJdkkzMKiB/vfmEXCLX/UtinjinR+Z05HB+R64iEt7AbNlXEt51dGHHy6sv+OzuTxjCji5sFKBMS1zrrBFMQ0HMBjvJ37VXuW1zr9IaSq2w1PP5+myyP5vil2vw4t1VbGDrAMsiQq5/9z9+vh87/tXA03OE+QJ4avpLl7fTEElWw96MfdOIaq9vWeQGUNflhpQlZO3SYafVwRqj57FG2At51WVa6p0uHInGZirmor74YqCM1nmWJv6GkfM0566BGVaFmWlgm3zewnQy62NpGV+WS6rLNflWrth0KYxcY2mt/tThDKEjpsw//upXxGkkZLjdGv78M0s8P8oG7xxd3yPCxZ7x+MQ3//CrhSqcFZyrubLdv+Tmsz9h/+IL4mxVkFyBn+YN6VG0tt5ahzUiSt6GF72/pQtee75KvWtBtw4uUpInp/deDMpGu0SZRmJudl4nijOSZcslSknQKG0pG0OKZmSWCbYyPKSWXDb/630PrOWLtm08Vtkpzi9Z5JwS8zRisHjNQpQiWjdGu2qsF9qu+XkAKqBdps7SutRZjx3uGG6/pO8HcfLOT5TpieP9tzy9/TW232G7LXbY0129pttcEUKPrzM+P/Hqky/Z3X1Omh0xVubjd9hyZj6dpMtkmcAUNt2e3hhmHCYaDk8HzuPEh4cHackeI7UimVHveXl3yzAM3L14TehEE+qya9Uf+lHTDCAgjGacmu2QzcphjcVbB7XgkO4pLbANXa8dLNvauNBeUwvS6PO1iiC+AOq6KWVhN43TJHOpynzKKeGcUS2JVgNuVeBQwLGcM5myllyUCtYJaGENQTcX76xmfQQSHk+i+TZN0ha3da1LMVJLwSurZ55nxmnidD4xzbOAytZynmcIQQSpFTDLKZHmWVhJcRZwS5tG+K5XAMySc2aeRm1skEjTjDeSJMibDlMjpCdsGrE10tlK752AT33g8Tjz4TAy9g7jAyJrPvNwmPju/YHNbsP17TVd33H36WswlsM4cR4nTqcR0d1yuDDggoBgNkamODPOsvE7a7XrpMPqc7XqhBYVXbZmbUUuGca1q84iOAcXYAvrz7VpvpVFKL6JNbcN2yDOT7NJbU9sIqZNC+N4PDJNI4fHexnz8UwtGZOyJh0CtUr3wFok22+cw+eI74ZFy6nb7ElppkwjIMCTD9KxwTpDCG7ZJ0vOpJjwVjr7eS/7S9d1OB/ElhdxENdkSbOJF6Oh+3/w0uhgu7um3+7Z3tzRb7YMO2Fdhk6yks6oCmRh3VtbUGZYmU6tpbKW2LVgIi8ZwZ/O0YCh4Jws/5IZ16TnAjxZBecunS3xWTToXZIlum/ai8BYP6vUypy0kYeWclqrQA4teLLa+tkvySmz/E21pKq0k5eunYbeiaNcqrCEWn8Us9xG8+0EGJBOs6I3ZKuUqxkDWy9gk1NdxY0zbLzoROWKMJwMImxeELYR6q+og44xooVlpBsfaHmYuRgIhVBaKXMtdmn8ongfzlg64zjPhb/+6h1oqUZOlhQdplpsFdDGeNFGshZSNM/YMqUqUKfldkaTCReSb+vWg4BzGIfFQ7U8PD5Jx9soQZYLFuctm35D8F6Ap1woVZiSVZkDex/onOWmk/sPIdBhqHEWu17E3+2sFQFuszLNxHlKOj/06bXYQMfa6u+MBjtlnnHJ8cJlchF7nOfINEXmAo/F8mHM3M8F5xyuC/gu0HUe4wrnKqBTqoZkLNl4qk0KPssclUSvlC/iwbi6JJgaMJCXvOGq3yJznzVmu5jPEgZcAFp6q7Z9NwpKLjGDnKMl6lseepletVUYaDJ6AYZZF+5P5FhL7WTyNhaH5GtVh62ujNh2rKwLAQLb82s4UbP5VUtAufxaxvDjALte4DzmRz6nAV3KSG4PnzWOWeLFCzvR/r9W7tj1BZfAkr5vTVAqQt/GyvjlvdUYvO8omigyaWY8T5r01tK6BTwR+1lKxBhH72+xxrPpXzDHA6fjW0oMlPxagTEpV8ulYoxjt7li2AZevbziar+naOnynDK9Sjp4bwg+k/PE4+MT9/cH3r878Plnr7kabhkjnNOZVBKndGAzDFzv9pzPJ6bzxLvDB57Ojxhj2PYDx3GSZgXMJHciuQPJWbrQY71Xv6KtE+k4UbkAnpQdam1LDK77EqaBkpV5En9vnM64pHqpNQihwTQ9SEOl0LqhmmoWpt6qnSRYQNNpkj1XfLlSM6nOGGPZ9rcyPwukMnPKj0zxQO83xDwz5RMxzUzxJN3uUiT4DZv+lpvdp7y6/pJWJRGRMWqam7KUpKOqKT+2ZmwzMMvvlvC7LZyGuH98mPV1ixk3rQTv4g1Vd0b18wT6LTrmv3+vut/7lZcMnY/BJ2gP2izMlyqWVxztyiK43fSMckrLYi1VQSMdgOZYWrPWD6YkwIg1FuOtKqxLdr1kYTsZ3TxlQgpKKYKx2k6Q1YDlvJazLd3p2rUqwNYU7ptDUtSplc3E4n0Q4CWvAJQwruRGigYnbUyU+bY8yKVtNutcaKg/1IXqGUJH33dc73veHO759//hP/D6pufWfo7nLCUixqkBzqRaGFPhnIJsltXiiGxcoStnOH2LS6+UEu6Is7QXyGuqdDnqEkjI36w++0tavoBNDmM9RjsmOS8ofOsOIQ6bXVgZVe+/prQg/+LELp+sm7oyyhbheeVatfnY9rWW6W4LzQpd3fksDmjbuIqUilYjIra1SMmd1YBQyieLCs1Z0CB2KcG5cJV1suhcv1grzZVWQMr4gO02DNcvsXnE1hlXZ3y14BwPNjPHic31p3Q3n9JffUK/e8n9d7/h9Pg/8PjmPzI+veHp4Ru216+otadWj7WZu09+xvlgidMjD9/+LXF84u6zLxn2r/js3/w5trvidD4RU+TDh3umaebp8CTsl/NJ1k4WMOLtd1+TS+U85RUw/Akcl4Go6M91WGvoQ1D2hKx/Z5wE8A5qVufXOkI/yGucXbpDiYE2skBU5DcWKY+bY9QtqQVTlTkmzuOsGit1ASec2rjUdaROymhs6PCddMdrgHATWrTeY7yn6wIueNEAiEnWmjULq+twODBP0yqYnlq5gbCwznmk5Mw4TczzTM0ZU+vSvTHlzDRHjqczCcuwE/0vEQwu1DhR5pE0SZlERcYyq2i/NQ7nxXmyzuNcouSZ48O9AFnxJK3EpwOOyqOpjDHhjGE7BD6921IxxGp4muE4JUoxdLsN13e3fPbpJ/Rdx8OHe+1Cl5iTtAoPoZevAgHD8fGB0/nE4fDE8XikzCNljnA8AAVvJZs0bPeErhdQb4keCrXmxSmlruVissbrQvlfMpBmFbluToMxwgazVfS42r6BYWGStFbCzovTM0+RcRp5fHxkniemcaSWhCmtFUyiVqMaP7AaP7muHBOmjqRqREx8GDDG482gtya6UOP5TFfKAsA2G92y0+WCARVTktLBsupUtEz+pZPT9u+mj7a/umXYbNnfvqLb7Nhf3Ui5Xd9LBtJJGdDSt3Fp/Kq7aQNXFnFxWXspiW5W1tbXaR4XX+OncqxBsOx9Ul5rP9qpP3qPUTDDVLyr0oxD2cKr8mRT2JYxbTat7VttDSyAh55XOmU2kEixcGvpg19aLlMFtLkK8OnGUI2jmsohFuYiJVEW2DrDTQcfPLiobOdUCdax8YHBC9Ab4ywl+EVKXEuVsroxC2qTijCdUlFmkCYRWQA3lgzukigyFd83/1TvcfEvVjRo2fErAsAZKXuupuJ8VfFpeW81MoO73ioYoSCbk/HLpmKKwZi6stPaQ74ELdbRfz4RWOOHolpcKcrFNe1iV8Wfmc8HTEW0XUrREh1EZ7PAGUNnDdsXe0LvGTSQFXZuYUpyfZIcsdzte7y1pKIln0XW3HmcSUtLeAXGAKzsXbFazqny7v6ITzP3IWHIokGaCo/jBNayHXr+6EXPq6vX7DvHF/ue694xDB2f31j+1z+Hc8z8b3+x5fWu449fDPzu7Ym/ik8MJrG1GRVSwlYD2Qhg2DrG6aFFO6KZU5pUw+LB678ug9kVBGzAlUEAWWvl383Giy6gAqPGCAC2LMg2iZ4/T4lLLhg4P6GjXCZoYGFlyjpp9mX9Kh/Z7ranPvdHL0GjC6kBs/pVC/lg+ezL7/+cb9v2s0s48qPDXIJVSAyh5zTmeSXL5T20H6va8RbnLosdo5veBRtPfYi+3+CcI6dRu5CLDqcATYZs8uJzCGAiwNKu/xnBPRHLSHSZ4/yOWgLUPTXDPM84Ai9vv6DfGm5uA76zPB6+53B4YD4XYWr2Ae86drse3hkenkZccPzsF3d8+umel3c9h/MWc4rc35/4p998zd3ViburB26urvjFz39J/35geOh4e/8d94d7Yolk9VXJlRJFt894jzdBSCe6r6BVJ2tlZdWYTBnPDQcgq/xKA7tVdmAB24xoXRWNLa0lBI1dlW3WtP6qaoPV9niq4BsgidlgpWdibZ/XdKJb5U5OlJpxJrAJ1wx+K03XciSVREyjiNPXQhc2bLprtv0VrTIra4K8ATw/MlN/ZGrqXr7Mc42PPwrrGzajXsWC51SV2GmySZcVFLCyv1qs3kC7ZWH8K47fG3i6LJ2Tz74ovdPfa8HZgmC3QKfRJRtgUGlUs9Y1ZQ3ga9UMARdopIJLbUF7Z6VmEwEvioqUrx07ZCzTR5nmhoxW3UGqaSUP68A3gIqL4EEeFmQVIZYsoVDOASISCDSQpuRmUJ93t2rIaTNC5SMwro3rsgEZFMRxdCGwG3pqnvn7X/0dh7stf/nznm1X2CjVsFwY75gLU/a64Vqchc5GfJ1geo8tJ7y3+CStHeVz849giqvBFmdWnkEq+Rk7ylmv2iTSOUUo6a28MS8Bm1UNmtqYU8p0a7IRWcfwmeE3F5fSWpaaZmBamWJjIcn1rOKN5eIOhFov15VZSYLieRqj6C2FpVWlEWT8slvGM+Dp4jPX53z5dzF6zvf022tCmSnTB+o0YzsUzCikPGO6gbB/Rdje4ocrnj78D7z9p7/h6e0/Mh6+Yzp9YNjdYN0O43r2r/+I/d0rjEtM547vf1s4HY688h3b3Q2//KN/w+7mE3KZySXz4f094zTy/v17xvHM+7dvmM5nPrx7yzieeXf/jvM48fb+ICWtP5ljtVVS9iNZnL7v5DkvIIFVYFlqvptOU9cNshk1u241uKYFANJtLGr53KhZlqrCEBaYYmKaZmKqxJTb8pZAUIO9ovPKuoB1CecDlUzNyu60IizpgrCHnPOi/5OS1H8bSEme9fHwKN3xcgsclZulAMo8C/05xpmYogbrVXRAnEM65SXGcaQ6T79VcAQJKGuOUtaVJrFxmoHKzb820h2zHzp1yhMlR8bjI6QowFWKxOmMoeJpVHsYguNuPzCmwtNUGVNmjoXeG/abgd1+x4u7O7oQOD49Mc8z57OUE6eKCJEPFazHuECOkVwrh9OR0/kMyuIqcaSkSPBOvwIhdOKo6H22DGrrekNdO25BC0bE4UTZZgsAdfmfsQhprrV2VvtfmvaXwQSn+i5WNZ+EsXY8HYlxpswTphZcKZiqZVMaWD4D4Y0+55yXYNwNFWsHuQ7TUXOmRNGOmudZyt+7jPEN0G/AqjgiDdxroveleWRLUC93rDeuLFJLPwx0/cDVzS2b7Z7d7R3dsGWz3ROC6JdJh8aL0pX2Zar6AdCyk22nXITbk+zvcR7JORHPp58e8CRLb2lWYEtLAP0zzt7F1iQ2ppUbta5fa7a2MbqbzwPm2X7Z9sf2eK1RrRFWpzyjdlW7bubc2C6wdfCyF7uQjcFbEf3tkI/rLWyDCJVaK75gLhVvLJ1zdE7mL1X27lQrUW1lpRKLgCy5thJ9AZ6MdRrjJxqcsOzIdbU1kqSt5OkiwFA2VRNexegzqK1EqC4MKqvMjZQ1MFHAy3kdKwCrDNj2LG1dA4IWRLcxb1PXXrgVi0/UfFF5fsIYEfkJ8WsEOC61YAukGCkpa9OMStdL+fg8Z3IuTKkQDKSbAYNbSr33fSQqkJRrpRpZy9ebgd57jP7+w2hlXztGknYGNTTdVLBkqoGIZcrwdDizKZHDJhGcjFdOhdMUCZ1jF3pe9IHXVzs659h5rw0y4IU1bJwkM4OFbR+42fZQDP/4/ZmhFgZECibpODd/sbHLLtdLi0dWXrc85GfzXX112QuM7HuVZ7ISxqwMuOaTWhAA/bJeeFmul87sGgtc2s5/Fhf5AzzW0me1XepTy21WHCwxyyXo1ACgNkaN7fQs0L2IldbX1Ash+WWltLOuANASi60aOO09S6R+Eftd+o8LqFQvYnrTmE4/PC7JGnIOLYFya/lfu6fKxfzSmNqHTuPeIHpydXqWTC16H85bbNVOxlj68AprA0P6FuqRah6oZsBwTa1GEpad42r/kmFb2e2LsHRO95zPR+JU6KyB4vHOMwwBDBzPkc73vHq95cWLDVdXgWIGphg5HR747T+95el64uH6yF/8+Z/z+vWnUm2QE+/v33A6P7bgbEnmiQaexVYnVS41S0xmhYRS2p7SnuWS0NOyOPVrG3DU5oq1LZUlY55yxtbCbIRh7lwQz1h9+sXfq8sj1nhOnrSULDuMUeBJ/2QWSyJgUi5NzkNiv+DXjvS5JFKZacy/zg8MQSRgqIWiFReLLmFFDdrz5OYltrACnT/iE8iku/jFxfsuIm3JSZfFf7IXcRGw4hm1Xpzvcj3++Mf/2PH7c6P0WIyDfnhDF1umo5WfNe2P1qGtObHLhbdz0Az4yr1ewJ6iVEzVgBLf3pDVoyq5kFJesq/WNfqhPpiiOk0KAhUFLZr4eBukWkRQu5XFtZK6bIpuKHqf+qBaS8V24x6otpLirKypi1I+czlZVtAOVlDuWT1z8+70GaaUOB7OWCz/+Z/9Z2y6wD/86m/pTOK7xxPXA/zs2un5JnKqpLkwnjJPh+b8e+ZSOeRAPkD+/oS5eeT23VuM79gNA4VOS0zk+eScyCljrHRT8q5RLkWro9LYTuqgKKNiniamlCBYvEUBw4uxwCEjltdgjsqada1QV/p/qzBqG0Gjvj/bvy82EbRuPgSDd2jmXbQTam46XM2Fs8sCMlQVg3QsOgXqqC+gU7ULmNrYao2a+Dwjo3NAkXBTMjadMNN77PgND9//jse3X5HTJKBQ9bz8+X/Gy5//Jdev/5zT+wfef/vf8fU//F94/83fYYlYMu+/f4N99xbvpdxlc/OKcP1CxkzneQFB1HNkzomQE6lArZbt9S2bWrm+fUEpmdPTz0lx5nw6Mk5nfvdPv+HwdODXv/uGeY7/SsvwP92j72STaLXhoZV3KnvCKYhQaiHFyPHwJDTYaRa2xrWwH10IlFiYk9TSo05oUcHpFJN2BSsSdFzUW5tWnlXbF7KJH46MZ2EtWuu4utqz2+3AWELocU4DhyZwXSolJkoVkb90EgZPZ4tkWTVyt8bQhUDxuqkoANXKkVuJRN/3hBCwXhiTLgQwEhRY56W8bpKyOqqUS5Q4k9NIzRPOqj2vohsUvABN3ncYAyVFai3MSWjiprQGBJZcLDFJCdtUWoAolOf9psPPQmMeDdIgoAvc7DZsQgAFGU6mMsXIeRaQLanNt8bjQiYAp+MTp8MT5+MD4+lA129F5FxLIaV0MNJvZ2wX6boe34kAORYB+XwQdo4LKmL5PEinBaWmaR4ZvBdAMmUpO1qiTSuAU9Y2xq21c8jCFo1JhNzfvX3P+Xzi4e135BQxJWJNpTPClAtWOgimtAY41nope/TS2IAqbZ1Tmon37yQgd2LD+76TLnNB7ikqC9moboa1FqxQ3EuGOWbGaeY8jqQoIrGL86dlnk3Ladhs6LqO3f6aYRi4unnBsNnR7/b4rqdT/SnvnDYBaeXlci9OtRqaNktLSmXV2JvnmZwK4/lMSpnz+SjjOZ0/ssV/+If45lq6CQvIsm6DqzN+MSFZWEsX8S+1idsKwFOM2AZri4rMs7DPVtZTC771PBeAk+zgF2VjpSqIzrIeJNFkyEU0FylGwXthKk3JkLKYR+eMdLUrmac5cYrC3s7GUI1lrhZTGntcNUKpC7gyDIOsgWFLqYYP7x+JMV0Eozo6uYG+l663ehzqVzsLfrvEItQKKckYWQ+mBYgYfCcOiwQilbUmS8jYqa5jVWqlqobTszKGNtpVLsPohzZArF2oXSg78r3JEXjbYY0ndMI2TdMs+9IoUgp93+G8xXnxX9yYpIGBMaiKIJbKxls6K+t9zsj4Z3g6zUSfueotvTV8se+JOZDHxHlO3J8lMesdBGe52XtKhcdzxjvDlAtTKWTVb3kcC2PMZBPoXGA7DBhj+P4wsw0ev7MEY/DGMHSOfedBRZk778S/M9LFtGAUdKy6xVbIVX17oCU9l4CpLqVyDZh1Voe+zW8VJK+q72UskATYbEy/FapoQEebERLsGsoz0PICg+AyUluu6qdlupbj0utev61zvzF2QOxI1m7nl4G2gJoriLTSHtrvLl6rmlot1pJpfsHovBzotsbac1N7W6XeWH3ry2ckD1LkVlpcv67lC1zqAvJiebjPS8EvxsA2AEnovlnJDC05GoL6VHlCuuxqHKkxW00FY7LaLwFVarF485JgA133SLaVUo9Aj+UaHwzbTcX4kfP4wDRPPB6PHA8jtorw+Mu7a/puw/FoKNmz2wzc3ez45OUNL+/21BI4HhLff3fgq9994Ff/+B0vXk68eDmz3X6F8ZXB9Xxy9wXzFOntwNf3X/Hu8I5+sIRe9vuh22BNL1UofhJQ31mojpIEXBcWTgOdpNPdJVDb/IQmdOi02Y1zYYnZDSyx93g+Y62l66poa4aOxp4zmEW6gotnK3NolcN5DuponOu083UVHzamiaUZivOElmqtUh1QS14B0IuZ0U7f2MiL7NA/k1xrgNTl2mlz/NmMM+u1omzNipBqStt3LsDY5XVtc7yMyTWZ9Xwc/uXj9y+1Y2UyLb9rIE0zJG2k2gbwLGWjG/OFA2AaeIXeVEt7wjp4VQCmkgsKbAo6WUTwOae0nM9iFsV/gyHZ1LwtCcmrDpJdu+5VqrQKz3m5N6uDqH6TdvK5NGoKPKmhdE5LdKIYlQbye+8u3rMCULnpKenkafpWbWgtbplAJRfG84Q1lp9/8TNKiXz55RdMpycezo9yrdfaQbBGSq7kWJjnynm0dL2jM16o6MmTz5X8MLF7OHF+eGC4umbYbMGqE6fXleIMxGX2O+fwqiMVQrdqJqjRG88zcY6keWI8j7ghUJ15VmIp99+8JmUJNMfYwCWbyS5edZvkK6L8zNlu1v3itdYK6OTdRebTiGZPzQj4dLkHXmYjLh2Gi/8sAkitLS3r+t6lBv1yvbQ5b7E1Y9KIiU/U+R3T/dd8+ObXxJyIOXPz+iVXr37O7ctfcPvil7z/u7/m69/9hje/+Tse3v4j++tbhmHL+fRALonOg/eBkkac15xOycvnNz2vmOWrtc7ebISyO3QBYyBOo5Rqpcg8jfQh8PjwwJxgnGZ+KkcIKtpspZTAax14+1qyB6VQcmQaz8QYmc4TXdfTb3bUCs53lFyZpqjZlQtabREQnOYoOGljDlBLwdaC9uZ+NlGmaeTh4X5p0VypdF0v2j3eY4ulWmEfpWZTszD2jK3M40g6n8g2423Bd15ALIMI47dMj1GQo4q+SbPVXRCdFqvfUZ0h6VxppXwpRRW5rNSchO2UI6UknKlaj5917WnXss5TSyHOAlrN55M4+c5pECfBaJLEFjkJ0xAjbMMhSFQ1JdEbsFY0iLZDT/COmhNphrFmphSZYiSVSsoVH3rS0O4X5vHM8fED49MH5tMj5uYFtmXbQJ5bycSUCDnTG4sPAeMaw3bt6uZVgJvm71x4CasTqmL1zuke0lhPGjDrJpmLiJU3kfkl4k2ZaZp5//490/nI8fGBmhPeJBWaNlTnCN0gTvrCtgXnIXQbEX8eNiJKOss+mcZJyh67Addv8MEL8OSDdAjLGWMsxen+vERJRsvtRKtsnlXbS29cylAdxnlCv6ELHbv9Ff0wsL+6YRg27K9v6YcNYRhwPmC11Xtj4OhKUUcG/RvLnllqK1uXJFScIjFGjseDfD88CfA0T1B/3Cn7Qz2a9kymrHbiwrV65u5ddg+++IdpDnpjF6iDKyBRwRWLMRJgtcTcZeCkZ7no7tVSjC2Qa878D4NnY6AW7bSnXdo0gUsqlblU2aMq2rXJEEthTJkpy9+ltM2SqsGVFuKr7WmBQIEuBHwIbK4EeDocRAS/xstRkiTUR579kkAyRnwEYyuuq8oOkHvISbLjtjWVETOJbTQwI9OvxLo8g1IFHK7qn5SK1MMpPfSZP4PYxiY2bp7/SZ63RVj6rlCtJDisdXgb8DbQ9wHnLdE4kTnIhmIyIQQJaq0kMEy2wp5stkeBJ2+tdOW1hVSEVViB05iooXDlHd5aboaBVCpvOy/Z8hLJFQ0MDduhk+Auiv2OtRJrIRthUT5NiZgqxXiM9fQ+EEvl4RwpBW43HVZzNME5rvsg7MYYpfzPybMo2AUMknnYSq0UeFoYSuu8brNBJDukZM45BQdbRzvNEXExVdA1U2uLhz4+LsEnnUdtvtd1uv3w9esq+ykezY+u6y+e/00H5eOgetk/Fwf7Ofj0fLzk50ZQWAEec/G354lieYbNh2/xCcvfLg1aXYD9y6C87e+Wy1h4+cj2yVUe/uX71gXe3tOAJ+lKW+Z5JUKoDi21kKyTfUB9/rY3ltyaKs3C9DFibx1XOJNFA5RKzCNUAXScM/SdlACP85HzOPF0ODKNEVs9ne+52m8JvmOcDLU6hr7j5nrD559fM4SBUizjOfNwf+bd2wPfvXmQcmdr+e7dOzY7w5evvuTm+o7x+owrlndPb5mnkZh6UvbSrMcJcA7aGdlU7UwsuIApqDTGRQyuz06HbwENW9WRjKWM3WXZZisnK3laNHipUH3bByQe9qZFhRcxozXrPtFATi4fvPp+miyuVbSRndOqIGv1Phsx5oLQs/Tvlf83aZvnBJZ/GXy6nL/mubFZp9oCGpmV6GItLPvB5TkuzvUj51ufxe9//P6MJ11UixaaLp7GNiqtdEr/ZlcusQIU+rb2di3YXDpf2PW9td0wLAKY7YYrqAB0XZBn9PUxJcq5Lir3WTPJDUl32imoCZCVrMKvC7reLhY1EvJlSisVXMEZY8oiSCQUNM2UIaVTFTUI1SzGszl03odlJJ4ZMNsmbSMVSkCX4oGu77l5/ZqfhcD/4X//f+T7b37Lv/9//J/BzDydMsFBCAK2+MFpu/CBEBzDxvP0dOa77zPv3k08/NPX/Pa7zD/97p6bmxtevHpJP2zot1uqc1Tv2Ww2bLZbtrs9u/010zQxjTOnw5GcpDvWPE58eHzgcDzy+OED56cnzg8fSOcT/+V/9Zf87Odf0Hu4e3FLSidSnpAWLrJYoWkcNHr2ujGVJrjYnEIubbmhiSY0em0bL4PU1ecsC6U3Umbo9DW5gUb6rJt2SJtc8kiFORKCZXPVs90PdJsNucI0r0y+lTUj7xVNoIAPnhC8GjTLdP8V07e/5f7rv+f913/Hb7++57ffPuA6jwuev3jxkrv9H/HmN+/4+7/67/gPv/4HfvXma758veHVn/xX7DYDfehw3Q5jA+cP/0SaHrj//reM45H5+IE0n/HOstndEPoN1gfmOGPHM9gASKczAzw1QKRqltNaSrXcffIFu5tX9PsXEoz/RA7vvIKEl0xHWVu1FBHVzpk4jcR54un+PfM8czge6YctruvoukExgUyczqLltji26wbQ8l61FNLchKgzJWZsKU2CQll4wuArOfH4cM/T4z1lGikxsd9fs9vtFNRKi20VeyFdTqiQ4iw0ZiP2x2lprjFSNuF8jzGW8/lMipExj+QqdGFnDVFtX0WYA3GaKKUSYwZrcds9NggdwVBxVLyBTd+RLSSrmeEkmeZ5njEYxnGEWjElCSiaE1iL9QHjIAyOEhzeyv2naCm5EJN2/quGijAujRF3MKXM8TQB0sXPG2npjRV713c9Q+jZXl3R7zbkmjgePpDThA+OzWagM4USJ6YPbwjDBh96ho2AIV3XL122jNI2qgZJC9MxZzARU90qNHnxnoLuF5o1epY1qyqS3FCqi4wSSJtkjATdOUXGp3um05F0eKSWSKpRysyHAeMD1XUy6aoWUiqIk2MEKtPJILSOBDlDzBIUm5lkDKNzdP1GRNidw/mA15JD0eFTdgwSHlkX8KEXHawkXQ5DP+D7jm7YELqO7WbP0G/Y7vb0/YbNbkfX9wzbLT50eD23LpIlOLgsh6gGTLEL2wkQAK0U5klE8g+PUmL5+HDPHGeOh4N0DVRm3v+buz97liRL0jux31nMzN3vFhG5V2VWVRd6Adg9wADgcECZEeEb+chFhA/8Qyl8o3CGIiRlhIRACKAbXd21ZOWesdzNFzM7Gx9UzzHzG1Ho7HkYYaVVRd6I6+7mZsfO0aP66aef/piOue5JRn2CkkUfg9KINfC0bKP+2jSHse6fElyjoIlpQYoxok3TWW148A6f1RrTuoRZinaFM8pckvIA42jo2DEW3oxZAKRkmFICI6yXYOCULftoCbk2QU8YI7prvXe4kDGp0BHBZJ73nm1nebXPjBQOIeMTRKyUWWmjlHR8IBe05EEFsItZbHWNJ6MV1lBflgCiCEvJZJrWmLU0ncjKZl343nrKXNQvFXC/uIKxtUxxCVTIhlQcGKMJzcUGGF2y9RrPmPnVh27xtHxW0koJT8CZQm8MnevAGUxxzFp+F6PsWUGZQAPy3vqoRX9QynilAkB9ayOJrDeHEWcMD0dD7w3vnwQwH2OQPcWK7ZOERMdHuy3WGrbGY0oihok5QClSXr7tDd4WKImc4eu7kTFEXj6OfHTZ88mVpTgH9GSDBNwFkpGu2F0vflbvLTYZSsgCbrrSyuKLyRSSdPPMUnrc9pci87i3cDVAX+s/gWed4cIbNp1pJcxt/CvwgPiL2l9DV+ECURVYujeWJj+17P/vWGI/NtipsYDWxnwV85wla80TeZNSWkOp5T2cfa6Wpb3zu1ugrjpfus7aZ2vchSaocdQQECqwk1tMqm5jA+zbcy5QVJ6jKPCl6WCJHwUJa8+2sm2WeEdecdpUxPtebEOWipGourQ1DK62uus6teOqC5QlIRpTloYpRipmjocTc0iE8ZJCwPpRxiHfEQ2cYmIKj9wfXpIwYLyUA7uRYWN5/vw9ijF8+e1XnE5HLrdbPv345/yX/+yf8/nn3/KrX/2ev/v15/zNf/oNxgX+7C+ec3V1xeXVjvH4wN//6o7j7SOvn3/Hs8vnfPz+Z0wpcL19xqvjt7x5dcvOfY01iW74jE33nK63eF+IyZGSaBoWRGhcgHaJr6TLrW3zQmRdFt1JKbcWn3ndEa8yBVKMpBQ5nY5CIDFF4ra+w2CbwHn1rarMgnOuPYtiheVZZ7zYhkVmphTpUG1UtkVINpackzbrytRmaUsSQH1EzuNTzDKvW4O2NZhZZ7Sp8/vJ+mhzP4NqeDY2VV0zavAaHqI4yyI7VJbTtu/+xyX7/hHAk94QNdiXC6qTPlbWTnXETUUJy+pmaw34svh1JPVvZRFbzFlQzoYia2at0V8FmXNOFzhCz0wqClyF28SYycQRIMCtDEsmxbQg2wpEtGe+jO3ZMNSNR19lqX2sb1qcPAlwly5YBgkwSgFrs07Kd5fmVaMS44zvO7rdBc/6nr/6p/+CzzcbfvXX/wMmZMY5UDroO7lXZ420Lt9tRR9q8MRUCBy5O4x88dUjd/cjt69e8+L5Mz7+8H0uLq+5vHkGfU/ZbHjx4gXm/ffZbqRkYhonpmnmtH9gPO7Z3z1wfNzz9fff8er2ltvvv2F/d0u4f0M+HfnJe5e8uB4Ydp5+p9l1VwGnVRpJkeVGoapj2qZGNeSoQalPorbQjsuDWQcqqv0guQhwIr9MbE+Fdl6zfG2bf8aA9YZ+ECFn3/eI2ERqC70Y09BvdPOSALZn2IgQp3OO+Hpkvv2S229/z9ef/5bffx/5/FVke7Fls+uI6ZJN/z53r37Nb3/7FX/z5e/49evv+eCDv+T6o8/YdY7eOYarj/D9Ja/zyOkucHh4zen4gEkj0v7dYoatdLFynpiSgE9OjElREXFh94HVrop932OtZXf1nN1l4eLq2Y8qeHO1LBbaT3EahQkyn06kEJlPB0KYGI97pmli//hIjImr0wmAGAdijKQgmaicklDus9aiW7fM1ZyIOQhNO0VKKtKdCeX8Gasgh9iy8bjn7vX3bIYtw7DFu45hUMZKCiqAqCxI1bQruQrDtwJ4aXrgROi/duSz1hNDbOzD0nrDqrZULi2oikHEo+dZvjMpcCRRqgSbzkDnpatSzqJBRUhS8hJis8WGgjdSZlhyVuFoSTZ4bynO4EikZIlWBKylJEe1/3RvaH5CFm0q7xzjNOMoBLKIVDuP92Ijh0FK5UKYmU4nctYMeddB2XI8PDCPB7wzOAWJ+81OyrRlVBRIogWoddytFXttQMuFbNPbWZIqC5tEppxRp5RFE+CJT6C+qbwnS1vfcDoQTnvSeKTkQCkzOE/2ntz0yBYquDFWxISTPIOlel0j6Zpdi5FkHYQZ53udNw6vwJNzTpM1yn5Vu2iME8aU78jeY32H63q6fsNmuxOG08U1m82O3U6Ap2G3oet7mYcq1i+sgyVrfF4+IT/zSm9F1l4g5cSkXRVPxyPzPLHfPzLPE8fDQexa/nE1RgCkC5yh6aBlEiJCUA+z3vqWo21sdRdcArol4KlrrAZppunOnZ2qfZqz/bhehLBsi+qVLW+eU+EQClMU4CnmAiaTjZTqzcUyZYdaDyo05qyRjpIg/0aSfTtvufBOy6IKUyrEYjRgMqQiep5hzsrCEYCuOtbrdQk09mcVd67BZU4IC7wmoOtruqZqkFnLrQxiIlOo4a28NxtE688uvsa6LKf6mtXHrwFDqWByvc7lXbUaUMvxxKeyuWBNwhVwpsObjLOQbbXzZulcrDlTi+h1NS55ESDRaHlaZWgVJIl6mOTzeyOaXLkkvLPEbJYmM0aDcApXQ09nDSZLNUA4ZWX7y/wanMGSCRFiKdweZg5T4Pv7E4PN5LTVZyV3nxSoy2osvXOq92qwaamyaKqeKi5fyGQFn+rcr3/qGGwddEZYT87ChRNNqc6rkH5z6EsDIoraxdweuNG1pslmHRNrhEm25gQY3fs1oFpWWZ0IP5bDrGyTjqGMXbX7i91ZlxKBAjRKbKjnqsc/ZONbYtlUdspCjngajK+/+4x9y7L3y/qW57UGuxpbvr6vxqrrGLHe1+r6s67xJU7UGFW1McHIHl2BK7P4Jcs1V1TcreQ/tHtlBpMLMQXRFg2JGDbCKO32co3mRDaZOQVO0wMPjw9Y3+M3N2AKxga6znCxu2A/Hnlzf4sFtpuB5zfv8dknf8rXXz7yzTdv+OqLl3z+26/56S+u+PSzGzbDhmHoebi95fXdPcTINB24+MUV15cv+GgeGdzAw+9vOe6PHK7fsNlYXvAR1kny1HtDVvalWEOrYJP+1JjerMHKBuqt7KUuVpEPWBIx9fnknMlpIiWLU+1U453q97llVRsBvtr3rrAJs/Kn6/ysgFLOiZTtCqxc/MXlfULIkIYuyyRuwO0y4+SRNyDXLKLfT+b+U0ZUW25LJw1q8oLVXLQrJt6TkawztXlq9V3/WJ/rBwNPtea2XrB5axHJa5XVU8O7shoTeXhoKYgih94vg5/PS4ZyTq3dJtAQS9vodsiC1N2/InGpivGqVoFMVgWukOBK9DVkWK2xC+NqfVRnpaCyLNWwVKBooaE1A4FBqyQXQ1OF1FWj4ZxNUhZDpjvTwioD7z3b7Q2H04n/7r//77EFLruOEhL/7f/8v+Hx7nt+/5t/x1yk3MRbK+0oSyblI+DJtuPmwvFXf/Yhr+8nnj+/5HCYebg/Mk8jd69f4b2XTHcnLJzr5y+4fv4ew/UNw9UNd29ec397x/R4z3x4YDyNzNMkzmIpPBs8H152vPfLv+Lq5opnH3/AIQS++Pw7Tqcjm67Q+Y08E7NkC5OWAKzRWaG+2uXvgClJp/viBRqDtNo1SPlUEe2PXESHJxXophPSHtRRSgUhV87z+lutEWOXLSEkwjGwP91yPe7oLl7hhg27zU70sPKmzVtjpJNJmiPh8Z79a2lPH6cT4XTg9Te/5dWXf8d333/Pt98fmKInmo5sOjAdv/7tF9y9vOM//O4rfvPtS8zzaz74kz/lZ3/6l/zpn/8J0/4NaTry/k//CRc3H3J49RseXn9DOh1kDpYk87jf0nUbhuuP2Nx8hO12ynaS9ywbody71dGMKQgd34mr65qGzY/kUDbi4nQWZTqNxBA4Pj4KsyhMzPPIYf/AHGbmcRR2YkkYsrAJnaNzG+Zp5vHhREyS6ffe0w9DjUpEOHuepQtSTlhj6WUnIyIsy5gKzlmuri7I8T2cgYuLHSUnpvHIfu8oWQCjKsovnc/AlYI1BXoHrqfzwkQAQ4wZYyPGZDBSVjlOM+M08eb2DafxRJiCgAoKklgvpXaz6oKcRhGcHq4uFPQJrfzJUrNxhXmO0gEvCFOpghZDr1uLdmArWcxgCJOs/yTbVwOVNPAsOk9zlmDzojNsXM/V4Nqc9TaSpgPGiiCl2WzohgHXdThjmE9HpnGEItmmOJ2I00jve7zr6DcDxha8c9LNDy0R9E4AcmOE4dXVDX5hO5UCHm3xbpzaoXPmk/i2RYMs0c4pVrpciVC3rENrrHTGskLLPuwfiTFwf3fHeDwyPd4RphNhOiq4KPN4ngONZq4bVNZOKWAUBDXE2eO8ZxgGaue8mjCqbZpiikzTRCkiXlqsBadgmXXkFBnnmYeHN7z8/isO+zthNPQ9vvPsLq7Y7nZsdzs2w4bNZkffDQzDBt9JowmMajNRtGTzaTa5WfU2hk0CW5M6c5hIMUpp3Txzf3fHPE887u+JMTDN0ypQ+Z/KsPxPc6SsOol2gWEyBkzgHME8t9kyntXiZZXDMAiNR4Ccuqaq85hLEe2ms05gZXVCFIwQkXyLxRnL1jlCV/BOdD6NJhyddXTOS3cvC5hEKjAAnTVc9I6bjedhChLgp0KOsPGOy6HjMURSgX3IpBwZc8CWrCK7cH+Q67vYCgARtZFJrPdShaWzaUGvOHGqIabVyEkb/Dktuxq2csMZq+C82LBaHpcRfaxUgCQ5KbGJguQUq+NZdWCc0Xm/+MvWG1xXg1sjgFKiOYBPQZIWAhTEBW1upFyTAM6RuURKZ5vPYyp9q4jGnkkGq2WP2ag2Eoa+G/DA0AnoPD0eyCGxLYYuWQF+CspCMewnMCY38W7XOpVJEPzq/oHeGxwFR8b1hr6TPpWDs3x47TjOiTFE7o+BX706MsbEYQoM3nB/iORkGGxgmjL3RwGWU4xc9I556rk/iKZolzO1xmLBQ+U5LxNXnlsT1TBqj4thzhAoDAjw1LnCRnVCaxxWdN5LTLJ6MFlelKWmGqFGOuxZCy7JSYtdOkHnJnqez5bX+lp/LEeh7vE0Hdl1qdLZe9VHrcynFpw/CaJb6VMLkBdSAyznbSVCpeq3Vj3ftxn9pSJB7UtqsxA5XzaJkgveuwYGgdEEpLAbMRWIXMq5RLoli6+igJHkgtfaOAokGTkfxmisBDHUbV78CWtFb9a5XoGwylDUn9mSizQNCfPEOO2JMZGiMoXCBb73XD3rGcMjb+6/ZJpn5pDxJFyZ6LrM9fXAZmNJaWaeDxyPb/j4/Z/xy8/+kr7f8Nd/93f8/ee/4avvf0+0Jz767Bnbm55gDJ2O52azxT93nKaZ3331FYWOu+MjH734kJ99+ksexjvIhXk68s33v+fm4mO22wt83GDoNXnakUNHQrWMi/qg6muzAp6s82KTsnnbfirBpKAAFfIMnLFU0GE8HbHOEbU0brsxMg+M6gOXJD6S6ZuPJDh4lW54mlBTQsIq2VZxDIfHeKvNZmJrvlVt2BNsR+ek0e9Y5mzrjtjesoBTFTg9n+f1/dXiVLTGNDtHHS/9mZ9gPm29sC4O/OHHDwaeFnqgHGcVfc2QLM63HM0NX35TnfMV+FSKtpiu4FO7X6GU18+JFrBtJQ7yRRW1o+06q5wT1khmxDkpvUva6S4mCZQMAhAZo6KPq13ALFaNyvISkEiMYO1oIu+pgEhp5z2jprHUcdafznm9z9K+p45nHT1rRZvnYX/gV3/7K5yxfPLifZ5ddPyTz37J94Pn89/9R9G9iBmcobOS+YtxhpLJFjb9wIubK4ZNT/Geb7655+XLe8Zj4D5MqHdFp62tL5495+LZC8z2ArPdcfv6FXdv3hAf74iHR+YYiDFxc7njYrfh448+4IPLG37x2Sd88NNPuQ2R4zzz3as33N3d89lHz+kvt82xyxX2aEhwlSrVIcjq5CCBUp1Tjcos9kDEMq2hN1aYAkaoliHLswxBWBSlyIJu3RnX4Gibm1ruQiZlmGPieDpQ7CPPHx7YXMHm4kofTCfCnTFqpx9DyhPheODh/o5Xb14zPt5xvH/Dq++/5vtvvuTl/YHv72c2g2MzOIoRHZvvX93y6ptX/KdvvuM3r2/5xYtnfPLBh7z34U/44MPPuCNzLJmrmxdcv/cJvt+SsyHnCXLQjdEybJ/h+0u63Q3d7kbLrByG1NbFAp7WZVN0owNjpA7aGY/5R5uS/38+zjcDAWUzcZ6FFTONAkDkSAyBeT4R5thatEMtrxB70tmOEqVLR4qJoOWXvpeSRrKU5MUooIvNGeuEJZSyzPyaobLWsNkMxIsLSkrCQNG1O41Hta0L8NR50ZbrrBhv4yzWoYCUaZsqyixAS9XmEJjnwOF45Hg4ME8TKWXJHhuD73sMlqDA0zSOGGuZ5xEfOnJOrZvVorsjTNf6B2QjBhSwq3ASoLBxiqkxAKwRW7WoyVT7qw6WgcFX589LuUSKWKOMr+IomnkSkEPeG+aZeZ6xFqwtxNOBOB7xFzeYbtC6/14cQmUvGWtapk1Ir5qtbpmlWlJZO5vIVVe2U9Nxau9e9kyrYLvFYE3BWUtWfaOCPIOcC+N0Yp5GHt68ZD6diOOBNE/CsCNjizi/KUVS6hp6Ll2kEyGKLlvNriZj6fqBvusW7x90TslFFm3Q4Vx6ssdLdi/noN0Nj+wf75jGk4Bp3uH9wLDbsb24ZLcV4KnvBnzXrbSwzBJwZI28iwBQ4vxpEE51lmr7ep1jWT43zVJidzweCbN2+psnxukk3exikID4iYbaj+HIJWsLcmH5ZoWKnpb1rJ1JWP9VHrbGx+2FJWNb9P/5zFGvwJOtH1m3gkecUY8wRrw19M7iTA0Cq88mYLRXfSqMaeX1wnqxbDqLt7U8QNhG3loG7+hdxrtMRsrA5pLwBdWXKoyzgGSbjQDySRHukJNOBU2inIFOOk4GVGqjAU9WcQrX67CEygoFbXir5bcra1UM2huBFnmaBQSp562YaPU4rCs4VwEIOUep7mVtDZ8RZrc5f5xGz11q6a41FG3hHW2EhCS2qDqjBUMFnwysfKKqG+acx1vLbuPBgB9HXM6S1DCQiqUIuZVMYYzLzJNrsmcB1uNpZOMNV4PDmoL3IgUBwqq72vgGjs4x8c3DyBwzsWQex8RxSvTOkkIikDlWRmOK5OjxwGkKUlqUdX5VEK/+OVsIC3AmfpBoh6Us4u+hGDpfFESDzi6dsKt2WjGroLDppi0h3JI0VeCpLpsWC+Rmospq+M4W7Y/KfJW2BwCrgFzGYB3Lnmkm1eC57h8rhkp9j2zAGnxTmU3nfmt7XzUuRhiCb4Hq63+VimlV0KHaS8DmBoqdfVfOyxyhys6UFjsas7Bh6uedVhzUFPB6jEBKvqTpaAUbisZCVrXwxLYVk0Tz2DmMgsklSRlZCIEQJmkuky0FR0kbSRZsHaEk9sdbYiykZDFO6kKcK+y2HV1nyTmS0kyMJzabLZ98/AuOxzu++vYbvn/zkrv9LdnC9XsXdFtDMkaTF4XOd/TW8+r2yO3DHf3mOwKJ91+8z7Ob93hx/T6H/QNfP/yWh+mW07wn5BMxeZzxeCN6Sc51kB0i1VIoq5K5tfaQNVbkq9oiXTQI2+MqpXWMMwouYgTcnMOMSeJjF58p/bCYEmNUPsdhXC3dezrnSrN/6zloFPRszFXtvLok2KrfVsvnlrn5tIyugrbVD23z/Om8b1PzKfPpKRAl39V2xmaroAJ17/pcndBVNukfc/wjxMXrwOiis3VDFmCodoYqWsazphKbdgYaCgkKMyTJfNaSt/W9VdG3iiyLTyE08zrZrLWYYnDGUQQQPctAAw15DlFExOuDkO4tbtk8Vj5JRZJlc69AkFXNKb3XRt08PyooV9+Xq3MnH2rgR9Kgdn2UUkT4EgVJioPiOB5P/O3f/Ufu7x54uH3kg5sr/hd/8Ut8mdnlK2J0PBxHQk6cwoHjlLndB3aD58XlwMW25/n1SC6GwcF2MOyuNpiyxRTRShmsMDp65zjMkTdv7pjTS+YcuBk6Ptt2XD7/iF3/Gd1uhx+2DJ2nd57OWLyxfH9KfPPFd/z6q695eXfHy9dvOB1Hbj/7mA+eXXJ5uaPrPd51WONINfB14ghUllgtyWhi8cYDRX8vY5tS5tvvH5hDYBqPWGO4udzRecvlRY/3Bd8lyIacvYA1xaoRce2Z1ja6zlk2fc/948gXL+94+eaRv/3NNzy7+R1/+ttvePb8BT/97DMuLq949v4HbHc7rm+ecffmFd99+QVff/klf/+rX3E8HXncP0qr+mnUwDxSbM/z5y/YdB2bzgt+P03cHo/sTxOPJWIuBn7+yXP++S8/4ePrDV2JEE/Eec/Xf///4bvf/gcOt99ijZEW6/GEHXY433P98Z9x8fwTXnz0S7aXz9ldPMNaz/7+ljmIyHMuuW14de5mBXeLFVZJyPOPCnaqQn9xmlRHKEgb+Um0nXzXYbqOTWcZTp5pf0twUTrt7Hbshp7eO6oWRclSF55bfXYkZyNljcj6Lyr8YI2hc5bOG3qbwYsdnZ3HJiBnEYA1ToE/ycTnGEVLSj3U6pYkb/HW0m0GbNcJaF8yp9NESoHWVapIQBTza1KG8XgkhMDDwwPzPJGUGWC1C11WcW9hgibJklM47g/kAo/7A33XkWqWPIldNRRp4Vui3LlmcLM2a0h1HFynr83yLGKWrJXWlznXY22WTixFQZ6SpSOkqTp//SIsqWWtvh/o+g3DZmCeZ6bHAyEEYgg4L5Rp4owpiTA+EsOI7Qas77F+aLTqooxKscyWqjknz9DirJeuJ0qNzSkTmcnJ0fVIttI2ZUqgllQX0YGDtv8cT3KN4+koGn4pEsLMm1ffMR73vPryC1KYVZC+0A0aoFlpLbx0dlGnxlpplBcDqEOr6DhgMM6r+LAV8C4GATG7Dt/1dF2Pt04ypym3OSQBosNbhzcWD3TO431P33d0Xcdms5HOiN5L5lABujkGeXY5trbQgHR3VDe7brcg+jIF9R+KdnArmRwjOWVO41H1KvaEGKS0LkbmWbolyp6+Yg//iA6nNmFhVNf/LeO6OC6lzeIW3ZZaolf3OcGkkyZ3YhL7Ym1Bm71pk5G0sK9h8YuQJ2iMoSp0iVcGCQU0SsaQ2TjDdW8Yk2PM4I2FbLFF9LUNSbW8lCVuLd7DYY7cniZiKThfsJ0D4/numPBjJjvYbIWAlFIRRt1scAoACxBfwC/3SGlcdfE3LBib5F50LNJcRLDbV5+32l6JRo12jNA+EkQNLGv1ciUitiFbjVk9n1O9qJo7NW2Qz3fd9ZPFAN5gvFG2k2T+U4BucFJF4DrRwrNZtYyEqmOslGlKkFPASzeoXAoBwxgS1hQutj2dd2yV/SoPNHPpxF0KzhAzHGdhrdWGplVlA2WMGGNJBd4chMX20sKuM3z2vMN1jqG39J3B69iOqbCPhTdBRM8dhqnArCzNy4uehGUoVhocTAHvRJg+5Ky6VODLAv43YF2ZXSsxtDbURjHCkOEwGw4BHiZhroTLzLi1/GRTyL2hVptTBERshFMdX4kLNKlVhI1cLbAzC+BijcG5os1vaqJTS4CUePEjw82pxIQ2y1dB6gJCnQfqVb9mYW/YJ6DVQnR4+vs/eOiGU8uJoYX2y/W9IyhvOoRvvbYAZc65FuuaLKL/df+uXW6XP08uS5MtbeuybwMJQCNlWK1IkK5uZaVbK2MR54kYZsbDIzGFpkdUioDLnbvAe4PrLCG94uWr7/B+w83lxxhnSRG82/Ds5iMudjdgLR99+HN++Sf/JZvhgtPpgS++/Xv+02/+Hcc58/4vPhUpCOs5nQ4cx0cej4nH8EieA3mO0EWGqx13xwceTg901nN3d8vN5RV/9U//Nf1XW767/ZrT6ciX3/2an7z4lOvdM3bdMzrr2WyvKMNAKZPE/3ZhRNf43qB6rsaAFRTftiopIbrUR7iAUKvJYZYyzxhmSkqckI7WQz+IVI8XnbkSggKIFQdQ/6OCjXVOabISxUysdcucavO27kqr/d0Yatp2SWfq69qtsa6J6hecYwl1xznXglofddyWXy9rCmqCtSzNz+pVnDMX/kcdP1zjSW/Q2SoccY4cN6qZdrup7Qjbe1c3u7792tL6vAserMyU/Fetcs2Syne61la3Ipel/bsaJc1wqFOdotAljZ7TWts6lRlMo7OvJ85iMEubQIbVhtuGaLnmxVFkQd0V3arXWVZ1iK1WGM1wYla/s4QQefP6Jd98+y1/96vf8eGzZ1yWwouLgZ8/2xBTYBwNhznx+hB4OEW+v5u42nimKXO1jaSUGXrPdtfjHHS9xxqPMx0bb9l2lk6p8cfbO46nR8ZxzzjuefHBC15cPef959c8v7lh+/wFw9U1roj7uz+MjGPg9Ri5P9zzd198zTfff8/j45E5BG6GnjxHxpAlWOkyzjqykyxu7yujRO7bezECvW7KVe+rZaAQwcz7hxPH08jD/l6ElW3HxbbD+4HOF5yV/GsVqM9Kic6mCgmqs24keLS2I+WJu8eZb1898p9++zXPLm+JpxMfvP8ehJFn772PcxZHxt/cMB8OvPr6K37/m7/nP/77f8c0TxzHUaj+OdNttvTbHbth4GIzsPGWwVnyLG3cj9PE7enITMEOnveud/zsvSuueofNovGTwsjd/eeEOTIeHmS+5UhOQtHE92xvPuTqvU/ZXb1g2F6x2eywxnIwlkb7r+m8GrIUCdaMemt1Xv6YdFKMNYL+ZmnFnIIATzlGcimqPWMZNj2mZDZdjzMWZwuboaf3kgkm1y52qeke1XAul6zBsmg5LWC2MDWdAWcyndWw21giStWlZm0WLapctF1uZrVBFUzWbEzfqbMigf40T8rcEg2PVCSYl4xwIijINo6jlmQgG221U9U5VD2mKsgY5hnjnJZjtcJXatvqSoKoJRZGKQHVGczN1qoeQVnbVQmijKXV7Dtf36MliklLC40AiM53YKWDmut6XL+RDmnOMU+JOB1JIZJjwJaeXDrICVMyKc7kONM5j3VbjGoUGdUzkutcbfLKYq0UaKuikOpZNIaQz17p1zwJOs/1BCpjK8yzgGNx1pLLSJhHDo8PnPaP7O/eUFJiux1WQpaLsGUrM69hVm3UkLOaRoPUy9XrsDJ2XQ9xJsRZA2DRk+ickzUiWZYGdtbzWyN/HFqSWPW0uh7vfSuvbPutgkC1tAdjGuBktTTbNUFQ3W/VNoUQyDkJqJ4zSf99PB2JUbSdYoxM47jSaDwPDH5MtgtEyBpWU6vhINJ99fyFtTO4OKPrgNaaIvqEmOZ7GQNVO0jdUVnvbR4sxzK6kqmvZkpMle6x+g5vYePUMhjV22sudrUbiVoyWGUUppQ4zoFsrAT6zkCxPM5iY1zv8B46IXVKRp+65mjrTqoKC0l9VXmPnM+o4rN0nNKuRhGyExsqCa5zJKCWEDbWyurPyt3l7VGr56P5HHUwF7+1nmTxGYu+oRiD9QbTWdWaNORQlEVlxSZa0TYtWUXeK9hrFQgpleHvmo3OCHgTklybV22tojdZcmHTaemrkWrfKZUGwohge72dIjbTCuvpGIRpnXIhbByfml67c4kOaR3aoJ0LT9r0dbCGUEQPrBgjnVdV/yYE8d9lDtcmPgrClQr06OxSwKnodS6rYuGXSMhimCKcAqQoH9t58LYwJ5omVpVSaXPXvP1HVc5aAFrBiLqqjFG1GmVTyXZi2rytPtiP6VgDOmYZkDN7/Z8DderPlpBC4sv16+/6bDvOQIYaqMt+bamlo6oltUocyflrgF7/bd76jqesk1qev74MOe0TB4GVj1BB4Xa97wjqS9FLrDZ0rROkvllBOthGKbPLJTUWusw5j3U7tamJlDP74yO7jTS9KlZ8O2s7LrYDw7DFWMv11Qs+++k/ZZqOHPZ33N6/4vff/JrN1QdcvPipgN6uJ70xHMaReR6ZDxNxkj+Xz3q2Fz2H/SOn8cg3L7+BVHjxT/8FH3/wKa/3bxjnwBT33D8eeX7xjE2/ZeszxllcN2DKVoX8YxuSHCO1HL8Axouv5tR2thSNWQTI4W3bvH4WQv5IYrfMRHYZr2C8LWIbjQb/pSws+OXZ0V4TYo4Ba7HFrXztSlpZs5F0fpgKn5u2r9RYov2uXbPgA8vnn4JJb6+h5fd1qte9qO6d9snr7z7X+vjH+lw/GHiq521B6hNNpKy7b+3IJm9eLqoukGY4yrnwd9d1KvJV61TlgVaNCHkQC+jUbrYs2dnFyVq5Rlay+RV8EnTaU7uipZQXqLkOqjrF1eDUSdLKBJe2Iiu0EUqJDcBqg2a0S12999WgVSSyDlbV0apK+vIVjjkmri+2/G/+67/iiy+v8aeXjGHm//Wf/prLYeCzZzfsHDxzmX1IvDwFxliYcJhkcPvM68PI714f8U5alcdkmKPB2UznMglHto7j8cjhFPDWcPXsir/66Bf87MMXKu1mGGPkNka++v6W03f33D7u2R9P3D48cjiNZHV6egovTOHD6510MJmOnF6O8PjAQYVptQ+xlA450eGS0h/RnLHW0ncW5yyd96rpIuMdscxz4HdffMXpNPJ42OOd5TRm3n++47NPPmI7WPIMp1Pgiy8emENmjlITa71voICAieIQOGN5OJx4fHNHHEeuLjoiib97+ZIv7+/5/Ltvub684qP3/iPvP3/Oz37yUx7v73n98jse3rxmM/R0fcd2d6mAhJjJaDRTVkRgc84Q54kwzeznyD7C+y8u+JObDT+/tnzgDuy//Q2P31hev3rJ4+MDv/niG17fP/D+Tc/FxvPi2XN22w/58Of/BRc3H3Hz0V/QbZ/xeHfg9Xe3/PbLLzmMJ95/fs12O/DJhx8x9FvGEM/monOVkZF+lMBTipL9MIjDWpedtWB0+Vem0tAPfPDhR6oPIowg7x2lFMbjSUpa54mUZTMSseWelLJ0mEuZHBWUyoVN5+g3/bLui8RYJWdKlMzKPM8cj3seHt7QD4N0ATNbnOtlI2Dp/tmroGpJAjYdjo9M88jD3Z0IaWvZRrFOwnzdlK2kZNlsLxQiWgVqqK5AyfjOk5UZk0thnmYK0hUv58JgUJBFQLIaTHWuQVJqV7V880nXyCYYztohN1QhDQH/ZbBsydiub4GCU7aNcdrC0wjjIs4TKRyltFi1uDrbyR2muekGSuMF6YYncgw1GDAN+DLobpsTIkq7UBlqt1TZz4oAkcYQVS/QFGWpVsLJE4CqpExJtXsJYAqpJPYPd0ynI8fbO+bxiLcSaOaaMTW27VvG2KajmHOkGKNNNZLeh6XznSRiTAdYTuNMNxi2g8d66DdFmg/EiPNZM3ECTtWGAwWIOUt75ccHwjThdH3sLq9kPlopKZ3GkRSCgArWtiSB7N967VoK6mpJlepbFAW+ZwWDp9NJNJu0hE7KXbMAUSkTlAmV0nlZYMs4/njM1nJokGWNBAUp6f0jc3Rxzs4Dm7Je4zX5VYAirTa8K8QMIYr4cRXO9rqmaxBdz/nUVW+BDzDHzHGOhKhaSGobQskcc+KUDGMSCQBLUZFomLLhECyxam7od8eUGUMid5IU6noDzjKehOkiCS/Y9QJ0nQ6JnAqh+v9O5qewEZXBlEpjPhmjsvxa6l+BFHU/iFmceocAHSWK7aoi05V90MLpCniBPg8FhWIbLLk3xYNNsZIgWJXslbo51BOpqnXV5hK9JgGOjAOnot5917MZNspc9CQtT8VGIOO0rUPQ7q2m6zDWSke7UujCnhwip3EkxkAIkjQ7jYEYM9utxzvDNMquYa3BKzu9FBgVb6rTsAm1azJadMMsUzTsx8zXtyO9tQzWcgqJaZYqhKETfU1nHCHB93dHvDG8ublgt+14du05WhjnxNXO8/GzDQ/RcfPNiTQlwikxeCtdGZ0RdrF0UwcVl6bUGW1XD3zRGqw7U8yGKQogNcWi+4XBYems6KM11LCBndWuQ8mmlZnPWf4E/TqLFEA6SislQ0G4H5v5qrt/s9VPjMhTP3OpUjkvD3r6nspM+UN+6rvK7p5+Z40YK3FhXZ61hiaqDMvTzeUp+6pq+qwZTpXlVudIGwBD28+pDKYlYBYfrTF5F5a3Uba4QPk1iRdJOTHPEzEGxlE6jxtrcHi8dbUSEN95Li578Cf2p2+ZwyO77oLdcMl2eyklzSWw7Xc82z3n8uKS9168x2Z3QeHA4/57vvr6c+7uXqo6ikXKmTugp+suuNhF4vE10/xAyjPZBrLrwBus167y5YKUnnM4ddw9Jm4uP2Doe767+4rH8Z7DfE8+jGAuuSiWrXlGZ3Yau9s2jLky4bSbXU3ENhZRLclTwkzVZKqMoxxbjbSE66uY3hi0QqpQjqL5VMpWWGOd6NnlFJu9Nhrr15I5ayxZdbsaCafo861zbdV8TUrqayMM03z3eu6SmzrdMgcpUOKTqVlnbsVanq4D3btK9X91D6rAZnV5Gyh6zlh86zBrIOrda+7p8cMZT3IHbVEsV7FcmNjglaGpm9ETZPuM2aQo27qTAaUu5vr7sxBl9d3LuZ7SN9dUtPMFXClvRrvg1AxvBc3UQNTgyBhWxePNWhXWhmQR8aqdhuTmaQ6HIFmmOZF18ys8HZsqvqfGJmdiSgx9x5//7BMGRv72xYbvbo/87quXbLuBMCVeDB3D5ZYxFU5TZi6QjSVkw3HOzFE0l7wVUc++E/qg10pDYws2wcM08Xp/5MVKu+kv/+xPeDiM7A8T4/0d+3Hi1XHm7hT45s1rXj888ubhgcfjkU0W0Onn7z3n+mLH5dAzeMd03JNCYJwmoRtaLwGKlqd0ToKlaCToMl664PWdaDgN/YCxwhLJwFQsUwi8fH3PaRw5HI903nGxO9B1BmcLnYMpF+KcuL09ME7iGGMsXSficMbV+ScZOHLhOE5Mx5EcA9vec4yR14cD/nDg7u4NV8OG+1evuHv+nPjwQJgnTkfRzek6KTsstaa3FMYUyTGqwymBVqa0EryQMiHDxabno5sdNz1s8sib+5HH48z93YHD4cSXX7/k61dv4LMX8HzHB90zdlfXvPjw51y/+JTu4j2wA8f9a+7u7vnbX/0td48P/LO/+CXvvXjGpx9/wtD3TDGebb5ts09quFvbnB/HkVtnlKzgE5qYle5ZtfuMQfVILi8BFb5XHn3JmRBFX2eaJjBGyq8A6wxzCYQ5kWMiSM9oSk5401OKr6azxiRQs6hZhMZFa+rUtIZyVvFCBUicdsETVp8l50wImXEcOZ0OHPZ7xtOJXEvEnDCDGkHVS+dCZwcFbPKKZVo0nWukbAuo6Y4UI8YGQohYF+n6CjgtgZYxNctcg6jSMkH1OGewmmWfaO9SZ01PaBHbXwXwKRnjOinZ8w7jO3UypBtenCdy1jVmlQuSNePU5voC2tRSL7lV0/SIWAFS9c+yFGpG7FzvUEA7SJX6jF3d+rLn1Q49CxNKHKBpPEkp5OlEnCcqqUrYR7YNW2Xo2lUCpBRUu3DZ3wTscWJnMcSYsF0RXQTrcT4Dru199RmaNasU1fCKQVhyIWCKMJW6rqfqcOWcCTGSUxJ9lwrkK4pRx9tro4+q7WiU+p7VsZunSTWcDsQQmMYDKUnJZCvFz1LO1Z7MmY1al1v8IUvwx3lUQKYeOVeB3EY1OXP3zFPjvQJ6zarsyFS2T/scincsa3O9AlqXx/X5lVGSciFGKZWqLxtjSKUQSiZkQ0yLPoWcX0q3QlZb265DNM9SVn9IARtnRFC2VHNepIy5ACOiv5lTtSgCFnRlCfqMLSIRQjMz7fpb1F+Bg/bPKregVqGWxa3j0AZatMch/8iI2LjSQq1DQJlVv7qnDn0FpLNZlVE2n1qenQQ2NBssrEUvzRN8J8mPXHTvynSmQ3qQis6p6TzGWTbW4kqhRNESjClSSiIlo89TwDwpFbcsEBm6puWanFXGm/rJNe6uADZGrG3OAlDeH7UJDpaQEnOU6+2sdK6ziCj6YQwcxsBxzgxDYegscxSphK7z3FxtuNyNbLxnnI2U5pWCyiDWSmP5O8teZ860n8zZX+tzkTJ1ASBT646s7FvWe8T5ypP/VztUGaBSDlWnZo1oaqv39onCk/P98R8Lw6P+greHrb5v9fNdrz193zqWlB39bWDoD4FP8vrTc9fPVMbHyjN5h05OWQXC5WypVj+hrtEaBK7GABRMUv9SfZLGNi61e3u9uwUQqYmvrHIIRZn8MQb5E6TTcQXUrFuS7M45ukG6iB7DIylPDN2GvhPgOhehyw/dhqvdMy53F1xsL3GdJ+cT4/TI3cMrTuNBbaeWVmcLzuFsT9dtMcYt5fImU2wBa5XxaIGeUjZMQcgCQ7dju3E8jneMYSSmieM8cRkOeHtk8FFBb9s6zy/PQli/JRfV+MuLT7MefyN6UWAwOVLVR1dnaut/sbmFUhLznPE+S1IPA11pY0+NJ+zCRKvf6RpGsP6WtX8JDXwqC0HH1D2oqH5Zvc93BGZlfa62r3D23nO208pXomIaa0zmHFOpvmrbFNfve7Ju/3PrbX38YOCptlcO2qq5KCvHeXmQ3ro2OIUFsa4Psga4a5bPGgGWrLGKfp+BWnXO2LPArQ1czkoxlve3wS2rhUnRGmxlDigKWQwkI91Zck6N9eZ9t9LRcGdBQyWKGCMd59YGcNbMjbUrNlc2jSr/9qTRc5ble0sppLRQCUvJxDDhXMeHn/4l1l/xb/7yC75/84briy+5O2W+uD9xl2b2YWbTOZ5tPLHAGGWcUk44C5uNiMzmDDEbmAOTEcS2gl5TiIwh4DqL6Tv+v198x9ePEy+1LebD8ch+PIkWRCl0FAZT+Oii54Od5wrD1hieb3ouOos3EZsT295hOgXTgFCiqDpkEXm3eZbNvahGmJMsHbaQMFIuhmQ3Y4E3MRFyAVPYbDdc7y6EJl4SZRo53R9IB8ub+yN39yNfffkdcU44kizkOg/V2ei09M4hAqVDCjwrGX+54ZAyuzkL/T8EHnLh9Ljndpp5+fDI1XbDe5cXXGx3vP/sOcdp5vF0YlTx2w2FjeosuJzx2pfIWoPre65NRx4KO9vhT4Xf/PpbXn71iofjzHFK7I8z4xT55jHzyI5Xe8lK/PQnz/H2I958H7i/e8mrx9/weDrx7/7mb3j15g0vv/8egD//5U/YbToRVXa+zefqGOYkhtNYRMD4bemxP+pjnGZKFo2nkjM5BiobxRQwOanfqZuIOu9TULVXowG+6tEZhPbvVY9INCYKcY6EmJimIGyNMDHPHWGeGHrPbhCdMpD24jFACQFToHMd280W5wQQ6H3HxWZH70TTaZ6kbj/MI2NOxCDfMY5HgjKthFItbZqG7QbfebzXzE02Ui1uBeANKUBOzCdhlhTV2EPBhGmeyKXgehHOS0nKOo3ZCKDlHS57vPfkVB0QKXcQAeRq98tir0sGqlh41XCoT0lZpbq35SJdo0wj0BZMDIScMQE4sTi0FThCs5a5MmarHRbApbbhdUY6LdmimeyCBq2JZCO2dE0AnpiZxpE5aNeRlTPjuh7rLLOWRqemndQrkGWbA0Ex6gA6tjuLj4Hj6UCMgYc3rxkPe6bxQM5Rn6MKSBuDKQVbjOgXUEgxUHLmdEC0rrpe7XwFEyf6rmd3scO6DtNt8P3QmlnYBoSqHtN8wpdBnTIpmytGAK3D8cjr1695/fI73nz/FXGeiVXfwBrpEEs5050uhgaUisi4o3jZT7M6n7Pal3meiSkynoRtMZ6OIooaJ2rZZyuDX0Eqa6yg+iM1sPwRmS5ACdkFUhFtnUQ6436vcvNnn6vzRxhMC5iUigRpyzmEhafEENnbqzYOC2glbrVEjXPM7Meg+mta5kkVGq+MKTjFwu0pkZIlaZKx8xbrCzjlFCaUDajJj1zou47dpmOfEnPITDETc8Ibh/MwHWXtX221BBUpJck6KapQes6aBlTfj8pWbyBOFYAWhqbrSksUlgIpiqB2zk9AhbWjv7ic6ruA7SSMWcAE/ZyK2JLEsHknzyO3yJVmFFtYpGCedwWfDcVJDtM5EQw3aSSNkSmemG1tjoCWqWaiH3C+51/9q/+KDz78mC+/+YbHw4E8HiDODF3GxJHH45EQEifrBCSxBm+sNnCxCvIXsWUGNl4DdMSHlVK0gtPRmZOw53Zby0VnuHAZmzJfvZFGAHMFZWLmlAs3vaWzluvecOOh1/k4xcwUYY7wcIp88foApfDxs4E5RoorGCdsBmct3kp3QhGCNk0j0CpvH2oyel0tQcWNFBSqdkdYrpVJNU4Z6dViyRWULEs5noCiy7zKZZlrlEIWyVFiVjH8M6Vxs54qP66j3dfKalVQYP22swD5/PewknR5+pk1aABvvaexlP8zxxpMegpsWdWiNEiX0Xd8up0jpZXfsRInXwJ6LZdXf8Q4DxjxycpSPSRMnXcAV3IyYtNHnqTBxngi54R3ToT8ZAXJdVshibsO6E6Eec/D/S05wCcf/hndsGF7cSlVHxisHRijYby/4+XD1/R9x2478Ob+nofDnikV/HBDjJb72wfppt0n4hwgWqzp6fodxvVYn+gGaXSw3V2z21zTOYjjHY+vn+PCBZfPC8OF5/nVB1xeXPAw3jOlkVPYk8p3uP6a5Gc25jmOgVS0jLDpOYv+ctbGB6VqT0vGgZwrGCh7UGtEUoF0XXvFVF+1zq063JkYA8fjHq9JT+ccfd/LZqcamSVUSSKtrLGOWkIt59LScWOUCa8ag0+A0wXItGvzdD6D10kLY1YvLuWkzf98a56vHDb1okQ6Sb6pajgKiCYYSFZsZ9kD64WaBgr+UNz8HwE8STeSrEZbSgaq+DPiZCOo/hmrqYKThbaA3l5DpdGDFyHvc6rjAiytjfPaDX37qI51DV7OEdAlc1/d1aybQO2sI861UtyXGbiYTjUuVaeqlRLWDKPW8LxNdWtXKN+sD1sMVSHnFe2zZHIOOGu5uPmAOE989tEnbLzjYX+LuZ/4u7sTc5SaoRfG84Hz+GywTqjnY5ROct45clL9F0WGSxEHRzJPIpiccxKQJUa+vX/kzTHw3etXvLx9w3GaOIWJ3jo6a3lvO7AdOrrO4X3HtXHsjOXCQa+1zoaC99K2sugYm1wFMGXiVsEsVwTYNFkEdbNm9UOuWTVLLHCcA8EY7OUO7xyX/RZnDLZMkBLzMZCc4fbhxP3DyMPjkRwiW015Jru0rbQKPFlU8NJK9xVrEC2J5JiBQ4ycSiamLO1HlQ3wwfUVl9sN22HDzcUlxhyZYiTFmYmCp6i2D5AzVoGnhGQgemPYehVejYU3b/bcEnkcRRPrOCXmWDgkCHQcZ+hsJsaenLc83E8kEp9/9yW3j3f8p7/7G16+eUMaJzbDgCXTd171aUxbOw2jXc1nDE174cdyhCjMxmmO6vSLkLR3amJL7fhTFJCWNvcx183JNMOLZsRqyVPSgIvqRCeZH1E7ijRKr+rvWFOwJpMi5KgAILI2u0674hVpTd13PYO39M6SUyCGQkyBeZ6Zp5EYgoBOMap9FUAMI+fqek/fie0cgyx047Tdc5LviSmS4jnwVIpmu0vBdnr9SfQAZEMS8MBoeRq2SGlfqS2Eq62UH0t2eBXG6n4hZn094daBo6H2ai2oI5+UpaFgIaVgfSeMLqMdooClHLo+L6cl1FbLKnMLMurl1bbEzcPUvSzGCLrfGVg0jVRQtF15TgpOWYp1WIe0/NXxqB1XfO+EuYGUeo/HA+PxoF1IC66rOfHC+gusRvO1dC9MYH2H7fo218XxTWRfWvmcUx2mmsm1GkTW88QYsc63jNqS9ZcSuOPxyOm453R4FIAgZ3BOPpMVjF0xXQCKlQ5XJmfRn8mOYo2U2FnTgKJxkm514+lECIF5Eg2ylEN7hqbujfrE6mwS/3DJEkpw8YdLNP54j6oRVlpHrlacZVbr7Q992tC654DiGLq0asbTrM5SGUXNb1Hwc1krwoiZoyS0vFXTqeewq/LamARkFztY558Cyo2JsrRYr4Cos9KNuMRMShCD3L9TDagUs3RC7isoVu1J1jGpgaDch7TfPh9TecOyvgxlxZSRQRLCpMJtbYq/Y3Nse6mOU0XesvpARjbW6raKTpEysdrlmvpEFotZVGcrI2V2uiWVqlJgwJuEk8wIZFvlayghkFvpo+Wjjz7mT375p0wxY/0bZgt5dmzZYoNhfzxK6Wy2JMRXl27ltjUTWvsFzlbwZJUoQCDzkiElub/BGQYn5XmUwuMYCLlwiHKvVqfwhbdsvOH5YNhZZRaV6q9KbDHFzOMxcLiQJE/KpXWcMqZ2D1VfX59jA5M0sqxxpawl09aIaRO8PqSyrB8LzmmA2BynZUwWELxCs0vQalYPtMa79c9TP+sHxm1/NMdZWVtdQO8Am+p79Bdnn38XQLV+7Smz6V3/Pluyqwi+Ak3VH1YXsF33+lwVvF++8+yqzz5TK27+EINr/cdWbc+kq19jTGGLLbP3nNlSS/ESKWqiMwX93qrppD5ZUqF7C9Ylig2kMjGNJ6wZuLx4D9d7KdU1jsF0xGwZUyHEkXF6xdB3zNPA4+HIOE2kXLDdQEiWeZwhO2yZRdYmCmDrXIfrHa7LWCfWuet6OutEly+emI4TRwLdzuI2jqG/YOc8UwrChM2ROR4Ifo/PPblcS3Jc90K5VaO+TRG/suTWGLQiCU+nAHUqribD8vf1z/ZwxefKMsbOd5TicV5FaFSDOoE2oEmqqXXuyy1lfHK9Kele2cBJWK50wUqWK1zu4mxKvwOwXZfKnc/P9Xt0jtcrNHUHWtuw6rOX9WxfXYCOlalj+A8fP7yrnXPYUvAVCU41IFHn0C4ruYI27bLUGTZ1MJRuV52MGrAYY/AqmmuQzTnn3FTVGxizDIsEikUy8utudsZ7mvivUoBr2z+rHdMwtaUl5OxIMS2ZkBzbuf7QA40xKnClOiq2BlQ6uRTVqa0bF/RcxqlqSLUObt5rMBBaeWAzXN6T/QXDzUf87F/8r9h98zl3949s+z3W3HOYM6+OMKbCr14fuewcH+46Bm941glwcsqGicKxiFb+XMSJk7bmlq7zrUY2lcLt/oDnJKVjMfJis+G674h5y5Uz7KzlRe+57JwG1OCRjV+AG0Mxkr33RhyJiUgsCWPkdxUMrKwvp1PSaMmQUUeb6nQX6YZziWHGMOZCNpkpzgze8fHlJZvO8fefHznlxK/uHhinyGQ8Q2d55jIOoWSqP4e6nDJvjWnOdNYF4lzBDxB7z8ebC+acOcXEKSYe5sj3pxN3X3/Ds92Ojx4f6bQz4NV2w/ubXjaGOLMPmceYkJ5xjoiodBgDFw5CSLwJSfV1stK8DclK+m9XDFu9xjEY/vpXv+V3n3/D7+8PPMwzpk8Yl3nvOvLT9274sz/5U148f5+//Gf/jOsXHwogcjqCkeA5xdw2OsECbFt7PyYH6DRnUoo8PJzIKeJJeGu43HbiWKMObgiKOnpysRjbScYJrbcOUZ1ZSyqFwyyt5iftXIgCd9Ue5AxTSMxpYk6ZUKD3hk0ndqLrBZzovCHHJMFUTqSU6aysBG/AmcJ0euT+7g2Hw5FpHFvg7rTL2TBssNZLTTlWWuF6h5PWeRxOM1PIFAIFmMeRmCKn01F0P3TDS3PQ8qmgAb2Uaj3c3bKdJi76Dm9FK8CURLSy0dd5ZJSFWJ205m3r+etm1kTJW2Cw/Cx1ZRbJpJtq51GhRu12h5G1YHICdbpauXIFsEppmu3OiTC2lNVmEdzVYEO6EWVRl7UW23lc5zHWC4icinoyhr7vpTECYruSakh1TlhVlX3mnNe9zoEGRdWTyMB4OnI8PPBw95rpeMAU2U+8HwTYdJqjV/Zt7c5oApSUmKaJrh/YbnZ0vmM7DORcCDHhnJP9KRdiyvgUwMoe47q+RUMi0B2JNuC7QPHd8tiAECaOx0dO+0fGxwesgrQCrGmDBgoW2xpDgLALMIYSi+gwpAp6CCsrKpA5z5PopqnGk3RmrGKhFQRT4MLImSVoFAep6iDUDOcCOP64DlMBAKArFm8zuUTR7mjIyZmX2g5xQ0r7U6yUN4aUtQGGloFZSy6FMWUB3dUTNRW00dbR1kii6nGa6J3oM6ZsWnDuPZQkzr4zlk61v4pKC8SY6NTT9cYweGXvWNHfyximGNiPmYdDZAxFtZAsdtPkOhRMEq2orPa2asq5zkhpnYI9MVdRVrHRFbQBWua7FLluU89TACeslBy03Er3g2bAFExr3LFaipeMgE4SiYjZqtn4BCQtG60+uynkbEjBEuZMmBOdM3TeNL83qW9lrMc6y/XVJbuh5+Ornudbx2U8sskT39+eeDxGHrvM5GD2YDq4MBMX5cDPr2Y+MImHviMEGB+vmEfPw7ffcXc4kW2U/ckWOm9EPsBZdkPB2MxhHimmYF3lIWZsEb1QA3QGihOh8lKMlKkHw8uj2mvXM5fMfYg4U7jo4cW24y8+vCLEwu0h0JFJNmG942ro2PiOgsfg8OqzShLSEICgfmsuVpl86/CpBkSqCYiwlGPOlLJOcdd3l+aXYvQzScD1kEQXrQZpa8CqSmSUsoCcxgJuKS9dFqjOk9o4wNYY6sni/SM/cmMHreI2cSz0txqQ13jRnOFC7XgK4FRgpzKg1jHiugPeO9lTDcRZznVWOp/Pn2n7fb0Es2gXSuy42I/lp3zTUtK03IcksKzsYbmASVSygjWmejlq5IQ9J3u1xslFYtkUZ1KKzNPURKytsa2zm3UyF7OV+dgZQ7YHxvk14/RAGK10px0u8J2j9146yPkNb/aPfP7qK4becLnbMKfCeD/x6v6BL199y/bigsuba2LyxOjJ0RCmif3jPfv7O6CI1qb3+M5SCNIx2VqKNaR4IKQjh/uvyQ8T/e5P8Jv3sPYWY+H55Yc8u0jMOYkGaz+S3R3J3mCMw/sNBoexUWy8kigcgs5nJS64rpMxVQyg6ihVyZuyUOob6mjqM6zzoq1xtSFZkoXWOUKYcN7TDRuVsvAUpLzQWavfJf6+dU6rpBytxLYs5614yDJb6rxS39oYpLv7Mr/qD4MhmaRMf/llXR/Vn3LONcB0DaiWM2mIFVhck6Y6Z52CUg2k0utq1W3l3QDxu44frvFU0VkWxKxk0QABQEXHNVFEo65p0FG7w7VzrIGp1Tgau2QtEknjj/LEoVyQwHNKpJZyqFEoeo3Vi65GrqDU29YtaDFgIJoduYioa6vpPx8Kue466DWlYSTztraahsUZXtD0euPV6C4AUDHLBJSyPREVy9mRjcX1O24++IwQIs8un1OK4TCduB0TD6kwjZH9nMQg4uiMZestLi/2frJAMauOgCK669SBSyUzxcQUg2ZmCoPzbL1HpEE9N85waQ3POsulpjzN2uiq0Sw46Ugi01tDStMETNvm3Rah0rdrdlTLAtxad6gU+mygCJBWmQoGx0Xf4Yzl9X3gIUa+3ktXr40ViU3rVNRR/erq/KnCTXM4nKHpyxj9XMFwZSxTzuydlN08hMQYI4/zLCVXFK42G57tdmyd5dL3zAamkjBJav2zkTBb/E8RvPZIW+ja4SXVNVatnjVCnDUGVCT15Zs7bIFfvXrF7Xji2ftbdruOn3x6wwfPLvif/fnP+OCDT3j+3nt0m0tO0yzlQG2jz2eGzrSfP64jJBFkHOdISZFsEsUZUpSaECHmCYhuaqYaqx2R1FFIFfgAjCWXRIyJECNTCKqp0SZzG0QpQcjYmHExY4ylU+FbYbBIxqTzXurHoxHQGzXsOYM1hDAxTkem8cA0jtTOJtYIOFaFt7MRUXHvHN4ZDNqwICXZ+Its5GEWenbUcgwrxrp1FctqrwszuRSm00lAlhQVZLDCXlGHiTaPZGE19bqy6gpaFoDpfJKVs58NfNJzVpaVBAk6JiVRy/ZEyD1VbKsBXWvn0ihIVZkzLRypz0s3+NwiCtu0AGVzXYQdc1ZR0ChlyqKNItcrSQSHc+IIVe0oaxEQXvfHUgohVvbaiTCNOG2vLc7zIiouAJ1pIIDsIdLxzVlxYpwx9P0grDQjAFYqRUC5UmSO1G52XafjWqDk1qUxp1WHOH2mSfXHYphJIVAQ4L5YoYnXsZX6IqGL2LbJKbOJpfNVzAo4xUhs3euSJH3qOK/mjMblwn8rS8Agj7mCjCs7VtaO/4/jqOBJy7wX2XtKXSLwnzHaq1XQ1lMWEKouJaAyyQs0ZtXTk5YFNyWXTMgRY7zYAnWgW+mdPDRhDZvKIq1rqVCUHmMRllEt46tlUTEn5lSY58wUqs2o2isLgF2tTm6LX0AjwXor+/HJWFHnrPpn9TarC1ltGos5byNZGffVhqz8ucoeE79T/mKq6rZeaE600rk6/lWTv5b0lSzvMcq6XoS76zwAZy3bYeD6cseHzwY+uHQ8nyLbECj7gjUJHHQWTg7Bx8JImg5szIT1gdwXJmOJvSekjikXTiGq7qWlH7QsWcHzrvOSNIyrwUEvsD47pDsxiHXOBUKQ4PwYCs5C3zsCMCaDt7AF+s7x8dWG45R4OCqL2Ij/2xpqIFQ5b3X/0Q6KSR9brchooFMzIss8Fp9vKTM9KzmRaGoFKC38gpxVyj8v5XMaLjawqrSdq75SVkHrSlOQ87+YOqfNk9d/BIf45bTgWA7dG1bgUwvQ3zY77XgXq6mWLD1lPtXf169bkhj6d2P+wD6h71lNoDWzqr3L2sXVM0tsx1PY7Mnn6ncYvdfCO8AxPUUL/OtVtzi3qL+ayCmKVELRgq3q41TfReAX/WEJBUI6EtMkEgk4rO9x3uGtJuacI+TI3eGeazZcX18TYmQcI/vTxP1hjx06bnqPzR3ed0xjIs6JMI0cD/f0fU/fDZqAc6SSFrauWVZpmA7Y5AlTJoWBNHTY4hl8h7MFG4PEVTZRzEhiwpQZb3d426u9Tc0rsEY8z6pTWUkmRjVHy7oVswAOdUIt+wFn/3lrTpYienhGfUKXsyQFrcN4ARWNWoNc9SIMDVxt88RU5pP6t3lhMqM+njz39bxxq1nKuV9gygKOwgocXebgUoK3dhzO/eTz+biKadYg/WpNVACqpiF+yPGDgac4h+VW9bmVZbU1Nff670qfzrlmK+X3GYTJFGLrplMXy1laQH9XnOzOlVCwON8LjVHkl6RUL5fA2qIvDvvqyFm7BhVpU6ulE13Xg8st+/rWBFwdgnTXbGsNmOzynaihLWhGvNKtWQRua4sT5BxTGpszbYxhGDZUrSgoHPb3eOfZXtzw/JM/4c/+6/81v//9r/mb/9v/hZwKP7myhF3H8cozniJ//ebAlfd8vB248Jb3B0twhmdZqPIhF+acOKXC1jkunGPOmTFn6AzFd1w4y85aemvoFQ22ZGECUeiMwVPpzlrGYiAYK0AZWuJRIqlkdRqEQZIpSN8lFJRaNnqjXCTpy1LUSTU64WGwYEphLBLMf7Tbsu07uq7jFBP/8c0t2Rl+/ulzKIX9/RE7zdzd3dMDz3ovOiZqkByycKuzOmfamrMGNlRnJLMzhQtTuDSOrR2YUuGQxGg87B85HI+8erjncthwvduSUiLGyBwjcwwY5zHWkVTPQqa+LlzNFNpiiElAv95YPIZes7R308wpRA6pEAvsXux4PlzyZ5+94L1nF/yLv/wr3n/vA55/+Gf0m2ui6QjjTFZWiKptLv6Y/kz57Xn+YziORxFP3QwessOVQI6Rl69e46zh6uKS3nsuLnqM8/heBLhdEZ2bMAcBY4Ns8ClLq/eQZs2ylqYf13WewoboJCAzdukW5p0jkzmGrAzBRAwzMWZOpyPTNDU7djruIc3qkGb2+wdSDNxc9PRXfQu4TkE7NanPVlmXIj5eSFEC+9NplFLDqsUURUi2+ibTPInIec2eFeUdqbJvKJlhu+Gyc2yGgctexGGNs1CcAHZZ2FkFmtNX2Z41zWBaOddKAPLpA6uOV/3cCnCxZ6/XOjzZI0z9RN1kdQFbK2vbGW2r63twHaYboBtww0DX9bh+wHmPwbQOdJAla+d8ix8NBnKmNiyvPMFSmSJASpauL7g6NmW5rilGxvHEab9nOh7oDBgvgZ21ll4TIu1/StcWdnERTUMn67gYQ0gJrMMXsK5j229kSLT7WwgCisdS6IaBja17tJQhppwx3uFykvJnI98VY2AaJ6bTSIqxdWOSUhaJ0hdgrJYuyohUJ3kOSVlVWVk2AjyFFAVkUu3E9ujfNR/QyV49w7oXGGELgzp8RhnMP6rQTcAZTGXhGqYkjm3WVu+VifT0WJhQCNhUknRrC5JtT2nBRIwB74Wt5L36HKa2hl/KGyVkELTEWAGVOiMBTcyFKWTGKWM14LS20PWZkIqwd0smKeiSkH12jNLxSzToxK+or0lFsGT9rZGEka1upxGmizBQ5Mqclf20F5IhMUlRrSS8612ID2q0w2IFuzB6DbD4qwra+t4J6zqggY0ObPXDKVLi5oFiEMmoCjhrEFFZk7rxqtoBORlSMQwmc9VFPnje8+HVBQ9z4XGSMZ3nJVgbvKPvOj6+2vLJ80v+5JnhowvD8WVhnBP70XB/slwM8KyDo8vMduL/+n//75isZ2NOeJvYDVu88zi/JRXDVBzZDmxIeBKmOLVxDmM8N1vYdJYxWS0nL/XOMcbQey921sqaLkmCps5IIm2MmWINkJkj3AeHtwXjM7vZcHcqPE6Zbw4zVx08v7Zse8uuNwxedFN2g+ODZzuuL3qsF8ub5qVsPSXLnKT8jyIAoEj1FQJRktmGFntQLC3LR32WSylcW4MKjqLP09il1LBGNuIbW7GRRQHUkvU8BrQqAIz4mss0k3W4jol/NEfjNDWQpVWErGxW+7upZcUqTVB91X8om6DPtFZar8vzatVMWfkFa8JCqa0qz0/HOihfs6LqnlcqcKTkCKP7qnO1oubJ2fSa3mZvyc8KmhQj6zwlbTwzT8QwiRZpER3klKJ0n0yp+QiuESmc7qMyzqIjZbAdxJA4PNwKo7LfMfQXDP2Goe+42g6cpiPfvfqa725f8vr2S3r/EbvNT9jHA2PcczyeuL99wBSRD3n24id88PHPOB1njvuROTzyuAdjRLPZugv6YaOBVEeIR47Tgb5/hru4otxCmA7E/SPx9oEZS9pdcDLfYsyB9559xnZzzd3+lnE+EPIX2PKKFxf/DO86fZqV0gC51FhbXkkKSjZ8onkHpfnMaigQWRsFjLS1WwX6Kqutxfbq0KYocVWKM855hn6Dcx1dPyCqHgmMJrRjlX0wjW1bwUFjjCZm9HqoHfpq3FlBxQVbyKVqmdrV62+z/SpOcT7/FlaXsVV3u8HszSlomE7dw6BVp9XzVP5Wc85+wPGDgaespXLteGI02oWoCLlQ60vzbNYIs4xtqQSldr63fCejbCAVBKsDYZrRWiJnA61LU9OqqCV1pTov+vaa+dPgyjoRG7fqhRgrC7zk6ii8e0zOdAl4O0O9ngDr0oHFgK1p2jXbW9q5ahmgQdD7FKRIy/qeYXfFi09+wev9gZAdpSR6KxoIrveEJGVdBsMxZnqDMH5YupDEUjgZyX9ujeXCGpEmLkW1ShyX3nHppfVub1B9ItO0mpalKwvHmUoXlaDIYnDGqOgwjc0WdCLUYHJxbmXemDp9xM1dnrQRh0C75eKybOZb79l4TwbmXHhQNsCL6x0GKSGKJTGmhXnXlvASz+gGWaVlTAPSqtyvRYJrb8A4Q8Yz2oIzhVMKHEIgECmzsJmyEz2VlCuzQDR+jLGtK5dcT8GZCnQZNSziwDpopYoWOdecEseUmUvhxe6SZ1cDP/3wBR+9d8PPPv057733MWb3McVtORz3IlivjKyWuj5DvVfrss3JH8cRQ8AA3lqke6OjmMRpnHDWsBm21A5gFfBuALpuAKlI57Cq4ZRyIqRUQ5rV5mBFxL2IzRSNHS3ZM/I8QxKdLwvEIFpQQev0QexKCDPSw1sYHfMcIGc2m47LwTXdi5ijdjSroAgLKI6UtaQUpfNbjE1bN1clVF11y3uCCgXL848ZMJF8Etr86XjA5MxFt9MAbZVwMMu6lXnGOaggN8e5tlN9tToCqzm58t3M6s/Z+VDtmKLBcN00VxtnXcPLM3JgRWgfFfi0TjJzVYA7q0B5sRlnHMWuSsNZ2X6etHYuRTOQFpdr8wkp6UA/Iy3LZ3Eo51lZAgavCZBasrbscfKndlARSoltwNPC5lDwRcUva4th0UFJEAPGWZ1n1RmW8+WVOHfNFsdYCHOQcri46g5o1imC1fNrG7p0vBPnWcpRpeNZXTuSMcw5rwKw6ji5lbv/9Fkbde418jO1WQiqOWaFNfgOEOaP+1g0OkzLOppl+5WF9dZnlgWz2PRS50NZsZ2Q9wkjsGhTleWMZSU6Ws+zlN2pRgm5lYLEVLREWOaKtWVhrsPZn1QEJJA5LLtvZZrUMvhln9K5UhZwKBfRQMpt7oo/4KzMqVSji+qnlaVUoA1ddfzbSJ3PbmGEC1ReKoOjOiXmyWyt+0auPitgVoz99lZTB1cClAzGQ+8KNzvLT573+EMimXUTEBljb6Sb385bLjrLhS9cuMyxFOZQGJOwiW6AnUU6SpH48puv+e4w8+wCNp3hg+trtsPA7kKaL2CsJF6KsBqbZ6pzru8sGPExq64TykKsc6GCMRi1P5RqEkSnKUOKhTnClASuCdkwZ5hSYYyFU8psvHTCdE4Tgkhy1hnYDZ6+WxoKrSS9BNBUQO9Mg4nSEph1H6gxR+HsCS4rqAWBZnlkpq6V5TzNhtX5uTz2Nm/XT30JHX9omPbHe7zFFmrzRf55ZqtXf5f3P/33+q3m7PcLcPX2e9Zgz1NWlPys4BOsoIh3PpuFQGBaWVO1a1Vu7+z7KO+4jrqHLd94FovUPT0rmBqlsUtRdLIow1v8jLyAGSsx8xr3yjmFnWUdEDLzPJISOLvFWi9sedfR+57TeGB/euQ07ZnDkZQj3nVYTWbGFAnTzHQaOR32XN8khn4gxUIYEr53WG8kMSfUTf1u8W0kARHI1kDnybZgSiDPM/k0EXeO3FliGSk88qFzbIcdD4c7KdlNB3l/mWkoY1tJpflgmAp0VgaBkkIayLhmHy2fWYZN/LX2LFYVV8ucVR8wi69ffMYriONyd/bMJbao8jk037SWhp+ft95VxSzensdS+dJmZZtXUpWwliY6P+P6XJUQZOp9Lxt+m8dnwbH6HMvaVSu2Yhb/UIv2g4GntcPdvtSYhrKu0WWK0AABocgWZZaUZVnnXFHduPoS+ZEqCKROhHXgXKdZXDESUh+bl82NSpG1jTWwDIFZ/TS0EiMFecIcwEYRjT0bVdlY6+SoL9UyuLU+FUC2WTIeCmSlOFNKlqxXWZz7OYbmZMtXlTaWIKLg6tu1OMMYqZc1wGn/gO88H3/6KXeHPdsPfs53333Hr//273l2OfDLT5/zk5uBD28+4jQm7h5mHkPi8+9PXHnL+71j4ywXznLlLZ8OQrP0zlKyp+TaOlao0N7BxsqflAVIKVaMaiy1fEwCdzE1aOcog8hUJumuhROmRZaJJ7Zes/nqyFgjaR+nk94XzR5RHWdxkHtrcQVeeA/WMafC8TTzH17fY7zhz//kA9673vK//OVPGefA/3CcuI+Rb4rU+FMqoCRm37KAmgWItbwBSy060uSyziERBb/xcOMKH/WFKVtOqWMshVOGucBhv1dwbTWvcoESqS2j5b4hFCGB7/zAxndc9R6HIcaJlGdeHSKHkDC9x11s+OWFYzs4Pnm+4+Zyw7/85/+Gjz75GRfPf0rpd4zzTEoPbYNSU6tsvhWFUye2VatSgYwfyxHGkzAatxucqdo7ns3VM3na1ikDIGnQLc/mNE3MIfJ4OGkZZCbGxDjOupkuDL9YEnOa1Xl34DzdproTkGIiJulGF5VdlKIIe8cYJIOckgZ9huOUMWMmxUBOkd3guNhsuL7oudp69seJcY7UglDJ6EvnAJOjPONcmMNMTIkwS5vdGGLb/EqBEGdSjkzjqBo7UkvQNlrd0HKciWRev3zJcbth032M906zabL+MUYy2mKoMWRcXhhOcuikq/u/OgjUoHDtP5olL0FpXIQGNAiLQxhhS9ZrCQQNyqbUUmpT09bOguol5RTIuZf7VXubQyCFRIlRAKlhi/WeVhBUaiP7JXw1BmFJIRnLrE5PLlZsns2YTvbC8Thy3O+5f/Uth/tbSpiwOeFsj3OWoZfOgw2MLxLU5KYjJpui7Te4fqDbbHHOk6xoj4VplG533uO8oR9Q5p0XHbBUuRMizumsUxzHiCPaDTwc7nj5+g3ffPk7vvr13zA/3DMd9ngn+4RxZtGEM9pZzC5AUN0bU0rKfpNn2/WeDoP3O2F39Z2W8XQKAHoqgHvuh1X/QeajtaKfZb0wakXLwdI5z5MP/tEfKa9dRgFynBNmkssCZutLq0N9FkWYchbgr/pVIg5es8GGUpTB2PyqosCrXZzP1fl767nsNgzeMTgn3b6isJilCFaAp5SKaBYlARia5pqtxFv57sWXQsEVy+AcnZfS4Ji0GUmugtfKBCsCSGRlPA3e0zkjHUSNYUpR/JOcWbCflTxDLd9rvxNWTi2BEMVsZUraTKqaBbSVr3NfOkFW/xQkWKn6b80pV5+vqG9prWm6aUaDsWQsY4bjVDgcEpGMsZmth85aYXXlwP3rN8THew5D4ndd5v44cZwDb2Y4GUNyYDzMJXPKmdl0BO+Zux2274ndQPKeoSt0NvDRiwuuLzfkcSanxH4aiSGJZnkWX7A4MMZTMIQog5BTlpJAbaLl1V8uNQldpMFPX2BOhf1BhINLEtvRW483lkTCu8z7O8tVZ3DGcZwyv331QN95tsOIc4beGTojfuHGW17sesYycZhlPEOEFAzMEAOcUiEUwFiszdp1UYG1gvj470KekI6DEWHeG2Tr6B0MvrDthMkVk2HTW2pvkOoDn63GJzGc0z9G52N9/ek6+2M/6jqryZnKMtS7btIG8hxqyTQsuT/xDXL7vW0/m9QJqKYg4NGkSTwL0r3q5+aVb1vBLdm/Fn+4Ao6VBFDfa1esogZUFyhG2TJlsQ3GLsmj6tPRrseq3fAt8G8gVFHAAdFwijEQp5EYJ8J0IqXArOXpNYkmnWPtKmmmAGxlnSo7OTES8oHjeAAsg/f4TjqOdx4yM3M58Rjvoc988skHPLu+huRwODa9YTcYrrYGwsTt97fk+AXzWCg2UVwk5QcuLh3zKTKPgf3DI6fDic1mw7Dp8UNHf3HJFB84PdxynZ9z0V8Qx0fC3WuOFNIxsw9fErnl5uIn9G7Ltt/R+w2H41F0VcNrcgr07krlJpICiNLxt2jFkkFZYEHHXh+y857aYR0WkFxAm7I8xwqaVvqjKRRjMK49MupsLikzTyM2RnLK+K5j2F40EDrHKMlqY5ufU9lpKEBobaVh1GPVtc8s1yQ+0ErqQl44WxvtDK3Ez7z1syZi6pyVD1QGlI7O6kaN+rerrxOQqg7ZD7RdP1zjicWI1G+rTucZUrcCZAxomUBRFE1vcnWFFbRpCK2+ltURLq5m1QRsMi07tlxPFV+r15JXZVLLtbMaLLHuzXCoMJk1RjLb69FTVK+ignUjPR+LinjXuu7F8Vgoboo55GosZfJUupp8l9YN15fTamyQWnvJmM84b9lst+wur7i4eR9/f2R/yvRdoqREPziutwN3JvDmGBhD4RBkMV46YSZhDR7DrmlMVZDLKnNJHTwjpW2DrZtw1dow7WFYI0TjUBY8edloa5mLPh+TW5iYMJxTXSXcslQNm2XuAaKPVIps2kaCn2wMc8qMpXA7TfR4/uxmy4c3F7zYDhyNYeMsB2uJxhCLgljtKbCiTC/TcM2qaxsQKCAoOhuDgkreFDa50DvLkAsuwT5GxhgXBoPVDgg1O6sBpdW/S6AqHdcchs5IGUOmqOZF4hQzu62lGzxXW8/VxnK98VwNPS+ef8h7739K6m/IpiOextYpyyyT/2xDbZth/XtZ7vPHcgi4LcJ6xRREj0Zq2w21nARql5CcBCSap4kpRMZxUv0IIyCOPtPOGBGTLdXZSVIqqcCzsVZAHHV4ooJMcwikIECQMI1iA9VBOwilSMkCVKUY2PUbvPN47/Bezi9lfgJqiz6RAjwKopVclMUkGjpS8hmaJgJAjEEFzStYRcusAWKTEBuZU2IcTxhTCFFKpV2NIptnXTe1Cv7U1VTnXLUb0EAnoG62FXwqpsI866NyRtHOaE8BBt0LVthWY6BSjZFZnD1YNpP6XaVSk7NqeiSs71YB+KocuG28ck+tvBxxcGSck3REzbRnLN3bJqbjgXk8Lppees6auawBcmV+tP1G32hUj8E6JyWPahurZpfXgNlqR7vq8NaESy5FAbyi+6XaKGMFcH18ZP9wz/7+DWU8kWMg48laClx1OZYnuBx1vI3V7nZW7KRVwfVhGPDeMQwbvHf0/UYSP+oQ1k4/6z0XlMmAaJoZY+X91uK7Dmst3v74gKeiU7rR7hW0acFZ+UP2+nxfbf+roGAWEIiypsrz1snEfyltnpuiIrZ2EcwvSKCTdY1WRpTgXqJ1kc+mb2m+lXynzkv18Q0Lg8ZZYVGVCjuW5RyNJ20KWAE9Omfx1jVtpHNmOs3OLPct96xN11pwIr82Zwwr68wiKPRkjNYPazmv+r5an1WyaRpv1ecwVI0bC9aTsEwJQiqEKKzLXJOTVoLSkuB4SsRTIXaRO5c5xMyYCmN0JAxzkeTXlDJThmzUmfNb8BvwvZTgMONMYjN4jPNMxQjgNI7SIUrNdvUF1WM6m0eY6ldUBvl6L5DtxFkjOpdRxeJLET+q+nlGusDvOsPGyd6SS2E/BfpUSNmy6R39rpNALokf2TtLclbOb6Q8vEisLY0MipaMs1xP+9fqWZmzF5alIEy3Ze44Iwx3awpeZTCcrWXuZknSL+7U+Vxpf2QfXNv+dyy/H8VxHgctnnadTuuYDo096gMqq8//oeNdjKclkVUBoIWZvIBO8npZwjbeBTrV7ziLd6u/3M5R2t4qYaA5+xx1TzQCLZlKm3t6H82ULMymHKW8Lrfudbm9v3astdauQmsF0kzdBTKlzKQ8E2LAGofptRmElVgmlUAsM6FMWA9X/QXbYcOi4ZZxttA5QwyZcZzw3R7fvcFvCn5byGVWLL9q+SVyhM5lsodu09F3jkN8YIonEpdkl8lpIk1HwqkQSuYQDsz5wGk8Mk1HfLfBdx2Tn9R3mYjphDdbqWyqvmUR7cmcoz5TrTLS50pez0Or+q5QtESvaYUuOxPrFVmTgOeLVAkLNcHB0ugsZ0ko2CJ+ljSu0LmnEgp1H7SqxtCgEF0TNam3/r42r872+GUOnbEM4WztnLP/3vr4O9eZXvEicXj2gX+8xfrBwNMaNSuUhWao3lAFmOoDrAYjxJrxMXoeXfh5YUAZU1tKlkptac4wqOOCtipXJLtmuNc2wDpBpHNl5VRnI9fMeGW1LDZD5qIAT6kkil0AJZmw55OO+opZHrBzTte6fN88Lx2WoDSU3HvdEFWd0TvbNmUwUqdONRLLGDujXe+coPo5JeYwcfv6Dde7C/5P/9v/Hb/9/He8uLrk+++/49/+6ldcDJYPnw30fcenN1vStSe8vyWnwilkDinzbcqYOWIfMr3TzV4nRe8sg7VsO8fWWzbFMGidrHUt4tIOcKLzZEFbYILJUtplVahSABcjml0mi9NXbNNwGo1kNG2pKLQY0arYYUzSxShsjZ13pGK4i4VTifx+vIfe8ae/eMHNxcAvXzzD5sL/89/+mpgSPXDVdeyudrgY2adAZ+Se2kpvwbKMgbhXyqzQ+SB6G6a9z5hF48U52CFimc+AkCxTclqqVVkSwpDMBYqFXCzOZKwtzNkRixXjN524V6HxQ85MJXNxfcGnQ8fzS8+2Nzy8ecPr+5GH/Qs2O/jzQ+EmOkoayWYkldjQagFWV4KIqw1yHanX1sQ/Jvcnl0SJmcf9oc4mSs7MaZKSzV7mZxgzwcD+uCfExMPhRIyJ4zQrY0RKmFJKQhUOSntOUcqHcsJah4+ZKoCbYiDNMyFE5mlWcCKrMKQwjFLtioJuBsVombDFF4NTQf+Q4M0+8HAKPOwPnE4TczbEbNlsCt5rR0ggxExOmXGaCFG614U4a7ndUppXS56eMkSLboiVcVSZnTFGQohM8wwGts5ijAiq1PiqUGiquB4xcKvS3GZTC2d7luwFf+gprl6QaLlt1Ms7aoCoc1z1riorbHE0JZywxgvLBqk9riyPXFk6RYU2wyxi6Sqg3fUbLaEU0CNoKdo4naTZRpYbmecZ7z27i0vpWDpbYkzcvvqe/f0t4+Md8fiISUECliTrNanIvdFWva6OWN0XtVTWOWEICQgl4E1KiXGcAEOKsod63yllPwiY51wbhwpryXVeYJ3jNM28fvWS3/76V3z39efs776nt56+93SbDf1mo+KhIizqvHTZslavScsXjRX2n5TByVh1XY9zns1mg/eeYdjgnKfrOpx1ymAySPcWs1oXUfdEDeyrZ6Y7ZnXM6p7/ozqcTPQa4Ju6throo+7nE2e4aLAtSR8WxhO1G179I2s7xExMEg46a9n2DmsNnUNYJLXSUwO1mAtjCsQ8cTsGbsfIca47ZQ1WBFqw1mrDkAg5YXLBZfC20HcG78TBztmQUgXMJSnjHeQi+2jXWToLeRa7OViLc4ahF19s5wQMS7WRRyqaiBS2o8lLpJ9RXcNSHXVhvpQoDKu6WRonGiHWOS4vr0khMT2MolOZhQuzbl1eTKFY8ftstxOmoe+IU2Dej5r8gKLAmc0ZXxLWX8LuObdh5vQyMI+RMo8csjCoK5VBtmjTrFp93kuWTnzrL/dFBWdFBiE5z4vB8/6za3YXV7x/tWNwlsPdb3mY95h+x9B7YIuNmXJ4kIYb6t/nLIzNwXVQMhFJVhzmhDWFq61datBY9LKcdWChR2USfBbblIomRyIWz3sXAyllfDFsLTwbDNtNx81up/uv6IYeZtm35unAq/uRYxDh4o13FOfITprBLIJ0sjZSUl+7zePVfrMCyTAyF2u5Zl1b1eTkIn7unKQUfUWGUO1U+axDLWypTLjF1axHfWR1W5IE14/nkCqOdwezsNhrCei16qOy0VbvW2sBP9Vbenq0mGz1vgoGYs4BhZbLeefl/eFrXgf29Rq871mYKQtAtQAIem2a3KmAfbtGtZlLfKrA0zwR5pEwHiVRqTbHqyZkFdAueZ0Us3RdhzEZ5wJzOnC//5rHw0tO4wPb4ZKL7RWbYUc2hpAmTvMbHudbij9xs3vBJ+//CUQHU2Y67vnu5dfsDydcd8E4Bh4fR4oZsf6Wa7fl6nrL3X7imy/f4K3HW8/z5y94dvMe3nd47/EbixsM3u/ZDkfsmJjCxD7cwRixbouJnpQSU4l88eVvebh7w88+/SdcXz/n+bMPMKZj3BvSHCglkpOnUwZRMpOIl6uvUFk8KczNX5Dwpmthjix58SlrtYdpTWGUobp+/vqfxV9dGElGgYUYRgEJc8b7jn7YKitNRMRTCc1PlOScJReHK775r+crgCdXsBiOytyqVSx1jTwFPtdAVEvwVp+SsuSaqxGscF3dB1sEnNp31/kNtAZyP+T4RzGeWk1iMaIjv0KFDaUhvvLeuuBWhuUsK1SvdjWAGGglTk9uStFE0YWwihouhrxdR0OllxOUdq2071rFPk+yYnqeOrGqa/aOET17sO2UK0H11WNY0+Uqna4Ki9Urq+yvej+p5KZFaa3FGacDKZn4aZrovOMXn32GKYVf/uIXlFL467/9ewyZ/WHkksLlxQbvDH3nGIPoAs0YqbHPhRILQylsiml6QgI0FaItJFsIWbrhSUPbZSJ2RjLrtZSmhjKSIK1OHRos1MxeHdf6fMVBKiwgTh376iDUcXoKicRSRKC0ZDpjubkaeLYb6DDMIfL1yzug8OL5Bd5Zul46Os1hAmPYeIG21kLbhkqD1gxac9HrzFwAzIUpJRCVUYfDGUMysLUqbJlzA59SkVK+qkEgjCjVSSgwZREpnrIAT1MxzMbyrPfsth273rDx8JAzIWRKctjSk4ojFykVq5ntNahU/2La+J4bt7P18Qc23T/Go7KBSgptzAtFyiBs1YUoxCi2Yk5ZunicRqL+3VgReBf8JEPWstKcSEE2mJSldKmY2NiDMUqr+BCkg5nGigJ219E3ULNKesEtqDTKKCoFEZsnYWLhOEXGOYqWGpmcPaXY5gRXUEtYVpIlW2sFVIeniW5Wz1qPtxw6NZRFWWExRXy0FCv1FefqFixzyBpWfYhXz2Rt+VZT7okj+BSYOj90fFZ7zjmDdE1xX/1se9Z6T1r2gKz6BLZkcjJY1XvKKl5a1HmpCYWA2j0tnxRRcglWS87kbcIUS46ReQ6cjgdOxz0pTOQYcNWute9XrZo2hGorM7p21QWoumF6P9bK869lQkX/bp0V66ygY8m5gYToc7DW4n0HxorTN00cD3vmeYKSsd7R9QP9dsuw3bEZeoZeRNl91wmryhoBoaxV+r/D6mvWdRjr6PsBvwKeKtOp08/V84AwmhqLrGUkhTqWUlI2odT76AgtTUF+dMcq0OHttVD30bd9lcpAkdebn1NPBI2Bu87yG7MAVu3zaiIysqfNSbQGpxQ5zolTUPHy9XJre2WDhfU7aXnGRS+n3oxp9sYY1fixYEtlQGkQl41k7J3Betf0Iw2VvfouEHJJJ67Hsb2tMq/UiSlOSuFkzRtc5zV5aHQ8itoOWZ8kvalWktFhvMf2PSaed5Ftfqv6RcZ6jN8QpkKaAiVKPVrKMEfFnVL1ORbWfSyGVCzeCauoakWGJKVgTnW2LnfQe8PQezZDx9AP9M7yEDPTFNj6jPOllSQXWLp8Vtte0PBj8bFFQ04AvlW1UbOyRp+LPLcV40DfkxVM6710QN76yMZC5wqdk46v0vlZgsGMJWYY5yTC6yljMk0gvjEBV1tYfT4rWUPaEliDTizzvZ1iFZDUj1bx8frvGkPkYhrrr/6+7q1Pttj2/evfFd5+zx/zUQkLf+g4i/bq/m10j63jZXTGnT3PxU6tf/f270t7Nu3Q+GOxmfrLs5E3Z9+3/o51EH8Wd1qLqyyWehZjzoSp5T6k7H99Scv5VhdZ/a0URRIgxaXzrPlDWpCoNIwBoxrBLkOOzGHPHI+SVDOGod9IUgqIOXAMB+Y8Ym1mM/S8uH6P6RjYj0dCDJxOB2LKONdjbCEX1alN4leYAikkTseZ3cbRbzybYcvl5Y0myRy2s1hvyMVi7UDKj6RyIoSRMRo20YtOUoFSLPv9IyUGPnz/Y3bbCza7nq7bEceJogKB0l23W+5fB3JZhajfIAnhgqHkePbkpSUALSmrD4+a2Kn4wRLLQmX0LvNkNedyJiPNgwCc74EiVUuL5YciadEqUdGqEcyytywgyLJeTGUf129tiPY7vOQ2R3gy558cZTUi7wr/TGV2ySCsmWSrdPIPOn64xpNOVgmviy4A0fgxxmCTa6CK1UVYSqGEqCBUWRBr4zCaISo1i9cChrIY+ZJlM1ODYoyh7wRVFlQvq7K76ADkGKUMxkq3Ja8aEClGYkrtAZwFGLmotsSqhlKvxPyBh1n1nc6fyfKkvDeAIyXbPptzRkpwDV5rcSuqHeKkSOXSDUH0AWqWt+pwLK6bBI0zho5UCp/85Cf8H//3/we++uor/tmf/hM+//L3/L//3b/lm/uR33zzLZ2DbWfYbDwXFwM730k9f4GcSgvSQpYObWMBX+D7XMhjwLss4rtUIEiy8UoVYGOgN0VEZFNmMIXOCCOi0wytQUrSLIZOxbQdog8gZWVCB8+YJhbq9IFIJxwLWa7xuzEyFnhwHrfp+Nc/+5CLTc+Loed0DPyf//2/53CaORxGrrYD//pqwFt4/mzDdLLc709sDTxXJy1mceh6C1JGJzyDrK06pfuzUwMlXnMtlatOdTLS2rc6PxiHNQ5MJpukDqyw7zrEeU+5MKXMnDMPsXBMmRMwATfXG662PR8NjsFbpuOJMD7wxauJKSTe+/BTPvjgGf/yX/5rPv7kE37yk5+KxkGYVVsiV88HqB38WBmV1abNux2jH8MxnUZ1FmttvdV/J8hwnISyP5VCLplJO3FFDXK9Zu1KlPpvp0Oas4A60zRJlj4lsTudx1kpiROK9FLqJs9D2kTXLHpvei3xU32lXKMYtLYoM82ZWZsLYERENuO0TDgTQ5DNUf+EOZBi4jSOjaWUc1bxZkNMUZ957Z4hD792oYO6ocqYGc045hiJE+zv7gl9DxcXDUCnsmJLoTTtPl1g1snvRYwKlXrFltV3rXxQXWLqfBak/pjqj+l6NBh1rlrZiqkOv5HOdU3zR0o3JNDVANV5jOspWCk7Skl1WpIy24rqI8j3iMORmY5HJmMY+hlnBagpSda3A0KK8iySByfJmlIKd7ffczoc+P7L33DcP5BTwFoj4p3K3ACYQ4SYsSlhvWO73QgjuHXDqmU3MqZhHCEVkh/AWPrNRpxg3+G8oxs6wjiS40SKM4dplEC970QMmAHnPK4fyFhSybjOc3F5ifv059xcXbDb7tjuLthsdwzbHf0w0PcDnbKeKujnrJP2614YTM53q/3V4LsOpyCXW2Vr2/NzNfAT6D9rGXzSDnjSoEEEUktKlBwaQAFarvojM2JVLNRZAaGrrmLR6NdQHVU5SqF1xCmO5vQbbUEfggKntjK3M84a+g58kY0/qc3prIA7JoklmCK8GQuJiUOaiUmB+myYi2HKAhRZ7S7nvaH3Rjt2CQMq44ildtWFOcpC964wDMIM7zeObmM4npKwqFOGDLuuYzc4shfWSd+J2UlJArz700jOct0G6JQBFVLtLrZiDxpxn0EZKaB+0GJ+S6pd0SC5RAxHYUaKS6P+pyHOIkBgauDiDMV4Qnch1wfKmw7qN/mmvZWTdCj0xrPb7PAm4o1hAuaU6V3Hpvdsd9cM28vmeY2nA/M0SqdI7cBpKGw2F3RdzxyiMGpnKeftewGJY4qcppG9NXTW8OYhMB4TN8x0PvN4GoX9NmcthBONKaPM/HEOnGbxqVMpOrdgHwpdzhQr+l7CNV3GsreQHAtwqHUusSRizuQs+lVXO49TNpmIx2c2Xc/19Q5pCtHhSqIrga8OgbvTiIszQ0g4oPOu2QNZDypVEI2UbCZWZdpLBcTyfp0gGJmzFDrn6KyhIxNRnScrczcnwxyydsHVc1edqxa8Vjsm8ywVabiTW7BTEbt3RXw/3qNKslRGU8u2FNuC2pq0l4B+id3WDKh6rqQaOm6lFSjNPKbz52qE1VaK6Jct4uLtyprrYjQdXmVS1qVKjVnSEMoaCy4EiApG1T3QGPEnazMpSUJW0M1QtLtdjpEUZsZxT5xHBYzA2U7tlJw3paJJH9lr/dBTU/aZkVTuiOmRx9O3zGHicvch15fv896zX1BsYTYnHsMbvrn7O5zruLl8wQfPPuOzD/85333/BV99+e94PD5yCJO8fnPJxe6C9148oxs8/daTU+L25Z7pEPH0PH/+ER998hNuXjzj6vkNvRvwrpPuylPg8uoFznc83n/DeLhlP75hP7/ip5ueTbng0j7H0vN4+J6740vs5/DszQv+6V/8t7x4fs3ldUfOcLg9EecjJrzA4NU/SBqrOrHHpVAciKZeZVK3CaigSW7PXR6vVGqFkPTtC+Pu6RqVOZA1mSrP0DkvzMgwq/8f8V1P3mylMsu7Zb3r3Kvi9Osp2JJBq6SQHCuwYgUq1T/1uqD69EviZ4VjtbgfaJqdT3GnYqqNlHlbY+CcJWFSlYGyWWUd/oHjf5TGU2VTvMUSqjoSK0PxlOJVF704QbWIqb3URqQO8/o76vmrBoZ8pDS0r12LkSwVWhuZzaIvZM46+OjXttcrGKTGpCyPeqkX5uyen9Yer9HF9fvrONR7rzdanUSZDbYhqBIYl5Yxye3e3n4eOWf6vufZzQ3OWh4f7ijG8Le//R2FRx73AUrCkfFevssUmo5TtlUUXJg/GSQALkInDqWIAGbO0vFuFSzW0qGNUTAlSgC9cYbOSjDfrYxyZ4QN1BsBnHpTcBS2qgUS9b7SE+CpUpDnAlMxHIqAM6l3dBvPi+sNu66DKTGeZr5+dc9hnDVIk5JP11k2vafExC3CTJIEZSUPvr3pt+Wu95z1xmvmcgGf5FzBCCtsnfmLBUJZZ0nQ8jtpIz2XwpRRJhoEY4jWYDqH7x2b3rH1hnAqlBiJGWJx7K5e8OKDj/nJTz/jJz/5hM2w0XmhWYCzIOzt7K958o/zl3880VuM2uWh2oqaMVCjGVLGanCbc5HAXz9R7VVR0AHUyCroXbvBpZxJUZgtsriKlo7kJeNWSlsvRkvArJYQmAgmF5LaVkp1sgTYfQp0V62bep2tREztc1TNppRiK6fLOQvoXTeqlY2t9nO57+X8ZdmyqGWC8zRBzvRdh6uC09Ds5tlhFkDobD+odqQ6bNCubeGQKkOh2r5SWtvZpWy6ZtBrlrKCXVZaxTZ7bFowZFbfJyUymewSpBaatuXTnp+eJytoFxFNwAqKlJSEkqBClUaB36xB83g8cDo8Mh4fmU97BUwU1GsCpFr+Y+QzJletI93zCiJUvnKCckpkq6LxTnSUrJOytdqtL+nzoSRSCBQ6rBcGbdVQFCde7rHrPLvdlt4+Y9d7trsLdjsBnYbNln4Y8N1A5z1em17UMgJrrYJpIuQv5QByf5UR5axbRFdh0b2zdU+v96YBm2Z6U2NtRWGgJf1cm7k/vsCtBTt22Z9bR9Qnfgwrk1+WBXa2PupqW+tGaEpEOmUWYW9mmYK6/8laS7kwpkIXM36S5EnMRQBL3NJdjmWNVb/KlFYUKHsgRkVw5TNWu/JSwLs6l6QMvS5r7yydtwxFzWxdzEn2t5Ak8WX94tMtt7nmV7wdPJSiF1tkf9DLojazMbmArckDZWMpy3BNcC9Ggr5iLMVqoiqn1gihannW89c/xojeirci5B1MHReDs55hu+Xi+hq7Klu2xuBSVBsk17bZbuj7DXYSlutcZnLMOCdAb0rCwp2cdP2b5sQUirCnS2QOmTkkakMoCUQWPyhpUibmJfCuyTuM6nFZI51/69xczQOdjO21djsIAN07K2O9GlNrDX0nGlTFdfhi6ErGOSMJopyJJas26LK/VNtd/exWgcET94hl21qvCvUW2jyq7PRzeZ7lvG+7Tcs+1vz9es+Y1XxcX8jTX/w4j7WbIHNjPRpmFYmvfLDFI199duVbtxjLtFjxXB8HWFuBGhcaswraF3/EvP10zuI5ebfatXIeJ66vQxKetcu6aWuptEm4xJFFI4qSk5RrxSC6TvW6NI49P5aSa7LqluZMLoGQToTpRAwjpWT6bkvf7ei7LdEEUnpgzieO0wO7zTXb4YrNcMXQXWCMZwojc5pJZJyREj/nkBLpzuIGxzTCPEUMls47NsPA9uKCbtNjvRBAnPfYucPaQtdt6YYd4/Ge2R8ZSyTEAykHbCl0DAwW9nNhzCMPj3eUlJlGkTNw3SCVN/ZIJpJyEE9xrRn9ZI7IPJLYO+tGadrY1WewmiKUxg6rz1IAKJk/ZwzkslTjNJZ9i88TMcrvU+oAJ/tcxQGq3TDr6672YsFc3p67q0tt3w5vG5BlLOo8X3/H+dhUNtV6pzxfKzVmMJo8rnt6TYD9kOMfBzwBIYS3DEYpRctITKPYdxUYqhSypFpPqej7XANZsj5ggxGmScnqcC4bW1u01I1E2owDKqBqKCY3ZyzFBCmTahvFlZO7XHyRkr0qTm6tto1keeD6XSBsnsYIKG9P7qaD1QzEqnteEeqzIOCdnkLO77WbnVMmRkya6dHAtN9sxGmvpQfKJnBOAtv7+zuMtTx4jzWO/+Kf/yt++U/+jP/qX/8r3rx5w+ef/57buzu++uZbDsc9t/dvOJxOHF7dYU3CE5pnsB06dkMvlG1nsb3HOq9ZVgnMcynSWUV1aDBuaa+bpR32bAwzhrtZs25ZCMgOhwUNIBKoptNOy/gKQQNtuaTmvBgZm1OxZGtxF5dsNx3/4pfvSXvdDPvHE/+P//gFD8eRh8OJQmHTeXLJ/P7VHZe7np+8f0mfC19vNjzGzG/GLFkyK5T0wUp2KpfUnPHqeGcgFNscllQyaQUKZATkzKVuAgVbMoFCKNVY6QZrhC0YSqHrHH5wbDeddBzsHJ23jMcj8+GBr78bGaeAGS6x/ZZ/9W/+FZ/+9FP+6V/8Fe+//6EAFxjmMBHmSYGNIiU/dZG1TQ01zivDYmuBI219/ZiO8TRS2RaiA6eOAJacEoeD1GNLa3tD13lpb6+syhCV9abnKxlijtJmPmdSXK3zbCjZUlzU7Ldm9IwAvTFnYTAYo+yO6pho3XROlKQd6GKkaK688x3e+bYJWLOUaRZtdZt1kytFBKxrgBFibDZFhA8hxKjAmQZEUHfQ5nyVIqwFmfBy98kYSozc397hnON4PND1Hc9urvHOSa1924AEfKliwLWCpgW/ZtGQWh8VIDoHsYoGP3kp3at221UxakTHxTgM0lmwWKV4awdC9Q9FRy3MbS2UUuiiCFh2vWTn9BXmecLkSD9IeViKMs7j6UhOiRAmLbmc5Ty96BY5YzC58Obb75hD4NXXv2M87kn715gw42xRJploZGE8WIvTrJw0fLBYHMYI21L0gY3ulZZcEnOc1amZ8G7DZjtABfpIxEnu1aF7WQ4KkEp3l367w/e9znnHxjo++8nHPL+6EFZRinjvcQoyVb0Gp2Vx1izOidPEk6tgGnXfrcH6OUiYdV+oZMCi2d9aQpfqfp4W8U9KofOVd2tb+Fb3iR/bUSn3WVkTUv4rXTCTZnStkfbzdcwEtIS1dEHvHN4abLdonoVcOMXC6ZR5M554M2a+eIi83icWIr8EgYrvMMZC52Dwks0feiPdv4qKRFdGEHKtYyyEJAkYqHpOylQqhZhEQHxwhdlIKnJrB658R3/pCbmw75JoOvUD3jlcnrEpc5zEvwhRGAkpVt9LSzbVrNbywmWfk7+1pJ+aFBHc1/lZwASxsylnIduQsFZEsK11+P66NXGYEzxMBeMcbujAijhWTgkTg+wHrlcQQ0uts8F5h/cC3pM1kTEnxjFyPMxwtWOzu+Dy5jnXz99n2u8J44mLq2subm4o6m9Qgae+p3OOx8dH5mnixEwMhc12i+s8+8c9MT7waBLOFEqecR6O4wTAcVa2J9JFr8YhIRXmnAlFhrVo8Nu7QimGOVmUFIw3mW0nQsTbXuxAzbu3hEd7DmLTNhZ6Z6QrrDJjnbXkBCkW5pCkpA7L4AtXfcf1ruPZrieNgaT+eWqsYXmeoRgyVa+lJlskfqg6aC0XsgKqCij7ZAElJBQwrdudc+LLbTrLxgtg2gSLkf3NYUSQ3ALa2XEBXGucZGvH9zYyP4Yj5dT2gLfBABoQUEgUbVogd9+KZpv9h8U3rbFWBeVdYxPpek1ZSy5lf+26oSXi2pJXt7iyrVLKGuvZ9hp6daXtXdX3UHGNFfAqDVpEU1GSOMrGdhLXWusx2FYmbozWjXgFopV4kKPsueNpz3h6JISRFGctV1+YUyIRZPCbDeRCPB2J48Tjq9ekeWZ6PBDDicPhO+gDvJfpdgPb91+w3VwQyiQC3ul7DtNLbu9fc7n5kD//9L/B2Y5vXn3Bd6+/5NX9NxynA103YL0l2YCp6yY5ymjZ+iuuXnzMxeaWm5tbum3iNH3H8aWlvHL03Y7Ob7m6fI/d7oZh2NF1AwfrMclyfxp5eLzn+XDL4Aeu+w95r9sx5XtCmPnm+1d8yyturv+a4+GRTz79BdvdBXR3kGfmE5AGvNkoIyc3/xBTRAuT6m8s86hT5lFOuc3J9syzJHBlfjnx7dW9MGonkmoByjOximtYKQNEGw5QIEun5DFHnO/Imy3OOXzXQxG2Z02aLnEYVEac+NC6jnhqJ/QTVvesouC7kU7MplYkqC9VO3paZxcbbCS5YRugWlqJ6ALm1WssbZ1RwGbREDSraol/6PjhwFND8KrpPj/WiHMroTt7n2xOpeSVULniZC21xCr6pSHCLSv65Lv0rO2BSd1rbpkNGYa8cn6XT7XYSI1GLSh+yuaqraDFoavC6aYFV+8C+Co1boEy63VnKKa1I1wQ7DqbF5RUgC0JqGp2ZaEDVoTSkIuUFxojLds3my1Xuwu2m4Gb6wtunz9n0/V8//oNxvW8ub8lYjD2kXFO2Dy3EjBBMUW3SbLgrfO4ZhQr7U9BQnTcdMfMIKUlyEQsGIKVNspJAyEt3GEutLafIDR9ryBm9QIq8GQxSLLfMGmN9FXf0W17rnY9G2853o0cjjMv7w/sxwljlk56BdhPAVfF063Fdp5YIo9Kzx4AbwxRn0rSe21yaUW1mfQ3uRhxmnNlAObmpGTEMTGKCieKnLcYClY2ROr5xEmvyITzhl67ugQEPIpJWvZuhx3DxTUfffwTfvbzX/DTn/6U589f8Pi4Z5pFuFpADRajuz7UaD2tJzftZ3UIy4/J91nZC5lbptoM/XUthZvnoIBrdZTFjuUYJUupNiTnQkpRQfhKOV3ZAs2S5JzqSpWfdd2vwGja3/Vn1tLhLLpMGHGQfakih6XeRgumGgs1i42plPDaQr2BUrqBiUO+/P5toHFtsxQwoGbpBFydQ8BWMeycCTspearaH7VTYzuMafpu8kNf/IcyJHWja+HK6vrqta2Bs+oxGmEcLBlN285X9LM5Jw0qxK4750jG0Pkeo1TLgjjPxILvEjZpgJczaRax9jmcpCwkSkKg6ySrlZOIKB8f90zTyOnxgXk8UMKMybFplqDXiVnsOsZotnbVjW5l92syhhXzrehe5Zxt81pYQolcReVz1vFaSt9dBZGMaQmHi92WQZNDFC1PtEYYVKrFZK2CPivgScoYK0Ng9XBV02z9q5ZnLJDNsudSFk2nnIqWPcYm/i5Ai7aK1oSSqXT1f0BT5I/1KKbm+k1b+3WB1eRp7TiWFSxeJV6XFa2/LKXqNBXGICynuUQexsxhisxhKSGvDMMKva/1bdA9Nq9maHN99L0pC7s31WrZ5nO1u9MS2EWTQ7q6ih5Ij+jbzUl8jYyw1lPOxJgViKuA+cpBb5Ot2sn1XmcWM9LGZvlpDAIS1M9XX5QarILzhmHoKNpdLRkDxUq3yb5fbI0ChpS6TpZnVyh473DdBt/1OGfJBt0HCiUVKRHufAPFox+JGAGLVZcNpAyalAX8sAv7UISWZY0754hhZBoDxcxYMsMgrJCYRLIiqSB7A/91jNbZ9+oVm/V7isyQlAArz9upporst3XTfYdvoicwGOkUVyxF51bd70QWQ3wto0Crd5bOyeRPy4We7RT5yVeVJ/+qPn3rrqzBV7vKOo/KMo/Ex1vNOVMTApzZuHdtc4uPda4R8w9thX+sR2MEveNoQ1tBcn0WdZms/vIOP+XpucxqLp5/xlpL7SZuzLvO9W5wDFbzxZz/dqlsqec813A7uy67MJ+WdbAwaYxZwNnqB6Y4k+IsSTKdKObMV9CLKlBSJhxPzMcjx1evCePIeP9ImE/sH1/hdrAZOqzpJHFXNNYlkfNELtKJrXNbLncfMM8jdw8v+f9x92dPsiRLmh/2UzNz94jI7Sx1qm7drXu6ezAznAUkBkJihBThM8n/mQLggRAQAgqJ2Xqm97vVepZcIsIXW/igauYeeeo26uKtj5dk5cnMCA93czM11U8//fTh+IHj6WgyDya0IupLmsY5Io4+BBUqLyOFI8UVcppYUiEmmHzEu4kuHBiGa1KKSjJJ5kvlzFIyU56Z0plbPDu3w9NB8ZzHmZQWHh7eczVc8eqzz+g6R2FC3EJhtLEfbL/SOLUa3tbRkNVvbvH/75lPzYbUDdR8UarvXSopxWyHZN3JKlVUpM17wZ5pWRARa5Jmdt7IOdVqFWr4tokL6uZVNZO3F2hGR5oxKe3zdY6Z5qdUIgK08r6Gnciz9bP6DnX/vORnbua41O1sq9r69x8/vqudgQuhd1aOMl8MfN/3Gwe/ME9nNneGIQd2U0YTrxu6upCGVJdnrzNdFY8G7nnjRMgacFQkEBG8qBZRC85yJpLaA6hvCl3fymFyLsxxUkTUkO/KnnIWIFSdlGDlA50PFzTOihBqe/RqWKRpxNSHWlsQKyhSGusgxsVuXVkZQ+goaWF5/EbvQzzO94TdSxCIRSe6C8GMVeF8PnE+nwldYDcM3Ny+4l/+l2/IOfF/iQvH4xMf7t/z4f6B775/y/3jE+/ef+Dp6YGHh3viMrPME0ucmeq/j5M5QZmYNcsqMiJSmoMUQofzgb7vCJ2nDxqY7HuhGINEqeT6CE6TY8kFraCntTBOud8YWRXDVHqfGtxXu0AfHF/eHQhO+Oq3bzmNM3/xm7ecp0guicMQjNWiTsecMm8fTixL5Cc3O5wXfvl6z/vzzH/4aqRk2BWHdzDUAKsTC9DN8GQF4Log1cuA4rU9pro3aAtz35aeZlgqW6auYqPOi2XBRLWCSl6YH544xch3BShCGG4I/R1/+s9+yevXn/FP/uk/4YsvvuDly9fs9wfGeeE3X32lbVZLNoGBZwt349S04LuWF289Mru2sgHTPpXj6upKbYnNsWmKrQOXPlv9cgUVK1wmYs5MBiylpI52bt0rNXMyL4uBs35drxswKM8Tle6t5VfKetK9O8GSiYs6zMW63MU4E5eJmBZSihYoQrRuaTUbG9OipYGbGo+2SRRYZq0tj3FmiemCOUJZGSQt4986Itm3Z45bza7Vch4hI1nXQsqRd+8UuOm7juA9+70yaIagwLlrG3alINQ6DjbfqR9e/3Hx9fzVdd1VB1WoDExHcTWLWJRFVpKW3XmvQBOZfNF9VO1pjpHOdZqh7DziHcsyE3NmOZ8RQe2/CNN0JsWF8/mBnCJd1+O8ZdVz4v23XzHPM9989RXzdCZNJ0pROXgnHvF925M0wDcGUdCSmKEflD3se2AFw1unlN1eGRqdlk+q5o8yOFOKxPOZeZo4PT0a6KTZZy8KHHVDz7A7sN/fMAwH+tATgtpuPwyEm1rmt3Ge9O5IBlxWVGO1FqXZ88Ja7lud55qUaetoO99KIdq8Vd20RIxR9+bJNC5Kwgns+o7gHF0/GMCl66RqkX1KRyurqJnHrF1wDruAC5mwqF33Yi+J6gg6Yz2VDEuCp6hiRVMqnObCd8fEYl1uC5niMkuC0wIxawMLLHHTfFyB4LSTra86NtUuZfWBSoZi7t5SYMyQsiZjiuh1BmdNTALsOwWVJGmp3BQLiKPzHa9uBrrOQzjxNEWeYiTNhfePqnNYS4vrMXiHd8JhUOblPEdiKsZCtvHbuND1NzizU676lervpMUSQx7Ea1JCc0TKpn51u2eZFx7jAsOecv05ruvodnvVHJ1n8qLd6dLjB+LDA8U5iveavIgLn735gi//0T+mH3b0w57lq8x8/45OPNfDjjR0pCHQd167RIYeGfYMhz3DMLSA6PH9A+M48uHpnmUeISjryvc9/RDwvTIxYlyYpxFkwbvC4epACJ7Hh5l5WcUvxEESkwPI65qt+0bVBayjWMFgwVGycBozi4chKNvHm7yGM6+vLVtRZtyH08jNEHh51dmeoc9ytTnKipGiujwxQ85O/TDjOahuqG1nnhZ8pbKKrWeguAoG1Jva7i4bgKkouyvlQhQ9x5ThOBeeJpiTBp2dhRVLKcYGy5p8jWJdFbcln3o0P6F+v7Cjn8bhauVLS9rp7KqJjhon131AWsC8BsWrTMkPg0pgGnCboz5X7TpJ+8wKQOXaJCWmNQFjbPhWmpnXZLweW8kDnT9+s9dUZu9asqTOnrZjWhOHGiILrqy6VZmMuM5ApESOC9Ppien8ZLGut/L0mkBzSKeg9/jtO+bHI+//018zPz3x+M23LNPM+XQkRtVzK53A7wLhtuPwy3d89tMv+cn/6ZeQA3IWXu4+51/9yRe8efln7Icv+P79f+R//o//Hd9+/R1/8xe/pu93XF1d0195wo3n6fjE+28+MMjAzu0IP7li/3rHMu84pz3B1mFJiWVKvHv4moenI+9evuX25jV92KtfU+6RcmS3d7x885KRM9+cv+Fu/4absKOcIvGcOR4TY1z41a9/zdOHR+Z45vbulpevbun6Ht8/UdwE6YZShGWaKSWpva4sMYvBxGJ6ZbWWzXyph/oiAgSbp65qLNszThajuuBbLA9ayYNBiCqjETYJoAIkUppIUyKlXrWffW8M7kTdvFcrZHtqPZ9ohZhrPllbNStSJFX3TP3jqqO9MpnWeS2gGn1AWhaiYTqF0jCfyqou5TKZk4ze2lbHc4T/7zn+gFK7FUhZk4qlIWNu4/A1wKcNzApcXTCj6mlpeaCG7q0sgRVovLyWNdCSi8ekx0e/MwdFNrtdNTY6YGqIUkzNoa4GqIFaGw+sTqYLzZLtvZe15vOHUFW9t+1v18C41QSLqO7CfFLx4SK4bofvr2BTy+5cMBV9BcZiVF6OdhwKHA4Hy4AJ4/U111cHbm/uuDrc8OHxiaubex4f7vnw4R3jeOZ0OjHNE/N8ZjyfmcYzOSVIyYJYLf9BstJCc0IwSnbOFGvjLZRGyQwmAqy4TSFY65VWz4yNuQilOMQrQBc6Z+Og3/vOMQRntOXE/eOZx9PE24cTc0wMXWeCvQpoFSvZnGNiWiLHcabvPP3g6YMzEVB1KnAQTRcsmMOTapwsUERLDCvLy/Chi4mh3enqXNAgUWzbKUY38U5wUghOdbBSFFIWYsGyblp6szvcsru6480XP+XLn/yEn//sF3zxxRtCGBDnOc8PTNPUZrkrNOO6TrJnE6/90hbuR+uqAsKfjgu0AkzWIStr0wLnVk9PNl9U1lFajN2k8zKVNXSpjgtO2907VLusZksTytbA5QutJuy1VMDHvuWc2jlzFYZvKJBYC9ZablQsO62A43P7AyvomU18vNqlXHWH8vP3bZ53eXayZ78GXTPaPjpRYmGcZyuLSITgcUHorLQHEdNueT4ZdR21J7ABnOreIe11tqe2rXb9/+UcXx3X9qd6/+Kao1EMHCqmwQXqJBVJ7VlUZlxLXtR6sE6TGCkq4ynFhZyjtS+umlGR8+mJcRw5PX5gnkakaNtxF4I6jlUmeJu9bHusmKPsm/Ney3/b/uI8vg1rWcevaOe6tCzEeWI6n5oj5X0gdHpOHwIuBBUCr1pM5kQF7+hD17K1dbOu2mYlZdVnLFxgiBUGaPN9u9+XWj6/Tq+259fvppWVYtTSBduPl2XWPShrpjBYJsA5byBjDXkxjZ1P6xBoc7f+3FhozoZ5Y0/aYfpEMRfOUUGF85I5zoX7KWogHVV7SFwmFbFgvjS2cDtV/Vy22dHVT1q3Qdn8sN3jja1FnQPFkjU1GafzoGr+lILpgenzLYKWesXMNCfmJRszUQ9n/ph7FhBejMdm+2uXivliQit3Egxwau2N3YW5qf5ZFxwlKfPPe0e/3+FCRzcMJO8VjEP9uOw0wy8FsOY6lIwPgeHqQAi9CtD6QICmTeqsDCt4T/C6Xl2I2jHPBQXSa/fHXFiMvVubFogLOJfb3qQlHh2ddwS3Ccjt/VVMVoEXFYGPSZtqbEaVis60UFzWsqMKJqSMJbIwMXYMeF/3k+qpJ5NxaI+orLPoYnvazI/GvqvlhmxiBtuPa1lILitTq71we/w+s1GozQ6V0WX3Vb9K0TLSWMGjIm0bqvZQfs/5awxU14M5zp/MIc/uZy1N286ksr72+fufgU7Pz7P9ub5+/b5lpEmbm5cB9A9f1w9/5iVbSpmVHzNsGyvpQlHyh476WbniBWr/cm7aTrkCGWKfVQNPdOMvMbM8nljun1jeP7A8HUmPJ9I8k8az+oBLIkdIFSy4ykw3Iw3STYUu7Lm9ecPN1RvEdSwxcv/0lsenB8bThKNDDsHAGtVejMti9tuR40KxZj3kgGSVadAKE2X/L/PEeD7iJTD7keA6hm6iC5Fu6PGdJ58T4zIR86S6TVnwOVCykDJM08w5jDw+PiCSuboe8MEBCzhUhqYEauMx/2z8685UWbH2AGj2bEPTX+fD+v35s5S2L6x7of7+YkNsH14bB5UcyUmIUcsvs1MJCSmrPIdeG5s5aWvlAnPYMJ0u3HXZ2JRLv7pxOTf+l/rXlWxjZa2unievw9SOGtOUj+3ojzh+NPA0TZMK/PU9iG6y2UQYK2Lcrk4E3yl6W+mNa3mdbm4xLubUrl2TSl7BFwR8UJRXn0UVVPXq/G7YHblUB1hLR9TWSdNsEucRCdQtrZYwVNQz58iyJOZ5Isa5BQRVr2o1WvrA6++0pCU1ptN6VNp5LSzT9+ayihar06GTNVUEsuljqNpRiSNpemR6/Jp5OvJ0/5Zu2PPi81/guz2hv8P3N+zufs4SZ07H9wpuiE6WuEyWkT+t5TcmiOy7HT/96S/446BtsVNeiGlhnEbO45llXljmmXGemJaZ8+nMNE46RvNsYuTaPSsuC7/+27/g+29+x/v373h6fNTuARswMlmdfXDSGF8iIN4CLXMavclDetEuT9d+IDjrAFIy83HklBJ/87ffMC+R++NMzoU+qAh3slI4jzrOu04FT6cl8jhm/v1v3nIYAj99dYV3wr/8yUEFUxedc85Jc5NTLkxL0exaKkiOlOOZVDQINSxDnycZJ47Jubagc1bwQev3nQVE61zqQkcXOvB76AMvXt9yuLriyy++5NXL1/zs57/k9es33N5csd/tiClznjLx+Gi1yjXDuDpczcspl78osLYK3dYps526drYSL2bzP/QjhACU1s46aU7S2sAqGCAeXO+RkvElUhyId2TJZpcysliZpVQ9kQSSm43zvbTAfYlRDXlMyhI0R0IsUteM7uo8qzi4iZWvBZ7tiFFLjZKxMyvoVIXDuQj+1L6mrPpUqVjGv7DStp9/wh/0wJsrrWBMjEzzCLbmvPP0TwN91/Hi9oahC9xd7ZVNkJ0FddUuGkOobZ6XG7V+s3DXbajLm422OCFbB0nBNDn0RWoLTXi9aRxZZJKTght1HxbLTs3TSCqFzhoeOOvMOS0TcZkZT4s9q0XtbFwA6K4Hur5nPB2Z54mvfvd3jKcj4/FISQkfgpXXeRXQNJ13V/ufw6rrJM7EgFW/EJRZl1JiXkZtXy6JEHpurm5apzfvHMs0MU8KeI3nE4/370CUGbvfX7G7uiHsDgz7G4bdFd2w07KdLuj+XBIpFZacW8JCn7pq2cSUGMeR0cp7S1EWcHDepp/xWIv6Ca45zOs8q3IA1WUptgcW61oXnODxxggV4izEXBjHk4LCk+7Nh6ukelqmq+FL+KQCN4AcLftaAxM0NzonGBc4j1nHsxLQzLCbrDWnBfI5U96dda+LRTVqsu67oVMtnyE4lgRnJ5yBNAPUMtd61ISgtNxXrpE5QggwDGiCxsr/AqLgR3EsZeEYk9qyVKD09C4QQsSTEV/AZR7niJwmnkpGvOPrxzPHOULU+RGXQklC1wvihbSw+tjZnGWhdatTTSUaSJutE1TXqW5azabGCurmsgLdFkSWUsiLvq8E5e1kMTbNnJC+cNWZ+GwccUukLJNutL2jeDjmTHBOS/udspd8Spyenuj7gbxLuJzZhYHTNDPFgsuFANxcXfPqsy+4Dw88hRMxzhzHmfPxnmk84v2A2+05+MA+J/ywwwVPPN6Tl5HlrOLCX/78j+n3V7y42dN54dtf/ydOTx/wHnwoIFpie06Racm8fZoY+8Tnh675b676FtugQyeG6neBAsLAw6hzSGUwFOjypVCK6u04ETovDL3XhGGGMWaezjN9F7jxHaEUAyCtrBD1vVLKKoY+Z6a5sDcmXQWfnajPKWKM1udJnRZP1mCvNACy+kmlvXAFuqpmo0OBqDnqv+cZlq4ocO+FKCvIpmt3Bb+KsFlZW8bOp2XAqgQAsjKdVikTZRwF37FCvpfAzzb2+iHgqibsWlm6LdmUtES7Hq6Wu9nftbtxYWPcLg6RZ35GZey5tURuBQq10kZJBpXxZP5IrtpxmoRey7QqC71CIZ5CZhqPTKdHlvOROI2E0FsM4TWm7Xrd7+8fWR6eePj3f0E6ngkPJ3xMdLsDqR849x0pF+aSmVPiaZzIT8L0W2E8LJzO75jyieM48vnrX/Av/4v/B6UIU5pUL/a84DJc7fdcX1/z4uVLcpmJj2dCDFzv9hATcTny8Pg9+SsHc4fMV/igyau728DLLxRYv727IS2ZHE9M8xOnnHn98iX9cMubV6/ZXV3x27/5Cx7efsf357fkJXITbjlcXzGlM35e2A+v6LtXvH975unhrDHizYGr4Y7gdsT0DvIAVqbngibO9BHa3EE5aBRM88tIKWwAqe3cg8Z2qs/c/0BFfwUiKx5SQakCmwZixfZqLRFPMZFDrwnbvgfZ1QwKDrcyBk00MZFr0Gl+oiiTXbbrpOqfKdO/Jbx9MEa4Rawt6ZohrQBTXVm5pHVtCGvXu3orVkWB20ahP+740cCTOpgVfaaBO7QF+OwhtGyZtIfdrprSzudAAYotKimb91Wx57T+LHl1hEvObe/b6pUUKTijdleAqw5Yc3Y32dg1atPPrvfQWoWz3ucFUNrup41UO8dlLe7ley7ZYeuYreUshZwXZV2kmbSMLOd7SCPLaU/pD0qnF4eUZNlQe68FChWcKFHpco2OKipMHrqO/W7HzeEaJFOkME0T46Qt2OMSmeLCHBfOpzPjeWSZZ+IyWxYPE0FeOD+8ZXn6wPnxnrkhquvmPqWsLYldBdcMbDKApOoxtY1fVA8rx0ByRpHOhWleWJbE42lkmhPnOQHCrguIU6q+UJrmhXdi5XA6P47TQi6F0xTpOsewU/2plNYSKTBR5IzqoWy+FE50uCra2hyXGizWciyj7IZi4sae0jqZqYHq+54u9LhuwHc9L16+5ub2lp98+TM+e/UZP/3pz3j96hV9r/oMD49aax2NzVI3wB88mobEZl09e8nH5XRCW7Xl+d/+IR+buYjFv8V0ZHJuQa9ZlJaJlu08rgiRnaBYWr6K6JbNZ9QYuzJPsnUcKlY27Brit5qdGsBfPJMKVJZq26puU2kZnZyydTSyExkQurKdSitPfjYM6+g8++Xft4FcUN4pbfNJJdrSLSSnWiG6XmcEayMtxgrDnLO6UerqhLLd/Os4SnsOsh0TkY1UgkYKVVfuuSVvj8+YrfXktcSaouytnBLiVFurRI8z/QFp59FnpGWMtTmCBl+y0WKap4lxPDOeT4znEyku9hkO1561rA9/49DoLa5Z+hUZttLsVq+x7nXee7SDt2n3xKhsp/oVFy0ztA5c4gPi/dr9zvvm1Da2FAqq+qyBfd23UlTx47gsxHmmlh+4AtnXdaBlgVogjYK41oFvdbjb0K3hRjGWjWh5enGCJC330YC0sl/XhFbOBZHSQJYa/H5Sx8a3qLYmFe0iZkRkK7O0l1UytK2PXFQj6bRoYm6K1Vfw6gs40ywSIdm+KfY566zk4l8Xl2bgTvUFt4n5GqCXsi5VNn/3Yh0OG1NY1++SMmNMxElfeJ4ic0y4nDZ2bGUxrNei/64JzAvLJuv3ips5K7kqzlTkYllRgtKGUP9d1v2xnrt25stFGUHVhykxQopIUkRCrPS/2SVRgNk7gZSZTifVO6EQYiQgRIQZ6EpBcqLkSEkzxfxCZVwuTOOJ8XxktxNc7whdgBJwXUC8006pbZ/LDLsdh+trrm+uCR7rSmnPzeZOZadlYFySdhzOmhCtvr/UoL1NErNfdpcVcFndzuozacJ6+2wUfFDNJu8cUbRbnaTMFBN9UpayGKilH12aXU+5MCfo8vr46vOrc7nOwS3rcmN91q3ko9le1kmzmVXb1aBzQExLUf/m2PqH9s7qTmznZb3Q+vmfkO9V9w21JT/ENLo02U1ni9XX+OH4cvN++eG/bT6lnbvqbF7EWvyAD7SZzxenES7e165NtrZIH7ir0i6Xl7G59028unmJJsQWbciVtQOyNCDDjGeBNE6k80g6ninnEW8AljOtyhx6BSpKhkXwZUaKQ+hxxZPKQiYhBLruwO3V54zLmePDV6Q4Q1JN0GBSEs5DicAiSHYE15GlkGQhxYVpPOOjIyQVdHc4urCj3/VcX6k0z3wemceZhQVi0aSRH+iHK3a7G1zXk71jSiOnErgabtl1e/Zh4Jx7ZXH6jpITMWbG84T3MPg94h0lamLK+173t4uxvjBTVB+q+f5m1y6e6w9PqPXv5eLburFtDckPHoaBpESSiIszzgs5BwRv3ZhXFxFZ47XSPnO1oU0S6MJ6WYyiKJGuwVL/uhFOuFhDz/z733P/z26l2bgfCz/9aODJm05RjMk+wJAzV+z3sSF97UJFs7nVtJdNxqHSC2NMTQBx1ZKwDg+i3QCyZIpknHeEzrMsM6lE0pKIS9QMSu2iYyj29qHoFhDIWTs9maSsbUI6ck5gNxygX2ngNRioAVzVRdnSzOGyw4JuLHYf1n2gmGOS0sboUQOQ9eGG0LUHl3Nmnp5I80lNdsnI8kSc33N//i2h37G//Yzu8AbiDN2evr8D6ShdUBDTmBrJSkdSTHjv6UIgpshyfOJ8OvL+/Tvt+hRc09VwG/bV1W5gCDvSIRKClScqvEMftJzmpTvz20Pm10Pk7XcJ1/U4HzQrVQp/9/7Mh3FRnQeEaLvvPKtOQ+e9dcTRRbTkOtaPCNK6CYoBVJ339PvAqxsd+8Uy9NOiFM9XvaNzZhyzKjBV52vJmb/65p7ghau9ZilSccZ8SgiaYXTmGNclOOz23Lx8gw8dod+tznPw9Cb+2Q87vHijuYt2q+l6QqedoDof6LpAFzzDsGPoB66uD+z3e65uXrDfX+OsFTnpTFlOPJ3VyC7ZuoeTVfC9eVI6hZpjX61LuTSOzaAYSGE5YKOj1vcVHM8AkH/gx3g+6j82QUlOmXk6k3NSLaecKTHiSiaQMIl407PTcS7VqRXAiTFEoDinDIQYcRS8FANuTTMu2wZ+4YMUy8DqtSS0PA8prbulJiqqk7sGd3VDKkUZRzEuLaiQ6uhtNPQAxLqFrXvIZYnwH3JUMAsquL2ep2ahY5yaJt5uGACh7zzXu06DzbCWE2vgqiVUKsuhEauywtTOqnh7aUFuQQNGFeZ2lr1UJkjVZVPK8GpjY0yUEtX6ixiYJ01sm/EE05kQC65fiEBYFrpeNepKipQUmcYTyzw1dtf13WtCv6MUxzgufPvNVxyfHjg+PJCWqKKztXtPKSzziNSgk45uN+i+VapTqw7EsixkpwL1zntCP+Cyo5SdMn9TJIkQF9U/SmlWzYejslWn04k4T7hsQLzNWb/b4/oD4ne4MGipXdA9NC+ROM1KBc9RxcY3znlcIssSSVG7dXmvYuSejMOo2g0Y1e+1pbWIimrm2uW0FLpNp0kfBO93YMAjBeZlJudIHwIpRsahJ8VETFqC0A871RYcVA/L+W3p4qdxVDAjJdWWOJeF81J4OmemqAklQTtqtUPMXsmW9aONNXZBWmAOgivmddheUkOhNSS3NbkxF6pKsr4pg5Wj2zkRAtADAxlKJBfhdie40HHlHYOHm+uB3S7go1CidmmMKXM/LpxjgifV0Jmi+gnDTnAB6yK08e/t1pMDpDAZI74KZSO1JAHECftedSD7XaAA5zjrvFwU2PJoWa5rN63C1kNvoJUlj2L2pOygiJW5aZlMHk+kmEjzjPOB0HdqM10AHyAEutBx6HqOpzPf/ec/Z7cf2B32hJTpUuGYHUd6bmPkZnzi61/9B777+q8YTxPzuND1GoiNxwfG6US4usEPO4b9LaHbkeMjZV5YjvfM40To9gTfM3hh5wplmolFO8YVBB+go7BMmZJVHgHg/jRxnhc6n/FOk2feC9k0ENdqI30IqajYuvdi3Z8MEK+Z+o3YUUGBIydwuw/cDoGX+4HHs3B/dJznxPvjEy+mROg6hqHj6sqRnKPgteTbZaZc+DAVCIVDVN8XO3esvjCbYGq7UDa9VcsG0Kr/pq4dkdY0o4Jy1R/wIvr3Zn6Mp+sEb/NoCyjVDmYKOsmqL8andaRkbAz3MdAjIi2urCWWyg+QZ/Kj6w/P5Un0d44QOvt39Y0uY7P1XADS9iPtPrdKDzwv2dP5vfrRPxRYb4N2PbdTjUinYtxlE7uIIgibBMwKGIjZqBQn4jyqdmvOiFcwyQW1VWmJxPPI6XffkB+PDICEDndAdXhH1Rfr/I6YE0xn0KVBf33g9T//BVc/28Mw08nAm+5PePXilxyuXzHf/47HD79hfPweNy2EBJ3fUUrkafoWt3TIuEOWQohClhNuF5ESiU9PqrQmO0QC4nt2/sDV7orD/o7PvxTm45nlPDIvC0tMON/jXEfKO6ZRCN2ew80NHx4eeZzv+VdXb3hz9TkPy/fspoHdrscNmRfDT+l8z8P7X3P/4R3l88xu2FOe7pHcc/fyz3D9FSkqESBH9aOG3YDI2sEwRu2e671vz3Z9JhXcWXW+KibQfuNWX7NskiDZGnB5qfrOUGsppc1pZX3GuJDSiZQOlJzouj1df0Uti6h+VF0/xoFq66aZNKlkC9UITRlKdq0pmgq+SNsvG95Sq7qexQOu/ljxrBaA6A35EH5wzfyY4w/ramefLebF1I/5KIAppVFdK3unMgIq4MTmvduLb22xP/r4Ni0+Qo6fv+6HtUvq51iRWKlifsUCg1oC5i6uZ3NLz47/9aBtZS9Z8MRlvmwrxlWz/OuH2fXaxqSBaKTEien8ROx7FX+MGRde4Ic7/E3AhR7X7yhYKVEpjQlWQ7Y6LrkoMyEWdeRc2hhhqSWFeklORQYUNOmCAk9FGLpAFxyH3cBh6DkMHePQqZCl960OvguTCblb9twmcsaAgO0vUbFJ1RzQsapO5hA8XlS0OHjH0OnCHpeES5j+k7ALjmBOEqLU52xeasqFyXSwQqysC+vys2Q8KmYvTui9OTAUDruBV6/e0A07hv2VjU0mBE/Xd3RdT98PeBcIvsN7p0BdCARrcdyFQBcCwXuGYaDveq6urzgc9uz2B6XbW1nkcorEdCYtmRgLGW+dutY5fQE6rU+3zaptIFFftUXMoTR8arvsPiUHKFm3MdkYa9VziyT7XrJmqQsFhZEq8MQqolpcHTFadwmbO9k2MWfdp9RpqJ24qmGGrR2qneVSzr/HKebCSbEf1I7aHGklShXELqsw4ToLLNP8LLv2+46yfVHbZ9ZNWb9z8fMGGts4fpllURB7nGcKHfu+M1Cpim0K1vfdAt0Ns7X+u117MdaZfY6iKdSWyY2txhrQrPsOrdRYHVvTYoK1OM9sZHaTBuOhU4e4dBTvW2lm1YZSIyGE0NN1Pcs8syyzNXg4ERcFWTBQvdjgFGPp5JJx2QBBKsvr0jmv3QjbHmLOuoizc2mpnyYWFtNeUFZqirExg9pYbpIpMWpnxmWe6Lxb78sSRDEtFGuVqxNfgad23pLR/mP12a12o5VSJJ3jvpa7LNHK0/WUwfvmS+j1+XUvLoWcPYlCFwIOyP1A9glZdC36EDSwD52WIfwQB/4f+BFtzmtXHJgozGaXco1+PzLYFZHZgM8G9Fb9wup/bJ8bZbum/1eOdSm2H3PR5IjHpof5PRq4w77TBNfOC50T1edwVf+pakBpYkpyJsc1cQds1silibrI/nJhJrjwGdWXx5t2FJbUSkm/ci7rWqzBxuZGK+GgIl61AU21vdlKpptt3j6P6v+JQ7zHd4Gu72FZmE9nTS5SSOLJ4llESM5pqXSKjKcnyngkTpE0RyTvkNBT4ghpocSR4gsl9goCphM5zZQ4UdICYY+Ia+LF0QDHbGO+fY4UBf0LGJsoM8aMd2ozt2Df6ndsTtCim/WXa9J2nXPb93qnDPUQhOCVARVzJpaiovOLdgINc6QXT+xdk9bI6DpJmVZWXnfU1bekzaHt/F33smf3sJ07GwfrYn2IxkNb5l39fWGdrxskazPP9YVtOsnFB38yhz2ii6PGaRd+xWY+/b4gtv76uY2qANLzeHJ7nmYH5ePzP48bn//8/Fw/cJfUG9jus/XRX7zkBx6x5hZMfzOllU29iX1wBuTGhbIslHGizAvBOcQXnGnzqf6sMUhLqUqSCBA6x9Xdgd3NgA/a4KTv7uj7gyaW4sx4+sAyHdUts30/Z62yIHl88pA8RrNuJAzJ+pk10eaM9eSy4IcO+oAsGaIxvomI60GC+tZZ8F4B+YkjS5pJBuDsw4HrcmvgTTIdP0ecEynNTKcZiY70OCG5owsPhD6hAgtCXmIDEFXTrj7fy01snZPPbcaGebfdG8QMQKU5yg/P9y3gUw3D1qfXWEDlOJzr8CnqU6usrbKxW2wY8c+m4MUcBvXdtte9MX4r0ade2++Z3/Lsg1oS5zImaOPxI44/QFxcR9W1Gtn6AYrmVgHfVNWYK5hjmegYaweh2go12KZdkTya+rxqmeh5JK1IX+3SpGgi9H1g6Ls1c6AjqwBPC0BUB0WS6qzkFFuJ0nPqWs514m13mnVApal4bn4nq9vWRGmN6VQ77NRJ2oVAoVinHnX81fk29pixB+KigW/XH/SdfqA4z5JmlvOR47u3CIW+/9bG+H9kf/cTXv3Rv2b/8ufc/eK/IubEFJVdltGsQ9fp52SWjyatOl5VrNSZEVrsubWh1Yxkjq2NcdXyeH//yPE8kUUIw0DoNKO4mBqjCwHx2cTTNEMkAnsHBU/ntfwuOBU+GeZAzJlxUS2lu33HLjh+ctPTW+lHKUJeIx172gMi0PtAzPD9UQXvDn2HSGEI2kngOKlQrxgf2uGIqZCS49AJX1x7rnvHm2tHRru6fPlHf8K/+jf/Nw63d9y9/py4LEzTCWHNgCpY53DNbStW179SjSuwZP1XCP2AdD3np+85zff4MuJYSPOZnGbE3eBlT5E9hU7Lm1izchcMvEL1+Flz1vpzNhXgbOyXCnd4e7jV6b9QbP0EjvPxCLKyNqs22ziOWoKac6tHKWSC141/jpM6idl0eZyt36LZS19Fq4HFRF0dyphCCsVpeUDKLQZcA/KcWtYlmxHfGu2ctHtkZekpk8TqwhvYEFV8stV4Q/V0hPq9WrItC/T3bw7VblaGoePjLmF6/T/kIK/OVn3PskS1LSWzG3bq6ATP1dCpyKw5Fs7qb5y/rJHXrGH10rPeK2a763x1AQkBqXVHepXEJTIvC7UKKRcrUUrWgt1AlK4LhOAMWMo4PyLecxgOdF3HMPT4oBpJWk5XCCHQD3t86DlcXRO6nu+/+4bHh3vefv895/NJ6/JF8EX3gk6sG0lWnYglFm1YkErTpFOWqelgWLA2LwsuaQdT7zx91+sTzYUlTpyOT7Y3Tjq/smoXLNZ5VkLX2rGXUjifnjiNZz58+MCw3/P+2xs+++w14WdfWumTI2V9f4JWEi1FWWNLVHF1cQb6dKEJFDtjYi4L5BiZrGybrFoDyhrO1lHWk0MwXSZtqFC7tTTdMkOogg94cc1vGCyp4oMmOPphp1nKqkPwCR2/PU6UsnblmkQYIyDKrlzLL3/oMN9KoPdNjkGZIOZbVZ8OKdbBq8pIrJnd5/6Cq+CSfYYyHQvnufAwws4VeleYonLhDkNPFzo+DwEfPNFAYHGFU4mcYmKcFZB0BlgUUVubszKPlU1SfZjKbLRrq92QnTrSLjjzWdQ2KlNY6KxjsB80E/7haWKJieOoXZh3fU8nMDhlPCVRJjQ5WeMT1a4swZNFKMtsZa0RmWbc6aj7cfAq2D/sER9woUMen7QRixfCYcdud+D6cMM5ZdzDA8RMmiISChIKoRPVN5LEMi7MKbLkRLB1ksYjyJHee/p9j8tnyumJp8f35Cx4r+MbUwALwFIRHt6/4/xwTxg0+z/OkSUHltkRF6Ek8xys5jI7IQLfnxYrc1Nw1wW3afutGkr6B1ejHp0dTaBdA9PO6yQcgkPl7XRfmmMmBrXxgxfe3Ow5x0KYtRHL41EbyZT3R14eetKLA/enmeRUS6l1lNtAqcXmj+DonMdLREwbsyFsbX+RdU9Za+gpRaUqFkwnyvZV7Z4nFAfO12Rl0SY15gFWIf6mTl5jDfPKvNdEanAZ3+KOT+gQNvajGANK1hjs4nZNS1MUgIDVX7oEgSqBQBNO9UFpzBIvEjghBIvr7J3bZ/5srLdg2AXwVCrAsAIOlzC3HrXBlrPuc5ocrDGmNofZflZj1dgpYpz1axpJ04x+mqcGXy54ckzk+wfy04lwmmBJdMOA8wkX1a/vfUcyoLZkZTotojalO3he/OyWw+cHXrx8QQi39OFn9N01b999xTdf/xW/+tX/wv2HdzgcKWaejk/scISdxy17iDtyWljySClRdduCpwsdfegZQs/Q7ei7PWUsTN8e6V50hJuO88NbHj7cM46RZc7cvPyc/dUO7wLed+z7HW5/YOq/Z4xPfDt9TabwcvcFn1//nF/Pf8fT+YFzXojOEx9HchQ+nCY8DqAqagABAABJREFUieOHJ+IcmdNXpOIpWcevE0fXdfzkFz9nf3PF5//op3R9r/6K1abXWAoU/MOeZfXJkJbCBbTLnfcaE7gSm19cy4F1Hta6d33Iqtdd4y09j5JCNNk3To8sy5lxfGAYrtjtriAERLr13OIbWP18/VBUq6lsQCiHAZEXntGljBD1uuxv+tWQx/XX1U7KuhJqsv1HYk7AHwQ8bS/p8hO2A/AR0mxWZ2Xc1F+ui6+h2Pb+simPqLS3NiFalk4D/eA9tT3mhZ6NyMZgrfpU2xtRgGr91QWzgPoc6kOwB/d7B3e97/aOFvjZvdSyrWZMt6IMtECjboROvGV+NRDOWVtLF+koJTPPGug6Weh2N+Q0a/BUx/JZqKkobx3j55O2jk81uhYUVzDORCW1BWlp2cGslBAtYSy2qYTamlRbxbfFZt9lk/nyVh4QKvBkgWfMDhI4C8764Bh6z/UuqGhj0uuKdg/OxCF9E7H3pmWR1FSIZtO6oF17hlysVW7NyAolGzXaOYbg2fXC1eDJqHbA9WHH3d0tV7cvuHvxkrjMTOeuBfZqUJxJyjuqqFsydksd52jZ1SrIKiVR4kgc70mn7/CMeJbGsMhdR3GBEob1yf49PkrbWzfg6vOt8oL91q6sfhfrwPdpHNEYT+t6NPZLM6z1t5cjVB3FRotdV3I9yfrqpPXaKvgemxBF1TrSz7dzVaH/Lb27EjVsba6Z83QBPK3Z9E3Huu2m8tFje3ZPXNrBrb0p7efqaNnGW51nKmBal3MdOyzLU+zHDYBmukrLHPFuYV4iAsTOa1li09LCaMuYVtNG08DOq0xb2+Ta9TbLq/ZVVpEPBfdVXD1lXeuKL2o5zzwvxJisHNk3xo9LRTvGFSHHiJREFzyu77T23sbDh04ZC2Yvx3HkdD6ZDl3UJhGWEZNccJnWDVCzXNuywHIx/nZLen+WoHEGqvns27NIKTKOo9rlZW7PpDLp6omq9pW+bjJtGqHkiOTEeQhMxxv6vscNQ9ub6hjXa65PtzZMkK0Kb33y5qQjpnmSbW0U3SvanlQzZigLrMja1UqzvuoA5rLVYatJKv3MEFQPoQJfm5a7n8xxjupILrlZF2JuQ8zGI7w41tWpRwWn6/hr6MbqNMq6fttzl1WYdTUS1Y9YP7b6XlrOp2RA71A/wHmCc3Re6IPggzAlWLKw5EwsmSVlllTd+jUDW5qW4oaJJFuv6tkNr3e7/rrNXd1vS1lZZEIhSGFvzOkK/ta5XssJfEzWPVDHQCyhWplNORcFvedJ9dOC2q6q+1YfRkuwbhqvSP15I55dStWfCi0EyMVbZzZ9Xe1Q6ryyC0pOG/ZWvU61pWXTdEEbVSQV/3aOaCyhnKwTax27Fpfoeo7ZyqFQ7TYdq8LK6F/jg2cRAhtxkY9c6CY90Z5qBaiUe7wrtQuwajnFnJgNqJyXrN1mt5O9RUCXM+Riayqbl7dZd/mOmrzZ7o2X834Tb9Tz2K8ydX3J5qTbO9dx0/HcDPVHV/0P+9i4/e0om7W4/v65tarvk8176vvXc8rFQ13Ps4II62fXrnTredYnvr72MgF4cS2bybt98lvWdxWXromj7bU/j423QFdNRuaUyDGa38HFtZR688uCzAs+JssSUJ1L2xMU+QjiyOI2fd0yzgvdLtANPSEMdN2OXX8gZ+Hx8R1Pxw+M50eWeaSymesYOQNjczKQpopgW2mXE2/3r3ZF5UIyac74OZEXKGmhJOu2Oy4M80joD3TDjoLgJOBdh3gHrjCmkaflkReHl+zCATc6SkzKiHKQFkeJjvN5gZh4uj+zLAvn8UTKgkOThYPv6LqOp+sP5BSZz68QoK+diFtlzYoJbOOhtcTO/mKx3vp8nL0/t315BTAvnuA6hy7mWWXsZVLWxkQpdOTUm+6lAl21Y2adCs/nr8aGK96yzrn6ni1A5DY2Z11/7V6bjdNarbI13ha71puVUuc/P+r4A4AnI9iKbJ+IOjLZGE3Wdck5Rx+C0ZLLKq5Y9LXq/GgWeOj8pkwg6qRmNU5VL0kRZGyCGJrtO7q+03KZrHpPMUarsV21eTDxXRGngqrGTmmBd6VL54VkXRYQVPjZOgk1JLyOeykfGZLg/YUNTDFZi9XacsUApqQBr9gA1nKGWrvpfEBKxpWIlAWZ31Gm98TTE+IGXvzRf0WaZ0733+IdXO079i++ZPjsT/D7l8yLdhtyXienijIqa6NY1tkiZ+rE8s7RhdAeb86ZeVnaqzo84h3zpIyzEFSzqFp/7wvOZfpBKLkjVN2tmJFY8JYE8wZg1dILEUVMh2CC4xY3LFHIxYGoAR6CY985DruOITjmqJmnWssfpOAFBq8jO0YhlWxBZ0ZEJ14Xgt6vaHvOcxQTaRdw0DmleVfwLJhwby669I7nIxHPkgMpLcR5bB3+qoci6DlVc8zmy0WQrkFf5wudg3T6mnR+y+nD3zE+fd10Alx3g/N7yg7oI7LvoR9oC1wqsl6tSg3i3Ca4s88uqyqHOO220Wp4N9ZCuBS//hSOs2WhnQkoh047X4Wg3Xt8RoOHkvFo1yFx0LuBmDPnWQGljAJYHit7iVqqmnIVn4fsILoCqVCSzr3FwKKU0tZ06lwxAFaSbhTRKM1xSaoRklLTxculNFHzjAHDbJhvrIFRY7WZ7lxutq7+3tz8sgqQ64WZXd7t8T4wdLsL0ellmRvgUTM8RT+QzT54ceScmaaJUjKPD/fMfQ/lgBMFnmpXI+8cqagt6QR8UYYCUjSTXLvF5KI21EoVm+iGiJaeGPMppsw0L5ymmfM028a5ioovMRJT4mR08c6riKawqA2cZwU2yoHSdTAC4giHa0I3cHVzR78/cJ5G5mniq29+x4cP7ziPkwZxKHtWil5jZQ85EXxxeDMZORcQtVXeOVKXzHHTPSpGFW5f4oJzjjl0FIrNk4Wnp6e2hzqb32KOkT70Qlo0wz5PC9P5RNXFWp4co/eU8QMyP3L36jNef/4TcJ6u26nN3jgz3hekozmYiGr4lVRwSXUYda9RhkoTWBV1csJuwHtH1/U4pQjo/j1paYHTSUxcFktyRAvsbS7Z4uk6FUb3QdlWXdd9pOfxqRzvztkCcXSuG6urfv0YU63PUV+b7CvXAAiowf7zEG5royoonlDga4lbd1C1vl5fe24Ogc5lOld4c9Vxtwt0ruBdIbIwx8jTXDgv8HieOS+Rp9E6yBZrfBK0Q17KKL3KAoNaIuckkaWyBC3YMl+zuKrfhnb1TCtolUshxsL9/YnOC7+4CdzsBn7x5g1jLPzbXz8xTZHp6UzoO26/eKks7hgpy0w8PuE6od93II45RqYlMsdIOZ/g++/wVesxBMKw0zETQeJCPwxacp8TaTzxNI2klNjf3uJCh+96SJGcFrwf6DrVdckF6EAyxKydJSsz3xXBJcHJlf5u0OcXlUdJqhlw66ZJURYmCFKEJcK8oB1zl8Su17Vbu7LUbL+WmhfbW0pL8lXIyNUO114z8ljVQgVpnJVPxyTEWIip4LzO62BsPBEokikCCU8XPK93PbvguNk7znPkw2lEivDuYeL+aebxFImxMARP5x2umj7DoTunAvd1bmcKtYtd249FPz/bPKcBRlubsgIMDYSy3JVszlEBSi07zQ0byEIrl3KlWOKltO54Kwz16ThflWX+cRlbdTtl8119tILu0WvwvpbSpVS1hMPF+dT+0D6rPh/Vv9O/O3tINQFY8eUt2OR9WCtXDBBa0bPtna2eXNUscy5YuXdAxOPMt4pxbudrgbxcjglAmibidGY+PrKcnnStiq5RMqo/Ny/404g7jbgpkaaF8TRCzuZLwd6aBey6PWOcOEatoCh5QVxmuNrTH/Z0YU/f7dgNA9+//Z4///P/yPHpa56eHpTU4A6EvnC4PrPfB676gXEqPD69p9sJh6s7ipvAjQR2eOkRCRazC+KEFB1xhsSCH0dcjtzs4fH+A08P75nSgr9/4POf/wk3/YHMAS+ZIdyQu4kP81tO8wOfX3/OrdwhUyCdPL+OXzPnkc/8l/R5z+9+/ZbpGDmZPSVGHMLt4Zo+dMjuQImFb/761/Tmg1y9uOXLP/klPnjmFBuiufpOVv4tQikroKjVTL7NTUFjVX2bb4CormatOKkd7bP5ymzmXd0/NVbT9Z/zwjIfyTnR9we6AVwIeAlK+oDN+rhEe3T+posJW+dbrbjR+VpjUnOuDJyp87SuOaMRs3Kc6nrwDYpr7/+Rxx/EeFInZzNo2JYjW0ZTRc1Wh6Y6NYU1SN6uZ7YI3VpB3oKoCkStcfLzjMrff82bZlRc/ms1KFK/y8ULn927/muLHqoRs7IUy26tSPeqv9IQfQMH6kaFbITKKrjlvAYkcyQtE8v4SJyeSMuMH/bsr18rGCaB4IX9EBhu3tDtX+D6fRMa3m5gP7SVXaCxdbVQN017JnUiiti90VgPXNwtCiJ5aWLxzjkkgbh1QjrrYOid0f7RoEvr+6HqFzmpjoiOvJbhOet84klZrM5UGROeKqy2bmrtUbbr188TViHWWqUg22e/+VqNjbOgtTQB9pS0w5OCcxbIgyWORf22yrncHAVHEU+JM5mF9PQ96fG3jA9fMx2/VyFB5wj7gO+DOnDZsoysC3+bYWvPuD3o7Rqp11bs9x9n9zZn+OSOFDVC8r7giqNUYdr2Ctso7Sdnc935CuDZE7YSX13E2RgybDSctozCKuyfW9lcynkztWowZxuXrdmUFAxJMZFiNpajaRNVe9hs5fpkq3Nfs/ulgpDmAK8ZkAa30yyaSMteqWaOZ7c7aL19N6gNzbHZlWzd+fSc1mVKtqyr9RPqUfV+NDEgLDHiRcs9vShDsGbRiogFSNopqga91U5XO9z2hVI2jt1aRpRaWaKWh+nrpY1FylY2kfRDvOmnVb2nKOqM1GtW21/oRVpHOHGO83jmdDxyPp+ZpsnYdNUOrDzclFX0s2gq03a7TWYqZyt1UnFecaIApyU+qpMco4J+mmxZ1s9M0eZstiSLb/uNL04lGYwB4XwguJooKeQ4M56PHKZrcoy4TkuFpLpCNgfdZs4izn6vgZxNptUZMQfOOQ1+1w22MtlWirsCiVXrzwBOE85XoNP2GQNGK8ClH7Hdky81JD+FI5c1HK1h8PMd5QeP8tELL15ed/RVM7D6WnUJ1/2i+m71f7T52/w9CxyH4BjEEZwQfKYPYoLBut6mDEuGswFPU8wssVgjFP1wi89xokyXvHHwnayBnjmi7T6UKbm1bDrf1devvkvdpTPOCYcAtzvPz1/fcV4Kv3q78FjgQ6037HT+Bg+JpALZOZOLNGkPZSHpoLmckWw6kYC3v2Vty6v+TwGMIT4VKOIIXYfvFHjKiyYOnHWeLHbtrqjfVFJk7eNY1udS/aVa6YYGoNje4cwHqh1PvSVps63hVQv0cla14Mac+C2Do8UE9fh7HPOV4Xg5Y+vv6x5ppqAJUnunWpld8KRSGHpPSaKMeHFahimOIJVpst3j2nRd44b1f5eX/SwOqEug1BfUgLKasU18svUhNmHNei0/8Jn12FYlbAO8T/HYgi/2m7qM2Y5hHbdNqr+9/zLYNvsjurdv40v9vvHN2qvbzH4WtEt77WXZ3fq3Z3dzCUZsgvZ2urJ578Yeb/eo5p2nZOQLAw5ELhPLMVFiQpaExLza6Sapovs+QTU0gw9EkjVPMfZp8Pgh4Dsr5y+ZeR45Pj3y3Xe/I8X75uvUUuxhGOhCwEtPKZklTnh6FQYP4DrB5R6XA1KqgPV2LTpyTDAXxJuesNfy1BwnSjkSz0fS7oDEhCtC5wdSf8VyGklpYYwnpuWMK57B7SjJs0RhXNRnPp8mxlMk2v7vbC5U6YDgA9559aunhfHxpONjunFtEm3mwDo/ZI2t2vb3w2u0gVH27J9XF8nzqSB1/1x/1+xqKdbhMOLiouNprNh17y1tfl4CmZd/W+faarvLxqcWMF3uzWs3sSRmj/UPwoZ4Ra1KKOXHg+Y/GngKvmOr4dR1+tZMWkEnqaVSrhnk5giua12vPWcVDoypOc2aoTCE2yatZvkT2TaO+rl1Us/z0pgAlQ0FUHVt2mvtGsWu6RJ91lEMIVBKpbyx3u8zT3aloim4M8/q+Ff69HNjJc3Z9hbg6Plqa/G03bed0O93xHnk/v0Hzu+/4tu/+3fMpwemhw9cf/aCz//onxH2d/j9K3XU0oTrdnTXr0jLwnx+Ug2ZHFtQI6k0ATSlepvAmgEpFn+wWLCWEsTsCCEQOk8Q68pVTFSueGUklQg5gsvasMUHQtAubt55pjRrBg8NMq+GHV0X2DmlbI9xJuVE57I51TpfOktgjl7Hru87hj7Qh54uqJBwLspC0RIOZUalogFstmCtC95K+zxOVHhXS+46HYu0cRCkUIwZVc1BEQHnrAY5KH1UxMrnSlvIfrOZajl/+Wivqq12fXD40BE//I7l4be8/9X/zONX/5GUtE37bn9NNxy4+uyaIdwhMiB+r0J8Ttlw66JqMGZjtagxqcR6e7Citb51U9D5V0s8zSA1h5JP6jgfH3Vd9Ttt3Q2mR6N2KsVk6LQG1n3w5tAqW09G0znLkQod5ZxJS6SBPs5ptyIKESuJW6I50ql10qsgTwVga0lUjLO2qI+RuMSWFblwopsjs36v+kV1PhTzRipQlaxkqdqBYrZOWaHatdI5Rxj2BN9xe/eKrh84XF9rGcainUCX8UROiWUeySkxLxMpJSbr3Jei2di0FdTdHgraTtNEyZngqwZGsfWoDMkuB7zLxFQIvlB6BXucJGU7eFvfxVjmRR22VOpGLIzzzDhN+n2JTDGxRN1rYlK6uRNdp0qUsDWhU8D2MpiWxEJCvKdPmb7vCcGxO1yzu7oBHNO48Dd//Te8e/eW9+/eM89T02iqpW51X8gmvikOQinsc1J2ojHaovUdr53ghmEg58z5PG7A7tSAptoZrjRAU7WjvDf9AbN9lETnPYcw4IaecDhw2A/cvvqsUeJLTpyf7hn3e+bTE4e7nqurK2oyKMWk893AwLrnJtMqpCgY6UNn4uf6FTq1s2XS8uwlZqIUiji8z42xkozZtCyzzrdpVEHlSbv7jPNCzoXQ94QQuHOvGFBAwVmZEESmeVzZe5/Iseu8BQ4K3hWkAVDbsP8HXeHm8WKl/kDJuAIdlqyxqV+xllRLKdiAiHYSobI6tGSu2htnrJKrwXHVB5zXLnAlJ6YU9bkneHdKPM2FcdaGGbudpwuC82rcirFDHV3rqFgoBKcAw9AF1VtzC0jGWatvohqFCLgMvVO78vJmIOXCh8dItFIyJ4WXu8L1AD+7Lvz09Z7/67/650xLgfKX/Pq7D/w/v/8eSubGRULfset75mPi4e0CCZZF1xRFgbRIpvPCfren73sOh10DTMZl4Wk5I2nR4oYlkdKZJUWmuLC7vePq5S39bsew27OMZ+Zx1Hvb+JS1KLnkbm1aYWZPqMCKIL7aGWUUevNnlkXX0uPDI8uyEHfaEbKWdigWvNrXmlYXk5kJXo1mnMSSJHmTJkb926LAvxMQL1AKVdqmwjJFUF0kqSCOI0b48DAhMXPTa+JtPyjsna1d4pKVQfPqWjsHdz4wucDvTpknKdxPJzwwx2RSBpoQjBS19UGTSUECgvnGG5/NXD27Jts/8SQc4q0ZoWnm4IqVBkPOsmE+mV4ra+OKYrGLcyvIm1C9tsXcrizrNfyemPYf5FFqab75O7W7q1ITocFLresr7fXtHC1oF7qua4CLjintZ6209lrhIVZWHpUZ6Fz6KCYWqSXbG999I0yvjI/cNJuUSbKeRLV2apl3Uw5bP8bCvurr1cTf5grsuyYx43JmmU7aHCRqEqll4AFOZ+Q84U8LjBEvjiSehFZvzHkB55Fhh+86Dlc3cHS43y10wN2LF9y+umX/ek9/0+FD4ni85+++fs/f/t1f8T/9j/8tn7+541/9iz/mu7f3vPvNW4ah54s3P6FER5kdKd5zXN7j8guuwp6rm57bFzuWc2Q6R1zcIUtnpXdo2bFX4fAyCmW/o/RwdfcS6QPz2yPx4StKGZm/v+Jw84J+vyfcfkGUz/nVr/49j0/v+evv/xPvhm/44uaP+OzqDcvbHe9Pj3z723dMx0fS4wS58PLFS/q+Z++1vPtqONCFwPX+BieO6TSRS+Hpq/csDyM3r1+xvzlweHGjcyHbvidaoue9zo8mMVE04eU3LaqrnA+ysjpFnCXOtGueWLJxy0IvlnBtuRz7vbiAuCpTkFimM3GZ6YcDfd5r1/MQKHWHTgCmuymXZdx1nm+n2yUxBpOE2JR5Y0lA8y/r/lM73VeA7qJ5htnEH3v8aOBpK1i1UhBpwZHUFIEFNjUgawFP2dx5vdxSB6H8vda2oYAXT0iNmrYKXM9V6/NXZ0zFlLNZp2pschaqUOUPfeKa8Sh2vrLJ9FSEL2+0WqpSPxfoe8u0NPBpcwsN/myh5faOSXEmLhPLeNK2vKFrjn3oOvrDtY7BJLgw4FxHdnlj0C9OuvncOvhrHWddLM5t3iLgJSFpUYfEqQPsGvWapj9CdVQ3gbUa9VVboKAbhZbbrWVizWGqeg5sGU96KU5WJlVwnuRq63h1lEqu3tcKJIEaAl/nho311vhvEeit5751AOrYtPptaEBm4blom51NNs+00F7T/l8djly0JNNKmCyhulkz6kC60NtmvDF4DZaQdQ61YRAqhXLNTbt2U9v/t0XMFuj4dI7qVrTRMzuWU17BklJZiGtJ7XbN67xRNzub0a0aG9XmVr2lWrpWW52u864CQ/Z8ndPPtrK9ZNmuKqhsl9qc4y3oVEot7S9tLmLXwOZaoDpoym5xXje1YN+7Js58wIeO69s7um6gGwabVuYoexXj9VZGoTpD4JI5jE6B/yS0cLXNrs2Ca138tm2n7O/ZqZMevK4p3RSdluS53LJH2PrQjblQdZ2KnWqx0pc5JgPSy2VGP0P20taJEzHwaTPI9owqAymmTO88Luim70NgmmaWmDk+PXE8PllZWGldIqm2oe1zdX+Wdu21BLOItvjVCHHVNaxgXTL2T4wqiq+Mp6onUAGBQs5WpuBEhYxFhctFwEumcwqsdl1HPwxNnyHOE/MykaOWrJcqWI9qZxVXKM5TWbwu1dROafalMs+q3RVZNcFWp7vuoWvGrRodBUpzY2SsTr46PXhte+wte+ncup9m047KqbJ9P51Dn/G6h/w4G12e/XvValpzFqWBFvonWddY1XAAqqDaGgCujKQqL2LuhALJktv+PefCEjPjkplj4ThlnkZjOOXCQaAPDhczsmrvqq1qvgHNl1IW1Pqy+vPW1hQRK8nT7+3ON0MSpNA5Ydd5dn3gatjjfWbXefpg4Aja6MWJ0DlwOdOZjljnhCDSQJ36kJx3TepBBDYbOrVcuYjqTGYDbuveU5WYnLi1vXfbmkuTiKjC1NUGuo0of/UFSimtA58TFbmOAJVVu8ws3uNzNnulPngNLFZW9eUz2Zg287Oq/6N/cSZJsPUh12UvFz/re3Ws1A5piVL1o72rz8z88WL34h2d6XD2nWcIntlXofKWs1ntCrSEy3oHsiYc2y1t7zo3H1Ds8yso9VGXp/VWaX9uvlsLieqwXewFRT9pcxWf8NGGfvVnLnznTQz3Q2FZqzxofs2z023s03Omx/r3TZS1IR9cXiAtxl1JBPp3kY1fXuMdu671KW7+1dYU1PK+em3PS+2yMZ7q/iXOOr5aB1tigqgi4uTSuvoGryVPMVdbaP9Z99IUE4TCcL2nv97R7QdCr2LV4zjy7Xfvef/ue6bxSIp79RURYo709ITQkZIwRw9Zk7JSCsQFkjdSA60OvgJ1zulaVvDY27jNkJUVK96zD47shas800fHIe3pUiD1e6IJlosLHOMJKfDF7S8Zup6dOzBIYh6/43gc6QsEUbmEPgSGrid4T9f3BK/dQ504SmK1uzETx5nYd20v/IFZ92y+XL6szqmtv3sxpYvGgm2m1Tnnac+oTdWCvrbte4WqtUwWZcPFxYycWDzoLuZr+0xqqejltW+P33vLzV997kNcePXbF/OH2q8fDTyN44iIaNti2dQ4207S9BXMC0mmWZI3zjFgi0i3Wf2VlQW4alAsCCm6oa115NWpWA33vEzM06TnBUKnnVOyBZNreVTtApVMnyhYNsmvhqFe+oUhUmc2ZW0B3YJM+3Pt1Jfr5uh920SFVRF/Cz7VOuVCMabT+gCTMRNknlkmFZuO4wPxfEbE8+Inf8T+5jPi+A5hwXvIMTIen+iGa9VcStmK1ZVRUC9WzPnAxi/lxJIi1eUJXWDY7TQr42sQUYgffsXy4VeU4RVL/wLX3dANh5alz6ZHQBHNUvpOtQ1CLeWIxkLSDm66MWdiLdcBRPyKllZauas933SEqkHZ9x1D8OAiKaszpd2dLKh0gCuId7iibbglF1JazCHwlCya/TTqegZSNo5QVkPQBSH41ViI1248vnNIEJBs2bTqMG7drwxEFTQuBS8BL4rAO+80SxYjOdyQr39OuPuW/elEXCZSmukPPcMuEPqAuMSw39Nd37EwkDYLvzKuLsL86iyZ01vKikqr4LlQtb3E5kP9jq1BZYv9flvwD+24GlSnqOv6hurnlBmnsQHqToSh1zWTswrCx7gQU6xdbiFpCUS0ALsyntTJd9ahzQ6zgyIQWDt+qj5HbA6XmChtthI2EYxJULPbQLO1pYH/lXG3itvWDnl6sdW56boe5wKH61u6fuDq+oau69kfDtqZbbfHh0A37HDe03UDpcDx6Yl5njnlMzGroC0CzveIS3RoFrEYeLKUhSyVsXPZ9U5tn26oKWdcVpA+W8ATUyLa/qK6aoG+6+m8Z+pna7HtqML/zqjTKakmSQUxlKmZOc8L52lhXBbGJSr7LBnzVpxlmjCBXGUruk2ZbwPK7ec5ZbIkXlzdcHVzQ3+4RnzHb3/1d9x/uOf7b77hdDoiXlqGrE2BugeKldgVzCGDOS5Ni6tmyiqAgzm1KSVOp5PpOc3Ubqjr2K5B6lqBlDX764Whc1wPHfsQeHXV0R/27O/uGK5vOFzfmFPsmBDiOJOWxPnpkW63Yzef1Y6HzpglYgKokWTPLjhBgrIScnHkVGxfnIyRoc8nR8s4S2Xt1GYg+qUliNJAPsThvHAYBg02gzLzumHAe0/f71oyIOdCXEbzN9I27P10jg1Ql5Atn7u+4KO3VB+3QCv71YCnOqnF9tstN3ZNEkk9B+u6qC5FcNA7iEkV0aro8+gKXqKVNgQexszTlHgcM6clc/9UOI1wc4D9INxee+6uO8Z3M3M0lkpWoNE3LSvVwQlS99r1rntfCAHOlqW1xDPXe9VSmqN2CFb8R6UAgit0LtF7uNof2O+uWNKOaZkZxxPzMkIfyAnO3zySve4NOyf87PYOHzr6wwFQAPkxeu4t4eaDBwdzTiqElZTt6lFEJC4LEgK+92TROV0QlnFEUkKWRRmWXcc8RaZ5bqO/3w/sBs+cCiVF5nlhiYnDsCN0nSVYFZheYmQYdloiEzpwovpu88w4qt+ck5bzhUGTWk6Coj11NjR/eBNk1F+JdgfVKWniOlJwpRBUM6GBRRcwsIFsuahNFi8cho6bw4HXLz/jqgORqGLi3ioUzKFRvS/B4XWvGpQVdTsIsdPXrzZQfeC2j26XyuYmNESjgXlY8O7E5okIvZOmQwWbJLqtheIwNpOeUYpo10dRP1Jl2ZQSVfKmqQTSvto1lEz+lMzXJuDd8MtYgU6rc9g032k+6fYUmzjNPY8JLxJbG2/XaVe7BvdVTUhqLHZxeS2mrayRLTi0glBre/vK7K2yIq0BRgPE7C6clkatkgwa+6a0XmsphWUeWaZRE48iuKB+axFR23CakNOIHxdkzuAC9I7+TmPR8Kj+Z1cUJJ/izLiMPJ5PuJc7Xvzp57z4k5/w4ssvSCVx//4Dv/3t1/x3//1/T1rOXB88fecYp8gcFxILpSQkC8sUeHgM5Hjg5f4FPs+k97/hfN7Bw4FCT2Zg6PeE3Y4w7AjDoA5sSST2ZAnquzydeT0n9svMy6sD11c3OJIRD06UOTIPnpk9jzevwHvevvueb4/v+OPP/4zd8JLX/TV+DPyH+z/n3dv3/PFnb7je77nuBnrfs99rPBz6XuP8YcC5wO3VHRSYjyfVLL4/Iblw8+oGjLWmsEQ2nTvVy/QblPM5iFOB8iqrU8qGwCEVbBTDHFQHTJr2WY3Py7rH2+FKVrBM/0SKE1Ne8KnHdT2hG/BhAKkfZk2IjPRSO6xvFuC6oISGZ6gGcmVjqq2teqgVGi/U+WqYjBjjqdD0XivA+mOO/w1d7cxBLpXvwQo1293V3zXGQDMkm+CY6mCvi68hwQ1F2562NCdKjfcabK25a1vs9vaGRpaPv+qVysa4tI9pEGT9Xbm41u3/NbgUaua8Ir3IJrCXzbhsRnIdjPV+WxamFErUDgCUjPMdw/6W0O9I85mcIst81vKXcSQdXjIc7lRA0qmxLflyvNu9GGpfOwjpZrmoJlFJiHVTIyfK9I48fQA3IOGA5BkpVu6ICVZvmB+ghrVqMWxrnqU9CxXSrc+0ZpWQ9f63I0x9rm18nWmVCK44sqz6LjV43DrdtRyAsoY6dW60mVPHqBqJzWeJcxQTRa/vqfdTl2bZbJyXHeHk2XfAgk3xHun3dIdXpLsv8XEmx4XgRkQWcpyJ05GcJkpJCqiJUiu3s+liXm0wqI/nm7TrvXxzXVs6+Nug+1M4QqgtUQ0WLLUrXFz1ypxQclDIMOocjTFaRhobl8rs2MzTUtRlLVDKM4fImEvaVCGtXUtyao6VmPZHqejWluZnn1nV2jRpng3Y0fKytduXrrtgm0Lw6pz3/Y4QOq5u7rSE7kqBp2G/00zQMGjw0fWtq1Jl4VRhc9UAYZ0bdS6JMVFkXZ/1EFmn1nps2YZ1s65NAnRMFEzTDTl7BbeDd4Ssa96JlpKFoBnCVFlrtWQx1Q5ZWsqdcjZW5ho4X1wn1SlYs5etpMW+nFemU9cP9P3OOnrOnI5PPD09kOKClmmGzbkvbUUbvDowBdW8KoK4uHbTAnMe9F0pJZZlMdr2KjJPdYTJGmCJAuk1lCpFTNuh6uKpRkoXPF0XDBhwGwfDsqMpscyLluIss9o8H8x2lrbXV1BCnGi7XmN1VNZT1QOrIIH33gBaC9Ct1LOBc6aDFm3eVaFK75xpju1Uc2zD0gKxsVq/ns/DT+GQzT5Z19Sldf4hW/0xIJXrWJfLV1y8qyXKtr5QPVVhQ+fb7H01RVeIuahuU8o4ScZ00v1eg2sT/t76a3XfKZuzblzDy51uvXnZeJVt1RloUJ3rlCGmuv7Xs6RcO1165iR8OI2cxonH08h5munE4aXQ5UyH0MVCCJ7Bq5j9IEIqhSlnfBsXvTerWNPMv/dE61QFNIZ8treIOC1BnWekKOMp9D3BBYa+Z+iHts6KgTXBO4Lr2Q07tZlm4xwayN9amXRNVpCVSbgbBvq+YxrPUIqxBp+tl+oEtQDaLtQedE18UNCkHqonkwuMy4IRblkZjtt5u/rd2yeaSyGVwpyhL5rkQ1TfsEpvrAZnvc46R2PS0uwlK/DVXrb15apd+MgB+vsPQeMJ/ar29eIFqw8t62VumXjbFXMxDqtb2sZ2Y2I/iWOdW3XCc+FzXr5Yf//R/T/bs3/oM9a5Jhfv3+7HLbDG5vAFhP38PdLes40ZGyAmqw+0xh71FkpLbrXbkpV4oPe4vQ6bD0n9w3Zeiz3UwGbckvSr6HXUOLO4XnUzg2/+f0ETQEtKJA/SO7oXe/qbA12/J00j59PE48OJ9+/v6UPhzas9w9BpJ2ATZU+pMI4z85wpc6YnqxQF4IiEOONHIdd0SNmR5UwOnjz05s6uaflQtFz1ugjX4rkLHVeuAzTOLRZrDQJRCi/6nqlc8RDeMS6FMZ04LY90XcfVfmAIHcF1Or2siYQzfUsXTB7FezPImsAShG7Y6SPMmWJNfCQ79eHXjlBrPFWf50Unu4/32GJ+UpW3oJbetbjVm0ZlZXZuDNJznCELdWdtvlXJSE6QFrLJGTgrqW7XUmosXS6u7eM1cREubnCQSz/+4t7anrDed6u4uByKv/f40cBT3/f6D6cOZDYV+I/suEX1VWMkGzDkvG6KXrytoxrcLc0RxbJGUkx5vVyWq+g4imbIY4ScEVxjL3kXkCZYmiklGa1Ou1IhGDNFR9NbG+bL1uaXDpewBgrt/kR/H7puc9tWtiIe6bTFdoqjicPaCS6M57N/2zkR7URSciGej+TpjAh0w47bn/wSgNO733J6+J5v/ub/h4ij399w+/qXdHmiu37D8NmfEVPQjm91IRRr00jd7IWMx5MITLj5CZYH4vmefPpAnE4s05G4jCxxZPcyMXQD5CPMHtdfIWFPlkhGg/iUIpgj4lxQAV6ZbfPX61hiJGfXhnMIKiwuteOJiUsmc0Y0MLJnbEbEe48vUQvjs9PuPMFByXinAdiUFAAaZ9V18UWzaBJKA3ILtURDqLW23lgLXReUxj10iA+UriN0jlISpSQcSlFXGYNELho4i5h4aHN2arkhxFKQVPVQMqEbcPtrut2/5urn/1ydppI5/ur/zfjtf+L44RtiOpF3L9mHHeHqZ/jhQMyzAoN23akGXaybo4hgbVT0N3V+UcEnDVCp/9ZJYWf4tEpVdru+/TuXzGKdL+IyNmNaMszWpv5stq2CidmcmbRxO6tjm8GCDbNX9teUsurWpEQxbZ7FGJKV7VGbsTWPs3mtuv5rR8YGrkArx4spNgFKEHaW9b66uqHvB65v7hh2ew43N/R9z25/ZWW6lbG6kcMvUFD24ul8ZFlm7t8/sGyEqyswVhqooBRq7Uwm+OIhgWS1l7X7ntri0rJ4Ust1m6ZL2bB4KpS7AKPuC7Udexda8BNCUAq2WMaZmohQuxFNmH2JqulSgZzaxrwGIs5GQIEsR7Ay5iUZuIM+j+ubW4bdjhcvXnN1fc13337H8emJb776NQ8P9wqMDB21FJfmVOpY5E0Jsdjvc4ZxWhCJTMtswb6VLVoZUjKgSe3qur5dZYLYmnab2g6B1qhhCIFD33N7OHC1H9gd9nS7PV23w/tu4+8YuzXDOM/w+ID0HX4YuLq6xl2tzm+xIBehZdSK0yRJMsByWZYGXoTQE4JvpZ3OBMFrJ9nJ9CyOZ2uDbHpWCuQJvu8IznNze6cMjn5ARPR1MbGk6YJV3Q3Dpwc8YWNppRNLBVI2bex//3vV3ucCcyrt3w7TbDT3RpxuoR0wdK6JcDdns6E2pc1f7Y6XiVVdUOBpyTyNjnlZmJeIDwnnlVlz3XmWRYHlzmKBaVJ9nnnOZAscgtdyspizMjvtc3TtJMiq9+TNKdT5qNfZdarLMZNYUuL9U2SZzQcz+5Cl8JiUsfz96BkfIsc//yuOpzP/37/+Hedp4ZXrCA5uPPQCt0HogmMXvJboLQtjTny/zIRpgeJJSZiWGR+Ew37Pfjhwe33H4/HIt2/fI+5MjAUkIzHS2IbniePjkWHXs9vtOFzfcB0Gfv7TL/nZT79kv+sZho5/9x/+E//5L/+Wn7x5xesXd/zyFz/nzWef8f/5t/+ev/m7XxF8Rwie//r/8F/yi5/9lD//q7/mm+/e8rvf/Y7T04l/+c/+Ca9eveA//sVf8u7DB+Kie8h5WYg5EiWTSbjaZtv2nKollWx3m+ZIcI6fv3nJrgsEJ4zzwn/+6jtSyuzLgCvKUBLU7upmWZqtkVxUv6sU7seR7snx528f+fJ2z+cvXlBS5HQ6EYKw3xXtdNg5anlhMTDoNEd+9+HM+8eZb4+Jz66EFzst1yZA18Gh17K8IAHQ3rTNvtu260UItXK36KqKxaHSqEVLWxJIVnJ+LXKpWoFVxcAH6AIM3hEEC8YLtStyLY2pCF1Kuk+mVCx/+2nZrsvDfKoK1JRCcTWBUjWezAM1lrAylrZBcQ2AV9CngqG6twRr+rNQ/WPZaDSJxE28V89YQSQ24FStyJFW+l0DQdUvtKTb5hSuMZmy6S7aJmjgeu3wF2PcnI/mH8UlkpZFrxcQiy9lGpF5oTvOuPNiwtmevuv19EFBpmh6m+C0G/PTI6flRHzh6b44cPjHn3P1szdc7V5zevyWv/vL3/F3f/01v/3NPT//2R3/+L/4EyjC8fHMfE707DifIu/ef8tuEW4mx+cHxy9vg/p5OTDPC+P9yJwKU4IpvOMYvqZ8/gsk/IJ+6On7gbQkchp5WSK3pfB51/Oiu8IPOyR06hOXTPA93gUGD04Wwt0Lvi93nMYjv3Mf+NX93/Bw/Ip/8rN/zZvPX/JHf/tTOtcTH554OD3x4nCL2wm+7/F9T9cPmmBzFicaE3e/vwYKMY+keeF8OhGiahM7CXjzNzPFKod0gXtXmUqbRy+CaO9f9d1QlpeINqFRcXNljau2sDHqLkAsWCsW9AM0sRpVJ84VqpBciot++YibRnzX463LfNPWMlZzJjXAvVaA1aRlnfnb9XkJdGzXx3OQqWz+q8nvH2+7fjTw1OpU63+G0FS2zyW8C5S6kCvaiRn00gb2ArLaAD2FjY7UD6Bwa5rgUkjr+WSoiF91StWObDI8sgbpzrnWPUgNpF27rI5fvQZBLn6GS50f2aLjIiAW5NVrtjGrY3FBM7UbaQFeWsGBkib1/+OktZ5FBfSW8ch8uud8/y3FdQwl0rDM6pzVrw084cRZw10hx5l5/kB8fMvy8B1xOhLHI8VDcYU0PZDOH5AwIL4H31Fcb3OgWFBX+XCyBmF13Msa4GwneBM+Fs2+1y4xFxpH0NgO7Zw1I1ByywhSrONNwQDgQu0IVoPMjQ+0GZO2P2yyla5pSon3FCujbPeDrPOwTdFN9qMF0dtpUhetfRgFIWng6E3AXBzOmYBiiuQ4k+JCNtCinqzUi4YmxL89FIjaGLWN8WjfpEEP7frq3z8+4z/co2qH6eNKDSgsZe0W5kRImDOUtAz00qTV0Sz6GgOaGjemFC0/tc+pm0YFnnJOqvVRTWWphtzsgj0LKUUz1DlbVr7q2K3PwzlHJx2FoJpD3rM/XNH3PddXd/TDjqvrG/phpyV1XacbqrFE2KyxWppXS/2WeTZB8UjOVRhxHYUaYCIVrHWIOY9uY+svtjWhZe+C77RbmlOgOG8zPKxsjFK0ZCGXTHJrWXLJhWC6TZVVWfcjbV9djFW2ZYLZWpMVdFq1Y7AuK55g2k3FJQXtbZ12w0C/2zUWwTxPjONZnUuB4GqHNXNgzZFtz7byQdaF1pIv6geIOa5roKelg6nZ7jaaAlunoWag6tNRwXgN3jv7CsFAe7vO2t2qNpvY7sQVBJznhXkc6ULPMES7o9VEtL2trTG32kzTE9OxrUkI1/ZqqX6EBQt5I6DsRNRBrC18xbWOi20vY3WAGlut7uP19Z/QIdYxUpqdr3vO5V763PGrKYb601YIWvHt6qNt/Zh1qLdn2trDggbbWy2dSoqJEeJSWBZYYuEQVJTa+Zr1XQMuMLZLrr7e+kml2ij7pcX+1kzB5r9s15i0cQKIUf2mFHUtr2tFPz4mxxyF+zEzlYXTcs9pHHkYIzkVrvqgBWQlUcS066QQ0WRmITOmzDkmZdo4LXfNKZFiJM4zKXS0vaGuYbcmPts+XErTNMuW8MjGIKxaWV7MbtvvBQNLvIJEzY4WtUed9024Xz/Kmjg4Rx8CfdchQEqiHZNs42qVDM3GGLDnWIF0e+590C6GXiB5afeycc+rt9PmXJtOG/NRgDklvn86ERx8d9zRSaErmoROuVC1eaF2+lqfpYKUhTEqeK7+m+C9bFiVawywrhpbV7XcpV1noQIP0i53tTGr2SubVbHeo9ohUy6wa7zYGdaTfjQPttfxSR4b/3h7/8ro+/E+58oyqnv7dtSqH15jhcv3Xb5389qL2drOdPEejQtrQtkuv5gBvHhrabZRNs+1+odbG3hZjWOMTdMvFICYkCXiYsJlk3WgmCg0iOXkfAjaaCVnTQhEbQxD53C7QHc14IdeSQ3zwvHpkWk84X2i6xyH/UCMhXmcmpEvsZDOMx7Ptfdce8dN56AEyANTibgl4kvC5URJMzFBOT+ynB7w7pbSD4AmZ3tgJ7ALgcENEAKEVQsqGLmgs6YIN84TC9wNex6XmXmZeUyRyIT4yN3dgXG84/unk2pTlqLl1mWNG8XGsu5RQPNRTPubkiw5WjZ7otncxqbeLNpS486tUSurTal+mvo8XsFEiyUr0Fq7dtadOhcx8LkZrGdzUz+37f+ldtZOqu2Z1rXl3KbE2IxxqYWEmRbH6mMu2+nYYpE6jz86qm2vdv5/w/GjgScXNNuQ4mIbpN6E1rm6ltUQ0WCBuOgHmEJgiVpFnSrIYg5zFUZ01hdM/2TnEX3PFt0G7cZVzMF0RlVOKSOiDwBMABuAbPor66xrpXHm3AZDsKesLSmVTZCVweRUld9V4c1SVARx4zzkikSmQpZESBaQ9B04j8YPmcWkOYLXYU8pKgNjnimoHouQKWmmpJm0LOo4Fc8ynXn89s9xroOyo+sPfPFn/4b59MDDN3/N+eE9v/3z/4G7n/5Tdq//Edn3iAtNk0OdmzrAKkjXdQGHLvCnrx95/M1fc/7u15y+/hvycta6389ecP36Bec5M99/T3fzM8L1F2Z4KpoLu8Fxte/IsyctzuaEb15sLpATTEULWbzXmt65aOYrB82Ix7S29s1ldZC1FahRT50D1yEl44pRPK2Wu/P63i5nfEQzeSlpNsuBN18wGv1/ifoZIaimVHBC7x3DoGynvleQLYcB3/U434EEUhZS0m5M0oAqj3edZvby2iq9bkKtVMUHPWd8gukDeX6gLE+E/We44dbKhlSLwxWhxEicJ7zR6UtxULSuV0Q7TDqpbZHXmtuqNZZQ5kSFmHztH2hZl9WZMuc//6C5+Qd7xFxBWmNkxLl1CWvgtAW8JoWIQ8VjV8BFQYJsNevkjGcDCJVEXha2ZWrRgKccVzacs3VRAdFMJm5KVbUrXNR1kAsxLfZ+PXa7HX2/Y391zTDs2d/e0e8OXL94ybA/cDhcm5CitcvN2i1sGo9My8g8LlYqVoGZCr6lJjapGT41VqpZRNuAk2RKNnDAgBOXHaRMKokkvtlDpDRARoz23O8PBK8Mppwica6tvl3LQm81m2q3MspsgVE2jSffQJSKGivEo46efqE23moevJXo6lOtGVLVBuz7jv1+R9d3Kkheim3kwu3dKw6HK0ounI5HHu7f8XB/z9B3eH+37gWiIbF3AURa1715mRVEjAZMGgDZQPjmtF5mw4tpZrWkCZcBzLpK8yYQhV0f6ILjsOvYDwNXux19P2g3FOcN8zYhbhHTddHPyTkxTSPu8YGCkKJqJXZdZ/vhFgha98AOFfz2Esi92b6i7DT1EYrtA2oDvdd9B6f7XimwLAtOnK5LW5Ndpyw07RybmEQz2cnmZ98Zk8q0N1Zr++kc4tfhloIJyBtA0UBr+OHSETHGkDZ+81I7vkEf1oC6rp012i7PzmKpFBEQ186ZLWjPWUhF+HDMfHjK9L7QOXjZBz67Cyw5EIvHyUzO0fKOpm9TYBv4CSacn6Amdpai1z8V6x6lU4dUdLlU+5qLoyTh4Wk2FoGVobmqcamvGaeBKQv/7qsTpZw4H79SXdBSOAwdX7w5QMk8PRyBwomsmhsxWlmZivmeF1Wd6nc71f+bR05xZD4/cHN9gweO48y8jOSSCEOPF/M90Vt2ouBc6Dx+F8gkpunI/f33DD7Tdz191/F4f09JmWkceXp64NvvvmaejjzcvyfOExRPzgvfffs1Li28f/uWpyftcOy84/z4wFOJSJrpvRAkkJNXyQY0gEk5kasu6KZRBdaMpxTVF/QF9pI5ONWwmkvSNjJiQFrZhmlcJGO1o2zBu0LwQucDT+PC//Q3v+Nu3/PbD/f89O7Av/75a2UZT5mhCEO3MtKDg0LGucLQOSLC27FwewUyeIbBcT2oyP00q+9bEwTbsEqvqaj0XIJateK9sqycK01bUKsqEs7pvll91LxhKVXASbs6Qo4gWVWwPNokIxU1uSvwu16PPF++/8CPKmVQSzqdaWy2ypRcKBsdHNVo27KZntmhj4Aj2AbmuSaDQrDfuwv9zBA8SVukN73I7fERc6PQGllUn6nGvDlVBp+BxFbOVf3oXKqC10cYIxg4AFi32qo95fBdhyuJJAIpIY8n3GnEjzMuZlzf4cQRul5j5wLOzQy7A8SZ4/jEkheO5xMTC+G6p7/dc/3yBcN+x/npkYf33/PNV3/LeH7L518U3nzuubu7YhojyxgJ4kgzcEr09xNvbnb8i8/2XO8CL68DyA4ksMyZ6SoxzyPTdOb+6cj94zvO3y48fHhH/sU/RoZrQsnsyFwF4dYHDodrdgNqb3KiMt5c1yk4Y8nJzxO8yPDdyzfc7G/4y9/8Je9P9/z8/BXSL/zJP/kJP/vlT/h/fbjn/XnWTWLJyBy18man/vaC6hjllMg4agS/YMBzEkhakeWdJiA10WPAe0wUVxqusE1qrv7fOj9rgwntMOzxQSuAfNe1rVXdnzrXXYvbEolonebFh3U2lkzTvNgAQzmqFEP2i2nZqrwGLf6zuK6um1IxEmf36C+6SF4k94ombAVpQFlNEm3//kOg7d93/AFd7Ur7QOFywC50FaT6LNWJ0EVeEe1c1pbi+uxqK+g6KOY4fuQ7/v6bWpHF6givA7e+W9opnFxmWOsg2puhbqB2ju17L4KAFrBbG9mkJVDz9IQI7O7eKFDkPaU4XC6bzypNP6WWLjTNoLRAXkCKZRaFGDPj8Yj3Pb73lgYLiO9w3Q7fDYTDHa7ft6xZVdOvu1k1sg0EyaobVHBId8DvXuF3j/jdjWXunojTTDyfKbmnZI8MZ2SZkBRVTFmEYIFgsMWaS64R0ooc21Ezc1XPwG6dVHTz37KQ7FG28Wrzqy7w4hQlqYwDMt5a+IqsTpCB4KYvIStgvJlmFb2tczE47YrTUOna1Y4qOridD8JqgFawqf77+cZTnX3iRJkeiMdvSed3sEzk3ZGSJ3zXk2PQzhWFStHarAX7rHrNsgYH28/G5nBp72urwc6wWbttLD6twK06Pw3ssc1OS3qggW+bEqZ6CKwTo2iUU/VrqjZTK9OtYu4p69pq3Yx0Hdd/N2A1V5DVHHxWJkx9jToitr6853B1w2635+r6lmG3Z7i+pdvt2V/f0A07ukE3nWqrc1YmVozJavcr1byujWTXlBrThlJthQJCdfNVJ8uBywbaF1SsG0rQlqz6eVrGgmgHIm0/q00Hhv2VOvIa6nDJav09Rw1+NpnBlDVIzHXvkXXmC1oO0fYlsxdVNFZES66d132jMp2UrtyBB1/08VGEYdjRDzviPBPjwjzPLMsMoqUAmnkUqOXctr8o8KTPWHJqnQ6b7al2rV34SrNmcy8bv4bK8Gk/A67Ue7P7ozKfTPg09Np+V4J21Cob3muzbWLja0Lrzq0sqWbbtnbCmA3UZ5LX+8Hm/NbNtuvWrl405oeySHPTgOq6jtqtrgJPQVV9DSjTEuP2TH3VqVE7GfPHbbM/jWPDVi71N7/vkPb3OmfanJCVRfPxR9QIePWF6o+XU3VletT9UkplKRkoZhhY2/6rVsqza2xgVvtVubxuu9ZaXtWEmW3urf/G5q8BH7lUmTCgBoHa0dE54WY3UBCOVRcuF7w4bg8Du1554AChGyglk4ikUnBZy6mTFI1V7PyN3GJM1ZIzswl5L0tsbeVdW0v2+qL3rwGKmM1W1uHxdOadu6fv1C6dxxHQ8tSns+Dff+A8jjwdj8QUgUzJnvcf7iFlHp8emaax7X/naVTAphT64ElJ9TH7ECgl04eO6tvkoiLhq9S4PVez6yIok5fClAvzkhqwsA2LQDbzx87kKiNowyQxOzLFxHePZ4ITvn44c917Xu067UxcWAWanVh3ZJ2BKRemVBhT4RzV97vuHde9cOhhCF7F6rfJpAYy1KSylaHadu/NntYV0Ty7sn7VfXvjnj4DGdTLcnY+L5rglDb3N2/QjMDF6P3DP+TCUlyOUL1fad+eg0qXrOXNWS9et1bIrK/fXkE9Vn/ZrYbJfv/3jLv51tUXUqa31GDVprV9bnUVpZmzi/so7drWq7q4FLeOTdXEdSkjqbRzN+0ne6PD9voQ8EXlF7KV6CdJbXxq4igus7K2pxMpzVwdAoddoAuB6DclhQV6hME5roPXJiW9N+CtAz/QIisByAzTzBCcNq46H0njmWU6m5yK2klPQVygeNfu3dmzFL+SC4pzBLPbt13PscBuODCmxBgnjtMTN1cv6Hcdty+vWOZFkw3zAikjuT4r15q+pCUiMbMUI8u4YnjFZm5usQzZWmvzQ58dqxVZAVPnVvKFlnpaN8CqiVpqEoc1tnQe5y3ccFU+oE1AyMpaoqydUGmeXAVAM85p8yLVtlrvqWIZ1V5tZ/sPxXy18dI6Xeu4XPoJF+DbxWj9/uNHA09xUt0GzVKupQW1brWVqFl/iCqgK4BzHWG/J+fMPI+IeEI3KM06qVYTeaEBL6Vsyt4+vpn6dxHV8VHNj9CALV10taPXRmzQ/u+DiqvWjW+ZVYMl5dphyLdBVYT7Mjiv8apSeR0SdpRSOL37lnj6wNOv/2fIkS/+5f+d4eYNYTgg4gheA95xPJFSZJknu0en6KyAkLSsbXlEQqJ4mBZHjgvn01u6YeDmM4e4BfE6Afu7Lzm8+Amf/+l/jR+udFHlgvfZgKXaXc9ZgBnJeWGZEq7r8d2e4fU/Zv/qv2B++1dMX/wx737173n7t/8L8ynyeP6e7jbRXSeiv2WRA0N3xdDvGYYDu77jancg7m+49w8sJZIr26GK9pq3Gy1Ir11AUvEUhBzVrV6zn/oIlhgRUVZIlqyZS28gHoVCMHdAOwD0vQqHMukWkZMy0RbRTOl5CfY5qlggbg3Qc64sK2HoOvrgCeYxSFAdMbI5paVAcXjfr/dnXf7qRtT6ybVdSMCesyeRT99RPvw1x9/9O56+/Qv668/oDi/orl5zePWa49uTlthlpyVbZW0Vvo0PqsaJfkJBZNPhDEykTu9BZM22SqoBiYFpxtHKpd7Dp3GkGA3QSSroPGtb+nnSjkHOG/LvjV0nvtn62ndG54cCxWlRpmIy8fF5WRoApdoP+jScVBaBM4HwAilRktmoClSV3DSRkglmW0qU3eGafrfnxd0Lrq9uePH6M65u7jgcbuiHvba4d8KSSgOxpphIy6wNCKaRHO17jk07rwYYpTInTEfKYeVYXhmEUgRKsa6g6/WKNzZOCVp62PWUUohJwWhlB2rXPPEe3wVC17O7uiYtE+f7d4zHR47373XDrHta9UPLmjyEVXWsOaRV8LwdFhDV15jApPg1QHEW8KhulKPrFQzrh4EQOob9gb7v2YcOcZ6oPhsvXnzG/nDgt7/5FQ8PH3h4euR4OnE4HOi6npvrW7rQ16sg5cUCSt0/np6OLDFy5ESM2QREywWQxnqrdqNoMK++EVgQVIEyoHVR9AY8hZo5zguuOHzo8cOBcPUCCZ4YtJNWzpm+aEc65z2+65nkTIoLXTcQfM/V1Q0vP/uM/X7PbrczZrJvdqXura1k0zoHRpu/xqXEi46/N1HmFQI3mL4Yc6nvCNbNq2WVjekqAsuSiLlQimoG7qy73W43rIBnKSzjpmHAJ3K0BEIV3UeTKBUk1uOHHD4DQp0x4TzWHU7fVJMwzaeskdI2BmuBk67BmDNThn12SFaeuhPfQGQR8F47c/pOy+OmDPOimkupFIoT/RJlmISQWwlesQ502tlS23YnYMlJQaesNibmQkwFkiasYtKxkSXa/Vh6xwmQmaYF7xyf3fa8uN7zr/7kF8wx8d/+u7/gmAv93S03+55//rNXpBT526+/x4vnzcvPWdLCu8f35JyIc8J74WrnWZICHimtui3V71Q/a8RxrzuIaT96J1bJUDX2VPA2dAFc1QbMTCw8PJ342/R106Yb+o6+C7x7uOfrd5F5Vn203TAoM9Du+d3bd5Sc2e32hK4z3XPhd2/f4r3w5u6O28OBJeoeFLwGik4Gxnnm/vhIzIl93+O9Iy/Kvl1iMkBK1/T4/kREeB8zUylaIhPQsjwpJsat/rLaCB27Q/DKKA4KhJac6ZxwuN4xLom/+Pae33048tu3T/zysxv+zZ9+SfKF65RxEVLJ9HRcX/X0zpOzgk3vpsT+GLn5MIP0/NmrgT+6c/yjl44vbjt2fUfvltaBuEJJWtopLVeEFNwgDE5awBzRe5wTLLkQizL8KiAKNZGtaywXagNPilPNqd4XhqB7nGtJYazhgn7up5b0c82XqvZ+TeprzK1PIpes3QA3Zdfww8BTBWvX1+ka17/BasA0AQ0KtlcfbgtEiNAScrVpUQMf6mcb0CTeU0ux9PelAabqSBYDgtwFqFgTk3Wv9FZulSrr3IBc8Q7xVYcHJBVczIQl42LBo8wr11mC30rDvDFWhuFAcQ43PgEwTyOzRLJPuAz7/grvAk/HRx4eP/D+w3eIS/z0J7e8+eyG/W6n/onpknVZuAqBNzcHfnJ34M2r26Zb6/wOFw50XWG3L0zTgTAdwHX44MkfTpzev2d++y1z2OPu7tjd3OBLxjNTXE/0e2UBkQgGJNdBK+JIIuwA5wo/u95zyAP35Y8ZxjPvnt7zePzAv/7ff8ndzQv+yb/+Yz58+8g3//YrHt7dc3N9i4QBTyC4geGwo5TM8f3XlGkmzkqUOHz5Etd3hoop+CPijIUn9F0w0Ebn3bLM1E7C1D1YJyhA63DoQ8CJx/vOfu5WgKYibagFUqAtaEf4DuISET/bHF4rvnKM5LiQoiaCxVj/1U2OaVH/K0a883TDoLpPvgepcDebvV3nXpV8qMfqYxvU7p35nxupGQFMx2yV8PjxtusP1ngSo2+1LHODxCoQAIjDh0Ez7fOIyESOE+I8Xb+zTKUiks3PqaVsz/RMmkZGqQCvQUitc5oNfM4bI1A2xk5M1LRikvr/bAK5IpBytFbDVQug5q+k/ezcakDWzJ06x84b6DWfiecHTh++gbSwjE+E3Q2hP1DEkctiwatqviRzkL1bjZlm9iNCwgdFsXE9GW23mYj40xnnFkQWnA+E/kAYDgyHF0gYtJSrZqUuEPmMlISTiIhlJQ38C75TEGp/R3/3E4aX9xyOT3B6B6d3CnzMJ8r8RFkeKNOOFKD4SBYVahPfrYhunSPFNnUDdlZE2IJ8Z1oEVoKn1D/NuGVajNyAM1x1Jus80FvTwEhLCNbCtk0WxEoz63V5Ma2eYvOgIg120loCWuf5utHp4lszF7T5r/OvwU2bQ1H1IubFlEJJkTgeiU/vifNoJXIJt0z4OOJip85pfU+jM9bGv+t6q5m6mj4QTI+qXolsSzD0GrfzfL3e7Q19Og5QDUp1Dqpjn9ManJpfrkebExo0OQqIAjoxrsLepeovbfSE1C5oQFXnbi6aFVfHo36EOvLJWr/XzpwVsAmdEIaB0Pfsr2/ZHa64vb3j6nDF1c0d+8MVXb/Dh04B2azlwVpCp8yaFBe1v4tec3rmIOt8KSuYtNFEWpfCxtmrLrrZ/9rBrWaEFb8tdFnXmu9660K2w3mlj4euY399wzJ1xPHEMo/r+evYtIdyGQDXYPLyRevVtWfHxjG0oFvBRGUwqm6bflXtq64fCF1PCD3ea5taFzyh6L12g/5dQSUVKk45K4Xad/S9lrLVziLzPFKKgkulFLpem010XY9ILXtWkdu2ip9jCAZWiz2n5gyb6XPoPQmFsHF0NUtqO5l4iniyOLT6PeGzkCXhwjpn88YB1jblA30/MJhgvermWSfFnBpwVtq8XnW1opVxVjHO9bgMHNa1Vlr2rmYKoXaitBRpRUcKqx2u+0ADKktb559Y7Gblo2KEpBqy2ZwpG0fwGfi0xY/Egq/a9bW9ANbxvxBXXu1VLpt5KmtSvnWL3PhwoPuKSE0ibomf28Vc7WNp76//r36eW41yu2f1IVbmYF6nhiW0bDxszjbXp/kVCo4uy0xMuo8GL9xcdVzvOnadMOYqoO3buMZkZX0oe3Vgyy6mMZoag9D8nfE86Wd7rw0USvOS1/261mfZPLYcroJQeWWXVX2P6uNu2bb6AlnXQqnsS31gypzPkIzVKI5drwnW4CCmwLxLBOeZ40RMkb5TxuOUluZTOxF88HRgQHBhTmrLJDxb8nCxHitIUEvUSrFLbv5dTQ4IMRfux5m3x5Hf3R9Z4o7bIdAJDPb3adaSdN139fpSgTEWimiickkwJ8ecioryA53XPSI3oyub9bJl1slH96HJGp28z251XU9tbm9dyudaiTVdSrODz8/zKRwfl8Wt9kan68bofDSgfPTe7R5w8Uu2cc7mL7aYtoymOt/a82z7UCZnaT7OegG0WIYLm3T5OaWUCz2ni5dtgKyL+9rsfTVR395mF6jdaUvLZEpR8FqSNtcSr8nSbtiRBIJJxGjZbEZqh7fQIeKJy6j6T3mh847DYc8waAKnFJUnySXjCvRO2Hdemyp4UWDGdTinJXHOfOOuC5QyEIeBZdnRh5nOobGuiZ5nLAHbDL5QhdrF1uTqvDmLw6xMdY74Aru+Yw/M5wcK2lwk5jO3nx1w3vHur78jzpFlnpnHiaui4GeQQC6JuMzkZWKIPUUEl+VCRmf78CqL7rkvvH32FQStr7+Yl5u41bXN1Z5rxVNk9ZOqfXTe40uwOE9/p/FBXplurLviNhCVGouWojIfIkDUOeRWJu/H97S9vcLH92va22V1ALY6Z+1+f/iMHx0/GnjyJkZ4WRNbiNmER1s3gA7nAt3uhvl8z/tv/4Y0nSmnB65ffs4v/nf/R50wywdyhiiOlIWFQIoT83SidjCrzpWykeaNcKnQ971mUp0zMdRJN12wMoEaHDlCF+x8es3TODLN86ZERoOBrtOsqxgZtoJtNes61m5YUSlPXdeBC4TdjpITy+N3nL77W777q39HjjN3/+i/IYvjsLvDiWecjuS4sNhnp6joe9dZDXFRYIgy4SVxOFyT54gfXrHEJ56mEcaJx+M3uvulmesXr/npP/4X7K5vONy9BtcRS4ASKdl0DqxLECR6t7BzE9H3uHBgWRLT+YncD4gruOtX9NcvefnyT7j+0/8zj3/5P/D0V/8jLt/D07dIl/H+gbT8hvywJ7z4I8rVF6RYkO6AhGA17hr05aLt6ac5Mc4LV4d9G2fnhF2n4pQ5znpPNpnPc1rrnouKEneh03aY3iNS9YmsjtprtqILzgxyohCJVl7VBU/wTsE8ETrXkUtmjgvZslclZfKipRxa61tZEx4JnWXtdeGnooCEmqCVYdS629kqFLA2x5hIeUeZzsTpzOPb3/H0m/9EcQ5ufkEJHUkC0/EDy/E7lihk5ymhgzCos5IXKAsQ0WJFUacPwTtF1wPKvnAoi9DZz/N8MkZWoiC47gDiiCZc7jbZoU/I92HRdLhpwSnTKZfc6P5aIqrBg2R9ncUqBl7AvEROx1Nr+d7cmOa0ADhlIqBOZyyFlLXNc2U11WAh5xX8KhRC6Aih5/rmBVc3t7x8/Rl3L19y8+IFh+trBUZ8UB25XLT0dl44jSfmZWaaRy23yFCytDryZALqGg95gnW90LrwzJy0G6XTNlYrqFtq0KhzOxqTzwVtZ9/vdirIPfRaV+7V1uoG6XSdOg1SnDj6xni6ZR5PkCMlJ7URWYGS6jg2BlD9/nue67rHX253zjKaITj6IFqm6Lx1V7NslPf0uwOhH9jtr+n7nWr3iWN3uKLre7pBWVv7/R7nHXhPKjS2he929Psrrm5fsdsd8J2us+Pje+Iy6z2aJlVKiRACcYncPzyxxKgMgvwDd7cBBArSGiXUol2l1gs7b22NpQrEJy31iULKniwDkY6xeJZ54Xw+0Xc9h0MmSWB3SEpHj4kUE845docDL1695vblK65vX9TZTIyRZV5YlpllnqndAZMFnzEnaidbgK7vzQFWMKDuzbXjTwuec25zrZUciaienwhLsu5D4hCvGnyaQXQWoEZIooyrvIIfn9IRk7FkrVt2Vevbhr4f33WbRMYot5LM7YtzDYBr+Z20t6RcWIrq+cScVbDaebwX9kGbktSgPxdI2dnYVwdbeVk5CSlq5bFiIba/lKJyHAmmKE1/srLQgxeCE+ZSKAkMx2WJJp5b9QyzgQgmIO4Dq7BqEcqir3NBNUQfzxPzsvAf/+ZXZPT+DjvPP/vywBA8Lo/M08i7h0e6EHhzt2NJmeMoxAyJxK53HHbJQIisnTmjBnhd3zdwKk4Lb9++V3DJS9MKqnuHeIfrA4gnV+mJvNo97zu6zhoE+LUbZO89nffs+0AmIxLQZJP6Hfud+sZDN+iegXKZY1yo9YcF+OLFNfs+MJ4Wlpi4CXvGeeF68ExpRryCVbMxGDtRHPhq3xFKYTxOyjZCJVJa9Q9Yx1ZFlmo850wIfV4iMcMchT6o9p44be7hvef19Z4lRj6cJ05L5Ov7kT/9/AWu+zl3Q+CLQyDPifndIx+ezpqwozB0ygZ8mApzWhhTQkoHZPa+8GLQhMFNL3wvysTKtbrZpm7dz3VeqnaZR6AmryorqoIn9ctsmJHwWLTYgK5KzRpuofuH6k3lUphStlJSs4FFfmAt/8M/akCea7mI1IAaaqxVx7M+g48qan5oq7xIOGxfsAJEOZeNrEIFxh3aMXZNHKakflKwxHgxcEqqLpVd8wpUPUt01ElQf7TrUu2n9XrrWDgRZShZg42uC5TUMztnkzOpxlOOSElIECQLLhVcBj9rY6LuakBCR7d7Sb+MPI0jcU7MaSI68NcvCNfXdIdbMonzw3vG6ciSJ/b9FW/efMHtzR1FPEvOPE5n5mUiAHvveNkFrnuv2oB9T7e7QQvmVKczRdVDPux7ZUNKYBoz03lklMQ0PpGWF5yzZ07KWCRnfEqq6RQC4pLGdPbYnOloBd/hxZHH98R55mroyUPPY7ohzRP3D98S4xO/+Kd/hpOBt799S3LvuL//wOnxxOsvf87Od7gyENPCadTyv1v3iq54huxxSf0zrEt0bZQCyoarANiWgPB8ble90HrU0m6cIOZz5qxspGKoayOWlO25nNr8Puge1+Q8NsBpVimPIpcNQ3zwqmVtzlZcFuIS8SGqr97vVKMYWQ31Zl43AJcNGCobMMv02IIEqGAahRS1zNu18/yvH38Y46n9oCajJVo2/8tptkkUKGnRBZ4XxqdvCT5xfv9rcp45n77XzHxy4PfQv1T0vwpS2zkru6jWjzvb3WrHue01YYPUNB+2CGNDMy9RzXpvFQXXl9vjtI18zXZUJ219c2PTGPCmAICvyItSBlMioSynfMGIkXaOQmmoes1YVaPonDouGhmundkE7VjUd8Hq8ROFtUxwxUTFxiBSykzOJwjO9DFK0yRZjawjDFc4F5hvXrPcvqaMGcZZry8mUnqijEf64RVdfwulB1cV+ysiW3BegbWrfcfdPLDf961tuYhoW2VBW47nDHYd3guZTPDRHDYrl5EqQ3cB9KIsjO1iMbS80QTFgFpbXBVdds7mmRp172ppiGslWFR2nX2VtkluMikt01GDLNMGq4sc1OkrqnGC90h/QHYvVMjOB4Ir2iFmPBOnI8VfIX4g9Af6/TXOd5sNVueCOnkRyQmRhBTdUCmFGM9QMuIGKMI0PpJTsvJHR+d7xMpKKyV5zQx9OtBTc1rK9jlVTZymrWwhmJVLsnGiRUspYoqt0xzoPKhDVU9fxy0Z6NQ2j7x2kFPnQ0FQ572WpA0qGn5994LrmxfcvHjF9d0LDldX7PZ7qr5YtgiulV2WGoIagy8DZdVwSrUe3O5RCmSRxkxJxfIqzl9kT+o0cE4oxdOFAM7hux3OB4adMpmq0KX3AcE1BmrtJCJOA4vBGFqhG0hLpRGX7SPZHHL5y1Kf2Me2++JdLWOkmlhVEFb1sdRG1mSFVBC60wYCw7Az++UJXWcMrUFLYMRZSY0K0nsf2A07rg7XXF1fs9sf6IcdlWHpfMDXgLlkQsk48ez6zOIWvD+3su56l79/u7Z9pTo8F/ZN90CHNuLISZv/JrT8bsmZskTkdGJZIufzmbwr9MNAjImlMjCKNiTwPhC6jn63U4do/XS9RleFgf16Lajddt4jZe1aF7peNSecp3Ya1STPJkiomTUpzdFr91mgbJ53yyo2QUxjLERdA8kAqvzxZPpkjgvWxUWMtVkb+sqP3ivbv2yZHJsv/QyoZFDvoPeePnTaDc07OisZcqKdxNq5W+KxxpTNSWkXsPpZudnLlBXQKRf3YcFi1cDb3IDU/z1bMCsL/XIsVp9Nf86lsKTM/XnU+ev0b/O8kK2b4+O44L3He21LrqBqXP1CFNwODobOsZBZ5rV0SoPT3O5pK51VbWNtWuO92pdaimf5LBt/E6g1ceNLP8POg7EG8LZfiZWtYDqV2gGroMK4uShIG5dIEGEXAofbgVKgDx3jvBB8ZlwmpjQzp8iDn6ycX32v4BTEHFHmWSy6HkONZ+yxK8ZV2jRoblCbw8q+Eqmd6mzvcVC8ozdpgHGJvD+N/N3bR95cDQz+wHUn7AcVIG7bu9lJrzKEOApjTLw9Cd89wddD4X6KTElBz1JYGRhIm37Vt8sG/LcRFy2R86Igm5PVNq6radVcaevr7zFJdd4271E+QeCpMTS2I7NdwqvtYBPvtb9+BCrx7Gd7+q1UUahsla11ew4YbC9v+6f189agvLE7SvUT+eg5ZwP5t9VALbbj8n42PzT/tGkBmb4RJV3EGdX+O6y6g9ohXX1D8QGJrjW3yaWoXRkC0ishRFWPepz0hODp+sBuNxC6rjXpqgkkseuuLETErs97KK5t39rnSMfJO08I6lPtdjuSDyyAiKdIIItnyU4BmPlMMYAJyRvfBpwPNhbaLVRcDxTSEllKUmlfUSmWaZ4hFELnuP7swDTOPD49sCwLyzgRu4mOHlIkoDGub2W0CnoXMd+/SpSU9VmJoPWzxcri2rzgB76ziYGl/bedqT84Acv6igLGcqvn1eddmja1lQVu8Y02OdeqovVX1jE1GUXBecC1eKVs32/P/ILct41jNz5ord6RjbtefvgOPzr+AOBpHZj1YrY6AY6cFuL4HgpEVM9ht78ind7y4at/y+n7QH74S+bxyIdvfwMlI5LZvfolL/7kvyFcvaF/8Y80cIpzYwY4Q75D19H3QyuZ0alSDFX0a8vm/z93/9UsW5ZlZ2LfUlu4OuKKEBkpIrMKVQVlgDXZ1qA1aXygkf1AvvAH8F/w3/GR1uw2NhoFFIAqlMjKDHnj3nOPcrHFUnyYa233G5kFRJnxARU7zePcPMfdt/veS8w55phj1M+WpPUk+ET0vvRSipaNMKJMmWDm4jsWJ6kk2lFam6I2DzlFVBYqY6VJphjJWcAwazuaZs325hU5Bez6Gpo1p3EEJlSUipNCrDO09uUayvsaI/S6KWb8HDkeT0zTgGsCMUSsEYbAqm9Fo8RoNlc7rlYtqwZ0eCLpjqQ3UpaJZaHSVpzy/JGYDozpHrNS2P5jUK4AhUXnpySuru1xmx3601/h1Mzw9teM7xsShjAahue3TKcHDDuc25L0Dcp2KC0OazGBj5m2s+xMx68+veWj6/WCZAtbhyUBDqmhWgrn0iAvujUKrUqVTyuc0litEWeRuhAgDndKHA+TKvRKY1n37eJqpxF2W9RahNKVKgkTUnKyijYausbSduIMJcGpgAMi1CssoxwlQBfXp8q8UgUcOmsxfXCkIA/joNnRfPSPWDcbrIpoIi6fsHnk4av3HI932O0a0+7Y3HzG1atfiXVzTbCSOK8oldFxQKWAVQlNZp4nYggcn++lymnXZBTD/pEUA6vNDtt0bEwFEhwo6SHOZc78qI5UgwmpwlcJtxpAtmVTCTESk2cYByAzL+5/EGJkmsR9smYxWStqViEJUqmclQS7tr7FFBYxcV02b9d2NN2Kbr2l316x2uxYb3Zstlest1s26xWrvseQ0CrjZy/gl/ciEF4cVWpyqKzDKoUnCJMpSetddWir2cxUFvJYNZtKKGLaVuZSKkFVoSC4sgY26w3WNnTbawks2nYBAAqMh0IAW6H5Ft2rOGOtZbu9KgGGJswj0c9Ce85ndllW6uyouCTHP2wjq5XFCsS3jVtsxZu2oXWOqiFYiwKuaWm7js12x2q9Fb0sJfpWSmu6fo1zDcM4ME0zx9PAcBrYrLeYzY6ffvZzdrsrbL9GGc3T857gZ1TjBPCOVtZS20DOdF3P7D2H07CYLEib5UWR5PvHkrBLL30FzowWVtmlqLGnuJepTEiaPHgYPPnxWZh+3rO7uqLvN4zTzH5/IAahpXddx2qzoV9vWO+usU2L94HaFq2MpTFC13dNkDVQqaKPkWiNKXt0FR+tZgxyxCSi+ynVwkthqOhaYZT1OMXC2iqsQmprpxFgtFYWU0lq/VTYw172UtO4vzPB+Id61BY5iXukGL4U8P+L3/Uc9iaECZmWoLa2xVNasSBEYSfnDH2j+Piq55evdzRG0Rt4PA3c7Y8MHo4+0xhorAAHOmfRTKSKR18YvhQ0QqlC9i8GBHM0EBQx1zkQIGdhIiuYoiZeWFwbU92MhVVkSkw8F6CgKd9X1tvCAsziXAzCQvUh8fQ8YqzixW6NVomv3rzHx8i7vTDur65ucEYzxsDsPSEPZMSx0mqLNY5GG/q+4TR45ulQilkS6MdYtMvajkjG50SRWlySMq11Yb5IHJ1RxfC6ilFLO20VpZV2ldpmnzBFL9IaJ06aJVm0RgptrmgxNUZYp14ZUszMpxk/eMyrGzaN45effcZ61XP//MQ0zTw8PDMME1/evWN/GjgeJ3SGlDwaaIy0y90n2V9M1litWKsLG++c8WXpXpxES3yduVjeS0HQaPm8qQCfzlh2vWMKiadh5suHZ758/8znr6/57/7wJ/zi5ZrPPrrFPkdivickTUhyrdaNxmlwGvaD583zxP5k+G5vSxyvOPhMxBRenlTyKQl2TufYPmVFKvuWVgpnEy2ZxmisSZhYCrbFJGkB1cq9jrC0uZdTUGV8PkSDK/jK370X/AM8anxeXU4XBLiCMxWUyXkZE+oCgKvs2CXrLIBOZTD9vpa7mh9XNhSc3XmluC7PVSoXll5J4vMZ4PEhoAvbRtrLdCnsXH6W+plL8SOJYb0uLKbLonRW8vuMMFFqsQaQ900JaztoFY07EhAJGFQ1ShBHTZUVzlpM1jRO5rWlOG1rS8yK0+HI6TjgE2RjcFc9eiOFP51bOveKvr1jvdmy3W24vt1hVMM4zsxFoDunSI4BjBEPOG1RukWZBmOdfKdUCvqYUmTNWG3omp7t5oqEIdMx4zC2RbsVc+o55J7+uKc9DTTmU3TbLflgLVS5tpfCVYqQMtpcowwcHr7mYTzRGo9VkeM447NiSgOusfz8X37K7U9v+Lff/TuO7048ffcdYX/i+iqgtGKjG2g1K2twTmOcAWdIJpNVZPaTaM6ZKldSCszqPJbPYKRaGLoVJKotk4uDcM0hclqwiovZcf5vGUcpR5ZKS9HVhEyWBZisItqWzq8EpIJBJOG1QsbYppxbjhA80YsEh9Ie27RFw1W+U46VhScx/4KhlHUv17bHMg8Wp+qidZyUpmoW/tDjh7vapSrelhfwSyqYBR1NkmREP0ASC/GUxGZxPryHOBHTyOH9V8zDwP7+joVS35/IJdk1xpJTXCZwZa5Ue8LLXt3l89TnIklgrsJ9HzyHoh+lLkCBGvyfn3cJPp6rMudWGqUqolgTFINCFo7kB5I/ofIMRHI4QRjQzRVKW8jy3UKKy/WUPFYXITJDTBrvE/PsmaYRPw+lZSrI1pY1KTtyEqFuNXgeH5/wyWJX32D6a9xuRTaarC26LAg5azIB0kyaTqjGUzM+AYIyxJk0D+TpRDYy2ONwB8xo69DttlQr01JZkkdlhlHW2RJAZAH4GgxX65bOmoVpFAsF20dpNwkpngW+U8bZLBR/I/eytQary0AvGkVUZFlJnel87xTOKlqnue4tIQpijKIIxevSViO0UKg6QBD7zPWmxVkjelEfBOm1dniu0JQ9bEmePzxKFJHPSHCmtj1prOtgtUPNz6gwEv1EDAM+ZFJ2NN2ObvsSpRzzHPExiGsToism7ZSB0+MdcTqgkkddsGFOh2exalXPJLRsJApi6FBaE+ZhWexFEfRizvy9lpH/ug9ZW3LREUvF2UfASpIieAGEK6hzDmoobJBU2jsoWVp937IulDUiFovlWMBTocmWCouR8WttI5pA3Yp2taFdbejXW9p+hetWYGzRr5BE2haGYwrxXMlaNKVYItxKD65MQpsVSieyFve3mviZwhi1SVo3ja7ClO3C/oO8UOJNqTw1/RpjHc1qI9pNTXFyW6JlWaudKxtadd8o63pOmRAn5uHI8fmBYf/ENJyoDn7ltMvMWmaYqpXo8ptzIWeZV9Utzpa2SVcetiR20p4ln0qAp5JIFEBZlf+vivXt5U+0xntZi8M8E0Ogcw7nrLQMO1eEgUvlDCQw0wa0sNOUkcBUZ1OqVpd6Lnn5wuryuy0r2YVbX612qVr0KTo8WdgnPgowEVIW2/V5luche5boNUmxxc+ew+Ege22MNE0jLKUiCo+SVhAhK5317i6U48hUgrJe2qdFzFJfVIjl3laXxoystfK+uazhNVko91fV9st8drspZ02V3lBA3kXUOUiin5VadDJ+LEfmzHRKF48P9qDf+7qL42JzUh9sVoWRkzM5CpC966Vo46zjdtWwa2X/1AUEl8SwAmKy/pzHrPpgH5SiEoQkkgpL22+979Q9/PwO9RZftk0qKkO1tMHAsgYqoHMSaJdaUWmxz2dW0HJBBAGoVekUZe6EOeBjJISMtedrmgoDoCazZUmgBsFnhkq5R0XH0hmLNgrbGGLOzGUuaS0yEX3XS0FVFcBpKTFrrFE4LaxNZ3SJWZUAYCGIdkuO0tZiFFY7jBbhf0oxQmtF37Y4a2mNxWiN9wISH8eJmEVw/XSagIyzmhc3O2IR+j4NI6Mf6azhME2cponTJExNrSRWq9qpqqxdtV26QmMXq3gNg5Y1/sPjzE7XZW6bcm2clnsbYyLkyOQ93z0dWTWau9PEforMqeopLdxMVNH7dBqaon07p4wPMMfMKcCcFSF/6EyYOINiGQGNQsokLeCg5CNnPT2W8wl77mIJ+2AS1lzi8qosGJM6X6MPfv7IjjML6fuAUTkuLswyq/Lvjpb6+0WD52Id+n5Od/n7DxkeVZMNav5YdYKXz1ueUFup5GXnVlW555Q24HLe5fOxaBDKkE6/myCU/XDRh9LV2cxgoiGWtaF6E4k+MERlS75VHIUNJBLDeGAY9ozDkXmeyLYhNw267VDOkvNESpoQZnJOuKYRLcemI0fNOEmxsgqI59L+OhdDh5ySxKE+UtnLFezOxdDLh8g0e6aQmCNkazFWWn4bo8F2BDbMfmDyCT17jJ/IVpOMaFFmoJL5K+jmc0NAk1nJdU5HkppLvJ0YxwnrGjbXVzizYfPyhuQtwzySUqa1Hc5YmmiX/SbrRNQRdCrgvmHpZUmZpDLVBXm56eUfdT/4fQzFBThVZ+ZRNXqiglf1ndJFt1N571zGRh1/C7+uYAVZGwznQrcqbDGyuhi95zmwjGbZoM7EAqXR0u5wOShlHpSiR13MVImr5HMWMJV8/px/z5jrBwNPvgSxxfYBjCFnYQIQA8ofSHEiTHdkPxEOD0ynI49vvyWHEzqNhPHId1+/YRoCj08B07S02x2sAzlrtLI0riNGsa3WurraCIqYSiX0fI1kVsvgsFI9vwB0ACr9MmcWAdR6Ac8aT2VDOK9WVKG1ipgrpO+UgvQppXHtSqrOKRDngXn/hunpa/J4DyTS85ckC6urn6LdBj9pYpiZj+KQYgvV2llRn29dy5Qi++PEeDjy/HhHnp8xeY/OnjlaUA7ihhACp+Me8/DIt++euNpt+cXDd9x8+it+9i8+IZuOaHYihjzPZAbyPOH9nnH/HswNaVdCe21I85E4PhMeviC8/zV5fiBN9+imRztZuNztT0jTgTwdafsVnZlYdx0r5xiCWnQcSIoYpJbUWEPvLNd9U6iRsQR7cr3nEAqtXgZyKEyOIG3ADJMsctvCQIo5kKNEvTpX2mNegoGQJXDYdIbOZFa5I6TMmAW51U60EFypbtmlPVACvq6VYK9rDDlHop8kmDOWpDU+1YBDHvpiU5OKTlpAyjoIhbpZbU0zCodW0PcbtNHM7+/xp2/YPz9zPB6Zx0TQt1y9+gNe/+SPeQg9d3ePRB3JKrHd3dA2HfPhPWE88vV/+l95evsFftiTU2C32+IaV1xrMvtxJqJ48fFPafs1ITRAYjjcY11Hb5uLNj6k+vfjwZ3IcQJAE9E5Y4zMeT9L6+tpFIbjPAfOzChAC3g0+7gkfVScoACgeUmopVoRk2y+cmJK+1JH26/pNjvWmyt2Vy9oVyv69QbbtNi2XebAPM8cn57FsSwnusbSWNH0MBcbWSVCF18ztClJlpEbZ7uir1bNGrRoLlnXiMtc0TlarTY462jbnmpjT87EMFM1OhQK7dolGFGA1oWxQhnlWoDzri9uY0WsUivD6Xjkq9/+LcenO97+7Z8zHJ54ePc18+zxc2W2lKC0rN+aErid90tqDFlnXyprd0QAGFP0mDpn6RtbGJAloamVeIoLhzIiJG5bsjZFX8SiXNGR04ZsLUlpjscjz08PnI4H5nHgql+x6le0zol2XOukdbZUg5pGksosdk5Sy8uQiJhpJGtNLHtLFUtWSi0tNkt6Uu5FRhgbwpaTACkBY6hC8jLPZx+kCKYUKs6M3tf8mPV6w83tC1rXkGJif9pzOu5xztK1Lf16Q7/e4bo1uLbokSTIerm/2hhIEvikUmyqFs3iAio6eNqcXeaqRkFMJXAtgCycW8aXwEYBSpN1LoUrisZoNQcRfZiFEZUS3gtzL8weyJgQ+N1Q8B/2EavZAWppTavCxfq/+OoL2j2wsP5KkpeR/TLGjPeeq67h89ue2+2Kn9xeibbXNHOcA0/TJFV4ZF415nxfLqbuBQwlrU5xTKQkRbUQz2CTAAvSwjeoSCItoFrORTOqsOaMFnaTM6CNKtdFrMatVry+WtEYw2GeRJMpSKGgcS2giHPVoUCA9+JCOQ/CwhsHLwmAtmisjFVyAXHFiUoraJzCOSWirRlMHdcxEbOIkHeNZbfuaJ1j23XELKCw1rq49Vm6pinW4rWirouupGHTtWz7lq5t6DrHNCemkHneHzicTgzzyBxmkViwFqs0RkkhMqXC4tCK6/WarmlYtw3OGOYQ8SHy3cMTp2nm/eOew2Hg888+4Xq74g9+9Rl93/Ldt285Hk9crxyn48DPXtxwmiZ++/aOwzjy1cN7phSXYmBOEUUmlAFV2YgGqExwsugblRG5pOiyBAiDs3dWwJ7ae5kyxmj6tQgDx+gJ3vOnf/0t988nEop3jwOHkJlTxpZhHgqwajRcdYZbDH0rC+HDnLk7SlLsY91HZT5YEMMHdX7MMTPOiSabhSldGYiyXuUFgBe31GJIq1h8ESjhXyFvkLPkn0YJM18SzApc/P2YA//Qjstk/CxtsgwMTBGbrsfvuxaXGpCXLU7Aok8qEiVSiDszpM6vq6+9/DyRMwopMY5a3kNrC0TRYitzfmmPTYWHmBNkVVrEJIdU6ux4qcwFY6a2iOazW7IyVpSTXIvKMPuJpCNZSxut9hPEzJQyURm0aiQmbBVzmHnz3dfs90+8v/uaISXidoe5WmGvb9CrFj+/x4fMfjjh44HNesV2s2W3ueZ0mnj//oEwe1rjCCYSjGZK8Dx7+tkSJk+Oihj0Eq86p2kaMU7wPrA/DTw8nXgePfshoK5b2s01m1XPqtNod8uUrtnfj4ThiZeHAy552FyT2x5V5EbEsV2K7SkmjnHFMbUo9ylN8qT5mRgHAb1z4v3bB8ZT4J/8839M67bc/drz9vYdX/ybv8AfR/I0sm56Pm5e4qxmcidmNZPsgLGKzt4KS6nolIYYRYam3rNLIHQBM9XvjNUKFunCVK0stxQFdxDm9vm9vPcLQ66CoHlpdUzoqptZAB6tNZqGbBwheEIOcg3QnOU3ZCxK0SQvwKkiQ8lpIxqbIRuLNq5mqiggVnKDNqXwJ3Gtqaz0FJcODsgiXXEB+/+Q4wcDT9rUarjQbP08LqCNIsmHwpC0I2mh6OfoGZ7uSGFAhT1hPHF6GokRtHW0mxtuf/pH7D7+Bd3Va1y/JSdRYF+okZTgNZ7tahf0rQ6JWqFIiVgEay8wRaqNel14KpiUF0ZC2f4W1E4VgOn83mr5ryrUywJY5MT0/JYwPDI9f8d0vKemZPPze8Bg119i2h3ZrKj6LkpTdATMmUpdNiVnLcFqVJqlRS56KKLVk088DiesVqzaDq0SMQf2x4lf/+YNr8OK7cff4lY3tFctWhnatiUEg4+eOI/Mp2fUaqQpk0hpQ/YD4fCGePyWePyG7E9kf4DoIc5Ah6EVMAbFMCumkyYfI/4wM5uI1mmZk8tAzAs+SO0DFuRWag6iY5BLFVNAgZSRSZGF2p4ztE6YVSUeoTKdlq3pIiFXSrHqDMmBDpqQwCBVfNs4AZyQ+24WqqQI0reubhp88NkvYe+F6VdaAj9kLuRlnCyQ81LRkABTAs6Ajkf0/Eg4PTEcnnn3/pn3jwc6Z2nchuMx8/Bw4uv9gccJXnx0y2a7PrMPjEXbBtOusd2G/fMj83AsG4ItVF4lFQptqK6BtVKzLBPfq0Lpi8DwR3HEUL5REWGOJWGvTlwhnu/hEtRQ+t0zoQwCqcDnpXVvSaovq13K4BpXAKcG51qatl/a6rp+vQBOQndVxBAJMRJiYpon5mmiqpjGYPGNpbWOxlbgQS/uFtpokhFL3TL6QSmcEnZhBWlMYWda56Ql2ViU0fTtCmMtjW2KXoZcG1+BoIwkf9Wxsqy7RkvIrnOt/Oml1VkXDROFMLXCNHJ8vuf0/MB0emYej+K6F+MSKNZZs4y6Or1rAF+FuMq0Wqj7WdprtVG4otfUNZaucQLLLQEmouGkDco0aO2wheWjlJE1pwSZ9XlCM1bMfmYcB/w0CU2e4p6l64ZcNBkKPT2botlSNnSrFOTEPA8SsIUg338pSZ0D7/pj+e4FOJP2OmlLqc6v9V6lmEvrXmUl10exOHcOYy3OifDxcDwxzSPD6YTerGnalqbtaPsVxjoBh8pdyVYYYXr5rDXgoph4mPM+trRWqVLwQfaLKOLkIYRS5MlljLCM4+W2a10cWDSKsxC/Kmt9qIWKEC7mYF4u2GIB/CM6com7QC6VVh9cst//mt8XBF7cw8u4JqGWuaeUuH5pJQHoMHv2p4k5RnEFK0mzqgl1eR0FHK546bJPlrF4ZmqdHWHPj7zcZ7GDzqUQWca7ls+eoBSoirtkThBTMTBJBciyWA2rfo1os2lCjLx//0wIWQx/L6K5ykqtzsRiaa/wPoBWOAdWJ9attLl2jVvig5gSwzQzTgG/tPQoWmvZFQB807fEJAwsue5ixNBacwaeyprdWEtnHbtVy27d03cNXdtymjzjFMjekaNDI231jXPCMFRi4W6KO7MpTKQKwPdNU8xVAsEaNn2LVhBmWYPePzxiVObmxY6cEl3XYY1lup1Y9QPWNYzTBCqxHwYO84BSiofDSIiJVSufIReB9BQFiKrkzCUMosZtHwIANYEzNf4ujOTF2bMwD4wyRCW/n3zg2/tnHg4zT6eJKUghVysB9c8xJ8vnkLlzoff1/Wlx+Zo612CJHWTsXrJzZazUAs3fuewsk7Xo/pRz5OVkhdFZgs4f0+p1CSrBh8BTvYYLePSfSVx/B6Sqe9AHC2FhBOcPmUd/F2vqw9cV1ngBHGvifW4bL5+dZSBJLfl3v7GMlUQBvT64GBfnUlI8WRyF03IObSzZxuVnEgqjtFqlUuAEvIrEBPN4YvITx+Oe03jCO03EwHqFWve4tsE6A0tjqUebRN+1tE2LVo6cPfM8E1PEaC2AdtNAgCkrTlGxP45omzAWcWnH0IRA8InZByYfOB5HDqeBOVuy67DdCrfaCqNaKbRrUEoT2i3jvOPgI/kw0OQG46FxImmijLQVhpwIKXOKgVPUGNvRq44prokM4rYepDtAoxembrPqaDcdetWgUiQ1mmhhjJ6QFFMeIWpW44SyBnxEa4tp9KKzpSrb6OIeLrHkBYhZNb1qHFyZ2xdZwXmcyY8zOpG/vw7KOeq4WeKbfPE5VFH1qsBWXUiyQuWyOZfCuBQiLjScKxJOXjrLlDJF0qCM/bLALQDt964B5T0qwzZxnof/pbikHj8YeGratlwIRfATp8c7cgxYK25j7XoH2WKYidqiphOndMf9N78mjCfyfMJPkePzTLtecf2TG17/6p/zT/5P/w/c+ob26mPiNDLvH1Fa0ThHTIJ4zvPMNA0SnMQs7kTOimCsPQsu1+DWWot1hQGFaN7M80TjGqxxosSfqsuUOPBUMclK3/x9aHqqbhZW2hG0AvzI09/8j5zef8HDb/8N8/ER212hjePxt3+OaX5NOD7gNi/pfvqvoNmI1TiKvi0CuKW1YfYSVO82K1xqOTAQ0hHvT6SQMarleJr5X/7qnle3G/73/83nQOI4HPjubs+f/6e/5mefPZJ8z8tPfsbn/7ih212zfvUxQ3jPPB+YD+95/u4LNu3HtDkX4e6G+fSO6ev/L+nwFfHpb4EWpVryeJDEtd1gmhUxGiKaL581X90ZXuuJ6+GJj163XF05jBIEdGmNjKJ1I/Xoc2pZNwOtpc/ZFYJQXuyeC4qaJTkXN7ZEQBIOo+okYnk+SHDbGMXLawcp8qRHQgJPjyqiwLJuyOSr9tL5YvOpCU1CqiDLhARpKU0JHzy1DTRfJMFqaekR4vbloqGUQ7sGqz1NPsLpK/Ljbzl+9wXv3nzDv/31M3/5zZE//vyX/PSTj/ntlye++ubX/NnXX/HN0yP/l//h/8zLV3+M0wqTM3RrtGvZffoHqH7HV2++4/3jEe73aBQvbna0bSPtQNpilMEqjXWixSICzGZZ/IwWJ8kKqPxYDu0HyEVnpiQpKWXGonMUShVflwhVEqXMFMJCtQfOQU2h/8boF3tuATQcTduz2lyz3m65un1J161Yr3cy55uugEYynmMM0k4bAr6sXdM0M/uZVKpkbdPgGseqb+kKNdo6V5yOLLoI9VftE2tatDbYVoAt66TNomla0Scp4FUdzwvjrwRr8zyJHlBhmKYynqXqposrXhFmhIVpqLVZdC0qxTyGyLjf83z3ljd/+x8Zj0+MD9+JtlMQi26jYaEI14Auiyi6KgC2Kd+1AsEx52KFLhu7tQIibTZrdrsdm9axbp3oBPpZktSYsE2LaVpMs0Lblm69pel6YXwiWniuMKCyUqClAn84Hnl8eOCwf2Y47kn5hTAujQhtWys+4inMhHlAWisVTbfGGENjLKTIMBzx08R4OjKeSnt5BkHvzslOZbaJBpk4AmpjaJwuLJ9JtAtLe9k5qKg5XS4MFkkiu82Wvuvp+57Tfs+7794QgmeeJ9q+5+rlK3YvXrG9fQlKmBEpRWIMtE1TwARhh162HhutZHxau2gdUO9K0VPzfsZ7zzAMzLOnaaQlzzkZizX5oCTg2sj4SilDjEzjUDQWK4NKQLdQ6P71vCKGrgTc+jFlbkDOsrfJ5cpLO5D63g74e1/Lh8HtWTT0bNKhs6gK5dIuaw3M3vPd0577/cTXDyd6Z9l0DTFD02jCnMghl/tXdHGSqj2AZ/BT4GnRyinAU8oCJogDXVqSsHkW9mkIid3WYo0qQue5rN0ZvIy/KfjC6BUB3pXVrJzjZrNl1Xf841/+grZt+PZpz+PhxLt3zwxToMUWXZfSrp9kLDernpzBz4GUI6fDidbCZmdxTvNi0+KcZd2tmFPicZo4Tp5v350IMeFDorGWrbNcr3p+9uKW1lnWnZXiRcqEEJmneG5JVcJ6SdKVzFXvuF6vuNmuuNmt6bueru14Ph45HI80NDQqMlgYZ4MrupNZFXfbqAuTXnTgrnrHqm1Y9R3OOmIKxCyV/HHqeP90YJw9//Ev/4a/toqUAx+/fskf//Efsl6v2GyvmKeZ58cHwjzxx8MrDscTMQW+vnvkr756xxwCn7x4ibWG/SRFnDTOKCROB8UcC5SjpG1Il8Qt5kTKIoxsMLRGGkgUcj0iC0Yle5gVO/CcHaOf+Nd/9TWnOfJ0iqA1fdegDYRwbvdTWiLDet7WwqaVs0zVm6OOVyiGGzImpOURnMoo4qLVtDgPJkgxi9ZnLO3BNUe7wFuWdmGVkbbK4o6nIRcXOwE9KuT141nAznFkWaerS10pEEhRoToLn7PW/zz8VkyBlhLNWcuJAgzokoxXQPv3xbM1X18KwqY5g6LkUjh0y1qmCmaqtLS+5niW6Lj4aKRUZFGAS9OMWnSpcggxhgIOiPGUQsa5bURv00YPKHLrwM9S2AoRbwxBC8MwxZnT/T3jNPD23deMOTDsOkLTws0rzLZltVvTrzrJTVRCmZGmzdzeXrFZ71BqRYwjh9MecqZtHKk3rDcNalI8ZwXTiXy6F90r06GbDt2uadKJNuyZvGecZx5PkftTwF19hL1+xerFJ2xff4o1Inlg+g2m6TmlkYPrOL79a+zTW676mb7taXcbXNdxkxS6TRw0DMC7aeDdNLNZv2Zj19znb5lGRZy/IoSJRhu6tsMokYZYXa9YD1u6T25RhwFWPT5r3r19hjni/QHjNK9Xjs4H2J1QSdFsNpgCfuWcy/5SWzrP43cBZgR1kUKu0iKpo3Vxm8vEHKn6nFUCYIGh1RmE/GAAodBaYqjFATulEm+LPIxWdomdU5Y8VVfNpSR7WCqamhJjipGYUmqhJkc/oVTR8cT+jh6bLnrCWluUPi9ulVmVYi3+FQazMd/7Ln/38YOBp3pRjHXkFGXDVBmVI2TpTc0x4qcTaR6IYSLFGQjiHOIalHXofk233XL16adsXv4c119hXEcuPaSyjmRiDIQY8WEWNfYsyJ0pleZaPUgpLNFVLmBCzlkuelGpBwpNTJ8HSRHBVFDc3c5CmB+g6yVYQyGuAUpYAckHTo9vSdMz0+GOMB+wbQ8qY5sNWguFTRuLPz2RUsIe3qC7a1z/SmiVRi1AF9UYUSHAmdGo6IkhMMyZcYYpSL/Jq2vH7c6y6qq2FHSNpms7vPd88eWXHEcPpmV19YKr/YF4+g5/mAg+0jWO1mY6NRaE1TAlTw6eGMHnlph7Iiui90Q/k4dAMhOnGQav+PZ+4v4xsLnNbFNBXXMV2mZBf6tddr3WpSO4XF/57VJtzTUBudx+v1cxyZWhVNT3L7eoknyh6oaX0EYo/akIuktri5y8JnrljcswusSp8/KmlSbfNp1QEWt1Kmd0SkRVe53re56rG5Tr4ZoG13QwnvDHB8b7O8Z3b3l3f+Ddc+I4KyKGYY48HwZGPzBFeBxPZK1oGseq64BCh1SgtGa1uUYB29uPmWbPeNyLuLNxovOlhQKuckTlWACIVkTorCsL4rmX+L9cIfqHdfgiPBxTtdZl6Q1fXJNgqZRVocRY9YdKwJAuGSUAWoSMndNo67BtT9uuWG+v6Ncb2vUO5xq0c4u7Zc6hBFyxiJfKtV4qa1qXYEcSrbZtcK6h71vaxuGcuEK6phHgyTmUrowThTEiLGicW0ARrTXONoU2rgtYCihhCy1VnAyKRIhaGDmkIgCeyRhQEAuTSReHRlIoe2UpK2sBY+ZG1o7D/Xv2j+/x44nkZ2Gq6lrZEZbRB4G6MgIuxPP810rTlMBUKfAhAWGp4AirR4JEYfpdNiApUAaMBAXaWFzT4tqVVOGslcRNCehhrBU2mi1uU0n2kNnPZa9J5TqrxfVSWpkzfp4I84xr14UNJUB68CMpePxwIExHWgu5NbSmrHW6btyyXrgSpFitF8ZTDVBy1ljlIFty25QKqf4AlJsLe26cAq4RBggp4qeRGGaUEoHjtu/ZXl2z2V3T9WvZw2XxFOi8iOmIhlJkZl4WTH0RZEhgJveqrp+1fSAEAVi1AmfFHdFaUxwd9dLmfr7/9adaKo6XzCYJ9KuO3bnlzJyjufOb/UiOuk+d56gcos10fs7vHHUj/f4fL/5/LsBfdfDyCY5TxBloYsbHWFzSLqq1qiTpuba2XOzBZe+TcEBBloRbafWB1lLda0MCYoEblGLTdyiUOJqhCDHgC/MUwCTZz7dtQ26L5pNSvFi39I3lo+sdm77ns9sdzjmeh5GTOReTLq+BDFVpyVn1HTnDwESKCsJUrvE5EogRTmPE58TsEzEKE6cWcKwRrnBjFde9o7HSVudjIiaPQeFK2+/SoozMC6MMXdvQd42As9YIQIYU2axRNFbTOkNOtuhdyfoQci2QSQyWipZWCBFvAjlGlDFYDSZraUMGjq0UbUc/EOfEd2/fE33k9euXpBQxrqEzDu9ngrNkLXN5nD3HcSrJ/rmtJGeJ060uYvM1pqIm7upiOFZN0PzBuCKfI8AqpXUeq2oBFoxWOKsxIYNK5/fjPCcoIG2kgp51ZZAxaXQB/T6YIOf1Q9ZAAXzrnlX3pfooIfvFXKpnPn+Oqhx0GafmwqwrCi/UFthz8eDHcdSvopYF7MPjdxPvGoN/+Jy/6zizQ/IHv7uUUqnveXmumnuUV1CZuqaA+/V1ki/InI3x/F71PDVvVLBIVCz3vRRJvv8d67kEuIgCFMRY1kZJIMT50orER9OQW092tsSoGXIkJk1MkXEaGOeR2WqCbjCbDtV0mPWatrc4p7BOijNWaZp2QxcC69WWxrZMo2i9HQ8nnLNs1yucTTRWoXBY1UFwzF5aIZO2aG2xZIaQGMdESAqfG2Ijxcl2d0uzu6XtV1hrF905WbeyFAC7LaHb4qcjVlthRg8zLmbWjaHRMFvLpDQxa1LpxdBkrOmIdkUMhqqBl1NmGvfknDAu0a4s2+srmqanaSwmgT+diENk2o+4WaOHjGnBIHItKadzz/h/ZszVcfP9MVdNVUTOYZnRvzOuq1bSh2PjonuLi3Wsvm8Fu+oYoLKtPvx8da2RPffC4IMPQdKFsVQ0v3Clq4EPY69lbhXtp3wB5Mq3O3+/H5o6/mDgSQQWDW3biz22tUQCOc/SKmYdMYwcH96Q/InkD4T5gHMZaxzWXtFsXrH+yT+n277g5tNf0m9vsd0VOcN83BfgwpBSwPsR7z3jNCztG65paNt+6SdNOZG8X4KxemPjRQ9iLoGFaVpU6R92TpI2Y2VBkeC4ivbWe62IxVmvqie26x5jHf54wI9H7v/i/yWaTsW2fvP6JzJAUnGK6l6SUuL5uz8n5zdoa2l2H3H1R/8DptuS/UxOktxlVYVaM33nSCdDDiN+HHl/gHHKPI6BpjX8t//kls3K8nI7EkOmjRG1c+w/+4jjceB//J//ZzZ9z+t/86/Z3b7m9U//gM3KcLszbGzkxfWO9UpxZR7IekVSiSmNZB+YY8+JjzilDae4Yf/4wP7xkX0IHOLE/jhzGjzTccaPnutX8PHHTem19VI3LcmnNoZUkH5d3b9UplKU68CFksNSJ1sZzgpQArDkcpNtEQPXZXdOy0RMJZGWazj7GUVCOYtOGpsMKSmmyZ8npTqLkaIX2GUJ9LMGpZMEH9bSdj1XVzeEFBmnEyEE5mkiqeIokCvzqYqyiWixdRbjLH27ZtWteH78iucv/4av//Yv+PaLv+LN3vDuYDjMDbazPB1H/PyW//TtHd8+HfjFH/6M15++5vrmhpfXNzw8HRnGCdsIMv/io5+RXv6E/dOBzfUnfPvVXzKcntBdD0Zj7YwzGR0ndHA0bkXT7jDdBmUalHECyuVL0eofujL8138ch9OSOEi7RmlBW5LUkpiUhyQKWSq1OUMBH2ISN6+kNVo7jOuxTUe72tL0K1a7G9quZ7PeylrVddQk3PuZedwTYyQEfwaZ2hbXtHTW4Yr4szBpCmum7Wicw7UCrJgyr5xrSjufjIFqva31GcDig8CobIz5wzC7gidSnQbvpV8/hok8eU7HPd77JejSCmkBnCexH5+OCwiA0qhG1shuvcOPA/df/Zb59Iw/PJNzwDWNBOvjIK0x5swiqyDLHJRUw5OIZRtnWPcd1mic05ymmXyQZjAfMs61rNdrVv2KvmsxOZU9QO5xUhaUQbkO7VpWmy3rzU5627URBxmE1du2Hbuba7p+xTR5pnkmxshpOBFLIcVaTdNarJV7NBz2+Nlz3D8zTiOr3W0RHM/kHDg83xOngeP7b/DTwG2vSW2HyqX6WwIIV9ogO9cUlpqsdVXwfhwnIZSoFmMtXddjjD4Luhd9sdM0Mc2ew2kkoUg6Qxh4vr8j50TTWtbbK25ffcSrjz7hk59+TtP1ZG2WqMVojVPCgAwhEkNAzYVdVtt7itVxJi/sYQm2hekUYyhjJ8r62TZ0bXeubithIabatswZZNFKCDQSyF9WrvMyV3POEGUtt9iyjvOjWrvg7IKl6jWpJgcLsvR7jstrUGJfmQtV2F2OlEVXMWbIaE5z5tunmdbC2goNX/QZNVYpEuBLKh0vTyMBwAIqkFVhiAvg5Awkk5nncouyuH+eglRyAwLe/+Rmx7ZrOY5HJj9zmmZO8yyuxUphFThj+PRmy6pp2K5WOGtYdZbWWT7/6CVXq54//snHoBRvH5447sWRKlyYRtSBnlPEOMeLF1dkFA8PB4IfCceDABNaERTMQYqhx1HaUJMWdnrnBHRqm4aYBKBeOcXPr3uJZbMTce5hRqNoC6B2OUy7RpK9bb9it1nTtxbjDNKCOKNJNFqzaiwpWTpn8KnqoCXGEMghQvKkFJiDJGJOT0SfWFlHq8E1BmMUZtUSOkeMkYPVnIYT4+T5d//hr+kbR9saPvnkFb/643/KarUGrYl+hIMwvd/cP/PV2wdCzBJTYyFrshcho94Je8dq2UdlG1XoVMC0XFeNxTKApQApOTWQMSVhqilOqbuidaZx4p6ltOcwIaz2VBgoF0M/JfAK5iiPWBYVo6HRoukU4xlMrUBSBYCc0TSNgJ0ahMGfRA4ilT1VVx+Fi3lXv1vKiUiSuLeGGxJSkLToE9Zz6pyLXsuP76jyEJetd0qJRMDvA5b+S8XPBdAphk9nqOCsaQNFLiGdC8KqopzLiDsDCZKz2KVokjLkEEqsZRbguhIFdG2zT4mQCxv3AnkKUSBFW3QQl5asss+KsUcg+IkUA6rqJ2NQ2mJNg3KZuN2QtCKtOpE68B4VM8TEHDzP+wfGHDluWuha2o8+xrgW125wbWLVnehaTdP32Gy4Ste07QaVB/wUeHi/5/27B757857rqy0fvXiBiYnQzRi1o7Efkf3EOBwxOeKyxyQPaeI4ZfZPCdW06KbDXl2zW1+zun7B6uYFtnHYxp4LjSpjcqDt1uim4ymNnLqOaf+EnU70T0fanFkZsCQO7ZqDcfjsACuF8zzRug1aZebxa1KcSVERfOT+4QvJ7zvY3rZ89otf4KdMVgMxeO5cZHr0PP/VnjYo3MtMbxSNAW1LJ0tKGKRd2bbNmbXGxdy8AIyq7I8uxUspYDZwAWDK2nCW9qmMvUvg6XengQQ0xftGGEZJ2Oh1sTy/5KK9tBQotS36nGX812KPruBr8gUnCaA1jRIDIa1dWRDPxXaosZ24LZ5bDM9axpIj/LDg6+/hapdFbDeXCqg/EacjcT4SjYXoCcOe493fEucTcdwz7J+IpxHb9KxvPmZ1+xNe/PIf4/od3e6jxbI5pUicxV1DNtu4TOKqF2KNxWiL0Yaks1DRygZQsMOiC3FGr2uF+NyXWYdOpbFJ4LYsNMVZbUEVcyxJQbWG1pAy0/N3zIf3+NMj0Q803WpZtBQKFRMq61Il0TSrK1Ly+NOjsID8HqwFXNmHhBWklbSTBD8TgrTbiJuWImuN7Ryt02w6RWsS42kstuoJYzKblSZGTbaGOWf2w0B4uCeo37LqHc+7ltt1QF8nTmbPSX3BlBrG2PL03Te8f3viNI6cTp5TOHD0M+PpyHScCGRChrVxbFeOpt9gs+bzFze83q5xWloFM0osMS+rW3VXV6WKpNQHEorq9/3r++WfRfBaLQu4DMx4EUiWDT+B97H08wvDImV1fs/L8y0RuJw0lyhA2ugMjWsAxXAayPf35N/8BusMTSNiws5aMoacbQEVAlppaVurKDgJNU+Mw8QY77n7+hvuv/qWN+8OvH1OPI1KxNkBazQhJ04hMKVIyJH1esXL62u6pi2ggkGbsgkmATJyjFzfvqRpW7p1zzQeiadnkp/IwxtSmklhJEVX4XDRoDGubJSVRZDP9MwfyVE1mmqwWGn4Z4T+TPtOKS9OizGer4NSGtt0ov9jW6EcN2uMa2lXG2zTYVyH0paQE8QAfio0ewBxFTPO0mS3uJe0bUfT9bSljW7RzCmguCs6HtbaItws484UJpMtbE2tq/NYaZ27BJ64mC9VSG45ZMMKRXwzFOe8EKX9bxoHpknc3Mg1GcioIu6cij5WzFmEIWMUoXEtAJ0qgjSx9JNonc8b5rkQI46D6qzrUn5NqMyzmFFGEgFnNNYa5njuL7+8RjnMzN6X6yDVuazlmgNMo2gtWSei+rbvsU2DOLN4/DzJGpUvVSeWgbAAzDEEgp8ZjkemaVqqlinMhEnhj8LWjcdncpjQ2eN0ZtM1snGXFqpc1hsBHnUR7BaWibS2FWvfXlib2so4adpOACpXWWjSgujaGR8CTVdcX0Dmu7ZFl8my3l1x+/ojrm5uafsea5vynfMilirXVnYoXcwY6tooHzxL4FwCqnOIJSw1ioaZtam4I8o4lXV2eSoKtQBJKYcCWsgbitZjKTZoTQiR2sK8VONSEYVRtfX5x5W61eqnLvtfZYoshZJy7S8D10xeXDhrolyr/DWUjDkv9vXnok8F/tSFo08VwM/nILY+qIFuXj7nsterKros5zqDiAIQhJixCVSC19s1rWsXIezjIE6F29aycob1qqVxlpuuo3OWj3YCPG1WvTi3tZbGal5drVh3DaveEROlcguLTVL5cDX4poiuDqcTOSt80dfrmhZrRW9TQRHmhtMkouOpOJimmNCNpnMGrSyqdey6trC3pY1GkWltjU3lHlDiEaUV267hetWyXnVsVz1NEezVSUAaYwzOGewk7bdOy3uYTsSFfY7EnHjawzAKwBIK66mu5TEqOsQ4RSmNzYmuMcRkWHcOTWIeRoYQ+OrNOyYf2N284urqCmeFXRRdg+t6Xr98yZwUxjkg89GuQ2tFr4sGa9Gh8XHGx4SdPVkpYYTVICyfWT5VOF5VMGDZnvLSUirtIBUVqjM8L+NVBldJ1S6nf409M8uaUdN7raXNNNVErIwNyelUAWMVCiMJsyoFT8UFE2o5tSR1VVy85iUXLIBc3pcMuYAl3y/0LePjR3Z8ACT9nu/4IRvpnLBfglXnvO6Dd/47z3dJIriAE8vaVRG+WpSr2pQC2sqQyufnnukn5f3Pp9faYK0ihyq8XIrQdUcs36eyXM755cUjJVII5ftY6qBVSqGsQzUNadWRVWYOA5BkvycRu4aswK0bVNfRbTZo22Bdh3ERozx5zhzf3JO0Y0odMSW69TUpHRmm90yTJxVnJq0sWsclvmwbB9aimhZHolEBHUb0fCAox0iHaXts19P0G5p+S7fZ0rbdwmyuKZtcglTkGowwz9OVMOidhtFDiMSs8D7hNXjZZGSuhomQE1YbsD3GdOQ8MU0z9jQwnAZim9CmkQLbridMMM+aYGY21zsaY4kfXePGRAiZeYj0U0R30oasdEYVdqXEJAmVZO3RORWwUy0xR73X+WKiy/0+t1qWyuyyxvznWH354neyf531lOqILU+QEb1oPUksqVMmaYWu76TP47eMqg9mXyaVtuEAKHTjCqha9c1k7zrPJ73EgRV7Ac7s9R9w/HDGU5Ab4lMWfYj9Hf50z/z0dekp1Pjhmcev/owwnpj3T8QpMj8l2o+2vP78n3Hz0z/il//q/0bCMo6JaTjw/P4t0c/4+SSLdhX7KV/GWqnsO1Osq01DzpoUz24vFCtEY825h3iZ6Aoqk6O02uQkVYhYWmhilL/7xZpZtF9cU4R4S/KisiaHxNMXf8rx7m9Jp3dAov/kVzT9ljQfhNbsKQGaODZtXv+KFCb23/wp4XjH7f5rUInYfEourSUS7Anz4jQ8M572Yt/tIyEbMI71ZsPaZm77mTDP3L05oY2m6Ruc1by6ETDh7emKEBLvh5m8f0P+7W/QTYPpV3z2+orj569QX38F6mseT4F3+8A4eobTxHGcOQwTp1ksdK0WB7jrtuG6cfz8xTWfXe/46c0NH+22tK9f0lzv+Pr0zPthgKxobFOpESIavmz6lMRAF/e3tDh/LNPkPKfKP1gWcBnlJTgpFpDSeypTWga/IqTM4ANWZ9Z9A0qLNenFZKntLdRFTZXguyAFGYWzht42nKbI27d3jG+e2f/Hb3n58oZffv4Zu+sbXn30CUpbjLWM88xpGBYNB0vGkvHHPfPhmbs3b3n77Xd8+cWv+erL3/A8TOwniCoRFbRO0xnNlBJHn5h1glbxyeuX/Mnnv+BqvYWsMdZhsxL9mhiYDu9IYeSnn/8B/eYabRtSivzNn/6/eXr3Fd/+zVvm44kwPeO1INwZhXYrlG0K1VJYW/l7gMuP4ZhK0qPyOVzNWQApCUSFQVHdR7wvvcsi9iDVp6ah22wLw0musW7WaNvQtL2MJ6NJOXIcT1ItGZUIHZY2sL7f0Dhhfhhj0dbS9T19v6IvP521kuwUavI5XCr/Wii8lAD8rLmjEIAa6oansFrYJamAa6G4hQFn5khpiUpZkr0YA8M4Mg4nnh4fGIdBdPpSkrYQrWkbaYnJiZK8JpQG6zJGK/q2wZJpVj0hjIQYySlgTW15uWiHkzIKCoVTEMu6HVNmCmCNiFc2VtMaTbSWtnVMIQnIZ4wIZDfyOPmJ0zjStL2IZ9pGHsge8Hh3xzyNwlTrel5++in9ekVOgWk8oXJkso6m36GMO2/WBXzJOYvWwjSicub+7h2nYVgKJWE8EscT7998iZ9OtCZiFaxai20U3XorwW6dY6a2WDYFrJbE3Pt5qeAbZ4oQfEO33pX2SieJqJKKvC332adUnLTEZTHEuLSaNG1Pv9mx3l1z/frjAlSvZY1ONVlOhBgIsfT/a4VrpE2xtmtK/BiZo1TNanJoiu6MtW6p7NU2FWABdz+gnXNOkuseLO5GlBbKvLjX5Tx/MH5zSgsgopS0AlT9sh/LEXJRDMl2AezO2oEXiW0Jdqs4s0/S5qN1RgiNJTgVTW5xQUOV+UZpjxIdnNZoWmuKxl0qYHGBupIipcJoKho6qYCFsWhOmLJUWQu2gRwyMUj8FQKgMiYjYDWKf/oHr/jZqxd897hnP4y8vZuZhoHPbnfsVh0/++iW7brn1fWWVdtw061prWXd99K66Yrot56wBna7hnFOZEQnKqcobcEAVI06mTc5Z+6+e4dohyVaZ3n9cotzGuNgDp6HwxOjzzwO0nITg2jQWSPtwrvOsWlbXmzW7FphEyUic5pRKK67Mh+UJLYpiYaQtYoXV2s+utnRrbes1legE0onwpQJY6JxguG208g4ZGHCasX1dsW67zBOoY3it9++4+5xz2nKzEHGhveeeR6ZTeRq3dJbs2jazdNAoyPENcPU8FUMHMeZ/+XP/opV22DIfPL6BX/0J79iteoY8poVmv/mn/4TPn965uH+W1KY6bQUJcK8I8TEcYpM3vPd8yPDNDONExnonCKhGYKsqSpnjMo0BqwWgEfGeWFRVpxJybi0NZwHKDIaBb652Afrvin/k/BO1jUZ9xWQlbaqlBW6Uis5A1Ipgw9K2hqzoTURZxLPPpNVwjloG7CBRfspZ3Am01qFLnTAKZ5B2jMABrFw3sSfpsYnl5nPj+vIWeaiKjfVaPPB35cEfXn+352YV/CpAo6XjYz1ebXbRZ53ZmVQYr3aQlfn5GVRL6dirVFJCDEWcLIYBKWqAyzvaJzDaY2aJkKQ4nOqhTlS6fYQh1+yIueqjRPFKCQW5tM0yjqlpBHXlLFs+hUYjX+xIx410+ktOQZMaohaE2520DjWt9fYpmV3dSVFNm1QKqA1xP3Id//6L8ldS3z5gmbTs/vkp8z5LU/Pv+FwPMnymAzGtBjrsS6IM2cvRVXbbegsrByk0zPpcI+dNHnUtH1Pt1qLA3Nl4ZuzPEJp/iBkAaVN0XXL6xvafs287YnxiHk6oMcZDwynxJgyk80QwORMGJ9JStGttjSu5dRcA5n985FxGNCtoV/1bFY3NK2msy9I3vF0/0jwM+vdmjiP9F6RnibG32Ty/cT6aZJC8OuIspoc5R5I653cb501yhSnQ+UW8CkjbCCRLMkljwrC0tW2DruLcZ0/+FnjpJzzkpdWoXulKYYbfvm9CJifRfSrzMbiNKeVaJxdVIfOzKsLxngFwqoe5zShdaBxnbRL9muMtsVB+AykihbahwXIXBawHyrT8sMZTyVby3Em+RPD81vmwx3jw9fi5KMkETbaoto1xqxJPuOayOrFR7Tra7Q2nB7eEELgtH8mhET0VcBKULQCDH6AQpuqMk9FjMVqMZcnn+0IL8TBlw9dA9SyMGkZTDl+WAGD89Ik56X02RqUsqAsqTjMxfGZOD6Lsry2pHkiaAPeQ04oDOhM9EE+h27K0uhIUXF6/yXNPOFe34C2ECc5e7NaKiei1SHaBqtGdl7TaZxKTFPGzxk/gTIZdCQkGL1mniFmLX3/OUr7jTMEBdF7vns+or/SS8VoP0UeToEUEimIhXuTM11jedE5Vm1L3zXctC1XjeOT6yte7TbsVitc3zGME09393yzf+Tt6UhnMk6Jk5O25ky/W5hLNSDIy/1cKg9ZsVjj1BuyVEcyVYQ4KwlU5NcacZGQiKRWs2ThrS0EpaUjf5/WWBvrys9lM6sfVZU2JnAKnk9H3ry5Z//4nuPhkZvbGz55eGC92nC1u0FZjTOGNI+Mxxk/DEzHA9Nhz7h/4u7dHe/e3fH+/j3HacYncW+SsEi+mEGhU0alTOMsvWq5vtpye3ND13XC+mNAp5lh/555PDI8vyGFga5fkcKA63ZkFH4e8cFjbIdt18Sc8GFink/o+URbKiof9vKer8iP5chZLayAnGugWDWeUnGvS4RYNZ9kxdeNCBWatsM1Dd1mh3Ut3WqLMg7tpOXJFacjbYtziBIBZXHoEOCpaRv6vqdtHV3R5lFK2oebpqVtRcPJlra5BVuCJXjSqribLJWTCyC1BlcVSy1tw5OXyNeXStzsS0sx5w0pQwGGSotajIzzzByCgP7Okb0l61SCMyN6fQXwR0GjhGbcdj2uben7FY1ruH35Gqfh3lqCDwKmRAmuFOdKNzmKBolGAKIqYFjuU4iJkFJhZwizS1xntAhXmlpZ04X1ZbC2oelWNG2HbTpUipAj8zQSgqfJImzauJa+X8sGn6TyPzNgmxWuEce3rl/xnBTj7NnvDyilSQiw+PR4zzRNGFdYPZWFGWcsSWzHjQBLRktLkQhBAmQK8UlEbSlAjFJgHMoomkZYjrZdFTdCK9e+sIeU1stAkfYFESi3FdApbQMxI22d6w1tLxpXWmvR8QsBP89npp9WoDXGCruuapDV/SmrJAWEUjCpZhLG2jJ+P2SmnrU2LoKVi2AoxlRE4Ku1tCrfcck0S7BfW/POD4oWlWzl5xaKH8vRWRGoPk4zCalIw3nunlMqOYwCbRWb4k5nbMKIcQ8f7KNQwLpLnZRKy89LoUfWlBLYZknWa0ybkrQrgezJogd13l+LRjwh1pYmVVyRslSuYyYqxTyLiYwGWmP5+csb/NVGgKe+5dXNjr5r2K57GmvojMLqLIUnVeKZDCpJgSmlSEyRkEKxUmcZG4pzW0CNa2PWNUYn5czgRcvJZmnXEX24JNPCQmcbMomQo7S9Osema3i5WWGU4jTHYnSW0UrWdCgAfWkPctay6hxdY7FWYVQWcKwkxqJTmvEx4INn9h4fwtJa7Zyma00p8pUGvqyFEWUpmnQyZ0KQNTSmtLT9tI0lI1pw5MyqbSErgvf4mHlzd0+MgVevbwh+g2t6mrbjs09ecb1b87wpArVxIseEnwIhJPanidF7lEmcxhmVM6HcDx9hKPqAtbhijSmOflb0qaLsVeF7gtB1rFd9T/GxUh/8/TKWr3IMubSXyu8u5ss5L1sOcTUTttOcMo9j5O0JXpFYO4mNqoYV+Qx0mcLsW8ZhnYtaY3NGF8mIyiQ1S7glT84KkaU4f4UfxXF5raG2x10EN39HmPl9TaTLLpbz+6UPrtXfxZi6PHLdY9U5v9P6ot0vVwBTLZ8vl31puTcVSSlx83IblWipJpVKm30uc7mqfOlCkKn7WFwMsCQWEyBKFWkXMWwp10wbTNdC9tA3ZAPTpEjaoDdrdNvi1mJcZYtzXCo5s9UN2Xvmo3QWebMnpUR3u2WeAtMoTqKVMY4yRV4k4axoilrnaBqHUxGdvey5TUejHeumETmIxT2zSK3U61rRVJWXFuM6BqxuUNqQsicrzawngpqZraXVornZGIP2AgSmIsCfC0Nf49CqJcx7cWMePUY7JjtgTULnEyiRULC2IaZMANa3V0Q3kZ9ORKWY9ieygXa8QnWmarbIfS3z/MN145wrVRLE8vtcWtSyEiZXWZvruKqdJZdjV/6/qgNpWUeor1YfArVlcJe30MtnqeZY3weczlNuQTmo2fKZIS7jMkaPCoom9+c88OL7n69DJSics8UfGnv9cMZTQujD85FwvOfp279gePyWw7tfl0q2wTYd26tPMM0Wu/1MkrxpoNvesrn9BAW8+fP/ifn0yP7dr7GrWzYf/wm62WBWL8qEDHKTSludMUVPQtVJG0nRE4KANbo8pyqqi6ic0LkVUg2tlbbq6DT7WdqTCv9cXO3sgjpqK5VFa0WgF9UChjA9keZn/PEd4fSObnWLdS3+8Eg87YVqrTR21YICHyfRKMEK0KW3xDhz/1f/M832Ba+ufoZp1jDtQRlSd7VUpmPKDEHU6V+sHdZq+q1mGjPvvo2EOTGdlLDQgmcOif1g2M+KKRh8ghFNazWbvmH2kafJ8/a7B/7tb94sgfqcElNKdFaztppP1h0/3fR8fHPNJ7c33N7ccHt9zVXbsnUNXS/BxxQ8Pka+/fYN397f85/e3/Ht/sAf/uI1H7+8orEtbdMwzV5cv0zFnsoum5NUEZYJocvvZUFJy2C/HO6KVHIZ68zSCpBzYp4lqJJilka5FkgLeDeHCKq4Y9XkvASGVVC3Tq4leFAG13a0aWZlJ75+fODP//V/ZCbjneLVy1s+/9lP+eyTz/ijX/0RL1695OPPPmW/f+Dh7Rvefv01X//mtxwPzxyenrk/7rk/HIQ6ax2NdbStW4JCBdgMLkGOmc2qw9meTz/9iM9/9hlXuytJXnNA+yNP3/4Vz/ffcXz8kjgfCeMTq90L+t2nKNPydP+W0/4Z115hbYMf3xPGE4fDPUFp1q8+X1h2OZXKYc6LKOiP5ihJRQWcQsqF2eSL/pKXSnzK0nrhOrR1dP0W27astle4pqXfbHG2oevWpboumkRt44ruklTNrHO0bct6tUYbAZ/6Vc9mu6FrLX3viCESfVjWLKPLGlbG++JIAVCSNWMU1a41leClxkv6ApDKOTN7SbiGYcT7wGmeCDEyzn5heMJ5s6w/U6H1+nkmp0jb9VjnJAYrSYvWBtt1Akq18rPtOqFlt+K6t91sUUrx8uUL7t5s+Oqv/wwfZk7HAai6B4rGKOnbL0md04lZJXIMZR1PhKgYg8cGwxQyIQnwZIyhbQxtY4tbmqy/2jhxreu3bHc3rDdbVus1MczkMHM67glhRgHOOjabHbc3LzkcDozTwOPDW4bTkdXultXuiu32iqvrF3zz67/m+fnEm+/e8vj0TPvmO7TWTNNIyon1aoW1htGI7kevwVnF1WYtQZ1tJajDcY66MzHNZVzK2mcqq82JM2Hbr0TPq+kEJAySSOcyNlRx1YsARtgfxljapl+An5SF4adtg+s62q6n7Tqi98zHI+PpyOH5iUovaNcbuu0W18qaTyrFmyznN0YjLryypzpXQFMrYG0NemI6t7B+OOZK12cBf0MQM5FpFmaT7iRorpXxRecpSjU5xkAqxSNdP5uS+ftB9eBHcNz2HYMPfHn/RMqZ280W0OX6CbMoAyFL4twYaKziqhOXJl/AuqOPhVVR3GyNVPvthZMkIO5opiRuWqGSAI6x3s9MYTwVAAqJHzqriU4RovxOWCPSfjR5CEFYoV0PQ4j4mFBBrMef9kfeWzFB2DYN/+yPPudm3fLp1YZ1KyYtKC16OTkx+5GUPSFrcbzzpohcg4kiV+C9Z/YTc/QluK6VYiWyALkAEqqCNoDS+JS5P45orWgthfHXYlXG2YCzltvViilE7ocTbdNytep4td3w+asXPJ8Gvnj/IPfCaWFqWlscmgU4ckbRt5YX1xtWnaNxAlineSDJHcLHSEiJYRoZxoH9ceRwmtiuGlrnWLWGzbphnsH7TI6GHDWdldjIh/P8m3xg8h5jFJ2Wgtq67+haR4qJxiiGeU3XtDzuT4QY+Yu/+YIve8d21fD65S0//8N/xGqz5V/+0z8khcDw9JIwj5wOe6IPzKcRP3senp8ZJ8/r5zWnaeLNpuU4jHx3/8BxTjwncTRVJmOsomtaVq3jqhPjFqdgjoGT96UyX9YLgbqlOKc0RmmsKqz5sm+eQQD5vezTBSwqLX1WZXxh/dV200vQVinwSbo7fvPsOfrAH90qPlrJ7tzp4pqWErZIKrROmIK1JUVALoV2qrSbJrQSTaeQwXDB+c1nQCqfcfYfx7EwkESVfTH++F7Sfe5QkeOSAXUWbj7/verx6moS9fsS83IieVlFkYSVTAZjnWjaXOQhdY+S85cCWNGHU9agSp6pddV8SuexqWUNqhIuAi6JJg4JcimmVOJEKM7GVSw6pUBOAVPMGIzpAIU3moylvdoQW8U0bInjyOHZk62je/US2/VsdlcSnyHgaVAKTaQlEYbA6SExq5nD/kj7coe72XJ8HtjvZ+YZkX1oWpR2WOPo25bObWmaFU3bsuo6lD/CfBIgpt2ItqbbCJCcI9VlVmmzFMZqXJpyKrqQpbUwJRrTo7Qjq4YcRw5mz6T2XHUdfdPSmRaHwYxSwUhGHJmD95igMHQ4HTme7kiMDPtbiJqcvRQElMOoNZvdzyFbhmMiGov9xSf4ceKRb5lPnqfv7ukOA9uf3KKzgRsxWolz0QWsewfn8SyAUPmNNkBxaaQIlSMyB6o4ilfQNdV8E1DqYrYvhJlUWNulxVgZlNFL0e0DcKfOi6xLe3cWwbvKfqqgUJ1DdT7kTM66gOTl/VKGHJnHEzHMtF01nJGvXYvcdYWKMS7f41zw+/8z8ISClGaGx3vG/dvyBRwxWXKUC00GbS2maXGrLaDIXYt1lvH5G6KfGJ7uCNOR+fiWZrOn6de4zWva9Q3KWNDtcpMXqn49f07E6i4E55tSblq9JEsirWThkOfWKjrn15Zm8KXfH7VQLRWi9p4imCKyOT1+iT++F6DN9ZimFb0NKwyGOEmyNk9PoBW222GdQ5uWbKG/+ZTkB+bnL/CnB8L+G1K7YTo8oUwL/QtyjhJNAkY3xUkkoVQke0+YI4cpSsDZtmiVaUwkeVBjwEbY6IxXYJVBk0SHAFhbQ6cNq6aFJGVIVRD8Tduw61s+XnX8ZLPixW7Ly90V2+2W7WpNZx3GWk4x8Xw88Xg88jwM/Oa7d7x5uOfr5z13w8Du6QTW8TJrNn3V/hCx9XKFz0wiNElX6ciSdFcHsYuA43IMGsSBavaFy5ylL7oy5ISemovuiSL4i+oHZ2Zd4lzZkCChnkKfqyFKMUyewzDz/mkkRMXr2xt8Tkwq0inF/uGBbyOkOXL79pb7xzuGwzOHh3ve393x9t1bwjzj5wmfMhhL0vIdVNnYnBItk7VRrDRMOTHHiFcJrzJPxz1vH98zJejaB/Z3XzAeHjk+fIM/PjCdRBD18d23nA57VoeTsJyMYb27wZ8CcdZMwx25Jm1JEPnKpBGHSqkgKWN+VNGP95FEaTPLEkScq2JKaMRa0zcCODWrDda1rDY7bNPQrzcyHoylaVo2mx3WGnFFK+LOosMh4uDCfBENp1xA5JLPl5YBcSKziAYOsLRxUX+jSzJUmFFCXT4LVJKEmVWT+hglYfdBxJy9l3Vj9qGAaqm0Jhdh4FgdV85sAQBrDBSHJXImzCMpBGnjShGtCtDQtgvgZErLoDFyTYyxtG1XmFoNq82G7dUtOSWeH+5LtiyaTkprLJpG26JfImyf65wYfIIx4IpOAErjs1rsy0HROAfAXHSZtBIzg6Zppf2u7QQ4M5YUZuaUME3HanfNantFt96SlWaa5iL23onjihddkpiE5eWKA57Wkuj6EMp6Ihu51TIOnLX0rbiSrp3oUa1W4uyiXQ9VjJfqupNQ0ZQ9Ky5ro1KabBzKGIxrFsc9ajGrgDaVHbu0C5T91xqHabslqa7NjRkIMcE0kp+k6hq9F8F7o4urX0PTdbRtS9MUS+ko+0guwu3ScaAKzqPPzCrvUSp8D9CUAVaLegphlZDPrEPKXt84cdoyRbusztMQPH72zLPojflpkiBMS3U2xEjMRYDzR7R2Afxis+YYAk/TyBAiIWZ8iEVoHpwTTbWd1VgNayeA7qY1RcA7M0clWpG10KrOdc5FXytBLpG07MJ5KYRVjlS6eMSsCnCYwbKwnYyR2FdY25DmtDCenJG9zmhDyoqbvmHTOj65XvNyu+J6s6ZvW17v1qw7R9eK+2/doCvzvdHi/Im2gJFkrTrqGoVUoU1h0YXirlviQmvou1bW5PL9plkYKaZgvjHH0lIoa++q69E+8HQIWK3Y9g0bYLdu2HUNG2fRZJ6OB05zAVZUDcWLTkjO2EU3RcDyZllXXImxvbQrljbJ2pKTQix7VMu679is2tKybQhxZpzlOxqlsEaJ6HEW9qdeNDqq3ES6KHiYMudg2wes1qQUmUMgxREfE9+9eyCEyPWLl2x3nvVuh7UOM6/J1tFgSCGg7YD1nkCmmWeSVkxzS2MVp3HGuZaH48i78R5CwE8erxVzCESrsVo0BLNzou2mFDFFpqIjSBKUdXHH0nywdy3ajVDWE34nDzrHeue1qUaH54TuPDemmNn7zLtBGKOrRhidnbPsusRwQLQGS8v5uQVV3s0YtbQMQj3ZZTn13IbMcvYfz1E7UJY443yJPzhijB+AS/85wfEPgaoPk90PWri/B1bloiOJUpiLmOpSa6nGV7rEO7Xlc7mDOZ/vmVKkrJd5VfNQySsNufytQFgLKCPi+RXpYmHu6hIkVsZ7BdfqeDbGgnNY15BSRq8dmJamX2HbThyUK6OmzG2VBfhKJtOsO/I8Yw4nsho5ffUOfzjS6ZasPROiizfOA0RxkcsqFXJHkbFJEh9GyppsBBRRS91Hn4ugH9xDVYAbafBKSpeYTmiCeR5geGZ+vGfa3zGiGHJmteloXEMXH2iniaAtWVtiJ/GR0Q05R1R25OiZTyMqK5puDVqR9IAiE+MRlTuapifZBrwwh7uXO+JhJJ6emOPMeH8kBWi2W/lu5d7XXHTpsroEQ9WFdt3CXpONJWtQKZNUXGL5TG0BleL174tXUpGhSem8UlQAqIJAy3NTOV8WLEMIHaYQwZcArABbeRl7NWeup1/06lIghsw8DQUsFO3qpWuprrcVeFquww9nm/89gKdMDAPPX/4H5tMDRjmsWxPSipwmbBrJaLRrsf2K7uplodsFwvDE09f/huHxHfd/8x9RKtG0mvbqJUadWL36R2xf/QLT9Nj+5Xky5kTMIiZKCuJmNw3U62+UUPrkmlbuyjmgrzboNVeDogiPiJ/aUhmqQZZE06aAVBk/HUjR069EaG3/5f/KcP8FAM36BrvaYmwjmiw5Mz09Mo9Hjk/forTikz/539Gsr8m6RSnL6uUvCeOB7979OWF8Ynz771HNiuMxotyW1H8iAF6KaDJN00OMzKcDKYizyXBK3B081jlub7c4Eus4oqbA/jCy0pqPGoNXilE7Ru95HmacMey6Btt1tOsNKsyo6cTaOrau4Xq74eXVNS/7jtfrnr7p6FtxgTJNh1eZQObd0yN3z3t+/d07vnn/wBd3d7x9fuYQIkNKBNtwd4r8cgq83PT0XUfjrCjsa6FGKwXOivNJLEGuKX3N5IIcB0mq5ihK+vpikqeUeT5OpS3DozVcrXtZ2E3Calj1stEcUkWspbppS2SZKsOpPLQuMpJZFk5rNXNIPB1G3j+c+JtvnmjQ/NM/+CUhBaY48fD0zLfffMubL77iT/2fcn295dWrW3GbCYHTMHAYTnRNS9d2JGVw/UaApSxOGCZGboxhZwy9hlZlHlPi5COnNDPGyJfvvqH7sqFvfovVmtM3f0l4vmMVR2wKnE4zk488Pz0CmfV6R9Ov+fk/+T+wvnrJ/r1iOj3x+P63YvkeQ0HsdRESNMuCIvvp31U9+od5HCdxpxynUdq2guhuNI3QktebK5quZ/fyI/l5+5qm67i6uipuXA7vPfvDnq7rePHiBX3XcbXbCeBUWpGcFT0xpTXTPHMYTgzjyOFwkqBn6W3PoglQ2RzlsWjzZRGWRimUEUFoW2y4yzMRrYCM9wIyHY975nnicDwwzxM+COPAGLFIdW0rrWhZAIi5GBc0F7pCSim6tsVay9XVFqM103AkhsBxvS4JiwCVtjjsdX2LtY5+LaycCsLr6iBqNSnMvP705yht+eq3vxUdPQld0NrRGMXWiUaR04pVzmy2LYfR455HUJasGtCWKSrmmKWVQ2v6roOcOB72BeCdRTNrtWW13rLebkUE1ximlDlMHrfZ8XK1YbO9oVsJ8LQ/7Ok3G1arFcfTQEATUUw+YJyl67qiI9UQU2T2MylFjFas+o6m6M20jeN6u6ZtLLuVE2DSNtKq026KvkoBJIuWoJ+KnW1p/bNO7jlG7k0mFyMDV1gaRlzuwihjJyWs1pimQbuGZrXBGIdre2GBGFtaOWAaR4b9M6eTiKiXJXVxYez6Fav1RloMux7nGpqmkb23iKnHEKmudtJupwXMugC1z5p+prTg1XZ5GfGVwRRiIBXgzFpL64p2QiGghOIqOI0j8zQxHI/iJjpP5JyxXY8xmXEWb8LhcDgzBX8kx796/YJ9jKje8e408e+/eMcwR3ySdWHVWvrW8Hrb0lnNTSNiyI3JjCHybsycZsUcCshEOud/ubR1ZWEZC5glf60un6lo4GQtIGdCkvBirESKoBpoDUwWXIQQwAeY57PjKznT2Za1MzTW4YzmDz9+wUfXGz693nC16vj841fcbNdLS3F1j0VJS512sr62upcwPxgBiJD2z6rBobTMHR/EWTFHobiEGDFWc3u1kVggCvvpzj+TSbSdJIvjNIt8hO6wxnJ7dcVxmHj7/kRjNK92Peui6WRUwhHwMfDbu3eloGNQCCAIUhhQKFprS9t1y3rVs+pXuKIFkvNMyhPBJ7xPYDXKGJF38IHWNnSbjhc3G652K5pG4pTJe56OAylFGqtoXdkvcIRgkPpFKVYk0aDJKeNaaeVddz2tdRhEz2rVaUYfePscmEPgL3/9JZuu5WbTEV7e0l//MbbtUPEaHRNd68kp0vgTKcy41hH9zPWmJ6dIjC8Z5siX9wNf3T3yV3dHjmNk3I/YkDhdTfRa4bQwalvXEXNiFSR+fToNIpKeMjpnKdzocyEnZ13Gb/6AObS0+VwcCtn/6k66JJTfm3PClsoco0ha+MdEbzM/u7ZcdYZt50DD42HiOEdCA96qArAqMKK75ay4XJuLvK2eTCkwhYmlS3fzjw41R+6DWRJTOb4vHh5CWIouEn/bZY+oz79soZNDU3ljv09b5hJ4Slni2pzSoudUz1XZtpXoUB8xRjFNuQTEFkC5CmYXqYaUlkK2gDRnF7BaeDFanzWkLokuUXSerJF4zxRWmJ+L6xjCqrONw9DS9SspkHYWZVtWV9c419C5FoCYpG3N2IaUFOM4oZvI6tUW+3Bi/uqAf9jzcP+Ed4Ztt0FFOHDEh8zz6QGTHU51ZB1FU9Y6GudIqSFqJ3rHWYlhiVFCHMil+0ib4gIdz99TFbg1lxY040jaLPtP3j+SH75l/PJv2T+84Slm9G1kdy3afrvwN4TjHU95xawaZuNQWuFMj1EWFXvyHDjcH5ibic12K51L6omYj8x+i1Eb1ptPBEibHKGbyK1mfj7y+O6BMA3sf/Oe9nrm+vUtumMp/gqOlFExo02Wzogi66C1WggNpEhe9Ie1QBdlVUql4FxJL3V9EpAxL2tVBYti6chSxa26Fo0X1+qLOSGaZQL8SLxX2ugupAmqa3kl9VQgcJlNBZAP3pPxnA5P4lC92sh71oWytNgtc7gUX6txzA85fjjwhASRttsAiXj1mqQsWv+GFCaSj0Q9M532EqiYvy1AgydMB073bwjjhF29BCJJBUJQnO7fYJob4nhA6xbVK1KcCNOz1B0qMJQVMURCTMuNXlTfq0OdKrjgBWsILiuuFZwq2hHUhO+iT5eCYAJpPkkLU5pJwPD4HcPTO9a3n+K6DW51JYN7PgkA0nZYDU24LnMto3JA6bYEUtLX7jbX5DgxH+5R9gRZKvJGCQMphgmdI13XQpwZDyIWWxfn612DaxzXVy0uZ7qgQHnW10IPtjFJ1Sln1o1l113Tdw277Yqm6+k3W/I0wvFArzVrbdms1uy2OzaNo+0ajHVkaxhSZB5OPE8jh2niq/sHvnt64uuHR94+73kYR4aU0UazNgYVE36ceXo4kMeJVSd28Lq0YJScgqbRaCPU+0vlfCXWPdhS2UzZLIlX3cBSStw/HjiNM/vhiDWaX356y6p1bPsGZ8FqqZJZowgZqUwkLToX6mJ/rwFLLotkLDaa1jDNnsfDwLuHI1/fP9Joy7btcFrRWUXXdnx8c4MPkckHsQ2dZigtISiFcU3pu3aLPo4JAR0DtkzArdHsjGKOkUOMTDkTjebnP/mM7Ysd15srxtFz9/6OaRrIz+9hOrEj0KqEtT1dI8CdUrIwxBhJfiDOB6I/EsOpLBIWZ1uca8t1OFtMV/bg7wvY/iEfMQmjot/sxNWrOMVtNltc07G9fimA0/ULXNOy3l3RNA3r7UZYPM4RY+Bq2OFcw263pWkaNqvVokFXEf+FXVScMq02rPqOVdfStQ5nHUaZws4x540nnze3y2QweHEmWypFKZJyLJo4wnyIMTONIz7MCzhknbBqGlfMGRqpjsfCUNBKEWMsc7JslErRlQp86xxGK1RqSVbGxSLIqdXShrw48dmW2uYcg+e4f8LPE8fDA4enJx7e33Hc788uWkEKAMOkiRqIUq13lZGoNTFLRUwS3ETMMz6W1uJ5KiLWtrC+pDLnXEIbTdvL+J6mEZPyotWSUdLa6j3dSqo/0sIlAF5Whqw02ogegPceEEHf7XZNnK5pmxZjxWlKEqUGawy7zYa2caxXHY0TpxutNcqIjkEuVO2agBhVwETXlAAiUpk/pQeIWukSYfzCULTCmNRBtm+ptpeUSmmhfWtdGBMidClgmTCGKjusacu9cwbnGtFBaMTpr1o+qyyuaVqJfp1KtgTfWoCjcG4VqIEQZbTWIKRqWuQCapTC7vm7XujOVH0oseyV++RDYJ498+wZhgnvZ8bhJCyS0yDAqn0GIEzT701C/iEfY4pEMlerFR6NVYrWaF7edrTOcNM3OKvoGmH8zjEQlLDA5iKEHUsxbkm3L5gHNTlaDC9zZR2U6m1hgCTBRokxL+tUJXFopWiMxuqE0QKOxxTpLDhr6Iym0ZqX2xW7vmXXt6xby09fXXG77bnqO3rnMDoTwgxV+3ApFCJC5iV5K7OBEq5RpVK1Eq0kqxJWFYBNKWkBtUWIvl6DnIvZXdF6WirJlUWo6duGvnG0xjBpXZKpRGOgs8IqywmmKRFiJsfSmqcV1oh4dp3Kzhha09A0htYZEXxXsThNQkaTs+guZZULY6DodClZg8TsRopqWlsRNnaWxolYuakxcL0WRi0uW3MIoDIpy2ezThfGkwBk02xIObPpoWstiYD3AaaAUvD0+IRWsHva060zuBXGKiIDxCi8SmWw62u0n6WaniI5JmxI/MT1uMbxL371CW8fDuQk3ymSGX3g4XASh0LXoLSitRqwhMYRk8FXx2Cjy338HsBcb21hKdRfAQtzr6RKywu+xyf4nbczCmwB7jKK5znhU2KMkpPcrDSNBWszTkmyOAdpPU2qmimwnPW8x8vrL+db/t6n+zEcuWrcLK1zF/o1/5kv+v278aEo85ltUmOXfJHvkX/X11QV8IDSAvZ9MfPL8+TzixZX3uVD5bwIhanCfEn1s1ycSynRvMxkYmHsVXBK1hkp4GVdYgBNESGX+HFpU8+17S8Rx4k0i3RCTNCttmjXibttYR4BaGWpwtExB2YGCCN+fyTuJ/LBC+M8JWwLK5WJXtEkiwowjjOWQEoem1sG9R6tr0irleg+OpGeQRm0bVBNS46JHOJyU4Wlr84C7fWqagPIOpODJxzuSMMz6vFL7OE9mzRgDFg/kIc9OStwHdvtDpKHpwODPxHnnXRp2A6UxdqVMDWPR8IpcLobyGtY7UCbzDzeo9VE464wpqHKWzS6hSbibrcwekIMmDjDNAtjqjDqVc6opMTdDkW2SNdKkUWo2EEdLwu4c7kOqfN1yGWcnq/XxZi/BHWoOp2FfVfW9YU9pnJZR85zIqUyRnPRis2Qtfo9rnNVz7E+p34HqfrlEhcH79HpzBZcKuQ11ivmJzmmH7x4/WDgSWWFVg3t7iPc6grT79DtG+x/+jN8OhHnQPaJg3mLsfecHr5GkVBpJnjPcDhgu2tWr/+IFALT8Mzkn5m+/Eug5/YX7zG6gytF9EfGxy+KZXlHwhFpJQD1UVpbrClgRN1U8tKmdQaetEzAsmiloh/krGy4Vd29ulKQa9uVJJJxeGA+vANlUSmy//ZvOD1+y+71H9BffUKzfYHShuPbvyYGj9lsMWzRboVYRiaIA7rbgFEkZrJOrF7+hDgdGd5/A0rR7F5incFqaRsL8xETJ7abNTpHHt4lIhnnNdY4fvbRCte1bG83qJRRU0e79mRl8aeJ4f5IjBkfEu1qx+b1x+yut7z6+AV917PZ7oiHI/HxCRczbQTXdLhuRVIQNWStCVpxfzjx/njky7v3fHP/wG/e3fPVwyNP08jRT2groNnLxrF1FhsT82HgzeHAHZl114vIsm1K368szG3vsM7QNLJoUimwViiYu1VXROqg9lSjxdnE+5kvv33P3eOBv31zR+sM68bw6nrNx1c9XaPQ2hNzorEyiVIS6micL/aRlIk+4lPkOM+SaM4UJF0zjBPvH5749uGZf//lt1jr2KzXvFj1/OLmiqv1hl++eCGTM0aeDwfunx6Zs7Q1CVumo3WO1jk65+is5TBOHIaRlkxL5pXV3Fj47RR4N8wclSU4w//mn/8L/uU/+8f85ddf8u3DHX/2F3/BN2+/Ytuu6UzDiyaxtoo//MlHXG12mGYFSvF89xXBj8zDI1YH5uMdfjqCQrRvui1dty2LlswJhbj4qSUq+PEkbz4lrGu4fvkRbb/m5vVrun7Ny48+outW3Lz4WICkflM0m6Qi1vQt1d6enIkxSDBvjbQ0WFk+FUIVn0NgnGbGacR7T4yiB7JZdfRtw7pvizaFwhZduoV+nRUpK0KKxYXMk3JkGE9M04SfZ2Gd+Fm0AVIqTnIyd2rblSoMFxFTdPStVOzbVoStYwFpjo0jhCDi+yVQ01qz6jucc+JqpDWtkfVzvRLns9qLYowr7YdVr0gAnHkSzY/f/PWf83j/jr/6839DnAMqGuZpEgA9Z/zkmb0mBWEoHq1sqE4brDW0nWGKmowRnZPgSTET44kUhVHonLSrGFPYq8bQdi22sWy2G0KI7PdPuHaFCz2+BEbjFDgdB1brAFlJG5kKjOMkmjPZYJqeEDJpnMg5YZ3m1auX7PqGru2w1tJ0ruwjskZdr9YikutKchhLS7iVwoP01EvVT0ERHJZrKQWQtOxVl4bhNc3OubQmOouKEVsAhRBT0bc0gBUnPqWKZpRU08dxYP/8vDjH9as12901TdPQrTqMdTjXSBCTSvt5ydZUEpYB1kmLgjbF/TAS4vyB5bkpQf2i77BU5aqZh1SppUKmsFkTlV6AJ2sL8DTOpOAZh5F5nhlOA9M08fx8YJ4m9vtHab8LYWGLgewPP6bEDeDJe7IxfHxzjWtGGv0NbaP5Fz/fsW4cW+OIOfE0jUwh8jzOEmTGSEyZMYKPmcW4Y7lAVSyeBYAp+vtkc3kV8xJrxpQFeIoFuJF3xBrRFmpDxukIORBTYOVabnrHq1XHdef45PaK2+2az15c8WK34nrb0HeWWFqU5hg5jMelilpUKQTgN1mKN8pQzURUsQ+r1WCrwepMqwNeByqT07UNLhfXPxI5RalDx6KnV9ZAowqTK2ac0VytV2y6lrW1jEoxB09Klt5mNg3c9JZhyjwdpACQkxZXT0fRFEpoLYW51jmuuhW2UbhW0TiAUITCRcMqqwaTFCZC9InoI05pGgOuVdjGYK0Acrq4ea76hhBmTifFNIEqDm66xFrCfk0MI4yzpu/EnbTvNAZF0zZkFOM4Q1ZsNy1aZ65XLXMIvL+XdePNmzfs909sX37E9iax+9lrKVAqYWVlZdAu4ZodOXhs16FSQAfR7/uJhZ8PJ263mi/ePhGU4TiMnE5H9tPMV3czfeN4sVvTt47NpqO1mlaLk+Dsg7TM50RCGFClUsaH8cplUVlW07QI6qtlDizgBWfgqaSBS4JoNSJkb2Q8vj0mUvasGoszms9uDVpZHo4eH6QF/DRDb0X6HHKRXJFzpsIQTBpSAQEXt/OavP6IYq8FeKpSGue/lL9fspjOoHCNST5kdpxfd3akM+dkvl7E88kvQMgCCqAWXcLf+3kvPpPSCmXN91D5+r51fdJiCqDO46eKalsrzOUYZnEOjgGVqqB5aZ1LCWsKI6usw8MUpa29mDE0jYUY8McDYTwxDBOYhs3VK2zb41ppsasogtJWxnzyZGZO+YkwH/Fv79EPkea9APD2CGoNK50gKp5iS5hnDocThkRLIE0eNWlQP2G7eylapN0aYyzZNGJ2Yh1hmpnjRC5EEaVFgy3r6iQvBVMRK7Xk8UiYBvy3f0F49zeY8ZFuPvEyJVKn0eMzpFnA+G7Hy48+5mbb05z+Vw7H9zwPHXOcSdtPyLalba9R2fL+23viNNKnHfPG03ze4lrN8PQV5Barr3HtBteL9iqmx7aa6WeviKcR//UjOmnUcURlSFfC7KLcC3IGW9vPFUq7i3Fe4yC9ML11GRRnfDmfxxi1oAhcFPvrWK/FlZSTyAsVm7tc1jylyrD7wCFSWjpTolRkhHlZXelSiQkhFy2yy2Fd750pY1GkSfwk3RmmiNbX7yn/yMLy4mJ+/IDj7yEunlBa0119TAojMQW07WRz0xqMKKBPx1Fo9TkJ82MewLT0t7+iv/6Ul3/w3zEe3nP3m39DPE3EE0Q/Mx2fiVmLAOPhLae7/4S2La5do7sXmI0IJjfduogf54VVAJTe1gDRy4RLAbSTFgdtQTkRyazsqByXJep884sLQNMIYOhnwvEJP57IfgZtcOsblOtAW1Lw5DwzPL/Hj8+06yuZiFp2l+H5PdpYOrtBO8gqCxNGO5TtMO1WVpo4k+cDafhWgh//jMoj16selyMP263QQVMkB6lg+6iIeU9jNCurcBZuX/aMewNTFAbaGFh3LS+utqzXPdfGYFOmOQ6EcYaQpfXNGnk4EbQcQmQ/TxymmTdPz7x9eua7xyfePe15fzyK0K9R7EyD0ZJ87Yxmo6A1ScRKS2CKn6T9wngWi0gF2TuU0Yx2KKCSLcGmQmkYOgGkXGOL0J4RQEjlol9TbCiVgI53zxMZw4vNiXWvudlKu2KMMM2Z989zcdUpSHFJ8lKQcTR6EV32oQhYGo33Hj+MmBi57kqAlTOneebr52eenOUwNvTWsnGOtuv4xNzKhI2eU8ocUyriKokmRpxSrEhYo2hgkRkeMjzMgTenmdXLNZ9cbfnJTz/lp7/4nPth5DhMGBpi0BxyZtBRRMidIhmL7hpOSuxKpxTIwXN4uiNMB6bhSPATIUi7gmsdXdey6qTVzCvIOZJSYPYTX777kjnM/F9/8DLyX/fx+T/6E5xrePHRp7T9ipsXr2nalu3VTlrt1jussXSulWTYyX2exkHAyRhLciDVZVdboUqAJFpKntMwCmiUEs5Zuu6Kxlm6RtpKnDWLYLZPsTjNie5ISEkSl/KeKYoL0DxL4l1bmLTWON3Iwp2h9hzUtuJKdbZFb8pWTYxSAzMlGWmcxWhVqmtAYUFppVDl/JDJJYgB+ZzzOJyZLikVEfSIn2Zi8AzHA8PpwDdf/g2H5ydOD3ekkNCILaupVRolaW8soqNT2WhnFTFeMxZ26zQHEYOP58+pSo98SpF5zhgrFbSmuNLFGAnBy5rppZXLe884Tcxe7L2jnxlPew7OsF6vULplOjwRYiKrAoTnKKLGpeKz6loaNthiRKGVJAmyrimyViStSEWANJV2yBCTrIelonR2YpIdKJXmD2FbnIVJpEpW/yM29aQsrbwpCYNKFwdWY4WaXdrSJNjJC0s0hiC289bStB1tMYkwxgjoGTOeIGPHiI5JdVhcKlvlU2utxDFn0Uw8tyMIA1AXKroSe2gEZDPm3GpXtclAF0Ff2RhiEgBhmoXZdDoJ8Pr0+MgwDty/f888TUzTcWHDKNSis7ZerRcHsR/L8e/ePYPW2MPE4D0rp2msYtMYnIbDNBeh64mQEj5KG6uTKtpSoawFNqVLzFOY9pUJIuPt7HgXs1rY4PXIWZiPC0sKiJw1u3atYdNarlcdp5D5eNtzu254uRbg6Xq7YdP3XG2kLVVpvbT3KSPC0SoXB08F1fIx58JcDUHiq6oZqSqcIOePQQwS9nlgP3gR4leK3abDOcMcBYw6DJOMuSSt+zX2EL2es7mJVsJaarRi1zl++eqGq150nVqjGaaROQiz1SjAKpwRUwGjFdZKO4poABpcK+1xzmoB2aszp9Nyf0qCq3Mml77oxlly22Fbh21kD7JW5mX0tbVVnNhCAQ9Vjsu6XaUnArEI0AqDkbL3JCWAfDWOiEEYdmQlvnFaQ06MMcMUuH/7Fj/NNJsrmn6FaVqyNsUWPqJTIhuDajpIAaU8lL0sec/GKT7aNvw3v/iI4zjxsN/j55nxeATg6TQx+UDO0tJrdNGoMwLLGCV6ZUqB0ZVxueTdUnuGspeehbtFN0tajuv4zXWRzZfg0zkhS7nOm7K+lffdT4GMYtdbWqNpnaG3GmukLVRYuhJfL2wIqhsfVPH9lJNopZX5VcHWH8txqcsk8+n3fzelqtaV+uB1LOtP/btexunSKlTG8QXliPM7FQZK/VnXlYvPV9vjcjkf+dziZ2prnGIBwBYK2/LhWfQIzyupKh0/8reUlJhhkKQ+pM7fsWr9RC8Mk1ziwgqukUVqZp5OhHmQ/NG12MpQLgzQZZ0ur8laAL+m62GO+N6QT4moxO28xYHX8DzT6sROWUYfeTpAVJFBTShzop2f2AeHHnrazrBaO2LMhJDRrkG7lqYT4oJa1mIWNFXCGi16esh6m4735P1bzHCHjgdhh5sO18gaKHWSGb+/Z7hfS6fA5obN9S2WhMoTU3hkP62Z46pIC6xxqwb0zPHwjJ8GbLvFtZYQFeTA4fi3oFpMU7oNiqP15E/gAy4FYpoZDgdcjuhNC8aQjcRlCYShHbzsnUZYmEvuWjt3Ktu7XItEloVHX4zL+vfKlrvYayvodDnIKsNXhvwZoE3lni+g+YXpUFaqnLcwgi8+05n9WycDF3No+XSkHMR0qsjggC7z5vK5f7/jBwNPMUWMbdi9+pwYRqbhgG4e0IX+m9VOxMMf3mGtwQE5RqbnPd3Njtuf/iuufvbH/PK//7/z8PV/YP/4G6Y84O8Vfpo5Pr6Fpzekr/6U6fkrjt/9GdataPtruld/zOan/x3N1cc0uxuiH4jTSdqJYiwJoSOnQIon8CMpTGjXo1yHsVuM7c5V2jQRki/CpBrRuqmVWEXTbTDWkMcT88N3HN5+gR8OuKtb+s0tptuAcYR5JPqJ53dfMp8euP7oc1zXY0wkE3h+8xU5w03/AtdnUA5ZeFqUMjg6cpzJ03ekMRCf/kLaTaZnDHB7veHQOR6OJ07DwNP9g1R+5omcJ/LdgfXK8emrFatVy8ef7Dg8zKQpkwcPjNzsVvzso1saa+mtIc+e+HSUyv6c0I0jN7Y8NMPgeT+NfHF3z2/v3vPl3Xu+vnvPfhjZj9MyCW+6hm3rcBgsmq2KdCqzNYnOwCFnppiJsycUkCcDDgGLTkrsyFOW9hDliq1msT7OVnRZ+vVaNgUlFRNtSqIewWpDYzQxw5fvBp5PiW0Dt1vL7abFKMXsFYdT5Kvv9qI3UayAVJQWmiR8aJL3JaEuvd5KUcNqlxM/2fackuIhwOM48s3zI401rBrHJ9stf3D7ko9XG36+W+PCjPMjD6cT7w4HDjGzjwFHxpLpckJblla7AXiO8PXg+evngf/2V5/xR3/wKX/yT/6YP/kX/4L7pxOn54lWr8ne8ThmfAroXhM6RbANatXx5GeO3mPDjJlG7r/7orDGhHo7TQFtG5q+Z7VdsduscK7HD5YQA/vTA8fhmf/pP/5/eDo88f/8+68n/1Ue/9v//v8owNPrT2m7nqubl0XAuSy8hYGi0jkImOeZx/snpmli//hI27bcvnhBv17Rr1dSvUQAmnmeGYaRx6fnQuO2rLcbXr58QetkjAjTxDPOntM0CagZPNM8lyRb7LLtRYKugbk8twZQzomodwU/VLV9RTajysbRZSPysy/ClWKYgBbGlVaOlCy+AGVE2YBMAWV9DCgMpu0kUyWQk+e4f2YeR/aP9/h5Yjg84aeJ4+N75kl+P40Dj/d3BD8zjQcyRWtKGxrbkpQ4XYmbWSICgdoyHZcNuNQnz1TtkkjXfDoWFzRjDdYlXBcIKTEHzzSPBO+J3pOGEynB4XjidBqwRsCR47Owa7X+COuueL6/47A/0K432KYjTB1GW/I0YGNgt15D30lwmDPRy7WtLM6sFFEpkrbS6pYtOSXGeSbliDaytjhtUUCIwnDNxUzDua4Ext/blsvGLi11aXEfAwNG9DDU/4+7/+q1JcuyNLFvSTPb4pxzhYvwkCmqIrMK6GKDRbKaAAGSTQL9xh/Cf0eARPcLgWrwoUBWVyc7VaWIjHAPd7/6qC3MbEk+zGW2z/XI7vIECTDTzXH83rvPVma2xJxjjjmGUsRSxM0rp1VjYdHLMNrgXId1nm4YsF7+rA3USzlTQxKNL+9w1uLt0gK4tCItgaTs+QWDKqVVWSVBlM+6AD9VS1InNsuG1PQwYhKQ0FnfigoSkYXG6Dudz8zzxOPDPeN55PXrV5xOJ969fU2YZ7QSFkXfOWHI+Ws6b3n+4iXO+f+fryH//zz+69+8xSjYmUpvNJ/sPPvBcdMbYq58fThzmhPvDjNKVTa9xhmF80301YigbTNDpBlBNX2cC4C0pNzSolGJ+Wkys8a8IuLeEvZSxZ66VGERfbofeLkfSNqTleOL6w2f7AdebDv2g8e6Dm0tC8MZKiFVrGsMuMYg1G2/L0U30ebQWJ3TKqS/tNxBOxcgTOJ2eAgzhyk27S/47PkVc0y8ezgxh8iHxxO1ioOkuDLKmJmiJH2to0La9jQMDmFv/d6P6J3hk11HypmH4wEweNNhjBY9SyX1AGsU3ko7hlKGvjN0g9iN+9bC7bXFW4v1GlJrZ66p6QFWYXx3HmscrrMYb7BGYqhaMmEUTahS5P6GVKWXuVYUGaWaRg7yMFpckUQoWNxDBaJaWGWWeQqUnKUNt0pRslI4xsyUA9/8+u/Yb7dsu47tzXOufv5LkZxIoYF5SdawfgclUdVIDhPj6USNE9e2cPVs4GfP/oBziLy6e+Dd/YE//fVvOZxmXt+ecFpxPBsGb7nZDyxmHVZrbGt5NAmsTqsI+3KijWSz6sQtYGlWAs4tWmYLUXIFrP6eQ9xA5X1VFUYcVN6eEsdU+awqtl7xo61l5xWdKaCF5aRAAMQGPC2i0ahL618uue3fZum4+0EdS2GiNrmDp4LN66EWdtjlNfU74M4ixwEC5Bgr60TNF2B1Kd6sQs9LZtz+/d32p8t7N+CpAVhLW9zCjKpKUVRex1lti+ZTtz0pNDXtTTkLKeQZQ9QGrQoxihRCsaWx3DOoKoyUKnp0S45a62IyolA1kXNgOt2RQqB215h+ix+2WOehBAGhi3pyWRvbxToGc4OumvPVHXUqJJPpUOxURwmFMI5svOazfcd9LDyeIOrEbM4UVXEGxnDk/XTH9Ys9L3/8jPk4cn44YroB02/45Be/4LM/eCluxDlRU5LWu1ZQEj1TK/MwF/Ltbylv/oJueo9NB+zmBu33K3B1frgnhpHp/W/JYeL69/4F3fWnPPv8PXXb07/+hul8y1gds9njrz7F9luGmx59Hnn4+i0lVKbHz4TteuMowOtXrwmhrtpdvfOi4bnfY41mZzVDruzvPjDEHVfPr4RV1znpjopJ2ofnGWsLzliUsegmNcETYzQZy4tR1gIwLXpQraDS/nfhWF7G5PLAwvpdxq5qi1z+iGGk1j165Uwu498sn9HerbGDta4XAKnWNn55Apq1x0uS1zTjoRWhqsvUqvAPXLu+N/BUmyNSTjM5TMTpRA4B2+8wrmdz/Sk5TDx8Y1AUivNUAkWPVGNxnUYTON+/Yrp/QzzdUeOEH3YoDdP5HSVOxNMteT6Sg22iaw+Y7T11vod8g5XyLqVVYpSy1BJI0xnCgRoPCCquUGTpC219+Qv4oZsTzrKQlSIAVl1cpMYDWkEYD6TpjLYOu9niNzfYfof1A8Y6xsd70nzCDtco26GUo+ZF70Lhrj6nVk0KM6XWVVdH1wZ66Eb8VbITnY5nQiy8fn2H05rPb0ST5pMXP+Z4HjmcNI+HkS9f3yH6RYbtOTMVxdAnrs6VcM48jAmbFb3rOWR4e3uPbSLIxAxTpO97Ntstpu8ww4bHeeb+9p63D498e/vAm4dHXt0/8HgemVsFy3ddc65R7BvDyVKFlqnAL/pqS3VDLwN9qZpXaYVoxVYRKZUBb8koCrFVglIU+mdRlao1calqNVphanbr3jtyEUG0cazc3lVUduQfu+acV1ElMZ9OxFBEt6YWoYYjyLqqFVNK0y5ZAhglf1fgUSircVU0E6LTTF4cg2KpHKbAl3e3HKeBc5i5Moobo6nGc7Xb06fEPgVSzqQ8t0BaKpqJymOq3KdKUop+8ChXSWrit69/g//LgV9//Xe8ev+akCLOdTwbBHT4bFBce02JZw6PikrClozTYJzFOkkChdVVKBhyVXzz7j0PUTGzo/NbKIUQA1+9/g23h1tev3/PcTr9w1aSf8THy08/v7RhOUNJEWrGtiBooV1f4hTR+eqcE/bPZrM6EBnTWEsUqfAuzA0lOiKlVEKKjNPE4+EgLZvWkHIixCDteCGsQU4qWQINLgGVM8I6sU1DKae8LuzWCvCkWzCVawNB2nu0qG1l4VijVrFDYF2blvNcNHXKAmZoRdVNW6Vk4jSRc2Y8PBKnibu33zBPI8eHO1IMjOcDKUZhrOZEmMQFb3CWosVda9mhtNJY44GLRkxqugemVelK0RfqL1BLs+ItwpKqrVIoiZYiKLlxwsaaeHx4YGECWCPONSkmUspM00ycA912YOgdfefoOk/OifP5zOP9HY/3d1yVQr8tlCjVrDCeyXFuei0a40WwvevXxg1Z71rLcCxVGL9Vrr1xXprgnASStQFXpemECLtDt6C1MZ5UE7NUF+q+bhV3SlnrqhLY6cYKtR/F2hr5TtZ6vPMMw0baRL0XpknKa2K2aDJYewE15aOEQSb6BJf7IhpkF5HUxdWuhtCAwcZIWMWem5h+FoOP8+nEHOamESYaZEorpnkipcj5JMDT6XhkHEcJuLMAY95aul6E24dhwDrLZtjhvGcYpGj0gzpaMpNrJdbKmApMka9uT5QKY0ykWujcBbBe+BVAE2EWCr4UXlS7hzQB8UudfhnLSwIvzxNdzWVwLXp0tV4C65gKY8hsveXHN1uUH9C+Y997tp3Ddx3KOvkxlnXIlwS1YLRrxh/t81viVJsTX6FJJqxLmSRrl/EnGo3GWBSVxzRxmCOH08zDceLucCak3JxNaUCLYj84emd5eb1FK8UUE2NMfHufKQXmEKid4fkg6/Hy9WRequYoKOCR0QZnXTMxadpMuqKUQWlLZ+3aFuydxVuDtzJnU8rEWAmxtqQtSQyrRVTYeotxMkeNkRgszKJLdzydORxlvpQShc1Wm6jt2uokleuaFSlFctLkIi5WInqs2G4HSlU85EBAWK25VFQTS5cuAziFQmHi22+/Znt4hG6DHzbS8mMs1ZQG6EisjrEo57H9hmIMpUZhDWSFt4abTYdRlZQ/43CO3FydmUPgdDoTS+Xd4xlrDL0zdM6x63tUlbbsZd9Yp0q9gKdrC/mSrlUZ77GwiuQvCdQlc3qaRF0ek+KIFJsq4K1mg4z7Y0m8zpXOKOahsHWw2UlXutFLQesynZf1US/6LGVhDbbf/6AAqO802C1A3N9zjh870F2KT6iFGLAkupf0WkTkm7jy5QkixvzRZ1z+8fSzL03t/A75Y2VS1frRd3v6pIVVLO+rRZutSr68vJ8xDoUiLUX1Upv4s4zURaOylCdkqsYKh0pOgZJmCQuswQ4DthuE2NSQ0wo06rDoSZZEmRKFCCmQY2TWicxMSo9sase2diij6VyHtVpA/1IZ2XFMVfJfVTiqCRM1bnakwVHmCDljVWG6u+N0fEUN8lh/tae/2sv+762ws3OSljSlKfORNJ1Q4z02HHHW4NwO7UQsfIEFfddLPBWOpMdKPHyBNmJopneVYfcoLc0hkspISIFSPf1wjTWatC/EUQq9U5A1NVc4HKXzo7YiM13BBEtFima699QMD/ZEUorNecJWhenFITivbDqp2uQc5R4X9/e2b17aSJ+AlG0XeRpRLdplC/Cj1GWuVNpjixZcKc1AQa1gFovxUBurGi4teetIkza9mpdHmubhMiELH8Ff0r4uUg2ygYgDwlO8q64b4gVP+T7HPwh4KjkSpxNpPjEf7knTSLd9hut6fvLH/5o4ncQZYx6ZYiBzJpkzOM+w0ah65v7b/8jh9d8w377CkOn3N2AV5/vfEI73nN99hdEbrHsBdWKu7zH9c/L5DerqJbZFLFkZlLGgDeV8Ip3eouIDKj5guitMd0UliV5BjhQj/Yql1laVtesNn+JESmlteYjzUUS9Dx+I5wdM12PtnmH/Kbbf44crrHfM5/fMpwe6689RysL4QE2xUbctwyc/pyrDdP81nB9gJ+wdt9yfJSnThlQqD3ePvD9E/u2fvsYby7/6uebTZ9f853/8Sx5OI1/dGh7v3/L//LsvqbWy3/RsOsPLh4R3ms1wRFWNKYaN7Xg57JgiHL5901BYiy4FkzI//vxTXv74M/SwRW+v+M3X3/Dff/Oar16/5Vdfv+IwTjyOI847vHdo5xi6ji2VgcpewwaQthdFrxW2sRFy20FVq2BSkUSMIp1BNBS3wlxkM+9URAETogFTktyrNImL4akEUq1k04M2WC+uNUPXkUolhEiJgVf5QJp60i9vJEBTBZUT0/0jIWaGTmyPacBTVAII+6Yp0VRv1w1AK2n9k95azXOtycqStON+mvn28czd6czXd7fsu55n2y1f7Hb84uaGz/qOH++v0GnEhDN3pyO3p4m5KOaqyTLXeT8lvhkzs9bsrzZonwnqyJ//zX/Pb159yVdfvuXD+0fGeabzAy+vO3aD5fMBdhby/Mjt+wesh043y+re41vv9ziPpJTJWFI1/OWXv8W8ueX2DJthS+8ccxj5d3/277h9vOPL968IKX7vReQf+/GTn/8+tRbmeZae5TAKE6TrxN1E2d+JhMS62uONobdiM98PPdrYlWkZ5pmlvQilcL5jDrO0cjXns6XVKabAHOXxnHMDgt3KsAIw1uC9p7OWvhvofHdJBgFqFVFvbVqLW1n1pGoDAqSKLW0JWoNuAgKL05hUfC8RrlS1IdLa/kwLpnKk5szx9pYwjrz/9rdMpwPvv/0NYTxzaho7U5gacB+FLdoYWft+Kw4uSt5Pfg8OAftM21hTzmglgLSAcXnNBUpRxCzJQsqlbZVNVD1nUpY1JxXRsDkfz5yOJ46PR277O66u91xd7ZmmkTDPlJSoufDsqudq19PvBlzfE2NknALv37zi9v3bVqkuYkgA5DBRS8L3fdNt2wrIsQi25+aaGASkCwtNX1kBqLoebTR950HB+SzObKmFBKJvpJG2ItWSbLlPwvJszobWShDS9rEVMGht8MLaaNbtaJSW8dJ1A8MwcH19LSCdojnDieCdUhprHc47nPdY69aqWcqiK7aMwrayN+tytQZJpTGf5hgpOa8Fin7oMZ20A2hjKEFMMh7u7zgcDnTDBmstm90Way3H05EYIsfHA2Geub+7ZxpH5mmkpMRuu8VYzc3NDb7z7PZXApbZXsTl25z6IR26Ch8gq0qo8DgljjO8PZ4l+O49VknrHci40bACzLoxDI1STfD4AhrVupId5ViBHJBu23pJAle5k9b2ycUJb06F01S56j2//Oyafr+n226JpTYtng5wYI2sTbaidKEmoIjmkLMdxgoIspgrqNLQ5iY2HlultyZhL+clf8uLfqcnq8ohHLk7z7y/P/Hu/sjru0dyKWw2g5xgA1pf7jtutp5/+ZNnaKV5OGc+nCbePooD6mk883xj+OLKs2nFhylk3jycqU183FvDfnAYZTFKtPGclfa0WnLTtnQYbzFGwKqus3RWNB8ThRgTcyiE0ER6U8Z5acdzXYftRGJCUbBWjFnO45HjKXB398jdwz1zzCuzRNHa7moVNklFCi4UUvDiUuxljdJG9FiubvZobZmnI6VGxjFIe37rCFiu//2YOY6J8fyXbDY9lsL+2XM+/4M/RjvfJDCgFiMMVdeJiPnuhhxnZlUhRtR0pvOGT82GT64GfvbZDcc58eph4vWHR/6Hv/6Kh9OZN7ePdFZzPViuNgOD8xit8K0leGmpkxFZKc3l7mJ9vmzvSsS/cyU9AVsvx1Pw6ePWr1RZeARUYOs1nYXHqfAYC69Tggq//1zxfFB8tgPrpd1V8oFLNUVVsEphW/hfihJgq3z3+/zTPy5tR3JmpWQWoe8VsFmfI8dT3adFnkMS98t7LmCh1nXVqWwvFgCjgcSrWHj9Hlf2CfquWkVmAZYWwODjpbJeZFr0ZbzkLGvT0jTvrAcrmprUSkoRMQeQQnduTpOLYYycN9JqWyspjpQ4gVZobfG7K0y3kZHZYgEJrkyjWnqIkE6BnCdqnMjzxEnNzJw5xg9cp4HnaqDreza7a3CKqjU9FlcNb+fK/f0HQs2MjPSpso+K3DvyOaBzolOV2zev+erP/pbDq9cc3r7l01/+Mz7/41/i+g7bdXAeKXMSrSxjyad70v1r3PEtbr6ju7rBb64EjGvakgqFbi7K58c7wuM7puvPKVWzvbrC7W7YhUdyZ9i/j5Q5Mc3PiFaz27+EekUeA9PxzN03kXkKnN7L/Jqz6B8Ke1FRemF2xjlJ4fh6x+wSOhf2KfH88Yiu4J/dNDHxfCnuVDH/oVaK8+3+mxX0fppTPGXGoZ4qyj0ZdLWiqpZ26NX87AJcLWO0lubfqQ3KmFXWQBbdfFm72mct+wFAVaVpRi2suyrIeJs31Mv8W9pNSyNk1FLaeF8Kn+3btQV2KWJ/n+P7t9qlSDWNdqUUw9VL0VPKgTQnpse3KG14/vNfMh7uOf36z8kpgjHkFDi8/Qp3fMBNgeP733I+nDCqUJNF2xmTJlRRDPsf47YvGZ79HtPjNxze/AVhOnP68FsRzA4zpttjhxvs5hn99hmnx68Y3/8aXUdMPdPbDmPFCaNUacVi0QhBif1lLuuGlauiKqkMK23RNUGxIpyrxZmDBCWN5Kg5330DCqbDPTlObK891g2M8UiJCaU6tHFshwFUZXp9SwpnElcUY6CJEudcoWRsPALipFRz4nESAdj419/yfP/AlCwhJl5/OPJwmqW1sVbQmlDh9izVMXuOGGVw2uJM5sOYsAq8Enq1VhpTK74UTp2lvN+RzYGkP/CrV6/4m99+zfvHI4cwk6g479k4w8YZnBZXI18zrkKvZVOVKrwSUU/V6MOtjqCoOCVimzJSFbmKULpViyZIbZWDhuy2QMFpmlOTPG6RCVmbcOacIihF32xXp5rQtRKztHHEXDG5YmiFAIownVq/tjNLRbg59qyfLd91qdjLT3PTQxYbQ8HVQtGQO8NRW3R1aKU4hcCb44mYM3dDz0PYsNeVK2NR3YZnxpGygA9j+9Fak6gMG8+mt/SdpyrNm9t35A+3HA8jc428uIZP9gPPvGUwmo0V556cGn08q7Ucq4AUJbWdqyaiOGGYi+LD7T1ZHTmMhc53DH1HSpFv3rzjOJ7JQUNx33dp+Ed/GCX32lkjVdgq7CJhhIke0roF1EJKEZRoBymjUK1dompxqkktsFCNfVfVoh0hQMo0STvINJ7pvGfoNygtAMRSUfVG3HtE+8bIvChlZV/m9qOb5W9DHNZaCcjYNFoLBbZVzhYNhZwLpSqWwlpp7iIhJwEslLSGOSNME90sq86HR1IKjI8P5HnmdPuBOI883r4nhpkcZqiVrhtwzqOdbRuVtLToRomvzfll1R/QMrd8CySNlmud8zIH2zpQWwuO0qQsALRsxLkxtCAVuc6pFDonia2ATzL3Vc2EaeSoJDAIUQwuVKNpHI4njDWEAj5mDseRcZp5/+GWw8OB/fUJ5zpctxHR7V6s213XiztWt0E7C86JW0iVllytDELulPtjjWhRWGcwT+jX3nerK+ASBLW4Q/akhV3UgHBtDcYaul6SZgEvpYVvQcitMfRDD7CKileUJHy+E8C0BRvKrKOdJaBRzclTKZoDmmgtpEb9XyymV0OOLLpkS5zxNPBvC+iqewAwzRPMM6EBpdpouq6TtTcXxvGMQnF/f8c0TZwOR1KIpBRRWrHfX0ls3cC+7W6LdbaBekaqyuqJw+QP6Fj4W7UIG3HRNrTNnMC0OvFSLF/HTlvV5I405uCT36tlW37S1VI/+nPJwD4GnJ6K+Or2U9r8SxUyahXBLylRyes+qpWw/UJIlComAZRKiCNGR9B1FasHIAvwpK1FGY22ovVYc2mCqeJS+eXrO85zhDbPrM5oxKLcmsbwWpJJJcUxqxWdMeyc40e7DUZpbA3EKFpIRmtuthuebTfcbHqM0ZznSEgFw+Iw53BWyVxX8llLwrk4O6q2xxgrcZLEI4aKWvWGKJdkVxyqLM4bfGfltUat7Aa0RlsrwuKbym47kHNgnCMhiohvrQWjDAXVYl9piZR1plBqbh0SYnQhTEdh6Vxfbek7h6qGEBKmaRCqxqyNYSbXgiKTx5nXr7/ldD7R7fZ0my1+u8cYTbCGWpQMMF1R1mEUdHVHSYGMuP+muRljoBi84Ytnno1zGFX58HBkNzhCjIzjxBgK7x/PdE6z6UUiQBK6S4J2SeWesG3qelPW81ZPqvUfjfyPc8Y1yVqYcjIX5FY4rcA2UKXCOVf0XHl7glQUXwyqOeOJk+ASK8gcXAJMmvAUbSD8JxaEf0LHqifztP36CaVZ3AIvcM7/mOj302NJiGG5fItGk1rvZVla+y7PXC/30++x5ICL9tlHn7OwltST77m+wWXvFACK9Xei9wiUBRCVwSKC4pqc1bpNUkUgXRuzCnMDYualjcy5OFPj3HRwDbbbYNywxoLaSUGq5kydA+l4S55G5g+vKXmilEdUmujPijxqYm8ZZ7ifzmxjpZ8GdDEo43BKs7Oe0l+Rbn7Ch8ORrz7cts4QxTbusFVjhw3u2Z7xMHH47BGrNae373ivNeF4ZPfpJ+xevsR2Hus9uWoplsYZ5iOmRIxu2o/akmu5sMUAvawVvRfW4PxIOTjKdqB0A3b7EmM6tvFEnTOz9czaoM0A1bPdfYLRZ+7ffaDEQAqiu7Y4ZprWEdB732QIhLFUUyWRGU3GpsQUZ1T0DLnIutvWFN2AoVJEpkDHSK21CcY30JAngJNeFxpZOJ6uOXWZJ2rdn1b64/oeF03ZBUhVlMt6ppa9fhmf6snf2thsRkRi+iZF3ksnWG0OhBcW+2UuqgZSlQtLlKegmF4Bq+97fG/gKaUgVeAU0Uqzf/kFikxKI3kOnN9/xXDzCZ//8b/h8d23/Pav/wMxzuAcMU7cf/kXmG6Lv37D6eGOw92jWOcOGmcqnQO/+4z9yz9mePl77H/vf8Htb/49t2/+lvPpgP72rzi9+w32t/+B/Rf/gme/+Nd0+z2762eMXx04fvtnOFtwruK3L7CupyRpN5ecqrSkSJGTCCnnsgT4CrQV9yPboUlQgvTPak1NkUokhyO1RsaHr8kpEKYTSmn6YaDfXjEd35OTQuktxnbc7LcoAu9Or4mne3S6QVtHcQNUSCGiakGpRDUO03eUlLk9Jz48Tvx3b75i13V8+fqAtxatFcdpFBYDgNXMpXJ/jKLTkQq2uXKJ3ogI+FolYpWailcwKHhVC/fOcZoTj2Pg27fv+PLbb8lKkbSmd55+6Lmymmur2BjNoBXkSs25UcmFcaBRCFmxMtVKXCaSUnit8FpCsVorp9iCPiN9eUbJoi390609A0VnZXGObZP3qllwZmnHG6NUEm+2ouVkirTexZiZQmaOVQwUFO38M6pkSlFNQFoSYlebnkVdpmo7ryfrhEa0qQoVVURbxKLoNewHy72V9zzGzMM0c3ce+c1d4Wa75eV+z493W35+veOLoefHnUXFEeLI7Ri4m2asgagVz/cbrm42bDaigfHVq294e3vLbjvQ955fvnzGp5uB3VzxqXJKkVhgTArpWFBk2g02EFMQN5vaMSvDfbWcUuFX377hPM/o8mt0o9ij4P7hSCmVYdih9Q8JeEIQeefWhVtrLY5oLTEHWSNyTqQwAQXjrQjNL+OXpvkQkwTs2rRkTjRBqoLY2rZKTuQU2e+v8K4TNknvWmXf0DvP4Dq8czjrmGNkjoHHwyOH+YAxSb5jcwdBSXCkkC+xhGvGyFogoEADropYe5Pb82tdgac5RAEWjEUpATSE9ZSpJXG4e894fOTtV79mPh05f3hLjoEQJwCcGzDGsNnsQCm6KjpFy6aYUtNKC1Hmd0vIjPYYJZbrWoPTFRG0F7HJ3DY8WQOaaHa+aK/pLLo1XQPp4qKzVEQPIVfFGBKnKTLNgXEamaYT3C9OfrUlodLOGHJiOye6YeLdu/c8PBy4v7tlGkd2VzcYY7l57vFdJ7p9zmF9L3RvL6ARpjmM1ELNoucAAqSgaILXms7KtV428GGQudW1Vs04B0ouxNh0JFS9VKqMRntpRdte7QDISXTFYgwy7jRYa9hut1QEmFuKLEYboZBrRUoZbdTaniLAQ0vR1MWlMWVpTcxN6LTWglUSrNEClZgSsd3rNXCCxj4ScGBhr1DhPJ4FAGysMxlDG6ZZHpvmMykn3r56xfl85nwUDcdhM+Cc4+ZaHPiGzUYE9J1l1ex4UtX7YcmKy7HGrKUlNq3Qs/ELyHYp0Fz+r9Y/JVleWsxYW1DqAnrw8Z9roi3cu/UzllaQJWlaSjcaCTpDqYQCsSpoxiAFcR00pjYdpkSpiWmahB2XpJ0OAgChRAoFq62wbJIsrK61Se/3W5xrWpBNnD7ExJ/83Rte350IOeOt4d/8sxcYDZ1VdLYxF9t51SoxSK3QW8t15/m9mytxbKxnYshSNNOaT26u+Oxmz6fXG0LKvHs8E1OVmENbhq5DGYnpjRaTF/mwS1CujcF1DqMrRhWZfwiDOrVka1HAVoCxTrTYeofvbAOtIbeWeaUNynYMG5FbiPEKp+FwmpjmSEiTaJgaD8qQQhDwmAYcksmlFWCUlj3IW7yQEnj54oacC6oapjngZ5EJ0LU2Ew2Zq7Ekxhgpv/4Vu+2GvnNcPXvOF3/4R2jjSdWu+oFVK7TPqGpxnaPEmUAmhZkpRkmkimbrLV88H0ifZP7gpy94/eGB633H6/eP/OWvX3GcE4/nR3aD5QUdc2rivmoZtXLpnzRQtXF9YUUpmmg6H8NUH79gwREu77voMolUQotLjRQxlZF195Aq5wy7x8pxhudWsfM0wXl5t7QmnrQ17PKxPyDMCbiAO6Y5aD5lHi3l6faPj1khT15/iS8u75tzfvL8RfPp0v5dS5Zr+yTh/533Xr5OuQCf6zerT5LwZdw0AKEui+R3zrMh5k8KNEurq5yrNhqLbQziCwCqm5YaSgALVVRjkDiomRTGZtLlUbbDDnuM7QRAAJQX1+VyHsnHE+FXXxFPB8Y331BLXpmSW62Ik2XeeiqVt4dHbmrmmd1Adhin8U7Tu4G93/Bi/wl/Of+WP3v/LZOORJ+4nm+wxbDdXrP/4jklKuIp8vjhA/dff8Pjq1d8+z8YPv3lP+eTX/4zbn72E66++II8FdHYnU+o6R5TA96oVjxxSKt0XjW2fO+be+9Mdoo03ZLiSP7kC4zpUddfYHaRG/Wefp5JuWeshrl4SoWrG0vfT7z69kQJkXhMlKLY74VZ7ZzERE5b0VW2llphCuIoeDAGQuQ0j+jOQU4oZE8S4EnuecoC4oMwqZzzDaRk1WBdxt063gBpHlfrhK9Pfvl0nKv2Plov7e2XXV5V0WNVlWac9uRVbdjrlvuoFkuCQumCLpWS1SqlIO+9aKXJ874LApemhfvdQ9WlNXDpyftPH98beHp2dY22du3fLMFBeGTTD8yHmbe//g3D9ZH+2c9I05GrFz8SpDZHfD9w/fxTSgpMh1uUgutPfyJVMe+p04Hp8RW6Uxjv6fZXXH36BePdJ2i7p+TA9HjA9qLDND+84fT6LynjA+nwjsev/5zTh9cMuw16uyXNE2l8RHU3+O0eTE9VHtVaUULOlBKwbfWQbUhjpgehrTFBnnFqpnOKaTySQ8CZgnYdehHbqhlqYf7wJemx5/btW05j4PXxjqI8v38MbDwY+4J+t1mcyJfCyypweMyALhRObKriX/9kw7uD5c9qpBT49vEo1GKtyTnibBv8bXAtOi4LguyNVD91bU5WtTaQSF6XgLeHM8dff00uhZgLYR653nSkKkK/G2fZOcNOFXYUulpwVUtipJfPEjaJ0A5lnCzrtG2D3uuKUxKU5rpMgsqTmsUqDLrEX1CpRYAe2sTRrTRYSFQQvQRtsE0nSzVm1cYrtpuerrc4pzmdAiFm0VhRl+9VmxCfRTaUj4Xa5Hq1gqWg3O1Pu4LVIv7ZqcpGw41VOCUV6FhF+wkqp+nM65oY54mH7cD9ZsMzr3jmt2g8e9NxFUeu40SntETHk5yzny1D6uiix2tPHhVjqUyniRoSU6rEXJmCAA0hyUb58trQOwUmURUcaiVUcdibc22iwYrUAr4YRI9GF2FgTOfp+y4L/ySOhQlSG/iSGmgxjzNQOZ0O8niM4pQWAyiNsVIFMU34XlsRhTYtAaytHSQWaYqy1rLb7aQduArVuu97drudaNwYjTVS9XLGSusRwlCZ48x5nBjHkXGahJFlJFI16pJYXv72JLRWsknUBu5qDSHG1QlOYqvWaicWUs3q1xDCJCzLD2+Yz0de//bXjOeTsDlTBCcgi/cC2uVYyKmQ8oTSGt+LXpBpzB+NtMlYJTpUvrFoLvqDEuCpZuqA1mulH0TvYhV/VZKJaVPRllXMv5TS3M9K08mSAMC5jHeetB1IpZCyOAXG1Jy+FK1tVjGHiDqPpJhRpUrb3M0z8u6K/W5P33Vs+oHNMKCsOJsotLT3xETNmYVgWFOAxiDQSpgeCxtNo8TJFEn8lVJY5VvrnFzTkiuoTElCYVYt0DBWAJbNZoNpAuKLQ18ppX2OelKxkxNUi7ZeY5+ZxohbqvYKROjd6zY+GkMyxXWOLCKgtYgmUyQyMq7jCbUk2pc2Ot2E8bXSqNpE4kulKDFtSCFxOp2IMdD3g1gyA6Vm7u5umcYzh8MjMUQRYHaW6+trvPdst1u5Hm1OOuefOAl9t9r2/Stv/xQOZ+R8Sl1av9XKVnoa5q1ON21c5gay55YkL9T4JeppBMCPLteaYDdAXbFqk4q2U3v86fsoNKXmJwYKs4jHZ1q7asu4kSC3FNEaIjdHxdoso2shFikEYSpG16ZPp/CyVOC0wmtD9fKepWbmkrk9T7x+OPJwFGHqz64q3hqO88yccxMtV6R8qapXIOXKnAqPU8BqQyyFzlv+s5+8pHOWX7x8xottx925AfZotBatN3GGk7jAGy2JpTWUDDEuia0w0tCSeDpr0PqSZEoXoUIpS0XmjHMK19GAWysBfVmEiKGWQA4FrSreG/bXW1xn8MPENAUeHh+YJjE5WBp+pBAoYG0uipAqYysOeCe27mcjhQhte6iavnNoVUk5oKgMXnRg5sGTsoFqxPXPViqah7tbckpcXV/jhi1mc4NGkbRBFShPXcgUKKNR1mKbjmEKkTEHyBFlFLpTXG89f/TTz/nk6or9MPB4mnj/8EjKiYdx5jAlplTWNjXReHqi/SWouICOre0zV5q2osweo7mAssucaEH6sssqBDhd4m5hgFxAXK9FhF7i2cqYK/cBvj0VNkFxCDBnUE2svrII2JeVwagvuMcP8lAgujRV9pjvAkFr6w9PdTdb1PAdNsXlZQuoJMW5xUWwtPibRnzS+lKkWNqIPmrDE9oTai3pLWyotaGogQ5PmIcsPoULetD6JrRa14aqRNNx3WXVpUClmv4wNTdEX3JR1SRLShxFJibN1JKx/RZlezFekJOS8TcH6hzIr95SjifUuw/oacJOqcWDGlU122pRZeAnwyfkGsnDmTEl3t69bySDG5QzqGpQztL1HTfDwE8//YTDaeT9w5Grw5HHxwf0xrKNe2Eh957hak+lkqaZOE2cX7/l9RhI00wpFb25QvVSrKQI6KIW92AWbcvldracrtbmzizM/aozpkZ0Cc2MxGJUwtZAh5NWwe2Oqh3jI9RcSSERp9hcejXOivbtou9am6ukTs3ZcwkSq3QNHE8nlNbcnM7oroMmf5GX+/UdsHRhh5tmkrG6IKrV768VkVtQ3MaEUuYCcLZxqZ7GNu3vl/bU5e+qjfW8PMqqI9WKhEthDm3W8SlAmGkt1M3goGQujrV1fa+nhzjmqfWzZNiXprWmvvfS9b2Bp09evJBNYn8tJxETNh3ZbTekh1u+/PP/yHDznJsvfoZxnhc/+gWlZHKc8dsbnv/8X3L+8A2HP/lv0Nrx/Cd/QFUdRW8Z3/+Wx6+/xW7B9R3D9Q3PvvgFx3dfov0N5fyB8fiA32RAo+s3MN8zdX/Nabji7tsvObz5LSr/CO+3pHEknj7gh+e465fo5l9Z4kRJgRISpYhYrFFgMOiqqNMZckBxRJWRTo2kTjNOD4TjIx0jdB3WidOTaovS+dVfUXLhzYfI7bnw//gycYqaf/n2gU+uNvwXv/c5m52iTG+hRlDN3rZUUoZxVigyQz6wN47/8g9e8OZUOBd4e5j522/uqLmw0VK9u9kslL+K0uDVIt4t1tROq9YOwTqYrZZWo4KwiN7fH3j35Su8VfRO83zT89l+QyoQElxbw5XV9DXT14SuClUVGUPWRijj+rIZLxHrEtA5LXpDnapYVQhVemxBAq2FbmxYKj5tga8tsK1NULStRxoN6sIu2ThxSbJaPlFj0Ab2u46rfc9249FacQ6JMSQMFaea2KOSYNxqhdMCnKWm8E9tgr5tIullYQF0Xdq2hK2xMKGUkdbBY9X44pgqnLIwjh6nE3enI7nAN/trPr0u/PL5FXa7Z7CZ6y7zPGpeRAmya6zUMxAU3ejZpQ196HA44kFzHAuP9yPTOBGTJmXNlCopVx7nQK6F30uOq8HAANXAgUKsmikXcoHBD3jjOdYTKWfiLAmiKR5K5vEsehg/lGPYbOUvVRbJeZ6JIXI6H4gpMM0nUk7M0yRBCZL0b7d7rPV0WqrOtol6GzSlFEJI5NZiorWS1tR+4NNnL3DG4ht9VxuxiU+LYKxaetllgQ85MU4Tx9OR41mc15xx9L5H19rGHGuQtIimtu3pCeNDQOFSKjklQogt6ayrTb1zC7VYwI/Dwx3T+cxvf/VXHO9vef3lrwnzRDd0GGvoNxuMMXilKDnzeCeAVIoRayz9ZoNzViy/S0E3cAZknnfN9rukJKKIJbWqoG2BoqMqtQaMtSKAUcwsfexaiy354B3boZMrUWQFqTUTUybEuGo/GWfR1jJPkWmKTDEzhUSmkKqAUfMcyeHApMVdaj/0uKtrrHUMmw3ee3Fu2u2JVZOrasmLuMWlJxVNVROKSt8Czn4BRVrTcU5xBTxRGoyI4nbeA0p0alKihkitoi+mjabrPc77FbgEyDGKNhMV33mssQxd38AqAZqsXthAeq3S5lKIKUmsU4Qh5a0VYKjN9RjEzWoROpWYqQFPIRBjXD9nGAb6ocf7DuccXd9jnW/aQpXpfCYGCTorhRQTMUQeHh4Zx5FPPnVsXCfXp2Tev33Lw92taA8ANzc3DP3Ai+fP6YcB40SHTUygFJ3v0VqTc2qAavp7K9E/hGMBnlLRTZSYhd3eTvdy0kuSJHNe9tBcLiDU03Ukt7GwHkvwXCu6QFKrXu2aii37dnn6GiXGFouu3Rhm5piIqVJya0euUGuixEiMiZIUZNeAJ4g5kEohZgGe9PKJCgGnm6C215reGLAdKE1MZ0yKvDuc+fLDA69fv0NRuNlkNoPjbpwZGxNcoYixuQFVEScPuTCGwu0p4KxhyoWhs/wXf/gjOuf47PoaqLw7zjK+lMYYGmNGboJB01vX2rLFCCWt4sJND0tJAuisb8HFUllGACvVWoGodJ3Gd7TWbiOBfck0Iig1z6Q44rse23t8v6ewZ3cYmccgCUSSlse8CMlXUNpCFU28VOA0z6SS8EZTUyLWgnaWzdZjjGUzeDqnCPNJipidJjlLoSflQmiFK9twxQ9v3zIeDlxvPZv9DTc/uQLjyK31ulb9JGmvwubEiuj4NDOnCVLkHEa6wXHjN7zYdfzskxccx8gf/uRHfPPhjj/7zTe8/nDP3/72gfuxcIot/VdSfBHgtJ3zEyAhV8T5s0BK4rMjDqfqo5bR0sTZL/OixYKCDDx57DLnekNLvuSX5wRTqvxaVXqjOBcIos2LNRLDZnw3QXMAAQAASURBVKDq0gqrraW2SQH80A719M8G/lx0nH43wV2uuWpxQc7l731urYXFqUC1BL6UAm0/WIGXJ69bgKlLq1BbFasAgzTXrwVif7qmruPpu/eoAWqwyA0oFCKKV0u6aK8p3UxAFDUEIS808ElVhapSxKEW8nygppkcRmpV2N012jeHx1WPpFBOI/XxSP7VVwI8fbhF54zLzVXOWJFHSZqd7djvr3k0J748v+LwMDK/fc/1bo/3FtVZarZ0m5790PNit+Wf//Qn/NXXr/jTr16x3d1z++EDduO4mW6Aitt07L1lc7Xj9O4Dx2nm+OU3vH34KzGnobL/vT9ge3Uj9yBLgVKMIJaVXrOae6nG5KJgvchTmBCoNeHqjCkzynvkCkdcGelxaGUZnt2AH/iQEylk4pQI51mY+lb0ihcGOJVWfAeVa7s30rJPVeSYeXh4pJTKy8MBlzO6l+6IFKTFV4x+xDylIt0QxloEW5Si4lLsVGppwqaJy7cem++44MlgK+ufAuxcxrxe4v32WClStFFqiQGX4ShjeV2YlEEusRQAtBIzJL0CT9K9sMy1y9D+GBFfcPll/6o1LdPnd+fx/8jxvYGn//t/+28x1nH18hNKrXx4/4Hz3Rve/N170uFEtZDymXe//nOG/RU3n/+MUjTnOAqyp0Ubw19/ikKJA4bfYnafYerM4eoZCcX926+pfk//7P/F/PiKq+fPCSYyz/fYbkM3XFFy5Hh7h1IPKPWanCPbq2d0XYemEB9fc5gf2MYZHY5Nk0VovSVF4jSSw0x64nhHLeRppKRIziOlBA7375inI+fiiGZPmiyESmSmKEUsYs+aUiLlwrcPhcMs7WRTrnx7e+AwBvadZ9sZdNZoZdkPGasUrkoY53pHLZVTCCgKPhxRSfGHNwMvOoutmfMUuXsYKQpOSVrY9lYoxn1LlvOT9VCtDKe60u1ylUHrteJmM9A7h6XiVGHvDDvaiHLQqUJfa9MS6sgLY6mq1VZWtJvkQ8UyUloAdKtQGi1BbKqVVCQgMFqEFZexrWj90UugWWsL1BbCnxxxEYZvGjFOSegXlzgGaft7edPz8qZn6DQ5V47HmeMpkItsI+5JcAAQ27aiW5Bb68WieZlsqvI7IpaqJfx6CRpUZUChjSKiubKayVRGXZhyYUqFOQbePjygS+RxOrPRmkFpvj2eGeNMSoGkFbO1OK05jhNTzKQ4Y0xktjNWK6ZxIsVEraYh9qzX1qDI2jJrg1EGqmY+Z+aUmZMsjn4LzitUZ8hFMT4UyIphM9B7z//qi38pVdAfyPHh3TtkbDWti5TIKTONZ6l8IW0Tm2HbtEkcxjr6YSuLtLYieNuAA2OWKlurbmVpQ7LKCAuvBRalaTbVdGGRVCOskIW2mnMmteTZGMN2GHDWMjQh6wqrGwosQIB85wtbRVNKajTzBfSxGAsl5UYll81pPB2hVB7v3lNy4nh/yzyNHG4/EMYzu92OuhlakqPpu17c9ZyR5CfMpGiJQZzPemfEqUlBUQqrNMoqXHMp0Q2wilE0oFgAEeMktKuFixPRUhHUUgywFVMlWNdGgKyYxQJi0bJSyuCssH5yEf0660VXIPlCHrK0/xRxkMwKSpZ74Zo4rXe+tRwubm5tBSiJOI8o4zHKUHMhN2FGAcYlMF2cOhW6AdW6rQ0OqE0svLRCmlSiStMCo9kol1KxVgwTvHNYaxiGAdM07EpKhCYib73Qua1t+l/afAQ8aS2tv3qxrlagijBLVr2AKsWJZUG7JAISvKtWHIkhME2jtKCmyHa7Y7MZ2O/2bHdbaXtrbn4VBOxMiRikhS5GAdPCJGAvVep+79+/BeDh4Z55npjnCdd13Fxf03c9V9fXdF3Hbr/HWkeIgVwyMUxUoHMWZR2urVPTLMl5jEH28x/QoRfguS7gj0LXdetd6qhPWB5PfurTCiZPUKOLxs0FyG6AVVWYurx+CY6lwmSUCI1KYKvWvVewnAtTjlLRVXTvhE2gJAZ04LXFusas0gtY4Nt7CMtx0YBcK+KN8TNnKLHiKKAKd3eP3B6OxBxRqqK9g1o4hEIkE1NZq9NGKa72PQW4m4IYE+RMobAbLJvOc6Pdet0UYEjigNYAUdvYiM6INotTDms1nTdUNAWN1ZWha4mMNvjestkJSNw5R1WaoprDnTHNLCCDBuO0CCNred6SqLMAU0oAKbkZDqyXz1FgXWxOnKDIzCETsgDla7FDSVwkY0HaHFOuBJ1xuYCWrgClK7ZzaKfZ7AZcsgxR1r7Oe2LOPBxG2b/STKZKEjkn3r3/wGYKmOEG129w22uqFikF0NRiqNqh3AatM6YknHJsq6bGQJ5E2ODhENAqcf8YhD2XCjtn+f1PXrA1GkLgm4eJQzwzx8wYRQbEGWGZ+QbSKhaWU8VZi/eK0twSj3PhHEsbom3dZNEyE5hB16Zlppcia6W2OLdBJyuw23JM0XlWcC4wtRbU1GI0z1LIrC0vlNj5I2D4B3QsLKPvJqXfZTstR62VnJqm4xMpgafP/ajF+qPEWP3O+303qV9aii573oU9/t3rX/++u7HkWb/Dsr0AW8tcVSjSE3OXRQfIaNPWS0vJMxqw9QBZiBG1ZNJ8FHc626O0xXQ92npoOrc1K2qM1Pe31MMJNQVMrqhhg8kZNUc5n/XaFcm/ZrDFUTY3nGbNB3XPKQUeTgd86Rm6HXmOjA9HLIUf9VtO1zf84ovP8dbwm2++ZY4zJgbprNEa7TXWO+q8Q4WExdJhqfdH7v/8r8lJ1pl+PNN1HVQr+n0thhYCwlLhUJfCbNMxsk5c8XQOEM4o50TvSlWqyozHI+cSiNsTqoMcA0YVPv3sJZuhJyRpFU9zJM2RxRV6ub21gfqD0027T9idBUuuSoyEjGWQJJps7JoDKq2aI+uFTbc4wWrTwJlSQdWPtM6ejjS9gFJKYkUBmsq6oCzj7en4vOiKNcYUVfKNRp5YpoB68o8ns0LGvUK0xFCgHapqao3rOcBT9uHyZSXWW9bDWn93zv2nju+dXf5f/m//V7z3fPHjnxFi5C/+5m8J4xF7fsNOTfzzThHymTd//e+5/uQLfvTzPyDXyunQpKaNxXRbumdfoGrEk/C7PdtPf4KqkbfXL4l54v2rXxNSEiefmrn55BPOKpAP7/D9jn645vTwnsOH96RwJs9nrj/9gpvPfiqWsxTC/TfE8QE9PuDOH8jzmZRm6XVvpY6aMzGcSXEmxomUAnGaSVEsGGMuRNuTtaXQUezA+SzCk4c0E0tlxpAqHMdMSHA3SZXjGIXC/Zu3D3hrCbVn03U4q+iM5YsrxdYWPhsK3oLf9KRU+HBM1JTZpAe08fyLF59wypXtxvLuceQ/nGdCqhyTaC696CTh65CkaqxCAQ5lQZRNY2hIX/lcRXy405qrbUffdaicUTHQlSQ/WhzeRC+msnUdm94zx8IUM6qWtXVvQVWl5Uj0hbwRAMgoAXOmLO1gwhBQ9K0lMMDFAnVJOxvotHSKtliXinz3UkVbCaVxrUYVcl1FyL01/OjFhhfPena95TRGHg4Tj4dJNG/qhfG0fGpc5NIUqLb6LJ8pgsdtciISG6WJoSvUWtkwClwDtbYK0X7RlrOpHHXlkDL3KnEKgQ/HkQ/HA3/rHVvfs+06odKmwJQyIbeWHYQKWZWi1kilrBbAF6CtSDuP1q2SJsFl0oZJOTw9VMV0fGSaEnMAtGJ71eE2iqGTtqU6R2rSvNzveXn9jP/T/+F/x83V1fdeRP6xH29ef9sCjMxCr14osEpprO8wxtH3PdbZ1tbjcH4gl8I8N92ilET8ti3EWit0Fc0c+RHwSdo66ioQnouALkoJoLKMa4WAYDFJgGCtpfNeaulPNqiU0rqoi8V1ZlFXEbDk0qu97CzaWCyalGegBVo5cT4cCfPM6e4tYTpzvH1HDDPzFFDAi+fPcNYwzzNAA8A0u8FRa8HEmRijtKopxeDt+t10S4qMMWy2W1QDu2MIlPMZaqsGGosyoktQc3oC6DZtp5bYXQJMAKkchhylJ78lCSgRxzX6QrH3XY/vetlMqxILb6VJWouTnGTYeOfEZdSJU6AclePxRJgDNSfidMZ3YI0IJZdcGgDV5qJC2Dh6Me1uffRchK5FN7awQASZSsmJENITwE3jfIfWms57rDNsd0JNT1lcb8aTuDEO263oxngnQbD08K0VL9NETK3T63hQpQrjoI08kCryGiqsbE9pg5TguhDDzOnwKELQtbC/2rPbbbm5ueb66noNiuZZxkSYBaiqOVFKbgLhiRRFpBykAvj6zbccjgfev3/PPE18/snn7HY7fvLTn3F9c9MAJ7smLff3d5Q5Mc8CFm/6Dq1h4wdQihACuVZpHf0BsTVB1vRFW0ZwowXMXPaCSwBbW/Dehnj7Wdi8EqyuxZO2EOnGkF6KPjlXMppSFj2wttappeC07MusCfP6+bW1jlZhcEhrfpVgtQnta1fRSsANjGmtulKxdk6A/VRKc4aS9tvbxwfmGBlTZS6VrZJY5N2HW97dPxBTQOmK8Z5SKg9Tluem0trrKlZrPr3ZgILpTipWohGXudp4nm0HdtsrQJyp5hi5PTyspg9aSaucNYqua4L+rfXTGkOuijlprAbXyXruvcf3ln7nmwi+oeIo1a3XNKcWlyrQVqONBeWkQs2SaDcdIyVgu2z4HpywHZVSODeBC2hVoWamMDKGhLVmbTUxShFqbYxGTa2a2DTpdM5NuD2DMdjegXJs60DJDh1lrdmVREiZnGCaA4dpkv2nKkKJvHr9hu3mQN8NbPbXvNxtwBhp1VSKkjVoB86gTMGoiPYFPwwiBHzqGM9n7j58IKXMHBO9s1xteq6c4/nnn/C893QUjHvg28dIzoUxRBSivSjFT2HmL86nU1Zcd4brjZMYFfjqbuZxTmsCrNvanfKlnU7TOiOUWueaVZWiYa36N2axwI+wceIq+zBBaCy+CiJqbIRxr6qCUldd8e/qUv2Qjqfspqd//n2CxEvs9FTD6RIPXd5nGfcswsuCogM01tDluU8/56lr1wIwL9viR/egxfn1KTC16Cc++dq/cw61wlLAVgJ05SbvAGCNOK9WZ4QtkiZyrfgaIY3M44GcImE6Cxt8/wnG9dhu0+KUSi2ZXKDOE7x5B8cRPc5SJN/uIBcMoxQSluZordCl4mfYKcfV9gVvxso3qlDSjHt8YFczm6sNeQqczzPdpuenz/bk5/BQK+/eveNvfvMV59s71Ps7rj57yfVPP8c4K0yfUnFoBu0JquPx9oEPX31NSJW5ZF7sEv2mh2gBvd5f88RER9XM4vgnBEkxutLWQgkwH1CbKyk6agGeToeR+1nTD4+YvmLijNGFL37yOdMUuL8fmcbAu1dvSSEKY1VJkVkpRTZgrcRNxkgMb7ShKEvKimkcUdqwywWwVLNo4EpObVuBMOUMRZFLBiXM9iVHRj8ZRwvgVSvGLG2nBmharSRZH548ryzA6ZOhpmoD/pSS4nPJCJdS9h9jDAv7/fLhCwjV5oc2steUikLiPKhPtJ+W79fmbVn2IXmXpdVU/QPWr+8NPElAAPN0EP2QOAIFt/+E7dbziz98jk1njq/+koLmt3/x/26J1Yl8umPc7qk10zlI48jx/mv0/SuOt68Zjwe8lnYFowxqvOf41Z/gvKPvPS49shsMhpF8fINOE0NnyHYgNSHt8/Eg11NBChM5Rh7mb9CvHpljJMREbHaVpcjGm3Ik58Qck7QctepYSIpcDIFCJlGVVOXHOYmmTsrNjlV0O6ZZFoFQhS74bLtFa4PRUlFfgoCHQwAKH+4Sva38ZK/ZeM2LK9Fp2nQe28NOS+2klJlaKn2JbHTlxVXPFAvnKEHdMQrFd+Ok5WvbhlJBNwaU2DAbarNrFbbTYBSD0+w6Q42VgkXlgkrgrKazhtx0VPq+Y7vfoucIc2RZTVOcKDEKFV9LgvfUQUvJQ02cX1raFKoJfYNFNtzWMLj23uv2WFnAoRZYq+bo5ZU4i40xUfXiTKYwVpLVEGAcM7f3Z6YpUWKAnFqfM6sDUP5OyLzoOJnVHUU2mNx2JMsloJffyqXQqmmdLJR2pJJlkAqtMouCmKVXlUEbaakDSo6cp9bj3ei9Zg1m1JoilpYsXKoA8j+lK3LR22NtYUhRAv7H00gqlfEcqKXw8tmWrrOoTQZXiLUFQFpTleLxNGKN53g6r0yCH8IRg2gm9YPoynR9L4BhC1y0Frt60Y+RNjsqTNMs7oPTRfPKWovyXasUCEiyiOxSCoVM1kkEmmNc70sti76JaJw45+h8q1ZrvTJvlmxyZTcUYccsg6805l9ttqYCEohNdC656ToVCXyqjLEcZ8LpQAwz08MjcZ4Jx3tSmHAaXOe4GgaM1ux3A0YrzipRS2U7+AaINfr3diAnsQZ+ahlbSqsCe9OAgFlOXIkOz6YJX0ucKJRmANMqKyLSKC0qFQnUDY1BVRcHj6W9rrWRtMq9swK0aSNVKt0cbpQyTQugBfalQdoVFsaPqrKJituMXL+l2rMEp85lYSG0MVNR0matJVnZbbY469h2IqAewlnajsaJShHdI63wnQQ5ulzaIWut63fvh160xFoP/jxJe09M6QIeLIg8TcR8OWpd2yoXcHUR4DZGQ9aSHDU9LPUE2RftqLICpSllcc4rUjQatju897jOs9/t6PtNmx/TOk6nORBCZJ5HYgzr2pWysJ7GSdzsjsfH5lp3WNl31jh839MNAiKVnJnnmZSyMOeUwjvf2gQLKQQe729xzmEXRzsWcEQLy+aHdFzQwfbHJQFGPfn1oitSL8ojUpFENBNz20/VxyHiyor6+MPWoaY1DfRoGk+rDgQsKielQqgQcmHOEUWkM5EcCyEWlM0XcVMFVbX2kpbwLy1SqbWDL3dw2Yf+47cPfPv+gdtDIOfKH3y6Y9dZzuOB0xQoRYEyqx35s93A4C3aJMaQ+fZ8wCr4+csNSileH8bWDlgoGTZdx9B1VFUJKXP7eGYKkbuD6JrJWg+1ZCmcZWmBzH5JohW1GgpOgClnQEkCUYqipCJyAFaKSQoBJrQGGmtb9KyEYUsDtFCaMkdyCtKa1jQHtXNo3wvjablX2qC0MCX3u0QsYPVMKhIPjHNo907usTUCPmldsEmSDxehs7O0TbsBbTVdN0j7npopuaCCRlPwVpOzJiOM0jCLUxVFEfPI23fv2I4Tuu/w3UC/u2rFNCsn3doPlbVtMFmKtShJu/CnAGFmSmdCqRzGiUXTLqbIrvd8vt/wR59ecT8GXuz6djEziqYZlqXNPGRh2adUiLFytXM823i0ceyHxP05cJgiaWG0suiPNZCujUgZ9xetFinqLHNqmYyV3LTErASVArrVytTmYFmmMgvYtQCMT5gFP4BDL8Yo0EKYJwCUupz3dzWfFqBJmCNLtH0BrZRaCj2t4MSyIF3Ap2Vve1pckbWwxRIr86nF8lqv0h48/V4L+PQUvOKyRq2fUOUzivQ4f3Qflz2WWslVWt6F5KIxfgs4zPYGq8XBUVWNGxrr0W+E6dSY7spIYbOOAcYZPUdUzAJY10qNDbTXYo5j7eXqqVzRKuGUYrCGuJn59OqGElPTjsxNUkIAC2sMJRb2xvL719eYceK275lT4bfv7/ii77h6foMaeqy25FxRpYoZxHNNrVn0k24fOf3l3zH8uMd/2tFX0L5HuR5MJ22GKGpK7T7VBua2PcN6jHMonVEEag5S5Bx2eAX98EivKilHwjQSHx/IcWIaz+Rc2Gw6+s6jq7TDxTE0h04p/q2uvct9XQo1SG6Uq7DzVSkoC8538h1zpCotQFMbBBWJ8VVzHF/GIkv4togwLolcqYIxqGX4Lu1AqrVHNzC11HUMPQVDJT9+wmZfH2ssC6VWLbqluAjqIya1PL/FUFpQg6ftqNJeqtbnKS7xdGng7fJx3+f4BwBPBq0FeJrnQEkToHHXP+Lq05f84b/5N3D+wN/9uwem+w98+Sf/HmMq+ytDvn7OeZBe7m53Qz6dObz9FTkmUixo29P1N0IDrJZyvuPw4Vdsdjv6ly/xFfzGEMPIfLiT/vPek/HEJhh5PDwQY2xBuqZUxcPxtxxOE+cIU4JYNYn2o8xaERwThKKkyocm16V6VchNywcqYxLb7pQlWLPIBrcgg533eKf40Ysdm77HWukHPYyPTFPg3d2BOSYOU8QZxYcXG656wy/OmeuN5Z99sWPoNPvBQsrMd2dqyQw5s9Pw8nrgHArqFMmpcJgStYLxml4prhvyqbUiVMWpSIJkGiRS0XilGJRi7zQ3Xq5DBAKJUAV48t42vYXEsOnY7XcoO1GN0MDRhuk+MY9j62fV60K7sBcy0pJXkUHfaam20fpILTRwSUbqXBGKv27Ak0xJqRRVCXwXN7kC3KVMpnBtpXrlHXirCHPldMp8uD0TQqSEgCp5BZ5su5uFsoqwqrb5iz6WtOQtYpVlUdNazoXLOcqcrhikwpKLMLssBVcqRokzjkMJMGgVk4cxVc6xEFNkXoNvYa9JYqsvy0pbCRcuxeWhJwBZE5ZTTVg4xAqx8O4wMceMUQnvFJ8979nvPXf2yKwy8wwlt40sVx6OI2B4PB1x7ikl9J/2EcOEtY7OP6PrB66fPRMwxfl1/a9VNV0IcWaLMTFNJ2Jz8dFarwyMpZ3JaEUxCqMauylmEX9WIgA9NZFwY620H8XAOJ44n45st1t2uz2bYcA3QMwY8yTxF+C31MaIakDIupG0269F9KYxniQpL7lgm+hzSYEcJqbDHWE8Mz48kMLMfHyg5MjgO6z13Fxd4Zylc0At6DxSa2W36bBW7LypBbvbCJ23AWmnaRTgqDF6tLPkUjlPM7Wq1vIn7J2qFEUtM061arIAKCpGYk7kNDcQrUhgQRNMb4GibiNfEoS2aWorTDPrcU4ArVqFmaYW9llZADtoYaa0zzQhT3F9ExZQaZ+/HH3b7Jfeett0IFUTFL7aXdH7jt1mQCvFh9uZNM2cxwM5Z/rmzLaxopeVImQKc43SkmTBanF5U9qQUqKUwjROlJJXdpnx7inu1ABJ1Zx7WIOfrNqaU2W9tMahlYCXMTbGL0g1tTHLahVr83kSgfvcWjO7fmCz33N1dc3V1fVqG19KYRzHFaSb59Cc9iIp5+ZWI056IQTO5zPTPPP48Mg0nTk+PDKOZ9AGax2+H+iGDaDIuTBNM1onFBL8et9hlBYx+TDzcD5gjWE7bPDdgFJm3ftq/Z7Rzz+R42mSs0aKT89xqUQ2UKfkpQLZXlJVAzplwzN2rR9JBf/p+6+vXJK8Bo4sezt1BarkmaLSUYBYNKEUQpaIwuvIVColwqJhIq2hilITSiVpB2/CqqUqSlxYca2FwVkqij//+pY/+dtX/PWX3zKOM/+bX37K59cDz6+2LfAHhaEU0KryfLfhaugwJnAYA1+/v6cqAayU0vzJb++IMROjALa7vmfbd5xLYU6RV/cnxjnwcByxWgkwrypJJwmwAzgr63StkFNBKYsxPX1n6bxclUIkF0UO4mqnmh4I6gnwtAJvmooBZanWYYzs5yVkcprR1Ytb4OBxw4ZqfWuPaAmRMihtGYYttWhSTlhVOYbEnAqnKRBSEnBea5wp1Cpt30YbdLVkC50fqTXhBtEB7LoBRWEmk1NCRxFW75wAT6nCXIpowFHJUTPNGaPesNk+Yp1iu79mu7kCbSi6tb0viNuCthhDzRGlC7lq/JAoWBhnYk5MYVoHqq6V/dDzxTXYCg9T4v0YOU4zj9PEOAfO89wKCFk0+qompkoIha2zfHEzsB96Pr+u/O3bBxHGT4WZpf3brGD9AuaXuqwvS1K2xJFmXZgr0tanG/C0aDQWFHOWfSuXNrkWna/2Oq1Yi64/hGNpiYcF4Jb7vQhsP/0dLKCSWo0jhMEh4OiF+bdE7OqCxa9/uaxkemFKNaSvfldBfgWfFkC+3ccnx8qWqpc1UnRAYV1hVQOfypKkl9U4gBUQW35TRNMJMMrJd/Q7lMnY7VFaUE9HVNWSP2oDfkC1vY+KIEm1UscZdZrRU0SlLGYluZCmKDGNsuJi25nVXKrmQmHGaM1gPXUb+dH1cw6nI+8+vCPngjWuxXxevnPI7K3jn9/ckM5nvhw2TKczX9490m82/PTliFIG4ztMqehSsX2H2WwwMePmxMP7Bw7fvqevn+D8M653FbPZgB3A9AKIrDQgKQZUDUVZUAZle4x3GF1QambOM0VZ3LDHOM+wzcxE7lJijiMPt3ekacQgpIPd1Q5jLLvtnhQzjx/uCVPg/u6eUqoUB00DnmpFCS7eQBtNqlIMVbVIvud7Si2EWdrilnbmZTSWEgDZ17SWNV8rOUe1sDLa2KhSrkY1lteTwXdpzauyS6ui2ropxUO9AtWVj4EnEFkLs7A5xFCrXuYYVVi0RbX2vPZmuixM2yKGbN8Bn8yyXj+ZOxUaaeL7Hd8bePo//m//923Sygbz4faWqjT95pqr/Z7nn/2cGl7ys//8v+J8/5b3uz8lTY/Mh1fUOXH/+kuM8/hhS5xHcukoylF1puCIuRJrlYmRDVFtGYPlcDtLf3ZWhFgYZy3VbpWZc2bOldCcSZY+rVgqqcJpNoyzJxXVqsGSXC5oeVZqFd+sVdg0XiliFXqt5N6KjRGabbRCRV8qFKb5EU9ZQKy+lz7+axI2TU0TRrE3hjr0bH1HzIV3h1NzClI8BPibD4HhMfI4V252jn/5ixsGo9nveyKB0+HM3Tnyzd2EtYYfPd+Rc+XgDCVlvjrNbDTMTrMxhufe0KPotQzSWgW0WSsrtUhr11SkSj0FNtd7bp59Iotilt+XKL3Hh/NEMQa/38niXRD7yaaJslZGFStg1HgBOMCp1nontk9Qm7BilUR/2YN1Q2nlOz6Zb0CvTUs4Jejtm16KbSDWdWfxRhOnykNKfIiBFBMPp0KaxUpd17YRKnlNw5FZtJpAbN2hOfksVSxkTMhoaGivaiHDkgA0xxnbEtvUgCqnEEq20vRV2GzBGIJ3zDkTSmGslamISOJlmrdDCetDkOXFpUAWD9MSDd0Wm1RlDk2nkVJh23fc7Dwv9p7OG6IufBhH3seZULIEuq1XXAGFzHE68d/+h/9A7z3/5++7OPwjPz7/4qcopel6cQerCEMoxAhcUH9hllViiuQkdt1aafpOWqC896I5UDO1LLX+irMGo0TDQVpNZCHX+kLdFUHuQJwnpvMJ5yylbokpoUOklJmSc6OPX3R7SmNR1pb4aaPXIKSWQoozNUyEeZI24dOJGKIEsrVyPNwxh5F4PpFjpDOKfujpDNSapeVAK4beiABvFVCiH4bmLCdtL2WB6Fr7WK3SluH9QK0VVy8JqUoFTQANXSfghjNIu43pWmApDoo1Z5JKlBSFEN60VBaK8hwDTmu80XjXsek7UqmEXIhJtMuKUgLkUuj0Yg4ggaBqNvKtWx2lwermiNkEi00tCBokgZ1uIJYwj4SFkEuFKqCLsU3TqC0Gh8MjJ6V4fJDgYp5P5JJQxgnoYzqqMoxTkcCiTfDOdyitcF2H0oaSIrVGQopPGE4K34mmE0tVri2ji5aYamvqynQx4sBYtSSFeRZmb4hzQ8yWoKcQg2g3hTAzTyMlZXKKuK6nHwaG7Z5hu6fvhCUY5iBjOcl7LuYLpaGAWl/2RdHSEgZbadVl0VbXvHjxglqeCbtDaTrnKCkR54lZQb/ZtqCrUczb/Fyiu3kORKU4n8/kAt2wFdewbsDWj1bQf/LHhZtbWXOtuvBikf9/p4p6KajIXqYvWNJFb7Quz2yPV3nMKtGtlfinEps+TSqVMVZiZt2zxTCgkkKmxsT7x8DXtxM//kTan0pjfqgcqTVTjCJrhXEKhUEVqayXLFQQbdXqugOKcZyIWdqtUhV3xJgSpzlzDIUXxjeHoiV1lzPqrWLjFJ3RTE2DLGV4fX/GGsOus3RGc9M5nu0HPhzOnIMAD1PMzDFTCnTeSXuUFi27vjGwRJdHZBaWhNpq6FQkpUoMjY3tOnGRi/EilK4N2qQVd8hRACyF3ABdEpTU9GWrzInpjPMViyLPowjC+gFct95rAR7NamjhvZdqtMv0paCNYo6Rmuta1Cspk6pCq4K1gUSlHCtuMmQ0zllmJ9c1hLMwgM9S5KCKDfn1dsMQE8dppNYiLHijyUozx8LbN7dsjgFrt3TDwObmChSrzueSVNUsbCVhJXdcP7ti2Hj6rpJzJKdJinsxE0NkOs84Z7ne9vR95WpXmELgNPccxpmH88hhmnkYZ+ZcSakyhkRMmW/uZF/b9T2bzvP51UBnNW8OI/fnwKSFfadNXZn7qztkXa430EohH4O3l6Jh4+iu65bowizAxcIyaC9WoLUAVj+UY9GJWdhgC9NpbXEDSbDVUgBpK11drqh68m9Y57i6/Lo2NopWi65hey/qanSyFhif6F1eLrOsUQvLWauL1MHynZ6KoX90n5/i/20fLq3IJYYXed37Pgaw6gpg1bZ3a9uhu4IdrlF2bg1Ty0iT+KOqps2YM5zPqHHEZNBFgJNlAVcgYLLV2I0UWE0SXbzqRRbCGUvvB252V6hSOak7uqrQTRBb28umYUrBzJlPTcd/9vwTXqt7vhwDcQy8e/WBmzHiYoUQsVla+pTOq4nKNhR0zdS3Bx7jzO4nHveJY6Om1Rxr+TSlDappCdpGdFjiXtOcN6vKZCIFQ6ZD2Q3Gp2bIYxhdRwmRu7fvyTFxfIw417G/fiZuzJ0orXVdL8CT7zDW4nth/hsaOFolqS1AqpkwH7Gq0OWLYZFiAXNgwX2We7rEP2oZz6rhD8pchk4D3UrJoJa7vsR6y+KwTBVhddd60a9Tlw9cR/oybnPJAtKqJyBtlYKD1msJWOZg+wytFWAwpqJ1ae3oCw25rnNX8qZLo11uLdvf5/gHAE//JbVWwjSJPsUsNHtlHco49PCMUjL9s885371Bu57j+2/45i8fCPOZ/Oo3GK3oOk/VHcVcyYKsC0UpShar05CqMI70jhQK6TwTsmIuijEqztEwZ5hyZoyZcyxMSbSELAanNFOWCkwohljNGnwtKEanmsC10hQt4IgBvLoEW0WJK5tVimdO0+lG5wT6xk5RRW7uMQmQMgxdExOLlJSZS6AqLZoxzjHstqRa8R/uOIfI42nkFDLf3E0YVXl9F/j8Wc9PfvwcazVXV4oxVk6HmbuHia9fPfD8euBf/fw5GcVbk7g7TfzdbWBroPaa587ywio6rdgaYfbEWmWhUYZUCnPO1JQZcyCEmXGcuPrsOZ/9/KfE80g4nVHzGTVrHpMAT/3Nnu5qR50SZY4461DWid7EkvCoZRLI+NPU1a3l8ovLplyrMITyAgE9aUNdEmdacNxb+c0hycQctDCpDBIoX3uD1ZowFaZS+PW7SdgGqeBqZaPlebqBiQuLad30WoVFJuqiJSXAZGEBIwVEWzY/DdSipeVNt0UBmtNZYxso1VhRzbehQjGWrCxjrky58CGK2HVCQNWlEgMNYGoiyDGLpbNqluV+ef9WQX0MiSlnPpzEre6Pbza82A/8wY+e03vDX7x/y/048u5hIqSCt1Jx8c404ClxnCb+7b//735Qrnaff/FTKhAXpgdSxQw5PaliIY42zf2rtkTaKIX1HdYaEUWEFkjIZrRoZxSF0HhzJkR5/aK/ZVrVLcdImCem8UQ/dOSSiMmACkzTxDxNON/hu04+U18EayUqrauIdEVA2zhPpBgI80iKgePDPfM4UWKg5szhcEsME6rppWyvr/HewSCOYpSIpjJ0BqMVcRbGX98PVBQhldaGJV/BaYOu0s6ktKbz7sk1LHLutQn9aui8whhxpUMbcJ24slgrTKkQRPNIVUnm2lqiG315igHlLNr3bIeBT2+eM6XMKUbOIVKattAcAl4VshEHK6tpveqwpODCUhMXO+8sFpmXtWZhWhRJ4LU2WKua+4mmFmnrW4Ao63xjOIr2y+HwKKLWOUCteG+bI6CIb2vbAaq11UrB0mjNdjMI824YqMB5FLHeOQQq0vKptb6MOyRoWQJgtwJPcpalaT1J655pTJBKDAIUxTBjjaZztsUphRBmzucj03RmPB0xiI5P13m2w4bNbi9uNMjECSFwPh2IcSamgDUWa8We2GgrwZDR5CTJ6aJNUBEB5UUw9tnVNb1vFV0Ux+NRALB5QlGlHRZ7CfjrZWxUFPMsbYin85lSFW4YMFqYUz+gvO1ytILGk8ylUd6fIkrtf+0h3TIzrS6V0UXH6akw6fraKoGsVaJh47RqmpGsxb0pCuO7VNXaxCRgDiETxizA093EH52Ezb6AJ7VkVEvclVFo26GUF13FLLpCtSRpI1sC/grjODLOwtTJVdpEUxLQaRMqynicd2tL7ZKUDlaxcZrOGLyWcRdL5dXdmd5Z9t6ie81n+w1Xg+f98Yw7a6bQ4tAgQXTvGyvBCLO798KozECIicMYlguPdxVrtYh1Bw3K4Ko4B80lNp2fpRjREnCl2r5D83Uq1Bwhm9ZmXYjTSJhHFkesMhdynkWjsBZUc7GUMSEFC6UFsEYpPLKmGwMhWuY5kVJmilHalbO4rdoUSVSmY8AojSrgncFakcGYGxt1moCq6DuHN5ab3YaYxIU05dZCqUXzc4qZ85tbhv5MZzz7myv2z4V1VvMFYJDEJq+Jp+8N3nXU2JE2qgFPIyFmxilxPJw5nwPOWp7tW9uVEqOGECO3pzPvD45XD2dCgTwnxhg5p9TWpcJhjPyzzw0vtz0/uhp4vhWgLiTRHwu5NN3CpvdU1Hem2AIJXEQbnjrbCeAuo0Orp3NRrWAV0k25gk26Mft/KEduxiimCRgv7Fxq/Widfqpp+V3HOym6NmCiAUwr6t7yiFoKtekELT+LccsyNngCAF1ExZd7US/agPoCXn30nZ6wzhd9vDWfUQuoCCnmphE3ijacXpL5p+yVdg3qhVGnXI9BYzfXqDhT4rQW4kQSQE461yJz9nxGnSdsAl01WCfAdWMxO+vQzuC2gzAix4hSBbxooBmt6buBm/01NSTulaGrGtMA1+V8wKBzQaXEZ6Zj//IzfKq8vbsnnmfefPsOPWeuijB77NI/TMWiUc6jdKKrgeObA49vAzv3DLfZY9wsTKx2nWVttECWvMkYiWcaa8i2Qm5VGUNkro6EQdkN1mX6fsBUKVJGPXH37p7pdKbbTnT9wLC9oussXddhtKHzAma7Toxcun4jxbRaWpeM7ENZCaN8no9UXfHlGmi/X0Bl1XRHuQiMo3J7TmvfBRHzVos0gLy21NyAyNKAIo3AM+VpytwAIiUaWLRVZhmbXNYelOQHotvUWppbHCxjf/kctYK4Eh9IjKm1XPvFibQ8ae//XV02Gdf/kJzxewNPi35EQlGVQflBkqlcUKWi8oRWmu32GpUz/YufM0aY7BXnoLh/CKAQxoHSVC1J3/K+sUhlOpW6VhdygZC1/LtN0FxEB8ppC0WSB68KVRd6bemMZbdqgUjQu7Ga3ghyqGrFKUnYI9JS1+mCpbBVBa8g1MWBbRHnLg1IkWCk+Z5wLkK/6xod3NSKygVvpS1x2xmpcNmKUgk7j1gFX2x6Qu+5s5Y5Je69FU2NnPkwFv7tn75i3xl+trNQDV988VP6Z4FTf0sh8+WbR4zROO+56gx/+NkVuSVjscD5GBi04plTOC1BmNcwNBEzb4wMRgq2c3TOsvUWk6TH19QigKJW+HFiCDM+RlwIzONIHCdqCmgrzAtVhU2EUuLUoWQhb4oqrDuEWuqRqgmkNk0SLtpOy+D+qEK7/ojII23a1LYpyTmJyPJ9Shxy4d0sAcauVAYEeAIRXl8Q6uXNFWBacrNwnEr70+pWlWhgbpuuT4KLshTs2iHnYFRlMfJVKOwqGlfRNWObZobRkK3CKkNAE2gOD1Rp5Kzi4GS1oVTXdGkyS5WmVjjGTCiVMSdyLfzo+Q5vNC/2PUNneXc+kcfKq4eJ4xSZ52ZtrGkRj7C1bp51xGyZ6khMP5z0bY7SujROY2Miichr33Us1G0JRvJKSUYrlL2ML9VW5boEyUiyQClrBa+Uuo5nScabdpTRwuboe3LekXNiGDYC3iqpFIQYOc0TW2dXICvXQiqFnKRarVHkGEglk+aZHAPT+UgME2meyCkyn06kEEgxUrK4Zxrf0YabOHyGirXmEtQhpghSsHNt3skmqbRQiBedItuS12pFmD5FSer61gbWZxGR7juH0tB1AnLkjDgoTrME50aTYuJ0PpGztPUCdL5f52cuGW00nbWYrqMay1waMxYBMLyXNlfrxCbXeYezBmfNGmQuVR3VWkxMY5UZJSyF3MrYtemBCPBlEU6hXrRL2+ZeiHOG1kaWc2aazqQcV2q/dRuss1grmk05t70zNtFH50GLqG+usZ276M6hVBMV163yp9bF0CxBryykpNQSRiWui4seTgEpDo1xBSasBuM7asmtLW5mHE/NrS6gUGw2e7xzDL6jGzb0XQ+lMJ5Oa6Iwno5M45mUAjlHTL9Bt4TYGMM4jiL0nVrSnCI5Z0xjNbndjloKg/dYLUyVSqX0npQ01joRTnce570UA1JkHIXRp7Sl6zbsr59LAKQtsRRO44SxCW39RwnDD+kotbYQryW8jeW0xHtC07+0weVFo+ZpMXTdY+W1yx6ytNCB6Bwujl2xwDmKptGcKlOsnGdpT0ul0lnNrrMMG8/GKH7/sz2/+GTLMAyckyKbBWhZEkIBRnyrMDvjhH3oe7S1pDxRSuLxfiRMkTGMnOeZEKbWviDfvfc9237L8+sdvXdSPGksR6MUL653vLzacEgjoSp0czb2xnCz6fnnP7rGW8vGW6xROCtrd24aerR8wjQBcGqiVk3KurUBSmy36BVpKlQxAtBak5B2sJIWlK+iVCalANWiqhdXK9VapFPGWYtzhlozNYqeUkkZaz3D/hl+2OK6HlWFSaGtxRjb2oMz5IipkVoCOQXGSUA7cb9U4gRsHMZrspFYJC7tukqMYbzgwGgtcVypUJSwPwffARXv0posQ2WrHMkachmIKTGFSK2V8yxAO7lSCHy4fU8sgWcPz/B9h+s2ouc2nsRkIouhhTKaVeMlxdYmrajKY2ylHyogsfHitpmLtAEqVdBVc9U3loex9H3HYQocpsDdaeb+PDOnwrvHEaMVj+PM893AfvB8frXhqu949Xji/hwYYyYk0RsEtcZ1cGl3rw0UXizP6xPw98nEWyZpe1Gb00XqHdJ+V9vP/zerxD+uI+e0Fnalq1TaeJ6uNyAxxWXdfqr5dFk35DdIvPVEW0vG69M4bgHnL3FbaXv3R+4K7eWscVz77CWZf/KjtejmqrZWsn70ExCpnUcqMh5TiuQkRTgUGOPWvfLCQKks+q5aq+Z6bKjFoGPjs6wDrbU2kVExYmPGpIJdshalBch0oKvCiU0Npih0NU3GpKKaZITWGj9Uhps9Y5pxm16MUlJGm7I6ixolMiXKVKyy9Nbz85sXzDFxPJ14ODwyPTjO1dLtBvr9pl0fkVYo2tBvN6iuo08zYw5wqjx8fcCXiqlRinnWUnVHxQqYvlJ6C0L7yFQ8FYOpCV0U52yJxVK6K9CKzXZPQXHe76mlsL26wRiH6zdY5zkcj4zjjMrChjPOiw5WM37wru1L3rdLXqS41goiKSS0DpRpBGNRumtgqqz/S2HsqeaSgIsLbUXWDXHG1heB/JZLLvuyakWUi4Ycl7WD5XdtfCgl+oklr+SYS0Kq2hB7ovm07v1PnrsCVsv3kcJxXQA4JZIYyxh/Ol8XzPgfIq35vYGn1CjTqUJVGuu96IqkGVUKNo9o29FvXwKK7tlP0efIZPfc5sJfP4ykWhvCoNEkKoqEBOBzbArqiNVpqYpUFKHIRWgd13gNe6e46SwgAFLVorW0sZaNs3hV8Lpg2mtuvOHKixuAUrR0QhOLJldFrxNOZ3oytgpTKlcNWgClc0ykkrFKtwBD0MlzEODJ24awt3a/wUpC4weDMppIFUQzjCitudpekZVicI4pJZw3TDHx4TByN0W+/Is3dFbzs+c7Pru+4n/9R7/Ps5SJ/cDbh0f+9FdfMnSWn39+xd5bXu733E+RX3048hAyX0+BrVZ86hR7b/hUGXoqStem8WREfrwWeufQ3rHxDp0iJmcB0KwF7fAhUmvCpIiZA9N4Ip5OsqRpVtcZrdqa3uZg4tJGt2hkwQUwynBx3UFaa9STNdYsgZ+SxHhu9FXdJo1GixinEhTXGwMKTmXmIWc+zEJfXyzUPzOyYaQiiag1F2RLbG0XwEtf2CyI5pPU8qS3fxmjF++7uqwP6yaoaP2udfm9QQs5nkLTgKK05FejjKZTihFFQJhZRsFcZX501uKsWZPImmdqTpKEl8qcMseYSIir2ec3V9xsOvpewMNX44ljTLx5mBhDoaOJJC/uBFSMVuyfeXLJ3J41Nf5wNJ5CSuQsIIfY1jsR9+6GBkIpcWZMrW/a6Aa2yBqzBEJ5UedtwFNdAPHlH1wWcwl4h3WvyL4TFlEVunM/bMQprUqlYE6RcZ7w2w19A54opQmG5zVhSzESw0g4n0jzxPlwzzydJVFJiTiLQ1JsOkFd32PdJRkXHbzIoPqPqow51lZh6pogaNtCjayZ3l+E12utFBshFUqeMFrTDVuZwzVBLex3PSCElpwL5/PMHDLzNElip2EKM/cPD7IfWIu3jmG9ZhIs2ipj33hPNZYpl7UFUBtDZwy2gK80kM/gnRUm1mIti6xTTSVZ9tnaWiE1snC1wDQ315JFXHMBolGQm2tIaRbsMQq4PU8juWRcN4DSGDfgnMdYB0oJ+FKkNVAp1jbK1KorKYlpg/Md1nk2m11jLMnal3O+xBFL4NsAGYyRSi8a55yw8VIilcQcZgkuncdoi7WeeZ45z2dO5xP3Dx/k2ijF0A9sNlu2mw277a5VGQ2xFMbTUcChUpnGM9N4kuS4Zvqub+L4BmMsMUWOpyM1148CFaM12nlc356PrLvrnPGebI1oBmpx7HPeE0OQosrxKC2k2uI7gzZL+QdirpRpkvHQf1yp/iEci77Moi24rEkFUFVYSVJUkz/lUKs+4vLzEeh0efd2j1q1k8veW6uwm8a4MJ5gDJVzEDOAlAt+69l3js+uBz6/Gfjp8y0/ebZj6AfGrDBenOyc880S26GUzHVrLd4YnNFsbp7hhoHj4zum8USYZw6PZ47zBXiqJUpxSGk617HpReNp6ASw0QpUkUD5+dWWT5/teHuSNlyVMyonvDFcbXr+57/4EdvOiyh6irw/3ommZynNcEOq0aZpwC0xXyoZrYyYpWhhNUk0IgzZlLMkKIApi/aTXPKsCkkFKC2BVVKeS1m0SbUGq4xYqMdCiYmaCnbY0O2uMX2P6TpKOIsMghVmY06ZHCOmRDSRmgMlB8Z55DTNbHqPMxarhI3gnCHbylySCPFL7USAJ6uEWbuswUBRDmUM/cZhNMISyIlxnKUwZmxzXCqEJC2CMWVOc5DYEDHyub39QCmR8fAJqu4ZdldkJSB5iYE6nyUesTIABUAvpNICS+XRVtE7hTUeb5zoZMaZeZ6YpjO6amzRaOXpnWPoe672mcdx4nGcMebInCuPxzPH88QYI28eT/zxj1+yHzo+3Q1429rpc2ROipArtmmOCXhSvzNvpIwLck8vBUfWeHBZq777gMQVLZZooNMPCXgS1rESJp9aWmKh1rw+5ynDSbe+wyUPWNqStFpS1QVcb0BRbbpPbW//bluc0rpJHyyucnW9BUtcd/kirPfm6ftcxJgXZo4QGxa4QM5hYcIXYeflTIqBlGI714pztXUvOLkOT79rXdjsYo5iil1zn2WcQWnfLaNSxISMjRWzOOhpDRWMFSKALRpVG/CEwjVZFG0FFMIghAS1pw8jbugx1qBiQrmyOjUbZVBGtbxJuoDUjRT7f/Xt17x/+5q5GM6TljVmJzGcqkogeWXoth3eGPopMIXA4+mOw+nAtq90XYLNDt/YcFW19jqtJCOqBZqObVXyfkbokpSyIRZN8VtwlmErn33Y7Si5sL26FodnK0Y+p+OZisLppdvDN3BtKWRKt0G330OphNNB3OFsh9KVFANaB3IYUa5DD/0aUzYaMStTTKk2JksD6kVvzlrQegH8n0wWtZZI1wEp4/xJu+XlySyftr6JrtAMYS7PevIyxSU2egrSLu+9xMYr8FSpVa6LNIDU5ur4HeD28pYfz6f/ieN7A0/fvvpaEDwjgeF2s0Ebw/ZqS4yR9+/eEubA6fQfCeMjh3d/wzw+8MXn1+A0f/l2YpoT42mmN4rnvXlSEFBUq4SS1ia4NYZMXYMnEF0er+DKW3m9kgsfsiKUhpBT8VrhlV4t7ger6RaKpxKR8YzGa7lQnRbGiUHew4r/CAFNrdJ2oash5yh9nlkc2Prtlk5Li5dcG6m6bbyXlo5eGA0piDhwqREoqDSSq2KbAr4UlNNE67mynpAyd8NArpmxZt5Pif/4+i2dc7y83uOM4eHxSMqJ+4cJazXDJlJQ/GTfSZtX6kXwNRVCKdwdE14rNjoxaM3eGOlTVYWhs+ycIR5HxvQWpzSuaQQoozEl0ykgTNScGVISNkERh66pgZHLhFnV/5WAL47auuBlgiyAlEYqas6otnksoK4MXNsCvtSojgvoo5QEMpoKqmC1/P3LxzMJeJ0CWMP/8g8/o9TK/e0jNQTujgc8lWsn42bpsV+2kkWxByTpXwCx2IIyp4USn0pd2n7lNU3rgdqCkieJauHpxiG0ba8NitLYMTIBbC30gOfjtCAhdPWSk+gwiRIp99PElCL3c2YuhW7wPB86em+xWhPnyPs5cPN8oOstP/t8i7GGP/rJc+ZY+Ktff+BwDsSQSQrsoNBWU0wCU9heWXz64SRvWmmUtuw225bEyRoTWmLurMxfa5ZRvAQ/MpZLXtrNpFVPcBkBm0sR1qc4cCwVi8UJY/kGDbxUUik3ynI+HHl8/4HzeOY8HnF9j+97jh/ecn64Yzoemc5n0RdRqi34RQQKETFZamE8HQjzKGAx4IzBdR1938t3bYFeiFEYKCFQa8E2kEYovm3cKYW18vh2u2lWrG3LK0XOp8r86fqOWgvedWil6LwTkeEojj7zLCLTc4iklDlPMyEXjnNrrNXS0vb8xScYY3Cua8EKUAulmRAsuXQutMQwrpWkgjyujcYZLcwFLZbn3hrQAryW5tYmLXmRBStOVpJe09qGdc44MjG0hCfOEuQ1cFbYO8IUqFS0cWhtePbsubB0/IA2plV1FWlt5RQ2mbjaQSmJhAR1KOTzlV7bjGJO0qZsvehNuOZik1PDPZdgt7QkL13E05HqmlKKbb9lEQ1/PDxw+/49Ic6cxxEacOesp/M9znUY4yhVEVJGpdJAs0RIkYU9vIjXayN7tKpK2oTTRFWKaQriTJYSNWe6rsNZT9/3oguYcxMIFw1E0SqraGMoSjWAVQIdcWi8jE3R7ZA/rfdUJFmT5E2KOyqEVfPuh3osnIvCk2LNUyr8+n95XqpNU7G9dn3mkpy191nmeq6QUuUcK8e5cnuWSmquFW8ML/cd+95xM3g+v+750bMNn14PfHq9Yds5Nt7S9x7tZExb57HOYK3MEet6zqFwDIVf//Yb3t89sru+oRsG9nqkI0IUlucwbFCuw7seo88t0q04C71XPN91bAfP0AnTUWmJLx6OM1Yb3h+OPJxH+sHjlOeLmy2f74fVEGIMSUwNsmiS1SdXWCuFM1YAKGVb8GFaIixrx7aX9orOaIyukpg5R99cnqRdV6GNRquMUlkq+UYKGKVGVM2YmlGlQmqfrhSmG9Abi+m3mG5AWSPmLkbaFsmFUkbSNBGDiPuTEt45rvd7Si1sJsdi012KaIPEEFA5c70Z2NMRYm4i2oUQKr7Tzd1IgDdnGkBfc3PFzMJSTfLnmOdW1GvFwdZqM81xdTi2RlqAy3Hiq69fsd8fKKoK0OwE2MrK0JpyWzzWmBd+iYpUG62SDFsMpJlqJBYsNZGUJlYttu650ptENWLms/cWpw37ruP9Y8ftcWSOgZgT394dOc2Rz683PNt2dBY+vxo4x5FzEOZsyuIEuOiBwkXDqTRQYGG+mLb3r+sXXACGJ7lZurysMRN/OHEXNCBJtZgIYekuufLCugEusVZzyjJN0+fSOifEgaVNaGU8AajaYrxFTLwVa9pnKC3FcdkLRXf3qeaNvMfluq/aPK1wrDGrscjCYKnLKtySEtnXS3Mtzq3FTkke+4QdWGshpvmjPeopTKC0wThpzdd2BiI5SSy0FLJVTqgojB+NEgC6qXNId0XLoZ0Uj4zyTd+2CoDkRDPJOEueR/x8QhtL2DiskhZFlwseaTG2Xhz1VDaYCrZUrvs93vaE88zh7hGbC/N8pEw9Zt5hnEM7i+k0xvS4ocN1nt3QgXc8zPec4hG1OXKKE/kcSSFiB432itCcpr0RWQKTFcYA8QRlJGlPUZbsPqXaHbY6ccBr42x38wzjO3av36KMJc6BWiVuVUqjylPYkJW2E8aJWmB78xLjpOhvncJ5h9UI09VaSkoYI8WTBcAU/a1FM1YKIPaJ5hgtdpG1JLVhp1jdl7nE67Vh7QvAuYyPy5ipLY69rEUgQGsLCFrhVK+fr/UTLcQnWqMll7YX1Sdz6snapZqjawM/vwsuXXTZPh7N/1PH9wae3rx5hTaGYdjinccbg+87hv2Wej5xd3vHw/0dX//67yjhATv/hs5rPvv0mglDsY/M08TjGKhOyeZG0wGi4s3yb3FW672FtWVLLohD4ZXi2mue98J2skoxF0TXKVdCqXi1CIULUGWWG98WmwOaqWqsKmhVWusdSGuFCFFTNbGIToZUaEUsLhcYW4vdfrPBOY9q9tS2aTx1VsSIO2tRQC6HtY2jUklxQlfYpEgGvOtlEm06QoVhI/ol397dE6fEr95+4MXVln/1yc8ZnOPh8cj98cRvXr9FW4g1su08P7rasbDIHkPm1WnmNAbuzxlLpVewM5oba+kNbDTcGKBqxvPE4eHI1abjejOsKv+6SFtYCoGUZzpn2BhNJBFLFtHtpepAc5uqQncXFzppj6tI0LMmbUpKYYZlA2goK6xMJxCgagWeuFSRBHiCrulYfXOcmWrlUWWu9wP/s198QgX+tGZOR8Xd3T0dhRdeEuexvddioLm6DaiLi520gCKioRqSEibX6mqxMBeXCdfAJ9F6Eg0qOWf5zygRSV5ab2qLOAwFqyqmyrWSFsQluYBzqsxVFr2qNOdp5H7+/3D3J0+SZNmZL/a7ow5m5lMMOVYVUN0AusFuylu8JRf8u7mikCsuHtnN1914aACFQqGqMjMyBne3QVXvyMW5quZR3SSTIuQTIk0kKiojPNzNVK/ee853viHy7hKYcuVf3XhuD443+z1eG/7hdz9wmhbsXqH6jr98fcfdYeBuGIix8PHjUSLOJ2miB2WwtlJNBlUYDgaffz7Nm0ZAYWdGQHxCSi0S+66AagQo9t313lWJsacIs6SUQioiK9PKtsJJCuxcRAYsDf+ajiEgLKwk4QZ2Ko1Wlvn0iQ/vvufp6QOfPv3IF19/wxdff8PluDDNCx/ffc/T+x8ZhoHOd4QQSTHR9x2dd3gvUfLT5UyMQZg/2tDf7Ok6j3GSSBRDailhgdgic2spOGMFAMj5s/mdKyITvHGumamLVG66LNJE0BKNOicSlC43LzeoJQtDq6TNd+npeSKmxGVZSLUyt6dYKRle3N09NPZZLwbYs0htcl5DC0SStwRhDYUahQptTQOjRTrpvaVrEzxnjFCnvRQ/oTVll2limqa2KhTFOZJz9LbDGY+xmUIWmWIphGUm5wXd5KghpNZcySM/7g5Y67i5uaXre3xLnzldLsSUSDleC1ethAFFm/CXKnJmRF4m/gUClKUsSarGSgG5sszy5k/BNq0SH5iMavdyBQ+88wz9QIqBKS6cnh/5p9/+L4QYmUNg3B24f3iDdx7nJLlQa0tFE1qyWCmlJTxezc4lwVWSb5x1KBQlZULKhAbu5VxIOVFyYjA9Xee4v71lGEaWeSLFyOVUiGFpJPoihugNmNXqmkS4MnXWAeI2q14LvpSaBF8Y1CrGrXj7ubyu0pHrq6Ao6kqeuH6xFKVr/yrte2Nmbl+o2sCkbtdVfCOQgUkVj8IpVZ6nxKeLGGFrrRh2jlf7jm/vd/z56wO/eDXyqzc7Xt+MvL4ZibkQipyTCYV1Dud7nBVgvx8GfDfynBaOceH/9psf+Jvf/DP7m1uGvudf32leD5ov7g/s+w5jO4xXwtozdgOBnan0Fu52nsOul6FLGyCUWnk6S3P36TzxPC/0vWN0li9uRt7sewyVkhPzEog5k1NtzSnNp720Aaiwg51xUlvV1hArjTMwtlCGwTuMVhLW4Ayu860Zln3ZWkutIieTOqOdCjWjyBgKurQLp2UYZ3yPHXdYP6DdwOpFo3Wm6krNkZIjebmQlpm0JHIqDH3P2A9QE4M3zZdLUt1KVaRUUAUOvcUYuMyJlAvTMpNrFnYrIjM0Ruof8S3OjdGRW/qqSAQvcaZWkW9XRE6lKCwhCUtYN/aF1iQW7PfvuL2c2I2aftyzf/gCVTVFiRS4pgRkNAmtEka/kKmgoSqqtljjUVGjdALWYYUmFwGeVIEaA8bAzhnohQV1N/bsvKX3nh+envh4inz/dOb7Jwn9UaowOsN+3/H9c8Cq2BhJULYGbH021yFl2cpAjWpDxeuAc/07tf5qTW8W/FGe6Z8j8GTWhlo+l5xRbFJ/2862EMPGqJAEYXcFndrzBkjsfJXGXl5rk602U3BJ+M3bv39pXJ7XhOtV8reC7+uA7cW5+qcMEbUZS+l209ZVKf+z/tzc6iClBHCutWXxVgGeUoqfARGKtT/V2wAKFNo4qT9JG6BZZdIkcrgKpgo4pNUV1LRKo5XBWBmMObwM9FURYKJzKGOxXYdFWJbKGOJgSPka9OAa8GS8l3SzbDCpYlLl0PfcW8N0uvB484nz8yOn85GyLJg5YbXDdcJO7nqL2Q/Ysaf/8gH/cMN4fOZ0PvPh/FtO8w/UfCGrgFM9uro2vzVkr3FG0a8SmTRBLSQ1kHRH6R3VjthqWuAPoCq721vc0LO7vZU+Lj5RS8F3nbBEG9guDSasZvTLPANa3r93eDugbcVZsSNR1kEbZuoifqIVTWqJg2tAkTDlKlfQR2/7RmkAqJy5QvLQ9ZqKua5rWZvrCb9OZdv7bftEXTcZtYZOcV1bNNZ+A0yvQTRXTtTqD7WGALzcfjaC4Aa4rgBT+XwPLC/+4//bwNPpdJTfn59JKfEfHp/RxnDz9g1hnvj93/4NNU30aqIziftbj/eG3WC4Ozh++cWex06j54mdrowqNQaTGFB3pgEVSnTURsX2O4SimEubvrSbs2QoWnZxVaGjbvRoofipTRWaQSa8SKWmlcZVcTFR7eamKjI6BVhdUEoKD1URSUUpnKeJmCN+N2KdY+w6rDEsy0Qtla79+RZvO0mspbWGajXVG0ou5PNCLYXRNISyM2QU57RgS+WgKr1X7N6+lk0wB1Kq/O3vvxf5WJXv+bAbiLWwLKUZ6Z3x1jB2Dl8rbzvFRRl8cW1TFqP1CYhUJlV5ipk/PE10wKAUPke6KbeJU6VDzNh1kWs15NISsQQyTEBWDTCi4LVcf0mmAafFGnkr6IpMX7ViK4ivw1qJTRUsaj2Y5f6ZFaRqD/LOiPPWxxCZcuVDiChj+OXbW27GjjQtlFoZDESjmNvPkEZQpgK1rQ1hwDTAqD15L+cRpQrdmgpuffi1/LuyHh5KySaORFRuSSXrlVRaKKqsUx6Rrsi+0eSEyEOcqnzuKRdCqZxTkVQWLUkxEU3tOn55s8M7w8NNz+AtKcrX37/a86B3/G/+8g2v7nq+fT0yduI5NC2Z+13HeYqcUxCzey9NQQryLNT0k/ePfxmvle4tuiqx7GveCtRKjgl0IZvrhO3z5l7YHptOuxSR4SlJS7Kd3Yqm9ZBRSNLXMl84nZ54/+47fv+735LmhTDNTJcTl9OReT4zzyeW6cLx0wdSEk+ny+nIfLmQ5oXZue39hPkCQOfF0HkcJQa8851M562T1M8oCRkpinxsBQx2u538u90OYzSXeSalLLKJcvU4my4XQgjNM6d5gxgx0le6GWIqhI6cE+fjMylGlsuZ0mjmpVSUMeLvo4Q9mVNj7aChIL49tD2yiqGhdRZjxm2+k0LE6ElS7EKQAq8d9FAFsEoVVTXaamJaoMyyaWi9NSsxKSp2A1FUrhQS6CBM0dhYWi0hsNaEVuDcgDYW17dpavNkUEaDNi2qvqC9+ION49BAa5E7xpBk2tr2mK4TA0tjRD67Sl5zKbI3NUAh5YQqaivWTfPJQAl9O+Xr1M5og+/6Nk2LhDhzfveR8+nIhx+/5zJdSCGyG3d88+2v6Icd+8M9Ssn9ASUyoxhQSTXjS3kWOt+xmbIWAW2tszjnBJiaAyFlYiqM+x139/eSspgCtvkfhLCwglmVivUNGI2SJmhQqFKaobrZmF0CRGn63Q6XZZIsoRQACt8NcrY36XQpP6eNS15rc0tVW7rli5Ho2nt99n9rbZ6Ya8P836JTYoS6DX2EzXsOlZgKBWFjGGv55qHnfuf54nbgi8PAtw97HsaON4eO/eA47GQqPlVDwTYZrMZr1fbJNnjCYJT4Tua0cJkv/P7dR/6X3/6A9x/Fo+xXtywPI68PHb31ZA01iz+KNd0VVKyFWhOqyK8NDUZYcO8ez8Rcebsfebvf8RdvbuisYdcPVAznRTqOjAzAvPfoUklVGBHearw13O9X6bFp9g8aay27Julodbw0fUokoNZqfBtwKd086Kyn5EQOevMwbbwqqVsbaFZzbEDEmpZWKDmgkHCKkhI5RHKMUCOVRKlZ9r1LZlkiyyJ7aiZTlGY3dmhtmUOQPXSWQZjSVmpqJxPtVAy5yFCgVs28BExMEiGuNdHJ2gsxk3MlFVkjS5BraaxFK83ghV1xGDtCTEwxNP8sRUiVx/PMEhM1R/b7G76NHj+MDHcPAmzFgCoZVQMVR8WzTeHa71o10M4adO2az6jGmog1QfayWhiLoZaOGCMhJDASptI5zdvbgS/vej5eZj6dLhwvC49z5Pj9E692HYfekkqhd7oxKgu50d0lJbrBEOrqVVraMyl17Sq6a42Wuv7Spj1165rN12f05wQ9/ekQ4Npbr4MMqfdlwCUkA93i3+FqOl4aKlw2/16kF6cBQqoNaltHbIwAS6XI5ie+jeJzVKmfy9ehsaLWxnodIipq82damU0bWKSVxNNvAMHKeCpbMM1677W51jZKNfYV7SylMfLb91Tt66kivS+6efeUTEpJ/t12IPDZmiLXVqtJGJFxVkAp5wXszAWsQQ1irO2MI6qZHDKRyrzrcFlTkkc5hy0ShiQssuYXpWisTvFBun31iq/Dhfd/gPD8jIsVcwl419Ph6G5v6A579MMefTNiXt+gbnfs8gNdydR3e8zTl4TH77hcPsFSYTkxjnucF39MBSyXhbpA2Xdo1zP5NyQzkvQI2tJ7hSuKUIoMJJWEr7z56gvGw172nnkRq5Wa6btOWJNGIJCUk9Q3Se55nI7o2mP6A8ZptKsYq+lGj66FGmZqbSC5Nhjt1pUku3azXsltGLj6JIHIrHMpFCVrpaoi66zUJtVdn5V2Y1vf+vm+UPmsSy00T6yV0cQGaOrmabqCqIWX4PkquWu2CKU29tV/uwvJM6Q3af+fPtOblPUnvH4y8HSZTtRSiUvgfDrzn/7mb0kVbt68JYeZj//0t4yu8Jff7hj3npv9Ae8tfW84jI6vXu3oqFx+1PSIn5JX0GuRMcnEXol2XiCHTVo3Ic2DRoCpWhWxXT2lBUBy4n6GrppUFalAUeLvUxtFf3XsUIBTNKBJitiyAh+qzf9VEVp0hVxiS9OYiSWyv7+lHweGzqHRhFyoSYwrnbXkGJo2RAoAfRioRjx+as6U0wVKlimdkSIlVchxQdXKTimwnv5wT8iZj89PzDHy23fvMVpz6HussdwMHVNMnM8LIWYuc2LXGbyuWKN58IpBaXS1FGWoxhNyYU6RpS2eJWbmS2S0loNzsEQoGXKCktl3HWPX0cnxzz5XRl2wWpgfpsEvkFG14rUWcLA9E1YJEENpUjmaWrcBT7EBOzJRoPmwXOtIKZGuvhNCc1fsnSdW+P3lwnMuPMVIr+HL2z03vZcI8SYT9FpAnZfT4ZabQGgbhV6ByfZ6mSwijU4VzyfYnsmsrsBTIzViaAgxL35gM9Bd4y91q1ZWT46CMLuWCrFcC7qnWLikzDlm5lyZtSYpxc0osrqvXh942Pn2zMAPT4k5Fl69GdnvHX/952/58mHg1kuxHyucbOJm9BwGh1ukObEOjIGSZFp8TZv5mbxKAX2dmonCqa6COkrKoDU5iyShquu2uBYzm3F4XX8XiZRuxoPbj2lMPzHejszTmcf3P/D7f/x7/tN//J+I8yIHYJIkw1ojtUbm84njxw8C2qJJKcv3WBasEwNerTUhRlJOeCsSwbH7iuGwp+8GrHVN6lob80h8q1Y2Vq2VYRjo+55xvxOpndaEJTLNDWhpB+M8z3JYuYw2lsNe/LAUGdRVJlorhJj58OmJsCxcjieg0jnTPJeaL4gx6Cwm+KXKtaJCTmLonrMwVbTVOCsMKKn3CtFIWlydZ+albsCTaoBxLoUSCxrxRcgxtrQ8OWSt7TCmI2VFxTV5YRFvoFpARfHXSJGcEzGeSTFgtcUojXUd1vUtictQaqLUwpIWVv1+yaWxBDRD56gKQslNAneWxoIW7tD3ktaiBMiKIUojXcomn4IqIF1bh9oYbN9Js6MVtWj5HMh9WAGiXAslFJb5zMcPP/D0+IHf/9NvAIOxHUM/8otvf4XvBrrhRsDCRdajMJsaMNTOMqONAALt/dUmh7DOoa0hhJlpuRBjIefK/atX3N+/Yl4uhDCT55mSInGVLTbDdLP601RFISFqmSJSRX31v1jNN33zR8tNnkeSz955uZZdJ8/gEuPPa+9CnpVr2Vmv0+96/SPqKhu4nnKrnFvYTleQqnmStzNKbUhVrmI2fW5yFLTmfrR8cbPjl692/Nuvb/n6bsefvTowesvOG4puiT/astSrDM0Y3WKv2w9q4I1RCqfkWZuXiR8+PPHbP74HRIr+ZviGziRKeYW3V5mg1RZjHKtQsIo27PprZYVV2a8/HEVO+q++esth6Hhz12O1oi4CWF9CZjX9RYE1Dl0hNonMvvP03nB/M6CUknVaxFzcecfh9oA14A2kXJjnCMqizICxis6B0q2GbMmWJVmS1oSY5JlHAQal5XmrSeS0FI1S0siIxDZSSqLMC2leRCKfEjTpnnYGbQQ4XoJIVkouuNFjvaUfenrnUefc5H5y/damxFlpek0yrQ6TVMEQorBTKBgjN7oqRcwrw7cl+K5Jw1UAR6uF9TR2MvCcYtjA05AreZKwgOn5E3c3F27H1+zvNYcvetnLlIYiUdGVSl6HeLlu91snhTJZvD6rR1eNwWJMQGtDrkn2FRwWxWUWJrHRis5qbgcJarm/Gfg0BX737pHvOfLd04mP51nYm9mTK3RWsaQKRQaCBXD1yoa5loriifKSsS5//8LLZQWedCsNaez6TSr12Tf8F/+6AsVtd/qTJnUFeLRZzcPLC5bR9RqLX+PL5rbtW6uapf1pLeUz5tMKAkGTGqHF9LsZaa3M9Q1kqmy1krwFMX3ObXi5pky3zn5jq63N+zoY2RLyVsYLLdlPNQVEWT2h6jaQMkqeL60Nyiqc89JjxAUSKFKzIqjXzX/byEFV6VskCc5gnBGygbPCkNFV5Lp9L3VNFS/LEjOpQhgcKWtq9ChjsKW2UBrdPodBG3G0M95j+5793S1flIXwfOSTMthU0VPC7aBTjm5/oP/iNby9Qb3ao29H1L4XT2FrCONA+fEVH7JiCoo8faDEC8YPGCf7iwKWKVJ0pvodWg+c1ANJH7Ba6lLfmIglXD3SlDHcv35Fv9/x+PhM1Zr5NEnA2M7jmgdcpXKeLzKgRYCgNF1EhWJv5TpaMM7ihx3kSI2T3L9mnq/bvW0nsxyrjSG+DrM/e7DrS4CzUrUUxKWWbeAnSqJ2ntfVfHx9hhRCulGU7Zs2dON6uLMa+78M03o5qNr+aAN14TPa0/ZFn5v/K/UCi/3sO/20108GnowG5x2/+PorLpeJd4+f+PTpkX/4z/+RzhT+zdcDN3vPt1/f4qyAPyTQMWJ04YuHDnLkD738fsmZqmFnRcpmtca2QyG36YhqXk+dhqorRWuq1ji9GqUJIIBqMYblxUZeYU192TapdsVXI2tF23hKISNFTiyNdYXGrpQy78B5dr1r/95Sl0wxBYzCekkjWKs82wxytRVadffqFcpabBJj2qEbUdSmN1XkUlEpszfP+Bipp4vIMZ4iTmluvWN0IrFR2tD1XiQzRqFTQnVJWAZpQanKcUpYLRM7aw1f3g4sKXJeFnQRI0fVIs2NFf8CpyRHjRaTnpUlF8PFOLI2zEpYQo9Z/D8k46E18BUpFEpm0DLp9NpglcZboWrrFpWr6/r4rehrBSXAoWYFCduZUiudUZ8Nd1VLmftuWpgKvI+ZpBR/9vaOzlmeLzNPpwsfH484o/mzL24YvOH+Zg8x8X5Z6HXhwct9bhwCWj5AA9Jako16oQGuq9yjTbbUFTm+6vwrkeaR0TYWAS6abK9CqGJwnqoUrLmtvQzEBnAVRCusrUN1HQfgAOhmYt87offXUng8L8zzQs6Fb16NHEbHt1/uOOw8XbwwfZxxo8NozWkW6cTpNHGZF2qVKVCeK8oUiUEvcHoSU9mfyyum0DbNpru2VuRynbCUNupzlUKitKJw3cCrEhC7FKEqd76ZdddCXCbOx6MUDtqIwXcMhHlmOj3z8cfv+e53v+Hp6RFTCqbzDF2/0Vet0eJ9YkUeFkMkhnhlWeVEyQXvHN45DmOPMcLqKTlxOp5Y5sDDw2vGcSfG6FoRF2Ey+c7jncH3h8a26VBa8+P7D4QQeXx6JuXMYX/DsNvz8PAKawyfHj8SwsLx8ZlSK8fdsU36d5K+UgSo+PRJvu756RMUSVjpvOOwvwNgXiLA5nWwLAGUwtoO6yxj85Ky1jS5mcVaRzeMxLAwnS/Nv2RGKdiNYuDNmjiqFTEnMZmtiRzXQtaLL1XJTeacMdoy9J4QFmKS5L+QExMXaL5rFQHnduOOcTzgXEfGUtDbueqNJPbZ5Cm1SGyx1qSSqRGouaUtSMHpWzqbMuJf1A1jY9XJTqetbcWk8C9lCrxOnta9UEAXjKFzHQqFczKpm6cTl+MjP373T3LPzs+N9i8U/S+++iXDsOfu/i3DuGMcb0m58Py8fl1GaY3rPCu/2jR/gvVXCgsxh63oTbFAFr+YkhpgqSHHyDxNKK3o/MAUEyUllpiJKUvxrXVLtFMYJ6h3LFdAd/VhA4VrABXKS8PWntMlZplutwbQtaSeVc74c3qtQ5jaPqvSjXHR1qMU2i21ZgWdKiwJUq2ErGQ/r7oB7vI1uZ1FIdSGM2luRs/rveN27Hh7M3K/G/jyds/daHlz0zF4i3WyR04VqKaZBluMtVjjMMa2xDUHWgrrUuRcvFwm4jyxnC7UOeCdZXfYM08Xak5tL3AMXceu71mqoyaa3DVvn08+cQOLgybGJF5FOaNr4WHn+fpu5H/89ZfcjD0FGUQdj8LENC2MpIVQb0OJcWjhI0rkvK7JXlSlpceJ2W2Khpq11KRVEuu00VhbhC1Iw+6syO20sdcGzntsV6k1UUuSRiZFVO/R2uPHHj8ObQKfNulOLVCNwnQG7TVNs9XY7u0ZdoaSVqmwDExJFWs1MSykJGx2azXTEpkX8FbCAfa9sEGXEIk5SxOkAeNRVkx95VrJwFd5hbGaVMYGvldyzfSDw1jFq9udhAZpQ8qF0PajWhGmqPHMSfH9939gPz2jbcZ3Hfv9KFL4EGSsqdQaDNgA8NQoQlFWgdYo61ratWqDES0BQaWiWqCI9zJ+tsayhMASIqPVMFjq/YFb37HvOj6cLiw58f6UWFIl5Yq3zWh+7R1Wdk6rS/XWY9DATykfhKF6xQlW79AVJ117ECt9png+/bxw888GAdv1W8GiFwAPSmGd4ZoUJ55Qa7z8S5YG0DyUxHutKrU18rUBT1LDqY2Nvv4cs/lFtQRL2jnSmnbTGErbPWsDly2prJ11tUjs0MqMzzk14EkMntc+R68AZav5BIigsZ/q9nnaBdl+adPy6oYDJSeUMuQYyTFQlaZoxBdxBYSMbl5UrVaJiaorEMA67G6P8h36Zo+JGX26UKnMnSIbj7e36AwxGlK11NL8oPoO5T2m7wXEMIpqLdl6+sHzetgzx8o5RsbGA7R3e4Y395hvX8Mvv0DfH9B3e3SzPzBOY6xmvL+jaMucEqm7J53fUZYjuUxMIcK4p9gOs38LnaccXqP8QHE3oH3baxMFAQONFouenGSvcU58Nb/+9mvmaebDjx+JodUjJWCchAsNgyGnynG5EGPlw8eJYdozHg70+4Hh7hbfeYbxQE2BJUxopSlhEuJLf2gs4cTKsFjVLavM88VNbs+ArM8iaKeETajP19nWLSu2UfkKuNLWoVlpD20ZFfIGwIoKb5v+bP+8vlhr12ewbrUmSrUBbWuK1t1qfbZWllSt28/9HIT6f/36ycCT1dB7xzdffcllnrn/7T2X6cQffvv33I2Wr/7d/5aH+x1v39xQKpyOEylXiXxWlfsbxzw5XOcoS2GO4JTa9Lsa1YpdgS5zUS1xyuF1QelCQhFVMxtTptF3ha1StBFUbr2YDR+8Pv5sRbVW4ua0bXBKQJRQFREFTXanS0XXDE6ivAcvE/V6PFOjMBLQGmMVyogsrxawvkPL2EcM0m5v0dah5yjN2X4vRcJOJBnTaULFwJAjdlHk87PE0i5HlPXsb1+TtaPrHcpodOdZYmCqGZsKncvkFAmzYkmRp3nCqkpOipu959Vu5DxfSMuRWpOY2zkvhupmZYJcp2BoTamapCuzsWQtcgyNTH5W7xu53nJtS8rUkhi1otOKUUOnJYHEaRqwJNI9g3ghSHEmh7dWAghWmi6+ncxOrwCV3EulIZTK+yVxypXHVHDe8tX9Hm81Pz5NPJ9n/ss/fs++t/zZmx2dNRx2I2FeeDpPRFV54+VzS95GYyNUebTX9yKgw/qwqu14qArW7IDPDqhWyIYqfmO0z7ECUZdSOedKaD4YuWQxz2+fLVUBoSStT3PTWcbeMTrxhhqdFFZWSGE8T5Hjkvj4eCbGxF993fGLh45/9bbnMHY8H88sU2IuPdoYno6Vp0vifFlYFpm4KhQlyFTReChZMR0hxJ9P9ZO3qQRQDdqJl47RAk6o9QbWq7eXbOqCOjV/e0oVWbD3ToqcnElh4fx8xGiNt44QAtP5zOX0zPHTe3787vf87u//VsxitaSB+l7YSd55Ot/Rdb1sHLVwPp+ZpmlLj5jnibjMGKXwznKzGxg6z/F8ZJpnpsvEMV3o+z3O9TilN9ZPDIG+9zhnNm27VjIJ/PT4zOl04tPjE6VWDoc7un7g9u4BYyyPz0/EVHh6fCSmxHS5tIhZadpiDMzzzD///g8sYSaGCaMUt+OIs4ZhGKiVts7AGiuT/gZ6O9+35L+WrqdpoKDHOY/zXUssCls6jLGWYei3vUA3/72yVEIRr5ZQM533eOepNW4MvqIKvv25gPSRnDIxLMQoIF5p1cB4ODDsD+zvXtP1I5c5ElKmpASl4Don5pzFiidF2wNXc13V5DOq+Vg4J2CI8Z14jXU9SmlyK1KMc7LfZWkY50XMes0q61VsEjeNmKHLmWlQYWbKhfly4vvf/4ZpuvD49BFjPf14w26/5/XbL7i7e8XXX/+aihTz58uZy+WZ1UfAd17ub5V9ep0aOyOgaIkzJYXtmVqBhByj+B0oaV5LjizLTD8MOOeYtaGim8SyYLTIdpSXybE2VoLBlkAtTV7UvBpq87ey1qKtQWklvlJK4YN4O4Ug3iDGmmYGbf5X2FH+133l1c9hm8i0X1sz2/arVuyCNDQrczaWSinXaaVGzinxciqcQ8Ebza5THDrHL1/t+Pp+z199ecf9buTL2z3eyvwtlUpskuPQRjUKj2tG2tZJYqg2HmUcWgsrJ4REjJllWQgpEaeZukScs/S7nhgDKWfZI62h846h81AsSbVQhRdJWOthLM9yIsZESlJwG1W56S2v9z3/5qtX3O563p+fmEIkhkwudXsmU7uGBmkGnQWqIieJ1zatsZWiJJKisBNzMhQlAzolil7xCzXi7QFsjKIVcF7/v/iKC3hf0kKOUgto77HdDjcO+HEgzjNpmSlxoaYILWlYN2lcbSEWaVoa4K4xpp1zVGLM5CqJd1q35qZUqLJvTotI0uzYY7Vc8wrMSyLmAipLsdPq2FqFCaWbUZExClsLOfWknAlRVoQ18rmNHoRRnzRziITzUfZjJfKiYnpCrnz4+J4Yzuw87G/23IxfUkvdZNmrqE2GyoVaGyu/SjIUek2hNS2Rr5CLwhQljF8qxkoQu0ZjdSblglKJzooBtDuM3DYJdG8Nv/105OkyEZN4ON5qg2vX9goYfL4cW7ahPKvt4XyBRW2/C7sArk+ryJdKk8v8fxJL/v/vr/8++1S9+PuC5EerTX4OV4Z2yfI86ZcShBV4UhKEsob9rFI31fqIl+mmkm4rV1vqDSuhPaXtKe0MV2tTzXrmCmi1MbO0WCgIOSpvzffKdiolN9nl1bZgAxK2X3r7mVWV1l+sPmB1Qx61ljG41kaSdJP4AgmALb1JbWmLYjMg3mxrb1azBBZUokjuhhHd95jdATMv6GcBnoJXZGOxbofOVcQuUcHS+lrnMOOAubsFq1FeQOisLM4P9N0Nx3nhbjpjpgl1uWAPI/3dgfrmFr5+QN8cMPsRjYBj2iq0rnSHPVVb+lkx6ztM11PmJ/Lj71jmGYMF2+P2X6DGG9L4GuUGVuaIUud2LkidscrHc0tXloGu5vXb14QQiakwnWc+fvgEtdKXhDKasdNkA0dmYk5czs+kuBAu34rXk+vwXU/X7SjakmwHNUu6qDGYFyztbZUqtZnSbzec6wBpXcer95jc09KA0eu/E0be+qxcn4FNSqf+xLOsDTBlDTZ2MPrlW9i+djO9ZwXLXpjmN8B1/Ufqxfvh2qm/YD69YHb+v3n9ZODpr//9/4DRhq7bkbLm7WFP9+UDw//urxgcfPnFLd5b5nk1IpWHNgR5V3ejYbnpePPmQLp46qPC1czSphadEe1gaDrV3joUwgJRCqxVUjw1N3rUddOuSpNlHCpFcy3iSUQzn233cNVlrxJi4e1UafjLGnVpiLmQSuESF1ItHN7c8nC4odvvMdZw+e6P5GmiHwYpivvX4veRZVPobnZoZ5pmV4EykAqqMSvcTibeRQtrBaNQ1WB3e3QnxuQSjb5QtYXdnlAqT+dATpUSJnqt+cXhRhB9FHNY+HSyxJQY5lFolwWcVUwhMPYDXzz8WlKnQuF0PvPp+ZFQMqEGMJbq3GawmZuBelUt8aSKObipMlEwXoqXFehLRbWHRxOV4lQV5wo1rW1iA3YaWGXa5HWVPHZGqKZ6Vc6vk6T24K4soVNKJOCCRVnLv367xzsxID5fEr9798hliYi8TfPu8ULfOV7vPWcDf/fRcq6FPlScLjiTtgcZ1oJBofLKVpL/rlXMoiOFVBWhtgKi1Kt5a2PG5No8Qnlx2OjWTBkp4hxAEk8S3R7q0YiRnrVS9PauMWEac+J0Fo+GmAWwOqdEKIVYxG/mU0gM54Xhjz+yt4rL5UItGf2qxzrD9580Hy6FHz4tvD9n8MJkrFao88spkZKsj5pf7FD/wl/WuWtRodVm/Lg6gK4AgWp7Tm0jyrz6fXhPXII0LvPM5fkTYVk4PT2RUyLMUWi740DJiRgCl/OJ56dH5hhRw8Bu3HO4vcU5AZpSanKLWokhsd8N7HcD1oCiScVSxHaKaju0hpICpfRUDF2/w/qeWk+UurDME0cFzom+33tDvx+oNbLMkcenJ0qB29sbrLU4ZxnHQQzVteH+/hXDsCMkUKUwHu7ww0i/GwjLwg/v3nE8Hvnw4SMAvvNt/WectQzdLdTKHALpeObvf/s7nPOM4w5QTJfA8TLx/uMzXd+xO9zge8/hsEcp1SKPW3JaXDinwHQ5M59PrPrzzjl2hx0ge1TKmRib8bHSImvLIvmqFvphx8E5UsrklLlMZ56eP4jMcY1F7was81Qqw36P73v2BzELL1Uxzcs2+ddWIQyPVaKnBDRpe6a0OIrONGPUxqpIaxpiLeJrFWYBfLf0z1Zs16uMEMA0hp3RVvYDP1BK5sPHH5jniY8//ijshhCpJaGV4nC44f71W5zr6Xd3GGuw3mNsx3k6SbJhTFymiXmaJdnOCdi32x+EQRIDW+ukpVDPpbAsC/OysCxL65CE/ed9j3MeYy05Z47HJ7mXfY8xjm5Q4lcWArXmxuiSBhwtjcMKtqutAbEtdVGMyo2q6KqpzVRcjgUpfmqthKX5YDn3WcPxc3htdh7NX21DwhuTogVNY+ra7sqkMxZhzxqt2pkuNdmUK0pXjC0MzvBq7LgfPb+8H3m19/zyVc/N0PNmlGj5kAuxVi6pNAmdRmuLNnLPtdV4b/EtjUmatkStmSXKPrZMC3GJeFWwqjAvgbl5qq1NOChyEXZWaoDSHCNzyKQUKCVvQ6AlFY4h8T//8wesNrx7OjOFwKuHgxhD+w5TFL/97kd2vacYqfFSrq2mljPANHZAydJMtvmleAJFxZyWJuXsW5KvgEQhTShl0NphraLvLKpmsg5SmGtDKhVSQVuF7Sybz0YpkBOlSYJRGuNHTDdgemF05hhRaKwbCBliKegitgWqrjWVQ2HwbsCaHmM8qQsoHtF64vJ44TIHQk6bP2GlkpImF0VMgUrhMkcZFnQeoxUhyJ6X1jrsPEuCX9eJz1xriHNjaxxG2T/n0MzftZiMoyrOGl7dekKKOFfFT3Bemmm0nMl4R6jw+PRIiCKVM85jh54W9QGrW+s2I9IIC3Jl8MnaF0alQ2dNyZZiJGW1oMi5NvljZRwcXWcFEAuRWiKKxNubgV3n2Q09T/PC+9PMaQksITCFvEnp7eon29iHde1JygogtIayPcPWyJ6laTIcrhjD2ptqAyqtcNTP67X5y5RVSqcaUNrkZyWzhoWs7PFKpai1WW9St2YrobRu/o3XXlppjW7NdEmJNehFrY3+C4BHzja9MWjhJUepfcX6/V685/WcV9t7qg1wWmVQK/ghw5sr2CTfmZe/abFVWIGs7S+1gSoWI6v/rTKGbneDy0mY1XamnoIwOY8LoFGdp7Zmt0Azareovkf3A3o/YKzD1UrJkVM8cawLp0FRa8drZbGlYHNBJUiLRo0j7maAsafuOwn18GJOrozDDgW3q+x04rbXpMsz8fyE+fIN9u0D5eFAGTq0rui0yPtRGo34zjmXKT10/pneV7h/BeWWqZxIKmF2B/RwQN9+idrds0qtFW1grOr16a+ZWk1jVApWkFtQjKli9/D27SvCErBO7CwkPELRDZ5aEje3kbAsnMsRVOLDD38khIn7b17hOo/rPMUoXL+nxJl8eZT+dDlRdfOnXFnkSom1wIv1L8tOZNsg5w7N+L1tEJSURfFiGoagmpSvihXKauWitjZZrkmtLwFWva3XRsDaXqsEtRYxkd+kpSthp2Eyax16BZTqZ2tZmFxsT+D/TxhPv/yzX1Ny4fw0YU3gdugY6p5v/vpbrCnsb0aR6VyEylybV0RKks6z7zXTaLm9HYhGE+dETZI2JNpWwc9iruJfoh21FnJNGCXmx4LmvnhT62agFBktxakGXRWmPbGNlCQ+s+vtqLK5lCrJK6lI9LlrE65QMgnFlEX69LDfc3h4YHh4QDuHmc9Ep+mdF+bCq9co51nOFyiFfj9KnGTfUVGETyfZCHNBaYX1HcqaZvjbEHFjsH0PxeGNoaZEXSaq1pS+Zw6J6TwRcyJMAd/YCdoYcIbTMhGUTPEHV6i5UGImE1nSwu1+xy/efIWpCps0P7z7nnp8JqhEqJFqDHi7xQoXLR4xkSJMsCLgkqZgdcU5i7WyQVKKIO7FgpLklNgid+csU1IBa1WLyK6YIpTvXkmCnTfi42QbcVAIYytlthLa5PbHJZIq9KNjZy1fvz7gjeKH90+cLgs/Pp2YY8YocfB6PM0cSuEXtyMVOGPQBT4k6HRlR978nQrig1S3h7iZRDZWU6QyV0m6W6qARrUUkTPUJsdaiwq1xhEbrBbTcafFE0KjcEpKKbJ8TqMUO28YnKH3LwAnpRrwB/OceJ4WLjERSmauhUTFeItzhmPKPM2Bj/HCTCHME9TMretx3vDxyfL+DJ9OkeepcNBamuki73uZKjEWSmof/GfykshTWHfrXMtG3V+LGKWFSVKBkiSut7Rn0xpL1omcEnGZmS/PXE4nPrz7gZplbXedJx32bSPPwno6n4gpon3HcLjh1dsvJRHUdVwuF86nE2FZiMuCs46bw4EUL4RZE4rEVhunMN6xxNwMEKXodl2PV3CZAjpEQgMLYhBm1djfM/Se8zIRY+Lp8USIGec8w9BLzGvf42yHsY797hbvO5KMDunHHTCy3++Y54nvf3jH5TLxww/vKKVwc3uDs5bOi0xuN47knPl0mVly5Hi6MAwjvxj31KqYQuQyBZ6fz+wqKCNxv8MgXk4pJHLOLEnig3OKLPOFME9SUDbWSz/0ci9rZV4CIUSp1ZQh0yLR20TZu47dfs+yzISw8PS88Pz8kXVwMfR7kdK0E/z24TW7g8jrtLZM80SMUVJH9DrsUJs3w1o4rrTPUhv7SesGnLRiu66eEfIg53JlbigF1bHRscUfpG6fUVUkFctYvHXMS+b5+RNPT5/4p9/8V8iFTjs67znc7BmGHa+++BrvB/rdnSQBtvTGeZnISdgn87wQQsR5kexZ6+j7gRg0oUohXdZIai2fOcTA5XLmeD4LvV9bzN0do/P4rsN6z/F0ZppnnPXSQFqLM5ZlXqR9zM1XMWdhk7Z7sTYC8ogKaLcCT7XUa/xx3Y592FqIIp43a/Onr6abP4eXWAasKTmwMjMbKXjDoeTEW1nDSuwOaA1OA0tTrsyxYk2lN5XOKr44eL66Hfjrr2+4Hx1f3Xic9fTWUYwk9uTGuOu8YvTC3LHWYZ3GOk3nLd5bUq7kDLkkGTzOM8u8sJwn4rxQnMJbCDGxZAGA188BV+NtqUNyk9DFq4wF+cAhVy4h848/HqHC02Uh5Mzbm5Gb3jM4mf7/8OmJzlv2e5E3r950pWZh2avWvDZgRlcBVFIK5FIJizwb2thtop1LZUni36R1FSmzFfOBksXriWraUDNjq6aaLAEpxkJpvk1Jkkqtc2jXbb+omRyTPF/WgYrkqqlFQA+zZaeLd4u1jor4a1nrSWGmFtlP52nmOAfxIW0ASYqqec5FKoUlFZwx7GPCGfE5VUBEPkOegiQSWoVRpu15jaGjYOhdYxxdgxtqq7GNVtzsHDE7KlE8qKI8q6u8qhoJqTmeLqRUcMbT7UYOXWtYV+CpRlZDBKHICuovqXat/dIKrR0laao2DWxCJIZKwPmqKtY78cLRAnavZtN3uuMwaIbecwkR7575cNJ8/5hZ5gaAK1BOJEdq/SRbE9aewLaHrzv92vy13pL1S1YWozZyZunPJGX/8l8rkPSnqXESJFQ38/A1KavWKuChWaVDVykbStjEKwNvBVjWl2qMqZwkyVevelfacaHYGB7tYNsa6pcIVkVYSFuz3RhFLz+TgKAr02n1dpIfols9ofXV0uXz1r+9Gjtnxb62r2t/voJOtdUdfugpOePDRFaK6j01FvENpgUaGU22jR1YxEvRjh2171CDlz0iV5aSmfLMRGD2iqoct3YQ/7SSUAmyBzP0MHgYPKV3aOfRXQfWopxHdwrXazqV2DnF5fKJeO5Rr27Rrw5w00NnZWiSm+exsQIoKydAmM84p3GuYtwBbSz5aQ/LM7obUcMOtbtH71/BfESlIMBTu2FyJhSoayBD66mRxN1SCrb5Xt3dHWR4nwRwjlH2BN/1UDLjboe1hjBdqDFz/PQRpSTgpuY1/ERh/UAqmZCi+MOGGWU9utu1OlRsPap66Y10Xacra2gFLFdmzBqMlhGVBqqglNgTUBSqlhfSzSvYsz47K4N9ZUDJX16/UM669nNLbgBU2Z4LGSYnUVxs77cxTjd09Mps+lOw6acO/X4y8PT04ZH5MvFf/+a/cD5+5NP3/xmrI1+/khjZsHouIAXS+nyXIqaRFuid4uHWcqyZHz5aVM4YhLKsjdk82lfGgTzH5lpMlkytUtCk2i6IFg049erxbhUoo4i5sDRQZE0x23TZzbPHVAVGpAu+MU3s/kC1DivbC8PtDd47oZ7lzM0XX8LrV4SnEyUmlumCWmZhTHgPRmLva151kBl0wR1GAJbjIyVnlvNFPmPfs06Q0QrloRqzpRikmKilcBjkQBVlcWH+9EGAKWfJwJ3rKQ5qp7ksgU+nE0/nyHcfP/L+OXGeLV89PPCvv/mKb4eeL1/dU9MFwjOqq+geQkv/uEyJyyUzRcUUFUsVD5VzKFxiJeZKypqVImWVxiDpQkq3zdNpdkW3Yk8WbyqrN4dMC1b2Wc7CFIprsbwu8tVx0co6uOtlvb3ejzij+fh0JqbM7378xBzE22rnr1OG754unGPizc2IU4p/8/UtlyXy7sORkgpmkVJG63Wutm5k16mMas1XrY2a3763Nkoo6ih2DSAr7YAE8bVxxkgssVLQqLnOGJzRPAyS2rje+ylWllQ5nxZyzhivMFaAu1JhrpnkKsZpOjSdkUUfGvj6+6fM07my/8LiByuAK5L8glF4r+kS+MHgUQyjALJhKeQMcRa2yMuo2J/DyzbflxWclyhTSVIrpXC5nIkh8fwsxthGG0llckYQv5QIYbkmty0XwrxsTJeqFCFnns4X2VMUPB2P/PDuhw2ELAVSajlGSkxIpfBVKFWYlzOPj4U4TzilUNpiTcF1PcZ5dtZKBK7tpHlp0ryHu1tuDjtyaglqizRg065vDafDd57XrwcqitevX9P1Ha/atWjJuShVSWnB9x2Vyul4JISFT58+siySeNf1A69fv0YpuLm5wRpL5x0CCMgBezg8SE1XwVnL7c0NtRbGYUJpAYOMsuRYiHPgfHqGCmmJrWEWNkJOEasNd7evpIFDQggen57RqvlhxUROdUsE2pataGeZpzWx78Q8n4hxxnvLbn/LMBzox72korUCVWj2kFJEq4zVFbumUynVpnWrDGwtIJp+v0JOESp4LwmSxrbooiTJdKfzRM5SCCmEiaeNpmbp4Gql0fRXOrpFAUuYOJ8W/uk375mmCz9++IFSC77rGfuRr998Tdf1jLtDG8LI/lynE6VUUknCHpmXlhoo3gj73dAkMUBJpLBAyeKBkmaWZSKFhVlrnk9nTnNkSZWKMMX6rpfkHaUJuTbwUIr2aZqJKXO4uaXvB/aHW8Zxx/PjJ5Z5FoN1Z3FePMdyKRAjzoofne8c1lo5S9bbWkqLO25Gm1V8sLTSdEOTM5qXERE/o1fzq5Q1Is/X2nTZ9oFbaPf2Namy+aqVAjFpeqf54sZz6A1f3XhuBs+XNzt2neVh9DijOC3gioRvGGVEQiexSE2uKkw24zw5J5Yp8nwK5Fw5HPYc9nuW88I0Tzw9Hjkez1htZAhTZciTW20oFP8XZ00tiFRAzv2XTfz2JcBpSnQ+0rse7wz//pdvAPjzt3cces+bXY/TiiUGlpIxIYldQJOpxJSalLSldnrxdbkESTCe0hrSUEk5kPOxJcBZclFMS8aYyq67yilCqpzmhDGZzkkAQS4JFzuR5hiLch1xmVguRypamDvN0qEsZ0gXthWvPUo7SppQBOIcySk2ppBi3EE3mE0+p0koXbDGkeyAMR3GJLyrKJ3EmwXFucp+2iyXiEmCJU6zyGBH70SuXZP4VkZhb3gl0lvtZL/KuRk5VzERT1WY0yElttuqQKVF+oDGeEeJL9XxcsEYTUgOoyqWyi5orJ/ZAcPoBNzsegGl7SASu5YWWkpq3VcDrNvAEFWaXUTFKjC1oqrFGU8MEIPZ6tax6+htx2HoySVxmhLTkrFOsYsK52758m7Hq7Hn+bLw6TxxCYklZZZcKKZ5mDbPQWHD1isoTIOi2nBi9US1urEXUNs5XCpynv18Si9pYF/GwLfG9KX3zZVNobemWgYUvNj/yxU4qpswTYaIDexpOM2VSdV+/lrLKhozupEirmDQaqvQvmuBlrAjj6GSyPtNgrcCHhVAU2v+bIu6NvH6inHBlhZWVxAgr4ZerZFvEjxRG8gglFJIMQgJIwoTZRgPVNezfKlQ54k8V1gi5XRCOQuv96jOoQ57cJ1I67CoXCghcDqeOMeZ73zkbBV0O3zzPi0pk0IEXwldxYw95q6jegdeozqR7Bknz6UtGl00zkU6HZh9JutI2I3Mg8dasMQG3OkNcFVGLC909ugKzns679Deg3b0+1tMmYVwkhdsTZiahVWuXggZS2M/tZ7MKivG/k3C6fr+Cq5QySlDKdze3Mge0thrqzpluHsgp8Tt/Uem44l3//V3zKdPfPr9d5Qlcv/Vl7LlOIupHXbcC8BUlmbuPgho6rt1NbQVo7bBxfrrJSC7fSkycGENz2km+agrACsAtWrgXQMpa5OE1rIpra6MO73VrS/7upesJ3l2Vq7ln0ClGxPqc8BJa1ECXT/DT9+4fjLwdH46cTo+8dvf/C2X4wfK9E+MvcV+9SuM0UzT3C5QA5+AVYpE88HwRrEfDWE2RC2miyg5fPV2eMhHrtuIoAEyymwfbDXoW29MbdVWbRvYCmZExFzz5eWoL35Rm0GnsW3CqjBG4Q87GEaUcWSt6YZO4r5LpebCeHeLUYqnJZHzRF4WUNDdeLQ1VN3y8nJtqQoCZ5i+g1KYjp/I88zy+AxKY1+/EdDKtIVknaD5WhrjlCUxbhC6DLVYlpj5dD6SlSZZh/Gecb+T66md4MGXC5eY+f7TiSkoYKQfDthhx81u5ObVAyY+Y8IHTBew/SIU+Hnm6dny+JQ5z5XzDDOJuWY+qootcIx5M6oEmvZdi4ROtSmBgrrZdYurViylJYPIRrBOa9NSXsQ+XxlzRShHOC1+VDedpbeat4ceDfzh8chxDnz/eCblwk3nMU0im2vl0xTIVbxm+s7xzf3Ix8vCbz6cWDKU2Kb67eHZrDDqSgWWB9iupxqSXOe16P29E7NAu1KDS94KR28NvnmPaCUAUsoF7zTeWva2MlooSjTT3x8T55Q4LoF5DphBYTztmoFRZjMYN1rhvAz9zklYWJ+mwqlWpreebA3OgFEFjEh6nFV4B9ZrbK64DoyqXM6VFCo5ihzhv+Fm/gt/SVSv/P+1YJWDXsDoeRYT63fffQ9Uuk6e993Qi4loCFtCnaSeyX9LLG7LdMyFJS/olsx5mSaenp9x3tOPozSDuVJ03SQKegOeKjEsnGuCHLANBDHG4n2P7cXzw3ZdYwJATZGaE7vdiNZwOp1ZloWlSf1iTMSUsN0gXkqjAFaHmxu6rsN7abjCHEgpczpdWgKHAwXLcuFyvvDu3Y+EKFJC7z3WypT45nCDM1Y8k2rlMs0Ya7m/u9tMLo2SWPJSMt5qlhBwLaGv5EqMiXm6QIW4rKl2QlUuOWGMyBdTLcw5kVLkfJmw2uKtlxSSXFvqF9uwo9GGmil54HJ5ZpqOYv7rDLvdgdvb1/S7Pb4fwAjjdrpciEtoDXHGteCLBkGLj5A2Te2tGgCttoIgtunsapZurETJZ0TiFIOwjHKSadYwDEKnlvEocu6BxAHrBoQVkR6en/nDP/+Gy+XCx08f8X3P26+/Yre/4YuvvqFrKXVLWPj4+EEke8sse2ytLPPC8/ORruvY7XWT7nVybraYwRzFhF/8CsTcN7ai5jItwrorUNFiAN/3aCtnzRpbva7tdQ3udjcYY/DN5PN0fBbGlxbg1fmWDDnPlJwF5Fh/Odv2oUpOpRkON+PWdZqsnTBLjd2az58TaA4rMLz1KJ8BT2tK6nW7rhvwlKswyKcQWxMkwMHbG8+rnedfvdpxM3i+uNk1dq4AVXMSBqy24KvCaotWBWMUzjgBNKyEAISUmZbE5bJwmRa0dewPe2KK4j/3fOTp6cg47un7fkvYW4+ZyrWJlM/aPCkU11py3bxfsCbmICm+cwbjDH/25o5dZ/m337xm14kEK+bMdx8iMWVCLOJT6mTSnFv61Dp0UkitNYVILIVYVjBbmBgxTBhrGbUlF/FAdBXostQ2SuwATpfSfKLE06xkkVNbY8FWDIa4LEyXC8p6jO8xtbahZqKEIBIipUBn0JmaA4pIjhPLNEMzW/a+p+ulSaE04FFV2VOMQ2mHUpKcTJMdoTSX2CbdqMYwE15OKdJke23BiLlsqVXsL1BMOhNNRecrCKCVwrVrWJXYESyLpNitPpkqyzVcPTRBvm4KS/McXKv+QsZwMweMVZRlEsChEzm4sh5KRKXms1UzSjkqtjWP13pSt4ivtafQaKxxbdvWIlvPid47VLWgvBj76hmlA9oUOlfpOycqDKV46iQJr7AwpUJIYmlMbR6mba8CNgPxl+yAtS8ScsMKSdGGYa2vKVfP0J/Dq9SCqmoDn64+MWvDWq8s1g0MahYUavWxue5/tSEXKwikal2bj+1nblK9jcnRvm0DF9SK4LP+GXz2Q1o/cGWpqTYYWu03mrcNV2XElUn14vxZv8HKWH15zvOiXlnf17q/rUCVkWE7ce2lRT7Y+Y5iPRmxYai7R+mmjmcBEuwe1Rvqqx34HrW7RcWK+rSQ88J8fuJUAx9tIgJK9Rit6a0VYKaFUERV6EaH2kkASLUK5ayEILgO2w8NzDeYPGHDgC4DJY2kviM4I0qjmkDZ9rnbdVDN+844tKnbea+sBWNx/YhOB1SJqBLRNaOp27BlvYbr/6jmO6fb99ZVnAytEz9WqdcLpUjq7ThKWim6qVlCRGnLcHhog9KRk//ID/UfiPOZ84dPOOdJMUrKndFgLbobmoVChGKEnakk7EDYcGlbC+IXtgJIKyNu5SivC0JAswLUdQ2rQlFXOZyqzTi/Me6vQGgDtOpLwEm/fDSur0ojxbyQ07GCT9eCoq4XeX325KnenlPxXrt+8U/du34y8PR//j/+Hyh5IR1/y6AiD1/eC7U6ZLISmptQ5Fv0eA5CETQCLIVUoSruB8/kRSZkFXTOyyRGmbbJyPKKNWPQkl5XocaMq5W9EUO1oqRpNrCZjNcNfIJ1kxepknh/yPWVLzBAZ+VQXioiKUuKWjU31tINPbthh3JOkNIqutgaA8+XI5RKWgJVK0wnKKf2TqRvKVJL2JhKMS1yuybRn6ZYqdXghlHS7vZ78brIYmAbLhPU0ijU/MlAsJBdQC0LLgZMrTiVUTlgLmqjd7sKr3rL8PqOu7EnZikgfvv9H/nu/Tt2fc/dbsfBK+56xc4v7P2Maciyrpq7g+Fun8W8TfVUPB8ulsdZ8/688DgJHb3USkiSkDOXQMyV56kwpwoNcLItFaTt6gIkrcZ4CryXkmTVfK/JOyknQOKGdTsYak785oePpJx5PC/kUrj1FqPh0ElxEXJprKxKKJW/+e6ZXW/55vUOg+Kvv7yR9xslzSqX3ICj0g6X9b0KE88oKZ7K6guEFOLeNj+Dmj8zXq0Vks5EVvoiXELivGTe3GteHRzf3Pf8xa0XMKQW/q9/rJw/ZM61UkzlcOcYdpaYxKdgraLCIgDWUis1VbIS341/+6s7Xg+eP3uAu64ZnlLRdSKXzGAre1c5dLBkxTSJjCUuipLXSVERg/2fUfO21hXUZmDddZt0aLpc+PEPf2S+XDh/+CApGbsdxRjUNAmg0GLmUwOQlRGARHvXJkRiuqwUbbJjOIw7fvWLXwrw1A90/cA4Di3BsxUVvuNE4JQtOSfOU6AzGm869jcHOusZ9gPd2BPbHnc6zixzbKbOid3OY6yh7zzOaPbjDqU0w36H8w7nRdffDyPGWCn458i8iPxqJeT2XuQXH378nnme+f6Hd4QlUEuhd47Xb94K26FJFDrfgVLb8z/GiDaa/TjInltlcrNczigEbH24PfDv/vovSSmxxMh8ufDPv//j1gy4Zh4uqS/iBVC0QylhaoQYyOVCLJVlzuQs3k1aSZHa9x4zdA2sn5mmiWm+0Peew82Bm9s79ocbqFIELWFiTgvWe5FQO4d1HmsF2KUKnVuikauwtZp8TCnV/Gnq1oTlFEkpMU0XZqVwXde+LjW9/Ao2ylnpnBi+W+dRCtm7U+Tx6aMAb0VYbbWE5rtSGcY9f/H6S7qu5/bhQbxn0EzLwml6J9d2mWQoYxoobh3ewzhmnBNZrneOoesJrQk+Ps08P36QyWPfE5OY01+mmcv5AsairMdbTzeAsYZUq4BVKbfPJYi/sZK+uhY9Oee218sU1zpPSpl5DvTjDu89Nzc35Nwo8VrjvW/vX8qyOU/UWljmC7VWdocD1ju6YYeieUilxDJN1yjrn8mrrImwbboJcr5IsAq41i+VKky34yyDipQF+H39+sC+c3xxOHA3OH71aqQ3mkOTdDvn2jqRay+m2gjwasDYgtUGp70k1aHpOs/hMPLHj0f+53/4kX/4/Tv+4ffv+OrtPV+8vuWh09x2mrvB8fb+wFJgDrMAPFlTMhjtUMp8NjGVIU0LndGW3eDQNjOOA31/aclicOgNb246/vf/7lu+eLhh7B3OGu524hn34fGJEhZGL4E0tSRiVixBGo+swOiK1RGjxR+slCJpl2X1W4NSZLBZS6GmSlwSSht2o5fhZmx+bLP4cnROobTUE1YruqEX1o4RWVgIU0uRlGtprMZoYTzlLHLuKkhJG4RqcljIcUKpih87rNthbQ9amIW67VM02WCYz4R5ptQFTCYnSFVx13d0zlBqoNOZiULKeu2FhXWuKpeYMEVLQhPQWTHPdVaexzlECuK7qoCni/iZWCe6glIytUiISq6FkKKcNdo2FcLKmBcz5mlObV6gmELGGE2qhbev9phSqSmhjMW4AaqnGsvy/MTHdz/i/cAw3or1g3dUxOQXY8TYnoQmI62OpusM1iZi0KQYSSET0ww1AQI2eWM5Lx1zcOiQMCnz5f2eV/ue+/3AZUn886cjT/PCcZqJSczYa6I1g9dmTGpJYeVW1bx3EMZTrS9kd2vz9jMa+K0vUQKUDfR5abQtrxV4VOtXoxoouvrHXwE8+dpcyuaj+FLGV0rzk5UN88V+Wbc+rnIFvhSNZbxJv9vfadN8kl7K4nWza2ndSVszOa8slrz9HHlJ7yNkqnWTLhsDxRhzBcDW4QKglPxMpUU543xHzYUcFmrNlCTvve96ISf84is4TxQtz59JCmIm1QuoQlSd+NMuMyEtPPvMrDW4HZaKrUV6HK1QRiS8NSdCmglWEb1Ce4cdBpTz4BWqE8NxCQexqMsTlYS24ola0FwCsGQwAT9YbCcsWWM83ovPaJgmYork0lhBDf/T4y1Va+KH31HmI24+YTpJbcb01CxBL9qIz11Va98mFhnls/uMSORq2ZbECkjmsiaztfVVJShld3ODofL1L74iTpHTu48YLOHpTLfvcaOjGCihFwZmWiBnSpgkBdTvWprcVUKq6uqnxObvqbc6aU1fLKxel6VCTFnsn5p0T/waG7gtk4INZDKtb34BwXKV3rGttT9lGW/+ZTTQdY0facOCFSBVTZbMKr1r63Z7zutP7xp/MvD0d3/7n3A682Z3ohssr+7eoo1hWZqpmrn6M6i2CNaOr6pm7FcVO2fpnCYpufDK2MYwXKVmhloTuaZtak6RDcWoijOaCIS2uaz+6qohd+sUkLpGBMvVKWLYsl4u+fBG01nRgYuZthhbKm1wzjIMwjI4BZGv1BgpKZFOF0qSA1JpiYTW1mwmxYREzZk8z+K1pLKYGscoNh9FPq/1HapRFlFKvh7IQZKgfOfbRawN6mjSNiMoqbFgVo1JBdXMW0tZMMZxcAM777i/ueHxMvGHj498eHri+/cf2e/23N2/4tVh5Mv7Azc28uADgy7sTGHnDfvO0lvobMErj1Oam8HxcbJ0RtMbScXJpXJeEksq1JDJNTEvhedFUkSUUnhPM3KTZC0ZZmtse8hMk+h5JywQ2+5ULPLQumYkOAehOP/4fGaOiXkRD7A3e09nNYdOgKBLlKmSSZpUKn98mjgslvu9ZfCOr27FPPgcxUQttgji3IyAc1VX5kGtmGaWnxudsZQiUjsr05ncvKvSBly1yS6lxVbDc0w8LZmRyn2vuLtz/NnbYWOv/PY54o4y6KxU3F4zHiwxNM8LJYdyIkNoLIBSUVZjreYXr0d+cTvyppP7iDGgKvUSqaXidKa3Ve6pgadLJSVh0FBo6HVzy/wZvlaTSW0MuYh/yDLPHB8/sVwmwvmINYZsxBRuCbGBqkmKEgtKNzmpkYkNWUDtda+RwYuh7zp6/wrnBHjSjQUjhUvFKI3BkqMlOMOUIiEEXN+jjaMf9hyGHeOhp995zsvCHEIDrjOppWqWdiA4J81N3++w1qO9RRmN95KgN+z2GGN5Pp4bkBZRtdB729LA5JA5PT9yPJ14/PSRlDK78YB3jtubG4ZhYDfumkRQUkWnGMi14ot4pQ2dNGSlFGFxZZlU9U4zjj3ffvMl58uFP373jhgj8+UkTKTOCdXaiDTSedvCH8RLyFpPKRptMilH5pgoWXyIxJBf46zBO8uyzPK9lzPH0xO+f0U/9Nze3fPw8JrzeWa6LKQUiSXjlIQcdJ1cq85brDGSdNfikamlXWOLs9KoL0FSodBriIUUlyEFKW6U3JuXaTurxECplk6nJQ1OzqYsJs6XEzEs1GWGWtAqyiQcRdf1fPGFSOt2+xsxqkSS6i6X82ZOrrTGKitSNG2wttJ1XkAFLUlOnXfk1fx5mblcLvTDyLjfS+NdC1Nj7vW7A8Oux1qRD9ciiVk1yeZhaxWQoq2N9RfQvHmk1NBG/LpKkcRb8VAz6H6Qv28NgYCP6oVfk0wCYxQwVOkb+QydUNqn85mcEvMkzKmf06uszBxabDhsZ8zLUq9UGf5MUYx6VdU4r3l70/Ow6/mLN7fcDY5f3I1SVaysF20FeHIC3vSdQ6uC1knKMiMpr1Y7tJKUN6mPPOdQ+McfjvyHf/iB/+lv/4mvXn/ky1cH/uLtnj9/tePw7Wtu9zd8OM1cQsTGNrGtFq2k6P6s21Zr4yegqbcOTKXzDuedkN+pdE5zGBx/9e0Dv/ryQcBgbUB5Ui48nU/opPBGoYpibuzIKZY2WNZYCyFmjCkyN66FnON2dld0C1VpE99axYOoeVrVUgmLFOsx1baWhd1Qa0FpYYSK35uWFNsWoqC1PJtqM52WQJuU1ljtCjWhSeIFFRZ05yVhqR9x/kCYT8QwY1RCK5GWgCLHhRwXak0oXVvaLnhnGTvHNAtDKmcZ5hVWmW/aACNdpS5SqjI4izMtcRpphgp1M85dWtpWvwKHyCAtJDFCviwLCkXnRIGQWnCN7AGFOeSmYtCUUhl6w9BbUhaj49pM5bV20Kw5UnnifDyRB7BuaENNj8jaWlvUwoZULY2pKgnU2mz0GUJIpCzhDNRE7y3OG0qVAWZqoFBvNQrPoesIsZApdGe5p8daJf0uF0xtqoUXEjGpJ9dxpQBQkgwoN+ZFC9iGMD+/+utz5tEV+LmyneTvKrUlxjVWkfTNIpFdUQmuLOMV4nuZ0LW+NkDqxXu4KmmuwJNqbJT2j1Av7kNVemvYN+CMBo8padDbd7+yNbfPuTJY5Get+7iSD3hNPHvRsKsVOFjfY1UY4ygqk+PS2I0iJbXWU7UhPNxT+45ymtAxoYoMlAuRjCYhtV5NC3ONPNtKMoraiw+ebb6LAtgVFJqUIBRF0opkFM4b8YgyBqxCOYPqvABPzoEzVJXFw9hZKpqQwcaCDRnbCchijJHAE6Ox4nkj9gN140IBFdWNUju9r6RlooSJEmd0v0cZu8nPlLINbxAWZGn92fWeycXURsKx1qHoug//qexNknc1XT+gS+b+1T2XxzPvfnxk7o+ky4z1hv7Wk1VFW09NUKvYUZQURL2lFVRhXpVGyb+uwxdMvLaudAsaK219q9bv5tV4vhSctUJDXtdVA3RNG96oFlKzAUzbz3gh/W3PyKo22ph+1wf1GmCyQqh1ffT05+f1i/pjk6H+RMrTTwaeXg1HvDN8/cU93llikaYrhwvkhMqzTDTHPVqZLSFNGnlFRjb8G294tXR88/bAcgrMH87oCouuOFPxm2RLpCBFGdAifdAKHDLpE/OrSjWrb0qjllewdZ1vVFy7TBnVEi8MVmu81mSlmTLkrkdbS+8MRQwviJezgDnWE9t1dkqhnSX3nTCTGkghC12inrVSzI/PlCVQY5CbuhtlItwSedzdbWMEiMg+niV9LE/i+eSGnnULKiWzhOUap20aU6pA9CMqZ3zNGOfo93tiSlwmTcpVYsKVoihNZxW7t/ec7w588+bVRhEtKfDHH97xPQlDpDea0RoOvnLTZfY+sOsCbw4jr3eOuUgan2w+is5aqDB4aSZukmFOmbkshJo2+Zxs8GCqFHkhSnMQy4ryt02neTD4pvdWSu7vqptPWQAgryrea972PVYrDr00VM7I99NKs+TKJRkxRqcQcubvf3ims5aHfRDPCWvaREq8w2IpIhHSUhwYpIawCpYCZwpTLnxacltVqSHVuRVw10NLlYIKVeKPncI7y512LHPhn/9w4bcU7kvgi17z4DW3Y+XNK01ZHCYqnNGkUHh6ylwuhbudYew093tht+iWovB2gINT/PqV5XaA/c0rjLVMpzNxCcQYyWHBYPBKYbJCRcUyCSNsN+hNZlqo5MU0yczP4xWzMA/nSabNYVmIMXJ8fiKGgAbGoefu8BWrsXFKifPpQsqZJSS0NXSmo6ZMWYKYB9ZC7yz7u1sBglVdvfaxLenJWIvzjpxbgRsDOc7i3xYTRivux55d1xHygc45Omslbc4bnueZj5czqRW2zvU8vNrjvcFajUJiY60RubL1A9o4UmmHcCksS2QJT63Zsnjn6LoOrSrn4xOXZeH7798xTTOn80QFfv3n/5p+GLi/e9jSyqBJAUreZDnTsrQpYsUY+f5aIWsfYZXWUohR9q5h8CiluL/bN+BJKNbjfif/3ghQotAtUlvYPjEdW1EhTXDfd80cUZiOTgvAMS8zx9Mzz8cnhmHg66+/5f7VK+7u7nG+IzST9lwTlIwuGRZJC52D+KFNjVUhsfCGzon0SylFLZlpkgCNmAWYNM7JZFMLe8RYK01qrdTVM6HCOOxa+l5rpNAiQ2h7+xImYgwMxuJc85OrFcWAMYbXr/YN+DKoWlimM1BJbSorEgMFSmRD8zTjfSepc97j+o4UAst0IS2BcJkIITDNklZ3mRfmEHk+nfBdJ8WXtuLPtD8w7g+NDaOZ54mwzG2QIJ5bphlOm8ZOFRaJPG/rhNq4jt3BkqNIGlNMLPPCMI7XEIBaiTEQY2a6XLZhwCpjxBjCPBGXeQNIHz98IL7wmPo5vepK426gyzb1z4pUK6cpNsmUTNHf3OwYnOGLnedm9PzqzYFdZ3m168QbrdKSLwUQcVY3EMS2e2jl3G31kjb2OuU3VUJ6Y2R6vnC5zFxiJBQAw+NxYQmJ0VQGp/h1rexGzyVWlqjovMZbzRwVpoofnkgFKwI9aLSydN1AP+5RymBF30kOeTM9jbmwxMTp+cix00xFk6siJkip8PHpiRAi05I302YtpSQoxeB78TEqUk+qZqjtvbADcmxpaFVkwnd7SedMSYlct3PSHOw1ORWWJcie72Q/6/ubBirbxmq02KopWbEQCMuCKg6iQvUeM3boJaNqIoeZGGboM9pEQkyEOTNYjVMd3vXiXUIElbHGYxSbWf++Qtf3VOUZp0D88EiMM+dLJCyF58vMEpM0r6s3URWmUsqZEFuymLHNE0vMvFdze63qC78LhdMC0ni3rktN0QplRPrijIAvqQ1KvBL/S9P1BJOIdUKVCkkYZx8+iadijIGH2z2//vYtfb+wTwHtBsxwx7B7y1f/ahQpTl6aB4/QY7Ra+fKiYKBqtljw5mtitLA4ahWvrvMpMU+ZlERyapxlN2pQBW8US0iklNFGsgS/vh+53zvuxp7Lknj3dOS8BD6cF6aYNtaCb1YNAmQ2D9EKWrewgAZQpSy118qq+bm9Vm+19bU2qFefp2tCVm0gCCsDpq5SupZ63QY6m7/in7xWXkc7NOQPVyCHFbiX/12hJKMNZfvT9lINGF7/oLwAuxpjSdKqc2P2tudoba7WZDF1fQu1ii3D+t/btdneamuWmiG0UkqM7KsMwsQsVPZD3cAaYyx1GKnffkGNiXiewRZ0FcZYzAu5wtxrcnEwHrBK4azZPld7Y81fM0E2EjhlNOclMriA1xFtHab36M6AhZBnyvnIFC9EKtpbBj0KQKGkh12ippwDSyg4d8FYQ3f6KInrUyJF8b5Vrm9AXMYPB9R4YB5uSNOZ44fvMKdH7v7s39MNO2IWD73STLrlZ11RTKX1C2Dkes+qWvcx3UBPva04tVr+KIVSBj/u+Oov/5LTx0eOT/+ZagLvfvMPHN48sL//CywaY72YgTd2aMmZqiKE5cW9FxBHK4UyhtrW2rp+cy6b7+c2eGmTbLFbqC+eF92Gclo8BLP4fpnmP/oS9Fbrv6vrUKU00kTeyCrrE3ddf7C5Zauy7fkohVZuA6oUSAqIknMDXoCuP+H1k4GnvV/wnef2MGCs5RIlApu0UNMCy1EOWG9RRuKbC40J0ta2MYrea3aD4+7Qc8yVYxEwKdXGXmqbsW7pGWV1ZG/XwrTnspQiXkoNwdNIhH1spuEaATqsornEywOujNCGjdbEImCVcg7ddejeghV9awmBgEHZRLVODmlnRNNqxecjVrmRV9RUEMEcovg+5QRGDnfVpttKKXQnEroYAiVn8nmmpkiaZ0l76ntAk5MgmjlFJLIzYenQxmJswRiPUYmu1GaaO0i6VQmkkFgWSRIqSuFdxzgOzEVxuFEsy8L5fOF4mXg8nYi5EFKmt47BKW4c3PjCYYgc+oi1hV2viVULxq8V2jZDcVQD+hQ+KpacGI8ZNzcfp3KdTGjE9SmUFu0cC6msm7AUghXoW0HkrIBPKZU2hZfv1XuF1Zr7zuGMondXok6hbuvGmTY50YpcCu+PM94YqEp8lgaPoO5JgMtScVq+n1WVrumGbdugzqUQS+E5FjEzLrQHrrBqyyV5BjEPRAwuvbVbY72ExPm88GEP78fCnfJSrLrKfgcnZ1iiQodKiYVpyhxPhVuncU5x33sOg8U4SSf79a5y5yv3o6JzBb8fUb4nzJIgk3Mh5SiFsNLooiArUpDm2DqFcwpt23Oa9TpO/1m8Uk6UnCWlLAROLU3u9PwMJeMA6wyHmz3QJFQzMrFNmSVGLBVfO4mjD0HOugrOOsaub5JGmarHWPDeMY6d7DfWEEIl54VaIiVO5CWSl0A3Doz9SIcmKQHFrVYoa6lGMc+RyzxTizw9h/2OYdix23f0vRWJUVzwXjyctBM/jGWJpJSJy0zOIiustbLfH3DG0jmH1vCUE/M88e7HHzmfL6AsXdfz+s1bbm9vefXqNUopfvzxvcROZ3mmVVGNKZjIbYoogxkxnl0pv1brxsgpKA3OWWr17HYDYbFQwHnHbreTm7XGJqvrNCzGxDSHJgMSdoaxkvIkproFrSo5R0IKzMvM+XJmt99ze3fHzc0t+5tb8YRqII/Q+QUEJ2WR0eRCjZqqZEMaxhFHM71sEce1VpawkFISk9Iq/h+SjKjExLMd5Tk2w/coUqn9XtgPud2LNYGvZgmgCMtCTkmaQQOY1ixVkZ7d3jyI9KzIv08t9jzEKABZL/JH06ZnKSYxokemja731JxFYlIh1EUazZSJMcu9LMIiG3d7tJFkur6XxDth7gndO+VEjFHYHNpuZ6q15jO/pVpF8pyrABnWWpz3LFWkiSVLIp1WGmssFfEdKLO8z/P5RIoJ572cn1rO5xDEsFiSIQOPH0R6rbX72TEGar1Ogv90Qp4yXBq4Uqph7BQ3Y8fdYPmz+57boeOXDzu8NQxeGDwhy1mtrcVZRe/kumIkGU2LRrvJWMyW6AZshVXJmTAHCSPJ4s8IhmlJTMvC47nneR4oFTpncTbjTMUajbMKU0A3puhWmyNMFa1WeWhHrWJyXQviP4IU5gVhFy/Nn+8pKkKpzLOwhi4XGRrE9r4710JCTJPlOlknIbXJtxKpibFGBqFZmiGtMs4YDqOnVsW0iBy0c5KSpJ1nXiKXyyzSdlVxVjMMUsPVqhvLTzeWQ0E8ghO1KGoWSbHyXq6HscL4T6r5/kg6cIoVisYoCS6wzpKzpRTbWIwr2FLxgzATQwCNwZkTCkWI8n2WEIk54zqPMVrk1u29oTK5nTUbA7qpEaTnqJvKYA1gMY2daJq6IBW1scpUM94ujUFV15pctTOOKunxyPcuOXNOwkAPMbGEzJv7PSUnOpUwA2j/gOt2uN0teX4mHn9sRrdNxnSFHpBdaHWHaZ4mpSVDWYUrBpTlfFLE1JjsWrHz0HlDSqYB4WsCtfQxN4Nn1xmcckxBhhnaKD5ewsZ6V4ilBK0HUXVNuavb+ah1A5Zb4Eg79n42r5d78Uu1yfr6HHSCK2zU0sCq2hhC7ZvwUq73+feoL2D56/f67L0oNgaj7KP12uzXzxkbmx+UWr+2MWlevAetGmPZyDcszS/xxXdpb/rFu1oZlG0NCPK+/pB6/Znt3ymtJTXcOmrOkOOGT4E8X9Vp8t0NNSZZayqjka9LJUlKu1PUasQXUSmRe9JK/VIgZVTJ4pPWVCdVS1/ocgYS6CqhJy0mPsdIWM7EtJAVqOZru2JvlQbILZmYMikKK7TMUaxIsmn7jUNZJ2ZntWB9h7YO5UeK7VguT6jLM7e/+DdiZ9MAEPms67USFpQck42x08AQtYF5bSWu90N9Bk1d15VSWOfZvf0CbR1+56glc3z/XtKKc7PcaPc+G9s8pBI6Z0qKcqZq25ah2sAv1FWptUkziyQ86pfPixIwjM2L6SUbXFNypjRbnJcrf01VlJvLxrBaQafPvZ1ePAe0a7St3LYu1fW9KKWvl3EzslsjuX76xvWTgadvvroDFNM8g7bYfo9WUBZFLpnL8wc53KYZ43vczWuUsY0eK81HLoWYC9ZWvn7d8a4kvrPChsrKkqo0yKqqTVolyR9QlSFURSmJUEQLmbIcKnI0qubFA7RtXSlQtbTgxXYAVVhKJdXCojRRGW73e/rbw3oPoBmdOmMwrhW8CtLpIiynllBhOr+5zudcWU6TLKzW/JHnBrYoVG4eUWql+0G4LNScUClArdhejHlWA7LUih/vHChL1R0oTV4WSkpYp7DV4rQYnU1R9PwoizEwdlJUZSpLXgifJkFylcMp8WO56zyvDztCkljdWmUiFFPk3RL5cVEo1fGUNJ9iZvSK3kt60M47clG8tNQoei1CNRJXTFNvyWHbGY3Til2TC56jav5TMrGco9C4O6/ojOZ+tDitSLmxKvTKjJIN2rfJulknSPJX64BkWwe9k/s/OGFcxJxJJTPFiGi/ZRPIFXZOceMMnRGfCqMUrk1ez1RMkmdOa5EPskYdG9U8KBodt0qin0ZDVWLeHQtTyiyxoKxnd3vAdoViKvMSeX6amatp8ckZpSrGQzfAN3vLt3vHr96M3O07fjhXzqHy/odnPqWF5c5wGA3fPrxi6HqOOkNNrPEysUDIsNRCoGAd6FYk5kxrzFs61c8IePrt3/3dxjBMMfH89Eit4ltScuJ4OlFr5f2PP+I7z/39PTkljC5UnXEqYQCTA+RMjakdIpoUZo7zBecsfd/he8/h4bBR/Jf5zNPHM7m0hCOt8N2IdZXay7NtnaP3FuMdl8vENM08fXrmOC2M446hHxjHkb7vuLu9ZdyNrQgSqYxOHaBJVZODgBgSalAZhwGl4Hg8EkLgw/vvNx+iFBMhCIhx9+oNr790jOMe5z37u1us9yxR/KucFz+iZZ7Fj+pyFtZXO1CTElnpPAes0ex6j3Iau9uLDGyeyLXy9DxjreHtm6/bYVYJMXI8ndvBXTHG0nWdSDFiRlGwOosJpWlyLWOYwsTxdCbFSGzG2ForjOt488VX3D88cLi9oyrN8XQSqZx13NxKIt/lchFZ3uVCChM1a6E6O4kL7lwnBuBV2BYfP75nni7yWUrhi6+/Yhh3WNvAjgK1VPpRGEpoTc6FDz9+ICyB58dHoOKtbWeKJGnNcSHlxOVykcnXSsVuPiClZHLJlBzR2tIPO1JKnM4XQlh4Oj7hvefO3GGdo+tFUleR6zTHhEoJ4kKYZqZJpmQS3SvJrcpa/LAjRpF8FrSY6hpD1/eS/ng+0vc9puvYjTt2444YxMRe5ECRXAvWZPFK06Dr52ya3f5GAIWbu+Yvd6GkyOPH9wLS5UApmRiCxMFfJkouuK4DLQOTlCLHjx/JKeGsbaDbSG8M9WWM8M/oVars3aqFc1gFgzP0znDT39A5w6t9z93o+cuvb+mdYeca+xAxcE5VCtbRCWtucE4YT04K+bpR6VuqogZtHMaKB5nSipIicZpBQ1EV8syuk8RU2kAHNKUa8fGpiozhsN/RD4px8HSdRR9n9CXineelAYK1is7pxr4t/Ie/+44/vH/mv/z2e37//pHDYcftYccv39zzxe3I06VQysyn8yzSrEaOaBhVY1Aqdr2ALPdOpII1iYfT2gh4J4Bq71yrX7Iw2Qfx/IhJJNq7m17SPLuuyUk9WlsBrpRI2L3zOOMlcdiYZgMhTII8B9IcyTFLYG+FHDR1EVZZ32m64Z69eoPEzVdKeSRnjfK9DEGb/N+PN7jDHSWKtYNOM+RASIW4FJYlsYSEQdhnQ2+x1tDvxOtvnkNL2ZSG2Vkx+k+bzUBpbFZFxSCuqxqjPUqJF5I1mt0oDLlcJD1RVZEI6dbEO6cJKXE+B6DiTGP/FPHF8cY2A93GEmnNz3mK/Pjpmf/6m8KbuwP+27fY8Il4mbHjDn9zjwa6w2vICzVeoCQ5/5RGDI1po1Fk0KAUtUlSKhXrOrTx3D94dvsb5mkmLIEQZkI4k4tGAtWqrIOYSDlzWYIA9blgqXxzt+PNzYCzjqcp8P2nC1NIzDG3HllvDa2EPgvzQltQGkYtQ9enWMkv6umfy2sFhTaf1hcSJ3gJFPDiv5s0/YX9Q0EGwS8b9M9+Tht8rf/+v9cMX8GklcHUwIAGlH5mSv7y30mc5CaR01Waeq3F11Pe7woArMlqn38mYUblBj41MOIFe2v7ufXqFLV68hhnZYCektQFjY1irRXQNUOxirwb0LrgxxYCsIFa4p1lV7n/yowB0FpkcyVTDFLntiEPqhKT5unTmeHgMF0kx4pSkcvzkeOnR5YlQmM96xaK8t+CGxCzqFxCStITlguqZAw7vOooRvqmNWBm9/oX+N0dz//8XwinT5w/fi+S1uEG5QdqjO3nCLtMWEW1kbjqZ0CKrI/rm6moZvWjMe0cquu1L5mCJGl2hxu+/Td/TrjMzB/PlHhifnrC9j2m61HZkFYGfaYl7YpX09bPN9b2dTG9XJtNvVVrA6HbPXmJ3kFjLbVU5NZnGiN79ioTFFXAihet1bmS/9/WS86pSYuLmPOrlxzL2tauvEdpHes287peu22ZC8O0Kij/fQbif+/1k4Gnm0NPzpXHY6JqcKPETKOVGAjOF/FiigXbBWy/EwCmu0aZCx28YHTldmc5DWt6hiKjMbVuvgPrjSntExel5PtXtU2axbdpjVJsWvmGRhcUpkqaniCjsCpZc4VMJShF1Bq6DjsOkEUbm5dArYnVa6DJ9gkhkEJEeaEgGicO/GUWKVxaotyJRsFUWqR0ui2i3DbF3DS4OURqzpjVaMzJtSqNGif0u4Kx7dBykqwXZyk0jG5GnFZS0VJLeAKD1hVjjWyMtQh9cp5Q2mJ0xvoO5zoGb9mrniUVlihGkCEtPF0yl1wIyRCToesU1lXeHArWyXTfW0NI7QFeJxVKSwGxHShyT1ZlqFEKZ8SEUyvZXIOWxR+LQuXcmCSKzipuOou3AjwB+GZomRrtddtIqCsI3qYk14dEIQDRJuerTbJXKjGJsWVWK00WXDtcrFL0VthOTisCCh2bFrj9LNN+Xm2FujHqxfOr0OsXViTJKxRSLqQsDXY/9BgTqCpIQtCciGjyiowr8U5xHu46zdve8NXOcb/3nGeJij4eZ/I0cVAKky0qJ6wWJLo2Y1qlVGs+EKNqavPVehnpK2s0N3bZz+X18cf3sg7boX06PqOBw35PyZnLdBaj6igmtvv9XjZlVZtxdcEg0yCVc6OYtgMuJ9He4/GdQ1vNsOuoKYkpbA5M5+M628L2Hus6WR9ONamDFvlb71hmMSs9nS98fD5jXc9+7+iHgcN+x+F2z36/Y55nYgwY76nakhp7NqVF0unavmM7kaCKVU7mfD4yTRPv338iLAFjLM45Hr74gv1hz+H2TgCaxgiIOUlM7Dpl0gt1lfGWija+gbuqPVd5O/S0RvT/SqFiaDLHJPKt3S3OGVxnOZ/PXKaZjBI/NWMlQSQJUKiUNGDiO9OeCaUoWZIGQ4jM84J1Fu89wzgw7kaGcYfv+2a4vaCbF1bXdQz9sBV6eb6gStu7UWBFOueMwVsnDNaUOB2PnI7PnOeZQuXNV19hncO0g1toztB1Huc91jpyKRyfjuSYOM8TtWT0MLQCTaZQyzzJe5wXqLJvy37WPCSUlCalZqjCKFrP0hCTJMq288UCtnkNuiwAecpJGDGxiPQ25W1frBqqkTPLaCNFS8pUtIDPWm9Sy7gs4jPgPd53OO+5qEl+dooSBNGKWdN2fNV8HNZmwDkvEr52vh/TQgoLl/ORGAJLWgRkSyKrSg0Yzcgzdz6fCWHhw7sfSCFyczjgu07Mxp0n/wyBp3UrbuWDVDealu6ouR179p3jVw87Hvaev/riBmu0gIexcL6IZ2RlNbXXbW0LMKmN3Sab1HbftsnqaqbfgKcYSTG2uqtATfg1OEStkhgtfMJ69UrqOkevDePY03WeY1ZMRTXT7XZmKhrYJU1DSpnfvXvk737/nnefjpwuM3e7Hbve8+qw427sWaKkPT0eRb48drqdaxJKYJU0Wt6JkfowDlTgclma9EA+a+esfJ2xZA0hy/o01lCLIidZy10nYQ5ipG02z6vRyKDBlNJYmSJVUdZIkd/k3illSqszq5LmqmYBbrUSaa/uB1S/k+l/zli/YNwsjABtt+bI+A7V9aR5IYeIykFuYZZrlxqTUStwWmSO1hmcEvZWyYml5FZPN4ZbBapqfmG51c2STFzWyb0yGBDDeaMZOgGeppZmt033WyNYNajMdpZYofm0GkP8DmW7aA6t1ZByIYTI+bLw48eE1YpluReQbbkACdcPaN9huh0lQImSgldrpBkyyuBXrdXpyhpoDKhaG3io0aOl62WYU3IiLImUFlAOlFlPhm2fjTETYkapgqFyO/SgNZdY8M7yeI6EVMTXqwXS0OrFqhTVCKtEtzVvgbbkPhvk/kt/SWdQtzW70sZespTkr9bfX/xLmTBvvURdB7r/PTDpBXAj/6ztZ60uWbt3AZmuQ5facKIVTFLQfHZeQFaN5bTuiy9N0Ve5llJS+6//Lf9s7VPL9h6BBia/+AxNhvjfQGkb5tDee/NRzlpd/UtowFVVkk6roXhJijNe1l0qTZqBXPONYKWa0LD1zEopVFZoxGh9TRNVKFLJ1CliO/GjFc+pQJzOTKcjucrGvcqKV2/M7exq9WlpUuncfq4rCVsD2nRYbUnVUBqIQlH43T2233P67u+pJRMuz6AdQy+epVL4vlgRSm3P6goobhBPrXK8VVlDCiQ0RRu8F5mfBCMUcpilj9QG13Xcvn3F8nwkfnqm5kicZ9AaP+6kF4wN5G4eb5ugU71Yv+ubVGz9snrxbIivX/vVsKDVUki+pK0lJbfTtoTo1RdTANNMLY2Msa7Tuvbiq9y1AZzrvsRLlt0VKGXFUFfw6cUCXb3SVFu/qrb02f8ngPCfvn4y8PTDOwFinLc417G/2aFKZlo8aXHMiyEtgbw84/xMShq33zN8uZc0h2aOHIJMHV6NHctN5uHVDqZMOEWsLnRKDLNrTVQtCXayS9uWdSAFe68lZSqVgjeaXrdiR0GsmoTBND+CmjI5V1KbAtvOY6zlYDTGaHoFNTQWQxWzZq0saZpIl5kpC6parQVvcIdbjPetYJOHSaXMcpkoOePbgtIG8Ulwsvjq3PawtK4vGXkZLxHmKVdqTtTpAkrR9WND0qxMz7RDzGYXtG2Gbxu63t5H8xmpKZJUMyADtAnslSIniTGvRUk6QlvotmpUUfTOQH9g1w/cHfZc5shljnhtuFxgGSwJh9IFQ8G1tbYyzmSSf6WaKoWAfy3zuShhFTklPltRA7WwNI8FSbRTDM6IwXlv8EYTUmleDeuz1PTYzS9l3WqcFvmkycKCoqXRrdZ1thlLGi1FsdbyN3ktlEvFO5F9aC0skrVpksaY1s0hQ45WN6/nW0pX+YBohuXrU6hMc+JyCTzcj/zqtucvvt7zF1/sqJfCMgeOp8rH95Uf54XnuPD61nAYNb8YO3Z3lr986PhmtLz/eOZ33x/5zceZx0noV0Z1vM4VHxT/97/5Z7R/J5JV4KYbUNbx/lPk46VwWjJTKvQ7MXLveims5qlQs4BcPyPCE2G6iGzTOxSV/dDLXqbFdHA/DAI8uSKJHCnLc2ndJqGquQj7olRqrlhv2e/HtvbXNQaXaeI4XaipUKIwnG5ubkUO4awwQZQ0akZrUkjyKxd0zKRcyFT2Nwf8/oZXD6+4vb3FaKFMn85nQpRGUla8SJy6TuRgx2NhnjOPHz4yTxMlxsaYWachAhY9vLoHBQ/3kox2cy9smVRgniP5MkMVkEf2RSlsQhR25n5/EDCzPR+lyaCsd+SSeTw+C+itxJdnuL2VAz+J1GUJkSUEyimxLIGcpDiTVEvdjG01XTeQkoAPIcwcj4/EmJjnpTVDYgR5uH3Ae4d3Ftc5vBcj3lSyyE1DYspnwmXmcjxhrCGmdt21xR1uOez2+L5H2b5N/wolzrx/9z3n05GPHz8xzwtd39N3Pb3r6Izl/Y8/SJoaRZigncLScz5HcipYMoM3lHHcZK/zMvPhwzuWZeHp+YlaK74fhE0xDnRdx6vXr8Vo3TpqKSzTQppnpmZqPoWFrBX7+3t853HDDtX2ypQycwzigzPN23pZJW1SIDpyFpkIbTrr+4F+GBHJlYCiMmEVE/GUAvOs6ceR/X6PtY6+77mcj0zzNTxCTJUN3kujHmMkxoU//OEfxS+sZGrJLNOTALdNtuP8iLGWru/EXDRGYVTPMzEncmteb+8eoFaGcYdznnF3EFNTZX5y8fMv5XVZCkbD2Cs6q3nYe/ad5dev9+w6x+vDnt5qbnqROZQshb21FusVo+/lTDJ1C0cwShh5VUPRVZiCxkoST1Ui52+pi8Za8Qa7TEzTxOV04jB6xr2wfYSlAi0aFbgOGr037HaOJdUmz5yhRGKYSTFImmxF7pu2jS1y4v/0H3/Df/y77/i//N33fP/pzNtDx7f3PX/19RvudyO/eHPD2HkkfLKgtUiilxBJpeKtnPG9E/8xhUxlU8pbqV0qLDFSKw2gUZhWlIcs8s77/QOgCFEGNTRJVwmTPB8u4zrHfrhrwH9jQDjXzPFlCJrbgK4ojXaOYa/wnaMfOmpWhEumqgxqwpQZU05YJTLWzmvUYY9xBmsq5DNpOqPrAcIg7MAUYTlDXDg+PXM5TXx6vnCZAyknMQVubCLVFLyqGlYmj3h1SGHqdPMXbZ41KSZUyVyozQRXzq7OG5wFqXYV2jgsld7JQDDb9jNNZegsztjN/yblLOAfBWXE0FgpK76BIaE1jINDKzgGhXsO/OMfP3B/0/Pt2z2lXJif/4jt93T1ASho31OToqTVmDpuA0ilEqqB9yUVSgmUnLb6eU1q6rykLZ6VeHGe50xIMpSwWjF2iuJEero4i9GlMd87lDL8xVtHzIVv73dcQuKPn46cl8gPjzNzzJun2OptWorUiJ2WZvPV3pDrz2j/Ule2GbSeh1VaJyDmJuek4UXqCvCUKn2BpH+pjelxlR41/zaZLF6BJ/n211e9Aj8rGLaxfhoIszGOqnzNmsRayhVAqnW1i18/S33xPQXVWD/D2l6vP1fsUho4tg58kZ4JpV6EYry8VlfAYE25U85CLvJco7Bt39ZWQ1Go4qgqk0povYkRiby59iXrgOAlYKOVBgMGDypt11K3oXUolcvljH73O4yTgeU8J+mLrMVZv+15RmvAyWeuBa0EbBe/OEVlR1UjuXTUGiQ1U1fINMalXCvjO6zq2H35a8x4y/z4jsuH79G+p1dg/YBSPXE+y/XbQDQ2EApoP1uUOqgG3KHASAKv89K1xxipiNenAmKYUCWJ7YIy6G8q2jriNIHR+Nb76XbPtWlJhkjAh/gptX3zimS+WDvl/8Hdn3VJklxZutgnkw5m5u4xZSIBFArVt7sv12o+cfGR/51/gHwm78PtZhdQAHKKCJ/MVFVGPpwjahaJLHbWA+/qSgUiI9zd3ExVVFTknH322Vuxnc4uQqUk/I5B1dJ2DanW2MdYihe71N4OUMn866LmDdpVGdJZYXxancWtqvB4azSTdf76jkzqOSsS3m4ScNOBNH32GlD3b/4Pj18MPL28VLw3PASp5gzDAC2zeY8xjlwMMcF2jgypMR/OGBd2J6mKaP1kxJnuMDgOk+dwHMg1kp4jjYZvhs5PEs3ujl32Hmirmjtd6FZcEFx/QEBcL/rodKBCbRZBdEIYBgZnmNSpA6XCmX7nrKWuiZqrVvcr7u6IDR4zDJhh2oEqax3NqkB1luqyM2jVTSeJ3pumwIUscIpCO6nSNnVWa3GVoGaeMMaJmHenDpuiqLVhCNJSWJrF1ApNbW29k9aXlPRz5QEMpeBI2JTI6nlgasWUipPGOJz1+GHAey9OMnbBUfFYcjGUqk5TCqpYa+hbRz+vPui7SKBRSq3tOLAYjXojroXuBiHu4++dZXBiBz06eWg7QCs4ljKerI6p0ladItoi3nidv53CaHVBogkgJgFyT+Gl2tH1SoxRMFP/NIx+ji4StwCvkYWgtg4ON23/M7sgaimVVArzaPn67cyH+5F3h8BLtFxaY41wucDlXDivlTfB4ILl7X3g/SnwdvacRsefPy589xz58XHhZSuM84EhBHKrpNr4+OMLybzy9s090+Dxg8dZw5Yz59gkCaiNOYiwbBhl0GyU++g8t26b/+6PmhLNivOfPDeeXuHpX1drKbbinNMNTNYAAzinLYiprypiOT5Oo8xfK0yfbYvEmHhdF9HtSZW7w8z98YgfPMM47M6JwVmCs7RSiU2qUjYLkF5qZRhmxjBxPB05HGZJ0oq0QeVSCF6qHZ1t5L3bhb1plWW58Pr8srt9eU0ih2nEucAwSevT+6/eM0/i3tmMIZ3jXm2utWqtu6k1rNDErTUMh1mFsrmOlXMM08AWIx9j3J0fR2M5jaMENsWIztC2SktViiK6rvuE0wBTbJENu0OakZ72dV1FBP31TBgmRnXxO93dE4JnHLwwErywTrvAei3CoklETNwXAhoiVO6GwHx3z3w4imW8cWznF+K6sZxfeHn+zHK5EFNmng8EH/BW9qL1fOZ8fsbaJmtvekPwhrSsojuExTuj4tlF2zg2Pj9+YlkuPD89gjE8vHknLY2DWIOP08Q4CDsrpcSyrAIU6dimWsW5cJ5FCN1LwJBLI+tas6XE+XKReWzU/XAOGOewIUisULQ1pRWcC4zjcFOcNnvlFmQsc5aAN4SggZAl503a5PV/XfvCW4d3nhgjJUWeHz+zrBdqjrSaqekCLRH8jHOBEGYMjqAt7tVYSsm8LheKmnEYY5jngwKTk7ixhQEXpHr5a9N4KkX2xWAto7c8TAMPh4HfvjlyNwV+c3/CO8MgytnCmDBS3HHWMQVZ0JtR0EX3wKrhUU8/bBdkbShjW9kgRoT+U0zCSouJ4yTgpbSZdKp+Regt9rpPOyOtViUrm7ZhmrSd1VL2wLfrCG2p8rpG/vTdI6N75S8/vvD5svFffn/HV3cj/6dv3vDh7sibhxOD9yxJGHyHLWBtY0tpbzWwFoKzOwu5tS7sa3q+uDsqqT4qFinNl1ZUk1GYU7XVjk0gsam0sMteEJjniVphi/UmE5FzoBpNL6wkjl6MQ8ZpYD5MbJdMWhMNdUB2BWzE+QnDKOYJ6vhpDLQaqTXTosdUQ01RZBxSpOVE2iLbtrGpE6q1V0YqX8SfWi6Ukvt+z5xmQEZvaS3CkE45a+FE+IzOCrjXdDwNFmMbzopOjAhBNzHE8WCN253sYspEmyTua4ARIfZUyh4vBitSBanAORY+PV8YBgPuSGuJvCW5N4PYrBvvoDlMUTHxpon8Xi2UmLu2Io6lJV7jOCcMKe8a1lni5sU5tok2TfDSsjkYaM6wDWp17wR4ckbyoMMgz9rdQUx2oPJ42XhZZD9dW9uLxKUndg08AgrPg+EGOvkVHObmb7nYvaWIK3uo7zX9tfu/W9tzJ2PYNf70h1dQxhjVCDZffGyvSe8QhJ7GzvDo377Z5/przU1bXYU92G+0nnTQ7epvc5crcKaavkI3JyUxMUB1yIx+7rXVydDbmr5kdakIurFgqwpLN1rukxfV3dH3tQIolyZSCJ0M4OwtyMrO9rrVNZJn2IlmabU3Q2So1ZJTYq1n2fuHgVwcDSftZd5dgV5tkWwGAbqB3p2EcboeSl5cmsfbjDMF20T+o2jXj7UW6wLh9I5qHK/f/5n48om8vlLiHWE64rwnbXq3tftkH9ubMQSjrLGbOWmdxEJdC7MUGo0mC7fIG1CFXdQM5v5ecu6ccVn3gD6V+j3vub2pmuOjwJ7888povCa01zn3JauukyY68Nnnj21mj9Hk2bkBnXr+rT+8FfKX+XjNefvr2g0YZjoCdjt6fZm+/ZFRQMuoe/q/Ie76xcDT+t2C8SIKNp4q49uiQolShXQUhmCYPrzFjxPD+6+x46QOGWV/0CWNkd7ucYDffjXyaCt/+VgYlM4li4gwdVrVgbBt77F1zTIoKFX0YlOr0lsOeN0QpbxQmCyMg+dsDJdSGYxldCKsaR20daVtIrRaqtLxjPaCO4vxIw7IMVO3TE4isDZ6J3Q2L2KqATkn7wWFd0FYCK0FAS4GJ72rOUItONVpycsiN7wJqdkdTzQgJRHyrYjLxqFXxzJQVVTWB4bDQYRs84L1Hnc80FLCInTqFqPqj1RBpu8GhmnEHI7kdSFdXtmi9K1b07AWhiYBabGGNg5Mw8g0jDw8eI5HR1wyKW/7wu6cjIUxGarYy26qGt7jMAF6JAhbWyNXOKdGLOrq0aQFDpDqgRU3qeANuXUtKZ3sTZB00XIw1wXUGUxtNMr+sNZOS9UFzSBAlPxcHuzuOtL/SM+zIXir4ILoxzRnwTfcaAkehkF1ZZy426QoOk55q9qDraLoNIbR8NXdzP/5f3nL//U/fc03Y+L86ZFl2VgSJBzVe37/LvC/WMPvHgLvj453p8Bxcnz3aeVPMfOnp8zLVvnPvznw/qjBsXWEIJR1m2VhGgbL6EWwM6fMv3yM/OUp8fxSWFJj9BkGyziJmPHxjaNWQztHSvkVIU+t7m070hdtVF8mYwwMIQimiyQiL0+PQqnXikVMUpGZxpFxGLi7v2McB+5PR0pOxPVMKw1HZrCNO2+pVhwy5/nAcDypwKyjRjFj8DVzqElE82vh42PmdUmcLy9cljPvP3zNm7cTDkFc4xrZ1pUwBGnxnYCg7b+58N13Z+IW+fjxI+fzhcv5QsoJZ0V49v7+jmmeub+7JwxBHPGskXYwLHlTh041ApiHQGuNFNe9RcQYoyLmTjWfrAhQmmsBqZaMpXJ/OoIxDOOId55pmkkx8fL6SM2JGjdCCNydTpIQnrIKiYsL43J5pWTReColq5h0xhrP8XjH8XjPOM3Mh5OC8pbgA+M0C9PDezEMyEUEdbdMqZL8jrO6vIUB5wNhFHF/Yzy1Grb1QsmZ8/Nn4rYwjo4P799yd/9AqexC7k+PH3l++shyeSEnaRdrrRKc43A4crp7i7cj63Jh3SJ/++u3oimVhenhnOFwPDDNB0IY+eq3v1eA0AsrbE3i+KKJ4qjtgUWLKKlKO3bMmZoy5flF296KApzS6uE7gGqlWFBrosTEGheJe5rZ12jnVLeOHjhL8O2c3Z1/KrAsC58/fdrd7KyRyqs4RmZ+fPkb63LBU3FGxPudtXx+emRZV2VZNX7zzW85nb7i7bsPjOOMdQNgFZAUjaeUImAJfmSeThJIaxUnpkRWN0NfAofDAbsH8r+O45uHwOgtf3g3cxwdv317YB48d8OEN5aXNe5AugFxLApFK8+GWp3ucTpvSlVQV8wuxjHgnWcIRp61JJbQVttwx2Eg50hOC87C3d2R+TgxTDNhOOMU5AWuyZw64i3LxuOnR56XxHnN3B0m5nEgLkXWnJt9pjVhg5QGb+8G3p1m3r69ozTDHz/ccT8P3M8jg3Oc18ZLi6QkrZnGVEIQIfNSYXSDFK+86LZsUWIVE6UY6J2wvQevekaI09rxcAJE/8g5T4piyhGcvI9rojM5jBPdeajkzOXpScALP6LpG9Z4rAuAV0fZTcR7raNZMSGIa1G2Z9tLb61Ay5U1nrnU1/5u0hpYKvNpYpxncflbX0FjE6YTDcO9GZgfNor7HvfyyuslsUURKbdWgBwByYRhuyU1FUATEBXoTVWeM59ljCQXaxQjOkefXwvBO46zJNj9fWLacNby9m4WBiRO3T+zAC7OMzqHqWqeo23O1jhSyTgncVktBqPxqLeF8+WFx6fKtz8EToeRdw8HHIkan8ANOEZMbWI/nyIlZqptNFv34l/ribcVNKNlbZ1vDYwTF2Zg8AF3tGIMkgoxJSkcJmFijF4Y06hubEqyvxirmppO9L7+4eHIh8PMnQuct8Rfni+cY+b755VcCwbH5OH+IIwUV8uvim3e6jUHkMPwZX56+/wL87KDkVIUbiIbYISZ1wWYO5jTk+pcOzPK7h/W439rhNm+M5o0V/gpuGPt7e81AV3bte24i6Dnknf2U3e6aygbC6Nt9J1BxReyFb241gs5t9dgLFxbnRtVn8M+Sl2306rDblVjhNKqrmlOQHYTaDVS0qvs16bQmsMPo8IvmpPUPhY6ZsZo3CvvtxdKVSh7GAZsa5QmgK2AEA4/DNIfjZI7mjgci0mYFINqzdeCrmHXf2t2oBGoJpFNwQvpilQ8pRlp66uF+f49w/EN5fyZ7fmO8/f/zPnHP/P+P/5fGO/e48KICyM5rZJbOzFtEKzhCkIZRe+tMuutl8JCB6asF51CGyZaLeRto2ExbqB5B4PI49RtpQYHOek8ksioat5sWhEGEKr1dAOkGrNzkwT813tgjJp8IHF0N/oIRorE1z1e3qsqWzgE2WPMXkK6grrNIBJCrTu3qzasjomxBqNg2y1IfPO4CrCk5956d4dBmbIGdsC2/eSZ+tePXww8pXPCOENzlWoc2ybiu6VUoTqbinGGYZ5w4wE332F9oJYmG7a9wtatQaXiHdwdHcvZkkyjmI5Yt44l7DDb3j+owdVO0NRJU9AFqpldyLoiG5hTu+ClmX0h8VY1SKyhpQxZdJByrTLBnMUMmsh7max1WyWobxehoA9e+lqnSQAx5Pytu1msrFXvJLPrJra0QRXRXFq9urXYLo4bpO0rajWugXUVb7VVxjQqQrX0zonGU9XeXWswQV2FQlD0leukdw4TBtw44qYJVzMuWmrOuFawNWNKRoiSEIxUDcdBaOHjICyZZOwVBVXmSBdh7xuGtMsYBfE6OisAU9KqT6qNWLq4d0dxdyheEe+uUSNPgqxtAjSWYnYY9hYtlhmhm4guktVcW6P7ufSFqYsf7hUSHUtruhhkvw7J0KwXFzgXJLjvyVqtBtVtoyl6XFQQdjoETvcDX7+b+ePXRw6XJ+KykpII5ReEin83Od4Mhq8PnreT4z5YJmf4fsn88LLxaWksBd4eA398F7A6v16MJyLj5avBO9FTq7GScuXpknk8F7YogF3JleJ64inOdrUZ3NofvF/R0QSA6wt3LVU0jqxlGoK0vjmIrar9e6M2S6mFLW0MITDPM34IzMcD4yCuS9k04iYVB6dzxnkvv9vEwcuGoKxHDWxqxZDxbFrgaqxx4+l1ZVkW1uXCw5t8pbAqmJBikgRJN3ZAbacTT4+PnF/PfPr0mctl2XXw5nkW4ehpYj4cOJ5ODMOAD1KdSqncOA7toTnBeaBSkvJPldpunRVmle/uV7rZdVaM0sUHBd3HaVbWkgeSAEg5UeOKs4bggxYkPCklas2k1EgxklNh25KCKEIDdi7szmjTNDMfjqQsBRCxgg84BZ6EEVvUaTCTa6G0gq9NaNM+4MOAVVFdTE8iImnbWNeFuF6YRhF+Hyar+4e2pq5nSk5iadsqcVspJfHy/ELJlcPhjbRTKqB2fn1hWReq2i97FRm3fmIYJx7evseHrr9SWC8v4qLopbLvlNFkUX2UUkm5CKOvioOsJEdpX8/QCm7XdTBGij6lNtXjknuzr3O6B4n4bdffUZaD9douUIhRXAanccCaYa8A5ywg4fPzI6/Pj7K/UDmdjozDQLycSdtGKqKt56xnGo/c3b1hPhyozUrSeW5yjlU08bqOxjhOItyuz1HKWW2F+7P901rdv//jYfZMwfLVaeA0BT4cRwbvGZxoL6Vc6eYpFvC2SiW5FA046s2e3IhZn2UjltrWWJozmFbIObPGjS7UX/IgBi01SfXXBfwQdqF+6/yelKFJXU8uGkbebxVB+8uaGZzDG3XszTdiuv3QL4+T5+1p5EOY8W7gN29OHEYvAEKFyyURU9F4TN2WrCRf1giI5K1Vsw9kDWkNiiSvwlZEhK6bNDx4b5kPozJSZCaVIlQo73scIAmwU5kFjMQOOUZs4CrErsOAcYJzOK/9/47qPM2PIocQs2rA7JmcjoOh5ETKSVvuHCUWcq4M80hFmLk1VUxQb+EwYFxgPFQxu3gMxNVyRpifKQmbKEptkJQl+YzqZtlMLyLUff0QYfprDiWsdREOXlMVqYtQMFjRr6yFLWUp2GlcZKs0dhRTqFZidkNjDH4HQ40CQq5AqY5SGhF0jgKtkHNki57X80pwHXgotLRJHFfsDqg2EFBA7RNaNcp6vwLq4tCkVuAaq/bX9YINQPDCXIo0cpZ57lW4tBTtsqhJc6EEpml+YTgOgclBPRWOg+clpeuzUaTQmntSDOxtLb+So6mg9RV86uDOT1/XhcZl1l1Ftr98cWf+SDxx1cJtmh/2OL3/qvzSDYOEzh66JvCdGQKSZ/SiaweqpP2/7yxXPtp+ipoHWRRsUZZo7Z07tP382NPY3i7IzRpodraJZjT9IzXpl/M0nZmq1yQ5oVHQwuC8sMPz1oBC0Wu13rO3Eu66T70tbYfB5F5YeT05i/mIEfY5NdEKu36fjO1Ne/ttHqW/hzGifWRvbrpeWlUzC4FuLM4W0cDCQJV2sdrAjUeccUz37zAUnv7630jbQrq84Mcjfj5hrMeUTUFAfb57TNvPb88RFXhSYe4+5lbHsLPnjNnkZK0TwMGLy2WrmaZyAdeJejsvOsNSR2Of2+16TzG7Q9yV5WR2QFPaSgVDsLfPxD7UCnjdzJ/rpqTPgX5+U+26etMOf2UBthvNMMPth3Tt7OtzewXNen3vesf7HvY/Pn4x8FTjQgUez40wr9jwLwxDZeRHWlw4jAPGWMZDwI4Ddp7BBwgi1NqnVlVV9mUVrZAPR088DQynCVNls3Et46pUORsO2wxGxX6hkRtcqgTFI9Dplr13ejQNZwoMIxwGmCfaOPAew9cKIliMVKicpZWN6hrg5R5YK5twipAafprE5tZJ44mnyTnaAestOW60hoBe1gnwZBEb4FKJVel/pmJqgcuZVgTkwhiMuiI5vb/VSIVStMa1CmALcfmRkgrL66LrpKW2BZ6lKma9B1tISSo3BA8p0rYVUxPBNlqw1GlkzZX442cClcF6TrPnbpqJSRLtXBIpZ5zxBONha+SyUcIE4yhBmA+7BalRkK1rQkjlQkTAaxO6tjWQgwCOsch9WFIjF2lxq03cBpsutEbHUyjvVapXmqgLe0npp7ppdTYLplc+xMa7toZpDqpU+/qz1pq0nJUKW6n7YlgGS9Dg1FlhcgVrsYjYcS3a4onVILpyvmx0ZNs6ix+bML0VWFti5p9+d89/+eN7/vPbid+4xEZiKZnIQPaBVDe2mLiESnCWz9lQEhyqIQDPa+a710yYBt4dHc5bUoPLeaWUxt3XH7g7TLxRDZWQX6AkfnhNPC6Fv7xmvr0IIBcs1NSIpfIpNYwzTLMAcS8vRQUJfx2HswIUWCOo/+enZ3UPk0RlCE0SltHjLJwOsyRyRsCLWAreW6bDRBgCtTYul5WXx2dZl6gEH7h/c2QYBo7HmdoMuUKMicuyCmMpSsXb1iIiujZQnWM8et6GmfGucH49slzumA8naoW4bdAg54gxjeenR9Z1JeZEzkVYO87x8vzKtkXuH97w1dffcLg7EBQcc87v22JqhbStnOyEd47gZffwymev+iyNwwBAGERYel1FwNp4S7ui/mpgwM7Kkcq5XLtpFRMztUa29ZGckoh8m8Y0DWAqHz/9IO+/rXsbYsqJbV3pdPzT3YG3b99KOGCurAww5JxU40f0jTDCAlvWhW3d2JaVl5cXXl9eGI8HxsNEmI8c7u4ZgliTt1ZpRRw+LI2cVtbtgncWN8+0JsyAdVvFxUi1v7YoQu4Pb97jnac2x7Jc+O77j8CPxNyY5pmk7X737x64aw/M8wHvhQXWWuPlcqGCiGqnDWf8ro1QgTUlYZmF6SbYrLtG1d624B3OVk2EKjmlPQ6oyo4Ch/OOIXhhB1kRK3dWYqshDIzDqICFYVkXLpezgAfrKmyyEMinIzXNLC8Crr++XsSN8fmFy2UhxjM5b7y7P3E8jHzzm99zf/eGf7SehuH59YUtbsQt8ePHR6oRYPd0d8J7T1KxchcCOEeoTdd3r8E90BrTPNGq3BPnxHyj/sqSt//bf3qHd5YPpxnvrIIrIhBurcF7CTKrogOGRHAiyI8RsEm0NQKDNxwnAZ3FgcnuQGotG9B0TWgYMs5YrEkCvAyzgLPGMgbPPAyMQdhSX7DMFPSKURidpRqcDcyjY/Aj3g44l/G+4VzDuoJpWbQ0guNhHvkvf/iK//zbd6zFi1unBrwxybr3ctnYYlE2XOPhKNIJdwepArueXFoZo9PdSNPCkDGGQQtGYXC0ZoTF7iyHwyjPioIxuUTErEUc4YZh2J/FDtIY53BBio/WWtEvKyuNjPHXJBYkLrGqG5hoxNqZmAnjPdYNhOOR6e4krJ0UMXmDou21qXG5RLYkmkPOWLbnMzkn7t9/YDoNCpyhwI/FWAFfSpXKtlcAO2prd66ZUouY21iLKbKeyHJalVDqOB5GBu/wg4AtLxcp0CzLhd4e3dkdrcESE844TPNy7lm06aLqYHonmYEzIxjpNKgVJj9SShVHPiNmNMZ4rBF2wuPjmW2JXF5WToeJNw8nMaqYXhmmET8fsKPHD/ektJLyItOySbuf8UZYw+aIqU0LO4lSMl6Ts1ocrcDgpfDqrehPXZZMTJWYhbGUqzhaizyOYSuio/p8idLyXM1uBGFo/OY48TAOeONYUuHzeSHWyvfnJCQsY2+gjV/DIfuT6WYTmsR2HKD24jTX5LvRVJNHwY6bBJodeLq2dYlLXNrfr4MLYrz0ZYrbQSdrrwyoXojeoSgnHQC1m0AVKbaw/67Mx1KMAiPlWixvvUhjscbRYHcnF38MBYnQPMaodpSCn6115hR0MKOKQJzi0ldgGivmUV2vShBaQ0sCzgu7pRMnvOS7yM86ycHAXjysrYI1+GHci+3VGXB1BxSMCVhzwrgOkgAtC1XaCOFBK/lybu0WO1TERd9b2nylENYa5CZyDc5CCI3QGmuswtDcLoDh+OEPHN79FuNn4vmJ+Pgt5eUH7n//vxIO9wzjQfLimhXAyZJHKmvHmA5Oyxi4bprT2w+RYLbp/fZBxiIET/VZNFOdwRSDs4UaF3Ae58brvK6ZWgwSJHd9pPwFsHe9u1axoisrqtYCNdOcx/mG8yPWj2iPtAKtdceJdvkDrXj0IuMNHPQlWFVV34mm2JiA76b/r8nZmX1Pd9ff7SeuUjfGCENWmLK/DHSCfwPw1NSdYV0rOTcuTy+UsWLDBVujBENW2DDGW0kCrNVeScUTW19YkNYNa5gHxzSIu5HJjZR7c5kG0wpZmY72Kp2tYsXBR8E9ecUNfbI1edCGEeYDzBOTaRxoRLVEFSqaqOhXkHNt6PeAEhF4d5Q+MUWVbRPXqL6ItioUYucG1UaQCdCD4FzFJcAbccYix11Tqu16QmZ3EZCJIu0NxvQ++kpKCzllUlzlXJynFYjbRZkAM61ByRsNB1Zc8igF0yrWiggwzlFTJK4bxotgafBCJ6etUoUrCZOj9vEbFUQvUDy0QN8A+mbQy3x9UfdOAoZWrkhpbQIOmiYAkDHXjbnqnavtFjvum5GVILntaxq1g4c3m5Y1ohclKPIVPa6t7UuA4kt0umPVZDvreTndzER7ShcpDSi7XlPtJ6mblbjVFawDF5wC5ELz7GKCpVQOg+M3dzMPg2UmkynSWoCl4MlVNqlYYC2NS3b4IpVaSyOXxpoq09EwDZqEK2U+5cIbI+48Th12ai6kknjeMp+WwkusXLLMY4ehqQti1O/1Btdta7+qVrvODjJNAoBtk/ax4APVytrWLBiE+TEM4tSGCTQargrDKAxCee2Cq8tlwVnD6B0mOIZxYj7M3L25RwkpPD+/8nq+kHNm2Ta8EZ2I3CyxGar1IqZsPXbom7u0jQn7Jkvwo0DEuq68vr5yvlzYYuR4vGMcRrZN2rLmeeb+4YGHdw+M00gIA8ZaLpdFAZ1NQQ2gb8CAaTJfrWo5ydpj9yQyd+BCK1ito7TcxELKqLhtbxUWTmFdN0oWoXPrBECopbCsF1JKXJbLfr86AGWM3QWq7+/vdb0xbHGDi2j/5Jx3zUFpJxIR45hEDyumxLptXLYVMw241kDFG53zqumlbiGqC1JLppSEt5JwxCTnU3LeN3jbrFKXG8M4M44T4/xCKfDjDx9JKXL/8EwuGav3YDoecNZxd3og+MA0zcLqwZCKrAWmVKzTSqmOa2cjuH3fV5ZGL6jRtSREO8HachPcXNMYCVgEZHDWMQ6DiIx7Lzol1hC8J3h/daBpIii+LBdeXl+ZppGxTsTgCE6cBVstnM8XlmXj9fWF83kBI26EPnjGaeZwvOd0/4YwHjA+4KdHlnXhu799y7quXM4XaWGZRk1ipaXFOhHBRrUc+zzr89Bqkcho9lBrU/v6X8/xuzczzlruZinu5dyBAbn+wV/3gr55Sjx9C3pIcchaKxp3pv/c0JqTYLsJE886i2lF9Tkl4zHW7gB2Q4t32obZmWZAD9u0laPS9U2tNbjmtd3TYU3Zz8F0DZ6mbWze8uY48dX9kZdo2Aq8bEmZOSKGn3ImJtn3dMWSOMrKOmbqVRjXWosfRxmjLHHbEET7aZpEVDZuRcA8bylFHaqAloSl0+McEc+X9hG5XoOxAdudSlujNXWxM9BqpFVhpEvA0McMemtCa5VKxRlp9XDDiJ+OVDUBIFZaTHusU3Il1yRFXd9IKbKtG6ciFuWtNmqp10K7JgXiKNUIVu5Hv0+tR18WjYmNjt0uhSfPsnOE4BhHaZ17XRJFmfdWx6JPAVDnYKPsgc7IrEW0oowhjEHacHUTKrZijcXjyKqN5YxhcNKd4Jwl5cayZSiNliWZPwyBVi3GJJwDpgFjB6wdpP0ti0to02TKaBxvtAUZoJlVtc+quNNU0UCzXRzbqvt2cRhTRYg3i5SCQdoBpWope2OMIjeRtMWv62wdBs/oG7HCJWZet8iWG2uR+2TNl9qk/96PPXfbj79vtWutv7LvZ+yA0A0cJF/twNUVxLJdS/WG5Suvvbbk/RTg+ruTRFv8NI9o+/u1K0CljJR+DZ3Ns2f519Sd3r4mQESlm2dA1z7rOUjTFru6P3cdONtPrpo9zfpiIKyhW9g3A/skNMJ47QTUrp+H6mOJJpvdlfm4aQs0prOd+1i5/feM0QI+KPDQGV0V012W9nvd9vfciTrm9uem/x+U9dgdUBsGZ7P8q69fJdOaYTzdY51jenjEWE/89GfSGgWYGkZsmMAFkc5uRbVJr8QE+jCam3toJc/reWNraN4qLXlW12UM0r1AASeFm6pOosaPsrZYJ3Onqm6pru/XJ+Dm+vt93M/N7PO36zl1RlVnYmmF94ZtJneg1HqVIOgtozefJm/bc+geG9YbVPCqbfblYW7+voJmfVw7gCUg6s/8+r9y/HKNJ6TN6DAHhslxGgXxyy9P1Jwoa6G7gPlUGd13GBuobhQgxhmMc/ggbIBUHMFajs7x9jDwj785sDwnfvx+I1TLVB2jhdmJRsTQJ2Au0saC9ESPzijTqXEKnvkQOKfCSy74MOKOJ8bDgWGeYHlh2S47eJ5ypaqmSMlFhMeMFTTLOlp1unnLBjgHDYDXhKmVHLO4tjphn/jjAeuc2vQiSUxrQu8plaLaThQRKbbTUZIr6wQoiGJ71yrimvXhgdoKr5fPoiWzCQvptURxbBlFByO+rjQcpQ0MPnAaDxhGrDlCzvhRekA78mnSxkhhnA2mIkyzmllTI+dEoRE0GR5KIZSN4DzeOo5Ben9jSbR0nfylyaUNPnA/O/7L797yj++OQsculS0LhTV3bSYFcFIWQHNJ8j1xn2mA0FW9Mo+i68GkrsBZ9IiKK7vbnTUweUeqos+TCpyTAAAHI73e2B40y30dvVQlJqTCN3vDm9lzGDzeyVwwquFkrazmLTfKUokRLhFtCar4AG2SSkIYLDmKvkxzFjsGvCmM6QVeGotW8I/B8nzO/HApPC6J11S5fCzYCv/wHj7cwz/ODnuwvD9aUvU0W7Elk7NjzUZbCQ0vn5/Zzgt3A3gLn54TL2vh//HnxHevladNlhd/s1dKX71sNClKCJpTr57/Oo63b+6opfDyfMbgmIcJ6wxv39xJX7wV56PDQYDblKXylCtYK3pGGFmoay3UnIDGOI7CXBknrDWsEXKLbPlJNM+8Y1lX0iaubEMYmA8zx9ORukXWbaOWQkmVZmS+h9DEZdBI5ePjpycuy7IL+a7bJrbhpxP3IfDh/QeOx2NH3zkcRWjaDWLNXSrUUkXI1HiGSfV+glS9pSpVyZ2JuoiRQhcjP5yO2DAwa3CyFzWqACLiTFW5bCspZV5eX/c5FcLANE9Yb7m3J0pObIuAClsSVtPT58/UKi0+0zTx8OaN6M2oxlQplXEcd3cbYxzOBw7H7nKjQputiZjuuir4hbzf/b3qLRReL2c+fv7EtmycX8+8ebjn7nBgGDzD4FjWM+dzIaWEw+KttO1sr5F1XenOX955jBOaNg3G6cBhPvHhK8NyPPP9D9+zRgFhai389h/+yHw8cf/+a5zz5C2SU+b15YWUBRhrrYnroQKcDSMFgiot4DEVHp9+oCFVXO89h+OB0Vjujk61VaIkoSlJFbj0Fm4B8KZpIIQgYurOiQbOILpYooPhiOvK0+Mj27ayLQspy70ZguPrD+92bawcN54/fyLGlZQ2hmHiMA3Mh9+Acfgw4Jzn7nhgGgdya/z4+ZnUHqmtakuSwQ8DQxPh4nq5iAj/MGCNiJJ3V6Hnz5+J20bcVlqrDKP8vjjudSF6y+FwkmT9V3QcxpMWZaVtRVgsljEEQNpJe+5mTFOTAUMp1yquNRZnGltOPF5WesJwnCY+3D3gbBNWcavqQjTgnJVEwBq2XESkXpMj1wyhWS7nhS1u5FYl8dEA2uyJXAXbqEnCHmkzLhgyFm2j3VvuqrowJv728cIhPPN8SWy5Cntcg+PWoJQIrTIOsi/7IK1yTvVPaMqq8QHrLNM8Y9SgwFjDOM90lk6pDVsE4L8sRXVpmrK6pTDx/PSKs451jKJ3FrwUI0aP9dIe25q0mtIipi20pdEeKw1PY1DgxtNKwbaCaYVgHW50+HlinI9MxzvwAwYrWFyq1Ngom5jYjIdu8gKYJqCYBztUat3Iy5mXz09cXi48PS1clkSpUvHPmqA44wnOEbwwEoKfACnmCc9NssXByb1OOROr4fPrgveOedW1t1QCjWClqBl0TynKKvNGCpDHSdppUj0JUHi+0M1XusNrruLsW6qsBa1USlZB5GaxpuGztIkcRqtdALDGje8/ZuYpcDqOrEthec2EaWQ8HkSL9fSWkoSt3moSFgQVaqXi9oK4dQ7nDmCMCIsXTfxawxWJP08nYZmkIm34Ly8LW8ysUVrtjnOgYXh/J/HteROG3pKSSC5UYQiPwyA5yywi5I9nEcm/rLKf/pqOnya/HeAANWZq7OwY6KDnVZjbOu2k0CJJZ2LUqmlva3v7tXy/kPM1Ye9s38425Cfn0w9jvRo9KSDkDa3LyewtfXUvJve4wxqL8eCtk2K15glV2UgoiOa95JOi1aSfqQVuEJmNDnLtZ9XEFKRZLY7peDZr8EFc4/K2UEsl500ZfQGLF5e7psmRE0IIgN27w/Q6qNgmzBXgGmsh+VIYB9EmrtKu1UrG1QI2U01T5/mmXSSdaWVuAMcvEDO9xrqfw3WOCPEkF8OgMiGDlzUkJsHvalxp1nB6/1uOb79mPR7J25l4/kw8f2K4+4AdJvzpLdYHcFKQpESu6J3d3ZNv2xd7kUJGpEpCmwWwdC7g3IB7N1O3M6mcaS2THr/DDEf8w6Q6rgFbDa5JPJ1VP6nuLXl97iso2ue5uY5Wf/p7IbXvyXSmk5FOA+tER1EKp033LUPW9vDW8YfOyNufO6s/tze3RtmqrQOhnVVudmLPF89Nh7WUuNGLU780a/zFwFPv8/ReNs/gwbbKGiM1J3KSE3WpgEkM8UJzQYStLFRnsH7A+lGTF/VRM4YpWB6OgbJVLhWGKsr2TithRqt7rXb63hV1dlYYJ0Yf0OAsLVcSkpRIZVuC7NLaLpJrjFGLcUSAthSpIOqDZJwgoTvCh7Jhel+jVvdbbYQgwsHWi0J+q3stSye2VIVbFltatPJinVTObOcjVg16qsE0RxiDtIotmdIySZ2KUilUKqFBqVlaQJolt0z1A0djtJIY5L0VXBGku2BqxpkmdNKmWj9UUtdpsQaLlYp2rdSaCRiCke+Je0GH1GWjqGivsTUE43h7HLmbPGuU814ipNLYVEdrzUJRjjbrwl6IpeGtCN+5vhD0iqqCRoI/XhFsY8wOOnUR8E7W6dfcQWCnrxGNL53PxmjSItT142A4jgI6OXfzuU6ZbFqcrUUWhNwg50ZNjWIatjRdwBTBbk11fxzeNgYyLWaSydhpxA8DpVQusbGVQqqNvFVKbLw9Ve6iOKoZYA6W+8myVWWINbSNQpCktEVaLsxVtMleLoXPS+Xb58q350ossplosVPWfNO3elnYS0PZDr90Zfif/xgHT87X+SL6JI7jYZbkqrLrAwFgtVKfG8575nnU571QsrgDWmOwqnMiujxKyW6ZVIq2ZQRSynu1zTmPDwPDNLM1Q45FdOhKgc6UVFeRpnpE67bxej6r06S0+WEd4zQxzTOnuzvu7u4EvLZXnbWeBHZdl65vIcLVvVqHaqbIOZRSxZpbgVvnPVPTOWMlILMaXJQka0WuhbI7+kXOZ2EuTdMoLbdaMWr6nOYo75OyzN1yI9QpLTADwzBwOMxKIS47kLCHMVZAIWMlGE0pkVIUXYOcaKrlJ2DLxDiNDNNIvZy5XC6cz6+EEJjHwBS8tCph5X1ilAq26cnzlYFlrbRzyYavOhOtSbBnBWwJQ9kFLDtLShxCR06nO5wPnOszraH28mkPKHu1Ua5XnXR0DEqpLKsIJNsQGGkcjVzj4Edhf5V8XZe1ktUDfGNF/LuLgd+ur93B0xpHKYVlWdjWheVy1sKCCnsfDjKHfeA1rmzbpsBTZBwnhnFgGA+4MOLDhHOBaRSH1MvrM1vcWJOYeJyOd9qy6FQTrVFzJm6RVpsIjdtr5TVtG9u6sJ5f5X6kkVuraxra5h6+SEJ+DYe1HqNRfTNctQe1spmSxhlcIR8waLeABNhNgsWYC5/Pq7JsGrla7uZK8J0lJYmQsw7ngriZVSglsyVxM7RA9JkY0r6+9bihA096Cn3DFmBm1yHLpJyIuevisO/BwlisvCyRzy8rL0sk5oKzIrUQgjCUBFiqOp+tsr+kJUIKRAI8dQ0qr+3/VQNkEWQ1xCT6PcY4qhG9zdYZzXo5FXH0s6YKCOIMLkdC8Dg/yVjbTGmir2ZImJaouVC2DMaLvskg+nOWuief1loFsS1hHAnTJDpnTRnJuYjBQhJgzwVxeqtabRM3KYsV6i61ZHKMpC2SYpEOAk045Pc03sHe6LnJ81L0soUBobESsDVJaiR2k4jKGbMzEjr5QuIlYfBj2NeXoJUuUwMYAQhpyhQyve0GBQHrrvUtwtJd/L2zwiSW7/tXLplLSUCVGD9DyRLzueCkYOoHWnfwyw0o/QOg2d1hS3RhHMY4bBVbdYwRsLRV0fdygLH4arT1UQxKaitk0ySmx9KC0ZzfiPkDqqtZ5fveSD5SzMiaC6UY1lhIqUiB9Fd4XFlDX/5bimwAkkBbvbed1XSN9e3+vc7ivDp2SXeIvPeNHs5Pjlu205evMQoC9C4OKVQ3q47a2ibXQaddF0rj+2sLrbaPoUzGG/ZVz9+7tmyPu/sp9b+vTKX25Q/6d/Q9bbfw1nHocaQPVjtv7HWctUjX4Kr7q0lA1xndx3UHviS3sEZZPEBTEyiDMIubMlW/YNP0r/dr/Mm90Geq9dRl/6wrmFhM00Kj5GWKpUge3SDMJwFd4hnrA5ePf6GkFRsmXC2i+eQcOK+Xaa8JD1dG2pfnhbY5Wt0M5Xr3WNA6rB+oFGrwoi8YV6xVuYZ9HopugQEBr1oHatgLJz0/tKaz30zHcX7m6LiH7Bu9G6EzmHeNwC/mdWccV3a3uvZlE2+PDZsO//446H25CuCb/fWdWXj9nOs8/XnG1M8fvxh48rVgnGM8DgyTxw8OihGh2FTAzHK2pVJTYVk3nK8MB0+JiZfHJ2wYGe4T4/HAw4evaKWwbCtg+PBmZFkT57aSayMUg6dSTQTjpL/bgqlWtJY0uFxRh7lg+XGN/O9PZ3WfClgKLi/wstJeDa0IqJONpRgjfaBVWglqzrghQBjE8clBMxO0Ji0OGqAAtHEAY3HjiHGeME1YY0kvEhRXp729UYOYtOldlWAh3D9IMISH2qhRkqaSpXJ0vD/gxgC+StXaRorNLCURU+R1uVBb4eNTFC2FLYHxuDDDYcTcv8UaRzBO2sskDoMiNE/XDCkXtlRZLwvLyxk3eNzoGcaR4e4gjL4q6vw2ZkY/i434MMgDLU+ViMZh9olrFOA5jgHTPG0UxDk3bXUrgqzGLNpKQp+Xr3NpfF42cqncTZ7BSwAWswSuAv4pqmoSvd+6NaFrWw2uGjB6y/3k+Q/vZwxwN1ql8cvG5TV4H9SNL3jVfNBNJGjlAxTQ0uAQJ8Fr0ajeGamO+iBVi7IVaq6UbFUvqzIfBt4eRr55e+KbN0f89srn14W5GMYKMRliMWTbqANCyzeGu9HzYRbb9ljgYRZNDWGzWI6+MZiGCQPZNtH1MJUfnoW99v/8y8r3r4V/+Vy4pMYY5Lqv621fUK6Li230/sNfvIj8z36cz2fRvFB9moc3dzhnOcwBWpPW0ta0RQiMczInY8Y3z1iFYTLNkyD8dQYkaSi1kmMip0zcVmISfSHZ6A3jMHKYD7LIO6l4nZ9e2JYL6/lMr4ZtKRNjZlkj6xbp4oTOex7eved4dxKHPE3kvYI6zhgKjXVbRJB63Si5MEwTLniGYcI6qdLSFGQCkm74JQrwkbaorXSWECx390esc2zbhXKRa8QY5mnCNFjWRdeejVKlAJFzIa0XfAicDm84HI98+PCeUgqPnz4Rc+bx6QVvLcfTgbv7e/7Df/wnUoycn192EAyk5dR7z+l40sDBSEveZcGHgB9GaaWLSdoQqwjavn97T4rCEPLOkmvjeLojDCPVWIomYcvlzJMzlLTtLXfGiIjjNIp4ei5ZnK9UJ2ucJqlaWqnsh3Gmtsbnx0/88OP3/Muf/8JyuWCN4+3br/jw/h3jMPD6euGyRF6XpImnVC+m+cAwzbg4SYCoSfI4jeRSeX16IufEpvdmmMaOJ0GDbYtkm0lWGHWtZLwx3B9PlJy1pVQswa3qDeZmqWXDO08Io9gjbxsxSRvmsrxyfnlmCIEhDLx/9xXvP3yjDAMjTKht1Wqh4Xh6IAyBD199xZu3b0TnpTYeH595fnrm3NflKhXALcv9eq5NdTqEaVCL7MWPj5+AxjwdxVUsRXLJPH/6KIyny5laK6+9lcGKrkV/Vqxz+PCLw5p/F8f3jxeshXloeGeYpobFELUosS4ZEL06AQWqJv6ZwTveHidKgZeU+ecfn/m//7/+TCqSFB2HgQ93J94dB/7h/cQ3D0f+82/fkVul1ChgioKf2yY6aKY1vNmYg9PqKtcMYk8sjTDTM+TU9vv7/adXtpT5375/4S+PC//8wyNbLTw8HBndHe+PM3fe8f3HZ7YlIp2WhncPB6ZhZNCWhpoFDBPNJcsQhHUujE/PGCZ9Rl4ppXA5X8ilCXjbGs49YYw4wlor5ineiOZTzobzq7CKiiaaTtkDW9zkMm1jHAPT1Bkwom1Xq9W11lFzoySDHxzDKKBLSqKjZVoTR80wiOmENeQt8ZoeGYaJMI48Pz/z+OOPpG0lx437t285Pdyrc1PicPeO45s3rOcLcd2wTWKow2lkHKHUBd8iKTbWVFjWTCyVcfCix1EzphXOq8RgQxDQ6BBEc3TNUhSMqkETWpGW/yyF6KJtjmlw4hAdpPA7jyMGyLnSCpwviyTnTmLwYDWesx6vYx+K6Op0p9UUE8v5LDGfFVAr+N4iKuy5mAqpCKP+smYeXy+cDjMPp0KtCVMSrVRlIsxM0x15XSjbQssXWltpImAl7ZDNkVPd52pP9qBx7XM2iI6PuBwep8qo55VSJmeJWSsCEE5DZQhWHSMrr2siFQHxaI37wXEKlqP1suafREvq13Z0DaQr8AS9MAsaGjWoOVOtVd04bXVSc5K9qMa1de62Ja216+cEncM/PYfb3/tS66m/R2cpdRBBivhSWBQmsemtaQqefAE6GTGu6W16t5/9RZpu9v8oG0a6PcREROCAonIsnaEiCJGs2wZwqjVpNlmbai40Z3CDFueCiokTJLbwUiDtzJbd7RuHNSoC38SNm356OjZC/pB2vaKFxAa7YU4phVqi1B5Uf7FL5twKe+8wkxZS+neE8XNlkcXUiE1zGgsYi/Vmb90u20Vi1fkBP91jx4mSNtLyRE6v8OOGsZ5weo8NE/5wh3FiyHBbVeiakdcWXC20jSOtFNFma1KRl5bChnEBe/cV5A2/nMEP0AqtZkpO2FaxVeBsF4I68HIFuzvI3UtERgdNX9jBdue8EHVsL7w2ZT7p25UiBeUmoKHTIkwHRrdNipElRxVCl8ETPcw+tzsgJ3Om6T1qpiljXtsdjcE6eab29tPaAceyx+h/18b6rxy/OEIzrUqVxFt1iUMGoFe7VDyulUIzwmbBNUWzK9tlxYaKGRa82nmXVtmy3KB58AzBUm2VbrSmYoW1yqaA9uzTyytSMUgNgmrwbBWeYsGEymitnHPNSlFrNBzNOEqDYvrA9Q1GF4aOsoO03jUDukns6LIPosSq+hNde6Rswv7qwFSNcrOtOjIJimqxwyBaAbmLhZUrXd5YbAhY72it0ChSLTOV0oSZlXLWCqQKTsYitG8LtTmw0t5odWHYUeduo2wsIG5PJRcJhmzDBaNCakEdhURwswMv3YXpWsnUuSEw/vVrFVq0GLoUQjXsfcetQcqCbm/ZKxNNmBnBGVKpe8DZuGXf9P7pm2qI3LK9uqaSawRrad7w9iDXdBws3iIBkhFrcdEP8HjLDkg5IxWwUvumeOOC0aMe06txjaZJZGdDXW175RkoVRxOjlPgNHpOU6BEQ8yVUBqhVGqxSp0H44w45jWxeh6dvG/W95kDjFMQe/KSRG/MOhwNayUwvMTKy6pMp5fCRQX6Jt/nxH7X9hspFXX2a/g1AU9Cuza6MDvmedxd7FpVnQZ1xsKIjgf0WkAD3XD8Driqa6Q15JRIm+gmlZJIcWO5XKRaYmSUT8eTJNnOUUpW2n8ip7hTZGPKbDGzxUSMaa/e+XEUdtM0M80z02FmGIZ9PuaUlO0i7Jp120gxUY0h1Ir3g1rHXsdDsEWpdJXaqEVYBrVWdYEy+CDP+uvlIq0WqwC9g7LCur5SjFF0V5T5QKtq/uEI/qqJVZsEUilm0DaVcRx5ePuGtEVsQ5KNy6LvXwQodF4DRlkvUhIAzIWBUkVguweLzlnmcZCqkgog5SIMpGGaRIdpGGWdKEXFzi3OyTPkXdDP0+dcK5Pd1aYzg9DAy6kl+MvywrKufP78iWVZ+PrDB7lX04EhBLYkbRSFZ9VWmoRJdzxKNU8rfV9UzFCX1Sz3tdErnL0q2DWblGKtyaw1yP2ulYS0zpobfQupjEoIVa2AQa0Utm3jslyI20LOkaDg5jjN3J3uEatgsVaOQNeUGsaJaZ44HE8cTydSTNJuRKWkja7As1tVV7GETySMyYQgiX/Vat62rdQimhHCZovCkEmRnCMliy1zLzBIMCTxgauVnNMXe9Ov4VhT3hm9rRlCq7pHSSFnU5c6YXVAlzE1VgVCdc/dcuVpSfz3H1+IuUg7avB8fN746n7CcGKwjvq1av+VSmkad2T5ntJmyLnutuKm9Wp+TzBk19SXUnIj50oqmafLwstl4y8fX/jTpwvnLeEsHOeBuzFwmgYOwQsLeEu7iy50VoFTwEgYLN7qc7mvW44QxFTBACldqKWQUiblyrpGiophWWOZBgGTB3U+7u0CVdQRVOQYAU16PAqSoFV3jd80FmjI+tiaGMQ0CqjbVTdfQAF2Y72ybCTxyKrJKC3XnpIi27pKQWOLHO+rst8MUPHeM8wTtTTAUdaVmqOAxMGqOLjGubWqk6XoLBXVnJJasQBnwRvd56Tte0lFJBR0HvbwpyejVanlRTsUdNLJ/cCoILw4b1orLJ/eFitJXmfpSmQ/eId1lnEcSBZqdJpUNZyTdkrReq0UIzpW4uJZSaVhcsU5zzwm0Ri1BjuO+BTxbpJEzgWaK9SyfQEEiKaPFaC+XJ2i+n87TtD2FiK5XmcdzQvbqlYrosLNkPv6ZI2YI3lHsYY1S+uNaNk2BmWhuLFRqhXn6l9R7NWHqrVb7aor+NS/vzM+NC7pya4x12f7dg/rxYbre93kH8bsf38JTvHF79y+tp/WLZvjCjz19jD7BbNH/tm+7MpgD6Ovl6rFrp0pdQM6ffHi/j5W4sbb1rr+86t4k4IXTRicTQs7to9NB9WqOsR1jSdlQMmcbzfDYXbx8lstpnaT21lrqR1ZMmZ/RQciaquad8rvtJvx+Pst+foZfPFzzZ6qjK/t5+h6DNNzQmXfDgchcbR7TNjI8ZVaEiUuWCx1OOjbnvb73fon3gBN+1zR11gncgfN2h3o6aLbWIsZZlm/ShUswOhYVFnzWtfsUqKEqGRVRNvG7Ndye/X7yvLFedlr/r5nJDdjftOasj9H+vorQNQlQmSf6kxy525HXe7rrQ5W1bUWUzG7ItjtHq+gfMdOdgD3f3z8YuBpWxNugAEnVr3pDHmhA069f/71/IKfZx7ef4MfJ8x8Tytn1vqIjRXz9BlTI5eDFzbL1gjDwJu7I189HPnj798QnyPx+4VYGhftXzRGPkm0Ay3HeeAShYYs1TUYjwd+c7xjsoXJVDwVciLTUVpFbOOmwbw6AliHG6RtoqaIyUIntlYApNb/dNckYwXLTQlaZH15wZRCe3nG1Ip98xYTvC4C+scY3DxjvSe4gAFKS7SaiTnSMAz3D2AMl9QweSNsjxhXOQ4BWxofywuldJHehncD1ksPfQgzx/k983TEDkesBeuKVLlTIcdEfJGE2FjImwQ1rhXeHWeZRHHDOEt2FqzHWY8/njiMk4qPAzlRlgWKBkF6ebv+kW4gXXYuVk06ke91ML3o4t3b+iatKI2DAI4xq/2xYiDiwNCu7W66ALrm9POdjqk8FO+PVhdfo9fcl5u+cQiI5YzV9Vwfaj0/y81nOGlTMSZTVQxdxPx6H6xcnOqtaXInwXlKhcnB10fP18fAbw4Dz3HgZRsgjOBHOY9seG8zfxwbZpCWprtgabnw9FopEW3zMUzjwGhEwyoWkSTz3jANExj44YeN714y370ufL5U3Cgf5azcgC50ahUwvW4PMj4mV+iV7F/B4dyIc5bT4YAx4hCXc2G5RAC9t1a0bpxjHEfdoDrIKXP5vJyF+TJO5FJJSyJuG+eXJwFhtkitheCVLdcarokwbHEVUxreO6bDCLkQWfjLX/+Ff/7Tn/jw1dd8+PAV93d3jF9N0ljQGmEYcT6wLguvL69UKz3X0zgTwqA98CJGHsaRA5YyVW07tQLoDwHMQENc9gQASrRWRXw8oJoawq4xBtbLBsCP3/3Iqm0bPnjmcWYYAnfHA61V1uA0sZMN0Nr3EpTkxvPjMz9+/qyYvaHlLOLV1mDihTUv/OX8BMjzWEpRYK6SL5khDKQta7tgZVlWXl5fBew4RmnJuztKojkO+FYITVhKLSc+n194fF2k/UHb1969eyfgRS2Mw8QQRo6nOxH6zqI/FwYvLobTgHeWT58/s24X/vK3v3FZF+Zpxnu3b+ov5ws5F+5OR94+PPDu3XuGYWQYBFQ5BGmRfL1cqK0Sp8gwjtx//R7vB8w6kVLk6fMnSs68IIzK5XIWDb8tSlI9TDjnGKdZntoq65rT5Dt4R06Jy+sr6+XM48cf9kD6eDry/quvCSEwzjM5Z7ZNkvBUK9Y7Ht4+cJh/x93xTtqvk4B63373F3WjzVQFKMdhYv7qRBgHXAikVPj08TNdY9cby2GeJPls4BVgcttGygIk1Zy5qJuh6Kk0qc61hveiR+X8IK0yd4jo+0GAqOUijLvOkKu6eG/rKuDkr+jwTlooc7WUbEhnae/B9hYAAcKr0TVbASjX22gpJBrnWrjUylosMTVKqmxL5OVx4XKecCYzeS+6QK2xlYZzUqwZB888DaQkbnUFxxKlYNTjT4AeENQmoMDrkvj4svHjy8bzOfJff3ji26cz376sPC2J98eBP7478Mf397w/Tvzhwz1vDhP39weGUdsZSmNZEs/nxBgkFhCHtsrzRViq9/dHRjtom3hljcJsWrcs76EVX9EDrZzPC6bBNEQG7wA1X0HA+CWqk5RqQnpnwQkb1DlHGKT6G5Po5NUizMlhcPhxZDrekXMkbhephMeLrHHNkFJl3TKnk+inhHFkHGc+f/yRj999z92bO9rbe5ytPLy55+lTYz1HkY4YHEMJWFPFCmTdMLXijGW9nNlenzkvr6xp45//+onPzwtBXQeHYLEOci0ssTL4QAgi3m5zYR6DOrhJfFCKsBOPozj53R9ncfptkpDEKM/ZMI547xi96mJa0XkpyPphjchjlGx1T5VCiPcydq/LJuCSUXugKiLp0yhueLlqO5MRt6pcM1sqnNekhjVSMPQmEEvjednYSmbJkSFuDE9PnB7ec/cQ8dPMcLwjWmHht7pBuSCpUG/fNnSGcEWYalmZJjWLbIapIjqzbhJL5CpFZR8EoL3EVVwDixStuziwsxa8FMMsYiwhbFWJS48h/B+4svwfdDR28Eg6FNQESlk3Bslvoe3gbzPCLPZBDJuctrzFGKXQ6sIOZHVttc5g+unRC46tdb2m2wS5J+L2po3u+r63AImYnYDDg2EvguytbDeAlxz9a/mq3LJD9XWC+fTinH5m0dZ7Xd/FMEPHyQrD/fb8fJhkb84b2CpaTWaHBbTI2LTFTtq1NSTb78/1bPVb9epQ2TWRvGoKtc443TZxLrZZW/v6PdEkk78HVzpYYvX6axcobz33UqBGWVO5VjIVV6QY21TEvBk9jyTdBa02sIHp/T8ClXp5oaVIXB5pl0/k5UkcQw8PGD9gDnfqai/sdaUPaJurFCZNq/hhlHmjBYdWK8ZYhsMbeY2XTi/jpAW8IuSbXKT8U40FncvWepwzu/HGPtY7GNhvhFE5Bxmz2hD3TcxeBO1kF/Zx4+Y99VnTIkBzorFXmszXmDK29CKzmDZY0+/ZTRtgszJJbsBX1Aij3bwOc83rf+nxyzWeShVx5/0kCrRCV+sX1FWSbVO00mYctVpKs8IgoWlrXiTHldYstYijireGcXDcHUcusZHcJor91e7W5B2ga4pW0hkuTR4UN3gOw4QvG7aK2jy1KXXQ6BqiFMlSdvs/47X6oitgp6Q1J+gkrt0gvGYHUcQtrtHWBZMzTjdiqgTRIq7Z+r37ewTTCPRVOgruHA1DjgmDMKVcaPhJ7JM7qk1ru8aMJByewU/Mw8zgR5nopokgXdE/uVBSVr0iKwLouRCcCLjVKk5mRsenu3U463CD6BM5q4tEkR75L3qUb5D0HXHVoKD/2Zmd8MVDJjF0b6W7LsKmdn0aVE/girZqSUTGRX9mYBcaH5yKfKsbQelQmL5fF8+2t+/ZZG5d394ouNRpkR1kVSvSn66rvbLRkWkFHp2BwRo8BlPFvSFVsd412RCzIScRaz05j7fibjIqyJZyZQXCYPDoBlmFVp9z6wUICaSa5ZwMzxFp32uGwcr6ei0w/EwNoj8ifQf4FWk8eWXeDIMMQkpN1yoJGryHLsAsVtmdpm10o8y0JgE7xurGoVX8lEkpq+WuDJrYuncLXdUHQitZxihzylBK47KsfHp84qTtt8M4cDweSLWQaxFRQ+vIOXM5X0itUGjkQ2EcJxgHZRApNd2LnohtwsXr4q1oQJaN6rFp/3dwfZMSYL5VMaPPSa45bqoXkrX6ps95B9daTlRnpb0Hiw8jtTWWKKYNjy/PgGEcJixNNUVQWnIj5iy96i5IYphFMyrlhOgV+x14iimSchQzh5QIw4APgWEcmaYZm1eMamQ4K8LT67qI2KbzBOsYh5FsLDkn0a0yluAHxmEi26TuIOzXWlsjpcwWI6/nM6/nM61WBhV2BjFkqKUxHUfGQZhVIQSl3qNMqc46KJgcsd5qRU0reA1SjGLuoBWqkpNrx9zKAABSaUlEQVRU9XOWgLoJE8hrm7kUXTporhomrVBLIudIits+H01D2+sCQwj72iRVsYq1whI5HE88vHlH3CLrsrJezqzrIon7DkYbwjAyjBM2eDXUEBafV4asJJZeWu818bIaNFljZJ9pcm07gNRECB+dn6VWnO9MloFqZR90ymDBWKWby++KoPbV0e/XcnRRcVSrqRTZSPvz7a3uWVYX8Q48ITpHVZ2Ac2uq42OvxZFSqTlx3iznNbFGYU92AKYHv10nSbpxxQwh17YXkBp8sRc2XSO3XDhvmedL4tM58eNr4vuXyGUTLZ/7KfD1/cTv3x756u7AN+/uuDtMHE8TYXCsayanwuWSiKmIwH/rLTeWXEV0vLdodBCzqNOwMHxU64K6n2NRIaGcM4ZGysLoTFWAg6zz0NGDfFlCJen1hGEAZL5WZcuKW5887z4MEnfUSE3ibCyuaEZA3SLCszkXXNDOgFJEnylu+7M7DGFnmhsrjCDnHa2qdkmPxYyAtnFdWJaVJW5c1sRly5wmh/Va4VbWUb+3zqr1u23XliHTkxkZI2ctXhNPby22SrF3N/a7ad/viW4XLe5rpDDgzDVf0HC8NoQRZRomCNO7M476+Zp2y3YwO/u11tqbX+hNO6XAlorG1cIkHraIc7I2Gx8Is8U4j/EDLYk+1A4uKECkm6Tee0nAGt19S1iksrc35BZIq4zR2E3WZFn7hAXRwQtZz4QV1vbWof74+Btdu1/n0fOw63eaxuXXjgKzx96Y6/MnOUX7u/W9f+9L/aaO71zZSJ3A0No1jvlSP6oLnP/8/vFFwo+ACsa2v7tfP9fi97Pvdf1C/t3aDsgBV/0fPSN536uOVI/ZrTLxa416an8/RtcPpuMV+1rYWtf+afvb3oIsO+OsM0Kdw3TjitZ2F1m5TeaKtO3Xz036fXNet4vGF2Oh+SNSkGxN9ORodc/9m9HezNZhOBkbN4wYK+t7NY62PAkDarvQXMKFSdhHtYJt12vXHI8u5aLtxRJ36YB1loWxWDdgTNmNAKwy85v+XtNz3bsmGvtcNtSfnSPXlfLmZpmeS1+ZgWYfo5tsWtel65p18/r+WqMtkq3uXUS9U6jZL5mc8ul6064TZT/H673q14USGn7Z8W8QQ8gYHMNgGQcRzi1NRMXBMd09SJBuB4xrxKfvqc2ypUDKjbRaxgCTLwRnpZLgvLgaYFlfFkKp/O5h4sU6TPMcauWhZuq2kdezCIWFwFIb6/NKMY5iAq85s+TEN9OBb04z62ZZNyvCzwmsb1hXKXHVvlYD3tGtgp330l7jPVgrbSMdEbRotQxalJ7HHDzVGkIumFppiyYj799hw0BxXsV0FXxKFmqlvrzSjKHczRjvseNMtYV03sgp8/LdD7IpDQPDELj/8A3GVRKvbDVxWRdqrtyNIpj79sODiqAbWjSUlw2fwWyejGFrjbRtrK9nLA3vC4N3zIMjGcuWdV5bcMOIC3fYMGCHkZYzLastcM2E08x0mKhjoHiPjWkHm9iRYsUsfhKMGsO+t18fmD595aFKVX+n9uBFfrm3aKDWo52+ibVi/a4WDc7IuXRwsjNWotLBhY2kqO2+AJirYLlp++J4u1kZZUylKhalwzQwNcNdNpSUSGvcE90ORjm9ymF0zCMYLM8vG//vP8PlObHFjS3CWja2GnlZGucoWP475zhOMCut3AAhWHww4AzFGL5/2uBpZY2FXCqf18yaq4jtNcO/fMq8bo3T5Jgnx1oTpQsdNtH5MnBdNPfFTDeJon9+Jce7r95Je0iMCkYkWmuif2Qt4yQA7jC4fQ6llHh+PmsLlAhtj4eRVi1rFCahFCEkiB12DagGpbAuCy/nVbUoGg9vHnj/9m1P9fn89MJ//ee/cNkyb99/4MPXX/Ob3/+GMEyEYWB9fOL55YyS1Pj48SPPz09I+23FffiA557EDCWQU8Y6y6CsmBAC3hpqLmx1pWosnbK0EizrIqYKcRPGjDFYL0K3tRSenl/AwOnuyPF0pCFGDfPhSAgCbhkqh8MRaPs4FRy5VEytlC3y9PmR1mAaR4bguD+NYKVNKKXM68uZVArLTduhs44hBELI2pIioOAQPG/fvBG9AicAyjiIsyDAuiXWl1cJ4F1gDIF5GIi5EONKOBzUFUcqR7lW0mVhmg+EaeR4OjAOgc+ffuT1+YW//fWvvDw/saoj0TTPHI93vH3zlnmaOJ5O+OB3naGUhfGWYibViG2yElQNBOZp1PbyyLYufP/tXwDL0/MLOUaWyyuGxjAMAkxqctUXRW8awRqmwRNT4vX5k4KiUbRSxgGqFoms5/79b6Sd8f6eYRBHxVwLr+tKLYWGIYSRcRYAL0wjOTe+//RJ9A1yhpYJo8fgbiJSmZQxLpAlME1bJKfEPArTy/nAPA9cloWSEsuySMv9sgjop2tOUJdAp5XHktMO0JVNGvW6FlSv9llXmY4S3PWiR99zcozXyvKv5ChIEn46CrjcsgSXQdtGg+rnTKO0Pzo7QauUskobb86kKnYug/M8HCcuNnLOmWId1U2YMGiLcSOXqELW8nVMDV8yrUQw4mprbCW3Su7stSrAs9VCTW2wpsZ3Tyvz8MK3z4nP58I5G8Zx5h8+DDzMnv/49ZHf3E/8w+9+x5uHB46nCT84tuVMTpGtNkpqrGvkskaamQjB83A6EJzDB2HMSTte5fIq5gbLpuvzTYsnNE7BUb0jWKeMagnQt5zIpfL4kgDD5AOYRiEzeEtwE9Y7fHBY18BI9XqeLTFGnreMswF/OIBxLOcztSZS3kQgvEhb9LZGxmnk/buZdcn87V++Z5w98ylgMLz/5h01w/lxJQRHCI67hzvG45H7dw8M84R1HjdUqhXzFlvFtObl9YWPnx+JSYSsH44njvMBo8GXz7Lnb7l80UnvrCQeWVQpaKqRZq3HqSRDa4XLZcUaQ1YnydZUQmKT7z+fBzV0mHHWMDkR5JbWEynUWGMZvThHrdsmbnZRzDpaDWyt8pwvhCAajMY0BkSgt+RGLhCTpTXPOFoFVGXbTUl0n16WIvFOrQzBMQTHw3Pi4dMTX//2N3xtNsJ85PDwFcuzZ3uV96ZWkblwnpJWWklS/G5S9LYNjJPWU6wkv24IGAexdB0ViS1Op5HWhCFYSuXp+SKOfloQvb+T1p/XizhTeydtUaXuad2v5uhrdENa9PW7N2DEVbPJKcjqw4C1bmcoGdWk6fv3HnMokBFuiyk6gKI503EcSaqdczqfZQ29NaKw9ipQbjA7gGq0K6LWziqR7wtQewWQOsAt19zzoStY9rOtf02AjNZzxd0978qK2cHgnpfg90TLAG70ohNVhV1Xc4aapSivYvjGWYxXrc8qYK4iO/p8AtoB1IHdUhrOii6smD5k0dPU4gU2YFqGEjHW45DPUpGnfoHy36pt//R8S8fB+C+zQcVouhaSGK141RKuUBMgzvZtJ3GY/b61vIkMwnDEDQf8dKLVTF7OtJJJ2xm2M1w+S9x+/wEXJqbTW4krDQoIFy3mCOHAK8NOyCQ6ca3ZXVStH6Rguq77PWvGYay4XFbEubMbwFhrdpZQB4LMDmy1W/xH8+JCbwnsjp63Py9FAS9raC1pe3WGVjRmcoRxxO/AbdtxtKqSSXTwV6U5btsBO1grF8cX4KWzsl+Yf4Ony78BeJIB6U4Y8mgaOp1HRLQaNgxAJm8LpaIWqTp5dlwVirpMGC8PkbAC4Dh6Sob5BFMpTMURWyauVXrWvaXkRkqF5uTByg2yAhdup3pfF5xu89hapZWqavd2Z6zYjuY6D+qKV03XlEItDdtVK8qpaFqVBMs0mSh2nHDjKBUb0OkmLnCtGOqWBDwtRR9OSzOiIFOaaJxgjOgshIAdJowtxHyhNHHwoDYGGxi85zCLs09RsetaE1SHaaLfkEolxUTcIsFDGEU03Vqxsg1OEVCDPHRhkEqQiuTJ4pZpOWKatCthLU0XQrODODcoqY75l5un+cm/O7xzfV1V0GkHrfoP9ve+gk4d/b9WATS+7CBXv7HX4gG9V7lhRJOiz2GtEPSPubK4+sa41wJ0qktg7ZylZatstb6hdIRZq9Ga0APEWPn8mrC5L+CV19g4JxXSy42H0XEMDo8hWJnTRQOr3YzFNKICTlsu5NL44ZxYUqUZqao+L5Uti/ipt4acpU8568ayP9Gtg3J6r6/A9q/qGIYg1f0YJQTXFdM5vydKtvdUIy9opZBTVIcdCT6HOkpFolQtfPS5IOKizrKvESCV2VK7Fpi8vuQiQs4xsqaE84H7+wdOdyfmw7zrftRaBUxSIEyo/5VWM60VYY7mSHEeizh0mmxxqgEij4Fq5xRhO1Sa6o5Jxb3USs6yWTlleVkVJ8waIA7jsFfbu3jhTrtVMACk0ituo8LadM4Jrb72FqpEsY1aPRVDatJukLOwm9Zt2wMhPKCMgtY6cwuptDknO5xxOxMRXTNSLqxbIjjRhbFGKvUCtkny0qn41phdmDypVtU0BmqzxLixLAuPnz/z6fMnqYY5t7fkjePMNE4cDkeGYVR2g+GyvJBSUtvuXlUyNBXulHZgw5aE3bCcz9QGy/mVnDM5xS+Cawl5bmpbtSrrtYh7VY7UmiTZcarpYizGBgET/cg0TUyHI747rqrOVlVdQ9OksipBjSTjNaV9vgmLzu1U/daAqiGqLti1GT3/THZWWB9e3OV2unjpmlVZGFydxWE0fvBd70bceWqKOyXd9ADUyHg0I1bSrda9hbonBSluX9DYfw1HbqKjFIJY1ItinQg5Oyst8M6JBIFolTlqNaRkKaWJYHKV50TaxoS5YiyYqguXMj1akwSqF1y6yUihYk0BKyLQfb/FaHW3XRM229+nif7UecusqbKVhneek3N8/XDg67uR37078NXdyPuHE/f3J/zkMc6Q1osAkOUaVLP/V5yWrHXS8lq7+y3knAX02jK1gh+ChjKyjjhnsA1CcNiqRUVknuVS2VLBYPBGCpPVqMOpglT2JnnqOhmie+kk+fJBrr2396kVdt8Lai0Y0xiDZ1sycY00Ms1G5lkMXLa1kJPuMQbCELCjww8BqbYHSVCNUaHhhqXua1kuwvwZvNeWfNHhs+ZaT+oFwt3hCo29atv1JrvQbNVKYC4qJp6KJtIq1KvF3FotzjWMk+LyYCWZ6gz2VKqwv53sZ1nFe0uV2E5JRMRUrom2zqmmQENVFQARJ7c7M7trWJXaSK2pFmoh5MqgWqqtZA53B+7OM8dxFCdq57FuEAC/FnlP1Qxr1ej5a8KJjrWB2guuVmaE7Zpeyujyygg2GLItMp6t0e3Jneu6ZcLgaw2qkbbYXxfyJLGQ/Pcacyp2tMf3t3GpMarltlOP+Tvg5qeAjoiE1xt9rGvC/OWAXkGKv9eNYt93jSJNVU/xSzZVB5767Ly91uvn/NyN/Ds2W4+lMJo8mf23fspa6td9BQSEwWms09Y1BXyURnfNZRQMMnpe5vrXlV/Tx/N6/vvSoC+pte5gnHxf9AOpRT6zr9H90vfX9dZK/dx+D7kWva+AYdt/TzRSJRc1zYneskk7cILGoDdDuSNXxmu84Lzcx1xoJpHTIgBx3DDOU+OGweq6bDE3eoJ7sNO/5przXtNTzRusFRakrhG7a5518ja6f1SNqcDtt7AfTT+vrzQ/mSlfHK1dx+6WvS5reN3NEWQsv5zv0t5otH1Ph5J+qY1m9ef72N4CuPz9ed3k6L/0+OXAk3NgHSY1mqlEU2mpYkPDucZhEmeM7byRSubzErHGM4QTozMMAUpJPL5u+DYxnRzTHHg4HaBKkuet5X0IzIdMOHjMlrCXSMSyvDTsYDjdBc7nzHlVgd6SOR0Gfv/mjryt/Lc/P8rEA4YwEIKnWUdVGrT1du9t7CTdai3Fevx8xA4jlCdqWWklY7Letv4EGsuAsG0MgiaOb95hfSC8fYPxnvr8iE1i/WGN5fD2DRhY3WdJGhBUent+1Y3SUy1SPaEze6D4QDPS7rLljXXZME20PnIz5OSorbGtkbglLuczh9OJ0/0b8rpy/vyZkjKlJPwwYOcja9l4Xh4ZCMyHCesC1g+KfjZKyqRlwQWLG62IF68X8kFELI21uDFgl94Ve7N494FvHRgygqJq4AKo4NrNUl31UdXJ30ztbGx5IPa21b6aWV039UFTbanaWwK4wlqyYXRKaL0+IOYKnlrVMzDt+pD1vzuGZS1Ix564f6U1Ey8R2xrzMAjQ1IEqY/YkrYNRJRUeY+HT88L/VmQz60Fea+raYg3nZPDOcFjFpVEYIDAFg/dSt6wGnl6SsG50gd6qLDgHY/DGULOIDK4JjLXcTxPGGn58fSXmgnW6YarFdS2ygVkFS35tx7ZJZdaNo1Y0habb2zpzjuTWiOuqG4SAJaILUHhdIiZm1pQZxpG7uzvC4JjnmVJG5mlgWS48fn6U1rsoDLM2DMwPd3z46j05Zr79/ns+f37hxx8+M84jf/ynf+Lduzd8+PBWK6GWz4+PPD1+Yl0vQOHhzRse7u745rcfqCXz+vSJ9fzKuiW212fIlRJGreLB5VV0qN6/f8c8zwL+GLgsi4JJcu+ddzjvqDlLu4wRYOn+XpxPLqu4h/lBvn88nLDGivteTnsAHtTSt+SItZbpMBOCZRoPnCZHS78lxsiybLRWeVUWWYpS/Q2Dx0yeh+NBhLf9SAiBwzQryynoRi5JaFI2j3UDrTaen54IwROGwPPzM0+Pz6JH50WH73g8iJvVIqLT1lqGMOCtIw4bOSceP//I3/76J1IWofaSxWW0i8R/88033N3f85vf/I7j8aQgljDmvPcK+t/YwhuHpXG+nKlFxf+t43gSkfngAjlnnr77gUZjOhyZphF7PIACK1L9DVIhfn0V7aenJ2pr/Pjj99JGPATGYWA+PMjYhYkwjBxPD+RceF3l+j6dzzKGrYn7olblBLOzNPMiAuGnE+M0cTgccE7aQarqbsV1EU1ABSCFGXhNBPwI1XtySizxrCCSaD2ZYRAGLY3gLc4ExnFUYMrpIttbDgUUkzhcKn0A4ySMnN66Yg2UWtg2YVK1UkVrbFl/dcDTD08Lxynwn755YPSelK77pbUwDgI6WoTh+LpehNmSEqY2bJEKcakCfAs4I4LPzYAvUuE+b5lLyqy14ovBtaJAVMMbkSfw3hKMZRoDh2ngMAWGUcwCrpmK5iNNdJPGwfHNG8/Xbwxf3R95OE787sM73t6fmEdH8BbjDEuKLE+fSDFyOW+klDkv0uZ7fzfz7u2JvsPHuJK2SgiiQ+WdGC4sCXKR9mhQR2KMuvjBpiBZzNqm2uT9vDF4KyybWqR91jvL6TgyBK+6f1BKxBsYXKRVw+VV9tg3b+4Y5pn54Y6atfCaCqxdVFwE4qdpYAhBmGpDYDwdqCVxeV7xboST53B/4u7dTNoWUlwx44FhmCk0Lucsemlj2CvgZjvTSmWaBu7vjzw+L8ScZC31ju0V1lj5/LqyxoTzktTn1xWDERe3Vsm2grFsReKKnOuu9SI5UtXnThIsVyW+HYOMfe0ZTEmyrhRPrrBWKQq8nFecgdOhM+Ocxn4DDTF0oUmsg4KINGlrK0WYe6VUYil7q2IHm7rQfqntqsdUG2uu1HPi2Rt+DPB42fjrtz/w+z/8nt/87hsO04G7uw+ctaU4p0xd1VW2ydiIcUjeW4+8G7V1smFNEta9k7bFYgKtVWLetL3TYIzjMA+E4Hi9JGKqLFHcvPsDY5wVRlX7e8Dh3/MhS4K0a958V9vervvH7nBqpN0z+N6q3kGJegO6fHnsLMsK0F3rrp+Xs9w/rXHgvew/vQDZHVevraZmjxXsza3obdzCtLoyPDuodj202NKJCreg1s8k6X3ZND3BV9Cjg2hXDSDAqE6Yghj7xxmDdaOCDmUHrQEdR8sujm60cuCMGnCZvZi1X4GxhDBoQVZyrKb7rLTcW3AjJUfKcsEUFdEPk+zpmrz11sQdpDPs1yQav3aX6QFtma7XArnIMhuMkTyrxax6aNo6bSfZBBV86YWu1qLkN319P74FIGjxNp8faTWTLk/k9YWyPuPCyN373+GHifH0FlohXh6BRnc/FAMivR8NwNGaocRMaxmvIDM2UBGnTIm98p4fXuf0l7lqKxXyJroo1otEkGlXuQxjueazV9ytx2MSzylAWPIu99Hj0/7ZvTDtg2j/9Xm935sqLLgeRnkfbuauEYIOIrckBYy+6f//AXgyenEtV6qFkqpMAAPGNCxZT6BAlQ0BZ/DDQHAwhkxMhrI2aqqwVqxr2heo/eveEgbLgGMulUqhRoPxhuYNeCPF7mCxg8Nqe7azhsEaUi2s24a3Fm+sRFRNHwJFIbtIoe1Aht7A0pq4xvSJYYB60wN6kxDYJq1d/Sa6YcDeaHp0GKYLDple+fUWsjoKNdUGaYrsWosNwv7q54mTSkiuYosoCY+wbISJYZWZUSlJbLMrhUKWPy2BEYc446BaCQDOaaU5mPykFEwvLA6l27UsG6lcSOPWilGwt+vDo7Pj5t9cq1Xtpz+RH+4YDx0f5icrt7Z93QJZ/XNu3rB3r+737Ob3v/ybLzcs/fe+MPcF8eZEbhlM1miFt0myU0qh5qqA9g0jAb78t24YpUrVdk2FNRXRJdB5ZBH3uoChFWGCVAOxOgHdWiNWg0/qfgU8LYUtlutwGP1kK4CcpdFMI6lTotdWpeA0caOj4DcIeINd9PFXdiQVnvTeYp04BrXWMLrhdtef1t0nO126O3V2kLO/TtcE5wwGRw2edbW73tMao+oWeZwXUGTbIi/nM6+XC+fLynQ4cP/mgbfv3/Hhq/es28YaN3bntgbeW8ZhYJonLCPGNEyJuFbYYiLFiHMJmUVyrp3Zk7NotTgcWHaWU5+dwkiyN8+1tj6puGmqiVoFpLROmAXGGOoW1XVMqtROgd9cCrZVbaOy2jveGAfRQooxa3IgiWyqEowOyqIKweG9Zx5mvA/aMmh3YIsmyZFRbZaq7Vi5FFoNe6KS1Y5KAv7O5Lip7GhgUzHKSqosy4Xn5ye2bSPlRPBud/EcQuB4PHJ3uuN4PHKYDyzLIolIEwZDZw+hswatOonjYCEEPRcFwrtzZtWWFXFYdFgfpBVbg/LOJrNGdAWztvyVKkLv0zypZtOgwpUB7weGYcK4jC+iLZOKrN+miPugMGt7EGRBWxpqKRjU1aqzOpUxVxuqf6UFh17l62C7c3KeOWngI4wPuOr3CUBvQfVknDLYJGm9We9vl+oetKP4FIZm2ceG2rQtUFhtIhz/6wKeYqqMXuITr2KhEnhW1enRwFVbJFLWhDwryV+LSu2LPyi417dyYULmKoKuMo+vzKWdRVkLtkgSs4dKNxo/0AtJsmZabdWYgsM6x9cPEx/uDnz15sj96bgzq7YsroXLshLXlXXJ5CwaPaVWnJsYBkctyiRtooMmrQNXBkTX4Km92tu6TThaEW7KjNCWkWZFP8SpLpbqKhadd8F7gneaGPeCkhSL+r7ujLjpeS/PDU6YUK0oV0cTFmeFbWaMtuwYcN5BKxQcypOW9TYEirbQuVv5g7J7Fu4xUilFftYTcwNXD2/Rq4qpsKVCzIXBWpzR+9zQ6l5XSmqUVugsX7mXVRMadrkT6PGCMoY1gJI4qV4TkqbM7dooudJsI6ai66uhuwJ3gLPrSpkmrXnyRsLwFidG2YdLlSJE1fkqjDJ0DitroAkImcq1dchbaDVxVIaxf+uZhnkHP0pL1CyMK8zN86IFOuc6GKIPnKzkWO0zaeZGd7a1Pb61TkXZkXFJuherX9EX8enPYCv/fo++0Pzd9/ki1twTW9MZR32YO5Dwc/H9T+L6/We3TCb5riTe8CVrCLp72s/lzAbpjPg5XamfXtP+TO4qy7eff5tT9Pf71++zoXdzfPn7HeEyGvhfC/76GuM0/CiYv3u/K0sHo10fRp4/Y25ZVP0l1/zny2ts1/dQNo+0aWVqzdi9/f3m883P3aefXrTpafpPvm2uP0fjFR2YnvbsG9ltFqb7z86ZVAMhyesLLa1iFKAMqBwXaJWSt12LEnPV0+rA387corOC7HX+tM4EFsDLdHFurue656ytKTDWvy9j27To3XQf2n/PmNvbw8766nPLfvHDL/b6rufaHVu/AKCs0fNs+3m2Dmi2n4wp5uY+SHxg+sv6Nf7C4xcDT8N8wBrD+vRC8oZ8kqCmGUcphfMP34oIbGpgxBFoOpz48LvfYlqiLp8gNsbiuaTC9/+fHzjOE+kpc/8w8c0/PNBspZiEzWr73mQzGcbA+69PVOCZjfuvTvzhPz4Q18p2aVw+v/D6+RMhON7dnXBGGj6sto01F2gu4JSaLraqVlwnamHbEmndpJoVHKYaBndFWfd9piN+eYNacdMB47zofBiI338LtTIO4oqVqmyUl+VCNYZFK0hBASbSGdMacxghOMzprSTIzRAmzzgati3z+vTE+eVVNu7WWJZVbdJHqBlXLlhvmd7M5Jr5lz/9syRx80i4GxiHA+u28vL6xMv5zMenR94cjrh7z1gK8463SzC5C6olwHgYJ4x30q9fqwBTPw3udzDoOlVlzZSvev53Jf7Jq/dAxvYWtf6wyKt2iafrPyQgUM74XknRh2rfH/o/unaTPrgW++Um065vizHCWjBX6r6Eg+K8R4UcMzkmcozSguI8ig/vQOU1BzWY0jeairEwjl080nYflV3gDW3vjAm2lPFG1JjEMewa/J+85SEYRiMA69FbcQprglw/atX62yURW6ad7ghu4Hfv35Nr4Z9/+J4tJg5+xFpL2QHrtoOL/6ZV5H/y4/nTM9ZZTvcz3lltzxCNCWmxKDs9lR77GkM10Jxlvj/ivedwmIFGK5EUE+eXqHFxJW6bsJDixvmycDzM3N+foFU+fvzIx4+f+cvfvuf+/i3/+J/+A7/95mv+4R9+S6mVtVRe1sTLy5lSG4d5YhrvGIeA92EXrbUG3DDjpsJl/cjHz088FMthbrz76mvm42lvJdxSZn185HR3RxgCIQw45wUwAYZh2LWgmraA5JqZg7B4ptNMa43X5UKthXVdoVbSsmgyJ8nY4AXE27ZMipG//vVvwqCrPVmRDdyFQLAj/u4OYy3eeWor5ByxVloPgh+Y5yO1VNaYsNaQRIlcqlMpsS4rMWaWNe5Cl+NhZj4eoMHd/YM6f0Zezs+cz2eaEXe0nBPn81ld3xZSEqDpcnll3TYOhwPTOPHHP/yR9+/ecThMhMGTc1EApnB5feH88kKKkVcHxlruHu4JYZD2JeByeeFyEZFfgIc37ximUdZ9IDRp8Xzz5i21NXwQfaNc801SIgWHWiopS/JtvCPgmNzENM18+Oo3YKRlUPSyHnE+cF42Go1ci1Z7y16pTCmxbRJchRA4Hg+8efcOrwDpOAyMPpBLZls2zpcL58tZAsqmTlheWIOdOdhoEtgh4+G1bTNtG2izYG+5dMbivFWHTnetqCprU2id7HuR0SByWRZu2xAH76jWcK5VNKQuZ3LKLK/nXx3wZPGY5shRAEjrOpNI5AtKFbDynAR0iylhQIwDMMJWr4YaFeDTIHNn6ernVKQd6nXNWCqmZRWzNngLoTUuUVomj9PM5VJ4et3YkrQ5iQbzNclprTHaxik03t9PPBxnPrw5cH+cMDYR11e2ImDX+fzKFjcBVmojVzmfMEg8lNNGSYlchSVzGBzWO7Z1E8DRrhgL8+BwNJ63TVvbZG0ZJ5k3tYrZShRTMgFTnRENxdaoTSrafhQm2d2szDwXcM4wBEcInuM8E1NmW86671tyrmyv4rA2GDGPiGtmWzeWy4V5FuOIkhPPz+KkNppAuDsyTl+LbESFvCwsy8J8euDNm9+DH8AHShKNwhYvlPUVEyPkzKfPn3k9v/Dp8ZnX84J3lmEwnNdIShvfPl14XSNNgyZnBcBMKm1Qq8QVb+ZA8FaAnNZYk8ytrCCKMVb1niVoy0aq+MHJXAthpAGrmiIsKYoZgGogvn0ItFZkfa6FGIuwZMMoOkivScAcU7BGig61FlLeVGoCvHNMYSSmymXrrXpZDCeco7RKbkmE3KuhNEc2HoPonbxskZgjy//+J/7lT9/yH/74W37/u684no4c54lzlna3pmt+xdEIlKb6hSlBk1bkntQ1BcdMg6Yu3LVVETfPUmyJRQrGdggE14irtHZetgRIgaY/j7+62p+gkDtg0Pr3mrDoeot/b7HDGlJOWvCScXGDuIbdvOkX4FJWBiOozp3rrrMNieLDHofXqmy6HaRCiyy3znPIPmdvGSHX9xYASQHWG3kF84XQjZyfmANcW6K6RtoXgBQ9/obu+th1c3e3PbrEg16nxl5ooVliVolbBT3XazR1/13FCCQ3cWLs1RAw3ZuBjqJcNabkPDUbE6JTuIJx1nmKFfCcfMGEAWs8zdYrgPF300HfTRlt+zmBgEPNdF35/XOkaNrUpCdgWtQc7yo4fvvwNDqA2YGqdPNcGcaHrzAgJhQlkV4/01rh9ce/4MJITStuGBnmux2woRRaknWhN7z3z7bqLGvr+EUM14tpTgXgmzHqeJ4x2mdnG9jdHl50pjvJxYCyAF1/ZG7GRO+RxlDyOkO1llqMmISUrM17Iu8ACEnGiDxHaV1A/ioz0tspRUJEhdwx1/nXuOkQQtsF9R78wrzxFwNP1lpMk6prqwaXtXLTJImLKSqAINUP4wzOW/xgoVqa6FVKm09spHVjbZbzy0YIjpilhS8bqWwUpdX2hN0Pjlikwo1rhFl7P00jXSRpt9YwOI9Va1Z0YleM5tNXVL0LurVuO1mraKY0g7MDxjicipfpuO+VPKnI1L3Suy+omwRBzTrt7ZSWuVSqVLJ1sWk7uqs6UlYCdqMLnQdlGMhCmWIkJ1lEvuj81CdWhPJEgDTXQtoiFtEpCD4wziO5ymYp7lCFLYkgOxZ8lSqbs15E7pQWKVUGu1Neq4JCe1/qfir6wO/gk9kf/+vRUWn+7if0hffmCr/AT3Uh3QHApq8yDakSXpHtL9En9s/8Oc2m/SRu16y9YnhttdshsWb2iltnyXSYvt0s2DsWvS/0/RwQEWelyItkrwJP/QSMPPgV/bkxu/5VX4wnawjOMhmLx3CnwFMPeNYqc8xphbZWsZGe/YDH7dXJfqa3fe7tdjx+JYdY3ipoaq9zrda6u9HtgOHNABilXvvg8U5a06giEFirEX2kxs4Isa6zQIzqPxn5jK2QklTYwzBwd3/H4XRkmicu66ZuZhJEC8VZRLOncbh5DjqAK8Laoqsj59+ZKCGEvY0z63XtWj6m09GtVO2tnKMzHpzowADK1LIMwyh6YkV1edZFdIWS2N1b02hO2Fm1NrYtsm0bL8+vwpTS8RMBZHlPsSEfBNiaJnJOXC6iE9KDRqMulblW0WAx7MBTTnkXM47bKiwb7zBRhM+9d8rYcrQmOlnbtkkh0BparOoOeOZyPpNL0lYyGb9xGKT14nQnulunmTAEzuczKUW5z0plb62Ig6sxClhK8p2zgDsS2Mp4uuCFrqzgu9wLs7vNyeYO3YBhd0dEnncfwi4w2qtvUpWzO0jftXAwhZwTjSsr5ArC65zWJK2z8cZplIKMvYJEJRdpGc0Cfsn5+h1wslb+9GvvFVJpV3A7E8yafp58saZcA9vu+NeZBXVnorVaqUYTwKzBU2+J0HGvOj/lGRJmcLtVTv4VHU11mnqM57TNQ9afq35brdISJawwDY7/fyzst1GFJFK6EDYjGloaK1XaHj94WwguaztW3zqN7s/X9+6aPnOwHAbH6K3oDurzs8VKKlIEiDEK8NCatCn0SMCIsyu6L8oaIWeeUhWGlxHB52Cl4l5KIdcmbD8g1KpGMQpw9mpzH4E+RHod3htp2Q0yz6tqAFo1xKGP6b7ny9wtKQkTQEFZ0L2mqICv6S2lIrztLATvGKeR3AoJdVxWtrLzXt7LWggB4yw5rxJb5ExbV+KycLksnC8r52Vjnga8dxrnqbh8EY1Ue1u5/yLGMlz/p0y5n+YSTTkEWiTrOHFPwK9zqO1/y2+InlhwZme9tg46NACJ8zuLFNuwFG3zy8J0agLKofdeIxcdy6uOop6BJmlXNr1oqSrblsb5srFdNh4fjpwOAe8d4zSIDpg15NJbfqxIY6i7lsR5subtTJjrCX0Zet4+appzWGNptmFtwyrDvOMy1wT8VxR83R59vOhAptm/RudVZ970vUA3TK4tRj+/tvdCdY9lOzjauI19rkXh7nAnr+2/19lPTe/lzYy6+bfpCX6F20zmp3pR7OtXP//6xfz42dZBY27SpL5e/+uFlOsY9of1ZzSibte5L85Yvtc7Jq5ueQ2UISbvc/M2+/nqrmHdrr/Y1+6bS/m7a73V5epv/pMsUe93v4c3+n66/shn9fxPtSdv3AZ/cnk7oHIdBoN1QUEuaTsuPogOc84Yk4QBBTCdblNbri2cdgeBJN5HtYOdaD3puZv9HMx+O2+ZaqIZdbNwaIyGuX0evhid65j27zZouznWl3t8u1mYb5+9/e8Gxsn8aT953x6P95/1ETRN8AzDbfvs/ht/fw9+5vjlGk/dXrtkbLW4dKAaz0s6QouMVEYPH+4HWoN1axAXzh//gjEVW6NozxjD4BsPYyGWhb/8NfPd4wv//emMC+BGg2sZXzfppbeNaAqrK9SayTXy4/MTHy8XpiEwjYHhreebu29Izxv5JULwV8FMa7XnfqM5T7aWFkbwni4TKQ5KjpaTVDpQkddhwrlADVZQxRwxGhSIdpFkna1oIJ1F9Pf15RmMpYwzzXlaFtTAOS8259oO4/0oN8FJQOGM0OYH7zEetrSxrBcen5+JW2QYZtEKGSemMVDimZQjl/RKQzS3fAu8C29w1uGjJGPeWkYfOI4zccuMLrBsmX/+7jOTsxyc5XScuXs4KbV8AONoOGwtmJqJtfG0RbwfRW+odvDny8R4f6T0WSr0fKq3L/VX9Kfw+tAZrg9O6wFab7K2N2iXAZTG2H/cF9R9cdx3FXmB3c/vS0Crg0tCnGp0ccg9uNeVI5de/bMUDNU0sbWvN5R+IwvPzmASIad9Ea1SRyZYAYq8aTiaaKBZg1O/ucEbqSA2iwO2Isw8XcY4BcvQN1KlCZQqrnjWGN6GgfsGsRjOpfD48kw7n/nD118xhMCb6cBoHK/bytYa8zRLQJqu4N6vKfa5Ox3lHrRGy4XSJDFZ11WAmyLVC3HWYtfPuXu4wwfPMI3EGPn8+QlAtBxao8aqlP+CCQO/+cM/iIvk+UwpmS1GEfctlTdv3vOHf/qPHI8H7u7vKLny7bc/cFlXLsuKD5ZpDvg54DnQNPAtrVBaw2uy78LIdLBM8z3jtIDxpNxY1w3nL/hxwjrH4XjY510peW8Dtv0Ga+A1zSPWWUodoIkGnrFW2hC85+7+npQi//zf/iuXy8LL52darYzDRMPww/aZnDPn5UKKiefnJ7x3fPXhPcMw8fDmHoy42VhnCWNgPsx89fXXXM5nlj+9si4bLy/PjNOk+izSLiTrdtwTNAHqK947TqeJ3BqpVtZ1EZbZ8cDpeGKaAvenA9uy8tganz994vl1wZhOJZY1Z55mxmHm97/7A/f399zfnZjnkcNhZtAWwZwyBouzA87LKjJ4qOrw0lpjcBZK5q9//hculwsJwDjeffiKYRgZJ3EaVIlc0CR+y5HaKg4tOISB2irblrDO6nkMnO7uoTXiKqLn3333Leu68t//+38T1tk4C3vpdIcPgWGcyCWzLCuixWVxg7QyOud2e3bnHMHLH3HjiyyXizoxFVLKzMcDHz58EB2tEDQprgrFQ9YWFGGuNnJrFODlfGa9LAzjKK513hOGkW1byDmzbZtU1RSo7UniZbmQcmbVdsbghdWzbeJI6xU0O51OGGP4/OkzKUbiet6BrF/T2gVckwGH6HIouLNsYiKyRHlmsmb0pjWcd4zjJHtwaeqM11tnrRoYXBPeXrrxFubQcM5i7cgQLNMo80PaGa2aoQhjptXeINb39V6Zl+8cBsfbOeCNIabG8zmzRMhlo5TEZc3EWHFehLOXLZNKxivWUqs4ly2rsJc+vL1jHDxbksLkDy8LMYnzrgHOk1XBZwmKX6voGD2vUr0NmoQOfmS0Fq/j6YyIko8uYK3hdPJMg+d0DIAhFsDo/I6ZuGVyLmxbJeCxZqRWuFwylohvMtb39xPWGpYlU6vn9SzacKeHO0nuasYOUEzGesfoBlIu5FRIKXJ5+pHmAljP+PCW6eEN2QWKP3A+/4n19YnzZeH1kvj+08LHpwvjpMz9JqB+cIaH2SNyao0lZtYtMw3CcOosjcdL0lZ81THRNkhF6shKjTbK0CzK8v74IvpVQ9hkHfMB7yzBenVMlT11CI5UDJdVkrZBs49UIrWA01Yh6wy1FWIVNpB1HppqYXorQvrWMYSJmBLLhq4/fV3yN8lpZ05qzKkOX6WK4cZ/+8tn/vzdM//rf8r84+8bd8eR+4cjz49PLDERy6aFnVHa6XT/rKoxYxQglfZOqKYIU887QjN4ZN6uNsj4FSim4k9WWGWrtEJe1s40+FcS6H/nRy03ekRwBWxVVsRp0Nm1nqRVVtghphnardgS7Iym3kZUStmLb8DOUq5F25G93/Xebs0QdiT/5tRqkz2tJ/2ldKe5/ntyj/o5wLVYJK/P1Nr2Iox8Jn8HunzRxnb7fWVHCdOKPT+yWrnqDKx+SBFIOmlKNdQaaVWKj8YYsXsxYhIiBbIOctbr3vJTQM+IVmXTRK52PKpd9bmwBj/NePuOmjdqXMQtL0srv3SxGL2fElPsAMwOZl1zRVqHs66gi1Wb8roDvdrGZvr5C0XativJBI15bu/pzYVBg5o2CYP1WqaHb5CiW1bNaSm0mlZkfXTidjlORxqQS5IW/7RhTCNYBW+auKEaxMDLaiEEi+yhtYBRGYWaMS3TSiW3LEwuP4rRl7+aBMn8aioT5PbUdm8p71/XzmxrdHa4s4bSyv7aXuDrrd4G0X1slD0u7vPQq6ZUax10kj91B7g6oKZr7b9h3frlwFO9fjA0Umkk4DEaaMK+OFrDByMtWdZIO1beVkQDStg2NNGgCa4Sc+O8KuugNYbBMh89ky0cXaQ6MF6s7GPpGg6FmhvFaE+pKwR7wA+O6i1dHm0HNkCS81qp6i5UtQpmjFNHuw4MoOCyJKLGsIv+NouKRtf9oTF6o7rui+gLCIWt7YiGUXX+znS5lje6i1bfGDuu2Df8qwuQsBdC8HgrVG/vDKjDUa6F0qRVZrKOu+BkgjbU7UNGxbuR4DeCC8Rc2VLGVIOrllACU0mqGaE9652C5zzNWHITWmAPVq8gUj8MP6sS1CeqDPoNuNT5Sn0h7BO5fVGB7L26P/e+/TN3nOmKA++fYW7Oof/7qtwlwdjNiX75+JirkGvt137dq/b36BT03qYnLYB9rmilQcGnoJpkzsgDOFoYnGy+DsvoxNVuQFhPlkq6Sc4GBa5qE1H1coPmGyP+kdYYZi/VupdUxDo+Z6W2D1gMlyT277dMp73X+6eVmH/Hh/danaiFahq5NkoRc4LOdjJaudnZKN4TvCTMnVotwoJGgwnVjVBNCa9sHmsMNGGLNN0UmmlM08z93R3DNBC8o+TMFoXtlNTdzrkgbEek7arU6+aSEZC1u+w5FwjDJL/nReyva1Bh+7pmrgFR1YqIBuK9ldRao8m/WqLeVO36uBgsudQv2raSlULEtkVyEYZMZ2xZ5wnjyDCOBAVwUHHF/lR3Ic+ujZFiwhhHjFEDedXrKGWv1Bt9hp0zOG+gCBOm5CqJWkzEEPEOiheKfMmVGCOXy0V+z1ktNAirbBzE+W2eZnGAG4ereGdVkGhvoe19/Wiw3KteEpimFIkxYscJ6z3/3/bOrjeSI0vPT3xlVlaRTbZa0szsYO1dYwHDvvL//w++Xtgw1oa9q5kdqdXdJKsqM+PLF+dEZrHVO9ZcCPAI8QpsimRVZWZkZMT5eM97fBik+5oakU1LpbEGjLOYgqyxTfOotjK0ppMlnfmolaRBmlYeOs8z3gfCMIKRTm+tHbXJzbhFy8sdg5ZuDuO4M66aMZEbU6tsXatAShCGYSCEQBgCOQoLCu1oBy3YoNCMXa2ik1NKpVhlIJvGMkxb57/b5EUF1mUhZWG1NbaWARYti41q8IcQNkbhVvJSdgHNXx3UId+6BKpzlLN0RG0lZFBwNJ9CXtvKdK1tJd03e2lb+Ln9hWj1eGf1qyVc9Pm2Tp/f3XbZTrLezIcqx5V23MJassr8zCVKiUNMxFgoKtQbU2ZtZRVVdYWqlBKWujtwa5KuZWvKLClBlsCTsQ5rxVaSEs6i+2Y7991g3s67tq7AUopvNbK36WgYs+nXCsNLNcyy6gZVcM5L8A/R0ktxZRg8w8FruaJXgVqQznQDmAgmb+xT4xzGe2zR4GLOpCVjQhVDoVZhLPpAHaS8tZVl6MVjjCVlYRMhKTKcdrls/oEEKXWM1fatFS3Nle64mIr1Wlqndm5R7S+re0nbI5aURZOpFJxzTMZtnwn7HGldKlNjp+j3UoXaakwLP6jtpk6Qs7LSShFD01E1OAeuWGk6gJSNyPFMi0ShnW30NhvVV22loHBZE2aOPL9ceTlfOYyeCTbGMklYo8YUPb/P1he1Z/fOwLqvardvrLB2fRaH2LeusFZDtFn26tlqAvtLdu5fMdqw/FtMpT3q0F6/s57Y/n393p+whLZn9fZXOxOxzaf9feaL57OviXX7jNuAU71dE2i3ew+SfJnptNtTN1ew+yvmteYUsDGe5Eh1H4fdebn5zJv1zFpJbbekfSkagNmDORtjsX7BT7s9v/0ybl732X0AkTjxAVPSdrNrla7tptlKW2DiC+Nd94utN74SNEuprR/yX97OoZWG5W2k9hhis332Y7b9qH14rVnXiErFYb3a7gRqSZSaxJctWdhE2wfpGrONy+39NZtf2f5km8bMNg51e5XRc23nVuUNesH7M/DZiMt+ZMyN/dTOrX5hzrSxr69fux3z9bXta3ZjYzb26D7vjR7n1kf/S02unx14KmScMdwPgVzhj5+u/Bgz//XThULh3cHzzWR4mAyTE+2amivLJ6nPjhXdBEWY9jgYnmPhn+fIjx8r//t/FL66H/kPv7nn63vH333tmdfE02VhXTPzdRWxybWg+o3EgyM9e9K4UMaEXQveqrOfqjAbqEitnhetJ+ulDfVyxTsvUV0rk8FjMdVRa6RSqGOA6YBJFVMKZZUW5jjJzrmcoBSWnJTCayl+oDhxKqbjhA0e4yVrVrOlqrOKkTpRQxUyT60km7C4rX16vMyslxliZjCG+wfpLGWrOCOmZq2ld1zmyI/Pn3h3X/jm948Yk6imMueFTz88M/h7TsffU+oda3Q8X8/MLx8xLuDDSM6W5+eZ0Weij0yHO46HA7gj5jBRVNQ0W4cE5hoRvs1hczM167bgNI2kliWw6Marz1XRDiQ51ebHbPPNVG2tXWU+mSYgp99k4au0Rd5SCboi1KKZKEQTqgWntmVahdGcMp1uH9e6nYNeqRpZsRauKZGpjD5IJg8YveWkYrfVsAWWSpUWw0aPtzn5VR5eb4zqLYiBPhpDQEWSayF4MVptLZhSCZqpTqUQS+XgREtiyZLBq5tTIpHvr4Pj0Yv2xDlX/vWHH7E+8J/+7m9F9Pm7f+HleuV8uVBqZRwGjNOT+RXJpIjAa2FdF1LKXC5XCUpE6cR2PJ4I48D9w1spD/YONPCxXhY+fHgipsQSk5QoBaOBBskQZ4BSsClhjeFwPHI8Gaz9SgJYYdTyocp6vXI9v9BYct4Vjgfp7BQqUracVZg6ZrTRjzBBYiSumRwzwzDxm29/x2EaGAYpBTTWUlMhpYWs3mYT3pdHxnB/OmrgWvR1xKHIqstjRXixFt7/+IMyjyDGxIcPF1KM+HGklMz1cqZWsO7AIUj5oFWR8GEIvH37FkNljRfpopUlIH89n4lrFCe5VqbjiZSKOEtzpPz4xDAEjscj1jr8GAjBMx1GNQDztmmL4xk5X2bWJfL89IkPH95vjvbLy4t8nS+s68zj4wNv3rzhb377W969eyeGfqlcLxd+fP89y/WZcRw4nk4SNAuizbDGKAwnTQCUslJrYRwkSPWyRlLOjMcjYToyvXmLc4G4RNYlMn98EnaUqVhneXh8iz+MPE534vRqZtKPEkCa7u7JOTG/PLO8nPn4/ffCKjufiSkzqzh4685zOp30+x2lFOZ5kW54JeGtZRoP+BCYpqMEDJwwYYfBM1+vvDx94nKdeXl54XA4cjzeMR5GpkneFzSg5X2Q0l/nSHEVDSqEy9qYSE6Dn+VNZRwPqt0B67oQl4XL5Sx6aPNCiol5WWR+aADcOjGMh0H1NfT3KSdSzKzzLOu2swzjwOlOxvAJeWbWJW6d8H4tcB5CMJymwBg8L+fEmop2r6usSZ071eoJDlwSkejBW+5HR/WVAQ3C1/b6240USoa4Fi7XyPHgOQyyZ8saUFlXYag93nvuDo6Hg+fD5YojYUrZug1JINOILk8pxAov15VYE3er5xAsQxChbesM1hde5siaVyl/LYU1qs6iOlJ3xwnvHUtauKwzzy9XKbGrmUph0ZK/aCRQ9jgWgrOizWisZJNN+1nY5LVWlpg0E1xw1vJwnCix8s/fnQmDZ/k6Mx1G3r19w7JmPn7/RIyR63LFOc90PDLYA29Ob8hU5hx5fnriT3/6yOk0YQ8DxnseHiZJwNpMtYalGGx1GAKHMHG4uwcrZXWGGVsS8Xrhcj1zePuOwzRCWokvL9jhQHg8Mqa/oR4OPLjvcP4Dx8PIGjPf/fDEx5eZT5fIkjJfnQIhWOY1EnNmXiVZcqdJFpQ5XWom1cw1RmFiagLDGeERFLWhxqoBTFRzdBX7d71k6Uz9BkbvsRTG4Hi4M6RS+fHDzJoyz1fpChRsUVO9MjjP/eTV+pKAc6mWgw88TpPaYlJOHGOUNaYKe9n4IHo2uWCKKHKWWlgpW2OcluRYk2FJaHK1iA0WLH96/8R8jcz/7mu+/eaBQ/DcPz5QPj2RLjM1S8BcBOSdlNtXKQjFGFyQ5I+vUZzaJM+Z9VV7DElplrej7Ks6dgFhJDorQujndd27lf1aYKSrI5UtadcCeFvQpkj5Ti1Vq0qVlWuVXacMpBY4fvXxRoMVLcHD60BPrVU0Dk0LFImdgr4vaYK/qrZZc9Al4ZS3xJIcSzpm7vpFcj5NC6q9rjGKoelG1f1ctxilJqq1xL01+cHqAl3aC5HSJpWJcMYDLZnFFrjyIVCyJbkFkpHmVc5JwNQ6DSQZaJ3mMNJFvAVmMRpR2Vk07T2SNzK4alGJKV0THNkOVJtAOzqSrpgwghk0gAvGOKqybOsWadm9xyZhske65G9e50HTu3LGaZVdaxo2Q1VJCQDj9jE1Zmtw0HxLlfLd7p8OL5SIcYHxeMJaj3v7WxEdn58oOZLmCynOxMsnjLH4YdSGaCOlFM7XWfxdp506S90Cb4CcQM4QV/H9kHI8EwI5e0oO2g1QGL4lJk0Y2k3mIKvMR7BB2GvFYlvw0bBpAKYkEhJNM7hpnbUE+ueB29clruzzuMY9WWP2e1I04GVacmd/0tgnzp/Hz2c8Ka3UOxmYuWTOqfJpzVtHuGDh47WyuMrBiWEjLU/hmsHZyuirTG6TmVPhmhPXWIViPfnNaTBGMiRrlE48Zc3SESnLbLEGiAWs0MSySZB3MWp0wEut4OoeRTStflhpf3Znq1iNBufteZBon9moLuxsFytZuIoKuJZKNo5qJECDFa2SlrFtN0yEfJsuBoA+HBSdLLcZj/Ze+e6d1IibKm0QW6DE2oAxkaIio0uO0nHLiL7UvCbMOEEwOOuZxgNzWresTtMcompG7ubLqJZIyyS3ulsDOiGNMnm2ADLaV20TiJcJLRO7tHE1EurJuthHFSjd2FQ3XVk0p6QD3xbHfYy2h6I9H2ZnOrVY75ZGMG0R3YNQt89KvfmdnKN59ZftXhjJ5AYr9P2gq7Gx+je9t1X1sqgGryyntq5608TLdUGsr+ugS63SUYimDSWie7nexIW2zVSPd3OmgzW4ApOz5Fo4x6jHEDr8cdRF83LRevrPLvVXgpSaMxNJKbPGuG8Murg767ZnwRrp5lVSVs2epMFiVb/QIJJMbbOxiwCMNXi7lzR57VCUYhI2T8nkGHVtkGy8BDB1g8xFNw8pNStG7I+UkohMayefMASGYWAcpVxC9mx5nmqV+USVLLqaeVswuIkQblmN0sQbRaOk5My8zCrcaslJM93W44OTDXlZqBgGFS0fD1Ky5wdhiknnwCINChrU2S0psy5alqG6QUabBEiXQSdZlWZQqHUgxofbgnaiC6JM2JxYlpV5mSXRbAwpZZwyfKYK0zSJcPs0MU0TOQojajZy3JQS1hpSSsp0M4Alp7gZp8J0kMREcJKhb2tYGAawjkGNkvkyS7CwBVZuYrrFGOm8iqz9Mr4qtlklCJBjJGfplJhSZl0l0NkMqxCCim2zjV1W5lITEjZGWW03xnmJUUo4Tdm60Im2EkBjFHmGUdukl4JVlgfcioLWne5Na4ddVQ9HKfbKWkpxJW5f8UavS8ZWRO8rAbdpEzUNq8Ym3phjSEdY6yyH8aDXKcZ0K734NcE50Z1p3eP2FvJV98xWgiBbWVZHId8Y8xsr+At24far5u/sZDZqgdxYf0r3d1YC5EuMzDFxWSKxlRBYSQCN3nIIjgossbAUYa4HK6wiZyWoK/u9YU2Fa0xYox0zq1WLE00QGbyzLClKKVoWBr2xVR0o+bK6joPOF6T0MLibdbqyzZOYEyVXYk4E52hZ4FzApMqyZrzLm/FetDQ754JpZRRmL3mQcntLtY5UYV5E6N1pcxbnxGzNOauNJI6gdV5utAafihGKVU4q7VArNSdKitA0pqzB+MBwODBNE0PwpJz5dJ6Zl8iLs5i03/BS5bqAVw58s9F2Vpzck1tWWNX3iy0ne5UxzZETu4esdpOuCUl1pVLJOsY6bqbNOtXnbLal1Z2qqh3lnH5ZGm+llqQ25s4+f+VMGTbftdICEDv7pc23liR0XubEmhLn68zTy5XhEHi8O3KaRqxWGOT0uZaOMhO2Gbof22iggKbhpH8yRrsmAk4ZhCI6raog7b58gR3y14rPYwyb1g+vl6KbWANwc083+3n/vbz0Fc92//3nTKbmUFOlZI8qvsVWbXLzHLT3G5mH+9wpr06u1n3PhsZqeX3uX/r/m1fsTKCb1xh1Wur2Xp1Hn41TC8K0ANktS0WCcPsYNZ/i5tDtnZvv9sqd2g4MrVOcYf/8up3v7k/Js2CbXomyicp2FvuBb1im+j8/uV+3a4z+vWk7GX2I9qtv2k5Nu+umjmW75p/W4FR2r669tjHCRDze48MoQessyUDjpZFDzhFjCjXvpXxmuw5h5bb5/podqb9sDnZtjDiHsRVTha3a4hPb2Hw+Pq9uk/jVzf9rvQzlbS2YuDP1hKW8GwE/0duikTsEpWqF1zanXnvD27xrY3pz7v8v/OzAk4kR4z1mOpCr4fvF8j4tIvhdMu8vcJ7hcoHRGd6MLaBTWTJ8mCuDt7ybJFpbigScnq+VwVr+47dHfv/NG/7LP3yLcwlrF+I5kuaETZUTnuIdaQg4U7C28FANj8lQsyHPEeMDOfhtkW+CrdmgrISMKRIQCc7ja8HnwniY8EMgIoZQWZEOQOeVPGdC1SAKFvxIsZL9uc5RSlDUSvODwTgj0V5ruDw9Y4Dp7g3GWOL5LF1bqnThyKc3YEXQjJKx6yrZ5eMJGxyH0wG4gjPUmil5xrqRwT+KsZYz1gW+fTxyOd7hhpGcVv7bd3/gdBj4+v7EumZezgsxVMzRMBwc3359T/UrHxZhWXgSkz9xmt5IMMVYLI4YI/54xB8ngk4wU1dMXEWLahARdmNE418o9KgQpBjEa5LsWoxiLM5J2DpXbfc+K1vgvIoA5ssSqbXyt+/uOR0C7+4m6WCkD1JzKdQ8bT2T2tltj0Zpztj2JzGCbQtUbb+/3TSaBsu2pVDZy1EclclooMAUJud4HJ1oPVU4OMPJG1IuxBTxbu/61dYbU0WXJm3ZZrslNzKVqzZWNljOpfJSMg/e8eAtqTl6ev1FdQoG4zDOci6ZVKvU5gKuSonLt4fAm1xY0pU5Z/748SPTMvH7d++oRRhA53neghqfiwT+teO7P/5hm4sGwzhICdibu5MEnTQzdT2/AHLXaxbBbWMtbvC44AlhUkHsizj+w6DMkQGASsE7zxiCsD+cJ64LL58+7NtukfbLyzxzuVyZ1GkgF1KJzJcr8zxTUoaUtvUV66nGMY4D4c5xmibGIZCisB7PlytLE4OuFV9Fy2UaRukM4yRzWHNhLQuWAadJhFwr7z88sS6RD+8/SeAir0jntUeGceDrb97hnMUgRkV+fBS22OkoJX1IoOfp+cKSEt//+CMGEYktpZCTGOljGMBIUMX4gBs84ziKZk+tW1ldjgvruvByPjOMgTVKGdzpOLEsK5fzhZfzhY+fPhGTNEt4uVx4ennh7nTi7nTi62++4euvvtrKBG0zWgq8/+H97jxYy3Q8SlC47BR5o/0sr/PCvGj73SJlNJRKsAPj6BnHI8Y6hmmSgNOysi4LP374gXVZmU4n7BBwhwFrLWsuxLyQl3Ur23HOcedkTXv59CSBmudnrHWM94+MxjDc32/PpdXgccqZ+Xphnq88vzzR2n63rqZW51xaV8oaWZeZ88sLzXQ/TEfu3jxynE5M050EnIYgLDpvuFyuXF7OUmrnA4fpyDhNVJkJxJhY5yu2yvrYmi5cX554eX7mcj2zrosGFCspSqlm0SBuGAIueA1qVQ4H6SLmBwl6XS5XaauO2cphaylcLxdyXJmmEWMsa5ayq/M8bwGyXwseT4FpcCxrIsXCeUka6DwQamHI8nNKWQ10p+VbiWoMc07EAikZSszSGKU2D3k/jvQSsVjrqVjWJMKuda3qSMhaEzH88f2Ff/145r9//8I//umZj5dIODgepsDDIfC3byd+90Z0cf7X9+eNZUlOJG9JZWBIniUVYiq8f7nyco385u2B0yFoMs1CSrIuUCFnebZSZhoDzgRl3FWKkeKyd29OBGdYljPXNXO5Rqyx/O6ricEbhkFm/jxXEiLwnHLm08uVIXge7+8JfuCbr4/CiFqli9nTxwsVGA8WPwyEQyB4x5u7A8YW/vT9H7G+NU8Y+M2//wdenj7xP//Pv3B/OvLtu7fYwRGmwPp85fL0Ae9HQpjIWGwwOB/ww8RcKjkm8CM1RFKBdb4SciHEhfMPM+uySFLLGO4fHnj71SN1PlPjjCmFh9FwOlier5FYKkupxGopBqbJifaSrRoY9oDlNBlOpnJKA6VWnAZA1iJl1M/LIiy5KiU800GCh8cjwJ7sa2Vxa1pJGdYsSYZgHcMUePswyR6gTWKcFd2dXCNiEw0MxvDgrNheWhbjsVQrZeZb97FWUmgrNji2XgrWQHHKHlF2VEliwxtLScLEHwdLOAib4LIu/OM//YHyT3/kP//97/j9b97ycH/g4eGOp6eFeU5UW0mmgg/Y6qXSp6ClmvKMVNXRKcWwRg2Ea+xCdD6V6V8qa0mkUliSBAWF/fJT0d6/WqjvfJsofxVyEvr/FpIopapuq766BYg0meGck3LNlF4dZuuwWm/2b03QtEDpK42bG4e7chs8ahpQu65TY898rskk57cHj9rr9iDbbRJkD9a0YON2/Mam2pJvEiqRhBw08f5csgQvW/XIFujRa2lrufoaxYjsAlopIf4HGuCoiKuj44EktIX4cVMKqMGTLYFRoHVJkeSpMMesCxAGSVbGFWsD1QnJwpiKdGb2mqDVKhRTlekswWjnhP3XmLhbsL/qHDEG6/U+GAmD1OL0ehsjLdwEp27dGPPq562M13ms8wzDJI0jNJJXs+g8D6cHqJXx7h05Llw/fk/NkZwWTIUQsurbiV1SUtyILUVtS6uNW0QAXFlFRUggzo3C8HN6n4uUDOeUsCG0kpz9Eox6qaVsZI7GrqtZ4gjZoDq2UXWlbhsMuVdBv/ZZICzy7ZnZktFCVGid8149u/psl0ZEcfbVM/Ln8PMDT+o5ywQ2JGPQKkiECg9LhU8LjMowElHBypIrn1YYS2UU/V5KYVtsgzMcvHQ9OR0CFch1lUdVKTBCKLF427QvpIzL600sVKqr+6BuJ37DAtnoPPvyJ+KrqjlCC1RoQKCU7b0Vdp6e3nyhvpWNIbUdXjM4OUu5WC0VTKFq5hsSG+0GOXeqlPO1Rcga0XTYaG4VWtiliUFKW3N5eIKXVtfXkphj1Fa0ojeQUyGbRI4rjCPeS0tra40sJFUFaK3bmDWgC6JBtEhAaH2ZLZrdFlpuNspWlmZvIvFUNipl0jFbY1batwSgrktkzYWX60qlsqTEmN0WRNT4tkaXP5/cX5js7fgatW+3tWI0C3Dz0s/nzO09p8V55V9rNDNlhLEU9NyyziNv9qBXG5m6zcG6C2S1g2z7xR6Xb9Os1ErWh711tyvIhtWyFPIRu6nSPsPcfA/GkDUTTUXEW3Nm8B7q3r2xvprsvx60kriUZP0akTEUsWW7zZWSG8VfAk8lFYyrOMKWyW4MkFvDZmvdW6VFuVCDd62QoqVU7WdZ/8oNpbVpoqgGRhJqZ92y6xnjrbIPbxgpQ4AK6WYzba1Qq16Uxcj9VZZKY122Gy3ZERHRXuPKdZ6Jizhb3mkr4VJV70oz7aXgNINyGAew0nJ7WxtrJSfZHbxtGZi2LN6sZzdGotPWvhsVujTR0ERORjsJ+v06SyGlSNTykazB3pgkkF1qle550yRaXLlIwCNnYorklMGqZopBO7rtE/92fWhMm9bRruSyGbmoIWet0851FhbtINoo/KjhbC04q5kklM2gned03GqV62rMM4Mw1HAWr+K7sq6IA9Y2/qpUbjF6bhgNbfCrZPtTTMRlUSZZwXsRY7XW7TpTN0Z21XsgJTd2y6Q1A2rXvih7hq5WmbvabW5Z5m28RDSfLTvayiSaFkJrV91YVW381QTep05jNqlRKuOgHTx/ZYwnL76DCqFqWQLCgsVY0ZMpt3tay6irMkPdGVG7VsPNXOf1fth+KGqY1qqZcwANLi5RSqae55XzEolFRHy9s4yD4zA4jqMKcydhB0lnqUIpRvXx9FqqaA4lpeO4pq+jTo8cVs652RHWi9ab0c5oUoZiNl2qBUkipiwdOAFdm/XKX9vPyu5UZ8oYgg/CiEpRmGVZbKF2Xq281DvRUYxpxaEMRG8IwwFjX1iWyDSqk2zsVvJScqbY8kpeoDnXrRyoMQm2rHXJ0nkpLuTlCj5gvMcNg+wFJVJNZgyOMTgG7xh8JsUWnhMrRvYsvfKbBJOz4hB6bcinKgakqoHiltFWu6Vp0NnWfrPdK2VzlSKMM7IkwUIQsdsQVHdGA09NA0yqseRzhA0rewI5fza327HMfh9rW0t2HwCzmX+bk7Vdc91Xe1kqZT5el8KaCvMienfCLPVYFzdyU5sj7E+ETs/9eWnD1MSY28G20a7tnepIogVPN07zrws//7p+kvO8Ce68fuHrzxYpm9s9fH9f5eYe1PqFg8jnbNb4K2O4vvqsPw9Ze7c5UNvvbj/353xOe83m9Xx2zWwMk1cfVX/yP/ultd+1j3tl5LRvzXnZ91z4zHa79e1a0LAxnorqWN7sF6+oMZjbR+eGtcP2nu2jvzhGn+8Jt7pKXx7bW3+x3vy7rRlNy9i2B3w3WI2ySyWuKfZJqaIzvcVEENu+VfO0xP2+LrCN5c4K2pSe5DgG1WE1X7yH9bNr++L05fVE2DXK6s18/imUT/bqUzafdF/u/200/+UvgKk/lxvV0dHR0dHR0dHR0dHR0dHR0dHxF+BXxOns6Ojo6Ojo6Ojo6Ojo6Ojo6Pj/CT3w1NHR0dHR0dHR0dHR0dHR0dHxi6AHnjo6Ojo6Ojo6Ojo6Ojo6Ojo6fhH0wFNHR0dHR0dHR0dHR0dHR0dHxy+CHnjq6Ojo6Ojo6Ojo6Ojo6Ojo6PhF0ANPHR0dHR0dHR0dHR0dHR0dHR2/CHrgqaOjo6Ojo6Ojo6Ojo6Ojo6PjF0EPPHV0dHR0dHR0dHR0dHR0dHR0/CLogaeOjo6Ojo6Ojo6Ojo6Ojo6Ojl8E/xd/RBTZ/3/IXAAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"filenames = [\n",
" '../scenes/textures/image_001.png',\n",
" '../scenes/textures/image_002.png',\n",
" '../scenes/textures/image_003.png',\n",
" '../scenes/textures/image_004.png'\n",
"]\n",
"\n",
"textures = [\n",
" mi.TensorXf(mi.Bitmap(f).convert(mi.Bitmap.PixelFormat.RGB, mi.Struct.Type.Float32))\n",
" for f in filenames\n",
"]\n",
"\n",
"# Helper function to display a list of images (use dict to provide image titles)\n",
"def display(images):\n",
" fig, axs = plt.subplots(1, len(images), figsize=(15, 5))\n",
" for i in range(len(images)):\n",
" img = list(images.values())[i] if isinstance(images, dict) else images[i]\n",
" axs[i].axis('off')\n",
" axs[i].imshow(dr.clip(mi.TensorXf(img), 0.0, 1.0))\n",
" if isinstance(images, dict):\n",
" axs[i].set_title(list(images.keys())[i])\n",
"\n",
"display(textures)"
]
},
{
"cell_type": "markdown",
"id": "fd857493",
"metadata": {},
"source": [
"For the sake of simplicity in this tutorial, we will assume that all texture images have the same resolution. Moreover, we will make sure that the pipeline renders images at that resolution to simplify the computation of the objective function."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "c9aee1e8",
"metadata": {},
"outputs": [],
"source": [
"res = dr.shape(textures[0])[0]"
]
},
{
"cell_type": "markdown",
"id": "6cde2511",
"metadata": {},
"source": [
"## Scene construction\n",
"\n",
"The scene/setup for this experiment is straighforward. First we instanciate a `perspective` camera that points to the origin where we place a textured plane. Then we place a `sphere` object with a `dielectric` BSDF which will distort the textured image when viewed from the camera. Finally the whole scene is illuminated with a `constant` emitter."
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "707da8eb-5f05-4053-9452-f64ce505446b",
"metadata": {},
"outputs": [],
"source": [
"from mitsuba.scalar_rgb import Transform4f as T\n",
"\n",
"scene = mi.load_dict({\n",
" 'type': 'scene',\n",
" 'integrator': {'type': 'prb'},\n",
" 'sensor': {\n",
" 'type': 'perspective',\n",
" 'to_world': T().look_at(\n",
" origin=(0, 0, -2),\n",
" target=(0, 0, 0),\n",
" up=(0, -1, 0)\n",
" ),\n",
" 'fov': 60,\n",
" 'film': {\n",
" 'type': 'hdrfilm',\n",
" 'width': res,\n",
" 'height': res,\n",
" },\n",
" },\n",
" 'textured_plane': {\n",
" 'type': 'rectangle',\n",
" 'to_world': T().scale(1.2),\n",
" 'bsdf': {\n",
" 'type': 'twosided',\n",
" 'nested': {\n",
" 'type': 'diffuse',\n",
" 'reflectance': {\n",
" 'type': 'bitmap',\n",
" 'filename': filenames[0],\n",
" 'format': 'variant'\n",
" },\n",
" }\n",
" }\n",
" },\n",
" 'glass_sphere': {\n",
" 'type': 'sphere',\n",
" 'to_world': T().translate([0, 0, -1]).scale(0.45),\n",
" 'bsdf': {\n",
" 'type': 'dielectric',\n",
" 'int_ior': 1.06,\n",
" },\n",
" },\n",
" 'light': {\n",
" 'type': 'constant',\n",
" }\n",
"})\n",
"\n",
"params = mi.traverse(scene)\n",
"key = 'textured_plane.bsdf.brdf_0.reflectance.data'"
]
},
{
"cell_type": "markdown",
"id": "810bd5f5",
"metadata": {},
"source": [
"## Wrap the rendering code\n",
"\n",
"This next block of code is the core of this tutorial. \n",
"\n",
"\n",
"We define a simple function that takes a texture image as input, updates the scene and renders it. In order to use this function in our PyTorch pipeline, we need to make sure that PyTorch knows how to propagate gradients through this function during the backpropagation phase. For this, Dr.Jit provides [dr.wrap()][1], a function decorator that automatically inserts a custom operation in the PyTorch `autograd` system when evaluated. Under the hood, this custom operation will call `dr.backward()` internally to propagate the gradients through the rendering algorithm and properly assign the resulting gradient to the input `torch.Tensor` object (here the texture image resulting from the neural network evaluation).\n",
"\n",
"In this tutorial, we are inserting Mitsuba/Dr.Jit computations within a PyTorch pipeline, hence we need to specify `source='torch'` and `target='drjit'` for the `dr.wrap()` decorator to produce a PyTorch custom op. Note that it is also possible to use this decorator to wrap PyTorch computation in a Mitsuba/Dr.Jit pipeline, in which case the `source` and `target` arguments will need to be swapped. The decorator will then automatically insert a Dr.Jit custom op in the Dr.Jit AD graph.\n",
"\n",
"[1]: https://drjit.readthedocs.io/en/latest/reference.html#drjit.wrap\n",
"[2]: https://pytorch.org/docs/stable/notes/extending.html"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "0ec8176f-90fd-45fb-b1d7-b0b445b16cce",
"metadata": {},
"outputs": [],
"source": [
"@dr.wrap(source='torch', target='drjit')\n",
"def render_texture(texture, spp=256, seed=1):\n",
" params[key] = texture\n",
" params.update()\n",
" return mi.render(scene, params, spp=spp, seed=seed, seed_grad=seed+1)"
]
},
{
"cell_type": "markdown",
"id": "d4c5f114",
"metadata": {},
"source": [
"We can now easily render the scene using the different texture images previously loaded."
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "dac391dd",
"metadata": {
"nbsphinx-thumbnail": {},
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAAEQCAYAAADxkb7lAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOz9aY91yZbnCf1s2PsM7s8U0x2zsrKqmqSqoVstJCREo+Yr8ha+C6IFEioQEhSqplVNdVbeMe6NiGdy93PO3jYsXiyb9nF/7o2b6oSKwC3CnzPtwbYNy9b623+tZUREeC7P5bk8l+fyXJ7Lc3kuz+W5PJfn8lyey3N5Ls/lf+Bi/39dgefyXJ7Lc3kuz+W5PJfn8lyey3N5Ls/luTyX5/LjLM/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKc/A03N5Ls/luTyX5/JcnstzeS7P5bk8l+fyXJ7Lc/lHKf77Hvjv/t3/u70XEVJKiAgiGRHIOWOMwRjTjjPGYK0FDNaadm7OmZQS+o0BBKSd1W9qwNSjhq/H6xtj2vW0PoK1FmstItLuWd8bY9p1a13rdcbjQZ9JRB797pxrn/V5EiK9XlIexlqLMQbnPMZAioksWtd6H2ModYWccqmP3dTDWre5j1Z729Ygm+es92/PTK2r9LYvz2WMxRqDKW12/cy1HUQEY8t9pbdr+6O0a2tTfRYz9GOpKoLos1iDADFGcs7UhvSljbNIOVavLyLl3u0pMQikMzmcuP/m35HTimCw8w03X/4t1u+wbqeH54SwfaZaKWMszrk2Bmt7tb4wvW+M6c9fnze3tqK0RWkHTG8DY3DOYZ3VuZOFlCI5p6HfHPZqHmkXDm1crouBlBMiGWddG9+1jVs/6UNgAOucPsfVpMo5A/WZhf/yv/pf8GMoX3z52fCp9reh9rMtbeZ0wGKd2cqHcppIHxP6PrexqcfJ5rptfm5e9F5SxsJYan/WK42yUSSX9xkETB1kgAyXsaVb987gLbzYe3bO8vo4s5scr44Ts3fMk8Maq2NW4LIGYs58PAXWmPl4TqxRuFsTIQmXmNr43tT4Si5X2dfHXPm2ytbxWcc+MYMArb+J0XYaj5Ph/fbo7bem9sRwjTqPatsbg8FirAPrcPMO6yfsvMf4Sd87h3MOZy0773HWMFuDNeBEsAgmJciCyRlT+wYp81KIOansMjom3DTjnGWed3rdecZZi/ceayx+8lhjcE7lsh9ejTEY58BYMI4MRIEsQizr4LIGYoycLxdCCFyWCzFG1vVCjpGwruQUyTEgOatMFEFS71tjtV2sczjvcc5rO3iP8x5bZQ2m9JMU+SStDwTIpctCke/rupBSJNTXEBDJWKf3Or58xbzb8+azL9jvD7x5/Rm73Y4Xt7dMfuKw2+GswUrGSCaHFUmRsFzIKbJcTkhO/G/+t/87fizlb//5T7HGsPeWycLtLBw9/PzWsHOGw+Sw1jJZh7WGaYIPl8y//Wbhbsn8/mPEOjjuVRfDSJty2kcGby0753k5Wb7cO2ab2VsdTzEmUs7ElPn8zUt+8uUb/uZf/FP+9l/9C25e3fDi9Q0P797z8PYDYl8h5gWHL/+G3We/4Nvf/pb3f/gDv/u3/3e++w//ni//yV/x+qsv+fm/+Ge8/ulXeGtU99jdgvH8+3/7b/jm97/l//J/+q/53W9+zfH2hsPxwH/5X/0v+cUvf8HPfv5TDoc9+f5rJF5IZiJk+O9//ZG37x/4P/6f/6988/Ydv3v3jjUlbneOw+T5my/e8PrVK/7z//n/iteff8XP/5P/MdM8IfFMjivnu3fklCBncoqspweMsez2e9y8Y37xGdZ5jPe6EKRY9IUZNx+YXnyGnfb44y1gkCxIzkhKZc5aBEOm6qAGUoAYCPfvWT+8xTiHdZ79q8/Yv/4CMZZsbFlvyhyxfa84p1z0766zQddnr/XW9nvVydFn/eb/9X/j4dvf8+t/86+5/+6P/O7rP3I+X7g/rxiEv/ryyMubmX/+z37C4bBjZUdI8M23F5JYbt98zrTb8+rNZ2DgfL7n/d0d//q/+W/55v0d/81/+JolBJYQ2U2en7x+xc+/eMX/+r/4H/H5F1/yN//yPyMx8WFx/PpXv+K//q//97z97lt+9ff/PS9v9/zTn33BX/3yp/zP/ot/yfmy8u79Hf/+11/zr//Nf8fbuwu/e/dAxiDDPvrtZHg5w0/2hp8dLK9mw6vJsJss+8lwTnDJ8PaU+XBJeOdwzsLskcnx9UPg/RI5LZkl5rrsMjuLd4a9N0zG4HLE5Iwt+t1uEpzVdcX7if/sf/Kf8tnr1/zkxQ5P5u1v/p7lfCIsZ1LOnLJhScJvPl44hcx3p0DMwv/h//H7/6/Iln/s8u/+7tdAVQOEGONG71a95mm7sduPeoWcRedoXcPpNlL7ZjQfqy41GmfD9Ue7EcBas7G9ru3G0b59an6pbSLkq3NqeWw35s287fXQZ/dezfOUUrPbqHaTAdfswmI3Fhs7S27PKCKkGIutkZCcm70R46qvYdE6FRveOa82tPNtjRcRUrPx1U7yfsI6j3dT00GNMVoPoRtBGJy1WOuoGqJk6TpDeaBqk2Kg6xbb8VS7suIK+ixdb3HWgem2e9ORr+xjfVUdS9tsY1Q+6rt67mi7Ux7PWMs0TYz68HifcTyP/T/20fgMzd67wiis1XZPOSM5E2Ns9eEJ3KOed/25ljr2rVN7czzuevxDH7/9GnXc5s14/s/+1d/y58r3Bp4+XSk1jrYgyPU5gkgFP4bf2ciJ9l0tZjignWfkymj5szXv12ujohtI1/W+buzHz1IG05M1/1S9iqF6PYva9WoFeTTRrr9UwAPMU4YafaA97o86gD/RV8NVnvp9c+B1Nesk6Xe5qpfpzy7jb9vx8KdLN8L7lU1vEKQJ15wiYgwmJzXUxyuUy1wLleuad4BnFDJbQ/vJVjJjOwyl3MK0D/0iVZjTxmS/Tv1s+iUeARr1QzPtpQoE/dyG1xVQOV5gO+a/d6f8IEp/bn1mfdSywGF6Ww9ArC4oZUxIN9YQo8CCESSbQUa1EfP0tXtlaAuUMUOtap2G3zfAUxnn7ZXNQjlgK3qupYDEVg0NM/7VA0y7RwOI22vuMqYf9gkZtW1r2Yz1NqphgJG2Y/HxRfuMGz7XfqjvHxXpc3xslOH9ZtQL5XpF6SjKl0hWuSG5rFtd+R3BSFPl0abq9Xr1pSsg9VBblNMGzo1t1ABl0w3UekyVQ0Xe1baoo84agxiLs5ZsLc46ssuqsFSlxFodF6JjwVhVHAyA7bLZlOPrnyl/7bPpm0qgY3JY7dvYqsATxqjCJIKxCnhirAIfOWO9w1pVZn0DugrY5fS3UXlrw6DpIrn95e+/qPwwioyKcxuq48+KhYi2h82GVADlLHX9MNgyKXOZb7meW0ZpFiGJEEVwUBebIg/6ulZ6FiRjJAEqK6wr4skaTBka1oLz4CeLny3O6/jLksghEAqg7vAYv8NYi59m5nlmN8/4ohSnApimNZC9K/O01D2DM+CtYTd5dpPX8Z4TWSBlISQFzmIIxKDAq2TX1lNjLXYwCLryP7Zz1fu6zMgpYgqIa6xDcio/CZISOUSMNVhxiLHaIBiMcYM0LHOxyepBn2OQjtcd337ofQSf1t+2Ol5RjWQErzK5GhFSz6D3/2CESq7Al7avKzLNDDdo8qBcr1X/unoiuiEbFayv+pwtoOT4AFmEkBIhZmLMxJzL5mR5PqNiTMcDOKvvrem/GWMQQwPt1wzZCM4IRgRTjeJHpa/P4wJX9TPTvpLhbzjb1G9GW4IyRrUdY/n7sZRru6mWbhD3jervYw+0JXto+42eK+NYLcfQW/z6t+3vj+dN1QvHZ/iUrftYhzbtt/H1qXM/9f1Wdx20BXkMqG3G2/W6mDM56QZ1LhvVMsiT+pzW2EYuGOc89A3awYwu637uSldVWYeqmqfaZ1CpN/bMoLvVvpWN5Pr08+o3KqNl+Fzb8k+VRxroNS7Qvr5q9wE07Dr7p8t1Pa5r1UHIOra346322Uh4uK6L6SDBk9d+olKbejwFOn3ixFbXv7R8b+AphqhvdBQ19PNT7KLKgKrCRRoA0B+qDva60y9CQULLrYzBbawEWoN2Ns8nKjw03hY5V0U3jwyRUu+cc0Men0KiR/Q7k8dbbepom/Go90wpt+fuj9E7rT6DNbZKgHaf3qZqFOr71D6Ptkk9fst06kX7wzS7qN5f+8a2PuvtpMKuobS1XenTqzNvKitn2w1ViOUsSG7qQRNqldFEGQ+jsqItof9pe3cAy7qqwBVUfw2kcGE9fSDFixo1KUMOGJmL0DSQs9bXlnbNuSt1beKWNhTBFBJWzoKx4Fxhp43MD1PHqqHUCowh56Q7NPWpSn+BMp0qkGW9A9wgPOt46Oyycd6072tbGUOmsw97/xV2jC2tWAy3phRKHeu1zZ8a0z/84rxvSsmo3NRF1ZYxqoYtuKvdtiLyAJVPyem4qUqybMBNA41B6BqY0xSlunKP/VBnVDGAdC7ZLhtBd6uKAiGVGTjIuMpus0YXQO8t3hrc7LHOYqYJ4x04jzirWrkxVCDNTg6bBD9bss24aHAmYaNgyTp/LJDNdooPioL+X4zO+kN5tEH9HGT+aFQMmgr18WQYm9cKhGxeito6vL+uYK+PlA5td88JjJCjUfaPAZMjIFjxUMcHDou2sdVOqYuWGixD3QSacpeSMl3LvqSCQ2JxTnfJUi5ytDCMbGE+KfMOhEwqa5MxBi9ZDWWkKIoOsGRjyB6myRNTwntHCAHrDHF4NcWQV3mYEGv1WbI05qttjKfCcPKuAUEVBFLWk9V1qzJhi2yybsIah5QxnlImSSaElZgSy+VMjIE16K6r9x7rHLcvXjLvdrwqzKcXL16wm2aOxyPeeSanoLCEomek1FhcKQXWddnMxx9DCTljMaxG50NMkKzONcEQchnJSZkXLsH9knlYM0tSBsbkDAevjJuQhSCGc6w73BQmtoC1uAgvrOHgVR56LCbp+u0MKg9ywMQzJAPJ4vzKfMwYb8HNTHuL83C4NUhyLD/dYfOR2zcTu6MlnD9y903g/PE94Xzm8NVfMd2+ZtofefPTn/OLX/6C2SQul4UswsN3b/kuZ24dpNsjuzlhrRBCJEXhZrJwnPjrr15zMxs+nh/4eILzqgzOt3cnkli+/ePX5Jz4/Oe/gHTDfj/hnGe/vyHnSFov5AhMlR02AtG2YiKqp6aFtKxYfyLGiN8fOVj9LcdECivxfMI6i5sm7LzD7g4KsDmn8t86ZVfuDgVk9Vg3URmxug6kds8sqWEeFTB7bFDoOKlAbd3ZNqiuYMtfSpEUAjkEclgJi/4tIbIWZoq1ME2OaVa5hLWkcyAsmeXhTBQLx0DEc4gJ5wzWWWV0Y4gZLjGxhERMGe+qTokyF42QYyDEwN2HM+e7D0hYsJLZT57JVx1d19zlsvLd+3u++3DPtx9P3J8DyxLBWmX7OcPOW24meDMbXs2G2wmOXllK8+TwkycBpwzvkvCHNWGMYEjss2HawZIGOwTTNyxLu9ui7zoLTih6XzEGi34tlCFkpKyJUK3yomkSsyjD+JK4XyPvz5HwIwKeYlS7sdoQVW9Wz4KtIa5zKzd9Gnhkk4C2awckywrZbIvSR4O9V/X7aquOxTRduNt2Mnq6DLZtZXRU5ketf7Mbq23UkJmMDCDA6BU0GvfNDh7/ME1/z4NeP+p7bV/QlKesdmKxFWJcFWhKkZwSYV0UgCpeH1X/t6ZuUFZWjS+fq/5qyjOa1p4GQVIkIxA7W6wyA5ucLO3srENsVp2i2SNPyK3av0WfSJKKraSTz1hbgKU82K5d/1VG3JaF1gA4io3NY2bSOBY2gM5g9wIN68j1QUvJOT8aXyMrqp7XAB0V0E1nHDfVKhOv9q3a+YV1lnLHCwpLfHPN4VrX4/ZpPODai4HGrKv3vb7eI/DsewNVvXxv4CmPivq2+t/j7NHYYwtOSDcXmqBuA1aZUiO75xrIe+pZRUQn/FDDTcMNM2IEk8bzn7rmpxDDKltkQGTMULl6vxFXvO5I084ybNv0T+0CDAbrE3V86tlqhasxbYy28YgUb1H2+hgDc+O6E6gfzWD1DZWuRmQFnZroenSBTbs9usHm+8oaoQjgjAI6kZyCAk85UpkL43nKmqMDAFd1qPWQett6WgN8tui2GbrMDAPAjL9Tx+HjGWPGg4ZGG+9XGYP9hKvxVEC5TdeUMaeMnX5eHah1dD5Zvs+0/oEU5ydgmNftkbX/R+DJ2i5o3QA8VZEhxaVKcsYk28BLqOOg7hpVw9w04K/N1QY8Xbd+AZ5s2f0ugt9QFw913cgV8MoD8FTc/qzRXd2puAS4qbBGpgnnLXYqQJQvi4pUKaKGnE0GZzJuEhwO54VsMi6zHTdVdplrtpg+5yNlcZgv1MW0NRrD3B6fie0z1s67li/tJu0KY4si489Cn/+1V0pfmKb2VOOguKbWP6NKmi3VtoMsaNdpi0CxUkbFehhMmzo1wKaDjpWt1tqmib8CdAo6Bi2Ywl5zdmDqGcNUxuWcYhlD6mKdivuPjl2rfVgWMFsVjQouOY8tDKTKSrJlfOqxdYy7org6jFVQzToPRhXFKJmcBT9NpJSw1hJjwK2TAk+T0vsPhwPTvGO32zPPM/M0M00Tky/juBokg8HQd3b/cgXoh1BECjsj63iMGVI2ZFF24WinluGtbKf62SjRxjszGEbCZdADMEICEkIgE8WQcW2cGyNFTpZ5IkldxdKKRI+kFZEAJKzJCAlyxJqId4HdXjjeOnYHz7RXMDdm4XK+cLm/h5sHkp1w857d8YYXb94QlxP3Hz8Si0toWBaW04nJgfeTgiAhEmPG5IgncXOYWdYd+9lzXh0Pa0SSGvdLiFwuZy7nE+FyZvIOmR2VBW5QwyVXGQuYZKG4HFqjYK/+oG2fYtDNs/M9Qma67FTlSIm0rsTLg26SpQmRiHFOwaayHHSXa6t6WB3DOQEG4wqYUWSKZOli1PaNyq3e91id2OpexVQrroA5RnKMpBSJKRUjU+WgKevjxlUkVxdalZBr1GucLwuTtwouVflddJLc5mXXa2wZfDkG4po5P9xzOZ9IKUI15JoMLMfmTEqZnIqMNqaEZdB1c3KKGe6cuqHOVj97B8719TUBq8CaDWvWMW0MuCzYXBhff0Lv3mjspgJPg4rVTh/6a3ONqtdpW8YsCginHy/j6VGpugPVdqHYbVe6g/TNb66O3+jg9A3yTzKTxqs/9bvIpturjvKUsa0/dbvk+knr+vRIF7q+FhQW/eNnbK/VvpT+vQJZmwuX+VZYiyluXOtSioNsoeilRS5UvbUxLzvr85q4IaOAqUpVXXiqniyD3Sq6XiNgxSBiizlXr1/brs6p8bnrTNKDtk35uB1rO/RPQ9+0zpempj1pi7Vr9D68Luapk+HJcSLmiZn/CSzh8fW0FnX8j2bwhtX3xPUesbOu6viIUMPQaoLiLvL43Ou15h9Svj/wlHND7qrhUG5dQJftdK0DdWQw1Yq2iURdEPWDKT6MOmkK2osyVKx92jd207iD4rmZwFcC7qlSvx+RybGMyN81E6pDDL0tKsyigmLrg2uK0lK/lzILXFXsittVjSXTJs/wfqxXNZCv4xZV+XCNpDdf29ZvfQCOVL/2Kl0B2QgUaPdrbaOV6kpHUoM4Z301xRCxdUE22nrWWMRUI77XVbR5i5vAwKoyVWAKGMGajCWR44LEBcGQ/YykADlS3WKuFxVj7aPvxueqoGA16Cvd1GJbfbbjvysUGGnuK9UgrKyaR1KrLWQD8632wfBvHy8U1P3KzB7kYWdLDU+3MWDlk4Lk+4nFH0a5ffGG1ifj+K3zwZXdnhJDw5VdVldd7ko7CjSmU05ZDSLJyqwr/aZsD9f8sfsOUgcW2oo3dE+rknXF6C9/RRGolOkUgzJoyi52zqnthIsoM8kAs3d4aznOE5NzHPee2Tt2O2WNTJPu2ubaHlFZNXG34GJi9WdcjKz+hI8RswRV+quLS1/9gL7z7ooR0GVlWQfacR1kaQpNWxN0J0nKDmIuSpM+Z1eqyo23nSzNBit9JW09gD6fuy+/DIO9yC3roM5Ra5mswTnD7B2T0z/vlElmKbtyIhjbaJG6ZpVYMYha/AbBiFX2bhsfTn+zFuMcxnlwTt/7Ml6qsieGZu1RXFrqjhgaf8pYg/PKMMJqXJhpnogxMs8zIQYulx0hBubdnhQjawhqeKZYYpTQ2BAdeFLWU4351KTZoHgba5UV5RzTNOP8xDTtcH7Ce2WU5DL/QgrknLhcNO5UCCs5Z41nZS2H45Fpmjgej0x+4uZwxHvPfqfxsCjjI8SAiM4nJfF2cPIfqAv9R1tUFRIuMeMteNRtbk3aHwkKeKIGsC/rgC2Ak/UwTYabvQJ3BsM5ZHKORBGWlMEKxsFiMg8m443lLDAj7K0aCc4WJicZEy+Y5T354UQyd6zrhfNyxh0m7H7PvN6BO2DTW2bzHa/fLBwnw/TygDu8JqQjMU58OP+G99994AVfs3t44Gf/4l9y++Zz/pP//L9g+ed/w7vf/4bz/R3x/oH14cy7P/6Ry90O+ze/ZPY7Hu7viMuFfDnhUuSnnx+4PTp+/c13GGN4f1pZs3AKCbusvP/uW2yOfPjj70jLK+bppzpvciKFwP2Hd6SwEi4ndfvbHXExke2Mn3fs/Kxyy086h9azMofe/YF5tyc+vG3ge46BtJy1D6xhOr6C/BXT7Rvs8VaZhk5ACispRSQIxnqN9+RnzDRjivtsiqvGZSsyzHhfGInThuGhZasLN31ETAOg43ohXU6spzsuD3dcTmcu5wtrUADKoe6L8+zZzZ3tWDQ53PGWmAxvzwFZIncPZ/az56dfvmgxO1VsyWa9cNbinK6PRjLn+/d8uDvzq7/7LW/fvef8cE8MK5P3eO8xRn04U0gQM1aE2RleHmZ2k3Dc78gYEpbZJPYm8WYHn++EV7PhZjIcJ8th9iQ3Ee3MfU68XTMfA5yCKJhpDUkU2M1V8azrTFlTMsUltbAQjVFXvqm8NvkzrGkFiey2TjG2DZBR99ZLylyisMQfH/A02kyjN0a3/2hzxtrHIFO9zjUoU20oazU+Ys6qD43nNzu02I1mqE8FDas+U9kytbQNwitGSDOs6vMNbrojIDaCU2MbbK5fnwXaBmbT+wtLZ9jyL7ZUiR1ZXOQr+67amilGsqQG2KcUSowoZZ9ZozrvVGJI6eMMNuI1479cX+3GsR22byrTivIsWanc6IohSDYq7xrsoDGW+iYkRWczjVHU4v42m0g6YHRti2/Cz0izHY0BW9SxLKnVW3X/vindbdsrvbE20tBnT4Ka8pg9dF2uWarX9lfVez9FGnkMvl7pYhtb7vEcqvcYvWO6Td3nRDfO+7gYz//Us33f8r2Bp1Z5rvr3yQrUtjDXY3N7UP2hMjIY7O3h5/bl5ofry5lGazTDeU8dfY1WbgEX+WSn/8nSZv7wXR28A4LQJ0wHoOATDJxHjfbpwf9YMJc7y3VDPlV3+kI5gBdb57fhwKdKvV8FXhrQM9SrHmNov28YQqKDXcwItUibFHrYiKyMn3WBVx9mFXjSJtgIzfR/Ny8yHCDjF9szB6lVpqYB8xQrrbZlv+MoGForDWMC6iLwdF81kKKd9Lh3HtXY9IWjzbW60A3Ctb8a/pJh/0Mo+/2hje/NPCn9YV1hafgOGFVA15gSG4V+fio74nVhz6lTqNVFSv+cK7FGvFKX7TXwRJcNbfhV4Ml53BPAU4xKm05tZ3rrt1/H2c47nHXsJs/kHPNuYvYWv/N4p7FWrDVFYUKD4CZhYoIYmbPFxMg+G1yMYFZSA566kd8UxhKLxRXQpDFhjBsHYl/IatuWOD80ZlNuz5VzKkrUE8kArgdpn5b9K6lMsOF9ruBVudY41SqTx0+YBqJ45snjnb46OwBPNTZSCSouNVBpkT2q8GQdA9CDixdD0U8ljlEJYm6970BUdV+jUOpLfCvlGFQ33SHmUQH71Mp1qsBXN3iqazK4UIw4H3HOaVsXRpQC6z3RRGUvmdIuFLfmPpfyBkC0BYDy08Q0T3g/K/BUXV0Bn1xz008xEievNHWn82O/3+O91/g+3jOVtnfld7KUOFUWk01x8dNA69iMdb4r8D+SokaatFgwIQshG0JSvWW2IyNviGtji8Jd1+NyzGQtKcPOG0iwlPikuRjWSaTEm8n0cLB9HdGlJGuA7ajXIK2IRCQHJK+kcMaYB8LDPeHhjnjRwPagbjbJeKyZwTmwkCUieVWDaLfj9vUbdruZcD7hjOX9w5kYF87nC0ImJMGLRYxFHV91Xux3EwnD8bDjuAS8c6QsJFF3zxhWwroS1gtx3evufzb69JIJ66rHhKBgjo/qGltiOFWjs8qvXFxZ4nrBGiEtcwNpJWl7ZBHIkONCiiuuMHqKxYuIMoak1MGGBbdOpb8MOK+x2FIiR5XziG72ifkEy28APqqhqkkA0OcVIa0X4nohrgtpXYgxElNuG55FBKlLXEkCo5iIGoF2slgLYUmkJEgI5ORJ6Vg2GovaLoP6XsaRsiXVmAnLwuV84u7uIw8P94QCfDWdqI9AnPccDwdevjjyxetb1iysEUKGNYHLKz4uHHxmZ4XZ1lhPKicThlXgkuAclWWUperJ0vcPpKnvWodBR+5Mw6a8NffrniJGv+8XEDA1GQkt/lpu99dr1zn8Yy7diqi92h/4T9lcg43drrFlfXwaEPj0tQebZrzWE4e08/8EGFBPuGaj/OnnGskT3TbqgPFYj64nSUlaUgEDkJKsSDdEc4oqn1rcyjF+nWG0vbYP25+rP/O2n9oxemC3zx6ZiNW2UEJB1uBwxW7S0C/VnjElDExrh9au3dhpFuZ1l13ZbY/0xCdM1yqbdFzJk+d/iqiyKVcA2GNiyhbIaoDm1XeP7NSxTTcVl+tH2Z73ibLdhL0664kB/9S4fXKtqWf9YwBPhoocd6FhUP1jrPQjxkz5fSNcqEyV0cjtQEW7Nn0S5joBB0W7d+jTlMDaeVVxG+s4nl87fUQagSejxOuzPT0ot3ViGFymfS+ALw89ovEwMJeqQgIom8f0OTEI0ZoNb4y0L+3A3q69mp/63jQBpfaJxh9oAVy5Ot/03qyMoIpQS9EwqpKapfbiuIpXhka9O8oKsSXwaRM6vS2dU6N949tttM0lGyRp8LwYVHE01mJTLO52qRnkmoeqqkGmZWCoYJcpwFfNZld3ZupdK/NvM1lLv+gZfUJYa0Bsa68ROR6N9ya8y5m5ALFdOBd0egSMqr946Q/aXavLXXUf6Ey9LEIms8nU98TrtR/8D7189eXPVGmu4EVzjSssHe8xzuLnCWMKADUAT64HaFDwpzCOqptFTn0htda0gMi+ZP96BMZYW/pyNBp0HCroUAIqV+DK2qY8VMApxliAoJKpJMfyXDofZz8Nmdgsh3nCO8duN5UMaq4xMEWkuVhMl4WYElNhpOxOZ2KMXC4XUk7ElIpyXttQwaNpUtDE2ZHlVTKZjGCbqe00xCZp8wEF8qTQw5OCey37DNXle5h7xrT5ZzYKXwW/q2KfB/BqyMJRY7zVa0HL2ubnGeccu2nCOcfsvPbvOJ/pVUlB6xpWfXVJQTNt58qkMuX6lmneNZaQtQ4/Tfp9HS/lwhbdqbVVeSyy1pT2rKwkP6vRa/1UlBsdN6FkP1nXlRj1VbOVxRbzoTapNbZkeumgoKCBb2tmncq4q1R/Ywx+mvDesdvtmOcd8/7ANM1M89wAWGNMG78p3WwYbaYgGjXW0zzPOOvY73c4O7jYofNXY4QIbprBWHxK2DRh3PT9lMUfUJm8MjGWmMkZHoLK8u/OwmHKvDnaEsNJWRt7b1iyYT8ZoghhEWxSNoXzhuNsmYyBDA9rYgkKMsWylicrrGQuRT/e2cpg7oqwyRHCBRMibg04CXgbMJwx+Y74IbPGj7z/3d/x8dvfkfMZkYUv3Mp0tPj5gPO33Hz2gpxfMO/Azyu7m5n9ixe8eP0KI5nJT9x/90feffMt92dlVfnZ8/qvM+7o4fAS6/cIKzZZXh0OHKLwi59+xbTb89u395jzhVRi6SzLwnI5s9x/ZOctxKCYJZmQAw/396zLwrIsOOc4isH7gIhhPiQOty+xdlKX0eBIkklpJS73WFkIPul4n3fF0NM5m3MmhgvmdI+dDqSwlrVICJcz54cPWInYFMjhDOGE2x2xu6Nm2Zx2hHUhrmsDlCZjMUYDredBr6is6hxDiYG2loxWRSYW8P3y/jvi+Z6Hd9/x8OEd5/NFs5smBep2hZnkvcN7p+ASghiP9ZbjyyMmCuvpLZdl5f3pnuNu4qef3xJjauBNYzyV8eWdXm/yE0jm/btv+eM37/kPf//3nM4XPjw8UIPFtE0HA2aaePXZnpeff8ZPf/qGX351JIkhYrk7Rd7dBZYP7zm9/YYbWXjBhVvnOHplbmbr+RgN75Lw9UPkD3crl6VkxXIGsKQskIQa43zUnev6QxaiMSCGZNSIskbj0ebiplddKJ0BZwTJEaEwpXNmSZkQM6eQOYeSldjAzfzY3vghl62No0Wgxbapa3Zdt8cYu1B1tHqmxqPT77fG/bav+vfVrfxTrKPreLgjcNDBALXfnozfM8y78ZpVZ7s+/rqM9kVj18BGN6xur7bYsZKrC13QNisNkErw8FRYkS3rcnHPrUxuX/SLbk6OdSsJVQTdtVCtoIfroNrspsT8zCTRZBSVSGFMAcxtbT8pep2C4DUupTFFD7Z1Q7b2h2kdWu2xVruBFSamxGO1Vu1P6Eknqi3jhlipRpp5VrujulRv+0r1/KGTuq1V7UYzftqOn2oTj9er47AeY1rfbjfJ2hjd2GDXY30by7ceUck313bm2HZt3Jbn2pay4VDOH7MwPvam2r6HMr74fuX7A0/VRmgPaoqtJA1oeFT+rPwcTfr6VZ3Q7c4dtBqAELNhmXwChRsAkmsEVTGhCm+NNeoCsV/maV/JP1ca8DUIlAYPPBJ0QzvU4+s9i0tHnfjj+R047SLrT5ZNXcY2kWIAflpI9kOvrjG+kd6G4zMZYAS0NzgU9RzTFJTHAtFcTZaBKtsmZv+rJmEFXx6PztF4vXqIq1XsepRcj9pte+rYvO6n/vtw9Dg2Sv9Kk4r9rn+qT9oYH+8zUrWHoSVX/TY+2GMQ9fuKkP/4y+F4LAvzsBBDW1AqEODnqbn7VuDJFjeHWrJI95mvbJy2qBTgyVfgaeqMJwpDpbirdOCxjjft+8o0sTXQbDk+F7ZOyppaN6ZITsXtr+1u9QDXcwGc6utunnDWMc8TthgT1dgXEWwBBMR4fE6I1QDVYj0xRqyf1HgqrB4ZgFljDVMJiN3ZYr49SwWbxjavLttVC2jt0VzsEinHAXiqCx996tZFug1d0y6pQ3tkURU3voH1VNOUN2lVlZ/S7tOkbTX7CecsUxkXtiZ1YFA6BKL35KSsm5wzrjANaryECjxWZp2fduVVAU/vJ4w1RTHs17cUhkMJYj5S/5Wxp7GYnOtsuRpvKWfBWtdi1ESflOmUMjHFBshR71XGfN2Vk7Ijn0ofxJiwNpFtB54AjcHkPdM04Sd1kfHeaZpy7zp7sADpyZpyb9dljynUe1va2rkCvJZ+lQFssxbBtQDtfprJzqm75J9XPH5QxRSduW6gVXegU1B5fkzdvaOsOrrhYEzHZdH4McEIMakx463BFwafiMa6kQQpCdlqIHLNUqdvyvJO0xVqqrL+LTlHCAvpYkhr5HR3z/37E1kWhMiLcyKtCTcLzgm72RL2Dj87/OTwvrBFp1ndBucdftqRBUJKXNaAi5Fl0dhOdtqpK+e6g2Tw8w6ccHN7w23I7HcTawikkIg5E1JijYF1uRCWhRRDcftqj9XAElONN8nKXkqxZK1T0L6uFThf5rQyFGsMOSkGmLZQVeB13YhhLW2YSWEhhYWcAzaHwpZVJpfDamZCgbiuxBC72GwbSLTknPpZDZOcSuymdW3GatNeRJAU1B0wBl3LctoYJzW0QHkqYtZwEMrA8jg3oY53NTh9ib+Uq1FVVRG9nreGyRpmZ/BlDYwxcl4Cp/OZ0+XMZVFmLSLYouNX3dAUQHreH3AmQXxJxhAxHO8j3q08pAv+wbNLgTnqPZ21ZGMJGM5JuFsT55hYUm6xa2uf17YW2rI8jPv+vsZQu1YGr7ZYa89T2fhJFHg6h8QaM6eQOIca5BkO/soW+P+D0rTdK0MWHtvGGxYO9cR6lW6rPQaPePLzdRnP+9TvbVP3z+jIf5ndWB5keGkEhAqOGP0xt1hN1ekVkBp2oSa9gZb1tqyZlRX9aGO5iQRdYCsDqQ7kStsoFhpVwRptLK3CYIdvnrvrYZQMkqbYSa29rR3atjUgRSve6Hhtlsl2+nX7RvqhpS5P2qtIB6xEttcaGqbq1FKF+uiRMrYZw9gdxkZ9pgrqjMSDTxVTTrg+YgRC+7W3cVfHYz/Fomr3GMpItnjqOt9rLH9Pu/EvAJ62D6e7uFJ04KErWwdszm4vhqpw1uwF+kMZY62T1DUFTGGoqK94DfKoAcoqmlqf91HjVOSvVGjcEQJbQMUyacpsHwd5Qy8HBHF8xscdlzffP6LctTm77fwReGoLnfTMgM0QoBtT1eARUXC0ghMjSNLr15llMtRzM9XapCjZbZoKq/+ObT0W2Uzj0uZVOJRMcNWEMnTUtSLbDWjKmgGi0sLbTkjNgFCUaNMQ8daC5TpW/7IBMVg74dyMdbMGub2u7whKaichDLTn4q5nC4ttFGIM/SpVO6m/IdSgeY9aSrbt2o273JWYWkORlhZ825+F9VXQ5Xa1unDUelHjURXjkSE2Wt3lGcG34R4bNsqPoHz1xVcItOw+Yzs1IMBYXAlw3D5X4Mk56viVCjxJzTzR2XFiaEwn5xzTNHXwZVgkjeluoA10asPStpg5lXllDAPwpOOzZjlLxViooEodqr4oGBV4mryCKFNh1Tjvy9zSEVdjRsUCpilLJnO6XIgpclmWAgCVMa7Tg5qhpManq7Kqscmcp7LB2ksFnjpC1NN4p9TiEaTGeOox4ppssB3I69KlFNOmkl5zoJuPi+hmWS+giKl9UAEdY/El/pArdXclkPZmHRAIobOzlF04yBoDvgJP5XznJ/2t7PiNcbLKAAVRhpORynSSbhHR28K6zpiyTllDfgiqL7kahbV+o9vkwNIc10yKe1JKhBhLBrHu5tkMWREFm5xjt9/j54lp3qnbnVeX0Qo8NRlXXXGajNtqkdNUMvvZouyWZ1bXI4MxM77E98g5M+32BbR8bPr9GIoxMHtLFiEmOEXhd/eJw6Rz6HZneTFrvKtcAKEKHDirWOX9JbFaIUWYrGE/O3aT5eV+4rQmLksmR7gEYX8UOBiMt9jZklYhRt3dzoX9JqmAuCjrJBjPcllY4lvSvSGd4Ovffc03v/uOGFR2TK9O7G4uvN5fONxMvH4Be7zGUpr37HZe9T7jwTisO2CnPWsSTsvKu/d3ZOCX337ATQd+8k/+Cbv9jjhFJFxw846dwC9/6Tm+uOff//prLMIf337kEjIfTgtYx7u3b5EsfHl3j6TE/rDXrH3W4azH2hJnTRUmcrgg3iLxAk5lxTRN3Lx4Qd5NhEnb2/u+cQCAq4CTgHGEEJHzGfnwTjslJy4fv2O5fwc5QF6J65m0nHDzCbs7YqY9zLsSe8gU11yPHw2TIpsMpoFI4fRAWi7kywNSMlwB+N1eZU5YIK7ksJLWlbAGrR8qTyfvmCeHiGZSvESLMxPu+Lq0jyMvgUZYqPqG6Dq1pkwoc9IBb2bPy9nz+ex5YS3hsvIQE1+/fc8f3n7g7Yc7YuprGKaCQarkunnPzauXfPXVF6TLDesXtqSUMXz8uPLd24X3+8Q363vyOZFPF3aTbrbc47nLnt9fAr/6GLm7BE5rwIlgXfEWzYIkYTIad2lcJ6SBUiqgUqljEqMMJxHEFJdOkba0GUmYFJFkSZI4r4G7JfDbjxdOa+TbcyYUmbX38Ho/Fa+DH0e5jplbQY+NrTTouiMDZNRBrw326413dfveMptGu2+bZZ2mxz9lZI/673jP+v1THgHXxvmnbEToenc79mrNMsUYFkktOLjqPbnoaCW2aPUyKetjSqm42sWm19aNVTPoF5u4moxxL8E0Xba0oTFk0+dADT6uISW8Pk1xwY8xUe2cOn/rZ5EKakfVaUoYCZGphRsw1jWXVtXHgJLOodqFTW+s+mCdmyk3EAkqPrHpIb1OBawGO6/rIV33qp461LlcGF8tYz25Pt4Gc2g2xZC1sdrp8GnvqqfGSjcrlek8gp0bRt2VnfgpFlXVla/L9ZitzKU6nnPxNngSbB3m0V9iN37/GE+mI39/royHCdIBwkGxrJZYIdNt4QsxaLQBS09xJ9sLM1yTQRfvVynXNZvvpNWvC4am9A517s+yFSAbg2V4noa1tkXnsVH/ZK+Pd22P2uvTHr1dbgvSVcCpLtYtfeeja9fGGiLkX7XNFhSrLVj/lcE4vn4o2Xxq78bsce3rAQwb712eu8734tmJaacUQKcaLk8AONuKDZOh/G0Bq7F5BuECFDi+Ylqtrk92XxH8Y5O3qoxjqr3vRt6jtnn68ptSFbwOGbRK9Lq0Z7KPx8SmKz597++/U/Mff5mmWRdm21OP1sW6UUoHF6hKRdYYS4W9Y7ryk6zGXEquBPgeJoayiTR2jwJPFbxsw6wDT3XxafOYphz4wviw5b45G8QowyRnnbu5ACTZ5rb7VfvZF/ckX5gwvjxbZVHVZ67jKJc4UpW2bEtslAwlC5kbACBKituaurVPl54JUBUSZ10ziioA0xawYfyNi5wyq5ymAHausaCg6iR9bldFpC/u7YpNoajue9d9PxptUEGzGtx/cLVsTKfyjJWC3K6gF/DeF6OrgGjD9RWc26antSWlepVNNVVwjcfU4jKohtSDjzTFQuWULeCm9xVUVOaTL8FDKYq5tVqvCsA2sE+6NK1gf11XUs640v/WWKJNDbjqjJesDCfnmOZJWU8FOHWVtWS2wFOuPVTjzrR/azIH05lO/edB8TKIOLwTsu27ljk/pqH/0EsaE7SUGH0ZWJOCHecoeKdBia0x+CykxjbRbF4W0xJjxKQ/uAJk17lrQa+dUX3BaMZDMVZdtIXNn6Dxpi4hcR8i70LgtCTOywU5G7jA/eXCEiMa1sgouLFciOuZHCxWVrxNmoHTabB0jZtX3OOdw00z0/7AvD+S0BhADw8n7u/u+TxmZkrg28ISRQyHm1uOEW6OB07nM9ZqmuolRs5r4P7hxDTNnE4nzYa22yM4nJ9xSbDr2mSK7tRH/UsB8tTcta2bwCf8NGucHyM929woYOq6XRQDTUCQkMI4ylFjZFFYntY6svFY41QdESEbhxg/GKylnazBJKnKQUsYoCytBJIxSAO4nfOlXSdy1GQA1Uht8kVEN11avS1iJ8TN2HkPxms2vCJPctmEAZUZMSVCygokoTGWDt5y9I6DtUwI5/PKJQTe3z1w93BhjRHJ0g2f1npF9y7jkyKvnCnePmiw8eNkWCfLzeyIyRGCykDjPSlZlmy4RDjHRKguOUXD7STxZiUMutVoDww6+RNzterk1la2mMrHkATJiYeQuF8TH5fIaU08BAW5JmswjRz8/Yy3H0rp9sbjUuX9UzK7g0z96G50VXtre/wGUHriog18Guy5ze9/4jk27JFPnF+/a31Y6rElRHA1eKTp7nVwNb0lZ/pmfN+ck7LuNvnU2iu3i1dds+lLTQ/VdtomWin3pW6k9qQdPTZZxhiHNQ7rJt2Ia8BTrb9sbeD6uT5v+6zrickZYxImlw1L0fVmsJBKV9X2HO3cq46TkfGuB44bW6oPVnutax3Vftt6UQ3XpfdNps7psYbb468B0y1Iuo3n1PCF/qCbMgKlTR5eH/eUvBjG+FiXes1rsOzR+4L3SK/4k9e6Hsvf1278y1ztNp0t/Xu2D9R2uJENsm1MCdQ7CKHm6pDLw0Lbod7QAsvEMAU4sS3uQLkv27bpwmyoT/m97p73DGP0iT+8zyIV/9DBWVandr6xfaA9cb6R4pNbJ3YzwOqz19d+XW2rwrIpB6YWS6MbRoIu7kgxRI1RJaVOsNYfva90Qexxq7aCtCib9WmH83rb9TrVPuW67Zsw0g+mH1wEQWkbM4A5m4la7jKASQJN0WttPGQQU/aauiSRMpIqY8rhp7nQ9b0+X6y7Vx1ArIZOk1oAtrdhbXvtxhrLahBcQ1vWXcdGsR/8caufc33mGsS3tepoiPfm3F7bdAZcda9qQulqPFUjkuLjXWMLbfpveE1JF62UflzBeQ+7PdDnbcuUAWDoAENhOqnrU08v6wpTpcYXawZ7rsyWsttmK1tJDe6pBJG2FRQpfW+owFNhK6UOiDTGU3UxKmBNxpCzxaDsOCX2GVzZERJrB8VFgacae8laiy+Aky9sG1+BJ1NBm84oqg2TRdjv9mpIxDjIWWm+9NWQqu3pbAWH61VMG+sVJBlmcZH5FexQpSrlTAyxZA6MDSSp2VhqW1fApd6n6zbS6orUOdiBq0doRh0HLVC22/S/Mp/qYdJ2jqoEqFKuU9zLemgaZA9Sd/DM5hzqHKWDcU1BKLEdpFDoc47N3bJeSV30OmA6ujs2GWu2u2w9Q+Aw7qgMMn3NxRWxBpSPIRBCIJYYT03mlT9f3OmmEhTced8y1VWZWOWmIMSo6+lmQ4Xedp0h1fY1Qboy7YoLp2bmEWJxxUzj3P6RlPOqK0QhmRcdCc5BgyO7B1ij8MXBsvdCFss5agwZQTjsLM5YDtYjWVgDBBGW6sKBjmtXloqUNYByto7sLNk5oomsklgzLBmCGIIY1kviQ0z8/dsT/+HdA2/vIu/vIgdr2RuLOa8gK96pq++ynLh//y27/Rmbd6TlHSafcfYVzs1IEuK6klZNQ+TnmcOrN3z5i7/CeM/v337g/HDh17/+Hff3J15/+VMcMGeDNR7rdxg78earz5luLvziJ1/hjeGbd+85XxbenS6cQ2LnvubD/QPH11/w8vVnuONrjNmxv3mD9RfWVWNDShlXJmdwIMsd2QgxvEREcNNex72TAk6Frg9VfafqQtZiJ9fX7rCSlwvhciKsZ5VRksgCMSVsSNh1xU073DTj9je4+YhFdZIcV9KSIHlykYXGWG2/mEjLQo4rk3fYyWHnnbrk7o/6Ok3E84mbV29Iy1nlByhgJRmHxVtR4N3PuMMr3OGW+eUXCIaP337NabnwcHrgclmUgZUzl8vCaQl8fDhzf14AmJ3lJ8c9rw87vtp5XM78/g9v+XC+8O9+90fuLxcelhVvDUc3Fympz+nLupxDIiwrp7s78uWedP/Q5LwJwq0R2Bnsy5nF7zmbgEwzMs0sZ+HdIrxfM+/PEYrdkRmYq0WcjVpY1RVzrtaHzpdRd292SAGwksDsDJM3xU068eGcWEPk1+8X3t0v/Pr9ynlNnJMKwFd7xywKjP2YGE8jQ6OWjfE92HD1+KpbtbWyAJ/d/pASAmwr5+saN8blvQYBrm2fzTpWbY6hjMyS+nrN7BjBgetnHFSyR7Zwe5ZSh9wCi5VEMmFR19zCeKK43FedqN5zZCxBsb/odkjTB6x6P4QaA6qwwJxxZX0dE9YkkkSSLIR8QkxCTMTaHc4emNyB2d/i3Q7vdlRrroNfdQZL0y03fZUzmYTETM62HaexfgXMwAIf7KkRxBntNYMtoH+tR9cHmi5I1d2h27at0crczg20ql+OerWIempZU23uHkKgAV6lgqPN8BS404HVuvnYGYLX8cEqY68es4llbUYKSTlneD+Cj8aYlnH0U/Ua5wm1flfz6Km6/rmMfmP5C7LaDTNoo7A3NEE/lk7rINl2wBlKACy2D62Xla3xPV53A0h0BbYaEpVV1eYjqkxVBaCyWbrBMBzVLJRRmF115nDddpHNQKOgtdLlIxWEMRuwpT930UquRk01TTYWnEBNhytmhEyulWwzfF19S8fjnlbKe1c8cb0/9b4N+ifQ4v8Bi/o5lxSdgGnBiw2aFSaQQ1BFMakxn5Mer+cWI06qEacBoU1lHfSnaI9nmtCpz90XvrEZhuFwXet6SBk3W7S8jnUDJd18WXgZx/Pgw9uu2hfsp0ZAvXxnFGzR8lHwdeBBhjn74ypVZWkAEMOcM32O2vG1LtwUY5fNKe1VjUHTAARbXcCay1ldGKQptTWwIKL9POIgxvTg0ZKLIDUgaWC7NKYJqAaW23xvNZMy3gt4gdVzRJSBqkCuxVSAtY5V05/OGaNKfzZlbHS3QgXvaLKNAuy4KqgHAKuCBaPC1edZV5AyFL9hnQ/GGgXURFBdZFSieryCCm5VOa7GgtahVmWUgRu2lYE6u2yRJ9Y4amB07dOyQVGBQ2s286i2mRd1S2mMhwo81UcdlRddzPT7yhKrwFOVRbYopUVhTEm/I3VZ0RhZxfC0tb7jGKeOQ50J1rb9v772NQCw7zz2BCBdMNR2r21LYWX5GlC/BGLXmDfVVbScbwpZq44b03fVTFMipS/2TSnvY7tlnzIKcLbA7UaKmLafWOF+uEVp9oIMOoy6WyvjKQtEkcaAcjazJmVAVa95a9T415TSaqzEPKSHvxL8CgIL2dIDLRtDyHAOmYc1cb8k4ipEk/nm/YWvv73w9m7l/X3k6C1HZ9mnzC4ljPE4A+Fy4Xx3x/kYcXbG2QvWRqwVrLO6lqdIXheVeVkD6B5evODFuvDi5Uti0FhLYbmwPtyz7CYml9X93E0YNzPbG3biub255XTzwH7yxBA0sHOM3J0vWO/5eHeHnWZCzBqTb3+jYL71SBJSjGAy0USsNcTLBezEVLKu6WbOGFusp+sepLGO8RJ3TX3TXGGSKcBfgWX9E5LLeNTtz00o+7UkbmhrRAoIeo6xWmeMJYVuWBjrsFPZyJh3mAIiKeNph+SMP94w3bzA74/43Qm3BEgR59SF2nunrrS7HW7Sa+QkXBbNMng+n1nWwNFPZBGWNXJZA0uIhFhAckNxi4OYMtEklsvKw3nl4bJwXtRNOZeEBuZK/U0pcT5fcNawnz2sF0yoSRFUFlhr8M7iJ0fyugEUjGUVwyVpPKU1KZDeNpQFqLKuzS0GZv12TtQtAxl7eFD8jFF9Y3ZWXWNzYlkD95fAeY28P0c+XhLnICxJY7UZo+xFMJyC4P5c2vAfULm28a5ZQ0+xiMzmeH3tYVEq0LfVYa/u+qgef4qhpMvN9hrXzJQ/92zfi+nxSMHuz1ABGxFRJmRjOw2ZuQfWdr2ODPe2QzvoJmjRWttaXXWPfi2ozOxMzoEsiZRWskRSXohyYUl3CJFkAtbMBXi6IebI7I/sRFRO2YmOBXR781E/D79WnVRyIlewpijGFScwxjQmc9WORjBJ79Kf0TzR/3XcXIN0VdeQak1tNsO21+/1v7YI9Hcznjj0z6eKecJ4e0wIGWKKlZMeMarq93/iXuP1+3WfBoqu59Ofmgf/UHbm9waech4pj8ON9e6MqbxrhXL7PAh122M2AUOnl49Dw2wAG2uwQnNfqNHo9eAyycpE6hMUXUHENuxAUy/nwQjo965Mhh5cVSu9ASPqNdrzD4Ot5sy+WpCs0bS3dcnKI6PEFNcOqQOaMrjAZlObSF8Lc4Vqt2B0ITS5V66azEbQuEdVaX0sKEcEfjuwtgO/gxM0IVgNCjVWGITkgOKaYWBKr4NIDb5ZnngE4uq71tbaZimeySkQLh8RyfjdEesmLC8hJdaPH1jvPpJOKzkGook4HwjnE8Z4pvmo1wkP5BQJ64K1nt3hRcskJsVQr/fVz9vgwz0ocuv9Pumb0JA2FBVo7WJKjHvUtuNnikElV7TPLs86mNDnCCX4/NXiqYOm+TX3XZZtrJutz7qCJz+mYlKVP9JAvRoNrcIgRlB3lPJn6gImALkKr6IYKNjT0rYbwYgtcXhoLll1MWoisBoYqbjGFQDJNLlVdvKKItRkqfTMQD39cgkgK1u3qQp4ZefBWo1VYTUNvbNWd+6tBn0x1pBL1o+C3bS4T7YxShyCxZcg0ClWtkthGlUQoiAKtirsqY+vIkRLO49KUlU0DYjK9yqoXZNjyu6UCgq5zsqx1jbmC3QZ1uWQacZC5fWAGrgNtGrrRo9vVAOjuwHcNnUdkNpGZlgP+poHYH1lHOm6I7krlmRpmQHb+Gyy8tpFh9LHOl5iciXmQ2ptX3fVVDaZHpNM6g6Ujg1Twaeqlg3ZgjbAdl1DRHf1rLVqnDpLniZSi5dVlPMydqtLXXMRbUwnLbnJm4hIZZiqC5cpY2Q0AJLoGj2ulfoMJYNkkWeu7oxWANO1h/jRlKor182B2ZXAz077UIwQMnxcE5eEuhQl4Ryyxq4xRmM57TzOKJh+WhPf3K2ElLnE3FyNFGzX+bteEj7BqqGIsNbyEITlY8TMC2Y6c4mBcwz8t7+947/93Uc+PEQ+nCK3s+FmMvz0MPHF3vHZzrKbDR+/+SPh43vi/Z7T64nPf3bg5vXMNAt+byAvpMsdD99+S7ic2d2+ws07vvjFP+Hllz/l4eGe93/8Aw/v3hFOD3z4+reY8x37n7zGH3e43S1mPnDcf4E7rvz8Zz9jtvD3v/p7bI784U5BjhRWPpwX9re/4ovLwpf/9G85vthz+PznmPMJefeBmB5YHj5icyRwYb7MGAz7ENm9+grrNTaJGEGyHyCJ6n4t3UDKlKDpE+JnmPe6f+AT2VjNGFrYT2IsGMv+NrO3jv30it3tS5zfYfysa09a1U0vR7IKIXWFM44sCmhN8w4/75iOR/w0KThWsrZijMrYacfNT/4K5gMvf/N7kplZkhCWC7udZbefON7sOd4euXn1EjvfEnEs64VvvvmW796943d//IYUMz//4nOcs3x7d+b+svD+/sT9+YIYSBjuY4Y18sfTCjZyNpGP5zPffnwgpkgsQfLLaqiy2agcO51OfP37P3B7PLCeHtiZwNEseO+Zp0llmzdMs2O3n8kpMIWJUzS8XzPfngJff1z5eFY2GDXoeNZ5NaGMQm/1LzUDuhi10t2Ps6FMQF161MVSv5qsZox8dZw57GYulwtLCPzdNyc+ngN/98cTpyWyBEr2Yp3Dd4te526JPyrpNTI1xlJtjirTxuxyqks0jRcGXeipDdLRdul6hTQdYdR1r2NIdXaUbI6rv49r+/Wm7fiMVY+2m/OG5zZjRu4Ozuj9SiynuKpemErWuhg2YQJyjt2upav7tU1UH7CFuU2zVZqtPOgh42smkSUQ04mYF0K6I+WFkO9Z4z2n8I4kK6tcMEwY2TH7l+ynz7jZfcGL/U85zC85zq/LY20Nl2LWFFu02KxNG1PQKUawObHNelfbsOpxNMY7VY+RoQ/o+i/tDqY8uj57Khu41b7vOIBerDLtrnW69jD1mVqYim5Lm5oRWPq4r3/WudYu47gaM/bxCZv8mt10PR4345SnmUe1jluygdmYjNfg7NaWN08y/8byl2RD/4sYT922Ndc/dWXZ9F9H04JHr1cI4tUlH6PftcGvABTqEOzGQIN4yuIhLYq+ub51v04VOEJbUP6cAvvUIXXhZAP0XAurzlgytY6b65p2TJ3IwjgY60NUgElndp08/Zket51+n6+Oq4Zvqynj5OuPMHRyO6wvyvUXqcJmMAZrv4yXq8wPM7bJ2GSmP39KgRwurKcPSIqksGKthzUhMbG8f8/68IF0WZWayoLhzOndO+ISMWVHcl3uyTkS1oCfdky7owJ/DgUJhrbTqj8WPP03nRCm9FkDN8cmG0uRvtcL8eaRpbI0ZOxAHQNtTsijc7egk9n+tqnIUyyCMouemBc/ilLHmAqF+mV/GRagVsriZYZzakym6vKkAfFp47SCGG1Rz9VPHg2GWAPyprqjJZv69F28MldkGEsD8NQUJKQFKW+7YkoDQUjFrVPrlKljT+e/FCFnsm0LKYbm3qfNNczzIR5Vl7BVBl7JVenjV9rxqJwqVGUadb78WxTOBmCnQrPImeqwVuVlBUVa7KMqcOr9sn4vNZPdxsWVNr8USBpkUqNpS8toRXvKQbBXxfaqDSqA1Fg+pVq5NE+ut2vtuJWHXUIOq57pMqE1cV2IZWg/tCmyKYq+1H6mrB/V9ZtB5nbFo1+7DbiNDKrAlcWUOGBFHygbLW0j4goM6w84rh197WotWduL7SkynFuWmy7/Srdo23al7skF/gdculwusW2swVqYNbYrgn5Ooi5yQo/BlKXg5IWQo8wnQ3SG2RcjINa5s10zpARzMqJueM5ZEnAJmY/nyDcfNX7TJQY+ngLnJXFZE0vMeKMA/jJn1mR188MIOQdCFMJqWJdMShPIBEYwVhRIkcD5dM9yf48Yz5Qy7njLft7z+vMvsCLFRe3C5eGBewPr57dMeQ9WGU/WeZwXjje33Ny+4Ljfc7pcMPcaZHtNGR8CDw8n9sd7Luczft5z88qrW9u8I4aVEJVZFMKFOSbsdEKmPS/CCkazKVKMqTpT2osqbSrHbd35p+lZQjUGtn9g2uaDmG5Aqbxqu45F7tmrxUvnYJ2nyq7SZDp1wqhdXwB5a3H7I9PxBTdvviBmYVkXwnJit49MswHrWj0Eiot4IkR1v12DJqJIWYgZlpC4hESImkmwzulLztiYuQuqj2VniG2T4GrWGtPYfEtInM4L7z7ek3PmcJixPmFmW2LB6bNZY5nmiXk3ERY1gtaUub8kTkvkvMYSc6rLXpWvypj0tomUqwm4fXv9e/NOMOBLVs7KQr2EiITE+bJwvoTm5m+Lflz3GmybdD8u6dXXf7PRUTcb3deNerV2dFus60f9t+E4KBT0Rz349H2vzv/U8deg09UB28+bum9ZOdWOq0Kgso9yzS5bACeN4dRjgNb4nW2eNF2m63QVRGtgx+aeVehsKB6oW28g5jMxLyzxowJO6Z4kC0lOhHQmyImYV0JeMASMRHT0Orydmd0Nzk7M/rZ4DdiNftVs9laXoWUGe6c9swZuUwC+aFkt+DzVA6TaYvpsMa1F/616mC6OucRHzFkDZKcSnqYnrep2gOrpRYdmC6JUvaLqIP3NVsdpGbM/MU6u2UwbsGcYZ9fHPa7L9eW3uuDTVXg89keQ9frYp8b7+H2dG7Q7/+m5NJbvz3gq1OLmy7hBWIaHaTXUIWMrBVlqQ1vGuDcVnayTp373qQ7otLvRV9NVO7FEyoeK8KnfrCmd6oqv6Bh7YyseGiRkap1o17tmqIz1gm3HytgupZ4tdk5HgMDQdqTrtVr8qqcGK0NzV6XGqFLS4v3I9hm2bao75tWQGBk0vTtrgMduzI0Kads1HwCMKhSb0VEFQ0lZ3oxT+oDXuVtBteEGw9tcYuGE8x3hcsfdH/570nrBmj3GeJwckRA5ff1b4uXM+vCBnDPJnjHTA+uDYTre8PoXv8A4SHKvbQXM+xfM+9vSz3ugK4c1VXhFsFtXln5R1oFprIm2s4IMfd8D914j6J1BNrRtziV+QAHkykJyHTh6I13+xHjMV31nWptud3a6HVuFh3nqsj/YYsZdBPqOURP2VTaVRbNlNRsVCNGdqZwSMax93hiKi4fFIGQnLZAtOZON5r8wIpiscjTFVHa2qqsAVL2sLqg1c9Rm4JU65+qKVxdr6fGmanwicU4BAqc7SOI1G2gKNUZSkeNlV8yUnSTv3dalrSy4KVXlp7ZJOa8yPAeQQkTINTZT3pLYq8I0ytEGqOUat07f1zlUXRhJKvets0UtyJC7wddApiJzUozEFMs6II1+bptrWmdPGVOfWUFosVZdWIxBsiu7h0VmpiHWAwZKUOSqqjQGW+22IhdauuOaDnkAvYwuXloPW9czUxTTooAWplyONcsIA9hTAl8aQwqxjKcaT2uQAGXcVref6poH41CTHtB96LxqLDUXuRo7zvAIaKq7f5XtZajsZRrIpEppcR2yLTVWGf+pxOHrMlffbHesnUt1irbv/gL95wdRUllDbGnr2QuTh5u9jv01gTclvgyoPLKF55dFgR4jxKRBjI+TBo1OeeJ+SSzFNSuVwOVVYc9RWZETmtnRO8uHRbi7BM7fJH7/7qTZESXzzd3K/TlxCZCyYSkeZw8RjhmCyYhPRASTApdFcKdEWPakkBESxiZiXFij4e0ffs/9d2958dmZ/c1LfvYvv+L46g3/7F/9Tzl/fI+NgQ/ffsO333zDu7ff8frLz3D7Ww7TDXZ/S3YzThyf/eTnOD/x1ZdfAoavP5yJKXNOmbisfP3tN4Sc+eYPvyPnzOc//2tmY9m//IwkcP91Yj2dOb//jtk73pxWXq2ZF1/dsTtm5sMRMYYkuoOsbpFjzI9BP8SqDmgzJidSjIS4aHDxFFo4Adyssar8DG5HwhBixkrApqxMb+cQvyvrtILz1nplNVmvAXptWQPEkGpgIlPWHer6YZlefo7ZHfn5v4q8ufvIq69+Qjjdwf3XmLyQ7cyaLLuYcTaSUiCtZ8JyZl0uXJaVlOGSQZKQl8j9JXBaFJRyVrPPvV0i90lY7MJu8rw8GA2Ib8GKae4MKi1UfsQsvL174O688vZu4SdfvGG3m3G3nulmZp4cu9ljnMf6iSkvTOmWuC4kET6eFn77duEPp8Tbh0QqAfhVlimgaizsrGG2wmSq/AaVl+WV2pf6Tko9R3PPGjjsZrxzzNOMsY63H84sMfHhw4nzGpkkY52QTPVW0Os1A/hPmo4/vLKJi8Rg4A56abUl/hTLY7TD+ndbe/F72Y25b8ZUBvv1eXXz6/q627LVI+t1erKTyoSCCgy3DcMSLFyyAk4xrHrPGIYYS9LWzpRSB4/qdQBTZU1Zw6cSm7TacxXkFFKrs7aHujQnObPGOz5efscl3nF3+SNJVpKcysUjQkJQADnGWPRkS8wPLPEDMZ/LZkHC2z2T0z8RZWqZGkuiqLIjwaMRHtBD1AG2ZsYbmUeDHh4LxFG8jlIOiCTO6wdSXov+bPHuFs2MWgGoHt8SSta5auPTTHEqaFedmqpdUJW7XDwG6gafs1U26GtKqcVobXjJMBfquKr3r8l4rkGep/CGawC0vm7iNUnPvvhU5rzx2vWa19d/Kv5TG3eyZQ2Ox1n7lNvr0+Uvy2pXXrc3hVFYNmOO3hBj9dWffRQg9fxOG9tQvYZUk9uHGkGV7etVxa/Oe9wRFcypjKmtUXQFKElHm69R+y1ANMYxgXFnfYOtCD2WUENxB4yhCTW9kDD48g6TuRp/I0KObPAeNWKKcXYtbMeaU+qeH9NA2rMhlAQ7HbDqjzc8y7i8XF9u0671FmYb96b2n1F3uBwTaVlZLhckG2y8I4fE5f17clgIy0qWTMSASyT5Dn86YZzBThYzBezkmW9eFMOrGJsird37uB1rscUAKlhDMcZHFkoF7zbgztiKI6AxNsd1C8rQEJsL9L7YtOH4c/lt0+Stox51RDGCqzDix1WqsSpdgdm0gTH9D+oUKJ9HcDW3xAeV8VRXLSuqTFoREgrstJS0mJ6ZqDGe6vky1KEqs6aBJXVcDpN9O67qblihEIvQfeMHV8BkQMpOVB0+DdwoQJQGovcK8vguI4AStJnCuutyskYIqMpEBY2au1uWYa4MXdKUkb6YSS5U58JYMpTsQGi8qdpFDos3PcB2fSOiMiubjJBJJuFN1O9sboaYumtZrUQuwA0Wk1UWCImcezZMQ0ZyBana4NB+N4XpaCxiTWEV6bgo+f86zTuW+C0xFtembaNoZhfAjcqwgpUKOBUQraYtLv3X+mlYoxsgRR3rfW1BRJ+3hNJsfQJtDLVNm/G3+mpoO4l1RVBl0LQ+x/Zx2uRivX9dqzayqCh4dcGqccXKWKtuqRt9ABgDmZpHa/2Pp8jwp0AfTDXviqh7kC2KrremuAwZjfEkJaZTyiQLWRSQ1ONqXLoxs1ebyv2upgAE5T5ZhCUISUoygKRmgzP0+zuYJ8N+ZzjeeG5ezBzmmdl7ji9mdgePna0GrmUly5mUzqQorMuF5XJht664eQUUMJ73e3I8YLyCKw+XFYDTeWF/XngRIiYkUlpISZjmPbujsp5uzhemyeNiIoRMzMJ5CTycL9x//Mj+cEOKAWMs+5tbcgrsji90LvCOkOGyrOwuC8v5jPVTyzCl2f8MUpM9tLW06lMgOGUbpQRhZQ0ryxpYYmYVR8KT7Q5jZ6zbkd2MuEkz2ZkCbFXdJINYZbJaU5L2lOiErQ8FTO5yp69xg1ZW1zPA73bs0oHD7S3OCmHdIwFCdkiCZQ041I1XSsp2XQNK7CYRXBZsUkO1tkI1zuqGX5IeU8xQ2ZIMspW2FqaUWdaE90IUy8tlbQGDa0SALIKDxvAyhaGVRbM2xpSJSd+PKrtB55EzMDmYrdFMeSVOa1vS2owY9AO2b7vBasE6LlHX5I+XyBKUBRhzt2OqmNNXnVv69KOm+eMoT4nkp55wy6DYHj2uJU/ZofX8+jrqSCPY1dbI8ftNZXlkAz76/cqUeQqU2mzulrWurl25bDwp2KwbZG0ejnGc2sir1+htMd63bqK1QNatvXK7d59fAiQyKyHfs6SPnOM7lvjAOd4hhQVljGZDBQVvjGSMTCjsZJHsSOJYJXFOZ2y6g/iWyc14u0NQ1lZf0sub2nbNNNaJoMlvXMm6rHrYmNin9ltdo2r7xHgm5ZXL8o6Y1qKNWiafMGbCMEORI1KNViy+Jv4pm3Zl27lvMNa6lT5va2EdSkhJRtAqNHT/43G6tdJGVn0fs5txdGW7XUuFJ8kodZxd1eVPzZWxXG8Gf9/yD9G5vjfwVBHrceIKtDgn9Ttl8ZaFmB6Mtg4wjUlSUbpuTNTyKTRvfMAtEj3efVxS9bieFU8HqvbDgIAzgDBm22nXyF+7VrVei+FUY260tqrZ7ppOXRRjs/VLrWPiGt1UA7enLte66zWsqcFdt9m1KIKmBalMmZyCmrEGKFROrbT6o2q8LZo2K+iijfUaI3PckbdjwOT+ffMbreycjYXSM0CowpRp3OKhp8bea+Bfk1haRz8dkBiRYAkPkbe/+jXxshBPmnkmr4Vq6XVSh5QKwPkN1jm++9UN/jBx/PIVx1ev+dnffsVud8M07zHOt+dIw27guEB1Re3xhJSsASvHR79e/MYnHd2Z2i+b/u9iRmoKe5HBr3gLGo5XUsPQbIQRbe4peNDnZOn3Mgi28at+RCXFYREobTOATCPLqdIKxBjydh3QtNExEUNU17OUuvFvLSZqANpkVyqYUwOWG+gU3aKM9P3SbhQIpgGZVQa0LHwyyJSNctJ30TSxmunsnrIDI8nr56rcjyl46fN0mnVB9iVOUY33laUAHSWmknW+vLoObgjNjTDGLXOpmhTWFAOksn+a7CqAQvlsJOGcZbbKzpiswZqMMxlvLd5aLBlXQB6DaBBuVK6nnBGTyK4ytUDzVevuezVqUpKSqMCRkiWjfwmD87prLSU2iqkgdaGAV3cKStvWtqmdFLMqX9VQCqGzr1T2X9G5bY3N0GNEISV9csqkNTTGVFVM6nwfQajKnOrUewblTXvCSvG/ygYYAKYBOEyp7j6WcToAXBVgbxl+nOvKjxVsAsS17KE9xlNf23Jhwtb5gaEpftmi65QUGVjjYJTxtdVgS2yH7y8RflClrpRJysarMTgLR52CTLYAUc4wO8vRW5wRjpPKmBOJnIVzSBiEQ9CW2k+WkJVBFbKOV9B5mqQHg6YZLuCtZedhSYlLUIZiSKpvzFYQr8DUfta/N68cX77x/OynN/z8sxe8fP2a4+2tTkUHu/kB8SspvSeGyHqBZT3wcP+e+7s7/OEl2Fn1Su+Zb27AZPAzQSx//HAihMAvvnlLNpabL+44JDQTE4b55jW3fuanv/wn2GnHi9/+npQSpxCJMfPu4UzG8dvf/oaYM//04SOHmxd8/tVPOd7ecjmduXv3HR/efSTEhfd3J8Td8eHtW2IW9i/eqDg1Cnakkjg2NzafA6r7oyUlyCkQlzsu5zMPDyeWJbPkHWJnmDJ+2unf7iUy3yLTnmynHqsxC0iiLlC+ZJAEi8lFNzW5xRpcQ+jyZqNw6zqU1guSIvN+h3eGvLxh3c98OH0k4HgIEZMgfjzhp8BhtqR11bhu04RYS8qZS0wkE4nGcI4RUF1n9gp0pqTzPZtiDKN1tNa0eKYqvlS+pgyXNfH+4YRzjnmO3NwcdROkgDUimRAylCyuWEc2jowlZohJCCWguHpld6PSGMNkYLZw42FvQWw394unaXOfqU034Hdlvpj2HMZ5xHq+eUicQ+Dd3YU1JIwUWVptnpLswxk9d1/itqm7349HklWbyW7G3WM9+npzXzflynojmm3sGkwaiQrX51+zMh4xO+q69cT9dQ1lY+kroQIstunRTzGscnHxr3aZVLuH/jmFoEzRsJbj0wZ4eIqwod/n4dU0G877qdsUpe3Uda8kVSoZ2LzziCRivhDzHffrb3hY3/H28ncsYeG0nEAclhnvZnYcsDiMmXAZyII1DmscMWTimngQuM/veWcuePcN6uTrKGkrFNxxGjdzBJTqLPRuwhrHNO1w1jNPM8559vsjk5814YN1nY0u1YbWjbGH8x9ZwwPvH37DGk8lrIFlnj7Hmh1Gjog4QlAKrrN6v3l3U5KgzFjrmP00uOxSPAJGO20L9iFly3Wji2gZsypWy70bxtsxd40dVMJKHQMjeKW6eE/sUvUmGV4ZNuYqkGno8dM2duPwbE/hTN0+3AK/1Sa4xkX+EgDqL4jxNDTiWLkKwpRKXpnTZdLpCqgV7781hXh4iOtyzYAaBU67BzRFWI+7Pr9XvCGXDOcXhfzxVB+efTDy5er7R/Wvvp+jYNPKNNey8pHNAY2SefUQ7fqiPq6psANSJGd1/aGBTomcAjlFYlg3wJPkTrlUlNw3g6pqgsZJic5flJTB0C0etlT2ll63TJKUijFf+mEY1J32B8bW8VA7ZNue12PXmKIk2JplatLMNQWQCimQYiLGFSnAnACpAJySBIuD6CGWiWs17bL1U0mX0aPItPteCQhKzz9e5MZjaMeNV+kiqJ9z/Zyb0w1UM2oEpK7r9MnxKtKBlQ7RtzHedz763Bmv/WNjDeSsSrApCq1Ug7/GA6ioSJVFT2SVqeBFNfe3bA7KjlDWLGyFcmqNaZk6qnLKOLelXhmKv18De5XgUZSI3JWZzgbshre61PS0sYMKhRgFcrLRnapcn7cApXXjoIIKqhRbKjitQEOtpQGHUtRrLKGCGDQQLfeg6Y39AoO41ZFmGyOsdAW5tGHSe0tU4GlyuMKeMAUSshicOKrTtAg9BknJFmWcGiGO2q9VpumziWhaYvX51w0IcpkFRZcwEjCuBNLBgp9UThYgCvHqkueyxsqy2iY1rlcqCmUsMRtiiN2FEkrcuXF+K/+o6LhtrcuhMJ7CADw1MK2vLQ0YKqCjVOCpBUPvjC2RGvOlG1E6NDvzLFU2xwCqV6urrduFFQZgRUp8Gcj1PuXCdZMkZQVB6us4hiyWbLY807pej0Bsj2tGW9Pqbu9Ibf+xlJtZE7IsscZoE2pgUFtAqMYaoYox097X73PWTHZL7AF/00hzquNAhCSawS5kCGq74KGtH3pfQ84F5DSdPeINHLzhZja8Ojpev5h49WrPy9dHXry+5XBzSzYrQsSREbOS80IKHiMLzljmObE7ZA06PgvG1KCwFmM9u/2Bw/HI5B05BnX5Op1Yz2ec9YRkEOuY5xnrJo43L7h9ceK423OZF+x5KeNRN6kulzOX85n1cmbe7Tm8eIUAL958Acby8vOfEJcH4uk9Zt6xJMGHxGkNTRdRNcg0wEKZLKO+I4jJhR2US3ykQIiJNdHYodmiG2jGYr3HOq+udaNBOhjXIpkYTbtPBZiq+2tlztbU5DVwr8YqzITTHSkuLPfvieuF+7ffsp5P3N/fE9dFY4o5yxx0AydiNb5TyoSkKctjzoQYm2zIKbXxWZe9LMoMVmkqzXW0AThtPHf5kkWBI8Hict4EbVfbQp+1xsEKSTitmbsl8XFJnGImZhgD6W6GfLFBFDjSwOGjc8KTKtaVrla71xhIKZMlcVoz51XrssaMu7pErYMz3fXPGgV8f4Qi7M8+VJVZtYwWmkAzqE05+Npu3LCa6ueqq1/du62tw/H1WlWnrhvgjxgkdB1wrG/7XsoaWoAfBamKDlaBpxrTqW4WbsgV4wWf1vBNCR4+EjAGrfBRqXZ3yspmCnFhjQtLWAkxkaIvGUT3kC1ZJnL2JHFF21IQI8UKsiRSzMSQyEllnuWC4YGqz2hb5rY551z3LlFgRuvrrFfgyc846xVoco7D/oZpmvHO45xjmsrvdqK654sklvWBEE+s8UyIl+KlY7H2AWtisXstlyWQs2DxWOuJOeDsxDTtsdYju4PehxKuIldg79pQ06ZWDKLrar1vHht23YTeAj7j5zquC4L05HTp2MXTZZwbfVxsQaFH86WcadozDd8P7x/jLtu6XBNS/lz5/sDTgN50QkZVHD8RpKpN2G64P4r2XrLmVAWoyp+R3QRDdoRBoDTmknRlvt5u/L0ra7rj2r6rjUZRzvP2nrWMvpLG0HaaOpjVjS6KQDNs6z6il3X8mPH8kn2vN5seYKTGdClCUTJZosaaWWumtwckRXJcySmSwoUUA+ty1j4qz2yHdjcNfNnh5gPWzRi/w7gZnODchPWVLUaPZ4N0hLXWXVT5qFmUOgOq74inEp/EFuTalhgyNUitHXcghvZXpp3WJ/sZv7/FrwF/OBBzYrm/Z2XllFeyCL5SJ42ou0dW4EnyhGWHnW7wuxfMx5f4/W0xmkwzljcz3rTHp9FWpRtBpgI2Q/vUnbS6OKiQyhtlpxmNm7HWwQhbsjR2RNm1dq0KHG1892lWl58KXI6LJ4/uV4VcX3B13HY/9R9LCeEEmAK0GoydwFiMm3sAVvXpAlvh1abmAAVIqEBKtTIK2JtyahZfZSRaY7vhX+aegpxSprb2Vh1LTS5QRWvZJU/qypJT8Q+vBqWeXdaqHqS2hcOWAoZUYw0FCVopMqnFASh1iDFirSV43+StgQZmGF+YU1LiBOVq5NRGypDH61ZGrKlBgjDW4F3JW5cz3iR2NuNITKyqqOWAswbnFWCyRgooooEtJVuyWKQxlBzZeAX6/ITxM85r3A/rPNb7boinADmRlhNpXYiXEyksGg8qRWJK2taF8ZSSurSYqQQv9nsNuGsnBTHdDqy6AmPMEOBZZ1UIGrthDbG0c4kD4bq/v7ZF6X8JZQ4XRmtQA1FCDT4a2vpRVWBpCIPVLJ3WlGydgxLSDE8F8l322xEuNGBHNzAUfKoAWlM86hi3tsXLSuV18r5k1StGdwU4SpuGENpaIV0IIpNuhjihBOmnyaZcgsRXFlZOxT0h93hZdb0djdYfS/nZK09Iwjf3sYAl6q1lMXhj2h6RKyLmWkF1JStjElijcLeU+BkYllTcnkTTuFc3qJCEUxS8h2OEbATvCgPK6K7nPDl00GrsImeEnVHWxpud4fMbx19/sedvfnHkl798w1dffcHhxWfsjrdc1u8I8Z5wXkjhgbTOkBPO7bEu8upNYJqEw8vMtM8YG8k56NjzM28+/xKTM9/87jfcy8r57gMfJXH/3bfky8qaBOMm/M1LnJ/5/KufYp3nyzevICfe3p9ZihvWJUTef3jPbr/n/uM7pnnmy1/8NYebF/j5yOn+I/Nuz/n+A2+//hXOWR6SIVwS+cMZnLLEM5CzVYAvpbJJoCxYbw3OWQXKsgJel/OF8+nMZVk5X3S+5Zw5iC9x5jx+3uN3e6bdvs2hnOrcLLG5ahy7oktVdrp1ygJSA5dmBE5es3XG5UyKgfvvvmY9P/D297/icrrj43ffsq4LcVE3xlevXrKbZ3bLAjkiQVhD4P68cr8EzmtkjZGH04lp8uTdnhCjBtpuGxJCjBkryodwpgTJr/oJ4IwpjDqHYFiTkASWlMkm46XqPmrM55R0DwCPuiEa7hfh93eB33wI/N27lbeXxDkpp9NZo+52DDpTWZsraMqw5o2shZH938B+aIBRBX7Pa2TNiXf3kYdF+HCJhCR97dkA62XOIlxcdZn88ZWnxHGLKzgym544R9WKok8MNkx1970mJTR2uTFtM67DMjQ9p/4+gj5VT27MEOgZhUu2tWb4UPuzxJbUxVPrWjaaQljL+wI8VRe7ukl45VZny0ZUffDqrkfTzik2let6g+kbDuMaXb0mCt+YlIUkgZgWTusHLus9dw8XQhTy+hJSxsdc1tZMxJKtKwztQEyRsK7DGqwMxhgToSQXiCUWVQPwBHWdc67JHiUQmPZsxScA5zzO2PZsx4MCT7Ycf3t8wTztuL15xTzt8M5iDS0D3+lyR0iLbohag3GCsxM5zqQEHz+eiDGTExjjOMwvcW5mN7/E+5nj8RV+mjkcjjjnEXaMrn7X4JIxpmWwruNSf6t2n46floG4D5ve59WOLDhIHbe2JbkZdKS66TCM82avNjuxeh0VeeoU7s7F6yBXXXyYa9dg0tPAVJ+zG9JF3bwen+F76l5/cYynBpbol/3dBih6bFhr+2yRPFP+azu15cpPoWejUOnxbHsHtiJ9mlagp9WjxTzpRp6eIpu4U70zxuFCAX/q7r65agG6oWbqk103oSkIqRRAoty91b/sYBXlX5XqVNJqJiSpUWZyRHIkrhfd7bvc6+9x1Z3qEMqOddA4Rs5rKl83YazDOmUNWTdrBhi/UxaRnXSHv8RCGQP85Wogl3ZofSHSBt+mr2pfVMCqHpezZhksbZVbYPNifJe2q0aSpEQmE9Yzcb0gJIwz7F7cYrzlFFZYVy7mBJJRD6AyeUXIUYXf8cVrdjc3HF7cMu93pKgplVMIhfHluyVXDPpq1LVJ3x9wUCTKrr6po6H3a/99VGR07GwmfMOFNujUZoRu3g5AweNTnpj4n7hsBaYaFROGev54Ss66E6s8XKsxHMwwXytDBLRtkzKkKnJoUCWlpYpq00CZMllSYQmatlva9NRyD7FmK6YKMNgB8WFhGi6wSX1bBH0DncordEZJrV7dqJFsCgB7pdJWUKMFui4jsCwgli7LMKYER68glNEd3LIT3kE1Cmmzu4Ua35Ukaw1+ciX9tGAkIinjUGNEvQ8ckjUKQcxGWYoDAJFiLkpOJmWIWVr68Gw8YhzGzwo4+Rk3TTg/Yf2E82qMTVaDOhqzw3hPni1iZ4xdsClgl4uCP6kA/KnE24oJrMdNAWN9YV46xMfuoozVWFpQQDGaQVkV4SorhKpEDy6uMvR5rn1U3Msq06eChoPUEEwba6aAgqbK6aLIjOO9umubKrcqoJ40Y5WkAXiqCjMFxDQlMLlz2Jx1vOSkivOgUFvXY87ElEqcodTc5cbdaGMM2QpgMcMGTM7V2M4lMH8xtttrKHNJZ0a+3qH8EZSvXkysUYgJQirMQCAUdo0YNCOrAZOUGbUkKWyU7ibnTNdThRL3qTDwhNFAM8QMlwhTyNwtatR7m1kTxAypBKwWockJdXXqMjJlYQmZ00UDmK8xsJMVWLEErKmp4y1GHGSHdRkhMO+UzT3vE9MuQVpJy6KJGRIcbl+QY+TzL79gv/fcvnjB/nBUZhA6h6qLizWGw/GGdVl4eXvL5XJh5z0pZdas41rjLS1cTg+cTw+cTieMtVyWC0tYiSJkY7HzvgSX9UQxnJdV577TzaVU2rMFsbYGVxjkxhRAHCWOhmyYVmUNGRuG2Hbal846pmlqgWqBpu8aU92XaPGlmht1W7f6XKxyJecSANeo+1nK6qZmnMfOO1wMuN0BbyypuO2prCuJCDDEGFjWwMNl4XRZdE4XfdVaU7JzpeZaXmMt5SyIVfcyV+IpmUGBbu1lDFE0rmAa1rRrHasloBLTgP2HJfDufuHdaeX9OXIKmViPhWHTfFCLWrOZJoc3a/H4vv5T1+frySoZMip7C4N1qPZQhudA55R5fLUffNmyLx7rlpUt+/h30wx4I3QXyVEnGc5r19OL1ZsP9+4dr/ZeN+r7xuzWbq3X0mDzpoFY3QzqIJPqUJXBVBjKRX9oGSsLMFVH9LYtHtuLo7I5tqEdEqK0dqPeVxlVWRIhrmRJxLSUu0ZiXjmvdyzhxGVZCCkQVtWpQmVkp4wxGStZ7c+ciCkQ8kJKSTfSUi6hChIxp5ZkQjtl3LSNiFhEHFYsDgWVq9VnWlpoh+DK5pvBhkwUdbPTxCOZKU5kYnHBq4nCLmSJrFFlkHFgsykmm4ApzEuXsTkSYoBsuASDSxMpC8561rji/cwab/HTxDGrK9487XHGMfmJcRJXxtNmYps+ZpHHc9lcj2G663wFkap3jU6LPic64vB4hLTXKxt8451Thv81sPQprGVz7vDMm3OvEgb8JXbjPyjGkz5lbgZzFwa0FaIGJu1UNf2xGbtVKFirGS16y/RFYGiELZMKhFwU09xNsCsEnAoA1QWaIe5UNQAa+DHQHRldkq7YPfQFqgMsej1bshGNA6w/eX3mSjaogkoVAlU0lP0Vw0JOkfVyXxhN9+S4Es8fQCI2L4gkzYIQVpbzgwJPJRNQSlkVBT8z7Y9Mxze46cB0eIHze9zutoBMu+J2VBkudeEthmLdiTcQgqLeUoAPDcxtO3hWmsGUIHf1+wosFdNIgyujzJGudEhhY/QFxRXGRXUbPN19R7w8EPMFJuHlz39KipF0c+ByPnP59i05BWaXscYwTROCIUTDvNvz5U9/wf54w6svvsT6icv5IzFH7HTETTum/Ys+TNs4u/IVrwKgGHNtLEtZTkRaAEHJKNjXAvyO7TEMCuht2Ba9KnxMAyv7pC7xUnIJY9rqMl7rupRrN6Wq7sAVVprYjcpz7R//Qy8hrcVYViVamIrAt0XpLlnEkLaD3NQfYzDGaVyNYvxrh1R3n0SWqPNETAng7XTxFSnxdjqDTIZ/c5k01QjswJEUMFCZeDXOV2U11fhMpshLQ52BoyJc5mdRkjX2nqXGFapASIxrizsEYJOAtbhJeqYxU4MuAjFomzhtG+cVxNjNM8ZYXAUmJt29mucJ5z27/Q7nHbvdhEGVAEkL8YzGdcqWnDzLaokkljwRk7BGBX40BbuwLJFlWTidTmosLksz+Korna1A0zRjpxk/z7hpZnc4Mh/23L54xfHmhsPuyG4/Mc0rTiJufcDFC5m3yHJivZyIIRBiLEaa9tk077HO4SeND+DnQwGelEkntrjkuR2CIa2p7NQz2Cw9A5bBDlnhqlKcmytMjhGyYLIM35fYfoPcEAGsxTplNBhnm3xoAE9h91mrbjyU9bEqnDlFBXOSgk8phRIMfcwMWIKAlg2NliXQWfykVPn6WouyloSwhg48FXVK5XzGlCx4tsbKAmIIqhSvqyq9iyq/qcTLqhkmqfrGj8924z/92Q1LyBz8wsOa+O5uBYSHtZI1O6MpGA34vSbhIeiY1YDjlsnZpr4lgSUq6BFz3XnV++UMq8CaM0s0XAK83OlxSUyP/1R8Sg0KOrnCTrZlh/28ZN5+DHhvOb48MR92+J3G6jH5Hi9nNI/bjJE9Nu+xkjDmws2LlfkQmPYB51fy8pElz4jouv7mq5/z6rPPsfnE5f4jFh2T0+6gMdtixEjGInjveP35l8zzzC9/9lMma/jNH74BSYTCFDpdztzd3/H2u29JAvPLz8A6zpfAspz5cDprlr/jK4wxROdJ2bLe3WOMbu6lrPJKMGSjsVemecc0OYQZ5w/44y3eOybvsbsHstmRzR3LmkEWiBlrLN5YdtPEYX8ojMiiM6ZU1v3qrqyMAC+CJmAxTdZUZqHqKVWXKXE/jFHmggh2d2TyE8cYmW5eIX5PWC7w8QM5RexuwnrH7D3OGt4/LNydznzz/iNv7+65hJWchRBWDBrAPlW9T1B3nqRZsSZrmB3snGFyFm/qZqxh9o7JWZwzpJhZYyKkREKzNlb9GVTWaaJtg3OGEDJrXPjj+wf+/R8+8vtvH/j7d5cijy2x6j+ijGaNpdjXS2WEtip3k79uCpW/0UzpmzUDeJETNsNsMtEKs5NW36Y7AtKAK71+LFkgN66vP4JS14CRidHsKEzzjKjfd5Z/BaT0SEvxZLB14+OKfVE3WZrdCHLFH6t9Jkk0nu9wbmeWUBi33f5TgIONngTVlV7tN9UdYwGY0mDHVeAJaGy3pq0XvKGDaa3u0uvVWE2mP/s1YJAla4bMlFjDmZgjSzgR0spp+UiWSJSFlCMhLIQYOJ3vFTiKgZQiYQ2AoFlmDc6DSCJKIOaVNV9Y48plOZNy3ZAabA5fNiCs6jSVeZXElIWqkiC8tm89V1AGubEtHmZeHzDR4tyMNZbTqvbg7mGvct5v2Zua0keYZq/xJrNuAlsjGCfMu4yxidN6R0yJS3zA4DDyDrIlRI1b+uLVa+Z5z+tXb5jnHS9v3jBPe7x/U4D9QojI6pZrBx9aQ2cFPWIOmcJoLLLcDMfVzYT63jmj+mTBJerGcx03WyxkuEaZYyNhhKs5MmIpjdn3CZCsHz+O2QG7GepRmXzft3x/4Kkhq49LexjpnzcMmAHQaPGPnip1IWj/DNZ5O6RjxnUx7qd047z+2yiKLSgZDZWUfjOt5XW1WlUf16M95/YSV89m2g23l27LGqYJrPKaE2E5ISkQ17Puuq8nzYCQFHCSHHT3uwavM0aVLT9jsTijLiZ+d8TvDuxuXmH9Dj8flenkDyXD04TUdrmu9ziooDxD8a1lGHgGmk+qzT0LQbliZWLUC4nVZ++CtjbyliOmCpP+pHRcZRTYaa/KREjFJcpjzMRkJw2+KlGpz3g1343B4JQ+ugaNATEFHAecnxv42HpFet88mpDDGK/Vrvy3VnWzeWlCpV+ig5nbnZinxph59H271FDnOqX6bTYDsn28Dl3UamKuT/vE/PyBFmXZGSBjSJis1P0a3av2e1UYQjVmdaQroAxY9aWAysKQzmQpE0Blk6kQd42XVsdT56hUeaUgYnGTKGC6Fp0PlZJcXe20Xrl1tinXac8KbTxKUbGtqZk6dBdWMA28iC2FbwlYKWCsU5c1q0DOONebUiK2MFoKaFICQGqgS4f3CkpMs4IzdlIXvYTFSDF2EyxBitvwSlhXTg8PhBi5XFZiSqwhKp07Ro2JsiysIbBcLoQYWNdQgDuoPke27OC74mJn/YSdJqbdDj/vuH35kcPxluPxyG63VyPIwt5kPA7jjjA7NJPdgpUzIkEBxizkuCLZqRt0cZ9U1+WkwJ5NKqNEjVCJqXRRBVRK3ChF6nXDgMpYKIG0S58zxMyqSkY1JFufF6tGGQCZjDIaKgvP2EG2GVPcJh0uqdKmdaUF704xFtftWICoEpNCaowdReAUFNXNEnEOkcJwqsrKoCzlCqAWQGtkPLX4YiIkItlKczWOUQNXKwBVd1sTcdVxm8pclRJI9cfoqoKo/vVy75idIaeSqUsUWFqTtndKynRcoxCzzi3BNA/fzSUbyH3FZq79JSBJCMCZjDew83WzsMRTE21vax3eqbQMMREF1gR5yby7DxgLX9xfeH0681k+Yr1mmLQyK+CIw5kZa2bIEyIWCRM5RsQVl4V1BTmT4oKIYXfc4Xd7Xnz+E/Y3L9Bcl5Z5fwQMNig4l8OFbMF6jTNyc/uCF+czL25v1dDxSWOKvHzDfPOSgOUSE+8/fMAYq/InrI0ZqkaOaDwjDJlQYphMw6afushNky9xqCbm3Y7dboefZ7xT+einFT/55oZijSVtNjNpHWfKVkQuy7Um8OnGczbKPjVD/BSbKoAtRbfeGkPGO43RJTM5WfbHW7yfEBHCuuB2e3JKzFaYrMHsJ21T+0AyTkFDqXpbcYdNSV2Wq8yiu4Ebavwvy95bZmfUHa+uTaVeKYumb29x4KrY6glsqg5aWSeXmPgYFt7dnXh3f+bhsirbz0oLsn41pVpp16/HyWOVqFoc46smAaEtuipDpRGj62wygCv7Nr56azVbqfRfeR+qPvkjKX/K9UaekNdPsibMlZ76iXM6oKXjo96/G/j50bGd7XRVMxnf1/NqRxc7tF1rCB6edWMI6RtIG/unvqH2fdf96/Jc529nOOmgaUmrSlyDlGMLUp5y5LKciClyXh6IKXBe7olp5bTckXJkbcDUSgyR8/nc2MOpsIetg2m2OA9+Vl0kyUKMgTUsqoPFpQBPqYz7ajsPLLWqM4r+JSkhV2TCZdfHf4lr54p7cG1LKxM2O7wUrx2ZNIxFNOphYCYNfJ5Lu5QkMzYp+BFT1nrRgWPo61eNv5Wj6qHnS8Iah7jEPO9wPjGHPc5CTAcmP+HdzOQOZTwWAKo8SIk29wh8GUGeZldVGT/Ojet5Mtih2padXfQUYHQNJrXfK4rJn56L/bby6H0dp59iNP1DPGT+AsaTo1IUx+nTXQd6JbaIX8+cpo1t6RO7K9M9gOn4EAMibPvuf2OX9Ju2BWHo21afcqX2vqUPTqpMV8py7bCWLr1Kiir4xnKFND5VGlpfBt3GrQxdEEUyEheNyfTwnhxXwvlDMYLXIsCK4h9XNWZS7EakMdh5h7UTbneD9Qfc/nUBnF7j/YzfHUu79yCY9Xm6QK5t34WHVFSjHG+dZhXQNhz9OatfsdW0mE2ZqLE9ZNNHet8rdPRqIcgh6NFGfV2N22Mniz8kUlg5r++JMSN5xoiwtwdS9kg8qTByGn/FiEWi43x/ISyBnFam3Y7bzz5TF5ySDaX2pWYI3I7Dx3TEYYyauoNVFCdrCjVYn3UTe4zuv3s1Usrz9++39xv6ChoAWKsyzoOrRh2u0K9f/624YR0NuQpv81Qdf7glpVjmH2o029R2JpQJpOMzFbbHcr4vBnLEGDVYnLFMbtI2zoJSkIu7T3G1q4qriO0yqtKOK7AEKOCU23jLhanYAn23sdCVplSMiDZLGghRISq9eTUgs6gR4kqcD0sumYN0JKhBnzQOQU49xp7VgPuuZMOrAbCr0mVKfJf9fsZMHrefFXDaaQaS/e0tzk/M+70apNOs9S2xSZawkjOENROWxMNDZF1W7u/uOT088N23f2RdLpzu79WlY7mQogIOKSn4JENw6rbQXy3mlela1w5lt2n8o/3NLfPhyM2r1+yPt9y8eMnucOT1y1ccDwde7D5jf7D4+SMunsF8iy2bASKBvEYEQyrx6tJ6wTirTKiyq6eWjC6veU1qoPk9xniwyjQ1BYCq8QtzBZMb8FQCnyddc6sbYwU5MTXA9vBqgBSLgkodLQriFFZQRt2Pa9Y+4zRGiqCuzSnGwqZdirtAdcekjAlLKmmPrS9pkH0JgDxlcnRITKTqamcq8MSgnA+udsYgSYpC2L8DSnysxHK5qNJcXtMaNm7lEjXg+jah/I+jrFEZ0T97OZOy8HLneVgTv3m/cImJu4uOD1eZr0Zj46xJ49ocJ0dLdgYNsKiAU5JiLLe1RNetmIWUhEtA3fZEM+EddzWwf3EHc8o22gk8LCuRlbs1sobIOSa+/XDhxasdx6Phq5/f4Hc3GDtjzIxzM2nNmPgCk/escSIlQ3g4EFawySMTGDmRnGW9rAo83fw10/GGL//pv0TnhBoz4f6OtC6kyxlJgXT/AdYzu5cvmZzly6++wnnHz77+AzcPZ3Yr2GnHl1/9hMPxhovdkS6Jh9/8Bp1lyhiyjeFsySlxLsy7ECPOGt15R9eA3eGG44sXHG5uePn55/hpYt7tC9NpwjnD5BwxJXb7hfl8wTmHOEtqWURzy5BlnDRmm7cGJDPSBXIBYtyk89BYBZRT2axoiV3KeKpzL2dlHiQ/ITkzTztyTty8/qzHcsmJeDlBTngJpLgS7k4El0h4dT8sa2lKiSAav6muZy0GYs54MjsHb/ae/ew5zJ4QEt7ohoQrutEaI0tILCEQszLYvbNMhV1bgZ3KGggh8P7uwq/enfj7r7/jV398z+V0JiRhsiWO0qDSSAUOBknRYjVBA0NkeO32Sl1nWw6KNl/UZU4IG/CpZ63zFo5OAcSOK9b+1vMvaRv8/IdebIn3d22QV92lbGNvwKEKEOiBoJtJptublPZ74rrtlDLgGzjZWMQtkGK7ntoqpuvyucbqrbpUmYdFn0i5u9c1GxbNVpeK5wk1eHizawctarCPhxrrpv5gTlZboTKAm21rtU5LfCCklY8Pb1nDhbvTO9awcv/wgRAX7s8fiSlwWc7EEDifL8SYWc6a0fNyibompx7nc3+wvHgzM+2E3Y2y+WO+EGNkDQspCTGWBCGpkANqXInBHtyChX3j0jm/iSFbN26rTV7Zu5p9zqqrm51wdo9hQhBcnjBW8MZjcsmyVmxUEcEmizEeZ1P1tkZntYaZcRhCXjUTZzgR1sSH9w8A3F32zPPMZX3FfncgxDsOu1tA2M03vLyZlNhRwMAW61dMSXBDA4hqHEx4DPqYHozx8W8Fgxg/V3dr84njn2IyjS5w14zANvKGsXgNIH1foOkRu+t7lO8NPKVikAujhlJpYpCpaejHim0ftAIxepwKmArCdIOqg3TGDA8zoFcaz8AMZ1F2d6sJLVVePQFE1WsNYJQZjLe6GJltA4/X3UAJw03a8VlaakOggVjVzayluRRlWeSyw6zXs7jpoAaH7MpxKsBMDPp9ydJVY7BmUaDFzzcYt8PubvF+xzQf1e3CqoGjCHB9xAIoVSNmIx5bLzUsQ2obNEEyDjRTgpp2Id7BjfpbFQz1attt2KoM1DEmA1Kr1/fgYdrdKFNJLGkfyOKYL0UgLheWh1BYY4sqohGitdgUmXYTkzelrQ5M80Hbxw1B/TZzasuCG8d2VVvssLDUc6S2m5E+btqCYjbXo13t8X3q0BpB1g4BjH0lm3pf3YbKdekPaAfQCRq4OB7yRGa3H2qREgxCjBoRUtiCOSdMApOK4hyV3RFDie9T3Moocc+syBC3Ig3GQQZjEbIyV2QAx5v/PypTqrzLue0Qp6qgNFB9qHs5twIt7QoFhLIVeiqLUgWeRGpq7Uw2JSNQQSKEAjzl1FztUjFOKlvHie7uq9tWj+Xkvcd6i50njHNESpyZmPEmYwW8GLzRzG8x67OuiyY8uJweiGHlfLpnvZy5e/+OZVm4v/vI5Xzm44d3hLCyXM6kGFk3AS1TyRAnrV2azDV1RgyLb23EOthNzYAEIajr1uV0YjmfmPcH1tOJ/eHA6bhnP08cZGWSiE8KEolxWFMz1eSWgkgsGBzkAvhQ0gYXZdnbaoitYGKpqyUzlXk5ocHkixtkHTOpMKVkO7/r+8oybkpMY6+WYJK507ST5OIqrUaRcw6XMtZ5nJfSNq7HoipuBdr2NWmEVt1cKyqurwWprntVAaztX4P6phpzpkykkqEGkyFbBdmqkQFtfqSYCjAcH8V6klyibVcg+S+UD/+xl68/rjhjuN25YoRrivrJG0K2yjARcNXPsCydsRAjVwvGCGsUzRBJX3vqHNqsMaaAHHpEkytLEpxTNpUvIEjbgGpqoUa2yaJxonKdoyZhXcS4CC4oKFuytqme5CFNSNoj4ojrnnDOODeBTLi9wzirMZ5KYCtjHX7eqy5YxmrsqUNV7pxP2LCSndd4RtMOf3zJm5/8kvmyMgcw1nFzc8M0z7oO5FwMGqvxL4sboWamDMSUiMtFNy1zxmLxUty1BaxkbNZYXFYKK6zuWg+u15oKXRlPzjqSGTbzyryXGrgY+lxqCkBXbrtB0v96VibT4sKp3qITueqPtjDYrNdsTr6sXabGe8tSjGmNC3p88yUy3/DTn5843N2zimFdV2zWDVF1uMyMSoY1huPseDE7Xu48u8kzO8fqLHtrirsnJZmOPpO1VtuveXzX7G+m/cWUWJaFjw8nvnn7kfd3D5wuKturh/uoszf9v7KVhlL7r3XAtdgtzI66MSRN5hYgt4080+ZTPX+yMFu48cr6qve27VbqwnpfQOMfS8mp2oXbh2qbqLlszg26PvT1ZPs6EBZ4fL2NAd6mUd/o1+vUezeB1W+7qcNgXw6s9rom1URK5Sn1+wI6VabTcENgW2NTvm/WRNUR6YBTa8OsQbuTaMzfkC7EFLh7+MAaLrz/+C3LuvDh7j0hrNw93BFjZFkfSFLc5VPdvMuEoAHEw1o32dVG8xPYSTAukkmEGEgSiVHjuIVQAadS18GL6PoBmx4y2Iv6z+Clg+k6St34LM1m0X5MCawNWJOxOJYlYoxn8jucrQx7q5gAhnnyOO/It6Ks0rLxqu5rhv3uQM4Z62YF0NICEpi8J0suva6AW5KVEE9YCw/n98QYmPyB2e9w9kUDl0ZBUeXwI5CnPHNjSH2CGVXxlDZ+nwCMRpCpnTO81o3MkQE43vtT512Xp+7xqTr8qes8Vb438BTWAIbG3lHsorNlOpAsm4ZvQdCgAR5d6RlYQ+X7aniN7lr92PK57D5V466uF31wa92q4d4MfoEqJPR+lQJcDxyM79qQ9XlsTUsLTYiNca9QAZXLIDTQ0rK3NJqx+gCrEmBKDI+0XhRYQuPN+Pm21KVWpsZjib3ORjMBqGuHL2DKkZru2xbXl9IU7bwKsnUBXnYTSl9WcKkLwv7adwaU3rhFVYe4WLWpkaJkjfEjclEa6+Jd2hoVghvKf1t0wE97xAt+2gNw+0bb+/jmI+F8xvqZ5f6Od+uFcDlxuXuvhuuifshn59kdD5p1aT6yf/E5+5tX+N0BYxwiI9AFT012kS4wKvCUK9BmOgBQx7Fp41n/Rqr4dhFtQ7Z9rsCVtkRfSCuQtRXyfVHtCija9qYb47Xu/fuhDJfVOEL8aEqKqTROxFpIrrDpYsCIskREShyZuBIuJ3UzCov2l3Nk62HeNVkhKA25GjgYHQuYrMwxq91X4wIBbHapC/iVUmwxb3LqWU6ajCrjR9kJuelKVXlSCq5pc7PtwpXPdeFNtmvhAiUApRTGU27Bn3N5PusmjLV4P2OdZb/bYSfP7rDXgN2HI1jLQnEHXAI+Q47CzqIua2IgJMK6cv/xA8v5xMd333I5n/jw3TdcTifeffcNy+XC/d0HUlKgqe5M1gxOo9GwWYhNpxS3Hckmp9gEENXz9fNyPiGAm77TYOO7A26a2N28YNrtefnqDfvDkc9uDxznmVfecDAzk51wPsN6AalAIBSKpfpTIPh5p6xPXxMWKLAX1wdEBMcOjCWZWd19ZIfgyKJyKKYSP1H6WqL3Gd5ImcdWnYxq4GBBmUVCbmy6kJQttoa1sMU0u6j3O7yfNS6OnbBuam1eg4zXAKJdNnZKu7EJcVkDQmfBukyOmWR1TWlZVOkyqF2nKqS2jtUyhyQixhQjToihAKSrxpqKa3W104xBOaw6/0q8q63K/uMo/8/fPjA7y89fzxxnx1cvZrBWGSMpskRlWtR4pKp7lLhuGQUds8XZzOQMx7nszJZIy1kKg6P0Tc3yZWxfy7LAOSSMMXgn2EkztGnsFQVMkwgxW2K2hGyI2RRgA/yUmHYBOy/gL2CPiPWYNCvTZd0jcQ/xJZmJ9f7E+aPByA1yOOBvdphp0v6PuvHm3MTu9hXWTZqhLawsRsc+WWNgXk4PukYvAXGePL9g9+aWv/5Xbwgpa1a/lLic7of4fkkzWroJf3ipMsJ54roQlresa+TycKfsJu+ZjGdvJkCHt88ZEwI2RkxOWCkBtU0Jyl/mhXOe3bzTVOHe4SpTvOnJV646pQjNjqECTGxAJ0q764aaocypGIqOV/QAS9F7dLx441VP8eo2aEocNaEYZUbH2OevvuBVjPiXX3B3f8/+9iX393e8//YbUgjIuigQXCJ4AUzO8sXB88XNnp/fqB4mxsMaeeMsZxEeCpCTUfbA5J2yM1PqYJPVwOTeGpyFS1z58PEjv//mA//dr77lj+8feHd/YjKwcxaxpteiLI0iRmWkKc9fpFN1va/9mOuxIpt2hbKR0NZi00Cn3P5MYUXpWr53cPDwxU4BKMom8DzYHDHDN4sh/gUG3H/sJYQA8Ij5UW2r62fd2o5XBrwIGqz6iXi+FchqduNwzADqdCCo6GLNHXzs3wI8VV2tAU16QN20q4dW74OU4obN212eyol16av6SdFXWtzb9jw9lhMIIQVyjpyWj4S08P7+jyzrmW/f/oHL5cw33/2Ry2Xh3buPhDVyf39p8dyMhWkq13O9GVMWwqKJQfzkcJPleOvwu4zbL2RZuawnBZzWmsVOSttX9s02nlE3/EzblG1tVJhMWaTEAbZtfUGqjVw2X3NnSDt30WOZAEsMVuM3ZQdimdwOazRwuTGW25sD8zzx5Vev2e93vHh5ZJo8s3dY6znsb0AM66r2tOUji1tZL7rBZUwu7MhAFriED4R0Zg0r+/kWsBz2t0zTHm8mjCsYQAF7TGVujZsIlLW1AkEDQFr7uemxBeQYx69e1w7jeGzzXsbjx7m2AT8/cd5YxnrpuE6PgbSr8/4S0An+AVntVGGpq141tvuNRxZMrZAa6VVZ7o02QksVoBjRvi4QKmqt35l2z7F+5VU6a2DLvGIw5LenSTlvRAqf6sD+bNJfzPYjo+FYgofnSr0su/WmDR7dadK07hnrJm3nIbiq1lGNTmc7U0oFiStKh2/BxNXi7YJzrBO1CQZQq4EaUtO61wcZ2lh9xzZAiDFdgOr92ipc6IfbMmAqfTzUU5ES0M/gmnHcJ6pAm3i13tYaxGY1mozjxWdfsjveYL1hvZy5/+4PhHXh4eMdIEzeszsc2N/cMO00q10MCzEsWKsZ/SqY1Oq8mVilnqbOgT6SZBy39bjWeduB+tT0lM0P5vFRVcFsx5dFdjCy+2Fd2FTwq4Oq23hU210maUFJ5cla/nCLDm9d4SQncmEX5qTAUxXkEoP+paTurcVFL4kgVhqI3tyFC/2pXrv2Qw0abqTGYhr/VH72dPVxY+TXWDq1B+rYytffV0WrAEVbmSjteymuCtb0+DtCcYGVTEyhAE+5BV01xuK8x1nY79SFat5NWOeIohTrvCxgLOI1E+Z+pwaU97qknE8PGnvj4Z51Wfj47juWy4mP774bmE4X7j68I4TA5XLuhl+VoVUmtbbYvpqrLwXZLrLDGOgMKdoakStbRiCGVVPCTwo67nZ78uWW425G9pbVG25NYCIrG4wS3J/ujmPIWEmN+WSLK533XlkQZq8VKIa6yQERUyKDWRyebIrLG8UAo4uPjtn08SRFedbxUFxopLoVaKYXDRouhRUixSXP0jLG5az59zR3dBuqjbFXWZ1l3TdSYxoIUhJiSE6Fam7IaFApsWqomnJOf4g+l1S2GxonXmjjVAd+z+hXNFK9X6ouDdKvWdvmR4Y8nVZhdZn358gShcmrTFpiIuQ+rhVHMt1XCFC5rq5yl5DJUjM61mWhgExDmxnTGU0N+IbmlrfEjHeWmHUMWJNZYuYchEvUwOYileUDGIgxsSzKZFwuO/xscd4gKDPS+IyxGVkC2UDMGtstJSFlwDiM9WrMF6ZbDEE3FbCNZZBK1sQlZULKXFImA+l0IVvLIoaQMncPF9YQuTurG8n59NDkq/MTh5vMbp/ZHV/irGd3UAOGFJiMIT18AFFmlKRMWEORq+pqlYpUmI+3SBamebdJ0GOKi5qynWyLwzcWM6zbbXNUf9GeFdP1aYFsMiKx5FgosY3MyPAt8q7GHNSLQJE0FmlZ34wB8WrkwVziu+l5zhicT7x89YZpt+ev/uqvOZ9PfHz1inVZOH38wOVyYX37tjFWD87w+Ys9nx93vNrNeGOJEdYs3Jap/hAz2anrT4biqpJbXVPVLY3K+pQyp0vg7d2Jd3dnPjxcOC+a5VLdEjvDtaqT4xqytR9GdrtsjxsFSpPFula2azZzyGzOH7+urzXfkkXn2QgYe6sG94+lfMr9pumi9bN+uTl+BJZGBsdwke31P3GvUS1o1uSwbladaFPnscsr44kqa8eAz/T5lDvYYobp2u2o8iwV3my2an3VdVZSYThldd07L/eEuPJw+UCIFz7cf8sSLrz7+B3LcuH+4Z5lWblcFkJIxJDAwDQrmL3ba0ZKN3UbPmdIO7W7psnhJ5iPgvEaikJKNt8U9a/t7TDqVaYvv0UD2jR6XYiaXaFL+MaGyvV79chJRU/Rva7iRmeUGWqtw1mtx7roZt6y6MLnzYQ1juAnDIb1EnXDNSW8t1gH3oE1CjTalHEIu/8Pd3+2JkeSZGmCPy+yqKoZAPfwyKyeuehv3v+V+quursyKCN8AmJkuIsLbXBAxC6vCvDKi7xwSYW4GXWThhZjo8KFDs8c5KDw3f8g6yzyPTTMPU0hpY4s3busLmMIWF6Dg/dDGzM44vR+/74E2d8PzAWv43332Efd4DzR6/3vvzJ//zfffBbAevtNIFv8bUOuPjn9dXLwFPPVGrd7k/c1Xw5I79kQN09u/zA5gVMZMr+HUvrTHbHcdsweUjwZln1yiSQJ9yfjm4BoDVesl37N9KKpj1OqSt1veY0lk0DezVYOlVBlOoQmqUiqjCK1+V62Sw401ncU3A9x3aL2mywnY2Q21wsMuACwhTFZGVVLHPHf5yfX7tS3r+VOm0Un7nYa2QJu99Uzrh90pyuy51LnmaddrVEtz11+9cZddrNK+1aWb6PgxmhhfGXdWgZXp5BgPmenpmZISYf3/EZYrv/3t/2a5vPH73/8TSuJ4mBinmQ9//Qk/zWzLhQL4w1nSEudnuXpFlrmfTBpz3QGr7VNFxl5lOHH3ud3JKYU9AMPQAL02wPtJBP0/7tbCKsjRlQ43prWq9CHsjnQdagrutQU0110iuUvZefnXDMif4ahAb86JYjKEVQQgNQe7pEGClrCJiH9YpZx8DGJXjMUYJ0K4tgLDtN0NoxO02LqzmmmYExIMyLBQW6ipCzmqTpQCUFWUNbX0TdPS5+92xOp7+z/2wdHbSXSXuPtdnZykulIxR/0t5cCNVqs8HEaGwfP8NOGHATOMZGO5pUIMG9frCtYxnZ6YDp4fnp4Yx4l5mkgx8vLlM7frhV//9p8s1wtffvtZAOGXz4SwcbtcRDdgXRvI1NuY//Lo5todW7Nrktowj0Bq0c6pu5hxWWTcmxcKhtdpxvqBr08fmOaZ2w8nnueRvx4Np8FwspnBFIzywqVAcMaRsMVg0oYhYbOKnA/CUKn3klRXK643CV65yXt2JGHBDCQssXjZOa/OWbceSDhUAbrU2qCUqn8lIF7SNMWUU2PU5VzAZEmlMUnEz51UhimlqHZ9afa8pdnXdd6YqhYIqdcXEDsvwsdGsuf0qZs+lT6D0/LssmtaAQrb7Bg19TQlpQ0mUN01YhSAWLVjTGuXPTj+no6vt4yzEqRPPnLLEQMsWxFxfnX8c6mBrcwDq5ohUo0ukZfC6MW3GJxhHiUpyhlDMjtDnFKYBsPTJKLzWcGmayjEVLiUhLOWyQtYYUrhvCRel8iWMlsSnR/vHdYVsIVlC7y+Fd5eXjl/SByfCtOhUJjADjifgEBebqSwsqUba1gZYoKIsKPcQClIusiy4McrXlMnila/jUEKDlxCYg2ZSxCtquv1lVQKW8yEGHl5feO2rPz8269sW+C6rhRjcNOBYZz49ONPPD9/5MMPf2Xyng8fP0FOPE0Dy9tEub4Rt5X1eiGmQoySkrrFKIDJ25mn24JxA08fPzEdjo2BJKkfXqszDTjv2lpSj7reV6bPXrn2MQig2fSarmJdxhiH98JMzzHoOiN2R/CY3S6aLliufrFoRkmBlmFUa6PzrBZBmLTt/+3f/p0YIpfzC7frlb//5//k5fWV5f/6v7heL1AyH0fL//nTB346jPwfxwMmF27bismFvwIuZ35bA9E7gpX28N4rI8YoeFo1WQU830Lg5Xzl//n5K//x6xt/+/2NmGQdcMYweNGDSsDOkulS5BrbySpArha67P7aHnvUtWX3B1Mu5GLa/NMe6Xy1PkTf9aMEaJKUxKpBZZDf3kCx9338Zz4eq8/BHsPdpQNVm9XFY4/f0b/274NUMOs+v8eNpq1Z+i1o8WFpmxZ1Pawg0v0aZ3Qpynfs6dJE+2us08cKNbNhr/iN+mL9NYAOzKobRrJ5FJOIhZ+vX9jCjd9f/sG6LbxePhPiyttVUurO1zMhRC6XjbhlLucgBYIj+MFxOM6Mg+P4NIqu3FTjRaP+j7JRR4txCeNFNHyNUlgkbJGk1YSlLS2lBsGt/4yCSdV+afyDkWyCyl3WIKgYQ8m6SYppMYgAT5YUpT9iFAB2dE42AuaJwQ8ipp4Lr19vpBy53iIpwOQOOOsZrKekwu28UFLh6Xli8AY/gBDQhQxiUwRbeH6WVO4ff3yiFNiCyhs4sY8xiw7WFuR6X41liwun4yfKdGIahfhg62aOdnmzrTrG7yrNPRwNfzDm7nNt/LQgfJ8L/2yM9k3WTs4S4/Zz5eGz5eFatvv8e0DtN+zDf+L4p4GnykjqA/H+5vr53l5//0zdeYqCQzV42+Pw/TpmD+y5b/C7h9Q4HrOjye2Nwp5HXJ1kY7pqYPf5ihJsQgUD7hpVB0ONk0qdVAhlu+oA7Cj5fs5KSW8AkK3L0+60t+dvV9fvmYIp94O36KL8CHJWKOO9lr/De7pngV0wvFK3jaEh0ubhPA18ahfsF9l3et7s75UK2ZT+rfvn2LWz5Rs72NaBK0XbxhocUNRhcd7z8a//Hw7PV6wfSDFgcsS6quUT2JYLtaJUebx3fZ4e/EMfsY7T2ms1mKzjWe7L3DcY5p2AqLRx3Rh2XVv1bfjYmj1brQVqtNtq91GPjIrfdeO4/dy1dT2//afj/z/FUVlNWcLgBJgkQICIh0tlrKTBS4lBUgU0zatoQFsMmGylvJ2pRQq0NL0ByJ3zjlRwrFUoS2VAIZXRlLWRO+CpAQU5K6wAvcP7zQjqHd6uv9QqqLN7/7vO91yE4ZTU6bFWqtSN44jznmme8H4gFBGTjGmjYAh2AOuYT0es9xxOT5I2EQJbDKyvXwnbypfffuV2vfD5FwGc3l4+E7aVm+oPbKtWRqli/mp0O83Fb487YKoZ7/aFavcbENg11F0M8diOVAdUZnXYNkxMXK0jxsBlNNic+OAHBizzkPB2DzCqL9dmYcniSKm+hbUWk21LfU5GqiqaTvsOIxGIx1CMOFdrFLbHBtQKSrtN0utoSp04FfvGRwWemj5W2VMAit5ftkUduQwk2Q2UwdHWrz7dp65/0rxWHdG6flbB0N1hF/JNZVGUJuIP9RzinEqgq5seRdi+1VEVsCmLYHqOAkAVSeOR4hql2UCDNOP3ZLqg2hltjiLMJYNUrdtib7dlL8LZOtYN2ZRGJkuIPtMSMknBvqyBck1jqv3jjIBTyFfJGHyuKcYCAiwhtUB6U4aRBOOF0RlGa7FGeJS3DV4umeuSWNfMfBQGm6GmrNwwJmLtptpHG36Q3WfrLBAprBgTsDYQtyvr1ZONU6a4jPcvL68s1zOvl6toxYUgIrJbIMTE5bayxcjnlzeWbePL1xe2GFi2AMbg1k0qXU4zox8E6Cwifmutw0wHYgj46UBMmS0KwyomYRduIQiw5D3GeZ5uV8bDoYG+pnlPtN+mAlEK+tu2obH7WQI+VZbgHjze+x9QN50qgIiRYJY2/4W90PQnte+rTwUSBFbyY+8fOidz3FnbViNJzR2wxpDmA9ZYfvzxL0zzzHXbuF4vfPn9wMkWPn0ceRpELyvHxLoFlhBZYmZJhbUK2pei2oXNHO22D8DujL/zGvl8Xnm9btx0PA7WMHnLaXCEXLTK4j2QUbfPS/XBqv/NPp+qf7SvLvtnksrX3FWwM53bZVqAIPOn7OmsWdPsNLS586+tAftPBm9/hqPGdu8BST1poP9d34fH2GyPtXLuNv2687V50KGGdY3q18g7R8DQrlXjEgl9NPpomk16T+Y+dukizW7s6JUfgvJ97abNx5QiqWSW7UpKgevyRkwbl9uLVqU7k9IGTtjr02HEDoZIxIVIyhB9lvU4y7o6DI6nDwe8t0wHh3UG59mvm2UjtoJFxiScF6mEqitX553YmBb1ycClMrPry3Xw17Uqqx9mRfm0VMcBubY1whbVCdT3T067zfHeMw4jh2lmHIdWEGNbZN2IWyG5wnEaGPzI89PMNI7MB8847X55jBuQdCMuczmvpJSJQWafd4OMJ+sw1jL6CYzB2oGSC0F993W7Ya3ntp4F1D/oGlXzGN/1ML8d1+9lVj18UmKOGks2e7/HpJVg8g0A8M7RWIPd9fv33rvH+l6dc33M+Ag+7c/1xwBbf/xLVe0opWkYVWPZUuT2W334Xq8nVB8G+kpq1hqcE3FGiywqOZcmWF0fWp6MtrOzP3WNSe7hkbp4t4ZSx9s6ybOvBuQOle9XATpjUep1758Ddg2nWCvw3K6UnPWZDN4Pd4BOnZzGurtOrG3bDGwpUonJKphRNWTLnhZlbMa2qgL7zlUB2Xmu/cS+CNRqIH1AYUDbxTZEVIxv3gW8uqbp0+zqnKishR002duqfl6MsWltqmu56Dy0zkLznyUwEefItfPUxi8Gcca0nTDgrJS7fPr0IylGfvw//k+29cbL7/8gbQvx9gLrjRCumrIRKT61dqs0WNkNe9RXeHwucQhzUUFSo2GX6RfOOiz3nN+6uNWFruWEV0eQLnoy+692J825NPvYr+OmOVSFfvHeF19deNjH9SNN1Lq96sR3cRRl/kUVVw6bLCphwxitGFG0omFOlChAFAocZGO1WICkE2VtLwGcpFKRtcLiMBSS1UQpk6HITrMpBZOlZI3E9yL+JOBAJKZASFHKpDfgaV/sqx3sd/7uD9PmUv9+DfarH7y70TomdFEbhxnvPR8+PDGMA8N8oFjHJWRiSFy2TMbij88M08S//+XfmKaJ03GGnFnOL2zLjd9/+Tu3y5lf/vafrMuNt5evpBBY15tW0QsarCirqwHKtpsnlaW5P8u7a+tdYLD/+52P7Q5fe/460/X9vGtopShV60IIOOeZTSZuM8/uiMsDRwPeG5yrWkZ1visLSTnpJW5QnFRVco7RyTNlm8hkoXgXQ1GhZeeFETHlTFJmyWYgRk1hy5acUa2/InpIRcZQe/6yV0AU7bDdvlRBVGkli1E9p2QCOIOtjKciTKOqP9bE78vefnUdsaoXJZcvmlyo9tsYUm3zNg6rgVeQti6JScaCdX2qOOSg4sZRWIjkDXLCIFXs9vGjDD/73gj4cx+D2/2YlOGySqtuWyEmyFnttlVRcPWBE2CKaXo0qYhTH1PBR/GznBWxcmflOlVfwzvD7KufInMzlEKIhTVllhAhCwPZGbhuiTUmZT6Dt1L9zjsBR1+vBfc18vUtcbklTs9Va0htsQmyaeQs3hmGKTPOBj9ZZd4s5Bxx/gppZbu+iL/1ehZG6jQSc+I///EPrpcL6+VNUqoV2D9fLmxb4NcvL9zWwC+vZ5YQ+Hy+EFMmJElP8d4zzzODc3hrSGGlpIhzVsRs3UAuMJ4+ssbMZQ1s68LleiGqRp2zlsF5Ui6cnj8yznPTf6kBWg0AxPdxDMNAVDFcSb3bA2tr61pjdl9QyO9y5H0nu64YTa9ICyGIr5ealgoUlWowUt23rf/qpalN3G3nXpHKaTp1tLaTkXBY4DDNHKeREAJ/+ctPXG8X/vG3/2TMG//NrRxyZNhuLDnydl15va68bom3kDhHWfdszvgapBZJX7S2MkIAIzpIl01Ap//1+cKvrwtvt8Bp9Bxnz9Po+DQ7tqSgVqozouylz9X/KjpHehCpuX33C4zYJAopmztQrHq9ym3pWhIN9gvZyPxNpgs82yokn3c1rv9Ojseqdo9sisaS6fyZP0oXqr6rfIaWqtr7uTmLblH1d+UN/VGmeR3/dPdSL1A0F6zGRGIPNR39jpXYHKrmf5caPzzErK2Ca/2mrsNVs3eLKzEFfn/5mWW78PuXn9nCwrKdKSXjJ4t1agutx5+eSDnhDo4QInbwxJiYDlX7zuO94/R0kO8NcoOFpGxRlXaIor/lVZDU+Uwsol0qzwy5ifD3VkXZgrWgVwWderDcomm6iV2EvBJNClbbOSv4lLW/UqclZbBMw8RxPvL89Mw8jerjFkKMWK9PFTM/fjwyjzOfnp8Yh5FxHCSN2RcgEbYbIcKyXdlC5PPvb2xbYr0JoDhNE957np+VuT8PODfg3ahanoEYI9fbCyknXs+/U3Lhh+d/p1Q95ceY+h2Qp/7bWtvG1bfzob3S2Kl1lvSkgV1LrH72XlfqPQZT/5ke/H1kHt7fx369/bM78WJnMFYf/r8+/mngSUoq05z7uyyhB4Dh8ejAuneOfnEzd99555NVq7A7OVrKkGb4u0icBvIY2mIP7MAH3DV+dbz3M9SbL3cLxH6OfYc5q3PhrASqTlPqqtBYu74x94axBxL09cbKUse6dMGNzvaH1VF+yXlz9/fOlegDtL7P2j30A7XsxqBouzaj0gEoBhSkYQed5EUxHnUg312HpvbY1oZCtwTX85S++d/BQsxu9KgTWtOgVDtimA9gDMN0omCJ1wsUK5RmM2Kt5A7vfdrlfZf7a7W2oR+fbZRo4FNptfs3+76uBrjthrRmadN4f866kFF0J0P35jpDJDuTFZToLmhoNNa78dw5ku1B+slmvgWK/+xHCJXRpGXqATDklDAYct3pL1XkW3WGNOUtiWgGxQrYWdRJbxoUBUkpKTLfJbiuwJPky1MypCRDuu66tXQoWdTuGE+lc1+rk1poc7DOlvZ3GzP3k6RqGLV0JP2Pc8IOHKdRQJF5wjpPMlLS/nJbyRi2rJo9bsL5gdPzR4ZpFv2MFDl/+Z0UNs5ffmNdbnz97ReW5cbl9YWwbWzLotXIQltod4Babqan3n9jE5ot/69WtLYYybyqD4p+v73dlvCu9dSH0gVtX9YkcGtAWVtwTZ/l2pq9DxQrKNzmeNmDESGsZ3wJAnbFDYzFIBp9xjgNQgqegifpPDfdI4o4ZsoC5t2xGHV89anW6HiuD2ztbluNajK1VMyCsv/S/lOLYuhqIuNcmKZQZI7UsKuUPQ28sQ3lHtpmUO3bWs1Gc11stnpf0gspqkZVDrquiVRwA62q5a3ryndkt745dMMmpvq72xPS8a4uWhvmZn9LPmZ2AeQtFVzW4Lf2v6GS77Cm9ldp5eadMXj9XZkyjZFCF4zr66j/U0omRViDYVkNMVlAUrkoQmgrFHKUNGXrCm4wlLIQ4sDrywJnyNcvlBxJw0dMLFzWs1TPc+LIr9cLJayMSFp1KpGYIyYJ63mwhuQMk5MKjt46bUPV40yZFBNhWwnrItU4wybz1oquph9G/DRhh5GCVGRbt02Bp1X8P5/ZtpVtXQhVCD/vvoX0hTrrCrg1BnwNKvqxXIFea2UfpQ6J5g7urKhaxrttDtaA+sGfufNvjFU/SOdnLoS4EVPidruRSyZsE955js/POOfww0ApIg9Rq5fVyrCuwDAMHPKBHz79gM8BbzaIgevllWuwfDWOL1h+TZnXXLhmAabnUto6mHPdhEXtUmYLcn6fC7ctssYsWmc6zq0R6YbRiXJVIjd7vftANPtXagyi7dmvP7un/OBD9edjd6PaOlBnY9nP+RgDvRfjmO/MfokGm7adroHtP6VbSx4b4yFo3APi/SN3DKeHz92fo3T/677f+wx6S6bcxyttHTedD1/q3Nyf6z3iQr8m736NADulZK1OF7ncXlWz6ReW7cp1fSXniB+kmvcwey1WIudOCIN6HEeMMYyTx7rdN3DW47zFeiOvO5ofkItUq4shsq4bLhvsoCzjFmM8QqdtNOtz7c9477t1XVbuv9sfpdQU/NpGe2yTVYfSIPbQWofXIgzzLFXeU8l4BdemaaCMcDrNAnqfJgbvdQ5mlusCBpZVNjQjm2j6LQvrGnl72Uip4BQ8Ol+ujOPIsqwMw8jxcFJA37XxW3LidnvD24FluwIwa+EhKfajI83wzbh+z4utQNR9G5a7cVVjccr9638EbtXxB3QA1WM/3J+nf/89oPjxnr9lN72/8fve8c9XtQsBNLCGKqBL/U8zuMIeEhbQXRD9cNOPuby5anR0IMwj+vdY4aM6v8WUHXyqDpfZB3yjLbcArjMge3Sj4nDvrBA6Maq+UA0kKgUzqmZHZVRUFL5VflOx8FoFqbFqsgxOZ+5ZMvWwxjWHQ4IpneR6Pzv5sw6QOol3rZ7KqHkv1/rO7+j6pO5u76wDo5XIOwX+nNRh2w2wYQ+4KjvsfiFgp1BrRZVaMrwH4er9yNN1DlN1skDaosCeFqg73tr2xkpZe4zBupHxtJLNwFZeEeq8A3fADqNS9VHjnN4BXu5ZXXKLNe+VFlRaa8WRvRtjNMevdFtZPfBkuvtvi3L3u+iOZtJ+8c4LE04do6TjsN/9oewGJ7eg7z4PpV6zXvd+LH0/x7pc93lRtFxx9VJNt4+j/ZRrwF4gGyO6O9aSq1hpS5mVXfDsC85mGMQYW2vBCPBUcpRUuyzpQlKOnmY/pNRtIERhPcUk6QZ3i7/pGIIPR1uszP7ZDjlpenM18KjpgQcvO9enpyPDODLME1jLeZP0ka/XGzEDfsT5kQ8//sB0OPLDv/03xmHAlUTaFj7//T9Yrmd+//l/NYZTDIHb9bqDInkXDc+914K518ni3hExCkB0Q/oPj/rZtvjVBfUdV/7OnMhiI+V4zeOHis6j1NKoKQVnLc5KQC7zSs7YGAnKTminKjvQbBAxctkJXCWIjpLGSDpQrMf6JwoGb4GSmcqNqOPFFEMswqaQYDdxW6S0e62OUyOovS2rtphWQ7UW65zaDHkunyOmiM6XVL4TIDTG0AToS+4cbu2znAu5Mp70My6lPS2o7gCqdqNzIqRs26aCwCCmA+sqePUNe6sIg1DWlapJZNu4r+vi/36k/PkOAQ/UYc+GUGRTJ9SUhN7Nqu5L2eOuNhZN7T1JP4qh4K1o1DgDXsVmCpKuJ1hgaVXunDEUWxisaT9SyW7fGRfgqXTVPOvuLoSYWVbD+WYI0ZPL0NyHGCQFIm5ZNEp8YZwhlAt5S7y+SUWn0SWcMxzME9iNv/92ZlkjWxJA8tkWBls4WhErv+ZN0uzThsuJoxPtossoorCj95QCm/puKSaCCazXK+s0S3GE4xFrwCvolFJiOJzw1yvZSDrXdV2JYWPdFgbrKENkWW7crhfW5SZC6LoxWaqOh/pTzklwVZkauQJPnb9o62et0wIEpdkoA+LvOBUst7axn1rYXW1QCwZlM0v6WzZWhPnkqEUI8nUhrIGXz5+JMTBNI8M4Ms0zzjkm3dRLw6CVjywxREJIuGKYxpnBeQ6DF5+rJMq68MrIaxz4h/mdX4vlf4bCNQr4NOSC1wU66Jio60YpoqV1WzayhWQzb7fITYGnrPbDWRi8YR4cRtPivd13rMvdT1fVsekydkcN9vSb5Y/WkwbSVlF9aed6/lL6tLyactl7z3tf/nPJKn+OI8b7qnY1U2OPG017v48HJSPFYB7OVzWFH/WSegDkm7hRr3sf2t2DThUq7ERY9/OVNmPatet6BjSNqMe44Y4hLC9QkLU1l8QtXNjiwq+vf+e6XPjl1/9k3W4UIwzLH58/MY4D02HCGEs2Io8QUxTNPpNxgyNmKbIgqbCSnWStxY0at9lqUxIhR5ZtIayR23VhGCzWDRQsQ/b6XObuZ7cZj+2nLdcACG2lUkE2o+/venL1PavNnas8gK7dSQXNvZfCWd55hmHgeDhwOh2bZMA4fmULgacnjzWWH3544jDPPJ1mvHWsayDGzMvnCyFqXUsD/pDJJfF2ubAsgZ9/ORO2JBX+jOFwGpgmz48/fWSeZ/7y449M08yH0ydA/LqcgjCeSuFyfYFSOM3POGu0SIT6NV1M/0gmuR/TUuH0Ed9osXhzgPu4svzBeN/P2SpD648ItO/WpcaH77EG+7n4yKLqK1Te+eZ/EKO8d/zzVe309BLLm4cG7Ru4Cx4o3DPfS7M5DQ2u7ygIUzvH2jpouZ/QfdxS6ECn3Zj3DbWjzg85wPsZ7167N0c1cCnNIZOAUYM5dYazlkOvKGAVD6/Us5aKoCfvH6EBwn3nVsABXbr61bC2XX29M853DKruIrtAev3e7uDXNm4smnb+x3aUi+csE7Q0x/Z+IWlt1iqnlPZq/+C7cbpvg0ck1xqjYov7s9WvdP+hgpZtp8/KxEtRKKVx2wjryrZuEuxthZINr7//zjgdmJ8+Sqqh861N2nnrX6a/4e7o+m9fnO7Bp70td0PeJus3R6FWrGnPZ2xLPe1ZA83QI4uL5FK/cz72ALQBTd09Nz+W+/nwPRzrtunzq6PQPZ4MvZqKpgZXtZ1yQVPrnAYMujNkNH/dVCaHIbvSQCdXnDqiWk0oVeaTaLNINQ/xcqVcvVSVi1UjJUv1qdLfYam92Bk/0PlvNNVUJ1IxzWFOWSNAmR74ccA5z/HpxDgOjIcD1jmWKALEl5AJGcwwM1jHfHxmGCc+fPzEMI6YFIhp43Y9E9Ybr19+Y71dub69th3+GCMhBnLKLS1sr4xWG+DbKk798fjWo1N314N/fJouQNud/rt3C/dzcJ9YTfdmD7zBWwnGe7NtOntBnX6mgnymgX07jlgdEP1O3V1iU0DfkIshRppmTrX1omEiVajSYNiMYVUHLsR4l1rXb7AI2JlxxlKcxeUkFqhGWyrUXZ1zYRukJkLftJ6QvyuDV9YNqeKF00Cqpv2Ybs2t47c4is1kHY9VfNSUbvOlrpOF9uwVQN9B/X69pJ2/goPf01Efp+nKmLp+7qyVgml2LSYNvl1tSkl5DJphkttJBTgMQFZ/1KopqWNeAmkZ+zUNKFsBqUZviNlgTSHYPe0cHT9bKsw4jIXRWWZvsThKcqToidGzrYkUM+t1I4ZICVASkm5sIYQXtnjh8+cXruvGYfYC1KxfwS58eZVKTs5Kyl9waFW8DUpiXa4qth+AjPciFzG4grcFS9b6cxpmaeqsCJVvLNcLy/VC2BZJoRtG1aAacH7EqyZedYMkiMoaICVhAGnl0qR6UHVz1pgdLHrXFjanXsd905qpfum3G7Fts7PdS1fJsgXf1ce6/14fXOZcuC0rt9uNry8vhG3lME9M08Tzxx80YBnAGrX5iXVZlLkb9vRctUdiW5K08nzEpsLhp3/j4GcOLzfyunK7XHbws1Q9pJ3hbUomhI3X1zOjhdXJPSry09ITcx3e74AStUWrw1PtXQWU6tf6edX7sF41Rr2tBXEMMcMtiK1eooj5hyRMuFyLJnHvIddDl2YS1RT31/uOjhqrPATi9xtO94F1/1tP8s1pc4u7NF6wVbuzpjJ2rVkX7T1Vp4uZ5D+mSwuT+aWpdpW5+xh/3d3X4/3VGEfWzZSF4RzzRiqRLV/Z8kpipdjAMFvwgwBHzkpVOq8b3GaPl4wxUsTEVP/Ckm3BOlPNutqM3DY6c8kkBW1SzsSUiArIbCtY5ylZpF9aQYPOtRIfrsbCMkErMFhX46J+dGuLh3aqn6u2qQ6Lx6YrCmY5Y3WTTzTwvPOEFOQ66lcNTtaDcfSMo2MYpGhJWWWzc902ti1inbC/BuR7zu8/KQlAV3Q8xZhZllXBGsc43kgxS5qjm3BuxLmJnDdu6yvOGlL+EWNGBj+1tXmf5vcxbRuOnV1qAvMPWmh1zrR2fidGvhtx5T7FrweJqj/az7V6zffO1fq9VKbifl6o/tbeif9K3PgvAk/1cqgQ5YMxNdw9DIY/EMTmziD07B2nz3dH4yq7wyl47H3AvN9BDajl71qKW1Dce2f8zjlt574/esaWqQtCKcQYpLJBkhzdmobh/IDRHayqcmqowFO/qKcG3IDuSNZLVQBGHnBfCNnbrbKydsG7HsTod45lEvcOTFF9GWNrWeUKkBm9bt4X+9bH+yCtAYdtbZwbaAh1MtEoq63Nu3FtYE//aI9cJ5cOZqOBlu4C7p3T99I94lodOQEANB0hBsK2st6urLcby/Uq1QbjxnpdGPzAfHriY8r4aeZwetagye43+8717oObPfWmIfhdXve+MFb032BKTfnqDIjpT90bEMnBtqVDmhFj1crNF0kTkPfhHpDs+qF096OPWHdW6w7N47z6sx/XZQH2R9pZYRVAqOlotSqYsjARqn62MhaLpifRgANLMpaUCt7VlDuH915mZAOeYmOD1D0k2WKVQCRFFaeNWQW38136itx7R3XW/9QFWOaJ28etMTtrURlPzkuAM2rw8OnHT0zTCH4kFcPnlzNLiFxCIRvL8cNHxmnmLz/9uwQbz09YY9iub2zbwtef/8Z6u/D5l3+wrarlFCPbJkHHtkoZ7Zji3TyvQNm+zqmNeXde7c+76zE176u1DKWmGj54MZ3D8965e4eo6DmrXyXdXNNWJMjwVoCnxpBrjoNOJZ0/BhpDwarz1OtD7H1mlSmibKIkGicpr8RiCMlqWXZNSTIS5I8m4i04a1m2zO1miDGzbZtoOMTUnL66tslILnhrGaylOAc5kZ0jp0C0luBWebKyp2zt4uJZNbCqHl3XprY6TQmbIsnKbmWz6EX72UC2VSujvlT2NdsYapphO72CTakGse15OpZoGwdlF9z8jo4GlKv9/vbppA1yrqCUtOfkRCPCWQjZ8LYJ27MS4AyFVAR8chaKglW1xLuk1+n41vMIIKCMktGSkgTaWyyaeifATsgJAjwV0TCavOM0OAYGiJ4YBtZt5O11ZbklLi8L221htFKRzNoErrBcr1wX+Nvfv/LytnH68AE/TKThZ4oZiFpx6dNhwnjL6iyUzLpeZVyHK+TE4ET0fvJO5pCXe3YkLALCWgPGiS+Uomg3nV++cpgm1tsVZy2H40l0qKaJYZoY5gPudtPuuXfmU4yEsBJDEOZgDIQQNBgQ+yHVHW3baK2gas+AbufLOwPIGNUNUja7qcFixyBNquGWc2pFJPYfcM5gsApWWejmfU6Zy+XK29srv/zyC9ty4+k4M88zHz5+JMfIMIwYa7lersQYuF0vrVBGSaltoqRQ178o8/z0ATceeDYD69NXPp5v2POZa4paLZO2Dpeyg6CUzLos/PbbF0Yn4/vtcmv+pejDdWB1nR2dne6XmWz2tNMaWVTfq60J0CIOQ2FwAj6NzlKzm7ZUOG8yh0IStt+SIKSqr2baNXZHWf6Tym4fU/P33w8C/8xHffLGfHrQtrmLG9vr0CCNuyDg3l+tjmzza6tv0IL0Lv5o13oMqmu8J/ajoAzimmr/wGh6JDG05+xe2wkYQlDY0kLKga0spBJY0hshrUSzUNzG/OQZi8F7YVSPw3BXgawRAlQH0ypgLKzJQvIiLp5LafrFRmXlGuCUs2qJ6uZgMZhrxrhCysJAFcZUreBcn1f7zJiuPdusoYZ4dV1p/2vt1PWDfjBrVswd+KQ/ki67s0EHL8ynkGUj0xpJTz4cRsZh4HAYmMaBcaobXomYApfrjW2LjKPHD5aDGQWAGi25OP1dCKHoPSFFKC5XltWyhhuD91wuZ8Zx4uPzj0zjzDwdyHnh7fIbhswW/12rlZ60vaq9FbD9j6rt9hXj7jSfyi5XsDPvvsUv7ixFHR+dn7kDW1pZz0BJ92P3kdn0yKISDa6iMXUld/T9t7MP/1nX61+oaie/G6JcQZ6Hz/UGW25m/+7+mX3X8u5h28Jbz7SDEe0z7yBzddHtL3R3D/V6NWaBd8+zX/seCKjOuwSQu0ixqS2haU910e8posXsKHR3x/Rslhro7wF/BSlqC+yTut1PM+Xmm87uwb2+IfrWrEvp3XdaTKfBIfdMsu7DGgjtgZvpzlONertu3zf1Mp0hLaAi4vtzy2s9yi+/v03xlO9Up6uJcBrRUiEFctgItwvhdiYtFXgKhJy4fv1CXBco4KeZdVnww8B4OKmOwXgH4vDQn+XxBvtnbu2hhtnu/Uk1JO98vmtmegT7rgva80OdiFXbpbYd/Tn7oX0HcEHXe99bzAbAGoTuTTPESknWRrGd2GQDDRGHU8hDKkdabdYOeUhBgJxa89rsJFXPgDFF2JEqwKodqmu2rHI5Z1LZNS1SLh3wVHYQoN4P97at2c06o/U/Ra9lvbAvT6cD4zjw4cMHpmnk9PyMHwauWyKkRMgQi2U6HLDDwKcffmQaJ54OE9450nIhpsTl7QthXbieX1hvN9bbhW1bCWHT6k5RHbUKEvxXvaNbCX/4wUIV8Lv7RCl7hY76me4r3/xZul+PC5T+lPt/NvDIW4t3Fq/gkzGPi5o6u/Z+HZK1YQ8Gay8WFfylCEPRGL191TPJlfVUBc+NoRiHcSMYi3FuT9n0gacIg5Y+37ZIvt5kLMXUQCODjvdSWtWkfb0tmGz3NEhjW/CTm+adsi3q37UP2AO9bDPWKOj00D6yBliczVT2Jmav2CYsEGU6t+8aSqkl2iySdt2vWdKZpt1DbkDr93TcMW3rOLn7AG1drSt87T9rYHTyO3lhZ2xS40BSjgEQZkYsBTLYBLHD75wRMMhZSfVD/alMafIG4qv01qky4SUtUoovgPd1J99hrVNmX2FbA8uygpfAfvAyb6rdw43gHCmPkLzqTyVMCORc+LzeKAhTKpdMjAulJExesKbwNHm8sxzGScSlbca7jDUqcl40xd5oao4CR9tyY12urNcLg/cyZ42RQGgcGaeJYRSdPJtkg7HOiVZRUhlPdeNh7zT2zzfHZg+a74KO1lVl7+yHo9otMUe7D1v9yNKfQv/ozWb9TgiBdQ28nc+8ns/cFtGpmkbPEBNhXQnes17PFODrly8sy8Jvv/9OjIEcI4bCaETuwGXZfLC1cqV3pCipvZN3/PTDJ06HiWl0xBDYlhs5J2JI2FKa3RXQX/xwWR8N5L2yosbCvWPzv49Pynuvl7t2qq/L9S3HwYrYv/ZTzoVNP29NISQRUA46h6RdSwNxWyW7Ir5D7nyJOnvfcff+tEcdyz3z4pGV8UfH7sLu0c8j26MPrL/5YjuBxGiV3WAMZKPSE/SZMJXV1AHIbcOl3vP9/T4ytfo4LRfRRgzxSsqBJV5IOZDYlIEUKCYzToNUnLNSnAodFYV8P9Wb6dhtQLm73zp6S3suMBqm1dhK41WhtTbbk1MRQKK35/VxW1r7PkfaDSkgZ6hZMHcUidamUPawusZ3XYvdTVsjm2rOO7z+GCUgpJgIIao0j6Q/CyjlGIYd1NxCZA1B7sEUhtEyDI7KAZGNw8I0S8W/QTNdBq//Hl1LUywG1m0h5Yg1hnWcMdayhRVjHDkHjvMzh/mJlIMCZdMdXvGY8fKej1IZSj1R445tpOtAjfFsN/YfAc/upHub13O1tVm+3zPk+7m0k0bK3ai/x2joPv/NI/3h8S8xnhp1qwMRqpTWflN6P62hd6CjoqDi/9bc9J0auTvlLRzpRnu/S97dEzRqYsk7+na3xJT7zugpaHLPFVhK7xqYUgolZ+IWGnsBUPHwXcndmC5Xkh1kEHu3O4P1zvdnLtwPxupwuLvPy2f2gbcfdRrvn/nmfHSToGsHeb7983u7oxP0odFL366P0eDuQNUF43GXv+4iPBrsIt6RpgWaPRCs92tUHaoKM+uEAKmGKOKcgpArhiyBVgyUbSGcX9kub8TrGzlGcoywLrzlhB9H1ssZPx+YPp4ZD0eef/yJaZrxw3gHOu0BZD8xvwVE7xDjIqJ+tjgt/y3PWHRxbHTZxpKSsd4j0X073gGLIGMQiCpWXG38HZjVLeLtznJdaOw+Xjqj970ct61WThLb5ZywMazRFLsGPNVUI/2NYU8L0/kNOs3UNVDnxBjZ6e0rrchQkfNCuRf4Lpp+UMGnXIg1UOmAmwre6BnomU8V2GiOd8mgNqjOm2EYGQbPpx8+cTzOfPr0iWmamA5HMJbz7y9sMbIlAZ4+Pn9iOhz4b//235jGkcFCSZHXr1/Y1oXX339hWxfeXr6ybSvXyxshBLZ1bTvyOe8MlbYbfTcfkMWsOkQdjfy9wdfKyvbrDLT27EHwd4/eXva2trNBRe1m3aEu6qw6axm8Y/RWd7u5ExavTCRM1S6qKnY74OSUgWnqtXMFnmqvSv/FImkxKUlaVc6SBJQxFGcxfgI3YKYTmMJYEkOU8u3bFnF+4HpbWbdIDoGowJM4THKNYi1Yh1dhE5vF7mANJgtTt9dNqmtfbTuj4FOtDCQpQBZMUgNjew9VzmuUkWesFHOo7WENXkXupZ/Rfm5KgGLFSx37lqIAcLN96t5WDbFaKeh7OnZXRdd/U1f6biDuLllz9TEFZwyzp+k4hQRXo4LYKuhd1CkVtq6sSSK+XZl++08y+7pc2baCFe5aZxS1VN3rrqbnjZZp8vjBY72nKPC03FZulytmsmRvsGbEVaaftRh/xI6FWCZy8syl4EwkrQspRv7xeuEWIl/WjZAzhoChMPnI4OEvzxOH0fOTe9bd8oxT4MlWLT4N8hKOlFNj8dzOZ67nN7wfBMwyMEzCHJ3nI9N0wfuBlOK+5qoNTEEKR4jfmLq1mT1VpQsc68ZBDTZa6lz9bB0Dd46XaTZf2GsaZHZDwxpN+GnAVV0jdECh/kKBdQ1cbze+vLzy8vLC+XIlxSjV6nxku12l8IETVtUv//gHb+cz//3/+Z+s20qOG6Nz/PXDE5NznJyTVMgKwg+elDM2Rw6j4//77z8RQuDff/zI5Xrll19+Ydk2zucLBYd3UcBIW7AlkUMgO0jZQEpYU97RRdpnhyl1ZvTvPv7cp9rVCnr19+BErPx5skzeEqIwm25BNM5iEn80JtGr2eIO7Fqjmml2v3ZNEqgC/I2puE/l7+Mw1f5/W03rW3bQfx251visZwQ+fr8/v0wnK6lq1L4uWPa4rWo41jhxZ18lZb+Xu+vWa/TsLHmf6s5QUJ3EHLisL4R04xbeSHkHQ4zG0vNhojBgFvEhw7ZSGcZ1Ywr2Eb2DTGisXMdt3l/v26x1hfaFMxhnmnawyD0UcgJqmrWVCrFZ7XdpdqkHZhXJyzSbtceS4t/ISl0rfpsGeOz3pvHQvguCQeK5YRCW0zD6pi0dYmALW8vSGPzANAjraRgcIP22bCvLupJJGCcA0zA6rKu2UzRYD0fHlD3u2SOaUoPYKCcAkABOidt6wayGdb0xjhO5RKZxJqSV2/oCFE6Hj8S4Mk8nnp9+0NS8sbHS9rFCq3Dat0UPohb1sXIumBbT6mbMA5axM8r68bGnKO+tumudQafX/SDN0LOw2ri+w0NEr9h0c6+/xj9z/AuMJw2WQZkadRmsl6xDsoJLYkVlN5um+WPVCNjSgypF/1/qyL17htI9nDS0vFrBjEKhlsO+y/l9CNDb+UpNBewnCw3oaoBR1nLUmlJHza9X4UZ0sd91hXYEHUoDUVogYu7R/vu21TtV50NeqoNk32HWL9x1cRUBNw8Oxz4UTfv3Hw2RGnDTfed+F0HbvH6ic376a7wHDrb+6xcHayXdrL7eHqZUy313zzbX3bmiH1OAxRgF/yQoigi7pcRAWG9cX1+4vr2yXN7YrldK2HTnUdo0xI1EJr6BWW6YZWWYDrxdr5xOz/yUM34YmeeDtK+x3TM9NGCdHw+NIHNmdwObg9n1Qz++/4iN9whm7b93h9J016+/ldnfjZt7EPfOAWjP8v0cUee6ME0tZF1Mq6NXDbeCpuJQdEusatoYStO1aZal7DoDqWQJ5NVY2w5Ml6FbWZKlrj5aNUwAp3jHFCod+KTBZMlU8KkFJrkCmBmTLVa1pqZpxHvPh+cT0zTy8eMz8zRxPEwiDu4cxRjGaSJZz0c7kzB8+PiRcZqYB4ezEJcrMWzc3l7Y1oXlembbVtb1Rti2Vo2v1+KpqwOdk9HwzDqHm8Mkgtl1Inw79B930vbjbtQWvrFp3xzdXHkPeMq5rl5yph50mrxraRa7/k2Xqrz37INDYbo7LZrOmYQl1wB4kJLeOoOdl5Sf4rHG4ewEfsQcPmCHCXd41vQcyDEynW5s24Y/Xzlebxg7cFsWXpwlxI3bImCR7LJKKWNT0LFDt+YZLSJRO0+dj9yx9NrYrSavUExqgVvtr9o/RiaClmJ3uAJFGVW1iqBVNlMV5d1xq+rJ7+FY28DSICFrCn2KItgatYLl93S4LmBtbav/uF+B9+fOpbBGWcMHJ+N1dobJGQ6DYcuFywYhF9aUBbzLkCi4rOXl9VxN38wYgqlppftwoMhnvDUkJywO7wyDKzgDxoiga0yQcqSUCESMiXgXGX3ieLQ4PKN3OGtZoyetlreL47rJtvNgCq4UbIq4HDGlELeVLQSWbeMWItcKPGlxh1QSPoNfVpYUZQfdOnIy5JKEhWVpaVO7wy86KOu2cltukmoxzVIJ1Vi89wLqTyPjODIOIyVFNu81WOyCiG5DYU9d1UZU07dvJnVHqX7T/kL15B79BVNBqm5jWPzpKs7d4MhWvc46p9/Re9VU1mVduV5vXC4XLtdLSz13zsmmjZHA6Xa9sobAP37+mZfXV/7X3/9GDIHZwTR4TiWQvNPrqM20BuM9CcOGiLpv10U0vXJh9AN//ctfWNaV0XvWdeXtkvFGwB+MZdV0tmgyt5CJqXQpa7WpxP+vwtB9wz5ahx7sqUzAVESzyRgZH4M3TN4oOF7YkrCbQMb47AVYCzaTsnzGZkg6XxpjSy9WuzXDPl50rn1f1kuOR5v8X9voGr3I713z9zEw1DW7mw/19zdgVkE3w/p7KC09dPcP9s1xyr7J8Rjg90fPaBYNp8R1+0qIC2+339nCjbfLV7a4IpVrLU/PzwzDIJsvuuFTq1xS9jX522sW9SXr3LeYmlNXHavaPhRKrnGAxTqL947sM94L8GRyH1vU9N8o/rIV4EjOZ7pr6N+lX3X2NhCfqtJmK9UMDW71k2bfYpKwr+jumKTNOrdLFGTdCBDgKahPvafj1fuPUYobrKuwNo2RlGLnDc4pm7wkZAOhMHjxp70WbqjpjdZJkSjrZTPrqtlOMa5gEtebJaYZ6wy5bIzjxBYvYArzeCKkG6OfOc4fGfzIbE8NLK0+4nvHfYz3SLbZfdNHwKpPN20EAu7jxjuiR/f7EXDa40Zzdw/f3Evr+B3z+Gdt17/AeKoDrQ0tvX7ZB1OpD93ujVpJpYEEdgd2KthRCp14mwxSKe2rn1XnV6K53TnYc+Pl+2JAkr7uHubqPnlznbgPqLn8uyKThdLKSSvLKVeWlizcdTffOb8v+AVikt0zWw1l7zi3v7sKDrZ/v7a2afdRq+HVw5p9st8NnHrvVhdd8t7W0khdd94bsrrjaapxeGdh2E2TBuXV8a2Axv6f9wd4uxEF60BFJ7/9THOlFQzLVvGoUtukB560XQ0qaplI68J6vfD25QvXt1eury+ERUojU3JDtLewUsJGut1IGAK/YYeJ4fQbHz/9iHOW4/GJwXsVH+9n4R5hSexc28zopJWcYTGyvXuzt0vdZWxOZXUkMSoouP+8Z0CkCdPda/fglZq62kZ9r98FL/u83Wn/38cR825TjMnSV6XqlCGpRz0QUXOXqVM3iz1ypbUl7ABR6lLtjDG4Uqtamua47L1fGtBlGvAUm8j4Ixuwgk9JASj9ZnM6itlFVY2RChXWwPF44DDP/PTTDxwOM6fjgWHwnCZxdJIRWd3pcIQRhucRrOPp6QOD90yDg5x5vZ1Zb1cuX39nXReub6+EsLFcr7rIb8oUzQ3AAZTaXvpJq+6T/rc5cVbbp/PI7+ylfHeXkdvt4v7f7niwXQ0kLLvjWPodHr1nmQraxhoBOGdbW8yDZXSGQbVuaunyhtQYq76Y6ebfvZNszH79ynYrua5/kIslG4txM8Z4rJ3AevxwxPiJ4fQRO87Mzz9gnMcNg6RrhpW4bTydX7hdrozTxPl8AQPX21W0n7JorkDGZCO/MbhmwzRdvJSKrevranuK6cYvzf5X7YusjshePUhHghVH2nupupltxhlhKJu8aw8YPFijO5Ls63J1qoym2qmzW9MfJO0mE6NoitXd4u/pGLRNqu5bNdXdfvtD0C1aTrcNogNvYB4Mz7Pq03jLkmBwhVvMxGUHHUyBaCXwbowmTBPW98Zgdb7WtQ0UeHI1SQRGD6M3eCc8tZwDISUR2M0RCFgTGHxkGhM8WQ7DiDEeiuXts+FyM3x5c9w2S0mO0RaGFLA5Y4qkroXlxhqkPPYlRM5LEODJSupTzAnnCtGsjF5Ak8l5ZjeSc2FwEH1NIywKgKACvJHbcuN6vfL2+sI4zaQkVfVkJ35kmmameWaeJkpODOsg/oUGhjJGs7CsNd2udJ3Y/Ly2BtVONK1f+w1Zo5/tK9614NPajlli2tyt2myoaW2VJW0X8KLFWFLmer1xvlx4fXvj7XwmpySplqq3IsBT4nJZeLte+Z//+R98/vqV//t//A9KSvz0fOA0DjynhegceLdr4BmLGaQqb/YDW8rcbov4R84zjSM/fvrIsi7Mo+dyuZDjiqFIlU8st1C5j5nrlthSJnapihTTW96u3XT9rDaee9AJnWMxF0153/WlJm+YB9uYY2vMLKEwexis4Wk0DA7WaAhJ5k/I4DRmGNwOPBkglbp1r5vXejN1j/B7Od7bLJW/aX57gW5e9Edpge9jhkrVEK5FS2rcWH3o/rN1LalzofpwNUMmaREA1Idv4LP6Xvfngp1dvRMF5F8yV0NeiWnhvPzGbXvj9fw763bl98+/sm4rpow4O+Csg9ORcR5E/No4sknKRKKLg7Qt6zWqRp/Oe9GKVMCqX/qqOSl7VoXIh3hyKvjRi65kyBL3FgWvnRVNUG+wqV9pDBVwKhr0lHZX3R1Wn0rBp8ZqUj+pB5/ahldJMm81nnMKkNmquZeTgk4rW1ibDrGzTn1eiaO2ENnWwO22siyrfMZZ/GhwXmJz2fyQlMZhFP959NI2h8MoG2RuIOWM94Z1E0a/6AUvpGwoLAzbRLGBNZ7BZqblxBauzNOJZXvjOH8g58xhemYajsL+tho9vzPJ98wX9dMqiHo3Je5jvKK4RsVBjKkFPnad4VaJ/jFuTKnFMP059zhTLdSDMa24xeN8/Vfixn9NXLwugt3pizorDa8xLdTV9+/wiHbsaWb39L22e9wmcwU39KcP2Ns/7wONe+R3N0Z1d7m+2j7aziAN12s55UqPNkK/w9S0gVrGniYChqmMF2XgPAQgDZRrc1XvoToZ903dHne/7/4TFaDYX825NJ0RHY57m6hAWGuR8l7b1T7b27gZLsydHkCHU+zt9809dieFvdLeO2PzbvCz90djlz0ctUpUTXWskw0NRtblxnK7cXl75fr2yuXtjRQDlIx1luk4Y53DjQOFWhZaHIpsCmm7cXn9wt/+43/w9PyRnCLTfOD4/KGrfkejq/btsA9TNQi5tPycaigeICD6tIk+gL9frO+NRA2cK1OPPuAq3/zRgNI757ZNNdMAgPcYV3/mo2LW2vQiqFgdzxbMqTOvv+tQlgpmyjRKSUXhO8aFFheoJzTWqqCj2oMCNVdf+kpdzbY4pF3EstDGQYHGZKpHNyr2eaXBuQQFjtPTkWmahOE0z0zjIJWCcqDERLSFkh0MnmIN8+GAx5LMQDFWNIxKIq5B59GVdb2JjtO2EWNope33AP9+gWwWT8dW/xzf2LGq7VakM0o3Nx7x7/8qpa7Ovd7+7+AS3fX7GzXUfTerFYuMk8oyx3nidBg5Tp7D6BjsXlQB7cndoao7jxWMqqLitVobuipKFa3qkMk9qgPnBjCO4iey8SQzk91AHk7YYcIcPuCGCTcdcd4zjJPcT8nkFDkcT6zLjXE+cj6/YYeR8+WM9Z51Wbic33R8Z2r1pILZx3/R3c+S9jZtwJOumagpq2BiqWwxeaKca7DcN7PRTY3SKqO1GJG66ZEA09jFNX24guo517RBCd5T/bcCTyFGUhLntKUGfieH1zgkZWU+2tIwXUrPoN3tVim7xsxlE/aGN8LMmL3h4A3jk+GyZSBxC5kUpdeE9VE0AO/p+WgQWKs8ivaT12jZAC5mnM2cRjhO8PEIn46Gj0fD02yYh8qGkt+SggUpwRYyl1tmDYWvL45lMdxuiRAzacsqipqAgjOyph68xeCYvSVmiwOixkpSDdcDhZwjKRluWyS5glU0zzkrFe6cMA4jdTNBGU/rxm1ZeHs7Mx9OLMuNYZzx44z3nmmemaaZcRwpORK3SQPUwjiOeOdxLceqtN/7DnHXsOzzTd7t1uH6fj8wOse6tB/T5hYaxAmBwpCVTtNEyKv2nKnLkwQry7pwu91Erykl1VERFu00DXgnu4Avb298fXvjt8+feXl9paSo7B/pj8Eg/aQbMyULO5KSQDdIfIHn0ZO135wBj2F0nuNBhHqXdcUUtZspc9lkrm8hsKXELSTWuK8vpWtXsVf3wdP+DmqM1B/OMsdikvedBe/39OqUMlsWP/sWCiHBYTB4B5OHycn5rCncovqkugZa7lO0+2413Xuui0m+p+M9xlMp37Is2gjXMfzYFo+MJtChXkUD7z/9jS/biAxFC7/oelKNZp0Hvb17DNh3f1tutKbFrfFCTBvX9QtbvHK+/c4arpwvn7mtV76+fGZZVgb3xOgnQgxMKel1hEUpt5c0o2P3M/uJb/T5TU3vtxabFVzoN/qq46tfMk6+572nDIVxGiixkEgSzxSHbB04YVo7S3bKrFb/rDMu939rvFMtV20T2rpkm7tlOrt132e6qHWaUiBs2S1sxBy5LQIoJa0QjdmJLABhi6xrEH3LXBgmL7pNqs0puluiwVozIKRNrIJdQmbx3mCzZYgWkWwtoLp/2RZstBibCdFhTOS2DuS84Z0nlhVjIaaNwU1Q4Dh/ENa3Gd4dlz35wmhcCx3xopRvRvceC/ZLy8NYfQCc+nmD0Uq0D/7S/v16T/3f9+fuj3/Fbv3TwFMNeO7sR0H1TWSXf7+ZsleB28PZduOPbIwGMtyhbbTP1/fqfciAs80odDfYgIr2ObkpcX51Qu/A1o4E0v2kEJsgJKVQK0U571X3Q8qqEyXFpFaTqvDBbkxt9zwdS6e+3+6vtoXpOrk+QSd2XN5PpYI9wLWl2/HS/UdjJIf8j3p1v14XaFRmWjXCptylxMhtGuj67/G4Y5TVQOMR6q2O1h2guM+kRwX9+rz2oQ2aw6a7F+vtxu1y5u3lhevbC+fXV0pOHGYRAj0+HXGDZzhMFGjlRd2ysYXEZblwXq68fPnMx48/YHPm6eMnxnHCDYOw3swO8u3jsAdRq5aYjKtahaY+YtW46Xc06QzD3cLaGZAmKnfXzpDbWKYFdfL9vfP7QLyWUL5PC9JrfWPm/rxHV3Rxp9631+u8p1XEKl2+ubCdJDUpG4PJqjZYoO2KVaqytdimcWY0pah0ToSWt61OTtk1nmqfaA90c6bO7f2e5HO1b8Xeee8Zh4GPH555Oh748Okj0zRhrehfmBSEKkwhO4/zB4yxHA9HihtIOAqGGAIlR7Z1IYXAcr2wLTe2dWHbpOS5lAfPbde9P/bbrg6P0ZRaufMHN0P+W4GXtuD2zo2ctQXWD5f8I5C0rixtvP/B/JQ/1L4bRzFSMt15x/F44Okw8jQPnCbfUpbakxrRHWq6Rr0ei5EKm846rfZF00dC6yVW0EbCVCsCysZT/EwxnmgOZDdSpmcYZ8zxI3YYcfMTw+A5HA44axkHDyWTYyBuG8+ffuTy9sowzby9vmCt5e1VmGopRtK2qc3q54BRRm9HY+nsljS/2ru6sQI7Iy/X6j/K0DVtJGOMlXU3G2qGfdlPT0EcwpLBJJljrTqjApxJAamoWk5N0ykFFRPdNBjd3h2Xf+ZjsHtqb8tCLyiWq9agLh/s74tOmATSISISCVPhh4MANs8Hz9smvsXLDa5LailGVXMuFtmB3eeMBMfOGBwwOsPsLA6DNwZnEy4WnmZ4ng1/OcEPJ8PzyXCYDYfRMnoBnuQHgjOkVFjWwi+fE29Xw+ViCRuUqNorIULJrbKo87L5d9CU4ONgSQo8yeaAgSycPoOMyUjhskWCywzGY42AX9lb+Z0La5RdetlhN9zWFX+78fr6ynQ4cr1eOWAYpwPOe+b5yDwfmKdZAOC4NZszTxPee9EfpbM/Cv72xqwxP8q3Nu6b4Ozh9Z1Pq2tFtUF6XpE1MC21tq9819tP0ZfLLDdheYVtI6fIMI/M48BhmvSZHClnvry88NuXL/z8669cLheKpjIeB8dhcAwWvAZshUJKYu0Sku43GREH/jiNpFy4BRUMxoAbOJ2esM4Rk6Qm2xw5Xxe+XlZu68bLdZFA2whQ2trjoYnuWk/nT/dxmVNtrhRCFHsoYuKG0Rtikopgl1Xe31KVuHAMDmYvoG6h4BIMyhpU7KkBgN9CI3sqKwjI/J2ZL+Bbv7/KE9R48M4HLXvUCDWw/laipL3JvS5N847Un6gMJvn4nv6adQMjK5i9xyE98GRatbG6+e6qv42uoWRyidy2V5Zw5u32M2u4cFve2MLCy/k3rtcLv//+G7dl4zQX5jERtk104ZA4YfCjspeiMDpTZfUqu4tuTheVrdHsHmt3iZnCI2ClvpUVRtMweEyBNGdySMQibB8p5FE3lxxegSfn5EFz1eJsKXe62tTL7KtPF2uX6iqpn7UzqhtBpZrG7iympvkVAZ7WbQFjuC0Lt2XBGUmZNpgWx5QC2xpZlkCMoo80DI5x8FrMpJCLpORbK6SXVkDGC8vL+8p0t7IGBkv2ViUSMjEGjClYVyAG1pDJZcU4COmGcYYtHUh5I4SV0c0YY/gQ/wJMWvFabHIf994BT23DMiPk+Nw0of6reVVfey9Dpmc+1TnTPtedpwe0Ws9ovFPnBOaBPGGM+I7/ZEXOf43xxB7EVpf5ETRot2PqZ3cHdDcq+wM2Sr5+dg880CChdN+v86h/6MpoUhes9Nfuj/vztMAxm9axIv4o4EXbza8BfusYbfTa+M1R2PP2a3uIONxuVOvuUg+itXM2Y3c/kKqheXyS/vU+xUvW+e7f3a3bLogtfUc8GNquVbWt98WhgiX1lu7bpn5/fx5jNLB8mGBtjJqaVlnurts+3572of8a4+neKStZdv+3dRHW0/XC7Xplud2wFg7HGT8OnJ6fGaaB6XSkIJM7xsRh2Ygp8bwJELWukdHB9etvEFZ8yUzHJ04//CjC49Ncm0mfV+bA3aRvbdOlGLbWu+/vvp32NkCdt67Nu7/uDEHZg/tveFX9+UptW2nfHsR9bxz+mY89yC3dfN7fq5TrnHd71mZBgZrjbmICkzGpju89zUjmhqUYzZs3hmLyPt8qlbyUTqC57L+pC/EOsshNa/5+Z9BrMG+MYRxHBu/5+OGJwywpdeM06hwoxLCSU5RdXwzTPOOcZ0wWN4z4bLB+ILuJCjzllFhvVykDHrYW7FMUXzG6W16E/Qlgs93XA1Mdsj0t2Kpuwa4X8DjWqt2QZzUdkdCoge/nkry+O66tZaoNhof2Lc0HA6MpYJqe4rwIOHoBpedxYvCeT08Tz7PjNFkOmo5TtwwKQo1vTkL3uwJZjVXbQsMMRSoclpIUiC7IVqQAT8V4tuIIxbIYQwLyFrF5Jb29MQwjMWXGcQRg8F6vIWufcY75eMJYRwZOzx8EgHp5YRgnbpczL18+iz2JsTmpNUJq2wgt5VMr+ugT1DLHdf1pKW9aTSzXlC0F43Z76DDWY6ywRe9S7pEUaUOtwFf9gGo/hbFS0+lzZTrlLMLNWdgPOSW2GL874Mko2uS0n+smUpEpRfVJ+43LFlgXCWQ34LyJrZoumdME3svceB4NrlhK8qypcA0ZbyVlaA2Fmy1sCspsSVKIrCkMtjBYw2mUIGXwhbIUQpKU1NHBabJ8OhqeT5bj0XKaDeMAFAm8zpfM62vh598KX78WXl4Lywpx0yIF266BRykU1VnzBik5bsEUw9FZkreMFqKBJe92iGKxDYDKRAohJ5yxDNbhPYzeSSASYlsTkslsMbJuK+fLhcPlzOVyxljH0zNY5xiniWmeOMyzpK2moIGTZRxHDocD06gAlJazBt3Brvap9XMFg/Tfeh5rzN1PMUbYXGpbG5BkXUuf0xPu59Hx0gfzVZLCWSn1lHOQSn7byrYuWGQcHKaReRo5HibmaSTlzLpt/PblC799/sy6LuQUOU0jh9FzHAcOg2d0Vsas0CX0Xp3o5Q0Dp6cjfhiY55mMYUuAdRg/ElLmugXenGVZpWrqtmRiMS31POakz8037oqkLteA6WFC3buUd191RsBQnGM0wmayIGBTLKzKdKpxSLsemm5cVzgF5p12uevS7PofAXH397yBxHd0qM91/9K9n1WBUjnMN/Hbe2yp/rgDrtQR78O1GkeW5rPtP3S+2M7WAdrf+3dr8Fo3VlIK5JJYwhshL7xef2YJZ67rF0K8cbm+sG4rl+sr19tt37jzgeg0bWxbiWHTNVxAFGc9Jhuyjfuzari2xxgVOJD5W1xRrSNtn7ZZUJ9HfCODkXTZwVDmQnaFaBLeCXNUJozBkLB2EA28QZhQooPFO6HBHodWH1BixlLDZWqRCVMdlfY89W8ttNLYiXKekAJbsIQosevttrCsG8dpFh1MZZlX331dI+sSNQaW4iXeWzC6gaXVo+tQER0pAd6crZpSah+1Gqs1e5uXDMWULlZI5ByJcQHgdnshDrL5kEvG+5GQF4wxHOcPfHz6K96PTOOhjd078LWO3y71tG5q78P5Ppau3+/nVXu/W1/6eVO/U4kRbYzU6+2f7OxnF5uXIj50f95/we365xlP1fncJZCAPd+v3vCei7svcHfnkZO1c7bArAU1dRXRBqtOZFuM29LZ/q3/15X14ek7NK8aOfTsVdNIaHmJkiQoyKkvn0nb8Sullm017DfUp/B1kx0khqIijVVs2DTG0z3FraOOdo5HMSKKXAO5GkD3IrCm6/fCvptgraueV7tuHdA7I631Sjv6fGqjNyTsnn6Fr4MQNSTmbjDnVg2C9nsP6EsL/o2uuKY8DHZ0cPci9N0EENypAwAplCwCzzkltmVhvV25XS8s1wvL7YYfHMZZhnHg6cMz0zxzeH4Co85MTKzrqmKgmbBunN/OhC1y/fwr8XKm3G6cPv3IMI6UwxE3jnfAT9EArjIu2m5xqfdbO7HFyG0otcf8xoDUkqU0Z7Nvkkckuz/uDMNDO9bx55yhlP7731fgJmtpZW3IT033KdVBzZJaIkZfvie6C0VYTCWLA12BC+S1gp6709iguLaQ7LtPuenE1ST9vl9sBaWrMau2zGQoGuhXu6gLoVUR8Xma+PTxA0+nI+M4Yp0V4CluXN5e2bSqnzGG+XDE+4FTNvhh5FAMdhgwYwJjiSESU2JR4KmyZHrmaXWQimpKGSDZREFTuNRWWaCo1lnJ8nlqOfa9d/a5UP9pwPZDsHNEey2HQl241Y7cnac0u1+dmLZQVKDIe6zz+HHC+oFxOuCHgdM0MQ2eH46Wp8FwGhMHl/G2UBNSi9pTW4O9Ti9FL7IHkpQGOhkVtiTvei/GeIxxO/CULCuWW7HEDImIiYU1vTL4gRgT0zThnCeNA95J1RcLWOsZjgPjfOBwktS7548fefnyBT8MfP38O2FbCevKGkWLsGn7abtVICk17bgKBpnm7FYAso6LnLPYXnXIWhoPgOrJSIrygOnEQKutz0nLSKd9fW+sNTTljtLSPAVw2oGnUBlPMbxrB//Mh4W9gGw3N0oFZ231A3fmk3xAfuUCOUFIEjRbEluG05zxFj5OltkZBms4bxluki60RQ2eTSZm2LICTwm86g8OzvA0OcYEW4YtJa4h4h0MvnCaDJ9Olg9PntPJcTpYpgFlVW6cz4kvL4W//wq//Q5hKeQI3iQssC0rKUbRXipQRoe3ltlLmslghLV09MJ4mqwIoC9Z06O1+IIxHkMh5Q0obCkxWJgHj8EyDY5SBARIZdffXEPArRtvlzPz+cT57YzzIwUpPiCV7WaOhxlvwORATZsRUOXINEtannNO1+89AK42vbqUzX6IcdttSGMpVU1Qq980UNce53DON78TuHMmq9WsLzlnm8C4AE9ZN9sWtnXBIP17mEaO88TxcGAaB0JOLOvKL7//zm+/f2ZZFsiZ0/OR0zRynAZm7xid62awrAXOOQ7HmXka+eHTB8Zx5PnpBMaScaqxBFvMvC4bzlm+3hYKlsuyEhFZhFpB1VgBwncPf2eOtcIcZZ87/eRoaYll952dhbEYBidskqz2L8TCdc2sUZiEtUpfnWYZ0VVrEu4dmGTN/tOYaHrHe8rqDkT1Ent/9qPGe/eMpP23sMH3qnc1pnk4wzdBc+8fQwVhpF2FiZTv3dii/lrZZQJqZdZ9ELy/+b+PERko2YhtCHEl5o3z+pklvPFy/QfL9sYWJOXufP3Ksi68XV5YbivrthJCJg4B5wJBAd4QNgE8vNViIq5duJSdGVZjqFKMaoHJTpjXOM87JxtVJunmhPo8zQ0SG+K8yAA4Y8hDIVoFYtqOoQBPzg4UJ6whSiFGibHuNYdNA5KaQ434rY3tVAnhCjq1QjF1LOgMqlpSxqC9KAyjdUMZ1YXL9ca2BaZhBmpBBbMDT0tkXQKSTWcZBscwWEA3rnJq+mDGGBEet6onZV0D9ysA5vq528bhnr0iG9aREG8qy2PwcRHdybxRSNy2V8K28uHpr1jjOcxPDMPUfKo78Elb9VFHqflL74z9xznR32MDVtBZpSynek75qeBTXTP0P9VnbpPA7OdF0qgbnqLX/Gddr3+J8VQnXn/0bJ4++O1Bmxow352rNk7p08f2tLcdad4hpjpY6y20IE3/9VgNrQ80daTpazrgK90yikDuDgzUc+zIskwgWaArYvptfN4FRK1NemCgPXxbHEEpk1Sgqw/J7pF7y75jVoElAZE6Cpw+ZyvhqAahtndv1O8Hy32/NeCnBcK6SOhH910GjRTZB3ilpjbwrj3XDjS2uyjdpGrXfezbx0FXF/D93DVYCttKWG5cz2/czmfWm1TfwsiOoFN2Q9HnSUkC7gbiGkuxMhlrWdG4BeZhgAzpdma1hrd/eA4fPoqwnffYYWxtK6yPR+O8LwCtzHybT6ZzSGu702GmYghb+N3t7jQc+MFw1fH1npHa2Vh5BwT3bv7ujmpj7mxOobV30oo6dV7vJpb2OdMW8S4cbnMKihFB2ZKLpoN0rDe9dkuvaD+1Kys1vMLqdwnILcAQGyG2ZJ4mpnHgh48fOKp4+DgOMmZy5na9sG0b18uFEENri23bxEEJm4CnOTNMM+OTBT9AKe35enjI1sDGOnB0lUQKyTkEPBBQSGxSD5wKHb0LQajspXuWXbVfXeODpEGYXYdB2rs1fZsnu7koTefH9PPMyoetl1Lufpxxw8A4H/HjzHw4MAwjz9PA7C0fx8zRZ2azIkpweb/vdq87u0kmUQWj7D4fizpVOaqml4BOEhgZinFk6wlYQjZcE2ylcMuRSCIsG1B37zwprEzTLKK304zB4L1UZBGGmQCVznmm+YAxBu+lWsvT8zPOOc4vL/z+yz9IQco36zY9lflXHbSaTtrSB60l2dxsYx3gSRlPtX0qMGVV/NN5jx9G3DjKjm5dU3KAnFXDSTd/an8VVB9MHFGx8RI4hKCpd1HuM4QgujwxfXfAU3hgcNVgtl/RK/Opxg4aZyl+XbQNDbHAeVNdDyuiyU+jsIieJ8fkLdOQ2WLhGhKlwGWTSl0hi/ByyC285xQzIRUG5ziMjjUkTZlKbDGpEKtlGCTVbnAFS+Tr1yshJ/77f0R++S3x5UtguRZKKJAhlChBZBOPTy1wcNYwWUMZPH5wOGN5mgassXycZQ5sORAK5JSJGAYtL2aMweRCqNoqFhyGefSAYXBBry/rRFQtocv1wvFy4Xw5M84HSfUEhmFgHEdJa6Zg0oy1TvSdhpFxPnA8HBjHCa/VRGuaRe2o0ves9mudS+j6vFfEKw18qmuDiJVUUGtf99tZNbgoqt1WGQmNGWEkSE8hEsNGjpJuPXkHzvB0OHA4iI6V9Y7Ly5mvb2e+vrzxdr4IcOIdp2ngNFbQyba05KTBj/NOClwcD8zTyPPpwDgMHEYv915EfzEXSINjHg8chNLGl7ezVCBOGT/NzBg+ldyqWm6psCYa0NT/7AE77H6otJWo7amtMlKZEQOhSMrpEjMhiZB4ZTr1zDTpq0LKhmgENItFNpKcK3hj8Ij+09C7tIg3V7WfavqWNzX8/r6Ob3xQUB/JNne23+x/3ITvX+vHdx933vkU8gegWk4pCms2yrpRs1oeA/Y+FtpZUL0vXghpI+fIef3CGi4COIU3ztfPbPHKtt1IKXBbr7oholrByNzNClZs28a6rsQt4KxjsKMCqeJbJSP+QU513latUGkPq7GVc56CyC0YY1paun5pb/BSGdhqD6zD2ALe7q5szuRUKDis8VibcN6Ss1SGy7lQYu2Qxw6t8Zv6aqbcAebiInU+M7sPfq8Zim7+C9s05UQIiRgzy20jxizAUrGyxiUIRZix6xLZVtGIdBasE9A+pkTKkaSMbNf0serG4V5Bz7Q1VDa6atGfPi5rBX1anFooJRHTKvYj3jAGVjdKXInXNdfxfPxB0vvcyKgAmjHaz13c8M0cUh+rrgl3cXM/J2SkNfvUx4x1/egt0V1GFhX0eowb9xiUGseXXjqjJ7L818e/nGr3eNSbrYh2ReoeU41k3O1BxT7gigIlHWNEF/27SaNHuf/P3vkd6FMNxC5J1LpiP58OqpwiUXPZnZeSzzUIrMif6EZVdk0VPN0/0p7w7nq0QXzHSCm0Z+uBmfoE1Wmn9B0vz9i0odSpd21HRq7fA09GJ1VzbhoQsg+qvqyv/NoDjJJ3RpjeTjewKirMjvUZcxds3inq1z5pDsAeJd4znfaxcZ+y132mnySPEy8n4raxLQu38xvXyxvrciNsa2sPq8i2OAuFFDNVHV9uy2osaTDeM88TOQTCOLBebrz9/soaA2wbJQamp2fcNLfF4q4uSeeg9JBQDaBqI9S2rPa6d0T3RfnegLTx1TXdPViHVvzY+6RnstVz3o2zBo7988j1n+Goum6mSDWcapPQOZBqdZPSN77uegAGTZnt7E7tR7Vy0nYZjMnkKih9V4lln/eVxWlKtRFFK3ju16Yufs2gq4XQHR5Jq5v59PGZ5ydhMTlrSUmEV2/XK7frleuyEDvG0qCsrLQujOMgu16HI26cdQ+9Yxi2e1EAwRYVyi078GQMVoG7bIWVUnLBVOAZo8CFBlDagqZz6kp5Jz34biL041EXwNJavn2r2s5mY6qj2s4laXDGD9hxxM8HhmlmPj0zzAdOxxPTOPFxtByc4YNbOJrAlCIuJyGflQqeUw1x91OLTwhI1xZ0tApXipQsPzlJ/n4BivMU4wnFshbDLcGaC7eUiDmzrisUUZNy3hO3lWmescYyHw44L8GvMUIXN6aoQKbHDZ55PnA4HDkcjzw/f2AYBn77+R/crhdhhC6LzIUu5TRVgKzajwY86aaGq4Km0vZJgbS7kaNt4azD+wE/jPhhwLphtzNbVlFyLTkftSpdrmtTtw5QWgVFYToJMJCzlDxOORN1bf6ejpBkPXTaFLbZBlq63e4S7gBUX5Wu+kUxw3nLLAmWkDmNhvzkeJ4cPx4kPfNDcbwuiXSWYhvXrezVvhDtGor4B2vIhFw4jJbneeCyJs5rwlDYYiapfpv3lnm2DC4r8HTjy3njv/9H5B+/ZMxWMBFsTlhdy2ugVRBNr5gyKzLVDl7EwU+DAJtPI3grwJPB8LaJRkpSxnFKwup1xpCtMLOqi+GcAE8GhOlCIag4dCBjQuByvXK4XLhczhyOJ2JMohGlwNM8TXgKNm54P7R5OUwzh4OkPw/j0Cow7RuB9wB/jXp6kf7cAU81eLXGqFKcEeDJqiYamv6qmxx7gF/XlAo67bqDVaA+xiCC4jFACkxeRIZPx4OkDE4ThcL5euPlfObl9VWBJ5i84zgK22lytRCDPINwz1TIffAcjzPHeeLD6Yj3ltFLGFIqg7hYZaUOPB0GxmFg8o7fXy+EmPDjhLOG2SYRgA/Cclyipr43YvG+xdmDT7IxWFsf/YzaTCPrfEyFnGDZMteQWIIArNVXkxQcBa90blgr86vWGvEWZgWcJmcYAFv7RIMTa0SFzKmv970CT/VoQW9bT/a4scY1tY/0G3fgU88E6dOTvgGPWnxTC7hINbOclBFbgd3mD5bdqHY+Hi1Q13OSiWklxJW32+9cli98vfyd2/rCul6IcWMNCylFQgxqtyIpVxFxqEUytm1jW1fCFvDOM4wjBiMbM2TdzERsYbuteq+IZlPVHKbI5hIQlI3eVs1ClwhU4c6Cs0il5qGIsH7Q+RGL6Dg6j7VRRMa9wXspAlHy7svd9S1Iu1IZRXus2oNPfaVjtO0FDCxtUuaSSDmxbhsxRm63oMBTJCcoyTTgKadCjpkUE9sqP85bYTM5qZQb16T9IM/oK7nAVqZTlUqo2IX4Qylm9Tmk71v6oM7/ij7oKiWM2lQIUYpaODcQs/gmW5KU5BBX5vHENJ1wdmjzoA6/+u9HMk8udXO3zqXu/d7p6bCUx5jxcU59w6hif/0R3NXuupuf3TT9lwzX/3vgqY2bctc47z1U/fwjIrY75p1+R9Wy6b5bStcwf3hdebMHUsw71wRUGFcDgRQx6I5+Lwaud9bOY9gF5kpF1tEYURCYBh/VPjTtPzQD13XaHRBQA1PKHw6G+tqOyqphvIO79u+VOyPdfV9z9wyVmbCDGvfX3Gl1O8BX21/0sVrzt4H4zr2Xu1/NCWpT9jFg6T5b+3PvkfvvGAVLUtiI28bl7YXb2xtvL1+4vr2yaeDtB6G+V4H4mERx1bpVdRRkZ80KGtB2E4wB4y1lHsglM60zORbWy1tr8On5A4e//Bt+mhjmk44N6ZvS9Vftpbun1QDBKBK/o9baRg1o69qy1PEt569z5hGIqhd4HEa77k4Vl6uC/AqClG+/82c+GoBaU9f02B2TfNf2Nc2tzotqER7nWW9v9sivJWIJ+HJnsHfHZofLUVBLnXSDCBmii3uRoE/S6yzH40FLTj/zdDoI02kYlSpsiHEjxa0FEbR0DnXKU6Rkw3bL5OC5jQMprPjDkSEnzHTCGYt3Alo7LwuoH0aMteScsEkrkGnOfM5Z38s4P8hulaZCJV20kwJR9fcOprHbvup3lNLKJO/G6f7YbUSvadY7WN3c0aDMDiN2GBiPJ8bDkfn0LIyEpw+M84HTPDF7z7ONTCZzSCtDKZh4X8FvpydXx6NqDVRg0KpTovY1RUqJkIRJUEGTUgzZWBKOiGPNhqUYtmwlrSmI3ty23KQvjCFHx2qMlDMfJ2KMWD8wDKOw2bxnnmQ8TKNU1PLOgbWM08zp+QN/zUkq25TM18+fMRjWZeF6vpBTEgCo7KxVsS3SnjkbrJUiFrZbL5rNe1hDWtUdp6WRdXeRGgAia0hqLKua9r63dynVgRatp1KKMp0UeCq6M6mO2bcr/p/72JK0p68pC/p6g+QqEKXBdE29QwnPrfhBx5zKBRXSBs6ZJQAFRi8C4BYJlmOyzQ7VSoiUQsiGWAova2Q8b1BEL2mwhh9mTzYiRjt62Sm3XvyO318Ly9fE//x549evll9/L1xuMOWCL5pGWAOlooEaVVvMKKBiCCnjbBL2lQHvLAdj+OEw4a3lZY3YELlETRO04BySHlwK0RZc1iDJOg6TxxnLcYrYmNlyEuZNloqJl9uN6XLh68sL43Tger0wDiOjc8rqs2St0Fd/BHhJ3biuqdl1PbcYctOGMwo6FfUxhY2fcM7uLOnqI1IXp25A6DwxBrACtLWqbW3FsbrhIQFtVt9asF65z8E5pnFgHge8czx9+MA0TWAsIQY+f33l989fud0WYgg8T57D4DkMjtlZrQK323pjDH7wPJ2OHA4Tn55PzOPANEiadg5SiVLWKx3bxmCsp6SCi4mJxIdpIMeJ8+FICI6tCChoUgG7M2qrby6pbyo0T7+MqM1h14ICYTzFXMgZllC4BhR0Kk2vUKVF1V8u7X51iW3+sLPy3uRQkXUl3O6uLL2hMoZapuLd9e57Oe6D1j7Wgdovdw1TgZPmB3e92AXduTsnDYDS4i0paUGUqDpFeyfsm1S7P7HHn/Uzcp4tLoS48Xr9jev6wpe3v3NZXjhff2MJF0JYyVmYNVlFsUspartk465YtCJb5Hq5QTFcrzfAMEwjxgwYZ3BYst0LO1Sfqc7vvoUMojfprcc48F4Y7tFIKr2k9NtOe1PbKMkmU9wSKRXCKozSmCLYCD6Kv2wtJUuqvBSwkjkiJPR9U7DeWx+qG0zFxPf4pOvjQgXIC8YWbIFihKHEFghBzrLeogiGBwArjnKRinMpCUAUo7K1MjgvKYUpZ0osbCohkWK9RwGbnHGNoW6bVIL0UUyJEAJB0/lLyRgnMjeVSVXRtP2REjkbQrxRSsZaT3JRbXrGGNeqy58On/jheWOejpwOH7s5IhtsLVZ/OB5ZgU0P6mGOfEs0ULxA19SqKdI0Af/gOkY7bSfS1Hlq2rnMu3jMHx//r4GnnklxT+vl7rW7G9FooWdm3FUFqwZEY5Le/vYPte+U7w+razY7yrFDTjt7Rr9dqZcpSol0oC+F3T7Zrkc3wd5pWMNe8a0DVO4+Wx3th8DoHk9Qw1KnbDXG9e71/LXjWwDXO6PmnYGpC6uxdQG2oA5PKeVOlfQOLyqw07tr6ohRsOQ+KO+ftl6v3Wf/rqm/HkAnc/fr/iZa3+5+VgPvjDjDKQbCunB9e+X69srl5SvX85ltXSmlMIyDUt0FeEpRaY1bLZ8p1HDjNJSsIKS1FGMY7EApmek0sZ5vrC9v5LASbzeOf/krdpygfGA4nLSvaU66tF1uu2X3A/wxf7uy4Aq1YllLQ31YLOu4aN+rFr62Wxs390BSFfaVHcGHFL2WSvb9HLWtbMmyS5w7g03dTaaNVbN7Ifu/aXxEoB+n9bOd3Upln7Bdd7RvFzAKVFdHU/TbFKzQ69aKYU283BoOh5nn05EflOk0DAPWibivNYZbTqQYSAo8lSLsg92+ykK/pY1kDTdvyWHj8OET1hiG6QDG4bwwP53uRvshinZbSlgni2JWtlguGeO8BA/ek1MmhI2Sst5DwWqOfmVCVdajaWmu3Y5lllSguhN23977YWjmAe4AqGoTK/DkMM7hpwk3ThyenplOTxyfPzGfnjg9PTPPR54Gx+QMp3xjKht+MbiowWkdMxVc6sCn6ny08sYVbC4SjZQcIUdKEgFsAZ6gmIGCJRtHUuBpLYatGLZcCCES1a5RCtlakhNGWk6JYZiEeeEEVA8hMIwDKR8ZBg9mxjtxqrCWYZSqOeM4Mo6TVNIZJ66Xs4yz11et7hla4LuTTU1bW2yuwsT1uXcw3dqqcbUzpJxVTYkKOtX2UjtTNTkaUJkTpKz2U24g17maYkuBKhliyg14asyQP7QEf85jS811wiLgRmVjVhPTMzjaphTsAFRdV/QoBVbVfFpDUrZI4cNsmbzMnNFZFpslHbSoFp5eI2XRtHlbhcE0usjT4PEGPs4DAdH8mgaD8+qoO8Pnr4Vf3xL/139mfv4MKThyMsogKbuBpCWzYkD1dAxJ9YtiLoQkbCtnhXHjHXycR7w1/HpZyaVwDhspK4MpmyZEbV1uwISxcPAebwqHaQCTuGyFkorukCeutxvT9cLr6yuH44nr7QYFptNJ2H9OdthFkLbI/RrxNetPbpoy0km731mDmN4PVM2llPDJkX31t6uPmJEkQdr5UDvffAZj2saX+LXi91UHJaedZSI6YAKOeWcZh4F5mhiGgafnZ4ZhJJdESJkvL698/vrCsiykGJhPE8eaYuedsIZQ4AlJt/He8XSaOR4OfHw6MXoRGc8pswVhhoTK7CySKmOtpWSpxjeSeZ4GYhKtqcUaQozid8cIMTbPWYJrBZWQPi770q1rq6wTNbVPzLj0TS4iIn7Z4BYk7VSYnlWn6T5dpfkOpTZtocakg4fRGFwB917ooLo7DRZ8b6H7jo5+nb/bnG4+aO977pugj59vsYvapKaX23wITU3VWK+k2GK+u/vp/bd67W6e7efMbGFl2a58Pf/K2/U3vrz9g+vthevyyhaWtlGDLeK/m9z8f2vBuoLLMu9CiVxvC0WBJ2Msp6eTVMF1TuI8nCLxe6x0D9QBGqtQwFvx1Zzzzb+q38uIVqnYcaPzX+4lBgF11iUSYmJdAsYmjI/4oTAcDMWIALe0VIJUMQCECd61VR/LNcDpblN8HwN9Wp41heIUFE6p3V/Jhm1JpJixeLGt2UK25AwpFmJIhCgAWikFp/Y4FznPtgnwRKGl/1XAydXCMOq7FbWNKSZCFB8s5UghYRvwZGVNqwJWBYoRVlTJkRJV0sN6/a5RnUrRBlu3G59O/yZ9zF84HT7UpmlrgGlrxE766AHYO5+5+b/7++/hADXW3ONGsPZhLrYpeY9j7Ne2Or6lg4WYI+vPH6UJPh7/orj4t7DL48P1r7+Hft0h1w1o2kGddo0aWL8LotyfC/ZUjTunS/8jIo7cGaOSBXDCdu6N7jplvX6PINbgfwe4WsvQ8pQbc4R2/d4xqMYytd1cHS5q6NoCVCduh+gX2EXES/0ud5+vARxahaq2n9E0sKoJVfNE5UHznV7K/thqfLuFtIExxrT3ZcFQDazSLRpdMNn+ZhdR/mYg6b/rzkXr234cm3tDBrRdjOV8lopNv//G5fWF1y+fWZdF7t0a5sPMNE/4wWOdos45QwpCdS5OqsWoB5+a5kkHAuSEHRzDPJKeDpSUCdczizol6YefJNVlGLGqvdLf/86U6wBWOifm/uNtBPVsv9rCbXe0m0NVVP7x2OeQjLusu8YtNab71c73HR1VwDKxj59qF+SZ892c/mZo7rHC/bvl20/vadDfDvLdHtS9Z5mCBv3D6rzsFxXEqJ+OB+Z54sePTzyfROTVIIBrTlHTGTLb7ULQikSTt7tmRqUL62+jdOgYAsbAdnmFnLHTETuIZou1TitKxVYwwHlPTomwrRIYZQn4B92RTxq8hG0T0ecttGpnpRQVCd6ZlNUmFgWwcpRd9xjq95Si/k079xsBOyjS95kRPjRunLDDwPz0zHh64vmHnzh++MTzpx85nJ45HQ7M48hcNsYSGW4bbsukUsEi2fF0drd/1eGoGxamA5xEkLJgEDHxnAIlSwqL0P5V9NYK4yngCMYRjCdiScZKwJRFt6BGNc2hVoAmbBsFw+12xW2eEALOe9Z1YRgG1vXIOA6k0xFvtaywl1SYumHhvACGv/3yCyVnLuczry+vAio2gVYJosXcG7KRlBGbazvsgS5FHcjyRz8ZioylkquGQtLUw7aiyVqsi14zU6VoiXIV8i1S3Sp3P20z5js6GlEpSdBbbYYT/49aLK2Ktpai5qcyn2o36sZm9Xis21OF1lj4/ZpYomg4ZV0D17j7Ur0uTl2+lpiBiDMrMRWOg5agHwrTKCXmx8FwXizLZ8t//wf8/XPh1xd4vRl8ybrLLT6UMwaPkYCrB2q8BBkCFgA5E5MhaMrbqBtHx8FhgU/ziDWGty0CFSAv2KRtkgrWZLYU8dYwHzyDh4+nA4NPXDdYTSZkqfwYU2LdVl7fBHg6v71hgKfTSXw7FQ5POWGSIaYgwZGJxG0hbCsuig5ZTSOtrtDeI/vRzxlMZWBL1dSagthsXgda6cKm/kC1q4ZKszKYxpAuuYCRlJ5cZM5Z73j+9JHD6cjx9CSFKJ6kAMvryxeuy8rr+cLb5YoFRrdrO43WMJjqZ2iwa41W/Zv4+PTEYR6ZtY/iukpwd7sRU2RbBHiisc0Kt1j4vCW+Lhs/v9x42wLn2ypMR+vAeeww4bNlSjCQMaYCatqyLRBorjZ1Y0LAHtPmWdZ2E7tS55XZK8/1XaWToIsgWm+W6rCXfeVqv4sAKvtrvb0qDyPh+zgeyQl106IBKVTXx3SdRPed+8D7G/Fldt+1VigXDd/Y5AcaMFTvqQed2p/7OlV/r+HGFjY+v/yd1+tnPr/+jfPtM+fbF9btwm2RFLs6CJwXgLuKz3trMd4yeDBZUjZLzqzrAgXO5wulFE6nIzkXDm4WINs6TDE4JwymRLwDD/QhxO9wDuPAZkvKUcasXRV4y1AyOWQMdi8SVUS/aNsCYUtczyvbFrmeNwEWbGY6wjEb/OgYDrJRJt8Wm1pd3RoDQtHiF9W/E6ZqBXv2ca/xpRG42LkixTLEPBJDFkBpy6RoiLoRMDgwzpAC5Ai52nPd5BpnK5uMowB9a4gUMssqDPzBOyxW9KuMaP5aVxlPhlppeN0CYQvcloV120RfrqTGdqqbDbWgkDV+9wuRRsk5soUrKQfdpA0K8mvdSgPFFEK6iR7ncGAaT7v/czd3Kpha2mst1c5U4/+IV9zPv/6lfYzX5eL+8338XWP4NufUkMrWeenO8c/7Xf8C46kHSR5usC6Qjzf98P0acFEbrAET9fsdiMLjUnx/6feQv29AodI1UkF2UnMPPNXqTBVUqnTnumv6sCtl7oGnntnTAwS7Qas3+9gupVsAv223ep167NXvyrcdrIBQRY8rsLSzYFzTH2opdtUZ7bRSvumtukjTo+ym/YhoY9ZUCtM6bNddrwv9Dj7pSepwvQ8Q7tqU5hi0UdN2eA0VxKNIWeQUAsv1wu38xtuXz1xeX3h7eWlBtbED4zQxThV4sgouZkiaQuWhCmbUNhbB6bpLILdlvcVNnvE0ES4L23IRoG/bIBemp2f88UkYUB1gWR+xGo86LuWRbMPydkdkn/i17ft+6PultPGhBqZDsPre3fuz79dKl3xwdr8j8EkC2t1B2YFaNegPj/otZGQePvfHbbNjU48n3cdA7et85xh3Y1+bX3ZMZGzM88THD898/HDiw3GqV2qaNyYLu2lbL4R1xZIZ/J43Hq3soCfQz8uFUgyYktmuFwCmbcEYix+POFOB8gFnnQBPToAn5xwpZ1wMcq9Gg1IFRsImu9jOC+Mwg1YOTG1xr7YLdRYr4JSi2GYR/w97g9DNpLba0YAPQ2XfaAdbB87h5xk/zxw/fuL44SOf/vrvPH/6Cx9++InT00fdrbeM2xs+3ijpBVLhVoR2XvSebc3/r8zY9rPbRamKIkpZplaxy4GSAikFSkqq7WRIxZCLIWKJOKICT9lApqa6VWFLtR1mT8OJusu/3G5Ya1m3Fescy7YwDiMhRuZ5xjrPNA7CjvOOwYrY9zhNAjzpODu/CeOJ11cKPQDd22m1F8aQjUF2/02zYaaCTtzvxvX/pgKRVddJU/tK3oGufa0VxzTqXWTKHiAq8FQDjj1d9vuxXbCvPRWsKOWhQlbZ7VoNBFrPmf0cJe8sS2ckBSgWAZe2BLcggf6ahLEzOENUQeWqNddEm/XcaxLx5ZILS8j8dPTY4pmGzNEbpgEGB9fVsNwM//Er/M9fCkswhFg42MJooGhU71CB51zXTbm6s4ai6b9Jmbo5CwPH2p2VPXuHNfBh9mBguizEDCEJ0O6TCunGgjMQYiR5rWrnLU8HgzGJaYhkImaTdJWoYsDny5nT3nzQlAABAABJREFU5czlemEYBh2uBusdWKPaJBJ01JS5GFdCWBliEGCqONoe9Y4+UdEjGcI7uCeX6Db9yh5IWC2YUNqixt18y+08DWahFInWipUUHGz1n0Wo+On5A6UUnj58FO1A76Vi5Offua0b58uV6/Umds5ZjsPAcfSM1uANCmxV0MwyjSOHeeL5dGAeB0bnJHVp26Ry6roSY2RbFrFxKRFTYQmRc0j8et34ugZ+e7txS4Vr1BR2YynOY33BZcOUMq4kSfuobVtKa9/qb1af8nETsxQRQt/BbPmeNbumUzezaPFBnX90mFTzf2kAFJ0fubsSOwhFP+S/k+Pen9c/Wqx0H7e9u2la2/mdeK8/f2v3WhAjd6Li9UdfNzrnqo/ff792mqyxsgm2bgu39cKXt1/4/eUfvJx/5rJ8ZdkuhLiwrqLpJECEYTBWNLuwKjLvsYB3BbwhBAHBtm0jZ7herwAsy4KxhukwKWDjsYjPBSD1OPeKmzK0lfFk9rT2lEcoVVs4N73eHGUD1pqaSVE3sKQS3PW6sC6Rt69L86mOweJHyRIZzYC14KgpurphW/vWWIztNgRLaczoHngqefcTjIJPlf+Rk8zbtGS2DbabIQbIAWE/DgLsKYlc9KZ0J8ZYwzg6jM04EVRji8J02jbZIPVOqpiKPIKmSddiMGhxlZSlTdbAsm4ieZADNdVOgCdh8FpnMYgWHsp4r30kPzcFnhKFJP6zkj1SEb0nQ+E4P1EOPzAOx2+Bo+o/v4OzvAcy9e/fzZE7/GEHMCUVv600D/O1utoaK+kLMl870Km7zj9z/POMp1yo2/kG9tzDUu4u6rp0nwYU9OeBO2aMqzve3yJG3esdzb/LW6zMhf4yd4i2tkrOUi0na6pDc9rMLhq+ixDuHXC3g66f6JHBei/fdLx2DObxnO3OweyAzD2lrRrkCj7pjKxOePcblAKP5jJrNZIYVnXqA86PDNNBaIV5BJCc9659mwxdXbBRJ8TapgEgRkNmeG2rWu2vB5b2qkj5m36tBr/+fUe+1B312qaP5VdbgNlaRBzhsC5stxtvn3/n8vqVl99+5XY5k2PAWTg+PTGMI6cPJ4ZxxI8DVgVE28QrVndE1KFOmRhkNyBsVcS2U04riCZTSuAdKSeWyxnz+Tesc8yf/sKhFPx8wM1H6StTU0I7oLQ/oT6c6X4LQ6VDth/a83Fc7UO3jqu9fyogSaGNnR0o3Z0CcWbfz/n9sx61nUSj7e6d9v4+1+qvTr+sOax1nN+3+90a8fh2s4W77XywdDqSTS8/RdUKEqbTzI+fPvDh6cBhHnHeEzaplpLCKvRxXYVLjDjADVKlSdPwWUNoTMuc1bYU3d0lsVzPpBQZjs8MMTK6QbWDBpwvyowpTPORUjLbepTAT4XLtRaZLEI5C4CUpDR3KaUFRpld00emhXqdVYshiJhk2MSZi0GYVcIaKupp1NVOwQpT9jbTdsM4zDBg/Mh4OjEejzz/+BNPn37kx7/+Nz58+gtPTx84HI5MRIaSYN0w4cK2Xki3MylswuACcaqanou/+/He46ykmThrGSzYSrlOlTUVSVF2YWMWGxqtlBAPxhPtAP6AKRZHwmPESSqFUqsNGtOuL+xVRIBzXVpQaqzFLZJ6t4bAPM/kAod5kv4bB+zhgLGOaT7w9Pyx6QlQCqenZzCG8/mNl5cX+koqYh9kDlTWzf4j+oeNXRMlJc4EJ+CQ9fiUcSlhrBMthpKlf3VHujKTd2q+kXGhRquoUHVB9Vmg1UrU29O4/H1H7M96TG6fW/UoBTRbvAFRO/NJPuPUPbJ2T40HFam3iAC0NlxUllPMhrcVLSRQAQydokV28se6PhhNucuFJWWi7uzetshWDKmA+eK5ZsPXtfC2FX59saxRtEsEoyhECsEaNmOZnIBPtXx17cnm33krqXOaUrEFCQgW7xi9kLoGa/kwSrD3PHoosMZAKoWQjAg8W6lCtobEYMVnccZwmkYMidMUMcZyWVUbJGdCDFyuZ97Or3x9fRGQd12lep9xhGK4hIRLhYD4qt46bIxMIWC3jWFZ8cp49NYyOEn7z8rIyKXg2AsUeC1SUJk4pQn+SUqrmMECJu+gYOqrdakfAEjLiqYVCtShG6/GWubjgQI8PT9hjGE6njDWsS4LeV1Yt8CyrqQk6dtP88hA4Tg6Dt4yGNDSPBiDCiZ70SI8zMzTyGAtKQRSjCy3GzHI7xQj2yr2dguJJSZebhuvW+Qf55W3EPnlurLmwiUmFR93OGvwVqp9HuYJlxM2W4ZBxnj1c0E2RY0RYHMeLKO3zF7+HVLhTGFrjD+xdRJo7wVgmgugcykXSMWwJtGUugUBc1ORtX4AshNAztdwRUGoiiNao7pgxtyBxt/VocO2z3iQbsmUYnDuIa7rjvcCa+fc7g+3sV6FxBMxbruOb8ec7LMHOvSPBvayV3S9LheW9cbvL3/j9fI7X97+ztv1C0t4JeW1Aco5R3JJWl3cUIpWgTOemg5rrGUchG0TNkFLYhJ7eb6ciSny9Hokxsg4jZRxZHADGNGHqsB6jdNag5q9cavf7v1AzgU/yO9cJJ5ZroGSBNwxOuZE02lj2yLLsrDeEssSANOKJ6RgIVm8tRQ0db9EsjOtmqo1HdunNWtNedNiK6rtSDHEtGl6/K6DhTHC9k4QbCHbQnLiU8So61ByoosZDSnKNZ13jN5QyGzJ4WImFPE/r9eNEBLLIjso82Ao1mKtx1mvjCf1YEpmWwMhRM7nK+sWuCkbM5WEMQXvrT6Tw1oPxWGMx5oRax3ejm1DKJPJJaq2VialjSW8MRTZTC3K5n+5/Yb7MvBpuwKGeTpxmD/QkxZ08L4L7vTz456Is+MP/Ybc44Z7jevrXDCtINg+pwpg6a+z/9F8QPdYmOiPj38eeOotrtGbqKADVTjLtBvRac5jigQahJgOhfujoLogQYw04L6zfH9f9XgM6fSuiwAEOQZSlFKxTeunThbt4CrgWHGUFhjpxBYs6R4Iu0/v2HeaekCpRxxbkNstiH2gW8Wd+8f59jw9MKXX1eAsxY24XsgKQPlhwppMdgOOBAhdG2PEBW2Dry4EHQxhDbYoI6HsfWIKimB/Oz5qG1bE95Eiuz9vDcPl30aFS3s1f6Cxt/bv6hgzci2pYnfj8vqV88tXzl+/sC5XSk5Y7zmcDozTxOF4wA9S5Um0rkpbe0pOJNXRyKVIdYQlEENiXbYGQNXgxlnHODioosohktZFQEwNjIejINd+PuxP2huOUt6puriPBTpg4G6c7d3T+q3vBXnNdOfaDUjd3anjt++M0v40jXr+vRy5VNC41wGqI2A/ejB3h4RoaNI+Du+/V0oXGH1jgvYFwIDSYksbC3WaixD13u7WyWI+zzMfP3zgw9ORD6eZwXtNT8vEsBGXK0mdLErGYrW8tXwuYzoB1dSxJ4GSFbQqbLcrOQa26xkKjE8fMSi4Yiy66dbYleM4kzUYy6UQq71WO5qiLPx+uUlrWbHhuAqY1MBS26PI5kAKGykGtuUq+kbbQoqRsEm1s5Jkt94o6FQ0FQY05dk6jPNSkWWcsePE9PTM9PTExx9/4sOPf+HHv/yVjz/8xHGemYaJIVywcSGWQI4LZbuStpukxiWtkmYMxrimF2WdsIac86qj5Bic6AVI2exCLIlSuh3XXCvGCWASiyVjScaTrIdhFmp9DqQszjUlk9XJNqguQQWeKCoQusk4r+CmtbhhIEQRx7TWE2NS7QeYppnBSWnz44l9LQMwlsv1Qqbwdn4Tpa1I5+BKH+8uZtnHv35GkmySMvZkfBjnJajORVKdNThOYWsbQzQAeNcTlCmRdc2Sa2cNzjJVsWb/X51n39Mx6DIt7K7KNlZbYwBTdsHqCtiYvR10+LbDIKCUrxIi+snNSFWuLckOqAhky2freQYjTKgalK9R7mvLhVvOxJS5rQbvHIMzlDfLLTt+vsCXmwilh9qB7GlN0Yluk+gumf0ZFDCraU6lqAh0kt32oEUMtmnEGJi92L+TVqk7DZaYdJsqF2KSVBCrz7aFTHAa/FiYh4FSHIcxkoqky0h2XCGmyPV25XK7cL68Mc+zVF1KiYQlYLjFJCl8pahI94hTrRAXAuu6tc08nMPiFXQqjQ1d/VJnrbAdjKaAqF9lDZLwUtnZ4njJfRaRchBgr1/vtbZhXX/I1CqcAtQLM8k6yzhOOOdw40zBKBi0EUJk2wK1NPxxHBiNVBicnJV0tH3ESRU77zkeZo6HmWkQMDCvKykEtnUlBmE6pZTY1o2QMtc1cNkSv15WXtfAz283LjHxZQ1sOXNL4nc575iGETdLuszgDCZFbALvMtaoLpz689WGemuYvOU4OgZbmqh4yoWYZQ7UUKzGOdW8dVgFmJqSKoBmLrAmAYQ1Q5VZwa/kd3Hx3kWo5xUBakBry34vxx6zAMU0DdVqq7OyXx5jnKbhtJ8J8c0eNmJr2mjzcbNuWG3IxlRs/de3fL9WiC3dq9xVrcHbcuV8feG3L//g95f/xXX9whLOZDYKkZi2Xf+nZApW4phclJks1easGmbvHJJWJlp1MUQFR66klDhfJOXu+cOT6M7mQdg11uHac9f5Xtq97yGDsJm882Sfcd5hFeSPMbHcNklfW2XMewVrcg5sIbCtgXUV9lPVq5w2T44WsscZ31KiSzZEW+PB0lLOdkKBDHSnRUVEu8pWy44NhmgCOatguTI6U7EkDN5mks3CfrUK4gAlO0o05GjICbGTzjFMFmMTU3SYkNhuwla/LZJGGDZZVXKC4sWXa6Litsa4hW0LbFvgelvZwsa6rSRlK0ma3aCFUoTlZHAY43BmwJmB0c2NeVZKIpaNVCJbWkkE8Y1KwliNd43jvHxpAOo8nDDWcpifEbu9Bxalmwd/BM4aYxrp4xGbMNWHo49T9nlVv9/8hpLbhgcUykNs3uZsBZ/+hbjxn0+10xu1dqfBAxhru8VPWSB67Old3Qn0qfub7VlN8nbnQNbdz+6adw/9AFY1VoOBHDW/V0vEGsqez2lrukTHdtKfivg1kVjur62Pqil2u9GrTni9+TsDSU9vU0RSRZ6r6HcfE/bR7OOzNoCq3XRpQFMKN7blhRRXwnrB+5ESL1g34sdZgjI/YN2IcTMYjzGeYum8WXFkGnhmumdsCKf8t+T7Mtrt8c1eErJ/hjZw+3bSheiROriPg7pyiBE21cnWFKHl/Mb19YXb2wslBZw1HH/4yDRN/OWvf8GPI+NhlvZ21YuQiehdjZeyAEyLGJ7L640QIst1U52b1MA3awzeWUlHsFYc2Vwo6kClItVwjj/+BKXg5gN+Pt47HG1AdfBH3yZFjKq1D25I9RvvzrWzw+pCVNqKalq3yljvr/1g1BoQargf8H/yowKmprri37p2tW8b5te5mXdtUyd/F96ark++AW9NHcdGi+WVNp8qq60GVLADr8fjkdNRRcRPR+bRY40RRlDJrLcz27qQtpWS1LYB1hutZGbugKfotIKQGhkRChYQOhUReI0pM769kGJkfvoo55w9WKM57LYB9tNBnjUlYaSEXFknVk1SpSyv1DFulDVUMKo7om2VC+SoaRYbKQTCeiPGwLbeGrhckginmxpopSibCUqvb6CQH0X343DCH04cP3xgfv7AD3/5Kx9++JFPH3/k+ekDQ474spBvXyi3V9LLz4TzF9bzV7bbmRiipthpHr/36kgNGO/FCfEKclmrVYmEeWpKIm83SblJUYNLlZXLkpqYjCUbT/Ejxs8MhxO2GAIL1jrSdiSFII5rW38tfhipqX6lSKn5UhRcNNIHko5k1WkQZkZMidPxSMEwjQNPhxkKDOPM8elDSy8pwHw8Aoa3t1deX17uNgBM69EHB0Z140w2TbAylYILjphEH8yr49avWxV4pEhKlawPsgbXVKGaVveo7dS0OHiI6L6j42mQRwtZ7FdIwmRMupG/p7+pALIG014ZUEPdiHRihyr7qQowF+QFpynzJdNsUyXYVFDxYC3Pk2MeDMfBcN4yb2vismYuW2JLhRTh62pwg+dsPMPmuETLEk3rv5JkvkfVMDMlsUaLwRO9ZTaZwRS8KVj2RDFvwRVDUuZTauyEjeAdZh7w1nJwFjc6fjqMDFa0npaYWfX5UhLGU4gQQmFdI2awzF5S+p5nSWeehwGAJUjK8BY2bsvCy+srwzjzdrmS40Yohi0blmxkE2ALTOMIbsDmwhYzbBG3LCKInzJ5HHBGguWdhd+tKwquWOtUfFwsTAGybj6WBEKVNbsWGPVcNYVf520VFS5oJ6sPp8K6bhgEcBoGvabVNJ2sWmxS3WkcPIdxYLQTI4XRWnwDZ8RHtM5xOIi209PxwGEchL2p+n9x24hbkFS7bSPExPm2cQuR3y4rb8p0Om/CdNpS5paSjkXTKsBJNTxhYMUiY8Max4rhpmk9tRy9sYbRWkZjOI6W42h180LsCUVAp1jqvHjwge4cOPnnpgzPqHNqiTIvk7rvB8ENUfm6b0EnIyCoqxURe8T4OzkkFtCoocVTvX6taP31n2+xEygoAPC+eLEATkn1nIKsuVqFrI79Pi5pGRotZtv1n0opXG5nbrcrv3z5X3x5/ZUv57/xtnwm5ivZbKS0CZOFLAWUqNpFtXKvrI7OiLi0FBzxOC++3TgJyyaXqOL6C7kk3t7eSCny/OFELgk3eJxXn8bQNHqNEYH0PoIw6r+qp4W1jnEcSSljpRqFADBr4nYWraHBG0TjTTbZty0Qo2g7WmjVNr0dGPzIPBzARLIdcWyUfJO5Y0tjaNLuzGCKwXsvzMdhwPtK9oBtWwlhE9Aup1YJODpLToaSEoMrbA5igGveiCZjk8z8Cu6Mo2ecPMOUKKaQkSqkb28Lyxp4/boQgm7Iekcp8v3K9kypkHIkbFK97u3lzLoF3s5nYgqEFMBk3CBpdYNqBDs3iEaUHXB2YPQHvJ04DE946xj8RCGRSiTmjTXdSERCWTFkQrgKcaFAKbIWypoLa7xhjGEeT8zTiV4O55FVdocnPMbY3WcqgabcrRHSVzVurEhmZYbW+Vk/9968q3Or6PnMP2m8/uWqdo+I185WUgp8MyBaqUTveQ/Mduf1HljR4KxDtO+vuX+/5rv3QEx9rz9/1kBFdq6D0uPcXrq2/tSW029WoGNHcO+Px/SxP0orq/TBXUC93H2/GmChSO5sq/06+7ke0f/GakGc75yTsJ3CStyuxO1KuL2QhxFTJOWupAPWj7hxxgwZ6wYwYtja6bPQQKsRq32RS1FkrCKOe1tU2vx9f307Ce76tQu+eee7e5WK/XUZU6olosm9kmp3Ybm8sd6E6eSs4en5xHw48PGHj8Jyck4dhJoUlNU517GXMzlm1mVjuW28vV4IW+R2WZvzVX9bddKHQUqXS3qNI6WNuK7SlqohNhyOjBjcNMtD1/HUA0il+1UaxkZdqOvYeDzK3ZjdYZKGfbTx0X+uRRHdee7H5R2S8h0ce1P0gfPDJ7pOaaCT2oYGDT7Mwbbwv9tUtU0rktVDWXXm7osNprS/rRWm04cPH3g+HXk+Tnhdb5KCLWFdCOuVEmXhFpq+aWk0Tp09g2S0e807cFao4I0lqeMhhIi1ifV2gVJI202CnlnSLoqXnR0/TC3dqw9etyzy5v2uiKTcVWUCsdvW+eaoFeTLRSJBAR/a891U/+NGWFeW60WApk1y4g2FGLa9hHFKQudWppMbZ8anZ8bTB06q7fTDjz/x4eMPfDw9cTocMbdXzBrY1jPh+oV0/kI4fybczgJ0FQnynBMmlVU2lTCO9Leyj2STIktwlTZKjuS0KdNJK1uVmpohIEHGko2luAH8yDBKQYIhyrgYx4nU7cbVdrVOguGqaZS1slspqgGlJY8xAjxlLCFEcjGkVBiGiZQyo5cKMYMfmA9HrSJV1HlOXC8XUs68nc+YJLT8CkD0BqxQ0YnS1lSTReA3KSs05YzTlJiqp7AHxaVVczI4SQ3LRQO20tqtptbtujXd/+6M3vdju0CC1wy4vGvENNYTtRAGugOsTp2aeWvR8vbCXBLRenRzRGxd6T4rdRh6n04vpAGxs3AcLM+z5dPsGKykMMRUuG5yLyFlLsEwBIfDYYNrY706W6mm1sYk2lPFsjnD6KDgcLV6UBsbElw5I0NtsLKaxSDV6ZYQiDkzD6KuUhk4H6YBg4iOF2DTakMpG2wqxFgIrrCF/z93/94lOZJs92I/fwGIiMyqfs455OHlvdL3/0KSliRekofkPLqrKjMjAoA/TH+YOYDIqp4zwyst3Wn0ys7KzAgE4HA3N9u2bVslukqIyug6DYnShCEGSq0bEFeKaj1dbzdOtxu3eYZWyeI28Em7LGWa84wCsQm5NVwpLGtWMFg0UVBj2NZ2B4L0cKYP47dkryYveuCx65r1nzd/2n6j7/PbOu3BtgJAbnum2oRBkwohalC1+ch036dtIF8KnjFFTj4xICTviJvPoOf1XhlU0zhwGgfGZPtFa9Scle1RtOSulsKaC7c187pk/nJd+LJk/vvrwi0Xfp1XBVpF9VVS1ADXo/ejMYfu1c1BdIEijlW6n7hP4eh1TKfoGYMni5Z6dg20Liq+Datj12Dk0cI4FKgSIFf9zZK7fdc1lyskb+tsezb7yftj1+Y9zsp+fn/HsSv2V1Uu0ra48SsmB+ws8W8cG+Hh0DRK91rTMVMxW32OX/nTPXGh8VO/nnm583J94dOXP/Pnz/+N6/oLS36BoN3eqijLSQW41b9SW9ybV2kyrjWPcwI+ASZG7RxD0uR5WArSRAGY2rjdrog07ve7djC2qokQVAjb+6CJHdfFGWwMxDzU1oz5qvcZY7T9NgCOUhrrWrjfVhyQkzJXXVDmlXa3s3hOJYuMiReJfmCIJ/AFfATx1NIsHmrGxA50KZoODQ9xIMXEOA6qMWmVMtEnclgpNW/Na7wz+YEKtTQCjeCgRCizs6ZZ7J0grcwupUBMYk0vtOHN7b5yu628vS3UIgxpYBBv16f6TuB0H5LGfV7Ia+btemddV273O7VVxGXV7QqeEPXzQteFclEBRZ9IfiSFiSleSCExpRPKtizkthJrYm2zJiGlUctibF5v809HTUQIIXAen3QfSyc4SgK9Wwe/BTwd//5t0OnxNRbo6DwyWuY2r9xvM5oe/a6dyfhvHX878GQffgxSldHk9os0634MyL42KDvAtBseHi74AUB6b4i2zfB4w4e/g7FwrJuQZcg76NTBpH0TeARSvjG2h9fuP/cN+VsP4/2vnP3y66zsI9Okg1zb5tYeH+MWeBw0eHTOdLBIhWxbnmn5Tl1fadnTlldCTKRhUuBpPBHHZ1LN+HQhjuCc1qpu4Kr3e+mPxc7Oe+saIRow0sGjd+Ml9pwcm7D5+y4Ue8kZm74TGCPjAcXa/3HcNMoys95vvH35leuXz5TlDjVzeToTU+SnP/zEeJp4/viM8561d/OyeROCUs+dyAY4LffMl09vLPPC65erMp1yxQenHaG8J8adcRW8BvQdzmlVtaBkXWhvV2r4E7lWLj/9gSdpG/NJn2V3wvuYvQeMvvqhjwI95Hr8wyEQPK6dh03bPbx8+4g+6XZ096vP/T0cx1sFeOA/yfEVx3f0f/2NY/Iw1LuFMZ//4XOP5+2U/vP5zOVy4cfvv+f77z4yaFqXddEy4WW+kdeZVlQbx/USu6AZHBXZ0e9KvdaSrBgUsC01PGxgzSkI1NCSknmeaU24X18RgXj6YCxR7SCEDxZAaiDUGa90hyeoEGVMA3sLakeImqWKMSLoWmmtWeBZaaWg5Xaqh1QOJXY1Z/I8a7l0XvV1rVFLJufFsvHZ6hMDcTwRphPT80fGp49cPnzk/PyBp8uFy+nM5IW4vtGuvyC3z9SXP5JfP7FevzDfrpqRr5rN7DU5zjucjzgfIQ64mJA0IiGY0LYY5b7g8gItU9dZ9SKKAkPF2rPn5mlOASF8JI1nGM5wvlBFn0fOWR3yklXEuHWwRY/WGi1nc2607KhviYKBC1XANXIuOsPus5XswOU0kXNmGpX55BBCTJyfnsH10kzHME6qQ/H6yuvry75Xm72S4zwWdnfYvnmne2QrFW1dHPbkwTHwMsdTQtte5xxbiVGxdvS7aGfj2C2xd+yU4yD9To5TVNuxus6k0E5lwWkw7qyzTwegao+11DUjqe41p2S2RxxFlJ1RmtCqAtXVCb36/pgE651eBQWYlty4JC1p+zBGTilsgfxcVO9mPI04Wx/NqVZks05TYsktJ1YyK6I6SRXeXKMUjx+C6nsEZ2zsXQsH9Hqdh2x/W0uhtMrr7BhCwI/KEP0wRqKHn04DU6yUu5ZrFQOfSlUB9TVXBt/wNKILnFOktsZpSFoiOmsk1qqQc+U+z1xvN768vCrIX5VhmJIK+9ZSEA2dqOKVrZYr9XpnSJFaqoI1pxHg62ToAYPafD6vTDfX4wRnmd3jfLd9XNeUrrXWO5puaGRkq2Hszp0FYVIdzlcFrlvbOnpKa8QQGFPi40VtaJqF0CrR9cy9zrsUI8OQeDpPnKaJcUhE56g5axVCzvZVyDlzWzJvVlL3ZS78ly83rrny621hbbIJwzsDrDt45jpLoGotsGDdBUPgLoW2NiKeZG3pz8OetC5NeFvqBqpNEYboyM3WhBiA1FRPbutWux2P7Onux4uNZfI6V4cgDN4RnBzKk/dziRwYiwLuSFv7HRxHkAn2uHEvpXuM8/r3Hi/sLHW297Ml+puVsVcr7S+7tpOxnXQ56MTsVSfY1/ZvNMkxrzPzMvPL5z/yl89/4vPtz9zLF7LcqG7FkUEq+K5J5FVguhlIb01DOgu3tJUmHk8g+K5f6InJmcZiVD2iVRC0tK+2wufPn1jXhWEYGKeJS9AYJsUB57zdIyavIAammN2wiaXJxkiKiWEYyKninEcarIuWH9Zm7NjQqK2pvwCkITAOkctl4sN3Ex8+nrhcRoY0mk3zRCdEX6liaovikNLZ7lbK5iLIgGMASdCSTQplgxEC3iVaqBu4nqKCVzFqLnJdGrnoIpzjSs0NL57T08D5aWA6JcYpUZ3Og/uycrvOfPl853pdub6qgLu/BELwxjgX5rUQmoNZk5Zvr6+sa+b1RfW2clnACTE5QnQMg7JBVc9TwaZeWpf8xHn4wBAmLsMHHfcwmg1X8OkkZ3JbmMuF3FbmejP/qdLaQkaYs4Hjr6pL+ENW+ZYhnRgHZaBvXaAPGMlXlVS6cN5hKHvk08GijRH7Dth9MHMbcNXnWD/NMdn3uGb/luNvBp4ewrFDlsXJodTu8LpubLpGzeOx3+T7i31vaP5tlO14TmcD3mhFdTWk1Y0y6I1SvA+i2y9Y+jV/fY27AXu8liPSuD8PeQDfjmPRS8r6i0U6RrhTycUc8uOY9mzN16VoQEfZpalRbIXWMlJXWr6DCFW0zEHyiI8jsZyQWnA+auviNFm5fziMI/QLPWISKgxvwN837nXbhp31DnDa6aGXQR7H7ltHk7Yh2jZ4+3dbICJCyQt5mZnfXpmvr1tAOk0jwzTw/PED42nidNESt3ZftD24aziEFO251qqlQmthWVZu1zvLfeV+VVFkjT0jKQZiCkzTYNejo+P74u86EAiUgsyzZulyxsVAOl8YnSeOE7uu2DuMRw7jtzEIto97nH+HNXCAkx6ewreOLbHaZ6Nja7qynaeDYL/DY8eF/u17/KYtOPzqr7//EYDXHw7r+avT6ZwfxpHn52een5/48HSh5UVLOXImLzP325V1udm8awS0FKUHZ9jvnW1rDrVP0dhP0YAi740e7pQp1cyhX1ftUpdnbfEqJlqugU+wjLuVylnWaWvn6jyEhAtRhfWDZxy0I94wRGUGpmgaUNoxpqzZsuArItUaJFRqmWhFtRpaKdRVtZ/qao5l00x5ySulFkrJ4LV0ME5n4unM6fk7pg/fcXn6wOnpmdOQmIbIkO+EsiDzC3L9lXr7TL19Ic9X8jJTTDfG+WCAoIF6JmjrfISQ9MsHpGuJVM26upqhrtrMolWkOdMCaVqG0cR0ipSPFtKIGyf8ONHEUaruWVLLQ0fBDrLUWtUrK8Xmk+yPvs8ykY2l6moDCs6vmuFrsnX8rPVEipEUVPx0PJ0IMVBKNXH4hdeXF0opvF3fttKUA5FvA6C2fflgx5rtD801y576Qwk7OMsCq06WOc19v8VtJX5deLl/3zQ5tiBCP+/bvsE/9jF2tQIDnmQDBrV6rlmAvGlfyV7C282Od2wBcHBCrtCajXfV0i3vNXjyVsbfZB/JPqy1wVp0Dnm03E5ZlGp1rtnhC1oOGpPZF2+CvSrFILWiFe/9+VngI8LdKVNg8uDwpO5HGHHHo/tgsH0seNVUWVuF5rivmRoaT0nbi5+SdbkbI87Bp7XQcHb/ej+lKqBWa9tYVWP05BoYYmQ10BTnTEOpmtD2yvU+M4TAaPY0hEQLjU242wK12hytNPKizRI8UMZh84O8676pPegD8qQJ3t1vbTbPdS8/IE/mM3ZAt5cI7224u2ZaeLcB6fu1LLfRwu6n9TJmULZsjIHLaSJJxdcFV8FX3Wc6uBWCJuimceQ0DqQQ8Agta4KhlboBBqUUlly4rYVP98zneeUvt4V7qbyuWZl5iCYtOh4nGGgp5nhhu6BHAojzZPHkCgOO0SkTd0yb9DlrViFxZ3tlcDBF8E2ZhUthB4r6/v1u4+7n2r3k/S/aFVJB3+h1rXz1OvdoO5WFvFd3/B6Or5kVj//eknHb63SUeqzgt3lvYyfQGUqtaVl7r/ZoVefV+6AcdnbtFqOZn3R8HjlnbvcrL9fPfH79M9flC2u9UWVBXEZ7q1ZNRG2xjajukDjTaTPgX8QYM8qQQpSJB1GT3s4zJI93ymLXkjtlb79d32it8eHjR5zzqsPo1baA2ormrOkGe3z44JQ6Z81PqnamDCoYLqLMJ2y9eg9BZEvi4BwxeYYxcr4MnC8j5/PINKnYeRMrnzdNIxUXKAq8bZpzDlxAXAQSjgSiQtxdx9o7Vf/33tPMv9Q5ENTuJz3fMlTVp7qqxmcNGh+OU2SYtMwuDgGVKlUt3nnJXN9Wrm8L95uC0qdJdg28JuRSzfZrue/r642cM9fbnSYVfEEx7LDZM2WDBmOfKdsp+oEURsZ4ZogTUzorQ6xrSG96widyWxnCwFLvsEKRwtoWGvr8tSQz8HbXCqQYBs7jB5srp3exf7f5si2ijkW0w+/er8F9/R3jQGxva4f589VbttfTdah5xG5+K6b/1vE3A0/e+wOwwiaY1gPw3p2uNR4W/rcZS1vY+xAqf6s28fF9j3/bBsI24taKBillpeZVA51h2MGRfv6Ha+rQzzsQgF5fvG8te0md/mGjP8uWSwJzrB/YI9tY9Ovd7gLgnRDkbix3ZtPu/h0v0Xun7SdNRK8WrT+mav9JJ5lWVuo6Ux1k7whpJI4X0nrT94xXal7wcSLEE/iE82nP7oscnpMxrpwai020uY9tv7sNLDpuFvLtiWmA2vHGjsywPidUZBO7z8z1y2fuby9cv3zi9vZKqxpInZ5OTOcTlw/azS5Ey1jGim/VdC4aDnWEc1Yxvevrnftt5vp6o2bVDEgpMI2JcUxcnk4MQ+J07lpRpunStbEarEvmfl0oVVQ3Iq/kt4b85c+ICM8//7OyRwbVoHkch3dFcIe58uiGGn3YhtnhNq0wcftG1LM7RzaA74amO/247Xf7vOPhWfx+j23m6vEAJD06h998b3dEvzrnwyl/44dH++6cY5wmTqczP/7wAz///DPnMSrNuFal/t5u3G/XTWw7uKZqH+aJ98CztoKrspXv+qDghvfqDKQoOG9r19VNu6zjyFJUVPd6u1HxnOYbznnCSYvDNPBXhoGAMqDQ8ppeDuV8YDyfSTFxvpxVYJZJxTXNPsakzkgIKq5bgrMgIhmwNNBba0utWlJoTSKU2VkVeLJyjVKyMY8ccToTpgun54+cnj4ynS9MpzNRCkEKcn8hXz+x/vqvlJc/Mb98YbnfVOy2ChVHc2EHiO3L+YgL2inPhQGiMTqk6ZqsC46KMzGnDtL0EKaacG1u0DxK0w6JMEzE0XTgLMispTAOA7UW1mWh1sayLNSq3WfojB8RK41iu05vIujB2Gd9jypFbV4t2nWwlML9PFNa4TJNPD+dCGiJ39OHDwjKWPZeAVEVQr1yv173QAmDNx8CCdnm+Eas8H2BaXlnz7Q5UdZCtc56MVa8CYYenaxqe692wrGfmzwwnvo1/d6OZKCLeB70mYLTn6MBUtm6pRULAqrofLtZ+U9yQgqOSxSih+cBVqueXBtQdlZGL+UXrPoeHdu1NL7cNcBas/DhFPnurImZ7y+BVD2paPm+88GATi2hpVWSCN4J0WspWQVqc+SigdqyNnKGII01BtwUqVFBhWg37p1sLoaWEFqysTVe50ZwjuhhjIFTiqQQ+O40kILnJVeuubJWDTprc8p8MqZLlaqtz723c2gJoMeClqKAiVipYMkrkQEfBsZh4LsPHyl5ZR4SaRi5PH3QMnsXFHBeVpwIyaO2qzcdkF1ovVog2MdORYrZ/A5pVnNp/udRvqBvCeorHcDaLtyhzvu27wCbBlIvEapFywR7sJ5iQIaBD5cLQRrz0xOLh2W57ucWUQ0b7zmdJs6nkefLiXFIJAMHcylaPp1X1nVlWZXt9Ott5dN95X+8zbwuhde1kFuzvQSis7b0zr3zodVv9k5sRQiaKlCGlIRIpbGiJTZBYMmNpTTuWZl7U3DaDdGhYvh2ZtWoY3O8hK7FyPbZ3jnGIMoopPtdyiYcIwwBTgEmYxx23/gh0Sy6vtbe6fAwt38PxxbDWKT7Pnneu9Mp0NRjqyP45h7mtfq1zTQTyyG50/ucAoe4suvndqBF2v6a/jm5FJa88OX6iV+//Jm35ROZK9Up4BSCGCMnaqKt7+dFz9ea7n++OV2rtSHNaSJNhFyz7lfe410Fl8Ab8yl4StMSeJUNWPn0+RO32w0fIufzBR8SwzSSRi25S3GgVqesSunEAwXonTdWuSgoVmNVPdrg8EFwoYGr5g8o8NTJEN66taUh8fQ08eNPTzw/n3n+ODEMiRiD+kclQAtQA61Aywra1+4DSteH2ssfS4E17AlR741M7sMmYxC8J8Rke38A51isy9x8m7UEP+vauXwYuTyPpEGBofVWuN1X3l4X3l4XlnthXayM23xkaORaccVxn5XRpInGzO1+o9YCLuO9MIyeEB3TKSnwlKxiiv4ViW5kjBemeOY0PDGEkSFNWooXTNvLB1Q8X6gtM4SRqS2M6UyRzCoLpSkABY7a7twzVCnEqMm4H+q/M/LDQAzDHhvD7psegag+w6XjC8Y6777SO5D8+E8llWjp8k4U0TWkvscjJrP5gdLX2F+zBvvx95XaCVumswM4Dg5sCQfUjeHTL+7bp+th9H5r39J2+vo8e8DYUbvtps0Z6GynELT1eB9Qx3ahh3O9P9Qg9T/tuVdHk8reGewb42Mbo/NHCOH4mDvyrn8+XrcSCHaRaOcU2e4DvNNEd2TzoWa5WcvxqiUrSNUynLrS8nUrPwxppFUt4wghajDXIKQzbaj4OOLjCR810OoOJ64DcPum0IHIDThy7+6zj8A70Gl7Fsfn+u5R7OOuY9uF66qV4sz3K/frG/Ptynq/IaKlMcM0Mp4mhmlS0NEHnAkEi9PMGYLetyjzoqzFSu1WlnndjFUMjtOUGKeBy2ViGBPnywkfPN5K7lSQVbNv823FO8ftnrV9fSlILoS3F6KDNJ2ZPnxHdE4D2GNQexiDB9D5/ZQ9jNDGGjiuyf7GQxB21G5ytim7w2f6Pu9a28b994Q+yWFAvzmW261+46/y7V9//fbHF31Nze/r5fE3nYGZ0sD5fObp6ZmPH54JUgk027QLy7Jwn2daWVU802mW1oeOgTUD/RtN1Fa5phs7BhY7p3pFOA2sEGG1yaO5364XpEwXF6IGVikbQNADIlhz0aDGymjWYk5WqbgQWKswDAkXAjU1YlIHM6UIIahOhzkozXtrRSxmu5o6NmC0i4ar5lyaKLFIM32QTrEvyjAE4nQhThemp4+cnj4wTieGccKtV1hX8nqnXD+rntPrL6y3G3lZVFizaRmTccX2L9c9paClKiFtpYeqI9Go1tXGdeGro1iIZQO3rnbd3nsV8w1pYBiGTcOl1UoIgVorISRKLQiOnFfcsmgAI3uws8/Bgx6VD/uegpWtNR2rWivFWriHqMLzp9OIj4GQItNJqd151Uzy7Xrl8+dfFay63UybywAJ3jseO/C0zXQxuNxqhRwHZwnFpZwBWN67vYzdbFprHSiw5M8GOMn+M79P4Km3YW/2tQFQ9t07DV4DVorXrIysKbCzVABh6USXaBqF6PBm8y9XY1Z5US5Al1HoPouwM4MQoVbdgy6jZoIvg6fViNS465iZBABScbUSvN5P8lipoJb4taIaHblUBC1Pak2YkoLm0fRUnM2xYOCJdz3horZpyaotdl0itQlTioTguJjG0DkGZWu5zhRT4KljOSINnDdwDNUv8n4b41Z3oGULgIP6Hj4m0vlCyYnoHTENTKcTBG0GIE0orRC9o1Zd2/18PSDojny/lj7vcbpne+uy9+hudX/zKHtga/FQjrr7Ze+Y812bzjIQrVacMRSBjal6miakZJ6miVgz4j3Zsa1Jb63WVdtpZBoHhhiNSWfscmM5Fev0t+TK21J4WQpf5szbWrjbXiIooOO7X+26J95v0YCnDW1T/oUT44J4rwxSVGvHO2XVrUVBp/vaCKMnWafE6N2m8aSfuduxR3+2/6xzZAg7O2rRrYDk96/BK1jadSxct9dOvytYrGPvvNs0pX4Px1dx3jvgadd6avQGK8f3fSsuUHvfwd8j+GLMOz3BuzeKrdl+/v1PvWvjbXnj5aqd6woKOuGqATaW4HXa6gBxurY2AFGQLvgvQbvBVrXY2o5e8OQtBnFO3QiaI0a9GNV/g+v1jWVZGIcTeS18/O4HBIhJE0khxC2qFAOp+97pMBYoDmlh6ybnvTX88ALOWMvNxtyBD44QlO00nRKny8Dzx4mny8jpPGwl8r55nHjNnLUAVWjFUYsz/8n2pNBwvhmAK9RQ8d4WhwhDUs2kaF1IvVONqJQGLWczLUiVN9FrarVSk+450ykxTCa+7h2lVNa1MM+Z+aagU1ltTgTQzq+a3KhVtdiQxjLP2kV5Vb8aX02/1xOSV2DL+x0MU/4tHu3yN4SRIUyMYSKGQZun+EA04Cn4qIUAHmWvE0kyksJIJrPKzFpnKFBbpdSVbILnb/NIiiPjcOaSv0dZdnGL/fsk3pGGr/2fLQZkJ868X5P7SWyN9HccznX0AY5rx7nOlH3AvP7N4+8WF384RMu4jkFuvxp/MCz60n2hdP2f4513R/M9+GQnZIO2tgh9R/h0AXUa7woOa3UdNqaWez/KR4DrAKlrfer+mQpsdQd3v7890N8f/n79frsnu8jtfce4fisr7B68va7TDoOBLa3XK9trmgm2egM9dvS/aFDaHT2nQVtvC15q2QIrTTA4XHjFhV/xccLFC3H6SDp9z3D5yHD+/gCo2bjULu5q2QPXgwWllrvtPuXdGOybTDeSGvB2avjjM++bewi7GLyIMN+uLPcrX375C7eXL9xeX8jLDE7wMTCcJobTROhBb8PAQjPKzjKXVQPXdV5Z7gu3t5llXmhFDc84JqZp4On5xDgNPD0b8PQ04aMnbppPes9OhHVZeXoeeH2diZ+u3O+F63Vlvt9otUEacAjnH3/m9MPPhDTgrWvOwzzap9k+19iR6oDbSjLZsoBsJQ/gN/AS9vLRYNoq3taff7/OumPn3/3+H/6Q7Zv0Nc1uE+Rbrz3+Rj2Z7cEcLccOK3/jLPJb49iNgDJJpmni5z/8zM8//4Gn00hAaLWw1ML1duPt9ZXr7c4yL7quqTQPzollhZ3puwilGtPJbAPO4VtTwARvQsOelrT0rRjTpBTLgomu2XleEOeZb1dwnnGd8SJUKeTS+PzphVwr+aiHIUIuapviMJLSwO36xjAkrpeLBi+nkSElLueLrp/e4axVCySlR3gGnBc8QpSq5RWuWmTckFDAVZq3LxwVTxg9wWjYw5A04+eg5Jl6eyG/fWZ9/cRyv5KthXfWkEWDWEtf9/INXAdyjAVqJYcNpZNrNlxwflD9Bz/gRPBRNWxqVQ2o3Aq5CRWPuIBLI344kaYLaTozTifVckiJ1hqDgdc3AwBLVQfWBY+rWiLZy//6fHSulwN24Mlt37tjIsZS6F2qSlXB5CbC5TTx8emCc57pfObDd9/Rs8I+BP7bf/0viAj32415nm3r2vf2x/m9/7vbe2XaH9jOfU+zniTV9pTg68EX0A1T2IPctn3vAQWHtfj7OrwFqoGdDWEVCxvzSZyW5KnQvwayvhgTqin49GWBu9fueMlraVGVzhqC5BTMEnEPuGlzXX/GbKE4lqIBm/OVTOF8CpxOkUogGmMvl0rNlgRslSCNEWfBuCc6j3gHBEYn5OK5rZlcG0uplFZJwbGWhkyJMXimgGojWXLIifqayfR/VmP1XZeVXCvnMZGCZ0qaPf7xlBiC4/OiWk/0WMhFnE+Mw0jwnlo9pTWG6BmiistCY20N1xrBCcnBlByXKfDx6UT0MPlnE+IuWo6RBorA0oQ1F+7zyhAc0SkA53vXvk0cudBatAC2g0e21wt7wGiJM+eatfa2kiTHFoR3bSd6lttKKHt5tIr8H/ZBaZt2jIPN/+zMTdcELwpwhn16UoyxH1NQbafLifPJtJ28N79813YqWbtIXZfMy33lT9eFT/eVX+8rS62Upowlb6y43vFP97OdL+S8JWZdT6bZymhlA3Twe8kjQBax7pBavhmcmG6Y2wA/5c50AMNuUnpgpz862Bp5RN/HQ5/RVsLpjq79oy8QnJaLBqfn6OBa10X8PR7H2O7rhkwdXHSbq6Xj9jiXO9hbijbuKHm1Ob4Vnr3bh7YTHa5Bvxernni9f+bT6194vf/KKm80Fryr2tAlBsRr0mcTfxdba8YQbHgD2JV5GaLgWqAArap2GlKAFecKKaAghpWXpwl89eSmotrrcmfNC3/+i2cc3xjGE09PF5z7J4YxkUYFgkpaqbWQi4qFb+BRtJLSqtqeMXhidIRYiakwTELJjWXWsjUvagtOl8jpPPLd9ycuTyeeP07aPCmaOHnTZFVPWHX9RZMYplXMrxBKaTQKuRRiXLfn0fX9hkFZstNp0LI+FxiDw4eopYFRNfpSVB2r02nAvHe885yfJ06XER9Ut2qZVTT9fsvM96zxlgghWHJWs4GUmiE3Aw8b6zLTWsG5QohNNZ2CY5iCldntutBWYIl3kRQGBYXiiSGOylz3yojzzhsA5Tcb662G2+GIbmB0Z4RGc5W1LSz1zpLv3NY31ppZ68Jt+WKgot7jx6c/8PHyMzEqwPVba+zhZ5v5nTCz/90qYR7s0hZ52jo5vOcrTKbbwh0X+TZ28+3j7wOe3oFFQs80it2YOb7fvIhv0bA0qD62at7+cgSG3ON7+gSU/l/PDBmtT4Vgg21MfsuIbJuADexXiJ8cgK0NAdjF4vol+u2iHimhG0BzvGtzuL8awx7HSm+DezSMbstuAdoy107SH3bPFksfv3bQerKt09kbpFVrPZ51EqJCmbooAvAKYcSFE8MlI+LxaSCdPqiB7Kr67I//KzYNO/jWH9p7plN/ZvvgHIalv88CiC0z5ztdUZ9DXheW+53b2xu3t1fWZabkhTRGXHDEIRIHbdntvEfqoQ24rR8HVh/ezAkqrMtKXrXLBN6TkurSTNPAeBrMQCbGU9JOCoMCmzEFOi9iGD3j6FEK52rBvHb2qqUxvHxhiIE4TUzPH5AQgLRd2/E4rqHtT32ebEbw3XscVnbjtu4W+ozUIfJbltjmnzs800Os2IGp38uxG0bQCWbj8vUr//pPm4/07fd/bd/2effta4GYEqfzmefnD/zw/fcq1NqZTjmzLNq+e11Xcsmq6eTUyRLXy6xEqd3YvHYG5AOuesRr8Kqgo9pnFcWHGLRTimbSOzihpXRuzazLQogDra6q1dYiJRdu11eWXFiKlkQ0p2BnztpaK6TBRLEraUgqkh0j6zIyjgOCEENkHEYto8BZyUSPdjUIc3U1+Ef1rNSlMq02X3EUhIpQaS5QMUKSZdOS0ZUdVkKy3inLTfWc1lXLPzaWEwe9Kn1IYnsaTjuhdKq9OP3CeQMBBFw0YCzipOF7JrYpm6N2gM45xAXVw4rKdlKgLlmJnGo6BR8osVCsQUeM0UrSuuaUIg7OdxEgu87OY7ckyFYmb8+2JwN62VpP+qSU8M5xmkaGGBlS4nS+ICL8MC/UUri+Xfn86ZMKls/zYU7vzr68m+iPLMrjd3u1YE6QghyAsuBcLzff7dERcNqAtHcO0O/t6C6Jh41J6dAhVlKS7DZJty+ylXTSYBVrEd+gaAzBGB7tktqGzjDZpj+Ws6G36epSCqUJpYFfGuIbLQh+1DnpDfxQ7ZICtRCkEWkktJ394ES1b/oeJ4HsVN9MxeQbpQr3WGmCAkfOkXzvl/Q4Pprlx8ZAWEqhIawGrI9R339JkSZsmkyNzgFWgDnGSPQK9cWgHe607E47RHbmZ0CIVro4xqDM6Bh5si56zpl2nvOspeCXjANKztpZzfVxPmgVmR+nsMe+Zvuxz3dlpfpOe9sAGHuh1U13MffuZ/dSfK1/3Vk329rtvnxXqbdTSkcgxUS96QxFA7VEu2n6EAgxMo4D45hUt82BlLZpe7XOeqqVJVduufCyZF7WzC0XsigrSZ/xMcF7GITuA/mD/93nbAfPMIapOX19PKv4zdZ3UMsf1tPDFxs8vkUcx/XS10wHkDacw+x8kP1yH3End1hrB9a623203/Oxl9ZhyWu2ZP2W4DagUZ+FzeUtlukaYarzuD+pg9/6sBnog1A7ugNP2gEtc19vvN4+M+c31XOi4Gimf+SoNpccvWOvB3FbtYNSeXf/QdBqiFoLztn6aI3iis45HxRwtjkccFpSGvVeayu0Aq/5hXle+fL5C61WvvvuO7x3jKczwXti0PC91GxjhyXrvcWFuveH4Ax/VfZWSL1E3TwXUdbQMAamU+Tpw8j5rMLdKUUr75WNnbnrLO6gk7QDANW1LKVQayNHrRRqoqxHaY1xTCTTXBNgnBS4c866a5oecwgeaZ5hiKqNZ+yjcUoMQ9zi+Jwr61rJSyGv3e6pX6vAk25irVaq6xIx2rylSQGn7KwuJh6TVz1K/4hjmOKgdfpLynLy6dA0ZY9ZlWVmeIhZIBfMJwths9mjZKZ25upfjen5xlJv5KKd9cZ4IfmJIZ64TB+s0c+3gae+hg4z/xuBiXQMH9kWxtfv76V0fw1LOvp+vXHD33L87RpPfaM6MFl2YOHgdNpk7hfg/SFzc7ipvfxHt8VeC9y/y+F/Dzd3uKZmNfBqhDJgZQNbllQdoG3YbSPoyZNu1GQ7sYbzezM3NWQibIKmCKrvcww+t+uU/XfHDf3ob3P4rim7DWTpE7cH/lvdc//vYIj1y1lts2XlQ0B8oJgF6gZcRBkROTdcLVBmypopdw0cXBOcMZ5EHCGdkPJBF4oZyp5662PxHljs4Ndx8vUtVLowxeHYMxvHRe1o3xAs69n5kjMvnz9xe/nCl1/+wvz2Sl4XBRtDUiaAOWHNtGtqLsYYM4fOrrOWqrXD95X5vrLOmVqrAU6J82XidBqZLiPjlJguA2nQDgreKyruvAbIrWdcpOE8TOfE9z9d8NGBVOa5Ms8L8/VFx995qIXTD39g/O5HQko4MyRu+9/XhzuMyeNvGl2c2sEmxHrA8nQKGgja9Tuw7fpRnwWK1G9fwD/4sQ/b/7EI9VvlPH8t6P3W32KMpDTwww8/8E//9M989+GJcYjUdSavC29vr1yvV95eX7jdrrTendP1L2NAdJymBxi9e6NzNK9dPJwreF/BeXyIauUscOgaKXtSwzbyUsCt3K5vCPB0fSWNGRcnfCmU+coyL3y53imtqXOGo7e6R4TgA2/nMyklnp4/EFNkmEaGceDy/IFpnPjw8TvGlHg+X7R8xjvt7NMa5BXmF2rL+DrjnAZ7TuV68VIIbbWATSCMEEd8c/gWcMXj173qrb78ifL6K+X6hbLcKbVRCJYFrxTZW2GzBaNO16vbnSRpBSmO0p0MZ50uxYNLuPQBYqGWBWmFtd4pFDKB4gIynHDpRDw9E0/PpOlEHEZ6q2HvvQZMwgYIiQgxJWprxJRowFBOKjSey7afaand3kRDHdA9Atr3kLbtn3UTaFU9qdYaz5cL/ln1Jc6XJ+oPRbWnamUYBv7z//6flCm1rLS8vgOfvrVWOvzUbP7J1ia772l9gDUIVOaTOzYncYe9r+17Yt/X++f83o7Q/RX3EHfv5r/7Wvonomi3N0GsjM49vC9XZWQslS3w3hNgG56JE/aSNKyMD6g4Y2x4xmlQ/ZFhJMbEnLXMPBtbb3AK4IzOM+C2Erto9it6TbAFF6hN72Asnre1sFbhthbmUvHOMacG08AU1ViFwxAE83WmGCmmQ6fMJ2VQeTfiHDyNCq5+N0RupXJvjsEFgmWwL+cnonfaZMF5zkMkl8rF2DtOMqMTUp1JdWasdwbxTO7C4ITBAJgYvGpsSUUoxLaQZCXJQqwFlwuyOOrNk+8z6/VKmd9oZUEiOBf33b11SYCVdV42XTs6aOE1cAy9dbqtubIs1mBH10lP8LqgAHoaho11qqzXldbaxn7dynRL1nKU+0xeFtXbk7YFWZ09NY4D02nkdJoYx0H92F4SnfUcJWfmNfM2Z/50nfnluvLHt5m3XJhr3fzzDYBgtyHOJmdnZPdyPDNy9hqHc81EkMFVscY5TnVSrLPdmrVhRwpCtH2wg7h9v2i9U1m3SfSATLb9sttXb/5+L3vO1mlyLRpkxZ2cZUGoriEtO9W5HBzG6v2fNhX/pzv27nV6vGc69ZhS5xO614qBfDZ35LhH1f5zsdinB736MLZzi7H8ZK+ocGazmijL9/X2hc/XX3i9/cpS3xAWZdq2CqWR58KyZrIUqlRiEnzUue6d7yERujEZcIbDu4Q4T/DVEEfrOlsVoHWu4EXZOA6v8aSH4RQISRlSJQvrrGzsXz/9mXm+MU0nLk8X7bAWAylN+FBUAsaIBs73GNxs+6alJITQ8L7ifLMvjc/j4BlPgeePA5fngeePg9r1ccC7SGtOO3aXRqmmPSfNJrN+qfj5XmnRWtHklCuIJcY2/EAEaNRqLMSSLW73nKYTMui4dLFt7xvTNBJiUDA7BMZxICZlhtbSWNfCumRLXFScF0IUYrKSRtcQCrWuiHjzMxq4jHcN5wUfIA7OmE5xI64oO4pts3HOqY6TDwRrnmV/0Ws2a6Hzw7jJrmMbRipxu2Z2RMuRXfIMbuQWL4zhxNoKa83c1xf+0hrihFJXPj79gefzj8SQVPv47zjer0W9n/ev6aCTTvBNHtBe/B7b3TAbeTz/Xzv+JzSe1AvaldM7zZ1v+nzvmUv9ur7SbtqQf8d7Z/UYuW3P3xBr6UynWm2B2UTpoIYcz+TegU9mpA5O/hE0twvb7m1zrt8/KGT/fhij96D7twJed/x/z/71ANAMyCGqAKymV9QF3DJaHYk/8nQ3cEyRy9oDupppvtDyCq3hWsWnjE+NdPpAK4vyJukb7A4eyj4QO4jIPkG9b/Rc1QaWsTPU9kv7xu7awTl7VK6POwY8lcx8u3G/qsDtcrtSi5UUmhNkvGwFx5oaSdqmjrFtTq1puV1ZCyWr5gAim5DcMCSGMZKGSBqSfQ/EdAAHbSx6+YqgTk5KAXcZtVPeTVkK93vVksCqzKeUImE6k56eldF15K7bXOwAweN8c/t9uF622CcYu2HYgIR9PO1NdLE2LdfrG/T+CX9PW8x/xOPfso3u+I/D0PyWQ/it8/2WAd4A+RAYhoHL5Ynvv/+e0xiJwVGlUUrmPs+8Xa/c78p20t5IVprhMFAY9jndzEFQW1a9ZRSlaIZFUFAY80bMjDl6xvcxuFdmTWFdF0KIlHU25zzgWkXKQs0z8+1NS9W6nXUekUZdM9578nwjpoFaMiFG0km11+ZcOJ3O+JCop4lpnEC8OikYC6AWJM9ImZF81TS7bxvwFGQlymLeP7h0wvuGayO+TVDvkAO5VqQ22v2Fen+lrnda1iCr4lXgWGQrF9R8u7GdDIDaxqevdVegmPZTaNtadQQkTqj+g0dqppC1fTuB6kDCgIsjfpgIw6iCmjEe7L8BM0HMJqnDtVG/YyQ0IcaEc97KiQ1gogNlB2TiK6dPNkBf7eB+X947xnEgxcjTRTOrQxg5nS+0Jsw/3mm18vnzJ375y58NwLcP+dbCOOwRTjZrs93j7hAcghBsq3S9LN89BBa6B+73sX3cb1zGP/rR7bk3872Pj/3dvvvD35xANlZT7npcxvToc31tOrOD35lO/bSGRe3D6c2HNnJd8NqJMMZATKq14Y0VtOS8CXCHoOyiyTuSsyAfsW6ce6lRcI7mHbkpCDKXRmmVXBtShVuMNOAyCEGwbnf96CUYGFsJFQ8X1Z4DLdEM3jMGj8TAKWqQVAQDvzTYGIeRaEyG3BpD8IzRM5pWaAmF5CG2QpBMaCtRBiKV6FSrRMXNg67hWvEUvGR8ywQp+KZ6V5RAW+/U5U6eb9R1QWqGlh4SUGqPNVlWivortWS7c7XrOEcaNNjq49I18PqzKMYa8Zakwznr0qTgXzXtt5x7Ms3Wa1lpBhp1QWPXk4/GCHDeWTIl6VeM+/7ZqiWIG61qe/SlVF4XZTu9rplbrmRjXkaTBDjaXGw+9hgBt/v0rdsF6dqhvYuogVS+KbgWlE2hldTKqA3+sJ9u6Tj7Ouz9e9zxbl3yzuTYm4sBVrlBaVpqrUUz/R70qzOfgn3/HWFOenR/1Oy6+snQ48b9u8UxD36t7HOnqah/LSs7A8p8bv2gLd7YfPK+vxwAA+cdUlUyYMnKdLqvb5S2IJJxmN5ZbZS1scxa8lukUosCTzFi2kWHigTz14W9O6UypMWeegfcNCYRsK65bMy9OGgMkwaPc411KdTWuN3eqLXx+voKKLtHWTW6xnzUrnoi1fbXts2jbss1f2aSAB0sMlfBB9U0Gk+R6RSYzpGUIjEF9cma27rBaUOTto19/xTntqpWXNXnXGuhWVIclAHaeZwabilg1cSAo6wMKZ0PDpNL19K1lEyGIFilSSR4TT20hoJipdK7cHovZuucAnxO/eFWtRqo1f67hpYrY19aTtnlXfrk2aaR79VI3rS69toTXdN+wxO2uW2/7zF6B0L7eT0Kuo0hEH3a50+5UqRQ6kKpleF2IrpEiiem9KQA2L8BPPWQWj9LNmCw/7wvU7eNe7+u7b4tJujlzkclQR7u5W+PG/924MmuZOvYZpa534gImiDGHwK0gwGgOz9s/37QdOqby+Fzjo5of/IbgNG0w0jOyyEIMwqtt6yvjaNYX2DnndaE9gHbBqrvaI8Pyv5CsAy0glqWCXIc7k2vr7MOHsrrZN8gHTvN831Qe7x36dkT6SqS3Qi3DWWX/vlAz8g7H60sTa+3Np0k3kd8aASfVFQ2Z0SExco5ogXBcXwijU8M04UQlYEjTWhd3KHvxLKPDVaHvz2jwyIEt2U8vqo9ff+zvU8F1ftq1bGTppoiy/3Gy6+/cP3yifV2o6yrlVXqDi493kJoRQUy1dDIJkYqYmKOuSowNGfWJSPVxMkH1XY6nUem88jpPDJMiWEaCManlqZ08G2TMxppB7NogjRHGhMfvn8ipEAIUFahrCvL9QVHIw6Tltd8+GHTsuJIVxRlBTibA730slUt3UEey0V3AHAP6Pbn0t1zMaMqSH1cc+6IXPP7OY6lll/9zb67b/wOebQGX2NJ71zPv2Hc+qb1/PzMjz/9zPfff8/5NOJaYb3fuL29cX174/XlhbfXV9UlKllbu3oNkqIFat4dtgCzM1o+pfT10LxtkI5gjlLvhtS6jou18pVWzMkzMVqn2efb7UZrjfvrF6SsfEgR7+GHp4kxOO73O/OaWW6zrgnU6SjLgsNR5zsxRVpZ8THix5GQEuP1xvlyAef58PyBp/MTLqXNWfPWJty1FV+u+PtfcJJBFpCMsNDaQql3VOwx4McPhOk7XLnjyo12H2lxNI2RTH17o96utPmm9y0YUCY0sXbvTcC612wOhlfnh1aRCm3VzKXYXhjigHOeGEcDv1WPoAqIi+SQKRIpSXWk/PkHBZ0vH0nnZ9V6s7IU1yeRaAAp3qkQO5FxHHHOcT5fyCmD8+RSELdoRrIaQ/adA9Edgq1Mp+1sJ93DtVtgXu5bSfa6zNRaeTqfeH66ENLA+emJH9sfmKaJZV1wzvHf/vW/8qc//pFaNWj9eoH13fbdcup717Z8Dszmvo309fTgLPXvbX/97/zwW4kUIMZscloGAlhwo/6NiBbaO1HmE8AUlCE5euXG9s6Kt6I2YCnsAHQPINifW6D/3lgkDsYhcRpHLtPI5TQCjet9Zs0FmnDyqo10Do5TcCSHdaUzvUradi9OxIRY4RSDijw31WZ6XbTD2VwbFZhypeDwQ2R0jsEC9taqnUdvJKKMhCVr8DbEQAqBU0pMCX48jVxSZcxCSIlTjExRNZ5S0GvBeZ5OqmP2PI0WGHjO48AUPAMCZaYtnvn6mRIC69X0Oa0EV7taFeZVtY3asgC6F8/5hbhMXO8zt+uN+b6S7yspOlobleHRGq4UENEGE7c76zyz5pW+xr21JZ9aYxgGgvlk2tF4pWRtEDCvmdKagt1BbRxDQmIAcRbYF+Z51X3E/AjXVqQWWl1BCil6JAV8DPiq32MInM4nzqeT+pIxIFK78Au0Rq2VORd+uc38el347693Pt1XXtZCrsZwdM58tXebtc1NLPTo2jJ9/YuVgCrQpW9QFriAF2oQYoAUPDEp+23wjoFMkkzsWk2H4Pjdx2/X0AP5B0CjrxEL6HPTdXgver7J/haOYAXd1zrYbJH3d/6PfRx8SyeqSa1+eI8bDwk0dB2DARy1kldl7eWyql9R8han9ZhE6D5e93MtLgWLT7Rsqsds9+XG6+0TL9dfuS1fKPUGspLXmfl+48vnF15frrxdb9r9zCvbJI1BS/gHMS0lv1U/+M7W7mgOqleEg1ATOGdlXQ2xZLlIUcCbnTgQojCdEiU1A5uFJV/JdeW//4/Ey+sT58uF8+XM83cX8J4QErVllvsNEG1Agu4F67Ky3Gft2FsKte2M+DQokHN5Hrl8GHj6MHC+KCNddZYSNBU5aE7Ala8AWS0R1IRnc1jjCWMKVjFmlSdELcPVBJqpFtpzL3Vlnu84LzxdzgwpEYMmYkNU5tHJAKpk3eWGpDpXrRkLy8p3QYG1kMBFSKMCSrjeFXfV67O69ZCspDIp66wnUDSO32UCVE9Vn5lIpMs9sAm2y4N9sNr0DWTqgvIbeCOyrftuA5xzJD/gktNkX/nAZbhzLzP3fGcub/xyrapf7T3P/LjZcb+Bnd3v6z7DIZF5WCPH1z7iNQccYvO1jhVOxwoZw2r8/tn/32c8vb/Y90GXc9sg2y0c/n74aQOhhMdKffY4zh1/8Y0bsQfVmgqKK6DUPxcL0v32XrF6lCNC3YGvw2P4TYPvLLsmzvXt7HAvh4ds99Zw2t1o85btf9uDfjdGDx98AA16idphAjwADYeAemM8bdluM8BgBlEFKCti2QOlsabocD6BS4R0IqSJmEY1mv3CfguJ2D7XbYZkn3d7lnp7XQcND2PwDjnZdnjXgScD9PK6ss4z99uV+XbdnKm+4/cgcDtVs+BQdjph39+k9Qxis+yhtd30KswXTcMpJdWLSikSrYtdtxSb2KGBgT1oLaWL5iodc5wGSi2UEpmlUNZCzQvrzZFvb5TbG+l0YeMzunfDIfJwX50BoMar/7IHCf33O0D5fpAF8AYQtuP8dapJ0F/zN9qPf6jjr93Tt//0bw3C3zZIR+DVOWdU4YkPHz5yPp9IMVKXTM2rda+7My8zyzojRi3fMi32FdxO74e9nKoBVHDWMjeIGIuoWumDnqf2Da/WrRTjYe407diS15XgHOt8V2ZAy3gXuAwBWmSKnlqcAlfV9J5ao5RVHc2yUqtmq3yIuFLwKbFWbRt+eb6R0kCpjRRlB16dZdGk4uuKzzdcm6FcgRVpM9JmWr3iXURcQrNXfYNHOdY+InlFSkbuMzKvSC4bQ1Fc17XaSwDcJsLrDpkqnUDStHEDbi/Jc63hQtAud2IsKOdU+0YczSeqgxag4QnDCT+cCcOJMKit7VoAx3m1BTPea4IgRpoIw6BdsmKuBj5p1q7RbZIcT7PvG9K1HWS/X2MMN4Ri5Q7eqfbXOI7EELiczzgfGIaR8+VCDIEffviR29sbXz5/IsZgAcP+ef3Y9zrYkkff2k7egUjvHRh597r3e+9XDtfv6OjmP7BvkSp2a3+3vbKXyHU70EXHe3etS1TcuYuNr20vu4NemiEPOlL98z2wtTUWxxA905iYhsg0BOa1aafLqtn25B2n6DfgKTpr7NHcLkxLz4UbuOZUU8k5ZRkJGBPGqQ4bjbmqo39uChIMzsAF9rHoIJoApT0yny6D2qJzCgTvqFhTkk2ENxKDB0kMSRhjZE2VKUUVeRcYUyQFtcE0bWhT1pnqYGWLQehbcG3axruWiuS86aMUiayyaAnb/U5ZKjVXWjnTteF6iZyrymAqa2ZZV9Zl3e45RGUBpJSoIeBR0fauedqM+bSuWroTcRrg1kpoVponjt4VuuRMLjsw7duqgt2tqnadldV0LTm17Z4hJdKQNkFerMyvZ/tqU3D8uhTelszLol3s5lJ7PmT3ZXnnFh8Xgj3bbuc646lV2fw79T+92RsH1noiWst4L9oUIrZKaM5Yd30e6sc8mBL3/t8dbDr44IfvnTSeq3aOrdH067Z11e0VG7Nwq8r4HR1b0Epn2P+V+7O5joh12y4PZeCaNKkGsvstlpDDfnDYbcwmetNS8rYPNnJZuM1vzOuNXGaarIioUPm6LNxvM2+vd663mfu8KAMmKLMmJn22ISmwHcLBR6B/rDKceqMPJTsELY+VzkxuW1mcMpHYkoQxacyWBg+usS4rVQqvby/U2nh7fQMc5+ezAqXeujfWrOCc6ERzOF3zJuivCUbZnkmv7hinyDhFhimRxmiJ8t6Yy+Pakf3jHrbqDVixcNuhoBPmh/TYMARHit6YVHErk8w5U1vVcrs1kK36ZAc1eoMUXSExBtNP0uurpjfVNr9H168Puu5D7HKXnRTSGZIaW3krsQvRWE4mU/De38DuXExOXj+nW3jza/p+5h7evI2R286hKMHRCZIm+OAJTudL8iPBD8Q6IDjWulLbyn0t3NcX7usz03ihNW2G9RA3vvOB1Fw5A4be4TaPy+8r0Enf6jhiDcqH2eeR2tqvTvdXj78DeJLD/21jdf1fhu1tqNh+4d3p3TWf9CRib32gZ3WHx8qBjo7PI6iguk5IL6/rzJr92jbjbhvZJsB4uLZtE5BuIHWB9drxrvp+vOf9CRtiz97Br6PsPfjpSGCva4ZDVpe+0RzOaEFfB4z6g/WWivQ+7OvAmfHtDAWptJppeaUsM3VdVNS6FqqIIuPDCZcccXQbOycNE8N04fLxJ55++GdOH3/m9N0/EQZlI+h4P1LoepvlfXL2gd9Ih19tLx3hPf58BKY2XE52KiPAvC7knPny6y/cXl94+/UX5rcX6qpdLQg71XurvTUR4M0gqvundNGilM5lWZnnlft9IS/ZNgCv3exOA+fLxHQeuTxNBKvB7oFnbw3cASdwOAnQtLyvrJUyqxh0XldqKwwxEC6e05SoxdNqY72+8PZHoHdCOD8RpvO2Nlw38rZgun7A1nGo/34z0tsT2p+JztRtHvbn1J/B9ntnz7NvML8v/+f/r8cRdJpOJxUS//FHvv/he8bgqOvMutxZ7jfmuwKrUlaiE5MOUMdYsQ/ZcOCd9KqlaYIBoHQdtqYi4s4RfDPQqrK1BIYtMPD0kgPAGagvQlkXFhFuxnh6Pg3ElHgaEoOP3D6eOQ2B+3xnyYU5q/NDqzYDvWW9DTyThpRCXmZyDMy3G8s4UWqhSTK9g6iaLHXUzm8lag1+Lbh6gzbj2hUpMy1fVWjRDzQfaUE7R9LKRgtveabmFcngqoMaoAbVKimFlhcFp6xkzaF1+71pgFQFZmrLmvnrwh/mcJCUQSAOiAPQEBe0q1drrBLJzlHThPiIP39HnM6k0xPDdCKmaDorqI3ZHBgT2fXq4KaUcM5RTmdiLCqDlbN2UCoVIeteQzUHd+8IBH1/6R3h6haYSiv0m8+LcJOKl6aBYy2EEDifRi6niREt/funf/cvTNNJn1tr/OXPf+bz509fA0ZHEEqn6sM+wONf+coh2hyJ97+Wh/3nHT7/uzqSCWfv9t59ewSt4xfmHAYz5eIdQ4BzBMyJXKuCUfei7y0N1tZZJB0M2kGn0JmWMRHTwPPlwscPT1quXnbR6MHBkBxPKXBJnlP0TMFvotS9HCIX61DYmoqUd7aAaEnhoHVzTCnivAJOucGXuXDLKjVwip4wJsYuQC+6Xj2QvNcMdVVXf1018JqDdks6pcgQhCE6XIw8DZFzimClMuOgDv/zaQIcH6aFnBqncWQ8nXj+8APT+UQNJ27VsXx+Q2qhLDP0xgJ03WFPcwYe+0AKnjEFA3krwTW1y1iw3aoxjmr38vfAxveZ0HaRbHVylVkQvAUw1hU5BkpxSFOR5NrjJTDQaBfF7YynvC7kXMg5I01Lmp00fMvALgxWwJjfDvA6N6yd+JbgRX2uZc18vs58ut7515cbn+4Lv84rt1w3f6cztbYQ1x3WtNvc0a2bVm0q71CabOLGAMjOCE7RkYKQvD7rMTqG4PAx4Yj4Ar46YqjgDDyXLRB5CCT35KWBnW5fJ71MrpesgjHrxVGajlPbGIp7jKJNJzQYdjq634oJ/6GPhwqQx79YDtUSIU07cPfGKq1Viv0sm5Zq93OqBcq7hm+PEz0et2kxbf0GWcqd+3Lj7f6Z19sv5PpGjIXr9cb1+sLnz6+8fHkz0OnOsmQta6seb8BTyUIojhA9dfAGQAViaiSnr+sMFy/asdd71SJyvuLEacc1hJJVb0msQUgyBpWC34JchFoanpVahVZurKXx6cufyPXO+YOyk9JZOxbP80peV5bbbOvBUUrm7e2N2+3O/VZY5oqI2oZpHDmdB3786YnTU+JyPhGHASQhotpO2rRmi0g7OrEluDp7uiyNdRVu14XbdaUYuUEZ+p4hBFLSUtwYreBaFMSR0sglI3Pj7fqG86JyJU6b4HjvN6A4uLhpP+GcCZlb+R+CMxApiu4EMTnTme4xqYFGoIZwq2/tDbSM6WQv2WOmzmb0VF/IbcXXQK6zxefWVMaL+WthmwcPDMfD4t5i+/7JlugUUR9+CCMxDAQ/MKVn7uXGvdy4La/U9p+32PA8fmQcnnaAqNveY1LuiJ9sAIx+d6GXNKINiw6+1IMeW/9uoFPbOo+Ufkf8xkL/6vi7GU/7qLH53WyDdvhYy8bvIOQhGP6Gh7gj46CBlLP91m0GXtgnfauajdnHVDeD91kKtUU7cbz/eQd9DtpDfZexxYU77gGHB3dArnbK4AFusfP0Dn89s/cA1ByH4IHBIruD+W64t83c7tc7r4GQuTjairfsHR9qr3lFwY2oJSniEtJU8ymNZ4bTM+PTD0zPPzJeviOdnsEPe4D6W1nkLZLoz+gwAd61j/0KhT2iqPb+44TfygYsA3e/Xblf31jvN/J8N9HMhgv7onrQSLFFsJUB2jXUquVI5aCXUIzK7pwynlJSxtNgXyqd5SzjcmALHMC3zjaiOlpWYcKcVfDOhYaLMCSPS451USe/5pnl6hhvb5TLE34Y8XJQArDU8xZ72RLa53C/L5s3nWXXHaftNbK9Tgyk2ECMPuO6IaKXOf1+jh2g+T8WmeoQ/bZX+E3dssPftH5/4Hx54nQ+c5omXMu0qvoZeVXHoeRVHX5HJxjYbJbt/xub8WglRLZsTpVdEVDnLgY8KSC1iU8fMhnKeNCMlbP50Gql+qxaTx7ycsfTGE8J7zxPU9IuJVG1ANaszAS3zam+0euFOXMytb122USIN8fBGTtTIoSoLCnfG0Y0XMu4tkKdkar6T00aLoDUhVaXDXSWmpG2IuuM5AVaghZBRpAETfVPejbf2vPhguzjLSio39rW0UosIHTdcXb6GupqgX408K5plh9HdYEWEoSETxN+OBHTQIjD1hHlOLek7xHS546JdxJIg1L305oQIMYMOCu1c7itY83uOOxfe6e97d97OxpaKWQR5qBB7Ol8Yp5nxiFaYBshCU/Pz4Tg+f77H/j03Xe8vb5qBrLu2crjentU+PvW+vjtv31r3e02r79f/trS/Ic+eiAr29r/jcPpvPHmRPaguIt5p95Ix9a6EUS4FbMnzSpxD+5JZ3p7pwDYkJTF+3Qe+HCeuN4X1lzo7LkYHWPwTNExxcAUPUPwffMBEe2563uJK1sQsyU96NesDKgqHqpmtpdSKU24RQUJyiDEzVHbvUzv9p8RoRgjL9dK8J5kAVHA4UJgDPq7XioTvCOFxhAjY1TGU/BCjI5hnBinM2mYEJ8o0liWRUH666sBTyr433Bqv2IipYHTeLIMvN+0XXqwgrMQz8phN40a++qg2hYUIGZp2f1NS2L1hKwEt8sROLeXCBuS07VMnFPGk9TOkCqUrI1bRDKehhNTzHaCOE1u9DnUE6NbZ6cNpFFR5VwrtzUb02nldcncS2WpbdvfOpv3OEf3WMaukR7wCqWqP1eqrv0mYu3hbeJayWhwCrIOQb9Hj4kDO5wr4KqVrfdmPodY5a+stWOY5d59ia3XLsy/JQqPMQLHZaGfW39nNmy7Y3n3y81wmzfTdr1ejV2yJdXr5m8fT/LQTf0wR6AH9NpZLPiwvb+2ypLvLOuNJd8QVrxr1JqZ55n7XQGneVlYc6UU9fcdbQP7uwZka514oDZBy8kEL33+9jjE1ph0YoPFaoLGL+KoNJxACDZ/rePwMESqr5TRU0pjqYUmK/N8JUTPuioba0CZ1iVrs4+3txutimpZlcrtPjPPC3lVnSrsM3rX7vNltA52g5VumbZTT3DI4evwc7fbUhulNPJSyUtlmQuCOpG9QYWy9NWuhp4UkH2cWqvk0ljzwrJEcl5VRN0PBJRFrqCuaWiZDWtY0wRQbTDzlXxQ1lmwxGtnR2476LE0bgMRHLuep3uI7/ZIyZKZUrRrnwnP9925n8/7I5j0uOa3AdziVX+IucxnBwNNPS5FYphoCLmtlLZSFxUdn5cnUjwxdBHzR6TltxflYQluH+vcrh0pO2Fo60B5BKA2/6uLj3fW098WY/3NwJOaxX1D2TLm3SDYtez1zv1BNguYD0YXNpZQL/c5UuX79R+DRecUfVSjpIapB9D9CjeDY1mf3dnGLq6Hanqx2+f0h+4MSJLuuOudeqPsdmdgA8N6gKMXvmWY+/10PayOuIrV19a2X+sGttmDU7T1HcNom7h2btHzqkGrW2eist4oi3ZHqfmuQnyW7Q4hEoczcbgQT9+DC+AjMU3E8cLpw/c8ffczcbqQpmdEFOHfWi4ewIkjAr6BGVtPncOO2l99GLPD49J5EI6IsONxgxHmmwqJf/7zH7l++Uy+vlLnO60U23g8oelYhhBIUYUtvXne6oz0SFoF77Sb3WJfmh2I0TOkwHRSxtPpNDJN2vITDmKGzdqjt/6sHFLRzgpzZr4uLLeF++uddVlY73ec03rg82Xi9DQRvIr4NamU9c7901+o68pTbZy8VwAqpW3+9dGpra8zse4Yj2O9e0M9iN2isr7otnV6eAQbQNpXW/s7ROL+IY7tnmVba8DDWv3bzrO//lslPX/tfCkNjKeJH3/8mX//H/4DQwys9ytOKr4VZTvd3pA8k1whBGjOI1Wd7K7nJFiWt7NhnAqjbs/UHPCu71athDRY6/J+nmBgjg8qhjuNg4IYVTPKazk4BgLrfIdWeHv5TJlGvk+BwUd+vIycoud6vXCdFy3pkKoi2g7VLjoIY6cUERxFUFZAUZBcqrKIvHfbputqwg8nXJkIacTVgDptFaqC7Cp0q52jWptp5Q0nGScLraxIXaFkKAVkRGSA2hDJ1GWl5YLkArXiDfD1dk6sy1bN6tRUUZatM+ApBbU7MaItdduCr8okbTjW3Cgi5OooOCSecHEgjifSqCLrKaVNOLzVak1wdiFHfKfzBxgc0TQUYihIg5SzPq81aydC6Q6xgvZd5HNP2rQHppPas7IDT9UhBVYarjW+mBPc6k+mu+CJMTGezvgQ+Zf/5T9qiU/T4Pvt7Y15vr+z4/t6OPomRwfpt0Cjh2TNN3//19//ezhi2JAGYC+r7QMph3He9mUDmypa4tKd/w5EdZfMORUfvxfTpREVQ3buUNonukfEFPn+4zN/+PknG3ANDHPOBKlcgmjHN9EADKlbAN4/n6gl/w5lpeSquiDNRHc7kNETltEpWys2R6uQa2OtwidUkHq0srmRrvW0+6RC3/KclnpJ5TqvqtOUogKrKRJi5DREptT75DkrkRGmYaA24TxGaoMWEtPTB374+Q+k04Xx4/csy8yXT79wKyu/fHqhlUxbF3AgzpHGieH8xNPTyPTxmXgamS5npgFOA8hwJ/s3EjM+z7jeedSeqnfKBkrJM44BYSBGRxHV6uuaKMMwWGc7vY0wJFxwTN6TasWNlVIbPia8j1zOZw3utAYSqSst36HccSXj1lkTDy1TUT0TaY37sjDPM2+3mXVdtqB6SINpZEWCU+H2XCq/vN35cr3x//71lV+ud/7r6027FdZGRUhhnw/OOWLQ+dc1LXsOs6HE2bU0ShXWvHcvVLDVusN5BSyTAaCnCOfBcRkdMQop1q0EqvpECw7XHKVqC3iR+rU96UFoD1bpQWtnBr4vvevhq9tPsL3n4NOZP3crDpyw5r8O0P/DHXL0Vc1/lUZtulc1i4l6IrnV3r2uA0/G0u37iflej0zaXvVgsZ9Tkf/uh9VaWPLC2+0Tn1/+yH39jLgba9av+/zGvN5pNOIQGJomdnxwuFUDb2laytm6P5YV/CpF7ytVj3MRBmGIQUWtnepa1eq182FQ++KqgLRNq7XmFZyjZS23cqeREDzDkGBQO1VKI4QVRFjrF/ySebt+oMqF09OIlsoG8gqff7mxLpn7ddlkD0otLIvGtNM0Mo4jH7/7wOUy8f33HxnGwDQNCh6HQeNDFLTTxk6FnFdKLuQ1k9fMMucNaFpulfu1MM+F+Z5Jo5DGbvfRhBaOmgUf2qaLpM/VK7ghwn3WTuunaQQE//S8gVVHBpFq+XUNKU14xBRJY6S0hLPGLCnpfGgmreBDwznBRzEpLovRnSY4g4l7Ox91jhnDvaGJ3NoazhWWMoNzlLYQW1QbaWLvzppVKBnBlsEWhFjs3w0JIFIp0jsT9/I1j5Y7eIKPRGPVX8aP3POVudy4z6/8ufwX218DKU7EMOxrr9vN1jag8LEqrcf0O7mB7ne64/5zKGvd4nrenYuvcIu/dvydjKcOIOjF7QBUB586BdVtzi+4rQzkOB6dieK2O5b+XDi8+R1YIVanqoKFx5phEbbMzpbB6Sc8erhbCLrXHuvnfHuS7KnY7rjr+Zw4o/4aZ6pnY/p7D8axG93uinfD6Xt3KbcDAo+Z4QOQczy2ja7fe88UZHV6qn6JBR6KxAZCHIjjmenyEdc7K8WRMEwb0ymkCR8HWjXA5mHCHSiXh0vs1/0QURzu8/HSd2d5AzOPgcnhdkWEkjPLMnO/vjFf37Rkpm9SCDQQ6ZuN0TKtK8o2nj2rImJaTG1jPNWijeCDOaKbxlPS7z64XafgyBzoJbriTNupkVc1ust95X5btE3y7Q7WPSE6zzgk/OAJQ6QV3XzW+YqIMN5/YFgXXIwg8WEpONxuKCx62wEOd/h/nzfvQjVn8+arYOXwvq+ArN/Lsc/Nfa4e/vr3AlD8Nvj0W68NUXWdTuczTx8+IHml5hlvJU+1qMaTtKrNEjwETAT8COZ288LOpGwH+9ZZBK3p33vgiAjNyVay1+2HOmgQQ1S7HaytuqsmmK+fXkulOFiXmeAFaZnoHaeUQCJP0wDSGIJDqoHtcBDnNnDY6/04My0909mOtsI2ZucDLqQD66nXaVtiQPaRUENQaG1VnY6igZSUVUGt1kD2Li2aqctG7Vdbt2cpjVtiFBARobqGqxkFngrailevKUjC4/FNOwi2Zu28swbSVQLVBXXAvccZkyv4qICcaTv0bqjdX+nME+92xoJzjmRtiFPqjKdEbZogab49OBa93LA7/BibAhv3Tfy3a2uY81BzpjjPcr9ze3tjvlxY1hU3DtqRM+l8ef74Ha1WPnz8jtP5zLzMML9fAY+7v3v46WitjhZMHt72uzNJf8cRDj7IcZTk3XcwSVNhY8a47uf0gNkAoOAhBWWsDEFL7YLNOwWF7bz2Yd57FZCeRr57vjAvK/M8b+s30IhOrDuXrieRPfnXo3Wdy1iLbaE2j7id+dTMfoktAgXKnJVOdZZNYy6VKsK9aAlxCAaU9evuGW7b98RsYDZGXosBL0J0zspB9DM2Hw3NRGtHSU8KWkZDTIzjwOnyRDxdGC7PNBcQ/0Jpjtu8UtaVstx0HXrH0BySTkzicMZ2TKcn0gBpgCiOmCt+EVwoCjLb0f1jhwIxMXiGIWi7cPFUcaRgukrBb0lSBW48EIgOfItIaJaIiBuQGGPEb8nhgrRirNICNeOq+pXQqEHt9ZIzy5qZTTtmQFd17N03vcejNr3Uxm3NvM6ZX+8Ln+4Lr0veQCeBrfGL2rquydJlEjB2lT4Y7Vb3yHQS2ar/FHRyCjqNQcvqBu8YgwJQIUB0ur86DyUEqnOQsyZ63nkH79eYO/zwbW+h+2Lv//oQhGznNDkcFouR7q1rB/5Ojx5HWPexnhxpVZNIUitN6vb3bzeRkMcNocdDB2Di6Ms1UfBlzXfm9Y1cZ2CltZVcFkpvjOEgxkBNgoizLm5Cycog3/zvKkhzuFARPCWqbUtDw1eLio1wgJXRuXbUnzQPQzp7zzw5KYQWaGPXUQtbbBhCI+dqLslKaZ5lvRFT0H1cwIlHqjPwZ+Xt5W6SCZo0b2J2PCWGIXG25kmnaVTQxvwsfE96u81H610pa6nU0jtsasyzLpl5rsz3wrpUSq6E5LZ9x9vzLrnuv4uKbfU9pvsAHeBa15U1RWNQN5w7sCk1AN9AXJzpI5l+W4gBcRGk2RiyLVwXUE0t30wOuTNPg/nCXaw7WNlZswZPexzcWlOmUytUdHybdO0nm5KWXHmMN45ztjOEZPPT+v7nXJd20Zd6HNFHnI8khzUIydRamOsr63oj55ngIxLSA6YAPOh66Uf3AWm8t0nfPAzveFjCx/jRHWLTv+V8/B3AU2esKINkP3mnNPdXbVi+Zcp7yUUPYPbA14CJZjW6HY3zuxJ8Z8tg56i1WhtZ2Sh0e/c6t+kEPASFNlG1Nn4fl4eyvk3Q1u5JHqfK3l1O9vaX790/2bMY3RA2A+dC9/jejaghARvSuVGrcdv4QO+Wx/a3rdVjn1xmuMs6U/Kdku+0ojTp3vZWW1COjKcnLh9/IpjzI1ZyE9JIMyaBrNYxRfbswlZiZve7jcFDfNAD5D2Y7+9X5sQODPa/l1rs+djGYem6YiV2r18+8/rlM9fPn1jeXnCtEoBbLTq+QYPJlAbGQduAB+81Y4LSa0EZIwpcqshnzZmWC7SK955xSpxOifN54HRKjFMgJYfSbDuw17baaRFHLWJg08r19c4yr9zfZvKsddZ1WSj3WfVzEGY85EY4DYRpIIdE8ZG0zKRSCZ/+Agjnn/+ZEFXvZmPj2dpx6r1v61GHu6+Rw6x1fb7YnBE1YEdtuYc1cpifbuO4/z6Ovqltty6/dW+Pwe/2229Evb8JOr17u7fypOeP3/HP//5feH664E0kU3p74JqhZqIXYvKIT6YhptToVkX1UGQP0GoXVnWbJQGUqt8ZT7V7tk6oVnqRUOaTE7VlTRrehU208TRMgNdschPWdbWMiWr5rOuCd8J6vyFDZTglGAI/f/eB8zSxlsZ9WXHhTVlXTs+borZcjyFo8GClasf1qK2/i61VFfHWDqURwqBaTi6YCKR2esMl0/irwGIMsQAuqAZKc+qEhAQ16gZaVy29KwVq02xXd1ZcsC+lfzegNNWAo60glYiCg4N5T55CFI9rC0glz5VchTlXzfr7keYTpBNO0i5iHCMxquaBlha3DRjfs7zaVRUc0TlaUIAplQooGLCuGYcwDwmy6j49CF/aPtsZYlTN6tM1ZFrb2HOajetstJUy31mC520aGVLi48ePqjXlA2kIfPz+B07nM/+Xly947/l//j/+b5RVtQVbrQ+JoMcyaD1a1zW0wKvTuJvtt9uW+FeOvwMv/oc8wkYm3jUcgG3jPbqPXtSh1Z46X7uBPbgHthKks5XgVVHB8Xnv2aGBvHd8eLrw84/f88P3H/jwdKaUyrJkojS+GzxSPEKFJmQRRApLbaxFQZtNvNvEfn3QbrvOQQ0eVxzeSj074F1bZ6urOHnzjhLANQsEq/BlySy1UlJg8BDFdNlMhDiY5kpfQ9X28LtbicbGrDh8zogPvN7uxBgZYoJWTXhdhdQrDgmRcRqYzmeGpw+cf/iZON24LyvLmqlEcsssa7OEgyeKJ8SB6fLMx5/+iQ/Pz3z3/XdMQbgkgZcXVvcrqbzgb0BUfSldmg1pnuZVWDecBk4ugTNAW7z6aWjwpL4zWnYSE4FINN/27PoYqK8QowJcrSngFFwjhUryDZwGVVW0GUptlWteWPLKv/6PP3K/33n99Bkvwr/77jumceB8OjGNE845ShVerjMvbzf+919e+OX1yn/69MrrvPKSi7F4nTI6LURTsV+b7w6zibtdyEW/dG9SuxCdI1lZ53mIjNFzSn4rrRsMgBqTY4zgqcZm1bKZ5LUEOjNS0KBU9bZ2f6FZdLzHC/qzYNpola1csMgOJiEo49WYhNW0YwRYzahdrbx1bfreu+k9/W4Os1UPzCZpm5xAKbq39u7THWzqGpO9U+qDb7v5rs6SWl0MW2MjpGvz6Dxf1hu3+RNreUX8jVbv5DZb2VImpsDzhwvnqn6T6ps13t5u3G4z831lWTIl160RUUNgcdSinxOLV2C8iomDm96Qd4TowHlq3ctiNe6z2KrqHlgEWq2sq0daZBy06cg0TbQG3mmCqdVGCLAsbzgP99sVh2caT5SpMQ4jZa3kbKxwFMhKw8AwRJ4/nDmdJ77/4SPTaeR0frLmJcGSfZr0bnZt2Ur45ttd/z0vyqi6L9xvhdvrynJvzNe2xb4peaaTxwdBpLIulZwXWvOIqKi5j544BEJy+hUctVRWt3K93WjSmIaR4JyyKDcRW6GWjDj1aXCVYYxMdWQ6T+AdOauGVAgd4Iko08nWeGBrJuWdIwZtOpGCMp6UKit4r8BXtSQK6D3WpmV2pWaK13I71Qnu2mL9WtsGlKl+4L40Si3qW9q837AKAkjQczm9XqGRwkiIAymNfDj/pIy9MlPryuv1z5YoUekGNmv1fjkeWUruK9/pKMuwAVU4A+H2mP79uf5/Vmp3PJ8lZb/+w1/7nWy+ExvEKZ3l1Jk0HbTiMUEgsJc5tQ019qZCv3+se/TJOlLXRTftL9vV9fPvGBA9vKd3NuIRPMHtYuLbKd55xhuo1R/UN8bHHT7vqwf6fugO5/kWJNC1O1orauDtCysX7EBeD4JjGonjxDCdN7QV5zTYpdAI6sS4sAOERxDQ9YzqkbX2HhHdg4gNm3PvRkIUNBEEL13lTcemGiNpmWfm+528zJR1YbCTKy1fs34CG9qtc8JtCLJI3ecUYsBRMxDJynsc2nEhBmJStpMKihsqyP7aTrRoTcvr8lpZ5szttrCaWHlZM9mArVoKPX9ZloKpJWjHsMGRo9cxb7DMN+J1YPzuB3Wct5qIfd5sxuk4EWR/Nvtc/AoO3Ob4lhX+jWNjNf5Ojm+u9988vg0+/e2f9fhebZEbmKaJp+cPjEMCUb0gOqBZMk6alsB4B1i2pQoueKX54lTs0Z5vs0u16ututQyYcnunj+2eBd/YyjBEMG0iNtvWOxNpGYKuMeg6a3X/dy2UkvEh4BCiVyaEOM95GnHOcVtXinVY8S5srKf3JQgb46mpOLG0aptc1SwhoGIdgZ6mds4cpM1O9WC6gWQFVfAI0b6cptiaN6C+7l8iKv7pPOqNhA2Mb6YrU5sJ/baMk4qj1yA70xQRXdVNS+VKXpVRuSrwVCNIEHyrQNvYXxsb7KCzspUk9LXs2IQ0u0ZEtM0tJWUvpaiZwRg8rR6ygh10EnVcFDyrBjq17f57csLhdgAKHSfVH1tZF7XD5/OJ1pqyGrxnnCZiinz87nt++uln/vjf/5VhSJQsVGQHno5Uebs2AVrzD3NVu5HqXBXbH5w7mLV369S9N26/w2Pbv4TD/Dj88vAb3a+Ntbf9efet+tpTvSDtzBY9DAKjTjMD/fS1WrakQrTPz0+cpmnr8FqrApbRO5qHWrVLXBOh2P7sulNN0Gfp0ZIY89V6Vr+aFuU2NzrwakvB4Qiud+pzBqwLc1HezGhyBphvIqL6Is5Kdx9ZgEKpOhK1aqlGrQ1XKstaKA2aKDjftUGiCbDWoHbSx0BIiWE6UZowjCdiGrdUfrPCXcGZ/kskDiPj6cJ4fmK8fGAMQgqNuFbCMOPTggvJ/K6efNz9P2+Z+WDX0IGnuku0qf3vpVyWlA1Rg5jotcwxG/Ajh7GW1vCuWbfUhndq0xrNuosV7vPMfVn48vrK/T6zzDPJyptS1K6bIYYt8J9z4bqsfL7NfLovfJkXrmtmtTaKqTNh++x0spdk9rXsMFY79M7BtQuJi47JEDxT9JyHwCnp98HD4CEZ4ymZOH5HrKS3fPe6N1XnVRzYNGRcB+4f/Fe7oO7HSmdg2dZE13Lav3ojGOPkIv27KD9i6YBTte+/R8aTxRjbPr99rxsQ1YGpY7z1dcXEDjrtXtoe2/Q9rLNlBS3lqy2T60JtK1BoFGOpaPMPHxyDS9t6yyVSStN93xjC+/UbeGgdfBGoWedUGZSpUqunNWVhOmdzQzrr9DFA73GVzm8F31ptNN+2GDaESAgOEWtKlFfV6KuZWlb1xVwkhcSQBlJMqsXYYzZ30K8dEtN55HSamE4j46ivV5tsbB8fbQwVNGmtmS5uoRjLMRcrv1uV5bSujZyFmFSLMkRHjG6rNqm1krNQi6NWR6xJgW+H2rSoN9ukUaomz0Lw5FI28LGHYzpmXftLx6x36IspEmvVDr/N6zOArXNgiPY8LCGhe5mWs+m9J/NXuu116jsdk4EOtYvGcmr0Dsn9ue5x29E/UbO2E2qalTGKU//MSfeR+u68gz/QWXCJ4EbTXdwcNXKZqU19X+kAV5/Qf/syte/v3tOv+984199TMfJ3MZ428OH9ZojbFolBEyrwt4E4u6bTA92rmYF3R6fo/U10p9QEXd0O0mhtYw/C7Rz2MNw2SffF/pUNc/3e9FBH55g/PNyryOYw9TdshhLUkduYTeZUS/t2a+KjauL2sJ0FU/Z6EctMYUJ2PSixOlOUxdJMQFx1QbqwZAAfaMaIUsei0spCWV5Z3/5EWQbK/GkL+FwY8GEknT6STt/j0wmfBlxrGvfVQ3HWIQslNrl7J5MOgFQDdvomEII6PR3E6s+4B6De9w1f59nr6xv325Vf//wnXj//Sr690dZZs2Dec18zWRqnwatwakoMg7U59tomGpTlAxrEt2IZ1VwR6yOdgmo7naaB0zQwjZGUvKHMJjBYO1AFrUDJleVWmGels97vC6+vN/KaWe+LtT1eoTYbv15nLNou+bqSl8J9KNyHrC3Vh4H6+oVSC+npmTSMDE/P2i2Lh0JGEMu6mPEteaa1ajR7jw+DzQVngXqf3/qs2rYx2+kMYPDKceextfs//pGGYdvYO70ZHg3sbh90vhx8g8Nr3MO//xZDfDqf+Pj9D/zw40/88MMPULN2UKsFVwuuFbwUYvT4eNoAkVq0a2Mqgdq0FW9tTZmAtW008C1g786L/bu2XdhUgFZks53Be3xyYAAVB+0y7wMhJoZpBBzlpBv/7faiYKhXjallzQieNGZccJxPZ0Ia+akI92WlOU8ulXnNNn91gFvOVFQ/TlkNlVKz6qGlQJ5vCA0vGV8zLS/42vBuJIQzfnjGNQ1wPBWvygF4ChqhKG29CXg3In7ESaJKwlsnVGmFVjK9g2ZMCZcmnNfAUU2DIJLVYWqayVRBDsEHIaBlRdELwak+VM4ztcH97cqSC/c1a6Z7eII0MT59b2V6sgm598yY7gtWItyiZs9s8+jJFe8DIlpzH73C2d45csn44FjzanoQGQeU4m0/65GpAXslb5Gqs3OobPmmycsmZFwLss4s11devbN5Gjmfz5xPJ3xI+BD453//Lzw9PTHfrwQab58/Md+uO/AU9qAO57d5W5rptBjzqRRl1hUrp9bWygoM9AD522uN7mH+rmwXaFLl6HN1w63be9/jzeswP0jFXBWE6NpOx8DHieq9Rec4eUioM9gEStpLztI4ks4X/umffuI//q//gfl248+/vDBfZ5JYeV2ASqA6DBho25fun9p5LHpHiaqBMoRA9J5oAqoCOF8pIkit2mGPfi4Fgpr1nXfbvcO9FNaq5a3ROy5Bta0Gp2vUS3ea+xrS8anGtL8uq+qmpYHQhPX1asB7xAOjVwBmSANFVNx8WVde394oYWDMKuz/9PyBdZn56ed/Ii8z64dnsxHC6Xzh+cMHPl4uTONojEGvfpUPOD/gfLKvzro8+Igb4G7aT1HBntY8ThRQ0YC5mX6d+rIhaOY+xGTlb/pUe4PnPQGlAVRUg6YAtvc41OGZ7zfmZeZ/fPrEdZ754y+/sq6Zk4MhBM6nifP5REwKcM25cJtX/vXTK3/5/IX/+59+5fN15s9vd7KVVXch8SPQ7X3vrrQLOTezEbkIS66UIpSsz3oKnvPg+TBFnsbAx1PkMniex8DgHVNUlmh0ji5InjPKnMpaKkMUCJXgHKMfWGKhNMH7lV7Go/GEgnneiwGbuh3cV1icsbRQ9lNtO/CUlSDBUtSu3sz2L8aCulX9PjcMOH3w9P7hj2alrbVk04Nb1Neoma4f1BPn+9FjhB142krptvpLtiD9GNxtPppTf6+0hVJnar1T6koulXXN3OeVNWdKKVt5Xk+mpJR0/cTA+Wni7VV9/OvbneW+sszGfqrWkU2EYsyasirYUUtlOntCUuTU+4aPZo+zzg0ty/NqeDVQRStl2pbskqZAjrLSR0RgLNVAV+tyu66k5LhczqSY+Hf//g88vb5S5U4pmVLVL5hOE9M08t0PHxmHkfPlTAhBgQpj4+n665o+morSTnzCuqyq7bQslKLPKwRPGpVNFHxjmDzj6Dk9OU4Xr2WMreIzuNKQYusjN2rxiAtWbu2JZuN9cNwjiBTW/EyuaQPBtvgf697rKlAJyROrslEFBZZEmjZZcGxEAh97IuwRsAw+Wsl2ZJtSCLWpzlVpXhl6bd1iA3GiMhcOk0JQ/0YMrNvLP7tNk620MtdVGVMtbzZGG//0z/dGFDniIJXWMjFOhDgS/Pecp2fT8FqRllmWN8bhgovT3qCin0GOQNYO8G5rCvXJHkvydr/jPRC8Y0BWNdWN4N9w/P1d7bqDY6DLxjHdL30Doo501eNxNA47IHgI6h5PqECHFXl3oGdzvvo7DJX76gO7874N4vYhh8/un3U0dP1ebZPumNLDdfbLOLwHtoxjR+Y7ULO9bvtwG6XtXg6g2fETbMx72dXWyaF1IPDRODt/VP7vgakFHmWlLleadYBqltV2YSTEE85H4nDR0pYdavrqODrBx+vfWU6H+39/nsMz2N+5s3ikwbIs3O937tcry+1Gy6pZhVca6Nq0U8pon9GDuG1YOzVJ9jHSDU82lgUiqh/hu7ZTrxO2GSwo6NQ6JRYVEs+VvBSWe+Z+nZnnleW+UHJmXVcFCXLBi9HHRRDv9XKa0IoyDjKOLFB8wAXPnFeGxZOXmbrOSD3voK7NI32eVrNt3bhKnmm1qNE0LRznI2zdwPooGyr/uMc/GJbu7h7n+T/6EWICEWrpzmxXl+AA/PZb7pbrsET/J46+FmMaOF8unM4npnGkLI289q5vvSeREEz/SAUt9Knr1ir4Ko+dCMU23gabppOtwx7Q9wxrz8BiXVhqUxioidXei2Z/m83Tfu0xate6ECKt7nOst04tteENBAteTGTbM40jgoqVe192nYSqNmzTMzhaTzFWkTWOUH2QAtW8lAbORSuZG2DrzFfxDDgKXjJIQRlPemrxEee0NbBIwFE3vSt1ZDTbHWLQ9tohgU9U1wxoMv0J0XbYfZDFi+0HHcwzxmnN1AY5KxU9rysVEBOspIt475PkcT8xA+i8A/Hb88DtrFV9ue4DIQRibMQYSbWSTBNBhdyrgt0GRGz7hHTmU2c6deu7B/TmDivw1JSVV/PKOt+VgTrPDMOge5JXavjpciEGz/fff8+X73/A10Iw6rlzKPDkDdpyvj9Wa4Us2zzxOavTVrK2nXb2XXrnQw77KjxmdtyDvfu9HJseJtA9rO4LHUGo7q9seAU9OJNDs+j99Zu72adhJwTSA2dHGiPjeeL5cuLpcmadF273mZqzMf1ENYS8tjFvXgjNkUvfV9TWKHDoCL7hm3aUEzBGkjJ4glhzgbZf52bTWp/D2w6FoIBWc425qgB5wJG8ldZbPNoZJhvo1s/bhFIr4hy5VqqrlDWDr4hTMKIFp+WIg+q0aEa+sOSVkPOWjU/DoBp+lwspRYbo8dKINMZpYhpGRmsk0B11sNJ318Eld7AJznRD9/tVUFUMrLIn2vSB62lM828L3N0G5HhrRNOBu/3Y/aNjuW3fC0UaOa8s68r1fuftfue+LNRSOQ3JNGNUoL0z4NdamXPm9b7w5bbw6bbwcl+4WxnlZuf6rSM7iNDnb7fh0nU5NRHbrPzSiXVZDE5ZTilwGTxPg+d58FtnxWDAUykKglL0GmtrUNCEdnO4FKwLWlTb6cvead1imj6+fV6BltIBBMtiV+kJPv2qx68G2R7vfACcqkC288Vt7H8fR2eKbPt7yfTudZ3pdIy7+uT8mu1ks/kgc9L3xN/8bGm0lpFNML7ZPGrK3ulsGs8WfHdtJg+MY8IHZUXioJS6vb9ZyVsTS0qJUFadGHn1uKDi2m7bSEVZN01tnmvObJ/QDa+wr7stXul2y3uiTyjZwsTvjSHTGx+lmHA4Lk9nhMbT08RaVDYheM90ioxTYpySNiQweQX7xM1vOj6IPtYiet+1VtNdsr9acxX1Tx3j6BlPnjRAiGrDWnGbedu7GEJzXbBdmdpiDSQER62ZUsNWst/jyv1x6061ERkM/OkaT1ECrTOeHKTUm+l0iR7dCBTs9iZerlUzWwyuSJwyvHvdgbwvYLeYyu/EEGwsj4wl553m/9QL3rS3Gjs5ZT/rjmdsO6Hre6mRBJzHxxEYzQ8wzbSW6R2ij2tIE+V9H9RTHrvV9b/vWMa7XeIbcdBD3Ngv8280Xn8H8KSO6t7x6uAKHRxBnY/KDhIxA38YgH6TwRyPrwCnY/DX1EC0WihF6YXarc5eYRudbpY7arc9f1tIrosu9km6Ddzj/YnbN0PY9Y16VlHtQd3uu5eN9IfcJ56WGdukEWM+HT/JbqAcLqAHFM5mvcMma58sx93ueB4woEGDRImJGAeqFFp228JsUql1YZ0brS72O6F3NwpxIgwXTh/ekJJJlx+JggYLLh6enz3jd9fSWtv9I+foAmlboCw96NSx3jL9/UGZw1Wyisv9+Y//nZdPn3j79S8s11cCajzX2lhK4eU+U1rl9GzIbqm0nFlvN7xXtkXPvvaxKqWw3GbWm3azogpDiowpMaRIisHElwVpRU2bKFukZqEsleUts9wz1y+d6XRlzZllXrT+Oa+apa1tQ7q7ZoU4NT4RT8QxlIrgWONK9nAvEVc9p+tnwq+eMIykcdLNwXnW9UrNM6UsiInLSWus+U6tlTQoA2GYPuDDQBwmE+h8XKdHYf+Nlr+/bEPrfy/HTz//s4qizrN2OFmUIVbK3gZ8AyeBHRA5nsVxNOLfOo6/DyEwjCPf//AD/8t//N84jQOuFYITXAxaluK1jMqFkeBNo86uo4SFmiOxmv5G1s4kLme8L7jicK5tpRVtYxnsQBTC1jq7ZxQdjeqE4JUFoAC1lS/Uxn1eCUU4+5EQIykNkISzPGnHuuWOIMxrJbeCpAWfhdAiVZxmtB0M1pUx50KpjbWsakKdx4fINIyktOtyeOmsHIsq0Or4JtpxpIUTkp5xdQFZEDmDU1aQkwxtxUvGtUXtZROaGxCSIRx7EB69I8WAdwPJJ8J0xg8XiCfwA+SKL40sHmQhy0ouhZY1eojScEEoJRAczMuCc5n72silcXt7Zc2FtWhQSxjxLmrZrTF6OpitDl013Ti9b29B5wbRbVnevcTAORUaFiLn80SIntIqMdrnBE8tWXUniooQizGf1EmUg3BzF3E+dErsQbpUJAv5rg5uiIlm+/cwjKQUSSGQhokYIv/xf/u/8nS58Kf//J94+cufNtarWKmkSedTDAcrBiwUA57WkjctsVorq61Z/V7JpjlWTa/qyIDS+N3/rmwXQAxapvbQQhw24M1Vy6buGavNjwlgZUY986pxULPn7+xZS4DRppmaDI+EyOX7D3z3L/8LPg18eXnj18+v/PnXF6JUklTVaoqOMXqGkCyR47gvKkC91EqujWIB2yyZtRTa0Bhi4JTSpv/knVOfyHlCEzxVmcpOKE2Zh7mpjl113rpl2bbVtFS5FXVqa1D9KrxDSQfKUOwd1GwkWUomtEZYVlwVGqr5dDedq8nDOUX+3ccTVRprLvhlRV7faPHE85qJITBMJ87Pz3z30x+Urbou+FYJrZBiUvBpPOlYN/VFgjiKg1LrpuFHvzYLfI6sVgWQgmpjbQ0JFECTdghQLUMWpRAahFIJzWOEsa3ZT2ell/mGlJU8LzRjcDnnKVWFxD+9vvByvfLnz5+Y10waRqbJ8/F84jKOhKQ24fV2xy8L17t2sft//fEX/vLyyl+ut4392YEvQecD/iAu3kGHnqxoKiC+FmU8lVVLzgfnOKfAd6fIh1Pkp6eBD2Pgh3PkafB8HIOW36VgzD9HLo1ShOu9cJ8Lt6Ux03R+5opvAyTHOWrp0XUV5twoUqloCWJfT7p+OoCF6QDqtdde7tifZYOKdYsU4Wrhw7XqPPZOCMHxMQWG6Pj5MhL978d+5WVGRO25+lzrFiQju6hyD147k1zBFD3HMaEeY7SYqPVAhA0NtEMZKoWcF+blSskZLxGpnrLC/bby8vrCmlfVrMTAhxgJPhBSME3cwDQM+GfP+TQyDon7vPD65cr9tnB/0wRTLZWWhRWhZkdKjlYDQwpacRHZwAwfRKUqTZtKxHQn6QnmrutjlS1V4xjvOyM6EONk7/EbC7pXxQzDwM8//8zzhwvEzDzf+PTlF7r+UEigNNAdnGitmh+I+l4GzoqBa4bxbABwZ8nEmEjJcTqxCVjHBCmBj40QG7I6SvfpHPjgiMlZkt8RBsHHgo9oTipqkwTxhcbKfbniA1xOJ7zzDEO0BK2W2a1lZi2ZeZlZlqIl0+JIcQDnSEPYhNo3eMH1Pc4iH7d3QXThUHUEeAk038x/LJoQxZ5f0G4FmggIm45FB6vBbXO3YyO9RK+ZVpRn12sOHfj2gWNXRmyNVAqCp4ZCkIp3Ee8DQzwRfdLz1oVaF+uqZwwskQeQ6f3xXkftqN30/j2/Velx/Iy/5fi7gKfH727/0R1/D32HO1Ljt5s6PP333aUePsmMUev1v61C0IX3eA39Adt7bRE7en3p7oQdQuzHz5N+Djm8ptPO7EodFqCyBUbu4RqOV79nkDteJIch66/a6aXu8PnHuzqc2T5X9qs7/L1PcE+n6DUrsZKeCkWZMq2o/sLeslTHNqSFWAoxTqTxGZdO+HHVErx4HPP+bPo19FFQhkYvn+vjzeOIbpuJODH9LXZDgLY+zTlze3vj+vpCnu+0vBIMfV6rMp3WUimiRhljEbVSKUvGe0fJdcuki636Ugpl1U520stmDl233MNY7Y5Da0ItjbJW1ntmva0st4VlXpR+mjMlZy2xK9WosoJ4p4E2mhmuol/BxiSIkFojVxVXrKKOTs4r63Kn5EX1f0LDeU/NN8p6p6w3Y1doJkBF+7RrRmhCTVk3EtHOQn0iHmfpwxz7xqL4t8rI/pGOy/nZNldHLcWc3qJrs4nRvdlYcHBwHLHl/k0K/P7z+1jXh0BKg2o7PT1p4NepZp3/a5loz6ExgnRmUzPgCAMl1FFQIcqmoJWA65l9TG/CnBC1L3sWRu2iqFiutyzyJt7stjLMUq1TS21WF2/MrRhxQM6rBitN2YBr0TI3nzMNb3Oy7ZlDZ3a+6ebmvApXJ68tr4foSd4y+fuIsxV8OU9zEXyi+ZEWJmvVbs/ECUhvkWLlvk23eGcaT48KGz3xoU6G9xGfEj4miAkJiSCmqxWsZBkTba8KzlULhnsZUC4V5xrrWsilUrKyHlsTxHlcb8xgAeJxaW0btvcWEO6WvztFu+NycABQlkkQ1VdpLTKkRKuNNAzUph1dmjEselJley9bmmMDI/o+qclABaGw624lg3Osy0y831lXBeNCCBCsBMJFnp4/QGusL19gXfYOpKadVa1LYxGnAZtY4GbZ41iyXnsclP3mPbUUnDhds5ijZGwFfar7fryXu/9+DuedltV7m+5etvVML8/pLGu3uSf0Vi8bmMjuk/QGKt1+2Bu2+SDeIVG1nc6XC2tp3O4Lt3nhNq+MFrwMvXNa8FZC54le2XoBwWWbzVI1ADeNnhzURgyh0azEWzVde/mDx7kG7lB21XoJsdvk2pzN1Wo+lqta/pCc3v3Y0GqWgw6PM5+Mvvaco1iQV0sli+OW1VZn62yU67iJ7bZacTlTijKegu+BamI4nWglIjEq8FQLMQRSSlbGoYO9de8zJpdIB55239Yu0Y4Dorj9o8/1Y5DeXyt4qcpKa6C6gZ1FZWfsIs6lqgRBq5aoc2g5rJb8zOvKvC7Ma2YtlWmYSCEyjhPDkGxdC/OqbeFf7zMvtzufbzMv94U5V9bau5PZdUv3B3cf8Hj0YHpjOlUxgWXVFBuCY0qeUwpchp3tdEmey+AZQ2A04WDvHNk7ijf726zsvrJpDiEqizCEqJpVISo7rTbVRuzAATtTcNNzEky+wG3M42O0tL1GOvtut3vR9KeeRhVF/+mSSH9Hycr/2Y9WiwXEB/1ZdbY24GP/MnvEMYjdfZiuEaj6l3TDwjZ5uh9E13Yq1JrtXN6qzS0BvazqZ+escYg4QqiEEEktEmPDB6/i9Ul11Yp1vsuLsnDzov5+NZE1lWgSSha8FyU4V2M9hQ6uKrCER+szRS20O3pA5j8dgZ7OvtnLDT2qcXnoHIqCU9NpwgXh6emCD8LbPe7zvHdq66CT6Ye67ps2VB7EhrbHxhpD7f6HloHpuJB8N6iEKIQgxvSy75uPanIwVrIfo8PHiguyaTA57/EbMFbJNbPmRWOsVEjRtDgxQkWrVOtKWGvdAu2u9RtjskYWXWnXfAW/zxtl0m3ekO2Dtr96p3a0BZRpr5uw37TgDniG2+dqn48dCdijiccorJ/jGL/3+eBs6Dpjl00LbU9SOHqTDgd1tYRcpbWCd+nBFfotwOiv/f14dOzm/et2xtS3YqRvH39nV7sD0PDOudO6UFS8jx1wek/h2gILi3g7+0eQzbDoabT+t2attY4x2ESPD6K5zvXJ7Hc/zCZDp7/20e+LzZCtd/eg1+WcbJPX9YDdgsHe8ruzkvr7NmduC/Bl+9gOXgE7g8lbwOffj42+odVDFrdfN6IaB/3Bits1qnzAWbtFZ4r2/Tl5J0jAQC0Fm8p6t/btiwa4reH9jRzfVDSvNaYmSBhJ00d8HPbNs7WHr14jK171urwPZmy6k+e3se/jvjlUDm3n671RVwuf/vIX3l5f+dN//c+8fvqVMF+JragAZHP8+nbltqzcl1VHZa20UFg+v+FuK7zecDhyqT3MBBzNaaB8nxcFn1bNmHvbrcpaKNFRlpXgBUpUJ605aq4s15X5deHlz68s94Xry027X6wruRZldoiyThrQzPEV9iCvIZvYnnPC6IQBgVpwqwZdkFjzjesd/C//jeX+pgwXV1luv1LWG9XKnlwY9dnHCUKkhQDSqHlUUC0OBNc/fQ9IvIk81FrtkfT55rfp9W2I9h/z+Pf/8h9prXG/a/brdnullMI836mtktfFuncom6J/r7VsYICOk/QF+Y1jt4vOe06nMz/94Q98/Pgd05BUuFUakrTvd3UjzTVjmoAZwW2L8iEiqVint6xlk34FPK54cAXvq/bMMEaBF7RTXrNATGTrcuX7xmYU44bXTh1OGY0+JLwP5KrsArneCDFuWiHaiUo7njQaS1W7ke8L+AJz2zK/rQmrCevTCr5lUptxzjH6SEyOy9kRp8DpFBinwJS081UvI/FxgDYicUTKQvOB6gOehq93FdGmUak4tKSuyYB3A+IquEJtWiKXi+pI1VoQKiE4kosQB4gTDNrXXMKA+IEgleYaISRcaDRx5Ap5rbRciK1SgxC9kLPHhwI45jUrHb13kgmH8kA/Ii4hLm72rweaD6w79o19z5bpftFqBec2vbxAIDZtC6w2VMvuBBiHhLTKMs9ILRQHlNVyQr0EuBnAJBvradd4wth3Ot2rKDPL+UBtwjSdGMYTwXnGYbQV4Hj6+B2n8xnJK6fpRL7fqHm1T1HGU0PFfJtz1mihMwWE1bTMOuNpud+oJXO/3Sg56xoumfl+o9ZCWRV0b6YV8nsDnUCDU8FtAQG9O1avJqcHt257bgGNa5y9TjXFlOGWNN5RuyNggpybxRccpIRMF0gDuTZ+eXnjX//8mbfrjdfbTHJC8kKdBmLwpC7C7WGKjikMyBS558KSKy/zynUp3LJ2u3ubV2U41cYYCyl4gs0JzIY6H3SFizLkiiWSKm7zhTzWgdKCztq0dCFXHbeKZwg6FsnADO/Q5g7spbIalBlrVBz3Uii1sq4LT0PknAzAaA0fCq5UCzorEoWQEmmcmC5P2qSlZkITYu+u5xxxnDZNNNXElD0QFBX97+WkmL2mM0CqdijG/C4XVMBc8Funvq7p4WqBuuLQsmVpAfGe6hOtl7nKLiPQmbKFiHhwqeEJLKVyX1au88x9WZmGkdMY+MNPPzPEhK/a/e3Lbea6ZG65UEX49Hbj5X7nv3/+wut9ZmmVKrLrvIoF0Oz6J4ohGAO0KUCZS6NUoRYFjILTufU0Rj5MgZ8viY+nyB/Ogecx8MMpch703ykEUvCb/zfYuU9j4ONZWNbGsgpv18xtzqziySLU6KgxcJtUakKvp5G8MkL1u2o31QY1m17hIS6XY4xui1OTjvuafho80Tt+ugTOQ+Bfvr/wNEb+/fdPDDHweznW9Y5WG6x0dk0f1+PRtnhRf+7lqD2+UKaf1WsdJEZETHvXwLomjVwW7vOL7glKCcejZVu3+ZXr/Y3r/VUbgOSK4Y54p/tqF8k/LZlhTKQhElPkNI2cpoEhRZbnlSG9cH2beXu5sSy6nmoR8tygOcrsiC6QLPmMM4/FKTzWUfAYk+3zxqLL1cZMyQJr1sSo8wHvC0GKghMuGVChSb6cV2BgGk4AXC4fqc1R8p9Z18K6LqRUcQTyUNV6+kA86C8qM0ijFgW19mSs+h6eYUjEmBiG8dDgS5N7KoHQLPYR1gzSWT6WDEsxcr4EplNAwgo+g/WOiUlL5bwHcY2325V5Xhn8mWWu/PDDB6ZxoMWiPp5kFdWuKl/imsM1rzbWaTdRHzzetJKkFR5j/w7y2j4iXjuA99JLUQaVQ7stx6gaTN5rR+Ge5+qwoQ+O4PRvfsMl9hhCHLjgiS6ZnTAtKEzTyQeCdWk87sj6/2pzpKJsf60AU6dOmVre+U1wPqULMUzbeY7aTUfm0hG4fP+9H1t5Yr8i+XoNH6/13zr+Po2n7tfJ8VdH1svjx25wijsYZb7GxNRp2v/yiIKbAGqvofROEeqtkHoHiDrYoT+5dx9kr39A+Lqhe0Qht5/7P78RbG5vc4efN9rVN167A6Mb6LLVdm6vfx94fOsxHsotOsraM4Sm77ODU3sAs723qRaJfhXoekdWFlfWO3m5kfJMKytaWrgPhjq8sgFPoItwn4THJ6wD7HgY9sexsa5O2qGhcL/duL69Ml9fWW5vXKRaPxwNTOacua8rpVWFU6x4vi6ZUoUl96y4tem2Daw5FXwra94EbDGkFnPsWg3bd2mysU1aaZS1kBcVD1/vC3leKNUyhbVaR0AbnyPKvH3JBkT1wzgdxCbEql28aE3BwbKyzFcAgltwZJbbr9T1SjWGUxhOuDAQexalVfAmRGXdHh5ToX3ibXveFlg+PJNvP6p/2ON8eTKQ1FGs1XwpRVlklrGu1RhRve1vB9D7vx+y0Y/HMdbtGak0JE7nM8MwKMEJA9X7eIcAQUs7fTeQfb2K4KKCl/0zQ1C9IR8qQfYgI/hm5Wi2mdDtaa9as2e+qQsr+CTov/uX9wEXAjRvAZytKwsu/CZy6La/C6ZX5oRW9ZydcdW7RurGXQlSTMDVM4TGJUKMMEbHEB3J73X2zntciGCMB1yn3hekjDQpSA2qF4K+DPHaR0ritqFvHWmaBojNKP49UeGC14jUe8S7Peg1tuje7MBZ9yLZAiIvQs42NhZ0a3mvZhN79g7nEeuWh/Nbx7xvziSRh99vuoT2/82y2npXNqs6i1GElNSZGYeBVisp6fcYA1KDCYmKCgdLU1BSVNurM2OcXZ2C1If9yOx+yRm3zORlYV2WTe+hX9f/h7t/a5IcSbI0wU+ugKqZm3tEZlZWdc8MzSwtzdL+kf3/j/vUU9NVXZeszAh3N1NVAHLhfWAWAOYRWZ1FNL276QjSUHMzvQACERbmw4cPx5QJIXB5eqasC8FBXVS6XAbghIoXd+foJsY5SlZiUeApprR36hsCsGWs3aLi6LWqjl5rSkL/887QX/cx5oHf54Pmx4ewqUeBKMvrozogaFLOfJzzww+7MuZQl30/GEAgIYCVVW61cV8LX28PlmVlrRo8NQdb6mxNqEFo0g0QEisdDgp+41ir6sGtzeEqtCZUp2LddhmIt+QeY8887NkoH96zv/b73dWxn8WMXzHdurXrAFQD31Qe89udeMxxA3hFTP+p89gKHuG+FhN6dQRLzo3yEmE45iq8L3viUwg97GCgyhbomj1O3bwDOc/f49x2/1TQBjGYbIOIsggxVsRg4wvqz40OxdKspN7TgjFIjW04wO8x1riAeNGgth/C3rUpq0O7a0Uu00yKSdnoXbvX+ToSb8Lntxuvy6rllqUeOoOYz3rcttM46Ln00/iPbXfc7+C0ZHSKjjkqQ+gaHRd7zNEzB01gBH/IeXTR94oA0due64lBGaxIxzdH6FA9NA+zlYGmEFSg3IuxrXTLaLufd45Z3s0ovv1Xl8PvmoKWp36cI09T5DdPmac58+OHmRy+H+Bp6PPo/Dx8qm9lC74t5zmYIN92fD2OdyPshjSK7ve1bXZv2R/d2O3dGDKja+1g1XnEwBb2pDoYszh4QlRAY54S3jvut0wtjSVFbYLRh/aT0KsgzUFzOPGaFHTVpss3OkHma5wvSux8Ea228K7voJ3GfSNpHuhudAhs9KBUMAWRMt4lenO0CmVTAKtsWhFRa0HC6fOsuUkXA1TMlp+JFM6YTqqJq2Cgj4fnoEbYSlGt/fm7mMfWZcqBPHm6dyZHoH5esMYJ45vLVqgIj8dCIFLLlZ4CQt+T+Ax/a/8P02IarCRv2mBK3hDOPvtx3iqp42wfOeEKjAoq0xF2MLoSv7uJ45XneYvZiXe3ewi4Y0z0g83n9/cde9+fPXaXXF8/mHDVks8haAJ1Z2aNb/9mLY0y12/zdn9OWuRX4JD/8PEXA0+DheMG1XEESmaAnWkoDeryuCnqv75fZDvFEjHQQv8gsG+izbRNkH4Klg5kXM/F7QPW26Eiz3kQR8b49J7x3X8OEJHTD+rs62f6oUt1+qzz87fv3zejMfv28zi0O0aQqMZ5gATj/RyBry0sxvkYyq/lLDOeQn1ckXJHLCO6i0ibGO9opS1d0W4fJkaLDmEEWG4XzxvnqfeoHW1g5X12vvdu5zSueYinHfekm2N0iK35Y/E6eHv9yv3txn/7P/8Pvv78E4/Pf0Ied/LTRPSRz4+Fx1b409uNx7qqZoN3xNrwS2H5+ZXmHY/9vo6xHBRzLXQqQz+gWumP09c+7ivOdeqaCB7WRQOlKo7lbeXrT688vt758sfP1FLZHsq4OjvCbnf4NQM7JsMo+Wuos12dEMVYBwixd7JAf2xsODYfVIPn7TPL40bfPiP1Rlt+ptf7jh+l+QMxTVYvDk4ueJJlt63UyYLfw8DKDqqNtsHDyA2X8Jeg7V/38eHDCyLC9XKltcbT8qICsavqxmzbQjMG1M6EqoVlfdCbMaJ60426n0Gp8Q3HJpVSYr5e+fTpB37/+79jzoG+Pgg5k6ZZg4feABXY7MaS87jjPuIUGIidFgIuVAtqEi5EWi24EAm1Im7DV3XunVPmE2hnFERMB8XhQ7JslTEUvJabRRO8neYn7X6U8jvw2llHsW7rRgPIxmOtal6qBjX4TW2IC+YLdFxvhL4QpXAJizraF8c8B16ehDBDvDrCxZPmSJ40kxZixOW8B4hSZyRNsEbEddq9sNxXfH3gt9fTvLUZ3lZ6W+hdwfXaqrK4+siQol3hTLCjIUhrdKn05uhllDTqWOp1ee3chWepyqIS6aSgtHHnRnIEQpo02HUz4iI1XJAwq36U0aIHCMA+0od+4tjDen8P/JyBSbDyTA85RgPtAjmpRkvwnlI2UnD0Wigx4KXRa6Gt6N5arSRSvAlQs7MqBkN16Myo9XIQ1J7eXr/iUyalpB04YyBFLU30znF9+YSPkVfvWZzfywa8i4jzSEzK4ktJmS1yKqkSoRTtgrTZGl3uyla83V6V+XR7o5XCcnuj1sLj8UarlXVb6d8Z+LS7xgP8FXXqB3N61xG0fdyJglK+6mtouicm760bWBhuttqIbvuCoH0iXaCniZYvfFka//zf/sCXtwdf3pTlu24WANm+tpXGW/Z8yFr2dE2BpxS4JC3Bu04R7x3PUyLdN15D4W2rxqiprKUyhUAIXtkjwFobWxNK17KkhqM5Z62nAevWd15H52WyGpjat04K4F1n7rq3JXfSs7Ix7jJAOvOynKOJ8LpurLWQfSPHyHWamHwm9W5A2wC4Dza9CEjrh4PujJER4q7d1ru14W7dsvWavOqm6SJYkBcjzgD0Ugq9aTmbeAWK9r1dzAd3jrps9LLyaCuuV7q9xqVJ16f1FFc9E4eEjHNRW3WLdSALKxuwto6gSc3JJ7yPLKWx1MZPP39WncRWcU4IQdmQX+6LiosvK1tVNqizCHSEeN7p/qMgqPrkxcCmat2cFdB2pKBaesk7nrLnx4synn6cPR/nwA9z4MMU+XRJurcFr8LdtWtHPLs32k3PGCLRk6Pn2U9M10Rpjtrg3oSlw2+eJqY5U3sluI7IBtJMAxQ2N7zj4e+/D8fcybgLYsCnmPi947dPiZc58r/97onnS+b3P35kzolPzxfid1RqV+oKwJAVGUm8Iy46gKgzsymEoXHj9vWth5XKx7gz+McLmlS2srJud9b1ocVooknFra60XrX8KiUu8xNbqbhSab7j/AHcVum00qmtszwWliWTc+L6NKs4d07Mc0ZaZ54zzsEtB+63B2VTRk3rHbrHEcle52XB0aSqbmJHdSO76u961zVf3IWymoSIaAfi6As1Cc6pjZQ8wOcCzhObllY91pnWZ9P4FeiRXiOPN8fj3nl9XUmp2HlvmlsIkZ6zCutbsi/tolRHORvIHq/5lIghklJS0MOfoGQLvB2aVArBKcM8edoEUwqkFLg8eeZLoJnuo7LpPd5PeB9Y10bZOsvbnbpBXxJP88rlknFeSKHionbilBS4zhPJC/Wx4qSZZmSn1Y7iX8EyD+wxrSYZA4ij9wH2DCDUDeNtq9pAIbSDn9tlJHT/jSEQrJmTM3s8QnCx+T9Shwaj77Gi3wGtA5DaEzAiDIX6MCoThl51V8b/6CjvnOpZUSvSCrWsSMcASCvHc4LIqFOHAUSJqP/6bqV940ftrETvCed/n4Cs/8vFxd/R/znKyUThTcSZYRELFk60j2MAOSG6R+C2I4uyF5XpjZJDl+OwU0eIbO8+zmP8W2C0oj4fO/o4TopfvubfO9zZw/mV353O4Pj4d+f47eedzsUN6tv5nA5E94Sc7Z+0lxQS6D7ig5Xb2UTdp/mw8m4YfTEwL9giGeiqQ1v6hgMpdu6bEZL9+k/m5nTe496Pc//mvRyI6w4C9s7yeHC/3bi9fuX29StSipbVWK1u7SoEuZbKVhoJCDh8F1zr9K1QnQNjaLmBPJoIqQytFk61+fY6bfvcqFVp661aNgSUqlorZd30sW300lS7xAAah+F3zkrqDDyQd5d9zuTCyLk6tNIhIqqDULQjXq3art6HRl8fSLnrc33s9ybElebQ1rS9MCQvD/r68MoHG0bY4ffx5c7tDuG7Tf47it1CjCCazQpdywtjq3gfaCbIXJsxoIwJVU3TprWKc4e+zA6KW6ZsHMMOhBCYpolpnpnmiehE9elEcCGYXTDtEu81O2YA0ZAmlMG4EYf3HYIgXZk8IapN7KaZFJqVMfhOCNqlsfkRkA0g3rLxPhCjAk0x6BwJIeJjIIREjJGYsjJ1hkPYFPzv3RgN/SjP6KIaGbiuII471oOWaTWtj6eSfWX2nmvsTFG4RsFHIWjzRXVQvJ2zH+xNdmaP7jMFtqyZ/t7pdcNvth6Mq+2c1yxrVWes943aOtVKXgBUG+E0QczuKiB7iJ3uVs4roKKMsEirGwhstVugrE5Z8uZAhGE/I+IS7C3Sj26j71ioJ5DHJpMt0W9+f5ywnZm5RDaXUlR7mlKkVu1c02tVoffeKDGpFkk1poSrRycrATfcJBnnJO9YHVrW2aBpA4h1XVR7oVYLlobN8YScyf1CTBkfozZz2CNPA8RD0AAiqLLo7qiJrtneG8F7XYMo00mkmVissa96p5aNXgvVKTvK7Szd7+MY7tEo5YehOWn79kig98F60iDXjftq7x1Cy9FbhpTB0DUgS0RBBhcRryDr2jqva+WxbrsI9pAckC6stXP3bdcxHA6xnoPtQ1HBAOccU2xsqbPUxmbgTm+gnSxHIsftXQ47J6YTHHvusDXHFqdlhbbKu63prav25No6Dk8JCtYm4Z0NeM81PIKGaszStwWm1NXJb5Xa+95EpLWm4LaV3vVa6bUc+7vZgyZi2nn6Hi29V8bNKLV9x3ga1wmmS6R+yt4Jz5sfN/7zgPPqz7SOmJ/SLaCK3avNxeM8hMHA8oP1qhOpA64p0NxsPTtja4pzrKXSpPO6LMo+tL0oBk/rwtuysFUVlW99+Bzs1/W+5ANGAq9ZmXbru3OCc8oyit4xhYPppOwmZw9lOWVLxOJUH6eafuY2uo+J7Em56IfOn5ZDueCIHeqmweoUPc3BnAJzigYStH0t8u6K/vy6HfNTUJbU8IyzMZ6epsTznLjOmSlrkxv/HQFPw08ZBIEzs1D/sIc/p+TNiXW873L2/30LGaxkd+zXIqrrtCf3vAIOBjoOYCuGRE4TIl4LZ0xPSG0au7i9AsEWkIuQczRtIm2GkHOi9840J2o9Gl+cD4cjOE0MNYk7iIEYyD50nBzaSMGYlmKideKgFi1fa63v46hj0UE8zVdcV5/VO09t1YATr8yf7unNUTf1ycqmzUdqLbqvNu0oqmMZ7bzHDZIDNDF7HnxQm+b9aQ2PKOjoWjz8zyMJ7gjREaOCUT4M306B4NE0wTlvDC5RAGrpPOKKl0DZVFcvWtJez0f1oqSbLIQXpLZjXij1X23kWMDuYBqNcz13TGVgHO8W+Cl2HZN3/73fQe09MpZj7gpj/h/v28eGgyE1bvD++mHbrRLA7/H9N9iGxbrjUHKPaT35eOhdD3kjW1vnCxxj85eyxn8JNv3lWMpfDDzVqgFYMMjfiy7QUlQ8tPXDCdYB7fvgwXsaqnNQKPvAO6uXFDAK86h5H8yCTmuA68dNcNoacXToQrDOIO1UF+wPpwQO4c190E/DfuAmRstj3zB3bSc3qHNuv1Zgd8zl9FEg++d4p2P2/oaeJrAFet2NzMx7VtdAIsfn9i5GVLLOaSEiKZPmZ3p54NMVX4uiuV0QUc0RHDurysdMSM84H/Eh40LCh0x6+kh++pH55Xfk6yd8nBgtT73TTKrzbtfPGpuDDwdNEE4i45zGygy/tr3UWtn72xvrsvIP/+W/8PmnP/GH//r3rPdXfrxmcsi4GKm989Nj4fX+0DK7Vvk4zVxCIIto8L2MLL3qNuzAi9cMfQtyyrQ7DYYsi9iaIOuGC8L6WIBOXpXx1AXaslBud+pjhVJxXbQdtFP65egM1QQTEYfKDvspVdt5y/B9S6fUDGxwQG1sAqu/s5ZCngsxZ1LMxPmTlfEoOKB1y3qtfXujUXHzMy5NSomPxlwRdSUV6xjzaAS0vHNunU0y4f3m+dd+NAOR1GYEUs4EiYQUDUC6qqbTh4+aHSursifWhVqrCb0X1uWmv18e1h1vNeHMQW+G5w8f+Lv/9J/58OGZbOXyet8c+EhvQmlQq3brGSBjsE09xUgKupl6D0QTRnQeF4rOXQOYWyvaRKAUGg5XPLWDqx2cZp+xjSpPMzFGrs/P5JSZU7Rsmq7NNCWCD+Q0Nn9AhLJUKy8rB0DbtDW1akk1nPfk7HA+EKLT9SeqaTWFQgqFp7AxRc9LCuToeQoF5yve9JjoG6FnjbAE00HR8jttlZLpHlrdaI+flLH4eMDrT7YfBFyccGlGurJlpFWklr3ETtejVz2j3TkwB643xqo12TtwARdgvr7g0oWUL9S6Ud5+ppeFR7njauMCpAh5yqoPkTIqzjvRCHRv9jUmQkykpCCf2NypZdOJKsO5G5uR2fwBgg0WRzcWKcee43HaRccc8eDVeZtSAhG2JWvZ27qyOuh1o3lRfT/pGqBW0SC4jXLTw3nrqK1r2woihPsbxMTtfmNenokxMk3GXhYh5ZkQAvenZ2It3H/+meVxB59wLhAV/tPkgQ/4eDidcGgJ1jzRW2POE61VLtNEq5Xt8qTMp/lC2VZy8KzbosBU+76Ap8HsCSbCP0A6dHvHGzg4ysurdCsvAowpnr3nEgIpOOYYTi6i3vMuWv4mPiPxiVUin5fOfau8Liokr46+AgwIiNe97rY17ea4wSV60+GpXFPgZU48T4nJhMef56TMOOcIa2Updbcpe0cw2JlO3eaedgVzdHOgtULWEcORsdWrGaLcumYWK1PxTpi8x7vA5B0u6Z5tFR6aRHCdVitFnInVKrhUeuNfy0IKkbfSeJKIe7tT0xuXnz+Tc+btdmN53Pn8p3+jlZXyuBOdjnvKE/P1mbQuTKVxmSY+XC/07EiTp26brr+u4EbvJyaVlQa74Kk41jZKX1TA2JmN1Cy4AkdrFdYi3N9WtnXZfb7rk5BS5vKcrb14smAmg9NyNDW+DxqoBl5IxOlC6PD62Njqys9/+BNbrbze3ui9c0lB95Kg5c9vq4L9W6kKAO5yNjaPB9aFmrytKti0lEPDLHgFZhRwguwdz1lL6z5mz/PkebEOdi9zYjZ2Xe2ijKzSeJRG6Z2tdmXNiRjAenBkszGkrlNmnhPFV/omTEW70X28zvgY+fzaua/GpABq1/LNEUzKANXRp2jXl6OOa0WF8VegAGv3VAnEmMlRdYNSirjwfXXlHBIGe1mSgU4yqji8V53LlGwuD/bGMQZjnoDuCyNuGp28e++m4VjYtpt2zhtTyexlcIFLfubH579hShcu0xP39c5tubOVjdW6BjdrMNAG+7B1HuvKsirrfV0zH16uzJdMTp4YZlqrzHMiRFgeK2Ur9K7dCr1z5KRJIJpQWyGwqU5da7R+NJbpXZAm1KJMKJra/uWx0VpXIX+BmLyVsKkH0GRFWuO+fKHUCR8i3idSvDBPMx8/fMITuL/egcq2VJxDGf6W4ImmhSRouZuygBQgL9Zp1gdP9FFZ6cM3c6A6y7qiBjO+iya3NKHZSMmaWJnB7SOmT6ZZGZQ4MRIgZassj8rjtrE9OpkHvQjLslC2zNQiPnqmNJGiQusxdh73gjhheV3NX3UEAnQHQecXYGLjxniySSYORqnKwP938GmAUu4Qc/cGIqlWVtRGNe541vmnjNFBtNFO0poICsFwj+Fj9RH72y5vnxlCIsRMDJkQMiHac9C/D4KB8wEn5gvjUApdQSQhoswucQ7X2OOhcQx84wxEnaV0zq8bOMb++x2Ie4/z/HvHf4Dx1A1RO3cp099rtw9z9vzIJnd731j8cAYQ1XAYiDSMtpjji+nv7C/cT0LfP0TOT583nI3dMLmB7LmjIdV73Af7KHYQcmfynNAqjt+PFNl+u8aN+9XRNqz+3Q0+X739/4QWDpaWXpucv+j4WNGpPAQncU61SrCJGhIhTvSQcT4oWt3BncAEhy68EDMuZEKc8THj00y6vJAvL8R8xYe8L7SBaY8N+wxy7gDTN/vlOxzUnA6/33O9X+uyKNPp6xduX79QVu1il+KFnBJb1/KhtaiTOnRdkvfkELRaRhFL+zar6x77XO+WqRMGw5BdEE+HuSPmaHorKxr6VSbi2rpq2VjXhOFEyemhCJxqFIw7PQDRkfkdYprDSI/A1zkljGgLaWVctc3hQkVM8E98wseLOjV5IsSAkwVHQ3ql1xVpBYZ4nn3+Af6ebs+wpfbD+3m4T7Pv5thLVX3YAWaHU2aKyK5FMpyYEJWeHaw1fYqRWjeCd5olcqoVJaiGQXWjBbVjmiauT89M07S3rceyEbtYLCbFaCKqtXW6M8aTO4JvrNOG86pD5ES7sBHAd9UU8yHie1edKt+Nqq6BmS50zbaHEK39bSalTJ6yOg9WYjWYhXCY3ME+He2Pd6YDnAyv4AwIHxoY3jkjQQnZdxKdyXVygOQa0anEtB+KMtKNFdaOHX/YSOcAbzQOpUcJ3jpCNXrZbE0p6OJC3PVOlK3TjywrR6mO2NobkcNgO0Fn74zqvGbCM0hQWrmvibY9dDzqpmVNBlDD0MxSTSeRgGobvdcb8N7vul5inaPONn+nRO/A2MmoIKd/H4t07Hl7ABiDZmRbI+cMvVOSPtcYcXSkKQDgmn3X2Fewff00fgN4wvRjaq2UWij1pJl3Opz3eOJevikCtVV17JzgWsOFvtvJI1F0MMKGMGf3Dunq7EqudK/dppqPSFHQ9pEzIo3wbQfW7+I4gZCnTda5g2mrwPYI6tzOcBKUBRlGaa3zROc56lQAE1QVES2l9InaFOQoTTV+tJzeHObRFMXWTxNlBuleolR+71T7K4YBjCjLxHtHsmA/BU+pVkKHrsGD2TRAJPsbx10d82U48M4dgNX5ENEC0Y5ja2p1l6a2tYh+vje/bzCvW+s74LV3EhVhqY0mqkHmS2EphbxtPNZFx6dVlsed2/1GXRe226uBJoE8aYIg4WhRS4inFJl9QBIn9ELs+k4syHHdbnDKRqLVQhoLaIY5g0MPa6udtfa90U9uHR8Gy83bnhQsQWqMKeQAgF3Qv5s9K8Y4f71rYuy+LIAQ3ETwxooUa+ZgjLCzrMVwEd3ZtcZkCLoynnSOWRImeJJXQfEpmI5T0J+z10fyOo+CsXw72iGz9M7WtJve1jqtO5MDNZFvDUy4pICIZ56SNWnAEoSaaM0hMKURZGm303G+/bhlp4mpP/oRXHp2bTHs9d5BE2Xfa8BobIbvCHAax7sqjjFe7/azk+33xlj7NpCw14x5P/49fK5jKx/Jkn7EcBg04JTpNKWZJtbxrgvFGuy0sYiGz4/ssdMgQ2yl4DzUkmnJEujRkZP6jXka3eMarvV9onunNjCIxmPBRQPDI51m/gJoJDLCYNvnRXVIvVVj+HZI04xhUhvVqW3DOUepGzE6YoQQPfM8U0oh5wlltGr546F/2QnhtH+LMQ9r30E46bKLZWtzE2fxu9niPZDwSNfObMjwdwLeKyv/HDKr5tnB5hkJBI1t7burMhBra/s+tFdf7R0BNb7dGUTBIh+z6doV2mKdYetG+bGN48BcfuE5vJ+q72Io/bddIwHvjOk+hNkxoPv9O/f5O/xBJQYc36w/qW0ewNMOOoVM8JokHmL47/2D86coEYdB4MHwDvM9f3Gpvxr0HaSbb/9+JuP8+ff/+vGXd7XzA2w4NkewLx6aTwxqpQmLHWe4G4aBpwwn813LbSuxc6IZKp3V4xQPZpNuYoMJJYfhGhMI9oHqtR3C5GMKmNPS903RjJcJKnr9OmUL8f7z4ED6dgaJPY/MZN833DFeCmIc+8owGsdNw43PFaWHnsbtCEi0c1Hf1OF/fX1VIMJr9i77SJ6e+fDD37Hmid7u1O1Gv2+KpPaGc1rekKbM9PSkYEZ6Ik5PxMtH0uUj+ekHfJoJ6aLnPwJCsWsMB2PnYBOMXcVugujO7IPREMPRNcHhuN9urOvKP/wf/4WvP//Mv/3j/8nj7SvPyRGnJz68fCCEwL/+yx/5er/zp69vPNaN7AMpRD5NE9cQeIqe5BzZAugzIiZollQc1BE4jcx6jNo+2eYbrtOkUaXSugYvTgTfwLeOs7a6yZ/U8pzbae/iHA0hiIEK7EOmbBbvNPsZ9HzDMaPVgDqY0AX5qB2hsorqWhFecGni5bf/K/M8kZOCBuvXf6QuX2jllVJuLPlCrSvx8gPOZ4jawWKMybFGR72xjdMOXBtQ1ft3Fbo91oc5vKN+2jbZsW5NVyBZdxHnn9SxtxKIVgutNlZjPj3uN0rZuN/fqGVjXR7GPPT85re/42//7u/odWV73Eh5YrpciXlWQLiDDx1co7NRu2MrponWtCwqxagZ0BhMdFuBK3zARVGbKcqiikkdnK12goD+0+Oi6rWFmHA+crleSTHx4fmD6hVMk5bciM7WVgsinW19mO1SG1a3FRmldahT7nCQowlpajnUZVL6+TRptybfna6X2om9MfeqgScOuqfVB+IDcVsQn5D1rs+t0lvQcirvVSAU9VJ6adQmJo4bqE2o62oBuLGszIlzp8AKMX0iA7HE2l5rV6eG9II46MG6avmM85GcM4FIcirIO5hwr3lme7yxfvkjfXvgXQUvNCKuR3pXHaPSVUxbA1zTRsjGeEoR6U1ZJt3KOMf+ctK3GI99j8OpfoTDgE0seEFFTB3klHbmUzJwdZ0ywTvWJaFadlG3uKIlVB0V+B6Bwd7tapRXooHScOj9tiHLwu3xYLrfuV6uXLuMzskatAbH5fkDPgR++uknttrZyp3ehQue2ASJmWQgMM5r6aUzDRvAiQaGAQV5I9BrI/tAr5VAp2yJbbsRg+Ox3Kmh/g+2KP/fPTraOauM8gs0oL1EbwH6iGp1XqcuON/J1cSavYolX1Mies8UB/BkHooIVbSbV3czD3/l0Rr3bVMtMwOFve/KEDLxV4QdrMHAp0eFrXXWJsStca+dr2vlw5S4JmU9xaAg2JyCZtIdFlScQFVzaI9y4QBWjqfnrN+vcMAYp+FjHg8EuhPuRVirrokpOCAwBcfHqGuGrdBcY6kKSt0brLUaMNxZa2XrneYCJSzkL19ZxeOf/qBiu96z3G98/ekPbI8b9y8/EZ1jioHpcuXp5Qfy9Zn542/47Y8/MKXEJWYtxXWq/4QbGqIWNJnTL94jpq0SZN79hn2sjH39rlzD/MkhsA3KKok543M2xnvGh2D6cGir+67Ms9pFZRtCoohjrcLn24PbsvCnr6+UquWvIXgrRfYKpnQDK7t2/ZOTjVIGiO4hsPeFoVTrENcVnJxTYI6Oj7Peo+cIk3dcAyTnmJ3jYlplc7T57BVcXGrjXhr3UrmtldJFO+NZoFurliEWY9ldUmBOqqmZg/phMXlCqQRp5Oi5+kBME2ydtWxspRpLa9jMI9M/AKdknRSzuV/VOr3XLtAdjyo21xxtbw6C+dPfDwA1EhJjfIZWsLf9LIa4C1aP5PR4/QA1doaJzW2tvAkn0EmULWhxihdH9ImREPduyAsEUlDGbTepgCZtr0JoudOlsVl8VbaV4vW59ca6LQrueKGUjfk6kXMk50CIEyKN+RJ5/eLYtoKPIK5bhYdnjjNdMg3PVCo+zBRLwIConqGrFF+MtyEIjVI3RDrLEunSyZdEdI4Qlak4xrbKhjThsX4l9VkTjNnxP/1Pv+e+vHB9Tmz1wX35Cee1Uc1RLqX3AoHHY6OslfttZV037reFGBTAijGSU2aUsFlO1ABjLdtTQfUAEolBSLFr8wnfdY9q0KoCrimOhKvez1qrCrYvG8tDf+7NupImt5c5evHQPNumidvbY6O0tpfTxqGHWC0JWXTDiNGkJEYrFQO6BtP+nU7fSAa4A+gU0b1T/5WIYSaFmRguBD8TTKPKu2R+tOkhWiMIjTV1vIY9ECsvVp2tYEynRIyZGGZinEhxxodIOJUjjiqj1gcgp0lMBVUrrRW7t6bpN54Fi9HleIZ3ceJ7EEnH7iwtAu+ZUOe1/pccfznwNPx28zgc7MK1wyk+6FonUGbcuNPFnjV+/G5shtMqJnwMw+EeLtIOHQ100uhKZ0CM8Xc4Nm45Bugd+HPAlqdfGRT1DvQ5oXrvv+I8Qrsh/PY83r+TA3f65nVufM67V8s+8N6YO6A3eduURu1FSMHjpwziCGneH70VG/cx0Y6FtNeNhoCPmZgmQp4IacIFbdUpMmAUPZd9qAx42hljp3SPhUrWIMAdr3Vahyt01nVhud+5ff3K7ctnyvpAalGR4aT1wx2nXezWTZ2Y1pi810cITMGrYCoKvr0DRmW33QPSPM7QDVHL8XItWfvV+zPShxb/7gi5fQ4n4Al0mPeXuxPw5ExfwxyTfSmdDm8fEMQ6ZfWuHSmsPMvFmTQ/k9OkNdqPmV7vtE033lZWnH9oGU0rqn91ApV2Z/YdrHSe784u+XuCnTjYmG7MjW42xtkcF8Tows57YhytTI0BkhK9NkIIlKIdQUpZwUEtm4kuqsDg5XIl5UzthW3oMMWktNgTpXiUyw12TBcFIaofmgjuNL38vqY4rdvzQ8GzZucCymnxhJjwIRrTKZFSJMWoXUm8h66dThoWgBp7pVnmsFkHMdm/W4VexQ+nT699ChCDZqdtSagD0IXgROe0Rqpo7XnHWSaRbuVdo7RrMA5FTEh7UJGH1pQF46JZbAXhVKDXiTZOeAfcDPtn83skMDoGLtKNLWKoiQFWPibTvEsIGhy2Vknzk55HfqNJt8/udNHgS3/ldiaUs1S6lscGS7awZ1Tbu0DyyJC5Y/Geypg1OHHiwI+EhhueEjCy9toWuvdOyllBxZzprRJTVh2eEq2jqd9t2Ah6jPuljRHGWOlJ7rp4qiWj7Kfam4mHn8AwFPhMWct/nfe0XqilEkvR8awVHyLN2Lu+KxC+s2zNSHpbm+I9Loi+V9CSxV6JIVCDOm7nUvXv4eijQ1uTfTsKbjAqhGj7rDrwCkyHrvuNBgS6P0Z/gD7gzH8yf0sCIlEBXfFUMT2nc4aZI7AeedaOw4mWWDTnzJYIW1MWQfRHoKm2NDChjT6cUwZ0CH5nKWi+6kgG7sZkPwPbm/Zz2hVF9pWz/30s9H37FrbuAM9ive2rh+DUJ2kOilQ2cZR+dMbF1oGIgipbrSzbRlhX7svDWmA71seDx+PBdr9zv90IDkr0ygaLiYKn5wvretVgYfjEO8Po1Gxm9113B4vBHhjsgp0V4ZyCV/taUZZFDJ4e/K4BFsJoVR724OXsg+9sMwsqLWxXwMZY52uplKqPGAOBYz+yFWtjZX7EHhPIvqexf8/hXg3TG5yKb2djNk3BMQdIXsvtIhCdyRf4UZLulbUuJnbfOqUJpQm1iwkNY01ehiaXlY17KA7TLmtAwPvjPFUTze+6Nl0ctas2WRM5m919hmK3431QfvhVAgZ66Hi90y2ze/+9HMN2HIGs7nF7DDh8mD3AHK85jndldwOIPv9elIQw1ryzWAlGNAUOLbNVpoixUmzuej/WlfoUPepN7dF8oKrn10W1l2qtbMWTaqQP6ZngSCkgRFLWPci2VV2a3hGNrZ2tFD83wbeOeJVCGc1rTkEqA9zvTsv+muk/dY8xV4/xGjItrVd8L/RecD5wuU74AGt5Zl094u4IFfGr2YKw3weAVhtbqQpAbRtlq/icjrEK3tipbbcfyjwVXB9jOzADY1XuzBz1xcS0p8b9Gva+i1WfGNNpcBm8dRVUDScPXZMxdWustbKuQ2Ovm57XiFHlyLHIOJ8jXSGWsHk3Z//sbB66vGO9ei2tc1H9RRvL8W+cWGPmwV4X9S05Tmjngw6fc5TWhUwMEylOxKjgk5bz6b3aY3hLHrt3lzCSFqpF23rBS0IFGY59QuDAOTji0V9jLo2E5PFat++Nu1992qv+e8dfDDyNYEwnlGb3g+gGJyL0PAKEsZfq5ByivLsTPUyBDVzYhfRMnsxW6ij7wByWNhTUGYZ7iIWdnHXHrqskBlvKMEpjosmxGQwwZPdxfMA72SfvON9g5WFHR4YTKHU2ort/dHKC9O7unwVjQXCc9zd3a4cABrtAxlhFXIMVoZaNz59/Yl0W3j5/Zs4Tv/34iTlHPjxfiPmF+el3OBcoy6t2eupFAx3nKKXB8iCJJ8eMp6o48dgsnaC9ZE5UaUYMN+7CYEZ0My7sjxhHrfZhtHtr3N/e2NaFf/nHf+Tt61f+8A9/z+P2yhyEpw8Xnp8veO/5fHvwWDf+7aefud0fzL1zDYEfc2YKgd/kSPaea3BE50jhPThYWqeJsEqnAUvX4NQ3FUKdvIeurem9d0wpMlmdfTQqaW9CK41atMNCM2d1gEjO5hvuCDSjBZsj9BnO1GjvG4aRtrF0DLun5x8QZhwJxx3H6uBxv3NfN67Pn8hPgSlOhBgJ+UqvKzV8xfWN7fGVbXuQnv6oAXn+oJnNIW7aqrEkjvIFTmMmBpScg43v4ait7gCkHnLYCytDU2Ou98eZzoC3mzTi+qld6b1xLS+qJ7CquOq2PqwznAKCrawqutwalxi5PH9kyhfmyxMpFVKadUMJEzndSXFiWR6s7k7rjbpVSmssm2fKkRwjyY9SFXWcvAmUBysJTamZ0+/xvtNdBO/J04UQI1djPF3nrJk/D951OtrpspSVWiuvbzdKLTwW7SaGNJyDy6Tve7pcDNRQxy2g2eLLxREC5Kw2wzUFlpx11RrlHqVZB5fSCF67OlG1fEuadg7sOLpb95ILZzevbSt1K/QiNEl0l+hxQvqG71WZsr0qWDS8fxf2/WYY6KGt1FyjjdbGTkE0cQGfJggTPj8hISNRu0HFam2YxZEvH/A46nJDHl+QurG1ju/KoBQHxQckOHKeSPOF6XJlulxMrLRTNwUvD+d8zLezkKSevDYTsLJJK4uM6N+9vf8QclWh9ilF27sca07gIKZEd45teQCOEhYrRVVnsZdN2QoWbB6Yu6O7Yz8qXXC1sm6bzt11Y60bc0rK2FLIncmA2OdPP7CVwn35J5b1gYRINO21tK3UshFCJOe4A7nO7KbD4bq2hU9ez6UFK6uJQHekGGhRs9p8R7YLYBUNpP/lVlmr8LopSPOSPSk4npLuf8/ZkYwJhQHhIsowucTAZUr7XiT73q3fUUhsXLgXz+el8tgK27aZzomuaY92kk1ega+AQwIggdqcMksse1u6sFRhrQXvHV+WqmLKOTDHYDp2yp7OBjSIaPa6ibYj732wO48g04r09Vw6hN7x/oCcHB2c2J4qu+s1rnOtneqFn1ZRraduoFzQ0rUbQhG4Ndk7IwnsQVmpFbeufP36hdKEOD8Ro2q4lMWAp8eDZXngRFgQHltl6cK8NTYXeLpeVP8ITRL6VPBpxgUNDgQsyFS9GX9e82GU5UB3/ejU5rxeuwhTjkTfye5Cu8TdL5quV0LKxCnhYzQ/WOgm3t+b6rVSK/RmrBTHsm3clgev9xv3ZdH9FAV9tSGFlsFqJy8DU8S8W4dpUekzDLDJ0Rr0rmB3cDBnxxQdP8yeS3R8zI7s4OKVSR6a7KWi2QUuKTJF1XZamwrWv62Nz4/CWvTfAxkaYJgmODoBPafkde2IKBClOjAGGjmYHSTgeZopEvhya2ytURsnBsBhb4bf4EzcPzpdK5PT738wfGt20XfZkyS6N+037Ds4mtVPiqjmbYxRy25jPHwvDXbMHxsAilLEBqvi2yqTPQkzysVqQXrDc5K/gAPRxNGksZSVR1m4bzfWutJ6Qcyu4SI4Fd3vMZNTprZCDJ5l9dSic3/ZFlpXlnNtmZQjIQTtypu0YU2etMtrDF4ZdNETknW0TZnWhenSTAB/0Ti5Cxsb3j2046WMSiFtYlLqCq6zrTNJHHkybbdg86np3Gp9wzVh2b6S08zLp9/Seub6MfFY71x+hq0uLMsr3gVSnEkpkaeZWjr3+8LtdeFPf/yi3f22Rn+GyzQjXpMMA1AeOkU6g7VjNxZvqyZgwruiDKgekG6leE2bjkQXSMFDqOA7ra1spVE2fQQfidnz4cPMx49Xnq4z8zRRtkp7VP7tj6/cl5XboppOKRuDtSswN0AvLx7XTfIAW+A6gcBbKRkDE4DR7V3X+CGYbr1/NdkQJlK6kNKVFC/EeCHFi55zSLrDiulljtSH4RFdqgE52kBLwe1EDEk/N07kdGHKTwZEpd3OD2yjmSYgglXN6P0IMRDEs64rta7gPLVt5PzRmgqFA/uwMRgJB07PIYR3//42XnSipYSdZmP1l1fK/MXA05nmOEAjMICJbxgj4/f+AC32DPQJHdjFuvcrOf68D8oACi1C16Zc79HzXz12dG685nR+43N+5filsN+Ocb4DNt7/3Z8QxzMmCKfagyNz9Sv/F+TPfcFAyfbXDvrpaAn/5esXtpTJONp1Zs7RujFkvEs4F+lSMEY8IEhp4DacS8S0KTPKNIKcNBDtFCXfjMm7Ed/BP3cgzOdMxik7ofW6jcf9xnK/8/blM2+m6SR1I14SOWpWSZzjvm68PR6s20YrhewgOc9TDMwhMHm/B+PqTPtjmEWzrd3Sqsp+GroJHdc18GNo04Blgy2z5f2esVNqtliXHQPd3NCWMCN13ujsvp9JiKqtcehuaGYaAyjPM8ZeLzptAvqorVE7lmm0TDRK33Qh4ULEtaCboQitbPS62QZwmkDsWCl7dzveB74j0/o9HYe5ONsE+xWa1fcclO6duekOVqYYSOW6prFCU3BqdIkLMTBNGemVWlSIUt8fTBxQnRMEiNBTp7du7B7ZhRxb26jmJI8grnWlD4/NRVSUCSdhB8ycD1pD7wNeFDzDBwsOrGNdDKYvZJCxJQZUQLJSSmErha0W1q1YFx8thekpIN7h6VbWq/M5Op3fU4AQIPlDmQUHznz/OtahMY86XpkScmTCnIwsuZW/DnTQ7lezLknqrAfEa/ctt9eKnme6fSZaQ79rRIwJYYEAw+lldG1SBtoYP4J1s/NRGyq4QEgTsXfidNHSlO1hDvCmn9n187sZJB9M68jmgLOguJ+AXv2NnbkPygYL7jQPBdoQHlf3qfuu7t2Y4EPb4rQ3BxFSjPTWSCnTWiflCWmNkjK9NXxMmshpFVp4p103NHaGxtNgOXf0Xqmwq1G8W0ei4E9j7c0pzdPEdLkoM0IatW6aIFjX3RdQqr+K3gdrHOJsvNzQEDIAqps+mBd9vGe+fEeRGwc7Ym3CvQpfV0369A4pKANDS3oUxHEMDRrdn0fr+jhkDfxYa7qR6acFmkQqQ9ep7yLXe1cgh43zSECO8nY4Otka68m01OoIUuxnES0ZnJOVnfvTvuggKN0N77sCTiff69hhdV8cOjwBdnZ18EB3NCfGxtL3qGPNLna9tY4TBSyaKJO8o/pO1c7x3MHP7fZLM/KlFGJZKSa2P0RiHewMVKU+auDRbI2oXswuVKHl04NtMDJR40qFd3vSSHqOV+ylIAx7dox18B6JwTw4fUMIQ8jYQKFR1jV08LrKMQxLNHz21rVrX7HHMMtnfw935PG/dWj2yzrNZ2WwDoBKmW87yyk60wNUNl8QFfL1ovotAzxNe5mgfndpynZaS9/n8LAL78bRfjeGHKcsrdJU4sO5seb05+AgR9V6UnFitWE2299do87JY756N0BaHZbtMM/vDh1CeRcDfR/HETE43K5vOKRWzkynPei3d5xBpj/HejoH89IHQ5rDbdj3IoPaT6L9ql/I/voRw+CjqqlZXNFq2Uvyex8sEmX6eu/xUUFh501LKurajzHsTWIGC9l5BU59hype93lnzHiLPQ5WTj+t+YMJ3lrDtzDwHQapw/nhRwztpkIPER9EOyWGCXxjXmf8JrS24FwgxUQyVn5rZb++UirVgKe8NWpVSRIf+27/gb16RN0aZSLtnTdFHyJOtZa6s9hSS7+81/1enFYdiKCdnrsg3dZ68OQcmSb1Y0PQErtSGsuj8HhsLOuq7HOS+g4jLh07iPnUyGlG7lPK7bHYjmMMnEPMguy+qDtNlpEcDLghLh6SMutCtPtmlWA7kGjSNKbFInTVavJhB5iGnlOMEzGaplOIY4Uge/3O2APGVdh1eKtAQwGu1jY9j94Qf4p9ToDSn4v5zqWug7Bgbx6W9Zif74z/v3/8BxhP6fhQC8ZwuqDGie+OgTvAkYPRdByyI4kG6tjuM2Sdxmvs+uwzDRHHMYRP/5yJFisNkZMR8ra57ELD4r6ZeEOjyYzaHqTaz6evOkze/o26sN5pHQ0dK96dxzdv1F8PZpP9rZsjMFgCGMDRbPKmGIxx0Hk8bvzXf/h7nMA/hokfXl74X/+n/5kpOZ6mSK0TtV1Zt8btVbtQtQbBNYJbuFxeeX5+5Wl5EPqG6wXx4KcPKtQaAs4nhlfRhtCos8x8V9rkIU48gidjOllniK8//cT9duOf/+vf8/r5M3/85//Gcn/j+TLx4ZL59OMnYor86esr98fCf/mnf+bt7QbLQuzC386zMp7mvGslDcHSsUGMc+oi2jXCCU7qzudWQWBF1jtAF6JA8oHnKTNnbbPqfWCpsK6dr7fC4175UsU0ngJDcsc59nUAaiRH+HMu9hgMqaFntk+BAcaiLCllEEK0T2ldoHUKQnedr18+a3fJeufpkpVOPz/TyjM4od7f6K1Qtwd+vat2zC4sp4J9XVSI2nnrAomtifNyco4/t7b+Gg9vnSzGrjPc/mP3sblhJXmtqa4MVrLVnTu/fWdkhDQyPeZgBsft62d+/vlPhBi0G1Ce93I37wM+R3KayHlmni9KZS4bj8ed5XFnXR/KpGqbduPzqlNGt7yLOTkEh3NNxSOaioyHDjE6nOva4S0EpvmiGfmcicHjnNqQdVnprfF2u1FK4e3+2MVjNdCMuvZdt1IdT/LCxReSd1yj2zsOee+Z8qBD6zgda051jnqIdPGImxB/QdIHWnpG4hMuPhHSBRfSXp7hrRSl7bX3KMjjAoQJyS+QX3H5GVdVzDj4SHCH/pwbulhj4zQNE7W31kHHZ3q6IOGKxCvdZ3rIBmpZ50rQPcAilXR5gpjJW8HFmaUUIFAeFRnAvRckKBU7X67MT09crhfmecKJ6haMrnHVSnqcdVrZAc9QOXf6qa4wOsA6b6Kju07GcOq9cSYM4A7atSoEBdNSNvuWtfvNtjzwMbGtDxWWDgvFOQgFfNyd3aFZ5/wB+OG1jGirhbUU1rJxyQkf/N6gwVnr9pdPP5Bi5I//+s+8fhaW21ct4dkWUp7IVo6Xkjrf2UoSp6jPQwQ/WYJBinUC297o24aUB1JXkAryfXW1Q5c/SxVuRfjDTRMR0TXVekqOFOBD1uD9w6QagtHBHD0/mvhyjqNcU3XSpCto3X2kSubWZ25t5b7cKKXSajPtuU50sjNWFFjSZR78EAyHFDwtqPbNVh2bV+ZT7crSUgBdOypdop7Pc/bM0fOUtHQ+hEDCkaTREUKoCi46LStUiW24RmWrzEF1RvR/jiVqCea96Pc+tqaB0A7O6nreDFjSpFPnIhGcYxNlPC2b6oV02z+9ZZpbUz285f6Gd47t/kZ6euJpeoHoeY6Otj2xXi/0ph1LcR4XE/Ok2fqUEn73V84Mx0Nc/7ADWClypSwPyrbs29bQFtIuSkcJxdDkDEGvaTCYe21IXxU6HFohOKRpwira/U0BGFoqHpZt5b4uLOvCZh04hz7rXoLUR2JgpPiUrQaY2C92H7R7omJcyjS5JM8UPB8vgTnAx6Q+UGoN32XXcXU+EIPjmhPPU+bDJROTlm0upfP1UfRx3yxh06ws9KTjOsDY0Q3Re6o4vm6dRy9M2RGj8Pmx8XVpPGVHjo5P15nLxfPz68KjNLps9Fp38Cp42fWrvNPSwOhh9vpzMmC2dwXvB5NTGaUGoBoD7fvxvIyp5KxzmfeklFTzyPa0EVgp2IIxC2XXu9W/HSPyrf6MxpKqj9lbPVWlWBn62C/gSJxYYyXfC66p3EDvyjzxeKaYrKxJ99PbdGFZ77zeP/NYbuqbSWVZH5Sy0uVKzkn3MB+4XGb6lPbOm2mKhORJOVpSSSUCiqxIA9+00iaGiR4cOc647nUro+OcRhMKJjn13bowzRMiMMW0A8GI+RWtc1+0fPS6vWg3y8uFkBzNfWJdJ3CdECJzvuJ92PW2tlIIi1ffszbeXldaAWmOaY5cnhIpB6YpEs0XHj5aa4113QxMd0qerJ62Ocrm8ChQE8PMnGcuOTFNgY0bFf2OWqA3BaWnOTLlxMvLlU8fn5nnTAyR5fHK223h58+vvN0erHVT+1wnYgzM07w3tXACvVWgUzbwMRByNiDFbJQPBoLbnLPp170mVVrrBhoFuxde4143GEozOV2Zp2eLD9QRDieZmi5DQkLvi9pxXQsxJvwOxGkHu2TaTgpIqhzH0HJSfeuqHRwV8bNYNJLiBec89/VnSl9Um7UvxHTF98y76qxfWVPe9tKxvzTrchxCwOMVFORoKOdsQ/oWIP73jv+QuPgAYRhZ2PPfTz8MI+9Q9O3X0iBO5dWPXw0xtR09MyfnVy/kCIzFsifulP3Z6ymx7x1ftSN8B0o4As/z/3/lqhB5/5dfHse572c4UNPTdx7x/Xvg7Iwm/uJ7ZFAuD0BrdC9yDmor9FIpVendPz+/cJ0i/jmzrZVSYCuwbGJijpolDoxuBQ6fMnmecXFWoXGf8Gk24T3btHF7WceR6dLzGhokQ7BdrFtEWVdqKdxev3J7feXty2duXz+zLXfatuKfJmJSYcEOPNaNt8fC/bGwLAtXEbKHS/Bco+ey0xItOBug3RksGfPTsS8yN7RHTnPF7Rkto076AOJpXVv8rlW4l87SOqtoGV1wKBBxYEbHd457zigJ0MPb6Tl7mXw7xdzpZ5sLHoiij+E8lW3jER5sW2aKkIIY4GedZ8ZcsS5hh7N9etqBl3eW55sT+J5cn7PjMtbjYRuOFWuAtbWRdQDBvb9X8v6H0eVD24sLoJoAtRYtdXGBoXkxxJr3sgjviSFBUqdL6cscoEPxFKdAkUPAY8kjDRatl6tlW8ZDg0PBmCK2YfnBBhTdLLp0Sim0Vlm2lW3TLk31xCga5abBKcMpRmf6MBC9kLyYbgz2u36q9UfDQ+fpzSsryUcFIVyGOO0PiRMuaNtujVBONte8mXGPBkMAH+31GXzSf49xHRlU5wAFnjAABPruoGnQESBEJCR9ePvZB2VUmWMiMqBbp98TonKkUibUpiUyPqLd9oxlIc7uUyCmpC2IQ9B2wggi1q7Z2BDHRBy2yyO0PYPrzIn2olo6noMp1d3o4mNv94Ntq8ZFy1xU8ym1TkqZ3jolb0jvxLzp3EwF3zu+1uHLqOovJyBn14fR6xv70mDu/WLvMqckpUybL6SUCDGwbpt2xtvSztQIISBN9XKIauN9DHuHxu6UQeUBqYXeGlJXpG5IK0ivZve+M+AJw3JRbZliQuMFZVN0EWLQ9ZG86pRED5eg82aUSh56mjYHnYnf+0jrgSLOql77zszZ98vhv3ShueGyKbAc8ScGsCN4bSUe0JnjLLhuomCQzhlHMf03ESEZEyc7T7CN0g0f8mRXvCirREvWjbliD3HKAPMC0bon+sG6bzqKYx8enmLpYo65JiKqDLb0aAt+6IXsi1TMv2kN17VYd4oqpi9upgVPdEKrlVI2cA5xXoPTFDUBwHtf4Je8rt1T1u/rnV4LbVstK29lDoJq+7mwB3vKsup7IN5qtbJFBd2jOHxoVubkoGmCygV/sHWMwYE3bS5jv+1luftpjk7SsoPNhzsxQrvhq1uCduhlOp2/KSi4ox3rIDotrdMSbaHXjgS9tuA06RiDM1sK1bovLqWx1kapg9EiDKbe8HhGmDDyzr3r/W6lqy4ZjSza0XHrQu5C6J2YlM0ypcCUIutWqM6Yel7MH9X55jnkFMbc9E4nqHectHE54qQ9nvrvBhp/VceuI+aP5PRZr9BeNH7Y9y1dG+d47NufOfm6mjQU06VkJJrcYIjYZ5vfNUqhYsjEOBg+h2/mXSB6Y4oH7VTnrVxJpLMVKFWFmweZoTWdVKOBkvc6L7wB8967HVz2uJOWk+3R5vUfjCfTRfqGlTKaOXjrNudtfQ622FGxoL5eG4BciKb7Fsgp03slJhWrjgaEBx8ILRCSsraiJTl7F2ptLI8Noau75SCnsI/z3v22a8mqC8oo1XMQLatt7Pc/+LgzrVII1O6V4GXg9M7UDaq5muycBplDNdpU16nWtjdM6q3TnbcuxQfLUSvSOq4pu8rLaObw7dw7zTY3bNdwas/Ais0nF42xNBhP498DOD35ZaIgojZQO0pHg+k6jc8J47Nc4Jegq9n2nbEnvzhvb9pTuu+IlvUhiFSEhoiCYv8eSHS27zur6hvI5oibhsv9l8eN/7FSu3FGZkiAI0gbJyKjpOl00r9iTM8ZGumdjhqPUrbDvDj3vmTLQKYDxBmDYgHifiJHraFuNtrBYHzmHnyf3qOMpfb+XMfmZM7XwVw63ASc2x1nsez8QWfWjxsi16MmfNyggcqr0qbsAc4wnDKQAntq0tRxSJnL5cqPP/xA3RZ++PjM5y9f+Kc//At//PIzf/jTTzxfZn738kJwlSAr21q43Rxr7TzWoougd66T5/nyysvPb3z6+QvPnz7z8ccvPP34dzz9tjI9/UCYJgU2vKcHazVvRvRMYRYRWim0Wnl7fWNdHvz0hz9we33lp3/5Z+6vX3l8/UzbVqYcefpw5en5iZgzf/z6ymMt/P0//jde327cX1+hNX58uvAhRX43Zy4+cAnKOBpCXYNm3WW0AR/jqEMbvCc5YcYEiQfw0BVxzjGQohpBIXJbhW0TXl3hsTY+3wtt7RTnmJzHeWW/JQe7adl/Hiw7XZY78HVaHwNf0PcdwopDgHyAacF5ZqctmKsBJPe3V15vN55nTwpCmAKW1Nyzj2PSDSo9okDDcGoERbD1/Ia4qP8lGPUdgU9DbHpkmb0BRdoJRTcwkUbtyrSJ3uOC6vOM/w5mmI2U1yxe8JHL9cL6uPP65Qv3+411K4hPhO5Ztsrr642UNqZl23UxBq065bwzPtrTM9u22mNh21aqCcXv7LWgc9j7CNK1/CskYwJVeij41sGnXUC241i3DYdQtwe9V9blQa11ZzptVddPyjMhBC7Pz6pbFRzRKdMpu841FbIXLlE7igVnXWFEQZHoZw1MokN6pNEgVIIo+ET8iMvPhJf/BPkJ9/Qb/DQTr0OPzDLxZ1trj+713vV2pW3PSH6ihycDllY6iSYm9ugjVpAG3SHN4fF4aYQ44UOmxSd6fGKNH5B4hXBFfKa7iLhAc8H2BTDDDjhczoQeiddn8IHwdtWynMdNW4IbGJinJ9LlyvX5mcvTE1PWjL3UDXGOWruVeIyyvyNLi3P4Ibht2eGRNY4i9juzv31sy1qitoOXxjZ2YuWQOe8A+5q1o1WeZnxKpMcDUsIvC5Im3LbBtuBqRUrdHY29o0qadhbfcO67CY63PkpZnHUqgzxfiTHx8dOPLI8Hj9s/sNxv9NYJMVKTUuSTGyWcCkqU0AlOyF4IDqp1VBVRm78uK1utbPc7W6mU9aFizt/RocGQ2Wt2626C3lCL4AvcVmVd/FuA7OFlgo+z8DIHLrlbuYfuNV0UZFldYvMXHqvj69q4bZUyQL3ecNI1ayumO9RlH9/BaI/ekaInG7MqeEdyygCNDaoIoThK8yzWmfJWGrJpp7kpwKMk5hT4MEEOQVmeTpnM2qBARcAdowxX/bhm3aJjUEd6ChnxymqoXcsJSxe20hADrXRuqn1ZTZdoG4GqC3swOUBh5yDEYIGwZQC6EBCuwfExR37/8kRwCtzUWlnX1fzZsm+rMc9M1ysvcyY5wfdOb2VnJB2w7djLze71ipRGuX1hvX2BVpBWtauaOEYXzul6JebMWjZKrXx+u/FYVx6PlVrbXtL46dMn5mniw3UmxYgX1fDKk7IV05TAGL0xqVagOBNePvn1vTUawrougHa0G5UMI+gfvzeXa0d9goMpOqbo+eEamaLnY9bS4NgqUjrrUnFd8E0I2TFPnmsKvFwSc46Ig6U2Hkvlp9vKHz7fWUrlvlaCzXXcsKcaRFZrTmFEYbbeKL3TaHTgw6VzyVFBqC58XQu3rfHjh8Rz9vzu5YKPAZGKe1Tt8uiU3XSGDofChljpURtlRDYZhi5pDgqkmdk2QeXvB3nKxiyJpm8UrXud2Brey7RGjGdA6wACTitC/78HXlgZUaGUlXW5GyPINIVRBrYbezaOFGcuAt5FUpzY6sJaHizbg6XcabVQWyXHTAqJp+mZOV34dPmBLp0vt5+4LV95e3zmsd1Ztwe1bjgJ9AquJwKTVgd5wfmGc0JIURMoYQBvJ8kYY7H0Lgyx6hAi3ZLKfcSVXeejSMctG612YnqQcsJ5CNETk5W7SjVQWhuIrOuqPglBu0ZOz4BnvjyUXZwNeHLRuo87XPes94Lnzu3LxrZVbm8rl0tkWTIvLxdy8pBVR7I2BdrXdeX+uFsJoLCulbJV7o/C41G5XrTJzdPTlR8+fWC6OOLkKLc31tJxHXx35BQIeC6XxDQlcgqkqH57a5113Xg8NmtK0gnJ/MQAuKOKQ3rFOUFKw3khStZOz9HjQ8Lh4deaj5m9EJOGUJ/UsIABFvlMjhdyfCLFq+k9XfY4oxsBYCRQBEElKBXrGCCcHwliF4lB/dfgtbSutUZTLhitl31+K+DfOOtH7wxYpx2xc7ywpQtbeWOrhUv/gSQzoPI7g404cIvh5w4/44BI9Nw1bhy63H7fQ4+x+x/AePrlnTkdFoztzzoMHFjt6e3f/Gb8W8bme/qM8dn6ulFDfgKMTijcGKh3sfP4CDgCmSOvwLdXstfMD2N4eu8vzmnPqh/X6Mb57SNwOq/Tub+rz4Q98zVu/PsOEOPrjjN2OCtvmZjnmeenK+u64JzQWuH1/kpvheQc0QuT72xbY9lgrcKyKiCBacwgHecWM4xaW+ryE/HyARdmfL6qjpBPep8G1Y6+37fWVHtoWxZKKdzfvrLcH7x+/lk71339wuPtjbquSCuQNZhqrdNLVUG7ZeFxX9jWFS+a1bzEwBwjOWhree/dnt083d3dcduBHRvQkW0K32aZDCzSLg2al2sCtQqbEx4o02nr2hCzeUdE204H1HnBWSZr3MTTvX43BwfQaJvnDjydXnPM8mNWDjn/iC5UqZWKo5SqpRBR2Sh7pmf/hGN3VtzXVs67+SV2WsJx0qc59v34PgdiP1hyzijXoo+z9oM2f+wg3kRtj/U57Nv4O9g8Ml5uLYVW2wGEdqG2xrZtts6OUtUYFIAaZXve2gPvgKQBZVvx1OrpLah4prf7Jl0Ze0HLRTRj74l4Wuhotzxjw2EAQG9spdBbZVk3aqts1la6WaDngnZzizmTogYEwQkZT3SNGCD4rsQjJ3stPS4YU+gQatd6zoSIwyXBu4zkK+QrLl0hXXB5xkfromlj8G4VDDNrtGlxDokRFzNuMKfairhogJFHXER81JV2EnlxzkP3OJ/wXllOhISPGULWz/QZbX1ruk9jvYqdl3MM8fkQIz0mfJoIqeDTpCvJdKFC1i6hMeVdgNe7wzYNRoXaLptkpy1lbANn0cd3D4z1oGo2GpR3t5cNMNa7jacfgXyM9K7llyJCaZXWO7kWFezu3ZolCOKCieDaeVhWOISwA2HeSnbOx5FtHmU3HkIgzzOXy5Wj+UhBDNyQ5m09CTjNYAbfENcJwdhqQ9PFWbctW3OtFXpVsc1v2/5+L4eDI6HF8E30uWHSYrY39QBTM60iDpfFn/ZBfa+nSGAT1cdpp7Hb90iGPdPgp7YRRAtROt0f/hInvUu1YRpIBD/YOQ5nLKMuyt5yqOg3KHOyy6EvNpq8ODeYv9/8PPzBPVjV59F5MwQrkfO61rzte2Pfrvb5tdvv/ZGk1DVoe+Ivtki1DB5tCBJRoFTLex3NexqCiJVjO20FnoN2Ex0MruPcGVdzvtvsgbg06FVBp7op4687Ld3yAr4Rswr7l1JZS+F2X7g9Fk0ulLInt2LKdBHmpB1KRxOZ1kDE44KzjoYnUe7xGICADLbJISDdziWNds3yzfsHkyE6VNMpanlo9urjaFJQmU7SBNdVID44p5pgQRtbeJtPrQtb7dRqZX5d9tK6Mdfh0JUqXRlSWxdqdywNtg4V60Dqm4FDeoNq1+Y00nW/nWPgOiWmFFg3S2y8v1untcDenKGN+cQYg2MOCkKpSgNb13JqbPTXf3g3EiFWOTHWku1Nerz3e8/HweQ9//3YD3sbwM3RCRf4plJGv1cZP5Euuu+9A7scVLfh/UbyynSKIZFi3pPHtRUGu2fsecUHY6Z4ZVD5jI/md/gCbjReGlIxBorZ/X/vrw+f/aSX5g7z0Jt+bnOqtVSLdpVrVRPJPoST427r00AOTSToJqAMG/M/R8kshx8s9sXDD3VO5V9qqZTolGHUZL+PI+5VnUfVvlLnWZlSpVRj0Zpt9oPFFAletBlLU2ajJsm8AuJOiO+YTpYAlkMXdcRNu0Se2ebWurJ9Wj/uRQCq3gRlbmq1z3n32i+Icyx/mkY2LsFHok/EMNl91/LMc7dQtfsnuRy70x11jUfFxGC4nbst7t8vo3KlmzRDP50Lp8/eV8VOJFBmX2YtQpNCk0IXZa29uyScsbtAjsD6tESdzcPhDbtz0Ho6jV9fw792/MXA07uynXHjzHEeDJ33Z/H+wt7dVzk+T9Ca1Fq2fSINptN4g2Y3jxt4vokSZF8cx5ce9LNjA9i3zP0E90z66fzPgICM8/lmLIIFSPsE7eOm2OB/83nDaR/tb/cJLUNN3x8GxrJt7J/FbgiM5KOOuo98eP6IQ/h//u//D/7wh3+hLF+53R786edXyv3B6+NG9IEpxF1zpZTOuhkttTVuK3y9C1/eCl++PPjwYeHjn1758NOdlz+98fybzzz/+EqaLsTposhsOCiAo2Tncb8r2v31K8tDAaflduP1808s9wdledBrMdX9yNaFdSv84Z//lVIbX1/f2LaN9ljIrfFxnpmD53fXC9cYuYRAdOftyUbWvMTWdC7WQfV26iSFkSUOyvyoXh3D0UlgDsrkejShSOXRGpsT7t5KA7xDosflQKvw6N20g4XsxuePDewMO9o5mAN9lCa6fRrvUcR4OtJkiHSiFexd7brvrbG0xtvbQwPVrXCJDdm+IG3RiWjlPeKDiUc3nKswBDHfrVMBce/aMrudXvr9HHVdtXRAEYydrSld13gr1cJzva+hd6LvzO6giIsIFbVDpan1Cd5byVOjbBv3m85h8YnaHY/HSimN7VG0zCmrQ5NSIqXMlDM5T6q/FKNSn1PEXa609kTvjXVbKGWjllU7vnVjIpjwpM+zlktditGctbyiN2MgWtnMdl8o28bt7U7ZVh6PO7VZVzfnidOMj5Hp+kzKmaeXj+QUecqR6GCSlUAjsxJdJwUTYtVtlO6zlpvFi5b4haBC6xLoseMTSJiQ6QdcfsJ9+C0+X4hPnxTomibVXghHF7phT70PhJQMaIHmPtCsewvrG2LaUM178J4QZkK6aNbeO6St0FS/jl4N5Er4/IJLT/j8QohPSHoCPzHcwV7rEQSBOpBW5hsAuTwRYkLKbyiXCz5FWtkYpY5PP/yGfLnw9PLC5XIxR8vvbdr3ZIOBgwxbMhhPI1u7gwUG5o2QW0ws2WnApi3NO642fHjvIOzd8ILHkbTbTkysZSPPM/NyJV8uLMvCdFVbviwPtm1Tu9zUqXT2mdM0M00T83xhmia9tnCUU0T7WTYLXjWq59OPvyOEyL/88z/B58+sy6rzNGpHyck1AkJ3G54OTueb943modve012kiWMpsDVYF2XtjYD5ezq6jHLPY+/wzgh4nPwEs+dtgDkNtu52YfhRiuXdKCF1bN3zc3V8LZ37VthGJhanbEocXjxr1URMacJajgDFGxMthU4yBkuO1l3H5BmCd6TocN6yvt6xFahNs8Jrg741Qmm8FVE9uXCUK4ionlNAS9i8U4254A4wVuMNzTDjVEw3OsecI7UD3kCsrtnjMCBRcyHqEFA/A11e8AZIDb3NsX3ugYVUpK7U+1easxbfrbFsZQdnglfQKSbHNQiXoKBL1A9QN8Afa3ys8/GzE8G1QpBClkJrC71utIYiGkEZtr0kWvDc7nduy8q//vFP/Pz6xucvX1nWbW+g0gU+fvjAhykxR483Zsa6rgo23z21Nd7e3njcF2Vmdt07h90BrDmGAkQ6GEcyZk92iKMUAxVtLjzZHHmZvGqSJbWnrlaoQlkb1I4rnRQ816wsp998mJkvicscwDvW3llbYylFO4l5SNlzSclOwlO7anatVVhr5751HmU8yw48YYHtrXT9vmvimiNL1zl6XzcC8HFOXC8Ty/0rQTbua1EgduwRtkq7+XXF6c8DIO6ipekpqpZWbZX7Cv/4k/pmP70u1N75f/1fbkX+f3OEkPb5MGI9DWjliKHcEXe9By5haD/toIyhdx3VuFmXu+osDVF8NzQZrRHADih7Ysx4C8andKH1SuuFrW6UurLVlVJXsyUwp5kpTuSgDKjr9ERpG2/LV9Z65+3+lXVbrNNt53l+IafJlolQ5E6n4ENjiFaLlWM6gWTNZuqmlGVpjlah1Eap7RBCb+oobJvGCDk1tLnlg5Qj3osyE122JOYAaDSxU7YF7wJl2bSTXJqYEjxdPyLS6F31/LZlY1s37m8P7m8Li/mM0FCh6kaXoOsdiH6I+2v1wLatLOvKY1l0wrvOtnbK1ilFE7ExeS6XzOWSuMyJrYy4ceV+L/geuWbPZTKWWtbmPTFF07VUwG00fVIShjOBd8E5BWce96oi5a0AnZArPsLFXWl9Im9VuwRHdjwBdybQaHzZ6VayZ1p/3hN94mn6yNP0iY+X3/E0f+Q6vyhIeQI+BvahQKPf56V3Hh/1OYS4+7mjMkPo5iMO8HBHERCO5BHeESS8w4GGFpNzjnn6AM5xXz9T2sZavtq5zHinHVTPx1lXe8TQx7mdhMXtOo7zcnuS4S89/gPAk42nWdD9Bhmb4Pj7t+88/cLO84TJ7kH2AGT2eHwE8uL2t7rTDw6U6STfIpb685F1G+f2flBOONi4Y6eB1FfI+TXn9wzn5GwMv4X/Tq8b33GAd8fz/opfa7O3j9X7zx6fE0JkyhMfPrywLHc+fviAA97ebiqu2Ewo2KjhdF2s1YJS6cd5eLpmivyqiyS+In6iuUwjkucn0rxYd6a0B4fbtlFL5XG/sa0r99evrI8796+fWe4P1vudsizaac2E3TtaHtBEuN8flFqpy4LUShati36K2nZ5Ctpuc5SS7YB+f28kdmBviFsaWLe33bGnMbe0g53Hh0B3sEmnNFgFqldnQdAMrdgD7xi+XhPeZcZw7t3cBPYN853uzHmB/Bl8Z59N5s8FUaFYL+oYl1JY1o0tFKI0XN3MoTbaZkiEkNkV0EXM8znP6HcrYL+f3/7+ezh6q7ju6aECYc+GiYlNj8Jy59wuXqv6qqMjlGd0W2vd070YADHKfg7BPwWxNQBxrVOpRpPWzFyLdWc9nUX9jjWt4Ia3wKvLEPJXpo2WZij4hHQVwDbA0UtX0NHq7PU7tAuLLn8FpkZ3xNqaaUF5fIjEmIlpIqVsLJ1IzInoIOEI0jB5QQhDqAOb1xl8oIdZARCvHeKaX3VNepSFZCwjfY7KpAxDo+rQfjiWhtuX2PjZhwBpQvIFn5/odaGvs7J0vMOFCR9mBZu9s4DIutW5qgCZP7SdXEy4mPExKzgGIA4vDnEqKokMPbVB34eYMs470nyxzGPBl2KZc0+aL+TpQkyZYOw2572B5cJgh/jBbRxA0ygv/wZ4UsDfH5/DyZ6c7Eq3aLq7gwW5a4LhDLAIpKR71+je1ZqBiHI48OO+NNOUGEeetDw0p0RK1tnRtC0GqP5rvkDKmfmiJUEhRkot1FoJouU8wRl13pnD61ZtGx8ariuDRJzX3+Hoze/dseRsa7+n4+QHDMv93tvh7BAdy5IBArCvK32Dgk4dR8WxdpTZ2ztNTu6lebODnTQ6vlkcpAyifgTZNC2HC1ZmMU7pHWBm8nTjeXRXbWY3qZ3qoYkJyvvdlcd7FTCPHi5ZS/yGNt5gDYqBbH2M1jdAEV5ZKm5Eu+eRldN5jkE96fwdvuI3Y2/MCxHZg8bHttl+K6oB2AM9Zz1Dp0HHaCpz6Mi9+9TTzdfP8U47h7qg+0sfJRK+I75rQMth57dtZVsW1uWhoFII9BA0yduqfZ7b9Ylqq1oeWEVZU8vKum6aoLD9ap9jmFuBMt8QcH4f7D14GaW2zu5fdKrnNLrXKaAoqh3a1H+jqZ8zmsfk5FVbaYrkpOXE4jUcxvbr6BX07KKMv+GfNZT1t1bhUVSz874dwNPWUdadB+cdS9H99lI7NSj7ruMovbO1RoiJKXimGMgpsJaq+jXHVHp3C8XWz7delbKhO/dNk173Umki/OnrQm3fT6mw+3YqfxO8fvu6c6x1pgrsPrUFwLu205kFYh90yAcPfsaxaP1oODL2VN2sTBdHmSxDhCyFfNKD0sRXMJHnEDSxG3xSqYbemfOVFCdGnaXrQiOC2zArymENtWGLeAg+qg0Vb76jJQyN2NEtMdwbZrs6vUPcdAVsm5YRpzLK+bytP006lloIvlC2QhADvLoCHV06rTbK1liWjW3ZeNxXlofKs5RSd0Hr3d1w79mEI8FZm3a/bK2py7V32tQ4KkanJWA5mM3BKgIKtVRq7fjgFIwx8f8Uw66NOUTM3zPFzzHNEU/XqoBdLSpRkVwjYPpyHZBfZ9kdobl9nsh+3zC7HUNiihfmpI8pzsSQVP5izDQ57ONONjgFh7vumc0/t79M9veOmGJc344FnN4joxJKDf9+7irfEpWBRwBx1FYofqF1jRtF4nu/4Hzytj8K/PI17w733/n7rx9/ubj4bkhHUN9PJ8p5lNnZSJxuoG1AR/Crf9uDKOxmBNOQCGPxHKZofLezDKpmh927zxPRbNcOVDhn9PvzdRhCZ0DFu0lsQYPbwYtzvfr777HTUjqfOQbgdmdpaA7tm/Y+lmPBYkLXMGh/wsAKzlkUZ2M4xDyUCeNjYr584Pd/+79wmS9QF37++U9cItyWjc+vd0qVXTh42zrSOlKrBtY400FQsbbHKtyWB1++rsw/r1z+5Wfm539hevrAdH1mulyZ5lnbcdsFbCYeXreVVgrbcqeWjW1ZaKUYI6pTpWtL6FppXXhbVYeAZcG1xrMTnpzj45yZonaZyyFwScHExFXseACE6uh1FZWVfaUitVmgLdbFItCcZ1OFXXyKxOi5XjRADs6xtM6XZaM4YQ26CU0p2c0SuoetqbO3itJBJzdkM00o1ObibhL24Mvt9/ygrb5nCL7De7BgUESBhO6IzjE5yAJJhNfXN77eH8SP0GYh9ztBCvHykZCfuDz/SH7+DWm64GMyp/ZowbnbCRmbse4o3jLUg3H3vRzlccN5T68F7z0tJctiGwOsFryDHBPZwVPw5Oh5igrkhRDoApsBUJuIlqTlZBu3gqouJHCd1h1OOr0XKLDKut//YJpi0QL2nDI5ZyYL5Of5wjzPyoqKiTkERgcLDSg2WlPRWv2dOV5ZwZFQNhXDNJYKAxCzltjrVljXjbWo4OyUEzFlrk8fSXni6eWFlBKX6zM5RS5z2rtHBYQom2msNI1BYgYXIF4MEIi2Rgu9rrS1gCtQrRvS2Ni9lgFKiOBVk2lQz8ex/yTsts85T0imBWXlhlu6UEXHyfWGTE/IfFVBTR+grtBWfFvxvdCd6ZrlZ0hX/PxCnp7p+RkJswUtQtjKTh3vve/Aj7M6mWmaAJjnC60U5rdPagutFv755QM5Z+anD+SUCNHstlc7n0wUHRP5dTt7cjCerGHAmDv2/SGEdwN02Bb9hdLQG61WBhtTmWSO0RWPCIlETokpT2zzxmWeWbaVy+PKuq0si+qNDb2adiplmKaJPGWerleu88yH5yeeLrPqMNhe1RhZsoNZcnn+QMqZj59+5O31ldvtxuN+p/tRHlVJvuNCIbpG9wXvrVmCE7pYibab6AS6zCDeRD0do8rhezr2xIoFbuLeX+R7v09Ft3OAa1Jm0CV6sjnt1ueahucmkbceeW2ee4OtVQscTE9OtHyp1MZWO0trtI4qToj6uebJWKLLnFXx5NhJwUrmnJX/iQaB0QPxAPSHnycCS9M93KFlJNkaGlyTllr98Jy4pMDvP16Y8qHBVqoGWfetUmrnj2+blnlsoj6O7XEx2hpuVYEz19+hA85hndaUeTkCv7WoH1eaakOqu6vJAAHWsrGuG5+/fmXdNt7uj/2zcgxc5kSn8/LxI86h7FbTsxOEYsmIc4itwuAN3yuhN3IK5OsFMtAdxQT6XdQyVpmjliF/btRtpdy+Ut5+ot2+ItsCacKlhKsLvl24zJEPzzPJbyCFttypy8Lrz3cey8Yf//WPfH698fr6xv3+2DXp/O4Pn/TvcHsic9zTZgildB2Ha9IOhr+5RnJwPEUNzn1RZmnf1Bn1TbQj4xS4TJEfX2Zenid++OFCiJ6UPU06tTccqk1zSZ6nKbDUzr0INwOYXtfG16XztjZel8ZtrdxW7QrZ+vARrZogOFgbW1PAs3RhNjH4N9szf5cS1xR5ucx0EZa1sm11j2/8QH3lBP5yWq6i3/u6VkoXyj9/wTvH61bZauezdeT7bo4BXluMNxISowRvxItHcH6+djlyNBaHDTHtVtVONUvEuRFwcoBOI5BXSZDxO91XParPKZKJwfyo6ZnR7l5MF9UJRB8JLhCihss5zZRWuOaPlLrticQUEsEFAwNg6880qWz9jS4bXR6mOaRlXtc0a6JsK6y98ioL1Mq6qp/WuwJa0vT8t0WfvVP9qnXppBRoBVIO9AYxBy5P5t8ilLbxZfvMI21IzeTpwtPLRz2v2ill4+32xvJY+fLzK+tj4/XLnW0p3N8UfHo8NhAI0cqFU1QfNqiMwrpWHo+Vt7cbj8fKtlVC9PrwEZ9hnnQMf/zxysvLhRAdW1n5+vWN17c37svCVgrPHy/McyJOgRCHLqsnXxIxBzqaVB0M7NYKrW2q8+k0Bh9gXNk6y72ACE/iyS0SJZGYSGQCSX0tHO87ySvYpDNH98JOJbrIJV+55Gd+++E/8Tz/wG9f/o4pXblOTwa42/zpY98eIJ3fAbszcOed3+ftIFGMuW/Lg117cACAA78Yy8v2qFFuOkBR7zI5OlK4Ev2FtdzY6oPkP+JIqllMHlGhff9YR51Rhvotk2lnGduaPet9/6XHf1zjyQaFb2zjkan+FfRrf/mRsdv/dHKoGJ9wRlP3Nx83ZC8GspsyQJDDQfv2WzSjM/CJA10/KHX7uQ9Q0g1s/YTovUNDOf3ONlj7HmSIx+0X+WfG8ZvT/OZX+5WOybd/4TFa3lpkz/MTHz58opXCh+dnnLuzrCs4YWsCfkAPaszdO+9cHYgGlGo1t043wK1B2irTYyXPN7IBT+O6aym0UumtIK1RtpVey16CV5tqbpQ+gCcVcdauRo3cGkE6c/DMfrRVDlyiAk7RUOG9LerANw9YmJ2xIqP0h/3f3duCcrZxjbG0soOGozkoqBYGXrOAOfjdeNfWad4NPVPTATpu7wju3t2n3Wqc1oZtuvvU2NPRv373x7N3WjaQvCeJp7RG7Z3SAqWhYsOAD5mYZmK+kPLFxH+PrPDhEJ2/Q3/5/nfy707Zv7ZjsIM6TgXyd+fQMlBdu4MExJhO7CK5Wr2lNz6YrlMYwFMIKjhYYU/nu7PI39keYaCjliccG8UhZKvdgQ6HSbHLMYe0tbUPGuh4o3eP0pADVLQ7aetCNdiaZQf7rtE2oqwQImFoOuXJHifGU0paKjI0nXrQNdZV+JqkJXKEiwLiLhogrCVUysBq5hiYTok1cRiW9/x4d9841soxhmrAfYj4mPH5ip+uuPwEvSKt0qMxnqKymnDhKD9tGzsrxk/gBwNLO4lICPvcD1G/S3D43vcSuAE8BWu3Jr3jQ9QgMFSoBXCkaVbGWMpK6zZg2lsHMgUq9XlkwBQ4sOcBMA2H2SjUwftDnNQdfz80Vc5r2K7BgvvRyXO8B++RCEKkiXWG6YfTMVpK995OjoUYUJq5zNoiPict39tLzU3U/TAk+hxCgJi0vG8wxZoGguKEFhquq6PXfVfGmdIHbTI4NLzbZ7zdy6DdpDzIr7GHv4vjl0bZnf6vP4mxNFFWiT2if++ZKdtpdLLTEvXRuWzX+rDflz4SRzbmp4h63N4uHEwTMa1FGWv3wHZ2X2/cNoYO2Ag5TYHC3uTMN5GoHXxzjFymyMuHJ57mpLYHx1a1e9L8WFisZK9RcUtRe3ugSowvd8Iu9DsSjePSBtsVFChovR0bPwN08oSU8FG15ZqoX/NYV24PBZ6id7SseiWlVrXqTttt71p4uN0AHvPaEmzSlRk2AuakWpuud5CqLkR0qssUHN2Spk46noaXRnKqk5a8kDxWrihWbqvamYjXhEKvbMuD5b6wGFNqlH2oO/OrHv7upwsKSO6+tuheGr36VDkomJjcweAek+fQc9LSyhQ9OXlSDsQU8NGbYLTDdbOlNsY9eGNNQaWxdXhU4V4VhLoVLbFbqjZz2MtPR8LNZCxUd0x1o1RTSohBDPR1vYQAAQAASURBVAySvdNjDKpDM1q2j4g32Ockbww1P0j3wnA7ANbS9zUDKBDVOre1fl/A0zeO5GGvjj3rfbz3a59x/ovbAYKxJw39zF972/CFhG4gA/t3j8O7cLJpY+8ck5hdx3K8J7iIeMhRCC7QgtrOeGq0oTdbaFIRKk28CtiLw7mqa9RHRFSHt3m+UfcxS+AEbW53xH2t6R5dvAIca6r0DnlSgkVMqlvrvJi8yoa0wCMsdPHkqdJQndh1qyz3lcd94XFbWB4bj9tK2aoxntoOKI/ufCF4I3coaDLK37ZNS/YUvPF4vIp4o2X9KUTmOZNzwJk93ErRqhnr8KtbuSNER4jWBdBrh71gZJQuXfWkumk6SsNJwwt7IkIM3BsAeXCJ6BM5KEMph4kQEt153W9sc9qrnvZ5oM8O7WqZwkSOF+b0xJyupDAZ20nnVhvx1e5jcfhbnJ+P1XCa5Mfz8O8Y8aV+zuHbHD7eWGLnfRuvnZxVsHwix5mtLTpmUulS2Mv49rWw8wn3z3yf1Dq+Zzyf19H/kFK7X9Kpzid3dLmzM9i1nwaKpnb3QGOGUNhY5K13G1y/B1rqvA67cwRrioKG46badyi7qO33Mxi4MLLJI8DTCeb2chdtdXl0vbLL05t4XO4eBQ1a9TE2+jwccxlUy5OhO677mzHdgYcDnBiaMk2so4oP++TVwEAz6nt70PDE9cXxt//5/8bT9QXXGl++/Eygc1s2vF+4rbC2TkOFGA+KqSP5/fRoCI8mPO4r3BZwX3UsrfQnxKg/m1igLkilb6qQp15KNUezGmV02ZQJoDXxbRdrfMmBpxD5/Zy5xsDLlLWV+9CRMjr66NDULWg16VENqsc8srHXW6M6Kt1UwEeteHTqCDnvaTjuvbOIsAbBR8/TJTHlyA9PMyIqDr0CshWIji0cTpU4k1hw2q1jdCkwxOB9QH0gZnpP5fQPu+9nYGr8yTvHFCP4wAfvoDeW5UEthcc2q1EOCR8909NvmZ9/5Pnj3zA//UgPE+CprRj45E67MXsHGmxER6lBb/XXHYC/1qMsumG7je6g+SFijAUHnkhgcpEpCHNQ/YUUTAw3BN2XTPvEOaetp6ekrCO0M5ePGXzZx1WzZ7oRjFbUzgJ53bitbe2u+5SY55l5nrlcLkzTTM7aBWS04xULePBavoFT56N3BYPqttLqRlkXBYBtrtT1TtsOLYQQI9EH5udn8nzl6eMP5Gnm+eUjKWeeLzMxBOYcLWgwQdTdZlsXljxpB7mkwFN3EemNsr7hlzfk9hOubVBu0LSsDu9UJLcrMC04fK2IlRgCmnE8DCsNY56K1rCHGHHzk7JMvUcItLJSy4qkmZYvuDTh84TUDVqhVdN6QhTAChlCJKQLPky4mHZWk6AgXxcVqDznMob4a0zaOTDmSfeSkKm1EDZld11enply4vJ01XJhAzqjBZIuJmVhGuPJG+NptJv2PnzjwIy98dDLAN5tKr2Lio3u2bMjO1Zb06K+AXCKdjiLSe9x9J45JS55otTCaozVbdsMMO275tmUB1sqk7NpRnllnR2in2NPVOfGOWXpOu/54Te/pdXCf/vH/0qpldYrXjouaoAcpSFeaKigfvdajiO7LoFHnEdFGiLeT3jRANd/V8aLfV/Y9wpbg++cPnS/9WiJ2hwdv70GfnON/OaiuhnjM8R5KpE3N3Hrwn3Te13rRqvafrv2riW5rbHUxsAHHOg+r/iJ2TYraxLVSirdEUYJHmoJW5ejTA8YOpxD2HZcFU5ZL8X0umrTTPacMpnAh+eZH1+u/O//9/+ZHz994Pn5g2pGFm2r/fnLV273Bf///q/89OXG1/vPbFtlqwpueZ9Vc8oH8CCmv1Ja230g7xyXFEnBM8VI7Z2vvrBuykQIzpFiUvbAxx+Ypwk/X6hr5euy8fp249/+9EcFRYLnMk98+vDM5WOluojETJhmQpoIozPkvqa7tSBvysIYnS1DIMaZ6AKRQCASb5W6btrJKUCJgeqDgUuNa2jU1MgXT0uRPCkI/jwHLtkzz4lpzlwi0D2BhpSVz3/6I1++3vj5pzfelg1pDe8cOUYTmh+sgMMoOhSg6yKY1vEunnvNnik4Pl082cPsdC33VVvLuaJBY0ZL8eYpEKNjniPznLg8ZdIlIUllESqjcMnAP+dBGhvwtQr/chc+Pxp/ulXe1srro7KUzmOzAkznmZIjR0+0UsMqh9bXVhpv3rE19XtjVHDSi7C1Rq6FKSY+XDyX/EopYWfkj/0yiDIlXC8WDxm+VvW7/njTkuxiY9YsdkhOzub8r/4YQsajMmXsbUO/LJg/8K0tGyjm0UTD/mhxY20btW6UbdU9p1X9XH8qrDPg9ohTxdjCJ2ah+YCjhH3EjN4Ze2WU8/W2J3Kc80SXiDlxfAiH7rEx6XOfEOlM/ULrhbW+0mRF3AOoClgHqEmB1Oi0AsN7IQRRW0hXTLOPvR3WR0W6o2wau66LinCvSydPkbJNxOyZLo7WhMfbjeAW7q+e6+UJ6YnaK7fllcfjxp9+/jfWx8rXr6+UtXJ/3WhVKNsRs4bgSckzTbomc0rGrGmUR+F2X3l9vbNuhdY7yXlSSlwvM5d54umqz8ma1rzdFm5vG6+3G1/vd3ANRqLJi+YKI0xZRdDna2JOkfpQJtO6PljWO2u5U+qqDW86xKhtvmOy0sme8AR+eP7IZZ74m5e/ZZovXJ8+QfDc2oMqhYfpp474UnHkjlDxOFKYmNKVT9ff8Tx94rfPf8clPzMnK7Mb03d0BbSEiE7DkcwbOIrGBKpJZVBP/5V1P5LIe6g4EmuibNIdGDuBTuO7xLRRfeTl6W+Y8oWfXv+Bx/qV1hdqv9H6Fbezvsa56bzfV+GvgElnDerz97dvcJF/7/jLNZ5GOuN0gt/ITe0B8wCo5fTzAF/cNy/cM7RjDzvAtxM99YREns7ocMHYz+QwYCfUmF+8jZF+OH3d6eudOiWddx3t/vx+cJog8ude/Svv/uZX3940BSFOJ8lAPI7rO/Q/EtP8xDY/mOYn0mPB+4j3iq5HDzmpkyfN75I/Q4NBs4/H6XfBkO5uwKBS330tu0PhnYprB++RqOKyQxtpdAkZnVF6bdAbUUxLyjJN1xi4Bq8C4tGTjem0K6kbungGY04Yzrt5Is4yqE6ZKyrqOESjjR1ic6mK0BCaldKFpHXEyTKAA4sbet8D5PRe94N389gdoKWzcrU/O1kGBnmeeGdE6nS9g0ml9EwDLIZwPkLrjioeF2dihjQ/k6ZnzaTgjqBP+IVRk3c/Ofh2nXxP0NOok5aBrem1dStvHdlIb626nbm1IqNfmJjWw2lU9nWn2RzV8Am7ET+072TPLIiIgihO9s1m0GSVidhPgDx7xrv1tnf2OMAPW5et0VulVe1WV9aFVjfq+qDVYv8upvfWbC47Ykz4EMnTfDzmmTTNyl7Jk+qgRdPtsZr7sRYUO/H4NKlGU5wQ53E+0nsjtEJPmzKIrJzE1Ez28dNrHNcpZmtt3E77zbvpKR0Z7W+9U6ZSnPDThe6tM0ia3j3wHlrUcpSW2Gv2veo+aYs+u297AsCyhgLOH3uUAHQDu8daHYBQCKpNEkxMNyZ7RAWmxQChHXiK9j3agTAMwGkHnnb1aDMTx/0XTmvanbYdutngIyA8LMZpvx3vd+xJhOAdIp6U4u4kBXPGxYROgwFPg26fYtxZqec5fmzd5vgPoy06XjlPzJerAojOGfuvUZ3Okda0tLN3oZ/YymItbI/ZNFTZ1EYejMHv6Dj7RX/Jy50mQ7RbmLZtj/6YA0PbaRPVrqkGdAw2xwDl/djG5Oyb2GJ818DlNL/cexs53nG84LS2x+dbtmXYpjEvcaYjJQeLSkXyA5fLhafnJz5++kTKiWKdzZz3pHTn6TJxXzYLCKzLEdaBTfzeqOTMgh5epEPBJ9UY0jWYvKcFFecOIRCTdoWc5qu2NI+qcVebluNtpeActK7l1aV1ahe6G81kxuN0c22Ov9cwwWxM0HJkD04KTqo5/vvtYKz0EBwpBOacqPNEcJ3WAjFN2shhtHbfk10B5xW27IIxEeoeSKcYmXpnigGHdWAbfhEWMIljCGuPPeI908mSfo6DEtVUtsDj1D91hxC9atXohzWEKp21aRDuOgYIjL0EiliTgSasTViqsLTOWpXxPwAe752Je3vm5AlBv7t2YytUHUdN/IqyAUWTBc5pl7va+15CeZ0yrbWd/XQ1/RopIL3RjQHSRf3hTRcgpcoucdF3VgXGLP7L1/r/vx+Hq+tOe5rbfeXBHn5PbFBHTQZL7JSc1aBdgaZ+khrYo7S9xfkBPo0nZwz03eac/s5+noffLdbpd/+ssUBP79j3ZQbpzZJa0pUpjGrtOO9ofsJ10410gYASDGIoClaaGxKCAveWVdM1I9Czsp9qgd4cUnUp1dIRcayPZsynQGxqX3oT1qVqnMZG8Fn1lHqjbo1trSw3LRNeH4WyNWU5NR1L7x0hKfiakjIPYwrKRnKabGjt0Hg6QAktwUopMs2ZeZ64XCYGAaD1xlY2aq8K9jgtzO90RiOxIU0RUzCWlaP1pprAtagmnb3fy/ARjOljkilJJqKLXOcnLvOF6/SBKc/M8UL3sPSF1p3NowbSzN8yyR+X8D4w7yynZ+b8xJRUzyu48H7uDt9u3xN/Lbayyqh3M15svPnFa3WafluF8uug07u5ajcihYzIheBVXF8T4nVfN7sS2unz/txx/ttgPL07j78wbvyLgafe+m44jtpEZYQgZ2d2LFZdpN1arOxiZIYcKIptrR7liORHK0L2wdTSkDYEBXYHYWTdbedFN5VBm9xv/El47he3f9/0D6QQ56zNpEPLc8TKVdDMisMccew6Dhvm3SjP0r91c7Le+2zDwzr9ys5uN4ocnzfArD4C1XcX0pHuES/4mLi8/EjtjvnlK2HplP5P1LohpTB5z+VFWyvec1ej86h6DqKOVfBjEglOnGVhFLAZ6L8K6alj65xStYMPVGNzrE2p+as5WhF97ZODi3P8kALJJwOYHD/kwBw8H1IkhUBO2uKzuwEq7iGMRR5ae7t3gDOKc7OF6YLOy+asW6H2+NUsuOmeVByPdaUHT8kBguclTwTvuaSIF2hbM7ZDQ5qOQfBOad9NNO2GozsNyuO506E7AaK783iKo8+G6hw9noI97/Qz49iNvMd1z9AC8ziqBDaZmD79npcPV15++78wXV6oEimPlSYrANOUlTU3anHlCDAMgjnOxQLtb6zcX/URtIhSNzgZ7rLNLgP1HEHLyJrQygI01uC1DCsFuvM0gunMaMen4BRcmC5XOpA+v6oOgAOso+BY18NeDLZMt0y2q7qOtk21d9ZlJcbIfbqTc94ZT2my0jcDoLoJo2/rnbqtLPdX6rpQHm+0sloXSQWkpHe2Uvb6bx8i6fkjMU88//g35PnChx9/R55mnp6fiSlxiVHnu9nu0a1s6Az5qKUiwVg77HpFAWmdGjw9wDZdkV5oQQEeHyMuRoiZHqKu295NV0aB1XGMwNbLYDw66A5xTV8PKgp+eSJ6j6sVX4sJYgdinkk5HwLyXcFvGJlJq8cPiW60d6xszjlHTlrKMzb10TGtFMuONY1WRpmSoLpVIWW8h3memXLierkSY4B26M+Bw6fEXvZr616fD2fGnf/nhq0b2bNw7IdiIL/ZqxHAyr6UxQK1Dq3tDDon2pUmeJCuTmZ2kd7TztI7l18N4Gns52LlDt10sOTEogR2O7Lv67YHPr98BITr8wfyPHPbVmpteOnUKkQRehCy0yC3egthxOG6ggBdAt2Nrm0GQHn41UYdf8XHuJpf5N5OYd3+d6/BffTwlLzq6gSv5VQGqVdxPLrja4W30lge2uCDVgkIKXp6h+RV56i0TjNNnLPD6x0MDHhPDXmnv/PaQXHkfQeYoqyYA+TBa0BoVaya7Uc7P3W7RBFjUtVO7Y5O4OnlEz/85nf8/j/9Z6bLVVmprfPTH/6FL1++8vf//Cdqhxj+iEOMtYd1XFTG0LBrOGUYdJGdSTN8seQ1udZSIDhHuXRinnn59MKnH3/kh9//HcF7zdTdHgp6rIXb/WHXpXDMPD+xVqFI1H1E02+72y/i9nLr1o7upAA+xJ2hGkODoiLgW/OsGzjfcb6plk0ULjkjH65E+R3Lpyfuy0ppldoV9JqerqRJtflEPPgMEmguU0nW9a3ifGDKjr/54RNbKQTXWdaFL2+F2sW6TipwhEkZiFN/TxlSgRQcn6ZAcjDR8E31eUSE2IXgHJccyMHzYVKdv2Bg0ya6h5ZlI/fOffhIJ1B9lMLftsaXpfLz0vj8UKbTY1O23tpMRiF45uS4ZM9TVibWAGWbMfduW2ep3UTHO/fakM3xYQ7E4FlaR7bK8+XCUwxE9yNbLTzNmWSf753w+vUL27bxeIiVESnwFItJXyyq8TRsdwrqT7xM+vzdHII2jbDSrGTl5QoEcex9IewxnVjcqOWsI4C3eLI3al15PF4pZaHUu33RYJLrHjFisCG+fJShd9V4lPfBvErtCF2aJQTPcepIPL3XAZKdJKnn6A1EE4vXhp8dfQa0LE+k07gCFXEbXSpTLgiVadIy0MtFE36dBAgpKQt8ulRaEWIUWoHlpu7MtnZYhW0RQnSsSyNmz/VZtX4et0IMjfr8QHpkM+3K9V65f934+d9urJuW2/Um1A1j40fmS+LDy6xgWHJcLxPPzxcul4mYgrJirWRvXa07tJXjxeS5Ps18+viBp+vEZZq4LwvrunFfbrw+3iiyQK5065y3tQ1fHLNTHc/LZWaeMlNWYHdZFm6vC6+3G2/3N7a60qQoGG2gdPBez89nXvJvmMKVHz/8njlf+e2nvyXljM+RKoX79kZtC3W70aXqnuUDOT4RfWRKF1KY+HD5kTk98ZsP/5lrfuLl6UeiT7s/PFhCR477PfNu7NXOQKlBKFCYQQ79ZgYwO97LgU1wJNX2+Tw0qgc2cLKO47tzeiLFmdvys4F6jdJuTL0gvu3A6bdA1uiOty/lX8SEx/oZMe5f6nv95RpP+yjYv9+1HtTn9yjyGTAYmkey/31f0Jxe+ivnPHhVbvfADSG3z96pmOPt4xR+rS38/mVnp96dJof9TmTvfDXOAeTde7H3utPNON7y67jfzl46n9Y3aOlgMX37uzFe45Pe/U2s7MUHfEyEPOPjhLhIFcdaKiEEcggEp8wnuqdFrdHtTTf6ILYgbIKHfSEY+ObU8HYvWr/rRrb/ZOgHqGG4UHSOBMzeMXvHU/BKYU+6kT/lSLZ6+XgqO9nhmDGXTiCfs81sZAREOr6fZAmdQwEz8N2p/pFNXe0QoWZOnEDQmuIUg15p61oW0Lp9bTfxeL2e4LVEBXea7wxQ1QzCOAdbE87WwJgZvwY8DVD2DO4OYHTvSGaO+x5ICto6O8z4dKVJYKvCfXmjdYe3Tlraxv1kRCzw1fbRp1jmbFi+I+fnzFrkdC/2NS2AjCYEBtYAEqt2zfQqbNy8OjWjRk/LXIO2fLUyrcEeaW581xnEk4EjH/MDnWNatumA+i6T0MW6hfRGrEo7DjEwRMPLtqmY/7pQ1gdlfdC2jboumhG0jiuDeeh9Ah/I00ycLuT5Qp6v5Em122LKCm7FcEoWAN40igZLJ6X9WSNGA0FcQHAKSMWETxO9zpAuOB9xaVYmUtSudjLKoQcQeNojdjvvThv2fhvl2I6cx4VkejHu6JBnjCYXLEL2HiTs+5Mz8XU3QLOTs6Arzyj35ijLuIcWcetm33etLl3CnhjV+UkxKnssqkDt0K4Z2JrfNaOsQYHNHW//Pibw8eOR0D3YlQ63C5oi3sTwBU6MOji0xw5dxdMysCnJbn8E1xV07HI47YPtOlyr3enpI0EjvwSfGISywSoTZYxM8y6qfzeh6dYNdJDxGKCF28tVdOkMzT0L3p2BUs59V4wB2K2G/fzeTAPsfz62I52L+4qxMi4bx4qniKM0DXRaO9o3e6d79tAKqkEU1KW/T3z9wrXS+d/HfoXsa2mUNDvbH9UeG/gkY26ODzrmjhvX7oRujJTSOpsBYV3AmUadT4neRRsPxKSlT0NzbD9HdgZds7rBwRray9zNb2ndwK7WbK3o9eUYSDlysXLo+XLVRFmre/fKYOxvsGSoV+kAH0xQPAzA+JfO/OkuHwEvDs5+Fs603x3dtI6cJdm6b8Ya8szzRAiCC55SG2sVmjhj6A5/YDyEwf70UUvyZmnUJgYYaFKOFngE04OyoR3rTaukFdxyzrScgjOm00nPqRszyxnDKXjTcHHHPBGsi6X6Yr006lLodm+cszLhqN3sHtUAo9pNs0x2MGnMtuAh2jnleDq/oOM4/ClAQYWuCc1iPuH4eWh/Re+Zp0RKynRKwZE9ODqLd3R/MOdG+nvoPqVwsB5EsFJnyGH43d/JMdbVHru9+6P9//3z+djXwykA771S20prG60XnHWHVaxImXvvffPD9uwfN1jn57B1/5/pgX4TiI+49Tg3eWcLRYYfc1ydnK7Ou6jaQ5IQ/L5nB6+MnhQDOXnmrDpuTVvdEUfDDlGdzWkSmlUMtgqbyF6KR4N1bbTWVY2hd7a1IbHTrQHDGFX1Mxy1CHUTyjrKElVPaZoS8yVzfZpHTpE8WWm9JUC9H3HPMQ4OjFmobOkYNf3QeqeUyrJu2s22VYRuiW5NDg5xd2dgZYqRnJPacjBt26ZdogfTzY0YedgxZY3FGFS6Il64XlSTacoXYkzW8EI1QVsr9LbSpBF91LjVQNJLeiLHmafpI3O66r/TVUXTTbJD4+Nme2yH5uhSba8e9lsTihDYiTu/XCz7IJ63hTH/TiHDr751DzmwHX9P+mmcHnwmeW2I00WBvrHPuG/2oz9ngs4Mp/1cz77eX2i6/gPAk5GyeldHvLNngc9Bwjutp/FWjPkkoz7cnMdTreDxH3s8OH4zbtIejL9D4U5imKcART0edeaPoen7IJ8/S6zUZYi/7uUCA0Cx1w3q8T7O30yCcT8Gq2G/PbsnfNC7zx8wDN5uyHYYfky6fppQbvcT9gnT1Cj4oCUyl5dPpK9vtHjlUd/4t58XpuT5cO2kHPkwT2yxE5NnWxvr0vZs2xy8AkEhkPdSDzP6MpxJZx2LMBZAN7FLxeiDc0xRnatnA5x+CI6Lh+ek2a00TYQYyHnaW8iPUgkdRB1rFYYWEGU4BK9OmPNJQaGqc2DUl4Y9/nI0URFJL1AbVOd5WEZRtUOc0lKj1/rhUrm9LtTaWJeidOp0dKnw3pGSCoWKMRzUIvtTEMi+2XYbN2fO82kG7EDqYDyMgHN0cVAn01Gd414bW2+8tspbb+YMd6XE+oakD7j5N/z0ulHqwj/927+xbCs//vgbrpcr8zQzpbwznujjLmLdIb9ZS3xfhxtdMxEDEQ4HSABp5lSuqwI1IipcXQUXM+7iFViJ2jEzeW33Ok15bw+/rUWFua32fQfXLTR+Z5vfOTp6L4Zu8+hgV2vV+RCCskysrWxMCjypThlWUrfx+PqZbb2z3ZXx1LdNN0Nj/DkTs81PT5qx/+G35Oszzz/+jjRfuDy/EGPSTd4yVjsd3mlJm3OeME1aO25snRDCPpYMAKB3nEw4eaI9/QbiRVu6+oC/POOmZ8LTC+Kjti/mAJ52fTHRgGdkXQ6mrbFiOcoQxcrrfEgQuzFPdU12sJLjk5Cdjb4bG7rdFBXGfB/gi8ihN9eddmEywfatFXrrlFatRl9Bp0ueSTHw8vzElJNqwAyW2juHgj34xR2s4OB/fX8YBWyGD+0ae26wPtGgaHQ1qU1t81bqkTXrHlWm8wouSLdg6yTsaSBQ3/cf057pBkBZh8XzYzjmo8PPnoCwawt7Gape23S5EkLg04+/4fX1K6+vX+iPB01UZLh1oToNIL2D0q2Qp3uclb125+hhAE9qi4N1GfueDgVzBgB48vA5F1GeS53GvBETSwYaOKfMj4eP3LvnXjqPrbFudWfK+eiZo+msEQlOGc5bVQHXowzMGHXm4A7d7SawiXYX9N0xme6h89pFt5sf2QZw/G4Nspcf7z6grfXSBVc6X2/KCP389c6H5zs/lk4UR/QT3SmjqEiga7pJ57TZs/HZrTXWTX8fu4FAVl4/AtRHVYBrLZUBSXvveblkLs9P/M1vf+TH3/6W3/7u9wCsi3Z//PjpIyKN2+15v46np2euTx94en7h6eUj0+Wq+i64vVvpDsrBOHMQZXgMYfQmoqzJ0pD/D3d/1h5JcqRrgq9uZuYOBCIzyVr6LNP9/3/SXMzzTJ+lqg7JzIgA4G5mushciKiaOSLZRc7MRVcY6YkA3N1WVVGRTz75pDRK9VRJ+KpBWd0zta1EJ1zmyGX6hMiFe1bh6rc1k0vjcrmQ0kLwEYe2cBcRfJqJ8xOff/qFkBZqVpuxrTf2faPdv3HzDdkCm9dn0oFF7yAZmNXtZXSegLDQcFrDp13CRMHMp0l9r8sSVfPdwDpETPNJqFLZtsa2Ot5eN+4Fvm5NA+MUeJ4Df3hK7KVxz5X3vbKXqg1hOvjUDHTyjuvk+TQHnmbPNTnzdd2w90vy7FX4ujVuRW3oWxWSNfWgwV4bPz1pcPrT0xXnYXI7gUazknfXsnZYRedcFi1LEmOXviwg4odPjREervHHYjypppL67IKVuo6k6hHPdF3bo1zosA/QQadKrRv7fuO+/kYtmVI3HB7vJxqBQMO5iHdpxHi9OREDADvsjPq87hTUy/hOX8Oa6a31HNwwvwZ4dP9BrHveWbTZWawG6oc4oElAi8oCjkyatAnUp+cLMQnV/cRedu1sJ03XNxFSzDQRlqkpEJ8dNQvv31T36PVrppbG61dtoPL2Les1i7AsgXrVJGSIGDB+4f6+UjfP/g7vXyoxBS7XyOW68Md/fOH6vPDzL8+6lrRmzR0m5pSY50htgVQ8cfKE5A04UtAnpciUJuY0k/fC/f3Ob9++8fr2zj3f2cpGCxkfKrUc7OomVYHzeeL5+cLTdaFloRZhz5n7tpNbpdJw0UTZR9WyLhxpClymxM+ff+Y6f+aPn/6ZOV15urzgnON9/0armXX9xrZ/Y1t/Q1wj+Cs+XHhKC8v0zB+f/wtLeuan538mxYXr8lk1WUMynEHHULGSzyoq3p3bOnwn7xMpXkhxIYbJBL+1CU9rZQymvgZ0n6qP+wN4OuYN3W44ZeSCxuJdFF8EmmnCKMDomeMnmD33/TdK3WiyI5Jp+IdOwN4IHd3n/r3yuvOmY/Tv2/6+rnYd3BkAhG0fTuT3TmJol/SL6JN8OC88omUDgDkC9k5ROx/jjL49ZMTd4aALxkw6P7iHk/3+jH+3zlEOapk7/fe4yAOzFBn40HcgYP+9fbgX/ec4tIFRH0/lZMvGufbPeK9gzrwsXK5PTPOC81rSsm4qaKiByameODqrm1fdm4oQjRUSeoDTQQsDiKpo+FJKoVaDoZrS7HWyaYD4HDyzczxFBaCWFEjemc6AMji6xomM5+PwVHNIzbEVz1idh5PtEa+sLTey7MdYUl9GyyK9ObHiPHgt3VGBZx0ztVTyXrjdtwE8xehxLmlgF6DrUilRwZ7iQ9bw9HCds645x8PqbKhDK0cdSi1j8uagHxn8Ko7aYK2NtQlbVQCq2sJWa8WVwrplbuvG69uNddt5ff3CnjMvnz7R5nmASX0OPLANH8ZRv4QfyPPhALvVzpyBa7Ml5uB08FL2HVdFnZcKMRZcwEoa3ABElOlkYvshPPzsQsydBfJx0p7yMzAWsMMeNDrjTmhehamrZXp80eywd46adxUTz1lFxEsxgeB6AE9oxtnjrGwjkeZZWU6D6ZQ0G29zsKFiqq07Zc6pVpPzptmkWzVwfnhY/ZxRu9vChMSKTE8K3qUrxMUYVGedEWffVaZi43HR7cmN890bZtNAld4tUJzgfcO187Nm2P/uKKq9FltXuniy2phBy7fsOmZnxqgxUKaX3/UytGAMwylFkr16maKT3sPLVg93zMG+zwezQtdwOa2Rx7A1O2d2cGi/6XPo+RkHI+N+ntd9zPefA+Qa97y3lZZxfw9AicNJbL1zoj2XD2aY/nmaMbotmeQDISaW5cL1+mSArbcgVoU3h9Sf56QHEk2TK9J1b5yLhJDQ0sPw+Mx/hO3AYR79rtPzPGfaz35ITwjqbnRN0W52yh4qxnbS59kDMvu8Pbs+hkJft7DibIexj+2c3MFuEtS/qeLUjsDRTdR978OcLvVh62NawU9hy9VK2W68vt243d7xMTKh3SjXdWNbd3JWv6SDIjG4cdx+ba1BdaIX0YFtO8EBrjVtqx6dOsuTd6bvY3M8puEDzMuFy/WJfdu4Xp/sXjbm5WL6eTMpTUSzs5yC3Q64fHyynbGo2lQVkaKltKVZyaIBR/RS2zbWEbV13sqYHCloUBi86vb1hF0pgDSc0/KaeVkoVdidis3voonF4ITotJGM+g9a5uGtpDCZrkpnJwQUQHJN8NadL6CyDjEoKysE0zVxes8d3SYLsfsqxmC6Z3gvwretkUKgijKHsmk4lSaUKsZOMp3SMS6d6Tlph9ZoQFTwmijtn0smqLNE9RvulQHi59JIruFR9kY15pYHcqmUlhFbexX4aqdx1Ds9qj3tUqC+Pztb3oY7+cNsp4sxlqr7nbc/lvmcfebj/UatmdoytW7W1Syr3RdwLQBi5foHc1hcn9XjRD78HKtfPxkLP3sQ3x7mJh++9XBBVgnhztfEYUePGNTjJKJl7gmJlWW+4Jyw12dy2fFuo9TKnk2ORqppSGocEr2nBqi54H3j/q6JrZzV2ramoIx3Qo1auSG2Xne2fk909y7fIXqmxZhOzzOXp4npMo2uyFNUn0Z1l8IRQ3lnZcUab8UQSKbfWFtj3wvrurOu2qShgXWoDIjvsgedBWj+iz/mhCZRmtlqISRPahEvCuA7axKhn7fSba9dm2OIxDgT44Q2bBFqK5SaKWWj1B0ZTasaDpNV8ZE5LtoFL2rJXfSRYOPNCiqHVESTSmkbpe1s5Q0wplHQzs9BrJy095c/j/M+os7g68n/7SHEeeKcsY4xV7otsyO57t85TGz8EBMXA/kCjzsfvlz3509+/e9vGo+fSQz/3va3azzZQX0Ti930EH5YSzvp00V3Gpwikh3J0/cHe4jDCT7bgxEcSw8MLNPt3HFjumPkjvrafiOwc+yMJzBU/QRB9zK9bmicjFHe93J87hTcaC17Bw/6Z93IWItokK+BzBmsEjs193B9Z+YXgrFp7Dune+1O/+mTUdAVtredjiHw8vKZfd/5r//1/wA8//Nf/43b7Z1/+/ULyxx53namKSkVe1Itk5KbvppwM/0YqudqGdAlaSeDmBIhxSGWuW0bed9VlLEUogl7d7HFxUrorlbvH4N1bkiTZsasHbuYlfF2X6s37bAWjH1mC4EZBociXM45Yz7sRuFW49SZaoZLE0OgeQ8p4adAvE74GJii1yzB2533+8a//ukrpaixv0yRX16upCmwXCZ1pkLQVsUBLTc0Wm+Pi89smo9zYzzHrpHSA2+LrrreUBbtAHQzfYKvOXMvlXcpbFKpFIRK3Tdybfzrv/0vvn5741//TZ8zrhCj5x//4Q8E92TzTXMswEMAycMp6vI8BNJ/kC3n/Zg73SY4NzpPNMtS9S5hbd1Us+iWCdOFRRJxmpi9gkwpRZZl5vPLS4+KSSkxzzPLMrNcFrJ3uFZNC+gxyO8B+VhMhqFpDEFLC4qkPrhE+ry8CeJ6kKrMpv12o+4red0061qKBioWSE5hIrhAXJ6Yn565vvzE8vTC84tqPaV5UWapdWTJ2RiGKVpZrWq5NQOdSs4ct9SpthVmy1vXKIE9XGnTRGPBB4/MC1gZnmbFdfxHr+VhtRQtWxvgqjki3hFEcMGWLBHrqCWUUsmmW6AUc3+IoRtQ6J3XDlKhl+BYaXIHoZ3DhUKrjVpUvynbNcaUTmvHscaUWq3zVwFRLbUpJZ6fnlimyPP1QjL2CIjq38jRpr1H39U6Dbo+IE66FGDzFV1PgMEAPsqUfp+l6OjOVzBgvr+hB26jRXwbX3DN0Vx9WPM6i6nWo7PPYELZc3rwAE7rVQdem4hpSynzKZnw+i9//EdKyfyvf/2f7OvK5KqWg89OO0vOpsOSjPlnz44wIz6Q0hPBJ3x6RnzETQtds+BH2XqJoW5nsOn4eX7+HUj13lk5k47/Jo5M4MbErVZu28Z9K9xXFRp15qhGK6mvrZFrsyYrWhJ12LA+HnXMjqYNp2WjtJ4NtlJV0dUb3+OHHnXCId0AnT7Vr0NtdCOL8OV9pbTK//u//wv7dme6zLx8fuH68jM4z5/+7X/x7dsrr6+v3G43goclBZ7n3nGPAQSAWNc8T4hdDFc7CGcDnfY94xAmLywpssyT7nOKLFNimRIhJtzTE7TCt//tP3G9KgtGQZ3Kcrny8vKZl59+5vnTJ5bLRe2Q10Br+JZWboIBL87W6JwzrWR8vePqiqsbrhVKdTRnGnZNKK5SZae1whDKRUAcwQWmIAoeeRU2ztvGiqN49auCDyzLlZ9//oVlWfnyl7+wtsp6f2e933A5E6XxaZrIIfC2Z6pphnjveDJh7eDVN2tZASvtWidMoppZn5ZIMqYTDu1eKVbGBsxOSM5xsYToe2vsRfhyL3zbhT/dGpcp8JlEirDVoOy0Utms3K6Xx3XfOwZYklONp6i6Z3PQ4D34nrLWssAWIPrGNTX+cqu8tca2FXJuuAuQ4L5nYvD4pqy69f0bJW9EY/+rcLKCVUWEvVrXPxt3UzKNNGNvVpvgo+vjD7MZwMrJTsmJNWEX233S4ZsCnel8rEWVbX9n21/ZyqvpC5pWpjhNRDRllHg/E3wkhRmPivKLWEmenGKykfA6YsJ+otJOyReOB9NX2/N5nq/XmcxLPceNIqO0DQOecBOewDx9ZpILLgilbrx8+syeM3/57RvrtvPnX79S807JWpoWk1dm6jwh4rgsje1eyRus98y6KvOpFhXjT8GTXKNuhbpnSt6t1H1mXhLTkqitsFwnrs8Tf/znZ15+uvKP//lFGf3Lor6WMf+WqF1spxBUkylaqWwKIya+XBaer084PPfbzm9f3vj27cZ929hz5vIceVpmJGyIK6x+ZS/ZBNYbzlmTH6lWWqmC6C410sXx8vOFpURKiYgUSl0R0fHgneCDEKJ1b04Ty3xlSldc8NRWuO+vvG9fud2/sJV3kGJgHiQPUwjMMfE0f+KSPvE0fSKGRIyTjVcT527akXfbV0pdueWv5Hrntv+qWqrpwpyuiKs415jbFYiD0Xrk/JzGaMaAeki69t/xB66BG+Owwz0K4Ifxnd5dsTcVCm5iio77HnE4YwvecFFjg754j4YwI0BkzNUz+NTJKB1QHdIcf8P2dzCeHk/iXKKgP9zvf7w7JBwAkfnL34PI54ltD+QRQ5Pu4Zzvxek3vvttuOQf0Tg5GZCx6w8a9HYOZ0PVofMz6HQ+zumx0NOB7iSk437nrOV7z9G0d4Tz1Zh/djhp/e9iZSe93CwE5nnm5eWFl8+f+emnn3HO8f72Rm1wX5X51Eu7Qghan69CM4A5AtLI4rQbiwE5oQeLTts2O6eUY+c9LnqSs6xW1EBhiiqQPcegrWtNB6drxaiws6NnArrgGnKi3jpoRrnvD6gH7H0SeucR37S+DUcXzBanMFV1WlqiqS7Tq3FQizqXb7eV9/vGbd20S0PTziW5VlxVozACRkz3ZTys49WBwq4ZMRaxPgado6MGYt+pWEYXBXi3phm8W1WR9rVWtlbZpVLERETp6Hwh50yMO9IyjsblMjPPE0+XC8tyYXRDkw7onsa/nEfica4PGfT/4JuWB5stEYHwwI0c879KF8BtiG8qtizg1jtNGnGaaMkf9evG1OsswjQl0jQxTbMyOUuhVYcmlOVhMbHq6pOtOQyExhttBGDCAVjp4zrEeBXVqqeMan8JI44BxAUIEZ9Ud8lH1SNxNncx56oDBb29MyZUXT60SpWSD8eLXnJ3OJNNGq2oRog00F6WQaFa0aDMWRmO6kEfQLJzclr4Pi7C9l4zFk41Jlgp2p2rFJ3b9Wgf3+djB57GzxjxMZAMoOpYbLMObv2Z9KYTH9e48TzMYDsDRlJU5kCnKo9zhmEf+tfA9AvPqeAHsy+PB3OPb58zYs0uYCxVzo1uV/Txb2NNusN9ArR6sI879tuqgnA96XI43Y/r9CPA3j/zUWBTz9GfmhnMy8L1+sQ8LyqkjzErTDMlzRqkptRLQLWMp/kJ8QE3PSE+4aersqCmy+PC/ANs3/sWDB/q97bumwzdIluHdM3yFPEU0S5wpTYT+BcQZXPszsbFSSvnwQfC5vyYXxz2aPh8bmCofQx8Z/O63+NOv7gDdIKTQoo901Ibe658eb0Ro+fz//oL7/eN6/uOc55f//wrb2/v3O4bey7qcAfHFD2hCZRu481vGsfRlz+di4h1OhMoGKOmqeZezllZpiWD8yQfDrb5PLMsF0qthFqZ5pk4TaoD2LUWxR7iSW9w3JkPS680y63nCqXgWoFWaUVZW240zNBzr2Ybc87KvuklhqJzMkSbiyZiLk6btQg9Q68JllorJWfyrsnFLvkQnFedT+8QK4HtjLjgHL3Ytetzaumg6RgFZywn0311PYEsZv/VfwxO2ereuJqNpiz7od30eJPU/mEcBLu9Nh69Pzrs9VfwB4PvbFCd03NNpkk3h8ZenXbWO2kl5trYSyVZyftaGiVXZtGV7ixzpzCD2Bw4nrEtY+b3mWviuxLej7GNpW7ca3m0z91H5mOs93FTpogynTKYFlDXBNKkdMC5hnfJAlvTCqLhqhhxwZ/WSPcw187r1NlP7qd5fIbjDfO1vg9/H5wxuhWUD9cp3ffvH0NLVaMI86TA0jxN4Byl7TRpw//0XpNaIeqc9qEnjW0+2DLbsK5zVtWx72qz4tTlQzxlDkxLYL5E5mtkvkTSrN3sehtv5xlr8CGk3nVzLT702iQnmbaliLDtebxETLg8aEfc5po1JIgEUwhvzZKJWYXLUwwKpKNlgmnyXJhJNZAztJZZt0Kt/ZmfHpjFSlUqrWUER6k7ue6UmulNEaKL+OCIPinA5IMC9C7gXbDYgSEs37vgdZ2xXG7kurLnN/Z2Zy/veIlj/1NdqWGiVk2Ci0s6Epza5Iex8zuhVyfdjLoup3a/x8djTeEYv2Ns0l0087edyR6IdrfrsfJf2/p4FQ7t2WM2uId//nVW1OP2dwBPR1ANFji4oxOPP6FfIkKlmh/hBuoLWls6MmaYvsQIKk6lBdJGVnqgxvRg25hFyOFYDweFh/PASl6c7/oIZ6bRcWwRwTdPtZIUnDvKZNoRYI3W2di9cAwxVV2YDxN19qf6d+D4fN+HUkVlBJd9v6eodAxGvea+MzfOvRWhlmqMjMTLpxf+9//H/4Nlnqkl8z/+5//g/Xbnfrvxpy9fWabI033j6Trz8rQwR4+fAzk3tr2yZWHL2mEot4bESKhCDI1QG6lVnDSaB4lqjII4UgenojpiMakwXEjJxM8VcOqk6jpK+iw4tOxTC+4I0J0GktIA144FzB64w6tQsTTEdU0oT0VxtB3HzQUVU39SplOIntaE29udt9vK//kvv3LbMl9eb9aRRZly9y0iCPOk3eWGfo8DzVqodk3zcThL3cnpW6OXJqgXJE674fVyxb3pPd7VL+ZeKltTwGlvja0VslT2lim9K1dnfvlA2e/UCE+L5zrN/Jf/8l/59PLCP/2n/53L9RPzvGiwJnIYoj5uz7ZDDjbOj7SVWqCPLedU52bUQTqagR4qKl9Ztw2NUW6ENLHmyrxcACF6IYU/qBh+THq/GqRp4tPLC04gbxv7eucWAtUc91qrdfA09lnXx+nz92STjrt/wH/V2APjGXYaso0DTXoruCNGSW9V9QFwjilM+LQQr59IT59Ilytx1sw7YF3lGBpXtapYojcGUc/IqoZFpax3tcnV9LMsoAoxGXMg6TwxtqJm8BvNVZxvhNaGExN8gNQYrFZd4fV4tm502nyzfSropFpYed/ZVw2O9n1Xm+BdJzQPZlSwbndpmgkpMV8Wy+hdmKYJMWZPzoVaqplY9biCQEi2jnS73x1YO+8YI1NMLNPEPCVtlmDzTu+RjreHjJXTAL6ve3A4wMPmSw+NbX1pveRYP1yarrVaUursmVrCw40wrC+Kx7ppx631VFJwBp5aL8OqY0T+NdPQfYCe3e1dXrrzM7K+QZMIIWpHq5fPP+Md/PLLHyjbjreM5fN1Zo6R56eL6UrMR2dO56he7bFMV1M9vUKIuDTzozGehhGQw6HsWwd5HvwFc3aD7zYPcJ5GoGhTbbZauG9a9tDL7Wqp7N6x+QoDPOw6nt3xtL47TkukVIRVy6ZS9NYW3FGMEd3ZJ9naxp/Ln46EU4/PbIw7cE7LtPzwtXT+b0XLJP6f/+1P/Pc//cb//PNXLvPE0/WK9571tpJL4dcv39hyxgfHMkViUPbkfSta+mHt7LNplno8Hi3vUmvlaQ4tZxOsg1Xjdc1IXLl++Yabn/n29SvL5crT8yecc1yenqjSeFmVmVVKISXVAUzzYrICjq4t02d8Dxwe2Mj2ak217Mp9o6x3aDuuFjo7KnhN8iltK7CVxrZlfv3yjdt9Zd9VR+rpemWaJkK8EAIKJjUFSpzD1kMVQPc+cL+98+3bF75++cq2rYgxHmOM0DypNryrVBFjC5jvZz5zM7sUvSYrLzEo6BTVhy6ts9PtOsSYTsETg2dOnlwczSlAWNrBCHIoO8F3kFSEbOBa9/uaE5yJdU/Jc5k8SwosKTAHR+rJBukBkwzG/SU4LgHKrO3sf1srexVKjZTquG0aRD9ZoP26quTB5+iYbMx6D9FMcPIH+HTGI7LoNd3Nba3uEZf5ETZNUitTuo8JzBc7N9LRWAvz6XXrcZ8G+ztb/qad7Eac1ShtZWuviARgIvqJJFeCS4Q6EXwiholw0pRENG4YZW/Ofbe2dc28/tsBHsnJFmusYRc64k71UeqIdfWjun47E9FvVQkDW9PywVteabIDFRfg6enCPM8gjm3f+fIqlFpoTsvWFdiBEJoyfEIghDZAklbMn6/gXeX9bSXEyOvXV67PleWyaKe6TxNhaYRl5vpp5vMfF56eE8uzNx9gtXsVCEF1QPul1yZsuyYYHZ7LvPD0dOHT0xOXy8K3bzde3+58+3bn7X3lcpm5Xi48XWYul4lcI6XtFK86jc1Yi+/vO4hnmZI1btB7dnnyxDnx4q6AY91ulJz59YuwbyvbbhItTgDVXMp1Y82vlLZRpVDrzm3/wlpuhOCZ/IQLqs36vDwzpytLfGIKF5JP2o2wVQMHNf6qLdNaIecbuay8b7+xtzu38hdy21jrK6FG9nplrqsSI1ol+YUpXYkuGQCUbMz0tMwxZ4750yVh3LFuckiIPPheZ3yjj1fDSJTh75Uh7hJNtDvpzOcTtuNGVVovyTufi9i5CsZYdqdkZPswgf4vtr8ZeBoOzmk7U8HowBHHBXdPqDsWugcDf+wqDoTMjX12EMabUFlfFEZnsHMazR2HdwPhkQeQCbQs6gzOna/p0I1SUOfI6h6Bun6+Q6m/d4PP90ZOP+SDQTsGwu/upd/n4V+eAxDNAHaG1OMCJWMB1cDUM88zT89P/PEPf2RdV375+Re+hsB9vSMirHsxVpJnSpHJsvPBO2rQIK8AG8LaGrFVLakTIUgltKaMC9NBcE51YPAe8UFbq9u/xWlLetXhMMp+/5+gZXJOAD9GEafH3IO901M+jTILBk3rpDsiBdgc7M5pe/eojAS8MjhKqbzfVt5uG7d1Z92VNeHNaa898KrWJrw743bHm4PqHAVltRwmoZ+nMRFQNk3vulGdcZXMUdpbYxfTKQAFnGpjb5Us+ipSFbWXOhZE0WiTLvL88ukTIXh++vkXnp5fWJYraZrpmYnTJLQ41CnLb4x/PnSA+zG2Md/OwryuB0AdxD6KOHt3rVK1ONGvN5yDvK/Uchk17WNHTgbgO82TllI4kFooWZkvrVYrP6sjmK+16+SIlebKMS9Ex7WzY3hv52+dPHwX/XaWqZemjL4OEuQd6ey/TknwpokTrItbn4fCyOSUWkapHADFFrtV7XDZV1qp5PU2gAm9jQoKdHH1eZ5GhkVjms6sMu0r+0kUCGIJDI8PRxBwsHmcCfA6A7u0pr6WQimZuu9GRd8p+zZWoNK0G2AH+pzT8DLNM3FK5P1CmmdqzpR5QmeEM42sZlkmtYNOVPTaIaN88Sj/tsXfAK/+7zH+PsyosZQOe3186tHRPabsQLkMMXpYN0/7cWN5Oh+zF5KIib/LMf7H2jpWPf3/CRR9YLo97NaNn11fYJQTn69fOmCoUZjqvOuO0pSYlwvzfFFKf86AENNCTIk0q/5TWi7WqUwBp+ZVa8xNF9V8mhYIARenHw54GsEqH+7/73zSoE2bc8dzATTZAbrOdKZgbVbKdzCbhpU0ALIdlDgNaJzTIHow2nQwOVtTvM374NoBHD1cje3cHWd97oLX8699yT/PJ2c2estaRvbl2zu3tPF+3wneUXKh1mZruQV6zqvuixei6RAhyqDRUzfWljuAjN7drgPEXVOu1MaWtUzx/X7n9f2dIoIPkW1bDbRWO98lFPpl11pZ950YAqVUTXgQHryG4dOclupjjdLOa1IFit0xEZg8zqvOmY8JXKDhWPfC+21j3XZqqXgfEbyx17uuy6mDpnPgewKkkfOuXVOLAvHn56feVh8LCs4EZ4wiO/finQEJomPPnmHoQPy4zzrmgsM64PXn3Y3ZoXt5zix3f9xwruFrnf3C7s+eGU9psJ3OepenGMDGXD+nyetPR58njM55I36w9dQcq2PdNia+byBeQagHJV+bR12TilNO4UfYepLlNN3tH4+r3QH+MQb/eX3qUgil7ib0HcB1MWoFF1Tkw1b/6k8l4woWNIk0icYQ1JYBCqj4EWQfC6PZ0XHePR55JBT0czx8ZwWVj0ZM52v+cPkaqVgZ2c6a75S2gct2zRrPJJvf13LRxjNShw+obKN+nUdpIA7TlcSSZSo+XUphz5mUiwEXyi5uLpBb0DK+IGYHKrUKZS84Al4CzStTR9nQQinKThJRHy+myDxN6vOKXlsXSffBkVJgnrXLr+ICDqkOJwFPGvO4FigmKN6qQHRHkwgcMU76zKSQnUq7tBooVYkBveNclUxpCjyFmmhSTd9pp0lRf0JEWWMhkOJMijPRK2B5XGtBfDPNpA48ZXJZ2evKXu/kdqe0nSoZodLEUWWntn0wo2or2jCr21HXAVhNdowSBb4fL+Ie8QmOWXIead+991AS6kxf0wfb6bHyDv+xf/Z3tvMqzP8PdurvAJ5sIeiTTE/bBByPAEl6ptoMxlmTqTvoZ4Ck6xl1QKpZph1RJ7mdb5rdHP1AG4HNmHSHJ0MPXBoySsq6PsRgOBmSCJgwbRsoYv8biHVJOtD5gSya5fn4sJS1cHLYHu7Z2cl/vLfHw9Zg1veg8Oz42/c76wt3BCFNa1q0zMQ7rk9P+BBY5pmXl08E7/gf//NfyLnw9v7Gr1+/cl8z93Xj5Wnhp08XfPBMU6AER46OvQprEXLNvG/CZXcswCSNJKKldU5rYlPwNJ9IwUpNwiFgF1y0shp1tMY1DVaZMSdOgRxgOgcy9I/6zRbLRFbRPFLzSuvUjJdwRxlEX50jB8+2JFz0LEuk1cbt/c5t3fm3P33jfd35y7f3QaPXMipHLp511+520tkjXp9dc5CBFXN2jO01W4cAZ9m50oQiMnSbisjIyOWm5YxFjMKPUKXZSyjo4tCw8rrOGrDZ0kQBhSlFrpeF//qf/xOfPj3z+Q//zDRfcUH1TmpVwOqYGzw4A4dTz+hO9CPBT6NUyveATJ3E5k5lmgjitINhk976dYO8s+8beb+TpsD1MquguA8da1eNohS5XK5jbO/bxuVypew7+7Yq88kEwHPWQKBUFcAtVcGRKgeVvwfrfcxHoGfKgaFV5I3RICUjtbLFRN5WC8AsZHIeHyI+Jlyc8HEGn2guUEXHdqsaLOV9U5Bs3+13/bltK60U1ts7tWT2+x1pmukCICR8CMzLQoyB58tCijougw+kaTrOIwTipBpvaZosc9e0a58kZUZU0zUaGc/OBrASvqxaBXnfKPtO3jbyvrFvG7ns2v1k37nvu9K2S1Wdo9aYl5kpJZbnp6MJw7KwXJ5Jk3btU00oFbx2NvcbWqdfrTzJhagdRarV0Hs/mJsOW+O+8yNswZCTnsWBLo0gfpSG0kHIbvtPe7J1bjjLY7kxGzXYYs6wJq/2tu/TItw+pvr6dGRsbTwORq/u/0iO6NhSVk0vme4OJVjUqc/OQI6AIBKs5M6xXJ8JPvDTz7+Q1431/Z1WK8v1hdk6tE7TxNPTJ21TP2l3Tgma4Ai9W2dMWC3AjxW5cTz70VHu/J58f7kKopieoumXNe/JBPbmeC+F264BQS7F9Lu0dMi7g1DnOcbDd/v3zjrIdn9EReGDE1xzBHQtz1bMpv5KH6vGsNEIH8FRay91Vv/JY0DQ6XiaEFIB+vtW2bbC2/uKQwysUOFr547Oan08hKCiw0vS7naTAdy52lxBz8d3do07jiviwcCBW26U+4777RvZz1z+5//k6elJmUXbyrevX1hv79xvN7tXnuY8tRRu9zt//suvlJcXppSY/IxzyYClrhVpgY4FBPosPS54sg8IXoO9rQy7QIq4cGGan0jzhL/vtK3w7W3nT7++8vr2Tt4zRTwvz/DHf3D4mEYX1iHpLYI0DTbznrm/vXN7fWPbd3LRJCXuABu9c0Q8YgoGc4wkB0kEcY0cA7UJuajPIyJEzcKpqHfFnpmVtzlH8tpVeQBtPZno1AcUe6Z9PACDCVWEwXhqBhSq7wlzcCzBcwmOJZhGYo8RBGvYgvlEboCmkxdcgnnHdJpgq8JWG75qZ2NtkjMRa8X7gncNb40kFGfyqoUlgjfmhDuDT07IotexyY9luz7qnPbKmCMGhB6rHSD3KRlq61O1IH/dXpHaCO6CIJRW2MrG+/6KdgAybae6EXwihVl/tsnWqGCald6cXYd3Wp3hDIzqNZrB/t6b/mDn7P0RN0IHf46F/tCp6rHrKX4+bSKVJoW1vLOVd/7y/r/Yy40qdwCu05XoI5enJxwz18tErcK67wquFwW638pGzoUtZ/aS1U9wQkjdv1VDupVC2nfe32/46Ckl4xxcn2ZiFiSspMWBrzTJ7PtK3jL397vqZJFUIHv5rJUwuXJfM+83lSdJaeK6XHj59Kw+Y954X++83d7xPnC9Tnz6tPD0tAzfrmYhZ3CSiC5Sa0BqJa+eFSFvQkmNeQoE55mnxAQsyxPeR6IT9j1wm2c6+19EVGM4eHJ9QyRT2kqvVhIRctlo0pimCdxEjIEYEpf5hTleWNIzc7go0NQqe77ZM2ymKbxSW2Ytr+S68p5/pcrGJu9HvCZZO8Xi2cobwU+UslLDrCPDOdP7VdelSRvzAjqO0MdKZx1zAkA7KnrMoz7ejuRtG/MsBZUrSHGmGfNLyIiYJqClE/6qTpPra/dHvKKf498eM/5dpXYPB/nwb7tVhwEZNDB5uJn6QGQYFHnYWQ+G/72w19A5OACgvwK/ueMbhzEYP7qnzrHYt5PwXf/sSaPp95DF/pfWTkyUYVAfz8Zx3KuHd9zHf6sj8FhTeT6to3yx7+0w1ka3dFrydrlcePn8mX/8x38il8qvX34jxMC6roCw7pUQdu36ESNp0k4BI6PphOYa1SmYA0pRD01GPf6MI4pj9o2EN5FxIYpmuINoCUVoCgBIF5e3n/1Z9JKa3m0ODHzq5SBWHuns67XJ0EYSUfHQKnAXR3awB08N5hkFZZ7kUnlfN273nfd1Y92Ldac6AsFm40G7l1gQ5sfTRZyCSGtrZNQpSd4xW3t5j4oLKqvJQCdkAE/N7mGRRmkH2NQMfBK0LlkLUnt2s42xKqLOlaeNkrlpXlguT6RpIaSZXj/+cTb1+fWg43QMzPHrj7L1bjlNThwiOdsGOAxpz361495VzVJ417MuYYheYuBVZ/u0VlmWizJ4BKrVutdSFCjJWbPIViY2ACgL8vvP1m1Hr+22RaqfbQd2RxmxnWOKgbKtKkbrnGp4nO3jycFTwciGeGfAUxutg2urtFIUNCuZ29srJe+s72/a6chYk5r11cDfh8CeVXS1bnemFJHyRIoRqSaoa8BTq1U1pmxcRxMn9z70GWZPBRvzKnJcK7SaqWWn5I2yrZR9p+yrgk/ryn1bWbeV27Zz23dK1W5HrhZojbwGvU/7O3mZqdsL03IZXfHStBCCw3kF8n0X7HDaDaZPk+5KdmbJSHB8cLbH5DoBQxjoc1zkscfzkiOnr5+Zif1ZwijaO/4kY0SbE+oGs0A6aDTuqxgTqS9Zll0+r9EP6NnhQHcNobPTMz5lQfT52pzD9GqO/YcQkGRB8Dyz3e8K5DnteONDIsQJn7Q8MsyTlnWaTp+P1qWllzD5H4vtBD1IOzl2v+scdV9l4DnW+qKrF6nOYRGnwOmp1NcGzenJ/nvno+tw87osOxqlKqtIR9xhO3s7+w6muzHkT4kzOo/Jjm/AmfERxuc7M0mBXfWNqgoXkS2xskwKTk1ev9UFzDtg1531aGVWfdnr7Kdxgh/v8WkoN9EuZuu28fr2RrYStLytvH39wr7dWd/f8d6r1ACOEgrbuvL69kaKke3TM2WI8Z7v+sk+27NxxtjRMolANYbGuCJLKviY8CaAm9LONEXmKZKnRPCOZZ5YlplpsiYxUV+9E6RIg1JGovXBR6aTl2RoyXU9Tu+1xHK2xjGhVRqeSqUIrPb5JELzjjlgAbECT6EDjPZ8hx3sVQt9QJtP6+z3zlTuuk/H6zTebN+d8RT8Ub4p3TdrRxc8PbzQ7NzGtdr5tiajdDTWrthkJeMxmibV4WeoTpX5avZdml6zOMFVzDdhaFj9UNvvBrHn5yzHcx6xHA/xU28736xlvT5XZb7UVhnt3B04L2aBal+yEakIVa2JqL6NH8ATCjxJMGtjDYPEIT4SCIgP+BYe1u/W/FhrD42j/v5hPhynN7qBPq+Xto9h4+ljQP1/L07zKQ5SMi1eu26cKIM7RGKo+J53CapV501203I0+CiIb+SqCYeuCRyjMsFCjOr3OL3ntSqjfN/zKEMuxZKktZGLJpNE1AZMk+okNWnsNbNnZfjghJS8NafqSf1qcg6mseSjPT9HlaZyBTEwxcQUEslHoncU04CSisU9DieeFCekiT4vEZa0ELx2DcRValuHL60+kXbBCwZGHR3+3Li/pRb2suJdIfpixkF1xbRsL5PrSq6rlgtKHjHbwyx2VsrtAt5riV0n6zyI15+/Ncb/8OyGTTk+ogOmVwNw2stHcOhwSTsDOFgy4Ii//9ra32WQvo8k/7/f/k7Gk/37OyDkWCSPNsvGsOg+93CGzZDUMoKf7ik5G3iC+3CMXl51OLqaATy5wcMhGYVaFhTa8ZsCCc6fTILN9NpUQLWYxkfXrepOwUAgxwP4EKfLY4b5YD6dnR0T4EU1Zx7CkhO634PM/vcz+PRADTaDp/fsUWdLDCRxAjEmPv80My8LLy+f+cMf/8iyzPyf//1/UGrj7fWV3778xvuW+e3bnetl4vk6aendFHXSeId4qF64i+PeHKVVarHVuglzghSEqTpihCkKMXii00As+kpwnhCKBma9faWV+HTD2zUpkj863PWnqvZCFZOHCLItREV0PGxVgZ27Ux0lpoSPnnlJCMK6Zu7rzr/9+Ru3decvX5XpdBhBHT2lVrKDLWdS8OSsrIYWVTqzOcfeKnupmq0tQvSeKUQbN8bEggGMNdezqwol1dbR8zrAJjHvXI1KNyNikkSak6nFFjunWj+laHnBvDzx9OkX4vyED4mcy2CJPCDkTXrX1z6hsWny/2fz8n+PTTsXabmat1ICb/e3q43pQws4r7pZzjfzCQ7WzTRNTPPMNM+EGKlNAV4fHTEmLtcwHPqaM/vTwR7qAtg57+zbTi26+JeiTKjOOiitL8gWGFk5hC6M1tnLOztOF8rW+nGRxvr+Rt5Wpinx9vUL76/fyFl1j7oYdysmxp0LfXEqeUM78FmpXdZzvL1+ZV/vfPk37SJ1e32l1qJMCYGKlTylBWcMpuBgcoUpJf7w+YVlXvj8+Sd1bNJsLbc1+KlPz6RZWUahVR6AtpM3Jx2cLdkYTit5vbPd3yn7Rt7ubPc76/3Gt9dXvr6+8rZl3vdsTLYAxmCbXCFRuV4m5jlx+fQz0/UTP/1v/wdPP/0jzy8/MS1XoFpr5oIPzRyI77UgtGGCI6U4Sg2DthgxJwA6BR9RbQe9KKGzHY4slTEPxt5t3TwFWl0361hT3Xkx0lIc1xl+es7NqW1zp05imrwQ02s8fV9klNp1LbK+6vVMb2/DfF4bj8d1OD29zKkDtR3cTKVYYD4RQuD66RNP72/cXl/J+67jwAcFnOYL8fJEnCbSRXVyYlJhfG2PPO4SPxhhADgBkJz/8fET+lP1VHjoZqfQkGdziU0ca1F2U+1As63FUX3/k66S7noAmMKwiZVeZS8Upy3tt9JGOZOzfSjjtw1tJ2eg0mAGdvDJObD1TMSRgn6mY76tN5UxfyT5gAe2ogyd224aHERSRH2PYMEllt8C1Yt0EK0EuAtgF3GD6TT8ua5TxqFrBaoNed922tsb7t/+lRgT8zRRtpX12xekZthX5inxfH2izRekQc6V17va++tlYYkO3LOBaAw/WTWdyng2ySfSlJimiZYnWt6RkgcYF+cr6fJMmq+kKXG5bgD88vkTrmVerhO1Nv7hH37h6emZT59euD49MV+uxKQ22Vk5eM1Z2QLmt2m3T49rnla7r6ZzPVpZ8XVWtvunJeHRLny5NFYprK3xNWuJyuzh4h1PUe/97D3Ba3mdc5iml38Y76P8HfW5DOk62rcL7KWxlcZaGlsxXbGiIFRyOpZmr13yJu+I7hDNz6Wpz2jAT0cYBxhm4zh4x+ThVholC1PUjqfFSs27pIEvqn2qXdZg8tpSfrKGNV1HsvsXnQWfq3a+28qQlP0hto+l1+efoxqmx3TCqRmK2RuLz/Z8p5TdEs8OT0KaY88rWbKtFyalQbMSJyh1Vf+pelSL6Siv65GFNyBq/M+qM6LMhJZUE8dHBaTwClI5P9xz1WriAGxPm8ng9P+YbdGLPNjOCnYFP+FbQWRFqEecGJpVYeg5XOdAa8K+76x7ZrtnpMI0eWp1hFnnUogOHxzT5DuUi4uV+7aS1sS27ojAMi14D0VWQhIF76Sw75X1vvH++k5wEynAkrS747YV7vedslecQJoi8zwRomMtK2/vN15v70gV0gzPzxNP1yfVvQxQt8y67lotED3TpKyj7v9dlsiUAp+fFq6XxDR37cCd3CrlbuWTG1A9n+YXWjoSZN66tKmt0lJGaebb44zJ5ggxmI8drHpKx9t9u5N9pZYuhh4M8O6wZtYSz7ZSWuZe3mlSKKKC5b7jEU7HU4oXpnhlSc9M6UIIEZWQ6IlhGSBQt35HmeiYTCOG892fPyUxu7/XQREtxfQKRtq47/cm+EhGy1QbBaSAi6fjcLAPLSrsVWydjf+Ii0CP4/+W7W8HnvrtGJmjI1DtJyrdqJjDffhDnaEkw3EZJ9hvlj8cETfwt9+7kAfIRz/Tb02f2/Rf+leE0TXotLj0b3O6hp5R80atHDCTO26wfHf8v3LDutGxe3HOWHYn7Pfoag81mRyA1McH7cYJ9+s+3nfNyoo8IBq4DubTP/0zeyl8/faVX6dELtlYBOow3Lcyath9BwNjRLveWMDhBDxD/FsHsQJSvoh2J2ruBDypqHioxYJKI0P3YMweXp+w0ZuZt+fi+8Or1YQr1QnqLUuLHCyi5lCWk9Xz9/rmVpt2rrt3TadMNg2Y4xke4F4V1cLItbKXooBY1fatYuLFSu8W9qbOa5H2YCBsqtp90qNYEdEAaTsANeiRNkgGI8kmU6ePl6KsGPEaVI6uXqVSayE0bUfau36cBtfD+NGr/QEjtQ9bMQZgsLJeDLRTb6GNVvPdDxhsD2yeek+IiXlZFHQy8dVH+6eLfGyiHbhs7jZrIa+gTiVkA6ZqYSrKeiqlHOw6YyN0+3kGnsbLq5B1CAEfgwHOOpfWeabsK9v7KzFo9mdd77gQhw2RE7NJWtd6MptiIHaICcBKdUBaRkqmlY1q2bImjkKwNFvW1tlAdUITbQF+i4FaC/M8E6PSpL0P+B7w7btmuUpWcCwp20UdSA50VNDx3Cq1ZqoBY7VoyV3JWtK43t+53955f3vjngv3vYCPiI/4mnE1E8hEV5Bcwe1IXmg5GXjXQRt/2NYRdJ8zUI6edVensD8jP4Lpvh3TzY196V7dAXry8A97//zZY18ddHp0DNzDbsa6JeNPdPfDcexz5JltwEnrLCcDXHvCxqltPtai06MZ16czQstIvl8VdY0WeqJKmlh0503PabYgY2fPOz4EBeVHaTvjnjsDvrqz1XrW8MHx+DE28ysfMuljc7//b/fhLXEO8UHXxtaZSIeQdecduRMVVA4H6OT/cRpfWpbs0MVXK1kViOpbkyP/K8hguYBKCYzq+XEezjLR5oOZnn5nOPcz60kYLSNV0KiNNbKDuX4cC2zOiCZdVA9YxrzwNhHd2WcbXz2vlxz7qo1t20eDg7qvbLc3fKsk2REvuJaQ4il7wolQnCdvN2peaXlBykqrG1K1K620Ctb5t+v46bw0m121C5FzyqbBGJYaKLShUZli4NPTBdc+seeZVhufnp9YLhdSigdgK6c5OfaPAemJaZpJ0cqfLXjTJChDkmBOUVu2a2tk1uzYRUGatQj3outCwFH7eHK93M2N8XQMmz669PWo29TN8smO2birjQHuHPblUUdKx6zOge7j1iajTK8PcOkYV49t7J6IHPqPuWpXyJ7YCiHg6sEy1yEldj/1P8GA1X4tg6HVBvn/hzJf3T/SH4ddGKLiZ4aqcMQ541n0JLsm1nS8+OMeme91aJa5h/t3pHrNC7cyut4JEk6MZdF9BWOENMlEPyFMBBLeRbRHnrKjOk7Qy4OdDyhjnodr+ti1/LEMz5P8jAThOn0mhpnoowLO0RtjbkLEk2vVGMzQuRA8Uwo8X1Xi4fOnJ1IM7LloaadXFlSa7eCtaZLS1R6REIJniTO+CMXNuFDxLiNNyHtl3yv73khRSMGbH8aQpsFBjIGUPCl5BO2muZdMzkU73E1BPxMtEWD+tveOGL1KNMzROgFrifTVgKd5SkxJGzch0AqUXdROikNawItniYvZRCuxtjiu1mJaU/n0EDQp10kV3d9TMKVSW2bL7xS/GxFFpWOcxcIai1UalSI7pXVJlMM2YkkK7yLBJWJY9NmGCd8F7k9jQUYlWG/0wvDDxtyRvh4fA6r7VAID2zw+YetZ/44NzBHD02hSkVZovhpb05/2fqzbj+PWEJrvsAv+5u3vKLXj8Jm7c85Rw/vA0qGDT/IgsNhvJoNe5kapiH/QZjgtHGea/3cT2ma1+0h1fAwQBuLclLaILVzD6RJ1YsTKY0a7yA5I2L6agSRHve6HLK/rg4RhEA+joyJpQgdZOPSl7IEeIp7Y+90498yADOVNDXSN4fThusUWQkwLwzmnBuDTJ2JKfDLm08vLJ/7bf/vvpBT4+vUbv/76K2tu3LZVy+68JwZIQQ3BZUpMKZFixJl+BOK07r3r0+RCwxHyWZNBg1v3MPh1+PaVtsnBDgDtgtKdFc3idgesjqBraJmY09Cc3gvvPdfJkwKkqF7Nvu5sW+Zf/vSF+5b589d3SlXG0nhmp5+1NVyFLStD69v7ymVO+KAAQ4ja6Su33nlOdWCk9EHqRvvRMWDH5ctwgjtzqzt0fawdgYAzY39kGvesLZJ9hNBg3TbW9c79/s79dsXFhZbMiNmxu6ujt7v/3ZsBCcf86gEoP8621YrDEdEFJuGHw9O8ZrHUCT+o29WeD05L6Oblwueff+bTy2fmZcGHOAytt+gp0PU4tJQspckYI3UE9LV0kXH9+8fudr3MCXQodBvQgab+M1iZXQhdg0DPJe8btWQu88zXL78Rp4nXb9+4r5sFm1UBm7xTetDiD+ApJRUFT9OkQPTtFWomSMbVFck3pBRK1WAvY0LlDcua7zgR1rISvaNud5ZlwQHzPPNJXrQ2P0RqTOrI10KcZlJrCqSFSHRJncExKHXu530jbxvb/U628rp9u7Pf33l7/crXL7/y25ev/PrbV+5V2Cq4mHAhEV0j0pj8Dj7jd0cQh9tniAHXtFOrD9Fan3dg6JFpSi8HtrVvnhIxBpaUmGPUshg3ptIDQjMCPc7ryJkZdQSDZzAQDkC0thNTyfbjcCoYeXZyZRz2OJ5l4bR84XgdLNrOgumsUt2RN3H6zhjU9erQcDocKDfa/J6Bug6O9c92BltEHcXl+sT10yf2mnm7vZKmQK47z9tn1eaTyihydAew0LudadTWmdY/kvWy4AZb48z57IyKc/Q9RlNPfPS3nNPmHmHWznV1I3dx8SEuyrAhOg51LTqSY+r4drxed8xYizMWUMvj+O2Or5aL9FInR6xt6PQ458y3OpomxOC1bKMDWmPN6rplQcWsW9DVzVXzASLilAkagydYyLnngjQxTTo9Se+025jrfigqvt7XaL0L0n3t497a+6UWbrd3nZO5UPeVcvvKEoSXCfCZ0KDtO2vJEGfYN9anRL79RLlC3Txte6dtX2n5HakbPqn9CSESvHWW2jfKftemDjXjvYoC+zQRo7Ip97zjSsEDy5T4z//4B9ofnq2ZheDSBRd0LesdsWptOKdaL3nbKHkHaYTguT4/U6Xxtq24NVBy1vGn9A6WKZKi5/N1JgXPEjy5apeu9yL8aa2sufK2V9V+mgOTMZVGS3jXgUjoyeHDA7LCFjkYSdbTeoBPiIFOVSil6StXBZ+MZqd8Eo+n0ZojV9Uu3auwVWUb9XK7sab7LpJvdl4w0EiPtRVNQN73nRR1zU/eI9nE20eErmMmeU8TLUf0DvZaaQ1jOQmlak71BzNdY+36yHTyIYx5BwbecCQ8HmREpKkeTat4l+wZHWuZd4HglAHrgvoioxmQgAJPDAavnRk96TL8Y9FGScH8jilcSGFmDhdimAl+VvCpRRjAU7d5DtykHdAemFXOmrwwbLXIUWLmXeSaXljSE8v0RG2FvdxoojpL2gQhU2vmdv9qDEgFWK7zE1OcufzjzLrtBOd5u90IybOXnbXewFfibDFT6XSOjPiM88K0RJ6en8hlYrqLdggsb6rxdt9Yb5n398rTAk9zBBcP4DYXvIPLkpgXz7IEXm/vvN3eud037uvO509PPF0vXC4zc0rkXLX7uvOkGLhcZy0JnlU7NRqz/+mamJLn09NEmjylVEpt7HdhXRt5L0hzXOdnUpz5/PwLU1q4zCpzUSXTpJpmVqHUbYBK6mMXg3uMfYZO11JW6yz+bj6VdmOf0oQPmvDFdQkaIxGYLq9YHKs5DY/3ieAvpPjEMn1mmV+Yp2dlrpmch0oPHa/WvgeeOnNq2MY+rC2mHCff55gtVsfazfF3TFxcgjUH2qltw9cEPh3HOm3dh+uJzoH3yLH/R8zl39/+ZuCpT9jHMoBT3ffDBZ425w5j6izbxFldpt9k/XcH9qA7Vo+o2gl/Y3gDD+9+OHb/Yw+oTThTBgBwfEsdNj+cIcW0Ru7ivGOcO1NiT++fAo2jTv7xzN2Hr8Cx4Om/P2g7jfPv+x5e0HdX7TgBUbavVqsGDdZ9a1kWPj1/4g9/+CP7nrnfbzxdvzBNk6LVe6YrQ3hnr2AdcarQROtjnbeOOPCQtWmitfxqWLvmSUf8/Mgk+QOr41QMZs9HA4pCp8P253cqSTNHBHjIpInv+kzCbdtBVCxz2zJv981aSFsm/YjKHp+kDVulY1fWrDW+aVPALbagGk21UWsvx8IywLoDjzs69PR9uv6wDWw6MQw+gk9d56Jf65nxdtYoalYqWEzAutaiwEgfc6fvHYOMD2Ooj53HoOVH2KqVpNK0tM43DWJrU/2FamXB6ohrqVtrVQWQnQkoh0iaZmJKgw1zgIfm5NigGQGgP9kSbyC8ZeYGyGSMEsyufjTgzluHKKtBjzGMf6vm1KHz5JxmulutvPz0E845Xr99RYXUv5Fz0WM7jgUPLcFS4B/VJOlNFGoiX59w0lguF6iZ7RZwNLJ0ENPOt2k2DhfoWTnXnJX0ZfZtwznVCAhBFz/XemetomO2BqtXryABxKkdOLV2HyCsDeDeXbA2LcPL20rNyh6gmVNoxiF4C9oR7aBk5TgpJdK8qM7QpMysEMMxPUTnUZ/j5xJAtXFu6H/1l+sdjsZ2WggYxuq4LhjrTC/Rlj5H+/utg0Mnm4E5OgMsOB9SxrFOWMGwnwfwJANoOgOlTdphCeTYZV8z9TboMfoz6bkgxjM61qGPtmgAWw5CjMSUVB+iZG73G7VW3m9v4B2XTcVB4zQhGGuud99AlLLeGq3mE+D+Y2ydt/qBv3rahnNw/Ned/2QaT1ir+a5baA9z+AzjGZ+8Mx3wx3vnkdSTQeMUehh30tixU/Ci5++aLvqFXlqlu6nSZ7RpNxna1vehQb/qlnin5yROG4k0+/fZ2VY9JGvjbiCTuA5nnJJW5g8qC/bErun27cNd7nNMzOQHs08xBYRAq4E5NK5TZUmV4Hf9pmgnQC8Ol98o919ZX3e+zZn32zvfvr2y3l6p+Y5bFlLSBIPzAcpOrZmy3SjrK04yTirOF4IrkEGkascpF/CScVK0tLiqrmCpjbxmmotcmiYY5qTgeiu9sYTq+W3rjVoz06QdWud5obaGd978LTnpJvmRXOzPPjft0Jur/qxNxcT7Hexj4rwdrsgBPnWwtcjB0ustuzuL6bA95ncKD69ur1pnNtmx+rkN1pMdo3voYuM1nM5DQyAdkH3/WiLXmEPEe0dxR7WHrhm25rguwN+1o9Rn3ivk2oEXCI8x33/47cHndCfP8uTv6O8fP39e8xsihXYqO+rMkKFlc7zTwwzGQJIelsmpG3Hfj4OH4L/Y3BbV4sFRXSL4yNHyfqyig+WieGxTBrloMtM5041ypivFIc5/3rwLOPFM3iG+EZ2ug00KIo1cV6rL5JCtM9qKSGXb76Nsynt4froQgue+Zbay8bY5GoXmV5pUMhWVV4eQIERIyXO5TIQi7C0he6bcG/tWWW+ZbS3UIoioD+xdBxLBB7MDNuBrbdTSqLniGsQQxiucGnSJhxiblrd5AacaXrXqfrwItTm0C2FDxGtZd9VOd3lv1OKUSDLPBHdhCs8mCn4leGWrNRoxLDSplLqaBNCOoGCeAkbFgCh9OTFw3caa981C7gJ4emfsoSVpNquX6eGM9GFC9tp+Idq/j8ZmA8T5sHWySrdtOj6OEs5RnvrvgTw9MTU+KqefBnJhGsLWLd2fxvd5lnys9DpDMh+rs/7W7W8Gnmq14KxfyYcDOY4Ff/ytB7HuZFDcQdMSWygAxLLNzh2BOwMR17+M7OzpgQ2xMHj47wOQMFgjIK23yT6+1R9IsPRcD7zEnUTCTj59Rx+793HOAPYfIyvjDidmoO3u8UGdH97h9Dw6k/3fPaB92GyMHkinZYFFLBFccF4IogHm0/UZ90fHPM/88vMv/NM//AO//vorf/rTn3h7e+f17Y2SVX9GX4V9X9n3VVtjll27knhGBrDZZOoU/odzdtAFLDVo1wBaO464B5Ct16NWM3A9o9C1lwZbZwBwvW5Vn9kUHd43pGX2Kry9FdVWeLuz58L7bR2Otzo3xwKn2hPWVc/GSy69Hbuw7oFclQI7TyrO1vUr1Ok5SlAc0NqhifLRTAwG04kW3qy7Wf90nwkje9yv24UB6HmvpXZ7zqyratws111r0kfQIecDI+cp0gNWXCf+9FD2h9n2ToWXMkQlvVe2hnNOxRxtntZa2fZ96L45A33ilLhcr8zLosGAU5FDmoow6r78COBxh6YbMDRzQn+WPWvA8Tzsk+Nfwx46BhMgnBbxHmQ5zuKI+t3g4P7zLzQRnn77DfmXf+F2u+NT1DJRaUMIEedVGNUHlqvWn6c0ISJEL2zvV/av/8J99rT9G9vmKLcCFfaiTqBYOYWIavokZ2V3e2WXxvvbm+mQXZmSEOOkc9BK7fK2ApDKrIkMo0x7EyP7uK4JzjQdtCtTycVEfV+p2x1XM745fFOxyloLMTqIjuAbKTqmFFnmxOXpE9PLz1w/feb66YXlcmGaZzqXvtq8LKWCs1LaAfqp9kAKnhh6JzEth+zrCvQ5bMDV2fbDAJr6IvOYOTJHh0N4vhTNmIoFX62vC32fA5i2QK8fzx22SLs2mrZYZ949MJ1kOPbeOe0qNQDzdgDqtsgdDJdDr0rktPYNW4etS3q8/h1tjHAl18J9vZH3VVm688y63kjLwqVkZSxOE8DQaQBByq6U8Xz74YAnbVDRhgDyAEDc4YactzEWLJoXp3qHGcfelMV7rGsM/6jbIpEeLOv+xjjuDmj3NcZ2co5OQOcxRlFG5AB/UFFlJ8N+9Rmg7oH6jS24wR6cTCg3mdCueKHQyK6SkcF2HhpQQTPq0QD/LSi7t5eLqsi9ARFO1z5xjuqcsWtkgGfnmzrKDZp1ZYyRGBxLAFcd/rIzucw1roRQienO3jZK3UgkFrcStsz6lzu/3mba14X3+8rr2ztvK+S74J6fuSwzKc14n6j1Rr2/sr/+mfXLvxKpBFeZ6pUwL7R8ofqJ6i80N+HbjmsFX+7QMt9eb9z2zJetsTXH51/+geVy4afrhRg8X/7yJ7b1zr7dERP2dc7x9PxEmibebnecD7x++QpkSxxqJ+MpRlKIBK+Bd2nCWhq33LhnZRXVZonpPqZ6Ke4JKOzwwRhzzhqyNNVs2qsM3aaedPNgYudujOUHgfHmRkI0V2EvQvXCXp2BYwzQqTR73vasfdPzKiaYrwoPYgCiglFFhHsphD0wz6rtp8CTlv56m7fNgQua/FJCjqM0x1aF913YyiFun+KJAfYDbL2KQ6VLBPEdDKwnv/+IAc4d4UaQboyV1qxcSmQkjbVLnXXKtvigl931TRNjon7zcH5PoFZzBi4WWtuhVY1HBQhCcBPBJbxrZsw0cmhSjLVeLZC3ktfRLW/CEQh+wblAjBOjc17fDY6AsmjmeLWEVWeB6Vq8lRulbjiJ7OXG1/d/YW8bt/WN4D3Pi7Jo/vGPP1Nq49OnT6z7yq/ffmXNd76tv5FrBrfi8UzBMS+OefFcnxKff35i2wPNb9SvmfU98/6+8eUvNy1fLSBXz5SUleRQ0GqaHb5oCCatsa+F/Z7ZbwUfHE/zzGWaWKZE9AEvTjue+y7Bb2V/spNzJWeP89GkLWaEyDKrj5VzI2dhvTXu94YTBXQin5j9J67TP3KZn3hanrRhiR2hWbomZwXfhB2oVNkVjCsrrRUF91pm9e8KwofV1ljBuYb3RYEjhz0f0z92HvHmo4mBcjjtAugmgpvxbsZhmk7SoFZEOmtzDFK1f31+cPiJR6xwjOcjhjsDme70MhzAOZtTjPlRW9b5JMXGcKa5THNasP7XQK0+Vz3nE388z0e84q9vfzPw9HAqzoyInYw+C/fof4yLP3CqfkMHCHTa+/lazQabQ/Ld0Q9U8IR2y/m9I5Qe/z3O2U5kGKoP+z95cj1b8nhFDJCnX9PDWcrxycdr7Z85H/MMStjAO53Nsdezm3foEYw/9hI/FKjx7qPjbdduzpagOirTNPP09EwrRfVX0sTtduft/V3ZMwY6lZK53W6s651tu5O3jaHPZC7m0CuqXRfkyHjTAw+OAEwJEkcQ129063gSB/B03Hw5vboXc4CEzpxrB+y2aK2bZvvue1bKeXfc5aBxK/hyBPiqHeG7b4QApTUo4LdMrp7S2mOGtI8XO9WuVfW7MdAIyE7A0/h3O563XaK3E4mhl6aqrk51Og9aa6bvVEdNs4ixa07jVofmY9B7DMPzhPx9w/Mfdevzz9vPLsinjA6vqRTMaa1FNYyM+eGbaR75QEoTIZjJlNNta6foaiwKp0CN8xznAbg4b2d7cgadDsPex2M3Kg4MQHdmtzpAlVKizTPX6xM5Z5bLRcew1zKr2iq+lhNgcICkjHskWnaWJi5PLyCNy/UZ7+/c8x1xjVDFnC0rXXGa3Z56LXwVaJW8Z3zIxniSodHTzXEtlRArUitiq+9x/aav4brelbJjClgiwpmGmxhVXliiU5275sgiZGkk674UQyAmp2K8l4Xp+sL8pJ3tlNF22KNjIp46TdkbMWmpnjeNp9FhsM/nD9OoM2A/jssu2qjsRo7PmPE58vCn8dBtyGm96s0mEKwMXY7z7/bXxk5n650FxHtS5xi+nQ3TywnU5reTszOApr6GG+XpSLZ0m3YawGhpUF8zEEeIccwv57yyNErmfn/He8f99oYDFViuRTPS1kULBMkrtILsbz8c8PRX7bGZgI8uTPcNRhCPMlV6IN8ZnQNE6Y7OsVyfSE6nP3IcS4zB8TBeT4dXeabz/D0tPbYTERuX4xrUP3OiLMwmDp/0iymYELWVv1Ybbx0k6jbQud4gpNn+bcw7xrmod3H4W3ZohO4THD7HORBANJzxNqa9E+YgTNHxNDlc1XLUgAbVzcHeqjFrwFWhFlhX+PZN2O6R9/fEuu7c7iulRXILUDciymbyVBQeKwQKkYKXHSeFVqC6QosN8QWJisrV7Y6Unba+UvPGr19eeb1v/LbDJh4JE0+lMtGYgufLb79xe39jXW80afz08mJNEtLonNpBdufcAH6OssOxsj34QR9jkB5yO86B1PlD5uvan7TEzl6W/JMHh8v8RelMJzGW05HU7phDFWViVdGxWESfyVHCd/hyfcz09V3XN6twcL30Tm1o1//UGMcdr3517hFIUjvZr4nx6vs+xuiPsXXf4vw7Nnf/mo+j29lYKKO1SR0Gp7/rjUnyvTbNsYiO377THpSHl5Zumu8hoOIMEe8S3k3jhR2vd1sU16+p0mimfykgK+AIToGnSa5WupVw1uWs+z/KiPsQ5+ER54he9Tbn+ITDM6dPlJrY8ysiwlY2fC3UqGM/BM88Tbw8f2IpEyEJW9kJt6CAh1jMJG3EClrOWCm5sm+VvFdK6T6MliF7k3iIUYGjULUaJOedkht5b2xrppZG9MEYp11yRaVh+vNpVWUfSsm0VnBO70lIEIj0pkg9QVVr/w7Q3NBLWqYnlvmJKS4K7LlAZ5qpH23P2cqRhQlMfF6kEZhpUolhpbaiQH/L+BJoUqliQLsRJpS11oFNZ6CTjh5N+Kmo+eiOiILipWo8veeNEBIJTVQH3yVo/AlTkFNp+Wkd/26h73Pm+PkxphjzDAW9tDqpUKp2HGw9+WzWbzCqvpuDx+/qH8g4scdE6V/xVT5sf7vG08noCobGiliNuBoAb4uAfLgZrjulHIj2ACVc93uOya83cJiCcQIPJSgc3Y8OeOBxf65nWWy5EznObzinwzm3RY9TaVPrtLNT+O50UOlNN40L6eVf/eD2QD5cayfKa538MaCOjDTjnPQcj4V4mCWHiZOp0z/2LWJsLvu7PN4vEWOtGRvJAct8YZ5mfv78E/u+s28b27axrqt22yravarkwrfXV17fXnl9feX9/U1bmBetPW61aDcsA55ap/I3GQ5u3jdlk2ybto8vGvRWH0539xAi7QCRG4wmd9yf00To2mBdBDKjwc66KdC07kUdmNN1jy4p5oyAZlq9N20J54nGWOidF7fS2GtjzVUp5kEdMR+OMhvdf6dU/473YJdwLtHqY21MabHskPN4r1nV4LU06LpEUgyEpC3Fv+2wN7S9/b7bApCVSWDMvpGddjyIph7jizH+D9rz32Y8/qNsVbSbV0WDnCANxKuOlzuehbaYLWzbZs+oEryVuKXEcr0yzYsF2Me87e1M+/TvjtXZyToDPH18nPXxtCTPD2DAe2eChyi4dGKhdK25ETCiWlUDAHGeKU1EH/n5l1+IaeLb2zv4wG1bKa2R844gzO2ClyO4wIAIKVnPIyam5crnf/hnLk9PtO3G/f2NrfyFsGVy2TRbjAJPSxSih2tUU3OvFalwv99peNY148OkLcBtMRcgm5h0K0Wz46KdgYLdl57BFNE6dLzHb5sB2oGcG7UUqIUlwGUJbA22BmsR1lKZverVzfPMfJmYX/7A8umFpz/+J64//xPXTz8xXy5KBxezpWg5n2te9bG6/oQBbT6pLkFKkRj1/ouV+T7ykA5Hu7d/fhDxxlibnDJYfR2xZ+xMlN37TtWuw5Z05q+erzfGpgH7XsdLp3h3wEltdR0/W60PNqqX8jk5s5wO50PP6dRNBej6rR1warWXdKot13IdWyckE4t2wknTzHJ9YpoXG69v1Jr58ttf2Lc7l8uFfX3H0ZimhbItKrLvwNFw+R1qhu0bnDvB/DCbAiqPytd8F0cNW48zFrCnOU/BszfYW2PPmVzq4SMM9EgGatBsLRrAzcMx5Tysj+XC9fXPWeOLU+BtAXU/XAdxu+s1lh5bp3PVoCE6BYmfUmBKx/x4L6rjs/eyX4/qXvkGrqKlOY0qB4jdAyARTEj4ANhKnxPeGAsOiy91/A/9TQFPxbdKoPIpNS6z46erhxZoOanO0e4prbLlShEtqarNQ7uzb994/RYwwqxpE1Wuy5Xr5QnJ35jdOxN3EhuBneZ2Fr/Two6UO62stPXOngPEJyQsuNnhImzvXyn3d96+/Jnt9sb/619/5be3G7/WyEZgq8Lnzz/h8ieW6Plv/+2/8fXLF17fX2nS+K//5T/z9PTEH3/5Iz7EweD0VlY3bOPwrfXGDL0bYNQ+9uCIvub5o3TEnUCB/tO+0kHFItrtba+qz1XFDfxASzf1UMoKPECmaiyoDuzkquuAYgUG/ICC6jwCTyM53Bd6GNeGc/gAyniBdc8oMNVMv8y6vFZjIrvOVhaLm5QFVSqUquNiN3mKHwhvGtvhA7nT/O++prKFnVeQBaBXo+gi1EYFQG27lklJ1x3s8znSJOIlDgBF3z4lAGEkYjpIpGuc6gJCU7BbHE6igQeCZyG4K8E9Ef0z0V0IfjYb63AEqlMxfi271HNc8xu57gOAckx4F7nMP5PCwpI+E/2ECzNOTgl2uyePiSZHCgvBJUiOOWzQHHu98U0auW683r8BENyN4BPX+YUpLbx8eqa2wn3/zH1b+fOXX9lz5v12xztPqQZA1Myed1ZrvPT+trPdC2UDvDMWaiDFpN3rloDLCrjd15332zv3t8L7mzY+gKqd6qJTFriJiKdkQJuDfF/JNXO/3dm2TUW3Q2S+QJqgtKjNmmoheCgFchEjLHiW5RPLdOXz8x95Wj5xvbyQ4jQqpM4gMM4R/UXvs83yAbbFYlhAplHYyjdK27jlXylt555fwTXT+3Q4ou03PKDEPZ6q3iPNIc3jCdActRbu2w0RTwwzKcxIeiaGaKw4r1UMZl8PMLBjB+bjD81NPWLHPjrWNCq1RuzR/25dGMsOVchlZd3fyWWltg0hI66MRh+/Jy3UjwmGazh3sAd5PN7fsv0d4uIKqHznhJzAgH7zH4La/jejDdaOZNZOW+w10fYAzRNQCngHoo4gT52VEwhx0AQ42Rk+/PNw592HN7qArB2nv//dddp3Xb/SEfidfocRACCdmivD6eqBpeu14qf7Q8+SyOnIH4EpCzibsQzkhJaOezHu/XGhZ/4X0rMNx75dCEyTtrVOKTHN89C66a/lcuHp+ZmXT5+43e/sJkRZaxlBSweepGl3FW1/rkLK6+2dnHfeXr+yb9sAono2qNPamwWxHXgaWbbzw5POoFKv4pxl0vVKDHwRa4t7lD05Z4u8M8ZLNefYmBCTlSxpTbeVKkrT0qzuoDvromQOwwFCSB9S9K476vAePzsgFcB0f0QnPNbi084jmEaFOmsNT2OZtDNESAF8YG3Qij7hJk2765Q8wL6HUXCOFdzj6Dg8v852+PuMyP/dt1GjLA3BjzJL7fzoUCdSyCWP8T6YIXDK+lqJXWdKnUredFMHszORxoj0neFhDsV5UYSTvTnAcBGgHf2gBovNwPBuf9zp2WkXsmBjVa87hMg0TczzzLLMrHnHVRUYxwBhRIjh0DA4U2adVKgNH2fiXLk8/4Tziae1EKedwk3nus3lJWl77GTgSGmOSgDraikWmmrwEQ7mkzA6N0kI5hCe9AS0LRAhxnHvesdA3a/H+URIM5FAdJHYhKlBrEIqjZi0c8p8uZKuC+npM/HpM3F5JkwX8MECYmWE9EzRMPXmMA+9Q7v1x7x+XLD7s/sI+H78F66zCOxYPcg9TPZY575b4B+cjGNdHMeGsW53HYMOPJ0P4twJ6OzGwoR/xMbnGag+/B8ZYFNfih+Bqx4A6JzotkgM/O2rXRfKTzGRYgKn5YD7vhNCYL2/4x1s84KUHV93DYJ9w0nD53dc23H7K79PM/2Puw23T/66aZbTB9WtOhziKo7SIDvt0FpbNYDncGqPvXz821/Z5Pyj+4bHm319cR/mxMdrGnv54Jc50XkVvQozz9Ezx3Aqg2MAC62d/EQ1y4hvIxFwzF1jlnT72k/k5A/1vzlPr6o9QDEbvIc/W5C60UqglECrqrG458JtU8HZvTVt696g+katxh6gWnc0O58meJ+Z4kbe3thvv7G+LdwuCfZ3XL6B7MSI6Sx5mu9pLo3mknfW8KVRa2a937m9v/N+e+f9ducuE7tL7Plgshfx3NeV9/ud19udJo37lklTtRL0Mzhpt8cAp7Nv7uyhHeyW8zgazroBUEfiZeTnT/f/vL/zd3tcofpIQq6W+HVQ6sFw0vVBhj+vc0DXItfjC/tbJ7fVYeO+H/19aMoY43bddo1yPAW8P+m/iDG1pCelhNK0cUkf85q0P47y/SryH3sTY7Q22sMc6zFILwt/ICP0z3DIqzQTyO9stiNha1o6tpYM0kC3Pn3+yoe9y2GjuuvlCcMn8eJJ/kr0FxMVn3Auceg2gbikGWtRposu2wEV6xcVBW9Zy/dstMQw05oQw8wcnvA+qmC58/jqDn/o1ADHo3+PIQJiJXmOJb3g3d3KEKsmTj2EsBJDIk6BEAMXf8H7wJ4z275Dc0zTMkTztStnYdt29i1TspZh+6DdhWPyTFMkJX3F5CkVpFX2vXB737jfKrdbISYhJKxznqeXU/ckfSestCbK2CzQqkOCGl0fPCEGS+hjfnM1yRgG2DhPC8t8ZU4L07SMpjvOMIWP8gKdXd8BziPBG20wTsqocxDaRnMK6mlCotDIOqJsqXKIsn56o5kOeHkxMLs37gFo1LqRS2Dd32mx4l1AJA15F3zkADQdvdLnYVky3VDvZCQBD2zk/DI7LMf3OvbQaKYTZqV2VGU+tYxI5XBWv7dCf80uHfHV3x43/p2ldo8o8vlkeqDbGTU9c6U0/a5fowLIImJsg+7sumPlbwfrpQcYWsYQhrMkJyTznCE+SpX0xB4Q7/PFuMf9u34hA8A6Vp+x7J2NZusZ635P5OEzmh0+ApTesnG0PT91b+go9+9AehzsL2Mw9Vri2vWwLHALSe+FO2hyYzkcg6GXclh5g+07eG1nOaWJ4MMpUOhBg07Qbd/J+862bez7zrptbPuuC4KcBGkNWFT2SGPfN0rJvH75lfX2zp//9X9we3vl9dsX8raNMbVXcw5KPTqMAFPq5WWW7TSdkGL6IKP1vD2rbkydLSyT6d740LsC6HjMpVqZSbX7oIDPMk8qKmji3E0wIEsBtJ7FOLqRdWfoAAmC3VcV33SkoK+Aty46HKxfL9ZBBeY5WQtj7RzY9S1oKiY6WfbApYi4yN7aGKC1NvZtZ73fKaVQW8Vh3TfM0em1uR24ldPYgGPxH4HvD7J15iI4mnW39AhSZLzfLMjt2jcMsAMTm474qPXntWp2M4SjpvvwGLsD6cc+nA9j7DA+ZjbMns3Qv+nrZQfibYFsUg+2qNiiRw8ABnyAd8UWedVISmliWYTn52dEhPfbO2UXyrZSnCeGQE2TikTGRO5dZpqGNzEokzVOV0KcePmHymW9IWFiW1fi/MU04DYcjTloYU8UDVyaF6p4dmZCnFBKsdbyhxBwwRZFUVZNzUXtUG1gOlHeOaIPiA+qkZUaIpMyEdcNfEQI+DgzLc9cYuMSdR2pIqxFuxf5mHAhcn1+Ybk+sfzyj8wvPzO9/JH49Bl8oNYy2GXOd0HMAM6rXoecu8Bp8/bONDuXWOjD02f0fzmd3Klm3j53AJQ94LE1Qvrvp0Ngzr2eyTG+eoCso36sN8pwsrFkA0fXki4Q3Gy8tbGGamLEvPPByuoJDHOBOmPOmADS2mne9bXxPKY5WHwIISbSNDMvF5bLFZynVWG935FaeP3yK2W7k2jM00SbJ6L3zK7gpRLrG65lQrmhEto/0GZrxSiN++gpnH89AwEoSLGLYxPhVgtbVgZzreVkss5JFf05Su36ejH8AmD4GT3I43FQnmbBOXv/cfDqmBgOy0PZqHeanJmD4xI9z3NimTy3omLOyjCAUlTEOhibxkVwURDXaK4LUjM0gHpn4X780E/XrtM7LW0fhRLePDZzSHRqNlot1LJRtleyeFbn2Uvlfd1ZS+H1bm28u2BrEwPSuh6mMl5KEQPX9CTmKNze/szrrzC5G6F+I6HsqlBX5knIIeDixFb12VpqjSmo/yBSyXnjW+/y+dtv/Pa+8haeKFE7YG05s5u+3re3N3779o1fv32jifDHf1wJ08xeG5PzoyS2N6PoTLYe9PQOcOqOtO+G5zmE6j5nNGFyHTqdiYSyJ70B8dIBpJ6U1eFRmo6B2+4GsLQ30SDRgrGh/es0PigNtipjaA6ZBWSUevbheQbyHUJHsBwMjbLgusbpcbkOXad8CFSnNrSWnlKSwbCvhs57Z+PWiyZAT9PhR9l6rGSD44GRAt13BvdBF1bf08Yvo+FLEXq1nRgI5V3Ei4o4I0IrZsOaMXGDxlzSUYOxdz2Aa6LLRXN4URAo+JnoJqb4RAoXkn8i+MVK5ExLE4cLmpwObjZ/aVMRcN9o4qm8sbeVLb9qV7r9C8FNPE1vpHDhOv1C9DNTvOJ9RGjaccwna0wT6To9iCfJRHARxDE1Lbvb6julZbZ85339DdgprTFPM8vTRIqJp/RCLZU5zGz7xhy+KZDlA5gPtd7uvH27cXtd2e4KsqSUSFNgvkSenmYul5llmViWyJ4h58ztfeW3X9+43Sq3W+X6HHiaAhXVyxvxTfDaCbxUZVpZaV7JjrIHYgraGXJOzMtkGsAOFQZvlAK1quTFlAJPlxeels88XV+4Lk/adc4rU40e+57GkzfNUOcOvKED5zYYEBpTfaJKJtZncr3TSOS2cd+/IlJpUtTTctop2zdRe2bMPQw0al7TC94J4jJ7eVMtpVqZ0xWplSktOIEUZ0KwjnKnZCuGIfTGQUHsLF2D1rGEboP9uNaOL/TzOWthtlbY6529vlNkRyjktuJqIIViMj1++BtCrzY6MJcB7g7AqZ/r7/gmf2X7OxhPR8D0gKpxNrx6FufDO3k8mf6bO//B8QC8OB5P/1gMzJEe6LiJlPWAeYSX7nQQNzRdxjmeL+N0Nh8ZCMO5ejihI1v8HbvLFshHcK57VOON0zn8NQzxfJLQ2WKtKpul7Jst1BrU+mS1rRYgdWPlMFHYDtidl0jXF011iqp06n2ftu5hJdSOWiqoFlMipomllPG+CuH1bKCVcUijWJe1L1Pk/v5KW9+YXMPlG7urY7G/56oCkM1wWbvt3tg/KaSRIREDt3pnnjbuq6LqwTtmYw8l69bVqVX9eDWaeIO6ngTrRBWj3kO858gmCkRPrZWcNRNf6NRcBclox7PvtbspOKbgmZNnSUo9nYL2unMDSHSDxj7PE2mamOaZFKNl1UCKQ1oxpQ4ZjlUMntSss09r5JJNMNg6jNlgc+PuuPG3h/Fn93Wg5IdN+yG21gE60exEs/veadu9m1cxcFEZTebQexP0NvFt34X7eaTyPmwjy2IBfa816QwP4eF7Q0sHxn3vAPoBdHTnXw47IkeQ6d0hLK6OnDpgCtwH5nkm550pRnLwChoL7OudWorN7zQYRX08aAvjHgwIIc2A4/rpJ+K8UfFW6rmCNKIz/R0x8eIJmniiqM1IaRrHwB0OgXcHcHMAabZ+2KTtQUu/W90B9D4Q4sS0XHGtcJkc10ntfqMRizBVgRBxPjJdnojzgp8uECaKgMuZKuByGfY8WDlgiJa5GnZe/9NZcP1nn189EH+EoQ4gaATsMlY0i/s7K8PAHBsvA4gaiZFjzenrQI+Aelarf/BYs2XY9+GwcCp1kX6OOoBGa197rzkNOb3Z0rOmS7/Kj6Xd5/HcnZLRKtt11lqj+oNpF5MGz717TjP27L5vBAfbXUvqQt2p3oEvBKlIu+GlIO1+PKcfZOssQf338Vd4tDvHZcvpBc05mjgrOT/G4dlT03HSbROdtHkcsx+ug5lmsHogfmyncdHH34ODePw+woOHZanPbayBiSZbFBDqzNEOJB26P9rB/DQ/LdnXr7D7Cd18WnO90Wy33w/p6EI/0ZPv2F1ZJZ5qImHLO00UqtpL423NbLly34w1ayU+ziZjlf4s7JxQ8Xfnda6XWnm/v/PrV08VYds3JickD4tXYL8rsa3Vk8Wbkoijio6T3IStNlZ7ZYTqFNQJ/vAN++V1Q9EBH7Exh427Mf6682T3uK9/nb304LOfn/vpVtamguPeKRCk7CcdT70D7Eim9PXLm5SBUwCnGvC0FgscnaOMcSkEr8CpVUoiKLaQu7yFe3is5yE5ntNf89H7eHX9nOzbfZ3uQWC1PdRu0znPuWOIBg+hdffUnWb6j7ENzdJeqtSfr/lEzmxKsxilndcQE/nW+eNHcqRJ78brBptjZFFOtgXz7Ub8KB1CV+aLlrmZwXOO4FSwOrjZBMUnLZfCHXGHN93WHoADzpkP0Kpq3zmLIQCc0ChUMtJuVHZ8juS6WlgxU2sm+AkcqgE1dV/iQyKrzxMfCBKJYUEQYz4l1Uuiqs6kE7a8KZulNqRqTAae67LgvWdaZkKMo8HT0TEEjV9iZLlMvLxceHl54ulpYZoCTRr7Xnh/27i979xvlVKa6uxGj0+iCYBeqmzlY6Vmct4H47JVR3CJKUWmKTHNyqgKBjr1e6yJcL2fISQckRQnpjSTYjI/Tb/TZ8+4b/Jh/nbb133NMb/178GrIPziIfiZfa6Eog2pSt2p5V3BsKaJG2VdB6I3sXGvi2f3x50XECv9xlHlTm7CXj2iwjDUNtFkJ/hACHGsUf08uxTGAMBNhsUm2EiQdl9PmpUhd5CNbnuV3dRfXd+ptUJ1hV6GCI+2cQQWZ1v4nZHqIN7fZr3+LuAJDvTrOCejOJpD08vLRvmYOcTfnfPYz0evpO/38bjnNa9rsuizOHRR9H33XdeVnu09L5T9bemekRw1km20Vz8YP+cH0eQAWE5Q13B0hr7V8Pz1GA+Zb2fYpnOHg/94B+hmsrWG1ELJG7VsbLdvwwvyIRKnBR+S/vQJnxYDouIordCPm8H2nb7pDCQq4/724MR7pT268ag0KJjmmbOGVIxR61I5mF8Pz7MpaPbnf3vh/dsXpnrn6+y5yJ31xtAc+bYWtiLsDXBdhV8ZGzGoZo13DgbTqMEQge4aM445KuDz01W/tyQd4spWeBxtajiOhV67jZgQq5VSaWAM0TlKKaybI5fKXkyMWiNFRvWkUyZMSp4leq5T4GkOPC+RJXkuycSsO0usVnyI+OCZL6pxkqaZmNIIJPMa9dnvG7WWsVBMUVtk36pQamHbVtb1Ti1Km1Rk3h6giAFZZ2HgY245TLHs3wND/wNupdVx3YcWDmNuV+vmVUe3MNPWMjA3TQqYxBjxo2RTnfjuDQxzfV7QulPeM2TdgZHDFjUbOGdA4Gxbaila+tfB9RH96LWNDnfhzHiUAbZ5H0hReL5e8cBv80zZNta8k3Oh5V3tRCk2vxcd81aCrK2yHcRIcJ44PxOnRpgvlJK5PH+m1EJeb+ooVtXHwtiAU/E0gVKVtZhCYponWxu80aN1oQ5dYJHuINhm98MbCNiDnhgiHv3Z6dbL0zPXJfF01cw/0silkavQXKChbAFiwi/PSFrYSyPf74CKgTqLRud5ViYOCkIN++F0kY0xkFIgxUgMHbA7Bd5q4MfapCWcVo4BRwLDnmfXvTlq+dv4HoAzWzQ69th87iBNz0Q1OqMVVD/gbNtPzLoRS3aWwgnUrxpY9+XROYdrDQnhENg82YqPyZfz1o/R2iFs3Z9hKRkw4WHnmeeZy+WKDxFwlNpACvfbjZYzk4ecIjIFondUnwk0ZlZlhVB4DIH/428drDjAp7Nf8WEbwVAvNRLr1OYo9RAyPvwasyfuxDrhKGui/3Q2fgywMVfrxMw/LSaYzsRw72Sc2vGrjIXHwWhz3v2pFLXMbgqeKXii+UutKuOlmOZPqyDVbOPhrGiA6NW+iuu6Zp2hzFgP+0lJcOYLusMn7GiJoMGPoAkLrPtphtfbSgiOt92z58brvVBqY8uV4MFkTQhOFAAMumcV6PcHiBFUd3Ivmb98/cL99pXrX/7MdZlZYmSOgZ+fFz5d1SaFGFklkYkkhIDjKo4Jz70Kb7nxWirfSmUTKM7hY8CnSOjlyWI2yKNNh4PDi9Okm52fmAz7ucSpj5HhT58ZT6P78Mlnt3+XponFt9Ioot+L3jFHlXF2nZ1uz3qUWgaHkov1Oe6tQXG4TRMCoYOHeuqkYe8OoKF0HaURvuiJnUKB8Z6CQu4Ym31d7YCtgWHB98YKyjjPtTB5hyNQvac5Z8c9mOl9P8FDFIhedcWsOt5AvB/Hfg0wDtNE7UHyWLN0jdNSH7tXZhekabMcFfIP4JVBDdZxGO0epqV2Tl90EekeE3bNG1A/69C+cxLwLhB81J8u4V0aXeywEj5dmxvqbYs2OaGzUzoj2tGCNjpxPuFaHH5hpVDZBti0lxVPZA2vRD9zSb+QwgJAShdi1KqLHncNsNL1sadr49w+Ed0CF8de73jnKLKztTcE4W17xYkniAl3t0gInpfnT8QYmJdpNEiKRu3UEmdHip7r08Tnz0/88z//wsunF3755ZOt44X7beMvf3rny68rr992tR8J/NQIF4+fwSX1S/FegY6cud1X1m2jbp5WPDEsTDFyuUamp8C8JFIKygI0f6Sii4nDMcUZwsxleWJZnpgmjZc6oN63g1EHB4nkxN6hz+8DeAJIUQHAOXymtozzF/Z8RySw5XfWbdNEWN60t51XpunkFq1uCMGAP/X/XOjSQipUTstIWRFWgp/Y8qJll+lC8GkAX45ACBMhTMQQCaTT/HmcYx176KBa65pl/XfDZUrJ7GWl1I1cd4pkhEZ2G4h2AnSuA31HXHi+n/3f51C/l/q5v8Nu/d3A00cRvAegyU70cDiO7UEf4/TZgdY5zagbmAwcht92cLrIhz0/7G/41I4xsM6L5FhcfifAHgvmeHUArX/ifPP19/HQzz9Pnzs7cP2v8uFaHuvi3elB9gWvD95MK1mFJWuhlh3vPWVLKgI8XwlxhvaseidxGXdFF8jOypGhpXUEIx+AMbsRvTtdvy51PI4PKkgnJ8P+eK+k60nYcw9Ou7Ol6Kmxl/YJqahjGEOgirbBFRhsoCHmLY7WHDl7EC1n61cWnGcyLYhliqSg/8apsOcBE2om1QPR2JlNtMvJWrDMoWVYgrc6XFQwzvcWz04bYLRDs+C87+i1nXOKgSkG5hiYo3bnwSa3Nq9UCqoPqj8T7OXDMTVbLAhi3ZzaCBp7KCKtau+bXJTxVM8aHn0u+CHA3h/Rw+O2wPI8Pn+UbQDE7YPR7PXm9SidOobvMTeD1Y+fvFac07HZnYuDTXJsY0SI5YxPdmQE9PZ7t3V9DImBhdIFv/s87SKZnIHvww47CwZH8sqACu1aqZ0rp6S15U60tM35Rsk7ACGqjoBHr1datXGqO/PdMQ+R6Dzz9ZlUKzEmBTBUdIyeu702pxnqvY5gt4M0R4mXMy03Pxz/AR5IZ98Y+OIO6rFznYmpgLj3uvhfn2aeni7UqmzLkAshVxWaFcDK9hyYNh242g4rZyys/sxDjThnZWaOUVYXYyTGNJzpvvU1spMOO1OtL+c9AD8YpnqdD8CTjY/zkDrYUZ2RB8deT/89LVnCiR0yAM3H9W1oEYoBT7205nQezh5MP2/nj4xzj75klDIcQeojqHaUipovqeCW81oS4R0hmP2zNbCfXykF72DdVlqN+BaIHsRXAo3qMt5Kkr5zPv6DbwcTBI6HgHWWO/sx5j90u2+/N/Eq1FwPYXx9ppaACp39e6wZ57HXTnuXcRQbez3yfjgLO48Hz5Vh82QgVzaG/MFc6Tt3HhVxdppUKlXLbkszHUm7Bu12edjT1oG1vjr6DrTqpOhqB+oT2t/RMa2yuB2kcsf8NBTtDD605ixQ1qBaE30Mu2aXbP6AJq7wBwPHOc1KD7svmsjarP/LluF9X0m3whI9Swzct52X+0RMqt1SXaKReHoOXBZHyS/UtLDmqsBTFl4L3MWRzZ8Jfb7q3T/9PCQdugB4B56aHDp3jz7e4UsfYM7hex8f6uNIyE1Bsb05mnNMwfGEZ/KqC9jFvh9fMsYEro8JZXaFfg7YvXVdG4YBevU5IzIu/Vg/Rjzw4dXHBz1404uqH0TTu+1WRkQjouOhmK7XXo0Rf7oWEYacxHk79vx9bPIfdRtaiU7XLWDEZef1EPNnqtknnXMKcrSqicODvWI2oxmIRH+NBQpcM2aiHRBn8gU2XwkENKAPPum/XdLSPZeM6XQSqj6PyLHA6oBqVk5b2mavd0p7o8pKY7ckgNc1U7rfLojbrcvYHe+EKhuhBUQqIt4YVnr+w6Y6DjH2HidKJDAxx2cSOxFHpZLbRi2V+7qqXdwdMQae68I8T8zLbGVinnlKLMvEvifmRZlH8xS5XGZenp95ul64LBPrtnFfN+73jffbxrYVWoU0OdLsmebIZJIhISQwTdVKgVbZ8p1t36g50nJgnhMhBqZ5YpmjNXfSCo/S6lEyi+ru+jjhWJjizBRVl3gAie4c3fSJbpUprg+8wz6fP2aLBLom2bGc53n5TI4zTTL3MLFu33Di2Nu7MYgrlWD9TGyBsfVGfbkCxnB1TgGhIg1qo7SNzEr0ib3MBB8JXoXoPRMpXpjShSYzSaz6R6xkcDRX6xNN19UjOd2XeT3H1iql7cra6hrAw/9rNubasLWIO9n2x3vWkw8Pi3u/hX/j9ncBTwJDu6kj1u0c4I7TcKdf3HCqzzonHXns7A3vbWFv3fPome9DqK8v590/OZ9PP1ZnEfXFgx7UiB+LvLMs/ijfM8PXRSo76t4DhmMh6AurG+cBlnE+j2WbAHprjgx2/153uHoXqaGD1cQCm8CxDB0aSrVs1HynbG+UfWW7fwVUbCzGiXJ5Jk5P8PQHfLrA/ILzUTWg0IxSL9vRuXFibllw4iwA7AOy1WZ6QT0o84cj7LvQMuPetq5VY99oRpdVaqUGDzE4phRgjn14sBYQKlNqNNP3aGg5WWcQ9S5GIo1WIsEL665Uc3EKBFzmyJIiny6JFAJT1PEzutqZYzIFj/cwBdN8qo2tCHIvFFEarvNes4SY1pI0SlG0qVQ3nHMP+HaMgRgMbEqByxS5zoGnOVqpnaNVE52sSoGPUVvW91eIEyGmMdm73kwtqhvRF0KH4EWoVYUz9127Emq3wd7il2GU+1zrhqkOALSP3M5kO8b6j7DVM6A2TJMCTjpPHxmHo4MausinaSKkOII/dXIVeNDPyWBzyMkWqiMkh82k23Q3nCt3til93XSPnA0tlXkM3Lsd7Y6vAgWnjI492864mqcJJ8J1WSj7pmNBhJw3BIhJgaMYA0jERT2PDsfkWuhtpEMITMtCdI40XxCRwVzp400zR2pLaimst3dKzqy3m16U1yjsAHa7mL6NR+EoqTZBVgl2TUEz9h7VqJqniafrE9NlYb5cuL584vr5E/u265y4r+zrqtpnpRxlN0DL2s1EVwLtsBd8NDun8yEE01qIlmON2lZ4nmfmeRp6WkNguYM7Tl3G1ks6T8AQnMqe7L0OgCrwJEbpP9YxR/+8o5ehjDEw9tt9KLNMNla6fe9Azpm12yxaHyXdrQt6HkmiPkZbsxJH563cJKj+4kdtl74onI5xdLRlgFql6L2PYVZ23jQxTbOVjfcSvWZ6ggoy7SFQkyd62EIjOCE5ZTo56UUuP86mpZycDbWOJWPfjDKovp3cLwEKJi5eCsW62XUH2zkxkO8Ac86oUxPwfYye4rpzFnmc1+nrPSjrJ3T29bHvK3Bs/pl3Q08JIAQ1Ec0pW3kvOh73XMldaBgDnrwfJbmtqlhtE0vqeLPtXu1JCDpP/WiB7kwLTkv4itPEUxXThBKbh6eYU+zGKONZuxf5mPDiCEHP04tYRlwTVVM8nktD91vHvTMmTzEAquqa3tqOtMYSHUt0fL5GPi2RKTlidFoaHSL/9MeGf6nk6ydyWvi2ZX69F/6yCb9tcLOSvMW6J42BgTtawvtDJ0RLyoOBTgo81eaGTpG3JgHnUvIzaHPCZU5/U3b41hp/vhdicLwWYYmOXwg8Bc81mo7JYKmcbBVNg0gvClibz9bPI4YTiGQOoYgChLVXDJ8Ee4MzBq3n8fwtnu/J6n4hrZnH1byBUAo6YutyrpW9BpKJhu0GOt2KgkzndL0ClodIPhzztScxf5Sttc6alQfwaZSTfwhoB7u7xymStVutaKK5A0Fdz8dLwLeAF01YUxum7qj7dL1ML9BZSt6FwWxKfiL6meRnA53UtzAV0BNYKXQ9Q93xEU9WKQiVXN/Y6421/MZWXsntjSp3cHLS2cE6ajaEjUahSICWqfUn64qWEa/dI5VF6Me9GmX13S/A41oiiON5+gXxhRavlLbxtv3Gvax8e//CvmnXuSklfn554eX5ic8vnwhemU+5FF5eLjQpPL3PpBgUdPr0xB9/+ZnLZeHT84VcNt5vb7y+vfP1txu3206tsATP9TlyfZq4XidSmIlhRpx296xtpcrGbbtxW++0fUZKYlouxDlwuS48Pc9a/iWVumuVj7eElDZ9mgjxieCeuCxX5nkhhmSseWMfDrT5WJO6L3IGUQ63psdYByvR40hBO+Q9x8+Ulpmmhff7F+7rN5wE3upv2lxCKl4CLenzkND1kbocTOE4ktfucc2R5a4l4lWGL+t9VLadn4l+Zpk+c2mfmeoTLTVCS0SfFBTzh5/aLFnYPcwDFFK/sxRtArbnlb3crcyunfzBMsYwY15a3AiDHHQGtM7j8TEh8bfFjX878DQO2p/koxjc8D0egryT49lBHEONRGQAH/q9YzHjZPQf0Mnu9djFeVBa8Blq6+BS/8K4Sef3j78fnpQ5xB0x/HD/utN9fmOcW7/2h3t0fMY9BJLHZ84B7xlVlA6ynX7vrKdOdWwtU/MKrVDbTvWBtr8T00Jdb/h0IS0/4acL6fKCDxNhupjhMsCLU3vGHvjy4X47RinH+POIcBj3DeTx787b24eAbD+0lswo0t7vTQgeZaxWHPUU8HSBYVFngV6iIoMW2rr4moFUMWhwGIOyjgB8OxhJ3o24d4wLvf8GCDrLiljw2a/t4fXwt8O+HZm0gy7+HWLM+b4pIOhMlFLL7lTIuj8LbyKGLgRcDeNZqcC1srGKcw8B4yGA3KehsQmlMxx4EPF/HLffs3f+I2/9uno5pOM8T0+LFOd/2qecV02zE7PleO5nG3hmNNmBbNff2wV7rg5M8v/4+5iD+n0XvAFPjdbsGauEqtoCs10KWtexAHearZzZBF67wqlGWyLkjCvFHL2qAvomOqxsgWOBFh+QU3rYmeB/NIH1mJI6dtYIIqVp2PpaCs45ct4P0EHaEBo9R8rSZDSJENPkGsCFBX6+zx3nmOZZ/+YDaZmZloXl+YnlciUEvc4YIikmStcWsPmrHYcauaiAZTsPB7tnCrAYcOvD6C4Tgh9sTPr5ec2qnq3lmOPuCHzOy0//zBHM27WfxuJ5PT8vW66vxacxq+P7+PIZXOolpY+dgtoAAoQufKx/ryYwP0apdOas2mMnp+eHgQnjuP1Cbe4Nm8TD1sGuzoYLIRBTPOaaBeVacidsOxRfoAWCgxo08RK6/t1ACX6c7QC8TxH9B7P1cM2nNV1wVmKKOsqts9p0nKm5kbEuHgeFDtDYozE9TaxDlxtd4+h//+7M+/py8r/GjGCsTSapqGNroM56vNKE3cHWmgJoYqUX7ljHDzaSvqQqWCSj+w8nIX39eejzKDOrVneaZ8fNdaDxbmdKdX/S9/vb/agKNB2L/hCeVqk9TQyd74BqPB3rclEXj1oVbK1jGDvVJmrwvjeEQsxaopViJUXP8/WNOU5s6zvTpCXQpQlFnGrw2atxZudq1z3fuiff2YuHD67MssJW9JVrI7cu1cCjU40BauOZC95rYizIwdoDZx3lVGjbG0CTnFCa+nfFq1B4bsoOKAbQOO/G/e2+VS/X07LGgxEymG9nV9Wea/+M9x34PPw2N66/X5YZPEssHP774aer7pB12nNOBf2rsBXhtjf23nHP7gt2Lk302ktjnNdIcv4g22jEZLp+vsuYfOd72j2pPenSY4Ce/A84Zz5tO9ao7ucCozuefscm0Nmf66x/543hFA1sigN08i6Mce26J3QG0Dl8qwECSaNJobSV3G7GeHpH2BEqKhKumkGOYFpSnmggV2TGu4TzDSg0KTQJZlNOMXGnS9o667zDt+GsIM0jEoCEFyGxUANclwvBZfb9jnPCbb3hvPDldeFymQmTJwTHp+cnRBr39dO4boewbzspRpW3walcwpSYr4nSCnsJLE+RyyVxWWYu88UAkok4RL3NNwrqg3oChEBaAtPiSVMgpUjO1pSmP9ug1+Z91H1iXQBtXp7Lfw8/6xhXj5VNB07R/z606U73dtj04acH5rhQpyee55/w4rhPv2ncXVaVmnEV56CK1yQeamOLlGFHlPF0iJt3X3eMJ/F4drzbiX4Hp3FhZyTFMFPDZCV5yrYPEsY9OM06+6/ODS2v28lVOyBWqSMZqnPUBMtF50tnBupp6xxQEP+j//ZoD88//73tb+9q9xA8yXi4Dw9QTPPmDLxgzqx1A3O/E8gj0FwbnXGGg+U4hWWHU94nvfcHg0PMm1fntzsOei7fJRDkMHz9bp2ZHo8/T1QzC/SOxakDaepBPQJJPHZw+Dg4RMW+cJ3hxDAsPSvsXAc5OohQaa0gNdPKRt3faHmlrN90AfSGmoYLYboSL78wP/3M0x/+C+nyiThf7HyC7escZcnD8xS7L93AncdBE+ufZNpKIIiJiXvXr9m8ytZAuii2aG18cKQYkNR1USDGSmx1PFP682gNvGaogtPAQsW51c3xDmVvWBA8ncrbUvTMxkqprYdWxhRyR3eW7ld0FpfHE639O97T27w/dLQ6sQekR46u5yCOzNX5d7213aypk61NaQIuRs2axkRISTuA2XMIYot2TLhazHnRe5mCZYcNiOiaQK0dukA6Zg/gtNaDUnkYlzEVPhix//hbB4geL6vbqePaj2ySMxYiOO+tjnwybQzTEGg6Fx9gox4T9ujMHfbtWCAPezIA3Qf75EbwrvvySJAhpF9KgQoVLRFrtQ5GV7+Gvm/nnIrUm+iic544TUzzwjTNlFzYts3GtwJONe/QGsHOVbqtjVbSYouh854QopW4WVmq96o/EgLTvGjwWBulZOI0kfcd74OKkW9rx3ZOsfQh0tpqGwKKKkxZcQae+BCIyl1muV6ZLxfksxCniTTPxHkmLTO1VFqt7OvKvm3knFWA0+x7zoVSK7d1xe07ufR7abnRvh6ZQGYICg5PUyKGQAyBYA5Eo9HEbJfpY/XA5GCz2SJOn2ePr56BqjZeh3bTWAE51q4eaDtww+aexjGHre5jRK9djIV6iNaPtc/GaW1637TzWRcOPgJKJ6pX42iEh3nlxvMcHe3svVqPrBwP41vsXNQux6Td7Xx4BHlzKVTnBms2W+n11BMInHTbfrDtHAz/ezHpscrZSuc84oJ12TU2nbGQxYBFHbJaBq+Opx3Xw2CfYH6cHABUE4adHADPg291DuZlADGIAik4PcZIBJkorj5N9S221nSsFe0It4ko8GQaIKGqBe4lNVKF5mwuOSuHN39KHKqFh6CV7MqAaGJddA0NOg1nZUo1+yk95NPzVoaWAta9oUf0Al5Z3WCsluoGu/hw0PvkhQfSPgdg0kW7cQpIla3xvms5qXeNS1Sdx2taSDSen34ixsSWNwWJxJEJZALaOFvBp3N3Sye9PNGSCScAai86/+/bzm3fuZdKrU0Zqj3Y77bNrrWI6DN0QgjHuAjOgE3HYJOJlTevxRHQzsZdPqGIPvutCtl0XrwDH5x2kEKLq6JX9lcKjim54a/WJpQK52RxHwOM5OchXO5sIjwycI6H4vpPM97qk/eup24IngcbVbfcWPfG11W7qu5VI5Pg1PfUsSNsRf0H78xP9HqvfpRt6OW2au7WedwcovQjASIHUcHZMxcRgo8mISHDP6hWdtsrVcwhQqQiHEwTjacNYPSe4AzEMAHx4CYtr3NatiWj5XQHnTrgBN03OJeZN1S/Z29vbOUrW/3K1l6psiGuEdwTzicm/0LwM1OYCS7YOMbssHY3xBVENp2TLVmpWU8mevOpdDJ572mhd71ztGLMqKo6vJMr+BSpnyrrtLKXzJ4L396/sZUNH+Dl5Znr00IMnj/+4TPLorIC275xu2mH2NvtnRi107B3yp6/XGaeXhYIjRZ2nj9NvLxMfHq68nJ5xrmIdtVWO90waZQQSZPg0gQSWZ4iy3NkuUTmOdLqTi1i9qkgQf2v5FVQ3MuEJ4EcZfitNWPAPWISY5zx0Uc5QPBeaaVu3ynxJ2r0HVpJs8zPeBf4+fmfmOPCvr2S8427a3jvaE6FwkdzBpOOKU0rAcRiy6HPqX+l02mVze7M7uuYrKJWO5c7e7xrh0VjksUwkdpEDMmuinFNh0yCxuT3/Y1cNtZdGXm17oNxiNh64Hq1hpg26XGePbnd2YjnssaOA30Pfv1fb38z8NSOFXMY6B4gddyrgxVnOOOhDrFvBii5D2+ccLYRsH30tA6k+fQ3O5dB9zdnpwNII5j7DoDqQcD3iOHxXRj+8+m83bELBV9GcNsppY/nB70s8XCOz/ewX5ucj22BSC+DaLXSaqbmnVY2pOxIyfoSDU6dC/iQiaUiLuHjRM0bIS1q/K1uWZ+hCRyJdLf9ABg/lB9996D0Ak5Co4ponx/ZQHZhdAFxpo/kjTHgnGbAfDiU+s8GRXErsXM3UFGMdt2PYo65tyApeEeMWobTW97LCcRz/dkfmNtQt2j2PJtYMNMd5ZEVluFEj/H6sX1Pf8890r/7uHXGjDDZGGM66Us1npSp0SeOQ6zkKyFSVEenNUJQ0x48BAt6u15GNwxHoCpjUoxSS8wgnj2sPgZ+vPjt2PoY77PPnX+ejYSBNUnFo/vnzELp4tQBpA5YmVN97IExB4RjYTxnWEc6XT0kC6AZvxtGaJ0Q22CvlFIUTDhn/Vx3ho/FwXtlH+I9aZqZ5qIC9jkPkLfkjNRGCQEJRUtFnCd4rXlp0qzLmjrvnZWX5oVgTCpv7DDvPSHpglhrwwUrWYsRkUbes96/1hArGewTps+BzjKLaTL9pdLvuj1CA/HC0VlugBYxKEhogU9LnTHoCSUOEK8KgzUk48ka4BQOZuFAfOz5afeR8EHbqbPOHL3Vl+/AXZ+Hckq4wNBy+sikdMcIG2uPIFp3xHlqqh057M+x1gzb0ceQzevOdhmlmx2MsN8VlDrZAPf7psAJxnixz9pYM7dcSxykAwl2Xv40zq0MsN+9rvEVQhgNK5zX7OHp8k4giO6qiq0fdtd+RLM12tlzdqB/b3vUfOrrgDhFTzTmts6QXmy9NCax07IwGLGh7vG0Pnrhe+BJoCuO1b5mciQL7UzGWjj+6pw9w15WZSDBOLjOhWq1SNGbOLfTaSDdV3BtrN1O9PO+tVFSGII5zQaa0TSgbdXWZ2RowfQSqn7vEEZzqu6G93HmQwfjNVtcBBX1P2lJ9fsjCLV8P3d7Ymq4puZ7SLN5ZaWHtdmztDlXuz8r+t7bWplvmc/rznLJBB9Y5onn61Xndq1sHCyvXqbfJ/g8z1wvl5FYSVZavO4btQlfbu+83d55zxkphSkkemGHlgjqvX7fdu45k1uhStUxZ2Mr2PhK3rFET3Cq85m845ocsyVHOsstm31u9jBc9xlFAS2HSvDG6JhisJ9+3F8Rwbt26EIhY70dCabTXejrbQegug9+nm/9b/1ZDD+P7uB5ZRiL+dd9zaCPL8GHU+Lh2DXRdyH1Hwt48t4YGV2Yu8dA3UKcgScYMdnwV8/+EB3saac7q387tJlUVuTMZteSIWXKhP45lwj9d8YgGT+OJKEdt8ednOdxX5t6cxRl+aTwBDhaUG3WKM94JubwQnBa2qcgl8YSrak/pCBzU10oEZrM0MRAlTAIAD54EJN6cJ24IFQxgXYD3ytq04IEkk88Xy/kUkx/Nir47rQbdrBmUh7PZV5IIZJCZErK1mq1sG13kMZlufD58yf+6Z9+4e0tMS3CNDnmSUFjJSGoptPhPwjeRebJk9JCCBPeJz59euJ6XUgpoAn1BsYedYglJDhi5aYxXC2Z7HbqnNVfa+HEoB/uz2k7rSvSH7SCPcfmhu9Mjz+ljkXQO88yPYM0Xq6/sJUJ8RtNFHjs3eH6vjqAqrbgNMZOpyNdEN8xxlgvrawts5cbveN2iTslqBh59BOlaVe/rvfUk829EqJZ57pcbuxlY693cl2HlFC/USPB2sf2yd8dpzt81O/v7e9Vev1729/OePoARHwUVO1nPA5u3Okzujicd/XKP0zmbkR68NYGgNMXiwH4jIC8xysacLeqDkbP0vYM3bmk6nyDPpZPdQfpzKACRWv7AtMXptPeBoPkLIjaga8DBODDsToj6nfu9QDvehmCqeKXnZp3yn6n7HdaXml5Q0z/ouy7nqX3xHnT8w4TZb/j00KtBe1zaRopwVnw0wX99HpGaUtrw/D2Z6eaLP50D06u7v+Hu39tjiRJsgWxo/ZwjwAys6p77uVQVnYp3P//m1b2Gy/lzvRUV2YCEe5mpsoP+jBzZPVODUUowk6vQgIIRPjDHvo4qnrUOqW4gw2bK1o6WuSkHVxyzuBi9yFKOGxVcXDSNo3OWvRydATUJEYdShJrwgmKnSyvlowtZ0XqgZmhxAAWPhIhV35i3AsqsIenlPu17HqJZoSWrScz+UYNQ2SCU85hYVau2ifmMJIBd6lMZzvXqlkbdQvjiBIh9YzRbgAJxvkAd9aoaiKUol1tvLsMpTk/2rHKomqmuIKI2hzBi7hQD+CncuD+rwSi7Xqduw8lpbD526zL4EWOiIKhXnLmfDfMYorTBLgbTiGz/Fr6erIoiAMCLud4zRhxxwQIWdBbQ+sN7WzBLeX7zpWncxQpqJsstfmOG4D9/qJZRJQgLOjHgUGkpRGlILGWPVHdkCRBiqb8snHCpFJQtl1L2krRrpNZO7y5lyniXcx0XQ/rnHc+D4AZvZ9oz8ech5Qi4887O+77DX0MgFJE6QFdwzlne++Gfd9RakGtW8jYRLDMHAXfqmxgFi2t69p9qg2e3qXrmKzAExlgJ7aGXM7kklFLjf3mxswwha5KHEDOoQeAhbvJPI/1d8HUC2Rlys6f6DJ1kn3P9UpwmYJYnLNrK9m686jekvXiNf4rp9MYZrSMH/eM/NGPEqVE69oGXbSCzkWanVCd/d7BfJ+flJS3ptaqAKQBnv5obvLrWKtMn0bXNOB+tmPEHMmU1tMH+hGNchvF03JSjiy8RISSs5ZNmC7LhChV0o+rt7BmrAnUiRGZZUMs3iXPmoHYPcV6D99RLCAEK4cx2yjWpb5flyqvniYaBCOJ2gxEkGz6Ohvw4TnXTv5sJORH68icUMxsbbb2hmVgZAtAZXtWZrLnWuxUIwNGQpS0OE9iztaJLqmEaNYNRYyHKGUrpeg6RmN4cI9iajKRgii2nwWiXELG7QKoPPdSPLbsMFgHr9aBQsDLWwfowC/vB273AyVnfH55wV+/fEYtmimSiaBU3G6bWKSdCC+3G4QF960BUH2XKOH98cCzNfzb77/j+9t3PJ8HkjBe92JOra7Nx6mcIb8/nlaWd6KxAU8Jyn1FhJqUx+m/v1TUrB2Ik8kKuzN0ATCAbnM2YHohAzkLMgRFPMgI1JKx70Uznko2h0ut9iGaJUtpxDom4w4jK58UOABqb7H1GsBQ7C2z7wTW52+xDVWRQ5tWWJDGJKD1BASLdVg0MNHluKl37EU7IN4K8A/cgn/Kw2kieCgI4wHkaBYCXIAn12NkfoN3X/TJISOS9kP5cTJK0qBsph0EtWl8LgnZQCfjzzHwJyclwCbksLMAxFpxQ+3ip4ZJ5oHHFPea04aa7riVX1Hyi3sr2NJnFNoVeEraMU8zLbVjn+ABkY7O7xAZGPwOQUXmHUgbhHfL8FSBnc1OE7Pha910bKCZUr0ZhQDEgoQZe9mQP3/G4IHn/dRxyUrPcLYDOWVU3pAp49P9E2A8WRrkbODRNPOp7vj86RNSSthuBb9/veH17zCahqYNP/rA6B29s40UNHhbC/Z9Q9kK9tsN277hfr9j3zZj12QAAyIdRAOUWPd9mSC9mN19HkqYfru9mF+pnJAJKebKfXnAMx99b8nio8ucayAayrBoAEObn+g6SJTxevuCWipETjzO3zHoibO/49vxpuuBOdYohYaZa9Z13gy+IdYVgtpF76XxiXEOJHogUcVW7qgGPOW0YR831LIFEboSrXtpHhuReMezvaGPA0fXzCeW2QCIoOsjW8Of4I2UGcx2nGICUouiX7CQ/58ATylnOBo97Z1VTevhqWTXjk+Ap6+tWQITusAEleQq6/1N1ywhmEDANJBCUa9jQWbcTkBLlnN9BJ50IbrQ8/r9y9hiOTM8BLXWAPuhz3zNpFoBqPX4+B5vZU4OiAgD0sHtiXE+0I839OMd/XhCRsdg0vtO6vSllJHLhrrdUfc7yn5Hrjs0w+lDVlKAe5qKOnHDhPWxBT/et4+RD5LHnC/RHLMy/aP660R2vZwHZOVNbpzZnDlXkiJQarmSaFkAG3EnxfU1iyonzXjQDWXAk5OnWoq0c0f5tAlm6uZgxildHaHMSBAUMBIYOVkUIemzexTYfa5wCMgNTIpsLy8nYBiNsbX7XUGnUmpwPTmA5KViqVTk0cAGdiQkZCbrMGVzltK8BTjSLv6QsUqD88KdtRAqtt7/vAz5//vjH+27OMTduWC7iE1PlJDLzJzTNxpZNLNiADRBCaTpBP14H3b2da3Ad6RYdgibM+bkf/qePhR0Gd1SkA2ocjPWr+hRj9m2mEJxEgilbBiVse03tNZQakVrDeM8ICI4AaSWAoAiImhobJYsR8tsl5AyMwB9kBx48NLVbPpDW4EP5JIhnNHdkatF1//mBPs1vtxTGKODWg8hv2Z3TX60bDpEAOkQ4ni/2HiOMdBax3GeOJ4HzvNEaz14CLkry28jgHOJqG2pG3J4hAZkm5PomYNuHLnuu6y7VUY6IuX7zhVNrEX/sJV2ipWrxRqkAN4TsmF9torlWuL3Mctu6rzJrbR+xT3OlRtrdy6C2CmLgrQSCaZ4Jg/irEGNdd2sWV+ARnHrpuBTsTJRwPlbCMWep3pnwTzLg4h8J/xchwfQPlha//D9/hfN6rPGB+xBrIEZSLGOa9auXsvDljUcRqieMdnPgslPlAgYnonnaoY8YzhUoWW8ILrVsi1/N7NnYoreg2cfqZxVp51IZuqREDy7ykEBEVjrbcY5gATlhSLAnt/5dATEYm6BDat3bqNllMPhRXBC1jIzttftoECoPpiCu8YyYOfwMQw3J4ywuUdVbAjEBoeH7hQvBVPuKLJzJXMNBY/GuJ0DR+to/cRWXlFqBY8veLndUAC8v7wYEEj465dP+PLpBZ9e7sgp4dcvv2DfdoymDsnLruT+b+cTx3nicWqp3WBGNtmlwRa9/c5aCn10/XItWiwTQ8tY3J52mxwxzyyCBuDoEwwVKNF7l0V+gWI9JXj3YHPEL/6DlfWK2myFXLfOkr+opnJ7dXGqrltt2kTOHgECcrJ7hV7H5XZXDgWcQ79KItysrJPt+kq0rtf0czrwVPPPBTxt+81KyYxnkNy20XHzwEJ0alUhvtjs0y4XXOlAZnZKgWCDCGPLDczGIWSHZkQX5FTNaVfHPacCJR2fvDt6YgBeRrkAAWtUw31uMQBBgYFPSKkiZy2Tct1YcEOmipLuSAtHEYvaRJpBOnQ3y4CAwdzQxwMiAylpiZmghq4DASlraadnkqec4ZlaEAKMv20M1vWfgIyC133TPVTEus8VQIDjPDWTvjWknFBrjkZQRKSgfW9Q/l7Bbb+BP70C1HA83/F8voGH4DyfGIMVeLLgR8oEEfXNtrpj33ds+6a0BTWDe9fS2wGAE5JUOBcXYSYP8FDB2toJZuA43iHQUrsCIJV0WSO+v5PV+V4TYWyywx6f80zJX1wcV2iZWU4Ftb6AwXjd/4KcKs7x1Ayl8TD7z/JSzS4TA5lEfH1PJ0v8mgvYIKEHGaABIeDsSs+Tx4mcKlgOdN6MlHx293Mbqw3Nwjr6u3I8tQOdz7D7yJRQpoySivnONLtw2veodrPxitH7ADp59cSfOf408FTMgf/YAWoFGHTczJEoinR7XSCbASSsG2Dt3OB10nAgY5rs6hivoBOtoAzCeHe2oYuSsoF1AMP5p1ZA6MeMJwmDPXK451Cbapqeo77VVaIJTBsjNkK9q1O/gFrLPawbwlNtibxV54CMhnG+ox/f0d5/Rz8faI93PQcnaCqmAg+5ZJT9hu3+ql+3z0YsnhaXcNl6iyCPcgwDgiBr9heWT9sJbBN5Ny2P4uv/EmWCnqY3P2tZGJSse9X1vJQISTyLiSzFckRyQskEgWY3DSNnzEQoKaMkyyAqOhYAjIuCIUPRNeGp3aejqJHbPhhHP7X+Nycl8swaJa2qK1CSGhLE7nRLWCcKOOECNvlzpAxraexrmFC2irJv6nRvCkClUqJ7FyAa6dgqmDeMfoB5IJNGsnMalmDobUV9xdJUQnBL1wCEBTB1+1csKjD3zs9xfMzMDCPTgWiIYci2upNH29SwqcWVswBGOijCCoRQUcfJDVoQkFZDxtNTp+Of0kwFdwAA8DpvAz8GWyaTOiSaoaNGweTwUoPX5SFodolz4Mk501y2lLqDQdjvr+iDUbcd7TzRHu8YvYHPM0qcSimRxg3cDL+ZstmvfxnbxRlUB0E5qmD3wENLP0qpEMs2omwE7tuu2X7bHgBUqZuBYJqlRHQqMCeayUUpg3JGKiXKVHV/6/2NlXxTVCa31nGeJ57PJ97f33Gcyv/k8rwDSDbGnr7NPLDvO7gUhMFgoNMw4M2DKdPk0X+czF/lnYsJI3QEoowqdJrzzLjjzwYijLE4SbamkpatJPPWCGpwUrIMk8XYumTe8gI++X+eXWT/TmdPbzpkP82/I857HRMHqtbIWVx70SeDla9P11JC3TTLbd8q9q0iie6vrWYLBGh3oJqLydVs69JGnuYT/CyHZ6rFQYRr+CjgjFhfgGbtgpW0uQ/lcRMexpMo4bxvhYIvEJjy8aNtFP6XAWEiyqNzsdHdaXRHHaobHXhKsLIja/bhbp338Y3AlMtmUpDKK3I9mdf1GxxMtb3T3UkdGhTKbH83UdWdINXSttw9TckskGzBL7crTa0XTRjFfZ+BJBag2d7VLrcGFrEa75rlYiBacGURXKXHnMH3qb/ue17vW3UGwJnACTZzWo5Gwng/GFvpeFoXz0+fv2C/veB1v6Ez4/Ntx+P51PJDAP/611/w+vKC3TKbhIHzbAG4C0izQds3PJ4Hvj+eeHseIB6oSceIMkVgrA3G2RmPNnCOoc9LSTlsSDmayOddLo+tpXpD5+1sEn9KiZALYZABSwASsYE9CsbVlJTjKanNrJ0NWfWKtjdEhhhps9g8O5hgpcDLPF8CUzYPydYXkWcHKkzhXfESGMQjzt+EIAw8DHiqWffVbuYDQ9fNOfTZC9QXuhvwtJerb/TPftxud+PgSRhj4ARAo6H3U+WIkYi7mxX0Hwzr7JZCTyH8JLd3ErK4nNlBWcde0kBxbh3RUrWci2U4WYZI2hAgDqZ95v4a2b3QAoR9PNyGU0Lygnv9FZpp1zAbN5ARSmtmlupQlXqhe6VoljE6WBrGeAejoXVgpA053fSCdAubVEBaRgzScisRlJxBwhjmV8gwUHdY9mEh1FrxevuspcJVMzNLSThbw/PQzr/ncWLfK/b6gloLtq1aVzQtvW1DkEvG6/2ObSO8vhZ8/fp3/P3vDe9vTxzHA31o99GUCigV9Um5ouSK23bD/XbHft9RNw3qHqNbcICAkZGxgYiDe8sDA8wDMjr4+QAlDZz20VHKBhBQSl1sEgf/xewE74Zoi235Tk5AF69Oez10IRTEzLLhtn1R3jFuKOWG1p84+jvOpqV3QlrLnZIAkpEUsjdGHlq+EHoTgqCrCZkEBqOBqKOPBsID3nW0jV0znrwbIyyN02z03hsGD7TxxJCO3pVYPKXpx6tuydqIJxUNFgwKyhkPnFwO3yfrPphG6R/KgY/Hn+9qR0tEF1NIO+AAR7scTOElK0CcxJIuiwLu6BFiw0++CXdh+GI4h0ELmx263p/eGzCJwiwdm6eS+aFEUE8QmUZ+al9sehnd5LoObUII4TDAx8QlqN+HI4Excuv79eReVnh53cAyTd8bgHRAGsDK78TtwGjWwjzVcEKcK0PnYID7wOgNVDTVNQxIWbg91pUlOqbhXwZwthxuYC5cIGwDwuwE7OaoyHyPj4WXxbEBT2kZI90EjK3qeN22jOKRIAII05EhW39CHknTZ/ea1ZRmxlMSAUtCEgOeIrlb10oWoBTCbWOkoZFEXZZsw+XggEXXKLYuMEcW7pBF6Z/xTGnXPk3Rj/1Cyr+Rs3IIlcV5zqXGmtDnEJRcIaVh5AwZGZAEMMU9BiHfGJP8elzTknWK9Z49Ku2T6msdc6X/JMfce3q4sRlSZMolIuXYKhn7/QW3l1ct+yrq6MZaEFKZYmVKaw309NOu8s6dMx5eQjWdf17Ow6wgwxizk9sYawcXBzqgneYWcCGnuf7X38XKt1LOyFxQtx311rDf7hi943j/rm3IhxrsvR0QGThPjSSWYwMza0CBGWetkDHwtHUro1vmkYKfpVrJHXnWnj43i3KyeGZntrK2YqTkoITBgufRUIaX66jcj+yYRWK5s8aDMdJAoh6KsPemJYnnidaUWLP3jsf7u4JO37/h/f0N59kM1HJgUPkCFPwtyGVDMp4ql/+rtaD7xoImNMvDYXrIb1aWdfdDmfeib0Lv2KVcpvLFa1v35wT1CaYHfN2ZLvEb8sCCdr+00roL2fiiw12ouXw23es6eAUi5jis+0DCqQjd5prbo26mwz2lPaWCWiv2bcdt31GsnHHfNuSs3BSJtLMgJec18IXwcx7ODxNT80deEKB/8JQdmSv0aj/pOtB1roGRnK3kyStOxZeuZzSb7UO+NskyfefNaGnCBODFbsWbeGTSsrBBrrfNkU/X74On4c12D2RrUIz+QwgBJNkdx9gININgsJfOX417a44IYfKKT113sWfFHBwzhWTerzZGsfd5mShPval7Vb/G8MwnskyouNPFfqLovCduk4mXw/p9AtpkxhzgHKaU7kvAgJ+Oo504zhN3Q37rtqMg4VdkvL52uwnCX758tv2kNkYfhFo7RjtVtreO4NSzdaf8WDqXx2CUwXh0Rk06942hBMKUUY2vs4sCnt1k8mPo7Pz9ZAOM9NnPoV38zq4T6nxjmxjKmKFZM6xAWwYji5bnka2LiPGyNlMgEWQME308wUqy4HIsnUXWxYJabHXbKzl0gwNfVrJoC1JGw2hJwUEGjgG0Abzu2gBh00og7dTHhN8PBdweQwMX741QhmDwzxf0U7tA7YHCGzgy4ZQ+hFmDSmI+iW+RRIRykV3p+h3uIxKgcCBy2szfLKES3BfwzCflV5rBxT+65zkDqjvTou/cOhbz9ShsMKvI4IKoqCBcZLI7jZq9leISSRJKfgFLA2RoGR4GmE+08R0sDXns1mgomwVAC0CSFv/axp3U3xGeoA1JBteMTBl72jQQXgEg4SgHhggGTpyd8f4U7KLvERHkXBR4aidYimPzKGnHVm+4317Q2gA9n7DRVV42CwxSyRCiCFrAS4rJZN4AMCoSFyRoZm6hhEzOQTQPMWHb2gkQcJ4PQJSEvkgBuf+kE2ofWko6yefMJ0nfELab22rmJEXwxdZTydr86b7/ipQqxmg42zsSVQxpaPxEWKouTgTa/W4tvbusP1k4pebXJXsLFqgUoI8GzaXqBqZ76Z7e7zD7zoHQFWQHGMtpYabrLIk3He70M7FQfewvdy1/8Cz/18efBp50/4SlGWAJkmdYaIaMd+9gM0CHlYzABAXSEin1c5tgEUu9dGXngiVRCkeenPhLHBiYdyhh5E/DV1guBKcT6ZvfZ6mdgQGL8Q1ZsnH8OcVLHjy7JS+CaC5QN8hdGNgKDodAuTSWMf4APFHO1g2iQ6SD+ATGAW4PjPZEbweIlOeEkvKurAAW9w7uSkaeSoen1xElOEHxet2pbKfBOqOd62Lz6DjFQtZHZQwfSyNZJOEJUGEqIs/OSiktzqUCNSUrEk8E3Pes2UZGOCcWqfRygWSLgMXWiZ3TCYBzLhDoOtSbtFREjzqaBVuKrrb7DuSh/ADupEF4WSMu1CnWXtgs7t8RLCqaAnTSe1HgiRJpOQopIFDqLCsq9pVLjXMnbcGDUiuEN3Rz9J1sWFPNxbh/uka2Rwf3DueLAchSuJ0HhcLIXqYVMFX+85g+ftCECF1GuHIxuyADyo+2bajbhpfPv+D++hnbfkOtW8y5l2yp8w7wyAA4MlhkkTGJEsi6VuqQr869g06CwdaN0ACm7sCTXcvX2JrllIiUzBQzw6kUA1w94ykruMvmnGkZLlBvN+zMuL28gnng7feCgRN9aNT7PAl5KCcT81BOp9F1f46OIyWMckZJ3mgHlDdOQZu63+Bd7lSjZX22Yc9Pvj8UbK3bpnwQIC3dOA7k1tG6luVttQYAE56eGXueWRtAi41taw2tHTgPLac7DgWg3r9/x/vjge9ff8f72xu6dYKMTDED7/O2I+WCbbshFwtZu1HiII6IuXNXcMWdYMRe8vu2bqaunxyckcm9dnlEcb49MSNoCcCEvliCGzTXAlGyUkPY+6ZBoka/cUwE8DTCOKEQZiaDXEYnWp4TsYZdH7qcdx4pPzzi6PfLvGT6kZaSAsqftW07brcd99sNe9Wsu/vtpt0SLUsj5wJvjT1xuAnA/UzHkFlq4tJlWhl6xHrBnGedyum4abaHvoeA6OpVTNf639xjknnmH4x+X9/eYZVFE6/ZM4CtJH6CNkBNGpMdomVUTJZJZN8TAQ1YSleX7WYlcqzLxPiuoDYGQppboxcrN42+BRROny055WcEApBIUBOHGLgY6KxgQzaD3Ph8jQTc7DsBxDJdmAk8HHgCuM9JIb8bniPrAXDCBKCHdWObgIrZc1n5kpxji2yWzj5wNsLzOPB4PvGZGUDCtt2RSsXL62cQgGKdIPdakFMOnQCq6H2gHU/w6MD7e3Sjg9vQLJZZLnh2RkqM9zY0S050jYo58lsxsBSMRowHqU57Z0YTAMcwm0Xf14aWnrUx9VrNCa+i62IT5e6CMBIzsjAKaWOVJIB0dlMoSkoJggoJ/jLPVpra+Y/WtuuUORe+PrJVaTh1hwpEwYDZAE0zcYdkdEl4dqANzWT6XAm/7vos7w04hmYKEghvTdAFGIfasmeZJe0/xWF+Xi4FSVQHMDNKzmDuOA/CGD2aATDPssUpt5xCgsOvSFFyKuZnkPE4mTTIEjLPzwFyoGby1Lo/KJd1MYPKIpMv0/0/l7MeDPDMqMiQCn/TzmyZTV79E76Q2W6i7TbN2e8QaSA+0cY7RBrORkhpR6kvkCxIaTPwySlrJoDmdohzjpJogHrwQOsdGAW8ZVDaccufkYogV+O92xKIBV1OjH6i84EhSvydjC+3n5otnoeCRrVow5rb9oLxolmXKX+3gJAgVwsqbtqMBpQCeIqMNxoYnbUBw9hAIyEnz5JllIzI6CEiK01kkAhae0Jk4PnYwZZJrwBUBiWNEnhZrZD5c2Ev+1xP2+yj47MScate0+qimm+aQZcy9vKCkgrO9o5abmjjwKN9B0tH5xMsDX2cqqOYDbSeAOG0pJw+wzsVpnlTNOWUd6xrXazz8FoOirCtPIBJzmsVn1dMJPmCMbvCO30S1J/WRgkCGXKRlG5f/JGc+rPg058nF1+d1Di3M/HDvDeZzmwYJjNL4EdA5wr8+PnXSZkZVXa+BQQILx8AVsLo1QojxEbXj/gQLhYYlgFzA8GN2mVRks3+Fbxantneldxwiw4nxj9hEWW21OO0nt+MqXmlNSLuNw9f/TEemhHVoCmpZi6wIDVG6wlNMuj2C3YRlPsXpFy11At/tEhMkJOXeNiCJ9KOVrGDZ2Q+DDQbEy+ZtAtYRo7Ntz23Oy9aRzsBSFnGPVvUvhYFnpKFObVd74DXfs+xn1Fc8g4N7kSKlbmIgMi6bCw8JAm6EbYK1L3i7IJS1ek9noc6haNPg1vmCqLlPzcFM2kJYCkZtajA1vbrauQPa10sUODJ+ahmVEa/1vWtoFwB56JgWinKw8pATmycA54Z0sHjxPH4HenMSLmCUkYuN1VGFn1aHQtg7pMfpO8/+TFLiGyekkcvNSqSjMx4v91R64bXT1+w7Tu+fPkVv/76K24vr9j2HU7Onmhxy1gweoc7/cAE1hMlDLI9avtIFofc5SJHxhMb8DS03t3Jnw3VdDlA5vBRArIAbA4lwR0kN7icl0oztFThEjL0WUGEl89fACK8/f6byhweljGnmUlar6/ZkjkX8GAFQF3Jj46cC/p+Q8pJeZCMa0Czq4xsMRfjqpFwGlksOg2gnw1CA3yc6EOj7okSSinYt4qX+306iSkjl4w1auTk1TqGCr7289Cv44l2HDifCkId72843t9xvr/hfL5jGPCUk5ZzeUc7SrNLCNZsIJNlWmEhk8/Q5aDQ7PimE2DrcJWbS7aTv8f/Hs7zcg6y+wKWlrwy9YB9cuorB3ckOtf1oeWaGnSwUk4ZBjxNwleIc/yt+mECtf4sAMCh/9fXPz4bZqAqxsP1nuh4sUCSxFwq+HTTrKeccb/fdS3sNwNWvcvkdBz8uj/bMcsiEXaVGtKXocfqQofuEC21GzLPMaPkMGcH+r5pAn28A7OJFjuVXJ66SeJBLfzw5Xfm7/XsIge7nLsokYJSSuY9AV2/h9Wsc5PIT+z5DzDgwPfgDw5FOBE0n4liRUYJnsfZcnKKOX1hGNg0ZC2BXK++jKHN2xqzc2cUomI5AJ7lg2HmJ6ddcNlvBNVQOZrsRvsQnJ1xDODZgUcHcgdqUrspW/m15IJCCScnkOiziAieXTAGMJAglCGpAEl5UyiluL6//+3oGAzspaHmgZq1jGQ4T1aUBuu9DQOthpXUyalrJdk4dXZuTZPlAKqVr9Wsq28wK89mEhSoU1qTlt45T5cTfxdywEk54aoDh7YAI7Am6/r0tUOXCfHf3LZKsOCTBQ1PStrAwsijhky7mKDX3jO0lM5KTWsibFlwmsvSRflbCMoRleai/6c/1oCzfk/ajTnfNAOHCKN3yxQc6L2FbryQiMd/M6gCB+RF14hyvLp4kvAtPlaTrGpIosHFYrvB/ZJJVC3Le6br6AEgvWYKeec6aWZv6bmtxDNdHXlPiMh5h0gFqIO5gbp1JuOuWYXtO5g7St6RkiClGsEyDbpnSOJF8BoohQwyKhpmQTsbEmUcT9bmC1WfrpaMUSv222Yd1AfOfuL74zu2uuG230HQ7GPPHAQYPNRW2uoNL/dPOHtDHx1tDOSyI5eblThWUFbyfe3K3FANAExI1gChQkvT2EbdMjV92M2ONqNIM93RjWx8oJYNXLsFNdWPCjsm5PC0tYIi5YPPw9b2dFbRrCX9EvdcsnUoTAlt+4RcdrRxYD+/ovOJs73h7E+8j79Ds4/UFl/1nxDBaX1kVT6X71dNqPqFgxd21W8ODIXd6dQHV9EWCpkMvIyFDJXNxcrOiQxktcL06QNPu/a/evxp4CkIpkJLT0GtKOScTIhGO/TtOsKzLGve7GWTWvoY4OVYKbJGYkIwla46b+4YzEGGv8sNNX8lDOIpBBFryFE+NgEyHUzxLeuPbztg3jqFIynigs7THvUzuagAZbsPRSzJav0n8OZZXKA0jfEFlFuNRRtmHbfetCPVyOpUtIGUT6RnwzkA1FcwMm5f/rsRsG02N2mOybTIFlNewkgN446tjwz7M7ug1xvLNm+xMG1j6bxNB9wzk/zKSzwQnvmUUsJWsxLLil57LDXhXqakc2hOqGc8ZQefNKJASUv6fC14aruv0WqcBalkHE1QSsPzaPjdBGRrVjpqXA3TKVNHE/G4ZKmYCjptpaCWYuCTIcqiGWdMCQzPElES45T9ewZRNpBOHbyeK7g0lFJBrMZfYkEpmvoeSpI7Rj/Q2lONn9uLpdUnABWlambccMvd9kp0u/sBkPznPkIwuvHo2XZGrFjvL6jbhk9ffsG+3/HLX/4Ft/2OX379Cz69vuDl0yfs+x7gJYcDJmYs+ZUcULXIl0Ua1gopzyzxvewt7R2YH6xd61gkgCfxco7lcCJpMWDV96wTrnrWywiCcv2eUgEycL+/INeKT19+QcoZ33/7BIhgnIeqetaMq+N4giihtRMpZYym6096RykV3E7kXHDuu3a3u92RSwELNJtpaH19qjDDhyMb1ssiIIJ2nugseLaB53ni+9u7KeaEl/sNv3z5jGxd82rdcLvdtBOH/2eyTOfjnKDTeaA9H2jPJ47HA8fzicf3Nzwf7zjev+N8PDTzhxmSC3JOWgpg2VopJ8s6dU/RSJqNKHWm9VtElghiOosNJAxFYE6lZ0pcStT8JzMa1G/19yLW7XScXC8snwkjXEwmcYB9g7XF/DCuMB49SOq95C4CA6QRr+x2CMxgl+VeTY8h1rE+wWW/XTYhR8tgLO9XESRx/WQA223fcd5f8HK/oZSCl5dXlFJwu71qt0VrlOFOpFj2sExX/qc5WGYjgevIrmvHDwpQxc3pMVjlipsxZrNFpyBeoEsheN7merEAkqAaOzqoRqdXnYkJQk3uJ3I7Aoj1lZaur56R4iAUeOG5iWAXFqPapR0wrWiJ88eTx/vtustg+fnN1IKvRcVeJQCGTFZeZSd3jiiXq8z+TPMZL9fmeW/Lrca6ZxcPYZL6njC5ZrYUyQJE288gpRBQTsqEw0CntwbgFFQSZAaqqD1EqAAyOms2WhsdzIyjG4AmZo/lAioc2avujwwDML89uxKBpwNbyXjZqtoo9kYSLRXsXQzgVnDpsJLDp5e7+Jh7BpguTiQibEasvrMlp4ugugOaBZkExWo6yfwRtd11TmsiBXgSYctaspXJbWiKcdQ1HRZs+CvTN5mZMAZFmMmXwUR4CKETQTKBM+FpmWruvG0GPL0a8FRJS+9uhXCwgEGq97quizNN+/5nOEQmByUBkMjM1gzinCt6b2Dx0iGTRzwMXNLzhNO/AELK2wqEJHDbKxw0zM/DoeGrnwjfa4tnPjvn0fwy3jK/jt+TPqNJYvfNXPzEvdk6siwg97embtfn8Y7AeSSwNFDqGOPA4/gdwg1n+4rCDbftk+592jRwTQlsDZUkjcgK0+uaHwEt4WIWHGcDpOCoqhPSTf2hUgs2VNxYeT+fDy25628n7rcXlFyRU8Ft2+Cd0yAAj4FEBfv+ghceEBKcvaGNpsHuskPrZbOBGIw+GnJjrUwh5U0iKhDZIaKldokMfIo1NPcvbO6dI+x4vqO3gpqte3IukLKhbg4eXm0TcX1hVVKXLSezIYJmxyFKRcPvI4AoI6MA5YZ7+oTBHbf9C1rXOTv7A+/H3/E4vuJ4vmNIA60d5YgiMUKrLnxtMIIIMNaQXBx/1QEczxL68cP+m171xA9mZ4W1Mcva7E0HpGazsYg1A8rAqd4VA1D+WQls6EJd+J8cfx544kmWBiAcm5gHUsc9Q41xHgtosqTUexR5TbvXdeRZQWvqvA/mNNJ/fLLViEec82PEFZhG73rt9f0BurhyMkGSLGEgXWBDv/YiePyVxSEg0la6FEtgXn+exRe/ja1fh/xeXBBq2cwEV7JNvD5D6x08GO1syEVQqZoxb+nilkWEeEZRUIY8mjrHmZcxifkF1NHldfOHNQvQLFXhABLnHF0iBsuzJUFkaLCokdzPE4kIz1wwMqGQWnGDvWOMBPe7GxxBPEqmJJKRD0OQ2EA2BsQ2kq+7nAj7pllJ215xNEa33O3v7wfGSNatRJ+FA2BeBKIZTJ5xUnNCsS4BJSfUkqOsYYinWlpnOis3yvkKPpFFHD1TjgygyjlbpzG9Ke1GMKNyyu3VwHyq0CaB5M0UACCyz3ESgxdJYt39CHP8cx9520CUUHctndp3BUdur68odcPL58+o24bPX37BVnd8+vRFSRhfXnHbKra6WYced6LcsdD94fBCgNpsToi1cb64h7avErlTwTG/uj55glHspaVzPlxhKezuLRUk/iasXYVE6yJ0v4gauEIEFF3zpWoW3MvrF/3++RcQEdrzARDhPB4QZnTjketdM5BkKM8TmJFLxWgncinYb3fkWiGCKB0VAXLdprOLKf8FqlPaoSSj8v7AOQbejhPP48C3t3c1UHPG+fJiJX0KPO23m6UsJ9zud81+guoZtrU/zgPjeKKfT/TjgX48MY4H+qH8eNw7wANpIdfOJEFcS5GxqKBxztOAYQMHvdRR592Nhmls63xTeLwOFM1Aictd++0CHsWET0PXvF//jCt8v546cBw8BvAx7h3d+K16n+W4Y3TAS+1MT2vGQYbyL8yIn4DBkjB5FF0/hJ1tS9wjifrPqoJVVs4ssiCnJ5PnSY3znDPqtmHb9+BXq/uOUirqtl+AJ/hIss0j/3zA0w9mD9mLZEbrYgz7+lhdLDG5nmh+wWSIq2IWJYlm0TIgDRRNa2cFhnICigApYyEQd8NWZRuHMwhbUwZ2fXw0UfLtHNUCbh/I1EREEdth21K87JlpnM/xuthpix867TuZ9uDFeps6PZESims2i45Jn0nldj6yf+e4+wYl/zy8eY7dgSyA04dpVTtaIkodmbVERp5t8wHPvklgFAwUHCPjOTIeTZDawCknUpYY+7eqnYtcyzutRbPy55qSBVs1IBbdeMmzcHSk+lA582wdQ5QWIRGhd8/M6GAWPM+BwZqNpUGtj3b3nK91vQ4WdCIlMSZgiGYubTlZ+Y1F5F3w+B6QWRZZkwYT90y4LcCTOlKTCmRZFesCWcCf6boRpt/DlpORkNCQ0RKhk8WaMNeWE6oP0cys4Gvzs9MEX0W0W97PBDw5uuf7LvxGO1LKKAXYb3eUsYGQVIePbv4iIUrJ/TxAcLypLlnnSy7iwD979QVNYsV2ouUvH9eCnYvms0zwYj0o1P3F3AvtSD/Oq9sM5G6WrrKcNpBklPQJhIpSTjB3iJwYDLTxBsFAShUQ44BNHN3tKCUQTz9bM3I0mxskaOMJkOD9mVGRgFuCpI6RtJSZOCFRQbUEBQ8MPY4Haq6QIlbunsLuFREMYQWmbi/IvaOMBlABqET+EiAQ0uzG1rRkNnEG9YzUixGxU1x3Khib/wBPKJ5PRarafmd7QoTxPArq0DTCnLxR05yL1XcnTPAEtk4BT2xZ9IzfvxhQTwDZeyhpmedOr8i56nXbZrY8cNve0PlEG94UhWIha2BwuEUIMR5iDc7kGAcHy5blFv/E2Aou64x9TYvf6wLAhi9SULL6SHBMR4BZmeH+ytwvzB4I0fNO8Ou6K/7R8edL7Vg7nUU2UM4hkmGON0g7dinviWfEeGtTfaacciweX7AA5qKwCQlwCFcQ6SI+lgF2dPnPgE4z6mpRd1PAHlGOTziE51iYoYIroBKotkxLwlMs3fB2HgLP8AlEXgAE4qpCAZigju2wH4Anb+dbStJyiiHgIWjn0G4CR0NhgLJ2sfFU9vxB6Ksgn85L8GuFO6ukmwgjjeJ7ivpkHw99Jgee3GEWGxual0SgvTS7w1BWQE0NX30OArDlgZETtqJjGI60yMV48O5xlGze7GcnBc72XbPXEiixCXlBzQm3vWCrBa8vGx4n4zByUHVyBsaYDtV85sWwpskxVVJCzUqyWXJCXYCnnBOItfNEoqwcTw46xZeWw+UAnoatT/1bzkXJJqC8Vzq3ZHXwmvHE48RoDygbq2im1P5iWTsMwHjJYg2Yg+mh1Z/oyPuOlDJur59Rtg2fvvwF27bj81/+gm2/4cuvf8G+7fjy5RfUUnAzfqItZyU5LcqPQT7pJmDFvANXqrMcfEw5Iog9AEzfyjnrZtae7riozw7Q6ZpGG0SWdh5djx5tFyvNQ2RIdHMqmBR4ykSgrEZFKYSXT1+Qa8Xrl19BRHh8+wqIoB1PDJEg/YTdfT9P5Kztb0su6OeBUip6a9qBjhJ431G3GwAzGl1huvwwGc/MaOeB3jqO88TRGr6+P/A4D3z9/qZcUbWiHU8UAkop2KpeC6IA1+gDUhWAdUL90U70dijo9HygPx8KQlnJ3WgnZDQQOwmtyoUECRJh7WaYUWu1MtkUU6qlatZVxkrMnW/CjRRxA3UxRH0d/FGGLkwXqYzyV03mWjH+GjAJAEs08pVEwNaxxYEngZJ2t9bRWgvQqZ0NIsOyzRgiM6MrpQTJCWBg0LA0frNymOdSFM948lV91c+qzi0beHnUbHVWE2z1TFID1433q26btVxWwGnbbii1ou672RAKPAnckdcxZB5hhv2Mh9uFAGJPzceduj10lEx7ilwnJi3LN/fLdIagdwUVjq7AyAi+JjLCZ+PcyQQqQCE3aDWDKTKfyAMrXgCDAJ/En4GAdc1MXrxwCyGXR/LMaIlnW52e+eD+YbdL57iBEMCXgzrrep6XowhkpWz7z4Z5uG4Ut+R8X3qE2g0Dtr4KFpBKXt6ldsWaPQhantttwOQywp5jeUa6/JTAyOhScHLGcyQFns4B6icoDePVQ+xlz0QLQNzO+LrvyDmhCEEoTRvKyw1tvFtnDAEebaCLIBeVja1pNuX740QfgtbZ5KI7ktPu90V6FYUzgDNYCcvzUEL4rQAvlbR0LWmD9UwIAEJPR5HxW22d3nPCvSQUk+truXMA98stuDl/8S0wg8HFM4mNN5Ek40TCw21P5xWzMWYh42hz3qslJ9PXmJfXEYLY92c7XHd5ubi9iJQLKGXsKWsgBNpBtrcTWkLk1tUauscCOE+9GK8v8l/nc/pml/cuP4TYWO853k/zDXENxFqKBhd+LltEvpbXa4afJ7rvpqyc/l6iDUSCkgeIKmp+YNCBs71DuKP374AMlHwHQcFkyUWbDwmrDUYp5FOmDLFyMO0i+cRAhxyMnQrSuYEyA8UyfSQjQVDLpvIWAyyM5/GOkXeQELaqpXPMWj4mrNmNKVXcbgWld9ShVRldVH5ZsR9AXrlCqFSQGcg9gUYFcbZsrWUeL4DTOucJDqN7Y5R2HuAxkHPGKB0pFUgRI6k3nq5L6ZrpE7eZTHdQTkbrY1lqUJnNPre2/oSg3QpTVgAHOwrvSKmgpN3seOBZ39D5gHZA1H3P0jHQzG6d2UtRZE7FaHEkvhZX25b1zLCURZ8RpqybCsYEm9uP9tectOMjUV5GxcfE6ZK0oYJfmxMpF6HbvSFP/5zt9V8qtSMzqN3Z0dpEy4RKi2ggqLKONGTfU+vWnolZVwBqXvNjZtTHYxUAfq4V3XYB4Chfoivw4uUwyVp2RjcoB2hsfWrC1oyE6clnzbunqusDL6i8LMv7D5ByCkEDMwLMLDIODx+tYaTR53min80IFCU2ZEoEFEFFRh4cxnsuCZQEPE5wO9CPB/JGSOUWRqtHiWVZjPozzU3ACZw0w2J9hlU/ztJGtrRw71pkxpeVv62dKRys0WfVsw1mdB44WlPAKA2UnLAXAz1NyHVeuCtAKCaMshGLX+bRrq+8CGzzolcsmZCLAUN5crW0ri2Cz8Y4OuMc+tzJfTB4mq+aSx4N1m4tCjhpR7EJsrnhTy4wkyqEbCBTzjnAp5xLAEm0ZLk5/5OkBCbrhuhrZTGmiCjalJN/uYkfgtyIx805FLKOCjSf7Wc4/vV/+9+RS8Gnz79g23Z8+vyrltZ9/oJSK15fX1FrxcvtZmWS2sI90Sy1AE3CZBnKP6HRtKRrCoTFJzHjdQWWVDWEDPEx/mgoOdcTjyBKdR4Ds2Js39taXQFeAL3N9GdvIMAigO09BoHyAMHLyQqq3HD/9Bkg4P3b70g5o7UT1E4IzsjwASRatGo2UgFItANjUoPxOHYIgK01gJKWsYGQcrdnZnA/MdqB3p44nu84zxNvb+9oveM4TiWJxFAeDxIkDPBoivEUbbjAQwGmcT7Qk4ALGbdZB/cT0hukN2A0gLvxGBmnkWfbkALBQuqUlaL7sNQNuRbs+46676hbRSneJWd1AG0eYNkIKzBkIM0lAjpnOd4HTADdZ/GjrnOJ60tlDa5MB1xijpg9ICDGpWCZTt1/7lqOO7SDjji3E5THa3HXVc4YSD91J81FPgfjh3tewTFaPqcloFrm57YBDwYbr0y2boJKDjrLsb3b48ySduBp6pvgkvyJjrCYEiFlQS46vw4I+lTIUK08zVS31dxRYyP8lgBDNEvXuIasjNx5efrwkjl18pEJqRCQrGORAckJ0My/7OMP+07BexJldILg4nGgKtMk72aoOkrJ7Qlf3/qzd71zmRg9Qz5+QWJsdAzo6lhKmPFmTNuaMvJwv++IH9iJoiF68M9kvQ+zA51XDdClmwDjtDGg1ICIMfgSOHP7cnJ96I1NkzlciLhvB5JK2VG2HYyEswse72+aEZo3pFSsTMIcZCBsBneAnUNwnE+1n9Ag3PF4vOE8H0oMbxncw+/Lni9sGpprrrNYgBBhA4JURqqYXOxg96QwbTKhqXsdSCoJqJmwEXDLun4yJAwyt2mKZToVUvDplgn3oplSiWbGkQNB4t/X5bMukphvXQvF7NBqsmcIIQuhJw3s1FrQHdy1caHldJ6tv8pF8r0BoOQfROnPdXzwgdw5Vh8ho9YdLENtXBngcQKDp1+ykCbPFWP8Rr5JL97z9FSmP6mfib1F098L0RE6hkPPeFOAK5Dk511zOSVkrtj6DjkCRFDwIuBsbOJHAIkqkAglf0KiLbg2+3iHSEdKOxJtKOlFM/1KibGjNGKMkpGpJ8oYfOLteANRwrO94QU33OUvyFDfSRrj8Xig94bzPLHVgvv9DieehhCOfkRlSk7akVszVvX6w3g9tbETg4YGBDt3WK9RCGWAMtrQsSsjIQ0Cd/ebZ5AkuZwxn9GIkaBcSebfBcWLJlCc7dT7SBk5V+zM2hjHCM6tqfmiA+gy7+oPeYzUbHhbR4vIUlkmjDFa2Egsw3iFM7Z6Vy9aBvpoaP0BhnYt7OPA0d8AnBgYEP8SBwBNzkcXw1hxgTy53Rh2IVYgSm82JcsOt0wqNnJysWdOSTOeNBsxgbHaUogACkFLv3IiJFE5yAL0vtoYP275Pzr+6xlPDjjZRdjb8jkx4JqxFETe18262OjLa7IIhXnMetqVy2kx8P+BkXkFpf7oPFMQOcu78wrZH+c9+CT6YsM09idoA4AmODeRRVNdIYQQkxPpdv7ctP7uBpWSF4/e0M4DrbUwWsgsG820IaSsJIyUlRtIlaRA+onRn+jnA5SKGQJznDzLKRbysiF1u7F1YYvRBYGiG5gaVGzZY3ruNYJI5tjlZG1MiaxMRe/bNI+m0JuzfLRm5Z2addKrks8ZXRYas3EOxEKZwJNxOyUDbAAxjicrFwHrtUlT4Ut2AnDLGBIHngaONnA2nh1Xkj49yBH8ub4TTdCpJCVRjG6Ml+fWFUVG9O2cTprNlKP0LkRNyiDheE/KGTIyUhrR9Ybouh/IFxBb1Ej8+3Ta4MAcEzTlc5G4f1aC/BMc//r/+N9RcsEvv/4V27bjy+dfUGrFy4vyxexbRbYMFx032ws8zHGwaId1/xKrK9c9y5bx5GDt8ifA9oS4ZF4cZk+pXzkkYEpHyZ8dPJpO9TS4ctEoi+9XMudidI1w99aMp0nLH1LR7LmSElLZkPMGoGjXuZRw+/QZSMkAKMLz8QYQRedLNod/8NBEOxE0I5UttSk3kjDq+QSI0FsDpaSfJ7LOf+aQOvB0PnEc73g+nvj+9RsGD5xdr6dsJEl5SoTBo4ETQbhGKv7oJ/r5REkAV4pubdI1o0lGB0ZXoDA6t60dKme3GxGoAZW1g17ZNtz2HXXf9PeazdEPz3YCuL7QptVqQAmHgeDvvx4euJitboEpO+fhBs8in5fvAIJ3T0Wprt8hgrGATb13DON58vETUaMwLc8ygz2wcru1PF6/JhA1xzJsfqJZ+ubrM5xoiXUlMgyUINtb2TJ5i4HweQKsNmd9DCTW8h5ggucc5YI/j9zyQ6D2ScraTCBnBKjjosUoKeAp+dcT2NriRQZB7QYv0VY+DS1zGV2DOq1zyKtioFEhRQRICBlJr0cuxaZDP9ibXVjJmXUp8sPLtxRgUMAgJ1IwRk8bHfB0DPSZmfVZFXByI/tDUO9qJsaPzkkxeZTUtoNo2SBgWdM2lrqWp7Fq7qrqeSOHYtGAllJLmJ0s+jkisk62qltAypNBOkCa+TxGOLS4gGh6Ax/cdMDNalLuvJwVKC/1BkFG64zH4x3cT6S8g1IBLLN6BoZn8BiYGZL9UFsrUwMb8HScD80KL0oZADh33ZR/bjN78GWwoJv8gVg3ubCFP8o3d8qnfalZGpMQ3MGnLVFwJiUoyXjMi2X012w0BwQUEtwy4VYUHE2k5N1uN3oJ3HD1bLafJrHOefR1kYwqwQFbgNBFnbAnCEyawdHN9mOagIMv/bW5BmydOShLEJSfLONpnetwG5fXvOkEkXL7FdujKWtn5g7NyJ2+idtTlkHohN16NcQewce94+s1LXoM5nZZ+eTqyNs7yB1vlxnAbI7kunDxe8PUgzcecJL01f+dwcjVV1ozy/V+KzJl1PIZgw+k8Qbmhj7eMfgE0Y6Sbij7DoLyygqbP+EBMWAptUvgzng/vsKzi6V8wb/IZyQUJMpgFjyeD5xHw+PxwOvLK15uX5BTwr5lnO3EcT41k7ozbtsNtWyxX8/B6N2TPDIGNxA00NXbASEFPYh2EGV0TiDOEE7InNQHcdlMHmyxhBB48B7qs7gNQhRzouPO5idrID1l5bQt1gk3ZSgIY3ZfzIy7P6sPZTej2euyzI0vHn3PGA0w3eDrJxvwlCyjaAwFm/o4cfYnjvamdj4EJIcBT92aVrAvNoC8PB5wwJTc5zAao0vSSNhBdq8C1QHwwKYFXi2rNlNBSZsCXC6rFyxgciOy3Uu2hB0NpKhdHVfDnzn+NPCUi2UBLMCM348KUo2KijGSesvxmV1hRirrk7CjchdjWwcrkM3LIHgkzTfzPO8l9dEct4k2X8mSr4JQhQcnMYd8Kma4cobdJ2YU2060AE66DBDPGRe4LOT1Hu0NiM0DzDIa3Rn63uHlfWKdBro6XuZ8eXe3VHfc71+MeMGEsTDKdg8DfrpM1/thnmxJPu4xGy5gCXFPutGciNaTHTHX3BwkeFZATgmcZxbSVXC78Wtdt+xnBlmqMqkDlMjAEYAlY3ZCgXKDSbKMJ4psIxe+kZqZJOYkkYRBQZ5bTwlCZJt/rdE309XzpAlmvEiUNklaNiyuBktKzn+VZvli0qwTF6yRpZUWgUqENBJEZsbTuvZVYaoBi9QBUmefuaO7A05FI3NtQNJAGWyGsUxiaiIlJxR1cn5wXv6Jj//1f/1/IueM15cXlFJw329IRlRNREgyQMzBi+QKxx0PLY1Q8MM5cVQJWrbeGGp0Y86ZiC6cVR75OX29uy5ZjSbtajfXkBuqY3SMMUHu1AxUNYPZN6x2iDHgaSjwpPJByzQlb8hCkNJVXlv3xLJtqNyxvbxCAJyPN83ygQLfLSkhfh/KWzWzCXXEhJx/Ttc0Qw388ziQWkM/njp240Q7nnj8/h94vL/h+fY7juPEaO8QERSZPD85C2oBtgxU0qj7VoumTY8GOZ9ob4Q8DpxyKnANKH+TsGWCVmw7QCljUAFyBdIDSBmUTrSUrIMgGyn8zMr0w0sfh7HIl5Y1q7OoIQPjDyDjT/EIlE6O79PFwLR/2PTJ7MwzDVd/k9gahHgF7JLujdi8izxF6D4eSio+xlCZcPne0ZuX3PWQT1h2gOvitdRv6oMU14r7XOR+aBoDCPwcDsIqJ4OBAESWps+gsfD4iZc2sRJaiu4zooQUGb/ZjPdlvH6yI8p0PLATlsliX4g//epQATC7hXmC2K7vnb8nkxIk03JmP4frZ1/D/uUZU+qS2b4zneoybh6idgrWta2vr7ZFXPOjvQRYx7SlZCm8QJ988g/YoGEVrrE+HABZL+f/OIm4gwHxOZPBOSXUmnCrGf9yv+uzC/DsA7+9nzj6QDOkjGgZA9EoPKm1DiIGJdFmJ2qWgBhgK3NnA9hobrPp4yzT7xlj+gdGGyeORsjEEC6oG5AzA1ZGccmGthPScuJh4PzjfMPoB96+/47H8YSMhgzW0rZE2k03Tdt88GSycZtxZvHTMg7LwANY7e11jSUrldsrYcv6OwN4b4yWAB5a8rmTZsllew4ifd9Y5GxiQRqI8kK31xx46jx/DlvOl8pcPqik58q8cDDRtOcFynEzMKyL3+y4tk7bSnAfr5GvO7LuxPhpjgun02JrAle/CLCxSGTcxwlj2YQzIG7yP390XcVk3vqZq871NbKCpfZWtZGSNUBafIYAGOIs06dFnFN9Lv8MW4A3AEx71ikOlkCTAGI+Ca8VM/6PEBI2tdHSKxgn+niDCGuXu9yQ0g6CZvJEZUWcx8YL2gmWQOijWQWTZh6r/wEQMUQ6Wj/QR7fgkHJO1VKwbcoLKmTULuNEGoTUSPkwc0Zmy4y0OdNM2YLeGzIltDHQR9f5SwNFBNlsnrlfyPwS9YWTcT8SrgAefL0YxckkyTYrTDTTCGzdmZOms+ZUIFWB+2Kk4Vp+Djg7YYDyVpIOAUgMdCGr1CEHmtzmm/6xrRRkKnqPBeDMYN4xuGPrB7Z8Q0kV53jH0W5o/EQb7+jc0UefcyjDwCnzLywoEX7CCjZ90G+KwUCpGCwrxMGqRBklbShpR047PEHGO2z7Zy9jLgIxonr/W0kwHskggfpPjz8NPDm57mpRkKhhK/ZdcZZFY4vrfnfGgOA/CkZ2f7vEg+YkoOxOFcx5k3jfeqxCwLNlrpkfapzNVEqvWVyEEMNKCO1u3Xlc71DWMqapZAVzcpwg/Xp4x5C5HKNtNbI6/0v5GREhlRyOSQhIEasFHcbhow6ER2lKyrh9+gW5bijb3QimD81wyiqUJrgnl7F1EjF/tkSTNM4BkJnS54pW59FJy30u1oUvgPIEALNMzOfLDCZfF658PeXe142Igk1KbAuwlSNasqA5MjDDVgVCNuAyu+LwDesPSFq/64RpIajDWqTF2J9fAAXhPEDhCHgUJlIdw2GkOa+ekp5UcCSBrvG1LNBS592BDGFqZIHRrS8lsFnImrFngqIPgIaVHA2MfirRMm1InFF7B/IADwElNuHpRpn94M/wJwXIP8Pxv/wv/xsoEW61RvQUQKxlHt3W0HDrZxrCcPnDkNZ1r8iwdWaCGrr2WGDzmMOY0UYLHHvHDU0hz4Rzv8vB9SW7Kc4hUSblIBYl532zRzGxOloPUvAxHJwWFLbypbqrjN6Uv8fJO3KtKLxjv78AAG6WDYYxMHqLrBSyElhf3+FHqseg6RjJslCE0c5TR8dL3toD7Tzw/Pobnu/veL59Resdox0gqCzJlLGlhJIF1XhlqpdaVCVxpDEg5xOdOhqfaGgKouUc5YeJCMlSq1PewFSAXIwZbQZOBgYYfDVelgwBz0pyEG9Y2Z068wkoDli5vFmBW7FUZ8xz2XyHzBCPRK1Oz7IH7XWPlMe5zTMKmeFySaCcC5Y5NwZPY4INeOoL8MTWfjhKvF22pLk+scgyAoK3a9ELGn5ZndvFMQuuFwdjZ0BJx9K6PVq0z+nNPGrch0t+CsddDUYJOfjRKP1ZDr7IA3+V5noBsP7R58xtEbYyUwed3Alyvp9EhPSPxu5ieE67yfXr1Jfa5ZH+4VysN6u/67uC3Wm+by4VkyMGCsABLj/V5J7EuieAy975o+8X+9BOsZYGKseSrUHRdZghqER4LQX/+vluTibw7Wh4dC0jeW923jQfw9c8SBu9OOgkFvCEBWNBnkyq5bLJSxMvMzB/iaCZBYr6aDibZvoIF3WIna8kqTx2W3jN9vSswsEdQwYe79/Rzife3r7hPA9gdKUbTwSXZKuDf+lKJ7qexDPFaJ3ZaXf6izOABqSsGU4lG/BUEmqGAQKC986opPwiWyYga2ZsytOeFCinjJjj75lOCT7HMtcUO/Akkfnkdp8fsYpZ9dAQCz5mk3duQ1iTiiHDgHM2ECO8hMs5Yz5tfJxDK6cg3PgpjhQ6RY913fgRGbNAOPIaoPVMulW8kenzOoEVu4KWg+XFr5FYkzEDJrs8SASC6ccRdDJuGXxMbLjK13AEAhTxQFxi04MGvM5H9X0iUW5HoKgm0nbJBtrKsl5oQ0JCSa8YyGhWasf9DYMbSroj0Y6U7uZHWSCdVn8uKwhCCX10A2QMeEqescVRAtbHQGftFJtTRckVe91V5oFxnAd6O0EDoCZI6YacimWlJ7MrlJIhZ+24l6BBvtEGhgxQHmDi2I+zganPlpcJOvBE6zay9WLVLRZA9YcWM6Q8c6idJ0bqdj/aMTFnWTinvbmZxD24/Q0DD0EUmaMOqGrw1/wD8uxRMblN6n9bmaOdFTwGWm6o+YacKs5xRy0bzv6Ox5mRx4mEQ0veovSuL74sjM5GIsFn9Rd8nGZACgCU15HZdaUmGuRUkXNFSRVKEj5xlI+ZgbGK2QFSqyrK6qcrxoA/dfzXOJ58I9i/AlwEhr5Ky4RhefBpSbhT4sc18mHOjBvZJkDMZA1gw4XVKrTCmFjO55f2hRRUSoSohfTR4gBZbIEv19LzXcdEFWw8hRruBMwMB4RzG2NzcUl0AbjAgz+LTbgbByUXjGzk1CSQYeCTK3xfSKWi1B37/VUX95lBqSKVG8rtVcmlyxaC3EuKLiUWtqAmSIVp/FAC03yeWAvi4zi5NqZQNiEdBt4EVkIlE2GvFXwD/vrlBfet4L5vRm6q41AMwMoGGuzGQ7GVDhHgVgtuW7ZMp7SU9GnefpK0KAPWRUCAE82xQJ0e28DJrrnXDGFG2+q0mwnwjmTeqrqWgZoT9lqwVyUqryVbSVQyS9SdWmBBsK6KMuZzastEgJhyYHKDc3Y1FJBmBiQoGNy9DOldS5qOAaEH3g6Ayg377+9IpaJWrevdaol1psq7/CDg/5mPvaiSKNYpKUoJjUNpNO3+N6CATimampyrGjfEOtetnSaLNDqmHDTTUGUQyLM44EohZjOO2D+MKMPU7WGCKTvxL+k9ispDDgDB1/A0yia5YjdOOC21c4B/JyALoUaavxng1gUvZJYp01w2CAvqpmvElWvKBqqRyoNaN+RSsd1elA9pv6NuO1Kpmso9jEPofNPsu+c3jHZgvP+O/niiHW8Kqp3NnLJknZcaSKo5VQMngNEaRrd9VgqK7EC5g7gon5k5EdESXjQaSbWibAlbKpBS0QWWTWlzRwM0BoqBwN6VzzPaxDiuJBmX1xhg0nKxlBKYzXixduRpyXwyNTJ1h4GVAkSQ5MoViGlc2CZkc1yVrwtwvoEICpg8yqLp1LSUfws8a441W9bmQ9i7KVoHRfHybVJiUieoCQfRfgljWjl8rpnKU1/AMpxcnzhIqcAFIsLIg+c+CZWp6fGpblo2TgmSEsQ6SUUwabEsXGc6mP4zHWwZFGPYVxcbYrK9j+moLA6LuCNlY3MxCt08owkEpNAtpiEtqqn7Up1jV/gMW7e2HoLXhyegOg/PXJ7OvTuSTmXhAaQog7Lv8T5RN43h6+QfWLirnfzheS9vC5tRl7Q4dxSTAUMzwyqA0qT7uaSEl72iZANNkuBv74Q+aD6UOZ8+NTy0zXnKKs+HDYKw2374MGYG1nrmlpj9SGYnwsuUtDtlHgmEHTklbNuO27bjdntBrbs2fUhleXYdoVy0JCdb5i94QEbH73zgSMA3EJpny42Bj0fvlrVIJwCELaTrbmaNWRGEmpuLvvyjw3VTSoStJtxqwpeb6WERFAL2BGwE3LP/LpeAJcyBZGEcLDhYZcVK0O6AOS9rS/2SuVTIJQxZyafyIuveMPvyFEIToAlwimY9zY7ec2+FxqZ5Zt9OyeeXEFxUP8sRa3rxDz3LNXyOD++/+B7uO6jRrZw9ksNuCgCAZmBWlr3kp1Ld5rfiekl/Hk7u7Ne+3NK04+JWRS7i5ModTNBMBm20te5pLxkEC5Bc/1pJ8jJWckmLcx7cjFruSFzAcoDlRGsPMDc8j69IaUPJzh2n+t00ovLFMtBFAYaaKwQZlAm1VvO5Ga03tH6itQYWoJaCWovKiZQs817Qm+qgwYLMjIGGIRmDVVfXshnxD2kWoLB2704FJVVwVruj9QOZ3iHE2MAotKPkXbvQVeXGI/cZUwJhVnusPjI8sE9q78HBbKRYH45qafCQDVBLEFZu51q3eV7y0rZAHZTXFAqopQTNUltATxBFlpbagO4W2+et0UZe7Cvl9S248QvaeMXZn3jZf8HZHzjaOzo3dD4wRDmhPOHDZZtpQ3gTD8cWohLBbAHPPrX4goJNlHHfvmCvr9jy3bramf7yMbeAgC/FuadsPyQvQUxxHbnsnX98/HmOpxU8WbT6j6iwDXaAOjChasaPT8ZSthbglYV41tSxmVINeLIU1gEAZtnHcqylSNOPN4ONSQ1jRzLtH89GCRtuudYFbfUPLQuP/P5JjWm/3sWgiFsMC3txAnXSiQgYbGnwWsqRs5WeJPdbpuMAb2UI0o1dNmz7i3K7AKBUkcsdpd6Rtzso1wUh1YEhG8NEPv5h68S9Jw8F+hOHgo7Bte8WxbYIgDsa87N0nSv7ea+a5fXr601BpL0GQaVfb4400M3ALVmBp5IIW1WC8ACd4KmQi1NEBEiCup7LlMqMgol43T1hK1r3vFdvd2myyYGnzPAuV8W4HLaaUauCTsl5w5b1GIg0ZsbIVDUSc+DvUAU7P5+cD8OyyGD2KcQMIx4Yo2G0J8b5wLMPDMk43waYNuSv70i5Ytu1Nfn9dkMpGft+U44bBxt+kmMryQw828ueVcTaMofbAc9WU9Bys/dvOkOk+6C1bntUkEtBMePSIXQxo/IiuxYbImyQ8E/UQJc014QqL0/71X2tBrGDB1eeIgdKPavlOE+MPtR44BFZDdkyf1iCV9F4q9hKDKzltWXY5VIAZoy6YZL6MxLrPhUHhOuugPd2Q9121P2GXDaLSFo2WW+Q4wHpB+TxFeM8MJ7fMY4D/XgG8XWGdR7KBG0XMJAyQWSgMdB7Q+sdey1I+4aRBXSvIBmqdpktE9K4AkwvlKLg2KAMyQXnGOjMaMOJMAkjOOiSkfvnkFMTpNHUc3XEKLJ0nKfCAadQ2L4p3YlcDs+iCz4vmanQYcguvBFq9C2lUmF0G4COFOtbXNe58yO83OuwzKcFdGLWoAsI5CTf7sF5GNLbfAtiP8xrSMhZX+/J3odVb2K+ZvGyCVJ81Om5BHipFlPWEmg48GSRPZXu0TKefiK55ccQ7ezlwBNbh1VX0hc/DVNHTp/vqnMvZszyPexuxxzFX5PIztQpVrkzDEkQSABFa3mRxNVMRrmOFV+jCPnJ9oNnEV+znH4EBaZJtdhWi4rHhzGIZ1/Woo9b3EdwLFHYnWummbCObU6E+5ZRS0IphC4De014NntqA4zivFZCR2TZEDFnstzzDFDM7SAxlz6ege2S7uvBnnnZVS9lQt02bPsNt/sdW91Rt1275oaDrCcpFnDyAJRmyTf0999BbIEA1mYamqXvwTq9J9U563heAWQvb3PibM9WW4GnqeGuqzIRoZaEfav49LK7hY1CwJYEFYIbDVQSbKQdSZ1DTAD0wWgDKue7ZyEo2JMuK1N/8jUTAWoiKx/RI0DWYbiB7ZUmpF+smVaaPTVta/c5JlcwmaOoV3Mb1PnQnPfspzlk/YEiIBGqxAEpIqx+n+9L9aF17lUWFeWXMT6anEoEYT1otQJP0x5baFLgakjlYrZs0PDZ7O+u41RfypR/a2LB8gwAYu1AgKz09zEIPKybKHnQ8HpPkVhhgL8s20IzS+5IVMDyisFZgScZONo3JNogtSq4a3yHfm8JGUiCLMXIwCuE2JoqabAZwgp09KZlXsjBtVjMFlL700Ani2kqsCQYotmSmRJKKnYfk99UA/kFPRXkpKX+gwfO9K5NjSjpPQXXrWYyTrBwNlpyJaU+5kLdQivQ5O/3Jhg6voM7mL20X0m3vaGK80u6PzznVGItIHbuNI38/rwbHZEH1mRZTwzvRk/iHfAqquzqr/En9HHgHAo6Pc/v+nNXPq/OJ1gGWAYGugU29LxzQc/1OH1uM5+MWkV56nQN3Oon3Opn1KKZV6skDtxtPbHpJM8iY7+WfcoTWP7M8aeBpwtYEIJ1PpynSK4gRCjX+DzNwXCj/vJ3GAcUo9uCvdgN62vL35IDNsCCgNNFOKyqDZDgngDms/hCvRhxsfKxAAaytHz0MjQ9H8nyGXt98mL5R2I3hcMCaDnN4IHnt28KfgAAN+D4ivb8Bu6ndmmyulPdMGqUkwiO92/o54HzeIJZnc9cb6i3Dip33M4DqAClOp/bDRkRJYqfD2vCd5lLzE3oDlYI61Vo0zRSL8jOxQpUtSsmXbetWhcENxpGOGMCNbbnICI+e3ZvBS7IOeHlvmGvE+zxI1Ga3EUi6tiSaE198nuBRfAUCOO94vPLhttWcN+KT1k8VziP5tg5sfnrfcOn+45908ynnLUXjogCZu4o+snI14qvbxZI0rRIz3SYZZbjst5ENF20loK8qYOdEyGBAT4g46lrUgogDQLgeP8GRsL3bzY2VgJZSkXKCfu2Gd/Yz3GkdV3C97HtZSIIV8CAF1WQ2QAo6Ls9K2n1VAAgzY4hOh+zfCvkzSK8pyghv/wEIu1dYpdhkSiT0vmfDlB4KIwAos6umU6P54HWO3pXcv5iGYB560DK4cy589hHx2BGOw5NR+4d3EeUq6kyzyhFW/XmldKVCClXc2psXw6BkDowBAH6AfQT0p/68zhAfKLAOteB0XjgOLQk74RgywlSM0o70VrHoIyGd1CpoG3H59dXbOkXsOxAVj6pNhhdgMYI4EmbLGQgq7xgOA+XRU6zdVBLSbkGkmZMllrV+DFdog6UlScBtlc1g6gTtCQRxs2RlC8hBCgmr5FLyAn6U/ydLaNNgChTSe78+mcWz9pXsv8d5vDAjGJm1hLG0XGeh3YjHD2+eGhJpgM4FBcyR5M8WyaBJIGYwDTCcJrX1VviuBv7XRAkyOuaj/eb5arPzLE/yLg7yn5D6cNKZByMWx0VHwptpEHZyrhTxp83f/45DgePPTtpHffJrmOHyxX7qzrwGY1FuR5Zs/YEArCgA8ikIJKuO9eHiPU3dZ5GXFmSyowhoTcbizrfzBfwSfFTlaGJlnv3PWUy2TkeF6MD11Vuc8rT3gIwG3zEOZf3XtbB8iz+V5rYsO/HMSS67sV5MU23czDeW8ff3p9aEpYJXx8nHkfH2Rgy7KT84ep2z+xy/MPfXb2Iz+GSuDdBawOwbYyEABLWBgIpobeBXjqO52HAF+EsDVs7tWGJ7RG3d3PWTAEHnjQZXEurhdmyiFLIBgeV2BehT07vP9jz+kwW9AjzV7MCPJPtapFbWS1ZhmfRa99qwV8+vWIrGbetWrkjI/FA5hOJGdkze6MUGTiI0YVw9o7v3bs0aqleTUAhWFlfQiGyhjBeajl9FOdq8u/nUN8hiWg5ZlHQo0hFloI0cvgjFCvY5nzZqg4wxfomWUpf8dMc2SlaRMx3msdHQNzeaP/a/rPGO7kUkBgvmtseljGSiCIA63pmBZ50/J03d15JuV0TIAVBN0IL0OCZuDkWrD2KNc4w38RlGK8bGMt3F115WHApKR2GLvpIdFjBT0BMz2P5OSGniq28YnDF2E6M0XCeD82A6t/ATGh9dn/V82ZtkpMqtrLj9f4JIEbdM16M97QPxnk2tDbQO6MaB2qtWpLG3PB4dry/H/j96zvIUhqdGgEAhnTkpN3Ud6qopYLOJ9AEHQyCBkJzypp5xANdnmBqoEqgPCBbhhSAtoxUElAkMq8nkJRMh1lSgZFc+xjODKnJxTS5hX2VaTl/HwroaFAgB2ikvUtm1k/UINjvXt7MDvzIXHPus831nYxLaq5xhQG8A3tGFk0aqXzDVl6w11ec/YGzP9DGgdYPMLQhSx9NAbShJYu6dmcTousuQ/gvxYIPtdxR0obb9gW38smIxb0R19osYrlfWe7cfP2JAS14wJ+UXf914GlxeoHpV62py1NsLIhfWC/uYFFs5umArUa5PyjmdeJFRyDtZzvXBJ8U/VzLl2gRRHr+iVo7gpegob65YRUQWsEn/bYMcBhZEmPjY6ItfGX1OENQhfFFEx1laWit49v377pwB4PQsfEb+HxoqYp11CKCcraAoJ4Voz3f0OgJPN/ArEBW2V8AZNT9Ae6nCvLINlsWqTtHf7B41rkO4GlFN2MupvBch+gH3bJMrl+yloJa1Bhi9pr5WQLUu8+XriM3jrsRLvehwuO2Fe1OZ5BtzHoCrCZFkV/42MusqabQj5rptAleb5p59bJXYDEKfOOt9+m10ret4n7bsFXtlpeNg8DL+TSb4Q8Gx9erfXkmhae6s0VmVgHHolk6pWTUWrRMyHgfwA0yjigzJGj669k6Ootmx1h6PARKMkgJ+15xbQ/7z30QLCMFmMpEACfcR9GuGiz6PiemD3/LgWxgGtwyX0/GK+CRfC+BvdxDgIwyZaYbFOGRT5k4S+u0Sx3H2sfctiLGPaQgc+8Dx3no/BofVLU06W0MJOYLTwpBFWS3z3snkLU5g0ePUs5QTjosBiQZ+WOOMRW7J+4dAIN6A/oJDP0iPkHSkA10SraPztYt5YAxMiFxQklZs7eY8OQEygW0bShcU+dnAAEAAElEQVQk+PLpBSKsDQdgkW3WVvCsjE1qeBg3HIEwQFFOTW64lgyIroOal+gpZcvy9Bmc/Fw+AYNZObCsDMW73km+8hFcdJp4ObKdJQxd34caWY/ACU25NDWYn1snI9TPAjqNMXCeR5Rdjt5MhvRoUKEBhBl1B1a5YyWlFtYTGwERjUZKXN/vKS26z+8dH22gOCbh9cD6ZDrmBWXbUXoPx/9HaWTntzowz/6aXA8/z3FJeddXPpqWcPnha3TKLuvamsX2qa5VBxCIBYMsU8nGVMmc5dJIYxV82kpbS8vUkgK6Jo9GxlJoarv3aKYgarTbgy223yJvp3GFMCTE7UsFX6aNOM8FWT/74xq42COu6ylEKSBiYzLf44/u8r+x4NkH/v44Anh6e3YcjdG6wKtpLobrYjMLf/i720qXmxMbq/kMIT78s+S2hGYepc7WsXLgOE8DOhJa0Tbm2RzJ5OU/Yhn+hACeMiWVv0Mz6rXr4awmmNlfZHJMYoAIsCzwRTdER8M5FCSALsFrnpP5M9GUQkSDhVst+PJyw32v+OXlpiTnGJDegEbA0J9laHMQzywaQqABdGG8j4GzC84u2JOW6u3GI5USQFm71W3ejXhBftrQjI6jqQ4+rZybRMvt96r6IqEgoyCJNrC5rj4KWzdeWfZojA3w8wFP7sT62on8cD3c91mdW9dDEASolLICT64TtYxKA2IrgHWVC1e5Gb6pffeGPn4EyOB8iEkulTnh1dr9smUNh38YJXlr57y5uYkHkvF40kgYvVswga8ywO6RvAbTrpuMxLykFyQu6PwA4YmT3lSX9ncwJ4yhPpSDYArCSFTE3LY7KAv2e8bdqhz6ILQ+0PrAGIySYb5LQsrAaAPH8cT7+xPfvr6j1oJtr8Cm3esA5fkDiZbwpQJCwmDlJk3UbX07lYIoiGK8qoWK2hVlB2oG1Q2pYHJVuWawMrWwWgSXzER9j2U50fQDk4EqLu/V1xronZCM7zYJzyBi0jUWDb8Edh6aQXla1qzY+iAPLLACS9k+gxL+YkhIB0yR4bpVhFHLDdu44+xPBZ/agTM9oGQgCjwF+MQ9ACn2bnUfCNI9GafkikQZW74jpw17ecVWXpR03jPHYETrgIKisZPm+S7fZdGVq0D7T44/z/HEV4HhyNfkalpSGkOTx3DGZvZaWpipsRI7uy0bn48Fh7m5YX8TicH4mBYLGzwWARkqvUYbAjDgmQETZttqEOiq/iBwsMiC6+sfx8hufKb/2Yf7/Kj+Pad4jj46/va3f8fz+cDb16/IGPhla8hyoPbvGOdzjodl0hAyRAbev/+ugNOwiDwz6nZDf75DxsB+/4z9019Q97tGhlPROendZzQU4Jo2HUBTdG6YJZHro/i4OZhGljXizsg6dp4W6Z0Y0kVASCxgX9zDswHsJj3DwjklxugQuKLSTnEudHw2sdxHZJ3YV/aacdLa4n3L1jbXQEFPlXeQYHkcLPelG1xL7rS7nr/V94txZVi3K0sIjeeB7yEeVq+SjJNlhHHl69+FbykJe83Y9w1120x4khIEjoGyF2zlhi9f/hVUXtClYAjw9v5AHwPncYJ5oFukM0pQf5LDU4VzRD3cUGAlaZcMSYLEqqRr3TRt2zi02MAYbc9qZUXZgZm5/2nhvNHEW5lrf/EcWDjmmaD2s9dtO/ioQFJHb904u3oAUV4eJcw4W0MfmjHUesfzONCadsUQFjBrxLCeDUwJW2uQUoHetV25dzlrXTmU2onRGrjrlxhZojr0DsLPdFtYCRq3E0MY5/t3pJTQS7IIZVPQ6XhT4Ok8wdYxhUU7RWkU3kqKhpXsgJFIkE/GEEJnQt133Leq6cK1QAg4WtfW5GezbkKAmIGWy4ZUN421saC1E711HMeB8zxVZniHRwAwEISyE1qqe6TsQtMpcCfavQkJrhs7BBASK12eusuNWAeMeQxz4mfpG9w499Q3AqJ7oa8zl5WuN3MOw2cw4zg0w+n5fGhHQhvzfh6Q0S2jYUS0NTBwn0+obKEBK8HTvwo0gs25AGkagap//bvr63SR4bTIYYIoEGZlPG60RHq6AJQKcq4GPDkPxmqI61h4SWTch3zw8H6CYy2Pmi/6D9N9t/jvXKcASATdQOnhDpXrdpNRTvQ+szDmend5mUn1VkowvWY8FuL3CJMPGsxx6y/TbA6wZ6ABINZskw7l5ikGTmQiZNbStBQiUyYto30X8QGwdbrYLjH1dP0ev7rH/4PVYofRP7p9SR7EEV19bTC+Pzv+x29vZmsAZ2d8f3S0LtOusLovCq4PRAYzZAFownB3Bwt2LYnn+2iTxmt2jj4EgoFv7+94nifK27tmb9ai2dC1IGXNTEhEIYe8jDxZN88IY3YlFG/tBCAoOWMDcFqHKL93v+3sayTrHvXOwwls9pXVHTo/ww/AMC0TMG3qMRjcVbekDNykoJCg0sCggQ6N+PehznLvbFmtwDGc30k5nk4ricuUULX3O1JR26nWhK0kA56WpjQAaDD6EDQZQCecQ3AMpXbIQvhUMvat4sw3ZBT83YI3bge4PR37MXwaueISiy36k+HmepAF3cTLGRf/QdbfV/0hc62Z74Hgdsrw7rf6/ml7qdoMxyP8SpcPDj6sGgXh46yZaoA3mgG8jFjCnLuWeRnHjXoh9tBpXhjaEU3Mp+TctVJidPA4IVayRgswl23cQMqn6FnFhIxEG7byGZk2DFZb5jgP84W0CzjIsn+F7F4yctrwcvuEXIH754L9tqPkjIOgdmMfZgYZj2xSYIa54/k81M48uwYzUsGWK251B6AB0ic3tPaOLW+oeUPOBS+3lwXU0+7MjsCL8RQxGgZlcGqQ3LRJTVZ7PKUUc5JSMnsnQ9h90gVDMGAouV2AheYEU8Y6bsHcIZLQKCEb8MRsnEUpgUjL8HRNmZ8uguE0FimHpA4bbUGjgobBFlEyrl8vyHHtFZlKZgdlVGww+px0w5bvcAU4rLSaZYDhCQnOA2VttxYd7+u0pGpcvndkqlpml28BPEEQfKKuW+wxEAkz65Zext3H+M8e/yXgKZyo5WbcAXEjYQxLSgsgicwB4oWXaBoAnoZNFyFhkadYKPZg84mjht6FyjwkBsGTXELnOQcGlmyVMOZXgIWWs80ZmOvJzarlmjIzHVYjG/AMLAqJl8xR0YgzLai/OoJfv33F92/f8Lf/+f9GoYH+Sthzx5fyAMYxBaoz7BOhtY7joXwpx2Ft34VRtx3ST5RccfzyNyVMFgZRBuUCkbY84zTGHGxZn9/jrE5qGimhy0jEPHq5EmZUfT3I7j+Eggl4B+muzp1FwVyp0ASe3Inrw0ACz5g1x8cz0xd1/8N68vXqPBbZiC1LTpYR4YpGzDCnxVhIMWq+Ki4AlQEM66bWTLhpbUT65hx8XRssEJr7xtu6u3Pmd59TQs2ipX1bRc5Ocq/7LueCuu349de/oNy+QPIOFsK379/RWsfz+UDvHc/HG0bvOI8n1k6H/+yHA07qpLqDa2uDod3QRLvTacaLtkBNKauM6N2AAvV+NAvNjRxVRNPf8d9l8ivDgW9bC1aeGXPqRjbPstFmgFPvmlEjnonkzqPxDjR7T2sKPLWzoXUFo1zxJBGcvQEpofWO1DvyGMqZ44TlVn7Fff3u9+P19tb5w58x1qF2zyMI+vEAEWEkfe6MDnAHzqeWDbcG8Myq8pbuAKKUQYEnKHAFDWSwAFTMyExKjCsAWu+TD0Y068JB9cJANunDgGZ1dc0qba1HuZcrCI/kk3hL6+k4hG/oezXkh3uAEwz5USbOd/re9q5zc06nwofrKnOw/UyuLy7BGjPMRLR8bbCS4Ld24jiecz8bf4sMJRCGrdswymXRpSFrJdRCPBkXJB6zC2fSckaahEB6Eid5kpntEYY/JDI4hWdZSkpkxLzQc1uUG8DFGdR9Z1nKHnyxPwYn5E93+Cr8aHsAc3bsnasDa0EZz5q8dF8VN2U58ABaP28/ZwNYEilQ5IBLTkoYTrIQ7344h4NZDj5NR3K+L12ucS1BorDjJQCbuR4/gE7LSIVEpg9j9Qe2cTiSPpby8e1z7XXLEG69xxuYjUvX9yuZTCOAktuyMBB1lQUqfi5CZkntk/h3+Uw8McyOcNto4PF84lj2oDthxbJePUw5Oy/JspoIhbRr3WtJVo6me6xktXFK0n03KKwovWWznWpOdn8pZgcQy2rFj/W4/suHOXF5wcM4DXsHjYQNHQXARoxOFtkXoyEYWkqnBT1kpZ8SxN9dgA7CIAIndWpTJuSaUUpSAConFFvXIXNNONIQSAKaMA6zM0tS/tWtZtxqhWADwQB1W0c/6A9gkWPrqp1v/CmBJ8AFUjjoK/jEi18Y+pJWt8T1Xpo2mr0Wh+h8ub21DjO5klu8gEWxLrKD8NEH9PeSODfToivhHeEIFFWFduNRNeA6MS6HxBl9dABk4IeYzzbtCA3Ge7UC9O9wvy+j5DsSZdTxAqInnue7cgAJIKIcSFMSKgiTU8G+3VF2wutLRalZbTvAbM1ZKh1ZqiRgGThbs6DmgDCQKaPkiq1s6KOhjQNdtIRONkLaimalbcXAkoEzEY54RgOeRMDoYDQwNUjqkDSAlHUI01wDKSVIThC2rCffXDFvnvls/iUmaAWTUxfA0zgByDoW56zZoe6TR6noslcjqz/829UXlrgvgWhZblJ7Lmw30yduD8L0sW8RrbwiI2SvyNTRaQ/5wVZeZ2EjzXySCUb5625Tun2VswFP6YZEBVu5I6eKlAoopRmUiic1++2jDo1tseiakFt/Tnj9aeDJb8CFqW/mRE4QOn6INsXAhhEbsVTdh0RWwrFchvQfSsuJwoiaA+Jk1x9Ed3yGzcmLlH+imbavZByLQzCtoVUYutEx0zc/DskEQvSduvgv7zcn1aNLiz0UmkhMEDv4UXICMPD1628gbuDHwEsVpFdGpm4OA5mzrBlOrQ8cp6B34GxmyMMM+d7A7YHx/A45HyDpmhqcs2HyZE7AlXjAI32CmZYa9czG5aBD52jo4hDZmZ3fJNJXbU4CnElr1MABGPH9GGtofGCkHIS5rsKg8wUadGegOYtw/gp1LAmeCo6wCie/hQfsM2iZM/2M3dKioOwai3PkIB0RomOO3bIa+2Ii0dqMTzJ2PbkS/uqnNCvFs14m308iJTd9ue+oVbDfN5RS1NCLDEPRLISUsN1fsL98Qt4/AZRxe/2sXDDtBA9GO59atvWTAU9eXx3lc6TGyRBRZXg8F4Ala6YFTOmZXCCQ8UEJxLLrng/rrpLy3M/wdRsek762rP8VQAqCabbOaXaCMdicc5nABHPsUy+H8Oym3r28blwAdP9iAzrO1oB8Ip2nAuC2VhS5YMjo4H6CR9Mvz4aUCQzrA9mqtVInxToZPA4AQOcOCINYgSctFe6Q9lRvy7LxnNz7thXkrmqcBTiHg9WaFbXVgm3fcb/fUHMGj452PPFd9Ln6YHNxCKVuyGUHs6AI0HsHzgPnqTxW53GgtcM67il1MUEj+ykl4K5GYHKZYunLMOPQ9dHaXbLkYkSn+hkvWdPpdFlgH1wyY3U9JqRkXeJgBkvoOtGe36uMifIACSBaM7oazvPE29sbetOMJx4dvR0xt8rhZDpElkwkwmLEf9R3k3RXREnr3QGQXJAyY01rhz2TqigzrMwOIHc82EFcy1QCLIDgpYuawk9WhuCdSsO4YzOqWY1XB1aGc/79ZIfrBT1cIU3d5H4VmX/jXwTlsylGKip5oCco4G6Eox6kywRIBmq3ZZrcjtDoeyHt9LplzRrZMmGIoBtfZnCZ8eReWuETB4DlwxfDulFaGZNXiYg/42LvJb+OB8X8Km6HuSnng+aJdz8sCdXlYdN+WPoOiEqo99X+0MxKd0gVKFX70vfQtCvI9hpA2cZ9vRe7UTdT598uBu9yTFYvMrSYLbd2sAPJS2MXUfJzUo/F9t60TXzsBEBmK/rYC7aU8GlX/VYt4+ClMnom5Gb8KAxzaJIRrlfjcFH55DZ478YJhmElnTa/9tARhltIyDsDR2c8D+WV2WTgURmbLcZhOq+1juPsagMPq5FMGTUDn5LSHLzsJbJh90LYc8ItE26ZcK8Ze0nY8uycnJZMG0kMDEYe0DKprEETpgSmBFiAlUWJls/WcJznUkLswQvPbkfY7z8GZM3e/nO+2z/FMenJpg70Lw24TXvF3hDftGwxQ7IYn61/fqkgWUAjt7libfnp3B7TV+CBbfe74jwysz/Xe13vK96/nHeVHWKf8z2tv6+ld5o9zgBKto5yMpC4o7fJHUUABgaItfGH3rP7Sp7llQFUlPwKSEYtD0BOUHoAYo04JINFKyAoZZS0IddPKBuwbQJKQO8nzjazmcAJCQU1byjO4WkpOnUr+PRpx5fPd/zl11fcbgV73dBax+N94PE48XgcuO933G93/PLlE758esFtu2GrJWhDWnviZANILGtHrDOxDACcAE4QNpsi9ECCQKkxJMZEKVqmj5pi/FddSWLJIeHfO3BJsWbmepy2rp63qK/qsygCGUO5qOdyMCDLM5xUKes6M404yIKtzqNknelgiQmrbWjBglBkpl8TrPog6VrTzCfWAJPMbMtJ7K7ZXykaTFi2YFpKr3mpACMbF8uMjWocvy+aPoDahQwweYEf/szx57va2T8TTZ4bkuAdeRYFPtW//To3NOA6eXL1XFArmhNp1gcAiijwR6dKPpxbT+fKY6Y/+1kjNTIU5CwPvN6LnctTkx0YsPN41oPfHy3CaSKNU1i5wscihPQRPWpHRm6sY/r+fIP0Azgb+kb4XDK2LKp8HXhhRJpx64LeBW2okivJHWWNdnN7QMYJkqFdQJw4EsAYpGz5fk/i9zmFsBv/6lSMILL1Z3dU2WNh4r1zTaD712wH7l2ZKECBuXZ0TMIntqFzglIfy9VQ8zX1x0uf4l0Kevm0CVYGUcvwDccyVqXoP6txSG5Yxvyb4SlzXZBblMC1Y6JMg88/uz79grpZRG9tge77QEuCbltCKYjWpxQO6XL+lLTbze2Gev+ElAt2R7iHCv3etASnncdPBTyl7CVPvlN9aHU8nYibQMgGGCR36hb5A5iDNRiAZhmpA74SCfrhgKgbNBM0WgEnHpY6u3BtCTDbzLujLhKZo9EJja07iDnrM0NJQt55jbzfQ+8DqXe03lFMoQeROATgrgCRkT8Kd5OheYKqLktpGlXOCeRrKcq5RodwB59PyFDiWgWknJRf99RWVA6cLJAh6F4LL6Slb0X5y3YrJZXBaKJlDSr7lDwdlFFZsFlXO6QM6epJH8czwKdZViqaAQqBZOU0KEY4TpmVQBay7OnJ9eQyMaes/GhJOQFMVISx4atirg+K80joDeWem+tm6hETsWYopUn6rHcdwGVrDWc78Xw+0XvDeR6WveZjrjIb3C/2AfuzLDrper9uPJnuZwYlMwphZpt3mzEdIN65x4M/4mtZIouJCKDszz/3yRhLVjQm4DmzSNUhVLBDS0qd0+w8zp8PeJJ/8DNw0RtuN8X6hGcpWVZRThqlJbII7FzLWgpEGKzZR0IKRLlZ7h1itVRJS5KKpZQLFCzKAlijOzi4//Ex5g4STIN/6neBZwbHTlMdSwlJCJQYXrl1efAYmpnFB5rjM4Gdud7W8ftgrZrokR/+SOFI6B88e1kB4Tnu/n4mzFLBD/ekb7taPfQhK+jyTMCHm/T3+HiZvDEULtnecYEiDsq6rW7AYmQ4DEYGsNOmTRu2GxKAkhKIlFQ+M4OFLMtKDych33I2km697rCggM+lYFydfVwGInBUsa6CbWjzmOM4cSTG+RQgE3KBBWqMWL0PdBa0ziaHjfQ4EWopeBWyrFigGpC2Gz/XrSTsRcmEs9luq+8wzIHPWZBYJ4gpQeyLjJRXfTe2Dq3d7NO5Sr2zFsWczzm9uExuAPxkR8x4AEsTePqjEh2iBE5imSd/wMVkY3jx19bv4u78VZ+53p46Z/HPxKSPTZ1nFl/vfQbIIyP48oTABytzXs8/b5kyycA0zsUK7M5YA+wyA17yr/QOsxrEr5GRaYckQU4VIw0QOWG5VrM43xBR0iy/7Y68MUrpEAx0PjF6Uy5I5SoAQbPKvGugdpcFSkm43ze8vGz49GlHLRp0AxPO58D370/8/vsbXu4Dz3vHtm349OkVpVTkXPF8PnAcm/LJQX1BhickLHW8Qio8xZxdl9tJM7kkaZAxeXDEbK/ABBAusuk6/UUT3NWu9HUWMygqVwQCGoTEXt2QUWvSJIHQJzq3YwzVs85vJ55YE72jY53p5xhAtjL1Za+bnI5yU7etQZHxJeY7h+2ZlS/Lx2+QNiczjaDxUhEkA5iUfmZSIOj5U+yhKM2z64vjHR9wDLf/p51rA+2pvX/i+PPAk0ynaNWsjq45R08OJE/mQIrd/EVJLxsRmGDWYpyHf+M/yDzvehBgwl/mVzhs85QhsKxu30tH1pbOAusuZApTJRBdyE39fnJe7pWuQnWOm1hpDdTxhJWT+TMTobdul0nY6ob/9i//gpwJ//d//Vccz+8Y7/8BToxn02yXUiUcPU3zFnO+AGYV1EyKJZ+DIAfAbw347Q0jf0X99Bv2l447SpRq6JjkULrqBKXJ/+AlcGlxsMQJ9qZjPSxdU2wMS9Z9w1Zi44TK6yaNjkWgcNbcuHP97V0LZBlXd79iFXwwvNd15LbmGtVXg1vXbs6ewUA2R94q+AcrcPnFFeDypx+cBJprNIzSa4mhl1ppndCwUHWOVNfISFn3ExDZJvecIZSR66ZdvPgJ4TYdtlxAWTtXtK5RlES+n52XxWqnU8KW/3wi5D/D4Xvbs4EcyDueD/Te8Pb9m8mxhFI3UNYUYjf6B6tAF1AYmAIBPxeAZxFdfwRAKUg0gac1uuZfvICp16xLO2wN6/s9c9DKHKqDJRpdjv2QrM1wKaCUI1uKB4MTR2RDQQn9Ih4gDJAMeI6CR3Jg2aKRXk4AWcYJjJtMx9iMb+MmGwPRilc5qvR9w8iIS84QMG614CTWJB8bu5IztqpNAxIEMhrO5zt80D3jiXIB5Wod6yqodxBpe+AxBo7HG87jaaVHY4mOLansnDHGQOoDZYeCXt5Vx7NsQ/5ry+GUc9T66/w4aKtzmEzZB0Tte98MUC8PS8nkr68vi0Kt3IFqsHPoShEtMem94/39gfN44vvX3zF6Qzseei8md7NlbSXxDkpLKj4ReHHoV2M5+DX8d/+PEsAChq0T8ijjYrQvckt1spXI+bnydELcERkGInlWFMQofqbdFxHSdp7azfGhfFaPx+MSNfw5jpnd89EnXU2hCPzEHOm61lbz6oTLGNpwwEiwE6luzwRUAiCMUQSZ59UIysFUkmZOOf+T2mSqB0Mvm9PkYIMVRClPm1jJE0fyTfgYmre28KhYtLekCniUGwAd6hx13x8fB8HsAgVwXCAvA2cGfnRbpCnD1wHWoJn5fqpmw+4l+13mpz7M1rwP5gmuhTmQzA75mP0Ev+d5s2FdyHyMsDUz9DnydFRiv5LSBARnpggG2b4aats6Dya5zQeOLMgJzlHMdU0KTvcEkJC6tSLolnXYNfUNteqtbVnLYioVnJ3RGqOBcY6h+LdYZp7psK1a5iMLstlhnQXPNvAswLMBwoRkwFQfjKMLzgErz6YgLy5FG7vEZNlI1pRQk2Y4bQGgKhfZj2ACsFdGZ0EpHZ86A7njpQ0InLA3RZBK7VULsIpcOyJOfxI+dWtW4mUZ/Enn7Z/huPiNP/xtljJF1qvZulFW7qBz8vcBV5t8Sp7QsaZPPiYCfDx+SFwI/w2LfT6vlUizOqLaZvEP53WwnGdyPE2uNn1mIc10YiJAOjgRhCt4JCiVqIS/O4zXNYvTkKiudf3NkgApIOwaaEjabIqT+ZXo0cU3ZaBUAiVB7wc6Nxz9gcfzgdY6ZAhqrtjqhr3uyLmCWbNk9rqh3LVJwaeXF3x+vaN3xnkMfH878Ntv7/j96xv+/vs3PF8a7s/T+FUFn17ueL3fsJUbfn0ltb9A+HZ8w7M9rKLjXDL2U3TizClp+VmUWktgCNHYxrIyNRBCIJ5BfhJYEBdRpUPmjHkWmZ/H/Vy3VxQYdTvbEyZUpvj7V7vnIzLxEVR1e10BVTa5q+vDTn/1JUOFWYn14u6KqGwSC9K6vUjOTWyiX4N2STOf1mQKs+sC65s3qZ1dSX1DX+cO0n2UV9GcbYrZ//T4LwBPCGWqAyLhBAEIFDZa8QWAcLGM4mstS3KB8UcTBSyOnBuwjsAtf7+6ev7ey1kuBhkwwRTCdP4Qhv988EAJPwJeF8E0n8df4yXq4Ub1x2fSS1pXJGu7+PnTZzB3/PrrL3h/A76eXwE0tGFdoMoUttqGW8xnVGJHsWdiEISVWgXPAfr+RL694+Xbdwgy6v6KXCryVtUeIudDWY0xNwRXR2Qhw4ZljA3l7dBsgoFxnuAxsFcl2WYr87CRinmKc7qAtiGLqJPQZdhdP8yRpWX9AF4K9weryGy6CWjGx5ODTvqd7XnDynMB8IMCdcXla86v4U8578VPcY172XOLrhVizQQJxt+UNAthBZ1Wo9TmohR1tqkUgBL6aVEOG19vK+8RSGaG17vbqBn/YLbLTkLFn+HQfa2ZRcKMYcTSx+NdS5Ie76bsMgYz9naHCJTfCzCQhC/n4zEzHgMCpekUhKNuczaGpcI6MTiW6AbW9e4XAT6u4umEhMsWslT5qxRAzswGJhLISfZNsXrGlmfPKdir46PIw7AvdRmj+EssgmhO2xp1BCTGiLuVc/maHQ6eKEiu+JSOn2COoToaCYXJCPi19AzmGJeckV1RDsZoZ8iAYc5PYlGnpIyZTZYHejvRzgPn8x3n8x3BrZWrlXqvu1KjWNmVKS1g+6JnCIjXg8PP1xouk6gRtwU1WbN1kQCyzCHnH2BxIMwiggbAiBtMZuwKdCzbGGhnw+PxjvP5xPP9XSOY5wMu0VMY5iaPUjLOiatOjTXu2a0pTVnha2q5f4EY36JbXvpTEjfIXP85f4CuC8rTSvHrfswMXMdSSToNsIr3cZSYHs8nemt4f3uzMpef5xDfYz+8/uGI+Z0BEX1Zggg1m7MNSUjEBkBOEnBOCcWy/DhPeeRZUw4UrGePdQ7T11BZIXHnDkCpbnWQYP59JgRF4Ms4OnJV3SWUISB0y4Ybw57RAfFYf/ZN9Lkjsn0ZLQq6l2m+SXwOZnesNiTZueP9HsCK6y1eAua5orRsqu0fv5Y/6Qd9j388I6bt4vfuhFiOBobzlCNzM3QFA4RhZYLT/lWaEyvdiOeYV/bLlKRrSzPibIbFqCRE+a8IBBSVDTUBQEIqOlclJwvmTXkmpjQ1Oymbs6dZeoDz/g20jsjkr3bPfajc76LLgOHPr9fai2Zq5KWBTU2akbVlBZ+0NND2DDlXoIR9W7JeA5SwDcZTNNOgsV6vRAB9zrfPeVBirLvF9hAtc7v6Muuc/wzHlP/6+1VPYurVi64Qraawxe7gk9tXbgLJ4n/GuC2f+aP7mC8gbCf/db7sgpTMN7G/0QwczQmcutC70rqD7h1Ww7G3H1JKauKzFlIJFwUjraOakltPnrBoyEWuu/Uuhfw1z0mtSBgRwCLSLmhIwwi3CSlrZp+QWHc05YJs52ll6kCmYh3wqpYFCoGg8uR2q/j0csNtv2G/beD3E601HI+O97cn3uyLzaf5dt+w7RklJdxqRUkVdS947hooerYHDpDa5W5nB/itAT2lR5nz5G6ZB0DXahvfcWJvJoQK0M8vlC1Bb5LShSuSzOdz+5SIo5qAqMda9MD/6iZelpetr1Vz+7JKiSwoIXYniJLKdb/EWU2MBKBKZhEsfJwuexygJLvYLNGcdsHKfTxti+UJaHqHwLRfr1ai6+tl3/7J47/E8XT5vhqNAejYpMucYI+7hQBe9bMtlgly6EO6QPFNHuivR/lFdJLs2vo1M55WgYJAC8xxgjk+1gaT1hXjFoLMn22L679uOFs0zWvZV+E5h0vgvFfuXHlLx2yLXDAXje4jQS4Fv/zlr9huN5ztwNu3v+N/FME430GPfwdjoI2ORGKGgCBnYNsSXiSrAKJi3ZIGzpPx/mj4fjzx79/+Ha+/d/z2e8fr58/45de/ou479rt2uYOVtKRStCxr25FLQS4VvVmWhGULjK5ZBOdx4GwN7+9vOJ4HzucD/WzgdgBj4NdfPuN+v+HlllGKRk63raA1zczyKLhQigiRbjCKaVjXm8CNwTn/q465boz15+sGdil+2ehihksYIz53wII76GnW+SYYl+5q6PrdKAToLxJgmRNGkuggj4iWRNIIrgMRiwIb8TOiFzPi3lVoquBMVbsTtGdH7ycoV41037+g3n9BKjcglSAjvZbAzB3iq/5nOUbX8pt2HGAe6MehSu/9Db2deL59U71eKjYeGO1V/QqpNmc6TmzAXe/G3+BKxXl/MMt41/WhxoUp1HAokvGPqFHlijJEkWdDLd+95fk0tmbEBV6CxSlKh93pk7i+8h0JEcboum6UCU6znoSV5yV5h6KEYRFLjTMYCMyCId3vVNcQd1vD1jbX7otKBpiQUMBJryWcrIW7l2P52Aly0q9iAPAw/pjRhxo4h5aPyegW8dK0a29mkIt2cNJknA5pgt4OjH5ARlOC0CgjHOChkbWUi/IZlDJbiK96yP9blLd3OhzGzRXk66uzSoiI0UfOp0TJIqjLHMPWzuIABmgjc33BrjOso+H5fOL96+84jyee37+CR7MOqALCsHIY01k5AymD87WuZ5W3iUXnS2AlTosDYIaaGta2vmUGb4I7apWR5tx61u9q+E9ATxQgPA6c5xOtNR8BdB912wOjdwwe2rmvdXz//g2tNby/ff/pgCcHGfXn5fWrnXh5OeBwsVJSochy06zYCfq4jNBLCXKaeE6YzW5Ek2AIg1mJxT2LqbF+HzKzmUAO3M5SSSKOGxcgyMmd/8YBKY9oWxMgeGcnL40PJ9Q23Ec7XcYcFJfHfj/LIGHaAet4I2w832sfh5zsF0+uU1B4AhYCBXMv3kh80E4ajP7+ieXPJnNdnoQztd7EYqf6/iICFKJjFGItH/OHyAkDqq40Q3U6aHpZmsDixXx2UvoPj2Bz1cdAN92QE6H3jpIS7nuOgHTzbrzLgPisZVJi8s97BaDgTYIgC6MkLevrzGhDM/eUE0wz54brpZAg2oOUrROq6s0R9theMjYL3KaUUchl+1zrqw4vtn5BhDpUDt03xnvT8r5q4BWL7Yeh1QfCPj5zAc09vKxfXJfIz2N16bH6oqt/tFaHeMJCVFDg42c+AElukxEBkpaLyIfPIfwsLOBigEkfbDSf9+niXmfD7+8SWLw853wmEGmWdHAgwzh45kNodYXJOesiB8ngNNT/MX1asstEfUYPyLDb7WLVJk0BeXAFhJCyB29OgAaEgAGGjBOjHzjGV/TR8eyncn+CkRKQ94xatRsys+D98QAzY6sbPr18wn/761+U02cA375+x//rf/w7/vYfv+G3375icMPtlrDvQN2A83zg7791jPOJx9t3vN5fcN9v2MsLyme1r7ey42ANHB3nGwjAvu3IKeNGL8pNhAJCxhhJw2icTJyYnZkcOMpwPGKdX88umuVi03fzHerZSLHefH+KlvITkXH/JQPErMudZeTO7LwfwR4RN9PJ3m/Xw6wQI080WNaUQIOwq/3pMpXFG05F6BuzlO66X0DTJvD161lizmv1Ub6L7Z7YWTJl9nqkZQ/9WQn2/1VNzcUtjU04/07rGzEVvw8kLW900MkjuV6XqETXq2ReMpIAxEwKLHI7F9bF4VvuIwwed+jS/Bstgyrik7Q8ABYdb/cR7axjgesVf8zamoudzPhzx2HlAgHUQKvbC3Ip+O///f+G+17x9vv/xPme8Dj+rk6Yp+SRK1C99rYlgDJSLhhDcPaE1huOod2fnud3vD8FzxP49PoVz+9v2O933F9ekEoBlYqybyj7jvv9BfLK2PYbUsrakrl1NONIaeeJ0U483h84jgPfvn3TiPvjHf08IeehpTvnv6B/fkX59RPovunmMxJfWqOGIgsyvZpZH4T/8vPFaXE5cfnYP7DS1z+RGYDwtanKJ3uaIs31MCftqpMIWBDkeQNuzHzcHB5RiY6O/rlY92l2DYNlyHjHs8szzPNouaC2kRdr00qpIFFGrnfk7QWUq3LeyMwYCOApnoPMmv55TCB2DqveIiuPu5Iut/PEeR4616K8Zzw6hI3YWBw4NHfOwKfV+tfcQnU8YOvHywf0HR7Nk4u8m5G8pc487pnDCFOCeNgETeAplCUAd04zqRHDloUynFBWBGKRG+XnUeBFzIhT55SVC8Yy/yCkqeB2Mb28j4ODbuKeDCJryp8RCnQIAFgjA3C29HIjJAxyF3Mf6Np+1q/hIE9zviJrfZuzZvqlVMKA9ZI4iUxMA255gEQ7IRF3nVsmLTNGiuwmcuDJ7suG9wI6AW4YegahOigzpd7ny05BmNE297/cAPBnDSNo/RcLqMN2Xb0GiwJPrZ04zxPH84F2PNGOJ7g3jPYEWYNxUZIfUM5Tj12M80XGQekVPLFaM7Z83XqWVzZ5Y+t1KQd23XyVIK5s5975QcIItJNjaxhdv1ym+3s9E6r3hsEjMp2ejwdaV0L18bMBTzAdRateBMKa+jCQayYRAMu8mGAgHKz2U/j69PeTf62OHADS0ATbOR0AGAYAeDfKAJ5g8mnRUR6PXl3FoL6Er44J+Cjw5EbxfKq5Q1aAZ9lfWExEA6/mzv3BGph/WId8uY+Ph2MoMygKIC02JNm+/aMTry/5Ag+g2a2QOUA/2LGLaCJZ3+cwh3YDVQjG7VHCMC4iWFnsxzFzWTTHdh1x02NY97b+JToOsyWCsWYckTVzKSkpefxH+8UOzaZKuFXNAHFSXGItBR0yvzT4kiJzTvVQijGPpxdfm5axtDwqkZbceSfUdB16U1/6jG7jV6h8fxWgJA08tSHRAU/X8WziEZQI4jOyLPJ17v9gafyMR5gRAQRcfaILKIV1f/74d/galDlhkXEoDupRnAswB3/deh+uG2vf/dAfHgBx39PH/GDbX+7ZOZUU5Fc7Z93fS3AGi31hNgiHDS5IThdkkp2tQgZeVcRKbzLYSnulxPl1m2u5mOjmRB9PdD5wnE8MHkZFoPy+3hwgZ8+GZIzG1sio4rbf8fnlC46j4dFOPJ8Nv/32Dd++vePxeCBXoG6EUpSLrfcT78YrPNpp3MOaTbXXHWc7FZR7Wle8fuBMhD5ODGk6WknLxBKyBsN4rSUhKDvhmvyhikPH1MoRHVeQdWUtthbRsm6cxHyxncVt93lOcdDLFI1nv/v5VuUxqX1MB4Y95Uairck011TYfTC+s1j65luwu2oS616fPYTYZfH680wcwt67lHbazcYanUx0NharjvXxmgPzB3vhj48/DTxFCd31n3kTgqsWjJudD6R1m3kKHxZ06ROMAWJxOPDkHXzWiKofBDKuIVyVWti/Rl67AD7q8+h51MGkGNCLgS9zEYY2WuYA9v61DagbGrMMbV3M864vP5F2BRFBlEE9vr9hjIbWBIk2/PXX/4Zz3/FtvFt3ut8AYSQe5ijq8+kmBUoGuJCmWpMWWjyejCEdrT3wt3878fXvFf/xb/8TtVbs+45UCnIpKNuGuu+4vX7C/dMnbLc76u2O8zxxng3H+xuOxzva84l+HjjP00CphjE6ijAyBPtWlUtCGmQ0vD/ecfQD5/GOMYzEDpMcDiEkzUk3gZyXsRN8mGcgPh8xW9/HH5AhCsfHNp8Z82LGizvAWidLmJlLMx3Sjdy51+Y1LpFUNz7X5ULz3SnBuGOs3jcTyNJgkQSUBE40rOnsVv7kvCcil1Xk69/RdFCCpIz901+RcsXLL/+K7eUX3F6+IJU9fMMPt2sZ/pNr6Gc5+nnaftcSnmToSi0FJIzNyn5yydiKEqRmmu64ZgNZxiLBoh/Q7BFCyJUgyKcr8OTmhsiskfYMHTdQXNa4TOno6NLR0SEyM2u061eHdyz09FrPhorf7W+9jzCw9aYLKiyLjnPMOYx42lWO3pMBHZiRyAlAeFTcDWyJ7aX7zz0mhmZRKARSxMotxGWx8sgxiTkgOjeyZXsOJYktSTN3uJ0YnNElg1CVt4BSdKQjCLg3NAdURTPeuDdgdCRoyZZkjZQKPEau85dzsq88O6XQjDaF7oKEcUipg5gNiPHAAiE7/8AHoznKidwIybpCYk5Z/kCf6fpV29r4sYzb6Xy84Xw8cL5/V+Dp/TtkdIzuGU+sLcRrAXLRtupZjByXEB0bLocYUKYds7wcB5kh4lxUI0C6yAY2WT5LE1Xw8dDoHPGUV2z8VUkm2NjOA8/Hu+qY3kPeObA1uzk6t9M7etcSu947ns+fj+NJwcy1LTSmz+OyWxb7Lz6n/2YMZMyuPwoMqXQbonMzjLyVYfsAQIHbRrpENGvOycenvgttJ9PxS2ZLFQK2RNgTsGegDaCbsT1EIAMBMKzBSV+3bTQFqMUzINkyJQWeMTQ5wJcBgYNGJpMtsEWQCfAutlnowVVpE1wpxkvr0nLM/WL+fvBF6YeEDAESIS3Z0ZHIrNvN5NLVpXW9Ih/uUdieIc3PggdAWj4v3BVwJoKTbxFmwIncdvZrA5gRWbebteQ8Je0c2W3SCgswlFR+yi3g0QSpK++elr2p/GhjdkCU9bkMGM1QWzarYoAwodhDiijxvUDvp2Qx+1Cfp7OgsZ6/HdpMQtC1FG9MLrDXveBly+h7weCCe03YSzZwdMrkRAQmKLm4EA4r6zs6o/HMDuh9gEk78B0daF15TuekLzZrdJF039BsDHcxlq+f5fD95f7jx6D8R3v+mgk1wYSUCyC292VWkUybelJyeCa0XQGLUJnnTqb/fa8ttxXl7g4MmQxZn0HCh5hT7XaT0x4ky8LRcjAYeMFgNAVMxwyoRWMYaCZeMrtQZc4wfTk7lq2+qnd4PI8TYzT0DgAJSEVtr6LBI6EDQxrO8xs6nzjOhwG4uvlzESRSDrRSCC4QRIBad7zeP2PfXiEoeB5P/MfvX/H3b9/w7f07nv2AZEGqCeWWUWpCLgRitSMezweO46n+7fnEl09f8HJ/xe32im3bIcSgB0HGwHG84dm+IRfCJ7lDUG0ObGwlA1zdaoNyP03wQ9dLnvYHXG5OuTpt7yttjL/B5yK6sg+1jZm8sYp9h8T3lSdKJDkbUchuB8LWLL5L8gVkERtTi7PIxCyW0ptkDVay0xPYmvDyw+gyi+mHzPU8S1spETJpdtv6/o+fuYJTl+HyjYM/e/xp4OmCIC+bzTWu3tQ0VLDcoz2eGiQ0BYJALKVZtPtH3L8hjKDryRalK34zuqMXFNqFAqZha+EuTtoi2zOWNDg/T+oT5alr7mxcDAlzxFawS8GthQQ25QAdZRm7y3ERhIbKjoHWO97e31UQdVW499srChjt9oJGgv7Mkb4pcOEI4yoyYAO++Ai3QRjckZ8d/VAS2kSEN1ISxq1YqUn9ADx9/oJqwNNxKMj0/P4Nx/ubltQdh0aeuyLqCcC9aP18yq8oddcMA+44DgA9oZ2H3otliUwDcZ3eaUG70HfDLpaBGdqzW8giYOh6Dh3jZeH4CWUqDp9PcaNCKDLhP0ZpfTP6BSPryv548RkvvXFnNMbnSwGLJQgdAsqFgH1JWKWXtRjr0dZZlDhRQtlfkesN2/0z6v4JuexIuWp7+VDIblRLjOHKTfYzHK7UXXh7xCDnDOGMkjMgsE44lvlC6mir+LE4PPn4jBhrFUF2voW4PspaPhg0IQctY4SslsQVK/MAU1I+OFunbEaHf3lHHy2ndbBJMz6NGUAJ/kXLApnZSHITyuhIwyJqPCIRxWViOGQAAHde3Gdxw9m1M811GsvFsi1kuoF+zuQgB64pzcHLZn/OSUsvRASSJJwCJeIewRclkmM/rRxMMkZ0J4HxTvFo+nymHGY8R4Ie5cLnlGZUiGzOPu77yHgaQyNVZljACJin/lgkSAyX7bcwfKa2vGRyhv6TmKMhgDCjD80O6udhX0+M88BoB8S72bnMyGxjSGAeyucnDCCZnJtywIWxOqYWiOHF5oh7SiDRjn7ir7lDFXLO5jmJplGtn4frej+xZzxZMKO3AKx46Dp24nHt2OfAkwJOYwycP1lHTgBqWANw5TD31ZW56MOH4juJZb94JuBi9YQuFeXK0ctQ7EOfGwWecOUzWwwjc4f8Lu0Vi5TTJCYPEmd7x2DfN/o0ngEc5MyWQekltw5ueCz2x+cnf4Rpt/2B+fVHTv4iwsLe0IssfFSujk3RMy92xsUoNgNl1f9hi3y4J4Lur5nkMHXFx/ufKuZqYLt5QHrjQgrqhVZPdJ1wlymLbS1mVKt96+Po3S71HCSCNBQkSomQREFDJESjiGFJrywqZ0rWBx6CmD+EbaUPoOWWet4tqSMp8KzL1UabpSb+WV8PnVUfNpORQ4A2GG24LnAZyigkKElQqGh3RlNSq8xKIMucUtDpHPMaDgAM1tYKfTAGK8/PYLYs5EWeLtmDl7kMvTL15E8FPNmDrYDSn+WCcX2r3ZutPCnWrOmPxVYhWuxg8ozsKY1iw4QjDQQNhh1zn8tF308QKuF6LJs5AIUUIMTHShglbE6xoD2Awzzi9txfdaBrEC2chx8qgcI27NbhmKEJvwYYk5Xyk2CgQ+REGw/00dD6qbqAVADlDKucSFpeGuOl/FP7/oJSNogktD7w/njg8XziaCcGdy1nLIRclNfNOStFBK11tTuycs3u2w37dkMtFXnb8fa8obUnnkMDSb0faOPAkA6GU1lQNMOSlCHW8W6WijvQ5HMwxz5JCk5Tn8+Yn1hDyyoI2bqAfFCuI+/KmyBGIyEg1rlizoikhri67QOZ3+c6TctiX1TI8iKJyXNhfQ7fA2a8a5WAk5Uv5PfME9Nwh/l6aoT/SlPGrssr1j6uf9PfXYdcT/lnjv8auXjchEdDxQaO4oacw2FNd58Tx2EUhtO2ZgUIEF0QBFFKJoLo/BOCAKZrLUo8+S/mYgtF6oYuA0xzIX1U6rFIPgibKJOxBZVzisWjp1anz8nlIu3T/3UFsziucU1zdoYInscTb2/v+D/+z/9TgZ73d2QIPlVB4hMYxep3K8YAHmcLYTQYOHpDooScG3JO2EoBkLBvqtIHV7wl4DjVoD9aR+uEkzQ1uhhvRyoFX//+O6j+G6gYafWwjlejGUeKPmsh7Xay1YyaM25FM532lxeUfcd7H/j+/R3fn0+crYFHgwjjl5cNe8247RtKyeE4slyN6ZRWY3b+FGMpJnpMeKyZedMuc4N1dkqK4hLSa3TiMKIEZBkjpMKNdJ0mm3+dU1dltN7W5d7ckGA3mgXG46KgWxKAFPNAEmiEwJd4dPoTJGJIYqvpnsTNMIMuUY7yl5Qz7q+/oO6vqC9/QSo3sGx4Pgd+//5vmlpuQMnry90IDXU0eHjXxQ8P9E9+CHcDo20tEQE5o95u4FpRLPMNqRjHjyqX3nR/9aFgRykFo5TI2iyWEZNLNoXtEpsDjFqN+1UqRBeORRGpISvRIrq1jtOyCp1LTR1yy3gSWQBoqKyCycuhmU6tNctWIiAl5FoAKO+R8ktX47Pi2CfME7SPDnhmvDugkJ0EzZxhXIBSyxw0gRrFEDL3shoFCaUoH8fMXHU+o1kHrRFo44nJCTkp0WWpG2qtSEUJKMVSxhWos0xUiEb9LzLXwD7LDqRSjIB/qcu/ODfzWNhwfngvXM98+IRbNq4/yCbM9YobrE4EvMo68yP1/RbZ6v1UsOXxhn6eePv2Df04cLx9xWjK7aT8VW2C2QA4JQwijKHcE8WAxFB8NkdR+k2auu/ekEeKk40dGXjrJKoAZgYUe0ctk9O2HtmymBR8nQCVZ5CdxxOP93c83r6jtWbrV8sJeTB6t+/tBDPjabxt56m/93HNNvgZjui6G87zP36vWgNXY7BA+SA3yhgWZEoiyLkrWDAkOHO0kxwCMHDZ4hlPDtB6KRMD1iXRdKcZcvqfg+HOByXoEHSwOvOiIAWL8koRaYaLOyy0ZJaM6Eo0p9e325pBE+LIeHm8sVSYgL7dMi4+I+bwxs8MgJzj0cfWbdP1JhaupjDOaT3xtAd0S9hrdg6Ovy6y3D47QVlaRcl8JsDjIprFuT6rZRempM6q2h80xwgqYT46GFqc6xYSRTapd5obOJDGQO3aup2g1xr2SH3M8RpAlLmscwe4dFNdc/aB748DNRNGSUgkyCT6PYsG5pIHjDQ4lKFd785MoHPgHIKzM76dHUcXPDoH8OQT+34reJ4ZvdeZacIZW0mo2RsqEJhUPx9DAadvB+PobDxmPrcJJwgdwDEET+sa3MfAJh6kMSc01s1ch6vuJnjww2IzP8mxBjQBRIOlj8F4f31m/SSVLaxlRiQEsGcqTUDSr/LR+xV3pINfdb5Bs4U9i8iylm1TkXngHhSyV+0pklUjLGVdDjYBRj5uHdKsrFUdfr1yyRmSE0RGhN1jj7tcl2lPzKwtKKexDA3e2Ps1CGMNnUaL4IwWCyVANs0iL4BQA8uBMU68P75Z5qiYHtfOvLVuyKlgLztutxtutxtyqah1x7694OXlFX00/Pvf/4b/+P03/O3bb3jKifppB3FGHhuIBJxYO032rlUaQ4ExkYHx9g3v5wNMwKMd+PXTF+N9+oSSKn5//oaja7n883zH+/ObDvGWUBOQ6UWpFXDTB4txnJVHni03F4Ta5pIkMt38dZ0eijn1wI7bo34OzQ2ZtpmO9dAs+pSQx7BGNQK27tGJvClNCmCIR4cDmAJY+eMM5ugtLFnkF2XvHKLTbiQA4hyhZreR2ZqDfT1M3EWvMbvIL1tG7YY/lD00ddeip8aSZUW4rtf/7PgvcDxNBaq/XTQI3MtwI2mt4Y3PC6Ldn//tarC7gybrRxwiuAiwCeLIhwlarOjlFgN8wjJx8f71URZWHp9Yf689Z2RBsXfqsWuYszOF2R9rkLU8b32fRm6f+I//+Bve39/x/u07tkzgT3dUYtyIIJyUJ4U7elPlNYa2H382VXQ5MbaSgRshZ6CUhJKVA+o4tVZ9DHWoPUObB2mnI1v0gxLYWjIKEQppNKqSoJKnKpKSkaeMPWvm1F4LasnIpYJywdEHTm74j9+/4f35BLhrdEs+YexVIxmifLdEKYwwj2R4ZNMNLloEvc+rN4GzQV3mchrtXnevKZOe2SGRoq5BBmttbqmbc8141oNvdv0uH5cQXVdTZDYtRheLWOc6QESVyVwHSi4ncQ07J7kZOLmGLiuWpuBMlFDqDZQE2/4ZlHecTOij4+v3NzWKtqIdKvYtyscAB3fV6ac/itD9kx5ReiMSa4hAqLVCcgLJXfexkwZ+dJbH/4e8f9uSJDeyBNEtAFTNzD0iMrOKVazunl4z0+f/v+nMw6zqriKZmRHh7qaqAETmQS6AmkeSybPWeWCMkp4ebhe9AAK5bIhs6ebAezZMsrR8A55yjp0indjZeA1vM9Q80ZBgCdWpM2zdPby0rtampNrGRVWrZhg68GQ+SHQH8qNb57rmwJNFY603pJ4VoOkFUrIBrBhqU0a5nlhpS7R+TZolA3sWikDTrm2OW2SV0rR+5wVjayOlZBw0ON2DZyal+DhF+1zNFivIxbLGkq4X51virpwHOhwCLVMd6wxZ+aBgToG3m52zW2MoHXz6zeVwHvffPsbmzNhBGvtWPkgz7H6G4P35FIRp9dBytH3H9vrVACclzZfeBsiu0w4R5WtwUM6v7bZOpgkI4GmOrSdgicm7yeguYsqjUUcyQh3VVh4QkHWU9Ja/fMqm8cl3ea0Gtjr/Wu9dM2V7C8CptWqZTzUApxFIfD+6Sw/3gB5f+w25G06TksNDkKH8dV6OPUBWwPdPdVMC5kQOKysYwJPqT5gvN0rkdIOERv5AgE8SsuAcPWx/q/NqDQSg5/LyZIROkLCbQyYn3Tk9LoCxhqcMYjvdN8eO4v2hhP06kycZetaTgYfsyrtZmElZwycwPT82uMWCYw9qJqkdj3e+5wh2x8fEda/7E5P/qiTdfs8Szzhs4Li3GDuoLXGLNds97zpXagqwUEw4hCQyhMTneKZ9A6IsUe2jnPyOzoyjdTATEliByARI9mBMfxz4LEk3PFNXW3MYiN2ZsVfGa+14ORx46jHmugkiWDOwZsElA2s2OfY1MunqoynwdD8atibKnEUUTWG6EJqQEp2zZX15tm0M7llCQmanOfdZM9H9vo5THKZ/nDb34ev8nEDgNp/Y/CUi6641bK6v1cfMpdCZ3zAFvhHoSQvfMt8Tzhun8yyp0UxqlE2FkwM6lZ/PyoSMCuD9htb5JgcXkG16Wznp7B24rWOnXuijI9ygCVHOtJQITJq2LtJxtN3moajOJc2Ezkmz/5dlwVKK/l4uuFyfsZYrlmVFbQde7y94297wdtzR0JGvBcQZiQs6K59mt81KTVhg8z06OhiJK9b7K4gIT5crbpcrlnxByQVbv4ev0FpFbTuOuuCSn5FJ49Xsm4WywDMzBbbh5GP7MKk6pjJkbSLklpjwE8IwnWJUOyDsEI8NEBHVCSLoKStdCpICXRGoAkAK+Rdow4/YqJjs0UigiUue7yHub2QqedwW2sZff1fqHVI6jY2PAU7Z6OP9uOL0qit1H0t5d99/7fjdwBMb/4fBXtHRDXDj4vWgetOaSTH+HoRpY9F4oPyI7CmyrM/lSLjZ1gjexmDb23O9JrkBfjyvD+I5lW58Xt8Lj+Pk7AynxsGyMBWud3KensWzvBwvH86Nc+j4DjeLAmi9NRzHhpcvP+Pz58/4n//+7yAR/K/LBZec8dNtQUbHwhXCHdUM68vRcHTG665jWlLCuiQ8XypKSViXHA7efe9oAm2XvSzKnxJM/M4x4wFtRyEFrW6l4LoouLRkzYqinCFJOyS5NX1pHb1W1P0zOoDXY8deG76+vuI4DljfPci2K3H60w3L4q07reNOGqUzvmnuCK0H/iX7fOv7znOlYkfmJDK2/UBrHa9vd8sWqEhEuKwFS0n4+LxiXfT5EgmytXEXc9pDvmy5hqNnMxv6iCZZmJSH7g53cBd1ghobuOAaZ+yQlFKQc7Hf2UrwyHhpxNJxeVKsdAqgQQVCi2XLdHzdvqLyF/znz59x33f8+uULhAX/9b/9Gz58+IAff/iIlFbk7DsH1Qzr71Me/yjHI/CUDTjKOQf/hYjyQ/iuB7Og9xa6SjOGLH06ObkgA94tKiWUXMyp4chOmUv8htFxuQoIFJ4RV43Ef983LW3d7jiOXTMg6xHdJEMvnRZIWKEAp7w0SUwe665Ox3bfIvst2+6i0JRdET8cxON68wTQqAvhGTWD6WHV3Poyn7vUJLOKKRUgKW+W2NzE9SxAIFjJo+mFaHubtIGCpl3rmAs3SOvgpllqxFPeh+j9iq1P1xmJFgXOc7Hf3nnLxpYF0rV0Ap210xsJspOGmjXi3k0ubDc0McTKJkkEZLYw1qztuo2cLj0cdNRU8xagy3Ec4N6t09uB16+fUY8dr19+VU6kl6+a4dRa8DIRRLnjiAIkchft0d4OF8wDgH7KGotNHw8GJuc67K5lQKVpjYxdxDQRq+s8RxdT+9vbOb98/YKvnz/j5etX1ENbPffeUOuuXERd51dL8Mz5Nl3vAMX3djhg6Gs74IPpUWn67bbc4e1Yv6xcZG4vSiKABc3XMhOQtWQ4JdKOXzSXs8N8KtiSVxnO4lkyns0nkKTAQ4UADPTGyCzYWFAFSvhdNOiZVQuLaIkYnUvpgsIjEUgsiyYhEhkigPc4MNn3J8c/7pvIsgIQJwhwZNJlqgJ0nF2uRiw5+X3+YbsGWfngvMI82DxJ58m5HD9EGKVxGvEaaKXKKwA1U9r+Mc94zr5BgnN2djA3xaD5XJG9bxkbWa/fWbOtIWNeyR9SdCOSCFiL3lBNmgUHm8fWB6BJoiVDwSkFxJiwaCnb696QErBVzbq7FAoOpsjAIt+wABbjxmtdX2MRHCx4rR1f9o5ftoZmGU8+pI2VFBx2X50VXHpaM65F/cqcSLv/CfBWO/Ym+PnecD/YMqIzruuCkjN2EA4kNIMGWu+orWNJ5yynMb1qowPEjGPaTMX3dnhWxIgLv3UQKS/t6Zuin+/UIs4c5dmTT+XuNMgyay2Dyv9r/pY79e5/eelwbGzROdPF72vWsG73HJD1906bb6Et/fvfel4EJYOQdfz178rQtXza/GMwK9DU6h4dxlk4NpEzTL+XglQEKQtEGjo3NNbyfJACyYkyEi2gRFgKYS0rnm/PuF2f8fH5ByzLFbfbB/TesW1v+PLyK/708//C67bjkANYC26XT+ovs+DYN+z3DfXYcNw3LfnvFSnrfejGhuDr2wtqa7iUGwgrPn38iKfLFUyEy/oBe39Dk4rNeKESVrSl43n5iJQvSJKRUCymJpDx0PlQ++YaTYNNlJApmb/oMbhmy8c8hjydV2G4hDzpLtfVEM22Z+162VMCd+P8XCy5wv0h37hO2ZojaBaWrws9rxheIpO8j9jB4854RgegQtQlANKEhJxmf883Fn1DXYIPy3nthg2cn5XOA2F/jM2+h8/9jeP3l9qZMVXj48EXgujRgwezO9+4gemmZDi7w/eU8RkaT+i1iY8YMfx7EwAQqXI+ADFA4vb74QThP7x7/fR7fopAVO0/NJDIMByzQxFjM/59VpZiDosFqNzR645je8WXzz9DOuOeV1yXAn5+wiUTnovvDivZ4de9Y2+Ml60b8ERYl4TWxDKdXNkTjiboNmqwbIGB4APctRTM5yeTkYMuGbd1wbosWK0DHkpGpwymhNY6emPce8VRG+69ozLjdbvjqBX3N+06tJCSR74mAh8LwILFymZSSgpoUUIqHtDMc4vILuGlGNBk9x2lejD9Qeidcd8qam348qIcIK0dyCnhdl1xXQuergVsqeTJ+WtM1CE4KyDxdudneYg5H4IxZNAMCUPJMau1223RzpgAaPplKcV2HBR4KkUBwSUb34bv5ntQEdez4A6aqdWaYD8YL9uBrTb86c9/wuvbGz5//QIA+PHHD1iXAoiY0jXyUFPKetrfp0D+EY5RFiETRjNKm1CKgjDNybRH6U8o1qm2P4BnB6btNbLsHYHtZttuLHvLU5HQdVGyod+Gk7N6edG+H0bof1i204HaapS+hY+jFwfByTL1OT2zJH5IM+l676DW0VpDqg1tHSnuvsM9YlyPxgSAt3QdgZnqz/F3aOkgzh12gTEgeAeRAQJFeaJGbrq7OboxJRtXB5rIAadcbCJTpJiLdC2rOz8Egr3X9ELsDAInZ2DyJKYg2/RyGo6Mgy+zbImIleIO4l4vg45y3Vl+YEHUwzkCTOFunA3ddhB7dHzbN+1ct729otcDdbvDuUv0/mDXm53kYX9HrtPD4U6UyOikiWFj/ZwgzWyaHQ0xwEkSGz+Wcc05KD7JSMy3jDFk27U99h3b/Y5tu6MeFft+1+duh3JZOAmrSIimBrc+199f4CbTghse1myXzp/3eR9/63hRgLoOIJqsuPy57Nu6K8lLXO16FiwPLenXkrF0PG4iPV8HVCcykCGorOVXZrLgScduQFm0dG/m/DzbVYQO/+ZEu34fX0Gc3kGAWTU8+IiP5xw6e1KFf+0QGXzkswml06+4zrdPR+Fry8PL8BJCd29Zy5CYACTr/mQNF3y1zw9GgJYZ2nfPtBCub9UP8gBmztqV6XQ+dyUNXU8MtDTeh0yAV9yF+frTg3UWHBAkFnTycyoA1cU6cdrE+rkS0Sk7iaF8TJUFe2fca0frgmqcS0Tqz2Yi3I6OS05YEiNRD39vYfW1mmj56duhvvXr3vB2MC6iJailaPlfJ0I3/87L56LMfJrfWGv212Ng+90fpu6zKYrZ5vkxl5d5QJ2M72s6TcjQ/O+QChMyDsK0x5sYv8KW09iccZLyeV14XBrx2qOPP31Or/Led350px/XdcSuJ70gw8+cf8w/8HIv92e0YgIGUlv2fgKImo0pG58Uj80o8qzvjJIyluWCdbnhsl6xLlesxsW07Xe0poTkb/cX7K2jSUfKK8p6ATN07XYGpYYupJvsTTOgCsgyJBXEPpoSrG/HgaM2EAqW5YYLHyBK6HvVTdbWcEBQ246UCnjR6FUHdPgW6md4LO6bp2Mko6rENi4kGViSPGstDZ0K93nm+fOyc9ej82YMIru8d/WNul1bG854RpD5tfZ9sWqbBCulDKOmZXnhi03A0xAzf06vQJjWiPtannmHMRYa1yCqtVQWciiowCOmhx+2fWAfepfpJMi/F3QC/s5SOxEYc+BcBDBnHQ3C3fGi/ydZa1zP/ZIRqEx/DWCHRjqczFczR8qnXEaA4GnPo3uLWBerFM7TCPwkBAeT8VLnYiCJ83W9w1F8OHZdZ+XpjhqNlFsnK7fveWcGEd1RI9Lg7+l6AX94xv/xX/6ATxdg+/y/8Pq24ZfPX3C/A19eXrCmhA9LURJGYjQRvDVGZcbWLFOACFtlvO097ocIhubrzqYHJJk0QyqCHlHk+nZZ8XS94OPzE354ftKONkSovWFrrBkZzNg74+iCzTho3jb9LZYuuZCm+l+J8ETQkj0C8nZHPzbc9w3HBDiRlcEECmsBoZjg++vLogBUWexz2Ts06dLuArTe8fVVga8vX1+sdKmi5IQPzzd8eFpxvSRo/x7riNUZrQm2e0dtwP2uIbMYD00oquSZLmO3ROPg0Y5U3wdqFRyH4L4z7lvDdlRse0PrHa17d7JBbr2uBctS8HRdcVkLbpeMdUlYspNYeznLcC27CH79/IqjveD/+3/9O758fcXLcUftDfv+BpGO63rB5XLBj5+e8MOnZ+XHMSL8WT5d/r+XQw0bzsS2KRnfBYGh3d2i1TzrGHgJmgyqaM1sWhY1+tZZq7UOgFCygkyamdGtDEhL5pQvaZQ6cWfLQmTLrjKwoWmZWG01Ml96a9bNztJ73Ukh0kygWR/LAI0DxDevWkSzKgWEfVdiybIU9FyQnLwy9Jvq1uBncp1nfCbiGURugF1/ymwCT5Y83hCBlccNvRs2wfR/IrcnuiOYctFMDdcHgBFu9kg5F+5K+Djpcu/253XoDnqN9u6Y7tacUM/iib+nsYQ7gqx61J0ZkHK3EVnXwxQ2RES5EHnaXfX5mR0LnkHFaUC9xGy7v+qO4usL6r6jbVt07HNHhTB0oW8oOCdZ9s5/cerBbxH3EZf2nbExeQE+acQLYAQF3caXUw/bMm8EuSBqxx51ukSgz5s6Xr5+RWsNv/7yF3z+9efoUlfrESBc6KUHZ0dt9shw/n40lx/2bO9fPq0rF5sz8CKAMFJirBlonJCXRfVEIggDy8lvHf5NzD4PH8vb2HcWDc7hnFKsRIXTTQrIeJzUByIgyrgoGZeUZUaxVUqI8U2dthoJwdV0woc948lAjkk1wlz7CDL9vsJxngEif18skwrAjByofE3e+Dzekwdr2O/pOkQeoPrrgzcLjzNK04+Nlb8uoMFzk8mCFUQZLYFQUjauzhLcjeb12mzo70za1ML1QoRYop9ZuCIJo0gFQTtnciI040rcj4pmm2CJCGtW+ew2pt5opiQfO3fhZcab9dFmd9pkq8GI7kkz2JU/SZS3KTFej46aCb0DjTWLfO+M2jWrnwE0AQ4BqgCHBXeJgNz1zbUKcmaAOliU32xrogT4idBY7+XzVnGvjF+3jq0JPnHCdSVcVqDY+Xcbk/0QtGoZyWnERSFew0iPv2WSMThn6fdzDPPu9sL8Cn+DzIbmM1ge8ZeINRhJhlB7R1WTq4DBxb8YYPHQgSOmPAXHEbfaZ8xuefXOaWPFN9LEQYnxeX/Kk2kigiuYGaIQGfyZ6ieOTUm9Je/gCjhvEYt2ctVmG80yoFtk5KeJ9yrI9xOhLAlIHUwHmA+0ro031uWCnBdcb09ISTO+cypY8op1veD5+gGXyxWXdUFKgtbv2Pav+PL1L3h5/YL7dkcVAneNg4gTYDoo0YqcG1LaoQWCQDc9kTxjMwP6n4zWMvY94TgSjj1jzR+wlCsoA5e2glOFEKPyBjTBvb6COeGSni12vdpGZGwFAlA7IeRxjHV1hgSNBqXRGGg2mMkz8sxvdJ0oYC0u8M7UE8DFwkbtoL58IkLPjOxdtK18UWUrIdlcqzjrRih3mbLIZYCtbsNPTs/5dYFWXrgEhf+aBmDqZ3B76R2vlYvbm+pkUEnwDtZxyWHiTL/rXGfjgJz5WX/v8fuBp7iJaRfkUUW6cNn7Fv7A67nJHIqTwX846PGcfplZidNJ1eCcGuZOmgzhcU0337L4s/ju0RCkGWGk6UqzM+EvjLGwS4h3bBrXGZM4KUdAvRROsVtbiqbw/vjxGVLf8PHpAmkVf+GK1jQYLZTRlhVLIjxl/W4VLRNyfUUQNGhHDx0vXXApuXLQAC4TwElT5NmDYFPaqwCUM8q64nK9wne9au/YWsdrrdhqw702HK3jbduxHwe2XXloEmsL+ucl45ISlkVL9AoZl0NvQNdSSiaKDAYNpJOS/RIFCbMY+ESWpdVKtvTQHOV3hrJpyrMAdQKevr5axlNtKMVRfqDWhr5SeAXCCj7V2nEcjG1jy06hINN1gCtZSUJKI9ijBHByOWBkTmhd0LugNsZRGdvecd81M0zJKLX8LtmOy2VdsC7F6rdXJCyAZKTVuqBhUpgw2RXCfTtw3xv+9PMv+OXXL3hrb+jcUXJHScCnD1c83RY8XS+4Xi4DrBuL72Htfh9Ht1R7bThGGiBNxLWxoF13RQt5C8Bk4pcz8NO7jASQ5CU/to5a70EC3qw8rhtJee9eUqVlXN1AJQeoZPoO83jNbsDWSUQ15rxN8+bqbtaZou6SAhuDQ0oN5uio4g6YK0r/Z1R+wFWZDHkhDxNtDcmDmp3mQuMJOynhLH86CSOwC6D3MSNpAmymrC6P+oI/RLw0ZDYfNP3vFOf56EYA/xg4Dida9WWy1PjEqp9StEfnKBWKXScSJJwBoXlQ5hJtD2jdd9VOhl27vR32Uw/0VsGtW2aSGMBlIDk9/IRTcwrpv3GMkfJgMQbm4f0IJMaHofxwsKyJoaPcQddAd2x0OIhXj4rjqJrtdL9biZ2WHYqVIPr46PkogvhxV98r8PRw/Jb/dAqy/EXbbYWSNedktAcphXx7Qw0xeYt4WAxeJAmZZwObgq/Jxlu8s7ETbSc9mXM5uWJy0m/XKbA/IQZA2XVPa5ZUrk8P6utrGotYy7FW6XyiWR/qaYeOlPET+g0P78eXJ2UwT4Y55hDog6QQ/+me5o//xkT6y/Yw8vA9/QxZt6OhyzSuS7GB5bpOnBvS/cysvJzLuiKnHGAgrJQ/N4C4I7Wm2VTCSpPHZCV0jC4Mo7w00nGCdleS0JVOEg8y/jDzT+dGgPPhwaE/axMx3iT98TK5oysdAolmCrduTTlsA88hNg16tfzP+bSqANkIw3f7KV0021kQZabNzve6d7weHa+HfvayCnJ330GznbyrndvzuSz28ZCHf8s33vxu9ZcNi2YNmR8LhE381uF6Xn87T49noHu040tmzMt0BltGk9Unj0MlfCW3Tf4zSphSyPD7iXF7Nnk76uC8fw5M692QAI8dXdfGMBmR3Mh66fDOrp17ZAd7TOZd8EQsto4kD1KOH3SwtDhfSQtyXrCUFWR8mYkKSl6x5BU5L8gpm35m9H6g1h3bccdRd90ElQSWbDrUNa9zBBsNAY24zRMHvFTY/QFmoDegNULvhLVos5hVrkBiVOelREfjisYHMh0oVEFYdVR9o8tkQO0MIeq9Y0yH6qZZMcP1lwGJ5jvqpDgIQ6fveayvWWR6fpcnSQmqeQTUKfgVKUXAASIvq0wBZiZWf1Fcogm62fDbliLkbrZZwzD6HxjnMCAKglPsMmf+qW2MhTF8PDdwk09HJBBOELIOr79Tef1u4MkVgy/iUBS65aLGCQjuhblLgSuW4dDoLm6iBCrnRfqYgkkTiOMTL4FGzoOin4hdTxM4d1gicCMnh0Ocw6/njq2noGVLQRslCrCGJG7o1aHXxa4BpZdWDMPrxncEha4MdcIBEdado/WChI/44x//G54uV9w//4xfv3wGScPrduA/P29onfHzsaMQ4S1pxtKS9XrXNMgdHXJjaFaVdjTxjCgjq5tk0wNmf15OCY0IG+uuT60VtTW8bhvux45au5I22gIlKNB0AeO6EFbJyAQ85Yw1Ea5ZuxIkd0pclnzHolcdx26CXQc7qBdziiss9XZAROjJFZy+zqLp/bsAlQVvtaExY/cOgKL+VTsaji3h/rZhIUbdCog062DbO7583rBtHV++ViPFRQRSKbhmFHBKluFEtuBzSihl1M02ZvQumul0NNyPivtRsR0V+9FQW9OWv6aAlkVL7j4933C7rvjphxs+3C6gj1cFPaCCqAEeIecCyQV/+fwLfv78gn//83/g89cv+PBhwfVS8F//+C/48PyEf/vj/4anp4/4p3/5b1ivT1pnzC6zo2bYg7jv5TiOqustjfT8nDXPDZZm7MZfWNCNpPpoo2sDyHiDuMPJk2trICt/yqXoDoJl1bXejBC5G4hkANMj0CSjK+e5hEidHUpWBooyxUbuYA2AnI3JVaa6cH/fATKBGNeLZVex8wakoQtNxnNOIMmQnuHUlhCJgjsGIjhy7Ti0pDsjxnkUOmfs/LuTdjJqERxZrbm4jpTgmPoWaOLyGiZWgLn7I1lA5iCWE8OSXkA/I4NvIcqQHq6gtewdUiso9QCBI7OoFKSU0NmIZ6mBMLJ8UslG/r9MDi5CL3mqfykrQA25LZaBqqDT/fUVdd+w39/Q64FeK0R6zAE5kmA373bXwfLIJlZBB3MDQawblZzk0P8d56aZPxGT8+Fj9PC3DNlUfdXH7KWEZNmGKSfkXPDL15/x+vIVX7/8iteXL6gGOHFsbT/oI5dnGn6JAOMZv6PDs3EtuoCuK3vPYxn7rMCzlhmNOwobRwgaRDZAUnAKdpBu+hTrUmfAUmVBJzGAYPhjrkOipAjqlgcvhDnWtrGNDC0vH5WtpKW0ySER7UwW8goJ/8VJvEcqk8eaJmcub/4f8UE4r10V4cF1NAPKMZwAYB3gggB7tn9zMEsUqsrHG8BciQ34bMnDuZTEKjTVN4MJGuMV2X0ynjMJaTdciwvExjqBcCnAkhmFKhLGZkI0orBrL+uKZV3xxz/+F9xuTwEibm+vmj25vQK9Apv6ZUfd0dg7ugkO8xMyaUZ3Tk5qK9NjaGlNAOiiGcciyjc8Dexk84YWz0kz8b16oHXBy1bRakevHTkRFs/UB7DXbmVxCp4lEizJeJw809TsWBXCWwPSrhtMjYGjCy5Zgiv0sAyqX7aG16PjXnVz9/nCuC0yfDxZwJxR290yUVzYJcbhUR+dIpYpVvR/fAO3+Ic90rwwJhvicZlzSs78v6fyu6QZIpSS8TYCAI3KmXBExi9KWp0xbJJ/fvqQHTKtLY9KEuXByxiABMYk+eaNAbZRVh52PIzm2QZO906iHXrFM7jMDwwPz4AmEeM1NB9gLjfPuZzAECfzV10pSKVDqKHxhs6HNYNY8fz0E3JZcLlpDJCTVnxo/1PCVg8c/cBWX2DeJl7e3vDl5QvetrvpAbteY3SuOh6S0PaOXgXCpGBWYaQCLAshL4RSlEMtY0HGAumMeuzY3w5sVJFowUILLssHrOuKgxcwDmtAQWh8B0DI9AIkQRblFyZZzZ9yv2/W1wQhts8hwJfwl8xiSBgZGMA5cIRhb82vnbS3+ll5fMZmXJwn1sCdnDLKsiBHMxYoaONynxJkai1w7rI8iblImLtYXiIjk5TUkEUyzUng3UU0PjNK0zk1EceBzHiSIFI/rx2e03vl/09d7QLp0z8m5M/JDT036FGRBB95LPzYqU4YK2U6/BzjgmMcZodCpkGdgx6dhBmh1Ikicxp8IpmHfMZ9TcHQ2UUYV4g5mcckvjF+03zD9mUxpzH8JA+2SLsKoCx4fvoAaRU/fvoBJIxfnm8gAn553dHBOKpoS1cBFksNJli7YzjW6pCO/sGA8wFbFykJx2t2Vl3Qc9cdL953VBYcR8VRK163O+77HkF0weCB8nvJRLgQYQFwy4SFEi5JOSN8JFXF+wIaZU1jqIZC0L89e0tfYwse2QwZwzspaZndxpqyvXdNAe+W/RUdyyyzqdWGVhNabRos9o56NGxbxbY13N8OA56GknGSY2/v7sDTHOyVKdjzneGjaZeydjT02tBqQ60NR2vW0cUc/8ZGcqkZbberdpnwltIng+pGlQjbsePlfsd9f8N+3PEpLVjXjB9/+IgfPn7EH/7wB9xuH3F7/oBcXFEPxRK7L+/d4X/owzuckSv3UNzDgRjHKDf1TohiUYQTo7rO6w5aWPc7IBkRspbI1aNqmZRlPjnY1Lz0zjt9ueCbHtDDQrMExO4gjezLARKO8qNzFonqldNrgPEVWRAyPZ/rNaJJrgyIiXbGgHbi0GHSMZkDQNdlk1aO93/L+47obHbQPIwRS6CYrz+5cDTmjk5hj5x/KJmhHYTX474l9OHsxI2Hms5qY8qdbUfIOs2YTDjvobdLd1uZRcBEKICWDVjg75cKU+eObEpIonwtRKQZP10dz2rZTkokro6pu0IBRsdcUoBpY470mdwGM0gdegcWQlYmZ/7kcJ8n89ECjr8kxmzIizuG7hDpbm2ihFoHkX5tRwCpZN+nd9ecZMAlgGYZ+H4OT78HHl2/8zF7H+GHyZhroAFSQKmYzaRInfeD4fpIs6Z9Pfs8zuCTAGCSsTHknj0wjDz7H8OvQoBPsUqQIKO0bFIhJ9UoZ3GM68Sg2LsmaxBzvYX8RqY4YzrTpLa+4V+fDgrploegFQ9/nG8pruEPI/OX5gtSnNt1+knHxnfVViRSkCanhDUDSwZKEiQyfjbRjRSy5jIgQiZgyRnPz8/48OGjlXszMhjtyJod0QjcdzAx9kP9pcrDNgJWug4K3pShe8jW9sjE0owjeRjnAQg6huBTf6IxgF7/aGycVgp6RYMjAY6uG0VuswmDz0k/5tlfujnZGDjsnE6ir7GKXnNvSiHxejDeqvqRzstIwOBG5QxQNvveMKGsJ337rRjn2/L1fR5zvOi/Hzf+IVMwa4dTbdC0VoF5HQ7bP4MDo+McYkNnju1GTDjdo5+ZhgyLnZgATO1nz7/dX3JLnMZ7Y3VPfov/b3ouD+xn4C3IxHsL3sdoWCNilBsG7rlaINFSriSgJBB0MDdo1hSUA24pyEUznhx4cgoWgaB2bULRerMxYNy3O7ZjR+1abstiHhMLRDq8dp4bg5uX3hiIR9roJGVbX4mgtNdWZtYaeu2oe0e/rSiSkGgF5QQYX5RAybtFOhgVjAOMBWwMa9pvM4VvMY/0LCOhju0fIyIdseaY3zO+oFlROtBhoux6pyqnECrzsTwbOItRERE4sWWne1OUM8DlPXwcePcMv5Opmw968O/efY7eyaH7TO+f2x9jvhnBzLX27vCx/J0K7Pd3tRPb6zaeo5SzTeBYyJBx8RS7Eeb8tAZv0e01hL6bq4twDCxbVyh3nLxrFJFzQ+himI853pFkDquc1ftcs+uDHm5EeBwyOQoKWsxQ5inVLmpz9SqJBvcIAM1WIArkzYPF1uz+bey8BTRTAVLB5flHIC3443/7H3j6+Av248DHr1/RmfB2VPz5ZdfSrWpj0ToKAdek3bquXoYDBaEOUYS6YjhMYRqnIMl3rgTA0bSOf98PlHQHd44OCpl1oRMpsHQhwq0krCkpbwNpNkkmA6MsACIy3hSMzKfhKAhOC8ZlKmZFbE7MUbUxDpDNHWFRoKd3458QI26zEr41F5RMuJaMhQht69io4pdfNwgEe+u4bxW//HrHvlW8fNlALFo6aPcNO595INEVwUEnT3f31328mzgI1oHekVpHsawTQMBJ799b+3I3oKoxWheALC22FFPk2uGLknYXrO3AUd/w48cLPtwS/sf/8b/jhx8+4b//9/8Tzx8+4unDPynglBZIEMPNrdXlYeS/j6ObUGsLaEFbVI8Pd1DXhANDx3GgdZX9zoLWu0+1OvhLViCxKgFiOw5op8UFnTuqlcm1WiOVVXUZDz4iYIpE4EiBcYWZ+05qcOY6bbYdHQaHs8vMkO5Ois2nOSgBevkcGwFlqwcoEWqtAGDA6XCikm5lQ3ICadqkGl5xXTfiO3eY5giOprF9eEQ93NDODpf/TzB2DcM1IAOIOM4tBiSJfe496ObXJYwuNKM0N5wge2bdMFHnDqyAEchSxf3ZmMHSMBIKLDuMEoR5lAQC4bBmA5o4s31u1PPrx8yBTNlsrAC2E9aZtavhdsf99QV1v2Pf3sC9QXoDCJFZ4DtOCuacd9ojdBXrZmJymHNG7sqrhzR1ohUbU0ik/gOWvXw66QApZwBjgFcerZneTzpeLhlk4H2rB/btjpITrtdLzImPzfu8Ab8HXyuDU+p7C99oen73Wb7hd8ZTjyxHRmdC7d24mHbdJS5XUMpoyNC1WtGhWU4AoUHXJUX6z/BxTuV1cLJxiayZbj/WSBK+s6oAmHJKsYzyi5wVPIGQkVWLlix4UEoAedMP+Ms05PPk4w3fjEIn4HSuGCuvufAgwsR0uJU2yidfmuxUpmPodNoxKa4YSSKLW5LrD/dhhn4ytaJj0+exM39DzuGubw6UpSDnhOfLgstS8MM146kkXNBQpOPYK3rreN0bDhbspBt0t8RYM+PTJePT0wIriMQNC+ohOPIFvSVscqBWQn17w9EZd9scE5PDSyGkPACgnDMYgtTldK85U8QGmik16WYZG7G+mSpQnbYkzcEAs2axH8AB4B72cIDanoWn5XjqW1/yAObCpoKMaJyM10lt6tGBJbvAAXcDnr4ejK3phqzzbz5fV+SSR4aCJM3YbwcSMUpWfqs8qsaHfDmQPs+ljLn+3rRX8CWlmbMV0/odfEqxuYcRVwb9gH5qCoZhukHjRpehkTygtnZk+1p8KWP0aZJDuwnEBtasV2SA4jpnc8l8it8+byOT/BynzmAZMOJYl4Pe7fPmu3HXzaXWzI9sxulEySodpvJ1eyz10rTUv8uGLhuO447ODZAMoox1fUZeitnZBEJCbR33uqOLlrSlJChJLIP/wOu24fPrV7UjBFBOWGiBSLFyuYZWO/btjuN+R+8VBNGN+bxadz1YCaDbNAbLhtYE95fPkF35mKUXXD9eUPKq64gO5KSd+3K2bPG0K0chPWlJLWc7pz4PJVtUDuz0HnIyxp5G6bfJxOBrVh3iCTSaoaeDLPBEBrcPs88eQhM2WN8fXQlTymhNqySWvg6qGFHwbPgxar9TrJvJ9odPNapuHjebYbKs4N/AK7rF8r7ucraGFLZG3x1unx0r8Cqj0+J5WDN/4/i7OJ7EWeNPTqZgvhr5fyJosN0MW2Rxs4Hqno37vHsf38HUbWtyFHC6hXEfc8nKBG3GZ4FhvOPz06Hg2VnxuNE83eMwfSYIepmQXRsHBaS+oejgSnYqdwEhlQuWlfH88UeICD5++ARhwYfbZ4AIl73hIMbRWIkUnbjT7iWbJiOi0y4hk1gp2vBkAqXHCLCcq0akA501q8h2mpIpUgWTFOS6poSnlHDJFK979lVOZN2e9Cda9nq7ZAo6hLMT93CIyd/JuQNiR3wYHHuvsznHtmCtZjmbo1SSIe6d0WrHtjV0Edxbw7Y3vO4Vx9GwHQ2JGYUVfPCxdTDR29T7zr0DTw46eWqxwMoeYUAjM4gZSbTjSnYHZHI+FECwshdr1xcZG1NHigAZrf57XTIuS8KPP3zCTz/+E3744Z9we/qIvD6DkmVORSwhp7UzDe13c/ia64IApEdJh9iujQQReIsf5WyoVQP8lADkDFk0PbobF9N+HOrIZi2ha13ToVur4xpTMMgGYs6BkBut0EsP4NPwyKZyYhkklWzZU8IzADV4ozRY1IYHMH6n1KwzSkqQRPCuIEOmtRTHHXa4DsZYq4NDaV58bvK+fXz7PfvuFNC5mgpzP0eGjwFhTPQY63h3Gleani2AcAdpCJMu+S0j6nZsrBMiDRq0XbjEenRHAbAAy2xAsrIBBRWdMJnGc8N1hjsK3tHuQKsVvXnzhh6A0WzPaBau07j7uGqqL0/zFaTfj9+TaTxkcA28c1AegaeQh9MMDYCKxt+xSSWMUgrWdbXupQlzuvn5mSYjS7qziodzfy+Hm5zff+i8+px1VqAa6ABxtEoQa1ChLq4CSMl+ExAg87yWTF0GF5SW3BlHZPhsZq8YgIx5c9/IxC+6lMEyZoa8uHB4aZw5vY9jINPP9LXHsXNdcfa9hhNPD+cZfgiNL/3W+D/oqnExvW8NWjH4pMT9x6EF474Eg9PD/YBp4udbcCBkMV7Q26Xg4zXjeSFchVFYCbmrMDoxyHhxOoACRoEgk2Y55aw3t2ryDlASGhJqyWg9Kfm2KLcTi4HPBIDmtemAN4c+nfmeQL5Z4Q82dL1XUJJXIAhZ+aBnrDGYgWbjWgVBcO/T5nZIg1Ad0JImfTjbMXF+MeOssk6q7MEaAVtl5YBqgoOBxXzbkhPWoj6ekOftmw/PDQnWMn768bkNm/Eo5t/4+V4OkfdZuIAPwbx47aDzS7PdOa0EA6k8iBi2eGQ2jaXzDVtIwDk7xs9LI3Z8/M50jbBHk0/hF6SpNEkmtTXil6GfHx52+C6e7eRJGBMNxpyNPkATRNlVgoJDjAbmpnEBa6ZxShk5Lyi5oOQFkfFD3bibGg4+lI8ta6OUfa/YjgPbcWiDl6K+Qs7ZeH0SOsyXbM38Xgd6nAfX6BZCp/sYdLBUtLaj8op2NLRVwJwBSaC0qO5PhAQ2kIaApGWETA1EDWJA0cAnzvaCHpT8ScfH7xlMkZCDwSI2+Tf2Ofe1RkXYqEoAzA4ap9mpnNQ+ob5PRgbASbt6inOa+nUSKa3ZFEtCRvz8bl3JLF8UfKMjbhjJDup/pmmj77fl320bnRTbNFx/h+v1u4GngRTbw1iWTrdF4QiaH6NOULsEeOcnHaAUNZGRbkhnh5+S1rIzp8gCEFh5C0I/2CD5YrV7Jd1VI/vgEIlv7c6OnfawiTQ+Pw+sT4g/6zvEz45sz+YIoo+ct2+PewdC0XgmGECgVJAvN3z85/+K5foB27bh+vwLXrYDy+sr3o6KvXYQdTXIlbX1K3flrREta7samfclkbaZJYrOIe40evCl/6fYtfSHXggopEY8w4EjUZJwaLe6JQGXlDDTdcVyDoDG66dtHmBZPZSUpBeIoMf5YFzchrGmmItQI7auxRZYMqdkhSrgLqLkj1D4MgEoRLiUgiVpZ4b7JnirO6oIXruWvb3eO7gxuhAWEK6kpTLZPYhoNW5jCQ3YGaOUJ9mYhqhZhEqi97FCF+AC59SwfA7b+lqgO37ZugINrqms7eWzdgLUDkMddXtD216x5oylLPj48Q/4+MO/4PL0zyjXJ9sVhIIUsNa2JulDaYzOD9/LURkAeW867XYoEKRN13y34Gw7Klrv2I5mnGf6o13KnJzfd/1hQV3Hvm8Yhks1Clt5VEi16eqcCEtRtTvkAkPOkaKcVODgw8ia6q0Z4GVlfLXqdZyfxwAorS0XK+fjKGNgEc2Uy1k7PJaMvq4oT1cFiS2gQc6hH2DPrgGj3mhyA+4ouxti/w032CZX7oHZYh52S8xhwOwNjO/5ucwpI9GyyQQCpk5uAV2/U8kUSsJ1u5KV6xpKeUFaFqSyRvks/Idcx+jYJhinkGdsuIG2ORe3geGU2tpiBZv0t5UQ0tgxLUXvSVPLEOCk84Md+6Y/2x312NDqbo6HmH5Nw7ZhOKZ6F65TbafKQIGwtdwhvSPnAmDVhgNJd/OJyDL29LGYZYASnuVpgq2O07DlMbseOHi5o3FOeShRloJlXfH8UUt+1stVM7FK0czRUjB2rMe5aTr//IpzPn2PB5G7j++Wk39CVwLBNQe0jJ2NCqWCKIO4m+wUMHcclnzdhcNf0hUlcT1My1xAwQflgFN06BQ5g7L+I86hZDYsjQ3E4IyS4Re5D6a75HIO4v0+7LuzG6ZZjIjPD64o8zlkrIcxblOQQhYnhNfoHzHrOJcSzj8Yfh4EQ5/ZQ7LpJjHEzu9bgMh4WRNhKcpdtCQycEU3Fnsf95itu+3TWnC9rPjDxxs+PV3whyvwcQHyIaAq+LwT7lUpBzIElyR6/3yAKuEv//Hv+PL5F+SiASG3CjDHZlcVRgOws2BnbSwjIihBXD66ZRIp4JU7W0c4RpMe+ijkgTQTSMdIfSPnfhKTCaMaBUTLA+9Vv9MmVvLOQLPyt86iDWtIN3kzKQXFWkYGv68Nlxv/rJdyw2KGJtpR761ZJz3WTKznknFbMj7dLvj0dAWXgkMSmnHzcD3AdQehIyeJ7ovDP0QQ54/8nRCdSZSmjNLv4vCUAfMXbLEGVYCDL2z20jZjyKkzjAeXsGgmsusjOxd7OZhnpqQ8dMhUceBUG+HlCqbrj/MNQMG94cmeOtDqmyExU5NysjjZYwByofNn958Hvw4ikUXeRbv1dst4mgECvTf7nbLJj61HL4lKhC4VRzvQedfSfAGICnJasV5uKCVjzQu6MGo9sNcdL9tnMBgdjLUULOWCxoL7fuD1bcOXry/IS0a5LLheMi7XDKIVKV2wvd3Bog2ZWPaIawkZiYplOhNAuvmh99nDh2ttB9WE/W1DwgVluQFCSAuBckIuGZQT1uWClItmhsqBzl/BOADKyHTVxgmW4aOBYXo3/i5zBEQTqxnAG3PqEkxw9atjzzHfj1/zkrmZvkQ/N+6Brey9GQiUkmUcZcvQS+qD+X1ISmAatjkynEzeHNAKOfb/WYKBbnQPQLY3jRkcV5l5QPUZXPLHrxnEDXDv0Rmb1ubfOn4/8ASZNilsAiEDiX0AYcbu6zQzhEhxjt2u042fzmDfH0o6kOx4e3KK5pgjPDM6n5rsfuagJ/45OxRkvshQPsFdIGN449rTPbqyeSw9GOPy7h9xL+IOCyn4tF6fIMx4+vAjauu4Xp+w14aSFWwoRR0SZrIgU+emGQGlKjPfPdJLZcDS7i3TyO7VMw7dkPux0PxjgSmgHXIArKTAlJfUeeZRLFp3ykgD6QE8Ifw9cQXtQborbvJYdDrhaYodoJq5uGS0zgWQbX66vRvEp7ZjoMlHgq0yKgQvzGidsYndvAFzY3dE4t5t1uAo9+AucWhtjDsBRpBIcQ7PDiPMuxSw9aEgVxYJEmRXJGKGzo1gY3X2tNtFw7rcsCwrluWGZX1CylZeZ+1XXWGFdy6za3DG7L+Hg83DV/k2zosuuoMK2Ph17HtF74za+ikgco6o2LVwZ8mUuToPUwBEXrstk/4yvWDrZJbv+R5npwoYqkwJCi24s4wq9k55vUc5lP+7ezlVBIMWsJKCy7lWgLTkLhHQW0HKaqTnUj/NgPLnGo7ySffCbYK+MNviSYOedCXwuKKnYG1+7fTX/N2H608tqiKD7xt2RdWrrx8FmLxrHqVkXVceMmxOk+uqm4YtcnvgpHr+nFNtvBt/BoF6D0Bel99wRP28vjPlpZnd2ifr/PbpPiZgE5OTfBrXoS8GP4HoDTOZU5qQhQE5d9wbgNWYAxYlOfZsZbiDZc8b2SuPc0mTTMV6UABwvVxxfapYllWDWyNqz7lYavcAuYZcSKybU2T7vR1Ew8f4ux5vAIw2SYAwgs8sad0Dh/0apXNeAnvyrfxPcT9BQQIH6HvYp/O907ywZfoxQIIcrJq/6HbRppzSOMfwth6GafpeXJOm98KTCMfCnun82ZNiNn81ru7fm39mbSfDZ30cjHkaYjpCfynWvWTgUgjXklC7bppQEzhHlWDwH5WUsOSES8l4WjKeFuC2CKgT0NVHU/piBBcnEtCkgXvC29sLqB7IBu5lOJ1AtjnWEm2rtI77lRgEv/exYSFQYEyY9D5onq9p5siAHwicxsTPH8MvXj5nPmKcRoHPyrZp1PUcJTm/lXKNLvlRF1LYQgfq5+yzADMZAfqJXbNkBbKWJWFZMjalb58aMlgG6mT//Lry8POt45vi9D0cs7OMYZtjrY9/wBcagQZ5uJ1Eu1tL2Ca1pbPBtVdn2xUj6psfvz2wsxnRORh+8Wy36J1/QOeTxCv2LILBXTdRszyCUGMMLCPFEzqY4+25ozVh3IP/1iw8ASXrsCxdf1i3i5JtuJVctGtdyuDumf4NtR9qBxLAonVxIrCOjQ1HrShgUCLwoqBySoRcMlLRLuHq7/D0bM4veU7kEHJ/1LZHpKNzM76nhl4ZvQJiAG6yM+WUkXNGFbHxqSYLFeRwBmHMtav6oPLhs28U9/WtKBPjdXcpT/M+bEb4nMCIgeUkUTHHqmMEGokP/0/bcag9jCZmRFNjK4x5n9bVO/xlAtiGfqO4J6f/cIDu0d999K1nI+prI9bI/Puvarjz8fvJxe3izDzarz5cZK4tJBq1u5FuKaS7GsJjMcLHyWtdfWdCH4I9KOaB4rnxiSE5OaPjXmIgyZFnRySHtScM3pR5/YfgPrwWqZxxjnNxQjjC0OybOI1/x5z1BEIqBaowRiAa058Scr4Azwk//fG/A+sTrn/6GW+ygOkvytfAFZmAclUApVZdZbvzG3UOcChBwSOy4SK9CQNhEACVOhjJ7kM5mpZEWIkMeFJA52xg3ZAbx5JLDFkmkI214t9k464BGYEiwJ/HVXWYczS8d1q6jaOPfbZPuClaLH1/Tbq8iTTb5JYzlpJRrGvF1rVLy+dWwYmANQO54OlSwK2jZQK1jn4IiBlFVD0Us4teIig0RmMI4eSnEuLunOHEFV4xcRb7zdaRIHEHdQLVBjka6t6w3SvKsihRX9HA+fV1x9t2YK8CloLL0z/h6fkDltsn5PUJWmJlxIRmvGPnxu//MbjG93PstZqRFJV16SrHu8pdta5ze21Bnmr5JCpTniLbdR+u9xUAUJYFrVWNGNgBgKHEvdOhB0/J1vhoDT6yBsRBJXOmZ79EZHAdOPjQjNtJM6C6OSoySuta0zk3npYgMG9N+YYgyEdBToS6rihg9FJwyQRvnz7sjoMWJjsWjFDoU/uYr1GR+PcgTZlshQvd5DOG62gL/ARC2SAMXRMm194fe8TKTeOXGfpfgzWo45hId5RSAkh/62uaiZuLkm8me2ZhhqAHB1JKRXWP7zoBRhKvAGTU49uzcO9j/GzXnpiAUpCS2yrWbuainGK1VeybZjrVY0evh2aqCCtwCUTauZcvDw10dsDFojlXpWTAqO4gE7QhOEE0AjW7FWR9OuoiYSd52phwO92ZIytt2pOGa5KUi+lc5VFIS0HKBct6weV6w7/82/+GH2qN50jZOgFmB8J8lzeFTAhgPBiW4Sdj5/t7OsJew31ZXQHuHJ68sGk9McOITdncWmAhwa0AgoTLZQXA2A4r8yftJtnN8Q0wXGDcTP5vOYFN3hSjT0Mfaw3ADDb7M7iUKAejdUkKnePlSqKgCMGymIwAV0bXy3eHnJ3m8AyjzMV0uvuZ7m+kFNIqolxL+uxzEIBh4s1ZC1B+/MNcPDtztwAL83ok+9EAxJvDLJnwdEl4WjOe14x7FWwVSIlBbTxbMdW1EGMRRu4VVAmNtBNb23ZwrXg5GG+HAjQCwprUBr72A603/Pllwyak6pMIz2tGyQkfrheUrOBTF0bK2o3JbUwyH0LlgYLT8rIIMhOOnpG6Vicw5DTf4eOTZp6TgWMutBonTfYPCr41ERxsuiApKHR0lYfGgpI0c/xCxi1aMj6uGdcl4VZyZNS17iWDnmUnpttso7AxEmvWkwAoSGAAP91W/Hhb8GEtWHPC5yp47YyjNvTWwe0wEugJwBUHZS3bCWNTWuXgvIbflTl/B0dKI38+4h8ATjviIGME7g7MnMI0Ov/2GEIobIPTBJCB9DMtyvzvx02V8QfiM6eXHsAqveezn8+iscH4zCztEs092Dqr6Trqpx/uzbictImIsJOCT/66Z/PSDOLo62SOpoDBxJDeUNuG2ja0XkEpY10KlqVgXVajHCHU1vF2vOJeX3G0N6ScseQLciZEfYt12OvHDm6kGddMyOmC5cJYiSBygHJDLh15EXDr4Na1gyUBRMovpRmsBJCSbjc0tfcogAC9buB0QX3LOgb1DSgHLteGsgDresVCKzIJKAla3yB8ACjodKCkCwouoFQwEgI8MhQdb5M13QAz2fDNvJAN/cs7Xgd/DgGQ4V9FttE0T3q+QQlhH4hYViyjTT/frGQxI/WENnGSpawgm8+3z7P7OZ5551lUY7P6rE897mCLE1rTrtuXdNU5Sd7Z29bgmcAVrpm8gmu+bixZk/ffq8F+P8eT30IgtuPvRw6AAAloeAdntNkXznA0HBlORKfzxRjOQYqo4poX/1mJzIohQprpvHN20cMzxKXt+0F4N9//dCPzV/xp4m2tq9VbmxyZQExoMsSzMjEgJyXdDb49Y912LNdnlPXNutK0EHZ1XARcCNLHjk01g5/EOnzYtQp0/BxsyjQAKDeAat8deEpYk2Y8ZQzCy/PwnkVuVs7i40kjs0rLVQSBnprMR0KsvDvlPCtw0RqmyBxIEJimZzYxEXse5Z4ypQF1aKoIDhZQIizZW5on9ESQprtYXC0jicPnnP/z7gZDvibpIJA5sY816zbuvt5dPkVLi2Dk0b119MZGQOoLPaFZlg5RQV4uuNyecX36iGW5WAnNWLdj0L4/J+e3jrlNLUidT4I61dotR0Gc2rxjBwBolp6vWQDopKW/3lnEU17JOJhmUA/kAMAoAXBezTB4QoNHxQwkO6eXTGCsiPE4jWwn6d7lhK3r2eB08i5oLH2UVblkCbRcrSr/VDsOJAjasSKJoFA2PSCxbmO5W6AgoOBW05sfpXMk01hPtmBeB55F8Bg4Tm7luObQHtOn3IG13aiZjPjB+DkgHv+2s4d+IprshemoNNo9u2X1DCQKQzQ5GbOTG+/aPU/vscsEs5WSGygQA2FEmJHlpJwJ7JlOwgbq6S1H1yearodJP80jIdNd2fOGrRaM+/B7sfNjcnZIFDRSosz5uf0SDzu6fi8T0K1XlOFYGch3e3rG2vnUpGE4OYh7p7h3vU5vzZypps/Qvd3E93Y8ehm/cXxLrbu/RECyTOWSlK+mRk2Qy4Vt9gmC+8iTPL1MLkrs+uhypuDTMC0iw9a998XGXyGCrutivY/yupmvf5Ly6Xxn/9OD2Uc9IPP1BVNHY73QfKt/K+s3hmx6jm94iCcd9+3zkc0PIlOnpISSE0rnKCEjW/Q+LokQmdDcO3qtqGDsLGhVu0RtTXmKpqQJEBAbEved8dq0RFYjkxVryVhLgYh1zYJE115OGZb/dHpumI7NZjOT/YSqtnGQ6SZcLw9dpSM0n9c5l5yfUNwLF0JjsrbumhGlc6K+LdsE5ZywZi2RY1Ew4yBGI7JywAGa6vV0XbAokFVMnoUostCyjVUXBcQ0mFMddEJLwq5PdmSag/kv8xxO4/m9HKNkTSbbefoEQkj8n4QYP1+3sf7p4asBSqUB6v0e9R8BhK2/B/1K029/Mf6WcV3VX/MFx3zrOWYb7HrOOZv49G/mPvF1Tn7BbEPnuMr9HVtII8uHIWB053cSRpYUpYdOqaCqh9G4KshlPHDZeGrjWVX52z2pzLelqu+YMnhZINIANIDYiL0tUSS+l977ZwRrTMFgKBgj3CC9otcKJIBThUgF5aq3ws7lZHQL1hiBpQKSIWgQKRDJZocmH8X94AB83VeZBUPGPdK435DJWZFOfo8LyG9l1Z3iQQOOhCb/zWKCZMZgJs0n52JM+szCuvGSvGRJvKJour/z1e0XR7aTGGH/Sa4EVko+YxFjsiLjzykVfsOu/57j7wCedIK68VjMDqLelA/UmeuJrNMakRHy9g4n0nak7t0iPz0uzFBh9j7efy4U0BjIUU8sGLkw41kitpCz8M3CQNCUToJ34/PPji+wfHvCmWlyohHKIdnum/Oj5KgZNoPLPLgEIFivVzx9+Iif/uXf0JDx9Ok/0V++4PPLBkLHio6cCE9r1l2dpk7hVjtIBPeuXE1XIiyknE+auaMKN5EGQZ7OmGxRJ9LMoZKMf8B5nmiswXhsG8sMdTr1vZHC72OtpWejNE5IA6Buqj/Sm02wLRlxmhs7jwF6I6Q2BJaGr5ugD8OU0KyMBlDOhC97BRNQCZAEXJ9XXNaCn354MgLJjG0/8Esm1HvCVitaFdxZrLyQgk9A4EmTeHefp0yEcLQ8E8afwWdav8Qmk2RyK/uBJsD+uoEoYb2soJyx3BIoFyAtQCb8l//+P/CvDPzrH/8NT08f8ONPP2FdL1pCBQOwpkBXTl0MHhXw93M4kV5tuh6aO4hmxDp3+9PrszFlsCF2RVtr4KZZhpQIS1nQllV3gx/GTjNzWNeSAU66bmz8mXU31AjMW+uorU9ZBByZUJFlIhJgU2cFIrirc9GM+6k373LnbXcZp6DOCFBYGKllvBFQlwWFgLquSHJDydr5DgLNBgKg/ENiungAC1FKGsbXd4AeMp2GJQ/jH2MVwYcCW7NJw6Rrh072eZ3neAb0/Vxjp5Aiq4mipM7rXGfAxAMb0okHqIMbQGR2KnUFz1MGrAud2D15OYADQu7giHUxJKZweCl5W13rjGNp8C5nrTYc9zv2+xv2t1fU7Q3SdCc0k4JCxfgAoruNnZOsdiUKAX29GwAbpbolI7jjRLnPkJQDKCMDyTPFcsyf63MfMy3lHKDV0C+mmcnL6vSHhUGdsawLLrcnPD19wPOHj4gmED53Q1wAnEmrZ2fSATklXGfAdzS/o4NNV/gYj7VyWh5jvEzmcyJkGsGy9RJG4QOLZKxlQS8NOWWFE6yrUmcz7l46xwo4crd76RKguP8On9fsbkifDNXhu4dGkwaQ8k36/DpwRQkohZDttyWUmn9gzU+6N0HhE6YKRDxxCg7OQcLsb04SRwjfBiVZs4bpHKeDIvPTD39+nYI0AbJTxunkqzu/kGcXSiroqeAQQmqErQJHZdSu5f/hP5jd2rYd7ajo+4bPmXDJjEISZMLbLqhNUKBzskO7ur4I4RBg56Sbk3QB5QIuF0jJkFyATEjUkSB4flrQWsGRM3pnHEc1OTGeJVZ7qUnkhJIJLOZNyuBDVAoxCWJvzaqwRjOzQ2m2islK7UQ3Ur1Le++MxkDtzoFFSgBun2MQSgauHVgLQZCwZEJZCGsXVBZrHDJxk9k85cy4MCM3wcU+21nwYcn4sGY0Br4ejLeesXMCekPuO5L0sF1uR1wLz4KpsuC2y7MGrNxZEP/+Xg5vHOGbfzRvNpO5CcaZOGfxOJ8RgIgbCZaBIh5TKL8YRKwJCuCLdc4UcuSApvMFsGU++EyUPyciMIttwDyE2aF0RtaaLs7xfBr7jWz1Vndw7zj2Db1V1G1D7xWt7tYF+TDwSXmrHEzLkWmS454EE8hhsTdzA6Oh4g21veKob2h9h0Cz3JeSUDKBkkBIAacmGzp2oDBuzyuWvOK6PiMhITFAYJA0EDoyCWrTZjvcX9AO4PJ0xfV4A0uDSEdrd3Af3Zy9/A9MIMkoVHTd567ISWc0aWh0gDJQ+xvKniCpI9eCeryilwPlqMgL47LcIMy4XJ5RcgGtGSIEbgKSBpENHK5qDrBH2DOi6ySP0Eynyad0vmPf7YhsNecQs80Z72Af2d/TMifCOTPbfmYMI+5rWhvoNHiXKEE4g7lHk5VkPqdfUIh1N3yStxkjOeEg5lf23g2MFCtbXCyTKY24PM43nj3oH9i4gUk3aIcOk9Dbv+f4O8jFfaAGD8W3j7MC8NdmYOh8cwM4eH/Rb5zdkWp7e06ffI82uudhzpGzu8ukLOzZvBxw8nZDOUZDKchJKUUg9TctxXs3J1oGz8/twUo41mzKK6OUBbfbM25Pd9yePuBoHSktqrS5akaPgVXhqCVS58mcwU5KGOoFFp5c7mTiNN2j0MO9+XARTsJ9uvfp7RgS5/2w95IvzjDR47xiytsD/1Dtk882+daqXKYdCw1sJLqkQCjKUsKnESX6bKzd+noGEmnd/mXNeFoLlpywLgVJBK8lQ4oF63Zv2XhbhvIf+xoy7hpztoXftI/PkNXZ3OpzJ5dPC9CdvL+3jla7tl1lQGslM1JeUJaE5+UJRBmfPv2I2+0J62op8x4ETkY57lbGWI6/vzG//9CHKUXjO+q9WTTg6bcOOPn4IAJmf93L3BIhSLnLsljHjoxR2mtj6EC3BwsARu20l9d5FpOCT8rfNECnAJ9cJxjw5IBSBP08ZUNFBxMzFtOzmSsFGOeQAGhNyxBrrUhE6LxGmYveMwVQcUKQMdb1Ofp9/B2fnsZmvEtRPI+xuKfvyPkE02r5xvnpfAo3xkR0/jedvvWN80V+mAWxbOvQMnZYdwbJH8bn2e/QdoRizhyU0Qc2Em4BswJ8wgxOgzfJgcXemjoLrWorZdtV99LmkfE07faCYs7OemboURt4DY6d6JOGfvQYMMZo3syxV3kCsHVtCeTUn3SQuZ70iYgFqWrTylKMz6kg2vJM8+EODZuzpDujs96ym01Gyv9Q1vU9HO57+eA74BSi905dTwDeZK9V5ZkTjtGmOVoxEwFMLu4Y+Lzam5nTaYCPk6zMzvf0887PmZ8tHFb991yW7BlA7jOcQa740sP5Jg/0nUpS+fBHlWk8x9BRxI8qysMmPHpDJ7U36xQbc/cCBAKvTX48z/iadkkTyuhQQCcyyXhQTkQmOCkgw12A3lETsBEjk4N4gtp0zhZosCAsyALsAhyiG3AMBbwpFVBerGGJy00HCVCMDbz3AhCDWrc54JiCoc/J/J6xa65yQvDW8urf6UwFmPYNvR4VH5PNUI5GoDOhm0x2UzvEQEtAE/txmbXvZ9KyQuc7Ua9Iv5ygn1tJM+WbiN5jYyRoM51MhGZtmBtr1lMWBlkHr4eQ55vHkBkaMuRjKO/E+bs4VP8PWXnHpkMI0v+/5QOMuMGpXCzhwdaqjAF+OPd5ZN13Vx06b1L9tdj2t493Lgy5HfaA3fy83oOLtfemG4XG2xjZKB6PWXmxghET9+Ic+0xOj5ZUdzBXdPth6bGAfONN/TBGR0OXDqYOSoJlKVjygnVZIF1tOszXhAMnokkNVDuOdCAVBXTVj5iy8APY8y7fGTkVZNsoo9SAxBADrCTZpoY0dD5ALQNgNLLnSAcyM45jx1JWrMsVsPMJCIEcaw5V4BRzxh3Cd+B4n9nmKswfKcWLzWGwOATmINMUhDGaVvKwFSePcpIplzmXHLW1HPZXfUSYCyUa40H1lt2uXvmEqXizl2+YJHtN44QON6KeAeeS6/4EQocPHlJz8qant+/QuJJAxjr+G8fvBp7YgjRH5xSoSSH8kW422Q9VpqrYZVIsbpjESl3mUjM313OZyUDE1SERGnWOQ8DHJIx/j0Hxe/adU2BwCgwjqZ9NUwZSyLQrEF3x4dj5Q83AVUrjXuKhQfBW6N12rJxwtk9jYneqDp/zXknCuiz4r//2X/Dh6Rlgxs+//IySMl5fv+Ivf/4P1N6w75s6a4WQkHBbCSIpnLVDgEMErwwQa0aNEoVr5k4hIw6HpeJTwiKCJQFr1u5uhYxE0qQ72pJ7SrioYWG3pPYsUccfYycmLiMzBHZtte0zhDMta5nndnxe7Y5fA6b09XeHdivpnXGXCk4JrWSkTFrzvGb89PGG21rw0+2CQvqcpWRs64LUGfd1QRfBYfdfRYIzC3AGkkfD6ncwSYHLL9Ho1DXdM2SsB39mrspjsm87kDJa026GlBeU9Yaf/vlH/EAFZb0hZ21H7mBIj5pmUzantTIpKoIFj2cl+V0cDtRYuVo9jsiOIAy5ha1vL01wPcO2VltrqCmh94br9YLLuiLngsvlokSs3XhwunI1sZ2/w8vtdLdWiaI5sp1614ynZn876OSE4m4sFcSw7nZWStcsw8kznrgPXqfxPRsGIGTNu5K2WgERHMcOQFDrRfVscTJnrw/U3x48BIgK3Slx4kyx8Y41PqbA/xXBxGlh+GsPZjN0uAN75M4lhc81Bzv+XbJ7Jv+JkshhDxys9icRBqQLeuuAkJEvk+5E2Z2lrIA1McMICzRYSxT1+G4/WtW5apaNw5b5lA8lzl6vF+0waN/hpPZ13zbs+x1vr1+xvXzF/vaCtt3BdQdsMwLmrFD24C1FxtPQsTFMJtsTDwVIdygsYgvOK3tm7dA5Ji85wGUvJbuHREM+wwcAwrafHDVheEfBy+0JTx8+4Hq5YF3KyfY5QAIMG+9dGlvr49wiumMpAvWU9X6+N9zc11UycDIPU6pjNetrD0Iwldt37Xq7NaBjx74JerkC1xWZEq6XJ7RWsW8Cpo5qeqc3ifI6GCdRZ1Gwwy42O9xEI5FwJBTaOnZ/gDDWXcyTdwEj7ZZLSuRcctLdcXLOpTl4QASys7XF9NppQOwdE5PYLCQDIihp8JoM+SpWbtZ3lTfpc7Y7IsVZIJa9ZUFdKqCckErRz3YB9Q7u1cZwujuBdrjNCSktkLSi0gXSm2YjVC2bO4yHkqHNCSy/0TwbmL51X2v4QOpzj+Yyupkgo7lM1kyr63rRzpJPH5QHpggSGO04jBNFZa8s2lkqNSsD5tGJcPjRmsGfWTM1NFgxPehNOkx/B5hGhMdOxhBAMgIAJIY10gF6E8u2UvCpiT2rANV82XsSLImRiVFSR1uUq4XFugWKXh+kpMg2FCAqIAIutWPrjNe9YW8qE5WB1ghAwmHPvvQd1DblXbR7mcdkXhtEI1M/+cYOjWnTDK+zxP6jH3PJdXjzk+2PSo8pfpu/h9Praie7gTie8SQiSAzdlLDNRZetxBavGVn5XBbvPkJK5yBbKwQQMWzoMJ9Eez2+Z88ygvjpGky6BqSj94retESttwPtsMynukPEKBQm3aidxkYHeJFxH3PpukZLDOEdnTds9TP2+oKjvkEgKLnoT1lAKaH2io6KnV9w9A2SDixlwYfLRxRaccnP2Pcdr9sLat2x7XfU3gDKoTu5ATU1lJrQm2W1gVG3iu1ekdOCkhZcrx/w9PSM6/WGy+VqYAdBEgOJ0XsF9waihk6MvW7g1nBFR2kLWjvAueNod0huKPQnvL5+Re8dt+sTnp5+wlIukHwBkEFdQNwAaeYjWYYQux8/Nm51io3PkM0fdDG1uewzkG5vzgkoXgEW8iFnWQdgTdmGbwwats88T/PZTG4MIGLz5bTrXQo/VbsvZ+P4zCGHuejr8Cv7Rez6tR3q2xIpCJgXlLLoHUxoma7H8MAja01MWXmm02y/dV1PNd1/4/i7S+2+9VpwbPyV70bAcXJWHpyCx0gEmAKF6e+/Ehj/3myNcFos0P/WpU9xkL03ED16nKHJ4X+/q+7j5GBa/AAKAk2n0XGS+B5I6+yvV201/dOPP0FE8OOPPyER4cuXz+ht17pYiHarJAZ5W0k75ynj3ZUlgCyCDEKDKA8StL59gdbBNzPWjdVA52m6vTwvm0OUDCyLXWkbRG+grYI95tBTrB83qscoTythmg53UsjOwfOUiEmZQ8MwskcSNAcSSBHfXBJK0dK6NSctPzQnmcRBOQXbOCUjxz93erGLxvx/WwI9GB6vyDTb0QRren6XT8h5xyTkJmWkVLCWK5BWLJfb6AIFKP+JuFIQnIdy7PbMzqoa1Qev6R/8iEDF1pyDOuiWPULDKHjqq64XS6cVz3jSIKRVQi8FgISDACZ07qEfBMOYxW4fadp1b1Ze1/sJfApi8Mh2mlJcpwwmkVFyx26knC9gbpRgv+U0mbNnD0TmFA9gjq0m/70ITGvQ15aXDc+nfj8DD/8coLJGSP6HPHyH3p1SpvsYa2XabAikhcLbHyn34/f5ieb78g0K1s6gwzVAEoYY0VuUqwGAdYOLT0/g1shO02DNQTmRBO7aXEKBQgWzFESsaFUd1FYPcFPnLLrFxA3L9Pf82DNjxXttdBpDAjSyc1Bu/jyFGD1eJIBDd1ZEnU+XEGYAyeTWrysSjmexjKeUkvFNTIYKlifyIPcu68plZq8bqXjyHXBPk/gODxoirX9jWjp+2FpksQYcrAFtY2BrggbBLhUkBXTRYL/koiCmt4o2++x6k203eWSKfOPeHv5w0Tgt68mhGmVJ07MBxq+GyHTS14cWOF3/N3wGf+txXOC+56yOLBPJFbQA8CwDpTwhHcCHAQ7+P3/VEBLVL5qJrOe0NDH4OpqA9/BCPaMhA5TB6ManZjYLVlZIBDbYCb5x5evEs9CmsfDMy4Ch2T1LdQRSMt8tUXSLSrlA6TIs46rrTrwOn20+qJIbPnRc0/2faSM5AGV7flGgTvzZfOKdIyFONnypBJ0CL+E0lwjOhShiw0wUYJiW4GmpXGXBYpxObpFPMkKDXysnLY86WAE65bvROeu2FqT7KhEQd4BblIrakhsJGN84pnDh3SESru53dpyjm/Gay//7h55f06Debfg3zkv0/0Oyq1/3fH2a/qF3ePI0ThN4ykKK38OnPvkXky+gJXXekZjDfwPgCOgAmGicPHwvANrp1b07gWb6aMZQZy2H1XWu69rJobt0dGlo/UCXBpCC3+tyQaEVhVZUanGfndX30Owl0bjSG0fM/qn5kMJm53PBsixYLxeslyvWyzX8L8+0Jsrg1MB1V24nKB1G71X5jEgB/94UvNv2DQLGvt+RU8btpmOmdANZF14Sa+owYHrXPbNDM+ZGFYiP46yGVM9ZMsnETTpXIZzEzhpDPdrokIH53zT+EckKvjHhfrsMPcshAz7m2XhCE1KSaFzjT8Yui0HXoXKWUhm0E9OGn/t0ArUt+rizhvdzj7Uyu6MyG6C/cfwdwJMOZin6Fb/h5IG41yna5xx58wnoxuWkBiXFDhcEli3QkZJEdxHYZCekoQC+gTDOP5o2TmaQxq5opCRO9z2eCuH8ui8Q1wggSex+8tm5MSORoMRpjkoOXhUXzuEtCqC7tobO69jo/Xn2UC7KvmRF8borlghP1yvWot2B/vDP/4yPHz7g18+/4J9++hFfvnzGv//P/xvHsePt7VWVDld14rKOZezI56RxUjZeJfgGHsVacBLuJACxOvaJPQXe074pxjCTg1BGkGZWmET/XggoBBRK7joBgAFSggIv7bGdimnhutxE2vo0d5rxNMaWRZ3AJlorvwvQILgLo4FQc0IqwPWmmU4/frhgLRnXnIDO+PXXV93trRrQdAtAb5cFCUBtyt5eu2azNAOoiKDEvyf5mpw+d6Ct1nze0XnUR/6fx+6RrXek1kCkO7JpuSKtT1guH0B5NRWhGRsi5jRidvD9mnh3DFX8+5XHP8rBfA7YPdNMy860Nh4sxhfjXe1gO8wIPdK56y4DM9ZSdNcNhGVdgVpxHEcASk4U6V1LFDycwSLLKuhWVmWgT4BPTjIZwQUCEHEScfYsLvFMJ+9ucX7+WKWhhkbQpKW4RlxPDfU4AGHlfDMCbBs1K8eaZDICBg/EHuU/hhzjgiZpJmqj9bjd5Wylv+FJKrhB43ngGT/uQMICaNImDGlkPDkRfIBQwFQTbGPiARHr2o91S2RgByElT+NOkMTabc7ATCJC7sqJxM07PXSgd3CrZg8YKeUAL7kvJg8HWmt4/foZ2/0Nr19+xX5/Qd3v6PWAcLNbNZIctg6zRhDifkfy4ZmCv3Ow5fpy0k22e4aUIGkCooggiUYTYpvLKF90J8sdJiAI84k100a4owuDOiGXBbksWC9XXK9XaybiO2UU8uuyz02Dunoo/0Vk+FV1jLUDECvvmvknU77Xd3EoEb36KVm0TDwCbhkbggQNuPcmSMT4y6Ydg7ooH85bNS4vObDegI+XAyANOMDAQYeBIuYN0HDGdenOehRnwB6+YzwBBuIgxyhtcvWjPuLw4VxLFQOcivtkdu4T35IAMp17lJ8N0/UOn/XXPOvorHbUdrM+E7Ho7lqchOCdsiK7zPWiIBacUALnxdbRokGIOfC6ZqAmB4gyFgiAQkiUkVNGyYt2XZWmZWFJfa6SElCuoLIGL4dYiU5r9bRp4Q+Xpw5JAFnWIJsekeiapGCfBycdB3eAO7ZNS4JK1ufrM69TZxDPOZSuDUwnWAaSA0RsXElDloDF3OwyEkxi7ToepX4oYp9DIKh9ZLQ40iOkPD9MhN6BlhhHI+yZcW9kY+jE56re8hREpeQ+MpkuMT0E5Qi9N0EnRieVw2tqWIiBXiG9onXG0YGjA7UTjqS+bWUvaXR9O9m/SUSHqH5rg/8f95jjRMD9XsuiACbdpRP+yO3k8ZtXCrhd0xjLq0I0+0d1RQeRbib7mQGrLiHAAZ2MUbEzlxuLcHD2kpFsp6myx0NxfzZKrqPcz8QAfE3JaYaPxnPCHe3Y0eqOduwK6nBzZT6tAQJw3gzyCMm75mqMzcGvxNjQ5Q1H/YrWN6SckNOC56cfUcoFy3qDgHHIHbXf8XL8AhAh54Lr5Qk/fvgXgBOkJWy0Y6879rbj6A1CwHpdrbOcZWnmhFwSMiW0xuhVQJJQ0oqnpw94ev6ID58+4fnjB1wuN6zrRUu5BVFGrITmggNf0fIdtb2htTtSVwqZQisWKmhV/e0XfsHrXXXp0+0ZZbni6UZ4uj0hp2L+EMCo6nsLnXS+Vkw5HQAmugQbf/P5ggPKPsfdMxXP2XCYKsBABJbR+W0AkxpLn+K8iEHgVHjTSeMSJrvDzguAxAkp9ZBf7zKXS4kMQLXjLjf2DLZpncuCnCzLnEY4GHiFS5qlX77v0Gdy6VxjprO4d/xe5fV3d7V75FNyUOBvHrbb4J9U5WGoW58BhfHgrmSmaHwCksZlPfCY72L4B5Oinz8jEicI58ecBHfoTl1OPAA5P5SNgSlNE4TehzD6DgiJO2C+Czwh1Sb7WpRIp7PPnWFSSiil4Ha7AQT89NNPSInw9ctXpJzx5esX3O93HLVBekdHxchGGxLmzta4gyGgFIGkgkgxX6ICluwzNI+GwIy1IItxLJljlQx40tp5QiEZwJMoX1KCCqKpWhAkOu15gqE7lV72OsVMce/ulzKUt6oDqAAarCNZIqRMSIWwlIS1JCw5IRPZ7oPg2KtmFh3NymdUILw2WcFFDaZYoGVUft/kQZjf4rjRGMeQmunF8yNNr01rZlKOKSVLtyzKzZDyMLwyEfG6EvmN9emiNQcP3+MROxOzsnev2HakvWxHf4c/q/Lk42mGUndWFVwCdLeltXM9v2doyMTlpMDTALjUGXfQaYBPHEFEDx3i+kQ5nWZS50eQG79T+c8WzoF62wAgQk8W9dAIsP7WaceupN+DSvtYEyMoAr6hT+XhH7Eo5OFjw5LQWByTjtbIwrMPRpmdl1APZy7kwB1+27lzcnmCl8XitL6IBUimL/3zbHfmun7qOiie+SASpba6S5jUYSVBa5rtdBwb6rGh1l0znrp3uRmAvI8m+e3bP9xcTsMSds/tzGk0fcxoHhP7zORsYz7v+ct2TnPWcf7Q0EOwwMI62WX9UbN7lkX/LdO/wzFnMfm33dhmO7tQ+XM9/L0e4QqFPOI0oQLP9AA2a/elwJNga2K2EaCmXCPk5KLJc5aH3GvwNPMXTlcJ/09iyZuLdfo38KA37DUHALRMYLyhJXpnh3nOWP3mMYnpu7E6/fc3xnK6R8+AkjR9gyafE+PzYu/ZE+maj98PN+MLjwDtqn7Wg1rGOgiO55Xo5cKpZKRl1cAhF+V96131U1L7QY7OyXvgSQBt6Q7VR5HZBfOfuIM7oUkHREu/vaySSNAljTJwicuM5yAfx3HOc7axfo5l/lGZVN+PINPIOWBOcFmRyIjTMs5hy8UUlKsKz/gLAnHRH9DwsU96wnSdiG3EimfH+wbUKNFT69ORpeNU+imPzzYyBJ2n6uQ049ty+X0ej+thAowf3p7nZcRv51jNuZ1m4CpsO03nxVn/jNfHhpXtr4Tsuj3z+RrXO9/oyX8JHxOYxPL0O7KCjEDc+Tn/qgwIRrzm+uM0Nm4LG7gfWs7HVWkerEyv5NWyi7OBx1bK2ytSyliWC0pesJQLuAOtqY/Z2OgbwBoPGoeQAn3aNZJymsrwWQH0DORSUJai5V8eNzkYIxMIYyYn5Q2UqwK70tHQkJhQZAUJIUkCc0ZtG4Q7tv0OIuA4dqzLYYCR2H6Z6KYfiW36Wpmlz+fjvCGE6LzxOQlPZB+5XTh9btZDMuTnwWEaMgZEqefDKaLkzb84G6n4rBgnlJhvagkq5uQ9PsL8J8HocVJ60H+YjJr5ljT9fXLRzspffJz+jhjy9wNPNBb3eGkogOwkxt9gefcXRJz7Zz5t0sxk0WycORPEEcaxCzC+6Mg4PSqG+Lpe3BFAfc8H9JwpdbrdGFTf3ZLpc3w6tw+ypzC6oVfDTIEwngbRvxcXTDGufp4wqeyiLJMDSFjXFTknlFzw4w8/4McffsCXr1/wx3/9V7y8vOBPf/qT1ui+vqDWA/v+htYbqnVNaEeD1x0P5aqDmaOd5jSuHihBiR3dGXAHFZ526c7ApCw9GE22EIklgjiIxI6WZz4l0d+Lvb6SgzrqnsSYY2RGERBdbxjqaG9CaAA2AJISZFUl+OHDFeuS8eF2Uee3M4694c9vO/aj4eV1Awx0vK4FP364Kh/LolkMTVh34TdB7R1SGwoRVhrOumaN2wQ7J4uPWDjmFCVvMi9YD/ZC+YiCZTkZH1XB9fkZz59+QLk8Afmi5JrSw9HT+x8qYE6pBCSAUc3sc8f/+z16Ux4jb1PrZUtkPwE+RZaFlcZNaa5jt1uLeupRsb2+oawL1utNebe6dtc6jEMqwCbLgOqeVu0A1FwqZ5lPA3RywELGvEIi+4ofACfv9nUK9OeDJAx+APaA6QGg1wpixvZGaKVA2oqUlWeFaBD8qlgO2NldiChxilIngoMHrupcV6uKcANr7/mfMtZIWOQYez2S2R0nIB7OpuurBJB1nYsf7WqHyeiGS8EjY4yIwNKRugIkZB1JBQR0HSsiJcbMBJDojqg+riqhbs/tGQbeeU36KAfT+E/5U45tg4hgP3bU48DXX/6M/f6G+5dfUI8N3FVfB5l4ZG7peDhYCuHYFEiJkKHEJcFfYUNqvsspwJvPp7yLYp1PXH+Y4+j6QnDSN7PdhGjGaDcCVZGOvCjv3O3pCbfnj7g9PSnnA9HgapzFVmyTw9o/ExYwZ+NJ6wAndLBuKNhaUlP0EHV8B8fRNctjb/r7aOcAJwJ6aMbTvQqaZTISjbKfxmGxwdxwbK9YLk+4Xp4VcM4FiW37i0Q3WpIgkViZN9CNb2c4p5bpTKNELicrUU9G/ozhX3iW07Jo9zPv+Bti5BwtFpC5xe+RbOX7/npQDMOwr7D1qr70DH64ajLdFX41AUrrpnomud+H+F0WXUNi9rp3AzdgmRjZOg6RAnhi9VZkQZyuN5s0gm3wkXWl1GynlBKyXVO4Q3oHNwYtRQPD2xPK7TkCRW060M2uaYamWLY/AGTTkbBxOI5dGxZUBcWds0lLyIHX/qolZ8osbFyIHSXr6Hqp2VE1Q3gx5EBmYTQ9yKwdsBrrD4uEv6NZd8DeBR0Ea+qHbD6uQnDDRSZ9ESvp5tpSVKZztjnTIQOzoJEgNUImQSbBmghbSyhZsHTBhaYyTgyZcNLyozFqF/y6VbzVDjZPs5Ft9JUFqSx4kjtusmOTjgMTzGhypqV+ABtZv3dA7vKweSAIu+Pq73sqtTtt/MMDbvNHybIiPR6g+fMUMZX7PXp4rKQgKLgDSXlvACBlz8FTmRzhpBgQM8WvXubtvoxdc7qSxaHuX3is5vZ+6JfwdUTAxjXv91FrRWsHjn1DOzYc+9063Jkfan5JOsVWg7uP+ih/BmAclJYNzA11/4LGG7bjz6iyofIbmATLcsGyXHG5PiOXgrQArTdsxxcc7Y69vuF6+YDn60+4rZ9Q0hOOduC+f8bb/oa37VU5lyyzJRUCJGmn0eCeMr6hRVCSYCkV61qxXhNyYeWc2gWtV+S8opQLcl6R0wWLcU4REVq5o9UDB3ccbVcfQgqWouV/Kz2hUMde7zhkx19+/lnJ0JcP2O4bSrnidhUsi/rocnSL1hlaF5PUN/LubeaHsn0qZZXDyOw+gZ/QeQKibPrkO01xKXnJnslrl/eA5XzQpJ/nDL+BO6TxG0AoxslGuqhx75ENN65JYROXZUHKBevlgmVZtXv1dFtqG+c14/enFV3N4qPeOdYFTfHj2NT928fvBp7cuZ8PB0X8JpUE/BuIX/ilE3LmHsPwHPScvtjcRZouK6cAA9OJaDgv8z2PtWoBw/nNE+I33du4JZnePnnF5/uea8fejc6sSqZz0Hg1sIbf8Jn92kGYZ2z0y7LoM/InpJyxHweu1xtEgG3bsK4rjn3H631BrQe27Y7WGoDdSoB8wUzofqLRTeEUoZqBxuREOaASWQ5jwOdpjmf1iGcyCNkMMcn0A2Ah5Z2q4dhOjhsG8DS61inWrNxLhEMEnQhdvWHkJaMsBZe1YCkZxQLk1jr2o+P1rsDT1/tu3E56zue2oBSgQI1WLpoJ0hJBmNBt+kUQ3FnO1zQfs2MysCWCD0sE6yHwk4E0ec9JCeRyKUilWK2CA7M8JulBjmn690lw7cJzxtv3eAQv0gTqjEwntvbUlj0UAA4CNAGGPDsQ5OU+lNO0bh0EGsDR3J1u5lJ6z600QCcJ0MnTvh18Qrwmjz/fem6Zd1VOinSIgZ+f1QT3pmnfNRESay5iIrKSNf06yfurhX2IOnhfCH7ByTl/p+P+mrESnIRa4MbGrzrOEKguPfzoayezaPNl0e4ohzS9x9CUZgXWpwBLoLIjsBRkUqJMjV7g5SrCylPgcqfBpC1+0Y0JsBIGo1awMOq+oe476n434tFDQScv1HBjHwI3JlS8c4/pYBG3nXNGiX8G4eSfN2Cm8z1awHAuzuOPSfbmDQXPSPI1BcB2SYt1gzTwj0U778BtNM13GtwKOWUkInC3AMMy8nLS7oIDmPz9zs8/yuFZG2xJc+ypmHbMvo2IBbciCjSRrryxgtzpVgDeszYVXJ5KUeF8T0qELIms5P5s21wcPHtJiZppbFwZUEVkBOJe0mQlKCnWm96h2u8hRycXbbrmfPzWfMtfkWMX39Puu103dr0FFrDO7d0p7k+zbFQ3wuwxpTzWZvi9pzsY950sgMtZ7Xq2zEzQ8JPD50ujE6SVqxIU+EqiwXnmYX8g1hAAYyx7ykAWzbI03lAib3fPqKIdTouhZspJxwYcUnSI85KiOeiZDeW8WTJzH8VHTSadi6mzmY00xVUP8+s6wTPiVL5GaacEf6qBSEzorABsO2U9Wedjcjul99tFn21rgqMztqYZgi6zAu06GN0WhVHQdBtqfrbp9ykeEX+S4YXN3/gNEflujm+4DHEQTeNmH3QC4/FdGZ8Vt1kmKe4700iE8O9FKT88s2nyq6f/nuSNaHpPf0Y8OvvnPPwnTPPtNtFka+Zz4q6ldWEbIcN3Ap3uKW7MbLV081WabmC2Q/2DY3tF4w17vaNjR0sNSIRcVL8l8qwkAJZRNLq+FSzlhpxXQJRO4Dh2HPXAUavRwoyJOrNH+vpTwDwVv2HWzSLS5IbWKliA1BnMhKUQaCkgKpZoQOe1Kx1dOpp3whRBQtbRYfUZjkM3te73N5S84jg2LGW15I8MoWZ2qto9LSc/yHXGWQ49ljy9OibB5PNbWMgpwDNfTM/j44zf+sK7Y67qOt+fjfrEqzrjEhpTYJKl4Se6XM2dbIdDP55/VkQjrhmZqEOfudPhvuc8Vn/7+N3A02PtrR+PHVU8jdW7YcDqEz1YYnOGtD51WK8IoGg4QYCdzzJwEg8jOGdwAIOHxRd+vOPIoMhwdk3K2wlhPCsl5a5yIcC4loxpdOOqAI5ZMVCAAP45JT4zNn94raXWJwOIHfM03bsvEI2LxBRGi7O6WJdlxU8/XfHp0w/4l3/+Z+z7jq8vL9i2DV++fMW2b/j68hVv97coxfv69Stq3XHsG3pvypNhXRXcifQFH9k4Yq9N43wyljFGtruebIfcduk9061bqYQDwa7aubPHbhDRnRCCCqiOHp+6Xj0CT7pTId7nBZwLUiast1W5nD5esZSE58uic187tqPhL7++4X5U/Pz1jqN13PcDiQhLSth7x1ISbpcFpegu8HUtqKToMkN3/5x17CKCxe5l1PQOWSF3VkEjMURMxsOgqVMmtpaEbBc5J1yfrnj6+IxyuQJ5VfJri0LElEocMVZj/k5r1ZWnWUwd+5GR8T0dx64ZJa1VLSermkFC3EFgJFGwJTieolQ5jR3VaX60VXXFy+sLbnLD5XqFME+OvgJH3fhoRsZTs3a6o5SuPwJO3wSVHKjVnT928InntSmxXmcwwKdcbYplG1r2E0CQrvrxMP3YW0NKCfu+IOeE2+2KnDPWpcSOvH7TdBdGoBZ2PZwlwGXwwcbB9ZgPq+XSTI5NGAa7TnxNHR6BZaz5Dfn5knFB2PP5ecOHHA6E8iIY6DQZabFuhQwCFYAo23pVgJc7xs4XNXgHFDHerXpoeVxre+hRQGvwEyXtmMuMuulaVwev4fXlM+qx4/Xzz2j1QN9fgd6VZ4sAyup8+S6hp64P4BjhCOvwqTLXMqrhxJ+yITGALLKTeKkhd2f+08MzrjQL2cpt3KG17FxmhvSOWpUY3ct5UkrIpWC9XHG53kAAej2GDbYguJQSgX4iBaoAJSMX0ZJnZkZJCdwblpzBnVFbtXvMf82n+4c83mpH67AMEl/rwyn0HVI/oqzJNyzM1lhGvg4Pdxz7G0AJ7bar/soFRQTrorqqNWO5S7Z0Msx/m1axLZtsdmrJytPkTnwTxW2zaYxkpKZ54vjUm1bZ9M6ekREd2bozIPno3M5Z6XauOaAHwtGg89dGdzrTVbo+VHMkz8Sx7rcOynUmy9bJEFqAXEDLEvoDIkZ6TwA6xNiohw+gRy6aLXu9PeP24QNKIqwpobcdzEBm6DlShiwLLuuK5XpBLhfkvKBTQkpFy1gm4Jjd7rSqHQ0ts0L5UzMKVoh03UQjQq1mi6p23yzE1qVY9Xa3dPJm+zW92+5/STGMAgNHZZS1KZOp2hvBo19BqF2zqAClVuCs470QAs8L+2CPVwQoWbvalaTSwFAidm8c01iDXM0y6kbZILFBCOTgKfVyv904ml4OxlsTvB6CvQPPl4RryuipoKcFBYwiB1bescqGu/Mwhp0leEbFCHRH2T4lLweWYdM86CaELv/+jvOa9fbx5L4uaTmU+6iz7zBncWvWkgDIQVtACZqKCSDnYj6R22cPyDl0xBy3uP+k+nTmfxz2MqUcnFQAgkM1ki5MsejUm2fkvhtrFnyrO1q9o9ZNO7X1USIu5h94ZrLnbJFzCncBesfx8op+VNw/f0E7Duwvr+j1wH7/is4VVV4hhUEfBWnNWH/MyE9dO3JmUkJvNBAxcs64XT7h+foTPj3/EcKEt23Dl6+f8T//9O94efmCz79+RRfNhtSOnUry3Q9GEgW8l4VQ1hWpLFpel3cc5iRKr6i9aZkqE5gJZbmi5Auu149Yl5ttKCXs2wva/oYuFZwYtVcIOqocWHjBKjckWZB5AXrG2/aGjoZ1+U+8vb3hut6wPb/ghx9/QilL2D+hDpIFRM+AZIhomiQHBc2MFWACY2yzxgCW7LpLRsw6H7MJVv7m+Q3EN1wGHYtIdOYtBs56Y2AtPOTTZC9N/izcxsfmObRjMoafmHJGypr1lHLRmJDFOseS+qWklVomgDoOrITpKRWDoKb7HS666feBE/214+/meJJQDBKDoFedIgt3fE6TKjG7Em1lMb7j52fRzC7bzbAYxhyObyhlOX//NIczGjjd+2N6m99/iEggeZOjRuTxw3ups8DgFNfHufQBz+VWLsQmreKd4GwH3T9L0yTKGE2ZXggnPRFKSVHLe71esSwrtn3DerngabtjWVfc3+4oZcFx7Ni2u7bzPPYoi4Bo3pByyHhpkHfSUoJFJ2eO+wnAz4Kzoba/NRgPDqB90oA+ralH1P2LDFGmSCUSK7c5A0+A1uILGYG6ZTrlknVsssJBLIKjduxHw9tecT8qtkMJIlvr6hxDybyP1lFyQjNyQgqidu1yx5TA0B2zTnr/fx23USFSWRrCO/nM03ghni15ttOyTAEnLKlkrLNH1DpEZeLqeX9HDiTa+pgV8HdwsGcPTV3bYJlOJBZciQylzaZraKD54pFeAOisncfaEoBV1E2rsgn9ciYUn8rrWMuvggvqAXCKGfHzYQSVAxCWmNMphnv3L/2TXJHGM4VZs13ybv8mAlgyFuuMmI1E04PZhMEn9Fvu8jkc/o0XH/X36Q137CRUJb37ojltcKdff0e3JP/s6Tq+BifHdopMU8/G2dQhnBD96+NcOnIK1FNkgDnwxK0qd9cj/xBrUwevz9cKUMGx78rtdH9DPQ4lHW2HkpKLtyB/yFwaSFqM66PTjLA543Nkwc2Aq3z32E/iQ+/rQQl7yVvqOhAa4xgzpK88yHvwzCRNzQ8i1+Bpsk0hKUhJszG0pO9BN9oj+U54TgmQHOf3+0qRcfL9HJrxNDKBwmU5fephYdGY9XCKT1+QiW9E9VfKSbP8aPgr/kNkWSIJk1ON6DxXoryOjIxajyQIHapOMMK+wu/Y7b4MIOC81r91fMOQ/dYxqYIRKpq8RnOD8xC5CHmGTckjG4xIy/iFsmYKpAxaLsMHtOxRYuUDjKgAZ/urGdQL8rqgrBcUDybS2HQdm1LmA0zd5+YAYy4hckeV0SabIaEjyLlaTo6KDHuUVD8l70RutWzcMbWqNx/GfuRBNnE6s/smOE2bqOuLbkOkS1vAsRl/9hJdZznZOPnzPMiCYMhRZ0HtjNoTji4oXZATR9aUlg9qGevRBVvTbCclBbcrkmeWJyQRZOlI6EgTn5Y8rr0xbfEYJ/ny/8jfJcn/sMe35AKArU3zsaYYbP7eiCVneZh0iG9ehP1DfFYbIIzNFV/7Ml87zOUUp1m89y7zJOR9XsjTnc3PY/IhTuMQjWamDnbzk01KiqaAkluD1Ib2tqHtO44vLwo8ff2KXiu2+wtYKio2oIhmOF0F6dpQsgFPTPBU1URJifbTBevyhJKvaNJwtA37seHt/or7dsdRdTMH2cfN7HtX0m5hXUti9ClOxJ4nehyfm95FmxIwoWcBoUA6ULICT60e6Nb0IAjbWcDQOBSmc0gIxAm9M5p0bPuORAX3+xtyzrjuV4j0yIgmLDa+XWMmTtOoP+oNmeTHludsEETlST88KTObc3HCzVk+HETAhGecZGquBPiWxzzkXqbrx2lPa0am9TJ/SG9yZLd7MfODB2F+VMj+eGd6Tr/FsYbGLb9fv791/P5SO3fuJrBmTtWfa8nVCfQUVMfI6OwAzOSGfXyPmZGYIFnCKSA4T8FwfEnOwzKXDERL8fn+gUDyvpnGhmHIzumeGMoI52e0N4eT5vcGA0WsQ5879sNN1zrTkhJEOqRtQZSqH8igVLCsN5A56+pITEaOoWnyvaMbWJJLQSkLPn5c8IkIf/zXhNYbjmPHfhx4u79hu2/4+vKKbd/x+vaGVqumVR479n1DqxW1HqhNf7emu/G9NbBdq/NA/Hu31y2TwzusoCvnkCt8595ILgdT5wcioHOCCNCyd0qhEHBVeA8T5voj+XasobpQR/GyZpSc8HxbtEMOBL01fL531Nrx+WXDfa/485c7au+47xURUpnTcrSOl+1Q0CkR1iXj+broju5lAUDGCaCAVTNHqpByU51i39Ph8uPy5TqCrMBBAQ/PMCjLiny9otyeUJ6egFIsxV7gqZxDLkcQ6cAEi0wtQk9qCoBlI2IoS9uH+ead/yMemtEnqLUFAEXCSGzkoPAugM1ISUfANcuELTtI091JZx27X1YgJVwv15GBJhJ8UromdA11J5Y8da3TQ6eNJn0H+CxFxqg4B8oApwBM0yUPv+dj1t2mEx2wZQW/m4Ep3sFPRLleal0U3M5a8lSKZqQs2de2jxhB+aTEE27G4d4V4Vyu9wBiK6CMxy8+PGJ4i5ZFYcSVpCURAT7BwZAGkjT4irw0A+bgxP1oYwLpC4gyskAJ/IkAsQw4r3UX5Q4bGwnqhB3G39Cakl5my/7MKYElBdhy7Ada63h7fUWrFfe3r+De0I9d7UKUQamOG86zOQ2m8+LZk3FQGLjj/xv8h6Zv0sg2m52F2UaBRbvlJA5utMTG5zDvHk++AETQWkOrCryxMJayoiwLlvWCsqzWrj2h1holiACQi0AMnDLU0+yxbcpM5bLeuIKA2DH1LrrO9fE9HUdn4zgyQCacvQfrQsOeJHjDj/EpnrxJJbatoH7gON6Q8orLegVBcBya2hRgrAVCxZPUs90AWdcxA5uWRMHxxOZkW2drdGCsN4zM525Av3c56p3BAuRkgYyV+DL7DvTo6MezivsNwCNk3x4luDKtJNX5S8KdTPpDNLqclZJwWQucw6IJofekXCW3T0AqoGUd8tkVfOaU1D9qLXgVR9qZgk7X5yfcPn7E0w8/IrWG3Cr6fgengpya+ogpAZmwLgXLuiAvF6RyUd6h3Id/aeU7WsJmPon7blFqkC2TSCKI0aWjHKMCfeZEAl1KYl1alV8symbVbUfDyGorgpMedRfOs93D4wm7ZnPatSOniGXnZUERtwGEbIS+TkadkwKdJatPbLQtob+cWPzoAKAdNTUTSrC1jmvJJqeExrDXGXsXvFZg63ZvlEC5IC+a1SYpY5EdV25Y+ECSZpwuwz8IUXNVbdwRzpF6WrOx8exr+/eGbf84x8k+AOFTuP/usdPDyMR3RvMU4BRB5YxkWXwsyuOZrBQ1FjsGd6AAp2xDAFFafOp2G9/FCOLFiOknn2WUro3sFbsUkvkT4pye/UBvh2U97Rq3iZjdnuJLj2HseXmvkNZx/PIFfdvx8h9/QrtveP35F/SjYnt9Re8N23bXTGtqkAykDxn5VlC3hv5Dx6dPP2LhBfmyIiPhtn5Ezhdcr/+EdXnGuvyA4/iMX379GT//8mf86c//gX07cH/dkZeCy/WiuoIFXAV1P4AOUAeoJyy0aEZYWUGckfgCWLc6S6VA6zv6UVH5AAthK2/K+WT2u+SORB0pJ1xvV1BlgIFKFRvfUfqiHdIbIfUMroTaBV+/vmHfGm7rf+D15QW9HbheL/jw8YOWJIuAaAHSAuEFbF3umLU2JmUD1DBKmofsTRGTC+hDpzh/333AyNiLONJK7eA2JU3y7MD2yBBWQH9K5piQHZEOZo/vRnzgG64SMQHFjU24E4h0w8L5BGcfzuPPAbgObeUbFX5wVEM94imPWwC/ffx9GU80D7je1lkhyPnDNIK2MXz0jc/K9C/f5beQz9L+FXwYQda4j+FsvT/ve3/kMevp8XBFIw/fpPjP+aTTvL5Xno4oxFfsEwQDznQCuVcIN/S66aeMyDDnDJKMnE2ZTp0VBFNaKhgQ3Y1R4c4GROVw3JJxZCxlQcoLrseBy+WmgUKr2I8d+3ZHrRVH3VEdgKpVwScni23ekUEFrxnw1FpFbx379oZaq/GTGLeJDABqeL7JEjBsEb4bUznR0sxv+s6pA5cDxdX3E1n3Ot9ZFUZrtrO1Hzhqx9t2YKsNtWn3llnJxPVFd8tyZxxVU7aZB8dITgmUM0SATowGoE4O1uCm+hty8vB8LjpRTlMKyH5SLiPAePxurMWHgTMQ4KFKdwr4z9ce5/o+Dk0VFY983j2bz7f+e9JFY+tg0kkGZNg7GmgfSKUgr9dQ6K4rw3niEcB7Rzrnbzrfx8PtTWD7Y7fCcFof7vtbkxdrcPqIPHxenTMtX+sW6GmZRjKjrGm3CsgX42jJEJIB0vt/iQJ8cqn/PW71Gayl97/mxUNj5siueSo7wxibMNKi+lLg7ZcR8xOSwB1CadqlVI4uShocjE0Sy3RzPWzgSG/aype7FpskswNiQLFn3h37hlYb9vsbWquo+2bAigFaZjj92RA6btalPuLzjtb4mXXu7CBQnHcezgd7FdG9QMjK7/yz3u7ePn3ursjxGc90ytm46bzDIKaW6HatuPIk46wbleDutlKzpIKo3z9Lw7n7Ldv+j3o8cuQA+G0DQuffjyqdpr9EdDOutwZQRlko5szBzKFf7LtJG4W4DHkAX5K3oleeJ1jJSUipyMTDIwGec3BXjQ0Qd8AdUHmcz1Dh34xWH57d5dvRuoHaDVN5diXjH/N9pDQyBwkUvHc5ZyArSbewgFjASXRDLCUF9s25J6j+OK9Rryej0307yGWrFICDiRSZBZSSdtfE2LQd3U4n22736oGyaklnxNQMCSQtmQELlmyU2mQZ8DRtpkzj7NlPXlo3y+k3xVO+MWX2ed9oYZg8QOV+sIuMuRxyMXisaDIOYveiAJSWCCo5PwfYPoAnLc3bLONJifxhxPoUzSmSNV9IYGRpoIBW3z3KkPmzuY1ntxBjyPH0OcJvjN13dJzXM41BeffeJE+ntTn0gme88TeUZADnkGkVPZ4nTT+TfYTzzuE9CDEe5NEMxwaviqM3l2ngXoNy4Rzr2Jfn2EhgIE+DHA39vqHdN/TXO/q2g+87uFbwrhxPUrVDHqMDmdCthL9vHf3atAFBz1HemNOKpdxwu3xCKTckWgAhtK4k6LUe5vdB9RWSCaxzWyIWl1NIpN6RO0MbPRqoYQAjJSCnjpxHd19tmAKANC5NIKSipZIpFQga0NXv6tKt+kY31jIykmjWDndBT4x6NBz5wL5vIAIu11XnPSkXXjKaGhHtcnfCEggWI70PgGaxO737Ti7nb8rpd9gdiwkc6polcbrk+GPiSQ3dYi7aqaycvlFjNMlmrJOUkChj+Eg0PctEOeTnOdnFb2klF/rJ6fidcePvBp48O4KAILdyYzRrjkCBTVijGwG5Efc/h9NPgCHXjCSOOOp73DkGz4mxIusplJaAO41Az0+AMUFENJxUH6bJ2Hs64OxEJ99Rpght4rP+SihAjIwoN/zwkYl/K8KdrWyBawP6gb5/Ra8bttdfAyHNZYHUT8hlhawftO3x8tFcBi3vapalkGwMiACxzni1CfbjUOegK99WWVbk5YKnp48BsLkR9wyn2poBR8064VVUy3pqTXkAeu9ozldjzv++3VGPAz//6X/i5cuv+PzLz7i/vaJaBlQ3QVcHY/weskuYhCP+PSPBIN+lkOi8t1jmhYNy4abYjvt21+CwVr3/l/uO2jpe7oeST1qnqRwk0WOBdRFstQXnROsL1kwoJeOyZHDJuF4XHDWhgrAxY2+MLIJFBIWUr6CQ8hFkQnTxi0BpWNwwYOF0l0UBp9sT8PSEdHtCut6M04EnX9VdSVujNKs2il3dGF67DnsHBjtLmsbw9yqQf4TDd8nDYZVkO6QdCYSStGtDBhvJqJx0RegV42bT1/Rn3wSff2Xcnp/xw9MTSilY1hUijF20U52XsbamXc46N3gq8SxvGuefeZ66g1RR8jrdz6TLZDrJY7bneOv96xQSZKvM9LU0vTdty0vBtZItm2ZZdOfkdtEOm7IWZNKsh2GsacpMdWFVyRSZZX/o0hzfPvPkha52h90EWkhTFBgEL0cLc+/zF0usm84hgDjsRLexDa4qUoCNctHv5qIgsjVe8Cv0VifCUAcWJ1Jxs22ZsoEnmsG0bRtaq/j6+TNarXh7fbFuUwcg3jJc+Y2IyAjsR1e5uEfXEwbmeNnZKGnzTllpLHobl9CrFlT7SM9Zxe6QRKex3iIDN8AJO4eDqq0165CWsZSMZV2xLCuuTx9wfXrCermilCWArwiGU4YSHdsaqD2uDRkdAt3mNHO2xa6vhOUZeSnfHfB0coIJ05p6CONNKT0+/WOAO0RB0OqBl5evuN5Eux/lhMtlBZGgtaw8PU5iSIRCmnGS3Z5ZtlOaOka5vwxAOSFhpcmsPhaL2l22EkLPSgC8dI+w5BQ6h0CatcITuPENFRdemWB0sDSdLw44hX/IIeOn4H9y6P0N8ugJZNl2+p6u0eQOGASMrvnK6KQ/o8JF7Pl0rHJKyAJwq2j7ju3tFYUZhXt0z+yi2UTEmkVBMOJ2K1fspM1NPJO2HpvqHicUyhklZ2S5nIIgbjuEG6SprVnXC1LKWK835JyxJC1Fv7/8glZ31NqCm9WxaCLlRWIAL3vFpeco3hg/hAFN2/DOrsUD4qdzaw0HktoH7Xw4Sh4p5E+znpiVi0tsPtw3d+JylwupjIMFb5Ww5D6V2in/6NEVoGogdCGsa8b1UnC5rFjXFeuiGfTXfuDKbyjUggPLbY7L5SP45u+x6dOgkwjBcw5Edy6+H/0l4u68ghH5lJE6nnOO0wDrnAVfjm5nkvHlum0X8LJqLNJ2SGwKAaeJsC6dkQRBdLKPwByI+ya2AuwC5SrTBYDJjx6ek1/KQXX3FdtxoNYN29sr9u0Vx3ZHa9U2SrwrHA2OSAikQwGn2lF//ox+33H851/Q7xv458+QoyK9bUDvWFpHYrF4kKwKBmivKu/t0tFSR90qUIBcgVQWrMsnPF1/wh9++v9AANTaACL0dkSnTLBmE5esHTUh2s079YwsGSIdLA2t7thA6F3QGyHJAuISHZHTkpGuGevlwJM0bNuO4zjAXayrX0dngNYrcl7x9HzDsq5oxj/cX3fc64G1bxB0XGhFyRn38obUExIVJMk4DvUCP//6ivu6A2Cs64qnK6PkFUIFJKtRaWQQikaKFgvM8kIuuHAdFt5R8OCej2EzxvwP/CGZT+Z+bwgLDXkPv/2kHydOp8BZhh4eFx2aJlxs8jWXFMzLBUtRXyznPGVeTaAqnaR6vEfn2Nj1XHRLpoHZDJ3+14+/I+NpChLEQR7ECHiJhN+0rseIjP/6YcpbyZSnQMzP639/E14844sz8DSXAkyexG8/oY2oKy8l4Y0n+sazPDh+PjE8JmdckSLAAmA8SY6IH5qOWe/RZUZ6QSkJ4FUFly+QdAEoQ6g8BJFOWi4AWLmHmNGMu2Em1kvu5GNWwITSC5alGMCkwUPvHdX+br2rg2OBVrP3fcz3+xuOY0fbXoB24Hj7Cj4ywM3ahOrzawcT56wQB9FHF4tYNGORBRAzOYlCgFjHI2V8GkR9Pv8MBJBw7A21d2x705r/xtFxhcj5BQYw6nOnvFbGE9A6alNgcMkjCyRnNYgMoCd9JhbjyxEBO1G9n5q0wSfBrzkWe/zDDJKkDMrexrcYn8Nok4yTEvqNIwL26YOnv8/rNJTXd3JEicoD4OHDPM+D0zvaSh5j68CTvgw/Afeu9entoiV8EAMAUigBD+TNBT6rIlMhc0q6ZwTI1GnPMwJc38U53zm5v0/xvxsjjPEBRlaPO8Wa4kvgNHYGOTNKTsoFlXWHP6dBFA4b1/n+9FoWkAT4Oq9z/1RCGFJ/XTB4IOJLg2Db9/L9eYZtHsEP+X9o7FcHx5bLBTMIqudACdQtr7z3uB+ByUNk3/TIwtHGGnbNCfDxErtmmaT12LWc+dhDr+rZNVNCSVSnQPgROTg5y/7S38h8km9JyDivrwVMDpbLm/6hnVMG2buec5DjW6cesy0OUOVSRqmdR4rTnPiTukz75k8Q/jtoa2VD1bjHYt2WghOI//+a48EHsYO+8epYa7o94/PKtsnUnevJwGVKBGL91gyeuB/hAFSyTSAiTOtPIthm7yrWHeQdpXWGK550MT3IcVzZfapJ/86/45ndfwixHxsxs79+/sfQU8MBn0dx0itn18tuik8/mjk6+a5+Rg9EnEi462ZePXZ4tiB1zYpoUCAk2/mZG7gd6gOCdC20hu6l3HVH6zXuPSXNjlZfQRsCzGvLy2O1Y17Bul5QSkEhBqTjyBncRwZv/NgcOIdSMyJv/z2PzzyC7/0Uk92HMEEwspWSZcN5zfY8W+9l5nwdn28H8YzJHJ6F6pvRLITK6puynSSlkRXlVQOa5dR1bifQadz77O2f7d5jFBLqnB6/+f6vf+Rj2G+axsT5IiXW/my7VK37ih08t4/ZrGTgjZd+x1ocH3h3H+rPjO6R8SOzAOGdQP62lnV5GyC2xGahrk9uVX/YuZ0mO+v3QtqcREQgrYNrA297/MheQa0jdVbKSbFNOkoolNAhyKbVmUk3V6PUPpatfj5fUcoN6/KEzh3HUYMWQrgHE/6YMQ+GdCORlKhS35Wpa1/rIGT9TEparUMFJRcgExIVKBVIQq8NnNgoIzTTSQGSFTmv4KKxZacdAuVzytCMnUKENS2aBWUbVipTpBlQjVEP7dDZygEIkNKhfkZfoA+Ywkf3jCf3ZaJfzcMaVr0np9fOm1wP69btCPmGqM0CTaWldP7aKSabfCS/PX3hGwrzG5e3G5z4NQ1oDQBJMHuDgW3FjeH8nn/2tB5mn1Twe0HzvzPjycotBODuu6JWamAp8bF7ag+Xs33ePAxmOd+rTU5OyZTQMDDzQnXjFA6FodvBwI4RtA1HQ4dnuA723anryvx043r2KiO6i6ng+Jycd4eTrlIlPAXQ+ggefcwwORtKLtfQ24ZeNxzbC9rxhuPtF0g/IP1QY3fckMoKvv6AvNywPFftZpafAYyd7GSOfDfC1malHK23k+KPus5khJmUYx509y5bNsMS6H2kwE+dZk7Lw8ZSiXF3/HhJ+OX5gicc+FIYb29ArdaDjqwbDAu+bA17F1QPqPscdI41lGwRBIl4opCzRIRecmTCAcYdIZ4poplOvQv22sMBPtXQms1xPpro3mhzx8KoXcC7ZjQkaGc7khWUCJecUFJCLouW8O3A0RitinbzEcEiwEUICwELCdZEWBOwpKQZIuYcRqZNUp4aKQW4XLDeblienrBeL7hdV6zLgqUUbd2MKdPLPDBbmaHwAFircyc7PGsomhTNg6r9Lg5pBuYCcADJ5ZggyKY0SWspQTDgwHhAQqZaj3N6mad0Bm8dlBLWly8AaY167y304/wbUBmOtvfe5dE71cXOvpfnOafTQ/mEyKSP3sdRj9lN58yqkWkV53CbIQDA0EcVSHNDa7rUnL+9VOSUUFvHUgoAwZIzCAuyybYHBJivAbUXXjeewjgbYOUlew8G3v8YDpvtTJq98UAa5oBEUO1Wcjaw8ZeenaMTiL6T+ABRQhMC5aZ8I6Uic9eOIM470y3783BOpzo2SkizVjW1WYku66EB4svXLziOHS9fNeOpHbsBX+bMWfe73jtSEuVNSOO8DiS57nWOKy+/ceDAuaW8a6qGTjav4gWHKjzOdxE6JIBPGVl4LIB0gBgsCcSDS6tbZqv4TgJoBAY543J7wtPzR8t4Klqy7TbFZUK0pE5xL72+c0HVY7eS7gPMgtaVOFk7tCSkUjADkN/V4c6cbYSd81SBbzm8+jUHbCdSZvvtiTudGXs7wHIHpa9Y1gXX6xWCjlIzIAzOCSKaDZqIosFGKRSZKH49tvs7WMlkj9ZRWVAbo3e2zmfOWTduPSeTw2TcSsm78VlAJ37P9qUZrSQCGZjsGVPePc+HzgnLw4cRjABLxrBR+AEOqqkcu37pXRuJiOlvQzTAUo3bqQ0/tA97MQIAzUxcS9ENsbc7juMAvb2iJPUlqFZQZyW4FsLSGaVVyOtnVN6BtACk3Rx7lwh063Gg9WqbUxnrerUuRqqDvJNWa5vep+26lZSxLAueb09Y1kUzPbhhf/sM7l1pC9hKKCGqX8U2ESF4PTpql8jsLknHKpM1JpgCrneoHQ0bEZtprJuG1bhf1ccVbaInI4fKO+9l41HqZFtGNKaXRDOYhHUjsLEYaOQxihaONsu+W4tyR10y4bokzbzLBOoHpHUQDiRUpKSZVuQ/NB7P5drjlZnOOMxRvCIRYypv5HfmfVl5eE4WatraZ8sg0rFL0WExNsgfuHYiS9dkJPyZdQEl47u1gfQNKPerQ8ZOanJkNkVgb68LJPwB993iWyP6HwDnCThQ+gXuWkJf9zcc2xuO7Q7pXXVN8FHm2JQBgH50JRH/8oq+7ah//lVBpy+voNpQLBMy5QJOCYUILIyDMzozqDYFoBIhrQXX5w+4Pl+xXDPKJWsXzfWGDx/+gKfbj7hdP2Lb39COO+r2hnp/Q993EIvyTBEA6eBegU6QRqCWUWTVdZ1sg5YNXJMDiYrFZxk5rVjzBeuy4nYhYCGtPOkN7TjQqnZOZWaUsiKlBaW4zhKwJPT0hk6Me9vQueGHyw9Y04pP6w+48hW1MDgBS9GMKeGCXgmvXzfsZYc0xlIW9EWQaEXiBsKCpRCQCoAlZJJEIDmBZMhf+K2R9a06Ped0ksczhIPg0XTg3+kF4MiEODYxkZJPUuQyp8kkBpQkIwV3u266dWxUR1Su34XOY87KsenZ556Q49975OeOjfPwj9UX65Zu7Do5Wywea+KMwv/V4/dnPDkcRqQOUAwRbL3L6WPxxmk4zXGYbBDZ+fxLkaXkg2hjfj6TTZ6bIBm/I5CaPung1incsECLMM/5gwP3bgzwHtCbAjaZLi4YBtUFJL4i3snq3O1AetVa4HoHE5CoIRetUeVeQfkJlC+QRRcNlQvI2TBhpOp6gXO5X9yTxCKiRGAhLa2hFKBHDIHdc0oGLFpqno+nD2QELMLICbheVtwuK67rgmMp4CUjSQfI25wrkJMTRfq4H45JhpzEQCLII70USFO/1QFK5NkBo1TJAbPaeHBJhEzRJL/nOR9riCJQ1uvpju3eNE17Lw0pJyxlOFnuNPekDpfyHyAQ9RhaUTJObW5smX6w9GtAndxE2qa5FORStKNdAhKxOTu+Fum8Vh7FM8TeR3Ue3bG4xle/K7cHAIy/x4dJHXWK4GUaE1eqEaQ4ka0Dr3MWCCFJCidFjemOvKwo62Igbgal9o0bQnio7tgM8nAL+Cf+mlHyFw/xXlOdnJ/3eswdt3fldmZE3CMezvHj2NhTm9HrXc/VDIzz3wtrLl9OKtUJEzGhjbdnL5LrZXcMT47lWVf7A6pZCY8VXgLjeuKUySFjqOMZJELXWAMzAALxLEgG16r6JhXNzEgJyTu1JWs7KwxNO+cBzrvunHZWBVCQqjUtaT4OJeHu7Xx9v3cwknXHSiaHwzueM8XeW8b4N8XH4YNMQGQsI8ZHrJGHPMxBshJEmibCjYkCZa5DzmnbQ8YopYnQ0koL3MUnhEF1OfBJDsfIMms7d+PUUtlMSe2J8hgquJUn0O17O/6GZ/Luw64rTq7NNH0x1GYrO3fUWiOjNqeEkpUXpGeCcAq/we2OnnJkDioOY5w/XbOEmxGGd9tw4pjbSZxDHoZcYzpn6OAp2NPPT89Dwwn2znl+MpcZl3VX/X7l2Wekx3NPi2jIuJ2HAc8MjGy/B/mPswZY7DKa1eYzQ5ptLOSkfFG9g8QypomsLEvLWHHsADUASbMFpo007hXSG5RUuUO6FwsZKMvNfE3loIOM4GIIySxAY1R+K6ZQAErQyMjHbciGr/WNL03D8tdeF4zMJ2F/WR2qGdxJBPOXJ3MGKEBG4zwx1xLTEaZDgQoFk0rW8tGShi5k7gBXIFm2EzBk9SHgmF87fc5fkMcXHyXmO/LBpgk5+R8nuyXTcAx/9J2vMh8BUhlBeLYybWZ4iZK6B5OGmSdGpl9BGO3XHR8I/+TdrXzjPPYPzx5io1iITKIRAQRoEfZboN3nOoOPBjkqpDagNvVBRGC4q2V9W/a56OY2yHLESTt655KxXhYslwVlKfpTFuSyopRL8AYLM1rdR5mdg2OTnmNmECfAf8Qyn2KKQ0kjfETLKEpIRjVgpfnFfJZo00rosJK5lBWMix/LBCOgg9FEN3OJCGtedG5TBVsiBSEGSHkLGahLBViQ5UCGIMmCRIxEVcG1yX8Jv8rBomme3ft0/07mZ3c/NkRzjqZcsmcBIrg/Kg+vzcdjGRxmP831GQ1/d+BOvv02AbkGssbDUFhEhH16kG0fkzi3+xMRJMed4jwCf/v43cCT1txS1NhSMuGzgfCb68ZbkiaET0tFOIRYFwmFchg7egAl21XqmkKVctbPppFlpM9OVtMae7iYpzkyo+yeU9IWjEG+6E7UaZDn8SQ735i80+AD8TdYrCyPwmAPJJCm61jmRK/R9Uj5QBR4Yq6aAfXyC0Q6dmKklLFcnpCXKy5PvyAtT8i3PyCtT1g+/AtSXpHyB+3NZZkcfoejxa5rR9aOTSLos1AmiiwLf14fCTJlrTt157RXlVcNLJdSkGTB7XJBvV3x8ekC2S8oqGiLOapEuFcFnjYWMDEalBfFODLNYVEnFSYaJNDxdV0Vz+qT5agywg2eFQcBWItnBulC6g5MGfF0dwViDkye6lZFNJ386B19Y9xrw/2oWJeMp8uCUrJyACTgdtGgtEJBr6MKMguSMC4p4ZIIFwGuIrgK0DNQiJEToUMBq54LpCy4Pt1Qnp9xfbri+XrBmioKd2T6oHObEpCyBoDTvIeht5kf5NqDEDPWaHhfZ8X5Hbk+aMcOAFGf7c5qTipXrQ8emUHQqlmdLN5pyTOe3LlWAw87I9GGr/QZzx8+4fnjJ7R2we12AyA49h0eACnAy6ET52ySeH0CngIoeXDCTmYqnJ9hcH4LfPrWMb9+CqziLMNCinVl6r2pDAoUiAFp5pNoFyjQos0MLDso23nG7reZ/HTWsSMTyj43A3T+rPpFdTAtU3behNBAzQJqN94CI8AdXDE8Pavu/JzdDEoVlBLKXnW3cL9aSYpnEdio9wbpDowISl4sc/Sibc+hdur+dsdxbPj65Stq3XFsm9ov5wNI9nhWOtCkKYkmEZCzNZuwEqhEyv30EL1I+BGzc2syQ7ajnkizCkRBTu5AFiedzEFgrH8zlBtLRmA9AUxufZ3jaRIUiCh/zO3pA8qqY+GOuV9rjPXZEWfRDJnd+AZ7105AuSiX2Hq56Biv+juXJUqGHsG4f/RjioMAAAT61uqe/mW+mMCbap0+JjJ/XzdIjtrBr3cjUibNgHl+wrHvIGi2L3PXzKSkgX6DbkoljGzd1tW+H1XL0hvPgJPfAk23O/lswEkGBOO7XprnemC4KCrfnp1Uiq8X1R/NbB9bAxHp5rSbrxansYCC4P4rWUYLRaChga0ToxOQOlCb6Xbn30PoJSUZGukwKWfkdVUewGUFqvK6tdZRe0crGa0YnxwMNMlaRkOdwdsbjsO5kEzXywiUxMr7dJETmHeAEti6crJolhO3rkBOupgfzZDe0fY9yolFOnp3TsMTLDAFnPqvo+lueCJBSYTrkiGhG+bgWnTzMRBHCruoIiGTDNgzQHAoBQ0q+fWHPBEsM44A8cRONnnEoHSI7Bc5t5+gpO8pV1nCbc24rRlPa8Z1zSjWXrXuG2S/g28VaUHwm6UkVjrp15DwQynuV2U8wTL4LZvPbVw8v0A3g78j9aUxRdJyUUx2aQJhTvGw+RojmJ7jrUEb4l2yncNmXa+aPdw22/AzSoqcwxaRxTG+him6F+PkQ8H8idjE6JaN5lyQM2oJIKoOjFe21h2tbjgs26keO1qtw8ZZ4wHfNOMuADN429D3A/z1BbztSPsBtKaqLCnQJIDx8yght1cSNRHs9rl0KVieL/j0h0+4/NMVzz8+o9wuWD9+wrI+4+n2I0q+4Dg23O9f8eXzf+Dly19wvL2i7buCX6ybPUBRme0LUlsUHGPPAKXxP7M1iRRoypRRaEFGQeaEJMl8mYyUAaaksi5k3yvIaUFKCwj6O2dBKhnUk46pCDp9ApLgw/IBSMAbNuXVI9voFI0T672igYHGKCmjlq738v+Q939fjiQ5ljB2ATNzd5IRmVlV3fPNrnY03/l09CLp6P//Y/Sis5rdne2drsrMCJLu9gN6AGBmZGbPVOutUt4dFZEMhtPd3AwGXFxc4A6mBaczQLyAwgoYo5XgJX8MbGv3gWDz0oFN8iARE8A+HQ6IzmvbJV0mU2hYgDK8R7JsAFKCEZN3j78JhHRN+Rz0NeJXwhTMR+TOfh06TNI/X+/L15Gvy7HWqu+Z/qrbs95oA+jlsiQdC/g9x9/BeNKTj2B/XIiY1ZTpjubA5zEIEkxFlOpEOdVMxgPpJXZCEH5ysL9zdJjBrb299l0j7rcx38vT2dx5n1wijJuf723cU2sm8C0+DbjfYx+aZ/SwD5kCA6oVYl3uWhlldKWAEMHpQOIVAUCqGXC9pingVHYDxrUKDCm1pyGtGw01XtwNLmiwYXyD1z9r0G4FOt+HM6zPyUuG+oZO3maZITIWSTCquhr1waCg7ozYZ9M4j9pTeyZi8we+OY2n4E4Ik1K+3Ynx8+hbrQWvtW1uGMLc7myyb2x26trG37cmKGjYbcGGUJWVYLR+x4NicEaZ0bybajaw6DVmIQQAwYa9iaCRiSXHAF4SQkqIKSEGQuAGalmzo/VAa9/vrDIf8vTdfx5GY3Ynn9fpj3OI1JENs+fstHYFQFo3tAMIQgcshl2zsMeMsXSwTtfncRxY8oFWtBuQl65OV4K+Ht2psp8H4+lRXHw+Hi3P90zX37CRf9POzWM0vvfwztbWN7PCgCDValEgqtQKEJDte2kmAguAhdAmlmyfgQS4jYTZ+NGd0u9WPRp6AMKm230GWaebcUp/81JJGczHNv9sv3cyx2NQorxET3CEEEFQ1hObztso3TQ7zKyOrz1/L33WBg5ZHeRceiKkb6cujt73UNXDkdbUNhjo04cOTw7wmI5whgie9gO3iV6GJdN7m4ixq3jsfwR1WqiBxAUpW5+Ic7vrzoiFlq06IJQMdJo7eM0adQQtU++Aw/RMOhBse4sySwNijBZwLF3DYDhPP1Dk1o/JFs1BWz+GdfB1MEnjzFvr5L6Nv3f2YikVtbSxH5p+obI8RnkR+uwaz6s2IBdjOlVtX+8aHs/XOObiCMwf7tadaQEemJ/Tfu9n1ICSRkBI6P5VtwHT2hnjMX3qtJSGbXI/lcY6aT7XLXlpbRfd7gy/a7oWjGujp6/5gYlAz0+kZCSzJd4IQQxN7KVH9klMjNZvZbLbtaARm+0k2wf9mYwR8DGqpUD3R7M5Dhg+PJgx/H6vPs6l6ZhH00IcfzsM0+MMGKd8eP7TPzxR+M1Ml3EpA/BRv1HzITS6jZprKeRe7TiTxwgukp/sKwRG4NBtkHZzrpNvT/PV4OF4Mskap1IHnpoMUOq7f/8DuWG+tvszp/H6g19qz3jugmtvfBCkf4zJpj3X16r7Uw4Q9A/QP+mPT6Pl8Sg7CPjvD74DCbMvA5tXzd7Qeic7Yzt10d9hAzCtf9eKlFwgOQOlgMyHhJiltL/pDB3YaiLrCEcTgB8IITLSFpX1tCyIy4KUVqS4qvYbSLUmjzuO44aS7z151PfzJhA2W+P2aZr+HXQi99vYYiiXdWHTVQJM8HacxKp8tDmLoIUKqsE+EwC8A5v6BWpRKooUFCmItCFwQEIFoaIYy7OZJqF3VC+oSlrgrEynRmAqaPUNzAkIGc5KJ2P5hhgVDAtaBumxrFjjCJ1O86Sc91Lq81ymLhtjKvq8Hb7OY6JstorfnYHjHAJjdI499iE+mLo19vK61lzQ+OFsPrlnC92ZTnNztXnf6ifQ/cS1I3/P8buBJ54Wid6V/8fgDtsNnNEkdrFshkJZNXqlROhaPT6je+BVvTuQBou1iWWI0oQ0f3vQNOF9wPTtrjFluj+1DiYBhwdH3x2EjqY/OWZwRPBpM/bNaHTF09+GMBlE+IMcKD51Y2JCjTWjlgPHvivt8TgACEJ4swz6XxHXC07HgeXyM5bzR3O40FlhENYMlgAikyYNAJBqNcwoqoCVPAACBxeGlD6ZPTDzsfQxfjgEyMeOeuw4rAueQBllMQWQGToBEJp2D/OyNGZ1jNgNnHnKytaykjxC18cS0WwWFerODsQ0GYhwSqxZN+t258CVLwhnOhyloop1ZhHNjAbL1g3gScGFanPexTRbbSi1YS8V91ywxoC8RqQYsCwRKxPCGrGHBg4NR7EvMVYTCAWEIkBu1h1IAF4COEacXy7YLhdcPnzAdjrjlAo2vEPuX3DsO+J2ghAjxQtCWPHs3s1d7MjnmfgY+MYHzOoDuhd7Kdm/B2f98Y5aDggGY8mZLcKW4TbHwLPW1Z1ac2JIfD04JKOvNSstkCYoOeNuDJaUEgSEZV2Q8wHvnOJ7rp+jYbIHU+e6zuL8D5wgP3xTmWOPh+/fOZ7P/ch0ml//5tOm1zVY9euNIQDEpj8WEQMDpBmz6H6kmK4Ta7DkYocdOHBtB/+v9OK57rTMgayAAK+nbwYh2zxurSHnglwqSq197VeZmGxWZtSaA0/U141r4oVwgImxWEeQsq6IMSAtSRlXdh2BAxCM6WRi2kSMfX/Hcex4f3/Hfr/h7fquXdnMOXLnLZgQqHvbDNdtqwrg1aot1UUUHJqjG1B3MjxArrWCqEGMxRIC9SDI9ZxcC7A21WdShpaAOcAFVylozppoOMnNhe+rcRvcuTaAMcaEdV1xefmAl48/YVk3kGXfAmspgDa6eEwQZOtWV6teV6mtA3QAsHAAp4jtdEZMCeu6qR6W73mt/XvT/g95OIQ4L+jvuI3Q9aBiybVpm3hNwuhve5Ucj3Ow6F5basOeD3C448vbO5YUsK1JddvWBbUV1GpOKdn8MvagNG3WMX81B+4nMEhzaNRvw91Z9wNH1ayDw1ANSG9EIsPh7/ubzSH3J/y8xfb1I2fz9/R30YKl4HsAkcvtPQSUAjJpAFvfZp+17BOoLgB67AoyRy0xVt1FC35s3yUaYtUcvKEL2zWHLpbALhhkD0p9uwCCd+BrUDB6AE8MQZv2eU2QqZ0szVqWY/brAEGAEKtmk5DaoubAInfx/6M01Kpl1bUyWkX34btvT7B9DNirBnbuRTxhfd0Xf3DhJ0BgKnwYPjNGsFsnP6dvcVbyw6wdhDv7qI1Yt/WAyv2fYW+CldSdEmFNhMuqTKdtW7CsG+57xrHfUfYD7cgoK9AigGYxjIiVHZkv0Z+FfoVAiEHXYAzD72AA1JMxOgBC5PndH+YI0brYOXDc9Y0ewWa3797V3OfyDP5p/DH2PdcacyzEu9q6YH9MqzGeJss5xWAaiw4QuK+rPgFlWvcjIUhdiNznkz8wIw7kHXm/4bAvL7Obmcro8YygHQdaLqjvV7TbDrrtoCMPNqP5RI2qhncU0KBdeJsIioxSUmaAFkY6JZw/nXH6dMHLhw+I2wnr5ScwbwicUHLB2/U3fP3yF3z98hdc3z9bk5xi/REMpGgN2mtANOntfhxptYXGZ4zIUb9i0pI+K6+XQqi3CiVVAA0ZQhnlfkPeb9j3gpwr4loR4gZwRIKXzxNCXNBqRqYrGjLeyztEGta0IXLCCYSKiq/lC4pkCFlSrArQSDu/CyGYaHo5DHSnvwIUwGEFUUAwlvqyLIgp4fXjB8RlweXDC0IKWLa1Py+frw4I9tgbPjaTITOq0zO4RGbzmg2oLgufh48dVx+wVlh0RsMudt/dP5MJFAJiTNbFTjVDW1W9RQ481hHZOrK1AWg3w75tkxPy/T6Gfe7JIWfsdxbWf3z8HV3t+qhOGwMN0NhTLk8GZWzliog9ZHzsfmwc/c/7JqoBxKDvK7j26CHQdB0OpuhL+j7fcIHxgMYxIYXz69NEGcDRcGqe3joeukwB4wMq+Pghfczsy0vtxJx/reYNKiLZg9MRuA7vcbB1xjVNEd50oT5287WLyGCb9dk9rtUD0Qf2g/B3nfvegUv0Yc4OIYT7uLmDOFD/eaio/xzs+QVbkIHGIiEB2CgrTICQZmcDE1JUwW4HkB4cSXsEWlajASixA0p6bUv0Uh824FMdUGb9vNbnlbEomoJWR1HmR1B6lAFhQApkz07VbkZ2xmqX+1jpJh0WzeJv66oi4iEg0gGWAyQHgMO0GooFe/NTsDlrz36+e/j66LGKl2PR0zl+tLANaFJtPtcBIJParA486Ru/CeX0mAAQccjInEWg051FBPnYsd+uCGlBWE/GGPBuEv1sD+u1r7PZPv07oNPfMi//vx7duf/eQc/z4/laDKBuTdt7mwaagh7KiPINUWHukRTQEh1bw/ph6K7439q/ZNp00c2S7hdqTO1+jNFkwWIxoHkwnWAdtpp9F0sEUQ/QubkultoDJoK0ihIIQFR2JAfIJBaq4stDZ0jLdAuyaTsdVlrjHfD0Xn0e2p4gCkZpoY70e5lZcPL0UJ6Hy4FSAGqvLSEz9ueRpOlJJZgdb7avkHXgeX4YRBYl2t44l8obaB8NeItpUeHQEHQMw6MAegcP/NRMvbzQy4EbM4wAAu/O8uBD9L1fTP/iB7Nh8vAN3YjT2OYnt9edBDwvXPeOxgyY/FnRQKOUimPPuhbWZMCrt4L2roV6DU08oadC4qVq8s2r4AXTc+3//cZzwLzv91vw95p7Mnys/hf61u6e+Q9uQw1IoZlxQWON2fhx0NnC7jaRjGuR4Tf0xGizAKoRQBVUqmaNFF169LFk+K7dn1RP3Xw9T+gxOOh38gYwfS3ZdVtWWevJfAd5AiSnMZh3mb6l+HcK5mMqqNbUKeqldc4UGiXJ48t90W8MDqEDTi6T4M/Kx97H93mvedjPvrH7z28enzN/Ngl1X1CIENjGpvn4oY9rZ4eQgk7OclqC+o8xhh6YlVpxZBWOHxdO3Y464DTfy9Ol2WeO0rpnMfsew3z3/v/Yx0M0OC3yeU/5jxJszyzBAWh6hcmIN4gDIM7c8dLw/kHT+vjetfp12drqtuf5/cOaPTwv0+z1suRWB4MI/WOH3erAQalAUT0nlKIlFrX1hhv+tz7jdP6yxSI8sZ10IXEgcCSEFBFS6BqLISgBoNaKI++4Xt9wv1+1jK2WnrBWX8b2Z6imE8T1swReSux7emBjJzlrmWyXcb+iqWwFCiDUDBxSMEobtBQgHxAhlJzBHEF6qSCEfm4QUKUgtwPNdDV1VLgDZVm0wQtXrQenQlonmdVul6Oaf1N17MIBooAUF3Bg1GW1KpOAtGakJSI21cn6bgm/AcY+T59/NybW9BynDUZsTsw2kKbxGyzeab1g2Oh5ZvZmMzSRLh7wmGnf8LUg6vORXwOAXm3m5x3unV/1N0vo8TP+4+Pv6GqnZ4/BO6HpRykFDbbYBJpnGItkHmSAEUICkVLrVW+jPp3PqMGiNZviAZ+fRXTzcsd5OBWjbMvLyHonKN8wh/sB8CPKp9cwHGEFD7zEb2YDPFiCsefDyk4wah3dOH5jtgwkAYkuoHxDzVfU44ZasqKwvCKsSSd2zQrYpATeXhDPPyNsH4C0QTiqw9CvarrGjsSbIyHjdh1RhUhv++vPQLvYmR6K+JPTu6y1YurV0utgXa/GBRpDJKTEYAloPCh4S4M6BoHB3Hp5WxeZJXc5dUOPgTqoBFjXHGM9OfuIhLBEQmTGy5awRsbrakGgXb9nTBs8KDVgye6xSusLVaDsvNIEe5YOQjUWcONOTYfoe6Q01FZwWInBEhlLYqxEWBOjRLashLKd2OqzAQXmYwrgyNjOJ5y2DT/9/AkvL6+IUbVktnYgtTeQ3AEUoGZIzUO7Cb4ht/FMeHrWhmg70+mx088TJXmaLz/KUfLRgwbAeocReubRei6OdYDOsUEvqZAGMgCLpHUAowcjogCH1IKWD7x++gm/vLyiriv20xkiwHEc/W/coOpnPGbhAEyeyfePb8rwvuewfvMaffO+TnHXf31zQi+BFXl4eZpbCtpKVn0sZ5/EEBGrBqwMBZIJoxS2GbgQg2Y5E5mNkTFPh2NnV2hpPdfHMn4HRjtdLZ1tTRkPuVTsR8Z+FOw5K3umuU17KueSsX+w7QOBx3cmgtSir0lDjQFSkwIhMVmGSUvKYkzgGK20r+D9+o7b7YYvX79i3++47/vImMGZz6RZTCIbG9cOgYpjQgP7QKpjwGIAet9jh7Oi5dlDj0BMSLL/jp1tNAAe34t9LrMxY70F7wxY2JO3OeifqYYlxYgYAs6XF5wurzhdXrGdzr0bYIyx6wUOXb5+SiQBGjfUVvW61oZYY3eUllWF+9XnUKCEDCADOVP2x4reBiA9O3zSwZNn4Vtn8Vh8DLbyo8gj0WNYQ38PoEDDvh/47fNXfJALLpczQkiIgVErg7Kg1KoMOdH4KFdBzspyKrl2f4FAk/7/CNSajESZJr7svogsl+ZersA7mHUPygNBuHM+fLYOfJg9i+bHrYt23MzG1pEydP6IGGFJ6uvZ/im1wHUrmpjWEkhZd7UhFw3QchFQqaAGndurrhWKse8fVAqoVbA0LREFQK4DUyuqDX5ICqbCAwXbB7xsBfNzNn9tlP1JH5gRbMwFOXYQIDLYpALq2k9FADKdJ26tg+YOJJYC1CIoRTUIew6FnZFpfiPs+XgGXEbMRb42hR4Sl/PU7UAlTb+b3jD2nOmP7A/6MPn9WyAn7KQD7s+ZOotemU5bZJwWxhoJ22nBsqyQkNCE8H7b8fXtijNlLObbB6aRRCTrwmnzdE4Ce0KRCQjBNCVtTJy3o3qiYx1Ow/lDHP6snD0s9oyCxZH6HtP0hT+/Kei212JUJEIrZ5TJ7EE7T/sYoNUX+bhDrNua60HORDKfJ8rWHd1cmajvgXOyx5M2swQHeHwmIKjlsMqPO+qxo5Vsgt3mX/iAODjTjCl83yH3HXy9g/YDsmegVP1yEKq5/i6DgpXdg1FbRai5+yogIC4BaY1YzgvSaVX9w7ggcEQpgrevv+H9/Sv+9V//K/b7F7y/f8G+71AZRUZMCUEEsQWb5QFVgFKLgVoBIen7mNls24IgCcQRynwxYkRTyRHZm5Zwh6raeLWCUNDqHfm4I5cKogRYN9/NWOWMhMgbYlyAVrHXHaVlvJYrCITECxiMtgtyrbjmK2orSLKCGkOuBa0Ax7uWkJfsXUftzjiCKWBJC5gDVgOe9q/vWE8bWq1YT5uxr7R0sWMEPg9kYqCayP3syxNsf5nmnv0EZrMfky/lRAsm7qWO3d+39zYReMfI/jcpKcgYo+oJBrbqDo3z3I/W5JHAK15alX5dPfru62ma416d1jVJ1QqOCqjfb7h+P+OJ0B1Pd9C7teyDNso9xq9pPoGxC2zhwfMFT55TR+rGJuzgj44L9ddgG3V3UKbN6ZFF4L+zk/i55hvs1zmuTW/PM07+XumgldOa+6WNt9j7qKOT8xiJBSVSM1o59KsWSGvgoO1yOV30slsFMyGlBWk9I20fENcXECeAIjrlbXzw06MbY9yf2/y74df1oNidE/8vpgDBl9PzZ4xDRtljmEJ7mTcW32QnpwHuUA6giruTMI0nuu1+mGfMk8hoGJkAXagemKpD20jPFo2N1XrWXsEt70WWTfDXhZQFGB0dZDjFDoTlLhaHbpQDjUXd4MwndOclpoAUtaVxTKpdol2aAKaqXzK6YnTgwozeg4sp8zOW7unMT6eDqX1CzE/2O+vxD348NDYAzDFVs9sIeDab/f6bGWnLTnv2qot/95JW71DZUGvBcezIh3YJgQiWJSFnDbi9hLMXzc+f59dBhBlY+nfwp+8e8/nGpjGv0AdL5b/+G+f6/u8f/i3O/DIQpxpwUIFa2BuNwEr3LUNkAYyBImx6AhqsyMRAGNfwPAwe5BAJiAdYXtv8JY//rgN48v1hbkWr+7mtA3utNRdUV+Cx1gIioFZLwkg0gq2Xn1i2vBSbD4fOiZL1NdPDm9cp2fipXZOhP2iMTBLj2Xnw7XsbPIAfzNQHVlTfD6XPXW56jaop5WxOVtrHw9g0iCiQpwEx9YFvvvf1UMtAOxP4jmlBWjctdXiaPI/Bhb1mZ3LhSne6YohoNMr7o4mIuy6DO/RE6BpZP1TkhmHm/0MzMI1l/6Lx9TfePj4DYlpkFTkrSzAGQowBaJohBiq8S6wLfvcADY/Atjvok7f27T087U3PVzdzer53//1zm7KXg4Fsa9BStmhO8e1QW7A36URhImjZC2vZmQZJtZ/XP9fLWHryyteYGAgM5w+ppp1A7G+mElT7ktogRKgkqudo7D1tVqCBpdW6aJDpZcQ0/A80A59IrPZNf+GSCcO3GsGK/cbuTS3OaC5itqGqbXaQ17XwRvL2Ozb48XENl+SbJzm/MHz2b58nntzzsVf1UOP5AmjyC+EMWh2EZlvt8C/tOZECQc52isGToSpMXZugSFWR/FzRooCCe1pzYmran+zFv7Vf+/XP1+G+rauu/h2x2x/jmOKsbypBur2aARx77TsGa+yX+vUYsOvfBA6o7mf5Xu2SKjSNr88RkYfYzvdW7/D9ACXa9T+4zDDAWkzGpRb7Xrv249g7hyEWgcaFtWkXy1JBVcEmMbDJv1vdsrF+bazI9WGl21gCFFSNjBCtnD2wAf8K7h1HxfX6huv7V1zfvyLnK7pOo52frbyRvNtJc/kat/Gu30gIxq5hiSAZnejGMyUbI9KqKAfd4Mwci+1EGx4g7xAOQCAQIoKNX+AACVFLGVvFUQ9EiiYBYPpSEtSGV9I4rAH1ACQL9l2Bp1qMaSr27AIQqKFC/Z9KASRAvu8gAMf1BgKQd01eRxtTTHO52wG3T27rHxbBtCTsnsYieJhQ38z/+Tyz79drVmw+OKOcp/nvcQqhKmzCAoiDvsZ0elpjbutdxudv3MbT4SXe/957xvG7gae57q+nEx6uRj+UzdJ0nSRHtmkINAJimXTu2j6t1e5dKMKdUESZBrASNJ3APBxzDIf10WFGDzRbG86sP7ixkY1F4CcTuAYGjU3fHzBPTn8bDApHOx0s801p1G/qWUKwTDQEIhVlf0e+f0G+/hX5/hX59gaAsZx/QVguWD/8J9VH4mgaTwti2rC+/gKKCZQuAGiiSNrYToZer2tg/QTb8XzhzY6FiVh6ptEeGwDPvhNG9zMygdoxVppNgrUzVuNHEiFM3WHj0EB1BB8haPpMWQVjS1cHsClTgjRrS+ZgNgzx8GKOk77HupMwIQXLTNGgykPsOwTS7O+enJoG1cfYi7YHLpZpaKwZPbU5gibc55zXgDdrH30Uwl4YawzYlogYA9Y4dRqweRJCUIG8FBFDxOl0wrpsiDEBYARkLCiIOBCooIEA0c5hzUERGVujGKWNTDfCnUb2OpXZUIEsuB/Gov/zdxqPP8qRjwydU74ejdloNGUHn3rzBFh3uarZ6VLUiSgmLlpr7fYFwLSGBKVV5CODQ8J2/g1xWfH6+gEiwP120zVZClzcdQaYOq12WpPfs+TugM3PaTA6qZ/LHQQPaGjy3Dtg7psYTXPI59PDB0zX+Pw7DI2GUlWg9tgDatAgig189fXJtu6ZCDUGK4tgBAYQaTjlAJ612R8ZE81AkQZU6iw0LWsruB8Zey7YS8GRVefJy0m6W0Df3os4swoA2NhA9jpbHV60ktooEZzM6Q2hi2g3Ad6vV+z7js9fPuN+v+F6vSHnPJwf0r2sWUcWMoekitqzQAwWAljvODQBqPXyRWqt07wB7Tzby5j9Xtypbg0FBdR0z9UslbZZ11JQQEXUq3YAg/SSAYLvk/wwF+Z5R+b4pGXBsmy4vKq2U0pJQVkaGo8wZ9m7QhJ8r6KudRBiwMh0+3xGf90vYYi+68bT6f4/0OFl9o/O7Ijp1Kbrawr+AYEFkXXfDCPeGX8I9GDcXxDRrHEuO0JgfPm64Hxa8bqcdY1RQWsFpXj3Ot33cvWkIPV9eE6F+UfMCRP3l5zkZG7G8DHNP3m0c57w6zsZirXuq9B9bl0YayD8+cOKLQVcThsghL98PXA/Cv6tXJGh+zQY4C2BAiMEZeIc12Ilh03bmDfdF4SsrFDGPkKkfkhkxsqsWXHW7pnF1g6bYC+pUBUa1Q58U1rAi5Z2xXXVtcsBUqvpwlAfJw9aJ29bQSzzRXvZnr/fnsNjTEP9nPN41prhzQ8E3qUUqLV2Nuhcauds7Z5Q7YDA4/Ty50QPn//IsPWfBaPcxHWb/CQP7AKa/f3xOb4nElkDAoH6nXj0ZwiaGFwjY02ELRHWSFpSEyNCSqCYcHvbcb1nvL3veL8dOJ8B6vJd1jFPpDP/2owv+mdOccHwqwiwNRnYtJ/E2Yc/mOMFe/5T4yWyMk3XmVXwEw8MKODbPXmwnzw+DLoe60jIMjN4WSBSkVNUX2C/gYMyfoQZAQ6MwPwfi9MsuBPAGEqDkSx9vdMIyHmAtjVn1JqRd9UtKrsynqRWoGnFBAX/GzbQqUEOZTbx/QDtB3DPaHuG7Fk1n3ZtYcnSehzHtjcC1oGtFuzHXXWWAgMxYDktSOcV8ZwQTxEcCQ0V7+9veHu74l/+P/8D79ev+Lf/9S8I3LCuGks4MzDGxZ5NQC0Nx71BWkFpBxIUJFcNx6Q+CrO2564BwTrZdXHx7jdY7G5aT4EXgBvWdQGhotwLpB4IVwIfV4T6gpBW61LKQDojc8K1fEaVjK/7Zxz5jk+rIPGKhBXEEe8tQ0rG7ardcMvXipYF+VpNx06fqSYLSEucmQGK6mdRQK0NtyrItx0kwHo+IQTGetpUnzJF0NKtICCCKtX26bGX+lwdMjme4KTu13ady+/5LL6ftlGpM7OfPPEdDJjz5+I+/1zuWVlF05WhrywvsNd66H0EZtsP1KdKKQLgkQT1deNr0YFUi2W6FtTvOH438DSLZwGYAphpUxBBq7kvYOLQhS39PU7DBbln/+Sg9C3JnE2naLaqjqUtfnWayOw4ja5t7qCZkSd73xRzTZ9H3/5rus2RUW7D2fHdxa7bM1/9ep/Qy+EQUv8QDZgKSt5RjjvKcUM1aihRAoeEkFYspxdQWEAhmUGICHFFXE6AAVIaLHrZydMzswugfmNPHqeMANWvUQGoafe0WlyQ0WQnGuX43/NhgYqp6vuG6n+F7kj558tgNvkprDuBC0F3Vsr0b+8i5yj8/NXFO/3ePMD2adJ9Ml9E5oQ1/ZDA+vNolauf2fw5y5hPWgctfci0rbSWxWTXfCICgw1IG1TvR70rzbb5ZCXJXdtJWrYxM9pwr6dGd+S/h7E/2zMPcAE8GLGHP3r++Q9+dNF0kR7hkG0Sg7fhz9NKTE0bqHlDgs5wkv59sAMfM+GCipwP3G5XnIixnTW4WJYFtdaurfNwzPO0z2M1dN8DoJ5tmb+FbIMYwtijM4g7wG63Bqtl/LvxdLJu2wXfWeTfGWdn1QwxUGcLeckXoIC1wAD5agEHOxhjDEhBfx+ND7Dzz2Ptzr6zMNpoT14bSmc5TewMTAHR41bQ94CHz8RYXxo/NjThHmT0aN+yfQ4MHfuOfd+x7wf2/VDgq9UeuNpN6pk9WIJowEta2guZGE8yldlM464aLQ3Mel08NkhzGqZMGdoQSaFZsNV9C9ZufkKmoTAHAY+1//0ezADpfIuIy6L0/s520ve4I0az3XsYZ3PwPSAx5pn+nQYoLkbfm5xMD43mS/qBjuEh0fSK/yTffd3f/Wj/Ba7P8+0QTXYQvo4ySo0KbMB8GBfFha/38WkOGj0ABU/34F8PwMI4Q197w9H+7q1N59Q14qyjhYEtMl63hPOS8Ho5QYRwy8ow/hxMiJ6kdzX1bXXYT/cNpnGEJxXtSdh98mRbu/dn65Q6EiHdRg3sTWydPn6G+jWE5myDp4MnmyjM1vHSn/Xw4zqANx9+jf35qD2oIoAoW9f9WSLXeBoafeNKx/h/8xE+OHb++X09gPe3TF1hZybRt2f8dl4/rAAZr3c7PtmEaYfs5cvfMp0UtBbRwOuwxEUuVRmqpnPzrYf/tC8/vDSAL3l6598yUQIP4H6MY/jXfvhe1N+g32zOfA9weo4wvhvPwPcKARnrVlpGbUUtDDEI0TqkPx66RQ5QewbIenTwzSSjvlZqLaheVudfVr3S9z2Pe4gGYFsbUEwnrlRQU+Z3m753nap5rLxEROw6zT1jZlAMSNuCtCWEJYKjlqXXWnG7ZVyvV7y/f8Xt9qbliJGwLGHYJziDKoApoqEBUnRsBVO5bwOLwLUp3UjMwus9kdrHXyDQZglsFnsx+5ms9nRBRWwZaz2QmLSqJzAaMThE7Kw/FymgBuSaoQnkiEiMgAUBUNApNxxZgafW1O/RTsReyubJf7avgGh2QMuiRQHAIyPfdpWRyEXvKz3aFcC8owkP6LOfHt+n8/wbM/lgr93nn+GG4cP5G6j7XX8TvILvO46M2/dZ27kbLd8f5jUqfXm5yX5autNP39sRvn/8/q52KsQDZyy5gCBR6B/dWkF+/1XFj2tGTAuWD59sRDXTo7t9gPACAT0ZWfH/250GxLSqlkPO1qLanNa5YpesFl+slAoj8zbHTt4VxEfON3t3CGCAgh+lWCvMZ7dvAqScVTSswrgonp1lqMGQBqsFvuH29lcc199w/fwX1OOOljNiiljWM5bzB7z+/L+B0wmcTuiGhiPierYxDWiiHRwUsS7dQXQHYHYEJz+ozzUOAbHTvNGDbqkFDQWS75ByB4jRwKCwArw81FXTeGJjVL2Vo3VI8Sy10l7FmD/GeIM5AP1cg0bIUFCN++LVJ18ZoAbTfholdlrqEVRjxs4JaBbSA+3h6Ax9Hw9qC0Fp8EKQoJ3uNBNgn/PkgBGMks4woXHNhOWsDktughQaUqhYUsASGWtKSClaGR5DhFEaoVFQJhsUdArtHVGuQPmK1u6geAZCQkgL4rJZLS9bts3Yd7p1qDHueic+5436a/O9lTzmL8FKNxWh/5EOBWYtUwUHMUXFINUiDK0R0S5ntTXsh2aClek0GGSdITjZKwHMQbWs+PsVR/sLfvkT8OGnn7GuK14/fAAxoxQtvyoljyABNMocbEN4BqjmzahbydlRI6iwNWkbWCZGTNNaxdAB8/LB1gZ7q3/HBK4122xmRddn0Ay+PiyzidYzkaUok7HZ2LuYvoOuNaimSG2CwNxZO5GVPRl4DpbEHlt7AP/82ZTaTAy2YM8FRyk4ctE28bVaCaBfu3StD9+vveV1D4wwAnVAbQjZ5wgaFkALZ0NSnSdNn+HYD+Ra8dtvn1Xb6ctnHIeCT+6M+h7VtygHHEEQtgyniAptsxZixFpB8xyx5++MIgGe7LI7z2pNa20AoWtJcW0mfj9aBuvcYQUOhXTMpJnkjl23d7sjXwPSxcLX0wXn149I60nPC7VNZF3xQrAESoga6PX5J/Y+fQBdkB+PjtV4emrTHMDi4PN7AFg/2iFz+zXgwZedXb6hVedMTv979yEnB2jyCYbnJSgl43p9R2AgnxbdJziBuOo8r66BoifSZ+Rx2TAYw+cwmzlEoMbcx7zm9F9dZ7K5WLk8mB2/XGdrRggSET6thJct4P/88wteTxs+ffikuor8Gz6/3/Hr1yuqVFyzXl8jQaCGQAHCxmgGVL+FGdECo+DBFNQecggIMVhpvHZ3UhPlLP3x1TtB+o1i6FGxAz22xhhDB8dZlv5seO5KCdWEE2L9yXyhed27r+5TxvXgwpTMbUI4akUtBfnYlaU1dRjtcCTBfLk2/IM52IQHxJMsgQHYHogJZl9Zs/4+N9B/b0G9vfLsiZDPdTUs42/FtBtlBLw8TS42e5uCgk5bCliT7pPBdfpiQq6Cmg98frvh89cb9iOrcH4bcgxz63p4II6x5saVou9NtWl5JUTxhgcrRba2La76m+AZbAABAABJREFUG/HjH/Lo92Kse5/LqgdJgAEBvq/N7CIAPYYaZVvjvCNpMoGPpEygZVV9npJ3EFXUWrAsG2KMZmvoyf6NcFqT/E+l9nZy358AQS3KAD3uV9RjR769o+x3HPcb8nFHq0UTQlH9ArJETDOKnNwP7V53P0D3DOSqGnRtNG5Q+YCKObnFlkzUOe/xDJCWBD6vuPz8iu3nF2wfTuA1oUrF7X7gL3/5jC+fv+Jf//VfUPId+fiKdU3A+aL+QdMYXXWWAwirXmcNGmtRBrcGKgcoNNBBAAdNEDVS2x5I75VdbNz0N6dxExCC7AgIWDgAMSJWlVdIqAjSEAuBJYPCGeAFtxBxIKKkBTc03I8d93ZHogVbK/iw/oIQFpyDgErGb/cD93vB7e2A1Kqd8oi7BuUSEwITFuv4tsYFgQPWtPR5SkRo94xSgWv6grpnbKcNchLt0mub68xkmvEA7U9g0ca02Lu/ByfEmO8z+fwCf/bD8fYKrh5pk/s+ymbqpJxp/wdhyBUZgYamWnOXtfHno81dwlgTDk7N/rfv3yFgEEkAbSL2+3yvv7OrnbktBuLo4A0kreU7ar6hlR11f0eNEQE7CKZnBKBJAMUVYf0IcIDwOp0bfVB1YBXlBFT0UJ9XgzTVf/CxgG3WvrH5zQugzIbJoZqRwv69ezEYG7b4ZzUMNGr8XTde/cqnTf/hXmwyEvV6y1aLIeMHWtlV0NKFXIM5MsHLLypgqL00dVSUGaXaBF1E0T7ucc8SdGpPD5AfpwZZnafXm2uhf0FrGVQPoN4g9QZQBFG0dsEB8G4HffjcgqOPTWdZTJvGnBkcD3B6XvMPHT0fQ9+7+Niv5o5YND0DDVQcfIEFZ77Bo1sCz2MStMyOrSsKs4CbOpyVZF530/ycnPvgzC4xkKt1MKJTDPpmquyEigaW2stH4Cg8A5HVIWaqEKn6XDgoGy4u4LgaiNcnMHrXoVKVMNYv2NZqKwNMgKCUos6vaUmEJFAhg/BDhW7+nKj/bHdnIEu1gNe7omnLbGXOuHbXAJsn4EnGvHU9DH8/agEdh+n7HACAdd1wHAdijKi1gNkCfDKD3fn6v+++HlayAQEuBh2C0mqDiTmzbxDOcDI7R3btfQMFMATnCfD2tLbwxAf0yUF0anG/tm4ObGOz91f/TFKRfREtC4IQWnBxfKBZU4EWHrP0fr1eDuaBmQJPynRStpOW1dVeKiJP3ZDo4fuYH2630AO4sU+IATw+oay0KyhTUaDOwZEz8pFx7DvysaPkom2KJ8d6DOOwQwAG29QmljK8Wmcgtc5Qa+jdR/y5GcD6TevpbkJ1nH3eNGlWStTM4bHg2ZxvBtTM95EijNXjG4oYKBEQY0RaVqzbCWlZTEhcS4z9Z5+f6PNm3KM0TzBMe8fDZ/vc8j3cN4qxv7RvOn3+8Y9HkzDs/e8/wfhb+c7rBNO7iQ6yaHOMUyQkaqBW0Jm25BoS3BN7ngUVGTa0+7rdgcWDf/Jgj/2H+bLmeya3NfP+7Xupvp6YsARgS4xTCrisC87bim1Z0ASIzL2hi18rRCClDn+iNXOIjSnKrBlwwmBAGDjdpjk6fJyxRtwz8s/RRgBQW9jHy4C1qqxagowOSUyIINM6GZ89PzwyYFaIu4meH6xMa2n++4fEpAx752V7Dky76RtPbHzvLppfS/fvxtvmIoRuo/z9/Vm67zK5g49O7BhP37NoZqCMvWjcuc/0ybYbEMWs/tVgXJKNn9rKUityUfHqXJrt/WM/e7yq4YOOKUA2Hs/vHH/f18rzbf6t2/8jHw/rAoPkZsc3Ze4euPv+MBkCnzPD9/p2BB0wYOviFkJU/6Cq3mIpxZIa4du/tRNoguNv21j/bD9nLQdKtq9Jq3dMGPcn7F9NIFUG06k0wIAXnRc6L1UGYsRLjz7KUyKUBLQEhDUinVek06aNE0LAUQr2I+Pt7Q3v79rJTlq2IZZhh9yXqqpbB9eibIIgwEIKGKRWESvAhUAUwJyMVEIQFABWJTPbSLN7WrrVTCeXEEUrQRYOiBGIIASQaeQ6JNLAFJCI8B4imiQtb4TgaBlMAWIltIkjCgsYDDQTiq+iZdUGugdWskXwZicUun8SvDlEdxZNHueoqLEg3w8QM2op2tWvl3TNz7hbw+E6PwSO83v+1iR7nPvjzY/r4THJ+DhP/M98voxzN+MiNJNiUJ+2A6zTX8++3uOK6E7lQ6zwe23X3wE8qUH1DGsrGWhVS+taVQX/fMf96/9C2d+w//YvIGq4p4jWKo79ChXM3pDOP+HyD/8X8PKCcP4zeklWhxD0vxxYg+yii0TbYmdtEYH4YOxpsmhe7qGTfdqUTGA2cOgU6Yft03aD2lRaurm2lJ2ae5mTZY58A7RZ1R397mcJHNl0b0paQT5uyMcV+fYF5f4GKRkkgmW7IC4XpGVFCIxWrpB2APkGEWir8pBAUjXLvpx1yzd1+w4y6c2okCwRSLiPyfNcJikgKQgQRDSwHChlB/Idku9AvoLzDQgnUNzM/7T2lVQtCCMDNUa9tQaLauBlXJKBHAMJ9192HRD3UDEtLDhmPjxlbZBiQJHPGQK8DWhgzUJG0xHxwNrrUIcz7J81aO5gQbRAeAkEAeNeDIV+WPQj++j+TzOB8UyatT1qBVfCURpiaUgh4CjAUgTEDeCA8zliOzFAASEEbIlwWQVLa4jSkKGZlSUuCOsL0vYR6+kjEFcVKIUy81rN1snjDkgFiwKaMAA1H3fTctBgfNTyLuAQsb18AscFFDc8Wqo/9hHI9WNMJwwavGtpgQLBImpmRaDsGNMKErGyD0yG1zYFLdsagJOL7NamJV65FCxvJ3z5/BmXlxd8/PQJIoL77Q4RQc65bxy1lEchVwDPQabPMXc6ZhDdSwViSgghYl237nh5VhBAF6NtXa+qwJlPTbzEgkEwJgo8QGpPTuCTa903Nxn/E8D14jzDr11MpTt4bB3WQigIxIgx27+NfRPceRktYmfgxTNAIlBR5FIH08kBKHOqYE7duPQRmPTSV3osf8X0BMSDMWZlGsQETitCWhEswJVS8fblK+77HW9fPuO+37Hf76OMZQotXEsKAnUcbR8TyyawOQdUlHFXo+otKROXezbYnRhpTZs5dNAJlsHi4fg5WCoC1GEHtQlE6GwHBeyjAfCtzzPxLKxp2Ii1ro4pYTu/4OXjz/j485+wrhtSSipwavaYpq52HjxUF+UvqqcWjY3hlHg/nOFWpxK7zoQyV0vB9PpNgPhHP+alri98xzaLPEasAgCPLPBnh7cZGMCkXWFTUF3Cly3ZzwwKAqo3SFgg4aRtpmOya2qoVedHMX1DL8tDX//TXosRrLuudWdKmSs2s19gto4smPRBmGGGSFrSfkmE08L46ZTw8bzgTx9e8HI6YztdkEtDMnajWWyzB4J6OxRIi8rMXMxHCYsm2UKKtic0ZCEcRJ1jQA+og4MbZAAuqe0zBnlzPTYHrmGMhlx6oCAxQqIgRtV8TCkhxkX1LwOhlKpJkVrQakOI/LC2Si72e/VbHfR19mCtauPFdO5IPBhT1oKaB0ErWk6iTI2hsdV99G5D7Gl411z77wCfrJqg+RwwP7n/epqwNm4P5dVPoNIcXPlztNT3w8QX8Zk2zuN7SgyEFNUuNuhEFAoKPDXC9X7get3xfj9wzyob4maz9r15BNSBmjWBsQQmjft6Xo7OYKttlIpPtz/2Gfw4R5doeRqTPtfq6CYNiy217Nzityk2I3uG+ozbfNr+HmeOpLRApOEsFfvtiuv7W9cvTMuKtGw9VgA8FGjW9OMJVIbaSjbjpXrEgnLckY8Dx/s78nHDfn1DOXaUY9f9fopj4OCAAFwqpBTgfoD2DD4qKFdVNRECMaMFgcSA1jTuA5S1F4AuH9JMaLtIQQtA/LBh+emCyz98wvrzC5bLC3KruP52xeff3vDf/tv/wPX9DV8+/4oUCa8vCwITatVYQG0H0IqxL2uGFAEXwQIgMYOpILYDvAOcVRuJOIGQUJGBBLTEQIigRVmaIUQ4J1Cq7vdLJcQGXISxEuO8JKxIqgUKszUEIDSAKm4hIBNDtg1vhZHLjiwN13ZDloKP8hMSRWwhgSMjISI01jK7WsFrUi2+oFpu27IihIAlJQW1YkJgRoqLsiMtQdeq7kP5egBVcN2+ohwFaV0R14T1cuq+7zPLvCdldXJOeMPze/tq6UCi/YkmHYl6SeUDAGT+D0jB8+6/YsSkZPOlA+8QZZnDxO9BqGbTAE0ghonQoIQZZ6z6mjaxfv8c02cz7uHvsgu/G3jy1u0uViUe5GbVJqq76hTl62eU/Q35+hsgFY3EgKcdFBLi6QMQNrSSQbENB5/GxjKew3hIzg6QVtGIAGomckhwYdxv7plG6NZ9H/fB+mR52NvgrKnnY9708M1njQnWAZAOPs0TywKmVpTl1ArQqt0+I8QVISWADKC6fumirBr8Qd8TAjhuIOt+Rxx6VyVgsIAcaZ0D2nE30oXbIQVCxsI67qjHDTXfUfMdqDuk7qBkhp6T6ktRVaNDRiO1kjiCj+3InsOcMAeGaBpHMRCoiQ7a6AA4eaoP4yyP//z2QfXnNFNxWTzwcjoijwFyZ5YAsjbOvZ05E7iJCh+3x0yIhbw2nnq/zIQgps/STKrKzt8EKFa/TVU3Mhal7acYVXOAgUDagrnVglwrWiMIIkALOGyojbWdM1dAGK3PbV0f5f6uTLp8s+fbADTkfBjwZABcfxYnBFnQ6qFzMai4+Y9y6J04yo9u3JuBAbXWbhtEtJTKuzbJtI77zJQBOPX1ZTNByDoUWcaNOFrbbBX+S8uCdVtRSv6+1pMfDwbN1+4EGgAAqDP7YlJNHaeTO5gYvAOYSJ+rItKbOog468pZj1rDKpPt7Z81Gb/fFdyPfbYHHgoYqZNHGB3TmggqsWoUMYGbbaKVOxDiZSKDdTadD1Cwrz2xnNzBnzfsvvk/3pcDGQ/tme3a5mCITcgxRG1dG4ImMrxr3nHsynYq2ZhOgw7/MCi+541XpucvD3PSwb9KTQW/Cait2d5h5TkgneYG7vm+MgIh6gG9f4Zr1qHps9cs2Dw+0ESBnaFR6x30Oj08RqzrCafLC9bTCcuyYlkWA0FDZ8j4mD7sSQ4KTuP7kCXtM27s0/PUE9vonOnk4O+PdPy+u5n3xsds6ph5kyNsRyDCltjEaSOWwDgvwcpdFbSqrQAUTPDaWJVUTYdLndfWCAxR30zkb1yzz0l03+vh3xj2xjUcxYO973hm6lSrUHNkZT2lyEgxILDZ3qpNQo5SDZTUKws2EKEJAhqi6TkmszMOgAYBqs314hutGQPp96QalYHYZAvUBnmp+8PctUUtZleoVdRKoFLG/QdvJpNwWjfEGBAiY98PHPnAcei6SVHBqcXW2f2+K9syA7UCy5IQQ8C6rggx4L4f2tnKvjvrY1tXtBSR8wEisoTUFCjRo/2c85vfd8L+xtP/zvrVU+hgkj/zhzNP89r9eZlfpu5zf3MtAmACNcd1EJpoJyyQBlpVANSGnLVU25tQ+GnF5p+KiQtaI/PtHm9j7Jborm+3o3j0I2Y77L8n+v6I/mEPerwbB5D0d997+4izBPKNrOBjYP68r/tJ9RUm1iZVIZrMSUU+7vY5Xk0TMfZkj1GoA2bSP0f6fBBrGFCLxky1HKjZmU61xwgenD8EmiJAnXSdSgVVbWSg8596JUsLpjXEane9MYtHIdr0pKEy0CIQTgnhvCCcVoR1AYjRWsX9nnG77bheb9j3AwowMGLS7tmeTNIctVhjBSBUQqhAEmChii2o3Qw+xK1BUIAGFPEVohUxkhJaVZkHCX1o+3NNAFaCaqBywImBxc7NfdHQ1HWUkZnw0gIECVtMKK0BFahoyHIgtggOC0IgLDGqXWQGGncdKlKPqEsDsDXuYmO4uqY0mah2JzyYcaq5oh4F5dCkcduqysaE0OeOTpxpTs0+H2a8YfZ79N9ejdLnub+X578YU13nqmv+2nd4RPq4djz54X6W+HerLBLTY1Um6rM497jQTgZ5ivPp+QP/neN3A0/FWoOXfChwkpWN046vaHnH/vVXlP2K91//u3Zr+/LfUPOOcn9HrQ17BtJ2weWX/4RGC84lg1rFEKDW0rJJRMfmtgDECDHZQj8GOMHKEJmzKQC6gegDPAUqgIs6c0eiHzufSR+7GTjRt3oWlvrn+HXqw7FN2lbZqMf0h6hAj5QdUoxRVA9Ea+G6nl/BaYVIQ96vuL79ilYy9tubIeEJy/YCrjvi9gEhJFBcQeEyPXwD6UxnQERQy1Tq5cwBaWBUoF7R6htQ3tHKV+TbO/L1C2rZUfOuQAwJwvYJYf0IMSaN0ALhCIobmBd1RNlbpMMQVjYBTHRHjU3IzcEnD6gaAVLH1uyC3vNc0O+P4M/jvuYosi7GwNwZT2MD0aC3i5eSP7t+ChDpNGwMLEFp7EsFClm2sBsGoMpIej4wNJhQim4yzaiMFeq01NJwSMXKEWsIWJYVHy4XXNaIc2xI2MH1wLHfUY87mCKYEyh+AKeP2A/g9nZH3Bicmrb4JNKSzHLg/dd/xXH9jNuX/4WWd7C1I28mepwrIMRI20WBTvmEmDakJQFtHXo1P8jBFvjXzvL5tjuds+G0VK6NGvvZ4cZwfDrwBAfxjJXDASEmayd/Qtpe0EjXadrOuJhQuYjgen3XDKgU+4QBgohvQjL9u9u5YWNCVIbTdjojpQXr6YQYUxcV9yBQ7F7FsuGNgK5RZx8qzbLktlg9mBcIhM3xInXcRwviKaKaBTknb1/s92LAzDNzxe9bM5rcbZiexrM1ZMFxGAGIr0P7+No8a9fsy1holmGeS058w2S4rfIyDOqsHDIGawdJbJzismhXl+2Edd0Qk+oD3O7vOI4Db1+1i91+e9dy1lZ7x7oOws9HB4bwCAwBBl7rWGVj8xyZESxb5d1ExxiyAYsKKLJno8wmOpAFm8tdDNN0/ppYi3jTe3I7StP1iAjQFABb1xVpWfDhp1/w6U//gNePP+F8ecG6rEgGyrloL6DlvbNwvzP9HPTkiVHs96RrcNJiBEZgYHbYS/+98+QPdfiU+CZifXbybB71pTeCpfntfi4BsETCZUnYUsSH04pAqq9WW0OuFXspeD+MtSMAUUAMCS0aU5Q1OCFb/2o/8cAspunifZ0ry8kZInhYj2rY7MGT2poy6Tx5WS+RlummINhixBYJp2XBtqzgsAJIuO4V1yPj6+2Ot9tdQZUGJGjSZysVkQkbpGfEAzOSN++QhmxJoGIBoheAOPANCohB9UO2ddN1CmXO6p0byAQAPh4ENKkQKail6rpYFgiUgRxDwMv5jE8fP2JdFyxLwpcvX/H+fsW7vONWGy6nE17OJ1xeXrCtK/7622e8X694v15xHBmvLy84bRs+ffyAdV3x65cvuN/v+PW3z9j3HWtKiIER46U/m7s1Q2itWfdlQa3uUM+lI17yNs2vaSvotmzatwabzb3oYfcAxRi4uU9GPXbr1sfdQ3Oz+3nY5/14Ln4hCryPRiwNhCIMEkaVgIUSAi8oOaPkA9fbjvfrjlJavxG/PhEFMfcCbEbIcMlAZcxiAEdk3mif38NXdZfTbfEU03WdwR/l8OSa+zx+zMHr9GLf9wEAorpDfh5gMF9HYP4IcvucFBFwiFi3M1qtSPtNm33cvyItJ+Rjx7KdsaxnMMcBONAow3zwDZsSHRoBNR+qiXa/qqaTaTtVYzrBq2TYWdrGODYBcbofwFFAN2M85QouDQqEAi1GCDcwGRvYEuTKRnbNoIZSC3LLKFGALWL95YL0pxesP31AupwgiMjHgc+/vuHXf/uCf/tfnyEtI0Vl+lzOG0SgieiqX+WouN8KuAIp74hEeGXGOQKfFrXPQVSLM5dqdnHHIYx7Y7S4o6Zdu4wGZcZwjLoOWZMTLA0vBFzA+BAjziRYgnU+nuJygMBBS+GaiYqDF7y0iFs5IYSAL/c7Ss24lq9okvESf8bGEa8vJzAR3j+/4WjGGDLVHAKZBnBEXFIvy1TgSbsSR1a0rDchKqqvWe8FGQf2rze0UhFXY3Vb8pHdx/I5Pjf2wfCZe5dHcmbSYPK7vuEwFA7Ejn/DfD1PcIeYEDh2X02HcAK2pnhnXI8yTIldM0z3RuXVm6bgVA7t85Psbzhw99k6VvI7Xa/fDTzVcljwoAurI4FWbleOK/L9Dfe3z6jHO/L1Ha1klP2AgEG8gtMJy8svWC4/Ia0viOk0NgX4ZJMHw+LGytxOCwaMLkYEy109HI/nG8gfjUhjjJE446aNjnvzOSaEj50TPjlSw5ZOO04/Bww9tNeamNCkMp50LOvIspvzL9YGsezvqDkj394MtFHh6eP2BSBGq4cFivLw2Rq8PM+AMRbjS59fzTvqfgXuX3DcvuJ4/4xWdrSyKwU9MIgSyHSeGjEk2OoKpkFk7pgb7m68JxTP7ckD40mGLg65S0d2bT6+097U4IHI473J/Lr0B95pqUyD8dRkYpr486TxYfTQeU7b88agn8FCxqKYPtmdMtJR6E4HAySs2ntTsKkIdTBHdcEaGUsAEldECOpxx63dcbvese8ZS0qIMUCuFQkHSnlDiw0vHLAyAyHYHAoQM5hNgH0/kPcbpOradapwhQWUaQEHLQfQiLINcOMHCt5UwBi9Ta6X98zlOwoiqi0oDjhNFFNxAGZydASk4Ldp14SYEIxtFNKKZT1h3U6IaQM4ojQAHIwRol8aw0/i5VqTNi7e7H5fL7bOHRhJSZkly7oipUU/2zdRkIlED9Dk0Ua5g2XsEt+QaNi8h9h2cvzRQajH3w+gyPTVSDexzgp7susdvCIPHGxjnFgw/ZwGpoBmgG44782ArSHCOF3X5OR2B9M3/e5wmnMU2MpPuF9Lh8mIEGPStrWmowV7dtpJJZvuQ+lgSLc9jgjMF4/HH+nx5TH/7D79HgGghqqOkQNDpKXH2sV5uClMZK2kHwEMdUJGkCatqaRBAxoYYEF4cu6d20cMBDDSsmI7nbHa17KsSlsP/JBBdKfL99pZIB4iXTycJtBpiuD6XuLj4POjg6O+jzt78Uc6LND+W8fTFvndXwwfdvJfxFg+QUWXVa5idIf0Ly9HrnJAOEKY7Jkx0FT5oIkgGugkAGBrhtj1eOxvuqOtV/XojwzfQPrvx9/Oa0Eh4ZlBZeWhptezlwahgrd7wW0/cL0fuB9ZS2mgQuRMQCQgkeJcgVzpB12Q1RMQtQ3wTRxSsfWoVQAVIs7GHGXJv28uDmDGmYRi4951Rk0zZu5C6n+jYvJ9dUz2Vb8cUA/uZ/q0snXlzWWWlEzrRW1M8fJrD/YxwKQpJprmk9nv+SUZb+tggz9bs4MynacB1sxSz9cnxncOD3ZovqHZYZz2o7HvWZk0B2hXaAUFS6k4jtJLs+dmGrOLP8K/x/nY39sN7Lc2/m/chT5HHzTBN3mJH+3wfUB/9v0Hk8mfY6jvD8YD69tfm/87/54DYlo0CQRBLdlMofkpMSGEZKWp/PQZ0td0q2pzatYOduVQDcdaMmrNQ3+x71k89jUiRSlntpMB2UFg8SWpzwEFnkSqxjthNGjS6zI/Vqo2GIgEWhh8TginBXFdwCmiVUEtFfv9jmPfUcoBpoaUgn0pI1S1XmEhgAClghshimAlxokJ50A4RQIjIAAo1BDBKNQQFK1Ag6C0Askq1dL2K1qIaMa+13s0hioIiRiJAxKLVnp4gwYaiz6wlxNrm6kTAhoRLjGhiODGh/nsBw4ALWZlPC0BtSSs66ITrnizHLOZNs/IY3r39TqLQP1ndpFLF7kHKRutVP3yLnc9bnqcp/T0LzJNpb6h0+O75OGnMQ4jXOXhnxthxYEzNgmhh4z1tC76vvCAYQggA1PRo+o+2lzKQfr3znSyl/t+ZUHS7036/W7g6bh90QfBykzyjhSlFtN2+ivub5/x+X/+V9T9hnz9ajR6IK5nnH/+Gaef/hE//Zf/O9bXn3H++Z9AHAEOHZDw7KUKxY7MqG9U0hTFVo2pw/4m9g2mYwA2iUaQqIYgUIA0F84dVDbPvvojGqi7ByQDzSQywTJ5dO51ijwGapptsW26OykF7XC2UwZa0fPH0EWmS76j5gP7119R8477+xeoAxHR9jdcOaDlA9vLLwCAsL70+9bPmWl6U5Dp/+v7uagw3vUr8td/Q/7yP5DffsP+9a9AOxQd31akbdGOe3lHyxmhHKD1I2gRSLWW2dJAJAhB6e7eZc6LTFzceM4+EWDGsaGxgT3mTIIVKGn+DGiw0pSZ4tkm6mvo4XVSJ1S1QmAiaoCAx3NrrvkEdE6v0crVRQFi0JGqIBUE9/lpoeio97eMjDtarA1Do33eLLQZY0SMCS/nEz69vuDDSbsxbFSwouLr22+4vr/h168H3m4Fry8fsG0rwn4Fx4YjXdFiwj8Hvb9lWTQATquObVzReMHX6x23ty/Yr18gtWBdNCCMaUGI2vkDgazLgQeBJlr8A3k/5dCSuty8tG4SpgY6w6lYiZZ3Pus+0QRsALasmEEhIsYFy3ZGWleczi9IacF2uijraVGdpZgWUIq4HhWREs4vrziOA/f7DSEoHECkG2hDRa3DefcNclgynY9pWRFjwna+YFlWnE4XpMU2eKLeJUwAo9CqqKNM9gB2bmIGNWtxSwLxYFGG4KDbV8/3u+XrTt8EDnnHJ6Uy08Om9NyNrrMYfMt1cOjBnXQbMGxw71hKM/sA/dzWCgvo63MEtd7dcABQ5oRah0/vVOX7SC9ltbFfthNSTAryxaT2pBTs+x33+x15v6PkAyr2LcbiGmM+NP+Gr9KDzvFk+hscBHUGbc4ZtTojjDtLzL9qbSAm1KCMYIgY5T0Mp2WeA+Y81AYDKRtYVPPJg/v+zJqC1CEEpBjw8uEjLh9/wsef/4QPH3/Ctp2wLOlB+24AlFp2X2sZe64tshBi13UawIPNTxCIxRy+0jU2RMT0rmSsze84f3/0g2j6Lr7qHkNen1NjDehvO5Di8+8psGUClqDgU6CmjA7ryFpqQzbQJbeKve2gsIJis30vIkQBo/WmGLlUUBVUIrWjPfHmkaU83JNPwb4GeZ6b1BlsrS9ptxPqb7i/EKxsolFClojfbgV0b/jL56+43nf8z1+/4rYfkKJldasBsScTm16stF71ABtECqQBR9POtHupOKp1LDULqN2WDxAaclaQrMaIVqt1iGr9HmkCfDCt/9nKOTDfWkWpB3Lekfc7WBpIKvJxKLBdKsS0nmrJKOVALWzaT/bVxs9uh55iOjhYtSbNlF9OJwOhgFIq9nwY+FjhQuAC6TISI8jXE3rJtvS5Nuy8sllD96tcF2q22WKBTW0mc+A5ZRqjpGZEzH8cZdi+h2gCZYAOzA5m63mEAhpFhLAo2xvKBLjdtRTpvhfzAzAFqHb9c8Ljab95gOY9nnMQwuMS+B40rq8DeqNPxDQrftTDGR8OSqPvXbMfAYxYzMdFnIHi7nrfZ5wR+8iIEmngkLCeXlBKBegrcr6hXL+gbHeUvCszfTkhLRtSWO3zxjmaEQHQVDQ8368o+cD9/SvyftOudkU7i/vDJqh/qHGA2bTSgFy0g91+IJi2U2wACfUusECEoOEgsfi3jSSowDREK46WkVEhJwZdEtJPFyw/XbC+XkAxYC8F+33H+9cvuL5/RTluWJaAy+WE82nF6bQiHxV5rzpfC4BDgHtFBHAhxocI/LIGnBLjg5VgMxFqUcmOUgpyLrgfGaFl7HUHHbuCUF4+HLTpCDEj2X5zQsAJEVsEthAQ2SViBqALKPs8WEMSTaQCmwDv9YQ1RNxzxhsO3MsNR91x2V7ALLi8JixLxPvbC24x4f23rxpr1oZQNb4hB5gccGTWLoveuIsYgZKufbN/TRqoEdpeUIlQ7kbIWZNqKXYDYSu+M7MtJO06efbvbzCDsbP3uFcs9rC/Vx9bS0U5JMS0Yklb13iqJWsnRG8WY4mQ5uthajim16HEkVahwGhQ1hesUx4xTU3aTC+XSCuqiFDdI7F44/ccv1/jqR42LNEuWrM8rexo+UArB6Tuqv0kDRQWcAxI6Yy0XXD66T/h9PEfsL78jHT6AI5ag+qogYMlTbwUZa4z96dCRttXD0ua613wQ02uO7O+UOEPWOaJgY5+eobq0RnXn/vkgAcJMtBHTMHhw0F+uf3fAmiZXasQcwi8VtjZJq0cUC0FRR+dSschwXczadIdjloyyASSnXYsBMDqhV3sqe/D/RxTJhEMUAIoQiSiCeuzKA1SDi2dYwHxHaAI8AbwAg4ncCggCwLccdTM2ggQ3VvutOhps3D/q8lEsSZ1htgAJHeS2/wMZDJOhIdscA/k5gDbPrM7XG38+4ECOdkAv9ZAhMaCIITQyLSevn3m/RImxFc3UFgHh3EtKUYsS8KSVFMjQEBSUI4d15zx9n7H27uCTte9Apyxlx3Y3yHhQLgIwqYm2sfasyXCEWk9Y8kZy/lVBZaLdt4A02C+ANpdwtYYGwvLaZc/EuG7GAti2BidIe5cVgMgvXuds2WGK+nRUQRImWUUAkJaEdOC9aQNAdbzBSktWNaTUm9D0oAfeu5cKihohjkuKy6XizoyOaPVBuaCLkwLazdtdstBIbd1KS2qF7VsKnRoouIjsnh2wDy0GZt7P3yXA7q9dQd5dg4BBxHcAffFR13AUJlAwdhADsg+yr8CA4iQMchmu9Wj7NCWSAdKFDzWf7dp/Y4131GcB2ffL9xtubMZZyCKLTDSDT0Y8BT6puvzgIi66K9T3509V4synXycZkDo0WDQdL+ud0SoPc0+ng+5kSR0gKXaS6VUMDcA4QF46m3M7fyFWDW9MMrMfTwePsufyQTmqaM1PS8b6RATYoxYT2eczi9YlhUxxF7259NqZLZnhtMIwjqQGLizUx8Omvf18WxHeWwzUE4vsk1z9f8/D/n2X30KefAygv7agFwFTA0HVxQDnB7xO33urQkIBaADLiqr5w5QIIhBrI7tgFDHXJfHqxqgrwEEbkPUhXEtsE726QG9n2LYMmXxViHsFaAioJv6q5/f78p2yhW5Snekg5jQKql1Kj4+3o3JGFsKPNl3ATrX3/zPWvUeStbAKMWswIWxa9FHweyq9P+YTRvAOCzwqk337H0/cI03lFJw5ITbTTVacskoteLIWRN8QYXD7/cb9uPQ/b4WHIc2arjdbhBpqjuXszWWUDYbAb2jHsHFxpXRHqsCRZlMz8gcXk/YD9/XH8b0hqc9ptseMv0sm39KsJiZx2IlnX7+YRPcBvXjyVy4/zv+ZgLZibo/7d2ACaaH16rabhuXb1eR7Rs+Pupq4Ruzjtn/fHrdX5MZoho/+K19c49/8GNUrHw7WKPkZ7zv+e/05+ezalwxhVdjwjzu+lDfhBFDMp9pA0QTQ7UcOHYaJd8Wl3nzI1hsWF2rseSuE1WOAyXvKCWPJlT9sP3VDa8xUB51nZS16wL/zNrNjSwGEiFjUwsqm/aiAZxVBrBdqQGRQQtr2deS1M+HoOSMnHccxx217OCgDQlS0q/AbAl/dA0kFi1DXohwCoQtMLYYsEaVORgdTa26hQIIPPzn0gwYU0JKO3bUY0fgAIkRBK0gYSiQyyGAgiWWzCg4b1IAA4SoJwGThfHnGFFEcEoJBYK97mjSUCQjICAuqut1vmgy/ni/oWYD2HrZjFjpHR78pwefowOhliAWY0WJQKqg5gIKbDYU2jBqIAbD/7G/nTgtY56K72MOWsv0Orr/7r6rbxa9cyNrh75pYY09xT7M7xGYknv+8QIADVIB70ynyWjzFWWwvfqFzYd4Yv57lu/7x+8GntpxNdR/AUAQqZB8R7l/Rb1/RTve0I6rihoLkE4fENYLzj//E5bLR3z8x3/G+vITLn/+Z4S4gtNmD0+BpmKIce10Lx3oEEYHHOLBrmnQvy2yI8QEotSHuJcL+UMwQzV2d+9CNfRWRADqgcIATRwwUPtRx2Y7/d6nln3g+C891iu3mrU++NhRj3s3drDyxXz/Cm1lHyAN4LgCFLGcgtbSHjc0IeRjBx937Lt2mwm1KHOMuE9iQJlaOvFHnbL6Bb7aGMILKF6AcIOECxq9o0lEzVfUfTcB+R0tN4TjQGuM0AiJVyCspjGVrFSQkGJAs9KwEIJ1d1MARwM3njS22JwPZx41BOuuogYZqKTdZoj1nuqE/I+jk8wfOpB5FxkigANbkKflJIHZWpcbTbC50+TTRgbjib3bHqtjTm04xr4+JpbMKDeyzoc2m2F6Zqdtw2lb8boueEkBCxVQqXi7f0U9rvi3zzd8uR647sBegC+3Gzhk3OUrCgh/+s//iFd8BEjp8cmYGgUJIMbpwy8IyxkfrlfE7QOEE/J+U6F4aaBg3Q7RwFKRQkAKCSlt4LQqE5F+HOBpz9alUty4j0DKS+u0G2G1dS4jYCN7bszgsCjLadkQJsDpdLogrQtO5wtCiEjLYk6LdFAiFw3qsKr+03Z5xbZo1zmvvS6l9GvumT2MjUcgiGlBDFGFnNeTajsta+9eV1w7x4OfNgLzwVqZs7U9DOygMKAbDzcXemQItb7uHt5na8zFGdOyInDAsiRzARtEmdjo26uDYOZkDzDZr8c33rFxj+BhMGn8389b3WDbTGyn6f48yJ0Fy5m5M52SifWGqBlLcWeWlD+ynS5abpdUPPPY1TE98oGcVbwzBAZheQy//F5cp8FeqlWZdqg2QvKoZ4TpfQ4EEumzZWaEUCebOjLGrTVUVgeVmRFrVMajaViN/WEAkjrWnjkGWh1MP9+TiYBl3bBdXvD66Rd8+uXPOJ1fFHTsumL6Pv9bD+pEKgQqvMyY9LRsPj1qgTyEnWPtShv6bBbgtzr2uN9L9/7DHJ1iMs/14Xl4SdKcLfbnKdPf9Plm49NAOKrgehTkyr2EUx+Z+0uD8VZbhbQDUhvickKKCxS+IWg2RwXHAwuYNKjxQLC5doW5ZmT3NcAIzab70YqV/FVBqdKTAjMAqiCNXmZpjEMivu7AvVb8entDbQ1/+fWLthK/qn+5JQVHgwU4RTRgqMZ4pu5Eq37j0Qi1AXvTbHvFYFa4hlwrDBhYRLDSrTo6hwJuL59QCYbpqFEv8dG9wrqpNsG+75qoCEH3kGKdOmvF27VhP+54v11VXPw4kHNBLtr1jvGG49AKgXVJuFunzyNn7RANgTDh2FWjiqQhELDEiMDqZ9cK5EImWzNd/IS69PXWYEAa+nyE+XfBSq9TCDgvqa9s1X9V/axqGpTOOPb5MFnLPvUJ6BNpLHfqcgJ+id3/s4YQHKOVVWnZTy4H8rEjG4jg8jzzB/kptSyRkCIN4Ik7qeE7IRdNweMjKCWQxzVrf2yd33+Y45nR9Fw65xpQzlx9fM+U4JqCdIJ2YlQfrj39DYMc2LWXQozatdkYGe9ff8W+X3EcN9xvbwiszJFlVdZTTKvGlD5HS0YrRQXES8Fxv6LkHcf9ZnPGmU6WaPOuYL7P5wKpFXHP4CODjwI6ipXaAZFUozU645fdP62oTMitqFZsVT3EXAtyKzgko7KA1ohwWrC8nrFcNmU7t4r9/o777Suu1884jjcsqWBbA86ngG3VcjsxdiGBQFUQG5CE8MKMn1LA6xLxYdMYY03W6TMkSCPIAgXFj4zAd13j+w6qBdd8Rz4KaljRyGxuDKAgiAGIRIjEiJERolaTMBnw734vSOu4jUXPxNhEO4/+3FasIeJrLYgh4l+PA6UW7O0GhIaPLyewJLTyAfdrxv3LFQe0qkBqg1Q18CRKcvB4jWxhN5j9sPLtEB1fsM2rNkhpyngCkDeV2VA3kTtQNaQAYL7b8M/cTnq1yfDz7eXJ7xcRBfnM3xYihJA08RwXBI7w0mwvw1MSh9sdBfwgY02yGTeXpmiiJZccK7xznbLelQEVnD4NdNtLMvblNgnr/0fH3wE8vYEIyMUcy3Joid2XvyDf35DfP6Pcr6oYHxO2Dz8jnT/i5R/+C5bTK7YPvyBtLwqsCDQzLAJMDCevkQVmQxW6k9FgIAFsYAUKjFTqi17ZGuiAk29QHsDhIbDRc/kG54DTs7Btf+vDYQ+VqO8oDTqRdUNxVpG/vRnDyWjQ1o661gbUgsYMygeIAsAJIvaUPUsDIKSTtu/eXsHLBRRU4LsDbQ5bT4evHQ+kH3/PoLCClxeE7UA83xQY2296vTUDaCo8VyqIDxWrjnfVfyo7pB6QlsDQIC2QgoXs9MiOIg/crzsGD6M5gBvbr/sG3YS6oPwITmeHYzzPeYMfI4ApQB3orxsDe4P+0bRpGTYHbkBgIAoQmQCwdpKYPshL9hzf7IJrNDShNEiMWFPEaUmITJBacJQDRTL22468H3i7V9wOwdEA1ScvQG3YQajECCFg21S8N8Yw5mhrkKoieCEwLq8fNYhmQj7uyLcvWqJa3sBQ+j7Esp0Eo5dql8IfCXjyrmSD6SQ9SJ0zrr2kagJTQKGLrXNcldq6nlRXaTtrN7llAcekaVDWddszDmyMNnO847IgLNplKKwJ9/uO7f3dNnDdxJx1JWhmTyzLAhqaTsumLJMuJE79b583rG+ZT8BYIdP6mNbD7HyTXf/QMxu2koyaHIzptKyrdZOxfcK0D56DLg8gvzWs8vDt+VfdTgCdPTC/1df5cFiHyXGgqXertHHloOVqIVoGKcTesU7ZQWxMQXUMY1wMpIodCPJgcCROqJf5jj1ktkDDIQCRiRYLnIHnz7Ibtf5v9DKFh9dI+8mo40p9n9RnaqKScCBhlDEIaPyOpn13usYheCIWuEWkdcN2fsGybgo4sZ67iTl0k1jrw2yioEGtHd5d5pFVR922DxOv4zADa76GGYwqo1HA9yfPH/l49EHGPHJ79Xi/A7CGMnpkfp3Gv+09rUG7D/f9zNfN7L+M+dqM7Q6pULaTBVkU1dm1AML9ML9Enwo9kIeV5JOzDl0jyZJRJm3kDQKegVj3DVojHJVARfB2L+CgJSqlNbzdswp3C4Ew2MGu4SS27toEZggUlFMuupbWNfEkkw6EWHZXy7oaSlGG+nFkA09UU3CAzdMD7C4HwbuSgoaUgAKABTi0rMYz2q258Kx+P46GUhg7H2Bm5FJ6wkFEcGQViWe6Yj+CNjZpglKyajhBQe6j5K57SR4AE9DMvsWgvvbBxgvrZczoQdLD/INNPIxnNpIc0rtzMQjVwSWu2sFXRum7v99L+Z4/Z/bN55+GTzdsrU++Uc6pdqr16oM2ve879yQaNHoJzZjD0n3bAVCNv1dfcLw+Ln7+QR793h/IfA1/gr4Z1BmE8n30MWkg8EYm9i6L68Yz/67f00/Ro2QACj6mrr151uY9paC20tl2tRbEfCDGBU5YaEVZgi1nJQDkvZfWke3fADoxwsELZxBTbaDSVEQ8V7CznTzOIAecfM/0vW4I4xOTloqJltnVWlGtSRJFRkgmERA1pG/SsO93HMeOWneIFMRIynbyuAFj7ByAYQCRGVtgnFLEKUWs1iREk5va6EhlgZRMEJuu2dgqUm3IsSAWgGvVCqiSIaVouSL32aDPF9yTuyoraevBnp/7Bwq26F8ygDUwGgHnlJABbMsKlKDi79LQqIKZsZwVDNoui67FrNPCYyVUteHk+575F54cefA33baQ7qMQtfG1VNRc9D3RuuEZ099RAHd3+8w2/5zcB5Q5bfSwAh5sZ4OD+LH7qt4x2PWkdT9peFhw0h7szzd7qfg1+Avus/e0K7x7njed6WWw5nMNr+Q/Pn6/uPj7/wSkoeZd27zf31CPG26//XeU/Y79y2dIa4gISKdXfPrP/we2j3/Gz//8/wCnDby86CQTzcqjZDvzRJkXR7AHcBE4jq5CtfTWviESajkg+bD2pjJKPGYdIaK+WbuTMY86myizt74FzV2CpqzthETqaJvjgCmwnYRNCQRm25REFHQqO6TsaFk7xuWcUXNGsza2rQEUIkLaAAoAr7Zz6WIPS0RYzlg//iek7RW0vgJxU0eyidL8bOcaFGMDngSGKFtGkxjCAbREhOUCCqsBWydQSDjiohOq3NDyFRWqWcLxXYPw5YQWowmiA1g2MCXEQGgxam1uTGDelXk6iez1Lx6bkZdIONPIM7WmJaypIEzOiAVV3VHtz2GwntrYncAUtFTHdCK0BXIDXBDUgmCx7HEwo9DrZPU0aMLIdi1VoGwZEUgdc0rbKo8OAM6oiUGZIC+nDZ8uJ1DJqMeB2/0deb/h7XrDbb/jXoCjijmjhOPIKE2QOQAhYDlt+PjxA86nM9a0mgEQbe1aMxiCFAP+9A//GYAg539CLQd++5//guP2Fe9//X+j5RsgGahqGjUIj0BIgz33gxzFgwvxwF5tTenOhvT5omCKCvXFdQOHiLieQSEhLmeEmLQbYAyIq459iBY8G0Ah9ty1lbw67mxg7LIs2LYVayBsUedezQcEqt1z2GQrteicInfM9Rzb6Yx13XC+vGJZN7NdYTCautitDKbTVIrUnTt5wIGGQ2ff3enSTi6M4ObRS6MMlHHAKW2qZ7Vsm46hCRIftzcTynWn8nGDHf99uqAZiOg/+XVLdww6YGw/gjzrqA7cM8NJGRnUGzowEYIxnNKyDHH4EIzRFAyA7Go52E4nhKCtegWmhZOzfpXSRZVjMH2AEPUyRxRmZlrHJBhrh7JpalUtwR6QmjnTVlPvg8KW7fWsb23Bgnh1WJuI6Z80ZaCEhhCDDXPs+k8acOLBNvu88xI5v460bFhOZ1w+fMKHn/+M88srVlsH4oLURNa51BtT+PMxQLIH4WINO9C7HZI9z5EcksnO+/MMI1CBBfjIvfT+Rwrc+mFjKNMacV/5KVTrtqwJ1A50UMOdV3Oioeyn0mx+GKOuu0KAdatDB8MbFPTgWtBqtmXBAHlZKsw3qnCeI2BujN8IubA/dRAiBM36l+o2Wruv5iIo1ctR+11bxzWgVEID4T0DexN8OXaIEPajoFZRBqII1mSlIlFLgG1w4C5zQ3UPvI9rgzKcKjDe18dCX2mi7GFp0H2kmTNOrFpMbTjvcwgDgukEepmssb+rZp9zIUAUxOpjFdzx1wGtBnZ7uenQv9PvxYRvr+9arcBhypgDaM3AdwhiYGM6MZiifi5IBcZrRWZlS5VakXPpHe/02c4RDUaDDLN57ttp9p8RWcGtJQQ0AZbI2DMj12pfOllLEwQGWCYx4L4WqNsR7wDle5b7/v09MH/SfPsYCCgFUjNqvqMcuzE/JjCjI6Wwa1d/zwoS1X/sXRmlY6/MpAwKBpjFpCdg81xQn+IysWsbY/T4uX/0I1hX1VFy/cxq0mNmvM7v1wfsiTdnYNujl8GYetSObA/nbU3nHoeE7ZS6H/P25a849htKOVBygXegi0G71pIlmlwSxeVRWlXSgJ4f8O63ZJ2EidW6SilAE3BWhlNwxlO2UrsOhAbTNLP1aZqr2p2c7fwNFYIiDUfJnfUkkZHWhLQtWE+bsu2hjU7e37/i/f0LjuOK1g5sW8Bpizhten8g1w/SzSI0IIFwCQEfloiftgXnLeFyWs3PjCCOIF5sjyYQV9NqNnBISBtj1YKjqXxICVe0dUPLK1qIAILt3Q2mEKj+WrAkJ3xdGShna1kMdAIBLyliEcFPckJICW+tImQtlz1QUGgHB+Dy6QXbecGn315we9tx//WuQui5oApBFgXTR8mdJwHEyrC99M/nLQ+z0oB66Dw4rjvConXXHJ11pFVAo3qBABkNr54c3qfvw+cxRVqIEFgEkRghaiOhxSoMYPE0iXcQHtCel+XoMIolDhxkmm2071Ca8FYpFjWyRLB4xhKyBooK0Jsz/T2G63cDT7fPf4FIRT1uaK2gHncNdPMBaU01m4QQlgXL6QXJ2ABoGVIUhRQE00lxZgXMcZJ+4UQOOPF4yKIG2VE38vQAEhieJSodZPCM7+Sj64AaCOSbJnVU2t71gKZPQIcDEzQP7TzI7u6hB0xCMETcyhJbQWtZy+1aQTW2U6kNtTT7XM3WCSJ893KAhTggLhviesZy/oC4viAuJ3BcuuHrQRn0mnVaaO5OF7NNfsboomErnOICXi8Ip49IeVcD2xra7VdddKzpR6kHpNzR8jvaHu2zKxgFFFdIs3KhhwDw8eub4TOnQS/HswDdC3BXDWNRTufwYW+CRqMbj4NQ/bn24McCayagmfZJB56mIMdpYgJrH6zXEbtYHCstmjUzG6asMzMrAAfNlJIJpqYUcVpXRFKR3LrvqMeB/X5HPg7cc8FetHV0E/QGjD7HYgygJeF02nA+nZCSOtFiotn5/oZ83FGPd0irJugXEJnBMSKlhFYWhJCAqgJ0Og8zSs1YxJ1kenpAf+yjWJBQHYCy+aGsItJnDe1k5t3+FEQ5gWNCWi8KQC0nA55OBkwk1QsxxkyMU6kWa2YpxIAlGUhjwtVLWrAExhoZ59cPeL1dkU0IErByI5+Pdg8Kqg9GzugW5lRZKznye3ui7z4DPmpXaZ5g+jm23hRIsM8VQEzolaNSnmNaQMHH6gl4AnRvKISyBzTyEsKxkt1zVEDm73+m07L47i/dcWGaNBSY+3cNxKzEzgJSB8uVRRaNyaO/I2MBEhFSWrUMD+4oGyNCBN4ZVcwR1XmQJiB3PBMFSdS2OvvOn30jDWBkmgPqKMgYPnu9NVEAoANTbdhQMBoJRIXtQJXQuOlX0xbRvbZjspEPw2nONRNj2U44nV+0g92qJZ7jUdi1+RRjwBlmoPD4Pu/uAuBB7VrQ96/uEInrs41rM1NlNvu5jPTHQp78Xp/vi2j+ojHfTS9D4/GZPWb7//f2YFi0PP3CrcX4fA/ABVwrSs7Q5mCahw7B2OliyZ+qTqzvq67d4wFX/xnTuefyujr242/WuQU+DQQI46gw4W9N/pWizrACWsCSFHB2AFkbRbEBSdZFblpUsx+i1zlng4HBEHXxYzGgS1PqAjK7XIc972AIdb/IH6Bn8z0Y8IWggMmztwkDBA2QeR4bwrSGB2AnMoK4WU+tNrUX7n/15jpJEBqh1mSMqgqmqslAuzdYQDZ8484xmi5L76tO+xKJdrdSd0rBgyWyBXh6D9pRj+DNlTzofPDB7ZH6p86gefdtiWzf1LlArQBSQC1rY5UHC+t3gYf7qA04KnDLgmsWJJb+O8D3GSM9exAL6uuT4RpX6ICVG/EpH/E8cH/4ozOAp3sSkYeqkr91zCV3/b9Pb/+Wyf3tm4isO5nN02U5ASIox459uyHvt85O1BJaZzMZv6aZBq+Xi7dR0tRnCk0zxtdv1SQS5woqxbSdms1l6g0HHHjyfztAMUBUPXczgK22uXmB+hkc1HcJIcDLoo+8I5cDTSqIBEtKWJaEtCQrBUP3hz1eDERITFgMHE6sSXRNwGlXc3i1kQAIAiBAWkRrCSVnlSEIgsjVqoCq+ibNO6Yqw7bH/SI2IlYmSTNLkKYHb6AutAlEFMHCAUsQrGlBIcZ+7BDREmpGwZoUDD5/2NSnvVe03IyppECVV0+RePmZjf1kATSB05ThD+gYkG+KgFSTtrCKE4lt6GxapVa/lTma9f+YIe8zl8Zm5HPCG/ekpNquMabuy45Pmnwk2CX6vXTc5GlDIeeRDYxDMHxbJmtK5HGE3nIvMXY2IxkG8XuO3w08/frf/1+QVlH2ryp8ra41mCMAVgYOJ8TlBen8itPlA+KyQo43zRzVAlAE0kVLVtYXuHq8+xWKNmtg40i5DuCwzn2giYGYgGXRWtvjOja16FT88UDU+JjzYIsAU/AGTJNCBngDmGMCyyRjiO365l3Na5LpwaCDFwIY4NTKHbXcUIoahKNUlFyR71p2GLKythZHuamAKIDCooHt6QOW80ecP/1viMsZ6fwRoyxqIJmtKdBUoaKheh7NLjYwSIJS1G0iCjF40SAbIYHXF/D2Abx9RP7tX1BAoPIGlHcg3wCuaEFQ5QZp7+B8AZVPwHKBVFYBNtJsnnYVsQokTE5y39pti7bFw8FFRp82mt6RyxejG3kd79oEoIpcG6LR7ItwZ58wz7opYuCbGGVUjMr/+F1BTXeYBVTV2Yyi7T+rwLrcDY0nD9ICE44K3KuARYHU07bh0+sFlA+U+w3X9zdc36/YjwNHVlZTdScf5shM83LdFqTzhk8fX/HzTx9xWhdEZhz7FTUfuH3+n9hvX5FvnyGt4PLxZ8TlhPX0ESEELMsKqQVx2QCpaOVd66L3G4QjtlatSxCNB/YDHLmU7wBO0EwLwcBbFfwOIWE5KWi+nV4QUsK6qXaT/j4gdaZT6HMrGJsthIhlWVR4eV2wLAnbtiAY8OQAlLPimIDFMmW1FHCwkoeDkGkEjZ1ZlDTTEVgLq/yevEtYrZ6dG624Z8fM//vg1JGFPOLOgK00trbTALzzR0yLldRt2gXOOukt29Y7JYo05Ps78h6Rb+9oky0HbI3YhviQIXDU4e86/A8mW2KvsNm8EFQTIgbvtqkAFJuA+NzlUcvolgE8dYBRmWXEjGVZwSH07mxCakurKBXemXMhJsQQsRozrTfAsDbl2n1EnRXNyAbUWgGiDkp5e3PBALXQh40eh85K8CSo+CeAh71qZg2BoCU0IIihip1KjskvMac3pYSUVlw+fMTrT3/Cy4dPOF9ekWLoTlNPtJA8JpB4sDAcSKoWtI491rd4grMSVeOn9PcQxj03Y1Uoo6/1LLR3vPuRDu++KtNUHyATkAKD2ZMiYs67oJgzbX+COQHjTu7s/fj4TltrB5p0H9SOY6UJRA60WpHShghCTCvikkBFE4Y5kyfuO6gqItYymzog6T+73l7OCjodWVBKU62kNp6/ghgC50XXFlBBaNnuuRb7reorfjgtiAbyK6NF7Y0CpnaeVnGYvYSBAp5gYgOFRqQ1vJDObLD9v0H9OdhYD3apfScy3ItAgTta4YGBE4Xc/+zARfeP7BlZ/ODPS5MFg7Wo4r8WSNhdihiLG2PM/eOK2ZptUb9tMVZYi8qkZWLtCCaEo2hJSa0VezbwK7g3NwVq0j/e/Hdt8lFI7R8YiAZMp6CM2mNRZuj94F5yKEzgNrSbWNBvfrD6O5duAAAO7hl7WxM+EaFlcMtA3YF6gFqdZBym631YG8qmowx83gWBKgIB56h+J0EfpbaEhzaiMZ+XSUugmYBAsI6x6EwzixhG+w3Bj9RQGCV7InrMj77HfAd0ek5QO7gzP1Y/4WAezn9vJU5zXOfnMDJDjAnb6QJA96Hrm3eErGilqA1pDSQGDEHXXH0CnPqezqMkThFci0NzBpUK3g/wUVTbKVcE37uDl+7HrrM0I/RKstBYUBr1bna5KNupUAOBwSkiLAnLqs1umqhm8u12xb4rUSQE4HxZcTmfcDptECHkPPuOel0JwCkGbDFgi4w1BSzWuCbEFUCAWAMsZVQDIVjSgwlSG2rVjndHrhBW7R8yplitAbkBhYBK0suotSwmGCCvyRPmEQP6bhXMCibRcsVTrKhEuGwnoFbk1lBrQZYMaoK4CSIzfv7HFxzXAhwNxzVj/3VHKw31KAq6VLFEmbHOjCygpkvQmsfiCk45271JBTWgGfOpJgWxQlJohWVoVMP0jTstuPvltrfYzfY14FiDsb44aFObbbvg5fyqDNg5oeeZE2eJOW5hoOujbzTsP7HKYpDfsB2jBJmAMCdMm46VDDsMAqj9fsP1u4EnpaNW5PsNkGq032ilWQtCfLH24is4Msr+BS2/oxhjprUKThvi+ReE9aIixiGBwtLRxpkm7IbFBbPgGyuGI+s112yaHE20bEWFLRX0kMmIPWucfOuM6eu+UfaHQGNj9VjJs7FigM/cTcfPZ3cBEc2wQDIg1oVOhoZBqVDACBXUBOBdDSgVEAekNSAkIKaEtKxYFhWB5hDtEyaQbLoTUigWkKIGUka9MHmixycOWEXC04YgglgOoFXgeAPuXyB7hcihi6Fpx7t2mP5JqwictNRIFohY58OpPEX8J6IekEQeVHtHmoKXv1gWi11Y1f0+mngbYoM9BS8ulObllw7i9GfIziRw7/pR+wmmZdNYDJ+ycxMhGHXaaZlBnH6NKZsIAzX0MwU6P1eOSMzgZm2R7zfc7ruCTrVaOZid1+8dI3tmlwZiQmkFe97xdv2CJgX5+gXl2PH++S847m8o96+mI1YQ04rjfAeHiHrcAWmIcQFaQa63zhYstfSyLHQX98c4qtO3zbbEqKVTnBKITSw8KsMphNRBlGRaTqfTiwJL69ZLspiV4eQlpA5kuGhzSgnrumBdEk6nVed7YAMlra00EU7nC6QW3G5X3G7vKv56HANEksH0cNtINNZ87+7lrKcu4uxdUPTowRImGzE7g0BfI77ZCQCHJJz1M8A3BZ7SqiDMYiywtK5mH1QXYWZmdc+xX4CMb32h+lvtup7fO97w/FaLNZzdZM/EbE0I47t32wscQIG1EUKMJhiu3W+UXZYev8cEFVBfJop/N6Jmo4bj4ALlvWTPPClnkyqA0tCILWmiTkBt1i2Ln8CZpzFwJkgzR1s8C2/nJGo2LmT73AiGvfxSu+I9OhX+N10DC7Eznc4vrzhfXoztNJfkzgGD2nIvoadmYNS0Vz3sxVNw7okB//4QePg8EHRnubhQcs6mmfjjldp5k2I2ZzhaciYF3SeX6ALdOkeKNNM+6qpEANwXmQPebzG6ebk1jGeipey+x1q2U0TLUGqGBBWxJijLqNWARso/cuCj/91kjMQ+p1RYiVkztpPu4xAZe5F9JoFG6b4Bm54rdod9jQo0n7fFuqgZ67VaCX0AINRLqKrLFmkc+R1rM4A6F84H+W1IlzuQKgYcPFjavv78er3EDs5WJ3qQ6nJfyf0lLwvWZKd5LMSq1RgsyTpplPZAFuglZGHan3QPaX1P0EeusyIYi5eNPUEClFBRS0XkgFoqMus+o40L3MujnrQDYdi0aW45oFRZ/cgBQgJLYLTGSEFt4NHLLucSY7L7saTMdJ9izwYiHXxzXc3AmngmqaBqvm3vUfg0/6cNkszetAYUErznhsiENar+ps8fX3+RgErT7iTDTdX7FCv5dr+7jQ+epvmPfMz7TGfXwcdjfJ/+otspLyv3131P8+/z2hjncnuhrHGN1yqW7YTzyweVjsk7ijUGadUXtz97saYDIx6Er10a/o1AwRDtyCEKOuXStZ2oNgOl6GF99/15ms/N1nGT0AEzWMxZjd0uDGWdLwuC6YxSCCjmO6qWW1FwKDLWdcWyqC/TmibJahsNaAjaBCoRLDbjYXs4GKOV7WsuxSLrkBcQYzQNKf1eWHV/e0yPXn+DJj7GVWPGvlHZ+EI629PLiIPpYdWqZ2FiY2qxsqCCMZHI9fkKGgjLSVll548rQmDkt0MrsWoFm/4Uh2B/SqNLnMtw2N5WqQBW7iyW4JEKUBVlPRVlPNVcgBjQ3L7bDEG3DX0Htv1x6OYxM3jSeGZFsLVSYjkZEDg0lP2MBBgwP3v949/uf/nYfrPJ2ZycfQK/ttYKas0ARBt+iWtpD5a+6x7+nuN3A0/HTZHT4/0rSBqWbUFMG8J6QVhOSOdfzLkGIBXHl/+h7SrffgWkgVgQTx9w/tM/I738Gen8UUGVuGJQC327lk5ndDqv17zStBjcsY1tAaRhv99Rj5s5zK7KTt1RaXUqb8AIVOZMLwDTgmr92URzsF0HSkSRwGqKl7Vpm0Y3IF6HzD6xLMMi7YBI7kFhbYRSCbmYM54ziAg5lz43QlpAYUGEIK0nLNsZ2/kFFFcgrnoe78aFNj13X+IFJDuUrxws4NJFVdvQQNGpQAhrUPApLmjrGdwOULmjvjXUdgBUVdH/uGvpYNlBISFow3cIv/YMHnPotb+wKamOgCBGRjLn0ANyENlYOyA1AT+VHoJp8/PADdZxSzen0gS5NeRWkRr3+li9BGU8uDMtxlIAXEhqZA+5weaf5lbh0iTRa3YxJScIXhYKEI7acM8VAkIFYUsJp3XDxgCXjOP6jq9fvuJ+HLjnQ0vyyDo9MGMhQiR0Fl3wDZUABOCWb/h6+wr6tWJ9i8hf/g11v+L+27+i3q8o+xWtVcRFNYq2yyfEtGI5vSoosmxgJuRD2Yu5HEA+UGtBaHXczw9yZBdcNwBg2S4IMWG9vCBE7TAXU8L55VUBJwMWOGh54uXyghgjNgu2lxSNfZQsoNCsRhUHPRuWFHHaVqxrwuW8GfAUuq3xOZhCwOl0xpwZz4eWL5dSOqDkNs+dAYh1PTGnodp7ay0GuA5dHjNOFng+jo2XgTqo7vzZ/qrZvmBgjM4pExE3oCmEiPV07uygavoZIg0hBBRjig6PmmCUpx7sPGBO80+k99CBYg8xn3xTB0o40GCVmW2JUbtChaBlp+SaT1G7tKS0IKQFy7ohLSuSgfqqacCd+ZTs+ceoJZbVnrXbDtelIxNfDMaeSuvJPj/ZRq3izMcRlKVjoC8zP3Q4rL3Tk7eyH6CNDoU5Zt4mHlA9HyF4Zxx20IpH0sFLMmtVAU4VK1enliwoCKyM1WjMr8vrR3z46U94/fQTXj781IXYMdsmC6zZEg5atjCLXM5PdjxbmC3WLKp3T3TAlTvt3p0cZYsVFeTf7yil4H6/G3PsB0OdYJR3grWzJpyXgBgI56TJm1PUvTKwspPeckWpWhLUs63d+Rw2wAP12QX2Xzgg1L88yG76FUgAUt2TAoBI2YMcIlJM8M6atftxhFpV68Z1coAutYQjV5Qi2LPOmVq90y0MlxnAg4JvpotijLvclDXCQUGXy2nFmiJ+elkRmHC93a3jp60H8+1KU4ZVtrI+slKpGKV/1jM4oW6eazk521nnXiml+zvgidXFtjas+ycHD1qHnELHqnrSzTXpjKHZwWP1O9mCGrWHpoBCmrJyMEeDNv25l2aYLait9rlBgDHURLvcxoAtqbj4FiNKqWAwjlxAUBYxUbOkzgA4RQS1WALL43T7jydrj1LUV4wMsbGIAE5JEzL3pWAvwFG012CuzQC3YJ29NWhlnw+T7+7MOjDArAHwkiKCVAQpCjqVuwJQolom7HGYjHDw+ciWGPxtb9ibjtglAWsM/dksAUhstno6p2Isur+69idz6/IMs8l6YLH+QEcHB+1mHXhyIMkbpDyDTjMjVn9l5T/MfdweGHzypMVja0jL3tU+efnr+fIRMWmX9tIK9ts7dljpO1dIrV3fSdpUvm6JK2LXX+qbk67No4BqRbjv4KMi7BmUC0TRdcC0QL2xQPddAA+SQAKEYFprHMCsCRVpgtIKilTIQqAUkC4npMsZYVlBkVHzDbkUHHlHqRkcCcsS8fKi+qAxJuRckevdumSqdlWAIBJhYdVfSyEihqjNDcwP6IARNYiowLeuH2X61LSgLg1bUZtaKaLOBAQKaIioCpnrPKgAWoWI6supDI8Yc1qfsXdtTgaal6NA63cUfE8csAAKrDUGWoFQQ2k7mBtOry+QS0I9XnA/H7j+dkW5KTgHAC1XCGt5HCOATEKgSgFaQyvF5kmDcABLApjQrAs7is3nUCwwJbQWp2SDEhrI/dmxMPSZ1toNj/JJaPhTVka5bRecTy9YralQxzf6d9PYanOTNgfj8QA4Eci6us+b7PjRpyKJNmCgRih57zrWzAFi4un980S+azu/d/xu4InjBtQMFWNukFIhXNDyXRHI+K4lB9DF2rJqQOVdWRZEFU0I4e3fAEpoxw3MSUWsYN1w2ghD3GEa+iTw+Gk4Sv33ZKUQJqraKsp+A8mmBi8YgmhGqGEItw4aP03TwZzh7hQDRFO20BkFjvQ9ZOtFAR4AmBhHkGIIsTvi6nx1JSYXvRZB80CC1OnxdrrBSkUMdpmAmHkC9SXeP1skG50O8JI1BWOoO/06Pcm9DxBEuz0l7eKFfAbyGSQHAG27KMVANa5o2w7JByRVpQKRB7UTp4JgZUmMNUXkteFiZUjiwA/7c7L7N7ZbA6OLtIltPyIoJOgdt2CUd6sjrgYsBRmf30fIsyum9STWjcdjKDEHjueuWWyJUgG85Tm34Sz4PaBZSSOrzk9iRoKg5YK9FaMfa+YrhahZYQGSZRsW0szZAc0QcgxIFHC5XLC9nNFE8H6/4b5fwWgob7+hHTfg9hVUdgTrKERNwwatYa+IaQWFCEIDPaRXLZtg5UR9Hv8gx+tPv4CZsW4qDn66vCrgdNZSuu18UWbT+dK1m9yhjTHicr700rnAUzv64B1EFIAo3uK9NaQUtaY+RkTrSuQtpRWoMraMdSE5nS94/fgJ1+s7btcrqrXnzjlbm249eraQ6tTKdP4C+rOzdLPuN91L02/2owNODlz0kg52cWjrVrmowGR0wMnKzRbr0JfWrYNjkAkImTckX4eYoyw8/fx4EOlae+hs8817BpvgEXQym2mgU7AgxwO43p3D3hMtUxdjBJu+E4gRUuwZvwd9rZ6ZM8DJ2Gw+DsnYUy5W7i15vSws1NozmXPmNhalbcdYQVZCCcjovOTj6n6E1d48PPumr3/LLupnMOB8tKTmLtI7xtW7N57OLzhfXrFtZyzL0p37nqAxp7hBVE/qe88II0AYCZ/xSH0+6j4/ssF6m8bsM0FlXRcZ+36g5Iz79WZ6daOF/Y9ybEnBtzVGxEA4LQGBCEtUp3/pjBP1BQIEta8XwUyleZoiHTf0l73LjvtXDji16WcfXg2WBGwZ0ZIPJIIGeUHn/8Mn90CcUBSp7+fKRdlItere3fFMM1S+ZqOBMGvS8hTlrQgqnG2la/C0RmU9MUBoXRi72lx3gNM7vVWrc+s6Qg7ykGb3A6vXVF2y5nvggNkg//3McHLWQIyh26metIAJV8yBNAb7m6ekJ0FLHtWuNnhSbdhwHmtNL6kDT8HG0csdmUzk1+2Kgb+emI3OEgWhJX1+R1Km05ELqmipcfGOkpZ4aSQgFi3FEHFYCyC1k6WpoH0pzcZVBz0QGZtIfZAcDWT2+SoCiDXh8e7DLobphstAQWcYM4kGtS2jSQE39cMhY+49PELMO8z8Bl0TRTTGvJuPXqFrUGw9rH1NCpJVO8r05YHnUyPKvi6lj9ePeThhYLbRD6wfTD6O/a4f4gH0/HejpPTh/TS6m6MnvkxywxavrscF63bG+fIBEE3iVzIwAv5ZEyBmD1Fo+p3+Al7CQjlrZ4S9gHIBTNvJLmwAThj326NQAggOTAXTebXKEos1BcaqTAGUIsK6KuhkTVBGYlz385nRHUIc+34dbCexpNNgII6vueumx7qzN+bWptsgcoZURKCIQAHCwSoOAhAipAVUBNU7Nm0kYYaEMKQG5/PyAPqItLogwKquyEC/KkDTEm+YHSo1g5mwRS2/3l4XEBOWs/lit4paCSVnK2k0UN9YXUxeUtf0vLWhUTAJZgvUhEFBp2ezUmtK1XCRCjZwW5/LnIibcY7JH8c05kSI0bpYJ5XwcLbqOM+ohJjPDczrzGYbaVn+jFmo3zlmMvpshAcPijgYONaqMWFdPsFB5L+Dbf67gae4vqLmHZCgXXdIKWzl/gYpB7T/ByB1h9SKctzRqqAU3SBJDoRjh0iFVMHll/8dwhFsAArVfcp4EgRxOEZ+/354MOObJhkqHDRoqCXjKLduJKKxeQg6YVEHDdgPehzz/jHuAamxsmysl7W0OoAnWIAk5Hw3wEQMpWUFaKxzim+0ggAgqLq+kHXn0L/V7htavpWSsiyUIUQgWCvjViZH0ieSTR9pQMuAHJB6h4RoE7mNaWX37DRCgoBaBVoFkdbXp2UDLq+gdge1DMlXtLzr/UhBbQdEKuryATVuEL4A3CyoCz0wg03sEBiJgPNpUR2B1rBnbaNrBZWYt/6udUJz6aU6I62pQ6jOl05+z8i6FkXx99AkHAfpG5YatTbGj7y7knm+LCY6p62bHYBUP5W6CBOZ89iIlRQmmnHb4oKNgFUq9v2G6/WmOi6Cnk2oJhi4EbASIUEQAVQIDmkIacO6rPj06RNePn5Aaw2/ff2Cz1/+Dfv9Crm/g8qBF6pYCPhwOmGJUYlc0tBu72C+YV1X0LICotkCn+wOogQLup/XwR/9+PP/6Z8RQsDLh09YlhWvH39GTAtOpzNCjFi3kwJLp60DF2JIf4wR5/PZmE7JyrhMmNGM7lEUJNqPo9ulJUVs64IUA5KBHoO6HHrArxt0wuvHnxBiVJZTVV2EWitu16tlUG0DaFW7ezpYAXcI2oNddLv17MKOAOURcHLQ3jNLbGVlDsBEA5r0u5WbOfAUIpb1ZCCRzSuyMLi1AZwAj/si/AX5zvdhk2efD09/PoMkDjYlYzgl+/dgPHGnJxNI2VzuIMVopcwLlmVTkMjsl5fYub5VZwM+jD9pB9bYsJjI57qe9HzbqYvCg4BWitk1F6PUPYWJVTS0CULV9umlTnon5qA2d35932midsttrUA17ExMX8xGdq6oTAkeYz6BCGxsR6fGMzOW9YTLh094+fgTPvz0C7Ztw7qdrFyhWVWB22Sx/W2wU2Gf0zv3eLloUMPpZdY6d0bgEEy7IARj59aizRBKUSH+fUc+Dlzfr8j5wPvXr9pJ5zgwdzX6EY7XjRGZ8em8IAVWZgiNpBwmVpw0FW0O8PQSHmxANw1QN0XYrEQHn+ThfQ6Q9y8ZTKTACgAwKmo5VHyaCUtMuvaiPvODPMQypnhtyF0QXj+nFAUtSjUH3698mouBCed1UZbopuyd63Egt9a72p7WhBQDPp4TlsCIpHb2yHp9tWkH1yoBIsqGLbWZRqT5CNDgrwv+EtCiMqO4jM7F0sdrJAq1HAVd5JWMgemNJ1zPJViZzgCuB7DEtgZ9vyBbJ7M+Wuu+UOukcvZgdgKeANfVggExhGisAbe0HaytngDWJPAagiZONh2rLS04SkFkxp4ziBtyKbiXA00acq3mdzVQY/hEGUILYmPeEAAcVBCZNOBl1WFCYFyWhMiM2gS5NtyLscdNfxOQrr3V1wFRl+Bw/cUlBuVVtAwpO0q5I2q46zmZ/hy/d5AvBBrvKyI4GvCWCUcTrE2Dymrd+i6LAqtMgmhdpN0fbTzpzE6f4eV8+nH09I4/9tEDarPzXlHgewNPmm8z8FQN4e1avz2uekxghDC0nuZSPdemFF8PPO399qXdZhnnywdLuBJKLcgHo+iJII0BbpAoxoCSvlYVHIKW1QmAqiATbofqO912UK6gQ5lOD3Iykx/yyO6lri8UIiC1aLK4VA3ppKGiKbi7RvBpxfJyRjproynVVCJIG2OhPs3StUcV/Fcw3rVB0bwATgzsIqsaUh+JwN1WN9/nZfhpHbiwuI9jQkyCSAkRES0kCMcur1ORkJs2NcotK8hNro2kY0yAPTfqUgVeohxFyQIqf1IVkyhilTHUSSG5HCASUBLESHj50wnLOeH00wYEwvvthlYF+/0OacD5tQEsRlSB+mskyFWfYclVy/2KlubFNSlhxhgJDWL60QQkAQdSMI1oCH/7c4cn/1w7jDszFn3vYSzLhvP5VUvt0mJ7fet707y+lC5bu5B7jwHIwU4HwMQaarT+b58vHffwCi/zGWvJaGy+ogvi09Cwynnocf5Hx+8GnkLazFAoVVGqoKKi3K6o4UArXh7WdOKlV/AakeIJrezI138DCKjHjrpfka+fAQHuIUFaRjnepw/bQMsLwAsQ1h5gAeg3pkitgS9VvxOaGqJqNPFyoOwEtBWcRomG7iX+oPBwXh98EMCN0JUcbZLAN/wpcHcDMsAcDwDruEapvcRCfHP3CQelFXKnWDsY4F2sgqG6WpZR810vKy0dXVY2lrLRtA0grNa4aJkfBMIRwkPMwPJndt6MVg+gaNc6FV/cUY8vkLYD0OcqnIDQILWZyDzMWVKD9ST1B2CUpsEWCLOK1gHAS61YYh0i3W7cdKhRmwJyrglQm53LykOCLa7AreNvrvFUq+poecbMAaL+jGGCeGKMKRH7uWGE7Ay4zhSmYFjg1rbPJQWkWMeACdHKRBZpWErtIsKN1AnRBB4Z/46xkAJOEGVrHSLYBTidNywvL/jTL3/Cp58/4X2/Yc8HbreML29XtP0O1AxJjC0SzmzlDlYSJCWDW8WxX9FqBlCsxEedaBUCDp0ZouWOj4LQf+TjP//T/w4OrGLIacHl5QNiTCb6zFN3utCdHwJAMRjTSevCl5T6OV0jx4M9IsKyLKrLxdYuOsUePAjM+bQOH1rqNGkziagW2PmMlw+fcLvfse87WrWSOxkgAXOxJK+Va6BbKJ2PPdocII5PZ5//HvB7swZn8oSY1HlPiznwi5ZcLSqoHhcTYvdyQ2dCpQQRQcm7XmfOqCV3x6Z5okAeM80z3OSg8Bwqj+DAwInupOv7dP5SZxX0ORzDg7YTs2cTx4mHE8rw9rDeiRPuADCrCGgvG+a+h3Thb9eiIRMxTwkpqqi4O30KOo2sJQGaBAEQJKKRlZTTcLY9u1VNN8BLf70kzpkEc5nBmKDoYJPjE1N80wNcskBtBNz6GGKMWLczTi+veP34E87nF824hah23oNbJjDMltkHiNlLf5IjCMbYIieAY6Ah07PvwZ6+z4Xc92NHPjJu71fsx46vX78YAPWmWnUl/27n549yvK6qUXNZQm/LLiJdFBrirLOmHYPExcgN2MG34BMB6BIb9h6Z3ugw5XyeNr0X9taFCUvUbHbjgC0RliioYE2oRYYgwrPvCqzD9lqYXRh7vxsw8sYPtkYXK8u/rAtSUnCZCEDWC45Bg57TEpAiYwlAZGXIaTlJU0DEJmCdtfF6Z7MR2Lo+nDOAmRp4YvL5GHigqNkpArTipAcZ3ngixmigeDQGkrMmrSzVwKVA1iHVGDvRAmIFiLS0rZTSu1q52DHTWM+A23kP7j2RqcGbf/c5UYi6WDABKkkRtONlZMbZmmksMWnZOoA9HxBUHCUj7oRSG275QKkNB7PGAfOih9tbHZtioJIIGfgESwACKWj4e1oSYtXSJGUVG6jdoHp25nsRD5DQkw9LYESGBqQ1WxK49Xnt66DPe7/O/sv5KT+CU/43TYCjKvBU2lDMYgYSK3t9NHnQ/cI7bs8n64EfjVn4oxzO1AOGDfL1JQ+vAj0h4vFJ/wN6AI3gwXFH64Y/7+/vn+R/0wEe+WZ/CCFhXU84nV5QS8YVX9BK1a9au+Hr9tEnjv2O/OswdlMuoKOAS9MudrauvALE70X7uCnY7eCylvIFm35WltfQiQ5dT4cBWiJ4TQjbirAu+l4BpBFa03t2vdFkAuGdcWYG97Fah8zmS3+PiKh2ESzmE98/7FmZrIMKiqutzUVLvYuonwAHr9j15TSObFhR5UBpqtlUSwGXoj6tleH27U0MFpNxnfqoreMwIiANrbEyIgXQZhMNzFpOSMyIS0KSgO3DCgFwfDnQMlBLRmFGzRlEjNTaJBrvAu/NmqJo46rQmvqVwqBCcLkgAdCCbq7EBI6aFKYQIFEGuIQBQrGXjndml/qRMWoiNJmu0zfH07x3f8uTeePJTu81EXIxJ0Dv8dF3nP6q75n6O5X4gAhq9SSsPw95+Mx/7/jdwFPaLsYqWlW5vmgd656/gIhQoj2gkBDWF5z+9DPC9oLt0z8i37/g6/+wrMP+hnz9iv3LX/Tn4w0t35Cv/2YbRwRvn5Be/zNoeQWfFhvEAMCdbnMAWjHgKaOVQxdyDJBSlH6dd5RjR9suCOKdhUaphT/4GTH3QIQgrqw7nofrFUxldhDAxRr9wfcyuJafrrGM7gmtQaTCClzNsdHJ4qUa2m0pdW0HPceOsr+DW0NMG4AIDgmAUpAhzQTRCIICaQdavuuE4QRQtaeuQYNUQSsZ7XhDu3/VLoT7F1DdgbZD6gGpB4AGxGRZNmciFYTuMAGRBAW+AauxcE66ByZsxve8JSwpIDIZDd6zYeo0F0NsPeOfi2f+lRHAPftKIGqInpGFbvClNJSgek+hKZ0dZuwFgLeNb97CE0aDbBUCBrqT6VReJ8T7ZMAD0kwUUBuQK6FRBFg1m1YG1lKx5gNUi5YlAKq5YqfyFqIu3fdemupENcEVwE+vL/jpz7/gn/7pv+BPf/oz/ut//2/47fNnvL3v+MtfvyIfGuzLy4qXNeIjJyxpAxatA5aaQbXidv2iTh4Egoacs20ImqFI1vklpvhDAU//1//b/xPEhHU9IcaAbTvphhy0i46v/1wyvEMWB9Za6hRxOm29TEKaWHlB6ZohtVZluCwaXCwp9JKGTo1uQxSyNtcxqR1QEhFwSji/flB7WsxeFGVxHPlAKQVcMgiCKDC9EMBuAsCc3dB77w6aDJCCMIk1xtRtDQWlnlPQTm/e6Y85mD6Wlt7OAM9qYxlTQqsVeb8rK+W4oxy7ClyW0gGT7wFPHXCaHMjnrO9MqH+KCTqYHSywS5bt1nKLwZbwhAI5KOeldhx6hzvf9IkDKFpZnZfX2Xt8H6gGBFYHDjmAIrAuK5aUcD6fsSwrltMZZBn8NgV4HJMFngJuARVQpyep3lNrDZXHHJMmqGRAJaAZRxrZqp71JYJRWcyZlz4P3bn3DJgnOIhoUO1BSMuK8+sHfPjpT/jlz/+I7XTCaTs9lE9r8Aw0HnX+HXzy+TgJ4o9yTp+T6JpM/XlLz3UawKfXnktGyRm36w3HfseXL59xv9/x61//iuPYcb++m2ZNxdPU+cMfP58TAhNeN7XJ99xQmnYNGqCJun9aYt6mJI7033rANgdt/m9nHJMHFQ4yiTycq/Vnpvv+FhmvWwBxNLtBiAk4BMhCIIQO+noQmqVAqjN3xnlHwDlAYu9Audne9PGyYV2S2lER0P0OgWBJut5ft4glMk5R97m3veAwllxpykQlIlTRdVVaMR01Y32Tl6VZuUiM4CoojAd9KB1S01Fi67ZEWk4tgDW10fUco7Jlo5Xeq24TwUskPPiIHGz/0DJBFekNsOoP7DnjyBX7cSCXrPcgk9/ojAl7vL7eyTWeQuyMNGbSbkcACqsNO3K2EpyKml3APuDD5YwlRUvmVWwp4p4zUiDcc8byzjhKAd2AvRTcc1YIpj6C2f5MqwiKCPaitiMBCGHojWqJpI5/rg0haLfi+6FAa20CeKc7Tzh0+6/jFwlYqOk+XXagFZBVCMzNl5p4geocMQ3Qzv+Fp381USZTseC82DmWoODwGhWU9eYNKvtAoDYSAfOn9G1anne+P/Yxi4cDY3939sX8Wgc7IF0n13+v7CRnioz9xbA+K4kah0z+uc8rAA/6N36ktCDFBSKiCaImKMeBuu9oR364dnJfyxclKqg0cBPw/QCXCrofQLYudtWrSRxwMtF7AqLo/QQHHxyM5mBSH5pgcq28Yh33KimwkbYF4bxiuZyQTieAovolhdCq2SMO6o8syRJZbFrH0pnKnWPnoIlYkrRpd2RtyNDQ64wx1rOLk6umVMFuX0dpyBWoFCDBuwKrZAGFCOENVRj52BGbdninVru2EmEBTLvQO0Eq4OxzxcqT2Tu4HQrQFUarmpwBu+YesJcDCIz1wuAU8PLnM+IacP/tjnyrKjYugnzfAWhczIAlZIFCjEZkzGuA0dA46h5V1T9EMB+7mj+Y1WfjyGglgQOjWsKWu1yHNrhJXh1EyjTjELEsJ034LSvWZdFxEfT575DuA5mCoGMiqlXWO91N66yREizc0nAf06e14UDrA4illSCNCLAOts4W/HuO3w08ESvAkU4vWoZQN2XKFNVwqk7T5wDiBen8AXF7QTpdIO3omRhFynYc17+C9gS+/qZgyv2z3kSMSOcDCCdEMOLpU3deh3FuxuTRMjK0CmqKlIICYmQAG0pWAdKSdxVMNSCHogXbk7gbJuPX7/nhtbFQn1uUN1FRMq/vd0gDxnZqlq0tJaP8f7n7s+ZIkmRLE/xkU1UzA+BLROZduqm6ZmhmaP7/X5mZ9+6i7q67ZMbiAMxUVRaeB2YRVXjGrYp6GKLJsEwE3OEGwExVhIX58DmHzcS5tYyIsZ96ojeobWq8VptS0B/rTpUHYX5jqkKYnggihOUZHzW4YEWEtDwAKKkKeNWyaUfbF3XjHpI+Z9dxRfZ36uNnZPtGW3/FtR3aRvd8oqkvkKKfAZyO1WwSENQovTZOCSTD3HJ03+QIWKmzuGah1qMoK82Ao6bJ6J7VxDc4S1i8G5T87uXknCNXYxKpAcDokPWPhlkBeKeYUj8AYXQy3Bla6lI8euH2Xbdz5HeaQDY8RSA3Z4bj6n3hC4QmTM4NY2oFL/vUPQWBxHUgTdibcG9CtqKOCCFBkcxWNva8s+esQQ3rijo3PBn055vJnQPXCr5VapVBJVNqZIXguO+Zum683u/szTHXo3P6R3g8G5iTJgVNpjQfkjk5hgN0FqJ+uKGE0N1/sFt6ItA70EoLF0JQs8VWnZnOQjdyHgd9OyaJVEteFAjVdRzTxHK98fz5qya05k3y/v6mXSqO7pfzTuNO9znop3MHmkbu5sZ+H8W/xT89AIMynLp5eAeaQlBfMB8Iyaba2SS/4XNloHurVSXO690+FCCoWSerjG6j3ZMRZw3wOF5sByCOg+xDF6UfhuOZB+gUQyClOGQ+wWtSp+yFo8DrnSwtWMIBNJ3lL8466SEMg/WuadHkTOxs0fjejAkAbhRBobMI7Wd3H7lS/ZCXqLzZWBVd2tdUGh6jnqnJzPFrbTijxyPHVNUeX7/Lp0/X7ANKN9bAuYvVl0kwptbl6YXnz1+53Z6Zl4VoCaGCX/V0Jh4fH+9vG118Bfnt94bw4X7qnhCymeNjMbgXLA3dM+tjJefM/f2dbdu4v9/ZtpV93yg562vvDJX/sRzo/+8fpemUukdWb8W1aOzI9WDqOGd577ixAx35cPt7A0gAL72IO2opPeM/FsQDhBotiwOUmmPg0zJxWSaWeSammZASj+JYK/y6Fd72Os79Zmukn6FnY9KKnk8y4oEbEuVlTixmN+C9Y88q7eog7hSVITRFRwwGarXGVgp7riN5HqybHodP7PXBHBryn/MWEeu8y7gW3ik7MTg14/0gw6b/Lj/ApOAVGOnMpg+gLJ4pqrRtTollSsbsisrabsK6BdZYSB62DLXp9Ld+dnRZ3nGvtUnoTTWSjIE7mcl491nLodrPUQDZ29mv7AWdwuyAy5wQEoJwyRlpldWkrdu+U2rFO8cas8ovvZn9W+7UAah+fbKgPp0dbPCapXnMJyl6Y8Z4gq/jOojUcY+UwRWJ0TNFZQYm76BV9lxU1lzr8HU6cnp9HYd3mVgxe1r8v/EQK/zMRmbspSP37SwIR/XwUINRSoPgZTQ8D+auG2D7AO3/41//d/s4N0f+46/3nEUlR/3huwSpn7DC6Vr1a3eKeGNPWfXhRmBETle3exlh1z7FCVlu5NuLNtb3Qr4/qPtOK/mYCmlT6XzT9euyDlxymzGezNOpD/Zwzh+xR9/0iKkarntDxoYN9LPPgN6cM7vtr1Kb1QQBNyf8nPAp4qJDVTWN2jKtFVSlAskfjCfFj2zoQz8+nMc5VXlUcRQORmIojZwLavbNhxjqnYz8N2f1I1XwqZKrUMQhPigZJSZ8jEakiHgmEE+tE7klYst4qYRSNA71vBIbpBO6x56edaVqrVhbMEVLJ6jMBqBt0PrzFbTzoegEYO9ZntRUfnmZ8T7zuG9UKez7Cs5R9wxJbAK1w9vUVmUJC7np4ANfgsrai8dJwAdvoLuelHUrtOKRakynWMzCIuBTJE6JECNunvqqVOuKaWGaZlKaxlCivn7PDCQR0fd0jvvHAj/yfzj2lAi4hqPXuKcvI7hOHXHHXjrv3e4v5c0TeEhPv9vb/63H7zcX9xGiMD99Vt2pNFrJbG8/0Uqm7KtR9hMuXlievhKXJ6bbC7Qd73VylyC0vLJ++1e9aGWn1UzdHxoIYmR5uePiBe8j4dM/Apq490RbWlYWTnlH8jsOozOGBG7Cp4k4JR7vdwWftpXW7kzXJ024vEfrCD8S3I4ifszR9aJ3oOAj40lGguTsxh/GlFWBH6n0MYS17uR9I+8bJW/Usuv7ED3YNSAGk155aA4p0Ki49wdTroiPzNtOSAtTa8zXLzgfbTx8wLmkMuOy0mgKzJWNuj2Q5hBfcL7ikgJPztu1zHfa+jPl7V+R9Rfk8RNIhpaNJRbARRzK5MF7xAzjaguqfW0Ob/NltUA+scfcQY3tY5Cn5AClRDc5ptgoAKWBrzZhC47ShC0r4JQNTc5FfRkErzR6G8G827ar9vdahRoM4XeO5JzSVJverFP9i3RZHaq3HYVw68lyT7v1IZZJKVAYyIJOPBF17/Kt4UshOVh8wEfwwVDzWsjYQaKW/GwGOj1q47U01uQpweMmR5ihyM4j31n3lce20pqmaSEmPGJsD49QKTXjnJqYx5ZBKjVbkmTXeq1K2eWxMfFgev2VORcuufFHYjx9+fJ1FKbaee/+MtbFznYImwxWWht+Ec6QJx3tXQfrrtYueWiWnGtSgmg3S4EAOf27STvkkHc0A+u7DCL6wLQsOjHOB663m3Wd9HX1KXd9GpmrJq8QNxLr8WHB6AMFnUNi5y2J6pP+1LspkpareuWdgCc/WEDqo+ScIxlTyttks5J3yr6y3d9Y72+s76/s64O87/a6j06v9GoWji4NB5Ck/z3AkFP5R0/UB4iE06lIUScQTkk9Xqbgu2JuJEojsfUBOpshdAp6HB3JTq1W0Cka08mPTmSfIKiJ1k7JymRFtLAIYxqcfgRrdGD33hWTongdQuFCGwCcl0YUGZT4EBTkCcaSdU4Zoq41O+iNqdnBpwFEHZfsaJIYW6kDa3YtpTVzyNUJfsvTCy+fv/L1z//E9XrjcrnSU3f1deoJiFjio/vjXAz05gyuvyKPeP08EnBksH/Xx6p0eKNue1tnpalE/f7+zr5vvH77xrquvL7+yr7tbOtKa1UZbcHrVJvv1vzf+yOXCk7BFAG2omesSsfMa8n3IqqbTXd2wJHTHB5htlrcqZC2GKfb8bT3BETcd4wnbQK1JlxS4E9PM19fbnx90WENISZet8rb3viX151wV4NXZ0k5/vBXVNa+rUFhmKL39RaCJ4XAbZm5zol5UubD/iisudieEJak8v3FuuTrnrVpt2WVdDlnEy81FpSi66pZTB9MJ3+SO3QZgZz8rVqH+lQOOAUFui9zIjhlNPVr2v1cgnkl9cmm6rN0eJx5r0ypDjhdponrMjHZgAotshrvj43HtnMPjsfuKVVZt4eE52B06/1uR1PNwRQTMXiWabJhF3qVu+l68N5YvPomcy7sJjFxwNN1IYTAMidKKSTvWfcdL8Jj2yi12teyenuVgmsqf/kgrHJa2mQRaI6ExjxtFKiVj/piKYs8BCHmQGtOwcYmAyAMQb2h5hS5TMkyscZWKtu26UCkltUEv+dzJ8BV1zJ/Cz7Zq/0gQYEP39dO+ydbvkrV76vBkTwsXvfMNjuCQDrVGB/AJzvb/lh8p37MH036s5dM/7uIjDpsMLFNViRjbx6NUDnn5P3nIoZq9jPuNNV8nP/HvhxP73IuhGlaiHECEVKayO93Hr/8Qn5s5Ps7LqWjUec8rjRca7i96J/tc6hN6wvpgPCpFoKOWA7wXmX9juCU/VJ9GLljqZV1W1m3lS3v5FpoU1CZ3WXWjyniok7IVbn5rt67KAg6zzPzlIghUaQZC72NmOtdtwhxVIG9CXtVRq2jEH0G1wZoM6Zkem2M5lLY9sy6Zdatsu6VXTyZgHMRn2ZCsgm/KRFTwhOARikPqJlQK0gm7EXzIPOVcja8pFW9YB30yKVRGuQaKM0jbsa5hHMZ7wKt3RFR6Z8gbHsG76kUYkxcPi/EOXL/6YqPK/e/PmilsT3uSBUu1yecCDHO2twPk6455xCa3odW8QLNGE8+iZJaAJwOCZOi8bnaNEuxDpGLgThPTNeFtIBPanqOU3uLy3JlXi4s8zxyto+kGD9yOww07Lmyxvy+D06b0YgtrgntOyBUQXnbIc6M5s95JEeTqJM7QggGmut7a4MF+N9//A9MtVNZSkgJbJR4q9p5KPtGe/3pSEJrpjy+IW1H2s72/jP58a7sqKyUNvd4HUU7BPz0Aq0aQLOS3/+q8p/LJ/x0xc8vuBDxYaKWjbp+Q/ZX2v4rIWqyo9IJMUDAE+cFfCJvKyXvanq+rcd0o3YyZO1R6fToXd1qhV83uj7AipOe/tQe65KtZgBDNZlAzpsynsquRl2WVHfaYCNqp6TD962pz5TfKKWBe6cUiMsbVSLT00qSQJyLBoOEXtOgr6VKoZWduj9oBELM+FgJ/aBrDSkbbftGW78h28/I/orkN/OmqopYew9uUtCqOStAhNwcOaunXl4bk6/EUAmUESg+lpOMTTSWtHUQum9Fn2gTarMEWUZXr4kQiwJPwamRJQIl6OjKEhrkbrpsCcKJ9eT9ITM5xrFqclbbcSA6Z1P25ICb+vLok8S6jZaIGkvuVbta3Rgx75k1Z9gzj+DZQmDxsHij8YfA5GDyjdLMlLOo6WXznurBp8iUApXMY7/z7z//G7/ev/HTt1+5P1amUHm5RJLzBISXyTNHh68VyYJUu+6dWeP0NVfRDt1qLLX313fCVrm7/0pMM5flhv8DAU/evNPGNJ8QTutRO0g9gRURJIoCMwY4NPR+1158gXrIydGRqiajjSFSa/rQ4R8Akzdxgw8GPB0TBId5YqdiP2nCsD0eAygAWNeVvO/0uOROvkHAx4NGjjR2FKNDYqeU3xCTfk6zGWxPBjyZmXiaOBtzhlNnXwtHjRPb4428Pni8/sq2vpPXO3nbjN1ZPxxIfWt18OFc547XP5LIIyyL6HXHDuH+fqKN+k0pkiY1FU5Bix1vv8iNheBMOtffe9LJnTHRhyGIOwPSHTw/DEH13HIDBKyt0mobHR93ej9g4KA3jwKnIIFr9vMA7+0cUi45vTMfo5hngQLhKen9rvWY3tZaG4MXjs7pAexgr9+f7mFPTnRd6nnlg5qgq7zuB65PL8NA/mClQJM6AC/6+raY2E73uHs/YMyKZkB/Zwf353aD01J0euPBONX7veeNWir39zeNqetK3rNdn8D1egEgJaWyT+bX9kd6rObxVSyONSvmOsB2Sj0Yi90dZ9a5vu24tH65F9oHi+dIQI/nNjn+fhRMmOcOA3h5uWpxEVNkmeG5oGOg58y/va34hxm/O6cAqxng09RsulSn0+0Ghi4fYoIIbEXX/V4rpbUxgGWKfsj2QXhsmVKVFVbaITHW9S6jmdivXzAgw4fDDw44AU4y/FU6YBTCwVK6GJiTRsHMSP474BS8TeVzdhbRGVGeFCLLFLnOiYt9TCkxpXiYnzcdQi5N/UyyE4pjxKQBNkovyi3Oen1O98ma+rAFY2KU6sf7LMWzmUlsKZXdF7a9EIMOvAjec73M1JqotTLviX3fmVLgkXei97xvOw7HGjLVOQqH/NXRmfDOGm6wG6AZWkOaI4jZGgzQ7MRAcweDtU8s1QEejhSgFlHWhRXCHh0TfwaQxAbEdNDoCFv/Qdxw5z8cjL3zR19bzQCRrQqlOV6zet18yvq8NPV2Sb9v4yDkgE3+OOBTVwqMxsfpfn7/cP/h307mx319S78TGrf62ne9uB7fLtan+ujxJO1sm2GFt+3radJp6M+fvtJK4VuptHVFcqFu6gGE8/hma9QYTxT1eurA0vjR/d30a2C3vJt4K2vcW0Pf/EBFyHln37vCYddJkA610Fgm4mUmLhNx9oQE4nSCeZMdkWLpjlPp6ZD1K1P/zDxzRsTA6qPSVLmxFlVO6JS9Bl7G6w2uaQ1mZ/e6a5zY9saWGzXMtJCUATsvCurNswJPMSpwjCDTQpXM1pQZz65gUZVALMI0ieaq3ibH4cBjipZjcjlEnBecX3TAV5vQbHFXcLnalOg9Q3KENIN4rp+veBd4u71T1qbAXd6p+4YD4lSO9xwiIU00V6x5jPosekesDRea3Ved3tdVLGpnU+w1V/Ag0TO1iksRb9NfQ4ikaWaaZgXnnHrviRPcmGR63hr97xb/OczG+xnlxt6zPeXQpp53R+AzEo23PeJ7s+o39tCHvd0MCDRvPr4b2Pbfevx+c/E46Wi/acYDl6dPiAhxvrA/3lm3B1LNW6lm9vef8Ftke/uZ/fHK9v4N6o4TZThJy7gw4eITPl2Iy2dqvlPvfyWvd7Zf/wWkEuJEXD4RnzJxfiJcIqU8yPefaNsvtMdPKv+7PIOLwKw3wXvSciMtAee+qUSgFGTfrBOdaF6DxPl6ngsd7ECstQNE3cC6y2OOgrAfPA5RiVsrA3hSNsBG3jYDwTYFz2rWkZZdr2qT/GqVUVQ4Vyi1EcJOzo15y/h4pRTP8vQO4pmXDMnjJw28Lihzp9g0j7zd8RKQuBNT7VJUoCL5QX38TH38lfb4C7K/wfaqMqGGTmlzHh8LISQcEU8w4Anedlg3WGJjksolFCZUB3tcSDfy4WOMtr4InW50ZkNY8KsKDIWgBV4KXoNx0Y5X9M7AJDf8oUr9qFHtcjuln3YjckYB3aVLfQy4VYGABcUOMjlRb5eRoCsARTson2s5ZIY5Z+6PB+u6cX9sPE+J55T4PEc+TYmr81yCJ4onSiNXNedczTigOUfxgTBF/JIokrlvr3xb32gCeSvU0phj5foUuLpIcjB7ITjBVTVwVdN6tKPitEPngNIcReBRYRPh7ZdXqrsTfl3xIbJMl6H7/SM8uqdbCH50oOkFiGN0ZGVKI+B2eRm90LPkRPgoLyrNOqsACCkmljLjghsTuUCU0RS0U+aHHPIwF+8m5DHqwXy5XAZY9fT01FFUfvn1F96bqAdUBw7QWa49EnWG4Rkw7YdQ7+bHlAazycVImmelQU+LMp+m2QwOp5HoO+fMeN6A29bUxynvrAY4vf/6V/b1zvr+pp2186QL+R5KYkxG6YWy+xAfjnhs280SuB5L/DDunabENE3Mk07+Sr6zwNqovjtzSVlM0eSEk9KZDXAb49CxJAdjQIQwpHD05NB8F9T4upgcmfGd/fV34/POkHTWIFG/QRDiYBUcnxUcrU27SsHr+RO8SkeKeUABh7cTxznUL5ze88MHZTB8DTR1gHj1Vrxcn3j69IWvf/pHLreb+Xd5k4aaL6Gt117I1wE8Heut//yRhXhn8dLpXnOdXSAK2tZCzjs5H15gzTx4Hvf3IbEruZD3fciBfEpcLvoaLzZ5Mk3pN4uav+fHw6RqIXRWThgF/FGYc8pFTlX+aUrWB+DIfvaQzXEAPXonv5PhHVtY86LGkLmnGHhaJr4+X0hTIk2JKh4Rz+2y8+WhjbExEc8VomvUIqN4S96RC6zOkauQiwwBQb+bgrDuyjLdirJ0lqQ+bnPUz/uugNP7upNrY6/OkvqzDE2G3BnXvTwUDIrBEcKR1/Vpfh38MXx3gEyXlJhT5GmZ1cPJptpZyFE5vEl6Qz+DelFgH1MMLElBp+fLxDJPXObJ2JtJG1O14aWRnOBaxSPsHnI5scr7PW2d2WaFhMXvJekZdJmSAWEKglXbczhl1/Upmrs1wtZtV4APiNEzLxMgpODYdvUivK8T256ZQuB93fDOcTd5ULPiCWkDHHAITTxFhLU1YlNLAmnCNGLHOIwNoNHv9cFZ08Sk1TGQovppPlpl3XYe2877ujEHmIPQvEqDxAr/wd77zh7iw/45VXnniNJfWTcT77Wft6ZxFWWu6/c51gjPE1Rx3CJEU3T7Y5l9OBW/Zxr8PT8+ABwOTBdynFf2ucuy+9f+psg1QFxOfxcYdUX/BX2a3XiOaEqv99v2fOt5fR+McW7ceeb5wjxfaCUTp4nyfmf79ivy9k59bAosnCBCVzWGuWZpjDGbPgqPeiwT/W45TMWHRNyApyoan/Z9U7bTurLtG3trlAAsE+4yE28X0m0hLYE4OSAj7NS20WTHe4090zQTQ1QASdyHxhWgTebgaGbVU8WxiXDfKjmoX67zEXwzlnsjUAmSzUZGgafHXngUx6M4Xdw+4dJCWm5MlyvT5TJ8i7vNjdQbBWj7imsbNW8kKZTqSKkizZEm0SmgXesnajtQmk6ZrALiIzSH9xe8RJqbaTSVHLouF3Rsu2pinq5XYvI8//hCmlZ++T++4dxO+XWHJuT1AU1o0wUfgxFuEnGaqd6rUkuEUs2vsBZcC3jxeDzeab2IWHMyq8/gvq80Dy3ARRrhshDqRMMRQuKy3JjnmSlN6lsmYkrlDuCeznuOdexGs0RjujidDOy9XqtmDR84T4rUH9hctxCyKCTdRP4MGjNY+IP5JM2k8VXzjK66+B2P328uPi/U7Gi7+iXt3uhlIRKmmWm5ms9FI0yzJralIHWjbisqI9OpUK1BzY3gAtP8TLy8sHz6J/bHL2aEXdnfv9EntcXrZ6ay0pZnKHfy21/J3/6Vtr9St292IE6EcDU9cNBZlArjkqYEsrCvd8qWaftKRhC5avFhaPPoqvRE7AQ+SI9ydtj0jsVZKuL7dw3Gk052yvtG2VdKXql5pdXd5HeazFQxuVbV0NTHIGKBtjT1edjKypQdLr6Ra+Ty/Eqrjnl5IE2IaUJaUf56q7Syj4keTirBCd4pOAHC8MYqm0ry8q7G7FVozVFbp/M1XCk4D5VGJXBfM+teeX1UHlvjFiuzq7il4lIdMiVvHSqxpK2J9KOHccSPRLgnvAcYGDqIGBU46vIo59ygyBc75HM9xkp31Ffpqo5ctMiqSacHdhYC6JhLLwqAja69AU5ifj8fknCsYBao9A1YkVIhq1/S9nio0V7JIDqOc6+Reyk8Bc8tep6C5xoi3gVSbEwEJgqTa0xOCEHZKBQhr5WtKLW+d1Sid+odJZrAl9J0ksQIHKaHTo7oIQXAOdbmKOK4V8fe4L0UihTqQ6UuMb79oZKfHqS1Y23MRcQkbHZ4iAw2Dd46AlbBO9zQdp8bWj54okTmZR5FfrIpeD7ohJ0eG8ZEIwNtqlGUc8tD2tDNLQc7ynuu1yeCc/zwrlM/u0Tucb+z7zs4N77f3i3n1Pl4/z1mmZm2jxq7u/Y+TYSQTownk+ClRJ8W5J2yTIAxEbHknbw92O6vbOtdmU77alMybVJbL2gd42AaSaQwutFHZ1s9UPr7GXKhzqKh3yYt6OKYGhXNU8lAP6WmWdFzMJe8mTeGEPW9BzN87F5P43n+o+xmoEmaWPVifbAharFCrtnh3KeWHq8X1AtMEFzV1+g8RuGWj58lApVqxWwIEQSC3YNiUxiH9r5Xxe58LY2thRsxAfS1pJSYp5mLTVL89PVHbs+flOlk4GitbcjhvgeeoIMW/fceE3v67fb+6LzBQcfukp51XbUTafJFlUA11u1BKUUBp6KAk7RmbLvIPCk1PaWE94FlWYbk8kMn6Q/wODw1XL+9wFEWdxZOv7+9kD570PTnn7+Pv/l6Z4v3ws4NdmdvtvVqT7fjyUPR/n3IYqxAeJ4jwTnen2fcMMJ2bK5RgmN2QYeSzIFWK29rZSuN903IBWOcqr9VERnT3EClWVNSdiOon8eaC6VUtqwsYnFhFImuv68TKBpcB9T7BExnnV/zlCyNXBSE6XJh551NTlMQZ0mJ2zQpcBXDiAnaK5ARz3zPh84fXv2h5hiYU2SK0VhUQQH0oDmwR5iCowSvU/uKR5oHCcdetLvaXB/Co+9jNB1gyAmjSRi986OJUk2ymnMgO8bk1nXfCcGz50xKgaeoYK8DpimxbTspBd4fD4J3vD5WvHe8rRubcwN8ah3W7GsFDdHZltWj6TAYyVXNmq0hW9CvV/QNhJSGn98UjeUtwr4r4PT62EzeDc1/NK7v+duxP/rK73lnj58HCKv/PxhSv7lHGccCVv/pvcAatMZ4ukXUo6tCkbGdTmfLd5vzD/IYQJJ9GgXzbwBMzdQJ/e8fn28/ZtRrzpo53ykpxu/s36+/3I18Qi9+GxOr+0o4/jstF24IL3/6MyKV+7/8K1v7hbZlxPz2RMA3Z3OorLIxUOXDsCgDm/qEO++cARQ9H1PrEhzUotNZt+3Btj3YS2avlRo8LTrcMuEvM+kykZaEj05rMyk0KYgo2BKit5iUCL7HpWYs9Ha8jtCtBwKuQmuORiVTkPbxunoRAqrS8FLG1NC9CHtzVLT2dmnBzxfitBAnbWqGwervYLJDQqKFmRYm8BOu7NqQyLp/nQ/KrHWe2EQnRfqg55LTWkdRB82ZvJ8IeFpdVNHDprG8qu1JyXnEvOAc1+crwSVuX58JYeXt/oYY6CcC07YSWhq2CCnO+v1T1jqbCt4rmITVEJx8x+xM7nlUrVV9rC8T0+XCcrtxuT5xvd6Y5wvTvFhOo1Ls7mF4rOnjY/RsjyU78gFd1o1aOyB0PGl4nlkOPjxivb5g5zUv7cDZgSWdACiOfEQ4xcrfGbv+B4Cnizrsbw+aFdMhTkxPn0iTY7o+I9UmtPmgQb1myuONWjI4pfo1CSAF2XdCikyXT8wvP3L78//C+uuF7e0X6vaN9fWvlO1OXb8xPX3WqWvXT7j8Sn77if3Xf6PmBzXf8c6T5gt+etZNEgJuUAs90zITo1NwZa36HvI2CkuJ6k4ffDeX1QvZR6V/7IYcmV/3Kxo0btTbqU+yU+BptwlPD/L2oOwPBZ9KB54aTbx+9FPH8vhgLJs+Aeux7qTUaPKNPXtuT78gFa7XN0Vn5wugIBOt0PKOlB1qHsBTHMCTbpradigPpKy0vKpfSRaqeGrzNtWgIU6DWSFQxfO+VR6bAk/3rbGHykUK8VKJU2NKzvwStPio3RuhGfPG901ypNEfbU37NdBOknMaOGPToBFjswNKjcmD9zaeV0G6XJQaXqomu6pX1r9HPCH6gRA716npYmPK0URbDgDLcXRsFbdz0ISK+X/VhuQdeTwoj5X1fudRG4/SWEvh193xLUUue+RlSjxPiT8tqn2+eJg8TLKzuMDsKrNrqicPEclCboX7486ed6XOek+aJ5bg8VnHtuasReFucoXaGjh4WrSTmybAOx4SKDjeqmOv8G3N5KpGocPk8Q/0GEVv1TXRJbMlZzqDCZz5GHE6GI8Cig8FnR1yMRJNGgcat2MHnrzXg9wOiTSAJ2/rcQc0yWi1Kv2/OR23irF5fOD2/KxeT7VyWZYPRZMIyipq9bRtzEfgdLj0M6UDWsEH7eJ0wClGUprxg/FkJuPBpjCZ34YCTwlE2NYHTQplX9nXO4/3b+yPd7bHm1KVcx7dxfMu14cdgBiN2G6Ss6LIOe0CuvEsDIxXdihoTBim4jGOCVAxdmbBGAtAZ30oCBNMRqmgm3rSxCE9ZEy26/TqDkT1iuAAdD54djUdvaxS8zoYQn0SVj9fnNOOk4B2zsBoz/pnvE29dM0AO0doVeNPVOZLKhGHI9aCq6eJctY1dnYxe3LembmNDvrra5m6kf2nL7x8+coPf/4n5uXCtKiXSwebuqn+AJ7kOzNLe0/e5JdhgHWafmliZOysqu9v2zc90x4KMJ3Xc6mVt9dX9n0z4Cmbib7jcr0SY2RZFkKMTNNsTKdpsAn/aPFLJ8EefmX90dd2B3TtSDqB4wdDF3oR1z0gPv6ODlB1phMcTJBerH9IbkWldqWpnK0aUIXrXkN6H16WwNOs/iOX4IafzruHvUSeU2PxgpOEa5Wf3zOPveJD5bELe1XG6T0XfFFPJhDmFIhBWTxT8Opv0hrrltlLYc06MS/aFLsB2I1Gor7bPvFSp+IdHnbK+hHWvR7Ak13LgMoL5xS5zRPLlHhaJpPUeeuE2/CT0gYYd4CHfeiBDgaZU2CZIksKzJOynxabkBrNq65WIUdPqZ45empU0MlziqZ2fzoLsVnR45ABiniUXdZfv+8FqSioHw1gclnZAa0J67rjUOZTZxhNU2KeI7Wor8z8SNwfKykE3h4rwTu+3R84hxqQOzfYrYMB66Ch0uaKshdibZRc8NUTWl+PxgJBhrQ6xcA8JRYPlwh539k3ZZh/e1/tPWse1MIBNvXV/mGfyLG2QcaZ7eTDl/+bYUWBPWXin39eQ03UX3chV7VamIICT/nULxqzNNzpz3+wx/csp+//DKdz/sSUggN48iaX75NY1dz4/EsYZ9NZ/dABROecrQW9SSIfzZrPv29arkzLhVp24jIj+05eHwY8Zaja8A0KIVnTSmuVDjh10Nk5h6uaW6t7ESa7VQmXC4EWvJ2BygB+rA8e6501b2w1U6JHpkC6LoTrQroq+BSSxwcxsDXTJCMUYtT4kqIaaavtSDMgWH04nPcEr+bkpM4Og9qKThgHaM5qHm38B5tw52xoVq2VvTn25qkuIWEipAthuREXA58sz/TGsqRLC8NES0KNC+I3Wrvjq+C2QvWC4Cm5AZ5UxSwSnNoLoI3/Ss+ZHCHM4CO1LLaO3umsI+c0Tjhr1sXkuH56Ypoqzz++EUJSr6e9sW0rrTaVCDYdTIb3mid7rwbutdDQ2NY8NK8TZUU83mKHiJIumsXJ2greJ6bLwny7cnl+5np74nZ70el186z5efADfxh4w7HEdd/0WrV/DUv77exv32EXAzgiGHBlgc53vEN/phNtKmPN5e8ffV13/OPIHn7/43cDT//+8zfKdufb6x3KzvzYiGniyQ7qaV7sVWkCmpYbrewqP4iFJUyjA9TySrn/ouMUy07IO1J3BAWzJEctFmqj5Z18f8Pxb9THK+XtZ/L2zv54BdTAu6zv7G+/gEt4n3Al49M2EOmaNwXLHt/w+W4aV4G6U5cnpuszYV4Ql4aWUm9cOwKU3d6Dxj76aKgBmtDaDqI+Va2qp1PdleVU8wZ1g75gq8oKaoU9C1UMRXaeKVnHPagnRq2NXIXHmsnFEeMD5xPvr6+05kjTX0nLnS0XvGs42ajbN/Z1Q0ohOBR08kL0jckXvbboiNlWCrUKRQK5JbJALp5cAznr5CY9+Cu5qWb9vla2vXLfKnuuxLkRYhsyQb1avQOqgcKNL/ZVdWwe+dvTQzeBHUwjwfI9IdArP0UGBT54T54qpR5wsEoC1JTcOWcJpFgyfySkvTg7/BGM6dQTCPudquvVpCFXoZYKpRDzjtt32HemVrl5R3Se5L0m2whOGnvJvIomsrUJj9J4ip5L9DyKaCesiU4/M1mBC9qBq1ujVSi5IV54z5ndV8gFqnZnm70uTaqaIdKBGB2TUy33owpZmn42E0QFFZwCoPX3a3X/Hh553w3AVWB4TKc0U+ZRoHtjPg5fM3dKSgxsUAqNFhLB6b2ZpiGfUJBG/fB6YPZOpR6+G0yLAc5dGmpAc+8iSxPE6wHWge/5cuWpNX74092Ao0iKv/L+/sa278Pwuo+TPwp/fe0dVO1ZscOdum3qeaRMINOyBwVdJvP5mWIce7GZf13JO9v9jf2hnk5lX9W7rtO4O3ArR6dyYMvOiorTtEjHATpFk8aMItAMFH1zg8LuTSLWX6u3Dj7OGgb9F/bA470BS93fSiXXIerPcAN08sPXqo9U75PthAO47GtEpI8dLjjUBLozM/rU0uP9/Uantyfk3tu9U5aG+KYyoKrdNgWslBUnQCjWZ63+VEz3t3wAZL0jHEzKuSwLl+uVTy+fuD698PnrD1xuzyyXiw0qMKDVgCZpbTQ/ap/gZ+b7Idq0LpMFxaQMsv6+1AOs2bBIA+hExsTZbdtMbqfXazMG1Pv7G9UAqRSTJmQhcLko8BTTQdf/0JE9Ma7+UA97S/JdYBYneEGvtRyeW+0EOmkjxX7I6dsFTt9j01hPAJQbzzq2EO5g+nUQvpoUrNU+vfP0fPs5tykiNx1oMafIv72u/LruBCdUJ7xMC3N0XC6VvTTSrxtva+Hn912n+IlQRAZTKKXAFJXt5D3suXfe9fu770uPyX1FHHFJX1c0id1k0/J80DM/VwWP9lIp9Wg6dG+nOUWVx006bW8xNqvzynisHHlFT3n8+bNTv6fU2U0pkpIOI/CdKdvrAj11CO4AjaYUTmwQGEw3OCwERu6q/6ADVtpR0Nj9dl7bFVPSa7CYQX8HnUutbHvm2+sbrVU+vVy51JnLZcalqJ+d4+m64Bw8vy/69+WB9577ppK73fLqHvJ73tdkkFO1YVYa3kMQ80Y06WNIyTydEnMKPM+RxQtPQXhrhZ8fxwTZbpDbvBZUHZTt66DZuRA8TJYH+oZO9LK1rST4c9U3TtMBIo7t6Q5sqk8wFwzsc/reigivGUJVW6AsGGD7R4PK//bxfdzqnkvNmqMjU/n+bLSHP3TFHNH+bKRvf/ruYn78Wb0YF2ueoDmR/c4PZ+j4ATAtV24vwv7nf8L5wCP+K3v8Fd4UhCq1at7lm4JMXnMXVeb3GpERc7zzpuTQnKLZ82trVGmsm05s3bYH275RpNEcMEX8EomXmXSdmS4TaY7WGzV5uiihwDm1dwjG7JYmbGWnljoGf3gDfYPXHJhorEzxqpgxlk+xte69H4yeJtAKNPFUiVQXaDFAXAhhIV61rk6zyetCMP889dDrwbB5HeBCmpH5QikPnDS2XnNbnRqsSTxN+n6r9xQcVdrRZHHKCndEWrpSK+T8qrV8LVSqgtouUEum+ki4BNziefryjHeBb8+v5EemPSqlKQAIUMtiw2YSISTSdKG1QrV7hw9I8FQnGq2bDhTSszFTpUB0TPOF5dMzL3/+kevLC88vn5jnhXme1WYj9GnRRojo6qSR2nWLhlNNfdoHxx8Mq/iwlTQw9dyw7zpxh2eqpgndK+qwCvmtvdFJGgfjvv+O//7jdwNP//LXX2n7g8ev71BWLhTmeWJaEmlamC439chIMy5E4nwzwGcjtEa8AKKFbTYj2oan7DulbApSiSKLbYtGHGpUdjXm2u6jGJCueY8RHxPl8cZu6HfwgZA3mB5qjl0bNW/UnJHtgc8b+aEGpa3s+O1uulXtduO6/wojSJ2vd0/IRiAxgASp5l1VqGUfk/6KsZ1qXnUSX92MCWUTqpqOxtXxlRXvhZiiMSY8tEbdMnsW3h+ZGATv7kDg7ddvlFxxLpKWC49txzshuqwT/9YV3zLBqdQqukbylckVqmtUm1w3gKca2Jtja4GtOtbds++wb2rmudfG3nRU5roVtr1SsnYGJ2M61aL+D8CHDp/zTj3I3Lh6dj0NFbak5MM50ZO2fpCLo1P/Ah7vBJwnim4SNRONOvGg+2SJUKpOwQPYshY+0Wj10Qqz4D92DrvakfFnXQfVgKdHEVqxjmbOTPtGzhtt35hbQ4JjxrOIY2+NXewalspWPELmXhu/7pWXOfGU4gAZ9gE8CS33YIEBS0LxjeocryETcDrSvTUMV6H7ugsKPFUHKXlmb8BT0SmED/OlImHJvE4YzFZQ/FEeSptVs8Y+lRJs/3qvsjLHCXCyj1MyNJ7fR5A6ZdVEr+Op1TD2PCr+o/66++y0U5HWR373n+2N8qqFuho69n0xX67Eaaa1xnK5KvvvVBx0sKeDWV786A5qd6R3YpW94i1BGoCNycxUdqbsoRAi0zyrrGTSrpkOShAzYdzY7m9sjzf29Z2ybwY8Ff52hHZHnBjJoyDU1jsmB0jdp/w5p2BybVoRiNjUK6f+Jd4r22mAT8ZUcga66rnbE1bABfVqsoQsRp2wEk1q1yfX9XXgDdCKNopYi243rnH3g9I4Xs0zSaypcCR4p7d9AJS9nhmJtqBtMk1YxakBszgU+KpOJ9yByR1laPXV/+ls7m2AepeMWsLuDSC6XC48PT3z+euPPL185suf/kxKM/Oy6Peq8ZQ2J8wXQ+n/xUzAs14br0M6gk/Mk4JDmmT2yV7KKqw2/VFEzcRbrerFUzLburLtap5aa+V+f6fkzL6utNa4LBdSijw9PTFN0/By6hutlDKQFYeMNfBHfIj0XXQAjAjmhWRdS+FjztLPLtxgcDj7egeQmrgBPnVgpH/zx+P62MMKWlkHvdSDvd30/O8NHdA/P82RS1KpxadrHWessqXgdrvw6ZKOznp8VdCpvpHXXb2damOKGtfmFJlTIAVNu1VeV9iKTorVKb+Hr5nTBGI0Hbrcfor6nDmGIXktzaY11TYke7UdsTx6z5Iilylym9Tj6ZI0lW62Fsc17CDwAPs7GKbNiCkFm153sDa9GaZ/AJ+cDIncFIPtJ31N47rL2W/ttFZOBUJ1nSGpgPgAx5yDFImhkXMieEcplVIxGWzll29v5JL58vmJJo3rbSEGz/WyEILn6abekC83tbx4uSx45/iWVpxzxkhvHQobco5D8qbFzN6UrRSaKGPDy2BoxhhZponb5PmyRC6+8RwaLW/8ZPLd2pssGOPJ8rZw3jZO3330eo77KgSj9bWq7AU/cr8z1IHdR70nPXQ7Y4ro8Bn3Ye07p/9WBL7tZn9geVo5vaaxs/84qdc4S75nMH3wdhK0oUxvlsCIM9KvoZ51nc3bi+1TVmHXzuqI8bOOs+Ds8yTtcOjydEsROV7nCQybLle1mqmFeLtq/SmVumdk33XyatVJ0NJzqsGCd8easfetfm9eG35OwZ/m0IlztSjLab3zMACqSKM6cHPCLYl4NeDpOpOWZAG7UVuhtYJQcK4N+wGdZqfAfJ/mqSB6n/zrcMHjotnnOGWfthoNTWjqC+zASUNaoTRHrpqHVYkQJyTO+OmCny5M1xfm2zNpuRCnaYDGmnc6egNDGWsJ0oJIpeaHSuqrqi/Ezpbgs05ynSe1MwiO6g5z8WZjBENIBDxSr/q8Mmmzq2SQNgaT5Jz1uUnv19MPL+pv+/IzOG/T7TJ5X0GEKe/ARPILOG16tFYoJq12COI9xSnBoNastUbRe1KkqLLgeeH29YUv//gnLrcnnl8+E2NS5naXO1pDWERzwj6opZ8hY8hNbyT3JS7OcHJ3AsLl417jqMvF9azBZNnWFOi2ErrnHDaq82/Apy7pq72B/z8An/9u4Ol///efcTWTmEkxcIsFFz37465eQq2ofGFe8FHROyeFEI1BkXcrfDyIOsW3Vtjvv+KccE8RKTu+vBNkJ5kUyqEulqXqaPjDx0Kn0nkRmryS941t3YjffkX8AmE2ZlNVkKdUBYRqYd92SqnwyzdcuvJ527l9+oGnzz8wX664oBry5q0LWOugIjMCob42xZ2yTYHb1WA9byqx2x6UbN5O+4NWlHlVLTnKRcgZHnujNkcVjw4NVBq5H7RdPUSd3fycM+v64OdffmZ+rOTSSPPC8liJ3unPkJVYN6LLOtK1NmUpbCvr/Y1adPLa/X7n/bGzPgr3VdiysO7CmmHNjX1r5F3p9LlWOzCFUoCmQzG9h+QjyUeC84SxBI/OUC80Rzb1YZFa1+F06sr5BDYk1Tk9JMRQZRFHcJpoRdHJT0uKBFfJdo2r+fpspQNO1UzJFXhKQUZBqOdd14A7G1mtwNpWNYnZm8r18l6RkmFbcXtG9g1fCrFX2g4SMHlH8Z7chM3pRxYdv1tK4b0pE+c9hkFFf9TCXqtqmMeVMq8EOYqB3YC5XgjLAMc7UKJnUmkOqY5q6lKdVqE/0xuAQoDqdaxq7wz9UR4heEvSJw4Tyz42W039tEi34gFGwdZBEueA4HWMvXVBezMCK7Jb6wG6m+8dTziMnWXs5xj19yn92A8acvedOkuoekGRlis3HF/+tBKnCXEqh3t7f1P2yH5I7w46ub3e1sxDSgEw37qciwHqK/Ore0wdk4NCCAqKmmfddn9j7aDT432YjGscHBDuByB5XEe9SKNIO6qOntT3gtGkL/UojI9C7pDa9Y/eaTw4G1pIDhDxO1BRDRWtGGoy5L8a391gMIQuuQvd3yoi0gZo1/d7L+Y6CFVbH9nebFKTJZ5BjZe9czqRxfb9wYjrCYKyt7wZpvoQCAY4qR9YoJsHN0En6pwTbutShhiY55mn243b7YkvX79ye3rm09cfWS5Xkk007BWS1M74FevaHdP7+uvUAR3qtdTNMFNMmliCPb8N4KkYE243dt62ruSceTwe7PvG+/1OLjuP+4NSC8nAxMv1wjzNXG83UpqYl5mzyWXJmqC2kg3gZST9f5THOApHMnn+h7/54whdx9Jyx4QwOc6UXqK1D89ldD7d+SeeAK2xbUWbc7VP/G1VKcZNAVOxfTb2qhderol5Dmz1ynWJ/NvrxutauO9CaYWnOZF84Ha5gk/8cs/KWM6VijNprcqWp+BxJkntsikMOgvDq80dL3aALSqJ8g6maNPmoq6ZYu+zVjH2tn57lwBH36fQOabguSTPFD2TN4mddGmp5RS9ELDr6jGPJa9MpzlFlYxNiWlSAOrwm/JHgeBsjHmf6GYglBaQDvFagI3iontzGOO7iUnvUfA3FE+N1V6PMSqdAgXJ4lMyqfi+Z2oVHuuKSOOXX98otfJ0uzJNWlDOKfF0u+K95+lyBxFuy4wA10mLxb1Waj2GdQwpqHQg4pgWqHHXptYlnVh6WWYuKfLpMvMye/58TSQqsyjrfF93gvPaRDWmljZqOZ03WNNAY/Zknll2WvG+N9bcWIuqDKou56N5cjqzPoBLtmGsdTT+8ThP9Am9KVjtoz/Jyr/vNvjf/6Mzxv8GADo13IARlAYT4/T83wKQ+j0cuU0/u06A0dnPTWBI4jtg2wNeB6rOhfW5wNZ76JkvT+A85R9W4nzh7iN7+hle78i6m/KiElvBVfDFQWjazLK1PV6r03xEnKc5fQ3bvqnE7vHOY72z7TtbLVQPLQTckvCXiXiZSJeJOClQcVbonJuq0fxjazVgftvYdq19HeZHZ3mOOPVm8j4S/IxvDdcSTpoOaUFwruFaxTXzAKo9y/K4OBGmBT9dCfOFtChY1xtRPZZ9vK8abzwBHyeaVCRdaK2RM0jJuNZoNKJ5auVsgyqc19fcb1BfE5bfez8hNLyfEakIq9rR1Gr5yE4pkdoKwXtuL1eCC9y+PuNDYP/2oBUhF/VRLTmDc6TWIPRmcsD7RJ94D+qBjCidUZniGRcc8RqZn288/fiF26dP3J6emeYLKRobrINDlodqXt7XScOJH7GkVxW9lj6AV+G3dLofmUqHP2MPPMce9XgvONTovlrtUMtRh3wAnj50t+zF/U7U/HcDT//lX38mefjxsnANgl8UVd3XO3V3UAs+BFLdCfMFrlccjRhNatS2ATw5ydohaJn9rv5CoakuPEU3gKe+mGqtSo0zqr+LCR8nfNSEXrbVfFd+BZ+oEqjEATzU7lNkyUcuOimuhSviZ52EuW1Kdw6edNGNUrHCHS3amnVoeqdDgSdBmjKdqAo81bJR8kbeH4Px1PJKK8oIqKVSiwJPe4F1q5Tmji57VB2r98YeOk5n7ZyUzPqAX376iTRNbOtGmhcu95UYA8sSmHxhCStzLEyT0axLQdxGda/kXNi2wvv7nff7zuNReF+bgk67sGbhkSHvjWLAU6ntSFKbg+ZGB3/ykclHog+j+LAj5HDcd0fQHSTBftDanhlHgXykIHfwxfkDWBEEmh0YQTfNPCldfN1VppGLjnLfsxpchlCozYpa72lJTeaS+a8MrEu0KNyLyvTuuxp3b9UhtdL2Hb9vhMddpxjuG06EiNGrvb7e7l9QvWOtwgPhUQWckEtmlcI956PQdYyOZAcb+hXoiVOnu/YioFPp+wHd6f3RO+vgwvB5Rtiz7oUpBXyAKThccpToaajE648EPHmjswXzBehafG9AhO+AgnT6dz0OMhgMiuC6zESLnT6S19n1bwZk1H7/BqjRGKO6XR/X7Ugx2nSkwxBZPXQEaqNKl2uZP5H3TGbY2JpwuVypORNcj0tmbll0comcPIbEDKHVJ0jXsBjwBAeV+vyhxU8HdqIV+oW8rzzeX9VQ/P5qALvGNml9Wso4GvWzs45/74D268b5IMXAEi2qvJn1OqA0pR47N7gDH4CnwzuAA9uzfaDX1qO6SD9+c5db9nNhvGbnRmeuA0XKRND7VGuPJWF4TXD6eeo3U4aZZAe3euwL3iPG6Oohx6HAEh0Mc6KBBD+AJ2U4dcBSDgDLtBz2locEEA7p5zzPPD8/8/zyiR9+/DPXpydevvxIjMkmGB7NgS6HO3s8VWMq4dww8U4pMc0z8zIzTQo8WTlppqNFZXSlGMO3WtMn81hXS7If7PvK6+uvbNvK46FMp08vn4yddeVyuRrwlEhpwjlnkwQrm4jJPjPOqYl/n9z3R3v0nttv/2N/zqkB8V1eeKw2WysDcDrA6VMtbEnpOGGOHyaotIM+2bOzCBR8cqKeG00Y4E8Kuu5fJjMmDZ7Pt5liVgP3vfG2NWKYCXPidvEs08Rfvj3IpfL62HE0k1pF+1Agp7N9atMSUtdoGOegvgVl2mhhosCTSuz8kPYKNhkXBWk6qwgYQHgMOj1vCuq1dElB/fuCN2ZUHbkP7gSC2r3r5t7JmEuLMabmlJhT0nHjxsIJOIv7TT3tnHpDBWfAk/cQoHm956HnDDQF613PqXoe7ZAGpVQ8npaaeS8dRaEDA+EUGANhQ3OSdzPt/vXbK7UWvn5+AeB2nQkh8fR0UebTdUEQnpYZQbjOEzi456zraEgzLPL1usVAtRijNYT8YJzOU+K2LDzPkT8/zXxZAv98S/hWcTXjmzZSPY5svpqP7NBWmvnLGRinA24UsE/Rc50079d1UIihwVagT5ICOuupr6d+dvWv+VNB+LHM62effmM3FC/tyGPPz/2dddvf3eN7+dzfSNrs0Y+uLq3ra+TUyjYQsSkA4mTYZJyvn+MAnjrQ1UwS33++nNbe94X1+e89v5ivT6T5AsD08kLNO4VmuVSl7ma23dQuX9+DskK888jIUQx0MmsHQSVj276ybSv3xzuP7cGaN/ZWKcEh0eOXiXCZSNeJuCTiFAnJH6BTj792TUKIOPHUosD9uiqwVUoxsLkbnDvEB5xPOBIhLjalr9pk4IqTikOHUbmqtV+rHkHBszAthPlCnK/E5cK0XEnTQpzS8HZyrjM5j7XgnYfg8GnCOUGmhWq/p5mXVG2NlDUnz6XopPOg7DI4gMZx4IkCTwqWTThXEFHBci06AKbkTAnKzo8hcvv8TEqJ5x+eccCv6Wdaqwo8AbXsVkdUEF0P4rz6TbVKO02il1ZVYdWU7JIuE9PtxvL5yud/+oHL5Znb04vmXikZ88x/t+46YK13SdVAXWHVrLk7ItLp7Z+bvaf6cfysHs/sa3LU5N68jl1Qppuz91MpH17b+PYTcMvH2/rfffxu4Omf//l/JgXPj88LS3T86SL4tpO//StSdvL6hss7Zb+rEVfLqNeGTnbb7q+aIFTrhpbNLqDqg96ljEKj1ULZ92HwWJtOFqnSKBVkbzSXwVWcyyPpqLKqb1RzlKqUaU2g+UBBHkwYl8FF3up/4fmnV+6Pjc9fvvLlz//A5faMS5NqN0Xv3GGUaoUpBZFKLQ9bZCajM0+nllf7UClhT95LQxOuAlturFlf2+WiSU0MEIP6MrUeRDpQ0mSg1rU2UpqoVUjzRmkQUyBviSlWSsqUJPjWSLJR3DvNV1qo7HvhsWbur7/w7Zc7j/vK2/vOlhuPXQ2qt9wRYtNwiRC9JziliCcfmEMk+cDn5xu325WnKTHHoIu4F39DtnTaJP1vDoYo/pQYd8lMf/JY1Fas0bsd3thJ0nCihn0SVI7SS8nWhLIXgndDZldFWShzUaAqdUmKGDXbOoWb+UvsFTMjUGldWFdc2SGrj5kmI8cBO4a6OiFIN1TXQB+dMLXOfFL4Uj8OFsjozY5LdlSpbvy9Jz8DlhuvwYEa8AlspeEMRe3Gps475snbRIyemLaxX+Q3kPO/18c8X45709ejO9bj8MewgltqG8kBWJLZg7Z3RLx2Twx4Vu8oGfKuZuBVKVp057xZ5zYarXbiMKhmvBbnrFiQ9uEAAg3urh3+VHFKzHLj5ctX6xB7Hss7b+8T+76zPlZyOSS9HZwsRSf4aaHuFcivQUGoDkSJHIeerWelK1fyvrKvD/bHO/vDfJ3MQ6+dWFr6fgzn4dgb3h1Aqb0xuwf9eZ1hdkjSzp3+/hxxvSg7/Jh6t7SDSr7fax/wLozkp4OH1a6FNKih6nTIKDoSPfTrf0gZfQcsnQFexvoZXk9W7R/T36oV45YoSJdo9il1GiVqbedLAX4Q8xn7/nQ/Okh4MJ8izjVLVhRYVXAoMc0Tz0/PPD098eOf/qxMpy8/kOaZlKbBwpOmHn6DnWRg03g4ldXFlEbClKJOlGtVp8CUkseaLUWBoZKL+ZmV4YNVsnon7PtOzruOOm5iPjMJEUhpUtb0CdTr0ve+Sjo7UFpj31ZAf8YfDXg6e3ed0mzk9Gd3+higUweWzl//8JM/nhfj94EVM2oBUM/5k51PtSm7Z82N+6YTV2szrxM5DTvw+nw9o3tMcDzNiSkm/tMPwvMy85e3jfetsOVivkoHazB4mKODpsyiaGeYd97AXcZkYG+ToYI/zO3HuxVGE6wDSMm8nRyObgpeazMcWnMu6H54DMBnCo4paMMqeTekKN5h1gb97Ph4nb1zpBCYUhhyvXnujKfElOKYrOdx5rcGjqJATLNc0Dkk9NxKf0dv1sWg8mTvINeizO0+Ghs954uz6+ugtTCaqd45phCUDaY6Rra9qKylNfYsvL3fERHe7w8AlnnSHColWm0sy0ypjcs8UVrjMiVtdJlPYOkNEdHXEywv6ZYX0QrVZBLE22XheZn586cnPi2Bf7glrtHxnBxSoeXG0zLxw9NlMNK2XHUSYlOJcK46OTN3LzKBZr6Y2bcBJL4siUtSL617qLzvla3I8BHtZdYAVukgx7FX5XTnT0nuKXczltrp+49998d6tH6GWBz/YFtwqlSPPKOd/m1kughwDlIj18Xi43dSvpE/Dda4sbut060ekN/lz7YGOyPqLA8ckkDnmC9PhDjR/qf/hcvzJx5P/5X87VfqT7/Q7isl29lfdoIBGwo8RarFhd5MorkB3D8e72zbg3V7sO0ruzQKAnPCzYl0m0lPM9N1Yr6qv1NMQetsOQYKOBuYFJx6QepU2Mz6UP/EWgQl95+8TQmQJjyJ4NSzNIgQEKJreKmEZpPcSqaFSgoVcYHmInGaibNOsIvTwjQv6g8aIyGGoS4Y26IDcHaoqE1OwqcZb8Ox8MaorYWCerDV0iihUaPm3weK0j9U8uh9wJGIYQEqUpLm5rVSvfqTlhDY9wcOx5Ru+OS4fb4i0pifZ3a/k3/dkCKs64MmQrosuGhMJyc0qgGaVXPFXuOXHR8c8Slxebnx5R//xPX5hdvtE9N0UUsLm7iq53SPh/aexLycuuTOgsVY9ePT93XaCWyyWOR6je06YIQN9ZH+q/S5dgk7OOi8TlMN1iTV/XCKUiPW9b0pv/F6fvvxu4Gnf/qnfyaFyA9fvjBPga+Lg3znzTv2+ze211+RukJ94INH6sMYPJ6ad9b3V+2Yl070Prq7tezs66vJAqIG9eZMjqZMk2zjR0tzFFEGjgIEmiDVJuwmX9uKAidd260mtgobKbrcqWYrDse3R+W2/ITkzPrrz8QAXjLx8qTT8XwanTut6NUKsdUNkUItq0rsyqYmZnml5l0/l5VWdvvo/i5ixmfCnpWBgvM8BTV4TgGiFzxNOzPuCIqtqT8GZB1jG/WwT/NGbZBSIC8TUxTq3KiTI+LIbSfLg0Jml411K7w/dh5vr7x+u3M/AU9rVn+DvYgCTq0RHUSnHaIpep6mxDVN3KaZJSWen25cbhfmeSKFQHUVs/ikS2z6Gezs0D2H/a417au4n0ldGnU+sLSvqcG1J9deuf2EoGN7YwhaqGBro+hUg9LaAJ5iUAP17inTf1YVoVQ1g9wVU6DhCK0xtYrfd8L6QGqBXbsb/f39Furbv+a9I+BJTpi9kMWRxeR7ot5OuXdorFr4kMTYDxt/+1iPfACe+j8LjlIEoaoMxTsuUyBGzzwFXITsKoJQikm6/mjA07LQJVx6gcybxwJ+LkVNDJsMkMF5T+htB/TbvN3gLvc8zPWq0WrruBnFJGn7vrE+7sSkgNO8iHaAnMqCjo6EGyNFNF5957Ml/ZDQJCqmCe8Dz58+k5J2KJZJabvrqp5WbHZYnCR7tRR9rXnHea8syBCtWGwH5Nk74Pah76+Qt5V9e7Cv7+brtCrbyUynWweuejLnT51iLOEG1eTLOGP7RTh+5wl8On/+sMFOksCzqbTuV4ssvpvFH95NCAq0SLYJdIIPleR0LHJICS+R3lmSVmlNE1IP4/eFoNPw3Pl3Y4yhIbOrBiR2WaPJfFF2Dijw1EErXQo2QcG5DzHgYGJ5vPjBnOpMvibdh+ZgOV2vVz59/szLyyd++PM/cLk+8fL5C91Ivt+AztTKWddtrcpS6slPSBMxTjp5ZbmYf0QYDL9ay4cusRpNnz7s76VoAbjnbMCTej1hQOEUJ3BaxKpJ/3edwCY6hcX1+K97Nu+bFi3CHxB44sMRcAagDuDpBEH1JPaUl/fhdyol7/Ds8eM+FsB6/nTQqedYHZDqRU5B2ErlvitYVKvGFmeDOegZl/cwJDGaxD4tEZwCwl9vFe++8Rcn/PRelF1sPmkKPAmzMeBTUL9KnRTlR5OoiTZvvMnGuqF4Z6Me1w1junR/PpXKVltbxSR2nfAbfDcK1pHowasheQpeZVrBfIKcNomCc9qc6CB5j2V2j5T95ZmDTrO7GONpmSLRgJYO0Hvp3ytU1FMtmEVAsAOpg+sjNwVi1GJWpOGzDR3pzRVRAMnbGPRgsV18l3xDih7fHFPs5v4eirDvBWnwfn8gItzvD2uGNvOPi4jIAJ6WeSLXxpISTdRUHgehHJ5bYhNjOyCvNhPK+p+niWWaeLle+Hpb+J+/PvFp9vzjLRJoJKnUAhmhzQ25LcwxcEmRrVTWXHjsmce+87ZtvK/QxKZ1NWVA5dpIpeEXxxw0t9VYq55aOiFQwZNBMuAMwh7L6/u/n/fseQ/3XKJ/qWe+PV/7Iz26vPP7fOI/itHN2OEiZktwukJdEnQU3se1OvxrDjBDzER/sJpHlfGRudHlZv3hrKHhbW1/kBg5z3S5MV1uhBjJP/6JX+bE/ee/soqoV9PrA2pBskpZm0nQJWjzqvs32i8jW5Pm8XgzU/GVPW/k1qgemBJ+MeDppqDTdElMc8RHf8Rka8z0PEE9wrXJmPfMum7HgB2nNRROrQRwCqY4l4gdeHIqj54ceCn4tuv7KgEpUIMgPiI+EtNk0jplJY/GlpmKn1Uv/X33o4rm8D7ivQ0XkwYt60AAU6xUxOqyRijqqSXnmZ7Sq3tQhmFAvBDCjFBpNZm/V6YWUa/SEti3Fe8C4hqhA08I8/NMa5XHz5ojbttDv75f8RKJQY+05qwZbH6txQgmuaykmFhuV5bPV7784w8syxO32zMhTEQfzVoBBQ5bB637urS6v/sfi+AlmC9Tv4aAHNeA07oeMaU36tzHGDQWf/+DnL+g8U9ZgX4AT7UenrRH3n4M6vgfiVy/G3j6f/7f/x8E73WqTAhcJ4+UjRQT29svOgHk/o3Xn/53Wil8234dxVQzjX4TlfzoRtENXQ15bs0WoqtW/DsdIVvV26OaGV9ufapYD/7dB0klRaUJrXmj0x4HvgcOey4tTKJTZkrMGeSd13//N3jcWWIgv/7C7csXQzh7cdHNtizhFTVE12l2TcGlVnXCU94pm/k7lUwrVWVbWc3E16xytr1oOIzBc5kjlzko28kDTTjcFnpRJSOY46wLVQrN7XB/JwTPtkfm5GjFUYsnukjIELNjq457dqxb4e2RWR8P3t8erNvGY9UJdVs3G2/q+OMRG+ur3bAlRp6mmedl4tNy4TrP3G4X5uuCnxLEwCYKdnTQqCddHw6RvoDHcdtTRXvP7mM3op8N/Q7qnv1OBkBP8Pr36MYs5luSqx5se2k6nWaKRrHuFq32OlxgXP1WiWXH14LPO64UWs64VumH2UjarV48H2R9Xwe0EPcCEcckZrBqY6a35thFWJuwN8zjyX34uYzriF25UxFhn6r0jpzCCF2itMwqCbhekk5M9I3ahPe9UKWRpRsu/rGSn2712mw99WA8Ggl2bYPptqNN6uwyKj0jj0zT9yDu3YhhcJqo5RzSKvn0Cno7oRffZ0wJ59Qfz3yUjBZg69EAGukUXvXIKVn96vL2oOZd92gMXJeFFAKOxjZNvHrPviu9uku+WpOhWa95x4cwQIZWskpDS6YbZSNCtil26/2N7f6m8rp9VabT+NnDqnAATipRONLpfiDaVRkAdPdoOTUWR8GmIF0HnrAi1g2QxXdTdPrN7L/kYEGE0GO4Fj0Kjqgs0NeG80XvmwhpXoDeLdUOlnOOVsN4gc458zkyKvmQS8rhK2jdL/WVOKR8wSsA2j2+slP/ggNolP7yT8l1T3yxrqwfzKkYI62JdvpCYF5m5nnh5dMnLtcbX75+5Xp74unlC2maNLYJJ3BIQYNcdJBHKQami177aEBWmtTc1ztNyLN5LOn0ud5R/titVklco5aemNkoZ9SjY5qSmTWnD5lRiEn3H4C0sRY015FD/te3loHK6mfzsfv99/44rqazs6SfiUdpNs5Q6eee/M1m68XtWFyuO3SMOgCR3uTT3GsrmNwcqpnSBKfM4uQcyXxBBE8x9q5znZVzMBKDSWf7dEj11Ys8XyPzrGvp5Tox//zg2z3z1/fKfYfqPNVMVyfXQSeV0LfWWPcy/DJLM9DRKRBET9z7fjqdzSohNlAdzRvVz1HPRETjTzA2VDBQRpkxylSa4uHNMSal2n2I3o8YBr2wVUApGeg0R/28TInLPB0MSjtzpGrhPNhA4yyy92E/PYRDJu28IzU/JB/e6WAVEb0+euZpkVqbmoc3iRxSMmdgmzAljWlTUuZhta7+thec23h9uwPw2SR3PihjSSf0KSNySkVN02tVybJ48089TG97U0gtJgKXZWaeEp9uF54vE//05Ymvt4X/9MMTl+h4jqj3TKvkXNiDTmUFR5oSy5zIpZJL4bFl7lvkdY28TpHXrfC+ZVabflgavG2qtsil2X2NXGIgXvWaL7Hyvhf2Kv1EHk3tvneOFMz2qJ1TrtP2T0/6ePaf9uixVf8wj+8Bpg8A0W98XVnA/XyHD6MOji7dIVmjY1GnmDjOUhlA1SHrd6Nm6Ow0ac3y5BMgZoBsB6H02BcDOPS5aZrxPvD0wz+QlhuhefanZ7Z/+3fq25227ioVM5lvqyqB3WvR/MhHBB0OVGvh/f6mjcp9Za+FZhI7dzVvp2tS2dYlMS1pMIgOP7qem2jjqjVHrY1t29m2nbwXpNdyo1nWmZmaGwUfNKdxXo3JPczB4VrGFa82IyHSggLwLiRcVHZytPwgWtOoD2cZUzqxfdEDseu5t5ivZ1DgyQkiOxLA1QLeqUm3iHqjNWts0XQip8NAGgE0xw0+gkRiXHBOaFXlg9I2mhPyrt5N6+Od1oRpueKJ+Bmma+D2dcH5xuOXNyQLW17Va+o+aROZiwJ7XmN/aVmBLSph8jx9emF5uvDlTz9we37hevlMjDOIV4b9mBz+cQ2PGtdpzl9rL/xU1dPGIT62AgOQbb0eNCxlgKudzSSIMznrOP+PvHrU2uOn6B7rTP8QGs61YUXS2YPnhu+Id/+dx+8Gnv5v//n/ohfGzGlD0JGEcVp4fPuJ17dfKX7i8Zd/Yd8y2+NVe+cG1jQXrduim7+PQezGh6UdU1LUKV+fW2ovUNyYKJabJkXghkbRAbUDTg4CfZJbFy0YbdnuW3AwOyFhwFPJvP30V/LbK7fkafdvSF1Znq6EKeL6OHS6TMeYDjRwTYEn6/jlTVkAOl58t6lxlVwgF5XYjY8KmLHwMgeWSYEn7zQ5+JtCDU6JtYOmnlW9cPPeE7InJw9EpEWmAD4IIQuPvfK6Vh5b4e2e2fbM47Gx58K2VXIt7FmnNrTWrJvnmexz8go83abEyzzz+XrheVlYrgvTZaamRA2B0lRS+D1wNJalbbCjk3As+996DJmNXZBRyjo3DoP+ewYKeyqCtHurxYpzji1rIrSUhg86maxvcO8DMR0orhMh5A2fM25boVbE5FUn9ujpcUo46BIchnQoGDDUn2HqadamrCdf1Ues2NePolN/kz+bpvaVIUeA6dPxmqhMMFhgXial+F8v6qHwmnf1r1oruUukHDbK/o/zkB6Ye/ph/+lJeA+yodOge8FrC8B92IHjR42OGPBhvTnnad3nrCMpHexofSy9TkLDvISioEbYI+B7jlXex9pXBbT3jbytNsBgpeasxU6wpD2pB9CUkg1l0PdZwcbbC6XsmrSUjC/RpFCeVnXwgwJPRpUXIW8beV/Z1jvb407ZVGLXp9idu4ID9LWr5vQUpOeKY231YrgDTnKi+55/jiUmzrVT8nL8e/ejQgR3co8S+4XKvI3j/nQArkufXW3KjDKj8LPHV5fMUcGXYKOR/PBQ6BPvusm4oF3b2n2eDHSS1o54YgyQEIOBbPvHrup3QfKca/Skd0jt0ITAe8F5IaXE7fbE9Xbjxz/9mcv1xucvX5kvV27Pn05JjNhkxUItmZx3tm2196uGm9FYIyGogf1kRqHOu+FfpYb2G90PRacLds8tP55X+hRX82bqsXOKCQkq2z4XE50F1o2B+/u2xaw+iSYj0nire1enj/1mGPg7fxxvSr77w/fv9/u3/1up4Cm1VFa1/bkX1LnCWpTxuxuo0ye7eaf+gVPw5qkVDHjqIKB6FHXQqYPD/sQ+DEFlmrfouFhs+HSbKLURnfBtVUls68BTCur7I/p6S1XQZN2rDT7RjniXzvkPCbDJ8i25dnbGdcNwsTy0DxKp7RDh9LNWAViVyc1Rc6AuSXOOY//2nCAcoIozD48e05QtZebiZjC+TAnfp2tajKzSLSHOuYwm971kFKcg1+FD52li02mLNg3WqL6W/QwYuUHVKXcaDzVDHn45DlJURuaU9PPmM60Je9ZBP+/vD7z3NiFKJwOq+XsipaLS8hwPJpO3exm85WwfWZwxKOvrMi/clokfX5748jTzn//8wpfbzH/6+qTSH8tNa62kvYx4AzDXym2OZudReWw772tgSXq9Y1SvFrdmmmRyqaxFgfA9a7YVvGOOgWvQn5mMVeJyodSTMXjTm+DkyHMP2tPpkDrtuO/bpH09DlDqN/bv3/MjeD/OxO8fZxm19Dpu5LZH3YDlBiP+27k/aobT3tBHP0s/8sf6tT1HBp2yqHlc93Iasj/0/rTWVL0hXbqkvy8m9TaTLz8y3V5oreJuF/K+a67VGmwyPD91aAcIu703rY1LVv/ix/quwFOxSXkpIckTLgl/TYQlEZeok+TnOIAnBZFlKDwUTLf9XoV9z+xbNmNudBq8O2gZdIABBeRTTMc+Dl5lzjVCdqroGfHGq9dymsewkRijDiUwILxPvx0RtUsdu5+QfXizRAghgROqzEgBpoyz57batFZqQBV0anevwfRz+8DYD4Qw4VyjlBlaoxSdSpyz3oP1oRK69XFXwG1aSJfA5dOiANYlUKjs7xtNGvH+TpwmCOCCpwVHk8ZezVoo6FT669cbTy+f+OGf/pF5vnK5vAB+AE/N9UEtbYQM7535z2LAUTMWu0nugEHFHSv62A/inIEAjJV+1Dt6ZRhEO6/kFidjzx15eesoEqBsX2lugMJtNFFPTCerRz+A6v+Nx+8GnqblwtCRNmHbdHLbtit1lTAhaWaPN953+LfHplpyu1DBi71oxs/BwBItPpQ2XTq6PGo9pxIv70loBV2c6NhCe9sBpTh3MV1yjmSg06A8Y4ynTvlGmJyQnOhkNgchgKdRv33jfc+4WnhcLywvC2FSWmNPMqzMR4BihVcz7XreVmot7I8HrWbKpoFlzzbJrnqbDqeh7bJE5ilwWRLLZAtCtNvVxxP3CUNqou7Q0Yla6ChYVzQx9M7MhSMhKCCWggNfwGXWvfK6Fh575f1RzGS8G7dXaELyMBFwY3pM4Joilxj5tMw8zYmny4XrMrNMOnFEvZ/Up8i1pqO47XoMbKlvhsH7P4r4o2N0fF3OX7d98MH0Wr77PjmMRrX4650KY6k4Y70c9Y0Faj98BUJMjDygFFhXfNmJ+wPXKqHZveZvC5yROsjxbo/3eUopnLKeeoVtEKEmxJbITE5Bp+71BOrZ1A8JPVysW1tV1pibjRa13xujJwJT1M7tMnlS8sTJ4zxMLkB1xE0ZOLvp8ZvraPYf49Fa0+vczQ1P69E7R4geEUeXMA+66zBx6OtWjjjCAfANwMmKZ+/VyDDViSaNVLKBPCpfWh/3sU59N6j2qybP/WeOdWSgtgE8eX0Y+KRso5oV2G45Q604K3wuk0peReB6ybzd7+Rdp4hVY+GUvLOvKpvQ+N6IKQGi1GSnY2e9c2zbSt5XBdX3lVo0/ncZ2d/4JXCGTc5/t2t8us6cnnEGi93p32Q8xaQvfQpgZwLgjqDhHB3MDyEOSVz3eGq1ILVSUTBEsxoZrK0RTKSDhbYvvBZcOv3QmXxyViaQSR+b8wa0ZKW4R/3sfaDkbD5S+s5i0J+TUtSzsnZjdk7vV9+bdLBogJc67EFEBvi1XC7My8Knz1+4XC58/vKVaV64Pj1rXHPYfdcOa86Zah4ozQZ3eOtwdVAtxWReS94YUjvkY9BHyWoW3tkY3uJSE40je87mK1GGR0AInmWeEZnUM2IA+NrVQxjXogMbH+WM6ltRarHr5IlpIcT2XanxB3l0QLPngq0n8efnYOyesx+TG+vp/Pit4rYJ5Krmx3sRcoOtHPKs7mt0mQLXOfI0R16WxI9PM39+WfjT5yeu14sy6kLERdtzdv9wAXFeQaysyJYYnR+nQKOXxqfJE66Jx5qYva6Le6lswasXWs7Q1IIAUZNwxMOkci4/irEOLvchHT3RP8drbzmUdPtGtWawc8A5k9VaHhmD55IiS4rMKZIGO8Ou+SkncByRsANJfaBJimF8qJ9Tj36WV46c+JDQ9CmRbeSE3aD7KLqigU9NtNCb005r+ntq9zVtx+9oYtOUWxtSYkRG8d39Mvs54r0//AursG47KUXWdcd7zzRNY73i3JBBKjDY2ItORh5+SRajp6RMietlYZkTP7zc+HSd+U8/PvPpNvHPX5+4psBlTtrIaR4vQmxCiI0QJ2La8SGqxD3vah6cyyjKfAxM08Sy7Ny2zOtj533LvD423reMtMYjV/xjZy2Vp2ViSZEp6ATCWgPRC2+b0Iq+/gp46TmsjDvY70vPX50T/EA9zqficdTAwcD+42Re0JN7Z6Bbj0fdy6mvtd5E6mmPHzmA+ZwaG78PEOnDMPqG6+d/ZzAKMhpMvVI7g8N9f30ApkRGY/psB6LPPd6NHstuFCXBByQllpfP+DQhubK/vLD/279T7++U13fYTaZW28gzemwqu8q57uubnmuu0CL4a4QlkZ5n4nVieZ6ZrzPTZSLNwcCJzrZU+xdlB+tKVBsbbQ7tOds19wawGYlCIxM6rCUO5n0Ixub2DrXNaziJWoOIGyCyjwkfk7IVh6yusy87a9/ukOtL/WCQ9RzQO2fAU7T3lWiu4YoCUdKERhlKDt8E7wUvQpCGtj5M9kb3pnSEYTI+o2Oeop51uSKy81jv1NaY5m/EOLHMylpK18CUI/PThHOZum5UqWz7Sm6F6puSUeaoU+4mR5wmLi9XLk83fviHP7FcbsZ0mvBeWaXW5x6N1r4Pxurq2IfJJhtKHOgbQ9xBOun51vnRzW163sjAK4x447Te/Qg6ciQE35XX0G2KDAAL4Ju3uvnjTv+tXOM/evxu4ClNE02Mooaaidac2XNRtkRMtDiTw8KDyr9vSUEN07nOwd5K38wdQOgZdj+oemAWnTYWnXZcgwtjmkcTqHQE3Jn/ECQHyQlTcMy+a+/t4nH4AHTpx+wa0TWVQCEmUarI2xuPxwOpmbjM1PzMdJ3wCTViblqAYEn2lrMe7OKMRleNnbAhVcEdRVnVHF0Pe+1M4WCeIsusOv8pObwZxX7wzJCe3BzXqwN51TynKCYX8Sr1MUk9k3XWmwiPXHl9FNZceV8zpeikqmGcjbLBVH4WWFJiniLXlLjEyNOswNN1nrnME1NKpKjdrEF3HEyB81j5M77UF6gbQMDHEtQ2CPIBfBqb8kPIOv/bcb265KL/veMHfmyyTjHUz2H4Csz62ves0yrWO75m/L7ikcFgcR9/9Xhf451Z4jEUD+f3Ya+lA3EjXXFuyPGSYGNWj2c0nAb+fu/t62tTgLdPRBPrMsWgEqUlquHmPHli8srmCpDw2jEN3mzLFMDy3aLjD/Jo5jnivBamw47VUP5gBn7NHcnHMKTUZwJHYD1wiS6J6nKSOPx/ojRiTNRaCTEpo6hokb/nrMUOEGIkxET/wT0xGctUNJmoRaV1ZVPgqeYdsSlyasCi61KbHQ5vfiE+eHJRs/QtbuSSR1JWRcj7ithnHNSyoLKyqjKXkqnOkXdltpS8Gdh1SOw+ZMs92T5d/yPVPv406Ov9Wz909b9jS30fL8ZzjwmB9ERwPE87Xt6SKL03mhBVjpjURnfnMG6Hj14QvcjrAFRwym7SyW4KOsWUcMHjinZIa6mUWsxLIKucsWp8dibLC/H8uVpnFDB55biGbiyPU4Oj2ZQ5NRGfZwWcrtcrX3/4E/Oy8PTySbuW80KnU0ur5LySc2ZbV2WmlmwxWLTb6QPeR5JR6EOIOPzh5yRtMI6qefH0qV/SRE03be+MyXZmPB/sHqQuY7XnObsPzcA0b+f8hy60O/ahXtuq+9p5Ypp0T7XvzoU/wEN3TjfNt6+c1scBpvc84cyo/XhSfSi1ThdKp9Mp0+lR1ONw777AaKExp8CnS+LrbebzbeLH54Uvt5kfnhY+Py1c5ok4JQhBTWWTxrYQElW8Dn7Jma0ow7a1Row2OMBA86fJMxF4u0aCa6xNcLsyFktr2pgsZcjc+6CMbgrcjXZ3m2CmTTmbKgnmYfAx1vTcqPVmX89J6QMO3GAATikyx8Bkk+wcxzlwRLjOYjmDTwZgGUus50x937hRXNgZM86X3kRr4720U57Tb2SXxKagZ7qIsr9yCYMRFU7eVR3Qav7wYeu/uxczIfQ8Qj0xvXe45obcZcuFtClrPqb4G7lpVymIgU/KTuvklw5ypzQxTxNPtxtPl5k/f37ih+eZ//wPn3i+JP786aLyTofmOPU4I0IVYqjDay/nDb+ZbP5kmB5TZJmq5rJzVmP3ddd9JY73bWPL2lRcc7FhPs5YXJ69BBxqpr/TTZwxRgK2H3t9c+zVcYe+y//GXj7ltv2+/6EePfl1cnqP1nQ7PanvF6FjeB267SfxSNsP4PgEPAEDyFIiWrN675Sdn87yjy/weF2dWXWwrtzYi6c0fbwWUIZ8AObbM2FeqK3in2+UminJkfdV1+zWwPLA1hrbrp5L1Ro5+77q2epFp3QvAX+JpGsyb6dZ/Z0WnWaH50ROsBpwmHMwAOucMznrEK4AJ4bg8R7duZF3atYFj7KpCXirlIM4WlNpnA/dasBbk8HYne7jlOFDk3q61qdzzDln/pnRlkvCuQZJgSdyMUN4I/WI4JrgpeHFG2tXq6SDsePxXhupziVwCZFIn24nKIGmNWF6vDGlmRh1ymC6eEoOpGvSiXV+Q2plzzuuFapr+BSIYcY7ZYfFS+T5hxduzy98/fEfSGlhnm52TeKpav14HTAsY/y72FuwtXuWzH3Iq507nf1254c36IEm9ad8BKQOwMnR99oRfD6EJcHqJ6++g76A+IGjDKXN/y+Ap3//y18QUcAp58zbzz9R8kp+/IqUB/XxV1y9c71O7LURpgu5ZcpjJToNMsGZz4392cEoHEKfNtQvtyiQEZ2a/l2jV6qzdybJOxgfHjtc6GwnBaO6N0j3duoJmbNDItrv7VTzYIdQscN+e39nW1dq3Ylz4vL5iTjrCGkfHCGZNIMH3hdkXTWQbFn183m3aXf1RJmDlBRwui66yJdlYjbDZ+9Us9uasOWmLKna0XE7mPqiMl+LDvBUm8blgicHNZjcSuF9cyZnbKx75W0rOr1uU0Cs1YoXlMbsjQZuXb1lmrjMkwJPKXFLSf88T9apUop4A6Q084ZwOkWkVfP0OLGe3EGP7QeNLu5+Krljw8Ho0DE2B2P79f/2Z2jX1jprpZoPRAWa+iCITrJxrpvXBi7LomyBeVYq7bYhOePu77iSYVtxYqPpkWNa3TmJcIPBaK9IX1lfl9KTEdf//RSLcWPj9isSgU4vFbpBPmT7XESZUAX9vJaq191eyzxpQptStKRZ8+3rRZl1X75cSEnXXq6N/xI9b4/Mv1Sd+iKjjffHePRV05rBzv60ktwp6HbAtJbBLFFg4PAdkPGdp1VpxYwguuZqZV3vvL1+Y1sfPN5eyfvGtj7Y7bM3P4tgB3cphZqzFt428lcL857O29zDZl0t+wjG+An+mNgGjG5aClrA8XSjXBamFNn3zP3x0MlRJdNaZbu/0WohpQmkIcsFJ2EwUDpwJqUc0+u6Z9ToJNJRpA/X3oHKy06P88Empy8YrnQqCnt3vh9sRscfvjEHE+ZIoiyR6qDTafqcd34kJv3sUUkdIHJIty1x8gZodSD9zOjSqXGzfSwKNJZCNVbkvm04HNu6AjBNi4IqwYzO7b7N82wT5Dpo5RBnBaE7wLdiAE4uKp+cL1fSNPH88sk8nT4zLxeeXz4bG2vR88HAoZx3tnXl9fXbYDy5U6KZ0kQMkRAnnMmnqlbvKo1p3tgRKj/sMsxzCltNymlwku4R7/Ho+41GvZ+SSq0OwEnXVMn6efRiTZqlqNmxqrwPSLAEVBo+xAEg/NGKt+9q0w8FnENx555A9gZVO23H/n3HidtjmIJNWz1+cBVHbSqVuyWvsvo58jQnPl8nPl0nvj7NfLrOfH2euc4Tt1nH3c9TIk3aAXchgo/4kIgp6ejtBn99f+Mvv7zz11/feb2v3JbEnDw/XALXpKbbU9AR97kKrq6UbVcJnAjTlPBzskKk4XabwCiaeJf+Z5MG1iYjbhzBRYtTLKaozK6blFvN4g7Q6cxU6mynKaoJNpbPSDvkoM4K6QEsmAm+yhu8gU/eppHqE6vlYP43PG3OAHitbbCfeh7VsyXnYIyJ9xB9IIVgjVuT5w7j9wN8qq3ZpGcB147Cxd6A932qcqB5qF5ljyKWV5bGvlfWx05twv2x8/bYeV033tad+1545Mpe9Tp36eUyz8zTxOenJy5z4sdPN748Xfm//vMPvFwm/vHLjTl6UurN4gZefUb6inZmkhycYwJ80GtfLM6EWPChEFtjbo0pJ645c5kSz8vEZUp8us78el95X3e2Uii18siV0jYukwKMajvRm7K912NnE9bQxADf0SDuci19/gk774n82J0HlHZCq/4Ajw95f28cYJL/3mQ6/Rt/AyZ1d97+A+0/dvk64Dz2SgdlTSFyNKNPTWjLL0bJ8QHEZexpZwBKf/3HexKQOnykhn+j0+J8vj0RpokgUNY777cb+f2d7ae/Uh8Pyusbdc/sTaiuUREkQotqkZCWCCmSfnwmXGauP74wXWeev9xIcyKkiPPYxFhtJOkEWR2wIbVSizWHSrXGTx3edjFGayZ1z2PNi2KIxJD0jA7BmOSGgvR1aj593qmkvk/0PcdLbQQ4YzxhMUpGU6qfSgPLG3mdG4bbLSSg0ULSexfUX7MZ8613LZ00fGsEmtbvTVlRtRWNDc6DS3i/KEjlZzsjG1RtjDnnyHnHOah1xqEN+mmOLNdFJX/hQZHGXnQa9BQCaQpcXmamZebp6wvX2xM//OkfmJcr8/ysOYrFyMNy49gTHfB3dr54VII4GqscZ9H3nmhjHY71OBbv36zjsZ478NRVA3bv9El9zxz3+yCOHHJAUOWIcOTCcIDvv7ft97uBp19+/YXWGrvJLX759/9K3Vfa+jOezBLeca2yLIk5N0KacdnR2k5DR7sGB7NXgCPZ5o+uj5h1IzfoIJF3ahI5B88tOQOhrJPS9K0f3SlIGEPKcZhLoiyR/tx+EKhxaicZqrSoY3gdQd4fq7K8SiZMEdLETCTNPaGKtlh1YlqWClXZCF1u0T1C9HWqLjdap3uedTlclsSUghWPnVotaphZT74DzWC5kdzo++6vt5SMSlECsXpKFZxTA85qXac1q7/TXhpbrmOMesSN6zYFx2LTQa7zxGWZB/B0iVH9DZKO1A6m522CamhRRlepldKqMY9k7LYBOvUPywDPCTJYXOkw5NhXMg6l88Exni9QTIKS7XPXo4ZghYsF32mOpJi4LouNup9pJbM/HrBtcH/D1YLLarTbD6xhGtl/7/jcYYgDEDs2+8fX2a/Dac+P9+lE98eRTlriIocf2vDhQMGnrVon2Eyxp+hJKTBHNU7v+2+ZA5cl8sPLzGVRLXYpwuORSd7x1293Tb47TesP8uhvpbVO1/anf+lTIY4ERY3/1KenTxDTZWcTtjgBps6Nn9dEJUL7tvJ4GPD0uHN/e2V93Hm8vbGtdx6PN9I0Mc2TASOJfV3Z1tUkqnXIx/oa6ea80Q712DtLKeFtXG0f0auyrKL7OgTwXYKho1E742rbdh6rjovN60MLoOumXle2b+TE9lEPu4LYFL9zMqe/99gD56Qai/FCX//Hfte/HnRs7Cd0bH3EgdNmd65PYDpNuzvnjR2cct1bppuLG9DUAuKbHcC92Owdf0vF+uHfgSlB33P33nIQY/czMamdsapaUT7bvu8459mzSlE0PjtibeqpY0bCyUCY3qEUYz6J9wN41MZCGZLoEALTPLNcrnz5+qMynJ5fSNPM9fqMD8rA0/Ws8pP18c7j/s7rt5+G312aZqZZx/vGkE7ssDDOYWlNO12uT+xrA3js18sWACI6AvqMQzozKx7XLOjEqhgjXfpQrPvb11vAzmqj7DNWkzsKDiCIIOKtiDmk+3+kx7G73N/8g8YgGQzbnuN0AOU/vhbHWZLNNLxfuyaO6ALXKfK8JH54Wvhynfjzy4VP14kfnmderjOfnxaTjCX1SHNe/UMMWMUFBTWjjbIW+HbP/Msv7/yv/+df+MvPr3x+mnmaI/WHK19viR+ebzrNLAb2JLhaqbsCTw1It6uya7wa3dKqTm6y199ZDtItCmzvnsFsLYTMpkBMnt5l6nbdjiS9M56OKXiT+ZjoEAo+5CGdLTRyMwOzh5G7xe9htm6ha0guZKCIepdG4SwMD1TL93wvLGS86FOR4iwGdNBJc+l2ak6Ivb4OPrWm3pLiT7GWDsJ1RoTYvbV11hR4KqWy7TpI4LFl1i1zt481V2W5maGuC1r8LsvCZZ55eb7xNCf+9HLjT5+e+M//8APXOfHpaVFguvXhBdZpt4moCqO2Ea8nB2oRcFwb9e0LJNFcMKXAUtRb62oG8dcpqu9WCgpAbToFeSuFJpEp9rNGQaduKSGnPTau6fj7kbs5cdpAkA4wnQtuxv120gH7P9LDonYvnJ0GKQU5tT5RxcFhqg/fFdxdPn/6ia7XQR3M+i3wST4CUTrVrJ2aVfI33zt+h5j1ihYsH/N4Ebv/mjOcmVLee9JyJU4LaZqUMe7Bvb2yyw6To+4rRQq56LS21qdzp6CA8e2CnxPT5xvxMnN9uTFdJ65PF8IUzBqimc+dyt1VMp/1NdUTS3L4K9YBTIcYCM6P93XkStHkcmHkV86AotEANXDNuaCTf+2effQ4/Qgmas7VWeajkhvXssdnnE6M1r0QcVRcCIgECEFJCJ0JpMEL1wTnVabtcaba0Jpc46z6tTqf8DLh3ISThogynWpRaWUpWUkqrRiDKdCmwHSZKHtDgqNVYZOKl4DzjRAh3hLz7cLL189cby98+vInnf6bdDpes0O1yfen9zGF0MsB0DnxwzPOQtxp7R+Z9W+dD/1s61Hme6yqA07D08l3yZ0xa3sOPADV0z46inC7r92DVsG9Dx5sv+Pxu4Gn//f/5/9lY7hXaBm/fcO7yjXuhCDMSUgBKomG8MOnhSU46v1BaI6ZQnJwteA920EYjX0QvB3MdqBVsYV7MrbuLKnoVEbUDE3UQsvZVCO97mKg02HY2xlX52PC1i+m1XZdo6+SnCpa0Jd9w5WM/+VX9nVDamNaFq6fnolTYr79wIwwLU/UvJNef6HsO/f7uwaGXTeut3vnvTeTdb38MSorpTah0qhZD/L7VskGEOVinkVthAtj03REsptDG23PUOYqMkCYvVS2XFn3Yswgpbc7Ee0OOf/RQDMlLlPiOh2MpyVF5hCZU2JKcUghmtPNVauQRQx0Ml8ChGCvdxif9QOD/ne6TN7+03vm/R9OBw6nA14UKNyM5XTfCzlXlT9aEeOtW9cNeb33Cpo5r17BOVPuDyTvyPsbrhRC3k0G8n2gZBRRH9dQfz9ujK5u49/d6IJ9+DDq6GGw38y4stke0H8vYkCTqHo529+rMxZVCiTnFLwMKomIwbNMKg+4XBJT8vzjj1eul8ifv1yYkvo2bLnxNAX2KTAlRwFKB9j+II/g3Sk4C61a18v3JPww9ONDIFa/smZMQm9rVwwRGQVBVZZUyZn18c7rrz/z+vorP/37v7KuK/e3N8q+s28rtaovU0xRu/dOgZGcM2U3k2lLjo7D3xnl2RgjwePmWZkF1sHo0z27XKuzDB0OvIL2ALLotCIHlFJ5bJvuE6el/v6402phWhY1GLeCw2FTi3q3zIDjUeCK7sUjqe7JyLkY4uhYMc43gGHSe8hO7Dmc93r/6m8kOd5ZIX7Elv5v3W+gJ5xi3ned8dQ5ls3udQfW9Gf0NXGw5MQ6bSFE0iQslyv7vjMtF1qt7KWYpK3g3M76eCBNSNNCKjpSOcRovm6aaCjr1i6Hrae6b+rrta8KRgb9vsvTE9M08/L5C8ty4fPnr4QYSWlWk3Np1FzVj6tmNht2sa53Si44YE4z6WkmpZl5uQ7WU7/f2PkxbpbvfhxaXOvEzR6wD45qNZap8/qz4qQjlUVsgqDBJ00apZYDpjR/tCBAaIiNUXbd38kAxG4Sz9L3dO/KYbG0Ha/5j/I4FbOO0z6wz8f+EJ3+29y4Hudr0eU+x/TEAxgcoEqK3ObEbU58uU28XCb+9LzwNE98uc1cpsjtkpiM4RRjVK8y78FYhn2EtjemWt9XNTfuj5Vvb3f+5S+/8H/8+y98uyVuS+Q5fmX2V77eLsossfxwz4XHY+P1sVKb8DwFlgjpOuOcZ13mEwuoEtaNXAq5eVyRMXBGfZCcAdEOcd30uBuLG+OpGYveHeATlqQHrwbaU1QmkXfu5KdlhfD5wtqj75kBOvnTlDrOzap+P41JY7LWIQP8UGScwYujgG7t8Lkak6JCsHMDGk0nS/ffIfr+vRWG/acNwMkARedkAPf6u5xNPWzct93yF502+O8/f+P1vvLL+4P3bSeLgPdcLhdtjE2JKUY+3y5cUuCHSXiahT/Pji+z4zapGXgMOrNcjnaxvl2ve1ya4KkjJ2uieZ0Hgtd4FkshpmyAXqNkLcSnFJm2rJNgp8RlinzeZn65TLxtO+/rrhMTW+N9q+MG7aWNAlpZ6W6w5wa2wqnvLwxA2DmtM2SsrZHaDgDyD5R2AXxkZaDFr7LzLK8xyXU3hx9AE309n5objlE0a5HX4718/H1WhGuN5C3nMFDD98JZTmv5b4En0Gab0D74C4Jlh6JKkQ5mibQjf7CfFaI2o55/+AeW58/Mlwt5e/D48d8o24Pl/Ru17trM04wTnCNcFkKKzF8+EZeZ5cszMUXSZcI5IeeNUgrv9we1Zrb9Tc/XVkAcTsJhKt5l7tIOA3Dzd6q5QdM/O6cspgFK9HyMIzfTxwmoks52MhD9JBnW3OEERow8Sxe9k79VgAz9qt45HEH9NEOFEMHiYWlC6jmYmoMwGUV6FR2UgKtWd/X3N+O8KPDkmtXedYBPva5/+ETwkciFVsA5JZmE60ybEjONaZn48ucfuNwu/OlPf2JZLry8fGZZblyXq3llBbq3oHNHPB1X8bz26F5PHvG2tuRoOjvbN7b4xrUdX+AEVI3g3Z/b74epzCxX7ufO+Fc5/QwOywnQo11Gc/jI68fdk+PT741gvxt4+t/+t/8VpCF5JbrKc9qZI1yfNclIISHBcXGBUiOfrhO+Nt5SwBUhNvVfmj0k51jCR+DJO0sM0IK92MhscUbzhdHF6JI9BTscVcz7RvpltJt6VJOG9J1RR/V06kBhAzMoY9y0hugozFy18Hy7U/ZCjDOtOqbrMz5G5vlZ/YHmhVZ3kMq+Pcg1K+urlsOHxV5/N4AU0cLQOQYC2k3It9woRf9cy0GF04VoSPI5Ifnutgvm3VDFRg6rDG0vdTCDPN34UIvxYHLGFHp375DdzSkyx8gUoo7ItQ5/p4vDgbSPzrgV8OrDeVD/xiIdcekjX6IXsZ153j3BxuKn3yPr2pbGNkA6k9mNBEGnMvmgRpbddFhN/QVKpb2/IXlXplNreDm20Tg0Txf4w/b6vlDuSRKdem3g0+me9NfdpzdWseRX1OC1cHRgi6iR5flz6+vbOaYYTLITSUHvX/DKXEvR8ek2cVkCf/q88LREfniaSEGNXh+usiSdXBGiIygD9XSl//4fnW3TafCIqA9Gj5mugzSMADqKCbRIdijQrQ+7k8JIQErObOud99df+eWv/863X3/mL//6f7I+Vu7v7+qZVMwbjkbcA2WPynxx3ozHD3Pp4L12rK1AqTY2VlJEQlBatplT90Opd6+V2WWHicWWYGw4YSJGBbZqbUzzpNKCdVPgO68KmhgDapoXJPTOlhaTLvTJnidDVKtqRT4CR4f0xMA6euI2ruI4lMf/7MTtkbvflP78YRfwHfjUY6PQn3A8x5+BJ6/a05HEOkZsVXZqpxxDB7n6o1ORRZRRECUyzTPzspDSRE5JAU2bmpdzZt93wLFvGyKQpgyi7DNtb/lx8Dsw4EsZZrVmasl0iV6IkevtiWW58PXrj0zzzPPzJ7rMUuNVG54ROe887m+UsrOtD3uOFmi36xNpUuDpiFnHVT9irbHAupGzg0rT5NEO0H7NalUj8RDVlDQEBZ+kTwpsehY2RUkPk1jzD9CcWBMvxFhpZ98Ik/mkId08wPsuN/+NGuLv/CHjk6Y4RxIIZ+Cps34YXj7f/5j+PDjvIWVEXubE0zLx45Mym/78svDpokynyxR5WpL5mgWcTWBTwDLpGnbevD78AVI463ZXnWi47Tvvj42fvr3zrz99I2+JpyXy+vXCl5vKKryxSrzDmDSZ+/uDWgvuhycmIpdFJX1+mpQVvm8aY01ikXbtwvpquig6kOKGPEQs51LAyT6O7Pp05Q/JXQyB5D9OxOvX/5wfnJP0EYPcwaQ8GJXHfRhxzuJk95zqRcA5z9PzSk4V4fnfD9Zmn/ipXlIN3xz1ZISta+YEOp1yYue9Mgr6azUgrucypaq1wbZXRDK56cS7n1/feV833radNWeVEnk1Hw8hcLXJq5+uM5fgeInCc4TPCZ6T1gaTTR1UqUofca+TS303QjcvPO+t0PUeh56pHdgLwROiA1QuXGKhlDAAwOg9SwxMyXNbElP0XLZkLOad18fKWtq47uV0P+zEO+63jNv/cedKx1Ks9P4uUR+38I+GOnHkUKevAAYg+QPY9P60/l0/Zz9+/3nqYh+sNAzD/uY36He4oWPRfNkbY9lw4g8AwEfGhrFV6LYwftQvBwOxg0+6FsVYdT3A9ibJ5fkzc6uky0zJK/Epkrc76f2i3p0tI92VzzniPONj5PLphTBNTLerxVShSiWvKzk3tnWj1J1cHho3sRgn3hQw6ilaa0UQkgHQ3gedrNZQZa2o7kcZMYfxdA9LXUYqlg9xztUGMN1VAUcA7ADjKSkbYK3hT/pUpwfWKeWyPNCYsxJM3+ppReuTnt96EVVQeUGcEF2j4ajUE1jijPHUUK+nAqK+rmoL0Ch7hiZsfiWGCR9mpDqci7jQ8PNEmBo+wnK98OnPX7hdr3z94QemNPN0eSZNC1NaNBezWKWA0rHOPtpCdIlaj71yXOcB1B7nx4gj1jQ49hKna3zO2vrzTl8/5csD+ZPjuzQX/rib+jk1mtmunz8dZznu7+/1efrdwJPLdxwV3+7MEb4+TcyT5+maiANUUNbTPHk+PSml7dfLTMsev6rTUgeYguvAkzdkz6isdph7enA5Fw3HJWzu1NXj44UYCVV/7YZSeLvRcv6+frV78owV9MGrb0cI44YkSxjYNxrC+ssvlPtdJS3TzHSd8Wnm+jkwlx3ChbyvpMcbtRT27aG+BF4ZCjFFk+f0aUVKVV63Qs6NdVP6swaFrsZ1hy9WCIj3eLxOyHNFg7nRwFPolDqHEw/ugBTO160foh3dHvfHH6aaYRhh9mLYcy76uh44ilA9BPEEL1pAWFDq9+Fg/3xc8T1w9ZTvONKt6KEHfZU01SY8bJzy21bYS2XNVf/NNkCaZ4IPzMuMN31zq5X1/oBSCNuKqxW/b9AqUur4zR/2c3+Vp+S9X0ftpcn4szu98m75d15znc2k7CahiAzwqVoSqMCS3Rm7eN5o87EHc9sQvcOZSyVXZU8ED9cZlhT5NDduk2cuG37LlPdM8477Dve98fq68va+U3KjFjmN4/xjPIL5ALgYx70FBhDRegrZr2tnz5g0b7AqDMxs9aD6t6bmkNv64P31G++vv/LTX/6VdX2QVzWkvyzLOCz6PoheTWZFVLKUc6Z4leYq40n3Qwo6cVG75FYoNGHfdloVcB4Rk+I5N/TYzgDhDwUgfRqYAs8AT9cnnHc83Qq1NdZdR2bnxyt11wELOuLbDzBExOQWPtDQjmKXPH+IwRxrvktu1SS3d/AP0Ck4P96jxqCP8f7746x7MH2gdTtnANhxyA/WQk+megzvTC7vcZYc0BNKk7PFUxLZr995V3Tg/fb0DMC35xddTzmr34IIpVT2bUcEHo8HpaiXUwzKcnPmN9OkqdFlrQoQSbMJhY6n52dlOl1vhBiZlysxJW5PTybRa0grwwOq5I3aKvuuI4CryXiWy40Q1ftpmmaWyw2wyV4mt/Fnf4fRFMIm3ai8SQT1kcj7qWi1xNFMn0dh1vR6qmmpoxYQ6jApd9VZcmtgpreRw17MYFPvS59X530HN1TuM2SufX2dJgP+YR5HLjkSejlgSpoBgNq4YAApA0QYCaqu4Bi0sXSdAtcp8PU28bQkfny+cJsnfni6cJ0jn28TSwrclmSSOpNhxqhMtG4iHtNgpDljFOiaFErZKU1Y16xM6323Yk3zrCraFBMsDgz/I9SX0aRTreme9LUQW+FGJjrY7T1Py6I/I0adzhjeyKXwboxO9VBTw+3u2YT+5COXGZmHAVCuS/VMEgFM9vq6THcUSqfEe/hz2E07mEPnWMUpd9Jz/QDcDxD9ewDs+5/B+eujZNSP7icVDHwaEJU1KDDGbxUIYoCS83T3yeFVZLG15y3ZWB1rzoiDX9/vhBioAnsp/OX1nXXP7K0hzrEsC945ljkSneMSHcnBhcwkEJuHsvN4vBO98O2viXmZkfKk1+2Ux2KWE4jJPGjgrWkZg8aO4HFVK2ZfvYKPNqRDF2j5cF7FoLFpisp8nlMkec/LPPFTisqA2jW/zK2M7G6cB+eDoadmvajua6qDKHYc+fHvp1zyDxa29KEXpxfcnU3rxlo+MZhA/+1DAd2/7MfzT9jGMAv//mx2Vk+I92NDdIZsb86p92CPO7F/45C6a9yxc8wfwJTGr2pnzUfGk8gxFbK/hpgmEPWEFKlM00wpK9v6K7XtNFmBivT6zHx+fNQm1l53pMoY6PH2/o09r3x7+0mJDm7He8dlvowGjcNRaqbWTBOVk0VTqFjvDKlWWzllPNHPYAMaPpYAcvxP7D4N0FCBQz++74hvH2+i3Rl32gsWs5ptpFED9slrTnGAPm6naAJMc1abOiE44RJ0IviOEFvl0TIquksc0/sCTZ2gUeqKVWhiU+4qbBSa90yTgxqY0gK3xNd/0Fxxul25XG78+R//mTklrtOs9bCgIH2rp87o4SPaJdgH80/X9Pki9+ZsQ+m3HZD1rdGcsT5H3Oq/o58jx3nf8ZLW9Hwb+6o/337CAWKdmLQGqOoeqH8TlITvGLcYeUZ+437/Nx6/H3hqG45GlJUJx9NlZp4CyxwMFFDTwuCFFBzXJVByZJojFYF9OChZonnQjo8gZImkFSRq2nzy8rALeKS1fTscl+X7grmznI4PK2N6EmcLfVxIqw6d98RlhpSOoJmzMWQKDSG/v1P3nTDNtCqky5UQJubbTGtK6Y37A5yj5N08Uo5xnbhAE1j3Sm2wZ2UJdWZSqb1YPYCnvmBVfqOoLdHhmnVT3KnLFY5pQK7Jh/fZP1x/z/RAwNgo548RZKxTcQSoXtDpYu5dteDUrL12IzLX75b+vn7PBgetX+O+QftIt55yWRHUTR1r04R1zQo8KQBV2YvJ+8SkSZYsT5NS80OI5Lazbxn2jfD+Dd8asVUDlQ5G2djgH1cUggzDbyXjdm8JTqCa/lvl8N3o7/NgMonJ6PT99K+fn4tjTL6ZYiQEM8Q/vbAeDPYOuFnXGJeIoXFNwi0JsWVchroWmoNtd6x747HurJtOOPyNBtLf/UOB114MyLHwbf2O+OF0PfY1PbrHxaaDWNGU9zL2SauVvG2sj3e+/fITb6/f+PbTX5XeXAveB6YpjYO0d6G7T1O1yWc9NrVaacbs71OQpmjSFeesg6VS3FYhRdWkI0GnWdrqG8CB7dMe8GptxqzS97/MiwHgWty5Vy3Ytn2laBaG84EQE0oJNmChG28K5p/33f4dV//o5rTTxyiIe9z338ccLUxPONKRnLseB38DeBqhyb7R4hLjMrhT0mQF4bj6MoDAY8rT354p9B/jPU48y7LQamW5XKmlsE4TiLIwqoiagTtP3neVhzhPiVElQE79QlprbJuZhO4bzmEszcjlciHNM58+fyXERJoVRE9Jx5e3Uq2xsSqz6fFOrYU978okCpGYJqbpwjTNXK5PxDQxz4sxYQuddu49RyJpEkvnZDQduvRBpI5JdV3K0O9zP16BcT2ddVqba2MdHdMbnY4kNglUv0/irACXozjTLrkyv7xzCkD19dWg1PJHreDG2xqf7YzqzZh6+jhLYEHXq2AgolffzOc58XKJ/MPLwufrzD9+vnGbJ74+XZinwG2JClJFk2CY95frHk5epRDqCRIHGOgwwMZiTStFZR9bNr+R3qbp7KweD6yh5rssDTRJs8S4NbxUghRmKhFN+BFHiAveq0GuxtDKnjN49fvYO2uwy2u97+GHQyh/SjlOiXyPqc5pzI49ZhyLfFzgU1gb7+fIb3sOexQL4+v+yKFGduQcH7htR2Jy+tqpYXeEPItPh7xvxEiOWOx6rtLXS4+DI952nxEr/qTbKShjMRdVAryvGy54tqIy42+PlVwrBQHvmGIihcCn60LywoWCl0qshYj6tFGFvG1sHt5fI60szEknfsZptvzP8t3OYBv3BRsYYuCZ1/dg/XDFsjs4YPc0BoGoN6xP34p2fkavRr9LjNSmNUlpK6q4761E11fLsW44lkQv8cZetS+e19eH7/1jhizbGvqGj7Paf5DWfZAg8RuX4rtzfhDPm4zY13epG/ugnyyqosHWQBf6D+Y77m9eQ3PHz+17xRuIqqC6ynoH4HS2OuGon6DXRCYnDAugk4xLzaTbQm0bzT20UnAFQb16lU2l+Ugx25B93Skl835/J+eV+/2V1gohVlKMuOVy+PY4lQpWUXDMOW9sp27G7k5ng3n/2P+Oa9fBXatJTrXNca1/4+PDfeBY7x9CWa/7+to43385PedD1U4f+iPGKu/+zJNamTKLxoNNrEFKAYK9Lw8ERLx9rY3fVtXcluIqzjeasbtjDOCF5xAJKfH08oXL9caPP/yTEjP6VOlq2MAY3hBGjdDzzLMX2N8woOx1azxuSLO45bzlZWcuuu0J+2tvwPa1/fFenC7saT+d78cBOrVxznYg9ciBjzx6QE7jfh71/O8Fn3438PQ//XjF0ZidY4qO59tkUzn0FRzIsxA9PF8TiPDpZfn/cvevXXIkObIgKNCHmbtHkMys6urb8zp79v//p52d3b1np291dWaSEeFupqrAfhBAzZxZPZ33w5ydouVhBhnh4W6mDyggEAiw3zMerSOpYmhzrNGXtQUimI+AQaIczdfsCeCIQTOfpdAoCmBlZmlifOXAO2MGzA/3oPkH3dPgR0qtyDnj8uUn5MuFNEcR2OMOjEHHIwnyskJKAcbA2DfsH+8YrSGvKyQlXD79BYsO1Msnaj8tV2hnVlpEUNar68wwa/14bOh94OXtgdYV9wdLOgQCHYrHtpOy3iPrkqYgLTUzGiSRerwuBa83D0zMsPXsY5vQVND6gGC49pR6GUXU/CuaUqB7HwOldy5u91Km4LAp1kJhxnQCRxIMw5K3uuzopl5qoX6vdkyOHbMyA0scQaIcyicwA7bOEsGvHzv2rvh63wk8bWwXisQWoHXhPZVCPZvH/Q6aA0VrHR8fb9DWYFuDqKJEBk2etvfccpj/9q6KCOaSG0QEVfRgPikIPs0AWIK5JUcJIUDHGVzL4YDHIIgQeJLEsjn+Pl+3D7IZmjuCux+skoBswNe9AUnx7Q2wXaDZUJLBLny/r5vgbTf89vbA1/tAa2SjSPl7ofY/7nW00D2ciTlXhuk0BOAwekNvHdv9jtEb9v1B/aYPMhZDkDDnzDK73vC4f+Dr19/wuH+gjYGcC27OTFnXC0KvwFwHoGSCSjoStAiaGDI6LIMUX7dNZVnY4t61U7JTp4NR0PoOQGFayBYIsf/Bci14BntZ2KlsXVfUytIYkYTL5cZW1OJCrZLRe8dje7DbkTJw3LaPycbp3QUtBwGVlAyaI4MkJwfbHAgNQPbQ4oEHWVnI1lpKdlYFhR1zpjbLmF7OOUDz8+JUPsePO4LUY7593IeeOgyRIg+cAkC/38l46gySJWekDDAjyPuIbnmSCwyC6+0FIgmfvvzEzk+9o20PNGcuhXZSVyNjaHtAdsHH4+MpAK21oCwFLzc2PLhebyilYL3ekHPF5XqDeFZSx8DX+6/ovWG7f9ChcSAnJUGtC5bLxZtgrA4+UcQcQgBp2/cDxPT1L4Kpg5dzcmckwCIK7uvo2PaGR3RxHYPC6i4aTACCmebWOxMoHoRJYjccgA689n58thm7ofk5dQ7Mc2G2VpzdaUZKPT3iI3GVUzq5QT/G9XQmIgAnJqICNFATdLXZ6j7K7QRRUiS4LGwP//my4GUp+OdPKz5dCv7y6eKaTlcsS8FlKSjZ1bjE9bUyO3AGgBhghEgAF3rKyhOk760DphBVbHvDvtNWDh1uD8QDoABnADgAzv3n7Chlw4c2DG+P5h0q7yhlx68fHc2Azzqw1IqXy0r/Tb6gjYH6eJD5dL+zA5SXMw8vG1CNzyfjsmS3I3NNkTF0XVZclgXL4k1VsquF6snWxGQFuB1r/hwIeGAYAHpIFcxkh0+0iFBj8hRATGb5fH+PH2aAfIBIclo0YTdpf48G85PVBQeU1Gij+LHoRmbUHhIN3jH4EQLnvaPAYB93SEoYYFdB9TK315JRErsjriXh52ulnIUCOgRtGxDwM/owbH0A24769Q3b3mAGrJcFL68sS65L9RMmAqzzPhdKViBCZoMZ166pABrAQOLZgQClBKUISk8YStu1lI6SM647mzh82Ttergvue8ev9w33veNj29FcsuLo+nQqLYowUc4AsD1pt3C5fG+rBMdP//EvNZZkR+FIVC7E9buGSU/Nb23KHJiEzTn9OOJF2LMUx+GGzH3F5AbLuScicponNz5P93ZmKh5YYbB+ngPyQ5/HnvZn/AY8buA9VZScAHyGWofhlV1sscFsAPjAGA33j9+w7xt++eWv2PYH3t++oo8d2/buv7ex+2i5kP1TCgTJwf0OCLt5Xy6UF2GX6wwbIKil4UdViBTaYviCPY8NDpyCTXdA4Cex6QgsbKlL/U1/7JjHQOXn2MVbR7wVYZ4ePtzsnOz+mvaOPAZkKKtqIFhgSFAkGRgCaDE0S8gy0A2wRH2r3QYGOlAMIyWoLKDHvTNmUgCSIbgiyQU53SCWocmAodgfHVkTLrjhkl5wWV+YHB27d3puTMa1DeL+XpwhwBGDnP29OTbhE/sgTnAtJ9owUEoo9AnDB4xIla4WNa4jptERchvHPaSQLfCKpUMP1kEmZdSqXpo5Ez5PtXdnsJcXQeRDp+2PXH8YePr5tSKJ4ZKp13NZqS8yNJzSOAyYVbuuCb1nXK8LkgKtVMjghiCZ5YSnnmtE3QAcwQAH9+/+CRaQsWvXBJ0OKzFfPXtXzQE7UT5TgbijZQKkugClYLndsNyuMzAbOcF6nwKpqRZX2x+wDoxtowNdKBpc10+AADkXjLbBdGD0Ha1tEBGst9eZjVY1rB93tN6Rywf6MFw2twGWvLyGoNX22HxxctF0zzwPbRAxJFGsNeG28qAeXszb1dBVULv53AVod9LB8WAxnJDoEFfScIF3P9w7F1sRDx4jUHZHanFRyKGgMzl4v65seRgckWPTAYdBfzo4QocALopOwcetDbw9mgundwCCZXEtp7LM4N2UjjBMUaxjbx37vnkL+05xdYQuQhxgccwcB0f8W+3oojMLS/4O6KRwWUwXfM+J4rkBhgY1dTpBZ3rH6StLDo5MsCrfN+ZmGwNdFc0IPKWSUERw7wOlAY9tR1Egp4GaDBXca48t4b4DH1vDfVcv+QSynj7+B7hCTNddlEOPxuDdj7w8x7wVfPfAZ9+okfP+hrbv+Hh789d7BqlkAlGj43G/4/Hxjr3tGKYoiYH/slxwvd4coOpThDzKXVSM1OrRQCEnMHvrh0sphVnfCLzdGWqtYRgz+91YwixeCy+waR/ODWGSsIMaYx6yGGpdvHzGgSOjNoCAej0fjwdMO8b2QO8d++Mx2VzmJVwMTnl6Huep0UnUCAJONG236XT8waYG+dRmPDL0AGZ3PX/bmWU7Z/FPWZbfOfJ+cKopoH4OxIEKHL9/um928HOdJe9seGYeTIc00wbWZYGZcZ5VcX18zHI1nfbO16EqtDX/KAWcTZRLZjv6knG9XVFLxcunz8i5oq4XSMpO1cdkdNzv79j3De9vXyEAlsR1clkvFD5fL8i1YlkdsHIHIe5Fe/cyJD3mBiFKTOBJQ4zuBOIN149oraG5Nlld6AhS2ylPu26DVpBnaJrrOJIXA2MyYCQ5S4GD7J3SDsbtuf3v1F9TO5IUgslu/JEu++7r9z8NkGlYlBxiZrRFKF9Qs+BWC25Lxp9fFny6VPzLlwteloJ/el2x1koNp+zC2ZPVzHUT4FOsewYocQdc1wagt0Zds21H2xt9JTP01tEdlJoNBgJIC3uACGJsltbpFI+nj7l1xX3vqI8dOSc87jsDjLVCxLCmC3LJQC4EUSQR/FTzr9tMMJiFsoqLEIshe/CoJ8AopYSlFCyuaxltxMXg5Rx+ycm/9KTaYV/OAe8poDsBSzGkEVB8f50ZBvMlsc8itptBzNMvznEOfybMcMR6ikNkPLqvDQ1muR3dgtXQQqNNKVSOvTGBGgx8L2FaM3Umf14SLiXhT5fMpGQf6F3x0cV1tTi/bSikdbx/PKBDUd1OrOsCWHEGPxxgCt0enAYtfEqKF0sWiAZgkeYAhE8YjAn6r87mNDLKBYKamCC+LhUpJ9x3diVdSjt1ez1KXQHwLD+BS8c0eIAZHczwtAzmNP39Pf6Pe9kUjD58+dgKAZjyhfD1f0o0x4LGEdB+Pz6zPGl+jJ1/6OcQ3zzAbQPYSyUSkHLec8/n/N99ptN9z2TACWQ4e/Gn3zoB2jwfi11hUC+xM3R7QK2zU6sm9G7Y9obfvv6G+/0dv339N/S+Y4w7bd2FYJLIxeMDnu/UqRyMjxMIOEW5rbGsnhUlkTzIOMpr/4M1GNNk7sec/hgw2ZPHLNhhz6ddPPxAAc/qp2EPEHGCGzaBJ1MmMMwZ1qqASkKCosyvgiHi7c0E3QQDHWoJSQZ66ugZGEnQU4GaoHm5JJuTFSQsSLIgyQpqig0YOqTRL6pWsciCWhaIeMXLKXa10fx5WNYrf2clPK+OsxZT+KoHkYdv5R2ET+WHUeoNiSoDQdTKxPl1/rgARyOZEmeOyXHeYrLZz8lbzIRuXAfQ7m8/wbT/E4CnIjtSApaFTklQ7/TpJsOwk7a6loTbtQBD8a1mBn0j87D4rgzkkP0OepgDSzGp/oCh+ySAl8+YDzxZKNOZUOqRzcGLwceh8QHxNrHrglQKsF6AWiDLAskF68sNxds+iwgsARgDurdZPoAkEGcZwBQ2OvrHG0QSWnTgyRmQBZfP/yMMhtE3AMCyLki5Yn35BJHEwF8VbY9Wj2Ew2UqyNaeQ741K/NvmpRVvBLT2dyQMJGwoCVhr8pKuhK0rXh4db4+GVO7Y9o7l0RxJHk4TNHQk3IdBW0fDhocaLl1xdWHxaym45IzrUrHWgrEsWEvGWum0Yl2AVFBrddHxjmaKbXd9md6mn3AcFKfAD8d8G8BnVcXbo6F1xbeNpXXf7jv6YBc4SMblUpFSwuplLpsDS9/e311n5YEiwOcLGVDrkpBTwdtgO+ZHJzcJGk6Zne5mnpxuIyMzGcFrCN+zRGiC925QgvIewNFc6a5ncynMCF6KYEmCxhJffNsG7k2x68CATdBPHeRqyTDEiMobXKg6BFQFOxI2E/SUoFmQqiAloyaC0EFLyVCygVrVMsVMf5eI+we+giGog0Hy+/sHs/LbDgBzTgK8Hq6V83jcySh53NF3ikSbstRARLA30n11dGzbA9u+Q1XZUacUlLKglIpaKg9JARoU2nmgdusQGxCjk52XZeqNpFK8pKW4beGqWRJ1oWotMyMEPWBSSSwnDZYNO6tkrJeLt5b1V8YGk3BW+ol1ycBRTXFZVmBZsS4L9QUyQS+oYuSja1UwGcdw8I5iPpOZauJUY7A8I6cj6CqJDQxqye4kHQ7Iud15/Im1OQMxxL/DoTUEc0JDpLsnz9Il6OgOLB0aTqdTB+EAnBlUpuE0MmuElGa2luNc8PrpM2pdUBPL6vbH/WCegQAT2Q5kW4U9WLw72OvrJ2op1YXOaSkwYQdUaHd73wmE9ob7/R0Glu7VUvHp5RNqXXC5XEGBS2c6mMFA4M1c8+kI0qiZhHCmlaV+Vrx808chRMNba2T/7Q378KBrll05m8ojaGpI8Op9ACYopbrW3gLLBGOP8vNEVlYm0KGmDuAlrOvC36tcw+F36Ojcww4CSmh6/EBXTBeD2cNTimRM12Aq8zyiqLJgWQvWkvHzteK6ZPzpVnFbCv78esGlZny5LqglYV0IqJikOZdwEe6UC6p3Z8q1sInHveG+Nbw/mrMTWZJXUsJoO+1nHxhdUXyN754kGQ5aPJ+vvttN3ZHGcV6KhKa0N+BgwuC6LriuFT99ekHKCX/+9IKlFKwr7d5bo97hLS3YO8HOrQ/k+4Y+dNrq3sgMKEvxcppOBo5SrLcUL+ssBZYydhfkXShK4hp3BGMAt0GntR/BQQRsLNE5l7u4AIVr1rEkwwM3TT4WGTmbawJmNAfoI1gZw7BjILXODs3KwHbvTEhtjcm65qDxFPcNH9xBxuZ6bJuvo/vOpN7X+wP7GPi2cewaETWszvwqy+rscgJO1TqyGG7C6oeXAmqxKBlw0AGcNP9apz3cGzW+HvvAZVMMJLx2RV0K1svCkrdXeD0AAJonSURBVE+fD98BBPKHd6eauii0BTmxeYMgzfIRkeysjIqcBaMnnl3uBybJ1HiqBa13XFb6m5c1Y2sDL5eK+97x+VJx3zp++3jg0QY+toYWDRQmyBDXKW3hgb0fcfPM8YKDOac/ynUIJh9Cy4AneIkiTtAnkipn+x0MMgUrMyYIJeIl2JHMOtLD5p8XZfThtQfoweWbDgz4DHIE+/2UrATcj4nvuN8S4DXwd15vft57Nc3xYUACNX55Cyz7YlSRqDmXCkZu+HwVLOkDX68fgK34+ts3v8eMlAyX9YKlVqzLBaVUjFNpXu/D4xEmewBB7+4D9A5ohvXMUmQYxBRDWI4sZtCcIJX7JyeDjgZtO4YKukaCNCFlRVKb2nzqSSoRwMQTk0+A3gFWWSS04tuQA+TwBitj36FtgzwekLZTj9dLBwm2ecfOwqY3NVEP6kUpxN51h0KwJcWwgfcMNBO8WcVuGX3n517KDTWv+Hz9J9S84rJ+gQ3Axh3oG2z7Db0D91+/Qgzof9mRKyUokgDoi08vfU/RznM0mPKxZoGTfbDpd4XsQqzHIx8qk/EV1kLMvAzP90CUaTt5J9hOUWI9F2aATcq4cZzW+zEJfg4bkPJ3eydK5J+x3ZjVJ3DqP7v+MPCUU6czkBekhOk8TOATR7cGgXeey2zxvtdM8MUzUBYRwlMmaI6O71E5BuPpigyPTOZRTNAZeYzD3k5vI6f3JpCU2TWvFNKzb1fIshJ4Khl1WWcnoRBwNiXDwPoIFVwe4DlN5143LhLzbGG+ktlUry90zMcOiFHsrVRcXn+GpMKF6s60gcEOD6XCg7XpdJZ6a7jfP9D3B+7ffkFvD7RHhmhDdsNUkkGR0C1jbYpcFEgbHs2QUwOMmjHdFzdUMTxowFAMdAwI6ftjoJUBLQOjMCBRd86gXEamilQLkhlSKigloXLQ0Efzg0d+N6fxHQGeM1hmzmYaeLvv2Bx46kPxvpGKnT07Wwrpq0utUB24fzBQ+/btG1pjN50lJ6zpQp2GkmFcpFAotnFkQGMNTYAp1piDSP6KuSnDOQ59mjCnYqy7jQAzvs7Dz4GndUl4WTJel4RbEWwdbFWsinsHOug0JjtwbQOgyUEoz6JNGrMHDSqCMdchM4AEnhgIi3cyTF4fnRKfUeMDfpCLYAVLLHtr+Hh/Q98btscDgGvpeMbIjKV27Aq2UXOnseyKreJ1sjshMoGn1thBBOKlWN7GOntpCldFhg7BECC64TnPkqLxrumTU0aqBVJYEmcQp0aHRh4PelM6GYoxD3iygfxATJmsl1ywXlYym5wFqF6e2Tud9hDUbr1NJgsArCvFE5ea51hkB1Z6cmdRFd2df2CHQqF6ArgOD29u9tkgwTVTSj7r0sXhfDiWZwHEEN59OlPhzDHER9ABCNbS1KYy19HSQ4Q6AKynNPUJdIpg4rg86Axn1wPGdb1yrt3525fFAxp2MxTf92NQ06t6SeHlsqKUEAvnOWBg1ygDEC2b+/5A23e8vf2G3ju2bUPKGZcrHc/L9Ubg6foCM0MfY9oiToS/jwd6AO1nddAmxoyaY4rjt40Mp33H3liG2vpAV7eBnshh2XiU0LsN9PFSNQwXyCTYxTP8iQUSeydnnu9mKIUsG5YJHk1GQuSc8+ifJbSxPxrypMBRhi2n4Mb3SLCd4ufRreu2FAeaVrwsGX95XXFbCv70ekHNGdflKKnM6VlcNljoKUXnOuo4Ddtx3we+fuz49dsHSmF55VIS1pJhbYf25ll1g3rH1R7A8dzDccTYXJ9x7J9LyqbzjbklYSZYasHtsuL1umApGT+9XLDkzOZHBiQz7IlAwlYyNkso3dA1uRaieMkyGFwheck97ZnRlM81Bx+fbixj724OzDg/XadvP+3PBLPtMCkHI82/h2kZYA6amL9pMKWTM3biXg7x2Jh/gzmwB2H5S0qCNgigdSVbaeihTTkvN6IGoJsSEwLn6WNvaH3gbdtYYtcHhikG3H5PcfnCrrolIYvhRQwFhpsMFAHWFLbv6PoVwY1aiMsbWqdGaO9kyi91R0oJ+74jZ3EAP4AlgyF54KSTiZlmgHU0qBAx72BIK5fEIMiOt7nOnghUvHutS2vUnFAym9WkBGxtICfBY6Ue6L1Q3iGnTrmDDqj2I6kDzLLYIyaLc9HmRg7g6Yml8INcZ+BJJBiqXgng/4UnzZjNz+T4RhATzJ7AnxkrzA86fzlHxt/9XDHP7ACQTKM+4fAzpjGKmPG4KZz/fy65i28fv/o9K/s04YADUsfvJnMdZElIaeBSB8QqLssn9KZIaYFIn2u3lgW1VpRcWeLvvmkf4e+Eb5I9GUg7oQ1kBav7++J7PtHh6GYQzRiemFZg+odD3RdNCZY7zBhHicB1kRx4QZoJ+KfT2I45jvGz5x/79wlQW+/Q1pB6h/TucgIWRxSiUURN3nwpkZyyOpOyKRtZrMJmJkmA3RLaKIApyqAdWZdXLOWKy/oFNa8o9QWWFCMPDOkcN+3YP+6odcXYGyQJyrrAoJBSIEZ296H1lH6/dhzX0Chfm2fa9zFxnB58EcXwaT+THWWbkKMM9PDFzMEreVpjkVqN9X0GWQ9fbc4A2NRMQF27/zgkNLh/EvvlD1x/GHi6VNdgMqq/I4Ln+Tly2lBATQlrAV6uBaMr8pJ5QObihyyg4qKF4kkXuLCs334CASyIHHTIGFdwwIaxW12aR3jcTRg8pxOCTkSOSFuY/R6SgMzs8rIuKJcLwady6FTo6NAOmGf6lTxs7+4i3ppbYJ2CZiyCNQw3OKM3SCrI9w9IzsjrheV4lytSrlAUUDjRdZjq4g6Lf07KSBBkPUyeqeJz3zD2Dzy+LRjbG7Y3g40HsA+knFGXBZJXyPKK1oH7bni/7/j52wc+3t7w26+/Ytt23O93dkRr3SnVA7sZtt6xqSK3hjUn1JRwKQWXQsbTpRRcayUFPbE8Y7ndkC8r6usVeV2QlkTAo1QyATo7ioTIaJRPZGeHqQ3HveigbUPQVGCpQLLhshYMNZRSMOupAYzOrmz3r79gjIH7/YPU+u1BfQin+f/7GzuFvVw5xrclQy3jupSZgTP/yvUDBFIscihOBUo9TgdlIN7hDNKB88MWzoYycXom/y4ieK3Aekv4y0vBP10zHk2xD0PPAy0rRmMQmqsg5RD5pAMMHIfp3HuFweT/+OmKT0vGP/+04NOScM2KLIo0NqgOlNxRh2HNwJIxk5Gt/ViMJ661gY83lsy9//YbRmvo+04gzxmNAGZmjrblKPUAopYZE8QIfbmUEtK6oqafHJxnydOyrl66Yu6QGEoR5JrRO8sW2EGyoFSWuNRaUWpxJJDBwxiGQTjHhSoNVQoAAy4rYHCgKREsL5lMp5RR6uKBihcxmQOVUMAIZvTe8Xb/QGsd98edXfvgIs6JbJx1rdwv11eM0fH+5R29d3y45tP7B7/e72STbVuCDgplMtAQiKUjvykHUCspuV4agyfx86CfyjzUM/XRXZNbzQ946PF3D0TggOAQTLAputhhzqcw4VBYfliXCzW5LheUxfXxxqBjrAYRdvzTj3cGiH6QhyhjTmBG/nqFLgtazRN4YnkPzwcd1BhZV4KBl+uVJdfLCkDQleD6/X5nSYjTwYdr3pgaSi5YXglYXV9eUCu71UlKLk5KBxQIR5vlfCJC0N0d5pzYCMIClNob+hjuJ8t0Xvo4uiEOquyiLJcj2M6ZQpg03tPRPtplH4Kyh7PpZ1tWRGlpaFVQr0JOIuLOFgvw0EteyWY0np1eBvb36e3/uBcTaDLtDUBbMhRe5sNyusuaHYRZca1kNt1qwV9eV6wl49NKVuFlKXOcc5ID3CuJQGQtLLd0za6ciutLZNx3xX/77Y7/17/+gv/Hf/0bAjj66WXFz7cFf7ot+OlGMemaudfI8gkxW3p2T/CggZqZKfk6XnBZB66Dumc5h/6S4PVS8fPLgv/7f/mCP32+4fV6QSkZSy4QAbZtRx8de1NkHRDpuIggL4JWBV+WG5oBH+MT+jDcG9f74/FA7wMf9zv6GNj2jcGaMWB533Y0309LLdgHdTGzUFkjul+FDxvs5CQOZA3BAL+RuqK0AeSBUg1FjIGTBLPSJopFvyKYzGmeLUWZNOgaTH9A94GtG0woO7D1jjYG3u8dezd0iy52OoEvcX9VDNCdzOABVjTsg75uSwVWwbPJDKspkgg+rZXdEYuhyMBFGrIA18QStgK+b+96AOHuM/VBlhiBMSYtWj90UO57d/3KgduFZZPrurAfVV0IjGb6bF07dACjK5CjSxfPzwjqRJgIN8GMJQKYSilhdIGKM5aMAXdSw1rE15ZgqYqcE65dUVPCvne8rBWPNvC3t4qPvePtsXl3Zd7/BBoRvqSLNZsH/3KAJWf27o9y5UKGaiQMJqAETF9EAAQUlU+M1Rk4CxwID3KBHWwnByFyccYrTuCRBDMW8YYkTajNTq8HIJBcyzHBZHgVgR33gYg5/6Mn/f4HkZQzSIpEmfg9BEDz/H6z4YEaUsq4LZ+x5iv+l78Yti8f+HT5jG3/wNv9rzBrKMuY+bwxyHQZY+D+2NBbx/1OTeD2YNJfd4WoQDQjWWZJnwxYAkZKaG7nRy7QnGG1oiegZ7icTGdCvAOWKpAXpFKRayWzv9Zpn86l8ZPJEzd7Rgl9Lwb4HknCsT/Q2x24vyO3O9bRkKGsChEm65ZaUK8rSi1M1GZBTWR6Zz1kQ4ZRU04toduCbkAqBQsEf16pb3UpL8hSsdZX5FRQ6goUQ5GEpVSMt3doG9BtR7t/4P71Gy7jivVG3cO6rBwj72YMdcaZ72tMv/NgD52v2Vk1HWW7sCi5o86oqsHARFsyVjekp2SRg6mJfjZ/foBXZ72pM+A08d3zEvZ45WmFx2t8PxxsNkdb9O/tg79//fFSu+wPMAcsVs0JyTt9bkoUz11LxlJJ57ecCPi48Sda5zWOPgDRvS6q5MRBp+mzHJ/sS9jOSxmncf4OfPPDW1JApZMGKZl/cilzEcMPNS4SpwbP8gxE5OSgE42jddZJWmdnHZbRih98Gda7d4YpEMkQkIoXwEF05kiZnfQCWJEokZE86YUCRbIVoxUs6YGxGR74Bu0KzRW5FNTLDbm+IN9+Rh/AZRdcHhuW9QPfloKkDfdHRkmKbe94ZMG2d3ZjG4oxDGoDMgbGcCq9DrSRPUjs2MfgwewO12pA6QO3krGkhLVUtnqfnR0KxHVOhhJkSnHYJAGGi2CCTCt2ffNnT8YuKMlmWZQ4Ghzdwe7vby4ITVq4jT4PmgHgfetYSsJSybSolTRUduayo2TIu+pNNFmOUrqooe2ufxLr78CKT6BTHF7mwpJwAVgzJGNXHkssc3u5JPz0krE1wd4V//oQLM1B2QFIdXadYrKf5LTn4uC91oy1JPx0K/i8Vnx6WfFSExahS6kbgzVmCwwlCYpYMNeDCf/DXJGt2beNfx53aDu6yUGdoehzOTufCDOzBqL55+54QADDpE7nIiyXy4lMxmA8JUEWAzzriiSwLDAl8ykEZ0upWGrFsjKL5SX4sN1r0BNtpeNRyMnZal73zRIlMqZoy6qXaFRnohz2UmbGWTEGGU7b447WOtpOunV1wCrnjJIL1uWKlATreoHqQK0VrTeUZUFrDQZBaw3RzXOoQpMDdyE2dfKyYsuHM0anTqZDaM6qHXboVTFAjU6dQKSLeFDrfEJB0IcPEXGOIcvB4tcPcXKeBXVZkHP1YNu7pWlksTDfS6PePgW4EmeWz0kpsEzdAQpoB5POGXJOjV6djbYEU8rPHHWgrXknVG07glkHz3SRYXVBrQuul9tk1xngXadCx8bHOwMw6p0kyFzbdAo94DWW1LVtO9hcPkZDyZhQ5ZwUL7866vtPzuMRNyOYULM9MvCc7Xf9oAjao3Nqco2sHB3V+Jsn1szRffBgrhlMPWH0A10er05f50hucEsFc/BamUAhw6ngXz7fcF0y/nxbUTN/Hnta/Gty9m92keXkrMOUyIKaekaJ651l7g1//e2O/+2//ep+Qsdfvlxx/3xF/vMLXpcXdgZLruGjB9BIPyz+jnl2zbn30olSCmrRE8OH/sVSEq5Lxs+vF/zl820K8cOzwNwjguIqiysM1X2oISxr7UhYraCbYd0H2ugoKWHvHWbe5dFLUmnbgN1Fyd9TIvvYWZo1Z3+GYDgxmWApezLUn5F0G2Tl7++D2fY2FMiGZBbUtmPvzCvG7WC0puRtu21MrcJhBtEx2W+P1llq1ynMrnZIVYROhwC+96mTSWZiAFTue7uYfIQAyRRZKOVQk+CaCJ5dZCCL4TLNszlAGsCSA+8mvyufjpI7Mv3JkGRHxYSPbUcpmd1kc4EOo0aPp5y92pzPkb6LnuTYI5H9D+YpAGRz1WsHdcfw+A1kRsFZ5CuiIxhQMqUpWqGN2hqZYEtlN7IkQt/TDD32KoCT2cNZZNyAaRt/NOQpztFDL+l4QD63xfaZICvcPjwFtzO+5MSFXx2BYYBDETepl+0eLxFnZRzvM7+P8O8pEM5y1ei8aXPfYfoZp0l6Cti/C9TnXwLAOp+LAszO3ad3FEDA5OKSL7C0QF4NrX9CFsG2f+CXbwVdNwx7h9qAGnXrhrI0trWB3qijNvpA2wc7jG4DyRJ1Zg0AOv/ifox6XGypQkpGH5X2IgORle7d0Jo68NSRaoXpSh/aFFbohyUvCz53Vo7Onb8fqSNoj3hbe4O1HdJ3SNtRVFEBLCmh5oRaM8pSZhm0OFP+SDwpovcA3e/EGCxVqAlSXiFSUNINWQqWdEUSJlqZZCkkwKyM0S7XK3ra8dg3aGvo9wd6zbMKRkqFdqBHalW9JtsB0JnYjkM7xsBiPeDpdXN9BjjksaSo8X3VExUnr2COpmMTc9yfV9gBOtn3v2tPS/v4/O/ma27lA3jy2cMfvf4w8JRgMBvQ/eHCfOyYJGXlVylzI8cA5pzIeFLFp9cFWxJ8PNjFpvtBXaaIZVgezyAZwYUMp+MaIFTBPi3TOEaCpn2yAj4oFgigH9iWEihok5EqS+rysiBVlrlZb9yAenT/kMEgTQKxlBPQcKAN0NZhYwCuO2GlzLEQdxJsKO5f/x2QhPvXXzzTfYGUgnR5QSoLltfPDCIr27BTWEwgIMI9UgKgSNooZpYFUjLK5QLtgpEMuV6Qbz+jrK9YXv6MagmrJdz2B16/vOPLbxd8Wju2+xvub4p9b3hsgr1XbA3MSA3P+EcHKGA6gVkAFcMmDU271x4b1rSjjAJcDagDdX1l2+OyACJYVCClUbek7QiSn3mWKrtOgCi73SJVqBrWxm5eX9/esbeG+9sbxY73jWh+c90tbchmuGTFEAazeQBNCWQ1Fyz99Z1tcy/L8OyuB+cz0CUtsyagiKBmI+tMCIbtSnjpvSv/HXomM5t/KjShHSRK7c4chM4VFHh/DHzNO+5XoHfqIZRqeLkCLyZ47Nlp3Ly/MQAbwKclYymCF888Jq97/lQp7Pk/fakUj/1yxVrZbctGx2O/08YYHd7s/poNo/7QHzUK/yDX3/7t31h++f6G0Tq0s/Sp1jKNsqpib+0Q9hNBKjIPQgqRsu65pjpx0smEc3s3nacItcztgRLALaZIJWPJCWNdJhguzkpSCHY92tNLrlhzQr5lFxef4b3vRw8MXSxc/ZAyADoMY1DIemadPCCL7nTfvr0RcPIa8i9ffkIpBbfbC8HrUifoClAvCwakvKKmiteyQlXx8voJo3fc7+/oreP94w29dXzc72RA7WTrtNYwbxAMeGBHB6XhTy6CmQVX14UBXEjRSBkfY6C1HSIMUsQoFBuolrtTCNG/EApPrmGTHCzPheVEAYCrDmB4EYAkSObXAUADxLNjTAPm6G6LzJlN5rRwOjJArhUACAa6LhOFywv9Oi9FCY0xmRGVAJboFE1B+Ix1WafIMTsOsnQ0HEmRiHl5tg4lYy6V7IAYRcL7vnsAyPnZ9x1DB3ofs/QtuplFKWipC0qtB+g0KRQB0IcPkCezAAIMLyMPAfKyLGScnep7VZVlp54BNrjQtBp2Z7BSQNUwep/lOwAmGPgjXTG0GilHYwJkLew+9+my4FIz/nRbcF0K/vL5ikvN+Om2ouaMl7WipITV9dNKznMfzC43WVBKJOIyG4mk7BIC3oChsTvd+2PH148Nv7xtuG877o8drVED7PO14C+fb7ilhMuyeNAtaMZzk+zoPMHaWD8EyR04TwVdQZbOYBIsiczGA0mA0RratuFdlR3VBlnSj8eDjO1Gtkl223wRnsiLECT/JApFQqsJAwseLwuaKn67f8I+Ot4++D6PbSNj2gH5ex/YhmEbdzJM3eZH45WaOSdL4b8zgKTUpykAOgZ2NWzd8OiGxzCsS8d1HSgloxYyOlMS7yIMZ85EcxgmvLpRC3IfmGV0fXAvxAlBsMk4jgpqOCnwaGQuSuZ+yUZQxkDtlmW9EHgM5kLY5LEjmeICIMOwpIEsIAsJwOpJkehToRqyA/EVU7aB4LSdRJGBlPh9hcsp3NXZxYrPLw/0oXh9ucLGQFlWrJcXAIJSb7CiKKXTzp4DfL7zDI0kebTgCWSe4wLJCSrFx49g2TjpXbK0SaCuu2WVawtmWEuC4YJHK1hzwtYHfv14YGsDv3wcZYpnMhvi/k54DBsD/Z9lRf7/c507Xcnvni2aUgWwk6YcxxE0y2EkcAawwldXP2uSv5/HSsGulQCVDv0gSQQTjm6S8+g6WGgTaAofDw7WCnJW9088kaRR7hlJMK55GJw95zbcxjOYZueQ/vSMkdDKJX4RJS9AN/Rlx8vyGUMb2rij6473x1e0vuHbx7/D+sbO6V1ca0+gbUCGYOkM+K9gjHFJiiyGJQXzPkrud6ALMI7upSFbYN55EpKgkqG5YpQFe65IZUGuC3JdUZYVeWE33VRYkptOTSsCYIxEIJlOCts/gLZh3d+B9oFFOkoFbpXJk3Vh2fd6WZBKhtQETdHkzOUJRLBbxkCC5hWaMrZcoUioa0VGwjUtoF1gJUAW+rkkhaTZUKzIglIy8M//hP3+gI6/IRfD9vYbUhroj8/UelrKBD1x8kdMO2D5iAWBub69D8EEImNpy2mtR6nk1Apzp05NER1+6SM5KGpHgoLr0M4r7ABnJ8jnGnl2iIvzV0Mb1HeAwM+I0NT215yAp+P7//n1h4EnwDPlfadjPTpZQ+L1785oeTISSZxdkrGuBdoJHJn70/pkeE+/a8eAzUdxtJrgzwE9xdYljGWnn8TL5DBEvugtseuJVII7qRYXJ2VAQw0cHO82F5LTZP1tj5/zC4OO0wT68B4UWk50axsDlw/eV15WUhZfGrKDULksKG5QLXs2bZYqUMhczQNaYUYv1QokAiKp3pDWz0jrK9LlixuVjLI8sJSMYg/IfsNeO27pjm0HtsdAG4KtC3qnUzNcuyYAmZgj8wJrMwIvA8wWYhi0Z4yxQ3UB4KUzmWskF4UhIZeHB5TjZPUF8I5rCVwjtaRJY++J2TYMtivf247H/eGBIlvzVurlBYaJkkkbT+IZUTPYMDzMxf9EkJOigqVL5mtPzbzUU1CSHU6VAE3JipFBYb6mhu0EPM3r5ACJcL3zvvxwcyCpdcVjF6ekK0oio6UWYKlANUFGgnXWabNKivT8a074vBZcap7A0+diuGTgpzXhZU14uZD+2gQsPXJg5Gw2JJa5Pj/Cj3DdP96hOrDd2aFNlQ5AygSeQq9ujD7LLWnL6EGrDncYmf0qzkyMTo5RClRLPkBH7yxigzZBdMy9mkVgkr2jiDjYjgknRfk3cIjbrosH+l6YH8LYObv4uIcHIe49ojzLAeGjjTEzU9u2obWGx+OB1od3rUq4XK5Y1hWfPlHo2g2di0ATyDUIJBUkGBYHU2AXqHYstaD3hpITWm9IJaO3jpQzu+VJ6HIcB1/oXUXWOhy96KrkvheA41COksgQ6w2gOCEO7PQduOV7Lpg8EnoKZOfG+JgDYJBwEn2PpAQdAvHPMkRpRORszYEnL42LA9rXRvI5EiRUL4nL3iKaMZBNexhit09Bit9zygVLXZFzxhLlgEbGUvd1S3HuEDXFdxmuw/G1APB694wp9Z+6d2BsvSM706lAIFJmQDrL4dyeROIh7vhZp+c4/9hd0M8ycQZs9gRHOGsnA2RukGJM9n33tW0I0fNgupxFYX+kazqOh1MDEaGYds34KQCn1xXXpeCfXlYsJePlQsBpKSxXq663VIpnolN2Z5bAU3TNxGQZpZMzTf9reEn+1jru+8D7veHbx4bbwrPm0QaZNymhlnIAZgaIwtlUEq7YBOrPwaaBQFIfR6lSMOgJJIHrtQeAIWiddnvbmzOgHVgovg79XC/OWFiTwsSgOUOFZSZNgVJXbH2glMpS4lLReseHsCT53pUND9qAiKJ4x9mQGlC4v5GjYx7nLScwsQP/fXVb780DDIJlFKjmqXcXwPgw9XPJpk7TMEwQalfvPty7d6hksDjsSNqSPU6m0a4UaRenBBQSON0OJiTf20utBPqgEFPkzo5bNw/XstHnyqAEQZUEceDHxFnT3qnX3LcCXIbgBMIkodyGJDCj74DE3vgLv72xbOm6VsAML5cFqwlqWYFckDL9TEtkmeYn9uvZgmJGehNumG4nA+/Z/UsSRHQ2WwmfNDTkShYCJYWB820UlETbtbWBoYqSO953SkugH8K8sSYkNreA7AX7Doz6Aa4zUPT9ZQ7MRKA7o74YB/j3BQ5AHa97ep/Ttw3hPxxg5/H+/NBzYkRSmvbNJwLizMMQZ5tsKgCATo0xnNe0a7IBvz+DOK8RWwQp7/vXHWvV3K8I0K4UJpysDmheseYrzAa2cUfvG0wLHvjAO+5Mgtni71TJ0NcBUUU2VowsIlgEuCUm6pY8PKlO2xHgNZNErAYJhjxag7QN4RdarvyTKpArUl2RlwvG6CiqjK+VJbrZjE2OUppjH+NuETv3BvQdeezIo+EqipqB20rB/+odJstCX8ScMDA8v9jc1j3gwFhZYamgpQsMGSmtyJIJNMGT/yYThIwzMc6/OK/W1xf6/muBmGDsG8ZeYb15eW+GJsa5pgIok9umxDy47jAZd3M9P+EZp2uCTumZNebr+skpjqjDbO6VA1yKtRVTdvp8j3vMDsY7YP/BnpWn++KvB3h2Zg3+MeP13wE8uVPed2jbsd+/ARDk5UG9ousnlpHVy3RG2RUEuCwJX14qkhneagaGUizNnfw0jcZR5iIp+aF5dL/w5356wPl/H1nmZw6Mj44Ae72pO1m5sHNduV69k9TxntG2cbKnDDMaZwmIO2NCrR2h8hoQoAZkorpnTRE6YC5g7cEhwRJA9wcDhfsbJGc8fvkrUq1YXj4h1wX1+gLJBXm5MANdl5gRPnF5AdICkYXOwBiQXKHlhp5X2DjEY20IFBW2vGL5/F9QLjeslwv6dkfb3p06T4dvDJui47NWOpzDELZ0kd4xGkzHFAj+9HPB5VZw+bSirldoWmGSIXlBHwqkjN4b9Uhmrb9RtHYovr1RFLzvD5ZKNQYc7+/UltF9h6hiSdE2VNyJiQgVEBMUr/HNKVS/uGLoPxj23iEgXRqIgh2+cs2CxbOP15KQhd0adwVGNzxC/BdAyJ5NNyccmok8+/9C68Kzj6pen23u8JcMMzrvvSn2baA1Q+80DqLAmtn+958vBV/WjJ9fKtaScW90TLF1NCj2PFB6gb5cJuMu1nIEBMMInPWIzRPBth/p+vbrLwxeY61tG0SAWioDmlLAsiMDOUNe++raFKr9cDzE9eZSQkrUSKEOjTseoTvjmTAxdYfeKcHxX2KWNUqYttaxNQJASBnLsqLWiuv1gmVZvfNZ9uBa5z4NT3WEDpKa702WInVnrzBgJ+h9Lk+qlyvWlLF42dfL6yt1VtYVSULAlmK7atEpTmfJtSJsXUVOBdcbGw/crrejXEzVu0wObBu1VO4PAsa9UTto2x4EzIL5YqAdziz/ED3WLTwYI+Op+0HL0lnk5KWI34sqgnbCEVZTQ28G6WkCYuKZpVLZVCLl50xT96+xO7Jr+8HLwpaSwdbEPE+urt2UUoYZ8HhQc0GHA/ROxW5emrj7WHUHUeL+cy70iUFwIJdDtF7N0NvOoLtRjHdZKzLoqCW32WZg96ih2LyT3OgumulADsvoyASxlCEZ1G0CwQA4oBfZZTP1DopeDidchyyBG4iW6yYGg+sOqGt5+BhRNDzDQgdrNIze8dG2wymCM5uGYt+2WaJtZmQpjoHtcZ8g74+GPVUvM7tUghK3hd3q/vx6cYbTBWvJeHVm07WydK5WAk0BOEVb7eJaX8lLqDAD7jybqdCqyGTBRVaitw1mLEWTRP+KjF/g0QmoQJLbrtWztRmPQd3C62XFZd0mqB0A5VA2Efn17QE14P/911/x198+8H7fAFP86fWGkgR//vyCL7cVvRve7g1jbCdtxgO0DBbXWmnjJXNf0owIy+RhgHQPOKjJ+bIYejG81xXdFjw+XdGG4mOnoP771tBHx2MjS7A7G6n1Tpa4dZRh2AxT64msnvjq3ZhkYGmKdWeJ1uW+Y60V6+LdPUvh73qZqw5D85Lxj63h0Tru246tdex98Gfup0VpZOQvhgfkJrSP5VpQIJSVSMkBpmBpARgNsB1pe5BFamyCcUnqYuEHwB9MtCSCpYYf7nMhZPpbdgarpSkkDrivZixpywLvSOWNB3x6VBUf951+ubHraoLi5XYFRkdZViyX2xQ6T4ikw4BYfwquAEz/J4ADxJrxH0+mJRJK6dQM651sMlUvg4bHAwjLSN9QBLeasWZBzTc0VSyl4N4G/u2NDKjH3h08NAQZFyC7X4hlzRKhH+Hi2QrXmDyAqOdE0gFGREdCgFMyjGwdSebnD+bPny4/546Oh4IQnocDTefyogCogGdWFhCc8HPL+BMJ4lTGHWce7afNNTsboPj9RvA/EyYpeawSiaFTphFHgwwJHyaxTCyVClFKH5gpFl2gi+JWX9FGw5f1Z+x9w/v2K1rf8P74htZ2fLy/QfuA3TfI6Cj7AzUBa0moAlyyOVuTibHYgGbeFETtaNIyMkbLszKgq6DpQNeB1jfouGNsGXZf0OsKqSukLMjrBXldIbkQJwgGlNuQNDaINqz9HVk3rEVRSsaaX5ATUBZKP2hm06QONiAZo8IkY3h82VCgyEC5AKkglRUiGat49ZEznGLsPaeMkE7IZYGk0ImLOFGQXl6QS8bn/UEt56ZIotB9hyaBXS5cIbkQsEbMf4CRnhDQcxSKZ4DIkztHIganvXL4g7Eux1CYdagl7yxIRpk5oKV2JOiAkDE63j8llqiLdPeLn7fUOckba/P8fTgIdiQWj9j5P7v+O4AnR5B1QEdDd1q/qSCVgVQvfFk9ZRmEWZSc2blrqwmpMBNNqdzjVgP9V4laedf68c5gE+WLYOL4iDkQ5wHgZ8hEbPkazwSHc1XIemL24XQIuXMcnzcR8RAhTgfl7YwWzrNNgpp2UN4CjdcIDJXMnQOlBNA2QBIsfyCVChsdeVkAU6RSeS/O0uCk82CXTAdSCscsFQMkw9IClUKGjD8fbzXB8oK8+qYWbvKSAYuOTxraLPxzJAU4N5Flj0CUrIM+S/Fu14rlUrEsFJ8bqUKRkZFhSVGWC5AoSIuh0G1D14FHoxP37f2Bbd8wHh/UaWpkEzy2je0ivfSxeOqIX2KzHoufxkPmV0uct2AyqMYqZHA2Tr+XfY4FiSwkAZbknercqJxcmO/W5nE42ulfsYS5l8LgHBmOlBLYStR1qbphdCOA7u9Tk6CK4LUKPi8Jn1yzSrtit+japeg722bGv6OUZ+6P058QSYeP0x8Erv8hrraFrRoOhrRpaAMopaPgWUcHnmYgMxQmruVjcXBYxGzedvRZO2n+AR2UQ3DW/8vhZA2o9SkGLSBwQt2ngloXiqpWZqGndo/4H79PDaq32xb1/TtGd8Bnm53QxhjeQS/jdq0odcHlekUu1JgKFpVIYqcO12cK0OuJvBsZZHemyAIzsi+hUL1CjWM+RsfjQaZVKcW76HWfD4IW/cRcSap0ulQhAY7YcfgaMPVBohyHVWVyciuP/XcAwcGioouJKK3MBaH3FLtazDUDhEyGg8EjFEtPoU+XfNzotKSUcL3e3BEmgNebotuYwCT9A0PbNy/reUxWpgCuxSNTtyC5szDBH/dqQ5uudzLLihYKmp4OyWiYYMDUKjRPgOg45jaEcHmwmDvaz9xIORmzsFvHmukY43D6w2kyO4R+7TjR597QYPM2F4XvbZa9mNnsKNl2BqHqY0dAtePx8eFC7j8eZbO48PZ1KVhyxpfrgstS8JdPF9yWgr98uqLmhEstE+QIqYNg8yW3NzmdgjzvZhjAUwiIhy4LQHbwGJ6w0AHVftg132Fq3HfB4oG/d4mOZzlDm/Lc906O6bSPIDx/moMqIgm/vT3w69ud5Z6gqPhaM17WBVcv4etdsbU+mY+M0YLFnA5QJFFYH5CpU4ZpxxUJgiIKE8ZcIxFE7hBsltDUcGkUul73jr11vOUP9KHYGktSyTQiyAMzJ0wwqZqELIckQA5WIgzNmKGvatiHYR2Ki4MVtdgsuQtdtRD2/2iKrSk+2sDWBvZO8H54UM3w0WaSJLoNRaBcHCiu1bvRVTaHuRSmbftjd6HcnYkTB55q5drKyA480eaHnlcsJ7Ji3fcyD7A9FkgnjUTEa/weU/yC+2LBNmqdEhNv9w05Cd4+FiThmgDAknlZIKjT0AsO+xrr1cLPnwkJzL/H38jGy9BCH6D1DmqOR9LFQPmgoyQ8mLZJBDULiu+nYZRgqGXg0QayEESUodDu3cI0QDkv2T47iz/AdZTOeeLejtgtrnOsNNm4wHd2POIxnt/fx3xkGEdXSP5bjql+HlN7etf5PvM7sztuyLgcnynffTbAhNBkOE/Ay18nMsvIx+lseiqHUjmeda5fB63cniKlQ8dICaBIYky45BVjdCTL6GPDulT0sWNdL2htR8krS5PLA2g7kDOKAKXQ7tWkyIlJ9ilF4GOnGmcvGd+mAiuYICzFxhV7pz/RVbzzXYN1ajShrGR6wsGzoi47QsA5C1DGhqwNWXdU61gzG5RRsNzlcSRNWSxFgiKho0BRYOkKTQUdjDNLvTGJmxcIEit+Jj4Q+AJAkFxm9VaU2EXZmEA57on+7Hq7QPeGrg+yFLXDtE6LIq5hfTCUAuE4mPtPjKIAfMwmYDR9uzOcY7EaT8vYjtLSg4nH96OGp834FjCoBZgW5+6xzp5wJ9+kEcbO2P980/4LwX6KF/5Rz+sPA0+5VogYHkpa88cHNXVKMeTaYHlFXhTrcuNDzuiaQfrrlaKALy8LxtYxmpOSVZGEWQNuUnMBxDzBBIDaOnRCxwze0umhLdDjAEVgznbyoCgXlFqRCztH5ZKZUfJ7BGwyBsbQ54nIhxaC5OKdF5yKqDbbB6fodpWOiZ2yDLHw1Ig+n8v3/OfYqcdikmA5Yx8Nkgva22/MxrsmSKkL76ewq0C53hiQBIpcF5bOWJRT9LmGRTtHJhWk9RNQVmB5gbQH5HKfTr8NtkXG2GFjZ6mQjafDgauYYq5karjmV6oo10/I9YKRFnQp2DuR822no3a/U+j57dtv2LYN//bLL7hvG357f6D1Tr0SG/hUqLO0Jq6RNZF1FqV+DE5waITYaWM4m+4AgqJkMTZffNeZQoLw0jhWEmAQDQozp951Md5jHqpg0PndvjGzYy0pD7Vgj9WSsGbBnz4t+B/+dMGfP1V8vhW8fyjubeDjw/Dt68Cj0YF5uWSsRfDzJeNaEv60ZryWhPZo2O4Nv9079k7GXhLDtfC59N++oS537wwFJAUgGfvouHfBe1Pcu8H8mXJJv3MO/pEvCfV+NQ8GAiFWsHKT+3auBre0NswdZrIBLqvXgYeon7kWxM7aYVOdAFPJFXlNE/BI4CGramSZANQi6Z2irp6prsuCZb0QbFqYfWFnJbJ+GLh7xiYLOwWpYtse2LcN2/2O3rozEY/An2WyCeuFjFQCTQVX13KKUunWFb3vaDvBoOgeM7zcNmXqI6Ck6RDBGzQAZN9ER0eRgrxmZAPKQmDjeqEA+ZdPnxEaDd33+9DhArSYYMq+s0tV25uXgvVDg+1UEpS8lHoIHc9xVFv4nAFFqgNBBwU5wHTAdWZKQcmhR+BBrGeSRCJQp+2oy4KcnBklYLlXN+R1QSmCWgQ5U2hWjKWAWTCZC/u+YYyOb2/f0HvDtu8AxEXOC9brBUXYHZElUtQWCyHh4dpM+xhM4pTC7nLeYa6NaK9MdtjWuq9ZcxAruT1MDjxFWZW4nlmZrN3jOd3BMJ35GXZTrKhlITNgDGwbWfNHtmwihTAY2vZAA/D+9hvMlOtmDGoWns6ZnJcJBsZcqAi6C9kPZyKId35NPxJdwK//+edXlCz4+YXMps+XBUtJ+Om2TA2nmjMuS50ZZIDOJ9k8keH0v39H3c+xh2fgJDBjaWNvDgy7ux8B1TxX6Vn7nsUJuDRP7qh7a/TGQguFrxOWqXfFr28PXGvGtivWWvDX3z7w8djxz5+v+JcvN+pGrQv++fMNl6Wgpgg4FX0YtDlb3u8rwLoz24iuXjDohwMRHINoLMFkVsKXxQHoUnif/nsdzDTf2wu6CjYFtjbw7bGjDwJIESx2Vex7dxYjgfMWmwbArsC9K5J25K4oe0fO+9McHtfBoO+DQFcbxvI5SdAsHqRlnh3BipSDkTRD+tAsdUHg1O/smPjgv3PbJmsRdgg1D6E2XjeWbhcvz8sJDmjS7zKXIsiJazAlgRntlyrLE80Z9SyPpF4Oy80SooFAGzy/KE7PErb3R8MvXz9gpritCRfrqEWRdYWIshHPifUCOSeEHIQyBVtze4RgkWwdE0xNUORsWAqD/JC3aGDyTgBkobRDFkGvPCOq61pdXFp+KQVNFZ+vFVsf+OX9gUcb+OWN2k/vzoAyPzMnifkHudQbtwCY9oV2nHN0MIP4s+had05ySyKIPpMebmOilH0mxeBrdQY7R7naZH5E5hfPgfsTGDBBI0AQFSs25Q341kcli3/UfAY+m8zbiER5qeLxQAT1BxACs7nfDnSOfkWceXAbpqZevsvPi3P5ut6gtuJ2XWE28E/2J8ZaX8gybzuTf/v2QaqPNkAb9vaBZIqOPsFTlmN0+sxeqie9+fcHknlDhKGQPpD6QGodrStSH87qa14MNGDFzx13yrL7xIHa0pZkpHxDSobh37e6eMdc6iTtbffmKeQa1tvPSGVFWT9RX89xlpTKBG8EAX6fgCeXVghcxiS7/726j8O51ulIch6urzc2JkpkWEbXYqLRvo5oKjAPRgcseSx40kfSXLPxusBVzVxEPNmUJDiWpq9dkDEqcsQsjiYgGJzT9wqMxKsXYu3BY9NYu+fkI2CUZZn79tiPESvNKrFgj02/+j+//jDwJO6c8CBg61IdXJyGhNEHJJ/KIWLg4ZkAZ2Usa0Yb6m2u8cQgcJ93AjXJfzLxpfNG999JiNzGAbzBDsFxA4EcuIYJ6eRptruVMFpmR4nKCBbMaeBPKGFkcASRmdFplGau3UGnY6uFTaFxJHXY5oKEkc7IZ+chOGBAStDRfHUwA94jMFouyHXhe5WCvFwJRKXKkoZMg6Gi0yEzP2DpHBYKk0uGoECkQnqDpB3oO0Q2X1QCkQZYiLRH2YVAygJJhV9zAfIFyBWoN2iq2IdgKLB72+Jtaxi94eO+Yd8f+Pb2jsfjjn//9Ve83x/45e0De2MpSIZheWHHgnWJz+bmgm8wBTcwS93mQgEgUN+zgtNu8D0Ukjc+9HO+jzhUnjZlnHHnv8fZQufVTocPDkMCJ/UGuGhxeBAUW0rCbc34fC24rRlrTfhwu9+bYd9Y1mcKlAVYRXDLCa81Y02CCuC9D7ROJ7cNOwW4htwNH4+G3BXLUpATsDg411XQBtA6XxuZUVZg/EDej0U0ZL7nnp2MyXoLp8QwjbDgqPWuIabsDk6AMcP3vw1D8Ux/ZPzPwFMogHTlBAdTp4/hQbwcLcxdxBlxIKhC5SgXnTZFbbK49n3H/fGYrBBYiDiz7ET8OXImAFUKQY2Usx/kgPYxgaMwTUAAu35wJkBcn2iyLXM6ZV/IgkiuSTQdLTMgFZgOLA4AQQj8bevCDFpvHsDaZGj1CUCx7IelvTptMGJfIgLq2GsMlmmLheCaC3ZKzHc4mQDZGc7QCBo4BIfYrwM14TqWHG3m+XzD7HQOcOwSzIFPm7PGbCGF0VtveDw+vFFCI3idCeZzm8rsWFdrhZmhO4CkPvfDz8V5RoPsrNmFbrAUp7UDtMspoeRT22OEXVVQZ+8AJeYzpnSyb6fxgzholwEBVAStkbpuwaaCd/UUUMDVRcY3B9+a62OJ68aUEHv3VsKElc5Z8ePchkUnMWef/WDY0+drRckJP10XrDXj02XB4iV3JSfUlFFSQpmlC47xnTswxUb+zqyfv22GCTSrBlP28BcO/1OOf/h1hHPce8Fs4znt68q+z8ISqOpqeOwdH1tDkgcepWD3tfrTZcFlyfjnzy94uSz4crtgCXF8ZaZeNdYVDnubogPotD4zDoAdyZ/Yo3FLAq6lNQE5C0qlbp/ON3adpLGgm+BhGVtT3O47mhruTV0gW7D3jo9MuxXaU92ZUQruk5BsGGpopkh6LN4n+yTC8rtc3O8BQfYE2gwz1IXM2Gu0Gne7VZ3pBgudVsoi2D6AYTBtZD8O+l3igZRYZOnpG+hwCDEJByRx9M6+UayFgx3idiUBCQnqUgNqii6KNICRnclgrnWYPGFmrgXlM0MQfeCxN2x7xt4aShGMXtzWFJgs8DZcCFDUwzGPBuPPPEGPnxlBkhlbCPMqOctkDsY5FsufzSyi6/fByBDXXGSpJAWm2cDDcN879jaQZDBRCIKIAd7+SNh5+FTqXcVm8ubvXXIOrOXpbJZoUBEG3gN6Mpx0ljAxeD90nuIevi8XgkQsGb7h+ab9JRKgtH9b4v39+/5acZXoo2wwI0qo6PIbgIQgUpvf6PfMqQminW6C4ezJrxFMRnSasTEXanGtM56bCpEVYyjW8sIy9dZZVbLfnW3+wOg79LG4XvBOfyzBm+I0iDGRjTG4GfzvEWYlHciZemaaOizxK7rH0WJQOfba+eksYig5EvzJG2Agu2h4Zbk2GU7APhK6drfXgpwukHJFWl7YDd4bYQVwr+77H2QQDvW5pJPfcHJJdJD35MtRAsP3KLVCJUGazvGYgGQ8T+ignu3LXFrhwySwOx3fPELXWL/HSMXny1yXsX5+d81D2ObajDU0v/u0F373KdPew8zXrc31HLYxPivAu7g1O3/of3L9YeBp29gNKmjXpSRYSuyeVldIuQB5wXAnIGojYTS6lyVBNePzp4IPMTy+ha0XijyGwVEDokMBmE2g8JmXQtkxkTLNu1OMfRNqFqgJurNxouViKZX0YhFkM9i+Q/fmuhZ+uTMwt70A1hrQPUOWM8zpeMGQgroulDs6EeyFgHAwu8fo84CHev1xHNrgBjx3HdfhnfRy94O9A8MwNsUQQSoVPWW0b7+QeZQqa2iXNR4GwQybdHOepJNSGRkfllByfkfvDqQsUEnQvCAVn9PibWXdgmrMhgmsC+7vBI7+9vZf8fZo+PXtjvu+o7ko7Ogbx6BvgJLp0PrA148H9j5mBqi68YmOc7UUlHQI8cYG6Tb8wHbPM6AgETpxQqdZT46MCKZLHqbhvGHMl2AYxOyMl5zIYOABqs6k06kpk4ROCje3QL1MzoLe71fKgpqBnz5V/Onziv/ln674v/3TBV8WQ3YmwTbEqZEJrwV4FeCfLgWva8bnJWEtgvuj430YPppiGPCyAJ/WRC2QJFhXanugFDqL7tEMNYyu+PWj49ePgd/eB77til15yJWS8NyW+B/72rftBBACay2Y+XIz7I/NA+NYV85cKhW1FNxuV9abLxUwpc6dUnRV1ZCGkmWSWMZQPPOcaj5KFUxRbKDZAIyZofs+8Nh33LcdpbAkNQlQMrNpw+1tE8zW5zErvbF17v1+x77v+Hj/QGvNS9oGaiEosq4EmNbL6qAWQQRSiqlTdTjbmOyXEGuOIDFFmUaJVuy0gZIPQXVVgWrxg604O7PSTgyW6bArHhV/QpQ9CU/3MQbEyxFGH8gloaYybWSAgcf1DOoD4fTzfxYMVg9SA9A7upx6OY6DTZy3Mp284QEa39imDYHrHXF8BoYzWLfHnZo42wdyzjBVVAfmzeC2ruPj3TtyevmwxD3UBSkXvHz67GfV4nMewZqfebnQBjqDL6fMQE6VAe9gOQeal9x2Agitj+l4CAyaBOJsggNVwHFeuN0rrk12JF9Ae69w3bDG9YmTc6POsnrc0fbme4bJBBF4uY9gayz9jBLL6+WCUirWy821xm6uD8LxfjzudJLBUsBlWWmvF7pQOtmLP871z6835JTw6bqg5IS18CwayjnbwAxzzh05keFiBvS5V4TskmHUeMrq8xvjRKYdpp9QPCHI9VKy61/kjFo7ct5OLMDpvADiWk2t47FteP8o3uUts/uaAr2xm6JOjUhmViNNeFsrXi8Lfnq9QUTw5bZSv+pCdlcEFMGWIXtCUI12p6TsWXsCqtER07z5h/r6L9Nppl2rLpQfpbopznMHsXKJMUhhKAnwSsYwwa6vrnfl8g4iaMNmB7m9k+m9tU62q+JJm4p2RU5BpgcuFoGDuQ9ysGjD6IXo+lILO+Nl7777uGO0hu3+jr6xSUyU2VKvK0ryXZD9u3L8c7BuQr9BAGgiOtIGO+5BWBZYxsFioY/GxjLVNcWyFGhiBYSqoaVTibQqRnSWBt+3D67r1nX6yCWxwmDbBF/fElQHahGsaiwxtcHIQeA1fDrBoqP898wG9qDUHcJgR4sZoJi6XKGDJRC0kd2meoJBDUsx5GQY6nbR5zdDkZLh05IwTJBwwd4HqiQ89oF/q9R++vW+o+vRDORHuXimy/SXjyA2Lk+qOdUrTYYH/14qWZw5h76lh8oBKqlOax++W7A84XMXvxdNQXiEZbcFUQrI7uEaQTcwmdQamp/4bk+4v8junydiQtBBLQJ3FzBXj1SdbRnVEASywGYjJ2Ag3l9nrCjwIJP344wnakARiIKxiQ3cP0iScFkuMBMslYDvbX1l4tQb4IzRPJZtfs/uq40diNiwN2jfptROAE9TNqYr0hioRlAhmtAwcMxsoFUX13g6ugjX7I0v/LFqJoNSQlMyFYhkzCpF+YrRNuzvX1lp9HjQttcbRJgwhPv5wAHiziUXQF2ssbC10c0uh68BB9Z4lsJxiVQXiAzYGnIcXoI+dohlSGF3q+KJVdFBPMHB0EPDCfSh/PvJm+EcBTcy18CUEArwzNc6m0mlExxkT7bDTu9DX9k1n4YLn3tJaHTt5jiJ76lgQx2l+cdJZHPf8ntedXSyqf/Z9YeBp97ZSjG61yTulAnqIBXA6XAy4bt4ZEHJrCldloRW+bs2o4R4qT+uz/p0aoz1z+pAU1xnJQ/+PZ3K7zgp5ihmCqZTcpFTd47j0FdaEAYsUWPpnx1aE6l3JAtHPU3DEKN9+F8HIn7AYqcJnn+eZ0n88w5U0R0Pz8SQw8yDl15SAyRB980XdyGoVOmMmx7IeM7p0LUqC6RkpFKRzCnwrgszvAwkOjFRB5cZM3aBK67cT42ZoM0HkPa4P3Dfdvztb7/h1/cP/PXXb3h/bBQZHp2lFDqQ0Unv9AP8ow00p6qrAbnyYDjAnxDdAxC6XwIkFS/riRmIwPNEY/WtQnp/GPXz4XcEr3aKwfg2R7YrnY2GG6w4NFKymWVFlDhOKTA/zMzPi8xD7bJkfL6xvO7LpWBNDeLgGA2tMyucyn7NCbcsuCTBIoKvnfTzh+sFfL5kXIrgZUnstlOZCRwpHeAmXBRwGB674b4bHk2xN74HkrOxfhzfh0AqfP0moaMQBtbBAzKX/BfEXNOJYu91qTMAJ2OQWhgwfiU0wXKC7IeqZDoz4qcJxz6o/TaBgu46R5IyXH6TNi0cpXDEHZQJS7m3htEHgadtnxpOY2ZfWP6WS0FZFizLyk5k9Vw2Bm+VC4TZZVkE/ZcA5gDQAIs7Yy5wTVqx02xNESC3yRHEUlhbI4blc8A/5/S8ItnLdwaSmOvysdwrZwoihzU9Mo5n4CnKdw77qW7TeqfOVS55MnNyyhPMW5Zl6tEQ5OAB3vfk5dS8+YaBpAFUB6XZmSFGPS0dA9rpbG7rBq0GYm8szR4uVDtGnwd/zgxiJfMe1vWClKnpFYdCOKpwwAxm1HGy0JOR6TAf2V89ynyClefB7MwCizfSMMxxjflJ+WDI+cF43Iu/j46BkThOY0ShsWv/OUNt3zf0/YHRG4q3DFcXNu6tkfXnAB+XG8sVSlkIvuU82V2YZ7PvL5/s5HtjeILqR7puCwWyA3Aq7gjGmRZluCzBYNJtMrgBD6gBuGCuuGMtXjo3df9OgRobLbiGjZ/9wRYP5tt0iOflYOwgcNxbd50VBuSqYXMP38fm/xjkrzXhuhYsleWmn68LlpKx+l7tPQAS10Kb90dmVbATk4PKgNuGs98orkfkf6eenltfmxZ4gj9RfsJGFCcRZGfSmySolAlEmdumbsDm3fb2RtbhtncM8+5Lk+1KUf9ZmOgldR66TceEJYOuAShe7ggCOyWxe3TOCQWcu7tuaKaANcjYYW0HXNfNzCA9/MnuTS7U1dee8+Dc9TL9o3CSzAh0U9PN4KEvzoy3KPGLDn0CwKJM0v0b0wRNQPYqCbqTnKOQvYjTgnm9YIx2T7Z05NSgvYGMrNDpi/N3rs4jaIpl5wHVmcV3SjsjymKKA36j6AQVBpTCwoDvSQf0YROUCoxAkiAbcHGJj9dloIjg3qjL9r53nvOnUswf4foeRDtrG/HncN+D0d3xutin0WFQTu93BJc23+T0ee5zJzx/VoBIEuCD6gSaJfwWe177sTaen2MaVL/XNAGM+DfXiLreD88mkSMRcI54E+SIV0S8HP38iuNcPNgyHiufP9f9AtP4DH7NnlyM8q6cCNKHJtzwCpzh8akagScZDjQp4zZpD0A7ZLT5FKKGpEAaijSUurhRug1K00jKyIUyB2zgIpNFXUplGb/Ak67i1ShhoKmRieFAbu2AZST5gKHTngljSoLMLvnijy9xwMjznjrkYryiZ64zTyyo+9rhw4v7qaRfM/mnOuNe8yQIkP111Eed4OCcz9MSQASc9N8ImwTkc7r8POYL3W6ecIZ4uc3DVE4fwn/HORIAEePREB//Dos4lidiScrZr3p6kMOWHp//n19/GHh6/+UX1nxuD2A0LDVBJCNfFkhdkNcFkusJsT7fowGmyGK4XTK0ZdRrQdoT+sYNmhxwER/UkDT1xAN61ODhUJsPMlscFymzlCLXwpKzTO2hHMDFKWNGp02nc0agRj1ociaSM5dCGwbdFzjqLLuIw0lONe48P41gXVB71SjspgPJlaLldxtEPLjDBDREFLDuNfFO127UbErR9tWZXUgLMDJEG3QYxt6B3oF9Q9goSwU6a5AJ5OXYAGpog91bOD6G7g5UqWRLXK8Vl7XwnmzM4C4Ckq8fD9y3hn/92zf8+/uGf3974GNrM4hOoux2mOgcBaV6Gwz8uzOahrLuF37w51xQsmfoDS56zPbEUHaVCPsyt1vyeQZmJ5EzsBQmgY7O8brTXp6AW80UqKtZsJ/0pI4uBTKNPvexHWi1x2zsRma4LAUvNeMvLxX/85cF/3xL+GlRyDDXbgA2TdgVaKqeTTk5hD5Xj33gfR+Ar721JtzWhLVw7OqSkZyhAgGS7rAx8Ouj4ePR8a9vDb98DLxvSvBKeKByTf9Ry/B//Wt73CEiWGol06K6WLM78uZtv82S03/FdWuYrQeYkX08tunI5lSwLKG9U9zOka3TnGHyaM0ZT0omGwADP79IxiJKRqFk5FyQ3CHoXsIHAzs/unD0mIeb616YzW52l+uNIIGLMZZSKTTtDJ9aooNROQBceDYNmJ8X3SF7TpO1YjDPeqTZhaxUCrkSePZOmEOnSH3ysuzW2K1s3zeY68eJW8XIQs5Obv73AMBTsFUhpFGfDlhmAD3jk+gQRDAae2+0jmEde2vY9o48DCkDt7JiWa5Yl0O0neVsdHDZaXNgAlzheHqQPjOS48iMSspYVnby+3j7hjF2tP7vyDnj5fUTUi4YBkgW3F5ubod8Lt0h6Mqa/rKs09mOQN4EkBFZ43Ri5ZpHN3aUScUY6FGONzPF8T93OBJc7PnEYguQPWfXdkrJ19mYrLoo2VvWBbVW9J1jGU7M+8cd27bhwxl5NnaYKV4uC5KDa7UuuDlzpHsDhHCmxwBaVxQHm+bcApz3VEDQDIDvZeBw8n+k62Vl5921sAyhBOsmgBcv8ybQKOjuFZlnPhLiQBOfenEdHs+MOzNF/NCcJWsBdKRTe+mUWdIXWdC5JyOhQfsXnXFVjeVHiiMRJkDoP0Wn2NdLxU+vF/xPf/qEP39+oZ6Zs5dEKO0wVPHYyfSkb8UgKieD40Z0+4UAURKCuQFSE1jjz7ML9UbJRvKud+w8xe+zyURkcQsDKXGf0O0h8sEc5VyIB4XexWjx5F1nqdq4iJfiwZN8nvhUIYiVMlKtyKUShjJladzotDeqrsd3Fminn1gceDIbnqHvEO3IukMGu1HTnvMaSv+r69ERz+C+Cg7/KIJClp55yV+K5wS6KkTFE6EH2MBzQ9BHcraQJzvUbZOXxdTMgC15R9DhNpZgpboGI9eneAe8IoZ92/FuBgzD5bKjbQ11qbhcVuRaJoO1hOZTyiSEWGT7gSSZeqepIMpB6euTbSx+vookJP86hqLkgj4UubmeTaH92poLzRu71bbh2mB+NlKixFBTglTgT7cFW2fAvg/F18dOvdEf5joF3n5uPyd9w1bRE4+1k1y4PoJdswi4Cbpgfv8ECkj4Lyf/xoKZQl+8BEPbjqS2uA8RJebhg5yTkgF4SUrT509Onpil6CHB4mCQOpA1QVPP5mqORil6eu8I4eFhYITzXjqdE8qyECwL9tfovl/P9p3jYcevuzOfXBt3wgROogBgCcjsyoi5N9Tju+GNPkLLiN0iw08wF/keFh1NZYL5RwfcYLZTpgETQDuAtEhIBFlMJEYkzTUgCsj1E3S5EgRuG9TBMH18g4wNcv2MhIJUFweV5kp4cgs4nUezllTqAeq5fxrzTX+fwHICYGNwCY4OaxtSNmTrPqwUQZdcXNYj2G3whBDtzrBg0mPO9NRmmjd6lPCp+r0m75w8z+WZnjj5x3yHqcHka0zDP4xEpDGhOkuII/ZBgEy+gCzi2fOuDVaZzB1+ZkX9Z9cfZzxtG0QHEk/QeehFBiz0d3grseIPAxEbsmY6Bblk4jG7YECchopT1v/8Xj6Qruwup4fG+fUiFLktFWlZXI2eNORo38xftNNiCMTOMzqwwH/mJTPgdwBJs78mHd04Do9qBgQhiiiBRuhgWV6EqfMZjhkVn3waUfi9uubT2D0o6w5w+cY1X4xmEKODpEOhrcPaDnvcaVBg0JSgXvphBuQz8GQg8NQG25WrA08QFG/nLn2B9ACe+ixj4SMbtvuObevY7u/Y7xv2bUfbxxQsyw7CxFMHGGSnUYiNZDGzbuQiy2en13AthK5WdJaYSy7e8AAXj28Bf+fv53kIRzJJOOCHsYzfm+/pD2DeGc3O9Itj2dGI+T64FMHrknDNwCKGARc+NQJwwwxdKWKZTgYExr0QrU6D2kuRT2YFMw7Bz+zAlQ5FNzpHH7vifVd8NEPTODTMg77fYe7/0JfqcCqruSOAab/MMJ0RnbQep3lHa2U/z23oBMURYGjJWJYlNi5a7xjuVAx1nQxfrTqzGsm1fAS5KPIohy6AwUu3ONettdn5rfU+gX2xWIM8XGqtqEulEHVhhmnWsQsmAyDAdzkW7MFqmrZMkGGwJE+dNkJ/KIJQvoMHasPLBKKW9XR4haaRKvWjxA6R4RCH7qPPQzd0qyTHgcpDl48SHTUPBycOZN94Dsp55jg6bg2FSYKAtsjcOUhlOUCnub+jheTzQWqx4XGcHdyMdF4YzFL4snfFGBvX0bKiFEMqDgIu3tI3ZbeD4mK6wztrZRwOu076tZqLTp5soPlaBIL16WcNziDc4dT4okFYUBHMtu3ZncMzwzNYCgTVh3dJ7IguiuG0kEkZJeSGfaPWWG87eqNg+HSkU+ydCsku2D+i46SLy0/QjJnis/MfBlWeAphjyn4s6wUs+dSpLR3+Bp3LY1LD4QwwJQ5Z72kRXtQRcMADMv9XzOMsRKfTdboTvmLqqZ2+bQDOoG/sFd+S09+IiEj83iMxU1PCkhOua8XLpSLnyiDf32+Ae5osIZ2l69GtLx43HODswFgqEfwQaIpOf7UE0BTjSPmA4/693AyK0D/g92XaobC94Ve6OgAH3YFxSa7HlB3AnnYTTA6OKKNNsJSBXJAXdhqNshnrCm1kUuowBDIYYvExuDmTTa0DUDFkM2qmKX3PYEBGhHLKVSPK444I5PtpP9bB/Fy/OBc69YlOK3LO+5kxcqyzwwaFCHwsOYKh7l/HmrF4rR3+TOvYUnTXEy8vAqrpXA+W09MKd2cdXp80AyZBnos1eUI0fIVsPufZ9eQgbpco6ZCE53uARmkQeJTIUZ72AfxeBckZUAn7aih9oA1F/6GAp+frCGh5xSqKmCks/FwYEQvY8Rtyev18DzniAfNfoG37Lr5KaTKKROgfzNLWILlMvaZYt882MDSdMEHfZzsQgPw8n9z5P7Sc+L48ps3vx0ux7LQH7fTrkElIAOAMJZmxDZ9N3Nif46fzOMaZEKMSVgzTl4qgxnzRqnYIXEcrdYQ0S8QVCgp/DwNGjInAMYHQB44/x6PFbMWADOH5fwBPvsdde3QSh3KFpIK8XiEpoY1GQH50AnCjTxZ+xNIcjMSytvN4xb0lefKV457PekyT/Su046kUxnojGFpOMOHCch/fJuOKOIAdK/y0nk9L+TkuPZ3TZM+lY8ROh+9hiU92207fOp29Bwil01c7MwplLrpjr86SUGACdvH3U7j9dCf/2fWHgSdsHzAd6Nsd4geYZENqOxduewe0MLPpgQmRRK/7BkUOb0uBXoBPnxbsHx3vDwoM9qGoAlydCZOFgxALJR5SJGrvfaB8gZgILBeMUlHXC/L1wvp8AQXHlBkysuN88CMTnKjPovDA0K1ctMANI5fUHexs7NZRZNKiITIzRQcbobsOxyDzQSmcKh5ERdtKG8FwMAqYrczuq7AGt+8b+uhst+3Ov3+SO3wCkYySV5S8YK2NxmV4sJ2yOwE8jJNF3Ys9LUaDsuOeZ3qSKrIPfkVFsULWgAFDu6PgOlkTgM32vP/0esF1yfh0qdi6OrPpYFhEJqINZtqKv0ZcnLPmTJZRItNoorviTpa6Fk1OPNzDqT4Z3dBjMS/dAcJx4foJQwIAEh2kQQBnyQkvS8KtZpY4RGeYJIezr4B1BkfdhbxkApk2WXBy/mAjnfRSEl6z4rM0rKMjbYLuOhj3feBtG/jtMfDbvSODv7pmBluvJSMX4FoFUfOdgiGqQHN2jTx2tsz2AP7tvuO+d/xvf2v47T7wr2+K902dZYZZFkFC3h83Iv9Xv15vV0gSXJYFOScsdfHyDJYGs6sMszcEV4rrefjB7qW25izH5CAFMz0JzX35lELPLbIDiV0QMw/u5iVb7NzJrjmlJCx2lBI9tg2Px+ZaGwcjKADy6lp167qS1eQHfF1ZDphrJfjuh35kX8Mpmm6UO1QH8ONlX6H95KB9ddsWIr0BjgXrZXPR7/vjQbunipQzLpc0xxhwcNRc9NoMozWM3rFv23S6cslY19UB5hCsZpe5UpfpBBzPcApy3N4eXe94oJZakVoDUsLWGvpjQI3Cv1M8uTqo7kt+DNd2Uu9u6myNmNfkQEAEGbWuLkaeYWp4f79jDGDb3gEAl32HiOD6+gmlsmshJEE7Kdpb22lHpXEfxpi73ZaREew2U5Yw0UmSqbdFMKfCjKWFY7DUzWL9ejAdrIWcM9dSLVhmKWl1IE+clTAIHPU+/9AvNtScINVLDHRgf+zYgnbuAFHOCbfrFZfLdTJkbpfVWWYVSMmZbwJLBRBjkK2Kx74j+VyG2Pt0zOHrZ3QK6ZvNuTN7zmz+CNdlYcllMBUFYIAkmMkYEdeVEXgA78Lyqnj0Md+r5IyXdWVJw3dg9CypFAKhFD42iAwynYph31jaNOLMD5AZB5ARAYaA62gYg+mmhtYbOx9GthW8f5ajKe6Pho+6Q1KnvXJnfQw/Z0eHDgesElC8/DCXgx1FW0z/sy51AtczUSqhGUNWnXkCB6YnkJPAU2uGLmSxMBkxmDCo3ligRvnncFaQETCy7jbKNdpUZsli3KdmICMHlYhNWUql/kkusN4OXUpf45KdMeWleUBk0dkdz2Doe8NoA/u2Y9+6s88c/IC47+NsSgFqUUiKseZlMauxzsAurGqK0oL95mG+78kExVGGCIiQCbIUvn4ttN2agaGD+939XnaDTX7u/R6oCRZeFNDRh+OLRu/YvPxuqxseW8XqzKdlXaGXQdHiGFtvyEN91jH9Yj6u65dmL9/115kMIBuqFsBYVmRqWLx0cQzuiZw3tD6QM3XISmeXvtY5B7WTXbY1nh8lU6x+qRldDS+XciSCfoAr2GYHg/coJTxAkVhDMtdP9bMoR03sBKAcbDoBBPz34a8G6/f8+mA8zQDf/Pc9FuM6D0kK3sOZ+XSOF+MG0gQsMcv0ALeDEevEc53GRBzgiE6bKgEg+WZz9tf35cx6/ozkXdWjy6L7RkgCS8JSscSWNrRPpHWIgwgWgJcxikxzDM0/PkCYxMofMiwoNm7JYyCW0lpKfP38ndj7aT5rkEWOWNOOzX2ap8BcA2zOE1zn2Wa5gjHaT9DRUetC+ZaxM3bZ32FjA2yw+mm5kKU2QZsoX+bczeY7s1LLq0NcZ1UKE5rJxkxcwAy1VGjfMYQJNW13QCsghayosnAcUqKNGSe/1NfPIcnjRJqZ1PCfnxbrcbY6eywHdGPAlByIdWqxnY65xnM1wPma+8VOwC+OOMZC6me+oZeBp9/vzRNU9n94/XHgyZlO5jQtAZBEXfOkswwv8DwlrQ85Q5zuLZ5xKjl5h7uMUaJTk0TyYd72kaOwY2MjsqtnY+Ogk/9B0KBThrieRAjExkBGtvbQucB30J1v/GO4YyoQVsr8niaqegrqZqbndLjFT7iX4ylkHr4Sh3c4mAkEWYZhWMdQaoOoDvTRQL0GBhZDgSQFWgRQwZKIUs/6Vt+4hwmLk33McoyZ/Qp2lmvRJGd5JU1Ixmxp3Ku5sYznjUfLSXCpwV0D9u4tjw0uoOh1xQYk13gCBF0NwxkYNbOungHoCTWPKQgD52CT+vwFMm4mswRhticOp9Tvke89Z8KXgVCYu1BTo2bqJU3EXvB0A26/mYm0w5iaG/O5rmQuE+RExlMVYBGltsEAzHUwgqLdhmIfLENNAFo/AK4EvseIAyGdNBQ8AFHfpwGG3Dcynb7eB357KO6NJY7f+zmBdP8oV3U9mfgazI4QEpxkKBBsKbXMTAipqWGAQ9vEgeZgnQ133BFZfxxBWXIdkJk4dwpzHCtORzZ4NzkvaTreJw4RX6+ZYAE7GNVZCpXj2byOPkqx9FiS3BcA5q49lWIFSCHJkNJxfMS+i06e8FLY+L3QT2qtzbLlLMERPbRg5g34FYfUoS/DfZijpCeHHhMDvOxg2tSmwhEonQVGcUajJoDlDC0HT1pvSHvCZWlsNuElz3F46/i9wOv5XzML5uN00MozTHRudDJPwnGFP0d2EC0xyzcoymkQpOg26iCNeCZf7XjGYSzhhp91GQCXMZ+TsgIJNsvQuACieyvkANzDZnzP6EySMHw9Dh3onXpi6jpjcw9NPSzMphRxzmUvdbfMUDHKwuuyoOQyz8vZQTGCaHipurNaWmOZduHi9GDA5uf1fUe0Nw+H/486P/8oV5r+Aq94vgiWAUxb5PjuLBvfx8D71qYtWUpBkoylJOpu5oTi+zRNUFemAwt41jYLBNR/fArA5o0A3w/7tDGi7Lo6lN0VndEZ5RrUZwJCCH/vA8n3UTyrnsrXzf2kdNrfxYGnKLkMoPMoEUxzjxwlFfQFNAUrXZ4fxSJZZ+juTwCC5O1yLZvrmdiMu0zU/ap2BGMQGNNHTJgKXA1JJugkOQPZgzxPZmoEH2ZHeQ/ktFsQuJ+vAb9n13ObSUE/BCwcVP/t5AuIc2+n8t3TIAimv+fEJiZqXHHV075Pv5TS6dwIH07ie8H8cIDb70ng8bHKfK7AJCJojY60yRng8eiq6l2Nva25+9nZxzHngiIJkpn0JaDPhKSBz+SI+gTnwr4y0HG21al/dobAkk0wJSVDVkHvR8mmeEgf/u3wgokQU08SwTbPym4KRZ3l6j/CdbCAzt/leDz933AA1hIJ3rPf4DHZ9L//g886/cbfG8VzaDzjR/8vPvtgEJ+8iu/mZLIcf3cvBthBQohnDIsdty92PNPTvfueCx2f88/E96ckccb3d096vpX5QcefCWXMcvQnr+l54CT2XWzEabFO+yDu7+lDTx8bu2VOLKZ/Ns+t+Mt3Q/jd/R1rw5MjhZIP0A7rGWP3emZTYLA0WSIYmszo05oKPOEEAB3jdNwr9TPJNJ+gus9FEoMV1zvWDkhoJ9lcz/G5x9NEmvW7qYoxOo8XB+h5nE5TGnHGcSIc69sQpB05jfFp7Od5ED7TMTfmbJ/5cguwDAeDS07PMM8fw9M8/h9cfxh4EhswGxgtMsF0rNPWSDUtD/J8kzs5QyGloFxf2B3qeiVwAcFYgM8vlU5J8bXCCAIrdFJ5k3jpXQRn8+kPx6qrwRxwzcayMRsNaGlOQOiQBOIXehIxYoH2RsmSEwQn6ypGnTRpYV1//N0AdYdb49/KrKt0dgkIxzjPgNZBIXVQxz8/5wQpCWVh4DBc2K1pwz4aPjYyn1pzRsToMAhU2Urzui5AVVwrAAewTCi2Zuqd9xxYGuZdQ3pH35uXJfLe6loBr8O33mGjo5SEWumw1pKJdsFwTjCbRXc3w+frgpdV8WVUD2DgZWR0YJoHFt1r4HdnPN29Zh7gAf16qSw1mIEJ2SlxJaEZzInGNLLCZnSqr7UgieLPLzJ/ngWohU5rSTTgOZh0SWYpXMkJl3IWVvcSlGwH0ODAQ29jGmYfDTpqM4PnNeYl4bYW/PRS8bIkrGLAUOyPgd0ydhNsTbGNgaaGLmTeZfPD2R2XkgSf1oLbgsnAeakUIo/OLNoVKoq3RhDrf/3bjq+Pgf/1l4733fC+k+3EccS8+/MB/iNcnz9/5n52XQ/GD3Ggysw8GchyWpd6ot8CZgvgQVRo7qgO7Pvm+kauQZFCj4zZ9XVZeZAlBxN7w2iNHR6Vel/Ub+Je79GmVti0oXjJXAibJ2ep5EydlZwO7ZvRWB5WDUjZWK51yuDFNdTFTzs1lXprU+turu8krnViU19jqWQORIeV7qyH3bvotZ2dsUplxqeWMhsUWNcJVBkInr28VpgZXl/Z6rd7GWHJ5w5z/Bp4LkH2o2uN+r/Na+GTAEspM7MUmb7VtfsU7LqlY2B7PPCREkw7+kIWTnTuYzmTZ9Y9cAXYHMPMXPvvcDrNOLeP+zt67/j4uKP3jjo1wFakVLBvO7U+VCAnEC2XyvKndGqdMcErdXaPYvc5G1HO6M6tpEH9kexJDHAsikRmEpjSxeYg0+xmCowGREvgcFx67+ht5/nQG2qpWOqCZV2xLpfpAO2tcQ0NBsrVhdov1yuWZYE5Vb7t3deU6zmFILuz+cSp7gFqDKc79N6YjPFOsqEDdv94Z8eux53v5efRfxSU/CNfbeqUwAEazmmwdrMH+iUn5ASsAPah+OW+47f7jv/nX78yidEVayn4cl3x6VrxLz9d8fm64F++3JBzhgYjxeel99C8AXI2jGxoraM3B6BOARV/j27BGIbWB/a9o40dfRh++djx7dHw//nrV/zvv75j7wNLzXi9VrwsBdW1U97uu9uPzG51Xu4cmkY1G/Uhw1dx7cnLdUXJmXYK8CSdzW5yBwtV3DdiprsUMumqM1i7o3baI4AIP5F2p/VO1qzRTtEjoc6JAJ6dZ0J2JrRc28Rg6AAbFIg4wOyaUR5QWdT+qaE9Htjvd7RtQ983NkFYqrPABWVdD/aOZ8AiKSwgsJEFE7iaZYon0E/cx+XL+DXE6+PaR5/gMgSQnb7l8PMlAV6am51Jx7OpOEtRwDPX1H8/GXICak4z286kgyAl80QQ/UxTnZ1Q4YzNkj2hmGI/cK02A/YmeGwN696w7w2XvaHvHev1glUHyuXqnbVo71V2ag+OBhtjdrc2pCNeDe9Agj3uoaOR8QHzM8LXWO3D1+BAGdyvJTFpUBLLlJdCW7f3we+3gaGCJcuTEP4//iUTa3gCEmZc5YF8ciZu7PfvQIE4K4HYx2dg4pT4TqFj9HyFHEjEZvEWM4An9jfBpzPope5zhE/0Pah6sLAi+Mesmpn/xgkUmNlAB1L97AvQfAw+Q++Nv5yOZ+B78fNzLbEBECCKWYJk16GyQCmC9eQNWkR4f+5fuKTxAcmdgKMkCUXK3H+mbDJGbV0FhGwYDS2mp7EjyEIL6aBOaHc5ID5HzP1UdUJCzM9w8gjczqgN93lcVzO9wOwG3VdWA7W7AwobVHeIDkASNFVAqJ8XieMZi0s6JQ/l+NkErgxC0+VnEdgpPCeovkJHh+4Pxtr+PKrq4CPnOlj8dtadipguRWJXnj4/GrTw2T0hMc9am/ZGvAY5mLTwNRKJxEjaHMlissW5bmzGKxMojGXgUhCHZihfnyTWYD4BkyER8ceuP854mg/qXyFI6hs5BPjmyxgIJVWkwtKJY/Cd8VET27Znd7B9n0wBUcCdZPHD6ntaIsGnPk2ahHQhWQXOclK4XoSFOOkxAbP7AA6qPoAZVPDA9PuhRUJkQSa1Mg5UO2WMguoW/Ga3cFFCEd2uDgMaE33QsPmZBohCnU7ZPThtfTjwNCb4JaEt5G7HRKt980cdMiCzpMpUYYPvw2AlND6i2BkIMcDigEw4KzFgQQWdc8ZvuhMs07kYvi66l9z1QRBqOPC0ZP675EPoEsAstwu0P0yk448cz+PJENkxBYNHClcm3Bb+dvGytMVZTCUdAFSwzZLQ+YoOQucMXhjkCOYJhB1z+RT2WJRdwktG/LOyYJltj6McwbukeNnVmOXC4Rz688V57c+SgdnqObZTBHthnPameHTFt4fit7vifTN8NGeh4VRu+B9s/X/0q5QKIPQ3cFqsx6rxb5zAl6DfHr9jycUmfV9T14ji1fF22R1amdojnL8BroXeB/bZvtr8j04x3hkMiDA7m8n6yV4OVqJDZxh8F7iOAzs7FZpPE890OEJxEEZZ3BPzE5g2XgdtTuvUXpp70O0Gu5jpZEBExvhkGo5xM5vlgjwHnJkFg1ly0OD03CdnM0nyLkFReogJ3EcHJn6wHSUe4VwKM48Hg8p1B+YzULQ9uhzmZNPptTQNDORpjeCUfXJH0dkFu+sZRUvsnKsLMTO4VFVYH2ipTfYTJM0DO/uZcBQu+zkX5ZbjYMLxzo4z2eK+pkMbRFcfc39mySmUzOjQ+fxQDHcgGHZjhB0+l85lL3s8aN65dwx3wiXlqd20eCfFyTIeR8lCAIiqPNNUFXJaX7Sbw9fpcOdHEWWeEYx27xKonkAJx/dHu2Z5ugYzKFjgPsfB7vW9QADIWLL96Pjb24atDWxtYCkZ2z6wtQVXL5Vsr1wz6QRSqpe2wTAZLyJup0JwO0yGD7lBPMlEMeU2Bh77wN4Gvn1s+O2+4+3Bcm8IsNSMy1JwWyuWkmdHva6KpPS1sq9d8b2YEmOB8CUDKM/eabMEQGkGIBjd6iXHwS4R5KQHGycJvcfT+nzSqpoPChjUxdKVGnjqVsg1OEKLMcpljpE5nHcV+GuNsaA/W5RgM9g0aB8Y/oddOQ0FJ9voNoSiwYC25kCZ34/Zd39wGgNMzaTvL5Fgjsvx6Ba2xMs4vbNwvMc8Pk6AQUohEB0+kINidviOwO+D/amjAhf5DYTJ7JhzAVKi/wg/F4YakgpGUk8c9cl2SyV7V+eBVJU2OXkwLjx/YqqPpe0R70QoYq5w+A4R6DlwyrMmOpXyuRMI2kJlSkNYTmSlG9kUJelM/n3nRf4Q1yw5+943CCBkAhOxDv6jMRAcTCSZazIAFQBz7Z0/+7AJT2+Fp+/Ydz73BCcE0LNfcop9Amzys0f8H981dn9aOmFn4jGjC/xkYSY7ESPstLdw8rOCoWrMTAfIZDFGguMDjj8RM83nTOL78Xynp7uNuDViXfMGXBpzerBQv+fyxP0aTvHyKV58ihmfriNJMO3OnG/vzBprJrkfWRcyx7WBWpMek48GSAa1+QyWXSs0B+vre4CT4zTXDw3YwcSM/yehtnJe/D46SI45rV07+EfxZnGO+VPGdJ7WfpQpx70cEUqATu7szbGFx4UmT6vs6dmOte8kHNUJPPEs+W4K5Lgv2Hlt+Ne/c3D897hefxh4GmN4WR1I8/MDrO0D2RKykkqsSGx1+sE6fTWg9gW10sk2ZCQDbktBuyheXxY0adg2ZqiaM4CaCDsaAshO1Tc3ygFkaDkMVgBaBQYZA9p2WHQpmM7u8LIyd6ZDlJqeMQLxjMy3+cFHDakIZISaUUP51RTiwZlVKtrPy8G44p3FQjtGwrkO5+C06BSAtg7IgAi1oaiM7yUPw7tmwMAW5Bk5rah1xbq+sg1xvUyDiKGT3YDOOSQy3DB2ZnmSDZbVqSFZYlInSluSQEpGqYUt1I3ix+pjqXowkE576jBwEdR6QFXdhuXkmk/FHaKF3+9RSuHO9hS3BQBz3bhTB4xspDOnydwJ54Wv/TllqAFfPOMRTlWOEjt//ywhPhqbnE8xnSg/jJIDV5LGzNJDuOmf9l04r870YtaLGa1bzfi8FlwKywmHKh5DsVtCR4IO6om95IKfFwakCcAlE2hqzXAXpUh/onZayXRkeaiRCQNhEPLvD8PbJvj/flP89lB82xVN7TAuPi4zhj/N449wzfpx5cwGiHKISQdkjVnehNNBmnOZzJPeB7Zto67EtrH01TNTBmPnvJRRULwboR8Yg9obb2/v+O3XX2eGpS4LmTEFxyF/cr76INicx6Auj3fmi3LB+Yynv3A9C4V3JU3gh+sxSmvhq8pLBp0x0jwovN8fZDL1wXsx6sPUSt0OSwQwYAmWBEvUnPueuH98AB6Iqg70nTX4GV46aofujABTV6gPNiwYqkipo4eGhtuEPgZSLpMJlktByt5iHuwguO87dmt4tB1b62idQTCFvd3Q+IjpCOeDABFBPa+gcVvRrKOr4uN+nxpSMHN9AJmdBbe9YQyb8/RyvaEU/j0l7mt411ARwXK9IpeC6/XK86YRhOubM+mUzJLtwbkgwCkzaIoudHBG1xP/RAegHdp39O2OaEFel4Jcrig5YSl1egvqIFzY/JQTLvXqDq4cSQlJBHucXTG8w8tSVyzLhYyMkikOnZKfgZElc1DTbNrSyLaq6xxGVvkoD6LdzqWcymNxlNDUBZrGCUhV/GjX28Z5D2sSHZ8Y+MscX7jH0gZ1nb5uHb987Pivv95x3zreP3aUJLgtGT+/rGit4V9+esHP1xVLybiuB5sQrhsJwOcMaMO70AZYjedwRc2wNcX7o+Pf84YxgF/fN3x7NPz12x2/3Xd8fdCG/vllxf/w5YZ/+fKCn24r/uWnF3y+Lni9LlhqcRbPUcZeHHTweMTBD//08J/c3iD8iBF7SPHYuDf3dgDpOSX0y4qUyXxSNTzcD+3D110+gShy6KkR4HIWEAIkF5S8BJICeCcoEYIPqh17M0RysNSKuib6eCm63HW3Qwl9b9DRHSBXZDVk9yOyM76CLWEGjMeGvu94eEfJt4877vcNH1vD3ob7VIf9FwfKJHnS1rdOcT1LPQd9AiylIongUgv9IbP5qEmO+8kpT5a4gQAaE78nDSgAZgz+jrWLpzg5Tc2a8KVk2mZfcTAMdjkcitYPNgo7JJNJv/WBtTUsjwfWx4b1vmG93rCsV7d1C/1fAbr7tlxWLt9h7hPIseZNhrM8XJ9V+WcwD08Q3kWZVQzofQbngNs+SYxX1FA0SvJOcd4PcAWLezI57LBdAEEXA5Cye0rOzjkAJRwxBCIO1nkuRJyjqrOM9vz979lIANzvI1AY7L/fs/zF9zvPqDhVJqMqfi/8xVPMf7CHT+92AlmRokSVvzjtqep8D0pD1Pl9M/MS+iiKMgc5ALhQ/oxpE306JiCTOzPJq3QwwRQDyGYVhzRcy5T6cfDPFHZtVvN9YVDNMBuUoPCu60jF5W18DBwccXPszHk7rQMfQxzgow/HjCdhZM8ORFIlWPNAdHaTFKybAkS5NSaNmzjAaNDeHIDxe60XIOfJnJVp3/OTjSK5Y7ivbBiA37sAkpHWGyuJ6oXnVcxsgD0O7sy4OAUrSDwZGLGJd87Mse4dnIxFD8w5Ea+UmqBUPj7PoiLg9DvHW9hcu4DH2BZMwDTxkJKDjX/sJROBN2U89tmEGHwvpj8eNP5h4OmJqgyCMTDSuMSDa+iRLRuddc/aGylpY5BCG+UFiYynpSZYTWglIQ1jICPOWPE5mCV2PqlUIOJ7hSAcxA2KL1Bzqps4nc0MXioTlHx/z9NG4eaDUxuPQ0ZlAoxzg0c7RSg1OmAAcnLgOSbgqBuefxz1nCixO3UCX0v04CBiQIZ3+MB0wsOQRhvxJGz5XnLxAz+DWRx33HEo2GMGn+cuQTYz4Oc/05lzamFkFk+PdhrHYzjjyxOI7qiGzK5exOeSHQdPvDZpAFByWnOYyLc8oSU+OTgZ9tMBkgFI4fyXmWXjHE5xep+PFMBTbJ75aGc0PN7fjaffS4BXf/c6eed0QHGUkBq76owBNAWaAd0MfQA6KLa55uSdB6MTSpT3HcGx403TEe8zMBAMA+4d+GiGRwO2zrJWag2cpufv3fePcs0OcJhzeGRkZYrkRRcbCzvg4F1MbpRMTtHJ+ScyygpNeX7v7EkzqGZJ2b63yWSqcMHCacxlfnR8VjAAeTjFk2RYMkTnkFN8MFlxERScr3By4vUzcAxb4TpDvQ8PhAZmu9t0Ft/0QC+lObBkPMB/38szNPRGyKrM4nZM4zkPBqq5do+4QILlyFS6ILkzrAwCyXnSj0NzSEy8IQTPAVNqxgS7BgAF5acOyJlF6YEYhUZ8P9ER6y5a3lqjlpUPGrFCmd38IosZXfJyIVgfHflgEUyT/j3G8MOaezX2cHQKHR50BruMtOuDSTB9NaUeDrucRtmMOxVxbkR2C17ScHauInum6mef64a5HlD2M3vW99sB8pg7VSnHXOQJiM49YKe1OA+0ufCO97NjHYRjHICoiGuqTGDYg/0UWeIIZp8d/h/hUncQIgkT7tBx7sjc8HQfGFB1NexKMOjRFB97RxaWjNQkzj5a0Dq7FPdBmQOO8FEKOs1LBBLfTaGc/KMxGOw/dkVNA29bx9d7w9vW8b4xEVlywutlwcta8adPV/x0W/Hl9YKXy4LrUlByIqt7hK01NgiR07P6Zf7/ADRZph/C6gfQPpxh2t1XMzVoUpSekSxKvlxA218vQi0fPuNRhhyNF8THJO4k/KRIIKgCYv55OImYux8rqsiuDyhgkKOdItZAgvnvxiALP2BKIpyZIUywqicLaKt6H2j+PGfBaveQMeMnhG9z+Fji1vG8l9J5DEQQSsByeuM4t6LE5vh3+M2Gk5fp83mU+oXf/bTOUzAfwhelfYuKpRBgH2rzOfowSPdSID9TqU3FNJ6kgpQrWVA+n0CGpNCO4KKPAOsI8jlevtOm3T7OU59bL3MWiXs6Pef8n5+lvreRgOQ+8g9zWQCtR+QYtoTfPPxpzAqUv/tG8XZzTX0PLp0ZTX+X4eQzN1kg4jHfDALxtOJnLHGK385381TtIXHr5+CErww7+gQ+zaDnCJSm3/nd559CkVOnvPjGcUNP9w452Ddy/GGJoxz3/BS5+P3FbZid/NJYww504/Df4HrA379PuJkRuwWQMrWHY3zm+8yiX8TMAMEKOrFGn+bMz/0Y21wAzGwW0CNpM7jnHFSGul2IyqfTmB/JaHdc7Lu5j3NXBJIKJPQIfV3SDsrpGeKRTvYaxxwAsZ59wOTYM8f0nD6fA/Lkv4qIy94E68yN0tNYf3/x52pw0kJ89rNNj08/xuC0X+Sw2f89jtcfBp6SL2RLlaJ8Et3qFEOBdn8ASOjKIGU0hWWB9Q7NmXXaCdTHgKAIcK0Jf/5ywaMWfLWE1DvylpGV+kVDmI0ZCG0SwYD/24AizMCHUHSUr7GDmtLQnxZELNoZeOYEpOxgmEynJflERtmfhuMFA1QcaDJI96/eJttS1Ov7RHk20lxVUP15JLObVjMHEVxHJfWBlBPWlJFSYdlUijJBYqklCdbbFTl7xxZkJBRkoU5CFm4uNWNmupNtkOBC4UZWADULjKKhrlklpbi4ZbhbNin8JVNPQUoGCrslEPG2J5ApzuAI0sPwhPa2xuvsbPww7W9kFIrLy49xZIkMOBHK+AuTBpqivESO9wNQ5pP457rVP7aQBy7TuHLbyWnDh9MZ3wz9n1QoRD0wkFwPI1D8M/ob5RBFOD+tGb69d/w3TdgfwlKRoXh0w66C3+6Kjx1IA/icE5bMMrpL5n0OE2yDZaYyDI/eITjYYltXihAbM3//7dvAx264d7Y8zZkO1tH5I+7U8IwY/igX5zayGQQDhBoUJ/ugrXtZlwcaFaTFQ2e5Rvesv8GDbR8udXbQEHYTAgR1dcOu1Eb5uG94bB37UFzqgvV6wfXlBS8vrx4YeUey3tFbQ+8d276htUbx3Jxwvd6wVBcW97KmlPMUGZ913q7bdHTYHF7qR/aj+GEe4EQ0XFDdfc8S5CpuG1JoL5XKEtbCfbqOo7OmGrC3jtY77h939DGw7+x6yiw9kIpAh6HvLh7tDKIeOlkG17Iio2kU9RjgKMMKoDjnjOqaJyUnaNvR+9FqnSVY1JhpQ5FzxrJ4t5F5QJ8O78w93VuD9o77xzv2fcP9caemlQP/y7KSyVSWqb0lIgeTwNdb2BadwsUScRbMFPt2R+uZLeMhaDsZrfvjgRBdV9fTUlV2G5XIYHopig205qLeRgAhZwaFBIbUASTarGWpuF5vszMKs7PORMjU30qlolS2dI/fo45SP72vn5UBgkXwZl7CO6g5VlJ0uKVeD8aACEXDz6Aa/HkTgIguDwfIExBKbbUoMwqn2MwgKU+w7gkV+QGu6nameIltycntlzM350omSDf1LP0gZKkntcWUXjE+2sD71vGxdWytQcRQK8HbbKF36OssRORj1p8SV3gK7D/2jl/fd+wdeNsUv90b3reBYRmX9YK/XAtuS8Z/+fkVP71c8JefPuH1dsXtUlBL8uSY4u1tw6596hKJn53FGYnqjjqB4YHHYyNAHmXmfo/UdyKYEM80QXYAW2tA946ACupa4QSyiIPIyc+M2aDC/V+LMuHkjR+qjwnng80xB0brJ0CLmfq2K1pryJlJWPO50ZFgSkA/54TlsqIsKy63K9brSnA3pblHTAdsKLb7Hff3d7y9feB+f2DbuyeoEkrhPSUzlree2sinc8LWDCasLhg2JrgzH8qTzQZzNoBDLQIoFGkQAEs5ud4WFbAghtjRwxOryYO7qEAYFjqZXM+h71Kyr3H3/ZisEPQhXn7qzKlEP0sN2LqR5borRJrrDQqulw2X9R2fPm94fX3g9fMnXF9u3pyjQDaBNLflGv4lIFFij0gQePJkxgbhn2Ykr/wIEXSoohrFx0W4BrZtuN4p91StBWasBPiRoPPnhC1mAog+sic3cibrO0eSJgCi432Oygk7QJBTMK4a5bjBqjt/fiS3j0S2+DnJtRMJXZeMmSCTwSwg2PNnHuLadrq3KVFyfn6cQKsAqpwUwfyXzcTPLIGNuH4y4HxFeGwJYxI/l4poIhB2AO63CeDUwOSyAcHes6nZMyfiDAIaGA9H7KuUADlAZP+58L3Dbhx/ZJ4HFowKESTvGD0j6QgMY27mPJ9GUMjcClDHI0t/S3ME6+juCYDd3gQw9W50YCIY2n3c6PP27R2QBNWGlCuW6yt9nxRklukV0ucK/aLAg1KaPwdsSvLkGLMxAGNllM25PXhukeQ+3gf+fZ0DMH3UOONDF1T4k+QAWTDR1Zk6sSbha1nt5F957GqWYDlDnSHHOfK9Cl8HZ9TpdMUeTikYetNL+91r/6Prj2s8xR34IMANskbg0ocHaGwpHYvuyDgdDIu41ZwEa82wFVgvA2igSOroMwYOgHeAoMUAl96wEB6X+X58evNBO65j0R4DKQLPHp2YBh6AcoFiimdGZigoSWYKmSeyTaGzQOxj40fNdpzezDwnSDI/vLy9uE+kwjV6UPl5KQEjHYbCiJ4X1zNYagWQIJq4sUFnh9k1PdqF63BqayDTR/nDXNSesYazGmA46JDmtfXigIqEwxsjb2Gzfo9Z2PFlHtB2Lgvh/2YizI7Dii84gSEzA+HvaMcBAT8ejt8LZ1yOezvf3snWznXtggXxXPPrKdtxfjyJzX96HzE7jY2/dRjFWMueEX4T1g5311N5dGDvwm5znYuYeTjXtASd4+btpDuM8gRgZrS5cOijKboZhnKffOyKRzsOthSZi9Cn+G5gfjiNgWm4w3g/z+mhvxH73elkiXtV9HBYTm8KzEzS6eg9Hezz78DMuEPES4Tq7ExXaob1CKbOoCcPD9OO0RVmCb3tfuCIb4kATkOjxH/TjHX4k0kSbBLXkjrgllPThlgjBzhv4mVWE3jl8/LzgMh8iYmX6yZIsBVdi0cApEJ2mQ46bnCgrfX2xDCIeTozMp266lMZThzm6xGWz8iQmWK7c15dyDIfbKEY3nhNlLWJAL1RUPuxPbBvD2zbht77pGPPcpJcUAr/iOusnB1RDV2ZSGhMj5CfGzpG+74DcAFupfhjZLXmmYRjPMhwCtvOEh6+cABJJgsuGKtRkpdz9nJvL2ewqBCxJ4dPTr87vyrPHnbtc6dPwq889lM4PCPOjuzjHK+BHPvN91w4ReJ7NQ4FOs+nxFFsNISdFqScYWZkLkSpwg8GPGUvCY4SqBKNMUqMJwMecZ8iSiaOM+6w5wYmgYbh0Jdz26SmDJodTEnh+Po1z2rgODdwLGnuo1M31q5MOIGg45qAL7cVr5eCP73e8PPrBV9er3i5XlALdSao2RVshuf7Nn8WSeKlun72G8tdIUwahL93AATTOs9zepZfm8L8TFVloksA7+KXTp/MpZnkWO+n0GSW7wQTyiLrDt5P6L6RVSgeAAFqUYLyve13P5JOGsuJa2UjggBccQ6oo6yQ5clj6CmQlaey1hhR8zXzHC04sCKzeuzwgX0PBnAXiVrxYJ/PKGhJkQ1IMrzymj6kug1np0Ah5R0EnmZDCPgYA9EQkIEzjiAv7Faw1E6zOxvUmbFAJpaJdAbkagS+2LwiYVkXLGtFShUiB4M2ypaOuT9ihJPD93Sf7rQjmE4mrjXl8wcRJD1KcSK0Mzv2qEwpiR/kku++nuKBsPdxpk7R59/98ukMPPn9E6D5O+beTuEC3+kAOKbPf/q7iPswT2cZcNaT4uvt9HePLabP9d1nfgeqHFv7OMfsPD5q37/yAJ2evhs+p/vxlN3GPPMdrJm+0Xfxj53e5o8clZMsEDb/u+U5O+a6zxJj8fSacwz1FHB8/2bff7pM/yFiwyOM/w6i9X3JoyPzp5OR5PfpzHsm3AZsUCXaRmOEPAZSssnun/vcQcW5/+NG5bi/uZ7hTbw0WGeYbuzzgghDN7/MgZvxccgBTTeXf5nWJ2KQ+b2DURifF8nlwCuOzz6BwnI8z/cz87wfjwcIltrTnP1B1+sPA08hnZBCt8RFox8bGT397pkcYVeRCLL3psjJgF2Qa8Iand0ALEvC51JwuQzUJUO3Dv3I6I8N7b3TWIhAjZmsYXRqYhGH7orCGISL61HkNNkIp7VzLMrQUSkFUioCMBqNmkcBBMX+COMwy6R8A6R1oWN/uUJyni3J4WgmO6YAvTGQoDYTEU0F0A3M3DgwlSFsDFgXpAJYEdhoaN3ZFMpuIDlX1FywlJW6KH1A0QE8YChAJuLa2u5B13Anxo9nG8yypUB48wwwGAcY4J2iKNI2IJaRU2Vmu2ZkHZNdERsjHAP1seLc0TMIRNiASe8+B2GmUfftGUv//syUuCOtAhe0PDaNIBDqA/Q7r//fASmHT46JKJ8cCS6VAJRkrqtgSwE4AmODu/5ety1p3sPZXkCENOph+PWj4b4N/O8CZDlKBKLdbtzfkhNKFuyD4ucfiQDUN+8qEze7tYHuuhSqhn3Y8T4GPBo10bov5LVkGEAavlHMNTIax6LHD3NV73R0Fgs3NbSx+9993NrwcguCyXUYdc0crGK2W2Cu69R79w5OzhaSBMsFqRYMAR7b7t2dGlkpKePl02d8+uknXC4rrrfLdCwMFEuWBCxLxVILYBfsa8G+F4pWjwHrO5oO2qlcMfpAShnLqiilzO6OY3B9BKNoilLPgItfS87s7+DOdh8NBmMnSSEDhuvf9YyUnclYV37YxpzDwV5QsqDvK/YmGG6DdHRoB/pUzfPAAQBA4DslMp1qLlgXaq/UUhBljAYGDpJZ/hVd+UQEXYC2PbA/7gRknOFVUsZIQHJ7Fc0TWFrUoUPx8fGOSXUG0PsOHQOP+wff34OR1+sLlnXFy+0FtVZc1pVjXk7MORg1wMbAoz1meSXMyBZzIWQynHaYGfbHBnjQROfm5EQKUIQaYwSyFPvjzjnZHjOAkRTABIGmnDJKXZ+DNKeX72p0uDSYfMMdkYQymJlXd2pLKWRYlIxcEkYTkMwkiOxyuLhPzk1oQLkYaYpuRadkBjVi/Oxz8fdwosLfHEotDoqHGwhSHQ0nwm5Hi/LRf+eO/sNf14V7sDpro1aZ55OB7AwEuGzsKDdOHenC5WFyNdxTlmQ3NTw6/YExqEcjKshEsZyNk6cTnoTMkpmI8oMu1ll0GoYApST8vFT8OSV8vl1wu1T87CV1n18uuK0Fy1JRnGU4+sDjvqE12syhilyo71m8Q2Z8dpQuMZ63qQXXOsHekAUgC9F1S+woxTqYUa41qTrPTAhLUbODfWQ8OZgQrBwpjjW4qH6ttAWVbZp1KEI3hTqAY8YJKdFedpekMFOoCupSUevijKZyBBS5AC7qn0uZ/soEb0dHlNZGIhhCplyWBEgHBvBQsoCaRhbe32cmVuhDeasMMnuNnYf5+oHkzDkBgzTAZmfgsAfDumtEmTeYcbAZHOPeOA8lR1DHdR7sktCDExhI/BLv/GyzHDuAqjGM2mODfszw7w07mMnBNgCA/NFQcsK3jw0v1294vz/w+eMdnz5/wsvLC8+IssLQ2dRHh4+rj4GPndhg2XgEGJJgCUhpHCV/SZCF4u9VyNICgJEUzYGw7u83xgH+/0i4uQ7qGUahwizvjnGM/8LP12C0uJ2KLmd2+Nxz//tFYPXQOuM+f9a68VeegKFj//DYSaemGbyiccpMWDq75qkBDIAhz0L+318zhjg9OwBIjqxMPKc9TX6sh4ihsse03prKtcQMKVcASt/PFMkBYDYrSBjewSDiWkQZmZ/VkWycwMqMieDnSuguhiaQwMuXAG1QDY1TQLDgqWvc0580/SzVqHiJBmJuC07jaPFvAGSMY5bpBdNKwWcNP3XiQUnIWcj0HyXXuGs+0/7w85F6UP3xTtb0aEi5YL1+op9ZfE0EOy2wgYk2xng8wzP/v/autTdyW8meIiV193hykyyw//8fLm4wsadbIln7oeoUqbZzd/JhgI3BA8zY7odEkcV6sR7J/7MIzO5MNd4gT/WQ9ETfnGcRr7+1MOpYPApzmFN/rUk73R+UD9AIQCEvU/SDZVtG16X8kZrb66xvOI7zP2FMWfy/8DdqPPGhaOCTOFoo3GnYlP4xE+ZNUYoCyRwtpgSZgFl9AY7NWijXI0FrQskkRp8QWjhtdBTY5uFkJvGwwlDJRocIgllYIdZ+/bhe10rODIRdB8go6eBK2dIzsmlDwmJQPoKoA2Cx4d3IbC1OZsCRDgKMdZXogGGdF2Mk750lYUx65EtrCdZ20kKh4QJSQcdX7Q441gvgNZ8dED7HMTwy3LAPBEGxroSKau9i8M4NhOGz/Q+e0Mat4+tcZ7uPnL7Yc+ZDDZd4K4Qan4S3VZFoJwrpVwznU/CvgaHIecgUEqxH0q8xXqtnt9vrNrdHUVdMDex8R+YztsVkGGnL4qHalhaQUjev7nszpav22h7K0021U9yeyEJGDzSr2mnMFySjz+V0ArqyM65hnD7rUNzR17OpIqn4T1sbSw3wCKDUFX9zGraTwEay7x5eSPoo1qY5LyvWbcHlYl2/LpcNpVo9DtJIdFoS44/QYi4Jdup05TqlxaITQiC14BPSJAoEs77Ruc5CB4VYpqDyU97kwsiKOXv+uM8VBGjuw2M0T59X2PcF8RyaxJXuXs8uuGTwE++atixWwNe7XPH02QxbjUNo6w4lFonk37dC7L32FruYQgfBjs6Hm9ewKvWItBHb025sNHN2LZ5quG4rLoxSW5ZTpzwr3Kl4rj2hbIlrrwSNkCvRmAGMbsJECt7a089E4NHELVr1mnMwhVwKpSSxW57JzxYyp8uSVllLqrpzzeY4x9icRoIF2nhG9iCgEjXI2vEDamue/kIpt+tL0D1cFjGFxYrz+qSEwNTTd4HBoGHq9SfCkk2PyNk7uLEmEBDPeqLtUGLh8t+uExFprlww2o1RTxH+r2bQVI/stkzRJ2X5mZFgkN0whXnNFtG+rgt+fbngl9slHFBfLuZcz5aH7k5Dc9AcpQ6GaedR/bb9TnxGNjoxxzgADF040Q+JfEaCY/lVurrjfzOjlfWMxPkxdQPuVKooyWsv2cEE3+meBEYXsZ5T1zFI03ZV27te7oDR5cvqDRWyR9ZzmBpz17wuHNNgz/orgn+OxeGpL/X6dNI/HPNy1k2ahgp+StUf7RNtCk2e/gSLHuB1OIbxoDAN60GdBfAUPYgXd7ZapL1D4Xhg1x1N49+lNtN4g20Ikjsnc7YddHnbkJcUPH1bVisn8TR39AJEZPTwmpyoYeBNwy/Bn4d/VKIVQ+TW52JdTvs4yUWA+vpHTETHzYGuLQwTI/EfgnJGo1ffy6746vBC6Ltde+97AF0vsdfVLUod1pDr6vbXoMeP93t2gEmMX0FnK62VsUZw1Pzxj/N+1B84UousSm4facyuxthJqn38JhdMRzyRnF80dJj474myB/qlDY7WYF2exjnt8/pkrvb16EaT2SPCKHp1W228XHJ9uPOo0+BVY7/paf3o4LQBpLyYc4c2pEU+oJbD17LYoQZdJF7wXoSy4q82ar8f7ddhuX1yY4WG0Q+8FgpGhfavPEfPnQn7eX/p8PqzQ+t0MMd5GfYT/z9b2wMhhh77/Nwf7ugP8cOOp6OYgZpRbLHUTmstvD1Blkt06AEUrdxRmxW21EfF9/rAsilaXbFeMl6+rqZILYJ0VDOckXBU86S2tsQiLGnBkle0KqhVoKVBj2rpbt5uGbDTryy98KoVYRzaaLsyW5qFgMNrNdGAEG1dCIqnJA1wEwyLd+zJi3Wp02LhetI0nFNGqLb5a/JMdzdQm3fuYcjodr10w2vNSOsClYr9eOCxP3B/PHDsu52aIaGpWH55tQgaS9mwZ2uaoMnii/Pmm0ATSrVaDqUWHPuB67ICq9Ud2miXu2C18LbBaItNoeFjIpGJz1OQpe8y81STKT0zXSdjZ6ycJ1dT+uYL543nbKv/DAUJoPeesmrcyBylDPft40jxKXvfDRh/MG65qP00PDVbk9di9VdqadDahhNgDPPmConC6pPJwAgU0ZmI92JUnfkqK/ZKJyeQqag97XkqjtkZyIVKsj9hTmpFy5vThRj9rsuKBsXbw1IBDq2D2Po8yH6y1OiMYOcs/oy1MCcJDfe8eIqZRylG216YULFOOhX3h9WQ2LbVnE4AjuPA/b6DJ0O32w1fv37F5brhdruCLU31/h1HKebIEHjqVo4C1cfjgmN/4I8//o1WGx6PHcdRIchIW8K6edcR2Brux4FSKxaPLGUUBPdlRHABgHpkAIBtXboS4HUooL14+tEsarMVm59WTTmv5bA6ROUAmzewplVrDcuSodpP9ggqeIoGdonKOWNbLlFXiHSv7mzT2nDsR6SASEoWKeWpx82jVWutaPXAfti/UqwYP+AOmGr1Oo5jjzpaxbueJBF8+XLDtq14+e1370q3IeeM6/VmaXW+Q8pxoB6HzbU78KH2ejkO7I+HRWKoRUJmd6rlbM6RNS9oQ70IRuJWda4RCqi/7afqZHTaGlLOFh1GeWSCD4C1EFajXo8W9o6mpUBriygi1YZlXbFlr7exegph9lbkTkfWVdA6C4rLAvH6N6NzAKqoKXn0sM11rRWJBi7lpKp1FxOvu8bisqEo+7pRaWqMurCoK6NdTyNMVpeoFUbOfh5cN4+4zF4PQoz+rX6RohQ/xRwMe9ZUDAMZg34PBL84SsP9qMgp4XZUd7RYp9UsQElAqYKoS3SUHj05GI+mqFpE9paBX28Z//3Lhl9fbvh6u+CXlxtu14s1QcmWBmE8sqA1i3AqpXpdojroE34o5s9gaXgw5zAUu5hMo3FbikcfJEZxGz8D7NitVDpAbOw5eSUNUT+XMZrc1owlZ+sS7FFfxqeMfyZx7tWon5icTeLOe3HDydNps6fS2SmyJYXlLLjIYrVFsul9khcgZSAnpHVDXjakdUVaVoQRWQu0FWg5oKVgf3vF437H2+ur13bacVSLxq0NeH0c2EvF673g8CglwDv7ing2g4ZDs5dgQES4qdLQ7g6SMEyEczl2hbYPMQqOlKcqVhtEFbVZHTim+4nk4eJufAmQ9iHCodkhG03vzpfMYWk68HAAp+6UhPiaG45W8PpdcN8P/PHHN3z79oZfvn7B77/9C19fvtizJEGtVic1aiF6dLSyhqKPlw0rlPVT/cEYgBYRWmrlQpCS1zNUq6lVq9XKZdbEJ4H5AairD46TTB18qAeUPKIIlo3RDWnXwYA4pMieYs3mJwtr8CgswtAF/jiXKeF0TZHqqbl0xI6RxsbzeGZptcQYNSkxltHJwEMkvp68g1l3NGG4NwYHMJw3LN0doQj7x9WFuG5cxQ9ZjAZbBHlILQAPK0VAJ3yKlFWzPVUVSAkJpp+JT1i3iWw+NZvtilJAN7E6D2taoMXscAUAr61kzrjERe9jpp2VUswl9U6B2Ug8JIi1G+wxVXFnHSnHeZJHxpFBMT2dB1JWbqDbfPC1yV53qhbzZ9TygNbD5MKyWt3LlK0ZgQAZK1RddzIlLJxDGJyRkGQ9N/2ElhG6CYx4cjbX2EyFtQVZ+kA5Yc75SDecL58bPbmRwqlo9EgHfQvabK12+kK/RzgjMVxfGOilQKwV0Js85PiuD+WH8bdT7cyx0pD84cDODX7ak7Plm2qTCJtrteHQAkXGvltYf60aOYjNGbfSgZAAyZ0AkYG0irUnL96itY0eDPtJJ8g7ZxxoUMXqxGSiNXd62MyRR/R8X1DKhpoVTi0OgYUFfObVU79IMArx/HZnK664iQ9axqLHOTtR6mBEtc6k+kV9c1JI91O71qqllOQlNoJ1MrPUh6MV5JZweKHWpuayYAjn6LQZveI8PSSx/xidueKnTz5en+jzNQbOgX6OZDUCOJwuOHyv+9r45yAY5NzJC8z1f37dxQdojQd7Hxji+RIScx/1ZFS7Zj8+pyp6RxQNeo+W9grIMG4OY+Arxkia0VBSpuSQfhAlV4wxAgsdWE5fzRW7hE4jpix7/6KUcGJf583zj4fQkFU9FdzuxRvhDJT1OSTqaLhUG/Thcaaezjh9nVlPqTQLfzaH8orL9YJt27BsG0opaHoEjVmaUXc6Ldl+tsVOZlLq6VzmuKZ53SOw7Fk0BA6GvdKHSGdaPzWzqBl30Ltxm1qJVOaoGdea81kyPitW3mrFvj+GeyPqZTFKjPs9lB8Rd1KVSGVjG3HuAAW6YtjGk303ZpIArSHzlL91l4P6OlgB6yFdxOtOtWrpkrVaPadaijkosxctX1ZcLlds22qF3FOyNJicoLXXa6EsSkihLLAFOmtqsSYe59ei0RCGsURnTuuKeqos4zxP4BFMItCWQ1kelWTBee6I06kX55K83Omj165iZzrpvDTmnikFnV/2KCt22TK6S61Z9FFj4dPmTvdR0Xcu/04xD/Lysbr8c6W+Cfmvn9UNEYg0CD8T6BzmNrI6Tt2oZvTKoOAAOKlGH0LRjXR2BoPLI/h7aOYIFdeJLFrur5VMkyfAmhOua8J1zbhtGZcl4ZKNuAU9ysrSlb0Lm3et7Ckh4rXoBl0RpgtUGv+kdX+/+iEcT7gTO5oqD7S6qjY64sbfWYQ8e5pdCv7UU3oiMtyvHUrHWE8jNrHycYb9rBHhlzw6sRe2lZBHyVOQo2044Eae00C1RhTHvuM4Dm/uUH0uWbeqR0P3Gn5uZlOHBOWgU9KwwM87Mz4/0JGOnw3V3A7VIqWKxpfLBKu/pHFfCdkBl7nNVcfuGIh6gJBIDyftsp4iX4v3wPf7vijVrn1/HEhQbG/fkSC4XTZsy4J1W7Bg4WDCOGS0U1f5NR6+70PfQ/EW9fNx03CN3Y7wuflxvfqfgRPtjCrmkwFNY7jr4Z2XWXaNhHUCDLoYeRP1H9pU6Pvt45pZI/UyEtR3tvb3+jYYtXL4d7oN+O65n96gDvrh6voYIzDfa+D2KE95N5HPVxn/ZlT5SSR0Kyd02mCaH9g4I0/ka2Fs0S6ksR6DeOIEMf99HKrvKdz4zbBMyisMz/3hPA8vxv7imnQ9036yLp7z+GxO7uRePc2WUaB+QMkSNcouykkBGK/moef4vLyuxFxSJ0on+URaNXo409nH882/+BzjSj7bz3+BEE/k8xr2gfjcvb/5KBdcZjjNw/96B671D+CHHU97sXifvZl6u6XqHSeSFW1dYP+yefxTo5CzTjP3tzskV9zvwHZbcW8NKQvyZo6SY9+B1iCtoKCiLTTQK2QR1LUiIWO9AronYAH0ANrDl0DVTr5z8tMNALUrJ6xZoSJe8NK6BAEKacWVHBf8LuQTw0Y8MgqDkAGMOAGg7Q+w4wUgwGKdTbRWaEqoXJVhLwpgaW6SsKyMoMrRfcOiBh7Yj91a/NbWi706V2nVTgvt5MidF1UBTUirWNhwEqQlWS7s3U693x4HSmk4jopLXnFddix5wbpY+k52DihI4fBRCIoqxNvUmlIzMOZxanRQTF1h5T4l840tK702itIhiGeGLu6g7ql0SubKiCc/rQjDtnXPvauurhSbQpqHorU2DOlzKIx2OxcPj/F7ZxczbFtElcDzb593H6O/Rg99r7fBehLmMOo/e2h/RELBy506kxWfpzV7PQogvm8Hvfa5LQF7UxSt2NXbtQPWFVEEl2XBUQWHFI+2+GTwhStHCecDQMEm4QzIq82HnonPIgphHY+0eQi/AmldsQBYvY4B4EXEHzsagGVdcb1+wdevv+B6veLLyxcoYIZBKdgPi5Rc1wUZtvZdaRKXBxmSVkhaAVnR2o5SjSW1pj3SxQtGhxLrkJSQuaakJe8I19M+xLvDZeuaJAnFI2O+/fFvtNbwuN89UsgvJeb8eOw7aileJ8nbsaeMy8WjcFY7aRJ3pF0uF+MnqijHjrfXVwj6qfsho6JvJ0Tm9Ord/lgUmVGSKWckL/K9+lwsknG/Nxz7ju/3A98fByjgmfPOWVqXFdt6wcvLF1wuF/z2679wu93w8vIl9gggXmNJUfUwB5h3Y2q1QN3Aa63h7fUNpRSUajzpctmQ84J12zwtzmRHZgRL8tMu/zuKIbvBZimIguv1Yvcv5th63O82LkaaqdFh9gMHnlZFpB95ndfMgUdIpWSpJpfLZpFP22q3bw2lVRw7wmAXAZZl9U6yKdIhqQxRSWHECVxxe+w2Z4xgqa3XpFFV6HE4r7OoJ45393pZ+/6w+gbURZ25M5p59VoMh9dT/ExgLRxVj15zmVMqacQWJjOKQhXJa0m8t4z6taiAnlKNaVS4s6e2huJ7E6J47BW715skxtleEnDJgusiuK0Z10WsnIJWlGP3OjzOA1mvxyNWznQq4VwBGtbVU8T9/ce+e3qg7R2LJKJ+Ici12Zzk7DqIjbMNTl4RnngDrbIERDKn2XXBkjMumzWNYWMBzl+t3dkhkoCmqFqwu0ciqWcIpIRWk91XBFEY2el28ahNWVZLo8vGx2msWAMpd67mDKQMprXU48Dx/Tvevv2JP/98xf/88Q1/vt2xu+OJi3M/ajjez/arnoyiSGVGC6Nd4eQQjpRuIVKHO1pDFs9GSHR/d2W3ic3twijW1Q5BH7uVfmjsxuhKJA8baEyaDt+CPppaWQ12LGYXqp5aSVKno7sbShxzaXZHPKz+4lEavn37juM48Pr6Hf/1+7/w8nKz5i4JqMXkIetw9pqJnlrUrLkSwGQgT6FrLNxPXZkRcjZLOdu+WhbTWU/RDp8AjDgZnZUJlFHeYVksoiZ5iZH+eTqdcDpUIs/AyCuCl7lul7rDeIxqBwZeN/wTsVo5RUuX9y6jaNuEsyxozBxiykh4j5DqhzDn+zXPJDmn3RlPoCwLGap0lCuQEPsAXoh/TN9T2ia+X+H7hfUU+1rEByJV3+SGH2S11h3w4mUStEGryQV1ZmDyJlk39Go8iW4Qqp88DOMcsNYeeUhEMDk/obOGdGLlC3io5JHq2rxu0uD0ifQxY/KSMux0Y4hcA8Ug0+qcPyWxsYtgWzeoNpT8sOuKrf9+f7OaT9cbJC9IywVJM7BQ2CwW0OElH3qnWavLCclIqpEeTAdnsEdXqhRMUWR6sg86ZZMPOYORVCf9HtIddk5K1I16lJjGoTF/HyOq4HzzfNiOqJvICy5L6k5e19EA79wpwMcO3o/xN2o8dYWFD6PS034i51V4ItrDYxGbrkJLhZSEozRj0BX9NL01JBIUGRDooPDJ9LnnwvD0iEb44ES36YoL9GsNLwVDYtghVIfnYWgZnr51mhmXRJ6FHjfvpy8xFgD9AxjGPJxaDw8QhKrdiYKn53PR7FOmQTRUcMYaBRxP04baEqo0VKmoLQ1RLzrUTIJFfvWVpBQ/PRcZ80gf/c0BoQAOu+M8JR98wX/T4fPPFx4uI6f5fb9enQlhWNvhMsP8Uvkah3iin9PlqSx/6AsePsHrUWliap2c6uLwd4GneIp4qqffXzut02mxwL63cB+I7dskViy2ryRinB4zcE4r/XH+8Q/DWanre6rvFbhRAFdwg7Z1iBQJpWjct/2i/eRFwvmSl4ycMiqjN4Y9JLHmXTl+D4p2hOORfLKfJuMklPo2G6WRfCCUaQyJtw13wydrXC9qHvVghIgoKtUcaSa8BDlzjH1sjBbIXj9DGRETw+3czPQJkx/NFSJGFjI6tjXWOfJnqg2aW+xfyiseXtg/DUdRay2ienTxNJiUPdVx9ZofK1Y/RADYDGJoVxwL7qvhcoz/uEl7156uuPZ1eF7mYJJnFinip3Sd2TK1D04T0K7UvuNPQfcSvIeRcozEsuiKQaEdaN4uZw/ONr7nIpcDyXHcQXtUeHSoTTcI5Rg/oCleOCnsjLpKXHMdPicazq+I9vtE4FQCILmF3j3osecv+Fr9J1beNRo9/d6vQVnj7zzd++OxdtnFMp3iRMF9WxmJSMeTDilMPpYw7uLe/WDKosF7vSKgpwFw4KxXxZ+A9C3wrEx1ddP02UR+1elbBwq3OenFXGNyMNQ18gkahvSBPtQL63Yn4V+sGN8bPmf7s/ZadcVSJ0ttHjXGvYdhRDitrXzwmo7Edn7ID//q19dOlx6l0huy9LlMCUCjo1BOV+x8q+vPiiGiSZk6rufx/xCkX9fHau3iLW01QcwJdXi6p7bOowfnxfhPfAIot8a5BMfPOSFNjPsy7CZzslBP/5QYZZo/88i9PmTbAy3YZzzV9t3rA1+Ka/ef3UHVr/ssJ0IGgQfco77YrzfypfcYeMZJEJ6vR5lJHcm/eZLfXVsfrjLIy48PFvy7z7I/+N1ApxhsoWH8QHcgMV3/fP2BD3UGH1+nhtHXqeuDwc/HLI+wRsaxDdZJjHEYi/S9zCuMfDyucGLAwLuH4X1cl3oXyeRNG0K/AobaUZxrv8ZHOrWcaz112uK6fzy2rtN32ui/Pw3/B6AnWh7fUNehni4qA68FgBO/Pd/0Hb39AEQ/m5Y2MTExMTExMTExMTExMTExMfH/Aj/e/25iYmJiYmJiYmJiYmJiYmJiYuJvYDqeJiYmJiYmJiYmJiYmJiYmJiZ+CqbjaWJiYmJiYmJiYmJiYmJiYmLip2A6niYmJiYmJiYmJiYmJiYmJiYmfgqm42liYmJiYmJiYmJiYmJiYmJi4qdgOp4mJiYmJiYmJiYmJiYmJiYmJn4KpuNpYmJiYmJiYmJiYmJiYmJiYuKnYDqeJiYmJiYmJiYmJiYmJiYmJiZ+CqbjaWJiYmJiYmJiYmJiYmJiYmLip+B/AWi/0FNeebywAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"display([render_texture(t) for t in textures])"
]
},
{
"cell_type": "markdown",
"id": "b872dee0",
"metadata": {},
"source": [
"## Instantiate a fully connected layer\n",
"\n",
"In this synthetic example, we don't really need a neural network as we are only trying to optimize a mapping of pixels from the input texture image to a \"pre-distorted\" texture image that counteracts the effect of the refractive objects placed in front of the camera.\n",
"\n",
"We are well aware that better techniques could be used to perform such task. Moreover, further processing on the weights of the fully connected layer could be done to improve the convergence of the optimization (e.g. normalization). But for the sake of simplicity, in this tutorial we stick to the basics: a single fully connected layer followed by a sigmoid function to ensure the texture values lie in between `0.0` and `1.0`.\n",
"\n",
"Note that all channels of the image are processed one by one as the mapping should be consistent across channels."
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "c3c3c4a7-5823-4029-8140-a4739146e951",
"metadata": {},
"outputs": [],
"source": [
"class Model1(nn.Module):\n",
" def __init__(self):\n",
" super(Model1, self).__init__()\n",
" self.layers = nn.Sequential(\n",
" nn.Linear(res**2, res**2),\n",
" nn.Sigmoid(),\n",
" )\n",
"\n",
" def forward(self, texture):\n",
" texture = texture.torch()\n",
" # Evaluate the model one channel as a time\n",
" rgb = [self.layers(texture[:, :, i].view(-1)) for i in range(3)]\n",
" # Reconstruct and return the 3D tensor\n",
" return torch.stack([c.view(res, res) for c in rgb], dim=2)\n",
"\n",
"model = Model1()\n",
"if 'cuda' in mi.variant():\n",
" model = model.cuda()"
]
},
{
"cell_type": "markdown",
"id": "5d776ade",
"metadata": {},
"source": [
"As expected, with the weights of the fully connected layer randomly initialized, the pre-distored texture image are completely noisy."
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "46fbabef-1267-4cfe-b03e-ebae73508bf1",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAAEQCAYAAADxkb7lAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOz9V6+tW7aehz09fWHEGVfcqXKdwHNEyQRJSRZ0a/8WXxgwTFmADQO+IHxp+99YMGBbJilRlsRzmE5V7aodV555hC/15IvWx1j7+EZ1wQOShdmAib2w9lxjfKH31lt437epnHPm0R7t0R7t0R7t0R7t0R7t0R7t0R7t0R7t0R7t37Dpf9sX8GiP9miP9miP9miP9miP9miP9miP9miP9mh/mPZYeHq0R3u0R3u0R3u0R3u0R3u0R3u0R3u0R3u0vxF7LDw92qM92qM92qM92qM92qM92qM92qM92qM92t+IPRaeHu3RHu3RHu3RHu3RHu3RHu3RHu3RHu3RHu1vxB4LT4/2aI/2aI/2aI/2aI/2aI/2aI/2aI/2aI/2N2KPhadHe7RHe7RHe7RHe7RHe7RHe7RHe7RHe7RH+xuxx8LToz3aoz3aoz3aoz3aoz3aoz3aoz3aoz3ao/2N2GPh6dEe7dEe7dEe7dEe7dEe7dEe7dEe7dEe7dH+Rsz+vr/4X/yD/5JxGvn2+2/RxvDFFz9iPp/z4skFPgS+e/2GGCOVyhhjqNoZ0+S5vr2TL9KGtqm5PDtBa4M2jmVb8fxsia1bqsWar7/5hn/8T/4Jn3/2GX/37/zPuLnf8O2b99zdP/Du6j0vnz3j5198zm6/ZbO5Zz94doPn8nTN0/NTxikwTJ6Hh3s22wfO1mvWyyXjOOD9xGJ1SjNbYFRGq8x3r15xfXNL1cyxtmE5b6is5d2H93Rdx3/wp7/gycUZd7uJKSQuzk6oKse7t2/Z7/ZcX73D+4mL8zOapma9OkVpw7urW8bJE3ImA9o6YgjcvP0egGcvP6Gpa5atQylFVI6UM+M4YbViPat52Gz5b//iXzJNHoxh1jZ8+vwJz5895T/9u3+Pfdfxmy+/ZLvf8/7qGu894zBgdMYaxaeffMbf+Tt/l6+//Y5/9N/+U6yxzJsGUoA4Mnl5Vs+ePeOLz7/g9ds3fPXdtzx98pQXL16ybGtWbcPbD9e8v7qmriuqytFNkd5nzmaWdWOZMAQ0xAA5MfmJECO3u55umFAxonLm8vKS+WzGrHFYrbi9f2CaJi5PljSV5eZhRz9N3NxvGKeAshalFCYOOKN48cmP0drwr7/8Eu89P/30GdYY3n+4IqSEa5bUdcOTp5fUVc1iNmecPN++/p4YApVRAOQMKmd0CmijqZsGbSy6mpFSJIw9RkHtDDFmeh9x1jBvKy4vLvnZT3/Kl7/7iv/nf/2PWK1PeP7iJTFnfAxkFChNSokUE1ZnnMqY5NHR49oFrl3w3fff8/2rV/xHf/vP+bM/+WNSzqSceffhAze3dwxTYPIJ5yxWa7LvyHFivjqhqhuub27o9h2DD8SYCFNPShFlG7Sr+NHLp8ybiq+/+Y7tbs/gAyjNJy+fM1/Mef7sBcZYXn3/hnEc0SS0UjSzGShFP06knPjf/+/+wb95j/Nvwf6Lf/C/JaVEP04opVksFlRVxcl6RfCBDx/eo63h7PySnDN93xFCYBoHjLHMZnOstTRNTYyRvutp2obzs1Osdbiq5v7+ju+/+47lcsHTJ0/Y7ffc3N4xDgPdfs96veby8oKYMiFlHu5uub3+wPrkhJOTU4a+Z+g7bFXjXEU7m9G0LdM04X3ATyMxeKqqwlrLFCIhpvL3Aecc2hiGriPGyI9//GPW6xVv34kvO1mf4Jzj/uGOcRzo+pGYEvO2xRqDVYACnxQ+Jm6vrwgh0LQt2hiMViil0GSctVxeXJBy5v2HazKwXK2xzjFvW7q+48svf0PwEzlF2rbl+fMXnJ6e8bNf/JK+6/j2m6/pu47b+3tiDMRpxFU17eKE1WrBi6dPub275etvvsEaQ11VuKalmS8gJ3KK1FVF2zRstjvu7u9BboH1csF6vWLf9XR9T4qBFCOhPLOXz59ycX7O/f09u/0e28wwrmbo9vhp5Pbmin6/o2lnOFexXq+o65rgPTklTN2ijcU5iwIe7m6ZhpEpTOSccVWN1hpjFFpr2tmCnOG7N++IKfHy2VOsNXS7HcF7+r5DK8VqtcJYg7EVOWe892itmbUNKUa2uy0KRV3Xsh7bhpQy/TgRY8APPVobbFWTcybGiDWGpnYsFisunjzl5voDX/32Szmj64oQIn6ajj7IGIuzFusslatomua4Dodpou97hmHg+dNnPLm8RClAKTabDft9x36/YxgHKifrtKlrrHPklMg5M44jIQT6viPGcNxbd/cPeO95+vQJTdPQDxNTCNzf3hC8L3vWsZo1aK2423SEGNEKtFJUlSPnzMO2I6bE/+3/+n/5t+Vu/o3b//G//AckFIOqyRmIE85qztdzUkzcP2yxxnB+doJSmjFBDIF+3xFzZkyaympWrcUaTWUMlbPM2hqfM33K9P3A/d2Oxazh/GRF13XyTrJmyoZlW3G2bMgZMrDZ7ri/3zKb1yxmDbt+ZN+PgEahmM8a2qbGqoxR4FMmpkxbWSpreH/zwMOuo2kqnDX0Y8CHxBgCKWd+/uklZ8sZD9uBKUTOVjOcM7y92dGPHkVGkfEpoJXi2ekaozWv39+yHybuupGs4HK9xFlDSnLdSiusVpzOrPivhx6U4nTW4KyhqSv6ceLL765IKdFYqCvH6cmCtrZcruUZBJ+43w98+fYWax2r+RytMobMetHw8nLN1f2O37y6oq1bTlZrNB6TJ/ZTZjNmzpYznp0tubrb8ObqlrZtmLczVo1m3WheXz/w5mZDU9c0VY0xGqMNZ+s5q2XDvhsZponGyTPddz3D6OmnyBQS1li01uz7Dh8DZ4uGxllSeXqz2mGMZj96phB52A34kDBaY7Xm8nyNs4b9bkPwE92uIwPz5QnaGCCTUmKYRgCausJaw7yp8THx5maLInM2d6ANHkdKGe9HrNEs21b8RwzEGBmGkQREpWlqx+lygTOaprI4nWlM5u3tln/1zQecs8zbmpQyMSbqqmLWNuQcyTESUySGRFVX1FWNI1Blz3ZM7KbExcmc01VLUoaEZpgio49c3T6w2XV8cnnK+WqO1oCCYZzwIRJjIuXMrhvwPuIqi9aKh12PD4HT5YK6smilSSnz+voe7wOfv7hkMas5XbRorbnZjYw+MHQDMQaGYQASs8qileL/9A//z/9WfM2/aftf/2/+V4zjxKvv3qGN4ZPPPmG5XPL5p5/jp8A3X38HObGctRijMFbhp8j9Q4+PkTF41ss5P/78EzKZaRokhn3+jKwiPk1cfbjjd795xeXlKT/72efs9z3Xd1vevn7Fb3/za15+8gk//fnPiSkRYuL6wzXv3rzn2cunvPz0OXGKxClwf3vL/f0dz1485+LZE/r9wNSPxORJOdLOZri64sOHOx42e5zRaKNpncVpzf39PdM08rf+9t/i8skl1x/uGPuJ9elKfNeH9+z7jt3DjhQzTy+e0DQts+WClOF3X31N13WkHFBAYx0pRT5cvQUUn7z8gqZpWM0qULD3E6Bp6wXGaKpKcX+/4Z/+t3/BMPT4MLBcLfjFH/2EFy9e8Pf/47/P0E98+/X33N7e8psvf4efRoaup2kazk5PefHyGX/rb/8p33/7lv/un/wlygRsPdG0a5aLJ+z3G+43V5I3/uhzrt5e8+bbd1RzR71wPL285PnlU75/84HXbz9gTcKaTBohTfDs5QVnlyc8bLbs+55Zu6CqGnbbHcMwsN1uGYaRYdgTgufi9IzZbMZqNcdVjmFKxASLucYauLnZ0g8Tt/d3TN5jlUWhUNFjreGTz3+M0oa//Je/wnvPz3/2KVVlubt5IPiIT2Cd48WzM6wzYDR+8ly/vQMUi+WSTGLwO3JOqByw1jKfz8hZMfkMKUOMNE3D+dkFvR+5frhluVjy8vlz1qs1z58/56/+6lf8V//3/wfL5YInT57QjwPb/Y4UIzlEqrqlaedYlbA6MV+0LJdzlK7Ruuarr7/mm2+/4T/++3+X//A//A/Y7B7YdTu2mx3dvuf6+oHNZodzYAysl2e07ZzKGrRWdH3P6D1XV3d0XY/VGcjc3t8TYuCXP/s56+WSze09Qz9yvbnDx8iLy6cs5jM++eIFtrJ88+0t/TAQwwOKRG1mgGYM8ij+4T/8P/xP+oXfu/CUS4BprUUbLYFkEidMhsoZklYY5PdCCBIYagUZFIfEP6OUwjpHQrHZ91QRWlPjfZAigP4hEEthrWHWtlTOgQKlFErpckAqUowM/UBIGXLGOcusbckZ+n6QBXP4zBJgJzIpZXLOaK2xVqO1RmmFs5aqcviQ6EdPiIGUMtM0kVNiGCfGaSKW+9faoLUkg5kEgNYKU4I0eSQKYyU4DiEQjEFrSVBCTOSUJaHKWv6N0lgrwZHSFmMMIQb8NNH3HUPfM00jMUaccygFKktIYVRCAdM0EUIgpwRarsQ5S1Ub9DjhUyZnGMcJgLZuMFoTQiAld3xfKWV8iGQgRLmnGBOTDyQrzyzmTArheO/kREpJIHVKScCMJEPksiaUFGqy0qA0Smmcq0BJ8oSC2MtnTtOIUgZrLOTMvhswWklhT2mMUmgFEmEmlEKSEiCSCVGKK9ZYFJmMJIXOWpQ2co0g71NpjLFkldFZoY1BKYMPkc12xzhNVFWFUopxGMhakZWSd240PkVC9KSsSBqM0lhXgVLEGEg5gUISsHEkpURMkmge9lXOEY2Vz/MQU2acJkKClGTNkjM5Jay1kA1JG5SCGCM+RLQ2pSDhQGuMMYBiGAZJUMaBaZqorAYlf4+CmFJ5X38oJjejyjsqnkgcfpbnp4wmxijrPaajnwKIMaAUpCT7VxsDGYZhxLmM0oYY5ZnJz2HjyxqzToLTlA77PKO1KvtWyZ4AjJWk3znZe957Uincaq3B2BK4+2MArLVGOYcxBqV08Y3g/cQwjMW/GVLO5b1mQJXfU2UPKmKSe8/KoABXObTR5XMVWmlQkHMqCZxGl++Xe5Z9d/DPRhuSMVIJUgrvA5P3+B/8xJQw2qDIaOewVta7UoqU5XoQVyE7VoE1hhgSIQZC0IQgz845R4pR3qm87fIu48efLJ8UQmQq/jsDKSWIoawPud/D36cUj+cEpbB8eMaHZwGS0Bpry7VYlNJ4PwER6zygsOXevPekFI/P0VpzXJvie7QUngLHAlJKSb4XVa4r/f8t8Vx+R87FmCI5RXG1yRCCZxgGvPeUZV3uSa7BAKash/xxyxzvD6XQh/+fIcTANI6UzSRnRk7l9/Tx80NZ23I9+ehbjmuvfIs1hlzO5BjkfimFMOC4LkKMqCjv5rAXldLHvacPmeIfkilNPrz3LEd5znJWoZB9o7X4IJUJEVKUvUjZmzFBKGtIW/2xYKkUSSlZ4xzWucRIofydUkCW95Kl0ohW+phg+yirxBiNRsv7L3GOsQZlNDkGYkr4EOWzyvqVdX9Y8xCzJqbM5CP7YWIqyf5U4o90iLnkajksVh8iSZfYUmtqZ0mUR5AysWwX6T8V3wfHGOJQeJUfyrpSGCt724eIs5qYKE0Mjw+Jyhq5by0xrkLWZSzvinKlKXqMzjhjMDpCTsQUGb0HMk3tcEZLSUhRfLn+uE/KO8gp4UNgmAKh+K8QsxRcio+BKOuj7DXZO0b2LxyLhylnVJLm6PFZGIUzRj4nS6whptHGkDP4GNEZrFFHn6wUGGMwWh+f7Q+/T+WMMQpFJiJxmdYaRSKVdRdTBi33oJWs96gghEhWmRylcWCMkXNHXqW8J6OxRhNCIiR586Z8zuEaYj6cJRJPhZiIQCjfrco1GaPl/cSAL/Hu5COh+OFU8hn9g3u1xshT0ofoAlBKkj4FqhTpfIgoLWdQjKnEyhqltXyOtcfP+EMxpRTWuvK+M5QYFzLOGXKW9Z1yJk7STFVaoXM5Z5HGrlYKbQ0pJTbbnew5m0gxSzyiDepQkk4JrQ1t05R46njoYbSmrh2QGYcRleQaq7pmsVigtGbox+OZprTkFykl/DiRYpL3bzTWGEzJWZWR9zgMI7vdXnyc1iVeC3gfCKHEE8d9BeM0lbMbjNVYXAmbZB3KGahkvaaELbmHCgFQco0ZUPaYv0bnQEXJG33CT4FpmBiHsdxbpK6rY85U15Ws+5KXhOAJ0UsuqTSVdcxnLd73kJX45MFDhqap0EaV3KWcITmVXDcSQ4CoAc04TfTdQIxRYt8QmPJYznqJwcdxPMbTKWeJlcpm/xjH6rJuxD8650ApnHGoDEM34kNiGAa0sVI7APb7PeMg68RYC1nqCx/XqSWnXOL1zORHySW1gaxIIaLQWOtIGUyIRNLR3ytjUF6eTwyB4AN9P3B3d0/fDzgnZ2YM4RjDVc5hqwalrcSsfIw3lZacLedyXqKYJk/XdXRdT9/1+Ckc/fQhB7VWl+fvicGjkJjtkHsYq6ms+O2mqQnekLPE1YcGTdM0VDlLfqkUXdehRs0w7JlGj3Ny3scodQ+F5fd1Xb9/4UlrjHOcn59LUWEc8Aqm8QRrNC/O11IBTJau73lT0D1N1YpTSVkSkBipmpaLiwtu7u74x3/5K2Ztw7PLc7q+Z7FcU7ezo+PWWnFxdsrLZ5fyANBobXGuRqNodGa/vee3796wXK1YrVY8OT9ltfyMX3/5O/7qyy959vQpF2fnAMQwMoaMD4mun/CT5+LMsV7P0cahlObi4owQPNfbPe8f9qwaCQpe77aElPhwLRU/YsAaTT1b0s5avn9/wzh6Vq2jdvoY1EwRAprl6SU+eK5vbmjqipfPn2Ctpbu5xXtPmCayNQRalKs4Oz2V5MxaUoo83D9ADPz6r/4l/Tjx6u176qbh2ZNnUkwJ4izHQVA779+85u76Cj+NGAVK1VxcXPDjzz/j3dUNX333miEkvv7+NctZzR//+Av208T93S2VPmM9b/ExsR8Cw7Zn9IHZfEbbttzuOm6j5/ziktWq5X63Y7/dsFrNmNU1OQSGbo+rWim4kUgpsN33UpAqRabsWqKt0G7CoXj+bI02jtXJGqUUX331Fbvdju++e40Czi4uiCnyF//iXxCC55c/+QnztmFWa6xJMA6gMpVdolBUKhNj4G7XUVeOz58/IQP7YaJyjrOTEzLQ+8CQMv00MWtblusTYgY9SRfTabi+3/Kbb/8pxmhevvyEzXbDV7/7DYvlirOLC2azlvWq4fa25/7+BuMqXCXvcX12xm57z+7hjmkayVpzdXeP/d3XjN7jQ5BgjIwfB2Lw1G3Fom246vbsBs+b69cMk+fpxQWL2Yy+64hTz8WTpzRty263w3vPZrNnbwba+ZLFcs3peinrbApMIfDb333FMIxsNg+onPnk6QVaK15/e0XKicvzM5z9vV3Dv/tWCpF1VaGVRitIMbDdbjBac3Z2SoyJ7XZDjJEQvBRBq4oYIw8P96WwEXCuYj5r6fqBL7/6hlnb8uRCfFcoHbXJx2OS1zYti/kcBQx9xyHpaeua6skT/OTZbHfM25bT0zOadkbdCKrt6v0H5k1NWwuyRxvL9dUHHjYPWOsw1nJyesZsNifFIJ3eMDFNibdv36HUB9anp8wWS3zwjNNYkklJIpTWUphUirvtlhAC8/kMax3Pnj4HYN/tSSmikULCMEYS4GrpVrdtQ4yBHCayyhi9pLKW+WJBDL4kWIn31zcMk+fk5JS+7/lwfY3WmsV8jtEKa0vxWRuc0Yx9j/cTShuyEhTW3GhOFi0PDxO3D/cYW7GrenkHTy7ZbjY83N/LM9ZauvTbLSFFYowYa9HacvewoRvGkuRlpm5PQjFvWxbzGfd3hpgywzAwTSNt20pwogxoCTat0cfCP4BxjnmzxlpDW0sR7Ne/+52cabMdzjnWyyU5w/v3b8kpc3H5BFc3zGetBNVaYYxhtlgSY2SaxJ/fb0a00lRVTUqRbddRuYq2nZVMKhNDoOv2tO2M+axhHAb2DzuiMejcMIwD13cPpBDQ2pBRDJMEplXTUleOpm7o+p7tvisFeySIz1Kw140E1SEG7u5uGfa7UphLGOskAFeKumkJwTONE33p6A2TJ8TEYrmiquvSYFLHwsBqvZLid9fT7fdoI4ny6empBH1J1vf9/QM+BGKJA+aLBUZr+nEkJ2hnsx8UtP5ArJmTQ6R/2JJypnYWlRSTDzhreXJ5QYiB2/sNISV81AW1W5K2yeOVYgqBZVtzupiz6we+f31LU1ecniyZpkCImZAiKU6MfuKhH6mdY9YaYhy53/RoYzHa0TYV5ydzbrYdV5uOmTOsZzMap6mt4Xaz5+52y+nZCc1sxTRs2HU925L5T96TsqAn26ahdlJQGiaPj4nvPzwwhcCiraidpQ8BrTXjJAVrXfyoUVI4uX4QNKBzmlXVsF7NySmz6zv8lOi8pJ7LVtZpXVVAZtFIojuliPeJkKVwN1suUGRmVpqo1w9b2rGibWq6YeK7d9fUzvH8bAlKE6UzgQ5S7L7bjezGSNaO4APd5prT9YLLs3PUQ8fDfstu17Hf95wtG/7o0wtB8PceoxzaVDjnqJ3FGYUucYyPiQ9+JN9pFrOWpq653oz0o+fZactqOWc/bpjCdExGztZzZrWD0lyIPhJzwnhJVHKUhGZWC4LzdDXHGMum8wxTQGGwTrFwllCQTDllnp0tqJ1lsVodCz9iknTOa0tKiSkknFWsZ4YYFQ9TpjKKZeuIMdCNHcEHNmNkVjueL2fElAuCLh+TJmmQKtbLeWnWSVHAVZp5W3GxarnddNxtPfOmZjWvy7+P0riLmrEU2roxkBjpfGYIsJo55rWlrR2ZlhA9m+3EfR/pJkGva5UlwQfm8wXzthIYB4mLsxVKaYKXhDJmaeY9uzxFK8jRMw0D7wdPzNAPEyi4WM3RuiJIDZmzkwWuJMJ/CKaSwmnH5fklACYl8jTR7zuM0Vw+WxNjZL+Xxsjd9TXGWtbrU0xU+DwS4sTN/T3zecvF5Zq72y3/7C9+w2o149NPLxmnRNPMqaoWoxtyHBk6z2I+5xe//BlVI4iMHCPJRxbLlnbxjP2m49svv+H04pSz81M+/eIz1usTfvvbr/nyN98wX9S0M8dqecJsNufq/Xs29/fk7Kiylf03q7CmQitD70eSgi9/9w387ls+/+wLFosl7z58YOh7ut4TQiJOkxREjQKbefX6e6ZxYjavadsZy3YGKG7uN0yTZnFyQYqJzb4jZsUf/dFLjNGMr74XJPK4w1pLPT/BNQ0Xl+cCOsgeheb+psfke77/+nt2+57ffPkdVe345JPPyDlKMSkliAmtEne319zeXXG3uWI5n7FenvP08pI/+pOf8buvvuHDhw/s7jteT69ZrGf86BefcH/7wN31HWE5EaP85DBxv7lnt9swmy9o2zndu57v37/l/PyU1WrB/d0d/a7n8vKC9XLO1199xavXb1kuV9RNSz+NZJ1YxDUkRz9sGf1IU5+hlCApTWW5fHKJMZrZrCXGyF/8s79gu93SDZ66qnn67Dk+RP67/+afkGLk7/+9/4T1coFzCsE9ZLSG89Nziclvt3Tdnrdvv6euaz774nNyymzvHnCm4fTiKSkmtnc7+m7gYbdDm4a6bRn8xH67I/mIszVd/5rruzsMmsuLJwTvub+5A6uxzvDk/Amfv/yc91dXfP/6FUlD0pmFqqjqFX4amcZeQAa64v37K/7yn/8Lut2evu+YLRbUbYtW0FQVi8WMpqnZbLfcbx/Y3G8Z+5GnT5+wXMxpGoerNOdn5zRNzcXthmkcGeLAzcMtVlncvOFnn39CVVXstx3jOMh3dh3D4LHO8ce//GMqV/H69WtijFycnQkw5Pew3zu7rCtHSpocG7K0fQo9bCQaQ20KrUybY7fCaE1TVxJQjFOpHMrhNPlJOt8xME4Tm92enBPtrAHg7n7DZrejHzrMbEZTz4Xm0guVxFmLzgmdQ+lIlE568KUCB1kpshJE0SFgmbwmRAhJEiljDNZKMnHorltrMBqiT6iYC+onFapGLFXEgNWSLAzjREbhC8JomhLJaKpKEA3BC3zcOYPW4EuH0k+CcFGlmyyddwkoQwjHANoHjypBmlaaYZqE0pYSrnSPYwh0+x6tkcBea/phKCitLKgvcqnUG6xzQh8JAT95QggM3hPlwRzROBIgSkLtY8SHgPUThlTQUZ5h6CUBK91QFFSVY9Y0mKpGGydIDq1JCulEKkkOY0oQIj4kfEhYJ8/iQO0xh46CsUCmclbeXwhMPpALYmqaPNEkXDWhJ0HvCNVEUznHrK2pnHRdUgl+U5ZOqTRDDiiUSroEKRNiZvIBqwS6OE0j2/1eCgHOFpqHLh016VRW1hRkgyBlwpAKUikeUR8pSzdmKkUHH6X7VVtDZY10Nss7GMdROm2lE3tAKUh3UygTh66Ls4IGi+XzmlqV4oKlso6Hfc8wjozThPdCC9JKgk/p3gEFUZNS/H1dw7/zVtU1ZIhZ9lPKGWIiTBPWWdrZrKBNZG3mlFFGOmOHvS/oKPk86bhKh0doQwPBB6yRjoXsO3mGkqhJV8B7j7UWV1UFZSJIqTQK7S0ekTUUCoHsN2mKGtyxy/uxYy/7SKEiR/RDLvs153xEYOXSgcoFxWDKfooxlgKDfO7Hez3gBSgJnZXueoqCZsrph3CYQ/3jiCzSWpGUJsYAuXTFtcL7iWka8ZPHFaQWZMbJS0JYyzOcvPikFKOcGVqXIot0SvUBQ5szwXuGvieUokpKsudiQX2kghJQ2mDMYQ2k0g1XHPC4qnTPq6qibdtjV9Y6JwjdfPCgBYkUylmQIinLZ+asj8gp+dEHl4izVtBCQZLdmBImZQJR6GJK7j0UNNihSHlAEWgtRaDD9U/el+ef/1pXWc6pcOwqClomM0UvVMmCNk6HjnJB9zkrvuSwtr33VK4ikwt1JYhfSHKNfUElydIRxHAuaKdUzsmcUkEypYKqk3PIWotSFpKgOIyWQmgu9yawCLkmYy3TEI4IY0FMCaJVfJ+BcRIEDB995B+KKW3QBlkHBVWWyQUFpGgPZwMH1H8ErdDaosozU4cFDsez5NAQnMaCPjSChNr3I+MUjmtNla5zSBGHwmhBDeuCfouFRhdTQmtLXTm0FhRlCKnQgvOx059Lp9cYcyziRkCVaxDk2gHtADFnQpLrmHwgpkhT6KyHzvoRkJjkTHNG7jeVc/6HSBxBvRe0YkE5TSGVeOtQaJXP9jGW+ypoxXI/Y0hYI9cbEwyj7K26PJNUkMkpJrJOxUNSEEiGWe3wITJOoexXeT7kKNSrUqhV5R5iFJ8eY0SljFISj3rzER34ET2mMAWBlYG2cszbmnEUGQRjMpT3FSXfLDFRPiK/D93vGBNWA0pjtPxeKIjEGCPJ6I++qqD9D8hFZzRZH9BU+ohGt1qhEeRUOqAbUThnyvOUWPCQM1it8CXeM8ZQVZasFToXdKNSR/+jCnImpCTvSIPRwkOIWdbSAXmnFfgIISpSNOUZlmJcQfylAqXMKZGUeP/DdxmjS0yGoLS0FXRWFsSA0orKSaOrm0ocd9ijSb5f3pXkH4IQzQUT9odhVV2X80WQJCoLOmMcJqwz2BooDbDgvbBkjKGuHToodEdBz+myPzU5ZYKfGEfDfjcARvLTmLm/37Dd7Oi7DucUVd2gEGaCQuGswyhN1oZuJ3HaNE4Mw0RcRFk/SWK1cVIok6mqEa1tyY00Gjl8rBU6OkhsYgtTJv8AmeNDIIZYGpoBHyJWCyq5HwZ8DAVZJSjsFA3eViilxXeQSyySGfoRrSU/tEmjlcQXYfTknI75pzaHvw8YbahraWwNw8g4jIzTcDxPvPd0+w5rDLOmAqDvO6ZxlFiu+GqJgwOKjLOS48cYmcaJ/X5PDBFrHTFGdrs94zASgi/PcaKqPNEFQV/+IB5OB5ZBTqQccc7Stg1101DXNW3b0rYiI3FAZioFwQvaahwnfPAYbcDIntMFkeRsJXG9kRwIpQQR6YMg5suP5MwWHTR91xN8QOn8kWlVVwXZL3lbzophmI6oJGMMddNgjCk0wZFp8jjjSDHhveTmbVUzrxs5c6whKYmrtBapAGm+Sr4/Rs98HAs63zMUiYIMDMPAw/1GJITGiapuqWtQWSLxWP5NjEHi+BIcCOrOS35d2AVaG1xlgUS/H4ghoow6NqWrqmITt0yTx/tIDJItaAXWSlysDvGIF8mH38d+78LTJ0/PhM/dzZl84HrbMYXIq/fv0EoxrxyuqliuNKhEU9U0dcXzpxf0w8irN+/QOJbzBZOf+PLLX6PIvDhf0U+B19d3nK2X/PiTF1zd3PFf/b/+a9H+CJ6XL19ycnLC7f0Nr1+94umTCz55+YKx7xh6cKNH1Z4+RKa7e3bDyNX9hqQdLz7/CbvNhq+/f0uKAVJgPpNrc1XF2fk5Td1glGKKkZSDHFbO8uTyjKquef/hmq7rRBtKZxqjUM6wmNVopfjVb3+HD5GXT06YWcO7d1eEmFk/eYIxFr+5xQBPn15SzRuenX1BCJHvvv0WbTQvXr4kVY7NriP6kWESBNQ09nRdz7ura9bLJX/nz/5YHLmuycbQLtZYo+n2O959uOK//8t/wacvX/Cf/yd/lxgid5sNm67Dp0SdEjp5um7Hq3eiX3B5esow9vT9nqvbe/7Fb254+eySz188Zd/13G52dP1AyBG0BExDt2PY3vH86RMuzs65vv7Am+++4fz8nNV6hVKKycPLZ8/5/FPHJHkKC5OoNOwni4+JUILV3WZDjInbXY8PkeUwUTlD9NIRMSoznzecnl+itUb7jnEIrNYnEtCamm1Q3H64RuvMZ88ucM7y4f4Oax2nJ6ecnFb8crUgxMjV3UaKdn5iGkfuNzvRcFgvqVzFpy9eMIyeN1f39OPIw3bLrNJcLCqGKZCCZ4qezdhT1Q0/+dFP8DkxRQlOm0ogqav1iuubO95dXTP2HX7oGMeRcZiICdq2Zdd1bHd7qqrG2Qozq6h0SeKM4931LeP0gaYRDYfz0zVKGQSyGjg5WePMCVNUjMNIO5szU3BzdcU4DPheAprVvCG6wKvvvmbXdcxXa9pZw2LWYrVhtVqiteYT4xgnz4fra0L4/RzIvw/28tMfCT1i6JnGiZuba/w00u22VJVoQFhrWa2WeO95uPcYY2iaBj9NdCXJss5hrUMZQ13XXJyuGCfPuw9XtG3N2XpJNwx8+/33pXiqqSuHUTXD0LPb7zk5PWO9WJUiUCKEhKKj6/bsuz2L+Zz5fE7wgsjb7vZ8GHoW8wVN22JdxfnFE6HV5oRKkbHvBL5OljWgl9hS8Oj6gf1uS+2sJA5RoOKL5QqtDW/evGYcR05Pz7HW0ndbhr5nu7kHQNtKdI6ePsEaS7ffkVJiu9lKgBYkADCuIqLYdnuCD4Uq5rm/u2M+n/PjH/8U5yzjOArlaxowWor8m82Gr775mpP1CT/+8Y+ZQmDX9XT7HcN+S1XVVHaB9xMPDxtSSqzWa9GeMpb379/x6vvvOL98wpOnz+mGgdv7eyrnaBdLxrs79l2HsRVN1dDOWmZNzRQSPiUaa3BGCjHeBy6fPOfps5d0+y3eey4uL5m1czbbjQSHORF9Zt93UsSdJPAbh16Kj2fnGGs5P7/gJAQJhrSmaVqhiqFJSTRNpnFkv7nDaMWzp09RSnN1dY3Smvl8QVPVzFoJ3vtxQpFpChLvw/UV1lqW8xl1XbGYP2fyE1c3N3jvGUZPoysWzQJixPqJykpgp7UUbHa7Dfe311RW9CoqZ5nXjn3X83C/h5yke7bZsNlsyCnKmhsSXUq0bUvTNKhCr86l8Njt94zDwGq9om0XKDsw+UClwebA6vSSqm65uXrH0HdUTYM1uhROM37sSSD6LkVDbRhHmmZGrRQpjKJ/VVdoY4o2hkDrf0hj+EMwKQhqLk4ECdeVJtr1dsAoxb6fpMFS16gQ6Yd9STga0IG8F02d1bzFac22n9Ba88XzS3bdwPubW9qm4fRkyXbX81dvrnGVIOqMTuQ4MfnEMAVWc007gxgm7jcT4xTRyrAfPJtdj6vOuZgvsNsBpTo2u55t70tV16EZ0UTRT6sq5o2jcZo+JWKWZEg7xedPRLPpbj8w+oSyUqy/v75jGkd+/MmCeduw224JIdI0Qs3/cL/Dx0RbS9KRglCNz05EG2wcEyHD/U4kGHbDKBT6bkIrzXLWYIymcY5h8nz34Z62dvzkk3MUsOt7hikITcNYfIbNvuerVzcs5zWfPz3BaoO2DlLPtH+gmjUsViuyclxtJ5qq4mefLrm9f+Dthxvutx3Xu4mZzcwd3HUd70IgZE3CME2RECZ8lGT2fO44aSzdOLDvBpazmtW6pqosEc28tlgcCQva8PxixWre8OF2SzdMRz2027sHhnFiypasFJURut31/RalYJqkgdu2LUaZUuPJpagcGPuBOHlud0Ldb2pTKEcVViuWlUgZzNoGHyK393sAFrXDx8zrqw2KTKUTdeX4ycWCbph4fXXPFCLd6Gkry/myJseEzgmrDJWVpKipG4YpsOsnsjKMCQJSOHrYD7y93XG+bLhYtUwRxqQZfGQcRmmAaA3Wis9OME1SKFRJEbUhYVgvKs61EkqL9yRTg3FUzlDbTO+FkqeEJUhImSnBsjI4q6msFNLv9iPjGDhZVFijcao0G4xQrZdtxegD376/OdLH/xDsxecvyCnjeyny3F5t8D7z/v0tzhlOTlvqqubi5Iy9q7j58I6mqXjy5JK+63m4uaNqHBdnZ2hlGDYJnQ3PX6yYxsSbVzecnKz47NMXfLi+4p/95T+DJICB04tTnn36jO3DjvvrO56+eM5nX3yODxOTH9m7EdQ993dbHh72bO+33N1cs33YUTtHtx24v93wwdxgjOLy7BkXFy/oho7Jj6LPNFuw322YxoHZrGG+aDlZr6mqitfvbnj34QPz2rBczHjYPjBOIxdPXlLZit/++iuGceSnv/gR83nDb7/8ir4fWK5ORO7FWqq64vPPP8U6y/Z+i/eB3/zm1xhjODs9xxpHt+9IKdF1AzFkYkj0/cA3337F6ema//jv/Yi2mdH3I/3QQx6IMdH1D7x7955/+t/9j3z68jn/2X/690gp8f7tOx7uHjDZoJPEjLc3V/yrv5Ii3cX5vDTVHG/evOXr/+Z7fvKTH/GLX/6Mu9s7Xv3zXzP4icFPUlzzkWmYsHng2bMnnJ2dcb+7592796wWK84vz5nCSH+359PPX/Cjn3yB95Gc4OXLpywWc26uH+i7kXlT0UTYPNwxjp7r2wcmHzg7EZ3laRoxRvP04jmXp4n5shVpoCzgjPOL50zjyN39NXebK95/eI9zlj/6xS8x2vCbX38tLKsnS07PFvzZn/0pIUbevXtLSJGmbRnGib/85/+Kpql5+fQp7aLhyYunbHc7fvXr3zD0A9uHHS47al0TXWI9W0rzg8xi0dI+WXN//8D79x/oFlu2/T0+DdSN4sP7e96+ekPf96AyXT/R9SP77YYQB+5uI9v7Pa422MqgkqLCMqZE9CPvHiRWOjtZs5jPmF/OIWl2/Za72zvOz09pZw39MLLrJ6yOUEHaKaIHP3ZoDcN0SiLy9u079vue9eKUs5MLMkl81lL0X1enC2G5Xb39vfPG37vwZIvQmXQV9F/nIip1rEgeEElN09I0NVVdl26aHEpaHaqWH5Eth24Sh+7sAYmSkqAQknR3cxbEi4LSFRZmoatqVst85KZqbUS7J2tUVgXlko8dUaE0lKqfFf6v0L9K94SEKm2rHA86HxFd+t11JRXQA280Fz6nRnQyDlb6Z4WrX/5c0AaisSAV7FBE4nThiascUaSj1lTb1LRNLaKyruLQPztoyRitj93HlDMxftRz0YX/WlWVJK62ki5gEv0NZw1uMWez6zj0rYwxxNGzL1xggbQjekXaoJ06anKQ5Z4OIhsHnZxZ2wh6R0m3MsbAGCJZaeFpj6Kx4kuXQ1G0CEjkJBo1MSpi9BR6KxmKPkwQ0W1b3qXW1E0tNLUQQIGrZkd9EJCiWcy5INZEUDdnyMoUYcsBpRQrZ/EHjnPwxOghV1SuIiR51ikGBj9iraNualQI+CzQ9tEHYsrSFS4oDe89Xd9JZ7PQDEW8XLqp1hiBVyslazofumKFc5s0GYOzUvgYCw8+JdGWsrbGaOHoppgkIbeW4AUl0I8TrnB1DxSDlFLpUSpCFDqhHCZFD+0PjK4itPNUkDwHlIZ0wA+aOTnKnjqg3qwxZGtFQ8WKzpoqKCjK3jpQpA6ogBgFGaKswegDqiiI3kNVo5QW9I1cFdpomroWFOM4lo64aATJdUs3P8ZA8JPsdWvIIX/U+omxvC7pVJhCUzrc+EEPRzr5ookjaJ9cOre2FNWKKKr6qFck3WSOKLzDd8ai03Dw24c1kwuc0GhzRHfJZ5sj2lUQOkVPw8o+OSBihLqm/pq+iXSsnHDji38BQbuI0PahGyb/7qATYLSC7I7ISRHMtkfqRiqdoAOuS65MOl3WWryvj/fkgy/PUXx9inKtH5/BoSOL6Bop4dqDFV239FEP0RiDy+mIwjDWYtRBW6mcqUc0kVBNflhKyeV3ckGnBR+KzoEt6KvDOWc/6qEkKVSmFAneYy0FQStd5JTk/IzpI7IPpYghMhbkrPceow5oFEF0HQSMc0a6YeWdWWtIlSv0RoNzFUobSVzTx3VkjJHrLojCjKAFDkiDI1JNi/87IMgEmSLoMZ3yMZ44PLM/JFOF4pNkqx3f/2HvpZyISZUzQYaLmIIEM0mQ0s4aamcw6gfIH8FIUQiVx+cXYsQcUDTIPrUGnBX9txA+Io2tscxqQ58FQXrc2+XnoBt1eCMHf6mP6KKCKimx4AGJd0BCWWOI6aOeUFO5oz6QPJvD5wnC/YAoOa4HfdAmk+8/6txN6Xg9Rh/0LuTPoh0qSJvKmWOHX5A8QEEbOyO/e4xfC/rrsP+UQorrWh1RCBlBSI0hgdLM25q9T3RDpNbiR0JKDKNHGYe2Bp3kHp1S2Kxx1pTvFb2vA4orlz0liC8tQ1+UJsTM6KM0+7JoJeUsqJ8QEtpSNHLkmmPx4bm8/8NaiVFQVgd/rw8/WYEq348ScOoB9aM+xvYHHaX8g7PkoPkEiso5QZ4d1kU6aC1+3PMHjcMDuumw1gTlKtqHBy06ddBGK+glL/Jix3+bEc0vacgkJjxkVSQy5D2qolkmaz/j0aIVlYq2kJKYMMRYUPLpiLAVgT1d4nCNsQe9Fo7XJ35QlaKeOgpg/6FY5Wo5o9RY8gNBdhvDEWGYci7sj8x8MadtZ6KxO00YLbmH6IOVNaSE+p1tIjiJNQQhLp8v2pPy/SlRaOoVCoShk8JRG3e1WjEMI/0wFiT4xz2tlUZlTQy+aBVmjLWCAI5yVqYUMVrjrEMZjS5IKGvtgUiBKmhBQUMlrCso3fILB8SbyEAU3Shryv4payUXJGFprtgSnx30aBVREC9KUGZ18EdZFNFlVkda/MHPVc4VzdvyDnxA9r3skapyVE1dBszoI/U/pkhV18znC6rrqqDoASXMo91+fzyrDjl+XdXM5u0x9yWBygVxfkBZJnBloIk1krvEmASpWZCRKcq+G4eJYRyleGs/apwGL78nDeLiuXJBnqYosWKWuESpTF3XRQcrklQqelmqnFniXD+i2wMhFJSSOuR2Usiv6grbm6KPLPq62hi0lX1/YCKM44QthXPnpKkLgtxKKWGcFMKNMcQgg4z6fqIvCKu6rjDaYpSlqiy2lvU4liFEB6bDIXvLOVNVFUZX7PotPgRhLYWAslIED34SJC2C1PeT6FYNfU9KGeMMdSM1D8VHPcTJB6HOlpxKFa3m38d+fyEX7UhJ0U+BYRwZhh6UTBCqq4rT1ZKu6/jVl7+haWf8/Bd/TFvXzNsGpR3LxQ5rFGEaqJzj008+pe97bm+uscby9HSFMpb3d3tC0rx49hSVIzpHbFVxfX3Loq34k1/8jO12x6vvX2OqBlM1XFw84efrBW8+3PLm6oZnTy55eXnB29s7ru4faBuHyu0R4rhatLRNzRhELHuKiTiOrBZL6rpi2m+I08j79+8JWTGNHSkFqqrBGMvTiwuM0QyjaOacrTq8n6grmepxerIiZ1g2FqMNkzsnZ4RCF0csFZP3PHQDKkdm795QVTWL5bkksOOG5CxNfQ5K8ZPPP5MOz3wh3WAf8H6i322w8zlnqyeA4uc//xlt03B1c0tlLbPasZzPeXJ+wcl6xcsXz0BpEoq72zvevf/AZy+f8cuf/ozZfElIirPVQoobfs/tZkfjHI1z2Jyoc+DJ5SXnZ2fcbvfcPGxp65r1k0ummNltdkQ/kEKgJmHTnJg1KSte3z/QjRNPnj6jnc0YdnuGvmMcRevhbLWirizBj6Sc2PeDBBPdjpQyuzGRUcTuThJwlbBWsbCZdub4+ad/TAiB3339NTFrfvyzn6C14ub6HVPwBCUJ4L7bM/Y9DzfXVHXNk2cvmfzE6zffc7o+4dnlBU5lmHps9MwdnK6XfPL5T3nYbJjCK7abez5cfQBjeN5UKC9iyMM48v3ba6QAUNHUM05O1qQYubq5LweSk+l+5XCtrCUXTYR+GNlPXkSBU8JqzayuSzINTd0wb1uubmUy2bgXnZqf/OKPWa1P+fLLX7F5uGd9dsbi5JTvv39D3/XE97c0Tc2PPv8CZzS/+t1XbDdbpkkS1imLIL8utKz5rCWl+vd2Df+u293tLTHFI1pHa0EH1EfqZWYYR3b9QFVVXJ5flkBAEZygWbS1NG0ryfA44CfP6EV35PJ0xTSN3FxfkTJUVtM0NcvFknEc2e47VqsVz198wm6358P791S2TJaazTg7PeXt+/c8bHc0sxlPnz4lvHnL/WZD5RyVNaQUmIYOTUSlir4fmLxnsVxRNw3WuFK4leRxLOKFqVBPREhbs1iu0UbT7feEEDg/P0drQ1U3oCD6kZxrzs8v0FpzfXNDiIHtZkPOmf1+D2SqMoigrttjweWQCCg083nLbNawXq/RWjNN08cpZ8biqoaqdAxjTJydnlFVFd1+T9u2nJ2scTrT77csFgsuzs+EDjz5I2x91s54cnEugX6Euq4L5Hyk32+lrKoExnx2csLpyZrVasX9/QMPd1vqusJZi88t0Tms/oGobYzHCYLXt7eM40BTGg5dQXXJPYuugDkEi0rOOD8KRSoDu91eCoSFCrNazABYrpcYY7k4O+EwxS7nzGKxkIWbI9En+tIyiYXuPQwDCkRAOSXuH+6Zty0nywWVNbR1RXKOtmlxVUVlRAB6ChNdN3HV9eWZXpBSpmrn+Ji5vrk59A/QxrJcrpimidevXpXGDVS1Y1Y56nZO1QqCK8REv98xDj2zxZK6bjmbyaSdUGi76/UKbRwPmwf6YSDc32HMhpPVkvVqxeu3b9l3HYuFTLkLpRB2dXOHcxXnZycYY7i7v2OaJqYkdKD31zcYpZjN59RVRU4f6QF/KOayJ+bMMMlkrWGc0FpxumhLF1XodQ8b0axbz1ucq2SPukRWhsooTmYiwJqUZhhHbu/vyTmznkvcIrRWmLcOpTJh2tO0DfNmjips133Xc3V7z2y5Zr5ecVYZZpXjw/UtH/yEywnlR3QOWJ0lyXKO3RjofGRVaxpb4VPCDxM5W/qgaWtHUzmSl8Qi5gwx0daOunJURWPn9IuXZGXY73v6KUjR3BislqSsqRzOZc6WDabIIMSUGAdpVO76IlwLVNby/GIpaLJcSiyqUN1ToLaG1fxJQcuOkhwpizWK0xaa2rGaCRpouIxkMrshgPKsZhOVgdPljKYI91auopnNuNns+atXN7w8X/CLn3zCm6sH+rc3GFujqxrfB3ZDYDmzzJ0hO6Hoto2lqQyp0HQXtWWhNeMwst31ZdKnxSioqooUFD4pvvtwX4amSLOh2z6IbkiQkuOT1YKmqfBJ6GhDEVCWZw6VzkDkbrtn9BFtLaaqmK9WVNawRvbiNHkyCl2GaWQFIcNulGbfoWCz6ycy0Ghpsk1RU2WLsTVtrTldLdgPEyFmKlfh6hZCZEyKYRzpbx9YLuZoJbSrisjUe3b7XWkMO+q6Yb0ymBwJU6AbE5sxHtEnh6JAbaWotO0G7oaJ0+WMVVuzHwbGyeNpyFnJRDOruXvo6IeJPk94jfj+yvD2bks3elwRpe+2MgXLVJLYnixnGKPpy30dzopdN8n5aYWi1VT2B1pZ//5brVqmNLK529H3PdvdBmsdLy7OcJXFNAY/et5//S1N2/LzP/rTQrlU2KmnrhVVBQqP0glbG0LS6NywnNc8f77A+8jV7ZaUDZ+9+JSsApkRaxrGLrJcnvLJJ59xf3/H737zJa6wc87PTvjpT77gq6+/4atvvuX8/IQf/fhHfPPNa/aDZ2EcyzazG3f0vhcfqETu5WH7QFVbyBMn63Oasxld3+GDZ9+N7LsBZyyr+RzhKGSeP3tCVokUDSlmnj+/IKVI21QYa3j6VHzNkwvRK7q5vxF0+cMWgIfdRoofY0ClDEmm1p6dnwt9OUVy1sQTR86Rz754Kk0cBVPwOAuZhLENs9mKF89eUrmWzcMOYw1v3l2xWMy5uDwDVTHFzMnJCS9efsI0dfTdA8Mwcn1zz89+ds6f/tmfUNctfoos53O2mx33Dxuu7zes13NWa5nQVqnMp5+94PnLT7l6f82bN++ZzWtOlmuy1vSTx2KpdIVVtkypNaSs+O3XX7HbdZyuz2iqht1Ohmrd3skU3M8//UwE4a0Mk3h4uCf0gXkrGr83V9fEEGjnjTT5rTTgnz99Tjtr+enPfoH3nnffvwHg+ctnaA3T0LHd7vndV18LSKTv8T6w33c0dcNPPvsC7ydurq+IPvL86Qsq62jbRqRNmprlekE1N0RjaQbH5mHL+3cfePLknPMnZxKL6xmZxPXVHcoa5os16YnG2ZrgA1fvrph8YPSB8/MTzp49wdWi/2esFGRvr7e8evvuQOZmPltwdmoJKdBNA+uTSxaLNdebG4at5+bujmrn+PHPvmC5WvKrv/qG+/stpycLZsuWh82dSNW8ekPbNnz+xUucc/zuV1/xsNnTDb3QJbM0L8dxS86Zs7PLf/OFp7v7h4JyEgFYUzrWdVUXLSOpEjd1I+iQok9yUPKXyWofu9jHvmQWJ1w3MyksZKRSWTlUNpCidG2CJ0QjWkNBdKFq43Da4ENgt++AzGLeYo2IIKYok32MEu0dV1ALULp2SaqkKWdSlOQzpUD0QTogPooWFAptpIptjRXkjI8SHGXpAAtNwOGcY9ZwPOjhoL2QGfyEQmGVw8dDn+ejXkvwoj4v1W2puhqtadr2qIWCUlTOEoMtekKmdNcNs7bBGSvTAYFg5GCWzr9M5RN6ikMXnqYkasL7nJfqeEqpvL/IvGmZzWeMXWIM41FHQCvh6avSPdJkoSLiyMYcEXAxiCCm98J1nrzHTFPhjIaiiyJdJ6MVUWuIBeWRPmrUkASJ07QzclXhgwhGO2dxxlA5J89SS5fL+wkFdF2HNobZYv0RxVOel2g2+FIFlk5TKtNMxjIiuG0arDGM44gvmipKaZSRYHCcDlMP08fJGkqhlSlVbcdUkEtSePqoZVIWAPmgB1H+1hiLtoqUQtFakekIqXS0D9O2DmunH0aU3YvWQFmD1rrSXZRxoTKFTzQJfJC9eaxSl0V6QP2tV6sfoFP+/bd+GI7TAhUcp8YR07FokuH4Z5m8KPtGCjYHLaCP3ZN0+Dxrik6coHuyNHMwxkgSfNQgSUUnzss+VIIC8jEyTpMUMNoWhXC4Y0GXHqY1xih6SQoRRs8CDZEiSYjHqXMqhgIrjkeEzqHgobVMNyOIBo/4roMWkdxf3TQFGSaUChC0RShIo3j0WxzROgB+Ej0OVwLqYzGqvIMUI0nrj/pyh2kzBc4o03yKPlBO+ODJgKsqmTD5A9TEwQfF0kHK5bqtscdkJATZq85a5JJz8VVFE0sf9LsiprzhA/ri0JE/aKXFoukXCvoqhkCMMoFVobClSxWiP+qtAEcUqqIgQA6dVFP0RFBH5FdK+bhWjBKnME0TxgiaM2cKUkGQiQfUYiqoKylKiV6EaBSIGLloKRXNkvhxkkqMSXQDSoeMfBDO/SFaSBVdRH/s4mqlSwIu/1/+6ccJZYc44PD7omclk3y0/ojKiCUmGIuWhHQubVkr6fj9B0sHXZuDLzwI9ZVqZwHN0NQN+a/dw7//5n08rsvD5B2jBXVzQOhEranMeNQt+4iCyWW6oSKlglYv8UDO0jGXqZsyfcsUlI9SWhp11pAAfUBZCzaqIKsj3sOIXNesrclk9sNETLkU74Es07uc1kAm5INeYdFAyQpbUKMhCHJhUgmjMgdlSmNVQfEU/buCSq5N8ZE6Q1aCJM4cUdgHxM6BpgYUWqjEbZURXaEplKmkR6DoD/Ywog2kVUFGZQ1GlYlcEkc1zhRh93icKptSmYB6iDHL5M+jPtJRQ6Wg1H6IBIPit8seUzJtrnYOryLERFKHqb4Kaw7oEfHBViv6oyZp0d1T8sk+JnzKR403a8qzzRlSmZSKKlpS+TiZWCZHaXyZJpWQs85qobKkLNORVYmLQxStP6vl92IRRFLqsP4SOX9E3+WCehW0kBQRZS3+APkhDpOYRReQEhvGgpCqnEywSllyieQTYzkLTVm9uTRndFnPqaBSXPGVqfhmU5pSPkQqpzE5F0RbKverGH1ExYw1lrb+ge6ggpQVtZZ3c/j7yRf9zYP+a9HhkycATV0d194fgt3fPZSpwIJuts4URHGZHlgQkod4XGj6Ca2lwa6UEaRsiU+EhRAKKkfRNBVKyZRHpSxGtaQ84VNCIUjfEAOTn6RhMUoOY53ISuz2ndDiz05xVcU0ih6vPiCfgCpXJBULYmUgZ9HlmaaJbq+oXCtxtfdleutBT1O8l3NC+w1F65Uykc25ipwT1jmMNcxmDSketPMyMafCxhgh//Xpd6poFynNx2emFCWQRylFXUvzWFCrRuIIlDTcnClas4q2bRA0YdGSK77QWYlvDkNUDgj1qqoAxTgIPXmxWOCcI0aPDxPjNKD0grZtSVMgGF8QuPLOjZM4LKcMKhdhb4tV5jjd0RffNQ4izTA1IxrN5L1o+xbUYF1XNE1NX5gzMQRSiMIiKrBGrTSusticmc1aQToWneXKOeSoKIkYiZRgnERPrm318WwBVTSqJG+cvMTy0+SLbukosb3WLBcLmroWPx8+ouMOZ95+15OK/JK8n6IbZ0UP2TrHOI7suw7rKtrZ7ChDcEAm5RRFBocSExRWQdtWVM6w6/eSO6ZATIepzfZ4Hm03O0GMK5i1oqlly2TDTJKmt6vk/Ct5yjhOR8TrIV4WaRjFqjRSfx/7vQtP//if/vfM5jP+5E//lFnTkqY9xljOTmVa3NjtsMbxt/7kzxjGkVdv3mCM4XS9wnvPrtszaxts0xBTZvuwI/gRcmLWNjx/+YI4TYz7LT5AbyM+whCkSxL9xN3dwPXNLTFMeD9StzOWs4ZXb97y3evX/OLHX/CLn/yIu4ctv3v1mmHsGacBqxR1U1HXNc5Zrm/v2O52rNenzGYLhjLl7ubmFWHsmS9PqaqGHEWrZL5a4uqa9azCKsWvvn3LZt9zOm9wRkGOGA2L1UomDRXRtNv9ntEH+nEi+MB29yCHYy0TWGojU0tOVqeknHnz4T1ZKdEDSInd9oGqrmnXZ2StRM2/qrg4PWEcW6xKKGXoQyShWM/bo/BeDF66dCmg0sT24YaHuyvWqxVPn1xSm8Tl6ZJp6PnXv/kSYyzPLk4JfqLvOoZhYPAjy/ULfvTFj/j+1Xc8dB27ccRtN2hgNWuZpol9CMzbhmUt1DPrHGSBRW8fPrDf7SU51Irt7Q0b9VH8u64lASdFclBELEHZEh5kgZvrjHGCUvnxF7/AGcvrNzLRQUQdRfMoxEjdzokx8O3vfkMIgQ/3DywXCz7/9FNBH2wFcltfnDP6wJurGwnqVYXH0A0jD7s9765vOVmv+PkXnzP0Pb/61b8+UuC0tZxePiGbiu8/3GAUWJ1Zr9ZcXsh+EMpRZJoGUop0fV+0pBaMPrPtRoZpwhldAsFEXQLA9WrNfDbDTz3Rj7x+d812u6OtK0gJPw6k4JktVxhX8avffcUwTvzks5e8ePECY0RgudKQrOLzT1+wWC748OYNu92O24cd0+S5PFvJFIRaNFq6rsM1NX/7z/+c+Xz++7qGf+ftw9U1zhrO1sui+7OQouE4HqfYaW1YL0VD5frqgxTVa4HBHkRG64IimqYiopcTYMBYZnXD2cUl3gf6YWQaB7bb7TEx6buOD9MoaNF+wOgFTTvj9vaO3W7HxcUFP/3JT7i/u+PXv/oVtqqYleKMdfZYDOl2W8ahR7uaprYikNh1QmmzRibvUApFidIZMbTtDG0sr777mr7bc3Z+QVXXZTz9R3rZxcUTcs68/v5bpnEoI3YVYyhBeExF1FkXIciWEAK3tzdohUwhQ8n49hDphwGtlGiuGEs7W1DVrYyJTZGx3xEmGTMrKI0a7wNv3wr3/uTkhJThfrf/CEk3Fldbun7id998g7aO2axMx9OanCP73Y7zs3POzs7Ybrfs9jtCFNFFVzUsTyrRCJxGqgZqV4rLIRzh9tvdnr4fIMvhPI4jR6pdSqBtmaQyw1nLq++/Zeg75osTrHPoJMWvtsCUV/MFKEXX9UL3LWOWD6O2h0kSt8paQvDc3VzTNC3Pnj0n58xwfYUCFssF0zRxd3sLWYZWxBi5f9gwTiO3d3csF0suLy6AIs4cA/v9HuMqlidn0uW7uikFf1nrbdMe90MoI+wn75mCp521nKzWTNNIP42EXqbDCjpTgtJ2tiiwbo22FuUqps2Gbt8RQsAagx96kveiP5M133//Ch8CP/r0U55dnvP++pa+70vX0zGbzTDW8VCmLj7c3xFCoGlqnLUslmuMMQJhV4YXz1/gKvdvwcv8zdnVg+yhptI4Z1gsRUtRp3TUbiJFVpXGh8huCGQUtiRb2/s7Ga8chOpQVbUgWqx0ZxfzRgrjMaByRUqCHlvMG/opsBs8h8EEYKnnK1KG3XbL1TDRDSPPz0/4/OUTru42/Pr1DW1lmM1ahskzTD1N1bJoa3b9yN3eUzuhoO060XYcKoczUohPOSO4bFC2QlvLyWLNrLZ8++6OXTeSoxS6l6cnIixc/ONZVYveyW5LTBG0IWXop0DKHIV2ncrUzrBoa2JMvLvdEjPYWor/+gdJAkqhraN1licrmR5EKeD040iKiXVrGSbPwxTwE6LXmTPRWDyKIUQykzTn4sjKZfzQ8eqNZwqRZWWoLVS6iG9rW4qKFAplQptaBlOYjEmZfT8wTCPzylG3NSELmq2pa9racru7ZbvraJ2lMjKUJsZISJqkajBC0a6d0DAf+pEpJOaNJMr94MugCEEFvXi6JgMPDxsmH+imwOAjp/MZkBkmQYHOrExd3PmItZqTldCOpnD4/07Q7KMkQ5VT6BwYhj2bXc+799fM2ppPnpwgxW9p4NicUFWFrVti8Fzfb46FxaoStMF63nK2mvOw23O32bLvPZtuYl4bzlrDlBL7MVAphdNlyJDKLGdzzpuKrh/YdhO1c8xnNZv9QD8N+Ohw1tD5gE8Zo4Qi/upqw+gjf+tnn3G2nnN3v6EfRh6MI6bMJ6c1tdO8v+/pxsDV3ZaYM588OZemuR+F/hwC1ho+e/mc6g/If/3jf/RPaectf/JnP2fhluhGCguuViiViD5iteH5y2eM48Rvf/MlWisWi5acQOkZxswwdlaQLvdH2lOrHG3rqGtD02ih2k2Jbhh42ElhO+aRm7sN37/pUQl0hKaBylV8//0b/r//wwf+/M/+mP/8f/6f8OrVe379629IOdC0jkrXWFNRzx0htXT7nrfv73F1xWo1Y7Pd8eH6hvrdFc4Y1qenNE1L9JGcMtbK2PrLJ+fUTcM//4s3PNzdc3F+SV03ON2gjGa2XOFqR91UhMlz/f6BYRzZjvcybTmKjuYUO7RRrBdr6qamnokg+/u3b0kps1qfAgrfT2ijaRcieF3Xjrad8/LFC4ZxQPpemZu7K4Z+oJ1VkDVaOaLPXH+4RWVwyrHfbLm7uWK1WnLx5JzTdcN6eU4KgX/+F/8Caxwvnj+nG/d045au27K5v+HTT57x4uUL3vGBoU+EKTJsH5jPLO3snM3Dju1ux3w1o3YVbVNR2VqGEGTY3O3Z7zt859ERdrstXWHIhBixrqKpG9p5S9VWvL56w36/xyF01ptuD0qxXpxS1xXnzxYoowSl7ROozDCNxOwJQQTtY4SH+3tiSmw3I4vFgp//TFBo3/t3aOeYL2aM08jX339NCok4JZTSXH94w2a75927dzy5uOSnf/TH+Gnk4eaGbujZb7aE4GmWNV3f8+u/+h2uqmjahvXJiovTM2mIGsXYGWJObPdb3r1/y09++kt++vNfcn97zdXNNav5msUMdsOebuw5W5/w/NlTFqs5Tdvgx4kwebb7nv1uFJS4n4TaPVvhrAKV+R//h79kt9/yn/1n/yk///kXTIPEx3VtCEHxxWefs1yseP32Ddvdjrcf7pgmz/MXT2nahnbWHGUw6rriF3/0U9Fa/D3s9y48KSKkUr3TimnyWJuPHetxEg7iOEklMAZfEBfSWagrJ8gRLx35QwcjIyr99w+bIpabjlNIUBqs8CaZPvLCtTHMbEtVuWMXR6abpNLJ/wgrpgiCtXV94IHI+NzJS9e0JFFKKUaKsyoTRERLQNAxrmhVoCgaAKpUBg8TQTiiUVTpzgv/Vig1WsnUoVg4wUZrGuuoqwpXFR0sK5OjFKLdcxDPldH2Ahc/6DDkJDpFMuLbFk0k6Z44J5VqlJZKrREO6TCM1PXIOI6F9hePCa21UkmNUSrN1hiWs1YmzpSx6DKpJjN6GQt6gMQfJjgIncSgjZOOdk4oY9BOKGVaafbDQPAylbByjqp20rHNQnnUrhKh3zBBOtBeEoGRw8Qndejk5oyPER0TZJkMdqjGGpVJWRdNG1WSRoreSjx23ionEE2UwViHL0ll5aT7NQzjUWdEF/SHUhmyxThbUBsRUihdvHz8r1aK2jl6Y46aAuGgv5USOWmZbBBlWkDCkDWUMj2HaQ9aK5wVEUpjjaAQgqfJWYqqlSDYyIKoUQU50TbiyIWCVZB51rBaLvEhUNdNQZrIMzvo/ByoTH9odkBajsN4RL8d9CByyjLJIx1wZ4eGSdEPyZlpHADpTMcoHa6Us6DfUsJY6YA7a0lRuhapQKCBo36RcwU9UtBxB3SRLx0tXaZNHNBBVeU+oqyyFHS0imhEU0BRJopx6BjGjx2U4kOAj39fJugcJqsppUjJHVFhgqqRjpq10iHJKFSiTIZUGGP/Wnfjh88xwxGdUVcV5IJQ8AfdNOlI5ZJgppyOKKbDlIwQ4pGaGlMi5lj2r0yqI4eCGMioghqQe8o461gulzK9LUWUFt+bM2UaKB/13mIUbakDYsh76aaV6Xgx+lLcNgXpFI8aaspI8uG9Jx916oomWEFA5SQIysOExKP/zgnvp3IumCMKSCmFqg6aVKJd4L0vKK4ASmOVvMNDx7R8JKGsjwOir+s6QS8YI8jXohHnnKxX0eHRx0Kb0hqdc9EyE4HklCLTKOv0oI6WCxKKcCi+is7GQaPwoMWgVCjPpIgOF/2tyXtZKyYf9wFKEBEHzTFTfOYBHWG0BqOPa84dNMl00dVwH//NHxjgqRQ5VXlOinHyKBSVVeisjiiysWj2RGldSyEJOQcyMEwBZ8GUPXU4twcfIUdptAFtXeGcPcYpqDLBM0rsoo0gAZRCCt1FO8wX/R/xb7IeqqqgIvXHtRFjIpWpc84c9Ir0sbglcUSZfkjGlHeaf6C9kRFkTYgRHQQ5ARLuHDqxKYGz6qh9opBYz2iFVeLjYhT9n1yQ1SqnIwJHAc5KCSx+BDIW2ms+ol4FIV7iViW6Qbqg8WprJJ47oHkKaj+VZkbMB4RlOk4bNEYoV0pruTYEkeN9ZD9M5VkcClLyNJQSPZuQDlpycrEHDSyjOVK4dJTPNFrO/pBg8jIh8a/rO0pMPfpESAlTp+N+FH8rqqBHhGhBTB6QDILKlInWh8m8Rx3VgoqUmEje4ehl6lvTSIPYB8ktUqZMvhTkRmUqvC43jOQXpvhi0cUp2otKf8wPkPWjlcKWv8sZYrkPQaulI5LyoMcqiKsKZ3WZ5JWYfGBWiw7krKlxLpLLVDJFxhpNbfXRnyklTZo6K+raFQ3QQw6kC421+NCCcP5DsawKLq68LkHJKJhLyVDYMJGhCyWuKTprxoBWmEaGR+x2e2KSplAuzIRxGnm4fxD/hJxl2opmYFM3hDgxTUPZ24KqdGWEvTHqqAOVC5JN9tGBqaKpaie6nFNA+8wu7hn6UVApleR1kMUHZ9E4DJPohAmy3kouJrBP6qqiaVpQqmgpSvwjCOUi64ggsq0xzGcLiUs6QUQ7bUsTsaGuK9H9jKHEmcXJZWFOaEVpwMiUZWPtcTrmIReyxjJNnnHyWOOoGysxp7XH9d/3ia6LZfqf/6g/G2TwF5XC2VrOB+9p6pqL83OausJPcs5XtRO5ht2OjFxf13UMw0hVC7XUGy9xbFUVvVqJT5umoW7q4xAXa0Wr0yg5m6bJA3sZHIYg1RSKPBUW0yAU5BAaDKbEuJGx1CdS0sSQiCkcYymjRLPLaFPuOf0gZ5R4pXKOqCJEmYruo7B3DkiyzWZT3k+ErMok4YT2wvAytv6B7mlB3iuDxmCt6DqL1IO8w+AllhS2jOSFoeRpMUV5qj9A1KaUywRQ+QxdYsAYik63zrSzFm3EJ0YfOWhDtW1bkPiSM1hrqOuK5WqB94GmaQrqTc4ZU1gfEuP/G6bavbg4wViL397RhcD37z6IttPpGSlnrm9v2G53fPv9dzR1w48+/5yqrmmsxdQVp4sZwxT4cP1AXVWcnawZUezUwO3VHf/sX/2a9WrFJy9f0DjDsqpo6xo3m4v+yr5nHEfoe1bLOWcna4Fcp8Ry3vDJ03O0gnfXNzSV4/J0we3NQOwCTy8uePbsOe9vbrh7eGCKiX70Ai3WmnVjqazGhgV7o4hIgrKY1dIVaxxVJUzdmOFy3XLSGoYgYoI+aWJM7Hd7opciDQqqqqYuXfqUM3UpMDkjAdfFeimbvBKtjIukpDBS6DJmsaZtas4WNf0w8vZhR1NXLNsZ292O71+9wVjHyckJ4+S5e9iwXMx5diH6LGhTDt3Eze0tH25vYSfd6CkE+tHTVJZ5XROmiX3cFIFO4dm/fHbJNHnev/kW3/csnBQBb3cDd3f37DZb1icnwrHNiTCNYGswNcl7cvS0ixXV8oT1fEFlLF/+7td03Y4Xn3zGYr46dvvf3dwwDSMvn5/RVDWbHBhJ3N/1DOPIwzChtcEhE1C2+046YRSqoXB/CGicqzm/OCWnhKtkItSr12+lUDWJIyJ6XFXz8vklKMOUJCDddQMZePnsCcM48pvf/o7VasWnLz8lhomh2xxRLavFnMsnT+j3e+4fHsgxst3uigh9wpA4WS4IfqKzltFHrrcDTiE6UkmTtSaHiTxNxOzw2QryYRzp9x3j0NNUlvZ0zdnpCc1sxqv377h92FA1c5yr+OWPPqOtK757/T3v3t1yMhf9qOfPLjHGEYNnu92wnLWs53Nefvo5MSs+fPggya+R4PR0doLWmlevZCob/4v/5e/rHv6dtrapBbmjpfB99eYdxmiePXlSxI0dQ9/z5vUrrHM8efYcZx11Je4xpoQfJ64+vKdtW54+eUIMgfv7+9INf8C5irppWcxnnJ2cFE22JVPf0e+3kpykRNs6Vm6Jq2qqupEpYUDf7fj2/oaT03OePXvO4ANTiLTtjHnbyNhYPxGiTGKyU0AbzfnJCfNZy5TFNz3sdkxDx/nZGW3bUjWCcvCjIO9W6xMWqzXTcbTuBArqyqIUbDf3ZDLz+YL5YoHWgj4c+p6cE9WyRWs5OFGQomiSzWZzKc4dRSADzjmePrlkHAbevP6eGD33txXTNHF7e411jsVyTQhlnHZVsVytIWeWq3CEq8eU0CYx+YmuH47F8aaumc8aebbTxGEIxMnJCS+eP6PrOu7ubqmbGeuTM7r9ntv7h+Po9xSkYORcRUbR7/f4aWK5PsXVrSTUfsLVAiXve9H9uLi8LBMPpft2ffWB4APr1Yrl6oRmJsimDx/eMwwD3X6LVorVai3d7BTIYeJht0UpzfrkRBAB44DWhtVqhakFuZBi4v3VdSlMDljrqJo5VVVzeXkpUxg3D2QlCaStap7NZ+z2Hb/+8ktmbcPl+TlKG9Yn54UGp6m0ptZClTbWlAaGFhHvqjqOMr6+uZHzCM2+HwsK1R7HIdtCq7bGolxNSJEYBRGotaaymmq5OFL+3l9dc/+wYTGfUVc1z58/Zzabc39/x4fbO+qqYl3X6JIkj8NA8l6eSRH8jzFSNTMpVsQJlZH/rw191x0TzT8YyxGNjJGffOSb1+/QWvPiySmNM9jsmXzkze0WcmZWkFHGK9qm4dnTL9jsOn777WsqF9HWSALiA7sB+juZ2FuZxHox4/nFidAc/CRNQ+cYo+wxXVmMczRONCRbC3ObicHz6sMd62XLFy/OmSZBzJ3NZYLku5t7bh/2TF78mFOalDWXZ6fMZzO2u45h8MQ4EnMqCWBmXgkiJsZIP4Jzhll2+Enihs2uK6gdGcgQlSCcpAamaCtB2/QhyXTdxpauujQD7rtB/ItVmKxoEBROUjK8YLFYMPnIu7uOcYJ+kqC/Gwc0mUolpilysx8xCtraSPzaiCSFMo5p8uz7AZ8zPhv2Y2Q7eqHoVg0+7BnHQahrWpqRz88suzHy0CfaytI4w82mo/twJwgma6SYp40Uz3RimBJjyMwrjVUJa4V20Rihu1XVTKQytlum4FnNRU9t03vi3lO3rWirUJocfiSGwJv7iYzieZJC3H7oiFEKdFppopeEdJKuGVNMGK1w1hBi5PW7GzJZBkRYKWpbbZjNFvTDwPvra+xUkWxNU9f8/KdfsN33fPfuBquR+9FapnxVFfNZi08tfVhCTqgYiCgCipg14zBBFv3BGDOpiOF3QTOvNava0I+BYRRB4awUd5s9t+xZ1JbGacie7BNPT05o2pkMWPAT724euHnYs162tG3Np09Oqazh61dvePfuLeenJzRVxUkrdOiQDTEZLk5EC3G1mOFjFDoioEyLNLOkGOUnT/oDavo9e36CdRU+BqbO8+3v3orm4uklGkW379ludnz1269ZLJf8+Z//beq2ppnJMBGH437zwF/9+q9YLhd88aPPGLqB/bbj6sM1v/vyK+q2YXl6wnq54OmTC9pFw2y1ZLu55+amo7E19WxB3WSaFoxzWGc4PV1hlCaFxNfffAcqc3axYOg90+BZnS5YnizZ3Nd0u57pzR33t3uqak7bVDx7tqBuLPvtxDRE4jgxTB3zojd4cX5G0zZM0dN1npefvOTZ88SH2yuZ9tYPUiRXURDSViRr5osWaxacnF+Qs+Ldq3cyTVfPcM7y9PwpSsHdww05Z54+fyZTGUuBd4wB11ZcPjtlv9vzV//yG5bLFacXl+w2G7797fdUrubi/JLtruftmytOTtZcPr1kPltyenpJShMhdNze3LPZ9fRD4P27a0Y/MYwDbduwWrSQFTlpun1Ht+v49MVL/vaf/Tk3t/e8+fYtVWO4eLrg/nbD+/fv6YeOYRywRoTNo/f42RzV9OjK8uLpM5q2EW0Clfnk009ZLJf863/1r9nd3PLJJy9YLOcoI7IWb77/mr7fM1/OmLctVSO0wd6DH0a++/47iQf0j6mbis3DPd57xlGK2nUtxcNu6DDWcNKeYYxltXDkrPjuu/fkHIlph1YGledUruLHn37GME18uLvDWYPPCVtbXry4ZLvt+H//f/4R6/WKzz7/BNfUXCxXbLe3DN0tJ6cnvHj5E8ZhYL/boTVsdhtmzYyFqVnNF6JLDSL07QOvv/mGqq1YrITO5lUiEkh5ohv2ZDLBD/TOEaIiJcV8NmO5mLFYneDqhqu3dzzc3VPNRZT8P/q7f5vTkxVvvn3PN1+9Yr1eUlWOT15+Kgj7sWcY91w8PcHaM56/eEoIid2mF6rhtCXFzHy5xNjM6+9ffexZ/E/Y7114SkqjUceJHa5wJLt+KDxo4cbWdY07QJ8RLqWzlrZyKDPiehl3KG1ljlW52WyGq5xMC1AZryEbI5olSeDHIrLY4KoabQzjNAhtIcaiNSVVwgPHHSCWCWnjMDD0PX0/4KxltVyUUecfp6yoUqxpDwK41hQeslS0pwPHFukeVRxQFNLZMVrQEJOXTjxR7q9eLtGlUpxSxpRpP1lJ5z1OIoCZFeVQ1iKku9+RU2S72zGOE+M4Yktn2hgZMy3CmgqvMinJ5Kuu78sBLZXwEFPpulSgNOPkS2dNpgXpojmUUfgYmcIkFVdrpJCWJJCoqoqsDbnoQaQsyKB522A48GMLgseLDsqUIxGNdxPKCd+5nc1om4amdgzDWKZAiW6SLl3UUNT367pBaUOfpEMiaJwykUsp0IW5nyWBb+oKa8yxQmwLuoOcShIrmDJrBWm2mM9k6su2JxuDKUUKZzSuqohZMZ/NqSpHVJnoBDlhbaSqHPOmJkzjsfNJqUSn6I+aJ21Tc36yJmAIWJzOWJU5DGsxWpGPk9Ms1llqV9ErVSY7SLU9FjRO3TTM5nNJGEs1/qhHE5MIMKeMMhXGSicy5cwQJEmrkiScMnRQH7WryNItHHL82N79Q7EsaMacE6bQM30IZcqRoFKquiraWB9hE0opnLUiYlrVgpwpOneynw4Tiz529EMIxCzotowIvcYYUTEW9IcpVANBWBljSNYV1FTRoZtCoXRJJ8IHzzCOGGuZz+dHlEBVC7V1KpMO67o6jpvW0rI4aoKlGNHWFQ2hwtv201GLxBjD6P1RB0grhW2EbniYzGa0AaNQJqEOCMKiBZU5UK8+op5CkK7PoQtz0CU7To1RP9DtiIm+67BWzoQYIlP0ZV2HI+Iola6VoAQoKNHS5S/UEOscumg+HbWVip+PCHzBWkEtHrSLnHPHgzMUmrUqCNdDgRJyGW9vGdMo01VDmXpqDtPwyjMtXf3DVKbDhEKZEJvR2h/XjIigV0dfnMrvHtAOShVtFGSKmcVS1xUHnS1dNEqsOaBsHbO2PU5tUcZgTFW67BSdoLb4/UzBaJDJR5rkVKbGtO2slNLVcUBHiOGo+3DQ5so5yvcrIz4pBGnu8BHJVFdC6bM/QDQdQBSHsyPnTKXdRzRgzvhpIhZUzAFVo7VmDJNoYYRA0onk/XHv/qFYTIJ6Ff2sjCtFOe8DKidM0kWw2AqajoOGkirgFEG31ZUT32AEheN1QpOxSQEF9Vf0iXyMDFMko6mMJltNcLboRUZSElpfKsjGlCAU9LvRihACXTdSOUtdubKHY5lwZGhqS2ONnH0HHTwyde2oKotWUYpPRaB/8h590ERSUBXU3lCGk7S1UDyHKXycblVQYqKh6aXJVZJ+U57hgUZ9QHCpjzAIEXQfJ3w4nO0arWRfHvSRxL9IfAUSa0UrcdxBPy8TRAvIKIyKBUklujWxxGZ18VcUxIdFUSWFT6LdctBoslpQ4N5DVYtWzoFZIDFRLggsQX+mlEkaKTiVqVlNU+OiaE/FREF9ZloFVhVNsRRlF/0gkTj88eCzD8WTgw5iVSjhFA0kUQY7TCDMRw0rQQLJEI5oBWF16LAbJTG0MaKnJVRgQYFZK81BkD1gncN7z1B8tQxoSHQpFPQVWGtom4qQFCEfJhBSJpFlcnGIoQirq4LUCjERchKR8yyFyowUOGdtJVNI8w/V5MrUtUJRPjBBlBLmxBT00c8pFEWmD0Rq8aiHNpbJYn8wVjRlwiTauZUTenrfjygF0xTISdAXdV0fJ9umJHpQbd0yBc98NqNpGoxxGB2KrqbBVXIOhEILH8YBrR1aJ4nZnEMrh0YGLRgbSQmGXmIvoa6KjEBVEEpDLxrCwUtMNY0jfd9T1xVn56fMF/OjdEtVWTolqJimrY9rF52Pw0C8F1SKMaJXWdeCVO53O2KMx2nTIYk8yRQmsjVUrgJ0QbccKPlCm4dcJqhlUAedH8lNog9MWrHf93SdDMIJoSw05PqM1RhXdIGUTLzrux7nanS59sn7Y16vChoT+YgjYlB8d9ECVaI1VDUifm1LQ8oYS+Uq6tpLgT1CM6uZzWY0TZlKrBVK5aMG6uTlJ6YDbVEog3XjqGvHOEamIGdVjOk4WW4K4v+N+cgsOEx/J4kWm9B3wzEeQ6ljTJ2zIieFUZqsZGpoTJBiJhFIyCT62XyGMhp1J/6tqVtyTjjjUMrS9575fIarZICNq1xp5s2YzVpmiwZIDL0U2FQWxPs4TqQs73XWznj27BmhTHJ3zgp6OSsBphiDtYK8PEyvb5qG7a5nGD3aiJ9tU8SRaJqa1XJOdqDtx4ne3otGVdcZJm+p6gpt1PH5DP2INoHo5TlUzqI1jIMgtVKQiZ79JM/097Hfu/C0HTOVg6Wy2Mrx8uk5PkTefLj6KOzXNvzpn/4JMSYetjuqlKjbGbO25Wy1YhwHtDHHcfbkTDurWa4W/OiLLxi6jvu7a8YAcQI9DphhpDKa1mqaWctyfQ45M/rE1c0dr1+/4uzklPOzc87Pzjg/P8MPe/ywJ6ZMFzLvPlyxfbjn+mHLZt/z6Yvn/PTzz/B+FHpDFrh1QJOU5ZNnl5ytllzf7+hGT8ia4BP3t7dM08jJsqVylraSzuFVkkLDsq2ZzVpeX3f0w0i/Fx2s1ckJ2li2XU8IgfliibKGTZnc1vcjMg2kxrqK9ckJ++2G1//6X5GBq7tbchYB30opZnWLM46XL1+icqLWGZMD13Fku/U87DsuT8/45RcLhiRcz4Tm7PxcNB/2HfN2ztlqXURKQRmh7N3f3rDbPDCrLJqZdMqsxrkZqFKQMZrQCxrnxfkJnz5/yv1my67vSdEzDh1D38t37TrGydOdLGmbmvnyhJPzp5yvWiqrub69ZbPr0HUjQt4klO+5e9gwjCOfvPiEylW0d3dSIDGJWIQnldbQLMjAsN9jtebJ+QkpRd68eUtKifl8IXo0OhOiosuiEdOsViwXM148e8rmYcP3X3/DbD7n+bOfUBUKpCrFyBQFRu2tBA/OTShlWS2WnJ2cMI6i1yROPNFPA9vtXianNS2Xl5f88qefc7vpudvsKfKsjNPAOI3YtkEVqp+2jtOTU05WS7r9lvtNYrvZMQ4jbrZEVzVPnz7j4vIpQ78neM/N7R0KSqJgud3KuqoftlitsFVNypl3b18zjSOL1ZqmafjxJ89xjeHr2y3j6DFKgjfRw/jDCX5ikkLDNI4Yrbk4PyOlzG6/l4KGn6iqik8/+RTgWIyJUQ7zWTujbWA+X0hxFiXTNJ8+QSEHgAQZQnW632wkIB4mlss556enpBiIfpTpYjEx7Du6XiZkNE1LM5sLra7Qh8I00G03OA0auL27ZbvdcfnkkpefvJSQ/lDMSIlNd82w7/jk5QtWyyXbzYNoFo2jjJMOotMyqxusq1iuTshAN47EaWLWzqjrms12L6LT44AxiuftDKUU290e7z11mdKzWMxQKCY/SdFVKk0l8ZUk2cfIh6trCSZiwlZaRMCdJUYvxXBrCrXNse97Hu5vODk54bPPviB4LxD7KFM8Y8r4mNE5CUUvJYYgRVyHoCSK7i0pK6yrmM0Xsq+0pq4qNFKYnXzgZLlgMZsVkV7FfD5DKxEi3m03BQkh1LS6cpyenpBSpimTJvfdnn3XoZIUFF1do13F29evmKaJ84tLZm171ISKBdLfLtdUUaZgHWitxljOzi9RStEX7bE4DRitmS9XpJTY72RPhiD0v9VywThN9OMo1Oj5jAMdeblac/n0WQksZKiF0uZYyK7qhtmsZRpHuq6T4muhm0w+sd1tSWPPcn3Cixcv6LqO/X4nDYOmYRgmhkkGOChE8D6EidXZGcvlkpubW7Z9x37fMU0TT55cslwsuLy84OzslG63w3sRez0Ul7TWZU8mlmW63UHf5urqSgqfVYN1jrYSbcBut8V7Tz+OZRCD5yB2/odi4ziRsyMrh6scT0+FKr3f79lluNeGuqq4PD+V6XYPW1Q2ZFURAmwebkFpPnlyijWKxhXJAzSNUqy1TLnbbDzdMPHuboOPmWFKrGcVT1Yt3tbM6oppkgZeNwY2uQwW0YaoQBp0iRwjN3d3vH5/y9PLC/rTNZt9L1M4G0vjpOHT1BX7bhAttVF0xZ5dnLCYNYc8gdv7Hf04se9lSlguxZyz5QyrNd+8vWbykeVMYrKr1x/YDxNKC71JubpIKYzkGESs1RiWy1WhfnpyghpBvyvjBDEVAn7wvL26AxTGNTTO0DrwSbMLtdCqbKbCMqslid50E1lb1qYqiCfLEEeutiNNFVnNRMOtWS8hi/ZjWznW52f4CFMSvUhrMqbSzOe60FIG5rXhdL7gftuz7Sbms4b1rOYwJt3phFUQY2Y/Rrphohsm1KzGUWiNxvD04gxrNN++u2XbDeQoRblKRyqt2PQdk48iN2Ar2loACFWhs1ZVRQiRcRIK8BSkEHC+mpFzYrfdkkImlULT6UqmMecYytQ8j1awahos8nm1s6xqgzEZP404nXl5sSp+KWI1NEYTUfSTZz2veXbWcHWfeNhMhQ6TGELg2gfapmLe1szaipPVrCCcfDkboK6lIGV1xirok2aKCpUmSJ7tEOmnhL/5QIyB55enLBcznl6seXK+FKr9OHG3lUJ/XVVYrel9ZD+GcgYq5rUUYu82HSHl4xCd9bJFK03nhTpZNY4MfLh7OA4e+kOwKdTEpOjuO4yCT55fEFLizbt35JRxGf5/3P3Xs2TZleaJ/bY40uXVkREpoIHSLcgnGh/4V9P4RDNy2mgztKnurkKhBFBIIDMy1FWujtyKD2v7zeqnwcMMZzqPWRQKich73Y8f33vttb7v91VlyV//zd8QY2J/2FMMBVFtMauS7fU1i+2adlUSA8RoiBYWi4bFsuHm7pJxchwOI0M/8vHjJ1TS6GRp2orL7RZb1ZR1yzRNDONI97Tj+f6RdrmgXS2p6pKitqwWa1btiqfHAx8fP5GMAOQ/vHvH48MDP/3Zz7j793+Jm3uCn0EXgGGed3R9x5e//DHX11vef/xId+rYHw+okxWbFommWWFtwfXFBT4Km2kYRq7/8pr1es37948M3cD9/T3WaL788qdYW3A4Hun6jspmdbJ0SJnjLPap00BpK26vPmNMI/3ztxxT5LCX5OJxCCyXCmtKmqbh4nZLWVasr9akIrF6EC7VH37/lrtXA9dXS06nng+fHun7gclPVLrG2CoHgWXLu9ZiiVYjxoijR2mFC566Lrm6uiQi9/D6quHmKvLdd58gPvOTH3/B69c3DMMoQyUSERi6nuHY8/T8yKnrWD+tiT7QLhqq2rK9WFBVBR8/vOdw6HA+oMuKy2ux9/3mH35L1/XcfXbDcrlAKyOs0xy0crFtABjCiPeB43GgMJavvhCO5rvvPjFHT9tIfbFYVczzzMePB6lj/YGry0uur/+M4/HE1398i61b7u5ei3ouSLPnb/5GMTtH341AFtnYLUVZsd4subxsUcpxPCi0SpkhOrI/zhk5FLj77BV//Tf/nm+/+5Zv3/6R9XrDerli7EamfkZVS6qypioKKmu5ubnl4mLLP/7TP/P4/EkGCCGSrGJrN7z54povPr/jebdjGCd2T3v2zzsOpyPzPLM77EkRthfCEGtb4R3+4V/fM09O8DhlwZdfvcHYht3jvbA1kwRbPeyPuPCn1V5/cuNpsVhglMqTR3KKUlYFJIQHYgxVURJNxNWSLtf3vTSlbPGSNPQy6Tx3InPjyhjNsm1wXjqjKSTiHGgKg6osBoO1UljPTorzqihyWp1mdhPHw47gHdE5QpJY6PNUlcyAOk+yrRHV1tnRXVj7wqIyZ4ZTigzjwDkhyhj5+yGBn2Qav1gsqJuGOQQYJ4wpqCrFlKWU+/1OYLopiFIoBlJSlGUlPtDDSdJIjCUGxzD0eOdYLxfCAMjTaGUsSWvmzCUxWmZKVp9ThAqIEJLKk2tJCBlnh1LiMbYZLloVpaQR5g8wJEg+YIxluRDbzP5wkkl1LqCUsSgikURZFqzamqqwaGRC72MiTjM4h8sKDJcnqOMoB4xmuaYsDLudpF3Ms0Mbw2a5oKxKKi1MnLIs8yRIAJtGKaKWz0gYCvIg+Tx1ssZQWiMHvRAoMsdCZ75IYUHpRGETOqfLaaVkGhHEm2u0IrgZh6gMzgqOkIssnSX9KSs8Xry/QGGlcDin3/mYUD6gnMM5h8tcq9VyyTwNzOP4olDS2ddtshKE/HvrumazWjMOE+M4yUI2Tnkqe1aOqBfe1TRNzNlXnYN7crKLpEDYogKlX9Q5k/OijFLC7fC5iSCpNj+c68xwezngIsoOuddixbCFKOAAAt+rdVJMjJnTgLaZx6BImTeToqgttBHvvXPSeJ1mJx72shBlQMipjj4wOZ8nWMj0SH2vAgpZKh1ieGl8aqP/W9VMjKIO1DINi3ntKvLB4MyCAf4bZco50TNFaaSe1VhaK6Z5EmA6wtNJRpLu5gy8BvWSYGkyM0kB0zy9eMMTvHznmqYhBM9+v5f7g6zBIQoHpq6lANBa1BKiJor46dzKEEXWPI0vylhR/SRhAaiE0kq+n0kYGybz+EKI9MOQf77Ja5giaGm+lKWk2lRV/ZJu47wjZu6GcNiSNCVz0xlErVlYzTCOeO/lHsZIXdV5uiZMpqIs83N35tyUWaWVf2ZWmynUC/NE54MygJq/V3ApnfeJvM6ozC5R6vtkTPXybVWc9Uvfp/KdgeolbVWL1WmeCUZUtSmlfM8A4guTKngnaq4gyjKtJSVPKS0Kr9zcOSsNYjwnIUZi5ggURYlSg+wNzjNP88vf18ZQIIrBc8qXTHLl+Yr5dcSzkvTlkud/GAdR3yEqlZBTxM6KuB/SZe1ZoSnPwDkJrbTmpclrrZZ90SgWdZl5H8IiGueI0hFjQKEJmW0UUpRE1ZwS2NZycPC5+ThOntrK7z3ze8gNTJUUOokqUjhzklymOLO6DFVVvaTbgvSlNSqHcYjyiqzmkXVF/mgFwxxwXuDeMZz3JEVQmXPlAl4FUTQYk9WlssfWlbxOYwzz7PD6e4W0NTqrArOyKQ8llDH5OyXMnaYqMCpxOL/r/BWLOfauyFB+U2hMylyarHbQiHIhxsDkZI+vy4Kmkj9kpWcI4FPCx8DstfzshKhtQhTlhpHXXJjvkyLrWu50VZr8XZE9S9RXwo85M4tCfgZMkuS8whpG50mzrHE6M1isUZKSnGstrXhJrvy3ew85PUsUq/9WmyN1qCjtztwqeSBU3h8wBhVljTir62ISyHtpzzym8++RGui8NpichpYyI9OFKEyoJOmJMXP7AuSkz/ys5jXWarmP539XZ94TSQkKVc6GsrZqQ1NZbAEdiXnOPC4fXu7JWdF0fg9n5UXKP0j9m2fm3yrHZH1STLNYkYWpyIta4Jzm9UO5iqzIc/OM12KVVVpRFRUkOYBWVUW7WBKiuC0Auu6EQrHf76XhHM9zrcg5/znGiIvCX7242OLczDj2BB/xcySqJe2yAR9I88QwjHSnTs4cKjMNtcCsgw+Mw4iKORE7fwc05/1NnnSjNKooSdYQk3xny5ysVuaYe1D4eOYLKepaAl6Cn4XNG2RtWCzEtjWMwg4lBrQmK5AiT0/PGGOJubax2SJYZRW6G1zmuQmj6NR3xBBYb9fMznEYeoIPoEUlPY49MXoW2WJ7VhHWbY2bA9MsNUkMkijYdz3nAKi6LmnaCpKRsXnMTLkkSnqlDE27IEY4HDpUEvUTWpOUJvqZGCJt23BxGWkXLWVV0feCLzizglNIpAhjxkB0XSdq7spQlBXPu2diCIzjACmx3qwoyoKmaSmsoarFXlsWpbCgrDSDJMlY/pzrFVHwi/rLFsJAOrMGQ/QYpC5NSXh4UUe0EYXS2S1RFhI6cHYQjOMgjploJXjr1Gc+0gIS9Gl44YnGmGSzQxag4D3jOMp5Xilirt/KomC92VDaUuqr7Kh5UQrnNdJ5x+xnyqpgtV6xfz4wT7Mo2UqLN5XUTEkUo8E7fPKMw5DZa8X3fC0fGHMNLSJzScp2wDAMktoNshfntUv2yT/t5PgnN55++qOvmKaRt7//LSEm2vUFWllKm9NHcspRZQymLNmuNwzjxB//+A2mKFhvLymtyRs6lIVh9hAnx+BGjqeezbLhx198xqfnHb/944FhdBy7mVVjuVwWNAvHIllOpxP7w562srz57I6ikESnx08f+OP+iXqxompXzD5R1wuWi4JVY9ifTqgUmGeJKdyslrRNTTc6JudZL1qWdYXVWuDbTtLz7u8fGMeJz17dslouRVbmAvePkjrw5z//KW1T8dt//T3jNPHF559TFJboI33f8w+//jUpJW7vXlHXJX7qMdRcffalpBK8+5hTfzTTBPefHmiqgn/3F79i9onffzoICFxFdFnzcOwxyWPCKNasckFVR1brNS4kJi+y+8FNHMeR59ORVVNzs1nRLpesthe4cWTsTow+0rvIPA6MQ8922fL57RV/fPeef/jt17y5u+PN3R22KrFlSdf39OPIerFg21S0dcHkZvrZc5o803DAu5myljSiKSSmGHHHE7bT3F5fsSgU/8//6e959+mBv/jzP+fm+ppf/vgr1ssFDx/fMw49dzfXzD5gVST4gRQmdEos243c28xp6Y8nYkqs60qUdVfXombpR+YMCrZGs2xLmZ7rEZSiKiykwMPDEyF4theXKBKn3RNJG4KpmceB4+6RmJVwNxcbfvHlZ+xT4OlJmqOn/gQktts1fd9zf/9AQBOUxU0SBeqnkb7rubm948svXvPd22/YPT4w5cQodbZPWpHi+nlmOCXuri75/LNX+BAkKeXU082eupBufFMa6sISnIAZn59kSvD61R1t0wisHOhHaYC+evMlRVEwTwMxBD7uOgCauqaoSp6eRlKKrDfrPzkW87+Ha9nUxJSk4eMDs/8+RlZpgzECXa6ahViemgXTNPD08EkOtE+PFEXFcrMVC+tyiQec1kzzzOmwZ7Pd8tlnr3l+fuLp/iPDNHHshhwaULxsFtM0MY6DyG5rUS6qfHBLMdD3PcPQY4ylzuqSqm4kxWSucPPMfn9g2baSumcsymqWyxVNJVP2MTc+A4p+GHCz4/paklXmWda6Y7cjxsjN1RZrDO/fv2OeZy4uLljUJbGWdKjH52dCjNicOFdpYXVsNmtiFEikFP9aJs4h0BSlJJ10He+/+5YYI21do4GhH6jqmourG2IMuLHD2oQuSuYpN2zKmhilkbrfPbNYLrm8upaDSGYHaW1ESTmOTM4xzTPr1ZLNesnp1HE4PbFer1gvV6LStBrvLejEetXKZw+QErv9gcNhzxmUrc+BBFmi7iZJFfvii89ZNA2///oPPD4/CVOgLLi9uWa5WBC1wHLvbu8IGdScEixXq1zseOZxph9FkagVGf5ts9xevnPTAEoDRuJ+NxspJPfPjyigrCpZW2dpaku4AS+T8qS0JGwdDtL8957LyyvefH7J4XBgt3uWvW0SZpQ0XGdRfwRHmHrcPGfV3kB3OlFWDevtJf3pyOF4PBtRc3NO3otSinHoSTFgi5rttmWepNE19D1umnKjFZp2SdWIwoyUcrN2Ztm2WGNxweH9OaxB1BZiCFOk4Pnu3XsUcHl5KTaFcE4c/L4p9kO5VsuWlBT7k6zbfuoojOb6YosxWqClSmGTpLxe366YfeTxODPOkb0PaKAwE4XRLKtCVJeTY5hm9oeeq+2Sn7y5oRsnUXoPE8+HnhgarFUvzYaEQVdLrOyKQLYn5UaDSpphguVyTd0sc/FvcvR3bgCliFWKQhuSMjhlKIuISQkdRRn64f7Avp8plAC7r7YrYTtOkclHPjwdiCHw5u6Sqij4+HTAhcB2LQrn4BzBRx6f9qJSrEvqwrJshBNWlqL+G8IEKGyzICnNHKCymtfbinGa6btOks8yU2kIwkvaVAptLLZuwEwU44DCYCgorMJNE/3see5mFnXJ57cX1KVlVZfMWaE3JKmNToPncOqpq4K6KugGRzc6NsuW9cLQlJbGNmAK0AV3i4bSfA8Xn4JmSpImVxjD4XRknCcGp5ijogwRrQLLytLUJb/5w0eeDgMXy4q2tNxdLWhKKw3IEFlU0oCaohKQsJYQn+A8KiqsUmijCEYaTRiDMhprhC3igqiKTBSDbso1TtksMo9vYHKe3XFEKbhaVLIOJshJL7jZczrtCSHhgmKzbGgu1qTJ4YeRY+9wQZoTm+VChtHzjAoBH0MeTGYMQ4wYo2gqy76f2Q8+B8UkGRgYi1KSXGoKS2FLrq8WtFXFp6cdx66XZvcwMEdNSIplqSiNqBoi0HeSVLpYNJTWYhA4vslWs6pUmBg5HAUtMc4SOHEeNrzPrDHyUPOHcm1WJd47Hh+OpATtYi1sv9tLGeInT1mUbC9kf69qzeF45Ouvv8XagqfHJ+qyYrPaSLJ1a/FpxsdIN3Q87h75/PXn/Pu//ivevf/Ar3/zGw6HE4+Pz7y6u6VuV8Q44qPjeDixf9qzXLRsVguKbPOKc2Cae/bzM9M84UJg0bbSKC6VfJ62xE+e8dix2q6pF1JLee+5vr5ktWxp2wVKF7gAw+R5+PTENM785KfCYJ1Oe/zseT45QlL89Kc/oqoK/vGf/5VhGPnq88+oa0vTlIzTzP/8t39LQrG9WNIuapbLFXVd8uruAh8CX3/znhgd2micn/j929+yWq34D//xbzgcjvwP/+//AR8iTd2KwurDd7Rtw6tXryBF3DxR15aruyvmydMfJ+q6xXtNf5p4+PDAarPg9rMrmqZhtVrkHKXI8djxvDvQzY5pnLl7dcur15/x7t1H3n39DXevLrm9uxL0Q13x9PDM4Xji6vaSr37yhqIs0NZy6AbuPz4LdzclfBS8xOHUMU4z78J76vqZX/3FT1hvl/w//u//I2+/ecef//LPub6+4Vd/9ku2Fxv8POKd5/WbLxiniaIgC0V6IKELA4XGBxmmnY5d3hcqqspiTCKpRFGV4GYm36FsTdssKItA2x5w3lBkgczj4xPBBzbrFVVZMfcT/XDi3advUFFTUDM5x7HvefP5Z/z0pz/m4fGR795/AAWVKUQxXth8TxXjMHB4vqdpWpaLFYfTkfj2Oxarlp/+9Gc83z/x/PjMOPbM4yBN9qRIweGN5mn3yOgHtpcbbu9u+Ie//0dOxxMPH594fjxmJKDiZnPJoqrppg4/Tzx9eqDrB3781U9YLVcyDHGexwdRe15d37JYtBx2B6Zp5u0372SYW2pMadkdermXjTCt/5TrTz5dejeTgqdtWzmI6AyoUebFDx9jkhDcBMk5YhQODkozDT2qLFhW0h2cgkw+jJGO5HkyH6Ik4oQg3cTryxYVncRyFzOV90zzRNd36FRRaTEuJW1F/aK0WCyaBmMD1kfqWrgBq9UaHxVlUeSpSMzT/4lhzMWx82htaJuET5m5VBSUubtZFgUxp8oIvyMrooLE7hojByIfYp5Si884cU7ikfuRIC9cLk9GEtM0gtIvkubTMDH7QHCTKDSMQhNQ0eH9TH8axI6QpIgSEKYnDXNW84hKZ9m2FMYwuUA49YwuyNQxK7pSEC6GJGDpPK0uqBtJYBinCR0Cena4IOltZWEptQVlmLwkfcxODltKyySuMDnVJQkvyxrN7APHfmS5aLm92tKeJ4uHI/M00w8Tbvb0g6gK6pUA9dpGnjvp3uepPsj0EFFs+eypjjES3AQhUteNdGeVeJbK0hJDZBxOwreqq/824Sl36BPSCBiHQeLba0l6iEmSdGbn6IeR/eEkyocQcLOj6wdMUVKUmV9jZGK8P3XUi552GJidJ0byBDPTsbJCYRpHSi3JOLEfMLOo6ozJ6XMkvJuJHhb1irIs2XXCLtPGUFViUwgh0rQNSmtOXc+cD+cxJYKTBIdCy2FivRDwJUH4Pk3bvHBbfhCX1ugERZHXJvI0Mnfnz8o1ic6Wial3PivB5O+JQkYKZDcLPFkOW5Kwck5x01pjrKVCobT4+c+cJpQWD/6ZU5RtBLgME82NiDOXR2uTVUpK7KZNg9WiRDrDeqZRCqV57MXShaKwErP7Mh2J/kVVk/L7PaeAzs6JetJaSvJ7J/vaZdQhzJFCDh8pyjMyjqMkUCWZ2J7ZaWVRorTmeDwyjoO8By02tKKUAUFKSSxqSQptUUKQv4Pfq52MMZJOV5YvzCA3T8IRKFUu7BXJGhJl5hbJ/S9LYWaN4whJ2EYxc6FU/j2Ssufx3r3I4UlgrMpr4fcpcTarJxIdbduQ1GXmkWjmaaIDbFUL7DdKstRZu2VyokgM/+Y5ye8z5fctry9/rEajkyTnaS2pdjF4qqwCjSHiccyTKNrIyjhrLDHzylJmZQCZ96Ve1kaVVSYuKyFV5p05J6yIshLl31lt0PcdKI2xxYuSwWTbjlOAkqlnyqyYmM5q5vjC4yJbd89MqKIoKcryRd2bIE/b5Pm0xpIMDINA8TE6q8Pk/tV1ndkKtaTpaSOJLaQXFeoP55KmTakNyShsKvJ3OXNEonBkiIGUrDSdIy9rTHaR5WRZxRzkfz+n1qnMwzynO7kgDKTNoqIuRdUZM8PIBcfsYp7MZ/VjTsbR8LKmCUdMixsDmbBWhZW/e2ZqQm5AacIc84FchkUJUUUpFf/NFFWS6KxRGCuMMJ9VYJlwxDR7vFYvCZ1ndpOokRRaGVE75MZDyDy6EBHpfk41PvYpJyapF8X8GTuQUqIfndhLtKSUFUWR2Uxy71RWZy8anZPtJDlu50dRUidREhXGEJSAsbXWWCUcJ5Mb+dMs0HKlkrzI5OG8LvgZ572waHxkzopDqUMtJZJEarXYOYZRwimsViybgroUSPkweZyP1EZlxZqoh0orDXgbz9RDqfGTkobUnBlfpbbZtSBKo8LIs1kVMvhyKUgwTGFQQVHorECyVvYg70mIKousMElAUha01KlnLuJZRZ/ys6AQ54X38YU5dubWpITwuYKkXZmcFlaXJSoFVFZyqtz8jjESMojJOc+sjbzfl2dA57MJUnMnSbPyUdT+ISWpsRMsK4vVitl7UYFpldc2UTiUuR6WUA+FtvK73DT8yZyU/x4uhXx2i+VCFCVGFGZnpes8j/k/Z1IKzJMn+ERRSCJz8J5USIpcUolhGAheHBGzm9Hk1MgUc3qZo65KXr26Y9EKFD6mSEyiuB3HkdIa5rpEFzavNVLXW2tRVlHk82ddVVhbslwucT5SVoXwBDMvcxwk+Oi4PzIOY3ZbxFzbl9ltIc+ctZZJQSSitKSRTpN74ReVZcE4jrg5J1lmho9SmqqsXpRUMZB5nsLRFVWyJLRXZYXWhufnHX3fZ0EGNM2CpmlkUEni+XmPrJiiPKybCq00bgxSJzgn54KNDA7GYZYzWd9RFzWLpgXIDMsCKuGdmvw+6qogxcTQj/J9ybzIGAPGaEnkizBNHjcHnAtZyU5WSSt8SFhbsFquqOuaeQocDwObzZb0BjYXG5q24XDYM7mR0tj8O8VtUNctRosLwYcgLpHMPEyANgVJydoQI2gtzGWjFckYynLxwmZNKbJoamanOY0zJMU8jS84knMlJ3uexU+BY3+SWgtJjHVO1unoPW5yDP3M5CbmcST6RJjSC6vaGIOPga7vhDUWHWgYx4F5nkQBu2iFSxcT8zzSzxNN28jP8hGvhLt3Tsg2Ruc1UHAXZdOwP+7o+ymfbywRUd+WVUWi4PlZeH/jOFEUUksoDU1TYQtLvWhAQVnJ2Vzqsz9tXfiTG0/Pj5+w1vLm8zekBIfdTqCCpsL7wHg6kSJMSYMLTN0ztii4ublhmiYePn1EtxXNRc3oI0/HmdJa1m3NME2cBmkoHY89fTcQ5plXd3f84ue/4Jtvv+HXv/41XhXYduRwPPLw+MDU1PihoWyXlIuEVgXV+pKr61tur68ZxoFxHvMXt+TL1ZbPY2S3exbGxDwyEdg9P7M79nz36ZFjN/DVF19wsd3Q1jVF2bC9uCSFwHq1oiytFPAqcLFe4mPkm7ffErzn5uqKtq55eNrJIdaPKBK3d7eiYGiXKGWYY8ChuH96JoWAsZoQFc/PT5RlxVdf/RjnPf/4h7eSDkTAGkPbttgAlT+yP4389u1HCmu5Xves1ku+ePMZ3TDy8dMTEoXZ0TQLfvb5a3bHjvefHtkf9tw/3PPFZ3f86qc/JriJMPUSp9k2OQo+sl6t+bKsGfueDw+PstjGyGa9YrVoWbQti7riqZs4jo5DP3HqehZtw6JZ0BSKUkOla2KsWK2WlGXJp+PEh/3An//8Z6zbikPXM86Ov/uHf2SaHbeXWwpjePvdd3jvuf2bv2K9WlE3a2bv2R/30lBDDinGVoSUGLwjTI7D8Uj0jtPuAWsMn93egDHse5ERrBYNfd/x7tu3Ytu7vctNloi1BYu2JaHxSeN6GLoTbdOyvdhQW00/OU7DyP505DSO7LpB3qfR7A97Pj48cblesKkUqmyhWvC82/H09EQfEp0PzF1HSJrNqmG9bOjHiWl2HLqB/f5A2KxxfkHXPwpU3nlRvRQCnj+ddng38epmy2a14vd/+Ib7hyeurq7YXlRMY08/jLz+7BV1XfP2w0d2hyPeeay1OVVR8/p6TdvUfPbZjRwC764FTj7OPyy7ijJoo1iV1cshJsTAOI4ZWD3htJENPwbc2APqpXgwhUipry4uGMeR+4cHaXooRQpRCvVso9LGsFiuKcuCpqkZx5HTqcvx9BVMc/67ooDyPhCZqKqKuq7ke9Vcim0gRawpiQkWyxXtYoF3M8FLCgra8PT0gf1u99LsXrU1VWkpqwZtjCThOYmONTpHqubUIQU8Pe8AuLwQ5dPz8xOu614i79fbS4mWLQqxHZ+y5XN4D0DSMkiYg8Jaw2azxs0zv/3tv4i1tmkoipLFcpUbyA3DMPDNN3+ksIbNaikFjDZyGEAavtM0Udc1P/3Zzzl1HY9PT4zjQH865kSVJUob6qrMDULz0shdLhrquuJwOPLp/hPr9ZrVconzszTnfEWKJd3pJJv7OL5AkpVWlFWdbUIjwQe2l1dUVc37d2/p+46f//wXbDYbPn38SNd13N9/xM0z13efUVY10yyWsjPw2BpL0rJGpSRpp6TEOM+iyAQ57PgglltboY1Y+wAOu2e00WwvtjgX2B8OUmSdLZrWCveorfFuZh4lXljCH6RwLsqCw1Gk19qW8veGXuxIGSI6z462bbnYXjJ0HZ05Mgw9u91HLi4l4Sx4UZw1dUVd1wyzY3KO4XRkmkaKpsUqS/Ae5WbcPBDmEV1J6EdR1RhbsFytKIuSTw+P7A8H1ssFdVMRvCPEyMVWUnT3hyPDMNA2dS7gpUh6dXNHWUlBrpVCGWFpHHfPOVr5h3MFJNXrctViFDgnsO5+mvAhMc4BRaIy0mQMFKIs8U7UYkYJo2y1ZMqptFZDW5fCNJtnrBYJfT84TlNg21b89NWWcfacBkm+jCAT1OeDgPutpa1L2qakKSx1WYjNK3msyUoSIipGlpWlLbQ0mOFFVVhbibj+uPec+gHnojRETEmxLKQpEaUgVk4ixa026NWCECOHThLWirqlMJZPT/tsDylF6VzozDk0OUwlH/Sz1Wv02eJhs+KFmWkK/POnAVAUVqzIhUnUhWLTVhz7ibcPx7x+BYrCslguIQaUE6ZeSNA0JXc5Ee1wPLLvJj7uetbLhpuLFYUyLGuFTwK+rnSg1oFUF+iiYB4nnp9PFKU07TViz7Z6iSlKuskzDAPjKAfDyRiU1iwWLcvlkjqKIkpHDzHw7uGZOSQ+v9nw+c3qxdL3h08Hxtnzs1cb2spKjeIin69FJeaSIcREdzowh4iyJT4mdp0oqa+0ASJuksPXspaDzqJtCClx7CSAY7GoZf2dB0pbsFoumaaZ50OfwzIsWufmExCLJVYraqspjbCh+mnilAOCYhRQuYs5jGZ2VDbRNBXKWkJK9JNnmhyrRcV6UbFoGtrGoJNDJ0mOnUNkmkJGIsyAYnYeawtmF/AhUpeGQmu6uRdLS6hISnPqRhm4agtohm5AKVi/vqGuSp4+PjLOM00r+1VE1O1Xm5amFJWrNpqyrIkh8vh4j/8BpdoJJ7Pkq6+uiDHy8PgAKTIHuddPn97lfU4GUsfjAVBcX91CjAQ/U5aW7aUktb7/5p66bri6ucIYS38cMBiOpz1dd2AeTrz5/Ev+4q/+ho/v3vP7f/kd2mq0lcTT06mXoRuBjYaqbc4IHtaXG1YXS6Z+wg2Otl1S1w1ffNny+nPHMAjKYnYjDJ4PHz7y9Hzg/v09/bHjcOrZXGyoqprVckPfSVDKohXOcTeciFGxXAkg+v2He2JK3Fxv0Frx7bdvpe4pJIn4+uIKW1hW66UwJbuRwTnu74+E4BiPJ+ZZ8BtlVfH6iy+Y3cz//P/9n1EotqsrirLMCcUNr+6ueHra8bf/+ddYa7i42rBatnz26pqhnHFOmrlj11HXBb/4s5/w9PDMt1+/43A68PD8wFeff85f/OqXxBApqoKmrbC2YrVsMAq265ZC30pa3vsHCm0otAHtQYtlsCxqdvsjx9PAqZuYpkBZGmyhuby4om0XDGOH946bmzuaZsHvfvcH9sdP/Md/9x+4utpy7Eb6YeK//vq/cjjs+elPfkpbt7z95l1Wof2K1WqRmdKReYrfC2O0plosZQ89HIFAYRcoBaV9piosF5dXJBJ9f8Rozd3tJeM4M793EBJdtwdE4RmTBRUoS8vF5oLn5x3fPL6jrgquL1co5dg97zgejrhxJLlImGB2A/14YBg9p86xXa+4ubxjcCP91HN46jgcjlxdbbm+2uJnwR+8urvj5uqGaZ6ZZs8fv/2aT4+faJuWdbPheBgI9PgQKcpa+FhVSWkbrC65uL2hWdR8/cdv+PSwo2oqmlWDCzOnAb66vaIqK95/+MQw9vjHR4zRNAs5o7z+8hXLxZLt5gJrLVHLAPTx/vFPXrv+5MaTysyAeRYOyDldRhtLqQ3Fek1CfR9rDXmqOhO9F7ChNvjcXdysBKS7qitsIc0YkyL7w555nqiriqoqKayisBIP3FQlm0WDnxb06zVN5poUVhQ1VVFRFZY5BD48PFJXwvHwzjNNnXBBEEaUpLdJJ9QH6ea1tVhvmqZ+YZ8oxEOetCKk+OLtPHv4Y4bDhjPXwlpJVrMGPwu43GqTJ+wedKQwIj0vM9AgLZbMxUzwkrJQlnLYDEGUKU2GfLlpYiIxjLVIKKuapqm5ur7CGM1uf8jAx8yH4Tw1c/khndBas1mvqWuxH6Uof0LyhAgqBQie0cvE3BpD29T008Q8zcIMQjP7iHFycJYkK08KjhQKUtQYU1OUFqWlYSVcIZnk2YioqJJs7q2xNNWQn7RETIFFXRGTFXDsOKJNQZUtcg4kIjdlHk1M9BlSdzwdUEmaSFprjl0HWjrICvBJkkd0TnqKmcfgvM/pNQltLKaoctd/S11V1FUNSnMaJkYXiMpQFyWrRYuWbVPkqEuZLtiizMB2aErDqq1RKdCdDsTMCggRXIgirVxZIs+SKuQ8p9OJcZY0g6RExSGQdGHHpGgprZVFcrsFpdmsVpRFQW/O6g7porfZ91wXoggprfAOzp/J5AI+zpy6Xphgw/jiaf8hXClFYlTCVVLqZUJ2VqOUZQHkJLP4PQMunaevWW0zDAMhBOpKkg/rshTw6yzpX+M04b0X3p21ktKSlTu2rCirhuhnhl54FdoYAWEiyhmFYp4mgnfCC7IWF0ZSOifnaebZ4eb8e7T4tJUiJ3DKZD3kqbc0Y4oX//k8T3g/vzB4lFboIGlSxEjSkoyhOHNkvlfmCJ8v5aaJqAlEPfU9u0Wm0tnqlFlERfbanxlbzrnsjZekk6Zu8MHTdd9b9hSSRJoy2EH4U/J6rC2kwWQklSm9MBq8sBGMzuIaSTVpGkkb6fvu5XmQ1KfvJ5cJUaMJ80G9/B1hNoniwzuxosXgxQppLdoYsUM2rRzEswq4LIusMhHV4/n5Cn4mhLO6Kb3wTKYME2+CRyedFUtyj89TNHlmQSZrKlvW5J7O0wQkWZ9z00VpTZHvlTCcAt3x9MJPNFrJYRmyelSSUs7cESBznaT5pZTOrENRVTgnEn9jLG1REp0jepfVAgLIBFGr2KKkrGvqppZk1+ApbCGTt7LIz4Ls5WUpjSRbSKpdURTC7CuEn2Wz0kqUXaKsUSjCLBL6YehflF4/lKuwRtaHrKwMmZEjPKJEWcgzqzNlyec9/ezYOauLYlaelVYGD3UpKt65qbFaMUwzIYhSpS4tTVXgvag/bZE/p6qkqSvQRtTgOZnOWklSHOaJcXY0lcaalEWE8swaI3xEn6LAzRMvDKfCShM5oZh9xGpJfRUFsqgpE+RaLb28r/O6aY0CpWlrmVIX+TlSypOUpJZFhPEooH2NLSTePsQk74eEwXw/yVbqxf46O8c4SlDL5DxNabPdXaxUzgUUEQkrU5wZa+MkjXr/ogg1VNZIUmDwYv9G4ZICk9Am5YQ1aaZXZYlPiW6YqAtDZXIK7SA2rzMn0mdWUFKRJibOw2cFYnFUhqoAbc4phFLXai3Pwfn1OsdLwIUoWWNOsFaMNvMt80Fd2EpSE8tzJeunytzUMacnZ09ztpvLMxoTjNn2PftAYc5cKJXvvaYw5OdUE2PgNM4Moxy+SqOpC42LieQjGo1GLG4hBrFtnt+/kuemnxwQhImmJJRCa0WtNERJu3LB40NWT+WkO/L3ByVp3gnNqq2oCuEJyuDDZuVgke3DkjopSmOTP4tEISF+FFl9EKJ8l2c/yNDPhbzX/TCumALxfC9SwhpR7qTMu11kAPQ8T5wTgZVSmKizAsagNBkMr7m+uqZqai4utlht6E8dhbWcjie89ywXyzzsspjCoK2iaWuWqxUxRk6nE0VpXlTNVktCl9aKvu/ohiNN2VCVtSgKO4/RYuyRUCxPn0amUb/A9ZumfhkwxXhmyRmqPGASRZfDe1HLacgKaFEIaqWx1lA3JUpDVZTixrCiDhNuq36xLDdNQ4olcw4XCSDrnQHl04uKuW7qvPeLUnwYB0IMLBYtVV1xc32N1nA6djgn3yGUNHOTk3TGcZyZ3YQ2ivVmTdVUxCRFjDWybrh5ZpoUZSlMUOecNJ4XDVM/cuwGqtpS1hIsNo3SwAvOQ/xegW7y90ypRFFajFXEFJjnUf6Z1gyDhFEYU9K2LZv1RhLdjEUpWCxqqV0jeBe+Ty+d4/d1boyiCvKBaRjAB7quE6Wq4kWRDzmUxxhCkAGFuG0SPpw/V1E0jqNgBKyx1FXDdrulqgqW6xVKWR4eH+VMN80sFhWr9YpxMqA8SjlClPAbYzRFMlSpYNHUksCqFUM/ZFV5ZJpmhnmiKoWN9rRbcTjuRanb9XgCIYkL6bxmVWWBmx0uOQp7x6Jp2Gw2uNmzWFXZ8ntOzpWUx6oqadpa+MdGs2hrqswrnd3MMA1ob5jyZ75/3v+v33gqy+oFeCYcjLOloaKuSu42K/ph4F9+/wd50U2Dj4nnp2eMVsJuKAt6p1guGn5xd401mtIY+smxWG14+PSB3//uH2naJTfXN6wXLTp5qkKzWS94dbXh52+uuVy1rFdropsJ85SlYzWbzZbtZsPf/9Nv+cff/it/8+e/5M9+9hPevn3Lx4+fqC1UNtF7sfoFZSm8HP61Unz+2SvKqmaxXFCUBdPQEZzQ3AVo6RjnwJw3h2kUm0D0XiaLmWHVLpfErArz3kFWCx2PB7TWvLoUv3+7qOWwttngfWC5Ogh7pl0S0okUpUC/u3vNNA68/fp3TEWBNiW2KHjz6pbLiwt+9atf8t27d/y//tN/ojCG7XpJWRRY0zI7z/HpkVPXczwduby44Jc//zkqBUL0Yk8LCecnZteJNFalLF2Hq82ay+tLvnvccXRHHJY5aXw/cez77wtcP4IfCFOSh3u7ZrFaE9wo8sKkmEKkqSuqMvHd+w/4eeSv/+ovub7YoqxhHCfGYSDGwJevb9BasT8eOZxOvHn9BVVdkaLDzxP75ydSiJSlJDk9Pj1Ks8X11FXJdrMlhMi/fvMdWiuuL7bihUYSa5rFEm0sQQtz4Xk/yMHJjTRNzfXNNUVZ8ZOf/xKjFIWC0zjz7vHA7BwUC9bbDT//8jOm2XHqR8qmZblcZUm3yM0jgetNy9225XF34P7Dd9TNkqpZ0DtPOEV+9pNXfPH55/zu91+jlJKkv+PxJRK+aZaUZUVjpCAPTYsrK1Z1w7at+Ytf/oI5QnIjKXiGvsU7T+cdwzxzd3vNXZKDL0RKo19sTXOET09HQoh8uv/ENE1M0/By+PwhXCnzdvpZppk2WwhMPtheXm5xzvPh06cX4CC5OZCiJwaHm4R1s2hb7m5vqZuGzXbL/vmJ4GdJYHre5UaBAKXrusmsopnles3FxRUPFubxJLbdssqx22c5rOH56ZHd7onr6xsuLi4Y+4FpGqkXK8q64bDfMwynl4axtZaqKKmWYgfrhhHnPaYoKauaZiHKh2kcmacxS9ojzXKDMQUgEmg3z0SvWOVmxPF4fGH3xCjpS1prXt1cS2wvsvGOfSebsRbbhJsGfAjUdYs2mrZpcgNfNvp+mDBGc3VxQV3XXF5c8vT0xO9//zV1XXF9eUUChr6TZpl3pCTJKEYb1qs1dVXStjU+JlyEeRwZh566abKNTNQZy8WCy82G+/tP3H+8p10uaZpWklAynyFGSSAiW6ptttK4eaZZrLBFydAdOB0m4jyjU+Tbt9+h7Ue+/PwLNttLTFHmnyVFVNs0GK3pc7jEarEQe1HyAiX3MdvVFc47nvZ7aeC0C4w1YpvMthJrLdvtBqU0bnaZGSZFgtY6c7B2FP+m2aWVyXtz/WKd7vuep6dHzrH21zc3fP7FV4zTRHfq8jBFGFrzOJCiMAcX7Zaqqtkf9jzvnqUwUYrZTdjRcnv3msura0qjOBjF5Dzd6SBWJsDYgsVqwzZPMp8e7xnHnrqp2V5ccrl5wCTZF6y1rDYbbFEwDBPO+cy1qAUirfWLJH8aB0mpNDJ4OGQ78Wm/+8EpntZtPsB4acCehomYFLooJaFtKVanecpqDR9eoMVai7VJkWTYoxXbhQBRF1WF8xVVWdP1PY+7Z4qy5HK1YLuoWC1q+mGi7wfWa8OircVG3DREHzMqAaxVLNqaZdNyeJi53/VcbxR1UYgVN6acKlTQDT2TC4xuQKGyBTOxWjRsVy2Px47TNLOwlkJLg0wA0dLk7kaHC5G2LDBa0dTCajOFPJfrZos038TmOQ3yXRpmWcuaMoPMy4LSGC4uNviQuN93AjFXFu08VSFJkZfrlnFyPOyOdP3MNDmauuDVxZKyLFguFnTjzMfHk9gZi9x1iFHQAeNe4LrKYArLZxcL2qpgXRv2p4nnY4+LMMVEW1mWlSWg8cCqqliuFnx3v+PD44G7i5ZmVdN1HfP+KPY7YAqBKQTmGAlJsVgEmmw9SimhrcFqxVW7yGuG59g7rrcLysJyt/WimJ0nTnNivRClwDwMeOe5vJB1ZAoN2gfc6FEJlk2DD4FT3780AQtrKMoCHyNPT0dRQC1qUuJloBXQeB8Zd0dm5+nGSfhX2aIZk9jU1rWw+Ra1YXcMvHuUFN95GllWlutVyeQTvQuQhAHXDSOHk6PWiaJIFAZUoZkmx6EbRYGHDJmbqmLVGBalloGvV+y7jjGM+GmSZlol6xLIo7poW5bG8MVVy6q2fFtWHIeZ0srhbN0KI/b9/TOH3snA1JQYHdHKs7BZ9ZEHRce+Z3aeh4MoFHJszg/mimnGOcXuSZJb60bqCx9HytJwe/0F8+z48OEpD/BnCW9JswQYLYW7+fCw4/Lygv/4H/+DcLlqy2F3oLIlx+OBd99+hy0KPv/8S9abNSSHtoliWXL36paf/+infP3Hr5mdqJBsYWiaiqasMbVBV4Z//s1v+N0//zN//dd/zS9/9SseHh7Z7fasli1NXTMMjmkSZbBzksOmteH1F6+pqoJpkv3ZGrFSrpdLXFWJa2GeGDuP9wmj5byovCgYjRI8wvXtFTEGSSRNiWkUhfbTbsRow+1nlzRNw+3NLQpYbltR4H96zDaoGaU9Zd0IN+tyg/eex4d7hskQ0kxRFPzkZz9iu1nz05/8iPfvP/L/+U//o6Spb7aAYo5JeEO7HV1/ZBiPbC4v+dmbX2AteO3QlNS25tR1HI5HprnGzQ3DMDIMI1fXV3x2fcnvfvsHPtzfc31zTdku6PuZ4J6YJrmHpCjiEqMolCYlhw8DVV1hiorT6cA8O8oiUWxqvvn2LfEb+Hf/7q+5urzkL//sL5jGiaE/EoLnqx+9QmlFcInTcaJZyuDNTzNEsfWF4Jn6nmma2T0+CuN01Ui6YR50/fHtNyituFi3FEWJVpUow+NMSork5PN+3j3S1A1Gl9RVxWrVcrGtWW8vsLagbloe7u/5zW/+UfiyIbDaXvCjn3/F0HXsnlaM08ip6zFKY5WwftvGcL1do43h4eGJ+4dHQBrpT8WeKUb+7Jc/58dffUmII0oFDvuRt+/fC8cqBklpVYqqqli2Ld/u3nLqT/xl8TPuLi8Zf/FzXr1+w2YtTq5xkuTqw65nGhybiyWLVUVpa4yxrJYlRiv6rud06njuhSF6/+6BaZgZjn0eLPwvX39y46kqBc48TxLLfU4LshkKOE0Tbp5zu0II7YW1rDdrmb5EUZmQhGX08dP9y0YVksIlmZIUZQ3aMs4BFxNKG6qqYbu9FDiuE0WI8x4/z7hxwJYlhS04HA48P+84HQ9UhUyOu77Hh4C2hrLU1FYTDagIxsok3hoLhRQmKQU5qHr1Is0zmQfgfchJcSHDtFpiFdntJY7weOoEvL4UPsti0RJjEIWV96Re/P1VKZPoYehkEtUsiCkwTqM8KHVFij57djXTNIp3uW5eeBzC9JBUq93+QD+MFEUl0nkfQGmsk4nacZxIwHq1oC4tYZbOt/fu5fAq6VkWGVGKv9YWEt/sQpSfl20NKQRmNxK8o24agQ5XNY1zlFUtKgcjPAllSzCFgERRjBnwvFwuiKFCW0tIMM8zU04PVEpT1zJFeDr0OB/oj3t8WUISNVdShqgSwQlfqa2lOC/LCmPtS2pAla04IZHT6XIEKZoUYZ6FVdPWJd4pxjATyewI5TCjHLi9MaJAmiSGMwaBWR5yXHjfD1nZJVaQoihkmut9TjUL+CDTxKqqaJuWGDyj89w/PslE73h8Ub/YnIBXN41UPCng3YxPgcJKU+E4jPgYGYNI+682K6q6ZhgGXHTZYiZJHJAEFhpl+qeVosnpR/0gxc84icVuu9lK8+UHchkjG7nPjB/ncspbWYFSL3yGc5qfyuqX0goDgOhBabQpMjPrlKfNgb6TJlAk89KyRc4V7iWJTBLglHzfEjL5R5SWpbGUZck4ThIlH4VLppWSZzjJhPjMj7LWSIJiVjMUhc0cJcWZMZdSkmZ3cDltzZB8jplXwpgQWLCsdzHKhqiVwuSfVxYF0SZ05vqITUUSf1R+bZJEFnJSkERyWy0plLaQFzi7OXMeZD2dnFhT6qqQ/z7P+BCwmVtyngC73MgJUZI267LMKTNnldBM0hqlZdJ8VhedWXVF3mu8d9nTLxNmYzTOzTLdz5Y4cpMkBZkUlU39wmwhyURSVGvCr1KFwL3PCZTk13RueJSFrO9dP2Qe3CxWEmMxKJKfIImSKQFlUX7/s5KohIyW5DpjhF2UCC9r2nkqrPJrbDOTLXhP0ppkLEWG04f4veoixaw8sTKZ7YdeYPPznJFh3+fjpZhe1AxJu7w3Vy/phOeG6uGwJyWYzsk8nNUQkjSrsx0wZmUXWhiMonCDcRgkWMMuqKqKaRqZxjGrTyVtVLhAOdUsBhJSrAvjR+Dm8yyfaV3X/5utI/97XaUVxcc4iRojidzt5Xl32Ur78izGiFaJKnMGZeqbQdGZx2gLS4w6s7ssxgp/MiVFPzpqa3BeGDjLRSXKn++jpbKKNLzYW4fJ0Y8HfIgyZLSFJLtCnmgnjBLg8plzhlJ53VRYZFKvX9Yweb21Fe7G7GVAdlZyapU5iDlVbAogiiJR9daZZ+JmYfFo5O8XRuDg0+RAB1H7hkjfDyQSdSFqupf1LgncvKmKFwVQzIwzhURguzkz1RJMkFPcsmJg9hJI0ZQSjuDFEt2P0lBvmhrtI8nLgRUlKcJGy3cnxCjKqqbKKupCEptjzGmn+QYrRWnFfl2XBVVhZW0OkSpbNTmzbCTVQPggTtI5p2mmyM9KW4m6MEwjMcO+QVITo4I58wELK2t9KAvOCawpKyZiTJlFSP7vMrA9rxFa5yRAZVHLFqMkTTEmaVYYYyhtKYo8J7ZIlaRZb2rhwByHCecl6Oe8fqWUaEqbY91F2eCywrcuixfVasiczkEFoldEZQEj629KVJWAp8+qMe8DHk9ZG4xSdINY2IdJGqGigBKLsctsvJREPaiUJkWXa5CUOTOiYB1neUZ85lNVVfmiMv4hXKulJJ3NkyiffJDkNpOTJc/qRaM1SStiVvhebDeiusu3Qik5Y3788Em4NRamacYFSURTmYtz7I6UtSTkloVlvVpSVVVWMcreh0KSzlAUpeVwPHL4eGTsB9qmwfvAfn+QZPUUKYqCtm1xvmd2CaUkJTx/7V4U4NYaTBKF0ZQHmLos8cETw/cpuU2zxCjhYHrnOBwOlFNJMsJYWrTLzBM7QvKkJByexaKlrmupfVIURqWT9GSlYLFuKKymroT1NOYQE2NkMNGdOuqmYb1ao1DsDkdR9iipXefJoXXAWEk6G4YBrTRX11csliuqoiKEma4bqUpNXcnnWNoCo2RvtoVlYZZi2RsHQvQS2oawRsfB4wZemiLWGnE25fqsrAqqukJbUbTXdUNZVEzDTHACfZclJDDPg3C2cuI3JC6Wa6y1PN4fcG6irBQm35NgxVJLSC+1dLtoBEEBhJDQWpitotIX7uY8e6bpIDbh7BBw8wgklotFtuSKusgO8oxVVUmKia6TGqswBSSpg+Z54unxgWmSoJmzK0KYixbnAvM0S62thQFc1nKmLowkBfbDwP2nB0wUC2ZRVGgzg0osly1FaV+S5VOMTIOsqVVVsd+feG8/8fT4xDCOXF5sqJuGw3FH33fMs8dHcXbE0pLiOZnSE/L+q0jMg/Q1pkHwH9urLVr9rwwXX69XOOcZZjkQ2EJk75UxEAP3959yAalRITD1Hc12wy9+/uNMSH/KNozA7nnP3797/7IQrFYrXr16TUiwubxjmB2f9j1Vu8DYis32ClstiN7zdOx4Ph7ZHfeM/YnxdKKoa26ahn/59a/5u1//A5+/fsXrz+4IbuS79++BRLtcsGkqVnVB7RVThHmeCMEJYLqwTF4I/YWK4Ao8lqAsJnpUikzjzOxFGqyU4u4zSQn75o/fsN/vQElM+Js3irZtubu5whrLvpcv8dPjIwRYruSL+fvf/ysJuHv9Oc4HPj7ei2xQy7RyvVnjnefpUXhFF1c3QuTv+2yvUYxDx2/+6V/wIXJxccU8T5y6I9YFnE+c+p77xydub675+U9+zDR07B/fM/pIN0c2yyWX2y3GGowtXmKtN+sN282G56dnnp+fiWiaZoFRnuQHjscDXd/x5vMfsdxcCmSyrCgqsZnVZSly5maBNoUUTkbz6eGBYRi5/vyNcAuKks4Fnh6f6U5HVusNdV2zXm0ojOabd+/pTh3vx4GyKLh5dSfNKlvKpPC0h5R4fX0pU/66yayPHUrrrKBQdNPIOM08PD5LMb1co4m4wzN1VXF3dc00zXyMYr8cpxk9jgz7J7AVNEvcNDH3R3wIeBd4JsjGN8+4sROP7WopTJvVimM3cJo7DqeR3eHEsrasV2vW2wvWm0s+PT7xfBp4/+t/YDrt+ezVZ1xdXlGXJST46vM3XN9c8endtxx2T+xOR8Zx5ouvfsJ6s+Xrt+94PhwJbsJo+L/9X/6vXN3c8d39I/thpl2uqaylRJKvpgywc7NHK81mu0UrxXfvPjAMI6OL1HXNn/3yVyza5k9dGv4Pf9VlJXL2MBGjZx66l9S4pBSn0ZGypSCBqF+sTLNTjMzzhLGWul3Rdx1v335HQg4kJgMWpfCWQ+A4yabU1g0pJer8n6fDAec8tmxx3jEMM5dVw3Kx5OnpmW/efsur21te3b3CB5/ZQ6CspShKsaKEhsJotC1yIp/YePtxwDmXVTtWVFh+ZrO9oCwruu6EczMmJyGZDFuNfhZ59CzNEJSiLEuWixatTU7xibTwcrgIKdH1nXA1pgnnHfvDCVsUfHZ7iy00SQecm9nvRCFb5GbH7B1VVVM3DXGecbsd8zSxWK0hJYZpxnvHOI65OLA0dcHlhUzv5mnKTf4TTduyWJZYWxArGWykBHVZ0rQtx8OB4+lIipGmbqiqirIsOB6OdF1PXYlNO2NFcLOA0y8vL9lsNgzdSWCONidz5SZc2y4pioLCajlI5gLQjT1KKZqmpaobHp6epHiNUlg0ixXWQuxHCc9oWopceJ//b0oRm6GipqxIKTKNAz5ExtmL3DsEKZpykuzd7R3OzRwPe4LSmEIOMJvNhuPpyMf7h+/DL6zFljUuRt6/fy+NrBipyoKmKpG4dLFIzG5mmD2hG2jqms328gUavtvvOZ069vsDMQYuLi5ZrdaQG+dN01DXtdh0jGa333M4HGgWS5qq5f2H9zKsmiQW+dXdHavVkj/+8Wu604m6WWCLguVyibVnwLoc5hPQ5Of+kGX749DJnnz3OoNYfzjXotTMLvI4jPiYMKU0Go0WNeLxOIqapxJbZESaApdrsbXMXmVbt2IYRx53e7QtqRZrlm3F7XZBVSdWyyWHfuLj45EYAqtG4ru/eHWZ03K9FN9nJpjzVJWhqWu+ef/AN+8e+erzz/jyzSvGcZRmhpFptlWJSnm6JHYrW4qNdcpgZh0CMbMsa5UbZSHRtJqmULzbefo5UjQ1lTFUBDSRYZKa7KHzuADLpqCpLNebJYU1DMNIiFCoSKHkXirg3XPP6APdNGdQryicLrYLsQjbAqslMcjoxPWmxflIN87S+MxNhuPTHh+BKCqrqffSaNMwusBxdNzUFa8vlxz7nofngckFdqeJ9arl7uaGYZo59WNuIkmzoiwM3nnG2VHVFbdVTVlYkjHEWeFTwiqdm1UBpQLLZUtdN1yua5ZVQT85ZjezqS21hW72+AirpqA0lt45nI88Pe+Y5pnPrq9Y1A1XqxZrNGM3MEVPjNIEL1QCFTnGQCTRZjB2W8mAxmdOz3y23uV/fnYI9OOEMYbtqqW0mlUtDEVbXjCOE/dPO7EXk2jrilVb4mPk0AunqSRQ1JamWTA5z7cfd/i8Jqhs+922BTfrmuMU2Q8SHOHdzGa1ZLNe0XVH+m4i+JneOU5dgphYLWqaugDv0REuNxvWmyXd4cA49Oz6kWH2XNmSsij59tMu25xkyPzFzZbtsubrb99xPPUE5J5tW2HbHXtp8h2dWNR9kpbWUzczTjPkxuNm0WCt+d9ppflf//r8zRvm2fPuw5PURvOANZr1us1DdVnX27rEOUUII8tlwy9+/nPGaebbt9+hgNpq9rsdv/3n3xNjJEbPcr3g9tWNwP0XDfvdjvfvvyMqzxdf3LFaNJSv32B0QdeNzD6hbUmcA/PsUZeaZlHyj//0lr/92//KF198xhdffonzgX/9+o80laWqLOv1itvbO2J6xPkDKTmUDuceKmGeGWfPcrOiqEp2ux3TNHG1vaAqSw6nHh9m5nkkRM9m84aqqvn2u+/Y7/d03YmiMGxv1rSLlss3l5RFhfcwqB7UAW0Ud7c3WGv5wx/eZlj3zDhOPN4LG/izz95Q28S4kWHS/f09xsiZY5onPn6852Kz4avXb3DjzD/90+8YpxFbF0QvAU9KJbSWUI/D7sDt3RU/+8UviEHhZ3juZj7cH7i4gLptqaqCQq+ISdLolqsNq82W/e6Jh0+f5PNuDEl7Zt9xPA24fmZ7tWa5amnakrKsAQ9ElusVy/WSYRpxIXB9fUtZ1Hz48JG+77nZXFNVBZGJ3aHnw4cH+m6iaAxlXXJzc0dbN3x6/3f0pxOFVVRVyeXlJQnFsYvMQVMUDmsti7YV5a222T43o7Ris12SIvgxME4zn+7fo5RiuWyASHBH6qbhi89f41xk/3RiHEeG4ciiWVBf3zKOA/dPjxAT29WW2U10w4luf+Dv/ut/QZkCZcS6vlw02KKgLiuG557H570oQ5OiqQu2F1uWyyWLxYJ3n+759PDI04dn1Pz33H35isu7S8p6pPQTX/3oNTfX1zx+euC4P3I8jjwdRpqFoGD+8PVbfvvbbzgdd6QU+fJHX7BcL/nNb554uL+nrJZYW3C5XWGt5nl/ZJ4du530HW5fX6ON5vD2gWGYGLqJoiz5s7/+cxbLxZ+0LvzJjaf94SDcl1yY2gyHPPY9WUaBD0EWkvNEKxfzPvOCRPZVE2Li4uLyZfqqteaw3+FzYl1IkuzmfeD+8Tknfol0OEaZ0LhxxGeuw+xmpnHEFgXbiwvKqhZPZhD2kNLSTR2nkTAPOCUNJauhNCVRK2IMlKmUCZwPzPOMxxOBIU/5lBHAoE8zIJMtnaJ0w90sXeokjCBri3yP4HSUzvLsRVVw7AZRAGR92DAMxJRYti1KSaKIQrFaLHLB7aQgaxpJqtFyaDz1AsWdfXphTmmluNhuXzz7587ueXqf4IUZ1FiDMpZxnilzUk4IHuc8XXcies/snEz/44xKXgDItZWEucxY8kHAjvN5Iw4JTSQEy6psKazlKR8w53kihsj+2KHNSFGVL89B07RUWTE1+SDx4LkIbBcthS2yckmYEJoSu1iSTc2kpKQwjjk9KonVIwHWy8TrcrsWS4rRWWAgiqt+GP6N8kKDlqlrigGFwiRRc9RVSQyB0niUVvhpRhGpK+GCGSNsHqsz1FQliI4wD5h6QV0WeVLr/g1nKDOlcgpGlW0EVVlSmIKirCmqFpQoYqZ5zmBsB9ELq8EY7nd7fNIYU7BarenHia7vKZDGqc98BqO/5wWpzCAoypJmKYdFYWn8cDgp4zwBvLAqkq9AyeZqbKDCvACtlQJTVKIcyfajkNk13s2QIlVVvaibRFXzb1LjkigIY4wcT8cXC91ZVxOyKu7M6ZGURLFPLdoFxlhRpGmd0y0kdQOtBYyoRHV0Tsg8c5DqsqSwlimnhJ0j5bt+YJq9rNtai9Uh84uKF/aSsBXOaUJnHovSmmkYcEEsWFpJ5KtSoh6MIb78/bIQ7lLMbI3CCj+mrmuxbaaItpoiJ/Y55wheIrnDy/dOkqDm2WTFoRTnZ5VPyOqG8+8MQdJSEmTegCgnUUoSh7wklEqKaK4Ss+KsqIThR0oCtTWS+IdSMmAZJ+GyKFGqnaPLE0lsh9NEVUjzI2aLSFmWKK3o+p5xmoV/x/dKojk/h0ZJilFhhZFgbJGfNVGzGKXJcrTckZJnq6qy6jiKRN1NE9EYVJIGxJmtElNido7D8cA0zxRFSdSaeG48Sdbwi/KkyAqSmJNJbFFgQ8AaR8oAYmsMTd3g3ISfpZFWlCVpmuTZyPvMCx8gs5vOSjQ3zwzDIHBxY/PhQb5DKUaOp5PYCE1B0y6Yvc+fn35Rhp1Vfgph7gg6JmX+QCvKqiicmh/S1Y1O1mNjRU1oDInEMEyyz0ssjyRmqbMqR7g+MYGPAZI0gFJpWS0alLbYQlGoSHDCaJi9qI/KnEbWT47CaEqbWTTnNE54CSk483CEZSaA977PKb/EF5usD5EJSSuKSZJ+m7pCzx4XIqVSWCJRRVJILx/2MHuck/VGp0hBwiqoywJNoh+lXjRGEtCK4sw1k+dunAPD5ET5ohVP3Shq0nRejwUr0NY11kqtoZTs2ylFRu8BSSg1VlOWktLVjY7gHd0oKlaUMBibZpHT+WasVbS1fCeOw8jsRL0ZU8TFyDA59qcTOjdv5qyOnvJ6bBQUWhGiymIzqb8Lo6CSZyClIIMISqL3DP3AUEo6XkygjKGfhWcasqvg2IslWGlLRJT/RXYxoBTdKNzA0ctnMzuHiXJYDzGI+kuprKIC5UUBKWxBUXAK00madCqrW87rQ2GlzplDREVJj569R2WDbkiJ0XmeDtLIJzOSqrLAFFbWsKSoyoSJEW3jv+GMmcxaUTSFYUwe7yUpUziFUhNaJZh7sRgLEweUoCAqAe9X1uBzM96OHuXjy3lD0lADLkZQnofdKSdQyc8fJlHP1qOjtLlWVpLkF0EGm16YnZQGU0raoo+R6NL/P5eX/02v46EXxW5WlJus0jweOtnTypIYIn0vlv8icxVF+fZ9kpY2UJSG1arNabtSw5+OJ6mh8mfTNA0xwsPj/uUMag3EbKEvTMnEwOxm5mliHOTQfHV1RVU3BC+23cJaGZCVJSnA2A+CIwiBuq7QRobDUk+Lu2Pyjuk0Zs6i4ng60mUVIFrWjZREpS7cHNAqiro3RbS2FLbMScbQdz1ddxInSPA8Pj5iraXvxXKachN/vVphC4ufR5TSLFdLynl+4Q6fraLr9ZqiFN6QT9JElzQyS1EZykUpQ7+hz84N81Izytl8FidOIe996CZheyKJuc7PGD2glCW4QFHmIAiEh7paLKhNRagDRVVkIh4IS0mU9+PosIUorLUyHPcHUjrKeqgNh8NRavDaojQohKFZVsKIPB5PTIOkfUYQvp1WOBezMKTEGIVziXNSckqgkjyXMQV00hgtbpBkoaLk6vJCnmEj9eA8SRhMn5P7UvL5fSDDnecnUZspiSg3RqMMKCNJqj4ErLGU9ZmvJMresjRUlaVuSuHZjTPFoma9Xr+o3wlRhqVagdV5iCyqLpUCZVmgjMrMUp2V647W1NiiJHYn/DznZFjDp08POCe18mq1pusmpnHGKBlgxeyQebF2T5nvaQuqWrG93GCtkSErf9ra9Sc3nv74zbd5WiER7nVVMjvPd5/uIcFlK7GF+8OAMYrVsgYi+/0+J2UJi2m13rJab7m+vkMbTVEUfPj4gb//+1/n6O/IYrXh4uYV4zjxm9/+K1VR0FYVxhpsaRmGgeF4wAeZwPV9z/PumeVqzZ//xV8x9R3TMFBXjhRnjBEY8NPjI91xT90uKaqGV1dXbJZL5iDS5aaWNIFv3n7H7niCKHDvLonv/ubygrYq8ZzkgXXCzLm+uaZZLNjtjlK4VQ1100q0ond89/Yth9NJNiVjefvxQWS8poSUeHp8oigKXt/dkhLsj0esNby6vGB2Myk4tLWsthcopVjHSNd1fPfuO7GmwYsd6/Lykp/9+Cd0fceHT5+o6orlYkFhBdQdE+iipi0lDbDrex4Pe5ZNhUqStDTMM89Pj8zjwO3tLTfXNzjvGfzMZn3F3e0NTdNyaPZgC4Zh4HQ6cTwcSHYiGUtXldRFQb3e0pYl//R3/8q7d+/4/O6W5aLl+dMDs49sVtKM2a6WlJutxGlqxb4f8cGjtTSkbu8+oygKng7CbFhWJabRmMsLfIh8engS1YEbsg0gok2ByfGcTXTYuuKrVzfiqd/tcD4wK4Pzjo+f7rGFpV2sUNqAMRmgLDL1IkWqwmDqdQawO7pxZnfsWCxaLi62+fdVlGVJWRhqo3A6cfAjvt9RrCvWbU1SiXnsIEiaULtYUTctddtirGZd1litWdYV1liaxYZAwcPzARdOkk7lZoIbKFSkWWwwtuQf//UbYvqG//iXv+T25ob/6T//Zx4enzDJY7Rie7GhLMos59acTtLwLMqKuml5/eZLyrJgdhPTaf5Tl4b/w1+7/QFbWK6urkVRaAvmeebh6QmtDZeXYtnoDjuM1ixWK1SKuLIkeM/Yd2hjCFFioS8vtjl2XOCE+8NOmpNGCpa2aZimiQ/v31PXNavFgqCUTEERgHYIsimEGBmmiaZp+eyzz4hRJsOr5YLFomF0kdlHora4BAFDUoa6bmibmnHocW5mvVpgjeXDx1kgkkE4L4duIKK4ubygrkqxKHtPXTfUTcPjw4NIcafpRfauz02FBPvdM+OUVT9a46bx+8ZZtgBaY9ksWlQuUpSSZKGUpPng3Ux/OlAUFdvLa6Z55iGzAq3NytmqpC4r1qsl3TASksqwWzl0d13/MmE8v0bvPcfjnrpuaRdLhkEKNbqepCWMoqkrtBOO07l5UTUNRd3gxp4wT5RVQVGWMBnwntMwMM6Ouqml0Dt2jOP4Ykk+PT0LyLSpKK2lXYoCqlmsUUrx8dMH5tnnoYp5ifc+HfaklFjmn2uKUlRgpSME/2Kh03UjNqQMg8ZII3tZlXjnOQQ5+PSnHqU0fS5Wz5YCHyOn7sRhv6OsGlabLTF4/DxKw6gQ+/TkAlarbOWKBOewdU3TSBNHxUA/OSY/ZQXVWuKLx5GiKFkuNYNSjNk+3lSlnBCUpqnyZx+lEdL1PbvdjqKqszJNLC0piaXvu/cfMMbwxRdfsKkb/vD1v3LqTvRDjzWWql1KwzCrAY6nPqsJJYTk6kIKw+fd7gfVNAf4+HwSa329QCtJi52nmafng6i/mgprBa1MPiRIIIqEGwzzRGk029ZCXXOxXuQ9Upq54+lA7xKHMaHRbJdi9X08CntnUVfSuJkdPq8RISaJWp48xs5YY7nargje8eHDJxZtJQqSpIlBMYTICGIrCpHlouH6Ys3h1DNOjtoK7DkNAeYIOejh4TAwz57WCq+nJlBqw2bZYozm4TjhEjStHJLauqQqpbmaYuL5NHHqR7EJKngaRgpjuFgtxW6GhNe8ulpjrSFi0CQKHKPzvH8e0NqwXjaUhaasxcL1cSc8jL7rKaxhWcNFu+RHb27ZdwPffnyiKA2bdcU0T3z78Zm6LFg0DT7NuDjwdDjy8PTEq8sNX9xdsTsFum6SpDUXuVm3bNYNbhC8g1UpK4wUpq449gPDNNOUJcbUPDzvOfUDJjnmucVriylr7g9Hpmli09aU1vD+0DN7z+3lBU1dSmJuVWGKgqAUH55PeC/PjTR2O4xWTJOEaFxldfk0Z5t1tot4P6GVZrncIAmocz6sCXpgvVqSUmIYRlyIHLLSmHhu7olFyrmZvpt593CgbSpuLtZYrVitGllfdEFjoa7qnCAYKTRUBkhyiK8LQ1Nodl1gcsLz64Zemh31gsJoCmOYgyjurE6gI5frFYtG1GXGaoxa4OqGzkWmCJObmb2oLKOP2WoX+MehxxrDl3eXtIsFH057uskxuURlNFfLksJq2qbGR3g6dEBiWWmsKSnqlpDgcXf8Qa1f3/3hPcpoirYSrpy1jNPM7799hzGaV3c3IjC431EWltu7LWUpybDzPBOTE2ZhqVjVDZcXG5S26KLi6fGR3//L7/IAA6qm5vbmFT5E/ulf/kjT1CxXLXVZ0dSBFGFRLpi6ka4/sT8caR73rFdb/vqv/4Zjd6Lre66ahu12QVOuKW2LnxyPHx/ougk/OS6vLkQR4xVEaNoSYzV/9+u/5+PHTyyXFxS25N2H9wxjz+vPX0siuS0ximwnE/SLtXDqHFpHqqKlrVfZCh/59PEjh/0B7we00fzDP/9GQpMyRkche/mXX35OSpHjQZRPr774Eu8DhbFiKVQG3Wgury44ng785rf/REJhi5qybFgvtqxXC968uWa/P/Dtt99SJEsTS7RVjOPMNPUcuwMGOas5H3i631E3Fe2iZhhnTqeO7jhRPOxZbxesL1Z0p5ECw3a55vXdLUqVKFXyvN9zPHWkOKHSzDBOjJPHFj1uUmIbrCx//OMf2O/2vP78S9rFkt/+y+857He8un1F27YsVg3NoqZuC5RWfPvte7wLAvsmN8+s5nQSYcjFZoHS4OYlznsO+70MOUPMyIkZow2lWWfkhqG1lq++/ALnPPePD/R9z+F0wA0T7uM91miqQoQMLsjg8e3HDyzbBa9vX8mA0ygaXVHYNf0ws9sNLBc1FxcLgZzPnqLQLBaWmBqiWvHw4Znd8UD76oY3r1+z3+057PfgAlXSmLZAF4aqlbXlYrNErRvqpiQi+53SCh8dkx/RxRV1u+LwfCDMI4v1ClOW/MOv/4kQAv/ub/6Sm5sb/vPf/j1PT8/snmSIc3tzQVlavJVa7rA7obQoTxcrQ7uSeu7h4V7u5Z9w/cmNp5urKzmULVoKK/LqyXmWrcDfVquFWC+CTFPqusxwU0sikLJNw2a7QgizKGuGka4bJCLcGuHatC1NZXE6kaKknSxXS2SCll5YHUoXL7yKw/HIxcUVF5dXPD488BwjhS3QSjONEy6cFS3FSxLRHDy700k60koR05jZNmI3mZ1MkitbgbGE4BkH8emfgaZGK479wJRBp1oruuOe6GeqQgDTyhiRlbsJhXqJhu6HEzEIpBMlXm+Qs4b3gcfdnhRDZhpo5qzqaptGUp8QP/RqsRD/uPeUZZ1TBibGaURrw83NDSlGHp6fX/hBIUicPNHTlAVFVrAZLZMsl1JWyESsJicCyuHkfPBYbzY87g8cuwMuBGxRYusaUwi402rNYffM0J0ITlJZlJLJ3aqtSYiCqCgKFsslZVFyOknyko9ycK6rCgX04wjThM/pF92cUFrTLpYkoCosWkE3+Hz4leld9HO2Jcjvdk6KnbYW5V0shdB/jKIMWC4WwozIHeG6Ff6ANcK1GacZTcIoTVHVbG0tSpBxpqgUxhZM05wbFr2oaozhcrslAY+7Pc1iSd0upfPtnEDRY8DNE6NJ+Jw2o49HJhf4+PjI4XhCacP24irHo1fEBLaQ7v40e/rhzKeSZMPSyOG7rRY5rljnaZEmKc3kxszvke9T13dMc2Z5/Imd6/8errqWg35hhdHUZHZOXctnV1pL1ApXlqissBEVjXlh7oj94vt0NgFyS1PkzOIpC5vT6ApsBuqWpRyMA4qAws8uJ7YlUTd5T9d1VKXES/d9L+o77/HOi9/bBWSC7CAnFokdDYZxymuBqIVsVk6dTl1WxiS0IisZ1QsE9ng6MYwCgjw3olRuhE2zcEiEpyLPxjndY7uRyYt3PvODRrFHpIRSkZDkeRe7iUxFyOw+SYmTNL1z8uaZZUJmX0QkTSlFWefLnEo3z7MMKqz9XiVmNKUtMyz++5QrH0QxoOuSqqyYpxltJpSMyGQKpzV+1vgEOohi9/wsCF+J74MjSC8KXxJi2SuKlyTBqhL+yjTP0uBxwuZqCmkIzbMXa6YRAO7sAz5GGiPb77mJ55wTO1xmPmmtMnvAQzIvz9mL8jXKGnZOZ1WcE3WEl5FUhjOnkJlfYoGRe2VoqipPTfM/z4o95+Wg5nMxpqLY/fb7vXAbMr9EZdYQKsea+yCSeyBFj3OWaXYvqVd1XUuaJpLcY7U8V2eobAjy2WstPEEZcFUYI6l32mTF4svSdFZWK7p+eHkPVv1wGClAVoooqpwaplMkGAEiK2DZCI+mrLJV3ueGXhJemvcBTZJUT23y9zwxuZyIFmQKq8mNyMJKKmFuDsasDlJakVz+nCHzUmS9bKqCZV1Igu7khMWjdFZLikqKhChlioJpntkfjgyTqHyCT2gk1aw0im6cmWeH1mS+lCdkRg4hsjt2oCQZzcfIspB7oIEUgoD9YxJVu9WSJqkVq0Ujz2BW+BEDEc3oPDY3zTWJqCIhJqkrtCQKKkSxIgw9j8mWMK1BqUSIgSHz1FRKGBKlQQJN4vdJSCnK97HQGl1lzuI0vygFYwLnhTPSNDX7qcO5icoUoCQNurSabhSFjQ6JpKLAzoGyKoVzGZKkRiXQSudmI7RVQV1abG7UGCWf7zDJYW3OCpVFJUqOc4oTWj5vN0sSYcif61k567oeiBRZOSwpp6KIS4iSVCtFXVhJPFRaGui9f9lrtIIiahSGGEuqQpQNgUR0SZg/Ogf5lAWTE+CzLcyLclTU+CqrSwqWbWKeHYdTT1tX1JXUQS4ECdbJATkJOA0j4+xZ1NI4H1xg9rLWtVUhCWeAUUaUbZmvGaLKD3hW96qEVpL0VxjN7B0hAEp4OMJdSy9crNMgPC0FL0qyH8K12a5RWmFqcYAs6ppiGmkfa7RR1G1FDJHVqhVsgLUoo9FG1CXWFqKObFYoIIUk58ajRM07H2TY1zaUVUld17g5gHdUtqCpZM8hiXJdVMeJqqxws+Px8ZHL6ytuX93y8cNH5mmS4WzZMjtH3+/QOqCVDKGryjBPE7tdJPlEitCPBcYotLIZ4WGIPtE0LbawpADzOKNQKKPY746cjGEaAykaNutaQkWmidPhxND3QE4KVgLit0qxXi4pypLxNBJCIviEV5F+lL1vch4fEw8PD7JWGUtQktitFFRVyTxbrJX6osnNMFvozODMir5ZXEKr7RqN5unxCYjCp0yRKcwShrJoZWBYNXgXsMVIyOzl9UVL3dQ0tfxRSuHcLDyn0jBOI7v9DkPCqERZSfJtVYkiqe8HUhelL2AMCg1JsVmvZajfiFJosVxSVgXH7oj3jujk7203F+ispg+DNC9B4Q+D7Cl1g9Um860S45DZ1UWBVpntel4UYiJEj9KwXW9FoGI13okFWNwpov0CQ1UFyrqiqRrqqmL2M6fTUVKWa0ka3F6s0CSGbpQGEcLA3O8DXT/SdzMozWK1ZJwmvvvuPSGIm0ecgeIuCLMXuPowQvCoGAjKUMyBx8cnDs8HdFGyvbzI6cqJdtFK/2Ga6YaJw3EvfYgU5cxbVSyahrZtcqqkIUSFtgVEERElZsq6QEXDYZfvHZrC/mm115/cePqLX/5K3nCuNY0WSKUPYtXZXqwJwbNoJM4wIlahuqoFbGosyhZUZYX3niGMHLqO958e6E9Hgveslgu++OILsYYVFucMhYHNesPNzQ3j0NOdDlSlpOnpvFD1/cDu/Se+/PwL/sNf/QW/+9ffkcKcY4gNj/sHHnc7Ljcr1ssV2+0Fy9WKD/cP7A+PNO2CsqxI7ggxUJYVy9WSp1OPd56L7ZayLHn49JFxGLAZsPvuYcgqrz0xeG4vNpTG8PHdt1KsWCOHz7qhibA/nlApcXu5xVrD1394Zp4dSYmXc3eQiYxVEkv57XfvKAvL69srSHDc7VgsFry6uZZpOMIT+fLLLwUWO4oV6HQ8cDgeed7tub295Ve//CXfvn3L3/7X/8LlZsObu1dM00R/OLFsKi6XTT7oaFI0YCNTtrIoEqVJWB1QeMbhyP45sbm45vL6lrcf/zNf/+Frri4vWS9XbNZL2qYiZivO22//wH6/Z9m2XG9WmaOjeH1zRdvUzEGk7te3t9ii4LuPH9nvd8JQMYY31xcYo/n6uw8ytasFbPZ8GEhKcXN7Q1kUrNoK5y33h54QIquqQCnN3B8l+asRXs/peMQWlovNhTThVGIYJz5oSTC5vrpiHEce7u9py5pXn72SZlkM7PYHPj4dBOBXC3/k9cU1T8+PvPvuO5bLhXi6+4FTNxLcSJh6lqslP7q55v2Hj/zuD9/w+vMveb28yHGe/Uvj6RRn/GRJ1oI27I6SdPCHb7/lcbfjr/7qr/j8q9cUpkBrRd0uGKeJb775lv3+wOCj8KmGDteULOsSy4rb21uKouDthw8SAas0CU03ibz5ar1Ca83HTx+FLbZcvMSQ/hCuy4uLPOmsBdxqRYVzhkEvWlmzDOGFGQGyURutGIwknjVNS8yR7fPs6LpeBClGDsmLhXALtLFoUwjbrC5ZLUUeHmJi7w/s+oGiLKmqiqHv2Hcdb16/5u72hvfv37Pf75iNwSgYJsfgPPOgMBrappV/bxjp+oF+ELZTPQwU1rBeb1itN/TjjBtGrBaI+DxNBOdfIIYf3r/HeY+bhC1yd/eKoiw5HiVpaLHaSDOtFFXm826HLQqurm8oy5L9bsc4jmKRDp6ENGssA0prhnGkrGour28xhcDXrfmeSRVjyJHDksYm8P3IHBUuitWzrSsutmtOpxP39w/UtTR8QkwMk2O1aFmuVi9WNmvETnvqB6a+w2zWrFZLvHMyrc9DhaoUWHnf90whEWeHCZFFLYDYswV6HHtRjxQlVV29hEps1lkd4QSovlxJEtu3f/w9fXdC6QJtJZHHGMN3Hz7ivef2+gqtNY9PT8JAKQoBBOcG0zCOwo/JDURd1qQUxFJnLZEVprBsqlKacmXJOE18eniUJgFRnu9CYPYqN2ZUmEneMedUs+AtTbtgs1kx9B3HvTDPrC2+f76niXGeCc6ho+Owe2a331NaK0OKbKFDSYNr9p5+FCu1y/ZsawyH45FxHFmtVmwvLrLVOFEtW5TSDBkOOk2j2P+iAFbbVg4iy7YWULyR2HqyRU/LsFkOt8Dj/QMpJa5vrl+sBT+Uq60zRL6W9xVCAjSL1QKjFbcrGWRRlEyzYxg6UhL0gVgkHDEqepsEUGphdImnITems6W8xFGakjqzbqLzaCR4ASVq7TBP9OMkKpaqlECAELm5WHB3ueTh6cjDTnhv1hi6ceLYDzmKGi62a5Zty+F44vnpSVTfykiDKiWu1i2LwnDfdRy6/kWpeeoGabCGhE6e9w9POOfxWLQxvGlLmrLgcBrwc+Th2UGKNIWi0AWnyWOt5UevZIB6/7RjdKJcDkGxO40Yo6lz01xYZYrtsnkZBOqkZHgWPdpPFNayWEvdOw0Dbp5ElewDKgYsisYEJhXxQeG0DLmid+jgaJua1aIlpMjj4ZSHDy2okdlH2rZmu11xf+wYho6mWKJURVOXrJuS59PM5CZCipiYWC5aqgubA1YM86EjTrOoLAordl4CN9s1VSEMKB89VkEi8bSXtb8opan+5nJLVRg+PHVMIWLLWqx4p17Wmtx4b5eiHhg+ySAmJLFaL5sSCHSnDm0cJoPPr9dZHasU3TDR96M0NouCIgUqHQEjaY5aoYxmdoF+yNY94GLVipL44Oi7jmK5oLBLQhJLdPSB4AJNXbNctHzz/hPv75+4vdjQFBYXAgFwXppqoTDYqHna7xmnmat1w6ot6abE5BPrtuRiUecwD50bUoEpKAITbo4EL01PFR1WBSoNq9ZSWcN+t8eHwGol8GN0HjoYjY+Bj497Qoxcb1byXf6BXD/6yWvIQzdjDMv1imEY2J32oODiekOKKQdhJEJEUCVlIiVNXS5o2paLi1d45zgedhxPR373+6/xzuPnQNsueP3ZK4EeG4MbPWOaWC4WXGw2eD8zTyNuHjh2e0CxWm04Ho98/PCBV6/v+Ku/+XOsgdNhx6JZsGi3vP3uWz7ef6SuZPBxc33JerXk8XnPqfteVW5yuMnF5RWf3X3O0/2OcZi4vLrFVob9/SNd11G3kvT77bcfmSbHaT+TUsGbrz6jqgs+fPeRw/OO5bp9Of9URcnzPqC05YvP31BVFW//+JFxmOjGEe8cD+EJlKBVQgi8+/CJtmn5yY9/ikmJ09wDBU1bEGLNcrGhLC1XVzIMdyGgbWSaJ/ph5HQcWV8suXvzioePD/z+X/6V7WrJZ7fX9LOkQ15ebrm9u8KaEmtrkoI5Dhx3I6fDkbs3V6y3a4ZuxvUBBRxPR2xZsaha9ocnvvnmDywXS+q65s2bz7i83BB9IoXId+8+cTieaOuCxWIhNmA0X371BdpA33XEGLm9u6OsKt7+50/sdjsu1hc0TctXX/6Isiz553/+R4ZhoF3KMPn50wNaK378k59kNiuEGNg996A0VzdbrDakAIlICpGQEsN4pK5bPn/zuQwlw8Tp1PHt23dAoigVVhWUphELYCFIk8IUPDw98PHTO+q65WJ7yXqz4fWrW54ennj3h3fUTcFiVXM69nz6NDJPgWmMtIuKu8/u+Hj/wL/8/vfc3d5we3MtAS1lwdCPTOOUB9iROM8k56mOI6Yq+P3v/sDD/T3//v/8f+LNF18wjWLRvL65RqP5L3/3az5+uqfvT6ICCw5tDRebFbW1XN5ssIXl8anDuUBRt6QUeHx+IgRPuzCEoHn/3T0kxVc/+oIycyb/l64/uULrBunCGq3yxiwHKfEnKvq+F2p/tjmF4MViMQ7EmHDBY7RmcmIrmJ3Das3N5YaDhak70DQ1TV0SkqQ9nH3U/TjyvNszDB3dcc88TTSlFKPKFJSbgovNmhgj37x9y8f7R/bHE9eXl6zWG07DSDdNJG0YXZQGjR7wXhLU3Ozl/w8OlST5DKVISSboUhyPjJPDhcSiFWjquD+QYmSzWqG1YrteYpRiGsXulULMqSugtOH28gJrNMdOfP3WnuGfkrY1u4nCFixWS5TRIpE0lnaxlCmLtpRVhQuSticdSSs2GYSloJVGFyVVs+Di4opF25L8jFWJVdsKuDrzaApraJqazWaTfaeRcXac+p5xmmSiM82c+oGUFE3V0GSLz9PzM28/fGJ2jqvLS5aLJWVZ0VQ1bd3kJAfxXM+zkw61lUOdD1lFohXd/ijPRBQ1WltayoutcMIQdQDZq2ysZc7TKbICYZ7nzK1RkpiRPFqJKkGR5F5rw4JzwpIhYXJ0rcJajTaaurDE4Hn49FF4Lkm4BfM0iRrJjUzTRGHFHlpVNT5E7h8ficGxvdi+pFMpbcAWYnFLNgN2pVF1c+UoraHvO8rCcnV5QT8MjNNE0sKe0EljlGG5XNLWNYfjQb5bPnA4HGmbRtQ7KVEYzdXFlkXb0E+S4FUWsqBut1uJAHWOYRw5HE9MTnhhRmvpkJOIYj5+YRS5EGWy/AO5xtx0UEZAoMrNOZEpx9bOs0j+lRRHlS1AKR4eBQwYQkSbzDjJByRrrXxvQpBi3YrH3M0zp+MBEJaaqFDICW2ikd5sNi+JbVVZUhUFKNjtdnTDwOw8y4WmqmomH1FOoNckxH7qZZIck0xKjOaF6XY6dWgtaSbWGlIIsinFEaU1dVW/qN+M0ei6FrZSWb5M82OM+HkkZZVnIrFarTGZLzBNY07skwMpSst9RV6PqCBELZNCTvswFqVSZrx5Sa00ktB3TpjT3uGnAaKnrkrxqp9fqzWZ4SPWYpubMwJSD8xuEs6cCy88qPPnZQspXmwGqg/DIBL2mGjbVl63kqQqncHegNh+8zOhtCaoCFp+d1EU9Jn5MIwjNgSqOqfLyYL/MqFSKaJJODe/MI8Apnl+YVCdm3xKCW9G6fO/n15ek/eOqJSkeWpJwBK1SZXB6wNKJUwS9deZ11RWNUkZrPModVa8RvY7gUuKvVmjjcE5KdJBmFXJWlJVgdYkJSy0eE5hMZZRj3kSHQhO7gcpyaSzkYbrWdXmvSdYSWCMQYNKed8oOZ3kc4wxME+jJL8asQCOweG88AMKW4jjUikUmnmeSDG9rF1D3+UG4w/nslqhz4PErIaJURLYtBJlR4iJlJMArRGA9jiKisYWJYWVCPcETLMDpblYlDgfGUYn9YAWdYlzXviVL2k/kqg6TRLrfbleMHnhH5VFwbKpxSZ0HNgNM6c5sC4KytJSzOeEVzmkpcyidDltzCApV+drmhzRBxIGayvhr2lDSBqXImW290rQgRJllZZpukqByXlh2BVyeHdRWJrbDG2OWYEFOjdPdV47PRoZeKaU6KcZa3XmbiqskbJjnEZJEcwfiKRwJlFqKmm+F9ZgGmFGmfNrVKJkKaw0gOrS0lQFbVMKR8nL/nDqRxkOIYy6YZwwSrFsa+EPlZZTP3E49kzOUVeG0hppuleihjJZVXhOlCwLYX0lL7WSKAXJDD2NcyMpSaO/qWuU/jdJgjHRZw5Xpfz3qckpYSIYnbDFJDVd5rmcn5vjMInCWp8VFYEYNeHMdgIJfqgKXEgMw4BKCYs8w02Vld9WY4AYCtmbckP1cOqZZveSwOtzct7ovESTG0NhDVVp2Kxa7qYtTVUQYkBpQ2kEs+C8f2kelNZilJL9pyhwMZCUcNTGOeEiL3wqH4Q1uqhLvI3fsw6t4XK9wgVRk/uY8BgCKg/9pG5NMZEqCUJYNs3L3uvinxZJ/t/DdTh08j0tJV16dg7nZ+q6JAHz5IUXl4d9RlncNPPHP3xHDIl5DMLncj43mhxlYXnz+hVd1/P48ERZSZjIOE3sdjuST0QXMSPYo2aeZlGEJMXt9Q2TE6D7TV1xe3uNMZpvvvmGT/f3HI5HtpeXogKyOqtDBZA/zYFpFsHF7OXzk3JHFofj6UQ/jALXV4m+72BI9P2Ad552saAwFqUiSkcWqyXGaFarDUVh0OZBVJNjj/MWFzzKaN68eUNZlRyPA30/vfA4ldHoJOwdpcBYg8cz4zGmpG1aApHajWiVOJ5OzLPPSiepp4IPzP2ITpCWUJYF24s1i1VDVRbUlfwcWxTM4XtOUtNWLBYN3iecm3IqucPNwgieZwnq0lrTLlrqZUHdFOz3Rz68fyS4wM31tahPjaaqLGVZkEwihkhdlzhX0TYC5x+HjmHqedVcUZUV+6dnxnHk+emZqqpZLhpKq6nLBmsLTv0BNWiGsZe0eHNerz0xKZ73O7QxjKM4r3Qh51FbKrSWcyOAKQwmafQcUWqi7zsZ3iX5DNarJeM48Pz8RGFLlq1CG4WJ/P+4+48my7IszQ5ch136qKqaGnMWLEllJaoKAqDJr2/pAWqALiSKJDIzuLubG1P22KWH9WBf0+wZogdokXYVcamMihA3U9X37jtn7+9b65kXbIxh1a4pypKisMzzyIcP78kRrl5coQ1Yk5lmzzxLer1uHVVdUpaO66sdZVku/FNPURSLFf1RDObeMw4jzlhcWbHZrGlWNU8PG7wfmOeJp0cZFkk7Qf5OV9c7SYudT2LyM/L5uN60lKWT4Wg3cHd3xzwHtvsV2ih5bmUYBo9SGudKAPrls+sv+fqLB0+fHyS+56xsjX2SDfZ2syaEwN39ndiSrCHHQBg6LsPI95+lu/vyaktOiW4U2NwwDrRNxTdvv+b+oWXsOrabFZtVzamfOJ4EqJb8zDDNPB4ODH3H5XRk11Zcb1qSKgi65PZ6x+3NFT9+vON//l/+E+fTmcvlzPXNC25fvWGKmTkpxmniOHp87ii7GQ0UuhAAr59xWqDYfT/gY+D65paybnh4fBLV/GKwWG+2tHXJ6XzG58ibN29pmoamLCW5cj7LBSsEEgrhgjp+9eYGReb3P/xETJmb6ytKIJ5OMuQZeqgbVrudVL3uHinLiqvra4wSsG9C08+RmAUinlLidD4tvedaNs1VxbZasd1dYwiE4UyhM29eXIkSXqnnmsjVbsubN28kcncZeDyeuHt6kod8CJwvHXfOUpU1282O/W7Net3y3/75f+Ef/ts/8/d/97f85pe/IiwHuvVqI1D0KNu0/XD1bIDSWnHqZlFPIgejz3efeDocISWcMfwP//1/YL/bcbzIkOTxeMZ74aWUxgi4NIEta5SSlABMBCM1JBtnnLVs1o2kxt49kIGrKEm2zXpH0oZxDlibMa5CG8u6LDgcj/zhj3/CVQ1XL7/C+8jleMT7ie5yAG2pykpYZesND49P/PDjn3j96pbf/Oo7/BwYhxlTGEwWeKsNedGDOl7c3PDq5oqH44WHhwdevrjm5s0rPtw/cn84EoNnCp5aWax2vLy95eWLa8iSxjhPE+/ef+Bmf0Xb1JRWU1rDr777Bussl74nhMiqkWjr27dvyCj+yz/+Nx4fn/jw+Y7gA8XCZCHOKGXwOIyylMUsF705Cqj2Z/J1Op/RRoY1SulnaPGqKYkh8nQ8SZS+KuSi3rR0lwt/+OMfcc5yc3UFSsuAaql7NHXN9fU10zTzdL5gFJRWM5yPfPjxT7iypl5tGLWmuxhikvfT9c0L3r79iuPhkYeHO7bbHfvdnoeHe3748QeGaWaYPDfOsd5smEIQ+UCKxJzRWi4PX0DgRuVFS5wIEQ7Hu+VwIdyOvuvwswwfMxl3bbFG7G42WVzhltqhvJ/ISV6H/UUA9OME2vDy9Ru0UtzffSLnxGa9fa5tai0VU6UkbJwXkGsKmjiPUpUqxALVXc6gFJvNFqPFyjaNI5cFiC6bdMt2vVp04cswsJChblgkFVUprLKiLOn8hb67CLMtRNEszzN+gSZXVSkDphQgBT59+si7Dx/56utvefHiFj9PhDDjigJnHUt3RlS2UZYCOSdi0qi02DsLx/F0Yhxn4uGIs5ar3Q5nLZeLwDBlKC5JOqUSYy9bNbMMSc6dpMPa9Vo2ga1UYr881z/fP5BzFlivUs+pIJUFBDnHhNWazbplGEbO59NSgZvkZ2slEVyvtphJYOlyELJ0lxOPH39is5Y0cc6ith/6jvPpQNuuWG8k9SZWP6mQHo8HTscjRSE//3Hs6YEUZvyYSMjvbLfbc319Q1kWXM5nST4NA8XyORCjvBevb64pioLHx0emcRTb1CWwXq8xxvDh88MyKHwixsh2s5XPk6pGAd3lREqJopSL2/Hx4TnJ+HP5cl8ajXkBL89ShVqXMoSLCcLC6Mo5Un2RG5w7tHXUzYrSQlNmxjlw6AY2bcXXL1acupkfpiAXfVcy+ch5mJYLu5Ok0izngIenJ75+9YJfvLnh0+HMTw8H2trx+mbNx6eO7z8cGcaZcfLUTU1Tl8zLEqcfPdMsB98wCz9pmiNlDjjL84D51I3yntOOqimxtpRndtZMUdEuAydjLXkZaGut6PsLA9B7WRhWeknnRIXRhl9cbyiM5nAZCSmR1ZJMXeCrMcxYLIWr8SHydO6oq4LXL7Y4ZzHaMY4Tn+7vRaCwPCOmWbiZHotVZqn/WqpCaqw5epxRlAZKJzUGpxWFTqzbiv2mYfSZ3icOxxOPT0eBaRvDME4cjkes0dzud9RVQVU4fvvDR959eOTViw3X25bKFRTGYpwMzlnEF1qDMora2oXp6AlePju+LAwSMI4DOQaxYtU1s5+IUYx8c4gcupkQE5tFejGLowSVo1Rfk1TplC2wSuGcI8TIp6cTWsN+XWOMWobTPF9O5gXCvF03nLuRj3ePoARzsa4LbuoCqxVOZ2ZnKJY6c98PTOPEh35cft4GkItbN86cupF1U7NdNZJMrwusueJqs+J07jhfOupGLnbd5GV4ZZYLYl1ROS3sq8KgjKcIkVM3Mc0Rrb08vxaMblVa2qoQALZS1I2lsIZvdmvQmvd3j3TDzExBVJmkZSl4uXTEGKhjS+EKXl/vgczHu3upJv9Mvn56/xlrDdv9hpwTh6cD2mhubnfkBIfjQFqWy8YYyqbkdDzxz//0Txij2V2vufY3vLh9RQgzQ9/Rrlt+9etf8PHTJ4axo13XbHc7+o8f+eHdDzhjacqS0Tsu3Zmh93Tnma+/ec1f/+Zb7p+e+PBwx9evX/PtV2/53R//yH/8j/+Rp8cjh8OJ21e3VLXGlVa4ZyER5kQ3BDAz/TgyziNmMRcaa8la8+nzHeM0crXdU5UVj/ePDNNIClJ1vb6+oXQFxmZMztzc3lCXNTc3tzLcLn5iChOn80HSwNOEswX//j/8e4wx/PM//5ZpmqgrWVDpQgZeGhmafBFyhUFRFyt2+x0JYfkNY8/n+zuMdux21wgoOhL8xOXxCNsE19e0bcPX377GOSPDn9WK66sbEolLCJTOsW1Ldrs1+6sNh8OZ4/lAd7nQHQf6TlhN3WXgdDijlWF3tWOzW9GsG/6f/4//mX/4X/8rf//3f8ff/uY3nLsj49SzaiuappKzbUpsd2sJYSxp3z/88CfO3YWXL7fU9ZbudOHwcGDqA2Vd8+0v39C0FWM34+fAp7sPTPPE4fi4MJTmZXEp5+Af379DIUs4pRSuUjhnqBuN94HP959BKbZXO5HhRCVDoXQnIgItz7nb22s+f77nx+9/oiwrXr5WGAPOZopCFoiucLy6fSMDplJzf/fAn//8I99+9x3/7j/8O6a+pzseuXQzwxhZb0p2uxWFs5TO8vL2BW2z4Yd373j303tevdpx++IF0zzzdJQBnJ8C11fX1OsNb96+4sWLHcF3VKUkzZ4ej8/IkbDxlGXBd7/8mrKseHp4Yp4mysIR5okXL68hZ/7z//bPPNw/8ucf/sA8T3zz7TdUdUVMIg05Po1oY9hs1iiFmPj+Qj7dXzx4WrUrckr4ILT8vh+lIpBlgyJgXU1V18TgufiJpmn47qv6uQahlOZ86aUJqaUeEZYhRN00FGWJ0pqyKNltNOPQc5nHLzVL6ZU2LbZwJG2JWbbLl35EPSwH01VLoRVt6TBkTscD49AT/SRaX1PitEaR/j9gsxVFXaHiDDmyWq3QxrBarbHWEbxfKitfTE89yY/UdY0rCqZxwE8jvdWQRCebUJAjCsO6bYXRUDXE4BfAptQ2rNFUVUEIkfkyCj9qHlA+YFQmhpnPd/dYY+TvYCyucigy4zyhMguzQFM4R/Aznw6Pz/wUZzV1YfARqroRJsgsw5m6cMKtMZZxOvHw+CAgYVfKRSRJdcssG3ljZaJaNSva1Zr1arVYuCJxYRXFMBG9lRpPisLoUEpMIDGKtS7LxuecRbMrfeOWoig49TOeM9ZIhdOHwDjPKCUJpHGS9EdFsXAvJHGXlJY0QtWgNVwuF/lgr2s5RJ3OVHVgv7vCOeHxGKVkCxijwMS1ISBVR6sBMoMPxJBASW1TbHpZdO8KrrZrnNGcTyesLWiamsvjgePjHVfrmv3VNbMPdH23bFuXhIzRhHnmfD4R/CwbvYU5EbxsU47Hk9hpUqJsGoY0ENKXnnqizxG9vLdqVWO1RllJzsSUaFfDElGFuq54+/KWGBNOK1Ca7W4vHfq2lv+dl81v6iZJbfxMvtq6Qin9nIpIKZCTYppkU1pVtfwPNaQlmQKw3y11s1IseJfFUueKAhCDog+B4D3KGrQpqJoV17evpBakLTlFwnIRttaSYqTvzkyjcO2mceLSdcSYKFyJNo6qkmFDWDgaKSdJ42hN266o6koArUtyKy92MIDNZie1KSfPKucKMVZNkoIyRoxEhXPLc1WSUl13hpyf4YDGumXoIB/YbqlefjG8+SAH8LZp5GeqNAp55jynjbI8C00Gt1zU6rohJDkIxGVTnZLUNnKGfpxQesZqYawVhSP48JzGikESTOXCz9ILsyYveSsQ24117hl2HqIk2gor71/jFph4/vK7lgRbURSURSFbS++fk2F+nhfWkfwp05fUA5Ju+DLEHyfZ/IUoW9ppUbWHKL+fFBaG0/Ke/GJ0G4dB2GJLWqjvBZyttHyehJSW57tFaYXW5cKWqpZ/T1rYXAKBX6/WsjmfJqwXAYdSUFWlJNFipHCO/f6KsqpRRlIYhLgwWWSbZ40hKzGRTX4gxg7v5+eKjQwUS+q6wS1WQ0mbyfd0Ph0ZR5FEfDkDSLrNy3siw3q7FSaa0YTFNBpT4nLpvuCjKMuS3W4ntQYjCRhnF+bVeoNE3cvnAUL8GV3cgOcB0DBNyznoX1lcWokZCiDFvHB8IkZrVu2alGH0MylkYTiDMCadZZoDcwjkFGBJ6loLdbkMKJfUyxgiWYt4IyvLqRsYRrE2DpNc9FNKtKXB6YK6EAZRCFLVt0Y9GyCtMZKAMJq8WFyBJY1oqKxU6ePyfi4LSchtmoLaSaoyxoR1TiD1CINo9DIgHj0opVlp+bO2TSHsNytDlsskQxRXSI26aWrIGafFhKaXx4g2loymnwIuZJyVyuGqbSV1EyTxmZdh4Bfz8rGb0MrjzLwkETJzSBSFMCjneUbltNQ89LPhyC/m55zFhKQVsPw7cxZzFMvvVgHGSJk2ZRhmz0hgrSsqq7kM05JqU9SlQ2Wp0n1JEYJw8OQCkSicAyvJnMnLAjGmxDBH+c9LQirEjEpLGlpBsbDwppCeU/QoJTYysrC5ECaYyhpTy2eSj8KQjHFJYGr5frU2aCNiApTicB4onJHKnpLEXoySEHVObJwhRGlPLMbaGCXBV5cF1ij6ceYyDAzDSD98AQ7L53fwYUk6SyrZqIW/FyNJKULOIlfwMiBzzi5pF0lm5pwxVYm2Fqc0WstQzftA7yGjGZbz6nYlg9AU5TxZ15VgLIpiYdgkGfIid52fy9d+v5NP5SRni3mStGB3Ef5s4SzKOcySGkoxUTrH12/fgAZTSm398elB7kq12KNzEkPddr2nKmt8mCgKy6uXL6Vmudit+6knJKk+TWHm6XTi3F2YxlGG6Y9HvA80dY26gqapaNtKzhnaUJc1ycp7oigsdjGUGSUJZWcd1kjl+OaFIeXEbr2Ts5zV9EO/pAwh5cgwDxhrKA3EEBjSwMdPH8kp0Q8jIWaMFUPxeo3Yhwt53p/OR+ZppqlfSJoGFqyYVKjXmxV+DlwuIyEFPn78jNKZcerJJHabHcEnzqejpNxLEebYyjGHmXc/vlt4bmLuW69b5tELzznM+HnEVoZm1eIKJ6bSeabrBD2BEgZeURUCQVdmeVaOxFw/J+vrWsQQMcn9L0ZBAlitOXZnxnFCG1itK8I846dZqveFY548p8MJHwNYTdOuqZuW81nYqJWrZWjXj4upXNKK05JgcoWc6QpXo5WkxhWgrAIFx8OBlDJlVUmC+jJQFI711Y7COrQ1WCtcT6UWnmiUZ0apMlVtlxbFBDouvGHBO6ScmKdA4Upe3d5SFQWHxyc5R5YlMUVOpyPtqqRdr/CT1Pn6fuZBnen7gaqsUIrls19RL38PrQQiPgw959OFwmmpqlYrhknObSkmIoHL6cJoxWBXugpXSBth6AfGYeJ8OgPC06vbhu+++5aUAuUihrGFnEPJBqM0q1UjZ+nJ/58AF7+6xgfP/eMDU5w5HB6JKXM6XSiKgpurLVVVst9fCR9iHFiXBf/u7RvGaebdxztCzDw8iN1jv25RmSUCCdvthqos0NrSNpbVpuDh4YHL4ZGMGKGKomLTtKAgLAdiHzOfH5/48PkTL25uePPyluRnkp+ZQuDj+3ecLxf8MLBar6kbGf6kEPBJwICbzRVl0xCGMynMfP32LZv1mhylsqFy4HyxS4VJ8enzHdPsefPtdxRlxR9/989czidyjigUumhw1pGjxzjNi+sbrHXUpRj5LuO8AFxFhbtZNYv++kLymdQdySnhjACn/+X3v6cqS15eX1M3NW3bMhE5Xy4Ybdi0wuRpqoq785F/+ed/lDdXUdK0K/ZXN9SlY73dcrl0nE5PbFYN66qmKqSueL5c+P77P2FcSVmvgZ4U08KEEMaNLUvqdsNqc8319QvevHqkLApJg80jKXrmyjHpTD9HfMxsVi3lfsuHuyemfmC1qrFWNu7HWep81jlevHpFVTd8eLoQHs/86u0LSmcYpol+GDDakFLm0vXPlaXCWla1QJFzlANnU60IYebhk3Rvd5sd0zTxxz//mbZt+cW331KVBXVRkFMgjBf5sLcFyZYEU5CNpXQQc+IwzAsktMA6y6qyjD5xOp2pSsd3b1/RjwOfPr7n5sVLXry45ePnT3z44Q/s/+Zv+Orr7/jxp594/+l7Lv3EpZu42rbs1w3j0NF1Z1LWWJSkYuLMGCKJmQ/v33N8vKNeb2i3O4Ygl9Bh6On6xNBdSNFTFBqldpRlg9WGP7z/PcfTiXq9F5PYqmK/23K93aGV4vd//p45BF6/+UoMVgtMPMcK7z1+vvtZbd2udhtyhnGpYaXgF0B1xLmC7XYrF/5BXltzvxhqlsSYT5lh6Lm/+7wYFl+hlGKcZsZxZBh6VN2gbcH26prN/op+qXNN40A/CYy/qkqCn3m8+/yv1pZ0Zpgmqay0LbaQ1BVKgLd+qY2VRUlVVVxdXbPebri7u+N0OomC28dnaPTX376RZ7D3YrR6juIOAqGfRP/a1AVaCXfOe8/50Mm2Qkt9zZX1Uh2cUEBpBCI8TTMhBqq5oiwKrvdbQNF7Yc5Z6/Befi4pQz97rEnLJtux2Um19HD4IIOhUj6oiuU58nTqyDmhUnyGMTonauN59szzQFGKXtYauwwi7GJT+9canlZykf2SJJ3Gnu12hyvXlGVN264hJ8b+QlnV8qxsWpqq4ng6cTod2a43lGXJFDx+Fq6NUZrL+SSHk7KQ2HkpaazzRWxQRSEQ8UvXEYIXoDMsTCipwkodTNIW5+MRkAFDUIs9ShuKqiYrMY06a1iXEiN3tcAh67KU3935LLWcvqNdrdldXTMMA+fzBWWlOvdFQjFNE+fTibquuX35Sl7vIaH8TE6TQOtnzzpnnLVMi/3ufDpxPh1ZrVpWrUTvrZVFkDYWtVSf++5CCAPH4xP90D0vWNTCmQkhMs+eYRnE3756I1IKa3BW44McRA9P98QY2V1fU9ctTX2DVvB0kHRwuVRD6+ZKuFZaC2ssQ/gZPbsAVk3N5AOfnu7JGXabLSknTkOPMaIYB4ijMPtC8JRNzdvXN3TDyB9/+ICPmZA166bkm9utXGS6kX6aiXHCmAJlKgqbKUsRtsSYGVLmNHpKV7K/3pHjzIf7I8M0M0+e43kgxkRTFdysKxEDoFBZYKmkSGEUthJoNguqoXQGpzIxK/LynwvnaGt5v4sgQ2xVOUPjpLb5+XBhmKWqq41hWA673SiSBJ8yxhheG0VTWrZNuVR1NbMPPFwGQky82mlKZ6nrLUYrqgW0Pc9ibrNFSV6GH1/YcWXhuLney3O1WxL5weOjDPBH77k7DQK4jnG5oBRUhWFTF0QfGLqOsiho6hKlDXMIzD4wjZ4YPIqIUcI2VVngulnJ4ClHRVBSb6tKeb+FCN04LlYkQ1M6DqeOp3PP29sd27Z6/hk1TQVINXP2iRhFktPUlSwHQ2IME06n5fU1M80RozNKwxzk3BUXYYWt5e8wzBGUwpVWzubL+WzdVMQU6fsBrMGt64WPlGQpmyRppJf6rXVSFdy2DcM08e7zgbapwBZUTtNWUrXLSlOWBTfrhqdTx/HcUTiH1YJQOHYj67aisJqPj2fe3z/RdT3dZeDNyxe8fnlD8jPzwrjUGowGq2UwOc6BNmaqItGNA5P3bFcttSvoR+HgpHmEHHB6JxUdrXAajt3I5CP9fCJmKAqpQn71ck9hLX/44T3T7HlxvZf7RF4q63xZ1sDiqf5ZfH37zVfMs5gu51EaAZlMypqyKrh5cSXVoWrNPM08fPpMW9f84j/8HXNM3J97xnHgx/c/sNts+NUvv8Mai58iVpe8evEWpRPD1NE0JX/717/hdDzx8dNnur7jeD5iXYmrK7q548cPHxjGQWpwWTP0AWMzV/s99vYa5zSFq5blcMGmXcsgNSea2lIUit5YrHHCJ6prVLZoZdjfrmlWFW25xirH+tOKrrsQcySmyN3dHZduol01VKbgcpzw04Xj4UEGA8h7oCxb6qakrko5i1WGcZj4fPcJPwdev3olgw8t1eUwRcrScXt7wzjN3B+PDNPIP//zv2CtZr2pWK1XfPPVtzw9Hfj+T/8FbS2b3RZtNMWm5vh45Pt/+i0pZ7LSrNcrXty+oK1r9ps16qLou57CFuz3e2xhmYNUsR4eDgvrSlNUBcYZyqrG6IJ5vjBMHesgErK2bbm6/mLFnJh8YPJxaVMZjocD949PfPX2NZvNivfvPnK5dOz2e4qyZLh0nJ6OTDGgSsv1i5esmjW//eP/zjB0/OoXv1wYpD2XywXrZGj3+PQgA+C9nOl2mwajrVjjyZhCuK8f379HG8Ptm68JIfLxhw/UTcMvvv4GVzqUlmHx9XbL7CMPxzPjNMtwXSu225ph9DydO5IKrFKiMIqqcfTDzPHsaeuWr/7qNZdLx09/+oHt1Z7b169kXvH5PTcv91y/uOLjTx+5u3/gfB44ncZnxpNWgjZyWrNtV2SVSCS8HxnGEecUQ9+TsmG1umboI2EK5BjxMXJ86kkxst9dUxW1WGCt4tP7R/puZJx6Eon91Q37mz1//+avsNbw/R9/YJomNjdrWWwL2ZWqqEgxk2bkLvIXfP3Fg6fD6SQ8k3EgBYlqxZiIy5vSGYNCcblcRAutDSnLf/ZR1PZWJUyKqBzp+o5zEuK+qJpXkBKn04mYFT5rhqGXJEZO2BQpjKWqStlyKUWtRcV96Xsu3eVfzR0oojYokzFIbzXFgDUKRaKpSoxpOJ575mnmcjkxDD11aSmdqOZBPmhDFHidsY67+weGcSSkLLamnCFFmrrFaMOqlYrTw+FMSplhlodJKiZMiMyjcI9+9c3XpJwonWyELv1AiolVIwfI+8MRbQzX+z0xQz/NAuRd0i8penKM/2pw6XtCTGhToBS8eXkrFRjr5FDvLD4mHg4nyJnVekUm83A8MWWNT0ouLXUtHXSVaJuKVV2x37as1y22rDFlST8OxLvPQGa/25By4nw6k7PAPP1iOhkG2YqS5febs/A5pjkwzp4Y0sKpapdXmJKaWF2KpfB0BAQiWxUOP8v3bLXCakNTicpckdA5Uxq7VH0ShdFc7XeIUbDEp0xZ1ThXELxnXrZdKkcIYnDQTi7Gu91GNmkpg8o0TixveunfXwaprKSUUUmjs9RdyrJhmmbev/8J7z23ty8xxnL/8CDq9fWa1XoLaMI8Mftp+a5l2q2tWHlKXxAyUnVTkhipFh6Y0RqjFGUr0OKcE/M0UxQVVVHhXEFGwLwhBApnpK986bgo2ZC6RW2sjaG/XPDTiLOSVknIcKGsG+zPaO12Onfy2lg616vVmhAjXdeTVHhmyaQQCDEwLYnAajEMzWHhlVUC8R2GgVFNdH23VPQqrBG2m/eecdFLxyAWn7qun1k+X5IElTEURUnMskk31uKqSrbcwaO0RRkZyKxWK+njx8A0DbheE/0MX7bfWuGWhJJCLt7TNC4sgIRealrTNJKzcD+stQtXSHr4dS2pr64fYPl3fDH6oRST94Di+uaaFJNs88mM07ywQhQpQT8J16Npmme2g1b6mcsiyQr9bFCbZkmXqeVncHNzTQieeRyEaZUSeQ7E2KONoV2tMNbKVkzP6EkRgqcqS8ac8d5TuBJTW6qqpnCWFB05lXI5nCasc2w2m+VnlUjjyOSD9OidA20wtmD2i70pZQEgh0jOgZiRi1YhRs4YJQHhFr7KPE3PYgZrDMYVz0kpgKIsxVLqvdS9C3lumyU1UJTLdjwvPJxphGgJQaLoc0ySVIUFtC1Gw6ZdUZbV8mdLyrFwAgz3OS+mREkEpUVXH4MkkFKQi68xmlXbyrNyqXRqlVmvW1atvEbU8jk0zxN5SYtJPIlFUmGFc6c0ZjGiJliSG3Ktcq4g27TwqxTWFkQXmcMkn421JOnmWS7NOaVFfiE/17RwjWYf0Cou3Ki4JCd+Phc3gG6QBU3hLEppSmdIST4TlBYJiPDpNDkLJD6jOF16GTokJAFVlhTO0A8TsxdGDkrSjV8g4TElgc3mhMkJUqLQCqvz8yVZacOqbdisG2EcRTGnOQ2Tl0Hl8nKQROhiNctKUS0p6+gDKcnQibyYDI0We26Oz0zDjDAlun4UmU1e0vI5QRLZjV2WdzklummpcYUEymOMPMN8kPfTzW4l3DSWdGca5Zlcim15DJmQFE0lNUanv3wfHrNwQkKIPF0EGRG92IfS8vy9XslzYhhn0EpaAnPmFONyTpCB1jCLgSrmjA+iM3DO0tYNxgrb0xVS9flSP5nmQJwCWmnWjQzo5FEkfDZJLEnaXhtDiFLLHGcxBwqfVaqIMgOUWghako0gQoLJy7LDKkW2X4x+YJdzwpdamdELR66SxF1WCzfTiXl0nP2zfMNYIxKdBMM0oshUTmGUQbsCtVQAE/n57980FUVZyDA5JsbltWwL+d6NEZ18UVVkrelGSQHsVxXOaoblZ7VpaprCcbVuaOsKYsTHhA+SoFzVkqCEL68nJc2EFJ9TUTEkgpbXtbUacKhsaJblg5WwF9ZYUlbYECBK6tV7xeks5lp5z4o4ROX4/IwFSEkMjEb9fM5eP73/KEkPP6M0rFdL4tl7tFlSchm6vhcbt/fEnDj3cs/yPqCUYbPaYY3h/v6RFCU54op/tVDHOTL6mWF8ws+SxpQQw1oWRs5RGBEerFcN63VFjmZZKBUY64Q9HGZiMqRsls9W+V1kpSUpXTlYknV9P+J9oK1X2EKSe0YbpmlmyoGiLFBqxU8//UR36SSlkhWVq+TcUM04W9A2BSlGHp4OYlv0Hj2qxUSbefj0QEqZX//qF+SUaZsalGJYuMvOFsQcef/TB1LOrNqKVBeE2S+cR4NZhETG6AVer/A+oWPCaKirkl//6jv8wvnVWpGiZ5oUJ0S4cLXUzh4fDgLQtjD0s7Ce/EyYM5Urca5gv9+x3W6ECaQUMWTOxzNlIQMypeB0PDHO83NKmizijOAFd6OUpAZtUTJNgWmWmnZOwg5WWjGMF0KYqeoSWwg/WV0U2kBZOfkZZiQppBXX+xuqsqKpmoVP5OSeqDLJGPTtK/n/tyUpTiTEaDdMA36p6RXeU1pp+sy+Q+nEfr+jriuGfiTERFlYnNXkGESW4xHJ2jLods7K78VZvPccHp+wWvP1269o6prL8YJGs99esd0Kv5nlLhJzQM8DPgW0ExaisZphFL6WD4Fz11OWJWY551tr5Sy+4CuCj1R1SVUVgCWmSGEtwWhyURJz4nI6ibjByAwlpiQyhJDJiJU1KRj6QdLWStoGf8nXXzx4+vD5Ti4iXl4Q67bGx8TTsRfGwlLdeHh4lA81WxBz4v7+QfhD5QqbEyZJjeFwPHO8dLz7eMe3X73hl9+9kUn1h08Mc+I4ykGrrQp09Kg4UdmKZrV6/uDctDW7dcvHhydCzmiz9HEzeGUwdult5igHYC1q6c16y3q1Zpg/cuxGToc7wjzy7bffsl1dPVc0+tkz+8B2t0drxb/88c98/PSZ2xcv5c2/wHN3uz1KKb79+g1Ga/5f//APnE5nzt3IMEe8ruSi0T1RlwX/07/792hj+O2f/8z50vF0EJ7K69trpnnmd3/8E23b8j/9D7/GWIFJzvPM4XggJOnlpiD1rDl4uq7DFQM+ZlZ1wd/+5lckNB4th6DZczyd+XR3x/VuwzevX/L49MT3Hz7TPJ24v/tMUZRc7TaMs4D3NuuNGLLaik1TEbQlKrFznM8/4bTi7e0LfvzwkfuHJwFAWsVNvCKjOZ8vHA5H+mlNUZU0pSQkHp5ODKPEYo017HcbCmeFATHO3Fxt0Vrxu9//ln7oub15QVVXPI29DDyNMF926xZrDWHqIUO9MGAgYqzm5dVrYoZPxwGbNav1hsJa5nHCT54pJTRQmYxzjraoaaqKVy9vCEEevqXVbGs55M8xM82Bw2VYwOwWkkInT2EtrGuOhyd++P57NrsrfvWr3zCNPd//8APtasXN9S1Xuy1X+y2/+/0f+P0f/0RpjfAg6pZytSX7FsK0wL0T/eXEMI1stMGWJc5onIL9bkfdtoQMl66nbTe07Rpt5SC63+4orCUjm9fv3z8yzp5xmKjKgu12g9Gaw+MdOUbqtsYYS7Yl2ljq9U5YET+Tr88Pj1hjubraURQl2+2VVD2PB+ICMo1kAejOM13XYYsCV1ZLFWrEGMV2vcaHxHEZwvvZs92s+ertG7z3dOcT58uZ+7s7AR6uBJy8arcCkPVBYvnO4qyjcAWXvufcXXBFRd2uGPuOcehwrsQqaOqatmm4dMLI6bszKUzM40SOAaNAWy1Go0Igf9M40J3PzPNM3ciWubsINejsRgABAABJREFU965p1xIRL8UQ54MArK9ubtHG8NO7d0zTyDyPBCV1V6UUl2HCOce3X38DZD5/eM/sZy5dj9KKuqxIMfL0JEbKV69eyyBMSRTcewERqgUWbLSwtrrlgGG0cJ/evP2KcRh4fHxgHCfOl44pzsTg2e327PdXjNPMuevJSQYobV2zbltyikxjT1XXtKsNTS0GKL1wonwQ+HpRVLyoVxxPR7q+ww8CS6/KagFtS+Jr7C9EP8ugyFjmUQ6PwjuyVFVFVVYcDk9474VLpBXvj09M40hVSbqzquSgOM8z5CwpIa0JpyM5IYcohVRujWW72wuv6PgkvK3hQjSOqakBxThPMrjJMlCwWlGWJdv9tUSu5xlFZrdZP0POwxQZZxlWkgJ2NjKEn2fGYSQlSW84a7nZX6GsY44SNzFkbq6vubq64v7xkcenRxkOTv5Zd52QC5SxFuOSDHmNDE9VznglCTyzDB/1Ur3/chFzhaQx+lEq2+1mi9aaz5/EZjqMo7DInJU6ZxYIaRgEbm5UktQfGfszGzw9Hi8orWjKCmsNTWGJKdOVUgeYg1yw3ZL0y5VUvz49HuW5kxSryvF63zL7ICmRbuDHz49s1yu+/eolGsEeDHPkOM5UKrLSEaUMtbMonSAvcHztuNo2vNiv+Phw5MPdE4pEoaHznks3SZLFCNh3nj1KJpA0ZUFdlEyjJ2S/wHkzVstnoSZDCvhpYUEuFft3n+7p+pnbF3vqupTXcY5YDFjDdttgtOLh2IkBbQ4Mc0AvwxYNFM7w3etrIPPj+wepRc3DYpbckjN0U0ZrxW5Vyt8lBEkZL5e4nORs8OHxtKSDZ/lM2e1YVY6Xu5Jh9DweJY0/hsQ4Bp7Gmd1mxWa3YR5nzt0gKT+f5BmuoS5L2qoiqyUFVlhcaQmzJ86Jfpw4DzN1VXK93Qi0OmWUMRgMPma6cV4uySVTyKTBMywpVacEci4yEcWqFkNlwpLQaC2vm26cxGJkDMUykCRnysXoVi2VRx8DSi11ReAy9ECmKStCynTDTMpQFLJUS8oSoudwvmCNxm1ajLbookHNUkVKSctw0TpRjqsvCa3INAWwjrJZUThN4TRllWjWK4KPPF5GKqd4e7MiYTj2M85YbvcbgblXjvNZjMOzj3Q+s2lK2roQQ2IIgrOwmnGa6UMApcXY5YPca/RS/7QGA+zWDXUlS4oYE87J8yzEjCJxOknCrjSKqiioW7HWWTzEwBylLplzhpxonGHhPPwsvv73f/kXnLVc31xROMfV9Y559vzw0wdQGatFXX84POFnTzdNaK8IWZITMWWqsuTFi1d03YXv//yO7tJz9/DA27ev+B//p/8OPyWmS+T+4Yk//fATdV2y3axwrqDdbsgass5YpXHKsN62bPcr7j4d+PThkaJyuEIkPueuo20UTaVJMWB0QiFV/qIqKZtKllA+Mo4nyInilaGpHFZrrDKcuo55DuyvtrSrlv/8D/+Fj+8/cP3imqZpWNWtMDWZSAlev7rBaPiv/+UfuXQXpn4mzgK8zxke799RVSX/t//Lf4+1jh+//8TlIpUqpeDm9gXz7Pnd7/5EVZX83d//lbB8loHpMHicK5+FMpUr8BHmUeRCWidurvf89X/4JcM083A4cTwe+PjhPd3suZw8L252fP3tax7uD/z4/QdCmgl5Yr/fc3Nzw9ANDF1mu9uz2+95cX3Di+trrCtQusDPA/fdA01V8Yvvvubdu5/4/PkekOdznBM5yYDKz5HD4Uw/DBSuoWpWPD2eGMcJZ6VmfP1iT1kWPD7eE0Lk5etXOFfwwx9/YBwGqlVFW9aMR1kOr9drXFHw7ZtvRQy1cBIxCkiEWYy/r1+/Efv04UyYI0lHfBIkijaGkPNiCI3kHJlCjzKJ16/fkFPkdDhjrKGtS2F5hpkxJPoxIB92SRK/hWUqC1xZME0Tx6cjdVPzb//tvyGGyOPnB5p6xetXX3F1s+fqZs+//PYP/O73fyankZwmbFFhSmk1NWWN7XqGxRDc9z3X13uKsni+a6x3K4q6FI7hHNlsVqzWFTkbUky0xRO4SQRmKfH9939kGAcupzNVVbHdrSXpNka0zujFMN9fTrJ8MvVfLHb5iwdPkrBQpGQXuGuJmoPwL2Lk7vFpgS0GtNE02iyE/gFjLOVS4WhWG3LfMT0dcNbwzdtX7DcrLueOeVreIE5TtmKIGseOtizYXl8zBRlkrTcb9rs92iiGSfgdpTXEMHM+e3xK+JRpK0ddOlE9T/NzFzI9PnG6SO+xrhzr+gqjJAJ+OJ5IKIpy5PFwZJpnwvWOqnCs6prb6ytu9huqZbP8ZYiWk2yFy7KgrGrW6Get7aqWXmae5CH7+f4epTV91xO8p6prtJLNZQY2+yuaWjqo0QeOx4NEokuBAhdFRYyiVjd6lgSWEYaAMZaibqU/O83kLNH7wllur64wWnH/eEBrxddv5c2SQsA4J1sBxLxhnTAIhkWRPXrp+4/DwDSNbDYbXNMIJyZ4YpSp7jBODNOMtpaqaYTtlRPj0EGG0lnKYkXTSpVHXqaZmMSMkqLHKsNqs8WV8nPJMeCc9KhDFJPEw9OjMGWMwHrb5UKrABUUPhyE4ZU0hdW8fPGCGCNPT0/CvqkaUoochjNVWcmgNAbSPKPQVFVFYWTz6ONM1w/LQAjaquRqt0WlQDfNhByY87zYbmSCfTod5CJkLPM0cw6PpHli6DumUVSvhXVyULGWGDzRT+R5kvir0bj1irwSaL3JGescrqzo+p5+HPHTiMlx4WB5+pOA2M+XgXHyjGOPD54UJQarFy6LGNIEuJ+yRvmEI3OzazHG0S8mvJ/LV7mY3FJKBO8llem92Ih84OHxUWpkXjbsq9VaNkr9sKQxBBqrtEEbFs2tw67XVGUp7K7FileWFdfXN8C/mtKKosD3vbwHUonTNVi3DKEcVVkCmXEYJCnYDzStbNi+sJLiwgkKITLhZfugFdZIbSt4T/CeKQSxdQySurLOUrhCbEWALUqpqAwD4zhwuXRiFmpbGQKQnjfZWqtna2mIgZAzl66DnOiXaktCoRLLAEs2yMZIDDcGYZsppcTcl82z6U2GT4ulTH/5GQuAXJ6DXxI0YLXDlDJUOxyesM6yWdX0fc9l6PDW4IOY3bwPUqWOnmGIzPNIDMLZCt7L5cKJQZMlragKR8qOlCLTOCyD/QU4qwoZoChN1TRUKWEXILvVegGPS73IWuEc1ZU8u8u6xixcQIC6qkhZ6sIpZ/pLtyQJ5DljFu5LdzlLHSEJ22u72QoYc0m2WC12ucPTA9ZY6roiJTEsaaWFvZiErZKSvFbS8o+zhrJpxEg3TcSUhLcQEvM4LQwDhwp+MaTJJcsHsZ2GJaUlZRr1zAjLy+DJWSv17KUKx/KsQSmUltpj8LOkLrVinkaGTjP0F/w8i3klJy7ny7PlySw2yi9DUIDoRa2eovz3N9dXaKV4enoipp9X1e5LssVH4cCMRipF3Si/W7IwnapChqxOK2GqeKk5lks6ZIqCFlBa4Mmvr3c0TUVdfElvJ7LWJK3kUhxmGQraJcUzedq6Yt02wtsJCav0kiC3AjlfBuyVEXbNpDQBBVEG0N0gVd9uHBl9YL+uaaqCkKQi9YWPlhcOUF0VOKe43m1ZtYG2keFbjJGYMsM4ShWvMGSr8d5LSr1wwh1dTJFpSZ9KlRdiFnmAKdRzQu7LaxjALQm6YyefAVVdUTixfJIzTVkwa4VKCWc0hozV4IwlWHmfpcVmWVclm1UrW/5ThzWG1XqFJmMUz1wuH/Mzf6ooHMPk6foRTUbnzLSksWJMRB2E5WctcZgJ0TOMmdlr+Rxb6n4asa/5mHFOLwwlYcTlJEa3kDOgKQux4YUgDFLhJBlIwnJNWf7fUz8+yy2U1iQtDE4fpVI7ewGu2yWVWbuFQTJ7QoqUrgAF3RjwUWGstCiuVoJNMFqe/ZmF0Zc9KckQwmSFM4HoYUCYfw5kOERmmAPDGMXkWFTYnNFZfmZipZbXF8hAXZh2C18rSVLBaM2qqQCB8c8xyveihWGXksIqwTjyhdM3yZI6Jkn+igBEPvecEUYfGeHb6cgYvZwPFyvjuhUW7qVPi3Xx5/G1atvnVFNOeRnyLiyuYebDx3uUUszThFaatq6JSRZExhiaxcBmjAyoY4xUTckvNl+z2a6ZZkklGyeMozdfvZGKbpQE836/49R1PD4d2KxbtltJ86aoKIuK3W4nC+wxMA0T/aWjKWucMwxTZpyEgycmREXyGZWhqgtWzY6yKPDzzOPTI3OUlNPx2InMJb+laWu2240sgvY7irKgH0e6fuDp6UzKme22pSpLqromA85pjFGUpZNn1cIhe7iXu8vT8YlpnDDPiTGNUZbVekVdlVRlTcqZ80Eq/M5ZjBWmEkpRVi3Ke4YFqv9l4ZaViMNY6s0xQl3VbDfXQODHd++wxvHm7Usu/ZnD6fH5814rRYry+/HB8/j0QNed6bqBrh+Zph4/j6zXe5p2vTQLBqwpMMbxdDqiLZJkV/r5H5ahbF0VFM6yagtZ3FalnCmU8IkK6yidk6WEypSL2VvVtbAfySil+XR3L/fqL5Ka2i3nPEl89vO4fBSKSO3t61ekFLlcLiitZfAyZY6PB6w1tKsKlYU/JzEws5x15OdxGSfmEBhGMTluN/J67qdZxBRJUvc+BPIwEGKUv481+BgYplECJ3EmeC/J3lwCAR+lDj9PMzlGCldQlSUx1pIKq0qc05SVI+WCcZzox5EU5GDtfWQeAn0vS+rH4xN91xGyIS427y9pWr2kYlPKdGMHgMprCue4vrkm58z9Q08If9mz6y8ePDknvf8pZ9CKtmlRamQcZKI/zjPGWoqypnKOZunpP10uFMZypTRmvWa7v5L62DCwXa/55bffkGLk8PBERlGWLWUt1rBPd5/5w8MnNu0tr998xQ8/veeHd3/ml7/4Jb/87jv6oefUdbIhLQyXruPQdcxBKl/6ek9TbBhnz6EfJSaM4v7piRQ911fXrNcbXr+4YbNq+aff/4mPd3cchgnjCu4+f2YcB8L0mu2q5Wq75ma7YbtdY6zlz+8/crpcePfTB3wI1G3Nar2iWa1pV5ulHmVYN4XUonphcnz/4ztSTvjZo7RmvV6jgNkPoDW3r99SLgemaZr4+PETZVHwi2++pixLqroF5disRwY3MqX8vPl2RUG52uAnebPn6PHTTF1VvLm55vP9I3/88R2/+OoN//ZvfsXT4cjHz3fPKQhtHbYoKZwcYs+Xjkt34XQ+cTnLm08rhSsrVstmPnqpAggUtqcsG4wrWW2d6NRT4HI64v3Mm7ffsF5v2S3pk/vHA8M44mMkeE+KMxjH9c1LQswMjx+IfqYqKzJqYSJ4fnz3jhAC251YkbIRpbBRcig9nU9oo7na7aiqmuuXX3M+n/lP/+t/QmnNq9dvGMeRH396x6ptaVqpevphwJUV61ZSbgYI48jT8URWBm1lsPj61RtOxwMfP/602LQCKYFxMsHu+wvtas1qs2W8nDmdTzwai7KW1WrN1W6PcSXGFozzxDRPzMNAmAbWbU1dFLTrPWVVEb1A+MqyJGa4u7uj6zoaZymcZfaeyzjy/qcPXLp+eXBm7h7umedJwO2uwDmB/qUohrQhSfTdz4lGZV5e7bHG8tt3Hxinn8/gqV2tFlBrJAZhMj0DXVPi/P6DxGvLiqoo2F/tmKaZj58/y4P1aicVIqWwQOVkqHp9fUOMgXHslzqWpl2tub6+Yeg7jscnrBWTUddduJxPkBpKZ6Cs0M5R5iRQ0nHicj7RdT3D0GOso6pqAYMv29icea4e6UX/XFUVhSt4vL+j7y/EZTuXlzpYVUs9cL1e07YNPghs8Xw+45d0V86ZqqqEG5DTs6Jca01VlmRgOp3xaebwJD+z46Un50RZSpXui6nIFU7McID3E3d3dzhruX1xI687L4sKbSx2UZprYyThZS1+GoXvkgXkbRUUZcGqXXHpLnz69IHbFze8ub3hLszcL0mYsiiYp4l5mghlQQoTQy8mrS81v+gnYvByISlKyHJpLKwwolIS8Ps8yQCkKEpMWRKzJivFuqmxVngvwhSSalJaLmHWFZROqpFVWWKrFrRmHoX70q5WxBh5/+mOaZ7wQ4/VmqpyFEVJ1QgU/PD0AEBRiaX0arclxsjheAKgLAqmeeLh7g5bOPZXNzhrRc6xfK8hSsIpeM8wDEsdU1O6FZvNlmn2XPoRawRaPsXE0PfYoiCX0n9SOaHrGluIIXQ6nEhhRiuWCqb+16qVjAqp6gZXSJrOGHkWp5RAG/TsOZ1O9P3AZiNDur7vmOeJoTsRvJeDW4anw5HZB9q2ksOtk89SpeUgOo+SUpvnmaIo2P3ql1jrOByPJP/zqaoAgjVIiUs/ybANGUIdugkfIn6SS0jb1NTO8HJTSSx/FnhzXRUYo+lChiTD8E3heHW1XaQhTpTlUS7xVV0uPIpMqTWNM8yz53LuWFcF19uGvFyirZYqk9Hgl+H9MHvK0lFYQ7cY6dLyPkmho1MXxpgJGb5+uePV1Zo/fnji4dRz7GZGH9g1JXXhqGpDURa8eS2MkHmWGms/CJz6cunwIbFqSopkGeeJmCLXbUlVFlSt1JSnYcD7wIf7Iyll6qJG6QLrpDrGMnRKOcsz3igGn7h/OlGVJdfXV1ijREaQI9uVVOtVilhjcCrhNFKhSZnSWnIOTCGyaWtevbji7unI9z994uZqz8uXt+Qwk700AMZZztDd4NmsDXXdcDh1PB6OrKqCpnSMHuaosSFhSDSuoCorpmGCeeI8ezwyeLTLxSci9Yw5ZupCkpq7TUNZOO4fHxmnmSkIraO0FUYr/LLAuCk2MnzCklPmNAho+/54xsckS2JjGGOWS/ACRc9plEpoUeOMYl+Ktv3hPAgKoBZz4OEyYE0kJSid5u1+JSnuIAPSkGT45/1ESPK9lwUUVhFJXKYAaEpliCqTlaSsjqeO7XrNfltSKNGj+9kzTFnkGDmilpxXipFxVqgU0TnSlDVNU7FuCvkZHc6c+wGfDDErpmkmJ1BOiakvJVKInPuRfvJoZVHoZw5pW0qN2i7PtWma5f4zeiCzr8AWlhervfws58DMX8ZJ+f+Hr6urPTlJZTrGhLZ6WQzLs/tyeYfWAsFftQ23Nzf0w8D7Dx+oypLdVhoRxoLSCZ88V/sdf/s3v2L2kfNFJD+udOybmps3rzk8Hvjw4weapuXl61eM37/j4f5IUzVsdttFUpKpq5a6XNFdOrpLR3/quDyd2G+2lIXjnDLd4On6M+PUE6eMrxLKKdbrhm+//oar3Z5/+If/jfcfPqI+3QGK8/Ek5mQjaILblze8fHkjdwyl+Jff/ZbD4cDnD3fklLl9+RK2hrZdUxQVOY4onQXarMBnAdK/+/EDMUaOl6MMY+oSZ5wMnrTm6vqKuipp6zX9MPJwd8I6w9uvhF3lk/DimtUGNfQSCnEFbdtSlrUgapAEXooQQ2bVrvjVr7/jhx/+xH/+z//Eb379a/7tv/03fPj8gSl0lGVJYQoGNCkmeXbMEw8Pd3SXC2FhNk7DwDyPfPNtQbPaMwfPMF2oyw1aOz7dfebxeI/JBVZZrJZ/yJBjZrNucNZwc7OjqkqezgPjFDDaCQTbFdRlyWqzwhYWC6gMxbpYvp/M7D1/+v6HBe+QsFZzcyUNgPVqS0qZp8MTWmuurq6pq4q3b3/J5XLhP//X/0Yms9mu6PuR7//wnrZt+c2vfkVVFTSN1IlNXSxIoolxnjkceuYwM0w9L+yO3eYFKStOl0FCLUEWhNPsGQZZvKw2LZvdhnGe8D5w6U7cfRJEw/V+C8aA1hwfj5xPZ0Y/0BN4++oN1/sbtJVj1DwOhHmmaUuUgQ8f7zhfOtabDWVdMY+BXs18/vyJ7nLh0+NnhnEgzJqcIGtZJNtlwSFSCng8HETwkQs2K8fbr75CaXh4/C1+/svujX/x4EkAoVli3jHww4/viDFytZV0gF42AsZVOGso3PJPeYtG4bSoXqdxgpzYr1cYY7h/OsoD6Hxhs17z5tUrhtnz4/sPBD9ztZi3Ho9nhmkWMHXf8+NP7/GzpHGqsqSpGjFIMGCdxRZSrxCdNZRaMfnIHBPb9Vp4RjnTDxMfPt/z8HRAK8WL/Q5TNmL6udozzw373ZZVXfPw+Mg8TWQlffxVXVNYx93dAzFFpmnCOctuvcZozblbjAbRoZWwd1JK9ENH8olumoVbshElMDkQomh1jdaE/kIG1ts9Rmsu/SCVKS/8gwTYouBqf0WKgTCPzNPI6Xhknicu50FqkFZhtBzUNJHaZFKYOZwuTLNcsJQWC01hDW1ZcO4GHh8fpaaiFKt2TVU1GCUK90LDcDlTGM1uu+HcdYzTjDXCavAxLsvuTEpw7uXCf3UtNkA/zyh4TkBUhSNbjbaWpA1TPzD7iE+JjMIswOWUxdyzXQtfarNeY6wRVkvKVE46rM4J0+V4OjPPnt1mizOa1y9vRYdspV+7XrVUZSWckxQZfASbMCqToxyiyXB9tf/XZIOGw+nINA3P4FK7JPoK55jHgXHoaeuKTdMw5ESXE+M0MfQ9Zd1IioIEcaZymtLVfOpOHC4dISVGH8imJCnRzYdZLpDzHNhtt+x3O5yRXvmqEZZNVUpqq3AytKwqi49BqqkZxmnEB88vvn4j2vcf35NDkEqQ0bz/9AmjNGEaUD+jrVsKHq3F/pRS5HA8QpZt3Bfrjsxp/pX14Jzj5uaFgEOdgLgVYqjIhaRrPn36KBseP1NWNZvtjhACl8tJzGFFgTGGkBJKywAqZeS94iPdMMjlqCzxWq7uarnUi+HHAp6UAvMstY5121CVBfNSkyLDZCZcWbItShk2xLgkRKTDrpTGe0nkZQRG0dQ1qSgYhl564bNw5KrF4DdNk2xTZr/Y9Fq5bAbhdmhjyFmjkPeb0bJRG7qOyZglRSNR7pzT84eqsEfkYC1cI2GopJyWTTSQviRdLKvNZjG7FNRJnp9FUTIviby6LHDGkJEBY9OuFuOXpKbMwoEjZ1xdY8xKfgYoyAmQjXfwnqKuMa5A+0CMYqvKMTFOomA36xXoghDz8mdIOoucUFmg/36el6RRhhhQSawpKGQIEyNl4TBaERaz6zRNInJwknyTwWF+/hCXmabAxmOMDNNEDIGqrjHWLnUU2Xy5QiD1s9aM04RZXvcsAyltLf0gHCVrtKjBs3yOrDfbBf4smmHRyBsSinkcmYNwSr7YBK0R21MGLucTfd9RTjOuKFmvWuqqEstfkNdviJGqLLBG09QNrnBUlaQv/OSWjbjwiVZNTQiBshIl8dj3oBSvXr7CWsPnTx/xsxcrlHPc3X1GK/2zA4sD9JNYCevFSnjqZ1LKbCpHzpZQL+ynosAZuTwordnUYrDUWqGNlhROyMw5Mfu0MMsEFl2Vjk1bkYKkN3LONFVJVVja0hFi5lLKgujxcF5qs2Zh3hhhGS2JqrT8+cYaqsIudktJ3rSlpXIaPXqmEOlHz92hozCKm3UNGdykcEahVaIqDHXpOPcTs5f0NjlROUPpNE8nS8oBHzLozKapnw1R4zRzZZzICZxwdfRigBymUZL5TYVGPadWcwpMM3w6hEXCIDWxS9dhraUsC3xSYmbTirqWYY0xsphYelOA2AfrssBoGMcBlTObtqVylhSW2uvCVQwhUBeOtpLl0vl8wWgtKAKtcUZhnKbJCsmQyWeWT8tnl7Fs6wpbuOflRAhSmZum5XdTWlLWCwdKEkXGOCojy4qQJHFVfEmXh8CwcL4yWep4xrBu5TnsnJO//8Lp+jIUTVmeazl4VFKM8l9Tlm6BZ0udcVWX8uxa/uxuDmSlUErMwYYkXFZTyjN1DBA9w5AoncYVhpjERGeNZtfWwiMjs2krdm0hjJXo6eZANwWsQTih1uC+1N6d5XQZuIyBqHq6OTD6Sl533cgwebQBrQyFUWinaSoZrNZ1RWENhRP2Z1lUi9lV2FDTstzqphFy5mrbisVOCbtL2UxUmvtTh1IyoP35FO0g5ihczfWKEDw//PAjMSX2u/WSXpWBHDlR1+WC4Gj49tuv0UZT1iXG6GfT8KZZobPiw/s7pmnmcO7Yb7d88/YNl37k0/tPhGnC2szsB+4fPjEMZwqrGMee9x8/yXs0JdbrNZvNhpQ90zyQckQvScVplletc5LaiyHinKJeWQYfmH3m06cHjoczdd3w7bffMM6SqKuXe956VVM4xcPdgWmc2W5nCldwvd+zalq648AwTJyOJ2m0VKW85i5yTpjGhDaK7UZqwFM3AwGFQ6kkLEVjQCdCCDw9PXFaTI8pCb4AEo+PTzhnGRYm1Tj3YODq5gpQRL8IP4aJYRjoz5Jqv77a0jQlMcwYrVmvNyhlOJ5OzJOntA6N8HLbtqFtKi7DwMPDA1orqqaRZ5EP1I0ky1yhuZyfcNay210T5sg8D2yvrlhvVoQpL4sjRQhwODwwjRMvX16zWjVyRsYwL2IfozPKKRmYLKn2FBPZuIU7KWe8TEQrxXYrSzyQ6luIkKeAs8PC15JFZXfpJc2Yt5RlyVdvvpKhmp9wJnO13y2MVkl4zZOmUIraFgQCPnuqsubVqzWzn+n6C1VV0PXT0rzSct7RiqIs0GYlyXwf2WzWXO23SGYjczmfOJ9ObHdb1luD04JYaOoSAzw+PdKde36KH3h4fHqueIZpIoXA5TIwjCOrtmHVNrTrDUVR0q4qisJgC4crC25urpdFel5sfTMpJ4ZhIoTE22/eUpYFl8tZ8AzMjL7j3fv38l7Osnj+S77+vxg8RaxRbOuCy2Xmt7/7HdZa/od//+8oClF/JzTRyKG6cqIE32z3hBA4n8+AQKxJkdv9jvMw8u7jZ/ph4Hg48otvv+Hvr6/44f1HfvvHP3Gz3/Hd2zcM08Sn+0eGYaSwBafTheP5DwIqzZG3r1/z4uqGyzCS0JRFSVnKgSEkiTPXRjMOE8M48+3XX/PVmzf88ONPPDw+8vHugRA8f/OLb/nq1QsijoSmrUtSTtzudpTW8v7jZx6PJ8appyws37z5FusK/vzuR8Z5ZBgGtFK8fXFF4Sz3958Zp4mpk7rN6zdfySUwzAIAG0aMtbxyDmcMOkV8mLi/E4bGxxxYrTf85q//lpQijw93kPOijtXS3awqrtcb+u7C5w/vGPuOh5yZ58C5G6hKy6atMCoTwozOgdZmoh/5/CAPgKqq8SEwzzOrsuBq3fBw/8Cfvv+eF1dXXF/taddbyrqlUAGrAsdTx+XpkdJZXlxfLzWmIFwAaxab0bLlzJnDuedwPPLqZceqrZinkpwj3ssmpF0OaNqVJKXoO4mTQpQP/KWjnKPHKMvN9TVKKdbLRfPD4xPkTOWEH1OUsqW/v/9IU5W8uX1BYS2/+u4bRh/4fLpQkLne7ySxMQkU7jIntEs4klgbLtJvffPypcTh54k5JD4/3MvhyFoUBo2lbSt22xX96cTxCbarFVebNWenoTD0nz5zPJ9Yb7doZ4VdFmbq1YqqaXj/4T13T2f60QuE1JQkbelOon+d54mUEt/+4hfs95I2yzlTIBYwOchlNiuJQKoFNv50PDIMIz/89I6cEy9u/jvWbcv79z8R0kxTblBK8cfvfyDnyNV6vQAIfx5f0c8oa6k3a2Ex9T1Ga25fXGO0YV4Oh/M0S6Uui7Hs6uYFMSXGoSenhEqBbAym0JxPRz7+9KNEUjO8fPmKr77+mtPhyKfHR6qyZLVqpXoZZPDUNC3Dkp4jHVE58fLVK9Zv3jBNS01USdJIG6k8wUAMgWkUzs1mtaKpG6ZZOELDMICSbvp6veF0PDBNI64QsGC5VOvGcWIce+mFW8tuvUFrxcPDPVOMTKMkQrebtdRyZqlh5GnGOcv19Q1KKe4fHsg5PMsVviRsjDXEKXA6nWBJ3GilFmZL4tJdcLNcaHIGxQIo10qOBTGSjPx3KWdSFH3rer2RyRRgnaOpReAwTnIwbOtK1Ocps93v2V9dc393x+e7z5gFpJ+ThxRo12uads04jvh5lsFTykzTiXkcWNUiIJjnGUJYfrdR9MvTJBBw66TfnvK/VsOSDJ8u57PUepbXXfZBqhRK0kASrRa5Rc4Fsa5JMdAdn5j1SFWJGjcvFTa/gNpTymhjqJoV0zhyeHpCa0WzWolwQCtSSkxe2DrtIh/o+g5nZRAVsyRS5mnmdOkpnHApYlb4BK6saJvm+XOgaVra1YppmphGUROfTgeub25ZbbYsp6LnId793T13d/cUZY0rCjQvcFpJNXsZhqbFoCVgzYUnV1UYo5mWypRdnvNWC8NJLwmSx4cHYkr85q/+mrquef/+J6ZpYrXZoI3h3Y8/kFOiWW0x+ufz7AK4DGI1fHXdMPvInz+dMErx3e1GamdaP1/YBYQ8Y7Rhv9ZyYQl5GUJbfE6MKTD5xGUQo1o/jtzu11yvG+YY6LqBsijYrBoq51jVwuw5D2L4+nj3hLEFpihZNwWbpmCa87Io+jJ4kiF+UxU4o+nnyOQT23XLqinR545umDh2E8fLyFc3a263NUplTr0S2xiJtnSsmoKPDyeO3QhJeJ372y2lM3x+KghZMYVEUomXmxWKzO9/+ElS6GWNqku265JoFVZlfPRc/IS1llVbYTSEWQQSOXimkPjUTxTO8HrfihXpeMYVBRtdEqPCx7xcxtqll5KeGVA5yfvdGYMr5HdyOZ9R2nK928pwcLGFKqWIKRHmwNW24sV+y/v7A+8eD+z3O66v9yTviYsspLCGfhyX5IzUmaPSKOu42a/ZrhvuHoUveh4vTOPA4GW4HJqCGDX95LEhgTJS61nkAP0wEoKw7iTRNjKlyBSkRt42rbASN6tnCHdKmadukto6CpUhsvgm4kQCLkGGk23bElPmPAhP5WpdE3OmnxNzlPOWMYaqtpiURRpgDEVZMY4TYRIcw2XK0JSsmxI/B0YfWDUV+82KoXKsC8Oqqdm0FadLx3GcOV4m7s4j21XFpi1pCivcp8JSWsv5MnAaJk7jDCg264amlhRt9IG2VpROUVoojWbTSjp61UoKtu5GErBZNRQLOiGlyHHwjHPg8+OBFD3f3Da0tUFZh49AjoSUeHcvadZdI4Orn8tXzAFtHNv9lsvlwj/9x99SOMv//f/6Py5sQxmUXM4dRVFQVQ5Xtrz66jU+eI6nIykGpuX9cr3Z0/U9f/r9D/SDnKV+9ctf8Pd/8284nt7zhz98T1tbrrcV43Tmpw8n5tFTFYquO3M4XyAlVIx88+1X7K82hDwzTGciEVM4gUkPHZApl4t09IGiMqx3JdPDzNxnvn/4idnP/Id/93e8ef2Ku8MT/TBIIg7FZmUxOnN3/5nHhyMvb0ZW7Ypf/+aXFGXBh58emP0TDw+PDEPP3/31r6mqkmGYmfxM30WsM3zz6oXwDj88kvOIUSJrMkZg0djAPI98/PyZ4APv3n+grmq+fvOWmCIfPn6W+mhdLwmqSNu2vHz1mmmYePj4wDiMXLqO/tIvvKGC169usLZgniesMVxfXaO14e7ugRQ8tSsxWTGPnpvbPbcvr/inf/4tv/vDB25evuDmxQvMODCNIy9eXLPf77n/eMfhUZoEt7evufv0nqE7smrf8vLlS06PZ8Z+ImHwIfP+pw88PT1SVgZXGnKSYaXwTi8UTpKWXSf1r3mcpOZq5LUFsrzLOaMNvLi5WQaeHh88nz49MEWP0h3kRXaTFSmeFzxBpqoafvOrv6Lrev74pz9RWc2r25eLwTOQ5wQRtLFURcmMZsgjbdPy4sUt8zxzOp8YxpHj+YSzskzJGZTR1GWFcy3eR/wUubrecvtyz9B7+s5z9/mBn376SALKpsQ4RWks61XNtm15enji8HDhw8dPzHHk17/+Na9fvibHQI6Jw1F4Wd99+5b9bktdr8VK7GRjUNYFKSduVnuM0Zz7mdlHhqFnnif+/Kf3qKx48/oVu92GT+8/cIyBmAf6eeC3v3tCK8Nuc01ZFn/Rc+EvHjw1VbEABTPKOL795tuF2bQixcTT/UdR45YNCjimidIVjLNst8OXBIXyskGJ4IqKNy8r+kEOOkVZ8vnxQNf3otu1S7cQ6Y23Tc2Lqz2TF3CkVRmnM01V4f2EVtCWDmP181DAlSV6lMuZNgJXezocCTGTgmfd1jSlXQZrmnn2uEq67Y/Hjq7vGS+dqFrDTFU6jCvBWoYQMWlakj2K7nwm+plpvhVOT7HYPlJa7FhRaPuLaakslm313INzVIuW+2a3lvj10BND4Ic//xG92Ai0VhAzZANGEebE+RiYJ7GkhRDpLhc5xBthbhRV8xypP58vnIeJZCZcPVG0AkI7Hicu5zOFhrqwaKPZbtYUi+2FFCDN6MJiXU1RZ8qsni9xRVmy2YCxUlmpSyfshij96NevXgoXyjnGcSJlMfehDFYtf5ZzTEkYEVI5Ghb4uBMLlpIDrc4KayLaaNqmBBRXfialRGmFu9LPA8F7lDIo40i6YIqJh4eHZUgKdVHy1e0t8zzxcH+PWb7ndVPRNLVUkvph+b2J8tcZGcIGH4je4+eRpmnZbBpUzpxPZ4auZ5xminGkH0V5fbXdMXQDx+OZmDKXS8c0DszTxBttaGrZsG3XjditchCbTM4UC5PBOCt1sSjq9JzEBIEzaAVzTEwhceqFI1E3K2HuKOkgy4VXNtpKjcwhMfvI4+MTxmjWbS0Hv6JE/YwAvWVdP3MEYoysV5JIRBmSksSGXNw9eInkuqIgIubAMA3CBXPumbPkrOPFzQ0+CvtEAfefPzOOIxnkebOAnf00oY1hu9vhhgFtJOFolOhljTYUhSMkMXWYZRObUuSLge7LPz4ELv1AzpLKstY+g+DneVpYFI0MDOaJcRgFXB2DbLH9TAiewZp/HXAVJRExyAlk1gh7CfhSQRmG4TnZ5KxjDlGYbYVdth0yHFmvF/1wykSS2DcNlIvR7wunRxuz1BQ8OSeIgTBnLnxhEUlVK8tfAZD+/+n4RFkU1E2D0pbVRmCl0zwxjgPd5Sy2tZRRRoxsriywRuQGMqjRBKXkORCEB9IY+TmmFEXNbYwArHOmcnaxV0piYuhlG2adwLFX7Qqj5ULofeB0OhJTZLcXuPg0XORSm1nSmHKY/WJhLYxaeANSYRp8WpKikRhmprFHaU1MamFUOcqi4MXNNTEmzpcLIHY8twCac4pMC9h59pIMqpuWqCFGz5g8wU8YI+bThMLn9Mx3GUdJy34ZbsfgmaeJse/py4uo5FOkrhuqsqJtG7a73TNjCqQOBgq7/K5RmbKqJNa/pNuUlsrePHuGcaRWZvncFuB6jAmING0rPJZplAqgFgbaPIu5bLVayes1Z3L++VRVAFatgLMlrZhZN3IWy0rh0xfbV2KYFouYBqsUo5PfQ0KhdcR4AaoqU1CozNo4YflUlqauRKCxxP61VuTomXPiGCM5RXZtyTwHpilgrVSeSqufF01ZQekM67paUs9p2ZwmGZCEyOHScx4njJLKsmvkf+uKgpAlhdKUCR8tOcH9ceDQzcQo9bVpliVBzEoqsMv7ZJxGYrTkdSl8lLpC+8i4pHu0kUP2lzNWzKPYhVTCKEXWCtBiGlZRElfI0E4pRVlKTd2ojLWashXmnFKLYTHLMOpwWd43CNfs+bPAWHyIjP1FzpCqXNKtwi6KSjElOM+RpDR1XcpAOfiFYSJnv4Q8943WwgkZJnIUFt4cEv0clmcKXG/X5E3L8TIKe3V5PwmLKGOVQivhY1mjsbpmDon7J2FFriorLK/sJVW15J6mILbhsqgwBgonHMIvAxOVM5lMiHLeXq3lvfvlZxOSWDmNNeQYSVHS787Kmb+ymhgzg4c5RvpJOIFV0zDOgSFM9HPk7iDDARnqTxzO8tk8+4geJ8R+manqitpD64W5NY8jOVjm2VBsWlxlnquCzi2cPmcpjRGr4FJdVEgyX2uxiCot6bHRw3mYuQwT1liis0vhHZqyoLCWbtUIV8ZWRBzdMDCFtCT7oC6lFVHYJTn3M/nab3fknDmfnhjHka+/fisJxLomknm4+yipvFGSUafzmaIsWe/25BwZRwHWKwnvQBLI99uv3tD1A0Ul7/c//OmPHI4nrILSlbSrHZOf6YaBzaZl/aqh6ydZulhLWTg2m1Y+A7V89mImtNWUZYErClLw+CSDC6U19w9PDMOINg5nDddX24XRZej7EYOiLAoe7x4ZhoGnhwwKrCm5vrrGupKUFcdLhx1HfJhJKcjykLwMrAyZSFYBrWWA1V06jNEUpQOV0cflc6Bd4wpLUdcUduTliwvzNDPNkub5+OEnWeKUi+04eZxz7NotRVGQorDl0JnZj9zdfYKsqNuaqiwoXInSBpEUZeYhQZL3VV2XbPZbhs5zvvRU54KmKTHacb1/QVu2mASVK3BOUxUVVgs+om3DwkGD1WqD0QZnC3KIrFYr2maNDxMheF7eXtHUBXVVo7Lm890dRj8SQqQsK26upRZ56Sameebz3T3TNPP6TYstNOPZPyfvFQqt8vL5IBbUmBI5JapC431gGGZCSEzjgDFwPB1lOT2mJUkqhvTbV3tmP3N394BWhrKsqJua1brlcuoY+gE/B4IX2ZUthKnX92c0mgFN1TasthtCDAzDKEgVH/FjLQBvNG1dUZZuSRVn/ChQ+4eceHnzguvdnnbV0K5rzJTxwWK1IcWAXVoTq6bFGUdZ1GgjbQkfAmUWnE7XjwtTMwrTVWmc0+QkIaKr3Vaq1qcDPggbNsyBlA3GarbbtcwZrCSv/5Kvv3jwtG5Ec3/pJjAFf/1Xf/N8YDifT3z+/AmfwKz2EjHtRJ3Y9RO2cFRNI/+imJ63+qum4evba7phoG5qYoJ3n+6Zp4G6tBSFAHhThnmeub3a85tffsfx0nF/PFMZRb3UuqZpxCyHspjEkOGco6xb+r5bTDqiFfx0/8BPn+749u1LXux3OJVZeJyM00zVrihKy/l84u7+nhgyOcPt1ZqmKsA1KOOeP+ST5JY5HZ8Yess4fotzBdWiX++HnkRmDBGLonIOTaIuC8iRPF5QuaS9vqVeIHzDNPH5MdN3Hb/953+kqmu+/e6XOGvIOYAxqATBRy7HaYFiSmS770cxAjYSXS3rZQDhLEk/cugGknaU1cC6qVg1FcfDE6fDE05DVRUYa7i62mKUXrZ4HhUUpt7g6hVF1kRtBeboR8qqoWkanBPN5L6tqKuSOUh9sK4afIj056Mk3M4C+by+2tE0Ndf7HU3TcPd0Ioae0/lC1124vbmmaVqmJEkIbSxZJRwSl96sGrnQkhcFc2CeJ/x4IYQodQBTkHXJOA388OGjbE52O9r1mr/7m7/leDzwcH+HNYbtfseqrlivV/SjRHmdlY1eUzqu1jU5LtHUvud0PPDq1rB9VXLuB56OF+ZpYBwGjDW4womN6+qarht4ejqJNeF04ul45nC50LY1t9db2rpkv1sxDyNhnp/V46IO1bhRqnIheLrLkRSWWP+qFcV8TAwh0k8DGrjWVjg1WlE6y6YR0F4/zs/a68kHDocjzhre/Jvf0NQ1y0zhZ/NVNythOfRnyLDfblHGoIx55nqEJFXIL4M96wrmKIdNwoQrSnRRS+rNz5TOcf3mDeM883QSUcH7n34SZtGyQdZGM88z3eXMdrvn6vqaqh9whdSRnZMDkDWGsizBSFWzqiqpOCVJDTnrlveVZfQBf7lQWeEaNW1DUZaEIOD/uq6prBWmVHdhnjw5ycXcOsvY9wt0lgU47ygqqVP5lIhKY7SlKB3GqAWSmbl0FzkYF5JImZaqW1VVAEzjiDGW3X6H92HZVEZiiNgMVSVDJ2PFjIQ2wu9AKhmkGR88w9DjCke9aMWTwKok/twPfPzwkfVmw7WxtG3Ler3heDxw6i7ovkflzDiMklAjY5VAvZumWepBillJnSwuTIKyrimccPhCjFRViTOWyc9yYa4K4bcoUAsHKnjP/uoKVxXcvnxFVZZ8/nzHpev4/Pkj0zzx4vYlZVlyOT7i5xlXVosCXDaVXwCYbNYCUlcGHwJmmJdaniekwNidQSnZkCupfjbtitevXtMPA4eTJK2+yCc0khjrF8B8ipHtds1+s8Ir4ZyEEPCzp2kathtDDBCW5FlYqod992ULXRG8ly2jO4uRMMqm/tYVrFdWOIVK4edJAMxKgPNKK6yypBggQ1W3kjrrz1KbWlhR4ywCB+1KSiPpQGsMQyeXy/V6Tc7CivCTcL2sKxinGWMNX718gTGa09MjMf58+HQA280KYBEYZHYrsdlFJZDey7Lo+HQ4oZSmXVJkpbVLVdguhcgkpqe2pdCK1izQ6CDV3ClkRh/lZ6ohBcecZuYIbam5Wdec+2mp5GvqQgxnVWGZQiCTqQqBvCotKaQ5yJLGB08MnmM/MUZ4e7Xmai1W4roqpUYXxY5sVGYMGh/hw8OFafbc7ldUhWOaR2JK+KTRSVAKKQYmH+VwniUB1zQtUwh0s2dYhk/WaNqmooqStFZAqQT8nJbaqUahdaA3IxnF4DPOatZNtbCcwFnFalUTYqKfAiFlUtbLUqDDGqgKw5fa7BceXz+KmXjTNtTOCoREZWJOJGUYAuQxkJRh1TRLXXmmsMJyTAjHqCgLrNb0w0B/uWCLUtiSIZIHGeQXFvabPVVZ8Onunksn1mPvE4mANlkWjFazqiT5U1WG0Se+//jAZRjZrPaUzsqAPi9q+fxFt67ZLcn7KkRyTlR2AWiHQEwQ0diiYLu/Yhgnvv9wT0qRqhQRjnMGSGQ/oo2hsK0kMZ1mzJljUsyTPBdWbc3tiytSNxG6wDh6Hk8dbeXYtwXjGOj6HtALey7g/fhshZ0D+JDwfmQaJialyUqzbUoKa3BGhk9N6aiKgmphlCUtghrhkWfqspJli5ak5zB55hB56kYxvxpFWFJUzhjWTYXWGj9v8DGiXINXmmN/ZJw8q1r+nO2mwhmFVZqfz9gJbq9vGceeP/7xX0g58etffYcrSqq24XK58OP7H5jnSI6lMILmXgYKt69k8JID1hkZJCuL1QXr9YrXr2+Fc9rUXC4X/ts//SMKjdWOuqrZbG84ny9cOs/V1TW/+fW33N8/8fH9Z9brlu12wzQNzOMgcqJVi5kN1muquqYsavwQyXE5DCvNx0/3zNPMt9+85sX1nqubK9rVShZmp46idjRFwZ8PT9x9vqdfeF5/9cvv2Fyt6Ud5VjweTkBmmkZi8nSXSFyg9UrJ4CkRlkpm5Hw4ilBlt8cWBrPA+nebLWVZUdYr5mYmTsIJenw4c7mc+OH731NWBd98+w0KhY8zZVVwvb8G1DMqQJnEMA6c7o60qw0vX76lco7SlSSViSrJ+bITk/PsO6rmlqsXV3z0DxxPDwKxLixWOV69eCNVwBQpqhJbNTRlTaEcTd2i0ExjwE+R3faK9XpNVZQkH9jtb6jrlq57ZJ46VH7FOM5YU0DS/PTTe6Z55s2bN2zWa96+ecNq1fDuwz2H45nHw5Gu63j99RuK2uAfJ+bZU7pi4ZZmrFVsNmthmLYFOWUcimEYuX94YvYz4zARk+fh8YGUMof7M2Co6hXbfctf/9tfcT5dOJxOaKVpWhk6bfdb5snTnS6EGLn7fM92t+Lt16+IaeZyPhJ9Js7w8tULXr1+yfl8ob/05BBJITJVDWMXqeuCelUugg1LjjD1nqfzkVN3Ybves95u2OzWbM4rqkHEVoWR85ZxBYUt2K4MqY7UVYsxJcPYEYJHIe2G07njcDgJ2qB0bDYrisJhVUksHPnmihQTD0/3cMj0Xc88zaRZquc33+2oyoJxCnyhZfwfff3Fg6ePd/fL/yXaW7dqyWTuHp8YhoFqtaNSirLdkGKkX/SwNzfXYvCZZ3IS3o/VilIrQvCczhdSSmyamskHumHCakVRyiXveHyk73vCPNAPHU/HE6fLhePhCG1DvV7JYOQLc8AU2IXzo60jZcU4zZy6jrZZsd8JhyVFwfA+HU+0VSnWJQAyD09PoBR1WfD69gWXfsLHQMwIdNl38melatmGVWxQbF+9kCj0AkytStmyK60xxvL6hdTD3r07M02RzWoFZJKCKRv6YVx4CGK82DQ1TVnQLrr7drHEFVb6lCElUtbohau1quQgrvRZtsZ1RcqKw9Mjq9WKm9UNu82aN69fs93uePHilqqQKoMrKnZ7eZC6okLPEfJEXsYfkw9y+LCiDTU5UxUFpIifesrVirKqZMM59Kgc6Qfp9GfgfOmYp4nL5cIcPE3dSIJj9gwoPt8/YosLd3cP9OMoXW8jsfl5mrg/HIgxsluvhLVQyQf64XSW7W+S7YIrK6wrePVKM80Tnx8OEGfe/fhH+ZmuxLLhCsc4DvzjP/5X5nl+hhmnGDhfLpzPYjTcbVeUrmC3WmGMJhtDUTluipqHnLi/94yz5zJOxJxlGFAWmN1Wknohc7z0TEHSA7cvrjmdzxwOTyil2a9XhJS5XzTQzjjO85nzuWN3JYmXvu+Y/SwbV2PQShgK/SSbzIfjkZQi3bL5rrSwgj59+ghKCQdr2ZCGGHl4+Iwzcphdr1Y4Y7FGkxLyvfRS6fu5fJ0Oj89JE2sM1WK6OJ7PcjEPwkyxRuCo5ETpHPvdRsxsp4Ubk2RrLEBtxRjEcuisgWwJy8RfabPAgCV1lzOEpc42L7Uj2cDItt0by9D3UgE0ZmHTCVB+/sKxq0qatlm+B8vYd/h5ousHhlHEDkZrur6X77Uo2dpikT+EpRIqm9ovl3atNUXMmCTgem00Q98zj6Ooswu7cKcU281GzBWPj1KNbRph5HVSoZYBlCRyNFLLAJ5Nk5q8gGcjMUV8XJJXfU9ZOK6urvBz4NxdngcYkly6UJQldbOS1+t6TVVJ2iAt5iYA+8Wmt9gttVnSVUakGPMs7CGrNKRE8rK500b+finJECpFseIZrfliUAshLmwEj1neFmZJmaUYub/7jELxcDgyTRNai9kux0SYZ1F1x0i1JG6/ALf1soD5wvVCSyVqs14RQsVUFoTgZehnDO1q/Qz0DvPIhw8fiEtSVyF2rHGc+OwfmGbhIVZlIRvchY1Izux3O7pLx2Pfk5Nsmr33z59Z692acRwY+o4YBJ7vrOV6f4V1DjH5LTanYeSoJcVZlCXjNDKMI3YRGYhhMC51TNnqk5PE+vsOcxa2Sd/JYchohTWa80mMP0ZJziIs1sRh6OX5bb/Ay5NwqlIm5cgcBRz7c/q6P3bCX1uSrXUpANNzL0MYa4Qfd71dk5MMO5w1bFuxKI5eTDmrUngpbhkgBC+206IQe+Y4Dvh5ImcBxk8+4qNwalTWGCzdONPPHmMLmmUAeemFPUhOGCVGprywe6aUmUNmVVeU25ZuksRMU1h5/cwzMUsKJ8TEOAxE76maltY5UqzwwQp7aZIkltKWyUeiRJkoipJ1WWCtYY6RNGXawtAUhpCRS1pTAJnHUy+fw9e750RdyFA4WUKEJQW0XbeAwi0igcJKYvML3H6YPD5ELqNfhsgFXmV8NKAyIUpNd46RwirqwmCtplmtcaUjG7FTFlYTs0LPEaPAqUxQIisQm51a0tWBonTPDI0QM1NIjCFR6oAjk51IVtTC2Bpnjw+JYU7MUV4HMcsly+bMauEUnfuJSz9xGiNzSNSFo3SWpqpxRi8mQjlfKSUX82fL5gLlBuTZqxTWGakHe+FPfbx/IoZAWznAisVTaU6XXs6LaHJWcp71S+0aJYk4oxcTsqROC51Zl4phVni/JPqyDPfMstiwX4xWgE+aNMq5yBhFCJqMCCWcs8wR7ruZiGJVSYVpGGfqshAbrYeIwkd5jolIQnE894xzeLZuEeMze0VrLRbokLCFqMeHhanWzkHei5WjXFJ4orSXzwC5J/3//BHzf9rXH/7wO3JOKCVJ+tV6RcqZj+8/MYwD1pS4WtM2e2IInE4P1HXNy5eC7+gv/fL8TxQO6sUQfjidCDFQ1AWNarlexCvjMDDPE8fDga7vGIaO4+nE3f0Tx6cjl0snbZSqJCcwtiJNnZwPrKMsSzG8Lczeru9YrWq2uxatZGkW5omhnzgdO+Y5PZ8TulHG+6v1lrKq6ZYFktaGaZrEAJ8TcUlRFpWhpeL66gVVVfF0fOTSnaiqgrouUQs39vpaUmPv3n3E+5ndVnib9w/3WGfZX98I0HqWJeFq3VBVlrr+G5SGshHDbF03WC1nzZQSo/c4Z3hxe8vlcmaaRqzWRO/p5onudKDdrLm+vWXeJrb7M0VlqFeO1XoNSUtDonK4wqKsJk1hub8GcvaUqgKlUaUsSsdZ2Hry+SIJrLIoBMcTeqZ4h3UHSBM5ebquZxxmZn+UJOmSOFVkYgq8//gZYy0fP97TdYMsLtbCN+pT4nQ64r3H7XZYI1b5GAXyr7VZQiXLWdwavv32G6Zp5v7ugRgjjw8njLFsdlu0lsFnTonf//OfF9GEnI998DwdDpz/W0eYvQwyrRjliqpCu5L1Zsd33yoeH4+8+/EjwzwxjAMxBeFi11LfVdpyPh/pBo05abLWvPn6LdPoOZ5PGG252l3RXTp+/8c/MowD69WKz93I+TLQrhqaXDJOE/MstjtXFAtn1HN//8D5cqF0JVppDoeDcEbbkpw19/ePgnApChSK07mXxL6e5bOuLHG2IKFxhZDMQ1L0/fR8Hv8/+vqLB0/vPnwUG8p6DXVNYTWzD3z4fE+MiWZ7LcOPphLAsVW0dc2rl7fSbXz/kRilcpaNoXJaflnHI3VZsl+39MPI0PeyrStrAWA/CUTOjyPd5cLD04HT+cTT4QlnbthuN2StQWcwDpU11lm5aBm7GCRmjqczt9cvePvmNSpOEAN/+nDP56cn8m4PyqC0QpHlF+Fnvn71ivXNNXfHE/04MZwvTOOMysJDIQmMrqpqmrrhV9+8pnCaf/nd75imme+++ZqyKCgrSSV88/qWEBP//Ic/8f/m7r96bUuyNEtsmFpy66OudBEiRbWqBp/450mAQINkE0RXZVVlZuhwv+5XHLXlkrbMjA9z3ZP5QjIe+qV9AwFkREa4Xz9n77XN5vy+Mfre82q7kofopWeKidTIoWgcRf27WVTYLKNabkQxem5QCrLc4v3E+dyIaS3LqMqcN1dLzm3PkDTaWFxR0DcN+4cHrFbUxVuuNhumd+/Z7na8evOGrmm4nI7kRcnV9Y28qYoc03uYDwQJGMaJfpxwWpGriMlrXFZADAx9y2q1pqxqzqcDXddK4kdrjJPB2/7pga5tOLU9PkTevHI45xjGgWma6Kd7EoovX74wDgO7qzV5XvF1M3D/8SN+8tS/+p7MWcpSwNBPj1+IMcgAxTmyUoZzV1dr0dO3DZem5a9/+h15UfCbX/0KY62wBZqWP//hX3EuY3d1LRfQucr00+cv1FXBu1c3VHnBdrHAh0TrJ4rMUZcFfd8zeE/bD5y7HmusXNzqku2q5ulw5v7pSDecmfYHtuslb17d0jQXnp6fuL66ZrdZMQX4/HySg5V1ss07XnjtJ9CaS3Pmcj6x212TuXoGMgsr4dR07B8+03ctRS2qWFcJkPfn+3sG7/nuu+8oypJLPzJ6j/rySap3yw1VWVIWFUolppjw/cjz4Yiffjl1lf3zI85JMiXLcuqqoh8Gjscjkx9RwWOspayXJK1IYaLIM652O+HbXM4ApCAK66womEKgG0ZU+jp4Snj3FeIsxrOxmWPiyBa46zqG2VBHhBRmE5C1tE3Dcf/EYrmkXixnxXNk6Hv6vufmdsl6I/peayyfPn+k61rZqoXIclGT5xljJ/9+d31DUZQ0zUUUzn4ghvBS83JZhtKGfD44V1WF1orD4URKiVevXkm1EEkK3N29IsTAjx8/M4WJ66srYgg8fP4ZpXgZbg4KSQ8YGQAVM8eoPe3RSipgIUS6fmQcB87nM7vdlpubW4kne4FRD0PP5Ef6rmOxXFOVYmJab9ZyAUQGH9M0QVLzIEKe+Xoe3mlj0ca+8JKMdRIdj4Hgh5eDHcjQZhwHhmHEaOEC5mWFnSsyg5+Iw4gOCadk8CSD6sCXz58YhpFj0xFiYrtavIDs/RgYvRexg5aD2jCMUrvTGq3FIqi0Fuik1qzXq9lKJtbB+y/3WGvZ7YRPMAw9fuj58OGIc47VnDb6ynm6NI3UJV1GVZVc77bChjoeKcuK66triJH7+5EUo1QM5xrdoq65vtqx3+/p2oZpGhnHSJHnrBbXDF40wF+z8m3bMnpJTuVFSTgcaNqOvCjJMjm8e+9ns2Y+1zIjp5N8h39tCxO8XFq1whnN49MzwzCyXq+x1srlO0xcYsDMvDRjtKSmEOV0SnIZD+GXNXi6fz5jjWa7KCgyy3ZRMPqRzw9PJKCuFzinqEpJPp7bnjyzXK0qhmmi2zcYrVnXUl+MMTCFwDiMqDwjyyr6PtB3DeM4kWbIdOcDo5/EFDcZUrA0vafpPUUeUVqMqn3viQmICpuJoUyqcPI2GafI3W7JzXZBP4gZre+9VBv6nn5U83Mx0DYd0xR4t1iKqc7CNE08Hw7044jLSmHW+Ql8QBlLnmtudiucNVyaltFPXC9ynDVMxmKMZlcZvJ/48csepRS//eY1WsMPn56IMUoCCRjVNENwc7m0mblwPA8c4sxTa/qBcQqcOhlSrBclWkM/BXkuRXlmtL2nyjSFdljjqNcrrFagwTpLmWf4kGjUiNOSwILE9LUaQmL0E+Oc6MqMeQG1D1Oi87JA1VETs4JkLVpLerIdRmKQ+t0wQTunygoUWUoy1LGW/bmhHyVBNIXIq+stZZGzrOT9wlHS5iipLJZZhUIRpxnIHOWcorRBW0OVSZLO9Z528Pzw5RGj4G4t/KKoFNMU2Z8aUlLSE0SqmdEnTpOnyDLWy3rmvRlIAn7PdWJVKEiKczePbZJUwDNnyfOcsirngWnEjxPtMBBjwFiF8lJZzZyjLh19SDSnEYNiWeWcmoG2H9ltVsLZBCIj0zBLIxKA5unYcDg3FM7K7zNOZFp+pkYbLt3IFCN5Lu+ndgyMPrIYPZk1rEpHzA3ntkchw3MUNL1/kW/8El7/8i//TJ7nvH//nqKoWa2XtG3Hzx8+MnpPUYoY6vWrN4zjAGqkXtS8eXvLOEx8mfaMfqAbG5xVVFXJFCaeDnv5/JQ5Nsso8xXn85F+6BjGgefnJ/qhp+kuHA7yvmjODefTGW0NWZmTuZzClcTU0g8Dm2LNarl6aRX0fcf5cuGbb95we3fFdnNFXS35b//0X/jw40+EqHHtQJaJTKXpJ6Yp8u7daxbLmq4d8KPnuJfqnfdiAg6ZoAbywuJyza9/8y1FXvC7f/0dfhz5x3/8O5G5aEeWZ/z2179iGAb+8z/9C0Pf8w//8B0xBP7bv/wBpUA7AMUwjiilWa5qMrdmsfiOcRp43D/gbMZ2fc00jhyen/DTRDMO7LZbXr95zeG54PC8FxnONNC3HafDgTfmG75fbQlTpGlOlHXBarPEYOR5byxFleFyGTwFIuM0EsJACCNJGRQZZmWkrtxblFFzw8BTFksWVcHz8Ymmu+CPR2KKkgR0hvO5oetGjsc94zhyc3dDVVcoJUnXH376KMv3+z1+HNlsCjJXiOCpbTjsn5mmic26Qs0LqoQMl/X8XIFEUgHnMn796/cyqLKG4/HMn//8E2VZ8u7de5y1xAm6ruNf/un3GGtYbteQFH4a2R9aPn66Z71c8qtvv6Ouc7ZXC6ao6INmXVS8vrvjj3/6K7//0480Q0/TdxATmXOsVwt2V1ue90fhPMeID5Hd1Zb3v/qWH/78gc+fH7i9ueNqd83h/MjPnz9ws7tms1rx6dMDh2PD9mpJYqLrIiEorq5L8qoEFfFBbN33948C40ugrYgwUqxIUfH5yyN9P7LbyNnrdG4JMTB5CSss1ldY52QxaDQoyxSgaTq8/9/Zanc7X8y1VqiU2J8vTFGi0clBXdj5sC+bI60U0yT8mGny2Cjb5KHrUUWJWUrcb0qRbhilWmQM6/XmpeYjjItJtrHDgJuhh0bL9JQ5zeS9QDLD/MDIg0NlshUbfUSnyG69YQqBx+c9moBKkVPT0jQdKkJzuczgUyfTaOdeepd93xGmwHK1ern0KJi7/YlpttcNQ49KjqyoUDYnaseEhplj8vOnL4Qo/XijFc97+aAv53/m5tLgvadtO9lMWitmta6ZN/KyjewGsS0FP8wmjMCoAqezQlnHuzev8X6i7Vv6KF+8x9OJz59+5tL27I9nseF1LW3XcmxaYYHM5iHvB+ENvX/L6dxwvoixbhg6+iynLMCOA3ae1Nb1kn70jE97lpUYjdpGtgjnRrZaeV5KT9ec6Mfhpdb09u6WqijYNz3jFLi5vkIrxaW50HcD28UKrQ15vSANI1PSDD5iZuBz23aSxDIO6yM+XsgzR71bkmc5i+VagOVaBl15nsl7FD2nJL5nHEeOlwvGeWos4zCgU8DMZINxCjydhakUgidFAeQqBYsyx1mF9wNGKazJaduWy+UkVqogHeMxTPRDRtsXFHnB65srUJrT6cx2s2FV1XMdQVHVFVsvww+N4ma35Wq9pBkmTpdm5gCIEdBo+P6770QJP/N4hq4hhsDf//a3GGMZw0SMid16SUxJ2FIpkYcgHIKqwBrLerlgioEvz4df1OFne303Q1wFHjgdj4QQKasaUokliuRMUNiU8+DieDgINyzPCTHQXiRJOIXwApSd4sTkR7GmWbnsF1UlCZlhABIqpRe1/NcKmJgGJYkTo1S8tHUC7bWOfhho207qpOs1Sik5vIxiGLmcz1wuF5IStWqY06RKGzSa9nJmaJs5cShCAqwhzpUYI35ihmEkxsBms8E5J+nSaaJpLvI8n7kdj4+PxBTJnLDOLjNXaHt1Laat82VOlclWyfsJpQN6Vk5jZNh7Pl9QWqxpioxYC7D2dBKzS1kvhM2mDYPSDKMnIRul0XupxuU5eV4Qpon906PUw4Js1xPMqaEVIQbC5MVORwI7grbYLGO1Xr9cgtvmgh9HFssVy8UC76Uu1rYNkxem0mK55KvBLUwTgURSCrSlG0b6rme5XGKMJU0j3o/z96UGrUnRvPwZ48xNartu/u9IKsO57MWMKVxDSWLurq+xxpKVFSSp5ugQ57+ubPVQMuxLCen2W0uWZaQEx7MwpoSpJ/VJYx3r7dXLttEYI/+MSnE8n/EhkBelpMC8JyR5DhrrWGSZsOy6niLPKIuMyY+MQ49KibqqKPP8pUYao1Suur7HnE/0vZM6qzGUtTx7vnI8Yoz0fcdqUZGqUg5ffhCujRWoqGeUrXSSlNvXS1uK6eW98Et63WyXKCDTCVLg1LSMo1gqtdZkM0t9nCSV7IxwtYJ2RCUcopQi4zQPNcLEFCNjUExDIMaz1KmUIcs0u/kMpDXozGBMidPz+9QYrLFMMQnTRoHVWs4NM8/NGrh0E+0gn90yM4x+Yn9uRa8dI4dLS9sNzLpQrFZoJVB9pRTj6GlNT9P2+EnMu0WegzazBlNSg1+lICHUYkBLwoi7DAHtE2ipKzNZQhTuZ0rw8fE0Vy9kvHNuuvmnLd8BPsoZVmV2TmzGl4STPGMUKSbhs5E4twNKQZ0ZlJLkz6UduHQjSUni3Qfou5Eql5q1nyaeRzE+qpmHN02aqsjZbgq6bqDtJdUW40Q3jEQlbECtFHVmiMuSfpg4D4F6Lba10Ytdaxhl0OScFfabNbNxMzBNkuAPKMaQGIOkwUGWJLENrKoCrRTdGOiGCWUmrEnEUUC+2neSeA9iZyonJUtBV89Q+0CIiWVdYJSiyMQ0NaFABcoQmGJimJXi0zRJNdQaQVP4Ub4no1gOSycD+iwvyKOmzAO5E1aUm+uIo584Px1ASeUuBql4prlaZ11GrS0+BJ7OA3VtKMuMOCkiajYXaiLy548poueUW4yJKQSm4CmLgqQNdWZwRs7gIBcxpeFmt5Q691w1XRaGyQqncPjKotXy2QDEypyg7Ydf1PPr1Zu7OaUvqdqHL3u8n6irBVVKVFU5L8EETZBnOcTE/ecvKAx5Lga3rmc2vYkd1/cD0+AZ22HGmpTUi5JX9hajDdZmDENH2WUURY1cdTUJ4RUOfc/Q9ZzTka77yjMElFSuzpcL2ih22xWkxOl4IU6KS97yuN+zP53I+h7rHKt1TVHmGGXQ1tGcL4x9xziKYU0bKOqcIokFtK43KKX58vDMOAaIYJShnG3Xp9NF6mUuxzrHn9JfCCFQlsKMPB07lII3r2UZeDyc5xS0mIBDyBmSZzw+k1JEY5h85OHhmRQDKYq5rcyEm3TaH4gh8PrNK2aJJWGK+Ji4NA1fPn1kv3/m85fPMyR8Tdf2NKeWruvxg6fvBqxtKcuczWbF/nDkcBCsSNd3HM8HUBMhRgrncE5hHRyOTzw/B9a7FXebO46nE33XczqdmcaRqtqw2i5fJD+XpqUbera7Ldpp2qal6waudquZtXVmHAOrhZv5qBkxwNDLss9lGUolhsMB1NeFpabMc5Q1GA1BCbPZWsfNzTVFWbBciGTiNB7RNnF794pxHNg/Pc2SHWH15VmGyxxJRbpxYHwQbEee1fK9MkGWZ7y6vWG1WuJMDjqSjJhmH59OdF1HSBOgccbih4Hj8x5nDXevb4khcP/wmcWi4N3rt5DiPCPwGJOkBqwcu+sNeVbRdh37/QHBL0m1fFFVXO22FGXxUu1VSSYvv/7+O0mht508k62whZvzkWH0VOs0p3wN9qvBOsoyeRj+dx48vbq5kb95cyHEyPPpLJHuTPTIi8IIAFWLYeir2vjx6RlNxOJlkno5YFXCuNditRxHhnGkv5xZrze8u7mbBzMQk2ZKijhNTOPIOHn6cUAbLTWvBG03D57GiRh64tSjY4aNTibcTUtVVlxvN3R+4uH5WQ4cSiBvl0tD37YC0doKbyjPC3KX0bYdl9gQolg9Vte3VHWNRrar58uFft7oej8y9B2aJJvypEgmwycN04D3Iz/+/ElsBMhB6+HxmTzLePvuDaA4nDs6Hzm3rYDbqwVxioRweamCTHNaQJGETaUVOnh88hyVmJ2+efeOy/nEp48XSBPtMKKOR0ya6Hzg3E8URc7YtTRNw/7czJWjwKATViW+efuGb9+946ePX+j7gbaZ6NqOvlzQT5CnAaYgKbfFiufTmUt34mr7HXe313z6/IlhHDk3DU0/8v3bt2yWC4Fjtg3HS0sTO75//47lasHnvaTKvn/7G6qy4L/+y7/QzcyaPM8p6hVB90xRCTwytFIva2Xoh84wNtAPk1jsrteYPGex2pCVnqxaCkQwd2LH0w5tDFe3dzw/7/nx0xeUGRhVDmHEpIBOsnUc/MSh6dFpwjEKhC2v0Eq2ZM5oxmEgswId3B9OPDzcU2SOKs8IfpLecJ/TuJEiz3l7e8OX5wNP+yNXmyXrKucyQKcSi0WNUZoiF93w9dUVZZHzL3/6gdPlRG6FRxCmCavgN7/6FTdXOxk2DD1//uEHur7nP/z937Narvinf/5nTpcLN1sZYPzwJTKMnnLyGJWo5/f8erNj9J6Y/or/BWnJtzevxR52OjB4iTxrralqqU8WVmoD56YFmC+1sD8cMNZQlyVD33G8nNDGUc4Hbac1YZJevbWWspCEyXa7oxsG1PkiX0pp1lHPg6evBK0YIYaBceiYYkLbTKqszgmrrTmz212zWm8Yx56ubV5i3afTifP5hCsqjMsFUDsPnoyG5iKig6KqsS6bIZxGJLJJ6jlJaYZBEodZllGVJZeThTjRXIQXs1iuSMD9w4PEb60lmcjpfMJay93dKybv+fNf/kxKie12I2kd7+e6Q5Q0j7FMXqrVWebYbNbypeUEfn86nciynGqxYvLC/omA6sQW9HXoNI6jgByLksNhz9PjPdpYjHVSvYuB1XLJerXmcj7R9B1TjISYUNaBtlRFRlHXpOMRP020lzOn04ndbsfNzTWn85mu63h8fOR8OvHm7XsWqzVj3xEmTzt5uQyiSdrS9iNd13H7+g1VWXL/+ZMwZBTzRsgQlYBvhSkGMSb6+cCrlIDG83wizzKWCzF1DsNIAm5uboWBkhfEr0M2G7HO0Xcdz09PoBRZUWGtocznAVaei2b5dMYZQ5FncvjxHm0dm901KYoOOLOWuizxIXA4nrFW0moozRTFZxGnwCLPWVSlLBaGHr1eURY5h8OBy/mCc2LRK8tiHvJL/fTh8Ymu74U9oOdnlzGslwuqokQZMbCdTkf6ceDm6grnHJ/uH/CDWPZQcD4dZxaBGHryXFg4acbdTTEyhV/Oswvg1W4lAO22wU+Bw7mXz8M4kjmLMwDpBS6ezSKSqBxRyfsrJbHOxRQZgidGhY8a5Sf6ppGkYObIrWFZOIE0j56kDFluUTGgYsBoqSRMIXFqR6pMLt9TTPST6OozDee24/nUsllWLOtCklHjzPQCnk8Nx0v3Uttc1wWFs5I6V5phrr/vLy3jFHh3s6EucxmKxEgYOnz0DL1Amqcw4ZKekzGR8xBIRGwKKAX9kJGUwriMKQQ+3B9xRvHmekEi8nwRYYN8RhQ+RLSRFI9R4AiM48jz/ogyhrKU9E4xb/mPbU+VWa4WBcZYrBPWaEgn4TwZR/QTfT+Q6wxXWS6D59B6DBGn4mwGDuzWBXe3V3x63HPqemFAxYluGOinSJ1bSmeoc0tmKn4eL5z7kTdaRDE+TPhREmt+CmwXwiUyg2X0gfP5LDxMEKj5FBmnxO12QWYNnx+f6EJApYBWlmaYaDoxzlkd8EmSkmnsSDEyRqkMr6ZAlWfsVsJzHedq32qG4+f2a0JJo1XA5lJH6/w0V4UGMudYOUE0dOPIFBLjmKhyS26lHp5bh49QZeNsyJTkapY5LscLX54PuCwjy3JU9BA9yhZgrZgBC8XD8cL+3JPlOVurGKIihJmHZiAp6P2Emc/YIM/saZrwXsm5tKxZloK+MAlIiXPbCPvuaoVzGT99emAYPctCjFyfni9MIVJlK4yROiiItMlPgaYfflFnrzfvXxNDpD8P+MHz5dMToFhWS6w1VItKLspGo6IMnibv+fzxI2VRc/fqLSiR7EQ/zYOnSexlU2LykXpZUS9K8qJkt5M6elIGP3T0bUHEEnGAhpRmXmErApahR2FQSkQFaEXT9Tw/H9iuF2yu1vS953g4CUDcWO6fnng8Hsi0xWqNNknSkVmNtZbLSfiFKQmjdXW1JMsLMqvntO6OGDXB/5m+8RCUDJ6qGmUMh9NFFsKF8GufHvagoKpKYsw5Hhucs3z3q7cM48B/+k//FT9OZFlB5pIMjVKgGQWMvSgWjOPE4/MT1sBqaTHaUWYVOikOT3uquuTd2zeM48TpJPiGMSTOl4ZPP//M8/6ZT58/khcOow1d0/Px53vh1JHmCn3i3fsV33z7Dv2jpWk9fhwYhhatA4NvWS2WVGVFlmlclnh8fOLwfOB/vvufefX2tRyNp8Tnw0cOhwO//YcbVldXcw3f8PnxM6Mf+O7X32GcoW0aLpeO796/oa5rfv+HjmHoZhmEQMv9mOg6zzRFSm1QKnI5NaSUKKulcCxdBcxpUQ0kZPB0dyvpz8WC0Q88HTuczbm9ecf++Yk//en3Yn+OAh3f7q6FF6pE9nHZDyzKmrurkqgS3gii5u2rV4J+MAVKRUBSwPtDR2IkJo/RGVZbxn6kaxuqxYLXb1/x048/8fn+M/+4+zu+efee+/tPPD8/EYPHWuZKuOPq5obd9pp/+Zd/5fl5jzJqPmsqFlXF9796z+5qSwoyaPz5w2f6fuA3v/k1dV3xu9//mfPlwsLqGdHyyDh6bpIMnqqywFoji4Ix0naevh/+pufC3zx4uszskKJaEGLkeBZ4Vpg3+EMr21yflBhLjMI4R1EvCdNIdz4Ie+fmjrKuWVSl1A/ShI6a0TnaoeeHDx8octGUCgF/SdSJKSmCn5j6jswY6vWaKSYmP4iGMAS6rqdvL9RFzlhknNueSzfSjhF97gQsmWeznjuxWi7JsoJlVcg2BjkXrdZL8jxnGDw+RLrLGe89z/s9h/OF3Mov8Ksla7us0Woh3d48x5Sy1evalt57zpczKUXqegEo2kYGPUUmg4qnh0dCjOyfnknAbrMR7sZsiqlLgYlGDDGNhKnFOUO9Wr3YiyBhVGTyA89Pj6IE1zLtv9lt+CrDUyhyo4h+4Hh8xk8IMyUESefMcOWfP33h8/0jXdfTdsJDWSxWxJQ4X86YRUlZlXDxTNMomydT8fj4xHH/DFFSITdXO26Ng+A5HPfU9YLlasW6l0PLcrHAzQeKlBJfnp7InJVkQl7w008/SZ+37ymN5vXNjiLL5HcyehbLFSFEnE6QJsYpMbUT//qHPwnIt6iIMRGDJ0VhAygUMcmGSiFcluvNSi6EweOsZXn3ioRif24ospzdailMnfOEGjz2ciBMI0VZY63DGdly+iCX3IBAc40xLFxGrRcEZWj6nlWVs1wvpSOrDX4Y+PDzz1jnMNZKoql0xMnTXE50zQlFYhpHVoVDz5UhlxVy4bQGomwXp4h0qpWet3MTy0WNc5b1ZotSmqdTi1GKalHjrGHwE6O/cDqKjasucsrM/X95Evwf73V4ehAo88xgGGebxdh3wofRwvG5XBps5qjrpYyG5gFVAtlsba5m3bMkT4iBNCjoRXs/+gBdB2qPdRnbzeYltfn1cyV2NzHsDX0nicmv75koQ4Gh7wXk3HXow55hHF7YAzHK8EpqVAsW6w1FWcoBSGuyPBMwuR8YZlhEjGK6JH3NBCmwOcZY1us1IIfrEKa5piYXlBglpaLUnFpKYjVSQJbJAaRpLkx+kp78fKkU+518AeZz6mact7guEzYP83/fzsPaqihIQN+1eC+DHFJiObOl+q6TqmCWvXTqAfIsl8F0WSIjPUXbtjRNKwY/L0laNX/OUoioWECek1KSNNNqPYOqBz5//kxCZBLL5YqikGrPOAw4a8mdxWVSwVjU1axkl/rrOMhgxWUy+OmHATVXKzJr2W42GGPoB9GWxyAHlsxZEom+F+4VT/8mwlBakkykRHs5zTDl8PJzts6xXG/FJJjSfBCwpCQKd2MMi7nu2LXNvzEsUoQkf63Jewhz4iLIZTVZg3IWoxV1VeLH8SWdFxO4LKderPBT5Hl/JKVEUVbkRSGq3iwDbed6fZD3aJbTt5KEBYUxjryoyKuSrvvKQ0uoOZmQ5blAxq0TRgGwqBfyOZqHa2GamKYkjIKYqPIM/kal7/9RXl3fQpLv75AkcRfnhGTSmq73wtHsRowxrBcLMW71wvCq82xOyUSc1SyqmpgUU5Q6Z9vMyumo8FOiGSbyzLLbVkQUMan5uTRQG0NRZPNFOaLnqpO8LxMBQ9AZSXnQjqYbGYaBuqwoCvnMpZSoMgt1TjWDU+NsPa6KXNLEWrxgVS7DMJVg8pNUkWLAKYUyjtdXGwB2iwpnDWEcgTAnQBOHXrAIu3UmZ7ZeUuNlJomTrp8TpzNXZ0pyBrSz/GG9qIghcLkM+CCJAuccq9my2A891jo2dYnRiinAOHl8Nwqr0qiZdzkQk6YuM7LMkbRF6YjRE7nLqTJJQHWj5/PziUM70nQ9Td+LpCGAShGmSZauNkOHiImBq82KxWLF4AM/fn6iyCyls6QwMc7J6GFILIocU2lM7PE+sa1LqqricJBn+KlpJXWIVIGeTs2sYS+oipzbdTlXirzUIjuxly5m8/Q0BZre8+nxIOIhKwbi0Q9EoJ1mbp4VTlyYEyZFZvCTmFflu0YSBBqpAla5hRQ5t+P8XJRK7ZQUmTLCZ02Jrh8IKcrQyVlyN/OukiGiiWnCKklOLsp8vgZEDqfLnJBSLwzV3Cicing/SZJPK/LM0g4D3TjgslqWHVMQ2dpsWOwGSZv5vsOkQGE1JndYLfZF54z8vYyF2fYZYqQZRmJKbNbLr7PZX8Sra6b53JCISPI1pYRXoLyi6ztJ904TSiWci1inqcod2lqGcUApxc3NDdYZyhnlUnQF4zDRnnsmP/Hl4xey3FHXBfViweZqi3fgNHTDRNN2VFXGon5FP3S0rciNtLIMgyQ1tNEkNXE67DkdT4zDwP6QzffGHBLEKbJdX5G7iuWyoCikyp8UrDdLirxkv0/0PfN3X+R4OINK1MVsuR2Effnu7VtISYxkTokVzir6RkIb+/0zJFgsF2itOXaXueoJU0zcf3lgGMRGDrBaVmiTuHQXrNVs1hv5vE1qTp+DsRpjM7SWVKExmqwQHErTdJK8C5E8y3l9dze3SnpAsVoJ5uBwPDBOI0UpaR1UwBqZ1v704SMffv5I3410vdxLSXAKI80FNJKKN8ZSFDXr1RKjEk8PT1wuLdMozajd1Y71doNKgdP+ibIsqKuSxUasydvtijw35E4zGknkH08nQBbHDw8HFOCsY7PO+eb7VzKYbhq8nwhVggh5Jsmo5/0edYDHp3vhxVlLaS0JQSrcP9wT4kSa5H3cDxeSClxfX9EPA5e2oVpU3NzeoBQ05xbjLJvVUrAGj5/Ii4zFakHbd3RDS0xRzmoqkVRkHEeGoSHLDEWRk2cVRV5xaRouF7FSZ86y221xVs5WHz58ZBxbUHB9c8P26oa8sIQwcv/pI4enZ4L3LJZLvB8JUdKGWinKuiYvCi7HM0M/SONmPt8lpajrSszxi5qYEqeDpAONVsQwMY6BcZz4/PAwL68j1v1tI6W/efB0blucdSzWOwEyHkW56ifhV/heeoCjnyjzjHc3O4pMoFxD19Ecj2Qu42q7lQNlWUhFxfekOHNO+p4v9/csFjW3N1fstOZ6txOqflR0BKaho1ou2a5XnJqW/en8cghqup7jSd5Y3nsu3UgzePwkXKFvXt+wXtbS80wyeFotFbe7DYuq5HA80PU9m9WSqqpo+knYA0NP8CPP+z0+ROrCYY0WxpNS3Gx3lEXBYrHCZjm1UUzBczk8014u3D8+ExK8mhkex/MZlRLblaRmnh8eGfzE8/5AURR88+YVoHg+nkBpsqyYt7mKKQRR7DpLvVzhx5F+GAEwKhHGnv3TA0lbkskoysTNbsMwjrSNRDQzqwjTINDlvKYolujoMUHRDSNtCHz8/IVPXx4oi5yyyFmv16xWK4Zh4HQ+s6gKjCtJnGQAk+UY4/jp55/Z7/e8vtmxXi64e3VFvVrxlz//kePxwPff/1rqlFMPKbKoFmIcnDcO94+PYmiqlzhj+OnHP+OHntVGwOdvbuRn/XEa6YCFWhJiIPYNIU50ITL6kQ8/3pNnOb/+9W/RRhPnLVKXpCgZpkQKnjCc0FpzvV0x+sDh1FC4jNvbO85tx4ePX9htDLv1ivOlYX84kwaPigeiMhTVYgaqytZkigIrjQi7wFhDUVSUVcXTueN8admul2x2V2igMJpPDw98/LznardjvVqRGUVeZoQw0lwGTmdJ1t1dbVnVNcHkRG1fALvCGPq3wZNot41UKoJnuaipqpLN7gaUZvHlHkWimlWmzUW+ZJ/uP6GAN2/evFz0fgmv/fOjMHK2W4zWpCTDm3H4SvGUNMr5cqGsKlyeA2IGU1o2OcY6lptS6kF5TghiT5TBu2xDRx/woacfRna7K17dichgHAfGuS6cZRllnnE6HRn6dq7ZycM+Jhk89b30yLu2ZfKey+XC9c0NeV6Ixn5mNVX1gt12y2IhMOgQPHVZkjlH316EfwTC+bjIv7eZsJBcIcyhzXr9EoX/CsKUOopE2qeul+TOfBgOIWC0ZrUSsUIzf5ELs0gxT/VnXo+wNEJMDF6oJc4JBJ0kSSgzJ3PqxYJh6DnuD5KO6DrRKi9XdF3H8bB/McIpLXxBpQT0Xtcly+WSwQe6ceJ0PHI8HDBGY43IH7JMMQ49Y9+/VK1jkmrFYrmirGqOxwPP+z3LxYI8L1gu1xijuTQtwzBSLoWjVVmHMjIs00qxqCu0QtIXCHNHa0PXS6Ipc47MObabDdZajqejVKVmGGhdFQKLPkvlqRmkTnh3e4edzWSTH2kup5f3ovCiHMY5lpstYfL0XSOpBGsZR8/lfKGuK662G7q24djI8LGqF8I2iGFOE3uCnpgmsaSFECAYdBTtdV4WXGKg78M8eErz4GlJ07YcLy3rxYK6qsiriiwrUEpOyH7qmaZJBk/W8aXvGOeqn/DSJDlwaRqGcZDLgJbaYZYXVFU919/l+6GeL/wCvmTmcUyc58P39W73wu36pbz6rpvtf5aYlFSHQkRZR1KKtveEEGnakaLIXgY8l0aS3HWez0y0QG4t21VNRADVlxa6dlYdzObYKU4URcHVbi3fKVOk6YYZkK/InebSDlIvQ6y+adZSx6SZdEbUI0lb4Xb0HfbWUlUFKYhFtMwcmdVcbVcsqoKnY0M3eNarBVWRce7FFlbmGSqJjMH7iUs3MobAqsrIreb1akFuDXkhw+BL6yT5GeWif2wGErBaLbEJ/DBASiw2pQgiun5OyQEKTJx129YKZ2hR0Q8jT3sBrWtryLKMVV3TjyOnS4u1inVdSR1k1pmf244Ug9Qgk6TUbZZRFaUMmrVF6YAxkrJaLBYcz2fapmPfHun9HqslGZ+QiwCTpLiWC4WyOXqaMHHiul5iXMGfPnziYX/g+1c7lquKFDRWzfysFLjZLKirgjSeGPqJzUI+X7mztApOl5YQo6S5jOb52KBQLJc1eeZ4c11jteb52NL7iZjEZrfMHTEkPj+f8eNE048UueX93Q5FouvEuhyUoDjyeckYkiArCieWu8GLdTRJZxyVBCy+rCvarufx0mFMIM9nllsSO2rmHOMwSKIypnnwZMicEcGEyphGz+Q9Rlus1SzKjMIZmqbjcJqZdHlGrqVC4gxYJSm+YZwwRmEzy/4iPKzNylFoRQzpZfAUE2K58xN+6MkIlE6TmQzDRAgi94hElLEkbYhqIqRE04+gFG/vdrJ4/YW8ukYGStZGEpFx8nOtzUs1uheLatt2ZIXh1ZsVuavZrLeEmGi6jjzPub69wViNK4zgT4qBrukJY6RpGp72j5RVgd8ucZmjrnMmZ8i0IcQzx6lns15ydbXh06dPPD094GxOZmWAdTyeUSqQkoDJT4cTxzk59c3bW+qqJAVmZMWO6yvHzd2C5TLnp4+fOZ0bVusFy8WS0XekNDF6Odsdng7CZVxuyLKMbhhxmePbt99TlzXYkUigrHMx+Y6yt9/v98QgFkhjNMfjmaRgsV6QYuD+S0vf91wuF5yzFLmIOJ7PZ8qy5O36jpTgfGpnwZUksK2VymuMEaUN2byEa+bUZ4yKIit4ffuK0+nEl4cvKK1YrVbC6z0eIGqKKgc9oYyCSTpqH37+mR9/+onVQn4WLnNYZ2mbkeBHsb+taoyxlIVjs1pROPj54yP7Q8N2u6KqC25f31Ivaj59+MjpeOLdt9+wWkuK0GhDXkpKKM8MvYbHxycSitVafsaP9w9MU2C727FY1vzq19+RF44//+kvdG1PimZOBxumKfC0f2aYua9lWfDf/0//QJ7lpEkz+pH7h3sUUGaORKAbLiQiV9dXtF3HmCaqRc3N7Q1d23H/6SOLZc12teR0PvLpyyc5FzpN17WyTEIWp0klgoLBD4xDSzYPnKq6YrFY4qeJ07nFKOHYXV1t2azXfP78wI8fPlLXjqI0XN/cUi9WnI6PtN2J+88f8YPn6u4Ny+WK8/lMHBNlVZC5jKqqyYqc6emJvmvwk1Twwzx4qqqKLMvY3ghb9PD0xOVykTZamBgG4TJ++OkDIU68ubt9Ycj+/3v9zU84gTnD/ulJtu7Bk2eG17fXpBQ5nw5i1HnaUxQVb7/5bj4wGnSYqGr53zf9yJQUtpCt9uP+iA8yCbdas7u6kgdvSvjRczmf6dqW4+kolx7n2F8avuxP8xeyaFLHKVKXBZu6ZBx7/DCwXi25Lir2xyPnS0Pb9Xx6CLx785rr7ZbDcU/Ttny5v+dTilxtNuzWa2JING3Pai1DsmWZ0/cdP/z0kaZtWS6XZM4R/UgKgc+Pj8QY2Z5OFEXBze2tmJW0mS8JsuGXVJDGOUnHbNdrYox8vDwAin/4za9QWux2KMWiKkkpcTgcJYFh1As13nvP8/MRay3rzRWkQDeNpDCB71425tPkZ4Vtznq55HxpeHzeU84DrSklxvYiFqmv/ekpoI1ld7WjcLLlL5yDGKnyjEUhyYv98UCIgTzPxfKnFLc312w3GzbrBVVRoLSl7UZO55bD6cL++ZkYJlaLisw52k6qcqtFRZ5nGCM1SKWtRF/v7sQuMYg5br/f0+YZ+/MZPwmHxKFpRxle7Ra19IhFT0ZzPgKIljjL2F1dEWPieG7xEcYJrFVUxrIpa755907eJ58+4bKc337/DdYY+mFAa83d7S1hGhnHljIvKRerGQy9J6aIMrLVrN/coZLwfZJSjNPEOEoi7/ExMfYtTiWcs7x+84bbN++IkycFUa6GFElK9NnLzY6FEq7O4fLAzd1r6qJiGHrGPtAWmuQzPn36TNN2LOuC7aLgLz9+wE/yuzfG8Pn+SSbXl4ZpCny+f8QYw2ZRU1WWpqwIk+dwOr6kV34Jr7qqhBsyCIcjcznaGIqiICGcpXEYaefKrVEJow2ulrScD5EwTXSdDN8VArzt+45xrkMZI1/gCl4SQufLmXEY6LtWngfWcjwe+NRcGMdhjqUK46SqF9T1Aj+ODINU5G5cNqcbJvphJOz3rBYLFsslWZa/AMubtmW1lAgzKTH6kdVyyaKuGUdJMaY0a67DPCSSvzPt/OfXzAmYaSLFgNEKkmbwAyhFtViitKJrG7SCIs8JIXI6fCHGxKKuUUrRt63EcGer3bntZj4GgMLYTNJ73mMSWJcxjQPPT1JHbhux2Oj58zuNwk5brdaSzpkmOXgUBaTIOPQMw8g0HRmDcFhQiuV6PXfW4wvPqqoqiqKU75YYSXG2FCX5nVVFTmZk05NluQxuvUBGh2GkLHOMczhEu973vTzXiwJjrXA+EjO/Crw3+JQ4nc5oo9lsd2RZopm780XuYOZhxZRYLpZzslXA4317xjlJ4DnrWCxXxBCZJvmddt0ZYyxVXZMVJZv1mnEcOB0PaK25vbmaVd5iSy2rBcbODDtjKMtShuWTF6aPkiFdPh9ESZGkFMMw0HYt58tFBhMhkmeO1WpFUVas52GkVjLc67uOLJOo+zR+hcXLRt9Zy2aznasI6WUgMnnP5CcWqw3WOe6fniWBNz+HwjzY8H62282106peYJ2TFMnMcPslVVUAmq4HpEYrqTaHyxTbspwrmZK8XiZHkTsWuQEtpjthzMlC8DKMhORxtsOHQNONTHMFVSszM8LCy1B9vz/io1zy42zLa3rP82nEz5+1RZHjshxtHXke6P3E09NehlROYaLDqcjoPfvjifWyZlGXwhgKcuE8XRpy51iWlmkcOE+eqq5ZL0q6phE5QkyEBEWmyZImsw6lFV/2F1JKLFcLrBFjWqUVKQ3CG8uF6aSiDL61yzBas1kUxBj58SisuqtNjQI6L9U8o2Wo+eGLMOR8TISkUBimENmfLigl9jtnNX4aGMaJUyNcP2cFuBrChLWWuiiYEvL+nJ8pMUZSiMTJM42DGCBjRGlFltmXwZOZF3My4BBmX9cPBD+RpoiaJpL21LkmLXOck/8uyoCGwfcMU+DhcOHcDSgMWVGxP104Nb18/5Q5VSYdEzVfTEetiTHRDYNYMnXCaEXTSbqwzuX6IFXcRFZkuCR/Zms00+jRGqpcGD6Zc1KD0pbBT5x7sV0WuSMvLO+XpUhzmgGnNXVVzOBujzOK9aJinCbarsdZy922lqFeewEURZ5TGcOVtXOlRL7f2n6k7+X7tgyRMkYya6nyDKuhLiVBjjKEmLj0nqrIwDFf2PULTL7OMzZVAS6bEwiG3MLxIv//q80KrRUPxzMf/UQ525e9F7Oen4Ql1FwaSVdlDmUtRSbv06Yb6YZfzvNLW2HvdfNZZ1FVGGupFxUxBs6HE0M/EpNmsSz59ttvZ9ahw49BklIx8fDwRFEUbHcbhj6wf27p+47T5QIktrsd1hmUccSkGXvhMj3cP6C0pipLjocTH3/6SNf1NM2I0RNa91T1gqvra5r2xOFwwmaWu9fXjMMkcpBh5PHhwOs3r9jutnS9fIafHg883AfqVcWbN8uXu9vt3R2v37yhH/x8/ho4nSJ5VYrlXAmj98cff0Rrw3Jd4DKLtWIs1s6gvGaKSezSVqOMISEG2uvdjhgSf3n6AVLiH//Df5A052x8fX17B0pxfy/mbKdn6ZbWEBNdM5KXGavtkhgiT/sDKkkT5KuVOc7iFqUVr1+9om1bjqcDRWEoygXjMNF3At0fxxaihii28PffvCN3GbkTc2BKsN6tKOelSN96QkiEkFBG48qKu1eG7W5is11TVvJsHvuB5tJxOrdMPkGcz1gqMAwRiKw3W8pigXG5tBPmgVqIcjYfhp4YI8/PJ/Ii4zIn5NZLYbD5ccQYzfX1lmmaWNQlWmvaS4t3njKvyTLH2/fv8N5zfH4W6Uvfv5xDd9c7vvvNt3Rtz1//+hfquua3f/cbaRp0LSjFq7tXwvVsGvIi59e//Q1t03E8HMVAnzs26yVv7q4k2DPJWed4PnG6nDmfzi/Ll0VdU5Ulb17dcnuzI0wjcb4LHI9nnFVktsQsMmIVOR1PPD3tubu9Y7fecj6fGAZBDFkDD4/PnE9nbm7vyPOCnz/8zF/+6IUJpeH+aU8Czie5t7TtBa017775jiLLqMuFiIJOzd98b/ybB09FWTF5z9OXz/JlmjnyIufd61dA4imznM4Xng5n8qLk9bv3GOByOKDCRFlVjH6iaQcCimL0tF3P81EGSErLQXiz3kKSwdbkR9rLhf35zOfHZ6o8Y1mXHI9nPnx6ZLEoWS4XTFNg8oH11YZXVxvuHx54aFuul0tubu9kYxw8XTdwPF/41bff8frVHdM8CPj8+MjxfGH3P67ZrNY8nxuGoePt2/dst1tWy5qh73neH5jGgcWipigKQt8xDgN//PGDxOHOJxZVyWq5oCgqAf0a+VLTKc6DJxkIWWNYr1ZyKB8/kWUZv/3+O6YQ+Kff/wmlFK+ud3g/8WkvKaByURFmiKFEMU8sV0vuZtDZ8/MTMU4SKTaKIhetbYiRusq5ubkmovj0+ExSGpflhGEU1lPbzg9xuZK6PGNbbci0IteiR2behlVFzqVpOTYNymjyPJMDUYLr62vyLKcocqyznC49XTdyaTpO5wuHwx7CxKIsMYWjaUR3uagq1tbirJmrNALGtNzKJPqnjwz9yP5wIM8ch0sjdZdFjVaKVmuM0myWK/lZWccw9Dw/PxDjhFFiS9qsaqaQBJympFqgtJp/H0v+8e9/y08/f+I//9f/xt3NLb/65h19P/Dl4YE8z7nZbGm7hqfnQFEvubm55T5+5v7TR2kwZRmrRcXVekXb9lyadh6OTpK46Fqexp79Yc/dbsPNZsXV1S2rzY77zx/ZPz+9xF0TAVScOVUVv3/+Fx4fn9hd3VFkGe3lJNrzwhK95/7LZ07nM6//h39ktVjwn//1D9w/73nz6g1FntOc9sQYqNc7lDYczke00lytN2TOUhQFQw/H02mGZf4yXlVVvTBSlNIU1QKXZWLEjKJ2VyiMMfMhH5zV0g+fAr7tCTMLyGU5xjphA3Xyn6ck1YSyyGfWjGz1z03D0LW05yNFWbNYrTmdTvz88wdANKzOOqkFrDfsNmue96IBLsqK9bagPZ/p2kaGr00rg6d6wZTJhf7nL/cczxeWdU1VVnSdwMHXyxV5lnE6X8QcmZTwXNqGFMPM9E20w8gUIkw9KkWptSglgycUUzOKbCHL0EYzdGLWzLNc5AGnAwrNzc0NKSUeH+6xzrHbieL3cL5AgsxJnVbPtdBpGPhqbfJ+5HKR+vE0jvMXcS48hlGSAstqSd/3TJezbM3zgjCJCW0YPcPYSA0pJqqqZrlaScVxruSpBGW1YLPdcTmfaNuWFAIpBjAGpQxlkaFy+R5y889u8iN939H3A6Nfk+XgUCgEFBtiEPBxWQq0KwnLK8YwG2ImzrMVsR8GqQJ2YlnaLWUgejjLs2y5WKDU1wGhWMaCdywWS/nOcMK/auaa8eVyIc9F5lAWOdc3txxPR+7v76nLkuvdDu89p7NwZvKi4ivQPi8K8qIU1lRv5mqLWIM26w2D9yLuGIWD0XYdl+Yyc04CN9fXLJdLQA57Q98xjiPdqaXrWupaUmPei1zh0rYM3vPq9o56UdNezmKU/Dp4msT2WC1X5EXFh59/5nw8sttuJNEwDpK2QoDqfXdBK0W1WGCtI3cZIQQx7v3CXm0nVQethaWTZY48c9zspGb+uE+EaSJLkaJw1LlB2wxcJZvJXjiVnQ9MIeG0oh89+1ODcY68ql+Ss2Eeloyj53A8MYREO0Vy56jynGbwPB4aGdBrTVVIOi1XCa2geTzwfDhRFZLsNEmqd6OX8956WVPVJWkSPf2Hz4/sTw3fvN6xLCoOl57RB663a1bLmufJ06XI2E9MIZFbIz8Ha4kJ7o8Nw+jZJWGY3SwkyTKNAyoK7DsmIE2kKIMn5yyrOsf7iWYQQLtwiRT+cCElkb+MfuLLs3x2iyKT34ESFfjxcqEscm53a0AA+P3oOc1K70UleIQhKYyxLKqCS+85970MvIPHGoOzjjhNBD+8VLK1sWhnBdyuFLk1ZNYwJZjmqmI3jpKACgkdAmqaqDJNpjIyq+f6j8gEhinRdJ5EQ+YMN6uKIjMcZlyGyyqpsiiLUYkRYQF2IEyxSyPJtyBg2il4jFa82tRorXhuRwKKLM9kKeEsKqWZy6Kpq1LYc0VORNFNmmFKXHp5RmaFQKTfXZWcm4HTZUAZTVXlqBiIfsQZzWpRcrq07A8Dxcpys6m4NC37fUueFZRVQV3krOqS6UVMJImlph+5tFJtJ0G2rClyR5kbFHFOpyTOnacdA9bOZmylMEbRDp5LO3C93HG1KjlNGh+1JDOtYvQd3TDx5nZHWWT88cMXHvdnXl9tyJ3j1A9MIZI5qXx2TSsg9d1WUvGZE4HJDEH+pby0hTAl+m7EaMNmUVJWFTev7whh4t5q2qanbSOLxYp3776bf94NY+8l0dR2PD49s6iXLBcb+jZw2LcMQ8elbajrkqvtlkhiiuFl8HQ4tnz4+JnddsPd3Q1fPn/hd//ye5zLyV0BKoKKXF1d8/133/HHP/+ej59/5urqiu12S3ts6S893eBpLj3ffP8tt69veXp64nyeuP9y5HRo+J/+T//A3d0NT08H2m7g7ft3bLcburaXMMb9zwxDR1EVZC6Xz7r3fPj8M9573ry+oa5Lbm5usdahrAEr7YkYI0qiSiQmjM7YbXeSLGxasizj7//h7wlT4L/8p3/CWsXdzQ19P/Cvf/wrVltud9coFFYp+b5vB2zmWK5rmkvL4fMJhcIZ4d7azBGmiWEcWS0WvLq54eHhkefHJwG+FwumqcWHga7zXM4tXyGLq82a67sbVFSoBL6f8MPE1faKq5sNl/OFtuuIMRBTQFmDyyTZ44xmvd1SFAWfPn7meDjSNB3nc0fwSGU2jbOVVXS4q/UGvTEsFiJ2OTfn+bzb0HUt9x+ODP3IYX8hK3KaiywklncLrDUcjidM1FT1/LxeLuYz05nRjGSuIC9z7t7e0rYtz8/P0h46ywCprGt2ux3/8T/+d/zlLz/yv/6v/xvfvH/Pr3/9f+ZwPPC7P/yeIs+5vb7l3Fy4f3jgdrniu++/56effubnjx/JixybaVarDd+8e83++czjw5HBD/SDLPwul4Y4RYbO41451ssVV1db6kXJ8fnA+XRh/+MHvjw8cHtzzXq5oiik2vzl/k88Pz3z/s07bq9vaNsTTdMyzLW5x8c9x9OJv/+Hv2O32/LP//Q7Pn96YHO9xuWOrhtluVw6IPLw8IjSmvfff0deZFRFjYqK8/lI+Bv5mn/z4Ol5f0SBbLZJYBVZ5mjahhAil7bFh4n1ekXmLB9++IHMWfmgKUVeFCQGYpQhR9P3WK25vbqh7XueDsd5m6MxCjKt0NoyIVpe6X2LvnG9WBJfG6oip65y2m6gaQfGceTzwyPDMJJlOcfTiUvbE0msFkvevHpNVVasVks5CE+BgObV7S2vbm9ISvNlfySiSNrw88MTD8eGcRCo7BTB5QXTFBmGEaekOlLnDhVzNpstVVnS9h2DH+cLXsJoSEm4OyQ1m13g0ksaSRvhvrRdR0xJ4GSIhthow7tXt4ze83w+EbxYVayxVHVFShN/+csfsXOCIwbp5C7qkuVixzQFut7T9COHv/wVZy2//vY92cwwSMqSTAHakdAvl2ZtZMrurPwryzK5APiJYyMDlbbryOxMtney9dQz36XvGmIbQTuKwvKrb9/y9naLMdLvVVoOR8rINB5tSUrL2CslvI/zwKykyB271eIFVt52+sWW9JcffiSRqKoFRVGQZRmQGPzIOE3YcgEkMq3RznL/dBC9eoyyFdQKZQw2qwhovjw+0wwDN7e3ZHnBh09fZv265zQMPO6PAstXkeR7hvaCjoFlXYERW8rxdKG7NBSZZVlkYBzJZoAmdzl+HJi8KHx7H/jp54+EDz9DnEghgDYYLYOwqsj48PmB559+QgE317c4Z5m8aDH3hwND17IoC6y1rFZLPj4e+LI/s1wsKPJcurpa450lBqjLDGMsQyfbgOPxCaM1h4tUv5Zzl/uX8jqdTjIssXZmGMlwKU6TwG1jlM3Tcv1SU5r8rIxXCqUkqZjnOSCpn68pGaUUCUmhtPNgS2sBhhqthUETkly82gZtDNvtDmfFsjjNVbspweEkF4E8z0kxzDp7SaNsNpsXPk/bti9Sg6osKYuCoe/4/OkjeuYCpXAQlpSfZitSwKhEWeQz60kRYiQzSnTVWpJIRskF12aLmWHi/+15oKAfRumwd2JbyisxbsX5tFzUS7SWlIyahQ0xhNmeNzE08r+3Rhh2+8PxhfWkRR9ElmXUtSQXh9Hj25bz+URV1by6e8UUI21zIUyBrCjRNmCcXG6HeYOllUY74UeJvdIwDj2fP/08/zziDAa1sriI0/wsyyThNnhhnbiM7XZHiBE7SwSc0RANQycWUp8LeDefbWBtL5+rerGkXixmKUSQZEqMFLkMSR6fJUo/Ren62+UCpRTD/N/v2g5jPV3TzP/5yL+/lXytJ4+jqIHP57PY+RY1KiXu7+9JpLlaLvyabIbgW2OIIcxDRTdbGEeSavAhUhQli8WCcXA4K4DwIheYpDF2Tjmf6IeR0ftZAiHcJWsteZZRFjld18j7XmuqosBohYqRru3o+g60qK6tddQLK4lqHmcm1npOa2phByThyIQYUEm4YuMg3/un8xkSrOfq6C/p1fYD1hq2q8U8gMzQWtHNbDltLSglaaUED+ceYyfKAmKK+JlV6eYkXuuDGCRzC3o2f4VJ2CNKLHVGK0lna0Wpxdw2+hGrYF3nZLMhViH8T0m5KAqnud2InUlrOTvEGNlajTOaInczC02eu9vNitVqAcCh8YQk5rynw4njpWX0UiP0IUjqSsl7Ocx19nVVEoqMwoJVQRJxSoY9GYrcStpTKhKKU9cRJ8+xyYQNaS12htMLjyTOPwOHzhy7taQQQYbaIwFNwio5p/a9yEamaSCERJk7yjxjuyjpxlHMmgmeTi155nh7sxZZS9vO6QKxfTZdTz96fITSyc8xM2JrK2Ze0bHtGLpxhoFHcqfJjOLStCjVU2WS7AgYpikJYyZGFlVOWWSQZOGQ5xl55ni+9HTDxEIHHECmJOnk5XxaV4VYNKeJcTbOKQWFcSgST8eLcF2VFbh4Kd8tTdsRolR2M2uoigzvI5dO6mRaGSY/oVXC6kTGhA7QdpoQJtZ1BkpxOjU4qymdYZgi54uAu+vFAm0M56bD+4DJCsaQaA9nLlnPqWkpC8F5ZHnGelFS5ZZtXc4WRbmAywJgIsQJZ7M5GStCjNxp6tzw5TJyPLdUmWNd5lhr6HzkcB7ofMCEnCozTFHSoX/9+IhSiTwvuLvJBequFZu5/uuspBbPFzlnqxhJEwwhkZKmyt0LzPyX8DodTqDA5VKJdLlBG7kfiOVXhunlwqBs5Mv9E1rDFDpZmqsEWkydw9Dw17/+CW00ZT1bGkMu36VPjziXUVYVhCTJ7pBQyZCCIvnEolrw7v1byqKiLGua9sKlOTNOni9f7iEabrZv0MDl0BKmiHKOd3e3LJcLFouS0+nI8XjmfL6w3tRsd0vavuGHHzrGcSKExJ/++CfyzJGSnLEm7+VZqRKoxGK5RCVo2p5hHCjKCuvyGYXSoxI4rSmzjBiF66O0JnhhZR5Pp3lArUAnDvsnUlJYl8/cTUn2f/PutST1GzkXXJoGYx11LQuLH/78I0Zb1qsN4zBwPh5ZLGuudjv6wXM6NrRdy7/+6fcsFwv++//pP8j9TWekbGIsHM4sqYpSkud9hzMWoiyTUkqsN0vqakHbXfjxxx/oe88wBqo6Jy8yfO9lebdaYDPHw8P9bPNVmMzx/fffEoJwsKboqVyJsYr94Z5x6MlMiTVOKotaOJmj91xtrojLDWNrGEep4ru+Jcs0MQT+8Ps/yAArTWR5xjfvv0UpGYKOk4gcjLEsfKC5NPz5T38ihoA1jmAjgQtoJcvmmPj48YG+9/z2V7/BZY7/8s//TZZpYeLSBC7nHpQYRseh5/PHn+m7lvVmLUntPvD4eGToBoo8Y7Mt6L0lHxxmpyisI88yMpcBAvp+eLyf5yIJpRMhTRRlznq74vpqx1/+8gOPj08AXF9dg1a0Q8eXz/c83N9jlGG1WmC1oa5q/vLHv/KT+4m8dLx+d0uWyVziq9396mqL1npOZE0cno/Aifv7e2KY2Ow2wvr6G15/8+DpeDrLYfBqIzFaHeQX1bUCFey6uUsv/IhPP/9EUZbcvnojh9siZwqRlALd4DleOrbrFa+/uUUfj3x6eGIKEkXNrYHMYV1OSAK3jFH+4a0xLOqKrKwoMkuVOY66IYVE17ecjjIFdlnG8dxwaR+4ubpmu93w7bt33N3ecj6faLqOcZIN6t31lmVV8GV/5ul0pq4XOJfx5fmID3vS1yFSSrhMeBykRJZLcqnMHCpGVqs1RVnS9/1sNDBoNat3Z7A3KKaQIITZQiOAN61F44lSOGOFwTBFbJ7x+mrDpWm4f3rAezHXGKNZ1iXny4WfPvzIYrHg2/fvGZPoK6uyYFEtGHxgij3n4zM/f/qJ92/e8NvvvxcL39CRrIZMhj5SiRFgfJqBgNZaXOaoqoq6Krl/PnBqey5NR9+1FJklt5ZcO7STjr7WiraRNFi13pDlGe/f3GFV4uFwoR8mUYEDGIfCkJQhoV4AyD4Is2hVlSiVWC9q2k4L5B7FZr1hSokPHz8SY+Lb739FVihRWcbI4Ed8CJhchi6F1aQUeTocBSJpszmOrqQSmRVMSfG0PzJOE7ura0mb3T+SGU2dGS5tx5f9kWWZ8WqzIPmRsW1RSWqeY4QuRLpekk2vrzfcrgskJlHjtKXKC5rzkfZykmqKD9w/PPC8P7Bbr1gtamxeYK1mu16xXS/51z/+mR/++he+ff8tu+0OZwxhGnl8eubjly+oubq4Wq8pioLPz0d6P/HmWrZvAk2PdFYTlaHKM4y15E7jx8DldCCRBN6pNbc31wLs/IW8LpeLfE63a5wVxpBSkIJUnGJKaK2pFzJEGUcvKYxxEMhgvcRoGb5OU2DoO4E+W+Fgpflw3oVphs9moga38iUXolRNEgLcXq83lEVBWRRc+oFL2zPNCSmJ32f0fc84DC/Q7vVqxWaz5XI5087g8dF7rnc76qrk8+fPXM4n6tWWLC/ou1ZYGdogm3rQ8KIuTgivwBotzyUzyxXmn0VVL0gJjsf5kKPl8zOOspFtB4F+ZmX1MnhSSpN/rfuNwjHYbYVz9ez3Ys38yiGqawG6Ny15nrNZr4lRnkFZnrOoKrpBAJV933M+HynynOubG47HI+fTUVIaWYGxERsjdFJh+6obN8bMUFi5KD88PrDfP+PyQupBuVw2pkFsecZUGJPho4gWklJo61hVNUZrzucz4zgyeYHdDn2LH0emENDGYRfCeuuGkZgiu+sbnBXz3DgOjKMYBOuqJATNx5+F9fSVyyN/XrkETyHQDz1msvR9KzWM5oLWhqquSWpmas1cMOFtSe2grir6ruX56Qk9c5Riksqo1jJoUlq/GPWcy/A+yMU3BPph5OZanvkyaJKUzaKu5sWELF4ulzOn84WmbXn16o6qKiQ1aC1ZlpHnOWEKtF03D8Ezqc6kSDf0nC8NSYnJaL1e45zl48dP9H3HdrMhq8rZciaDSaWQAWaYIErlbhxHWXw1Ij+5vr4i/wXx6QC60ZOTyDMnyUOXy/tv6OZnimTwgrFMKfF0GXA2vCySgpf6trVWOEQ+iAAms1L/CvNwfArkTpLsRmu0UTgktT1NA8PYY7RiVeYUZUFVVZwvDefTZU6IGnKrqfMSH8VIPAdM2C4KlmVG0/Z0o2xQUxKYclEUfLzfc7q0FJm83/YnsX9Zl6GMFqseiRSTPLsSgBJItAIxA4kVLihh6Wilycz4MngKCcLo8YiRD8BajTPmZfCkiJIOMAqljJxBQ6QfJRnqI2iVyHSa69uygfeTR2lN4cRku64LjFE0w8g4Tlyantvccbdbcbk0qDASMEQM0+Qltemj2E0VVE7NbLiMKpcqVtv3BO9pZ3bpqs7RRSafgSlQXsn3fzsE4pReBux1KcPbvu+IQZhzLhNAfDsEilwwF2ip5vlOBoDbIscaRd912FExRvUCA48xcn84M8VEVtfkmabKM1IMPB+EzzWGSOHkzxBj4uncoxUsMjf/c4oQJyOgY+KrEGlROgYfODUdRS7JuTFM7C8teZZRV5WYV9sBtIgIGt9zPLdYo3DWsNuuKapaLHl1hJRDhHacaEdPSIl+EPainzzLhaF0MhxQKpJbRZUb+mHk+dTwq1c7rlYVw1w9PTUdl86Tq4DPjYwjFfz85Zlh9Lx9+4p1VTL5kRQT9TyAskbuMt3MTGO+oPsg7+cit7LY+IW8zueLDM2vavLM4pxBa5GIxHkhorWmqCzKJB6fDvPvQKpMWV6AThgj3MvP+48sVwvef/MGZQx97+iHjsPpyKJeUBWVIAOiLBVV0hAVaUpUZcXrV3fU9YLFcsXD0yPxPuJ94OnxmcwV7NZ3nE97LpeTyH6c49XrO7755jXPhwPny4Xz+cL53PL+/R2b3ZKfPnzkcDyROfkOPzw/EUIgzwTpkOJE7hwyT4zUdY01lvPxQN/ruaov54QUE3lVYGdzuwDp5ZoeJ0VIMoAVrIcClTidjmhlsDZDKU3XyZnizatb2rbhT/tH+q6n6TqKUrEt50Xlh0+sVmu++/7XXOKJh65jsSjZbBY0TU/feZ72Jz789CP/+I9/x9//429pzz3HpzOTE46bygs00lw5E7HGwlfmX5pYritev3rF7373r3z8+SM+KEJUKLPFFTnDKGev9WKBNYbn5yeeD89cXd9JAu76jjIv2Z/ODOOIs2uyLGPof6JpzpQZOCvPGGJiHD3jNHF3dY01mv2hp2k72uaCVrDeLZh84K9//Qt9P5AtLMvVku++/16GSnP6uh881iYmH4R/e/iMtY7d7hbrElEl0FLvTQnu758gKb795hsOpyO/+8Mfxd68XjL0E6dDR1Vn7HY1fhx5/PIFNQcF2mbgfOoYuhPPD4+8fXfL7d0bsn7CGYszVgxyRkIep9OFw+HE4XDmfGrYXi1YrApCimSFY7VesrnacPov/5W//vAj373/lu1ui9LQjR0PD098/PkzdVHi+xGTOarS8tMPPzMOA2+/f8/makUcRWwhmg/FbrfFWifg+K7ndLgwjiNPT08Yo3n/7TciHPsbXn/z4GlVyAOj7VusMywXlUTcy4oQ4ssDVFtHjPLLstbhJ+FsBC8R47JeYPOAzQtyZ2kaqfVsd1viNBGnkboq2e6uiCGwP+xRKXG3W2OtIaXI0PecLy16s2ZZlpRlAVqxGDOCr7Auw7k5khjivPXW+KHj+emej5/ved5LZcsZMxt1Rp6f91zajmkYKPKcvF5SFI5zdyaMA6vVgjz7anyKdG0/PxgcCXh8fsZYx9u7G7RW/OWHD8IGcrIJ9l5qK4XTL3A35xy/+c1viSHw+Pw0m00mYXuUVwA8HE4M44AzlhQC3djSp8jh0qC14de//g0A/Sig1cxqTIr47kLTDdw/n1BE3t7ekDvL54d7pGgjZP+UEk5r1us158uJ9nhkvdmw2WzxQ4cfepl8GoMfPedzw3a1ZPHqhrYTmHJeiM50nALD2HA6nun7njeZozQwBsOQ4Hxp6PqB3W5HVlQ8nx7oh56rzYbMWppWNJdv727RWvOvv/sdXddz9+qO7ZXiz3/5K8M4ziwGxfs3b0kknJGLsZiaJrq2JabE9XJJ5gRA3PcD+8Mzzjpudlf4IJHNopBDtFEJlTwKDWWBd+HlrzvFiLGWzaKiyDN0VhKU5TxOFC7n7vWSc9sRT2eYDJNSnLuRHx4ulFWkrMWCOPayVi7rmjEExr6lLAtu3Q2bRc2iLMnrGpeXYCynpkfPnXhtlADU+5ZBQV5kbDZrysWCvCpZLKRedWxEUy2XCnDz9nq12hBTRANp5njZ3LCarRll1c/JII1Rv5y892q9eeEypQRZUWLmVJJSM3sCBVosM2kaSXq2fxix0MQksX0FsuVAycVuTgMAL5dySeqMTMEL1Hy3FTZPmFXgIcycHisVXKvmTZKZuUORzBqMyjHWzgmTxPl85HKWz1VMAmYdvUcPGqU1Li9xTmCO2hog0nUdIQY2u2vyPOd4PDF62TyDIo7yLPOjVN++xr33h4MMp0e5DYy9AI6/Gt1CkJrEbrMlxTAfJKUiqrUSe2iYuJzPs5pdhmjVYkEMkaZpcS7j7vZOBhmjXATRWoZ3ecE4BWIYyTLH1fUNxjoeHh8Z5soac+JMzXwhbfRcZTbCzJBfsDCAigJtM5KylFUtaZ6+Y2hbNPLnlRScQOBlg3NFUVYvNTIQlpeat+bWyWa+riWJElGEmLjebQF4enx82frnec7pdJIh5Gzq+Vr1jDFhnfx5wwxFNlpzdXWNni9WIUQZbs2w3dELPFwZjc0yjJ0HxUn+mfOi4vZVjveetpN0RZ7lAJzPjbyvXEaR51ztVmTuTAwBMydqxmni4+fPwqkjvbxvhQX1NTSnBMaf5SzqBWWeo1DCTkuJpmlmU9X8R0swTpIAATBzbUr9u99jWRay8Z4CIfazPVETjQwSyrKS796uk8SKM5jZ9KKUJkTox18OIwXgze21DN3GQEwju1yeP8MMAzd6RCuNq0pGH0SwMsm5JLNmNggHqQYHGJLIAjIHerYOSm5T+JNZ5vAh8Hz2LCrLbpXTDxEVh5c661cboiFR5gYfIu04siwLsiwnzfwhbYQbMoweP00czw1tO1CXOXnm6PqJEHq6rpOLV5B0qTGWPHM0g2cKkV2dkzvDME74FHEz90iqzomo1CxLEG7Zw+Mzo/eSKlKK1PSklISrpoQfZ7Tm7dVS2HSjpAybYZIKYR7QWqCvCTBa7EaVVZK4HCcKZ1mvCvw04S9iJvVxQuuBc6Nph4nRywLNallo3D/Jede6HDN/h0ilDkL0dD6grcVmJajEFDzjpFBGM0yBwU8sqoLNekHmHNYYzqmhm2uml7anH4VJtV3WlLnj0o+MfqIdRLqz7FqIUoFVQF1kYoL2nkTidrtEK8Xnxz3DOEmyyhmadhIzspZnwG69IMZEE4RZM0wJhfD9iigw6cxojMsJfpJlhLWUdYX2E+HUEjEYW8j3lRZ+lqRqBYsQk+IwM2GWpVzsrUqgIc2X87oqqDIrBkFAkwje8+n+ESU+O6xSWK1QSZE7M6fYNGFePGVWTIBmUbIopBbeDkGeV7PwwbYDKGFsWSKFkSHohGZVlWLMHSe6QRhobTdQ5xrn5PtJBqSia8+LDBOifI8BdSbvUwMzm/CX8bq7vQWYeacZdbXAWIMPYjYtC8GH5N1sh5u//7z3OAtZpjHaUVULnCswmVgvvRcOTmRmouVOQNbW0LUdH374gDaaN29vZHDjZPg0TUlg8X1PnuXc3b0mhkCKE5nLcS6nrBW7aUESYCfD2PDjTz/wcH/geGwE5J0ZptHTHFv6ZsB3I1YbGcyvZFF5PB4Z+o7dbk1eZEwi+ON0lPquUg5nFU+Pe1Dw5tUtRmt++PCBru/x44QxmnZeCJfVQlK/g/Bq/+P/+B+JMbJ/3stZrZuwLmO9klrw8+Mz4zhglcZZS2YtaZp4uP9CnjsZ3qHYPz7gp4lqsXxhZ4rM5IgzhvfvviGzOT/89UeGfqBtOhLS5HHOkbmaYWiZfGC5yrm63uHHAT+O/3ZejGL8fPXqFbvdFW0v+AhrDdaV9MPIo5/oGk8cNdvFhuvra8Zx4nQ5s98/0w8jVVmgKOjajrYZ2G1uqKuarh/oB8+rV9dA5A+//zNDP/D67XuurhT/+s//lb7vmKJIde5e3c0SgyTmYjTBTxwPckZ7/eYa5xzLImcYFc/HDGMzlqsK7zPabk01IxlEACPPlGmKlFXBu7dvGEdP286CmcLgMoc2mbzHg7R5tldbTk6aTDoZNDl9O/C7P3zAaIfRTu7pQDLy8JAgSIG1jvVmw2KZU1WZhEeUxlpLe27JjGO9XJOXBdo5wSQMHps5iroiaoWPkVdXW/Iip2sunE+R5tIwDp7FosRmlmKubItAaaIfe8YwUNY59bJgvakxWlptSv1tQ/O/efC0yKUa1fkelxxXZkmWOYqilM1pmJXa1jKFIFt0bfABqSqNYhcpyoosRfJSev5d25C0ZbVaM/Ud/XmkyHNWuyvOxwPPz0+s6pLdZj2Drz1+6GlORxalbFiLIsdmBia57Ngsx7gMrS3aWPquYRx6/NhzHAUc/en+kXev7rjarOj7gW6uDpybFpMisSioFzVlZrkETxh7qmxNXeWcLj1jDLTDgJ8mjHVkSnH/LCyN796+IXOWp6dnzm3L6zdvXngfCsis1O5ijBhjeP/+G/qum6ewPcpoykLUtSjF/tISZiZAUJppGgkpkdqe9WrJu/fv6NqWT58/i/HKGDQR37e0l4bnwzOb5YJX19eMo+fpeS8guyzHpIBJE3m1pKgXdF3L6EXffnNzzfH5iePQopVUhyY/0bUd71/f8M2bOz4+POGPZ1yeU2Q5p+ZCN/Qcm5a+67jd1JhgGSaHT5rmpWKh5XLpR9qu5WazJtOa59ETopj48szxf/tfnng+HPn1b39LXVX88ONPhDAwzAfru9sbFIlj04qpiURMgb7v0UpRZ4aizFgu5TA1dD2qgGVd4UPk3I1keUFe5OgUSeM0Vx8NzkY5MPqJpu/RWrMsC2yWoV1BSDCOE1VVsru6AnPk3LZMc6KmHSYuvmEdFBtl8V4Ayrk1ZFmJv1zwfqAoKparklUpjIJyuSIrhV/QdD3aGKpK3g8xSSKBJP/8y+WCoixxswGqyHJy5/B+ZEpASDgz8zjqBaBIfnhhSSgj4OjMWpYhn21X8Rd1+Fksl8QQaC/HmSenRZ0Lc+JDqkQYRwwBHzwkNdfWzDxkksGVNYY8y4lJrFDh39+q5438FOQ4yhhYLZesVyv6vn/hComZzsrvgEQ2Cwecy2YDnnyGnTFkRSEa+q6laS40bUPfdbh52CDbcgWzgt44J3UcLYfwtm0Ik6eua+rFktP5PEMj5QtiHEZCmGQjpDWv3rzDZRnnzx/lcxolATWOA3r+eySUDCm0Zr1cEibP5XjAe1HhWmupcgcx0DZiO/Ve6mhlVTMMA93phLGO7W5H3/c8PDygtBIhhTGYLEP1HTFMZHnBYinP/8NBQIdpTo/q+XCYklw8lVZYa8isljpOAmMsdgYgoy15IRa8/Wy5y8sSl1lilIHaMPRM3nPrMpbLlUgXvAfkZ/GVuqitwyqptzjnOLUyELxZCWD2w08/0bYt79++xVmJWI/jyDB6rHVcrVdzxbr/t/dZkiGP1prlSnh1fua9KSMA0qosZWCj5VJvrEObf/9VLryVqqppLmeapkEbxDAYJIFkrSOLiaosWa3XpJTo20aWJFlO27bsD8cXsUSYh6pft25xrmvmeUFZWanazcbEECOn00mq4/OwijlL4ie5iANz8lCelV//Wb5WErpuJHqpN2qYE7iKLC/m/5v55yQp6KpYgNJSk51+OXw6gJvdhmkKPB5OxJjINFLjCPPSSAW0tri8JiR5f006kuWSVCxykRSEYcCjmSJYo8icRqnA5CNozYSgDOxcbTp2gbKAVZWj8Yy9YgwwIT/76D1aJXJn8DHS+4m6lIFsiIkQglTStKLzE0MI7E8tl0bkJ845xnGSYUM/yEA5ipp7ucywzrE/SwXtZplTOEs3TIwBnNPzoDEQQiAqi7aSHlBacWo62n6kXi5kINBK/aTI85caudGKm41wzj7vW/rR048BZ2aoLxDn967RCo2WlEGEkw84a6nKnH7QoCT5NIZJWFct9FNk9PKMN1rh/cTzsSHPLPXMjEpKbMSWSG/kfau1wWYZcRqZJo+PGhW0pIimwHqVsVkthOGEnsHNIinokL9viImq2AiiwB/o+kg/TvR+Yhh6LGHmOCaqPKMuMppBBjzbZUVmFP/6pw+cLi3fvNlhnWWKCT8ljIlkVrNdCNy+P0i6dgwyzCuKEkXC6lk64DJSSHjvZSlRFiQ1iEzFfE38y6UppEg3ThQzz7UdJvbHDmcUVf7v022QlKbILNtFSWY0eubFpRA5diPPxwuZ1eT/7l/KOjLjkLEYmCDLEmetsBadANZ7H+nHMGMxEv04YYwnMzI4sgQyPVfW0VRFTplZmn5EW8s4RaYwsilLCmeYkTR8he9mmZuHvvJNVjqp/xsSv6CdH7udWNAvhwadHEVRYawiDqKHr/Ol4EYyASe3l56QIuM0AZqU5CxeFAaXJ1xVk0IgTCMhJBIRZcBmFuekgdK2LYfDgeubHe++fcsURK4QgRDSXCsfKPKC5XLDOHZ435FnElhQKgclrLsYA6fLif39E58/7tk/Nbx9c021XTKNni7C2I9MgycWGTjLoq7Js5zD/pm+bymKW5arJc1lwI8Tl0bkPoWV6vrx4YGYIt9/9w1Z5nh8euR0OrNa7ciMoe/9jFKRdPk0ThRZwW9/83cyzP70/6JrR7wPKGTwkFKY0+oi6HDa4IxlnCaO+2eudhvuXn1L23T89MNHtLHk9eLf2JqTp+sulNWC66tbYvR8/vQZP3nGcaAoCuq6xDlDURZoY5gmsc1utiu6rqfveqxzJCXnsBAVV7srfvWr7/nrD3+laS4UZYHLHH3b0wyeoZtIXrEsFlyvt/z85QtN23A+n+m6nvFqTWah7wb6XpJdi0XJ03NLDPDt968wVvN//b/8L+wPZ/7+H/87FnXFP/2n/zen04mYZAl4d3MlYZROlsMazTh5LpcGYzVXN++kJhskASm4DUddF3gfqMolZZHjnJvZsHOtMibyIuO2uOFwPPP8fJpT5lrg98qRiIQwkdmC3XoNIXA5nWQ4rgzP5zMPXx5ZVAuW9QqXGZybG0FKrIRFnqhqhzKWsrTkuZGZh7WM7UjXyhlvsViQ5TnaGmKIhCTn87zMSUoRiKzWK1brpdT/+o6u6ej1QL2o5K851+ekORMYpwEfRlbVkiLP2SxXaKWFoRfj/6/Hwcvrbx48TUpAe0UlfIcfP4uu/t17UUpPSdF1A5++fEApWNYlxmUkLfHbcZhmKKwi1468snR9z3PXorUMY5KRC17TXPjw4w/oFCis/FJ9kMvLMA6EmDCZky+pvsM5Q5llnPue8+lMUUXySqFVQCvP5y/3PD098f7ta26vrgTyraSatz9KL98ZQ5Y56lShjCMwb96t4XS5sD8cWNUVhCipqBCoZnbO5XJhmjx3d7kcGmbOyqvXr9iOnpu7V2LGOBxQJG6vryQ9FCKTH/jf/tN/JiUh9G8ULz3Kj58/k2cZb1/d4CfPw9DirGGz3oA2aJcTJs9f/voD4vqUQ492jnM38Lj/gbysePv6FYuqYrXZCB9m1rEXecY0dvhuZBj3HI9Hur4T4O/QcT4eOJ3PHC8dPkg82DrL2zevUErx9PxMmCZRIxuNNuCMCA7sXLnwytEmx6UdGLxUmJzRBD8wdA0gCZwvD49YY8R2l2V8eXwGBbdXO5aLitOc9Hj/6o5p8jyexBawXa1RCCOBGAmjVDEKJ+peW5SgDc+HZ87nC6dLQz8MfPr0M9Y5Fs4RfM8f//gHnDEsqlzAqrOhcLfdEFIU6ONcwbE+4KMYBkfvuRye+PGvf5bUhdaczmeeDweqesFysRKT3diJQtw5VEB4Cy6j0oa6rqiKAutytLU8PB9ou88sqoI8y7jZCTvMzZeww/EoD+FBbAa50dS5lWGK0WKQVJpz19Gllt3rO8oi53xpBWq8Xgk35XhmnIIw14BSh5eL/EtM4RfwijPw7mt97Hy+SAJsUcuBl8QUJpqhkcGwkSH7OPRymZ0m2Y4g6ZnFcsU4DhwOR+E3bHdSqZs8fgp0w0g+K7KdtXStAL9TDIx+pGk7QJIqeV5Q5wK6Hb3HhySH1BggRS7PLeMUxBS52b7YLqyVAVMMgbHvSXNFo71caJXi7uaaqij4/OknzqcT3asWl2Xys0iRqqgw1tC7bAbM5rKVTYHgR7H3FYrFYgEKmvNpjtvuhKGTZEhz//AFUqKsKoqU8DME+nC+kOcFr1+/ZgqB5+c92miKspS6WFVDSnz8+QNKKZwTEcIwjMLsOYiZLS8qGUYBeq5cQYIYMUZSMkJEjvNlR5OiMKV8EAX6NKeMrIbr3ZrcOWGMGEtWlriiwM1w6jBzvWKING0DWuMnLwfRSXhZMmiyjKNUTs5NI7WeQg5gl+YCKbHbblgulzK0DJFXb97Jz+zLF1KYKMpS2EVGamTOCncJJKoepgmUmjv1YV5cSCVTKcXt7Sv8OHJ4fsJay3KxZIoydH/hkfU93o/oaEFJYjjOVb40ep6en0WzOx/m4yBKcqkNWcZxoDkf0TMnK88yVJbNnwekUlcI6P106OnGiXGSS3ldVQIAryryvMRYS9tcJLE5/7l22y31YsGiqjHW0jQXYoTRj8QYuaquKIqCvpc6UZrTYLsZnH48HOjHiU25kDSEiZJ8/QW99vuDpMnTRAjww+cnjFZUhZuruQVTTByPZ0KIrCv53asY8EPkeJRV+5QSxhqu6hI/BZq2RylFXpXoKTKNkgA+nhussbza1lS51Nsv3chlkPqWDxK919pgdMJajfEi92i6gdFPLMuC1WLB86nhdGnJc0uWCQA8yn6IYU4zKS0mpbyQiolAyzOKPOPpcJbPQlT4pJiSpFSUBmOE9TTNiUVr7csQpsodVjNLEhLj/HzMDViJlRC85w8fLiglBuEyc8RaPhufni+URcY3r2/EijTb71xmQStWMzfvzx8fJG1mLU4rlJELyONJhmtFlgnHSEutKKbwshD9ytDqUqTpZQiUWYVJYiaeRklMtT6RdCBqx2azfcEy6LmaWziFrgsZ7MZEQBOU4tiIpfh0vtD1A06BdZbcOlk0VRVuSjydOg7NwKJ0uNxyuEiiYbWsyHMnjDg/cbuSZdv+3NBPoJdy9i8yR0wJqyIqBbp+QGuR4SglMoV+GAlYxknxsL9gtOLd3RVTiHx5vpBZy3pZ0Y+Bc+OZgqLMR4YxkMJESAqv5nyQSrPdc5Jk0SDVqhAmmm7g3PQURc71Zo33I96PjCGRUpwXrWCznDzLpF6TyV//2I6oJJXNRVWyqDKa3QprJdGUZ5beB8YQ8DOAvcwtdeFICYYpYg0UVthfU0yEmAu3dv4say3EFKdHGagrSbqmaZTLuYovw6lfwuvSdIDCFRkpRX7/R6kgvXp9S0zw8HzPMIw8PQnrsazEJtu3PaP2BC/ogfViQeEceVVwuVz48vFAAuqyIISJyWt0UlxODdoqrq93lFWNH8Sod27PDG1Hd25IqcY6jVsuWK8XPD+1HM8nQl6RO1BWgYH7L194fnrizdvXvH31jtO+55kD3dhhOxka5/PCURtDCpbgjciknOZ8vvD8tOfduzcwcw3HcWK73eKco+sHpjDx5t3dvAAVycerV2/YbAc2mxVaKY7HCzFE3r19jbNW0vRT4P/+//h/klIiLzOK0kGIeO/50x9/T1kV/Oq33zB5z5ePn7FasSkLMYh7Qan84Q8/CG8zl+cRCp6fj3z5+BFjDfViwXq54fb6lr7vOJ9PkDqC9v8f7v6rx7YsS7PExhJb76NMXeHuoSMrsxJV3QQaRPP3dz0QBAGi2V1drMwMjwj3K00esfVSfJj7WtZbB4Ei2eUHcATCw0WY2bF91prz+8agyHLaass4LXx9+cDlciKyMC8Tl8vIPM7Mw0xYnum6M4nA7d2BEGceHz4R/ExdFNR1Q1EWhMUxTyMheVzyvFw6zOORx+cjXX/BB4+xen1uWtpmA0nx4edPfLFfuXvznrqpeXo6EmPku/e3XF1teHj8zPGc8Yc//grn3vP0tKCV4eb2Dq3h84dPa0o1kWWK3V7szQoILjKNnq4bOb48k/UZTZ1TFiXfvbljWRx//vEDeZax34v85uvDA23b8N1371ExEryTYIopMMj5bp4mhu7CvHQcj8/4GPDBM/Q9l9OFopSq9jSPfLqcaeuGtm4pq4JYRZyf8W6mzg15ZZndTD/K0M4tgeurPW1bsz9sUQbazY68KDg9PTMMPdPYo0kcdhv2+73wG6eZutkSoub4fCKEQF03NG3N0E9iJtztMFoxz2+Y5gkXYFkiMWlA4ZYR/18bLh7R60VAUir3z0eKouDu7Tu5ACWJK3/49Fnic+/vKBKYwhNDZHaRLCmqEnJr2Dal2I0iZLByoxSRxDKNHPuetiy4Wq1lIQr3Z3HSz9bWyl+7TGS2orCG48oMidpCVsjgCXh6OfLh0xfubq4pi4LMGoyW6lOKAaMaTJG/QlSTNq9frzGabhx5OZ/ph4HcGMZpJMTE4epAUUidQWlNUxYCsrVmvaRdE2Pi6vqalBLn52cUif12i80sp8uFpev553/5Ezaz/Lt//LeURY7RikvX85cPH9k0Nf/2D7/CLYYnAGMo21a2Q8owTRP3988UmeWwqVcDgmXsRz58vuft27f85ndXVGVF024ICUzfYa0lzwxxUXgvBqNxkou21urVKNgPA8MkCZl5mqmblpubDfPYiybcZqutT6OURMqjEXaCtgavLBOWfr4wjSMqRTKtCH7BLaNEcJXi5XQipcTNvmVT5byczrgQ2O82bGNDNwyMSvObtzdoBZfxI+Gbxh0w+mG9rK3DLWswNpOJO9B1Fy4X4eO4xfD0/ERTVby5uaVbFj59/ECeF9zd3jKOA5+/fmG/23E47ISLsThS8OAdJksEpWXQME9cLheeXp652m15e3PDMPQcu4tU8zYtbp7pO0fVbqlsgVoVgJm15LnwbNqqImhLUIbj+Sv3D/f88O4NVW7ZbTe02y1hngje8fScGCexmsUg4MUyM6860aIoiQmejicW58iyjKqsOF06Qgxs2oYiz6SSOC98fBGotcnXOLrNflmDpyg2nqKUysnzy1FsO9W/9pG99/SdpH7sphUmzrJIyHVNcCql0EbSHSlFQnBkeUHTbonB4+aRNE74YaTSJU3TErxjnmZikkGS9MdnbJZThkRtM5p2w6XrhOERvw2eIil4zpcLl65nt93SNBvOlw41yFDXWkvwbq1hSfVkGEd8iLx/c0tV5rh5pus65hVGHteBVlFk5FkBSsCoRVHKoT7JBtgagzGG/eEAJI4vL2IR2WzI85xlXhjHkePxiFai3FVKMWvFvMy8nDvQlu1uh/OeSz/K5qcohBNSlizzxNPjvShpr29kqDYvLNNIfzmz2W55+/477Jog1FpjEEYQKq31BTkksDL4jF4jwd6xLDLMi6+Az4LdpiUhQ2OlNdm65ZTanH/9WccUGceJpDRESaqGIKYkeR+YNTmhVutY4qaqyK1l6HtiDGzazQrJvUgS6k7Mf0/39/jgyYuCPM8JCFTdatn4S5kjrYYQkWvEKEk5T2QYR8qi5HB1TXe58Onjz+vzPFu/1z3Oe/msXhacD8hyXgZoav08jc7LImIcKQqprDi3ME8TVV3TNi1jv3A+n8jzgryQi2ZmRNeekLRgVZaMlxPj0NFNC5MLXF8dKOtaAPuxWoHYmr47s0yTCBa8J88ymqoSxpU2kgROSp5tMVKUFVXTMM0vwlZE0mDb7RbnPI+Pz7h1QKe1wRpFSr8cRgrIoFwrRVGI7v3h2FNklt/Xe4rMkBUlaXH0vUgUNrXUG2YfCD7RXWQIotezz6Yt6YeZp5NUFcsiJ6mA8eume5nZNTVX21IkB5NAqEfHWoXxOKMxMYhhzqwwcrRAaYeJeoU7f3nueLqMXJuaspRUybelqHMOn74NnvRqvpRhUVlk1IXFKCULpQQhaQKKgEJpBKgKhKTWirFZ+Xxiv8s08tfHREygkMVYZiSgOgbPx4cjxhj+rqnJrMRZhmnh89OJbYK2KlbLpPzem6JEKUUdPd248OnpQl0WvLuWOrfSimleOA0zVVmwryyFSVQm4XxgclGeW0bwD1IfnF9txVYrNJHkZ7yPLEtkIrLg2dYVm7rATQPzPEvN1Ggyo8iqjH6OknZCEZVeK3YLwzBK7SXLhL+2phar0qB94uksgqB9c6ApLadhxoVAXZVURU43DMSQuLuS99XT8UiICW3UauaTgbZFaptunjDWYO1GBjLLyLx4IhoX4dhNtGXO97dbumHm0+OZMrdUeS5VtUnSLtMsi5wYPCppvGYtpiWCD8zLwrQEToMnM5BbuIwLX08D77Kct23NpWetvQtTzKoACnJlyLOCqC0p8wyzY57dmvaO7NqWTV2y39SgElWRkxnLHGacB58MESisEXMiInEwCnIjyy7vpcYeE2R8G9YKC8pogV2w8sUW9401mX5RVrtxFNlH29S4Zebjp4+URcnbN29ICo6XF/p+4v7TSRoM768I0a/VdsWyQFs3HHZSV9tfbYhRBhzWWuq6JQaDA7xLjMNEu6nZ7jZoneGXyDQtXC49bhpxY4fNDWWssEZT1xUvT4lx7CEaVMhRmUJliseHZ37+6WfevnnL9eGGoviZRGD2M2YWm6dZB4lKGVLUpCDPEGVEFnU+X/DOCSJmnplnz/fthqZteDg+ohw07QGjFMYKTUcwM5Gr64YQogxTlObqekdZFlzOEy/HE//bf/pPaKP57//9v5fBO5HT6czHjx85XO35H/7Hf8+yLNx/vccYTdU2gIZgOZ1P/PjnP1NXBe/eX6O0DL26ruOnH//C9e0Vf/jj72jbDYfdgU5bpkEQBN9szFVR010Gnp8emP1MRM5b4zCzjAvL6JiXCTphn+4PG2J0HI9PxKRWAUlJWVWczZFEIBIJKXAZJvSp43S+MAyCFDDGrAlpQ1VWBB/4/Pkjzi+8efeeui45nc4457i52ROD5/4oAYZ/+LvfYrVlnj8TA+z2exSRD3xcJUIRYzXNpgZAJcQEO3mGQXiW1hqeHiuuDgd++8OvOR7PfPn8IAPsVe7y4eeP3Nxc8937d2I49h60JVM5Gk0MYkDthzPnS+KLe5Cz1q7l5dzx6fNn3r+54fpqQ993PD0/EV3ARPv6+eLDjA8LlYassAxjR991nJ56xstEW5Uc9hs2mxptoShqjMn4NFx4enrALQ6joG1q9rut2AcXR1HWRAynY0/y3xA0DcuUxGrXNGSZYZoODOPI/eMZ5xIpfWuEzHj/t1mF/+bBU241KSa6lai/qQqqqhLrjNbEaaQtLX/8/W8l/m0EgK3CItFIt6CSZpkUbl7E4jEvuPUAzNAxDQPjMFA1DTc3tzjnOA4TdgkULlIVGdf7vcRZB9nmPD49czoLTDzGRNlsKYqKzJiVHQFXhwMKxWWY+F//+Udcgru7t2uUMrLEhJ+cXNq853e//jX7/Z6n45FPXz9jSNzsNti8JNmcq0MuYEmfWMJC3W6oU+J06ZimATfPJBKncwco2raW7WBR4b3nLx8+kWWW68Oepqq5ud4LfPHlBaUg+oUQAm0p8fLj6YzWhrs3d8zTxNPj46suNwUBW+93G/7wm18RklS89rs9282WrChEpZsUuVao4GnLCuc9z8cOlQI6K3Hjwrkf2e727A9XlKXE88qqFoV1ECbAPI+E6IkxEbXwN4xWnM4npsVRZmJB2m62NK2kyXQShsw0jbRVQW4Nj4/PPD0fyfOcuijEEpeSxC1Dz8vLkeA9u50Y1vq+h5QY9wL69dETYqJfLVtqvUD//OUrWiu2uyt8jPzTP/+JPM/57rt3FGXDMgcSkaq0WGsYZjED3VxfgdKEGNHWcnN1Q1GWouIdRk7HI3VZcL0XQHVe5AzTzNFH6s2eoqy5PWz57u6Km/GKu9tb+fkoQ5nlVCSyrCDTMPQ9x2GgbWrqpmYY5XB97mXI53xg07ZMLnB/vJDnOcYYTi8vYkI4XHH95j3zcCG4BaMU0xJxXYcyFmUMZV2z3bR479hutzRNTfb0RPIeW0rKIx8nAppCX1AhMntNsIardvc32wn+W3jlucSHnXNiJ1tNZ9raV6Cztpb9N/bMGp3Vm63UJxZhs5k1FfP56728n8dRQNBrOsOFhM0yrg8HUoq8vDwTYyB5L+m3/Q1Jn6R+oTXzPPH4uPD49CSMJytD6zyzOKfxXoDnNisYp5mPnz4xDD0pymYrhCgHWK2Y5pkQIre3t9R1wzDNnLuerKi4vrllHCdCfBKekM04nS8o1ZEXhTBYJumi+8UCaQWoKzH/gRjZQuDx8ZGiKKlXRfZ+tyWEwKXrXgcySmfrcDPncj4LVyuTxGz0XpgKgMlydodr2qblzdu3LPPM8XjEtw37/QEUDINE4M0KlzZaovLLPL/+fL33OCcm07JsgLjaPqTOlRnRkccQGYOYpmIMVGVFXe+5nM+cTieqssRmGVpFjEqk6Ahu3daHIMDyLOfSXeiHnqauZYDmHCEEunEk9cMKYBeIM8DlckEpxeEgVhBlDMTIy1EA6fOyyGCrLuX9ZzOCDxwvAmLfbbcYrRn0iEKtFxXH8eWZEDzXt7drCCxKbaPIMVozjhNucVJrspayzFdZRM48zVy6jhQjeWa42u949/4d4zjSdb2YrJwcGLdtu7LGBJAqhiupQKS1UuVCYA6RqmlojGWaZi7dPVm2JqViwhizpqmMcNe0ZppnHh4fyS/dmqRL1LVE+GUYp4irll1lVsx6xrx+Vu8OB2GmLRPRLRSlDMd+Sa/ddrvy42SAeLUVlokyOREtZ6sY2a5KaL2mfJpMRCbTnFApkZtICDPTOLP4wLTMLF6zhCCsMe/RJJrM4JaZnz8/SO3VWgqjebMrcD6weEOIinn2wv0JHqOFrVasVi6tFJd+xGix4DnveTw67Gq600qGCDJQDWISRixBeWbpZzHxoqAsM7SSGlWuEzol+rU6t6klQTnMC8OUKJQUo916AC4Kqf2dLhemmHi2ktC52jW0ecb7W0lxnQcRwoR5IaG42W8oM8vTy3EF14oQxQdP9BG3yNKnyjS7KuPdlcgSzsOEVRlWi6GSsBAxBGPJipyyzSAmglsYl8Q4JubFEdFUuWVTabEgIyyi3CrU7Iizw0SDiYolRVxUAk3WGuekbpjQZCYjWxPLuQGrElUltt9vPKHnfkINoI0smNpSGILHy8C5A+fl+Vyut4PFpRVOZDBKkVuxsU4OTEzrcDlxGmYgkefCm/v0eAbk55y0YrupMVpR5fIceTp1OB9oG6npFmWFtp79+rm2TCPT4jn3M2WekdsaazVVrhkXzRzFwJhZSchtmpJt23C7l+/9OI2QAlWe4de0HABRYZYFRRRgf2boBoEvF1lOZjOe+5nL7Jln4YQtS8CrQGWhtJZ9qYlRzhQPJyfYAqXEphbD+s+1ax00veJHqlwWKFVREGNkWALORy6TnDHuKvlc/aW88ky+58MwkmLken8jSwZrQcllNrcZJsiivyoLoKAqC5Zl5nI84ufE+VJy6c/cP35lHCbmKUBhSEoWDdEbyjLjcFOtw5Ynvs3vdvsdf/z9H3l5eeLx/isxRV4eH+jPHR9+/iTtA5OT5RllaXDJ473n6vog2IFu4n/+n/8T0zRzdX2QutvsmfRCcIq+k8/8m7sdu11Ddzzx9NVT5CW3d7eEpOiGhaIssFnGw/Mjj6cXdCbP6aeXM8FHyjyHBMfjGaUUV/sNRkmqenYz//ynP1OUBbumRavAd9/d4b3n6/1nrLG0RYvznru3VzRNzen5BCS2283K2VxIUZGiQyt4e3PN4WrHv/mHP+BDohsm9tstTVVhrMGHxDhNHC9PBB8oqpzZDUzDQqdHrD1z6UfGyVPWNfsr+X75NIMOmEyGEjEZ+c+YCCv0vSxriqKk6wZeni9iIM8KqlI+S7RyhNDj/YT3C5tCFp6fP33iM0kWp4Xh3fs3cm8cOqZlZh78amzNAMHvKKVQ0ZKUYh57Fud5fnlBaV7FEP/yp79ijKVuZdj3418+oo0RPtcm5/33b9FK0242aGu5f3hkWRw3t1fCX3QTaLGON01Df1k4Hjsenh7ZbjZsdjVZVtFuanxweIwsT7PE1c2O3/3u17x/d8sP799BjKQQaZsdP2TymT6HnjDMDK6nrhuqaoc1mSxlZs/SC6KoyEtO3cDwl0/CV9SKoRshjuyvbtjsr9BJQZLlzfNqlVYaiqqhbSuurw9478gLi9YRH0ZZ+imP0oqQAjEFqtwSY6K7DCitqNstfyPi6W8fPGVa4VNkWmFZVZFTl4VUMkgYAmVmePfmjaQHLmfkNOwgBFH2Jo03Gp++9dCjsIpCgFl008uysNlsuN7vOZ4vPJ3OWB9ZIpR5xratQVvmqBj7C13XgZJ4Y9tu2LSSJjIrM0IpRdu0GG24f37m8+Mzt9dX7PYHxqFnXiZ8SPgYJNnjHdu24d3tFT99+sin+3vaPGPb1JgsIxlL2xRYq7k/TSze0TZ7MqN5Pp4Zx4VZSTWn70eU0vhFEg7a5qQI908P5Jnl5uqKoijYti3zstD1Hd57lmnAas2ubSmsoetHqqrk+vpKYqZfvuDXKa1wCzJ2m5bvvnvP4gIv55628bRty7R4LuOMIeGMPIrLXNgK3TBSZIZyNb6M88JWW+rNTpIvWsmBRRvmlRXjnHAHlC1QJhcms0J61eeO68MVeVZQ14Uo2BNyoHNOLkFNJfDik6Rx3r15S1kVZFoqEpP3hCVwPp8I3tM0G2FOTAJyn5dZEnZRuvejc7JBRGxQT8cjWZbx21/dMM8Lnz7/C3Vd8/s//JG6kj62pEQmAOb1799uWvnnLQ6tDZt2izaaxYvBaRxky9zUDZk15JkhhAR6ocgLqu2Wm8OGNzdX7BbHYbdw6meeO+ETCBtACzh3mbmczxgtFr5Za1RKnI4vHM9nmu1eWDg+MvQTmwRFbrl0HV134frtD1zd3OH6C36ZeHk5Mk0T8ziB1rSbLVlmqeuSGCxVXVGVpXBhSJgsF3NeVmB9ELApgSUoklYCis9+OWaob+8XN8vgScxb8sxQRvTwJhlUrQTK7tMK8cvxbiG4GaVZBQGSQoreE5zDrHW3sL4frbXUVb7+PpwhST2obBqqZsPiPEXRA+CdY5wmhnFiu9ux3e3JtAyeErIBLUvZrE3zTN/3KyknvdbCdGbRWuGcY3Ge7WbDzc0N//SnP/PycqQqchmOLAvzLOw2bQyXrifEwJWRarB3kqBbnBaApZvXQUFYtxmOZXGcLxdK56gq+f1uqprFLRzPlzUq36C0oVotbeMoz8DMyEBLAOTr4Mlairxhs9lwdbhmHAf8spCUAmMZhoHT8QWtNRGFRp41aYUcpvXS6tbnkjEyVJHfb7l4aiV8M2sMixd2hPfulXtVVzUvz890l4vUljK7/nvSypLwkhbznrqq169pIEXhd9V1jXUCTn56fhHrWpSBk/ORRKIfBkmReicDT2MgBBmmK0mX6nWAL88IS1CJfphkQXFlV6i3XCgF7u4ZOrEubrc7vPcMXYdSUGSyX19mGbIpLdvCPBPbXFnV0vf3Us3OrKZtG97c3tH1PVmWc7l0TCcZjFWVAJu1lgrqN8g4yLM9xoCPCR+hLgqqqubSDTyfTjR1LdwmrcnSus1XUgfOsozz+cTS91g7Yoxls9m+bkJfQeZB2DAaszIVNL6Ty3bTNMQY6c8vxARV3cgA6xf0qivhaI7LDAna1fzGygWL3qMS1EVOTBEXJOmdGSDBEpA0YJZYgmcehUUmv4WKxQuHyBIwRiqW3eR46gZsXpCXNTdtzq7OWJxmdIp+CrINnhb6aWLbVOyajKrI5DwRE8MkS6GmzDgNI/00s60r8kIS4QpJhqTgZUmjtSAAypxLN7wKB/LMvKYarZKaXTeJJfRmvyfPLaduZFoWtF3h0ut71Bq1wuodzke6OSMozW0mdtPDVjE7z9P5IqDycSTLMnY3G4yGrhPZiUpRtuBhlUO4ADFSWE1dWK7agnFxTMuM1VbqvN4zrc+zmBS5zWmammWemfoBH7ykqaIwu3IrtS0f4yrF0VgtVe8pBUz06CSyk5BAJ4Flu5BwLpBlkmT6hqGzJDRQZDnJKpbVWNwNI857tg3kVkDJAOduxHkxHmoFuhAotgtpFSpokRlYQ/Ly56X2KBeZYXFo4FDn+Bh5OfUklJyXjaGuCqyWdLb3nvNlWNOvufB1cnlOtOWy1qdm5sUzTiJjEMj7+vdHSbwZqyhyRV3l7DYt29qTXMWxH3k692ilJNkfNTEYIsJVCt7hk6O0mtxkUs9eFqzJyJSmGx0hzeRaUrTeB1JIbCoZVGkjQ4MvTxeGacEaI8m9NVGaW/tq5PzGg4REQcIgUOYYI2lyUi1zXhiK1lBkf/O17P/wL2sVMSSGaUaj2TVbiqpYL7tqXSRY5GqiUDoTvmqWMQwd3fMDwbHa0yWVHkMiOMgsoJUMn6Imywt21xueH48cjxdi8sTo2O42vHv7DqXg0ncMlzP9+cLijixL5OrmwPX1AWsNWaYJTtLmbbuhbrZ8+XTPxw/3tPuKdrNhGgbcvDArR/CKcZpxfqauDYfrgsevzzw/9WQ2o9jn0gaaPXlmyXJ4Ogri4vpWhFnnbmCZFkorqZauu2CMhSiLvJQkwf3py1fKsqD8QWO04fpqxzhOfP7yFYUhbQzaaHaHLUWeMXQDxhiaumZZFsaXcU3Ty+fqYbvh7uaGX//qV0yL4/HpSFNVFEUhJuGuY15muuGM0cIgRSmWOTBZQUZMkzBJ2yxnt7siREdIToYqFmJQqChohrQOYEPwlJWgJk7HnsupI6ssNs/JcxmKKRWIYSQGQadkxlDYjE9fPjGOI9/98I62bGjbPVppXi4XZteRnEElTaZFRqJCJhbnpEkRnJuY54Vz16GNJNu99zw+Hsnygt9vd4To+fL1mSy37G9asspwdb1HoTFWBCrH0xmlNdv9RozWg+APtlsZCM2jZxgmTpcLNtNEPMokiiLHZJaARuuEUYnNtuG7795wddhzc7jh+emF+6+PVIUwmi79mUt3xi0LLCKOybMaozSESHABN3uqpiYrSs7njqfnM/v9hqouceNMdIHd7TVF21DaDI3m06cPIv+JUo97V9eUZc5m2xB8WKufiRDndbHhQZl18CScv+DTyiHWNLutLAz/lufC3/oA0XmJco4UPVZrbq+uicB//H/9J9HVrtP9pKSeVhWr1n6acN7j5wmyjJhEYV1nJfM8MXVn6rblu/dv6fuex0wePPcPD2Idubnm+XTm8+fPEG/ZblqGacINHSoGqjzHhcgSAoVR7KqM4+XC1/uO796+4c3tDefjM0+PX5mmhRQ8bpkZR8vxeGQYeoqqJstzOWBTcZlmPj8dweRstlccmoLSSqd7mCbqKidqzTgvzE7AvJkVeFsqCqY5ECJr/F8u+yoFdPJUmeaHv/97rDVoJRPlp5MwHN7c3pJi4nhctyLtlqrIZftWlVzttlhjaLY7ZucZnVTK9k1Jlud8+vrIME7cP71Q5pZdU6OiJ3nHaex5uh9YedNyMlGKZNQa4y/ZbvcS5b9/pKly2qqQSlBdQVWQ2PP8+Mjp+MLuuqbZbhkuJ459z6YqObQ1dd2QFwXDIjDRcY15L8uMTgHn/AoDjhglA5WiyLlcRpbFMTrpum82G6xSdN0LMUZsZtA6Z3ARHVbIY4qcn+5JKTH08ub/7Q8/oI1hCoHJO7HVGcOHnz8Qg+f54asA8ryjKkrevX2DsRlZURJCXCujC/fnM3VVcldXbNqW79+/oyxLbJ5x6XruHx/XmkjBbtNwe30NKfJ07rA2p6g32Nmh/Mg0efoQuDoc2O93GCUT+ag0s/NoFClG6nZLtdnhowxl67LAGMvYX+hPI8vsAIubZ+a+I7kZlVYjZFKcTkeJ8w49i1bUhQybzscXutMLyyRJhpfnZ7quF6bXOPL5Xuxbv/3tb8nzgueX59X68gt5xbDWMANKKw5rSufTp48ordl9s94tE0ZrqrqWZ9kK8/tWBZGeEoDEcvOsoW4adrvt+gF8xjvPxcmH5/4gw+3T6UTfDxxfnvDOUZYCZU3pX2P1TVXSViV9d+blsePq6prbm1sZNg4DepllaGisMOBiIpLox1nMmjajKUqpWQVJGFqjXlNU2ki/5dsQ4dLJkHuaJtmwrpVX772Ao6UNigtSDdm2jTyj3txJLQ3FvDhJaQK3NzdoLds5HzxjP8nAKc9XQ2fFvCw8PYttKsUESi50yzLx9PRIPwzcPzxIJW67le16Ub1WZeM6CDJGAJExBlIIYq3LS5wPPDw8UNeVJLJWnXhe5OR5jvMj0S+oGITxd7ngpomqLPn+++/l0gDYvMRGZBHRj1JPsXZNkqj1c04OUcvimGeJGAe3kKKjrcSaODtPiIFyTQC8PD9jtFSb8kwkHDFGUpRLclmIDnmYF2EwRU8MMC9OLr/GELzn+emJPLMc9juMta/DNeFOLXLYsZlwtLRaDY0WY4Ur8fD0jFaauq7ZtA2Hwx5rLc8vzzjnxVhoDXXT4N2CW2aKPKfIC5yXi5KkzhaB4UaHQQYkyzyzjCNlbnl7e7MC3yUdFRLYLBOu0MrkaZsan+do/S2hnNZKnSTWxjGuxUNZInXdBZKkyNxaNVYK6mrlyXSXX9azC1gW4W5NiyTN9s0KxH46o1KitAKlX0IgzzNurvaEIAnaEKW2lhlNWximJTGuv+uFFc7jftMSgmdeK/Wjc5gs483VgdlHGajMistkhVOEIbewLRNGy4B52xRsmpLFBY7dxLYpOWwqHo4XzovHebE3aiMXjPOlZxwnef+nRFEU2EzqKc4t8tcngaArhNvmI+y2G4zW9F/FcnQeJwqfrfrxTHh8CVD2FcBvlebuRgzBTVWIqTYm+mnmx48PKKX44c0VisT5vFaflgmzSj2KzHLdFkzzwseHo1SoUiTPLZv9hiKzPHUzwzjz8CLw8G1bEyL/yiFaIsUsAwaVIjoltDbkheHSjxzPPU9J2HXbbct+tyEAxJWfV8u59/E80dQlN/uaafHMLrIpLHktv99KG166kX5wklaNQc4txjBMy2qL9BgFm6qgLHIuXc/ixaBlbMbNriGzmvOlw3mPtcLSm33AxEhd5HgTmIYeViC9UrBvhdu3uEXq25kFJSPGECLdML/KE6xWkoZfcZIxOB6PJ0KILPOCtYaqrNmWms1OrwzGiWGC5xNrTdFSFzn7djXKjRM+RnySRbVeE5Y+SmXyTVXK88nN9KPnpXOcJ0+ZC8vvdr8hroM9okOHQNQyMJqdgIPLMiPTMnhSQFkWoMWiarRimkWOU5WFpJfXYZRZDZTDOK8paeGbPZ17UoLbfSOg6WEBlv9/PWr+q780lkQgrc+Um7s9PkT+43/8z8QYKSu7jqCltrlpE1rnaNvIYrQqsTanKhup5nqPd44QBvK85LBpcUtg0As+Bj5+eEBrxfsf7nh+fuHTxzNPTy98+iiij9xkULVYbej6AZ96NpuWN3dveH565tOnr3z3/Vvev3/Phw9feXx4Yp4nqUBG8EExjI5pGKlKTZ4nyqqksRWLM5xePLMPJB04XB+oqhKfwCdFXdZorZi/3DMMA3WTkec5iog2SM1+fS4YY/DBY1Vi1wpv7O7dG7JceJfjOPCXv/xMSvD+3RvyLCc3DZBwcSHPLXUrraTrmzv6bmAaREzUTQNFkbM9bMBq/vLTzwzDzOP9EaMVefHtPGjouoGnxwcUAsbWWtHUG/n81laGa3nG0E/8/NMXNpuK7abCZgZbiHFWW7lrn05nyiqnLmvGoeNyOnJ1dcf779+hVUKpxNOTnJWHoed8OkviMCWmWTAUeVFjs4rt5oqmrljWO3h3HnDesdsJP2tahHua5Rpl4OH5EaXgcNisA8yLtHZ8oixq/u0//AqlNYvzzNOCVYB3PH15kKZNNxFCZPaRpm747Q8/SL27yHCLZlnlQfePT1Rlwc3NFTYL/N1vfy2L/6rhfL7wL//yZ8qi4nq7Y7drubu9Js8sz/cvJAXaKpQFbGJYeqZuZLfbcff2j0zDwDQOBL/w5eEzdZVTFpaQAtWmwmgLEdqmoWlqQvRM48A0jHjnyYcSpaHatGR5xv6woapzustZ6qBB4RcoV7PhMs4sIxR5Q7SJ+68PQOJ8GZimhS8fP5MS/Pq3vyErcs5P51f25//e628ePCmToUIkJTkkt23LOM98+PRZqkpXN6ulRlHkGW2zI357SKy2o6SVHCGVsD6Cd0S3kBvF9X6/2rgkBXC+nNm1LbeHHefLhePpSNvUDM6LtWWZJZGTZcTkwDmsVtS55X6ZeXx+5u3tNU1dkqJfAWVAVATncYswSvquW1lAcjmxxgjPp+tXYrzEz4rM8HLp5VAUxTzh/L9ePFKQzr4iY5yFK6DWwZM4kBI6ySXpu3fvMNZwf/8Z5x39IJPptm5QJOaxX/kjJXlZCPiyKmmqCh8CRVUT9AJxwWQZzQqTfj5e6Pqe+4dHdpuafVOgksAZx2Hg+flJbB5JUZUlbduQ1npGlmVUTYP3kfPlgqaitGsPtxCNt7GWy+koFw4t/ej+fGQcJ7bXO3ZtLfYokzH5QHSRcZpFfe3lwBViQAUxh2jFqyUpBEkxDIMMnm73t+SZ5fzphXmZabdXq+ZbLhpmvaT03UWqHmsn9fb6CrThw+MzS4wURUFKkefnZ/yy8PL8iPOecXFsNxvevXmDVgabFSgdsN6RFjgP03ph0lInPexlM2M007Lw6f6Rq92Gw6ZkW5fcXh24dBeenjvqOqPMBNZMWPDLwjAtXB12NHWJQmxNl3GiHxecCiig3e6omoZzd6YfR7Gs5AXd8Yn+csZHufR651imCZM8SiXqpsHYnKHvcPPEskiaq97uyLOMoe9kw+ekVth1HdrOdKth8Hi+oIC6KimLgp8+vbzq438Jr5TCazLDaktdVUzTzMvLCyiFsTlaQZhHsjyjqquVcaXW4bF+TZpIRkAGw3leUJQlVSUXQQX4KM+Eqixom/WwFCLzsjB0F/QqMQhRDuBZlKRfmeeUecbJLZxPL1wdrthuNizOMUzTmjBJq5HPEokQRaHt3MJhXwqEeZ6ZFyf1FyP8Ff1fbGOzLOOb8jQGYR+xwpi10oTgXm1hCYlHo9VrpXq33WGM5dz38gHe91ibsdkIsH4cBtQS6devy1hDnuc0TbMOtoJAotM62Ury/+HSdfS9cOPaJrBrGzQyqAjeiQp3VXLXdU1VlaSoiVpjkjBcuq7jfLmsm/8NSa8mNiu2G0USTtuaBJjnkWkaubq5ZbPdMY2DgLhths4iyzAyTRObzWZl2K2TKSUDSfn++de0mNQsIuVqFgwhkKIiyywpJoYVCr5p5XvRjyMJOWwqhPmG0sRRDjmkKLVKL6wnrQ0uOfr+QihKbq6uJOGwJqGsMcwpMYwTRZFomkaU7VqAzdpYFjfw/PxM0zTcXF2x2Wy4u3vDMAycV85eROx9AigXbp7NMoqyQC0KnPDPnJtxi8LqJMO6LKfvLszTRLvdUla1DPNX20tI6+BUrfY0K8+3zFoZdIKYh2JcJQewLGJw/fa+HceJFIW/5b0XeKfR7Hc7qXedz3j/twEu/1t5+ZVr6XzEWoHQLz5w6qS+0hYSbZrcQpNqijyXKl2Qb2qVGXKjKa0mBrUySRSZMdRFwfWuZVk8FzTjPNPPjjK3tHXJZZjoxxnvDOMiJiq5GCWskiRiUoaqKKiKTBZx88KurajLXNKYXpI2Ka2cNpuxOM9lmNY6jJLfOZtYFjkvJm1ACXxbTguRGBV1WawsqCMhwjRL7d8YSed0LhBCIrNa9GPrUHa7adBKs10vuuPimBfH/cuJPMv4x99+j9GKxS0479e0VYbOcsqq4Pqq5XwZ8J8exJqYIDeG3aYhRehGTzc4LoPYmw/r8+Kb6cgFSTGFlMiNosoknWCsJcSBfhyZZsc0O5TN2O13qzlSzjBFWdHPjm5ybNqabVOsNUppGmxKjTIiEHi5SH1vWaQiLH9eibzCydBJr4O6usw5n0/4ZUYXDdZaDrsNRWbox0mGTUZsoW5dzOWZwSgYLj0xgS5rrDU0ldTHjvO0/gwMfEu2RZicJ4TINC+UuaGtNxgFiojzgcs4rbW0RKU0TVbIcq8sOPcD56HHucAyBzZVzk1hKDNDU5V453GLw6XEgixXtRYQvQ+RMrPcbEouOtIlxzFGTqNjco7CKq72W7HoTY7ZBVQUWU+KkgxcfMRFZBioV9iUEsZdRIZo1ih8iCQfKVZmrE7yHFdarYl64U1N08LiPMfLiNGa37y7IreWTy+yOPrlvCQNl0JAZZZ2U9MPIx8/fFnrbFuMtWRZSZkbmkqTrEEpIxbXIscaqT+CIsvkPK90wFpoyoLFyKK/6ween8/s9y23d1f0w8A0ians5fmJlMBqi8rBWLFEmmmiqip22y1fvtzz5f6Bt9+95bA/8OHjPd1FxFEiwlSkqHAuMM0OY6SGWdYNRZkTgmIYgvDatHz+bjYtL5cB5wPK5mijV47igFuWdTED2kDyKyJAf0sXh/WuJs/R9+/fYIzl6fkZ30UeH1/IMss//ts/UJUVyRtCiAyzyFrywlI3JTe3t+TZhdx+YZkjzkXyHKqmJpG4f3xi6CYevxyp65Kbu+16zlVMoxiHhZto2W+33N3cyHtbKWHMZZZhWhiGjsxoDq3UJ/M8J68KGUpczizLQlUXFGVBf+noThe+++573r2/I61DcrckUjIcjx2X84gxXupe3pOSGFONsZRFTZFXzIPDLZF5dDi/kN1oitJyHiaCD9RtiTaKc3dBKWgbAaxfvjzgfCA3ljzL+e6790Tgz3/+Gbd4jFLEGLi8nIkxMg2ztB36kavDHvObX5FlkswjJYwS4/vL8YmlqWg3GXmW8fbuGmNzsrxgGB75049/5v3bd7y/e8ft1TW/+fWv6M4Xnh+fyIqMvC4EMKVhCTOX/szN7Q1v3r7h8vLCRcHzKskKocK7Qv6+KgenISrKUniH5/OFcREemnOOZZ6kTdGWIvhpKvJVMDansPrJElkh1fZ57IUhnNckozid7vF+wTvFPDvuH2SY94e//x1lmXF8eMEt/5Xh4h8eniFFjM2JKP7pp0+gFO/evJXLeZ6hlZYKi9L0S8RNM5fjM1Xd8Ps//JFxnvn09YGqjLxpa/K2pPzuO7TWfPz0SWoDuwMmG8SakRWEmNjvd/zbv/83eO/581/+uh6iDChDNBmbXctdntO0LapsKYqCJpd6TTfObHYHfv+7P3K8dPTDyKaSYUrz/XtiesfLWcC+drPF5CVWayyRXZERcznwLgGp1ywLnz9/RSlN01Rsyoa2rsgzS1NW+BD59L/c0w89b68ONE3Fm3fv0FpzHP6KD5GHlxe0guPLiRgC//j3fy/w40zsIPvrW9w6JBnznDpTmGHm66lnGAaenh6lAuYTfhHLoFkrOqC4u72lrQuquqGfjjw8PJDnGe/fv8P58FovM0o2jJfuwmaz5d279wzDQNcPlIVUGrQRmFs3zIxLR8Cyv76lbqRz++7NG95c7fly/5XPf/5Zuu5r1SbPZKNdVQ1PXz8xzRN32x3tdsMyyYPhNCwce7GJ2CyjqUWT/E3PfX3zRixeuWzKvVtEQasNJjfs8xKjNW1dobTh3I8EFDaraXRGcSMVv5fLSF6W/J/+u/8eFzz3T0fZHMwLSht2hSEGiM7QFhnvd2KcmiaBMvd9R1OVlNmeXVPxx9/9mraquN5v0FnG0+kkl4Cm5njp+PHDJ3IVqfOMMsvYti1VXjDPAj12XpKDdVUID2uFpKMS26alrWqen194Wn921zdvOF46pnlmGjpUEGtKTImq79Fa8ZefP3HpBg77HWVRiCUlpfXi4MhzSbtMzqNCoixyitzyh9/+ILwCH/Bxkp/dmtL4JbweHp4kCtq0AHz48GGt6Qh77RtvRFtLQjEMg9TwrLBy2nYrLJrnJ7JMqk1ai7ZWa8Xp+IL3Xi47KeL4xhdStE2NfvtWkijnE3XdkOU5bhrph4Gmqri5OmCMpFWyvGB7uMHHyNPjA847ysxCWUjNoKwESL1W+56CJzqRJEQfyL7ZkqqKhAwhxmEQTpLWDMMjKSXqqmLTbthut2RZRkoJ7z1//flnfAjsanmOSlcejkEGIMeXJ7SRNE+KkXdv36CVYh46YooCsvWeeWWlhFWV/nX8KnXBoZeUA+AjUvOJYm1LCa5vbymyTL4fbmLsO0l6KUBDMho3jzw9CDD5W/qpqiq8y3GLQKpjlIFTYSUZ1Y8ihDCZJHFJibqsyPKCl+dnPn74WQ41VobQRVFSN/61Su7mWYYkmTDrYghMY888DWs6DvIsI1krNVab0az/P4IPrxW1b99n4JWvtdvtV7uixnsvteYY2Wy2AHSXM1mWcXV1xTIXzMNFbKp9R1nVXG8P65DPYvMCkwnXQODzwqvQWlPkGU1dc9gfqOqKpm0JIfL5yxfh7HjHpe85nS9stlsOhytYobhlWaxD/ESIgbrdUDZbYa9kGaxp53arqZsW9V/U8r7ZP0OM8j7MMi5dh3ML5WoCPL08s8wLZS0VvKZphN0zDHgvKUGz1g6AdShvyewGFIzDIHBem5OZX86zC+BlFIh3udZqj6th7XovF/c6N/gQOHYDKM2X5wsAFkWRGw7bmmVxfDn1/8oO0VK7JEUeHp+l9lrlAvse1GvNMc/E9OpC4OPjmX1bc7Vr6YaJc9dTlyW7piLPMwE1oyAlZue4DCOKSFuJ5VeZJBbETHO939CUOedRANFNVYqJTkW0kp+j0obF+VdFc4zw4eEkKdW64FAXAvJ9rVMljp1c8g67PVWRsW8KfAz8pz9/IcTEr9/dYI3hMsx4H/jde0nlPXUDViuaImPRmm70KKOprMEtjv/lnz8SQ6DIcxKO58tI7xNjFLOpVZJo2WwaNnXJpqkBzekyv35N2frXKcAFAc/GecFYw93tjdRfQ6RuapKyoMT4Oy8z07KQG83d1R6lFC+dYBKaQ8OxH7nvJgGqG6lOZkZTNI1UZJUY3bZthVKSVI0x0c+eOSRhGblAqR2axNB3eCuVvbLIKKx9HaLFCEVeonJhOwHkay02poRHU1Tt+oyX5YIk1zTf1TnORx7OEyF4nk8XmjLj+7sDPkSskcGT89/4sJ7ROY7nDk3kUIshLiVDnmnq0oI2nMdlTWjAZZh4Og80ZUZbFWRJjNshJZ4uUteKSCPjegNtndMUYhs22lDZQE7ksgSmVRqklLDSxC4qF/eXY8+yLGgjw81hWkgJylwG6uPsmeZApqQa/40DGZKCBGWxPr8ys7KhAktK1KVgL34prx//8uOaiGxwMfCf/vOPhJi4upVkypvba2IKnM4vhDjz9WkgswVtLWmVN7d3dF3PP//pn6irivfv36JUS4gHSHD/9IS1OWXd4L2nsAarFCnA9eGK//6/qxmngb9++EBdy5lncQvTMtNuGt7cHWjaDZObsYVhdxAg/vHUURQ5b9/fMPQT8ySVvaapeHOzJ4bIw8MTXdfjl4AmEMoANnJ3ewNKDL8PjyNa5Zik+Pzzz/go3Nrr6ysOhwN5kZO9f4fznv/1//lPDMPI7aGhriv2V1uU0nz65Ak+8Px0wVjD5dKjlOb/8j/+n9cFUSnp9Cjimi9fvpJlGqUnuq6j6zxDP/Dw9EUqdJcL02hZFlkaFoV8tt69u6GuCg5XG54eX/jw+AFjDO/fvsf5yLJIcKKfZ3x/ZplHmrbi5m7LMCz03UxRKJbQUdoDdVNz6i5c7h9Y/EKza6mbmjKv+dWvRBr29fGFP/31Z3Jt5d6dGbSBpjHYbMPldGKZPTc3AmQf1vTOl6+fUAqqokIrw26zA2C321MUGRZN8BGTSz2wSMJznmZJ2V7t9mK23m1W267Yzo+nJ7z3XN8ccG7h8fmBuq75H/7dv2OeF/78p79ijOHpeGGzSfxwfUXpS1SCoiopqlIW3TEwT4HL+YXNbsu7qwPX11f88Xe/5vr6jqvbG0IK/PiXfybLCsptzf39Iz//x0/UdcmmbajKnNvDDZtN+xoaUNrS1jV5btntD2zajfCeU6LIKqzNeXj8wvH4hM1KNrsd4hOaMEqjY+TDTx+Fj7k/YG3OX//6mdP5zJs3C03dcDjsyPIMt0AMCbSwnYwpUFjyXFPViX/8x39AKbC6IHjIqgKd/1eu2r10PVYrrkrpJn/bFP32/TsyY9BIEspkGT4mLtPCsnimaaSua25v73g5nxl/ElVjZpBtUlGudqQX6qblerPHhYSxI0obQopUVcW7uuHr/QNfvnxh2zYU2y0oA9pSVTXX2w0qL0hWzB1lJqagefGUVUOWl0QlBoKyMJRWUzYtNivp5584dcLb0N82soDJZIg2RXBrYiIFz3noCREOm5pNXb7WBnbb7eshexgnSX7VlVwgtCQPFh+4fANlDyOZtXz/nRihTqcTxEhdtwz0DH2PX2a6cYfSjsnL97Pv5d8fWC82KDJraVMhmsu2oSqytUee6LoL+/2e7XYrELdpJoVAXJM/l76j2WzZ73YoJbyYLBMWiXCytEAeLwNGGcq6JcvlgtdsWnLT8tPnz3x5Okq0Wmm+uz1QmIayrMFkvKxVi7Kq2G62zLko5O8fX5jmhU2VkVlNWQjsWSw1GU2zwQfhWaUYcfNEDBG0laltmZNnGTeHHSEm/vL1EZcgrwSQXVMz2Ynns6RZfvjhBwE9mpx5nhm6Dp97cqMJyGGqsIZdlRGVwTlhvPR9L5ffGCiLjLviiiLPqWtRU1+GgTKzNGXO9PjMh89fuNvWbA6b15qLzawMd0IgBrEzFVZTNzWb7ZZlnmRAVIgt4+uXrxyPL7x584am3dDPM7NzuGVGR8cUwCdwy4hOkaeXFy79RF1VkgREEgSLC7jFUxaNVPdCJIVEXQrs095cEUNg9IHkg8C3+eVwUi5dR55l7LY7YoySdELMFsZYjKzUZe1EEpi4Npik0HlOUZSSxuu7NW1Ty6ZKKUJwjOMASVJ4QSGH4PXwmGc5dptxOh05nSbyvFgPsqK9b+uapmlwToaR2mRUtdTa+l6Ay3ZlHoBE+8u8ICRIKXGxhlEBUcwT3wZemclACaNknmeMNmBYnx2Bt2/e0tS1cKWyjJSidMiRC0ae57K1XS/7cR2Y9H23Mpf0K/iatF5WvGOa5ELnQ8AEqdfE4BgHOagv8/z6nJUhRpRKSvJkeS4wda1eBxdunjBGYzO72oAUbpEElM1yskKGpJkVgHa2DgNTktSWzTLmKbzW1bS2RGRolhUFZdXw6dNHvn7+TLvZUlQV211GXpQURYlRWoQKwcuHrNEoa4gaOcSESFaUqJUjpVBok4ntU0sFKqzfBx+kxjb1Ip8oi3JlgtUoJXr5ECLezYCibOUCdzq+CPS5qsiMlgHXasmxWY5d4fnpW5XJWklaOPcafVZrIirPM+oVil7kBYtz9KfT+p7RjMPI8/MzWV6s/6wIUaD5UtkUe6LNhVmYW4FKhwgxpnUTKoMH7z0hSW1Y0klevuYsk2fv0EvNWRu6vmfoB3ZKkVJJWdUojSSMF2GopCj/HuEainChbmpSgufnZ6kIZr88uPjoEtZAWwpzYRxnjNHsthsya6iscICG2eETnIcZoxW11eTW0FQrYHt0lHnGblfJeyHLmcaJY9dTVRV1U8lFeq0UKyV8myK3zL3n1M+UuaRDnY+cx2UdThswmrimQlkZS7NzKBJFpnHJ4BXy2aIVTVVQ5hkuDfi0UGSZQKfxKKJUSowRKLQPkAIxJkl5Jfjdmy1NmdEvnrAyEAVeGyXhkufUVUFdFczLwsulZ3GB2+sDWcbKI0rcHVpigud+wWrFZiuA35jUmpDQUrG7fxHExK7G6MjkIso7ligMxypb4eplQbEyi8bZi1o9gSZgtDDnSBBWrqgLnjzPhV26xv6+JZckVCOpysXJ705dlgzzxDDNVJuGTZ3z9Txy3znazFMYQTtYrckLgTi7ZSIGT1nkwuBQktqYfWAJgckFlhDJoyQ0l3kiBUlSZlbOWAq49LMMkQp5xloFqESWizl4nB0aSSWklFCE9fmXKHPD7a5mCZExKsZx4ulyJLOS6IhBTHU+JBYj7yGiQNyP/UhTSGJJaYs2BcYoMivGz2HxWC08r3HxnC4dVrfsNxUGjVltUv0k70eQr6spYVeXtE2JCxAi5EZ+7h1SpdZr6jmun68xyvP80k8M40hTF1hr6OZICDIQz7SkaWJMJJ3QSoQYMUaSku9/tso2ivWi9q1ymtkMyy/n+fX49Cgc221DSJHHL48Cbb7d09QVNzc3LG6iH5+ZZ8+lG7HGoYKkozZvbhjHiYeHr1xdXVHXv5GFnzEM/cDj4xN1De12i7UCv5djulSiDrsbfv74M3/58BOJKOf14Jmd42q/5e2ba3xUzF6GiFUj1f5xWrCZZbdvUcqg9ULb1mzaimJdLA3DyOXSEX0kKkkrAWy3LVlm+fjpE33f05Y7jFrlQG7mj3/4HdvthrauyfKM7W6L857/Ofxnpmkhz7bUVU7VyEDJB+GPdd0oMpJpIc8zfvO7HwDF89MLzjtCDCxOFpxZZtjuMuZpobuIkbzrLyzLzDwPLItinifKomS7VTRNzea6oaoK6qbm+HJk6Do2mw273Y5lWdsoCCdwGHou5xfy6o7NtpJWQAKbRXyY0TqRFznzs+P55UhZFxTVahA2GfvDlqap+PGvH/iXf/kTZVaS24w3b3ZstxVFabC5pb90hABFWdBupPofg+N0PuF84O7mjrKoqMsKbQxVUZIVllSv0gotvMsUDCF4et+RYmJftxR5weHmIGzghyNDPzCMPQq42t2wLJavTxKI+PXvfsMyzVyOFzkzjZOcPYuClMV1sZ9TVhXTOPLy/MTsHZeuJy9LjLU0TcXd7TW73Z6mben6I4+P9+wPV2z2O/px5M9/+ZkfvnvLzdWezOTkWYGywkL8Vn8sipy8kHnDdnfALQvBewmDFBUPj58Zho7tvqQoS6ydMDpilEaROL0cuXQD1pRUteL5+cTT8/OKAIlsNs2a2IcYwMQo51ol4iqba7RW7LYtgtyIMuTLDHJJ/t9//c2Dp01RkFvL2+st3juGcUCpwOwWrK14//YNy7Lw88ePJKCpWtr9jsP+3wOKHz98wnvP4XCgyC0+KpZp4nQ8k2eW6/2WOSR++vSJru95fD5SlQV925KXJXXTkGc5N1cHmrphs92itVq16AV5mfPzx4/89OEjm6qkqVsyrVFuou8Gun7CGsXNYcfz8zMPl463d4r9VlOXFYcDFFYsfFqXKCuA7MwazDjJMAlNTJrDbkuW57x//566rrl/fKIfB2JSqxZXKoDayH//6cPPoDRFXoIyfPpyDyTu9juKPGdeJFXz4csn2ShVLSkGNtstisTxdEIrhTaKTBt++P4HGfAkzeKdbL7LjKuDwOY+fvwocEkj5o2r6xuSX/jpx39ms9tz/eY9yzwxDh25X3W4wTH1Z47PD3z68pn3d2/Yb95grUVpyIymzC2n04nL5ULXXairYr1gJ7Qy/OqHH3h8eqbrB27v3vHD+3d8/vqZy+WZq33LflsTo2wTmqqgqUp2+w3FvNCdjsTg+e137yjznJ8/fmKcHe1mQ24tbWlRKXLuR6Z5ZhxFp/pv/vAHPPAf/u//D7z3bNpWYNLLjAJSXDDG8Pe//zVZJkkRrTU/vHvD+XLhX05HFufFrrgmiHyEOYrNpy4sKmpGnfBu5v7phcVHhsWzqUtu9y3dMPJ0vPDuzS27X/8gavKqQFvLFBPaC8um0PKH1oayLER7nBTTOBPCSR7+24a+7+WPUSL4T8/PDIMwrHZtzX7Tit63KDHG4KZRKiflhnGR6k9CeD51XVIYjXcLT8czyzBJrcEYOSgqJbwB53k+CdNBxcAvyenbNDVZllPVNTFGmnYDQNVsKIqCw36P846Hh0fiN2W7UmRaEf3Cw9NECIHtbk9ZFlijCSEwjONr7TOkwLxIFWyahFMyjIPAcosSpTSb7ZZy3Q63TUNRSCpwnhfOlwvny4WmrqkqqdaWRcEwjsyzGG/yvOB0OnE/TVxf39C0G4qipCwrlBYjo5x9NFUrX1tW1Djn6LoL3nu2OzGrNU1Dbi3d+ST1Zy2pCVLEao22GcpkhJWPZbOMmCLHF4F9H27uyLJsHSoETt0gNdok8N8iz8jWQWtKUYa9WrPfbiSlYHNSDIRlEQ6LkZj45fgsg2eb4UMgL+u12aYoioxNnuPcwjRNa30yrkmlbE33TeRlhVmj+cF7iRmvsXazXiJ8iHSXjmkcKfKCu7fv8EHAs01Zstu2dEaxzBalk9Rb19pkmWdkNiN+qyKuEouyKlHA8fgiiaVGuB2ZtfKBf5S4+TjPa5KuRafI50/ymbnbbuW9sT2gjKbd7FAkmqpEK0lDoTTv3r1fE3RnQoxMwyDbvGnAO8c8DpLIyzL5eeYyeDieL7hlYRpHeZ8nsTJN8yyJk7ambRvu0h1VWcqQPyWS0ngfmdJC8EFqcDEQ3cISxL7IeqUbphG/yAU1wivHTGuNLgqskWre1eHAbrslX7lWu+1eOBVlibYZWS4Lhf3+gHeOaZbPYLumucZpkn9mXgJrnSsEknKvVdJfyqu0kjy63stz65mLgFqdw2rYbVqcD/STI6EoSjHhxOBYQuTHzy+EEMisJl8B1DEETsMLoKlbufj89Okr0ywVuGLJmQPolU25rXP2GwFu9+NMU2b84bsbtM0I2tD1E30/Sa1oHTCVRY5zgRg92zLjqjUiKDhN7JqSbZ2zzDM6KqrCkOWW4OR3MLeKLJPzVm5gmjw+BnZVhjGGTV1S5VaYTs7T9w4f0ppCNSQ/4SbHixtYfJAFlY2MXYez5l9taLnB+0hcJmaleJ5zFIbdplqxC5K42jcFKUHvhXF1s6sxxlKU5SvD0/tE183Mk2cYnVS7rcJ7xRKSgK21JJ0FRm2wyqx8MzkXPR8vXF/tuL3ao6IwVWVWYhjHibHvmdaBEc7TX3rc5Ci1JBLmGHl/s2PXlsIlChGMISroJ0ccHXUpbC+dpA69qwt8sDSl1KlPgyMmhzYCN9+UUk2+DDOz8xw7kSWUZQFAd38iJahL4Q8mnQEJk2Qg1FZyTpmcPHPumozRJpLfUOYZk1tr3z7IQkUpeZ45hwtRPl8jdJMnhJnFndi2DW9urxi7kfuXM7um4G5XkSGgfB8C3eheRzjWiN1U0A6a5y7SzQvohcUnPLLEy1KQepy25EX9Wq8uc3nubEpLmSl+9e6GiGKcpfLb1lIrnBZHP82SPrOatq7RSvH48sISAsoAKXE+9aBkeW2NwNJjSozj+Iti1G12e6qq5O7tW/m8WZPQhc0o8px2Y5mmDBULDIq2FQvxfrcHEp8+PTBNM+/evmezaTAq4uaZfpCK9c3NNfPs+fDhC5fzhYevjzRNxTCOtJsdV9cZJs+4vblm0zQ0VcV2s8PmOWUuCIKvn7/y4eNXmrqhrRs2Tct2s2GaRoZ+ZttuuL0q+fLwwKcv97x/e8t+t8VoqMuc3W5LVVXkZY4yarXrFrx/+064lk9n+nnm7u0bsszy/Q/vKcuSx/tn3KljnjzeB8ahwy0jWVZjbcXD/aNYiE1GMJGfP/yMsYbbuytsnrE4wTr89PMXnJsheVJKHA57jFFErwlJoTMBr1+9uZEfSkqkkIgukOU5dduyLI5PHz6ILEorUoTbN+/Q2jCPAW0Nu0O9slIjys+M2srzC808Ljw9nNgfaqpDhda5LAqNJrOGeXSMnWPIHVnW8XI+kecyQPzV99/z9PjI+XLiH//x9/zmtz/wchyEhxY10zjSDR3D3LHf7NhsWnZXN4QA4zAzzoHDdYkxmn/+l39mnhcOhyuKsuDqkJNS5D//+U9iVgwaayzFO83kBv7jf/jPkKQllFIiN1JzzG1GWze8f/+evMhJHoyy/P73v6Hre376+SPJrwn+ELgMHc55pkHkMlmZEwhks2aaR/76489yjhkHnJPabdd1PL88Y3TFr39VsGlabq6uqcoK7wJuGRlG4XEVhQzsNtucaZmYl4W+H/CLIytzbJHxfHzAzQtfPn/i4eGRy2UgywuaumV7qNkettRVRbs7yGLAaiKJX//mBw6HPSSFWzx5kdFspMUVvOd0PuOcx6coMPbeoZRi1+4B+PrwiF8ZgfyNS7+/efBUWEuRZ2yaBu8XCsO6XfKgYLtpGYeBaRKL0bbdkBUVeXtgHAY+fvwZYzRt02CtJiaJ/J7OJ3abluZmz9INPB+P9MPA+XLG+RqlLI3S62XCsmkayromLyusStgVUG2s5Xw+8dNf/8Kvv/+ew+4dRiuInmWa6Pqe3bahKUu+usDLZeCwW17Vpw0KFT2KICkfY8myjCK3OOcEALtuP5rVEta2LVVZEcID47yQtAyavtUc0JIeEJaMptnsyYDzRaLy7+5usUXxX3CtBHjWIB+QVVURVz6TXr/OrKrY7/einESJCWruKa0RgO80czqfpOKQZOp/c7imO828PD2QFwVVJewnN+lX9bH0a0emoaO7nHGHgxiYtEYhWnKrDW5ZuHQXkp9ZxkwsLzGxP1xx2O3ka+vloX99c8fDw2f8PFDVLTbLGRapt7V1QZZZqqpEa83zk8fNM1We09QVx9OF46VD2wyqEpKY3+bFMUwzp/NZ6mBrMuLPP3/Eu4W/+82vKEv5+lCKAFSV5e76INBxF1ZWTUOKgYSwdkKQwZMwThDrAAprNFYrjErEEOiHiXFxnIeR4CpqC6dLz9PTM7tNIxc+I2YSvRocVQIdwa7bMqslGegiuJgkIeLHtYZVErpeVNdOPpCGYcQ5z+GwoypL6qamrkraWjYrw0VqWrrasITE/ZevLMuMzSx5kVMo8C7j69ML4zxTrRdl7+NaX4w4F7h0Pc451MrB+aW88hVwnWWyFc+LAlBkeUFelmy3W+Z54fHxRYDXUhjBaNns932/DgurV124d5FlFgCtLXLialr7BsB03jHOE1VZvYKTq7JaWTViiyzLUoxgwcvvf9eRZ5ZNU1NkGWVVMs3LCnsWLf00TpxOR7bbnfxOZhl5XvBfekyTkq+tWAcwwXumWSQPZVWv34tMKnIrq0lnuWjDVwYfK2NF4NdiAtRaLHVmZRBoY4hB3r/TapnLVtZKnkkNLqx/f4iSnqjKEqUN2JzgJMVptFrTmTPTOMgQLAuSOrM5Sgldy2a5PEfcgjYW50RaIPB3s9qDwusgDVajZpTBVwZg1JrggmWZcbNU1Np8S9eLFjlfobXCv0osbq0ihgA+SjLDSCJO6bSyWCRdpYFpfGJenKRDtGJFMOGWiXkSU5NdGQkCND6RgLap5edZlsIxKCW9U+VSD1x8QCvFZrNlmicunYBp3SL2unme8W5hHIfXGmhCljORxDhJ5dY5BySMUrL9XSQJo7Uw/dpWoPTee/ks1N/sL3JRVUoMNfFboiHKc0Qp2aLO47DKK/RrVcXYbH0PCZuvroSjpteUTFWVcmb5ZppcTXxlVREyK3DRELAZgKRglIr4ICm/sNaUtIl/s9L3v5VXZiC3alWNQ9YPkqILAaKlyHO0Dq8crKYU1s44R5bF8XyW80OZW6yRzzUfAuO4Hkyrltl3vKx6+8lJihqTkatAqTxVWbLdbhiniX4Y2TUFh03JGGAMMM2O06Wnyi1FLj8/a81qFFKUmdjfnuaJaZxE2JIbqkzjrSKz8vMOXhHjt9SmkmUgsCDLmzIT82SeWRG0IJy4aRaIt9Fih0zR4xfPsgoSisxitKQ6U9CUdUWmNZnRqCgWq4Bm8InMaJoiX41ukmSochkO9F6GqG2VS02lrGSA7sXENs9OOFeLp8g0TWEIAUJMoBNEgehK5U7Sg98MkdOy8HK+0NbFKxtI+IRCCXXO4ZeJJSZchD4Gllkul5lWjEvA+UCRWbZNtTLAPFEL1W6eZXDe1gVFnkEQyUORmRXOLimc0+CY1+ccFlRKoFj5XcJr1VqTjMDmH489IgMQ1pO1q4MDj1aGMvvX84ZW0OQaoyxduS7OfCKuqdBvzK+Y0mtqSKkVnu+ipA36Xha7SssCoZ+orcJQSE1TSfrym61REmBSpctWcyko5hAxS4AIXgm/KSqxAaIkwZbW2nyZWXJrKDLITKJsG0yW8/RyZJpm+UxQMnhyLlBajTVQrKa+hMLHhNEyjB9nsTLuGyluCIsqvdYgfymvsqooq4q2bUkxSiU2Iecmo8lzTfAakkURKQoRDVRNKQu5J3lvbbc76ipHkQje019G6qbkcNji3JmXlxOXS8fpcsEHL5+tJqPd+9WW2lAVFZnNqJuGdrMjxpkUZy6Xjk8fP/P9d99ztTtQ5JIqJ4nYY7+V4dJPHz9x//jCbtPSNtVrGrSuS+q6JmlJFmttsMayaVvqEHh6PrN4x9Xtgbap2Ww3ZNayzI6+HyXJGzyLm4nRY7RFK0vf9ZIcXzmdx9OD1HLfXIvZ1QfmaeF0kiSTVZ4st2yv9hglwqKIAqswxtJshVVZ2JzoA0s/YTJLUdf404nT8fh6dm03O+7u3uNdYOlnSmuo6pzkxaI22tUaJ5lAvAuyQG8rjJKaNKvV0WjNPDnm0bMsHmU1wzhgrdwp9/sdL8/PLMtM07bc3t7hwzMpDSytVJGPp0fcMHN9uKJpGhpTEqJmHD+zeIfJLTZTPD4+cjl3ZHmJMoLRSCRejs+czx2F3VDmBT7KOf0vf/mJlBRtI3cpsy5BxcJZ8+vf/FrQQd2IQnN9c4XNDJ8+fiSl8GoOnt3Csrg1ICCAduGrSoPo5eVICv+KlFAq0fcjp+PAMnmsFmREu9p+YxAesl/nCUYLsyvLc1wMpJV36peZxraYwjCMF/rzhcvlTN8PwmI2RuYVTU5RlxRVRVs1ZDbjPF2Y3czhSt7zL88ngg8Yq8lyKwN/p3l+8czLvDZoEuM8oYAybyEpTqczzokl2uj/ylW7spTaxeyDbLGSAPY0cvD96eMXvA/ookUpxRIifppYwhPL4l5rCk0uD55+XjgPEy/nMwD9eOB47vjy9SvGWNrNThIxmxpQ9OcL+23Lb96/4dyPvJw7NnVJ2VSEBOdLT9O0/PH3v2PbyqbZJUXnwUn8h6+PT1L10Ibr62va7YayqtloS+H8eihWlFWNtZbPX7+yTCPtdi+JibYhK8XeYhT8h//wPzFME++/+56iKPn08QOLW2g3LUbviKpg8oq4jCgUSz6RULy9uZLLmTFEt/D1Wbgr39/dEhJc5oU8N/z63TucW/j0+aNMU30gLXLBKIuKzW4LWmGeLcFHXl5OjNO8DqwCwS20Zc52U6BSyzRcYYylP70I7JsgVb7LBUPCpMT1fs9vf/U9LsCxH9nEQK4jyU+EMNE0FdrcYZBeszU52ljGaaS7nHlze8Nvf/Nb2qam6zsml5ijpTuPxDTx5vpAXRYMw8Dl0pEVJZkRpos3gWhzVFby5u6W/W7H999/T1EWTKNcCquywGrN9W5PllkyLZegP/z6e1KMvLm7FTbIItN/rUBry6UbMFYuw4t3fL1c8CHwq+++F57Oy1GMgVWJUgvjODNOI48vwjbTaDbthnfvvuP+8YmnP/3IOFtehkBRtfybv7uiLEruH18YhpHcaKqiYLvZsN/tudofeHx84OHxgcNuy3az5diNdONImQtH4f7zR37+64/Y9ZJ2e/eGw/Ut3emFeRq52e847Hf0w8jzy5F//vEnpnnhsGmoipzdzRuqpuD8/EhwgdPLkb7rGc4vAjR0QS5pfhH2xrbFaM3D2DMtjmGQmOnf/+43VEXx/+ER4/+4L6UlofTw9atcyAYZblSFZQ4Ln4MkvsZRKrBFZoQPVNYYLx+WxhrqWsCEp9NlBdQHykKYQJd+4PPHnymqSrrT6+A6eM88TdR1xXazwa2x6cxI0tB7j3OBoii5u7lhu9nQbFoiim6YWXwgIAwb7xxZnnF7d0dVNyhjOBwObDabla3CCgcPPD4+yGYxz2RQpBRVIZs4Ywyfv9yvUesCpRV+GCXSPc+EEMWclufcXsvXUtcteV4S1mFMCJE4zSzzCCiurw7EmBiHjsxabq6uJQGzuFU/vmCKgma7F8W7c8R1MJySQgVJDpWrdc9Yu/IHSpwTU2MKDu8XYvTr5SIyLx7USIoyzPi7P/6BEBPTPFOVJXleCLBXSdU3+ij1rtwwT7IxkkRBpMgNZV6hbYZDMy5uVQZP+OA5HK4py4rgxP6ltejMp16Me2Wmhe3U1FSVsAmtzQTe6xx101BWNU0QeLfJCiCx3++FEbUylM7PTwJwVgh4dd0kiaUp0g0DALdv3hBDZFplFE3T4JZMKive83w8Y4wWyGdesNts6IeBfhhQIRKCk4p4WVLkwhb59v4stcLqnLKuqZuGy/nE5XyiLAqquhIY8jhJqi7LJQ3mHdpYqmaztoaSwKeBw3ZLVRZcLhf6flrZPYm6rsis1OXLomTxAre/nI+QBN67cnzlADvLoHG73a3DMal2jvMMiEky+wXpyAHKskIruH8+EmOk7wcUiqoumUPkz19fBBZuRdLxdJQzlZiYPIWWC29tEiosPL28sPhAPzo2ybDfSMp1WmRws61FwLDdtizTyNjNtK2kbVk5bt5HhsnhorCX6sxgdo3UXTOzsoIGVIKqLOmmhZfLKJwKa5lDpJ8WktZkpdQ6WRPsKhmOY4AprVa7NT2nZKDkXOQ///wg9ttCoxWc+hnnI3meoRQ8dvKMqArBBWzqkrRWPrXWa51dcZkcMSW22428/1fjXJFZQoic1vPptyHCb2+3IkRYZiYXeDlfiOsg2zmHiwsWebbXmeG6rZmcXCzMmjhLaDHazgvD2FMXOZkqeHe95/31jmVxPD0/s2kq2qZm6UfmqZfHVF6wyQXtsMwiNSi0ptSapiqlFga8XAZezh3jtDB7gW1vm4KmkmXhMC5YJay7Yy+ga5+kApblBVmhODTyPXq6jI7pXJYAAQAASURBVMSYuD1s0Wu9HMR0HZMM0UhJDEsxCJNJa653Ldpo+lm+51kuKdauk0Tm3a7BhSjoCZCkWpKhkffxdVA2e4GJH7Yl/RgZR003jvz48QtaKW6vNjRlRkSjtV1rm5YmN1RlTlUWr7gBtAEjA9jCKAqTyE2Snl1MZLkVppX3qBBYlogLidtdw7YpOZ47LuOEO83EpChyJVD6KAub/W4rg6VpYHYy3FUKTv3EODuaPJJZza/f7LFGholudjyeBlCK97cHkS38Ql5FrtDK8fX+Mykk5ikKM3eeOSfPP/1pWLlZM0pBbiuszkQw4APGWGxmaLYVGk3XR86njg8//8xuv6Osc54en/npL38hyzOub3aURU7TlCQVeDk+sWlr/vCH33I6dTw/n/EklJVqZ/CB7WbPP/ybf6Bta6qmYFom7h/vufRnnJ/48S8/4l0gKcvt7S11U5NZw/XtNbvD/tU0nBkZhn758sC8zJR1hbEa7xdyk9i3NVVZ8X/9n/5vnE5nrm/vyLKcz58/4ZeFqpCGzc8PH8lPGTdXN2Q2oyor8iwn3F7LYCsplnHhvvtCIvH9D3eyoO56qqrkd7//Dd57Pn74gnOO8+VIXde8v/sOm1lsaRm6nvOpI7qF09AzTxPaQKYtNs/YtC3Xhy2X84XL6RkbSlQ0IqfS4FNgnh2Xc8/D1xf2u5bvv3/L0I903cj+YGjKhrpqqaqJxIAyghfIs+J1kXo5v9CNF969u+P7799T1QXny5mnx0dens/cPz8wTgNv31zT1NfMC9w/XchzESi9vHxlnmbevG0p84q3b+64Phz4/e/FJnc5Xpjnmbc3b7i9umFTX2EzS1WJNfDv/vh7EonNviIlGCbhBgYCLsxcTmf0Kr9y3vHwJNbc3/zu94QYOa84jP12yziMDOeeYZj5+vVCCA7nRq6vb/nt7/7Iw8MT//JPf8JHj7aGsir5u6s9m7bi4eGJvuvQKqKNQueGq/0Vh6s9j/dPPD48cjhsqdsMf57puwtlUZDnuQyMHp+x1pKXNXdv37HdHV7vDG/e3HF7d8vL84njy5G+kyDD/npHWRVs2ppNU0EMstg+dvTDzDJO69ndo5IitxnGat6s78Pj04VxGOlPJ7TW/P4f/g1NXf9Nz4W/+QlnjbB3fIz4GGWbiRwIgw8cTxciCmUKuRQkMQjFKKkNlBjecqNwQSwfi/OrhUmUiNM8yy9P07LZlpR5QZllOO+ZZtlE31xdsfhHpuVZ1LhZzrw4+d/znOura/JMY4wmAJNPkjrRin6cOJ9OMnTatMLwyCzFatExNpNpdZ6BUlwuF86nE1nZYPOSLBfORZ5ZUvD89a9/5el44ur6hqIsOJ9PzPPM++93FGW1diQj+LBO6h3KSKJBkkbgnBezntHcXB3EOjaLCn233bIsC49PcsiaXMRHsenluVRMrJVNTkhJTD8rMyB6R0iB3FrKIsMVOUVVo41mmUZYN4gxBqlbTDPDMHJ3e8NvfvgVnx9f+PTwRJVriIaU1kTDyn5KfiYF+Z5nNudyOdN1Z95//wNv373DqsSyzPiVRTXMEz5E3mtNXeScu45xXthl+ZqsMihtV26XYdM0VGXB1WFHlufce08KgdxmWKXYbHYyoUamsFc7AfG2bUtCMcVB9M0KYVTNCzYYyjKXatBFHhjb7YZpWjjeP5Lnmfxs1km59ysvwGiqUswEV4cD/ThCSviYGF2kbgpub65YFk/Xyy+1tcJiKYqC7abl9vqK7nxkmUdSal8vR1JvshgFfXfm+eVl7QBvaJoNtqjwy4SbR6qioK1rLl3HMAx8uX/gdOmJ7+7YbzccVgOfNQpNYpommBZeXo44t5BX8rWlJAr3Yt0ypySJAecEkH2139E2f9sD5L+Fl1q3P30vsVhRRFuSd4QU6byT1NmySErECofBrj8js1rR8syyrNUkHwIuBLKEaO5D4HI5r9Y6eVZURSEp0HFAKyUJp3GUrYJSkPRa+wrYzL5CsvNihdA7h4+RhJLB8zSz3bQ0dSU1KgQ2LhvhVdfcX1iWQN/3OOdp24Y8y9b6y2p304rzapG7OuzJs0zYTMGvG5nINArXyPstxhiyLEcbQ1lJ3FqqPIFpmrHWsCuv5O+bBtmutS0hRob5SIxhTVNBlperqU2WEQm5KMUEKBncqHXIkmWWosggeWZk+//NHKcUawopop1jAg6HPddXV5y7jvOlI6X0ms5CSWonJeGfZFmGW+TPERWoJHwOo+Xnuda3nPOvTLaiEP5Bf3YE76UyiEgn/DowgSSXXxRlIeBs5xxuWSjLQi69STh4euVnlWX5+j4TY+WI0hq3zDL01oV81ipDQqxQWWbZbba4ZWbsO6y1r4YVay0uBMb1Z6OVJJnKImdZljUDwCqlUKKy1/pfGSYxQpLIfZ5l1FX9yvBKRYG2GSmN+ODJklRQYgx478iyQnhcURIbXkIechmoSi6XC7Pzkr4KAWNlQ1asCTwmJC04DIQQqKrq1ZarlJbP0CRA48xauvNE9MtrlTPPs1+UGAFWc1aMdOtB0C0OozXVmqLo+4nMaK7qgkBkmJaVg6WlJqsTVityLYPFYZ5xITG5SBkiGqnY+tUOV2ZWLu5FTnILXYjre0gu7MAKgY6rnRMBZ5eyQDLGQvI4t4DKZAk4RLphka2tlfPK7ANJSbpOvf6M5Y/JRVxMtKUAs7+9Z2OMxBR4PC/MPmGvaopMMy9BoNorl3NcVlOnNWQaCmtISb4fwmOTJN+8yBAlz3NCgjA7dJLUVAhptduBKgu0MezbSqyKKuHDzLzMhKREDBAkEQgyDPuGJwBYcjHZ5pnBJ1jSyrBbFoLRkHI2Tcl+U/H54ZmX84mqKjEmA6RKr2wG2pAXOdU6pPZB0qjGCHfNWEv0jnFeGKeFYZqZgqSi9puSKjfMTs7faEmSzs4zLYFq/XPGWow21JXwvO6PZ3yIXO9360BOQNpBSb1ZrZ8HWos5b1ncmtKQn6vzHp3AAD5E+nGiyDIO2w168TwtbuUd5UB6TaTGFejtvIdkqTKNc/I8dy7wfL6wbWpu2orcGuL6XLXGkhkxOVZ5RluXdMPMvAR5Hym9MqqUDPd1Qgf5OoySlPs3huKcJEmZWTkDPp0Sw+zFRuwjN/uaqlwttTrRlDlaa8Z5xMXI4pYVth+YXaAwkuTbNyVZZnl6PjH7wDBKdbjOM6oy///p8+X/m6/MfrNPd6QIYZ39+RAIc6CfZ1n8JEm/GCP3Gdbav5jTDFVVEHxi6gPjuHA5nbDWMM+OcRw5n05s91vq5lqYj4UlERmnkf2+4frqwDgt9NNMXhgan+FcxC+RIi95c1tjMo3JFD54XC8pDxmkHjmfOu7evGe/26/nKUVdV7BW4EOMZMai0VwuHcfLhe1hS55npBiwRlFkwqL8+S8f+PLlK/9dvWGzy+jOkljKrAzZLsMFPUn93BpLnskzdNPU33ZkhOgZxwFjNIebq5WlGaibhpvra6Zp4fOXZ5ILLMssZ8u8IisspjSSlolyFnZOGEHaKEkwaUtR5JSlnF9j9FL5jUlqevAqDpmXhaEfubk58MMPb/j44YHjsYeksCYjszlZVpD5BR9lEVoWBcZkKG05xWfmeeLw5i273W79mY4MfS+W4vOZYRr44bu3bDcbnl8m5nkhhoAiMk8D8yymW620LGFD5PpqT14UPD8cBQzfbtBGs9/eoI3BxxnjPTc3cm7NC0sICa2ztS0mEpVpGjHGoow0n07nC3khNcpxnnj5+pkiyynyLd5JU8Q7x+V8IaUAST6rb25vXk28zhtc8GyymuvrHdpYuq5nWZwMnbScveqm5ub2lvO5E8mVd5ACIbi10ZKRoda7+8ButyPPC9rNhqqSmvA4DDR1zaZtefj6yOl85uH+mXGcwMAubbk+iP38XAn+Yppm0rQwrjzYqpBltVmHq/sVCfHycMQtM35ZyLOMw3bLdrv5m54Lf/PgyQ0XgjZMOpFItBuhqcfgCSSKXDaTOiWxka3bkYRwN07942rtCKAkQu/cQttusFnGMI5kNuM3v/qVsJsMJDfw/HCiajYc9ldSyTq9cP/whc8//Zn6d7+h/e4t8zRyOb+gUkQT2e2uOFxd8enzJ+4//kU6t1nGH354T/G7X7O/uqZpt9w/3vN4PDJ2HX5euLl7Q9O2nM5npnnBLU4ehlq2h3atc9w/PLEsMzdvv+dw9x27TUNpFVWeo5JEdn2K1FZBjLwsEzFFdF2TKUWW5cQQ+PL5Ewm4ur0l+MA///kn+f5oTVg8nx4egIS2GU2Wc3Uth55lnji5hdNZFJFFU5NWZa8KcokK3rAo2ar7lGOzkv2mkeqaKQnB4WOgrBrevssFJlyWLCrn/jKL5cRqUIYpZdhMsWtz7p9feD6dXlM60zQxpp6YpC+8zBOX08sKXwaVIk1uya2kOFCacQVlWpMx9GdCDNwcdsKTUolxGolJahzny0Um42sNrC4ydLIUFoE2es+yOB6fnwFF2bQopXFjL3yTIidFxXGexJq43TAMAz/++BeyLOPd2zsSYIjEZebx4V4+BxXsdjvevn3Ly8sLP/75z+TGMg4Xmqrk3/3bfyvVmaGjNGLpCsAcod5uefv2luAlWvnp81c+ff7MOPRE4K+fvvJPf/2CyXOB9q5gzLKsuLoS/s0SFcv5RIovHE9n+mHm5/tnjuPCy9Mj0zDw7uaKX71/w+nc8fj8wu76hqTE4pJ0vvZtEx5DUBmbWoYQs3OgYFgCxiDJwdyi+J4YA5++3qP1LwdwmWVykCvKao1pn6UqZkV7b2y2mgtHtDa0rUSS50nqac4vKJWv8Xuoq5J5npnnCe8W+kFA17/+zW+xmRw8vXOc5gmthNWjs4x+WpimmXkaaKorrm9u1pjqaa31FpRVTVnWzMuFZXGkIHWBm6srsjyjroUNJQmU4+uFLLeydZsXh/PrRUCtB4Uk0GmF4uXlCe8cah14NHW9gsuVpAHW6tN2s8VYwzAJyFbqPJpN28qBfF5AK/b7HSEEPn/+JEMdYwDN48tR6hHzBCnJAMEYjs+PxBhxywQoqtzKEOZ16OLWQVpkSfHVQFdVLT54ustFlgOrqjvP7OtSZOh73DyjjV2HLBMP6++ctYZ5kg9sTUJFucA7H7FrLdCuFcTMZmTrgc/lGXkujKZxHJjGUX43lETdAfZX1xit5cK0auNjjDw/P0nqa2Uw2SwjU5q2beQ5OI6SiFvkwKKGEYDt4XpNCKzvJS+Q4jzP8HPg8elJah3DIAO6dfgow0KpZVZrxN17iWRnzhG8VOre3d3IUHFZSOhXTleKogF/d3eL0hqjNdM8Md5/FdFFSNzfPzDPH7BZttYFJ4gyyLZKMU8jfQiUa610nmcW7/ly7wVePk1456mrCmMsMXqWeSIEie47H4hRUVSVfKZ5GSiUmSXPFXktCWi/LATv1s8MzbaVWk7f9Yy/oGcXgI4OYsIkSaxmTQtKsfiEMZFdKTbcp/MFoxVXG6nNDtMsv5NWkitRy8W8QJOhKCqD1fB46nE+crtrSUmYTNM883K6kGKgbiqUgu5yoRsmuiWS5aJtPvULL/1EbiDT4LwnAaWVJWPSCaUVd/uat/sSneUoa7l0I920vA6SN4WltobeKZagIAZUgExpCq3w1uBIvHQDznuaomRbGzSR4CJVpgQEPg4opbjebdBac+4GphjXC7DUb4zWxBjQSS5aiw/cvzwLt2IjsPrTIIzIfdtIsn8VrdyfZCA6TRMxwW67W+G/DjC0Zb6aLD2XcWYJCWuVnKUQyLRfa7OZVlwddlitQYuN7jIs2Kzg9uYWqxJDf8Yaw9XVFad+ohtnWWhZu/LXYHSBtHgqFEVKkuy2GbvG0+Qaj6SsCqMIXqr+SSnOlx7nPdfb5l+H7kqGQxCJToZz2zXpO7sFHxzZCpD1fpLB0Pz/5u7PeiTLsixN7DvDHWXUwSYfwmPMzOjMqupikWgQRYJ8IUCg+c/Z6K6OysrKzMgIH81tUFNVGe9wRj7sI+JJvjAeCmDTBTAEIsJMVeTKveecvfda35rFHmYkDGjVNdIIK7Zt2/bEFDkcjjgfOJ0DRidceARUsbYL1+kyiGkqw/bVDcdx5t3jnoxi9qI8fnG3wYXM6CNaGyYXJfxjysQE3aIrNjk4nEf255EYIcTM6TwRU8LFhM/QaYupLAQnQRcYoq7AGLRKhNOBcZ758HTgNDrGKaDQ3CxbtIIxZOaT42Zd0RjN8XzGx8QcIGTD+6cTKUY2i5ab9QKNFJVPg1wDbRvazrJa5ZK8N2EG9/+jlea//et+/bIMBBpijOy0xNNrpdEamqaVOyBWVNayXkmDVxlLGCcmN4LOqKgxCupe0fmWzd0Ny/WauurZbm741a9/QdPULPsFKWemOdF2NdvlEqsrTkfH48dnfvj6G1a//w2vX/6Gh4dHPuw+seiXtL3wDReLnv3zwGk/UOueRQuvf/8Z/UJSYJuu4cMPb3n/4QNaS4L39uaWvl/w/PTEMI6kEOhsxaKuaLoa07eQFd//+BHvPavNmrptWPSWykT6ZUcdarQRW+aL9h6lIcfEOE7kRuz6qbBFn/fPggspUPK///t/IsUgyeqLBX9eLFAorIbVsuf+dgMKPj6+F8t8DIToyTgJdKoWYuvyFSlrUjL4kPjh/VusVnz++Uu89+z2J1lDtcJaw+3LW/pWgkCGwfHtt++Z3US71Exu4N37D/gQ6Bcdp+OBYTeiVwpFJEbhtk3jQAyB6DxpdkyDIgY5W7Z9y5s3r4lZQlmenp5Zru+5uWnYPT4xz57PP3+NsYplv8Kqhr5blbVmQKmR0zDiveduvaSuKrpWzrrzAM4lTkcJXqiCRSvDcilup9VyAWQenj5gtGG12nI8naVurGvmSQYWyYu1+oN3pARdv5Sk4bstu/2B7777ntlHpuHIatny7//938qa6YI0U5F1P7iRdtHz2/sN0zwyTmcePz3hhszxMFLXPd9++47/9Q//pdQILVXt5axaVSyXK2KA425C6ySpinNgniJff/M97z8+MJ5nvIu8evkSaw2Hw463+x1G/ZLlcgmmwrQJHz0hRoZpIIbIcllSa8nMyfH23VsUkjq5vVmh9C/IGb774Ue0+W9stQtO/IIx1qDkUJxSIpWOvoJivZPNpm0adGFDOC/x0XIwl9GHTGjr0oAw+BAwxnCz2ZCSJwQ5sI7Dmbbt6NqmQEVnxmFgOB+J3ssGk6WQsVpgiHVds1gsyTFyKjyUtqq4Wa3Ybtast7f0ixWPz48M5ef5aeIm3qFQzLPjfD4L26QkXYndSmwhYr8YhdlUIKhGQWUMwRiBIwJWC3I1Fc6IKAUSGoGLHU9SRL18JXHrz/sDMQSWiwXOWM7DpchRWFuxXC7w3jNPA272YtNqGu5ub6UJiFhKwBKAaBMoQ0wKpQT2mZUlakOOkZiEvdFbgfPauiKgOU6BFIV1AAqfwGpLZWxRNUxYbaitJsRZFgoFVV3JoWyUOHoKw6SxBnN12wtzwRgpNI6nGednbrc3dF0vSiLvC5RWVDsXxVKKkaURC4qwHaIcKIKoQVCqdK0TOQrHRCN8ltkFbFH1zLNjfzxQVxWrVV/eiylcjBltDLaWtMIX97d455gnxzzPeDdT2YqX9/cMpz07d8JqufkzkFDUdct2u+F0PDNPR4bxXNLApBjcnwYeno9sthvW6xU+VIQoaYyd1ng0IWvCPBLdhHMOHzOncSaiOQ8jfpp58/olm9WKw/FUGiEzTTMXQKfmEq2WlSYrI42NpiJmAbj6KDHvdS1TaLda4b3jdNgVyPbP43UpGi7Wt2k4X734Sv/EIuKyqZbEmRAEpnzhXWWkcLtA91TOwkbzAa0t6+3NJZhI0i3nibpp6eoOtP4p0TAltNGSODEMPzHUrADttbFkEH5eErBr1wlTrm07qrrmeNgzl+InAbmuxboXIzGm8m7lXQusVKzR0zgwT5M0MmxdGggV1joyGZtErdP3wqbaHfbEAni11lI1kvoyFWtT07Q45zifT+QMq9WqFL2TXIvgS0ql2MrmaRSVpXMiDS6NOmU0KcigggwpxiuY+vL3QhRGiyn8Isp1u1iknfNM40i/WLJoGsZ5YhyEY2NrUQjEEIjBE7V8R6nwibTWGC1qjcvES2v5zKZwmoZBGkXNpWlSpn9t31NXFeP5LKqgLGv+OMkkLnh/VWtkuKq6zgVyflFKiQ1IWGK6MI5A1IiaEimfM9M0o8gYlaibjk23KOvmXJQHoh6RRK6ZcZpKFLrw7ZaLTva4MuTImWsKXte1LBa9FGEx4WdZ95z3171vt3tmtVqxXC6I0RCCLpZmRYoyCLikN6bCsDsHL/tn+ayVtdRNwziEwuWSyXgonL3aCqB49rJ36mJNtcaSUWL5jJTps8DoY1Fd/dxeioQmy76nFbquyFlUkDpLEleIiXF21JXhdtUSgjCAMgpzYS0pKfCtlcYpWtbD0c1opVl0dUmmlIP+OM/UVtPUFaoomJ0P+Cj3vTWi2plDQmUwVpFyJOVEpYwkeBVVTddY+sqQbU02VhQoXmJzVLG3VYVNmhGukMpZzpNamE9RKSYXmFxgtTS0TUX2ojQ0upwXSvpkWwlrcRcDLgTIGm00ta2vCthc4GspZU6DKE42y04a5kFCFtpantVcGvLnyRGjMKWEA9JiglwvXdQyznvOzhFSZgqJRVvR181PqXtB7AuX5FAJ8siEAtRWWtP3PWEe8LOjanvqpuU4uitEX9aSLBzRIBDxOiaSSRhEadTUFY0RGHpGEfNlICHr2eykaHp9X7HqW1KQNXdKYj/MKZLQNNYKgygEogKlZIiRYhCkQwjXJhhZlKNi70b+WEvyMM9OgMgRVIyk44i1mr4VlwRFZXQZYKwXnfCAtCT8hZTRxrBoKoxPRPzVhUFOkKTpXpXkxZQzzkdmL6w6rQzj5Bhnh7LCkhMnhgUVysBRkVQ5F1B4nzFyHp0kapYzQFtrKqMYDnO5/+X5dM4x+UDCkrKS+yUENuslbVNfAywmn1AqsWoqSa1tPComRheuzK+fw6trhHvath0hBSlmo6gOtRZ+naxFNZXVoljUBooyO6VEjpGcKGczTdVUtH0nLEQtgP/bm03ZIywuSHNFKU3T1Gg0bg5Mw8T5cBBlUNcJJ8k7UBlbXxTnC047R/SgMVSm5v7+jpcvX1A1Bm01H398y/l8Rilxamy2txhbMznH8XxCJaiKqlJUjhKA8fHTe87ngbbrSuCNRqsk1mRt0LYrLgxJht3tTmIHrEThnVRh7IyTpPjWEu7y+OmJGAM32wVKwW5/KAm7mcqaa934dHgWnvAwojUlnUzSTVNKGKOIUeG9JkTPdDyyWnTc3G45HTP7+VTUONKgbvuG2tYYY2XguTtgbMbWGh8dh+OJqhbrHhn8FPCtxweNd8KMjDFI4zElUgi4WZXvDqq6pmosqMw8DkzzzG1l6fqO3SOkkFm/WNH1NbWuURTFfJLkv5QSs3ekmLCmkveqlNgFY5Z108t6ikMGBF1FXdU0dUeIjnEaMFqU/s7NHE8nrK147kVx19RSy5/djDYVTd1jraZrjTDrlCHFhJtnKmt4/foF0zhzPAzYkjAao/Drlsuem9stz8+Rw2nHcB4JoyFEjzUVh/2Jb775gdevX/HiZV24eNJ8N8bipkj0CWwq7FFJZ93vj5zOZ4yqMErYY13f8Pz0idPxxDw7mjaRtQKjyTGRcyBGX7iZGlubgkeIDIcjkNlubkXRV5JnD6dzqT3+v7/+8saTn9CqYbXoiTHx3du3WGP55S++JKXE+w/CFKnbnvM48I9//hZNosrCTrrtKlKG5+LvruuJRhu++upXqJxQWewuzjmoGugXTHYgRrEgRDdjTYu1HW8++5L19o6+63jcn/Eh07Z92ew0P/74lj//+V/48OmZx+c9c5JCXtsal+HTcUQZw/5wAizKNugaZp84DZPEWofEYrXBGsPj0zPvP36k61cYUxExmLrjsxcbuqZhfzyymx1zTKANy1oURG4eUWS+/PwLse6dJ4L3nIo3P8SEocTX5szdzVZArcbSdh2b9QrvPe+eHwk+8N3bH1m0LV++umfQI89PD6gUmOdFgcaJQinXDcdh4LQ/McWMSwmrMo3OKC0bdCITkWn86XiibkRtcToOPD/tWC86NquOYRwYn5/YrDfCn+k67rdrQoLROSpdUbc1b+7uWa1XPD3v2O0PPO32DNPE73/zS169ecXf/9d/5NPjE7/46kvW6zXTLAWHdxL5vVktWa/XPDw8SlGrDGh4+PQgyVQhycazWqEyPD48kGNktVxhrOEXX/0Kay3rzaocQhwqQ9/3aG24t/W1OOtuNvzf/i//J07DwB+/+wFrE3c3d1hraSsB/Y3jSPYzh4cPqOj45a9kovJ8OFNVVrzKRvHq/k5i2SuDSRFdZZa1oak7fti/4x/+4b9yd7vl5f1tgZYrFk4OHlpJOlNnoEagyBnY3L5gudwwj2e8m7h/EYkxU1UVxmjSzZIcA0pLjPbtds1q0ZPcxPHZ4aeJGAPRiZ1zs+xRWrO5uaGuKlIS7tDHj+9QSvNXv/4KpQ1//PEB7z1f3NxQ258PoddqgzamBCMEjoe9MFGalpgSHx8+ARKQkFLi/ft3GGNYLha0bcuLFy/xIbA/nATyX4ntbtn3JQFDC8S6NBFSFJWONcUKGp1oDKxIge9ub4gh8sPbHyW4AIjB4+fMPkQOp5Gnp0/sn5/oFzJBGSdHypJ8l4GpqGNEAh3xZGI0IjkuRWrSlGZXJo9jST6bSTHx+s1r2rZlfzgwDGfOw0RKmb6VeGjnPUpFFo2oxbKSz3g6i3rnPIyFKyNNujcvXxX4oEjjl32H955Ph5002/VA23a8fPWKeZ74+P49MUPdSbGhQ6SuLC/uXzBOE7v9Aa2RRLmYQHkSGVOS2tw8XoHSSlkwGudkiKC0oWqaa6OvtYZF33JJ3ApuYh7P8vesZrXo6fsFs/dMzrP/4QcpFm5uWSzXnE4HvHcCay9DkhCTWISNpu96We+dJ+ZMcp6Uoe8X16ZWjLFAOD2PT4/Famex1gpwXUlksNblEKoQZQJSdOcMbh5pKsO/+7d/x/l85ptvviFmxSZfkjKFwZOTFFEoJUqyJJbDw1GAnk1VSZG9XsnAoWokDW+eygRaczjs+fTpgboSZkptLf2yI4ZladZJI66yFtPq0sRV3HQCmEylgOxb4VZURl+bq2JFcQzDWBrCNXVpth13T0Tv0HYp0PdeirDVUva4YRjxwXM6nVDA6vUryJlvv/+BmDK//vWvaH5GfDqAZb9Ca8Wiqwgx8XE/kHNmvWmJMfGwn4qKQOxJH3YTSmXho1jDsuuk+VdSOOuiBgk5YrRC12JbbNtGmEFtS4iR4DxtbVkvJK3RxyQpeq0hpyjQcq15dbO8suq0qbBa8Wl/5HDccXu7ZbNeEmLiqDyTP+GCDK988PR1Q103DCEzn51wfYLYJitjCis0cRwmnI9SFDQtX75+waKrefvuI+dh4uH5SEyJz1/c0DQVY0jkkNlsxBZwUenEhHCw9jLUe7npWXU1f/XFPTFlQhIb9HbRMbnA1+9FXbjuhYO2WfYkpdBRFcbHUJLbahkgqMQ8Oj5+esJYI9Z31TF3HdE7wjzismHKhnEI6OFIW1u6pmIaHbOXa97VFT4mQrQQwJiIVcLSSkEs/cYYFk3Dstzu0iwO7J8nfEh8+fKWzXbLbncsxUWNNpqn3ZHZOZq6omsbqqaFqiZlaST5JOof5SKoxHkQTEJxL1IpYW8tFy1aK6piba0rSyYzz0gqrNHieDifCCGKIqCp+fLVkuMw80/fvqNtKkkIK0DflKHOGasETWFUZrPqaKxBV821Yd3ViU0nTVAXIi4o5phZtB232xXH45nd7khdV3T9AqspYQqRMGVMDOgcSKkiZLB1TW8qUVbqLLYjpQirlraCtpbf3VYSNjPOnsmXpiKQUmCcIoZIa2AoYPRV36Coxc5cVSTlyTGVpFp4ue5BgX+MhJS4v11S2b9MNfD/Dy/vA7aytOsG7w3xg6RKf/bZK2bv+Prbb8k5sWhrcoIP7yJ1XbO93WCM4fPPPyOFxHF/pK5rVts1tBBevKCylphGjE4sFj0hRlwQaHQKHmKNQUGOhDBz93LDv/8f/pblcsk337/Hu8h2e4cxinE8sd/tcHPg3Y/vefj4iZvbLZv1isePLTEkZufwwXHcn6nrBuc8s/Psdk9iDzueCVOgbSzGas6nidPJYfQRcuK43xFD5He//2uWywXf//CNuBlGAU5vN5Kgez6NGKN5eX+LUlrcHjGA9+QQhEtZBjq2qvir3/6VJLqmSNXUdH2LczNvf/yBnETx2nUtb17dMyvD8emMsYqmloFszImqrli3a/b7Ew8fP4BKksCYEuQIWbPol5yGE0/7R4GOz5Gm62g7Rwge72fu7ja8uN8yDRPOjWxvNnRdTbeoWN22OO94fBTumdLw6vUbtpstp/2B0zDw+MMzwzjx27/+HW/evODbb77nsD/w4nZDt2jYPz3z9PAMGfpFx/39PV1f8+PbDwzjhEKU8DmJFXAqeI0HbTBKM5wHyNAsO0xlePXmtTzrRgbtOVkqW7HcLGWIFuXva6W5u7vj//E//t/ZH078/d//E8Yqql5A3cu6J8XIPJ1QWHLuaNuKz9+8oW0tT8+fqOuGvl9h65pXn68E76MV3kfmydNZQ3SO54c9X//xR17c3/HqlcVWIqZZrVbcbO+pq47gEjnKcDn5mRwjL+9fs97cSNNqPtMvFwIyzzLQWfQrqqphLgFIL16+YrvdsujFljccjwJ9NzK4fHn/AmMtdy+Ep3w+nZinmeezDDi/+uUWbTR/+vN/xnvPr377Fc1faBP+ixtPCple1JXFE3DTDLXAQUOI+CAT0aoVMOD+fEKlRJe98B1utviYOY4eYxSGRN20okxKgRRmtHayYBiLqltCiBgrCqsUPSnVwovoevrFilASeVLOpQCSA/DpPPDp4zsOo0x0ZheuMafKVqQ8krP4jCW1R4CDoSRTxZJkYitpIM1PD5yHMyhLVWeyUmhT0Tc1XVvx6TkyzlJsoBW1NdTGcIpyQF8u5OA4Tl42dieNp1zUEcF7URl0LaEkltgioRNbiqTe7U9n0mqJMS+wRhWLg7xX9GXSra+d+JASOXiYhHFQNVZuwuLJz8XaMJzPpCzefu8CmZm2MmizJBQGVd91ZAQ+2bcNp9Exh4BtDMbUrFZr7u7u2O+PjNPM4XjiNAzFC93j55njfod3L8lRkhN86aCqDHUtVqOUkhTjWqZ00zjinYActTH4pXhIT4M0V+qmodUt2+2aqqqoa1EuSQEFdd2KYqLriSFw2k+0dc1nn7/hcbfnv37znahKyne9XLS4ecZNIzkGplGYKKv1StRwXibqlXHURtG0jSQ2KbBKDmWm8EjmeeZ598x61Uu0tEiiiq2qJhWVQ4yBlCQKJiuJol8uOoyKeKPoUNcEKAVoGtnIzoMkUjU1dV2JMsuVWHGB/kgMfVWjKzmwVRcFBwLZzqUw1sYwzg7vJcGoa34+nAFdDrViKeMnnogxkDLDOGGNYbPZ4J1jGIZrQ0Brib0fxhHvnzBa01TCzRE1jPBAUhKVI2VSDKqoFYWlk7M0oypbseh79ocDp9MJXa5/zlmahREikWkcmaeJuhWFkayvAo1OSQ4qAKQoiUxKDu3yK/OVv5dSAiWK1RRjUbLJWtN1Pc+7nUyinSdn0H1XlK2SGlbXFo3CF+ir9wIL92XCH2Io8PGelGF0oUToWlKM5f6OKBXExlbXhBiuQN7LdDeliDEVXSvFdC7T75QvLDpJOpLRXyaXqb9Y2y6To1gOh/6nlKQsqqjKSpOnshV+GnGzo26aoqaSAswFaYafzyemaWK53kqxUKb9XddLqkhMpBwwSmHKniONF0lyk/dOsdFq5slcLY/5ogBWir5foi/pX0p4SuqyhsNPVkmti7rYUzUtd7fSJL9cH+B6P5JL47OwTIyNRRWMRM9ng1XqJ6WurbF1LZc1yZAopcQ8S9rPsmuptDQYK2tlnW4a4fcVZao25RoYQ9u2smfOM847idjNYhO0xlDXtTSQJofzXuD3xpQENA05kqLwv0QpJ/dIVdfCemK4qsgodsIMTNNETJmq2FV/Tq+6bjBGsVq0uBBQJUWsrQxOweSFy9ZaUQyOTpIi+0ZUc401UBrjxpT1KiMHV6Wva2PTyHeTFajZEb0vzUIrcfdR1J+VUYVb4wU231ScJ3A+F36SYQ6Z/eDoFoFFSITyUJynmdl5cg4yIKobtJIGU04C/M0xY2qFLoqqVHhSPsTruWjRNSy7WhiFSOJaiImuqem7hoeT3A+bRU9lpVkAmXkW7ujkQlFNZmE4LjtCjDwdz6LSrqTBfBgnCYKxJZExiwK10pK0FrxEjVdGUrkUstZPs6NOhqYyJaFILGzOe7xSRFURYiAHj1GKtrbMPnAaJlSuqTXEJLZ54WhJ47oqa4Hzns5Ic84aAVyfp5ngpakxzlF4UG2HUmdJh9NaQlyKNXDZt5IOZ0xRRSuSEjZqzBmfROk/zQ4fIy7Jta6ysCD7vkEjKmG5RvIshmCK2umiePTFvgeVNWxXRVUWIyYKM9Ra2aMzCpORVOIozZm6EhDx5awuDX8Z2s5eGjxBJdn/tKapa05qxLmIrYR7ZbVYQY35iW+XY76qUI2xGKskcRhJtJV6xxCTpa7k/bVVUTrNHh/zNcHRB4kb10hBfaGS1VW5FkVdRVHPxQtXtjS4YtnLmkpSIX82ryypgLaWpmROsp73ixYmUTCmGKhMIoXMae9oGmmUdF3Lcr1mnhzH/RGtNFZpkrU0TSuDqQJjrpsaioIvl+EL5dwVY8B7qBvL/ctbYtQcTmdqayW6Pkrj5Hg8sd+feXj8yMPjA1UtXK9LqvF5HCTcQoljI2dXwmPGshYIxV9p4Vi5ORJDgjwLA9E5UIrlcslmu+a778GVFMSMkhpOZfzsSMbQtS3GWoZxRNyvSdQoiasltbIVtzc3xCihE7YyGGvILnMqDV+wbOKKz1+/QCt9SWoQFp+SxFulNE3dYsyI9zMosEj4zTjPVLqmMXVxjzj8HHCjB0TQMU4j43BmuZRwmBg80+RIcYFGUVWGuq2Y3Mw0zthaYa1msey5u79nOg8cZsd+f+J4lLCBvm+kmTNOGH1LWzccjjvGybFYLCUAqGlo2obZzwzjmcq2aKWJURpPwUkq9DCKAv/wtAfgptK0pmVRgsiycmInnlJhmlYkq2narqjvoWlqfvHVL3j4+Ik//K//IApPA6YSlbp3M/NY6voke+2i61AmM80TKEUdI1Xd0PVSn4pbzJNDksGk84zjzOkwsl7N5OzRurCl65qu7YXpHH9KoM5kco50XcNms8LFEZcmKtuIgr8oNdebLU0JwHI+0vU9XSd/JydRt/tpxrQt1hr6vpfzVNtijGI2mqAkwTBnqBpJbT6dBYPT9jWL5X9juPivf/M7IOOdZ3IO23RgDJ92eypj+Pz1Z8SUGH2grmBdElBUkO7YOHvmIOyApq6o+obz6cDXX3/D3d0tf/W73zA7j9JGLBXBE7xn9J6IgL7C8445pmKL0Ly8f8GbV69xBIxP0rCylpvtDXVl+e1iRdcv2O33nI4nnnY73n965P7unvV6Q8FkEtH4bMhao62mqy1WJZH3jQMv7l/w2r7m+XmHG8+slx3WGL5++46QMjfbW7Y3PRfIagIBt0U5ED7tD9R1xatXr4gx8PU33xByuvJRvvv+B6w1vHl1T0LxfBzwfmb3/EzKiabrafoFL19/hp8n/v4f/4nlYsHf/O3fSkFgLOPseNztoUh+VQq83C5QCIzRGi3NsHHm037PZtnz6naNip7Toebu9obPPvuMDx8+8vbtezaLCp3W5OAI80yYZ6Kb0RiapucwCMDSKIUFpuHEaW/Y7fbs9gd+88uv2G43OB/5848P9KsVX30l6rjn3a7IZzNaGVSZwo2T5+npkWkcwUoRdrtZk1Pkz2/fSyqbFZL/y5cvxDbSSkFC8vjZ4QYPSmOaHpRiLgvleRgL9O0A2vBwmsk58cXLF2gjBVXbtWy2NxyPBz4+vBeAXc7MEQ5zYr3s+fzlluA95/PAMQZicNR1S9svGKeZ4+lMP0Y+zRlsw7/57/6Wqq4ZStSxD8JzWbQNcwi4GLm5e8nnb14LsD0ERud4+/Z7aeKNI7lYwL747HO2mw3TOOB9ZIrgkkKnDClwOI84H6iqlsZWrG/WWGs5HA54H3je7dBKsz+Wv9f1kOH7t+8Bkb93laXb3NJ37V+6NPxv/nV3e0POwh8RJY88+fPsUGTuthtUsW5pY7jZbrlEmDrneffxQZp6s0icfVWibAswuu8XhCismhDlEB/LwUChSbrCzQ6337NTqjAPatqmKalhS4bzkeF0oqoL0PnNaz5785rT6cQ4DhwGgSjaSwxxsdxNkyN4R7+sqG1VNiHhYcQQ6BZ1KRzF7nxzd4fRho8PD3L41WLBbC5A7AIlnOdJAJJW1ER9L8XCcfcMKrPoRC32/LxDa8V6JXD/eRKW2lRZQghURlHbWpLOgO+//RpjLfd3dzRtx2Z7yzCceHj3FqU10yRW1xcvXuC9YxqkyNZG4aeR5/2e5WLBzXbD6TRwHg9lQNBwVmeBZvogh/i2pel6jDVS7CLW4qrtyEpA/FVdYauKDLh5ZhrO3N/e0jYSWvH88I6cM5UxpBjwTuw/Viuxe8eIL6DHy8saDUa+55jh8emJ2c2slnJYajuxH2Q/E8koY64NLKUQKHPOBG2uts2Uskz3zyOnP/8JrRS//tUvxSYXE0kFjJJhw+SE0xO8ZxgGPn36xHK95vWbL6QBUcI6zoWrWDctrgA9RaGlUFq+A5Bz6uA8w+yZnbs2S3Vhd/Tdgrbr5Ds4nzkcjzIw8JIO6kNgu1lLI9cYEjAOZ4bziaY00fbPzzjvyMGhLvB1bYghEXPkeDwCXAc2bb8AFFOxM3ZtQwiRx4/v2f+MUqEAqgrIkcenZ8bZ8/i8J6GYQ6K2hi/ul8QoDB1tLPfbFTHBeZpxIXMYR0JMhKyx2tJ3Padx5nF/YNHVvLpdic0xiD3BkEgxcJocc0ic5yhWq9KIIGXWy5ab5YKq2ElGMil6TFXR1JbffnHH77645XCeOZ/P7E8D53Fis1yw6FpClPt6d55Ix4m+r6mq8hwYTVsJ8wUl958PCWsjd2tJlPqXb9+J2ne94u7mlmRE4aiqGpdkQo2WZldKmWzE6p8Qy07fyOH9u4/PWK25WfWFLSfWtafdkZgyr+5uxOpshZf2L9+/o2sqXt5tWTaG240MLKe5hLSMZ0iZX33+QgqjThg2RMfkAo9j5m5l+PV9z3FwPB0U2hqUgZQTs48sOwHKEzMqisVxmgcZDBjE7hgitUZipbUMZ50PDOPMi01P09So7Hl6esYFDyozTA60p6prVkbisnNWDMOImeeCL8ikUtwSxcZ4OJ1wIVJ3sn51TYvVSoYkhduqlaItyielZEgwzgGlRT2Wy3dITnx82hMT/M2vvhRQ+3gm1jU3m400ledJGqaLNefDiY/PT7SVgWVLbQ14wQn4kiSntTDfxvPAh+DZnSZak7nb1MwxsNsf6JpG1LzasO0qDpNnP3v6JBD4vqlpK8s4Crz46IUt93Q8Mowzr+5uWC0qjnMEEo/HgWn23G1XtI3hNEx4H7jZbGjqmrqV4e44SlrsOEr6a0aGBTo5NLA/nshZCRoiCQ939j+fxtMXv3wjAwJb410iKZi84/vvfsBay1//5peE4HnaPaIaxXZ9K805YHYSjOOcFwSGtVel7bdff8/Ll/f8+u9+j3Mzh5NEuq+mmcPhxKfxmWnyPO92jOPA8XgUaH5Vsb3Zcnt/S9809E3LNBmmSbPZGPrFgi+/fI0xmv3+xOk48PbdB8Y/f8vNdstq2dO0FVWtOZ3OjJOjX4obY7XekJNmGg/Mg+Pm9p6maXj//i2zd3z+5jVVVfP3//Bfcc6z6CW4o6llvdqshEv3eDriZ8/pNNC0Ha9evyaEwJ++/ppI4u7VPSlGvv/+LVVViWvIKtxuICTDPHXkBDebG4w2bNYbxmnif/5f/p7FoudXv/4lXdey2Sw5Ho98/8P3JD9jlcFqw1dffkkmkXWgsjVN0/Hp0yf+6U//yHa74Te//Q2PHz/x43c/slkv+eIXX/Lj+/eczifqqmWz2EI6lqAaSl1f0XUr5inibGSx7Oh6CVuZp5Gn5z0fHp74xa9/weZmwzTO/PFfvqGuDZ99dk9InqfDDm0V3aJhnAeGaaB919G2DcNpwk+epEXpe3NzS87w4w/vGIaBZcrUdc2rL98II680s1NM+JSISYZoISYySepEFCY3pOQ5nHbs9kd+ePuAUvDb33yJMkrCyeqW7eauJK/P5JQYBsfz7sA3P/zI7e2W3/zml0hqp+F4OPP4aSdNUyXJzOPoZDhNorI1v//v/hqlxVmglUcrWRPW26XA9I8HXr665/7lS2ojg5XD6cw//8s/cT4NwpJ1Iux49eqe9WrBOJ4JzvH44QPH45H1VuD3P354L7Dx7LG15f7FPW3bMQ2OMHseH55JJE7Ho5zpux6tNA/vn8kpY1SFrizBJ9wc/qJ14S8+oW23N8To2e2fZcppLRSrUK4b7tZbQkrMhyNaKen05USKVrgxx7P407N0YI3RxBB43j3S99JMyChMVZGyhyQWrEtn1znP6Fzx4ss0Zb2UuFajNVaLtSQrRV3XkJfc3orUOMbIOIy485njMLLZbIXnUrzuaF0UNhRbiEw+Bid+/pvtmrZr2e/2pBhorKaqLD8+7Rld4ObmnqoW8jtZOq3wk199LsVu17VFgSCTj7ZtSqKcFLSSxqMxWlLTnJuv18Ray3q55LBPPO32aGNYbzZYbcgh4Lz8IWcsorTqmrr45n9iyOScmZxnDXRNQ1dsgV2JT35+fv5XKQaxePjlTyisLumUqzKNFJ+pc455GkUt5Dzr1Yo3L1/y9Q/v2B3PWGtZLhZMXooeU6ZDupIoZedFaeXdjPflAGwM9bJDIRaD2XvcLIXPcrGitobGFiBmkGIzzlNJfikQWjkdkcuEfpodMcPORZrKcr/qUMaQSiF1Sdjx5efpUsz5kMlomuYnVZbwtkbqCElXDOMsBxBd4e2R3ihubm7xhTMhbAdhnTQF1haTKP+65Yo8W5KfGaaJcThzPp85DyORDApevXyN0oaEkgSeJDHJxcwrE9WQqCtRAtiqxlbCogleIMNaKeYQ8VEUfSojQMSUZSpYCWxb25+P4unynTnvrwqRC+/HaE3ftVLgFwVOU9eF/aDKJOksqrQYSVpkvCklQooyZTXCg9DaiKJQa5m2XeaeShNTFHtYkqSe1WpF17ZUVUXbdYV9JFNho6FpumLfmhnOJ+Zp5HQ+09aVfEdVjbkwQwrQGoVI5tTllshopYtShLLmSHz9br9jnidJhywpRqowjS50KCikqMLHyklYJCC2TxUi3juZ2MZYCjeBQ4cYiUlS04wxRSXjOB4OtF3LzWZL07bUTYObxT4FipgzbduxWIhldsxJPlOWqX/wlxSqBmMdlO9MqzIRv2q95PswVS1S+zK1UlqLvazsYbooK1P5TmNKtG3Dernk4dMD0zhgK0k7TbGoNEoqUgwB7zyDGjBl+maMFtqb+olpODnHPE20RUFnyp7lvSucFmnGZLkxSTEU7IscwGPKRTouqrhpHOjahjevXxNiFPtlUZTklITdFiPRe7ybmaaRrl9IclcIeH+xtU9EKyqWeZqYplEUUymxWK3pl0tZs4JwXGKUw5kxBhMNScdrA8paS13X1zRFUbR6nBNlkzSM0pXbJYmJwuFDid18miZRlpgil0ddv5OYCnOucLWMlfSZi4qvrqwA16dRmg4/o5fW0gyY5plpFjtoRmEmDy0sW7EQHxCVRldXhJQZZlnvZh8kLR4F5btSyjO7QFMbrJF71ZckKUUu/10S5GKSAJmIsJd0FkVdbSukxyotnZQiSklYxrKt6ZsK5wL7o6TmnoaRVS9slZxF5emdZ/YRW8kzpa2Gy14s4LDCDzOYkhpWV5p/+WHgOEzcrtc0TU3fCzMkATllGRz8q2soK6s8l2I31Dgy+7MXdVgZYGlEySThCYZF28o5JUe8zxxOAym1UkwbTd9YZh8ZxkAICTd7jNVslj3aWmzTEEPEzY6YMy6KkmvTWWJMHKwoRJWiMDG52nN1jqiUiUmeWUmvM2WNEGVzjAGdLDoXVWSMxR7ZcB49UxCFakYU/jmWs6Ax5CjplbEECxT+eWFRZbK+MAy9NJ5a2RnkfYgSiwwhxKs6DdRV8emiqC2rkhJrdMZ5z+Esyac3qzXOO56eztfkSshy9jQS/oEStohG1LYqJxyJkBRTEjtfW4nKPXgvCAifuV1UrJuaOYgdSjiywnjpasvZCeO0vGMqrWisZlb5yqUdfWScZMAaUhZOVtknXAk9iEW560PC+Ygks1q0kibbPCuIst6Jw0E+o8qy4jsntmhNluZv+a5+Lq/VeiHXJ3Id+IUUOR7P9H3Lq9cv8cGxP+3Lub4npcw4id1zHEfZg5Ko+JVSpBg5nwbCTaQvg6UpzHJfKs00OkDObsLrHdjtnrFVS1339Isg3JpSc3knDLjKVthKkq5XywU5v2MYZoZx4vlpR992rBe9gPNL/ZtTvtZ5VVWhsIwDxJBo6oq+b4qaOLFcLmibln/5+hv2hyNfffWZqEzVRXlqyxmq7OMhUqVE1/UllEuYu13fEny4Xhtj9VVZJvWnnAebuqGuajbrNTEkHh4eiSnR9S2LvqPvOuZ5ksRMNM45jLYslwtSDsQ8Y21D04iK5XQ+stmu2W42jOcBW1lR2ayW7PbiLBFF6iWpXBV1sgxgq6opPFFzVb/nnKV2nMVmvVwtefn6BV//6Tt2uz036562rTmfR3wI1E2HsYY4TsQQGcdZ6qAg54rgg7iVjAEl6Zez89Teoa2m7VsZOGakhg3CyosxkhD+Glk4WkYbjLKQYJ6ldjzsBxZ9y69//TlKCYS9srUwSL0wli8Keed9aTyvaRq5r70TJdjxcELrhDHCHz4Psyi0guflyxe8vN0yjmeG8YTOGY2wlrpe7IpxlDW3rmq6pqapDM/7PYfDnnn0BBc5FUfMdrsiLVvhj6bMNA4M5zPL1YJMxTAMHE8nlovmGjLWti3jWYa4IcjePo7yHm0tA8Rp/ImfhYYUIYT/xoynzVrSjG42G87jyGn6M9M8sXt6pu9aXt3eoJLE1QZgmoT/sFiuSeczu9Mjxhputzf0bcN2u6WqakIIrNZrJucZxonDucB2K0vTyk2ttUAbV+s1n9etpImViPKHT4+0laFbbNkdR3bPe7HupcjTN98Swp8Fstg13NsbtpsVTW1x8yiFtoG7zYqM4fD8icOnM21VYYvkHKP49OFHdI4EVdN0PZvtDX3XkLRlco44D+yHIx8/vMfNM7vnB5q64rPXb2ialrrpUFrzvNuTUma9viHnRFPJhPtue0NVVdzd3ZHJrDcbQoiMLpFyQsVACoHn9++YnKPv1/io+C//9Z+Kr3QUCXLdoFAYMlVd03QLxvOJ3cMDi9WS+/sXrLdbFusNbVNhm4bXr19xf39PBsZh5NX9Pa/v7nDTyNOnR47niTkpdqcBn2DRtXRty912zXLZMxWbzqfnA0/7E4rEi6383h9/fMfT+x84Hg+lSM/U3Qpja5QWgNzdzVZge71ICNvPv8Q5xzc//MhpHGmscI26rsdWNTlMTOeJj9MJYzSrwtkJiMWFlIjRcX7/SQpva+mahs9fv8TUFdYn/DTx/OkjbVOzrF9K40lF3DRwen7keDrz/uMTq9WSr758A0rzBjkYjXNimDPnoIlREmOssmhbobQUkuNxz/mwo+96xr4vzVH1E+yvLPqH04nT+czp8Mw///NEjtLsu73Z8PmbN9zf3eFd4Lu3b3na7ZiGI6eD2PTaxUJ4PcFLAZsSy/WWlTZUcYboeffd10zO87Q/gIL//b/7t6wWS3wQ6N5q2ZcYdTmAvkaK3+dPH3nOP5/jz3g+oYplzs4TH95JY9NXNaZt2NzcyvR9txOgaiwFdWUJIXE8ngV2aIxsrE1LVg6tRoJ37J6fSvNa/r53s1inrEarjA6O2miq1ZqQBZKaU+KpqDzcPHMu94LzgWqagQNKyffR9QuU1iyWy3+lNBElU1OJjUbZGmUsl1P/crUm50xTCvJL06ZrW7G+Bi/FFVyni1LRR4wxrNaiAjOoa4EfQhDJMpkXmy1aa/pWYL1d26J0SaMJgcN+J6qjTjhH3ntpLoxnYvA82ge0tXz69ImcM7bpJSHweBDlmPdipZ49xoiNol+s2dy+FC6NUWw3wp1zThrAm/Wau9ubK6R9mibO5yP2UrDJlEGs0LbleDzyNIwsV2vaTmTFL7uemDLPh6PYwUJkmCS1yRojReNGonoXS+EddW13BZ6nlPj04RHvHP1yRmnDYrGgbSUZRBvDPDu01nRtS84iic8p48bzxUkoBUwBr7eVIeTEOJ7EMqMUPkQeHp+uEPKUM8fzmdl5jqcTbdtwe3MrfJOqpqobpmnEzROn47HYERKxitcGma17UgqQAikr5gK6NUV9aqKkviz7nuPxWCTWjh/fvaOpa7FhL1dstjd0c0fwnqYVFVrTNFcVkzEi41ZAioF5OAtkuG9ZrzdUVc04z5yHM8f9gZgSL1++pK6rEu8cqY0qVrwKVde8efNG0qpmd20u/1xebnIyUOsXZBtpBzkoqxxRSaOtgEz3c0b7gDqN1NZyv1kwucD75wNGw6I2tFYao6YcYuuqIsSMc57TWZR7TdeijKVvTJl4i9Kkra0AxseJxsgAQ+UIOTK6gIuZmDSoiofdyDTtSoKq4ovXd/y6en1tHNYGUpbIex8TuqpBS6hCSpnjOEkTrTIYYH/YM/nAq9uezkhCWF1VonAMnsNhEPtv4a6tewlb6DsBIO1PZ3ISe6K1mmop6XXronTqanuF3PoYOZwkUGHTGUKI7PYDPiYWiwVVXXGeAqfR8e7TrhSKovqp2praVvRtV5RQqQS/WLpW8WWl2Kw6VN2xXFg+M8KUDN7zYrvg8/vtVUU0u8A4zSglzZ5V17BoGw5Nx9kn9scj73dPLLpWcBZ1xavtUhhWh/FqN/Y+FkB/ae4Ue9eib0SdWTYa7yVifX8e8TGyXa3QymKblmyCNFNSYHJirTNKGuKjk8Gqj+oKHk4p4Yp61StpHsqANPLpMGONJyeK7S8AmvMghdLj/kRT19wkDSrxuy9eygDmdGKaFc9ZF/u8JVgjacIxk7UVULexDKPnu/MoTcmmxYfI037Pdtlyd7OmaWe2K7HXPD4f2B+lGdbUUhQvbcUii9Vumh3rvi3A+kZUVkgxirJMAZrFimaRWfYVrc087s+iTtwPhJh4dbektobdeZLkTspwsLZYrXllVtIEM/W1QfNzeC3WS1G9hEDMAVSxvyVLykZA8Eaz7FdlbVAYq1mvlwzDwNsf38vQfbVisexYLqSR9ctffsVi2fPh6RPee4bTKMEVxV7fdpJO21YN9d0dN/c3WFVRqQZbW9wpEJWC1nI8jrz78BGlMqjMu3cf5KxetSxXKz5XmvubDcvVRqxOhX96e3fLarNkOk/sH3dU9RltNC45UXZNE+RUGJWGxc2azWbFX42/5nQ8k3XCp8iH98L6vD+daNuWu5c3VLWAqo2xApmOkbZuqK2l6Rq6vuHf/N1fUVUV96/u0Epze3ND8IHTMEozp6pAaU7HmXkKtG1LDJF/+eM3YtFKMkSq6w2kzOl0Aq1QVuEnx3g403QNi82Krmv4D//+PwhaRGs+//wLPvvsC3JW+Jj5/PPXfPGLF6SY2Z0PnMaBaQqEuOc8nFgtF6wXPTkusVZxPg0cn48cuoG6bqnqli9+8SWH457TH3ecjzPRB358954Ug6Qya81qrWjqhu12RWUtm20vIWXta9zs+ebP3zBNR2wn0PO6NSxVR2ssJibefv8t1hpe3t6iteYwTFKbJmmONXUDKeOmT1SV4cVLEdQMkxMETI44N/Pw/gFlDFkbjLacD2eG88D7d+9o2oqbuyV391uW2xVN1UjK6fHAhw8fyFnOoYuuY7Vco7VghE6nA8P5zOm45Ng7XBQbptEZYzIvX95xc3PD8XjmfBQ31j/+4R9ouo66aVlve7766hdEl4kh8+O79+z2BypbFVWlKOdVpdCtZZ5mki9hHF3Ni1d39F3D4Xjg8dMznz49E2Pi97//HW3X8qevR+IcWa+X1FVDYy0KWG/6IkIJzMP8F60Lf3HjSWwACmsMMUvSkHZa/NvBArkIeSQKO5SUuqqq0UYO8LWWlIG6rqVRUlUsFz1NXZfJapB0u2Kl01q60EoVFUBd0y16nBYrGTkzjCNGdXR1LbyiQcCaSiVOJ1GN3N/d0vWdHAySuXbNVYGRW2vRuuI5eMZhwC56jC5QXWCeBnLw2OVtSX+Tg/yyb6msZl+sca5ErKvsybEWT3hdo0r0t3NOisG2vYIopXgT1kjb9mQSKseSHjMSEtis8TnjpkuHW0Dtu92eGAUUXdc1y429coASCqUtKckCWLetTDu1pjECR7a2whR2xlAmksu+Y71Y8PDxI7vnJ1H+KIl8ZJyoK0tHpq4rqqYWyXNITM6RYqCrpBiNIXA+D7hpIEwDcxawtmlFVqq0MBOapqFrJdnQaINqW4ypUFq4JCJ9hLpEiyc3SLPNFQZIYYsEVVL0sib4xOEosa22amRD0gqNEaWeFg9yKFM7rRKJIDGj08RpHBknR9tJBLo1ojgLMYknPSOxoxcz92VaV1R0Egs/YpSiqmqqbFDWYNQlKcvQ1AKyjJVhdDPnYS53G9zebOj6lqauiTHx/uEjIAqd4GeRiZakl5xF9ZJiYlE1wkKZA4nAcDpxHAaGUexPta2Kb9ygo6GpZPpQkEQ0VpNi4uHTp2IJ/Hm8vHPCn+lUmaxSmDvSnbdVjVLh6rm+wJNV8U97J6yauoC0KaoahZbId+/E5lvUZTkJX8MoaTbmFNAosFa+4qTwJa1wnqwwUeYZ7wMU9U1O0nS+qILq1JR0NQNFRSRNqNIYUqLYvKgprdJFtSUT3ctLl2m3NAJU4azJhCwVZpBGFZVPGWOUKfgl7lopxPJnhc+jEG6ZNgbbdEXZtEMhnKOcuaaqpRgJiMpTaY02klJXNS2EopzyXtQ4Ue5tpbWkG1nLYrksbDuPqaSJcTqfmeZZ1sDl4vp7ckrCVagskFDKoEpCltZyrzs3MzuHMpamWdK0DeM44ry/Tg7DNUkqYpLoKExpeuScqQqnqEhmCcHj3Ix1sxx+6qZMteXWCTHKFOv/Tb0QkEdOocohKyNTWSr9k5K2XAeAeZ6FM2al4eiDqBPmkhhorKXKWZo8lyTTEOR+pVhiUkmaVQIiJ8Il5CDGS2KKKIwpjKau6wq3JXA8nQX47Z3Ad/tlURxLeEIIXvY6fWn8ycsWXlQuykFdfn/TyBp2niZRaZbUMl3utwsnSystz1f5LlvbFqA5V+Xgz+UlhYvC1jXaFpaXApV8edyFLRaVImWF83KGaovyyQXhMpnCf7skz1RWmjQpiWXKFQZJlWUfE66XKFba2kqaWApkCcgsSjwJKwkhipozC492nCOHc1Gna0XXNqz6lnF2OBdAawwZqqKe0Zr0r+4P4ZFlKoRR57zH+XC9V+vKXtWjMebSqBZepMmFwXfh72VhR6WU0LWRgA4l58BWV7JOaZH75KwhUFK3NJXWZC1JfWRZ54w2uJLINEwOLRlmJalZuCzGWGKW5zqDnL3IsvdXBqUtVZXpCcxzJHrhSq0WHcM4cx6lSIgxSaFbzt6NNdTJ4JBrPTpf0i8V67amqyuOLjEHWWOgQMdTRuliTStq3st3e3luvKfYTSI+JFKxvF7utws/MKZUvit5Fn0QCLkufD9rZAA9+4BOmdpH+bdBzrUuyLrqnZe9B9l7fOGxniZPyIquJEGtFi2DSgynTIiZKeVyj0ryYSpKop/SSRXeZ6Y5YGxFpxXOlzNqEmdC14ha7zDMDAUUjg5sjQwIrNJloCJ2oLoyGM01JKGrKzQwRiVpe1aUftZIQ252nmGamcs9Wxn5GTlJUzFrU9S58nw0tQUUEStpiz+Tl9L6J6W0knOVVqC0FbYuCq2k4I9lzwZN3VRMs2acJ5rcYK0ohXN5hparJabSDNMgoGsn9SDpkoqoynlJUohNa7C5osq12IbnSGgjwUemeeZ0HkrdKGtJDJ7buxd0/ZKukzqvaYQXJmc6qYFsrRlPE9550AmDLmm3qjSURaWktcFYjaksq9USawyH8xEfPZOT2nGaJPCg6e5o24ac5Px5OYvUVUXGoI2sBYtlh60q6rrCGMuiXciZ0jlSlIFUTkjjOSYqa8kZDgdRSEcf6LoF9/drco4E78ha1gA3z4zDSCZTdTVd27FerUQpZjR109J2PcN54ng8s+g7VuuG3e7A0+5wtcQ753Au0Xdyfq0qQ91YzseMmz0pTcwustms6buW4/mReRhIXpp70yzXpmm7K/M4l/qzaRqqymAttEoSDlHCS5udw1aFUapkfc8pM4xnjNH41RJjDOM0lKRpwb7orMkxczqcqBvL9qYnXmqsLAmromSc5d42Fq080QfOp4HT4UxKDZubDlvXLNZrVFboTKmJT2htqSo5ExptsQaszeVMKu4i5wLhsm6rjMqRqhLXkFaGpmp4+/2J3dMTTb+kaj3r7ZLVaklwmegzXduJcssI/1qunZwltJHkwhyj9FesoeuFq7Z7PHM+jQzjiEJq9L7vrir+yso9Z7U8u/2iJeXEbn8ghb8sDf0vbjz98d2D8GcOO7EcBEdfG5b9C4yp2J8d1hhe3d8yO8f7x0eUNXSN0P9NVaG0IjrH4+nMv3z9LZXRLOqKlBW22hFSpqlqvHPsz/tSaEuMqU+Z+PiML2kcbVthzYS1FcNxx/usOI8j53GkaZprSttisWS1XNB1Le/ff+T5ecfd/T2rzQZlKjBW0gymEZUT6/WKm+0tTdvy/uMHpmGg61fygDcLjK3YD57jGGS6mhJtv6DpeyqjiTHQlIOHrWrmEHh4eCIDr1/c0bUt27Wwnd69e0sInvNZLCKZj1hr2K5XkBINDkvGq4yuDGm1Qk0zx/FZNsOmYXWz5cvP33AeRn549yDKsK4Ar0m0lWWz3bJYLmmqmk9Pj3z//ff8+le/5t//u3/Hu3dv+ePXf2a93nBze8/sHT98fOCw23MY5freLDt8Apcyp3EmpiRd1rrmdrngxWrBh48P7A4DzWLNou+kMZOh6RagNNumWBELgHez2lDXNSEl9scTIYpEO/kRReKLNy9kYZhDkYf2hBB4fBTbJUogjSoLyqG2wtZBKZSGfrW5FnQpC7PBGIlqXS+X3P7uNxKZW9VS/IRZrDiVoY41ddczOc8///FPNE3DarVkvVzw6sUdpxMkd0apFm2XqJzIYaYxiu1ywewqRmvZbDbc3twxOccwz1KsK8V37x84Hf/MZtGxWrTijQ3Qtq10x1NmOI/4KOoYY2vWyxVtZbEkHj6+Zy4xy4uu5RBlmnSxiPabW7EEvXskZ8Xf/O6vWC6XUjAWsOg4TTy5MxpIyoI2JQFQ0fUd/c9INPDw9ATAh48fMdbw6vUbyKLKVCSeHh+vKoAQFIfTibqytG0riXFuIluLamrcPPFhGNDaSAPaGvqmElm3m9Epio2hNCwuhbJ3TiZg2oC2oiBoxeI3jiPj7Jh8xIWAYRQQfCVJScQk1sthoO97mlpA2BIJLgcbpUTE39a1MI1meU7rWgDX6/UGMux3T+yePhFyUdZk+Xd9UQ7qMsWYx0EGCDGhlKJvW4xWvH71iqwQmHmUQiamxHAQ+Ge3EMXU5599drUphhiZXKBKmbZfloaeDBK22y0hRk7jTFXVvPrsCwlg8F6SnDSYqqJuGrybePfDt9ze3PL69RthN5xO1E3LZ59vOJ0OPHz8QCp2MVu3LDY3zOPA6TzSVGJTjFqTtebm9oabuztpvsUoKSazYhxHaeoYS1X1tF0HCBjXakPXCuw5Jy2f/XwWG4CWw9J6c0NeSUGllGa5kmSt5+cnsbmlhFIa56RxYEvj6HQ8glJiu42Rw/lZkisXS4w2rFeS/tQ2NSlG8eUrSKFEsC9EEp92z5yOB74ez1dQZt8vWG82VFWFD6EMdUxhNMnhysfMPIvNN+dMcFMJDgl0XUff9zw8fOLt27cs+56ugOjFnioDhKo0V8dpYjgPwg2KkhSmVWY8H8qBS9F3Atl3ztHUwlyYhjNunq42ghe3N1SVDHAATidRWW02G6zVxNlfWSqQWS4kZebn9DqN0hBSU7Gvxlns2l1L11RURlN1DX/7y9c4HzgcR0m4UxK/nZFky2GKHIeZ7x/2VFXFatljtGJ0kjjWNgIAHoczTWV5eXPDODuOpxNnFI8KhslxGkfutoqXbY+LAhU/T57zIGDuWGyVi666Jhrujifefnik62pJVVSlEYs0cWMS5VTbSQriw25inD26szQleXKpZHh1ngIRwSNgZdj26k6jcpZnG3Ax4ybPeRjEtJkztTUsV6Is+fh4IGWJs5fmfcRazXbZknJDVTeEmBhnAei+uL3Fh8hhEGj5eZzp24rffP4S7z2Hw1GGabaS9+gkPZQUhCnSNAyz4+k007SKdddwOAX2g/DcWmsZhonnw5msDChD03Wslj1nFxl85OQVIXlcsfZ8+XLLbz+74zxJU85YW+zikuDWGFG/g8HHTF1skW1blTUn4nxk8NJENFnW+tc3K1FBSvuZlzeinh2GWYoXJUX9qmtk39S6FGaeHEuycpI0ZQOo4EtylKa3Lb9Zrcg5Et1IxtL2DSgt0eM5QEqEWYDS1lrmpsIoxd3dvTQRo1jcQ1Z0JYhlOJ+xaUbrjNaRpqtZLTu8D+yPp4J91/zwsOebd4/c36y4XcvZFK3F6pZjsbyJ+iuVoecFURFj4jjJNfAFc+C8K/tsA8YwjR5H5Hm3Z5wdn796xaLvuFn2KDLvn86FVyaWqt3+fG0EGqNZriqM+fk0nv7hH/5FeHGHvZzju57VcsNisUYBn94/iTV1s2GaZt798J66qVlu19g2oE0Lhfv78OmRb7/9nqZt2Wy2hATOD2U40jCPI8e9qNZzCgyz52l3Ej5wDFS2oalb2rqirSsOp2e+/TFy2A8cD2es0VirabuGbr2iaSq0yuwOe56fdtzd3rBcrghRQqIi0pDWStEve2HmNDUf339inMei5ITtzQ2ZzPu3b3n/9nuUbskoQgho4He//mussXRdK+rlJNH0jw87Uspsbze0bcPnX70gp8z79w9MYWQ8Icm8zzNNU/PyxS2Q6HtpOs1OzqUpOEyVWPQdGVHPrNYrvvjFF/jZ8/y4L+f+tgyyA3Vr6O8bmq5lsV6xe37imz/+iV/9+iv+7b//N3x6eOJPf/wTfd+xXPWMw8Du6ZHzaeB8PtN3C+5ubvj4+IFPz5+IuaBS/IyPjhcvb/nqF1+UVOWRvrW0tSWnFXXV4oMjpkizFEbYqltS2wqlozQHU8QPA6fTEUVGmwZlDH/1+9+itWZ/PBNjZP2rNTEEfvzuLW5yGNtIkEYngV/2NKCQhGulDGRNIDCnRAqJ0clwq60qVFNR30hqb9ssCNFzGo/kIv6Yp4FhOjH6M8fxyHK54vXL16zXK169eYmtLOfjiLaKqrEYBc4f0KZis2lRek0m0bSWEPbFxqsIJfH8n//lz/zhP/8zL+633N6uGaYzo3M0S2g6IwNQW/P89MRhfwaV2K4XrJY93aJj//zMOI6kHKmqStKanafpGgmo0g2WmvE8MpwHfv3rX9IveqpGM7szpzJkvNtM6JQ4ulFcTKZGa0PbN+j2L1u7/uLG0+E8kEJgPJ5QOdE1Qs+vmqZ4HSUhTtKw5OAfYyqTolxkvtL1c85xLLySvq5EIu+cpPAoQyiKpEv8dS5TFudEkZRzi7XSrNEKXEjMPskmEDzBiAqm6Tq6krKjjbl6foUXkYvqxhK8cDOappYkoqoqU2Tk8KAtypb/z1icL/aEMjlsi2rIZEmY0spck8JizsLBKoW82AMEkidpCx4dtYAlZ0ddVSw7UWdZhcSJJykOdbF6CL9EIMSLruPu5kZSOT58wmjp8KuiiNFGC0C3eJLd7Hje7ZimCWssMUQOh4NEhWtNjIlhmnBBlD3WGPq25jh5/ByYi8JCV9XVr9tUmsrKpKmuRVUzzpIQpbSRqVPpWIcYpIte/n2YZ0JMDJN4SVUYMBru7u4k1jkPECIGXaZGdSnqKfOiwkWQiAsiAvWt6lrYBVkOD84FbAVNU1EZw6KV5sDoy0FKKVKxrVzSEkI5UDbNDFrRNpVwAIxCI8kWVYl3zzGUiZfc5z4mSdmrrLAzygEHo5lmz/P+SGM1y64WQHFI1Km+Wg1ijMw+4UPiwh3Sxf89TxPDNLFuSuFXPrscsJGDn1KgDdpY1qs1m7UUv3Jok+fTOZECJy02rarYt6rC1fi5vOZZwH0xeJqm4e7+dVH7zOU6uDIBliImxkjQ+hoJn5OsYSiKSsZRVTVNiSuXVAgPKV4P4unS2AEoyUQ+BJTOoEsTw1akFK88MZmSCRjaVhWXxDeyMG6EY3bhaAiLImXIWaEQEH6yBh3FwhRjImhFNoa+k+f7sDvj3AymEuuTKs+LlXShy2e+qIZkXVekWjaXppFJzRxlAiQKV5lsKaVFKdU09L3EG8+zE7aMEoWpLQpWXexvTV2jfEAh6qCuW4jlI4QrZ+sC3k5xYjyf8MvlNc3Ke4Hl1m2LOktM+MVGVjUddSMWM+994U3J+qWyoi5JlsM4Ms/per0ve1dlZf1DawHCG1OUuKowFWTic0mmvDyLVSUpcZfktaYR+4QxmhAVKYgi9wLlVeqSbCTSw6KTK/wsjas8da3oCnC5rirC9d6Q+8CgSzKTXNfgHafTQF3VqMUSgLqq8LZCG1uuhfystm1kjykMqZ9YK6lwrJxwz3KWtLvDgcraq13uX6ud5b9J1LPzrijmyr1alDU5C+hTGWkSxMIMUkoO4yqGazJn29ay9mldFC6irvlJ3ZSvzzBkUtf99Nz8TF4uXJQCok7TyFp0UYaDNPLWfcM0a46nsRQQ+cqskI1B1HbnybFQosDgXynETImzl8Qt2ctdAfXnoiyZfGBwkXVJToxJ3p8vzCHnPLr8bLG0iqpGzhWzpJdZg0L/KwWcNOfT5ZyjRKUUYsJHsbxdbKqgCm8HYa2VZ7JR0lSJCP/QRRlYBedQOctBvyhF5TMW6HjOkCCSZf/WwuTrWoNzkmorv7+W5pSeC6tH+HWLtmHWisFKQpTYpORny9k3XYcaOcPkEiHm8neEFWQApWR/GKYZbWuM1XRGUrWm5Egu4WNRdBRLUN92rLoG1CSIBXP5/cIPkmspTahUlDhWIcltWhFCOVcHURK1OmM0tLUMH0YvqoW6kjIhuECMilCGFdbIGbyyARXFekmOCF2rqGdzliFY1mX9l/NkjIHBjdJ4r+sCkJe7wRYsgXc/KdyauqJr6qIYUoQExExVWbq6IgWLq41YSsiiLqlrJKEziTJBa6YhcDgNMhxF/cRCLPfh5f7zRfmlCpMP5DnxxZkRlbA2ZZ9MZYAj3yFlT48x0jcVq74VpmfKZW1XF6Cf7K8gKrwsioKf00tcGZHxeEBrzXp7S1U1tIW7eTifqGoriqeQ8C4UhbNcB1O+N5C9frffs4yRzXZbBsYOa2ts05BJxBSuZzBPFD6r97h5JlTF9pYbKgPjPDH4iXkMxCD1Zk7SgGmaRtIeEV7PJS03Rld4n6msMZG2rtFW+LC2qoQxmBUhJnSMtI2c3Xe7A97NtAupibRWaGXZrrdUVYO2AJk5jrJengdiTPTLBltp6rok2aYkCs5y5nduEJXMxmEMVFaRkjTRyIlIANLVVlvVlq5vubnbMpwGds/PUqcZIy6ArMGAUpa68JqCD+yen5mmV1RW6sbT/ojRsFy1BO8YTiPzNBOdxyzkzAnCgR6niaZpiNETc5SAg9US52dC8NR14W2FWphNJknCd9NhbM2iXVAbi/dnUvJEJc/tNAykEKnbJC6k5YK6aRhnj3Ne1DgpYisrVjklCcQy9hD1Z1bCCEVpLnzTkBIqyVptEHW71lA3GlNcNsJdKqzjLNfYWE2IkeNxQGGYlhPLxYKmbUShZStJz6yMYDhI2MpQ1Q3Oe+qmDDURXpRRBlQmkzidTnz6dKBpDKtVKwFsMRBTuLo0tDYlZGKktoq2qYsiVvb+i6tCG10C0BytbqiKOi6GfF3PlssFq/UKrSPOXZiCst5d3AIxJbLOwjjtRJH3l7z+4sbTdHyiqRt+//u/QSl4fnrEOccwCsxz0YmcLHhh1bRVhZtm/vCHP5CVomssMQSedjv6fsH/7t/+Gzl0J2kYnYcyna0b1sue1/d3cvhIUiSHYjMAxXk4sz+c6JuaRddwdhHlIisVqYg8PD3z8eMHfvOrX/Hy5QumcWAaR263KzbLDh88p90jr1+9ZrNc4MaOmH0BImbevv2BGAN1t6Rfb9kdj/jnHb9884Z+0TNFUTrVJar1xe0NdVUxDQ1unvjhx/fEmPjqV/dYW7E5nMSa4B2nFPj0vJOIXe+ojOHF3Q3Oef705685K022HX3X8vrulhAC58dHpnnmcXcs3JSezWrJ7371FTklPnz4iPOe7apHa4O2NcrIf+I8owtEJiIHRh+p+xW744k//P0fGKeZbr3Fpczbh09oEhWZm9WCu9WCRdex7Fv+8z/9kR+++Zq7uztutlspjELgcR5JwbPZ3vLVr+95c3/LerngH//5T3x6emL2AiRbWUPTtugkss+3797jnOeXX/2CzWLB4/MPnM4DN6seU1n2+wP6eGQMqYCvE1Zrfv3lZ6QM37x7ZPZepKFGs2gbcobH00DKib62JKs5ZfEx26ambTvu717ivePhwzumeebpIJHhv/nyjahPZk+zULx8+Zrd7pmvv/4T0yiT0+wmXvY1D7sD33z3lrbrWG82fPb6NX/9m9+I3XIa+PH9R8Zvv2eeRj49PdC3La9vlleFnULJQqQ1MSlOpwO7w56dkaJw8fu/5tWLO95/9wMPnx652ay4vdlynAKPw8Dd6oa7u4ohJFzMVJVEYgbv8PPEn77+xOxm1usN65sbQorsjgeGQQ7FrQHbVbhJDseajLGwWEpS1I8/viuF3M/jFWPEWsvtixtRVRSQdwhi4+oWwhdrKmnSbv1MDJHd/kAuViVjLJiapjZsCpOt7Xq8c5zPJ3JKYh+2Yq0SC5D5qakQg0TMzjPnUTbhrmk5nw5M54G269ls1sLOOR6LfaBA82Og73q6TvgitjQMjDUMw1DgjLJGHk4nyMJ409pwPMp7a19XtHVL2y+xTVdscpq2EeD1NE+EENg/P5JT4ub+JboxTE+PEh5Q16JMOg9QJkTGSuM1qksctCfuPV3XsdlsxIYYxRM/HvfEFIUhU9dstxtAcRql6XezXhWAsMIXldklwt1GRVCWyUd8ksPsn//8pyJldzJte94Jx2tzi9FSvNR1Q920HHdP8vymSE4SI1tZyzxNYq2uavqu52a7oeu6oqY8koJnmicWixVV3UCWhsfxeCTFyPb2HlvV7E4npsmx6lsMEPxPz44ChvMgaYk3t8SU+PD+AyF4pvEkhUiWAU3XdWIba+sCaxe7h1ikJGlsDoHT8XDlbVW2Yr1eA4oYPG3b8Zvf/Q3Hw47vv/26SM+laaC0JqbAcJkSKsjrDcu+o6kalsuWp+A4+lmsI1VFZ2v6fiEH3Fng43VtiTFwPp9FWRciT09P5BT5DLC2Yp5Gpmlk2S9o6ppxHBjHkX6xoKlqsQ/4IJG+/eIKB9/vnnHeY+uWurYoW5G1KcrVLGEhKYl1TCuabim2MyWphN99//0VQP9zec1e4Mi3mwUAtjLEGJmmGWLg2FZiayz2pnEWhdRcoPCViiybii/uNmQULuei2GzwJeGQbCE31JXYkJz3nIYT1mi+eHlTEAMtu8ORh+dnlr00+Jyb2R/2KGDRtIzOsz+PvNyuWLYLOYNYyxev7vnFq1tOk8DE+66hqS3Ph4FhnOW9poxiojaaxmjsokGljIuZV30rjQelSYBVAl1/saqxRvPhaRKcQy0MknVryFlz1mLBrIp1+HgSNujdeoFSUGspMp5PI/jIlKCpKm43SwywSwGXIQ/FspY1XWP44kVLSpnn/R6Uou+F6TR6YXdu2ophnnmaplKYwPk8ch4G3n6MTNNwDS2Rs2GgbyyLril27QmNBD74eeJ8PJDqGkoDTivN8TwzjI6uttytpLAx1nB6/ygckNIM7ruGrrLFoq85jjM+jLRF7TUNknKbu+baAJGGuCjg9qcRBby+kWv2zYcd05xQ1pYBa40iMY0DWis2bU2MGXWWz+6zqKCa2pJS4v3jsxTz00hb17zsesEYjCO1Nfz+F684jTM/fNwzp8Q5BhYhU+vIMEc+nTxtpVk1Faar6buKrtlwv17wuB94/3ik1hmdIotFz2azKYB6xVPX0naShBV85HieeD6eynBDcbPdsOx7pikwzJGbVUXfVpzPE/MciADGMowOFwKVtQJZrhRWZx6fz8zOsVos2a40p2FmnD2bZYdWmrZtUMaSs1j7L9+JLdyg0zD/rJpPp/2Bpq753W/+Gq0Vu+OBEAOfHj9KEmJjadqK2taEKlC1mtmP/NM//DNaGbabFZUxdFXDerHmV7/8ElNZ6rbldD7z8cMDKXp0HunamtvffiX7aUyF99aQYyCXdMNPj0/0i47lsicdYdxHtpsFzYuax0+PPH164vb2htubW+ZpZjifud1uuN3eQJZB9qsXr1gsFjx++sTpeGSYRsbTmf1+h9KKpl3RrVY8PIrC+RdffMZy2bMqbF9jxJq/fnVLZS3eCfLg7ftviTHwy1/+itXCctjJ2U5HjTs7/uEf/ohSmkWzpF8uuL3d4n3g2+9+5DCOzNOZRd/y5VevMTaw3424EDg8H/Hek7Jnu93wN3/7e3KG0/OZlCIv7u6JUZp+KWt0rfAuMkye0XmO5yPH0xFVWR6envh//k//CT9HyJrd7sjTYU9XN/R1R7toMc0dN6sbNqstHx8+4E8O3wdCXxrQWbF7HjifIl1nubu/5f7FPcvlkn/8p2/YPw6olFDAsm9ou5acJNnzxx/fMo0Tf/P7f8tqteY/vfuf2e12vPnsDcpoPn74gNYa78XOO54ntFb87re/klTSP33P7Bw/vv8RqwV5koH3D2/RxvD61WsSkfP4ROUrYrilrnu2t6/w3vHhwzumaWa/O7JYdPzyq8/FDtnMbO7u+d1f/57Hx2f+8Z//iPeeb7//hpAdn335gsNxz/uPH7HG0HUNn3/xmr/5734DykA2fPvd93x6fEDbnqZb0i1a+kXHNJ+Z5hPTNOFmUQCroHDjzOl04HA+kZXmZrvhi88+J/jAeRjYvHrNZrXm3YcfOZwO3NxuuLm74zyKBXi73ZJCoOuk/vnmzz/gJs/2dsP25pYQPcfTga5tJCVxfcOiWVAVuLgEwmXaqiXGyD/+0x//4rrxL248+WmkKnJ+rTXH45EQxYOYkCl9TD/xMIRdETidTxhrReJcUqK01qwWAiv3br56LJWSKas1hsWiL9OYeGVniO9eJt2ns3BrrK0wSaFjSbjQBq1+iqS2xQpwSR1o64rTSfysRlHklQKjDUEm5c5Lk6hdbqiblnSUaEiQyYhMqIpqoaqoyx9fmFExpSubSCDD0h1NBWJ2Okvh2xhQ1tLWDWQpMiPSKQ8pk0sH1he7g3B3FLYSRc5quWSaJh6fnsgpl/jh0rXNZWpdJk8hiJc5xChNipKGBMIhyigmN1NpRW3KNNxamlo+m0YsHTEEfAyYIJOJcZpxbmJze0/XLwREWoutMiOqAFUUaBerndaJaXYMg1wHrTUpiS1OaVFgzLMwjyTPBFIIJKNpmi1Kid86Azl5kUMbSadSWqGTeO1zUYWpMilFKYw1hKCL3WxmGEcqU7rgSmEqsNrQNzXzOGC0JsQg/IFpZhgGhmFkmCRxsC7JDG3Xi3/ZXFIVETWL96i2obFGIp21qDwWfY9OCRWTaLayqA1iUVtk5FA/DGe26wXWGlyYOc2eu/VSlBxJFAWXdMYUxC50Pp8Zp4nb2zu6ridnSZDSiArOKEBrvNYl7icWhoNM40Isk6GfyetykLtwwiRmVBraWhVeU2kU/cSSAV/Ae9baK9zwAjW1xmCNJihVmCnyO5TWV7XSBQQuXntLThUoeZ4ra8uEWpVnQKa6Y1mv/j8+gEzSjL0mG13Uad45Ugh4LdPuEKW5UhUFSSr8lYtCx1ixVcrvN9RNibSd5yuAXK6LLhwpidyWiO18VSLZoqTQWpG0qHVSFNZHCB4ffFEOhTIp8bLGa42xopwKMTG6CYuwD5TiyrZKZU9ISYYPhFAmMYgyYDhf1TYpuZJ40tLUAsytSkKfUVxVRTnL+0lFMRFiIPhQpo/6qmCsirLIl7973XeK8sNfU9p+UnzJYF4maCEmUpm6ZsSOoZOh7VpMFvVDjAJsv6g1tZKmp/5XKhZbgOhKSQNLYMHCL4hRkvou++FFpVZZS9f3uHmS+6uoIXOW7+6izqJ8fyEIZ8UUVYZWkC/pZCWZRitpasUgz4NwvdT1uVJakbykSknapyjWYijripE98TJtU9qQketny7W3JSo7Fotq1YiKRxW1WU4JlSXNMKYESZpL8vjKv798Pv8zazzFRGElyXohyZOUgRxi2dTS/PUhFm6OIiO2pcoIUL+rZf2plSrWI2neGX1JIlNYY2mbmlhUG1VdSxBJJU1c5xxdIxZjgJST2FiK+jPPYvuKSRRRcvNqmtrQGlGqxALqN6ZwbfI1mFWYTYC1GquUpH5lYYTV1uAECCTN2HJWsVamzj5mbLHeV0aU0JPWgpcpz0EIsTCnKowSzmbKwtFKOYML5EtQyVVRlwlZEsxAlGaLpmL2geNZErKaprBfcipqIFFRX5RN3vmrCmaaHftik9FGbHCzD9SVsKnImVhUyTEVFmFKpUF99UgzJ1k/WquxWthVl+n2xRJ3USIafWGZakIcJenNGgwaUpIE6qJkiimTyvXNyHvTQGX19R6EggEo35W8IwXoYr+VQeEFiSDpqPK+ptldOVLWyp16YdjpyrDo6gLgztf3ElIihowLiclLInK0qazB5SxeW/ZnSaAzV1WW7DWmqAvauqJroqg/yveVUyaqJGqpso6LQlmub1VCI1yIcpbUJXks/6SQMoUdGGPGh8yys9SVJB6KUkoUsZc1PQT53JfvxFpJeST7omr+ebzcPMt5uusLzPlEDp55nsQh0XRFZfOTMjOnyDTOVFVFt+ipjC3gd2E4ojVZX0D28qwGH2jbmuVqKYlibqauO7puIQOnKEmr+4MWLlAtz55CFb6uNKwv9Uhla7wWG7ewhCq8m4kh0Lai6D5WlXyfRYEUUiCRabs1tqoIITLPs+xdiMJaWLOylvd9T2UrjnEme7kmIQio35qKpmlF/5wV0UeO4xmtDat2TWVlWDZrgXD74MkErIEUs/wJ5X35eN2LbWVZr1e42bPfna/PSL6q7S5nmpJyGiIZX5jNGu89z7sdVlVYXTPHwDhPGGXoauFP1k2FrWxJ7xV2L2VtJ4srY548zmfadklVlOd1I+fzDGiUsEaNnFWD94QcmaaJ4TyilHxHFydBOX4zDGNRB8sZ/PLc3Rb8SFULamCeJoKR+1IpGchlldAmY7KsadqoK3fMVlacKT4xT47T8Sh7sjKgQdtI07bc3NzgvTSknYtMswzgpmmS5OB5pjIXPi+0fS91mTKCgSiqd2vlmrRtQ8ozPhiq2tK2cj415ZkwxkpvoNSowcfC+pSzlnCsJg77I+v1UlTSxmATUNWk4iJSaKZpZjiN3N7f0rTN1SWSsyj226YRN5cy5XxBqSuk0+CcY5r/G8PF337/PYvFktvbe+q6EbtA1mQMIUYedpIeNHlpJj0+vKepG/7qV7/Ex8jueKatGrafrfEx8Y/ffEsKgTDJ5GWzWuJC5NP+QEJxs15zOh55//CJ1XLB/c1W1ALTzDSOaAJuTuz9zDA7ztOMM4pRi/3ufrNmHs58/+03bG9uuL+7Z7/fczqfWC6X3N/dSNLP7AVcaywG2Vje/O6vabtOrIIpsVguCTGytLKB395sZdNuFihtmIaBo9/z4w/fMXvH5v4Vxlp+fPs9OUa2i4auMQxeIr37Mt1IOcnNa8TTPwRJ0fjq9S0pZf75T18zTTPH4wFjLf1qW+CQ8iCM88wwzRxHD4X55L1nPO2wBppa432QqV6Y2c9ngvfUKtA3lbBIUiQH4Y74KHbGo3PX4lo9SyLaarPh//of/498fN7zeDhhbE1dKWzdgq1xIbE/HHj6+F4UUJstf/3b3xBSJuZMdg5Solsu0dbwvDsQEjw8PrE/Hli0Lcu2w1YCqn98fiIEz/b2DpTim2++J5Qkrr7r2a7XhJR4+/YtM/DqXuK8+8VKpI4H8S2/frXCec/3795zPOwYj8J2mKYJRebFRmC4z4eDHLL7juAC7z9+wgXH7ctXUgyXAvq/fPuOmDJ1t8T7mfdvv8eNA8fDgc16zYu7O3bHgf04cbdd8/LuBjKchwEfgrAYqoq+bekqSRl68folUYliKXnPHBP/+OfvOJ5HVGU5jyMpBA6HE8Ps+IDndGpZ39yyXvY8fNgxnM+0jWyen72+F0VebSDO1CphteL+/iXWVvzw43tCmMqhKzJnUCnx9PRMW1X8m9/+4lpY/CxeOZWG3PCTNTGJ9927xPl0wFYV282NKEmGkaqq+Ozzz4kxMpxPpeAzTOPAn77/VlQyyxV1aSL6IPG2pliXhmHg8XFHXUvCUUqxxGLHqzUteClGtBX7qHdODgZFDRRjFGVcXeNL/LytLKaqpJETSnO9sizrmuIFhCw2UJQ0kGOMaFMRk8JWNSZzbXr5GMkhcBokfaxq2msKnsmaN599QUyRD+9+JMXIerORn60lHttqRcyJ8/GAQvHq5QsA/vTnr0X+ixSgtulIURL/UoEQxxiJfsJPkfMxopVEaOcUC3dFQXn/4+kgRVZtaFtJlBObb4ULkoyUskTFgjBdBIAuqXK//e3v2D8/cjrsGDjhnbA5cqIEGWQ+fnrE7HaSZrVcEFphKWlbl4Q/DQU+Oo4jj4+fJFGltnTNir5tUVqx2x8IIdK18gx9enqWJoEPVJVltVwSY8e+NP5vt5LEd7EYzfOMNvDZZ29ISfhFKUXOx32xETfUVUXfdcVGPIulRnNNrQshsFlvro3/eR7505/+KIco+5PdaHSBx8cnsQXXO47HE6PzV1WtNA4DGbGNV8pgbc16vWG1WjGMA9M0iXXaWA6HA99//x2+DKWmaYYssmwf/DUWvmlqtGqYXYFCIwVfVTfyfGZpzDVW+Di6FPEME94HhkGKgN2h3Bed2Cr/w3/4P2B+TmsXgLEkYH84obQCW0mDLme8TzwcHZXRrLuLhc1QacWqq6/gfpUj+3Fi8pHnwRfncKatKzbLFhci53GG3LFY1JJ0NyeMTjQxMbqBcDwTgnwnqqxXRmmW3UIaG1oLY6hYOk7jRJczDYnDFNhHSVa6XS84jhPHs3C5Vl1NKA2etjS1aiPnuP0gSqbZe8TKIOta14jt5DQHmMuwqFal0YGoBZGYcnImxDIsrAwJOA0jhkxfS4NhGgeyEmTA7Ga++/CJGCPnyaPINDaU5okm5iQA7JhJygqDdPIFp5CYXeSjm8hA07TMs2N3PJFyZtlU1E1N27Ys+47tuud0HjmcTuSYOJ7na79uPg48nyaauuLz1y8Z5sA0SwBKDB5byfABEqPz6LMTm6M1vL7fFPyBWEpQwspD/WQbezqcyChebRa0tWX2jhATh2EmFHgywHGUJvHH5zNNbbnbrklk/OxBQd8YwGDtSp7hMqj86vUNKWUGL823592hJPwpTFXTLZZYLQDhlATcHhK8fz4xTg5FpKoMVdeic2I/OtCWu21PDJ7DOKKNpq8tdSUA/NMwsD8euaGn6mqIHj8lzvOMdzNZGVaVYVFDV0P/Ys3ndyuGaWKeHdPs+PbDntPhwDSN9I00Jz48HdmfBu42S/qu4X7VobXicBrx8wytKNFe3t0QUyakAGTWbYPVmkXfikWbgRAyToutfUqKnMRpURnNZy83pSn283jtn5+Zx4n37z9Q1RUpe1CRmDyzkyThtm1JUZ67416S3f7u736P946PHz+QVEXVdZzGE1//4RtAo5WAll+9eMFwPvPp0yNVXdHVHQ+7B77+0zfc3N7y5rPPmKaZ8zAyjyO1LgDpYMk+ktzIOXqmYcBWFZ9/8RlN3TGcHG23ZL2+4Xh45nTcsV5v6W9u8dnzsP/A4M8E7Wn6hrqr6XrBiWhryvpzh/eR5WpL03Q0jRLEJ4CCeQ6Mo+f5ccc8z7RtDdSc9ifqyvP5K+Fk/vDuB3zwrBa98IlqCaPyKTI6x9PjE9Zqfvmr35BS5g9/+GfcLC4ipYRHZJtMlWe0qfn0sGOaZh4ePoklPnhBuxhNVQYP8zxyGp4R678MqDeLFd2io+8buqZn0S3xXtA50+R42u1RR8GJvFUPEuZlNf/9f/g7np4O7J4PSHpJEpeGrWgbsQD/6B+x9kjftfz2118QnSOnyGIlZ+yYWkIMPD7uIVseHj5yPB65u9tye7tisdiiteHjhw845+h7EQR89/2PkMH+u/+e5bLny8/f4Jzjh3fv0Frz2RefYaxhfb8SlTlyZv4//8cvmeeZb775lnE847w0zQyGru14+fKOylqedjtp1JHwcyD5xPk80C86uq4i05Bi5D//L//E7BxNU5NSZJgHfnj7Iy4G7m/v+PzNaw7Pex4/PdJWDYuuIYfI4XnPNM1MU6Rv1iw/3/Dy5Svu7+65efGC3w0DCRnWutPMf/qf/sD+JGE7795/z9PuPR8/PXI6j+j379gdnrm7uWfdduzcKM31Voblr97cl8CHkcNx4u7uRpwZC7GK3tysmCfPOHnc5Hh8fCBGT9c0dF3Hf/yP/wNN0/5F68Jf3Hhys8PamWkSj3sK/moHQMUSNZjxRS0RQigQ8AYTIuY0FKZHQ3SywEfvCJOAMFVhDTjnmd187Z4N40BbV9eJyDzPJW1Hom9dkK4cKZQ4Xl18qQalYBon1DbT1Bevo2yMXdOStSn+zpKip6Qbveh7+uWK4XzGe19g2WCiQ2UB9lZVha5rUJrzwTGOA+dxxPvArRWw+DSOxODZ9jUoUVCknOkq6efmlIoi6eIiFNVF14gVYRjFGzvNjhp9PYDnJHBYSWrJV2D3xbMeY5AkiSzpC9boK7NF5XRNV9NGmjxlfAio6+Zb2wyVNMdyjizaFevlgv0woY3YbS7pDUopQpQpw/l0wk8Tm/WGrm2v72lMiXCZslUVbdvSOU+MgWkKdI3I/bSWyY8MNi/5SqJykNQTT1UFlnWFvUwyL3Y6Y7GmxsTI2ch0rm1qQICnKSWmAi/KBQooaXpSgKuiBIhRPLJZZeqmFc84ifMwiexci+LEBYf3jmE48/T8DEDf9bgQizpFVCXOOdzsrqq17vJeraaqNG27QNc9fp4IbsYfjszjJH7sqkaryzRMeAnOiz1pnXNJkInSmS6H8raW+y1GmXhEFYs8XxQEV+sqXKcb18aHgkXX0jT1X7o0/G/+lZIkN8TymQ35Jzl7FpZOzrl4+KMoFUuBb2LAzRWXee6FJxNTRllRECzKxDaV5y0VNo5wjxSxkqZTCKGkVBT1TZluGGvL5K5MQIuHPgb53qqqKslz5TuDn1SgimvDRhkDMQjsHnXlc8RSCEoqh4brM5ALNyoVJUxEK7F3pJiIWlIddTIF1B+vINRMujYHLuokoyUpK6Qkz09KVFahtbACBA3M9Xdfrn/OF86WoSrWM6mMhfl3mWpr1DXtVBdFU13XoCIpy3TrovjKRaqttSrTtJbhJPyFFCMuz6I4UOanz58SeM2ibakqC0YCC9K/YjrBTyo2UYflEjFsRa1Zpvv58h3B9dqG4NH6J9+9KkWhrYTBp5AGsNKiLKrrhpRiUaMlYe/Av1LTCZPBl/sqp6JKK0D4+tKMVMJWHIfhChunrKyxKHxjlDXEBy/Kv5I6GtNlDygTfq3QyEGlqmvqAvptG2mGnU4nvPMl9arw967feuFnpUilSiKiCtf/Hbgqz2L4ifN0eV2UXZf1KhXFNBnqktK4XJZUvZ/RSzhNFEacXJ9M5sJIcuGyllcSvVxAxbK/WNqmIQbPOJ2ZvQClc8rXPfC6ZkWB8PoQryyulHJRUiVm56UM0aIWuRzU66LaMFrT1HKmMUbJfVOehhhjUSWIOkWX51zu47IPGWkMWWMxWlhWWqurmitEmahrVRpMZFwQMLooT3RJIKL8b7l8zqIS0sLWEQtzJClR0QhXL8nkukxvp9nJ/pkyRuWfcFTl54UoapyLmjAWhTu5XK8Yrko+SiNf/Sv2lbWWprb0TSOMUWtxyeNTOZuV823KSZpxlcUGSeDNmbI3pCsLa1Yg4CPFohG1TW3lbBNS+umMmSnnXcXkRVl1UURVWgDtwmdKhTsIZaQtih+t6PpGPnfwUtQZ+T6astbIcBRqW4mFLnhJEguyt2ptC0tTAnBSnEsKs5FG1SwDGUnRVjSVJO8GL6qiurLMKeCjKPwm58jZolVJ/uQntXYqylBJ1/JUlSRrWa2ojAyTQM7UOYmV2jl5Bi5OjATFFnlJgE2ibreGYZiEoFMap1VlqVCcJ1nn9L9iROVc7mnFtUmbo7qGfJjCfqx/Ro1z52Q/GaeJmCLZBlKS9Spn4S9pZXDOS32UclEDdczzhVsme5CPgXEsIUBISvOlsXpNRXeeeXKM55G+n4tKJTCNAvu3xaZ6UU/borBJKdG2LW3TYquKGFJhTnYMZxlWX3i5wfui7i4p1YXh2HUdVV1dOapd29DUUNkKrS3WKoyhnHky4+yKKkqGkIJmkKFkTrBYrFAqXR0vXX/ZM4siyYu6N8SAMRVtW+Nc4HSUxsPsJuq6YbVq5L2mjDK2/LtwVeIN44g1WuqGnDFK0mhTDihl0MqijSqJdoZrMndTlbqrwntpYKmoS1phAhL1Zkm/6DmexoKcSKQU5LNqLcm1LuDDiNKe9aYV1ICRNdPaUhMqafq0bYf3oswfU6Kqxeorz7HcC5ek75wSfnaiWC37RNe12EoGX0pr2q6jqiwuCmtqniQReLPZMA6DDC1Sws2znLOVxhoLdYPW6lpHycbiGdWE916cNspibENwifNpICGJjCFmQpT+xm53pLY1m/VK6rqydqrSL3De4WaPd5GuE9vhJfl3udY0XUcukPv3wwfO56Eo08WFIJbDUkN7zzSJq8BoOZmRC9MxlSAiozgdJ6KX56mq5CydigpfKa69hBC8DMOL6GWzXrNYLP6ideEvbjwt1tuSwqSY5pkPb79Da83dy9eQDMoP2EqzWa1IscNksUC9f95htWaz6nEh8Xg8UVcVv/38Dd6JZC2myLGk1fhp4NN8Zvf0qWyQVqDgPjBOE+fzibZp/1/c/deTJUmWnwl+Soxe6ix40iJNqhsNYDCzGNn/fvdpZFYGMsACqK6upMGdXW5UyT4ctetZuw+oFdkZWeQtiequzAgP93vN1FTP+c7342J1wfF0ZL/fU1clVxeXVPM59XyOTZLIzWbDbrenyC0Wz8VqwXw+J4wDw+i5uFozmy/INJyO0m011jCOA5uHW+4fNnRdz6uXz1nMZoxOHhLRWILSjMPA6Dzf//QDp+ORxWJNUWc0xxORE14ZvNXct4EYHXe3d2it+Oqrr2U0oDkQCewaiY6+nNciWAserxSr9Zqi7dAxUFcVb24uCUQOJ8FUT02HtZZvv/xCfEWbR6xVzC9XnE4n7h4eqeuKy6sLvHPMhoG+7zmdRF738PhAkRnqQkSx9WzGTz+/Zftwz7PrSy4u55R5RpFbPny64/sffuTZ8+f83W+/5XGzY78/EkMv427jjC4v5HCYlez2B/qup55JF6AbnSSBHFuMGfjmyzcYrfn57Vv2hwMfP39mdI4vXr9mPpvxu9/9FqUUnx82jM7xj3/4A5kx1FWJsQabSQLDV69eAFDUklaz2R0I3gkCGyO39/c45yitwpiC5VoIpK4Tr8GhaSmAdSHR3o/393Rdx3a3oyhKLi4uqcqc5byi6wcWi7l07UKkazL2Fop6TjFbsDs13P/X/8rV1SX//t/+KzbbLR/vHznuduy3G+bLC2arSyqdkeeWrm85HnrKaqAoGnongvWLRcWrqxXN4Bl8YFZm5NbwsN1zaluGrjvf+MPQywHdZrTDSBxG6kIWxcfNhn7oCW5AAZ92cvA8bHfEGLm+uZbCQhp5NFrGdT5vDmkM4tfxOux3ZFnOfDYnRsWpHdFaM6tqlJIUsRACfSsJKdfXN8QY2W4epXhZVTjnaZqGrCj5ze/+Rh5qafxo83CPtpY8L2nals33G2yagc6zDJvnuD7SjwPWGqrCMKRo6bIqkjheNux5WZDnJfv9nuPxSFXVzGYzlNHoXsvI7tindDsRYw/DiC1KtLV0TcvoBrruhHee2XwmBwAnI1DL1QprLfvtnn7o5foIIibXIBLzAO4olNfx1BCRg1ZEJWosRWbHyObhEVBcXkkHyOYFygdW85kgzX2LIkoUsNEol8mme5REt8V8xjA6XJACzKyu6buWw64VWqzOsNmMvKzou47T8UCMgWa/I87mqXNmmFvL4Dx2FMl7DJ56tqCazdltH7n//JE8L3n1+kvu7m7Zbje8ePWKi8srNpsN+8M+OfsMBEdvTCqEK4IT2iHPMozJ+PLr36CN5uOnj5xOJx4fH4UGW0pqXGEUhcnOXqLFfIZWmtVyLnJJI66TxWwuQuauo4uBtuswWrNaXwKR4/F4PvxZm5EtcmIMUpyOMAY5iBV5hnOOw+kgmH6Wi/y+mqOUHHbseVRQnHkxjaupoFAx0HU922FgtVrz7W9e0Xcdm+2Oru9puz5dn1CUFUVZMjrHsWnSaIJJnrGO+bxmuag5NR3DOHJ1ecl8NuP27p7D6Sii13GQVLY8pyhyCqXYPT7KeERRkVnL6SjUljYGm+Uyuh4Dvu+ASD2bk2eljBaESIyKrht4/+5tIgt+Pa/twyPWGi7XSwww9gNawXoxI/jAqe3ItGa+mIvfLUnblTIYIllocePA/tRT5Bm/e3lF7zybU4cPgbtdi1ZSsDo2HQ+7hswqqkzkuk3vkizekRlFYQ394GgHR1VkXCyqcxFstSiwWjGMQnfOqpyyyGmNph8zlLaMDq5WS15cae42W46nhrzIZbTTWpQynE4H3DgwBCFkxmBQQXNRVRRZxt3Dg5AMvYzAFXmOQnFK/r4h0zJq5yQ+ui4ydFT46IhI+AdExlGKDdbmZFZzUeeECFsnhSprJTF3PSsYnOf20EghN0ZUEnEPo6PtZZxZKykEDUPAmEge5XB6uZqfx91USjY1SkmHOcW3ow2mzKkyTZVrMiVJdLvTwP3tI/P5jOdXc9qToevkuWIzyzCOjKOnd0IP9k4K56UdRZaeCuExSiLLal5yuax42DW0w8jPnx8JIfDN62fM5zVFWeG9Z3s8EULgNy/XaK1p+hEXJdFPKVJKnkZrS0DhohOCNDUYBi8j077vIEqggDWaRWEJIXIapDnhohNyzOaMbqQ5HiXhbV5TFzmX85xuGNlGwUVUHDFJ7Ns6x+2ulbj7TFQTX7+6JqBpPZxODcfjkaKuKasZwcjoX9AWr3PGoZcD2RgYg2ZRZ1RFQXQZzg/M5zVXFyuG0VGXBVrzJLfXmmo2w+SB3XGPG0eWizmZtbRtz+gDXSdjv6MbCKlBarRhsVjKgS0lY4cgjaZPD08hF7+Gl4tRyBzX0YeBw2GPVorVaib76lpSSMuqwGaGZzeXhBD46bvvKIqKL159xaltePfhLXVV849/+AdGN3I47XHDyI8//0CMCpPn3N0/8vbtzwIWzGvyMgMc3vcMfcNsXrFYrtnvj2x3j5RVyReXX0mzTVkuLlasVktu7x54fNyQ55ZFNSOsV+S5FFWb7sB6tWJWVzxutjSnluXygqKouH/4zOl05HRsGEfPixcvqGs597o4kOU1WWbZ7xraruf9zz/T9T1XaYqoHaTY2TY7YoTbB9lXPD4+nJuheR7BH9Ba87Df4N3I6mKWSBpNjIqqytE6gh+ZlSWvXj8nBs9ht5NmUTGjLGesV0v2xz0/v3uLMYa6KGlOLW8/31GUBRfrC4qiZFYv6LqW0/GAUoqhGcn1gKsSGX01Z4yOx+0Di1nFcjlntV6xXC/58Ye3fP8vP3P97Jp//Fev+PjxM/f3j1RFQZFn9F1P33XivtWawc+oqpxZLS6hYzPgXMM4NsTo+Prr1+R5wY/f/8huu+fTxy2j87x584b5bMY3X32BNoaHxx1uHPmf/s21OMIWC7Q1oEYyY/nN19+m4CvZN+73stcq8hLvI+9//pkQItdXz5FwJ5Fvj4PAA8chYIxhNqvEw7xv8ARcJ8Wlm6srqrrm4uKS0+nI7e0t4zjQ9R3D6FBWU8xqivmc2+0jP777kav1mv/rv/8fabuBx8cNx+OJw/6EMhFlAkpdUpUF+82G7nDA5gUmy2naI23XMFvMuLj6itOxpe8Hrq4umM1qPn2647A/MviWEKRYeTwdISqsztk8POKcY1ZLqNnDo1BWx30rYWeLC7Q27A8bfPAsVwtMprlMruesmGGs5ee3H86aiP/W668+XZr0wBxH6Qx0XSsEUaIJJBFEKqJRSTT86D3tOIKVByo+0A1DSkorGLXGjSN939O2Ykg3KsVzdx1FVlCU0sn0MaYF+imBZar8aiXGf9nIiqE905pjdpLuXBq10dqSG8PgXZpZle6vUoroA8aIvb7tpWLcdR1d1+PdSPAOlEkjIE8pC30SrDdty2J1hckKYkyWea3REYLSUnX1Dh2ki6yjMBQhQNePxOApcpmN7ceJjJDOusTx5lRFhguBfYyEMEmTZYY9BC/g0kTxWPEnnB0hSqVxoYy6gqg1w9BjdQFKJJNGywx6nlnp3FjpnImATbqAxhgWs3mSFqdEDi0HUWv0udkknYYB77NzmgIa+mEAFMtZffZHZdbKgSp1uKfUO63VOcVoflFTpo2WUooxdWmLPIPUhXVBqJXgHbmRjmHbdb9AKIW4C4lyMV42pVLF1ml0YZCKMfG8GVepw2qtZVbXKYXOEVx2du0I9eU5tS1XRGazmuPphA/SCei6nmIWiOopzefcrewHvE9OLyX3UZEZPBrlY3KIyefsQ5QR1fiUOnWmMZTQBTaTw71SmhCgHyTe2vZ9SmWU8YGzdwvSplm+xqnt0H/lAvLfw2tKvgqJZvol1aQTMadIhwnFOX1xdO4v5t9d8OTWUtcz8eS0EZ98BVksyItKClh9hyoKjC7FUaOeCKOpMw9CiujkoCBRPlOxY3LrJHCEyR+k4hOtJykksq6I00Iog6mDH6LcjE8b2Zg6Kjr9vpCoHX++zpWS0YJpnY0kWaASbsV5R4warTJJ4hwGdNqAW2uSyFpIBms0TpuUnmbxDob0rUyjVVobtI+JsNHnX7JoPdFF1mb4TGJggxvlVwhMQIxKDpzMZkIxBEkk0tZKkXAYKFPKnU6JeMYIMTV5NqbB+xAiXkXxtKQCdkydoZgItSyfHEj6TCO5qUtfyDNlGKXIM/m0spQCGhIdZxI5MjmtxmEgpCQdIoneCvK80fIMnq7hJxJI/8JhlZbZ6X00cvhW0WOMFmTd+zQ6FzFBn4mSGCNuFEqjqupE04ZUcBgThj+tCepMiU0EEonIy3IZlRpz6QRmieYyyaPnwkTSyLPcWHmeTjHp1ugnqiXGc1z56JPrZhwTsJcouNRdDem+6Lr2F3zVr+QVAwS5twkycqi0wmqTBlljel5Nzykt3ppEUsRfJFQWmciS9ahpRicFpH7AajCZdKTbfkBh0YU9X1fn+0yBUhEI6fmfkf3imrZaxtW8D3j15B9UiWyKiZTOrDmnpznvyeHJNYUQRM6lVNy0CMZpHdQq7aeC+KRixKaDS5w63S65J+JEiEaiQmhIePp7EhkuxJY5e5mm15ScnFl99gL6oFOMupBDWst9FpHGTQwQkLCdENK+0lihWbKpSCPrqdCicp+LDHkiIzRWBWzynjrn0CpSZoYxJVdmKSFQisgA7vw5hBjxIWWopetiTPurWSFumiKz5987Jq+k0obMyt6HRD0VmRBavUtpRk7Mm3kha6ZPVJBK70JI76msIdMaps5exEwrkknrTLSnpVfe+xjQSva9mTFYLc6uPJvcIjFRAXK9jN6nZiCUuabKM3ovycdCKnlsKmBOf1lEHGdDIvkmek0o+OR+NU8eRpv2wv4XUwryR4zQfYmqmNblKQ13CPL+9kPyBeWKaPXTs09BVPJ+x5j2av+HLST/57+EABbPoVJKiJK059RpfF0oGn0+ywzDwOnUYnRGZnM0HV3XURZlSkIbGH3PyYnP1FppsnjvORwOzOdzFouFPLuVEHyTb9bYDJQ4ofRMUValED3I3y0FcC3PGibKV55J3of0jJLfqxFyytqcoqyIISaybkrJi08j4kxrjKTgDv3A6dTQdy3r9SU2XQ+yzxiTN9Sf3ZoocC6gtZyTVAiMXvZAeZGRZVbG1keXmg7qfG6czSrGceSwk29FKVlfcmsYxkJIl79wwAVyxG06KVfyPMdXJcGJMiCmrzN5T7Msoyrla1krASmz2QxjDOPoybKcxXLB4+NWzluZ7L1CEFrHRWl6eudwTihE8e66BLt0uLHn+oaU0i73XYzitJoI6SwT73NMBOJyPpfzq7UExFcXidS5hNlM+45pvxOsPC/b40kKTuUy0cNCz3on++fJB5tl9rynl2eFPl8feV6QZQV57qiqQpxR0RMA7SbqSzGOI/vDnvVywXw+kwmhpsM5T9t2ZIXG6kQQB9mnRedwIaKdZ+hFO4ACkxvyQpKjy7I8U3xDMRIHlwj2mMLaZKWRqQX3dA0kh1Pf9eJANbW4otoOyY1dYI3Bp320zWUqpzk1TxuF/8brr8caQmDoO3784QckejwDDfe3H6SYsVhis4KQ4phn8xXj2DNut8QQaZyi6UahCOKSPHuG1hmln9H5yKbbMq8rXrx4I4eiMJLbjDIrBAuLsoGfVzL2tj0cGUeXFoSR5rRn6BoO2wccBq8MY9vg+45H7zgdj2TVHJtXqCi2ztGJrOyH9x959+Ej3371JZfrNZv9iVMrVJA1mo+fPnNr7nn9+gtm88VZTPj57jPH41EeKFUFWQFZzqKsBac9HogR1pfXgKKwShDBpqHXirqwRAJ3dx8x2nJ5KW6e7354i/Me5wKZNTy7uqSuS8oiY7s/8vPP7ymLnC9ePWMc4LjbEkKgLivGEGhcIJst+OY3S5rTgU8fPzAMjqbt+eL1a/7Nv/4nPt/e8cNPP1MXOVVV0/QDd5sP3Fxe8fe//x2bw4mHvYxN7LoT8/Ul/3hxxXKxpKpKqrKgrHKur1+xXK24XC6YlQXf/flfuP38mWpZS1e6KDDWclnJAf+//Ol77jdb3r2bkec5r19c88Xrl6wXc4ZxZPCBpm24+/iWse/ZNj1oxSLTxNmM9cWaAPz8/hPDOLKshCpRabHB9Xg3sD0O5668QlEVJUZZitmS0Y30m0eUUrx8di3XWVkxDKmwNp/x4voyjV8F9tstf/7+B9brNV99+SX9MNAdGzyWiIh3+9MOazMur67wGN5+uicn8JsXN3zOc7QtqMqSwkSIMu6Q5RVlNePdx1tu79/zu2+/5otXL9jvd2y2O2LwEAKNFXFo6yJjQGiGopBrpGlkzDUEbm5uqOsZL57dUBYF6w+f2R9PvP35B4ah57e/+z1lWfHDD98x9F2Kfddsk+z+1WKGVopPn94nOd2v43V584IYA/vDHkg+N5vRF4Ugrb0U0ecLcVQMfUsIIj723vFwf3suEsohRogaF2TTuj8cqepIUYko8fLyGqs5/wpBkgMzTRqVFCR86DsZayxLxmGQhKj7e9rmlApWmrCLnJoWFWVMVhlxSYzjiAI+f/rIZrPh2YtXzOdLDtsH+q5lub6kKEqGvmMcBpbLFXmRi/A1emyWkyuNtgbnHNvHe0IIvHnzhiIvaDtxgE2i9aZt8d4x9L1satIalxeyYQ9oun7k9vb23N3Ospyrm2fkecFyseB0PHJ/f09ZKsq6JvhA2zaEKG6XGCPd6QhKsVpfIL1zaI9H2ttbFvM5V1eX9MNI07ToosCj6NuOrm1YzGYsFnMeHo7c3d9xalrK4wk/dGTWEoLQRVVVcfPsOdZmdF3Pzc0z3rx5w3a7o2ka8qLA2oz1akVZlVKM8p7vv/+O3XbL3X0lgRlVxcVqzeV6DTFyPDUizY2CMB+Okhrz7PqasizI8oIYI58T3Zln8lnmmWz8qkIitx8fHlCK8wbdOQld0KnhYfMCYwxVXcs5zTvKqmK+XJ1HEqfNxZiioDNrWa8vU9FcRkVHL8W1zBiUsWfX4egDeVlx/Sxns9kwjANVWVJVpezj/cg4JkdU29D3Hcv5jLqqOKXx9DIRtOIh7Diejgx9Sz2bi8cpjEIbOA9KnwtUN8+eU6bY4a5rOZ2OuE46b0orYlUBMvpPjOdx1sV8htZKRqT+ys3Pfy+vr14/Z3Seh/0JgHlVodIaIAViEdrv9seE2E/x7g6vYHCaphvYnyR1LChDlmsuF4pD03NsB2IMRC9pgetZIeNImSUzhjIzuJgxRk30I7iBwhrySmGsFHv6YaAbRkafihipWlX1I0Weoa2Vjb7zeDyNARcM9/sTt5sTr5TFKkMztowhkitNXdXkpewfZNxTXIltC62HHkvvOhk7I2Kt5mYtZNHu2OJjYDEr0+ZeNuo+NZtknCmFJUAaF4Rj06V7R4qjyo9pBEyaEX3v8V6aheJZK9DaYI1ce7t9hzGW9aJMbsjxXFTJsoyL5YxjN9KeeogeFQb6cWQIgXWluZznHIeRY9fTt0IDFJllMRPyXCtF5wPb3nGdZ1RWcTGfkVnD9tBy6gYZsTPJtWQMeWrSvr/bcmwG2l4OGTerGavFjJuLJSFCM3o2TY/rhcC/25zwIZDnFUWRU+Y5WQi828vYlDUFRgUO+62QwqslCjgcj0JujB6toMpFPF/UNSEEtk2bniHSYbc6jcj1HUWuuHi2RmmDsgXeOW43R4o842q1FDn7IMSfi5Uk8iKjNe0w4JzI2rVSWBSrumRRFvTDQH/YYqsSqiLdO567zYHH/ZHn6xmX8xLvHbtjpMzl522ajqbpOLQjvfOUVsb/jr2nGSP4gIqRxaxCz0pmixprDCF6+kFotdFHitlSxMtaYTXUNmBUTxdGYohoK4e4pvl1ycUXdU2Invdvf0JrzXK+QmNom17GmIaBsiypF8tUbKwwpsTYOcTAp9uPnE4N3WlkrD06i+gAOhrcENhtG+YLzcVlSVFkzJcz8iyjqgvqssKanDwfqaqC0Xnu7rcM3YgmhygUi/MOwshPPzzStm0aeTM8PmxoDi2Db3F+ILcVmS1wI/T9yB//+c/8+ONP/OM//BMvXrzg46fPbLeP1PWMLMu4u/3Ew73m+tk11ZSMrAz7/Zbdbscw9gISnE6U3vP82SXWam7vHwkx8vzmJUYbHh8kpfp42uPHnmy1QqFo2wGFYjFf4dzIP//znxkHaXJXVckXX37Jcrng+vqah8dHfn7/kboumS1LnNK0PuJ95PnVS7wPDINnuSxZLJbydU4nmkPH50/3vHr5nH/8w99zd/vITz9/pChmXF5ccTy1fHj3iYuLJf/+f/6f+fDxPe/fv6V3cDxFsmzGb3//e2bLGm0NWnkMA+vVNZdXVzx7dsNyteTtzx94eNyS5xqbKSGhy5yb62ustfzf/u8feff2Pe8/PJLnOd9+9YZvvv2aL774Bh8iu/0jw9Dx7u17nPP89PPPOO8o/9XfsVotWc4vcM7z5z/+SD8MvHr+MikYMmKMWGSkbnP/gHeerjvJmSBojFVkqZAlAyaK+VVBlmeSjugl2S2zOYvZEh8c7XDicDzw5+9/ZD6refHsmnwcQVtQDX0zEMeB4bAlV4oXNy+JUfPD+3dcrtb85rdf8+OPP7HbPTCfLVgu1xiraYeBWV2TlyXvP9xyd/fIt99+xatXX/Hh83t+/PlnVss1s6rm/v6Wh7vI48OWpmmZLWcURUWMJEijJXjPzfNrirLi1YsXlGXJ1fVzjocTHz59oO97qoU0DrtRQrMullcYbfiX23ucG3lZFiilebzb4P7Kc+NfXXhSWtIDxnHAaE1ZVCgl0mqlNNbmMrajFQqVEjVSSk6Uaq3z4dyR8sGdu8d6Su8xJm3OAyFINyfLsnPHJ6Tqs0pUjUmV2BicCE6tJQuePhqGqEVo7RzOa+nueo/yHhHeRvqhB6XohzGlwcQkXU3dttRVnbqG0/fuUvdVvEES1T6lFU1S3CmpQ14x4XoSe9z1LnURpbI+DgPRCuUjM7ciYo0hooo8OVVkk9+lWWnvncgSg0fcL6n6m1KgjNJn5F5SmPx5LKKuaspS4qpNGpnxPiVvWMtyseDYj7/omMq8clVW5HnO5BixiRDLi5JZXSeKKT+b8421+BDxo8MqSZjyXhIDhzE7kz/GaKpSSLXQ9/gxSAJA2+JdeijHJ4IjhkDXd/SDY1bIpnQcx9RhkIOXT06a4H1KRpKuykSO6OT0mgTEU1qYSV25Is/Tpl4kkV3Xyex1TCRa6uJPHV2dDopZKfH04+jJM4nLzbMMm0l8vU40QwiRmNxaPojbzAfZFDsf6J0jjuIuc06SnRxCQeVWyDRJyZHPNLPxPDdtrAioi7KkcoG8KABESlwUlGWJAplVlrtbup1Kp87K+KtKhsqLkuAdrm+JMWKMdFhDCEwNKTURREAYBmIUcsR7zv66mDxM8ewugTOSJF9GyE9rksshpnsrJb7FAFEulsmrMblSJnpnElfbLEuU6XTNSpKTSMojg5HvyaUUK+9cIjN9+rnU+XpXPFEw06FUG41V4nh7Ikc4d3LgiapRirRO6POSFkk0gBGRptaa4JXEqU4EQbqfJnLRhydXUIxTH5BEFIWzxF8bg1EpuSu9f0PfE+pKRpRDxNgMle4doSIdIYZETUgHbHQOO46oGM+jo94L6VqWJSj5bLNEMp5Sl0unn2cq/iki6EQYekccBrQPzKry3KlVgO46VBB3xOSNmD6LiZINUbq/45gKTxPVhkrfo2cYUvcqPUsnynYiWpSW3yukaMQl+sJmWVpbAiqklKpUiMjOHUQFKqJ8wEefqF9JhLMm+b2CT18vx9pMfmVW0tS8dGGD9/hE3cZffAZjSrbL0zjK9OwRF4JK9JrFdQPejehcn2nc8y8th2bvXTq0T0SPRiWSN6YxxuneU0hU80Sz/JpeU4rd+b5JBObkYUJNCZZyL/vkPLJKKBAXnLiQolBQLq17Wk+/JEEIOD8bz6QvaSxzokUiZ1rPGvFKOj/tnSLD6GkHJySQUrgQsSGiE43nvYSYWKuAkCT0sueS6ypR7Smh16Y1ZHCyRvSDQxEIUfaLNiUEJVj3vPeYEtHkpc5rjYskj9HkH0uUuDUoEjGdaJZIlLS3oCTp2Af5+lqn3xPPRYLJETpR5lopSYZLFLLST2TitGfgF5+hFK80udWYcUrpC3SjFwLdCB0T4tPPNBEZmVESXtMZhlG8TkZNv0edr4/JtTZdPzrdi1n6uqfRi6PVhfRciU+fTQyJzhFnlPfx/L46H9BR9kBnuiwKyTlRq/J3abxLpBDI2iqVclSUcASdnjUqEZvBK5yPksKUPqvMKNnTa/Fv2cQIeZVk8uiUHIaIpLXCjcN5BDuEIF6mKHvlBPeitWLwgTFAkRkyo+mSTmNwHudiIlJJBfNArjh7984Jp4k+NNPzN63XJrnLjAKNFKxUIp21tn/xbP21vDJrkK2PfyLVtCS0gmyHputTrgqNUhGbGbwTV9Mw9Eznm8lJKft3fd57nM9eOnnirEnPd3f2r03XpFJC/yoUQz+i053RtR37/Z4iL8nzgtGMidJ9on9JnimUhIAMg5OG+TCKl9OnPZN+oiqnPeM4OrwLQvRpyHKbro3pbCLv2bRHkgkUS1GKo+l04pysK78x3Q+J6m6aVkZ3vSfPRRuglJZEzUFcUOLBkhAC7+Qe1krI2Rh92tNZvBLflk90VoxRGudlSZbLWDRRJUdVh1JLqqpCa00/jpSjYxwkQT3L094hPTey7OmsVc9q1usVd3ePibiS9dInAjxO1JhA1YyDeOWU1ikNLyMEODUymt914nLr+1aSlpmej/JZNE1H38t4rUx1SC1guvqCS0T4+fieCEYVZZ1KhLgyoI1MCWkiMRcwxmYWFSCLEszQNi15en5rLZ7mcRCZu1GiBFLaok1GRM7gKCiLnCKXaaDMZmQ2I+qUUh+kMTKOLv0sco0P/UDbdlTlQJ7lxJQELaERkzNPRsPFky33zESjTxMwdVVDkGeivN3y/C+KgimdUSUndAjSlEWLa3vy6P63Xn914WmxFBogN/Z8qBEqVsYX1tfPKLKMeW7ph55Pd/cE78hsxugD+92WqOD6+prMKD58/ExRlMwXaxZVyavLNVor+mabcFoDTuHCSNP20q1Li/diPufZcpmWqcgPP/3Adz/+yItnz3l+s5QOsff0rqfvWlbrBTfXl7ggB/5D09P1A59u73HjyHpR809/+y314oKsKCmO4hfw/QDR8/XXX7FcLHjYHni4v+U0OEKE5xdLXlxdst/vcW6kKDQwsnncMAwjx0aoqU+fbjFGHB9TsSLEwH6/lc6kmmTTJo0VeLp+ZGgbusyiTcQNPfe3n5jPl/z293/H0HW8/fF7jNXM5nOitnhdQpKBd13Pbn8kyyx1tWC+yqmrknld8/BwR1UW/Ot/+lc8Pj7y+dMnqtmcZzdXDG7kn7//kVPX0bQtqzJnMavB5kRlGV3A+x5NpC4ydptHNpsN5bffMM8z6sUFFy8MNi9wSvPx43sOhwOX6xV1WbJczFjMal68fElVVXz6/IkPH7cSB6w168Vciix9R971XGQVxmbMLi7I8oxuSEK9cYQYmM9nWK25v7tDAevLC8oYGT1YK+l9RhvKeoY1FnfaY7Tizc0V3TDw+eGRqqpYrVYYpQl1wTB67jZ7ZrOKV89vqGeVHIqBt+/fsVquePPiBZtHQ3/apT+/xJgcmxWgNEoZdOhlYehbfN8QVEWwVkYUgqdtxMlQ5xnfvLqh73v+9MM7oclmS3abhxQPqlKXVpKjdG6x2tJEzRA1L24WVJnmu5/fsj+deP/pM3lZUmgp/C6Xa5wPfPz8GQWs6hmXy6Wg6yHy5vmlCAw9EAPXyxWTyPrX8KqrghgyMqPODz+A4EeMtSwuruSgECF4d34o5aWI6XUqWkwPy2GURbyuChGHaisPVCOHAeecYMpZQd/3NPvHcypiXc9Y1AWzusZaw2G/4+2P31HPl9TzxRnfHb2nGxxXFyXLeX0+dD4+PnA4HNLGwrJcrbl58Yqhaxj6hqyoMEWdrruOy6trirKkbRr2e0nuicg6vMhz2uaI9xnz2TeEGDkeT+wODbv9VlLFciFRFvMZRZYRyjQ60HcopSmKEptZFjNB4Pf7CjcONE1zplFG53jc7rDGsJzPUFrz8PiAtZa6LGjdyGbziDGaIi+IztGkBEKbZ2iF3OfWpnjiSJ5ZnHc0x5YYwWQ5USlJaDEiJ63qimpWS8EvBIahox9aynpOXlSc9luO+y2LqqAqcsauYWiPRO8wNuN42KdDoWwK86LgxcuXZFmB1pr2dOB4kKCFyDTKm50PpFVhiUHuMec8/TCkMZSA0bCYJ4S564hEinomD3IlKXY+pRyu1pfnkfFpZDgkAjmGKE67LKPIa8bRcWx6sjxjvb6kH+RrEyOn5ijR0UVB1x14vL/n4uKC66vXUnR1Ei7gu4ZoM1SWUVUlNzc358YLWornQp50rC8uuLm65OHhnoeHB+qqoiwKmtOJ4/HE4BzOB3EIzsVxYQhsjke6ruPlq1fM6hn3Dw/0fce7d2/RRpNnxXk0QgTvGrRhWct14FOhUUTSnua4lbHGsv5VpUIB3G6PKGBZy3sStSIQaUYZuS1yGYe/WM7wIbI9tOjk/ur6kYf9XgTw9QxlLNu9xGgHpHi4rHK5jqI/k3BRKUyAtu24bVsZTVIiPi4yy2pecbmYc7fdc/u4o64q5oslQzgwtj2ZzanyjPWsYlHnxChFive7Iw/7hlVdUueWwlpeXC2JRHZtK2MdRjF4T+cj2g5kwXNI6XZD36OIPL+6ZF0U6NVcSMmuwTvPvu1xPrDZH3AusD0JzbqsSzmE+XRYC2CUiKqt0axXNc4HPj1IA0hpCYDRVvyUn36+o65Kvn75HFB0abP/sNs/jfhGQzlb4ceRw+EoRd08w+aWeZkTYuTzRtJz16s5Q9vSnY4Uec5iIaRWhyZqS55BrBXaGurk2RyDomt6yszw8mLGMIw87BuMEbK2G0ZJtyOiVGQMPSFCZqQYVWSa+mLGxbKWIIA+choCzemIc+NT1DsBaxSz+RwU1GVOYQ1hFFmzxWOMoi7E2ZQ8zTICpKAsLVk0qDFHKShyIbYzLYTcrK5wQUY6URqSGmNR1/SD42F/Is8yLhbyTJ0t5rT9wL+8v2c1K3h5uSSogWx0VHnGvMpxEUavyK2mzGWcSZo4HV3bo4F5XeBC4Hg6iWdLadbzmldXKwYXOAyB3kVGL0XGzKrUFJJn+ug8o5Y1vR06vA+8vlowKzI+bI403YjaHtFasSxzMmNYLRcytjJ64tiT2YjV0I9SQA9RKOpMS0BQVYRfFfGU5yXaaK6fX6JUxIUBoiIixZ/LqzfkWUY5KxmGkXbXA1ESuX3HZncEBauLJdYabt99Ji9yZvMarS9QKkP6KTHJoVtULIhlzm5/4N3uI1MnaLlacHW1wmYZeZbz8d1HfvrzD6wv11xcrcR/YjSH45Gx2/LFN29YXlwyDBY3jtx9vmO32aPfapQxXF1d8uaLL8nygqAC69UVVTGn9w2RwG9//zuWqxWfP96y3Z748PGRGOHL1894/foVu8MB7z2zekmM8P3333E6nWhaod6290cya7m8nElBzcr+9bDZopSsLVkmfiylIdcWtIxjjcPIu3dvISj+0//2R/Lc8MWLS0Bx/3knBXEDfvR0TYcyiiy3tG3H42ZHWVgWi4oiyynnNToz3G032CLjb/7uN5yOJ35++x7PSNAjm+0tY9twv3lkGDxFkXF9taAfBwYn57Wx66nqOS/ffMHoIp/uHlmuV9R1RdMeObV7Ga1Umnfv7+i6jlnyHq+Xc67/6Q9cPLsiL3Iebh+5u3sEZVEYqnpBPVuwVxt62/H85RVKKW6uXzGbLeiHE23boKLG6pz5fEFmDfebO2IILGdzcpNRzioUUOoLkclXGdpoTDFBBpq+77m7v8fnjmW5THvzkeOp5ePtHcvVgq++ek2W53SnHhcc7z68Z7la8vLVC7LMcNjvuVivef3yOYMfaMdeGhTpeX48bbF5wfMXXxHx9K4VsXhZcdif+PTpnlmR8zfffMH9wyd++OlPrFYrlvMV3WngtHvA5FlyZBYs8pzZXFxgu48yDfD7333Lcrngn//4HdvtB97++DN5brm6eiHTHmHEuY77+5Esy/jdb/5GfLMpYfv65pp+6CVIKAaKZUZB9letC/9fEU9nukNrrBWPhcYKOo9OHa+BYZAxJ2IktxkqprQcY6iqAhVFFq7N5AhSlHmGD2mUQxuUlu7UgEiUg5cq8ZlKsSZ1GuR784HzaMFfdtbFzTI6n8gQ6Ww572malq5rWc0ryjxPHTXp2ButGJMXZnJBiVNnPKdzFHlOXeQ0TSMz+sA0oz6RMRDp+lYw0+UcedikTXzq/GilZTwi+LM/yCUPR0zOlsE52rYjL0rpIhiZDQ1R4/2IOBBSmTYREH3XoSigKs8uGWuNHMSQ72/yEhVVTVkUjMNwThUch4GQ8O5hdAzRS1U3ERHWyJ/3ziVPVyepFEaSraKXAljbtrSljDXlWmNzff46Ibkc8lL8TZIAoanqGmUs2hYobXAhwuhRRqVOnGz8xnEkaH1O3Jo6J0rL9ZHr6UCY0uGC2AVMJhGRE4kx+Ql86rgqY1K1PqfIC6qyYPSBPoREN2lya8UplmWpe/fUW52SuWL6kI2aXFj2XHj0KUHIaEVW5AzhKSVBGyMSdWsl/eR8bXl+wYoAnGXPoxMBvzmdyJ1DlUVKd5TumxvFXWWSi00rRdSk1MMgm6MQKYxGRfXXLg3/f/966hKpvyCBIpy7ZhEpRE300VTsm6r6kgIp76XzPs1Dp45UUaIQ+TFw9mbEmJwlQTpuZ99T6urmmSzSQoW4JJKOPHX/YqI/xU83+biCd/R9RI+O5VqRFzlD18jYiC3QyjKOPc4n19z0PSUKJiaK5nxAj5Esz9IVdTrPkk8JfsF7QlWikg5MqUShqHi+Cicv1dS1OwtTEwnT9z0x3ScAw0TUKSGPYgzE8zWXOjvJMaJQUrBIZOxEYXgn44riRcnOHefzN5l+tpjIozNNAb/oMCY6ahTJq1AIQtOMiSabPC5VSrsz5swOpHtcPtOzWylC0AFrLCElvoYYMVl2JqFi/H9zJDH13eKZ3ohMNIaQxMG7VHh6SkmK8el6mdYygRwkhWZyBE6U0rS5Oa9VMaaEn5h8VoFxHCThSonvwmYZwYkD7dwJlP86d/anz1zee526sU/34ETACegxPZ+nz0qKR+Moz26hbiwmHQ61jpBozieCTwnhpIQGHp08U7P0nv2aXkN6RuS/vP7P6xhnyiucf4kLKsaIjzIujlLkubz/w+BQOgr5puQ55rzHj5MTTr6mpLpNCajyXnstFBMoEfEjNLtPhFuMf5lQGKOMZFqjMUqntSi5w5T4qKzlydWkhLryIaRfBhPU2dE3rWdGa0nH07J2D72M5YrbKJyv8TEl/wolMRE/8RdPUHWmJvBRUpJDwBiV6Jskow5yvcoYVUx7kHBOXtRavBhqWldCIGrFXyxHiTSStTEm/1DA5CldLXX1fUj35ERBKvGCOgIeRWmFjHJO4ruH0dMNkxcmOY9CwMdk/wop6VCLuH3yVkHKnoqyHqko37s1hqA1eQyJOhWqibSeTyuVSx6baT2aiijayP1vEoE30VZTOqm1BhxIiSGen8UhcH4+TX9Oa/Fj9aNLz4P0/FLy+U+ki4nyOVmj0pqkwMq/k/REgzYaFyT5VKd1VOj2DB8l/CZE2VeSCVETlEKp6ef4RUEoLV46kYPeB3rnsek5OMGYRgsVqJVL5Ob0POb83oI0xM+jHL+i9Wt6x0w606GEfNUmI8vy8/Xd9T3jkGim9J7GKKPUxgoZY7Sm74Y0bWHJc6hrGY8cx17uh1QojEGuz0mfkSV/0TTlkOVWiKjBpQT1jsEN+JD2YTGKf3jo04RPAUQZj+sDgcjNzTWz+Zy+7+m6Icm/C/qmYfQe0vSBXNvx7BbNi4Kqqml7+Z6zPE/XxtN1A9C1Lc4Y3KrAJC5rWj90GiVShAkzPK+PpPvJjw7vI+3JEWNOZmt8QCivFIAC8vVM8tSFIKnZxohzKTMmeZskMX763oZhYLffk5WavBIPphsHXCrIS/E0ns+hZ4rLWKpqRmhanEthV00j7ugYGYaRGJEzYypoZJmlvrmkriqKPCfLM0IQgkyS2GTyRmlFUeYoFZm5GpRiHOUM6tK5XeZhIuPgmFJbAVTa3E6E6kSMZYV8XdLeVhvN6DR/sW9L1+noQiKsOO+76rqiH3pcN6ZahTxT8uRz1lpCM5SKaW+mzxeAMYa8yPF+SBNi4hCcSHqtJaEzIns2uf5yCAJlkJzB2mihSRNJOp0frc3I84JhdCkNT5PllsXiUr5RSCnGBqNtCkvKGf1AjB5thGSdJtmK/Mln+996/dWFp7Zp8CFwbHryIuc333zLrCq5XMwYR8f7z5/oupbd4z3aGBarNWVds7y4JpxOtHeP5FlgoSsihuAl/lCFkUwH5pVld2i5u70jL0sWixXtONB3LbO65uZyTVGUlHXNMI5sd5vz95blBV999Q2Hw55//vN3zBaSbpdpRVGXfPz0iT//8CP/5h/+wO++/QbnPF3bMfYdx+OR7V7mHu+372j6nmcXK+qy4PPhyPF0wpRzFosjuYbcal7NKjKbsV4KoXB4+57jqaGazcis5eLqWh7GKpN503dvcc5jSkleOz58QKvIq+fPMEbTNS0QOaTUsseHe1CKZ9dXFIUQR8vFguvLK0CoB+cD5cU1ZWa4mhfYrMBWcyk+NK04DLxs5E/HEzEJt5dVzsubS35895H/+L/+B7phoOl7ZvMl6/kM53LcWNC2LdvNBrzEUN7efubu/paXr95w8+y5FHXKiqoW6fzDZsen23vZHMTI/tCItFRFiQzue47jwKwuCdbyz999j/MyGz+bLfjyyy+pqoqHhwfGYeTbL78Apfh0/8ixafnzd98TQuBvf/ct1hj65kTTNPyHh0fyouBvf/MteZ7TtL1smAFjDVUtKUlVWROi4Ki9czRDz+h9ck9oSf05HPnn799xeXnBv/qHv0+jVwqbe1aLuYwULpYig9s+YrTim6++ZLvb8/n2TnwYucWj8SjW85rr5Yzl6HE+MlssmS9WnNqWU9cRnJfRFW3AGFarBXVdycHXe17fXFG8vGHX9jT9SHc64IY+JY8FcuWxOnDcPXKKAaUNs9mSmTVkyIGj95HxtIcYePX6C4qiZHfY0Q0dRZ4Tg3SH+2HkNEgxdJVNqP6v43X38CAPGTdijWG1XFIUOavlCuc9t48PEh6QhNQ20TPWR4Zx5Hg6CJ25XBG8Z7/fUeQ5djFHG82syhn6XuR6wuPK5iVt+FerJcZm2Lxg7Dva05FQFPLwsDmLi2u89+x2W8ZhwIVIkWfMrOV0PPL4cM+bV6+EUlosiBEOhz1tc2S/3UqqxvHEMA7MZ5BlnuZ0oh8ksKHICxarlXiAFksZ69AaNwzsN1uGoacoS6FJZzXL+YzlTJxnnz59pOn78wiLSlj7rK6JKJrmxDB5YNxIGGX81+aFBBTkBUVZsViJX6hvTwSXBIvapIhjy8XF5VMxQxu0zRiGgbZpKIqCqp5R1zXL5Yrdbsv24YG2bTgejlxcrLm+vkpuE8PoPMdTK9d/19P2gleXhcgvx2HAKEVR1RT1nHZ0nD59BqUpZiv2+y1d11GUlRS0QApM3uFi4GG3YxhHLi8umC9WVHWNNpauk5Smuq4BxR2apm348OE9IXq++vpbrM0EBR96Hh6E+nr95iusMZySq0+EpoqsLM+FeCA5xtR55FNSWWRssO863n/4QFEUXF5eo4j0zRGtNRertZTy0sj6MPRURcGrFy/o+54ff/yOIs+oq5Ku62m2O66urlgvl0k8KfdFXhQ0zYmm66hmcy6urunaltvbz5RlyZdffEk/ysHu8uKC+WxG03YiCPdOpM9pg7mcz1nNZ7hxZLPZcjgc6Yee2WyOtlYSbpVKGydLVZYSAd81xCghJApJkHfec+p6iFDOfj20wPTSWmjMx5O4berSUuaWF5cLnPO8u3vkQMepD2mUW7xCbWdldAgZp8pVhODYNYHcKhaVJbeWqqw4tj3bpiM3hkWZ048D20NDYQ3r5SI1A42kC/cj3Sgx4D7I2G7T9ZzagbbrpIhbyBr6aXOk++T4my+u+OLZitEtmRUZbS/jS5kCqxROGYLSZEYomt1BEoWr/BKjjey9MkU+X8vhpZTghu1B0mmbkzgRZ/MZdVlwtazwPvD+bsPogugHiGTIqI3SBVEp+iCkTDzI6P7DsZHRMURmfbWsqcqS51/PcQHudkeG0XNqGvLMsJqVstmOIzGNpWkVWFQWFxW9k8RQEwNVkXOzmvGwb/ju03tIfNFCO1Q2oqMIt/e7A4/bA2U9o6hr9k3P2PcUpYxf1FlFWchohrXwuD/y8W5ksZhRVwVvb1t2x46rtXg3SYfpx0OLD4EP95Is9vz6kroqWF7MUAQeDx2jjyzXS7TWbDY7un7k3f0RHyIXM9EliLzd86efPpFZzdevbsisoR1HlFJURYEB8ijNZ+ecEIspLKfKC4L1GIJI8rOCpuv54dMjdZnz6uYihWxM0mnNrNCsK4sLsGt7Mmu4uVjQ9iMPhxarFLlWnEJgHzyzumQ5E+Gz96LE9VHhnYwJ1mWWyKvIw6GlLHIWs5IQxGu6qmvWizpNR0iTxDlzFjCXpRB0mQnnoAuF4ma1lBAgLw6ptjkSQmRRlZjcMAYYgEwJ8TRi8d5z3B0BiEbCcn4tr8PpBDFy//BInme8fv2M2azmxYtnDKPjh58/y1lj+0CRF7x+/gZb5ORFyanp2WzumM+XfPHqK3xwHI97bFFQFiVajzjf8/h45KefPsieaVHixshwBEvBxVoS6FaLJc3Qs9kdsVbGn3yA9fUN+/2G9x/fE9J/btbPeH71jPvbe7778/f8u3/3b/j9738r9Nzo2Tw+0J5O7A97sizjw8f3HA573rz+guV8yWHXSOJ3/CP1vGYxm1HWBc9eXFLkGVU1I8bI7afPnI4Nl889RVHx9TffAJFdI6lin36+F+1IH1E6MPRCXy/WcxSRY3Nk9JqiMTRNw+fHz4QAi9UlRV5wub6QZtJzaXSfhkGE1cPIYj7j1avnBA9NmzQlBKr6BJli6Hs2uz3LxYL1asXFxZovvviSH374kf/4H/8Dp4PsPb/99ku+fP07Gcc3GZvDieOx4/Fhj9Uln28/cXd3y/pyzWK94OZC9hV12Qg5dPvAu/efyE3GrJjz84f3bHZbFmXJLLfSGI6Kth1xruGHn98yDD2r5ZKyqvjq61fM5nMeHjf0w8iLlzcA7LeXNKeO/8f/+r8wjAO//5vfk+U5aJkm+N//038lzzL+5m++pSxFMD+6gaa5RyvNvKyxWc7F+grnHQ8P9/joiUqglSKXIpg20LQdP//8mfXlBX/4h79HAX0jLtRnL6+lUQKcuhMfPvyM1oaXr67p2pHvfngLyqO0w0eND5rXL5/z6vkNo7tnf9xS1xl5sWLzeODj+0cuL6/4+utnPG5ueffwiesXz/j2b/8miegDqy8WVHXJ4+OB07ElONmT+6DpvWK1mrOcFbjRsdkcadsjg2tYzJeURUbbtvTDSG4KsnnGq1dfURQVzWnP6bDHKNnP7XZbhtGDk1Ci6PVUr/pvvv76VLvkAAE5H7hU1CjynBih7zratqVpO0kGSIeAKco19W8lhQONA1SKeCYK4aG0Tr2Up45b1w/UlTz8rZUIWqIkpk3eiyl1Qml9llCCVAytkqSAYRjT32+lUpdIGGukkizujVFcPmNFZnXy5Yhc1/uAj1II1HD2rTz1/GVu2Wl/7n6Ls2MaCAznVuJUVbU2O1M30/zy1FHSSp1nLs8zwFoTvWdMbiqbiRxtlugg0hytJHIIpaV9kAtbiWBzdNK16jqZZ/ZI10u6bzITGiNnSgakA+ecw48DIXUVfJSDelEYciUOhKbtzhXoEIRUy4ucPEsOFMU5/WNMzoTgizR7Ld9HP4wMfc9iXmGtPhML49BL8luEiQeY0kJk/ltmp10i3kgERTrLJgdNlJ8xJrYgck6k6ztJzujS4pxZc66Yn10aMWKUYgiBru8psoyySKlY6TDoxiFFnSv6zNCPBRFS+l12TlKTzzMkgiCmFAzp9jjvceOIKoTQmzwwxhhIlEwIPnmE0j2JCP8j4iYwWhFTFyOm90P8QD6NqAS6rjt3X6d3VWkl36v+9Wx+fvma3Cg+COER4pSIIdezMQZdmHTYF5Jkcv5IitxTapzcxUrm0tO1rVLXMngY44DKszTOIV03N6h0mBdvhlzOGqJLHqjUSU1dPbn2x/S11dmXYYzMZE/Xjk+fow8eE3SiXvTZSyQd+8jkovA+JD9cPHfR5HtP6S9GnxN9FBNdk/xFIa3pidoTUnBau548PRNJ8OSNiucR7elnNOmfT+lx8nZM7oanjT5M6VohJWaOqbv25HKbvE4hEWbTa7qS5euJTHIcBmwhz5RxGBnGkSwvzs6qdLFI5yj5JII8CFKn6xfrfupWx+S5AfVEP2mTij5PBO7UaRtHd77/JxdYjEG8h+nPKq3PBIl0+yN+GFIHPpF7SZo8DIOMeFpDDF6eecaiMvFZYFSiu8Y0ipULWRue0g9DFC/G5GvyXtaLSVgOQglmmQQy9F0nMvGylGtSpDCSApXniUD2aVQ5dfSjEH9akSiDyJRcOFE8EyURJgIwBALqTItNC7uPKl27+hfP3V/XqJ0kJ8o1ExVnMi9L6UuTb2h0Hq0iWSIRXZDkTNkPKDKbpKKDT26KiQ7R0tWFREHJtTY6n0brsiTMMUkcLt+DEEkxJQrG830xfQaZTSRt6mJPXqjMaAYT0CEldZ5JJKF1Yvr5JrdHjFHSPNN9NXkpp2tBvD1T91qe7RPpe04UDYGITsm/8pfJvmdy56XkKzhTeUSdCu7yKyCOLH8mMTV5lqgvH1DJwzc9R3VUmCB/v3Meb6f0y3RvaoPW4qzzIdGtMRJ8TDRDlE61TvSPEprGh5Tmlygz5wPd6JjDec0WmveJvomJBHN+Es+r5AoV2btK1KCIufXZnUWcKJxfrqNP34fyJOozvf+KM0EuvfV4LnqPTvZkZT7tL+XDiGfSPyQ67hdrcKIyJVnQ4EefCEB99moJiJRSp9J0QJFIN1mOFUQp2ItDSM4BRZ4T+pEhuHTwTp+dSq7Q9OwTr5R5cnjB2YuCHolR/n2RCcmQ5zmMAe+ltDS5YrXSBBJN4yRFcLpuJxrGmif36a/hZa2RnzEFIcgeXtLkUMN5UqJt27SX0uncoc4EsFbi/GOMZxIyps98ooMTHowxlhhimg7RVJWkeuVFRu9GvAuoCGM600UiAXHhxbQ2ZJmlqkpQ6uw3stbIiF6ek2Uy4iZFVTmvdF1P33f0iV7SWst93g+4okiuOqHkfdr/iZ8PSXIzI7qs0RpsZrBO1nafUjgnGmby7oUoZJJOXs1xdIkW5PweSpqsJqgoe7Y0EosKUsyd1TgXRLERAioG8Qmlny0kH6ZL+2PvA33fs98fGPoOF+Rs5F1I5FVI647slSbf4+TfVAjd3zVT0riQU03bYeeWwmayT4nit8qyTFyeRq6hYRzPvirvY9IMBPzozg7ecjFLz5kcY8Rn1ffy95kQz2tY3/eyxvOUqitbermgpnO91hrlVaKxXXKSybSTNZZxHIWY63q88+RpMqrruuSkFsbKoAg+0JxayrKgKmQENf1lQro6Wbv6fqDrR3zwaJP20wknjlESYauqQO2SWkJL87Fru+RpNpRFgTFHeYaYVLRAnnNGa1Rm0/8O5LloeLJEtmmTJiKsTfefrOTOOZwbGHz7dAZKDVCtdQrL+f8x8fTq+QtCDNyMHcPoeP/uLfNZzZubCyBwOBxwznNxecVsVvPFmzd479luZFYzM5q6LFiv1kQ0nYuoIAkVaAO2IJ+teP5K0EulFG3fc+p6rozl+uqa4/HI5uGB0Y0M40Bd18zmc05Nw/awp65KbtZf4pXBK02VZRRZhi1mrC8HqtmCdpBIe5vnPH92xc3linK2IMsLWh/Qec7D7sDtw4avXr9mtVwyn80w1vDx82f2p4amG7BaUx32WKO5WJSsFwXbzZaxcTx2J0SMmeN94Ljf42PgYjEjyyxXqzVKKzyath/4cHuHVopXr15hM8vL5zeCcvuIG0UUHgIcWqnUX64v8SHS9APr1YJvvv2KY9Px08c7ovPo4DBGkVUVy7LgYrHgcDzw+e4e5z2HtuPx4RHvesq6Zr5Y0PUD//FP31Nk0k3FWr746iu0d6jgeXFzydVqRlXNKKzi3Yd7Pt8/8OL6ksv1gt5rgs1ZXd2wXCzIy88cj3sRaxtDXZVYY/h0e8fx1ArBlmdstjseTkd2rYxY7jaPBO9puxcyj7rZ0A8DyzqJfI2M6xRFTYyK5Uw2tPuHW4w16LyUh1ZwuBjZtq1Epmclwzhyf/+AsZbrq5vkgpnRdS3/8uMPuNFRWA1+4O7jRzn0KcE+N48b2fx8/ohDMURLXcjnm+Ul33z7W477Ddu7j4Iu9gPN6cSHuy3r5ZyL1ZLRR9rtgarMuL5YEfqeMPY8bLfsDwdGd+J4qhn7QcaTjhV1nrE7NXT9wM3zl8wXS/a7R4auTWN+lvnyGpvlVPt9Qj5FJDsv5MC5izLq9Kc//5kQAq9ff4Gxlh+//x43jrx5I9f56OTA+MVL8bX9Wl6vXrwgBPESjc6xO8oo4mq5IkQZDY1KoYIcqJfzmdA4WorZ189eYq2hrir6Do7ThlZbKXA6GY80VtBlFQPD0NN0A7OqwDIjeidJeOOIR8sRPMLQdxwOR3JrZHObCo3WSPEhLwo58CtFN4xnMeBiuWR9cYE2Vu6HPEOrdHhwgeVyLcRRiqbvh46+bbBZLsht2sRUszn1fJE2X5HtXrwDBClIlFUNFdRlAUoe2M6PkuYJjAmrPrU9MUJe1kLkjcN5JHV0A3d3n8myjKuLC9CagAQKXF+sOJ0a9ocD1ubUiyVD33E87CjLihcvX9N3Lcfjjr5vOR72NG1D1zYAzOY13jnubm9Fhp0ovvmsZjZbMJst5CBBlPFak3F3+5nbh0dWqxX1LAl7tRSgjYLlcslsNqc5SlLqfLEiLwq6tiF4n5L6cna7PZvdnvbTJ/FhJUJqGEYZLYieKre8fP2GiCIvSiYZtDWG66trKX56xxC8eHVszvriEpXGD0KMNKcjIM8LNw4ct/fkRcnNi9c45/j46SM++DSWJjTbMA6cDnuUsbSjS5HIGYfTidvbOxbzGTfX16zynMVidR7xVlpomd12R3M6YYuSrKjw44BP6XaXV1dUZUVRFjTNEaUVTSPBFyIjt0KHjT1t03DqOmwqxJnUhPBDjwtewg6sZb1eo5Rmu3lkHHrmlRSymrSZetxuCCGyXC7RJuN02J0dZEpr1quVkNaLxa+u8FSVpRxUUpEwDCNORfpxxMdIllcywpFJ7HJlLSFGutFjjWZZy2dSlAWntmfXbsmswmTleYxdoahz+XOHvqcdHO0QWdSGi3khpIYPOA2ZjsmZ5ugGz2mILKqMRZkxupzRey4WNct5jQoO5Xu0VnRecxpG9m1LmVnqPCOkMefRDzTdwP1ji3OOF9cXrFdLjAb8QOcjLii6dkBrR9W1WA2zImeWWYIv6Z3j1DnAU+RyOB2DFIyiG1FaU85qQNMNHS5EToMnt5arZUUVLYQF4zjStg15plnNSpz3vLvbYmzGcnVB5R2FCszLnNfXS7rB8Xkn1M08s/TDwKE5UWQZ1/OSrnccTj2nznO7a1NSXJ58niPOZzivGL3CuYApSp7d5ORWHEe2mmPSISCqyIe7Pf+yaZjVBWWREzCy9qQUu+tVzaIUL5QxgSHK2pEbkdleLRcUmeXYdzxsThyOR0k9HsVtVRQZdSkKCec837y4lEacG6ThlVQK6/kMTYqQH2HAECJ0/RGjYF5kosfQMLjA5nCU9MrMimTaGNpu4O7xnhAURZZjtKFtWtBT4QEI0pT0UUYym3bAlyLHtRqerUr6Qf6584HBBXbHjlPrUjHPE5WRfb+1WF2yXi64vlhxv90z7k/ig/IyVm60oel6QvAMXqjKKhcSb3s40Q0jRWpaO1OA1jy/LqXBmRcorZkXsjewxki4Aka+lpPmUNPu5DowKjWyZdxpVmfnhu+v4fXNN18Rgud0kvTl28cd3Rj47e9LjIGuafDjwNX6gtm8YnFZAppTMxC84tnVDbP5nGqeE5uR0Q10Q8vutMMHTz905GXB119/k0aYDPd393z/03d889WX/P63/8jgetq+xfmAVfY8kn88Hfh8+5mLi0tevvoDfdcwDA2Xl9csL1a8IFDP5tjCsjk+oFRkXs+pqpIQPYZI9ANVWRGD4vPHz3x494HXb17x8tU19XyBtRn3d7fsHoVmL4qcmDxzL16+wFrNbrdn7A982m1SUVmKKI8bIfVvnq0piwxfWLx3bI4PDMPAZntM48wygndxeQFRUdiCIrPoTIJM7h824oq8XmJzSZZbXtS8fPOS3X7Pp8fPqKjIdYa0dzKury95+eIFd3ef+P7Pf2K3P7DbSirx2LXU9Yxnz18RiPyXf/4OmwKUFPDixRVVWWCs4/pqyWJeslouWMxq/vTnH3n77gMvXlxzcbHEB2l8FGVGNS958+oF1+u1jNYrxXxZk2eWzx/vOR1aXr58SVnl7Dct7Wnkf/tf/hNudBzdEVTkm2++pa5n9E2Pd46vv/mKSGAxq6WApwPaBi4u51hrOB2P9F0vHlcFs+SOHlwPfeDUlPTDwMN2R4iRvJAizatnz2jbhp9/fEvbtQxDQ9cc2T9spLEbRvph5HBspLDYi3Jmu9tSzytA0ghfv/pS6hqbLafjgfa44e1PP/Hu7TsuLtdcXV9yOjTs7vYUheX1i2es1nNmtUjaFZbmcOIh3nFI3szoPa4f2TyID/biek1dV4xtwKdCalQKnSnywvJ3f/e3RB/Y7LaM48h6vSKzlv3W0HU9f/zjf8Y5x6vXr7HG8NPbW8Zx4ObFNfNZhg+iY3j9+oYs++tKSn914cmHdLgyFhOmDm04EzQ6dWeKVPHPkkS57zuhNxI5YLSZppzTLOpTRwqk2y2pd0LpFIVERzvvz/6daVZ86sZP3gpjhFDS2kiq21Sd9gGfOspt2wKQFUJ1ROuksmqkSuhDlMXQe7I8o64qSTxR4mAancdqeS/E7SGH1el7B1L3VeG9k3Q8LZ0v56T7IekLGudT0l86jEzi8bqucd4zDCF1huU9msgBay06BKyXg6W1GdqM5w7g9PsnwkESiaSSHSM03UCIMJvVlFXFrCrxyEFHxvMlRcXajMGN9GnUpiolRlzoLEkd8ImAsjbHmFwcKKkjNs1UC6khziSbfCzWyvdujMFooRWCStV9JR4dnSJvVYxUZaIR5AdLxFoSVp79Mk+fhcyLR7wTCm2q0Gpp/IPSTD11cdnI+6cTpdf1vTiW0nsWSN6afiSaDJ3loKSKrXQ8f9/GZtgIeRDB+Xn2N3LuECuVk9uMpmslpdA5IZISCTaN2g2jiEJ/meRhUiz1lPhj0yHDednMWqPZnZrUhSB50SzGhrP/IoSADlPiik7kXxortCbN4z8Rjv+9vyZIThuDjk9OnKlDlOUZxmuiT8l2aa2Q2eWYEmme5IImdWTDL8gLkPeSMBExPAUJhICeMMxz50rWiOn9nzo9OnXBrbVSSDWS+hlixCXPhXxtK9e6LITp+7bnKHMhTopErklnaHSjPHCCJIKoRE/pRFKCPxMCMioom+Hp+3zq905eEHXudk9pNNNveCIHEu2TqDtQmOkAkN5HNSVo/WLdOrtTEtml0/hi53oZz5uooFS4CW5yaIC2liwVOrz3WKufPj+ePDBCS7m0IZnWKpL7TJ9pshDSuFkizuy05k6d2TC5o6Rb5qbvXWnZDJ8TA3Vag55orul6mwiPM+n0C1pDxZjCEBPNMNEliTxxKV313PFPKSY6OWZc8i1Of//UOfMpvW6SlU9UXZbZRJNKU8jYLPkj5D3IrBWSpR9SB02oYh8iFvkYJQ3nybsRf8FgR+ReRKszRTbLC2yWsdtuzq6ac6ramTJ88ipIgEM808DCnzy5YX5NL7mtpp+b8zN18taVuRWySctor6xDIV0D0sme3DJyfcuXcskjpM3kpIvncJMQwplEOie3JYJGq4mEFmJAa3V23mmtyIIhzyxGg9Xi3YnpGeV9ogLjxMJHpCwsr5B+ZZkI02Nwv6BCZJ8UY5Quvpqe/YlKiib9TEhHnIkAInXkZSRgonL8RP8kwmVagrRW5+TYp2sp7TR/8e+zzKTkMn1+/lujGRRnKmeikqf9Xj84rNGUmcXFgPHi6nCJeldaY4AskRwT7Wi0xic3mvep++yz5KDTyeGUHDZaE4yEEcTw5GXNrOgtMpscqb06k0pPCYBCgoi/KREgRpycIQrdqhJBL9dhTJ9Yco5F0pr65LeaoKPJAeicPztqfBrbizxNFwxOOv3a2ES8pwS69PsT7HL+vyQagChpjTYREp0bUTqKLyj9R66XVJgdJDnaak2M/tywg5RaR0QGNOXCmNKlQ9pjy55J3Hd1JtMYfZBRHBFei2tUGSAkej99q9M9oLWkFcaQzgBa/eoK5yD7E58adj5NV/gghXEyS1nm5HkhDXkXaNuOcRjJsoIsy5/OE+mZO5HN03N3IqflWorYTPYVLj03UE9055Q0p5T4dqwx0tAuS/JMU1UVeV6c6aYQxBMktIklN1kilXpCcBRFTojQtlJcyzNLXZcUeY7ShklO309fw+RYm86ndjrfyTM+RmQc1AWUBpWKStMkTySmFNHpGanTeQDKsoIIFntOTEbFs+vRGktUgZjZcxLv0yue3xfZB0hwTJblaGPwPtCcTgTvqaqCelYzX8zo25b21MlanBqdWTal7J3QWtzC095jHIeUSN6LSzKvybM8ncF1OqfKeV2S9uRnnzzLeVFIwz0Xf9UpebyiEj3BlNoXowQd1HUFSiZb5Nkg671NUwgxuVnP11cma04YBnyQySrvPTaz8r48bffls/I+fR6ewY00TZvoOHX2UHnnzpM4kh6tUlJo+ny0JrPiTyqKgm4YOJ1OVDMZFw+/OIeUZYF3juPxgEsNRZlgavHOEUOk7weaU3vWGqh0naSFFG1lJE7co7CaL7DGsj8e6VPTdHKviT9TkgIlCW9aC835c+uG5P2bXIl/xeuvLjz9+bvvJAFqfYW1luvrZ+SZ5X53AO94tqoAMEVJlhmGrqNpGh4ftsQImbXS6fQS2Xo8NuRZxnJW48eBsdnRdD0P+1Mam/Cs1yv+1R/+jr5r+e67f6EoSurZ7LxpMFrhhoEyMzxbL2lHz+Op5/pixfV6gVYyAtV0gkJ+/vCe7e0HLp6/5vrZC5rDnr5tU3EncnNzw7UyWA2H/Y7CGlR0nI6dpBK1HcE5VFWTlSXP37yhqioOhxP9MKDLAZt7rtdLjFLc3d1BDNxcXuB9YHc4EmNktljIwjCMxBBYr4T+ubq4QGtNNVvgvKdrG3mQprHF5cVKLqIY0cqwrDSZ1uz2R5q2I4ZR7gqb4bqB436H9w6bF5R5zu+//pJD0/NwaHj27Dl/9/vfCqbuHPtTw3Z/ZF2XXF9f0nc9Q9dze/fA24+fef3iBS+fP2MIAT/IOMhyVpHnGUpZXj9/xuriisP2gdPDJ477PYe2ozBWfDLOY23GxeUVN9Yydg2jc9zc3GCMOSc+2ZcvUErj2hPBjZRGE0zG4vIGk2WEJD2XDpEMMVqbcfXsDUVZMl/M8W7k7tM7ccS4gRgdbd+Sac2Xz68k/YrIOA60pz3D6DFZjkHGG7EZm6ZnMZ+xXq2xZc+IkTG6rqOuZ1xeXeG9+FJ2hwPbt2+ZzWasb15yqUXeud3tuX/c4mPg4dhSWE2eySauyAq++3zPv/z5X3h+c8XlxToRNIois5jc0HtoO0dhM2ZFDtEzdA2mKCnzktWspMw0f/rxA/tjwz/93W9ZLy+5++c/s9ntiQvpFuRFSVZWVNUMHzxd2zIMA19/+60UgsdeXFPOM3jPuw+fzoeTX8Prw8dPGK2paxFUXqxW5wXbWsuLZzcyepiS2O7v72R8YRDx42q1RgUpIqIU8+WaGCNt0z7FP4OkJsbA4BxlVXPz4gI3DAx9gzUZeVmDkRGLLMswWc5ilTNfXnDYbTjstyyWS+bz5flA7UOk60eabsB76ZIaaxM1pMitPR84vA80bYMbHXlmKYocNwxC1AwDwzjigzyEry6vKIqCtmulIzsOxAgXqzUAj5t7xnHApPGoSchrtSJGhcpkRDb2vSQSLeY479htHghJSqmRyGGtFNeXF0Sg6zvyPGc5m6G15ti0jKOnqmpCCLTHvThivGwgmtMJoxUXFxccTw0P2z2zquT65iohvpbmdOS43wkFtl6n2RTD508fefv2LfP5nHo2lwN4lINOVZZ4Ly6sspqJQygdyruuk1CErmMYevx2gzGWm+trqqrCO89pPMoGrC65WEkql7Li5xiS6ymvarQW6X+Mkmbkgbws0c5JV19BcFIkKhKx4MY+jXfoVEwXqk1bi3clhZFDXd93OOdSgc3RtifGoafvB2azmmc3z0UCutvjlDqPm19fX+OD5/FxkzZ7Fu8kqCHPcxY3zzg2DftjSrtqjxLtPDUMjObT3S13D49CBM+XjElEbROlsdvveHgcMVoK5TqTTv6QNnQ3l5eUZcGPP/7E4XhkfXHFfD6nH+VZlOUFeRbpuw6X3GwYdcb2F0u5h+dVTvSBdx8/4n0gT9HNv6aXb0/4GBlGuU7WqQsMmtwYvrgqxeXYNAQU3ha0/cjn/QFDYG4jRW6ZzwZCjKwKkSx/fHikKgsuV0vavud4Eipg9BIisp4VxBj49LijrkqW87mM6nk54PfDQGHgZpFTZBmFNeR5KYc1NzJ0nawZmSTFHo8N4yiC12EccWMPtgDz1Pgryhq05nJZMi8sh07Rj45xaBjS9Ymx5EVOmRsJtlGGLHdE7ahTQeM0yMb+ellDhGZIYQapaNoM4jVZVUIHECO9G3nYHVBKsZoLOdcOI9ZoXj+/wYXAvm2xWjGfzzBGs29dSriLWB2xWsYybh8OLKqMHI+xGetlxf7UsTs1XK/mvL65OB+kN4cT99sdy/mc9XJO37X0bUszeoZR9m8mkZzSDIDnlzNCGmZb1QXzMkvFdSk0t90ghRiiuKKynHpWkWlJDGwHR1WWzKqaeVp7fRqj9FFx7BxlkaOI9C7Qp2AD75UkpjrPGKRIcrOekVtLnssYc9slWbKSMSaRtRu+fD5n9J7N4UiMUzhNEIFuUAxB4V0kNAN1mXM9KyBEwujpx5G260BryjKnKjJmmaLpHA9Ni42BDM+sKMmrisf9ibvNgSLTFJmRg2wM5HXBrCr49LDjv3z/nhdXS65Xc3bHhlM7nJsfp05ChvI8T4dWh0Kfi63LSpJpHzdbmn5g+WxFVVjuPzxyanvmc2lYd04RoqGwCkXEO2lYr+YVSgv1S4TN/ogngrK/GDP87//1/Q8/obWmLGq0NixXS/Ii4+OnDygFb95cp2tOirxD23M8Nvz8w3uMsVysLshthQ6KzGQsFmu00bStpHeHEOi7gcOuSQlbDddXV/z7//F/4tQ0/Oc//hcuLy559eIFneqISIFgGAbW6zkX6xmnw8DD53tevLji5tULqmJOUdTs7ne0XcPmUTP0IzbLKOuMzNYYk+PVgMdRLWa4JORuji2r9ZLlas4wSrBKRBGV4dicyMae3/7+98wXC/qmo+sdXmfownB9PYcIH95+IKB59uw5MQTarqXp2jP8oU1GYTNuriSl7PXr50Rguz2KdqGTZvgYHbbM+PY336BQRC9Vk1DOyEzBp/e3DM5Rl/N0pnYM3tEcjlitedw8YrOM3/3d39M3HafdkcurNV//9vW54PV4v8P1A1cXa56/uiZ4CD7ypz/9mX/5l+/46ssvePP6NY/bLW3fETW8fvWcvDAMY8+r119yc/NSClFuoBslmTSMQh9uN7egAl9++TVfLFZ0bc8weC5vlmituLgS4t2WJWjF8bCl6/fMypnsPaz4NqXhMaBVwKhIkUvQVl5oitJyffUMrTVD2j/vB4cbI7vdkaLM+du//ZZxGPn86Y4QArd3t3gfmC3neBVoHzrY7/j+7VtWywVfvHmBMR5CwGpNUddUs5rFzYU0Unxgsztw/7BhVsxY12vm9Yznr17y+fNn3r9/R3s68en9e4qqZna5YF6VzKqKP/7zn/jz9z/w8sUNN1eXdEPPZn9iMVuwmM857Vs2d3vqec28XhG9pW883snatVrW5Lnhj3/8kf3+yP/l3/8bVheXNN81bDZ75tUKyozj6UjbNczXcyKKfhjwzvP1N1+k4lotdY3dB0Lw3OuM7K/ce/3VO7QQIypVblFyOFYo3OggOJQW18RURctSt9Om8ZMsURUmHabU1J3WGhdD2kRLBdzFiEfmS4uUtDaMDptJ18raDJspCJ7gx5QiFc5z2jLuItO7PorDxY0OjP2Lmf0YpesXoqSg5Fbi0fMsoyzEzTM6efiPyb8UUjdbnERpblyJf0kZ6XoYbTCacwVwXsrGsB8HqcAnKkGlrp9OXTPnPTqmGd1ELUx9I6VlnCaESNd26b0TZ0dzEuFr17VpHlooibosz5QTSjpKWRbIsoyikKp133W0wyAXQ+paWmsZldz4MVn0fYqZ9xFcjNgsYz6biVcoCqpvtDoLbKdfeerexxAI3p07RX2Uyn0en9wNSsUnx0qi4SSdTjYveH9OhzPWksVIplPqQpoH1loTtVTOhWByQtGltlteSDrdad8Qokcrg7WKYvIO/MKphfrFL0jXi6Qk+iSUJAqt50Y5AM5mMybvRFEUzGYVAZMq3ECUDchEVmilz+kCU19a3BsRvPwZZaRDOXpH6DqGINdenxmI+kxzyXs+ntOtJjpAiD3xqmmvGbTEsE8OGXmvk7MsgvsFbfFreIUgFXnvHQpLmU+b9Ce6R2aVE9mjdYqbSWvU1N0FWX+yTBD+5GOb0uK0Evpy6n5Pjo1pIxlSlM3UXQcS3fnU1Z6olie6KNGcE+127pRIR8WNIyGNJZydSVHSL9w4JH+VP/s8YDwTJOd7NQmh4YnSUkrixI0VYkDb1H12UypG+v6TO2xMdOLk7pmcezFG0Jq8yPA+cGra1OUV15P4CUacG89JeudUkeQXUNY8vQ9GYzOhuVLT+C/JPWtlXZ76efEXDo007qgStST/On3GPHXXpvtIOqI20Vn27PXohzFdS9mZXlXn9+PJPTMhFD6lC2orXVk7/TyEtA7oszdFKSEGxF+oJX3sF1SwpFVN1+VEEuhzco9S+rwGMH1SiRIZnZMETWtSCMQ0w5IivafkQC2JZXmeM9k2hHpTTz/vdJ2mZ9zkIEhveXofQKv0HPZSfJsKR6P3mF8QBs47IfLORGJiYaZrWj09J57uExkzCE9X4y+64L+eV0zrMjxd60JSRqKOZ+eRD5GgnmhDpXW6/h3BS8dTg3iJnKcb5c9MyW820XejmzxJ8me60ZFlT0m91tpEVD15Hs7fIHJdCmH+RMIAZ4rKWivPtgDRywFSa02WKZTJzwSRjA1Lo3IivYI8qBK1KJSd0vFM0xsdz6SOQq51pSQheSIdY5D9KIgPU3xFiYjW6kwjaiWUe0jrjo+SFqztRDopRi/uotE5jLLna7bMMykYa4MyBmW0xHMn2ihLawC/WOufaL2JjEkkkpdx7on4z41Q7C7K+FkKXZJ7Ln0m4mVLe0f19H4ILeIZJ/LSyFot62Ciy1I3X5yrMiaHimRJkHVOm0t7samAZpTsS877CTiTkFoJeaT8k2/V6Dx9f/IZ2ET/iCtGndc50vUwhSvIcpDWGoQAswZpdsjGO11P6XM6/yeeiTBFTCmfyQemxS87Peun5UyuB877Ke8nr02i9M//PKQJhmnv69OamUlDU4tbaGpSxWmPle4bIfXjeV/wa3lN3jXnPMaC1VOyZv/0XkdxLiql0VhIa1GWpdToPD9TlVmenZUbzgWZbPABaw3OC4GmtaTLNV0nxIl/otC1UejwRIyG5P0xcuEJjRaePl/vRJhvbS5en8wSvXh5HZ6g/HlNrKoKEUXp1MwTp25IOoJxlO/DRykAOCeFKZ+eg9aY87WrjWY+ryE9t70PuN4liMPIeTuCQie/nEwraKXQQcieGB1aCcEVfOB0kBAra8UZ2DRSzD+dmrS+SjFpNpuRZRnD0MtUSWbxicDP8zy5oTzj4BJhaM+E6jgGxiCuz+nzFwrb0fejJL1VFTHKlIdMcRhCL3TR9EsT0UYRg7yf07SPT+dG58WbZDPxWJGegXFyIcZAjFqon3TmPJOxVstnae2ZOp+mc55SRxPNGxQhSN1gBNq2A0ApmXjJ85yyLJnPZ1ibn/fZLk2CEadEaQ9Go9LzCMQJPQ4DqpxRViVeBRwyubKYLyCtbXJmSE7qzGCslYkHK9NlgxsTuSvgRAjihY1RqDk3ynoUnKxVXafxXp/3pX0voSDOjekMGNPalyhmZYkoTMwkmfa8RiUK+P/j//tvv/7qwtPz5y/wIdC0LX7sMaGTmOZMELpj72m7nruHDXmW8fpZS1lVMuPrPcPxQFmWLBYz+l6EXzbTZAaO48C7z48slwu+fPMFXd+xO+wpqpJuDASlyasKZS2D8ywWMy7Wlxz3W/a7DYdTy+39A+tFzc28JrqBzeP2PEqz3ew4HI588fI3fPXFa0bnGLsT+/2Oze6Qfl9kOe8oi4K6yKmyC069Z9ccBFmOIS1kI6Yb8Gg+PzxSHk/URU6WJJzOK8a+Z4wRpS1FlfPVl2+w1vK42dA0LT+/fcfYjdIFUdJhOgXPn99+JLOWq3mVBMKyIRi8QwNVLukfnzc7tFIsyoxT8Nx9fs+x6/m0OVBXNc+eXbOaL/jt11/T9COPx4YIHMaAzQtePxMfQMSy2Te8ffeOqqyYz+ZYW6CQhKq2PVIVltfPr8AP3H74GVXOUUXFi4srLr/6gn2aTd1tN4yjdNoGbyT5pm25WMxZzua4sSeGkaFr8G6g6QQF3LciSp/PZlhjOD5s8F46TUZlqKIiOMdPP/1MBP72d79jXs9ZdCInv1wusEbLwjy27DcnUFAvFuSuxqujLOY2R2UZdjZjv9nwH/6f/5nlfMG//3f/Fq0Up65FE6lMJKBx2oK2HDpH17Q0hw1t79g1Pdlhz+7+M/VszvriUjrv8xk3V5d8/eY1d48b3n/+zHy+5MWLlzxsN9w/PKJ8wAVHHHt0HHj9/JpFVVAkgq4fHYPzRDcSvMPqARU9RV6SFyW3D48cTieGTmR5i8WCoihYLxe8ms+4vbvj46ePHJs+kRI5RZFTVxVKKR4et7hhZD2fEYncPm7E1bBayYG63aKIzObPkq/o1/GaV5XcR11LMIZZVZBZQ14UOOf4/OkzKCjKEmssN89fimesadBGS+JbWoSncQspipecjkfubj/LiIk1GC2Fceccu+1GCJGiJIQgzh0llB4KgoLN5pHHhweWyyXr9YV0448HebhoTXADmsDFes3l1ZV4qoaB3f7AqWl5PO4Zhp71xSVVNaOuSjSw328Z+h6bCe7dJxT32CcXk7WUZUnbnOQBaXMhWhdyiItIIX29nGONEFbeezYbKeBJIdkz9i19Gzg2DXmWc3N9JZhu+v1t2wgdubygaU58+PiJqnZc3jzDjQO77YaubdntthRFwXJ1SVXPWK8v6LqW7XaDGyJ9Ky6u6/WSvCgpipLD4cB2s5VjmtKEqBh9pOtb+q4ns5ZXr17JAQjonKMfHPPZjKoqZWMZRKwbgkhCRzdyPDb0w8B8NqcoxLlUliVt19M5x6k5MfT9+bCYFxXa6JToFwhKim628Cg8d3e3eOe4WIt3q64qSAcfAGNzeVxHKQYOnYyDayO00DQGNQw9/TDwuNlSlSVfvXmFnxBwVXF9sWYcR45NCzGw2e1lfCOX5k3bnFK4h7jfyqJKG7nAcj7jar1ifzjwsNkwq2suX1/Qti2npj2X8oy12Lzg2fOXrK+eMfYt4yCpKcF7xgBeQVZUlLOMsReHx367YUiNKG0MP797L/dmXXN9fc3j45aHxy1aKZaLBUWehPzLJTHKhi+GyGIxkXLyGZ2aBohkZU0Oqbjl/89dYP4Pfg1RDuJ5VkgkfFTgI6Zvcc4SlWFwnrvDgNWK64VmpiMv1jOCH3G9J7eKIpsKlBn96NFmwEfYnTqq3PLm+QXHpuH2YUeeSQOu7ToOxw6lLHXlQBuquqZrGpq2oek9p96xmpXIhJ9jHFopCkUIaGxWYKxFWc1sVlHWJcdjS9sPdP3A6HouV0vqqjjrCh52e9puOB8al3VJVdZs24FxjJhmJLee3svIuTaGwhjimCK4U0OlKmSEo64lzejj7SMQeXNzgVaK46kRD+fhhNaa59fXqflocc6x3XV47WiNYhgdXdtCkaOWQif0o+fUDtw/HpgnmmY5n/Hv/m6ORzEGzeA93TCSlyUvn+WUmcEH+XO7Y5vcZDO00Zz6TgpMyqCtItd2mr/Bpf1BtaiY1wWjjzgvxfJT14sXNEgkOTFSlDlZloo5fuSUmrS7U8swepZ1Tm4tRSGur1M/EHzgelmTWcNjA70LHFu5x15cLslMznKxQMXAPJNCWRdFhDwO0vBqekeICoxIitU44FMBpx8cu+2BLM9YzGdo7+m7niKzXC8XMn7nRtm3HzqsMZR5ThcUh8GTmcgMGDW0LscnQnxR51yuSrbHnvvdiSLP+OrlM9puoGl7dGpHFEYcZc9WFRe1pa5qofXynN5HChXJFGRFkZqXMsa8ObS0/cjQd3jv+PD5jizLqOoKWxRsjx0cWxl/UVIkizpwuZSzQd/KJEde54QA94eOsXf0p4bMal7cPJNk0+aUAjt+Ha9n1ze44NkfN7gRMjcj4Bk7KZwMXaTtGj58ektZlnzz1bcURcHf/91v0camtcNQlBk60yyVI7cF83rF4+MDn96/ZbFY8O03X9G2PZvtQc5auz3eB5aLNVpZdvsDmIjKNBk5BsvHz7d8+PiZF8+e8eqLZ/TDwNsP76nzijIv2WzuaE97rn7/G37z29+dx7J++OEnbm/vccNI8IHFakFRFlxdPUNdKw6nI9vDnTzTQ+R0ahiGEecl1OPT+88cd0dUIhh32z0RWC4XoobRCl1kvH5zQ5ZltF2g60fe/vwe7zyzqiTEyHZ3oGl6NrsDeZHx4tkFRW7QyT3bNghVX805HBt+/nBHbjU3VzP6CLvNlu1+x3c//8hivuSL119zeXnBH/7+D+x2G969/wkRvhuM1VxcL6mrkiKrOO4e+fThFq0t83QOUQrcMNAeW9arBX/7t79HodnvjvTO44Lmzc1zXjy/ZrN55Hg8MLqBzeaWze6BU3Ngc3+ibQaev7pmsZpT5hXGZAy95/5+Rz/2OO+4ezgSvEuTVwW37z4y9B1lPcNaKx640HH3sCWi+NvffcVsljNfzHC+5HJ1LR7VVOzvTid8CByaHc45ulEKozavGXzP7d09u+2e//Sf/ivzec0//eu/J88KrM65WF3w1Rev6YaBx90RoxSbhwdprGjF6dRy//hInlnmtZBWWW6wSmGLksvLNW++fcnb9x/46c8/cnN1zf/wb/8H7u4fub2VlD3fe8wCypnl7//we37z29/g+gE3DAl8MShlxNOpAnkWQQ84AvvHnrZ5UhWMPzWE6Hj16gVfXl7y/sMdP739zNg1ZCaizIjOLM9uLghhxamVZPu6rAnR88OP/8IwDlxdv8LajFklwM7l1TVZlv9V68JfXXiqqirNGUpijgqjdL2cAxQmy7Ehnt09eerqSAcahlThn0idqTo7uSNSI0ts90pRFgVaaTHSp3GCKTWMRAOhkm3eT3k5KqUAiZNqSkAwRjOrSungGoPvZVwrTAeo4Amk5AyjsZkc3rrxKDb81OkVh46hLNLsr3OMSkE+pRApdJxSGeRwSarQqjS7ba34DzRQ5NJ1a/tB/BwEtJpcGomomjrVZsKFpXIvc8fyMJ1mx1U6FMs7Ial6SoljQ7rpSVAZQqLIPF0v8e3aGBHCaS1kUxBbfVEUKG0Z+o6x72XW2LkUOy8bSmstbnQ0zYl+FLkxkMS5MsKh0wIWgieOMVVo5UOPUaX51EDXdvJ+KQhGfAfTjP1U/Ze4+niu8qIUzrsz5QGSzAZCOD31gKdXIqx06horOQQaI0WDqBQoKzLLvj9TGd5LepIxkC4/SYUinv0EXUrIkoStgX6QDeyUYEGE0TmatpOZX2ulAzIMRKQyPzgnZFny0KDEdzC5mBxyfQ/jKNHqCaNpU7KDzQry3KYkMREMxkiqantmKQI6hKmr42Hy7KSO6K+JGRDqL57nuKfO5ehc6lrKQTV4D5Przaf0yPTP5Z2R+yd46dQ8US6SYENKmBJHD6nrkvDm9FlmxmAyK9dqn2TjqUstHZuUZBIjIXXVs0T/PHXpEn3wC/LITB3CXBxrh0O6RxKRIvSkwqRUx+nrTF/Xyw+SGrBPDr2JAlIx+eu0OKJiWtvkN6akukR7aq1TUpMUp0JKdjvfd4onP9zZE6OfRgykPX/u+k8JpPoX9OQwjOfUlDzPyMsSY7SsA4kMMMaSZxn9KPekFAx1SjXVYC06JQAGP9FfQt3oX3R2tDFJ7tsnakPosyfCJ6WrTG4nK2sdMUkctSGaJ38CSgiOM3WX/iLvEj3mnBC4KVp7+rymrpx0M5P3KF0COnU8Y0ypJQrp1moNyv6CBBKic0qCUsmRMfkXJiJJunbuTA8JgcU52SaQkq2m+yQ552JKu9UhCHUslz/aGDKkcKW0TsXzwKwqQaWxQR/ErZNN6XZCuMj3Np7fA2ukADyNf5KeLQoS6fXrKjzlyeWmdMZEVwvpEYBpnxPPJGRmNTqC9eCiMGsqEQMmXWuTQ0xFnhIXEaIpz8zZa6nS/R1J5IoGm/Zxkb/0pUliGoDCB6F3hdZEKJh07Qpd+rQ/Ucgeyxp9fkaGEHFBOvnmFxSA0frsuZtoR5TQ9jDRX4B7WuMA0JPjUZ2pa/XL7z8lmhbqKX03TClHPFGsE0Ej97o6p/oJESv/2+iY9jrJfpTuzcnVpZWEMoxJO1FlhirPUsCDfL8TRWSjOJGc98RU/p3IaJOKOaRUv2F0UvAgkTV6SnFL68GUpBrjL66BaZpBqIwQp6TA80YyeQJTApsKf/FnlSLt4SOj91LIdgGUJsuFhIxuSjo1KC3U20QDgxT5bCYjvBAxypzf1xBFKD56jw+RzAiJJ82RdC0jn2E3elxIhGjkL3/WaW+crq0pQW1KXYREkqTUX0W6DiYqLf3KMos1Kq014bxX8mmhM1qTlm3ZD3iPRz6b4AN1ZWUvTkSchzGRK/Lnfboefy2voizIQgA9R/yzQutM9D8KVFIP5Lk4bvI8I8/yRNsNZCpD6SI9/56S3eIvnlPDIHvsopCDr0+OLmMkUbzve7Iqo8iEEBHSKKRnrlz7zjvG0dHFnuDkOq1nFVNK9zmVNgjFGxL5ZrQW8qUQD+2xEY1IpkX1UhSJ3vaJdokRP3o5/5nJsRgTPZgI0ahlH6NF5m9tFNBDacpCNAGReCY1jZ4SwCMuOpyT1Dtr7Xl/Kc9TeS80okyYyBatfunwDOevpRNhPtFAw+g4HVvapqfrB2az7DxWej6LR6kXZHlB23R0bZ/upympXQIGTGbwbqRtRW3Qd2nyxkh6tBtHyKWh4dwo9BLhvC+NIeJGj4ojQz8w9CNVrdHKEOPkCJXnn/w+zpSYeIxM2t9Ghk60BW3TCn1mzXkfPxXDQ3hyi47JW43VWKvJs5yAoiiGlOA5rYlPTi6lFEVegJLvXfZUUiw6Ho/0SdHgk6dq+sxUWs9G5+jajhiFbu+bjrbrAXFhxyjhFCFOfqyUvqrAWIWNhhgVbbdnGLt0DckUwjA4FnWRAilUurfk/uq7nhBgXs/k/k3fT0zPisnRKlMPkb/m9VcXnp7d3JBZy+XFmqHv+dMf/zPDOHI4teRFwbPnr4DIzdUVRWZ4vl7hQuTx1NEPjsMIwQTWYw8RyrLGu4HT4UAYPevVitF5fvjpHavVglcvnrHf7/n49ifKshKPRN9x6FuqqsJo8Yc87A6MAer5CrKck88EPTbQDy191/Hq2Q03l2sCmsftnuPpRNuJ12ZeWvpe4iKv1wsuL68orcGgGMef8GNPXUl6WHV9gbWWspJ55cfHB1x7xMwyrMpkU20Mq+UcRWSzP9D2Pd/98CNaK+pCRjOe3VyjtaGqaoZh4OeffiAET1WKHFpF6W4dB0lA6QeJqy7qOcTAxaykaVo+fb5jNqt5/cUXVM6R13uMNpTG4saRD3ePDH3H6bBjPqtZ1Rcc25ZPuz1N07E7NNKZXlxxfb3km+eXPO4O3H2+xeY59fKStdHkVrNveg5tz/Gwoznt6foZp2FGXteURc7DZsP94z2dgzFEZnXFen3J7rDj4eGeL9+8YblYcjgeGIaWvJAHTUyxmMfDgWEc2e0PglIuZ+fIbmMsL54/gwj39w8452m6DpTCIkWAbhgY3chmt5dF3Bhmdc3f/O53KKXYbrdEN+BaTWk0//D73+Fj5MPdHdGNuOZAVc/I33whh3itcU3D9uGOthvYHcVNc7lesZ5XvLpaczie+Hz/iMkKsmrB3b7lw//+RywjOQPvH2553J8oS+nW5gmzv9/s+XD7yHRsGvqecRx5+eyGq/UFnQ+cOhHVDUNHNV8zzzLevHwu19XdHc3pxMFLLOyp6xmc42F7YBxH/vEPX7Jer9g+bui6jodPn+m6jt2xRSnD+uqauiwpzWfUONAfNtIxngldcPewOY9e/Rpe8/kCYwyL5UIIp8+fcU2LOh7RSjr7EPFDD8awmM8Zx4Hjfss4Dhx2W4qypLi6wbmR0/GAzTLG0dF3nRQc+57j8Uhd1ymh66kI7IaR0Y2SzrhYUs+XPD4+cH/3GWUyZosVAdgf9nLIEqABH6J4iy4viTGy2TzSnE50XSeFcKtZLpeEqLi5umQxn5GVNdpY2n4kKMNqsSDP83MRoe+leJKXNTazXF1dYrTi/nErHovoUSGSG4ULke1uBwgNNo2iWiNNBe9DCoVQ5PUsCXDlIb7f786FpzHPKQvxftxcSSLn/f0tWgt9MZvlzGbLc6FpHEceHx9SwS9SljUXl1e0TcNuv0sPShl3c6Pj6uqCL9+8YbPf87jZobUhzyXxqSgKHh/uOTYn8qKgrhZCkqKo6orcStLbqevpux43DGR5TlVV4pgaeqqqBmAcB6L/f3H3X82yZNl2JvYt4TL0lkemqixxBW4DaCOAphnFf2abtZEvNFobu4FmE8TFvVW3KquyUhy5dUiXS/TDXBGnwAd2PpBGIN1sW2Wds8/eER7uy+eac4xvOBYpQe0o6272W2lMK0lGmU4mSVEqx/Xzl8QYaA8HBufougNKCWvJaE3TCmera5sUtd6TZRnT2fLEiLLGsFyshJHkpKh6fFqnDZ1CGYP3UpAXibWCG3BRbEbeiW06sxWr+Vz4dm1DVGIzWK/XfHz/lizPycuK9XbLze2tQFYT0NMWJZvtlg8f3pMXMsjZ73Y0zZ7Ly2uWqzlP6w2HpkP3A0dOlTGai4sLyqpiHEWCfnvzgaZvadsDw9iz24ny7tWLF0wmdbr+A/v1E33f8fDwSARWqxVFlacNhXCnUBCStH273ZyUZD+X47Pnl2gFudGMIXKzl41T1w8YH7G5sCJLC1VpOT+f0w+ezc1arA4URGU/WfWHgdGlxpVSZFYGeB/ve/LMcLZa4AIMTviJ86k8i0cXyXFo5aXGsgVKR5QaGZxj37Zyz+lcmqUhYLUAfJVWDEHTtw1j32HzmulkikIxGE1uFVZ5QtQCSreGssiYVSW5tRKFHjzLyqAwElOtNbOppB/eP27w3vPsbIY2mk37JGyo0YGSol0rxdliijWSKuqcExW783QukhlNkawzbcjTucllIJUZjDWstMCG99s9USlilmGs4tnFApSiGz3tMPK03aemlWZal1wv54ze0w/yua0PHc5HsJZpnfN8WbFvB7aHXmwjNqMuDFVuud80PO5asWpg6bwmdIGzScGstBzSJnDXdBy6nrPFkmlV0TtP6wLTOiPLDKFtiS5Sl7KpX0wqcmvYdwOjG1IjBLaHVhqUylBqzdn5HKUUm31D4wMqSGPGjbLeDKMk6W728iws8oKqLLiaFyigOcgQYDafMwwjXT+KbcpqrM5YTivZ/DmxOtZpEzdGTdM03D88nPAcRWZYzCpQGUFnaBzKDzw+tfzw0TOf1pwvZuwPDR+e1gkerYnKgDJ0LuDbEec9o/e43QbvHPP5nPlkwna/Z98JEiO3BkxOVIa6rqlrqHNJDV23A93gedrtGIaROrcU1nC9mlIWlkMrHKyHpyd8iPK5Kvj162dUmaUwch61lbTm3X4PwH6M/MS9238Rx3I5J88tL179htE5/vjHNwyDDEy11kwWhpme8fL1c4qi4OJixTgM3N8+st/vefvxI4vlgr/+q78CZQgjdK6nH3v27RalIpvNlvu7LYvFhOsXZ0QHvo9gIGaRfmjY7nqui2dcrK5439zw8eYWN8JqvmQYPO8+3JJnhsxq9vuWcTzw7PkZv/j1F3T9wB+/+z2ZqrGqwDuYTec08cDYD5ydn3F2saIocrlPdjuaVliwRZ7z/EUpYVtIc2xsAyoqrq7OJNjGlDjnqesKbRRlVdM1HT/8+T0Aq+srWXsWU4xWzOZLhmHg7vEOT6DMc0GeeEU3jtw/bRJku5XrdlYBmmcXZ3TtgZsP76nqiuvnL8nLktlc6pk8yxn6hj/+02/FJh8tk8mM8+sLNk9rbt/f0HUDh0OLUCMi188n/OY3n3H3uObm7hFrc2xecLlacbZa8eObt7x79x7tRqzzuNGz3bd45ckniv32QN9s6bpeVJizBcVZzuPTHfc3N1w+O6ea1nSHkeAC88WSPCupMn3CzGxHT985QtSUWZ0A3Xu0Vnz95WtA8XC7ZuilyaW0ZpxK08QFQcjc3X5k6Ae6pqWuK37zt7/BWE2z30GMmDgwn+T83T//W/ph4N0HcTnUVUGeF8xnC2xuObtY0rV92nuN7LaiFp1UBZcX53z11Zes12vevXuP0Yo8y3nz4wf+4R9/y3w+ZXW24Onpnu//9K2wR6uZNCe15uH+iXfv35PZDGty7h+eWG+2fP75S549u+TxYcNuf0gNQNCDqC6XF1OKPKfK5lgyfv/NyP3DyGa95tDsWW8aQoC//s2/5urqgsfHR9qm5cPNLc2h4e5Waq9/+S//jumkZrVYCvjfapQOOK0ZnONP337zk2uvn9x4kgmKSv5Kd5o0SmdQfKZGQ1kWFFam+gKzAhdSoyB6mqYApUWGHUIi7msh7kdwOqWyJQlUSKk4Ppyyk4hBEtXG5KUWD+dfcASMTHqOns6YuB2DD7ggDatxHBhSbH0MkvrT9z1N02DrGm1teo8pISol3x2ZE0prxkEsg8MwIcZI2zY4H5nkmSSnRaHg96ciXJ1irZUyaUIlkdLaCYcFLQtPROH0KIypQcCOx3QUlRc451MSgEzetYI8S5YNZPPWDiMxuE/dZi3n9Zha4kaHyRyK5FNPUxud1BpjUnvJEFOL6kZLZLNPqp1Jbk7qIqHe22TjKUS+3OxxAFoL60ClRLA0NbBKw3FyPopn+JjQYo2mLMuUIJWYNs7TJwWSTkkH1phkrRb/vouekOxqR76E9w4fI73S+OCFseA9zTBAkKJUJVaOpOGNDMP4F2onUY1NqoK6qqiqiqbrhcdiLJL56wneoUziZYQo6XjGUhSJ62Q0ofMpelzslJJg+KnDfYSWKyXTbvncUvc6JTwURUGXpPEnG0z6nS4lSh1VIVpJElVViqQ+ePFTH6d+qJR+lSaXLnGBfi7HX4hKjn8i7zk9PENS3x1Vi0fb0FHJ0g+DxI57UQsdU+1i8tKrY2Jjlp8846dp8lFpopRM+BM348gRsNom9VSapik+TXL/4ntDYjL5IGqZYyNJpYTD0Y10fY+2+UkdqNLPkMlNuk7S5NZ7h4zg65S8Iq9nGIYTv0Rrnc4D6fr/lFJ5LI6PylNROqXUmDTFA4hpk3LkwFmbodLvOp7vIyfopKDwnqFp01qgT4qL498J68SfFA+SmOXSFOnY8DuyncS2YBJfUB8VEz6iKEQJlpRWxljIOKWcejfio0wJQ+L7hcSIQR+VbSkB0Y2gPnGthCVlTvdYjOrk9ZdzmZiHxqJVL5t5rdE6fmIoaVGAyCRJElKCFwVv8J7RjWitKUx+UqbIh/6JtReiDAKUkrU0zz+l8R2l16JCloRAmwmzwDtPc2QRqr/ghyHXXpbHv1APHhVciYWXVKQqPa+MTvLQpGyLf/F5xKS4Od5TJLWJT1PoozImy/OTwimExH5KajwCJ6XbkYH0cztiasSFEEUFrMSqS1JTRGICu+vjJZAUgPpkwfISaoOPArUXzpB8Rs55vOOk6oijqKmEG5EUM8HjgyaEpH5Jn0NuE2dDfVLkHFWTx9etfUCZVIeNI44B7UnqDkmp0kRM4hEeEx4lcUozelFMHVl7Lh4VOhEdE6vKB/rRY46qIYQTFENSuSQ7tNX6lJKsjajDBKb4Fyc8/ffxXj+unZnVeBfpIa17+nT/hBgZ0/09jj5xi0SZoQgnh8BRHSY1rbx2l8De1ui05nD6c6UUeWZRAayJn5TaSdFzYjkaQ24zsXwbDc6f1GzH9VqBNFTUJ/aWc54hqSxFzRaTCpW0pn/SQhzXlaMr4XhdhJjS5OIn9tzxdIodUJpuLilElFL0/UjMoCrzpMoYISqCPq6VqVZNLohjcIBWwoEdhgGCx2qN0RGlQmpoWUDRj54sKXWtNdiktJKPTpTrbpS6UpE4P2lfIncZkPivJMWUNYbsL5KmpR7+C4bj6Syn85UUFUfOZoyijjLp2o5HtWuQvdIpKPdncqgUAzYmTu4xvdymJDbnRrIso64naV/06d86H2jbliIvRHXhAz56NCQ2qpFhxiCJuSbxc+JRPRYCfpQ6wabgD39kL40jKsaUDCyfE1GUccLJlM/fp6TpoR8IyuCUBLj0Q5fU0TLMOzRN4orZkxLkqELX6bkmGZfCMw4+4twcbWQfOQyOtmnSM1TWHDfIun7kKtvMoFFp/zNQFLk8t2MKLCpFqV/kuSiUwngKHNBaUZY5MYzS7LKi3tdGU1UlSQDNMAwcthupAyqxtWc2QytzCiDp+15QELkocWV+IazaGCP9ONAPPV3fE2NICXpHpefI/nAgKyJ5ltPQppRL4S7lRUZeZKc9NmhUVCB60KSgFweQVho3NvSdNHVNUsTLey3lfrXZicE7DANuFNZYnufkeUY/yl43y3LZOxmH0fa0ro+DXLPRRFCGPCtPA09jkvI/7fVjSCnqztEPsv9y40heZMxmM+pJLUnVWkNMda851sCyRlVVyW6zo2kPKGPJixqQzysOSp4rGLQSDmk/iAtJJfWmG0eO6e6yH5HEYecdqiBxUE1KlLcYbUWt9RfK8q6Tz05rCe/Iiywp0AaGQepW8tSiSWnZPnHIgv9pas2fDhf3I33X8uOPP56AtHmWcXmxwvnAh4/vyTPLq2eSendw4DxEbeiGgbfv3pDbjHZ/kLjJSiBjZ+dntG1HP4zUZcHVhaQlHfZbXN9RaJF97fuBwmrmsyl4z+PERMg+AAEAAElEQVT9DfvdlsG7xFeyxOjw44DWNRhh28zKnM1mw4cP77EJKHaUHn+4fWC923O5mDKrS77983f4qPjFF1+wXC5oBtl4FFVNXVfstxvc2OCV3BQf7u8lYjJ90N+9eUvXD9ycnVPmBfPSUGSGQy/e+txqgo0URY1zjh9+/DNaaz77/Auc93z/3bfouubzL/8Oay27tuVwaHj75j1FblnUBVobxmpGWc9PqrF++yA8qbwScKtz7HY7bm4+spgveP3iJUVRysZEG1CWLMuZVB5FwB2e2JjIG2MpNJwvZzzs9tzfryURLS8ISZlUWEsxnXA47Hlab/ny9UtW83OyfI02lvOzM6bTGXlRyKaKwOFQkBUFURuKeoLNCx7XjwzjwOVqRZ5beu9px5HZbC7T/okkNrx4+RKbZdzc3QsMz3m6NDUsy4LPXr2kriuRavYd09zQdS3b7ZbcQnRO0mi2YpvcZRkqBvADLgT63pFnOauLK9mURU/fDzw9bRiGgeYgnuLgZKr1+fMLiqKkrCaY/YHRDfJw7QNVZlkucoHt2ZxmDGSbHUpLo1UbQ1XkNPs9Y7OnnM+YVBnjYGijIiKb7O6wY/dwy/PnL1guzySOemi5fXikaRrOzs+YLBf49SN5PzLNBbZcnJ/JvfjuLW/GEa0FCPji6pqqKjFJCXH78T37J0nOKsqakJX4EHm8FxaN/gvw9s/hiK5ndIqnQfhGsiiL9SwET9O2ouZcLrDWsNusU0Na7qXNbk8/OoqqoixLlmfnsuF2IyEpIKvJhLPzC7G0qCNiXJoFnfMURcV8UaOIEn0aPMqK7N4SQJvUqJCiKS8KbJYzDD0PTXNKrsvynGoy5cOHDzytN8wmNWWes99tAVGmTiY1fbMnup7gPS5IMoobxyTh9Z+K+awgyzOJUu062lbiYOfzBVlhiY281uA8ykBWlLI+J7ZOVZWAYnAjGktVTUApyrIS3tBuxzE5DaVQ1pJpwzTLJbmub+QzIj0Us4LNZs2Hj++ZTKZcXF7jQ2C73dB3naSHak1RFqkRHdgfGr777gfysmQymYhlbBzZpdS33GYsV2enTV/XiyW1KgoyK0kcmbVMEx/AuyEFIaSGG4j8eRxwTkDoWmmms9lpWt00DavlCmss7WGPUor5YoExlnGQNaRLcm7vPDrXTOtawJ1uwDlDkWc4Hzi0HVqL1Nu5kfVmTQyR7XaD0ZoytxCg61ryLGcxm2Jshs1LaU71A73zHA6dnKMQWS0XfPb6tVzT48gwOtq+lwLeiHLu+vlzirygLEvu7+8ZfaDIM8o8o8xzqqKgy3OyvGA6nTGfL2SNbJrT61VC2Jc0zSwjLyqszYQVtd9T1VNslpMXlez1k3Xi8uoaawVoutkLDwUFs+kCYw3L1flpo920LXmeE0Jg/fR0slwqpZjO5ieL8c/lWG93hAjdKHDkRWlRJjIWlsEH7jZ7Mmt4djalsIau63EBJlVFjB337Zrgc9b1JDWqLVkO8wxSS4VhdOxVL2lheY4KA60f0oZcmuz90BGCJYaMZnC0w0iZWRZ1+cmGojU+gFEGa6DteoZ+ZBI0ZQh0Tcuhbdh2O9oxsJjUVEXO4bElhMDL8wmzKsdqjdfyv1ZDYTRBicLXRdg0UuhmWUthDe3gGcbAjx8f0Aom9YSszNn3noAEqmRGU2ZS8q43B0KMTKczAqAbh1ERm8s5Nlrit5tDB0FL0a41ymicAqfkOV8XlQzugqPtBw5ty+gi7RgpM0NRKqIb6RtRVa73LT6q1FySptNmD8MQmZQZs0nNtulpmoFdIxaNWVVyuZieng2bQ8e+7Rm6yCGIrYYIF4u5cAhTc7frPYSBYRRsgPIeFeXnZZmlH6WW2uwODIPj8nxFWWTgexQRk2VpqJHgx0oank+HDmM0n784p8gztm2P94HFXNa2tmlQWpLxnA88boSjFR+2WK2YlxnD6Pj4sGM2rVjOZgQiQ9fI5ldbGRCPgcFJ7VyXOWfLOUZpXNA0TcvjZstsUnKxmFJGmAco85xJmbHeWxqvMRGM95xlGYvKJruiDFGVtjRa0yrIrcaqiCZFl9uMrCpRrif6jiEqXNSETIG2uPSMuZjVWKPZHlpG72lGj4sweAhRk+WGQmteXEoKYtf39M1IWVTkeWTX9mJRzYSpaVVKpv6ZHMPQ0raeH979KJYwxJY0nU4ZxoE37z9Q1xNev3iFVrB5ekx8LLk/mnWDGuDD928xucHUiqooWE5nTIqKqpxLU0drxrGn72StDCYKn+6wY7k45/ryBSjP7e0HNps1Q9dQVaUAwTkC6KWHsFpOqOua+4dbPnx4z2wyp6pqOr8nBM93P77j7v6R64sz5rMpf/zmWwKKX379JauzJV3b4H1HnmvKKme33jIOAzoTa9fbH98wDAPReMqq4vs//0jXdtzfSPNtdjaXJqiC6CN90xELz2w6YXQj3/zpG5RSvHr1EhUVT3dPFFXBy9cvUQrOz1enPUyeW6k7lSYESz0rmc5LaVq0LcZaiqREbpqep/WaH/78Hauzc774copSBh0NOgi0XMeA1o6yKpkulowOvvvhnsmk4uXzV7z78I6P799we/tBXCfVlNlkgkustPV2w/vbD/zii8+4PLui2d6yVyOr8wWTukTZCDpyxopJN2M2mZHlOd49MqiO/WELaK4ursnKnLfNB7a7PcvVQmyWJoCJvH7xmiwzvH3/nkPT0o2ikmu7lqoqefHqiqqu2G7WuNGxms0ZB8fj4xqlwfuBoRn4+PFR2GyZNBGnc49P4G5rMxaLJbnNKG3BODruPz5xaHbcPbyTyZDPOT9f8s/+7m9S8nDDODqszilySz1VzGZnvHp+RVWXTGY1ze7A4AfM0GG6A/W0ZLqY4WNg7D1lYSgKQ3ZMygyBwXuatmG/3XJxdcV8uaQoa6zN+PjxB/a7J5691Exnc7IyE3XV+TlFWXF9KY3Xjx9vePvuLV3bAYovv/wVdT3h8PKOcejYPK3Zrx+ZLVeURc5mL06d7fZJ+JvlUoaMP+H4yY0nUX7Iht8nZo02R0aJdNq0ki41KuAZTykcxIhRMs0RTpIiesc49OwPB4IPVAmAbNIUVSklXdUsQ9kMlZmkvpGJmvMyOTgu0cfJ7cl7TtrIKKHmC8OopChLDoeGpuuJUdJNjhN8BRglyo9hdBhtKBLPSeLXg6iUnMNaw7SupTAyoljIrUjZ3TjSR4hFfVIY6DQtsUYLzCqGUxPsyG0qC7GHGGNBadwom9+yyCnzjCJL3KFuIARHZjXBRZq2w2Y5k6I+wSWPXKEYRN1S5AJ1jTEw9LIhtdacUuvC0VuqIjh5nyH9rNEHMiPJTspYlIrosQccwzic5OpHNUiWGdng+CGpEDgxbo5NS/GPSndYKySKF8jytBHMMqzN6IeRIRUzfdel9A91+jfSgZcH+jiOGJ0YAElt4J1ch0dA/JCu00JrVJrWByPTJu+D/JwhcXcSf0wk/ROyzNK1rWzaOon3zTKxfRAlUVGmb/qkDhE/PykGWWxdeWZT4o1wCvI8YzqpUAqxTxjDdFKn5K2U3sMxueJTCsMxge2oDnNeoYOAozWSCuQ9lEXOpK7QVqCm8kyT5gZaMypLHBPvyTsm06lcgz+T4zgdHpywrpIU48TE8W5EcVTUBGIYE2ftU4KP1p8YdfIzRbV2Yjolhhvpe2KMRJ8S6PiUlnJcwWLkpMzwIaS0iGPxo1LCyKevPMmpBzcytC3x6EP/f1OS+JQwp7UUeMZmGG04poscUxuNDaep7THRKmT2NP3z4Zh6JK/LZlli18mhjykwaeE0Wsv6nFSTx4m6zQQSbaxAsMdhwFgoSkMM0syROHRRbg5DL81PdWSOHRU3sqj7lMCmEssl8onlErw8j4737ZHjJb58Q4zjf8ItOtrNxnFIyiiZILr0846ffUxKpZjUTj44PIphGDFJtZjneVLRiQJOK3WyxI2jO913RmsJOTBG3qt3iW8XZQqpjhOjdB5JAzUSNNsKdFwUJ8eEQ31SakoD4NPEXWtNYWW6Lgw8mawOKa3nlGCYlEUqqaF0Uuba9GfGWmyWnRgHoiJOiqtkwxRLoKT72MSYCVEUC7IeJnWf+vS5CXPLnK7zLCWTdt4RfeSYMptZUXP245AUJOakVDsewkOT1/xzOsaUANeNHqMUPj9O9o9a1/QV1QmwLwyVlJyrJM3pyIpyyVLlEvPIaJWS0T79xKMqVA65x3Vaw/o03Tx+23EtUAgrzsdjGtiRyQJGQ2aEuzOMosQ5JtRao1PqXjwpfU6vK6XMRVxiLkkCZW4N0RgyLXVhboWp1g9JvHRaP2TNrTKb0pzkWZ9lSZ1jDIQov+vTuxWFVLJ2WaNOa59PrKWj+q/ve7SWxgWIesiHmPgpotE/FqQhwuB8Ungek+SkhvURBh9o+zGltyVQ+OgZc5+UT/LZHNmlow9or9Iz7ZM6aUhMEVHCi85CcbwmUhJgqr984vzZLCmdYsCkmmX0x/RAeV4d2Vj5sRZPP8un1K48s3itaNvExILEVYlJNRrR9sjoUfIenHBGQ3CcVELItXtk10wnFXli6vkQcOnL6GMCXbpOk7T5aAMCTgpVhaTe9S4weoeOCm3k31kjqcNtSlarkmXKOc9RJqhQGBVPiqWja0CV6tP6FYPU+NbSDT0uBCZFLml7SYwagjgLTHqPR/aU8EM5KRZ/LodLSqf9fk8IgSIpUI5DnOOeoOs6lIq0fZ94i1Iz59kxHVJm5lppvPNsN1uUTum2AERCNBiboXwkRo818vdGm6TKFUU5cLp/JcmS0zNbqWOytxHuWJYzmUyYz+bcP9yz3e0gQlVWiREUMNpitT3xcIw1lGUlKbFaMww9XdtR2wnaGibTmnzMkpNDk+UW7wSPEonUqU6zWQ4WqrJMScoqqbeSYjHVjHmRk+f5KV33qAQvy4Ist1grvLkxKbSMtTIU3DfkRU5RVSkIpmUcRnR6fo7jgHejuC28ox8GQvSnwAI/OpwV107XCQ91HEZQinFwdH6gtCW6NkQnuIkQRbE5DAOHfcM4ys+3yb0yuKQkC/G09h/rV+c80ct7dM6jlMdmlrIUQYk2VpKfjU7DRSWilm7AZgaR6UTyIqfvOiDSNo2sMyYjWE1A1v1wfIam9cX5iDbpSosR7xzOWYIXNvOIrNsxJAZYCFidUVaVhAt0HX3fs9tuGAePsSlhTxtMSvU8ljPi5MlPydBZllFVJc2hOaUZeh8oypLlSoabQz9IT2JWkxfZac/tnNwHRVlKfZeyTo8OIWMUgUgMoqo1WtE1MrAs8oxJXWL0jGHIaHYHxjim+9Fi9IhDSfIekazIktr0f/34yRXa+vHp9KDwPuLGnnHsuXVywREhuMh632P0gFU+Aag0Jgaulktm8xm/+OpLhrbh8eM7tk9PfPPnH7i+vua/+md/S9O03N/die90NqMpSnyU5k9dV7TJx05myUxF0DIt9yHACEVmKXKDMQqjgwDMrOUszzg/X/H82XPOVmf89//2/8E337/j2WrOi7MlnRNVwOXZgklZEpWmObTCNrBzJhNZZPphZH9oqYqcrCr5l//sb8jznJsP72m7jl9++SWjD7z/8I5xaBlDlWxWEgd6vphitObQihf+9avX+BDYrCXN5/NXryjKQhot3YHvvvseYzTPL86oypLZdMp2d+Ddux/JjOJyUTP0DT9+fGA+mzJfntH1nvuHNVpFVqsVKnjub96jrq959vwZzj3wcPuOsp4wm6/En985VAzkOJ7WOx7WW/KiICtKmsOO5rDj/PKaydkl0RfEEKjUDmthvVnzuF6fbIs+SOTt/cMDh8OB6CU2s28agvesN1u6fjgJ8tebDcYYrq6uKPKSzW6H9568rlBa84c/f0fbtrTbNUYrvvzyF5RVSUzqhR/fvBXo2tBjFCxrYXyprCBqy2G3Sw1GRQywbRryzLI6X9INI/2mwTOwaw4QY2pe6bSRjPixZ7Va8cVXX7HZbPjt77+hGxyHbuD8bMXr16/w48DQNkQlDU6UEkmwiuQKdPCEsae0M84XEwRmrxmjonFwcX7GclJy+7jh3c0Hnl1d8tUXn3P/9MR6u0HZEoxluVxSZoktEyNR5XgtKpg8zzgcDozjyOsXLyiKgj989z1d37OYzzhbzmm7hmH0TOqSPLPMl+cobXja7GhCe5LQf/nFl9T15KcuDf/ZHwI8dTw9raWRmJra0/lSFDDNAWMM2yJPdgWbelNiI11MxTc+q4qUENdxaA7c391SVjWrs8uTFFVpg7K5NETbRpRMxgrjqWuwWSayXpD4Ve8Yu46yLOWBnmJjrdEYIpOqQk+mrFZnTGdT/v7v/57vv/+ei/MVr55dnQDdk9mCvKhwo/A+6tlcirayRinD00ZSxS7PzyjLStLvtIAwvfNcnq0kHalpcd7TdgNKQVWU6YE2BxTb/Y4YA4tpTfCB7W6P1prlaiX2iVYSNF2UDee0lgZqNZnSNA2P93eUVclsUtENA7e3D9R1zbPnM5qm4eb2Bq0Uq+VSiq3gsSlJybsEsrYGo2KSwTvySU09qWTK9/ggVl0j9qFxDBS5bEPavme/31EkEOhm/cTj/S1BiV3x2Oxq2zZxlvJkhZWGrNgOA0M/yBDCeYyxrFZnGKPZ7XY451muVhhj2W4epbBCtuVlnqELnd5X4N27d1L0pKbO2fkFJgTC+ongVRoeBCZlgfMCz0Vb8mpC1B2DB+UjY9RoHxlce9pYay1Q0zLPWcxnOB+4u72lbVvWmw2Tuma1WoIyRJ2S0QbZDPR9R4yB+Wx+sooUVc1svqDtWrL9lrY5cNjvKOsJz56/YBhHntZblosF11dXiXPR0jQt4zjy8vkzFvMZ3SAbkXEY6NuG+uycoirlfIaBi7MleWb54e07urEjs4YqzzEpIID1Qyo6M5TS5EUpAyor8vzFdPKTi5//Uo5mlA1r0ztpLmQZRimMlMmyRmhNNwbGoHBKy8CpbQijo8wzFtOKF9dLxtGz3oqC827fU+WGs0mJjgETRlQAHxKfzGQQPASH1cKYakbH5tCeJPsgzRRRxOUMTpLXcmtTs8BjdGA+zZnVOR8fIpvDwHI+oa4K6rKUoJYg90TUiv0QsSqSZyptKjI2TU/XO6pMkRvF+eVMwhSMqERzLaqtjxsJNohKEQko32GV4vnZHKM1H5/2RBQXF2eAcIuid2RKYMQuKlEZDIOwSs+nEoKjYBg8u0ZSOqezOftDww/v3zGtK16/uMQHT9P20ggxhojBYcHk5EUJnacZoco080wzeOicWB6LwrI7dLy7bZjVOfO6OCk0900rloqUzXYKAVCaLmhKo4RJ6R0xOjbblq4fKOpa+GxGrpWtD/Qu0O9aUdom6+JqtZTN2mFP2wwspgVKGT48tXSDI4wjViteXK6oioy6kKb/vunxoWW3F4vQs8szvLEMYY/WUBhJbsqtwSixZVhj0NZi0gZ6HB1vPt6QW8usLk9DhlF5jPPMJjXPrs7Y7xve394nNRnUpeXsbIkC2sEzAn1UjGg80qgrtITRyBpcU1Ql28ct909blMmEr5hr6jxjc+g4PO54frni6nLF3cOap/UmOQQ0Z7VikonqrveRpu85tB1FVUFKizRKsZpPKYuMp31D2w28OJ9SlxmPO6m9QjxaX3qxx5oMHSOHtkcrOFvNyOzPxyq833UM48D68UnsPiiKPD/BlkEzDI5vv/+zNBqsdGhjAn9fXV9TTwrOrmcClPeah8dH/sM3/5GLy0v+6m//Gjc6DocGm1nmixVjP9IdeupywuXlJU3TcXt/R1VPmMxm5PmE+UxwFPvtlmpSUk4KbFZgbYG2hkjg/PyS88srPv/sFVeXF/yf/tv/jt998y1/9ctf8ze/ec7T0y1Nu+f1q1csFit2hzXrpweWixX5dUFlLSpGdrsN682GX1z8isVyyZefvyAzhmEkIWoUXdfx4d0Nw+gY+pEsU8xXV+R5zosXlygib999YHSR11++IsZIt5P06uXFkizP6AcZ5N3eP2KMYnE+E3B/ntEeem7e3yZ1c81us+cP33zPcrmgms7Z7xre/fAWm2c8f/kKYmB9d0+uFeF6RdNuuX24oZ5ULJdzmmbg7sMNF1fnLOZTbm5uuL15YDarWMznrJ/2bDZ7FrXYKh8PDY9Pj9TzGWfnFzw+rPnw5kOC9Vu0MmS25Ob2gfVmTZULl07PZJ04HAa225ZpPSHLDOv1Dq0NF9crtDnjsPfEoJhMZhir+cM//YG2afBpeHX18pysyIjB4p3nT998I7ayVniarz97iQ+Bp+0DWmum0wqFYbaYyrCuHYg6hcwMPYfdnrEf2ZUztNVgwJqMOp/is4FCFyyWCz7/8nMO+4b/+B/+nuZw4OnxkbOLc159/jl5lmN1iXMdTbvDBWGJGmM5v7gUCLvJWS1XPLt+Lmrw7QPdOLJvA9fPnvPX5ys+3txyf3vPs+fnrH79GZvHPYd9x37fMLrIs2crPp+/QIWC6DXORQ59z9IPEA3NocX7wK++/prppOYffvsNh0PDbJqxXBZErsWaPsqgpZ5OAcUwSCMYDKjI7LKiLP+/nGp3TJmwic2Q5xajINOQwEEy9RwkOjXg0/Rf0kMmUwGtjaP4Pst6whAV2b7DaINL0xWV4qP7QYr7oyfyOG0psjxdrJrMiFfxNFlLE3eTprUgiRvWaGyKpXWjWDXylEAAiV+htEjW3CiMRSWgOa2QKXrwAhhPUexGKUJAUjQS/yJiQUWqssAamUCjAtrKhBtt4ZhaEI5pMJ/UDzbP0dpyaA70/ZCmkEe/v6iDxnGUzZfRDK4kRMiLHJslz65WlHmOUhFjFelVoZRmvdvjnGc6nYqFLnU4c2so8vyTtzzKxDG3hj5NwGNM3Cc34kZRJOR5kVgFgUFxSl+K8Ti1F2XJcbqlnPBWtNYpGSKmqaoUjahRgOOpARRCwI8DeCcb8ZSwkNlMYLrBU40Vehhp+k42XLZIm6VRBrVpCnBMQprU8nNcYl5obVJCCqcpm03qOA10KWHpyNgB6UBPjfAGuk5SF0cf0C6kRL8gDI4QJV5Sm0+sHWPTVE7YYdbYpBbwWGupq1LYG0k9OAwOq4SfZmxqMDWHlF6XUdkclBa1VtdJOpSTpK+6KrFG0w8Du8MB58ekVpRp+ZCiN4N3kCaf+jTJ/Pkkq/gQTtNtpdWJrXNUtBxT47SWpqFLqY3aflIbWWvlGharNyAJXUf1R0j3p9SpkjiiTZouxCODK0050pp20itofboPtBFg8lGBZZRKzczES1LSVDmmwBljUnKHqLB8Ui8GH/A6oJ2DxM07MsWOKSohHvl5YsE4JqIBokqICG8jNTqPrzeCWLpOzCl1+nLpujFWgO2jk8aLMBREOSEJTAILzvMcm1SMKIVRco6ypK75pCwYiDFSVtWpsXR8RSdWUDzqhJIaKx5ZWu40XfVpGhVP17vBHXlC8krlw1XJLBkj6igVUCk9LSkGjyrKYwqpzTKMiSltLiQFj5UkzpNyKz0r9Cdm0ugcMSmkfOJfKX1MfTJJGevxUWycR/XxSTngHEEJm4ykilTqmGr3KQnxyG0rchmEDMOAmEtGQp7JLExJk8ynlNAjb0km1+MpSe8Ihj+mYxqt0bmoLyPyzBy67tToPV4DwgkYTrZRkziFzo9E/ylBr8iLVFY4+qHDJNXFeLQqakfkmKx1TEsUlcLPiZEC6d4B8syc2EdKQQyfci2FcxYkSc57SAwjFJRFUmyPKeFWfeLwkNZ6n35HiDB6UWVoRfpGQ2agsAoXI9b4xCFLPyBKKtyQnu9FmogfVaPW2hM82hgjrLGUYibMpnhSXesEDv+kLD2qL4/BBpKyFpLSxv8n14CRVJ7Eeosck+ki3SAqdZvWDeGPfGruFrk9KT2BE7t0dCGt2Ral0nqXlNpHVWRElOEhJLA/sgZlVhLblFL0g0z7yywjE7nLpxRldVRbBWL0p/UJOKVJjSmtLnJUOMk6mVtRlw/On/hX8l3He05q96gCLiBpgzEkOLxBmWTgS4qmqKEfJe1InZ4/wvXUSZ0oiVGBPq2nxyS9MSWEjd5jokbFgCaSWbkeXOIAOi9qLvncPik35X5WJ7tuDCG5DyT9T5gokSwpgn3ijIUQICkmg3N0xKSWkdfqndwfQ0oH9Mk2mATKhOR8qAtRjB2fay4p4Ux61sbEpvWpdivzXNRhqV6OSupc5wNWCzxdXBIyIBF7e1LGJUWaMkdFtCRRuXTP/lyOo+OlKHKyYClyaTQf06araNKzSp5hSuK4iN6jMNSTmqIUha8yiizLJfCiLDHWnBw3ws+S9LJjuJBO8h+p4bK0b0x2cALoiDJinzVak2U5RVlCiPRDT54XWC37EZeU03VVJQbkUalrhEmZwo2cczg3oEfFEDwqKWyms6kEdFhLiBLc4ryoeEIMRCXfp9NeGBzGSgplP0oqHCqiVMSnxE7hBEmdEGJgn4b2x1TbrusIPjuljocksOj6TvZOZSFJ7ynlTfhKJXU9QRPRwaONYbuRwKfpfEZVFpRFBdEQg6jqY3LwQOLamfzESSKpc9zgGPqBOqnry7LEqiND9FifJH5mJDHeYkIcyF5OKyW1qpOGpYmRvhfWUlnUaGUlGS6lRZo0lNCJT621wmY5wQa6/Pi5HjjWqT5hCEy6Row21GXFaKXuUUrR9QPD4LE2w5rUY0gqeHFIZYRQUJSCGBBGndSfaEU9qVFac9jvGWzOmPmU9KkZB8cuHBj64bSWxxgI0UutHuSZbpMiSmvhbuVZzmw2lb0mwoHq2kHs1Sc3gmXoR9wQTiwpm+UobZNjTZiho3MCudcmKbS22LwQxVmqKfpeVG3HPbHUqaJuHPRPW7x+euPJiHxrnotffnVxhU6NJudG9jvhorSHTXqQHWO8BVb68tVr+q7lh++/Yzqb8/kXv2DZdUzm9yiluLt/ENlgVUsS1/sPFJllUpUorRi9pygSPV6D1RCqHD+fEpUlaosfGtzQsihLVmfnrJ8e2W7WkmpVlzw8PPBw8wGrNZ+/fsXQ7Nn3LVU9pcpzNrstt31HVcuHOIwdmbUcDjLdu1gtyPNLVJCmyPu7B0YfqTKDthU+Jai8fHZFCJ4Pd0/0o2d+8Ywsz3DpIT+pNMM48uPHO3yITKdTidzMKwbnuPnhB7RSnC9mRBRP+46sFTvI4XBgaA84Y3nMa4zO+OLVc7QxJ7DcZy+fC1Nk6JhOai4uLri9f+Df/8M/cnV+zt/93T+n7zr2hz11JUqqpu3YNeL5nU0qJnXJpC6IoWJIhZ/vWzbrDdvtjqvra1arS3LlMTje397T9z3RyYRMFEOGfhxxwdONAUZRdkxqxXZ3YBhH8qLEGsP7mztCiPyzv/oNk7rit3/4Pfv9nrPKMq81zC/QVpLwtNFkVsBpz1+8oh9H/v53v8O5QLG4loSohz3WRMrpHKNAIYvodHFO2w98//adJElUVZI8WiIeYzSTSc1nL17QNA1KySL//sN7UJrV2QXz+Yxnz654/+Ejv/3979FZQVZUTAqf4McpTUdrJstzYrLtaVsQVEE3BnbNgeurKy4uLrm7veP7uxtev3jOF5+9Zr3Z8rjesN4d2DY9Syt+4KyosPWEp5s7NutHvvjqlywXKx4f7tns99zc3NAkRcd8seDV9QWZtbx5/5GuH1gslxhr6ZxIMB/TOc/FQ8F0Knyex/Uas9v/1KXhP/tjGOWhsViuMMZQlRURGMYBYqSuBLpu8kLYQOtHtDHUkxnW5kznluA9290em2XUdU2eF1xcXqfN9HhSihhrsUESkmbTKf0wcGg6ykKYc8bm8vAbR5oodlelC7H9KU2Wy4O/61q6rhfWhNZiNe07isxydXkhyisXqEpJTGnalmG/P1mVtvsDSkGRZWijKTJLmc9OQMr7x0eGcUxNCoXrGmKMVLVYSt0oKWOdFzvVqThTkTEG7p62YtPQilzJJD4GaEeR9p5NJwx9z4e7mySXF4BsUdXECA+Pa7Is49mLlxzDJqzNOFstTw0eay15UdB1He/fvaeaTHjx6jMB//e9FDsxPQyHgagUWVmRWuXEYUxxvQE3dNLcJjUWveP8+jmz5Yqnxwf2+50oZ1KRKkEasqEjqTaruhYblx/wBGxmUEaz3W2JEZ4/e0ae57x/95ZhHHj+7DlZlvH0+Jjg47I5UcZiteHismAcR96+f0ffDxRZJlyLtpVEz9Qgwssmt4qRfhi5v71JzEBhhDUHKZ4UgbKsWJydS1PJi7R+u9+nxlxkMplwfX3NdrPm5uajhEw4x2Q6Y7k6T81LCdsg2UKCkCfxbmC/P9CPnrOzJcvlkqeHW9aPd1xdP2e1OqdpGnbbLY/3d2zWT6zOL5hOZ3g3st9teXp8pG1bJvM50/mcrKhk2NT1eDfSDQNRaS4vLoghcHPzUWwYR0t8gsXbYUwWwSOEWtbp+6f1/9/Wmf9fHRFpfixm01REij2/6xMQNDV8nEusEy9Ng+gkROPifAkxcHt3hzGaoiik8iulaXIYxdYYtaEP0HZO7Gw64QFsTpFpSePqB/Ksp/eR3gnzQwXHoRl58pGrswUXixm7/Y79viHLC4qi5NCPrJsDZT3h88mCOHbp+vS4MbI7tPTjyDzVQr1PkdDdgLWOvMgoioxKSzPjbtcw+siiKkQhooRtdL6UDcWu6RnHwOClGfDnmw1FnvH1i3OCD/zuu/eMzjGblJRFzvXFBS5E3j9IsujlqmR0nrePO4o849XlCrQU359UNIrz5YJIYL1Zk2U5L64uBC7bdVKvzkvarufD7Y6isLy8nDH0PX17IDMZVZ6njbCnMJFpDkZ5hnFAo6jyjPEIKzdpaGcsWFhOK5aTgnf3Wx53DWeTnEkugHGrLQ6xvw5pqNB5hYuKMMh6ls0EtN6mGPNZbtBo3j7s6Z3ncl6zrDIikryWFYLDcGOfwg2kUeJCxMfAencQHt+hJ7Oa6HuM1swmOS4qBi9BKpumJXqH0SE1dmQ+OaLIlDRscE4gxVvPphmx1lAUFbXVwk1tBx42bbJTj8wqy/k0p+s8T30gs5bVrKZp4BCFAXf3tKMbRrRRTKqMSVUx9j3d0HO5WrCcTXjaHnh6XNP2Hqcy6jynyi1YTa813ottcLWYo5eK4AZiGIVJhGGzbzBaMalyJnXG077H+xbvByBSFrKO9b2gKfISsYAh9p7HXcPPia8ZvDQGXr54SVkUvHj2AqU1+36Q58ooqYhPT3d45xjakUjA6YG6nvL82RXBOTZPO+pJzeL5AluW5JMSPzq2j0/YvKSsF/R9x+PDmqLImdQ1/dCy2+6oJ1Oev7xOIHhLdwh0/R6VWfJFRZGXFHnBYrlksVxy8+ED9/e3LOYrptMZdzd3bNdr5tMpf/e3f0OMis1+T1SGvJxwe3/Ph5tbypQe2d/fgIpkRjhwL169pCorsrxAofj4UfZKeZaDgs3+CR88Z+dn8vc3j+zdwAxNN2r2b54wRjGrShSRDx8eISqWyzMZIkbPcGh49/4jeZ7z5eefMQwD333/I3lueX59TRgjOircMHJ7tyXLLL/5zddktqCwFXqu+ezrl1iVU+g5k2nJ6nzGzcdb/vEfvmF1seK/+hf/QoZ4fUIMZJaxE9VQVVguL6cUxYS8qKmrET+MKCKHQ8dh33LYNcxnS3Isrz//gsViwZ//9C0fP8oz3hqL1paqmhKDBGvtdlts05BpmNYlTdvR+ZbpbErE8PHHB0II/Df/zf+W+WzO//Tv/nu22w1f//JrquqSw24QRqn3jAMslkustazmM9q2Y7f7LaNzbA/7k92wKHJsbiiLgvlszugGnjI4NB3v392j0KyW12SZISsyvHd0bU9dFlxczGi7Ao/GuYH372/wwWOKjOvLM66fXfL+zUd+9w9/QBtLlhdcXV3y2Wcv2W42PD2+E2u8Bo8H5dgftjyu79lud7SHgecvLrl6dsbd3YbvvnvHF1++5Je/+gW3N3c83K65/bhhvdlxfjFjOq1EwXsYuXu4o2kblvM5V+crdCbuLue2dE3Pm3fvqSYlr168Js8LvvnjP3FoDpyfX2FtxtPjkzTQ1QFQWDzEQJ1nhBh4/Lj5C3v+/+fjJzeeZrOZdA/9kKj/gRDVaSIV4tFbLxNTY1NKnZNJ6XHaQFLFOC9TNq2VJJL0vagMjMW5MXX6At67E1tDaUOlRWrcDB1d8pOWZUFR1vQN9MjUeN+IHHy5WGBsfmJZRG2oCin+t2OHc1rYF27E2IxCC51fm0TZzzK8lweX8w7tNW0jKhenxDPpQyQQ5IEcAjo3RLEUp6kWZEkKroloi3T3jaRNxZgmXEdUQwRUPDGtJGxDNh0u8bCiSukHSmNsRggCpbXGUpdVIvmP9MNI03aMicKvjv59N3I4NBAjmdVJBhwZvWcYR8pYoI2lridEk6NiOFkwrDUM/cB2u+V8MaGqJ5TlgbIT4HdVlnRO5LLWWkwUvojYkRwO8fnKFEKmsWVRiHJqGFBE+n4QvlQmE5FcCX8reo9HJuqyOc3lnOQ53srkAxWEH6E+pRxmuUxYxPs7pmtYJhkK+V5lRe5pjViQhr5PLANFVMekKZna+ZRwBcIOmNYVmf7LNBoByGVW1A0kxczu0Mim8DjRRCbD4zDS9d2JvxKSv31SHSeGSjbawZNnlrIs0chmMMRPih6biac7MxrnEu8mhiQ+E5VFnmVYrVEml/u3bwkqpKmuTGntzwjQW5QlwMlK5YNP0w5R41gjkmgSF02+XyafgZhA05qyrMS/ntQmxwSzEJLCKU1G1fF3JSVOOF0rsgkK45ik5jJly4rixCQJwdO2B3ndeeIqxaS4icLlmk6mjElpeGR9ARylHpJMlZ3W6RMXSUHbtAK7D5J0dgxaiGmyPiRIsyhBzQk0f+R4ZPrIz5DXc5zgHmNUj1yzUypVUoX51DwRLkIa6ipQRlIWW9lFy5/HT5ypMfHgjs2ozFppPI3jiRsYokyUxV4jyZaZEV5QVcrUyIeANoZCG4LrJQksRmziAhibUeQ5RVEIdyqpv7RScpPGeLrntbboXGPzLDEh/Gny7hLLYBxlekRSswl/QJqCbnR45SkK+f+TepJ+rib6kJSQJkHMRX10SiI9svmOas70HDjykYwRy5z3Lp3reFJuxb8Mqkw2mywT5WZmrSic4icmiqgOju9L7HH/qWJGuD4C6Y/CXvFerHBJSWjtp4QYokwfbWJfKEW6B9O1oyXdVgDvYm+MxNPUTliJkliV5Xm6X8LpNYJwEjneDz+TI7c68QFtUkDHE79JI6qZo0pVqEIx8UyEudSP0kjK0n3tvEzbRxeSEhcCnJgWSomyLtOaiNiVtLJkJuAjgIYoyjKjNYUx+MExeMcwevbdACjqMhOFrzEJTBtPivnOK5xLevikiopwYsoVuU1rCEmJLJvzdhwl7dgLyuGoFB2dJC0bifoTpqbW8uwMKRMpBklYCzHx1hInBZUYbnKrG61Odk1rNBrox3BKmAP+E3WOioqQOGsurZPHtb7pB0lzC54silI+Ar2L5Bpy/SmxU5ZvhTWSCuy91BL0ER+Sct8YOh8TV4NPSjBrpS7ILR3+FAYjCm45p61zeB8prMFqk9hDGhVCUonr48ouqgPv8Yp0DytJalbg0+/3Xl5zVebp3lQEoMiE99eP7pTwqknpoIntFTQQzSlNWJ2UbxKN7p0XNZfgvqVuPq03x1I5YoxCayvvRR3/Vi4Lm1QOx+fd4AJKSa2ZWXm29lGUWs7LtRHTOc2sTroxSUa1pz0Ep3pRKxgTo0gpczpHR4ZmTOooH2NKJz4mf4r6OMRPyZJGa6KKiZ/z82k8TefTpNJW2MzKQFYpxmEUJXiQ8CitDWSyDrgggyWxOLWoiHBllKLv+/Rss/jRMYw9UWmsk9CUo/riyDPs+4GiEueBH0ea7oB3DmMtZV1TTicY0VnSdx2Pj48ALJcrirxISddyH5VlCRH2h4au6wnRyyYvGTtMSjfOsgxtIHjZO3gnA6xDsznVUbI/ln1fTPe+8w4V5ZozWpFlomrs/UCIimOEWkjp08PQE4Io3r33CBs0JYJnRgaqSjP0AwRhQSmnGLoeo4SpFENku9mARhQw0eD9SNfBdouwm5Jbw9oMNzjatifLDTnhpPIahpG+G8iyIEqhusKmemwcHcZq6knFOA6sn544O1uS5Za8yCmLkrosqeqCputQgxIlWlJFZ9ayb/Z0vSSBZ1lOkRcYa5hManwI9H3LTkXarqcfRrp+xBh3UjtFJUqqrh8wKXHUe898PsOn9PMQoiAvrJXGv1bYQs7RkJR1WZbJeTYKZVRSRllqNcEay36/Z3QBbRQGQxZzbIxkMZDbHBXlmXNMJp9MpxQpKOWUTmplj+ZCxHtR+683G/pelG8hcZuHXgK12ralbVqGfhQFVJEzm07Jbc6RGBeJ2MxShOzkJhi9xwWpg6Vey8jz7PRe3fgpKVhcCBalFXU5BaUYmn1S1Uti46Se/ORgl5/cePqrr3+F8yObp3vGYWC/2eKCZ0iQwn6Q4jHPCrLMsphM6PqBDzcP0kTwkUxHJmWFUZq7pzXBjYx9h3Py70VuGjBGUeQGoqdp9wxB0TnN2cIzrXJuH+548+4Dk+mU2WzG5WrBF69fiaLp8YGPD2v+/O6Of/7Xv+Kvf/ElH2/veXhaU9Yz8swwSzDZd36QZkd3oHMDly+/ZLI4Y2wPBD/y8uqCSV3y5t07docDj+sNKM2bj/f0veOvf/kl82nJYS9snWb7iPeOfTmRhhDCRZjbgFID7zZbfIgsF3OUNkzmC4G2NTuk+JYLtigLDGDTojYtRH652e3RxvDi9Wc459ju92mDYGm6A+8/3jKpS55fntP1Hev1E0/rDR9u7inLgmeXl+TGsF0/cvvwyPfvPjAtMxZ1QT6ZUUyX7JqG+8cHTFGwzCuenV8zm87485+/4Yfv/8x0MmV+cca7Dx/5458e+Tf/6n/D519+yRBkkXhxfc3Zcs7hzUc2bc+8KgWKHo5Mpo/s9geeP79iOqkpywJjDKvlkhgjN3d3tE3LeiO2wCfjyZziwji0iozNnh7Fw9MGH4J4tjPL8+VEJikugB8lsUcFmq4lzwsWizPatuWP3/4RrTUXF5eMo+Ph/lGmfyqjKguWyyXb/YF//MMfKDLL2Uw4CVU1lQVuHOi7lndv33NoGqZVycX5itevXrLbH3h82kgjNQRyraiLTPgjNme33XF7e0fwAyYGcA43jIy9xI++//Ceu/sbJtMFRT3h8uKMIstEzTKOxKHFRc/l2ZKLswVdc2B9u2XAgrHMl2dMphOuzldM64q3H25o+4F6tmA+mbCYCRcjeolbncxXhBD59ts/0rYteVGRWcuz8+XJqvpzOK6unhOC57DfMY4Dm/VTsl3JxivPJRY6eCkunj9/yTAO3N3e0vc9+/2e5XLJr774kqY58PbtW4yWKN9j01prQ1VLeohWJkWtin2363uJ8i5yxrETqWoM2LxguZhztloyjBJocH9/y9PjPS9evOL62XP6vmMcRoyS5sDZ6oy4XLHZ7Wi77tQYMlqTGZUsqZbz8wuqquL+/p6mbRi6DueFOxVj5Or5K+rpLA0Cjg0Dx9N6TQyB6WJFnufMp8L6enja4L2XVKgocN+gNTpZUoahQyuZRgv7ReDnq9UZMYQTfLIoyuSJC8kuG2mahtsP4vefT6fJaiFNXBfiiRFVlgWZhm3Xcn9/S13VzGYzYe81DTHZdaapoJzPJV3zKak0J3VFXRXc3t6w3u85GweInjzLqeopy+VKkmP6ju6wp6wnYgdLjYyPHz9yaBuur55R15JSpIC8GHDe0xz2ovptO0bveVhvpUjKLFlmmExnRCK3Hz/gg2e5XFDkOV988QXEKAkrzqH0ihgC++1G7M3DyOAc610jzIfrSyKSGBaj2FWKomS1WtF1Hff3d1hrmU4nHDkazkswiAuRfUqNm04mFFXFdLqgH3qaVOQfrSVaKwJDGkb0NAexTVSZwcRAGDvZpBUl/eB4Wm9x40BwI9PplOl0grVZgpbLjmwxn5+s1G4caLo9LgTqqqYoK2azGUVR8ObtWw6HA1Zr6rqmKgopDlOVX9U1KMVus07JeiPGWF6+eCmKnp/RsZpImm1RFcQIh0NL9J4sSgM8KwvGENm00jQubLJSYxic5+52zawu+OrZSr6vcQyjo2kHSeqpc0nDDYrMiLIpsxlFXrDd77l/2lAVGX1d4oOkFY9eLBRlXXE2n2B2DWHX8rTv+PDU8svncz5/fsGmC+z7SG0zGVyGER08XVR0XlNZQ24Ny2V5srbFGHm2mjApLQ+bhrYf2XU9/eg5bLcE77hYzqgKsZ5rbXjaPzEMI1FJg+JsOsGUhkwXqQEkfJnHrShKFtMjT0PsotudqAZrIxatqsgorCFMC0Yfedwe0tDNEpUCJeiGGEaUNtgUs/24kURLYw27w0DzuMcaTWn1STnYD4GnNjBTmqLK8cHjvGPwisEbzuoZzy9XjGOPGweedg3x4KnLjKoo+LhuabqBYZRN7KQsMSbnap4zLw03m46xGfFBkntXs5qyyNi+e6RvO14/P2M5LWldwMWIRqw3hwRmz63BKmjank7Baj5FW4PV0pbqxsAwBoYgirrPnl9itGa73eOcIltU+BB43Mnw92xeJ36gpOVNckWIhn6UQBVtkuVde/p+5Gm9oypyLpaz1FD10oBSQAyMY4AQqDJFWWRM6iJ9FkE2ezh5FmrZYAad0XvN0HpW85rlbMIxIXNwkX07onYdjVcURlGXFUXhCdGz3TXs24E8W5KZHG1kKKL9CN6z3+9p+5HzxSRxzmTQsml6BpcatcZwdT6nsIZdN+B8IEvpikVi1wXxA3KxnEgA0c/k+PVf/xrvHNunHV3X8f0PP+C9DG8ELyINBlMUlLlltZrSHBp23x7YdS27p29ZLub88usvGd3Izcd36X4r6PqB7WGH7Xv6hJeYTCu88xwOB/aHA0/bHUU1J89q7p5uePfmDXlhmc8XPHv2jBcvXvC0eeJp/cQP37/h7Zv3/Ot/86/5r//Vv+bh4ZbN5gmbC9vnvDxDo/j+hx/YHTbEtGmvJrVYAG2BNRnXz8+o65Kbj48cDi0Pj3tGt+bNmx/o+55/9a//FZdnFzw93TH0oww+8Tw+Pp2A6nWWcX4mtdDH2w7RbGTE6AlqZAwjj489mbEsFlO0ViwXM/I8w1hFXlT86quvadqG9+/ekuUlV9cvGQeHetDpnrOst2v+9KfvWMyXfPHF17hxYNvc0/Udu/2eelKzulhSTWrGMfC0PkjKeqGoKo3WGVpnPD5teLh74PXrkotzy8XZM6aTmh/evOft+49M5hPOr2Z8+6cf+P0ffs9kVnF5fcZ8OsVcKZ69vGC+mNINHbt2T1ULGP1seUae5fzw9kdub2/5za9+w9nqDJtVaGN49uyaGD1v3nzLfr9ns2txTvH+wxNF2fLs6oKiEPtzCIEPH+7FrqY9eZHxm1//ApTiw+1HhsHx6tlLfPA8rB/JbMbV0tD1Pbd3G7Q2PLu+xAfHdrcmKovOJOn6bLFkt93yu9/9nrwoWCUu8+T8DALEFMC2vd+Bg+vra87Pz/js9UsOTct2t0WryHRaMaknTCdzDk3D/tCwXW+5u3sg0zJ42B+29H7PZt1w2Hf8+IPj/vaOLNn/Xjy/pqxrNo9PdE0ja50OXJyv0PqccRSXwGb9RNt1RCJFVfLs+TXTWc2f//gDu21yTBQ1i8VcGnK5oEg++/xLtDL87ne/Zbfd0XR7sszy13/7SyZ1/ZPWhZ8OF18/MjrH48MTIXgKI1NlUYKE5N9XCRAoiVrjafKZsZxNCX6kb3bkNlJnFk/AKw2IsumoeDJGOorBJR9/OHr6/Sk2uSyKZPUbaduW3W5P2wnI1DlhGRwOB+4fn2jblhg8/RAYnZD3nXP0KYmtqmqMroko2q7D9z0ERz+OZKMkuWV5QWYljtVaK9Oe4PFupB8GxmEkKAUmxaIrTdSJVp/OYUzqLYJDK0OVW/HJKtkgNI1sCo/e5EPbSUpcXp4k9kqpT5MxK/7MQ9vSD+PJj35MrtLG4INwMUIbcG4gt5Yqz3GjY1aVwn/Ic0JEpgsoZpOJpDH0Hb6qkGQYWaiEAeHJ8pzpbEZVlRQpic5oy6HrieudeGWVpMBIVoN09bPMUJY5eZrqH5NJXFKBjMkrTQzJ5kaahAon6dB2iTcmX+v1mswaJoUkWkhKxkg3OpTSFM5jbEhTBJmIG2OoiwJnDOO0xmglnuMscR68F1WU1mBzgjKS2JRlrCZL9oeG+/sniZA3Umgck2DiMVHLOeGcDAOFNuTHayFNAVyIjF6+lNEURXbaoBZlQVWUOBcYhhZNIDearuvo2o68qtCZFb9x30NWorRMSaO3+BDphlE8v0qfFFOHtkF3iixN3rKhl829D/gg6g9rhHlz5HH9HI6mEdvY4bAnpMQQJXILsT8lNcx0MiHLs5Q0JmoxrRWT6RSbZey2W4ZxEHsa6gT2Fk6bNFO0MShLSuFIKUf+U3IkkaQACid47PHvQmJ7iH1mTB59T0SSNiOckojGUXhdeZ6RZxndIUoKJjJJHUdRph4Vozazwjbre2H9pEL9mFBqtEFliiIvRH2jjpPj4+qVeAJG+EH1ZJIElzLBH4YRrRVVWaGUFgVCSqeKWqHQSXXjRRGWWBrNfifJUEYlW4+R95lYR0Pi0hybVQZRqpV5fkolPH7p9GA21ooi9Pja03t13jEMMr2ryjKxu2T6k3lP18v5Hgax0RxT8nRKjBFVQX5q9h1hHEd+1TFtSmnhD4hS12OMQOtd+iyOHLWu7fDeU9fT07oeEu8gBvH2KwVFWaGdJx+kKDVZJs2/PKkkFGmCKmtXPwyc2D8h4oPYJWfTqVhCO4k/j+qYaPfJ2uidpOxpY0EJg45cFDAhxpN6r+u7pH7wSaUkn11woi6R9dydzq9zwiY8KgJd4roodVRtiDW/beUZHpNS45g2NrpR1A42R+uUPklKDPT+pPAbh474n0i7/ss/BifMijG0J6aHVhrn9UmlGNFMS2E7ntSIaXI+qTJya2gHlxhnLjE5kOs2KT/1MWXXe6LWqOjhLybyJKWi0YqRI9siJiWQKLLGMKKS6nxIlu7gEwdCKUkBSmtYSCymE1fHi3IX+Is1UTgShRWl1JhZHPH03Gr7EaX9KckO5H9DlBQ+m5QwVvt0T4hKrCqytJ6JNa/pO4hR+FExsGt6hBMiqi/ljumAyRemDc55+tHLoNRKUlZZ5GmAKicrRFGYddFJsEw34qMwb4wRNaPzXlTOKXEqqk8MGGE7qVTLiepdK6gyS5WLwmkMCpRndIFtK5zJeLoGEidp+KSkMEbuZ60VOqUwSZKYpCfqpMZ3UZSwR9VA0w2yhiduj0/T8HH0kgyc1mGfros0wD8pJPVJvXgkvya1m+Gk5hqUZ/SRLIBSBtHiiQogKySyvOv6pJ5Nis9UI6JSimb4lPWojWVSGXFnRLmu2q478VV98EkhblLCtSiUxjRQP6ZKOR8k0TvdkzZ6dBReVCLTgRJ1IcmlkFuNkvgoBvefKu7g6DzwSbEu9+sxHfrncjw+SBjE+mGT1ukCa1NSIsI4yvOM5XIhNcHoCS6IcshqqqqmKHK2e2kM28RIjYlLqpUMwsbEM8y8k1CRYZRU2fCJ8yhKnBpJt5brqGmEqRMTL8z7wH5/4OHhka7tIcLQ9wx9jwoiDW27FufdKaSnGzxt2xNyRZYJ2iEbfVrLVEqhi5+er0HStbuuk4TxpDLWRjxWwgmV60MnBWQyLYjlerFIymMLIZ7ee1kV2MzS9yPWxpSollGUEnLlkooYJeerfWpomgabiULKGCVZEl7qy6ZtEqsyKdR8pO9bijIjy2Rd8E7URlopptMpxsi+cSwszhtidBw5buMAWZYxm82YTGqqsqQtCoZi5NC09G4Q/IMxKGWkZkyqzSzLKcv6FN4kqXAGH8dUY0tYvDCfwQdhbUnQmGHfHPDuUx252e3JOsPV1WVin2YYDU3XiDXPRLCSkhsV1HUt+8ZpLTWciqKgryYnFVTwgbZtRTUsmke5vrOM6bRmu9ny8LCnH4X3ZI48V9XiXArncsL17awwTfM8+4u0bRiDhwGiBqMtVSlA77ywwm9VmkOzZ98e0CiKqmQcHYMbxEJojDSeXKr90zpq0/5SKUFe1HV9YjTud3u61KCy1tA18h6PgWJ5JgMgN4z0uv9J68JPbjz9T//zv2McHTcPayZVyf/uX/4NZVnSq5zBeTwHqrLgi89e0jQNf/jDNzjvyYqc89WSv/urX3L/+Mi/+/c3rHTG16s5fdfxMPZpo96TlRX1fCERwNHjXUvft8e2B2Pfs9vtKbKczz97zWaz4fFpzRs38rh+InhH9J6hHykMfPf9D3z33Q9cni1ZLWZsd1sObcOhj/QuopHksc+++IKL83N+/+33vLt5g40OqwSgOplMyIqaWTWj1KDSlKQbBrzr2e16njYN4+iZTivyzIiXVymGtHEIUoGgfScQZ1eSq4zZpBb5W3nNoWv5x9//HmLk6myJC543t4+URcHnr19hrUKR47woBJSWRXm72/Pu4w1WKxaTkmldMa2lUdUNEoE5dB33D4/cfnxPXU9YLlZcnS/5m68+I+gMZ3IeHx+5vfnIxdkZn335FU174OnuBh09WdoUlfVMQNXtjrPzCz7/8he8eP6MWSWWRK0M3775yK5tOZ9NqMuMrj2wd44swdzPVnMuVjPyXOIdrZbG4+3jA23bMzqBzFodMer4BXklfIG3798yjo7rqytUCPzpD38ApHlTViVWG7p+4GZzkM3UPDFqxpZKKz5/9VoWkFKiNS+XMwSLJxae9rA/bX7yokRVCwYntsKXz675m7/6DX/69s/8wz/8lqwoqGcLlJYNvh8H3NAzDh19go53Xc/ZCmZ1RVnkhNmM9XbLvukph0A+OPKy5PJ8xaSuKYuCaiLsk99982fefbzhl68uuV5N+dP377h/2nL27AXVdMb+acfQNywXC8qyZLVYYLRhc9jjdy2vri+oyoLtvqEfBn788Q39MLBaTMnzjPLQEoFdI2lYq7rGGsP6Z8R3Avjuz9/gfaBpGvK84MsvvxSZfSsNqX50FGXJV199xTiOfHj/lr7vcWNPVU948eIVu92Of/qn31JVFc+fPReu3X73yWrsPcGP5HlBPZkQkY1617W4ccCNAvc11lIUJdvthsNBJgVZXoitIUmotc1SIsVH6slEHtDpeto3DX3fp+JUcb6cs1oseLq7ZbfbYbI+xaZK6MDQ98TgWZ2dk+c5j1qSKaIfGFpP00nz8ezsTKD5VXUqzmMQSDmpMaC0Ik/FzHRaJ5uGp2kb/vTtn1FaM5kuRImybwSsaVJkelXhxpGu3cp0u6zoDgfev39HnucslwuBcE4mDOPIvmnFUr3fpybzMcrbspjPeHF9JcXjIE0KjaIuSyZ1TdAGr61sQPoOP/YE17HfDWxRzCY1LxYLVqtz6ulM7LhEPn74wHazZTqpKfKcpmkIITKdz8mLgtl8wWQ6w1opBkj2LpegjIOL+CCx9dEaCQXAUxcCr19vt6IaKwq8t9zc3aXBTCnSZ+cYnZcBRGpQlWXF5bOXwgOp11IY5DLcyfJC7HDayGClbWibA/tDQ502lM5JAblarfjis9c8PD7y/fffJWu8ZvQx2ZYVdT2h2e9o2wNZWWOynKoSAGnXtfSd2Nu7vufQNGhgOp8zqadMJzVVXbEJI4ehY7t5Yr/f8cVXv6SeTLl5/5bddo22GdrYBIfNhAGkJKhCG837d28Zx5GzszPms2my3HmeHh+ERTVfYW1OPwhsU+KtIxfnZxituLv5cIKo/1yOu60wdZqmocwzfvXVS4zW7KJArZ/WOyZlzq8/f44LgQ8PO7GnBs8kz/j86pxDN/LubovVMC+lWZxlBkKgO+zIi4pqviCMI313QHlHiUN5sRwcbURH+5I01SNN59BaBmSzWY3WLSZ6+sHx4akR5mNw2KxA24y2k9SmdpBADqPEmvWwOXDoBqoUenJoW7zT8hz1gYvFnCzLqI0o/ZrBCUC1GUApZmUhASlI06H34GKkLsRGfWyEFypiMy3cT2MwtqDrRx7eiqJpXmf048iPb2+p8owvr5eYDMY4EKNYxmRzmLEPPY+7njIPFEVBVebMJzXdMLDe7vFBYTMp0De7ln02smsHZnXJ8/MF4zjQ93u63tH0I2VZUlUVPsL6IHXEOHaSEJqV7NuWvtszn0x4dTblxdmE80VFse85tCNv7nc87FtmhaXMNAaPIrDdHVJjJlJXmSALjoBxBW6UZnvXdYQYqesZOssImdi489Kige9vNozOc16LImocPMMQuHvciLVZSRNy00jjO08hQEYriJFS9owUKbRjYiWB2KgoNuq8wHlFFw0masYU/e2CYlIWvHp2wd3jhtuHJ4kILwog0vWDgJ5NxuAdh3ZM3E7NYjbhcjah64Uft9vueHi4Y0hBMGeLCYtZzWpWM68rtm3HoevZNz1dP4pCaprztN3TbqQuUkoxyQWOH6JCpeS7GBU36z2j87y6WlAXOWDwUXGzE9dHaSQoprSGAGyaBuc9WhKNuN80p0H1z+H4v//3/4M0nh53zOZz/vf/x/8DWW55XN+KUnnTUFcT/uY3v6ZtGv7x7/+Bvh+YlBOWqwV//bd/xd39A//23/4/mc+n/PpXX+GGgd1mjQ6BKp/igqPrOhEcOC9pt93I6B0aqbuaw46qKvnqF1/z8cN73rx5wziMbDbrNBzJ0BiqoubND2+5vbnjxfMrLs7PWG8e2e23HPYdbTuClqH4l1+85tn1Ff/zv/8t797eMJnPKMoCrGFSV7hBRBLzmQSi+OGStu1l3+s9d/cPDENPVUpy8GRapyZPL0P3ZGWdFDLkMzqQ5Rm/fvEbsjynrmt22z3/4//471AKLl9cQoT7uz15nnFVVNii5Nnzl/R9z/pJRCMBeW7++U8/UNUlz19cMptOqGtok4XbjSPbZsd688jb7wfKsmI6m3P57JzPvnxBCArvNE8P9zze33FxfsXnrz6n7Rsenu7ohx1tV0qjKoP20LHuHGdnF7z+7BVfffEF15dXjKNnCJ5vvv2Wm9tbrq+umE+nxKgII3SHHmcdq8UldbnAZDmtG6iyCdYaHm4eklK7oC4smRHLZdM3eO8oC7Egf/fdE8Mw8OLZFUHDP715Lw2tvGQ6mbCcLYljy49vviHEyLOXz8gmFauzhQw1M7HsTicTjDLkvCYAQ5DAlG6/pW1aNruGqC1KGdzoWbcbrq/O+fyr5/zpjx0/vnmPyUS97IM0J50b6No9fe/pOuElrncN8/mE5WpG2VeMXeBpveVpt6WMBSUFi3rB7KyiWhQUE8vYecbe8/f/+I/88PYt/+Zf/Ru++vJL/vTNt9zf31PV0pgkIJY/LUOAqpKh3bs374kRfvn110wnU+7vHzgcGv74hz8xDAOfffGKqqr48+7PeOe5vbsjxMCzqyuyzHLz/u5kF/xfO35y48loRTSaqsioyhxjM6LS7JuGEKDK5YF2e38vKgyCRCFXFXme0zYtXdvjUmdZRSmMx1GSMYzNJJrPj6ei3lrLYrEUdkfidujErXCj8C9kcYemG5iU4pm0bY/NBkmjc8I2InnrJaFJFB76WER5TzcMGKOpygLlFSoxpsbUNDGnKb4/eR6btiMG/xdJOjLBm9QSb/zYCfzQJXJ/07Z45yiyHF8U0iUMEnE7jo7lfC48jajwUUk3VBvafsDajKKoUM5x6AeCc/S9LGKSbmKZVBVZnjMG8Ig6wWaQR4HKnp2dURUF00klhWvbY3KFNUXqyk4x2tB0Pd3gGLxMBoaxJwaHUZHMSFJhdCNds2e/3bDJNYemoeklsciPAzFKjHueiUd3DDKdnqbUthhlY973fZo0GooiFw4YgUmdQJZRJowxpdPEKOe4nlRopbg4WyUptvDEopImQJ4Xwr5JqVP9IA0ooyRt5ch2OqpImr4heId3AzEG8lwm9cLKEq/5drfj7v6eQ9NISkdZiMooxqS463AhkBclZT0heLn+yjyjqmraTgDUSkFV5BADXdtSZoqiqiTdK3F1rLVUZc6krqSzn/zH83lINgDNmGcoRKHS96JmUzYBYZPyLvIXDIijsq3rGUdHVQusNiSblXcjCk78lJ/LcZzS53mekkNkPRid3JdFUsHttlv8KRkso6zqdM5kMnpUNhljUnqJB1Ri9xiiEd7aUdUhrJICNRN14nE0G4nJ413KutAcyBKA22aZ8CesJKZola7/eAQ9yyT2+Mb6YTxZ7sqylG2XkomZVpKqRtQycRpHSUZEnZhBx6Q872SSXlhLNJpDc0zqE17LMIitq+86QuaEwaJVapgFZslCNfRdUjZIM8fFSNAGbY8JRMKfkRQjmeBZa5Kl7TiVE37LMckUpUV1mrzvOqlDRR3EKbVG3ofDq4DHoYxIyoV5JemSUclmanSSRNN3HYfmwGG/Zxzk3pdUI49OKsXROUJSVAlzSVSNx0NrQ5YpBifnKK9qUf2Ow0nZdlQjHfkOxmjqSiD33onN4vjIVko2tyrxX4ZhEJVvWmtEkSbXdEjNB2EJCq8qSz8/HN+Lc/Rdz263ZRwGiqLA+yBJnAlUfUwjVVqRlzV5WVKkZ1Se57hxoE3P5Epr/DieWBt5KWutT3yqsixPk+Usy9BabNhFWaJNJoowLZqHGMWOIu9eYYywIU+8NC3r9ZFX1Xcdoxmp6zp9PjpxrD4pLH5WOzdEORG0wuWS6KuS8qztxOJZ5sJJPHQDIUqipNKa6OVZIFqKlDClZYIefJB7Hom7FquxTyzGxPVKTec8z0RxE4WBpFIyUV3Jxn/f9Ezrgiq3SbnyKXUzqiNzJQifMUY8co1bnVg4IWC1orCWkNQI/YCsW+lD7YZRsA4JJBqisEFFSJU+eKWYVQVaKw6d3GsqrYdHC19AuCujk5Q3NfaMzlMW2UktOHpRHIq13iduCsJrCUnFEjnxSknNrpgUSd75xJ6D3IOOFh0LyiJjWpfp9Q2SQonUkkVmMcdUVR9o+x68O3G8tJIEO11kWKOI0dMNjn070LQDTecIIWK1fF9hDUEjDelRVEBWy102ek87OoLSKUn6WCNI2mlVSA3SdceUTUVUpNpLmE5GKxxSl/h0vtBJ7XTaeyQVZ1rP8yxxNRP8XstHiYoRawLKSPrhkQMmamRpnrddz3p3oO2H1DCUhEJJvRzROqCM/K7ciMokz0UVVuWZ8EIT108bLUmlCvLcMikLiHLOYxSrZWbNKUHKGkNdFhijRWEZRJkm6rcRkPOrfUhhIfq0toWk2ohBhuK9j2gtDdy/ZNShQCeuKz+j2stYUQdXdSFDjMSJ6doB5x1VVaKV4t27d6KqIZIXGdPZnHpa0Q89/dCnWguKokg1+SeFpNQRKZUYLa6BVOvOopKwgr7jmNSqtWI2q1Eo2qZjvsiZTCdMplOmTUeWGWwma9iRJnZS36R0M6V1sviL2qeqitRgDad/YY0matnbOSJ5nqOUFuV9UnQrVFImwnQ6wRjDw13HGMZUbyr2u0P6fqlf86piTG6KvuuYzer0bBwIgdO+dbfbYzNLVRaYVFeJ4kqUT5ISaKnrCmMNTdvinLhZ8rKgripUWWFnUjvXtbhDHh/XWFuQWxlCLhYLjDE0bUM/9oyDY8wlEMGlZ4rNLbURZ4yKJITFgcfHJ27v7k7DNimChAN5TAx0aQ9flHlSWTv2u91pXzOpJ2x66RvMZnOUAvcYOHJCnQ8oJECqLGVYd3V1gfPiUBAlt6TmZkWR1PMGFRXjIHVgWVSA8O2UjujM4EbHYbcnxvRctZaqLkWllPYLbdOx2Vhub+5omo7pbCrhWKU8o5umoe9HvJdBYlFOOYrpJ5OKyaRmO+zpugalApM6Jyqps9W0Jq+OdW9MSXs509mExXxGlgn/dDKpCX6FscKkkoZmZBwHnAsJ1/CJg2xtngbkYgPPigwXnAzDR898scBkkrSdJhpSY6TH4k85fnLj6WI5J8TIci6xkHk9ox9Hvn/7njyz/M1XX7JvDvwP/+O/xRrN5y+umU4rrp89x42O777/kV3T4kOyEyQ41nov8vGimkMcGQ9rAtJ4OT874/VLUajYzLA/NGy2W3bbLZvHRyZVwYvLMx72Hff7lmfXz/j1V5/zuN7xtD0QhoYwdpgsQ1ub4i8Faqp0wGbSzHrabtm3LVVZMp9MORx2jCnC0o09KtZoBY/7ln4YTh/gh/sH2rZjMZuLV9s7VLS8uLrEZuJ77fqRduhx48j7m1uGcaAbRsqyokt7l+16TV1X/Mu/+1tGH/iHP32P87BYnBFC5OZxSz2Z8IsvntP3LY9Paw6HPXe3t1ibMV8smVYV12dLhhDZdo4YICtKbAHlZMrVxSXVL3+BiYEsjtyu9/zhzQ1nywXXlxmz6ZSL8xV3D498//5jmiBZim6gOOxxQ4uNPVVZYLOK+/sHbt5uGA9rNg8rbra9MCZch41ic0NnnM3mFJnlx48fOTQN5+fnTKdTNpsdXd/TbjcEN3J5cUWW5/z47h3Be14+uybPc97dbRhGhxs9CmlQZTbj2bNr6rLkarmi63s+PNwxDKOAMlGcnZ1LcRs9fuh42gcyrZgWsvnc9bKhN1lG27bcfbxBK5iUGQRYLRZomzH2Hc1+x8PDPbvdlru7OzJrubq+JM8LynrKYb/lxx9/lCJDaV5cXvHFF1+wfbjh8eYtl6sl19fPedrsuL+/Zz6f8uxiwaHpWT/c8vL5Nefn57TDSD86Jsf3eHnOtCrAO7re8+zZJa8zS0qcpc5WDOPIw8Oa/X4HwVHmOWcrASPGqGh7f2poXF9f0XYDf/rzd3jv+Pz1K8o8521SaDWJL7aYL7E2/6lLw3/2xxGyuFweGzuiLtkcGjKb8fryCudG/vCH36fzdE1ZWeY2T2yoPV3XJkmqSFojPU3bU5SFQPUSgDHGmJq0iswostmcoqppm4bdbiPNAOfIy4KLsmS/3XD78QNXz16wOr/CR7FnFWVFXpSnRlZANjKfNtdSnD5ttuwPDTbLuby84nA44NxAWUjgglESdbvdN4zOM50vKI3l/uYDfd9JUaI0XbNnNJbJxYU044eeYRwwSFN9t93ifaBr9mTW4LoGlKZ3nrwo+PrrX9L3Pd/8/nfEEJnO5oAoQ42VxCnvfbJBBHSyJEwnE4qyYjKdM46iIosxFW7WMplMKIqSyWxOngvj5OH+jjdvfqSqJ0znC/JUPPVty26/O0VhT6oSVZZkWc58Kcodm+U8PT2x3u3R1jCMPTcfP7JeP1EmzkSInmFEAI15wcPTE13XM1/MyfMcPySVbhAt7ur8Uhr+wwMuRq6urjDW8uObN3R9z/6wR2tDP4r1vCgrMqspi1KSVLqWcQBtpfFsM7HrKK0JwOPDHXlRcH5xhfeB9eZJmnJljneezWZHWeTMLs5BK1bzg/xbJ9Z0Ue89cNjvqOuai/Nz+n7gcGhRRuOjBHb0XUdZ15w9O5PNaybTwjyTdXDtRqazGZPJjM1mzXa3o55MWC6XdP1A0/VUZcV8NqOua/q+o66nZEaxXC6ZTIR9CND3MqHu+gTtzMUuPJvPk6XApCaqOimPx3Hkw80N3ge+/PIriiJnGIpPEHqlMFmB+cnlz38Zx8W0IgDdZCLNXieb7Y/3T2TW8PWLC3yIfPfuAZvnXF5doQkwNqAUrYN+PK5LwjMLTUu334jKcD4nEhmafTLFB8aoODiPMprlbCJ2MR+xRDICdVmyXFZ8uH/i3d0jn5kll4sK5wzeZxSFNBrHPuJS8qR3A2MIOK2wVmM1EBxuEHbntNbcrfccuhZiRpEZigTk//C4ZRg9dSaA7tGD84plpcgMOAKg+ezZOYW1/O6HG7pekg9jDGwbSdEq6wkxGtr9QPSBvmux1nB1eUY/DPzpux/xIZCXNZrI074jt5pFZXFR0Xix8OUxEL3Y940mKYAGNrsDRWZEBW6M/N2koDATpnXNcjnnze0Tv/v+A7Mq42xaUJUZ81oLy9QrhnHA+5FppphmCqfELjib1hR2wqHtafuOm8fAw7Zl3wx0g6PIM1Z1xWIiSWwq3Qfr/UFsYl5q7203sO0dVZ4LgD3PUkKnNIOv5iXGKB62B5rB0ZgSaxSZVRQ65/J8RZVbLtN1+N2NsOmcEsuYT7ZHqeMR64/RLCclg/PcJ16WSrBx5wJFnrGM4FxgUmSUhTSsx9HTNAf2TcvHR0njqitRiBSZ5bAf2O32BAxBWcpcsyg1k7pgPp1Q5AVFkbPZ7Nisd2S5ZjqbYrsB0zvOZlOenc+5edhy+7jhfDVjOa2wWtHlhroQm+r88gxrLPdPTzRdJ89mbdl1jjAKQ2xwkfl0Ig3CKAEYAwEfQLsW6xyb1hMReLk1WppOIWJMxChNVabB2M/kuLi8ACLXV4GqqilLS9eP3Hx8xFrDr3/1JYfDgf/uv/0/U5Q5v/mbr1ksVnz+6iu6vuXN+x/ZrLcyxLCido4e9o0wuIISq2RVCl/TkDGd15xfLMjzkrKqubu75d27H1OCAkwnE37x1Wfc3Nzz8cMdl9dXvPr8FTYNkzMbyQyUeY2KhsxUlDn0xuHUCEZSDm/unnhc78lzy6uXl+ybDuc8pbHUWUHMFCE67u7X9P3AxcU5U2P4+//w/2Kz3fDixWuqqgLlUQZevHhBnmV8fPeBtmlZzhxEz/ff/cgwjJyvZhRlzma/BwWHw4GiyPnFV5/hRs+f/vgWHyL1rKR3I9//8MhkMuFXX3+FM5ZhdIxDz9A1jOPIbCENivPzJW3b8+7jLWVRsVqeo0uLMpHFYsHz5y9kHdORb//8I//+3/+Wy7NLXj9/zXwx57PPXvL23Qe+/fE7cltQZDnW5mSZNOJ713K2umQxX7F92nLYHfjw8Y52GPiH//hbfvjhRxbzGXVVopUhBs10NqOoS27evGe/2zFdTCiKgqZt6fuRu4/vCc7zd//8v2Y6W/IP2w19N/Crz35FXdWMv/sjTdPSdiOjDRR5TVkoludLyjLn+sW1OLjuHvDOy0DVey6urwhECpuhomKzbiiKjPl8jvOOh/VGmtGzjP3hwHfffkdZFbz8/Bn1Ysr1y2dopRjGnrZpebx75On+jvc/vmM6nfHVL74mIoPRsR+4+fAh7W81F9dnvHj9QhwS/cBsVjNb1GzXG95/fMvlxYrPXq24uX/k7nHN1eWMyTKnPYx0m5GLyzPmixm/9l9zdXkuNVi357PXLynzmsN+Qz90DKNY5N5/vKHtW6p6Qp5Zzs6X5EVOUVRolTFbzignOZvDObvdnvfv7gD4V//NNVVdcf8kKjLnA+hAVpif3DP/yY2nq6srQogyXU8T43GUaZtMBySJ4qhIsUkF4JJnOctz7DCkQqNnt9vJRqgW33bTHqRvpiSZJaJlah58KoScfCBJqZJlGSHCoe3QWrGYTnDjwMfbW3aHjkPTk5tIbgTM7V1Plzb2PkEevYuoGFgWOdNJjfOcFA/Cafo0lfApTQiVMQ4dwTumCXpaFZKEpo0wkJ42a4w2ohaI/vS6rZFEnrKeUBbl6QFTFKI4Gp1AP8de5OXuKB1XBqIU6+PoMFmGzQvyokwNtUxi3LNMSPSuE4l0lgnLaujR0eBNRp4Z6rKi7ANZtieCTBS8kwflOKZEBYvNCxSSbNB2A4duJPdgk09ZG0vb9TyutzSdYxwDZ9OKSZHTJlhtGGfUaVKfp9fXdTJZMol35KMSFY7zaG3Ii5KqlljlaifXm048qOurS5luKC3sAu8ZvXAkYkhTTm3IrKgTDOLr7bqekFlmE+lch0FiB1WK2nROInuVMcQY6AZHjqJSkUkCswsrQT7HsiiTz7Wj73u6vsdkhZwzpU4R6D4Kl+rhUcDzs+mEPBfYnfA6JLUseM/QD7T9gGZN37SJOSPKPmUtg4+MYUyMmZRQB5IgYSSVqksqOEJkcCLltLlwebquZxiG1HzNZBoJ5EVFRKOtXJ9t22LM+FOXhv/sj9VylRSPMqk6KjzyTFK3RDkj49cjHwQfcK6DxKUQK4DwfUQdpJnP56CEAaCNpGHGNAmXW1YnJYYwWpQ+cociCvlvm+VU9YSIsKiOC3mBqIGcG+j7IJP4UWK8g/cpjUpRVhV1srFJ1LwoSSGpCdJ/HdkhIQQijrquRemlZXAxei8T2UEisLXR2CiKS2JMyUifJos+pjlHWsO6tmUcBpJw5cQYCSGgvErwVCjKXLzqzp/WkKMy7zg5Of4e7+X1fjpnn+4Zpa00MaLwoMIwSlNLaRQpC0lqenz8lDQlzTtJrBuGgcNeYnSNsZRlRVUWNK0ko+SjAyUpHZJGN57OhdUaP/Siihj6pIhSiTFgUsqclc8Kua6mE1HpiEr2mDT5iT0Shl6mt/ov0qWQCHftnFgJEn9LKU4sKK2OKYqiMOgHUchWlajqJLElJL6DOqncbCZpqG4c5ctJYpjRmhiCNKxSYo33nuyoKkvXX57lp/8/DD1t1xPcyGANY7qOh3EgEmlTQMIx5VAndkoIAa+PcccdPn3+p+dvOhMucYGMsWgdT4pMrVRS1SRVT/zL7uzP45hORBlXxaR8dHK9TUpJTc3yjDh6BucIScEqfImkrjCy/mil0/om6r1JXaK1YfSpYRBkWq8VYMAaldZEuZ+9F3SAIhJHR1A9RkUWVSbN7UOblNKRwovCybmQbE1emEURXABDRKtIkeVUhWHw8ucnXtvxmlbCITNKo3Xi6USocwsKykKsXMGJ4m13aGmN3KuiKJL7Ph45QEh6Z9/3p6RklRJu5Vv1SdEuCVnydUxwDs4TkobMe+FYHrlJPgjTz2pOv1en86kTC09SreQ8W60pE1z6yK3UAOqorhRMg/OBIY4YJWl0xwn14Dy9C/SjcKJqU1Dkwn7su064k4qTytInXpdNA9gYJcU4BFFcaiNpk1EbgkpcpRDTu1WUuaQ9i0NA2GKD86LeMUY+I6DSMv0+XW9I6p8yBp3UjOE4gCYm229ataNcK9aIWt1qxaQucQEGf+QAWjk3TtwSPg1lfJT6sSwLlNI0/cjgI+0oXLpJJWqBiCiLCpHc4bzUSv040nYDRmtJ5oTEjAowjIxGYOyRlFYbA0Vm0CRemEKUch5655PiSa7ZY4pxkWdiXVfCvDryJpUS5dmRz/ZzOa6uz+VcOWEBSg06MplUSZkrtiSZMcia7saB9foJFxxWC2dQJ0Vms28JwbNYzWnbhs1mjU/J5EZbMhuJoZR/o+VeJ7lrEGFZUjaOFEXJ5eUV3nvevX3LZiuYDTsV/uM4Orp2S98N9KMTlWSM4B2gmUxq5vM5zX6XkAYpoZyU3J4Ux1kmw8OhH0DBcrWintTMZhOstfRDjx8DT4/r5AYRpm3wogCyKWGzrCuy3J5qzMyKGi8EqRHG0eFjYHTCe1RREX2gafa40SWGbWAcMoxR5HmkKCrKcoL3wiUS3qKs8Uf8g3MelRkJGMgsRZ5jjMYHGWrtthbvIkVWCC/JpmdGhHFwNIeeImswKmMchZ+53Wxpu5a+7SlMxmq5YLFa0B4G7u/vUAbq0UkKIsKdCqM/pbuKAs2x2W4ZXQAVyAubUr0teW7xTq4BYwyXV2cpwVR6F0fFv1wbgX23FbV6LumJJq1F292aciyoJ7kk+44dwWv63jKMwgGUui9D0zP0I7k15FWFnU6o8oKhH2gODQGP1un6CBrvPPvDQV6L98Qgz47ejRyaPc73tP0h3S9yrfhUD1tr0MqgoqgwD01LtrGM3tG1fdoDyLOzaVraZqDvD3g3YqwkGs5nM6nhYmToe1GuK8V2v8doQ4g9zo/SU0jPEIUiuBE/aOFcKZVcAh43/nSx5k9uPP2Lf/4vJPXo6YmmbXn78R7nHNdnCxSKpmnpuo6qKCiKgqKeooxhs91T5Dlnl2dggB87mt3Ij28889mMz6+fc/fwyNsfvkNlOXk9SzDIKLycdpsedAID7/oRpTWz5ZLNes3Hu0eePXvG1y+f8+b9O373+9+htEUpy4vLM67Olxz2DbumY3c40HZdusFkCtgDf/PLBZ+/es4fvv/A7dNWditKYiqNVgLyDZHZVGTS79+s6buWL1+J57FvO5E2Dp7ROf7pD98QnJONqlL0h0HSliZTtLY8f/6KPM/wQ4cC5tMrtNY8PK3puo5m8ygP5YnwRMpCgL2PD/cyMa+nqKwg6Cw9vBW6KMnKijEc8N2eoqqYT2fsdlse1w9YaxnKgvziksXVKzqVs2paidPcbekHR9uPVIVlWpXU9YS6nsjivt3xtN2z2R/IVSRTgaKsmcxXbA57Pj48obXIo19+/Rmfv37F/+X/+n/jD/8Ld//RbGmWXmliz1afPOoqF6EjUiBRKHQBNHaPSJqR1oM2/mEOaByT1VZECaAgMpGRkRGurzrq01tw8O57s2ZMmnHQFccMhkwPD8/r53xni/Wu9azf/Z7Xr27YrNfcXN2wXa3oup7zuaNtSrFe24IlwIf7B1KMrLdbmqrm8uYVVVkyzv4ZelY4x1//9Tc46/jp/UeOp477/YF5nlmmUS4xuRp1beXAl4JEqvbnnrquefnqM1KCMJ3FFus9MSyEsGCtpmgaxvPI3f6eTVtzs1uz2V3w6ubXvP90x9//0+/QxrFZbzl3Z+4f7+n7nnPX0a4dbdOKbft4T98PnL3m8PGeH95/ZLde8+3XX3LuB7Hoap1hpBK5OxyOHE497+eB6GdWK4G3b7YXuLrm492eczew3kjDV1tYGudo64aY4Mcff+B4OkMIWGvpBon+2bpGac08yqZdVgJV9jGiQ2RzeS2CblhIIXB394mnevKfw+tXv/o1IQROnQg7++NJ3Js7WbvmSWCldQYICsR15Hw8UhQFV5eXlEVJ024wWjEMHVVV892337DfP/LDD3/IkaMKra3EkJNFGysXtJg5DsY9ww0TkZg07WrNxW7Hqet49/59tkMHqszbOh72HA8HubxlJopWiBVZOV6+eMmLl694++YnaeuLAZ8/R3KkGKCuG0BxPJ2JMfD5Z59RVxXn04F5nrh72OMXz35/FCZTUeFKETdjjNS1WJkLJ6DtqDRaaapC2p0+vXsjF9MM8015Q38CmS/zhHMFl7sdwzTz8fYeAOdKlBXBPgJJSUysKl2+2Ig9fpkniZO5AmUc9WqdK8+VuEqnWTZ85wTM6UXU8YjgOk6TRDgy+6OuCoa+Z/+4pygK1usN19fXrNoV3//xj+zPBzyaslgojKapS8ahZwiB6xevqeqa6eEBHyYOhwM65/+LqngGrjeNMP/ksmf57LNX4t54/45lWSirSsQSBB4/9x1KK1brHUrliF9Mz4JXdz6KAGqfDpCyr5TOULgsxvvAw+HEqm25vC6pqprtZkPXddzf3+bSiAllDHVT0/cd/ekojoVlJlYlVknRxLnrnmNXZVGwXm3w3tN1Z/n7rsUWPg09h/1eWlajOOxcIXH8cZqxxvC4f6QfRuFnlSWb3SVVWYkzM3qOpyNDN8thG0BLZKWupETkCQjc5ji4UlKRLqUOudghITD6n9HFDeDlyytpD9SacVr43U8fCEnx+YsdzkptdmRi9AHLwjgOpATnyVNYzaWVQ6JEuTXTsmCd4YvXN3TDzKf7Mx5Y0DgNtYWq0KwqyxIUkxfBZPELPr/bcRoIpzPb2vHr11tujwO/f3uHsQXaFljjKbS4QvsshMzLjNQDyLpROMNm3XC1bXl7d+bcjTn6JTXzlbPP/JymchTBMEyekBJfXFQ0pWXWJT4pluOJZfH8608f89oj4oVKjSQvlQwBtJI4zPF0AqW4urrGWQGuLktE2xKFDMmeCl1QmiUqgRZPUlQzBxlgFiZRWkVZWEIMLH7GakuMjpTyKTxpYpL3/ZAbkCtnWNUFu3XDsZ94PE1YnbAmYZy0RYEIdf08040zoaoIZQHZDXroZ86TR0eJ5JXFmvW64g9/fMfdw57KaZxV3Fzf0NSNDF1TZFeVlIVjf5ZSmmEQN9jNzSVlVTJpIEVxt1tDMoaoFZcrQUgcOilFGAcBzjZFhS5ULitQbKwlpEQ3zBK3VhqlDMqWaCSm7UNk8kqm/zoSteyXYfYcu1GGNaGiKR3Xu2vmOXDqF1QG8vrs0FyWSMARCc/i+MXFjv2p5+P98TnefbGu+fLFBY/nM4/nDmcUtZHP6DQFzuNMN0x4n9gfB9q6pCgdk/csMTB1Q46eyvOgvLiad02JUSXdtEgz7LKwzIn9sLCESGEyGy0LcZe7tcQEo8CD67IgJAHa5ykK8PNh1P0Pf/OX0irZLwz9xJsf3pNi4qsvXuchlsMYx3q3xTmDTpHudOTd24+0bcvX33xJXALWyDnt7dv3rDYrfvWbr/jw9iPvfnxDJIJJFEVJWze0TSkR49w0u0wzOoobQxkYp5lumHn96jW/+c3n/Of/8h/59//+/0lRNhRlTfn1F9TXl7x/85HbT/egCpRy9OMkRQ6LR+vEV1/8Db/85S/4u7/7j7zZP2Z0gcS2QpToZggL2+0Gaww//PAj4zDyb//dv2G9XXN/d8swDHx65xn6hf/69/+EUgIFL8saPy2QYLuRdrsXX7xCW01/OkNKbFc7tNb055FhnBjnkZASaZCSqco5dIrcfniHtpambVlcQfAaYyPGBtbrLdvtNagDzooLzVkgeYZOGjpd0bBa17hqTdU0vLx5QeEMIQ08PAx8eP9IXTteXF0T00JkxlmNipruOPLpw57uMNHUD6yyG/rNT2952O+5XK15dXnFb37za159+Zr/+//t/8G//NNv+fKLb9ntrihKhbWwjDNh9rSbGuNKukNF8JHvf/89aMXusmW7a7DOoI1i3TqcCVgncPXf/PI7rLX87l//wGnfczofpczBGLxfeP/hJ4wxfP3tLzDWMU+BaRr58c2PNE1FszakGBmGRxSa4Gf84ikrTV0XrMqW7tjz+OmRzabli1fXXFxc8uVXX/P27Vv+7u/+I8oEYuwhGVR0DP3Ax7vbPNiGq3GF9gunwyN/fPsWv8iZ7HJ3zReff8k4jxyHEbRmtWopbAnecTz1fLq/5/bhPiMX5JzbNCucLfjhj295fDxQFeK0fPX6M1arFV+tdyjg97/7PYfHB2KMWFfwcbnN97/c/DnI3Xq9WmGNYTqfieOATRFlxNVHiMyT5//vjKf7+/vMkpmYppnD8YD3Xiyj2lCXkp1smgbn3HOWfJknlhAo8tSiaVcyocKwBHFQxSTRjKQ0yuS8uXFYJ06ekAAdSckTQqTMHImYqexVmZuYsltGFHRNAIZ5YZ5lomsUVIUlPYFXszL9NHExWlMYQ0gh501lUrZ4jw4RKmlua5pGhJx5FrdMyNMqBS6zO2IIAhUHrNVAYr3S2SUz5SYZmbxbpUmoDNxMtKuVTPEVz5cur2AeU27ZEBbSMk/i7ilLiJHDYc8wjtJqpHRu80usVxl2rBTDtHD3IJcAayxJy3thjKWuKkpnqEsrNdh5AuNDZLVqaVdrwjwQ5wlXlPJ71mtWbSOcjqQYx5nb23u0UmzWK3xWdTfrLUVRMM/SqlUVMl0rC7ko9l6m6glxKHRZJDieO6ZpYtVIXfG7d+/RRmqXxbU2y//lFpWnMisfZHJvFEASm/+imaYZECBwCJ5umUgpsNvtpK1M2zyZXAheFqVz1/E2RgGGIu6XoiioQ0lblZRWsyodpmywhSOlSNf14nKzFmdBKWFd+TxdlkmbZ55mLnYb6qZhExXaVsxjh18m2qaWTHuKAlldJqKfiX4mLBBNmRv35qzey8/mc32nsQaddG7XiqgUMAp2mw1FUcp3dBGXjDGa9WpLinmzXuY/d2n43/xrfziI+waeuWIhxOcmLa1lGXyasD9NQZ7aQhbvM3tMJvLPTXU5DvXEE9Pq6QIsYOiiKHiamacorV7WCD8i5imy1nnXIUlTy/NEWJpPnlrvtFY4bTFK5Um2fDdTenL6yc+ktc5tl0Gm+vlZK0v5uxbOEpN5/ud930tTn8lOnacJbF67ZFKbRCTJfKkYBOYds1vqGUaOuDdVfh/ITrGkngQBMH3PvOQJu86TGwSo+cROiiSy1kJZCkjbZxFGWB1L/q6KM0grhbMmA35LacZU0kjj5xlrDSu7IktbmSFinnPtMXhi8CzzzOQmAX02NcTAPI0Ueb031mVHRHq+mDlnMnMrc3G8/DnS9iQcMK0gINO5J/aNcyLMPLlpY4y5VUyeN601RVkSgmcYeglARZGpZGIWCcv8PP0iJc6nI33XZVaPHACWZeFxv2eehOumnEXnCnptpN1PccE8jdnpKCULTy2BKT3xa4QRtiwLi1+eXV1Wa0x2HFlrUUn4Lc7J/q3zHuJcQZWEH2eMyY2K8p2IQT5bafwEkvAwJG4HIf6pDcsVZZ6Sy/dUBtkqg4YzD+tnJjydu0Ha6QonLr1hxIeASo4QwZiFeYmUVYlWmuCXLJ57QlAclTjRjdHZKSxsL5OHRVqDyQ4OAxik9cwYi48xNwR55lng36umFqEyBKzVUv6i8rOQ+Tty8Zqf3VUuC8LTIg4oaXJSIpRHidEbrahKaauU9io5FykQZ5BLz+5AZUTAGqfpGZD/3J6XzzribpU4bF0X8p7k/U5+Hv3cIPzUglUWNrcIyXpf5OdsnrOwEBMpKkiy+BVOY4wjJEWISmKfITIu4sConH1uo5sWTz/O4qbMTbMxRolYlQ6tIkZJQ6BSmmkRB3xCWvi0keitzW7XtpYBhJ9nadH1nqEf5ecuHEklfHpqQY654VIcPCb8af11zvDcUOgDpTXPrVok8jOipUFQKSpnccaI+zZmdp3OHL28fgFUTj/7WEkCAU8x4owlJmGHGm3YrRp5jmJ43gO8l2GzD5HZe0KQUh/LUwOexjUV1snlcpwn+kGaCYdJfq7S2cx0leemmzxzAJQ0v/rsklQkCiuNhG1VCTPN2eyylz1OE1ApZretxhqV1/X0/N6FKPsCiLPJJgVBzvlP7tbiuf1TYnZy5lWsKnH1+Hl+6qz4Wbz2j0dZq3VBjIlz1+e2YGnPqpUmEaWRzUgDpPeBYRjFfXE6M83zM4B7HAes0wxDTSKx2Wzx0Ys7yloZ/BlLYWSwGsKSm+0URWEoK0OMufVSy11MUC81xkg72TzPnE+duHTniapyFIVh8Vpc2Ek9n+sUYLSIocYUz+eyZZmkYT0G4Ys6y3q9xhUl87RwPp44nc7CZi1LrC1YoiERnx2mKq/Xq5U0rs+LR3m52+isosUE/Vmic1VVkADriuc1bVkS8xyEkTknYkjEFISZVAr0/PHxgXPGSaTkOZ00IXo2uw3GFizLTNdJBHuePatmhbEK48Th3dSWuilpmopp6ZnmjhQSwzhQNzWfff7q+b2qqpKqKri42MnfW4mr9nzuub97kNa+3RofFo7HPduLFuOKZ9e6DwE0wgbTmm6QYXqK0sg3DAN+9uwPR8Zx5KIo0Frx5u277NacUUY4b9FHplEwOMKU0nRdh3MlddUKzzlqok8ss89DY1njTycR5ZqmxDlLP0yMo9zDghcDyvF85scf33L/cM88e4qyyINZi06W3W6LcZp5kaZhV5SM00QMskaafK41Wcj3wQsSYZ7FhR4jGEVZVvKZGDBKYuzGaDQKP3sMmsIWsreQCMvMPI34eSFFyUVY6/I51stAV0nCKiVpxJa/6wrrLK6UGLc2Dm0UVxeSKLm9u8OHP68N/c8Wnv7Lf/lPGGPZbC4Yxomffvoji/c0dUNdlby6usIYI5lepfAxMs8zjwdxDcxKLmY3r7+QQ/40MfrIh7tbjC358qtvWeaRvj+gbYEpVzRtg6tqkllYkoLZs3gv09ztjovVmvjiJcM8MYw9RVHx4ua1PKRJVOf744l5GFmmibouKNuGYZyZZ4ktLFE2tGGJFNayqUv688wSPBix/06jgGw3tVR8vnzxipDgD7//LV13plxfYF3JurK40nCzew0oPjw8EmJ8hnlvdnJ4//DxEyEm6pWIMa4SePahkwaZzz7/gsXPvP94K4fzvmPJjVZaC7CdKGJK3bRcbDeMQ88f3v4RHxNLTLhxYl4867bhy88+5zxN3J86Hk9n3t/eUxaOtiqeAbzrumXXrtAqolTMLoJFxMYl8N03X/HVF59z9+kTDzk2FqPn8uI169WKQz/TTZ5Pn97z/R/+QNPU/PLbb/jx7Ttu7x5Yr9ZYozl3Z7xfqEu5QGzXLUop7kCaAoFxmXn34T2kxJsPnwgh8N0XrwgL/Ie/+4/EGPkf//ZvBX429fhpZgr5gGllUxhmqS9elXlyOHak4NkfDuKEmGeGYeDjx1t2uw1/89f/hhATD6ezWIPnnsUk+n7k490Dbz99wrqSthX2U7tqqApDYxVVBlQeRs9dPzP3HZ+Oe6wrc9NWzbqtOXUDx/MgYD8lsPnD8cgXX3zO9c1LdteKGBHezjigjVhfP95+4vD4yDyO4D1hBB8cXoNKjruHPcM4YYCqrPEJfIDdusUaxenUsfgFmxLOWX79zZfUTcOb9x/px4GQKz+/+eZrUoi8f/MT8zj8/3C8+N/267e//R2uEHZTCIH9/kCIgaqqszVX7O82RxPkkB6enVDnfsygZomwTBGUMYzTREKx2V2KYBIWiRCEgDWG1WqdLagiHpyOe9arNatmK0KCZCZk4hnzlF4btLWExXM+n5nnGZIA0J/4VEZrhmmUg808MY0d8zgy54iVMY5pnrIYJMKB2Yq7br1qQGn6vsN7z93tJ3GuvnxNUVbEFDLQVS4JEl9QbDcbUkx8ur2T2LGzGGMgx8kOpzPWWj6/ukYp6M4dMYJxAu3tBoktno4HlNJSfGCcNLx5T3c68FTbHhUsM1R1w2a7zSDKE8Nw4Hg8sVq1OT4pgRbnrKxnbct6vabre7q+Y+w6hq7j+uYlF9fXjMPANI2Z02UwrkAby8d3P3F4uOegDcM00VQlq6bmw8ePnE/nzKFqiErqz1VKpLBwcbHFGEt3Oko98vQUS/MopTj3Ui5RFxqfEr//wx9QSvPVF1+IQGesCDk5ylY3K1JKue3QcXV9zTzPfPzwQfberYjWc45V+mmgcI7Nbsc0jrz78I5xmrO4Lb/3fDxy++mTHDQLB23LZr15BnNu1iuquuF4OnF3/wAxMgwCiC+rKjuYAsM40eVnJnj/HEuVfUD2t1WzwmhpIX0SmKZ5wQfPZrN5hu4CRL8wLpNA3ZcFV1ZoW4Af84VCxPHD4cDil3z5VWy2MiDw80wIgSXGzG/bohUMQ8+8/IxubsBP725xVvNiUzPMCx/u9gKgXjc4a2jHgNKGi4sLWbeGjtkHTsNCSnA4JqrScb1tUSgBZmtxc1ujKAopG7BBrP6FUhSmwrmayY9My8AwjpxPHdum5osXF8y5CW1aFrplQRnLpi7QrkC7UpiBw0hVOKrCokoB697tjwxzL7XdKjFNM/1gUCQqa6jKtbjZwiIukCTX/l1bUliDMfJ3S9oxRrh/eGScJ4yWCO56vcYYyzA/gbQjRituLtb4EPlwfyQBl9sNzmgMiRRmzoMINrtVxRICD/sz1ljaqibFKHzSlJiTiGEoTWE0q1ouu2MwjEGg5SEFwtmzbSxX25pTN3J/kKjpMAonc902WK2kOMY4rrcrUlhIYSag8Wj23cj94cz1bsX1rmVaErOPVM5Rl44LK5/f/aHj1I+5AOWMsYaLiy2nfpYCjRhRQaK08+LpJ09IAvAtCkdhLSFEZi9NYLuqxWkBe6f0BEVWvPu0RwF/9YvPKKxceqd55tx1z5f3lOB06rBa8fpCHJH9uLCEwP3+hDOai7X8vnM3sWlrvvviWngrDwfmZSL4mWlO7M8DPgS6YRZERF1Slw5nEm1ds9tuxD0cAveHI+8/CcD77uFEVTguVi1PYfNDP/P2oRORVTuWEPEhsU7gVGJVC7PpZteyaUu6OTL6hIlRuKHLIi3YtkQbh7NyNjsNo0QdFxHMVPJoFBcXl1jreDwcmGepT1dG0xTiTj1HAfZO04DR8PLFJVZr3t4tzD8j5em3//R7XFHw+osvGYaZT59uWWZPd+qo6pKbl1ekFLnYrUgJxgWm0XM69gzDjFcyKNpd7ojeczodmJeBoEa0Kvn6m2+labs7P7usq6KhrVrGec7FT5rFQ9uWXF6sZNCnFWGO3H76iNKGV599wTzOLONCd+xYxpHz6cQ0dWw3Ky4uKlADJIMPZME1Ms8L1hQ01ZqyLkV0nyaG7kQ3T4SU0DpRV5Yvv/4KHxLvfvoj/fnMvpO7xndff0dTN8xpxIeF+7s7QvTo0lG4gtVGBvjvPt2zBE9R2Ox6FjzL+w93aA0vbnYYbUnBMI4jHx4f8YsnLDkDpQ3OWdq2oWkaXt5c0vcdv/vdPzOOk3xvreF02rO72PLNL76m6wbu7vYcT4HpjWezWnNzfUNUkaACm6Zlu9pQVDVlXbPf37F/vOPx/sDj/YGvvv2Cz7/+jPv7e/b7A01RUruCz16/xpU1f/zpR27vbvnpxze8+fENdV3wF7/5jh/+8Jb3H24pmi8pG8sic3X0NOKC4eJ6hzaGT+8/ivMyKOYhcn97T0yJ3/3hB6Zp5De1ZZod/+k//T0pJf72f/cbmrpiCQWMivtPD8QYWK1XxJh4//YTVVXxV//mispaPlCC1wznSQp7kpytP9zdsl7V/MUvviIGxe3dAw8PB/y8yJo4DHz4dM+bn/5OBqPOUFQ1uqgorKW2js+/esXVyxfc3T3y5qcPRD/zuD8RfGTTiInBFQXTkujniWEcpCX+PDD0E69ev4JSs7u4oK3XFIXGGQUmklRiOI6Mx47G1rh1RYhnYpqZhzNh7jgNM7OPFKamWa0Yx4VlmXn5+oaiLLi7+8Q8B+pGSpa++upbirLk8fGBaZpwpXDXfv2rXwFwd3/POP95hoU/W3hqGgGDLiGw5EubCwI0tNaS8qR9V9b4EDh2PSHEXKkqtb0JUNGjiRTWoFSGL7oSVxYkAmaykhc3Ms2e5oXTueNuf8huoxZjLfPTSDw7GE6nTpxRSS6QWhmKoqYoLA939yzjiFY6MyLkYmCsBZM4dWc+fbrlnBVoQLgJStTAwtnsogkM0yRfuphIyqBdkREkQab0UWO0OJGauv5vJseRfhBlWobRT3lu+c9KyQaolbgyFJq2rlnmmd5LDftTzKAuC6wxOXOfM6nGUDYrijzDCSHQDwLOnH3APzWPxEAKHp3EeTEvC30/oUPCIVMZpaUFZvGRpKS1y/tA33XM3oulOk9LZx/oMlRPpYg1WurRtxuauuZ4PgubI7s4hCHxJ/bNkhdFazSVs/TzTPSJoIUPIFn/xDBOKEV2c0TuHg+UZUHTtBRFRf8okcx5EkZN2YhIWNVSz7zdXUrjk5Pcb5knjnVTY4zlcO7EUTHNKCLrldTYu6KkTki7YhKb/hODYcrxLWho2hXaJAqjCOaJTQEgz2cMMr2zWhF8JCwLVVmgdzuM1vRDTz8tjHMg+Vk+I/WUmZVmjlPXy/ugZVJalSVaCWNoHAaJDirYbAUS95TVdmWFcYVUHmfX1TDKzyRtKxGvNMfjSbgKRskl9WfyUsZAnmTFKCJOTCmzIsQhoLWmzgdnaSML0sKlDTF6UpJJKwibIcUkE6Iof06MigWBzerMGgrZRfMUE6qrOue0xSllrM4NTuKOE+5OQVEUVFVFURbCA8qAbmOtMHpSehZvhnHkeDgKZyhKxNJoTUpPLi6en8UlBFQSdtcT3PmJuZNI0g6ZHU7WSoQu+JR//5RdKfJMxhBQz86ARNuunp0sKEVZFOLanCRSoDO41mphEclkUvhJaI3NvKAn9lLfndHmT040a4Qp1LYNVVmJRToEFr/gjEU72ROOx6NE/jJDCyUxhuClYSVkO3zwHpMS2sRsJ5f//RQjZSmNbs3plPlPJq+qoLJTTS5dC0qHDARXpMk/c1QAcf/8N2u8tO7A8XSimCbWGwGwS1xMplQAVVXlZ1MccWVmi9mnpkNjCN6jMo9wGAb84qUMojJcFBV1VT1//tbaZ9bLUwuXDz6v5Zqykn1Uk0gqZSdRIgWyW1KafMqiEOdTlPp4V5Y4K+uEz+ubM5poNHES11eMIoD5ZRIRVImFwBqDIjtegidO2b1rpH0mRmnmSXlNK1wpbMlZ2mpNZo7FEIAg8H+t85/783I8WS2UnWEJjF7agrUW4cPkvcBqTe0sISqG2aKToi6AJP9uYYQTmRT5OwHj4oVdssiaoLQStpuTRlQfE9MSOA8zIUJZN2hthEPnY/7+idj61Nyo88/r6gJVSzlDfGItpYSzmrpy2OwcCTGxLLnJbonU1mKtZl5SbpuT2MzkgzALowjpIbdcCRPOYoysHfKLibqQ71ok5DaqJTe7ifQZQxBei5hNZW3PbCcQh5FSSp7N3EyplGJVZracNuj8XQnBZ5expy4sCf38HQpJ1iARahLaSgy1LEtQiXEJuKRBiesx+kQg4FPMe464kcZ5ISUlDgHk0jt4aQD2Ofb1xL9rK2k/TDEyTvJ9X4Lw9BwSR3bOAE88Lclv+1Hi1OfR4YyRz1Ipkl9E4NcyGHg8nHHO4oxGFY5Tr3NcWNbSuirkDK6FJ+ajNLJaI+zAPG8RPpKCw0mKL/pxJsXEdiX8n7JwmKAgBshOPYmOa3yUM4y0+Mm53rgCedpTdkkFcS1ZgzGGVVNmLknKrC3Zr2fvM4MsMC4BO0dpr0ri9o8xMvjIvCQsM9pEgpd9aZomZh9YvHzebekojPzMMQ//pcVT1tdxWTKrTlMoSyKxhEQ/eYwWUXgJP5+onStkr5YhmrBqQhXk3miEBaiNYr1ZsSye47HHhyXzepwMiTIHVdAUFcYa5jniTMIV+plZI3cL0ZW6vuN4PnN7/8iyeMrSSmw0idMlpMDYzwzdzDAOuQnbiuutqajrElTExyU7d+1z82NCnt/TSe6NXTewLAFbSATvifPknMEqceGez5BMRYyydj2xn57OJ0tYCClB0lzsLrNJTjAvyyTtpXLm+pMzP0QZYO+2W3EEW4d5SsAocWIlK7xMY4wUzpQl2wuJ/qUo7s+iqLC2pKlXTNPI+bSnqmtCkJ/H2YIUF4KWu4Gxsg/3Q4+J4PIgVJ2O9EPHmHm9CZiXha7vWJaASoKxmL0njSPWy3esKopnLunl5QVNW3PcjwSfXZRoUhQXozONnEOCOF+rSu5v8xiJXu6TiUSR7y8pKKLX1GVDDJG724dcoHQBJYTk8WFh8U7cZeuWuqopywKjNe26EbHa6txa1+LGkW4YcVZQQikqpgmUTlxdXVDWBdJqKE3x3i/M84BSAraPS2DoJ4pqemYRGgNhiUyz/D21dngPS5hFyzBGAPHasV47Viuoyoq4BM6nM92pp24KytJB5tj5cSF4L22g44TRwpiypsVoS/Dgl8gydoCiaVfSQqw0xIQzDlWoXLJTyKA7BJZFIqQooRIdD8fs/nU0df1nrQt/tvD06vUXzMvC+0+3zN5zfXMtl4zg5VJhhXHy5asXdP3Ap/sHyaG2DUobdIik6AnLgLOGupZfxwpvpqxqUDCOg0zDrVwsDseOt59u+d0f/sjXX37JX/3FXzDPI+fzWaYISvF4PHL76Y6yqiirmqZ01KXl5csbbq6v+McQOO332RJZYozHaE/pCpI2fPz4iY/v3kKSP+/6xTVt2zBNcgHdthXOGc79yLkfngHl0RUUrsSmgEqBYZBM7jDNWOd4/eo1zjpOxz3DOPPx40eWxeOqRi6R4nsAJRDKlZODwDzPaKV5cSFtQeOyYLXhZrvBak1pFOu24YvPP+N8Hvj+x7e4ouTixWvJrpeau/tH/vlf/4BPibZdswRhGREWbJopdEHtHN3pxMcPH+iahm61Qjknn4mxArLEUlYNXT/w5t27DMyOOYpnOXYDt49H6sLinKGuK8qy4OsvP+dyt2HxgbKsKKwjeJlOGyPXt5g8XS/Os3VZop3hdD4yzjO1lYl8U5XCLTnKRGO92RJD4Lc//IQrCv6P/9PfYo3h0/5fJJI4n4UdsWqoS8vFbgfK0G4uiTngZI1mVZbS9JIXxz/89BatxL2kSHz+8gZXlDSrHQ2K7dVLTucjnz5+EF6GNQzTyE8fPnBz84Lm8gWYSOMMyRqmXCNLShwOB07njt12w8V2yzQG5n5gd3nJdneBVom7u0+8v3vkfn9mVddUZZFZQHCxbthut7z7dM/d4cxqWagKK+JZkta147ljnIWF9cWXX3B5ecnh/p5lXmjXO4xzXKxXGKM5ns4sxzNhGlEhELzYm3/88UeZPJeG0v15C8h/D6+yagA4nTu01ux2OxJkaF5gGgeqquTqxSumeebN2zegdHYyReZReFxl4URESIkYA8f9HucKmnaFj5GozJ8s2EoxZU7O437Pqm24urqSy5yPlKWjKEq67pH9w724QYylahrWqxW73Y7NZo0CxnHEFQXOlQKBDj4Lv0aeraM0P4aQv2ultIpoYyidwSjy87EQ/ECMiWEahan230ALwyRTf60V63aF1opx6FkWz+P+IIelPBRY5pmYL2rWFbz67DNSSoxP/J/VWoS3HLsoihJjJJL9BGKN+WCvjaVZVThrqcuSh4d73r1/R1KKi3iJ1lAWBXVZcnGxRaQ/zbKIo4lmhasbjucT/WlP065pVxtQcoFefJCq33FgmiaJUqYkjYFGInvtevNcJ79eb9juLphmj3OFRMdTfL7EJ6UIaLrjmZgSF7sdZek4nofnKK1WCp0PADJYUDSVDGXe5rjwr37xC3EdOIl/OyMlCk1d55hwwinFdr1GG5MP3RaXSyNORjONI/f3D/LPmxVFWUpsPQb8PMmFa9VKyUR28JHE0XroRrYbiWgFv5AxwCQiKUS56Ae5kDVVxaptMudAmlB2u51Elr1w+Lp+oKoqnHMS1wteInPW0J07Adfn0hFxNBXP0cTJj6Sk+OzVC5q6Zlk80zxDBm626w1aG24/fST4haurKwG+Z+fTw8PD82VVq5+PaA7QOEUEHsfA4iOrpkKRRAQB5hDRGfLto2WaI4UN1KUIPnnERcixSWVEVDr00/PnZp2lrhtMYYVTZi2TjxyHmQ8PZzbrFVdXO4yKnA4HPOLU7MdRHHI5ElcQKVTi6mLDbrPm/e09d/s9ubGBprQ0GSYeYmIJ0rx6GmaGxVPXJaU1PCwL/TizWbU0VcHHhyPjNNM4g9WKKcw56iyxqKo0aI24dAhcboQNdn/2TEug6yV625RPcRqJ2DjnsFpR1/LrSQl+wG0aFh85DhN+kYFWUzpergX/oFzFNC8Ctw2RcQ44o7hsK+YQ6SZZB8YAaMO6FsdqtAV1U7FerzgPI4+njsolmiC13z6E59hWTNBUpbiFDh3bumRVuexC9xxPJ/phoK0rylLEJK01N9uGbVtREjl1stYNs8cWNYWxtG1BYQ39ODwPwzSKeZSz7YckYnVroLYKP3QiqliNj4l//ekDxhj+5ldfYkzJp2PPEiLDFCic4XK7xmpQyRN9ZAgBUFRVJXGyKGLyxapkCYnfv73NDhJPXTq+fHn5HGkjeFKl6ObIfR8oIiRtGOdAPxxY1RUXmxZlHK5ppS5+8XTDQDcMVFVDVbVsVyUvLypxLQcZkpIC/RI45fKcafagDb2H2moKDcPiGZbAYfCMs6eaFqxKWUiCaQn4CEM0JGW43LasKispCx+Q0haDVQuayP7Uo7Th85stWlk+JIl/vt/3aKXox1kiND+T1/bihsUvfLr9BCnx+rMXIhzndbs7d9RNyedffk7X9Xz48IGUEpttg3UFTd2SUiQsE8451tuVuDn7kVhGqho0hrKqcEZLm6OBjw8fePv2lt/+yx959eqKb779HGsdS4BpmhmHjv2+43F/AhVQOnJ9c8XV1QVX15fsdlt+91vHkgJFXaNtiSsKiuBQiyEEeP/hI3cPj8yjwKqNXlBBE5PEgFdtgbaKw+nEg48UrkYrzTwvJBTrjezrs5eEjUoaZx3fffsrjNH8/vvv6bqO0/lIiBGLyyU2Fm0US+gpXMF3331NiomH/T5H1ba4rqD4VGFToqwKmqri5eUF7arh5tUN59OZP/7wAwq42N1QVxWXlzve/PQT//7HnzC2oO8WSIq2aSnMjE1QVQ5baKbDwMc3H+jWNX3fMo4zwzDL+cRaQaFozeF0Yno7Y5JDJ8MYPYOaiceBGJI0hq5Wz2aMb7/7FTcvb/Czoa4+YEoZtoZ5JHpPU9as1iuO+xPLsrDZbtFG8/HHWwHX2xE0bLcbYkikxRGD5bPrz1iWmX/8p39EG8X/5f/8f6CpSzwzox9Jg6cuK774/DOapskuM8/Nq0tSilS1paxqrq4/kyIpbTmfz/zw43u0UjR1SVVW/MVvfiF4hGlg1bas2wseHu/44cd7jIGb6xse7x758JOknqrKMQ0jRgdCWOiGAasdzlTy2XdnLrcbrncNyQf8kuT5vNyiIszniQ9v3/Hu/Xu2Vxe0mxUERYqa0knpxY/v/sjd/T3b9Ya6qqjKhqooiGFimRN393csy8K/+9t/x+XlJT7HD8uipdaaVy+vcIXl3btbxmlC6xnBVlhC8Hz/wx8wStHWNau2+bPWhT9beOpHAWjH7MTYrNcE7znuH1AgbT5K0fc90zRTZcWxcI5MAiGqRNIaV1ZcXFyw+MCxG+TIEgNWa9qmRfB6YrFGG+qq5vrqgqp09H3HMPR0Z7EUO2slKpQbN2JKTN4TU+R0PmOtYVpmlDFilc6gcIHjinLdbNeU1nLu5JJVWENhNMlZvDZM+RB8OPfM3j9PXwWmqGnKQip+s1opGUsjtYUhw35TzNGegHZPl7AC5+QQkFLk9MRECNJ2sWglVs2n3PA0oZzFFrVY5odR3ouuwzhHu16jUmSZJwDW6xXrtqWua2J/ZugHSue4uLgUF1N6ahuxaOuwRUHdiHvH5ymQK0xutpLGBh+lPYHConKLkwwJpdXlaSI/L0t+P+XyUJWrZ2ZJSjHzQHKLS55SxSStMN5L1bpCKtiXkKepWrHND/YcxEUxjBPGaOq6wmhFmmVKaDLDISwzEUU/SPPYum1QSnha47TgF6lVLvIU2RppiijLQlhhKBH7CkPyFX3mvYzzgrEF1zcvKcqKw/GUY0+DtHW5CmLM03mToboV2hWElJ6ZBNp1VIV7hpkWzhCiZxxDnmAqpmVBa8XV5SVN2xKXCVJEG4MYUsQpV5VlnvBZ4URoA0aiBlLgEnNE0+fPN+bmjCeShrykwedP//2/95fWZPdcwVMbIDyxlzRWJZx1uWlNmj6U1pRlJfwZL46AJ3dTU9cs3jMMg7g6ghfQdlkQQ8yuRmkRM1rTti1lmfkXy/KcS1fZ9VcUuQ0PiMEzjQNdZyE7Am12C8UoTTkps6WsVhTOYY0mhI4QZNJT13UuWJBa15g5Qcvy5HAShkvSmqqucc5Jtjz+qWVnzmtIjDKxrapaGBzLLFn9WgoPbG6YXGZxNvkQ0CkyT+MzX0U9PUrZbaOzw8h7L5u4tZSFrKmQMNY8t+6BgI3nxQsfS2cnWciOGPmD5WcqC6zaYF0pa1NRCD6LxNhLO8jiPWUhYpLODXTLorLwotApsSzy2cYURRBUSnhVuU1Sqadfk5HPMi/PzZgxBox14k4aLSn57PDS4mBLSdrjeIKHy+BBZScGWRyQ9z7z4OQBfl47l3xof4q8NY3EJ3UW0Z4eJmmXNTRVxezFISxOMRHDRPAKnE8nlkU+vxACYZFyerLb1boC62QtVFrEsZij9Cm75IwxmcskQGitAymZ/P4Z1us1a9bCAkSmsCRpSrFFQcRnTVd+hnlZSDFRli7/Xnk/nr4Lc+ZolVUpJlQlTooQYm65+/m8Ym7tStllWBeZnaOEB9dkB3TIDDZxSAkT7omvg4y4stPSSYvqssi+UZV5Ki7vmzidIyoInPzFtqEoC5wWzsg4DX96Loxj1Wqm2TPNAlTWi6cbJ4w1witD0AviiHn6W4lDSRhD+blFPbfrFdaSSnEVei9Rz3nx2alssCY7n5ApujQdJrTgdMSBrYRxFvL+DvBkXSyyC9DkNWeYgrgEzJNrQlhuPrdvGmOwzlCVAsGO2jArz+TFSW6N8DiKsiAtAb1MeX0XR980LySlqJ3BIFiBJbcFxZgIidw4LED+cZoxhbgspkVatSYfScOCMeL+MEZTVSVRKcYlN0qTxDmUBY2YhDGqjUE7OZsZUnbkiAPUuAKMJmWmllYCxA4x5tGoBiXOfwtsyS2f2YEkIruSdS0F+l7ej9ppiBGbXbelFd7UHCIx5eZrA9rKvjENkSKfv1J+Do1SuLKm1JE2ScPvuZPhdeFkON31g4hGMWGQ5TIYjbeW0mpKK3BvgHFaGMdRkhZKRNimLAiLROKDX5hGwGq8VhKj84HGaWpXoqJ8B41O2T0lrj2nhP+nySD+IOdZac5TJO+fm0+1UoxPDn6twVlcHqIba1Hx5+PYnPKAq7JSStI2jUTzh4GUIk0rTW1DL43dq/UahaKppajFFSXRB+YowsDl1ZWgUpY9ztg8SFaY+inS32OdpigtVVXy8tUN680KpQzDMDGNZ2Ly2e0TKStLSuL4nmfP4XgWM4Ep8EtEK2ninuhZZi9NocZhnGG1WlHVJcfUMU0LdVNT14Wcq6PEiEMfGIaJGBKqlYa+lBsM66qQxmmk9c4qcSb1Q//s/i4Lx1QW4pLyclZwhRgzysKilWHoh8yXXPAeHvcPLHOgLBuk+TYP/8oKa4tnbvHp3GFdyfZiJ+6zZUZpxfZiR7sSTMc0zZyOHc5aVusWlOJ0PoseEIVjrLSjXZWsN5plWZjnWe7j2pA0Igb7BFFTVDazmw0azTT3DMtIUdQ4WzCNM6fDOTtMoaoKXOGwKsp5h4SfZ5YcC/aLQ0XFuExMy0RjhAV2jB3BB+ZlJNnAerWjqDTX1xckJS3nxmjausWZIr/XYoJR2jDP0zNXVGvhYSk0d3d3LPPCNE8kIm3TCrutcBiXSw5SIMSAMVI6sdq0vHj5krppOZ96Fu+pm5KYIo/7A+M40Z075sWjc5tvJFFVZY5GVpjSkrrENM/0XSd/dllRuIKqrthsBZ+wzB4VpdFQFTXWFHzxxRfcvLxGRRkwGGfxMYAWp2hVlLnpVMoepnki+kDTrOUMnV1+yzKxzAPWqj+lkRAdJZGYlhn+TLf5ny08fbrfQ4rEZaIoHC9fvGCaJh4+fSAZQ5MhsLe3t6SU2LZ1tpha2XznkaAT0Tja1Zqvv/mWx8dHPt39jsItNE5TOsfm6pJ+Wtife2m2sQWXl5dsLzbMw8jD3S2H05H7x0fqqqKthXOwWTdMAeaYGAeBfo/zwuPjA6dhRhclc/AswyJMFaVxSmzhX3/xOddXV3z/4xse9geaqqBxGmNrfEzc3t7R9R0PhxOL93z5+jPaspIohdJcXV5QFo7+LOA8q8SpcuzO+JgwUWrGLy6lWnQKAa0UF6ta+CR1yTRPPJzPxBBpq1qq2ZUILyb//+5wJNYVV+sNKUYe7+/YH8/c3t+x2Wz47OUN4zjwsD+hUHz26hXrtuH6csc8jzw87Pns9Su+/Ppbzv3I4/FMUA5bNhTNinqz5fX1FZ/fXHO/f+Tu8ZGqaanqluN54NRJ/WXXj7TaolzBqq6orObQT3TTIs4nazieeo6nM/35RFxG1psv2Owuc+VoYBnORD9jlSJqEa1SlMz0MuVLoJYWn2lZKAuLs47XL64pnaVdtcyL525/QCnF5cVWLiSTsGRsIe1SU39i8YG7Q09dVby6vsKHyPu7PePQ05/P8vxs12IxxFDWFReXV8zzwvF4xmotE0SdIF7iipLDuaeuW379l6+4v7/np5/eME8j09DTbrZsLq+Z+zNjf2TVtlxfXoArUa5kSXDseqYIx37g5vqay4uKuipRBA6njsMwUVp5L89aMYfAL7/7msvdjrc//pHDYc+MZolyACo0VOsNrqwoihKUJlkn0VOjcCqR/EwEllkqbfvM8HJaIPdPMYMlKH5Gbm+cloNy3a5Ba3H+JcTqDFikXawbRWxZbSQ/XhRlhtaG59hcXde8ev2afhj4eHv37CwpqorVasUwjoyTCIPEgCsKcelF+TOGceT+7p6mqVlWLUYrVm0jsF4vlfLT2NN1Z1kDUqQoixxJWZ4re50W2/d61VKVJfM8M08TbdOw3e1YIvg8BevOJ6a+I8XAxeUVhSuIVsS07XZLWVY83t+xeAFdJuDw+ECIwh2y1nKxWgs/49MHErDbXWTRRkSQvjuLUJKn2XGZQGmUceikIS2Q4yjalNR1zTCOUuMKuXIYYvQUhePF9c1z3M/7wHmU74NSSjbfYcjRMYCEJtKuV7TVDf000Y0zTdtQ2A37xwf2Dw8ZLq9oV2s2u51AepXUx/YxPV+8u2FgmmeWeZE1QYkIbp3A4k3+OYzSkqUfpP1NYIyJspJSgGGcIK9jxhgudmuMNvnzDiJAJvnuqVz9HJN4pBJPcZAI2mbulbzX5+4ESaGtpXCOq6trQpK4htIihAIYI9FiV1dMy8I5i0JDriXetBXTNPPp4yeMEQFgnhf6fhCHXVFRViV1VQtzxy9oYymKUuCZxxPOSjyuKBy2KHmqXjcaiCGLe5ZXL25Yr1acenlvh7OIXUUhbCfnhCkWY2DMoPOUEqvNa6qyFgdVjNR1LXthdyYBl5fXaCNMi5hdWj+31xylxTD5GUNiXUul9ugjxlouLjakhMSnY6TUOXpXORGewpPzKUncqqoYppmHacAZxW6zyYOfSIowTAsuynO4riyv1leMHnoPd8PEx9tHtusVlxvDuqlZr2ruHo/000EGOj4yB8+pO6OSwmnDOC308wTIwK4pHYUzVJWjrkvcMKG8x+fGuFVT0QK39we6cRKRM0njkzaWdWFwRuGiwqfENPUC6gZ0kibLmCLjKN/J9WqFUop+8ChgXZcCIk+J2QfujuL2bCuHs4ZVXaJ8ZMzw4boqqeqSVVOBNkzRkqaZ87jgtGLdFFRFQduuUONIN44oFUhBLin7rqepCi5WDZMPHHO8LISI1xofYduWvNjVPOxP3PuJ9apk3bbcH3sezz3duHA/TaxqS1NY6kqYffengdM40xgoNNztz3lgKbGcJlegF6W4YMMyE5fAMkkkxpW1NItaRwwiljijmKYgwPkc366bAms0V5cyKJmmmSXIxcymxDKOzCkwnD2Fs7y+2EjsWosY1BaKOST2owjFbVljjaasHPM0syfgrJzzJh/osxN5tVpjQ8SVM6eu5+PdI9t1w8ubC4nydGfxsieFVeAM2NJSGBnMFIXCGRHS9qeOT/ePVGVB5Sw3V1suNyuS94R5YpoHxrFj0HKpfxL7P7vesWkrzsPC7IOIuyqRcqmLcjLUmrxnmjyDF8H4RekojObhLHHVykkl+f5wJKZE6QoapWmc7DMew89Id+J03GO1YdducK6g3jaM08jHTx8wRnN9fU1Kkfu7R7TWvHr1mQxLSktCnhc/LegQ2G63fPOL7zjsz4wDKGTI5UpL2VbsH/e8//CJtmm4cBdcXF3y6vPPWcaFaZjYPzzy05u3NE1Ju6ooSsPFRcW8wOwVXddzf79n6gPjOdKfFowqxL3WdQxzYPaJ1a6ibhtevb5ht13xx/SWw/7E7uqC7XZN13VM08z9DweOx06GKEn246oqSCqCU2y2NXVVElKBQtAppMTt3T3ee5qixLUrlBH8w+FwQqlI00hkrmla/Oz58OaTDPwcAuX+sMeakqvtl3i/8Lj/KIiJeoUpLNPsOZ97Pt7ecnl5zS9fXDNNI/d3t6Dhy2++piodRWU4HgfevXnHy9cv+PLr19w/7Hn79gPjNDGlQFQWZ1fcvLjg1esrPnx4z4f371lvVqzXKx7uDzzsj8zjyDJFrm6uqKsVq7qiLgr+8O4PPBweeVHVlHXD/vHE6dBx7jqiCmw2Let1yzhWMtibPP3pxDiNwu8bZABz7E7M08xn5SvqquTThzvmcSTGhaIs+GJzTVWWFOtf4PPZJcXE9cU1IMN9Ywy2qADF6XTE+yDDjrJkvdrRdx3//M//LHtsWWRu7I3c05MipcDoBxmo+lnE6rWjWl9x9eKaGOD9uzvKQnN1s+V47vnhp/cs08TU91RVQ5M5nxHPbrdht9kS8IQU8HcPMiQcRw4Pj7z47BVXN9dcXF7QNg0PhyOnrsfKKoJpV1TVir/6699wdbXh3U8fOe5PPJ7uGacBZQxFadltAySB4Hu/cDqf8N5z/fIF6/UKYwVHMk8npmEgFsJRbGuXDTgWHwKnw0d8WP6sdeHPdzz1uVmlEpr83f09wYc8zS/ZbTfPHAzvZcITfGBOgZRCdg0I28P7wP5w5HTu5EKnpHHCRYgIDPnu7o7NesO6rpjCQt93UhnrJI6xbhvMsxNHHBpNXbMt69x85PFTz37fYYqStm0IuZq7zI08T46koR/oyjMaqTctihJbFBxPHf0403VnhqFns2ozFFc+CKU1WieiD8Q8vUtasUzSOjMvTzlymYxUudJcjaO4xMxTE4zObhdH1JGiKPJ73gHQNnIxPZ/PwhbxAR9AR+EjvXrxIot+n/Lkv+TUC9zsWNeM00zf9axXbc5b95z7nu50YFk8xsrfuS4rxnHk3fv3HM5n9qcz5TBTViPTIl9CoxJtVVBohY4ejbTf1YWwYp7cCW1pKayjqRvIh5TD4UDbiCIdUfikKZw4CGKCoBSr1ZqiLOnHkX4Uqr4zmlUjAuPdwx6lxG6dyFM0pE1PKTBKlFuTuVrncWRePEM/MI0T//wvvxXnSVS5Hcei7VOsUOGjPMU2Q5FTWOjnkePx8dmh4YqZJZKFgMQ49BjEaq/KQqaF85Czu8IrGadZqnIXETBICWessNKMRiVxs8SY6IeR4/HEi6srmqZBKQheoPSPj4+cDnumYWSMEp+IymDKKk+cg7T7KHGfGZ0oXIHRiruHvfA4oky/TY5NPcWHpsX/N9ixn49rYJoF4For8XUJ00Ra52S6q54SdH9q6cnunpQEkI1SMnVK8vlMk7g9gvdMucZWG3EOzRn6XBXSBNf3HcZomdIWAnc0RtwAyjmMMpSlpa4US5BGn3ma6LqOuq6pKvlsY/JUT467oWccB5q6IRVQFiW0f2LeDeMkbXxPDqVSmk50Zgook7l1i0erWZorsmgRMpclZYeMOE6E/eTKEnlIIiRpGiOJ8ylpRUpGNs7MD9BJuFDO2uzaEr7QNEkTk3M2szJGnHOUTU03jHy6u5PGlKYRh0w2GKXs4FBJfoYUQ4Y3Wlln5plxnBiGgbBYvLXECK4o/8RfSuL6Q8u666ylbZrnuKIxOvOUpDrbLwue5bkJCxQoTVVVkCLTNBKCOKlSSnTnE0PfMfQySCjWG4y19IOsUd773CSq0VlYSySWGHMroSNFmMKE91LrG2Nk7LNzJXi0ljXrqV3uiZ+n4NnhkkhM48J+GOSfSA0TIaZcNS9Cc1nKfiNOJEtVVyJcR6kHH0CaE4OsUcZYrLW5ellYL7MXZ+A4i1O2Lh2lszyxDE/nTtpYFmlDG8cRv8zP3KmU4yXOCTPS52Y+aVtUdKMwyUx2hrmiJCVheUhsdsn/fm68+xm9pknOC0+muGHOPj+VXUK5uWvxIjC5/N2eMvDYz8LEqksnsaDRsyzi7oyo7L4EoyIxwuwTqIA1njEowgLKWApbUBeOtqmxxog7OQhsvrSKy1Ul8pYSxuQwLFgrkWBpJYo0VUlZFMw+0E+e9RIonTQSl84978HCTyJDoOMz8yzFhF8CI5FgICiTGZGWpCN+nqV5Lsk3oMxrvMticVnqPzkzo6wbxiiqwj07hmKI9JMA/5tS1n75O8ChF66bRzgtF2txYGtkrSyd4dwn7g4dVbHgxUhFU9dUpbjEpjCzLNPzz6lUwqgol8tTos+MlG6YCBH574vHGk3b1tSFpnR/GhS1lTTmRi+8kLKQM1AMAWLCR8AnMBGbpDkshSSNSVphdQIipczdWLKTacoc1fpZ8Pd4rVA+AjI9l+dGPnNpW5V2Uas14yJ/znmcZRA7zKA0UcleMEZhflknPFfjytw85SGf+7z3fHo45MZpEW2eGwGzc1OaOLNLMjNKlRIHmX4aai4Rn4RDlzLr1RWluDKym1Kclp55iWzXlcQclzlz6CLd6Jl8wgfFEqVunEUcn2EWp2VblxTOEpTEJWW4IUlTH6URTSsl7rIkZ2WlFM7Iczbn7+XP5TVPCzgwhSVlY4L3njqzV8vSklKiafOFOyzMweNnGdqANPAmBdOycHv3QHfuGIZTZqtNVHXJOq05n7vszhEEig+Rw16eHeMMVe3YbJq890WImhBhvdrQ1GvO3ZmuPxN84P3H91irKUtLXCB6RbuuWBmDD56hOzGPa3wtblFhqjpQhsPxxOl0EgZoCKxWUmID0o5ptBXHj3YoZeWzRwZqcs8TtmRpc/qiKrGFRUwqTy53OWclEsZJG3xRF8LunD3KGoyV76XWUlzTDx12sUyzJsTIzc01tih4/+EDxiiatqQfOn768SfK0rHZtCyzfFbG6NwAJw7WJ15yUVrqtsD7ifvbW06HM8PgUYz4JTEMEykmtAZXqIxZkT1nCdJWeLW7wGopWqkKhyvk/Vx8KdzlcaCsJLIvZyLParXC5KRQiJH1esVczDzuH9mjsptXs1q1uMI94whsblcty0qQE3kwgZIBoVYaEoz9yDRPPD4Iv+h02LP4hePpkN2v0lopfFRpNLXG0bbSqqyQ+8K7t+/R2ogLX/xGeG9ICBjeOUcKgWDz+Tu3YqoE4zDyGBJJJ9BJ7gtajBFtU1OVpdxzo3CXutOZw/7I9eVK7hhZSHr35h13tx/pjh3TOHE4H5iWCRB+1jJ7VIoUzlFXpazHSeGcFLp8/PCBvh84nsWJ5so1SiN32iTcupgiEZ65rP/fXn+28LQ/7KnKkpcvvmTxC//4L7/Fas2vvvuazXrD69evCDFhbMHQD/S3twKunobnw751llXtmKaJP755myueZ3xITGnCmYV6mrm9veX33/+er7/4nK9fX9GNA7efPrFdrbi+uKCwmqaUS14/jKQIISRebFZ89uo152Gi7yd++OH3vH//gS++/JLrix3dODHOM5u6pC4c728f6PuZ/cMjcRwwzrFrappmhSsKTh9uuX/cc7i/xc8zf/XXX7K7uOD20y3TOFKUJQYRmlQMWViC0/EkFyBJjFEUCus0F7uduMD2B1IK+fBgsEYTnaVtalJMNHXDNM98+vCesiz57uuvmWdPN46EBKdxQacAy0C7WvGXv/kLbj995O/+w//Kbrvjl7/+JQ/7I3//D/9IWVVcXO642u348pV8Rh8+3DEMJ47HR1zZUjYb2rphu2q5/fiBf3n/lslLm511TwyukqIsWdcFTdsSfCD4GVtqnDYUTYnShvcPR7pu4qIt2a0qYriiqtfcH/ZMDw989eXnlG6Fj5o5aq7aitIaTqNHhciLFy/wPvC777+n73t2mxV1WXJ9sQPgv/zXf2KeZ77++huaumLbFMQYeXu3J6G4vpDWI6sEBn9/ODHOM8fTQN/1/PTTHynLkq+++Za6bthdXGJzS4SP8uWOWZQIy0zyE/cPe/71jz9ijaGpSoqyol4NlEXBoTmg4oIjUBQG1Ygtdj7vxR1QFiwhMJxOz5Gdqe9QMQqzZrOjLjQmChPlSZT9+OmWl9c3XF1ccjodGIaef/jxJ46nE+umpXSOwQdChN3lJcWq5e7Te5Z54hffyKL7FEtpmhWQ+Nc//gP745EXNy+oqordSgSQOcll9NxnoU8JPP7n8uq7HlcUbPPNbRhG2XwqAV/aHBVVSUlt+CSX4r4748qSzeUNOh9uQ4g87PeEkG3508T5dMQ5abdZ5oV+6Nmu11QXO7qu5/FwEFj9bsOqEXBqP450nfDsCmNom4ZV2zAtgXHxfHj3lofHR17XDe16SzqfiDGy212w2Wz44fvfc9wfaJoVZV3Trla0bSuVxacTjw/3jOMoLVPa0DYrrNYyQQwRYwtxFI4D3s9UdYsCHh/uWDIMH6Vlg7WOGGSTaVp5llIWp4x1GCV0l0wzkvhDt+QokIhdNosyflmk+S2d5dmsKkIInE4nVus1V+1LPt7e88+/+x1VUbDbblmtV1xfXUmU9imuR8owXi8lAWXFNM8cz2fOnUzMrBHHoCsqqtWW6Ce5nCWBUVtj8iS/oShK9scT/TjmKbkTeHgIjF2H9wvr9ebZ1YPSbDcNTmvu7u+YozSIppT48PFjFgskSra7uMIWBQ+Pe9m4tdiU1ysR1R5GOXAuYy9slaYlKUXfdyzLwukkzW/ydzLsNmuKUmFdiclCi0YJ+Srl8c8Th+x45I8/vaVtG25ubkhJYrbWGIK1FFXJar1mWUSwc2VJ07ZM48Qw9AzL8swGeooglYWjKEtpZM0CVDjsmeaR016mbq9evqStSkIWcz98+sQ0z8+R4nmeCCFQGLmwhiSx9aqqBJqJHI5dUWC04XSSeuS2abBOXNMJePPmJ+Z5Eii5MWy2O8yfefj57+XVnU8Yo9msGmKC+7PEsNetXFZ9EKj9NM8YY2jbp4KXjmVe6DpxjtyUNbNP7IdR0AYBlhgZfaQw0BolxRNzzO4hgVLPi2e7XvHisiGu6hxh84zzjLOK0sCq1LxYr1mCCB0fH07cnUbqpqSocizLe7ZtxfV2w/cfH3k4DzRVidUm760iUI1enEtE8sArsFvVlE4qn+cwcVqkPbGspD2xco4EPA6DgMq9CLKvL1pBGWTB2DlZ/47dGZRiV9YUGraNMIamecIHz3laMFpxua6JwLAofIB3jwKJ1UZRF46vXl0xzQsPB4mjrOuCj/eB79/eUxeOq03H5W7LF5+9yK5CR5o949iTlAVjxbFspHxmf/AZ2h45j2dienKSJra7LavVikInnBZHZEiJq3VD6SwfH88c+5GLVUlbWvpO4kGdh26JtHicjSJIJRmyWg2oREwLKwsuKc6zcIuWcUJnh4VW0PXiqFtyTPJq08rQNEeFjVU467i6Ejbip/tHxmnh8dwzL8LxqgvHVy8vUQoOfs7lQyLwu3qFSp7Fi8usLQ2Pp57v39+zaVu+eHGDBtpS4OeLF+dmUZSMfqAbRgqrSc5QOktTFswepkUGDXGSuKLShqKsJE5kLSEkliVIqUW/0M+BV9eXvLzaMWT3azcFEfC1BWVynCrAMkHwHOdATIp/+91rdqsGRmnNc1bKlEJULEGGrVqJSyCqwLmX+5HRBhR0nXC3fi6voZ9JtcI1BfM889vf/R5jNL/+1XfUdSFsNaWpmjXTOHF/+4F5Wuh7gSqXZSPtzg6Ofcf5998zTyPdcc8wTOwPZ1ablpf+hv39gbuPD9RVS12vuH+45+2bt1xcbnn5+pptarH2hrEfGLqeGBJ+gRdfvuCX3/6C/fHA4XjkP//Df+Gff/vPfPf1V3z22SumUWDm1zdb1puW73//B+4/3nK1WdHYAmcMq1WDtSUpGt69+8iHD+8pTUFhHC9fvqJdt3x4d0vfD1zuLimrEq1KUE6GhsDH/YG+H7i9vxX+ZlNhrTCNlFK01QoFlJWI7SEFIpGikqF/u9nRnzvm4QcoNbZMKC/x4RBnHvf3z+y0snT86je/5O7+kX/4r/+VFy+u+Nu/+UvevX/Hf/gP/2/KfPa6ubniu2+/xjnL8XBiHmeMMjjjKB00TcXmouFwd8+7Hz4xztDPcDyMKJVwTuOcFvxMKYVWOupnQXe32XBzccXDw5m+H9ldtDSbknZsSUnx4f0b+u7Ed7/+BdvdltHL+fGLr75ks1lzd//IOI28emmZpol/+Pt/4Hw+c7G7oK5rXtzcoI3m7//+n5immS+/+Iq2bXnx8oYQIx8/3bL4hfU6P2fKkELg9Hjg1HX8+O4DXdfz6cMHXGF5+fkVbbOirjYUDilBS7AsiaquePXqBdM44JTh/fuP/Je//6+URcFmu6EsqhxfM/SjNNY1TS2CfQooZYgp5LOc4ng40nUDrnS40glDyxWsdzuury+oi5JCW8Iy03cn7j594sPHO24uf8PV9SXjmJjHgb/77T+xfxSXaFUWdPOMj4GmabHWMXcejaYuKnbrNfv9HehAWVisSvzzP/4zd3f3VGtHURast1coozjte+Z54vF4CwpevHqFdcWftS782Se00/kszTVerMrb1QpFYhxnSCfevntPjJHj8URMkaoqKApRtOfF0/WdvKHGoo2RiaqSTL8zMikIfuF8PpGIXF5eYp3j/uGRxXt26zV1XWGtJiSHBeIswL/tdsXFdoOPibef7pjGkXkcaeqKb7/7jrZdPV/EnXV0w8j5dJZIDMKEOk8z27KiLApO3Rl/FM7A9W5LWmamaSLExDCMnM5nxnFklVXCwVl8kniXVopxWQTkK5FcRkRZL09HQLHfPwIJvWlRyjOdOoHHaYGInvv+uXGqcAXGOtLi6YcB5xxbLUA9hbR4HLuOcZopyhplJPNbVRV/9Zd/KU6LwlE6J26KZWEaJ1L0tHVFUVfUbc0yT7x58w6S5/Likv25Zwrdc95fJ6nk1TisUnTTzLkfiNGzLAW2qDBWrKLWKoEZDz3WlVRVSXhM9PMibSFAXTnKwlA3K5w1nIYHvJ9FNNKJy82atippmzoDfgsSiVXbMDuXJ5VGWgpNYtVK/njV1ujM0knKUFYNSRniaaKoan79q19hMsDXFU7cRsA4C2NEK4kDDecTMQZ2ux1LiDRtQ1NV3FxeyGXbFcQQWKYBUkDFQFmWlEXFrDw+Cp8rLPNzZMYaeQavdlsuN2uWpNmfTtTljqZd45MGZbi+vERl59bpfKQoS+qmeWYDVWUlfAQnkc5t21CUJX7aiYsvBrqu43gUy2TM2egYhWW0aqT1Sj+xFOZJ2ChJDqTPkJmfyWucJuHG+QVjbG6vi0xDz6IUsXDiJFwkpiOH4Uy9UoppFA5dUchFL+VIWUgqt1c22RElLSN1WUKKnA57EuJYdNbhQ8IvMs1bppF5GoXzZi0+eE7ns4BlQxJXwYsbmqoUzlQI2UUg3uLFC/fr2RlVVjhr6PqTVJ06h3NO2n2yiy8pzTRJ22hZ19hskU0pYa20eS6LZwlPvJBI351FnMsukifwqUYajEIuZHji/ow57qMy9+Op2awbBNBeFcK6eorIhcx+CSGwzDPd6YBR8NUXX2KNEQ6Cc6QY8U/uoCSRoSIXWgDs93usc5R1LZdlLyyOFMUhFLyw3wrncq35UVpeigJILPNECgFntLjJemErVYVj6GDxuYLeyeQWEmFZSEoasuJ/MzXbbLcsvoUgArAikbKTSmFx5k+NT8/PW473CCvF84Qlf2JCKQU3V5cyXXUCOCZF/DJznEe0NjLBVyq3WSqUcjTNwmazpsnQ+mWZGXrhi8UU8T4w5ga6sq7xi7iL53lmnqfsHFG4zKErMh9rGEcOxxPbzZqqLCirClKin4TzE2NkGEdpSilKYoz5Z5OLl1ICl38SYse8v5KZKRKLlKmf0vm5ywwUuSyK4+Qpjmk0mU/25MP4+byWmEgKAhLJrEp5biJII1Zm+qQozoAnflxdiCg8L0+OITBEHEsmPiUKI2yLGIM4XNC0pVyC5yAthFVRohDnTYzSVBzz5TgmceqlWZxSIYoYUhSOF1cblJGLzjTKmW+YZh7PEosrnWVaAod+kkOu1vTDxOw9l+sVZeUoncZ7nZsfI+Ps8TFSF+LWjdMs+6p1aC3ipVaaItfdhxBZgEh8bqIU156wNIZxRCUg+me2WEyQkrQvPjldj+dBWps3G3GeRQ9RIP3L4p9dVP20UJaOX3/9SqDlhcsV5SdpLK1qQoyUhUUpgzLy/J6HBWc0TVVyHiZmv8j5zwq7S5oLwSpZY4+ZcYZSeB9w1sjZwGmGcWYcZ2qnqZuK82lhnj3rqqLQmjk8cQINymRRMESM1ZRYlHPCbqk1ikhphHelrZQgqCDCp9XC70vRQ0qsG+H0iXiX1/UYMwNOcbVpKQtHU8lZLio5Cx7Pcq5tmwatLAZhbzkjDby7pqSpHIVTJGMwWsT/aRYOzJzNnBfr9tmZGZNiiRJH7ecoscS6zI29EuM6nAesrqmcxIzrqmLBgg0sMXHqR1R2XhUOlE7P9xajDDGC1o6UNFNaWEJi9pFhXpgm4RCqJaCQ90KcukEGBEacUE9nsKe25aqUz+Ln8pJ748LQdznyKsP5YRzxYWGa+1yU0si9sW4oy0RdJ/zsOZ87isJJYUaSZl6jFIWrMKagblpQ5HNRYnexISXPTz99T4yRti1pqorSVixmJqnIEjzDuLC9qNle7himgd//8XvmWUSN9brl17/8ju1mg7UF3ipsDHSdYBT6Xs7h3TCyP3cURUFdOQ77Iz4G2rbhiy8+ww8+lypoliXQdyNDP1CXpbAfjcJNDruT/fB8PtF1PSDN2cfzkWkeaNNGoOSTnE+nRb53PihxnWfx47A/Mo0jdS1Rf2sMYVnoupGyKLi8UJnjI+tifx5YpoXSFRATjw9HrHX81b/9DdZY6lLc9ilp5iWwhB6SEi5oDBQhsMwLb358i1WK1WZHPI8My5gNFQZntQwn6oqyKujOAw8PR9rWUdYWa+T3hgiuMBz3R86nM9ZYVis5281zwGhLWda07ZqyWIhExmmk66VFr3COsiy4vrmkXdVsNxeUZUVdrUDBZrMW9vRTE6+S+G/TtqQY2W5FhJ7nUYauTqOsuCHLsuSXv/pWIqDrOrPpIiF6+m6Sc6E1JALD0MlauFnT9QPbtfCyXr66QSlhIsUY8JMXXIKS4edmu5ESi0VSFPPsWZaZmALGlNSVpLaMNUzjzMf3n/js9Ut2mzXtqiVEz/X1BSAidt/P1PWa1brkdNoDUe68zpLMgI+By4sLqrLmaDs5B84zx9OZafTMU+Du7h6jRb/R1nKxu6auy9yIGJj9yOJnrDW5aT0Qwp939vqzhae7+ztWbcs0TVRlwecvr5kXz+PhxOP+wNv37+RysMy0bct333yLs1KZfO57xmEQ8ccVAkE1lqQ0Plt5r7ctj/s97x5uqauGb775mnEY+OObN1xe7Pj81Sue25CMxbsKfxo49hMvXr3ky6++5A8/vef7P/wBtfSwDPzlX/5bfvHLv+Dh4YHD8Yizoq6/vbvn/uGBpq4pC0c3L4whcXEp08I33//Aw/7Ar7/5it2La4xxnLuBeQlMhwO39w/0fU+KO6qyxGuNK0qqQiJNp3FimCaRhZRiXixae6L/RAyBD/cPckDWn5Fi5P3bN1hr+ObrLwkKPtw/QIK2rKWCvSiI48j+cKSpK6wFqy06FfgY+XArLoV2s8Uo2D8e2F5c8r/8z/8uV3meOBxPfLi9ZR57pvOBpmm42G5o2pb1es2PP73jd9//gV9++w1/+atfwIdPHMZZrJ5aY4joMGNTTaE1p3PH29sHunXNqi6o2w1l2UCKVM7w8e6Oruv49S+/4+pizfw2cRxEhDFKsWtrgWOudihjiXd3LOOAq0tKY/jy9Q0ClxdQti1KQgzcXF2y+IWqlMpgqTpVXF2WGKO5WMvB7tP9iagsq+0Fuh8Jd2fWmzX/09/8G6L3vH/zEzGBzjXHp2GUOELhiH5if/eRdrXm9eefY8qST/s9V7sdv/zuW6kUnxce9w+8e3svMcGksUVNU69AL0zBEOZBqiqzc7owJZXRXL96wfXVFX//L9/zT9//xIurCy4urrGuoioHXFFz83LkdHjk0+0nfvXrv+Dly5csyyLQVS0gy9JIPf3F5fa5An5aJOryuN/z6e6RaZy5tRJ3iTFRVzVX2zVNXdNNXibXvURejZUqzZRynOhn8jp3PVWILNOEqRS77ZZlnvn4/idSgma1IYTI8dzJ2vbqRuCp7ZpxHHl4uMe5gu3FhXBkppHgI0tUOFuyrmumeeLUnaV5Zb1iGnpuP75nu7vg5uVrfIhMc2AeJ8b+xNiPz/HXqizpurOUBDzxgLYbNp+/5tx1DIM4sLz37A+HvDlMGK3p+p5hXnj1Qlxsx9OJ4+HA119/xWa94fbujnEciIh9tut6pnliZ0wWgFIWiJLYe2exUxsl8YP9wz0olS8FGp/hX86o3Dok8ax1K6LF+Sztk00loHudyxlu76TG9ovPXgMiroSYCF7gvyFEhqHn4dbjioK//Zu/kSr2ZWYYR46nU65yDSKk5+e9bmqOhz3v3r3hxavXvL66ASVR3mUcWMaRsEwkP1HtLmjXW969e8vd3R27zYa2beh7ie41qzVlWXL36Z6+O/Py1WtW6zUPD0ncT8ZSlpWIuSkwjfNzgYCwmATc/OLVVi69U08MnnEOhGWidJbkpLpdYodywairSjhau63Ys9+/I4TwXN08TxN1VfHd11+jtabLAsCySFPd8bCnaVo+++KrHDOLGZZZSgwlyqHj8vKKrjvhp0HiJSkyLwuTj6xWLbv1hseHex4fHrLQuQhI1VjquqRtGtrViqZd8Yc//sD7T58oS8fVxRat19R1wxJFjA3eczwe2e4uuby4xGjFmIGyKSWSqlBac3NzQ1XVPD7cM00jKM0cxMnpIxxORxHYgoDei1LaD6dpyi2OBYUTyKzO0clnUPvP5DX5RAA8BqsNm5WUqPRTZFkC3bSggVJLrssH4VVs2orJR3wWO62WCF1FZv0pqErLxXrFoZ941y80heFyVTLMnsMw05QFm7ZmCZ796ZwvWRUhRNQoYuEUI+dJ6uZJHlLgs+stLy42dOPCMAvbrhsNj+eBQzdiXcGqKujGhUM38dnVirou6M4dx27g1a7lYlNwPDli8JgcBzsOgwwbVw2FNUyTrINNLRgBOchDmUWR+ekwn8gtySe01rx8eYVC8fh4zGcWiav2k3CojK2QAJ1E0D/d3bNqWz5/9RJFwg8nmYyfpUwkRHGI77uJtqn4P/3trwlB6rHvHg/88PYDRd3QrC+wSDOh0RqjDcd+5u4w8nLXcnHRMi6BYfJsnEzEg/cS5TUJx8Lt8cjt4+lPz74SePflumFVFby7O3LsJn799QvWmxUfD3cMQ4/dOBprSEtgSRFtSpS1LPOI9yIoKqfYFLJ2N6Uw7Q77R2bv0a4QyP88YRQUmYkX/IRWiuvtBSnB2/szs5dGU4ltR8rC8fmrC0rnqIpCvs9GMYwzn+4PrNuam90KZwzWyIC5KgqcNSzzhHWOupSLm8LRDQsPZ3FokwKXm5bPby45nDse9ieWKPGo8xQ4DLM4PncbFu9ZwsJPn/a8vztQOs22LaiqUoTtMlD7wOQDHx+PXK8rVpUFLZdj1NPFPZGSxmoLRJbUM86BYZKBczcIbuOcZL9MSQopVPLoJDXxMRm6Wf55VVUZ1mt+VlG7+/t7mqbkcNhQFgU315fiODydcovsjNWWprqkqksuX+1w1lHbmv3+kbvb9xi9Yrva4oPneN6DNdT1lrouubxccf/4wL/+8AeqsuTzL1/z+HjHf/rP/yuvX73ml7/8Fet2xapcMw4DPi3PCYibVy/56ovP+f0PP/Af//4/0VYrmqrlqy9f8Td//Rc87s8cTwMxGsBz/3DP6XTCexm4Px5PTD7xzRefs11t+Id//hdu7x/4d//Dr7m53vH+zSe6c0+Mmr5b2O+PdOczzsI0lZyHQbhXhcFazcPdLeeuo6ortFHc3n9EK8XlMGC0ZcwRa1vKuSFM4qC8eXXJsnjev/lASpHNdkNVVRRFwTCMPDwcWbW1DLyMISRNWAIP50eW2bOupQnt7ZuPtKua/+X/+j+TAvgpcTqd+PTpjnmaGaee1WrNxcUGlWH4799/4F/+6bf88hff8pvf/AXh4y3HbqLM6BZrRKDe7nastmv+4/v/zG9/+6+8ennNxcWWhBQY3Fy/YL1a8+bHdxz2R/7Nv/0Lbm4u+VcUw+ixrmbVbLCmkAKUOHPsjjw8PDAOE5+9fknT1Hz73ZfEGKmaLdYUFLomxsirly9Z/ExdrqXYKg9OLy+uRBS/WhND5OO7TxL1LQ0qyJBxs13zP/7v/xqjNafzyLxMHE+PeD9xuNcUlWN305LizPHxgaZtuL65ISbF69dHLq8u+OVffMs4Djwe9nSHM48fHwhzICyB3cWaly+uOJ17Hh9FPDyfT7l0QgpWtps1L15ccn19wb//f/0n/v4ff8tuvWL13VckHalWJc4ari+3DFPg4aHjL/7iM16+ekmMnnbdoLQ0BJb9iRAWvv78C1brDW8+fKLrBw7njlPfcz5OLMvC991PEgf2nrKq+Orzr2nblsP+kWkaGSdJApSlRKRDEBbVn/P6s4WnlzdXUuesNCkT+32QKbBMZYUps95scc6xP3ei6MfEEoIcGPPEVClN0prCWtpKqoEfHvdM80TTrCiKMjs+DCZPfM5dT1lVVHXN3A2cTmeqsuDbb76icJb3Hz7Sdx1OKzCWhABQu9NRaP0kiTLNC6umwporZAsRCGACjqczfpkprOFyu5FM5/nMatXStivJHnvPetVitQJl8BGcD0S1cOx6YchMA3hP2QqY1xSliG6Imlm4QjgIUf73V2vZcAsrnKHL7U6m8l0PSEW5H0cKKy6fZQkEFYleWrFCenK1IAe67VYAon0vF4s80V6v18SqxNdSaZ5xoyQ07XrF5599RrteMYdEXVe8vr4S9kaMMtUuHdYWCOJUYVUSm7yVVgCF1LTPi0CKXSE56+P5DH6mIDCMA/uTo8qMgtMYiErniZvlPC6ktEgG3CpWteSjjZEM8OKlmWq93kiLFeKAwHtiEM6F9wKfjTE955O36xXOWW4fj6g8PXfO0q4ayeJPU24vKORpSJGu6/j997+nH6dnRsQ8SX304+HIMAz4KNXDlRO3wdD3xASF1fhJ2E5GycQ2RuExnfoJnx4xxvDFy2s0kYf7O4ZpZpoX2rpiu1nz28Oe/eHE8bCnzc6YzWYrhxRriU9tf8YS85RZa/P8zGsFZeWonELD87RjnqYcA6pQhaMsHMEDWtqjgp9zpOnn8aqrkrJweWouccolN1akJNDuJ3HFGM257yXvbWWTE+i8tGmkJFwOydpbVArP8QyTL746OzOKqpF65lHqxlMSl0JE0azWtNsd1lgO+0dh2iCfU8q8FpnOi5OjLAVqK60Xmpjb6syTuJM/07qqckOFYc4ZcqXyeCdBnVvsVHbsKGtBa2mqhOyMkAmcAlxVoZTOvB5IkzS3jaN8X5p1lRuGJEK1Wq3E3ZLb4HSOlZVVmQWD+XnPIKUswINSwmoStlh2lYXAsiw5LlqzLB6tl9w8KUOIFCPOSvTKGoufR5xRbFctg1YMJIyWn0Nr4UW43EwoLTSNNJjkCGBMSWqcV2uBmp8kElgWBcEvjEP/HPcb51laYwCV22VQY3biOOqyEtOEkb2yG4QnYJzAep+itzGJR6fL4loMPrPG5JkpC4kT7Y+nZ6cGSp4/oxVGX2JdIa1J8OyaGodBpmZ53xqniWmamefMJzQWbTTGFdLOlJ/hphYArA8Ba6VGWCmJx6WzuEasUtxc5sFLEO7ZOI2UhePm6or7+zvO3YBfpIHmqbGpLIWJMU7ispRmvChTxpQYhj5HiESvr8pCOC1eLrBPAHad998SR0zpef/zIcj6/jN61aU44ionTJ6Uzw2V0XgV6RePNlJnrLLDSflEDCmfMWQt9xkY7rTBK4hamszGWZhjdenE/WENPiWKRQORfhwxWlFmzpLwRzQX60Za6BZpXEpRxCFFYloC5zE3t2VeyTbzHa0REVzYGPKZhiUw6TkzcgzL4jkcO8qy4DLvdTEG1nVB6URIky5ccYn3w4hdZG20Vv1pbpIbnZx1GKNpKimSGIZR4iltjVbgtDhSqszBGr0WF53WFM6yW7dZdBbHitLCG9LGYGLCBeFZlVZjlSJl1mLMTajb9Qrj5O8mpA+JrWptaGsRo6vK4ZM889e7FdbZvIcXWFOJi3DyKCXOqKosKApHSPK5+pDoxwXnLOuVnKnOvXx2bVngY6KbxA2klKbvx9wAKS6efpLzxNpVaMSdRorSMK0NT1/KsnA4o6iqIrMqhdHZzZGUnn6brPtaWdaNcGH7fsQXAWfkOVo3NYU1xGWWM0gUwK0xUsd+6iSV4KOi0Ia6qhhy8ZAPwqmLkewQymfZpGSgmH+lsIpVaUhhZn88Mi0L0+IpjOKL6404WpfIMAemOVBYTVVYjt3IMC0s3rFEafTUWnh41hhh1i0en+8QZVlirAwoxkkir85asj0WlAzhUeI1REtEcV2X0sQ9z4xJCiJ+TsvXbremLHPbqXrqsAajNOhEChalHGXtSCry/t2H57j5PI6SIigrifAoEey0juIi8wO3tx3DNFFXJUVRoq2jalouL19QVivGyWP0jLOdNGNOwiVefbulKByfPt4xjzN1UeOya1KQABGjLXVZkQKkkNisV1Sl5dxZpnHMnLFA3w9oNG1doq93BB85ngZs6WhNS0wGHyKbzTrH+8Ul52yJc47TeQDkvGO1sIqtc5QXl8JSyq7xfhyzQ3zJTcMFZSmFBjEmXrxMLPPMPHYZhTJBCtR1Q1FI2x5+YZoXeF45E6iIcyWbzQbnLGEJzHNg6CZiSlxe7Zimib4X/mLwHm3F5bPZbPj6m6/ZbDe5LMSwu2xzIoectrEkhKeklKauauqmpW5bvJfI3fl8ZuhGjFHsLvMg+DTiXMl6vWYcex7296Qg+8y8TIQYKFyJ0ZbHwxFUEuesk7WiKEoMcm98wvpcXVTSBlfKoGEcJmKQZl/vPafzkZSgWjUYZanrBmMdD49nXGbGOWe4utiRkoFYISlZMZkYI46kd398y/k8oHUCpDTofDrx6f0nlmlmDhOFq4TdlSRZME9LRiREvPdScJTZYH6Zebh/FEecgi+//AzjNPvDA8fjib4fqJuG7WbLv/7+Rx4e7jgdX7JZrbDG0DYtdcYU9IOUtdiiyE3WCmvl7hpCJPgFVGK9XmdWcv6ZlolxBKUV1lnqtmJZLEQFSeWt9s+7N/7ZwtMvvv4Sow3O2NxiNBBSfAbvxnnB2YKbm1fM3vP+/l74G8tMUVZsrq4pi4K6qkkg/25yuNWKc9/z5t07qqpmt716hoMKrLEg+Mj9/sh2Z6g3lwzTkduPn/jmm6/41S9/wfff/57f/u53OFfQuIJgSmJ0TOPM/d0nyPZ7v8zM48DVbkNdVxyPB4Z+YFgSc0h8ur9Hp8Bnr15xc3nJ3f6Rw/nMr37xKzabHfeZAbKMHUNVimMkJCrvCSlym1vClv6MIdG+eEFdN7SrVkSJrmeeZ5pmkJaqIPXQ19dXOCMTHqUNVbvl1HX886ePTGPPpi5ZfKApSqyVut2UEtM4o4kURvL+JCirmqtXrwnLwmH/wOIDw+wpioKbq2uxTKvE+XTm8eGRmBv+Li+vuL6+JsREv3jWqxUvdluOfc+xG9htNmzWa479yGmYhF2lokywyiYfJhLnruN4PvP5Z5+z3e44Hfcc7+6J80DFwvF0YlwCbWGxSnHKsOvLTYsrSj5+emRaFl4oQ9sYNpuVxMKAcRTg27x4rq6vaJuGfn/PPM8QpAJ8mh3TPLN/fAAUZXmDdYab60vmxfP9m484o7hZO+qy4PpiS4iR41ksv66siMEzDz0Pjw/89g+/p2lWvHjxOl8Oj9w97vn9H9/IZKYSC+l2s2ZZFo6HA0UlToz+JJfN0hhKa4hlTVSG2/2Z4eMjr68u+De/+Ib94z1vfvyBoAxBGX5zfcXnr17xu3/9Vz7ePnC5+YiLnmq1pb1+wc3FmqYqOHQy/e2GgSUE2SQL+Pj+Lefzid3ugqas2FbSMmWHkiVEuu7MOBquXrQi/tYVwUvNug+BYRqFX/AzeW3aRtq9svA0TrPUbEeBGo/TRFGUXF5csPiFx8c7lDa07SrHBHIcc+iyUCLCTlM6pnHgfDyjtMYaEYalXlXaumJMHE7ihCqcMG88huvLK168fMWHd294/9OPuLqlqFtxZsfIOC8kBqzRIhRZR5lTkAoIy5TjuA5tLH1/ZuwTV1fXOZYptvCyqqiVsJxCCGw2mwzAPrLMM1pVkAxjkKl54Ry6lMO70pq2XUnleBDYbkwqu7s6jDFsdxdUzgpoG1Da4L3PjW4i6TtnWbctMSWGHLkrCsdTcyUpEfUTQ0jYYsEvEgsbRoqiYLvZCoNjGNBKNj+NsDuKoqSsaoyCqT/TNC2X2zVHJxXxIggK2DUsi/ALNhvWmy11s5IJzrwwjCOM0K7WrModx8cHDscDxgpQeZlGwjw+A6xP3cDiI6vVGmMMh4c7AZEvC1Vdsd19SVmWuL6TGGEvrafOSrzMOmE7LF7+nYf7O3yQCnS5wos417Yijr//dItzjsvdlsI6qrrMAmeFj/JcJ6XEjj1Nz2UTTmsmNCfTMwwD/ZhB7hkSXtdy+faTVAxvtls4KYZ5xpUVq/WGZR4Zhl4KQWLicrfh288/IyrDEiKHkwjkX3/5JS+ur+jOR+7vB8ZJmgtRGleW7C6vqKuah/tbxr5n7DuGLFikGDkej2KJr2VQ1bY7nJNKa78sIlLkfRMFZMfqOIjzZPH+zz37/HfzWrcFVhvWpRzmBylgoywMi08MYcIax+V6xRIi7x+khMSoJbN3ZP1aQkInESx10kTk0HsaJzSKbVNIfLV0JCWstmn2HIaBdVOxXrf4IJebtipY71oejz33h07KCGJ4Zoj000w4KKyKGBVpS0tbWWEkFpa+n5gmqSePkbyHw+V2RVkW3D0c2J/OfP7qJW3T8Ph4zzhNXG0aYlR04yQxYaUICfanM0Zr1us1zohwlmIEP6JVoi5EPLVaMy+eh8MB6yzffPk5zhrwA0ZB7RyTj7x9HDI2AGpd8ur6EpRmmhaBkVtBRuiiwKSIDTJIE1E/EuYRHxWLVxSu5MXVtYjqSmcocJBYoNE0dUlhFYuXqFbbVOxWFf20iPNp1bBbtXy433O3F/F5t2qo65KicIw+sQSYRuEcrdcNu9KxTDMP+zOFNZTritknRj/T5iHMw/Eg/K7tDmMdh37G+0DVbtAouq6T9co5lLakRTAbbVNROnG5pqfIpI88DIGUIdoojXDZZbg8Lwv3hwNFUdCU0uB7sWnxfqE2EoNcMq/PaMN5mPnh/T2Q3bWmYL1qGeYTHx57KmdYtyV+EYEvJXFyxKSfwfKoRO00jS2Y5on33ZlumumnhV998YJvv7zhvps59J5+8EzjzOvL/w93/9ljSbZu62HPNOFjuTRlutpsc865Iq9AihIECCIggB/07ymBvPfc47br3d1lM3PlMuGn04c3Ko++cQsQCLIXUOjdtauzMteKmDHneMd4RsthUzAOI6d5YXYFmU9YLUUa26akKnLGaWCcvBRGrkMrlOaXD58Yx4nX97dS2rA2SlorbgPvVgTHGkW6yYVR+unpmcl5xkWc6b+W15u39xi7wpWVJiYZpmVGBNioLNZmNNuSruv4w7/+G0prdrcHCpuxaVrqtsUWBRhD4R0hLGg9cL1c+fjhM0VVsT/s0SsCY2NuaOo9MQa6zhH8QAxwvXYMvePbd2/44Tff8cuP7/nLH/9KlmfsG4kFay0xtHFyWJOxbYs1rh9pNzfYTPHp0yPn8wViInrH+XRmGiZuDg3fvNpzvE48PJy5vd+yqVvmIeJd5NX9HdNmZBokwl6VIgRI6Y8IILk17DYtdd3w5tV3GK15OH5kHEeOZ2nIW6aJLLfsbw40Tc1ud3jhG/bXjj/96x/wyeEWwYDstlusMcxzwHtH112kuXNTg4okFcjLjNevXuPcQtdd6IeR4/OZw2HHd9+9ZRonLucr0zQzDD0ZGcZqXr265/e//3vmsWccO8rKUO/3DJ1j6B15ndNUNdOyMHQdRhv2my3b7Z7tbs809SzLxOPnJ7pzz+///gdu724Yx0T/cKEsKu7vLF1/YZguVFZMHNduxofE27f3ZJnlH//1n+n6ju/fvWW7Ebh2XTWk5JnGwNR3LItju9nQti0oeS+u1zN+Xnh8fGZZFo7HZ7SxFGWNUTnbrYhgP//ySFlmvHm7o64KXh3uUdoSKFiWmcvliEKE0cvzhb/+8a8oo8mbghgdfX/l6eGRv/zbX7C5oWxybJWR1zkhep6fj8SoSVGvUbuZqq4oqhylE/M88vD4xPU68PabN/zH/+b/wLT0fPj8nutzx3Ad+W//u/+G3/7uN/zxTz/x/v173tzf05bVygXdcffqjrqp6acB5xxjv5ZWWOFQP325MA4T9UZMJve3N1RlRa7FYT5PPc4NFHVLbnM2+w3eebrTQvSRsDZ8/i2vv1l4qqpSWmTGgRC85P6MpikrOSwpI4vruvHIbUZAeDlq5Q6EKOTzEGQaG9aMqAv/TlTftg0hBGa3kKIh5vk6GRWmybapOOdSLzyOI8fjEWLi9nB4ORTO87I26Di6flg38eBdWF1KidlHAgZMTmmgBKYx4gOSy41BnFcmYxhHvA/8+P4D165HBfdCgUetJPog8RKUYo4NxEQIYvUuvScpLeyRIGpmjKIsKhIp5cSkGVwi4fF+WXOrOVrBNI1obXjz5o6EwqHRRrHbFni30HcXrLHsdy3GWk7HI25ZGLqrEPXznOgXlll4IfM04ZxfN+qOZRplQRkHWbxtzu1+x3a7xTqP1iMxCmR0nkeWcaBtGuriO1QM+HmgLIT1sW3kALhtatq6wk0DYT1AXq9Xbt58y26/Y+6vjIujKCoqY5iniWllH+R5RplJ1v/49CgAS5PhnEcpgzFwfn5i6q8MXUdKkSIXF9cyDkQfuDvsSYgdNKWEUfIr18KrWuYFEnw5Pst1ozQpehbfoZXwfJq25c3rN1ibrVyLwOl8xi2OXdvKNVuJ+8hH2QSbIifEKAe0lMTBZxSF1Wy3Lfv9nsl5ZufJjKLrruJ0ilCUBWVRMC2Ox+dn2qbhN99/x2G/pyhKnPcsoSfPNItzHI8nhmnCB7mvrJlk4+fl8LpMAwTHkm+x2uLjTEiKuqzJrCWlQAzSHGWUJitzEZ6mheT/tlrM/z28xAoqkS98EBt+DOSrSyStzhxtFDqujJiUWJZl5TxpYVIEyd4TE1rLtCgFj9Jy4KjWcoGUZOJujCXhIUi7TV0VpOiYRoFsT8MAQNW0mLyQ5pMo0QHWv9eHiAtxdQjIBB4tMTdjDGVZkmU53s0vBz9IL/d0UQhcvB96aSRZHTP/3lYnrqF8bSuNbhE2x9rY8bUtbZkXsTgH4YXVVSU5fiuTzGmaBBLeXQkh4dcIX26t1J9vRJjt+17+/vVrz/NXIHIrMY6UiM7hnTQhmTwHrVmWRaIb65/RKaGsITP636fM+mvDkkS6fYjrIQTWmRQxIWLd6qxanLhxsix7aTX52hpjrZUNm3PEmDjsthRFLrW+IawuCtZGG2lzMuu1YI3BLxLF665X3CLvX4KX+t15GFAkadBTYPMck2SqmFh5NCsbLqYoDqX1fXPeMUxy74rbITKusSNdFpCk0WtFaYGW2J6xlqbdvAiYWqmXKea4iMMhhYhSeuULSpQnz3Pyr61+SuC9ERiGgXF1LdV1Q0IxzY6qabi7fyXtMSvoXIYl0vY5z8tLi2D8Gr9LEbfMuGWhLAsUimVe1naugFrvKW2kzQYEnKpiFKPceo/+mtyaAHlWkIBTPwJyjev1OtNKo20B2rDEREhgrEHFuPJuEs5HaZczwuFihVJHkH9/iYlafIyculFaalZnWWaF71VklpgcfolMzsMkPMsYvbjZbPESm5UvG/EpEFaRRWklTXsJxtkxz46yyCjLfIX+R3G6r8w4pS3TEojMPHcT0zSREFZUbqQJzAW/OlBl3xnCurda1dvc5Ci9tjISmF3E+YSxco/qFCAkpuWrYw6cjy/cphjk2VBWJSnC4qR8JJqM4APOjRgSpY7gFGn2L/eW0hq08ANjisyLZ5oXMmspipVJpWGaFjq/EKOsbXlmCXlGWNv9nHN0w8A4OxYfqQtLlUmzktGGqtCUaCaVcEajkT0A6/t47ScW72mbmjy3wlZFChlyG/BOIveGiDYKs/rgrVIEJe9dSqDW59LiZR3rpwWNnA2MD5xHWUtvdw0xRs6dYAbqXJx6bdMIH0QpnA9crj0xRULUhLQWu0QwepBBa1WQUiSGyOwWPj8+M86eTVVQZDL4ceswKUTBfkzLsnru5CxAjMQk+8qq0BS5pSwCoDh1I5du4jKIh78q5Pq/jgsRASMrLc9dF8UxeOnH1QkV/11EXFl0cXV6GSvuX6MUnvTC/wK5DpRSeC/PdGEGSuNtTEnYhL+ipHDbtgDM4+qUHkdh2mw36/D9itIJYzLyvGSz3YkrU1kUGhcji3eMc49bPNdrT4yOyExMirbdUVYFTVuTkjjv4tdnQZTG8Twz7A4bQgr0w0QM0F17TJZx9/o1Psw4PwkqxkPf9ySStM8pyziNLG5GmYyEkaRBEJZTkeeEAH7dB5rVGR5DYOivzLPi6eHKNC64RQYnbd2Q2Qy7usCqsiDPFENy67NRho7DcMUaaeVNSRG9JwYvbbKZQMmtMfRdt7o4R7kOowi5fT+glOH+/lbOb36Wz2S7JQTP+dphjKVd3eLH4xPOOYa+J6ZEUWYYo1bo/sj5cl1dnFIYEkPgfD5zeroSw0IIC5vDhm29WV1py0t73TzP637UcvNqR1OXZNpgahHQo48URU7VNNi8gGkkhoXn05FxGPjmh9e0m4YwebyP1E2F0lrcTM6xaTaUxRrv0xY3e4Y4cb4+MU4jARF7L5dn5nlcI2GJPLcYI2dsqzNev77n6w2oiDSV6A+zCwJpd54xJT4tR6zNKOtW3NhOyolijOIE27Uvg7GUEpdLRwiB3Y2koPKiIMsK/OKxWmNNRQhu5W2aFwi5Uoq6aTjs9jTtzH6/UFaFoD6WxDInsrxke8iYl5nPX77Qbmp+//vfcLjZkRUZs5vxi5xd+2lgnCacd0z9hHeeZR1ixxBIMb38WpwkpfqhZ3EL+2pLlmXibkKc08ZCqjTeRfqx+/9/1K5tGhbneDx+FnCzj5RFwa5tQRlMUb1EOrQ2lHlB0BoXZOom9bUCYXXOcb2c1xYxebhWZc6mqbg7bBmniefzgsoMqJJxnBinkUxp7vcbjo8FKUn+9MP7j1Rlzrs3b3AhsHjJDzvvGOeZZVlE8EqJoqjIsoIlgF8cHkOyJW2hyQ08xUCc1Lr5lqanTFsul45lnvjHf/xHnp5PfP/uWzZty82uFjB2f8XFyG2dk+c5ndUiqoVEmBxVIaLZ5AKzC7hlXi9QgXHHosBFxTBFaVa5ngUUWZWkGOi6K5tNy+9/81vGxfOXD89kNuPV7Z7L9cqXhyObNuf+/o6hH/j0/j3TPHPtB9q24fX9LSF5fBjprh3HpyM2LynKBr0sTCrx+eGB9x8+0mx2tNsDTdtStFuyacLqtR55mpn6jqk78+b1N9zc3PPp5z/z/PiJbNfS1AUqbWhLaa6p24Zl7Alu4dL1fHk68h/rijev7vnLn89048C7ww1lWfLTX//KOA7cv35NVZaURpwQH97/hHMOU7SgDcpkZNry5eMHlEqMSyTLMv7+Nz9gFHw+PoBSvHv9lgA8nCVLbsVRTmlkQzyOjmGceb4OFEXB3e3N+rDoqcqSzas7sjynbBq5OaeJYRh4PD1T5AWvbg/kWU5TlUzO0U2TuA+Kiq7ruZwFCr7b7bEGMgN3twfevHqFiwJh/fL5E0+PD0w+MQdoy4rddsswTVy7K/vdlsN+h9UCSn08nemn8UU0+fzhPd21Iy9KtP1aI54EkAqM3RWnFEW7x9qCJS6kmCjbnRwiwkwMidxmKG2wze6lDSktv55Wu6qW9rB+XtbplZNYZVnx9f3S2gjwM+qXw/08/Tu0mRiJQSZVARGAUnBrrMxQ5AW73Y5lcfTjiFIiDMUYpRraWjZNjXczKkXcPHE9nyDBZrcXG7rWeLcQXJC6Za1ZFodfQbJaAXmGVVY2OTYT6H1VMQ5G4pVaQYwMXce162iaCmMs58uFZXFkVmKr+/1O3JPTSIyJYhWSrkeJR/kk0bQmeEiafpwIwZNWIWqz2WCsJSsKQNF1HcsyczweSYAtahGljBQk7HYV4zhyvV5ehK8QI8M40jQN290etywrQ0Hut7wsabY7ondM0yTPiwgqJXQKWCslA13Xczw+iS19jZNam8shMQkVJL04DSDLckxZMPvAMk0C1i4K+f01IvH1YB9Czrk/Mc0Lr1+/YrfbcXo+4r1fBU1LUdXiXKhrvHeURYG1YsefSTwfn3BukQarlW0YgMv1jEriHtJKU5TCPdq0Gzm4neQ5IEnPRPBxBYJ7gk/M87QynIJE+QZxY1kFKUWaunoZsmAsAUWWy8R+mRemoUcrTWZznPP044RRYJV89kVZrVxERVlUFLlAxPOiZBx6xnHgfL3w/PzM4XDDbrclKUU3Tmy2ezbbnYDCk8QIYgj03ZVxjd0451+EAjH6RaZpZFkWtmmDVop5HFnWwZVGvcSuFy9FCNYgwrGS6yJ4/wJt/7W8irIWF/kXcYDcblvyXKOLEmMiOnegFdPqes4yI0OvWbhwwzhT5Bllmcn65yIBCOv7pFNar3dNNy48nnpyK5BxrTVlkVHlOVVhmb1n8QEXI73zuHmWa76u2Gy2DL0cfkgChPfekYJDWytR1+TQLtINM8s88+a+Zts2PF8Hhsm/RImNzTARummByfH52DOME8aKYP7d3ZYqtwyjPEtNnq2RYbfGVBHxdG0rCl4ccf2cCBHs19hb9KQI3bgQY0IbTwhp3TeCS4qqyPhm3+KdY5xOsLrFFhc4dSOZUbRlhg+RYXZr1XgmleRN/sKX6oaBL0/PbNuG+8MerEJHw7UfOT2fMQaBX1cNRdQYAloJvmCcZrrRMbnIrs3YbqoVgs4aRbL0RjMvMp12y4K1Bdoani5PXK4Df/ebgjIvhfGSZE+viXx+OjEtTmKCVmOUCE+ZVuikRRBK8nsJmBYRwDKVyK2m3TQ4F3g8PZAZwzd3b/AxcezFNVbm0nSkbbYK7yJYXq/XFW9Q4mNkmBeMloOQtRn7TS24jGFknCaOzyfqquR2uyVbo6fL+v2Os+PjpRfOm9FYpYUdiiekRFtm7CrLFBKTF1H/y/OV07XnOozc77c0bc3iBRAfUqIsDMbKoGdxElsdlw5Skji6thKpjIJlcF6wESaXOLFRCsfX+0AOZFqzxmEDJiqyTIajxRqrnNd47K/ltd/f4BbHl09fmOeZvrtQVSXffv+tDGiHC8omrC0oS83t/SuC9yQngvLsIswLXX9mnhzPTxdQEbJIpnNu9ncUVcZmVwrAe5D7NhEhBpLzlEXOqzc3pATXy0zwkeenZ6pmw3e/u+d4/MjTc0+YIn5JnM4nztcrdhWe0AF0JFGShQy3SHx92zbs9zsenp7pxwllFHbFGKTgOT9f8GHhT3/4hculZ7vdU5U1b+9fsdlsXtxt201FIkeltBZxzUyT8PXyLMNHS4iyN4xO1tqyLKgraaV+fn5mcY7L5ULwAR9lKHo+X2nblt/99jcM48iffvwzeZ5zd/eK6/XC+48f2G63vP3mW6Zp5OPH92IumBx1U3F7t8cawzhMXC4dXx6eyLOcsqhQIaGD5/jlxJcPT9hck+eGb7OM21dvsNqh6QlhYXaJcRgYuontoeJusyVLOSZZsrrBFBLBn+aBptnJflv1+Djx+fNHjscT3/3+LTd3ex4/POP8zKvbA0WZ8/HjI9M0c3e4FUA/HqMU8+CYkuPPP//IOA4yoMkMD4+fUUoxu0iWW373u29QKeP0dCW3lm+/f0WIkZ9/foQU2W9KfAhcB+HY+cUxDhPvz0+UZc6r17coDMlLrNZH+bqvXt3gQ1jXysDT4wlj4PU3t2iVYVSBD555dOiyIitbxvkiBWImZ7e9IeKIamG72/Ht9z8QQyL6xPP5mfP5zDxFxgl2u4a2KeiHnvP5xOGw5dX9HUUprvH+ONCPA904rANNEZqWcSB4L857pQguQIggcz5hy3rP6XrCOc/t3T1FUbMEERTzr/t7DM57rvMZF/82w8LfLDx9eFiBo86TgjQD+CHwh7/8SJ4XHG7v0EbjFtnseD9jtWZ3e0tIkWHxaOSgnhtNXKR+fBgdSiUyI1Pbz8cTfpkZx47FOYZ5XlU5x+xmplmmKk0l7JFuEn6GWxbCeigEKItinWArxnHELQ6lFmJK1JnYx5SKaCVTUpdg027YtEAK9JODfCFp2ewrrfj+3Te8ur3BZsU6EZdNkDIZrJsOHyWqoZRaG/+k9lcrRVMWlJnFxjuxsUdZqA77AyEGfvnwkRgTdV2/OLqUMeRlgclyvhxPhABWJaKb+fzlM957mqYURxrC0dhuGsqyIC9LgbpOMzazwgqwOSYriCHSd1dSVZEbQ1W1vP7mW+qypK6kYnjqO3EvtS1GG7SxdErhfWIYR+zlLHGcdkM3LXSfHylyOcCN84JPV1H064a///u/4927dxhtOD4/y2ZJG65dx/naoW1Gs9lK1EfB8XKVSVxUAtOO0trjnYh4u90N1spEFOB6PUOUDbU1Fp1lKwh6JkVRrpWSymSlFFUrkLmyrPDe8/T0hPeeeZJGQJRsCAJf2WCSEU4RiW4a2ej6KNPkw6ZhWZsB5PAThR2RSUvWqe+wJiPLperahyDXssnINdhsPYyvh2OlFN0gVb67uqTKMzZNTV1XzIunHyaKusXmAn6NMWKU+DqKXHgWWRJHyP1hS1E1fAyOZV6E/aU1uZWmr+1uA0rz8ekBFwKH7WZ1hPw6XotzgDBhkpJDQFrdN1mWcXNzhzaGaZrXRjHWCFJDQqqWTWYpG4lGhYQ4lsZBGExaMc8znz99QhtLlucS11zk2hMikBgpldLYtVltPj1jbYbN7EqKkDYys7a4uXnCzQL6+3rgMiES1do+CCyzVKNrJTBp5z3eeZQ2ErOrGmGF2IwguYC1HSyTnyWukOl5fnFBaV1QZSJmlkUp90u1XmNGGH/DOECMaPmmV3EfqQtPCaVYW7QSKTguF4lKfWWlTfMCJNq2pSgKEbS+couMeXH3BCeNbnlREBeHnycR4JQ0zY3Tgjaa7UbuZ2OM8AzWaU1VFuJmUwq/8o10UWBVhiag13V2WRb2ux25tSzLQkzCnKvrhv16EJ2nked1/ciLkq6TNpDaO4wVbpPOMsZpjekYYRsMwyCsMBuwmbxnRgvrIIbAMM6y3mghI4TVEft1Sl5m0gq3zBJpil4cJs1ms7rMhGfno2Qxx2laryZhaFWFtJ+K6yOxrA6jbIX3fo2RfOVyKa1QUdYv7xaG4CBKHC+kyLQsIjwNwjRs21barGY59Ecjz+sQPEVZYbOcLBcw8bLM+DDjvTidpFVR3FLGGPwysSwzZnWBbbdbbGa5Xi6r4CbiJ6ub1WY5KQbGUQSQqmpW19+v5/V8EWB/mWfCpIyBaU70D89opahy4UB06+Q7ReFQvLkTVuTT81WaoepaBl15zrg4puuAVorMGHm+LpEUpa7eGi38nZhWB2TEryJ7VRbrNTCKEw3ks2cgM4pNWzMtM+MkbiAh5KiX/ZhZEUwRxTjPqPVeVirRjyPjLMbSyhomL1H8TS0QXhEVhR+EUkzes/hIpa1E4EpxPge3tm9qRVISATZK09YCiV5mcTi4IMLoNM7ihszsKlzJWllmGUYlLtdOrjtlxBXTdSilaUrZr8iapyjzXKLEVkQ7t7LJUGp9r1dmS0qoGIgBMqNp2prCKgqrBAKLJAq0lq9vFDIwDYngA9d+pC5ziixjGAYWHzBrXFlpUFHuH63g9e2ew7YlKsPzsLAtCgqjGde4orYZpTYURt6vcV4YF3mOvJQBrL+U1mzKfGXNyZrTj+JcrHJhkc1ubXRb9ZOYRBCNwa9uAnlvitziQuT5KtHQrw68YYoUmWfXasL6XABNVBYfFYsPkqDwkFvL7X7D83Wkn8N6falVqHcvTWWGXEoHXqLyCa2FeahMhrFGnKxRntZC3dMYwJIIBFKSYbK4suS9/doa+/XZY1fHrVljW7ebGqXg6dKvkHupSjdGRD67MoUGF/E+0uTZv/PJfgWvDx8+SDyaJA2XRjMvC//6L3+QIpZ9S2Yzhr7DeYnr5nnG4fYG7wPnbqAoM5q6EHEuKaZ55HQ9g0l4rXHdyOl6xBgr7u/FM02LtIStB3/Wz6TI9ZoGmaXt7doxTh1+AaNzsloclUopiQ+Fr88byJqcpq4Z60ng8kqxOE9V1WRFxeIip7O4hWxuKeweReK7H9TqRJJrL5CY3Mz50uNCoGlkv56vhUmZ16sgKwOs4CJZpri924lgsIAxGWWVAYrzSXiJbdMKp8hfhAPXVmht+PDxPS4E1BojfH484/3CfitN8SEsKJVo2poqQGiERTYOE7FYm2OBzOSkJPsLE2Q9wiZ2dy1VVVLXFU3TEFygzEuyw40MHKxl7BzOXYmhgrTeg8pwPl+ZFkdVF9TlluAjgxuEx9dU/Pb3P/D2m9d45/n0/jNEsLni88MXeRZEcc/LWVzzfBSERH7uISmG64jznhSEd/rt23fkRc44TSRg6CSaX1cb+Rq2IiwLy7yQkrynOkbMKI7YlBJFUfDd97ciqH5+lGZBLDY3VHOO0YbcmHXoJmfOeZ7WJvZCzhJFgTYCkfcuME0DwS9fjymYXL736+WZMq8o8nLlxSkulzPXq7CorBZ3nbjjhTV6vQ5433F3f4exOUWxaiXdwLK66JVK65lkTXoYjckF9V5WBWVVcjhsyYuMy+XCOM4Mw4BbFkxhVlfXnpQSf/3LLzgXeH3/Gm3+tr3X3yw8/fmXz1gF+9JASsxOmko+fPzEtm35vx8OaKPkYeYX3DJSNDXv3r5hmCZ+fP8enSLbtiX4BZu81POGHqXAWsW0eL58/oIKDuNHhnnm3A1oLRfXOE8M0wJKsd3U9HPgMswMKpHphDIGtKbKrUAjtUSopnlmcethwjvaKqewGh1l6icPc7h/dUPTVHz48InLtSOPGmMCJIHl/le//x3WGn759CCcDGslBmZzIpFuXMhc5NXrbyjKguvxiRCcgHC1oirFFbZt1wnmsSPPMl69umcaB/75v/xnUJr7V/8ACTlwas1u27J4zy+fHjHasF3hrx8eHyjLgtev7uXwhibLcw77rWTmY6IfBo7HI7WqabItNo9k+cwwdFwvJ1KMlEVFs91x+823FCpRqghG0Z+fqYqCzW4vE4QUOGqxCXfXDr846iJjt7/hr58feDxd+f7bd9w2Lf04ErqOpm3ZbLd88807Mmv5lz/+ic9fHnh7f0e5y/mnP/6Jy7Xj3bt3tHVNmWuIgc9PR/px5nA4iPNgjQ64eSHPLHe3t9RVxbAE5nnm489/JnhPWbfrYT4nIuKAVlDuG2HChAVrczb7A1VVcbffcTwe+cOf/sCyiqZFUTJMa51xnqFSRMdlrcRVKGVQtiAqcDHSVAWHTcXzueN6EUC9OGGgzAzPTz2/vP9IxIAt8CskXRrMCiqrBcSZWUKSTbpSmvO143i6YO735NuGw+GWsqr4418/cOkGbm/vKKuSp+MD0zhi10llVQqwMlNi23/3+pa6aRmmgQviFEwxsmsb6qrk5uaGmBL/6Z/+Eecd/+f/038nzIJfyWuaF2EwFZaUwDkRhZ6PT7RNy29++ztA8fAojJ2UxBVzd3uLc46n5xN5nnF7sxMYdITr9crldFqbtjL6rufhywPb/Y7X37zDexG2jLFip0/SUKG0Ic8LLpcLp/OZtm0F+r9u7IuiIs9LgluYl1mm186RrwylqLVYyVdxZxwGJgWH/YGqKrleO+ZlRhtDVTU0a1PbXgiIzE4iz/M4CI9oPVhO4yQQ8Ey4P/X2gLXCxUopvdiPy6rCO891GIhBxImkeInulEUu0YKkMEquQec8p65DoVZreqQfR4o85/awF4dZEidVmedEpcmVJbiFZRpkylY3uNC9rInKSs1riJE8z7i5uZE4WJ4zTyPTNFLXDVVVvxyehnFiXtdtVRRSq5AifddxuXbUVcmmqemHiXme2e32FCu0NHjH4+MXTtPE62/eUZU1n788cO06NtMgm+X9DSYrZBo1z6gkhxi/gttNZsljxJAorEE3Dc55Hp6eSCmxXVmAfpnxMcph0ojzyHvP5XyWjXBw5Lnl5uaGvu95/+EjSSmKspLrKMqEL1s3s01VSF3uvKxRKIHS54XwdnKTWIzwtbRWwroIcohzy7we0oPwL8Z18t93TONAs9mw3++YZ2FkBW+wWnEdBqZ54e7+nrwoV/i8RD77vheW18oRktrrhrqu0CkwT5PcK0pxc3tDVdV456XMwS0A0mZqrNwrwTMMPd577u7uyVeHxa/l9eXpRGYMr/YbtFYsbmFaZj49d1RFwX/83Tf4EPjl+VEcMFlBmTf88PZeWHFrvHS/3awsnYi7XOkfT9KwaIy4fCaP1YptXUoEU0uj27I2TzovwlNbSUlAd135QdYwTjPn0fHmdsdh3/L5YabvO6osR2d2hdlLKYARAj4RTTcKt9HYHKUM577Hecer3Za6yBnmkXlx7NuGPLMMozjYs7XCuZs90+LR2lLk4jrMMkOcZci4JEGQszpQdnlFCJHjIpHPKQSCD3LIiom8lGtHihssdWHkzz+fxMlf1fglcr2cqcqSN6/uCEE4gV/LSazRVJlm8QKLhoTSUnteWCv3UUwoJP6XZ4a82FLnijbXTLOgFpSpUXlNbhKFkSEBMTG7hXEaKbMdVVPw5enKw3PH/U3LtilWN44IXVbBD9/ck2UZ//TzFx4uI9u7jNIaHs8T/ezYbTaUmZVWxBQ59jOLj+ugRIbCInhCZuHQlmRWc+5nXIhM44JKibaSA/SwSBRNr4w64Y8mgltEAMyljCYrM/ww8/koLti6ql5KGNoqp8zM6vSV/VAkwyfFvDiWJGP5+5sdb+72RGV4vM4YlbAqoVLALZFpmiVelRIOTV0UVLkV5qVRtE1Bu1G4uWdZxKnMVwi2MhgFmUqE5EjRM3nFEhSZiTLUXuQZtK1KOWwigoQ1InS8ud2SW811mpi9JyUp85EyIU1uFT4kujkQfOTbm4L8bzy8/e/h9ee//Jksy3j1+i3aarTVDN3AP/2Xf2W32/I//D//B6w1nJ9P67MgUBY13//mW6ZpIfz8kaKw4gpKik3TcHx+5svDZ5I1FDZxufR8/PzEdtvy9s0r5tnTdZMgWoJn9k5QMJmhKg3DdeLLpyd0ptBWhheZzcmbgnrd96okkbtlnohrEUKelWw3O6bZEdY457R4NpsdeVHw+PDAqb+SVzlZkdO2e/Is5/bulpgcnz+fGCdHINBPAw/Pn1kWx024oViZZ9ZqliAogLqu0drg6NBG8fbdHc4FPn3syTJL1RTEEJimCYXm/tUrieVeO2xmONwcGIaBP//5T2hj2N3c4l3gy+MDZWm5v9+jjcG7Sbhx+424cXTJ9Xrh05dP0hC3xt5LWzK6mX4a0CZiMgGX331zYLvZcdgdiB78HGibmqY+kJQhKcPz45llcQSfIBq0NZjM8PjziS9fjvzDf/g7bg83HJ8fGIaOui2pm5Zv3r3BGMv//D/9Ix9++cR3P7ymbkr+9C/iIvvtd9+xbTdkq9D/5eGJy9qEq5QitxUKxew6qqrk9Zu3bDbb1UE38+H9ESLc3x7I8hxrKpYE4zChjaKoSmJIGDXLPjIKZuLv/+Hv+fL5gX/8T/9EDJ6iMGR5RtO0lGXF7nCA9LW8yDNOIzGW5LbB5MK9quqc7b7i4cszv/z8SUpYSGgDplAMXzo+/vKRFEUw1Ebet/7aMQ4DbVtTV6VE9FbsgtEZz6cT59OVsmqpG2lubuqSvp9ZphGTpbVrSK5rbTU209hC9vJ1W9M2G+5f31KVBdfryOXac30+EUNgd7Ojbipubu+IMfI//r//J7zz/Nf/8b9m027+pnXhbxaecunX5vnSCZNjtyevamndyHPGecZ6DwQyK9BZozVfHh+FtzTNnEPkX/7tD2glUYmwRo60VuuUznKTl1gVKQh0/YC1J+F0KMU4zvzbn/6M1tC2OzZbzVttGMeBqe+weYHJC6Zx4Hy5UpYVeSET78Ku2fYU6cdJ7P/yPHyZuj49H7kOOT5G8qIAJdnzcm0Pmn1gDkJ7b9oWa1Z+0CSbu21bY63h4fGBGCJDdxa3TS2tAre30nJ0Op8ly43k07uuk8iHlpuHGEAprM2I63seozQWSUNUhrGKQzxQliWHvdTYTsuEW6fReZbRNA1FnrNtWkJKHI/PwuIoMjKzoSoLdtsd97e3dNPM6XTGpIBNgaquqKuKbhhZnLR9ZFYxOo8tcrKiEBcCickFDvsDm92Bw25LU5XEzBJj4Ply4eFx4WaFypZFzs1+xzRPjOPIftOwbWpe3x6kyvzhC9M0SluBySitxhoo6gqtFEuVYZRmHCfmeeHpLNEcY8TNhc2JSjbCzjthnKzASlAMw0ieC7/ALws/vf+IW2be3N8xzTPn9fpO6d9ZXFlmaaoGGxO2SBL1WKQtBqPo+sAyjSw+CqclRNDCGvAxUdUNr9+8oapKlmVcWTkB72Qh+7pJiakjrodzay277ZbNZsNNW9OUOS4m5m6Qystx5LWBpsx4DEHiKbsNZZ4xuSC2/2HAzZFfPn6mLE8E7ymyjHy3lQxvCPSL5+l0AiDLC6JS/Pz+I9b+eqJ22ghwdBzGdVLqMNrw+u07aeA8y8ZXa4VNhqTkc+/6Dr9+VtMc+fJ0Ej4s4oDRayTLGEtVN7x6I+6//W7PNI1AWo1JiWWZeXp6Epu+Mex2O7abDUnJ4q/WNrPgHfM6IQaZsEjrV8TrSPCDNA3FtEZDDFpp4U6sjpc8z1lcWN0KAbXykWJKlGVFZjTdKmppBXlmqetKWuHczLws9A9fBPK5aSUyuK6RwnKSBjKlJbLxNaKqlGK/3QkkuuuIIdGP0vjn50maWnJpwkprpE0pJRyAZcatTWx5WbHZ7jBYTCqIIGDulNi0rQCTtSZbheFpHDmdTuRFIW7FlNDaSkR7HF+cXCEGbCblGOMwSMQrJtq2Wa3r1UtkLi8KnFuY5kkEpJSkJcWII2Jxjk3bUpYFTVVhjAw4wirImXVi+bW9TilFlgszCWBeFrp+IMRAXVfCP1pmnJOnQkwJkgjdX1vf5mUWh1Ejjtr3Hz6QEtzcHAgxsrh/54PEGBmDRD+yxb9wj1KKOOfw3uFmWOaZeZrwa4TRL57Jr58vAoa3tlmbpuSZHUN8KWL4yskKIbxEGZNSNHVDXUsxhNF6hacKPLzvOw77A2Uu77FwXIRfUdU1WZ7zfDrh5plr17P4wOI9SUFVNSiQuuE0gpKWN2MzUFriO+bXs3YBVIWIIZdhRAFGJ4loNjnGGi6TgxSpc2F7GS1w/l++PBO88LSc8+KIQ9aUaV4oVnehXQd0SmuK3LCpclIUVpNNkKXEsHiuDxeqsqCuSsqq4NWrW4nppYhLGp/EaXK6DsKAQiJzeZHjI8zTIm4noRlIO51VWKWYFxFFi8zQFPJZzj6Cshgrey8fIpnVFEpi0SQorBXgdZWRW0PXCzdPR3GFKmtXp4tMc4frlZjSel/CmstBW3GT5bm0Z9n863RfhkgxiiO5yjNyo1BJWB0uQogJHyGFwOxGijwjt6V0RilpXfOLw4eIXg9IKomIZzNLPy5c+oG6MAyFsNNSshifMDjm6DmHsN5nTpgghfC0+mEWVMCNoS4ztDGUuXxm4zgxugBaBpJNbjFtifeOS+8oMkNm9SosBYZZnhkSHV+j50r4lEol3CIxiqfLsMZVRFAvslxcb0tA+UgyCyFIE5LRijKXweFlEP5UrcRR9nwdCDHxal+LCy2IA7utK6xRXIZFnHeZiHVNna8xwLWNi0Q3TPz08ZFxCdS5xYfAEoRlaLTBZpG2Ehe4NZkMTcPKwVnryiOJ5AMxfm1d+9pUynrYy7AR0BblPYkofJ8sYz6emf1Cltn155RG0mVZWBbF00ne42UOEGHblGgj8P1h/srPSrByg079gvkVCU8aRQyR4+OjOIjLku024x/+4R/Ii5zr9SosxXVYXGpx+/zy03uWZeF6OtMbzbW7CvtNi+NGa2ETZlnNZpuhdMF2U/Pq/sC1k1ht8AHrFdfzhX/8z/+MXjmvh7sDh1txrCxuWZmZimmaeDo+UBYybHop2EmyZp5OV5bZcR06pmUi+igMpqCxVvZFJlPMy8i4RHHjpsgyCxc5LzKy3BK97OeauqYsArudlN9M07I6mFccQcopy5K23hBi5OnhE4vz2CwjLwpSVMLWuVxQ2rC/3ZNUoqorUgocH5+ZV7E3zws2dSNw+2kmryxFWxFDZJzEMeWdCEmHg5QWHHZbfAg8Hk8YZWn3LYUvqOaCssqp24LrteP5eMZNkXnwcs8ZzeUSiTGuDXIlw9CjrYjvVtu1yMhzuNnTtDWHw4a8sGzamjzTnC8XTsczw3YSQaduMa8ygktczxN3t/fc3t7zzatXVGXB5dxLY7Ix1E1DXQkmoFkd0MvSY6xhGHvmZebL50/CPLUFOjN044BZZoLy6yDErCmhinmaeD4dyTLLu2+/ATT/5Z/+Becc3//2Hcu80F2uQGRaehY/McwDZVGIEz/L2W02gJb9/QzXQTFMmvPlzDQvaKuIS2SZ1v0QgaIoePvtO5qmWZEdkNaCkMxkBBcZ0gxaovaZlcKC3W7D4XBgf7MjLzOWccTPC+fnI8fnE998e0/TtnSXgWmauHu1p21r8kyQC+PgmaaTNKKX+epKVty/egXAMPQM3cTldCWhKPOGhYUff/yrMKD+htffLDyVRrPEwJfThSzPuX/3A0VuebUXHkU/ykF8UxnyvKQ53DGNI+9/+qtUO8bA+Xzl3/78E2WecbffkuUZZV0jS72mqAra3Q2F1bSZ4Xy9YI0RwFxMXLuBXz7+E9++e8ff/e637Nqam13D50+f+fjRUdYbimbDL78MPD+f2O4Vaq2KLqxljmIXvw79CtLOhUzvZ2L0dNOA0pqb/Q11VTE5eYgIWNVw7mZc8Ly9FyVwnEacc2RdDylxd9hjjeY//Zd/5nK9Ms8TSsHh5pambtjf3qFIPBylbW67u0WTuJxPLwdZozUqelAamxdM88zT8RmlFG1dkFtDXRVECrKypCpL7m5u6ceRT18+0Q8jj0/P7LcbttsdVanItOF4vvD5yxc2tfCXVNZg8pLDbsOr2xv+/NMH/vzTR1J0xLBwf3PAGM3HxxOfns5s6oK2KjBZRlaUFKXkjCXGuPDmzVv2+z0qRVSS0vgYAz/+9DMfP39hmBybzZa7w4b9tuXPP/1E1/V8//Yt27bhcDigtOIvf/4Tz6czNzd35HmOwWE07HctWZattcqRYeiZ5oW/vv8EwG+//YYsy5mVJSi9AuEdCXGZGC1ul2s3UFeJTEtd8B9+/JmmyvmH798yTjLd+OquCingQ6LRNUUj8TOFNPCMwyDNSllGv8yM40hVNWy2O9kw64m0Ck/1Zstmd8AtE8skB+iYkhwIDsSBZAABAABJREFUlkViLkq/uFu2+xvqdsu7t2+42e8FJqsSn56OnLuO07Xj3A1Yo9hUGSkIE6d++4rdtmWY5RB66ReGaeTPP/9CZhR3d6/lQVZuSSR+/Hyknz2fH58wWkmjH5o//fhX3Lqp/DW8jLF4H+j7KykGgcFWFd9+/xtCjHz69BGtFDcroyZ4YbSdL+eVxZvwc+DpdJHDuE7otcHIaIO1mbRJ3t1RVbW0i/QSzfDOsSwz0zgwHI/UTcN2s2W733DYbTldrjxfrvhlhhjE5TMHbFZgbPYCXQ4xkIJmHnrcMq3/vyUzFqUM3TTDOLHbNJRFjo8LMYWVoxO4XkVE++aNVPjO88Q4jMLxyTLaVg5Sx6eZcVp4eHoUgejdt8IsMrKBPD0/E2MQkV9pmSR7T3+9kOcFux9+IyyfYWBxjn4SHoKfR4yGsiyFyePEQaOUEsdB3zNME6fLld1ux83hgDIarLgiLl1HWRbs9ruXmGFZFDR1xccPH3h8fKSsJFpYVxV13XC9nOiuZ8qqoixL4cNlOd5JwYIAjKUSuCpyOWRoQ7tak99/eM/lcqFaheCiFBetj4kwz+z3ewEFrzDvP//5z3RdJ5toY2mbhiwXq7M4l0qUgqEfWOaZ4+mEUop3b98CiU8fJZZgzBq3SGEVngTqPk7S8LfZ7hiGkT//+U+0TcN/+Ie/Z3GOL49PL4KRj5FhCXgUNpd48lf2k3NOPhP3lR2mycuSqm5Y5om+66TgocjXZ1+OWwGbAqCMawQ8ewGFp3VzLkK/ZrNpKYtKRscJhk44jafnI13XcbPfU5cF/dCxRGmYCT6jXmPqT8cj4zjyfDqTFzOL94CiaWUdfnz8Ii2nTsDVNi/QwfN8Pskm7Vf0asoCFwJPzxcgre1zmvttTsRw6meMVuzLEkUk+hm/LPzll0eUShQmERNM514g9loiv3WRrzwiiQVpraiLjP2mYV4cwzSTKYmqPZx6PjycuL/Z8k2eUdUVd7cH/DIT5oWA/B3XYebxJDF5cRnI2jh1A904r/duoqkKyiLDatDAte+Yppn96zs2Tc118owuokyGVRnjPJBi4PW+pcoz/Cr4lLklM5pdLUDnnx+vzIunWOOjVV1KLC8Tbt/53ItzYtPI78cIEczKucjL/AVUviyOp+NRwNoqo9CGtsxIyVJmRgoChNW+QskD0zzR1KU0xUoqEB8Dw7gAEbMOMTVBokFFzngeeP9wpC5y2koQCUVZkXnI48J1mOnGmcImcpMECp5LEcilG2jalsNh9xJDtVb+3vP5yrUb8EmRF55NmXGoM56OZ7pl4WbfUuQZi/fCoJo8LsC2KcisoSjE0V/nFkVi6HsW5/l8uuJCwihFbg2b23IdoLp1SGxe4PLWWKoyZ/GROUxYIENKbr4cr9Rlxm/fHhiXyIejRGzaomRxnud+pMwMOyND2E1RkoInuUnA7wou3cDn44WmLtltWro50S0rn2rFGOS5QtscbSzjMstBbx0IiAgvYGil5HpIKZJZJZ+TtegsJ1MGHSJqGkgktpuWTVPzeOnx40yWZ1R1QVwgeM+1n5l9gCjw4GmWuP9hU2Gt4V9+fmBePDp6iY57RwqRp46X2P2v4aWVxvvA5+Nn8rzg97/7PU3T8g9/L27ynz/+jDGWN3ev5VlZVgx9x5/++CfBYsTA4hOXwWONoqm1YAdyi81y8qKlrjX3d4a2Kbm9aXk6nhjnUXhHi+F0PPLHP/7I27d3/PCbt7x+c8+7b77jfLpyOl6Efxs9P/30F758ec9+f8N2uyOsBoBEIkV4ejrxECJpZT65LJCZjP66oNC0O0tWaK7nnmmZ12KNyPXU4X3g/s2OoszoTj0uJbZtC0pxexBx5Kefj3TdyMOXL5ASla3Z7hL3r94SQuAP//JHcUi9ektRVcQogub1dEIbzeLvpSFw0zAOIx/fvxc2W5aRFxW7dsPiZmZ3pawyqm3NNM4MpwvjMHN+vnJzc+BwuKEoc/LshsfjM58+fuLm5sC37+5IIZBcYLvbcXt3z7/867/yxz/+yDUbKLOOus1p2pynpzPH45nDbsduu8VHj7aCgrEmY1pESL+/v2G7a4TBhCI3G7yv+Pj+E58+fWGzbymrgvub19zfvOann3+i73t+83e/Zbffctg1aAXvf/rPHI8n8jpjs9ny6v4VVVUJI9cYlnnAB0/XXRnGkT//258A+Pv/+B+wmeL8fF3RKm4VEGVgUlU1bvE8Hr/QNC3/1f7/yOV84X/8H/9fHG52/N/++/8LQzfwp3/+kXkZGKZnnPMM48J+f0PTbsmynKauWKaF7tozJs+SZtzsmQdHWee0G3Hmz8OM8wtTGNnUW17dv2Zx81pOk1AhotDkNmdxjmkUB10gUmTiXPr97/8Db958w5pxZ+x6xn7m8emBLw+f+eG3b7g57Pn5pw+Mw0jT1Nzd3XBzI466//l//hfOpwvjLEOUpmleRDBrDP/8n/+ZcRo4Pp0xxlBXGxQj//pvf8D/jaVUf7PwtKkLvLe4mx1aG/w8YsnZtRU+RLrxjFaGptqgrWUeR4L30lIQ40ur3f6wY5kXrpeL0NoPewBhoUTJZY8uMveBflwnZ1pjbca2baiKgswouTnDgarIxHrrPOPpmXA8MgwDRS7Z+Og9AYja0DYNeZ4zTjOLc1SVOJG8K6RpbxaY1jAMeOdp64psbSkbJmlg8sHz+cvntWlNnvBVUVDmGd3Qk1KiaZqXw11KibIQ2OA4jCJGJEMEop9IOiPPG4niuAVW4r0xFmUDxmjGcQDSyl9RMpl2nuP5Sl1OVNagtOb+9o5NO1Ou7JBPD0/c7Hf85vvvsZ8+8flRrPij89R5TluXaMRSqkjsd7IRKYuMushpypxumOj6gU1VyPuR59IKpRUheKoyp64Kuq7jfL2yqXLhWOU5Shtub+/Ii1IaWAiMfccyKnSCPMu4dlfmacQHj12boQ77Pe/evqYoCp6PDxJbGiYSE5fziZQiN/s9+XpgBkW+5qF91AJQ8251M+ww6/dqjeb7d2+lvSc4ILLbbakKafIzJpBZS1wW+nmmyHMO+x1lVVJkBT44AacCRVlRFQXbtl4zsCNWQ2kVuq0oi7UJKM/F2ZfSOqXJhVUSHCkJ16W/dkzDgM2kRUulAH5mnka6IUfL+sG16+i7jk1d0JRyKAxJ0dYNMYitPIbAZrOlzAqeCw1BGkTsWrG+LAtGyVTJqkRIkQ+fH0Qg3e8kEoMcMH8tL20sVmnKshRX0TK/8ITEcSnumc12S/DSPCS2WplK52t0UTb7wgHTaKzJZCq8NrehhV9wfHrCuXlt6ZHpqc1yGi38pwRSfjCOwtjQev09EfvUCsIOMWBW8HtZimB09gvezWTWkOX5et1nzPMs3/s44peZvCgp8hznhJGXFzk2wbW7cr1ecC6gtKGqK/IsZ5nntfZeuHNlWZKiuG5i8CiTiVMBYbN8ZUUpbVBaGCYpJdwyA4q8rFaY7EQMCptyikwcGj5ElnkUMSdrsFlO3bZrg520yR2PR5q65u6wx0fpKYqrwKrXAosYAsF7cXllGWUhfLqiLIVflOdkWS7MN61lg79u65VSlGVJURSMQ8/1cma721NXNW4SW3WeZew2G3nvjDg4Y4yERRw+cY2s1etnmOU5bduy2x9W1pVMqRbnSIvjcr0CrAw5LcI14k5hFcgVSNsga+RW/geZzbi/uwXEHeJDoG0amW4iog8xSiPs2miVGUOmJdqUQmB0Cykl2bDXDVVZ4JxjnmdhFhpNWRYraNrK9e494zSLLVuthzFtcCEwO7d+FloOhNFjdEGWC2i5nyaylb3gvMMtC4fDgd1uT2YzlmWRqnYlrYVfWTjC6Srk71yb7qZpIsXE6SRco7iyX8ZBhkXbpkbrauUj/q+0sPyv9MozGUhtmpKUpOUws4ZN2+IinM/igjlsanFIX4PwHlc+UabFAbLJCmbneb72WAN1Jrjo2XsyaymtMImO5+5FRFQIR6ctc262NVWmCctCshq1ujR8CPik1sZJSSoVmcRhUwzCg1OJam0IijGS55Yyt/ggw8CiEG7m5BKhk4N8U1rOg+zJjOLFleCXhagzQNNWIuZOXlhCWSb3umVlAylNWpmMSsV1kBDF6ZAsm1YA/KGXZ4LRCmMkZqgzLe7tKGJKnlmJn4Yo0HP1FSYcUTqgTSJl0qR2vlyp64pXN1uu3cAyTfgAwSeiRt6kBATZ11VVybYu2DfSkmszvYo3UBaWzCi0kvia1iLsaCPtxotzLCFQZhnWGjkop8RutxGGUUqA8KRcXIsWjGV0ER+dsIasZdNYUlLs2wJrJfIXneMyT+JWHGZCSjS5FA58jbOMo7QtKiNlOcs8rdetIcssUWmUUew2FaTI5ANLEMaczTJBEChWV2qiGxe0gk0lAw+NXJfj0kkzsZJio01Tce0n3FmaiFOSCPO+KckzKwUqHoKXtTRFT2E0WZ0zzZ7JLcyztGJl1pJZib9ZY1dQliai8SExTI5lkdhkaaU9uQ+OyipoChRRHGmLiPpKKaw2a6aBlzbHaXbkMVFoSCrxcLqigF0jrbJTEAH31/K6vbuTvXeWS+RpGskzy2bTvAxatVLsDxtAcbn2zG6matc0jZVGz/uQmBc5NxqTsW1bMpuvOxF5Tk7jzKfPM8MwkqJwuqwVB0jTtFR1iVsi4zhzuZzouoFh6BmnnnHqmKeZPKtQSeMX4UN552k3G6qq5nQ60/cScSqqAhUVKoH30gLmXCBGxbbZstuI07G7dgAv/CFFwi9hLZVpsVaYPDFGNpsNddUCUsaBkX3itbsKOzFpkjLSbuccKmmMtuR5hckMdS1FMk7NEHOaWpwyyUCV55R5QfSeoVtQyYLX5Lbk7u6OeZqp8gqjDY9fTuwPG7797g3KWo7PPVblXM8S7W5XHuO8jGTWcLu/YbfdcTgc0DZixB5IioibvCrIio04vrVhnGfyPKesC4ZhpOt6dpuWqipwfiFEz+6wQ9uMorQyICAyLwOJiDKKy+kZN4/gbuTeLS3bQ8Ort/cUZYGKAvs+PV8IwfP4+IWYInd3d+RZyWZ34GtjpseDloFI8NI8WJQZ1mqu3RkXFr777jvyrMDNsk+5OezZbFpSkMFaVlhmp+i6iaIoePfuHVVVoy2E4LlOwpzKioKqLtjuGoZ+5JQu6zMrsdm01FUDJoFNGJ2JK1YVwv1LChXFPe6cCOj9OGKtwhggqzA6Y54XLpcLyojj9nQ60V969ocDddtQVi0xam72t+RZRXCKy2liu9tRlSX77QajoG1rjDXEkJinhefjk5QqKRH9//SXH1FKibi4a8irt3xtG/5fev3NwtO+KQkxYawc1vw0Eohs39yyOM/HhyPWaNq2IUZ4vHRordnt94BYSjOjqYuMzw9PvP/wHmMNdSHg1GmWzb5fxAUyjjJdGRdPvjaqtLVEtc7nC58+fljB11vGeWFxjtP5zOl0lqanusYoSGu1vDeG++2O292OL8dnzl3Hpm1o6loWGB+Ixyf87Oj7gUFP3Gwqdk3O43VmnEWYCs5xfPoi1Yj7W7E571qM0Xx6fGJxnu1mg9GaeZpEcEtSvdr3IzFBwBKVIriRpCN5kQto1Ul9e1lW2CzDeoktjmO/brRliqfWzfjj8UhTFmysYrPd8fbtt7gQ2O9GPj888E//8gc2mw2/+/3vCCT+9Q9/EKDa4qhbzaZZeS2XqwgPhx2H/Y7bmxuim0nLTNcPdFXOtqnYNM0KwBM427zMtPWWuq74019+4vPDI9/c7dhvaspmjy0qXr16xevXr3k+PjGOA0N3IYaAUpYiL7icZWFYFpnml2VJ2274/tt3lEXOPPZ0XcelH5gXx/uffxGRbLulLEu22y2gKIoSbQyLl/jmvDIXNtsDmkRcOjKj+O0P30m7zSgi4M3NntxaEZ5sIDOWBbmh8yzn/vawwnELwhgYp4E8L6mbDdu25vXdHlLk8fERqxWVVbRVjSkKmaBhBMS6zMSsIKJx84ibJlAiWjw9PvHw+MTNzZ5i06JiIHlxyaBX2SnB5Xyh76/c3d7Qfq1yTYpN05IZw+l85uodt7s9bVPxuApPtzc3ZHnOjz/+xDzP0u6YZ1gFLgV+/viZlBL3d3ds6orbtli3S7+Ol7EZOiWqSh4s/er0KHIBbhst9bS73Z5lWTg+n1fBSMTCuhY2mwD/JxEfldSPG2Pk62uDUiLuDd2VVd2QyWxSZFlGXdv1MA1u8fRpwEeJhQl7RYRmo9cGtiCA68xamkrayKaxZxqUOG1yEYiyPCd4R3CRcRTR7G3TUNc1z8cR5xbKukUbw+OXzyKcWRGQv8aAz+cz3gdsnosQVMkhljXmpbHCt4KX6LNszg0ogT2Li08g5WVVC6g9RmJQRFWIg9FYfFiYxpGiKFDtBqstZVlSer/asgceHh8xr+7ZbL5ldpJ9D94zp0Ha7HIZFjgvk+Q8l5hd09RkefEiyuW5CNJGm/WwJBGKr0yRTdtyfHrky5cvK4ixYlqdrGUhk6osy1HGMA09bhGI9bIsjFN8icVlNpPvoSh59803wnx4fGSaZ8ZxwjnH85O0kn377XdrvMCKm82LYwgt0UNjzcrwWnNJKLI84/Wr1y/MsRAC2+2WfI0Exa8uTS9tnZm11I0cWLOV1TMOAybLKMqa7XbLq1ev6fuO0/NRoj9EMltQ1TXWSPzhfDkzjJ1MKm2GtYrcaJm2TbO8xzonxYXoHUYr8lwOds4v1FVJrizLyiy7v39N3TR0F+FgfRXn+2FkGKRqO8+ztakrlximF8E/BHFGaaXW5ifFMAxorXl9e0NZFpiskGjVr+hVZBnRRlCViJ8ukNmMzaaVyP5pwijF3bZl9p5jP5MQGKxRkVzJ8Gu/P3C8Dnw49hQktkbhQnoZ7jVGszjP+dpL/LYsJNpvDanO0Qic3C0L0RpUnhF9wPmAjwqX9DpggcJqciXPvr4fKeqaqhQni/fxpWWvGx0uRMqiRJfibLiMM9+8KmmrgnM/4JeFwoog9HKozGuMzXhzsyGzlvfHjtl5yixD54n0dXCiDAmNsrnAvIEQA/OyoBQUpUTjwwq+1mZlo2mFxeDrSop+EgIMV+KIPo8zmdHsjbiBMhPxKqGUYXGB5+eRMs/45m7Hg4bj82l1RkmrnrRsKoiJzMihcbcpud9W62E6MXgYPdRZRqazlc8WX0DcmdFkRtGPUrqT7XeURU5Yf87Dfo/ShuF8xE0Di48iDipNMjnDEtAqsGtLCmvZl/Icu9kUGA2fvoyMy8K5H1lc5DiIS/XvvjmI48tLPLIbeuEW1RuZ2l87lFa0G6nfDqvwdNhJM/b5fMGHuFaKW4R6JzE7FzzXYaYuLIddLVufKDG/504cUNsqY5tnvLq7RZsLl17YTDFGisyyqUtyqyiMYlgU/SSu0RQdRZ6RZSXOdbh5YZwWxnmhKTMMlqyoqMoMl4wMiJPGBbiO4gBsc0NlNcvY4UaoskzOMGkdTK+RYq0kYscKkhcWlLTvpRgpTSLpyM/HMwDfvTpQlznXaf5VOTZfvXm17itK3OIY+448t2y3LeNoWGZ5Vt3cbFkWz8ePnwnJ02xqiqxg1+6xVpPlmuPxzD9fR4wt2W8PkBQxJFSS5/kwTlyvF4lOJnFbGavZbmq27YZhXuiGmb4fOeXP9NeRrh85nZ44n59QKifPGlQy+MWzTFJGcv/6nvvXt0zLSDdcaTcth8OeZZzwbmGaRaDyS8BF+PbbO5q25MdfPnLpejaNCExfvjyu4pYlzzJev72nrHL+8qcHlmXh9797Q16UGLtG06NjCTOX60VioYjwFJwjZgaFRquMvGiwuaFupOVuQaLYm7YVrAeBuiyoy4J5mhi6GU1O8kaaN1/v8LNjV/eczz0ffnmkbWq+/e4bUJYvHy4sfuF6upLfyLA/Epimnswa7m/uePP2Ne++e8fiBxbXA4YYFUWRkxcZh8MNm82Op6cjl8uFpq3Y7Rp+/PEjDw/PfP/ta4zaMscFHz2H2xtubu8gOlIMXK4d0zSQlAhPp+ORCwrl5bxclJai3vC7v/ueuq759MszQz/x8PBE3/f86S/icNrvb6nrmt3hVgaXUbhi0oSgCM6BgrLKSCQu12eMtvzut78lRcTdHSL3d7eUZbEKT4q8yKFXXM8D5aua77//AaUUPnpZQ89nyrJms92z3W759u09z8cTblrQRooKNrsNm82eiKRtpknWp8xYbL7CVJPCp0B0E8MsCYGmyihzg6pqrM6Zx4mzOonjScPT8Uh36XnzzWs22xZrc2I03N6+Yr+TdMJpGjjs7qmritvDljLTlLU4/5+erji38PT4sJZ1JJKCf/m3P5JS4v/x3/9f2e83vGlu/+a9198sPI1eNsJN2wLgV0p8UAafPDEGvFcMw4TSmjKTadb5fMW7mbG/UJQld7d3TMuCNdKYcuokkx9CIEdjM8lYXi4drBDZkBLDNNH1AhDNjGGz2eJT4tPxSHCepmlWFoQ4GBYXMXEh+IA2lirPVuVUJjF1kXE+PfP48IUsk1psSJRFvtYQWkKIXLoBlRRlpsl0K9nhINNblSLRe74cTwKvHcSZpDey0KiyIqYoh8IQ+PL4hI8Jk+UYJfbsxcthNoTA7eEg/CDn8SHivLA4CmvXeNba/PfwiI+RpiyxWnO8dMw+oVZ3hNKGpiz4/Q/f0lQlP/38Mx8/febS9dgsowL6fuDx6bw2fyw0mw1v7u5ICi7Xq8Bju05gnzEx+Yh1gWHuSelK2zbsd3uWeeLxsed6PTOOPV+OiUs/0rSOvCjXPH58aQzLrJGWg37C+8B2uyHLhMcydQMR4TH9/P49eZYzzfPaXhDQRO4OO6TBp2deHO3mAFpz6Qe+tq6AtGmpFHFTj9ZyWFJak2U5OBEapXXAM2nN0zwTYiAvC9CK+5QoyxK3CMw2zzOsMZT1hrIo2G1agnf89NMvuBDY3dxR5RkYyzDPjJerVELbjIenI58fH6Q1cbMhN5Yit9ikiTHRNi3jZmC7adltWsrViZeAeRxXh5l+gSQXWUZVlETvmMM6uQuBqmmAxPP5xPlyQqGoy5JhXmAJApLNM2JwBJekrtUavn/3jTghtGzeVFbwazq7+ZeGs5IYc1SS1rq+68R95hacZm0HEyE4eE3wMt0Yxn9nCqAUVVUIyM9mxBDoVk5BUZYss0wivuoyMaztZCvrScTVitEtDEMiWzPweZYRy3L9YxKvS8G/gMRZ25rqppVmlJikJWcY0LPcW6yuLq21OFWGHkhYuzolFSL2KNBa2Cdd17001RmtXpxuRSENfkWeAYnjCv90TuznrC5Wt4ykGNluWoFTr8ydr3w0ce9EgjIsIfB8Eu5MXBsqx/6KXt9LhTDsyiJnt92SWcu16+i6jqHv5f3Pc0CjTCSMk7STJDjc3GDWFryvrtV5GnFBGuDUKubFFAX4buU96vtOro2q4tr3jPNCkRmM1jhrSEqzeGmpSzESUS88orrdkGVyWIvrtMwnuHQ92eyY5hnvnAjtwOHmACCtdyCxZBLDIKyibGXumHUNK4pCgMxrA+G8fs5aKZLWK4cncL1epTXPGPKV54CSFjFhZwhj5auImWfS4HQ8PuHcIhNpa8hsiY/iYFniwrIs9F3HeQUpl2WJ1QVkmThk8sg0jXSXM21TUzcbslxihSlOuGUm5hbSV95KBikQ/UJZVVLiMA4472TQYuX7XBa/bgjT6oQSF7HSmuhm4RlV7QrGtJCQyKfzL66pX9PrpenUyP2lEyitGeYg7WEIT+fp2kMSQL8LkX5ZCCkSkmMJEHXPMC3kOmFSZFmcCBhaCadpkQKNmJDmsHGWJikU4+w4d8NLHMwFz+P58v8lQCsMII1QmoRiSQqTldQZ4hrMLComdEpMs2OeRXQKMeJSRBGpipJNY0jrultkFtPUkKRhbVaWqBK3jayZ507Ee+/T6pAwwl5cWWp+XUvPnbAVY2JlGBXkNiOuzojbbU1KCp2SgPjXPdi0LHKdGYMj0k+yB6tX148LIvhGL5HPbB1GZJlFKfj08Mz52jMvcm3mGgyR5B2jc/TjBEpxaKTwxofIMHtpSA4RHyJtmVOXGd0wMUwzm7qkLgtSShJhWzzz4vl8PKNPnUSIjaIu5NASXRCnBHKfDOPI5ALbKsdm5sXZEVlEwAkL1sjPhhI+qlGRds1uuMVLo6kWN5nN8vW55dEoms1GxLMExIBJ4uSdF4d3QdqnE+gkgt+1H4hJYa2m1uI0MFoTlbhUMytOurZK5Fba8HyIPBzPTIujKMpVyMzXKLHHexiV4tLPnLoJpRJaRdq6okVcmnVVMq9rhtFfo/NK/mwMmBjkG1XyffoQ19IGhZzqknyuKVFVFXlmCM6D8tRrZNN5hw/i9ktJ2vCUgrwoQVtutxMg0X3hSulflXAeonAHbw4HQgh0RUZR5Dw8PTDPC9ZI2+nnz59IKLJCg9dMw8yMoz+N5EXGdiexsMKujNd5kTbyxQloO5aM08IwyjVstCEgsclpPEssKLOYLKPvIDjZF9RNwzgNmL5AYVFYYoo4v1BUBfWmFe5gZtntNmgNbnZ8/vhAjJ6UguzPraWqZcg1LiPTscfoxLYppDRDW8o6Bx2p8hJrLJ8/fwGV6IaRlBKX7kThSjKbrZxZhw+en37+Ge8DKQmPT2uJzA/dhRACzSbHGM08zigU0yCs35g8SSW0MsyL5/37D0zzTFHkQOTz588UVcFmacXNbhNlm/P23YGs0Pz083s+vP/Mx89iEsnzjH4ceHh8kqi+d+RFwZtvXpNZy/HpSNeduXQnuutI34kgnOUF18vA2DuUTmxaYU2djs/0Xcc8Trx//4nHh0dsptFWUZW1uCH9sjrNRdSPPhJ94PX9K2Hmzo5rf+U6nIkp8uGXj1R1zdxJuYBRiiLLePXmlpQip9ORYeipG2ms7vvryu8UhnBg3at7cctttnt5ngWND341qfh/H0BcekEXkCjrkm9/+Ja6rllmaZIvi5wUE1NVU5QlRZXhwsKnjw8M04hLgXwdfC9u4fHx8avPgC8PD3z+/IXtdsd2u6MoChmUGHH4Z1lGbnP2+z37vbj6yqIiEljmiaIqMcoKciMsoCLGCh9VoVjWBuF8bSkdpx7nhH+njWYapeG7KHKKIkcrj1KJssqpqoLf/vAtMSbZS4dAiUYofv/Lr/8fhCewVnO3VieHKLnogEAlYwyEkOhWp0hVlaRJlL5h6Hh++EDTbsiKinFesNoQYuT52ssGeX2IFcEzzTOX65W8qqirEu88bhTh6Xy68Pb1PT+8u2Xyng+PT+yqgn3TsvjEEoSdsywO4z1GJep2Q5WXZCtQssgMqcz4/PEDXx4e2R9uqJuWuhCuxc1OxIXztWeYRuqqkElaVZEQzoqKwtIIwfF46nDOry1iYq/9at1NQFgmpmni0+Mj3gfevXmNsVZgwD4yTOvE8uYGlMY5gcEuixxQikwcEUtMTOPIw5cHbJazv7nF+8Dx1DFMC4FIVVbsNjuaquBm9x3TNPPjX3/iw6fPnC+9TIWNQDhTBO89zi007ZY3r+55ej7x5emJ0+mZ0/FIVLIBmHxCL5Fp6JjngaZp2e/2/PLLzzw8fuFyOTENncQylGWzmSmLAhUmiB6MiGKH/RZjM8bpmXme+fbbt2w3G/745x+5dMPLwcE5twIbc3GbxIBRibubvYD+zh3Gzrx6+x3KGP709IR3C9tSBMYsF0S/m3q0MWRtg7KWLC9FwPNBGsxCIEQ4BcisoW0q8jyjKgoECr2sm/2ItYayaWnKkt12w+OXL/zlp5/Z7Q+8evMNRsnmebh2fHl4WgHsJX/95Wf+7U9/4tu3b/ju7Rtu9gc29X4FS2vatmWaR7abDfvNhqyusXnJ0PdMQy+WzSyTOGqCPMupi4p+6l8ajpyP7LYy/f34/ifmceD+9paqqnieHC4s5EaTm4zkHSFF2k0romzTEmMi+ZkUA8rWKP3rAfT6ZcZaS9W2KGRTklKiuwqY3nupk7124tLM85ygNVNwchBeAdVVKZvGuiqFG2Ytzjku14tAaZPYwcd5EZCllutscU6aDJeZ7WZDbg3TvDBMC/vDnqpu1iauJO4BH0he2Eggk9GUZNPbNC1F3XB6PtH3A8kJV+Prgacsa/I8E1fdPMkE39qVT6YEeG3WmqKU6LorKUWBIBqLW4Wnl8iVMeKyOR5xzlHU7erUSdIyOY3ibN1uZNOslEznnFiWjdWAZVaG4D1dfwTFKo4lhj6iTYYpKjJraIocUxby82j978LT0Itjao3OYANuWViWid12x83tLdM4MPU9s5P4RFijcXkh+Z+4srJk0p7j3cwyjy8NMs/nK8M0cX/Y0dYVJstIyrBMEhuXogqzlgM4mrqmqhvh3Pn18BYDl6uIzn4WdqA4PBWH21sAPn74QPCO+ivzaRxQSrPZSZOg/vqcWoUnk+Vre41AQLXSoCCgCCFwuQifQBtLbqXuXlzE7gXaGkJ8cVnl1q7CU8/X1qhsZffFZSY6afd0i+d6vXA+n4ihxSgRIpWxZJlM5S/nE0/HI1X1PVW7XWOJEoP080SsSlIU6LHNBFodnaPabLFZzjhPuLVJ1BgrUdjg1na+tNYaJw63d2RZxnB6IkZPu9nKum7tC9jcra6/X8+xTV4xyYRRGYnUS1JLSxPWWlsfQuDpPJBZI5B857n0Irak4DEuskRN9IFcyd5lXqQhMrcGlSLezfioCEnhXGRcHDGKQDNOjtN1IDOGssi5DiOXrl+5avVLjb1KCp0MS1IsSdMUwkOyRppbCRGVAtdhYZoDeq2l90EA6YdNw66tOXUT/eypigJTaqZpwgVPVIagYN9WVLnlH/965jrMbNbWu8KK00TEL1mPFx95vo54H7FKmJd5XqzXjgjud9uGkBL97FlcWIWqiA/CR8tzgfn2UQSmKs+JCWYfZLiwRPJMUZRfCyc0ISQ+fT4yzgvT7LE6UeiEIRL9wrgErpPjsGu43W5gHSyeh5kv5xEVvfzatWRWce4GjpeOItMcNgWzW4Un55kWt7JlgkRbsoxdNVNmljKXuGsiESP0q4C1LfdYbVlmJ5BhLwKnczmZ1Vht0MgQOdpEtBKnXJzDe0VR1SityDJWDqFEOttmCySmvkNFKasJKeLnCecTPsoQVaVAcIHLKgKUVUmuNRutCTExra2pmZVWO4kna4rM4EPgy/GEtZk4HnJhSc3zLI7VBEuCp/PI43OHtWAsRDSZyTDaUleWSz+ukXotmAGjUYBOHmJChUTCEHzAhYDGkBn5OhHFPA44F4SDkuVMeiGFRFPmWGs4XkSYqktxYmoNSqUVPxG5201r4Ygmfo2u/3rM5oQg+IrD/oaUElku577Pjw9450V4ivDx00eyXBh/CbkHltkxXAaquiCkG6JPVFkGWjOuQ51plAQCSYvw1M/C3MysIC6CtAtfzmf2hy23r25wy8LlPHB3d8P+Xnic1srXUEnjw4T3M81mw2Z3oG6kKfNw2NI0JX/9y0cevzyjc9AW9rsDdV6w3W8oy4KPH3+m767sti1NXVIUFUpllHUBOtCUNRrFT7/8zDiN5EVJlmVcLs+UZclmc4c1GUk5xnHgx5/+yjI7vv/2e0EYKEkQ9Z0w/9o2R2nNvDZzDqOAzkNykqowufDqPj+itaKsCnwIfPr8ibIq8dGTlxnVpqLMcg67mtl5/vrXn/n48TMfPv1C2264vb2l73v8sgi7dF749ofvePvtW07HE8eHJx4fH3h4+PISzc+LkioqLueeZXa8en3gcLPlej5z7gf6a880ThyPTyzLwm7TUFU5+8OesipZlokYAnXdSNrKR4ILvHr9msN+zx/++Ecu/ZXT6ZkQPJnNqaqKMmvRyPpV5Blv3krk8/HzE1ob/uH+P2C04fj4SIyJqtigjcLFRQo6vMGanMP2jgRcLgMxRZZFAPBKS5Ty+dyLMEairCu2B4nfLdMsxQzbnJQUZRUoqoyizpiHmdOXE1EngolkWhrxuuvA6XRdS8Ysf/3xJ/713/6V77/9nu+/+4HdoSUvEOEpzyhsTm5zDocb3nzzirKoyW3O8fkLfT9QFAWZFkTE4mcRnozCKLnO52VkGAdebV9RliVjP7wMjLXW9IMjhMRh35JZw7z0oBKbbYVWGqu/l/2HUfgYJPrJ33Zu/JuFp2UeUakgz+SAdHx+kna7oqIucr57904OYV1PkXuqpsFk8lCIMWCLGptXKG3RRjbDeZZTWGFJ1LUcPKoiY5kX2WwnGPtx5f7cUBUVVVZQZAWXq0DOt1XBfrvhZrclLyqapmFeZpZ5edlUL84LrX0cSSFQ5IaqrflQFugs5+7mwO3NDcs8SQOT98xKUVYlZVUxjiPTMrA/SLzp5rBjqQtO/YAPUYQkY1jGAUWiqSustVyuHSEEadTIpM74K8gQQCsFSDxFAW6eAIUJ8uTR0a2xMXl4hSjuhd/99ncr9E6yzTc7OTQWpYgl3dCtTQzy2ckkRVHkhtvDjh++/14El+BIKSfGEqMV59OZy/lEf3mmyCxvv3nL4hzOLfKwtoqsrWkbcU1crte1zrzg5nBD22zkUIhA5IzWlFlJZjTjIpXMGuGNfGVIGGOlpSEXVdWtFvi6bWRy70WEywqpOZUbR/F9u5Fo3TwTE2zLAlUV3G4bQoh8enjAec/sxXWxcQ5rDH2+tlnpHGsySiOwYL341cghHIXcajnIrVHQ00WmuxHDU3fl4/v3BO+Ed+Y918uZ3BrKXDY1202L0hZlLd9+847ddoeU6CSSkmrpuLoo2s0GbTN0ilynhTBMRBKbpqVpWhKwrK1kCcSqvjjGZZZGRrVGAOYBnBL2S1kSkmJaHJuqIaH4+P6BZZ65ubkhS/Dx82diSnjEbfDbb1+TWcO5nwhh/luXhv/Nv1KUDTerHX8cOpSCtpXceb3ZEHzgen5GK01VS8wshkBICRekuU1FT1oPB9rolVsAh8MteZ5RVzVdd6XrOnl42IzSJqqyZJonBiUAd5OXtGXD5mDE+m81KmVrw9zqbFwmvJvXKl8RsIZpoqgq6qzg+fjMNE3c3NzQtA1fk5H5ytSxuhYR5HLCLY52dyDPC5qmFQ7M6Rm3OJpGYsJu3cg17RZlNNPa/JmybJ3o1mS5F3eSWaeySiEYqERIAQgszq9xsa/tFiuzYp18bTdbmSg6j7WWuipFNAgS6+uHfv3vFEELvDyiyItK4ijbHSbLsHmBdw7vZMo4zTMhCkgzU8JOE5eXpiwKiiKn667Mo7TOucxRZJaiKAQerBWbphYb/Mqnk8M0a7ZQRN8Vy0KIav0upbFwWRaBkaa08hciMfp1miaOxeA9Smlub28FPO9FWMzLGmMs7XYLSSC+3juGocdYy43S8nWjsNemRdo69QqA0isA1Xsnz9A1Jqn1gtJ6BdwvzPO0/nNe3VAGpVe3mVIvzKqq2RCcx2eLRE2r6uUzAbW664Rv07YtKYnbpO86UqwIQcTNuq7JjBGuxQp0V8EzW8OyxkinccQ7T1VKBfnk4oszBWCz3aBQPB+fiDGuIoYRRo+ThtiUIofdFqMN3sd/f/D9Sl5lZkkklih8pCVEdIKChLGKu32NC5Fzv2BNQBkjgqvVBJWYg3xymVZ4rUha1oivroyvraq51QyzY7lK3MeFgDMGHxx5ZrjbbzBa8Xy5kmeWVzc7sjwjW12IooaK0NUvgdEFVBI3UIgyNS4yQ1nU9JNjCY67tqYtc/pB4qhFLvHY3UZcLf0gU1mJPWsOrdRjX8aFy+hoypwyM+LwUwlrBEfg19bPtLoK28IQrMJ7MFrL9jjFlecn62tMUaKLWrFtG0Lw9L1ciyFErLa0db2WgYgLx4VIjBnOyXBwchGjIYtKnIPLImK+gqYq1wY3ccGaJZCMW11JXgQrbagzw6HJsLrArk5bj6yfTZNAS427i4qQtDD5kPsxhISsKl8ZUHptZk0S1YuRprTkmaatS8oi4/MwSVRvbUXKrBGX7Dro8glikvXOaMW2aUHBczcRU6LJNJnVtHVNQnHpB/nZJ2lNdSGQgGmRf2qEO2fW9kKlM2kWMzLoqHNLAsqvbji3vHAyCZ45rrFIpVEkdHIEFxiiiP/OO4y1tJlFbUvK3DBNUm5ASviU1piipq0Kgm9WZ69iXiKLi1SZoSpELNfGklKPX0aus1rfj/ASo9fGkkIkrJB2HwLXNTaMVpjMcu5GYkxkStbExc14HzhdJ7RSHA4JgwyCw68I8jR03cpK3Io4fjxijeGH779FK82mkWatp4cHyqri5vYt1gT62pEYiWqQPZiLBB9FLE8Gk4ug0FZ7iqKkabc8n048X56Zl0mYRVXBdteuTmJLVZcoldE0JW1d0+42NJua23hDlkkuSaGZ5pFllv1Pd30ms9KGV1UFbVPz048fGKae7998w+3dXgQrNG6Z8H6irgvK0jL0I+O0cHu/pSwM94d7GeI9HpmXhddv3qA1XK4iIN3fvaYsSk7njhh76kaGf69ub1kWEcBjCsQVeRC8rG/jvLZ3TxKFzXIpnPFOXJHBe/Lc8pvf/yCYh3Wti9GjtDgNiZGpGxlC4HkRITjPKzKTUZUVNzd7fvOb71aXtcctjnmaUVq4i+M4EIjsbg5sdrs1FhywucVkmhS/IhnAzR4XPUF7ml1FUZWMY4FzM2Um+7mqqijKghgkvmiMJTNS2hL0ui5FwarElASvkITzWWQFWgvXTufyuWqjyfLIu29lX9r3V0Cx2bZkNuPu/p4QPD/9cmSZZtwoTkpTyN7nehV3mfMBpRJZLnvTxUvySYeA1ZYiy7CFodhmpKSYRmHGft0jdpcBFZMMYNYUDuRo05DlUNYOrSxa53z//Q9sdxsyU2BNjsJCFP5mkWv2EbJS2MOfPn5CKzG91E1B3dQsy8I0zzjnUWgul6swUaNeTScRnSzJS3IrxQRRkaJCYbm9EVfYpw+fcMvCZldjrebLpyeCDzwdz2ij+fv/8HcURck0zqS/ce/1NwtPbpmwWmxrPgQuZ2mce3d/T5EXbL75hmvX8fHLA6X3vNJSpVsVJTEEsrLB5BXKZGgj1nqxihnqsuBw2GOQG3wscvTK8FiGkaqo2O9vcNVEU5ZM08Tl2nGz37Krt+y3rRzA6ob9tGGehT+UlAFleHh44Pn5mTENhGWmvTuwa2rKosRkBbc3B757+4rPDw90XYcPnkhkv7shz3Mu145+GLm5VZRlTq52OFdx6kdciLx984q2rnk+HuXwVtVAYlpjBEUuk+z9tsV5L2owaZ0QwjRL24tEMBQ2rDW0OuJ94NJNpBghRfb7Pb/9zW8JIXB8fhYoZFuvNyKM08Dz8xNu8UzTQlEUNO0GlCLPDDf7HX/3m9/Q91dOz0/rFEaTlBJG0PlEdz5x++o196/fMvVXpr4jIPt5m1Vru1wU4SlFskLiQ0bLVI2UXiq299stZV5yupyZVoEthq/13iJQZZmITsuSCwkSqJuWoiyZLhIjycpK7PwpkBvDt29uUQr++ukJ5zybqqDIM17f3TBOM3/6y1/ox4nRR5k+OrfyeET4zEp5ILW1gHD5yhBx8zrFE+dLu91y7XsejscVuptzPJ356ZePbNuG17cHgvN05zNlVaKUsHQ2bUtIMj1+93ZP0zZ8+PCJDx8/ygPOGPBSUd+0W5rtgefjE9fLme56YZ5Gfv+731PftPTDILGVVXi6XK/0Xc/sRRjZblryPMNPA0kl2s0BZTKOz8/42fHNoUAbzb9crly6jmazBaX5/OUL87KQTE3dNPy3/9XvKYuCh9PPzPPyty4N/5t/xSTxjq8NJeNwxWjDbr+nLGv2N7f0XcenDz9JQ5aV2O3XymXvo7Q2Ofn3ZQXCZpnUv98cbqQFrCyliSUFlBL2U241VSaAxBAidn2Y1VVN3bSk4EheXHXG6BfX0DJplkW/OKB8CMR5pmo2K38pMU0TddPw6v4VzolITfCQIrrISSnx8PCZ7nqlajaoUuDLCsXD4wPTNHF/f0+R53z6+Avee25u77BZxuVywTuHXgGyZVWJ+L26d742PAZhMopIlSRCIiKK5MNDjOgo732W59ze3QoXpB/IsoztZoNzC93lwuIW+qF/gb3rNVIYE+RlRd207PZ7KVmw0nAZfMG8OMZpFqHJZtjVjZZbS5aJy8caQ3c5MQ8d3kdM5il2G4q8eBFOhK+XobWA4pVSSGgovgjlcT2EhfUgplag+jRNqJXLFPwCSeJCAGVRoow0JWoNN7e3KKV4fpYGtrqqsDajbRthQZ1OjIOs41mWU1eNZOujMAmm2clnUkj7nQjmEm9MCar1s9JG3FluHR7M8yxutJioyoLNppWfMctERAwek8uEVphhC3VdcXvYc+1Hrv0ASiKKX9tpmqbBWpliD0P/IkZmxlCsDgJSkr9/GglOKtrnRUT7eYWKf73+U5QDXERiJ5vNBqMNHz5+YBwHvnn7DcZma0Twa/Nk4rDdYJRiidIY+mt6Vdk6pAjgEswhYVJCKYEpt5uabnL8/NRLk1suomthNI7EjEIjwlPSmqjk/qmrCmPUer9pqsKSGDmdB9nw+4D3Gh8y8sxQ5i3dMHC6dLy+3fPqZrdunoWjlFCoGIRR2E+EFFExEHyUJkutqYqGqir4/HzFBU9b5bzatzyRGEYo8pw8LygK4eNd+4FhmsgLibrvqgKrNT89dYwu8HpbkBtFNwoj1GgBhC8+vqzfikSTa2JS9JPco0ZJFH9cXWPd6CRmTqAo8jUa5HHTiF/FPpUr2qbCKmmlS0likCEmFl8yzo7u2mN0hCRtXvPi8Os6UNcFb1/fMs2O6zihZ0/SDkskuoC2CqWhzDVKZRR5QZEXDC4wOeHvNdoITH3xJJURleyzrZHUgFaa8zgxOi/PE6Pxi1+HfeJCbUoB+m9WkPnoA9dp5qYRdIM10pYak7ynAUUAcQJoxXYrYvMvjxec95TbikIZdq0IoL88npkXcUxqBdMkpRVSTiAtecaIw0hri85kvXLBkVlNU+WArGnjvPA8xVV4kqFljH7dNxZy1UVPCIlliS8CW26N8Jhyy35b8/gk2AWSfJ1ca7LM0NbyNfgaD3UB7yPVXkp2TFaCztaSg4l+ylbnoOzH60IGRylGgnNrJC/QDTKAaTYNVgt/aHGeqsjIbKTvRpzznPsJY/SL0C7FM78extNw7QhlQYwSUXo+Pknb2G5PsbbvPh+f+csf/0LwirJoCVmkbCZ8FKfnV+HJeym0yFSiTBllZjnsN+RlSb3ZsISZiAiV0zBRlLfsti15Luy/r0UYm7bhzd0NeV2RNxU202zaSkRQNH0/MA4TD4+fOJ+OFJkhU+Lq3u+3oBLD1HNzs+N3v/2e87ljGme67oJbZm7uduRlzvnccb0O7O8iOrfcVfekkHj/y/+Hu//qtS3LrjWxb5jp53LbHBMuLcl7xWuqSoB+SP1hQRCEklAlVF1HkUwyMzIijt1muemH00OfZyf1IFQ8lFC6sYAAmIzAOdusNeborbf2tc9cup5f//Y72rbiT3/8J7xz3N++oshLPn16YJpH8vL2RXhyi6Ofpak4IDJ/CCKuT/PqzA8jWW65q3YoJcBq4SKO1HXJd7/5jhgS52MPOmEzeS531yvOe6ZpZppmLpcrm82G1/cN1mZUZcnN4cCvfvUt8zzSdZ0ssMYcpeB8Osr9VAV2hwP7nbjKnFsYp55pGUhRo5Q45Zc54GMQ4WnbkuuSaRLhSUnzgpTe5OJg9CGuzEkrrDstgq+PEb8iaLJMuHRlXlLkhZgqAJVbaQXXFmMUh71wI//0/XtCTLy5e0tdN7x6fc84DfzhDzPX65XruRM+aCH4kr47opQmLzdYqyhzJWeOWyR2HCMWQ7mW3Gy3G4Zh4fPDRc5CNzOPnuG6rE1xBSa3ZClDKRGebB4pqxmtM7QWB93vit/w/HDm6fMJjYEgJTZFlWOyjKZteHx44OnxAbd4go/8/q9/w/7wiufnI13fvwhP13NH3/W4RVyZ++0dZVGTQiStwlOKihTEUX9zswMF/+U//hdOpxO/+f2vKMuc4+OReZr49PRAURb8u//239E0Le9P71nm/41b7RYXUcpxPB2JUey9ISZO1w6jB6YV0L1pGqqqoi5rgS6SqKucqJChf216IAbJ5JelbNynAQcv26cmN0xLxDn5cIzXK/Myi7IaxJ1SVjX7wx0hBD58+CgbrhgZp4lpniRiV1fkRUFVVavyrbnOjtFdaJuG3373NSEE3n9+YJhmlqjJk8JExWmNMFhr2G4bYQxME+fnR+ZpIs8yrM15fHri8emRh08Caf7v/v2/E54M4o748n1ba8VWm8SavHiHzTNer8PYj+8/gBLHijWaTAm3YnCwOM8wzYyLp7+eBTSuEvM08Pj8JLZw78UCl8mF/nw+oYzh+XIlBs92s8NYy7nrmcaRaV7EFeQ8NivI8pJh8Thko9ZdO4yCqmkZp5lpWfDr4VRX1RrpSHjPOkB4yjwnywxlIZyRoiiwmWywfAjrZjHx3TffyqC+LHz+9BHnpMHr/u5O+CFFLoNkLZDix+OJEAP3hx3WKh6eTy9OLmsNwzQyLTPKZITgqZsWm5dUIVAUJb/65muc9/zw03uik6YcygLT3uJ84LoOMNoYglbEiNguTU8Ikd12JxuuGGmbhjdvX7OpKu72O5ZlFsitKqmqEu8W/CwiolKKy/XC8+nINEqjh/cL/eVMXkoDl3MLfhboYLvZSZRlntnuduy2rRxaU1xbxhJ5VVPmBfXKfBqXmXlwvNo21EWGLYRZdn/Yr5fphF+WtS0qp2l31HUlLULTzI8fPtFdL/zz9z/QNDXbtkVvf15W97+Gl1vWC7STIVeYYcI4SWkgPkaWZZatic1oG6m3Ta0IqJersJ9ScLDGKb8UKeR5jlJyRi2LNMPlufz8xS0jZwBKhMwUAv31IlyVuiREvw5I8rt0y/RSd5+ixDhijKgYSSiulxPT2FMVOV+9fYNKkfPpmXkS95tRwnLSRlwAzWYvopOxIjysUbrcWlRV0l0vdAr6YXxxIOaZFAiAknZN9SVOAaasxF3jHApo6ooYE8fLBVb+mDZmFUHEUeCWZS0VqFiWLUppAeOHwOfPn/DeM00jxljKul3dPfKMma9XAYUC3rnVTaYxRjhF3rl1yxzXmJanqmqqqibEQBiH9UIpYlHRbCnLmqwo8f4vz7MvmxprszVyIQ5SgaFHUCKcxBi52W8lFhYj564TB5y27Hc7aWlLcf0ZeWKKTM6jPPK+0JqhF1eXWgWv4IUDdVzmNRoV5JmzO6yf12ZlOV1AaW5u9iIY6X/BqUJhMnE3fPr0cXWSSkzZrJyoL+6uhBboZy7/ex5HVJ6jygIp+JjlDFtmxmlkHKTkQGuz8i/EuYCRyGRRFCv0OBLcTLfM3N3e0mw2DEPPMk0vcZZibR/90vZkjSGtmz+lNFXdUCbh5iglkfWEnPHG/AUQT4ykNYoToixBiqLg5uYWY3/2tea/itexkzhoURjQrA43mHxiCZ7LMONCoMqUON5Kaf4trGZ2gaSEmZNZ4fxkCqyWpiW9ishf2sRSgsOmppsW5m7A+UDXS3tRnlmM0rRVRWENRE8Ia+QzCjRbHlEKZQy7Tc00iHtAmQxtDf040o0DmdHcH7a4qHi4zpwGz7RE7LljmJc16i2cIW0lQpoZLcucqKgKiTwt3jG7xLmXeGZVSuNeP0pMwBoRsIZRll7bphF+UEoorbhtCpzzXLqelGC7qclzSwoSP4tamC+BxOIT506+9irTLD5w6SXmPqyOaashRZgmL82PizjcrTUsPvJ0kSbTxQVmt55bShG1pRs982WiyAxFbtbInkG58CLO5kZjdJIod2YwJmdeZDmitUQa61KaJfdtTZVldH3PMi+4KJy7Mhc3ejdInLBQCV1atrUsgsd5Zpwd+7ZCa8Vw7nA+iJsMzTyvXKpWGKZlnqGM5jrI87WtpOXZeWHblVac3pfRo5J88q0Wrl6IUnYTVuafd5oY5Dz2wUtjlBZnU0wJ1mZnbb60ZQaGyVOWGW1d4v3KITSWJcAwTwJfnxY5d5TEk1NUEGV5In+eBW2YXcBFeV4ba9dIeqAqS7abLVUpDB6JFKyLCAXYDJNZ2iSu+ewLiB6FC2sbapCZxxrDtq3wPtAvjoRingNaGQ67zS+KrznOnoRmGocVIQBu8nx8/xGbGaZlYp4Xmral3WwoqxxtDFVVcL1ciMuXpl1LjOJisTajaUu5TynDPDuG6ZFlHDlsWzrVM/XDWlrkGKeBa38V/EmWgd5TbzfMznN6vuDDggsLbpbmQrOesWWesWk2aKNZwsLxdGYcHYfDnr/927/BLZ4//tMPDNOMc4E8E2H1fJnQ3UJZ1hR5iU6w9BPD0hF8kK+90Byfnzk+Jz5+eIIE5t9mVHVNnhUEH8m0ROiMzUkoao3cEd2E1gV3r17JbPRPRxJwd3tHURTs9xvcsjD3jwzTwIdPHxiGLW9f30mM3wbGceLx/SPzvNB3sgRst43cmYLncr4ydNJQvN3tMdpwej7KXW2Z6YeBy+W6fnYUyyxlI/PkVnFY/lkWJ2fdvDAvC1VZU1YFozOEWeZGTxQXkckwhdwfm1aQJ+J2VVy6jpTg6++kLe58OXNeF+u5LXjzzbeUZcEyjcQQMKvr93yW+932sMdoy3AV8b2uN8QIy+yJYeCzkntoWTYonVHkFVVV8t2v3jCNI3/3+B6lNE29o8hzNpuKYRj4+PFREBhlLTPzh880bYOxgjdo2gIzBZw3cvYlQ12XHPbbtRl4QQNWSyNqjAXeJ+ZlYhgcwS+4Wdy+wJosUChl0Gstw3azo8hLrpcL4zCw3x+4u39FcJHkE3M34VOkrmqKIiesIpNWihAc6ITONIUR0U+rUvA2BNziUCZhc01Z5hI7tTnTOPNwOjHPjh9/+IHtZsNut3lpZP5fe/184SlEknOcz6f1zR+IES59RwqR41Hy1nf3r2jWqI9RUGeKaikJRkCOMSVhf66b9Lwo0Crhl4mQwAXhEFSZFXAvq/DUX6UhZRwlSmI0ZVmx29/w9PiZh4cHcbQYwzBOjNOMLRsaK3GpspTKSW0NXTcwTzM3uw2v7m759PTE8fECthB2S9KopOiuPcF7bm62lGUhDJd54vn5mWkYONy/JcsLPj89MIwDH96/xyjF/+n/+N/RNM0ay0gCIjZiYyZGsiQ/uzl4FBl3hwM+BH748EmGxbqSCnAFenHkkyOgmIeZ0XmG/ioXcS2XgB/evcc5h58Xmrbhzes3LIuwZ3xMuKTYNg2vbvZoY7kMA26aWBZHN06crz1lXVM30nDjkmGaHf3a/FfVjTSiTLMASJ2jLguqomCaAylJxGZZpD47V/alTSovcqn/RdT3cY3Gff3VV9zf3vKf/+4/cXw+krICbTPubm6lvSuIsGmrCuc9/U8/4tzC29sd1mgejxdiknY7rTWXeZLLCsKzqZuWao0LtG3Lb3/zG659z59+eM8yL/i5x6oGY+4gRbrrBbQMPkTNArgIqHF1ZmylXWkaaZoaW5W0RcmhbTmfT1yvJxFDi5I5RtyXrbuCrrvyfDwJpC3Pid7RX504vfKCsEyEZSCzJSavwGbYxbHZbNm2NeeziGJfsj5FWVK3LRYZXrtPH+VzcbOnqlr0yobZlAUqwbm/MrlldWyJA07+7A3TOPDnd+8ZxpHvf3zHdrPhv/13/4amrv6/ngX/tb28mwGB/McksbukE4sX0WLse2KK2KwQh2BdS1TUZkxrPMl7z5KEp6KSxDbrWlpENCJQjWtsKCsKFGq9QArTAiXw0hACY3elKXN0bNcH/Ro9jZFlnl6aurSWrYoIngmlIt31Soqe/f6Gm8Oe6/XK5XxiHKSJLcsFFKiMQWvD/nCgWFvr5llcL5DWQU4e6G6F3H45P/MsJ7OZCE2r8GTTGtddY1ydO6GQGKFAxyXgUVcyrAQvi4ix71nczDh0kKJ8jTajzDO6fuHxSbh3wYtYvNnfEEJgmiYWN3I+n+W/r0qCd3TDIO4kpSS+tSyyyFCKZZ6Yp0Gitdsd87jIRSTK9txkOUXVUjcNZVny/PiZy/ksXCWjKdYzq8ilbSlbBVznAxHF9XplmSfevnrFZrPhx/cf6Pr+xV20299Q1RXz0BGCZ9YLPgSGfiCmRFFKO+IwDJCSgMmVEofPujCJUaJi1hjy7Z48l+bBaZ4ZF0eeZez3O+ErBmmD7YcRdMIojfML/cORoizZ7m/kDM7y9fvKVxC0JcstWZ6zLAvLNJEZjdK1WPPdgltm3Czbz+fTiXYdDOK6PADWoU2GamnVi3TdlWma0Pf3NI24Ncd5Iaa0NtYVFHmO8zLYCwNMrbFI2XQqpVHBAeIsDCm9PD+/NH6JCC+DLSlxvcpw/N13v6KqfjlnF8C5n9ZG4GplxEjUYl7dHV0nEf8615SFpSxzSmvYlIZpCYxBrawcEVysTtiVs6bXiJoPIpBmRrNrK2KCUyfDYu+9iAvIYNVUJZk1EFanSRBHkAsBT0bAsm8LNnVBdI5lEpFHG8O16xjHic2mpW1autHTdQvXSYQYdekZxhFlJIaltYjo+RqN8ohzqcoN0cJ1mJhd4Dx6YoS7zYJKmnGc8CFR1xUk6McZozVv7wV+f+5HtFYcNiXzvPL0lGLTFOs9zf9FeIqRmAKLT1yHUdrtyBhmz8OpZ3KeblxoCsvrNUo3zgs+JKZ1IM1ygwuJp+u4+t3B+YgLggJIGC7TxPHccberqMpayhrWi7wgACQ+Z5XgAAorn+EQHN7L79NYS2UMJYl9W1MXmVSEx0RcW+2qMiezitPnI8M4U1hFXWZsKlnMXk4zPsLtYUtuM0IQ92tuNIbEvMxobTi0JQAhibjXD+KSblaQ9hLEB1eYxOwD5yki6xOJO5ZFyewDc9cL4mKRaPDspLhicQtlZtnVlfBUX4oDBFWgjcEvgcvosXlOXVVr1FvEnCUqumHh+XTCaHFoKtTLMockPDij1Apkz0hqFvaqkqVLXN28ZVEQUZS5Xc9KGQS7yeNDWoXVjEZrlBLGk9aKUzcRgojkwvoDaxRlWclS+jLgfWR2EWsTr26aNfb1y3jNSwDlmeeR8EV4Cp7Pnz6DlqINpTV109BuWvJSnOObquHc1nTnE84L2N17T1oByXVbYrSIhdM0cb2c0EqxaxvC4khJ7lWLkzbyfriQZzllLFFaUbYN49OZy6kjKEfA0V97hm5gu23YrKzXNjUkDS4snE9XLkzs9jvevL3jT//0Ix/efZa4LYlXtweauuR6mQgxcXu7keX8Am6YOF4uLN6x2dYYXfHp4yf6fuDzxyPWyrKrrCqyrJBFvJb3kMnE2ZwZ+Qxc55Es19zeH1aesZfP4/5mbeptGMeBx/SZZZ749Okjbpm4ns8UVU5WWual48cff2IaF/p+YrvbUDXV+tkI9MPI5TxyOBz46uuv0NpwOZ6JJHyMdNeB5+MZbRTawNhPDP0IKbImn0EnglMEr5imhWme4Gblh14McVHMcYG4UNUFeW7JqwKb51RNSZlnDOOMj4nj8cQyL/z7//a/4c3bN/xf/8//Fz6+/0BRNeRlybff/IrttuWPf/wDQ99htCUlGC4nvPdsdhvAMvRroqZq5d9fR+bJsUyCFinKhryoaeuapqn5+utXnE4nxmlEK4M10obdNlucC3SXThqrq5Z5mXl8emQ3O7a7G2GW1jkKxzCKG9VoxWbTcnN7Q9f3zKflJSJOMqS8xIeJ2c0M1yvd+UKZN5Qraiau1kit5M/TaDbtlu1WQ0zEENhsd9zc3jNcBtwwc9UanSJVUdBsmrXhM9J3TtiKJqEyRWHEIFMWsiC9nK8sy4xSCWs1RZlT1RW7bcE0Leg//BPTNPP+3TuG/ZZvvv5vaJr6Z50LP1t4+t1336yD0YwLfm15MtRVI/ZV716AjiF6FjcTvOd8fEZpzbZq0GsE4pnAB23QWUZTNzi3cL1OhBXEazUURnHYb7l780YykTGQL5lkRvWaRc+y9QejqeqWx6cnHp6ehNNhLafnJwENrm6s+XoRd4n30vKj1brNttR1i1239V9iJK+bGmM007IwjgvTLLGvptmwaTfMPjBdr1wvF7x3/O1f/xVVWfLh02c+PT6xaSUW8+7DB5xzTGsD05cIQlm3FEXOtZP4hzXiitpuhPXxdDrjVmeBVgqrNMEHPj1LnXbX96AMZb2lRPLvVV1TbfagNYdxEPZMU+N9ZHKONPQrT8WTvGMYhxWupzGNXFSqXFoS0jooTtNI3/dc1/Yum+ciBvVyiZyWZeWvyO/g/cfP3Ox3L3XlUo9dgc4wubTHTePA6QjKWPK6kYij7/lIoli5O9raF9jZ2zdvSDEyh8TQj3SDNPg0pbRvLYNkwRXyHquKkqjlgzhOEz/98D3zsmB1wlQFdb3DaM3T8wnvHW1dYbOMZrNjXhzP5ysxaKySqMq0SHWwc9LksGs3WMDN4v769a9/zbIEPnz8wDLPLOMgFDhj0cCrm71wY1ahwigRYL1fuFwvHI/PNNs9VaO53dRk1jJPI3/6cWCeJuy64TPGUOU5TVEQvSNFz+1+z6ZtGZ1nOZ2lKdBanodRXHBaxItvv/4KheJuW2MtfH56ZpxG3t7fvrSixeD44/ff/6JcA7f3rwAltdgxkufykK+KStg7QSKP2gh3aPae5BzzfBH2z074XCCxgfP5RLbC3hfv6ZaFlORiiVKURSkuy7rFr62R3jvUrLEpkScwRlyJ3gvvo+s6ur4jW2vrwyrmWGPIjGyhl8Wtw3bCZp2IVjFhbE5VK/IYvpBWqNoNWVasEagR78SRmGcZSkHfT9L+EyJow1dv35LlueTRfaAsC/Is49rJmWfWbcg4nwDWr9NKo1SQ97JWhrKqICX6tXFFaWFhNZsd1lj6vhd+zCKbp6IoWTn+GGtYpkHs4ctCkWV89dVXEg8LQZr6ugtFUVDXDfM8MQw9TdOy3e2Yp4w8k2F66HticJB4yebrmNDrEM3KXZLmEYF7Xrsr83nm9avXlFUpHKbomMeBaZbh31bVOjT6VcjN+FJ/fT490V/EdZRSlFh1EncZKKZRQLbzPKKAzWazNh+FNe4nThG18vvkPSCNYiEktmvsTBpuPNM0rUBNcQvZvGCZNfPYi5AwDmtTHNK2OE3keU5VS8TGGEvT5Oy2u/UZfF6FKb26NmfyPOP+7pYsy8mzDKdE7JZWRyui4+LXQdCy2R3Y7mTB9Pz8zLLGq/Msf7HLay1LI6Xk+St6ujBxxJUQGUYBY7fbDKXFIadSYtPU8j5dPBjL7d09cWXmaK15fHr62Vu3/1peX93vVni6J6QkbkSlqDILJpLXUv2s9Jdl1IxbFP0AKE1VCMPLKomgzT5irLiBQghcV6dTAuzK2tm2JUV+K4L6NGMUGASurJQiYBjJ8dHhfKCfPN20UJbizOr6kaEfIEXhsYXE7BemRQScyQFGRMTCJOp9LcKJkruOUpJ9nVY2ZD9JbAst4oMhQAosLhICfHu/lSbKRQT4em0IndZ2uIi4mH96vorgRiSzmuerROzzslxB6+IKOncTLkTcmhyoC4PSwo5bXOBDN5CUoixy8txSFcJ3rBs585NS4p4sSnzwa2QkcLz05EZTZhrnAvMcaGpDXeaoFMm1ROEyo/lSNhHiunDKLWVm0cmhkpTCjE5KV5oio58cp36iLqWtthsmpsUxrw7FlERsickSk0RhVfqLALl4DeEvzWv9ODObQNNUNFUBSpxIl35CIRwsrRT9OP0LR4+i1RLlMwgs22YaVGRbi9BTZALJ70bh8uWZIc8UuhBxbpCNH3meoxUsa7OwXd28wu8Tt2hbZbRVtsJwZ5xzLItEkZVS5BZudu0a4cwR/7fGahFbFy9Q9QyHiZFtXbBvS1CaYzeRiC+Mv8KKG2sJiaaWGLf3kQUvKITgaTMBiD8ez/gY1wgqfP3qhpSgbWtx0EziNvvqRgbglDzDGHn/WTg9v5TXX/+r35FixM0Dy+LJq5wsy9gfxLWb9+K6ZRXypn5k6gfejT9JW+6+WVMcGafThcu1w2Q5ZdniFs/lJGLO6Dy5kdbWm9sbdoetGA7qhrKpqJuNNPGuAuDz8yPDNBG04/Onz3z+9JmyKCizko6RZfYrKjAxdCPzPGNNjtYZ/WREHFSK25ubdW4UTp7Wmm9u78nzjOenzxyfnpjnQAwJbTXGKM6XKyFExnEGNP/+3/8tVVXx8PmR56cjWaGpTcGHj+9YloVxGmUxuor3zaYltwVPT4/y2VCePM+5uTlgjOb5fGQcBmbvQBv2N/fkRc6nz4/EFBlmee/lWUaRl9zc3JLl2Qtmoq5qdts9v/lNS4oQnSx2Hh57yiKnaSrGoae/jtRNTl2W1IcDr25eSSN0NCgtUeZpdoy9w1hNXdYUxr6IDjElDtstdVXxpz9/z+PzI99+8y37w4FhZdPNi4De67ambCq67sTnT4GyLrl9fc88LUTv+P5P/0xeZGtM1XDtBmIMHO7vEI7yyDiNJC/O7W2eIQVDF1JMbDZ7wTMUUnDSTx3jkHh6OLIsC19//TUksLklxMDjk8DQ37x+jc0ydvs9l+uFh8dH5mXh+Xgks5Yqyxnnga7rKcuK29sbirJErxH5ss5Y5pkPH36SpXhI4uB3nrqs2DUtRmdoZQnJERDtJctyjs9Hnp+e2GwPNHXLq1d3vH17yzIN/OHv/56xH1lCoGha1DpTF1WxYnuSpBiicLSHfuD25o48tzx3vegjSopsvv7uO3wI3N3fUeQ5/UUc7H/917/7S3GSU/zhH37AWst//9//r58LP3u6/O6r18zzwp/ffSREyclbYyjLCk0ieXEsRRIhBsnZThOfHp9oqoq7w54sz8mLSsBtWqOtpa4ruj4xzMLXcfNIlVuqpmDbNty//YZpGuiuF7LFSiWmNusl1rAsUp9ZlTXd8BN//uknbvc7bnZbgT5fr5gsx5iM8+lC311eoF7W5MSoycuCsiwpCrO2kchl+PZmR1Xk/PD+E908cTwecd7xu1/9mqaq+enDR4ahZ+g7AH7/61+x3Wz4n/7T3zHMM//q979Ha8U//uEPXLv+pS67qtqVHyQ1nV0/CHh7vWBvmobFe8b5Eedk86uVbGZCiDyfrwzjyKdPn2k2O37127+WaJ6OFGVF2WwkXrW5smlrXt/f8nS+8P37TyIYjcLrslrJJn0caOoSoyKZzckyuSy5tTJznmEcRXxqNxvK1bkxjD3Tak897Fr2m5Y///QTP7z/QAyBw3YrTTZUZHmJLQzKSkPUPE8QZMOVVyXu+YlpkOaZLC94W9UUNmNZt+uv7u+BxLtPEokcx0m+R9+ikMFKfoZGIJx1g1qt0PMy8+n9O0KKaCMQzs3uQHCO09ODOKTKkqIs2Ww3XLsB9/hMDIpMx3/BdpFctc0K2rohLAtu7NlsN9ze3/H+/Ud++OmdVLoviwDDs5zDtuFm20okIYFKEYgoBcEvdH3P4/MJkxfUdc2+Kdi3LX9894HPzyfhV1m7Ck8CVayLnCl5QoL9tiWh+fDwwDhN5HkGec7T8cS0OLYbqRt+++qeMi9oqoIYA8P1xDhN3N/sUErzfDqzOMeP797/ogCXh8MtPgauV4lNZmvFfFGIw1FgxhGtHUor3NrodTxfqKuKr75+u7ZUinAyzbI9J0nr4eXarRZ6tZ5xBXWzYX9zyzRNdN0VvcxrXEKvF2epsQ4xEkLk2l15fHxgf7hhv69YggxVEpMyuOtC13UvYFtrRfjKygpjpUEHEtE7WOOgRVnzfDwyThPeOWmGLAQoPC9uZa7JZeP+XpotHp6fCePEzV7E74enR5bV4ZiSRPKU1tzd7LE2wwdxdGkQF2ohnCvvFtlQa4vVhjyTGNcwDizzwul0pixL7l/dY7SIFjEG3DyurDVP2zbc3t0zzTPXrif0HdPQY9fWqBhFoGjaDU3bkhmFVRAiTOMocZQ1iuV9QMWIDorgq5col7UCGC+KgsenJ47HE7c3t2uUT3giyzyyjCN5nr80+nm/gjytIURFionufCLFANoIGWp19W63e7Q2dNcLzjvmaUArRVOXgGVZmwlzq9f3hxXmyeIIBKaVldI2DaBeYtXjMABJ4NA2o6zEGZCUsLGWacTbQMDiFseyzFhjKDKzRlUMVVWx2Wx4fnrk6elBmCsmI/iFsMyUVc2mlti8TK+ytDCr0BS9Z3GebG1iaZqassjpup7z+UJK65Y/Wx0zazObtCvaFc4sYPQQwourU6CYjqrZYJUSHgzSKJnlOUtaSDGyb5rV0SIi+/Pp9MLW+qW8Xt1sWFzg4+Npje7n4hixYt8vseKAwr6cSSEkJpcoioz7QynDbFIo5Vh8pEgRq8G5yDBOaxxMBAmlFU1dcLdr6MaR4zkRfSB6h0JEiqA0E5aQpBW2nz2nbuFgpF2s7yfGcWbbljRVwTyJY292ARdg8QnlEpZErhOHbSklDE5A2OIKEtSAT4nRBVJMWLs65TWAsF8i8Oampcgy/vmHgdl57psWrRVdNzI7T0rCKfp4ls/eoTaEaDj3MwnI85LMSJRtcZ5umHAhEdByz61E7ItKM8+ex+OVosi5uz2IMx1DlslG2DkZTuq65uZwS9f3PD0/M0wL536iKQyZyvAusrhAk6DKMzKVqKwUqFijXvAEX7bcmbXUZQ4BiIlx8HTLzL4pqYqM5+vE8TphVmB8Py2CI1h5mvLZDWvyAPJMXPXyW1Asq2BuVozDMM1oE7hpy3UB63DO0w8SS2zqmqRgHCUiHAlkWpNyjTaglPBVjMlQOtKUHrXGZmNM9NOyikNmFf0U4xy4TiNGK/LMQpJZwqzOSq0URidh25GoyoxNlYvo1k0Sv14W+Z0oAS3XZUNVCQZhmiX+KG2jHhcSs08kPFkK3Ow2bJqKp8vAeZhQBFSKlFlGbsRB6EJiqyvKzLJYsR86t+CcorUZOgmAf1w8bSMts68OezJr8Gh8DPSXCymGdSGpeP94YfQSYfrl3Lzg17/9jmmc+NM//BPL7FdHU8Fmu1kdGxYfA7OX98YyTozzxA8ffqKtK37762/EhV61cm/64T0my8mLGu86+muPS4EpBuEaKct2W3G420qCJibqumXTROZpZOo7UhQ8gU+JqALPz0/88Q9/5M2rN7y6f4UPkWFchCuXW7p+5Hq5rs7hDK5yd7+/vWe/39HUUjp1GQYW73nz+hWbtuH4+JHL6Uw/zasD6kBmM57PMjcl5ymynH/1N79ns2n5D//L3zOOE1/96g6bZ/zD33+ku/YvTd9ZLveULw2vp5OIIopAnmt2ewG4f//TD4zDwOJkmbzbHUgp8PR8ZBylXb2pK77+6g1VWbHd7WWxEWSZU1Ylh8OBb779hvPTlXd//sTQ9Xx8+sh+22KzA/M0MvYTZSER7Lbesm0OYtJYFpSKKITl2PUj201DWVdkK4JCpbQKsS13hwP/8T//J/75j39kU7cSW8stPqUVwr9Q1hXGWIb+il96iqrAZDnPnx+ZxpGffvoBFLx5/Q1ZltOPIzEGvv7mFcYafvrpJ+ZpgVhgbEa73awuzY4UkxgRjDiyvVd4v5CiRDG11rx+9VqKPZyUj51PV6wx3N7ckeUZzaaRhSOwLI7z5UxmMlxeSXvcMFKWJbvDKiQZTVlVVOWGDx8+8vnxEySDWhM7Wim29Y7buz0hQAwwTFf6aVoLQXKGceDh+TPGZFR5xc2rG24OLf/8z9/z6dMDeVmR2Zy8qiia5sVVlqJc5bLaQoJ3739iGAe2zQ25UZzPA/PsOGwLstzw+s1XKGPYbws0cD32EBO//s13hJj4/vufGIeRP//pw8++e/1s4elyPkn+f7fB+4rcgNKGcZrk4WILiAE3zywhcDZnuQAtM330/PmndxibURRCW397d0eeF5xPZ0JKbLYbrN5QWEXX9zw8HRnThWAfUCmggyd6+aduC2kJ05pp7AWKNk6Umea7N/dst1u22w2PxwvP64GR2Wy1iTUczxcBNnuH8zPMkeAtwyQ/tF3bUhY5D09HfPAMgwxuzjvcsnA6PjP2PZeuY14cb169Jsssx2vPeRiZxoHghRtgrWV/uKGqG5ITO5/JFNZAWiM6z8/PEqXSCu8d//Hv/k4a16oanSKPz2eUUtzva3yIdEPPtm356s0bYlLMYZHNZp5RWkVt0srfUCSl8cqSVy2vXwn41s/TarcLUJUYdRDQscnpZsdy6bk57Hhzf8e1u3K9ntHJs6tzrAb8gteaoFZIulF0Xcc8jXz95jVfvX69CkFBIkvGcBl6ZhcYp5EQPN1ZLpena8fiPGVmKQoRfvKiQMVAnCcM0ijzxz99T4yB3X5H3lT0x2ec98K/0BpTbcgUlFWBNZaoFdHLIFvkOW+//Y6YEo+nEyEm5ll+l5MLMoxpK9sp7yis5u2rW+bVwls3LW9fv6YfBj4/PpKSbPY8YiGfnp75/PjAtR+Y5oVNXXF4dcs4TfTDgNUKk+Vr5b3l4eGBh8fH1TUizIKv3r7Bec/Hjx/x88x1IxeQm90W5xzj7F4aVJ7PF/pxJKU17mKkCVCnRLVGa7I8Z79pmZaZz49PqyOgYNNCXmRopbl5/VrgoGUlw3SMeOfZ6S++mV/IS4HVhu12I+4Z36xw7lmEz1yGWrfy1xQIYN4aQgw8PT6uMHHhhxmjiSFwvYrgXJWFXJwzy+Ijp24Qfod3/x8g7i+19XmeS0va6uJxzlNXNW/efi0NbHkuTsJ5JEaHW0QcqaqKru+Yp2l1GkXS4jAh4pzwm5qqIstyhr5nGEaGoRfw+DpU9J18zcF7jFLyecqk8a3vJUevtWIYeuHyJGkAqsr6JS7DKrw4N7Ccz2skT6MUPD0/oRDYowqBbpyw1r5wivreU5QV336zJcbAPI7YvKAtKrTOMVUlMbVlEQbZ0AvfoCzJraEqS+EEKk1T17x+9Zo8zxn7jmkcGYaBTduy32yY55l5nkWMr2TznEioVfDwqxNqXhZSStzc3rK/uQUiTw+fKCpxwS6rSBdiwhhPVGf5HK4VwJvNRiJxm63EDCOrOOXWZkE5v9vtjgrF86P8PvphWlvnvMyFqcBoQ1mIYyelSEoKo+KLoBBXoTKEIPyDJDv1LJcYb24Nr+/uCNHjnFvt3QmsJpYVNs9eGvLmeVoXESPX85mu69nt9tzcHARIvizyO1dqdablPD4+cu16qipRro1/2hgB6zqHUWsDZIoUuaHrJ+Z5Ji9Kia6s7gUfQRsvraQxrEKUwXkvXJiiWC/XJ0KMKG0oq2zFO0WqFZ7vvYOUqDJDsprCmhde1y/l9Xy8kBA2T0zCdkrRM03u5TNkrKHdVsJVm/wqVkh8d5rdi6tFKbjbCd9vnIX10NYC7M4zwzR73n06Yo0itxZt5G4XCfikKTJLmWdEopRZhAApUuUGtSmpMoNO4hLup1lqp6PcEZqykPejEf7HOA5kRmJ/T+cB08+URY7VmuOlY5qXl+ipTyLmZlFEhajlvMnXWMe5G9FmIaBQ2jIushkuihxjDd3o0CiaRoDqhZZo6OfnEwmp/fZR8fnYo5Ri0zbSqjfJZyAiscZhGLBG893be3EGYkAlGai0Fr5bDGsb8SIlDd6Ra0VW52wr2bQnElmR0WYi9HV9L3fMZWGzqSmqmmFc1mr0iEpRCnOiJ4aFFDxLlN9nTFLycH/YcLPbrE/uxPwlorQshBVdQEpEtaC159pP+BDYNoYis9SlCFGLk7IAjyGS+PR8RpHYVhkGcXDGBNMsrVhZnmNTIiYpciEvCQmuw0JmNZu6EJeREcFpcfKzT0HOvYA0MbIu16pKsBYpRYm3VML5PI/CwaxKcTYs08g4L0zTzHVcOHUDh03Fm/s94+ToxxmlsxdGjveecV7oB3H/xuhRSgDjyzwzjjNzVVLkOUYpqjxjnqO4krW4sFyIuJA4XyUS2o/iZKsKOXtB7tyHbUvjA4+nHncZ4FZTFjlVpsgV7HYbiT8GT/LQNhUhJLnn/YKE87EXd8Sbt69xznG6nFBKvZSImEKjoiagiMlzPD3hvMcmcPPCTz99wFpLmQty4/7+gNaaz58/kmKkqAvaPKeqG4Z+5Pn5xLQsuOAESVG3zGvUvywrDoevCNHho8O7iXmZuDkc+Nu//TdsNg1NW/H58yOPj0fKsiQvcoFFf9Vyer7QdwNlmZFllmEYCN4x9APW5tRtRVOV/PjjDzgvny+TFfjryu1cAKWxSlNmht3tniLPeXh65Ol4pBs6vPNczx1KK3bbLVVRMrtRouVKYa3CuYngHcu8yLMWyzwu/M//0/+MsQZtEyqJi14bzev7A8s88/z4yKbd8Lvf/ZV8fdcz1ubsNlthLGqYxknQHiHRX3uSSty82lPvCna3DZnRFLklRS3R07LC6IqumziffuLmds+bNweO5wun84XMZtzf5oIusIp5mTleEiEkirzkdD7TdVd+9avv+Obbr/DOM4w9RVtiVIFfAvMwM5+lQf5hZayerwOLD1RVRpYZbna3FEWJzQHtyAqFc4mf/vwerTW393egFD/88F7a7de207AmisbxgvcZSS8vbLCqKjnc7QE4Hk84H7hcenHNeUW0isV4Igm9JEyW+Pbbr/BO2Fa5keIvO2tm78hshQqaaZkZ5gskUDGJIeYyc3N74PXre+ZxYRpmlNHMQZpe66zkfD3x8PFIdxkpyk/E6Hl1d4/3jo8fP+BCz/lSk4DbuzvmOeC9tCzHFOn7C4lIkVVrS6AI+bktyTYFxhqiSlS1QZvAu/fvcG7h5v6eqqpoSuEv120ld7CyIZJ4+0rg935e5H36M14/W3jquw5jLbv9XoY3N68D/CIPiyIjeYjO4bynU4jzwy0sC3TjjDEZeVFT5Rl3+x0hJq59j81y6rahLnIOm5KfPnzmn/78kYUOZTOqTNNmlhSEBZJZy3bbME0zwzAyjSN9P1BYzZvbHfVmS91ueDxduXQ9Re7Js5ztq1tuD1uGcZJqwbBmHElE7xmdx8fItm7IjOXj5ZFr35OvcangRe28dldGM0ocIMG3N6+pq5JT17O4hXmZSDHRjxPZ2oxWe8/SXUjBEzVoI5cA5wOPzydSiux3G0IM/PjuA01d87f/+l9D9AxdR5Fn7F/dMjtPN/TUdc3f/P73XPuBf/rzj6A0hckpDBQm4TRr5blcjrKi4iYrcNPA3Anvxi0BUwpkVhcVSWeMy8j5fOHmsOfmsGccOvq+k/acIiOurgqvDUkbElKxO4wSkfnr3/2WN/d3/OmHH3k+nsTNoDXjNNENI/M8iZtqlsjj09Mzzjl+8+031GUlTo2ikAuW97J9j4H3Hz7ivOP+Zi9AZ0SQuowzxliJYBhNUdqXlr6AwG51nnH3+rVwB2JkmhZOl555ke0vSotLQSlSEM7F3WHL6Zx4+DzTNBtub29RWvHx86f1QiTD5RICfXfh+Py4tl0Z7g47Xr+64/j8xDJepTnIZi+Mp5+c4/PjM0YrrIavvnrL/e0tP73/wNPTk7S5LJ7DbsOmrTmerkxOIHtKG659z/kapa3D2BWGCCbJBdhai80sbVORGc0/nK90/cj9/WuyPMfFSG4tu5ublb0iPLV5HPHBU5TlC8Pgl/ASIUncOCiBfbvFcTweZajO7Tr4yxYGJcwZY8UNdTqd0Os2RCupffcx0Q8SZZUyAAG3u2GiG3pxq7iZcr38KP4Cwi/KQgDOfiF4iUwU6+ZJoKUJiCI0hIDXjsPhwGazERFymsQlEhPJO0L0TMOA956qrDDWMozSmuNegOpCOndrC0dKSSzHbUtRFDw8Pkoj53YrMcBJIiggFu98FQa+RBPn1ZFyOh0xWnN7dw9KcbmcMcaw225JStxjSskA6LwnDbK5e31/zzD0vHv3k7BcjEQXqjzDB4+xk7hppgmb5RRVRVGUtK0IsfM8U5YVZVWJgDwOjKO4LHbbHbtNyxmBV+ZFQZ6XhLhCeo0R19D6j7hKI4fbVzTNho8/fc/pfORgshfG07I4YgKtDS4mEkocsMtMVUqjZlk3ZFmGW+PBfgXFn44nIom712+x1nI6PuG9cGAUQPSoL2eQlUFa85c2Rhn/0gs3a17dc957GdDWQSUFeTY2+x2zc1y6fg2WAEYT8y9g7zW6mDx+mvExilA5Tuz3mt12K2D3ZVmf4fMKOd/w+PREP0wCoc+lmlhrjVvml+bQBBRWk1tDWNtytLEobWR5FANhbfacB4HAZmvLbfDCYBBxNvH4dGSaBVaerTD0FBNlLiJU5xYRrqxGI86oX5RoDly6TrhlbbM6UxZCFCyB9+LOKfKcw40hRo2P8AWHE1NauTcCGNdKsW8KiV8uAWOUNHOtwOx5mnl8vrzUbG+amtvDDpImBIWyhiK3zC98NflpF9aIUKUSOgVCkHi6VIDDri0pC0tEgf7CcPMCVNWawU1E4H6vMEXGqRu4dAN1JsBspwtpKU4eTSQY2QwX67OvG2fS2kymjGHyXi7VucVGzTgJw2nflBijwAvs9njpSCgOhwyjFfPkKDLL/V1LCFJwII1sEtkdholNXfL67sDiIw8XKRExWmGUgiQCv2zHHfQDWiVxU1lLXWQMi+MyOazNyHRO8BKn8c6zLJ66rcnygjgs0ta5Mu2cCzgHIXhiCGhrUUaA8SEp9puaqsw5X0WQSU4a1qZ5FserWoHt0YFSnPoFHyJNLc/Hao34jZMILClA8JHnS0cKgSbbkFuztljC7MT1WeQrtHvlAGJzgg8Mi6eIwir8wgeLKeKDlzNrFZ5i0iv7SYTOosikVXEWQcoWOUtMdIunQpOXmmV17s9aM8+G6zBz7Hp2bcntYcPzeaCfHEpbtM1JxDW6I4Joip4UPXVdU1W5RJFnL612a6t0bg3LzNqUJy2SYV34dIOwuiYnDrIql/dPWnmD20YYTj98OHIdZqq6JiiotMZaTdvUpKToL0diiNRVs94f5e/7pbyWSebDm7tbQnBEFpzzjLOwGNu2QSWF9siS5jquyxTwi+Nz18tyMCsoq5Kb2z3TNPH0/ESe5bTtlk3Tcn93z4ePD/zw5w8sbiHGhe12T1Nuic4zjR2bTcPdK1mmny9ngo+4eWG32fLq5i0mA53Bx4fPnE5HqrqhKCt2bzfc3R7ozz3zMJFbg8o08zQyLyNWLRid0TSVJGR+/DPH45F2s8VmApl2iyd6wIrwpK3h9mZPUeY8PZ+ZZyet5gn6bsRaQ9s0xKpkGDUhesJ6lwp+wUXF+Sj/fVVZlsXxj3//j5RVwW//6lsgMo6DuJf2G8bB8vjpM03d8O/+zb/ldDrzH/7zf5Jm2rrGZgJev5qO4dqTQmIcRmyWsT20bGLFbdwSFoebF3F0GzDkaFXQjWeOx2d2h4bb2w1d3zOMC/umZltXcoNJkdk5Fic8vtzmXK9n5nnkb//Nv+brr77iv/yX/8LHDx8Ffo0muMAyLVwuHfOyMM8D3jk+PT6xOMd3v33Dbr+hab5l02xY0kxIHpvJAvDjx0dA8Zvf/o48z/nTn35kGHuW2a2sOXkGLnNPCBZtIyFKgUqJot1viCvDOvhA348QIVMlMYGzkUREL7KQfvXqjqEfefz0hNWaui5JSpGPC0YXkDTLLAKsnwNukGfhNHoym/H69S2XU88xSCTcBUdlK+qmwPvA6bnjfD6jbeT1qzfc3tzy6dMjx+cTPo30Q8nd3Wt2+x3Hp55lFqRGiI5Ld2FyC5tmS5GXa1GFpmkacZQbQ1KJopCs9eeHz3RXYVipGPH7G4zWVLUsBvKsABTqZk8MgeBXx/rPeP1s4en2/nbNgGZM88KplwNis82ZF8e7jw9Yo3m1a9a4SpCtsrIrGE3Ah3megVEMa/Z+cJ7NWpMbQ+Dh6Yhznrvbm7VeWSy5fd8zzzNDP5DnOXe3NxKJQ1M1G6p2z/n4yPn0yHLtOQ9iz/3m1d3LhWvsL/xwOZJS4na/RVlpXyqytcnIyqXZZnLVH4aRy/kqdejW8PbNa4o8Y16txVWzISmx1T6dLjRNRZkXvH3zVloR2gYfEj/99BPOOW4PO3RWsPQXTEwURU5Zab7++i3LPHN8+rTC8DxFIQBPqyvuX78hxsDp2km95o20HV0vR8Z5JtMBtyx8//5K0zTcR0XfXXk4HinHmTl+ycUL3CwrN6jgUDajKWryWuJlx0sn7JG2xnvHw8Mjx2tPv3hcTOTGCKg3ATiUEmiyUgq1WvePq/3Te09dljjvWTqxZ4/TzO9+9S27zYbnpyfGYaCpSqZloSgMKS50Q8/sPbe7LVlmxZGkNP/2b/81MURO1wvee/KyJCuLl+8r1xFNxE0L2hjqLCMCw7Tg/IU//OM/QkocL906iGuIYa1Zjjwdj7K1Mvt1W7EO8lUDwMOnj/TjBMpI3IAkW8d5wpiMm9vX4sgoMg6HA4ebO7lYZjk+yUbz0gmI2GY5v/vd7zDqSztNzugCk/PCtJAucc7XToYOFJXVYKTlwmqxmY/jjA+OuhQm1DSN0g4TEzrA7DyTcyvkPWMYRxEF9ns0lnHqpAFiFV0wFq2k2lf9grZuWSbuiGWe5PC+XiVGFTwhBB4fP5NlGTc3N8QAp+cnCXok4UTUZb4OcAIVNzYj4YjRo1VOXVcCDR9Honc0ubwn4xpN6/t+dalIROmmKBhXXp6xGeUq4E7jX2z2KUaKTJxOeV7gvOf5eMRYy+3tHawX3CLPxVWoBOgtrWEZIUrkhCRi5c12J/W0q+NwdiKOnC8X+bOSNKmplFZhSkCG17XtKS8bjDGM4yCculLA25utgHJDEJjn2PdkWY7a7rA2Y7fZoJRinGZIiaYqsca8iCdNLTDezx/fkWUZTVXJUP0vuFnWZuTzLDXfmYCpl2Uhy6x8T8Ezjx1ayXCujWacHZfrlaenp7WWPAct1e95nok4a8Q1laLHO8/ldGToe7S17A53JJTAT5VaGQo3VFWFthlpjY3N80RV1VJLPvRMWlNXtXyPXmJk9/f3AHTno3z+V+djlucopcm0WgewuLa2iTA0jwPeGKZaIL5+dWlF7wRmvhNnUnc5AZL79zHwdJR649n5dYCyL3XkShuKqmYcJ/rusratZhx2O17f30tEWWtS8NI06/zLZfF8vRIjvHr1WngWRuOmmWVZpNwieLQVMSoaGcaV1hRlSdO0AldPAracF3F91U2NUnodNGYyK1FQef/FF2eCczNaJUImdfLL2APC0UnJMi9f4KC/LNEcJI4gggH44OmHkbC2XIaQmEMiec84dP/isxjFabNyJpKKOC+AaqsSLkT62dNUJbvNlhgC535iXIK4nIwhsyK6Ph5PjLOnGx1vbzbctXtxW+LJjFmb0Dzj7KUmOwo37rBraauSqszxPnDtv/A1vwgWGU0hjXVJiYSlUmKaFwyKwmbYTHieh6aStt7ZEEMkzy0KOJ1WeOy+kK/FSGtaVJoQEw9HuS/I0kZxPp+w1rCpS3nfbxup4zZmZVp6LGCitNRlmcReo5fG0PubDZk19PNMipHayvLw+bqQZ5ZtLVGLYVywxpJygU1rkvz+kAZAqzWRSIyLUIBMTqYtJpPf08Pzmct14NyNlEVGkWdYpbFGEZPA9ZUyGGVwLhKCNAFOPq4uQHG0pxUbgTZ8/fqOpq4YR3E6NlWJj5E6txidGKbVOa2kMRPvsSrxq9eHl9+LAOjFvfAlApTWpiWzLmVKq1lSlDbZoOlH+Wz2K/B99qvwPQ/i8KxLGUSjtDd33bTOL0qePcZDiBgUmdE0hcWkgJv/slzdNBVtU7KpS6ZZmGVlWeJD4nQV17k1gqu43ZTCvnJa3pddhyLSVrLQnJeFaz8yLgtGaYw1FEVGmWVsW4vSmmvXszhH08gyRqe1idUHcY5HaRpU1pKXXxh2icu0tqZNa4vtWryg0iTPgvU9/Et5VaVwScusYApwOXmcXzC5xg8zf/7zT+R5zttv3pBUYlx5c0ZJIRE6rBEoWUQcjydhHAYwpaHZ5KTo+PzxPUM3UNcZWsE8eR6mJz4/POHXxVGzOZBlFkgsy0xeVtSbluEiJSZReZIKZFnOt9/9iiyX82eYRr7/8xVtLV9/8zUhCUy8XWPlcX2vmkw+0/MshgiUIc8LfvPrbymKnGGQZd7h5oBSiseHMyEGitVBdXt3I2JcUxNC4A//9CeWZeHmbkuhS6ZukKbXXNzDTS04mcvpaW33FYd0VQif8/71HUQ4Pl3RRvPb3/9eWE+Pn5jnme1my7LM/Mf/9J+pqpLbuxv6fuDh8wNFUbAZN+vWVmEzQ15mfCnzsEXJTVlzPp55ePiAMZrdoSUpceg+Px85Pj7gx5qprld4uiEkwVpYk/2luMZaPn74yPl0xDnHfr9nmT3Py5lxmAkB/upvfk/TNmur88j2RylEevP6FVVd0g8T8xy4vT9Q5ZbkNbny/Ku/3UGCTx8+4IOnrjLKYodVAtAuC3HOCobFsN1tmOeFz5+eCP7CP/3jH0jA+dixzI5x6inzipvbPc4tPBw/UJY5r+u71RErOoXznmmZOF1PDOPM9XKhLjPatsKFhbjI2YyOvHpzx+3NLbtdS7vd4bykmmbnuD7PdOeRR3NEa8Vf/avfoIhAIkbF0M/0/Ug/jLS7Fm1Kzpeeaz+SPJAE6WBtw/29mCcuV4lhFlWOzSTB4IJjnjq0U8KtWxwqJlRClh/ZyLSMoCNhXqRkCbfiN4Q1mtav6+e8frbwtN3uSMhhypetQUq0W4Fevv/8RF1kfHW7Q2kZNHxMBIwwSbSSNrrMQILZe5yPTMtCW1c0eUY/es6XjpgUu+3mBSg7O6nEnMaRsbtyOOwJXjYNCdbNd8swdGKFXSZcHNmUJXf7rcRaYuLT5wvPpxN3tzdsNyuMeQUifmljU1oeupHEPM/C0cgzitxye/gV+92WTx8fmKaZdrMBpfm7f/ojwzhSVQV5UbBt29W2phmmiefnE/OycLi9w2YWdz6SklxqsjynKEuGruPjj39knBdcyghRYOM6y9gdDkzTxPPTA2Wec39zQyIxDFfha6jE5BY+PZ9pF09eNfTdwOUq8baozFqvnVFVFfmmQQeL1opmu2N7uGcJn1genrBWU1elCF2XM/04MTlxTMSkiEFawVTyaALaWOGFaLUyFTqGcaIpK2klmGcRQKYZ5xbevLrn26/e8C63XC8XMFreS0sP0THNEz6BXaN3cxixRvPNNwK3/7/9j/8jXd9zc9iv7TOiXFslFyznlnUQF9fAvHimeeH9Tz/KIDn7ta61RmsBXc7Ocb0ORF/iti3jNPP0fMRaKxHJlCRP7SMJ8fZrEimGtUmsoGl3tGXGoc2p2y1NuxUoojE8X65cTxemRSJzdzcHXt3fo4iolLiOE/20sHi5dMaVydAPA4tbuGkbyqLAFBnKZtRWY7XiYVkILlBYS1HkLPNESFGGzACLD7gQMNZgs2x1J074qMjQwhhyDqPi6gqSJrSUwi8qrmKsJYbIPE1M88zxdCbGSFkI2O/jp49UpeTaSZG+u8oDvijJrKXIJJo1zBOgKNQaZohSj1wUBfM0rdGnSGkVEUVISiz8g8TbUkpst1spRVi3RsYYbKYkFrYOz8K0lIhbWRQUZbW2QY3s93uapmFeHYM2E1inSpFoJQ5ojF25OWEVmw3tZkNT1fSDCDdmmnHOczw+471n10qbjrB84kukaVib1razuFyGYURpRdVI61KlBLjq3SSC0NqaB1Ib3dRyiRIuloh4sr0X+29RFgzDwPH4RGYzfNu+uHkSaRVqMorghaGS4hrzcy8LhRQCbp4o1qperTWLc7I4uJwp84Ilz4T1l+WQAqRcxB+bMU0RHxx934Pq2e0OVE3F0He4eZaoZpaz223ZbjYokxFRLM4zjCOFlcvLNM3CPqkquWRFEZ5ubgSk+tNPP7K4harZYmy2Ao0NZWZJJOZpeInhCIB9JhrD4iSyGaL8/2PwWGOpm5Z5ljhwUqCtJU6By7WT4RSw1siQm4TrgjJkeck4zczTRJ7LJXXTttze3Ynhbj3bwjKvte+eMUwCz20a9nsR56X4YZQGPO9F7FjbM2NAWA6raFeWFVVdy5CdEuF8IviFspBL6Tx0BC/OZG2MCE4pStwwRrxzaKXELRWFHQGKut0AimEYSSQKbdDmlyU8lWVFTLKAW1xkmhfhbK6CoosJFSLzPEhBRNSytXUSW0zr/WcJHg0krZh9oJ8maRLKC3GPT55lZZcJJ8jggkQx+8lxGRYOa+ubVvIz/sIcHOfA4gKT98ze0ZQlbZOzqUvqMud47hlmB9FDCmiToa0Rp2Amw7tSAtJ3LqwRgJXlaQy7JqfKM55XQHpVSKX9tDimeaHdSWFDoSXW7JWWtrtuZHaOpikxKPphJrOGzSqAb+qKkBIxaXG2+EDQCr2KwMYaCBJBt8awbSsiMLoFg7jLvRNAexVExHEuMC+BYBVah3VHEPFAQGHW+zAxEaMHNMpYDFLS4LxjvHZch3mNKwpc2a6CkFoLANTabORDJPogEeIIZr2bxdXhKXOx5vaw5e6w5Xg6M00zVZnEHefFFTs5iV42ZY5WwoTSCl7vt2gFf3j3wOw8+zaXYp71jE5JREO7wuFzq4hBEg8pKCkCSII38DExBS3Lj3HGZhZTlqgkkUznA9Mwigs2y+X96gNEuaNYLTGl6DV2HYqVkjbHpirIjGJZxDWZZRmzn+nGaRV0NG1padYBOsQkLgrnKK2lyDMUwhXrxonrMLJd68Pz9d9vV2ZTDPK9bxpZEHf9JLH5EPBRMS/inFLGYnNBF4SQ6ONaDhIlIhySl99PlDhsu7bC/lJeRaHRypAZy5ICQ+dx3lNtLcM48/3372jaitffSAHMPHtAkVuNkO8jWsvv0nsv8a9V6NFaU1QZcz9xej7hQ6IorDiZnKcfBs6Xy8otlEKKL8UT3nvKumaz3zF2H6XcKC246KiqlrtXO0kqGHj/43ueH574+qtvub255dJ1jMtMXbe0dY0LCyFFlFUk4urIXtB6JkXF69f33Bx2/NOfvqfrBtpNi9GWd+8+0/cjX31zT13k7LYbsiyjqkrmaeZ0vjJOM7evhfmk+mUVagSUv2lblnnmcvpMiF/i1YrcZuLu3O+YR8fp6UrbNrz9zVu8lzhjilBXFeM48sc/fc9m04BKjOPI6XymygtUYHX/OMqmpN01K3PUkpclZd1yPp05n5/Y7Xds9gcScO0GuuuV7nImriiJqiwp8pIlzLjoaMqaIi9F6NaG5+dnQnDc37+ibVvOV0FNLLO4o77+5mvefPWK58dHhr4nJMXl2nN7uBHQ9ulIjBOv3rymKioW60g68urNLTFF/sf/x/+TYRi4f30rpQVIu2nTSLPNMI1oo6nF/olbAvO08O7dO5TSLHN6wRsUecF223Ltr1z6CzHW6KjxLjL0Um4R1lbOfugYx5lh7AlhR1UVdL0heSl8Ugb2hx1/9Te/W1tJZe4zucZPMpemkEg+8frtHV9/fS+Mv5B4fDxxOl2ZJ4kbx6hQKl/nxpkmryiyjLKoKcuK/WFLWRT88cefOF2uZFVGllv84OT3tDhk36DxLkBSaBSLW+cFP2E8hDkIaN06EqwNrh5t4s82m//8qN24vDzAApq2LiV2drniQ+CwbYTDsYJIm+DxRpPlMmQ9HY9s2pbXb1q0NoAWvsS8YK3h4/GCItGu1dHXvl8rNCNlmXN72HE6nXkIkesw8/ff/0iVWerMcj1fWaJinHoiltlNjJOAc5OSBp2iLLh/Yznc3JAXAomdLwPBzzIgBGkiIcDpJMylssi5u7+Ti5bWfH4683Tq6NfGncEHFOola+umkUWB3jZoEh8/f6YfRqrCUhaWyoDViayQDfb5chXyfVGgSdy/+UoA2Wts53KVjXRSIpT86ttvhXcQAs47+tV9gM6oa8s3hUTVvnp1y7xt2NYFWV5QNy3T2HE9PoFOOCsg3xA87nRhGGf6rscq2DUNh/2O4Ba8m2mr8uUSomKk2jaUZcWHTx95fL5w2O2oy5LzRYDnb1/ds6lrnPNcloVr37G4hd2mIc9vGPuO9z+9Y5wmkta8uruTzeSnj0zzRF03GJvx8eNnIIntPMv4fDyvlcKJ3GjSMhG0Fk4VipDlGG1oqhpWZoJzYqXWCpqNQGhtJhsm5x1FnrM73Ag/6z4JUPrSkWWW3/76O3yIjNMiUM4VCE5yWGtoNlt8TFSXnm3bcHd7w+V84o9//onNdsu+F97MtesY+56+u1LWLbe7LXmW43zELzPRiQ17v9kwXq8MXU9uNUYF7g8bcmvp+4Hr0JN5hzGW3gso+vOTON6WBHXdoFHYvKCuKvK8pOuuxKj57a++I6XIx0+PXM4nrqcnfFXhl4ngPcfLmRgTdSU/6+1u84tqhjo9P8n/sQ6xdVkKTJxEsnZtXhRXlLUZr1+/JcTwUm9/XCtTD/u9DHIxYI2iqcUN9/jwIBdgYwhOnEwREWrLsuT29luGvud8PnM5n/nHf/wHirKiqmqWZWYZ5zUWJ9GZEKRKScSMSfLieU5zc8BmsvmbxkG2aimgyhKjNDYrmBfHvIgYW2bC4HNz5Hw6Ma/MMec987yIq2YRJ5LJMrKypCgKSNB1TyzLTGZlw9u08p5YFnnInE8nrDG07QZlDIsShpnEEbU0O6VIkecCvzZmFTdF0FqWSX4lao0B395T5AW73RbvHOM4rK6gYuUaiQMhRrk0LvMsrXKhED6EzsBkaC3lE0Zr2qYh3N5L44yWrWmWZYzjwOnUU9XiwpmWhWVe2G531HVNSpFx6HHeEZLASY2RAe/a99i8FOdQIWyvcRyIwVOWJXrdhseUUGsj4bUXZ6FbIeJFKS16X5oj52UmpUAM4YW1FmOiblog0ff9CjLPUNYS8wqsFZFHKW5ubuV9fj5DSmzalpTi6izRZDYjxERSYS3PkAv4ZrOhLArappFSgR++J7MZ2eqMG8dRQPvOr214wsdxbiEk2eK32y3b7Zbj8cjlepGBWEuUpCpzrp1w7+ZpFKZKEuGp6zupgg5R4sJJRFyJwIhrJMbI/f0rgYD2wnhIRsR3mxQxBI5Pj6Qkz1RrJEaofkGiOcA0CudMo8msFgcmYGzB4jx9P4HSNGUl/Dk0zkd6LZHgj8eBorDcbBs5A724cdqmxUXNP79/QAOGhE/gopRMGaXWBteKUzexpIHRBX78fMJmUrs8LY5zJyDlcZF45uLcWuwhHI0YgrRN7Vr6YWReZnEih0CmGjJVEKTODkk6yxJLG0WdG/LMrK66hWsnYujpIs5rn+TcSyu3zOYimnS9NLoZa6ms4evbPUYraauNiVM3SJyllMjmuIjQtNuJQ/OpF/ePUiKm2LUYRilF9J6hG1YenjirCitAcGlNtby+3YmAZySuvXi/xvEiRsmFfgqRbvYYrTE60hSWtrIswbLEiqp0HDZOmHZaU1hFZpRs0PuJIg/kWcYwC7T9lZIWt2mRCPd1mJgXT55n5MbS9yMqJWbnCVGtEf1E7yQ+lmlNUqsrPEWausIazdN1FCFbGYzVzD6u7EK9xoL1S4tcStANsyxEM7lDDLOkD4oiw4TEMsod6ub+Vmq68wwXAqfzmcxmfPf2jsWvGIU15pjW56teW1+zPJJXFVWe0dYl/bTwfOpXNhkobWVBEKNEMq2iLgS6HpJEwJd55mbXsG1rTueOaydLT0zidtfy9nYrQqgPdNPCtAgzK7eGx9OV6ygxljK35FlGXpXCQARUWogmUN+2RKAbHcE72kZ4ajEIq6+7LrgozgdrLbtNQ/YLahRegjAF5/GZaZopyoR2iuA8KsHtzS1NU1HnrSxqX1lhX3kYp5HHxyPtJuP16y2JRNUI72ueZW778PEJA2RlzjJMXK5XNAqdNLvthq++fkPXDxzPVx4fP/E//N//B/JcRMTT0zOfPz4ydMLDHGdpr5tqT1EtVHVBUWYcDju2m5o8K3FpIZHQSRNTICRp9fLe8ziPJBWpqpKv3r5CY9HK8PR05tKNPDxcmMaJYZDCjWG4EKOnLCraesum3aCV4uOHz3Rdj46BOtPUudytrus96Ph0lGr7KkcZaHd7yiawO8h58/D0jDZSdpBvCg77PVoppnESbu3xgkKT2QprxMW12bZ89fVblnlht9tK+VXdMs+OvhuBBEvC4ZiYyddIavCBqqjYbrfiqFES0zrcHNDaoAGdoGwqiqrkw8eB56cT2aucujacTke67srbN2/Y79+gdUaMmmWRO8Nuv6EqCsZh5MOHzxAEIv/VV2+5WxaOz0cu117EXWX46d2PGKXYNC3GGH589154lT6gtSF4WAjE2IFSLE6ME0VZoJTifLoyLwt1U6GUuI2V1oRKlhLDYKnLCp1Bu63469//Huc8nx6PZJnl7n6H94F+rCT6byxGLYSQU5YNMUXyouT2/jVt23Bzs6O7dvyX//CfqeqSpm04XS48Hy/M00R0M3XdUNcNeZkzzyLCExLbw4bd7ZZoEHNJluG94/71HU1T0Z97pnHh3F04dSeGsSO3GR/evefcddzMe8qqpMxyrDZkhcZYGE8jLgT+5v/wW1KK/PTTA0PXMVyvRL/g50DwkU+fPxJTEgh/lrHb3WB/5tn1s0+4cV5BuTYjJkVVZMwkLr1Ajjd1RVWV2LxApUBuNTZBZnJiCMIhKEqalU6vlMWFgM7k8D520mZ3aEp5o7jlhcOR2Yqb/Z7oA+fzlWnx9A9P3DQltq24jItE69bKee8Ty+yYM4/JIrky6KxkWxbkar3Yp4juHSF5eaimII4eYB5GvHdkVUtZNaudGM7XK8vi5EEIOB+AJJufFeLorcQGlILL+UzXDxS5bO3yLyweK46mfhjJjCFbNzeb3Q1aQZ1LTGccB5S2FHVLlufcbWvcskiVo/PSSqUMNqvIC8umLGibisNug6tLykIGrbKqOT0F+scZvMa7Ys2qJ5ZlYOh7fAgYDXVZcrPf03dX+uCocoF9eicPzl3bsN3t+PT4QDfO7HYS8fjCFHn76p66KHieF8Z5lharZeb+9pb9bsc8TszDiLYGZQy7dovWmvPxxOIiZSERng8Pjzi38FX2Cq3gsg4eCsiMsJhikCE2KY3RUhNfFCUpJdlghEBR5C/ti0JzUy82SJRszIsso84zTpcrHx4e2W5aXt/fMc4LD09HaWzxbnWDBIwWqN40reyTuuJ2t+F6PvHp8yPj4ghKLIjXfsCNA37sqOuaTV2RtJEq38Xh5ontdsthu6GpK4q8wBqNVoltU7GtG36cJs6ztIRZbRgnUdWfTyeJWtYtXmk2VUlmM/JMWFJpdam9vrvDGs2Hj58ZhoGx714iL8F7LpeOEIK4ElWiXAf0X8qr6zr0GjlKrAyJmIh+IRlNVVXSVgYYY9ntdusZ5JnDQj+ONOswHUNg6jusvNnwznG9XrFZTtUI2O9LS1lEsdm03N7cyjDUdQzjwPPxibu7V9RNS4iRaZrkIR4Cyzzjloksk8PcOUeMM3VVsW03+CgZ9GVZGIeeqrCS1S4qzBqDdsGjVJJISJBNxjD0sjFc27/mRcDEX7gB2oojKMukbtWvcTZxZGVSAasNxloR3fuezBp2WxGkYowS3c1ziRxMIyCDmfBipA1OIOcB76QQwWQ5NstpbUZZlmz3O9wsgorNc6pmg1tmpqFf2+lWfpJ3hJCLCygpgTMog1qHNOFKFWy2cmElQVlIpLrvrwx9L+1gmWTnFyfusbpu6LurlCMkcVHmK/A9BI8fZ3L06paSuN4wdDgfaNscYwzXXuLi2600pYz9ZbXCB4lTZCLuaKVIMbL45aXi9kvMLiEClfysrzK4ZRlJabTNUavjwK4C0kuFb5axbdsVvC2Nr9pYVEwEZKCPMWC0pi4ryrKkqWvm4zNPD59XIGsjteTOEbwneIcuMokVfHGjra6Lsqyoy5xhGFDdWneuFGUpgtY0LWtD3UIMHpBN3zTNzMuCj9JEWuWGzOg1HiTiYkyJm4M0DE7Te5bFrb9jizHy5/TdlRAjNyuDTKIA/7sdNf8/eS3LLAJIVoijJBeOlcnkspzWn3mR52RWhD/nI9EnutlxHgZaFK/zXApgvHBXiqxgmGcejhfKTO5eIUFY3XJGKcrc0jQlLkIxeVyIPJ579tuapinphoVTN+JCwq0uK7c45jU+alcHUlvXlEWBc55lfW8N08JSF8QiJyn5O7+4Z9TqoC4yTZkJnNXHyDSLmNLPkRChWhlQX1hndo1vOBdYloA28u9vNjVGKy79xOw8w7yQBcOhLVFKMbtZXFZVKS2j/SQLq9KKqG/FSSfit3AiY4KoxV2dG+E1yvJCgNUgkfjFS8OlNBOnF0ErxMS0BKxJ5DahlaHKDCYzmGTQeYaKHhfAhURuITOy+BA+nPys+nFhmB2HTQnRiuNi8YyzY3aeoigEWzCv54xUzpGtxsCY5JlipfGGfhxxPrBpBEJ/7mdciOtZIl+LIpFlwlVD6fUrkYjsOC94LyI3iPPaWijKDFREJVlo7Hft2q4M3TDxuR+kyfqwZZgWxi8CJsiF2hiU0eKwtxK7rirhwkoT4Ywx8jPK85y8MMLJUyLYlZkiKbkTyVJ7oa1ueHu3Z54WzpeegOwYX+0bbrc1H57OnLuB2TmmdaGfG821n7iOk7SohowyzymyHLV+z8l7UoC2LVAKxmnBu/DCQltcBAJzSCwukHSgWIVMaaj9ZbxckCKWpb9KlDoDlGKeAzoptpsNdV2Tm1JEyEz4i/MUcItj7BxFnihKSSjEmL84yxfnuJ4uVEXBzaYlkZimCaMMhZV7+TffvOXz4xP9OHC5nvn0+T1vXt/zzddv6LuOp6crMaxlB8PE0I+EAN6vTeLrva+sMsZpETddApUkEh+T3KGC8/RzjwsLbd3IXXFJpJC4diP+OnC9jizzQj+IK3yZB7mXZgVlUVOXFTEFTqcLl/MFQ8RYTbHOtXE9XxfXEXxB8JLeKNcFaJ5ZvPOcnk9Ya7m9qSjLgsON3GePT2dJDQ0jWhkoMow23Nzdst20HA4HvHdUTSFlXFXD2M9oZXHzwjwKymMKMzFB0vI15euye7fdrOw/T9M2FEVJmGbCslA0FXlTkN5H+uuIv5Gl2DRPnC9nvvvuV9zc3DMMM8vs1tKdhba5lz93kXmyqStZYhz2pJR4enpgHDs2ux3aGB4+PxB8oPz2O5QqeHx+FlZlTMKYjIBPLH4ikXCLWV1mFaDo+k7wO6Xc5cqqkntaSiueQ84WZSJlntE0bzmdLnz8+Cc2bcXX21t8iOgsQ0XQXgEZLtqVMxoxWcZmt+f+7oZff/c1f/93f88Pf/6BzXbD4fZA18t7Ja0lEnlh2O6ludz5ILXNMbHb1LTbhuMqmhtjCTGy22149fqOd+ET83xmGC/Cxlocmc44Pj9z6XsyY4k+kW0tthAusLGKEDtCCnz1zVfkueXD+0e6cWIeR8HZ+IBzns8Pj8SQuH99K9iKsibPi591Lvxs4enPP/5ISl8aSjS7TUNRNNQbaRmoChGYTo+PQBIOjdZoDU1V81e//TVaaz58flornTN8CIzzLB/cZQSbwVwxLI5hFvZMpjXn04nHx8fV0VIJG6ko0Ao8kbwo2Gc58yzAyG1bc7uXTTzKcL1eeHx84H6/Zbdp2Gxayqpi9JEAlIXB2pWdo6CtGtnuaLnQmUxq17dNJc1Rm1a2yG7CLwt/WCMXeS6AVJMXWJOx3W4oipy6qkkJHo9HfIjYTD7wKKmw/fHzk7Qe1ZXwDlbORVnJIBvdzOgX3s8Sd5jXS8d+t8evltIia7m/vSHFxMPjkWt35dPnT9RNy93dPUPXMwZFHsDGgE6y4dRGo62lMdJqkxR8eHzELQvL8hcQcVVVFPmOsm5RWcFXb9/S1DWsHJZtXVEaTdu02LygLKXKs67FgbRrajKt+XQ6MYwjdd1gM6kWTQnGxaGMNCVopTjspfXKWqkcT2tNfFnXpFjSViWkxNPxGYDNfkdmLErJ4Tz0ElupawE/qyS26g+fPqOUZrvdopTi/acnmqrg6/uD5FSTDFbXXhwX93d3L212Ns/5etugVeLv//EfXoTRp+OJy/nE6doRlDjUlLbYLKcsIje7rdjXtUVrQz9O9OMkVeb7G66z4/TuE904kedGLLzbHUuIPF87ms2WZrPj88Nnrl1Hledrs5Bmco4QEpdzh5tW8KHJKIuScejwbuH8/Cgxp7UxKITIMjvysiS3OV+9fYtKibzI0UpzOZ9//s3iv4LXNEuEbVDivGlagX3PJIy14orTar14B7peKmyNtZRak62i1OPDg2zQy5IUwgp4zWhaAfNlxuLVKhDajCIvmaaJ77//I9pYdvvDy9eUWYNfZqzWtG3L4oS7lFlLKnOJZ6CY4iLMLmPIipxCyyG1zLINbrf7NcL05SVk4SwT2OldJgyCvMhlwC/FMYXJiCnx+dNH3Bd2ldbi/IxB4ntKscslGnd+fiTGxLyIvbbdbFEKnk/S2CYNWAbB66zuHGAaRYCKSq0xLoBElsvAp6z9i1iQEpfLFe+85MoXt4KpNcZmmBhfhJumbUWoG0eKPKN9/WptYpsJwa8um4l5FXY3mw3D0HO+XCiKitdvGlmAaM1+uyFtGjKdmIYrpChOrxWCK3GlRNf1woYYR8wXt+Uai80zw9BfgdUJt/77EESwNkaz2YjIbkko75iCDHzeeVk4lKUMtV0PQJlpcmvZtM26cHhEK3m/kBLD0K8tiVaeC5O0rxoSNhMhL6a/RC63tXAUu+tVmrDQzNeO8/XCMs+rY0H++4TCGkvTbuRSJlRvxlGcUDbLsDbjdBx49J4QI81mS5aJm3hYXXxoTdO2a7NipG1qssySEthpEgedmxm8kud5BGtFdLVGYtDKe6q6Ji8jzi14714ie/uDuBDLlfc3rgiAX9IrqgIfI5fHk4g4lTDKci3NaN++FmHbhcQSIksUuLVPiTy3fPNqRwKezhesgspIMce0SONUk1vy1dFjjbgWi9xSVeKsOvczoLnfthiVsCvL4dpPQGLblEyzY1oc221Dnm1xQcoPpjkwTr20kxnDrs7Y1S2bMmOcHdta/q6IIqqEIxKTDOiZNeSlsJ2yVZStq1qi6DERY+J4HfEh0hZWSiKynIQmK4SH2NTihvp4lOXKMErk99XtDq0Ux4vcE8zaqFZYDUahol3jrgteKYKVJs15caurKRM+WpaLqJGbtRdCzsjT6YrNLFVV4kNkXoKgCZLHZgWUBVmm2Nby3LFGgNnvHs/E1alvjcZqQ5FpmlzjQmBaAm1VCLg/REKKHNqCXVPQrG21TVlQ5zlVkePXBkhrNN7NuGnErQspLVlYEuIW6GdHipFtU6IVsihNntIkDInrmnrYtM1aKCBA+CKzLyJ6WFsUU4J2jTPWZYkPgfO5E1FTievoOizkVtOUa4teTLiQmF0kpERhFIsPXMdAZjSvNiUuBP75p89oJW6tafE8d3IevDq0xBSIKbAExXlY2FQZt9uKmCIuikMjBM/iIwHNu89HHk8X3CKieG4U2sqAd+nXaH1RyNAdHHXZ0tQVUSmGaeHpdOZ0HehmYbbebRvKzODXPYL34m7JjUJlWiLwQaLdicTb+xtSSozzRAKGaWKal/+dTpr/7V9/+Lv/RIoRNzmMNezutpRFRlkI/y8rZcHZ9VeJX04d1lg2zYF20/BXf/M7EokPH95RFDn7/RbvA2M/Yq3lfncrbZIoNAaNoiwKdpstwzDzH/6X/xfGKpq6oK0L1FpO1A/SevfV1xX9pae79tR3FeaNzCBJwTRMXM8X0us91my42e0oy4Z37z5xOl6oqpLdpsUVwius5gYXAkUun2eJfEvsMkb47pu3q6goS6M//MMfmMaRwmh08ly7EyFF6ibH2h03tw0xRj58/kxY47TaWLJcxvZ//uc/obWhbVeHUlFJmudGFkTTMIpTNIq7bhxGSIrbu/uXJWdWZLS7LUornp+f6Lqeh8+PazRrT4qK4MFay3a/wwdH6Wc59/KC5r7g/u7Asnh++PET6z6K6CLRRzabhv3dXmLMMfHmzRt22x2ZzSCI463dtOx2e6zJUEwkPIfDnsNhx83dPVVd8e7dO7quJ+6gyHM+DQ9rUY7oC94vEOR7szaj3ewxSlMWHZAwiCOz3bRoreh7+YCWtfA5rdU457icTsS0Jm3W5+KyOD59fAQFdVUz+4l/+uOf2DQtv/nuO4zSRDfjJk1/mTGZoa4rpnHidDpRVRW//uYO5xx//Ocf1sKDkv5y4Yc//TPH45FpmShcjvMLkKQ9dltRViIAVmXN9drRdT1lIaaSDx8+M/1pYlkCTVVQN5Lsmq4Tn+dPWA23r7a4DxN+Cex3O5q6Yo6O4loyTxPjODAOgzBup4a8EMeh1ZrLSRh8VdugsgyblSids21LUIq2aQRvsPJfh36Q99jPeP1s4enxWeJn87xQFiW3+wNFkaPXC+KmKRn6noePH+SC0NYYpdFJUeYZN7sd4zzz8elZVOT1oTgtCwQH80CyGSkExvUCVRhh2XTdwKeHBw77A69evaatKvabhnFeGOYJkxlybdaLRWDb1uw2jTBzgvB5np6P1LmhqcTN0bY1dVUyjBPWmhXCKg1tptygbIEKMypFsqpBG0uZaVKK3N3dUeQFc39lmkZ++vhJuClrJE/4BRl1VZJnlsP+Bh8C37//xLws3O5366EksbmnSycumsxilbT26LWmNsa4Ks2Rq/R0o2Igz2RgnqeJ6+WMVtC2DeMwcXw+8nw88/7jJ7a7iayocPOMixqTkNhcEgbHF+GpKnPaquDUjytENhKDxJEMwjhp2hadFWAs+92OTVXyfDqJGFLk1JmlLHK0lYaEBJR1JRt+IioG+nHkdL4QkiLPcoZFan6LTC5acR1O67qUgU9ZYtTE5GSbuDaLNZuWFCPPF6lz/+Ja8dMgUbplgXV4sv8i1326XMiznNvbGyKK00UeeG9uti8V1DEGpmmhrgzbbftyKSoKy2G74dL1fPj4cd24NTKM9cIXSxJaFvDnCkPebnfc3+yZpplxFBbAMPRUdU1ZNzyezhwvV7wTC3pelJRlw9BfWZaJu5sbmrrh8elRmGhVSVWUBGXJfOB8HZjdRPSK2Rjy8spULLhlIgXP2CWMVhTrsJjWuGahJa+9WVX9mKQx53w+EoL/uUfD/9+/FucggU/CCtitkQnvvXAVmgoAv0gMc1pm2WppQ6YlUjLPM8+nE2VRSgRqjRppo8mz/AuDcXVHJhFI8oJx6LmeT2z3B+5e7VZHWsYyTyyTiJu2KEnKEZNCGY1K9oXPoZxskZUW0SzLZOCpq1LiXVVNXtYkv5BiWEUcqbXObEZZZyhtXsomMiXwzaxqSElxPkqrzpe69RTDGiWUs+xLbOvThw847yEr0cZSVFKpenxehd+6kkrtIK2S1pj1cyjco/gFHrxySrLMrht0kcyE8RGZplkcWV5iWcs8khcVTV6s8Q7WbXdG33WMw0BZtuy2G67XK+MwCFBXBdw8r5E8Q1034vYbZ7a7HXW7wTuJpBSZbFvnecLNI9oICDPFgJRop3WgnKUt0AtfKnm3Pus2GGMZx56UEjebHVle0F0vq8NLtqfZynQSPpxncXL2pRBAa6y1K1Bb/latFFlm2W539P3AMPyA0YbtpiElWJzEgVgr3J130k65MkJs2+JDIEWBkZdZxhQD0zRKw5XJccvMPPXi0oUXqDxKmDlVVbM/3EiDzzS+sKe0ArRm6DuufU+72VLVzcrdEsbWsixyxuUZ3oug8IVhMa0x1mWRxZNPST5DJsOGRJMVKGPxXhg5WZ6TIdFTcbZIUUZT1/LeXSNPyypw/ZJeUWd4v3C+DvKcL7fof7Hcy4tWBut5xofE4OQ5phHX476pGeeFT88XCqspq/xFYEQlilX4+PLZtCv77Eu5xzALpHxblZA8JC+O7NlJG16Rvbhn26pg01Zch4VhdPSLDNKbZoXJl4Yqt1ilGVeHlnlhkCVkHE/r1yOCs84yciVNV43s68hXoWN2gXH2FNaIaKQNAfksaa1ocksIkT++vzIvDh0DphBWT0qJh6cTMSY2G3GeZ0bcO+QG51mZMyu6QokrXmC7FmssVSHfQ11k4tRYPGOYOV+uFIWclV+a0HQK6OBQJsdq2S5XSjhZ1hquneN8nV5cg3khLJfCZuRW4NTOR4pcOEX9ODPNC0UhZQW5tSiUiIhakRcZMYE1Cg2cx0GWswGJymoR08qqxBi9Mp4CN01ObjRai9hnVSKpJPFp5EwyWuNm4UdpJWeVT2lt85NGwS/337YS4PfHSSK6WVkQgWnxpGSo8rVMIEkLowsSNbYGFp9WoHnGprQcu4nH04V8jUkuKTBHz02T89Veymxm75hDZFw8+6Zg3xT0s6OfxTXnvMfHRERzvPa4ZaEtC8oiwxhFZqW5dZzlGZ9biyMSoiPPDVVdCrw8z/j4+My5G1iSJS8CbZFjlTRqCVA8YhQYDckqEokQJQatlGK/bdBKcb7y0p76S9LNP7//kRQVflEUVcn+1Z6syOTzk1m2NxuWxfHx3WeWeaLrz5RFxabZU5YF+5stXdfzw7ufaOqa3W4jDqp5ITOWTSX3Ex9kGS8Rsoy6rukenvjphw8cbje8+eqWYuXpOueZl0DTVLRtRfKRaZhpNzXNphZunBOe1PXcsd2WhE1FXVYcbm54fj5xPovztFg5oDFFTC4iszUJrRO2yFBGY3tHjImvv35DU1eola/6+cMDKmqMUqgYmCZxWeeFLJOKOsctjnfv/5F5XlbBRiJ03js+f3pcI3WVnCfarOdAzbIsHIcH8Ar/ZaHkHFmWsWk3LMvE4gZMltG0FW5xdJcr59OFTx8eqVsxPVibk2UV2TpvuuAwTv4eY3OywlBUlo8fHjl+esLmhiw3csD4hL7Z0Ry2jNeZMMzstnsO+wND1zONE23bsLGy3NLayEWQSNPU5FlOvdmQFzmLC/TdQJU3pKh4fj4zTQNtXcgcOfdE4HC4pyxrCivGBGPkLqrXwp+yElF9maQcrSjL9a4rLMRxHEHB5tCuDiBDmhfO58vKhGpw3vH58QnvPL/77lfSZrqmB+bJUShN2codf1xG6qbg9mbD4+ORh89P5EVJ1ULfXTg9fxaURAz46IkpvKQVqrpke2jJdEFmClK8MA0D1mhSkXM6nnl4eGS33dG0LWVZUlQly7SwXHt2r3bUm4r8UUwPVV2x3bVs+pYA9N1HQRg4icJbC1WVk+Vy/x2HBYUWFmmeia6hMsqyJbOG7V5awmOyhJCYzj0xhp91Lvxs4elwc0PwgevpiDUwjD3jNDD0V/I8581X3wjNf3HkWUa7lU2km8Wq19QVeWZQQeq/Q/DkWcZut2WcJk5HRIgaJ2nsKXOqsqRtW7SxLMtEjIEPHz+yHPbkmZWL7Gq91VZA3XlV/b+5+7MmS7IsOxP7zqTjnWx09xhzqKwCugoFdJPCfoGQ/53kQ5MgCVQB3QAqq3KICJ/M3OyOOp6JD1vNEv2EfEC3SMdNCcmITHMLs3tVj56z9lrfYvaew/MzrqpxRckvvvmaX3/3LefLmcfnI+d+fAXyVmQuZ2mAenN3w7oShw458HQ4Mk0TV5uB0lnOnbSBfH74Qkb4A2qZcMUMp35kContMFJVUJY1hRXYs/cSn3DO8ctvv8JYw0+fH/EpUxaiYH7z9dfye8WI0gpTVkvMK1JbyzfbtVTrZmk3GkZPLjXXN3doY3j4/ImmrvnNr75n+1DTnw9sdzve3l7j55m+rbFaiXXTCT/l1PXsjyfGQXM8Saxm21YcjyfOx8PCH1DiJApSGWmMZv/8zPl0xAdp0Fk3FXVZ8PT8zJfDgbv7t9zsrpnHnjDPoA1KGd7e33NztePcj2LB1hmjxDU1hczx3KGU5vtv3lIWBe8/fKbre572ewD+4lff0dQ13TCSMpiyRefM4SQclEK6w7l/85aUBHyfU0LZAlu1fP/dLzBaaqJ9jLJxc1Yq77Xh7e01GcXoAyGPTOmAUYq/+O5b5nHk+flEAna7K8bZ83y64FSiLi1lVgQ0t1c7vnlzx5fnPZ+7C0/Pew6nC9ebFVebtWSKmxrvPQ8Pn/A+4HLAlgUUYvGMYeawf+Jw2FMohVOZ3WZDWVY0jbRmffnxPYfTmcoZmqKkrBthQJ2PnA+Rzbqlqiu2u51ELmdpvJuCAC3dAh72Sz3zYYncaX5eB7eqrGSDHNPy3kqddE6JBMyztNtdLudlsnO1gOo92hqauhYRWMnDKyeJJa5XK1KWquVpnui6C9Zarm/vhTOgwLbNa/X7cf9MWZTUdS1w0hRJWkt8fhy4nM8CEy+ldjWryPX18uCdZz59fhDjCVlgp2XJ5XLmeDqxaWvKwi2CjoDNo4+4DEoFRi+uFBVmIFFWUgM+TyMxzFzOJ6ZJnKTGGLZX17xM5oL3BGVQzvDuzT1Kaw7HI7NfIK7Wsru+xi7NUC8waKW0iBHGUtYVaolkeO/pLmfQoDHEFJmmiaqsuL67pes7Hh5GOTw5iYkYJTFIa0rQ6pUpkpZa+X6cUNqw3W4XztWMrUqaqiCnwGEvTtv7+3t8jHRdt1jsl3VNK6kpT4nalVICsbingvdA5vbmBqVe+HGebK04j8aRlORAobUixUDy0iw6jSP9IG00X71r0EZacoTBIiK5sQ5rLN04L3HEQM6Z8zlgrVtA8Z5V00ic3Ir46Kpmmawayqrm7Zu3C+Dbg9IyySoKtrsdIQQuvbAa2lYKFI7nI2VVcX37hjCNTEPHer1hd30jlvyhp+8uXC4X6qqkLktWq5VEpha4eFlVaCvuuDBPVKsVVVXTDwPz7CVe3zaEGIFE310YujNP+wPDOC2RvNVrPPKljjylSIpy+DbakJaK+hQFotq2InJNk/AWp2mSjXJRvUZ8fj4viWc5K4LinDU5KUxMEBM+Li6vpelOIocKt7g4lZbCkF++teQYiX7GGIVZYi2zl89ymAPOKG4aER18lPti05SMk+dwPNLWJdt1LddZkorslKMweKwjKY1PmcoZagubWhNiJc6pS0cMBaOzC4w+ch4SPibaQlFYhVIWYx2nSy9OzKLAWsNxGIghkhd4qV0aj5/PA+PsCX7EWU3dSjy4shptlEC2c8TkSGng3f011mhO5445iDPGGMOqqTBaGtikBKHCmMjkI4U13F+vQS2NPwkuXoQwZ9QST5soC8vt1ZrCGUbvqcqCq80KH5K0BZKwRMqqpG5kD3O8zBLZSYnCOW6vd8yL27x2lrq0TN5zGUbaumKzXnG+9Jwu4+IestTOUTrD4dLRjzM3uzVtXeLjy95TuGdN27JarzmcO3nPogwZplGEruiXohZbYKzhcBmY5sCxk73W3a6lKCyVM7JOZYHYn4ZRYplL6cm6cq/C5BwiWkmxwW63eRXhtVIUhUUrOaMWZcH3X70lpsTj8x6lwCpoyoLdZoNKkRQ9q6rgN1/f0g0Th9NFGIrbAoDnsxxEb6+2mPNACB3jOPLHz55VU7BtCkJI+CCoi2H2kjJY1QuEXWJ5RivmAENIbNuSujAk78lZM4yBlC8cLhPDHKialvuipNAKreHcXegHze12JW6JBdyulMJqxTSHJRbrMFoTZnl2XEbhRzklXLSfy+v2/it5r7sJYzRzN0grlpbnuqsc4zDy9PSEc5Zvv/uOnOE0nqhyRbup2Ww3/GX9V6QUCPOA1Zm3b66IEQ7HE+M8cr4ccYXj/qsbnLFgEu2q4uuv7vFh5uOHz9zd3LBZbdHZoHOAlBmHiTlE4iIS+jlQ2pqmKnlzdYu1cDoduJwv/G78EfPjZ0jiOnz/03t+97vf8+btG1ZraR6FzOPTnmkaub6+EgfKIDHL//gf/wEQ14zKcDof6aeeHz59oCgK7u9vKMuSammGN1YYnSmDNobf/NWvMcbwxz/8IAxj66ibml/+6lucswznEz4qnKtQNlGvJB10d3+L0moZGnmOR2lH36y35JzZPxxYbVp+81e/4cvjnuihqCzbXY0xBdZWVGXJumlEIIkVXddzOu7RzmI7h9aar97dM02eafKgIxSRvu94+JiW4gHNYX/hfOlJMZETwtEqLA/9B3LO3L15y/2bd3TdmXHsmR+kXGG9qVmv3zEMM/10RhspLZnnRE6BUz+RyFzfBGKc+f1Pn+i7no+ffiTnzD//q3/+KpyllBjnQAyRU/dZmqavpADm7vatDHmen0QcVW9IMdE0NdY52nYlg9EhsKpX2KKgaRveff2GnBU+ZfwwcJrO1FXJX/7Vr0kh8+nTHh9mrm43jKPn6ekLVsHNdru4z+HNm1u+/e4dh9OFp+cj5/OZT5/e8+3X3/Lt199zdbPDVo7T8ciHjz8RQmK9XlEUDpUzzhmqquDh+Qunw55yU7DatOw2GwpT4EPgab/n4eGJ4/GMs4brqzXr9RXOFYxjx3yc2F1tMcv5wlqHq8U5H73w8qq6wFnDPMve++HxgxgZCin2+XNef7bw1NSNcD86u7gFPDEGDs9fKMuKzfWt5PtjwhaKsqohJ/wkE5zixc1TF8xeHtSFlY0sSvN8FoHCzzN1qWmcoS5L2maFnyfauubSjxzP8oHOfpZ4jBYegFLi3DGuIE49fhpYWWGT3Oy27DYb/uF3v+fh6ZnLEsO63bSsG3EznIeJq+trkhZHQM6Rfhy5XDpqm1GFY+hGhtlzOHeEELnZrV4rhxPI4S4jkzVjscaRtVjCw8vDxxqur7YYY/jw5VlahpyjKkuudlustVy6Xj6cZYKljVwEt1dbsZUuGf9xPmIN1E1LCJ7L+URdOO5vr4l+ZtM08lfb4AsnFdg540jYsqRsZBI6L5v2DGw3azZtwzkn/DSQjCEZzTBaEhqjwejM8/MXnp+eX1vtqsJQlY5Lf2Hygbs3X9GuVoRZKuajlQPSdrNBkRjDI1OQalmAeYHVnU5ncs589807tLWcuzOHw4H3Hz6hFPzy2zfoSqCqCYW24gobpkmm9qWA+DYbieI8Hw7SWqM0xlmurySi6WxCzUvbota4oiCT2awappDofSLMnjkIa+nu9orn/YFPnz7jypJ22zLFRDdOrArNupSIncWyamp26xWXy4UchScx+kRbldRlQZQPl6enJ87nk4h7SqOcQxknD4kY6Pue0+nEOHTEuaauasqqxZWFNC/ERD8MrMo1bWkpmwalLcf9M9M4sFk32MJRNQ1lUWIK2eT7vpdD8uIgmRfGzflyIabIqqn/7AXk/wgv58TlhVqEgeVezMuYNUTJLA/DKMBoYxaGW0ArLcBsY6kikCOkIPdkUeBjIiSPj5F+GGjbFVerDTkGop8kVlyW9MPA+XyGlETIJb86aVLKwuUYegGLKrMAVaFpW7bbDR8/fuJ0vuB9IKXI7fUVVdly7nr6caR2htKahRGhmILEHtSyyZ8W9lOax4Xzkl7X8ZQi0yRVvxI/M1S1xClO59PC2DBoLW2jCqSFZGlbM0v7ozGaeRyJ2RNDxBgoXIErC1brjZQUIM0pl/NJIIkocpJpnKpqNuv10haY5b5cani1QqbRhXt9z8R2JmwsP3uJtpQliZ7Ze5kOGiNsq65jvV7TtisOpzPTNIpIljOLqea/KOQQ58dLu1xKgRQV2+2WspTYSMoZsiVnaf7z3oM2GKz8Xingp5FxHLh03fL9hO3iQ8DPwkxIOVPU4jeag0T3XkDJ0csz9gXYWBXFEmdcGCeFrGVKgXOajSuZZ8/5cnllYFjnqBchaJxmmVwuDoR5HKiqitVqzaCVNAOWFev1BgXM80jX9Vy6DnW1o62EdVWWJd0ivjnrsLaQCJwXUHJZOMZpEueKlXZS55zEt6ee4KVBcJwm6rpayj4cSmumeZa22sXF9XIQJMnzKcW0cHTsYu++4OeZ7tKBgk1R/axaoV5eSokbGyBmhc6KkOT6n2eJ5thFuNPGCCPtBeqvNU5rVo0I2OfTvDT5WuYQlzauxDhFbGVoy4KYYE6yHhTOMo0TwzBQFVbcRCqhYiQskbrlByQvbo/KKApjyIUhZTj0E904L82EainsyPSTp58DBi2Q6kLi6LMPDOO8OAYXEWOel+pyEaETmW4SXlQKCavFMVM6S7td4YwRtsdSJKG14mrToJTip897gUVnhdHSrqcU4oA35lW8s8ZSlo6rTSMR5zkyhszUR1TOKBVJi3hXOsuqKUk5Ubc1TeFo64I5ZJIKGJUpdKYsCurSMnst97pME8TdVJYMnTR1FkZTGs0wRk79RFVXlGXB4dTTjQJON8ua74xmnGYO5462rsRluER5Xxrh2lVLWTj6pVgiRRlGhMVlrpbnotYGbSzDnOjGwHM3o4Bv3lyzqguUghgzCUXIEH0Q4ck44XIV4vLqhyg8Qi/rab3gEYjSUFk4ec6m5TpbtTXdMLB/eMJoTVsVVNZyu22ZponTUYaEV3WFyokvTwFbZ3aNoxs9x97T1hVtLdHP0ogD8jzMlIU47bxOWC0crqyUfGallX2wfwHKy73lk+wN69JxdgXGJxEpkpwXBh+XQVKFiRMqBc7jRMyKu92KwmqGSZgoZuGDBS+OgKaW+GMMIjhNPhJTxlkR5n4ur3a9We5hDSSi96SYwIjLcV7aVfu+o1217K6umf3M/nxAG4UyitJWbDctw3Dh6fGEsYZm3dD3M8fTmW7oeD4cuLra8ubtHTkJJ7EoLbvtmv3hwNP+wna1wSoDBkiKmCPzvNwLCEYmhkhZWJqy5eZuxXZX89v//I8cno8cTweB+N/s2LQ17z8ceXp6pmoaXFnirEEpuFw6Lt2Fql74cdOMnwPP+z3z7LnabLBGWK1zmJmOAesc19fXVKWVkhIrrvwYX86Nlru7W7TW/P73f5T4vDVyvr27QgPn4zMpZbS1i0vYUTcV19eb17Kgy6XncDyBgrKqhTl1OrFer7h/c4fC8PBpjyugbjRaO4xxVKWjrApSioRo6PuecRxQwaJ8oG1KrnZrTqeBMEHWgE7Mfsb7ILHbqqTvO56fDpjl3GiNxirN5XJkngbu375jtd4wDBe8n5kHTyLz5s0tTV3x4eMj8zhLi7pzDP1E8JFxjAvLU3jNT8/PHA8nPn74jDGKv/5nf01ZlHShx0d53nkv+0JjxBFfFgXr9ZZpGvjy/AHjDdHH17XZFeJANdpQF5WcqaymqAq2uw2zl8SV955+PlMUN9zf33HcX3j8+AlTQL0qmXygu1xYNxWr9XpZRxXbzZa7mxtp7OsGxv3Iw+fP3F7d4pylbiqwisPhmcPpQL201VmtUWRpxXOG0Y8cL0d88GgUdVWhlaUfzwzjwOUs0dLr65a6loY+50r6/sw0Ta+Oe2Ot8F2tk9KIcw9krNUYq8mTIobE6XDCh8DV7RVW/TeGi/fHJ4w2vLm/pyhKdtfiokk+EFLi8eEzWiluttJKdjhflom1e50S933Ph0+fQWWc1ZRRk22HD4G2dHgNk0o0dcVuuyamzOnwRIyJ7dUdV3eW711Bfznx4dN7bm/vefvmHYfTkf3zgwBP0WIBNA5MwZwy+0tHP3vquubX339HPwUmH9mUmspq7m3FLkZOxz1fHj7x1bu3rFYrXFFSt1Krbqwm5J4QA+tVi1IKZ4DXeu8A1pBj5A8//IDVGmcV1hh2my3OWv72N78E4OnpQEwygSvaktuNcIiOpxOgliYhz/F8QClFXTWQBayec2YYB6mF35+Y5plLf6FtGr66v6MsCsZlwn51d4e1lvPpzKm78PD0RFtVXK/X9Kee4/iZVVXy7ddfMXtRqpu6pHSW29sbmtWGGMWd5rPk8pWSA/Nqe4Or2sXeCsfzic/7jwLILkseP33gfNhTuGKxZUomP2s5YFxvt6ybGueEZ/P0/Mw4TbhCLJfr1YrSOe6udjSlY7e7AqUoqpakDJtWeCjvP34m58zX795ijGEaBNhXVzIFc2qxgxux3J+WQ9k0Z0JIBAw+Zbq+I+ckv1OMZO0XCHPP6TTyx+lMN4xcphHlPZdJWnZMmtmub/jl99/w+PjEDz/9RFsVPC3RUonQaGotD7bDMPHT+w+8//iR0moKowlK/qoLR1k6hmGkOwc2uxt2N3dUZUEfIUYvtdqDRF7qouTu5pbVWlrZ2tJhlGLarpnrEudKYlL8+PEB0OyudiJmpgTB8/jpmZwTtigXESZQWsvXX70T183P5GWskwexlk16XUikaZomcg7StqUU2+0GrQ3jOL5OKLVW+OAFdNmdX9vFQvJLXEiEK5US69WKum4onCMqiMETYiAsLXPrzUbYbtqIiGKEGTKO51fhIgTPOFwIIRJipC+d2G7Lgvvbay4XObBrY0hAVTdYV/Llec/HT5+4vrmhrmuJkcVEW60l2vcSN9Tqlb2mjRWYYpTJvk9A3zPP4rwRaC+U1vL9t18DcOkGQozC8nGOm1KmHPNwIafMNE34IIw1s2zui1BhbCH33SBOhjkEOVD6QGEtu6sr6romKwGdV81KRKUU8aNA0Qsn8eW+7zkeDxRlzXp3C8jByRrZtKUkrisRLWAYR86Xjnlx/YRF0DFaYoFdd2GaJrZbabXzfsbPE34OpKzEkVQUjOPEPHuauqFpV6/QSWPMItwl9PLeCodqLbG9hWMVQ8ArRduuSI3A2HOGumkwegGjq0xdCh9LqxfGYCFORCWz8BCCWOn3e8qy4P76ClCEpareGkVOmpzF0fn45YlxHDidDljrGIZKNhioBQrpSLOh05rZzxxPB2lmTCLwNHX9Ch3uesnxC+NJ4kxaSVwKo2RDOs+yOStL5nnieDzI+20NKRaAYrPZUi9gez/PbNYbyqrkcl7uhRQJKXI4SoV0VVaLWCzOp/OlQxtD1hpblmwXe/hud/0arf65vKZeIpzrpkIrTVWK81IpLULTEpOtilLWjG6gcIamkYa2ECPnceLj44AGKiMRe7eILnVZ4VymdJHCiXs8p4QOcamQ7kBlNts1SsN+v18GThaURpsCwgwxSuRXRbxWxCDCRMgK6wquikoEIBLOGrS2bJSlCInucuF4Gbi+stSVYV1X1M7hrBZXY0xMIVOXFmcUTSH3yDBWDJMhhYlIpp8Scwj4dMFazappUcpKRCdlvpxkqKeMpqoK6lb4RN0gcPEXztrD/ohWinrhFz2d5JlAFhj01MtacO56QUmsG4wCUl7eY4XOkWkYGMaZ03mgLh3lquJ4mvjx856qdFytG+YQGOfAui643a54NjL4nEOkP13ws4cYOJ8uzJMnhkRbl4sIrdmfez5O0hK6airG2fPlcEEvZTYSeROmapoy66ZkXTtxNPmw3OsJXUrxT1lYnNUC406au20FyFo3zhGlRPwtnKMsHFdNITXcPi4RXY3WhpubmkxmngVOfh7FbZCD3NPGR5xRrCoLRPqhJ6XE9W69lBhEJh84nHouw8jD84WqsGyaIAezENDWsNtuMW7CZ8s4B3748Cgtiz69RiPHKbA/9ezPI/vLIM3EZUFMIuopbdBFwzjN9P3Aar1m3RTk5Dl3gZw81ohImFNi05SsEdC7RHakPVk5YTwapUgxMYyBOfyp8TQthRWnTlpZy7JAGcOqFoH9zdUaa38+Q7/L+YgxhtvrK1xhqdtSBsL7A34e+PzxDMCb+xu0MXz8+AGtNbt2Q1GW5Jh5Pj3z/sP/ggKJBVvDMHq8j8QUcFZztd1wtd2y214x9APH4+k1Mn5zf8ebb74m+plPnz9RtSXNqqI7D5yOHf0w0PcD1uyo65KuO3O5dAxzzf5Uoq3hm+++Zn84cbn0rNct7arl22+/4ebmmsPxyOPjI99/9w3bzZrSFeSqZd20NE3N08MT5/MFozOrSrPdrrDG8unxI+M0UroGgE/vP+OcROyss+yuNxhr+B/+T39LiokPP34ghEBVllRVRdOKA3H/JBgcHw3ee56ePkuEdmGrPT0fsMZitONyuXA6nIghEaNi1Tb88le/pl3X+EkE4evdhpADIXqGc8/x8MB6veLu+pqn52fef/jA7e0tX3/7Dd4LT3OzathtWinFKZy0NU8TMSqkN6Uk5YKqbthdyT0j3Mwz++c9q3XNanvFfv+Fvhf8ScqJpl3JGVJZYoC76ytur7bkmEkhSZnTMGIrhzaaN3dvqOuKech0l57721tSjoQcuAxnrm6u5Ax16Cic41d/87diHvESsauKkvW6ZHf1r0SQalcMi2s9pczpcJBn7DxSeIf3PeRM26wpQsRYzzwXKAyEgqfPZ56fn/nw+afFMdUspWCB9bbl21//gv1+z8ePn+guHfunjtPzicvzHoPl9vYb0I4v+2c+f3rg8+dHlEJMCLbEGSulF1rTXy7M08B2vWGzXqG142l/JIYXfAMYU3BzcyUJtFKGSFdXW6qqXgqLBrRyhCny00/vQcHd/Z24yybBIzw8SCLLZ9EGyrqhNYZf/eJ7yuq/MVx8HnqKomS1aqnqhu16szAcVozTyKXvKKxhu9uSlaYfJ5w1lLUIANM0cukHHg8nrNVs2pqsAnYSq3GxAKBjcpRFQVVVDIPAr4wtaJoVVdvSbje8/2Hmw08ntrtrXFkR457L5UJRVLiylEiGtqA1MUnLxjx7tquG3WaF7aQFpDAy/VgVUsn95fGB56cnrnY76rpBa4uzIloorZb2j0hbC5CMKIyQFy5HxpISHA5HyImqtBSFOGBKt8S4MvzTD++ZvacoxO7eVA2gGJfNfkqZcRp4+vIov8utxS7g1Jgi565jmia6rmOYRg7HAxqBrlktiw9A3a5IMYrD4HJhvz+Q1mvaquLYDXx8PvHd21t263txDOlRNh1Go5qGsrFMkwB6s08En8gkEgJlK5saJcF8HvcHno8Su2wqzeV8pjufubq+o2ktCz1YyBNKNru1s7i6Rin9CnQu6xJjhINjraVtKqxRbK5KXqo6s9KUTtq1Xhx160ay1vtZFhBn7cKyKRf+r3BHBPgbFxeagC5TlutTaWmMMirgYpShbPLMITEPkdEH5hjIIaJm+V4qBaqi4Or6Vuz708gwCjx89gGUwpilTYrMOHv2hyMfP37ibrem3KyIJGJW1CBA3SDum9v7O9abLX4SrkxcokHzJH/vlql/WTUC+3NgVaauJDagF3bG4XQhpkyzaqWaOYNKsujH4KlaiRmqnLCLq0VaHn4er5cYj3WFuGicCDw5C8dMIPaWupZ2EB+CVGG7AjJynYUgbBsjB6aU5NqTB6g0c5VFKdetMZJ1VnoBjMpEqygrYJkuKyPiURbHYUwJtbSExCDWbHFiicBpraEsGoL3pBiWmJmAmI21PD6MHI8H2tVaxJcX+LnWklXXaok4CP3FFeIykVy9RCbSEi/MKWGMiOZlUUqUbrMhZfj48ID3/rVBdL2Arof+/Fpz7H1gmEZstBTTRFaK2c+kKNbruEziX5ygL+0hrigXtpbwsWLwxHnEhygtfFEaJbvLmf3zM7ubO7bXElsM3qMWTpKzFuckBqcQkPI8CxjXLyBvrZB6bq0EZj4M0kJnHX4UV84La+PlsxLxLrPZ7SiKCqXlMNb3HQpF8MKZcM5JlXFRIWaQ/BqniTFS17UILlH+BW3TLC1XS2unrRbHioy+E0quwYVfFJbBRHe5kGMNVzvJ2idpWdVKkTQLGFSEg2mSKuVgw8KcESeJUorCCF9PaWGbjEvzYcpZPgtXkBFWWtf1HI9H1psNK2clYqVe2F1KfsbZC0TculdnNEhDUNSaZCxlpXApS4Q+psX1WzENPTkFvI+vlvhMluGFMa+OsHGe0dqIUGLMqxOnbRqs+fnUkQMLU0viOVpLQ5fSCIQa4cnppTlSYPIeq4VXlFHMS4vl46GjdIabVYlVWXiPyGBEZwGKGqOlij5HtFqEX+/R1lJVJWEeF7h8iS1k8mm0eR1AqSRVzzFrotL4BD4r2sqJ29fPpOjRWgT1ioyycDqe6QbPZp0gJ0pnKRbnlgjQmZB5dXLVzmAWx0pImWkpBvFRIq8+TVhrqKpWvn45hJ0HWbMLI4UyVVkscOcZozRNWeADgmMwmlUpg9Nukumx1Ug00Qtf6XjuiE3JzaZ+dbCqF/5WzvjZM08TU9/jqMiNYxgmvuw7bq82XO+kgXJCOFWryjFMUlIzes9lnNFJBhvjNDH5SFU4SueWxlAte4pzz3YlDZN+EWxKq4XvpGRdjFEgw+va4Yymn6O0GM6TTMyXxIBZGvqcUSSrMMZJ/HVhQy49c8IRNIbtAiM/dRJ3sdbgnOV6K3DkwzmRZonAxIUhSFZ4IDuNUtJ4Oi/P16aW30GaXjPDONMNM6dhZl4cIP3kX5v2qqpiTopyjIzTwPlyIWRFSLK+qSVG1Y+ew6XnYd9xs13RrEvmSd4rOYQ52WuNE9v1iqYQd+o0x+UZD4kse7VCMAWzzzJEXhIFPsnzRtB7SaKZPuFKBQtJTwafgZfiImmYzEtLbEvxM2oUHqeBsihpmkoaUzdywN0fDqQozo/COe7e3BBjZH88UhYlb27vcda97hl+/OlHSldwd3WDsZY5SitzSmEZNIsYU5W1DIzici8axWq1Yndzy5eHTzx/eUS5TKMF5Nx1A9M0CmswBgQGPuEnT1Yzc5Co53otEX4fAq4UDs5uJ4Oqh8cvPD488ubuhs2qfXVqF85Jg+E00Xcd23VN4TRNVcowFInVq+U5fz5dUBqKweEKR1E7mrbm66/eEUPk7//tf2AaJ6pVQ1GW3N7eoBQMw2WJPsPspWhIa6F8K6Pp+gFrHIXJTMPMPE54n5hmqKuGq+trXCHuOwXCYPQT0yjNo8/7IzFmqqLiy5dn/vjHH6mrhs12w9CP5CRN2E1dEXLG5wSXLOfFhXWWpaMPVxQ0bS3CUgycj57zqWO1bimrmnHo6S4nYS85eQ+rukJl9Rp5c1aTYyaGxPF0JsSILR3GGlbtiqauub6+pq4bmmZFCJ5hOjKHiaosEdaoNEi+e/sW5xyPjx9IKVJUso9oKhFCtTOYy4WicMyzZx5H4cTFgI+eEJZmeSutyrLf0wSv0NnQnUfO557T5UThSkiamDyZSFE5djdXDNNASjJM7C4TQzcy9T3aFaxWW5Q2gpv5sufTT5+4utmxu95gtTwflcQa5KwwZXY3W5pVyziOdN2A1vL7vpw7BHtkQQngX5qNKylBSwqVE9EnDscjMUU225VEooPsP/0SeY9G/vslsXV9tRNX65/x+rN3aGPShJB5PJwwpwsfPn7CGMt6d8VOG8lxx4AfO6k+PJ2YjcGyhgX2PM7CnohZ0Y0BnyYwvQg6wS8skBZXlShriSkydCeurm94dy9MncvTF+ZhQBvLw5cnjucBoyXSsWpXtOsNKQk/RSl5MJssjSLD5cBwzlyGSSJzy3apaRvKsuD6ase6bUBp9qczjw+fGYaedH9HU1VcLj3j7Nle3bFqW3arGgWcx39AdR277QbnHCkEIKGVTIw3N3c4V/DlMkBKXF/tSCnRjQINv4wzZVny/XffMs2e//SPv1sgZ+KOmGPCJnHulJUwe6Z55rk9EkLgK/8OY2TBNNYw+YxPwoW4dB2fPn5abOZr5nnmH3/3T9RNy7d3O6xRvP/yDAgHwGhFsGID7YeRz49PfPryxJu7W25vbxYAJGzaFW1ditU+JOZ5pC0Mq/VKFookrVy7qw1Nu6IfJrrJM+4PhBDYVJITfTyc8TEy9RdpN1Qz2hjOlfBqZi8bDGNebpISBXx8ECfcbrdboJrIwTRnlBIxYQ6Bh8+f0dpwd3eHti9OKYF9pgzNAo14eD6LmDD710WpbWv+6te/phsGPj8+Y6JMrl5uvvPlwvPxyHq94Xl/pK5r/vZf/A0hZs6nM5e+px9nKueoCwfBM3RisfzVt19xd3vL9fUVP/70kU8Pj1RVTV0U3FztKN8WTPNMf94Tgmy8lfRtSNsClm4YyCFBjqgcGGeJL3STZ5o9oROGTFG2lJXDamEwtG1DjCXeT0zTyP58EijyZo0xhsPzM537+RzeustZILxLQ9vQiRBglEJbQ16I9iF4ZGMIPiT6rl+mkiUhBMZZ6qgvpxPaaKwrFqiuMKOU0oQQRCBd7v+6Klmv2kU4CK9uxn6pqbdWFu3COVJVSuOllVhS8IG6bpYo08Q0STTiBep8OZ+oKoH3397dcH1zTVmVZOQhNM+eru/F0TSNeD+jlrakoiiWNg+HtYG6FOaEdtJsKLE4ifkmNJ8fH8kvlmPnmMcBcubSDzjnuLt/yzRN/NPvfkcIkaqScoChv8hB2DqKQuzkcYmIZpAKFMSebs3APHQC4lUwx8i5F5C1M4oYAvvTBedKvv3+l4QYef7ysEzeC2LwjOPAMI7iGuw6+r5j1a549+6diIRAYaVh6yXRUBjD1W4nzX9kiqKSWthFeEo5M47zKy+uqidUzuz3e6Z5piyrBVo6L4160xKbUJAt5FJEHDIxeA7HE1prmroWZp6Cl7aHl+iixJCmRciyZLJMEy3UVSWHnbIk58TDs/DvFMtBS0u8c7NZM44jz88HqrKgrm4x1uEKico9759IwTMOA9YYbm+uGceR8/Eomf4MhbXS4LUIP9udoqlr2tWKtm3YH06cLhcRr6yjWMRMvQxqwiyDmdV6TVGUDMPAOC7PNhRVVWOWTVN3iZxOZ8ZlspYXgP+LIKuXyIHJWYSXHDgeZGK+3Yizr3eX11jBz+XVzxLP6cMyvMkDhbPc3ZRYrdG6JKXEqRNn1Iuw+eV4WYS6xDB5YpjxWHpv0XOA7gJKk5QMcULw4i5e16QkzE2lBR4bfGDoexnOVCtiToRpwsaAjZZNXfD1dUs/ylCPZUNslIi/OXrGMeAXnlQ3TKAUVVVSWsfb65a4KYHMNPR0k8T4rlWmKByEACFw6QPDEi1z1uD9JK2Qi7PeKAFdl1YLuHxpq9NECmOoq9WfwOpiiMBYw2Z9TYyRw/FMiImiqMhkPp9HSmu4XpdYYygKR9Ya4xMrW7BpGxSKOSn6OXLsRmbvCUktEaqEwrG+2hFj4uNB2st2m5qcPJ8/Py6Nfpovp47eC69snkSQfYkBlkYTEceN/G7qtbX56/trvr7bwnK4GEc5IBeLGDLFxNANhFnYcYXdorXhdBm4DBPrsqAqxT2oSFyGaVmHCirjhEWYEv04vUb3pIWzxCiLVjUskf2YIn4eGZWi7+X7aJXRKK7XtazlStxch4Vv9XwehfG5RIHXqxqtFZumICV5FjeV4xdvrwTgvqQsBh859yP7w0H2eNuKUyfnELwnBk9ZaMrSUReWqnBsmpIcPbt1wXZV8jD19H1HUZbURYFhTSwrsikYvIj3OQv0WEQsjQb6UWKfTieMysyTNODFJEUax9Ev15amNQWlUWidBWKsBOyeMpyOBxRws23RaI6XAa1/Pq12l66X2PXHH7C2oCrWGKupm4Z21XB7d7OIdBDjJBEyAtMQGYfI0/5I1/dS/Z4iT4cnnHM0raA0pnnkTzR2y3Z7YewHiJ71esPV7R3D0PPlyweOpyPjNDE/zDw9H9BaxHBhp5ZLtA/q2lGV5jXaGkPkcu6k4OPSE+fAYYm5Wef4/tvv+fqrb1AqczieeX56YpommrZk8i0hyGCyaTe0bcNmt8Fay6rdEHymWlonrZbhTLVeYQtHUUjByfufPqNQfPXtV7LOXzpSyhyOJ6qq4ttvv2cYBv7tv/0PzPO8uEk1IXiCt6So0IVhvaswBezGG3LKyzBS8ccff0fT1tzcXjOOnjkmTqcL738Sl87tjfCdP/z0gaIq+b/8j/8jxjp+/OnzK6JgmDznceZ0PnE47Hl42PP4sOerr77izZu3BD8zjWe2m5Z3b28lfug9bb2h7wbadU1ZOYxao5WgFRQwXma608gwCsvx5npNWTm684z3kdkPZCJ+CgSv2T/vGaphieqF1z2tNVtyTnx8/4UMrDctzlmm+UwImpSDuDWdIYbIH3//I8Yabt/ckHPm3bt3wvGMMpjuL5KQ+cMfPhNiZBxHXCFIibZp+OYv33K5XPj48RPaZb777pul6brm+fmZx/cPHI8njscTVd3wz//6r+m6ng8PP8m5McC6LthsBeRtlOL+/pa2bVjvNqy2K97/8T0fPn5md71ltW5ZbTbUVU0MnuHSMwzSarhZy/V96s6yN40ydC+LCmsdx8OB8/HI6dgxTYEUBCXxMswySi/IETn7DrOgLJ6fnsg5c393SyosD89P8qz+M15/9ukyIkDLYZwhJ4buTFXV3L2RWE5pDX6e2E+9MDumkWwt3i8V0aNMrpWWSzXmTFjAsCknQvCU2lA792rhTjkR/IRWmaaWw58fB3KMS2RgZH+8cLVZc7XdLC0DJTEoYoSXJ7E0s0XGaWSeBUQ7+YBPipSF/SORggbqmm6UGu/ucqbvLvSrFRqJxcwvk/WiYL3eLEyLgnEcaaqKsihgyZqmOEsle92ireV06SAlbjcr4IUJFZj9jHWZzXpDP44LHNfLpF29cAAgL4eS9XpN6T1zFNuvSpHgZ4b+jJ3dMi2SQ9Y8zwIFbRrWq5ZpHDgcDtKW1JRMMXPuBzmMWk2IMmmap4mx6zjs93z+/MB21VDqG+Ykm5+qkGaY2SfmmNitV+jkhYDvCuEfIDXXZVXQjRM+SFW9n0ZKvUVlx/nSSTQjBYktolBRmpditISF6fGizjrrlsVXbNlvb6+pSnGmpIXl8OJSmb3neOmwxnJ1E+WzcvLnjZb31KqlsrcbBSQ8DgLrLQvWquVqu0Uby9NBssDaWREhvKfrhOc1TBPdMNBUBfebOw7HM49fJM8dYkI5KJYWw+hnysJytd2w2+3YXV3z6eGJEKQVIYVAVRVsNhuenh7ppp4QRax1RtpRXhrHzDQRVVwiOYuYFuPCbJLFMOdEUbZYY1+ZTnphQxR1Q0QxPe9JKS4HRkPfdxKd+Zm85nl+jaNIbj4s0RRZJGOWCe5Ltjkv7hMpOlg+t2VaHIMnTBI10kYiKS8ckgxobUQAXvhzdoGTT5O0tZGXz2gS58BqtaJuXurqLaYoMbYQF4Oahbmk9KtrJ6YEapluzPPCI9Hi9HBOrqMobI2Xe0C+3hNDwLoCpY1wxYy4RbQxlG5pfzQyCRGRJoMW11bX9XJgurpGa4iTIuYkbghjqJsWpWX9iFEAujlnpnGBmM8T1miqqn79+QDU4tDs+k7aV8IsgGmkenr2AjwutWFOiTFEinLNdrdbHtxHVNNQFQUpRvwsGxofxMV0Op1p2xWrdkVY3I6lcxTWLDGJhDF2qb+Wf1Z2mQYBkP/EwfFhcZQEaVs9nxjGkdu7N8LmWlxNPgSJIClxjRlrF2eoCFdjCEucuJV65SyCglZ6cQ+JuO+DtBRqs2T4jV64M07WOi38iP3xiELaq4yRVhnhFkhzl1JLDLEshQ1VloTgF5Zhwvt5aTatBGw8jXIYRjhA1li0lWhVpSR62bQNTd1wPF0IIeBMIcBzazH/RTtfiEEmqUphnSOTFz6FfhWSrDVLnEocc9M4LZ4KJSwIxato+MKeU0rcNfM0Sf1xVaFRzNP0s4OL+yjrEkk2hD7M1FEOsWZpgk05My3MtaqsiItQoMSHLWDulBbXNhK7mkdx/OpCKuanGU0m1oV8zwTaiqvy5flkihLjSqKXDaxaDgiFLdm2FTFlhjkuWy+5lg0LsyzK/exDXDheWRrYnGVVFSgc565n8l7ApTELH0cLbD6nyJTy4hb8k0M054gxy7q2MO2c1a9rozYKlWTtFxFXDkopZXKU+66pK2bvBTqbkjguU6KfBNyuspNIqZFmYGUsTitWhZF9zSg8yHGWiH7MGZ9gDJnCGarS4seZSydiyKq2zNPM5TJhnMMUhbAgQ4IYUEmEMa3knipLK7HtlJYoG697onXTUDlppZvDy5+TSbSxhss4M3tpAsspLXsqcW6Nk2ezNA+nxU04LRwiayxWKVSCmBR+kD1cDhGjXsp1hNuX87KnjwniUpKQpTW2reTnqMsSqxWVdYyz59zP+Jjxc1wKAmaJ1wSHdpbCGRlqBnEDbYqSflpi2giUfA7i6G/qiroumGZZb00QZ5bVisoZKVIxhsoZfGlpCvl7rTIhBrlPjAFXEI0hY5hDXjxKS+kBanEMK8Zln7wYHYhhEcq1JSuYl31roRcxVAu7SbYTCuzSwjlOQIZNg8qZYfIo9fNqFA4porozRltGnSmrknZ7RVEsTMaY6E79oshJq6qfEzFHLlMn65I2pBSY/EgmU8yBsKxZwkSEaRQ3T/AeFhftZrdlDhP9cGGehTs4DFI+sllvaLY1bdOyXm2Yw4APo1Dts4jbVhuJfCbPvIglwXsUiq0SYXu72+FswePTA113YRwHpnGiH0aUsYuTWWFdSVE2C7TZUBQlhSspSlmnCq3E/VZLuYkxEu09nzq0Nnz93RtQ0C8JnnGaMNayWq9RS5mInz2btfA5X+Jsr87m0hJzQd22KBLOwDhO7PfP+LiiWbX4OUrJ1zhzPpxYbdbsdju6S8flfOF+teKrr7/mdLrw9HSgcJaqKJa48Mw4Tox9z/l04nm/5+7ulqo0dCER/URZbtlu1wzjzDwHVNbUZYUpFNpqCttgdUFe2KP9cGGcZs4XYT4VhSbEgsOhZ54jZSXu3xgjxETf98QQxMGWElZXKGVQiKNrfziQc+L2fk1ZOkKYiAoy4qREQYiBw2FpsVs3uELeY4AQFcF7TM7iXH3ay3Nj6qmbmqppMFZzfbUmJc8cJmGjbjfSFusqzpcT8zwvsd6Rtm24urrC+4+cuyPjnAhZicu4rjBkjIJV21DXNe12Tb1u+fDTR/qhZxUa4WiXBc2q5XI4Mk+zpA/mGVYLEzElQvTkvESil9jqNI7EIE3u3idSkLXLFBpj1atrVGvDS9EJOTJcJKWUb6/JJC5dh5n+vKHfny08Xe92WGu42q6Wm0GiGs7ANFz4px9/FNcSEecs33z9RhhNvaeqSn799ddM48TD4xfq0vHmessUIod+et0oJLQwAXxYWCaepAzPp47pH//AZrPh3TffcHNzxTdvbzl2A4dzx7pt2axbnp73/PYfPnJ/d8/t7R0//PQTHz99YrdZsWpbuq5nGCfhsFQtc38hhJnr62vevn3Dl8cvnC8XhnFkGidur64w1zvGkPlyvPB0FjdX9f4HLvsaHb6mKiupnW6apZLQUpYCqn7ee5gjRI/RUBcyOfz8+CCiTLOWh130hHnkP/zn3zJOE4flIHG3FaVys91RlhWr9YYQPH/44Y8YbWiaFafTkd/90z8ye7nQVk0jE2tlmJUha8vX335LjIHzMOKqml/+6lcCdD91MsE0howmYHg8P/PD0FMWJWVRsrm64hdFydX1DcZVzKcT5+6CU0rs7+KsZ3N9x+39W8b+zDyP+AXa97zfw+mMyQlH5ub6ChaekVGKYpTDdGGEF5JtRUbxdDyTlliKK2uuNiusEehomGfCLAr46FegoZjFwRAweB/46cf3wkUxYsX/h9/+nsLZhYcCwzwzebGoF85xc7XDqBK7bqQhsayYp4n/6d/8fzHGUFQlzhhc0ZJCwM0T5Z1ls96glObjp89YoyidtO3kmCmdwbo1N9sV99vVwqlIPB/PnAfP/nhimgZ22w3//X//LxkuZ6ax48OH9/z04ePiUgnLhlDx7s09m836VXiqypKU4gId1hzOHcM042eP956/+tWvaOqKP75/T3d6pmscMVUiMCnN3W6D2m1YtQ0pJdarhhQjP/zwwyuw9ufw0kp4RdvtRmITg7ho6qr8Ey9GSbzrBawqkbYFerpuBZZtB6zWNNUbEQbicqAKwt5KMUl8LgZShBkRl/t+XCDfsF6vuX/Tcjwe2D8/s1qv2Kw3nLue86VnbQtKqznuO56en1mvxDp8vlwYhoGyqsWtVFS4QnL+ZVkwTDNdP75ygTYb+V3P5wvd5bLwqCKrlWyg+2HEhiViWFWvcby0iCfjNINSNLWsa1fX18SUpA0uJ6wClMZqTYqB9x/eC4tEaYzTOGtRWi81uXIIDCHw8PAgjS1aomvny4UURaCwxuDLQoQv5D5arRr8OLI/HGlWa97cvyGnyPl0FJFhsZQnpThdLkuTm1i0d1dXrLc7VIo8PX5+bTmdFmHqRfCx1uKcwTnhcIwLLDwsh+MUxUmoycK4E2sRRdWQtQVtSInXCNvlIq6bFAJKSZROa828QH1jlg1w13cYbSicXdZhS4qJ52eBhGalxVV2Ocl6X9dSPa9gnj1PB5mWrxtxCFgj164tZdjz8eMnAJq6lihL8FikIadwjpvrG3JKfH54xBYFRVnLmts0i3CZaKqC9apGGYe20qhy6WXi1V0ulFbz7Zvb12a0fhhEFEAECRFzZUCiSVRVA4gjyxrNPPUkP2PKEqWlVbXIwqWx1iBpRLUMo4RnZLRivdmgUKSsmL3ErMZpZBj7//0XmP+NX3VdingoChw+iCCokkSAH/YdkGmcpnCWdbMA8FPGGcWuKRlnGZjVVcXbu2vGaWZ/EKew1ooQHVMpIHhdrfHjyGU4URQljZHWxaZtKAtpWpunxKiTTJSN4eHpyO9/+symbVi3Fcfecxn9MsWXddCHSOUshRXY+YvVIcSZ3ss0uR8iIWSquqYxhmEOXAbPfilW2KwaCiexsaAiq7aladQSyTco8sJy6vAhclfVAnlOgeADT8cTAKvVCmVk3Zhi5Pc/flxKCISVFFLCGc3bVSnOKW3Iy7UWkwgKs/e8P5yAjBECLbPTjPPM6dJjrWXbVgyj58OXo7iNKxFqhnEmoWBxrDaFY5g9fSf7kdKVNIVmpZQ0eipQWSKNIUhUqywyhU2kpIjIfVFZjbfipgkJ/CyNUraAFBQB2a/5LI4lDVROXGHTMIroVtYorbkM4iZ5c7XGGhkETD5yHmTPdupHae+rShG2nWNWii/LULCwcug9dlKacbtN0hZalnRD5OH5JE7LbUuKGqsiZVHQNA2zD3z8clrKOQpx8SaNUoa6cLjtmm0rrZ7HIXDsz3x4OuGMoXEWky06F7SVZVXpRcyYmby0J/dzRJuZtm35ZsFzhDAxzYHZR3wU2HfpDM5oCisMpmJZf4x24gjVEqDLxcJb88Km0YUc0vphYowJ7dUrM8xZw/VWOLEqZYnCes8UAukyvhhtfxavupaW3u+/+Q5rLfMkQ4emKfDzzO9++x4SVGWJKwr+4pe/ZppmHh4eKaqCr755IwNAlWlXNd9885ZxmHn+chSRpiqlMKG7UNc1k59l8J41T8979ucTVVlwd33DN2+/oqpKPj888f7DZ+5ub3lzf8eHj5/5z//4j+x2Ndttw8PHJ56+7FltVjRtQzeMTNNMWQnXModETpmbmytu72758OETD48Pr3G9m7trGQqNgcv5mY+fHpjGkc3uGlfW9P2IdQZlMkVt2OyEAayytEt/eXwEpfj+l99QFgW7bUEMiR//8F72Xk6cpBmY+p6/+7t/zzTN5AClK9lsN8J8bVu0MSidmcaRjz8J+qN0JZfLhT98eE/0kTgl+nMg+IzCkLPDaMNXX98xTjPv3/9E27R88923aGt4fHhgmmdCmiiQmNnh6cj7H37COoN1Bbe3b1hvrikKw8fP73HaYZXjeDhx6ftXLlFROaqmXCLeirmfmccLp+7INI/URcOqLahW12SlaGsn6JJTjwqR1eZG0kTpkXGc+P0f/wApS5FCWfL1N7c4V3A87PExkuIokesDTKVgMZxzlMWKeZ757T/8jhgSxlTMKfE//6f/TFUVfPvt14IKiJFh8Dw8HERQupbPrq1qEXIqyzx6/s2/+Xu5/stGGFMxoI0MEa6vtvzFb36BVpY//O4PVHXDarUhxZnNak0dM02A+9sdb++vyVE4tI8PJ56/nKQNuDtxfb1l93/+l4TZk3xg/+WZx8cnurO0KRvjlhIOEZnevv1KUhlxIqVA9LJHaMqalDL99MCcAl9/fU9ZFjx/eZY1c5RmTmdKnHP8xTd/gdKK3faKefZUjZxD//C7H18xP/+1158tPNVVhbOGdStT1DDPS9tQJoaZ56cvcrCpS4xpWLUNc4gcO/m67WbDWIx0l45VXXB3teEyznRTEOGmkoaoOMVlCisbX7QRAOLxTNW0NG1LXVi2TYF1Z2JWrNuGVdvy5csXjsc9V7srrC0Yp4mn52dxO9iCbvIMk6eo5J+V0uScqKqS9XrF814a0OLiGmhXLVXp+PR0YvJSu+lD4HI+keeB82ZNqMWiZ620/QHYJaMt55VMilEg01qRFEyj2HLb1VbsuArmEHh8emacZ1nknKUuC6qqlMNfIZDu2c+cTieKQqKFwXue9s/M08w4z8zTTFNYlKvIpdj0ttstXd/TDSNFUbHdrOnHifOyISiVIiHnsH4YOByObDZbXFFTlCVrrYVPo43EdsaRfhwxrhDOxHLQ3axXkAXEmIKSi3kc8SmzqRzWGXFE2QK3ABSdc4QQKJxMJrOtSFkxPH3BzxNlVaO1FaigMdJskyKkCDmK5T+lV3aLTMESh+OJlDPb9YpM5HA8CQhzLbXIolLPnC8dTV2Ljd4aSrPAhOuGcRz59PmBtml49+4OYxZWApBjwDaWpmk59z3Ph+MSCcoU1olt2xY4V9DUJeu2ZvAJ7SP6MhCSQI/TPHJz/4bd9S0PcWbojlzGmWGJqCQBVC0RGkXhiqVVSODU5EyxNGBczCh8l6Ux6Prqiu16xU8f3uNniVoZo1ForLHUSytjUkZcbKVjnEbO/UDf/XwOcAKZFqEOpRh9XCZQTiYlSi+QXPt6kHppzrLWUriCoCMuBErn2CwV2d0wCTNMyzoSxWbJS1ORxCMjHpnYlk6+13q9FpdP1wkXqihQvWTHXyqdQ/D0/SAtlmT6vqcfRvTSNOGcxRgrrCbniP3INM/CadGKphHu1+l4EoZB8DKFTmlpGhKx7MWVo424bZZFS6IoSi2NSFna3FLidL6IIFdI++ILy+J8Pi8xQ2GKSGOJwS1cK5VFpOunSZhOVfX6HuTl904LrFopvXCVNFXhiPPENM/UQF03TENH10sLn1ocMClnpmnm0l1YsaIqC5x1aFvQnw70QwfaoK0jJTnzsrg1jBFRUAQoJ6JTEBBuFDKm/A5KEnEvTCPjHHbJ9IuEJV86z/PiVJWDubiezOv1YYw4Nbz3RB3FuZLNsimQppWUMraQWHEKwviqikKcT0mmcuM4Yo1l3dRi1bcWZaSOXhiAPc5ZVm0rQPIlahkX9lfT1PR9z/ncU4RExIhLzzl0lHi6NTIV08airVtYLMLr8l6xXa9Ztw2XrhfHaAxMk3+N/b0IoTlLRMcaS1GwHFaNDBCyOHrUy3VjE3Vd4azDLyywl5JxrfLCOyqWSGGFUjMxCn9gGEfy4qb7ubycsygFpWGJCGdxdS17lXGStrh1KeKLs3pxuRkKp6mrEqXF4dlUBduVcDK6YUTlhCGLqKXAFQXaFCQlBzhrEyovMHLtKJ2hdhqVDCmaxUmq6caZj09yGNy2Yskfp0BhwRqY5sDoo/AjMQuUXpERB9YcMj7IsztEaJylLBzHOcj+z4vjkOX+e2l7cs6hlGFVFbglPhti5GGJihptFti8DMqGYRHUVwqjpPwg5MjhfCGGCIujiqBxGtpCv/75DMQk3BKjZN27DKOIN4swEULEh8g8e3FYW81Aphtm2tJgq4IQxXUkdjL32u5EzgQfsEuzqDV6ecYL90ot/4lJnGDOCND/JRarF86aMQadMt6LA6mw0oiotTi/ZK1Ssm8oLNbopW1QnmEOtTAxBRlhllhj6SwgkcIEwu3LmXEOFA6clZj26MXtaJTsAbvJU9jEXMvXJ+MYfWSYPHWRhUWmIUS7DG8dk0/040xZOKqqfP38pERCBNaN1UyzuM2CD0zzzHZV01YFyRiiXUQjo5jSn559ISKIiBe2XCVNU39yC0fG+aUAoyA7i9FmeQ/lvXRaYQGRAiEbS0YvzgsorAirl04+K5UkulI7KbSoCom2V1WBmhUhyoBx9ovD/2fyck5SKFe7a6yxnC9n0BljNfMkjVigMFtpD96sN3SmYw4TNmtW6xpjFGXlWK9a3r17y/l44XLqKFzBZitx8pQj1tlXdmTMMA0j83ni+vqKm92O7XbD9c0VIWb2hzObzZqrqx0fPz2wPx6pas2OmnEYODwfl2slcukGhnHi6kbi+EkpslLSCNsujeKX07Jvkb1XUVo+9yfGfmIcZ3ESL67pcZqxUcv74LQMyooCoiZ4z9D3ywBQmsps4fAEuq4npch6K4MmhbivP30+En1cXM/SgF5VFev1GshMYcQHmLw0YdZtTYqJ/f5MjhkTjew3nMaaAueEU7XZron7I33XUVcN6/WacRrpLhdiTqQcX2H54zByeNrTbtes3ZqqdtRNyzBeuHRn2nKFdY5hnEjTQLFwsgrncIsApJXGD8IAHMaOfuipy5LCVRSlA6MXlyJYq/FGUZQVRVmhjCUxcjweJXq9pDecs5SVA5XJQmiDHPELW3pehqXOWVL2PD/tSQlubhtijjw976nrkru7G3Fm+8A0zvTDTFE6rqqSpqq42V6TVSYyM/YjD5+/UNcVd3fX+OjFbfe6ly64vt7RnQf2T3uqYcbPmaq0NLVDW4VxiqauaKqSFA0xyvNh7GeyToQ8c3W1Y7PZcPyy53I8M44D/ThyWYSnpllTVnrhTimapqUoSrwfiUnieN7LwDcnYauiMuttQ9s0dKeOFKQhEg9GW5S27LYbrCvo+4FpmkAlxnHieDgxDuOftS782cJTiB5tFMZW+Hni8+cHlDGYdoMxjl//6ldSPboW5fDHz48yzbjekTP87g8/Cgy0XTMEz7//3U9M08xp4agUhRMo2Hb7WhVdlBLbapqGzWbLNA7842//I03dsG5XPD4988Mffs/9mzdo/Za7+3vu377Dz57j/gvbtuaf/cWvXg8Kt7st2pglMjOxbit2q4rDfs8w9KIUThNXV1usKxeAIFTNkice7/Cz59Onjwx9z3/87e9AG9pVizGGy+mItYa/+PVvcEVBXKqOP3z8gNWGrIRR9D/8q3+JUorf/uGnhR0CIcoF4qzjq/tbjMoQJuIMfpIq4x/e/4jRmlVdkVPi/U8/MvvAm7ffMAwDT/tnXFWRXS0sqG0rB+eipCkL4QTERDeMDH1PfzpRNTXOrjgdjzwfjtxc7/j1r36BD5kQM8/Pe56+PDK9+4qM4jwF+qgx3UCKYWEoGD4OFz4pTeFkw1Qs3JOn9584njo2331NXa+YgkyU3n77jnXb0lSlLEZBpgVPhwvzOJH9TA6BoeuZp5nTYS+27aUZ7P7uXg6C9Yqc4XA+kWIkLgfQw+EgroSipK5K/vk/+w3kxNh3S2xR0643/M1X3whfoL/QdTPD5YIrSzZX1xgF/91f/pq2bbm7v+d4uvDjh4/0w8DxdGbd1NxfbQnTyPl8YlVXbOoW50qKsgRtUNqyP1x4fjpwfXvH9d097tiRw8wYMkPOmOOZhFqspI7bSiaOHx+fOZw77t+8Zb3dksLE08MHVld34tgbhduRvUR4CqfZVpZ0d0tIGVuWJK3ZLvWtotgH2XznTAwibPSzLNRf3V5TKvjq7VfLpvPn8aqbFcZaAakG4cgA5CRtkle7nURDlvv1cHxcDuaNXFuHwyvUuJsnjqejtOBYYTzlFCicY7VaSXPZPMvhIgmjab1eixDQd8TzmXGBWc8hMU4eYwaMgl1bQYqcz2ecK7i/v3utjb+tapl2xyBxsaKQawwROgTYKtwylsOFNPVtaduWpq7QRvP0fGCcJh4+fwYyq7ZdHroimJmlpaxYpsyjD0wxEU4XrDX86vtvUUpzOB4WGOJ5ibsskZWqxFrHZrdbqtwNMQT67owCyrJ4/ZlTjNIAGOPiQkqocaJuWq6uZWpo9CIyLNG3x08/yWe3FAYURUnX9zw8PrDdrPnma5nqoDSn04nzWVwbrmzohoHj+UzbtgLgNwalFefLmRgi292OppHyjLpt+fGPf+RwPHJ7c0PTNAzDQIqRpmlpGmlA0kh9u9aa1WqF99J26GOgsDL1fnr6AkhJhdbm9brqOrGPRz+L8LlEms5dj0KxXvg0VSMswXHsyVkAtwrF9XYDgI+BlA1ZG6IfGQ8HyrLi3VfvMNrgjOF8uXA8nRjHidPpTNM07K52MuEPgaqxbDbiqPXTKM+/tiDME58fHuU9qRtxYQaBuUN+PSRL9MnQVBVVUUiEehwpCymJuJxlXX8Recehl+iJdVgrDWV5+X4CvHYywMniJJsGEbb8IioNozgD5hBf23aVVjw+fvmzp27/R3ntmgq9CEchJvaHIznBFCJF4fjb33wnEc5xIMTM06nHaM26lVjr+6cjsw90/URImfLx+fWANsyBYzdSFY7tupEDQBoprKJeb1iVll1rGXziPEZiVsQkwoQxEs+aY2KzbqjrAqM0p2GmrQo2q3bZzIr/LQPTOODnGWUNaM0YEtnnZZAkirDSiqYsaeuKphDGUH53Tc6Zp+OFafY8XSYyiqqQIczlckZr2K1WoAQ+HWLk4eEzhTVEZPjwF98Ks+PzcSRGia+GKAUHWhsRn41mU2qMUktczjN5cTCt1y05IXsfpbhat8xehgQhQ9YDSsG6lfhDPww4Dd/frphC5NR7Eea1FT3Je54vHZ+mibap2a4bQox03YWYxdH3IhWl4IkhUhSWwtpFCINzP5GGmVXhKJ3F2IJSO479hW6YWBXCyBNOh2FVWVaVwdclo5HItVIIEyqa10Nt5Qwpwo+fv8AStdDGcLPbkoHD6UjKiW4KTCFjncT3+n4QhohpsNZwf70l58xp8DB6dC9R9O+/ukMBPmX5PV1FQHG4DGgy767WFIWlaWsu3cSnL88Ln1B+/utVzeOh43geKKymrWQin5QBI+6qOWT2p4ksCjhJabDCUXTWgRYRbqFjsG4bKes4dqR+EuaiEwG3MMLt8kE4fiEmVu1qKRSRCvvT7Jlnz3W1xjlLu1IUITD0F1LMRG2Zs+H3n/fijE8ZYxT3V9JA+XgQxuHP5bVu1iLWEOimiX/8/e/RWvPdL77F2ZL/7m/+ucDvnbTV/t3f/x3WWt6++wqlFU8Pz4QQ0FZxvlz4u//f/8w8ey69NHc/Pj1T1RW7zXoZWhhO88h5eOb27g3/7Pt/weX4zE8ff+Tp0PD5yyOHpyPD6cypLqkax2bb8rd/+8+YR2m5q1cN3/3669dSmqvrK4qyYuh75nlit7mirlccjx2n0+9k7TGwWW8pyxprM1pnvvr6jpwVf/3XvwAyHz898OXLJ96//yM5JZpmJYydpwPaaG5udtiiAK1IIdEde+KYyAhP6v/6f/vXpBT5d3//93RDTwqBmCLEgDOa7f21DCXLSlz70TONIw8Pnyhcwe3dLRA4HY/42XNzfcM0TJz2Z5RX9MPMqnVsNgVVtWa1bri9G7i5fccwjHz88GkRUWaKqqRqKvbPB374/Xtubrb88i9+yegnxnlm/7xn/3xgtapp2pqn4cRDONI2EolVWUPUfHj+jJ9nvnr7ht1Omm1dYfnp0wf2T0duru4oqpJz3xFi5Nt/9pdst1ucK7h0HU3TopSm0JopK2FMKkVSUkDy23/63cL4kyHY/dsbck6cTsI+fXz6gtaGujoxz4FLN0OG6nSicJZf/eIblILz6SxnppRwruA3v/qamALdeMZPPd3pvAj3nqqs+Ou/+UvqumS72/D54ZHP/8sDZzq+6D1tW3G9WzOcR07nE9YKmD0xcxkHyqKmqRsu5xP/eDiw2qxpN2sCgMn4eSJECf9O00iawdiS9UpTt5XwnfqJ1XpL3QhW4XyRIjJtFDEKSiP4iZwlMaMUaJuxzsgQOCfKVQlOLSJR5tydOfcXwn8MKBSfvjyiNPzlX/2Cpmm5vt4yDP+NW+1ylorqvGwEh2FAGcscpGVjuxFgWrVec7509MN7gfpVpXAo9geKquJutWYOgS/HiwDHJgEQDrO4DZxRS/bQkoqSqk6sViuudlseH0dOxz05Z1xZM4wjl/OJ9XrNPHt2ux3b3RWPD488nU84a9ht1pIz9oG6EjHr0nWEyUuczDn8PDEMPdHP8sAsS+p2Jc0vZDn45EyqS6L3PH95pEuZ/flESGALR1kWTINwgFKMy4NM1MLz+SJtNEWFtZab6yuUUvzn3/2ADxLpiEsWVytFW1XoHFF+gPRSaTxzPB4oC8e6Ebhsd7mANqxWG5S2nLtOgMdacu51IZt6V5aonAhzJdWQo8QiUhQIO0gN+vF05Hq3ZbPecOkH5k7aHvqlbjwswk5S0vYxDgKwzNYu06LEer1CVdVrO170nnHoAWkV6ye54QvnaJuKjV9TlCXz2BPmmT1n8sLgkQiALK7TNInjp2nRhXmN8Hgr9azjPBODJ6PkEOtnOfQuzSfbzZoYA93lJE4UW1K4guurK8Zx5HI6ME0T566jDAFX1azqiqvdhna1YrvZMk6iXA/jxLkbcC8tS0m4PZBlMmYNxjrZ0ChFP810l45me4115cJqSfK5R5lEzNNEWqa4dSkumIfnIzEmXFnRrtaM+4Fp7KjX18uhK+AnTxhHcoy4TS2VtVVJzEv1ekq4oqBcGsFyyng/k2Ki1/Lvm4JEylLwAj1crX5Wmx9jpWo1LVGoeTk0z16aEstygdpO0ho5DD3WOlattPJMo1RpOyt8r0vXY6yjaDSkRI7hNWZLzoTFSSNuGkNV1RJ9yRKREtaJf41meS9tImVhmSfP5Ge0FojzC6S3LEqcs3SdHOitNRTLz/NSlaoXBxKL81Jy/bIZ323XWGs5ni/kSdpCU4y0TYVWDmFbqdcomTGGlIWlQojM00BZFKxaEbP7vhe21cLyeRH3rbW4wklkx5glzZZfOW1aiTspRvm57eIuexFU4vK9yrJchCdIMYnoMQ703VnEiqJ8dVaFEDifz2xWLeu2lRbKIEUB3eWC3lqqphX+wDBSuIKyKMRxsfCv5nmm9p4iRsqqwi2CmKxdN68uw6RYNrgOZwxxcStobRZ4vZYpkFgzgMw4TsJaq2qsFW4RsHDppBYYlVBZHBMhxqXN64XPJO/RPM2vbZzOWpq6JqXEsIBtLeIEGYcBZx1NLRG/l+vwT414M8XioH1xa2ktTYcvUG+9tNlN00jXCwzcLi1DLM+1nOLy8744M8Fag8JwWVgJLsvvKuD1KMOkBRQfc6aoZJOcYxB3nRZ4r0Dn1XL959f9h/DUMoOf5ee0Tp4HTYPRmmNxenUe/1xezoqryDmH0nFxkImjUmvNzVbaa7/EQMp+caBYNs6ScuIyCrTXL2DmYRzJWZEXcPN59KANO22XS3ZhchUlrtAUTgtPEmGPxSX6rZQhZ3FqlIWjqQumKTBNgbo0tLXsRbKSe8RozSFFgg/C3dCaGIWfJ2F/ud5fYqOlsxRWruxy4fGd+5Fx9oxe1lO9RBC9n1FAUwprLC6sua7rma1GFzVlYdmu5Z75+Nwz+4jNegGpyvVmi4LCKNpS7r8hSPPm5L3E114A70mYPWVhxe2aMyomZi+Cc1kVAtqOnsIamqog9zOHbsYa0Au/hZSZZs/p0lGWjrJwxGFpM00KH19cg5m4ALP1S2Ph4uzwUdrpSmNxhiW2uwi2PlIucTD0C/gfjBYXblxcrxlZI17WaBD+ZVBw6oWX0tQNTgmsWyLrTpigaek61mlpopM1QmYDWtoMkziYcs6oECgLx/VmJeU6/ShSupbnxRwipRE2lFug4P0wMU6jOCReXENWXEg+RJzVr1DlrNTrczPGxByjtC8uznBx9+rXdeLl+ZOztCFXVYHrJpTyr+KDuKaFHRuTPL99kMGSBItZ3HYJH+Nyf0ijrDxXNYoIypDQnAcZvFTOorWlLuXALG1T8X/H1eV/25ezDqstPgWmeeJ4PmONZZ7jsv9eC78pW2YfeH5+pmlbvvnFL0kxsH/+ItFFo/FT4PQsUf+Q0+IyT1wpcDc3SyEKkCMhTrjScnN7yzz19EMvDYXTTH8ZpG1yXq6pUtrjvjw80p3P4tKqyiWuLGea9WrDY4zM0yTYk9WK41Gc1CGGJfZXUVcNmRmIVHUpdfXbDVZrHh4fGYeep6c9IUS++7ahsCXT3L3G9/UigCsS8zCTowJrcWXB27f34sD+95oQpNEvLY5sbTR1U2OXNnC98O/CMrxPVSTlIPfXFMgpy/4yAeq87MkkFl8UhqouWa+3OFeBcnx5fORT93lJYURsIXG8aZr48vTMdrdis92QTke6safvB477A4UzrNcrhjDSDzPGLi2qOkDWDN3AMAxMV1ekJE5eYzVhYQ5lhHUUQmCePYUrWbUr1ps12mrhXaYszNLXZ6QMRmLOnM9nlFK0dY1zlrpuQEG3rGnjOMnQaymMilGGen72OKNYr9bkJND4lGSdt9ax3TRyPV+eSSExhkne79njrh1X11vqqmS1acWFNQdCioQUKJyhsNKwHVOExcGcovDmChJGwzDM9JcO5RzlakVSwpNLy5ljniaUUehk0RicK3Ba2k5jkH30/8pdn2aURmDqSZHTDKQlOiz3jghTyx7UGmwW93teYv0xJQ7+QE6Z0/GIdbIGO2dpmvo1gfBfe/3ZwpOfJvw48Q+nf8BoxTdfvROeEZE8Ry6zQD7n5yesMfzlr34hC7yxjJeen376ge12y1dv78Aq1qWD0qI2K6Z55nTuF9ZH4nTZsz8cWa023NzevbJBgvfcbK8YfeDHn37EJ8Xbb39NXRf4aWDsBRrbXU5cLheGUaxgt7d3XF9fL9PW5XCULHW7omkawnAh+omwTP79NBFDYFUXYDTPh4tU2Y4S72h316x2NxRfnvDe8+b2lrosiVsh5x/3MuE2KVJoxfFwAODtmztSGPl//9t/h1KKFCacioy9VEKGhcMw5ZqyKLi9e4tS4IOnKhS//uYdx/OF/8+/+/fUdcUvvvla2jjaNU1boVTipd49+Jlh6KjKmrIomaeJ/f4JHxOzj6xXLd+8vVt4Kopx9DSXHh8Sj49fxN4eAne313z95pY3b95yd3fPw9MzT/sDx9OZfdehB7GU/+UvvuXd/Y1MuqcJMtLGFiMpBrRxmKJimI/0fc9v//ATbV2zXVXCOClKnC24uYms1xve3t8TYuTz4yM+BL5590aiF0sV+7EfUFpzfd2CUfRI00q1XpOzuBAyoJwovn/3d3+PMZrdpsUZS+EUOQz89IffMfnIsRuonOWX339LzhnvI36aeNxnTt3IuRuZ55lt29JUNdvNTrgH2rC7vmF7fcs4z1z6gSY7nBNn4DzKe5ptQTdMPD4+YpYaz2HyjD5wvduwW7e8/9DzdLxgqjVVs8XWR2w10l9OEGeasqDZ3rDdtDR1yeGx53A84IMnp8zoR6zWIizlxMOXR1ja3JwxtEs7gq9rUlbsbm5w1hCmgZwix+6CQlGWNbX9GbXa9R0Al7McSjdtvUy3nUyluwsgG1BnDO/evJV2su4isbQQlpawlVS3LvXyCYlGTeOAtA06ARuOI64QNptRiv5yxlrLmzdv6fue0/lC8J7oZ7zWTNpQVQVlWROiCENzSPiY2K7XrNqWmCIpSfSpqkqaqqaua5m8Bi9NVgsIMy62fh/kZ4vB03XnJaqk2bQtcRqJIdA2Ajd3pTRh9f1AiBGHMK7OS+NhU4vr5nf/9FuJXpSNRKTb1QItFnEpBgEc5xRfq9iVUlztdvR9xw8/vRfXZtu8NjZlIKVB4hxliVaZ8XJcAJwFOQkjz1iLqVqp7m0qXuS9aRyoypIMdL3Y4vtRINNv37xhs92xWm/oVqvXpo+u6wWymBO77Y6bqytSVkzjKJ+vkoNKVQl7KGaBbacMnz994skamrphtVphnXCp5nkg68zt9RUZOHfSWrrZyqHCLNdN110EPFs4alMtcFCJ/4YQhT2WhSMBmX5aeGtZnl2rpiHlTDcIsH4aB+q65ur6lliUwoPRhqenL8Kncw7vJ5qqIGVHzmLV3z89opTm63dfkVLm+elxicIVxBg5nU9M0ywuFxQxSwuds4a+7xmHgbIsqOuay0Xcwi+b3pikvCGiicrgjMNaw6ptKAphTExePocXwX7R2gDF4XyWZ9kiqjZ1jasLwtIsWC4bzNV6g7FOnjko2tX6ZxVVAfj0JFwilMIZw91a3DTDLJvPz49PAK9R16uN8GNeikLICmcs7brALW7yyXv6oReOV+monMEg1e/nXuKf1mhidPS+ABLbIuOD53SeyEoqW17gzVoJ5NWUjso5zv3E5/2ZVVvSVA5nC4wxhDCjcsQg7CJXGFBWBm050ZQSLXcmE+LM07FjnD2raml+cgWbjUNdLsQY2TQlhbPUxQatwHsZVN00jhAN/RzJPrJiRGXL06VGKagKizWKmKQYoq0r2RsaI/w6ZMg2BnHhvbm7ox9nfvv+idIZ7nctGfBJhOjrhX2qssSsisKitcPqWiI7XpAS66YScU2JqG6MQlORMlRlhV2E4hgTq6qkrUqKwuKc5XTuOHcD3TBxOHXUqzVVVXO7a9m2JWYRU85LVN+HBGh89HI4dRIM+6cfH9Bkvn5zx9V6RVwE8JhAhURZyL34ZQiEGLnZrqWlMsp6eTkdxE1uNaWTiLBWmrIwpMKQ3txJVH0p5hCGomLbVqBYYPiJh+cDadmPOmfYrhqMsxRFTQyBQz9QxoxyJUqLI7MqC7ZtgyFz6UYKrfjl280iHElpe/QSb+rHEWOWuLy1VIUczjZZ0Y8Tn/cn1pWAxqfJL9gPMCrgp4F5GtFpJlpFjaPMBqsFBD0YB0kzZ0OOcNofhelnDGXd8Hzuyaf8GjVetxJfcsu9srvdksmc+omc4XQR93lTldT8fITzOXiGeeLzv39AG833335FUQjHMgbPl/1yDYwTGvhX/+JvUMagdeZy6fjxx/e065Zf/foXpJgZ6mm5VgUkvX/6IgdlIvM4cz5eMBbub+9I3vMP//HfUxjHL7//DZfLhcPxSAJsZbHGYVOx8AMNxhW4qsTPkXGOwgZeCe+w6y8yFK4bXGHQNtOuSqpKo8x6AVxrfJgE3aE1n798Yhg6ftIi1Ho/sVpV+LAlxszuakPb1li7k9IfLQOm+/s3TNPE54cnQPH1N18xjRP/9//H/xNIGDyb1jFPMnwIqkBrC9lglGW7riT+trSl/9Vf/YbD4cT/63/6O+q65vvvv8G5gl29pnKFNGNrMFZhrOIynkk6YcuC8+nM508P8pxWsNqs2F1tZG/mDH13wbrEPA/sn/f0/YjvEvc3t7x7c8e7d2+5v7/n8fGZ5+cDh/2Bp6cTxpwxRvGbv/wLvnr3Fu+F7TfPAyFOhBxQRmFciS0aYtwzjp7/9J/+gR9++Im3b265u74lRgghstlusa7g7XdvxXm4P5Fi5vrmFmsMfS8N8Me9lN1sVldAZhiOy1ol+8eyakgxMXnhMv3w+484a9neXOEW3EFKiR9/+sQ0z+zPF1ZNyy+++pYYPaf+gLaGj5+/YA0UBfT9wPXtRkS7GGibNUa33L/5lvX1PcPQ83R8pKoK6nZFCInng8QnwwJM18dntMlc3+0Y+55pHLi+uuH6+oYff/qRT48fuL19w2azo2rW1CtZV6ZhZNWucVXN9W5DVRX88MefOJ+Py618cuoAAQAASURBVP4Shq5HqUzwCRL8/nc/oVBstlsBllcOrQvQlpyhqSqUVrS7FoDDYcAay7fffP/fXnhiUUS7rqNwjvvrrbiSlqrVeZrxMdLPE03T8NWbN6AU3TgTk7Q4BV9DihJPsBJzeOEhKfpXu6v3nsvlTFGUmOUgPU4DTgsYbZg9w9Djiop2s8MqETe8nxkHsXL74JmmiaEXVk1VCXAzpow2ssFwS1xF+QEdFNpZEkoOfSESnEZjGMaJrpdKx5QSb1drqrKgG8alErKSautC4LDn81Gy8kWNsuKAEnaLWMofvzyhFKzqSuIxcSb5QPJBpj5lKQ6LsgIS3k9oLayG80XxfDiyiVEajJzkg1NONHW11LaLo0OUy/D6vw3jIHGjLArlbrtZHCCRqiypKjl8juO4RIUSm3bN9WbF1XbDppW4yTSOnC4dU5B2OK0zRVmy3Qi75uWwmZdpmtHSvpKVWVqfPKfzhWnytKUVSzf/JWPCUFgnOeTjAYDNekXpCg7nC2mWyS1ay4Ktlt4RJRMrlGKzXsl1mRSD9zw9P1M4y9WmxRjZ9IUQ6S7DAomWaUPbtqQY6EInTJqljS/lvDhPChyKstavyrMcvhoO5wvn0ZO1EeBxlsNARrhRaYlDaK1ZtS1ZjYQsDowX/tAcIiFDUlriXNoQg8ePGaoK4xbIuYGcAmH2+CjNkAoRFqKXGOTZCxvl5voGXYmTwGpF4RxZGaq6wTlLVJngZw5DDznjXLGMSH8erxeXRPQTxliappEHtZKNcQgSzVHINLSqSvys6M4nYXrA4uaRiXEok0w9w5/cHyEKvPalsc0p4XGlRXyprKOuamnuWaDVij+5InPmddF+OXCnJBGQsiyWGtQgYG7EUm6NxWhP0lqcTUtbUIiR6MMr+Dz4mWGWFqftZo2zlsI5wsJIcbYQxoDS5HGWpietl7Up/MkRoBSn0xGjNbubcnH+WLk3YpJ/Hy9T5CQxqSDTQGskYtf3A9YY6mpxLGm9cJ0kylE4aY+KYUZhSUa/HnhQCqWlYa1wbnFJCZupLOTPhSi8t3maJKrTVNJ4VJWSsVfqTw11KUCOr/yvYZoJIS6NbBIdtNYswthSp620uH3JNLU0CWotriFyQuUkLZtauDcxLxEWIz97SomLF1jjqm0pCkdV1xIPZMDoP11T0zyJSymKI84u4PuilIbXLvaLky69upaUlf8/xkTfD0vbXiLFJI48ACXNjn6eKauKtm0YhpH+MqBLhTElaVnHU86vYO9MxliDM6VAJ7WsmeaVoZPQKbMkV+Q9UUrYWlr/Kcq0wNRBxBGJXApHKJMXjpRfqtvF/aqaRq635f5QSRw0dSXOumHyr1w2fkYHN5Dm1Iy021XO4q5atELu6RiF1bS4MtB/umZfmji1kmYticFL/BUVXpljhRH+5MIuZw4JZxTOJKmzTwqDwmkILK2N2pLVSwX4i9MgvzLNQhw49yPOQmkXzhfCRSLLkEgEUhFLDBmV1atoqEjEFOinmX6UBsbCGrQtKYyiMJpIonQC52/rEq0Ux3ARbqfVBA2XOS28lEhKiimkRSRTmKyIUYQuY4UxYrXGqLzwS0SQyUqGN6NPXPqZWFq5TlEkZG2sl9h1DOGVp/TCjZx9YM4BUIsjUAQJaxTOKubCiqPVWPRy86Qsrqa2lLKaohT23OQ9p25gmGZ0EVBW2i1LZ19d9hL5CEB+fd9TzuiFEXXqZejw1f2dPAeyPM9Qeom76iXeJ/HXsnRYrZnHiZQi4ywxRxl2aFDmlaOolbBJ0jIATTEy+YA1mrKoZP1NmdlnhnGSuFmW90Ih7U2FNUwpMoWIMnL4yiiqsqAqxK2agsfP8lmuKomgzn7xHqUkQ48QUdqgjF5KCTROy/XfjxPDNFNbwMkewS/tpSHIMyKFQNKGpBQkDVmhMMtzyKCMOGYj0i4a/Uy1WmGMfP8QIoVVC3+vorAWoyXOvqqW5+Es0P1pqX4vSvva3PmzeGlNCoH9/kBZFHz37TeURSnX+BKxjyEwdReqsuL+7VcklTnPAyFIu7g4kAuwCpXlGepjfI17i7tY3P3T7KmNoyorvA/sn75wvbvhenfDPPllGyFONK0NZPXabglLiQV5eV4WNHVL13dMYVpc725JNChcNlgjiRdtNZfLwDyHpf3SMY0j5/NZrh0UVWVl2FTXpAxlVVCUBXUt7utxkNbJtmmx1vE5fHlt/00x8unTJyCzWZUiWmu5n9PybH1x8VkjjfBpacBs2orTuePp6cBq5fn227QUellSkaRVmYQyGWMVIQXmMDNO48KAlBhaBlzhWK/XKJUxOlMWlqKQ92yeZ4KP5Jip1w2bbcvN9TXXV1f4WfbHp+OJaZzRRtiawkG64en5hO+GpXU1orRCW4Fvig9LkTPsD0e6ruPt/S1VUTEuCQKzOO23V1cYowmjJ/jIbrPFOkdKI9OYOR7F7bte7zBGkeOwOPZlj+MKSdDES88UA5dzT1UW3L6RVFNdFkzTTNcdmIOUCGllaaqGkDxzHogRzpceoxPOBlKSspSUIilacdtrR12UNLsNT18eOey/kJXDFQUhSlxRZbUM8RLzPC2FYhUxzPhJUhBtswIF4zTK+7awaq0tUKhlzyvXR1mW1JUMPmIM5PiCrAigEjkL6+ly7okpUjftwlCUM3xVFGQ0ZV0t7DHRO4ZhxujIZnuFW/Sc/9rrzxae3r37ihgDx6OIKo/PB1BCS885EWaxxUXtYIq8fzoRQ+B8ksrFf/2v/zU+BD58/rIIAJulGjjiXEmzWrParF8h1d+8uRf+wPHI+Xzk+emBzWbHzc0drmx497aRekJjGeeRcRz5/HTg8sN7qqqmXm+l0nu7YrduKI04maZponQlbd3QlgWlypx6WSBu7+5p2hXPpwv95Dn10yJoKJqqpKkkC2l1JsWZd2/u0EoORtELjDDGhMeiXcFX335HUTje3t0KNG7qyDnRtitiTDw8PZNSpDAKjMEnT+EMtzfXKK358vwkF06O9MPIT59kIv03f/WXWKOZ+o5pmjkOXhgJwdOWJdu72yUSGRmmmYcffqIfBk79zAJRELbHLAfFqCzXd3fsbm+JQ4cfLvRzInk5wA59z+8vP/DbP/xAUzfUdUVVFjRVwWazoa0bPj8+8PHTe26vb1mv1lSFwRrFr371K94staL745G2NKxci09ADlJXrzU//PBHLpcOrBwkrlfSWHK3W0uVcggMixVUKRgmyeJOQ4eRESExRB6fn9HGsm3XWANETy4s7e6auip58+YtOScOhxMJxebqiroqeXt9RT8M/PTxE4Wz3Fxt6YeRT0/715uvKktW60YEpfiyQS6YZs/zfk9T1/zNb37JPI2MQ48yQFGwXa+5Wm/wOTMnEV0LZ3l83vPhw3sKDU1d0q42vP3KMFxOHL585thNhDmwu7vm9mpDP85cLmdSmCmsoW0a2rrh6ekL4zSy3WxxzvLwIDbw243Eq4zOqDBxuASstXz17i1lUQq7Z+w5H4/M88xpGJm95w8/vF+igz+P1+3NLTEGTqcjIIKjUom8PKgLo5cowCj3cvByiEiJqqp4d3tLTImn/WERgkpS8v+raG7hxDpbOMd6Lff3pesEoqs1/TgITD6Jw0C3NcZKpfY8TZzOZ46nEzF4YgzC4KlqmnaFLStskgPFPPsltpQWxkcSW/Iw4vXE5XxinkaSEthpmAbSwpoSgUaiKHf3bwEBXXs/My8w7fOyvrfL13/99TeLm2cixYhaYOFd34sYsYhkEi+TwyQ5MY4jWssUcRwH/vjHP6CU5s39Pca+uGqEN2eM5d3bt6+FCTEGqYLNiaGfGboLx8MzWRkwFqcz1IX83l5+t1/84pdiUzciKCqtqcqCshQWwP5wWA5GAvAMKdLUUm3cjROXjx9pm2ZxXIl04YqSsmzouwtD33Fze0td1ZyOBwH1W4fSlufnp1foZsqJeydR2dKAU4q6EWGp73tmP9N1HeTMZr0FZTjs9xKd7oalOEEy9Nq6pSEz4oqC+/s3KGCeJYJdOsOqqdjuvmWaZz59+iS1421DSIlLL+URIhhZ6tVmgYLP4sjbuEUYnSmc5c3tNXlxNzmtsQt4t6pqhr5n6KXWGaNfHW7ee6ZpBAVlURIRLg4orFasm1oYiIAm0/cdXSeR9KYSdlGMibYVB93zl0d5Ri9tsW4p7ZjmCT9PXF3fYK1jnKRk4nyW9tNLd3mNk/28/E7wm+/eMIfIx6cT5MT+LA4Sn0XwmRZhPSxu4HGWNsXSZJxzXG1lIHQ+n3Avz4Ocqat6KRqQ6FNV15RlYl3/SbxLOTMPPUZL9Moaw1WrlzjrjMIQsJzPHefLhaZuaOqauiz45s5ROmkE04Xj/8/dn/VatqVpmtAzmtmvbnfWHTudH3cPj4jMyMjMKqoQCH4GVfwE6qqESkhICJWKSwQl8WcQXIFIkMimksyMCI/G/fhprNu2m7VXM7vRcfGNtczzhvSLLArOcpmOznEz22vNNecY3/i+931ebUqGYcDFyLK0LNpawLveoQuD0YbdUZLS7OTEBhqhspZlI/b9cZoJPrJsK5SqKMsCrRXboySpTVMO5QgOrRU/e7aQhLYxQ2S1qG0eD5IY67yXxlEjtr5VIwEqd1uxr5ZlzTwH/urbd1hj+Oa1WHpSkEAElRJFYVm1Vb5enEMJZufZOmnqhGx7cfNM1wjgPcSEC5GuqWibClKSVK4YJfCDRIiex0Nk3omVQ9uKpg2AZrmoaRrL1Pe8H440TSOswQKWRYFJkd6CsQthFmaVV23EEqa0Ysp8wOADt/dbhtnz5bMNTWW5Wq8FtD3Kd2aMJWHYTZMwAa1YQgiTKPOdDAMm58/qWlJCW7HHrbsW5wMftnsZ5ilD2xa8vhRr/1M/kYDSjHnaD8PoiOGJ0mrWlSUkz1PGaDRVRT9N7A4TTVWyXi3EzuIDDdLo7+qCZVMI3H5ytBXUhaLSUBoJiFBlg52PlN5zHD3HKdJPYgW+WC+4WLak4PExMsxil6kqS9ca6qrEaoN1FdOsmJxncoG2tOjakvIzujuOGKP44tmaurRMOTzJKCWJrKOkOw63OwmH+Ym8/viXf8Q4DlgjgSXbx51An00JJKIKGaXh6OfAOP+Qh4SesrT8o3/09wk+8vHHO+qm4fLZNcMwsN0+4txI1RTUTUVT1SzbBa9fvmT3tOX29i3z7BiniThHok9oY7i+uZYmpDG4ybE7bNnte/b7gaqpqOqSblGxXikWy1Yi5SeDxaJsJNrIYrlgs95wf//Acei56Frquubx8SjqvlRS2oBKirooaduF2KByU/HlZ7XUA8OBcR5ycivstzsUii+/+JyyLHlx8wzvRWQRY6QoLpid4+27d8QUWS47QDEeHUVRsN40KO34cHsre6DW7PcH/sn/7TcUZcmf/tmvZL00lnH2HPsnjIbFwlDWLe1KGKXjNOAmxw+Pv+PwdOTu9kGG4IU4BIrSEFxgGj3XFzdcrq/RVqMLjd4d8TFRljVl0fL9D2/4y1//WhAOWs6kTbNgs1mwWDTcfbjn4faB5cWSpm3YXFxSVxXewWr1wPGwpT8+cbm+4PriM+4f7plzAmQ/O77/9gd2uz0f7j/go2e9WtEtGi7XksKsrCGQMKYBFbm7/06QMOslVVUQMYSY6HfiCCgbUaWblCi0pqhr6q7h8noDJJ4en/Ah0HYtzxYdX331Bf1x5PvvfqQsC66uLnnaHXjz4xvKyrJet9RVw2azwgWplaqqpmzh2O/Z3j/S1A1/8ie/Eih+Dq9ws+Nyc8nN5RVDDg5r6oqmLhn2A8fdwOHQ0y56Nssrqi8b9scDP37/PYenHdHNrFYbLi+XWKuJ88i7N29AKeqy5vNXr7l/emKaJxbLDdYY7m4/Ms8TF5tVVqdXGKO4u79HAV9/8zNBXuQght3DjmkURpibHX/5618TQuR/+p/+J//OdeEPT7VrapH1zyNudhz2vShacttMDqqKpAopeocR7xyH45HNasmLF8/Z74/c3j3KdMRadBI5vjFR/t3YrHYpqQtDetpz9/jEOPSMfU9dtfiYqIuCppEDgkYxO01IMIwzT7sDtqhYVjVYBUHUAaQoypF5oq4b6rqmMAYNWfXjUfrkETWk5HB50m6U+FJP2Amtsq2rkvj1/iiy75hTN5I2KGslga+uKIjS9JqP4hHN7JNhlMNcsZBJEFpn0HpFIjLt5QBcaMU0ex62OxZdx1erFSpFxn5PDBGXDCZFyhjRZKVFSkSvCXHm0I/MsxOA48n7HpMApI0BU1CX8utI4DAe89ROkpmccxyGmcM48fzG0HUthZXEgKYSMNrd4ZHdbkvXLmnbJQKj1LRdiy0rDpNM0FujsMYS5khI4TyZOh4P7PZ7bB0xtmQqDeQklYRhcllRkX3XKV9r7xxJpCNIpPaMsQm1EjjoqQAtKuF7lWUlAGgf0MZSNw3LruFms+JBwTQLX6csCqbZZftC9lSXmWUDmUchn3FMM+M4suhaNqsFx33Cj0eCEpVCUxasukauweQ+fQfBM43C0Zpnh7GGtu04PD2K2iYoFPocMdyPE/M8QwzMRrNarrKaQiaOZVlQloVANCNURUFVljgvPIHJB3yMMn0sLOMsXDPv5HP67HPeH/s8TfppvKqqxHudFZpyYD5N37WMngFpSHnnmMZevuN86G3bVhq8fi+TKhGn5cm1NI3PLB2tKYuSKc34MGGQCas0tHxWBGiMtdiyOjOaZNLqUSpP4I2VotbarIY5UaP4NNnOU60QI8o7AdRPI/M4kGwFyoqH/JSOYiQJ7wT9ls/szoow8ajLmkRmqJ2aJiF4GY8YSUB0zp1VNjFP+gG01cQkzQQBEEtiym5/oCpLLq+uMKeENDfjh5A/a31O6JOiyRG82DAmJ2wGba0kUWWmWsjN5rqtBOweAj6KEtQWNu8pBj8M9McjdVULrw9RSdqioKyqM8OuqkqqVGS1mUzdjLXSdMs8qqoSRaby+iz5H3P4w5y5Q94HjIlnZcPpeffBS1pebuqe1B7zPMveOklKolERnRWPKSXI63pVVbLGDQdiFKVWWZYsFks4HqQBlAqU6sTSEmNWvcjeprKKDYTnUpQSaR3niaI0NHWN85HohSOktPzMrm3w88Qx5ma0UmdLnChYpVFmrMTcn5hfRn9Kw0qZB+aykqlpmgw1ln31dF/GGPHOUdf1OepYKcUwSL0h3AIBU8sBRbg3c4aeT+4Tb+qn8lp2NZPzVDuD94iSQymSztjPJCmaU05UO+b48WQFKF1XBXBSP4XMhBOejMtMMXOammuF1ieWJyQf8rOvUVZjlaLMnIk5eVLSoorygWGcKYqKmMiKTIVVoLVwM9KJe5a/Q2vF0iXJmTarYYTPFqLUWUrJPSR/nyick0qiOMnKIiDzOULm64gKwqDoamGHjl5qTVHEpPO6Is8qVDFBEqGvSpIuppSirhXJJ3bHgbaueNWsISXG4VPsvaz7RmZ6SQHS0HI+MMz+/KyEvK6ApAie/rvUUoZxcgzjLOwqIwrTmERZe5yhsFmpby2hLCkKYaIG5zIgXab2baEoDJQWfFCYskBrS1lISVyVJSYIlsH5gI4S4y4HdZfZNtkGHQ3DcMxriCGCsCmj/FNkraJzPakSQgyQ1CfVtBLFuyQgprxGJGlAWMuyrRid57GfzirymJXGPkbS7NEU2NoQvdStSpUkXeUU40BVgS0seGmW2gRFEvVUaTXOkWtHDVHeh9XCeopZeVsYzRSEexZSys30gq6p6YeRKTjmEHExUqv8vWUOYWE00RgG7/Ex0RYFhdH4ePoOHVqOSFnFIGysk2LfhcTsI8eM8/ipvFbLDFnvOhkmOY8iEo3si9pGYTbFCJl3SUwoH7HrBTfXl/THke3Hg7A6tSR2yj4mbCOtVT73yNBv7CXIQkIwgnBZ+5520dE0i7P61s9OksCOPfvdEWMlKKq0mTWcraIyXJMkvtOeZK0loWQAnTRaCUPRZTW1wqCVobDiSCnKkiozn6pKMAH9cMAHjzYJkmJ2Xvb5oqRrO7pFgw+e9+8mnBO2UIyJYz8SY6Bum3MaZYwyTI1IPYICW5bZsnfHer3iF3+8EtajS8SQGEdHWWjaxmCMoiilsaRnQ/Ajx+NB3C8uYEudr73KiuZEiuIk6pqWKcxMXhKLjdWcUuUOhyMfbj/QLRrqVtJVy1KS2hddy+PjI/3hgC4UulAotaEoatq2ZZ4nnnKIzbPLK9qm4gGyGnxmGEf2hwP73Y5jL0M/P3uSF9eGSVIbS22bZJ9y2REQPVFuQkDhvfw+W/5emnPKeIes0g7BM84yYC1LSTR8/uyGh4ct4zSiNBRFTvYcRxIlLjSUKQfLJFBaXAvoiPcT/WFHU1ds1ium2TEMk3DRMuahW3TZhSV1sjXCYw1BGKbTNFLYgmK5FrxQ3xO8qMTrqqTrWtzscW5imh0hBq4311RVKfe3VtIULWRAGYKnLDrKzEAlhbzXpez60IxzIsSQa8uAm+X8e3//8AcHu6j0BwIR/jf/1f9aphk+orVh2a1IKbI77tFKsWoqvA88bp9wMTLnL9vPnov1ir/3y2+IMbEfRoZx5PHxkUXX8NmzGx63W/7u2+8oq4rlap2T2Ar2uyfuPt6yWq64vrnOUkJN3bR0i4X4RR8eOOz37PZ7FouWRddxc3XF5eUlH+8+8vDwKBJza9ju9hyPA3/0i1/w2auXAuqdJp62jwzDwGq1pqpqtocj0zzL4qMV3XKNMZYfv/8d/fHIz7/+grZr+e2PHzj2IzoJoOvZzTVFUdI7uXlfXKxQwG9++JF5nljmh3dCmhpv37xBkXh2dUGZmwtKGYKy2e8tRTdokTjnxXTfj6gUKJQnKUNQpTxcQQqe4zCyXi357LOXAqB0AYUopwSwnOiHA/vdlqvrZ7x49Rr8DF4UPm9v72nrmq6tziyapCSV7xThOPQ98zgwusAcIm1Viorn7p79/pCjG0sWjQDc19kvent/Tz8MRDLUNlvE6sIKKDJDaPtc2D179gxbFBwOB2bn2B8ORBTLy2fCBRkPEDze52jfAGVZ8sWrl4QY+OHNe2YfiCgKo7noapx33D08slpv+Pt//o8gRY5Pj0yzKE+00pRWpO37wxGlpVEQk0wojYIqL+xl09IPPdvdE89vnvHlF1/g5xE39vTDxKEfzlJHsaVYDv2RQ9/LpExrSSmYZ1brJe2ipe9HpnnGJUUANm1LUxa8+fjA07HnYtFSl5bHxwexlmYQ+IuXL2nqmjc//MDQ91zd3FBWFcMwSGNjnsRKV4napqpqyqLg5c0lxmge9wdiSnRlidGK//y/+F/84RXG/w+//qv/UtaukE5NHWlejPOENYbNek0Mkaf9Dp8PC6SETp7FYsHnn3+eN/yBeZ44HHZUZc16vWEcRx62D9IwzoW/yhYSnfkSRfEp/S5kOf+cYYnSjJCfs1gsZBOxVprt00BZVtiiECuzcyy6RiZCQQIJ+r6XlJFcgE3TjA+Buu0EcJ+L+H22DX7zs29o25bf/uY3HI8H6rbDFgWb9VoUJ/f3xBi4uLySpM5+IKVEXRZAYuiPuNnxuJMY5PVqLVY6Leqn2Ym1brHoMl+jYHKOhwcJhTBaInA3F5dM88TD/T2nQ+I8T+wPe9qm5fLqWprSsxOwdErZVlyJpXoUy561BV3XsViteXy45+7jR4pCrnlRFhSFSN6naWK93rBcLsUuPE3nZC+TuUTjIKk1xthcnIp1pKprrC3ONrDj4Yhz89kW1LSivj1Z2faHPd57sQ8h90JM0I8jKSWapqGwUowrpSXhL8OzjRYQpvOe9x8+SlNQS+rr9eUlznvu7+4orOXy4kLS36qKmEMDdLZUhSBAZO880zTmodGUQx1aTtHpgBxW25blciXNu2wtjifGUjr9Snmi7zFKbDE+F3Tr9YqubXna7+n7gVPSYdc2lGWRk2OHbFfVGHNqurkMLhal6263E/v6YpnVWhl6qeRae+fFtp5ZK4uuw2gjlgQlAR5Ka/6L//l//v/VNea/zdf/4b/+3woo+3CUYZ8tpcGZwyhsIXvTNM84F9j3Qx5EWLq65OXlShQlx4EQYQ7QlJaLRc1xnLh9FOBvVde56erPQxXhFoWz+swY+e72x56n3VFSv2yJVRFDFMD/ouNpf2R/7HPqreYwTIyz42LVsWhrTrfVnPf7KqtxHnYDw+yoq0oA+lWFNVoK6hi42iwoCsu7uz3DJOBuqzXLrkQr+LgVXublqsNqJYqHBMlIkISofQLvH3b4ELHZPtouViRgnETlXhoojGHRSjDE0/4glmudhzxKbL4+6ayKl7pqchI00bXyTErqoljqNAJk9054oXVd0TYNbV2yaGt+uH3k23f3rJcLLpYdhoRRkdFFJp8orMJYzTDOTNk6nSLcXKxYdw33u57DOEP0QDzbmC82G+qq4nH7xDiN+CjrUWll3d4saqzR7PqR2UmjUSnF9bqjsJp5FDX/7fbAHCSsRGkt1t9sw9AqUSqx8FCUxJjo+zGrz4LAwOv6NLFBay2HHwVFbpLPUViV0UdCUsxJixorOFGAIjytoijyPmvw2UpeliVN21AaRWW1BLr0UhMmEpWCSicO48xxmqmalrJqxAbpA8u2pq1Lhmlmmr3cr87z8nLFuqv5+PDE4TjIoFZrinxtpZeqaGupXz88CpOsKzLWoG5BGXZ95v21NdYaeWa05qaTYcB395Jmt2qEw/m//F/9l/+drjn/vl7/9f/+f0cIkd1hJEW5h0Pwor4sLM+fPWP2nne3H5hnJ4nWuQF8eXnBn/2DPxV8yfZIP/R8fLhjsej47LNX3N/f8+u/+TV12bBZXaE1aAPj0HM4bGkXS9aXV+SWKItuw3p9zce7j3z48I6575n6nourZ1xc3bDadKzWDR/e3XL38Y66rqjKkofHLfvDkV/98a94/fo12+2WY39kOI64ycuzraGfJlzwLBZLyrKitGJ//d0Pv2MYBv7BP/h7rFcr/uV/8xc8bnd03YKyqnj9+gvKouDNux8JYeb1y2cURcHTThiOKUzEFHCjNPe/+/5HYopcXiwpq4Ju2crePMxYa7m82WC0RatCLPnHo4RB9UNmRC4yO2jKz5fgRPphoulqrq43xOjxbqQsGtpmTUwBH50kM86RtmtYrNpsF9a8ffeR7394z2q1YL1a5caTZr974rDfs7lcsVwvcvhAEreNi2LjtYb3t7fsdk+sFkuauqZp5GxiS6nFhkEUqtvdI/M8UZWSnnx5IWfnw0HqhjjKSnH97BJTGO4fd0zzzHEvXM3Faom1hqoQ/IGtrTT9xigq4cYwTTM/fPejWOTaUzplgXeOh/sti8WCP/rlN5iiAK2ZnWf/dMhNNc3xcOT2wwcJFTBiR/OzEz5rJSFBdVVy6Acen/Y8e3bFF5+/zPWmZp5kADD0R/r+SFGWFFVJ8OA9+HnAu+GsOr++umS9WnJ398hufyCSSCrx8sVLVqsVf/s3v+Hu4x3dqqOsCg67HW6aqesF1pYUlQS4fPxwxzROrC8vKcqS4AVCL4mz6fz3pozE+eUv/4iqLNl+FNj4arPEGMP/7D/7z/6d68IfrHgac3IOWqJDl0tJpOjnCaOgbVqcm9kb6cCGbL0zeXMK3mOsZb1cAvAh29IKKzHvxIB3M8deYmtdqKTRMk3ojWa5WosaYZbEoJhOU7ZJwN/TyHq1YLkQlVFVWCR+XIqzCAKM9oFT9Lc0EoJsotaeVUCnaHJjComhz0qs2Qk3ylhDVZaM08z+2FNbTVnYDHK1uNxU8c6RQpAFyTkWhXS6RVKXzpM5cpFXllJQHvsZW1g2pRxMfEwYLE1d048jT8cBldI5qlgh6gcXIsM087Q/CPdinCit2CWMhkJna46LzPOYI2Fl2hlSFG7HNNNPjqoqBTztZmbvsVbnCYAcMEtrsXXN7I94N1MsOrq25Y17z+PTE7OXBCMVI6mOXGwSVSEHBJFiyzUajgdS8Lx8dkNVlPh5JAVHP4gEdRMCyspk1jnPOM1ywLAWawzD3pG8QxlRFZgERkkhdPp+QwzieVXk5p0c+BNJGAfe0WegfGEFoDY7uT+tNiRFpvoH+tlTKM7+fl1Is88Hz+xmhmlCBX8a7KIUct/MPU1dU1c1Y+7UXyxXtE3Ddhw4Ho8iGQ6SQmaMZU4QEHVCgswxEIZQTIlhGMW2ow3KiGQ0ZmWMUpoIhAQ+T69D5qkcJw9Ks1wIyNgYmW7WtdgFrjcbSez7ibxO0F1TSBdfK01UmTeSZdc6TzBBYZMUgzoIs+SUhFPng5kc2BNlJclFJqcbyqRXpkGmKDD2k8JQzs85jSrzdabciIhJJuZ1TqArbcE09hI7LuM9vJvz52gpbIEPM8HLpDqGQFQyNVP6U7qHLUqCk0JPGBZiK7HWSlrZ8YC2xXkabc+8HnK8uMaHQIoJVZWZIyNrjnNeJl+ZVWWz/QonZd5JGUhKGKVpmlaaGk4+k7EWkzl1Idu/xnFkvxOY+WK5RC7miWUnYOSyFNVPjIlkMudASXPCOy8WVxoKW3xKQSMnZZ3/fDoXMyHMZ+Dy0PeieFQ+qx0qtBVVVFVWHPtjbpRIY2boe2KUFDxTGspKuB3uUZo9VU5RSl44WcELl64oy7zOJAGc5+tqjDmn46h5RmJt05n7Mmd14jw7Ts84CFD5fLDLyk+tRSlJSgxDFF7GIPtGqmtC8MzTjMr724mNlVKCFM+wXufECloWoqY8MclMIemdbpqZnTQ3RfUnf17nZBmV1VHOOcZppFYKqwpSVsi5zLuac6z7SdWUkjRWY1ZZlYVFkVkGQVJRrbXQLYT9lC2kTbf4aTFSkL2IlChO19TabOmaxfpvRP0VjTSKSquzqkg4JieeUFNXTC4yeuENlVYzGVFqxij7f0xJVINaYzRoIkals6qKrBb1MUloho6gBUjdlgVNVUrtpaTBgxbl3uwc/TCyWbbSWJ88c4iECDFzVkIWdCpELSfNLlE67YOkkRojtZYLkXEOqARYUa+YDKmSBrfUKy6ra6w5Kb1F8SXjPFk/jJLCO8bEYXRYDe2ywloj6waKprL4mBhdApVIRsl6m6SmckFUR9MciKUEB5ywAFrL9TfaYExBCI7Z+bOa77SuhpgYZ886STiKrO0xI2wiSsl3aYxwvKZZFF46K/VDgnHyxOQhCf9KVGIqc7cC4+yQdpvKDSFkwKlFAWe04nE/ZyVtwCZRfthkZdjhI3Wda8GsOlfKoFRCE6Q5pBVBIfaavB6EKCEJ1hjaRpqJdWFIJ+U9siaHFDPTSaM1wldSoqCdfKQsFEVBrqF95oWJqmicPWQV2EmO5nxgdAFdaRojYSD9OGGrBltYxtmd18+qqrLVJZ4T/1SuE2bnGOeZohLurA8Rwon9B21T5FRAWTe9DyStKFJCcHYS4nOcPHoOVJWmzPZSrUSBZTQs24rS/HTWr3EYSCisKVCFoqmNOGEOTyiN7LFe3BMxBuY8zEliZ0Ep4VAu1wt8dBKY1FS0bcPhIFy3EAJ9LyEVSQVicMINswVdt8D7mXmWQXYISexB+x1hmgnjhLWG9WbFYlnRtiWoxDiNoqRSYkcdZ+Hs1pXsnX1/JPgozpTJyZ6pha9kjBKGkc1NjdnJ0MUYEVQcjjw+bLG2pihqSltQ5doPZC0JKTCOokY3+qTaycnyII2A7PywhSGGyDhMlJUoo4yxEMQ9Uzdile/3PVHFcxNXadnLx2lmHCeeno4SZFWXGENW3dRsLjb44JjdyHAcGY8yWNJGI0pa+Xy7px1tU1OWknI+z/I9CFO0pC5rYv5feOqZRk9XNDRNzTw7tts9wXnGqkJdXmKUpus6irLgcOjpx/F8dusfxZWwWi2oTZWb2IqPD1uCiyw3LQVFToGe6PsjWmuumxvKssANIylC0ZQooykq2bOMAaUVPqs2rbUorRiGMTe5JdykyOFV+6MMg4qyIKbINAvTuihMtlJLIv1w6KnKEqskCZuUmGePD8Kz7IeRqiioy1JCdwrF3m1FoLNcsLSKeU5MUxR2VGnpjwPjODIvW2Ks0UaeFax8hqquKMuKeZ7ZHw6UbYktJRim73u0KlHJgIqAnCNOaxfa46ZZmsX5fPP49ChniMJkxbqsmW3XopXi5csXFOW/Z8bT29sH6rLgy5cvaNua1WLB7BzvvWxQR56kq1yXTBqGcaQsK549f45WcHv3nq5d8PLVa1KMrBcyXf3r33yPUolnz58xO9kUirriYr2iyRProqx4fDrgvcPNI3cPj8yzp25aLi6v2awWJH/BcrliuVrztN3y9u1b9scjx37g5csXXF9f03YrxnHmw/2WH99/ZLVoqeuKFBXWyhc0TSMhiqqlXW4oq4Zvv/2Wp6cndPIUVcnsAv0g8b2F1XTLJWVZEP3IFGdmDz7CcSfT/1/97Gu0NtzdPxJj4vl6KQsKYktoF/Lv3/34Nh+UFF3b8vJKHvh372/Ph926qvj61Y1M0CeXD2GRYRjY7x5Yti2//PKP+fiw5f/5z/45N9fX/OoXv6C0hiJbfLTVXOpLmlrSmD7efmAcB47HXtgtwWGUwhYVoZ8Ypoh2M0o5TFFhbMlqsaBrG0z5QH3YC6guJpbrS5KtuVzUNJVld3Q8zZHlHFFlZNk21IXm8XHHMI4cnx6Z84TbJc3xOOGdo6g7amsxRYUyBU23oKqDJDrFxHDY04fAcJAo0ouLtVgDR0mG+qu//Q1KKapaJu4i9gcPFHXLVxeXaKP5zW/+hsKKCsBrx2EaiBFClMP1MPSgRBLdNA0vb25Q2qKMRIt776jLClcvuX/c8f3bf8qiLtl0DUVZU1YN0/GJh+0jVxeXtG3LatlR1yV93/Pu9h3GWJr1huMcOHzcsmhrmqpiHicm59g8v2G9XPDx4ZGjCkQ341Tk8y++wFrLbveEczPPb25o24511+GdY3fs8T5wvbZiKXUrOexaOUAe9jvCPLF9fKSqK9rlSg5zxhDyYf6n8IqmxBrDcrkUsGyQBvbWzbmTLzyIsm6xIWBsbuh4QCkOhwPWFpRVTdXULFcXhAx7NMawWi4FJLnbUVUVi0Unh6msAJpcwM8j0zBkCLmjrCq6hfBHtJJDoSIxDj3HXEjNztO0HU3TSeqHG7l/eORh+0TbLcQ6WkWsNdKESpEqx9MX2Y9/93DHsT+KvLmuz+ljAgg2+eAFbp7xztOPophiu6MsC55fX2O04Zg5A8vVmtrNHI8H4UzFgHMCzZc2ukbHyH5/zHatk13XUxSWq1Pi29NO+HaFJWiNI7FpGl6+esluv+d3330nUuaba4rCnpsebpbUmIuLDUM/cDzuGYce52aGsScZmxO3BGTuncsRxZp+nEjmiI4elQLBS1Olzlyn01raLjrKqmK/24lFsJFkUHJDrW0a4VrNM26KHPbyHgqbFarBURpN03ZiqTTSgFJGmk193zMMIw+9XKP15kKm4FrSAO/uH0gk1puLc8EJELLF6tn1FSjF6D0F0NV1bh6InXOYJpTKKk1kOlWUJd1C7n+brcfdcp2VgLDf7/jhhx9ZdB3r9Uret5WI6+MgvK7GWJpWUpvmSQYXKUlT6Gn7yOPDnTxfSgIqnPNUz59RtzV1LdDObrmiLOuzVXWYBKC+WnQSeJGtp+MszbqikERAnxtUq5WkQc2zNKTmeSRGT7eQtcuoT+qon8pru+uzEk6aIWVV47xnu5O0TmUtRkNbGoLVwuJJkRQcRkUGFyisZbMUhYdCAlceDmLBFy5bAOfOyk2rxa4VUYQILkOikzIkYwkuYq2mq0q6tqUopBnST1Lk9rPHR1iUBYsMRE0+sNsd2O2PdN2CqhRbXoiRwUnT2qrEolA0lTQ298fxbAdUSoaHMPN0HNj3E9VmIQ2mmHARBg/THHlzu6UqDF+8uMIWlm0vzJ4yW38XCyWHI+8IKTH1MkE2QFkUbFYbIHHIqWOYkkVb8dXVhnmauft4R0JRmlLe25joKs3yquIwOj48HKiqgvVSWGXKWFFGRU9b17kRH+ldZDcO/HDfM82ezXKBUTAc9hxnz3EKaMnTpGlbai18zUVdSRBJSAzzzI8f7xnHGUtgvWqoq4KH3YFhmhinWYIbrJE/lxt+OgmjahqnbK0XpLg2BWhwIQHyM1KCVzeb3JzLatHspYsZSj74/F32RwmgaBtRiA4uDyAChYEuD2weHx7RxlC3i8yJDbJvmjKrBGYJEKgqUUJFn2PT49nGa7SlMJrtYeT9h0eshsIkiTJva8IU6YeB0nTUbUu3KmkXC1Gn9T2FhrItSCmyH0bcOOFmqQusFiTF6APj7Bknz6LraNs6H9IiRSEhG11dYoziaiOMq8P+IOmwWlMVmvZqQ0Ix5gCLoe/xSrFvL7BWmlAK6JqG8ic09Ds8HjFWs7xsKeuSy4tLxmniYXtPTIl9v8fagq9ef8E0zXz4cCuDu1JUvu8+CHvx+fUNkRUX189IKfFXf/t3qKT4/PXXjH3P0+MjdVuz2mxIAYJL1E2DiSXzFJh2ie3dO/rp79AamtpSdjWVsdw8u2K5XnI4HLj9+MjHux3HwbHeXHB1dYEtShbLJe/efeTtu3uaSlMUSoYvlcWPAiNvKlFGl7mR+6/+9b/m4X7Lcrmga5YcDyOkp7PKWtjZkXHcEUOJVRUow/3HHms0X3z+EqXgt9/9Bh88189ucM7x4fEd3oEpCkJSfHj/KBb10QEGpUqcj9zdfcQ7OTM3TcNXX38FJKZ5wsdAU0TmWeFxLDYt3/zqc27f3/Ev/8W/5Obmhj/+1S9RaIZxJ9gEbegWLU3X4OeZh48PTNPEOAw8Pe2I3kEEqyq2u4/cPdxhtcVoQ38cUcrQtAVlZWlKi8oDAVJi0S24vkq8fHHDctlx+/aWtw8fqKqaum1YrVdSR+wrpnHifrxjmibevr+lqB5pi1qGopXGlBqfAgRFU0sg1M2zS0AxDEf2Oy/WSqP5rHwpQhc342bHw90WlOL65vmZ5aeUwpYdjVFcXq9JIfHb33xHVVVcXG9wIbDb7wXhMjtIUOgWTYA403UrXt98hjKgLShkOFxVI5VVHHcH/sUPH1hvVlzdXAoypSoZJ493CqMr2mZJtxAo+e2H93y8+0hpLVW54P7+wMd7qdettfg+O5uuPNgIykGcKLWhK1rWX/8SpTSHwx7vPJvLFWVV8uL5S2KI3D/umF3g6sUl1hrGeSQET9VVOWVYkB27rTCeNqs1ZVGAjoT4h1nt/uDGk4+JkHISR/bnh8wKELCl/zRBMiIXPUnLYvDs+70U5kjUt0TrSlFbVwXrrgM1cuwHFFLMxljRNB0RBCoZJAFhGEYOxyMm+2d1ASaKdFcpiRGXDqVMkwWSWuOD2AIen3Y87XeSbmbkJlDIn/PeyYaWp+zik505Ho60tcUam+0kLndIs080CfckKojJEiOMs0gfu6bBWsvdw45IEA+nMdI9jxFtZVp1SnjQSuF9gQ/iF57ylJck3ce6KokJ5qjE2xtcZiUESmPYLJfs9gf2h0OOYo+Z75TTl0gYI0lO4yQHtilPrlOSCarNiVVanw0jaKXloBKSKEVsIYqhshDuidIUZUUdoa4LmtKw6z0uJuasuLDGYJD7IAU54KcTryXG831WZJvOKalBa3OehJ7S5oKTYvKUwXJizoQQmKYpM6ZkIv6JxyBqqbYVBca+PxDLkrZpz4e8GCFGdWZGaJVQRmGNomtqIhKjqwGbwtmW45xnd9ijYkttDdrkxKuUsq9YihWjNVVZ0PeJ2TkqLZB85wQKDjLVTNlqdOpEKxIqxTxF1TRNQ103YrGc7VkFJsl8gWNOVqnKQqKxCykgg9Liqc8qnTHDgbtllq+HmNt0P5GX0qC0WB2VEqi9UmdWUkrCc1BZRWK1JpBIQb67Oas3i4rz33O6x6qqoiyl0RfzNTXaoBLZCiEKAud89pfLP4uy+r2Jt9zjJ26Rc+5sgzpZXgRrEJmyeqasGso622HQBC8/T5pOUgST12U3z1Sl8OjmSZRTMXFWzAjrQ2C+J4vV7ERNcbqn9secklKUpJSnu4lsg8vqBhRoRYongLtCGbkmJLmnrDVZXSNgduEtkfl6JcvlMitYJ+qTyiofMryPuOgplPjSZzPlay7AYEnfMzmO2ZCSpJuWSolKJMoabQQpScqcCPJ7OPEcTml9Mv3xxBDlvZ6/i3hWqarMuPJevmudFWqyD9rcwJHGlz1bUEQpNZ/SP0U3kJU+woICRVlVwmrKh5yYFWtlWRBJuHwgPClnU5Q1NIQoPMKcGHV639YWpBiI3p1ZEz4I0ykEGV4U1uBcc17TFOR7ImZVkzAc3Kw+qZyUYp48bhZwZlEUmRkz5fcu95rO1kiZ7Mp7LlNmshTFmV8j62WPCwFrrCgoMv/slPyoDGf1lcoqg5SvwelA/FN5zS5gjKZB1ISnSfyJZRVjZigpUYsVVrhLPohVcvYRrbMKSGusETbJnMHX1uQpbIYg6awe0orMxjglw0mTXmyhObHWaEqrzymFLoRs9wWpGXKql5ZEvdE5XIhUVaAsMysESeBLCWoF1ootXhuZPE/Oc0o8m52sf+f9NP8vZN5QTCnXUrKPFlmpp4ZwVolrEtZk8HMIJOKZfSbvVXOKNg+5sDBZkdjUtaislMr7hTonupXW0tQFY1bWS7pgVmJrA1GUp9qcFPailJ6cxLcrEoW1mYMUMrPMSzNF5WU0KVG0Wp1ZQUnYj07WKYg59tuevz+f95VTklWIjqSiXI+sllcRUFquCcLRiRGCEp4TCpr83A7Z/pwzBM6NcZWHLaf6wZyfVbm+hZZ7TWuVa6yQOVYxN5byepYbWTG/Z6M1SSW0MoB8HmNFsXe6BxOZ86UizkfKopA/lyf4PootsjCWotD02T5ojc7v89Tgl/OJCqLuCyFm1bywiLTRFNbi8z5ZFjZzGMlNeBky9NoQg+wDViuKnBrrnCMo+WwRQZdE8hqdaxB+SkO/mPJzlzAGilJS6U48P+eFHVYU4vaoqkqus8zE6fs+MynJe2jBNM0MhyNN3XC1voAYeYyyD5RlQYqaqDXWFAQvYPHoE2M/8LgXxMtqtaAuKpqywhb2jAnohymD9yU1+JQaXvnAw+Oew3Hk5mpJYWtQ4lY5Bbw0jYSmWGtIShTRu6cnurZFKS2snKwYPal7pXYXBIbKVtxpdAQrQTXacK4bbWlBgzGKGFVW0YF3n7i30siX+3bKCI95GiiKgrqpszPGoQiiKNOgjaKqSzYXK562O/peOM4Kk9X6ub7ItYTRijlKw3qaJsZxJoSEtSbXi/IdT+OIqrL6PJ0cFwZiynxKsWHLuiTXuWka2q4FwJ15cwlbiPJoGmaiidlKmNOJFRSqxGrhUsKpHgxo8ympOqE4HvaiGncOEwzeCZ8uRCdK1Nll5mgliv/sOrBFibGKulG4yXHc7uQzeU/IfYPgvPx+pCEuSlUobMGyW+CTZ47CwSptTryeJJzseOgpypJ2nKRnUdqMOuC8Jtvck5Bk5iApqNowT47JTdn2bsUaPXnmeWbOAzulTnzAgqaR1MQQPLORP1cUBVUjFcbTfsD7SFPXVFUJRliwCmmwqiQJ0tM0y0O+lrr/dGb4Q15/cOPpFz//JYrEnAK4QOsDIZHj/QwhelyMYs1QBauLG5RSPO4OBO+zd1dze3vLME7sDo8YbVhvlrRVycWy4yEl3k+Oqpzx80ShDev1mqfdlvu7W8pKGlFaz9kOkDfNvAm8e/+Bp92eZy9e8vNf/Qk+SmEl8u+C92/f8v7dW+YkrKhxnFApnm1ybz/ccTj2/Oqrz7jaLGlswijPZ882rBrL+9uPPD7tieaOqq5pm46qbvndt98yDD03FyvquuLy5hVlVRKTbCaPT0+QEncPd5JkkRwqweHYi9ceKcq++uJLQvBsn3bEGPnNt98Jg6arBaJnS5TSPOx2oAxRS7LTcJRkn9VqLZP6YaCqK/7Bn/ySoqwEQIalKBP95Hg6Dhz7gd1+fwbpbjYbvvriM2HPOM960bFZdJiUSMGxubxmvblkdjMuePaHPbunJ5qqoOuWFGUpE8q+5+BmDvuJUQlfqoiJ/XbL2PdcLlsqW2QZYuLq8gKjNcvGYk2gXHWkpAh5kVM5kneexQoXvdzsTdvRKMUiLPDec/f4BCQ2qyWLZcvXn78CYN9LDGrX1pKmVdXMbubh/gFjDC+fPWOcZr5/+04kkzpDeb0oGg7DTNNUrFYXlLVsjh/v7vn1t9/z4vqKP/r6C4ZhZLvbsug6Xr/601xsCD+h0KJem2MiJMXHx8dzokpVFFxcXjFNM+M0sG5qulXH5nJD1y142u15enpk7HdYrRmcJ0S4vrrh6vKC++2Ou4ctr55d09YV3373PT98/z2XF2sKa9ntd0yz42r9gq4Vm6cLgb/+9nthTwWB5D/tD1K8JkkF8z5bbn4iL5U3+N1uJ3wOLQXyYrXOh+YpM1QOkoZWN6QkoHnlFC5EikIKEu8cx+MBpQQ82tQlbV1JU8BYAQG60+YlLLdpdmij6RYL5nlG6ZG6rmnbhnEYGPoDUz7slFVJUVY0SqwPRHm+vZtJSjhV0rhxuGk8FxuHfmCaZpabS5arDdFPpOC5vLikaVrhJzjH7d2dWFGMyGWPo9zj5TDmpuUCrRXHw4HBTdzevpd1fLsFFFfX13JNlQGVGGaB77fZpjnnuHJTSMOqbppzE9M7x8fbD7mRIUqoGLxAZsuKFAP9Uabln716JdObmKhtwWK14dAP7MY9/faJ29tbabL4QNe1rLoFKjeru65l0Xbs9gfU3rJcLFh0rfA8nGOaBvw8UTUN6/VamEvFCdoocFsVPcuule82OA77Pe1iQdd13H38wDgMEnJRllIUKY06NQLS6SAWSD7iglifptnl5rY0q9frzdn6CXJI1lrTLpaSALTboxQ0VSUHmyCH6aQNhda01jJNE+/f/IDShrqRZLi6rrOl2hGjFytyWVIWBU9PR96+fcPV1TVfrS+YDweeHu8pC8vPf/4N8zQx9j1d03B1cZFtJQE3TXzMTLC6aYlB2DXGilWvtAZSy2K1oW47vv/udxyGkcfdkcFJXRCVHIatksQ95wPPnz+nqRs+vH/HdhzYXFxSFKUcRoPI2lECKA9RpPQ+RNbrFdYYwjwQfCCmrQST5MLsp/Sao3CW0u4gwOJc4G26UuDKEY6zZ7s/UlnFi7UoMraHUST3k6cqClxWkTnnCcCcNE1V8uKiZfKR/eDPTV43TwxDzzA5Dv0kKvflAhdgCrkBWFixnQVHPzjG2eXGb4nRARPl0L47jswhkYxFYdFWDkdu6sk9f4ZhZnaB5dWCVVtKsIPWVFYa2dFLE+379w/4mCis5nLZ5IanAImNUVRaYStLYRus0Tz1M2oUK0NKiRIZ2o3O43J4QWE0l+ulHDRiwsfIh48PEnvfliQUc0gM48SbN+9yiIE0h6Z+pLSW5aJFAYfR4RMslw2A8DbbmlVdsDvMfHjYERKEAIUV601dFVwuO/pRBq9lUVLVFU6N+JhYNBVdU5FykzrGyDTLf68ry6IuJDH6bsfTfqadXLYgy+HVzzN9DGLnKQtGHwg+YqOwqaqylKRIF8SuH+d8ENaoBHMe2A7znG1lDQo4Zpva7nGLUoqLixVtaXnVVECiH0dCSBQWClvy/GKJD5HHpwPWal6/fE4/zvzw4V6udU72I0ij0ydQKUKUwyFa83ScePdw4MXlkl99vmJ7HPjx447SGr56sZZ2doK2siwry+FomKNmPzoCR9pS0ZaaqAy6LCSJeo5cVAXLrqZci4Lutz9+4HH3xDBOKC0cPmskqKSua7azY5ojmwU0Ffzu3T2HYeL5ZkFVWOq6xJclVVVQlQZbyvr1uN0zjCNNTjh7dyd8yGVbY7TmzX3/39Eq89/O6+LVSyT0Jw8SiiMxRtbLC0l5nMS+9e7HjxgrCBfvHdvHR1ICowvmCbp6KxDwu0eU1bRNw3q14MWrK4xNfPhYoK1BG4WpSopVy3635/2bWwqTFWU6oZKmrjvWm2tKW1LZkru7Hb/57RuWmyXdquNl95zX6iVaJybv2B+PPG337J62DH3PZtkQQ8U8HnFu4sP7W/pDzz/6D/4RlxcbQJqUf/JHv+Dzz17y8faB3XbLXzwdxMLfFazWNY8PW+4jxJCom5q6bqXunPZMc+Lt7S2Q+PD+Ts5o61x7YTPTaaQsS149ew4pSWqz0ny4vUNr6CqLakq0vUApze3HW3mmtcCvH+5vAWmCRQ8hlFxcvOQ/+g//Bxgr6rxu2fH65Wc87XZ8+HDL8Tiw3R4kHMIYVpsVn335BdMwMh0HLq8uuL65ZPJHDsc9l9eXXFxspNEaI8M4stvtuby4YnO1FNSDyW4gN4p7wzvqpuLZ82v2h57jOPH82RWLpuX23Ud2uz2bi400UboGbQ1DLxxbE2Sg6cNMwpCiNDgfH+9IQGkFZdFUDTElnp52KA1tV1I3Ff/wz/+UlOBxt8MYw7Nnn6EUBD/ined46NFa8+r1c4Zx5K9/8x2FFYWstgGdEtPkeHh8kP2osqACpgjcfvjIX/z6b/ny88/5h3/+Z8zTxP39nmbR8Wf/wWdoFDpB3VY0y4rj8UjSkcNxT3grKY9lWZD8zOVqiU8yiF1tOurqgpubG1arFf/Nv/hXvH//jsNxR11VuJBYrJ9zcX3D5mLFx9s7xmHk5z//Oavlkn/1F3/Jj2/e8cUXn9E2NSoTmLu6pWtb2q5ico6//Zvv6fuRLtuNZzcLpsGJte8w7Agx8J/+T/7d68If3HgSi1NgOB4yud9lr7wU2z5vFi6IV7upa2IUWZ+kJmXZ6pS7cMHL5M5o6VLmol0UANJk1UZjrFDig3ek3/PEKyWdUq0VKsq/z/PMbr/n+tlz6qYRDkJKaPjkkQ0eWzRn5k/wjqAVSSHqAJ8nQ0aTvMOnSGnFl66VImZPZtI6x0HrMwfj1J09TfpOzAvvfU70EZCmm+YzxyKRP6tSZxXOOM3M88zheKQqLNbWOQlK2A5BIl9QKp0PbyRJBpIEqoDW0mzRJl8zTgdwUVQ4N+fv0BODJ0aZqhZIlHJps4KmEKJ/VVU0TSNxtbPAMd00Yc2Kuqo+fS+IYNs5h89cgtIa6e7OM6QmT8kzKL6uJXmksFgtSjNRuLlPzY+zEimep2s6JSmsyipbaYyoL0gorei6DhA7ovwcSZSwpbBfvPfSjTaGWSkpMBTo0opKxfuzCivkYTDkNIwQMqNpkSPahbNVFpZV2+UJbEQoS5IiV5alMMqmGVNoCm1Q6qQoI3u5NXVZCD8ry61jDIxDtoRpizIyVWnqBhAYtjUCy/POS0pHL5OalOIZ4nv+FaWhMo4jhRYGRIgJFSL9OOb7J54ex5/E65R8FELItjr578bI8ndKlHPenRWMp3XoNI3XOiuRMldJ62wIh09rl9bniYuIf/L0JQrz5qSQUagMWJbnNcUkCY9B0j2LrBAxWia8MQgDQ7glZHYOuemUOMWwhhjOFqsUhNdi8pTD+UDKqSsxBhrbyL2X1+2Qp9T2zNqJn55ZBPytUJ94WeZ036acLiV8Cx3JB3+x2Vljs6oHYVs5J0oNdZr4hfM1TFHS8RSSlqKNNEKVEvaWNKTl4DwOQ77OmlOaqFaiJDin91lztowVtmB2TqY8s6zXRZ5qyY//pIk8vYrCflLgeJcnrvb8nVZVceb/qdPIW0b2ZwUOMRFPt0TKOh9ZTCgL4WudeFon1aYkjKXze9LGyLQpqvPBivz7FDDPDm0iRRlyUp7Ovz/kwYKozvQJAJ/3oVNDMEVJ7OvaVpiEwZMyO+XE/ppm+XNFTuQ5s8tEuyp7hS4ksKCs8vemJVZ+9iR1muqrbGsUdZLN61lKCZ/j7eX9k/dIUaCevhXvBX6eojA1TopFaehqYkg/ucYTWUV3stt77861z0ldeEpQI4miR2X1D+FTCt445wllSmJpQib2wrNRqMxMs9YSvPv0TAZh12mtUTF9ugHzdU7IcMg7jy1PCvKU05qkUU5eMwqtUEmh9elZyc9EfnZMZtBFVObn5M+JEpW3D7gQWRQCxPbxE48sJVEK65Qyr07joqh5Qg7gENUW+f46qbv1meekYwKXmGZHYTVGVef3F1NknkQtipLr57Nqxp4UHEHWImsNZ4YbwpNKUVLkQkz4zAay0aCS8H2Mymm5ea+QPSMznYyRQWqImeMo7+lUqypsVg/J9fZemttlIYfUE+Db5iAFrWRfNFmNpY1G+YRSIT/ROTGVzA9LWRCnThX/p2uo0umKyr5VV7JmDhkLK0yqU0CLx8eAjqJaNU6UXSmrjuSGCNJshMwyiyitziENowv4PDRLCZz3lIWhqQtR+kVxZmhFVvmJOtd5TzCGGJUwHpUMOE/hLFaJItfmNNuYWX5KfVo/T+ywk9pE2FZJ1GmzJDfb/HPPZ5v8OqVGee9JlTBiJKFP0WbwuptdrjV/Gq+qESbSOPZEJ2lkAMaICmYcI/MkoUFVWbHZrEWtkmtQlRVr0yRqlBOX7NP+E4WhltPHTmmZtrQkBZMTBUpZqlyTSd1VlhWFKTCmYJ4du+2OsilZKLF8V0WJc5OEFkU5VxijKUpxdqSkcC5I6EtO7JbUL4ubR4L3NI2klT/eP4l9fBIcQdUu0dqcB9w+iPLxxDOMKWT2mazBbpaz9jzOeTBQovJZpLCiziElpqoU9t48i0K2kdpEl6XUik5CB4jiNvL53pOkYGkuW2NZrVaiAlUeY6R20vlc6WbPNM6yvhXCwy3KAkJC5WAnnZ/1k5KmrCRdL3rPNDmGYWS9EtUSZ8W3/HJuRo2aylpMUXKcJqZpzmp5y0nZXdc1Td1Q1RVKa9yU+xGftpVzrZSSOjuGYoael5Xcf34IWdkoqvKmkb4Fuwho+fuBKc0En3EHVpR74yzilVjk+v/3XEHCrtRYq7KKXviCx8ORaZ6kb6FkXyvLktV6gZ8ccy/PxykV2Fq5T8ZxBEqMlmfCGksILoO+C7quoa4ryjL3NaJnOA640VG2HbasKKoyC2ICzs+UZUHbdsQQRfwwTud9pyjM2QWgtcFosVw7F3BqFp6kKkkpcDxKs3zfH4Rz+we8/uDGk5kPRO/pd1tICj9OpJQYxyPeew79LBT3qmbRdlxfXeP9zN39LZUtqBcd2hgiGqUty7bDecfjwz0PKfEmShThs2c3tE1D03UobdG2pOk6utVapLPBiyVjvWGxXNJ1LZqEIfJ0HLHFgX4YuL19lxM3cwGeIpvNBS+ev6CsG2xZ8Ob73/Fw91EKo6R5dn3D8xtF1dQMzvH2hzcc+oGLiyuqsma5XFBVJU3TZY/jA8F7Xr94RmkN19c51W6cCG5EI7aNphZvZG3ApUTSCmUMm6VMORadcFmikYSYFy9q5nnm/uFOZIBYvIsMuy11XfP8+TNpfuwPmOBpqgLnAodhkqKFyDyOfPx4z83lFV++fo2PiYMPOBUl+eDighc319zd3/P27XvevfvAuw93WC2JHc+evyC9eMkQIBYNj/sju+PI4/YxM4Uc3ns+e/UZc1T5QB6Z3URZGA7HkXme+frLr7hYb9hv75mn4Qz5XK9W1HVD1zbCcKkqtNL048jsZp7u7pmdo25bytISkiEq6BZC2//2u+9ICX7+i5+zWW74+puf4+aZv/2rf8Puac/baocGxsNRpPZ6w+wD729/FJbX0OOU5r33hBipbe5GJPks4yApJIWGod/zt9t7vvjsM7752VeMIfHyfstitWQMgbZr+PkXryFGpsOWMUSOLlBqRWUU2lgu2oan3Uw/HND1BfViw8PjI9vtfQawysaYjOZhuyM8bNEknl1tsqVJCq6QEil65rmnKTWagrvbD9ylSFlVXF7f8Jvf/pZhGPjv/wf/mKuLDe8/3LJ72hGURB0nNwsgXeVncbVBa8XH+wdiimzW658UXLxbSKDBCZb8cP8RErTdgpgSx2N/PmhbbQXKrKAspWg/NQv8PKO0YrFcnhvDAngXsGVVWqqqoVsus99b2BkheIJPuJSYppFxGGjbBqUtddNQWEM/ThzHGSZhLZ0jaZNMpbu2ZW0tRd1iS0kqnOeJeRBOS2ELilMkfYps93tJxdhL2kezWFM2HcVUEU4W1wQ3V1di+TsfZ9QZyH1qDAsfSey+42GPsYaLzQalNSHJYW52smHWlViwjuNMBJoUSCHljTOxWK7x3nE89iitabqO6D3DcYctCrRZ5mJfeBc3Nzf0fc+Pb36Ug0+SQ0XbVJxCGoah53DcUxbCMtrt9uz3B7ElGUs/jIzjSN/3jOOQY52dHNb7XopQa0nB0dUltihJpqSphKmz2z4wT6M097VlsViKDTs3nJwPxBTPzWI3zSJ3T6c0ENDasF4vUQqe9kdp/tUVVVmw2WwIURS7zjuZ8CuBkFtjKYzBB8/T/pjvUznYxrohAZc3zyA3G1BKuDXZqiP/DGgbqYxi2Ta8eP6CtuuY3UxVFrx68Twf8KQAm+eZx0dh72kjU7YQSnSItMs1F1c3klZzPOQkwJGbq2sWqzWzm+l7AX8uFpLaY2wh4OroM6OoYkW2Uc0TLgSqpkEby+3790zzzGevXrJeLXncPkljTcvRti4twWjuPn6ABFeXl2hjORwOIskvf3qKp02dreJa4PHOOxniZUvX0AvAt7YVTWEpbIk2kc1S7gqMJsXIvu/R2lBVlaTdx8A4BX6cRTkZQqQuS+pClDhqKVzFtm3P+ASFDLtkKhpQGCAPTLQm5FALYwuMKUkxkKJntWiwZSVW8ZTOQ7qHfU8/OjaLlqay1GWBj4q7naTW1U2NLWsGN+CB55crrNY89jNzTFxnhYktcijCOJ8THWOCVuUEtiJHkTuxHWxWjQx6CrFNP2z3xBiwWhrxpRFLfFRigZ6HnrIoWF+shK85B8ws9gqTrQ8JQJncj4u0lWXTdviYuH06EL3joimxVUVZNwyz5zjMPB4mPjzsKQtpwkpcnqwDALvjyNNRBoXeeQGFaIHErurMwbRWWIGlZRpHwjTw7OaKrm055FSrrimpypLgZmajKK009WI+LNUWUtLoqPE+sd33JKBtW8rC0tbCXvr2x/d4H7hYL6gryzdfvSSmxNv7fQaIS+MFU1JYaK0cWn/35gOkRG0UKXhuH3b4mFivVqDAiz+YqEXZOwUBjQc/0TYVF11FjBKmUFrNm/sjWiHp0VoTk6GfHftxpik0YyFKl5+9WDPnpnZpxIg7uMjgPdHNRD/T92DwhJ3A7oN3rLoSkoYEPpAHeTKQauuSwmrc7Dg6x9VmzXK54u2He8bpiV98+YJFVzMej0xDoJilibruKprSsJ8iMSS6qpThdZDG2DwdM0flp/GqjWKO4OeZGAMPYcJoQ2la/JzY7WUwMc0jRaFpFxUpliiuUEBVGJS2jJMjolhfbvDOM+wGjtsD3//2e6q64vrmhrZtWa9X52F8V1uuLleE4Jn8jLJGVMttR1c3+R2msz3IjSP90xPjqamVg1S6Zcf6csly8UfUVcP9x3t2Tzv64Ujf97x8/Rlt29G0Cw7Hkd/85m/YPj6yvtgI83O1omk7Qalkfud4nHj56oq6qekWNUYbxnHG+5jh4IaL1QIUrC4WWaH0gaqs+aOv/4iiqrCVDAIfH4Ubtbq+JMZIfxwE59FUBO/Z3T/Stg2ff/k5Y9/z4/ffESNcrC/ESjo7OdsfHxiPE9uHPdc3V3zzy2+Y55kffnyLcx5b1FxellxdLrm/v+PtuzfsD/e8fftGlGZasdqvWe82HPY9ypTs9keGYaA/9oz9SN9PjIMjBss0JwbXM/kJPzmqpjnX0199+QUXmw277RPzPNM1NU1dsb5YYUrDzeU1dVlzOO5x84jNQ7xpkFRPY2qM1UzHIykmLtdXxBj5m7/9O0LwfP75ZyyWC37+i1/hvOf/9a/+Ndv7LcedNIVC8tR1JarcCNvHA26eGQZRrY3TRAKeX19KH2R6kmagqoh4korMzjOMI1XdsFyveDYHvvl6ZLVouL17j7aWX/7xL6QRNI08bXc83D2wXCxYHVdYY/ni9efs9nuedjvaxQU3N9fc3T6wv9tiSktV1HSLDcuLJbd3d/z2t78FDV9+/VVGC+XBD2J3VTqy6BqMVjzcPXDYHmnLmmeX1/zm198yjRP/8B//MZuLJfcfH7m7/0BIAkrXURiJjw/3aKX45ue/wBYFb9/9mBNnr8UO+ge8/uDGU/Az0QeIURLl5hlI8u8hyMFCa8qiEo+itYB4eTUy3SBPGFCKsihyHGCOep4cLYqFMXkymxkOpwSWshRLLTKJtkVBVUkkqc6dbJ1jsL2T1AFJi9C5+ImUqzXL1ZqyKs/sDfH3i0qpKAsKa+RAFRPjPDOMI+00I8kdMhHpGoHIHY57Qgi0qyVNLekBxhiGacoTEvGPf+q8RjilEiiEo2Q0VWlBSYpZgk9deyMdXvK0L4aQI7elCxq9E1vHabrOSamcPenhUxy2dIF1VkvIBO2UpGCMSMydm4lKEZDEp+Mw4Lwk08SUiN5lALuwVU5TwHSasjmBP9qqZBhHlNbnmNvpWBC9qCbkFsgJXNbmIvWUrjWjlNg7fE5LgnRWBRSFTKNOMdzeyXS+qWus1sRsQzrmSOnkBfAeYpRUur7P0/682ThPQiDxpJxUlyeNuYdNCJwbbSHD5uoqJ1Plqb8wN2TD8z7mw56hMMKC0pmF4L2XKXNVndVppbWUlXCyUhLlnRSy+XPney8qn9MQ5TNqJYqt49ALkL1dZHWLZ5ymfG+JHXOcZoI+qW+ER6ELkdgLFFk24VPkvfkJJav8fspVjCZP1zmrVFzmgVRVkVVJmd9hLMKNiYQT4waNsidVCdn2MKO1OvNojDHCmsnqAFGWSBzpmROUuU6yPsrkV2mXp+YBpTOnKf/ZU4x0WRYUZXFOxDutJTq/55Ri9pxLoS3NB7nnzofOaDNnSFgYVVUSs8rFe0lO0Urle1tepwmj96K+Oil1bF6LfJDkLWs0npOiRT7/SW2qlTqnXpyS9LTSZ6ZHQuC0p2QzrTXGyoFynufMFypQv/ecouTvDiEQjNh7TslVNjP6UgiZcyKNmJiv20lBGXIK5SkdShsjsel5gspp6p9//ydx1ClZLny6z9TvKzjkyzmpdwprz/9fCPG8hsqjJ1PzeXYQvLBEyvJ8j4WQbewpCfQ5itJL2FifeBF5F8i/5HVKJDt9zqqqzgwrpURRlXw4XxuUOjPMykrSedJJeaB0bhCKCo2sYiL/iiGKWgZRFBotqbVRn0h88rKFxUThffkgE01jTwmH7nzPndK1UpIreVJwkusDnZutp/f3U7IIn17mJC3JSsTgRMkdzvev7EmlEZ5MRA5NZSEKaYfcDS5ELDkJN0liXYrSEE+5jgvmtD7KfaCN7LknZa/Wea1JCtFunvY/jZbwG2LivA6GFM81TVlYdIqikEmJOX5S3VmrKXMKZEyioHc+UOV1OiaB4NdlQWUN20EU0WUhluaoTpNlfb6vQe4RlU6q0HRWrmjAamhKi/MqK0Ylwe90GD2LGJELqMgqwwRap/PUGjivKSHXx6e0PKNzAmCIGJTwFgtLURb4CEYH5iRsR5OfqdOgQythEs1B1uUQYlZuyTAiZAVr0vbM76pKi/KSsiU80IJxFJX2SW14ImKe1uC8Ap2ZSEYpqQPzWqe1qKoqa/CQLcs+P5eWqiqyRS+e0+WM0ZnDktXGMTGOM1pDY2Vdm30gKUliivn3QN6XFZzUlCF/f6REYTSLpsjK8ygsMiPXS1SeotQNAUJWsxVZjTa7iMZkpWjen4hndajslZzvE2MMZ7kqhpSUDKBOvCxjxEGQArYo870nbDWptk/qswjmk1K4BGwIxCQMRaM1PuV7KApP8KfyikFSwrXOa0MIqKRQgsDJzRaX96GspDVyXtQqoy9ABjJJzn4n9eU8z+x2e5YoLq6y+lgJezhm5XRVlswuEaLKVnYrCWgnxlJOYLVG1N9umoQFqg3KCFKgKAqarmKxXNI2HdvHLSFKmAsKqqqmbTtQWmrtcWIYB+qpPdd51hZUTU1KiWmYcDHQtA1d12DsaQ2R797muuOUaHx6Hpx3WCOq4rqusa3BzTPb7U6UhdbC6WyT94xEvuYgLiTvshBDnRV8YoGGeRxF1R89iZhZbKK2ibmO1UZhtUHE+OGsdCVIY8P2co2dC+dgGZ+h23MG66f0iT0n7psJowymLPIZV0JFyqzgIcaMI1BnBezpV0yRkIJ8X0itKJ8tD261Rqkk+IEg6cnz7HJac6SoClAQcwrf8djnPU8RvBW+a4Q586bk7xflqmANZJA7TJMgJmyBtTJg84gaOeazuNaiKreFwbmJolAUpiL6mNmc4Vy3e+cptckICEk0VlrnHoPUbsZYqrqS7x2VHS8CcS/LEh0yn8+5zNGTn2GspSorGYrPspaVtmCeZoZ+QGnkPXrpf4RkSZFz8ndRFBitqKoq14YpJ4FaSlv+QevCH9x4en+/xeRkKGMLVN3JGyGy3+/53Zv32KLk2fOXNFXFcRQrRNutiTHRB4mG9W6kKksuNle03tO0C4Zh4GG7JaTI/f0ddVUwjzv6ObDrHV1ds1l253K6a1vWWVUQ3UzUiqAlkrSyivH4xHB45OLqGZuLK0RnFamrEmM026cdwzix3R2ZXKQu5GJ6LxBgo2pSYXj24iVXMfD2zTvef3gv09+i5D/886+5urrin//lX7PdHdhslhTW8PHxEe8dXd1RlhW2rknAx4cnpmni7kmiF7tNwiSVNyhFMp0UV6OkM+23j/gYGWNuEBUyXSmWC6wxDP2OcZrZ7va4GJi9py4LrpYdLsKH7YDVis9ePWcYBv7JP/1nXF9f87Ovv0Z5xYzA2nf9CMrw8tVnLLuG9arj9v6Jt7cPbA9H7v/6r1mtVqxWKxaLBV3bUhUFVV2zWXQs2oamramqgmmWhsuiaanKgvv7j/THA11dQAoUZUGixSvD7BNv7+45HI+8evaMtm0oZlmoop+J3kmjEk3yE3h4eXMlsHFgmicWF1cch4Hvfvie4p1l+/gIJMZpwLmZw3d/izGWzeaSALy9E3Xafi8KqBfPX6AVBCcblM4JJoPzqKbmet3hvcSExqS5US9JMfBP//k/A6XPk/umXfDjDz/wF3/xb7i+vub169coFShVYLFYCKNsu+XDwwMP2x0PT0duXpbcXN1k6GXk9csXPL+55vb2joftjmVXs1kVfPvjkY/3T1xfXbPslrQL2VDmkLh/OtDkFIOgDFPyxGzh/PzmEr9Z8P72I7ePW2YXSOoEjIeLa0na+ezmmsIaHh63+OB5/dkrTnDanxJcfByOaG1o2xZrap49e56LmIJpntnvdmitWa1WGK0JOVbex8DJEhRjxDuxuozTSFWVfPbqJdM0sdvtxFY8OawtIMnhIyAA/kUr1jitFEpnJk5ZUFlNTCXBQoNCG0N/PNAfe8qqoqobKRSCTPtcgsP9vSipomwqXdexWi7Y7yRhYrfdMhwPKCJtVeLnmlkbpmwF/vL1Z9RVxa//+q/pxyEXuonD4SBNJS0Fz4njsdsfpGj3ohoV/3zAPz5SFAWXFxux5ygpnL0TBaFW+XAUxcJXlWXeqBuxLtoS52b64x5jC9Y3r/BuZjgesFYgvrOb+fHNG5RSLBYLASCWFdunJx63T7R1xbJrUbZA24ph6OmHHjdNuGlivd7QVjWnRowtJJnwZEVqm4aqKj+1Q3JT/nTqVFmCXWT58tD3DMPA+w8fGMaBy4sLsRkjlhfb1GJf3B+kEVzVIl1vKwEPd41YREgE77h/3KK1Yvv4gFKKkLIdqa45WbHHaWafpczamDOby+RGZPKOeRC1j8sF22IhgRKTtQTvKSZFcI4f3r4/NzClEVDwtN9x+/EjJjcuIopusRSbYVFAgmmc2O+2PNzfs+g6uL4CP4MbeXZ1wWKxZPe05fb9O+q6keulJ4J4GzBaUS87jJYAhoftjsvLS+qq4uPdPf0wiCVAKZ69eClF8DQyDiPGWrqikAFUSmIVMoar6xuxAZRlbghLE6Zq2n+r0fxTeE1eItmbMtcLUVNoRVUYUfV0SzkoJ2kwP/ZitWgLy+gCD/sBlRKlSlBI2Ip49OK5vjgMI7cPR2m+GMM4e/bjKDbxwtCVBYtKErqqssgNwUhpVN47waeEi0oYTKXAn2dKohK+jZuluU2KPO0O9MNI1zYsL5aEeea4nymaBlNYNouOddcwzIIm8BnZ0FYLuqbkbt8TQ6IpNHWhuTt4XEjYfFBbZl7QNI6S8LSXw9N6UWIU3PZHCmtRVxtAmFGlEtaOD4H7p4Pw9LxDK81yuUYrGIZRmnlRLEAhGRlOpcQ4O7a7A01VcrFaMM0T373d0rYNm80aqzWl1hynmfvtnqoouF63pGVBijX9KAqoZEqCMqyXLS+qkmGeGZwj5BS7ppb4cFKAFNHRoaKj2ixAF+BHiJ6iMKL8QtSr4zji5on3d48c+pF20VIWBReLBVVhpGlF4jA5fEo0lSjyLxZ1RiEonFJsVh3j7JkDhNGjH/aS+lsYQgzcPjyhlKZtWk72GQ3UVprvtq4RkLnOzTxh6wkjTFPagiIkQGozo+Rgc/fwRFdXfPVsTUgKFzXv7rf8mx/es1623FyssUQuTKCoK8pmIYetGNiNno+PPV+9uOT68hJ7HDDHEaUalGrkjOICy9LSFIa7Q2Tw6VwFFVWNUbA7HNnuD2wWC6qioHfS/Cuj8E5+/voGlWB/7Hl/6ElarPtuFLtrRIatP3/dUhjDMDl8iDz1M0EpdCvX7Kfy+uG777GF5er5Cq0NbpbGYllVhO0THz78FmM0X//sc+q6oc9MVoyA2J92x/MQpygL2lVHW7dcPr+RZNw3Hmsth93IPHjmYcxp1BJO0rUNTVUSU0fdNjTLTkD68TSw0qxWCxSJ/X7P7Yd7Xrx4ycXVM6KKRCKr1ZKubdk/7fn47o6PHz+y2+9pGklb8y7weP9IjFA3Na9ff8bLl894+/Y9dx/v0Mg+9T/6H/8Pubq65P/yf/1/cP/wyMXmirqpePPmjQx5mgpjDZvFEoXm9vaRaZy4e/9ECJ4XL28wRcn7u1uKwrJc1gAC1U6K4SDKxsPxiDYKlOA7Vss1XddhKDG6pmyWDP3A9v4jbdvx8tkrjkPP+zcfKKuai6sr+mHi//5P/indsuHyei1ndy8Mzt3TE2VZ8PkXX3Jx+YxnN694++4dP/zwA+Nx4vj0nm7R0i1a2m5B2zY8NTsO+wNNK5aw5WpN23SEcEEKntmP+ODQGT+yXG0yUqTFYhlHzzAduXu/Zfe0Yz46qrpEWwGKt5U07WOSxllhC5q6YtM1GKNZLdbMs2O5WHE89GwfRo6HwGH4K8ROVtDUNnOWFNaWhAA/vvkAgM5N4ouLZygFERnQ16WssS4Fmrrh2c1z5nFk0QkE/3gciAn+4i+/RREpiigWbpO4+/iRH398YLPZ8PzZDVW54PnzGluKpXOeZw6PB969v+Xt21ueP3vOZr3ksD9w6I88e3nFxc2Ghw/3vP3hB9bLJVc/+wXffvc9t3f3rJYb6rqhrQuUivT7kfHoWa+XdJs1h6ejYFfmgeAdn3/5nJgSH+933D0cSCGSkoEoQ79uUVKWHf/Rf/yPqeqa4/GIc46v1deEGChL+29Zi/8/vf7wVLvf8+kba8QelCdnOXKAE+Mnxcg0CZ2dzCE5TYOmHJGqjMWgKAvxa5dlKQyQecYHde6SjsNAqRUp1vkwl/JkXZF8wgVHiIqgZFpjjUxCYhCptC0KTIoIOYhzl3WaBEKms7f81A08pbgkRImjk/hhx2mkKGq0tlmpI+yUoiiEeG9U7liGPD1X50nsSW1zmuZLkoOmyMwelzvSonQR/pKPiYgl5GtvlMKelBOZMyOKMfhEwMjJCFo89U1dME0Tx2FgOU1nwFvMsvoQAlaLJ79rW1aLBU+HkaQ0MWWlBBIrW1qTVT4m/5mKZdtS1gVFYaQoOk0PrD2n4py69qdkvNl5AXhmG8gpjcEHj44CE5dixBAzI+I0vSvK4qyYqpsGHyPT4YngHbunp7NaxRhznuKGEMF74jDI9xMixe95d+fT74vh7Lc1JAodmUj0MYpdsqoZhp79/kBZVSxWa7QW9pjzAm52XqxwKGHliEKlykqmBEq68JCns7mDXBZF5r2YPGHMnIsorIkEmWMlX7Uk2CQoT4lo+cAMImWvKpI1jEHsjzoXPykr+6qmpiwKFm2D1YqdkSKwrCXm3M0zMf1hXt3/f3jFzHDg/N3IsqeNPnuaxeqo/i0ljMv2sRMb5+T1l6iJQhKCQsi8oyDngGztJQmDLP2elDtFkVGXVYXRn/g1Ias0zIkhYU1+b0agSdlCJc0vxzxNUtBqk6fWn+6pECQBShudf66wkST9UppfNqd2msxlOqWD+eCFgZCn0AoYRmlYnWrhU0JGiBGTn134pAaCPLlNkRhlCqMz10plvgIITy74bO5T0nTTwZwbdJLYFEXibc3Z1qb1700C83NiihJTVjlFLa8fxmRGlM59JIXJqoLCaAojqZBlWcqkO4bz2h7yNCyqcH6ulNLMmWs4n/l4J8XSOZcu33F53UK2QJsVrCd9yEmdEFIk+sgQJGXRlrVM8kxOSQo+/zx3bt7J+i6cCa0UAUlWERWpEc5VVi6I2jXliboT2XdZUZWy9sUU8xTQkzSoqDBFmRVRwjoR2Ho8v/eYGVkheGHTGJmukYQtUVYVKk9KT9dR1jpRyM0unHk7JwaUD4EiK3qqzN0ahx7nHHVukpH/nlP90TQ1xojyKsYg7IIgvLtT8t1P5SVbvFh8fu/WwuTpb6mlkaRy4MsUIjYlgpbnMmshf0+5k5/Z/BeJWjL/rJRTkWLCh1Pz+BM3KCLrpRT5WeGRVT7nBDejMqdMWGU65b8/q6NT5KwwOnHlfJKEVZMSKpHVT4ZhktQgqRNEeRpiTgvLtqeTUjdGSZ8Vtk+ulWafVXWiMEkxiJonBDT8HpNC1muttSy5fAJ5n5qn5+uTkiiQssLqxGfLXxP53AzplCh3UpyLUvOk6KoKJBEQi0Ixu6zMzJxQawxVWchnThGHAhUl0KWthNMSAik39IwsLqSoSaJnOz83p7rTK851l6jI1Pn7zrLC3HzX5+totT5/fqUUdU5om8PvKZxUVk+Q1UlK/j9RFEsQgS5kfUXl1n+uR073s83D41Ny8bmhb4Q7Oc+BVEmys0qK0zcna0jMKZiJyupzQqYPn5QpKZ30TWS1eP5OlSKmkJ2NJwWqKCfkM6fzHhLO6tlIsul835/umKooMEqxO0ScC+jqE+sOEAC21rRVtur5nNqV96nTM/lTeU3TRCLk85Am5KVZXBkBEDWLNbI/TpOoclE56ToJnyzMjkSiSS1oJYORsqCqKiTV1+NVwrnEPMvZ0WiF85nJmBvSVVXiJ5cRCOm8FxWlPSuNbFFSlhWBQCKraZI0zodhPCepnlQ1Pjqil9orxiBqXiuK5HlyKHVS7IKxhqquRLFkSznn+IR3gbLJ6sJCFCz7XS8/z4WscM0qV+Sf0zTKZzupp6Oce33wqAjjqLCmoKsKTrzElBIpn9f177ElIddIRtLhncvqH6vwviXma+WzKqeqK5q2Y9F1LFdLqvv7s9pYndYNK39X0zaM/cRoRpqmolu2tG1NXVX4GYKCmAwQ8vDvtK7LK6FEGZeHvymSz9pOeJ6Ys0JMZRW8ykrZspTaqyjFvdDUdR4gK7yP7HaHs1sBA4SYmdPCy5umEUlCz0n32cov5yO51olEVdVUdU1di71cUj2lnnE+cjwOlKWmayXJT9xcmRE2Sz1pjKFuaoxVmOKEvMh7dE6c9lm1XhQ5EVBLbe+yI6DKbO1xGFl2KeMfYlaxpzM7DTjXaFJLQ5MDqA79jA8+c4gVIac/N1VJ09SsNyuqqsH5iUSk7YRN7cL075/x1HYtWmmJJZ0cYdrifWC3O5BS4vWrz8Sz//gkSSqlTD/6fqRrGl6/fI6fBj6+eyeSxcUyS1wTZVnx8sVLxqFn//QoUeP1gjb1pHFk7g98+/SEC4HROS6WC55drKQAN5rZB2bnMblTWpWWsjAs15d0qw1+HolOGB/bp718kSRWbUVXRB6ejmyftuiiQtmCGCtUjOz2A+Ps8D6ijSVowxjhn//FX9E0NTpEieqO4cytCkFAh1oDubBq2wXWlhx2T0zzxJsPH2malj/7e3+CJvHjt39H8B5TybS26Tq8D8yHnsnNDNOMVlAaTVNanpmaQiuW6w1WK7rKsD8c+f7tLVcXG/7059/gY+I4zawwfIZEe795/5EUAsE7qtJy0Va5oJWD5PYwst0dedrtePX8Ga9fPj8zGdqcDDj3O7YfvqdhplGBrr5m2Sz48fs3/Pj2LZdX13SLBW/fvWO3P/An9YK6W9LPjuOh5+HxkXEaWS2XXKwWrJZLiqLAjYNwT5oGykLYMt4TtcUlzThNMrFcb6jKim9ePacfeu7u5P+7f3zEFgXffPmlwGqVdIw/vHuHG0Z8fEIbQ9UusHVL20oyUz+M7PYHvv3d77i6uOQf/4M/JyVPfxBVxa9/8zsWiyWfvf5cijtbsFiuefXqNcf9lr/9q3+NLSv+/M//PiFEjsc9dVmyqGoaoyhV4qKtqW6uuLpYi8/bR/7q178WhkOKvHn7jre3d6LoaBswhjkmRucZZ2mQGi0JObPztE1NXRVyrxpD1bQi8SSgiQxalBVd5k2oLLO83x1IwDfPntE1DWO/F1BfVVBXJVobpnnmd7/7HWPe1H4SL4VMvweZnk3TTEJhq5oYA21d4X3g/uMpWWXFPE/cffxIU1e8evFCJkn9iFaJOjNTDv1ASom6ERVPUXiMVoyHA8pKUTQMPftDzzQM9McDq/Way8sryA2sU+pdYUVhslituX7+UmJag8+MnJZ5HPHzDFpjq0a4G2XJcZzZ7o8iCc7NwqQkkcSHwD5PJZrcVHx/e0tZFlxsNlxeXBCSQCxPtooig7jXmw0A+4MwJ4wtSCS8EwDhernMtuIZ7z37/RMAVbsgBLFVxBg57ncU+Zqi6nODfjzsSAq6bkEIkf32gbIouLq8PNvGtJUiUJhDW4qyou6kCLtcryjLMqtrNDpJ6EF/3HNz84xnz56f7bFlTnSbpxHnZpbdhtVqSVGIVPju/p79/khRCo9o7CWtpm0XlEXBOE54N3Pse5z3VIWlq9esl0vKSnhb0iDyZ/l6URgInpAisxNb+eT3pJTYbFYsw4Jplpjkw16ieVtrcrxwHtQkzl6fRGSeRmIwGJ1tIEFUY/t+pKprrm6uRVWnEuOh58cffqAsSzZrYUhNs6MsKxZtQ0iJhwdRid5cXTCNwlbYLGqubm7QuQA8NYaqSsCvzge++91vKYuCorDsDj2HYSbOY44Sl8bF0B/Ybx9JfkFd12J9tMUZOjqMU95b5dDa5Wa4Njo3d+WwLOEaBVOSg2xTZWu4m4khsFwuUKogLJY459jtD7mY+um8TsBQsVdKSEmKkSk3YotSPG4uM3EmF+hj5N7NLJqaX7y4Ypw97++eZGg1DlIfOBk8DbNcr8vVGmUMypaUpmBTlvjZ4caRD/uB344zy7ZisxQLCdpwmD3j7FnWBcu6YNXWtK2sqzFFrM6NCBKKKHk5xrBoGmGXxcTTYUADShdyz8eEsiLnn+YnjkN/BvL/7sMeY3qulxXrtiQEx3FwlFqLyioH0ITcwAm6BBvpOjJAVw4Wq66hMBqdsQSTy3bkHAUeUoKkmJzEck/TkaYqeHG9Icyex6cdlTVcr9qcFBhYNhXPNwuc9/TjSGEUzy6WzEFx+yAqVJU8trA0dUlVmGxFEzvvcTpyuz3w7FKzWtSyNgwTbp4IbmI3ePajZ1EVrEqYtcFFxdMQOQ4z8zHgk2GYZ1wIvNh0LJqScRyZZi98SOBy2fJ8s0BXLWjDw9Me5zyXbUFhNdYWtKaiP+6ZQmJyEsoRsu3w+dWGEAMfH3fMznMYRRW2WrTYQnNd1BglaoAYEwdjSCiCFeCzcXLgkaRBQBvaquDVVXceWrs5cjhI+ttq1eC0woXEGODDQZr+wQcWbc1/7+//nH0/sd33tMuG9YXEhReFYfSJUUUuljWlAR8cf/fmlrY0NIVhPzqOU6DMQRLjLJabYRaIfalTVsYLM0zFhEEcAy5EytJQVZamtBil2PYTkxOQe9tWmErUXcNeaq3VYkFVnkKHAk+9pOWuuxoFbPfHn9T6pYpIxLN92MswKYj9aLc/Aolf/vyPiTGy344kHEofcd6x73csFh1ff/0l/b7nuze3NG1LXXf4MTAeBpRWXN/cMI0ju6cdyhSE3BgvS1Hz/vbHb/E+4X3i+bMrvnj9XEIsZod30hw0hcEWlmcvbvjZz38m0Hsr3EtSZBonDvsD0zSS8GwuOi4uWu4fnni831OWbQ6riqQ087A9Mo4zx6Pcx9M0ENOe/+P/+f9E3Ta8eP6Kly+fg9JMU6QuLVZXVIU4GIpSeHS7/pFhGGnXDcFH3r+/pWsX/Mc//1Os1Xz3/d8yzxN+9lhjWa8v0Npxl5mUt+/2lFXFs5uX+BjYTA39PNK7nqZt+PrLP2f3tOc3v/2O1brlj//eN6A0IWpMaeSZj4737+9QGBSWqra8/PxlZh3XoCMPD7c8PHzk4f6eLz57yZefv8KlgIuBi4sLNpsrhifHw7CDZUKrSFlo6try9u6Oh7tHtE2gEu/vPnLoe/74l3/Es5sbdscDQz9ye3vPMIzcPLvh8vqaupEBxzxNACyXa4y1tPc7UAPT5EgJShp0ofGNRxnFF1++Zppmhkme89vbDyitePXyEmMNk++zsms4qzBBUVixAxeVzso9y273xN99+9dcXV7yj//hP8RYi0qK+8M9f/WXf0O3WPD6y9eMw8zQ7ynKis3NpXDhjiPdYsOf/dkV/fHIw917NpcXbC6fU9cVbVsxjRNTP3Cx2vDlF1/gY+Bf/Mt/TVu2LOsFDx8e+PH7HwS03nX4qDgcJ3bbHU/3D1xfXlHXJY9PO/qp59n1Z7TdiqfDA3ePI8EBETbrmrJsmaZECFCWCxkoeeHT3m23JBJfP3vNYtGy323Z88gcJlCJZlExTRPf/vr7zHL9d7/+4MbTaaI+Zx4KSmwV4zSilWaxWBAjzG7M08/pDIlVJAGmpphjXvN0PhdR1hiaosyHrxJjLDHJhLwqC3yccU7SMESJIPG4xlpsVkrFGChtQVXW1JWlKi11XQvjZh6ZnKcfRoZhoqorisJyZm0E4Rsom/kDuc/oM6BVZ/WKRzylx2GUzaKusEZ8rCGKVxKt8/zjNEESBVBM6WwBmOc5J1plbopz4uFM8nvrqsWQ03+UeJxPirGQFQeaT4yYuiwZrTyASik5AMREEQSU3NS1gL/nmROANkZh2xgj0l9JCxrES410VE+e4OCEp+C9I8UThJh8jUSV4DMjxGUO1Onfp2liGEaZlibxKTvnqKqSrutEYaQ1Pi/yWmtUnmqbrKLwWUlmdMjTBk1ZWmIoctdXZ9aIpNyVVYmPSibAmV1xfsP53cvUT6ZXs/cM08ycv2uS2KGU1nmaKzMta0TpVZWidkkx0vc9C1vQti3TNBGCl0mhAmIkuBkFlGVxnjIcjz3TNGG1TK1n7wk+UudOtLM6TwblEHuavmbj9nkad+LgFNbK9DYfZAWqbChMZiykcAZKn9Q1QE6HCpjMX3M+ZIbPSan203ilmIhE5swhijHmDfaTiuKk2FF5MikTi9PUXudkHnMGOysl07yTdUmmWpKqEULE6Hie2pw4NadpkXP+PEWNv8d0OCl1irJEpvjxkxrJe2Yn6jeVp1QxpfzfZ1FWnZQeSTgrKfvyJT1DFDAuP8vVcim23WkWpYDSGM358544OrJ+y4p4YgWd9CQJeZ59Tjk9/blPDCtRN8QkQGTjT4wjUdsoZXJDS74XUWNJGmM43e9K45TKcMPME/j9NSiJkuzEMIpBLA1Fke1A/ve+czivueQJ0olReJoaqvh7qlDvcUgaScifPaWUU2+y2jUn6CX8mf90SiQ5WfdOPB7yAfy0T5wSWU83yu+nT54vFKenP+XP+0nF4lW+9iFgMwdB53AJUSeJVfTMyzKZb6KU3As5kasqCkJmFpjceDxPQRPC2sj3ZOh7/DTJJC0XJ9F5TAr/VnosWQl2+pI+Lb2yL8aU0FkxYpI9KwVPwk1rheVxmkJL/ZF3wnT6bJyfG1EqJ07swJ/S68TJ8SGSspoS+KR+yvflifl24rOpXEOUVhOD8G7OSqAkKuxocpKcyRY6pZF5sKh8klb4zNycvTS2Yoyi9Mm8qPxWOCXKWiOcSKJw7RKc1dZKSZLRSWUTYzqneH1aVzIP76wk+ZSYO3tJqVNKFEGiVJZ7TZHfjjo9S+TpdU6dUzHbB7LKS5GTLkXBpPRJhSPqG8gT9JCVS9Gck0vPv88oYgSvZC8vrMlKeqnRrCmIUyBMTgYDKeSaMJ4V66f1wYd4vibyzKTzd3XieZ32kpDrqQRnzuTJFh5yA3L2gcn5/J0lZh+IJDZNQVMVYA0hswoTJ16ncFzyRTw/q5LEJ+l1ZVmclannOiGrVm3m3P2+48JofW5cgXzeU12X5GhAlVl+J3aSNTp/p+msLimsqIdmH84sudZW2R4Z2R1P+7XJbz2ebfKn52DKqYghKlLSZ4dDzM6MeFqz1CfWp1b5XlRwghCYEz9KywE4pU8sqkRWJGiFLqTp1ufre7pPfRCFfd4Kzuu70cIV/am8Yo4nPCVmKWWlZpkmjDGsupoQIkM/nRW65KAXc9qzbFY2ZwZcCIFxHCRpe9WI0jWnUp4U2dZKIrCoc8EHdWbYhBBEJZz5XSeWZFVXdIvuXL+4aRKgdD8Kt5eQ6yh5NmNOWC1LUbeI2i8Iz2iez/VciKLOedrtGOeJF89fUpQ5SS7E8958SuTVyhBVkAVRcw4ecs5n/qGsD94HZueYx4myEIyMSeb3ajiy4lASm0/n5BRz8nzbMo6faseqEcVLCJLeXtcz8wxunkgqyUAsfkrbVUrhnGeeDqJsy/tCWZfgHSlk7uXprGJkTY0x5nPiKXwnyCauJTXOOSeBMYcDsxOlk8vOkrIqaRctRZnfT95XTgv/SakdYyB4da4LXA5/KHIS3+w/Jcud3pvO11nSJ0MOwIjn93xae2OS7IcpM6G6TjACojSXfffM6LWWokxUVZmVbMh+4RNNZei6Fu9OQ+N03pdI4vopy4qUEwyf9nv6Y0+lS0wlLOvhOJxuEqx1aC11k1GfnAHa6FyjkvleuQ7VOocy5FRrZbFWZ8W9Yp4VzuX9PfNEldIMQ09MkbKW9Xia/DnVUas/bO36gxtPx538sGGaJNXoYiNLaMqHOu+pyoqvPn+Fm2fuPn6gXSz45uuvmd3Mx9v32MLyp3/yK5Q2oDRPfc/3b97SlpabdUtRVFxe3XAcRu63W7qmYfPyC4rDAexDlve1TONEPwwUaDSGZVuxqC2mbLBlzYkjsOhqNquWN2++4+++/ZbDYWAYZ3721Rc8v7nh7d0THz/esd6sadYX2PxwoTQuA2yVVlxeXgKJD7cPjJOjLEratmOx6iisYczyy+AycF2VaAyVEmCeMSeQdMTPnuQmvILHuztsYTBdB73i7Y8/UJUVl+s/orAFi7pCaUOzWOG85+lph7ElRbMkTjPj4z2pLPHVBU3T8s1XX6CN5sPjlqosWS46SptQsWYcJ/aHA0XV0HQL7u7u+fXfveHy8oLnz5/THx45bh/RVcOL588oiordYUQT0ClwfHxg9h5MwcsvfsZytaboOt4+7jm+vaUtK7755ptcICpePbthvljz/t1bfvvtt3z28gXLxYLJraibhlevXrNerfDDUexqg8irdVGhraWpSkyKHHZPefJd4kOkH8Vzi5IJ2HEQ9sPrzz6nKivKosRNM7/93bcCS0+Joii5vnlBTJHD05ZhP/P2rUjND4M0NTcXN1RNx/1uR10VLNdrrlLiiy8+p64qFl1DWViaqsLHyHH3wDD0eDQuROZxoCwqlldLYvDEMLPb77h7fKRtW7pFh5sDx8FhMzdhCok5JHTRYIqSh4/v2W8fePHyFRcXVyy6FvPihqKwjLNjtWgpioLtoWc/THRtw6IsoNSE4PmLv/6Bx+2OF8+f03UdF8uO0hqmIHad8PGBfpq4/fiRpq6Ft2AMF41wUn777gMxJf7en/wJdYZA/xRebpJi43A4YIzl5tkzmVrkyPATLFmsYJqm1CzaJS9ePCeliHczRVmwXC3z2VnxtNvxww8/sNpc8MVXX+PmkbgTObhPIn8O2d5aWUO5WLLsFqSU6PsDTdPQdeKBl80inTeE4bCjLArapubu9gOPD/f43LfoFh11XfPh9qMA5LU0FbrFkrLt8E42aJsVVMZYYggM45DBjnI4T0EAkinb6LrF8nyIUMBuuyVGge0WVrHve2E3aS0pH09baZpn2+44OVlz2halFWVV5matYRpHPt7e0rSO9fqCiDqrO8tKAJJ15hpFOMcdS+PIURYFdbeAFPHziJsGxv5IVTe0nRQDp4S6FAPH/Z4P799TFZaqsPTHI+PsMqNwxew99/f3+TmVpnShwUSP9lEGFk3L8bjHHQ/nCPL1ZoPWhrosxAZTCytNZVvgcNgRvENrgy1Luk5ik/uhx8/ubLkde0mCHUZZn6wVe8ZJF6KKmhQjfpqIwWOzVFoZAdhqUxBC5LA75GAOCW047J9o6prNekVKiRcvXqCNoa5qyqqmaTtIiX6azhYRbSxF1bAwAmkuqpo5BBmGzHMGxEeMtZSVJM81TZM5Wnnfi/F8IC/VjA2JxWJB0zRyCNSatltQlhVP23umceTZi5d0+fd4H3j35nuG/sjV9TVNLWmG1ooCJoTI49OOeZqED6bF4m+scNtSgjc//khKka+++lm2X/x0XkpLIbvdHVAKLhbV2foUk2IK6fxcV6VltW6wWtOWYhvdHSRR8vmmISlFUoZxmNkNI01paAuxey+XLePk2O1FfZyCwxQF6/WKtnOslg1Gi3WhLCQh7ULXFDpyGCYOwwQaYvRZQWI4To79IGEf4zTRVBVlUXC3feLQD7y6vmC96PK95DFBoZRlmsU62rTCYdsP0kDRSopzFxWDF1uVUYnJ51TGzDmsSgmKKCNoHYleDiYuJ/1MLjDGyHa3I4RE0pamKni2EXhua1tQGoxlcv4cIKEQ9MCqKTFaSTMmCfph9p63DyN1YdksO7SWxDlzPDK7ByKWqCumcWZ7+8hq0cGF5thP7A89c4gsuhZtLYNPbGo5mN/NM8fJU2q46SyHfuRvRifog6wIXG/WciiMiWGamJ3nsZ+4fRpY1pbCaKZ5FIj5uqYpFEMQYPOLTXte+2WYKE2UuslqrnyQcqMMlYOvJHgvq5UWnSSqXi4aSJHHp5HRB/pZLCdVVuTNXmqfqqmkTNaaGKQhth8dbx8Glk3Bq0tRmrp5JimNi4qytFysa/rJsT0MzFkNrhSsm5K2sLy4XGGV4jC6PEwIjN4xOrGfqwRVWbFoKpx3PI0yZG1Ly5SHj5eLmrapMGWii0DwpBSyGtYyTTJgeH29YtlUPO2eGMeRH+9H+jny6uaSi6ZmUev/N3f/1WxLll1pYt9SrrY86sq4oTITmchGFQB2dbPJh36gkUYz/gj+UhqNDzQ2C2xVqAKQMjLElUdv6WoJPszl+wT4wnhoGrvDzQIi4tx79nZfvsScY3wDqzml6T2kROsju0NP23seD7IevTibAfCn97eEEHl1scbZn0+i8G7f5UbBQZiQV5coa2kqKXL4EFBacfZMOHUMkaoquXxxgQ+ex+2Wuin4z//XfyOquai4v3vk2+/ec3F+xmVO5a1nM47HI5uHB8qqYrGcE5Un+pGiqqmaGeMwsHncY53GFoazszPO1xekrDA2VpRG81nDvJnxz7/7J775y5/p28DYR86ulsyXNdcf7tg+7pnNG7HNlfJP8HAcZT32vme9nkGaceg2DH3H88WVODxMJPmWrpUicVAaVVQ08zXOydquElxdPKPtOr79y/f03ZC5t4pv/vzPGGMZvMIPhoe7HXVd8fpzQ10aLi/OUQqaX3xB3w9cf7inby1jB3EAm8ROPHQdVen4q19/hVKK/d4zqxuuzs5oyyMmRsaxoW+WhOgZQ8/j4yN/+faGq8s1r18+Z79r2T4eiDFxvjonJcX1/WO2ExbsNns290eGNLJ6sQQVOHQDdw/vGPqR9WLJ1fNzfBDo+eflG8YQuP7wie///D0vX79hsVxy9fySGBPPXlwwmzeyV46RQhnCKKrxkCJl6bBW03d7xhHG1BAjPNw8ig2sl2bd4/0jIUbOzlcoreiHvdQ32oHgA303ALKeihVUQ/Rcf7ghRujbQNcdURGGtuft23fMFwuunj1jsV7y9V99jXMOVzrms4bPnj9nt9/x6f0nSLnobQ1KQ9VUnF1dUZYFQ99y2B8Zx8RsNmO+mOGjpx9HlEo0pcEaSAQJVikarm/u2O+3vHnzhsurK84uziirirJ2HIc9z58/p65rvv/hO25u3vL1l19xtn6VGy6Bf/nd79lstvzy61+xWi1YLERQc+w6+n5guz3Qdz031/c82Ed2x0esMfzNf/Zv0Mrwn/7D/4txHPnNb39LVVc/aV74yYWnfhS1i6RyAVMHQE+oVlHnGGOIRroozhiWywVd13KrRa62WsrGf7s9nCTjU2daKYPKSWZT99VYhy0cRVnkDrNmUCqrqaQLUlUls1lFSDpHB8ZcEfYMQ0/X9xy7QZI4giR8HduWrh8YfMBYR900hO5I9CM/TpVQ+TspBWXh/nUXNndw9eQJhazkkp5dP/QobbClJaSpsyjpLoUz2camswXBSXJdhvcaJq6PORVzTuyZvFh3XZe7TnJgLgqp1nrvc3dIuk3OOrwNp5hObYT5I+yA3OkJ8myLUuw2KUXarhMwu0p0fU83DDSzGbOqwRVSFPNR7EK1e+LGCAMiYq3m9j4x9IMoGvSk/iJ/r5wWFXLlfhypY8yJO3LvhWUVT+OkH3pSfgaSTvfkpS2LIj8LUSvEEClKlyHgDTF42p3EawzDcLKfpIR4rp2lH0bpnFRSLCzzRtkYfRqTYZAkDkhihTJG2DJO41xJUIqQAqNKT/c4d8K01pljlaODc+efJAyGKTFwStoo8nOMIeKcpalKtgc5GEwMBh/SySqFyglAp/SVrJRLufrussprlIk1JeiGQd6LQarWVVXljcHP45I0s3yvT8oxTvyZlLsA0m3QudugaWYzgvcc/JgP8CUxyHh/Sp9Jp4OwSOTVqYsQR1lMpySOKa0x+HhKdLS2wLqCMArfLaX41H3OCqWJ6ZSUkeL1lFg3ekxhJdXTiJrOxEjM8/KkvFEkkQpH+XxT50ZlhcI0h4i6SZHIEbu5KDMls4iaZOqo5djw7Ok+KZCymkznNWI60EypHRNPaepMSqqdJE8Bpw6gtTYnnITcDYykkFNystJDxB7pdE/EkmokZeR4RNUVRiuGYaDteuYzsScOfc84cfJikO76j9Rt2si9Jj9Tm8HXxuSOZFbUTCqqMaddTgqzCYB94q5NarFJwZlTB8XDP/n1p7lzYkrlxEMFUfDAKPv0d8Y8X8jnlzTF6e+dkukkxcfktSqSkhWWSZSu+5QiND0Ll9cHhTrdV/I4NFaUXTI3hdyF1QipNeXOtj4pURRO+BVZhWOtwTnZxCl+pDxjUibk6F8fshrgdOtOHVby2qaUpLepAH0/EFNmSkJWEPx81JrwpHQWtTNMytfTe5DvUcrrptUZCF4XDKPn0PZYo2iqgjEk9oOko0rymBbYqX76+05iF/XEISRF4omfJfOZs4bCJAqjOfbDicnWa07PePBBQNQ+4H2kV6OksY0+FxE1zgp0+KSUmxSCZN6bNRROPosiZjWL7LNUVvnl3Vfe/00Jk9lyFybFUCART2rWSMqco6yii9N9lL8XlZk7WYGh1NRBz+zIlA/OyH2PSey2zmh5l3MYgKzjhojBK8ugx7xHfOL/xUROFzKZ5yEKt2GUezf6SFNaamfpI4xJUgrBo6ySGpnRaKMyZyORGPFRtGMTN2/qcieVuYUJdMqUorwGWKPQSaD28KSqC5OCMqsHTglT+RkYrU4qkpNgU08KPPIzIjdZYla4TCofSbkbg/BtlM6pcUoR8tqpM9cuf6Dp1HFSOsq8k57mkhhPHB+rlSjM87NKWWGmlaQzTs914tyYSY2WlRSFE0B0ignv89i3Oqs8OTFTJ1Ws/KNOCiedx0RMCGslTtweuQdiu07Ce/0ZTV8hp5jJ+5VOSkS5Ug4iER6QiglloCwL1us1Xd+z3e8pXMHZ+Rl9P3B3v31K1s3/pNzoUyBMX2NAiZK9zI2twhVEH+hjQmmTGzE1i8Wcbugl9Tlz4MZhZLQSLLTfHyRFNCj6vse0ir6XZLSlddQ5zGKy8AKnfY3J+4a6qUmIZdoaexr/sk5pgpr4RDI6h9zQ0UqSzZ21RBtRGKwzWQWYRE1p5CUTN4k4NqwVxYq2Dj3KfJeinMOGYcSPHu9y0IOS/UfM8x95brTGUBQOrRMoy+ghpl6eWQjCmM33XZwzuVmYEofj8XTW6VvP0AWKmaOsHd5D8KIwnZLJRQFqQRmMKwgh8Sl+zGl68j5YK4wmdCKmQMqJ7cPgCeOIz1pFa41YtLuJySp8r36QcAYTwmkeIz8TrRWREUJCo0Ab6qqWvUTGB2jkzBpiJPhI3w2EEJk1EiTWdj2ukPOBnKEEFK/1j1wpWhAdWlucLTKfMp3S36efAUm1G8aBfnDEFMUB5KUeIO9NOPHggpf7QBJXjiscZQig5FmVhRS/nBVKdOEcVVkKNws5Q0t6uyjzvDf5fJrnVa3xWsb/MMr7kWyi7wYUmmNWETpXUFX1T5oXfnLh6W67xWjNoi4yd0H+aNnMZbJVmjEkHncbkvdoIoU1zJcLXFmyPLuiqWtevHjBx48f+eMff09RFHz27EKGRhi5f3jg0x//zPPnL/jNb37DkCV3VhvOzs7ZbTe8+/77fPgxzFdLnj+/ZLVac3Z2xp/+/Gf+9M2fmTUNTV1xd/9AiJG77ZGkK9brmtIq7h/u+e7te5rKsVrMeP3qJZeXV/zhX/4jtze3uKKkdBaD+LnFLpV48/K5JGElkaPvN48Y4PXLl5SF49Ona7q+F/9wiNzefk+IieWzl5JuNG9YzSqilg7j1Xouhzprsa7k6pVMfp/uHrDWMp8vGGPi4eYO70eGvqUbLGNMdG3Lp083XF6c8+WXjfAAekkPsUZlr/xASlDWc2w5o5qdCcB8HFgtF/zVL7+SiU0rmqbGmAtiBotvtge6tocsBw75hf3Vcs2rF8/p+p5hGJiVBdasOO42bB8f+OrzN1xenLM/7OiGjqvhkrqZUZQlKSYKW6Kx3D88st3tUb4j+pFv3n6g7Xt+ZUvms4Y49hDGbF2UwppCUg/7fsiHNMN8vpSDnjWkLJ0sXMHV1XMUibPlDFeU1KsLsQBmFYEOnn70PGz3NFXFFy+fkxJstlvao2UcellolM4FG8cYItu7R5FFRs+sKrk8+4Khl45uUhaKGWVR4lRFHaEJMA4du91B2E/rJdvdnu1hLwucH0ldJ92cocc5x9lyxsvLFe+6Hd1uJGRrzLyuuFivOOweiV2HMwltNR8/3bPbH7m6esbLFy+52x643x25vbslxUDpJFHsxcUF2lgObScg9FESy757e5DNmSuoqpJuDKD9T50a/md/7Q8tRmvW6zMBzwdP8gk/jsLu2UmqXdXMJSa271HGUjiHzxtPrQ1VWbPdbfnu++8lgevqUmJa+5b2eOB+sz0pTrq2Y7sVrpi17uQ90NZRlxVVXVEUlUTjltI5bdsjrixlIWuPPPYPdF0LWjObzSjLit3hwH6/o64bzs7W1KUsWBgL2rBYNlhrOR72ImX2MqdcXpxTFAX3D490XXcqqJxdXGCt5eH+gXH01LWwJtq+J/ggzBdtWa5WgMoKHcvV5SUAm+2GcRg4KNkA3tzdScFbkQvFAr4uyxKlNbf3d0Tv6dsDVV0zbxpRc273KBJGiVqmWa8Faq40ygig3PuRgYSxhqquT1ws2pahF3B2VdV07ZG7208cmjlVM6drj3Rdx2LesF6t2G63siCXDcZIeESMkXo2y2BNUVcUVpOsPrEX5FAzstsJxNzkNfA237vXr14wmy+YzRdopbm9vWEcBymIKwG1C8x7zPJwKXDO6hprxdqcktx7YwzPnz2Tjdx+n4tJmfEzDozjQHs8UlUlL1++JITAYVKlTVDwLMHWWjH6yPF4oCxLloslIIfdrut4fHigqgpmTYNzBWVVyqZO9SeLTWUMdV0yDi3H/Q5blNSLFX4U/lXfD4zes1wuuTg/5+7+gd1uT98dCePA5dma1awm+hVtJWOsb4/c3t7RdS2z+YzVaknbtuy2W/aHI1pJHLwwsyxa1xx2W2KUpCEUfPjwToodw4DWmrv7u9wZ/vlcu/3xtKlWKA6dWG59lvU7a4gp0o0eFxOlGyhMKRxKM2JsR106nl8suX3c8bvvPlAUJZ9dnlEXjmVdcuwHPt5tsdbQNFVu9BSSnmcE0j12LcpYtHXYyjEvxE6rlFgyow8cfOBwhKoUrtrjoWffDVTOsJ6X3G/27NueZdOwvlhzvlqwXDTSXfWJKiWsgs6PhERWNGkuGtk0Hzph18UgYSa2meGsZvACvD8cJNnJJ2nkndI444gGilLm9WerRgo9ThRNm4NEuj/ujihlSFqKrEN3zHsKYU4du55DN/Dh5hFrNWeLksIaZvnQMQH1SRGVAoSRyhkuz1YMIdGNGQKuFMt5zWomiZdlWTAOPWPfoq3sea4fdnz/8TYXlAPnq2e8fn7BcYz0PrHf7zi0Ldtsobk8P2Mxm8mmXmsWjcIYT1VonNacrxfSmDIl+2AYk+zp3t7I/PV8PWdWFVyerTDasPtwJ1y4Siz7Y5C5YAxHtNbMS1HQHdpeGm2jE1C3rbAm8WKWC3bGEoOnUxLWoQjy/x8PeR+8JgG9D/TDwPXmKNZnLQX8snTEkHjcHQkxyZ7VKBaFwljDwQdiUsSoKHSiMJFoHVZV0I9EPTJzMC8U+2PHYXvAJ7H+jZGM9YBCS+pe4QqOfUfbj5Ckkf2iKVjPa26T59h6hr5jEz2bAdpgWTSOptTcb3ZcP+xpCjmwzSqBAC9nc+aN4ElijJgUSKPnD99dM4bIoROW519++MjPqO7EcPAYa1hdLHBlgSvE1n0YelJM2CAigxJZI7V0lVmdXVD3A8fDyHw+4/PPvuSH73/gn//Dv6coC77+6jOqsmQcBzaPW969/cDl1SVf/+prDocDdw/3qKRYrFb0w8jjZivcsXLG+cUFz15csVouOFst+eYv3/HD9+8pCotzlk/hAyEmPn38yGHfsVjOaWY1j/ePvH97ZD6fc3a+4uuvv+bq2TP+8uc/cHf3kcvLK+qmgbQUpdsgSJa/+c/+lqIsubm5pu+F06qN4fLZFdY5Hu4epcGYETLvvv2BcRhYn59hneXz16+yYl/W79/+9V9hrOPu/sDh2Ak3NgTe/XCNdZbZYs44jrz94aNgcKoZCnj37gNd13Fzd8P5+RlvXr/AjwO3t3cUZc1qfY5C0XcHkkrMzuaMQ8C0A8djT3vsmTclX7x5zXKxYD5boZJFJeH9oQ2bzT2bD/dUzYyymrPf7TgcDvz1b3/Ji5ef07UDQ+cxuqRpAl3Xs/90z5s3V5yfL+nawNgHlqs1PgZsoYna45Fmye3tR4yGNEjB5eOne4Yh8PUvv2CxmFOW0kje7oyoW1VEEWiPgnhxWhqu9WKeOWyznNwqe6tj1eGc5fmzK1BkRqqn3XUitCk13bHn/nbHYrHg7/7+7+iHno/XH0npwLzeCoIjSUEbJbzV47aThMTzc5p6ztnyjMPhwMPjPcZq6rqkmc1ZLJYcDweM3bE7bPl4+wMvnj3nxYsX3N9vGKOi95G+P9B2R8a+zS6pZzy/vOL1syu+73sOu4HgARSls5wtar787Auuzl6wXs2xRnN9fcN2u+PNy1d8/cbx7tM7bu8/UNkKoy2zRY2xmqKUoupm/0BIifPFGVpp/od/+EcZs92AKywP94+0x/YnzQs/ufDknEiLjbVoY09ePmukqxlygcIHsW+Ix3zkeGwZQ0DnxK7D4UDX97mKaaiqUpJyQk4Myh1ba+2pKyx+98zdiHI4OXENJsVU9mRKYl2PVrkyPQ4MQ/Z4O0NdmFyUaVk0JXVdZ0tK7jL9iAVijMZEQ/AxH54KqrLCd+KX9eN4UiakBGPu6CttmdLXEuRuucpqHI3JBxnZsYliRyrMlQC9hgEB1ZG7UlmZkTvnk4IlnLr9I4P3dF2Ps4aqkCj0IZPujSmk4406sZ5AkuEm4OZkuxB1lT51pkOGhE5CkVPnPvukJVLSckxJVBL5gORjhu3mzZ01U2dSuqE+q8/wg3BYtEFbdzqY+WzhGHxWOOTq65RmI8XedGIhTeNkUMLcqkoBsmolnIspzUs8tSNh6LBJMWsaqrLAWpP9xQPESN9pfPASwe4KyqoitD1t3wvnR0+ufJU3R+UpptyQuQCTeiVKp94bjfX6VKgNMTAOvbxPmb9ifvRuybObxoko0cpS3kM1KfrGkZjjLuUg/qTImJgglXvqYpisRiRNTIKnzoN1Tu5Vts38XK6pu2GMlU53SidYrfx3SZebmD9+lISuvutOXCZIdF2bOV4BbS1FIc97AoFP6UXamMwBQRQbTFKCPGKU/F9TdxSlnlgfWf3X970UiGJO8jICwFTqKVlO0tHkv/kkQG6lKklh+bFKMoSTikjpHylNTjeAfLgZIRXZyy3KrVNaCKdcLCB3GJXM/8lKZy+mmBUpgFY/UoUhcwvye6L3wigJMd/7KGy03OUGSfiMJ4XHkzoNBVqZ0983sWNIuauc1ahKGxKiFhFHyKRSelJxTXbEiQM3vc/CIJFO0KTIsG5aj3JnOxfiY0onTsGJFRIjSSFNiHEQaHZ+/5RShFGUnidGyqQKCxNfLc9bRlh92phsLbOnrpQ2snZOMOWU761SitH707h6Ym49JSbp0zsQT6q3SdWmlcJkVcH0/eS+CRPKZ6XY9CxQT382AxI4Kbx+NOZPjLRsvQtZzTaND2sMNhcRhZXlUSpSOnNS4ExjUk9d7pROLMEpoUc+1NM4/Tlck3poKnSm/P0nRcmkVBQ1nMpjNGYlrPzZlJ4YTRO/yWVOzXTfhKOocgdYiXCcp3EzsbOm9N7Re0mwM5PSTYvCJApfKOXPkpJEfkvoirC6jBF1jyKdfibl76C0QgX5gsMY0SriSuEH2fweD9l6PO0JfWb3JMhS6QRJySElKcRRnJWVk2ImM0RRGtvL/OIjKJXQOqsKsyrGOJVVBRHvc4rfj37/ECIhyjhH/Uj9qqIwmk4/K59xmlclcVXUZ9GI/YLMkIpB3rmU96Tk93xSjWid0zHDpNYSPEQIwu8CsQAW1lJYUadPKi8fyCl6/kesrZycFWS/7TMralLBTclrpMgpQSoJr0jF/DuVyqB44TZp2VAQtUGVRVYiyfxWFmLHNJr8GWJWwz0lNisFzmiGmNM3pzkzqdNrPq1Pp81lvqYk5YlxOLGuUppYNU8cNAl1kPlvmltE0Sp/i/C7dFbYTOOb7LyYWJyJ2Mt714+aqCNNZU/KsEnwNX26GCPt4BnDk/r3xHj5mVwC6pbm25QmDGC1IaopQVASvgIJFSNd33M4HCTBDGGR7rYCmdbZ5dI0Yvv1oxQUpmbOpHSMOZHzpPAOI8pI8ZhEtpAj/z1IUm2MnnGQdMnRB/p+gCQKkbqu2CpNDAGjJa3tiSslbFulwTlDbxQ6yB4mhCANttmCx8cHxrHPv5/T+XAYBvphwKKyc0EGypR+q5RFo7JjxTKxI6018v7kxsM4SsLaxHISNU1WbzKxnqSpNu0jhr7neDyClmeklLBL8yEnnzfDaZ+ltaau5YwxDJ4Yc4Ky0ZDTmOWeplNDbxrrE085pSj3zmr6tsscLjlnTnw6Yw1FPlM5a+j6MTM3hcM2tB4/xqwUnOaqgBo8KYpVbsj7TK3FZaQVJ7SEyYp0P47EoFAIR7IohN05MaBNZv7qWSP3OI1Ya5gvZsxmjViC/ShcL61p204QHkrOb846xjDS9R3KisUzkWS8pYizFuM0rjAnJ9WkQo9xOleErByU864fRnw/EKOkQ7vMnp3cDT86eGQ1mXBji6JkHBF78yCOnYlfXbgCELRFHzTWRObUwrnN85fSGh0TSkkDrOs6hmHMOCE58/zUc+NPLjz9+te/El7ATjpA2lg0iaaQwpNPsiiOAYYxcr8/sukGNv1/S1PXPLu44NPNDf/NP/x7FvM5f/1Xv8JYh7YFfXtkbA+UVcXls+dUTcP+IMCyvmsZxp6ua1HasTx/ThgH/CAySO/fc3d7R10X7A8tdVXS9wObnPQ0jiNV4aidYeEKZnXJsjKMlebq2SUXl1ckEg/394SkMPUcW9YURQ3aUYTA43bHOI7YsqZqGnbHW1J/pD8eiDHw/vYOYx3vP94y+pE3r17SVCXlbIbShquLc+lm/PkP9P2Ajgob4P4oYHWdwKGpyxpvLGM+eKSxQ2vDaiFJKdt9wjnHcrmgKBztsUVrzfsPb+m6geuHLVcX57x5/oxj13J9c0ddVZyv13THltuHDcPQc2yPzOYLVufndG2bu8sKrQTyXhcFy2ZOuoTN5pHNZkNZNZRVRdu1fPvtNxgjCUXrecWsKjhoxTZEdu2A2bX88PYjDw93LKqSyjlmhaGuSo6Ho/BwomxSNvsDPkTefPkL6qpid3/NZvNIHyQp5v3NHTFGXrx6SV3X/OLNK2JKPO4HhjGwP+5Phz6A6yiWyM9fPSeFwKcP7zDWcqUMdd3w61/9gm4Y+eHDNWtn+ftn53Rdz7uPH+hGScUyShOGI1VVc3lxxWKx4NnzZ7z/8JE//PlbqqrgfDlje+x5f7vl+dUFX3/5uVT9lcX7AT+IxeFus5fUw+hlTA8dTbOgmS04bO7Y3H7g4tkL1qsVhTV0XcHgI/ePe5QrWV5c4QdJCJvPZ6yWS4wtGaPh490j+mHH2XLF5dkZ2/2O47GlqQvqqmAoLcTIi2eXFIXj7u6OQyvdRJmXNEkrmqYgxYjTkVJFVk0l6YI/k6twUnAiycaTfFArXSEboFle9DIE0g8j+8Oeh8dHjAarxNbwp26gcAXr5VI2U64gZWlxnwuS2mi0LXElNItIzApDpUKW9CtGr0kx5DjsSFQaHxPKOHbbLcfDLm9+PLOmoZ7NKcoKYyxlWZFSwmpIYcRHRwqSIubHgULnjT8JbdQJ5Nl2HUkpkXtbKw0Epenbli5GDtsNPniWTYmzBYv5It87QwiBj5+uGUePzpvHx9sbXOF4/uIlhXVSiIkh/3fZ8BtrWTXCCRn6QfZ5GY6csu1gGHqBHKdI5Wouzs8ZxpF3Hz5SFo5FUzP2HY+brah3MoSzKAqOhwO77SOTKtMohXWW5fqc1fmlbLJGT1OvT2EAnz59RBsrTY9alLHHtmN/kHUteM+xbWVhVmCKisVqSV2WvP/wgf3+kGHyiu1mw+hHFosV1jn6tqVvW3Y5pe724YEYI01dUxQFLy6uALj++JE+y/sTAjjuh567mx3WGi6evcRYR9t2sgmNXhL/Ls4YvefuLmJmM75884a2a3n37r2ooHpJt6vq+lQ0tM5JNHQE4waS1gzZ0ns8HGgaYfqlONkeQCONmYeHB0lYqSp22w23t7cwHd4H2fhMsFGlDdYpttsNQ3s4hTUYa3FliavqnCL5wNh39PnAvVossOfnOe1TCh8YLcoabbIS19Dv9pLUuRDOWj8MJC9W56KsaHIh8fxcmB8/p2u9mJ3sOjEl2kGaMVWex5xWJ1WhHGYHxpgIbE6H4kM78O7TW6zTfP7qmRzoYqAfJap58CNWBYzSaCXNrOOxFU6RdWjjmK9k/d7tdgz9wOP+yNmi4nxRU5WOq7M1h27k2I8S5tJ3kIs7i1nJonb4Ueyws9JQmMhmt+VhtydGsK7AFgWusEQVUD7yw82GYzfy5bMly6agrGtKFONR5o3HY4cicb/dE2LkfLUUsHAU20RVWmKKfLp9lKZgDij49HikKBzr+YyySHSDFCa8kmj7WenwQXPsLGMCPwjvbhgFwH22WmE0FE7jQ+J6N1IVhovlHFJgs9tlFmjDvhu52XWMITD4SGE0pTO0bc+HwxFlDNpaktKockHyA9F3lBbcrJIDalJ0g+ft9SMg5ZC6cizm5+z3HV0nbDk/em7uN2y3e+paVGdXZ+csZjO++/CJ/b6lLAUse/ewYRhGnp2vqMqCRKKL8P2t8P0eDh0xJmazGmMtz2fSmDoOUqBqvYQNPewPp0JoaTWzUkC7lamk4Fw4tC5x6yXdMPLu5o6ysrx+fsY4jtw97unHyKGPjC5QWmkeSuNPMS80u+Bph0Hm7qJk6D2Hw8DZ0nJ+VjAE6MaESoExRoYw0ntBeRAjD9uO911HU5U0VSOw935k1jiaqsAYhzaWpNJp7ppslFK40oCh7Ue2h5Y+iP2ntoqmVDxEgw8KZwPa5JKX1izmM8rC8unmURKyclE/5saqT5C0Zt1UVIXj2ZWsVT+X682XX0hBN4d8+HHEKMXzy2ekGGl7CTTa7zeMY6A9Dlx/uuXdux+o6prLqyvevjvyf/2//N9Yr5f83d/+G7HCa0XXHdk83jP4kWa5IGrF7d0tfoxYHG1/5NBuZO5UihTAR83d3S2b7R0vn78mBUPX9hhgt3ngcNgSgiUEi7GJeVNzeXbB5eUljFIwW56taZqG3f6BY7dhd9jiY6CoHM2iZt9vGYY9D7tb+n7ki/A1pS2YNRVKBayyMMLt9QM+Rv705z/S9x1ffPGapq559fISrQ31oiKGxMcfrhkHj7KOMGr++Of3uMKyWtWgR2BEqYArNKjE4fCANYbPXp4RA7Sd7K+0NZhYUDZLIo7rT3fsj3t+eP+Ol69e8+uzJd3hyIcPHwS23lR5n7CXpMcuCNamadjuDrx9J3u0qpSiRtFoVvqMer4g+pHoPevlM6yTZuZ3331CKY9SgfPzFcvFnMN2Q9913N7d0Q4HjvvA0EfAsF6dcXV+zqyp2W/f0u6P6LoErbm+3dB2PaurNWVVcOgOHNsDh+OWcei5v3kEYD5bsFot+eVXL1AKvv/+nSTeRcc4jLz9+J2MSauZzRp+/etfY43hw7sP+OgZYk/TNPziF7+g73u++fNfmM9q/vbf/m9oj0f+8s237PcHto8PHJ3F+x5jXWYs1Tx/dsXt7R3f/fA9ZeVY2zkfr2/5eH3L569e829+/df4lBhiQKtE8C2H/Zbb6ztcYbhYntHuWv54/w1F5XCVZXfc8nh3z/nlJZeXl7TdIOD8ds+HDwOHtiWisVbL95rPWazWfLo+cGxH7h/uCcHz7Pklrz57zf3tA4/7Lc46FrO5jBWjuHwujo7vvvmB4BMXZ8+l8JUbkFXe15pCUzUlL15fSdLhT7h+8gwn3XJ92nQXOW4yBZ396UYUP9nGURRS6Z4UOyEI+bzrOppKLCYJJUlNKYk30Aa8dlhrGPqBcRgy/X6k7weqykphiYgfpTo89GKDU0oOjiZ35WRDnJ3AOVlBVErSVX5K+NGiWIhRvL9FmaHLmtGn7INVoDRt1+dOtVTBW6UylynB5CmPOWNlUkwZgzMCFu97qWwv6oVUYHOnMXip1hutUc5hMz7K5m6yNuLrLIsCZx2FtUTnMtNIEiPGEHH5UBkRtUvbjyht6HOs+GSXmzrz5C6c9+Hk1Y+5C260BiNdemtNTsSZ4n9zWsWP06A04tMmdwZHzzCMxAlSHXOHXZHHkT1V7YGsxjEn9ZrWFuvUaTNNvtfCYxB5rs1qo5jSKb3KmEnxIH7aYRwxifydQy5GSpcPpWkqsRWE7D+fNQ3kNBQfPH0/UJR97qgEjDUixy5LAiPGSiW673siipiUjDM/ykY3FyOMsYToc0ITRO+l82xz8mBZEb10aRWSFjaM8nfoJM+j7wf2h+OJgTL0AzFBXdZyaA7Cz+lHGc8pK86mxIwYRQFitBFVg5Gqvh9aYn4GOv+ep4yh/+Vfk8rilPA1qTtyl9I6l8MBhPdlsheaU8qPQYWckOaEGQZIklvuBpicbqezmkNSLM2JUWaVvEfTfDF1v4VDN+SEn6yAymqSiTMCiLIkd8Bs5rRNyrZEVgRl5c+UXHlKdlLk7tZTEub0Hk+8gUm56b3PChnpYEzqmBDlZwrn5ODvxzzHxlMnRmy+WSGVP5+14mOP1j6pNrV6So300jWb2EnTJrXtOlIUu/ZJwUMkRpUVMaJKkpTLqast92ziNMWYSGZSjOmcXhpJKhKZFFn8qGMt6jhRz3qsFUaS1k9qGnECZCaTNcJa09KpnrpSPieDTombT5yr6SDD071JwmJLWcV24kKlhA+yNk45qeM4SjpojNLpci53zmRcF2WZ2XceFTVKyxqXBStPCqsnsVJeAySaXNZiKeAHL9ajSUM0jaOTYCT/e52fNypAEBaVjBVRFSinc0ptOnVkldKEKOtR4X1W/MmY9ZnX5bT9V2N4+r+nVD7n3InlInNskTkQT+ytn82V9yBTupsx8kz1pHwhq3+CsLImFV2MOflHTalpAWPFmhdSYhwCUafT+LF2UsRm1UdElOZBiiWFs/QiIZJxGxNjEFVQnnpOl8yvJnf1J2V2yAoWWeuVkQJRygmXWumsuNKkzCKb5kRR0Cek4S/jZAwRl7u8otR5Uk1pLU17Z3X+bPLp6qo87ctkvMlcbbNqy5NOqi+dRK0dI0xUxklRZbP6ZUrrnVSpEwdqGDwJjT2lqKWn90aJsjNltZFC1B46Fz+YOsx5nZL1Qt63OL1bCWKUOXVSU05qD/LnnOaYSfEzvT+iABclEfmZa60ImXE1TvthxQliL+9VAv2k6tJ57p1UhtN9m7T+g/fYpDFOxuvo5ZmJ4pu8NsSskofSyXw15Pk+ZBXVMAqvUxhWonoLVtZTpSUhcfSRfgioFNCEzFF6Ujs/KTMn+7Hcm8I6WdO0RWmx4fvgT/PgtP5OfMJJ/TeMo6jhoiZouQdaa3wYGH2gzOpkICvpZF87naOMsuiYsNYTEzhrcFZjtTmp+n4Ol3MSXDOpccWyqim1E0VfHAlRzmUxxFNi4rSvmBRLfd8RQkNRSrOv7UdiSFhniUpRIYfscRwJ45SELXurqqyYNQ3BK8Yhq6uCMHK7tsWP0zjm9G4BT3ujvD4qpSQMKo9DOU/5rHK3J6fASXiX3432eGTndiilxDY6yJg3eY8iiqf+xB4yTliS1jo8nq4fGAfPajYThX2SxsA4GHyYEv10VouLutJZQ1mUxJgYw0BKohK0Mcr4UsJHDCGKi8IYxlFU/ofDEessgXRSecfpXJu/XQxii1VK5j4bE0bJPIST/L+APB/n3GkdiCES03haq8RGLwfe6Sw6+oCzkjT3Y7abVgrnipOzY/T+tB8YxzGrXEEpQ1EUWc0ozNZxHE57fmOM2GvJuI3gKSoprotYNnJsW2ErlbLGCm9J8DJlKUgS4SHJuJjNJaBB5k5RlRZlIcr+fD42RhA7ElYjSrmu6xhCoBs9RieMITOzRIEm3yNAkrpFnMZh/m9lVeT1W87VPiRiDtAoClF6eR+yEkvs6H0vqIbjsQWe2H3DIAo4bWUcx3wumMSBxkj6ozGKYA3d4YhSUNUlVVkRs1vpp1w/PdXuKKqY5bymsJazxVy6IhsZkK4qOewP/PDtt1RlyV//6muqqqRu5vTDwN3dPTGMvLq6oJnNicqw3+95/+495+dn/OqXUlHcbLd0Xc/9wy3j6OmGnr4fOLYdr5qGV1cLHh4TQ3+EJJsZ6zQhKVAGYxVlqdDaUiWBOw/tgbZr6QePVjt8AlvM6Nqezd09WglAuymlG7KezZiVjt32nuPxiNElyjn++V/+hb7v+K/+3X/O82fP6EZPaFvqqsZaR1XV9MNAFyKxH8GPGK1onWIcB959vCbGxK+//gXz2YxkLP048v7xjhgTZdVQFDVn6zUoRdf3eD/SHXY47VienwnJvqywxjKupJB1v9+zWq/4+7/+mpQC94c9m92Rm0NPNQS6ENGQX/DyVBQbuo6hbRm6I+RimQodNlqUK9G2wFrNfD4jJUX0I4vVOev1isftjv3hwOPhyKHtsFZzdb5gMSupnMA0rTEo7UjKcmhb+qHHOMe8qLhcLykLx/mmpu97dvst+80jY9dCilycryiKglfPrvLBVtH1Hd9//ESMgWdXzyisY7VaMfrA3d09Vmu+fP0Cay29h66P9F5RaFFCHLuO3/2338ikUJT4xZzDxZpjO9D2nsVswd//zd+w22358zd/ZrM/8sdv37KcNXz26QPGOr54/Yq6rlkuFydLwd3NNf/+H/49Pgp3wxUFZVlzvl7x7OJMDq7GojIv4Ob6lpuba6qq4c1Xf8XV2RlnqyX72ZFj14mktD/y/v0H7h8e+OKzN1ycnfOHP/8lFztE3bHbbji2Hdc3tyhteHG5pnKWf/ndH3nYbHl+vmbRyHiKaDoPPhrOVgtJIFvKO/ztX0TuOpvPQWn++U9/IcbE//mnTg7/M79M2ciCghSNq6aRAmkIpGRQ1jEMA8f2FuccV89eyAadCYYpG5pmtqMoK5ZnF+w2j3z4/i8sl2vefP4FMQTmsxn9OPL4+HA6eIVsZSwXFevzc46TwjDbktq2pcv2ohhlE1BXlyfI8jiI6tOVFco4rHMiVS5KjHVMxwKbpcTOCYxyGEdEOlyh0Gw3G1KKXF49oywrhkGK6GVVn4q+IXg2O0n+qzN3SCt9ij7X1vHm889x1nLYPMgi1vXElISPpcR2KwUrcyoiWaOoaok97roWUDS12MYetweKomC1WhG85+b2mq4f2O4Okoq132MzDFHg+y3Jj6ToSX6gNAIw7nNIREJYULFvsdZRVyXBjwzdIPHLVcXxeORwPAi4O8pm9+L8LB9K5CDTj14W9kKSboZR1FxlXXN5eSUA/rqh7zp2hwNd21GW7hSuoLTms1evMMaQ/Mg49Lx9+1aKafmAtZjP8CHw6foGnX/eWkvfD/hhoB8HjDHC+vOBP/35L9KNUlCVJXXmUVVlRVkWXJ6f0XUd1zc3Jxh1VVUn+KmzJkeVG2xVUReOruv4+PHDaY11ThgnVVVysV7mNyiynM9xRcl2u2G33WGtpaoq6qqiKguOXU/XjydL9Rh3cvC0orjabvfs90fp5M4XHO/uOHY9dzk98dWLF1R1zeN2x/F45PzikkoZhnHERjmQaafQSZpLl8+fo5Th9u6OEAKz+RIUPDw+ZpvTz+fabTcorbHVAmM1lXNi5c3vWPQeP4w8PGyw1nC+lsbWvC7w3rPb7SDBxao8AU5jiPghoNCESmPLirOcCCyNHlHvjiEyDh2FrVnWjjA4jkWBLip0UTMqeGgDYRgJ45gh3lH2RMWc7U54Xbd9yz1StLVWS6plUdIk4YGOQTbrpTOUVvPQ9+zbgVVlWZVGVMD7jrMkB6fdfk8/euaXKwrrsLYkIs220QcKV2C1ph/kAPq4O2C05u9/8xV1WbDrJMXs3YdrEomzuaTQRT0VfiPOWF6eL8WOni3tYxQbYlCarm25v7tnuWj48s0rSbZsO7rOs9t22CKyD3IonNdlPsg+IR+GUQ4BfSeqgrquaGrhNupiRuE0pdO0/Ujbj5ROrDW7duQ4CPfpcFDUztEURrikzrKYC8Ojruc4V7A59jzuj1hXcH5WUeqAUYlny+eA4np7yByuHAqRAipFzueFFLNSYOgDbzdyeLs8X4hiVEkDZD6boxW8OF+iteLQ9RzHkc3dA84oXpzP8BE+brpsX5FC86EdxLaoLE1t+eJswf7Y8f2nO6lhozm0nu2ho87zkaRnGmgKWNZ0g+fT3Z7dsed+11JYReE0demYlZn1phWr5ZxnF2v6fpQwnKrEzRvqqqIsCvrRM/pIN4x0Qy+HV/fULNkfj0Tfo1NkVjhuNjvhMpkSpS0vz2c0heEvbx/Z7lu+fHFObSv2hxalDcdOLEFN7fK7WUqj5PGAD4HaaYyCzWYrtsGfyRVzkIhPA2XheP3qubyXh1YO6TYRiHTHlrqp+fVvfiUhUs4RkxKQu6sxv1E4Zzn0e9p9z82HR9bnSz7/1VeMfuBw3DN0I8ddJ/axQ0s39BzbgauLV/zNb3/L9acb3r59R4wBH0d2u0c+KeG2YRxls0BZJ8yiqNju7tkdNnz4pNjsdsQ0oGwiEQhhBAwkTVkucMUcbRwpBHS0uFSyml8ylJ5/+d3viMHzb//2rzk/O+O7H97RdT2fr79ibh1lafFeEYPFj4ZBIYwl4wg+8f7TNSkl/u3f/4a6qbi9v5cz8vU9KM3Z+QXGWurKypk4p9zKfihRzXxGanjBRQwHUgxsth2LRcO/+8+/YBhGvvnT7znuWx5vNhirKUtHWdfMVytMMjivUFEzdIJH0SoxdCN9GzGqZN2UpNgSGLBO46worbu+43y9ZLWccX1zz8Njx86OxLGnqSqalw5bVWhrGdodYeggeWJIdP0A2uBcwXIx5/XrVzRNQz0rOBwO3N8faB9afOzRRvHFyzfUdU1E9gBWSVP5H//j7wgh8OLFS6qqZux6YkgUhaNxNb/5m99SFI6hbenajuvbe8qy4Jcvv8Z7z3/33/0jwzAw9B3DGHh43DH0I9bWLFdnvPnyBY+PW/7wuz+z3++5vXnLei1pgKTE5dkZi/mcZxdXXF4MvHr9irvbe/7v//Dv6dqB46FnsZhxtl6yPl/x6vOXkDQpKZqmYtZUfHj3gQ/vPjJv1lxdfEY911QzQzOvCB6ih+gT3h/pjgPnqzXr9ZJPHz/x4cMHwihWxv3+yOHY8e1fvsP7gd/+9jcslgt++OEjt7f3vH79nNl8xsdPH3GFox87koqgOqxxvHj1CtD8rjswjoGXr95gjOH7b384NV3/v10/ufAk4NNECh6fIm3bMvF+xFMbMzOCU8LF5FdW5BSHELISRpQbk9VAILSSdmJyl9ZoTdD6pE5IKSeeZD+2czZ3sL14y7sW6wqB2Oauhs2duTj2+EGfVD1GCbyRyUuZJG7VOCHNS0S1yGFFFuvx8cmL6304KWSmLj0x5g62Y/K0SuJFEuDlOOakOfluWmuwFhOEL+JDQA9i1zkpM7RBKUmDMRl8qLT4eSFJ5zIIz8Rax6ypGMaBrj0CYDJXq+sGbIbkQnjyuMeItZbZbMbE5LBG2D8ml/0nBZLR9sSJEWWHyt2xQMyFu6mjrnP3va4b+Vljsr8+UsxqbFGKPNNa9lO3++RNzb78PO5OSSpRFrFMZzh1IORnRQ1mjaiRjNZ0SNdqYmH5zEsQNY8c3FKMHI9HumE4dQHTtFDm59vUFVortrsddTNjXc/kmUNWsfV0fUfX9Uib1WVZwBMDZ+pcOudwRrNxFg2URcFsNiMmspLJS4JArkJP6V9psqMjyjsffE5HkC40xp26eQlRic2a5sSWker9ZInRuSqdmAWRRYpaR/hRKM2xEyf1z+VyzgIJlcePH33uqk2slJTnFv2vFC46p4lN+TkxqwYmhZLWOR0yH3StdZlBN/CU7Db9nolZMak2OHF2UoyZXTZxdoQVrpTCj0NWIT5xQabP/K8UUhOvIH9GILOagNxBjDGdYqZP6Tt5/haRhBSfE6LOwcNo5HBrc+LG1BmUYoYmhJGYv9fEj9JZnZXy3KG0xub0Onlfn5RU8JRIdPoskyISUfkopUhF8TQ/KHW6H0VZoExEGX/imyU0pJxKFZ+YfdLtmtaBzGbInbBJSXIaA+pp7XlSYercbRNpuXMOHyTlVRQVk9pC56hwWT9ED6CImVuVjIZsx5DUMGG8OTd1HoWj5Mcxs8hU7khJcluZD1RjVrGanGRTlAWjH3PyrKIsSow2wvTL66bKsqWpizux9KY1Z/pd5M8mlzqtuZOa1OS1IKXEMI4opJudv6yorTIzcOqqCSNC3imtJcllspzEGEXyntNxTFYpihIwM1DQeD+c5sRTel1W8Sk1Kf9+XoWniZNz4gWGgE4aa7LCC7Ki5Snpi7zuidIpv2fyYmdrqyLFp/UdpU4a1+kdtkbmvpDfb5KoWpyzApFOER9ATfMIUlSQJCaNNQJYtrnwGVJEp3hS8IE0qUmi0A5RrFtTX90ZfVIlTl3kmOe+SWVqTu+0cC4kbS7hXMppRmKZKpyTbjwTGyrvR/P+QlL0ntQ9k7J9QgE6owkqMcb8E3kPBjmNzhlGz2l+DEn+Rzel3FkrKqHcvVfKYHRmmdox8zlgSnS2VubHbpgUoaImcEbnfUrCp0AMUFgJiJEPn05zudGy1oyZ5VQbUfI7A0ZJwzjmez/6QGmzwhD5OybFmTXpNC/LGpMI6kk1X+QkKZMZUJMSTpRLmjHzxqZ1qcjJXP0wZuW5qIpt5iyJikBTFqL0H0OkyONr2lvFrEAacsEoJgnVmRRiIGqtaT2z1lAWTubWGNFaWC4xQTc+8QZ/JHY52eyUmtZ+sdz7KCoz5yxhSmdG7ldh7YkZqpXKZxyZA0VVFgjhSYHm8s9NLocp6fTncpVVSQiedpQz4PFwEC5wCPgYiElYZM5J8lzhCmGNGiuBBUHmLT/6fJZqxSrF5KQRZo+1jmShcKIetm7EBp9VL5lPk5suI4E0JvqhZ3fYobShrmshZRiFSqAiHLusTpvURyGSj6HybsQgYzHJ3DT0I62WBDmdU3El9U2K8t5nztF0xvAeWQsN1ri8nxQV4DiSsSSj7HHyd5iUqdYYSTJTijrvMWTu0TkVM9H3ktDtSpfPUU/rdAgQRsExVJUo+CdV0bTnafsO7Wx+7fLeUQkbzVpLM6tJUZOixjoje8Z85vGZJ5h+pNIVxIMUq8eMNLAmYbXcL2dLCtcTisllJHvZfhikGGmNFJ3q5nTOm1aSqWZgsoJzyA1R4+xJpS0MVS/7ciX8ptmsyY3NSpxWXYvw4CQBb2LttTm5zWTUxOFwIHg581sr/EGVMh8rwXIxxznHfrfHOWmAGp3X65AYe884+CeVmxYlsSRbSwJ5ipCCcKeaJtvajKGqKubzOT4dOewOOFfhrKMPgZCeVPyJ/J3zfq/turzHUtR1xdBn5lNms5ZVyXw+zzzvf83w0lox9iPEyQWihcmpNGWVG1rpp6vNf3Lh6a9+9VccD3v+0//433M8HuiGQdKNzkXREdKOEKJUX7Vis3nAHCyuOoj8Oxervvn+LdY5lnePLOZzXjy/YhxG/vEf/xN1XXNxvsZYy8XFpfCIjgd2O8WQVQGHdkApw9lqzbHvOXYd292Ww+6RL778mjdv3rA/duyPPSp6iAGrxW4zr0vq0nH00AeFywttdxQJXTUvcMby7voaxp6iqjCmYPPwSNd3GK2pq5q7R/FrxzFQKMNwPOKNYd7U+TAYIUSKqiGEwO+/+QsxBP7qF19RlRVjSuz7nlk9R0VIURJjNne3Eq3uxapYNzVjP3C3PVA5y3oxJ8TIfr/LHWwNumStLav5nMZqTFS0Cual4+X5iv3xyN3DA3XTYNY1Q+hpj3toZlR1xeXVJVcXF/jMCNlsd5ltY6VI0nXc391zcXHF6lz8tMaokxWpyzBFq2WhXwSJc3727AXLswtidySNA5v9nsGP/OLla9brNRaZuO+3Bx53e1arNbPasU+B4EfaruPYdnz7/Q8M48jnr19S1xWX5xekBO1hS9xngKZ1vHr+ItvJRkJIqBAgjowxEkbP43ZHSonaOayzXKwXpBD45ps/Y4xm0TQo3/Kn3/8Th37kZnPk8mzNf/n3f8uH62v+u//xP7FaBuaLBbGTDeHd/T3fv/0BoxVFUbJaLLi4uMgF2UTZNAQ0yXtiaJmtFlwsG/rDnL47cnZ2xnq55J/+8Cf+/N0PfPXZS15cXdIPnnYYqcqGi3OLspbOe56/esVsNuc//tM/8en+jjcvrljPZ6zXZzhX8O76nmM38F/9l/8lZWG5u7nleDzyw9sfGMeRz9+8oSkc37/9ntF7Pnv1grIsKEpH01Rcna9FYbE6k43zz+Q6XzR5IRXm283NR0BRVgLhJ+bktarGGks/5GJHfDqUdG3Lw/0dSmnszT1VVfH89Rek6Lm9vaEsK+bLJVVWgHjv6foRL6cExmFgv9thjGbe1PS52z0pnVbLOcvFjK4V+bcyAgRsu07eL+uo65rDbsex6yl8wJj+ZFXQyGKz3R849oMw5pxjHyN+HDCuwCpN27Uipy1K1FSUyFtja0yOBzb0XUuM/SktbL1ao7Vis9nIKp7DIMahF1uHsaSkGJACjUExjp7N/oA1FuMqscpOBftcCGny+BOriKjPZilyfiab1If7O4ZBUqK0tbiyzjJyizENzuZCL9n6E8HoCqMVu/2e7W5HU5XUVUlRiMy5yYl44zhw3D1gXIkxjmV+fm3XQZJDhFHq5GkvnaN0jqYR3p3aWpIyUuDXkaQMQQmHCxIf3n6P9yMv33xNUUpSagwZGBnlQG+04eWLlycwOkpRVDkt6uYaay3L1RoBSkesMayWC5RS7I8tCqhKJ5BkLQX+w37H+uyMX/3qV2y3W7797juquuLi/Dwf8iX96/7xIafY1ZT1nLU1UgxDCpWjDxm06bDGZcCuo6zKrHYqubm55eHxkZcvX3JxcZEbSj22KDCuEA7ZOOCMKOE2jzv6oefZsxfMnj3DWLFi//DDd2xubrm6uqIsK4IXYPsxcxSXqzVGa+7uD3jvMYWEgoglUA7+Sikqp4nq52NVATi/WBMjHAc5bN/sOgpreH11DiAhHilyNpcDhO87wmjovRT1uhDp+pHHbStFvOipy4Lz5YI0BEL06BTQcaSsapr5ClVoTNKEpAnBYrXm2A0orVkvZuzaju32Hm0txlhmpWZWG6qqpihr/DjgR8+iLiiMoR3GbOX0jMNA6TrQiUMv3KOu70SdtZd9x7PzFWeLGTf3G1EkpB9ZpI3jYr0igTSGUJSlJynoO7EPNKXMRx/uNwB89folhTN8uH0UxYMfJL4+ytFls29zsEa2rRTutGaUTnO1bBh9ZHtspfCSkHu+mjNv6mxdV1SFIQSLcgVDTOy2ByqriaWono0tQRsMFu0Ms9JRFIa6sHQ+cRgjy0JRl5b3N498vHnk5cWK5+cLqlIUmN0w0raeYZQCjy0rtLIYH1AxMPbiEmgqj1EGgid5j6sCldFUlUSIv7vesGt7HtsRHxKVEwu+NVLwvd4cSRHeXCxpSsNiNiOhaLuWrouMmYG0rqWgJXNGZN/1DONISAEV4dCLBXpWllgN80oz+sCn+w3GGJrZHKU1h95nJZdnNav55WfnHLqB9/c7fIhs94dc8NY8bFveXW+o65LVYsZiVvLiYsGx79kfW5qqYN7UJ5t4XQr38tC2dGPPrKmo64pP91vuNgfOM4PMaQVFyTB4Rj9SFgI3VloRSTwcR/ad58XlBa+b8tTA2Twe2HY9v3jzAmeNjH/veXtzTz+OvL5YURaWx60klMYgjejKFajC4rTMucfuye78c7g++/wVfd/SfbflsNvz3/w//owxltefv8EYTfA9KmlevXyDtY6hFx5kSBNIvGS/2fG7f/4j2ljmqzXzecOz5+eQEt/95S9UVcNidUZTl5yvzxj6geOhY/PwiPKRMI58uvnA0Isydn/Y0fYd948bPlzf8stffMUvfvGGzX7P9nBEJQ/JE5Qka75+9QXPn73gw/VH7h8fSEkCp4ZuIIyBUYmtrD9KAvt6vcAVBfvdDdvdntIU2LJhsz3SjWIDVVrx6fYD0tQpmM8LqmpO4QraTjhF3317g9KK3/z215RVyfbYsm87mrIkOUXXC1rDbjZiZxtqUOBTT9+N3F7vqOuaL3/xJcn37De3aK04O7/CjyOH3R5rEyH1VHXBZ599LoUSY9ju91zf3YG1LENg6DoO+w1VU+HqGWeXaz6ff4bSUrDa7vY8bjfUVcV8tuTu9p67u3sWqyXz1QJTiGiinjWsNdw/PvDp4RMuW0u//GLJulmhU8HYDGLHS4HNfsNmv+XN61csF0suz69w1vHtN9+y23ZgNMWsoHFLrDb45NkcNvzTP/6evhv4m7/5LfP5nBcvXxBjYPN4R4qJ5WJFWVX86le/lIKfT4x+xDqLKSxJwegD2/vHbKkbxIHz/DUxJb7507eUhePifI0m8vH799zc3vP2+3d89tlr/vf/h/8dHz985B/+/X/Lcr1k+dXn+Ji4vX/k+tMNf/7TtyyWc148e0mR56aubzkcd2ijGXpB3mgShdHMm4rVasXhcuD87Iz1ask//uM7/viHP/KrX33FZ29eMYwth7Yl6UhRlrRDR9h6Lq4kbfHtf/hHbq4/8Xf/9m958fw5tvwNSSX++Me/8PHmmr//u39DUzfc3H2S8/d+ZEie5y/P0Ebxp3/5hnEYKZtLmqZmvligNSxWJVppztoz/P/UVjufOUHwo+6xzilCWmMSBK1ziop0PYhQKEMiK3qUYr1aMnGXlILSOVJOzogx0o+jdIxjlLj53KFQWhar7W4vm+WiwMWE9jH74vWPOCuDVKKjcIgmr7CxFlcUECQ1zWiLtjmtKQm4uyxLdrvA0PXUszllWaH1FlKiydDWlMjSa1ErjD6gU0JZUfcYlX7UJcmsAp6qsjF4Qk53ibl7k2LMVV17qoZ3bcvgn9QZx7YlpCRg1SlWBU1RiGd0OliHLKWfeE3OGqwg/TFandRB8JRWFIMUcYwx8p0V+R5JN6AsHEVORAshUjjLYtbQdgN9BvGCsGT6vifFgMlKgIljMo6e47EV1VRmRchhsmLIcaKHYyuMEm2yWkOduDl+9BjjskLCQlYgWGepc1egaztihnj6EE4qiCCG/9wFnJJLnhLCpGP1xCFQiXw4lmSCspgYIip3pKZup3yGui4pqyqr0CQVJkXhmoSxxw89XekY6lLsMtpIVzqE3P166rQ+qZvkn2lcqqyuMUaArTYDeKeOxPTHhDeRk/LyO/FjhscpmTCDOYyRTgTpKc0l/owKT+TN4alIk5UYxlh5mkqq+MI1EubbiRskDwWtNWVZnjonSomlMnpFzPPiOHqxUybp9sQpncTIO922LVUlShnpbofsSZePqcidpQQq5jFE7l7ESPQZ6JxiVqSpU6df5eKLHKogpeL096WURFWjTe7QSfKoinmQJ+l+T0qWiYf1r5L/yOqwPE+cms+5uyJjTIroMSZSnveEOyIQ8SnZROmE8vr0fimEaQYTZy4RvKjyXFE8ddP1lPozybjy+6tV7jBGSJImRX6+zrkMRxb1p7BCRLkj91Sk0FP3NOR1SvghTylecnvlebZdl61sIQ+vSVk7okLAOflOouT5URppVgUbK7BN68Sa5wqX79MT40recymm+MwAtDYXuWIUjp8Xhpu2VngBbcc4jk/8Qp7SPLXS+Gy5VmrivZiTwlhndUS+s6c1SxgREWMiJ56MdcLn4amrFif7lg+nNTumSGGMdO/y95cUlSIrRiWNbtK3ngRWTzPgjzq98t9PjIYoneNJQZcmZdnp3/98rnFKFoP8TJ+604gYCpIimem9fUrmSkmUj8ZaqtJlJZ2kBpWlA5XVF/md8SFyzFB7UUXLsPfeE7LybEo9jDGgkyg2TGbmTCpyHyTpSbr/kqCHcoxDJCThHqmcDDYpc5Ixp3dkUohM49KarEKc3skos+OYOYZTp9VlNbGMpUkhSWYPZbXOxAIhIbgTYS7Jn5FBOHHkdFbwDV72eSHEE3tIay32Ni0JlpNye3rfFUmSA7NSYdJTTfs7rRLolNV7Bq0lwU/xpAQj7w0mdV+IsocpnagaIiknCSkBYqdw4jOdEpCjvHvdFAigZC86KR1lcMl3UrlxGuLEY3ma+ycZ0LT/r7L6ymWl05QsrVLCKEnTmxgsE1vQ5IPqlLaVsko3RMXo5fMUTuxokzV4+vt9yOtpEvVfUk/vg9Wi0DNKUplTTDkZNZ0S8yYVk8nqQZ95U7JORn7MPg0xEoIozcqiICVPP0rCYWGflMc/TtNTWcWkdP5eTArgzB3Myg+yahGlKMykNH1KrP45MepCGCV0BFElWuvyfrrMSY4KkkJFSaE+tmLHdoVYEcexB5VYLhcnpSIkilLCQsZeOEl9NxCMJuSEsa5/UqWPo+dxs8GqAueKzG60aB0xJmSFoeyNjVKnsQ/qtDaSx/c4eKQEmXmZ1qKsImnwbaDvvSi2i+KkEK+biqIoBD8QIPjscskzwuTEcU6Ujun07iV0mo4BwnBNSiMDP//uqDBWozQnJ8OYxIY7KZvb4zGf34Oo0vtBzruFQ2lN2/ZYC1VRZKaPnAOb7JoIYQSVZG41sj+LWYFq0ZmZJ1wqhTD1rHU0zYy6rqmK8oSdqKoSW1j6QfAeOr9Dk5NAQqdkPdKIs2UcRo7HDq0spdvhrIyVwhV040EYRr7DKE3SeX8sG+dTcIt2loQoTJWC2WyWlevS7ItelJJ9bpiUlRRTxswDm3idk1pt9D1KRfqxl6eYP39ROFzhZJznc5vJCi9hs058WVEOl3Ulc11hGf2keg2Mw4DKc9MwjJLwmNK/OrdP+38Qld2UuDwlPc602Ihj5ks7a2nqJs+lIypYUOm0d5pcMxOzVJoJT0q7J3ZkOKnblBJZcFIx771+2sHxJxee/vD73wOJejajmc8orcPYnDqjNZVVjD5wuz0y+kg7BKwrWZ5d0R723Hy6ZrVc8F/8/d/yuNvzL998y7yumdcVde4k98PI/eOOwctgkYSpHm0ctqh52Ox5/+Ejn795wy9/8QuSrQimxhjpws4WS2GVjD3d/jHDvMcMdwwYW1A1Cz48fODm7oGzszPmzSwvJopn52eszs74T3c3PB47vvx6zeXFuSSBpcTLl5Ks9rDZ0g9Ckk8xMgSRR9cz+R4vLtdoBd989x3HtmW5mANKusFdR1MVuFAwdkfGYRCFA/DlF1+gtOHQj/TDwKfra4zRLFcrxnHgD9/8RSwUVS2pIr1n3lS8eXlJSIHf//ARTcKpRNf1bLY7qsLy2dVaFvdxT11WPFu/krjQ0XP/8MDH6xtKq6msZjZf8PLVS+7v7ri7vWO9XvL5559hokdHjw8jh6Pi6vyM1fwz7u9u2e427PpANwR22w27zaPEfBpRPQQfOB6PtF3Pf/yXfwEU67ML6rrhxcuXPHtZ8A//8P/k5uaathUGzOvXn9E0Da9evhJuwG7DduixWXb58uKSpqq4vBSF3WG/o+t77o4t/ejZtQMKuDpficQZ2VwUDlCJ3XFAa0U9W0CCdpB0segWJHpW1YiJng/Xt4Tg+cVXX4A2JC12zKq0XFysKQsrFs+qIY494ygKlSEmOt/CsaU97jkcduz3K/a7Pb33oDXb/YHd4UBTlvzV119QuoLRR7QyFE6xj6IsXK1WvHrxgo+fPvHhw3tWTcX54g394NkeOx63e9kkZ8n73f0dgMhGU+IXX3+NKxxkGPNyPsOPI/OmoSgKMHIA2bYSDPCw3Z0O1T+H65gLBYdDizaGZ89f5YKHbLpTFJhq20tx/XDYYY1lNp/nog801YLXL5/T9QP394/C/3EOXTiWs4a267i/v8tW4l7YNtn228yX7Pc7bu4+cnF+wayZQYokLz9nrTyb9tjKoT3BOIy5aB0xztG3BzahZ+x7tEonq1MzE/aO71q8H+j6USwOVYkyYoEOEVZ1I12Q41GKw8eDLF56WggNxrhsd5BuflIJV5SgFIfDAZAFW2udrT+yabLOcXl5SYyR+9sbsYANcjBbLpcMw8DNzTVAjuxVKNVTlpIQ6IPn/u4O5yyzpqE9Hri7uaaezbl6/lKKeXmxExuGFHr6rmXse2xR4soqHy4iPkjRqKobVqsz2fx6Cbdou57Li3NWqyUP9/fsdzpv9gP7w57D8YjVmnlV4qPIlPtuOAUN+Bi4u39AKVgsFsLaC4FuGGgPe2meLFdYZymqOsvWpVGxP4oF+uXLC8qyojoVk+WZD1Ex+pGH+ztSiqxWa1KK7DcPaK1ZLYU3s91tT2dqayxaKbnHt3dopTg7P6dwlofbT6A0L58/pxvGvB445rXAVuu6zht1adSM43BqjoAUDLphoD92LGa1FPisZTZbgoYhJoqqZrWWZsTDwwP745E2J+aNQ89XX37JxdkFt3eivry8ekbTNHy6vuH+4VF4P/l3zucL9vs9u+2Wqq5OrDE5tMvm6my9yg0EIPgMN5disU+Rw/HwkzkD/0u53n66xxjDarGU5L55lZMdRbrfRIf3mkMfSEmRlBRRjEJ4QbZhNdf88uUF/TByu93T1DXPL8/x48jxeMxqRHjcHXj/9i1lUdDMaiwJlwJDiHTeM6trFosGn4sWhTXM64qqNBSFpe16Npu9wJdHLw0QLYm2S1dwv0nsBs+2i6TBc7WomFeWMZSEGHnY7Oj7nsEHhmyR09qwnDdYZ2kHzzAG7jZ7umFkVsia1wXZIL+6XFNaQ3eUA8lq3pAS7A/tqehpFRTYbIUVJfvl2ZoE7NoO7yNdP2C04nxeMfrIh/vDiZs2DCOb/ZFlU/Hi9QX9GPj23SfKwnG2qAnDwNi3p0ThaZ05JacOnqE7MtWWnJECljM6K/c0xy5SOsvLs4ZFI2iDbhjx3YCzhmdncw59oBsjrrAY4GEn89essGIrixHfjxyHwDAGbjd7gvfMZiWFszRVxbwqCN7Tj4nN9khIUBQmp1sGjFIMEfCJNOxRStHM5xTOcrWSQ8zjTlKvHrd7Yog0VoPTmLpEaZUtoYo+A9I9gLEsFgU+BGleao33UoR5dnlOXVhikgbauqnofeQweARVIWPu5WXCGUPlDFoliRn3kZAUh1b21VNRPIQlVsufXTYNISTuNjusgstVDSnSDuOpWXBsA/0QeXnV8OxiwXcf7njYtVwuKp4XlsfjwM2hlcaG0ViVMIVme+jwacKMSPqhJmGsJmnN2XkDCFqhz+E/xmiSl4LTseuz7fPncb1/+21upBkWszUv/80birLg4nyN0uBDR9+NXN9sOBz3fPzwA/PZgl/+6m8Yx57r63fMZjP+j/+n/z0PD4/80z//C7O5ZbG0aOVQ8ZL9/sDHD5/ouiP73VbqtRoKW1IXM+4eNnz3ww+8/uwNX//il3gSvQ/M51KsnDczxmEg9gOp69gfWnbHlrEb0EpzaPeoR8XN7Sfubu9p5hVlXXC+umTWzJmta1zp+PYPH9jeH6jrOev1nOXyAZLizZfPmc8b2gOMfeD+cE3XHWnmc4y1FIUU7RdzKTxt7z0pRM7PL0DB/d092hjOz+YY6xjHQIqK5XqNUonFWuyMdzf3BB8JgwQanZ8vGceRP//h96IKLivGYWC73bBYLvjiyy8ZxoFvv/lEUTqW6xntsePh8ZH5fMFvf/0b2vbIZnNHVVacv3pGP4y0bcdmPLDZD8zKknldY03Js7OGw/HAdnPk/OKKr3/5V6ggqZJt33M89rz+7CVXzy55/+4Dd7d3HA4HYdwd9xzaPYUtpBknPQyGrqc7tPzz9R/xIXJ+vqCuC168eM7rNy+5/x/+mYfbBx72G0IMvHh2RV1VvHjxEq017XHP8bglKYstHG8+f858PuPzl1+ggHefvpd1ytb4vufDO3FDvH79ipRgu9kiieLCw725uUZpcIWhH3u+f/eIQqOVCAF++YsvaWYzPn76hA+BX//6Vxz7jvuHexbzOaurJZdXa5R+Q1XXzOcLhlGS5vteuFPd4Yhvx7wmZ9SHNrRth9YIv6z1zOYLfvXrX1FXFW070neBvo88PGzZbXe8efOcL778jG++/YH7+w2vX7zg17/8BZ9uPvKHP/3hFIbTNAtW8xUfPt0Twh2FiRgFq1UthcYA3keWZ3IPnEuQRCiCUhz3R0jwcLdlHP6nVjz58dSBfEpEghgCmoTWJYnA8djiYyJNGSBpSkyxwgnJ6RsmH1xEOZSk26uEG2CMzh5ERcgpdDFFrHPM5guqssRqLd0ko1Glw6kalYSnFEbxzIcQJOY8cwakmhhxxlCXYtEYhiG3l3LnP4ryqaqqU/pTiJJK4cOPeAlMHnKRZQux3lJYLSkZipO/2FV1voc+K7+kc1X20qGe2DvGFihjMF667sIfcdRlceLFCCRuEOtg01BXDpJ0Z/ohYBXio1WKunCUhaVwlnEcGfpA0P4ELvZBkrz8MFDoQirWWaklk7eAhbvBU1tF4Ur6MdIOHaNvTilzPqZcsVeooORQnSRpZDxxRNLpPp68oCllppLPHvwidwYkArKuKqqqRAFHLZ5XlEGpbMvJXTspwvV0/VMyRFkUuRsmn8XnyrQ1ElvsU4SoGL1076wTqwrW4VWizSqoE+9ETwqkqfOucud52nzX9DrR+e7UuR+GgWHoxVeclVNFUUiBK/nTOEKFJ7VREt+1My6Doh02d8tSvl/WVpSFO6W9TByUqnAYa09shpOSRutcGZemZdM0BO+fksUmJpCaOjDSEfy5XFOz9v/zG8m9V2ITIxCCqHKmtCgZcPqUWCR8uInFRO5AqZysI2oerYSxNallYm5da62pKrEHTaq0iWdgXYHJz3fqog25UCKpH+6ktDTGUJzUCVJItDGc1A3aaEl6yl3XH3dAptQjbSxKy3xuMwfMZl+3KOsk2lzHeOqwgLwLY7be2Rz5LMpEJTyiJF1skCKGzPlzJkZUyt1kbeT3yL2QznGIAROnVE0o8lxgjIEIMYU8bwTIc3EMU9rdE8w8hkRS8jNjfobT551S4UbvT6qcRO7AGy0qHmWIUd6r4cSdEdvEKe3JKIzKeW95PTRaU1WVWPTyekAusgmTRD5nFouclE0KWRciiC03xlwkTk+LfogY5L2c1qiURK0W89hKScDNogJ76pwrBSkn7UxqkZgmJYhGG0tRqBMLYAKj+0G6bpPlVhJILXEMuYMtf56sIghZtSu8AnNKPyyKAlcUWc3rslJgehOFuRADJx6U0XJAe1IBPL3Dk2piUgmmdHq7T8q+U3LVz+hKaVIYppO6LqWsHlRgcxfah+kePBWelMgKZU7IShVnbd5f+FOKkKzlwihr6lIKRpOyKa8lhZ1UKMIWrMuCKu8xJNFH1vtxFPbOMHoqZbB2ekfkszpnGTJBT+bNwJRAJEln0llXSHDAMHqK0VPAaT+hkmyOpduuBTNgDLWTzzdqDToSTU7Z9V72JtpitSJp2dDHrPgJJ0mZrPs+v69Ga6KR9T4mdVJIzypHVeZ7hChYbJD0YpQSRbLVwoGZVHtxUmLldwXhc+ms7JFOP/gkyVsxkdW5Mm+PIdCPI8lqUuZvGW0mjVZmBU3qGi2Je8TM0pE955j3uhPLRWXFkoBsRfVts/pLZc7eMPq8tgkXRUPmaYn6JOR5UiP/4ZTcm5URQ/SgtIRhTAKhJIpepfRJQTS97Kd9l5re7SdVKXDiIRY5fdrZJxWBONtFVZfSdO8NE3d24pKKuled9gZKaZQRlYVSCWsiwSqmqUQhFmRJTNUnNYmoTydFGFk9SGbUKYzOGnklCiirJnmUyj+v/tXeZOJc/VyucXziTU7swylpbLr5IXoOxwNt1zFlwsXgSTH8KzWltYbCSVF06CW4SSuxm01qkGZWC6N36AkxMIwDSiuaWUNVlzgnrK+qLCmcwTlJ8GpzGrvWJrtNOkzey8l4TpSlcHQT8vsnxiKI86EoLFXlcDn5LkZRfY6j7DdIeUxYg8vFYesKispiC5tFHIaicNJILmR8Ho/CPz4eWwrnsbogxZzEq9LpXmqt8YgKx+Go65Uo7JDU0akosFgumM1m2JwMF30kWtkvyNlrRtM0VGWFH4fTeU3Wi6ym0pCiQpUVZVFOOs/TZxmGgcPhSOUcpXXE2EpDYRhysviA95IK7ZwjZSFXymmlYRSp7ZAT/aYk8idmp85nTkdRlSyYEUn5c5fM5jOUUjw8SKNVO43OfzYlSSFPKYlK3HsKIwnFdS1ndZXUScGTkiSxBmBIUSZtL2uCuIMM2jhUQtJ683jMm5Zc7zA5eIas4NWZ3dRgOnFNRCfczTAKX4usgkeJa+mYYm5qg0H2xBFJVhy9qJSKoqAsHWNRZCZnbuyZKR047/0g88ay6lVNDFBJwlU/moOEr6koq4qUZO0K3gtCCZ7eZWRO/ynXTy48yYYvQYYeH48tmkRdiBTVmEs2+5bf/fFPWGv44tUzlI30R9mMX1xeiq/80zVt9ux3/cj761uMFap9jAFjYL1a8/rlC+4fNvzw/j1t17HfH3j18hW//PprLJFCBQiQCqjqmsrUXN9v+MP7DywXC1bLJZvtlsfNPZdna9azJSoGjoeWy+WcZ+s576/veLi9ocr8j93hSEya89WS9aKhdJq+P7I7ttzvjnh9R1nsWdaGyilwNVppluulyOaMwmpDXThSgrqq0dqwWq2JKfGX798y9D27vSQ2jT7Ky6pAW8uoHVZbmkqsKn4cKQvL84s1wzDSHnYcW/Emn5+d8Xe//TXD2HNz84l+DIR+RBlLVCXzuuTN1Tonr4mS49gJ+yo+7CT+01l0CjhGlvWM51cX7NqB27t78cXP59zv9nz3/ppffvk5X755zc3793y8uSakROsT9/d7dvsjq/mcxayiKRyF1by/eeBxf2QYR0nmCwmvDK4SiNt62TCrSg6P18QYeX51wfNnV7x68ZKqrvH54HTYPDL0A9tqRvSRYtZQZLnkOPR8+/Yto/dsd1uJV9Waoih5/fI5IQY+vH8rAPDDHleUXLz8TA5n7ZFxDDy2A/PZjK+fXUkRoCx43Gx5uLvDYWiKQrgBbUfhHLPC4fLimcaRfrdhUZU8P1+y28Hd0IIKBAL32wfevXvH8xcvePnqFW9ePOfzl8+4fthx87DLMnLD2w9vuXt8ZDmfM2ugacTiSQoCqjQKP7Q4nWhKR1OLdPewP0AYReKtFc18QVHWMPbEENhH4RQcjh3H3jOfNbii4NXrzwCkg+o9+80tpMj5+TnOOc7PzqaS2M/jUrLg28yw6bsjU3S3MWIl9SGw2+/QSjFvKlGiDD3WOcpmCVNRO3ishhhGHjebLPOXjkBKkdVyyYvnz9nvD9zd38vcdTyyXC559foNKkVUCsyahsVsJlZl6+j7nn7oKayj1AKEPxwOnK3XLLLySimocuH+7v6e3f5A8F4iv5MUmpbzmrIo0K4goTh2LdvtRmynRcH6/JKiruUwk0RBUpYFrpS5ylmTFyLL6EeKbAnuikK62vd3KK05P7/EWIMtSlIMXH/8gNaaZjYTlc52Q1lVPH/+gqqqJGlvGNhstzRNw5vPP8ePns1mIx3RbIMZRk9Z1Xxxfi6HpWxt8aNnHAe6rj0Vj4qyos5y7vl8IcrCoTv9mcf7I+3xyOvXr3nx4iV910kK6P09+93uZAery5LCOVw1w7iCTx/es92Itz/EcIqLn4pMZ4s1dVWhrCMpJffPKC4uPqMohO8VYyLlpsV2u8UHjytE4dTlDZj3ObY7c6+KUgo0r16+IsbI7d09Ywz0ETmw5NONqJsVISoMhrKqMcZy7hy7/Z53795SVyWLmRSYj4cDxliWsxkxSeMiISykuqpYrGdSWBv7fBhX7PZHPn28ZrGYs1wumTU1q+WSm7t7dptHqqqiLEuCHxiHjjEf4MtmRjObYS/OscawXq9FebY+o6prxr5j2x2xWrGYN6KMGoV7pbVmfXaBK0q69kjwovxNCepmLg0VLRu6wHRoHJg2UioXd0Ms/v831/z/4JqXBUrpkz16HIes3jhSOMO8qUhpYN/KwWJeCWOtMXLIKeuS0Qce9l0+oDmGwfPDu48ni2REEVCslzP+V//ZL2nbju1mxzCOtN0gjInlLMP1HYu6ZFw0Em/tCh73B263YukIo0SAd/1IUZTChdSgkmdeC6do1we6MdG2HX0baLIFeT6rYVbT1CXWGG4edtxv98wXLYVzlE4UTotSY2pDPV/jnGNdCTRbDlmJVBq8Vbggxaq7xz0+JqxPWGtYlZYYYd8HkorEzUEA+kYRUuIwBEonwGprLOeLmmM/ct31NKXj12/OSUnRj0nwEnn+6gZp6Dy/umAYBra7Da6oqBrhGAkEXJQ5SskGvCkcF4uabvQch5F+HNl3QYolqiBqUX0dugP32wMu8zSbZkZRlkCA4FnPHOuZw+f0os1uz7HvKVxx4ucZbThbzplXBd0gh7lZ7VAIxwulGJImokRl6gMfbjeMPrBcLKS5RUQFz8frrewvoxTh66IUVl1RMHrP/cOGYQzs2pGqLHjz8tkJmzD6QNeOFFbx/KwRlVE3MoyezbEnNQVXC0dKgXbwwuqMcihqHGgU3ltKZ2kqe2quDd4TfQ+5IdrMGprZnOW8YtmU3G8OfLjf8XzdcLaseew8+yEyq2vqskSniEoR51oJtkDS9woNy1LW3hEpZBU6oZInRUXrhfs1cwpnJFxHa8PYiQqsRyLcycEmNrPtEpLIrVVCGcPFspiqkz+LKwSVhQdSwdtsN9L8DQGlEyG1bLZbfv+HP2CN5bNXryiLgv3mXrgxszVGG+6u7+m6I/OmJMTEh3cPgpEoCkiKqqxYv7jk9WeX3N7c8u1fvmW3a7m9u+bNF5/x69/8irIoqIpSFIZlSVVZqspy/7jh7fuPzJoZTTNn/HTDw80tr16/4PLqQhKDjeWLN6/hsxf88U/f8fHTHTo5hnYkaWjmkdWyZj0rmTUOrRLb/Y6bO9lbN3XN+dUlZVmyupiTUs3ZYklVVpxdvKQsa2azkhgD7bGjbY+EIBy1w0HWwfu7Wwrn+OVXonidMDKHvUgJ62YGquX9p/cs5gueP/81wzhwHLa0h46Hu0cuLy/5d//F3xOjfD7ZPxqcEQXZ+dmK86/XpAB+SHSuB1OwbwfuHjZM4SvWWAqbmDc1n332irv7e67vrokhUVrH+3fvuXm4469++Ut+8dVXHI4H7m9vCXHk7uGOu5sbttsNF+eXLBYLZrM5RVny4e0nHh+37A97+qGnbzvCGCjqhrooeH51xWIxwyqDHwIXzy5ZnK+4zCnoIe8FDIpxGLm5u+bQ9SzKGmUMh/ZIP/bc3Uj67WG3RQGL+ZyqrvntX/8GP3r+8qfv6fsRP0hgRlk6gtHSEPaew65ltVrxy1/8KjePHTe3N/zH//AfuLi44LPPP6MNnu12L4nvqzPKykmoQ5RE2aaoePP6BYdDx+ZxR9v1HNojN59u+XRzRz0vmM1L5jPLq+crttt7Pt3dsD5bsFrOOdw/cHd7z3y2oq5nzJcN64sFTenoLjpmTU3wnvVyQekKhuHIzfUOaxxnq3MOhyODH4k6MjJw+eycwhXstluxKHpBFc3nGWdTWWIK7PcHCffyokg1yojCsMrN259w/eTC06kznbscZeFQJFIK+CALrkz0c5zRJ67MMAxYY5jPZlmmLPa06YCTUmIcJTqa7Iz2OX1szIT3KflHkRj6nqQSSkWGcWAYOqGuW52tKSF733/80XPFL3t1y6oSIOvjDms081lNU9doEsPQQQxZDSUWDUBYQloiT/u+x2vFermiKMpTJ9n7SNSJtpfNcj8InLcbZHMscdtkBYw+sV6aZgbK0PU9xnhKnQ8iRU55MBqvpZOjlKJpauqqkmr2MFVvoS5l0RKblHCJfPD4GE7WnBAS0acT58VaRWllMt/uj/RebCcnhlR+Rv0wsD8chNtRFCTk37Vdx/HY0pQlsSykSmvlRSydI4SBoIQrVThJubDWUua443YYGf2IsiU6V52DFwmyzkq5FCVCWQ6o0u3tvRw9DkeJZe0HUQ+UtsBZK4ei4CU1ZhxPnKm+654SLlAUhXTxJH1LYYImZTaADzlGOYQMwZN/pFLeylhO8ZTeZaxhPp/RjQHVj1RVLVHnRUHpLN6PbHY72vaIHweIhhRN9iGPuZv7lEpgjaHIn/9wONJ3cmA9HFv6UcC/i/mMIVt1CucorMmb4ZAPkyPjEFHaSNJCUWQOz5OyZ+jle9j83Lpu/FlxBrwfxZ6TFYwuFy5T7qD0fc84jtjstZ/YTzF34qcxGLwoayQ9LNB3A5EkHaOsIokT1ysnmun8HCeuxKSykpSnlBVT5qRYilGkySqlE9tk8qUrVJb2S4c4hiDvUlnl9CbpPnvvscYJA80VlCf15hMrbUqmFHZBROc0nTSEE6MlhMAQUv4e0nU0VtQNuQnPBNIfsjor5i6PMSanW02R1HJNTCFRcMhcoxSUZSXvdp7jiqIU3ksaiblTytQdTjlFK9/zEIJYs8OUdPn0MzF4hmGk60TNJh1AUer2mVvoMgsqeFHf6jz3Tl72Iqd3kN/LKWElIHOyVgqy8uupc5/Q2uYOUzx9L+nmBiLCZIgpojILy+b4brlZKqcuZf5Oeur2GevE/x+FQeNz8p+xtbCrTiohUUWI2kkKr36M9N6jjEChURNrLGZVJdL9yko7l3krMQT2Byl0uqx2m+yL0wFNy43PKhyT76mnbY/CHswchHEcKKuawjjhOiQE/J4B80zPLndZU0rMlBy2o5f1SGt7YvwolTvqudAX/M/HJgwwvWwxSoOhLotshxRVyeCDFFWsPT1rpRQRKUD9WC19UpXkBK+EqJYTnAq9Y1a4JJUVfVktG7zwUEQRK2uVNhGb1VejFzW3cxYfIy4+qfRiUqfPWBSKMXkigVIrrIqgjaTpZmVESqJUUrnIYrNixftAUFA3BYWVDjJktl2SJLUQ4ykNjqx2sVL5EsYQT+piUbrD4AMmJkDYSVVhxfZmTFYYSnnTWfn3E8sxZlXGohZu26TssEYTzMSmEtXjiQf047aOUvhs8x6jFABJoImopImI6nz0Ob1LZ9Ukin70jFExKw3OiqU3TqpFJVxPmxUjRhucA5uEq1oWjn6MpCT7Ho06JQb6JGwnpyVtrnCiulJaXAn94BlVYnvoZH4yolIPmTdp8/xRWEmU0krCO8YQMLnQ/pSiyclFUFjzxKSaWFzkVNoYici99l6i1k/K5KxMK5yhdJbSGWKQ5L2p2x+ypS8mOXtMyrAYRZUTy/y7JvVZ8nIeGD0+tDlxW5gvY5I9o6nEHhoTFFbeH61llfdB5vXBS3oiWWWY4sQ1e0rEVSrbG7UETpwm8J/BNakyBUKtqUoZKz4MJB/pg9hqq7rMjgCHsZKWa1zBbD7LKjXhbs5mc/p+ZDi0mSno0cpgTYEfZZ0fs0vGOkvdSGCMHwNGeXw+k3Z9R8ISk2UcZN0PXv4+WdNTVtbZk4K2KAuc1VmoYFksZqxWKzmfjSMqeFRWhU/768IJ08oYS9fKZ6tnJdYplLbEqPA+orVnv/eE6Gm7lr4f8hwoSiutFWEsJc3NGrTVuMLifaDvB5SGqhIObVWWougqC1GgZE5PWZWUdUlZ1ZkbJPd0uVxk1idZsV+IZc+PWS1uiF4jWkfZI8j7ZqV5+LjlcNzLWRybeZqSUtv3PcdjS8r3L6VE3/W0bUd76PALgel777NaGZx7YnnWVQkluKrCOJv5SYauE3dLTOG0D00pntZKozXRGmmOZgeQQs46flT4Xvi6XSfIlRmc9q0pZtfQ6AlhJEUYR1GkivvAEAIYa/P/zrwtLSpTP3oRXIRwwmI4J46dw6GT/XcOkhlzkFHTNNkBNuAKiyvFddU0NTEmdrsD4zCiFcTgRUzRdrRtR+FqCifOIGNEMUdMjOPIfr9nHEZSjPTdwDAOnJ/PqKqamMAMI7Y0YgWOgaGX5uw4jnSt1C1W6xVl4Qg+QZS9sVeew7HDq5w6rxXBS7jET7l+utUOS8Rz7AdKZ/j65TNIcH2/YQiJ/f0O6xx/97d/CyT8IDayzeOG5XLB119+Qdu2vH3/AaMV63nJGCLt4NluN3x891Y6o2eXjL1nu9nh/cjQ95JCtlrSt0d+9/t/Zjmbcbacsz+27HJqkrMGiNRVARraIRCVwRXVKZ5TW4u2jrPzC9brFftuxKfEr7/6nOeX5/zx2++5ub/FJNAJuv0egMo5LtdrlvMGoxV//PYH2r7nv/7ffs7VxTm3t3ccjh3dMIosby+HnI+fPjKMAw/7I2VR8vnLK4wxPOxajNY8vzrHGM1Zf8Gx6/jmh3dopXh2cY5SivPLS5qywOTBtj8ecK7g66++oHAlXdex3+94vL9lsVzy5edv2B9b3n26oc7KmH4U5ktV1axWAkDuBvl33TAwb5ZcXJxxffvA7779I2frJZcXZ6TgCcOIVZp5M2O7eeSwu+fs7II3L1/TjwOHw47Hh1vu7u5wOtvPypqoChbzGbPCcv0QOJC4PJtTFSXNfIFzBaFvCePA8dhxaFuqBowNfPeXP6MUXD1/LYUbV1Aaw6Lc06uAH4/4QXE3FISU2G0fiRnEW1jHbDaTwlwzI0bP2XLB3hi2hwPdOPL+h++omoZXb74UbgZyeLx/uJciZFUIBycMtF3k5u6W0jnWswZblBTNnO32kQ8f3wtPC4llvXvcsFrO+eqrrzl2PdtjT1lWlGXFoilZVY7r60/8/o9/xBlDoS0ps3Lu7h/Y7lucLbDaUleRlDSldbgq8vi45eNwx9C1+HGgT/ckrfl3//a3vHx2Icyxvqd0JQrN9rHncDyw2WyFe7Xdo7Thqy/ecLZe8vbdDwx9z3w+AwMPO0n8+/VihStKfrj9C103/NSp4X/212H7iLGW2fKMoig4m9fEGEWRNwzc3t+Lp7kuJaUp84LGrsMYS1PKBlM2jIrSWQ7HlkN7i/cjY9+JldKVHNsjb9+9PRU+nDNc1EtiUmw3W8qyoK4qjsc9+91WxnhdE3ORIIwdYehRRBazhqYuTwVlpUTu6pzD3SoII2dn51xePuP9x49sd1v2hwOaxPLMUFQ1Z5fPmK/WqCgS2f3xwDHu+fzzN9R1zePDPX7cn1hOQy8S9X6Q4mPwHq0Vy+WSsnCUVg6hLsfsjpnl0vWD3AMfUGjmiwVNXTNrGvqh53A4kmKgLp2knm63whbpW8qy5PzZFX3X8fhwDwio3/tIQKxTCim8qF4gvFaTwb+J3f7A3eMjdVnQVJV0lmOS4rKzbPc72mFkVlcsZk22hEV22w0Pjxt4+RJjDd12wzgMLFdnrFYvuLm95XA4cna2pqqqvEGNsjnWGt/1p/ujlOHYdrT9QPTCl2sWwpeLUYqYRpHvsYylbhizXFmA52XdEKJifzhgjGG9WtH3PfvtlpQig/ei0JuvUCkSvfz+x4c76tmc+VISYcWuIZ10tIBOi8LRVI6dH9gdjsxmMxbLhhhGdpvHXOQ2JCVqguWsxupn1HVFU9fcPzzy/Q8/cHZ2ztn5GYf9nsNhz263Zbffi63bWaIfSd6hCrGH39/d0nfdqcjRHvZ4P/LFl2uWq9Wp4SJpdiV3t7e0rSTjee/ZHw6klLi6OKMuDI+t2A5m84KYEtvtBoCXL15gtOF4FFbCz+kK5EhrH6gKx5sXz1AKNvsDow9sHg5opbhczyGRrdOKLmlC1BTZtqLI0voQ5BBYV4xjIMQh10oT233L/thhbLZLKosrFb0fONzeZQXbjEPfcvewZ9GULBtp6Ix9x3IxYzlvOPaebvA4JYXAUUFUmhfnNWfzCrft2bUjV8uKReX47vqRh31HY8SS4AOEkJg3Fc4oVvMGZyxvb3d0Y+DyfEFTl/S9xw89t4eRFAMP+4ExCJzcaMPFei7Ku0Uj9zA3AIYgdtrCSmGn7QZQimIU3tJnl4t8wHMMw8ixP5CA9WpGaTUqyTvdD6KA+uLqnM4n7g5e7AokKmcpVsJli77PhyKNStKXTwqigsdjx+3mIImodYUmsdCBPgn3rW0HwiC2lLN5I+y5GLnZHNkce3716pz12ZyHfc+xG1kvKurSEceKWitwBWhLo2UuXS1mNIVh33miD2KzAx7bgSFEhiAH9/OscHtxJUnCx1F+78eHLd57HnYHlFJcrlc4awkZY1EUlsIoLtcLhjGQ2BMSPGz3WK1onABxKyeohOvNkaZ0vDxbotoe/9jRe9h3EWMt5+c13ge6fiSMAw+PewmOKAoBECdFbR3reSVqAh8YxpFuGClLTaFjTukaKZ3l1fmCqirRzjGGjsOxpXSWyknjcD2v2O40x9bw/c2Wh13L83XDvC643x3pxpGvP3vOajHjcXugH0bWVgq8j60oBfr9gRBijldPPLsoKZyiOwq4f75Yg9Lc3W8gwWp+IUrmh90JffBzuI5dJ82aYKiris9ePyelyIePH4SXeWix1vCb3/6V1D5yoW4YeupZzesv3tC1He9+eEdR1JxfPGO7feRw+EZUmdsDRVEwm885HHd8/HQtdiAi88WS5y9W+M7z/R/eMl/VrM8bHjYbbu8esU6KElUxoypmDN0ga1UYmddiEbNKiughBqqLBYtVw+XDAyEG/vbv/5rP3rzi9//yJ66vb08hIJKALviN8sVzLs4usLbgD3/8hmPX8V/913/PxcWaT2/vOewGjsdrlIJD+8DgB3bbHTEkqnJBURQ8fynnxOP+DKU1s7WEXJnC0h47br67xRjFfPacRTPjy1ef0cxqFsuatA0MbcRox5svzlkuV2hT4H3Pw92W+aLh13/9a/b7PT/88J4YcnGFEW08rlDMm5rROErlGHykHz1VWXN2tuTx8ZE//+lbigrKWjFrVsxmK8rKUleG/X7Hdz+8Zb1e8vLNZxz3R9q2ZffYcn+zYzFfMGtKDvuWEKCqLWcXc5JOuLbg8mxFXZeMoSemSNNYlE58urthfziKAlNr3n9sUUqxWMwoCodeLlFOVNXOaIx2EBSbuw0xRfw42W4FCH7hxCUwjFJ4XC5nGA23d5/kPR6kwXv+7BlaQ8SToubTp0fqWcWz0onS3stacnv/gFHQNAbnLFVdst3s+fThlmZWcXa2IsXIu/cfODs75/nrFzzc3jF2B9brORhYL+ecrRbsty3/w3//B5TyrGcVfT9wtz9ye/3A7d0jBitWwdCgUFRVgbOGu7t7Du2B2knx9ebhkW4Y+OrrX/Lq1QtuPt7Tth2L9QzjNH/43f+bu//stS3L0vPAZ7pltzvuuvCZWVXJoqkSySKJRgv642oIrW6IIkhR5dNnZERcf9y2y07TH8bcJ5KfFA2o1WQsIIDMm5H37LP2WnOOOcb7Pu8veXzcMk4yRNo/btEKfvLTV1xcNNzdClvs2eUzvJ/5j1//Dd57Xn35HKcd+8MkbrYfcP3gxlPIBxdnZZozzWfLXcfkA72Huq55dnUp3swgkw1nRVZ5e3cn06r4vR8apBNblTnqWZk8fT17El1WK4laR50neSnRDaPIuaeZujKUxmaPvIzJYvSiYHEFRVlS1zVzJE/H5QadmSxPKWDaoJURKCeKGD2JRFmUFFrn5pZMRXwwTLOn60eZsoWA0hbpCEu60qJtCaHElsJ2ScETSVTZN6wV3/NKYqIqhNavkWnOoq4xRrPvRsY5stnIwXm1WAkrS33PwhAocpfTVSLDOHL3uMsTTbJaCMqypK5bjn3H7GWa39Q11hyeJtJd10lKVhLOSGEMcR6ZJpk+a6MxXmHzAO/7lLQgLJlxIs0+F7hntZpwur5PI/ovfaQhyL1Wues+TRNKKaq25pzcpQGbp27C9EeUVlmhgZKiexgn7h8epHtelFQxUVY1ep6ZGHMCg9ivfD5MysQ00g8xH7rl+dSmyM9TwAePmuc8xdHY3IRISnPqThgNpdPsjz33+yNh9izbVqZhOeXLp4SOiUDI90OsqpvVCmetWCL7XhIjlKRQzX5mHId87y0OSEozDj2Hw1H8t0VJCgkf5Ps7nTphX9RiCVLaMI0D+z30vURXrzJrbblcEKMo53w4q21+6MrwX/+VDUpPqV39MGQ1hQDyxnGUSWexFN5TnrxoK0kYp9OJ73kgMPE9n8daS2EXTxBTlVkW51RNk6feIdN7Y/AMgzTlY0638fOcwfV5ui7mcM4JXtbabFkVLljw8h4KZ0llGGnKagf9/TuZFUAmA0xJCZsBqrMP6Gz3CiGg878r3Iqz8kCUik9KnZT+CyVizEq/lCJVLe+pyVPoMrPajscDIUTKshTVmSYrKL73g8dcoJ8nLf0wsN8fRGGbkCnxH00QPYmU1YyucE/3cNaKKaenwHn6IxHz8zSKIlNprBN10pkrJGqP9MQk8d4/rT/OiSVC3nn1R8mpBoZJ2EhBGlnaCJ/q/FmttU88w6DPKWTqbIeX6ZrKXKokh7rk5+zjt0/pbS4roeTxk1SllBRTkMaSNvK/nwGVKt/dkL/TMwNqnCZhgmXfv7AGxbpFEkiun+f8u+usUi3y4EZna9v36X9nRWnTNJy/Ue89wyifX+eJ/jllC3iaDEqCnzDGSiU8hXmSidw8S9S4zYfZ870ZJ0kqOqctaq2pSkk/8t4TdcRYh/sRKQbgnLzKk2JzyiovP3smLzWItZq2ESVy9LJ+GGOIKYoy5Vx3qezkyXu3NZqqdKLkGGdJ4MrpYGelVEJUT845YkwcuyGn2XpKZyV1D55YFjLxFgVvWRiqomDwomTxPmR1Zv4elRa2Ylb1CdNFfZ+4hqhuyNZKbRQmSpDNmBu3IOtESE9YDXlPjckYCM2Q1V6lM/Ju5EfE5LS7c215XnONlZ956mWIWJeSxBg5p7hpEpE5JCYfGabAGISzpYikDHRS6nu2ljYGZSxpUiQVxcbnDP0wMwSxD+tpxqaIVUqYQsgeEQNUhaG0otw6M4s0mYCRxWxKSQqimuZ8v3ReQ2Nm4sha5zOfQyv1lKB3FrlbJX9eZbVj8DErQSVJ7sxwKouCLF3NNZSAww/dKM9VIQw/5yx4SdVLRqOLP1avktfcyCk/U2ce0uQDVimUyQnE58+oxNLhrCWCNDitYZwjwyzBRkZp2qr4nlUGT8p0jygYVE5QVVruwRQE7m1SyBwoc9Z4PD0XpTuzMmWtMwoKq/Pjm574ZjY/f9Z8r+6d54j3ObFRadQfWdvPSaVaK0z68VjtUkgoI4wcoxWnvpeG7TgxDCPdsaeqS9q2FZzBbg+IVTEluLu9x/uQ6y+phUOMaGMoq5KNNsQEPniscxRlwTmpuChKnBMu4dlifjgm+k6UR1prdCH3PwRR3qR0Zt4YbOEo64IwDMzTzDiMonT28UmFfH72z3woSTBORD9jnaiTTE6DU0b4YUM/cjz1Txbz2QM5MEUaBxWgaKpa6qysni+rCp3Pwuf9PRGpmwoRloo998xvur9/ZBpnLi4uUEZRL0rKuhI2UF4P/ew57A+cuo5xHDgeNbcf77PCPuUa1qBKSSZV/ciY+Z1N03A4duJW0hplNEUhyZ/WSFCMAvquZ7lon9RUwmbK9vEQpZcQyOqv8OS+qBtJLpf6Kqtvlc4pnikr5vOZP6/jMYh1vMxc1KqqcjqrJL6qJHgC50r5nvsklthppqMTZnXmv9nCUhQuIxEABS6/62EWpbj3iXGE4/5Af+qfXFwpRJKGSHw6V8coKc3WFRgn9XN36imLjv7Usdvt+HD7EeMKsf6VVbYmR4ZhxBUK5wzej4zjgHWWZQ4cCUHwRylzaBV5KDzNOC2Kfedcvp+BYRBBT42gkOZxpu9Ghn6krBuqqhLVrYJ5CpyOPd2pI4bExXpJaQzrzepp8BxjkoTAH1h7/eDG0zh0GK25XIok7M3djmHo+fjmO/Gkj4HLiwt+9skrUgr0hz3WGq4vlmx3B/7H/+l/pmlbvvziS2lCeJFyW1ty8WLDv/zn/4yPt7f84le/oahLnl+tiVi8coR5Yh4HgbeVBdv9kQ8PW6ZJvK9107LerPER5gRxHgiTqBWqxYrLy2teXV/y9vae3faAj7fcbbecDscceZ8Y54QxFXW9pLAKo+B0OuK9Z3N5QVFV9KcD8zRxfbnGz56Pd/fcbfc4I0VemyfOsXtEa8Wrn/1MZJZWMc8z3/zh98QELz7/E3kIxj3jNHO77UApPnv1Ap0icycWwM3VJcdh4h+/ecdy0fIv/7t//WRz8NnCMI491hi6U8cvfvlrsd7UJXf3Hb//5js26w2fffrZE4T6enPB559/wdsPHxm+/prVcsmzyysO+xOlMfSnE6fTgaZpaJuWui6pqobDbsfYjWLnSVF87MpQWrHUyEYcOO7333M7YqC2mmVd000z3TDJpmytFAVaihI3G8ZpIKG4uBBmw/G4pz8prlefUTiHVeAVNLWkK52bhs21JPa9/SBpWo/HI3723P39P9C2Df/u3/wV9WrDmBTjOGVpoqMuxOZxf3+H0dLkm2LkcT+IdSEktC1pN9fEeeB4eAQ1Qie2tEW7oCpLFssFh8OBd+/ecasi3yrP+/st376745/8yc/47/75P5WkpsOBiKZqNyg/EsPEFBRzjDx/fsPles279++5u79nuz8whcjzm2vWqyVd39EdDyzWF5R1Q22l6ff+zWtef/sNf/Zn/4SLiwvef/zA4Xjk9ds3HI8n/umf/pTLiw3Xz16hjeHv/v5v+Xq3wyeFtQWvXrykaWr+/Oc/Z5onPnx4j/eesqio6/L/qwLjv+ZLGUkiLKyAo797cycNNmMI3nPY7yXla7lBaU3XD5LEVDf0Q8/vv/4aVxRcXlxKATmdIeTQLpY8e/acw37Hu7evKeuKzdU10XvmcfjeYhYDKYg89XA6yQHNGkLwDEPAWIcxjpSiWDakIse5kqpu2O3f8/jwgMsQ3ZQSy+US7yfhJM0zTmtsBltLoSXTO5XSk+Qc65hnz24vaR2GgCYfarOdFCONKmct1zfPAPjuzRvGaaZ0ArCvmxbvZ+7u79Ha8OqTTyUFrTtJw7dtGMaBX/36VzRNw09/9meyifqZEDzTOMjBTFuGaWL39i0xeObMgXr99j1NXbO5uBCguxL582a9oh96Eom6aViv18QQ2G1HOj/Td8KCKQpHVVa0bcvpcKA7HQh1RUiKtllS1zWHU08/TrnBI2Bqbazczxhp2pbVsqUfRrpTJ/HCRUHdtLJGdQN+nBhHAZOiRCEhGmbNol3gnGO73Wa1nDRbvJ9BwaJdSLF9PJBIORzB83B/h7WWVy9fYa1lvVpKKmM3YlG0dSERwsMA2tEsGmY/8913r0nRQ1a29MMkEOiqZJomtrs91mjWbY0rLCoFwjxyOh4pqwqM4fFhy8ePH3h2c80nL19SVrWsOf1I28pzf9jvxJ46TazWG+p2yf7xntNxz+HU4fdH5nkSxgAG5Up09GgizeZCrIJa0w8DTbtEG83u7iNjf2LfDfgQ+SQnyAonK/Dhw0fG8ZDl5JpzYMknr4SHdTgciCmxXG9yYfrjucLUZxbdCqU0b+4epMDzM+Pkud0dqauSm0uJHB8mOfg2TcOx6/n6O0lce3lzIYet3JpUKVAVlmbT8Hjo2R472qbicr0QVWCY8RGmAHVdsaxWbI89X7/+wOwjkw8ShuKc7G1VlWPEHf2w5+Fxx/qTa26uNtxtD8zHnsf9kf2xYw4Kn6CbarQVgD4pUhhF5Qz7U884zcLsME6aOtHTlAWVi2z3J3YKrldLCmvpoiKfzEkJAAEAAElEQVToSF0LIHVRFRTOcbnZkFC8GR5IKbBpJGmNXprv+Ii2sGxrUJohSuS9MpZumPj96/cs6pJ/8dNPiDHycDhIc84WhDlxnALHKbDrJeo8Ko1OERtnrDNUlcTGF/neVHXF9tizGz2LquD5quLj9sjx2DP0PX3fs6gLlnWJCQmb2Uf9OHOzaVg0NS5Jk3dVF6QICc1xlMZ4me/dPHuaUqyy/Tgzh8CCAmMtx3Gk81JHFtrQ+YCPwomxBpbWUlrDi4sF1jk+3O8ZQ5C9QsNiuUAp2KxaYogcjx3Rz0RlmGLiu9stzlo+f3klz2FdMQwT9w+PVIWl3tSEpDgM0nAxSta+3+1PT2toRLEfZqyPVEHsiOM0oRWYsqEoHcu2ZHscuHs80I2e3sPd9sTbuyOfXS/57NmGYQ70Y8BqQ2G0KEjnCVvUWFcxxURZlcwJ9r1nv93C3HNzc8NyuaIpLclb6qrAlRXPigJNop8mHoaBVV3SlIb96BnmwHa3Z5pmvvr8U5aLlirbi37/7Wu6vifFhNUmh4s4LteN2FSnAZLYJlE/nIDyX/uVvBd20GJBTJFf/eZrSaaNYrm6ff+Ri6tLrv/VM+Z55v7DPdY6nj1/xna75//xP/4/WSwW/Mmf/inBBw53t3jvKcqGi6ua5y8uub194Fe//prLVcuXX31KimLfjN7jp4lYKIpGcxp6Pjw+Spc2Joq2ZrO+YOiPHPsHsWUqxZwSQZc0qyXXL6747ru3HI8HSdA1lv3uiJ8Dh92R+/KB07FnngIXl5dUVcXj7R3j0NNsWlxZCAMnJparEuMir797z7t3dyzKjFFRoIyiqSucsTTLBdYZ2kYG0b/77WtihM++/IqyLLEa5mnicDwA8PlXnxBjYPd4i3IFr55/xv5w5N//+//EZnPB//A//PegYXvaklJimjt8GCis5rjf893r72QITuDDh8gv/uG3XF6u+fLLT6RuMYZFW7Fc1Xz88MBuv6duSp6/fE7XD0BimiPicPegJqqiYfm85v5xx/bxgVVbExcLLjcXkl67l/TaKcDuMFCVAsMWS5nn5vlzmnbBw90t2+0ug+EtLEXFXlhHYRwpD/ObqpHwkhhQAS5XFxRlye7xQOFO9P2JEANW1VhruLl+QULx4d0Hpmni8fGBaZz4+P6Wpm341//2X1EvWm5uLhnHkd3hiLGKpjLCBt53xBTBKsZ9Ynt7Sz/0uaEnA4MYIqOfIE1wPFEUNc9fPsc4gcsfdgfuPjzQHXpO+wO//t1v+d//7m/5i3/xF/y7f/tv8fMo/Ew/C65Hl2hT0I9b9scdV1cv+MlPrtluHzge9+xev8fPiYvLFe2iFmD+7BltIOjA1dUVVVFw2B04Hk588sknrNZL3rx+zX635/bjA6eu4y9/+gWX1xdoa4gh8ubrj7z99pbTaYexhpevXtIul/zLf/kXTOPI6zfvmGfP9eUSbX5Y7fXDrXazJyrYh15kt14O/+1qRTFN+HigMApyl6woSpnoaFEs6cw5OYeDYTRJ5QQbbYjKUFQNNzfXFM6SgrwIITM8YhLvtCRU5OmRDk8gvpRkkpMyY2WeRJmiE5y6no8PWw6nXiIAtcLmqHKlFceuQz1o5hDRzqEIQDwzS6XjOQrPaJ6mPM3OyR0h4CO50+plyuu9dDpjRIXAOAdJBdQGlRL90Et0tZ9yh1d+jZjVAz5PqIZROvNWvHbs9oenSThZF6G1EYaLj9goXtOyKpGJ55j5U9IU6vpR7CB9TwiBwhWEmNgdBORmtSTbkBSLpuH66ophmjmcTsx+Fp+x9wz9SO0kva8sK+qqfkqp8sEz+XNMrGGaRqYwgxVwblEUOGPEkhID1jkWiwXOC/ekKIQBpQGVEg/bfX5+LFVtKesKlGLoJQGjyLaoopAkMQXolHLSoM0clcR+f3hKoVCKJwXJ2a4TgoB+tVJPB1197qrnGOSEpAeeE1W01mKh0YamaZnHjmPXkZBocOuEBZSUki538ujgMc5hnYFz4QtPDBhrLMEpUFGYQyQBjfM9kPJs+0pKZ8aFTA3nzFypyzKnxsA4i11FKf3E7ZCJjfiEz+mPT6lbWlI/zlyPH8MVYoSAwMFjZBwngTFmG2tZlriyfEpqI8Xs97YYLRNykkxWEjlR7DztCoFxHABYLJYUZYVWktgUs3opJnmW8xMlXBAtqU1amwxNNk+2rHNKUEyJw/HAPE90pyMxeDwCGTbW5u8uK1aQA7n+owm7QngY4uVPuWEl6T/y+YVNlbIKJ8H3h/asKpznHI+qzslO6YkT5YPY6kQplTIuJT9HSnhIClnXjsejTP3yRPEM9k5RpoeFc8Sc6ONDJE4+v8/554VAkdyTEkFnnsj58xWFqJmUUlR1RVNVjONI30sxYK0Ap0NOwtOZn+WsfMei9DCY/NnOyqQQz7dDCUtQa4ZhkDRUxHIYrXtSzmqtUUqYDMfj4Yn/Jwkj7vu1BoEcn5VPkCicI+jvlVLnSeo8TzIZnEZI0jD/PrUuq/O0pKSkqEla1gqb1UUhhqcoeEkBk3sYsiWrKEuU0kyjJAC1bYtz5VMaWBqGJ9bh+btTWpIQ7Zl9mFXDThl0THnaXKKiPP/WCHA1xECY4tN9OStfQ4zCBXIOV4jKJaFEhZm5G/Lzs7LCZzWX0k9qMHlMZar5Y7rmmIgk4RgqRcxKQaukSVKXAuw+88GETSKQY5vVZZJMk3Iyl3riOanMD9JasWwr6rIQrqCfGSfhDWpEraczv0jqLzCJp2c+ZtXlNM+AekrvHabA9jjSj545w3CjjvgMsPZ+zuoTmSYrZFocs6ou5rpuGGcg4bJaWe4IkCfMIishT+rz7xfFnnpWS0Wgm+Q5nn1Wm2b+pcpgbbGeJUIwT5yWlBKnbshMsYjWCaMk1adw7olX9MR4i+CjSLCm2aOjsISU1hBzIp9WpJgYpkCMsj6o/EmbsmDZ1Oy6ISsYE6UVdcCpn2hKSRI8K2oS8vPOyW9nZWZKUpeqlDAKKidJWqfJ45OnUgpjFCZlxU6U2s9aSW7bnXq0FlWnMZpK6bz/yXNxZg0aI++gswaVOV7GGBSiZBz6kWmes/JI0Y9ekn1jQiUJhBFVQkAbaZ5Zkz9HVk2mswpMgTGSft3lGrIqZP089sJ9qfJzNEzCKPRJMYck/FKkaahzwpRTmSejxbudtKhIZQWJOYHM5YGB8MNIOUES5DxiLaEXxmJTVVSuyM/YWUWT9xvrxK6dVbJBB84JxCGIht9a86NqnPvMJtvu98SY6HvZNxe1BLhUlSQ0n+urM1dQnqGcrqwAFc+HPBRntbLG+4hzBc9ubmjbBo2kQnrvCbPHT54UsmpHCm1SVvykJM4LCVVxxJyolpLsp/vdkTev37HbyqBFJUWyWSGoNPv9AaVkzdPW5j1XhpxoUab6mCCK2kUbQ1UK0oBcR0mXIollVFlUUrLnkuh7URUrWdQ47A8MbqCq3B/VdVntG0MOLAjCJg7xCZ/wcLcj6cRxPIgLoqzldzQ2c5NE+W2dZRxm4tzl4aWcpfuhJ6WGphUllnFGeLWPO6ZppCjFKaS1pW1r1puW/nhgl4UdTSWcotOpo10sn36WKwUBULgCUsTP01PK3TTNwEkUk0WBK0qsNRyOJyCJ2me1JHhhphWFE7RCSigNt7f3T8xg6wyNlnPiMI3iFjL66e9WWlPritENPBYiGvFzwKeZ/f7ANM1Mk0dryzBMkgaXzwjOOJJKmBCJhaeuCorCcOaXej+TkkIljbWiVIXMVTWapm2AxG4ng+D1avUUUDPPIqwJMddLChKSetw0rTQhz5xDFWW91Iq6qVksFqSQuYDGopVmnidS8ILrMHLWScgeNU6zOJ+sqMFIhu44Mk/zUy/F5/PjNHnGcWbODgWFelL06R9olfnBjaehH/DzxDe3b0lKsbi4pm0X/Omf/zPCNPL6d78SOwWzJOxcXqGJ2DTTlAXPnr8UH7XkQhMLK0kqSTEnxd1xZLlY8e/+zSseHu759g9f4wNMIR+KlCzyRQHaFjRt+3SYBsU0S3Sl9zOH44njqacwGqs1X3/3hn0/0FY1VVlSjqNYBosS4wq+efOWaZp49uoT2tUa+gPBT3lRgO12i4+J41G4U5frJWVZELVs7kMnHIq6qEjOPfm4YQdK8bjbE1PicrUA4N07YcA0VZ03LpEsH/Z7OeygYQ6chluUUjxbFAzzxH/6m7/BuILV+oJFU/Hq+hLrStYXzzAZOnqWKXfDiC1KqrLAqMgw9Lz78EA/zNmWZmgXKw5dz4fb3xKnntolkrIkY/nJ55/xT//s5/yvf/23/N0vf8vlsmazqBiGgfHjPa9eXLNZL9hcXJKUZbVaUNc1t7cfOR72XF49o2kWfPvNB3bbB7788idsVitWS2En/P0vf8PjbsfPf/Ylm9WC0cshT8DoZBi356//7u8Yx4F//Zd/yXq1xhWF8A3mj8SUcI0kfq36keBnXJLioKorlNJsd1tOpxO//NWviCmxXq+pqwpnHToXYzEGhkG4Km1Z4g0YnyhUYJ56wjwSwiyW0jGwbBs2iwtRFRyPVHXL5ec3vHv/jne3j6w313z+0xuMVtztT5RlQbO5xO93DGNP2y5pF0v605GhPxH9xG63RQGLxYJl3mjawlJqT/3sOcpV7B/vGfoTOy8Fy8VyQV2WoDTjONGdevp+4NPnL7BGsz2deH/3wNdvPhBToq0bqmbFsH0ULtX9A8eikPm3AlfVlNqwausneO2P4ZqmUThe9w9ZRq2oypKLZStcj7KUlJOykHh3P4tCqliIt7+QiFxnRA4ctMEniNFzOh3p+47VcsXnX3zFPItV0nuBV5+bB8bYLJFWqCQHDKMSzhVUtWw+ZDn4ME7Z1gS/f/d7do8PXF9dsV6t8EmCFbSxoAVMP/uAs4bSfq9SK7Id7O7ujuPx8ATxvr56Jo02I8lgk5dmvUsKhX7a4EKU5tLd3S0ARmmUdQy5yRaiNHAENq45nbqnhpbW5AQizaptmLznN7/7LVZrlk2JdY66XRK8J8wTRVGwWF8BKUcgB47DhNMi7+6ngd12R9U0RCVqsDJvzrvtFqU1m4vLJ7vMxWrJ5XrFr3/7W9589y2biytWmwsUibHvCG2LJlE4KwmRpXwmpSAaIzJ/FP3kGUeJ2i2tocpgyw8fP9API9fXN6wWCyYjwHDOQPdc8Pzut79lnmdefvKKtmkpSpF9T6NMvuvc8PGTcDDWm7UAzXOzHCUqzdu7jyIBRwCd1ogBZPYZll4ILHixWBKjZx564W0V1ZMy9mzPVEple2KiHwactVxdXXM4Hnl8fGS5XPLqxUtmH+hmTxpGUpiYJp+fIY1KmqKsMK3L9vMgqa5Vw6IQa17TLinLiqE74MeBsq4w1vLh3TuOpyOXl9fUTUNZCiMrxEhIcHV1SVGWhKgY5pl3794xDpLQUlqxJcUgaq85qzYU5yanIvj5/8KV5f+aq/MJ8JymPUZrFnWFtQI3LirFarmUBmNeNJpCgNBtYYjBUS9aSgOFEnsJ2jL5SB8iKoiapq5KfvrpC5SShvrhONNly1ThDBaLRlEUjnbR4kNg9pG2LqgLRxcDYwhs90emWRhGpXN83J5489BRGFHTlBqchqQtSRmGrgM/4gzYtkSFwJy5TX72hCTKqO3uyOw9nz27oq1LShnXkBBoNTGi87AlAadxRk+eOeyfmnU+Jf5weySlSGmlodSNE85ZNtnm3He9NJGRZsCyrggh8Otv3+fIdEnom+wIxnK1WRKjhJCcm+3jBIdZM82efh5zc96wagtKLUEOjVWM08zrbsyKggWFhsIkrjYrri9W/Oqb9zzsHrhclFwtS3bdwMP+wFcvr7nZLDl2M6fRE1NiDMLGSTFITLsxDH3POM5Yo6iM5nK9oK5KXn/9nod9zxfPNyyaktrKdz4raYIVRUFM8Pe/f8fkA3/2xQu554XYUz7cPeJDoGnloFLWArZtSytWOFOgtaJwhnGcePv+IyRo2galFG8eT2itKZ0TWHNZYNTEbAOFs1y0+RBpJe6963us1rQuh2zoRDeO3D4OLOuSF5ct94eRd3c72kLzyUVFSIk39weUdWhTcBg9h25g2S5omxaroqAMlLACo5LnkaKFUFA4DWESa5B1EoB0muiGGR8iq7amKhyqKFFFwRwHZp/47JWccz4+PnL3sKXvB1KUurMsax4fhA/U9wN+Nsx5EBIypL7S7keFORiHkVMIfPf2DaCoyxVN23D9xY1Y0rUWhs/UAYnNxVLwAs5SVgWbixV1XWFMgAhRGawWG1z0iY/v91xcrPm//dufcTodubv/SNeP7I89cZb0sLJ01FUlSusCxtEzTz2zr/B+lBqsbNjvdhxPB1CaonT86pe/5eH+kcurFctVQ1peQOVIyoJN/OG71/jfjdy8eMViuaasJGXSVRVTmHncHp8shSklXj6/YbNo8bPYjMfgScFTIJlMxyGi0HTjBBoJWUJR16KK++2vf0tKcP38Gm008zCiFDw+ipKpHzxmSnzkAaUUn33+GUM38b/8v/43EhFdRVbrFT/7yU8IQWHrirZytKuKsqhYLtacjj23H+6whQEF+8OBP3z7HTc311hXMYdEs6jY7/c8fLzHOsVmU2JNjTM1Lz97xqsvnvMf/8Nf8/f/+Gu++vxzPvvkU/bHI6/fvKOsapaLBUVZsNos2axXNE3N9uGW0+HAenNNWbV8/HjHqet49eknXN1sMm8w8bd///dsd1v+5V/8JddXV3TdSZpwURLinZGm2P/7f/kPDP3EP/vLn7JaL1i1N6QE7z7c5X9XhqbNosVqy/ObG6ZpICZh//WHE6dTxy9+8TtijCxWG+oqUJgdyiiSThTWsWo2ko6tYBh7iiJhnSOmwDyP9KcTKIfSNcZGYUN5SFOiripuri958+Ytv/ntb1kuF/ybv/rXFEXJw8OW2Y+M04D3iaIqMCYBI5v1iuura9nokgftUdazXq+oq5ZXLz7jYnPJm7fv2G63aHGecnv/gX7o+JOf/BmL9QJITNPIqR84DTOfff6KsnAYu2I4Kn7zy284HY+sLhZoq/OwQPH42NF3gcP+gzT+65bCGJQJxB/YM//Bjae6LglO4xfCMzHZg66SLN5VVcnUOgF5au9TYPIzc0w0TS2pJFGisYdpEnVO3UIMEk3fRx6V53gUi1tMGqMkvSaklNO9jtIBRJJzRFklG5LVGmXzJEgLZKsqS2bE0186g9XQ1hV1VQjQN0nzwajEPI2cDntcnDDpPH0tsF4mHPM0YDTUlSSV9bMkU505KGVZYIzhFKMcYPPkfPbhe15BTkqI+T5YC4tljSIx916USdmGop340yNngYVMiJxGgOOZ/VBmkOuZnWGUxtlAVRRPqVLWWhaLhrqusMbI75OnyaBwZUVTOhKKpGTCeeoHOTwuW4wRlVBlRPIYvHhK+2FgmCYqH3Ax4qylrirauqSpRe5uMqvjrJo6/5k2VhRV3UCI6smOopQkB845QUkhip8QPFM3E3NcuiRISeNRn9NnsoqtLnXmh5WSXJU/g0YUTYXJSjyrCSkyzdKA6ofxKXXKe093OmYFjNiPqlIO2sMwCuvKOZKCeRb+SEQOv06LRWScJXlMG/OkCvDzzOmwJ0ZRSyltMhvIUpzjwpQiIofwoogYZCIYgxd/dE7Rijny2Bs5GKb4/USnH8RKNGWPfFPVOeXFEVWg6wcpmPMUuyhLVFYZnLkIP4arsFYmFPkdSnnScVYClEUpapOYI5u1TGqPpwN+np+aK+M4EqJMCFCS7vA05VaKIatrJIlT1iefIj4GAckjaTZFkdV/WV58TudROaZZkWSip42wD0hUTSOxrcZkaLZ74uUopZ8SxrSWKbEUM5KmURYFIYYnm5IoFES5co7QltSP9HRw19aiNMxTTgR0eSqWbX5nBYwUBPLOytKfSEESQWOe1qmsGkCdE+FEIZRyYso59QklPCprFaU786DAGEtRFjnlU9LnfJB163wplRPzrAwDxnFCay3qnSJHVyeZ1k+TwPeHYWAaJ6ybhLdhtEyrskJi8jJF9FmNqRY6qw6FhTUMwqtIOc1GS1BJViMlikqaLWf1oM+NSNSZ9yDfu8kTcp/3DFs4FEqS/tSUfz953sqypChlWuzklj2l0c3z9JQGh1L5P4esGEhZoaAJITegnMspUSFPUIWZo7UhxplpGERBlPea6D1a2czkkSuEQAqi2hXlXlbAhSDJnflZijESp/lJSajOStMYUD5zr1QGySvFOA652SXPzXk5Ou+D0ziKijg/X86Yp0ly+oGcgf9WrqosJS0uv9vnff7ccPtefS21mMvst2M3MMy5ca6E63NWPCktqUTSAJdn6JwcpbOCriokmThlFaKolCPOIKoyI/9uSqIoKMtSimDt5ecohH3gM8/o/I8WtS5KUVhFaQ3HcZS9ksxytJbaGOacbjZVBT4Y6tJRFY7RzznBTZ6XMHtCVs/I7yDPwDjJepZE7kDhDClp0Z6qRFE4eXaQtWuahd1XPDHsZJDlg0yUnbOiRDY87cHobM8jv4vWUBfycxKi/FFK9v6ktKjh01mxLuxB6wyFTpRant8+s46a8vz5ROVprdiCp5yCG/JgQ2mpOYyxVIWoEMdBMyeVSyR5gbRCanetGOeAGSY0wnuS10YxTJ6QVVlFZhCd01qf1N8pcwCVDAdI5+RSRZGVSvKzZIgojXRR1NbWYY2mzuuyzwpflM6NRHEqRHhSqAuWwchzOHlClMam1prZZ9ZgFGh+4SzDHJlmT6EN1snZwGkjCtwYQacnpajRMgyKZ5eD1pkbRHYjfK9mKwqHjbInoTXzHEhp4pw4ek5LnObIOMec2Cd/rlJ8UkwLr05nED4CSTbyTcT04+k8lVVBkRLaSQ0QvULrSIzyXlaVoyhsVv/IY+pDYLvdMQwjTSPNza7rSSExDzIUtGUpSY1Z2bffHxjHnuiF71WXFUMcGcKI9grrDQlwVuoVax113eQB9B85cUhUVUFRVvRdzzzNNG1NXVe0reBHVK9Qk8LolliJlXLoe4ZyAIRp2zYNPqSnVLsUE01dUZUFfRjwUc5naIW1osfshpxOvmhEcdh1pBRxZSWfvXCZhThk3EGV2WNa9m8vatJxnp9cRgLQHtFWsWiy9TMzdo3VqJgI/lxHibKxbhqUkf9unWHRNtR1jXNFTqUXvWlUCW2lQVi6mrIQEUB3PKGVZrleoYyhHwdmPxGTF47UqWMYhBksyZWaoqigTSxXK5pmwW67p+96xrFHn6C9vpbaxwlM/HQ6ZsX/99xhpWAYJGW3LAtRsmtLSpquG58Ynprv0wo1Hs7vo/dUVQEJ6kVNJFGWBT5EjFXYQlO3FdbZzAk9p0tHfJgzt1VxTioUTYzJfEQJP+u7DusKquxiGYaRaZb1TGstiYIhcjoe0UZRWEecJ4KfSSESVMIYhy40fhZFnNaWoqixtsRoOZuPvbA+nXMQoiilnCWkghg94zRQzQUoWYPPKYJnAcw0BYa+Z55FSOScfTo3dN2ReRo5nE7iEnIF9qyE/z+78fT82Q2kyKvLNdM0cfu4wxAZT3u0gvV6hTGOOYivt+87fBA5rHWOy8tLSak57DkeD3x8+4bVasUXX34lRUAM3D+e+PXjgxRPebrUNqVM52bP6Xig607UdcWibQV+WNTUeXPWTgDkKXhSmLi6vmRzccHF4Uh/6hiGjmka+eTFNddXV6L4OJ7YNGu01nz37gMf3564WC9p6oqbqyvquibmaN/SaaZp4ObyksIVvH94IE6ezeUlZVGwaBcyEbp9zzgOLJpa0oVCttwgh6PVYin3YvuIVSWvnl+jleLxo9jadh/u0cbRPHsBWjPOgRBE0VSVBZdtiXOGECaUSqyXbU79mFAmA9VRbIhPQMZF27JaLiidpS5LHh53bO9vcWVFVbcsFzWbZSvUND8RYuC333yLMZqf/+wrbj++5/7ulqZdstmsMgB4z91OuB4YC9rSNi0Xy5arywvqquLxfi3A2dnjDwdubq6pq4rVcskcEh8f9sT7HTZDmG/WCwqrud0dmGbP9dVl3lwCx9OB+/sHQohUzYKicMS5F9m0ccQkhYBWsKlFsrtYb6jrmsuLDfM0U7iCtii4bCXt0BQFPsFpjhx2O968/a0U3U3D0Pfs9zuqumV9cU1tLVXh6PqOD/f3rFYrnr+4YBxH7u5vOXYnyHYiPfcMk+fYTxROGoCuKCmrht3jHYfHBzaXosTQWg6nNlu6ghYbQn/YMfU9a1OITWXsCGPP5cUV9WLF8fGOvjsyZLlmnGeSnxl6DymK2qUfc4PDQZxFyt40eB+52+5EjVOIZebZxQZrNN1x94Mhcf8tXMs8aRXFEYxempYBhVGGZVuijGHMqg5nDP3Q8/bd28zYWeG95+Fxmwv9SNu2XD5/htHSVByHnvfvvsMVJU27xGhFW1f0fWTs53wKszk2fkVZlVRVLQcbH56e/2HQaJVoKmE7XV9fo61j6GTtWtSSWOSzBcVmu8O7d+/ZH47CWXGOqlmgjWG1WkqTPcPyy1KaZd57Zu9ZL1rxziP2hdNJeEPry2dobdidOuEdGYM2StbDEDjstiituLi4RGuTDw+RKSe4xdMIJLGsaoO1BVVVcnF5JRbAHDxAVUsE8dihjcOVtRwWjMk2xUSlDYUrKKuSdrGgOx3ZDn3mZGXJcIxSGNQ10zjy/rDH2ILPv/iCcZoZZ/8UmLDbbTnud2x3O06nE5MPlNPE8+srFsvlE2h8mib8PHI6CrPu6uqaqqpFHaU19/f3Mg1ralGCFFLEdsNITPD8+UspCoPPdkNJq1FPVhQ51JTNghACx4MoXqu6xbmC9WpJ3/d8/PgBpRSXV1dUVc3F5WUGTWtmP3M6HAScut9JczE3IxQZdjvNWCOpQglFP3vqqmKzXNJ1PfvDge50Yug75rYlJGE6Hh/vKOuGsmnF7jj2aN2Ak2I7BlEZRz+j85BGoSBGhu7IQKKqalxZ0R0PTOOINo52IdBfUpQGkvbZIiZNvxAijw/39P2AcQVl3TwVRXIYjex2WyChjRzYmqrMoOT0Y1q6AHh+scZqxaZ1hJh4txue7GUKaQAkRC2pjKFeNPTjzB/e3Ukq2Gotz9fQYQxURuOs5qKSxpNWiXH23G/3OOso83Dq2cWCfo7sx8BpmtgeT9SFo60cs82NYSI+eMqyZLFcMnsZnqkUUSnSDyPjNOcBi848zO+r001bsqgKbrc7Pm6PtHVNWTiuVi1VUTDNAsRf15JieLFcYK3l4+6E94E2N663R8/kA8vFQhrVRmy8270MKouqwlnD9bpFKTh1okJYOJPh+zIgPJ46+WA5HKIbx2ypKiit5XIjSvtITquchdeGc3IvgcIoloUiKs2szhY6lfl5lsDA6Eec0dSVpFA6ZyhVpFTS4Hvs5SD+2bXUST5E2cfLAh8D99s9h26kH4U5maJnvV6wrCtKK9vN9mToo0EnMCmHUKRAUzimKnI49eyPiUqlnMAkB9ndXpLVNguBGycF/TQTZhmsjNmaWWUWoI6zNAez+6DJcehORbTTkm4XhIXlnOXVzQWF1bSF4dRP/OHDY7bvOkKSMB2lBPjujKJ2mrKQg/b2OPB+P7KsCm42S8bJ83gcGYYJm2ZKW9A2NdOhZ5wmysLSFIrkLSpWAiMfB4wzFE4SFK2TYWAK0gxRWjMFxZiB6vKOiZ1otaxy2IcEJR2PJ1GZBnkbh3yA3fWebowUWqDa3s/EIPb7M94iJRgDWGv46pOVgIyDKPN+LNf19QXGWtZXa+Hcfv17UpoZukeMtSxWFdY6aRAnuTenU8c3336gKgs+efmMcRx59+6jDFinQNM23Ly4pqgrNptL9rsdf//3/0hZWJZtSVG2bNZr7u7ueHi4x8eZKXqc0SzqBa6sKMqaojCUhSX6iRhGjA4Yk7i63HB9/YzLzSojAqRRf319w2q14uPdHYfDkeXiGWXp+Pr33/Lx/XuCj7TtgqvNgvpixeXFhXyfg1jFi1oCsMZBftfLizVF6QhI0M3HD78h+MAXX36JcyXv378Xrlkh4VTXzy6IwbN7fMQVjpsvPsNZR5gmuq7nw/tHMWHbUdhqriDGQNQDTdPyk68+xRhDiKOgJirDNEWmPjKlic4cUcqxvrpi9gPDfGCxWvCTtqFtFyw3a1HYj15A4m1F3TQslwuW7YLVcslut+P3v/kGZy1//uc/Z7fb8eb2Hc4qrFXsjltCTNzdPrJ7PNJWS5pSs15fUzrDsxfPaRctx/2Baeh5uP9AuA989uo5L59dc3N1iZ9nvvv2W2IILJdLirLk6nKNtZbbD1vmOfDppy8pywJX1QQP7z/c4b2nbUpxoJSt8Fx3grP58PEDkFgvRLV288kLTqeeD+8/CErDBJarik+/eE5VNSzrFX038ObNO4ZhYPf4SEgRHxM2JJQOgkKxNUVhWTYFwzDy8eOWy4srrq+ecToeeX/3kd3+SFQWbcRC/fi44/72kZubG66eP+NuvGPoDqQg7gStpO8hjOsRY2pWy4UMYbTisD3Sb3tw6onvGXRiuVnTppbJ9zxuR3QBVWgwSlO5guADvZ/5w+/fcDh2xJyivKgWlHXF4bBn8AO3t6+zqriXhlXm1bkcxfBDrh/ceCqdQWJXxc5li+yTNhajFDgh2ZfOME5id0uIskArJY0o75lmKUKurq5o6iYnhEAMkiR0OJ1w1lKVFSoJc+g8nSMV4vW2YmVwRYEtK0or6QHZoYRSkgcyjCO7/YHu1DH2Yn/TWjONI8fDQabLzuGj8JmquubSWKpKmhI+CNDQ2SJPGg1oxznhap7mLKUcZNqoLSioioLCaPEca0M7BRKJphbFyakfZfLr5B72nYDbk7ZoK0lCKP2ULnSeWDuXuUUhgo7Y+L3NwIfA4XgSxVeQ6Yo5KxmUQH2nYURVFaVziLdZvPwmQ8T6YaR2hqZtGWZJGlFaYxAbRbtcobRhnKbMqYG2Kp8i5tUTZEFlT2igaVsuY+I4jEzTxPFwQKUc055Vaok8ebSiznDW0FQzhZOpgFaarhMu1ZSZLs4a4SypnBoSvNgsDxLZuygFOr7b7+j7ntI5rNY5pcnSTTMuJoqciqFCFA5CVYlqzBainkoy2QRhs/SDZ/azdLszC8AaQ1XVtCGynmeKwjEJaY+qFAvPMIrP21iLy0mL1oodymYVyNBLsRTP7J0oKU3dONHPnmM/Mo4zzTiindhzjBPmi8CmW9q2Zr/fM04T7WKFKz3DKClu5sy1iRFlhMlgtCTfiKVCou6HQRgbP5bLuQLydFPUSHkKmaOAggYDqEKRQuTUdUzTJOoirZ8msiEJgLqqHGVVUmTrgZ/F7zwMg0w6koC5RTGgM1/g+ymmDMn1U0qVyc9XzAWnzo2hYRgw3qONfYpIP/MgzirI0Y9PKpW6qoR9x/cJki7z0sYxc4G8cAHOyWQ+RlRObEspT0iUqBK1MdRNS4ySSqcyT+CsoDyznVLKNo8kE26lwSdJeMPINLEqJY1lnrMKCvJ0uiD4mWHw6JCIMhbnzDWQIWR8YhrFGEkoSQ7M9+M8bVc5LWUeJ1Fv5MOuUho56ypSboTJdEmmTmVZUFgjz4L3eWrNk6Kt73pSmrIyKOS0vOJpen5mmjhX/tGhJD6peoahx3vPOEjBt2xb4YkpnpRIMQa6vkOSPJdoYxjGkSknyGitcEa4XjEz3rQSgGXeBDgzVeboswrFZr7SmR8m64oPEatNVjDk5NKypF0uQWmOh72wUuoGYyWpxDmHalpMnjjarN40CpLRzCEwj+MTA0jutmKcRHF5OklqjrXyXKXCCjdllvTAsqooVWY9jUHe2SRJUzGEJ4VMVZZEl5hnAejrnHorbDX5eT+2zpPR8l2nKBZrkiRPhqx4i1GGLXXpSMDuNDDNZ46cqIdjDE+KJpsRBEaL2mQYJ2YfiCEyhIl+8pROsygsISlJ3oqGWenMg8tKPS37sMvPhDo3I+eZ4P1TGlDShpTVBJLglZkQStNPYv1XShJYZbKq8v45ibrIGU79yOyF9fb988WTuk/n30s+XTi/Ek9qG5e5RTEldJK0zphV2EFFwBBTfr7y2vm9SvB8z2RdNrnuVUr2ztEHToMwJ12+r6WGlGuvlO2zunDoQuoklRW4MQZC5thYAzidv9uAIeWDYmDOv2uIEau0wNwLhzIWa1SeWGtxBgQwKlEWlkWEfhIryugTkxc1rjOglSgiSqMkobcQi9z5O6hKaRCPcyCmgI7nRLa8R50V+NagQ+Q0SpR2UUmyWD9KwpWsVaKEsubMc5J1KAFNJaoCYQYKuywiSZY+KXokvlx3Apw3SmreiKg66sJKOrQXheT+2BNioKkKjNYCkeecxJrXdmezI6KgKB37Y2KYZhlga4UPSQYGOenMZ0t6QFE4+ftUEnVOjHL2cUoT5pkA1E4i3FPIbDzIXB2d1euyP7ois/gAYnxak38sV5WT2IQ4KbVYkhuB0hbnKrHat0sZ4N49MI7SMLRG0/eiSvZTwFjN+qKmqmvqqsBq4RIOw8Dp1DOOimkaaduIMo5EpGkbzndTSgBRDi8WS5QSJpIyGpLF2gJXVAzjzMPDluPpQN+fKKuKohA+19BPT+lswhL2FEXJZr3GOUMiZKWkMHyc1vhxJqQgCjqVBFcyTHQni/dOQm5SZLFoUQmqqsTZgvVqw+Rn1qulKBS705O6EaWYR08KiTCP+DDjClnrYgiElJgBUqRdLKiqkmmcsS7hnHmqP6dxZn8Q9tPkZ5wtqCqp6awy+OSJ3ouaEEknrMrqXMSilGH28n2WVYk+yhBSa4tzTlLU50rCS3PtpRTUlSMsG1xxvmcJH0WN7gZH27Zc31zTf+jpup7dbkfpCmIQppeUVpGqkqGftcL/rJsKFyKLRYO1RoKa5pl+6EXJWi4oq4KYAuTvKPnE9nGLNoqXzy5xheN47Oj74SlZzjNkZrFHqQmrBqZ5ROlIlhFDPI/GlCit1Dm3GebJi8UyRIKfRZ2XggxTM1vMGGFYpaRYLpckZEjqQ6BuGuZpxk9ekl2Noiwd1iq6fqDruqcURWUr0IrhKEozYUrPFKUTlZuT72DoB2KExaKhXTR0xz3T6GkWNdpoDvujnDeSJyZPWRXShFXCPzTn5PlK9u3x1GdW8P/x9YMbT8tKIIqjM+A85eTR2lDWC/FIG+E9bNqKBz/z3fuP1FXFz3/6JcM48vrdW2KSzW69WvHnf/qnpBSYx5M8GONA1x15eHykqBpaXRINlBEKa1hVJaFpWCUYhp6+P7IoHVfXF7KRJSnCRUZrSErz8e6RfvwgoDkfuFgvWLYN9/cP3N/esb68pm4X3D5sOXU9n3/ynIv1kkM3Mk6erj9yOJ24XK3koVeWoGDywkA5HI6cuo6hH0QavugonONqtaQqLBfXVyijMVVLiJGrZU1KkUN/R0iaerFGkfjw7i3aWur1Jbp2bNYj8zxxOOzJCmWcK1hs1iil2PcjZYgURZUlosJ0+ubtW4wtaJYrmtJxsaglzrMo2D2eeP/2WzbrC4psv6uqAltII2YYB/aPj3z6yQsur5/J5p3TUaL3rC+uWWyuOB32PDw8smwq2qpgvZSEp3EOGcyXmKPiNE5MMXF984znz1/xD7/6Nfv7B16/fi38pqixKCkOjHhtnXOs2hZnDHVTS8FoHLP3/N0//iPHrqOtK5mu1hVVVWKNkwP01NF3HW9ev5E0rs2SEDzfvH1HDIFFU+UkkRIfIx8eD1hrWHppONkUcCpy/eyZcMeCFvtPmjFKEzKYrj8en6bw1jhU9NRlyXp1wWrZs1kuOHUd+/2BRVtxuWyZImx3W6y1FEXBcrmmsKLgKJyjqmuKqmZ3OHL3uCWOHckPrC9vqBcr3ny853F/JM6TwEmLB4ZxYL1cUlcV+8OeFAJ/+S/+GZvNmv/wn/+W/bDl8y++wlrDL37xC07dCWcdVVVC6gkK3KJ5KnKstawWLSi43+7ETvYjueqmEXvOPD0pBUhirVVAmoXztFgumcfI2/cfJMHzYiNA2nGWyVE+mFxu1lR1LZyu7sjucUvXdez3R7FSbI+sVwueX1+jjcVVDcATf0RgoyLJ1hn23Hcdfd+JrU0b+r5n2B0kpSwF2tUFdbOUQ+I0oa3Ypg77PcMwsN5csFqv6buTHPyCZ54niqJElyXDODBPA0mqEVGaxJgTj5ADnla0iyXOWpq2zY0n4dKdZc13Hz/myZ5YAIdxyhZgmYLXRYEPmj7lyGEtMOCqlYPedn/AWUPbNDgrDdtTd+JwL+ko1pwwVpRPVosNJ/qZYZCEQOMKIpqiXhLmCT8NuVEkRURdN/RdxzBOGFtgnDSxCquflKtFWeaEqQbSWR4sNrxTd3rqWyxXa1xRcjgc6LuTTMp7gWGahcnfJqQokdyL5SpHzscMcpyZQuDh/p5xFAVYUZR89tmSoig5Hvb5UGwJfubh/g6tDc9efIrWhvuHe4L31FWZbeUCkux74WyR0tPgwRixAU3jSN8dpXGupBCpM6fGT5MkpAwDMcxyIMjNnKqqWV9es9s+8vr1d1xeXHLz7AXjODAMPU27oLiq5e+YJxkQ5KGSVorbjx84bB8oqlr2lNwk2+8PDNPE6bBnHDOrqTxbsB3T6UiKgU+//Bl1u+Sbb77h1J24XK+w1vD6zVvGsceoCmctF5sN2li6URL2CDNGK1brC1Dw8PBI8D+epjmAVVEO8hlsmrwAcEcgRIVNkbp0PLtcsz+N/PI379BGc3OxJMyex4d7eaa1pDY11mBys6IbJt7eSaJTaQsO/cDtds+ybbm5uqAqHE0tkNopJIljTpIcV+hEUxU0dS2A0nlm6HsOXc/h2HM8DTJlXSyIyaOTpFkllSiNqGk+bg90w8jlesUnywXjLAEgh1NHCIFX1xuaouC77oF91+fPI00AlcQKrJTUiBaDZkZFKfy1UlyuW2mqIwrRcZS69WK9xIfA67fvCQmahTSpLy9Eob0/7ABFXVVYraiterKROGdZNg3KaLS19NPEuw8Cs62rmsoZNo3YZ5VWEtV92LNatBRtiSOhowBqx3i2DCtUI6zBkLKlXisKY5i8KNencRQbfFthqoKrixVN0wjoNdvuuskzZwXTZlGxWWm+fr9j1wUOQwAVMERaB2ix7LeVOAZc4UB9HwG+XixISvHbtw+Ms2dVOaxRFFqajoOPhKS4qIqMJdgCsG4sISU+bjtSTFRGY7RmWZUy+J1mvFdMXoYPzy7WTD6y60Z0itRqZvSe/TAzRMUwRiwDOya0tlRODoNDVNTOcdEWHAeHcZbDsePj249cX6x4eb3hNHqOmaNVllV2Q3jWbc1mtWDRVjR1ye/myN2ux1qBLQ+njnEY6UZhe3ajF6ZZU1IUlqu2pirOQ4bAZV1RFJaHhx3TPHNzuaZwltttzzhLA9aDHA6NJnqx+jXNMjeeImEOnLpRlGk/kmu53sgwpJeAiqZaPe3j1jnadkPb1Hzy8gUfb2/5/e/+I9ZpvvjiBfPkef/hI8EnwpS4uG752T/5XIanSdMPnu3jlu3jlsfHnQgb/MRms+TV1FOWNS9evqDvOo6Hg9hgY6KpW148e0E37DkNe8CiMBSNZqEr7m7v+e3DN8x+wIeJZ89u2Gw2qIcD3X6mWRWsli3fffOe7eOeL7/4lC8++5zHw5Z+GuinCR8ibVthnWGIA8M0YKOcoe8f7+lPHdN4kPTddoUrCj775BOqqmSzXqCN46uvfiqqzFXJPE/88h9+ITVIKSr7/eM+K/d7Uoos1zXBR7rjgE+Jzsog8dWrV8SQuL3fU1clz55d4ZyjKUqOuxPfffddZm01tE3N9eWaoiipmwWncea43VFog75MVEXJxfrqKQwkxMjpOHOxMbTLBY/7AyGBVZZCl6yXa9pFwzBMTKOndBVlYXn+bMPzZytCSMQ4MU6eYY7oB01/Grh5fsPLz15xe3jg9vGB33/9Bz5+uCNEqKuaxfWNDOxzE9w2Dm00z+sapRTLusLPnr//x39ktz/QNC11XbO6aKmrimnuiRF04UjjxB++/j1FWfCzn/4ErTW/+/pbgo8sFxtiCnR+hzGGx4cD1nTsiz2oBCZiCoWpStLsIcgaVdiSpBNeecI8s9+dSEES98a+5+HhA02z4Ob6mvV65urqivv7W757/Y7nz57z5Vef8+79a37z+19zff2cm+fPOR4OnA5HisrhKsXStZTW8ctf/pq3331Hs2ip6pq0uoLa8vbte+7v7tkftgzjwKtPPmW1XnN11WKdYbfdopXhL/7yL9hcbPjr//y3HA4dn33+EmMUv/jH33E69vT+RPKei80SpTR+FjxD8BGtFdfXVxij+d12yzCMP2hd+MGNp36Wzeh4OsoE3EkaUPAzPhcAIUXmnPZwTh85J2zUdc00S8d4mib6cYQUmSfPPEv6hC0qrm+eEdGkKC/Ner3Osu0gnrG8KM9BqPxNVdH3A13uaEpXViwXIcnUpHCFMG4aYRzN44CfZdImCixFVVhSDEzjKOkfzjGc9ozDyFQLB0emYJF+6DAkyqqSyZcW1cKiFs5VUjDnSE9J4TC5OSRKoXPKRVmI8mgepBha1DU+Rk5FRUiQkhy2rKswZUFRSuNqGntiUMy546gQJc3z58/Fcjd7SJbCZaVFnvCslkvKssz+dZlMJm1Q3pOSwjpREXjvmaeRqe9kQqAVY4gyMQWUsZLMVpQ5tn1inGSDlkQFz2KxoCpLVsvwvYqpqUgkJu+pmwXW2JzYND8xYx6229xoE1UCTiZ9dV2jtWbZNtkaJJyDbhBb4DhNEEW+arRmnGdRiVlHMnIAM5kpo6LGOekwn5MWNWC1oTZWfPk5bSbOEWU11ok1JBROUnb6E2VhCBhsTpfTCiSBRgDdRWYYECMpBEYf6NNI8jMpBsZR/L1JSbLjmZ1Q1xVOlczzTP/wgCKxbGv6o6Q1pihcmaEXD7r3AUVin1WGINPOwlmscyyXrSQjknIShsoAx5IQIw+PD2ilePH8OTo3GPz844H0nk7SufdBmgzOOUg8pWUN2RolnIiUOVjynQhLLuFTZIoxQ3U9eprou55hGLOKx7BcLHKROskzbEWVoUBS6KxjHkeGSdJ3YmbwzJPYJYRfJEW8Q5GUIXpFDJJOZVV6YhGkGIkkrCuodU4qy8+71prgA0McINu/kvhFhI2UJBnDck5ik6mFNZKcNKWZws+S8EZWVs2i+AlB1JtifVIoJU20wkpRNU2j3OcsufV+RqeEsUVWB54B5jKdHwZRMkpzxOMnUcUINw/Iv+NyJdwjP8/ZYCQ3QhtDmGdROeWGmzGGpm5QRpQJMShSVEzjLF75rKJMOomKN793w9gTso1Ea01Zt2hbUJYVbdvK4ao7Ya3DZRk7SRRGMSZOx+OTeunMjQCeOHuFywku2U42e58tJpJut15fyAF/HIRDYcQuFyUoTJS8KeXgC/WkchJFjKjUUhTwvDFGGGCknDwiKXoxSRLemdOlrBVVU1aaiWW8FaiuOgtYlUx3Y5+b8YnxDLV3ss+fVdAqF/c+ebySHEibeXrWaMqqoiqlEdb3PUaJem0cemkKx4D9I1VO6RzpnDymlHACY8yqh0Q3iPJzsRTVzDzP3ycx/kiucZ5za0Leu/WiySwcef4knS2BEl6g0TmFDsDoJ0VJN3lmH+inKe+FmhBzGpnoh57qFWc1pRX1TkqSsNpUDmJiDhFnhe0zh8i+G+X/p1UGrSpJ2UNRF5ZCKwpjsdoIDyyrFmOSgUdVSD0k6jxRJ/YIM8L7wGQCxghvaPIBhim/H5qUJLmnqkSJLylCwio5PzMJ4fXEBOeVyQdpGBgtKilnZFo95caXy4rKpxQ/m5WkkN+fSPSJCVFcXW6W2UbFk/3gj1NB66rEGM2Y00CfmEh/1GN44oAq9cRhUpkfZY1mNhplNMqIMj5EafwHLwPXIfMcpTGkKBMYq7EKSiPf9TCLetCcmWgZJh9iYO5lbTda7p0AvMBqiFpRlxZnNDpPQ8/752htTq+SerCfxIZmtM5T/6xIc5L2iRKlqvdB+Hc6ElLMrKnIHCMxqeymABfBKo3VJSDPiSjnBEExe2GqxCCW9bapqauSwlkJrAmRcfZ0/UhhwBlFN06kQ5dt1TGr2MHHwDhDP050w4QxlqZyTL7HhyiKD2szx0mafaIKSIQgymNreNr/nNUkvk+QIolauagkCGSYPTEkTF2hyWy88ONpPJ1OJ2IIdKcDoGgaCXTxUbAGfd8BkcPpwDD0memoxUJtFUVRMjEzZjdA1w9YbXDaMo4z4zSgteJis6YbevxBFEjLdilnFCODF6MVQz9yOvVMfiYmzxzEsWIyO032T0VRGJxTlGWD0i1t24pKJnrGqcOMiaQKyrJguWqFheln2qahaRqGTlJvndXYYEghQZLaJaZI04jttyqrfMZd4QpHCIlhmBmnGWsSJFkr9ztRrGilKWyBLQTNkWJCW81mvSbEyPZB7rUoTcXqrJSsR7K2BFIKT8obP4q74uWLF0zzTDcMaCMJ3cbYJ3XY5mJDWdXM05zPev0TwkXq4cA09XmgJWEhrnDUVU3Xe8ZhFpukD/joczCNDFSnKRJ8ZBh7vJ+Y+khVdqAVTduwaBdcX92QkqLrehbLJc45USFOIxLIqRj8CFrnZDZLzpugbRcoZbi42EjaexIF8H53IMaENTUxBp49v8ZaS98P6Pz3RB8IswdEbadVThpWgqUAWUKNNSxaGb6QRI00+17O5pl3pwrDNAZJjy9tZhPKnqOUJHU2Tc3V1WVWa4kDpa5qgg/stpJ654qSeQ7s9x2xBipZNY2z1E1Du1gwjiPdaSBGT9MU+FBjjGG5aFlluP3Rd1jncBZ2+13+fTRVWWeFPWw2G8qyFldSiASTmas52bHvuxzoI26SM9bhh1w/uPF0e5qZxpGPb76jsJqfffkl1hi6oWPygWM/UxUFy8USHxXLtpUXGYVzBdfXNxwOBx4fXpNIfLi7k8U5L9o+Rprlhn/+xVc8PO749rs3LBYLvvzqS07HI7uHB5SfUbnI77zCuIrN5oJ+eM/jdis2scJQV46qaSgLS1VoXLXCFS11aSid5nDY0/cdk/dMh7187qplHjoe+xNffPY5q9WS2/dvOR0OlGUljMzgicGz3W8hBm5efU5RNbKoxsRnzy5xzvLm7pFumHHDjLMSleu95+P9/ZNU21nDctmSUmIXA64oeXF9yRwi2+OAV5Z02KO0pVhuKKuKZrkizAO+O4o1I1vbUj70/tVPf8bHuzv+7h/+EY1jWZf4CINPLJqWVfMFc0hMXiyE3emA80HUV2XJYrlGacPh1HHYb9k/3LNcLGjblqkbmE49aEtRNxTNgqKp2T/e0x33chCZZ959+Mhuf+Dq6orFYsGL60uWbUNdWerqkvuHLeM08WqzZNE2vH79mlPXEZUcfN59uGWaJj65uaHJQD9rNC9ublBasW5qlIKH/YFj3/H+NiesFI6qKvjzP/0JMSXevL8l5jQRQGKNtcIVFptA5wN6kQ+4GrFR1dbKQS0dmadI70VdUtYNpXPURpIe3t9+RBvD1YsKpxQqeYgz0Y8sqoJnG5ne9uMMIaD8xOHY83joqQtNXWiGyTNOnqtJFuZ5miB3kK/XS/63v/sH/vDta/7kZz/j05fPePNmYDef0HEmzYbHU0cIieWioXCOb757k5tpkfWiFDmydXz68jnTKHLkrhPpsHWO1eqC2c/84te/JgTPT3/6E5GTDv33qoofwfXu3dvMjBAA7quXL9FK0/cnxtGz3e0oq5H1xSUxBuqqFIuWkcZTozUDiaMXb/7hdKIfha/hZ88wTDRNzYvnz9ntd4zv3lEYqCuxBvcgxdBqxfbxge1uonACDBzGgWEYWS4WrJaLp4NSWZOn3APzNFGXjlIYs2Kf8eInb5eSHjYNHX6eqWvZZO4fHxj6gbGUA48U8o5+FHj+enOBKxzjKI3I68sLrDW8efNW4oGNyyBtscU+PNxJRG/ZyKEl220k9tqyubhgGke++fqjDCbqhnOErrUW68T2UFViL1bWMk8T28OOsih4dnVJ1524/XjE1IrVOrPh+p6mqbnYbDjsd9zefkBpC06m56asGMeR0/FA3dQMfU9ROG5urp9Ar8HLYW+aHhiGjqqqMEYSUWNMzCHk3/GB4/H4FJRhywXJFCxXa9qm4v7+gd1ux4uXn1A1DdM4SojEJNa+3XZLSpGry6tspRWb2mKxIMbIZr3BWgngmMeRrh/EapMjyL/66Z/i/cyHt69RWnF59UxS/vqeDJohkfDDSfyMppQmmZJmQ9vUWKOZphFrC+qqksCM/ZailOcPrRmmGRLM44AxDa4oBBgaIsvFguVigbSMzsWV5ng6cex66kZAo9PpxDQK/LWuSjCWdrmSAZQX3o4PkaYuqaqS5CsKo7jYXFK3LQ93dwxDz9X1NWVd83h/J0wBV1AXcsA1xrBsG8rCSVM+CnQTyM0XYUFJWukGow3H45Fpmv7/scz8/+w6nIbcaDU0dcE/eXUjTMjdkWGcuN/u0HPAJ4fSiUUhNk6VEpXVXFyuOPYT+9sd/TjxsD9gjbyTisiirpDoZ4+1mrZpWDaVKFeiWIlLZ1m1LfvjwMO+Y2XESvx4mrg/nrhe1VyvagqrqZymaRayx6aEThmsWxQcuj6ndmpCgLZuWLWKOQQmH2hLAQYfT4ohxDxYitSFWMpOw8Shn7hctZSFYRjFrnW1WmKt4fZxj/cy7LJaGGghJLpJAmaslYbKaZSk07I0aAWLIjL5yP3xhFJK1L8oJu8FN1CI1dgk4VpFPzOFxH5MNHXJn//kc45dz5sP95TO4ErHMHqOXSc8oqs10xzYnzoZNpFIUdZ4pSQi/jwcMDpR2O9VqIUVZaWPjiklbNXg6gXd0OEP3ZMl/GF35NAPVM5gjWZROQpnKLXG1ZbJB8YQaQqB3aZZDn/eS//rcXcghMirZ9fUVUlUYtlunaY2iWerGmcM3SRr5u7UZbWrDC2ur1bMPvDd7V6s/01BSjBMQZRKbYNCBgAxekJGSagg5wCLgNxPkwdtsEWNjYE6iHrVVg3TJAom7QPJj8xBcfRKmm6jWGMu1ivaqqCpS5yZqazi2w8PvH7/wNW64XLZcLvd0897rlc1F4uKfpoxWlTRw5h42HccuoEvXt5wuVoyRwlLWjcly7rkMMz004xWITPSAjFqXFFRFAkSBB+oS0tZKFISPMcxRpJWrBctAL97fQcp8cW11LneB8bpx6M2f/f+A36eub+/pW1q/uqv/gptDB9vPzBNI3e7gzRdYs/Q97S1wxUl2pQ4XbC50BwORx4eHuCYePf2I84VlIUoWoaup6kr/vRnX3H78Mj4redic8Hnn3zOOE+c+p62rambkm+/fcd37z6yWB8Z5hNdd2K/P7JaLWgXNdYYSmuZhwpCxXJ1RbNcY11Cu8TubsfxdCKkFW6qWV0suXl5xelwZLff8tOvfsbF5oJ/+MU/sttuIYh1M80RnRT90BFT4ObZlQzEg8Noy+dfPsc6wy9/9XuGYcSYUobWKTDPE6/fvsHPgWW9oqoryraEpOh7T1E4fvLTnzGOE9vbXzIPA0P+OUlHIpENEaUDxsykJA0472dOpx2r1Yp/+2/+DR/vbvnrv/97qrrmxYtPGOeJw/HIYrXm5aefipJ1d2R/2PGwu0Uri9YF3k/MfuKwc2wfSqaxp7CaxbJmvdkwvjsyPBwYxsg4JcrSYJySpHA/Mw5iV7z/cMdhf6RaNBRVyTBOXF1e8eLmBc9vXvDbX/+W3W7HsxfPWK9XfHj3lq7r0Dnhd38YSFHxxRef0TSWIQkS4pOXn6IUfPrpC7TRvHn7lt3xxDffviGEyPXFFW1T86/+9V8QYuTbb95jtOWzzz4l+Jk3r78hJo9z4jBIROH7pTx8VYqiclysG8Zh4kEdmOaeY3eL1SVNscY4g101TI8z2+MOWzmcq4WNGgUob4Cbq0s+/eS5hGcFz3LRkq6fc3u/5c2bP/Ds2Q03N9dsdzt27x+4utiwWkWiMjTLFdfPXnB5dcXf/fXf8d033/Lpp8958fKC5aplniNffPYJq9WS3/zudzxud1y/uAKr+foPf8Bqw7K9YrO5Aj2BinzxxRfEmPj44R3jODKogDawaDRRRe7ub8WRlWTIMHQD3ZmR+H9w/eDGE37GIoVpUTiWqzVKSfLP7CN9d4RYgRLf8sVmTYiBx61AaK0VDsD11Uao7FoK/2mcgCST8xSwSlNaI7DQFDnudwzjmNMfkqQPOUeT7QPb7SMxzCxagdROmWORdMAnSEhiSUIOGcELeLWu65wAJuX14ANDP+C9Z7nf42OiH0a8D8zBY/IUzBqLCbVMYY1MBOuyRCGTf0USLpERgv3wxDwKjH0v0/CqJiWd7UwpMwsS2/2eOcTMYwk0VSm8kxQI08hxv4MUJD0o8wN8CJzGQVQYCk5dT1XKVP3xcMzT+YopN5rmkBjzdGixWGJcKSlKKTEOHQqZ4ozjDEpi48eQsoy8ZPSSVKjChIlG5OCuICkBfAtgHcqylBQXFCEmUcjlFMKQkMMPHYeup+sHLusGm9MIg5bJHkqSdmLS1FWFUnD38EAIgTlJZHtdVcLuUgII/Xh3z5klYY2hKmWyFJFJamVFbdDnZLJIykl3MvUbxhmbUykma4khUJYVTVUyjYlTlzJ3zKBSJE4dylYURcs8e6wtUNaBLQhzZPRR+CchyDShbiidwlnFMPf4MD3FIPt5ZhoHhr7jZCSpabkSy+DxeBCF32LFYrmmrit0N+DnINyUJz6WpWlKrDXC1kiwWa3xvmW3+wPjMLJcrSjKkhg9xMgnz5/JlDinVZ2VcT+Wy1onoFJXUBSlNC4UmdP1faqgVsIhWiyXeB84HU+S8lGLx/9ivUHWKlEcDb1MNYqyzBwpnRMsRP3TdSexxs0zZhoZB1lfzmyS2QtU2VlDCF6S1sZRlIiI0ihk+2qMcnDSmVtkEP5YCIFh6Bm6Dj9Poja1jnEYGcdBhtbWoq1I/AtXkEzAWgGrli49KeCEUyQJgOM0Mc1z5srI2gnkRgeZy5K5d0pYC1OWmANZSQVlkVBay7RPK1IAYx3KFDnpUqwm/TBmgG6F1oZxkMbn+V6eTke6rmMYBmxRUjpR15wn6VUtHvi7u4/UdUPdNH/0uUUHqLMyrChL6rqm76RZF7yo2Iyx0rjL63HwEz7fQ5sb1UohsElEzRVjQGmdnzHx+eucPBiyBbwsK7mn48g4TShtRVmQlbDzND0l3sUo8mVjTFY85alankTGGJiGPvOa5qxOEa7C1Mn+UmY+V0qihF0sl1lRck58E26ic0Xelw1zmJkmsaRYa0Q5NE1PKt/zWurOe49W/4XKM2V1itJaGlk6oII0LXsvjSBbSIpjYY0EQ0T/xAkzmZPVNE2euEkKUbtcUvnA4+M9s59Foar1k0prvdlwTmgkJbFiux9e1vy3cJVOQhFCkncvBP8EWfchMkyBpALjPBNCoKmc1FbzTIyy72mtuF63T6y7mBLdOGFIWC1q30VtMCbgoyiifBDF+DwLA85Y2c+tPRfheZIePeM0se9kmDKHhFEBLf42SDxxmVIU9uTZ6jf5kNO/pG6zGkLUzEHWOx8TJiRiksO7yglk/eSZQsyMPI1Qj0QVpYCuH1GZEyRLgEGjcxKzcPLE2ivTXXknRW1wZmNpJWpFrUUtHGJi9gGjEtZEEd8nAfjvDidmHyjLAlLieOwARVs6SJHH/QkfkyTMZsW7NYbCGuYQRS3uA9tDL0EkxorCYvYkJD23iImApq1KlpXjFB19trzEWZJ7V3kwJwuHJiG8QaUU/Rwk0TI5QONzypPJKiSlBUQuTKOZLit6Cif37myvOAxnRZPYjYdpRmc+W0wpBxuIyi2mSJ9mlEpUTpSffR9FATHPaGOpSkmGGrMau66FIZPQqKTQTqhd8yyBGCkGlLJP/MJzCmJZnhlhOaHQS6rwMAWMtVysFrS1rEHMszChgvAJh2HiNExUpbBGm7oSFXpIHE49CkVVFKKK8/6PuKay/olKTBR/chSWfbt0BUkpdgdRTJWZn2WyHPZm04BST8nYVVWizI9n/ZI9DtbrDU1Ti+oE4cSEMLHf76mqgqvrFcY6Lm9ucrjE9skVUlcVL19J48Aoi58DY38AhDGmjaasK+pa6nRSZLt/FEbvHEBBUcj5szmzAAfBLDR1RYqRw+FAnBJhhhAU2lagRK3kCaggCdR1U1NUDus0wzDQD4OAsMeJ5eIjw9iz3W45Hjs0iaKwxCRDOhFi2FwbaawrnviNikRZGGI0dH3PMI7SFA7ivFAokpJ0snk+p8MqFJHDbs84TozzKIqquiYRCQSMsXR9n585hzWiAvN+Zpw8p9PA3d2W02mgqWtBbTyIbbgoSkIIPNw/MA4jp2PHHGaqukJrh9UFs7fYWdRn797dAqKGlPPmSe5x0xBCzzgONHXJ5eaC42FP159ABWICUzjKRhAIxjqmeebU9yyLJUVhsYWkOHenjpQCh0PHOE5cXl3iioJxRKxfSoaifS+JgEUhPKv7u0diDOy2YoVdLpfSNFFyDr+9fZQ628/YQuekWEmQM9bSritCSBz3AyHBrMUpYJ1mHCaOW0nyq2qLsSUpNThXsWiXzGGkOx2ZpzlbwA0271tGW+YwM4cJExVQMHtP3w2M00zIZ+nLi3VmRBuC9wx9h18t8lkEoo/EkIheHDObzYqUoDv1oCQV2haSxldVJU1TopQRhV9VUhYF682Csqg49sL4XK3WgOLduzeM08R6KZbQs6Lz888/FbSOF4ZZWVuS+mHnxh+8wtl5QBvN6pNPqeua5y8/IQbpzo/TzO7hjtA2aP0VZdXwRdPy8PjIf/6bv5HErKsbFm3Nz3/2FbOPbA89ne/Zn444DQunMb7AEWic4Xq9QMeZt9/9QQ7QpshwaEetLaYs8dPA11//nov1ilfPrnnYn3jYn7Kcbyb4JFymGFFhZAyRoCJ1s2CxWJK8TF7u9h2HfmT7uGcYeuakWDQ12/2eYRpzWpxltVpTuIKpFJtFYTQGz2Il0wpNIsbAerlg9oFvX79hGEdUnnz77vC0AAWlOJw6YWw4sXv84btvmfPGbrXi6kLk27vTyNCfeLg9UVUlL55dYZSWLvo08f72lug9v//txGKx4NnzF4zTxNdvPnCxXvHlqwX7Xc/Xf/hGip+YeHZ1zeeffiYHXKU47XfsHx/Y2RJsnVU5BVM0zGOkKUquFg0PD1vG4xFdJoydqZ2VlK6k8AiL6nroCVqKHrRjjppVUUoiXBvAFOz2Rx78zLvbR4Zx4nKzoXGGtiok1rwsMIWlnwRYe7lZkWLiP/3mt5y6nmcvXlE3Dc+uLtFac+wEsPZ3//ALtNb89CdfUZVVnowrohmxRDY20I2Rd30vsOhRCvNSw/HU8frte25ubvjX/+pfZSujvKiXqyXbPdxOkTkqrKukIXi6R5c3NO0LIophlgNssAVDmjmMXhQXs6esalarhqTkMHwcA5MXYCDBS5LU4cB9nJgOBXVV8vnnn7Hbbnn99jUXV8+5vrjh2fUFTVOz34oVNMjOxHq1pK0rrm+uKYqC797dMowTn33yKUbDr371Kx63W778yU9ZLBbc39+SYuSv/vJfYK1lf+rxIfDpq1f8mCLJ23aR+T8CddbZFqasE6i8K+QfoylKx4vqJdvdjm+++wVlWfLpJy9pmoaXL1aMw8jDwz3jNHI8nqiblutnz8RGgljq2nZBTJHb24/4IGk/PsN7p0kSe3yU+NzSWdqm5njqeNhupRDO8OiUFClLeqcoE3IJUiiohAHOfi/qzdPpyDxNLFcjZVGw3++EK5SCpINaYTcVbSvWP1egtaay+imqWg7+NcZotvsj8yzAfhCrrskHJZTA8rXWNAthQO33O6ZxYvTSpHBFhdaKsizxPtANg9jAksiFtS3ESjrOjJMcEApnWa42Iht/fKCuGy4vLuj7jvcf7iWBbX9guUjUVZOtYMImKIqK+7uPfPPN1zx78ZLnL149NXIKl22nxlAWkqh5dXXFx3miO85ieZ0mmrpmvVzSD9LEm8eOgSDcq6KUFMx55rDfcWCLFNCK9eaSopRknhBy6IV1OR455SIn8vq770SCX0qSz3q9hpS4v/vIPM8Mk8QgX65XOTrY4pXwtQpXcHV9zTRNbHdbaQz5XhIMq4pxGvnwQZKAnl1dkZRiTomqLNncXDEMA9vdXoC+SYItmsUCVxQ4VzAOA6fjnqqsMHVN3/VstzvKwlHlNNWmqTmvCknI0jijsBo6P9MPE+1iQV3VFEEsSw93H+mOB5arFXWGwtZlwWrRUDppvPkQaOpW2HyXG4qi4GG7Z/aBZ89u0Fpxf3/L0HVsNhuKosSWDdoYvlishB222+Fj4OZykxsFP55r1VRiBfVB7nV3hKQYxplunHnsJsqQuDydsBouVjX9MPPu/oDWilCVLJqSn3++YZgDH3YnumHmcX+UhqIr2CxKnl21dP2E5gTa0M3SOJzHSZoUSta4snQ5rVFl6OzEsQscuimbYBN6mtEq4aMiJMUwz5SDoXKGwmiqQuyUb08du6zokmdBGhf9LNiGOSSUTswhHwiNYIofjwMhRq4vVsLIiTMmBNrSMhnF+/cPucnrJJmnbXEWDGIfm7PtuimLbI2TJsnxNAikfLMQy68Vu3wM0vTYdiOFBldJKIlJMHQ9d4876qri+nLD4XTi3YePbJYLPn95w/3uwO/ffkRr+6Toa+uSdVNxvWrYdgMPh55jP/Hu4cjzyzXPrxpO3Ux36mjaBXXdgC1wVeB63XCxqLg3CmUcj7s9p27karWgrUuOw8Q4e/LsjjrXVHG7Y5pHdLFCGcvg5f7W1uSQExlKeD8Rw8TttiPExJfPNpTOsN13jHPg42kCpfj0ZoNWio+PO7wPgDTTNusFzmoao0UJGjtUMmyakskH7h73TOPI0A+UZclyqRlDYH8aaZuSF5drUkxMwyRDa2c49BPbx6NwXL3HKMFskARjYKyjqKWOJs3M3kvTaJg49COLquZPNiux6KXIcQgEPxPDDNFyOJy43R755NkVm7ahqmoiitu7R+4fdyyWDetFw+xn5rlntWipCkeM2eKe98e6ELB714szY9FWKK158+GBfpz48pMb6lLWWwX8/ItnYoFWDh8SFxtRk/1YrqophVv47IWkkS8XMnxTjnk+8eHdO5q25tPPX9G0LVfPXnJ3e8e//5//V6qy5MuvvmC9WvGnP/8pfTfw4f1HDvsD795/oKpKri6WOGdp1yvm4LlaL4hh5Otvf4vWJcbW+LnFaYtTjpuLC5w27LcH6rbk6vqS+7s7Pny4BW8hGHAOU2yIUTMNEyFMxDizWC5YrTZok0Anvn19x8PjgdP+wDyN7A5bqqbk8NgxTZ45LKnqgraucdayaNunpj9K0a4ErJ5UJERYLSsKB+9ut4zTnBtOUBiLsYqkA3MK9J0kea+WC1Az3379LeM0sz8JJPz59QUgYoppnnl83FIUBTeXVzkduGD2M91p5HQYub09UNWOq8tLhmHgl7/+NTc3N/zJn/wJd7d3/P53vxf4/5xYbRZcv7jEGUfhKqZpZhgmbm9v+fXvvuH59QXPn11x2h/ojz11XfDs+obg33M67ri52PDTL77imzev8TFJkJGKNOuWelmCLkA5TtPEtN3SrJe0VU3V1pRjz93dR4KfOZ4iKRk+/+qGzXpNnF8zjiPOOhTwuL0nxpkvP/0cjeav//d/5Hg6YVyirCt++ic/xxjL+7cfOXU9f/j2LUbDJy/WuNpiC4MyGleIc+qrzz6l6zp+8fBrfEjMQeOsKEsPuyO//uXvuLxa85d/+XNiKCmLkqqpubi55PbjLd999w3BJ5ytKWyBUxIWI9a5iX48gAZbVOKMud8SYiAkz2qz4uXLF+TZGvM0cNw/cHW1Etubj8xdYOompnrk8vKCtq14/+4jHz88cPX8hsWipqgKXGXZXC5xpcZHR/CG1XrDZrXk5YvnlFXJH76NDMPE809eYa3hb/7mbzgeT3z11U8kVfrYQQH//f/9UxKJr7/9jmEcWV7ULPg/ufGUUmT2kW77SN93rFoB5s6zsBVWy4WoiLK1YZplolEWhSTgaPFljxnWN04DSiU26yUqBlTwRBTTNIv1gXOyk0cZg7IBTaLPCqWQBOpKCuyPJ3wIMh2KohtWMeHyxqzOiSsp4JOkRc0+EuaJEDxWG4kVV4l5konrOAcwFluUT+lTBE9SkiSmk6OfetIYGAaJr3x+fYm1lvvHHeM4oY2lLKWgIkVMWTzFrINie+yEe9JKOtbQSTe1MKJOSOh8EKnxwVMVMj2YBplET5NYSJaLVjhCXqw2ZWYLlVWND5F3H285nU4oU1CVlkVZUNV13pwlpU0I/ZKwZkqXo39l0uaco64cbWkZm0r4P9ow+MgcAz4lTCHWkvGkn9K/tDZiFRp7SqvxQTrokHK6SKIsxYKjrSNpS11VOBdyapaWSW8I7HZ7iUx3BXWjaKoyT7ZTVq5FrNW8fPkCoxR1ZpQcjkcSSuDnRHbKE5NivV4zh0CXkyKOfgal+ezTT9is18KoiDItSUlgwd4HYrYJFWWJcYVMRYAYAtM40R1PwiZwoyjc8lTtzHhZLhr6UdQobV3jbgxXmxXr5YLt4cjh1LFYrrhYtsza4tGUrmCeJrrJ87jdURVO4KpK0jWmWZ6HU9cxzzNN2xCjxLf3w8jjtsQZTdW0LCMcTwL0P4NZu0F8zbvDURR+XqwAP5bLWlEM9H3/pOxRSr4zBTmVwQkjKH6fHrdYLDDGyD3J/uXZzznFxrBaLrGuED6ZEcB0yM91CpEpzLn5mtPVtExjUhRr16RnYvD4SRRE1hii+l6ZkhIimY6i2HnaeVJWMwQvzZ9GGmrei4Jy9j5PnQvKIk+RjEFpRZyFKxQSoBUzwkNpfUDlw5/SGuvck3pFKUk40pl9FWMihJ4YVX6fkXcDUSCeeVaSdCUpVHPwIiGexZZ2OBwgkZWMwlJxzlFUFfMsLIFpHLi/v2eaRk69gGrrRpLW5lkaX8rIfUopUZQV64srrC0YxwGjJe67KMR2Fnx4Usf0Xcc4TZmdICwDbcxTEtXTd5Whvt6LEqKsKkl8TFHUqGfeS/CURfGkTpvnWRRoKTHPFok8ke/xzFDRSsl+knkytigwWpRFxhi6viN4SQv0IbDbPuakQnn/h2EgxcBhL1aV1WopFkHnhLswdKgUGMsiM/j8k9JD5cbyeWKfcqKSNf5JKZbkUxNSwilJx5v9/MSJK4syJwyV9JOwdwprqcqCMbvdmrrJvBqT02VGUQYaR1nbzLkS3tOoNYu2QSaWvXAnGrGO6rwX+xBJ84QaB0nty6lffXcS9RnxSV3zY7kk2SwyTgPeaHzInDdEldOUVqxTUfgxOrOJyjLbyI1YA/rZM2bVizWay5XYyVISVpqPmoBYjGNSzD4Sc/KYD1LniNLNMEwzXecZpkl4m1qhDTm9SmGyZUxHqdUksSuhycVz9CgdUSnRFCbzfwzdIGwdYVsKdFlFT2ENyVqUEV7dOM3gJSRBJU9crMFYUhB+lC0K0EZUMUqjVcpqdPM0CU4pYRD1gc6W28KZzCwTZV1VSbrtNEqamsvqp+MofCJnHZVNWCe/Ayk9rSc+Jm63R079mN8Xy2ohdXNMiSkETuNIP83CXgJRFxmVFZGashT1skGA4VGRU6MT+2MnfC0Si1rYgPtjwKPyOiaqxDOHKGn91GDDS+0bQhQFUU4oJJ31OqK0CzHSjTOjD3gBXFE54ZoWOZG6doZghA9njKEpCyBxGnqBnmfl2qHriDHhNESrQQmD6dRLE2azaqlKOS/krD9SFBubqJ2EjQU5jXHyWK3k3/dBam4tSoKUEj7OmRknzSCF7M0+QtMIbmBZOVxhWS1bkrYs2orCGaYoP7ssLTFW+ewiKYtyHiBzusQaP07CdSxNiTaabpyZfaQoB6w1TyrMfpA/V0q4fIdOGEVRlfiYnoZ/P5ZLI3yY7faRvi9Yr2tJMMssoItLGaKWRY1Whr47MU0jVS0MJVFXKuY5PNUFWmsuLy9kXVPCV+o7sVjHlFMgvRerO8gAaLtlHibmycuZIr/vwzjT9yPZmwwqYa3GlAUq84h8mIl+FpZakDpy9hN1UfL8psRvVkQfGOcRP3uM1ZTKZeV1hVLSQPBBo6JmGCaxahlJgmubMvPqFDEpSZBVOXFcKSpXYbTGlcKw+/jxDlBP3Nt5PifVKqyR+sU6S72U5L0c4szQDwz9wG63I8ZI01ZS6yhLUVjKssis0YJhGPnDN9+JKjwmnCtYLmtcYZiGieTEMTCNI2Mvz/jVxYaicIzTIGoulbBFTbNsWXYL4X/6wP3DI8djxzBMWGdZGMXpODFMXgJLjKSDOq0Zuk5cPijaqqaPUqc2tQJlxfI89RSlRRuY/YgP5HVC0fej7Ec5xKlui+zGkedKGShKxyevXqC1oq0l0fywPxJCwseADorj8YT3gfV6I7bGw4l5SIyd1J5ffPEZq9WCRbtgGGYO+0GYVpMEm0lggMrcQVELay1csQ7FOMyQekiG7nRiHAaSSiQVMdbQtDVdN9H3E03b8vzlc66vL7m4WLN72LJ3mropWS5bAhMhTlxeXsjnmWYeH3dUZSEJ6CTKusQETUqarhtIMbFer0gKjocjXdezfXjAOQlbqJr6CWMgbD5NdxRGdX/s6ceBKYw/WLDwgxtPAuKeePP+vcRHJ4k89kEBmlcvX4qENSbGeWS3PzBM41MUZGENKQa2e0ldOnZH2rbhi0+e0w8TDw87AppT1zOGyASMo6c7HAWuaI0cWoYBrQ3aGqx1WFeIzHmeWLQ1i6YWmXQSYG5RlkxZohvmmdlPdP0kU7hRFoovP/+U68sLNFeQEr9/95HH4wldVNSuonCitoqTxFYWqyuUsdw+3kvjYpSC+9WrT2nbmt/85nccTyeWVy+FoxAGiIFUyoHjar1kngPfvXlLiBFnLkgpcdgf0EZzcXUpkrooEMJPXj4XvsXhwPHU8ebtR7ph4G5/YLVc8LOvPhWrWRQQZeVEJqlcyfbxkd9//SvKsmaxXLNeLXn+7IppHOi7E3134njc4YqKsmpompp2ucBHxRwVZVXQlo51U7KqHRqxzR26nm0/4pNIJa+amsWiYbd9YJg9rStx1rJ7uGXsT/gYqJoWEbHzFFm+WbYilS5rkiuzCiCCcdkgo/DB8/rNG2IMtMsVa2u5+v9w91+9tmRZmh04ljK51RFX+XUdGRnJzKrqJItkNwrd4K/mA8GHRqMBFsmiKrK6MjMiQ7i84qgtTC/VD9PuSb5VNNAv5RsIOMLDw+8Re5stm/P7xtht5D3xbFfwlKXj13/7L9DA6emRaZp5//EjKWW0lQ/JKSy07YYvvv1Lpmniuz/+kXmZeTxdeHl7w//tP/sXOCeGhBQDIODJvuuYlkDUBapQ1EZRVBXKliSEqzJ0Fx7v7lfbjSEEAfLLhzHRVCW319fcPdzTXS7cXh/YbTds25a2quiGiX4cef3mLW9evWDwwmSoXYHViv/3f/9v+O6770khcLXb8fLl9arBFMD7/eMjIUofua1rPt59oB9GwnShdI7DzS3t1Q3v3/1MWDw3+x3OWe4eHkgp8Xi8sPjAuPhflNLXlSXeB+7uH6TmoaSGmdYKyH6tDU/TKMOedTD68tUrYgxrtUme9mIQQHVd11xfX0va89Kt1R+9JpsEfD+OI64oKZsSbR22KFiWiRiW9cEjk8JCCgtt29I27bOuPK8Dkhg9KcrQnSTb2Zw1/cqpu335ms12JzdS4Od3P3E5n0WFXVe07VaqtOuTqvdS65rzJNLxtZK63e6oALk5SiUUWA8Clqqqgcy0HgwFmptxyyLcjhBQKA6rdcxVzfqgtn4GUHjvGaKIAO6fjrRtw+dv3yK1tkBRVDSbPfPYMw89fXfh8Xh6vpltdztub18Q/Mw49s+QXa00Wis2+wNXty8Y+47+cqFtW+pS4KC73Q69ArdDCDw+PtBdLozzTF1X1K7Ap0RMUueWZ08ZRHWXMykGqs2Osm4Eapki2jjQmhxmYlxo2y1aW+Z5IsbAPMrD7XMAR7HWHd1zdQ+gqBoUsNvUa21IDtNSKxZ4cZpnfvjuT7iiYH+4RinF8fGesLKlttstX331lTzEpIzvOvrzE76sVih3ZJykOimPlXkdhGWMksHZOM/rwMLJw+kKfPYx4QqxMC7TyDx01O2WqmnZ7fds2g395Ln0PXVVst+2XHoFk+L6+gaA+/uPdH2P0pZx9tzc3tLWDcfHB5Z5oRvOxJSoyoqmCTwdj5LYU3IQt0VJrRTjMJDnWVIP2pCNlcXE04PU2eetVB5/QS/nHGnxnDpJnV/tD1ijQQmz6GpbYdbFWEpKZBV2fZheq3ApZx4uIyFk5iXSVgVfvtox+cCxnyVlFDU+G5R1pJCY5iDpJaQ6MY0jZVVTNw3HbuTu4UnsVEVBVYqBUsYWCmc1zmhZiGVhNY3TQogZYzOT9/iYedEabjeiN3eF43/73Y+8fzzz4npPU5eYvKCjp253IijQhkQWUQ1Z+JJaEW+vybYmziMpZ+rNDshsCwH0X/oBTWLXSsX33cMo1bFFQK/aFcQY2dTrQ4kxaOvYbVpi9FyC3Btqa5h85K4L1JXmzbaidIZtbVi8pL6MVmy2G7ph5h9+uMMZgawfti1fvb7h2E98PHZ004z3M90cOU+RqjDs2pLSSnKnLAoZ5qiMUYG0Vm0ul55jjNyfOs79yBcvD9zsN/zw8YmHc89mt6Os62ft9uwjMSfQFl1aqRCnSPCBmCBHD1oQEUqr53r3rhHw7uNFkk+busZqy1UrqvvayeDp0Mg1+Ob6gDYaH+Vh/8f3F1GrW8ccIh8eHrFGU7kCrRyDLfExcv9wYr9t+NUXbwQsTWbOmUQmhMQcAsO0MM9eElBGM4fIsRtp64p91RCmjvPxRFnXtO0GH5Zna21jM07JADNExRzh5urAYduuC4LAm7rlVRaDpFaZNMyEENhtKrabmvd3R7p+4Ha/pS4KNLIUSmgSiqE7kUKgKW5RpeHxMjHM8iBWFZZNXdJUJR9PHSFlrg97rFEc746kmMA1hARPp9MvavBklGZaJr770x+xzlLWBmMsyzLinOZXv/qWsqzYNgcWP/Px/ifGaeJwu6d0krRVwKXrGXtJdjdNzV98/hX9OPLx8ZFxmTg+fGScIjFZ4XRNC4Vz62K14/19j82GArsGGczzEspViqKysD7ol7Wl2dQM/YVpmgl+JiwL5bJBW7j7cORyPvJXf/1XvP7sjcDLjeZ//l//He/efaCsS6xRXF9f0zQtp8sHlmWUIX5SPDwe8T7QTxNNU/Pm5TVVVRKTIgQlYhQNbSPojLbcoY1FW0Xfd/zj774TIctmgzGO4DMpImw3K0vOsqr4/Is3+CVQu5Ku73n/Xu7BHz984Or6wN/889/IvdWu/DqdcUaTfebh8Yl/9//5e9qm5fr6ms12yxdfvuVyOnH/8SOuKgkxyu/k1LE/7Pn8zSuOlyeOl0fqpqZ2NeWm4PrVNahM4QqGaeJ3f/wT3TAyTQs3t1u2my3TeGEeR5wrcRZq5yiN4/z0wNNjoC1a6s2eE4rZe3ZbGXL7pedymqjbBq0rnh4fWJZFvh9leHy6kIGqbWm2G26vr2WwZwwhrsyiquI3v/4NWmvu7z4wzzMf3n0kpkRU4GPg3bs7qqri88/fcj6feffuZ6Zxou9G3rx5zX/1X/3fZVFi4PHxxDTfybK7m5jGRcIZiKVUa0NEjKhtXXM6nugvM+Ow0J07pmlmHGaMEwFIURh2V1vG5Ug/Llzf3vLlN59xe3PN1X7H6fjE0/GBq5sdL9/cEJjwYeTrb7+irlr+9b/+N3z/3Y9Mw8hm0/Lmixs2+4YcIcXMw8MjwWfabcvWL3z48IHLuYMUKNeku7GG9x8+EH2kaSXBl2YReTzdiTWvn0a5z/wZrz978NS0DWa2a4faEBKEJax0+IRSkaooKJ08qBTNhqQN+XyBLJYP0blXTLOmH0e8jzw+HgG1wtTkhmWc47DZ0AFz31OVBZtNy9B1hEkuWFVVrSkCzeIT4ywPb1XVsHjZZE/TKAflmFhiwiRR+mpXCvsoBnSW+kcKnvM4Mi9eALwpk0KQzbBuMNYIjDZkquTXw4BsLbIW6Ov7jx9lW+0cTduyzKNMfxEdMjlhtNjHUsrsWtHZG62JKaHXi+HxdFltDCWQebi/X6ekAmLXViblN9awaWrqUh4ZQ1zTEMsiXKFFtgq7/QFrhK2RYpD0UPQkP1M4w83VNXFlJskD04QtKtqqpCrEjhdzppsDS8wENCHJA8k4LXgfnrf0OeX1a6+pqpowi7moqmrKsqK0BqO0KEdD4HJ6Yg6eZZKpq1+kkqO0MHeKqqIoSvw4koOkMbTWuLLEGfNPsHYnDxxdP8ph2VhsIfry2XsunQDZ8cKhub5ciDFKp16JoUUrxU93D1Rlwa5t8Gti75MRLYYI0aOR7YJWss0dppn8dOIyzmQj5qiwzHyyb4UYnt+P49hJys6aNSU10QF+ZepopXl8EgC7MnKT9GWJ1XKArssCQyJFzzAMz7+vEIIwsoxm/gROdQW6ka9hCZGUw8pmsGDz82DPWhlMHK6sbBKnSZgpv5BXjgFSlAchsqTwlMIn2YroNWFYl+Uzt0ipxDMqA4U1lrZtxfY4T4SY6PoekAF3zvLehSybKKNJOVGWFXVdo7R+5hY17UYOrFmzJNkIf7KEwPMfitaKeRHTZuEcTjtiDOQ5rxtxK/pnZ+n7jmWtjElCIa2pwn9iREGmrGvKqsJEYZZ8AjFfLh3TNK3pEkMY5T2QyGgtXA1YuUY5s9m0AkVcEwiyAJb3jtZidNJK4YmfltTCiVmTTU1TC++sqiEnvFpQWuP9sgKB5c/7xHgSi1FiHHqpNLSbf0omZfl5yHVcrHZ100gq0QrraFk88zSJRWdNSE3zzDTPlGUlh5gYyWtVTistCShWdkmMaCXctawl1ZmV8GY+/fvGcQTUakdMq70rE1cmg3OOvC5LjDGSKsys287MPM8CYC8LlNIUZSVWr2UWw1dOKy8wYLTm+uZWhnm9sMhOpxN2TWMqrWjazTNfKyZh0yhrhDNgDPOyCOthGhlGgUKGGKQWmaEqhZ+Xk6TuQFh/tigxK5tinkZSkJ9tjpGh78RW4yVN8YmfZqyjKut1QZJYZtHupvVaL9vWTEyBZZ6F3WUM3ofnBwR5H69fz/qe0qu5rN1sRN3etmLK+gW98pqM0+s9MQFLlAp+jLJNtUZTRkliWmfIQRK4YqCUz2mlFVmv5rAQOF56lNbUpSUnGEZZkJkcCSmSohf7UlEyzwvT7ClyxmpFVTo2m1psoCmistyftJLqul3tdqP3AhNfk31mNS4WZKzJFFaWcd0wEvsRyLRVsX5mA6VVYAyZT1tihc7Pl0hJKirFsR8ZvHCl5Bwhw32iDOTnNd177CckLdAQY5RUYkrrgEyuIyklxkmqLueuF9uxD3JNRRJNpdNYrVi8DOcWq1hCWqH68nmxWtGWkqAqCktWmn6S6vKhKWFN4RRJUYRMYYXXpsnkIPd/s7LaQkqSYgxrcnJFNtRVFgmEEslDVRY0paMqDTolMTMlWfLVhTA0p7ym1I1BaagKh3OWyUeS/3RqkQQvWu6Lca0HJcDqT2bSVTBhhVl37IbnLX7OmaYq8DGK2AJY/Lr1ryyORF0YUtKk1dL1cOoonGVTV8Qs30/OAYKkt6yR91VZmJUHKpbWS9czTpPws+aFxIDRkhRMOa/3V/UMBY4pE4KYe+dlYVnWFHBKuJW/lJIA37UW+19bWlQqhAHlCmY/EecgBm7kXmesDNWXmCkL92yMFYFFeJZdAGgl7+gsN3oKq7AZ6tIS4i9ncK50lgSLlc/p0PVk4P7+CXIWYc8qRJF7ZEkUOC8prdcAY9mtTF5jhV93ejqRFew3GyDTjRNKWfb7DeMAMUyUdcFmXzGNidzNVK6iLWt8EnPiOIwM/cBVuWPT7lbeV4IMUz8w9oMYzDMYZeXe5EeyyhjrcNbhjOHh/olxmugvA3m11QYtUga5xiRCSNSN8BT7vpTrZNYkn/jppw/CPIwRZw3TIPfrFKR6H2pJ2WUli8PbF9dyf65E4NJdTsTg8dOCswZXFEDi4/uPklpez7ky/LFcXx047Pe0TStV7E+J+ry+V5eAtY4XL19glJhDp2nk8f6BGIKYaZuKetuiMoR1ANH1A8ZYrg43VHVJXZVYDFM3MfSyVJ9GGSAP/cQ0L+x8Tc6KwlW0zY7dZkPd1BiE4ZhjWmU1BWVZM8aJqOQamFOSEIo2YnHLiXkJpMhq5ZUGVXrm/Gm55uqMNXJ22G4F8v/w8IDSkjR9ZvoFz+l8AaBzBW1bU7UycPtUSzTmhNLw3fffU9UV2/0WHwLb/RZyZhgu+EVMjIUtaMsNzhUs3nM6neinntPxzOIDJmowGastm42Ts/A8Mw4j3fksC/DoycmSYqK7dIRlYZ4D1tU8PV0I8QfGoSP6wDROpCjXsLqqKcuCorD4OTJcZhEUIynbotCMw0BKEWs1TVNIwjoschbPWYQQKZCRe1fSkj7b7jZUoabN+z+7KfNnD56uroUT8fBwL7alLJG7P33/PSF4YZs0FYWBZrPj+vNvMF3Hh3fv5SZmC8q65sX1nks/cLz0jNPM48Mj282Gz968XmtBF66u93z28oZ7o+hOR/a7DW9ev+Hu4wf6yxNNXXB12Ar4Mia6IdGNEy+MZbMT+9E8zTKxHjrmrPFZ0TpDZTWbsqZqGqwSRaDKnjD3/PDuIw/nDlfUMpX3stlW5oAtC4ZOjFAHP1GicWs82WT5cPzdb3+H1oZff/MV253lj999zzzPFIWYpZyTA8Kpf8AZw+ubgwxLloXkA6Yo8PPM+/d3WGt48+qacYTHu4+4ouTq9qUYkMqCuq35fNNQuIJt2xBSYlw8fp4Yh445RIYlYI3j7WdC6Pd+Yp4njscjpYXGwfX1La9fvebxdOLjwwPLPDHPC7c3BdebFvdJP7tEzuOC95GQFFPITEvkeDrTd90Ki8/EEClcwX5/YLfbY1Vm7Guq7R5XVRzqksIa+jkwec/T4wOXS48xBc5NHLtBNN1K2Cy/+vVfUVaVbLqnibxW+Kq6oXCWpReOxfbqJT5Gfv/HPwGZz169oLIFjc/EruP+4Uf8MpP8TNv1tJv9yhdoaeuKunD0s+ff/sPv2bYNv3r7Bmc120Y0mZd+InqPWiasUVSlwijwMTN0A++fToBCu4ow9/hxeE65zH6h6/o1PmxJaY3i+4XzPIG+kJVmGAe0Ufzphx+5dD0vbg7sNi1F3WJtgVaZq11DoTP4ieMpkrUmhYjKcHPYUhaOvu+5pMxut8May+lyYQ6euMykLJuHvB5Wc4aqaSmKgpuqASXD3k+Dhl/CK6zfd1VYUkoMg8Ro+yU8DzXKouDlixfPXA+VIWSxf8mDccWLmxf0Q8+l61i8p7u7Z7PZ8ur1a8Zh4PHxnrKs2B/2zPMs292qpt1s6fue4/lE2zRcX98y+8C0rAeMRRKYkrbhufKGUmutome/2UgdcJ5lgKqNQAFLAQP+9MMjDw/36BVyLbUEqEPEmPS8Rd3f3FCWBeMslbfz5YJfPB/u7sX+8fYt1jnmcZBB6CJbZsMKIbcOay0315K66QZJDhil8DFwvogVqvWybU5RwK51s1nh7QIwbzfCLdlstwKWNZISGod1gBZkWNO2zZr8koHD6emew/Uth5s3K7g4Efwi/wkRPy8UZc1mu5OH33WDP4wjl8uF0/G4/nyh63qGcWK7EbCpmmdSWNhsrqnqhnGapH4Z0zrYFdhpDGFVs/Ocxsopc7kc17qO1HuUkodjv0wySKoaqeeU5VrRkxt64aQq0l3Oorl312hj2Gz3LMvCOE3EEIirKt7PM1Vd8+XXv2JZJh4+vmcYRn766WequuLly1cYY7i+fSHq4PMJhdSErCso6oYYAsMw4P3CMo1SG9SaeVmY5pmm3bDd7ZjGnmmYSUk+K8YVlNquVUzD5XxiGgX0mYLn8eGex3v5PFlnUa5GGUdR1hRFJVyVHOm7i1zvVnvkpmgxCqL39F4O3FoXMnRbq6spSTIrrQM9tFrhz4bq9iVaK6q6+cVV7TIa1s+O0lKH8yHy/lGuY85ZSmeonGAPWudIMdH3vQysioJ6HZZoEhOJeR45dh37TcuXb27phonHpwuFgU0hW97sZ1zRst20xJSYzoE2JyqrUZuKojScu5HzuUdlAT07LcMBpxVWK+7HifvTmcNuz2bdlFqjqYqVP2TBqcy7j0ee+lGSpNuGfg4My0yzLcnakpSU+KxSzzBeTaZsGpTS/PxwJuXM28NOziuDnCOOyspwN8ug8+yFQ/nq5oqcEh8+fpTqrP40LM54Iks/YseZeR7XBeNaPc0yTNg0n2o8IyFaUFInHha/cogihYYXuwq0RRmBTN+dRw6N4/PrlilmBp/IaiFlqbaVhbQJ0jRiSrHFLTGy+MjkA3MIlGuarG1qirLFFZLMrFcZzdWmoq4c58vAvHiCklbCpnI0peVjTPgMbv2ZbpsS5yynjyfG2VNbBH69Gkj3W1lsnofxefFpPgGklKIoCxYf+OnuiFKKV9cHjFZcbVuR3/QTMWdGn8jKYm2BNQlVe7LS4CqGaeGPP92xaWo+f/MCo9ZltFIon7BaU1nhoW4rK+8JY5nmWfhuQRJco4+kYeawqbnZNUwBvBfFkEVqhyEk5mlh0IphmpkWz7IIbLwqCpyVxLvSwnHRWn6m20JTNg3aFjxdTnRdD0i99PawoSocp2EmpInbw5bSWaZJ6tLdImm/lOXB1iGQfYyBDJvKrPXZmpj+vIe3/xheymVMVrS1iDGOT09M08Qf/vi91NK0YrNtCXFms9ly+/ItCkuKdywp0o8zriy5utpjjOFj+cg0DDze/cTV9RXf/Oprzt2FH9+942p/4Is3NzwdJXW827XcvmnpnxTGR3b7Hdc3V1z6kVPXc7mceXp64Pr2itvr13g/44Pn8nTmfH6iGy4M08Bus6OtWnyYWdKEUlDV64O8dfz+99/x/Q8/U1ipYE5DT4yB6UYMu/Pk8SHTvGio65J5Dkzjgk6WNCf+7f/+96Ay/+Jv/pK6qrh7PIlsZRpRCtpdj9aaEDJF4fjm268xxtAPIrDp+z8yTzNTh1i7HfSd4v2795RlxcsXb4RpqqFpK17e3rDdbrjeX+PDwvlyJCsFOKJP9MNE3dS8/vwNl8uZuw/vOR+fOD0eOVztefX6Be12w+6wwxlHDIlpnLjcP/Ly9Uvevn5FWRqKwuAnz+X+wuPDifvjEb/MRL9wuUyMo2d/2LLZbqnrHc7U3N5saduScz8xLZ60RHKONFcbdvsdQxyIKuJ7GYhYs8Max8e7D0zThCvkfLp1NcYouvGypvMdFkvKAdByRtOGur5mmmZ++7t/RCnF1199gbYixgnLzPvvvmcJgWQs2/0W1xY0dc3XX3/NNE98uPtAd+n47//Nv2G/3/Hrv/w1dV3z+rNXnE8nfvr+T/glUDlH02y4PryUQd44cL6/cP90L+w/XeC0AW1odxt2hz0P9/ecnk6c7BM6BaZFqu9h0fhZ8eF0Zplm5qhx1Z4ffhCO1s3Vlm1bc5xPoAeMtlxdXbHbNlR1wdQv9GdJkyujefXqiqouOJ1OxMdEWxe0tePxeGTxntJV6/JjIeQASp4/sg1oa3jRvhCsUN382WnzP3vwFEMkRomWohVtVVBazdVh/8yYqUqBxoJi6i4sw/jp3gQ5AmK9+VQHU8kQnVQOfBAgoI+i9Y3eo3J6hsIqpajqmuvblzitiCE89yRzzkS/CCB1GDCr3ruqSqa2FYCtDzSFHNCsdSunRB7IlLaYoqKqapolraYmxaauxQoVM9M4EwG0WEi0gu1mS1lJXWCOchHVGqZ5IiXHZrOlqhpCFJOVW79XVUk0PiIH7ePTiZgzVSWKxbYasNbQlBUqZ6aVg/F0fJItgF+oypLNpiEBc4Rp9jyeTtJpz9Lt0CmRCAJMXxbReSbZ1McMc1L4KGkepTRVWTF7MbvkLHalGMVkEkKQ7VmQG3ThLGZlS5XOoZViGgaJ05YFKUaGcUBpQ1E3wivpe3xd4ayhGydJSq3q8v12g9aac9+TUmCzbWiqUuKjGpzOJCP2A2MswzyLxWcJKAX+eCTEwDKP5JS4u39Yt3ICvNzvD/hlZho7ilLAxs4Z2nIj3AxvsWFNxOU1qRDlgScmsM5hQ8CotPJZxES29B0+yKGwLEvKuiZ6Q0iKTVGx2++kirQIW2qcFnwQ2LTVYJXCVRXW2Wez09V+y65t2O22NHXNMC8MozzQF2XJuEj0vN3vKJxFaSvmrULSdslHQo70wyRg4sLhCsfDqSfExH7ToBQ83j8wZOHmhBh5PJ4BqEorTLNf2mtl6xRVRSZjF0lliH7erqmjT/XItA4VZMOdUmQYZMNQFsXzFn0JnvP5hF8WqeFZ97zVNEYYZH6ZBWRbN8Lned56CudHK6m8pRgpXUVZCQstxURdVZASzWZDU9eMQ0+Yo3CCjFn5PJLSqZt25UMJR4gM4zgwTyPFCryOUTT3cYWYfxpymdXQM3tJxbmVeZRWjpFbeR5prQHOs6Rwuksn8ob151VW/wQVJ0vyIGfhIqQUWeYRax0bJ9eI0+kkkoqVM+aclSSrscJlWaO7IaT1em8JMTJ0Hc5aysKtcXFL3w8sfhRmUhbajUbuFd6LAa5tBW4ao1x7tJHkjvcLxhhJaQbP0HfPDx6TFo7HOE7Chlg5WdrI11rXDRrohgFSpCxlSFgUwmoAZOG4JnEExBvkwQOxk6Us/76MJE+MMdiiWo15ktqQAIJmXmb53aw8MutKXJkoq1JSQvNENIaUrNSDmlb4Pyv7q7CWOcr9XJKY03My77l+YO3K9LLCMVsHGSlLyjOuA8WY1nSpQ8ym0gAT2YYSdpCyqxEridkvBk9Vg2M1AK68KwUr8yk9782cE17hZbwQY5AUl4JlmlgWjzYFxkDwktzLqF/ctUvsWwmzmnR0jlgSdSEJVaUF8P4pVe1DWJlx+tl+pJHUX8pSPcZ7WSJ5z8PxwjSL5ciWBmsLXALropiTcqR0lqtdS+ksIfyTESynTEavaUDhkqhVcQ1Z0sObjXBcypIQBEarjaRmautQ1uLKkioKS8QYy2ZNMiot9jWTkjChlBGG1ZrMzCkBSSyfSrGE1eRnzHoIlveCSvI+iog9OQYZKA+Tl+FvWcoiRsswpiwc5hMzZf23hCQmQK01dVXwiY8WfOB+Oq08OYvPYj5TGlkMRdkWawVGKYYJHtRq6DOawhlaVUlaYlkwzq73KMW8LJI2Qiq7YkOS713FJN9RlkqssYZy/XxOXrTfymgxHqVIN0lifZiF9VWXTrhOa6U2rNcE19SUzuBWrp9Vci/ZtTUpCe9yiXHllUiiO8T4/B6cl2W1T8q905UFBLnG+0UkLkYrSb9pI22CFdSbszz4ag1aQ4oJpTLKiMlSG7Mm4NTK6UliIjaapioIWRARVVGwaSrUFIhRuLLTIguMGCN+UcyGlXMqzD6zpgPR6vn9Oc0r2zN4Mdl2PSkPhAjGyRLVGI020msQ7p981nKUer62hrRkkkpUhSTlu2GS/03L+2BaJBE1zX7lwfwyXs6UZK2IOaIUXF3dCGqlm1nmheCnNSHuRM4zDvhloXAFADH5dVggyam6LsjR0yvF4heOxyPjOJHCuglazxBNXdFUFbWrUa2GKzkHhxRIOcjSB6F3j+PAw+MDdV1QVSVhU4KKJJtQTtM0IsWYY8CniDb/ZBedlhGtV2veumja7rZSb18i51MnqA9t5NqlrDA5TcHYTeQg91pUZp4DSsm5xBrHYuW8UK+LqujkXDcMIzllnp4EW1MXNYUpKGxel3pbGTSpEYC7e6nkT+NEWZTYjZwLJCk48vD4hHOO7WZDTBFrIeVA3/X0l57uMkirxFrGaeLxeCKpTFU7cg7YwqC9MDEl/Z0IQX7/IUh61jlHW7fksiSniDUjVTVDTvSXDqctdV3JoDx6lHFUZUV3PjMNC/cf7+m7nuOjCJXqosJVlnojTNEYPH5euL29pq4rykr4hru4I4RAznKO1QiMexwjqMjiZ5bFY1eT5Ol4kWueFVPy7urAvCyMi0cB3emCSgm921MUq0goQVmfsa4grKy58+mMX2batmHU07qIhqLUzPPCOI2Mw8jYT7SbDdvdhrR4wryInXS7E2bwOIHR9OPCssgCwhqNUVp4tBqs0mht2e4ayjKz3Wyoq4ppEkyIs4a2aeiHkUt3oa5bMRoXbrX3SYMmhkgImUl5Wa5sdqSceXo6EkLk1avXKKV4ejgxTaOYBkPiqetk4XFztf77/sOvP3vwJMrngFeiZz2skMTgXzPPC33X45zDVQ1ZKS6rqWdN65LzAhQr70mzLQ1OFYLzsYZxnpmWhSWIxtlPAypF2qqkXA+f292ezXZHf3ri/HiHdgXKFeQYCdNIdznz+FTz+uVLXr6QVIH3kcvpyNCdqaoSVzjGWTS1frWNKVfgmg27nVhQpkki7Fc7SZAcLz3DOFM0LdY6xpCIOXN7+xJtDP3lyDRF6RRrzfnS4Zzj9vYVRmvuHx+IMTyDd6umATLz0DGMMz///B5rHb/6q9/Q5kyaR6wxXG02pBTJcWGcZt7//LNEBo1hu9lwfbWX6tuSOV0m/vTTe9qy4PXVFlCYnFgWT+clXXa+dJRVxWazwaNYAjQhPwP7NpsN4XxhXnpiimitmJbIPM2QA6RAXDyLj7RtQ13t2LQN87Lw9PjE+Xzi9etX7Hd7xnliPA5U7Yayrnj/hz9yfHqiqmu0tfSXCylGfvPrv+DqsKcpLeTEzx8+ksPCi6vX7LYtm9KCgsqAtmLJQBvOl04SIivkcXmSjv0ydMQY+fj4ROEcn716ibOWN28+Y/Ezx8c7lILZj1TRsG8q4ZctM95rCiKG+DyECEt8fiBNMeB0wiqN1YZxmjl1HT4kZp84XB2oD3uWZWbJmrrZ8NnLVxhtmGbRIp/7iWkSyF9bFXL4qyrKsmKeF9zieXVzxbap5MHTOP7w3XeczieqsqRuWn5+/5FLP/DtZkflytWuYKjqVg5Ao8enRH86o3Lmm68/pygLfn44Mc2eX33xmsJqvvvDH+iHkaZt0Nbyp+9+IOfMt99+KVroX8grf3r40DJ0vrq+RitNiHKtOZ2OgJxbQkwolrX2I4kUrZHY7dMjWmvaukYpzXmcGeeF+cP7Ffot+lUBOCusc3JYHXtcUXLY79bBT4AMxkgixygFKRLDQlls2e8PTKPoZ3ebDW1d0axDbh8iwzjhtMG5AnIS5lTTgDaMK2DerUrru7sPzPPIy9sXmKZh8Z6s1HMMHETtXax13WGa0UrTVM36OVnIKIGAoxjXGualuxB84OHxEYBt22Cso91usdpQFWaFcAuP5XI5S7VhGqmbhv1uR/ALp/dnfAgC229aXr54ISwmVwhMfY1Jx+yfByHeBx4f7tltt9TlNbZwuKJkmhfZelm31nXlgDivZtKqrNi0G7o1bbP7dKALUoNtm5aiLHl6fGQcB66ub6jrmn59MDtfLtB1a7xb0mxOa3b7Pc5Z7u8/MEdP225o2g2b3QZrLD5E0jqEC2vKM8VIUVYyNP+kWLeOlBKn8wVjLdfXJUZrSueIxpCze5YIZIQ3BuDqhqwMm4087Ez9BWWMPBhVFfv9Nd4vDN1F6u6FJXqp2S3TRNd1OFewaTfy/gyB0hVYo0muIGeYxoHucgatUWpl4BhL6ZxE+02BTlIxccZIOisFSeAZw+IDS4giNphG+V2u/3FWrv1SE5/xITzDnTdtizGKuw/vWbzn9evPsM7xu9/+HfM8U1YiA+k6qfzPi7x/f0kvPy+ktcJutMImjyGzbxxhxQhYIwncnBPjen4pi3Uh4aTKOUwz2haUzQYzz6RpYpknvn83kLMiJ0XlZECUtaHKSq4jybOtLfvNFcu8MM0TfjV1xpiEV6ENpbFghZ+iopwXtm1D1W4o1iTJ4+MDl+4idVNrZThQ1DSbCFZ04yjNoRAI9amfmUPCxLgmCN36YGAJKZH8Ainh1mHjtHLKqlIGRw55iI/ZkpIMRVQKMrgMYlJTWnE4yFE4a4vRmm1bSV0rJ4H7Z7lOHLuRsnC0jSwPNYnLNPH9h0f224av376EGLkEMeIqZ9bfUcRpqEzm5ANPY2DfOG53FbYsaFvL+XzheBypDnvqzZa+H2SRaoT1YRQoI+IH4xwqjJA8KRlCkiSps5YpJIbRy9dnDXEJLEvk4SKH8WlcSDGy3za0dbkO94RlGYKnbq5pm4rK2fUBW8bAB1sTY+T7dx8lBZBlyjx5DzlRr88cwzCijWZTy+CqbBrUstBdLsx+4SEJmuHm6rBWOR2kJInknHk8n1e4ssEaRe1kWe0KAXcnI1DyGDOLD3TjzNWm4mpbMwXFEBTbTcvNfovRvQxX+8BDN1HoTKkSo0qQAiFDyPJ7NkrSSDLkkjPVw/HM6dJTFpLUO57OTItnu99T1g27TU3hLHGZ1yEwaDL9OKJJ7HdbjDUklUlKs6kNmsQP70/EmPj81QFnNadBFpL9KJWhX8qrLlqImiUsFEXB559/uaZvK8Zx5Ol4J0vdspbz8flITtDUNTGJhCrEhbTKg3a7BnLk6VEzTTM///RObh1RSbZBSZvgsNuwabfsyi21bWmaPfMsqAsfPDl5Mgk0nLoT/sfAV1++5ebFHuOg3DhcVzAOM21VUBWWp/PIPCxyrXWwhJmuP2GdZrttpN6bMre3N9RVxYcP9xyfzmz2YhRTyqFUwX4vC8D3wzuWFGnKEqVhHBZChN1mI1X4eYGcRJKlFElrMcU+HpnGiXc/vccaw1dffI5xBp8T1ln2e6kNOnPicun505++FyGO1ey24G6Fi/jx4Z7LpefHH9+x3bZ8/lZQLEWpWfzC/f3I5Xzm8eFIXZdsdxvO3ZlL3+HDTN1YYkwUtWVZZLCWkXNzXJIIE2Jcl3EVV0YG3cZoLn3HMI50l56n+wdevXrFdtfwcP9A3w989tlnbDYbPvz0ge400PXfgYboJb351bc7tvstu5vtihNYmMeRVy9uubo5MIeJmCJNXZCi1JRTSqRRBizDHAgxcDzdkXOibWpiTLz76Q7nHF989RZXlLx6+xnTNHF3fw858/jxnuw95vM3GFdwOFxjTMm5H3HOSup+6Tk9Hqkqx+H6gD2f6c8nnMlUtYQQLt2Zy6XjcurYbra8eHHN+emJx+FEUVpe3r4ApQkIY/R4OYtl2kdUAuVB1wpdakplUTi22wPabHCmQSvH+PMHhu5Cu9lity2/++17Hh4e+fpXX3OoK5q2kuUo8hy0LAbvYZkXjNV88+03FIXjh5/eM44jf/uf/qc0dc1/89/8Pzmfz1SN8EP/8I9/JKXIN1+//bOfG//swdOlH4gpsWkajBGrSc6ZlDUxK8bZS5rGL+R1S6WMZX99vfbFMz4k7h8eUUDVbshmppvkgcIaR1PJA72zhsfjedXEi91uHLpnmLi1lrKqySvvoCwLdjtRpg/jJFuiIKyIcRYla922ay1DNheazLZt0W0j/dSul6+rlPoKKAojCaZNU1GnhHISZV6mnpATzTThXIFzJVUVV+aUPHBa66hXK8NusyHGQGHkQDz0EtEtjMYVDlfVKKWYxhFyFuiZVuvkOHC69CxeDuPOWZrNlrapKYuSmDLd5YhKkS9evSDFQDcMlFbideM8Ey/dOkXdUpUl203LvHiGaUKR5UFnBbgWZU3disHw4eGRFWGCX+ZnbkJKidPxyImMNk5qIZsNbdMwDgPn80k22EqYTOSa/W5LVRSEJA9ZdXEl0+cMl2FEZyeGnnZD1pZTPzGHSL05ULqCsmpQxpLXiXVYIaLywCw8rpzTM7th8J1YXs5nrLO4skbliNOrqcpHhmnh6dJL1WcWIN3t1R605nSWSo5eGT5l0RK9sBCcK6jqBowjKrNaOhK73ZZNUzOO4wq6nen7AbJiu9kK6ylGNLId9msKwJaTGHFSlve3K7FFRUSJFS8lqTEYQ+Esb9+8JqbMvq0oncanzBwiJcJF2bQNVek4xSDpjfXruT0ciCkzL55pSrS7PUXdCGfDKr54+xkAlbWYXxBcXJ5JhC8E0Pf9yoaRgfowSDe93WwBufCipG7wqSPvc6AfJ4qiYFNWGBMwSHpQG0mISeJRs0yjfG4y62dAjE2fchiSKsnrYcBSNw0piCFqmhfKaX625wl3RMxTn74XrRV109C2mxXcOxFXQ19ZisVO0g+Zq6trGSTUlSi055nFS2LRWbEWaZX+TyyoRF5tJGZdO+eVB8KapFIKjK1ALYAYAGNWUn2bZ7K1VE7SM9MskFZywlqD3Wyo1gF88pI8skbT7PdixVzEAFWX5fM1vHDC1dBrhSemtCYxA5fLmaKsKFOWz5J1ZPKaQFPMSjHN03NCK6bE7L1YYNAYgwDglcgmumEQ3tsKn1yWZTVLyYNrzsJ3ENOOJ0aPX7bCmykrqXD2/cqUEZOlNpKmG4d+VUnLdVEGkHmVGMgC5vmaCWIPBbGoxkQIwsFSTh4Wh2HlMq0/37quhfnkFwwysHJO7EDktFY55FqVQe5RTSs1+bbFWbHMDeOENpZaG7SOKLX+jtfhh1TG9aco8/+JtSDpLGMsikxKkigIn4xPzsKmJVYFbSv1XqkQBoHhG9kGx5joustzskYpy24nQ9tpGlCzGPWEGSlsweDLlTX5yxo6gWzTY0oYL5v/eR1UChyeNWUhyaZMZpoEaqyNTAK8l0P3HDxFoShK+RxMMUn1Rwl/rC4rqsIyh8wSJPGLk+SdXC81CakzgVyHysKx0RZjjaRgFAhTXGprWa9w/ZRWNpnwoXbbVtKcGfp+EJ6JSivUX0n6fX2Qso7n703u07K8tMoR1j9LJ0ljqiy8ncpJgkbQz5JEiSmzrKt4GXyKwSrnTDdMUm9GIvoxQwyJZRYmlNGGlBJtVUoK31pSivRjAKV4e7unKBw5RrSCthZL2RIkGdQ6R+ksbWWZfWJY7VpLyGQ8zCJs0FozLQtPp4uYPb0nBw2zVIZTTNQZKkDlvPKjHFVZcDx364bcgjIkOUGwqUp0o5i9JJOUU2SriSEwzYpNvS5ECxkyn7ueaV54cSWJ6rzCQELIpBQpnVmHnIGcVyYiBqOM/LM+rckH+XkqpdBKlgkKqeYpY+jGmXL92o01woQKgXGW9Km1isJIqlX7QFwWdM7kpIgRfJB79KEp5WvXFp88w+Q595qnyjDNwvZSOUEUdk1RFMQM/RzlnmTWIbjKK7tOAOcqy3slK40z0pa4PmyIUd6XxmTiMjN5T1UYnLEYLYIKv4jAISl5IG8rgdrnFAnrgB5kwFJYA0oGlG1d/hPr8Rfwulwu+CCmZWMM909PkkhdrdnDNFHlTF1YeQaaAqBwhcUkLYeopDk+deQsbYPCWdpWln/WWnlvaRkMPt7fCQ8xBMw0cbpckN+D8APRMlQsioK2qTnsNmQtXNRlXgiztCjSkjAYSldQWBElGb2gFez3W9pWbK3zlCldzX6nhX+TE8aJlXGza6jbUr4Xoxm6nnmc2W5FQlKUJSlnbJbH8JAC+Ix1GwqnKWwNyLUq5cSlGwXyv9nirOOpOgIw+RkdNT4EirIg7zar4bJnGEeUBaeEe9lsWqpWLOnd5Yw1mi8+/4ycM+fTmaJ0bA975jmQmWWJWBXUlVjtliUyjh5S5unhgbJuadodswsYK2eRoRufE6nTJIn7ZxbTGIWllTOg2e22qP2WaRi5nM7PQ9du6AjJU1SWq9sDysiztdFOMAZoxn7Gbxac1VS1CIQ+fLzj0ndc315jnWWJUnWNIYv0x3u5L63pSplW5tUkqkkklrBwPD3J4tKCK4S3nNbW1zTPPD6eJGHrJUX8+uWtDMInSeAqJM1dVzUpJLa7KzEyG8GvVE2DsSVNu+dwtaMqS04oLv3Ipe85XY74MFMUFqWFvWmtXOtD9By7R0pqSgRkb3SmqkuquiF6SEHmCILYSBgNr16/YHfYcnt7S9O0pBxZZo9tJPm02xakpDifj8QQ6Lszvix4/eolIUSenp44Hp+oKofWW9q6xRjNl198Ls8ah8OzSfI/9PqzB0/3xzPWGq52O7TWdOMsjKWs8BHOw0TtDGkeyMbiVUFZVdy+uJUHhPOJeZ65v3/HdrORL9b2qNMJbbQcJI2mujKcLh0/f7yjLAo2bcviF8Jppmlads4KnHazZQmiOG+bmhe3N0w+crp0XB8G/DIz9D2XYWC72bDdHOjOJ8Z+lIirUlwfDmzqmofTiafHR8pmI3aptsE5JxfNZebqIFaxKUrP9v54j1+Eg1FWgbIUJtQnILO2hUQXW6mRWSOTatZY34f7RzKZN69uqZSmareEGDlfuueovNaKnALLMvPx4ShwyLqmrGpevnxJXUrXtO97jg/vOex2/LNffcPdwyP/x9/9HbfX13z25g2ni9gFN5stL25eUlcSQT6ez7y/u2caB+4eHtgdrrhqd1SNAVcxDz0//PgzddtStw2XbqTvB0pnKKzm6eGey/nE7ctX7A/XvLy9Zbvd8D/8j/8Dv//D77nd7disKmyF4uXtC8qy4P7xnmmauNnvKJzjp7sjl+MFFUtKZ9gfrqjaxI8//UCKgVdv3lLXlna7o/Cecy/clTCuN6KyAK1IQbTou8OBECLHS8/iPXcP9xSF48XtjYA8lSLkTD8HYpr4+U4GoTl6qrLg89cvufQ9f/jxHVpLfNvZK9qmhCQVx6KsaLY7ipgom60MAxBF73a74dJdiF7g349PR4qy5ObqmlN3YekuknKxlm5a6OcFYy1WgzYlRVHhqgZbtWL3muSB2SgoraiKv/nmLe1my+XxI9PQc98tzCGxAbQ1XB/E6DNPM8MAl9OFyVm++uprXFHwuz/8iXGauLp9KVvhNOCs5ttv/gqlNPfvfiCs0OlfwssotXbYBeJ/PB3RSlI8y7xwOp2pq4rms8+IKXE+n1FK0dRicotJQN3dONNuNuyuCoz3sg1XCmUKnDU0pZMbb9+tFhLh3BhXimFIQchiYUwxkWPEOkfZtJyPT/TdBVcOkvbJEbWmfT4pm6WiJ/Xi3e7A9c2NGCguHSBsqKZt5UF8WUhJ9K/amJXn4+n6gZQSL29vBGhJJsVETMI4GaeZtIKtnXM4v6wcLHnAM9ags8GWJXqRhGeOURIBCRhHAcQ2NTEluq4nZ4EfO1cIe8k5rHOEKBWGuml48/ol07zweDxSlSWH/Z5pkoFRVVVsNxtJe2gYp5muF5Pp49BR1RvqILVpGbLANI6r7TIzTyPLPLF4T1V7UXPHKKmaNc1YFgWPP/zA/cMDh/2OqqpkwxQz++2GsnTM88oVsAUo+PjhHfM8M+62qJyp6hZlHHf3D4QQUSlQ1xWb7Q6Ay+koNeVKrovzIhIAleKzMCHrzGyESzPNk0Tci0qYa8nLb9lVoBSX8wmQCp61ju12xzCOPJ07YRCWFVVVUVc1JIGj55xl+4cYC5umpSxL9MrkOfc9x/MFW5ZcWYsOYR1YSRqwqAxlWYvRaR1+pCBxe2Pder8zRA0xarrhzDCObDctZVmwra8ESLwOz54eHpnnibK4wTr3PPztLkfmsWdZpIL98sVLyJmf3/3EsoiZ1DnHZtOuD4qSwJkWv4LQfzmvuhagaT/PxLUqxSeM5woS+1TJDCFw6eT6s91tSTEyTRM+RPppoalh08rgtl/iOjyybNuK1zdXzD5yGWeCT/iQQRnKuuFTjSIw08+Rwmkqp2mcpdaOsHimJVCCXOfWa6ZIWPIzuLewGtsUvH1x4Hq/448/fuD+6YyzwoeqChEC3B9HpsVze72jKgvmaSbGQD8ukOGwqXC1ZZoNMWamKMP8sJ4DtpXFWVmKyqBK0mHnYRKhizFkoHRio3s6yzKibWqUMoIg8JHH04AG2kq29VfbBmsNZWEZpszTMHNoSn7z1Q3LEjheBoyCw7ahnzzjMlC5kt22oqllAXe6dCyPJ1KGwWein4jzsF6PNP0wcTz1aCMDtynAEuSMk1LkOmV0lvpOYR1NVVA3FT99uOf9x0c22y1lWZGTR5F59WrLrq34+PDEMHrqWpNZRQ7es2tqGYo1FUor7h5Et942lQzDV5beEsRQ2BaOaDTdPEvFz638PiO1bxWk4pNRqCz1FqkOC3+taStCDDxcOtq65Go1FO83Nf04CpPOOaraUVhNU1csaiIOkZwVMWRChNlnSqM4HFqydiTtmPzM6dKhkPqcs4bSaVSOEGecqWjaLZd+pB8m9htDWcrQwmr9/MCss4cU5FOmZPjVVpaX9RbnRHm+LAvHvmcJifbFNU1VynAwJS6I7CcpYckcNpLqPJ0EzdA2MszY77aU1tCWExnQrpKh/i/k9fB4j9aaw35PzJnvf/4Zow3Xh2vy2g5JKbJpHDkr+kHSsGUtwgOnHCTNh5+PFKVmu3dUZcluvxNAt3UUrqBuGi6nJ378/jtcWVK2LT4lJr/gnKIsFUlZMG61/MI+b3BG8XTpOF46pmFi7lauow84bSjKgrIoV7nLhFETL1/e8urVS97/eM/p6UJTb9lsDmAj6CSw6GXm+sWewhX4JRJD5P7DHd57qm9lIFXVDdZY8rr4O/cXYoKyhKaxWGoUhmw0iw/cP3TknHn9+gYfFh4fjizLQj8KXiTMC3VdkW+v8N5z9/iEDx5biIThcLVns9mwOWzo+57pfcd2t+ebX3/L3f09/8e/+3fcvLzhy1dfMQ8enTtcoSlbR10Ztq3j9DTy8eOZcTjz848/8/rNF9zefM5cLBh7ls/E04WiLCnKgoenI8fjg6TA65rz+UI/jBz2BzZty+3LG/a7lv/xX/9P/OF3f+LN52/YH/YcT4/ks6THbl5dYXSBVpbtRoYdf/jDj5yOHfu2QFeOza4ha/jDH/5EzvB//Vf/JfuyIngxhwYvi8NhNVeXlV2HmhGlslTEVCKSCD7w7sPPFIXl5vaaQhu2bSPf2/lMP4z8/NMdSiVSHtkfDvz613/F+TTx23/4Ga0TVSuYgE2zw+qSFB3WGYwtKKqazW5HVbZsmgPGJIyVs/7juWPz9Mj+4f1qk3bCmwqealOyaVvu7j/w+HjPPt2wyQdKFymsoSx27HdXnE8XhnkkxIgPgawS1sK3v/pSUBi5gKx4/+EDwzTRtFtcWbM9iHV+7M/0s+fp4Z6yKviLr3+FtY7/5d/+L1y6C7vtlqLYctjJ+/uLz96IDdWrZ+nLf+j1Zw+etFLklOj6DmOM3NhipL+cIMNXn71CkTn2E2VZcvPiAEpzenyQxNI4yoOLljfA5XwmhLAeIAuqusIvnrvjhRDi8+bzeO5oKsduUxGC5/F4Xutn4fmBCCWH3ko70T6vUX9FFpubs1SFgbqk0Jl+FHCZD4kl5RVM6AmXC0r1sEaB/TTivWceA5BwtgQlPAm/eI7dgFuEB8Oa8JH0VAdK0VgEslqW5JzpLx0+BMpSth2iac/st7VUaKZJeANFIRE4Y2naDX/1F98yLZ6Hk1Qi6rWi8Xi6kFLk6uqapqpZQqKsKn71zdekmPnux3ckMmW9ISvDebV/jMNAzEmGevMiSvEQn7fFOSXRKBaWJUa6rmPXNnz24obL5ULfS62yrirqsqQuV0r/ucMVFdc3L9i2NU0l6aqmrpimgWG4MM+emGSya8wsNrFaLEkZxTR0TPOC1Rp0wdAP6Cy69ZjS+gCV2e/2cuBe2TxSX2RlWmiur65kezaN0i9uxXoUvKSHKreaAEPEGE1ZNbjCgba4oub66ppPKvQYM3f3MjDrpgWXFNEM0q6KEs/WRj4fKSUK5zjsWrSC0+XETu2p6obSGZrCEFQi5kRZOJLWNFVFU1YUZYm1BSpF+r4DJWm+6+sbYdN4zxITx9OZcRIgfcQ8Q3f9PLHoLOB8rSmtJjmx7PmU+fh4RBvL5AMhgYmysdRKkyP89O5nqdX0/S/KaifcoyQsuixQWjLMiySb3rx+jdaK8/mMNkZ+9wjLh8TK9JINhjOyKc454wq3Xn8Edjt7+QxVdbPaxi6UVY01liUl/JIIK1dO+DcalRPJz2gFpRNOQI5hfU9p9Cew8KeajTGr7Wth6HtSkGTNSniRetsnELgxhODJ3pPWVIyzUmc4nU6cgaIWrhxJkitxTQTMqwrarDGtaZ7WZIukK9SaINu2ApBNOaHQlJVUakBRFCWvP/sMP8+cjk/yALhueruuJ8ZIUXzS4nqUUux2e2LwPDzcA8iBIEty6hMjJSNcMrXWZUSBE545f0XhpJ62WjrbtuH6ai9DvAza6NWZIj+veZ6fk1fbTUu5LgvEiicDsjgE5mla2VCNvBesQWWp9fngpSa2eMqyoiglHRW8/H1RHNe4lNbkXRY7SU5iBFOf6qCatmlWo89MzuBWAH6I8v5yWoYAMUoaSRlLzOD9vHI0DmsyyeK95+PHD4QQ8DFBFOvpJ7uTXc1LeoUxls6x224wQHc5y0NAWUmiy9r1Hpeeofx6tUuV60A+ZzlEs77/isKtcPjIOE0Uzq0P/YskUdaq57zI+805SQlX67DDh0gcpHJETpL6LSSRnJKkeyBzPp/XJELx/LP8pbyGcRSJyrhIqk9r2agiv7+bvSQfny4dWilur/ZkYF6HPVobnDM0RlLYpVXkwrLf1Ot1Qu77j+cerUT5nKOkqnKK5OAZl0A3ipCgKsWa5ENC6bgG39LzX1NErI85U1lLXZXPacEYHCkphskTc7cyKwwKeU/N84JeocNVUbAsQe7R5NUgKanMp8sg77EVkC3nr0/WsLwm8syaKo48XcaVRybvV2c1RsP1tmZePKdOuEJ1sQ47Ck1yjtLtiWsiOiNWtNkHhlnYdfumpCodUxA26H63YZi8JKlzpi4rsbMlWJZF3qchsqkdZL2mOAy2qpiWwLQE4aCW9tO6gbbS7LWhHzXDvEgiKyViBqUy3TDKvS1G4TkahdUiLbAaUoqMk3BKRi+bc6011gk8XPhO0gKwSrHbts+stBiEeUmWa2nOgplICNjfZAhKtvzBy1lYLiVq5bRlDMIoTdGTIkyT/J6sVpASl77Dak2xXrObZiPsnSXgE0RgmT3dtN4XrSYlBevZxVrDsnIHS6t4fb1Ba8PsJdHkrKWtK0JKOGdIYcGQKB1rWkBSNMWa+PR+Qa8MoMIaNrUixMhllBqyM+s1cGWNGTQxJrz3cj01erVGB+IMORimNemf1mRyyjxz8yat6McZUDSN3Pd/KS+RaGT6of+n80ROHJ8eIGe+/voLjNHc3Z0oy5JXr98QY+Cyfk7CJMnApDUxF1RVS4pyjjFWBkN+idzdPZBTYLPbs/jA6enMdrtl024IYWbsB2xRYsuaZZ6Y5pFlnJmnGU2mruS+kzSyjCNRVQ113az3yPUet8zMs+d0ujDOAz5NRO9Q0VAojc5ifUzacjlfpN1RtWIjTZEQPO/ff8AVhbBxtXq+RoWQQUHfDaSYaKoCVOZ8vuB9wBg5f+Uc0UqsttM8yaBWQbNpxCZeNpRFw1//5i/p+p4ffvoZ5wrazQYFfP/DD2ilubq6loZITmw2LX/917/Bh8D3f/wBqx2FrUg5MnQz0RfkKIuI29srHu4Dx9PTWi0TXm8Mwodtm4rZL5zPPVf7HZ9/9oquHxiGkdIVUCEgdg3TNJIJGGfZX+2pmwpXWpp2hysKUvAMl4GYJkCTfHxebjVNRc4K7xMxSMLWFXJevJweiX4UmUlC5CjAdifnisXLWagsi/XcnDHa8Plnb8WUeTnhrOVqc0WIkbkPFIXm9lbOtksQrlxdb7C2ZJpnUg7s9iWQ0DoSFvldz8vC5dKvRmA5D4UYMGYhxBnW4ELblHz26gXWGO7vHthsd2x3BdZqqlJqxypDVbbsdor9fi/v8aamrkrB/nQDMQqH7Pr6irYRkcw8eoxdCAGcTWjk/fjJRA2ZTSWM4GbTgjEoLcunH378CRDyReEqUoTgJS0VlsDd/Ucg07S7P1vs8mcPnj7Fp5+OF6w1vLx9SYqB09M9m6bhb/7mbxnGiX/zb/8Ptm3mP7neM44Tv/3d9wIMzxlnC5pWLEZP9/cUZcVhf4V1lqKsuH888uPHJ9q64vZ6z/F45u7hnhfXW15ebTgPCw+XM1YrCiMxS1HJGrSVTrqzEmkOyySQSCdMi7q0VLolNSXL4rksPbMPGC8cJL/M9OMZ7yMqLcSmZprl0HPshIz/Yr+ldIYwS53v4/GCsjPX2/LZaJBT4On4hPee1D9RlyVv3n6O0pr7x0diylzd3KAVDOcnlIIXhwNziBx/GiBnNptGori2YFvX/LPf/Jqnc8d/97/9e4qyZFs3DPPEu7sHNk3DV1+8RQHj4mmblq8/f8sfvv+R/9d/9z+yv7riq6+/wc8z909HPtlgDvsdr16+eJ5Ab3dBBk8ZUgzstg2HbcPP7z5yd/fAN29f8c9+8xf83e9+zx/6jrIoMGzZtg3bpuI8TIxzR9m0fPb2C+rSUljD1eFAU9f86YfvOZ1P2GqLNo7HU0fOkaubK5qyxGZEx31+ZBhHynKLsY7L6cw8DFR1LWfJFHAKrl68QCnFuRNgdrPZyXYqimHxzZtXhBC5fzxirWW/lwvIECLWWG6vrljmmQ/v36NUQb3ZiSpdOcrK8eb1OjwYZLP1w08/E2Ji9gG7JMYo9p5iBRAbJHofU6IuHa9uDjwez3x8fMAVBTc3N1SFQWfHPCXmHMFabJaH933b0DY1VVXy8enE8Tiw3+9omobNdofSlu9//IHj05Hh7gEybPd7ikIgzdnP+KFDx4VcOrQuqAuNTobLAktMfPf+48oKsRglqlGjFbpwxBj46bvfE0IQA5n55SjJ0zoQnMYeUJSVDILHaaauK7795mumaeK3//APNG3LV19/QwiB9x8+kABlpMJj1sOOn2dyTDJ8z5JcCikzLp66rGg3W07HJy6nIzlGmqpi8QvTND8fyovCUa5VoxCE2VJXJVYrcvQo7TDGrfBr8yxZcKsVbplGzkl04FoJn4osoFeVoLTyUDEMPSH455pfWRSknPn5px+Y55nXb7+kqmtMFp6SXwcA0ziQYqRdB7rD0JNTYrffP1fHjDYcDgeC9xxPJzR5rWILp6WsSj7/4ku67sLpLHygqhI1+/Eon0tJMmmmaaSsGm5vXvBwf8effv4DTdPw4valmAjXejJK0TYN+/1u1ZMvUuWOC2EeGfsOpzeUTcniZXj46sUtb1694uHpiePpggW0SjJoi4FhkEpb4SzVYR1oA3XT4IqK8/FJIuPj8GyWK1wpFiprRLe+iPbWh0CzEa5HDp7FL6hpwlhL07bCavBr0olPKbb1fZolVr/fSlT+w8cRFRO5kn9u8VIBLJUmI8lYpYW3lBNM00RRlLx69UqGYd7TXS68f/cO6xxV05KCJ8zDytEqcU5YOGsflboqMfrANE88Pd6z319xOGxp6gqFJNi6vpe4egbjtNQW6oa6aeiHgWmeV7izoiortDZ0Xce8SGrZOYX2HkVaGWqacRyZ55l201JoST7ZouR8lspR18kh/uXLl5RFSVoh+cNajby7fyDnzO3NC6z7s481/1G8Tl2Pj4mntWohVSdFqcE1hrcv9vTjxP/64zs2dclvvv6M2Qf++PODLPuMxRpLVZRUVsQuTiuc3q4sw8wwLby/P7JtKl7fHFZ7oDwoE2Yul54f7k5s24ar/ZZpmhnHSRJNeq2wrMuXmCJJKZKCsnTsNyJYSTESgiYGy7mfmY4DlizD8CSV8mWcSClTtS1V6Th38pk6NAWFXQf1MXF/GVlC4rBpKK2lLuX8ldY/+9PgaQ6eafb8+PGBTOaLVy+pCkdhDQrN68OGcV5YpgmlYVcXK4MUjDG4+ophnPnuZ7E5x5SZFs/j8cS2qfj6s5egFP0iPNKXhx3vHk68//6eti54ebV9rqn6YeZ8vtA2FVe7hmmODFPAOUPhSqbQ0a8MvE/16xQCh7bgsHF8eJIEF0rho1SiM4npPEmVMWXquqRwGmczu8pSOangnNfB4bh4KjTOQttUwiFcH950yhQa6quDyB3IRO/JRmp9ca1/h6zWtJgsEeYo555P+A2tNaIkl8GyzYs8WPuJnKALXthuhQztn45Hmqri5e0tSlu2O8W8zFy6C8yLDNZCopsjzmpqJ7VPo8xzTXSeFoZxZN/WfHG746mbuT+NNJWiLAr2W01dlYzTLNcnlaidorAyeKpKqRMdTxfmaXq+X1bOUBWWh/PA0C+UBKzKbNpG6t+2wBpZYM45U25qrFEQFuI84bMAxo+jJ+bMoSllMJEUKSWOpxM5Jx46D2heXKk/u67yH8PLGE0IgePpKIul/YEYAh/ff2S7bfkv/su/ZRxm/uf/6d9zdXXN/+Vf/hcMQ8/dh3vmacZPsySCdCKGmqawKCNVvKJwNJua+/sTP/z4jv1uy9u3r7i/u+fuwzuMcbx5WzM8jty9e6LdtuyuNN1w4dydiHMkzRFTOLZtLe9HpYgqE1SibmuuDzdrJSvTDWL6HfuZZX5inM4saSTHApTF6EoGncqCyfx895FxGHj79gvqul2ZVQv3f/yeDPzqL76maRuWlavovdxTT8eOeVxQt1sy8OO7n4gx8PLqIIPTFFDa8uqzN0zjRHfpyVqxvdrQ1A1NvadtKv7FX/8lH+8fuLu/4ArH4XDgfDry93//D9xc3/Av//Zfrra8wP6w52/+5i/5+7//R/7r//q/5eb2ml//5i+YJ8/lfMK5mmmA66stb9/esCwz8fuf8Itnngf84vEenC3Y71ref+y4f/jIr775z/lP//Zv+Xf//u/47e//QFVVVK4QILnOXLoLpy7hSsfLNy+omoqiLHj95i3b3Z4//fa3PD0ehcmUMr5fqMuKonUr3FwxL3EdPmWqWpKFD/fvOFnLdic2xJQ8Whuub8XG/OHDIzEF6roWhl+Asir41bdfEULkuz9+jzGGl9evmeeZx4cO5xTXt9uVLfYByoJ2c8AVjq4fUMD1i5rkI34UxMm7d+/xwTPO05podZRlwWZTo5VidpaMkcHbruUvvv6Cu/snfvzhHW8+U2x3wsFrGithjJxpmz1VfcPhqmG3q7g5XLPbbvj55/cCii9E2PD69SucdXz3++94fHgiRI0tPE3tsdYQkyfnyDhIe+DmusUWht1hT1G3dN2ZeZr4w59+i188n736jKbcMC9iWR71RAiB3/3ht4QU+eKrLymK/z8znlJYVhVpkG230RRFza+++RajFZfzkRgjX755ibGWh1OPVvDFl19Kxe7piRATXdcJ06M0mCScjqJwtE2LXxZut5UYe/xCXRg+e3VDU4tSN+ZF2B1KEWRGAusG2xiD1aKLjTFy7sMKsCwY+p5p6GiqWvrkzuHKipwjfh5oKkft9qAuq141ENLAuBotQKKKyhiysbS7HWWMLFlgatnP+PCJpZDZbncopdiUjsJZkpEpqbIOpxUvbq4xRnO0oq9+eDoTM7y6vkIBKst25O7hkb5auQtLYLvZUBYF2hqYYZlnziHww4+J0hVs2oYQAosPDNPMixc3VHVNCh5nFNd7sdDlGFA58PR4T4qBw+HAdtPQlEaGItNMrApIknQzRnO5dPzw0zvu7h85dh1OybaoX7exYgUsmedJtoMp4o3G6CN9Lw8HxljhkcRM5SzWOCrnxKCUMlnBZrvHFiXdFImricpaSz9OshHXknj48d0HfIicz2eM0bz9/C3OOfLal47pE8RZrHzH45GYEss0kZ3De6nN6NWUohCuxDh0kmRSYhwpCqlPLas9r3SGsirYbFpSCIR5RjtLVZXEGDg+PT5Df4uiYLeVKfDYdwxjzzD0FM5Rty0lhoQhZ3jqBuaYKBfPMM2EGJimSW562pCVwEU3bUPl7MrfEbuLNYpk1FqrqYghsqRJ4q1NSzHNwproBhYfJQ4P2NWSpMgYpdlvt8SUKMpqPTj+Ml5KW9Rq1EQpzLrprVvZhs7LQgZev/kMpTUPD2JE3G5agg90/UW23kMv2+sqrymOhHOWum2FH+KF37MsE9Yabm5v0dqwrEmcoe8pSolYi5ChwxWFbHCcwa7pH2UkwWmdMC+WxVMUFmuFr5RTJmUZppVVRa01XS/q7E9b8mXlvOTV0KeNWe15Ca1kWxKCpA3yykeSBIt8fj7Bf6dZQMU+yHvGGIFDLksgBs+lk8pr08hm8BMLqe/OLEtBXRbMy0LTSPIr509xXEkxdn1PXVVstteA4un4xOwXtrs9ZSGVNmuFhyC8K2Qr2As0VpI9BWVZMQxizhOTUEFRQoMixMTpcqHvB6ZpxKwbzE8HvrIoVjCk2I9kFKTQKzsrRuFOyN9WGOMwRYlVYk759DMrqwrtF+HCzNAUAkKe5xnlPVpblILzUSp3IWa0kRqCVmr9vH/aRGXZkubEvBoBRaawxrbkjS3JJz+vX57UjTLHlauiyUk2hGiBkYvh5FqYC9ZhVoZXiomQhL8Q11peVZQoMss8EqKwmEKMYqOyK/A0ptUk61BGM88CrC7KCmvdyiQTTpHSUm8tioJ5Ggg+g1YYbamqCuesVNZzxq2iDmvkfl7XpWy6i0I4VyvfSCG1qaYWYUdRSKLql/SSWm4SALJWbKqCwln2tfx1nhdSTLy63uGs4TLMkqRuCnxMDJMYs0IQioUPYgQL4kAQM2NV8tqJVTWsNq6ylCH1UzcwTALOFSPYLAKNZaFemZh65Vvq5xyb5AZCiJy6ca3oC3NnXCQ54zQUVtKFwygA2KwtaGGG5jUFWTpLzIo5CoC/MJkDihjlMyLcsvg80DdGk9dEYPTLc/rdaMN+01AUlnmaCEF07Tlnbq735JSZpoEJxTBJCuZKS0XPrqY+52SjXhUlKcG7u0eqquSw2xJC5O54Zl48N4dWEpFKURWOtnKM88y5E5vy6TwQYmaJGWsUbk3esBpE28IQVCasl51lWa3SKUC2KIT5FFNmU1pKV3AaFuIiQyB85pIzw6xISa1nGi01YVjTJxmnYIlB0uArq2+ZZpT2lK2Y/s6dgHrNOigeliBSIC2pxs2mxubMOIdVLCamPAENwzQnZh+feVdXjZivQ5KvI2bF6BP3px4fI924AJmybonBM0+TpNoLWSJvm0LMhkDhDNparJWkubUWjKGuSq6RoZGP+dkETBZD8SebnEYT4jo0I69Yg5Vfp9Qz329cBDK/LUtKI1xHlKZIiogSu51WxPV7qkqRM7hSKsU44QoS5dxZlg1aaQot992mzCglQPZf0uCpKhoWZvwsabWqrNCNpmoKCmsZupGU4Jtvv8I5x4/f/YjWii++eCsJwacLwzRy//SI0WvKMgE6CF+u3ZCjYnnrBdA99hSl4+tvP2ez2WIQI3s/zeiioFoi8xgYLgtGaYy21FXDZtvKvflypigKmqZhnCbefXzPdtvIMyhh5ZpJTatpG1pd8XTsGMeeOA7oDHMKxJwoXEGxEx5kjIHD1TW77Z66kVaPWtszKSRIiu1mIxzLQosUIC6kBBqLNpb94YCzjnkO+GXm6emBnBJvXr/49HYlJfjhx5+oqgLvOy79gCsNRSH2spwlGTQOIz/89JPY0bcVMSzM48D5cuHt5wL2dqbEbeRZR6+DXojc3d0TQuT65pb9fk/T1JzPHdPcE0Kzgkjl8/V4PPL7P/6J9x8+cj6dKIzDakNaQIVEVVe4wjJeJsE8oPAh8eHDe06nI+fuwhyCnE0SaKuwhRGDrzOy5EiK7XaLcwU//njE+5ndWjceR0/GU1cOEvz8s3ztDw9HtNZ89cVnIifpR7RWDKOYAofxjALe361yhayf2VLWCBPTGiMYjlnkX5IETxLuyDD5icVLar1wFUXpqJoaZy2FKygLWXJIc2whLIEYoSwrrm+uKUrLPHdM08Q4BDatoapalLGSco+eh4cjKgsHe5rlz5JzchQTegbrLLvDnu3VjrKu5OwV/PP5arPZUJUl1kgKd7NpqJuMYsbZxM31Du8DrhQmaqVK+XAr4THuDwdSTlSlxdo/77nxz77CRT9LnHSRDr2zmnbT8hd/8WvmceD3f/e/46zlL7/+gmmJ/P7dA/vthr/969/Q9x2LF9jZw+M9ZeEo3AaTwrqxb8T+kAP+0DL5QDeNNHXFm5dXxIzY2xJr5FkO34tfWJaZ7WbDfrOhMIq2tJy6gUs/stvv2FYlp6cL3fnM28/eyAG3KKnqTI4LS5i4ORxo65oly41+mBf8EFcoc+DmcKCqSpS1YCy7K7lp9N2FsCwsyyhDkDGQleHLL76grmrsejjPVuCguiif4dCfINVPpzN//4cfsMbwn/3zv8Zoxd3jA90w8uP7j5SuQCtw1nG12+EKh3WWTGYaR/yycP/xPbutcLNihmmRmPXnn78hxcTiPXVVcL3bkILH+5lL1/Px4z3WVdze3nK137KtLKdjYhwmfFOvDz9itnl6OjENI+8fHnk4nrje1FR1yaXrmcKZz958xvV296w39bMMboZhFDNTKVyXeQqE6Lm62bGpS4qyRFsLMZKT4nB1zeI95x/fsXiPXQG598cHfAzcXO1JKfGP3/1I1/WcT5KQ+/bzN2yqAq8LQkp03RkfPOSAD5G7+36thyRyLFlmYT1o69BGYLnLPPNwf7eaAx1tU/P69pplXljmBVdYtnVF09RcHXYMfc9x7NFaVOTn85mHh3tc4SiLUnTtrkbnQHc5croMHLue1y9uubreYbVDa8vD8cjj8UI1zbjCkYIMh4a+Z5kmYdXkTNM0HPYbrncb6qLg8SxWRGsU2UgSpGlapuGCj5GXr15RVaWktvyCylnMX8NAShG36s818vBxfXW1Plir5+fsX8JLG7uymIxUlQp5+N1vW3KGcRxxruDLr79lGHr+8R//kaau+dW330iHfhgI0QuM0bpn1lICqqri6upatvWLaFLP5zNlVXO4umYYek6nI8PQc7kc2ekr2u2BS9fxeH/H1fUV19c3OCd8nITMFawrKaqS6XSmG3o2m+a56hRXRlQyMvCp61qG5MPAJ6j45SJ9+2Y9OBsgG4NBPtM3N7coJbroGBN+rdYoY9dttECbz+eT1MV8kCGwMRhjWNJE8DPHk2jEv3z7VoZOSE3vdHySgdH68LXdbCV2jzwEqQw+ei7jCNpQt1uGceDu/XustVxf3wIZlRNuXUyknAkpMY0jp9MJpQV0XZQFVV1jL2dSlOSmKSoqbTGuIERJPo5DxzQNUnu1FT4EpmmmquThefGByXsZjqFADWJ2e04liW7AuEL4SetDblw3/nVdY6151he3NzcYo+n7UVJStiCTubu/k2FBlvj+9fWNcAA7qdd+0tRro0khMgzdmiTJa5R5HbpoSVv5ZYLnvzvT9yKTaJuGnIR7FVMi+IWm2nHz4hVqhYGHZWaZBvlZzLO8+VaIa12LuGEce6Z5ZpxmylIMnM4KkPJ8PtF1HcZalFbMQ88yj+vCQAZPRssDXFEUbNuGwjmWeSYkiasbY9jvD9R1JYyUnCjKkhL5/ymt6LsO7z39OMm9dB1vKGSQuttuACir8s+Oe//H8gpBKnM2i2H1sKlpqoJX1ztyzjyeOpSCL15fE2Lm8TJSGM31tmbygWGRavWyyAPObKUytmQxajqj2NSOQ1sxTJ7HSw9K2FLzPPPx2K8Li7yaKWGeJMFZVyV1XcsQYh2cKKWFR5Y8vY+ch54Xhw1NWbDETDcvlFoGLE1V4ArHMM/4JAsspS2Xy1m2sLstVVkw+UQKmbaW913b1JAyx4skonxIqwK6luUAYov080zwHpXBWc3tQXhCfzxfGKaF+8tM5Sz/yZe3eO/53R9/YPKRiYKmKiiKkpyTXHs1z2mztq4Zxonv3n3ker/lxWHH7AMfny4UheX1iz0xZrwXs9Lbmx1Pl4FpETjt8dzLz0praicVbr3+/Epn2JWGWStmY8hEpjngvZgiySuv0At8v94eOGwbliB17xgiMWeGMawpSrUmgwqc05CXZ26k0zIwWmIkJkldDpMwmvZNAUrzcB6ZvZgNFZnjZSLGJPXhouD6+gqt4akbSTGtcHO5zqeU5Hv2gXEJtJXjaitDu8fLtBpLNcscOI8nWQ7GSF1VXB8OjOPA6TLgjKGti2cmlCFjs6TbgtLYAurwaWBtaduC7cYye8+8LPST59SNtHVJU5VSSbSGcZTqVM6Sjv0EbE9Khmd101JXxVqjV9zuSprS0o+eJSRh8CiB3WulZOGZM3Vdo1WmqCqUNlR1wPvA0+MdMQQ2WwFEGyDnxHb9Pe03wn76pbzacotKmmVcMFZgy+2mYf+iISyB++/vKauKf/bPf0N36fnf/9e/43B14F/9P/5zvI+8++mOu4dHfnp3j8qReUlonVBqQm9adts9TVmzrSsej0e+/+kdV4c9v/rVlwSfCHMQ7t0wYVxJPUeGLtAfF6l1NQWbdsuL62uO3ZmnpydevnzJdrPj7v6ep+ORL798Q9XekJUn4dfBk2G321I1BafzhXE883Se8HMgWshG8/mLV7RNQ0jyzPPyxSuKoqQ9PjDPE2GeCfNM8gqlNIdrseMmZlAZ72diypgsz063Ny8wVvP+/R3TNPH9H/9EXVX8q3/1LzHWcn934ni+8Nvf/yPOGvrhlgxUtVkraEGq0xG6y8A//v4P7HcbvvryNcviOR476qbhV7/+Bo3FUNJsKg43LSks+Gnk6Xjmp58+UBQVr169Ybdr2G423Ok7xvHMEvaSONUaZTQf7u64dAOPD48cj0d2rUCpo08kFNtNyb7d8PGDPPP6kLHG051PoCLgyGplJGfQhcbWjqapcc7RLyM5RvaHK5rZ8w9//w9cugvffvMt7ablx5/kLFa+PJAU/Om7nxmHifOpo21r/tnf/JWcO9IDMUUu/Zl5nrh0j8Qo/91oR1nsZHGYFdY49rudJKXWmcjlMojNLy0UztA2cu+clglnS5q6od3UXN/uUFmTk8xQisLSDyOnU4dCMBZ109Jut6S8MI0nhmGgu3ja1lG3W8rSUZaOH3/+mY939wQvVubgMyRFWp8Bhq7DTwt1veV6u+Xlmxe024Yfvv+e82nBaANWcbXfCdfaWMiaw34rjZfcM40ZY27wIRK8IEZKJ4brJXqU0dy8eIFSmbqUJeOf8/r/oWpnAOEnOWMxxqGyojsdmaeJ0Sd8TpwnAVqRAiEsnC5npmlESO95BYtatjshoFtXrPyjs9jAlMYUBbuyFhZJL1vn4D3LPGGNomkatpstXd9z7jraqqSuJC2Q1sOqNpZpmjidz2il0UXFZRjx8Y7zODPMgUonnM4sIVEkKIuKbatoG+mgf2J/FKvpwseEj8sK94TGWcrW0TQtISb68ID3gb47SZ3BygZx2zZowCrp/yojvfr7p0fOl46iqtEK7u4FqL7f7SnLmn4Q4OA4zUxqIcYe6yzTPBK858VhR4yBeZlli7wEnHNcH1qi90x9B8qAkVTH45OHNRGBKdhf3T7/13Ga+fnjPfOysGtLUgo8Hs9MS8BYCwpiDDR1zUtrKUgoEm1dszGWuEw83H/AqszNYctmfcD4eHdH1/dUldjpfMgolVbr28Ic87qdlyFdu9lQo9g+HRlHOHcdnTEkZNs7TyOQub0+sGtrSqvEZnHpmEKiaVqstby+vpL+89OjDI5W6KP3nuADU1USE/TjTOEKMe6FgNZi1zPGoLIkJUJMHK6vxYySw2pXmpl9wGeNj6JpLquSzz77TLbCPhBnT4wL2iiB/+52FM2GzabBaiOGsaVj6C8sU79eiArqqsIaw6XrufQdZt1EC8wX+mFimpc15SKWH1sUXPqeYZ4JXt6f9niiKJxo220lA9wQuIwTIUYK7ymLgl998w1FUXA6n0kxYlfDyC/ntb7J121A9AtLilyiF2ZbyoQgCcB5nkkr5+F8kXpPURbEJId4lPwutRF7l3WOefFrf19+7mVZSvV1HEU3W5aroS6x3e7Y7bb4eaRzFmfkQSYlGRBba+VAPHScjk8C/Y6Jy/lEWGa6TnTA2suBd/EBY9cEm5U4rvzqlICwNevGLRFDZAxygD5cVbiVhxNjpOtmUgw4Kwa+eexlYOwMdv3cqbx+71oxjhPTLDwloz+lJGTDW6DY7mRAfDqfV/6xPFjZUJBTom0bSdetqaunp0dSitSVmI9kgAQo4WdMi5f7QBAr6afKYMqZZV44JzFs3r58gzGGy8rr0lqgscpqcqzWzaAmeC8PzVX1nDZyzmLdFufcmlK84OcBbUqUNmKXW/+dirw+8Ar4UcDrMrRrmlbYgN6zBL8mpmAYB5TS7HYHqabMHq0V3eUitkAtP9/Nqvbtug6SJhtLUkksVUr+/BgC/eW8bpFLYT1p88z2SilJAiyLFdE5R13LYW0cp+f3CCuvyTlHUVWySJlEwJERS6MxBhsz1so/96kaJdVRRV3XoBTLIvwZ60qmcZQ/f2UxFlWNdQXjOIrdL661warEWWGWhSgPZ5LQk/dZXGuiwyi8RRkCC+PCaM1+t8GuVrucM59g27+kV+Es0ST0IoPzxQeMlr+mlBkWOVdpKymgmBRewegzPsj7XQM6BwxaGE5KY61UoqzVGKXWpHfEWQFuzys/q6krnA0rC0djrBYYszFosgxDlJwP5V2TGeZFEnxKhin9tBBSZg7pOREDspxyRtggKUuqLcWZuhCLWFEIz8Mmsez5ZSF6RdFWWCdgaK2FuRFzZpg92ke8kWuiNoYCRdtKGnNYa1TdMDEuAZVk4dWNMwp4cX1gDomnQWxo98ezfN9Wln3DJOnYunIUztDUjrJwLD4IM81a9HrNkvRhZpwX3j2eGGdPSAljDLtWlh/lmry/9D0qJw5tiVGKblrwIeNjpim0iADqLJ9/I9v3qv5UdYOHi3xmt3VFU8tQ5eNxoJ88pdUYrYRzEjPOyrV48ZGYJVGns6Kqi/W6IKmsfprRWrNpatpcU5gEORGTLD/8mjj7+HSW4bLRmMKwbSpSzhy7aWWXioiocpJ26CcZ1Itx2lBUBQYwKZGzpsiSDO26i8gnnKEoLJtKzKb9OMJqhS3LgrZx1EWmUJmsJI3rg6R0rVHC9NJSm9MIgF6WkmtCNGVJfsb1PW0Nw+SZvSwxfJBnl7owTEtk8YF+EL5gWdUYaxknuc759f5UGEExYB3awOLDamrUJAwxycNXW4kRMERh0Ih58JfD18wqoVTGOSuLlOQJYWbuNH7xdNPIFDw/vfuZeVoIOTD7kQ8f3gs6ICzEMOP9RFM79octSiVCdCjj6IaRMM8MvTQVrq6vsdrw9HBe62sC0N/UNfv9ltvbAzEsnM9P1G3F/rDHlU4g3NawaVuGbmS4/IwPkpB7un9i7nvO555hmNk0ilwoltljrGbTblFY+kJq4XJOkMWNsYq5F2TLx7t7qe8WmqpyZGeIMfH4eCEGWajFYInIuaDZ14DiqHq5TyOJmOPTke7SC0uMzMePd7iiAGuomoKXL6+IIXA8niV1mJMworQlJfjqq8/Xa5PCOcs4eoyxvHz5GgA/eXL25DSxhB4fOuFtrZbZpq0oi5q6EoP4/d0DoHn9SlipHz9+IETPdtNQFRWl/SQBUVSuoDCWbCFrxbT0+McJrRWH/Z6b62uapubDh/dc+o6mkUrrPIykGOV+kz39IBzlYWVH31y/oCgcL1+8oK5Kuk6WZSEKx9WHhDGam+srlo3HKOGHPj6cqKoJpS11WXHz4oppHLl//5FpmlgWDwTmRbjPbSvV5fuHE9oomqYAJIQjS7tAXJl6OWvadodzjqoShq/CMS8zfddR1wVbJdKVN29eMY0TfdeTlaRUlZJE0rbd4kxD21Yo5bl0PQ+PgoExK3MzhIC1BaawdH3HOI8SYMiJ7V7kE93lwuVy5ni6MI4Tbd3irGOcBsapF4Sm0twuaW0YGIwt8X5gmhbGYV04ZOEmf/XNl7jCcTqdSClSVerP9iL8+YMnI4fawhkKKywlsuL89Mg0zQxLxCTNcQwSB06BsMw8PB2lepQTWslOtnAF+4N0LdOa5jgfn8Rep0SV3LRi/7i7fyQuM3EeyIBbJ3RfvP2ch6cj9uGByhoqJ8ynlBV1VbO1hn/845/47sefePnqNdc3txy7Dv/wwBQyS4RdJbDnJSaWpAT+6kpsIReO4OWhoe/FCNXPCz5ExsmTM3z72Uu2TYUpGkLKfDyeBSR2emTQCu1KnLNsbMYYi9PIZssYYoh8+HhHP45U62b653fv2LYtbz//Uh5EJ6n7nVbOwTSKprK+VDRVyWe3B3nAmOc1TuwpyoIX1zsupxPHuzPGlRSbHeMycxqGtbZS0LQbrvdX+GlkHjouw8ix69m1NVe7msu48PFhwKw2KqmseWE8VDXT5cgyXNi1DXW74f2HdxxPT7x48YrrqwOvXtzSNg1PT48Mfc/t9RVVKXYe7QPRB8YY8XEQ0KR1OGd5+eoVZVny+HCHIfJ4ORNTZt82GK0ZhwGjFa9f3kDOlFbgfPfHC0U/8fY2UbQtn798Sz8M/PYffss8TcwxPwNuFzezdZaQ4TL4FaTuVlikME9KJxWdh+OJumq4vX3BMo30pydiiAzjtA6eFEuMzPPEYb9/5mY9Ph5ZvDB4nJFtf72psWWNzlKbmKYzj8cjyzQSlom6Eohv0zS0dcPj6cL98cxm01KVJSnKIencj6KFnwZiCDgrSZTj5SJGRFOilcGHRwpnefP2S6wr8UnAqKdhZFk8pVFsNg1vPvuMTbvh++/+JPr4qvxlVe2QhI3M7RJhmQlkposXNklRolCMfUeIwlxSMxyPJ2HjVCUxhDX5Ig/xzhWUdf3Miso5kVJEo2iqWrasvSRByqoRO5mVuPThcGAee06Fw61wZ6mweGyrKW3J48MDH+8f2LQNdVVxPM48prSC0gWem7LwRrTxoAT2Wq7w5qqWNFcKMlDq1rrrPIut8PrmhqqUqk6MgeHyRAieohZw9jQIqPjq6goKuJwSJDF1QGYYBhYvlket5WaM0tTWYaxjf1CM48CHdz+twgSBHxaFxznLdrshZ2SY7wP3d3dUZcFhv5Wh9CRAbm21DAbnhegX/Drs+v9y96e9lmRnmiW29mCzneFOPkaQyczKqu5WQ1ADkiDo/38TBKmlVlWpkmNEuIf7nc5o0x714TV31remAHUDigMQRCbJiPB77ZjZft/nWatpxDrnnGdZFoZxZLPd8e7hDYfXFw4vT7RtT9N1oqEtChn+WyN1MOfY7nZ0bcfxeGQYxzU23q1Dc8vf/nJhmAbKVhg5tijWuqFCk74fNt0ildibrVSdeh9wznG5nIkhCLxZKYZhwFjL3d0btNac11TH6XSSF6/9jrIq2fQdMUQOBy0AYoq1ViMpJ2Ms3jkup4MYXptmrUDa9XqrmaZJli5aDq1FUbLdbsS6OH5Lf6469sLStJVY8a4XLsEJcDhLrdAWBTZCEVlTEwXTuKy1hoau79dFwkJhLUVluby8cLlcv1ew7kqp3p2PZ5Zpomg6bFGKqbW0XC5XnPPMTipdZdWgjcEbYRIOs5eh+VVqCmVhKIuS9u3D+lyRxcI0jb8pMQJAXZX4KGmnnGFepMq9LI6Q4LLIUqYoISdFyJAiDC5LPUEZjIqo5DFYSissMYwc5K0x+BAYZnlJLwqLc4Fpnmmqkr5rCF4GGEoDWq3QZuEqET1ZQdYapaQOOs4Lr6crbdNQVRXn0RFHR2UNVq+QeiXfpcIoGThrzXS94oOjrVu0LaislQpTjKgsptacM/u+piotdZB3NT9KFe06echQ2ojVkoC3VrEtZMg2DjK4PF1lcGCVIsfIeZipq4L3b+6lbvt0YJwdX58PVGXJh7f3UiudRgpr2G06kZbUtSS0rwNZ6XWYn4khSiM2y3LreLpINVYb6sLQV2Js3m93PL688Onrgaauud82TC5yHpxAvHOmqVrKqmajjQDXgwx9yrqiKEuOxxPDZeB207LrK97ebenamjk+MoeBujKURjGMgxxQylYqOz6QfMAqi1WKTVthrRYTovNchhmU4s3dPWVhwa+CICup8mF2uBD5/HKk0Ip/frujq0vudw2LTzyfJyYXuEwLWinapsJozWUKhBhk6VdWdJsSrUQQIcNIy7QsHE5HCqPpK0tdlWy7itkFzsMoy76Qud1qdhtLbTW20gxz5DR5LuPEeRjY9w13fUNpoK0MIYlSfZ4XWRZ+q7prDWhMaSkKy/F85XIdiVkz+0RXKbq64HidmBbPMFwJwXOrDbVSTOvZYJ4XUoq0pRGAfVVTAIvzMgxLkvoNCYoEm7bAaOGz+piZ1+H9b+cTQWfKokAZiMnhHcynzOI8l/VZNCzy75HI7Ec+ffoZawuqohUzmZvQuufubkfKiXGp0EZzvl7xy8x4uVBWNQ/3D1zOA09fX4nR4eNMjrDrO+5udrx5f8+0DDw+abpNy839LTkGlrBgrQwIPv3yyNdfX9nd9HSbhpevz3xZJkJSYsmMFjpDPTkZIm/2bLc3nLsDyzLTVJJ8ds7J8MsF5mnh5eVEBv75nz/Q1MLCjDHz/HIUO+444Y0hKBn+1/flKnOR6lTOkmZ8eXlhHKZVCpH59OkLdVvz7sf3NH3Jxw8PXC9X/vjHv5CS8JOstcQAfdfw7/7dH8RqOowsS+B6mdjuGt5//IHpOvD05SshBpa4oK+K00HL+0BSdH3Fft9Rlw1d3fH8euDr4xN93/HjD7/j6fmRz59/4eZmx/5mh1WFNDvMhrZvUTGhYkLXoArF4fXCcJlom567m1v++Q8/cnO7ZxhHTueRtu1pu45rUoTFrYsOz/k6CuPxIunMd2/f03YdH96/49K1PL684IOnbktsUeB9BGV4ePsgkpwsAYTHry9Udc37D+/oup7ff/yBYRz547/9BR8y1+FIjIGQPG3TcLNvmeeFx6fHlaW0pao6NptbjFJYEpdh4HgeKMuC3XYvFtTKYk2JyiXzfOXp8MjObyhLy+3NLe/evuPl+Rk3j4QIPiI8V62odzX6tiIrT8ZxPL3w9HygKirKovrO82xWGP7z04HnpzO2st8RHt2m5fOnX4XpvEhq/P7uDdvNhk+//JnL5bwOzxUhGvpuQ9fL0sctz0yD43SUGmJIgbZr+T//+H+S//3PP+O8o2zW94F/4PMPD576TU8Icd22gc5Rpm1FSXaey+WEMZZN11GVBe/ePJBS5PDyKKmf7Y6yaohZUVY1i3OkGFhW5kZV1vggD4R58VxHmTbqHPDRMy2OzXbL7d0dbV3jg8P5hXmZScEQg5aX46TRzmHIVFXFhw/v2W62dFXJ6/PI0/MzN/sbbvoeleTim+YZjBzaqqrAhYjznnGe5SCfhSNRaI0yGbtuhowWlpBbJEGiV25BBlKWg6DWlvO4YEwga4NOmZfnVzKZrttgbMm8OFCG7f09hbV8eXpe9UsWY7McLEMSA0xWGLNu1VISRtTxTF03vLm7p2lqCmPFmtCu9iUtU+8lJEyhv9voqrIkLDOzc5RVzZtuyzyc+fL1kclHpiVS1RV1JYkgU1a0/Ya2bXlZJsbhyug8QU3YomS3uwGlmaaZl+OJ6yg/1367p2pabFlhnEOnRMgZIhhbYpQihoVl9vztp59F2U5m07bktTonlR2IOQFiMzLG8OGHH4gx8fnpQMjgkmYOmZejDGFubu7oNoGojAye1prZ6B0xSfVOKWRLoQ1FBZqERSxg5MyyzLy8PMt2tmmwhaSIyiLRVXIYjTEzL57TZeQ6zIyzYwmRxLrhUpZlmgnXK03T0FQ1S4TZi8Wl2e/QtiBGqdnlHOn7jghUhaRgyqpEFwWFUuiUINdEG0jey4NicbgQ6Led/P4rifCfj6+AwpLpmxrz9g0hRKZJBot/+ekTZVHw9PRIipFd3/6mOClFWWJzZm9laGKNJqck6aaUcCGj1xpFbWs2my0gdRSl5LBd1VF67ytQNKTIdHiVg739u6niG1I1pQg5E7xjccvKShOO0Hg9CVC8FNPOOFwBRVYK7wuWQuxdVVnSNC193/P4+MjxeGB/c0Pf9ZiVTTaPA36Zhd3TiM45BC/b9ZioSotWZpUwSBpGrXU3F4TtIVU7qbGF9X6nVm7RdZzWn2GF0fIylXPGFmJkW5ZFWGjW4nPm9fUg3e8VRluXUjN2IWCB2givAG0EUDiK7WO7laSRKRuy92CSMDfWtKv3Yp8UoYSA1mNMJMBYK0bKnLleB4ETNx0pCwsqrQNdbQ217Qjek2PELYvU8tZUaoqR6/Uiw2JrJcFQ1KIq9osA3JWS62aFW6csrCpy5jpISkxUwhU+eKn5rPwFa4RbNM+yQNhuOmKseZzlRcB7ge5eLldAWCQZxJakFVUv/ITrOOCdoyirddmSUWst+lv90Dv33QAWQyQY//2fm7iy84pyTTQpvHMcDq/4ZcH7sFZUPHUtGnj5M8aV8Sgb/BAyRSHLJKMlgSSwckPTdWu1Uoa15WoKbBphfclW2MpyZ7Xeeu+ICWGnlPKynLzwZawVzXnOeTVkRbRWHI4nqfkpzTdD27dr97fy2W46nA9cRjFf3Ww7CitQWBcSfpmJWuMKSQ2XVox/13GhLAz3+w1+ZS0VRhEiK+txrdn6QMwZn+Qa0loSGU1dk4HL5CiMpm4ayY7mjDeZjMcluHrQMaB9JK+suJQzm76jbyraquDXw5XXy8jb2x2bvhWNdZLn9GOKwgjTWjiYyqzp8uXvHKcMKENVN6BYrcSSQjUqryZKi/brgiBJmsf5JIn31T5migplDZu+xvuIdwKsrssCoxTPJ7HRVaWkHEOS63scZbic+bsx1IfIL88njILKyvugLVaXW5Z3QJ8VOSp8yhgVKVSiUGK0+mZt9iGujA3zvZ6Wo9y/fUhcFMQQqKymMIoYPcsig1jMglGwbeUeN7vA62ViWKTalljlGkp9fxcR0pf6zkiNiMr78SBVXxmNCDckpsxlGCisAS9pc5TUavd9LZZW78R6rQR+PjmRbdSlpBbtahvMSuC4UmdeDZaF5ZvELa3s2LrQpGy+s/gSBh8z4+wJKQuf0Wo27cpwCp4leEkyR/Dx2/fAovK3tJE841KSKq81IlWpK6m4gwxsYwazpvyMMejCsjJ9CUmWTkopiBU+aJEcKSBFcpRrCTR1ZVfpDEiHMaFyZtNIOrUpLVYrDueRnBPH60xMUNfNb2rpV7c12mh2uy3KKPbbvSSKsYQ0MQ8eVF6fMzW3H+9IMTIOZ6oqs9t0bHY1798/0Pdb4RvFwHUc1yWQXhdqnnF2HE8nUlQoo1Y+58Cm33B7f0tZFVzPZ1KINE2H947Hp69URUlVSKo9REm4397v2N9u2Wx7/vxvJ3799Zmbuz3dtqOoBN7sfWIaPUWZ0Eatac3M68uBGANFaVFGU5YV1pRiC1PIPUwbLsMFt/JwtQLvHSlpslaQM88vp9UgX2ELSwyKlDW77Y7CVlyuozDwuhplDE9PR7QCq4QF1zSNJK9nRyqgbtQK0g5M08yXr080TcPHj+/p+p7tdosGznWNSQGbLNM8cbicaeqWzXZP29XUTUf0kcPxRMqJ7e2W5IVvO08TOWvcHBlOM8ZKxbLfbtl1N5wPZ4bLQJoSeU7UVUtbd6Qox63Hp2dO5yPLMlKVay3YawQ4LMid7IQHGKOYlHPK/O2vP2GtpS5Lbu5umaNUbI1dU9ta2MnLOKI0PLy9JcbI4WViXmaO5yMuLPz8uSAET9VYUB3V2lYISSy8w1UMfk0lzKaq7qnKRtjLCozyFM6sCcrEcB0pK4vWDTkrlJqp65KP739E60xMQRAThwOXy8iyCAtv9kGWMXWJGxe8H2nbiqYtMarEqpK+7em7HqUVrAkpYwxlralbRd1I4CElWTbawoi8pW5IWVoIy+SYxsg8JWxRYYxA+42VJH6M4fvCeX+/J8XE9XxGK8Wf/u0vVFXF6XQEEv2u/4fPjf/wG9pms8V7x3C9YDUYAhqNLSuYZs6nI0YrbvqWer/n47vfcble+Omvf6LrN3z48KMcakwhQ5Blwc0Tl9MBU5RU/VZgzW5Zp8SOwhqqspBawbxw96bhxx9+xLmZZRplSjzPBK3xWmGjosgGwgJhoe033NzdYbXGatk4//z5K/vthttNw/USmGehz0cU9c2euhII5DQvnK4jiw/su4bKrj18hUSXjV5Nf5HRyzZDEylUJmZNUgqz1lZO4yIx6M0GlTJPT08rvHhHXXtenx7RRvPw5o4QIj9/+bpqkfcYqzHGgQoskpvHaIvSmpgj0+J4Opx5uCt4+3AvW0gjla2661E5YUjMObGESKs0XdOIXaAqGa4C8tzfbLl7846//nnk85cv+Ag+ZTb9BnJPWdbYuqPvt+y3PZfTkZCVROpDpGtqum7DOE8M48TsA8oY0Jbt/oaq7SmqCjPP6CgDzJwy3aox9cuAdzNfnsQe89/8049s+w5T5bUK5chJot5SI3FUVcm//uvvycCXw4DzHpc1KmQeDxe0Vtze3wtLoajXwdOF4Trwt59//ruOfK2HFNZgC4tKHuXGFcqZmeeZw3Ris+l48/YNhS0py5pCZ2qTmGbHeZiZZg+nK+M0c51kGxhRRKWJFFynK9fzKze3D9iqYYmZyWfubre8vdtxGa6M87wOLSKbTU/d9qjs5fdYlgKWUxqT0lrRigzOE9bkhwuRrbVUTSMKTpU5PD/jnaffbqjbhvu7W1KGT18fmRfHH//6EykmGQIocDfb3xRnoKxKAXcWMjBWWaqe6iqWkuE6SNWgksPV2zfvcN7x9PSIglXfDtvNRhhIRck0DhxenymKkr7fyAFuNZ6lLMrzwsigZpwm6qah6zoBap9PEn0ua0L0hOsVYyWx4soKvaq5q7Kk6zo22y1/++lnfv3ySL/Z0nYdIC/D0zgQvOPtmzf0bcv5ciV4x3UYcM6z39+sLy7CI1JaWBTfLGnfwdIxEaJwLkz+lmyCy3UEMl3XC4h9+aa9FyPR9XJBKWiqkhg85/Ekldm6WnvfpVQT5lEA+dZibAHaEpNnHK60Xcdu/watLeiCpAzKBXIKpOBxy8JlmGibhnq3+T54cjoKXN8WK8RcLG7GGpq2ZxiuDFex4VmrqZueqm6Yx4uY6OaFEBObrqWuGg6nM8M4MVmLMZqUwFYNwS3E4EhagLLLMhO8+Xv6LIvw4Hy5orTiw4ePVEUpUW3jUFkMdt/UvZdBBk/vHu7IOfP09CwmlHVYdL5cZAheCiNpGoT3tNn0eB94fH5ZN5nN+s8p1sWElupKWeKWZT1YirnPe5jnFcqdI8Ya6nqFRK73uGEcvjHKGceJ6/VK7DusEkgw+ZvZaq2NxESVpVplvinabYk2hq7bUJYiXMgpCxzfKNqmJVX5+1J/nOV5P40jITi0LcX8UhaUZcnVTcQQV+GBEcVySszDlRgDL4cDCSgLeTm/3d/8poycADfbnsl5ng4DSitudz1awXC5siyeZZnRSrNYLUOURtIs53Fi17e8ud2xrMOlvFakco7EJAu903kUJseKBihMsfKXGobFcVptYdu2JUW5X8w6kFEsEbzLqBxQCIfIe8/Nbstu27NtLH1l+fmrbGnvtx1NVRBdJuXA8+uZ1+vAw92tJA1tiS4U8/XK4jwYkUPUhcEasY9prRivZ2IMdLWw6OqqJKV14B0TzjsimSVLzaxR6XtqEaWEieQD5/O8ym5kEPTpSQ5797c7yqrC2IJlcZyPJwBMIcl/azTj4vjp8UhfW35/31NaRVtmUpaNdciKmLQsFGJG64xViULL9T25yOl6RalE01SQFSlDTpEUHcFFFhfX99+Z+01L3Vek4FmmEZcNAcPbfcu+qxkWx+wc7izPj3EJxCwmvkgiZk1UivRN8JC/LUmlFvh6kjTYu9uewmr5XYbI+SpVYMKMVtA2PWVRcLupJfE7jgLVxuCTYnQi5GmrUsDqpSXExHmWYeHsVtB0KYlbsw52ohLOUVMZUpYUt14HZj5CnDzKyNCvrQr2bS1LjdUYO4yTiES0DJLKb9Y953ERXMpCX84Ci7eFoVm19lNILDFTrr+DrqvZdA1LkOdiQuovZSHXok4R742cBb4PnsJaKTPUVSWJJ/ivBk+JbdsIJ3GVOrycLjjvucweUChlflNLv6ZrsIVlf7NHG83N/kYWcF6zLDAODq3h5sbQtRv+/b/7Vy7XC//j//gIKlG3Gm0aPv7wDq0K5lnQIpfzFVaIcyITcmKeB4bLC227Zb9/kAHVMLC/2fPuwxumaeRyOpBCpGt6hunC6/GJ3faW/eYWHTPaJKq6omkrbm9v2e22/Kf/13/hp0+PtLuWh/6Goiy+D55CcDTZYEuprMYAz08vjMOV/f2Ouqnp6xsKW1HWkuC2pXBCz+cT0zSSk8JoRfALIcg7Ugqar09i/n3z9pa6rghBnOS73Q1VNTP7KIOsriXEyNdfXzE6c7cvSSnTdg3zpDkfB3JUqKwgSdV0GAY+//qFjx8+8LvffaRuWppuI+n0pqbIiZwjk1t4OZ14sBUfNhuatqHpWs6vJ15fDrTbjv3dntfHZ46vzzifIGmWKZDchKkypoTbhzvevH1gmjzz64CfPTEF3r+752a/5Xg4MwwTXx+/4vyMRlFVRgzzLpLJZA1LTASfSD6u3yl5//nzH/9MSpH/w//xf892u2EKwluN66LMGlBE5tFhC8vv//COlDIvL3+WFO0RhnEgIWiUuimomwqr5B7nomOeFh4/PZFToq1ryrqiruU9pywrtEoYlShLTaE1PkQuy5UmCts5r0uMtu149/Y943jmeHrkOo1MIbMMC8sSmdzM4EZQW8qy4TqMnM4X3jzcSVhFVVhdsWm33N3uGcZZFsBIVbioNVWv2bQVddmSk2cYgvCSqwolPUdSCCzTwjwG5imxayrqpqZcU8KHl/PaPJB3yu1Ozh2EgJsd/+///G/yHNEJW1gewht5vv4Dn3/4dKlUXnkSwgWZlgUWz7wcGeeJfrOVm6m2zCHx9HrAO0+3vcVaw/Pzk1hEhgEXIuPiqUrL7c0N2paYquN8OfN6+Erbttw/vCGnQPSeuoz0TQM5cTydGaeB4XKRdEfb4p0oUnUC5QN9LTDawlpUStR1RV1XvH/7QAieoig4XkdSVqiypihrqrJinJ3EaK8DzjlSkE5pipGooOl66cbPk4DE1g2S8xKpbOpGuCFtJw/+Wewy5Wo3MtZ+58IosvBavCemCNqsG5eMzgGV1boBTqQUKKzize2Ouqp4c7PBFpaqqsDU3E5BLAzTwJClJw6ZtqpJMaxQ2ZqPb2qstSwhEJcFp0bO48y0OPLxyOId1+GKrVqICR0TZVnJ9k9BCI7D8ZXhemIYrmgl5hgXEk3TossK5T1KBcZRTEjGyPDt5VlMYfMsfI+qqsVyFRaivKegTcF+s9qMqgZMQRwHYgzfI3xxHejd7HcU1q62usi+b4ixwqiMdwufzye0UnSNKIObTipFfhxIfqGuG2IMYmv0jq9fv9JvNnz88aO45oKliom630ns/CrWAzeNUEasEUaCSzIQK1RiGi48vbysyvsCaxRlNizjlevxQFUabrcb/DLz5dPPTLPHKgGhRz+zLDPeO7qqom9b6qKgKg3jKFp2ojBe2rrGlgV//fUz5/OJ+7t7+t0tRS3cHF1YUgiclys5Bi7XKykmqrqEnBlcFEjzPJNTYt/3KKUYSoGymqLiH85M/v/BJ8aM1mm1ganvqQnvFznUWnnRc062GpfrlZSlUiAVqQthZS8EN3E8nbHGsLu5lW261oQYWeZZqnlNA6x2CSU8FUnGRMIK/gshoJHta4KVCRKoUkIrsRf2bUXXbWjqiof7O9mi2WKtMAkXDTKFlZTmdZKBuXPCqWL9MyoyRSHsiuAcIcnvH6W+W6Gab8nGpkUpxThKBbauCuFceOEY1XX9HSCsraVuW7RSlJVsUeooAOyma0UAsThKk7gtKoqiEN7dCp7OKWLLGm1kiBWSJ8RlZb11BLewTGnVi3fklGSgslrfpmlmGq44bZisIcR1oLiCs9PKq2EdMqUo6UWlLdubO6Z5ZnFOwN5p3aApvaa60nfu3OIcISaMzStgvV4331rYd0FsploJQ8/NI8k72d6v20pQpOhl2N42KK0ZJ4GO911HjJFiXf0fz1dJYW16yR4YS1bIP0eIAsgvLE1dEULgej1ji5JtUQLyz1iWJdu+I8SIj3llh0niL2dLRmx71sp/N+XENEtVrixLqrpeh5QyhKrblr7tGaeZaZ7kBbUwKAR+rdabuOkMhSlJ1qCywQFRpXXrqDCrbvf1cGCeptUwpem6Xn6nawpxmUZikIOvfG3lOj0fD/LMjBGlFX2/QX9LpijFPI2/MT4dnK+zcCx2Up8dZ7nOYtZkbSiNpL1izqiUcS7Iy3GhUMnz5fmVmDJ+cWJuXSuRAmgt2fawhMhldlRFpi0MZu0mmxyockRnAZyPs+M6zsQYxCoEBB/J2UMK1GXBtlntwTp/H4je3+xQWoZHr6crpcoYBV3XoEv5Lo3zQlqNrSlLeq+thCnG+l1zi9SapdKUVg5GQlupdLZ1KQmSIZGjMH60Ah8l9a2uE0opvI+EICDrkBLnYSIjqUitNd6JxMY5GbSWpVkrdv26dMxUheFuv6EuxICXyLxOidIY+qogeeH2GQU3mwbvFi6jw+WFJV7WYQYoldDENe0E0+KZXQQUVVlI4rmwuJB4vizSGmgaks+kkHEhc3WJnBXaGBYXCKsRy+aM8xEvIAGxAivEPqcyGiSVmRJ9JZZdrYUldne7B/guNJhGuSaqWtJZl0nSr806wK4KOU6cxwUQ41FKUqlirfKlWFDp9XmYhZP39HLCGkVdF6AzVpc0peV+35GSDM5Y/Q4pJ7mGc4Tg0cairWXyidPkaUpF10gKPWcBHCujKU1eK28LzgWsrqjKQvADk5PfRQZQaGWkOp+TdFZTxkfRuVeF2OtGn3AuYgphS32zaX5LknnvSEFBKVY7pUWHMAyyCMlKBphFWVIXBZO/yvVn7G9q8HQdzrIkKeV7tbhASp7Xl1emcaZpJD0XYmSaJr5+fSKEwKbfY7Ti8CQc0+txPTfOX2iahvv7W3k+ozhfLnz9+kTb1Hz8+AesKShthVsWyqIgRxiuM8Mwcj5LXcgFz7JMzOOIVSU6WW5ub9httysTT5YkVVHwux8/kmOmrA3DxZPrCV9mNv2Wui6Z5wF/XbgOwyoNSRRFSV3WYr/E42MiLRbtFPEqIGrnEjkbmrbGalnWKKU5ngUv0veyZIsxr99pSdF7v+D9AlneV8kJlaEshL1XVlLVJy0UtuDd+3tZqL57R1FoylLhQmCz3VBWJfPiGadXxk+/COPV5tXSnNlsev7Dv/4LKsP5/Mqy1CzLzPl04nA5MLiB83hiGR1hDVyglHzvCkmjW2M4vLwyDSPey1D3dJpx08RwuWJUZhhGYRnPDu8ET6CUYh4upBSxZkU1VCXaarq2Q2vNcBkBz8ODXA/mW1JdQWkUWHmnSkkSPv1WsATXi9y7bm5uxBaaxWZ8eL5gjKbdlMISy/OaeA8E50hktDU0bYuPnr/++S/0fc/v/+mfaOqK3eaOqurRRc0yL98XnyD8JGtlKHi5XknJU1UV1+vE4dfntb7Yo6zGloYUMoeXA1Vd8fHDW4IPfPnyhXmeUSZyGc/4JM2xlCKdL6miPCv6drMml6VppZSi0AqtM18+/8pwHbm5EfzN7f2O7U2PD54UPKfjCas18yQJ+bqTGvzx5UQIUsNGKe4f9mituQ7DKmdYZxn/wOf/i8GT8CCbFeo6zYuocg8HYs5sNluUNiRdsPjE0/NBNp+7W6J3PD0/ieZ98czOcxhGHm5v+Ocf3qNNSbIN12Hg5XigrGvu37xhmSauxwOpSvTrA+BwPHG5XjieDnRty7brOXvHZZ7JzpP0TFve0badbHdXEO2m7/n47oGq0ByvwjOq61aSK6XUzk7DyLx43DSQvBfjmdbr4Emxa3vKquI1eNwSCWhUFphhCJ5N01CWlvuHB5TW/O2nX1gWqbH910YogbNG5ukqA66cUNkQkjz8VJbthw9rHSwFCqO5udvTVhVvbrYoW5CKGlUu3LmMNTDN8s9/uIz0bcO7uzucczIArGs2fce4OI7jBMLJ5jpOjItnmmeOr48EFLbu0EH02VUpPVIFBL8wXk8C0FMJozOLiywhE5VGFRVKz6A04zgyjCNd11MWwiEQ8KJAgx/uhR2S/CwPeIQnsukaCltQlDVZa2JwRO8pSzHPaaUxtuD+zVuM1nz++c/EEGR4gmKcJ6Zl4fOXLygFb2/vxGRYtWL0mwZSSDJ4CgGfZahz/HolpMS//Id/LyyuKEB5bSzT7Hk9j8zTwPnwsl5TBSE4lnmkNIa2KHgdzvz06yO3N3vev7mXypHSDKcrz4+PfPzwjtv793z6+sjnx0fqsqEqay6XC4dDgCgv73f7G1LKNFVBWVZM44XFOfL6ArZpaurC8vj4lU+ff+Xm7g2b/S17ZJt3uFyYF8fldMI7AZEDbLsaReZ1nAS2vixYrdh1Esks65YYpX747UXvt/CJUaCl69jpe2rOu+W7uj2lVSaQMsWamjFFSYqR4XIVK1hMTNPE6/Mzu/2eN2//hZQiyywQ53mZaa2RaytJhQUdVh4ThBil+rTWKXVeNzl8g5xKVUVrRdt2NJX00621vHl4oKoqLpcrl8tFYvxaU9cVhS0kgZKkguqdcJ3IwrMiJ+pKIId+mYjBrcMVYbVorWjWw0TVtKSUBWweI/vNHVobXo9SCdnA90qXMciQXWmKuhHzWoxoo2lb+evErIQfslanuqZe+S6yqbJlhbbFqmoPzPNEXTf02x2L0Ti/0FQVm67jcrnw/PxMjIVouseR+XqROgmCNlbIXxutqMqSupIBl19kK5SVYru7od/dsDx9ZbkO6/AkCA9HG5Z5wrvl+894XuUEDcIbsmv83Rhh1TgnlSWtJFGyTBNea6myFYa660ApLqcTEOkaAagP0ww503UdilVV7z3H40FSW10rfyJj1uvTE5PYpIqiYLPbMQ4DX798pqoqNpseRVqr6zJ4WnzgOjlh+xWWhHAqcgoyhFP1CiPPjNMsqbLGUhlLXTeMw5XheqHtejab7fqSutBUdj1oZnyMkNZhR9NIldUaNJaYFREZPGklvCmlNMMwcDgcuLvZ0zQNbd8L0+nlRWww84RxC3EdOgnsPHM+HZimCVMI3+bt25ayLLkMCyEG5lGqK7+lj1TkNPfbjpgyvx4uxJRli6qMKJlBrI9RngGaTFtATIHPTy8YJYDseXE8nS50bUPT9dhS6kqnYWI5D1gNhZakHSlisqckYpIwlIZ55ul4oakMbV2QfCa4QIqBmDzbtuF2txHW03rHTRjub3bcbHu+vp54PV7YNAVNKebFzhheT1eGWZ5xhfk2eLL0dUFdFsxrAnuarnjnWBYZhEuKMlFri9WWdh06XGYvNTwjw5U5ZIiRcJnWd1m1plQjkDmPeX3el2gl6QN5RsgSryo0bSP8pJQz0zRRlYa7mw2FylRFYnCJ19GzbQx3mxIXBWzclJZdV3M4RZ7mwOAz5ylQrmgHnWXwJGD4xOwDs4/UpV3/Jayr0+y5DI5tW9I2FTE7YgpSP1miiFa0YXEL0+xWMYQWMUNKdFVFaYwMy8kUKqNzJkaPipG+qqWmqjVKGR72G0mjBxl4y4BREiFKKU4XgR5v2gq7Mgx9SJxHGdp1tdxXJhcojOF2U0PO1NbgQuQySUr85XCmLi1v73qUVSLhKQ1l2eND5DpLajLFhAtSJY8+saREWTc03YbJZ06TR2vDVuW1GSDvb1hLpTNWZYheao/aUBY152limB2FMSvnSQZPKQmzMaeESgnnwmqxk3rz6BKzSzR1Ek7eOlBffFjrq46QE0pbtFEyxAcZfIRAUBZtCj6+u8MYhR1Wfpaxv6nE5nWQBHRVisF5cbKg+/Xzz8QQaZoSpQWDMa71r8IWbDc3BOd5eTwKL3EcuQwXPj1+5sP7D/zLv/xuFV5pruPIy/ML9YeP/PjDH0gh4OaFZZ4oi5IcM8Nl4nIZOR6uZB3BRJZlZB4GVDIkr7m9vWG/20HWKBRdLUPB3//4IzfbG37+9JnnlxdSmCjryHa7oakLTqeZ8+XMZbywuIXaVJRFSVVU1GXNEhZcdOhgIQsQO6yDTKWtpIjqijcP7+TZuMxkH9juNxhjuV4GYvKrvEYEC947SE4O5UnuceXKOa6rHqccpCOltezv7+i7jvcfPgCJ2Y34KP/8VVXLWeFy4ue//YV+0/Lu/RtyyESX2W63PNzteHx84i9//QuFrRiHifP1zOF8kGGPUlhbY0xDIktV0MrgSVuLNRWH5wPjcObNu4/c3N5zOSXcODFcrBi8lxnnAsvs8S5irdyjTwexzO02W6lj9g1aWTZdT2lL3OxIKfJmf7fW8wtilMETWqErQ1aZYVSgNP1ug1aa04vA6G9vb8gqc72cWGbH49cTxhrK+lakAGEix0RyAb8mr7QxNF2POx7465/+zM3dDe8+vqFta7bbWzYktnc7pmHk9VkY2OfzZR08SbJ2vl4pC0VT1TxPB37528+8ffee25t7ilTQxIrD65Hj84Eff/+RHz685W8//cKvX79KoqowXMcLx8uJ0ioKDbNvqJMwOPu2Xxd0gZzMuiCX5+Hj1088fn3G/uu/x97ecvewx1jLl89fGIeJ0+G4AnHlmWgLGZwffzkxTQtFqamqkvs3t2Jh/FXMft47CP/YfeEfHjzd3NwKKBXDsiw8HU7EGDHWUlpL220keh0k/ifMoyxcI6XYb7erVQqGaSYrRV1aeWlPC5M74OaR/f6Opu2k5zuOPL48U9ct2/0dmW+mJk3fNGz6nv1uJ5aPFaxq1p6nXzuSdWk5Xq48vsrAapo9/WbH7X0tHfYYOR6PvL4ENpsN27ZkTF6qe4X9vv0KfuFyqbBTwdOT6DDv70Snvula2dYOZ6Z55jQ6soJ5XiBDFeXlJrgJRUXdvV1fmp6JBDGfaYXFE0kYWxNSZFgnjm69gVrdk3Lm+TxQlCXdtsQvC9fTM2VZUNktxlpu7+5kQn2VFwOjNaPznF5OlIVl27aM88L5+CLANiUmLKUVu7al7XqpMk4Daq1GbpqOXd8wTRPLPPN6PHJYjXx1XePmmWN8gSjsr7v7e24RNkGOAvpMKTF7J5wmUxC1pW9qCq0FTpoz4zgxO4eyYqFJuiAZxWWcV0ixDAM+f/pZqkYrV+WuLMgZTs8jl2Hk9XikLiv632+wxvL68iRq9qIgEBlOIz54/OIpreXjh3tsUfDXP/0bdVVys92ilUCpXfDCeEiJputBKaZ5lsHVEin7mnqzZ5sUb7wcDA/nYbXWiC59u91ijOE0LFR1x8ePPxKdTJh3my1VWQrgbZT61+vpxL0Rdk0IAlEujMVow+vrK+RMWzd8eP8ev0LQdXCQIy6IWWGe53VzK3KAqumo64pb40lZ0fcyvIt+ZJkn2VpEqWTm/NuZPG023fdawTeoYlpfWqVmKfUdo2XLIor6yDjOf1d3g6QXrcG7haosccskw5YQSFGSKGpNVLll4Xq9YIuC3W73PT2TYsSYSAqBGOSaN0lTVCW2WGHf3hGMxmnD6XxlXmbGcWKZF7TR9F33nYEj4MNIYyxFWaHW78g30xrrtiPE+D0pEIKjrDuMLb5XV9zi8MFxHmcZcCKWvJSkk1EUYq1KQUDCst0QNojRah3eyd8j+Mj5fAHEqKf1mnDKicPhIOa2vkeRqYq/w4Pld2CIKXG9nAFomha3LPz8yyfKsuDu7g7npCKUAVNWktpSwmlpqgqhwIkRLQbPZrdnt9syjiPzPDEMVwF7O78eNmSrrrVw/HJVURgtCwNrsZUMNWJMZGBehDtUVjVGmzUdJQPbRKb+ZsWbZai+OCfb/yDmonF26zUyo7Wm3W3JOXM6n2RLNlwpi0JSa0gSD5DqSIrMo6S81Dq4vL+/xxgZQkyL4+uXL3LvUhpbFHSrCQ8tibdx5WOgWFlZYhbcdi0ZxTCMFIWhsvZ7TROtOJ+OpBjompqqsMJtKmU4ukwTzgnkfV4WGfYXJWmRKug4JpxZvnOlCmvW5ybMiyOEoyRRVrj4stZx5CDGd9Powxvh031LSslCxGO0VB79yrX6LX3u9p28X3jhP8iyKq8gb8WmE/aSwOelZi+sOblmlZefZVWUsrFFjFtdYciAvLIJjsCsVeTFy4FfK9FHx6zEuqlg35WUhaEqLYWB0gj3ByrKohBLcCmMm+MwM7+eqYpyZe5kmlLTVCVVJXUz74IMWAqLVfK7dmuK8DpOjNOMsgUoGF0k+CxJZmNo2ka2rvPC4jzTtAKDMlTWUDWS0E+zfPfK0oJSa4pGVOt65QFJSjLJNenT3wH8WgvzR2uejxeskWGdIcG8oKxG6ZLSJvZVQufE8/HC7MXwLJWGCWs0v393yzg7LsOMyqCSVIXSys2rbU0ZI21I31OY1mja2oIWuc+0eJ5eZ4xWq91ROCaZtPKpDMbIs4Cchf+kxDeIUmu/LvFt7WHKCoNi8YEcPdu+pCiMpEKCZ5klcVdYTU7w9HIgA00lwoBiHZQImkJYYlor2qqVX0WS++I0z/LOtsQVyC7pszf3N5Az4yzD/2/WWIwlxUgOwn4LSa7q0lrIGZWTJDkLQ1MV7NoGrRTnafluvdRZMkgJRUASlw0yCFq8oykt7cp19VFYhHnK1KWk1mc3M/vw/R1KqqQOrWTw67w8t8r1rOBCJsSMjgrQJJ/QKdI2JYVSbHdb8reFi1aY1TTYVAUxZZZl+l/13vK/9Of+zVtJKrsJ7wOHp0dSTGx3dxhjhGMaA8fLSVhfWYzQ03QSo9eNSEi2fsvleiFr2O92BB9wSfhF3jk2/YaqKvHBczwc+PTzL5RVyf39A9pYFr+QtTCnispSVAWlrSmKmqZuqOuGrBIvhxf6bkPTtHz+8oXzRQ7by+Koy5rf/fgDqEhWiev5wOV0oG4q7u9vaCcRDeikUGiqqsfoAkUiJ8fhcCS4wG6/o21qylruacN1YBhHnh4P5PV+YKwhrFKuGGaMljST3NhXkqi2q7DFQoJZW3KAl5UxFVPAFIWcIVLk0y+fBXi97yi0nNsVmXESLub+5g5IPD8fsLakqFrGYeKPxzNlYfnDP/0L0zhzPg9YXdC223VZGtaz+A2Ll7pvipEUItvbLXd3NwzXjnHcM0+BT5++sMwLRVmwOIePnqqq6duWtmmRyqn8UeuqxjsvkSXALSL2GsqBWHrqrqSoDdM8My0TthSruRi/Z+wiy8GAQhF5fXoGYBqkcve2uSXGwJ9+/cr1OvByGKjrivsPO3JUDKcrClkE+7DImZqBYRowCv71X/9AUdWcTyPBZQgZXWhMKe/Uy7zInKQqyEqkPCIScqi+oe83bLY7Pnz4QEbx0y8/0zYVXdvQ9g11U6M0fPn8mRgDd3e3WKNX6ZeEWZbJ4Zwnes1wXiitpSpKltkzzwFtpEWRXYFRms1mK1gLJe96LniUVgzDhHdeUr4xoY1Uy+/sLVVV8u79DSGImdtai0YRnBfGbcycTkdi/P9x4ulmfyMT1ySK+/PPn0kpcbvtxcax3xNz4uVyFe11DKhsIATp+K4bTWPLVXU4U5X2e03udDqRdMF2f0fTNDJ4mkaeXl5586bk/e6OeZFDgzHCKdr0PbvdTmw+pqAuBRA+L47ZeTpjqNuGL7985dfHF9m/Kbh/s+PNmweOx1eG4cLz04nT8cR/+Hd/YLPbkINHa3nR11qxTIN0KI1FmYLnlxfmaaJvGgqtpHKzQpyv48jL9VlMbJvNGvWMgGxqjIKqkRf8rGUjnFalr8lBDmpFBc5L3SUGkpsxgNWGlODlPNA0kbqV2tb19Cpd4q6lbiv2N7cybX16pjCarrJcF8+Xy8TDfsub2z1unphOB+LKBVEYtDJsN1vevX3DcD5yPSlGnxlDoq0r7vd7xrJgKkueXo+8nK+8KRv6SmKtw+VK31RURcnN7S1V13F6eWYaB9pKNkLnacbFIC8VylC3G5qyQCvZ+B9Pl+/XRipKorZEo7lOJ1IM3NmClBOfnz8RY6QqC9q6FlB6SpyuE8fzhePxxKbv6XrpLX/+9BPaaN6+fUBlUfI6H/DOc7Mt+fjunmEc+fNf/kjbbeD3/4wGVBBwtwsOW5TUbY/3Tm7WIRJdBFXQbG7YIhrl03Xg5Xhht5G47vZ2S9+JAeLx5ZX9dsP9ZsPl+MJwPnC/33Cz2/HFKF5zEg376ULf9/S5/W48KxoB9768PDNNI20nN60lJl5PZ1hGiIGyFB3xMkuypapKjNZUdUPTtpRWNMkffvdPKK3587/9R6ZllqRGiFwXvxrcfhufTdeTUmKYxAZ4WYHZu74XO1NZkVJch06JHEXHfB2FK3R/d/v9kFtYswK1NX6ZpTIQ182oko0pWdJUl/OJ/V7i2zEKmDkZI9FdBTlHTNagNXVV0/b9OsjyhCAvFS+vB15eX/mmvb/Z7+m6lnqtW15OJ2bvVwjlCupPkRAiKafv/x5jIIYsitngabodVVXRry/rT5NIHU5niTbvNi1FYdbDV5LKGpCjaMudlyqHMgajtMDGV2hxCIHrOGOMZtM1aG0wRYFbFo7Hk2hp2waNDPJQ6vsDSxuzQr6vVHXNZrNhGAY+ff7Mu7dv+PjhA6fTmct1JKGwZUVWBrSAE/dbGc6nlLmcT1yXha7vefPuA68vT+QUOT8/czie6FqBR+YsSQMBlxt0VZEKS9X22KKkqmZilLrt4j3zsuCdvABZK+pytQ7O5WclA+LjchJBhpb6V70OOqVukIjLhLUGa2+F1TZcGaeJcbgQy4oY/DqM8WgFupDt4DxKfDu6maYVJlkCRieCgfOrmFr2t7cYpSmKvydiYoyM1/P3uqMvClJM2HUQNEwz5+tIW5dURlFVNUVVS9rzfMJaS9tUWCuDz6ZpqepK6qPrssg7x/2bt1RNJ/B675iCpHht4WQQaQxd1zI7L+m7leGXjSRb48ozbGqDiNTEvnZ//0aWNNbKsO54FAGIlpRbWsHWv6XP7bbFhcivL4Mksr0jZ1kUFdbS9/U6wPNoY6iaBlb+n40Bo+W7WJUlPkri2GpFWxh8yvggCRFr/qvBkwu8XCaaqmLbVQQUOHl/2bWFWHqtJZhMsGKnM0YRE7iQKEqxhZ5fznx5fuV2s2HbtUCmKTRVZamqkus8MM0LN31LUxXfawPkTCBxHUXc0nVSkZhdxIfE3a6ha0q6NRV4uo6Ms2N0kn18s60lUVS3KK2IaSbnTFl/S6YkWE23KEVhxWbr13TQFNJaNcxoKwlO7wOvxzN1VdI+3GKSF56oKlHaUtrItjZMs+PlOJGQBfDsPW6eeHu358e3Nzy9nhmuojDvtQABAABJREFU13UwJLylmBWVkfqj3EfgOoxcBxlYNZXFFpo2Wv42TDwfr+y7mq4pvwPhQZK8VWmpFPhFDhB9W1Fay3URLtu3Z0kkkRCbs9Kay3ImxUhVaOrScHEeHxLjMMoAq2tICp5ej6SU+f2H9xS2wFojpsBBjG+nYaa0hrRvZcCdIjEr5mUhZRidiFgu14m2rfnhbs+8OL5+fSaEjDaLDPxLAQKbKIuykIRPWK7ygJSFLWLXwVNsa2bnuEwLVSFJMbsy6DKaiMYUJY21uPWAtd+0bNqawzATZscSAovzlEUn98c0M7qAtVKlcys3RltLWRjhirq8Vj41PmR8TJgs6VvnEzopul4GsXVhMAo2fQNkXp9f8T5QlyUxCScw/oYG5/cPbwjB83p4xAXPy/MjWls+/vBPNE3D7e2OZZ6YlmENJkS8dxzPL/Rdz5v3b7CmoKAQo2mKVFVJ8DKAv5xlgdT3PWVVEqLj9fjKf/nTH/nxxx/4+LsfhF84DLAOntqulSaGrbC2oq4L6sriU+L1eJBlzabl18ev/OlPf0aA+vDf/fv/jh8+fmBeLix+4tPPv3I6nvjX//Cv3N3d0M0twUsyMMWMLTqprbKQk+d4ODKPM3e3t2y7nu1NAxr+0+srp9OZrz8/kWLix9//QNe38vwnkvyMsgZj1HeJhsQ2C5TRVIUhJyi0ZfGe4+lIzhFtAmhLUYql9OnLI5u+Y7/fYLWhMgaVM8M4Cjpid8N1uPL4+IW+73noNhwuAz///JXf//4H/sN/+Ge+fvnK8fWC0QVNYwneEfzEZtPz7u0d12nkOg6M14VxcWw2G97/8IbhumEaJv7tv/yVXz8/0rbyc5+WCRcW3lY1fdNg6gqzPttJmb7bEkPi9HoQZqYTUUDTjGQC7aZF6Yrj+ciyOHa7ezSK6zQxTSOlEaO0qSVFcDifhGmaMk3TUNcFzmUev37leDxzGCY2256Y/omsFMNpwFrLZrMHJcww7x05ee5u9/wP/9v/DucTvz6emYaZeRwo65J+3wq3c3FkrTClJXmpk4bgxc5cCS+232x5/97w5esjP/3yifvbG6rS0G82bHZbnr8+8eXXX+l3e25ubzBK7oObvqZtKl6erxxPI8Fnhouj3BWUdUFKsCwRrRYUiUCJRox1/WbDOCwMw0S8XoVXmoT1Nw7zOiyDEqlKNnVF8Vaqdfd3H9FK8/mXn5kXL4GfGBmu1+/W7P+5zz88eHo9XQgh8HI8473n/uHteiCemXzgfL18tyb5EHh9faVtW97+4S3eLfz1l88C3WslfdBvNsQQeDkcZdu628tWLSlUClwvZ9wyywPxeuEvf/2zTPmspi4sTV1SaIjrVLiw0NYVfddipwU9L3jveHmZcMuI0Ymyki2sdxOH5y/M00x0juAkEn26jmhbsWlrNn3P4XTmOs6krDG2kq14Dtzv96TtRsCzykhCR/HdCPXDm7s1fSWRZL9ItUkXYtm4nM/fzRaFbtF9S86Jp8MFpRT7riN3DX1bC4vGbVAKhmUUo0ctpPqfP//COAyMi8NWwqlKMfL49SvzLD3cTdey29zQm4J3hTCQvj49Y7Tix9/9wDgtXK8jzgec91zHkcfnF5ZxYB4mlDHU1jIMV36JDjdNuGWmb0r+9Q+/I0SBN+62W5niF3aFKi8Mh2cBEVcNcZlJwRODI0cZWHZdxzyNLPMoIHGtCFkRsqHZ7GnbhsZ5Ykz0lUDm3XDGLZMAf5Nss5SCw+lERlFVBdu+xd3dUlcl4/XECi5CF4VMxNOMJlEZ2Gxb2qZinj3zEggJslKS8IiRkAKKSKkzbh74cjjQti13N3sulytPpzP6qNFGS/LBCB+BlV8wTst3Bfp203O73zIMI9fLmdPpzPl4Zl4iz4czbdfz9uOPAmd3juA903qQizEyLQvOB7TVNE1NW1ms1ZgsNpm23WM0XMaRxXtMWVHZgtubW8qqlINpuNJYTWnlulRKwJ0BgyoqrMnsyvI3VbU7nU8CpJ/EHlaXwsJZ5gmnFNYt5AzeBzEXpYjWhv1+T06JXz9/kghz08ghvSjXrTnrQbzFV17YbUqxLMJAMVozTyNfPn/CliVFWVPXFW3fMw4D3gd5+DSauhUV6uIc0TmcF6NQVQnf6RvXpihKMZPESHYySJrmGXu54L1YyApbcD6fmOeZrt9QFAL+zjmx2W4llRQ84eLJwa3VEocCbm9vUUrJNh+pVOe1wmOMoes6CmPZFo3YPkIgp8jh9RWtYLPdyRBnlG12WcrPahyuxDWpEnPm8eVV/vfeU9U1Xd8Q4je7mWeaJvnn7Te0TcuHDx+pq5Lz+QQo7h/u5QG+/qzcerg7Ri8AfiMQ891+z7I4Pn36RQ6VWYmdpe2YZhkgbbZbmvWwDoqk9ffao3er+c5WaC0pg67tKAor26Floih6MbTlTIyZkGVQst/t5RA7ykZRaUmNkRZyjGQl/qh5XoBMUVY0K8S2KKz8BmLEOeFeVXVFynlNOBjarqcoirUimpgWYf+YosLYcn1JFQZZTOvvsCi5ub1bTS0ZlGFyXvhjGTEbxoDzinlRVEpjCgF9l+tSZ3FyH1JKcx1GMekYTWk1NA1FWQlfYK0G6BWkK985GQDUlfw1bSUFRossZ86XQX6fa9qr2u8py4rLmt7dbreURSGMLeR74L3cH3OGuixAlf/r32T+F/x8eRHmx7h4QoyYQlI8dSlpxWGRfa7SBhczp8MZazSbppAF3uIhZ66rgnq7EfvM18OJoiyom5oqSNXIGo22BUrLIDgjLB6iREabqqRrhC3mvTB2KmupS0NVGKYlMrkodcllRuXITd9SWEEHSBLPMjtJY8X1nWmaF9FfF3LAiogRrmkaGZQZYdq9u9kIQ4TM7DyJWVh1xlJVUFer0axQaCWpwoxUoOQaTFI1y/KfP+x7AJYgyaK+rcgpo2d5gbarMXFy8TuvE6U4rtfpcXB0jWKrMosPvB4vOJ+YXKRvCt7tWpaQGOYWW1i+Hgey0rx7ey/XbhA7Zo5JUppJrcOMhZwSdSWmu9HJ93vxntIa3t70GK3W1Kimqc16WFPfGWc6q9VyKouI6yjykbubDXVZcLoO+BBpdcZqWBYnqbHFo7WmNopKG0oltWkZ0GcR/qTMuCyEFFFUf39ukmmtwlpJ9+acWaKkibW2wtlzE5C43/doozieL9KQMBprNWUpS44QPAYwuiCvf46qMLR1iQuRaQ5cx4Xz5NBZXH2ajFktiD4kirVqWRcCoH89nde/n9yrZxd5Pk/0bcXtpuV0GRmcpDaMUfgYiQmMQGLkX1qv716WVMohuW0aSb8i/JxlEUxGXRqM0QzXkUkr7jcthTX4IMyxwa2D3yTvsftNx2+JUHd+PeO84/HpFe882+1W/v/nV4bBMI2H7xiDEBKXywtVVfLjh98RQ+Avf/wj1pZstpKK2+135JwZRuEg7m9u8d5TNTNFaZkWeb50XYdzgZ/+9gt2HZK3XcNm0yFCoUxZavqupO87NpuOy3VkGEZpdDwfKWzJ27fv5MySAtooRjczzct6fws4lzker4Cl7RvKpuJyFX5V28gyywdPJvPuwwdyyngSL5cTUxpRSs4J1lj+6Q8/Sgpsu1s5RFfIwhg2CQ6nw2qjNXSmpW5avPf89PMXrDG8eXhgg6IbO/k+aklzutGRUqLtamKK/Jf//GeWZeF4eGW73/P+hz3zPPH0/JVhGDmerpRlQ9dsJDwSBZX0pz/9GWsNv/vDD4yjnBsv1xPT6DgeDiTvhZUGlIWlexDO0V///InoBd1S1wU//O4t87TgnWO/31M1JXe7O7p2w+ImfPQsfiZEj8rFyi8MxBx4c3tH09Ysi2OaHE3boZWAvJ0LsIpxfv/jj4TguV4kYaSt1H7DFMiE1RxpOR7lP9/tbrC2oqwnec8KSRZp00RZViglzS2V5R603e7ou47FZabZMQ5XmqaibneURUlBTTYJ0xjmxXE9XGnbhjdv7mTIeDkzDAOvzwd5N8tJztplQ0rfRDWaorTsb3bcP9wxjo5x8pzOL1yvZ8pKuKlt19JsKuZpwS2elFu0Ltb32YT3YgE2SqF1oltTf7LkzdjKoDS8Pr0yjzM5eYiJ/faWqil5fnnmcNTyu6pK5kXaDOfrSdAeEXLKvH14s3J0/+c///Dg6Xi5ykDpfEUpxf3dHSFGfv31V3moDVeMLShbgYQejwe0VtzsdxyPRz59+YrShs1uv6YI7piGC8+PJzabDXcPEqEfZ+GTjMOEW5MFwzDwejix3XTc7fc0haatZUMVvUyFC6Oo65JN14MyZKW4nI4M1zNucRglcdamaYlu5jSehXOUhfLvo+cyzKAH7m/23Gx7ng8nrqPU3MxaO8kqcbPbYI1hwhKUZvFBTFkhoMi8v7+lrmuWqPAh8jhNhBgpbIFKiuvlumpjLaq01HXLPC/88uWJwho+3N9jrWGJiZik+uSWhcPxmcJabtbN9OcvX/BuTXfFTFWUjMvC8/MLi1sYR6lMGFvQloamM5zPF56en3jzcMf79+85Ho/kdXg3u8Q4TWJjW2bCPNN1DV1VME4Dh8uJtMxEN0sf9e6OT19feT5e6fuet2/u0VqhgK+//Mx4OlB0O2xZE5eJGD0pBIl19i03+x1/Ph8ZhoG+qb9H+gOaut/RbzrSdJWXsuIGHwK//OmAcxNxBa9/Y+QczxdJfRQWoxryzR6rFfNwFjKLtmhbYYoG4+UFRRvFfiNMqWUJOCcWmKzEWpNyEiYViUJnxmXi8esj796+Y/+7H3HzwjxJNz9E0Zd2K6gbMiHIsEhbgy0K3r+558Obe/70l7/x+PjI+XLlcL5yvIrl6r/9b/8bHt59IH/9IlwF75in+TvYeXGOjKa2hrKRl/3CaHQS88vdfktRWCYfmFzElBVWKXZ391RVxevLMzF4ir6Vis0yrwMURcSgCo0FGv1369Rv4XO5XGTwNC9orejXZNHlfCbnjHZSz8h5/UPnSFkZNtsd43Dl86efKKxlf3ODsQWmqL+nZEpj6bpuPRAWuGVmHK6kKIDEZZ45Hw+0mx3bmzvatqXvN4QQYbhSVCVNVVHVDWXdEFImr6pwFwJ1VbLZdP9VbVKtoPJAThLnnWeHVsI+qSqxRE7jyOVyou06qcHFSFJ5hTErHh8fJQYc5B6bsvCNdrs91lrmUex443QlhkBMAsw0tqSsKkptpTo7XlmWmcPLgaIouPvdHevxTl4CSksMkXEQeKpdeVQvhxOQMVoGG1Vdw7IQ45XlW03RCkOoaRrKssItE5fLlX6z4fbmFrcsTOPINI1Et+CXmXmM2KrGVg1dU9PWPdfLhcPhVRYPZfk9lv/rl68M4yQg7u0G56NwuNbBk/MimCirWiC2WgxGbdNQ1fJ9couTn6kRBb2PSbh8SrPZ7hBUjhzS0XKIzCkKtFbJ93ZZofZFUaG0hdVsJAPGhHNOhkcxyaFYgbWyxNEKvFvwMbLMDmMMTdOKnh45hCqtyVkgyoUt6BupBIzzDEgCK6co19XK6fJBsTgwVlIo1brY8PGIHwbimirzbiE4x8PdDfV2gzYFiXXYFWV4pLSGlFY4/Cwijmov11PVoo2lLhSazLLIwD1FTwb5+9YNry9PeLdQ15UcYtVap0xiSHXLjFaK7W6P/Q0xUgCeDhcyCr9Gtq0tJMG68jaHWYajTVUSoufleKEqDW25IcbIvPi1Fj5RlCX9Zof3nufzmU3Xst12uGKt2hmDtvJSKoDmFe6sZHBoraHvOoZhZJ4XjJVlT1sV9JUlI0p7gdCPlEXJtqsJIYoR0RYobcheUrwpiGZ+WRzzkrHbBmMLsbFlRdNUlNaQg0PlzH7bY63l6+uJ2Xl8RGQHRlOZkrYwaCXfubRWnlMWAHcGiJIiVCtE/G7XEVLm+Srg2HZN7+X1+1lWDT7BefYoxM6YYuI0SGL6PDmB/wMuBF7PAzFBRLPrKt7tWqaoODkZrr2cR3abhrcPtwzjzOk8kLMM4cRqp1icZxhHmpXxlFGMLjPM8p3t64pN2zAvC857KqvoakMMmZgU+vuVowhahr0+BIZxwoXA+4c9XVtzvIy4ELEqU5gsBtbZsbhAYS3bpsBqhbe1pHGGkRgTZVEIi8ot+OhXKYLYXBWJ2kr9L6UoUPuQyFYGT6Qo2ACrud21uBB4OkvaxWiFsZqykLq1mz0YQ2FLcgiSACkMdWXXe1VmcjJ46irDvpHqkFlZTSFK+lEhg6d9W/J6CBxPl5XWp3HDQsiK//C7B276huv6e3U+iNnv2/08r+T39Z5aF1YSeknuQ3UtrLwYxTY8L46QM6WVYdrxNJBT5mHTYrXFRUlGTT7hQpaKvNFsN813ycRv4XM5Cffo5fmIAt7c3xFj4unpiZQj57MA8W0l18Lry4Hb2xs+vPvI4fWF/+n/8f/AlhX37wNd2/Fwf888T7wenum6nvv9Du8DRSWDinkdNLdNh3eBzz9/YbvdcH97R11W3N7erAzBmdJqdFuw23bsb2TJ6OZpfa+XlNvD/T1uGYl+QRnFtPLTltmzuIjzifNpJEZF3dYrrHvhcrkAsngLKYBCjNhFwc+/fmK8joxOBmDBB4y1/PDhg9jrsiWEwOOvvxK8pyhrbFacLidsYWmrlsoU1FXL5XLlf/p//ieqquAP/+53VEVFcKzJX49fFs6vJ7KCpqm5Xkd++vMnWTwGR1V3bLdbQvC8vDwxTY7zdWK/v6NtOkorfLnD6cRff/qJH354z+/+8O+4HC6YpFjmKyE4TufA9XyhqluquqO9rbm93XA4Xnl8OmBUxmjotx372y1ffn1mnha22x2393v2/Q1N2fF6eCSNjhgWnJ8pTIfWBSkLAHy/79nvt/z8y6MsRROorPE+fl9WWWv5ePsBVOaXT78wzwtaWWJIXBkB1mqyFqMr0G93lFVNWUwYa8ghyQJ0nsmsSTOtxVxvC+5vbyjKisVl5jkwjYOA2+ua0pZYKrG9VZp59gynkbZquLu/xQfHEhx6HMVQXxh0JVKtuqwkrT8M3wUydx8/8OGHD/z01y9cL185Ho78+uVnlClBF/zrv/7A/u4N8+Rl0ZJZ7eeQ18FT8BFtBC7eW0NZl+vyLtNvG7RVjOcTyxRhNRFvNxuatuann/8qS+2yxaqCZRnIOXIdLsyTI2aNNZZ3d/f/sA39Hx48Xa9n0SLblTY/T8JISjJJq5sWrbRsznPm5uaWtu2+J5e2/VZ633UpA6BCk4qComqwZYUxogKsq4rLMHAZBrQtuX94K4wb76msobAyEBiXmTxOpJgoqoqiqjmdr5wuw99BplVDZyump0fG8YI1xWorqKg76ZICOBTtdkdT1ZTWMI0TJDGXbfuW2UlE+e3DHXVVcT0fWNyMMjUK6bwH50FlqVkYi1aGy3DF+UBdFcSoOZ5OZDJpmUUVmyNGa5rO4UPCliUhRv7Tn36iKC23NzuU1qvKGnZreqHpt2AKdt2FWNekrqdpGsZlAaV58/Ag7JdFDtqH45GiKqmbjsLArmuZxon/+J//jaqqaXe3JH2WybxS5ByJOeFzpttu+fDuLS+vL7weXtne3tI1DW3XUdc1+34hx8QyT/z69Um0yjlhbcn+4QPT4vB+IZkCVRke+h1GK46HA6fjgZvNhjc3e0KWrWOKnuQXXp6fmIYLnVWonDm+HCRRthqQms0NMcN1mogx8vjyirUF7969Wwn+wq0SsK+h7NfDUJhJSR5iKcmwbXELQ57RxvDh/XuKouB8vpBiJCweqzO1Fj7U2zdvKWzBp8+fcc6z3e3kQGqMgNxfX5nWuGHftbx5uGcaB16fH1HRE5wcvB7u7shRdPFF1WArMWW5eVrrE9tVaZ++M3KquhFbnpLXpmGcCNHzcH9H29TMLjIsEymKb3GcZkJMdMcDTS1mwqIo0GUJxvB6GaTeeD7L5rMVMHCxmoB+Kx9Z1quV4YSwdrKYvoTdoCEjPzdjKJudcLzGq1gGNzusMdiixBiJ2KeYcFmYRj5ITU+280rqVUYYOIvzYq5pW+pKaqLn6xUfPOVqO3MhEMaRaVkwxtJvtmJcjDJwHobhez2iLOU6sVZjlKJpWrKSQ6i1lhgE0C1MEkXwnuFypmlaGlsjgqJMUwsjJWU5kBVlufK+ZlJQoiOPEa0U2Wh8lEHM09Pjau6TuvCyCOvM2IKU5UEvXCf5TmhVo7Vmu90BkHPCOVGua60lwluWYqmKAtyVaK8YOMfrZa1o2+8JquF65fD6ugKzZahWVaXUSKKArFUKGCV1aSMnUeqyoO87sQGuttPtdktMkfP5/D3x5J38mYo1IeucI84zVSmgY+8kTds2EtkHsW2FZVmTIHKfUt9qHiszKwcP6+AqpcT5csE5x4ub16i7cBBlRJdJwUFKdK0cxjfbnfz1gxfmzyQJ2LIs0Naw6b6pbJMwCU+Osq7oN7t1c+qJWeNIf682ai0mrFnYT8HJkmbTd9zf30sSKgikMkSpsu+3mzWVJCa+YAtJORlJNKQcv28I87qx1UqJLaYVrpOPiTBO3DUddVUwDlcx9WhDWVVc13uXDx7j5VlpSVLDy5nXV+FYzJNwtPrNfrX5Fd8TH7+Vj0JqvE1RSlVpcYgJTWQJlgg5MS1S0brbthijSQhQta1KvFGQI01dcttXTItUn0ARQqAqCn54e4fzgWEWK9ndthUilBKbV1taYox8fTlglKIqK2KGyzhzOl+IwdO1MvA1uqYsC9lMrxa+DJj1O1GXltIoXs8Dk3fyXDKW2cuAtCprmlp4RtPiuWkLKqtZvGfxYdXYW47DjI+JppEqnllbKAGxIBqryTExDEdiEmSANYbOmu+pqZyhKQwxZv786ytGKTZNiTEy7DVacdPKd0trJQD3WYD9WkvVZR4nFHB/f4fK8nxuq4IpgA8BnKNSUHQ13gf+9MtXCq2ojMZoBEBNIIcFHyJTgKYt6bqGEGX4d7freXe7ISUZqOi1aukjHK/Cd4S03m+ygLW1EauRhofb3QpVj5zOA9uuZt/Xcq2kzM22o21qMlnq/oUmaMV1nkkpy/fXVlR1RYhxbUFEjtcJo+U6UzUEn6Rm3TagoK7KFTIuwPa+sWilWLwYkYUTKMvkqrAoFGZl9hmtqCwkHwl+YtGRy2hkmLU+D26LEk2S4fuaNtt0DbtNi0at1+jIsgwYY/j4/i3jvC5stUVpGWS9nC6kDO3KD5OaYCLFQNaZvLYUtBZz1rB4+rahtJZhXvBBTKjWCgtqcR7flmhV0LYNKE1AMceV1eYDw5rCvm1qCms5uW+Zkd/GZ/GBmKDveoFIj8OKNdBUZcX9wz0pRo6HV1SMbPcbqkaqU9Mys93vsUVFW/diiDUCaY8ukUoZWtdVQds0HI6vPD6+ssyOpv52tJXzni00IXjO5xMpCPZAaY0tO87XheP5K0Yr2m7H4mack0TNMntyjpAjhfeYwtP3HfvdlhSkVt+0JbYQE3AMct6ztxumSeqc7z++p+taWe7ENXGfIvMKGffLIu9eSd4lXw6v+BCoakm0vL68EFPkdBXm4vuHD1gbGUfHPE10bU0Inv/r/+X/RlVXPDy8k3cv5H7VrviBkAJFYdmsKU9bGLa7LeM4oBS8//CBECLeR6rS8vnXv1CsvKCyUux2HeMw8D/93/8j2miBcFcl97cPMoBNko5d/IItb9ntbyQ9eTlzd3vLfr8HLUuM25s9pREW89cvz1yqlWuZ4kpkM1hdkSLEHLm/v0cpmEbHMr/w5v6BsqqYloHFL5S2JlvN4XRkXiayuscaw/Uq7MmykvbR9nZDDJHz+criZn7+6S9Ya3jzcA+bDm1OKLIw3Kzh7du30mQwmaK0vHkjfObLdcQYR1kFrNH87nc/oI3ifD6iskZnI6mvTs5dm20PCp4en5mnmc2mpyoqMRPHzDJE3CSyqoe393z4+J55HDm+HijLCm1KnF/oNgW7fY93tyhbokzBpt1Q6Ya2BpUrlAYfJkJ2ZBW5udlT2prFL4QUmIaRaRz48O4tXdPw9PrEOE1iq9OG2UeiT4BB6wKrC7JezwiF5XIecN4xTo4YIrvdVgRH+RsA/3/+8w8Pnsbhil4POKBwi2xRUopYa6mqBnJiGQZUzuy2O4qiWCslnr7r0FpRVwXV+tLhrJGh02qPK21BVVU471lcoKobttvdavtxqBQgiOp6Xhb8vOCnSVTyVcdlGDgPA7u+Zdu12KLFtjX5WUw5S7m+4G86uo3Q7RWKaCz17FB+gRiZlxkf/Bq9rpndgE+R3XbLbtMzXA4sbqGspDp3eH5mmmdu7+4oqwqzAn2HUbYnN5uGZDTj9YLzMoW2RtMUGmMsPkkH3dgSF2b+9stn6qqUKkIhG/DCaDZNhy1LqqYHNJv1JV5rg9Kaea2t3Oz28vITPZfhytPzE00U+4/Vir6peXo98tOvX/nw8SM3b94TQmAZL4QkdYucpTLSdD1v375nWWZOh1f2uz1vHx6+XxebdiIHz3lZOA4j+BmVAh9+/Gc2+zuWpy/EeSLrAmUNN/ueprD88U//xvV65Yf/4X/H3e0tn54PjMtEjpEUPMfDK9NYYrZyUHx9ecH7wE3fUDY19faWlBXx5UVYYM/PVGXBP//LP8thMwsktKhE315VwvEZhzM5BZo1pjqunX2/TGw2Gz7+8IAPgdNZNLApZlHx2kRhS+7udozTxOPTE2VVsdls1pSAbPOnceQbXq1tat7c3/Lpl5HT4QVSwAfHptuw3++Yp4F5HKj7HVXXUViLW2aMsbStxayDDVGRF3StsH10loTCy3ngOi38WFfc7Db8/OWV67SQUkQrMZxNznO5XIjB0TStQHltQdbCxXDOc11h22IU1BSryvS38kmr1OBbGk+SGKJeBRmSkBNkuZc1/Y4YPNfjk9gF217gjna1UhpNJONXOLiPiaKw6wu2VPEUGV1V2NKjTEFdl1RFIaypYULl8B3e7X0kZWHcbPcysJfuvFtB2H+32H0bPhZWBqlVXZFR2KJYD0oCe6wqMatchwE3z2z6DU1Tf68llVWFscIjSRlJnxi9xsoFEB7Xww1IjTTExOvhFWMMu+0epTXOBzngGUsInq+Pjxit2O926z9nsUJEN0AmBi+yg0k06ZuuIysxwykE2KrXIZ93C+MwiJp4Bb9bazmfT/z6+TPbzYbbmxu0MRSFBZ1JWioXKgWMhqKw3wcgZWHp20aMQz7Is2z9e1+H4fvQyy/zGt9vKauacRxY5pn9dktVFpzOZ7wPPLx5oK5rLpcr3nuCd8QQCDGgg4EUUCugWKFIyaOU1CpzyhyPR5xbmBdJqr1984DRGu8FSJmCBxBzYSkVzRAC87xIOmEcVvh5RWEEBp5S/M7xmt1Cpqff7oEsfK4kA7FvHCSlFFZrppSYphlSQKtM17bcP7zlfDquhkOJnheFPL+n2aGdI2hNsCvs28ifOcf14KtYTYdJLJFaUZbCkzldrviw8EaLZOTwujCugzRbyjX9rYoVbUBnAbujxPx6Pp/kZx4T2ljafkNhC4mJ/8YYTyoLSLwqLCFl3CDPZ4PYe2obV3aOGLZ2XQ0IaF0h6QyjwcdIVZbs20LyHkqqnyFGmrJgt9vwer6KvMRo9l3DEhKTF6tuX1ecx5nXy8ima9n3HX5xjMvC+XLhdL7yh48P3G0btKkoS41zJ5ZFtsjaCGuM9bvYlpaX81UYdaWwglwI+JC5bTrqquI0zkyz424jhsrLOpBsC0NpDI+vC7MLtFWNsVKfk7yxEgactSjCytaIq6peTEwKmFaWWFVUTDHw6eksOIf3dyIESJlCK7pKtO9JWXyQ+lWRJGmvySzzIjXW/Q6rMiVS/Vwiojb3C0VRUDY1j68Xfvnyyu2m5t1Nj9GstbkEUe7PcxCrX9M0MhxzUlnc9zWXcWGYHQrZNA8usqwDY036zsiqG6niowxouNl11KXl8fXEvCx8eLOnrStJ+YTAtmslaRQkPeCjRSfFdZLB0+22F3BtXRNi4ni+SOVtSZTWcLPZyLOxlDrwphENd9vA7AK/vhwhZ7rKkjIsXnhdKUFhFE1VrAMfSRVVVn4upVEsKkkKQsEwFcJIVZKOqtblwDRN+JCZfWBvDPu+Y3FBknHTxDVM9Js9D/d3HC8X1GWgKGuKoiKEmeN1RGt5jlujUHkFoyf5XZI0Va0prOUyB0JI7DaGqip4Pg+M08Ku74R5FYJUoEMgWUNdy3toBFKILE6W6dOayKuswRaW8+IlYfgb+XyzRraNMIvOlxdSTChlKMuau/t3uHnm8PiIyplu01MWBZfhQvCBbrMVDlPVUBWF/F5QRJ/JQbLVVVHRb3qu1xOX4wmloKrMurC1ImayhhgDw3BFrYv8oqqxRc3hcOL1cOLh/pb7240khYJnWSYulxlrNdoovA/Y4LnZbtn0PdM4kUnYwqCNYp5m3Oxo24KuKbhcX5hmqRfe393x+vLEHCcqa6EsuZ4GsXMGR16H3CEkDocXQoj88PGHtSJ9Zp4n9FlT1w037R1FmZm/WTPriuvV8R//43+mriv472WoVyipUW/3OwlrjFep6W1ajLV0XUtZlMzThNJKbOwKLIrz5cjXr7/Qdxvu7x6wVrHZNLw+n/j1l5/Z3295eH+PrQpuzC1+rQ0P08g0jpiioNvuqI4HjI7s9j0fPr5jnAaWZSZtoTIVX56fOF7OlAZJRPXbdZZgsEqzrNyhu9tbmrrip59+Yhon/vkP/8Lt3S1//OsfceOVwlRgDZfLhWG80nYtZVEwTTJEVFY4pJutmLsv1yt+Xnj8+pm6qvjD738ni//1/quUpHtv7+5WeRkUheHu7o5pmnl8fpbnRghsNxvev3/DvMx8efxCDInokUpbeYPSiq5vSSlxeD2QybRdS2UL6qJknAJxdvhZ0A192/KH3/+Ov/31b3z99CtF2aBtLRbpzrLZtMRlhyoKlClo65ZCl2vNXOr3PszE7Ekqst1u2XV7TsORyU28PD2zzDN/+OEju03PX/76V55eXkQiYww+ypkkIylVowuSZn3Hs1yPE/MyM88OpRRd08qsx8lQ+R/5/MODp999/MiyOH769HkFFrYQI8u84LUXq5ZSpBTQWgCXWmuWENHacvfwwDfFbgiRT88npmnicj4RgqMoDJu+p25bsSdnj9EVZWHxZKIXW4TzmexFFb7rWt7c3ZPQpOCYppHz+czNdsPNzS0uQUhwf7OnMqLfHq9njkZLOiVKXPfu7pYPD1sef/3MMI3c7d+x3WwYF4cPkT5qSh+4DheWeeDXpwOXceDhVrTVbx/u5bBf1iht+PLyIpsPlSlKDSmigbdv3wGK/aqVfT6eCCkxLg6jDZu6orEK3twAWQ5DZcnNfg8KTrOniLAvZzSZ25sdznkuw0CpLNumIefEcBBy/7dXsNubW8Jq71NIGqztOv7bf/8vlCt/qSlLmjfvWEJk9pFlGpjLgdoqvF/EgjfO2OdX5kWYVjJcm6XPjqJQMAVRgi/zhJ+vWM06RJMDaFtLasQUDcoGzpNHXUaMLeg6iUlqpYStQqJq7imLgvY6Sg0DRU5QRtlY9G2NNZppI9u8cRihqXn37j05J16PJ2KIuCQA5tv9bk1cJEYy8SoH1O3NnrIsmccrKE3XdvgQmKcRtCZZgd5ZK5rxuBc+yxRXs4xV6GjRqwlKAPKZT58+czyeCF5eVGKC6zQz+8TsPMYa2djUFa+vr1wvF0l01fVqhrKcL2dO57MAW83fD6ZNVVAXlhw84/UKOclDspEB1X+/u0EpTdtKDHxZhBP0ejiIhQ3hdmx6SX9dL8IYq5pehjG/kU/bijnlfBwlMddvSDlxOZ1IOcmLOZLMsFlhRkm7pRjFElUU0u/WmmVZeH1+QsIElqIsyVkRiwK1wpsLa77DxHPO3zfK07xIMTRDXVU0Tcs8T7hlEvh3DAQnLLRvg6dmvQbGYRRI5nVg+fb9Q6yau23PssyE4Njf3tLWDefLeTWHlOgoKvR5nnl5fmRZFsrVSNT1ouwFgQterxdyjKK3Xw1zKUplQinY30iV7vj6IrD0nLC24O5ONlJdJ0Oz4SpWuqoWRsvpeMBYS9u2FGXNfn/LN5CYtYaqbiSVk8Tm5JwXtXpREmPgcHhZeUWGsmr44Xf/JDU9a6jrhrZtuVwHlvMZW0gCx64WLQFrwzTLATlEsUUta6XRWktVlszzzDzP1HVF03bfo8i73Y682WIUQMYY851PtazXmDGGqq4xQTaYOSW6/V4OIXmQinHwYsRBkVceorWW1ggDbhhG+b/bjpSy1AZSgiR8rbosCVpTlRZyZFHCZrHGorUgdGOM+LVCa2wh95vrhZySbP9DYJ5niY4bLaDNILDzoiwpjKR+lTYcDgfG4co8C+A5rJyxuCYDtdbfh4vz7LheR3lJ0zLANKvZz3svAHZjiSmS12RbUdjVeCeQ+qIS0D3Aw/09OUvc29qCsN0TvSd42aqFKMMXtfJ+lnnCa7HP5t/QwQ2g64T7MM8jMWXaQgYi8yR8LSoZoBOljjBOUm/UxmDWEUxhNLu+J+fE3x5PTIvnPI64YDEqEZqawhhShq7tyCngY/hudZPhLd8P/IU1dHWBC44cAoWx9F2PsSUhSbVS58iuLWiKDS4IUyysrJ5hEqbTru/Y9R1P55nDZeHHhw27rpLaqdIYIiQn39eQ+Nuvz1zHiR/ud7RVwa4r2bYlVW1RWstBPkkyDqXXmpSSZ3KVeX+3x2jF5TIQUyTBKoWQNOwP727JGS5LpAyJ+86QguY0SPVOaS0VvMISQiYsAW0NXSPvfhqpQV/dsv73DdM0czmd0dZSlDMowz99fENbWja1vMwraxmnhXGcqSu4U4q2FHOQXwKXYSZ4x/FsJC0YhZ0mvKuEITLOwrvrSk1lJOWZk9gHUWK3MtZQrMrxYYks0ZGTImPwOROS4CFUzphW2Ew5QYhS9XMmEdHfmXW2yJK+1Ypxkvf4Xd9itGKJCRUTCknn3m3lPSOGQIwZpUUBf2P1yoizwm0Lfq14SvLn29Lo7f29pELiNzejJicZqBOFFVYVGmUqqkKWSVJzdmgUxlb4BNdJ7hF1IUD2GBa8j7JIIpCJpEKRrCTn+6qmLC3WKPmdBwd5TVCnRA4BtfJGkxfz7Pu7DSnLe5wxFl3IsOwyiHypMAby36udSiLX2DVt8Vv57PctbnF8+vRMTom+2xND5OXlFe9P/PS3v8qf31hKY2irVjiZo5f3je1ONJfacR4GPv96xbvAODhCyhRNyXa7pWpayJLM1KagqGT4nhGj2bDMMCfyOXJ7s+f+7nZN1IbveATz9p7dzY6sIjFE7u969jvFMA7ybjA5lsXhJk9VljSt5ePHe56eXxiHiT/84Z/Z72+Y5xHvHXf3imUJXEeBkf/lj39luF7Z3uwoy5J3796glGK6yjVxOp1QSvFwf7+2f0piTN/NgA8P8j5/Pg3EyxWsQWvY7je0XYUuFClmpusMjeL+wx1KKV6eZajQbzc0DWw2W4IPzONIaQx3tzc4N3O6HIk+4Bex8L55+4HFRT49ntbEvaSw/sP/5l/QWkmaqqvp2pbzZeBwvFLnApQk672bGKeFy9Xx9esrwYsR2PmFeZzlHY/EZlMzXkfm2bHb39B2DYtbCCGybRustfRbSSHGFJiWib99+onX8yuzX9DGMC4Cbi9sQ1VVtG1PVZcUhdzP5mnBuEhV1uv9RJaS+/0dRVEwTY6cFQ9v7oTPOwZSTPiwUJSG27tbQoho5N3IHg9YY7hZ+aAhZGIArSuUzViriCrzfHimrlr2/Q0hBmaX8F6SarHwpDoyuyChkabi/ccfUEbzy+dfOF7ORK0ZppH8/CjvXFYTo6LZCG+pKEpenp/565//Qt/vaJqWEC1FqZkvjum6cDAvYi0PjpgiTVvTdjVZaWYXqMqKbb+h7zcUtuSHt79Da0nDGWMIi5Nzz+tB4P+LWE6btlr5hwOzg/NVzk3/yOcfHjy9uX/gcrnyn/7LHwnB01UVpIR3oho96xGzAkaL0lB82yaHSFUJ5JWcCX7hfB15Og64eWQer6QcKcsSYwuyXpWR2aNVxhZGLFNAzJk5ZrGJBcfd7oaHh7dchivn6wW3co2U0vT9hnFemJ1jt+npqoLPn37hfJy4arFRjC7gY+bNwwP3+z0vXz7j3EzXVNzut6jLyLh4mpQxPjBNI1fveV6h45vNhqKQSpzVisFLn/31dCanxJubLYW15JxAKW5u7igKy8OuJoTA63XCOUdwgbLI3JYtqtRYehYXeD1PsnGzhpgzw7JQJui9ozCa7aZnnCZO1zNaGfrSMjvH9XIiKUXSAkTebbZcrldeXg9yUy4qbvZb3r65Y54d47jQ1iX9tmd0geviKQ1UWjZ6wYtOdJg9cGaap+96+JgyMa2VllXNPXuPczPBzWgloLm+lopSURagDdqWKFMxLB41zrRtQ20ExKgUK+w4U5Sl2AeqUm4Icg4jpYhR0FTVCj0Wbs8yzXIzvRNT1OF0JEWpMuqqYtvfsTjP8TzggyelQGEKtpsVMjpN2LKi3fRot7DMI2izDp7koJi1obEli4/Mk6M0srHTRqNXCPVut2MYrjw9vzBP4zp0yqQE0+JJswB9jZYNWl0WXM4Xfv70iTd39+y3W4nJG8swjVwuR/b7HXXdMM2id+/rispacgjMo2yWrFFghIPy4eGOti6JShFT4uX5yDjNXC4XFufoKqkdtOuB5PHLSR7GSmozv5VPXdffh3UCuxdofwwC681KtOI5Z2IGO42AGMoUejW6rTUsH3h5eZFBQ9tSxSgq+yT1gpzTOmhaobFrjSCnjItO+CGkVSde45Zltdith+qVb5OiwBirsqQrOtzi1kHPhHKrAYzMh7ah7xqCk5Rm17Rsd2IJ8l44BWrVhHvnObweGMcr+7s31I3mpmkpqwo3C9R7WRwpBm5u9hRlSYgCcHZOHvD3D28IMfL1y68ss9RLdANdK2m67Uai26fD61oDK4lRjG1FWa5AbIstKkIMLPOEMZauaUg5S6VvWZimCbUmFpxbuJzPYpArxEpzd7fDeceyzFR1Q7+RgbJaf/5lWa3b8/z99+qcYxjlnpVyxvtAiJGqqqjrinEcmeeJvu+/GwYh0Xcd1lj5Hq8VQaX/P9z9V68m2Zqthz3Thf/cMmnKbdfmNElBAv//tSQSkKhDNQ/7dG9bLs1ynws7nS7eyLVbutEmQBDnVACJQhWycq38VsSMOcc7xjO02Iqz8Jy0NjhXrP/dvzrfiqJETwtq/Zqi9co7TmuJl6u1kGCcZpxL3HY3r3G0GMM6hBGRRyukMSoIb0qvPDqpS8+vgpg2BlNWpJwZhhGjlLgRYmQcB2klK0qiksNdWlv9qqqkrWtiTFwuZ3EKrwUPyUrj07wE2raWeJOWyfJ16DlfrtRVSVE4pMMus/hVJEKBNkS/kFdIvjYCIJ9yBCUtaDqLwHkopW68rBu0Nvi2wy8CNpfmM3m2vvgy/SKxsWkV/X5JV1WVBB+4XKR9pipLApnrMskzYoR5RUrkrJiXLMO/oiQrUDphjKUqKq7jzMeXE4sP0jIWA6WWEVVT1ySgLisWPzF4+UyNUmjUCudmbfAyVIXBriwfYyxV7TDGEZLE43UKtKWhqwuuo2eYAzF6YR+S8FHx9mbHpql4OH/iMiw0Vcn9YYsPwjf74l5Mq7P009OR59OFTWnQNGxbiShFbYhJcV05baW1CFrsS5RYeEW3uxZy5uHxmcVL4/KX59k6x5ubLbNP/PQoQHeVJPhxDVE+CwvOWtqmWIWdhFZS+AIiCIYorFJxbsI4L6ubxmCc57Df8f7ugFUKp6GsKqqq4eF44jp5Cif7icoaVBbXyDDNjNP6eWg5/FRlQeHsGg0RBuR1nCl1QWWsKDY5YwsrKAv75Z8GGyzjksjeU1tpNI55FQdDQmX5Woa1dS+JaykY+fqZv65fVouIMi6ehADYtZahJFkaFLVS7NqKECPXXt5dKiKRzXWwY42WQodVCPchEhIsMbNpKu5vd4yTxDq/iPdkKWAgJ3TOOKOxhaYwGpXFrRRjQBmNtoVw+GaPyRKl8VEiyCFkliCxnpQTFo3OCqONfH6F3CfzNIpr1xUS4c4RsbiL8JSjJ6O53TUSfc/qde0LKa8OjMCmrdBrnFDWMNlvGBK/nJEftF2JUom+v0JW3N++IfiAXz4R0sTsF4l/Na04m4uKFKVJsSgs3bYl5sgYRobxwvc//ARZY3RJAsqTCLfirJLWYWFG1sQMPiIu5LDg/YKfF3a7Ld22o79K8ZRflnUfomg3LfM4MtuJtmkwtuLh4QEfEvPYiwv7OqG14R/+4Wtu77Y8PT0yTRO7/Zavv/mKz58/c+0HtluL94Fx6jmeZ/7yl+85ny78/T/+Pe5QcHt7Q1kUnJ5rpmnip48/EXPi/bs31FXNNM0EFdnvD1hr+d1vvyV4z//48T8yTTNl01KWjrZtUbqh3TQMw8SPf/mI0St7NAQen56o64bbN29x1lJYxXjt+XTtcVrOkddr5ul5Zh5nhktPt91y8+YNj09nHn/6gFEJqxNv3rZ8++uvmK4j19OVrqm5u9+TkfhZiUPpLMKTX9YI/8LLy5ngA/Na5LUsEzEsbHZbmqaiv1wZp1k4R1WBX12bTVdRVwVluULGiUx+5tPDJ07XI9vdXlABvmeYr3QU4AxlWVPXJcYp1JTwsydqcV8rrdBaBp7dZovRhmUOGGO53+/FUMGM9548zBROs99u5R6YxNEuLDrHrm0xzhFX56ZWBawtr4sfOV6P7JWiKN6hgsZHzzLDMi4i0ugskeO47t27G2JaeHh8kCibVozzjA8LyojDqa0b6mZDWxVUheMvf/wjf/jDH/j2m19xd/8GVEGKhnnwLH3gbM7MfhQWolK0bfvX5JoPOFfQNi2H7Z66arh/94ayrKTBb/HE+ZZxHPnzT39gnAbcitFoti3aaBY/Cef7fHlFOPz/u/7m0+Xl9MLiPe/f3JNyYtNUkkX3EgfYNJVMlReZJvfnF3KWZpJpHMh+lkMKYifctgUDnqHX1HXDd1+9Z1oC//Kvf0LlwH57oGkaNoVmxqGQ+lE/Txzub7i/v5MNb8gsWYNy7Lc76qqCFPj+L38maENQlkJlnNbsDgeKtfXJWMO9kU1z8DM//PQjWWu2+xuO14Fx+cDsJV4yrA0sm7rElCW/ev+OZfFs2komuShCgks/ElLmdp10OyPtZtM0r7nQTzhn2Tbf4mPi+eVIBv7ud38n+dYgYNXZy2Hm/vZmjdopnLG8vy3FuXF6pipKmttbyqJiuzuQQ+Dz8xFjC7qbN0zzzPF8JjGDHogJ2u2BsihoqgpF5uXluLbajdztOzalJgYvjVoZsnZ8+PTADz/+zMv5wjyNHHZbDnd3nM5nLv3AtinZlgUvxyN9PwiYWym8Xydws7DAnp7lM2i7HcY5LucXlmHg4aPnVBTS5OAsm66VSNCyrLycCCy0bUtRFBxPJ2LwXC4S+3j39h0xJj789CMxRspyD8C//du/rZWjFmXgenphmhe0cQKU1lBXBW/u7tamHZimhc/PR4qy5CaLI6HbiE3VhyjOq64jpUy18gRcURGXkTCesUqzW6N3z89Psik1mrbraNsNt7c33N7ccr5euFyv3N4d2NTveDxe+PnjZ6rS8dvvvuZwuBFgcVGijOWbr7/h/uZAP4x8/PABVxZYY2SxVoq7u1tcWVOlhIuJh8dHvF+42dRYqxl9EKDz8cg0ibutKUs2XSetaW/u5XDupdq86Zo1kvDLuEpn0SSZSq+b/aQ03XYnz9syk5KAlbVCYk6rUOOcRJG0FnFBdS33b99JNn/xFGXJ4XCD9wvny5nCFdRNS1k17A+GZZ4ZBmmwm+dF3DT1Kjw/iTOxblpYuT4oxfEoPJKUMp21FNpQNw2ZNXYDmDXalDOcLz1oQ1k3XEdp0FxiAuMIaSL4QF2JVfjdu3eE4Kmabo3nfYGES01sVToUAi3262Q6JuFwpBB5fnp4dXMpbdiuzKQPP34vTUh1Tc4I5Nk6QhCY72G/J+fMcDmh7cqIWg8G8zJzPJ1eVYR5nsUSryRKkoHNZvPqeAoh8PTyQl4PFW3TUlWlZPG/OPVy5ni+8uCPq/DrCVEOHsM4Ms8T2+2O3XbDsiycz2dp43MS9VbX6+v3czqdiSnijLgq5iDRpqw0WWmGQVgNX7hWOclB6HgU4LpdRbCwjOSUUEhr4t3NgRACL6czCthtNyitOZ9OqzPAvwK/mRcBluaMMg5XQrPZ8aVBc1nmV8eiLQqpEF5jRdJwI01/ZSWW8xjTK5PEGI1PiRQ84xDx87w2/wj4te0kQuOswc0zzi3s9nu2uz3Pz8+8nI6UVcX7zVaG00oE/LDMVGUpwmdOEk1IIpC79TOZvScvCVvUWK0Yx4EUI/u9OFBj8Pg4M/TXV0Hti8inlWK73aK1llKSnNlVMun+RV05o42mW4cjRVGIG9AKmyYrvQqpUcS6wq3svhOF0biuRqlIDBOGyLapWGLCFiV1Ydh1JUobzoO41EqjyMlgXQmsn6bRLAmayrFp5L56vkgr6v1+R8hZHAhWYPnjNDEvC7uuoWssPgYWP1OXjq4piUnEhWXxXHKisIpD6xjGmU9PJ2GDZRHQ6rrFGo3V8M2bG262LfeHPU0lEZqE4jL6lSVTo9VaDLKKISGsFecajpcBMvgkg7miriVGDeJWWmYM8NW+RpNJeCnFaetVtJUNfGkVTjnyZoNREqdLaALiSPLLgl6HVLYouLm9WxupRDx+Ph7XZ9Syz5qqKolRIljGGIwrGHximK+criPDtNDWBVVV0k+eaRCouS20/FMZNlWk0rBvKprSkbQhk3g5npmWyK6rKZxhGufXFjmlFJdB2ifLssBZxdUIV/RpiBiTKUtLUYj4pJQ04iql2DbCehr6UbAGhYgAUuKhVydZXhswISJMQawThsrqeEVlQkqM04TWCmskJhky8gsRbfwsWISspGAjxIDSYFC4QjhK/bRwGme08mg1E8KCTp6iKKmrgnFJzD7Q1JZNVfLx2PPSz1RFyaZxaL26IbTsY/X6a1mLfljjq/Xq4kdrfFbs2oa2jlz7kWGJMAasyVLsoBRL8OJSAworwpi1ht1mRwb6YV6doHKe+KVc5bpW3d0dyBnatiRGy/2bG1JKKCv7j3meiTkKJzBllnkh5cg0WZTRWC2Roje3B4Zh4uV4Zbur+ebbr1jmhf/1X/4TGjjcvcNYaQNLSRGjlgHVMrHp7tjtNkSf+fThhZACMQW6Tcuv6m9J0fOn3/+BaVyYRs/hUNA2cDi0VLVlnBpZw4qSYi3veH68oI1ju93Q9xOfPj0yDTNpSTLgnWc225amqvmnf/oPLIswWcuqZFlmxqHn4ekZ7wN3t3cUhTCCQ0osMeJD4Npf0UZzPJ+kgGsUx8n7mw2ucPggomXyGYvlq6/eYJ1lXKSF96uv7slZcXp6oSwd+0NHVhnjHOO88Ic//Umc+NqRVSR4cS++vJyYpoGqkLWhbQXzcH66cr1eOZ6PlG1FUbZoeyX/tY2CTz9/5ONPHzi+nOgvZ7q2wjjHdL5wOp+5v79ht33L8Xzi88MTGsd+e2CZPc9PL2RtyWh++PEB7xe6tsIZLS5+Y7GqQKeS6RpRKnHY3LOpd/glk5Xn+fmBcizpNreU1ZbnxxdSTMSQcc7wzTdfEbznL3/+mRQjbVthneHDzx8BMKoUFtQwY5eA+vlnlNKkLAPAm90Oax26rJiWmafPfxExXWvKsqJr9ygyfS6wpqTqalwoJHKuDUsMQCJGKUNom4JlGfnxwwtl4ShX1E7dtLRdQ9vVDP1EP0y8f3vPm7t7/vLnP/Nvv/8zZV3zT//df8v93T377Y4leHyM3N7Bbtdyvly5nge6bkdRlPh5IS4zdSXcubKq0MZwOvWcjj2uKmjaWlxps+fh5ZFhHDHa0tUd3balLAvevL9HAX/+818IIbK/2fO37r3+ZuGp74XSf7PfgQJrpH58MzcoYNuU+JgZw0QMnjj1JMBnw2I0hGWduiqUMbRlQfRycxVFyf3NDR8+P/Hjjx/YbRq+fnOgqUpqK6CumAuCn7Eqc7Pf8Ltff8fzuefheJGpgpK2lcO243y58PnhE5QtlA3b0uFKS9ttaJpO0v8rx6IsHD9/fuT5eqWuGpq2ox9HThdhWoFiDmLXNpuaunS8udFSFZvEip6BGJM0WaTM1+/eUFcl08oPiush9no5rjnSr/FBcqbWOm5vbnGFWOaSj/iUsUaz23ZSebgeDm42LeM48Px4FSu70lhX0DQCfXu5PNF0W7bdDs8FH15IeLKZsdZRNR1NWbBtavqh53Q+0g8Tl8tAV2pIDSmJSJEToBwvxycePn0krYcs50q67V7YC+HKwVq6uuTxYeF8OlK3LUUpk6159szTTPAzT6cz0zyz3ckmYBwuhHni7Ee01iwxUFQVh+0OayV28mXqlQkUpURnzqcXQvSMy0IqS7q6kna7JDBmZx1k+OnnnzHW8u6r71BaaufVotDmLJPHFUS7sxtyioR5Zgme59OFqvIUa3xnuxVnxbRc4MvBOmWKELA2o2xiigvLsmCrmqaquPRXLpczxVpDXhaVsLf2B25vDsQ1GrffdLx/c8vLpefp5cjdfsP9zZbt7kDdtvikCFlRF7eQdvznf/09z8/P7A97dFVJpCcnbu7u0M5RpEzUkXm4MgwD8zJThYpplnrgS39lnhduNqJ4b7cb6qrm7Zs3AHz+9JFpHOla4ZT9Ui5rNGRLWRYi2mjQaKq6IThxvYkbSrZ80sYj954xEjcwXwDXWrE7HJjGkZM/vsbVrtcz4zBAq2itpaoqNl3D0Pcy2cjSSlcWBZuu43g6cr2cqZuGumnlUGI0fT9w7XuJiqCoU0YrRVlWMrGIAXKkrBvsynAaRomHOSfVrdPkUcaAsaQkzgGlFNYY9oeDfCbWgpIC6rS2jfllplyLHlLO5CgTovRFeMqJ6/m8CnMRrbWwG2Lg088/gRLByRXlGuETR8uXJqxlWXh5ecauE8nXaF1MeB9W3pB6bZ3R2hBtwllpastZYorTsjCMPSCvuZQzzskwQekvfDJx+rycr2gJhwiLLUuDVt/3HPYHuq7j6emRcRxAGbR14sKJIqyh4Hg8Mk8z3WZDUQjgGSUT96wU8zLjF0/T1CKMKEXKMuU1xnJ336w/X2F8qJwxKtNuNsSVJ4fKNE0tjbAvz8QYsSvhP2YFKjIMEhVVxohToFbCJksSgzufzxRFwf5weBVKvxzggfX/s1RlyTQvLH4AJTHB4MXpFnxmWt1P1lrqpqWqpWmpWN2oSkHXtex2e56fX7j2PW+7DYebGxHLYiT6hbBAUTisc/TDiF8EMv0lpq2NIayNW52rMGvEOniPUgfhH65RvXmaVsG0EYaitXI/73Yy8Xx4hJRoGpnC/ZKuvH5m1Sqcl87JQd8YObB7cVeG6NFGUxSOaU70Q090ltxWUsgVFjQiHtkI2UJdGJqmZPGJ6+ipC0PrrLio1mYcwZTLcK0pNYfWcRoCT9eFtirYdTU+RXySGJ0PgX5aOPcTRVnSKL1Wpnu6uqSpS8ZFsXjhgkj0CLrKMi/CSVMqicdUG4rSiutKwd1+QwjC8HTWEjPiJJkn4grILpxl9iI4pXFeS3Ak5t4P0uQYxAomorBW2LWROAUve61W3vP9GDFo6qqQiM+1h5RwWpO1JiktEcewEIGgRHiKPpBRKJcx1tGVEhUpnHttHJUJdkFVlmssTD47ZSzGCntlHif6aWH2ga6pKMqSy+gZl0C9urGUMmgDTWHJOtNWJVXhWJIIOpfryLmfiDFQFu6VAVVmjUYxjAM5JZpiS2Edg1aErDkvCa0yt50wj/pZWt2sVsKkqhyLV/QXEeILI0US0xIwWtw8GXHMKpCDKRI/1AoMvK5fMWXGWbiqpl7j65m1nl2ifdHPpJgBtb6PIikpkpLIddPVTDGznEeMjli9oLKXYgKjKJ1l8p4QA9YWdE1BPg5cpyDR99JSOon9yZKpsBo0EMZFXBjI+leuTMeYEiFDUxUoBZd+Yg4ZtUSszhhnQCn6UVyjCsSVtQr5u40MlC69uAbqci3D+IVccs9bNruN3HO1I0fDfr9Z45oiVF+HnpAidhnJCXxIoGHxHovF2ZLSlew2G3JKfPYj1sLt/YFPHz7zw/c/sD/s+fbb7zAmY2wmJ00OmtnL83F3f8t3333FT99/5s8ff0Zb0AXUTc2hqbgcj3z68DMpW3K27HcBZzObtqKuS4ZZosWbuqZ2BU/PRy5ncTLWbcM0LxyPZ3QSNtg0jgzTyOGwpWtamm9bQFGXJQr4+Pkn+mGQSFXMfP3+HW1TE/K6J4qJJQSmeUQpxXUYCGHluRnNZiuuutNxIIYEIWON4fZm97ovqUrH3e2eefJ8+OmZWBds9xUg8cbZL7x8kmF7t9uRMcQAyxy4XK/E4Clcpq4dm11H9tCfRy59z/Fy4Y0PGFdIYyWIMJsyzy8vvDwf15Kc8OqKXbzn2vd8/fVX3N3d83I6cTpduN3e0dYdYQmc/ULdbDG24PHxxOl8YbcpKAtDjvJ31MqhsPhJ3M1ds0OrzPNJSkfO1xOlr9ju76iA8+mKzwspZpRV3N/dELzn+z//TEqJshYu6+ePzzLo3O6JKTPMAbUEUE84V9B0e4w1bNpW1jHn8OPI54fPGKPpNi3Oids4hoDOwkgqyoJk5cwecsIuI8kH0rKgjaJwhmG48PT0wKbboPWesqrZbDfsb3YcbnY8Pj4TY+LmsOPrr97wpz/+np8/fuDbX/2Kt+/esd9u6eqGl/OFNIxUpUGrxPXaMw0LXa0xqmBZJnxe8MuCs8VrBPvl8YF59Nzc7VAqMY8zy+I5XU4M40RTFGsD9Ja6rXn/7h05Z77//kfZE25Er/ib1oW/dQH5n3//A84Y7vZbisJRdxuUMex3B4zWbLqG0/nMp3/5N4xWvH9zi9KGkDSFs+y7BlYGhexmHNtW8d1Xiqos+PnzZ06XnsIJyC1kuMye3st0fZml+eTtu/css+c//fM/E9cJU44LOSwc3rzhzZu3/PTzR8ZF2sB0DiSvGDM0paOqrdhhY6TvB86XTFlWvK3bV4eT9xfCMrHdHSjLio0pyCiux8+8PE2g5d/HUSbY2/UDd1WFQSbUixeAcYiJH376wDTP1FVJieHx4RGlFe/v7lBa8/T4iCJzOT2jlOL2cJA2O6Ra9wv4VqEYp4njGEjaE/zEpR/4/fc/YpSirUuu/ZWf/qf/idJZNk0JCsLisUpTVIr+cubThx/5coKIKVGUjtMw8Z+//7j+d2EJaaPZbrdizbYWY61wi378kZQSh64lRThe5bPqNhuOl55hmnl+fuJkjmy7jqqq+a7doJTi3A8y5UahjOPduzc0TYMqapSxtFWJIvP4+RPTPIsibAzLMgqUtKhpigaiRyt4fPhMTon9yikahisApihxrpConq7Y/OpbUpLGkxV9y7zMvDwfcc5y2O3I2nF/61dY/tr6FSZMTrSlw5m1ttMHhlGiSdO8yGbVlbwcz/z+T3+mqBuqdstms+Gr2x0RTcwiuPbzwhITSSnmkLgOMze7Hf/d3zumWf7MJSZsyrwcT1yHkTgPJO8py5Jvv/uOfhi4DCN1WYoLq21pm5bPD9JOsNkdaLc7Hl7OfD5eJAoGwqYoxG1SOMvYXxmvF56fH9dabtmURy2QuV/K9Z//5X+ROGa3wVrLvEjzQo5hbUWp8CEwhxGjNHUtTBWtjURlEbaJNgaTWQV0Q1U4UvR8/vyJ4CVGt0wTz4+PFM5yPpVrMYJEr5xzzN7z9HJEgTilgud6vdK1DU3ZsliDWyfe2jlxxByPck86i3bCEZmWhWEYATmATsNATAHrSol4rIUNTemoC2nZkV8zKaZXMcJaBwqmaRKmldLoZKitI+fEdRjwPjCN0nxS7g44a9ntdhLvMlKksD3ciI13s/1rFC1G+nHCaM2ySKX7OE1UyCEy5My8eIkFlSLUf355pnCObbd5rcxGqfUwJ62QGQHOiiss0V8vfPz4kXmeaRtpD0lJDup31q6kh3Vdnld2nLX4RVxEShuadsO175mHgehE1Og2NWVRoJXGe7+6qdQa5RIhz1krHC5raWo5eJ2WWdxTxoFSnM8r/zALMDimTPKReTqTchI3W848PT2LOwkwKyvOFY7t9kBehbQUxZEUVveFNYaukabDcv0+tFKvMHxrHWXdSIHCMuFTYo7iFCN5NBIxWpb5NZ//xUl0e3e/CoORaeh5GfpXhtP12pOyonSGr9+9QWl5t+ScIYsAEdeIjkrSvlhXmevlxDKLjV1bu7LEhDUVY6KwFqPgej7RXy94LxyxvEbxqnLl1U0TMUY+fPwgzpZ5Wd9bX5xev5zr58czWikqJwf+xVrhCq5Rp9ttzTAtPD69YIymLnY4bbjdbXFGYa1aoewGvjSprWg7qyU+HEKEuLAsmmMOTEvkPHkqq+lKgecaq5h84sMxoJViUwkM/PPJs+lqtpuO47lnHBdcUXBbOOrCQUwUxtCuzUI+RhHCJJxEziKWtJXiOs7087LCzzPaliijuE5e2I9epsSfXi4AVHWNUpopyH36eDxTOEPXtGhtmWa/grdlePfl/rjdCwIhLTNRfVkHFVbL93MaPTEl5lmcK9nJ+nmZZhLC+Zl94uE8YTW0ToZn52nCqETV1LL/XF1HOXhxQgVxpikUfvEsceJoErXJ+HmhKwzOZQq9gAoEFdk1Bfu2IGbFqRc34qYpsGTCMq9CEPic8AkeLyMwse1KysLy1f2e+5uM9wspJmxZoLWhLS1GK7SV1lKBx0qE1yppBNRKMc3C20krHzQhYoxREsOcYiInaJXCKuFBfSlUMEZTbhpSygzzsjKaAjFlvE+vAlX6EhXOwoByzrLrtsScWbxHw8pslYNmZQ2tdcJvWTzzdeY4yPCxLkQcfbOt6Ue4DgvDtDCsnNi84g6er4quqfm7byqGceJ4vnK3qWhrx2lcGGZxJbC+LwqtefFBhLViJqygdGcUwzStTXsG4xTTusfYWXHUhRW+XK5uMYlEB16OV3EcjyMpJ2aTf1HC0//wP/wzxmp2O4niz4uIkF23EZC1tZwuF06nK85abg43GGNRGymxOGwbUk5MyyxA7M0O40r0+r77/b/9mXma2XRbjLYcz6e/RkxNQekaWDmzx5cjx+cXYsgUlWXxA+NlYLeteXt/wE8Dz0+eqhIxeF48n5+OuLXkqSycFByczzxOI03Zst8dOF0vTMvMdB2I0yJFLVqz2W9pUsc4TsLoHBdCyBglx+6QBlKO1GWDVoacFMuSCFmSB9//+QfGScqCXFEwjxK5f7++b1MwzCGxzCNaK3b7LZnMuMiQ83Q6UxSOFCJ+Cby8nNmlDaWpmPyZn3/6gLGG3baj70e+/9MP1FXF3eGGiDiUnTNsNtKm+/DhAaMtzsjesKlajk9n/uP/45/FWRgjRWEpS3E+NvUGbSQGvMTMTx9/xjjH119/gzGW4/nKzf6G3WbL8XjheDlj1xKKqgFbGH77m2/IOXF6fhbWZE6QNfvdhrZtuAwDMUVuD9Jq248D45jxs5fm6elnAIzO2NpRVw5jFJ8/fiKmxP5mR8qZ8/FEzomY5PkM3lNVFf/tf/OPpJSkYCVFhuHMMi+8nE6URcFdU1BY2HVbUBL1Layhqgx1tedw2IHKPD19JidFCjCMV+bLEa0s1hRcL1eeX17Q1rLZ3vHV+7f8+ruvYC0NW5aFn3/4zDxOpCVxfDlhtWa72/B/+e//T5AUfpwYtCH5yPPjI+fL5RV/U9UNb8qSsb9yHV7oto3gKXZbNt2G0/FCCAtl41A289PHT/BRCfJjRTc4a9jsGolRK8syBv7TP/8rMSbwhspuKIoabf53djz98PGZqrTUhSXlGtcIf6OuS5yzNJuWYZo5vTxRFA739XuBSCeoioJN274uIDkrcjaYSlMWjhADz6cT87xgrWyuEuB9ZA4LOXjiPLE/HNjtDrw8febhw88UdUPZdqgcIcnU4vbujpdzj7ZHjE6YHElRMSeoy2K1pwuE89LPjPPC3f09XdfxfBlZRqHaB7/IoaKusZU0Lz1+/Avn4wum3qKM43wdSSlSVA2ltth1whOz5Pw1Mo1/enlhnCbevHmLsml1w1gO206mIdczIQTGy5GyLOnevgWtuA4j3geuVxGe6qplXDyjzxQ+kaJnHK58+PCBtmnYbb7mfO3581/+wu1+y81vviNlWEIgO4tVcJoGPnz6SFnVNG0nrilrGJeF5/OFtnR0VYEuS7QtqZuasqooC0fhHJ8ennh6fmLbbWibVmoVJ8/NvqNtSsblZ879yDxfBSbYNBRFyWG3oywKlh9/ZJomcZdow/6wZ7/bMUWxzFdOk+MX4F+PNrJJulyOoOD9V9/JYTDM5BS5rC+arhaeyXWahatjC6wrsEb4Sbt9gw+Bz88n4Rish6LrtaepK4o3AlvbbjqUFgCn0Yoc/dqwIi4DHwRKfB0E9unnAaM01hb048j3P/7Izf173nU3NHXNm5s94xLpFxFcp9XRlpE/a1wCXdOw7xp+fnjgaZoISeCh137g5Xhk7i9EP/P1N9+x3R2EXTYPEkEoa8qyoiwL5sXTDyP7nbjGvv/wkXGa6ZoGa0UgMM5SrFG963BlmWeej0diynQ3NxIdxPxvWRr+i78+/vwjRVVRtx0oLYcseD1oO+dW+76wcIqiIGdea57X4efK1pC2LqMVzhlSTJxPJ1bsLsF7lnlhtAY7SDRLaYNdD4lfeB1dU7PtOs7nM9M4rjXfMgk1RlhorqgYh55pGtl2HbZ0r7yMfhwZx1EE0pWDNM8TVZUlcpYzGEPhDFpbLv3E4j3T2AtAcgWfl5XwwL4IUT5ETP7Cc1HijFkWlkkqs9FaIOGmASArA0pTtyIglHUrLqTg5bAxSnwi50xKceVOBTHk5owPEetW90uMHF+ObLcb7m5vVxep4LtTEgj2PE1YJ1B3VhfWPE8cj0fM2ooa1ihg4Zy4CYSyQd8PDMv4OnVOMTCtTLeyKrj0PcsyoxRyCDUi/mgt98yyLDK9f21JXJ2TTtaKqihQ66FBprly4J/GAWCtxV0/65QktkOmqqXx5PgswlNRViuDqaCqa27v7gnBM47yvvHLshYfjBSFQ7UNxmicK9Zp4Fp4oA1FUdJ1HfM0sow9MUibksQBo9zLX1xaSaJ3WmuapuH27o6hH+j7K8vqqKrqmqqqmCapAa/LgpvdlnM/MIzjGtFDIOLIsS0CtSvE0Xc5CecnRmxMtG1FUTgRsoIUQCgF4ziIs06wWJiixlj5TETInAkxcT6KAw8tbYjzXP3ihKeXy4TRsKvAak1a2zWrUoo1urogp8g8TRhryCljlKZtaqyWGULO4vLRKxhcJ6m1JosrJsWISoGYFT4lxjnQjx5dGnBK4i5GMS6ZYQpsasuu1ozLwqmfadqauqo4XSfmkFbBWw7l5ITVmmztOuyK4qhkPSOqLM17xnIeZyYfsUjsuTDS3jf79CpqppS59CMxZXbKYqxZHV+JyzDgjKapWxGMg4hqXxpJzbrGlqUjpsjlNJHIZFdIzEolYkbwCqs4YpPC+sCyeCbvsVZYacsSOF0HSmsoupJ5iVyGWaDhGxHZUEpcpykQyYQIOYpwHaNnmmYGq7k4aXorrabQGacjs4oYMlUpbt2X68x19JRGURdWooHeY90qZqwsu372+JCoa0dtFPutuASfnl8Yp5nCiZuxqeWdM8aMCgGzitZf4rKFkT93mr2UZLiCFeck69/6rIckTlQD6NUZ9+X4YbS4xUKMXKdlHex+SQEEsBZTCoeSLzy+FKm0Y9eJA39ehJ06z5kvvQHWGNqqoJ8WruPCEj2jn6mdpi01XWk5tAUpLvQDzD4wTdJqaLVmXtsMu6bhUNf88HHmZZxItcVgpel0mElJioxuNg1FKULXsESaxaONois0VhvmxTPOgaws2lgZSCZh26l1wBtSpMQi6WgZhMz9uDp+PZAIXpF+QcLT7//wA01T0W1+jVv3z0Zr2qoSFmPpmOaFcZhIpcTli6LE2pqqcGw2jSQO/CzCcVViXYGrHOM48/HjA9ZY6qohq8wwDqQgZVRVCaopKUooSsPx5cTDw7O4SHZ7gTpPvayt25ZPTmL8Zm1fn32gn2Y2XabWisIJU+1hnnh6eaZ+19LWLddhJMVZeJ3LAg1k56gbaXB9/PSZse+5nEeWJZCCDLCaTmGtpiwarHGkpAg+EYn4xfP08CRu9rahRuGXiC4Nh8MWAetrQgyE4KVVua1IMXIZhJd0eTnhCkdRlgQf6fuRuqqw2pKiuJLapubuZo+fZ378yw/c39/x9fu3zH5hmWasbajqhuv5wvl4Fh5mXYMyFK6iv468PBxp25JNV2Gdw1YFxjiqssUVCufghw+feX5+4t39W24ON6tJYORmv6Nra67XkX58kUKl7F7LV27v9lSF5ffzxDIvkIS12jY1213Dkmd8zHTbFmedME3V6nKNET/LgKLbSPOaK4R9d3qRoV+z3ZNT5vJ0JMRIWhEDKQas0Xzz9fu1SXhkmiaWoWecJq7DQMoJRcAYaKqalCMouX8KZyjLirbbcbmc+PDxR8gakmGaBsI04FyNcTXzuPDw+Ynd4Za7N3fc3NzyzTdfMS+BefY8DM8cn058eWEO14EnMnVTcbj5lsePTxyfz8zGkiJcLhfOp6PcV7ag2zY0leV8fuFyOdFsKmxRUNUVdVNzOg2EALY0ZGP4/OnENC4oJRHpupLPrq5LyrIgRTFg/PTTR4IP3O7vKIsCaxzqf2/h6b/53bevWUSlNH2/TjdDpKoq2qbEWcP97S0A4zSRUExLYrfd8O1mK79/FIDr5fiM0gZTVEJQ7zrmYgFlMNbgY8Roy7YpmCbFdZ2Q1lXB3La0ux3aFhgr9YFGa/pp5ocfvufp4RP95YWmbXB1xeV8oe97js9OCPlVQeks52vPNM3EnDldrlyHUerBvQdlpJFvWWiLRpTh3Z7Caq6L8Azubw+yiXECU7S2IKTEjz9/gJz5x9/8itvdlv/2H/9epm7W4Zzjze1BAGbXHqU0t3d7gg988DNkeH4W51OIEaUVX93fCCTu4SNKG97f3VAUjvOcGSOUhTQEZRS7/Z7//v+8pywcm7amH2eOpys+9gL7Nobf/ubXK6A7r1NTzbWHuEzEZeIy92xvbml3O6ZpxvsFl+TwVjrLpq6Yl5F+7Lnd79gfthhr8UlR1A3bXZaJmVLcHnZ0TcM49pzPJ06nI33f/zsYsyYmxedPH1m857/7x3+gabbs9we0tlgNEIXLkxP9+YgvS25ubgVwGuQz01YOffdWoL8PK4G/Pz4yW4OvG5YQ+Pj0TEpSQx2WBUMihcDx5QWUoq6EVeZjwBpHWUj9+nXoUdPMZZBmrM+fP/P2/o6/+82vxVGRE1orlpipqpJKi8Pg8XxhXiLTHGg3GwF6E9Fx5nI5MUwjKgVIkeP5yrUfCVka6IzK7DcNvioIMfH5+ciPnx7Y1iVvDx3bg9gxL/3EdZi5TJ45SeuQMYbb3Q7fBupaoj7Rz8ILyQkitG1HWVaM60TzN99+izaGP37/M/Pi/7fsL/6Lvu7fvpfIapINnmgs0iKjtaYsa7TxFM5ATtK06QOX64WqqqnevUdpi7Hur608SSwD1hnK9b9/abGTpjcRLUKQA0vTdRz2O/phIF/OAik/nUVYmmc5ICXI2mKLElAEvzBNI2PfowC/iinWGJYg8bdlWaQFKMmGTinxEfhlwQOuk8m/czLRD16wz18m8kX17+JhKfHy/ET2C5vtBucch51Mu/rCyUuocKsQk9HGsNkKu6m/nEiruJRyZlnvn/22I+csG30EpGusZRx6idGmRF6jWVYrDgdp5jDWsfiRy/W6vvQqyrKkLtcqbcBYcQZaa9cYXiIkiRUWhROn1iy2dLM2QFljSKogrU6gpmkE2h4XCq1oSke321JVDVVdvf7ZKDmsJCIprlDxFMlJM82y0dl2Lc7ZV5dU123QRjP2PcF7LqcXMrDbbUUQL9fmLivgzDdv7okxMa7w+GkYiCHwXD7ifeDl5UXWLiugW4l3KPr+spZQiBspIZu2oqrICKPKLxPTPDPPM9f+Sts0MgyoG5rtDnJiHHpxaRjDPM98+Gl1xqJompaiKF8P7yFGqdxNs1SZT+JiMkavjTdGWji1QufI8/MT8yLw6P3hVhwmKXJ8epSJ/yIOE7eCrlHyPq3qWloE1wOcs1bErSy8lM12h9KauqrJZI6nvx1w+V/LddjUaK2onbRvLvNE8p7zEChLR7G+sw77zWuBy5Izk09Yo9hUIjS0tcQZjdYsIeKDNHAVtiAYgyYxexGwtFLcNBrnLFiHWSfZwAqAjjxeFoYpsvhIP0wcL1fmZUbntE6PE6c5EsJaSZ8SlQsUVtPPkSlkSiPRrX7qyTkTQqYwBrfu66Q+PUvxKAJOzzmxbWtUhtkv+CXTFg6lNKdrz7JIk2PhLO9vZd85+YhS0JZO7pNevl7b1pBhDhHvE1fvZdCgjYgmTUFKmf58AqW42W6wRnPqZ5YggppSsAT58w9tReE0ZWnxPtJPImSLECzRrSlEhkV4WvtNR+EsUwgoJSUDc0gsMTCFzJIUOWQCcqDZVva1cdWVxcqMyiQQt2RONIVBlUZEv5i5LiMhI5HMDH6KKL1C140mp4hTsGlrnDGcRk9OAW3sCv1eo+fLTNKKVCii0SwZYsy82TZopThsK2KC00sv7mqnWIIwJkMUXkpKX1oKM9MihSu1m2UIUpbkFFlCwHkvsdsMQ7AsPjDOEssd58C+hX1bsu8K9puKp8vIh+crboX+jj7y08tAPwWuQYaGtVNSbGEdiw8cLwPjOFOYE9denBP94jGjJmYpxcm6BKX5eL4yzxc2Tc3dtubNYUNTlZz7gafrRD8LB7atCxEitUTJyxXs/u52u8YKV06UFj4jWd57XbuV9++5FxfBL+T6h3/89doa20LWDIMXJ/XlTFk63r57iyukzElrQ5g8c79wunxkv9/x5vY/UBrLJkXmaeF66SU2GxNVVfHN2tA2jqM8Z9piS0thS8Zp5On4M7d3B+72b8k544NHa8c0eRafCclyvkz8/PGBvp8xxkkcPwjj6HLuuXYddVNze9jTtQ3zdWbpZ16ezkwDHE/PjNPwasLIi8bkgMserTRtXVIX0vwao2eza1/bYK3WsgaR+fHHH0g58U//zT9xuL1DYZimiWt/xTjL/Zt7rDWcTi8YbXj79i0xRH5Isv+b+kgiYWzJZlNw2B0E+twP5KzY326wpeaHn3/i2veUlUTA0IZuu+Pv/unv2XRb2u2BdLkQnq8sKjK7iaqo+NVvfkVOmRTW1lAMvYIQJmKWtrm2cDhbMfcXxusFtW0p6pa267iLkWka+fGHH3lzd2C/3xLCxOk8k4hUlaNpBSS+3dbiaDqdeVkEUq60FpdYlJ9j8InhInEw/R6KSho8F2fXkiqFLWoA/IIMnPWIMYb97T1a6VfO3c1uyzRP/PFPfyIDdnMHSvPp02fmaeanHz+tqYWCHDQ5zixz5vhylXSEyZDEdPLlnDFNnk8fn1/b7Pr+wvPjC4fDhq+/+46qaqRJrrL000DdNJRFZrie+cuffyB42WO5ouCr9+8Yh4Fx7Al+4XzyXE+gVJb79NrTbbar2JmpW0kO5Tzz/V8eGEdhQ93/6pZ2t8FVJY8Pz3z+9MTL01HYvpsK6yz7/Ya8SZSlxZg1yq21wPa1YfALOUe6dofWmt/+9lcopfjPv/890zz9TevC3yw8fX1/I24e1taOq0xP/bwQYyDniDWabdcRYpA2m5TpJzn4FmUlD36M0pQzDWhbULhynd7JJnwJiYRMUawViF+M8bU5qHBWuDlVI61fWiJgEmMJUkl/PbNMA1Ul0Mx5mbiej0iBvOZ2v2Xb1oyjqJhZG8bFi5UvBNzKj/AxYUKkygmDtL4YnRmOV3KKbLqGcgWgkqXe1oQgAOwYMb/7NW1T8/X7t+uLUzYbu90WMgy98I22m47gA4+2wHvP0At7Qykoy4L9Zscwjvz08wfKqubtm7corZlCxkeh81sjEMOmbtjvb8RGHgKjjyxB6kHjEtjv99zd3THPC8N1kLiIM/hlYtAQF88yj3Rxj7EWlABuc5a6dWs0VWEZziPnvuduv6Vra5YgmWRrC+omU1mNM5quqanLgsv1wqUfGMdBXAvGoLVk9WOC8+nENE2vPJimafGrCJhSkCrzDPMkSrNZG6OIAmPUrsJaw6Yt8cvM6XyWVoXxgteWlBWzD5wuPeRErdW/+3Ol6elLLCXEtALhLVZbPF6cenKk53g68vjwmZvdhrubG6kajZ7JB+6HGZUDOkuDz3WYWHxgngNlXUsTFQmVpN7ej/PKLvCM48IyB5wbUEBRWJqqwJcVISk+PDzy9PTE9jffsG07uqbGVQ2X68C8eCYfhV2BRiupeM45i7igNXFW5JjIWeDHxTo9KgrZ5N/fHMjAP/f/yuXa/2/YXvyXfW12+1d2d1zjZMAqFgpsOSNughgC8zjIxPN8fI1VsdaTf7HJ5yRihDaGcq29zbC6WSLWWgpXCB8pRolEdR0pRsZBSyPiPL+unyEKfwgtzYgpyfMbFv/aKCdGGeEZxZRWtpwAwKVaXtqtFFn4JutzyypEZFjjgpm6qrHOYqtWYsLGEGPg8fFBxCktgkjT6NV5ImPuwgr3JUW1DiIkJrZMgziNkrx4lyB/56YS3tu0rAwnJ8KVXxZ8jHJYSooUI1op2kbeFUrrNeoyCetlFYEEnCzNR9qAyas2Qn79Hq1egdk+S/Mc5vX3aK1gtbq7oqQoS2kg9BGjRVhv6pq6bXFaPk+JbLPGleTgLQ1ieT0si4NMrS4pZ6Xevqok9ujnSdxVk3Dr2kaex9JVK7PJorWiaiqZ0p0uhPXglVKi73u89/S9DCrarpNhi7MroHltHzMC9JUUkxJIaQyMo7gzQ5BWmWEcqcqSqqoo65qqqpnLUVrzjHCuQvCcji8UZUVZ1biypGk7eYiAYRgI0RNTxHsRRWNKa4JbopYGXu/Hvu+59APtV+9p224VbyP99cKyLPgkh+faybvMuGptCG1wzq6iLv9fDAGlFEVVY61jt+kkavX0wry65H4pV1M5tJIDdYqRcZzwIdJPgWptAcsZuqaW9SAshJgZF7H+S8W4eh2QGcRxoZHhkHNSY5+MZQlf3IKGprCo1TKljcVas8YhDeMcGOaFJWRiTCzeS9tqWN2Mawx2XALDFBAPe8agsGgWH6VVzVncq4PNUxYV1tjXBjYBDqS/8jYlnEddFBilmc4XfExsW3FuvsQve8wJjeN+v0UbzbkX+HzpxFk5zQsAu04OJuMySmxrlilv5RJaWYlh+8D5POKso+laMjAuwvPUeo1mrMJ/U1qclWGeD5HFe4w28myhcDozr/vgL2IgOeNjxmiJWcUsnMElijObmEkkCgWFVUwJedbWdxfr+2g1A0l7sBE4Ngmmxb9GETPias0544wiWrXyQhVlIY4ObQyo+MrL01rLQCXGFckUUGiWJJuybS1uxrZyq2gWyVnEOK3X91hIjIuHFHEEAUjH/OqOZBWVQ0T4XFHKFUI2LMmyxMgcIvMSGWZPWzqMzpSlo6klKv+gpdXXWdm7T6s4OEctopOVRlDnLNPiGeeFZZImuTnKer6ExLBEEuIEVa4ka8P54cTLaWDT1nR1wbapqKuKz6crx16etwxstBJ4uBaR1qzFJF1doBUCzU6JmLUMOL1Hodi0wip9eLm+ogB+Cdfbd3eAQlMQQ1rbzDwh9tSx4j4rtLG0rewjgo9M08zT49P6bMlZrCwqYpC4vbglFc4VHPZ7KQtZGz6d1pRFSdd2+DDRDyf2uaOqK+Z5XotdJE0TI+RsGGfP6XRhWQJaC07Ex0A/DJyOR2IQB5JAxQvCEohLoO8nlqC59j3LMmCsgMtU9BidyOtgs6ub1ZigUAaarqCsKiyVtJFvKmL0vJxfpLCmKtnt9zgt5TQfPn5AacVmu0UrxeVyEvFktyXGyMNDjV883ktbpFaGonTcHg6Mw8T5PKK0ommlLOL5+MKySJugccL6rOqat+/fUpa1nBfGmRgg+oyfA2VVcnt3wzItTP0IaFCGxc8oLby1xSfqBEY7ckzrvqcmK2k3bpuax4cjp+OFu31H7Sz9MkmqKWdxbZXSjlpXBVVZcHp84nq64IOga2IK655X2IDzGF6H5MaKg+xLy69Sah0cKobFk0ho5ykKqJsNzhpSEC7iZtcyDAP5j1EMGdaB0lzOZ4Zh4vhyQinDfl+Rs4Yc18TRvK6R684oyLs1xMg0LDw9HmUvVDiGYeLh8YGmK9nd3NI0Ek/vh4HtdoNzBmcyyzzy9PRE9IkYEvdv3rDf7VAkgpfkgp8DcfFEHzj3V/pxlMIhq1EailJ0iRgiT09PvDyd+e6rr7i/vcdUDmU0nz490fcjl8tF3vmNW0saKrSCthFHdVxtpqWTJrzMtA4Kaoqi4HYtChj+48j5fPmb1oW/WXg6Xy64ouD+3fu1Mlam7STQK20+xshhv2dcFo7jgrGW928PVFXF56enlf1hMNZxd3OgcCXtZsviA5cVknu+XFEIe8DRoduOtq7XfG3JtZe/3MvLC5vtlt2+BaVQWlHYgtJquqbFb6Sm/PnpCbRle/eWqnAU1lI5S2E1ddPKYW+tU49hIYZI126lHU9BmEeOjwtGKzZNSdV1fHw4MvcjqatRBtkErUyNDPzTP/y9bAyytEU5o9HKEdMqTilNTIG+P8sEuyzwPvD4JGyYf/z73+AXz7/96S+SqY/ioPjVd9/hQ+Djpw8URcHh5maFHldoV2GsOCWmcaDvB56enkSMKgwKjVKOjGYaRqbFMyyeqlQ4Laq3QlOUNVXV4BM8PDxjVKJQmY8ffub5eKYoS4qiYBxHol8YxoHz5cLL6cx1GGnalqqsuLs9sGkalsVLy4drKBpHUfTCSUqZJWQ+fn7gdD6TtaZoGj49PnEdBoqqYWccH3/+Ab/M7Labtb1oATLLcCVMI8fTEa01X331NUklHlbw+t1+SwiR0/mKdY5393cM08znlyOKzK5rZRK6LsDbjfz52kjm/PzhA1et6M9HCqfpKqmAL5oth7biri2oqoo//flPMhksHH4JHLabFU4dQCv6YRQQJlkgiv1IzBpXt6gY0TEyZ0dC8e7tnraqXuMq52vPeRhwZYUxjtvdjqYo2B/uqDYbUozM/YWh75m9pytLnK3YNMJ66S8n5mmif3wkJeiqQtqp1vhQGnp88Hx8eiElqP/0w8qtkRafX8o1z7McCuoGFCtIXASSBMzzQsoyQVuWhWGcUMby9v1XIh5FzzQEpv762nTI+jP64nRKSWJYOUVy8ChrKUoBdRfWYJ1lGCdm70lZROz9rmCaZ8ZJqns1GadkPR2WhXGeMVo4FHatB6/KYrU6K3FcGYnehZXbVBiJSmQUKSbG2bPEvMZlC4ZxFFFcK4mkrOKjMSIwbdoW75dVGJbih5wzMWdUzrSdiA8+XkgZXo4v5JS5DiKi77YrNBQBbA/jiLGWu7s7lmXm5Ums8Wa7IymkslzL92uMFcE5BB4+f0IpxX63k+d0mohONvNfSgfUCqv9UpntioqiUoyLbAoUUmZxOZ+4Xq9r05LCWCsumiSxwHmeuV6v4kitCqwtsFozjqPEab0XztGyCNxzllaZcqwJ8a+C16UfmBa/CpJK3j0KdltxcS0rSLkoa7QRp5TWmq6Tv9fpdEIpxWG3E8HpcsZYy2F/wziNfP70Ea2grhvhic0DhXXsd1tSEl7W7L1w9KaZsCyUZUHXdqhckbOIM2/evsVoQ9YSc5jmB6mTXhlWKUpEJK/vRVJkngJjGlbQvmaZJ3FQIlk4mbY1siFMa0viPKGKEm0s+/2Orm0onRVwelFglRK2WM7C6HAOVjfZFxfY5Xohr5NGbYzch0pTNPJ3eXp6JqXI2H/hIFkK+8uK2l0mjzOaTVOSDKA04vcSd5hd2YvOmhWsKs/czW6PUeCUVLQv3mO1xliF1pmqFFalXzzDNHM89zhruN3vYRV4rJE1JsfIpZ+ExZUy1ljaWtGgyFmcgoXK6NJRWcN1nDiez9KEUxr6yTMvnuxKnDG82Tco6zhfrkzTJLwXbSkNOJtRRvaK4mxTtE2JVpqX85VhmmWyXhje3mxQQFNXEuNDE2KiLjRWK6aYyUFEfqUUtpOp7qGr131sWl0BPdYavv1Kijau12Fddxa0Ury7v2HxkceX4yq4l6gsETDtDHUh9ys5C2T4ukb0C3m3LymL4BekhbAoa9B6dWKJSzAnUESWZWbxC1kZSmuYlsB1CNTWUFrN5AM+RKqUMDkz+sDipXWzcI59W1AXhmlaVkE4S9X3CgCOYRF+R8zENXpptOblPMh7DRHgQxAYdmk1ymm6Rt4Fw+KJc6CfBSL+7f0WZw1TUISouNsKb5MkwtK+KZhmz8PTiNGK3VZg90kn6tJxc9gCmWVZmBZhjvmY+XQcMM7hqpq6ULSmWt/bLdYZpqgY+oWn88gSIvu2WqO6GqXy6pCUaJ1W4pTzIRGzDBw3lVsjObBvakrnVpi54ksBkc0ekxZ++6Yj3nXYuiW6gikmmAaiD5AybWGwVqLtSmtx/sbEaVxIOdO6jFWKbGQooRHB9vPzmZgyc4yyR2kaqir//y4B/9Vew7XHOcdX7w6ktA62lWJKMyrDMEhj7N2bG8Zh4tPHzxhj+Pqbt7RNw+PTZ1KK9KMwoG7f3IubtxQBaOwnwjiR5hkfI+ew0LUbXFHQ1BW//u5bXFnw+PmJ4+nE0+Mz3aZjd9jSxYYUFV1j6WqHijJ8mqfAeJmpXMnd3Q1tU1OXlTg+dWaz3+HKEmMLlDZMs8LHzG5/YLPZMozSwBqVQWlFfagoCgtZEX2kLkoZrtedlD5VBTEGvv7mrRSrjFdOOUppQY4UVbkOFWXf6hfPnGb+8Mc/EkLi4fGZonD85tdfsSwz//ZvP5GB4XyhKAq++9XXLPPM4+cntFG0XUmOGdBYbWnLhpACaZTSo6eHJ5RS7A4NoJhThnEkPX1mmTzTdcJYi3WOcR7xKQAOjaW/DMwrG63edXx8eODlX/8gTkNnCD5QlQXaOpKynC8jp/NZEjpdy9s3b9huO3IEP8zE1YgyjVKWNI7ilnx4eGAYrozTQEry79e+JOSAcorjy4kM/OZXvxV0xpMUttR1R87w+z/8AaMVv/nVdxijeX4+kVLkd3/3d7LXGz1GK775+j3X68BPP35Gac1+3xGCI6U7rDPs9juscVS24XK98P0PPxJPA8F/oigsh0MjyIS24e52w1fvbjHG8PJ45GKuHO2FYRg57LckoQESUmIYJ5wVg80SPI8vT4TFg7bkLAM/ZRxOV/zqzTuatmKJnpACfX9lnmbKUtIO3/5Gc/ump+wKpjjCNK/phwWVE2/f3GCdpWk6jDX0/cAyex4ffiLGyP5woCwKQhnRxlA1DdpH/vyX/ywD+vERa4xEVjft37Qu/M3C0zTNZKUpK2lhsPYkTRN2WeGrMsWo61rqfYeAM3Zl5iiufY8xVtqYlKZrGsqiZNu1XPqBl5OXLO88iwtFK1JZAVA4R1uXMkWZPfO8ME4jbdtSWLPi/xDOhXUCUK5EpBrHibLdUFcNm7qgLR1kEYUqW6CMkZhLjKtSKhuypmmYxhEfPHHpgcy+ey/MkCTKe14bppzVWOsoVo6OvReYYhrPBL9gi3JlJNhXUSHnJE09MXK9igAwjANa1ew3ndQRj7IpN0VB17W8e/uWa9/z488/U1U1NweJ7Cnj0HqtV/+ykRwGnp6eqeqKm8NONqtKUviijgd8DLgkeVoRpvSasZbJ1eXa05WGsjBcLhd+/PCB/f7Adrtl8X5ltnimWeJnx3Whs01L17Tsdlseno7MwYN2mMIId8laZi/uiC8bz6KWlprzRZrXuu2OyhWElFnWOKezYl+POROWiZSRza0xvE/SxNf3PVop3u63xBQ5D5O0yrQN6ksbi9JUawyF9X7ZbrcoJRGeYRiYxnXjOQ7supqbdi/TtbYhFoZNoRgmz+PTk4DMm4ZCG9q6luroGIhB7mkRKSQCKCIH2KIALy1P3hhUVmw2W+4PW5Z5JvjA6XJlmmY5EBvHpmmoioKq6TBlTRp7+RqLND/t2pqmkvtQG00KnmWeOJ2vEl3d78hlgXYFqEwO0mxwHSZ8TDw8vUiUS2ts4f7WpeG/+CuECFbWB4mwCbA4pkyOCh9WkcJKzXxMMn3ZbHcYpckrYHmeJ6q6YbPdvToFl2WRyKxea+vTGsUir+wcsBqUVizerzZ6iYJtuhZrpeb+i+tAi2GNnOXZchoKI9MXFOvXdVgbsClTWImR6SggbqMSmoReJ7hfXEhVI/ZuvUbOvsSTCycbCGMUUSuqwmFWJ4TW4lACKFwBZIqyXKMCPTFExmFcyxS8AK7Xxq1p8YTgWWaBcrddi+6VTHzdFyKWWmPrIt5YrXFWQN799UpVVex2OxbvGQapbg8mvgKvlVLijAoRH5bXKmb5usIyKZ1lmUfOpyO2KHDW4YpCLPErqNavTqDGFpjVgauUWh2TE0tYXhunvtiovxRIqBV6opC2Pb8OCbRWDIPEeW5u7qQat24IMco0DSTqtL4PyJlpGqUF707WJu9n2dTUNSmtLV8K+ZmkhF9EROvaVu4rNQpDZVmIWqZyRsvh12iJ+nz53H0ITLMn+IVlntbp7OpLyVka+1Arz0VAuPMiThhn7dpeJyIRSHvdZrNlXvlTfhqkBWp1jDV1DVW5uvaSOO+McH20CWIzr2qWaRKY6gr1P1/O+GWh7aTyPqPRBmlF1JFhHMURmITJWNUN+hfUyAkw+whZuHIaWcO+UHSUkrVFIc+zAubFUypNU5ciT/kZBYSQwIjTRStF4SwhJuZFCjOu48ymbWiaeo1SenGEakWImTnE9SvLAM0qjVph84WRGJlRhsIa+mFgmmbaWlNax7A65VnZQG0jTa/zNDJN4rhBS+zO6kxWvO5LtMqUzr2K48ssPByjxRFvvzh/UGyzJsSM9Edm/OoO8kGeBQF+K+rSEYJAb7/w24wu2e82Eg2excXo/UxZWLZdy3Wc6D89ybuhkYbUlAS17aw4UuMKkT73M1VhqTaOkMBHIInLLKNkDcgCu9YmkzGrlJhWfpTHOjDWkJI0BOucUdlIc+DqKFMkUhRBpXSWsrB0dUVbWfzimda2VrlXzBrFTqgcyMmQE2gl74V+Wkgpg1YYo/CLrI/GioDvypKU4TotTEvkOnoKa9ZDqKWfEikrukocwNdxQmVF5Yw0XQZpWy2sCDxFChTrhD0naR5NOaPXFsSLX6iyxLOdEVH5C1R/STBGWBb/CkFuSmnJzl8eDGSArY1eo56KmDIxi7u2soYpJ2JONJW0PV/nwBjWqFvOmOxxObLtGpwrOOWSORt8XNApvgpspdUUTgQ8KaGQn+U4S7U5S5SGvLJFaU2BDKyu44yPSerTncSvtf7ltHLO04xGUVfCzXRWk6LwB1VWLIu817u1HKgfeuq6Yr/f4Kyj769SwDJc2HQb7u87qrKgbSuu557+eJUGyZXLO0widIUgDY6bTc287tH660DfjzRdTd04yAUql1RFpnKZUEqs1k89YY6SgCgdTVVSFQXGKiKJsqqxTtiRKQuEXxkZCG3anTQEx5mspHVSij8KtBJxubCWuihou0p4VVa+391uyzTLsGtC9kM5Z2lTVhpIshcNkigapydiTPTDgNINm03F0EfG/iLlHktkt9/xq998R38d+PDDJ4wV44NRYjQwSni2BBkW+nnm+flRGI+3N4SYWRbZ36V+FuGpn3GFpcgFS5DoJIBCECHjNFG1FXVXcb32/Pj9T2y2G7quo3CCp0BJfH6ePf11oLzZU5Ul227Dfrvn/HKSSPnKw41hjd76RFjZvDEsUjagFNfLFb8spBxRBsZ5kvutFk5xcTkRQsbZUgabDw9orfjVt9/Ima8f0UZzf3dPCIGffvywlqxsUEp0BaUVVeWIEdqmwzpD2zUUrqIrd9KwGSGGQPAXttuW+/stVVXSbFpybrm92XG59Dw+PqOTps8T2sogeomBOQgUPYSANXJW/jIY0UretRlkvTQFRlfc3N5x/+aGl/OLcHv9gveBomxwruRwG2k3NbYwLNGz1ouSUkTlTNc11E2N0eJoGpiJceH55cwyz5IuW8V8aw11uyWryOly4nq9sISesii43d1RuvJvWhf+duFpHpmXmf/3//ufyUCYp7XSUZqiTsMi+eyU0dbwbi8TpfPxiapquH/7lZD2nz5jzbopKqUJTq/Q1sIVvL27k+hD8ATg4XiitJrGaYqqo2p3HA6RygLaiOo5i212U5ds6pJxlBjAZrvh5vaOIEcxSAtjP3PsR4bJ8/Z2z7Zr1kmT5rDfs9tu2B3uKMuKl5cjp+NRNtvOUlU12+2Gr7/+mt1hZL9pcNYwx8w0efrLIzEGilIga29ubrDGcBlG4TUJ5ZPT8cQ4TXx+OYPS3L0vqduWf/yHAlLk+x9/IoTIZrfFWsfN7a2otkrmkHIYjlwuZ2KINKXFaBFd7Br9qeqS3/76W+Gu5EzTtOwOB+Zx4nqRKYtFk0JgGEacs7x984aiLCjKkseXF4bnZ+ZF6m5/9d03/N3vfsOnxxeejieck99nXEVWjtubG272W9rNjqqu6Ycr43Dl48ML12HksGmoSsfN7Z7dYccwSTOTSRKAdKUTiPi158JAWm2S264jVCW9BxUiuqjROXE8CVRWLOaZx4fPlEUhEZn1MJ+SNMWM48T/61/+Fe8DwzBATvw4XMXq3jaoXHEeFnmoCkPd1Hz3q19hjaVrGowGZ8DaAmUsl9OJ77//SQShopZD2XVkv+loupZpHPDXEaegdA6fwafM5XrleDpzu99ws2t5PkWGOVAXBft2BSNnqWhOWpqgwNBtWqqy5Hw1zPPCPI4s08yurajblpAi8yxK9eU68Hy6rIynLbc3e6qnEz5GvvnmW6qyWg/EiV0nldHR1IzzIgd58cq8Hih/CZe1ssy9HE9r3KtAa40r5IA6jNMakxI3x+3NzXr4kIbDphExPc7LK2tG2CiW6L3ErFYOjlTSi/hyOb0AclAzrsBl2YQcDgdCTByv4kyZpxG33eLainEamZcFreXek+iSWitpE09PD/hPP3Nzc89+s5HGrwzaiNDk5wkfI8MwsoRA13Wv1c9FUbDddPiyoK5EYBmnCaZJJnSruJKVHIy0NgJ5DoHr5bIKLOIUe3x8IpM57HfiRq2EU3A8n4kh0Pci3CoyyRrSMpHCAtoQU+J6PkrTYFWSYqA/vwjMe3X83d3dYZ2lKCtcVVE1nYgk0/gqPNmiwDlHURR0evMauR5yxntpsxrHgW6z5ebmlssKwC6clQn9OMoLXmtuD4fVPxLxi0TjZh/wGep2gzGWeRqIwePWCGXpZMrjinIVpASe/gVIvtlsATi+PMl9qDWlEYdWSol5GlA5c3EWow3lKsqnJABl7wPTtHD+0x9JKdF0W4ljfJbq3rqqCDHz+HwSUX39/N6+e/cKBzbG4JeFJSViDOLuGnpyFhZcTomcAm3TsN8fGOeFfpxfnU05Z8ZJ3s8hRpq6otu0axxHJvzWGHJKnI/PaGP/evBSmqqsqOpGIPqzx6zQ6BxLlDG4siJrw9BfGa7idtZac3j3jqIohFe0LNze3uOcW0HHCaMzMSf2XUMIMjwwxlBWzS/q4AbQlQYFfH46yrMziWB52G/QSvHzp4eVxSPCwmYjLAY/C6tJkYgJ5iAjulOObLqWr9+/ZRhnHp9PFFbTVhatM5dxXuPjEZDooxywBUDtbLEe5EUgWWJm11W0dcFlmLgOE85o3t1sVhaIoqsszmR6n7i+THxbdpT1Kkj+u8utjLDrpcf7IKUFRcE6GuP9mztuD4HSihA/LJFMxF9kSJdfeRRyUDhP4vhxRYnWAjcOMfL9xxdiymw2DVrBrpM4zKeHR76AurUWjIHWBo9G25K3d3cyTDCKnCOlzRgl7m2AmBXaOXY7R2mgLbQIUihCEIaWxNYEW/BFyC0KR2k1lTOcjCFmxRRkX3Foa76923FaWY7GGRplWLzn5RzYdC2HXYufJba/hAITLE/XieOl5+7mwE1dr/iLBKkkrI5ccelYlMo8vZyYFo8t1vejkVa7kEtS1Iz9Ii1zQd41TSGxlmFa8F64LwbRfPLqBh5C4E8fJUpzuxVnUz/MUjqQM9OU+fnhKMKSAU1mV0u7nisKAbwHT7SGaB2Tl6jpEiLjWmCRcmZXOLqmZloCw+RXDlCkKhxNWXAeJs6j52bj2G9q+lGa7sqqorNyz/ReDrGV1UyztLA2XU1bFpyGmeM0sIRBAOeHBlMK2F67KE2N67vYWsPttpFa9Ura7jYFGA2jFzZjVRQA2LpbXXdhdZeJY/mXci3TQlgC//zP/0pKifPlgjaam5s92ihO1xGjLW3Zsqm2/OPv/k4GZuOCKhXNrgM0yV/wc2DsezSR7cZgTEJbS9k0HArLOE+Y3uFsIbHfqAlRhMCqqnnjCu5uDgBMvWcYTvTXgTf3txR3t/igmOdE3dQ0dU38d07vkOHzzx+5DD23t1s2mxpnKpxx3N/dcgg76qok5UBcIEwKr2a0WXDl13SbLd9+9x2Hm4HddkfhHJfLlZAS1/NJECuXGa0Nh1+9pSgcnz/9xDLPLIvcl49PCb94Pvz0QCJz9/6Oqq7Ybju0Unz/w4947+k2GxSaut5IxHDsWaYRlT3RZ56eZJh9e3OHUVradEnE7CkKx1fv73C2pKwaXFFS1w2X65Hn54+kKEJYUoo5esqqYL/fUtqSqqh5eTny/PzCcBVcya+++45/+qf/wMOHR54fnkHnNXp/Ah2pKsPXX7+hrjuKouRyOdNfT7w8Szvqdrfh9vaOqqlYvJzfY4hoE8gq4VyFUprLeebKQlQyzH93/w6tND//8GcyUFUtWhn6y7MU3BgR28+XK+UixRLGKMFeBMEEHU9X/m//9/8nwQdi8uSY+cuf/0JRFuwOOwBO54WyAKcLisryu9/9BqUVrpBoelkVxJQ4nq5cz2cePz1gtMO6huAn5mnmcLvl3dsbrv2IP0dsWeAKS/KJ63CWxsRl5pv373j77g2fPnku5wv7g2W7rVlCz8fP4p6vXEFbNWg0RakxNjJN8v6Zp8AyJ+7f3FA1FWl+ZIgjz89neLlSrm3Ob9/f44pbylIzLwvffPsNVV2xjNIs39QlsUz8/e9+wzCM+DhjlGa73WD/xmKXv1l4klxl4vRyJmeonFRg7w97tDbMPsgmds2Ed6VUh19PA9Y46qqGlJj6K7ZwuLIggnCalCJGcQjUZY0PnmmRKdEwzSSr0EmjiwplLVVVUagN4zzTTzPjOHMZJkwOFCrivdS2dmXJZrNnXDzzEoghCSi6Hzn2E7uuYdNUkDUKRV3VGK1omgbjSpaVq0Er0QhtDa4o2Ww3mKKgKhxaKcZhZA6R0+WCXxa6LlBV1Ss/J40zMQv0NufMOE7040A/zVjrMNZRVRV1VzNPEz/98D0xZ8q6oiyrV0jtFxFJr4HSeZ5RK7cgI9HHbOVlWDpLt2lZFs+lHynLkt1mwyklTscIKKzUaxC85Iq7usatwtO579eJXISUuL+746t3b5l95Ol4kimXlQaPrIT1UhiwdYOxBdNwxc8Tp/OZaz/SFlCZiqbegC1whWS9/TySY5R4hNYMw0SIiXYWmoMcKDTXWTZsbSWNXeNJDrjaFigllt5YyqJrjSWh5MWxRmROL2dh88RAToFxmWVTUhXCX/GREkVdiKNkt99TuoL9ZktMAb/McqBSYnV/PJ6o65ZDUUPKpBzIQFEU+GVC5fRadx2D8HjkIDyya0sKswHAx8zWGLqqxBpDyGqd1YrrJmeoy5KqlFhWXPkUMSYOnWRsSyeZ6v4qkTsBFhu+ujuwaWtmLy15t3f3VFVF+hSJIbDd7tBKcT9M9GvMNcaA1StQ6xdyaSPtc+PautUYC1pTGGmAmr2IblZLg2LTFK9TBqU1WkvMjdVt8OWT0asQ/IWd4awjrvyonCLLNL3GgB0abUQsqcqC6zgxTl5EAb+IeGQdGRGOtFYY8wWkLVXTKmeGoed6vbDfHajKAh8iIa2H+ZzxfGGuSPa9a4VD8qVVryyKlesiMP5pFRXmaXxd49U6tVVqZTF5cc7lDG5yxBjph0Eg0monjDlXEmPkcu5fBSIQfswXeHiKAZQm5cQyTxRFSds2LHPETyPJCl+kKMRxqoxEX0EAh+OQmYbrKswIQNpovbaVyETxi2CitCYukWWe2Ww2IiaqZ2FPWY21Gh88i/dsu466rtbWukAMQaZOMRFSxjhp88gpEpQ0g6WcVwaNCJspZ3FExYi1K+B8dYcdjy+kGNlvNyIIJDl4puDXOM8sDbGlWyOAAmYWV9XC+SIRz81mC95zPB5X4HpN+nf/f9MIAL+rHUaJc0QcYPK8+2WiHwaOL88obdGulNp6MjQNVVURUkZN83r/aYKXjdiX70dpEU+dk7hPUTiKwkrj17hQVuWrS4411lisba/SJhll4JbFwWWsw2TF2J+J3gtw1dl10FNRlZUAWtuWwhXkfJVDWpZVsiotwQgnRGuDcQ7zC3M8lWZ1gPSTuGFixDkpWkkpczydV1C1iCdVIdD5GIIMcNa9g/9yXwc5cNdVJc+7EheSW8WcOQR0zhgSOWkBpq7gavmZGQjyTgkxMS2RTQK9MqDGaaGrHU1ZsUT5fdKuCS/XwHWOvF2jHm6d/q8GrlfRMgaPnyaqugWEh5NzZtM28neZpVVxWR2q/TiTUqYqijU6VqLN6thL+RWUHWJmXiKnXuKydVsJdqF00orbD+KILmVy+8XBErNGGcWma8XVGoTjUhjQKq/MPUVWoLShKqy00xlxiWUUU4bF/7XxTQQsTWGFw1UVEtmbloCdPMlHpsVTHjbc71t8kNY8WcvXSJqP3Ow2bJuKk1/wKy/Qp8wwB/px4Z0xdHXBoDJLgNnJnluvkWNrZB+4LDKkK0HciOrL310SBYuPr2DnnKEw4qL0PpJWJ4fSIpwoJQNBHxKnfpF45a4RgbrvyQjP0OfApZ8oncY1bo35yZretA3TsnC8LOSsyUjp0HWSYc+47slEBBcHnw+yTn0R77VSKwJDsQRpGq0LyzQHUhaXc1OXzF7EI6vEdacQQd5aEfN9P3GdFnII0hgbq5VlJ+/3L9xHoyRGV5eOuirxCXxIbKs17nediElSFUobTCl8sOPpsoqR8DcWQ/1XccUQ8Snw8nIlpsASJsqq5O7NjbiCx4AzClNabGG5u7HM8ywttUaYsSEIW0wYUQtFoUnJk3Jch2SCukBrQvSAlF9kxO1XlCWuMNRlSekM12HifB0Yrj2n4xPbriGhiaszsSktVelWbq00R8YQOV+uPD49UjeapjM4JYJFWzfru85IY3rIRA8RL6UIK9tyu93iXEFZClN1WotlHh4fWOYFhwznq6qlWAuF5sUTg/DD+l5azi6XfsWCSCvgtm4JwfP4+IkUE+WK5qjrVhzk80xYZpTKxBCYgqdpOrpW2MLX6wWlwDiFc5qqbtHKoVRBXVXCkgoTj/GvvNCkkpToOEvXNZSuoi4b+tXl7RdPnD3ffP01v/ndr1Ee+ucrUXuSkjgxPex3G4FW21qg78MRPw8cjwPjGNjstlRVBVZTpkDpRqL3jPOVmPxarmCZejkTZRMwRtHuOozW/PmHDyze8/59jXGWaRgJXp5rpTXjNK+YDYfJ4p6P6/02zZ7nx8+gJMqdYuRyvtC0Lfdv3wpSoJ+BQEwB6zSHwwFjNWVlRVxPmThJscvpfOHjhw+0zY6b2wbvI+Mys0ca6hYv7DxnLVVVMkZhlw3jQD8MxLd31JVgfVLMOKepW8c4LQz9SFs3VCsjURr+EtoEtEqoJPuvjDxTTf2l6Rz6QVyXdWEoC0ddF2w2HeN4YPGB27sbyrLk/KxIIVA42e/eHm5o6onT5QRk6qrEmr9NUvqbhaf9jQCpH08/roeTGpUy87xQlorNpqV0ln1bMfQ9f/zDH1nWpg6tNWqddBq38mVi5On5yE+fnlgWTz+OMhG2y7rpbGi03OTDNPJ8vXIeZp6eHsWunyUusHhP0zS8eXvHoWvYdy2fn17oX47EbIlZMw4D1+uZpmmptrfcYGmqgaqwhBjR1giE3EvN8+gfUcDpcqWfA0lJxe+//PF7qvqBaRC4+M3+QOGc1GiGQFE3FFXNYSeK9mmNge23wuD48ccfWWZxhmU0/+F3v8FZy7YqUCpzHSTbr4tarPBNR1kWuKpmmiZ+/OFnyJmbm9vVYy8vydoKAGwMCXIkzj1R1WTdYQpDqy3jOPK//PM/0zYN97e3cmBebc1aa0KKTMEz+oV0ueCM4TfffMOnTx/5/OkTzsmmtCxKfvPdr+mvZ3GWrTEYakcqLAzyIBria3Wzs4a//PAzIcx89fV3dJsNGomYVGWF0ZrDYY+zltI94ZfAzUbYXf/Ln/7IMIy8u7+jqUqZ/irFst2SUdze3pJS5qefPnAae57Of8Raw27TYqylbDtcnXH1LPD7umb2no+PTxTWst8fpC1BZQoDbV1wOs88fv6EUvBYFGzalndv3gjQdRiIMVFXHXVVUjnNtu24PezJSsuGOESZvBYlrqwYLlf66xmrDbvtjk+fn/jjH//EmzdveHd7i1aKJSZRlNdFSgSJSIiJMUgN8NPnT/T9hW57oKobaV2cZi5zlMYa7yF4XC2OhD/++XupBP3Vb7nZiNVVKXg+HhmGAaXlgPzDh58ZpxmUOEFuDnvcL4iTUhaVOChjlHjoWZrB2Gww1tA0DUXhuNnvCXFtOFxjZdZajJwQaKpyncZfCH5hHK5SkxwExCqih5G4allQlyXjNHO+9kQ8PiXO57P8nNbnV5FxK7jXWS0Ru3kS8LeRNh8fojxHztFudtiiJmY4n8/CwjGGYRhEHEWkMR888zJxfHmiv1jGccC58hUWK9wwS0yT/N55Jsb0Wjs+jSPGLHLQXO29KSeCFyjvYdvhnEzNIAsMMSWMNShVrgdaRVWWxBT5/scfyasQpZXFakVVVWy6jtk6phUIHXNeq6cTTgsfa5xmLteTcDm6DtYY2BeRCVZ78+okiiFQGo2pa1xRgTL0w4hWik3TrGUM5jWmtQSPXqTJTUR4sNYRvTyHz4/yveUgmfh2s6UsSnGJEbl/+xVFWfH0+MCyzNSlxBI/fX4kxMDd7S1lUUh8LCeGpydSTty/eUtMmR9/+pkYA3Vdi+g9e4wRC/wXxoo2iqowmLXh062xyC/GRGMMhXOEGLicpAXxr/XxDrSiqEQIMEVFWQgs3DlHVRYYY14ZVCRhS4QA0zQxThP12gB4uZx5enqi6zraVuIR47Sw2obprxdiiKA11hWMw8A8ynChKi3LktZKdWHghGUmBeGbKCf3ckLx84eP2PWZ69qGHD1zDLwcX/Des1lhtNd+FFCqkcPqdrfHueL/uMXl/4DLKqE/LEF++WWBlDApUqzvlNJZ3t1uWRbPh4cXlhDp55nSOW6bSto112fcp8zDy4X/8X/+F2HULX5tGJafZ4iBqnDs24brOPP56YyzIqZMPjDHUXAH47yucyLKDn2P9wuozOgTc4rS/pgzxjgKW/LGJu5TpjSZabwyTwPzsgiHKCMsL625LJl+Tlyez2jdU1oR0O4OG8q1tSwGEeFSyqQY1mdBHCXHfhCAv9Y4pTj2MzFlruMEGd7eCpfo7rBBKUU/LSI0T+LOGedFDjBVAUozjAGtMo70ygpy1vHuvmVZS0syEql3zlEYhwZC1ozTwvnaU9c1u91m/UwSs5e4a0wizJ9neE4jRsO2W+vmncVozXVYcDpz31m0cWhjX2OtKUWuw8DoE1OymGlhCXE9XAhyou97cfoaLeKIM+QU8Tmh1nfcftvQNiX7NV7yl4/PTH7msJV9gdPiSHqZJzJwuL1ZgfORsAT60UuMsRLh2WqNKoBsKaxltxXX1fMq7m3qShJxai11aGq8j5wvI1MITGHAGsVu0+Fj5joHQogYBUVlOXQWVxQiwKfEdZjW+HCgbSo2jXy96zDRlgXb9zXXYeBf/vKRbdtws20lfrxyGuclMOUEOXHuR8bJM/kjVSGlDoUr6demqSVGqhhJIZJDJCnWuLVw9n789EzpLEUlnMfJS6vj80UGqwclzaQvl4Gwxu+tUdR1jf0FOTbv3r5lnmZOpx+Yl4WQI+AZz1eKsmDbdNR1ydfvD/T9wH/6X78neDn426qgajRJGXShUVaREC7sf/zn/xmSQeUKazWulD1UUciQqG1aTucznx4eKF1BVdaEsLCECXCgHArDbn+g3XZUTcmll2TKdZoFMB8UOWqKqqRsSr56/xW3h1uaTYWzBTFCCMKuCyHRtTXOWD6/fOJ0PL/iDP75P/4nmkZKChSKN+/eUpQl49AzTvI1s1J0u4qicPz0459kX9o1VHXJzz9/kuggsh/45tt3FM7x3bv3ADw8PMrwEsQBZgWrsNm0TNPI7//wR7KCom1wQJUTm67jzVvhankv+xujQesvg++EZuF0Gvn04TN1W/Kb3/6WlBUpIUO7ZUaRCMtC8olp9DR1w9///d/x84cP/PzhI8/Pj1S1w5aWb377HfMy4cNCIpFUhuxIQXO9vEhk3q4PkhJsxF/+9GdShm5XU1SOpq5xtcW4LQrF/dt7yrLkchrk89WSlvq3f/sL8zTz3bdvBOJ9OEgK4XwmKvi7v/8tAD/88BPzPLEsUh7x7t1bnC0oigqlLT54nLO8e3tPfx04Ho+EuKxtlJptW0ss8f4tp+OFP/zhDzL8qUvarubu7YFoNRYtDL6qpNk03Nxuadp3bHdbGS2riM4WnVe7aFb4JTJcJsq6YvNuw/Pjmf/rj/8Tza5if9+hrWUcIzlkXFJcjlee45nr5cw0DSvMXnE598zzQlHIfTsOI84ahmFhHKW9tHKaum6wxvD7P/yA1nD/5ob9rsM5Tc6Bn3/6yDwtfPfrr9Fa8/hwpO9HYl4oSsfuIDzvv+X6m4WnsqpJWeCJKUViXtW8KEq/TI0KDtuNQLUXmUpoZ1fvrbg+vjRDkcT58/HpxJfyULs6E9Q6nS+cpS6tWOxmj8oeHT1JOZIuXsn2TdvSNg1NI21o9jwg87r1IfGeZR5o2g2urGmbhUKn10mgIqMVK09IamPzl2a+NYcPiceXM+Y6oOOEgTUKI5PFHKMo70qvmXTDMIhj4vbuFpDftyzC/LFGc7vf4ayVdpGUhVYfIhi7tm0VGCccqpjheJKK4MN2AyiWELBWU1cOHxMBTwzrQuAKYSQYg1Oa6+XC50+fePvmDe/fviUjTSkCrTOM6wHM+4BfPJumYdu1PH5WjOPAMAzr5qVhv21JfmaZBnKMeBUI0WIzxEUsx7X7a7uUMZpL39Nfr+z2Eht0K7y4LAqcK2jqmqJwDP2VRStKJ1G58+XK5Xrl3e0eqwsKK+6Hqq5Q66ZbGsE+Ms6BaerXzUSgqmoOt3JQRUs97u0Kvz8NE84YqlJ4KjFEtBKYqiIzDtKep43wDpwTkXJZvhzQnQgGRtNUjrttx7B4zqOAqlk/e1PIz2HxAVdJhv/zp4Eff/rAdrOhWScrIUr7WUYcDPMsG+GYMiFnlNacLxf6y4mqlQiDHBIiS0zMMa9xiPTa6HA8nckp8e1v/4G6ESBnSolhGrkOV659jVJKOFvzTFV3aKMpC3kB/lIuY638TFjB1OsBLDYCy7POUpYlbdsyL7PEN9fGO63VK3vJWiPNN8vMOAw8PT+LU8DJ82qMEX7QyhKq60aiHTmjo2w8p2li6Adxqq0HfrM2PKp1nYwpYpIGI01C3nuskcluUVYoI1nsZVlwymCUcJHmeaaw0lz1BZ4+r9OuhMLaSRrKnDiplBbiSFqFnpQiTgmHzgdPSglnhVO1wkFISfgY5RrdK0txOnk/E1OiKBsw6zRda1zhiJNA/o01bLe7VQwxa/Ofk0mvc3KATHmF4UpDi1KsTV4DdVnS1s3qyLIrqy+uLVCJGGTTwbqeW2Ol5UMJ10spReEcxhqMNmg1vX5OIUqbl/cBV0gDl8TQIuM8S+telkNPu9mKUDNLDXhV19RNR3+9iFBUSFxumkYW7ynefy0OLiX8qZyEjdS0rUw155l5kYNxsa6Hzjm6tn3lhBmlsAqSVhglm0SJwq1NhWtEiZBfnXZmZYdZ414BxtpIdMg6R12vAlTTrH9//xqPFBdnenWvVVVJ4QzX68LxeMIVBZvNBh8jwYfV/QZ+WZjniaJucYXDey8usLXiWEq68msUJsdITvKzMcZI/A/F9SrtKM27t3K/rr9/mkaJYFUVCli8DJ+y4KSEAfM32r3/a7n06naMa6tlDJGkFTonjJJG4LJwtHUtAp4Sp8/iE0YncWsn9SoCpawY5oXn8xWjFKU1uKKiKh3kQM4eYzRNVdCPwgBsqlLeyVGadsbZM8we4+Qd+DrlToJmDkmcRkqt7XlWmF6lA6cyWWe8X6QWOwhMOmUpejFanMBLgnlaRGRWGWs0m042xyF+eWb/fXun/JLSELkntyvnKgR5T6Ys3J99WwoPqSrJKOYImYjWsqcMMQpfyhgymhCSlD9YiZnFlCnW4odhnHiOAbK4nbBGhhUZYhZG17mfMa5YHacZo+AyTIyzl4rymJh8/P9w9x+90mXbmh72TLNs2O0+m+bYa+rWrWJJAgUIBbAjQNI/Ifgb2CTYVEeAAFHqSfobklqEDETykqq6dY/Jc9J8drtwy06nxpgRedURk4BIsTIODpBufztixVpzjjnG+z4v/RxZNQVNVRGCQMFVrvWMgqbI6apG1j+t5DrPs8MF8EkUSMRAYSuKouKwf2aaR9pW1IoSka3wEtFJShqFlvCdwrJeNKJ2DYlhCiy9KHAro0CJwhelKMqCwlr6Xthyw+wv+6FSXCyvldWUpZZ1ES6uiDL/dylFCqMlhdNLwh8hXJRBy6IgpMCc+SdKJQpjWNaWuqlZLhd0/cjuKPiGmKKkyLYN+1PH7AJ1VbJZNhxOHY/7E21dC+crD6NiiJfzRIiRcfYMsycm+Y7WiwV1VRCTXLezqioJBI+UO2g+8x2P3cBgDDe5qeeD/MwwiSJtmRP/+ozhqOsajM1hQT+f9atpFxeV8/naBpPwszCASyuhUYtlyewGTt0R7yNl2UgKmQVthGOHkuHX8dTzpz//gDUV62ZLUVrqtqRpa+qmoipLFm3N8XSk6wdCESEo+rHn2B8oywVVtaRpDHWT1dJWZ7ZmxAVH8jM4nRtPJbawbNZrWCaS1iQNc5jwPjBOTup7a0lFZBh7TsORykh9d//5PjfFCkEt+BtMUeCdwztHSvL5ispgreJweJbApC/fQlmISCAGYjA53KalrsSh4r1nHkdhLRmFVgZjyzz8LBinnufdDlsU3K7WGCUq7bqpaVqB9WtrJAgga/mF75hIBIZh4OF+z0t7y2r9mkyIYx4nYSDPMviRmi2wXq3ZrNY8PDwQvGMcB06nI9bUrDYrilGEGqOfmL2HpElRMw0j3XCkXrTYosjrBxyfD/TDRNJb2tRQ1yVaW2xZY7RhtVrRNBUK4UwrJfXUbn/gdOr5i9/8gu16Q5O5hWg5P15dbYgp8Yc/fiNnzP1OVMRNS9u0bLYtRaEoS0tVl6w3EmKhslqbJGtiWcj3WtUNSnUcDieUksAirTNLVZ1rE6m/itLStBVXVxtev31L353Y73bC4EPWYpBQMecC7dKwWix4/3TPx+/v+eo3r9i+WALC4TNJvBjzONONE8fjkXHoxSZutMDC3ZxFQEb229nhneyfZVGKUtyWKK3luwuO29srilLcHmc3Q9+PvJoFQdJ1A103YApk2FLX1O1PC6X6yY2n+8cnVEp88eol3nueDkcMge3ZG//hPQDvfiiy7z9mSfQE6sT3nx8I3jPMGQKqa+qq4tXVklPX8/lpR7tYsri+xuKZuydUs6CornFBYrVvrza8eXHLqR8lgcVIdKnW0O+emU4nHqwVb3ZlMHHCjyKHXi7XNHVJVSja7RbFhv7wzDR0TNNEVFrsDoXmdJpxs+Pt6xd8bSzLtsZoxbsPH+mGjrZtc8peQ1kUEAJeQZxmXHB8/+4DSilhQBUFHz8/oLXm+uoatik3eByfn3fiJ/USrXt3c0VhNF3wRJ8YoydOpWz4wfP6bov3gaenJ9l8VUJVFb68wnk5nA3jyPP+yHqdKNsVMcjCdDgc6WbH590B/+0PbNcL7m62TOPE0A+0bcOL6yv2x47n+cjjbs/7T58ZhpHF+ort1S23dy95etrz+f4TIQbKppUFoCioyoLCGKZJGDWLaiUyzXWiqWvevH4pvJEgDcv97hHvZr5YrrF1yx++fcc8T2waSV67f3iQydBqyaqpsWVFVJZkKoqi4BdXt8SY+O7jR5zzvLjZELdLdsej8C/Wy3w4lPfz6f6zxPUOE9poNlm9MvsZ5yPHYWYcbG46wK9//WuZhIXAopXv8XA8cf/pE+M0EcNEShIz3c+Odw9PVFXBuq1J0dP1SQ5Vbkb5GRtm0hzxcaatCl6+fMnsA39+90Hk4krT1JUkZ6R4kaqnlFjWDU1TYf0d47Ll6u6OdrmkSB6dIjYFihgpmhoVC567E3OILGpJEPruT3/gww/f8eq1HOKIHms09w9PMo3WhqZuaEpRopxOp5xw9fN4xeAwWvPyzRc453h+vBe+0GKB0ZrgHCfn6LsO7z3HbDn0bhIOUtOijcUUFRBRMWCM4uZalIMxkdlOMyrDJGfneHiQ52fqO5aLJdvtlmmaqOsGm5svZ/XO7DyPz894H2maVuwZKbOkMgh7HEfKsqatBThdFAWHw4Hj4STAys1WioAQuLm+4jpd0S4EYD6OEz74nPCj6LuOcdBYbbCNDBW890zjADg2tgAVGfuRRLo02ckF5O6wI4bI49OTxNlvt4CSEIoUKXJDrSoEbP3ixZ2oLTIUXJeSbvb09CSHVWUIYaY/HSVq2AqbqD+dLkqcYRzwbqRplyxXG6Zxpu9PMuWsmwt7axoHxmGQJobSNOsV69WS4/FIN3f4ILZYW5Zs6+bMoZX/3uhsrWuyzQeGXpQcKR80hnGiy1MjrTXfff+dKEaiQ6XEPErhtl6vIUkyahckZMIYw9e//DUxJR6edjgf+Orrr4kh0PcdGmhLsSXNkxR1+/0+N0EBFHXTYKw0rKWROuK12Au0UpIsmESJV9c1m+0VwzjwvHtmGsdLHLFIryXsQII5TAahSopiYS3GHggpUZYio27b9nIQv394IgVHCoF20VLVNWXdYispPlL6R2ydDLxUWap/TsWJgygANltRKu0Pe+Z5zippRdd1zNNEUQn7q2kXVBngH2OgqUtKq8VOZQ390Emgw8/otR/kmbndrvAh8rwXi9PkIy46EoF5VPyuOwnUeRL2TWFl0PD54fnSBLZAq2QPnkODD5F5FuWLOx0uFkdblMQkg7kQHdqUNE0pgw7nWC8qtsuWlALRTYxeM2lpgq/qkqTFOh+DwK9jFNvIclmxaiynUeztLoCPStI1rRVrS0zcbBdcrxuapsEYUSyGEGlz49xMIyio2wqFYpzlM6MsCQGdA+w6UYFuF9Jg6vLB//nQA/CwHymsYbusKFTCqyST/9JK+mUhf77VQUC+gwwtZi9DosNBgmGsUriYGCYPyrCM8t9P88wwz4w+cOhG9MMTq7rkelmjk8dGR1KGMWoiYFVimj3O50Gkc5RFS1lWnPrIMDtSnIBJvs+qzI2w3AiJEW2EEWKyXbq+2Yo6cJyYfWB0AuzdLEpKo9md5ACtcwjG/bM0fW9WNdtlSaEkbc+nAm0KfvulKC2eTj0pwbopMdowTDOgKK3A66dkhJUyegqXsIUwx17dbMkpAzL+TIlunHk+jRilKAt9sU0rlTiOM/3oOJ56OcAhigyUw6NRWu6Nqiyl8UxO4iM3CZOkF+tTRGvFdrPGxcTnZ4kR9yFQl5a21IQofK8QIlppXmyXrBpR8MYYWbUldWWJCbpR6oq2KqkLGR49neQaO6Rh2Q0D06wxtsiDd53vFSCCD3KfKBQhRD7ci9r65/J6fHogxcTr13fMs+PpaU9V19y9FtVE33WcTgOfP3/OKekFisA8jRz28N2391KLzZ7oAo+zRyf4m7/4Kznr7A45DcyQcibhNA087iaOxwN+ciy2V3z91VfsD3sedxWLpmG5kL1dKRgHxw/ffSIEz6K1WCt2pf3uwPHUAwlrFMvNhqZuCEF4mPf3T8zjzHrVShLx8cS+m3lxe8PLu5tsrbN8un9gHCeaRUNVVrJPljXbzZZF01CXPfPs+PjhgZgiL++uKMuCw35AG8Prl28gRea5Z55nPn66x82Of/jd7ygKy+2La4ra4OaISqBiInrPsd/jk+f1my8kwXKMoBK6UIzDxMdPn+Ws7mfGYeKwP9IuW168upVabXZ0x4Hd4cDoBp72j9zeXPP2zRv85PFDwNiK1UowBdM48uHje/7hH/4ekuVq+4L15orlesnT05H9/p7SWgpjRaFsSrRJ+OQIaBI1i8WW5bJlasRNc/fmFgDnwUd4fnwmOMebL76mqEr+8//iv2IaR17dvRBGbpDn+auvv5ThckrsTycmJwzff/LXvyHExLff/YBznq++fIX3t3z8/iOSKLzCFBYXevph5Pvv30mDPMgw86uvXokLIln8FDh2R47HI4+HZ4w2/Povfo33jnE80i4rCcxyRz58/sDQjQQvTanDaYePM8M8UBXijmjahuV6lUMGCoaqRxeS0pmipqhKFldLRpf4+OGENb002BctbVORdECpmaIyJNNwvdmyaFqOXcc0z1LDWYuxitmPuDgTkme5MFSV4enpE9PsJL29avj+/Q98ejD86uvfUBYS7lVaw+ePn2W44zuSCdTNiqKoeH7acTqcftK68N8g1W7EGsPNaon3nv3hgEZUJClFhr6XRTQf3FGyiSUvjIljN5CSTJK0Fs++0ZplXeBnQwoOpaCoKpSLxGkklJVM+VIiRenMbbdXoA4M00xTGNrSMIyScpeURNCWOWFCpUAKKSf7VDlaVVgsxljG447oHZ6AQ1MYg83S2xAC121Lu2hZL4T99HD/mSEGyqKgyh1XUQzlrmYGch5PHSnBspGY8nOi391mg9GacZ4YlGLMkenjMFGVJbdXGyBl+GwQa0cM+HkEFMu2ZhxnTscTmoixAu4VG0z26E/Cu7JlxTzPRO8lZcE5fEz000w6HLCF4TYmvPeM40DTVLR1zTBI7PA4zTkOWVM1LXXT0jQLUtrRDz22KET1UxTYshClkJb0kOBdtnoI30Npxd3dC5q25dPDjmPXM3vHOA0kQCnN8+FI13U0L66xZUE/jDgvkn+V/fBJCRBXGUmZ8SHQnU7MzvP21Z1Y8LxHKYQpRuLY94zjwPEocazdciUTkUYkgdIEDLhZFB7HTuxB283mAvgtS3tRtvVdJwDmnIiF0rgQOfY9xiyoS0uXlQiSHyvTRzGpOyLCs1qtlsQE+2NHUYgnt8hxvOfCQytF0ior/0r8oqUwikXbCMDYJwhRFBBAZQu0MvjDiXGaWS+kYbbPkfdVLSwxUsQoRdeP+dAvDKDCaIyWpBh1Po3/DF5SjFuaxRLnHMfdk8BLi/y9ji6zs6YLHykEhxsGSThDYYqC0liJ904erS1FUxOTrG9eSUy1WNmMcOoGaXrGEFBaUWZILmiMEllzzEoGUXPErKwqfjxEKI01KdtJJMmpKKwoBcuKGJ+Zp5GmWlNXVV6DI3UlzZvlSg70u/2OaZowWT3h5pmkFKu2kSmMFRVUjL2k86VISgqfn+U6Q5tD8DJQcP5SbFRVzfbmVqboXhJAi5zsJulXws1zzuP7HviRkzSOY2aj6EtinDZaVKQpye+LGdzrPX6WYicBPkbm2WGyogcl/DtJ8/M5CVCaQ2UG5sbzIS03U+qqEhumF9WN0jlt7QzfzYojN0sCWIwSdTvPE1ZLJPrxeCTGxKqywl6JALKOKJWvWfBgDNoY1pstMSXef7rHObHiQcrMJ5n+oxSzFxXW7OSA42a5NjbbK30QRda5ITYBVWaShPzPrBU13zTPoopwLiu5hNFACMw4KlVgtDCmlJb00bqqGCdJBTVZoVoUBXUtPMF+GFDRo1KkrCvKlETpdv7MUSzCOifHphSyvZScLpYTWnKDqq5rjmeIvZKktnkWvkbK34vYFQ1uGohB0u+MVtnaqfHeXdSNP5fX7BPGKpaVgEq7QSwXPoJOctgKKTJ0wpqLSucGn8Djh3GiKCxlVcr6oZH6KylmF3BB1ijvxV523stTUtm+lhWEVosSVEFZGKqyYhxHxnEmaflempyApowGbfCAT4kQ0oUnZbPyzUeBnscka15dFoTR4Yk0VYHVsFq0FIXFkC6qAp1VXUolyvz3IUR8TpFK2cYPiclJ0269sNnSLvXpyQl0PEyBqrRs2kLYRMjQx2RVDjkJzhIg5pTQrLYyipxUKszMmAQyXubn8qykDFlpNTtP1w2UCmhLSAlNJCDJzFIL5eviz2ufKGi01qI0CIqYawpbFhhrM/w2r9nErGyUulQjyU5aafrZEaLDBWHGmKy8H2ax/LV1gQHcKBbrphaGqZ9nWTdRoA1X6yWkxKfnozSN2/KiskPlJDmlmEUqm9Vskp5YFoZFI2EMwzDIzySF94HDaaAqDXUp9bakcMLsA3NeB7VSWG3wKuF8wmbrG0ocE8RINKK+PIPHQ96jZyXrSlXJ7+9Gabh5H6T2qYzUXClJWnaUGn6zrOi6iWk+p/iZy/17TpOsCptTE0VxmyNahNGTGY9krIVSiRBFXROzulqcJBJ0EuLPZ/0axzFzcxuKsuB06imLgrptIcFhf2KaZ47d7mLJRenLXnXYdyglyryQEmF2NHXN3fU1++Mxw8rJShYAeW5ctnODJPKu1ytiCkxuZNnWrJcNzkdmF5hnzzRPlKWmLBR1WVGVDd1puKiutZIk4rqt8bMmeJdT6iJlYSnrgtN+zzxNbLdbmqbm+npLURYcug4XguyRVXXh2JVFgWgKAiop+l6wBy/vrtBaMU0zxhTc3VyhNZxOgRAD4zjSdT1PT0/UdcX1nZwrY4xZQSTXIMyiploslngX6E/SrCfJ7+z7IQsfvHBwjycwhhgUBEXKa7bzDnea6PoDVmte3d0RfSD6KKl8ZZlTdaHrTnz69JHt5gVXmw1VKUFbLjhO/Yll02K07DFW6xwy4OVcpy1FUVFVtSh8C0u7kACE3X6m7x3TMDP0XR4yKO4/P3DY72mrjG1wMlRcr1YorQh+ZppmVEqouuLm5ooQI//Vv/o9bna8eX2NAk5PJ1JKVLWwT4d5Zp4nulPHbC2n44m6LllvlmiEsRRcwM8zLgXG/sBmueHlFy+Z55HEeEla9T5wOp2YJ6ll5YwxwyCJq5vVmmUeEJ8HfsIp1KIIRdIQjTUUTYEPidNR7tei0JR1QUmR7ZERWxiSFS7merFCZVu2zqp4nZV90ryPwvWqDM71wiCu7rDGcjg8gYq8uv0C1ZxdHVoSBUMgJA9aWMTWGsZhZP6JgoWf3Hi62W7w3vPx4YEYI3XbUljL47N0sH/xq98KW2Q4AmKzSmhmDNM88/j8TMxVxjwOPPQy2d5st2xvKjZX1wLrM4qIJSQ5mJ8Oz1gFX7x6RVVVPD7vsUbz5sUtKSli0ozdZ+6f9tzd3vLi5ob9Yc/T056b6y3L1YrZCyeFJGlHn+8fOXU9BA8xUlRFhnGJdHjZ1lSFZhhO9EPH8VijtRzilqstq80WYwvuHx4YxhE/HEkxUDXS+a7LQngCXc8wjBgjFo+4WqC1IbgRTeDNy5egNGVVMk8TP3z7p2y3kwNOcJNskspQ1TWL9YZ1FVk3Egl5HCbquma9XvPw+Mj7Dx8l7SlFhtORb777wIvrDb/56mt2B7luLsIc4XA48Y13VEbRFBo/T+z2e6ZpxKjEetHQVMIlsYWlKkpOpyMpRdqmlsJMKWqTKExiDJ5hhqoqaSqRUz5mPogPnqJucEnSEZ2bxN4IfP7wPc+2QMfEsqkZPEwxMHQ9MXqauhWYXYj42ZP8TDIy4fQh5mIxccqx7g/PTxhtWCyWxOD5/OkTCXjz+jVVKVbQ84GnHwZ+eP+Buqp5++YN4zTx7sN76qpinq9RWqSJ46QZxoHH/YHjlHkY9Qpd1RKjHBx+nmHVUrZrVO9xUYELpDRyGieOk+NqtaTZrKliYpkSh1PPsR+4Wq242aw5dCP3+wGrZep6e3OdN41ZDgWFpdQNXXei63vevLhj0V7T+QeiHljUcrDYjI6iGAnK0kdN58WC55MiKo2xJRFNslEYBXMvG+uqFbl7+vk0nQCUlefx+fGBFCNVXaO1sN+stTSNqF6WC4k6NkWZi55ngvcENwMCCVRagzUZLGqwSprapJq4XMr9mALWWOp2Rb1QbLUcAI/7vTQO8iFea0N3PLDf79luNmw2G2kQ5+ap0prSaKCQpMyypOs6dscTh1OHUojdK6ZsE/CiBrAFIXjm2dMd9xL+ME45Ca5AG8PcdYQgRZNNFlLAqshqLXHi3SA2tKYqxBJXVWgt0d62KLi+usqpktLgeH56JPjA0ElSZ9kssMZmlg+ApFS+evWamG3FRivqcs04jjw8Psra0gqos+t72qbl9uYOnwMCxqGnO+7pOgGM26JgvVkLIH6Qhte5aVtVDWVVUVbSYH5+3jFOc2Z1qGy7M1irGYaZcRhZrlbUZwVUChz3O0kpLWRQ4ZwUak3bUDcNdS1NOzOOAu8ee+YUqRfLHMUsTK1hkGtk8kFwnCZiEutQipq+l4381HcYbYQ7pxRj6LFlxeu3X2G0AJBTkmvnfeCw31GWBVfbbVZjDBnuPJ3vfHzwdN2Rvj/RDwLmTNFD9OicKIqCqmzYbrfc3z+w2z3TtjIRHseZaZ6pqpoQZYjTlIbgZKratk2GVDu644G6WVCUVU72M6I+GyfhB6zXPD89Mg6DJL5UDUYfs/ohQAo5UKES9k0Qu6JScFuVWK2ZnKi1plE4M4vlRoI3cqPSe2ka/5xem1ZUPOMkA4G77ZKUYJglwOJ6VaIVbEOEBEkJ9HuYnKiWSrHfgqS6CTNQS7KWSdSlKB9LU18s3ME5RgKFhdc325yAOecJ64KYi+d9P/K077neLrlelrh5ZtfPOUVTuJmiYDMU2vC4O/L4HDLMOVKUkuSoihJVlKTJSaJkkEZBcIfMmFMUWpHCJIlvQeFigYkKg6hiZh8ujSmrS4zSLCpRothsL6usojCGRb0Vtakp8D7w8fmQodnStCgtGB+ydV2GilprrtcLxmnm8+Mz2tZcrRccupHvH6X5TIL9qWd/PLJeNLy+WVMYUV5G75nHgdFqurHCYygWG0rETjk7mFKS9TwlVk1Ba+Ug1A8jmiTBAUaGnkUhQTK7uaOfZLhR5cNOCDC6WWr1UGGswbmJ5CfKokJpSz9HBic2f6VAF6Uw/pQctgtjRdWVgdgvVzVVWeCjKObaWnAX83y2CxmM1RRFblJHhSoUdwtpXK8XFTElDt0J5wL9MFMWltvNEqMdu+NA8DA6gWw3hcqsFzmoFCRS8IR5wFYFuqglkj1AkQHtp2Hi076nmQLt5OkHSenUVUGtpbFWG8UUIpNzoDS2KBhCxHWOtjDUVrNcNLRLAevvjgPdODN5T1HIMGKVlZbvPj3QDSP17ZaqqbhdNcKj6k+4yXNM8twVs6A9Nm2F0Yp9PwgnTCWShiGHcZwbsz+X13q9wjnPh4+iXDIWIhPffvcPNHXDq5dvsmJxi1aGum7x3rHvnpjGid3TAa2E3STPhSNqCEaxutrwN9dXhCjN8xQTwYvaui4qyuuKzfoKYwyfPn7EWM3tzRatJCzg8fmJT5/vub255ebmluNhx/3znrsXr1isNrTLhpgcZd53v/nTn+i6nsIKvNuHkRgds1OgHNZqqrrCe0/fDXgXLmvRdnPFdrvGFobvv/8T4ziyaMVK750kFt/d3pJi4njsOJ06irKhLCvieokpDNYWtE3LF29f4X3gF7/4QhSuh4F5PrDb7dDaslnfYozCmAmjDWWxoGkbfvWbt0yz4/5+hy1Lbm63PD/u+dP774Xz5Af6I3z3reHF3TW/+fUvWO92FKXmcDry8PhId+r5/PFBEoczZNpNkX7oOZxO1FXDV2+/plkuaJYNITme7p/QCW42G0JwjFPHZr2hbRoennccTz3r1YrNakn0juen58wjDMyToygKgle51i5JwTN0B6Kfub7eslq1dGNPPw40layNKf5YdxqjqRcNdS0hAjEmbq+vmKeZ015EGY/7vSSB61sSsHvYE2LkV7/4mqqwXF2tpc5A0fcD7999R9PUfPnFl3T9wP67H+i84bQ9SgMQyzR7Hh6eeHp4Zv94lOGCBlMUXK+vcX5m6k7o1Yr1Zs3zbs+7D+9ZLGvW6wW7447dfo9WiqYssDqyXBj6YaLvOtbLW+5urnja7/j8+SOrxZq2XrNdtTRNhfcwOWjrlkXT8P7TB479id/88pdsNxtOxwDxRN0uqJqSerHEJ800zoxxYr8/AIn9mxMRTVFXJK14enzGe8+iWmOtYbVYypnCedJPVGv+5MZTXZVMwDgJfHGbJdDDNKFtwXK1RqvErEU0V1pNUoZZ15y6E4+P9xAjmjydmobcAJCbab1oJalimAjGQCFTCe9mYQM0DTHBMAysFi3LpmEKMDoIURoRKEVdV+wPUtyHJKk5OrMGYhKqf9f3wkvKIF2LxujM/dACw1bJSExsCPgA2lg2y5aqLGnbJSrDWPtxZO57ObhVNcbqbFMSqaJXUJWaqCElgeZ5LylWy8USYy3toqU7ycFgmiaULohRiuuYEtM0ia9fG6w2NAWMs6dzEtNeliVKCaFfkagLQwyBU9dztVnRti3zPEvaTYgEJwfV46lDNSWLspZO+iQdd4gyIc2sEVtYSAKSB+nUqyRFrlaIyDWKN78sLaXVTMMgiVheDhDee2bv8XkSfoYcj/1JJvXNWg7MSFHjg8Q1G2vyQVoOuTGIzWKa5c8lM0kuk0jnSObMEBElnraGu3ZBXctUPZGYZuFpnboBhRQtzkkBEGOg72usLbBlhQ8wu3S5p7TSWJtVWElYMOHMRzEmJzXqH9Uw2WKUclPDIEVUN805jUUYV8dhZvYRU8q1qauKRdvSnTyTF06GNoquG/FeEl2KqsYUkgZmigKbfy4l8NoSEBD/j0dycufaoq1FJS4KAVF85Ek3P5/mk1IasnyblKQhoMVaBuQmkMYWwiaq6gWzkzQ3P09MUVQ+MWaQjJIkxwgCwM6edDKPKDrxd4uUWNQz49DTDx3l+aClFKhsbxtGwmKBVpkLEqJwOLJiSCtFWZVUdcOp65lmaR6IIkrlnxNWkc4qTFEmCYhYOEmSRHT+rDEDVX3mdaScElYWZU536ogx0Db1Jf1IGwMhkRA2mmywYunq9wJNd9lLrqwoCE1WIVljICex+RBwXvhaVV3jvCTJiSqsIMSYp9gCIJ+dgNnPzJDgPeMw0BpNUSyEQzTN+Y6VO9dYQ3FW7Ywj4zRKypHWeTKdrxtcFK7WWppaQPQxBLyTKbc1BmvsRZ1jbSEqwaKQZ9AaOTj+I4uGyQyr8/d82ZBz4yidVT0KgZSfLRdKkvxUtmAqbVlkq3dp9IU/kwh4N2cWYonXATPNgKw1WmU+TUy4ecI5lw/WkkxGVhGT35lGFHko2W+KosA5T4ghh3nI/qmySkIUDlFUrVXNNHjmEC6f68w8S0kaVMKUajmY3YXFpM1ZuSJ/VorxAugHf0liU8iBXilyWlW8TFiNFdVH0rLnuXnO9+XP51VaSVyafUJraEo5wHfO5b1IlNrK5FVbIWmXXpK7krGiQEd6fLOPXLSXSlHkZLW2LPBRwODSzJZm6aIu8SExuyD3my2Y4pyZaIHJ5ZQzq5imxOS8WCkzsy1m5aZSAu2e870Y87OktaSnkdWKMo0VztjkHQYoz6rn5EkBfBJwd0jCOHIh4kJEqYDNFnWUJPWZrFgASaBTClEjak3SlnF2fJpkkGV0Vq4oeVbmJI1ZSFRFSVlY4Urlpm2V997RyXNVaoXzgX4YKPP3Isl1BhcDPkkNM59ZnrZEp4CNgZDf45klUhhNUxpmnyRpUMvnKYoiry05QTUpfIISUQkp8j6SFVcmSNp0isLEs1kR5c/fT24+S1KWQSsZCkrCZsLlRpM1hsKYS+PJGs15ZUv8GGZw5hWKXU5RFyaD0kWlOec0vtmHvLbKJF0rCbDxUb4n0Q3lZx9pQAUiMTpSPH92YbPaJGtOSElA3spd2JrCypKGnlZygJ2R+0xpGXaHKNersRqtoLCWqA3RTVK7hoCLkQLyGmgojJb9e/pxzSkLjTXQd4JamKOccVDCsylMLWzZzJMy+cue3TkVufhZqc3LUpI3x3EixsBqVaN14nTak1KgqktJ4SpF0dq2K5yfiGZGa9g9iZpQa0NSiZjk7BBINFXFdr1h9jP90OGmmTFMaG0oTSFKDq2ZxpGuO7FYtSyrpaRx+sg4ThyOBzabDWW2/nfdwNZ7UdBZQ1mJUjLGyPFw5OHxiapaUBQVZaWwBYToCYJ1/THsJEZxjyQomjorhWth7vRHDocDIOnCspYo6qqBBM/7Uz4jmczPEw7bmQW1XCxkfcuqqNOhF+zAMIgS3/aiXNWzhOgkS91ULFctepgu7N+6rjHmxNCPpOjQWvbq06nj+mpDu1gwu4m2rZnmUUQTITL0I3VbUlYShuNd5ijPM6UtaauWoimwtWUeZsZpxlqp/frOZ7ZTQhlRA03TjNlq2rbOITlzrj1yHYhGkudF1VjYAj+LikkGHAWH41GGhLZAoVCR7MnVpDPb0hipnfPPaRTeBebJ/8h/0poYE9MkirbN1YqqKmgXtQx7JhGxHLojGEVVVzjnST4RXcgMZ0BpQkh0XS89DRdJGjD5rGFKqZdzvSJBP5G+79EWyqbIZxBJg05R0qmLUqNHsb9bo6nrivjs6fqORbPG2oqmbli0NafTjHeespZnQdRyA0aLqrQsKqydpd7MarOyDMyDl3Q/J6oo57zUlIXFcnZJJyojnGNjJM3UOSecxp/w+smNpxQVZVHx61/9Qv4+ieR3HEecm/n23TtSikz9UYqVVlRCyhRM4yhpW8YKwFgrjLpmnCbev3vP1XbD1XqJNhXaVgJ51lKwxBB5Phz5eP8kXIfgiDc3LJqafnQcBrEfvLy7pSgKjv3AaZwZXOTQz+hjj0kSv3zoBQJ3fXXFl198wcdPn9ntD2K7KQVUWJYl++dnTscjb794y3K1ZH8amGZP9I7BS+GENixa8d4/+Bk3jQzjhNbndBXw3mON4cXtS6qqxE0DnXP8+fv3GGP5J3/1Vyit+cOfvsM7iZ60RrNs2pyM8SDbujFM3nF/f48iooM8PB7Z6IzRrLdbfvvXf0twM2nuUcagbAUk/vN/9a/Z7fa8//iJr778ir/9279lHAe64x6rhWtymgJjd8K7iTBPtHXNoqkZ5wwrz5L4VVvzartmvz9wOnU5LWZEZ5AZFChdcHO7EElt02JtyTx2eDfRB8fsJ+5ubsRi93jPNI4Mg0SEfnn9FU3T8FwoYgy8uLvDWsvzbicqr8lzmBzv7kVB57zHFpbbqyuKwvLla2GQ7Z6fGYcBrcFoRQweTc3V1RXjNPPh4QdI8Nd/8Rucc3z7/XcURvPbty8JCcZ8sFk0Ff048vC8w6D41RdvcN7RTSNjP/GHp0cWbcNmtZbEkj/9GaUNL6+3uHlingZqo1hZUG6kOzyBMqA0bVmyfPkSreDheceqbbi73lKXBUVh+Pb7d/zuD3/g7du3bLdXrBtLaTSfHx7puo6nh3ueHh84njpm5xmOCaU0m6trrm4rgeOHwKqQImihPKUfMsTS8qbeEELg4ydhyTw8PqGNZXl1/bMCXBqV0DkdRylFUQlUcRxEwfLu3Q8CbVxv5EDMs1hWMlx2tVrjoygItDaUZVZE7Z5YLdfcXt/g3ETXSSRyiIGiqGiqhn7o2T09ZvtsvKTkjdPEMIwoEjfXW0iRh4d7nBclQFUWwkfKG5X3nu54gBBYVhbnIiEk6laKoLON2c8ydajLEluVjKNEsGsjjfV2scTaM49j5HjYXw5pCoUt5jxhsWhdigQ422pDDDw97wghUJeSoPbp02e01rx6+Upgs2XFPE98+vgpb3QhAxUrwjCSHsQfHryHssKXVmwdTSMA26Ig5sOEMYb98cj+cODDx49cbTa8ffuF3OvjhD5D1ceZcRyk4XMpMkRePGdu1TxNbFZLlssV/TAxzTP9cMgKppbN1TUgUvGiqjFVzUprljEIyFdprJeEq3OjaN8/E2LIB0XF9kbWqnmWhJm6biTRaJLGzzDODEw87sRWQP65urJoVbBefZHjwW1utItKN8xI8lS9xMfE/nhCa82LFy9EYXHYU1UVb1+/ZJwmHh8fsZWo0oZh4OHxUf77u9tsqRIQ/afHZ2lcarH1Ja0Z+oGmqiDFzM8qefXqlRwAg+x7mAJbZEUXETcPrFZr6rsXl/v18/09+8OR5XJJ3bSsFpKCp3mTExQDXdeTtMFWNeMkxaY0CwqqKku4lzLgWq3XFEWBLoRh1lSlDFcOz2J1Ovf1fmZNJ4B+zgmRtQyYXFakbmtRIH5+eBJLhAuUZcnV9TUkQ1QCBi3P1jStCVFjdSRGOI4zdWm52azEQpyb2aRIUZSslw39MLE7+Tw8iqhKVDWnvudxf6StG/7yqzUpRU6ngWM3cOwHJh/oJ8/VsuZm3fK4P7LvTpI2tmrop8jkE01TUhcWFTxuCmLrCIFNW2X4tAEUMThSDEyOzEJSKANd30OKtFXJopKmmgyWZoLRAlw3iik3Ox52J5TSvHxRk2Li87NwDm+vtpRGs24Kptnxw+cHBh9z8q/KiviZKZ7wPhBUwYzmOM3MIbCoCwqjWdUVkw+cmooUA3/8/iPd5HnuHS+2S37x+o7ZR567Uaw7NYxOVEPBObyfKcqSRVUyThOH44S1omKtazlkzS7STyNdL+mCi2XL1XqBjTMmBapaY4qC1bICpZhmUQk2dU1pxRahtKKbHCEzHtGGxiasDjweBkJMvL7ZUpeWdW1wQdGPE+MccmiPHKytUfzi7UsKa3FO9qB+nHDe0Xc9MQFaU1tLW4lNpKsamlrx+lbCB+53ojb46vUNPkT6abrw7GYfBA+RInWlSakkVQUuJB6PA3XpWYYIdYnV0BSWt7crkhd1/KKtMJuVgI6dyzZqAfIXRSGctJBoSkF0LJuKprR8fD6yOw2s8t+/vFpTlpbn48gwe+73B1RKeG0pFktO0TIPCe97GT4hNufzIGjTSKMqJEUIiu2yIsTEcXCZuyWK3bos+BkJnhjGIxrFX/z2F9IQVRBioOuOoBTff/8x2ykF8VFaCyqh1EyKivXmWpqYVufAljvmaWL/uENfXdG+XFJ4SfnU9QKzlXtbacXT0573P3zMe4MQmLVN9N3E6Tjgg+Pu5hqIfH6453l/4NiNfPj4kVN/FLeHtgz9kRACVzdXvHzzig/v37HbPdAu7lgt15S11Gl+PzOPni++vGW1XPD0uGccZwqrMDoSnYNoeP3yC66vZlEqDWJZiimye5YwIEzCFpbr2y1t3UpN5Rz/+u9/TwieL798jfeO3/3uD6AUX335JS9f3fFP/+lfM44T33z7jhgjqqhJSHNqt9vz+9//SRrJ40gqxKZdV4ablyuM0rRljQuBfhoZhgP/xX/2X/L8/Mz3P7zj9esX/Lv/o/8h3jnGYSQlzTTCPEsQ0uwkIXh5teL66pZ+7Oh2HeM8Mc0jr16+4vb2hk/vHWPX8enTPe8+3NO2DdfXG6qmBVtydSuN2R/DdsRmts+oiM1mSVg0jM5JgFkQ++DXX31FVTXc3z/hvefmhSRzPzw94Zzn8XEHwPjNn/MATXiWL1/eYI3m5ZttVtRp5snRVDWQcGHGRCiqFfPkeXrakVTit3/9a6KP/PnP31GVJX/1N38hg7J5pCgt63XD8XTiw/vPFMbyT/7mr5nmicPphJ8D/+rvfyeuHxVI+iNBC2D97ZuXoDUKw2LR8urVhu3qhs3mFbPvcL6nKTxXK+F53j8+8vLFS379q19hyxJtDd/84U/cf/zMm7dvuLq6Ynu1ZrlcMKfI1fGOaZp59+4HpqlH68Tz8wltNZv1DTdXL6VRFgJv375BK8X19RVFWRBtQSwD+vUV0zzz+dMzR+fZ7XdYW3B9c01Z/LSW0n+DxlNCG81i0YKCefIyjZxGQhSbQIyReRil66uVqIiMTGZ1nhLIAUNjtSbExDSNeNdKV1lpNMJLKqz8zmQTSgkcK3pH9BJxfYajOufQWtM0NUprJueEM4XCRYmstclhkWnoNDuqsmSzXvP49HyZRCskCvfc1fU+UlcVq+WS2SdgYuwngneELCu2ZSOKBmPx2pCSeCdRWiBvuagvy4qyKOj7kWmaOPYS3XgebByPHSlF3t5taMqSzXLBMM08nSTxQpk8qZxHATKGnAJkz2kREWMtm+0Vfp6YOzl82aqi6zoeHnbs9geeD0fexMjVdkPfGbGt5fQiFzzdOJOCBy/JIEopQpQI55BjNDe6pWkaun7IHBLP5DytFobW+TOVZSVF5vqKsmo4PDgGP4lsOtuTtLEURUlwPqc6RaxWlNZQVTIpqTKrxhiDD4Epg4ZPB7E3llWFVZaqLGiqmqqumKaJx/vPAnsWwUEuqLNawXmGcaYsDNvNmq7r+PDxPcumYr24ZvKR7iCpdionhE2To61K1ouGcdL4MOOmQD+MGFuyVKKA67qOpm1ZLhpUCnivsUZTGY1KUVK3VCBhWJQVbdMwTAPTPLFeLljm5qe1hmHouX+45/buDmMtdVXTlpZ9sWfUWmyM3kunOUoTLqG4LUvaxSJbgBwqNMTgsUo2G1QSmHlVEKNMzJ3XzJNHBck7TPx8Gk9nRonONozzlCkhbKVh6LHGUrVLNIHoJ1FslE2eMheoELLi4EeljEwrRCkTgstTTLEuWJNE+RijKK0gK4sSCnVRZxSFpSxLpryBhygTX6s1QQtGVRo1wo4wWhSVQeUDmJGfnyextJ6VBKqqLhNomY5plBa7m80R3VqprIQJ8lxojfKBlC0bNidRGW04p9+dJ5dlTp0cx1GaEHVF0zS0i5U0Oz5/zowNRF2DTAGncZRGDYkYJIo7pSRNBSVJbJLpIfXilFlCx+OR1XIhzYtxEut0VoxdAhqMsINQUniGEMUClyG9ZxXhNMtkZs5TunaxFCuZm/HBYcsqFyYWks7OeXlvKSVpxIeAc7IPnZUCRVlSVhXOC0dJ/PTmMsGW6PPIOPSZJ1BjjQCZrTVUTQPoSzBHinJtYpA0O5D7Z55nyqKkrmpCEAWvtZKYGaPwZICszJI9p6pqmrrO0PEyKw9cVr3AOI0Mw5ibpjY/G2IzbOqG4OdsOVWZVWJExYao/Ky11E2TE18i8zzTdSfatr2wmco89VVaczqdcN6Jqs9mflaIch9kBkTUmrqStVDSuOR+VChsKQmBfi+qWjLXKAsPf1Yvn9V+5fm+ljMUpQEXE+M0y+TYBXyCZU5CQ+lsG8uNJ2PwIRGDxhHxLl4U58n7zMdKFwWsyawxYZulC2tNayVT4dmzajWbZU3Xj/SDvA+pGQJJCUy+zmw7l1U7VVUyxSCcSiMsi5SicDMyR81oTWkt6sx8Gb2kiYkQ6rIGz0Ea+k0pgGsf85AsRom4V1KH+QwEn2afG3Cyrg7DhNaK6/WSprSsW8tgAOQzzj7kFE1IITHOUl9yYS7Js1pYTWksdWmFUYdiGgdOx5Fu8py6mZu1WB7SOHEYHSZzmXzwjM7nZkmgqoTVNo4j3TRToam0cIWE9STDiXGa6fqBxbKhrgr07FAZP2AU2MJKInJmTslB+ryyprzOymcBsQGrJHWECynvVaK8goTzgaRE8XrmV0kwiaQqulkGu4duZHaecXaihKrEEmeUEqtJVjkt25p+EBdFXVUsmorZe4ZpgqyyFEC7w2iorELUDwqfPLMX9l24AOwTxmgWVYlXCR+ccDObimEQ9a/Oi4MxGm1EKeaiKI8KI/U6SjM7Tz+MNKUFVdBUJYum5NDPoiQ7cz6VpOL6pIgBvBNFfqklDfnMsqsKUb9NWdFXW41NcJrSZcFKea/8iW6Vfytewc8oW7Batpl9GbJK7Dx8GOT8EXN9o4RBUxYJa0uqeiGoRh0pi5Jm0UjozywJh8ZYYsihFVrUv2i5z0JKdL0oPKTGDZf0374fKEtDXVeAOGnm2RGjcKlQnrZZUpc6cwYd2+trNtsNnz+/x/shK5xyc/HCxEtUVUm7aOSzxYjW8pylGEhKUdcttqjoDlJHSDSlEntZDNSLKltWC4rSkpTUMvvdgRA9r98IfmC33wvDsa5YrVe8vn3Bsev587sPJJ8wVliAKXPMTqde3jMJktynSiEcJV3QlqJwStrjnefp8Zmn5x1PT3tevnzBi7tbTscTfnaAIvjEPDn6fiQlUTEZI3XMOI14J9fb+ZyS2tSZa6U5TSP9OIlVv6lFHQ0UZUldyeBdG010iRgSfX/C5bAfBVKnEglB1GlN07Jolzw9H/FR+J1FIanNPnrCIGvJ4bgXpMNilYfQlroqKXRL8JHdriOlMys0ys9GC0oYfsMwUlQFm+2KoRt5eP+EWq1Yb1fMs+PxocdYhTaiMB2GkWK54upqyzAKDubUjeyPh0s4Wt+PHI4HrDYsFg0+gg+Jsihom5I6w+iT8iQ8VhXUBQxuZJonqrLientNUBFPEM7W589c31yhlKQ+VnVFu1jgUqLf7XCThABpLexBvOZ6XdPWDVrL4LPM6axVJTVZCAmFpm0rjBEHl/MzMSoKK8r4swr3v+71kxtP3dCTYuT+QejvdbMgJZjmCWssVwuJSzbrhXxhZxuLSlRNzXazpmlabm5f0vUdHz68o2pr/vIv/1IYKbrg1HV8/PzANA70pyNN07Beb1AKXt7dZNCZQNpOGYJ9tSgZx8gwCjDXTzNtU3C1fEFCk4LncDzQdyeubm65u7vm1PUc8yQ9BM+pOzFNA90oDaFqsaBdrdgfTxyOR26vNqw3LX/c3XPsOt68/oK6abl/PjBOM01hWRQLrq62aCNdVu8Dm5sXKKX483ffEWNkuVqjtObF3Qu01jwejiiluN4sMEpRZ4XDOa7V5qnJer3O8m8vzTFbij3ETUzO86//zR+oqoLtdsWoPacEjS3YrtZYpRj7E1Zrgey1LafdToqt7Ybjqed5f2ScRPa3XS252r6iNEaSQU4dznVABiMiAPWmrlDXW9LTE971XG9uubq6Zr/b058O6DgzdAVPzzu0sVRW7Ixv3rwlJfi7f/gDj/sDf/nVG1ZfvOXz/QP9MPCHP39LjIlXL19S1xUfPn8mREmS8kFi3yFL5REJ7xgTx9ORvu859D0+N5ZciMwxYYIcMo/diW/+/GeR2O4eaeoad72RzaJZoMuSPpV0U8/9004iI3u5z5q6odAKN01URcEXr14z+8Dr147gZtzYs17d8ObNG8Zxou8lNadtWrEIKgFQVtZyGiZp8iVQKgOjjeHDp3v+9P37i61lOB0ptGHsTuweP2PCmqmq+PC443l34Ha7YtM2TJHLZFajSG6iP8xYU2C1oigFgq1KTSSxfz5I43a1whjDZr1hs4Yqw/wfjx3TNPzUpeG/9y+f2Rs+N2xtkCL0/tMHjNbcXl9TVjWr7ZVMck8nYoo5OQumJDaA1aKVQ5WbMUqxXa8orWF/2OFmxzDl+NjjUWDaGTq7vbljGnr67iQ2sXnGWMt2u2UYBg5df4FEt21L3TQ/2pu8RO7qHEs+hoSPstaF3Gj02RYYYrgcwAV2b3nz8o6mrvnh3Tv6vscvlxlcOTJNI01ZYEzF9voGa2XaH2PEajl4HE7HXNiHiz1PgTSQlOLLr76+gKedk7XWzS5bA6vLBp+5sxkcLYW/c577+3vKsmC7XuG853SSGNg6S5j7aaIsCl69fsNmvRbIopZ/P/SdMCCynbFpF6xXq0sh3/cdQz8LYNdayqalXm6YgjT3mqYFLZNUrcUK4+ZZUpK8pBTGGGlaUX21dQWp4PsnURy+ePGSuqnpchDC/f3nDPGXpt/9w4NcqzwomWcHCtarJVpr+mEU+HCKhDny+PweUNRNS4iB4+kEKVGWBUaLSss7YY55IkMnXJp57Elh5n3KEfPzROcdP0yjWKAaCRlAiZy/aaWBVxXCAgve07YtZWEoTEtTVfgoDdTgHMf9M0VZUZTtxVhTFBaQAIeUEg9Pz3x6eMR7gYEbDavlItvWJeJYKcXHTx85dSea+pySYkmJSwMyxUBMSgCjWmMIqBQzXzDR9wMxyUBCKUWzXFInqKpK7te97Ok/p1fIUe/zOIoyc7kkJPjUCbj3anuNNYrKCDh7TpLwpmKkrCzX2+WF8dSNsvegDKtWeDwuBE7DyMPjThI6k+LUTTzuTxd7u9YGbQtCSszTjFGwbmsUiWPXi90gRdarBeurDeMwMU4Tu1OX7XWRsqxxQXPqA6e+Z5hmitSi6lKsTme7sErs+5luCry5a2jrivuxx/uEsTorHRMqwXohn60pcjObihAjRkmgx/uHAylBlYdi62UNKPpeaq8X20bg0CaRouf5OJESfPHiBucDu37AaMWqEZWs89JMSY2sGd2UiFGxakphko5O9tRFg68si9KydJ566VgsGsZ5pixLvni1xs0j8zhAiGgSRVVSLhqWy5b1skUZQ8xNntl5VinRGEW9qEkLTaWhKS2btqYtC/Z9ou8d82lPQNHWctBrKwmBWTYVGvj2857TMHNztWRdWrSTgeNzP+NCYpkTfx/2R2KCqizBWPoL968S+yIy0Ht4PqC15thJjebODLpRmnzrUuF84n7f5SGexylIQSwcpqhJSnM8w47nmZDgOCRSEIwB1hCtJKRWGcJbl6LErcqSqtCUFlzQuGgpSmisISpNcBOF0WxWC1nXg5Ohg/doU9CUVlL1DmK3jNmOv1mvadqWoioIyjJHhQ+SF7NuayqrpeGUpAEco3CcMJZFVWK1YgzSLJ2iZgqSsBVipMxIjqIoKWvLtrnCec8P989iw/yZvFwfcYx8f/hO9mWt5d447iltyauXr6mqimbVCquxn3Bu5ng6YG3Ny5evKApDWSiGfuD+s6h33375lrIq2fc7jvsTH959YhoHuuOB1WbN7YsXODezvWpJyZCiDK9TFDt9eaPxLuFcxCepqa62W968urs0v8d+4vm4Y7GoWbYLhkPPsB8ZjxMqWsbTgA6Sxl6WFU0tDLTn3ZHDaeDlixtevrrl3Q+f6bsBU0cSopoZR4etoFpUvHz5BcZovv/2Hc45bm6uUErz6eMzMT5xcyWIiOvrrdQFxw5jDP/i3/kXFLZgs1pTWrFDxxhpG1Gr392+EEB1EvRA1YiVL/nEMAz8/d9/Q1lVvH75BeM48/y0p64L3rx9yzQ5Tvueqi5ZtC13tzfMbqaoLHevbjjsjjw+PjG7wOQd6/WC7eaGxXKJrSKmUtjKoKMFb8XlgWW9ucbainXXM04Tm+2GdtFyOB05Pe9xo6xZOg8MlqsNZVlzvV2xXlb8P/6ff8fDwxN//dd/wavNNY+PBdM48c0f/oRCc31zTbNc8O7dR+Z54nAUTmdhKoyx3F5fC9+1G0mzZ+pH5mHi6f45Iy5KZjfz+PwEJBahxjmHMRXjMPL48ETTVNxcLwizxxSWSGS/e2QaPbuHI0rD4+MTMSXqZoEpSmbvqJuaX1x9xThMHI8nhr7ndNxzdbXi7dvX4vzpOqwu0KpkHya6kyakmcCRcT7R9R3LZiUMztmgnOG7H97zx2/+LPbjpATivhQ75tAPPD7d0w97vvnmO2kivrhhuWlxc5BmkrZ5+BCZ5kGC3nJTaVbQzSJEGU6yNzaLBq1KXr5+QUqRQssetTseOZ5+muL8JzeeQJohfdeDUmhts48xYrSwPEqjqRtJ1Bn6Ph+sZQpdVjVl3VA1DZObcXmaulqtZfKevd/DONJ3HbvnPYvZgy5o6pJl2xAMmEK6kT4EiX+2hlmrC5DRx8Siqlg2JdMcmV2evvY9V9fiOT4eR/q+k4SfJLwjRSKNI7N2bLdbbFXRHw8EN3O7WVFoKY6dk83UGJtZEyFHRMKiFVvA/iASpbaWImfOntV6sRJFTykpIOM8o5XEpRvF5b0IYDz8IwaDzWkzMkExhfBVvJakl8PhwGJRc71p0SlebBxntkpdljIlCqKYmMdRonhrgd9GMuU+M5WaRposhVZYIxG3CkUSyMYlAaqwVvz5ClEc1TUnI3JR56QDHibx2m+WS+qqoq4E7CwchJGiKFm0C6rqmKdMA5NzvLi7QyHpej7IpFLYTzn5q6oF1MskhdksvKRDJu6LUjvbbvSZt+Q5nU75ADcT7FlxkdUBxjL5xByEb5HS+T0WtE1z4Q6clRNlBW0L/enEfhwojKYqS+ZpZp5nbE6rs0Up9741VNYyzIGU5pxwIO/VGs0wjDwdjoScxlIo4SrE4HHzyDAKu6kbJrph4nqzEsZKYYjniSWIki1EVGbFKG0kJQIF58Op9zlpKmX7l2a1XBJSyjHJP5+xm1Iy+TinxSRgdjPjOFIWkvpV17U03kJgspbkPfECKASMosj3UYyZ55FVOvM0CvcjQQgSYDDNTv78qqKqWlHfpaxeOvMyrGEclaga8/U2RmwAzottISDTe6USqJwyEoR9E4PPiWxGGghR1GwKdWGl2aKUBgtc0tvOjKeU8vsoLG0jEeoJJewJYlZTymdz80zMa4soIUXl0i4WwtbI8eHJeUIQi7ExkrCm8p8p6h1RPVgrUN95niTlxMpkPsSITj9O5VMURVFd1xhrL2ltZ+6CczOFUhgl0PSiKPJ3LBYSlVViSknDSuUJtNEaW5YYW4giK6WsWJX36Pkxsaqs6hxDKxv7uQF35jbMPlxSRUP+51prWZPSj1HnLifhFIWoyIZhlIN9FKbOOEp6qS2KfJ8l+fnc9DvvD+fGmvdeAjuSKLtOp2O2TIoKqXdOWDtVI2uAkvurLEtiqFkuF3jnmCZJYBE0gUIrA0HLRNE5+T5ThdIGUhBVL2Qll3CqhrG/WAqD96yXLU0tIF0QddI0K/q+pzudcoKmzjafH+8PzmwYK7xFggCenQuZ+SCMSVuUeW0XRVmV7bPadD+ZM/Bvy+usMBLeg8mJhDD5QJG/z8pqFiWi7OklcCD9ozVF5fpCoS48EmsUZz7i7APD7AFJnPQhMcwOq8BqQIv94byOKiXPLCRmL9zGlBKFNVRNjXcexnRh7Jyf+ZQEcO6cvzTLU4w4L0lfcp9DCpGYVObpSH3nQ8ScuUL5s0lCsaYwwiszOpLQFFpSwpyXpGWryfywzGAJHq00dS3T3HPC2DiLimbZtFgbGLywNNq6yAdSaWqqzCd1XlJCjZYUKBeFG2SNRmPRdUXShilK+tnsPbUtqasSgmOO5wTRJD9XiDKwqkqqsqAsSpyfSWdLL/I5lDaUpaHyNqsm1cWiPPrALB43vI9UhaFUlsIIaD1EmIOoE8qiwOKlQZMbKKusiD30Mz5GirJCI+yqFCNtWWS2IJBgGKX2Og3SqNdILR6zBlHUrolhni8Mw6SEmxmS8FOTgmGaZT1D7lXvM4cpSXWjzqlwWlMo8ucxea2Qde+8vxqlMmNO5f0isw3zenKu5SstSqQQAv04MzmPD5HbHJBgrOwZISVR/uchljHStLVJlG9xmknI/alRVIUo+eYkMGOfGVNzVudKI0Rf7t9FaZmNJCSP7ufTODfKEGKgH6WmVLnmnqYJhTDLqqpgtVwIgzHq/D1m6781MqAojTSzh0EaVZsNaBimgWEcRf13kqQ3HyNl06K1JHHGpInRZEakPIe2sqQYcFMkSfYOZVmyWi2YRsc8O4Y4Mk8zi1ZcF9PgcHMkuohG+IkxBILzeIzUXlp4w2p2YulshA3kvLhKTE7sm+eZsi4pK8NqtaAoLE+LlmmaWS6WKBQfwxNzTg/WStTqKorKWyvN1WabGU6KGGQgIHgXLQ6JusIam5XkBntOVQ6aaXIcjz1LNHXV4L0oGktEtU3S+Fos7MFHbGFzgrDKaiSVh0QyONNGi4K7MCid0AZ0ToAUpTj4zPUsqzqfueQ9FkUhNYybmbW6PKMAVSWoltJajEaGkeOIsfrys272OXAmcXt7Q2kt0zjJWTIr9KOBopCGsjWWKe+RbpYz0PEgSXltqzLDT/hGPgS0C0yjY5p8TsH0BOdJ2WmUILOpsjI4BEbvxdGTnQcoaf41bZPT6wzGwDieRJFUlXImjQGrbUYW5BpIJRKOGEXdH6Iw+7QxFJQ8P+14fnqWGhiDtlHSEznjkHpCnDjsdxx2e25uNigjTFtjEimjX3TmQCpyrZmEszk5UeIN4wxJUCXWCt9KqURTSsjE7tj95GAXlX7iCfN/95/8J0zTzJ9++IF5njG5+EimlIuaPE1d8ebVS/GV50LR+8A4zTwfDqAUtqxIIeCmgbqquFpvmLxn3405BWTLNE8cTx2nfuB5f7iwndbrNTfXN8KIykUQKdH34nc3RYUpSmqrqKzGeblxHu4/s39+5u7lK7bX19mSEhgyYPrF1ZpV0/C829ENA6cp4GLi69evWS8X9Kc9fp7ofSQkJLGpKNg0FYUxF0hracWS8rwXdsiilJS8q5s7jDWMk9hG/u7vf08IgS9f3chDEBLeOfY76ZIaW8oEvxH12Dx0l0lnTFIcFdayWi7w88Tp8IzJ/Cyx5QSRb08jy8WS27tbPt4/8g9/+DPb9ZJXdzfSiImJzWrJ7dWGp/2Bz49PVEVBXRSsV0vW65VAumPKXBPHqR8yy0rkpUYljIrU7YqyrCkLS2E1Pm/IwzjgvGNVNxTWMg8ngnM4xDLQnw742eFCJKJYLRfYDOvVSrFcLknADx8e6IeRQ3fEaMUvv3wr9sXJEUIiRFGDtW2DUYoSsZGgBGi573q01iyWK7yb2T3eY2zBaitxmilMDJPjfndis1rz61/+gmkcub+/R6DwkuZ3tV0zTROn44nVasnd7S3dMLI/ngTiOw2MLjDMgfVaJJYGJQV8tjntdmJ9HKaZYfa8eXnH7fWWP/zxG354/4FXr15xdX3FcOqZp4nb2yuWiwXPux19P3DoOubZsWxbqrLiq6+/Yrlc8t3339MPHX/xy1+yXi059T2zczw978XnnRtKX766oyotx1MvQP9RrGVvX7+iLIWfQIL/4D/49/8bFxr/fXz9b/6T/62oax4epNkcnCSnHE4URcHrVy+l2K9rQoj0w4CbJ077nRx8yppIuqT/WK0u8OiU1YlN03J9fS2HY+85Hvbcf/5E0y5Zba4IbsJPPWVVU9UNPtu8UrYmTbMUO8vVmuVqKXDwEDJbLUFOIovKENGXJkfbtgLk9o4YA7vdnnGa2K7X1HXFcrnC2oKHp2emaRKGhNGUZZnlxNJAaFfr3AzpL+BcozWbraTCDMPAOI78+U/fkFLi1atXWGtxOTjgcDjIwTMfhK+ur0gpJ7jla+SmicPTg/z7zHiLSme499n2pXFe1i6xedV0w8DD855F23K13TLPM9MoqXer1UosKUMv34k2tIuWZbu4qHZUbpxnZDHzNOHnmXa5pG6afJ0D6R8dSmKKwsfynuVqI+miSabh0zBkGLrOzAo5LFeFzddUGiiSkKc4dj3zPHPYPUOKXF9fYzILKkZpJGqlLoMLa3Jqoi0yr04YYSohhVuzkMN3tpoUZcU4Dny6f6BtG968epUP0aKEG8eepmm42lzhozTxm7pivVww9D37/S57kmAaJ4ZhkCTDsqSqa7H0ZaCkXCfx9R8OB168fM31zS37/Z5T111gwWe7T1lVWFswzlIUT2Mve0m2bb1+9Yq2bXl4eGCaZt68fXsJw/Dec8wKurMtcL3dYm0BSBPu8f4TKSXuXrzGWMs0ir3hP/wP/8P//y04/z9+/a//V/9LnPN8/vwoYHlTXADHWklSWwKBU5+bpzEx5aaIVtLQnWZp4grAGCCdv3aqomDR1PgQmbxndoFu9GgSRmU7ljEsq4pNK4rzQz9cbI0pN4OaqqKpSnbHjmM3UJeFKH0rCSqZ5wnvHLtuYJgcX9xuuVo23O97TuPMlBv4b2+3rNqayghg+vv7HadhFn6LglVVUlpDXZVykLSSVPt4GIkxcr1uqArLohHO5dP+xDg5Pj93KKV4ebMmobg/9AL1T1KrHk8nysLy8sUtCmGYlNZwu2qZXOD+IEwpq6T4D9mSLs0naeaFqJijKNhXi4qn/ZHvP36mKmWA2tQVy7aV/14Ji/T5NFIWhrqw3N1seXmzYX/sOBxPlNZQWoPPDQzvA8FHZu9wwbNaLKirGqMjipjtTJF9PzO6yO2mpa2KS5NatErgkgwdlZ8E1NtKOpHPluA5SPz3ODl8CBxOYhm/u1pRWE1ykmbnlQx3qrLKtfmPQ1QfIsdhyg2kkJNMi9wAr/L9o9ifev74w2c2y5a/+uVbYiInW3q8k31rs2zoJs9jN1EXlnVTXvZfOcZEumFm3w05ktyyWtRsFoKGOOMhEop+8gyzZ9mIIuxx33HoMtOpsrSLFWVVE3PTb/RRBrfioyAGhyJye3NNXdd8fDowzo43VwvayjLntMBdN+Wmrgy5V60oofwswwqHNHTvFtL4fx5kbfyP/6P/6L+bxeW/5df/8X//f2CcRv74x28Zp5F5lsRVawqsNbTLlqoqublZE2Oi7yemceJ5J0oVHxwkDcmSkMZv2zTcXN8yzxPH04Grq2t+8dXXnPqO+6d79rs9nz5+zjVaQdsuWK830uQqNd5POD8ydBN9N0oAlSlYLhsWi5ZxlsHxOEzM00zdFBRVgcGilabvRubZ8er1K9brFZ8+fuR43HP/tGOYZn79619wdb2h1GILf3jeMY6TAKxR3N29oKoqgu9RJDbrDUYbnp6OBB9YLgqqquDm1VuMtfSnE4fDgf/0P/2/4pzj66+/lEbQNBN8ZByyewKNsZp2WYo1DDDa0tZLpmnk/vMn6rrm9ZtXJMDPeYAE+BAYpol5nhi6A+v1ilcvX/D58wO/+/2fWK0W3N0K+/Xswrm5uub+8ZkPHz9jrFhLb2623N1eMXsZFnk/48PMNHpcbtyEGNnk0CvBFXjqSgDs4yzppNNpIMye9fWGqq6wGcMTgEDiuNszTxOn4UCIge32mrKssFrqWlMkQvD88P0HOTPtdxhj+Ju/+RuquuLpcCD4QBEllKBs5ecqU8geU1pm53j8/IDWmvX6JnPteiBidMiKxYLTqeeHHz5xdXPNP/3bf8o8Tzw9PuBmzzyObNYb3r59yzAOPO+eaJcLrm6u2D8/8/njB7S2aFvQDyPHU0/bViyWNU1V0zYVZFP0/nDgcDrSdyPjMPHlV1/y6vVLvv3mWz69/8Td3R3b7YZ+Hpm9y2KPmuPxmXHs2T3tmIaJ5faaqlnwxZtbFm3F9+/eMYwjf/u3/5yr7ZaP7z/S9z3H7sQ8zzw9C8v07ctXGSUhw4PjaYfS8PbNW1HF5lbSv//v/wf/tevCT1Y8NZnNUFYCLOPMLdEaMiOo8OYyESff0gmNjzGnJCWi6kQhYxRea/HbTjO7w5HSapq6xBgt8lUfsipEJq8xBEkl4UxWF5DvOVFCKwFJn6cq53+n1TmiVG5GknSmtdGSmFLIgy4sIJnCTz6ClhSyaXYMw4itc9x8jITZoZqcUJGnidPZ901OYcjKiM16RVGWHA4HkfpmtQkxgpYuqfOBUy9+56IUuGfdLmVKMkuqnZ3FMnU+zDUxyeJi5AA0zV4+qwKfztPhSJUPmbNzjNPMMAyEJOyIZSvNIjksKKL3jF4OJrKZ56mj1ZfpRTeOknhnC4pSpmbnmG9JGahIQVgMKbMSQkqYKKoAN08s1hu0KTg8P9H1vTQNrWW5XFKVBd3pSIqRsiwkEQe5xiZPynVO/CrLSorlTnhO1grks8wciKKsmZ2nG0eUyula0WTrgRRxxkiRODvPOE6sllEaYFqxt+YyrUg5UjklUcykGCmLgtkHTFEwDD2Hw4E5whyhmsUuZAqLtaWwdXJCmNEqHwYERHxOqrFGonyvNmt0tv+brFwap4lTJ4oupYVboVyAJFPqeZ4ZxjEDsCv0NIIXNVsIgWGciAmKQngwx66/qPbOhWKMlqoofrJX99+Gl7WFWE/IirCc7GVtkdlG0vEPeVM8q5pCTnwjytR8nGes1tg6F7zZAuPmmaospdhFfOpD3+Vmrc9rIhdLmigYxJJw5teEKEkrKk+uz8+dNgqVlLA1smpHK0kbInNbVJ4Cq5SNUFF+n0Z4BUrNkgJGTp4IkhZ3Vh0lZJIUdLyoa3TmgFVlKdcI+FGFJM+BpOc5nBNmQ0oJlVP7rC1FMTUMmccnFsV5nkDJ7zPWYssCF4Osr0aUhJDfh5WpMSlJct1sGacp//VM27TSxMspKd455jhTFAWxyeuwOaeVaoZxYJwmUpCiP0ucSFES1ZR8ScScsieMpUiMoj4TxRcXheA0z1lldl6LSqwxTNNMyjbpy3eTwecpynevgsAhkxJe3BlabzI3SWtNWZ9l3pm3luIF1E5WUCmtqarqYtlLiAokpszDyZ9N9qV0CQQpsxpzvqggohxm8xpSVWVWl8j9zFnVkp+Lc+MUZO0qipKicFSl/XEYk+Q7kJQYsQqqnCQVstr4rPYK3hNyI80WBW6es+ohZJWAvzDAJF7ZEwmXzxZiQEXZw5T++axdAE1VYpSko8WYmDJXrCnFkiCTZxglD4PC6POtLQqoeZLkydFRVZarwl7qp4Rcv9KazNgJxBFCBK2iNEc0JKWIF/WK8OWSkt+hUv5rxYUFl1K6sMZ0fu+FNQQntYlKeT3OKXM/7kMAEoFtjSYEYcFI6EJARVHaxEKa8inKPe+jrJtS88naZY1h1QrD5dSNoprLci+l5ZmafWYjhkDwYtEPMWblk8r2z5QZQnminSRdCyAqucfP/9NWEVUih/5CTrednXBRTE6jK8wsCWiFyUPAiPIKTbgczkhyxQujqcuC0+iEcemCMOZCHu6GzFsyosQHhVERmC8q0n/MJVrUFdYY3OQJPpK8/J7leS8KIa8jouofxpEYJHlLnTuVSN15rs+1SjklWl+amlgZIvSTKMhFKZyvaf6/UkoSGRHeVltX2KLIDVTwQUES7lxVFExZGUdWjkoyq+zZwhbzeV1O+KRoggSuyJ8VLnt9QtbeTEPLuANNW1mWbUVRiiphdKLWHKfA7CPLUtwHPl/7s6sjJrnGJt/nsxfFV8wKrNmLekRSITWE/M9zaI8kKioJTfhvdzn57/TVLltRV5QlJgSUFx5TVdWZP8kl/Vn2A9lnSaIcPxx2xKiIscBaTd0UuJyENg4j+92R1WIl9nWrmeKc08HFTWGMKKBlnZEFKeYmc4gBEDW5MepipfXeZSwDFIUociMRa8j7kxULalVlLEJkzvub1PPiihjHieBl3VBaMQ/CkNJakpAnr4nRM3SjJDqmfG7MB/jNekVZlZAC0/wjz1VpwSlM04SbPX0ndb1CUZUFy1UtA7Z5zm4kxzjMnI5ydhinEWsLOTs5T9/3l/ecknA8m6bODSlPP3QoLa6W8zBqvZLBWmFPKBTeeabJs14tSOLXlr3IGmxRMXQjp2NHzsW4XJMQpHasK1mTUj67ex8JLkotpaDUBUYZVlcbTGE5PB0Yh3P9BXVbUVcN4+CIPtIuaxLSeDTacU4QlpdCmcxfHYQ/1WxaUY6iRam2XDDPjlN5EDVQDk2pqpqYrbpKKco8bByGibWPNAtJtq9PNSpN+HG61C0kcJMjtYmyqihyrTzPnqmb8tl8kvuxgCY7MUJIBC/rmEICdU59l3mcooqtslpvu92ge0M/TXkvgHl09N1Iiikz8VK22cl+JuFevSgEM2MTssPL+8uA1FpDVRT4zDCNMaKSEocOiqauLuzF/7rXT248/e6Pf0RpTV03EknvJHa6O3UYo7nZbtFGsz8dCd7TH48oU1Cur4lIpKpMgg1VYVm3FT4mDt3A4XTk88dPuP6ATfKl9v2ILSuubm65Wre8vtlmBdSRkH5s1jgfWNQVL9drYTzNE3OELiaCmwhuZntzy5uvf4FVAjicJkniK5sFURuGSRpLw+xQ2vJXv3rNYtHikpaJ0nrFarXgxas31HXD7vmJYRh4//EjwzhepIOfPn/Ce89Xb16LNWu5JFrLH3/4gFKwrCykyF/86qus8NEkrbleyJSJKEqmL9+8IYTIp6dHtDG8+vpLQojs+pmmKPjF21eElDhOEjM+hCJPoiWufdm23N3c8u+8fc3zbs93P7zj4fEJ72em2dD1AzfXV7x585J5dny6f2DykbKWaPJpnkhKurk//PAD79694+3bt7x69YqmGJnsyN3tFVfbDV3fM00TEUNKmvvHZ0msUjKBnMee6B1qe0VoGjabLYUxfP/pgVP/hClqNjcLbrZraThNM93kOI4CD9QnSS143B+IMfIv/vm/oKoK/vz7v2c3Oza3LyX2tMhT8HkiALtplI3ejhRG82LTigLDTfTHI9/+8I6iLHn9pqRpGlbLLUvb8EUUG9Lf/Zd/lxukEJyj6weGsWd/2NM2FdfbFZvNimaxoBtHjrsdKkU267VsjD6Q/MzD/SfadslyuaZJ0GojMt6+Z9E0bK+2GAXPj4+8uLvl1auXbNYbFm2LSRGL53DY8fleisjCWq6vZMq2bFvKwvLp+Zlv339k6PbE4Pnu3Q/cPz1S6myrNyVVW3AnhFTmccygYJHH3m23oGB3PBH2h/8PIPLP4fXNN98ACRXlsF81rRwgkHt8uVgAie7UXQ7qWmma5SofaqPAfDPA+erqimkc2D09MjlHN4jUO+Xi082ekCKL1Yb1esXN1ZppHBi6RFKa0SVGlxWJxYq6XVFUnrYVaes8jRhjsaa4xIUXVSsbQlZISdBCQmcrwjyKuuXLL76kbRcMo/AyonekFLnJ/LkzELobBmGvZEC62+2ARLNYYo2s0Skl3r9/n5WCwvR78eI13kuDFkQpV1jD1fUN1lqut1uU1vggIQub1Yp5nnl+3tG2LV99+S+ysqDDe09/OODmieF0koIuBpaLJV+8/YJpmjmcTiQUhTWk6Om7E4um4e7VK3yMPD8/4p27WNJ83hN8gK470vcdTd1Q15UUkzGwWIjSaR57huMuH0B+tAsO3Qk3j1R1g7WSDDhOk6xdZcnjvfAkFss1ddP8o0OsY5hmDrudRKY7jzGG40HWruubW2E7dT0+OOqmkXSu/Lxd7HT5ED4+PIgara7lu89w1t3zkzTBU8gNa7H2vXn1CuEtPV5g30VZ0CzX8nvHGWM1V9sNRitOpyPjNGXrlaYspSle160MZrQiJei7U2apWE7zSN/3lGXJ7e2tKCTnibquRHqdhMkkjUnFfn9gGA5iu1HSWCysZfFqKUq8h888Pj7JIVspdvsD3TgxT2O2ZMj9aTLUfxw63DSKRUdrvvrlrwF4fHykO50I3v2sbMIAD4/Cn5hD5Ex/UQppRllD0yykQXfoUAqa3PBcmiLzgaSBWXWdXPuqwIfIMAlEth9nNJrVYuY4zHzeddI4DJ6rzZI3L6+Zppl+EP7K576XyPmsPDc5jt4nsVT1s2cOSaz5ufFK8DDnxpIpqWuw1mX+k8SRt2XJ67sNy7bicd/xtDtQNyXGWDarBcu2lhhspXg89OzHwJwiWicOvQxRlrWltAYXHGmKvH+UIUOMkbIw3Fwt8QnhDwHX65YYI10/olXF2xdbUkqMs8dguNqsgESX7S6vrheMs+fTrgdSBkhrrCly887S1iXb9ZLDMPH+6cToY1bjF2grQ87NssRHGEIi6YKq0Zjk0SkwTyOHw5H9aWR/mphbUTp1k2OYPVfLBau24nF/5NgJg8po+PTccRomrBbFYfQekwTO6yI0lcUq6EdHCBNVaalKxSmKZfD9/RMJgQ8rYCI3zcYBReLueoPRktLp50RTyNCjKVqM0dSVHCdG7/Fe1EfWKL64u0IB4xyYnOdpd5IIeiasMaxbsTv/6vUWbSzvPz9RGs2iMsIN7EZGF3FYVArcNIq6MjRlQRcjo89DBmUwtqBtamGVRU83OpKSg327XIobwHsWlaEtDVYndHK8ul5hX1zLANaoXM/C5BynbqQuCxaNND+M1iyaVQ7n8DzvTqgQqFTi2E3yXOUDmZd0DWorg06lFEkZitpQKcXLWrAcHx/3uBAoivJnVXv9v/7+d8QYmEOHspG6LVG5Y601rFaS1NmdJkmpzmcz58Sm3jYLCXKqaqqiYLNo8V5S8fb7I+/efWaeAoWumPzMoT8Rgufm5oaXL1/wq1/8kv1+z/3DAyRNDIZhUBxOgdVyzc1tK/eNNjzv9nz8+ChDOwVXmy2r5ZqkEykLHgCmKRDTzOG4x7lJIuvLmn/5L/8J2+stDw/PDL0IM4zV/Par39A0DQ8P7xn6jofHJz5/+pyT2wOfPz8QY+I3v/oty+USVdbMCf6Lv/s7tFLc3Eji7l//1W+Zp1ma/jGyXS8BRbqRYf/tyxtiCOwfn1EKXr8qcS7w+NixXi347b/3L3HO8fT0zDw6jm7MKXU9trA0i4bXr1/wP/53/zkP94/8/g9/5OnpmWmWdPCDMXzx5Vv+6q/+ku7U8c2f/sT+eODYP2O0xWjh3lV1xcMPH3n37hO3L264vr2mrpakVcHN7RWbzYrdYSdiFEAXJR/vPzONAylPMOqywVYFLjriHFnfrqirij99+y2H45FFVbJYVtytbjCFYZ483XHg6fEZ7zzjuEJpxek0ECP8s3/2zyiLku4wMHVHtA0UJHylQCX64SDq3zzAcJ8/CovvzSsATkPP6dTzpz++R2vFdtsSSosyGlNYfvPbXxGj5z/7v//fqOuW680tVhkKrehPR373u39D2zbcvbyVOikK3H2chKmKDiyWFdtNZpQqhZsi+6cTZW0pcmpqqQquN1esl2t0Ujx8fGC7WXB3+xuuttcslyuKR01xPLLf9wz9hEmwqJas11t0Ybi9vaOqGr754x/5/e93GSPR8M0fvuP995+x1pAUUrMZy83NjTTPipqoLFWlaNqaX//mFyQSf/jmGz5/vqew1U9eu35y4+l4OmKsZb1tcsqR2MtSkvGXtWIPmLJ3ehhGTJkoEG5EURhIoLRwbqqyIE3uAkzVeRrbj2PeHAJFJT7Ctm1ZrZa4EEF1wrzxHucjsws0FcL/yAeQs9w85XFcWVcslivwDkLAAURQRuXJtSTvhSAKIrEhtDyfBBor6XSGqixp6oreaJwSJVI/DLggv29/PGZ44QvkVyiI0M8jSiVqIylZTV1RxEQ3n5UXVv55I4vrernA+cDjfodWiroqcT5iJ0kmaaqSOUTIqSExF3zBy3RcG+HWbDZb+mGSznsI4v3NFkVrDYumkdQQ5whJYrx1DKhzWlFWf/V9JwqtrIJJIWLyxMlamz3rolKbZ2GGnNOl/DgSg/wzpTVmtaSsKrwXBc5iucBYeb9VWXCa5jyJUKAkNS8lYSsprVguFnLvxJwQl/3/VvTdkM6HN7EbzH6iLi3luoasFktRrIg6iDVSKYUtJCq9bWqGceB4OFEVhnbVopRMpFSSvLe6Ln/0Jqus6HIea0Uhok1E6cCUOUK2qHAxYnOqhqhKRL1VlQV+njmNjqvra1brNU2eSBqtUEqmpcM0UeQEoKauWSyWrBaNKCw+3rM/HNDJo1VimnPKUyFFUlJSIFqrIUraS4wapcxFaQHCDZqdJ89qfzavru/QStGUNjMhLCqeE+JUnrhLhz/EQMhwz3P6XZxmtIZCi9rCFgXzNDE7h3c+80c80zhmDo1HW5uTuERurZWWZMYkSrUQwmWyrI2wUhSSfJZikE1Qa/RZNZCbRik4UTQBP1plhLnkg6cqa5bLJS7bHKSRFpB0PnleARhGQpTvPOSUGUjUTQvn5z8lxmlEoSirSppMZYnSmnHsL6wLrTQ6T8ubphEFwiBATJ2LOGHKWBaLFbObOWX4fsyTkxADOsr6cubMxSTcJaU1RT5My2FPU9UVcRxxw3yZnIvaRda3C8dsdqLA8uby/Uo8umVKUdhbpkBlht/557wPVHky5p2/cINM5oQ457KiQV1YRzFEQuYDxGwzT0l4S3I/FXldHLIqTV/SXn8cx6WLEmjM9sHVohVOjzZZYSDKBZUtLTEJH6ZpGpxz9H2fOVaKlHS+vxQ+BkySRuE5ACTGKKrZrBQySqFN3j+jcL6Sj6LYMubSiDXGUOY1V3h2YqUSKBn5uzrzsBzKCIPL5ueirkVa70NgGAbqDGT3wZPmszLvR16hytc5eE9UkaSksVXXDQDBB2mihp/f+jVO84V9BFxCJGSLVChtz1vzxbp0Xm+S1tnCCsGLqrYsLAnPOXVSK1EyybqUOTYxovI6JGmCYqGcZlFNF9n+pYy6HMiEvSSKApS6KA3F6ppy01ysTlrL+xP+mUcpizaKti6kqbI7MTuHKSwJdVmr66yARo1ExKZKTAy5gF81xUXBl1Ji9sK1qgw/cqnONkSlaAoZmHknSpb1spUm33zME3sZRElSqaST+Zibaqhs/dOXv7bGUBaWti4YnL9M9quzEjRfR1E8C4dKAg4UJoHNkOphPDfkRFHkz2tTVmzZoriw6851+DQ7utFRWuEWFSSMEous9xFVGLQRa7ALgTJqjPlRyzrl99sU0gh3wWemkTC6ikKszBd1qxL+mM6pw0brjL8gs0ECYKgLsYZGvKjglCYmSeaTNUKayMumJCTF5DwqGSjV5dqrEJl9otCJxipJoMt7Xxb/ghJmXGGtKFQzamNyPidInZ8OaarLHEeSYBfW0Lb1hWN4VuKcURNGKUpzVj7I/mG04jQ4UTPFiEGuLUER8vvi/H/RWF3+9rw+V4WsqS5IerRS/ierBv5teB32R1AJbXK6m7GkCH4SxaJSou/yXtbwaRLrlTC7xEqsbUHVytmoqWv6YWAchwvX9WyR9THgXchnrJq2EVD/OA4oJecBlwLOBaYpsFyqzC+TfRil8nMua2uRf5/kp0mCWswq6BCjqH4zf09h2KzXvLi7Zb87cfQ9xIBWooxaLBZ0pyorOB3TOOFUIsTA/nD8UfGJKPoSicPhiCKxWksI0GKxoCxKTp00vcvSopVB65qqrtluN3jn6PYnlEpUZYnCi5qvKNhs1gyDNGdilBrJ+fPZTBRodVNzfX1N1/XS5IpRmJRGX1TcTdvQ9T1d3+PcBMTLM6G1ISaFc4FxGAk+02eTDLGssZnzm91RWoPSTNPM6XTKVjlDWVSghGMZUrgwko4CjI0AAFJmSURBVIZx4Hg80dgNqiwoSglOmEdPDCmzDUW5fW6CnDE1VVnS74fMv5X131gtkl2V8lla1HfHY0fbtFmBnzgNJ1G+54Q+eY5lDzDWsCoL+r5j93xCJYW50hdFpQ9yji4rS1WXYguPPyZxAmgjKri6qnMNGok+4pJDGdBF/ixa6mBtDMF5Tu7Ezc2Ktq3Fzp7V+IBgFqaJRVlS2oKyqbF1Ideirpimmf3uyNX1FaUuGAdposqZPI8flGBFTFaNxuymsEazWCwubNOu77Ha82M18P/99ZMbT0N3lCm8lvjQuhbL3egSKnn0bk9RViw21wQKunSkxrAoNaqsWJYvMiDNSOE+Ofqx48OnD7y4vuJ/9u/9TwhJMXpo65Kr1YJ+duz7kd3+wHff/ZnlYsnVesPT7sDz056I1Llu6jk8PVLWDWXd0DSWq9JiCpngzs7RHXeoKPa2w2lkGB0unYgp0ZbCJZq8Z3KB799/5P7h8dLU2XcjzkceHnaUhaEfBkLwLKuCVbXh/W5gnD2b9VLSM9Zrqqri85Mwm66vNpRlSVDCRHne7YULUzdobZhmh9aK2+sbNLDb70Bp7m5fMc4T3374RGktL25v8CHwp3cfL021FAKt9gxu4tAdKQvD9XZJSoE//OlPoqwpLc3VmrtljSkKTCXJAU+7PT4qbL3GRlFcle2Curyi60788Y9/xBYlv/7tX9JUBUO359P9Pe8+3PN4PLJ4/4E3r99wc3NDdzoyDoPIQE2Z7SWygAbvuP/0kaSgrgq25gqtobSKse8YBwhe1F7in1X88vUtxmj+/O4j4+z4zddfYLTmm9//G0iJ25s7lFYcj0d8gkUjkGOtxIZwtd0yTBO//9O3VGXJ21ev5BA8elarJf+Df/LXaFNQrrZUpdxv8zwT55HKGhZVkZNNNjwfjjz2H1guF7x99YKmrtksFzg38+nje9kIjBzOl8sFaAOm4PHxkWP/SawJCZ53T3zsT8LjWiyZfaJ/PvLw+MjzbsevvvqC168cpdFYrfj46TO73YGiWdAurzBxQhOEv7XZErLtYuiODMcnbq+vaduGV6/e0DQtQ3/Ce4frepEtH4+EEFi1NUVhWSxXaK34+PCYgXVySHh6+HxJpfw5vCLCDiqqHF9vixwfPuPdxMcP7wU6bYqLF75tW375y18SY+RwPOamiUzHx+5Id5JUzOVyyW9++fXl4LYoSxYLuZf6YaDrOx4eH1kuWrabDXPfczoecdMo8uxxZBolFco7R1mW1GWV7UvZBqgNxEBKAgCepwk3T7nRvKRqGuJ+zzSOPD4/Mcwzfd8xu5luv8PNM3W9uwAnjbWUZUVpNU9dJ5GsVS323rKgKCzj7HNDQ5oWXSd8sHGaUCTaOjeiiuIi61bRcTpIiqUtSubJ8fnzRzlUrDYAvPvwAQkykLS29XIpzS0tdu7bq2sS8On+/mI5qeuWZrGUpqHkuNLPYrEQK1iWLRuxR3TDwMPTI6W1rDZrVF6Djl1H1w8SYjCOBDcR3UzZCOw7hYnonKh6m1Y4WEYzzV4KqdycU1rk46fTCU6nDG8+hzFofvHVl5jCchpEpXjbNpCSTPRiom0baRYG/2Ma5aVw0zS12Gb7U1ZCif6c5IW9dbNdy+EuN4CKqsonL01dVCwWS+F4FQVd3zM87+TQXJaEFJmiu3xHCXJzRxqIKf+vHwdOp04CPIqCcRwvDYq6qnAhMrnIqXvCuZmb6xvWm3WG5Mt9Ms+eGD1FVWJNkQvKEmsNh91TtqlOaGtZrNYSG5wn/hZpzDojYF/vnNjHhwGtFG27QBPZPT0QY2QaTgQfsFV1GZD8XF77wyGDsCsBv8PFLjSFxHAUrpUMoOC5n7HG0Db5toiRqrBs7m7FZt3UfH4+8fsPe65WLX/z9Vt8kCCNVVvx4nZD1w3sdgfGyfOvv/nAqq3YrlrC4OjmgHEeq9KFpeOjJM6WRUFZFFwtKsqtJOuQEirz0VxwYi2IEJJi21S0hWGYhav5uDtyynzPafYcB0dMsGxqCmvwXlSWm0XNepG4fzoxzQ5DpLCKqhS7+u7Y55Qisdwtl0sATn0HKbFaLLFaCUvSKJY3K7Q2eZDmaWsB/x9OfT4Myn3djYE5JOrSYLVmWVeMs+d+17FeVNysavbdwPf3T1htWFUl22bNL263uCBK6BgT+26+NK0bq1lWlrZsWNYFn3dHvr/fsV00vL1ZymHXewECD46kOk5TIDoJK5jGETeNmBRZlYa6MBRGX6y+h25kPvbEbUtTFxcr09NBEtbauqG2EjKhlGK7rDFa8e7zE85Htnc3GC1175xmrlctVktC7rkJprVYVFJK1DZATghNQXMap3ztJ4w2fP3mTmLFhwlrFMtWBpHHThhMrZamjrYGHSdgzKEMhkJJc5zERa1b5KRDqw1Gg7aKcZhwsyP6GUfklBumy8WC5aKRVS5FHk8zu9PIl6rGFClziGaiMqQ8GFjmPTMaQ1taSqsZJkc/ew6nkdkFiWS3lrZpxAI4jcIoUoKZOJ4GsQObiqqEZalIET49DZJSqwuCMZy6Ltuifx6vuR/RRrFYSOO1aYTf9939D6QUOfUVVd1wc/2aafb8+YePtE3NX/76qwtz0JYFi/Wac9hF/9zzD7//Ha9fv+F//r/4nxJjYBwH2qbh6mrL6XTi6emR3W7H/+n//H9h0dZs1gt2hz2Pj/scOBVQyRGmCW1ElVk3Nb/4+kuScqA8ddlADjaIER6fduwPB8ahx7mZdlGyKFtiUkxz5Js//pkPHz+w23eMozAdJdAFlsslD08fmeeRzXrLZr3k93/8nq4fWK1XMrSxkdEN7N5L82Jzu6EoLS5bdftBwkQWy/YS1gCQwkxKA08Pn6VJvxAQ+HfvHimKgruXL/Fu5l/9/b+GJKErRampmgWHvefT8YmquuXtmxdoZfjjN98zjSNv37zlbUqg/jLjFBxVWfH+hx+YvadsCqr6iuvNDe2iYbFqGabAd+936LLmV7/9hTSZEnz4+I5v//wt3/2wZb1a8erla/7f7f3Hs21ZcqeJfUttddTVT4TIiIxMiC4U0CjAjD1pIwf8g2kccMIxRVmzq7rQBRQqZegnrjp6qyU48LXPDUzIHDRoxbDjYc8sM/LlvedssZYv959/v+vLGwbfM4YBowSBUtZLyrIGNTL6ns1mwzCOLOcNxsBy0ci42OjZ7Y7sjkeU1syqhsKV/N2/+2ucM/zuN7/j2LZ88cUnKK25/3iPAm5uLlFasV5viSkyn81wNk89KMUw9uz3B959/wHf++wwKe5wZeH43/0Pf0eInt1hgyssl5cXhJDojh1lVXB1eUVZOJbzmvVmz7v7KK6VV3OauiKR6MeBtj3Stj2obJ42r0QsoA2HXUu3P2CtxtvA7nDEx5HZbM5sMefx6Z7n9RO73YH20PL5Z695fXfFbrGnqme8e3fPer1D6Yg1iWa2oqlm1POKopD9rd8NBD9gVKQuK2bNnOX1HFdaxn7Mo9UybfHh40f8OHJ385qqLKnrkjB6/vj7r2UU83CQqYVh/yf3/P7kwpNwP/Lc+U+4GDFvyNnsQcYGtAFjJUFXIuNXrsBoRWE1wwBt6ETZkiJFYbm6vKAbAuOuoyhK5s2MpFr23cAwjjyvtyg0y9n8VHWeOqh4Gc8zRQXaiPwt80LKsmK72zL0ncjH82eerHtjiijt8giKOrGKhGPyMuso0OEjQ5+BuSmxbCqcdSjVkUhUrqCw+sQsGIaBOB0scjU9eM8wSneuLstTJThF4bUkhP0iSpQ86tD2UIkSqxsG+n4AEoUTq2qjpaOZksCPXQZRHo8tQydME6s1zawhGUMyDlD0XY+yJdaVJJ9IaaCwhqYq2O8jh+OB5aqgaWYYJayTibfQdr1wZ1KiKEpafSDxE36ChukpTEDf95KcZqaMdHwMIY65Iycz8EYLn8EZOcT5ccCPozhLGMv9h/f4ELi6usyuesd/wX5SKuUDjsuqOHHx8lHUFyjyuMEStCFlvlWML0oTrTWlk8JT3TQchlGeNeeoqjofSB2Mg9jaZ+bG1OVXSufrkLvOKeWFWxRQTdPgnCWMAjSe/rdhFNexOEqi3vUDg/dYpHtslM2KBC3KjihVemPkvarKQsaKyoqyLIXlFcf8robMphB1jkBAdeapSWdPn7rj2bHmZxJK6az4svl+cFKVCBvIo01CWydqmQzqttlFTWvpdDor882df2GFWCPJpox3TXwtSe51r4Wt1bYUTjhTMaYXBZIrhPcUsrMRnBbuSRFAVgyEmE5z1SFzTaZn7eT2o1SGxXfZ9W5ikggPKOQ1zeYDonTqpbsrIE5xgUv5PY8ps/GUOjmAxqwYUvn5mRwjyQpT7z06JZyRsblxGLBO2AAhBI7Ho3SvcrHGOosNVthszmV4oadtj9k0IOZR2vL0Pnk/Mg7j6XOb7G7knKMqC9pODh1FVtekEEhRrofP668bR1SMp65YIrNbYhAW28TOyorGST02qYu0MaLKmdRW0+KCoigLnCtkzAMyRDfRHg/EKM4x0zozXf+fNork5+nT8xBzURhkLymLAuD0DIYQ5DnInD6bWSuTCmF6l6eCX5y4J1P/PU0qq5QVC9KNCzn5AE7FMW3ytcmdupDVXzEE+MmeOrmWTdwZaQooJkWX917UZtrgnM6MKDmcKAVhyOBjrdBJOm+n9xZOri/Bi1GIsH5SZrb9vApPMSaU4eRKFqN0W0NMJCI+X9OpUTZO3KPg0ajMNhF1rTFGmIm5cGWNYTGrObY9u72oEMvCMg4GbXR2+xqFzxSyAjE/C1anU2E0pZ/IO1I6qTkma/IU1WnNFUWzsFOEeSNussSQFZ9KnM9SIk35Uf4jnyFSOCt7bC6UGi3ud5P60IeXXAOEZzmN4yoQUxRNVmGJ+kRrdVLWaa2ISZRTKl8nlZ3fAGkOZfXStEZM74/wOvsMVnc4rWiqQhigKdEnyaGM0fKuZo5W6Qx1KaNHfVYeF9YwjpExZdZUTFIE1x6LrM+TakeUnBpn5M/kyOaDGPyEWJ3UPCRZ0+T7kb+/5M7OWWnSgUDHM3tudzjK3jXlIJCLZ3A6A0wX/LSmxBPfaPCewimq0p32EpVzDTWNZSphLZGL3NJx11kBI8+XqJFA5Xtqcn49KWun+2dyPhOCrEXDMAr7LyMH5B0RF2MfhYk3jEEU4zrJ55musRIzHFE5SNHthfeVMsdFn/btODkgy1c4Pb9TTJ93zL97UhdolSXCP5MQxbPkSTbv+bL+j1nNZnEhMpkTjF5UP5OSNUVOTo8+jPTBiyo2Cvfr6uqCru/oB3FmbeqacRzQRpo3T09PxLigrgvGccQHOVtVlZgSBO9JvJgZucKhrUGZiMHyUwXykPP0mPMGeWY5qZVl+mWg70eCn/iDwtDRWlQ9o/dSrM8qwJTIjsqOEAPD2NO3Pud0S4y1okoPER88xCQjbUYmFji5D4urXVIQtKiZDm1HkxRNU9O10E5Nm5kUrkzeT1JWNJaFjOYdDgeiDyf1YFkV9P2I1i2QOByPJ/Wo/GOp64r5vKYdDuwPHYtGlFFG5NOMw8CxO2D3ovB7dfdaVO2tx2fA91T4t9YRkyhypzNTmIx9smJ3Mi9LxNOUizSkKjHPAIiJ+axBG8Pm8fnkCGytoSiF0+qsyyrsMr+nEaNN5ml5hkGcrVNMGGe4uFwy+pEhtJm9KTnN6efaksJZitKJ4910DrSST8b0co6W627R2mK0JZKNhJI0yqd77qMnRE9dkycW5P0ZMxZnHAbGYeR4bBl9pG07+n6gKBXOZcWStaf8a3LAdk7u24RJKKsSW1j8MJ6UWLJ+hhPX02uDamq01vJ7M191UkH9dI37/xR/cuGpqmrKouD13Z10pB+f6PuRqASC9dmnb1BKs+s8SiXurlZYrUghEoj0PsNUrWJ/aPnu/UfqsuDv/s1fUlYVm2PPbrfn/YePOOf48GGqAFqGvicpxf3TM+8+PnC5WvL21Q13tze8ef2Kjx/vef/+g8juioL9seWH7Z5PXxdcXtQnGJb3gRgi9aLENpG6rgWSbRQG0PaRw/FAUzU4a2kHsWL8yy/vmNUV2/2BbhhZr9eSODQrdFFxPSSWQ49KIlX+7rsfCDExm88E0qoNKcIP737EjyNGpxOc1hhDVRQM48h333+LMZq7m1tiHPj23XvG0dN1HbPacnO9ou8HdrstCYUrCoL3dMc9BZrFCsq6ovMeksKgaI8t3/zwI6vVijdvP6EfBg7bVjbeELi+vuL17RX7XWTdHgg2EP0oMOAotsoheIxzWFdyd3tHVUkhSuskvIGq5KA0MYgcsjCW5MUaV1uLpqI/CrBd24KqqqiaBp8UswxcXlUWqxXPe3Fi+8PX3xL8yNN6Ky+uNpRVxWK1oht67p+3lGXBX/z611it+f7dO0II1JWwnNa7HW0nfKcYPN988w2Fs6xmJWVZMFtdErxnt3lm0/X847M4Mi3nYv+eUmLlSnHEGD3XswqVAg8fP1KVBUPToK2hnK3AdJAU/TDy4eMDh+OR3X7H5dU1v/jscz4+PfOHr79mNau4WCxo6pq6qlgYB8ayagqO13Murm6YL5Y8Pq/Z7g/osuGimuGHgaHdcXl1RdM0HLqBY3fPYrmkKAv+8s//QjbishSgXITYd2zWa45dS106mqo6uSLu148kP3Ixb6ibhle3t4ze8/Ufv0YR+du//us8fvfziPlsLhyiywtijNx/vM9jOQFXOG7ubqU46QOFtei3n1IUBSmPBKQoiovdbitd+yQspF99tUApsc/th4HjsRUjgr7PI3AymlXXFf0w8N2P72iqgqvlnOVqxeXlFdvthvV6zaxpKIqS/fHI5tBy6QqaoqDvWhnry4u8JPeKoqwpK9lIhr5luVywWMxpu56+PYptbFVxd32FMTpvSl4yOciy7sDlpfADqkogvE8P9/hxxBXS5S1n4qC2PexJwHK1QmuxBR/SiB68OMD1A1prlo1hDJ7N8zNJwXy5oCorrpaLnED5E8soxch+txXLWi2JVEBGh6qyZn84sFmvpZBXV1nlofNYYWA+m3F9dc3xsGe/26JmM0onxTM7HaS0JDJaKWY+QApUzmG0omnmVIVje+zYHzt834uLUQYChyAcmLY9SrH/6hLnSooqCL+wEvbXxeUlzlnWz0+Mw8D94xMpJda7AyT47JO3FIWjLMqcDD9ijeHLL7/CWMv94xPejxzbFhAzAQHaiuow7Y+5m15irGOW1WM+BPa7HV9//XvKouLu1SsUcPADZVmxuriirGrevnlD34tTbFQTIDqQhkHG06Nn9CNdCIQEIUmR4+pCusfr9YbFYsZiPj8d9gsnSels1qCUYTZrqKuS56dH9rvt6aBRlPKZx75lHHuGviWlRN001PMFF80cYx1h6CAGAVRqzX67FjC+lgKD1Rq0Ruc1bnl5jTOWodszDgPaFWgUd7e3mff384nr62usVixmBTHC036kHz37/UHUhMs5CgFskwIqClx5N0rSa43FF46ycPS+43n/hNGKv/j0mqa0pDAwDB2bQ8v22POwOeQRJRndv1jUjMPIN9+/Y9FUfHG3ZDWfcbma87w98LjZYbU0ftpuoO0HOiVNtsIanDGMCXwSyHI/eC4WJbNaLOuttdiwF8CytRir0WPEofn1F69YNA33z1u6fkQTUClJYTolVsuaCzUjecEs+CEwpoDWFldYSfhJbNfrXBCz6Gxb76NAr0OI7B5EFXi9WgCKIUhxrq4NVeG4XmX8wfYIKTHPkONd2+FjYrFscFazb6VAv2oqBh94/7ihcpZFU0jDMwYGn+jGSFOXYkUdpXjbG0VnhEO6bGakpNgc2nywCmgNTaFxJmGS53JZs5gVbLYHjsce4wScPY10TQdiceg60pgFV5XhQzfQ+8hyLkBdmys2g7IEFI/rIzEEcaOLCZMiTmlCgH5I/PC4w1nD1fUKrTTdvpUisS1QKmGD4DNMbj5utnJgHYMnAZ2PWJVYFolD2/O7d9vcQJNnpS5LKajGiNGam4uFNDGOOzwwKFFzNnWJUZraKkIK4p41jBzagap0vLq9YLPvWO/E5W62spSVw2kIQZhky6agKTSz0hGT4tB7truOpipEPZcLkoehFxB9aHCuoDGaWWmxtiGmxLyQ5nWXIvuuJ7RDNkNSVIXhk7srQFFVovi8mItCv+47+nHEr/coo/jy7SeU1vz/fpH5V4q7t7doDWVtGceBH7//UUwmtGY+a/j1Lz8HYLfdo4n86pefUVYVpqyE15h6xiHQPz5xOB54/+E9s7rm//h/+B/R1vHhw3vaY8v6ec3aPnP//pHB97TDgb7tKEzB08OOH777yKtXd/zqy6949foVn376Cff3D3z88JEiQ7MfH5/58fv3vP30La9u7ujaA33f0XUH2uMRo2G5FF5rVdWkNIiit9I0usAWMk5eOUjW8Ze//oL5fMZmu2MYRsriTgQcVp61zz8Rdm9dS6Pyu+wYv5zPKcuSwXeMx4H1wzMheIpKcAtxdEQPYxLjlsOuxRrN5aU0Ru/vP8q5cRhoyls+fXsrje2+xUdPNIK18X2LsZrb2zfMmjndXtzQjt2B3WbPw7sH5ouGm7srYjKEYOmHA2235WK54G51SdsO7A8HXKWIwXHYPfLw/h3q+prGXhO0J6nI4mLGF19+JiNf1nF7d82rN3d8823Hcb2mqmrstSAPlGoplUElg+8Ch13PvL7g9vot6+cdIQ6i3NeWy5sVrnBsnrf4ceR3v/k9KUY2my0KxeXykqIsebh/4nho+eHbB+qq5N/+7V9grOGbb76nawf67kEKjKMITJJO9L7jD1//nqqsuFguKKuKlEa0huXsgs1my//rH/8TZVnw+u4WgBA2woS++JR6Ebh708j443pDqGXCyVlLVdUENEMC34/cP6xlnR46Li+u+OSLt3z77ff88Y/fcXN9wfXNhQDYtTAdlxeX3N28wjlHM6up6pL3797z/Pwd82bB5WqeWzKQtGYksn76kXFsubq+o65n/Ju/+ovcPBalqyh7A+tuFJMqA2Vp+MUvPpe9tRczpLefvqZuMqZn6BmyAcgvPv2Uwv1p58Y/ufDU1HUm2pfCAfBSBRMrW4OzLnfcpJKd+VinEGeJmDsKQv8vnVQvlYKuEyXPOIp8NqaYO9jSBSic4+g7jm3Lcj7LVtsli1nDtpSOjKjKw4kLkfsjMstpzMllzaBAi9tbVVaQlVfWvPCnrHX4FIlRuD/zupIZ+CRVx5gEFJxyl0lF6e6lKGMGIQTquiRFK92fPBPsvceV7tTRFkaHVEHlYGkyF0MkbMIkyR2f7AAjjC1hF0xdTpR0qmx2QEMpNFmt4EPmEmgimX8QIgThu8R8IBSeQBDnPzh1qqcO/OQoVJYFBlHAqRTxwwuDwjlLoS2+jwQSqRB7SusKxqhOM7TymSUx1ll5YxSiSsidhTDmzRuyUiRhrMEESzsEdIjUlUjwtVaEQFYtiDvFpERKMdINYukbm0K6S9qAzqDmEDh2Yps8q6wczIIo1obMQXFW3GfGcUSRZKymKCmNy51IuWf9MEpnJbswVVWVnQSEFSYwYNlAPFIAqApHuZifZP6DDww+UNcFpSsgeAQ7JLym4DPIOjuQifOfFEpQiDNHVhx471Gl8CCKQg5krdZZ3SXvls3jUjG7QEoVvPpTl4b/5kPeZ+mmBO+JeVZ/Ut1NroEKmcmflFHk7oPSAoESl0jEodEYXHZu85nZhZL72XWtwJjzuuSsQKGD90AhDj2FQO2PefQDyKoXdVK/xCR8oJCf5ZCB3SgpqkzdqhBC5sQZ+sGjCFgja3JZyXjh6MWhL2aXvZjVckV2vDRG2EWTIshYh8mdMAUnFyeblUBDZlslNf2sUz86dwf7kwuqqJtyNzr/k4j5GZbOllY/7XJzWndifj+j98JVUdmk4tRZeXEIDEFk0VpN3byfrl0mO4C4k1ubySpGpYeTalIrSR51VgrJPibdzUkxJWPOoJI6deGsKwBFSEkcWLOqB7LSKCullFIZhh5PvDCTlXUTJB30i1IECN7nvU3c6qYRncnFUJoZhhhFdTQpZsc8ijOptyYeVEwaFSMpj7MJX0KeY5QUAKfrNSnTdFZ5TZSUGOS+VGVJUdWZ1yN7h/f+ReWUFWlDEue6lAufEzfRWodxBaGX8fWJezYpBPSk7ZvupcnOoFq+06SsmFSmdlJB/4yiKIoTpyPEJPuWii/OjLy4+oprkFiqSUM+5U5uohtGujFwaMWOfl6KK57PqjFSwsdAN2Z+J5x4aGEc8/NZUFhDWdg8XtS9qOG0MIOs0Zm9M61rky5JXlux+c55k5oYPQIp10aUVsIMFZevpirEKWwcUVG+iw+RkCJNKWywpMR5buIipXxBjBG3z0nxZJyMz07PWMyF1pDHdmUNEQXT9J0EHq4zN0qutdGaERhDIKEpnMGoifci3V8xvxF+aTe8JMPTdXkxEviXDKfJLcnofzm5MF0zWZcSNo/TTrlkkVlLU2F/UuxrxUkxNK39YVpHJpkQSopwKRG9uOZNOVqMgRjU6XqNg8dPjDotDKyQEkmJmkzndcnkNUdYTunlmsdI0qI6g0g/SEHKOXmeC2OIyLOonRR0/KSgSgk/uQvHdBrljPkapphO3DznXngnE5/LZde9EOUs4rSiqMTRevTTszOtcqI8MFoUeIP32JCED+Pys44iMu0diuAjY85VU0yoPMZVupd91uR/Nxk4GK3QWTVQFpbqZ1Q4n88b2c+tKB19Vu9YZ3MzJhdk/ZaUoHCFqLG1luucc+ex7+mOHYf9kdI66rrCh8T+cKDv+3welWcJFYhKlCtVWclobz8CmqZuWMznrFZLDodjNub4l4U+rQwmj4arLFcTwxlRtZRlSV1VtO0gPE+jcKXN3DVLFAIf8/ksNwM7vA9YK2eFkIQV21SVLNhaeGfjMMq5pwni2JpEfSxTFZ6ikjFyyTUn5UzM76XKyqdA3/b5bC5F7CmHsdaSAgR+kp8kKMtKGs0n0bb8rGEcGEbH4F/YPdPERAiemJm1fd/jgxhsqZTInpE/WbsUReGYNTMZhzWiyAY514UQT9dUJmACTllUyiw7I8KNMAovUtx8RYE6PUcp5z1jVsMFH07TDaBOOf3x2OWx9UrUbUqTIvReuHU6CGtsUsK3uRmYWJyU2uQJFBICkY/Z9TSJ2sg6R98PcgY0CcZE8CJ8GUc5F55yWCXn8WEYJf9KMsHinM37VEJnTMJ0zp3Wu3JeslosRI0ZEVf2vmcxW1AUxUmNKWvdyDD2GYY/EFxJMRNhzJjZfmHMZ/9Evt+iMqurGqU0x7jPan/5g1KYaPL7o8S0pyz/pHXhT87Q/vt/+1fElGgHsV/EdzgSy6sVShveP21PYwFd3/Px4YFZXbP84lPqomRVN2x3e77+5lu8HymdY3c48D/9p/+Vuq65vr6SLspqjkfRRXmo5qWVauftFev1ho/391RVQT8OfLh/ZHfoeHx64uHxkTGDCD9/+5r/7pe/oB9HPj48osnFGqvBJEzfEcdAGDr64Hlerzm2R5ZNxaKpmC9EfXChl4Di2A1s2x2QSMaiiwqjDO32SR7KvNEfukEWGKMxKrHfbOiPB1bzhrIsubq6AAWFkS5uHyTR2e4PGK356ss/gxjZb5/ouo6xl4Xx7vaOoij43dffE2LikF/A/rgmJNnorFFUhRTi7i5WBAx9Bn5/ctxji0rsiIGmtBAURMXz8xPfvXuHdQW2qPB+II4dpXN8/uZOFGGFbAbOOR4fn1g/P7GYNTR1yffffcfXf/g91WxOUVV8+uYVV1dXbJ4eOR73TDa6q4sr2n5gs9mxXm8Z/ZCVC7I89fMGaxQfPn5kGAde3VxTLBZgZWN6eHrKC+eIVYqibnBFQde1eKWwSZLAdx/uSSlRlS6PcQqLrCol4TwEQz8kwu6ANZpmdYWbRXR1SfADod9zbDsenp54el5z/7zFOktZiBRTK5GMf3x8FOZZUdIe9myfH7FFgStr3n7yCW/evGYYpOtwdbGiqkoKo04SfZ0Sf/zD7/n9t9/zb//y1/zZl5/zu29+4If3v6OZzajKiqYoaJqKWSVjS8/bAx/Xaz65vWU5m9MdW3a7HfuD8Hz6o3RAXNWgraXSidoprEpoIg5ZUJdNTYiR++ctbA55Exp5eN4Aie9//PFnpRq4vliRECmy96PYpWrNYjGHBJv1WjaVPBq2Xa+p64ZmVotSpq4Zh57dbnsqLoYgi3lZliwXc1xRcn1zw3G34/HhA6uLSy5Wt/Rdx1FPclcB3xql2Gy3rDfbrAIZWO92dP3A7fU1n766pR9G1s/PGSYeBN5cuVw4Ele75IMAahNQJoxNzOcztF7g8u/a7w+nYilIgpJQJK0yrH+O1op3736k73uUq6iKhtLJ4a+qapSC5niQw0EhDJ6+a4kklHE4K6DBlHJxPUQw7lT0jrHj3cePUpDqh7zf5qK5nG5k/TEWMx0wSBTOcrlcSFE3JpwzlHkUBa3p2pav//i708GtqGoChrJuuMxFwRA8hasoipI0X2KKkhgCKRd2Ru8pncXOGxaLV1RlJa5NwUvhRSvKquZ4PPL89MCH9z9IMdkaGQ9GCpOuKE5OfavFLB+cpVjdtkcZ9UYO1iYXBGLwYA2L+ZxhGLhvZWy4KqQZk0jZXUwR48je91gnAN4JjqtIfPLpZ7L35iKSj4nxcGS/20uBarKtjnLQa1NAG5tHR8V+XBuDcQXLxZKriwu6rufYHrm4uuby6hoUJKVEwWIt3373HT/8+I5fffUVr+5u+fHHH3l8fKB0jqKw2S64wloBxLZdx/Fw4PLigqqq8iFt5OnxgRAT7WEn76Z7QmvLvKmZzRekMAIJbYtcdJWD436/FQbP86MU9bUUXp/X6zzC+POJiaETVEnUidJFgUebhRS6j+2pSKMU+FFTFpablThUusKy3nf85rsPTKOg22Hg4XlDUzluV+JKdne5YN+PPOw6KmdZ1i5DvQ21qVlWIvPfHY4cuoF3T9JlHgcZP+7GyOurJZ+9uaXzYj+viD8ZA8zPXakJaPox0u53jD6wbEpWs0oK1dayaGpUSjxvd3x82mTQdeTY9XgvFtpKKdI4QowEHJ7E5rBhHEdsKWObV4tGWBmFJZFeDEGyIUwwiVorPrld5RyuZxg949BK4aTQtEfPbzcbfIgcOlF2FtbhExx9onSKVeWYLNtjSPhBii1VIZDW/SDFWGsdplCsamEv/fjwnsJKUSSlOWVRYo1m1diTEmPsO8Z+QBtwkQy8zuOwQ2AYI72PvLqquF42jEH4d4c+0I+Ju9srLsbAto9suiP9mK/leg8KlrMFxlgeN2u899xezCicYTmfEWMSlRfSHCic5qkbKUjczCtKZ3nfd/Sj5zj0chippJi+wDCGwKGVazabNRRWHA5jTLQxkjDcXV/QDyOb/SEXtLPxhzUEL/buyliK5oKuPbBbPxLqWhp1o6fveoYQ6ELg+mLJL97ecexHDm2PtZblvKJ2htpmm18CH7cH3j0f+PLNNW+vVnx82vB8/8hqseDNqxtpdERpHhfO8rhrOR57lrM5s8JQFeJYtW6PtIPnYKTQN4zSNG+sxliHzzDg+ayRsUkv1/7xeS1w52HITQc50H77/vlUMPw5xFdf/pJhHHh3/x6tIteXovpRVoozDw87fPDsDi3eR7puw2o559WrS4rCoEzDYXfkw/2e4/GIHwMfPjzw/v09rnTUi4bFbMHd7R3b3Zb3H95zcbHk7Zs7nCkpXcNuu+Xx6ZH5bIlKJT/++MgP7+/pejFe2jyv2Txv+OVXn/HXf/PneJ/YbjaoBE5XzBoobMVuv6Ftj3TtlnFs2Tyv6dqO2zevWK0WLJoFpSswSr7b8/OaDx+fTvvvYd/iR4+kL5qL+QqlFL/5wx/ZH/ZoY2mamnEMKDw2qzYXy1rU+ZWwHFs/AAqrDFVZcHW1JKXEse3oQyCZkqpyvH39GmMN//TPv8F7z25/kPNiCoQxMBx6Ucw0MxarBVevrhl9oD70NGWNI5K0IaAxOuLsQKVB64rDoeUfP/wRH0aGMGCd5ebmNa/u3nJ9eYsnEFKkKiuqokJHg/IOW1is1Tw/rtmvdxz7HhXhi19+xqtXt8LHantUxvqkUrPebvnm22/54x++4divGUPPOAIoBt/S1BUPH58Yx5Hb2xVFaekGaY798bvvcYVwxJwraPv3eD1y7I6UqaRuChKBp3cbYozMGouyiaZu8viexY+Rh6dnnC3oDh5bWMp5hS0tn//iLUZbiqpmv9/z4eM9j49PfHj/EaUTqERRFNTNnBhh+7jHGM22ONB3A4dDKw1mEq/ubvn8szdsN1ueHj9wuWz4H/7+v8cVjqIsMFZjjeLxtx/5p3/6Z/7d3/4Nn3/6lj9+8z3v3t1TlJbVxRXLy0sWiwUqyXP3ww/v2G62vHq74vryhuPxyHa74+lhg9aW3W4rSAwtKvWb2xtmlw1PTz8y+JHVbE7hCoyaE2Lg62++kcaCNcQQ2W32aGVYb4Y8hfH/Pf7kwlNZlvgQ2B6FHwKScBeFI6E4tkMuwMQTD0S68fHkMAKckm/pIAXpYhnNoW2Z1RXLWQMhoXLnwhkDxhBzB9ZNSViMDH5EdV1WSnmGEBnz/G1ZOvo8110VMscZQ4CJexKyAiHBOIqteKpLqUbGmBURwljp8yiNyfP8JheOlB9ECZG7SOKYpaiqkhQCXdedut3S8VanuXhRKElFfTd6UVsVJSkrtpSCWdOIGkNrIjCOnpCEV+Bzdy9PuYKx8nBoeRiigphnZ6u6Qmkr0MJsxy7dPAvDyDh6lLE4PXEYEkVhKKpKeBD5GZDvIdcm5ZZqSpEYvNgrGwMpEvwokutJxZSEXYBSbNY7+r7HWE0W6OQDaMQjLBnp2FtsUVC44uS2Q5LuISrzZZQ6dQiNFktUed4CII5SooRTp1805o56P46EqNFJlHCucCgiwzFmd6tIGkYOx6MUjYrydA3kFk6z6rmLE8XVRDoiBbOmIaWWtu8xJn//3PGxeZ7ZZ3XMOI74k8uExyhFWTiZFXYOr0SUF9OLKkJmgD3jMHBoW+GODb08u1oO8E0t0PzpPYxJmANaSzLcZ4eoF+4R0vX2Py9nFa3Fta4fhswWyMpBYzJfrM/JfPgXKhXvfXZmmtghEvKfsjowz4JbV8ihIqtCjBKmVMiz1SZ3YCcV1cTGCTFkVUvI7DZZa4dRukrqJ8+bdHlVVv9N76Fm4ppMf29SGMQonBdRvnBSjIiTiPCh5O9lRkwid+0M1qoTv2TqmE2sg0kph54EOtJhTkmLDbISpVPK7LaoxdlpUgWKosmcOuBaTwqn3A0nd4tRJyZNUPG0FgnI1tGrLiuQOH2fSZ2ktEJFdbp+8t5m/lqSw4E8G/JdjUmZEZeVG0lUicaYzKfyrMNI13W5k65Oa0HMh8CJdSMHTIu18aQ+EMvcF67VpIIM/oXHlD9o/v/EUwFl6toLo2Bk6IUZYXJ3sizKXPTzpwJTilKcRCl0ko7U1JmarpOUrabufv7eWhwEh6wCsyd4dFZjZA6DKCGmkclw2k91WVI4GZ/SuauZktxLNSlcjRiMpBgYen9Se8QIcfRoHVGqQRtLCC+5hFJkhROE5E+udykrZqZ7MQltfi4xsUAGH7M6Oq/lWhGjOr2TE7NO2F75T2a3aS1FYJOfm0hiGGXfPrQ9dVUwqypciPkZMJQup4dJ1DbKZhe6fL9STCfGlveB0YtDojYak8AkJd3TrBDMNeYTpH5SWMesVFRZuRPTNCpLHhnxiK+UQL5DShkkrU5qm2jsqaAtRVlRkhgtY5rR6NP7CpMaJxfDtKawVhzN5IpnZZE6KQKF4Sd5l06gVRTX4rz+GjWtvSJiSFm16aywO0LuvMekMNlxUNa7dPpck6JIKU5qBVm3RSFjkJ8bY3YrkQ07f1edr+m0rmXukYbCWpTS7PaSa+SPeeKJiLccmWsy5v+/7F+TmpSUsFYYmuoFGgdZeRWixuQm4ol/aCcWkih1tRK1a8zuXeTRXmsM3mSeXHrhlcl6L8++QkZGmN7zlJ+FqQiX+Vc6q8W6weODTDsUVtRjeWs8saBI6XS/pzxWGriOISurOLVssgIKMOTrluQZ9iGhVUInfnLWeXE7TNPaR1YEZwaeD5Oq5WWP6kf/L3KN/38P4WQGYki5oGjlWmW3yC4jAPphEFeylKci8rlQzhmyTxtjT+Pqh+NR7o/V1GWNy/y6lNVndV1hdYE1Ba4sKMsyw+8RZVHo81nD03U9h2NLSpGytITMkHTWvkx9aLmXJFnzYuYgpuzgauzEMcy8TaDvBb9gXCH5z5Qr2ewAmTJvODcTxRFbXP8mpfHpSVAyDaK0CDJSgjB4lEL4oSmSjklGrxcLrLFZHRUF4D162laahUFB8vHkjvxT1zqY1KeaonRENFFrUJEQRxTC3BxUOKnmp8c1xZR5no526PBDl3NFGVtW2cBEZUc7UWUZylK+q8/KbplAEOVpM6sJKfB+88Rx16LshGWQd2zKKYdhODkNKyMKp6hS5nCCczXaZFWtJp8xtRRznMkqL2HxhhhwzpCXUvmsPqKSPCs2BLCiSi+KIpuyyLo8DiNeS13BWI0tLMbk9YCfnhslf1GJzEyViaWyFO7rOI40dcF81uQ8ObuITjlVVspOkxAxRqxzNLWo18TETUHIY5VeVPHOlRwO4gg5DgqVjLje57NgzM+7s/KMxcx3Ciae7vMwyCh/VVdZ2fmyL4Xwpxkj/MmFp3fvPjD4kXf3j3J4t9JxKIoC7z3tccfQD+z2B5q65s+/+oIYE+8en5iYG1VV8edffSkvbxCrv9vrG3Ztx/16g3YlZT2DrqXbP1NUF8zmCzaHlo9Pa5FU4mTPDQNWFdSl4+BEYTSra7SriGget7uciEeaZsZqseR5u2Hci7PRdr+nrhtcUWJdwcXSoI2h95H7H97TDwPNYoF1jv1mw9j3RCUFgy+++ILFYsG8Ehv6//ybP9AeW96+fkVVlpIEhsDD/QdiCBRlQ1SKh4cPjKMHZajrir/89a/x3vP9t9+QUmQxq3Knx3K7WvG//8u/4Gm74//6f/ufaKqSv/83f0bbDzx9+4MURlyNJVKpkaqpuby5Y+g7/uk3v5UX3Tis1cznM1IIBN/R9T37w4HZbMHy4orl1RWfW5PHxQIqBJT32KrBNjO69kh32OdZUENIMJsvUNYxJMUXX37J3dUlQ9syDD3/6R/+ge8+fOTzT95wvVqdnJrCMKJ84HjYcDx2vHn9WqSoc+FpiT39wL1xKB9IpgBbMZvJIcwVJSAOLilGXOxxMdGNgeAczXJOMVb0CXa7Pf/1t7/Fas2ff/k5SimeNmtiihgFxjm8X+KHke3zA86VXNy8YhxGNusdSWmay1cURrEs8yFtFPcR7wOr5YI3n7xlGD2HfmC+mHF1fYXJ0ECi5/uv/0DSlqgKGZUaB56fH3l6fuKLX3zJ5S9e8cUXXzCfzxn6lv/0D//A1c1r/vZv/oa6sJTOoF2BMpbHxyf2x4HGGup5SQrjSeXkgyhw+jHw5WefsZg1HPYHgvcsZjVGa949PDOMngudD5FBjAGU1VSF5ddf/RqlFP/L6BnGgevrm9NY3s8h1mvp5K6fn05JsbEWZUSiO4xZweRHCmf5/PPPiSmx3u6l21/Js1fPl7IxapUPv4q2PbJ+fiIBs9kMVxTcvnpL0zQU1jIoGGPAD4nei2Ojy3L7smjox0DnA3USV7S6bjBFhS0yAJs8SpASYehpu45+HKQjmyKri0uaphEL3pTYbHf0Qy8S61zwUsDhKG45r958Qt3MsApSDPzw7h39MHB1c4crCvCiMDHWAoowimS4z4ly+/GjKAkuLwHY7PaEIEYOKEho6qrkzSdv2e32/Mf/5T9SlSV/9utfMfQdP6zXkiyVVR6JyKMs2RHpkJVVMvoRSCjKSgq5bduy2e3E3WO+wFrDfDbDB7EHb5oG6xxt17HbbgXaWZZie9x3AiHtpwZJ4uLigsurK/wo42HffPMNj0+PXF1dM5vNqMoijy6TFTyOYrQ0TSOqnbxJ183sxOzz3lM2c5y19IPHkyhKgTEOgzhy3b75FAU8Pos6Z3kh19Lk4sDz4yMozWq5Qk+FL+/Z7db4ENmun5hGG4ui4GK1ymMzWirUYcBaRz2/zCctfXqOysIxb2p8Zu2MfmQc5F1XSjH0Le/fvzsdQl1REsry1BAwNOAsd7d3zGcLQvB8/c23NHXNl19+QVnW2KKk71r8MNANskYtlksuLlaMPtD1I37sicHTth0hBG5evaWqa/r2IHtmHsE/tD1+HLG2ywd7SV7rZoZzjk8/+5wYE+8/fiSmxGy5Orn9/FwiDh1jSDxsO8YQCV4K1NYKFNdmlc3T5kjhDLcrYfn98LTP70hDCPDpzVKeZasZfKRyhq4f+O7jEzerJZfLJXVRcr3UVIVhUTlRe+/bU7NrVhiWTYWyDm0L1pstT4cWVxRc1iWDD3x3/8S8Ekadc1JYHbLRhwKclgbWGBTzqsBpGFHs+5Fhe5DRC2elQWMcxjiOxx3Bj5RVTVM7FpWMCb6/f2IYPbOZOOx99vr6NIYFnEaoDseWMUS6QRTpb25WKKVpRxnL/zD0UozzibKw/OoXb2i7gd9+857CWj55dcMYIvebAwoBgSegTmJaksIoz6axeTzRYEqFs4ppfHV/7Hnc7lEUKOe4Xs64vWhyL0IO5SEm6ZLEKHblu5g5TCYX7QSW3Q8diorSKu4uZ1wta/7w/pn/8Lv3vLqcsahLqqIQ05wUSX5kv9/Rdj2vrpaZF2fzyJcjJSgzfaAw4IyUWZLRVFnlaq3NRSE56Hz78YHCWa6Wc+qmpho8bT/w9bsHtFJ8enuB0zD0R7RSjIUmKEWfJyOmIotxjhQjs4ygsFbgyc650xjnGBPH9oBRcHV9JYXYENBG08wrYkzM8pjcj497un6g7Xrq0nExq/LeceBy0bCa1/xCr7hazRmHkfcfPlKXji9fCxPPOkP0ihAUm8MRHyLOaG5XcwojDsy7ccgFEo8mUluDNYojGpmIz9U935MSPG38qdFDLsSXznG9EqXd1++fpDA8jdP8TOKb77/Fj57nd1uBc48dKChLwUo8PzwyDAP79sh8NuNXv/4VMUZ+97uvUdmJuKoqvvzlF4To6QcZrdtvdmz3R959fGCoR2L0VI3kHZcXCy6vLnh+3vHtd9/S9i2H456LOGJKQ1EYmrJm8zTSrvc0ZUHx5o4QR77//luIjpQs7mJJOXNs2zWb/Ya+HxmDIY6eRGKxuuD2VSXnxsPI7vE+oxxGUhJVdYqR9ccnfEz88pefslotuL6Uted//g//wGaz4+0nb6jKAuNklC55MRZIBNq253m9zkxSOcv+/d//Pd57/v3/89+jgEU9l2JMjFytlvzN//g33D888X/6P/9fqOqCf/d3f85hd+D3//UH0Jp6saR0jqtVTVFWzBZzgvf88Td/FPVdDMToCSlQOsusqdntdzw8PVKVFYtmxur1BbNfLX6SJ1g6v4ckBbpx6AlDz8EHOtOy2a3ZHXcUY4V1JV999Rlv3twSohRv/x//93/P73/7Bz777FMury6oaot1GmsqLuaXPJg1SUU+efsp88WcWdVgjSWmAe8HPt4/Mw4DHii04er6FoXBJykSHtqN5MvzBmMM24240lWVw5iK25sL9vsj3379HYnI9c2cBBwPIyoZynIJKbDZP5EixA+iyKznJQlo24FjeyDpQFmUrFZLbC48pZQYugPL5ZK7V68Y+p7jcYeeVVh9dTK18XHkN7//Dd4nfNL0IaCGnu16w3a94c3bt7x684Zf/ELqD0Pv+c//+Dtubq/427/9K6wzaCvQ7+AHtps97bGjbizN/Ib5fEFhS6ypMAq2uz3eB778/HMW8xn7vagPXSF7W0gFQ4h8uH9CKyitNKWrqqYoS37xmfDZ/qH7J8ZxpCgSRfG/ceGp63tGn628Y0S5ChWzO433mUPic6dWsZzP6IeBj49SJVVOk1Jxqgbr7Ig2nzVEFOtDizEub9I6q2cS/SgFqmPbyjyqc2idZypzZ3g6YE08icllBKSaSL6xY/5Z0i3Ussn7QOMMhZZLkVLKgMIOk+ckJzZTSAjnQnGyqyWlU4fCOZlZ1lp4Kc4VBB1OHeKJOTKEgPXizEdKJ0VGjNL5i0qhjKWqG8p+zF0d2ax07iTJJmbQyUMY8oFYqqGj91JB1ZoQEsorSEHmyHOPe3I1sFYI/OMwMGS2E/n6CaMgyIhe7urBxB2QbldRiOtd9KK+ObYt6/Wau+sr/DwS4pBVXvpfdPHsyRXGZGe1XLW1BhfzOE3KKqufMMPy7RR3wiCV7pQSReYhTDOtow8ok3C5C+LzQd05k+emhVnhR49ShnFyMjMGZRy6brAqovGkrK5LKIJANLDWCaDUeyms5rn0BALU96N0+1QijANh7E9V+ckFpSwKZrMGP4q8vywLLlZLiB6VwqmVMPFQ0BmuHAKJ7K7Bi2uidExFpWDy/UXJDLEPYredcqJHSvKf9eSI9tJNlL8f/tSl4b/5mNaKSdUkb4AS55H04sQF8n7XTSOS+H0LJieRSZFyd1zeZ41TwtWZutdTx2ZyLBnGMbvLiYud0i98EjeplCZFkZ7WB7KCIzsiZgVkyuqAST0Ss7JlStTJnY9xHOm7Lj8Dsh5MHI4UY3aGs1gth9WQuU5TEyGkkFWRAJmPpzW2KCCPGZK7NqcubpIubpq6gZnBM/1+ICuR9Ek1aq1l0mmd1FxJ+AHT3526YglRrOrcuedUVMtOHaMnJLmrL26rogiT+5rdt4IoBk+ONIBKZDWOzm56YqddliWDUkQTSFlpJe4nRe6CvrjpkdecSdkGWcWgJjc4fWIUiRJA3j8fpNAvh7kXhsmQoc4T32AqKlnrCATGQQ4zSalTEW26ppAYJ9WWzU6t001IE//EMrkdTtfm9FdiwiefbaA9yhhMdCd1309/V1lVHPZ7+r5nNmuoqhpt8j6ar//0LE2ss8EHeQezAkRlpYh8f06sv+mzTO+tjqKAyKKtk2pDa51vojopoyYOz88ltNbozN+LWV0E8t7JOj8JYORO2zwGOmSWYsgq74knU1oLBJxNjF6flBg+iOKntC+8omkvmNR8L+qPvOegZAwWKbZAfu+yImfao2QcNp32/mndEK6mzr8LKSKPHqs02ipQkx6H/O4YnPuJAyfCVZOfK3uqMZpx8Nlx8uW6kFUyKuee4uApa0UfM78PUULZ7Agpo8zppChyVgr5LhfKxyjNLMlr1emzxhRRMRGjqAckz3kZj4WItZq6MIw+O7/lrvukEpvcNLU2p5zMJ1GEnjrnMb+PRn7OoRto+xJnTFbmT0qvdMqh5PNkFYfWqLx2F9ag1cvPFkYIKCsKUpu77YWzJ5Wbmp4GWXxPLr1aq5MayWdn4UlhJKr06bvpzDcSrsm0R7y4YE7cTrlPU14jiv9AYTWFNSgVIY91nvJWHylsdvLM3wcleXLhLE3SbMeR0QcWTUlTFiSdmVZJJgliXoNOijZkfZneA6NFth9jwKeASur0uV/elnRy5ZpU/tMiJncmK6di4idP+88ihqHHj1mVkRk3sl7LfuKDz++XwRUFy+WCvu/58KEXhVPV5HxHzpVlVZ64bTGJ6ZXJbFQQkxRjDEM2edm34iSrjSEp8H7EWpXVd7I2aK1xmRk0rVsqiRJp9KNAn/sOkuzBfS85k3MFzWx2YuT1XUffDVmtI26LJDmP+RBlzyzLbNyTJxyCp6wqZk0NRlQmXuX9k3Tax3UwjL0/KUokh0mkqPBejJ78KCOsRSk8oH4YMC6P91uDsxqUOfGOlJJ101gxDhAMgmhLRSnvccadjCOmc7ZzoiCrqpJheGGtjcMAGMDkSZCA0wasXMth6DG6kOtvrGAbfIQQaNuO9WbL1dVB2MgYrDfMmyLnpo6yFFfxpmpO5+w+n/+sszhfZFW3ZlKi6nwP8mGSid0p58ZIWbo8gSDqoWEYXya5EhzSCCgKV0gxLqv3kpdGgDiEG6yxJ8WSsDHVyV03pXRSZ09Oxt57UdXKSBApqTwh4BlHGMeEUiOoRD8M4sgZ5R0oypJZ0zCOIj4oioLVasngB3wYs/Io8061kufH5P1iDGhlsMbldWrKlYWfrIzsXSl4UpLmw8vZyDK5SMskyHRGlz2/HzpS+tPOjX9y4anvpTNZWlBj5Gn9DEC7c/kgLyNFb17fcbGc8+b6ks1ux+/7lroq+Oz1He0Q+C/ffE9pFNczR2EtV7OS1bzh9avXYkPb9RSm5ObVpzyvn/kP//APssn4wOu7G7749BOZ+39cE1RP0pqoDLPVFT5IUls6w6Ku8yiDZ7d54unjj7x72vG0P/L29Ws+/+yOh6c1+8OB29UV18uGoZdCxMOTzF8brSmdJeSEOvoRBYzHLfs0sn7KUMowMHNykO2HEWuy7A5FMparizmlK1jNG7ph4Lv394QQ+OO332O04s3tVc4ILGOEvVeM+45//M3v6YeBi1mNNZr3Hz5QFI5fffJWZIHes9vt+faHNWNIzMoHtHHc3L3GOUfdNHy8v+e//ua3rOY1b28uqaqKop4JAyZFxr6jPe7ZbHc8Pm9YzWdcLee0+z3HvscWNa6ouF4tuL1c8ZvjH3h+fuLqYkFTzISHtN7y/Lxmv99jneP17Q2LxQJX1Xz48IHD4cBnn33OarWUg1XXUVcOnQL3Dw+MPrDd7wkhcLFcUDiHtRDHlvuP7/F+5NWr15JUIols23voBob+O4zRNDNxnfn6nTg63N7eUpcl5XxBP4xsh0hhDZ/evSaEwIfHNc5ZfvnlV/gQWO8ONFXJV3/2BWhLrwuO+x0PP/7AsTuy3qypmhkXV7d0w8jDes3z8zM//PA9s6bh4kI4BW3XcXV5yavbO+4fH3j/8XspPA0DZVVxc3NN6TRDuyP6HkVkeXnN4uqON29e8er6kt/+8Rt+/PCR1XJBU1c0Zclq1vDh/oHd3hO6HSlFLhYNlXNcL0Q588+/+z1t1/M3f/VvuLy45NgexbKcRGGgKgVofbF6g9Ga56cHhmHgN7/7PcM48uHhnnEc2R73PytOSlWVxFSgjQBqn5/XDN6z226AXDTQmnlTizry8oq2bbm/v8cVhuurS46HA99+8w7nHMvVhUiKy4L5fE5TVwx9z363yVDxmu12x/sPH4TREyOL5ZKr1YL9oWWz3eOcoXAZdB5GQlbdDF1He9hDSlRFSdu1AsccRBo+n81ZLResd3vathOThcIxDJL4Du2e/XbL5eUVhSsybFeSHptHfUPweWQPUY4UJSZ5GI70nYyvHdsWrRWfvv2Esiy5uXvF6D3ff/+9PCNbcZssC1E6de0RP45s1s8Zli2gxLvbW5RSPK+3GK14dfdaEom6YRh6Ns/PWCu2rmJ53cth1Gn2fcfTes0yrpgtlriy4vpGDidigywJz7Fted5smDc1cajxIWFdcXJzurq6ZnV5yTiObLYb5rM5VVUztEfuP/RoW4KxlPWMy9tXWOdObqIxJeqqxBrDfHFBM1+hkKQ3jJ6EZ71eZz5ATWEMx63sjdOo01RcK0rhBvR9L89FPomEDNjs+oGh7+VAp+RwlGJk/fSAtZabmzu89zw9PqKUcOsg0XUtVVVxe3snrnn5aBuSKDH80J/GhfqiIPhA13dsd/uT2kxMHizOCjdif/C0XUdSGuMcMbP/lFpgi4rY9rTHYzYDiXnM3PHw+Mhuu8MaKXJUdUNdV4Qo36/rOvzoWSwWlIUTEwjvef/+PV3f8emb18yamiH/3Bg8ikhV1mI2UtUni/gQAu/fv5OiRpQyxP2Hd6fRlZ9LXF1eZudHRzeMPG2Fi9QPI0OC3kjR53JRUjpH6TSnkXqlqQwcRs+Hpz2LpuLqzRI9eI7DgYt5zauLGUNI/Pi0ZVY6ruYVbdfz7umY1YRivdxU0oh7PnRYG3FOmEvD6GmqRJkLP6UzhAjt6Gm3HV3X04/CfLpcLZjPKg7Hjn4YcbOauqlwKALgx4gPPfOmpi4s9+sNXT8wXyyZFeJAZjQMQQ7rZVVhXcHloqF0NjdmYH2UBPxmWVE4A7ohhIQbZBSzHRLghesYA0PfAgprSzyJ+4cnxhApSknQt9sNWisWTgrQTVPRDYH77RFTOBbLhhAibS/N2d1hL43OtmPWNFxfrAC4XjRyb3yHsSXOFhzakYftkaIQdYdJYKNwzarCYFXC6MRmP7BpR5alYTWf0fnE+/WBIhfJaqt5tZJudjeM9HkMqDIymnx9sTyZ3mAMm04OvoU/YkhcX1xhnaPre9rBszn0hJ8cZOvLAqsVdVkRY6TUUjBquwEfAo8PjwzjSKECShke963kdp2nKgyFk8PgMSmUitTZNKdw0kQoqqWsE4OYL0QvRaHjMOaDapnZePLcPW2PrOY1s2rJOPbsDkfKqqIuhInZ9YMwG/eKymmqssK6CkxJSAOjDyRt0UVJVTcs5g0f1gee9wdUbvTNKkehLdvdga4XhERyluViQZl5gT4Efv/dj2wPR95cr5hVBSTBGWgrTajCyHct81jPoRsZfOQPPz4y+MB638kBFVk3fy4hI9yKspaGUbs5MviBbtxjlGZWz2kWcy6vLlmtVvzyqy9YP2/47rvvmc0afv3rr3h+euY//of/SFkVvH5zR1EWzFYrZqsL3nz2C3b7He8/fmA+q7i5WrJZb/jNP3+DD2I5/+rujs9/+RW73YH184axkbHuMSV0XeKHgO8Ds9sLXr96Tdcd6PqWzeaZ9+9+5Hm9Zb8/8Omnn3J9fcP3333LZrvni/pzXt3csO/WdEPLh3d71k877m5vmDU1x35kDIGy0pQpURc1pa55uH9gGHqKwrK6WFLUM3RRMI4dfhx5elqTgM8/fyuK5uslfTfww9fv8D7wX37zW6w1fPr555Dg2LUMw8jT0xPrzR5t/2eGYeD1q2uqqsKPlrpe8bd/99dEFB7Hfrfj3XffMl+MLG6WODT1rJExa2d5eHji2+/ecX1zyerimtliwS+aiqKoqRthUm62e56f1jx8fKSuS5pZjbEl1lV43+PDwJvlkrtXVzw/PvH0tObN64U46B0HPrx/ZLPfcmyPlHXNV3/2a2a1YAO2G8lZ9CvHrEm8fXvH69d3FKZCRcU333/LsT1ABIXm7uo6A9KlGff89EgMgcVqhnWO2WxBiond45PkFQheBVXQdwO/+S9/oOs60Im6qri6uMP7wMP9AWcUtzeXjOPA7rDBOljezBjDyGa/5mK54i9+9Uu6vuPd/YK+60Q91EaGTlSMRVmw2x3g+3fsjweenh4pq5Jm3kDUEDSriwWvb9/w7sd7fnz/I8qAclC5mvn8gqoqsSYxDh3b3Q5X1NzcLrm5veX65pr//L/+I998/Q3L5Yqmabi6vmE2m/H+w3t22y37/QMxJu5urlhdX1AWmrbr+C///BuOx57/7q/+nIuLJevtBu9HUpDC/sXtNWVVcbm8RCvN08MHhqGXc+Mwcv/xQz4TPP/JY8J/cuFpYhVNU8sxV6oHLd2ZFCPKGIpCxo2cNdg8x6pIlM7R+0TXD+BExpqMxmqdq4U1bddzaDuwUlmOCQ7HVrpt+fdWhQAvw6kLIgm8NlZYAlmdI45PMmYQg5dqdC+jZkopiiwfnlQDztk8s5umUV7gZf5Suk4+d8kCIYwMY8rsIXE8ICsTUu6yTfwMcdgwVEngcBOLqB9G2chnDqU0Q06eY4IxRNqulwp9dswYvdgZloW4kGkFR/NycIlegHTWOQGCFwJk7fqepnT5+2j0T9QQKVdHJzVYU5Unx4Oh71HaYR0nVzSFVHknFVKaeFM+MIyTc1uuqGuFD8Lxmu5RYR04ceoDYTj040g/jMQg6pEiK3J8yi4G4/jS2Yf8e/Os/OCJxuALYZCJO0DMCamTBEL57CQhzkCgMu9KeDpqHKWjoqApS5KxgGUwRgDFPjAMAzZznmJWK4zjQNeKVW/Ic7R9PxBClFntlBiGnjCOhGGgyNbRE0dsUkUYa1C2zAwzczqkNcNIcBZTVbissnnpYPusYJDnK8ZE13XsDkdikup0zMwB0kuHWmtNUZSnrqJC1IxdP4gbnvd0HS+D2z+DmLqt1mVXMHJHN0w8pyRW7Vrnir49dSaUAmssWmlRgGRlzqTYOPHqctdrckgJIdD1PZok3VJe5vZFwaFOXdyJjTcp1sRxUMsLnj/fxBGa1CZavyh/lHrppE+8HfWTrniMmS936sAI4yUhCi+TO3wnhUlWBokaLjuCFBV6HEXx6cWBw0yqJyXcuUk9lVLKHCIBUU9jc1qZk5ObK4oTm2ZSPE0sm+m5FqViEG4G/GTc4ycqBjL7zPt8D6RTM3334P1JZTTdu5PLaYz4MWCUdDuFnyAunC+OU4EYLCkrxbRSpzHHSRUw+jFzagRG77Oa1RSihCPff6auf3pR2L10vSflXcr7Xb5/SkY79EnRJIfJybnpxH0D4clkFUGEnyhGX9QyIf/x2XHLmswwQ0knmhc1WEwTtypf75SVpxMf58Qz4fRdhFXWQ2FRZlLcqWwykU7rts4j5dNY5eiHXOiLJ/VSjFmRlX/GqfurzYmlMrkZJlOIYmWUUcqfU0zKNZfdD4U5J/WLiHRLbUpZRZy7+VmdIWtYyp13MSPQ2qD0iztbVTpi7xnbgeDMKZcZs5Jwupw6u3uFmFAxonOn9KfcQ6NFTSNdU3l/h9HjfVZd5f1KwUktbrQhTcrPzMWZfo7kF17cxYywesQNLatx1OSkJ8rpqQDpw6QElGV0yneMUfl5nnI8ea7lWVM5h8vrSUyZTyLruUJhnTlxo7T+ifLFGGJSgBTEQ3Yp7oeRwvnTfZu+U/TybGsm5kfEWPlOOv9QpVTmwoVc7JbvBRZrND4los8eWimvj2ZSzU5ddsTQRE1sGU6MvxDFcc6EwMRuKQpHNww/UbvJfdZRnz7TC3tuYoulk9mGzw5YKt+DMWQGV5oU69M6k1X3ee8ymX1DkGs43YuY2Zc234dJnTf9+5gVX9P6+aJ2zP8dUAEK87LHnFRpMMkmT3v/1NA12T1Q1tn8E0/7dBKGozHErL4cfaTvX/JisoJTRu6yg51SJ0fVyZG6Hzy994xBmDaiaPn5NP2A0/qtNCfDj3EYiFnNa4yhqiqqujqNtIPkbVVZiSnQ8XDKxVOR3a21xdmSvhfu8KSICyGwPxxlgSSglaKpatpjl8UJL46xE68s5XXR2ZLR9LLW+Qyu7wfGYczNIAeKk9u4s1aelZBVb17OQNrIuQNyGqde1mVxnB6YWEqT8nBSjo85L9VGeE4qT7gYawkh0XU9zlkWswaVFEMnpkI+n7/2x0OeuLFYZyEJZ6maNQQUfRBjljGrjycl3uRC66xFoYW/6Kd9QkZJi6LA2eLEKBsHKa5rrfN9sygVxSEzSN5ZOCvX7KTCEWXZOHr6XvARSuuTA3g6KZD8if9XOAsYVBQXumHoabsWFTVGi5t7WQgP2EdO+aCMXIuiLmYHZjFhCYRgTm6YXdfT9wNl/TLum9KLy7K1hpjsKV+1hSWOgZjk+tV1idJynozBn9ajEzO2mJzSR4Z+EJ6rVrjRSeEpCn/MWYdCnhFyvlSYKk9a6azWlckNq8T1T/6I0cLxcKSqGsoqK+yq8jRNMI6imFM5l3DOMnpL23Zsd4esytSns6xKKtdGxOSirEqpHyhpbHWdnNvl3DgSov+T5Zoq/YvM8RznOMc5znGOc5zjHOc4xznOcY5znOMc5/jfJn5epfVznOMc5zjHOc5xjnOc4xznOMc5znGOc/w3E+fC0znOcY5znOMc5zjHOc5xjnOc4xznOMc5/lXiXHg6xznOcY5znOMc5zjHOc5xjnOc4xznOMe/SpwLT+c4xznOcY5znOMc5zjHOc5xjnOc4xzn+FeJc+HpHOc4xznOcY5znOMc5zjHOc5xjnOc4xz/KnEuPJ3jHOc4xznOcY5znOMc5zjHOc5xjnOc418lzoWnc5zjHOc4xznOcY5znOMc5zjHOc5xjnP8q8S58HSOc5zjHOc4xznOcY5znOMc5zjHOc5xjn+VOBeeznGOc5zjHOc4xznOcY5znOMc5zjHOc7xrxL/b1M3OgIzV7bPAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"display([model(t) for t in textures])"
]
},
{
"cell_type": "markdown",
"id": "0a466602",
"metadata": {},
"source": [
"## Optimization loop\n",
"\n",
"This optimization loop is similar to the one you will find in any other beginner PyTorch tutorial.\n",
"\n",
"We first initialize an `torch.optim.Adam` optimizer and use the `L1Loss` loss function."
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "2fcd5eb0-dd1d-4a58-b2d6-84997ebbfe41",
"metadata": {},
"outputs": [],
"source": [
"optimizer = torch.optim.Adam(model.parameters(), lr=0.0002)\n",
"loss_fn = nn.L1Loss()\n",
"\n",
"# Optimization hyper-parameters\n",
"iteration_count = 100\n",
"spp = 4"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "19ac7641-7401-460c-a855-985e6fe58030",
"metadata": {
"nbsphinx": "hidden",
"tags": []
},
"outputs": [],
"source": [
"# IGNORE THIS: When running under pytest, adjust parameters to reduce computation time\n",
"import os\n",
"if 'PYTEST_CURRENT_TEST' in os.environ:\n",
" iteration_count = 2\n",
" spp = 1"
]
},
{
"cell_type": "markdown",
"id": "cc2b89cc-0ca4-41db-aed7-37abcf9c1c4d",
"metadata": {},
"source": [
"At every iteration, we render the Mitsuba scene with the different pre-distorted texture images and propagate the gradients through the entire pipeline using `loss.backward()`. Thanks to `dr.wrap()`, the gradients will seamlessly flow through the rendering algorithm all the way to the neural network weights. We can then call `optimizer.step()` to update the neural network weights. "
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "86240e8f-e7f2-4e2a-8362-f92a164623d6",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Training iteration 100/100, loss: 0.27353306859731674\r"
]
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAb8AAAGsCAYAAABNUalHAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAA7b0lEQVR4nO3de1xUdf4/8NdcmBkYYLiMzACi3FS8o6CIly4rBa3f0q1t9beVxpZubrW5bLn5bdNvuS1dvtu6lWXrN/PWptW2tduW1U7pZqEoLt5CvAAC4gwXheE6AzPn9wcyOgrKIHDm8no+HufxkDPnHN5zHtbLzzmfi0QQBAFEREQ+RCp2AURERION4UdERD6H4UdERD6H4UdERD6H4UdERD6H4UdERD6H4UdERD5HLnYB/cFut6OqqgpBQUGQSCRil0NERCIRBAGNjY2IioqCVNpz+84rwq+qqgoxMTFil0FERG6ioqICQ4cO7fFzrwi/oKAgAJ1fNjg4WORqiIhILGazGTExMY5c6IlXhF/Xo87g4GCGHxERXfMVGDu8EBGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4XdDWbsOekjrsLK4WuxQiIhpgXrGkUX9oaG3Hgj/vgVQCnPr9D7kiPBGRF2PL7wK1svPfAXYBaG23iVwNERENJIbfBQF+MsefmywdIlZCREQDjeF3gVQqgVrRGYDNFrb8iIi8GcPvEl2PPpvZ8iMi8moMv0sEXgg/PvYkIvJuDL9LsOVHROQbGH6XUCs73/mx5UdE5N0YfpcIdLT82OGFiMibMfwuwceeRES+geF3CTU7vBAR+QSG3yUC2fIjIvIJDL9LqBUXws/K8CMi8mYMv0sEqroee7LDCxGRN2P4XSJQ2TW9GVt+RETejOF3CXZ4ISLyDQy/S3CoAxGRb2D4XYK9PYmIfAPD7xJdvT3Z4YWIyLsx/C7Blh8RkW9g+F2ia2Lr1nYbbHZB5GqIiGigMPwu0dXhBeBAdyIib8bwu4RSLoVcKgHAR59ERN6M4XcJiUTC4Q5ERD6A4XeZQCV7fBIReTuG32XUnOKMiMjr9Sn81q5di9jYWKhUKqSlpSE/P7/HYzdu3AiJROK0qVQqp2Puv//+K47JysrqS2nXjVOcERF5P/m1D3G2fft25OTkYN26dUhLS8OaNWuQmZmJ4uJiREREdHtOcHAwiouLHT9LJJIrjsnKysLbb7/t+FmpVLpaWr/gWD8iIu/ncsvv5ZdfxuLFi5GdnY0xY8Zg3bp1CAgIwIYNG3o8RyKRQK/XOzadTnfFMUql0umY0NBQV0vrF441/Rh+RERey6Xws1qtKCgoQEZGxsULSKXIyMhAXl5ej+c1NTVh+PDhiImJwdy5c3H06NErjtm5cyciIiIwatQoLF26FHV1dT1ez2KxwGw2O239Rc0OL0REXs+l8KutrYXNZrui5abT6WA0Grs9Z9SoUdiwYQM+/vhjbN26FXa7HdOnT0dlZaXjmKysLGzevBkGgwEvvPACdu3ahdtuuw02W/cBlJubC41G49hiYmJc+RpXxTX9iIi8n8vv/FyVnp6O9PR0x8/Tp0/H6NGj8eabb2L16tUAgAULFjg+Hz9+PCZMmICEhATs3LkTs2fPvuKaK1asQE5OjuNns9ncbwHIDi9ERN7PpZafVquFTCaDyWRy2m8ymaDX63t1DT8/P0yaNAknT57s8Zj4+Hhotdoej1EqlQgODnba+gsHuRMReT+Xwk+hUCAlJQUGg8Gxz263w2AwOLXursZms+Hw4cOIjIzs8ZjKykrU1dVd9ZiB4ujtybk9iYi8lsu9PXNycrB+/Xps2rQJRUVFWLp0KZqbm5GdnQ0AWLhwIVasWOE4/tlnn8UXX3yBkpISHDhwAPfeey9Onz6NBx98EEBnZ5gnnngCe/bsQVlZGQwGA+bOnYvExERkZmb209fsPXZ4ISLyfi6/85s/fz5qamqwcuVKGI1GJCcnY8eOHY5OMOXl5ZBKL2bq+fPnsXjxYhiNRoSGhiIlJQXfffcdxowZAwCQyWQ4dOgQNm3ahPr6ekRFReHWW2/F6tWrRRnrxw4vRETeTyIIgscvXGc2m6HRaNDQ0HDd7/++OVGD+97KR5I+CDuW3dBPFRIR0WDobR5wbs/LsLcnEZH3Y/hdhtObERF5P4bfZS4OdWCHFyIib8Xwu0zghbk9rTY7rB12kashIqKBwPC7TNd6fgAffRIReSuG32XkMimU8s7bwk4vRETeieHXDc7yQkTk3Rh+3eD8nkRE3o3h1w1OcUZE5N0Yft3gFGdERN6N4dcNzvJCROTdGH7d4Ds/IiLvxvDrRtdAd4YfEZF3Yvh1gx1eiIi8G8OvG+zwQkTk3Rh+3eA7PyIi78bw6wZ7exIReTeGXzc4vRkRkXdj+HWDHV6IiLwbw68banZ4ISLyagy/bgSywwsRkVdj+HWDHV6IiLwbw68bl7b8BEEQuRoiIupvDL9udLX87ALQ1m4XuRoiIupvDL9uBPjJHH/mo08iIu/D8OuGVCqBWsEen0RE3orh1wN2eiEi8l4Mvx4EqjjcgYjIWzH8esApzoiIvBfDrwdqBac4IyLyVgy/HnBZIyIi78Xw6wEXtCUi8l4Mvx6wtycRkfdi+PWAk1sTEXkvhl8PuKYfEZH3Yvj1gB1eiIi8F8OvB10dXvjOj4jI+zD8ehCo9AMANLa1i1wJERH1N4ZfD8LUCgDAuWaryJUQEVF/Y/j1QBvYGX51DD8iIq/D8OtBeKASAFDf0o52Gxe0JSLyJgy/HoT4+0EmlQDgo08iIm/D8OuBVCpxvPerbbKIXA0REfUnht9VhF8Iv7omtvyIiLwJw+8qtBfe+9U1s+VHRORNGH5XER7Ilh8RkTdi+F1FuLqz5VfL8CMi8ip9Cr+1a9ciNjYWKpUKaWlpyM/P7/HYjRs3QiKROG0qlcrpGEEQsHLlSkRGRsLf3x8ZGRk4ceJEX0rrVxdbfnzsSUTkTVwOv+3btyMnJwerVq3CgQMHMHHiRGRmZqK6urrHc4KDg3H27FnHdvr0aafPX3zxRbzyyitYt24d9u7dC7VajczMTLS1tbn+jfoRB7oTEXknl8Pv5ZdfxuLFi5GdnY0xY8Zg3bp1CAgIwIYNG3o8RyKRQK/XOzadTuf4TBAErFmzBr/97W8xd+5cTJgwAZs3b0ZVVRU++uijPn2p/nLxsSdbfkRE3sSl8LNarSgoKEBGRsbFC0ilyMjIQF5eXo/nNTU1Yfjw4YiJicHcuXNx9OhRx2elpaUwGo1O19RoNEhLS+vxmhaLBWaz2WkbCOzwQkTknVwKv9raWthsNqeWGwDodDoYjcZuzxk1ahQ2bNiAjz/+GFu3boXdbsf06dNRWVkJAI7zXLlmbm4uNBqNY4uJiXHla/Ra11CH2iYLBEEYkN9BRESDb8B7e6anp2PhwoVITk7GjTfeiA8//BBDhgzBm2++2edrrlixAg0NDY6toqKiHyu+qKvlZ+mwo9nKFd2JiLyFS+Gn1Wohk8lgMpmc9ptMJuj1+l5dw8/PD5MmTcLJkycBwHGeK9dUKpUIDg522gZCgEKOAEXnorbs8UlE5D1cCj+FQoGUlBQYDAbHPrvdDoPBgPT09F5dw2az4fDhw4iMjAQAxMXFQa/XO13TbDZj7969vb7mQOpq/XGsHxGR95C7ekJOTg4WLVqE1NRUTJ06FWvWrEFzczOys7MBAAsXLkR0dDRyc3MBAM8++yymTZuGxMRE1NfX46WXXsLp06fx4IMPAujsCbps2TL87ne/w4gRIxAXF4enn34aUVFRmDdvXv990z4KVytRca6VLT8iIi/icvjNnz8fNTU1WLlyJYxGI5KTk7Fjxw5Hh5Xy8nJIpRcblOfPn8fixYthNBoRGhqKlJQUfPfddxgzZozjmOXLl6O5uRlLlixBfX09Zs6ciR07dlwxGF4MHOtHROR9JIIXdGM0m83QaDRoaGjo9/d/v/ngELbvr8CvbxmJR2eP6NdrExFR/+ptHnBuz2sIZ8uPiMjrMPyuITyQs7wQEXkbht81aDnLCxGR12H4XQMXtCUi8j4Mv2vg/J5ERN6H4XcNXSs7nGuxwmb3+I6xREQEht81hQb4QSIBBAE438LWHxGRN2D4XYNcJkVoAB99EhF5E4ZfL4Sru+b3ZKcXIiJvwPDrhYuTWzP8iIi8AcOvFxzDHfjYk4jIKzD8eoFj/YiIvAvDrxe63vmx5UdE5B0Yfr1wcX5Phh8RkTdg+PXCxZUd+NiTiMgbMPx6gZNbExF5F4ZfL3RNccahDkRE3oHh1wtdjz1brDa0WDtEroaIiK4Xw68XApVyKOSdt4qPPomIPB/DrxckEgmGOMb6MfyIiDwdw6+XLq7rx/d+RESejuHXSxzoTkTkPRh+vdQ10L2GLT8iIo/H8OulKI0KAFB5vkXkSoiI6Hox/HopVqsGAJTVMvyIiDwdw6+XHOFX1yxyJUREdL0Yfr0UG94Zfmcb2tBqtYlcDRERXQ+GXy+FBvghWCUHAJw+x9YfEZEnY/j1kkQiQRzf+xEReQWGnwuGh/O9HxGRN2D4ueBij0+GHxGRJ2P4uSBOGwCALT8iIk/H8HOB47En3/kREXk0hp8L4i6En9HM4Q5ERJ6M4eeCULUCGn8/ABzuQETkyRh+LooNv/Dej51eiIg8FsPPRV09Pkv53o+IyGMx/FzUNc3Zafb4JCLyWAw/F8VeGO5QyseeREQei+HnoljO8kJE5PEYfi7qmt/TZLagxdohcjVERNQXDD8XhQRcMtyhjp1eiIg8EcOvDzjHJxGRZ2P49UFc11g/tvyIiDwSw68PLs7xyZYfEZEnYvj1QVenl1L2+CQi8kgMvz7oeufHge5ERJ6pT+G3du1axMbGQqVSIS0tDfn5+b06b9u2bZBIJJg3b57T/vvvvx8SicRpy8rK6ktpg6Jrfk8OdyAi8kwuh9/27duRk5ODVatW4cCBA5g4cSIyMzNRXV191fPKysrw+OOPY9asWd1+npWVhbNnzzq2d99919XSBk1IgAIhAZ3DHbi2HxGR53E5/F5++WUsXrwY2dnZGDNmDNatW4eAgABs2LChx3NsNhvuuecePPPMM4iPj+/2GKVSCb1e79hCQ0NdLW1QOd77sdMLEZHHcSn8rFYrCgoKkJGRcfECUikyMjKQl5fX43nPPvssIiIi8MADD/R4zM6dOxEREYFRo0Zh6dKlqKur6/FYi8UCs9nstA22hCGBAIBTNU2D/ruJiOj6uBR+tbW1sNls0Ol0Tvt1Oh2MRmO35+zevRtvvfUW1q9f3+N1s7KysHnzZhgMBrzwwgvYtWsXbrvtNths3a+WnpubC41G49hiYmJc+Rr9In5IZ8uP4UdE5HnkA3nxxsZG3HfffVi/fj20Wm2Pxy1YsMDx5/Hjx2PChAlISEjAzp07MXv27CuOX7FiBXJychw/m83mQQ/ArpZfSQ0fexIReRqXwk+r1UImk8FkMjntN5lM0Ov1Vxx/6tQplJWV4fbbb3fss9vtnb9YLkdxcTESEhKuOC8+Ph5arRYnT57sNvyUSiWUSqUrpfe7Sx97CoIAiUQiaj1ERNR7Lj32VCgUSElJgcFgcOyz2+0wGAxIT0+/4vikpCQcPnwYhYWFju2OO+7AzTffjMLCwh5ba5WVlairq0NkZKSLX2fwDA8PgFwqQYvVBqO5TexyiIjIBS4/9szJycGiRYuQmpqKqVOnYs2aNWhubkZ2djYAYOHChYiOjkZubi5UKhXGjRvndH5ISAgAOPY3NTXhmWeewV133QW9Xo9Tp05h+fLlSExMRGZm5nV+vYHjJ5NiWFgASmqbcaq6GZEaf7FLIiKiXnI5/ObPn4+amhqsXLkSRqMRycnJ2LFjh6MTTHl5OaTS3jcoZTIZDh06hE2bNqG+vh5RUVG49dZbsXr1atEfbV5L/JBAlNQ2o6S2CTNH9PxOk4iI3ItEEARB7CKul9lshkajQUNDA4KDgwft9+Z+VoQ3d5VgUfpwPDN33LVPICKiAdXbPODcntfhYqcX9vgkIvIkDL/rkHBhrF8Jx/oREXkUht91iNd2tvyqGtrQbOEE10REnoLhdx1C1QqEqxUAOMcnEZEnYfhdJ87xSUTkeRh+1+niHJ9s+REReQqG33Viy4+IyPMw/K5TQsSFll81w4+IyFMw/K5TV8uvtLYZdrvHzxdAROQTGH7XaWhoABQyKSwddpypbxW7HCIi6gWG33WSSSWI1QYA4Hs/IiJPwfDrB5zmjIjIszD8+sHFVd3Z8iMi8gQMv35wcawfw4+IyBMw/PpBV8vvZDUfexIReQKGXz/oavnVNllgbmsXuRoiIroWhl8/CFL5YUhQ56rzZZzgmojI7TH8+kmctrP1x9UdiIjcH8Ovn8Rruxa2ZfgREbk7hl8/YcuPiMhzMPz6CcOPiMhzMPz6SVePz9LaZggCJ7gmInJnDL9+EhMWAKkEaLJ0oKbJInY5RER0FQy/fqKUyzA0tHOC61J2eiEicmsMv37E935ERJ6B4dePGH5ERJ6B4dePujq9lDD8iIjcGsOvH7HlR0TkGRh+/agr/E7XNcNm53AHIiJ3xfDrR1EafyjkUrTbBJw53yp2OURE1AOGXz+SSiWIC+9678eFbYmI3BXDr5/xvR8Rkftj+PWzuCEMPyIid8fw62ds+RERuT+GXz/jun5ERO6P4dfPulp+VQ2taGu3iVwNERF1h+HXz8LUCgSr5BAE4HRdi9jlEBFRNxh+/UwikSBuSCAAoJTDHYiI3BLDbwA43vux0wsRkVti+A0AR49PdnohInJLDL8BkHDhsefhMw0iV0JERN1h+A2A9IRwSCXAMWMjztRzjk8iInfD8BsAYWoFJg8LBQB8faxa5GqIiOhyDL8BcnNSBADgK4YfEZHbYfgNkNmjO8Pv25O1aLVysDsRkTth+A2QUbogRIf4w9Jhx3enasUuh4iILsHwGyASiQQ/uPDo08BHn0REbqVP4bd27VrExsZCpVIhLS0N+fn5vTpv27ZtkEgkmDdvntN+QRCwcuVKREZGwt/fHxkZGThx4kRfSnMrP7jw6PPrY9UQBEHkaoiIqIvL4bd9+3bk5ORg1apVOHDgACZOnIjMzExUV1+9dVNWVobHH38cs2bNuuKzF198Ea+88grWrVuHvXv3Qq1WIzMzE21tba6W51bS48Ph7yfD2YY2FJ1tFLscIiK6wOXwe/nll7F48WJkZ2djzJgxWLduHQICArBhw4Yez7HZbLjnnnvwzDPPID4+3ukzQRCwZs0a/Pa3v8XcuXMxYcIEbN68GVVVVfjoo49c/kLuROUnw4xELQDgq2MmkashIqIuLoWf1WpFQUEBMjIyLl5AKkVGRgby8vJ6PO/ZZ59FREQEHnjggSs+Ky0thdFodLqmRqNBWlpaj9e0WCwwm81Om7viez8iIvfjUvjV1tbCZrNBp9M57dfpdDAajd2es3v3brz11ltYv359t593nefKNXNzc6HRaBxbTEyMK19jUHWFX2FFPWqbLCJXQ0REwAD39mxsbMR9992H9evXQ6vV9tt1V6xYgYaGBsdWUVHRb9fub3qNCmOjgiEInO2FiMhdyF05WKvVQiaTwWRyfn9lMpmg1+uvOP7UqVMoKyvD7bff7thnt9s7f7FcjuLiYsd5JpMJkZGRTtdMTk7utg6lUgmlUulK6aK6dYweR6vM+KjwDO5Odd9WKhGRr3Cp5adQKJCSkgKDweDYZ7fbYTAYkJ6efsXxSUlJOHz4MAoLCx3bHXfcgZtvvhmFhYWIiYlBXFwc9Hq90zXNZjP27t3b7TU90Z2TowEA352qQ+V5ru5ORCQ2l1p+AJCTk4NFixYhNTUVU6dOxZo1a9Dc3Izs7GwAwMKFCxEdHY3c3FyoVCqMGzfO6fyQkBAAcNq/bNky/O53v8OIESMQFxeHp59+GlFRUVeMB/RUMWEBmJ4Qju9O1eGvBWfwWMYIsUsiIvJpLoff/PnzUVNTg5UrV8JoNCI5ORk7duxwdFgpLy+HVOraq8Tly5ejubkZS5YsQX19PWbOnIkdO3ZApVK5Wp7bujt1KL47VYcPDlTg0R8kQiqViF0SEZHPkgheMPWI2WyGRqNBQ0MDgoODxS6nW61WG6Y+9y80Wjrwl8VpmJ7Qfx2AiIioU2/zgHN7DhJ/hQz/NbGzQ88H+ytFroaIyLcx/AZRV0/PT4+cRWNbu8jVEBH5LobfIJoUE4KEIWq0tdvxz0NnxS6HiMhnMfwGkUQicbT+3tvvvgPziYi8HcNvkN05KRoyqQQHyutRUtMkdjlERD6J4TfIIoJVjpUedhztfu5SIiIaWAw/EdwypnNM5Jffc5kjIiIxMPxEcMvozvArrKhHtdmzF+wlIvJEDD8R6DUqTByqgSAA/yriSg9ERION4SeSW8d2rmbx5fd870dENNgYfiLpeu/37ck6NFk6RK6GiMi3MPxEMiIiELHhAbDa7Pj38RqxyyEi8ikMP5FIJBJH6+8LDnkgIhpUDD8R3TKm873fV8eq0W6zi1wNEZHvYPiJKGV4KMLUCpjbOrCv9JzY5RAR+QyGn4hkUglmJ0UAAL7ggHciokHD8BNZ15CHL44aYbd7/LrCREQegeEnslkjtAhSyVHV0IZdJ9jrk4hoMDD8RKbyk+EnF5Y52vxdmbjFEBH5CIafG7h32nAAwM7jNThd1yxyNURE3o/h5wbitGrcOHIIBAHYuue02OUQEXk9hp+bWDS9s/W3fV8FWq02kashIvJuDD83cePICAwLC4C5rQMfF54RuxwiIq/G8HMTMqkE911497cp7zQEgcMeiIgGCsPPjdydOhQqPymKzpqx//R5scshIvJaDD83EhKgwNyJ0QCAN3aeYuuPiGiAMPzczIOz4uAnk+CrY9X48ADf/RERDQSGn5sZoQvCsoyRAID/+ftRVNW3ilwREZH3Yfi5oZ/fEI9Jw0LQaOnAEx8c5JyfRET9jOHnhuQyKf5w90So/KT49mQdtnDgOxFRv2L4uan4IYFYcdtoAEDuZ0UoqWkSuSIiIu/B8HNj900bjhmJ4Whrt2P5B4dg4+NPIqJ+wfBzY1KpBC/+eCLUChn2nz6PTVz1gYioXzD83Fx0iD9W/LDz8eeLnx/jqg9ERP2A4ecBfjp1GNLjLz7+ZO9PIqLrw/DzAFKpBC/cNQH+fjLsLT2Hd/ay9ycR0fVg+HmIYeEB+E3WKABA7mfHUF7XInJFRESei+HnQRamx2JqXBharDbkvFfI3p9ERH3E8PMgUqkEf7h7IgKVcuw/fR7rdp0SuyQiIo/E8PMwMWEB+J87xgIA/vjlcRw50yByRUREnofh54HumhyNrLF6dNgFLNteiLZ2m9glERF5FIafB5JIJPj9neMxJEiJk9VNyP20SOySiIg8CsPPQ4WpFXjpxxMAAJvyTuP9/RUiV0RE5DkYfh7splERePQHiQCA//7bYewtqRO5IiIiz8Dw83C/yhiJOeMj0W4T8POtBSir5fRnRETXwvDzcFKpBP9790RMHKpBfUs7frZpHxpa2sUui4jIrTH8vIC/Qob1C1MRqVGhpKYZy7b/B4LAAfBERD3pU/itXbsWsbGxUKlUSEtLQ35+fo/Hfvjhh0hNTUVISAjUajWSk5OxZcsWp2Puv/9+SCQSpy0rK6svpfmsiGAV1i9MhUIuxdfFNVz+iIjoKlwOv+3btyMnJwerVq3CgQMHMHHiRGRmZqK6urrb48PCwvDUU08hLy8Phw4dQnZ2NrKzs/H55587HZeVlYWzZ886tnfffbdv38iHjYvWYMVtSQCA3392DMeMZpErIiJyTxLBxedjaWlpmDJlCl577TUAgN1uR0xMDB599FE8+eSTvbrG5MmTMWfOHKxevRpAZ8uvvr4eH330kWvVX2A2m6HRaNDQ0IDg4OA+XcNbCIKA7I37sLO4BqN0Qfj4kRlQ+cnELouIaFD0Ng9cavlZrVYUFBQgIyPj4gWkUmRkZCAvL++a5wuCAIPBgOLiYtxwww1On+3cuRMREREYNWoUli5dirq6nrvtWywWmM1mp406SSQSvPTjidAGKlBsasTznx0TuyQiIrfjUvjV1tbCZrNBp9M57dfpdDAajT2e19DQgMDAQCgUCsyZMwevvvoqbrnlFsfnWVlZ2Lx5MwwGA1544QXs2rULt912G2y27qftys3NhUajcWwxMTGufA2vNyRIiZd+PBEAsPG7Mjz7j+9hMreJXBURkfuQD8YvCQoKQmFhIZqammAwGJCTk4P4+HjcdNNNAIAFCxY4jh0/fjwmTJiAhIQE7Ny5E7Nnz77ieitWrEBOTo7jZ7PZzAC8zM1JEVg8Kw7rvynFhm9LsXXPadyVMhQP3RiP4eFqscsjIhKVS+Gn1Wohk8lgMpmc9ptMJuj1+h7Pk0qlSEzsnIkkOTkZRUVFyM3NdYTf5eLj46HVanHy5Mluw0+pVEKpVLpSuk/67x+OxoxELV7/+hTyy87h3fxy/PVAJTZlT0V6QrjY5RERicalx54KhQIpKSkwGAyOfXa7HQaDAenp6b2+jt1uh8Vi6fHzyspK1NXVITIy0pXy6DISiQQ3jYrAew+l472fp2NqbBisHXb8fMt+nKxuFLs8IiLRuDzUIScnB+vXr8emTZtQVFSEpUuXorm5GdnZ2QCAhQsXYsWKFY7jc3Nz8eWXX6KkpARFRUX4wx/+gC1btuDee+8FADQ1NeGJJ57Anj17UFZWBoPBgLlz5yIxMRGZmZn99DVpalwYNj8wFSnDQ2Fu68D9b+9DTWPP/wAhIvJmLr/zmz9/PmpqarBy5UoYjUYkJydjx44djk4w5eXlkEovZmpzczN+8YtfoLKyEv7+/khKSsLWrVsxf/58AIBMJsOhQ4ewadMm1NfXIyoqCrfeeitWr17NR5v9TOXXORPMna9/i7K6Fjy4aR+2LUmHv4JDIYjIt7g8zs8dcZyfa0prm3Hn69/ifEs7bhg5BGvmJyNMrRC7LCKi6zYg4/zIO8Rp1Y6p0P59vAa3/vHfMBSZrn0iEZGXYPj5qNTYMPz1oekYERGI2iYLHti0H8s/OIjGNq4IQUTej+Hnw8YP1eAfj87E4llxkEiA9/ZXYsGf93BJJCLyegw/H6fyk+GpOWOwbfE0hKsVOFplxsINe2FmC5CIvBjDjwAAafHheGdxGkID/HCwsgGLNuTzESgReS2GHzkk6YOx9cE0aPz98J/yemS/vY8BSEReieFHTsZGabD1gTQEqeTYf/o8bn91Nw5XNohdFhFRv2L40RXGD9XgLw9OQ3SIP8rqWnDnG9/ird2l8IIhoUREABh+1IPxQzX49JezkDlWh3abgNWffI/Fm/ejxdohdmlERNeN4Uc90gT4Yd29KVg9dywUcin+VVSNBzbuR6u1+3UWiYg8BcOPrkoikeC+9Fi8u3gaApVy5JXUYcmW/WhrZwASkedi+FGvpAwPxcbsKQhQyPDNiVo8tLUAlg4GIBF5JoYf9VpqbBg23D8FKj8pdhbXYMnmAg6GJyKPxPAjl0yLD8dbi6ZAKZdi1/EazHvtWy6MS0Qeh+FHLpuRqMX7D6UjSqNCSW0z5r72LXYcMYpdFhFRrzH8qE8mDA3B3x+diWnxYWi22vDQ1gLkvFeI76vMYpdGRHRNXMyWrkuHzY7cz47hrd2ljn3p8eF4YGYcZo+OgEQiEbE6IvI1vc0Dhh/1i/+Un8eGb8vw6eGzsNk7/0o9cnMiHs8cJXJlRORLuJI7DapJw0Lx6v+bhG+W34wHZsYBAF77+iT+WlApcmVERFdi+FG/igrxx9P/NQaP3JwIAHjyw0PILz0nclVERM4YfjQgcm4ZiR+O16PdJuDnW/ajrLZZ7JKIiBwYfjQgpFIJ/nB3MiYO1eB8SzsWbsjH3/5TyWnRiMgtsMMLDahqcxvmrf0WVQ1tAACNvx/umjwUP00bhsSIQJGrIyJvw96e5DZqmyz4y95ybN9XgTP1rY79P0iKwIOz4pAeH84hEUTULxh+5HZsdgH/PlGDd/aUw3DMhK6/eWOjgvFE5ijcNCpC3AKJyOMx/MitldY2Y8PuUrxfUIG2djsA4O6Uofjtf42Bxt9P5OqIyFMx/MgjnG+24pWvTmDjd2UQBEAfrELuneNxcxJbgUTkOg5yJ48QqlZg1e1j8d7P0xGnVcNobkP2xn1YurUAFedaxC6PiLwUw4/cwpTYMHz6y1l4cGYcpBLgsyNGzH55F17ccQxNlg6xyyMiL8PHnuR2io2NWP3J99h9shYAoA1UIHtGHO5NGw5NAN8HElHP+M6PPJogCDAUVeO5T4tQemF2mACFDAumDMPiG+IQqfEXuUIickcMP/IK7TY7/nnoLN78dwmKznauFRikkuOPP0lGxhidyNURkbth+JFXEQQB35yoxR++PI6DFfUAgEd/kIhlGSMhk3KAPBF1Ym9P8ioSiQQ3jByC93+ejvunxwIAXv3qJH62cR+KjY2w2z3+33BENIjY8iOP9Lf/VGLFh4cdA+SDlHIkDwtB6vAw3DttGMIDlSJXSERi4GNP8nrfV5mR+1kR9pedR+slq0UEqeTIuWUk7ps2HHIZH24Q+RKGH/mMDpsdxaZGHCivx7t7y/H9hY4xo3RBWHXHGExP0IpcIRENFoYf+SSbXcC7+eX43y+KUd/SDgCYNUKLZRkjkTI8VOTqiGigMfzIp51vtuKP/zqOv+wtR8eFzjA3jRqCu1NiMDTUH1Eh/ghXKyBlT1Eir8LwIwJQca4Fr311Eh8cqITtsh6hSrkUP0iKwML0WEyLD+OagkRegOFHdInTdc1Y/00Jvq8yo6q+DabGNlz6N3+kLhCLpsfiJ6kx8GMnGSKPxfAjuop2mx3HTY14N78cHx44gxZrZ2/RqXFhWPvTyRgSxKESRJ6I4UfUS+a2dry/vxJ//PI4miwd0AUr8ca9KZg8jB1kiDwNZ3gh6qVglR8emBmHjx6egYQhapjMFsx/Mw8bvy2FpcN27QsQkcdhy4/oEk2WDjzx/kF8dsQIAAhXK/CTKTH46dRhiAkLELk6IroWPvYk6iNBEPD2t2V489+nYDJbAAASCXDbOD1+O2cMokK4nBKRu2L4EV2nDpsd/yqqxjt7T+ObE50L6wYoZPhVxkjcPyOWvUKJ3NCAvvNbu3YtYmNjoVKpkJaWhvz8/B6P/fDDD5GamoqQkBCo1WokJydjy5YtTscIgoCVK1ciMjIS/v7+yMjIwIkTJ/pSGlG/kcukyBqnx5YH0vDZY7OQOjwULVYbnvu0CLe/uhv7ys6JXSIR9ZHL4bd9+3bk5ORg1apVOHDgACZOnIjMzExUV1d3e3xYWBieeuop5OXl4dChQ8jOzkZ2djY+//xzxzEvvvgiXnnlFaxbtw579+6FWq1GZmYm2tra+v7NiPrR6MhgvPfzdLxw13iEBPjhmLERd6/LwyN/OYAz9a1il0dELnL5sWdaWhqmTJmC1157DQBgt9sRExODRx99FE8++WSvrjF58mTMmTMHq1evhiAIiIqKwq9//Ws8/vjjAICGhgbodDps3LgRCxYsuOb1+NiTBtO5Zite+vwYtu2rgCB0zhTz/6YOg1QiwdmGVlQ1tCFYJcdDNyZgRiIn1SYaTAPy2NNqtaKgoAAZGRkXLyCVIiMjA3l5edc8XxAEGAwGFBcX44YbbgAAlJaWwmg0Ol1To9EgLS2tx2taLBaYzWanjWiwhKkVyL1zAj55dCbS4sJg6bBj43dl2PBtKT47YsTBinp8c6IW9/zfXvx0/R4cKD8vdslEdBm5KwfX1tbCZrNBp9M57dfpdDh27FiP5zU0NCA6OhoWiwUymQyvv/46brnlFgCA0Wh0XOPya3Z9drnc3Fw888wzrpRO1O/GRmmwbck0fH7UCENRNcLUCkRqVNBr/LGnpA7v7D2N707V4c7Xv0PGaB2eyByFUfogscsmIrgYfn0VFBSEwsJCNDU1wWAwICcnB/Hx8bjpppv6dL0VK1YgJyfH8bPZbEZMTEw/VUvUexKJBFnjIpE1LtJpf9Y4PR6cFYdXDCfwQUEl/lVkguGYCT+aFI1fZYzE0FB/tLXbUd9qRX1LO863WNHQ0o761nboNSrcPCpCpG9E5BtcCj+tVguZTAaTyeS032QyQa/X93ieVCpFYmIiACA5ORlFRUXIzc3FTTfd5DjPZDIhMvLi/0BMJhOSk5O7vZ5SqYRSybkXyb0NDQ3Aiz+eiCU3JODlL4vx6WEjPjxwBh8XVkEmlcDaYe/x3D8tSMbc5OhBrJbIt7j0zk+hUCAlJQUGg8Gxz263w2AwID09vdfXsdvtsFg6Bw/HxcVBr9c7XdNsNmPv3r0uXZPIXSVGBOL1e1Lw8cMzMDNRC5tdcASfXCqBNlCBxIhApA4PRXJMCADgN389hCNnGkSsmsi7ufzYMycnB4sWLUJqaiqmTp2KNWvWoLm5GdnZ2QCAhQsXIjo6Grm5uQA638+lpqYiISEBFosFn376KbZs2YI33ngDQOdjo2XLluF3v/sdRowYgbi4ODz99NOIiorCvHnz+u+bEolsYkwItj6YhopzLZBIgJAABdQKmdM6gja7gJ9t3Iddx2vw8y0F+MejMxGmVohYNZF3cjn85s+fj5qaGqxcuRJGoxHJycnYsWOHo8NKeXk5pNKLDcrm5mb84he/QGVlJfz9/ZGUlIStW7di/vz5jmOWL1+O5uZmLFmyBPX19Zg5cyZ27NgBlUrVD1+RyL1cbY5QmVSCVxZMwu2v7Ub5uRY8+u4BvP7TFHxVbMInB8/iPxX1mDVCixW3jYZew/8+iPqK05sRuaFjRjN+tPY7tLbbIJUAly1CD7VChl/OHoHsGXFQyDnNGlEXLmlE5MGS9MF46e4JADqDL16rxi9/kIgN96di8rAQNFttyP3sGLL+9G/sOGJEd/+GrWm0oK2dSzIRdYctPyI3drCiHnKZBGMigx3vBu12AX89UIkXdhxDbZMVADBxqAZPZCZhXHQw/nHoLP5aUInCinqEBPjhsdkjcO+04ZyIm3wCV3Ug8nINre1Y/+8SbPi2FC3WzhaeTCqB7fJnpADitGqsuC0Jt4zROXWwIfI2DD8iH1HTaMHrO0/inT3lsNrsGB0ZjLsmR+O/JkThq2PVePnLYkcLURuowNS4MEyNDUNafDhG6YIglTIMyXsw/Ih8TF2TBY1tHYjVqp32N7a1Y92uU9iwuwytl70DDAnww5TYMKTFhSEqxB9nzrei8nwLqhraMDoyGA/MiIMmwG8wvwbRdWH4EZETS4cNhyobkF96DntK6lBw+rzjcWlPglRyLJkVj+yZcQhUylHfYkVZXQtsdgGTYkJ61WoUBIGPWmnQMPyI6KrabXYcOdOAvaXnkF96DvUtVgwNDcDQUH+EqRV4f38lik2NAIBglRwSiQQNre2O828aNQT/e/dEaAO7n2rQbhfw+s6TWP9NKe6bNhy/vnUkQ5AGHMOPiK6L3S7gH4eqsOZfJ1Ba2+zYrwtW4nxLO6wddmgDlXj5JxNxw8ghTufWNlnwq+2F+OZErWPfovThWHX7WL5jpAHF8COiftFhs+M/FfUIUskxLCwAAQo5io2NePTdAzhuagIA3DkpGiN0QdAFKyGVSPD7T4tQ3WiByk+KH02Kxrv5FQCABVNi8NyPxkPGAKQBwvAjogHV1m7Dc/8swpY9p7v9fEREINbeMxkjdUH4oKASyz84CLsAZI3VY2pcGGx2AR12AZEaFW4dq0OAYlBWWCMvx/AjokHx7clafHOiFtXmNhjNbahtsiA9Phy/uS3JKdA+OVSFZdsK0dHNOMQgpRx3JEfh/00dhnHRGqfPWq02FBnNOHqmAdWNFsSEBiBuiBrxWjXC1Aq+RyQnDD8icjvfnqzFe/srIAidA/IlEqDg9HmcrmtxHKOUS6FWyuHvJ4NMKkHl+ZYr5jbtog/ubDVmXmhN+smksNsF1DZZ0NDajvghgXzE6mMYfkTkEex2AXtK6vCX/HJ8cdQEq+3KRX61gUqMiw5GpMYfledbUFLTjDP1rU7HhAT4Qa2Qw2Ruc7QuE4ao8atbRuKH4yLZ0cZHMPyIyOO0WDtQ12RFi9WGFmsHLB12xGvViAi+cvmmFmsH9pTU4fMjJnxZZMK5ZqvjM6kEkMukjkWDk/RBePjmRIyODEJEsApBSnmvH5c2tLajvK4F46KD+YjVAzD8iMhndNjsOHSmAQAQqVFhSKASLe02bNhdire+KUWjpcPpeH8/GcZEBeNnM+KQNU7f7aNRQRDwyaGz+J+/H0VdsxU/SR2K1fPGQSmXDcp3or5h+BERAahvseLP/y7Bv4pMMDa0wdzmHITDwwOweFY8Zo+OQJhaAaVcBpO5Db/96Ai+/N7kdGzK8FC8ce9kRARdbIlebQabdpsddU1W6IKVbDUOEoYfEVE3Wq02VDW04uPCKmzOK0N9S7vT52qFDDZBQFu7HXKpBA/fnIgJQzX41fZCmNs6EKlR4ZEfJOKEqQkHK+tRdNaMkbogLL0xAZlj9ZBKJWi32fHhgUq8YjiJM/WtCFcrkDI8FFNiw3DDyCEYpQ9y+p2CIOCfh8/ig4JK3DhyCOZPieHQjz5i+BERXUOzpQPv7a/AlrzTKD/X4jQMY8JQDV788QQk6Tv/n1JS04QHN+9HSU1zT5dDwhA15iVH468HKlF2SQ/Wy80aocXSGxOQnhCO46Ym/M/fjyKvpM7xeUiAHxamx2JR+nCE9zB9HHWP4UdE5AJBEGBu68C5Ziva2m0YqQu64l2gua0dz31ShJM1TRgfrUFyTAhG6oKw48hZbPyuzOmRarhagaU3JeAnU2JwsroJ+8vOYU/JOewsrnYM3RgREYiS2mbY7AKUcinuTh2Kb07UOoZ+yKQSjNQFYeJQDSYMDUH8EDUClXKolXKolTKEBiiuWKS4ptGCI1UNqDFbEKZWQBukhDZQAX2wCvJuFjSuONeCL743YWioPybFhHTbuciTMPyIiAZRY1s7tu4pxzcnajAjUYv7p8dCrbzy0WXFuRb83zcl2L6/Am3tnb1Rs8bq8dSc0YgJC4DNLuDzo0a8uesUDlY2XPV3SiRAuFoJvUaJYJUfTlY3obrR0u2xYWoF7p02HPdNG44hQUqY29qx9uuTeHt3mdPwkugQf4yLDkZUiD/0wSroNSok6YMxUhfoEe8tGX5ERG6srsmCv/3nDMZEBmN6orbbY842tOJgRQMOVtbjUGU9zja0odnSgWaLDc3WDnT3f2+JBIjXqjE0NAD1LVbUNFpQ22R1BJxCJsUtY3XIO1XnGB4yaVgIWq02HDc19jihQGx4ALLGReKH4/UYF6W5YtykIAgoqW1G0VkzzpxvRVV9K87Ut0HlJ8X46M6W67joYASpBnZ9SIYfEZEXs9sFnGuxwtjQBpO5Dedb2hGnDUCSPviKFmeHzY7Pj5rwf7tL8J/yesf+hCFqPDVnNG4eFQGJRIImSwcOVdbjuLERRrMFxoZWVDW0obCi3jFmEujsFDRCF4RRuiBEhfjjaFUD9p8+7zTWsjsSCTAjQYslN8Rj1gjtgLQkGX5ERHSFgtPn8c9DZ5EQocZPUmOueGfYnWZLB74ursZnh434uri6x0WQFXIpxkYFY1hYAKJC/BEV4o/GtnYcrmzAocoGp1l5kvRB+NmMOIQHKmDpsMPSYUNbux03j4qAXtP3944MPyIi6nftNjtO1zXjmLERx42NqDzfipH6IEyJDcO46OCrTgJQca4Fb39bhm37ynsM0C0PTMWsEUO6/aw3GH5EROSWGlrasXXvaXxx1AgAUPrJoJRLoZTL8MvZiZgwNKTP12b4ERGRz+ltHlz7YS8REZGXYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPYfgREZHPkV/7EPfXtSqT2WwWuRIiIhJTVw5ca7U+rwi/xsZGAEBMTIzIlRARkTtobGyERqPp8XOvWMzWbrejqqoKQUFBkEgkfb6O2WxGTEwMKioquCjuNfBe9R7vVe/xXvUe71X3BEFAY2MjoqKiIJX2/GbPK1p+UqkUQ4cO7bfrBQcH8y9TL/Fe9R7vVe/xXvUe79WVrtbi68IOL0RE5HMYfkRE5HMYfpdQKpVYtWoVlEql2KW4Pd6r3uO96j3eq97jvbo+XtHhhYiIyBVs+RERkc9h+BERkc9h+BERkc9h+BERkc9h+BERkc9h+F2wdu1axMbGQqVSIS0tDfn5+WKXJLrc3FxMmTIFQUFBiIiIwLx581BcXOx0TFtbGx5++GGEh4cjMDAQd911F0wmk0gVu4/nn38eEokEy5Ytc+zjvbrozJkzuPfeexEeHg5/f3+MHz8e+/fvd3wuCAJWrlyJyMhI+Pv7IyMjAydOnBCxYnHYbDY8/fTTiIuLg7+/PxISErB69WqnSZt5r/pIIGHbtm2CQqEQNmzYIBw9elRYvHixEBISIphMJrFLE1VmZqbw9ttvC0eOHBEKCwuFH/7wh8KwYcOEpqYmxzEPPfSQEBMTIxgMBmH//v3CtGnThOnTp4tYtfjy8/OF2NhYYcKECcJjjz3m2M971encuXPC8OHDhfvvv1/Yu3evUFJSInz++efCyZMnHcc8//zzgkajET766CPh4MGDwh133CHExcUJra2tIlY++J577jkhPDxc+OSTT4TS0lLh/fffFwIDA4U//elPjmN4r/qG4ScIwtSpU4WHH37Y8bPNZhOioqKE3NxcEatyP9XV1QIAYdeuXYIgCEJ9fb3g5+cnvP/++45jioqKBABCXl6eWGWKqrGxURgxYoTw5ZdfCjfeeKMj/HivLvrNb34jzJw5s8fP7Xa7oNfrhZdeesmxr76+XlAqlcK77747GCW6jTlz5gg/+9nPnPbdeeedwj333CMIAu/V9fD5x55WqxUFBQXIyMhw7JNKpcjIyEBeXp6IlbmfhoYGAEBYWBgAoKCgAO3t7U73LikpCcOGDfPZe/fwww9jzpw5TvcE4L261N///nekpqbi7rvvRkREBCZNmoT169c7Pi8tLYXRaHS6VxqNBmlpaT53r6ZPnw6DwYDjx48DAA4ePIjdu3fjtttuA8B7dT28YlWH61FbWwubzQadTue0X6fT4dixYyJV5X7sdjuWLVuGGTNmYNy4cQAAo9EIhUKBkJAQp2N1Oh2MRqMIVYpr27ZtOHDgAPbt23fFZ7xXF5WUlOCNN95ATk4O/vu//xv79u3DL3/5SygUCixatMhxP7r7b9LX7tWTTz4Js9mMpKQkyGQy2Gw2PPfcc7jnnnsAgPfqOvh8+FHvPPzwwzhy5Ah2794tdiluqaKiAo899hi+/PJLqFQqsctxa3a7Hampqfj9738PAJg0aRKOHDmCdevWYdGiRSJX517ee+89vPPOO/jLX/6CsWPHorCwEMuWLUNUVBTv1XXy+ceeWq0WMpnsil53JpMJer1epKrcyyOPPIJPPvkEX3/9tdO6iXq9HlarFfX19U7H++K9KygoQHV1NSZPngy5XA65XI5du3bhlVdegVwuh06n4726IDIyEmPGjHHaN3r0aJSXlwOA437wv0ngiSeewJNPPokFCxZg/PjxuO+++/CrX/0Kubm5AHivrofPh59CoUBKSgoMBoNjn91uh8FgQHp6uoiViU8QBDzyyCP429/+hq+++gpxcXFOn6ekpMDPz8/p3hUXF6O8vNzn7t3s2bNx+PBhFBYWOrbU1FTcc889jj/zXnWaMWPGFUNmjh8/juHDhwMA4uLioNfrne6V2WzG3r17fe5etbS0XLEauUwmg91uB8B7dV3E7nHjDrZt2yYolUph48aNwvfffy8sWbJECAkJEYxGo9iliWrp0qWCRqMRdu7cKZw9e9axtbS0OI556KGHhGHDhglfffWVsH//fiE9PV1IT08XsWr3cWlvT0HgveqSn58vyOVy4bnnnhNOnDghvPPOO0JAQICwdetWxzHPP/+8EBISInz88cfCoUOHhLlz5/pk9/1FixYJ0dHRjqEOH374oaDVaoXly5c7juG96huG3wWvvvqqMGzYMEGhUAhTp04V9uzZI3ZJogPQ7fb22287jmltbRV+8YtfCKGhoUJAQIDwox/9SDh79qx4RbuRy8OP9+qif/zjH8K4ceMEpVIpJCUlCX/+85+dPrfb7cLTTz8t6HQ6QalUCrNnzxaKi4tFqlY8ZrNZeOyxx4Rhw4YJKpVKiI+PF5566inBYrE4juG96huu50dERD7H59/5ERGR72H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz2H4ERGRz/n/AiuaG0nWTAgAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"model.train(mode=True)\n",
"\n",
"train_losses = []\n",
"for i in range(iteration_count):\n",
" loss_accum = 0\n",
" optimizer.zero_grad()\n",
" for j, texture in enumerate(textures):\n",
" rendered_img = render_texture(model(texture), spp=spp, seed=i*len(textures)+j)\n",
" loss = loss_fn(rendered_img, texture.torch())\n",
" loss.backward()\n",
" loss_accum += loss.item()\n",
" optimizer.step()\n",
" train_losses.append(loss_accum)\n",
" print(f'Training iteration {i+1}/{iteration_count}, loss: {train_losses[-1]}', end='\\r')\n",
"\n",
"model.train(mode=False)\n",
"plt.plot(train_losses[5:]);"
]
},
{
"cell_type": "markdown",
"id": "7acec422",
"metadata": {},
"source": [
"## Results\n",
"\n",
"As you can see in the results below, the fully connected layer is able to properly pre-distort the texture images so that the renderings approximatively match the input images.\n",
"\n",
"These results are far from perfect, which is partially due to the simplicity of the pipeline implemented in this tutorial. For instance, it would make sense to use a smoothing regularization term on the distorted image to reduce the noise observed in the results below. Other neural network architecture might also be more suited for this task."
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "bef95350-93ec-44dc-a72b-069409839ea1",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAADyCAYAAAAMag/YAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOydd4AdVfn3P1Nvv9s3m03vHQIJCSRAQgIECL0J0lGkqYBSRam+IIg0ESkWqkoTiPTem7SQnpBG+mb73jrtvH/MvXPv3d3Ahhr5zVeX7J45c/p5nuc88zzPkYQQAh8+fPjw4cOHDx8+fPjw4cOHDx8+vmbI33UDfPjw4cOHDx8+fPjw4cOHDx8+fHw/4SuefPjw4cOHDx8+fPjw4cOHDx8+fHwj8BVPPnz48OHDhw8fPnz48OHDhw8fPr4R+IonHz58+PDhw4cPHz58+PDhw4cPH98IfMWTDx8+fPjw4cOHDx8+fPjw4cOHj28EvuLJhw8fPnz48OHDhw8fPnz48OHDxzcCX/Hkw4cPHz58+PDhw4cPHz58+PDh4xuBr3jy4cOHDx8+fPjw4cOHDx8+fPjw8Y3AVzz58OHDhw8fPnz48OHDhw8fPnz4+EawzSmeJEnisssu61HegQMHcuKJJ251HatWrUKSJO66666tfvfbxrba1hNPPJGBAwd+Yb7p06czffr0b7w9Pnz48OFj28Bll12GJEnfdTO+NWyN3OLDh49SfFlZ/pvEXXfdhSRJrFq16nPz/V+jdT58bKvo6bnUx3eLr13xlCfW77///tdS3ltvvcVll11Ga2vr11KeDx8+/vfwddOVr4pUKsVll13GK6+80qP8Cxcu5LLLLvtCIfbrwFVXXcVjjz32jdfj4/8G8nsv/xMMBqmvr2fWrFncfPPNdHR0fC31rF+/nssuu4yPP/74aymvM/7xj39w4403fiNl9wTfdP+Kceutt25zH6t8fPfovJdVVaVPnz6ceOKJrFu37rtung8fPr4BFO/5z/vpqTz7bcE//38/oX7XDeiMdDqNqhaa9dZbb3H55Zdz4oknUl5eXpJ3yZIlyPI2Z7TlowjPPffcd90EHz6+dqRSKS6//HKAHln0LVy4kMsvv5zp06d/419krrrqKg4//HAOPvjgb7QeH/+3cMUVVzBo0CBM02Tjxo288sornH322Vx//fXMmTOH7bbbzsv761//mgsvvHCryl+/fj2XX345AwcOZPz48V9z613F0/z58zn77LO/9rJ7gm+6f8W49dZbqa6u3uasSHxsG8jv5UwmwzvvvMNdd93FG2+8wfz58wkGg9918/6n8GVonQ8f3ybuvffekr/vuecenn/++S7po0aN+jab9YX4vPN/d7jzzjtxHOebb5iPr4RtTvG0NUwvEAh8gy3pHslkkkgk8q3X+3Xh226/ruvfWl0+fPj4ZuA4DoZh+IeS/8PYd999mThxovf3RRddxEsvvcT+++/PgQceyKJFiwiFQgCoqlryAem7xP86z95WIIQgk8l4c+zjfxfFe/nHP/4x1dXVXHPNNcyZM4cjjzzyO27dV4NlWTiO863JntsSrfPhozsce+yxJX+/8847PP/8813Svwy2Jb6gadp33QQfPcC3Yi504oknEo1GWbduHQcffDDRaJSamhrOPfdcbNsuyVscK+Gyyy7jvPPOA2DQoEGeOWDeXaWzX3hzczPnnnsu48aNIxqNEo/H2XfffZk7d+6XanfeLPnVV1/ljDPOoLa2lr59+3rPn376aXbbbTcikQixWIzZs2ezYMGCL9331tZWTjzxRMrKyigvL+eEE07Yoonh4sWLOfzww6msrCQYDDJx4kTmzJnztbcf4LHHHmPs2LEEg0HGjh3Lo48+2uMx7Bzj6ZVXXkGSJB588EEuv/xy+vTpQywW4/DDD6etrY1sNsvZZ59NbW0t0WiUk046iWw2W1Lm3//+d2bMmEFtbS2BQIDRo0fz5z//uUvdjuNw2WWXUV9fTzgcZo899mDhwoXdxhNobW3l7LPPpl+/fgQCAYYOHco111zja8+3YfR0b+XjpF133XXccMMNDBgwgFAoxLRp05g/f35JmVuKSVbsO75q1SpqamoAuPzyyz26tKUYL3fddRdHHHEEAHvssUe3Zs1ftBdfeuklZFnmkksuKSn7H//4B5IkeetfkiSSySR33323V09+rW/J/727GBWSJPHTn/6U+++/nzFjxhAIBHjmmWcAWLduHSeffDK9evUiEAgwZswY/va3v3Xbdx/fb8yYMYPf/OY3rF69mvvuu89L725NPf/88+y6666Ul5cTjUYZMWIEv/rVrwCXL+y0004AnHTSSd7aLXYXe+ihh5gwYQKhUIjq6mqOPfbYLu5BeZqwfPly9ttvP2KxGMcccwzTp0/nySefZPXq1V7ZxXshm81y6aWXMnToUAKBAP369eP888/vwnuy2SznnHMONTU1xGIxDjzwQNauXfuF49ST/r377rvss88+lJWVEQ6HmTZtGm+++ab3PK/YO/7440vKfuONN1AUhQsuuABw5aIFCxbw6quvevXkadqW4tF0F89m4MCB7L///jz77LNMnDiRUCjE7bffDvj88vuG3XbbDYDly5eXpG+NnPnmm2/yi1/8gpqaGiKRCIcccgibN28uySuE4Le//S19+/b1ZLLuZE7o2Ror5u033ngjQ4YMIRAIsHDhwh63H2DBggXMmDGDUChE3759+e1vf9vjtfx5/POhhx5i9OjRhEIhdtllF+bNmwfA7bffztChQwkGg0yfPr2LC/7rr7/OEUccQf/+/T16dM4555BOp7vUn6+jWD7vjtc7jsONN97ImDFjCAaD9OrVi1NPPZWWlpYe9dPH9xs9PVd9Hl9YvXo1Bx54IJFIhNraWs455xyeffbZbt34vojffdH5vzt0XvfF9OFPf/oTgwcPJhwOs/fee7NmzRqEEFx55ZX07duXUCjEQQcdRHNzc0mZjz/+OLNnz6a+vp5AIMCQIUO48soru5zfAa+OUCjEpEmTeP3117s9U/RU3vi+4ltT09u2zaxZs5g8eTLXXXcdL7zwAn/4wx8YMmQIp59+erfvHHrooSxdupR//vOf3HDDDVRXVwN4h77OWLFiBY899hhHHHEEgwYNYtOmTdx+++1MmzaNhQsXUl9f/6XafsYZZ1BTU8Mll1xCMpkEXNPFE044gVmzZnHNNdeQSqX485//zK677spHH31Usvh70nchBAcddBBvvPEGp512GqNGjeLRRx/lhBNO6NKeBQsWMHXqVPr06cOFF15IJBLhwQcf5OCDD+aRRx7hkEMO+dra/9xzz3HYYYcxevRorr76apqamjjppJNKFFhfBldffTWhUIgLL7yQTz/9lD/+8Y9omoYsy7S0tHDZZZd5JuCDBg0qOXD/+c9/ZsyYMRx44IGoqsp//vMfzjjjDBzH4cwzz/TyXXTRRVx77bUccMABzJo1i7lz5zJr1iwymUxJW1KpFNOmTWPdunWceuqp9O/fn7feeouLLrqIDRs2fKdxQXx8PraGrtxzzz10dHRw5plnkslkuOmmm5gxYwbz5s2jV69ePa6zpqaGP//5z5x++ukccsghHHrooQAlrkbF2H333fn5z3/OzTffzK9+9SvPnDn/b0/24owZMzjjjDO4+uqrOfjgg9lxxx3ZsGEDP/vZz9hzzz057bTTvLJ+/OMfM2nSJH7yk58AMGTIkK0b1BxeeuklHnzwQX76059SXV3NwIED2bRpEzvvvLMnWNfU1PD000/zox/9iPb29u/MjcnHd4fjjjuOX/3qVzz33HOccsop3eZZsGAB+++/P9tttx1XXHEFgUCATz/91BM0R40axRVXXMEll1zCT37yE+8gPGXKFMA93J500knstNNOXH311WzatImbbrqJN998k48++qjEDN+yLGbNmsWuu+7KddddRzgcpq6ujra2NtauXcsNN9wAQDQaBdwD2YEHHsgbb7zBT37yE0aNGsW8efO44YYbWLp0aUm8tB//+Mfcd999/PCHP2TKlCm89NJLzJ49+wvH6Iv699JLL7HvvvsyYcIELr30UmRZ9g4Cr7/+OpMmTWLUqFFceeWVnHfeeRx++OEceOCBJJNJTjzxREaOHMkVV1wBwI033sjPfvYzotEoF198McBW0bdiLFmyhKOPPppTTz2VU045hREjRvj88nuI/GGuoqLCS9taOfNnP/sZFRUVXHrppaxatYobb7yRn/70pzzwwANenksuuYTf/va37Lfffuy33358+OGH7L333hiGUVLW1q6xv//972QyGX7yk58QCASorKzscfs3btzIHnvsgWVZXr477rjjK1twvP7668yZM8eTSa+++mr2339/zj//fG699VbOOOMMWlpauPbaazn55JN56aWXvHcfeughUqkUp59+OlVVVbz33nv88Y9/ZO3atTz00ENevieffJIf/OAHjBs3jquvvpqWlhZ+9KMf0adPny7tOfXUUz06+vOf/5yVK1dyyy238NFHH/Hmm2/61iL/x9HTcxV0zxeSySQzZsxgw4YNnHXWWdTV1fGPf/yDl19+uUtdPeF3W3v+/zzcf//9GIbBz372M5qbm7n22ms58sgjmTFjBq+88goXXHCBdw4999xzSz6k3nXXXUSjUX7xi18QjUZ56aWXuOSSS2hvb+f3v/99yfj99Kc/ZbfdduOcc85h1apVHHzwwVRUVJScl7dG3vjeQnzN+Pvf/y4A8d///tdLO+GEEwQgrrjiipK8O+ywg5gwYUJJGiAuvfRS7+/f//73AhArV67sUteAAQPECSec4P2dyWSEbdsleVauXCkCgUBJ3StXrhSA+Pvf/96jvuy6667CsiwvvaOjQ5SXl4tTTjmlJP/GjRtFWVlZSXpP+/7YY48JQFx77bVemmVZYrfdduvS1pkzZ4px48aJTCbjpTmOI6ZMmSKGDRv2tbZ//Pjxonfv3qK1tdVLe+655wQgBgwYsMWxy2PatGli2rRp3t8vv/yyAMTYsWOFYRhe+tFHHy0kSRL77rtvyfu77LJLl3pSqVSXembNmiUGDx5c0hdVVcXBBx9cku+yyy4TQMm6ufLKK0UkEhFLly4tyXvhhRcKRVHEZ5999oX99PHN4qvQlfx+D4VCYu3atV76u+++KwBxzjnneGmd12txXcXrcPPmzV1o1efhoYceEoB4+eWXS9K3Zi8mk0kxdOhQMWbMGJHJZMTs2bNFPB4Xq1evLnk3EomUrO8t9SGPSy+9VHRmBYCQZVksWLCgJP1HP/qR6N27t2hsbCxJP+qoo0RZWVm3e9PH/za623udUVZWJnbYYQfv785r6oYbbhCA2Lx58xbL+O9//9stXzYMQ9TW1oqxY8eKdDrtpT/xxBMCEJdccomXlqcJF154YZfyZ8+e3e36v/fee4Usy+L1118vSb/tttsEIN58800hhBAff/yxAMQZZ5xRku+HP/xhj2jBlvrnOI4YNmyYmDVrlnAcx0tPpVJi0KBBYq+99vLSbNsWu+66q+jVq5dobGwUZ555plBVtcvcjBkzpls61t1eF6Iwx8Vy1oABAwQgnnnmmZK8Pr/830V+nl944QWxefNmsWbNGvHwww+LmpoaEQgExJo1a7y8Wytn7rnnniXr95xzzhGKoniyY0NDg9B1XcyePbsk369+9asvLZPleXs8HhcNDQ0leXva/rPPPlsA4t133/XSGhoaRFlZ2RbPHsXYEv8MBAIl795+++0CEHV1daK9vd1Lv+iii7rU0x0fvfrqq4UkSSX8fty4caJv376io6PDS3vllVe6yOevv/66AMT9999fUuYzzzzTbbqP7zfOPPPMLmu2J+cqIbbMF/7whz8IQDz22GNeWjqdFiNHjiyRfbeG333e+b87dJZx8/Shpqam5Ayb33Pbb7+9ME3TSz/66KOFruslNKO7cTn11FNFOBz28mWzWVFVVSV22mmnkvLuuusuAZTw4p7KG99nfKuRufNf5fPYbbfdWLFixddWfiAQ8IKN27ZNU1OTZ9L/4YcffulyTznlFBRF8f5+/vnnaW1t5eijj6axsdH7URSFyZMnd6vh/aK+P/XUU6iqWmKloSgKP/vZz0rea25u5qWXXuLII4+ko6PDq7upqYlZs2axbNmyLu4HX7b9GzZs4OOPP+aEE06grKzMe3+vvfZi9OjRWzOEXXD88ceXfGGZPHkyQghOPvnkknyTJ09mzZo1WJblpRV/iWpra6OxsZFp06axYsUK2traAHjxxRexLIszzjijpLzO4wnu16XddtuNioqKkvHYc889sW2b11577Sv11cc3i57SlYMPPrjkS+CkSZOYPHkyTz311Dfexi1ha2hJOBzmrrvuYtGiRey+++48+eST3HDDDfTv3/8badu0adNK9rkQgkceeYQDDjgAIURJe2fNmkVbW9tXorM+/ncRjUY/93a7vEXS448/vtXuWO+//z4NDQ2cccYZJTHGZs+ezciRI3nyySe7vLMlK+ru8NBDDzFq1ChGjhxZsqZnzJgB4O3BPJ34+c9/XvL+V7Xy+/jjj1m2bBk//OEPaWpq8upPJpPMnDmT1157zRszWZa56667SCQS7Lvvvtx6661cdNFFJbG3vk4MGjSIWbNmlaT5/PJ/H3vuuSc1NTX069ePww8/nEgkwpw5c7wv819GzvzJT35S4nK22267Yds2q1evBuCFF17wrA6K83W3f7Z2jR122GEllhBb0/6nnnqKnXfemUmTJnnv19TUcMwxx3zJ0XUxc+bMEs+HyZMne22NxWJd0otllmIZN5lM0tjYyJQpUxBC8NFHHwHuZQXz5s3j+OOP96w3weXb48aNK2nLQw89RFlZGXvttVfJeE6YMIFoNNrtmcXH/y305FyVR3d84ZlnnqFPnz4ceOCBXlowGOxiBb01/O7rwhFHHFFyhs3vuWOPPbYkPtvkyZMxDKOEthWPS56W7LbbbqRSKRYvXgy4MkpTUxOnnHJKSXnHHHNMiRUp9Fze+D7jW3O1CwaDXUzkKioqvlb/YsdxuOmmm7j11ltZuXJliQ9mVVXVly530KBBJX8vW7YMwFsonRGPx0v+7knfV69eTe/evUsYCMCIESNK/v70008RQvCb3/yG3/zmN93W39DQUHLA/rLtzwsMw4YN65LnqyrzOh+W80ShX79+XdIdx6Gtrc2bwzfffJNLL72Ut99+m1QqVZK/ra2NsrIyr+1Dhw4teV5ZWdmFECxbtoxPPvlkiyacDQ0NW9k7H98WtoaudLeOhw8fzoMPPviNte+LsLW0ZOrUqZx++un86U9/YtasWV0UtV8nOtONzZs309rayh133MEdd9zR7Tv+Xvm/iUQiQW1t7Raf/+AHP+Avf/kLP/7xj7nwwguZOXMmhx56KIcffvgX3kybp+WdeSHAyJEjeeONN0rSVFXdKlfwZcuWsWjRoi+k/6tXr0aW5S6uq921a2uQpwHdudXn0dbW5vGtIUOGePEvxo4du0U54OtAZxoAPr/8PuBPf/oTw4cPp62tjb/97W+89tprJZf1fBk5s7NMl1+veV68JXmypqbmK8tkndfp1rR/9erV3kG0GF91X2+NjAuUyCyfffYZl1xyCXPmzOkiy+SVAFuScfNpxfL5smXLaGtr2yKN9vesj56cq/Loji+sXr2aIUOGdIl31nl9bi2/+zrwVfbiggUL+PWvf81LL71Ee3t7l3bClveiqqpdYq31VN74PuNbUzwVW9x8U7jqqqv4zW9+w8knn8yVV15JZWUlsixz9tlnfyUNamdf73xZ9957L3V1dV3yd77h4uvse77uc889t4vGOY/Oi/+rtv+bwJbGZEvpQgjADX45c+ZMRo4cyfXXX0+/fv3QdZ2nnnqKG2644UvNs+M47LXXXpx//vndPh8+fPhWl+nj28HXTVckSfLWWjG6CyT4dWBr92I2m/WCNC5fvpxUKkU4HO5RXd0FFYYt921LdOPYY4/dotCwpThXPr6/WLt2LW1tbd0egPIIhUK89tprvPzyyzz55JM888wzPPDAA8yYMYPnnnvua93HxZbPPYHjOIwbN47rr7++2+edhdOvG/l99fvf/57x48d3m6fzB6nnnnsOcK0empqauqUd3eGr0oB8e31++b+NSZMmeVZyBx98MLvuuis//OEPWbJkCdFo9EvJmV8ku20NtnaNbYlXbU37v258WRnXtm322msvmpubueCCCxg5ciSRSIR169Zx4oknfmkZt7a2lvvvv7/b518mbo6P7w+29lz1VeKffRl+91XxZfdia2sr06ZNIx6Pc8UVVzBkyBCCwSAffvghF1xwwZfei9+lvLEtYJu/A3RLglJ3ePjhh9ljjz3461//WpLe2trqBSb7OpD/4llbW8uee+75tZQ5YMAAXnzxRRKJRMmmW7JkSUm+wYMHA+61kV+27p62f8CAAUBBQ12Mzu36tvCf//yHbDbLnDlzSrTYnc0T823/9NNPS7TzTU1NXb4gDRkyhEQi8bXNpY9tE92t46VLl5Z8kaioqOjWTS//RSOPraFLn5d/a2nJpZdeyqJFi7juuuu44IILuPDCC7n55pt7VFdFRUW3t2R27tuWkL/Jy7Ztf6/48HDvvfcCbPGAl4csy8ycOZOZM2dy/fXXc9VVV3HxxRfz8ssvs+eee25x3eZp+ZIlS7pYBi5ZssR7/kX4vD04d+5cZs6c+bn7esCAATiOw/Lly0usIXrKC7+IBsTj8R7tq9tuu43nn3+e//f//h9XX301p556Ko8//niP6sp/RW5tbS0JyN5TGpBvr88vvz9QFIWrr76aPfbYg1tuuYULL7zwa5EzO6NYnsyXD64l7dctk21N+wcMGLBNybjz5s1j6dKl3H333SU3WD7//PMl+Ypl3M7onDZkyBBeeOEFpk6duk1ce+9j20JPz1WfhwEDBrBw4UKEECX8p7u1CD3jd1srZ3/deOWVV2hqauLf//43u+++u5e+cuXKknzFe3GPPfbw0i3LYtWqVSUfZHsqb3yf8a3GePoyiEQiAN0emDpDUZQuX1ceeuihLr7oXxWzZs0iHo9z1VVXYZpml+edr5DtCfbbbz8syyq5vtK2bf74xz+W5KutrWX69OncfvvtbNiw4UvV3dP29+7dm/Hjx3P33XeX+Pg+//zz3nW13zbyGurieW5ra+Pvf/97Sb6ZM2eiqmqX60BvueWWLmUeeeSRvP322zz77LNdnrW2tpbEl/Lxv4vHHnushBa89957vPvuu+y7775e2pAhQ1i8eHHJPpo7d27JNa+AZ2XUE7oEW6ZjW0NL3n33Xa677jrOPvtsfvnLX3Leeedxyy238Oqrr3apq7t2DRkyhLa2Nj755BMvbcOGDTz66KM96oOiKBx22GE88sgjzJ8//3Pb6uP/Bl566SWuvPJKBg0a9LkxUTpfUQx4XzvzVwhvaY9MnDiR2tpabrvttpLrhp9++mkWLVrUo1vl8uV3jlUBLv1ft24dd955Z5dn6XTauwk2Tyc6K3p7eovblvo3YcIEhgwZwnXXXUcikejyXvG+WrlyJeeddx6HHXYYv/rVr7juuuuYM2cO99xzT5e6tkQDgJIYOclkkrvvvrtHfQCfX34fMX36dCZNmsSNN95IJpP5WuTMzthzzz3RNI0//vGPJfJbd/vnq66xrWn/fvvtxzvvvMN7771X8nxL1kHfNLqTcYUQ3HTTTSX56uvrGTt2LPfcc08J3Xj11VeZN29eSd4jjzwS27a58soru9RnWVaP5Rgf30/09Fz1eZg1axbr1q1jzpw5Xlomk+nCV7eG323N+f+bQHfjYhgGt956a0m+iRMnUlVVxZ133llCm+6///4uSvWeyhvfZ2zzFk8TJkwA4OKLL+aoo45C0zQOOOAAb0EWY//99+eKK67gpJNOYsqUKcybN4/777+/5OvK14F4PM6f//xnjjvuOHbccUeOOuooampq+Oyzz3jyySeZOnVqtwqOz8MBBxzA1KlTufDCC1m1ahWjR4/m3//+d7eC8p/+9Cd23XVXxo0bxymnnMLgwYPZtGkTb7/9NmvXrmXu3LlfW/uvvvpqZs+eza677srJJ59Mc3Mzf/zjHxkzZky3ROObxt57742u6xxwwAGceuqpJBIJ7rzzTmpra0sEjF69enHWWWfxhz/8gQMPPJB99tmHuXPn8vTTT1NdXV2iaT7vvPOYM2cO+++/PyeeeCITJkwgmUwyb948Hn74YVatWvW1Wsz5+G4wdOhQdt11V04//XSy2Sw33ngjVVVVJeb8J598Mtdffz2zZs3iRz/6EQ0NDdx2222MGTOmxL87FAoxevRoHnjgAYYPH05lZSVjx45l7Nix3dY9fvx4FEXhmmuuoa2tjUAgwIwZM6itre3RXsxkMpxwwgkMGzaM//f//h8Al19+Of/5z3846aSTmDdvnkcTJ0yYwAsvvMD1119PfX09gwYNYvLkyRx11FFccMEFHHLIIfz85z8nlUrx5z//meHDh/c4Xtvvfvc7Xn75ZSZPnswpp5zC6NGjaW5u5sMPP+SFF17oVsHg4/uBp59+msWLF2NZFps2beKll17i+eefZ8CAAcyZM6ck8HdnXHHFFbz22mvMnj2bAQMG0NDQwK233krfvn3ZddddAVcpUl5ezm233UYsFiMSiTB58mQGDRrENddcw0knncS0adM4+uij2bRpEzfddBMDBw7knHPO6VH7J0yYwAMPPMAvfvELdtppJ6LRKAcccADHHXccDz74IKeddhovv/wyU6dOxbZtFi9ezIMPPsizzz7LxIkTGT9+PEcffTS33norbW1tTJkyhRdffLFbi4Pu8Hn9+8tf/sK+++7LmDFjOOmkk+jTpw/r1q3j5ZdfJh6P85///Me7fCMUCnkfVE499VQeeeQRzjrrLPbcc0/q6+u9vv75z3/mt7/9LUOHDqW2tpYZM2aw9957079/f370ox9x3nnnoSgKf/vb3zya0xP4/PL7ifPOO48jjjiCu+66i9NOO+0ry5mdUVNTw7nnnsvVV1/N/vvvz3777cdHH33kyWSd2/JV11hP23/++edz7733ss8++3DWWWcRiUS44447GDBgQMlHmm8LI0eOZMiQIZx77rmsW7eOeDzOI4880m3cyquuuoqDDjqIqVOnctJJJ9HS0sItt9zC2LFjS+TzadOmceqpp3L11Vfz8ccfs/fee6NpGsuWLeOhhx7ipptu4vDDD/82u+ljG0JPz1Wfh1NPPZVbbrmFo48+mrPOOovevXtz//33e3JB/swly3KP+B1s3fn/m8CUKVOoqKjghBNO4Oc//zmSJHHvvfd2MXDRdZ3LLruMn/3sZ8yYMYMjjzySVatWcdddd3WJe9VTeeN7ja/7mrwtXXseiUS65N3SNaSdryW+8sorRZ8+fYQsyyVXKw4YMKDkCtZMJiN++ctfit69e4tQKCSmTp0q3n777S5XpOevWOx8rXFP+lKMl19+WcyaNUuUlZWJYDAohgwZIk488UTx/vvvf6m+NzU1ieOOO07E43FRVlYmjjvuOPHRRx9129bly5eL448/XtTV1QlN00SfPn3E/vvvLx5++OGvtf1CCPHII4+IUaNGiUAgIEaPHi3+/e9/b/Fq9s7oPPYvv/yyAMRDDz1Ukm9Lbc2PU/E13HPmzBHbbbedCAaDYuDAgeKaa64Rf/vb37pcu2lZlvjNb34j6urqRCgUEjNmzBCLFi0SVVVV4rTTTiupp6OjQ1x00UVi6NChQtd1UV1dLaZMmSKuu+46YRjGF/bTxzeLr0JX8vv997//vfjDH/4g+vXrJwKBgNhtt93E3Llzu7x/3333icGDBwtd18X48ePFs88+2+16f+utt8SECROErus9uk79zjvvFIMHDxaKopRcLyvEF+/F/NXUxVc+CyHE+++/L1RVFaeffrqXtnjxYrH77ruLUCjU5Zrq5557TowdO1boui5GjBgh7rvvvi3S4TPPPLPbfmzatEmceeaZol+/fkLTNFFXVydmzpwp7rjjjs/tv4//TeT3Xv5H13VRV1cn9tprL3HTTTeVXA2eR+c19eKLL4qDDjpI1NfXC13XRX19vTj66KO7XJf++OOPi9GjRwtVVbvwvQceeEDssMMOIhAIiMrKSnHMMceItWvXlry/JZoghBCJREL88Ic/FOXl5V2uGzcMQ1xzzTVizJgxIhAIiIqKCjFhwgRx+eWXi7a2Ni9fOp0WP//5z0VVVZWIRCLigAMOEGvWrOnR/v+i/n300Ufi0EMPFVVVVSIQCIgBAwaII488Urz44otCCCFuuukmAYhHHnmkpMzPPvtMxONxsd9++3lpGzduFLNnzxaxWKzLdc4ffPCBmDx5stB1XfTv319cf/313hwX888BAwaI2bNnd9sPn1/+b+LzZELbtsWQIUPEkCFDhGVZQoivJmfmZb1iPmfbtrj88ss9GX369Oli/vz5XWR5IXq2xop5e3foSfuFEOKTTz4R06ZNE8FgUPTp00dceeWV4q9//WuPrnLvKf/cUlu7k4kXLlwo9txzTxGNRkV1dbU45ZRTxNy5c7s9C/zrX/8SI0eOFIFAQIwdO1bMmTNHHHbYYWLkyJFd2nrHHXeICRMmiFAoJGKxmBg3bpw4//zzxfr16z+3jz6+XzjzzDO7rNmenqs+jy+sWLFCzJ49W4RCIVFTUyN++ctfikceeUQA4p133inJ+0X8Lo8tnf+7Q2c5fWv2nBDd07I333xT7LzzziIUCon6+npx/vnni2effbYLbRNCiJtvvlkMGDBABAIBMWnSJPHmm2+KCRMmiH322ackX0/lje8rJCG+ROQ/Hz7+R9Ha2kpFRQW//e1vufjii7/r5vj4FrBq1SoGDRrE73//e84999zvujk+fPjw4cOHDx/fCMaPH09NTU2XuFA+fHzbuPHGGznnnHNYu3ZtyS2Y/xfgOA41NTUceuih3brW/V/FNh/jyYePL4t0Ot0lLR9PYPr06d9uY3z48OHDhw8fPnz4+BpgmmaXeFevvPIKc+fO9WVcH986Op+5MpkMt99+O8OGDfveK50ymUwXF7x77rmH5uZmfy92wjYf48mHjy+LBx54gLvuuov99tuPaDTKG2+8wT//+U/23ntvpk6d+l03z4cPHz58+PDhw4ePrca6devYc889OfbYY6mvr2fx4sXcdttt1NXVcdppp33XzfPxfwyHHnoo/fv3Z/z48bS1tXHfffexePHi7yxQ/7eJd955h3POOYcjjjiCqqoqPvzwQ/76178yduxYjjjiiO+6edsUfMWTj+8ttttuO1RV5dprr6W9vd0LOP7b3/72u26aDx8+fPjw4cOHDx9fChUVFUyYMIG//OUvbN68mUgkwuzZs/nd735HVVXVd908H//HMGvWLP7yl79w//33Y9s2o0eP5l//+hc/+MEPvuumfeMYOHAg/fr14+abb6a5uZnKykqOP/54fve736Hr+nfdvG0KfownHz58+PDhw4cPHz58+PDhw4cPH98I/BhPPnz48OHDhw8fPnz48OHDhw8fPr4R+IonHz58+PDhw4cPHz58+PDhw4cPH98IfMWTDx8+fPjw4cOHDx8+fPjw4cOHj28EPQ4uvmjRUoRwEEJ4VwZKkoQkSQA4juPlLX4uBAjh4DgOkgAkkJCQJBkkCQkJgQAhkGXJK9NxbBxHAAJJkpEkCdu2vTpkWfbqyrfBfc9BIJClgk4t/zyfv7gPxe97v0v5vACi5L3iPufTHccBUWhDPmqWLEuAhCSBbTvg9hQl1/buxqy4PYX00jq99pSm4CVIkvueEAjhdQdJAkmSkWXZHSchEI7AEQKBQBS1R5akQvn58SkMB0gyjpHCNjpoXz8XxzYRSMTqt0cNliOrQdwSBIosF8rKjaPjhRaT3DKLG9kp7Fg+v9slkX/LmwvJ/cMtojB9bjm5NeaNUS7dfU8uXH8p5cddAoT7jiQhHKdkzYhCsUWNdp/tvse2fVPewkWLgVwPi4a4eGmJomVU+gfk16/3XtHIfh3Ycrg5UfQsv1fd9M9/r3OLO9cnUdLBTnWQW79Fi7N0bDrVLclyjpo5Xn6QvY0jcmu4S3W5kiVw3/TWmTv+cn5RS7j7RuRXKd6ecNshcj2WELl9VExXikmELCsEIpU0LP+Izavnk003UdV3FP23m0E6lcSxbYRToLdFA1r0azHNKYybKBo7OZ8spKL8RatG6jp/Um6c86tLKsqb/0MmT8/olKt0DnNVe8lynrZ32rt57DZ9l6593kYgSRKSrBIIhfngvXfoP3goG9pSvPfKcwgzyw9/eLTLV3N45ZVXeeKJJzjvvPOoqa3BtByefOJJMpk0Rx91JC+//DLLly/n+OOP5+233+Y///kPA4eOIJvJsG71Ck4//XQi0QjXX38Du83cm+12mMDAOjdgbdawePBf/2D9+vU0NDTw73//m8aWdoaMn8KogXVUhHUee+xxJk2ayN57781xxx1L0pL57+I1zH3tKWJBlbPPPhtJkkgmk9xzzz1sv/32TJkypaTPe+yxBytXruSss87igQceYMmSJVx44YUEAwF3jeTe37x5Mw8//DCqqnLWWWfR1NSEpmlccMEFBAKBbsdz1apV3HzzzRxzzDEMHz6ce+65h8bGzaTTGS644AIqKio6vSE49tjjePLJpzjjjDOIx2PEYjGOO+44YrEY4N6kKsuye4uNcNybfe7/B5ZlkclkuOaaaxg+fDjHHHMM69evJ5PJAFBTU0MkEgEETz75JK+99jrHH388M2bM4KijjippxZFHHsnDDz/s/a3rOscffzxxksjNy7n3pQVsak0CMGLYEMLhEB9/soDZs2czZcoUfve739He3t5lPE466SR23313jj32WJ566imefvpp7rnnHo499lhuueVP7LTTRObOnQvAySefzMgRI1i/YQMHHXQQO0+ezN333MOa9Rv5bOMmnnj4QXaaOIGnnnqKectWkc4aTBozjF/+8pfce999LFq0iCVLlvDQQw/xj3/8g6amJgB3DQ4cyI477siUKVPYfvvxJDIGFRXl1PWqJVDWF2GbmG3rkGSZ6upqjjnmGM4++2xuueWWz+UF2wKa2xMkEh20trTQ0tpKIBCgrq4O03IwTJPm1jYcIwuOTVl5hUsfHYhEIxiWRXNbBxXlcVRFpT2ZJhQKous6wrawzSyOkSEajYEkYZoWqXQK23aQFYWgrqMqCu1tHSiqgqZpGJaJbVmYRpZoJIaqqtjCwTAMHNtC13QURUGWFdoTSRRVJRKN0JJIYTsOAU1HExYqglA4hKYoqKqMrunYjkPGMNGDQRxH0NLRga4qqLKCIitkslkymQzBYBDbtkinUtiO7cpXsuzJd4ok4TgCy7HpSGaQZZlgIEBleRxJkkkkkx7/VHJnCFmWMIws4VCYqqpKTMshkzXY3NKGbVlYpsH6jQ0EAzrhUJCammpM0yDR3kY0EkWRZSzTcM8lkkQkHERVVWRFYc3GRpBkAsEggUAAWZFREGTTaUzLwnIgGAoSCOg0tbSSNQyyWYOqijI0RQHbQsYtV9Z1Nq1Zxeb1azCyWap696H/iHGEQkEkJAzLJJlKYVs2sVAI27ZxLBvbtpFkCUmWMHHPUoqkYFkWpmnS0tZKRVmceDRCe1srALKiFOQBSSIcjiDLMslEAlXTUVQNRdWRJVAlQXNLC6ZtI5AoKy9DURQ2N7cRDOjoqkoqmUBTVYLBANlMClmSCAaDGJaNIwSqrJBIJEmn01hIRMJhKuIx2pOufIFjUVVehqLIbG5sQtc0VE1j9123XTnal6E71+fL0L4MvfUydI8VT05O6dNF3dFJkZNXvOQ3ojt3krcQEK6iIL/m80onIZwSoTnfj7ziakvorJCRcoV3Ti+0TXT7TmHgihZXpz0kUVCMSUg4XdqVL6dz3ZKnT+k8VsXorARD5DYJAkVRCumlzSrUXaxYySlO8MbXfSpTrMTpRBOlAhHM9xHI69TccrwiHYSwcGwDI92BYxmuMsrKgmO5ir/c+Ijcu16fJZCd3LgXPfP+W7T+8+vDbY/AEfnNIrkKPKmwuYpG0q1LkQujJERh9xQ0U946zRMgb0QkgZSr31sGsuwpvBxHdFHEbusQTvE4d0YRZRGdkvPvd3lRdJOWe62b/Vfy5heOWfH73e2p7hnm5zHJLvkk4dVUWky+PvenUGauTqdrHd6+LW2eW0dhG3Z6pzDeHpMsejVfr41Aziu2c8/kvFo3p3S1cwrSQoGlbfbqzK1xV0iXcRwb08hgGBls20aWNXc/dWpsnjKLokclM5LfXl668Fif+1cnWllMY0smQCowQkkU9nYR53SfixImWrx2O69yUTL2UhGN7cxn2Oah6gFCsQokWaY9nWXemiZu/NNtiFQbP/jBD1DVAg/dbbdd2XmXnQnoOqbl0J5Mc8df/05rSws/OPJwHn30UR5//HGOOOIIpk+fzpQpU9hj9iEMGzKYv996kze21157LXLuIOg4DqYtSKYzXP27axg3dgwPPfQQ8+fPJ7NkJbsdcgI/3GsnBlYE+Pe/H+Hpp5/mxRdfZJ999qEhq3HXM+9zxcnHMW5QHeDyt+aWFn7zm99w+umnd1E8qarKhg0buPDCCz0edskll3jPHcfhyCOP5P777uejjz7i9ddf54ILLuD22+/g2GOPQVVdEac7vj9gwEB+//vrkGWJNWvW8Ktf/Ypf/vKX/O53v8M0TWzb9vguuB9mFEUhlUpy3XW/x3EcwuEIBxxwANFoFNM0+dOf/oSqqhxyyCEoikJLaxu//vWvSaVSufYK5s79hCVLl/HsM8+w004TkSSJo48+mgcffBBVVRFCEIvFuOyyy+jdu3endrhjomma165YLMrll1/OM888w2mnPezlcRyHiRPGU9erlsVLl/Pss8/yzDPPIEl47+fFFQm4++67efOttzjqqKPYb7/92HnnnXniiSdQFAWBQNM0VzHhONxzzz2MGjWK//73v+i6TnNzM1deeSXT99mf8674f3z47tsoiopl24wbNhBJkrBsG0lxFR6WZbHLLruw88478+qrr9LS0oKsKJ58JSsKhxx6KGeceSbrm5Pc9dfbufD88wgP2gPHSJFc/SaqqjJ27FgOO+ywko942zI6UmkyGQPLtjEtGyTTPZxnsli5eQ5FImgy6JqCrKgoqoasKBiWhWWa7gdCuUDvZQkUGUwERk7mUhWVQCBEe3sHmWyGYCCALcvIQhDUFPSATiAUQtGDmKZJoqPDVV5ZBrKmEQqHkRWF8liUbCZLKpVCOA6ObePYFookUGSJeEAh0dZOOpNxP7BqGpqjIRxwhINt2SDcfROPhN0PeY6DZZkI20IWDrqqoIWCVFVW0NrWjmlZKLKMYZquwtYwMAyTTNagsdlV1lVXVqCrKooik0wKDNNCCKgsjyPLEoosUVlZiSxJWJZDJpslmc7Q0p4Ax+0DkkQkEqGqshwHGUlWCIXCrvJIklBk1TvM2qbpyqG27R68crRE03V3P8oQDgURjqA9nUWWJQSyq5iSZRRVRdMCOLZFU1MrkaCGrikojiCTzZDNZrFtB8sWrpLNsorOJTJCEm67TBPLtJAlCccBBwlbcuVcBRPHcbBtB03V0FQNVVNRNM1NdwRZI+udUYLBEKqioqkKtm1j2Q5YjruecNy1Jhx3/eHSiqxpomsqsiwRj0awLJt0Jkt5vAzhOCQTHUSiMRRFIZlIYmazZNIpbElBQdAhCbKGCUgENPcjuKKoBMMRj75sy/Bl6E75fBnal6G/hAzd413u0qrSUh3HKbF4yv8uy1Jh3jyFg+z1yCWlkJ+b/OHeEe5hv6C0kjziK0TOisnTI4jcl41iZZXo8nvnf7taE3Wuy/EURIUJkrwJknLKJUFB4SDnrLcErmCZV7jYtkRn2iF1qtcbWwr1uf+6DMjdb2ILglWphrKkj/l+O06J/sxtt1MgBFJBySTyFmZF4yFJUs4iym2oZxEm5TaCY2IbaWwriyQrYJtIwkaWZU95lmuU+48sIwmBkPPWWG7Zkqf0El57vPUhF5Rlhed5BVTXUXEVn5KnKPTmzXHLcBxR8p5nzSbn8uWG1NV7u6NmC9eqrWDx1p1l2v8qCkRkayBEV1b29aF7pvidQGzh9+Jkj+qWZpbEFl8pGW/RTX8lJEQ3BZTwinyNObpR2Nai5LlnzOfk6JfjYJomFVXlRNTBZDNV6GW1mJYDQqBIwnvHEy1EweLPpe+SR/fydCNPKjv3r9DQTr/LxRaLefqFxweKyHthX0t5O1m3IXL+pVyxIifM5dXOrnAhFbHtonokcJz8e9s+jjryMC666GIqq6pQZcH0kfWM+dudCMfGFpDOGFi2IKTJzJkzh7vvvperr7uORDLDAw8/yi/OOZuhgwegKApnn3c+x/34VKKxGI7j4AjBUaf8lJryGAJIpTI0bN7M4088wZRJOzFgwACef/t9hg3sx7hhQ5l20AkM6NvbG7feVXF+dezerN/UyKLVm3jxpZd55N//5p8PPIiqaozvV8/NPzsITZFobktSWRbhkTfm8smyz/jrHXcybNgwTNMk3d6CoigEwjHuvOMOUuk0QsCbnyxkXUMje03cDscRpDJZnn3tHUYMHUwmm6G6uobdd5/OxRdfzHOvvcWPf34+N19zBU2Nm1m3dh0Td5pIIBDAsR0s02Dthk3c9/jzHLLPdOqryzl4/9mMHjGCVCrFEUccyQ47jOfKK68km8liZDMkW5v5za8u4vzzzsPMpnjosTk888LLKKrKK6+8yk0338z5F1xIPBLhlj9cx8xZ+zBg8GBef/0NLMvCMAxeeeNNetXWsNOOO7By1RpeevlVdp44Hi0QYfiYHbj7b7ezfNVqVq1ZRywe5+NP5vGfp5/mRyccT+9evTANk6uvupqLL74YSZJoXfspqab1RMNB9ttvX9556w2QJNas28AjTz7DcUcexugRwznu5NNZt3Y9jQ0N9K4uJxKNEi4rZ/maDSiKzOC+vbn0d39g/abNCOCGG27gwQcf5J///CeDBg1CkRXuu+8+PvxkPjf97T7OPOGHTNphO5BkNmxqpLW1nWeefY63Pl7Ahb++ksuv/j3D+vfBTnfQkHFYuW4T115/M/tOn8q/Hz2CU08/nT1nzuT000+nfvhY6keM48fHHcv4HXfAsB32PekcKvsOY/OmRqrKYuw6eSJn/+IXHHzIkcyf9wlnnvY2f/zjHxk4cCC77LILa9eu/Q53Zc+RzGRRFIWy8goCobC37wwji2XZBAMBcMAWYFo2sgO2LdA0BdvIYqUTKCJOSAsSqoyjaRqKopBO2wRDYSKRCKoecEm9EKQzaVKpFIosI0syQhWoqoYtIJXJYmdcBathGKjCQZElZEnCdlyrlaxhIZAIBILUVinYtruO4yHXitA0MqSSCYx0muqaGlRNQ1HcY4WiKCh6gLaka9VXFouCcJVX6UyCTDpDNpMmGAygayqBQADLdkilM2SzmZzVlU1A0zAMAyNrENRV4tEw1ZXlSDmrrkwmS0trO1nTxDKzBAMBQoGAq2wTAsMwSafTpFNpku1tRCJhgsEgIV0nFAwgCUFD42aEbaFKrvJHUVWisTixSISAriEJO6d0swnqGsiKq9CxLWwEqqpiWiamadHW1kEwFCIUChLSVTTJtSBSFBnThI5MFk1T0QIKsUgIUVlBSLiKrVhVJfFIkI50BtOysR2bdMbAcQTBWIRAIEgoCKZh4EgStqQQDwWxLIvW5maCAR1NUUinHdLZDLZwaG3rwLQsDNumoryCoK6j6xpIEpZlocgSquJ6JSTTaRxZBlVFUhQcU5BKJCiLxwhpOjXxCLaArGGQSCRIpTMkUxmG9K8Hx6apsRFHgB4IYFomwVAQVVPZ1NhEh5ElnUhQVl7m9l+RvfNFOpPFtEoV7P9b8GXoz4UvQ+PL0AVsnXpZ5FUXbsUi17FShU+hXZ4+Jd9Cgae8cn/tvCAKHfdMxIrKFwgkIZVMzBabugXFk1umVPJvkVKxcykU6QsLTew8urnVJYmcoiiXp1QpsuUpKeiJCg0pXnBdLXo87dvnDkR+sXuLuUhp5ymmRFH5eSVbkeLGU4blJ7tkZ7hKLMe2cGwrt+gdJETOVU/yFnFxP0q3c/F85HLlFWEUNn++m3KRUqp4pYiisesy7uLzF4xXf/79LYyk91c3hPyLvk5sE+iybnv4WjcK3fzreUJWstc7VVZqUdh9ud8GROmmKkqHIkLlPeyueVvb4i4krlM7SvlIN+uqhCbmE902iq6Dnnun8KbLLIryyBI4MpIkIwkHxzawzRS2kcQxMwjHdL8i5ZmYlN9fbr2SKLZ6LCHpHvMuqT/fdqngglxCQnLK3vzfhT5SUBx7SYK8S2yRk3ahx8Uv55h48Y4uUJXCiOffkwp/brPYc6+96FXbi+WfLiVeNpFwOEQoqLM6lSJrZHOm3e5Hio3N7QhZpX//vqiyTEBXqe9Vw+DBA6mpreGDBUuoqa5i6NAalq5eRyQUJBaLMmb4UDTJZs1nq4nEypBlhVg8jh4IoCgK4VAQXXNddsaNGEx1VQWW7TB5551JJZPUVcZoaW6hA0F97zrGb789TU0tBINB0okEm9auoaa2FkvT2NTUiGNZ9K4uZ7vRfQmGQrS2dUA2i67r6EIQjkQIRyJUV9fQmDGJlpUzYsQIQCJrmLRnbSrL4qSzBhMnTsQ0TMaOHcvyNetRclY/2axBMpXGMAxa2xOsXL2Owf17AxKxSBg1Z4Wz06Sd6dO3H5Ik0a9/P6prarBz5vKmZdPUkaWisoyoIrNg0TJ61/dnj+nTCQaDBEMh6up6M2L4cMLBIEvnf0JHRwdNmxupqShDDwRAkvlk8XJqamvp17cvq9ZuxLBsjHSaMaNHEY2XM2zoUILhiKt0WriU5qZGKsrKsC2b1uZm1q9aQU2/gUTLy1mx6BNamxpob2hgc2sHgWCQut59kGQZLRRh6pRdqK6uQZZVYtEYdXV1xKIx+tSU4cgqGUllyNAIEqCpChMmTGRIexsSUFlZyZAhQxg5ciTpTIZXX3+N8dtvz/bbb8+MaZ8xeNBAIpEoK9ZsRJFwD+dIVJeXMbRfPaOGDyMc1Hlr7iLq6vsS1FRqKssZNHAAo0aNom+/fpSVlyMBk3baiUAgwHZjx7Jx40Za2hNMnTyRfn16gwQLli7HEhKTJu3E4P69EWaK/Q/YnwkTJhAIBFi8eDGmaX6ne7On0FQFGZCFQFUUhCwjIWEEAqiKhaapqLLsfkmXXTqN5IaZMA2DTCqJZZo4jo0qu1bl7gdDl87bNtiG6VqSyDK6HkAIQTAUQldVVEVFVWQs28G0bJzcUSKgaag4hS/hOWtu23EPUY4AVZYRjoSwLRRJR0gStiMIBILoqkowGESSFQR4VkECSKUzOEIQjYRdxZaiYNvux09JkjAME0Ux0AMGsuS+a1s2Vs7qUFcVZEly3dSQXAs8AXbuEBfIWR2ZloVpWmiqguOoOSsim0w6g2VZ2J6SRUFVZGzH9pRuluW6vymqgqIpqKpGKBgkoOtomoJjQV4alRUFJBlJdkOCSAhs2Z0jyzIxDANN19zxs21sy8Q0DMLhKJqqoCoKjnCwLBvHNjEyKbKJVhRJxonGELZFOmtgWbZn3a8qsnuYVWV3HISDneNwmqZ6krZr/SYRDLgKSSTJtfx3ZITtuj6K3BjKsmtJJeEqG5FAODaKIqNpKrIURNOsnCGBa6Um4+DkzggCUGQFXddBuKFSwjlLOUkCTVXRFHBUlVgk7HrNCCd3GJbRdN1dI0Kgqkou1Mq3vye3Cr4MXfjDl6F9GfpLytCS6OHKnT9vkVdm3sUIOrmG5TrpmSOKUqVC3jVNKhrYYte0fIydPLGVcr87ju1ZpUBO+ZAfoSKzl7zFjhd3qXh4cu/mNerFk5G31vJiRIm8a5pLlCW5aOKKCEB+0br9lPMVuf30rINyRDrvdlYyJoVpdXK+7fkulWpy85XllUAFK7DuZttrY24VS0WrQuTbl2ceokgpVKSfycehcgmiKCiqcrmRwEg2k+nYzMbFr+LYBrKq0mvorgTjdQRjvbx5sx3bK9+bi5JlJ3nTWLB8ysfryo9pfm4LeUTRGIu8xZ3k9aawNnOj7HRaQ55VljfQRW51+bWRXws5xVvxend/HG+Md5te6iayrWH+vMWlCVKepHVK7obJdUsmSjiCa1qee0BeN55XJnZ9tft6e4ruFMqdctB5NrtTPnvpojhvMdPsbAq9dWyzdHl1Jzh0LVcU1SnlOREerywwUie3DnFyfusFFiLh+qALiZy1XnGtMiCj6UEaV7xF0+r3yCRbKe8zjt5j98Ulow6ycIo4UZ4zFuiA99WGTrQBXOaa/7oDOAV/Xe8rCuBaGUqyV02xUXaezeVEBHcwRBFrlSi4AXtv5P9bzMmL2ssWXGNzSbtuwzGe1qzbwF//cidXXXUVH3zwPqNHj0aWJH527nk0bN7MX/54E6qqkjVtXvh4MYN71zB+6ACSyRSyLBMKBsgYBqvWbuSKW//OSYftz87bj+Hqv/6LEUMHM3XSjvQrj7Bx7WpeeeFZpu21L7V1vckaFuGge7hr70gQ0HVCAY3VC+eiBEJUDhhKSFNRJNclf9OmBtra2sik26nt1Zv6Pv3IZLK8+/5H3HL7PZx71imUVVRwz3+e57C9dmfimJEgwdoNDaxZt5H6yjDRSIRYeSUvv/oqju2w5157sXz5cppbWxkxbKgbD0RRUFWFdNakqS1BbWUZAU0t8AUglUqxdv0G1m3YxJhRI/lg3mJuu+cRLjnnxwwd2I+sYRKLhtE1ldZEhlAwQDgUQJElHNvGzGYBQUsiw38/3UhcSpNobeKyG/7GiUcfwinHHo6uqRimRTKVIR4N49gWLZsbWLhwMY2bm6iJadT17Ud5TS/+/uiL9KoqZ7cJY9iQMFFkGFimo0XKkDUdyzRQJEE2m+HMy29gwriRnH3SUSRTWdauXM5T//gbux5yHOGKKv5w/ims/WwtyUSGi/7yEFUV5QQdA1lTiMdijBoyiIULFrJxw0Y2rN9ATa/e1NTUUhnXWL6hkXeXfMZhM6ZiGgZPvfwWB+8zg+FD+oPjIMmyJ4g89Mgj/Paaa/jHvfcxYtgwJOHw8ccfs3ZDA582Ztlj8naMG9qPf/7jHwweMoTdd98dI53ivXmLufDmu7j67B8xeewIGpqaKS8rIxKNkEhnURWFoKaSyGRACAKyzFW/v56GzQ1cd9UVBEMhUhmDn17+B3YZP4YTDt6HxuYWdF2jrlcvLMdh3rz5TJ60E5ZlAd/+QWxr0djSRiabJZ3OYBhZNE2jLBYlnclg5WL3BENBVFUnkTE8OpxJp2htaWbF8uUMHzGC8vJyFFVFkd1zkFADpDMmiXQWWYKgrlMej7oxxIRDKBhEkQouGIlkivZE0o1ToqvEwiFwHBzHJpVJuQpXIBAuc12/bAddsrFNg3QqRTAaQ8gSHak0FbE40XCIYEDHNFzFi64q2EKQNS2WfbYeSwgG9etLLBxAkWXWbdjoKiGERDabQdc0N06asDEMk+aWVhKpJKZpUR6Lutb0kkw6a6JoGuFwmHgsjqYpqEBTczOJZArbtoiEA0RDQWzLJpPN0p5IEQoEkGSJjAWhYABZllz3TllGUWQM2yGoa8QjISLROLquEwoGcwo4h0zGIM872jo6AAlFVbEtE0mS0HUNM+cSuLm5hVg8TiwWJdXeRiaTIZVKMnjwUJBgw4aNWKaBhEN5WGfN4rls+HQRsUCAqoHD6bv9LqxvS2ELQSQYJBwMoKkKWBbhUNAdZ9vByrk9RyIhLMOkoaGBkK6iKgooCrasYksyqWSKrGGQzmRpa0+gKDLVZTHikRABVSXvCilJ0NLWTigUJl5W5taJS9M7Eh2uVZ5pIWk6kqKSMVyXSE3TUBwLXVOJxWOkswa27aArMuRcK4VjYVk2pmXRns6iajpVFeXuWdJxXAs7xx3fKZMnfXcb9Avgy9C+DO3Cl6G7YCtk6B4rnuZ9srCo/IKCp+BqV9CiFStmPFc4qTi2UUFfUlp7sSsTXl5XGeQUFEQ5Vz7ADbDnKW+c4qIKE1r0b+fyS0eDIqVZUcM6tSf/3NNACuEpntw/3XbIntKm0LZSjaXUzUSWtq2geHFyAdOL9JQCKHJ/LLYMy+cVjvA2miPsolILyrp8CbIsI+eVWyVleoNdZI0kMFMtZBNNrF/0Co5tIqsavUfsTjBeix6uck2T80pKj3i6ky6KNlV+rIoVX54VVm7ubMfx2u0phYoUhsVrq3gdFfv8un3N55NKFZglg14YU08RCa4wXjQungtoLv7J1N137lrWNoT58xYXdc1xx1sqWgtiK90Hi/y0Xd14QfkKDp7/dTHR74aBFaOnjHNLLrTFPtoFK7jcj8ivIaBzP0VhHIrb+FUYpltGaXu39LyEaXov5VMKTEBIhT1QvDVLWU3+x91QjifbFPouSTKaHqDx0zdpXPkeRqqJeP129B47G0coLk3D8pStxbOSv/ShpK3FzBxRaFeJUJUb5yK/c0mWSr/25HMXK41FjmkW9dCjwwVWUCTu5Olm4ffu3bC94fAybsuKp1QyyS1/upWLf/1rrrz1r0yasAO7bzeK+QsXkkyl6TNwMPM+/pB169ay+/SZJFtbaVy/jpq6ahwUOtI2Y0cOJhQKsmLNeuprqymLRVm1biOhUIhYLMq6z1YiCYdoKIyl6KiaTk1FnL/ffR/vf/QRV15yMY2bm1ixfAUjRwwjXhanvLycTSmT5uZmlrzzJkOHD6W2ro4mwyESDBIPBykLqKRSadZtaqRv71ps4fDx4qWMGDqEiK5z/ZWXsP2OE5k6bQatyQyKBDFdRg6G0ANBKqoqXdecbIaW1jZSqQyJZIbVSxbQq64XO+0yhWAwQENjE/989D/ss8fu9OtTx5//dg9jR41g/JjR/Pb6P1FTXcW+M6czdGA/wkEdI5PhvkefYeWaDVx2/pmsWrWa5ctXss+smWQNkzVr1jOwfx9a2zt4+KnnGTl0MNWVlaRTKWoqyiiPR3n6vwvRhUHfCCxb14SkaAwdPIhYJEwoqBMPSFg2ZG2H1qZGZD1EIF5JbXUFiiSRam8nFNLJGBZPvfkxE0YPYdzwASz4dBXxaIT+vXvxp3seRdgmB0/fkWB5DZKisGnVMpo3rCXZ2szEfQ5FliXMVAJN19nY3Mpzb33A9Inb0aemirUbGpGtLMI2WJOyiMdi1NdWs275ClRFpt/AATzx7At0JBL86hc/418P/5vnX3qFX5xzNjgWzZs3Eavpg5HNsHHVcmKxKOFolPp+g1m2chUbNjWw6w5j+GjeAp547iV+9cufEY+X8enqtbS0u4HOR/ev4YU3/suCZau45Nyf8sH7/+XBhx7k/PPOA0nilZdfZ/DgASArPPPmBwyuraBfTQV9hw6nqbGBdatXss8++7C+oZG/3P8gZ558HNgWO02agg1IioKZaPlO9+gXYenK1ZimiWmYyJJAVdyDu6tYcT+GqZqOJCs0dqTAcVBw3TYc28YyMkQiUVRNAwSpRDuZTBoLhUTGpD3pxhcKh0LUVFVgGVkkIBIOEVAVNEVGVZSc8isNSGiqQjig49i2GxDccuVESZKIRKKYlk3WMJElB2E7OJaJYTsYlklrewdVFRVEI2GyOQWiDMRiUQRgmibJrIkDBIMhdM3lLStXf+Za8sgKrS3NKLJMKBQiHHCtKWVVoam1nXQ6QygYRFZUkBXaEyn0gE55PE55uascEaZJW3s7mUwGWXEtshzbwjRM0lmD9kSGutpq95IBxXXV0zWVVDJJW0eC9o4k6EGCukZZWCeUizcUDOikUyks0wRZLhK1BZLsxhhVVQVHgGGYOYsni5aOhBcvpiIWQQjHVdjkZXIE0WgEXVOxswlWzf+QNUvnIWXSVA8YzoAddyWruBaSmuJarimyTCSgE9A1dFXFRiKZU6rlrYna21pRc+espGkhaUFQNdKpVI6fQ1trGxKCSDCQsyQDyzQpKy8jEonS0taBHtCJRCIENBWEwLRMUuk0lmWjyBJZ08K0beLRGIoiI0sSmzZtRJZlKioqyBgGjuMQ0nTPwi4Q0LFMk2w2SyLjjmcgGKStrRXLNAkGg6QyWTKGwREH7Pet78uewpehfRnazeDL0MVt21oZ+itFcuusIHJ/yf1HFOLo5Ix+vEdSPoFcHlE0YELkFDJdF5m3MPLRuYqUcu6rRQun0+YrNirrPNGCrrPmKS2k4gdSUb4uesHSurew2fL5Rb6vonjBd2pzzpLHWwBS0RgKCSRBcWT5Ekun4qJEfrMVt8KrxHV5pFB2/ktnwaLHfSBJAonCbYSullUuGg83QKMsKyV6poJ1GiULwXWdLB1dIUQhW15DWbTxpO4GvBiihB4WpbujXjw0Jfqw4vRcpfl58siw6Gzh97+FzgS8aEcU5SlaR0WPuuttl2EuUnx6LxVPfTEl26p2lzLGkjYUWQ+6a6eI2HaqyzNvLWprUUEl+7rorW7aUZqvM/H9wqXR3ZgWresS5lPyist0itdkZzfRfFElvcjTjcKGzCnsbYRj5QR1A+GY7sUAsurS4PzWF5RsqhLle3E1eUvEkvYVdbvE5TX/9b2QVjzPUvFGF6JkrAq8ptCrokq8RueXW/H+/Txs6zt6yZLFNDRsQuDGikmm3bgYffr0dWN4IJMxTFKpFAFVJunYpNNpN1C2sEkmM7m4gQLJSOXmWqK+ugJZVVAUhaxhEAoGqe/Xj41Nrdi2gyLLdCQSNDY2IeEeVBKJFFowjCNk1m/YSEYLkzFM2lpbQQgCAR0j0Y6mKFiWRodpEAwG2G7sCJo3N2Jk0vTvXUMooJPNGjQ1bsYys+4tTFkbYZkYmSz1veuRVI1PV6+lrrqKeDxOS0srlm1jmCYdHQnvACpLrrtLW0eC5tZWwqEArW0dCNshEgrS2tZGXU0VY0cMJpM1SWWyhFSFZDLF5qYWmpqbaW1to6MjkQvi6wY0Ng0DI5sh1d5G3m2pujyGrsjYlsWmTZuJKDa9VDeYs6QFsB1BNBajLB5BdkysVBoraxIJBRCaDrKCmc0gFBlVD9LR0U5bRweZrImDhKbpBGWBLruWFemsgeNYOIqOqiromk59XS/CkkUyrFFTHiOZztCUTBEFspksbR0JLNsNDlxZWUmmvYlURxohq0SjUQb2rmXhhx8RDOgM6FOHaRo0NrWQzhq0trWxqaGBDY1N1PeqZeSo0WxoSZLJuhYv1dVVxKJRNEzMbIZEKkVZeQWSrNDQ2IRhWgQ0hYG9KmjtSNKRytCWSLC+oZFVazeAcMhk0jRs3kwynUbO3U5WU12NogfY1LCZCBZRFSZWV5BJtJFIJt0b3ID1GzeRzRoENVdh06e+DzV1dd/p/uwJ2joSuSDdFiFdw8bBti30QAhF1chTb0E+Xmhuv0oSqq4TjURwhBtmVpbAsGz3wG45ZAzXfU6WZAzFJJU1wLaRJQnTdlyLJ9yguo5tu25ikuTSZfAOU4pcJH9BLjC1jZWz5JdxLfQd20ESAsdxrZTa2jvQFJmAprmBqnEDYmuq637n3hKn4MYYJfeuG/PJtl2Lf1UGWQ4QDkYIBrLYjoOqqUiyq3hSc3RKVuRcIG1AuDRKU1WQwbAs72Y1kFzliKK4t7pJbgxaVVEIhYKk0hkkQM0Fts7HRxWOg21ZpNMZMtksAV3zWEsgoLlyq20hqe4B0zAM8t4EgWCAVCrtuvpFQsiSlLuUII0kyUSiEcLhCLqukREmakBH0XSyiQRm7pZBLRAGWXGtD3E/zGqaipL7yCnLine5jien5+p3XfwEsurK14riuncqskQ46LrF6ZpK4VO5e7C2hcj7SHqKBAlQFNkdG1lGlWVXqebYhIOBnGdE7jYxx3H5kGHiCAdVknNtVwttVlRUVeDgBlDPGgamaaJqGoZpkTGsb3T/fVX4MjS+DO3L0FtET1fmVrjaLey6wSi6prCoY8WWQIXNV1hZiqKUXFOfe+BpAmRJzjENXCuTXNm2beWLKFpYpRqWLovFm+HSAOje8xzp8KxX8pZLQngudsUKB29xSkXubqJYuVIg2sVMIb/AZEnxrGiKyVbxjX7FcIpM/GRZ8sa2s2tgvp35HylnnVR8e4BrKOa6reUtsGSpcFOba6FVqNcryxtL93YOWXZvW8l2NJFpb2DN3OexbQtZC9Jv+5mE4rVogTi2bRVZoeVdF72h9wKGO47j9g0p55ZHydx3DgaeN8nNKylL254PQl+Yu64LvGByTmFZFjZY0XoutqLz1uQWlE/buqvdJ3MXFu1DuuyFbslGbkBKGZ6U+3+BPAogH3muUEohX4Gol9ZRTODFFr7UfBGJKvnC5N06UkK6vbQvJHdFdqf5rwv5vpcyx65Mc4tFds7UiSS6g1BM3fPPu2GaJaxUophZ5ouSi/tblD+fU1Y0JFlG2Ek2LHyNTcveJpPcTGX/7RmwwwEEI/UgKWSzyVKG601Ugd4Uo+CRXMT0RacZLxrEQvbiscxZzuaSHCFKaFieVkGn9Zsfo+L9Sim6mr4Xqs//3pOrYL8raLnbiRRF4c2332bosOFkDJv5ixYhHJuZu05BIMhksrzy9rv0r+/NmBHDaEsbCMtENtOooSjzFy5ij9134/obbuD4E07kv+9/QF1dLYMHDaQpmUVTZKoiQSAX+NUw3S/vkoTpiBzvdghoGp8sWMRf7nmAn/7kBIYM7EdrUzPx8jJA8Mzj9zN42BhGbTeJJ199n7JIiF3GDebZJ57AME32PvAgTMfl2uXRkBuMWJYxDFeZkU4mKKuqZuln6zj5ot9x4U+OYb9pO+NYha+ItmXh2A62bRMKh1EUBUcIXn3jTdatW8++e8/ESidJJ9qJV9flDolZ/rtkLZqmM2vqDgigta2N2/5yDxMn7MCUnXdCMl0lnS0EqZZGNje38s6CVYwbM5JIOMg99/6TmXvsxp577MYn771JJF7GwOGj0XOHbNNywDYxsgZLV60nFlIJ6wpPv/0RddXVTN5+DA8/+m+CoSA/PulE/vWvB1mzdi0//ekZhEIhUskk2223PXvttSe33347pmny4Qcf8POzfs5lV1zJ+DGjuP+3v2Dj+vWksxb/7/4n+GTVBu56/BlG1FczdEBfDthzD9555780NzczeYdxNLa00ZZIMmHiBGRZIpNO849HnyCoaxy2z544ioJhOaxpaKB3VSXxSJh7n3oZ0zQJaxp7T51EVXmcoO4K1Zs2buT/XXU1Bx10ELvvvjsffTyPqqpKhgweQKK9jVWrVvLk009y2GFHUlVbx+MvvkYsFqeirIJdtxuKoqpYtmDxytUEAzqjhwzi7Xfeo7mpkUF15ZhSgJQl8fHCBQwbPIidJ+xIJBwim82yqWETvWp7sWLFCiZMmMC1117LmWeeWXTb37aJh55+EV2VCWkqNRVxEA7ZTJqyimq0QADDFgQDAVRVpS2ZQhZu3J6OZBpZUYiEQ27MJMchEgzQ2t5ORyJJU0sTsUiEirIyABxJwZJVgpqGpigENAVVllAkCQWHREc7bW1tBAIBopEw1VVVnneCZTtkMlkM08IRgkzuRrmsaSALgS7jtTEQULEcV9mzavVnlMdjVFdWEgwGMUyL9kQiR8MdTMskEAig6xrRSBQjmyWTSWMbeSVvllgsRigcobqmhmQySdYwXIVSTo62bRshyQhZdRWWQEU07F6uYNu0diQxbQfHEVTEI7mYoIAkYZgmmxpbiEcjrkttUCeVTJFKpSirqESWXYWaqijkPTfWbdpMIpUmFg5h54KLR6IRJOEgLANFC2DZNi3tCTRFRg/o9OnTh9a2Nlrb2jCNrHc+MC2bYCBIXe86QsEgqqogORlWLZ7LZ0vns3ntGqr6DGLw9rsgRytxkMimklSUxQgHAgQ1NRcDS0LSA9iOQ9Y0UWWZdCbDhg2bCKjuLXFKOOpe5CPLxENBbMfBMAz31i1JJqDrgCtXy5JERzJFMp3GsgXhUJCyWAQF0DSVWCyKYboxskwji21bCMdxx0ySEQgam1vIGiaGaZJIp7Bt1+IpL/uFw3n6rpAxDUzLJm0Y2JYFwg1GnrEcDNvh0L2mfUe784vhy9C+DA2+DN1NU7ZKhu75rXadFlz+sC9L7rIXORO8kmkuUc5Jbq+kQmtL3KFEfpDdKPT57PkYOoi8O1tO4ZC7Fi/vv5lf4DmHNvIuYYUG022sphJXsuK8RRrrgnZb8sz0yE1mweUtV5vIBxjPWyuJ/Fp3lVLk8+aDyeXHIjdqxXsrr30u0mbmTRdlSc4ZfhVv6uJxLfQlNxVF3csvavf9vKuY+8WmsNHyC9Q20ziWiW26X7lVLYAeiGBnUpiJBHbaxBE2EjZ2NotjZCFgI+wsjm1imyaS4n61cr/qFer2xis3D57+Dqmw4YqWTmGscsHHpU7umfl3cpvPo0MlG8ZdZ6U6S3egRKcyOtPDUhe+IpfH/xV0YUzdM7MtvFzIKYRnRVc6L7l9kp+0PAOQ8IS5og1R2BPFbcg9LqUmpWH+i+e8lLkU90MqSevJVxRRtDbyAmt+vTld/Ly/HErkj5LE3K/F1on5DVAqinQts4gDO1Knryh0UsgLBxxQ5CCyoiPJGrIWQgtECATjufLsrkulc0NL6GtXoaDzW/nxLL5BI1dZgbHnvzjnGVqefHZh0AX6ULQqtwolMmP38to2hXwcG0VxD5FBTUXXdMqiYSzLQiBoa++gI5lk5JDBxKMRbNtmbVMbRtZAtQz69A7Rr28frr/+enbddSqaptCrvh7HSLBy0QdU9R/J+o1t3Pf2h1TFQtRWlTN95wksWvopDY3N7Dp5AqmODlqamug/cCB96+s4/KB9qaooJ5vJ0Lp5I6ZpIGs6Zb2HEopXg3AYNqCOUEBHDQQZM34HbNsmoOu8998PWLthEwfsNZNoxHWBmTd3LsFAgAEDB2Ckk5QFFM48+kAG9+tDyrCI6Crvffgx73z4EbNnzqShYROvvPIqxxxzNOWxKB+89QZltXWMHDGcW/58JxPGj2PyhB341xMvoWsqg/v2pn/vXsTjUSzb4ZO589m4cRNTpu5CWJdZtWwhqgQr12zizQ8XsueUHSkvL2PsmBFUl0XQVZn9Zs0gk07xnyefJqVEKE93YGU/Qo7XogdDVEWD2IYb1Li8LEpQVwmoMjuMGEI0GiUUCTNt991RVQXLstlhh+3pVdeLW+/+J7vvPJEJ48Zw+eWX0buujkRHB4uXfEp7R4pzzvkFo0eOQlFUmh2FmCbRV7FobW2jLBJin53HM7BPPZqq8sG8hQRDQQb274seDFLbK0C8wuT5196ivlcN240ezrB+9TiWScvm9Sxf30DStKkfOoo3P/yE9Z+tZvuJk1i8aDEvPP0c0yeOY9WqZv7y17/yo5NOYNDAgRx6yMFEyytYvmYt/fv3RcJh44b1zFv6KbZlMnOPmaxvamP15lZ6lceo711HPBbjjr/9jVEjRzFjjz1IdLTR2mwi0mlXcVFRTiQcINGRwEokKItXEInEUBWFu+7/J5FwiP323pOHHpvDu+/9F9t2eOTfj7Hs0xX86Zabv+Nd+vmoKou57nWyBJJ7nXwoEnXpj+MQ1FQQNqZpg+0GCdcVxY0dJsByHDfQtCx5VieqLGOZGVRVxbYtUqk0iqoSiZWhybgWTMLBNBzXasmxsWwHTdPcwNCSRDKZRFVV1zpI1bGFyFktga5pBHQNw1CRhECVyAWDllFkJS8o0rtXL88VTM9Z50CUxuYWTNMkoKtYlont2KiqSrIjQUdHO+FgEFWRKYtG0HKXGBim5SoyDCMXJ8hG2DmFs6KiKO4tf6Zt02YXAsurmk4g6LoTakruI3I+VIftXnve0mLQoSpUlJWRyWTIZrNI7a0IIbAsk0g4nHMRU4iGAgQ0lVAohGlaWJZbl+0ILBtUFdd9Lx5HlSVURSKdTiFLEvFoFE0tcxsm3Gt35Jxy3bZcKwlJmDimgeyY9CoLUVEWoSwWRYnFcCSZrK6iyO7tcynTvQ1PVVXsjHuzXCqdIqAH3MDpEjiWheQ4RBSJVCZDNmsgWxFXSZUPOq8oJR/HZVnGzH3UL49Hc3MnEVDdOczHrrJs27XGUlXUgIojch+oHUEmm8vj2N419clEB7qmoaka6bS7JlVVxbQdbMe1wDNM07N8klU3bt82D1+G3jJ8GdqXoXuA7s1sukGpEqZYwSGXaM0kSjsoFf+vszKIosXv7bGCMshV5OANarGfpFeSVFjg3mYu+ulcV3GLyNeXey//t7d3O5VVUCKJgpLGU1J0GTCPuHfREEtS0Wbc8nh3p13MW/s4uaCHnZVOnUrxqiut3/tPSVLeOsuLR5V74FhZrGwHmY7NGMlmjFQbViaFmezA6OjAzhg4WQvHsDCTKYx0CsfKYpsprGwCM9OOZaRxbLMwTp3HxuODxWskT5RLt4W3ljornTp11luz3YxKsZUbeWWboOinsJELmzZPpIuqKlor2zoK+7B4mIo4WxG2nJp/KLxMBYJX+CkOfkeOERW94s2BU6zs7LTXvHnKM72i37u0rLt9toVRgG7WTvFke1mlEvokd7fe+HyC6wl4W87R9XnJ4He3eaVCepfyi0fNHXBJFFO9gsJdUQLIshtfRFZ1FDWIqofdUjzr0NxPnhgXVVX62JMyumkrdBZntjwcxfSg9J2ua7LTChFd822JF3SGu263be1TbW0t0WgUANvOuTVkM0RCASLhIMlEgrb2dhKJJDXVVUSjERzHoakjxeb2FM3JLMl0hkgsxqmnncqIESOxLJuq6mqEY7F29acY6SSbm5p57YP5vD9/CYuXr8YwLdZu2MSST1eQNUzSqTRtLS3Yjk1ZPMb4McMJh0NYpkmyvZ1ERwfpdIZIeW/0UAyEoFdljPJYGNMR9O7bj779+yMcwZp161i4ZDGpdIZEIklTczPr1qylubkZRdNIJRNokuCgGVOpqSyjI5kC4LP163nj3fdobmtnzboNvPr6G2zc1EBTcwtLF84nFgrSr19fXnvzHdas30gwGufDBcuYt2Qlm1vaKY9HqKkswxaCNWvWsXLFakaPHkkooLP2s1U0NzayYuUqXnrjPRpbE0iqRq/aGqLhANGQzqQdt0eR4JO582jMyjSnTBo2rGXj5iYaW9qxjCytra00t7QQCQeRZZmsaTOkfz111RVYpsHYMaMYPmwYDZsb6d+vHyNHjuTN9z9iyacrSaXTHHXUUey0005s2riJlas+wzAtDjroYPr07YOsKkjROKGgRplik0x0ENI1th8+mGED+1FZHmf12vWEQkF619WCJBONxaiqrmLxilWs27QZTVGpqSijIhoinWhn1epVfLpyJUowxMq163n7/Q8Z2Kc3sYDK6uXLELZFS3MTj82Zw4aNGwkEAozbbjsCoTCbm1qIx2NoqkJbazOr160nkTEYt912tHYkWLVmHb0qyqivrqCmLMo7773HkqVLMQ2DZKKd1pZmNqzfQFDXqaqqJBKvRFNVJMemvKyMQCBAOpvlnfffZ/6iRQQCAd55/yNeefNtqmuq+eDDD7n1ttu/y+3ZI5TFokTDIULBgOtmJkDV3JvnbNu9dU04uZhAwkHGvU0uEgwQ0FUc27XI0XIuXkFNIxYJEQ27t9Y5tk0mm8YyDXRZoMkSSk6pZefiHhnZLI7teK5PwhGkUq7lTzqTwREOtuPG1RRIaKpKOBgkHHCthEJBHU1VvZvRpJzyoqKinGgkgqqqaIpKQNcIh4IgXAt7NefpYJquJWAmmyGdTiOEe8NfJBxE1zVkRcYwTUzTxDIt1xXPMrEsE8d2FTbCtrBNA9PIFLXdVcyEg0H3Bj1F8XiY6xrovpNKJeno6CCVTpHJZskaJslEgmSig2QikbP2MhGOTSjgKvYj4TDBYABV01y3NEdgOQJbgCQr7u2b4TDBQBDLNJFliWAwSHlZnIryMsrL41RVVVIWj7uWZd5t0HYujpdDeSRAeTREJOz+RMMhotEIiqx4FkumZWHZDlnDyAUtT5FOp8kaBorshs2QhOui65gG6WSSdDKXJ+taPNm2jWlarkuiaZEx3Bv0BIJwKICeu6BBVdyb5izTVQBmDYOsYUIutk3+PGLn1qthmGSzBuDKSkbWDUbuODZZ03TbbBhYuUuH5NytgJZlkc1kcCwTpYuNxbYFX4YGX4b2ZejusDUydI9d7RYuXFzSAPcjR84gTQjX3zvnc+x4CpGC0sBVwhWqypv1dlHuFCutJMm7EhRwLYxyCpd8FPdiZYy7QgpKqPxEdqfVLbV4KqDLcHh5XGog58vKtSdfdt5qCChyfxOdiEpO4ZRbuE5RwGw55ystBJ6llGcyR94dEC9PcdkSkueWVjTY7q95V8UcofOsmaTCYpbJW/EU3+gn5SeQZONqsh2b6di4BE2NIMtBFBEm3biZdFMD2USTe5WvpBCo6kuwrIKyvn1xRAJHmAhJIlJeT7isjkC4DMjXVWiuUxTUvdSqqGiuOo1Jfh7ygk3x/HjPvBEunWPPl7Z4vjsprQSiyESx0CaRq8v1Wy8Qhl2nbdvBxed9sij3W+ctL7rQZq/XRYSIzusPPEIp0clMVEiQi+VQyo+6405F73VB9+SpswI7T147pxc/636qpRyBLg7+n6cbndtRNBhOZ+LcbTO3qBAWxS/nquz2HVFQkEMh/lnn+SlpauliRxIOSjCKJOWuobYMhHAIhUKsm/c8Gxe9SiadoGboTgzZ5QisbOEWUSnndmDZ7g1LxUPQGZL3aUXqlKdY2CmdIU9322lyOptI5xlo/vKDvPDXdXi7Uxh3ypGjh8WMMv9Fblu+IKCpqYnbbruNyy67nL8+/DgCmf88/jgX/vx06msrufeuO9ljz30YNWY7nnr9XQb3rWeHUUOZt3IduqowpFcVj7zwOumswYmH7MPbcxeyav0mDttzNxYsX83rH8zH7GhgYN969pk5E0WWaepI8dh7i5gyrJ7BteX8d/k6+lVXMLxPLxzg448/5o477+AXZ5/N4MGD2bBuA5WV5Wiaxgcffkzvul7069eH19/6gNZ0miQSZcIkoCgEImXUVEQoj0fo3bc/Dz46h/sfeoQ//f5qKivKaW3v4IO581EVhdl7z+D1d95m7bp17Ln7NDTdDcAc1HXSqSSbN23klbc+QFVVjjh4P2xkbCFIJpKEwyGikQjZbCZ3xbzOg8++CsAPZ88klUqRzWTIdLTw8dLPmL9iA7On70Q4oCEsi7KKCppa2nn8+VfZd4+pDB/cn0R7O40NDbQ2NzFk9Fj3IIZAsgw3UHI0yg133MuiZcu57Ocn8/rb7/P2B3O57Ffnsn7VCp5+7GGO/ckZNDS18tOfn81ll/6GGXtMI5lK88ij/+bFF1/ktJ/8hCVLP+XRx/7Dry86jz59+tDU7sZBCgUUspvmc9Mf7+SBh57gn//6J1KsitUJh7Xz36cyHmG/ffZB19w+rFmxlFB5FaHyKsqjEUzDIJHo4PnX3yEc1Nlv2i58uKaJhGEzZdRgHMvAsUwi0Sgd7R00bm5k4ID+SBK0trQQCofY3NzKFdffyqGzZzF9yiRefPlV+vapZ8L4cRiGQSqTpbG1g6a1n6IIh4m77kEqkSCTThEMR1m3cSNLl6+kqaOd3rW1zJq2O/954mna2to44pD9+WzNBhoamxgwoC+r1m9k3qcrOHDGNHQ9wLrGFt74eCGWbXPiftO4+OKL+cudd27zH4A+Xf0ZmXSaZCLBhobNSJJEPB5D2DayIlNeVoYsq8iKQlk04t1EZ9quxUp7MkUkFHSVOELkeK4gkUhgmKarGJBldE0jHg671lFIZGxXdsYRSLZJKpWmI5lE1TRsyySdSiJJElogQE2v3kg5a6x4JIxlGmSzWbKZNIosE9Q1DMsCSSYUCtPekSBrGJRXVrg3TSpusHJwZeGsYWBbtluOaWLaNpYj0FQFTdMIaDrCcTAMN8i0QCKRziCEaz1TFou4ErDj3jzVkUjS0NiEZVsoikIsGidrGIDEgH71br22Q0cynVPuCcxsCiObobWtjWg0SkDXvQC/juPQ3t6OrgeIxcvQNRVN14hHIq4lqRBogQDrN25iY8NmopEICLBsi1Ao5L4Xibjxp2QZSYZ0Jks2m0VX3ZhX4VAASXHHxLYdNM2Ne+RYGRpWLGTz6qVkmpuo7DeU/jtMxdJCrphhGpim7YajkApHxIxhe/JnRyKJcBwCqkxZvm+STENjCy1tbeiaRjQSobw87ik2DcNAVRVsR9DQ3IxhGji2Q22le4uhaVlUVVSgKipCOLQlkqSz7s14dbU1VFdWuDGzHDfofXNzM00tLSxbuZq+veuIRcJo2J4STw+FsIWDaTtEozFkWca2HRzbPetIkuSOmWFy2DYcXNyXoYve92VoX4b+kjJ0z13tipRNTm7FeIGnRWFSCxo60WXyPQWAVIi3VLjtrbPSqbTeAgoHfVdRma+3sGnylih5bWVxHwrlS/kCOiliuuYXufYUJrjoWU4pVTwRhfeLCyu01fXqEu7Xm3xQQC+T68fu9d2zjlJyij0Zr1sivxwlpJyySgLv9jUhQC5eup4ix51Hbwxzv7hpjvd3/hY7RXO1uk7WpqN5M7Zh42QUrEQHZjKBbafdL0ACUpm1aM3NpBNtqGEZLaQRq61DUTUveKboNDaegrbTgOXnvrBpcmtEuPtSKjIVLBrmbucbWabzDJcQH6/PBYWkyA9WLnNeoejGpMorCntsNPidI39DRikZ2QJTKhmYoryiiDgWPcstaS9fjgJ8TmtybrNd8hQUoh6b7bxv6bxWyO+CgolttwypeC/kH0lFmUpjiXVmEFKn377ojPN5Voil7SpukyjJmqNOJa0sbr/LSAp0NZ+WZ1Oy5Ab1tI0UeStNPRxB0QJIkoJlWmSSGYQso6gaejCILNveQQEnH6TV8RT5nlpaFI9NETzz8QKd7k4c6tTbonEoXace3Sr9T5d13IVJ9uDri0tjQTgedd9mUVlZSSQSAcA0slRWVrHbzjtRXVVBOBxhyMixxONl4NjUV5dTHnW/vKWTHViyRDIaYGB9LwzbYWNLG3ogQK+qCtauW48KbD9iCAsWdCCQyRoGS5YsoSOdYUy/ehwB65raqSuPYWUzLF66nFg8iqbp7L7bbuiBAOlMllg0jKppyKpKfX1vsqbN4uVrqK2tJmoYNHSkiGMS0lTKqmtQsXBMi0zWYED/fsyaOR1hWaQSSbBt+vfpTTKV4cnnXiGoS9TX9uKTxUsY0K8v/fv04YknniAaibD9uHEM7VuDLQTNHWli0QiyBMs//ZS+ffsQi4RZ8NH7lFVUMmbc9gzpV0cymWLegoXUVpYR0DTWNbYRjcWYMK6MeC5uTDJtISMIB1X6965h+YqVbNq0iR3GjqKlPcHyz9YzdOQo2pob+XTFSnrVVhPUAyiNjQzq04vyaJisYVPfu46dJ0qsXrOebMZg5NjtaE5myTqw/377oKsyn61ejS0k6nvXs8f06QRDIfr168u+++xNOBZ3g35v3kh1eRxLVnj1jXeI2m3sP74WTdcJRCIMiYdQU4MJqgqZTJrNmzZiGwbReBmKHsA2TebO/ZiyeJz6+nrCmoyVTrJ4/nziVb2JBcN89N67DBo4gNpetTw85ynqe9Wy47gxfDBvEcGAzvjRw1izYRNNrW1MnzqZPr17YTsOfXvXURaNkEml6EimsWybsCah1PZCOA6bGpoI6CqaHmDp8lVIEgzs3w/WryeTzvDCiy8Ti0UpK4/z4byFxGNx6urqWL1+A6ZlMaRvPfPnz0eSVbRwhFGD+hKNRKisrGLfffYhlrMG3JbhOAJZUQgG3WDijnAwLBs9FzTbsm1CquvaFtA11/rJci1OLMtGU1yrFpFzl8tbqeeDTgtAlXOB9h0bWZaQJdAUCcOwsUwLGQdJltD1gOuyB+hBN4YRkoxhGASDQTRNRZZlLMsimUzS1tZKQNNRK8pQ1VyMEwpUU87Jqk6eUwqBlYuL5DiumxbkPjo7FvmPeTmTKWRV9T6aCsfOJ+PYOZcVITBNC8cRqKpCLJq7fS4YJJ1WXGse07W4EUJgmVmsnIWQIjloqkosGiUUCqGqGqZpIoSDLElemiLLmDllkxkIeDKoyw9NLMOAcAhd04iEQ+i6lgvenQ8CD4GATjKVIplMkkS41mi6hplsda2bZAk9Xu5adKYSrpVoaytWKkM6lSaZTBIqD4Ikk7eEs20bJRf8XJJlggElF1zdjdmEAqriWrDJOVdFTVeJRiKuW59jY2SzkPNosC0LggGQXIs2VVFybQ+6Y+Y4pDMGkuTKAJl0Gtt2iEUiaDnLOsu2c6cxgXAsJISnULMdB8tIY9vCnVtFQVU0gpJ7E6AkuQHes4aBcHA/JEhuAPVtGb4M7cvQvgzdta6tlaF7rnhyBMi5uE5CwkHkLHOKOpBT5MiynAtgXaSjK9J+FittioM34+UtdNYR7mTl3atyObb4vmu65mmeCu0vUmx5Gy/fZArpJUHW8u+IfLBuubAgO20I1wgmt5xKlFJeYQUNKK6wYFsmjm0jhI2wTXcrCge72CUtV69rxqcjKyoir04ShTqcfNmSewuOl+7qN93Fnlu9BTfFfB/JCSwyQuTsqwTkb6LQ9DCWFgJLpmPTZlItbWTbs2DbSI4DmmsKbNo2ttmKpCioG9YS711JtLqSyj6D0PQQqqaXjEWBABZvjE5pkitoOcXjl6PQeau5wsR3M985yyZPIZlfPrnyBe7NH0WL0yUSeaKaT5fI3bxSWHOSXFBebuNnVhdSyT8lKPA7qYg5FD/L7xG89dS5tFINu1NSX+GZVPRTIIZFbLHor66D6lkfdvO8s6K5a+eK2iFyMm6JINEtF/Pe61z0loWPLSuxu6b3pMRC67rveV5xWmCYDrjMS5KRFZVM+yZs273WOlweJRCNYCazGFmTVEeKYDyCpOhogQCyIrBME9vOujHbbBtJ1UD2DI27Fxi2tAdyU1q8ZIr3/OehS4680FbU3+K8pcP5eQ0q5kN0WfPbKmRFQQ/oYFn0qa1m9x3GEAqFAImdd5uJjoWZSTGyfz2BYBDHcUi0tyILQbOusP2IwQhZ5ZNVa6mMRuhVHmfhgkX079eH3Xccw+ZN65AVmfUNjTz14kvg2Fxx0YX8d/EqFq5vYL9JY/j001V8MG8RQwb3p7ammqN/8AMamlroSCSoioWQFfd20wED+zN/8UrmLlzBwfvujhAOobWbiEgm4aBObd9+rFv9GW2trSixBGNHj2LyjuP5dPFisskk0VicMcOHsmbDJm796/2c8IMDGT18KHc/+jgC6FVdzd333sPQIUPZcYcJbD+iP5mswfINDQwf2JegJvP2m2+y886T6d+3nheffYaBg4cwauw4th82kE0Nm3nh5TfYccwwaqoqWLWpjVFDBzBm+CA6WpppbG5l4+YWKssihHWFMUMH8MRzr7BpcyPbjxvFhsYWPlr4KbtOmczatWt46flnmTB5CvFYDCfVwQ4jhlFWUcGGza0MHzaUCTtsx1MvvkFleRmTp81k0brNaKrOWT89nSVLFrN0ySJSlsTokSPYa+YMVq5aTZ/6Puw5Yw9WrN1Ec2MjrQ0bYPBAzKzEQ/9+gpl9LA7boz9OKEJZWTl1tTVUxSOk0ymaWlv4bNlSbMNgjz33xHQEHak0L778IqNHjWbEiBFURAJsbm/mw3feZeb++xONRnn0uedQ99mbquoq7rj7n8zcfQozdpvCK2/9l2g0woTtRrN6/UY6kklOPPIQ2hIJEskUo0cMxTIM2lqbWd/Yiq4q9OtVQUVZXwzLYdGnKxnYrw+VZXHeeOc9Rg4fyp7TdsVwHJYtXcZ/nnmes352BvV9+/DX+x9g5m5TGDp0MC//930G9O7FhNEjuPaGP+JIErtMncrUnSbQq7YG0zTYb7/ZzJ49+7venl8Iw7ZRFZVwRCMQCrmB9G2HSCiErqk4toOmKoSDrsuTaRg597ksQgg0WUYSNsIG03RyMZMcQsGA9zFRzplNWJbtWuIrCpqikLEtDCODmlMEBMMqpuO4AcNzt0sKITAM07XkUVUkCff2yESCTQ2NRMNh4rEIsXAERVUxLAdZkt0LZ3Lys4MblDbvVpfNBZE2swayqrqKEuHK9pZtIytOTsZVc7KC41oYyDKyJGFZpmehnjUMHMchFAhQW1NNQNeRJNAVGcPIYmTSngLMyqYxci5gsWgYVdcIBgPIquaNlWPbONhEIxHyYUOMjIEluwG4VVVFliVs08jJ6yaSEAR1nYqKck+2sSwLSUhIyAR1Hcey6ehIuAHabYdYNEpbUwNYBhFdJxwOIakyibYW2po209zQgOKA1tFBW0sz4XgFiiZjOm5cKtOy0SRXOabKrkVZNmuQNAw3LhcymiIj5xSJpuXG0NNUlY72DhzbJpVMYVmusg0EkiKhqhqhgIaqaq4SLxBwb5qzHVKZjDs+tqv4VBSFqvJeaJobSyxjmqiylLvd07XmCIdDSLKMZdskOzpQ9SBaIIiiagQDOqFg0I3bJYGiaK6SSzhebLAv1ER81/BlaF+Gxpehv6oM3WNXu3nzFriKCEnu5kY670MF4H7RcBwnZyHiNrLYJMuz/BEFtyoovUHM+xKSVzjkys0roAqWTp0HQXhJnRVNneE4juc25eXLKyuKLV+Ee1OaJMneZOeJN55CrEAh8sEMbdPI+XGb2GYGYZs4VhbHzOLYFmY2jZX7XdhGTrNKblxUZDWAGoggqwEUPYIaCCOrASRVx3P5ojC++b64vtP57VNYrI433rkAgxQszyRJRlXUXN9zwyC7Bwgr3Uq2rYmmT+fRuHoFiabNNDU2kTVMTNNC0eUcMRXYhhs7IBiMUjNwIGV19QyeOJlAtAItFMeycecUStwW8/Ps5BQ5HgHME+k8QSghzIW5LbU0E96/xS6QxQs1X2fBFVF46cUEvvhd27aL2pVTaBU9nzZjarfrbFvBgvkLvd+3SPDdiPWFrzVyzs3To1DdGeLmXi0hJZ1qEPm0rkyTwpUAlLKFYtPdrwHevHd+UKA13bxU1IaCMXLJR4FcvnxatwEbv4hpduG5XRlTycgUPVQ6FeBNnaohhINjWax48y5sM0FVv6FU9h6PQpjlLz6D0b4RK9VMVpGRQxWo8T6MnbUvWlChed08Nq9bhW0Lhk86wr3SGtzrY3PK1m7Fq87jgOg0tl3Hp8u4FPeoU77O+654CEuV/fnXu/KBwnosapGA3WZsuzdTCiFoaWlh48ZNJDIZotEog/v349obb6a1rZ3/d+lveOHll1i8dAk/OfEk1m3azIJlK5g6cTwBTSWZSFJZUUHaMHj5nfcZNXQwfet60dLWTkBTCOoqS5YuQQiIlZXT3J5E0zQmjhlBU+NmWtvb2ZSGqniU+oo4rc1NrFm3nrc/+IT99twdxza55ZY/ctzxJzBx0mSee/1t+tbVMWxgf5KJBMIxkYVFJBIjkUzx1rvvMH778fTqVcdbb79DVU0tvfv2BcsgoKnEI2FsB0zLoq29naCuIwHLVq9GVjX0QIB4OEQoECAaiTD3k4UIIdhxwngWLltJU0srE8aOcK0SZIW2liZC4TDVtb349WVXYJomF/ziHB5/+gXWrF3PKSf8wL1CPZliY1Mr5eVlDBk0gOXLlrF27RreePttJk2cSF2vOlZ9toYBAwZQ36c3999/P1WVVUzaeRf6961H13TMbIZlS5eSTCbZeepU3nz3A977aC7HHnEwCxYu4r5/PsiF5/2CeDzOm6+9xcQJ21FZWc57H3zIsGHDGDRwACvmf4ik6ATLqglHopimSeOG9dT27k0gqNOwZgkLXpzDqo/e4djf3UNa0lm1cTN9426cmZXrG+lbW0U4pNPe0cbGlgQtyQy7jBvJpqZm5i9byYh+vSmLhIlGo5SXl9OWSHDVTXey/957MGPqZFauWUtZPEaf3nW89dY7BHSdiZMmcM2fbmft+vVcdtZpvPfhhyxZvoKTjz2edCrJ+rVrGDR0BCvXbeDO+x/khMMOZPTwISiaTlt7gmQqTTSo8dLrb/HPf8/h4l+cSV1NNZlUhg8/eJ9MJs20Pabz4fwFrFq3jqMPPYwNmzazcMlSdt5xe0zTYuGny1mybDlr1qzhrZee82ShRYsWfe4e+q7xTu5WLCEcGhqb0VSFmspyArkg0jKCgKajaRqhYADTNMlksrQlEli2hWPZhHPWOXowSHtHgkw2SzQScRUQskR7Mg1CuNYvkhvGIaDrmJaJbdtoikzGNEllDFLpNKqqUBYJk85kMAyTZCJJWTxGNBKmLBr1Ygnlg0XHYzFCsRiS7FqsaIprrRXQNfdSHSSSiQ4QoKoqzU1NmKaFruvujXMCVE3FdlyrmWAoRD5sh+K47YtGImi5eE/ZbBbbslxXvXQqd7uagabrgETGcAORW45rvaQobtDzPJ+Q5ZxCRrjxiGRFzZ0lcjKzYyNyPN3BDXgthMi5Kbp017QsL+5UKBgkENAJ5/51HIdkMgG4VkfV1VW0tbfT3p7AUVTXRdAyWPHBG0iZDvqXhakaNAIlHGfJyk9p2rCW9sZNRAMBDEkjJYWYuNNkQtEoyWzWdSsUMGa7HZA1HUlRCOTGJZVMEom4ll+BvLsvuBYaOUspx3YwLTeukytjOxiW6Vqm5uJN5UNKlMVj2LZN1jAwDIN0OkNzSwuV5XEi4TBl8TjkLOscR6AobiD3z9asIZmzdKysqEBVNVra2hG5m7DrqsqJRcKURcPe2ULRNLJZE1s4aIrKpo0baG5u4uCDD/kOdmbP4MvQvgzty9DFRX45Gbrndo25BeeQV7h0hkQ+fHp3Zn1dru3zBr3QoeK4PrlchbLJW7Dk/3b/dbdhYQOKzq+WVFr0ahERKGlfkeWLVPR3/qa47hayhMgp2dzbN2wri2OZmEYqFyvBwDGSOJaZC7rtKqQsy8i52+Wsf1QNSdKQFA1Z0ZG1EIoWQlJ1JEUDSXFrK1KIFXdM5NotRKf4VfkuOQ5CkpClvDaX3M18EpLkYLuqUE8RJRzXt9UyMlhWFiGDHg0TtMvRjSxmOoOTzaKoIMmuwkuoAlXVCMfLCcbLCEQiblBH20K2LRBKYZHnNe9S6QZxF39+jty5lbxZ7qyvLpnUolkRnTaJKHqtSPFUNIb5TVfQO3W9BaLojy0yj20VXVucH4ciBiYKI1z6GSW/iDrPQdeN1v3+726eSvdTV415/ubCruWW5NqC6XC3leTKLXqIRwuK6FH35XRtvzcSxbS6U31bZg5dGUk+WZQOfpfXuvum1dm02/1bBkVFQsJOpWheuYJsk4xsB2lb8SmyZCIrAsMyMNsasTYkWFfXGy2i0tG6DMux0IIxFEXLCZt20f4oxEnzLBG763d+f5eSc28PFpfT7b4q1SqXll00BqJTQl7Qc61MXeGvtI0FpXXph4xtFxUVFZSXl/PJosUguTEQa2trkGSZhctXYDqCysoqNjQ0kEpniEXChEMhNEXGSKdJplNkDJOKWBRNxqXtueC9mbRDZXk5qUyWhsZGamrrCAdDbGpoQJclKuMxmrIdWEaGjg5XDgjoOuVlcQzbvTWqoqqarGnR1NJKNBz2AgZnJGhsbWP5ihXssN1Y1+ojFCYQdA/RHYkU0XgWSTgkDcs9mCgKHYkOBNCnvo6mhkYSiQS9e9XS0t5Ba1srI4cMBqCtrY1QJJo7AKtksxkSySTRSJhUKkVLezNVleVkTYulSz+lLB53g/+Wl1HXqwbTsgjoOrYsu1emhyMkUlnem7uY8pBKeUUF/fr3o1/fPtTV1tLa1o6MRaa9mZqaaurq6qmvr2fu3LloqsrkSZOIl5WhKArBYJDGxgYWzPuE4LFHUlNdzcAB/dEVGQVBRWU5eiCIqun06lXL2vUb+HTFKob3qSYQCqOoCh2tzQBU1VSjBtyr1KVMB5n2DtqbkyiKSkALEAkFXTcloLKiHFnTsJFQNJ1wKISQFALBELKiYloWqiQRDAaoqq6hqaWVppY2xowagW3ZLFm2nCFDBpFKJpk3fz6VZTE0XWfjpk2UxSKIXrXYtiASjlBVUcnqdRvQVZloLM6GDetpbWmhT+/eBAM6tm2RNm1MI4skLGLhKJFwAD2gYwv3xkYn204oFEDJ3c4WCgWoKCsjnUqiSFBZWUF7wo1F1Lu2lvb2DoRtMXz4cD6ZO5eVK1d+Z/uyp1AV2VMGBHQNXXOtcFQJJOFgmyY523c0VXEtQnIuasIRGKaBrunIipIT9PMfIIW79jUNw3QVOu6tY26e/EdHRVFcixVAsx3shGvFbZiWy3Mk10XPNAyyskxaUXBsG1mSiEQibsBuWcI0TZDsEpptmG47HSFobGxEVVUqystRFBX3I56rACpiICDJ2LZAll0lRl7OliXh3qRsCbLptOvmZpmuBVjug3YmY+AIMGw3yLdAwhEgOyAkgaZpORevvBLGdU2TJNn9QJuPHyu5DMrB5ZmKJOMI1y0xz9vsXKD3vFWOY7nPldwtbHLOLU4IyGbywdvdD7cOICQJy3YwkinWt20mlbWRg2HWNzYiskl0TUYWBtlkgobWjayJRwlFo2QlGVtS0MNRggEdISs4SJiWlfto7NJJVVVRVBXTNHGEQFEkV4GUNTzLMS3n4mbZNmbu3GHbNpZhYNk2CEEsFs19vJZRFDVn8ZUrX1Fw/j97/x1n11Xd/ePvfept06tm1C1bsiRbXZZ7BfdCsTEYQktCIIEkQEKABEJCMwYCJPRQQjE9obpj3HGXbEsukmx1aTSjabefun9/7HPOPXdm5MLzfT0Rz0/79ZLm3nP32Wfvtds6n73WZ4XKHVMiCALljSI1SSaTIZQSP5BRP0gy2Vwi5zSnbzrFun4QuVOaxpEd1e6oDt0oN/UjR3Xoozr0S9GhXxLHU7Pb2RQ0jmhSpirQsGZKWxBBTCzdKE9MI+dOmhUTmCMUKi/if831kono4r8yem6q7nEdG60CEVveqLyxxU1I5Nsp4okbt2Uq8BZtTJ5DGHj4bhWnMo5fL+NWx5CeQ+jXCZwqMvBUdI6gsWFrholmWNiFTsxMHsNuwci2oRsZdCuPblgKBEoQ4rRVEKl2kcg6XsyljCx6Yjkgk9CKYRCkZKjyBr6vBpUQkbIAEFItHsKpjBMIh3xvF5nOdvycjZyYxC+VsDU/2vxMXB8y2TyzZs+n0NGJnc1TKY8TCh2JgZFpidoSRhNAJKdRicVT/GQpG9Bi7FYXg48y7gsxbbI2ohcSjccGeXk8LhsTXUZjTibFp0EqqcUTXyA0gZARwBpDjjJkKqh6xCbZ+KBE2Jgf6SEtoRmgBWJAc8YN5/keOeOG8Xz3Nc/k5y/neX473AYb/ddoskiQ+nStmlo5dTUmtUE9T11eaFzMWO3U/zP9opasVK5IYdZStU5+D0KEaWJYOdp6FjFW8nj2zrtxK4+Cr9EmQqzWAno+x2SpglOp4RarPLB7F1pWQ+8IWHrm+fTNXYZlZXA9hyDwozqIZiHIKbVONkwxXbbJPtBwm5Wp+2SsaM0kNJFqvZwhT/PSnPSHWvtEs3xleu14fjaFIy3VQ7UW6brOn7/pjewdGuZjX/0WV11wLuedcTo//tWvOHbBfM7esBovAN/3sHXJ3uERfAmrli2mXikzMXqI/WNlgsBDI2T1ihPZPzTMw/c+yCsvnENbPsN9v7+fE5YvZ87sQRYg2LFjB48/+CyrVq5iYKCfxccfx7Y9B3BCeNs7/pJ9B0fZsm0H52xYQ9VxGR6doLtg8cimfXz4s1/l2ve9k5XLl3DyyaeSiaw6qo5yCm+xDbbumaA1n6GnrYXhQ4cAQXdPN8MHDzI6MsKp55xNdft2Do0MK+6bMGT/6BhLlhxDzrap1+pI3wPfYfzQCMMHhzlwYIiVq1awe89+bvvdPbzxT65mzpxBEBoXnHsGvu8zNDxOa2uB3v5++mc5/Ob23/Phz36T737+nzhl1Ymccuqp6qAoDOju6+PBe37HbXfdxJ/8xXtoaWtHSskr/vEfMXSd3/3udyxecpzSk3Sdfbt3sPH+u3BqVVavOIF1a1bx7NbtePU6F15wHsMjo5QqNVavXMW/XvtZvv7t7/Lgnbcwq6+HwPe546abMC2LMy+4kJLrMz4yxH2/up6Dj28mHBkh8AM6u1vo7Whj69btaLrBmhOPZdOTWzkwWmL5cYuYM6ghCNm++wC1usO8wQE030W6dbK5DE88sJ2x8Une9oYrueGm2/jRT3/BB9731zz77HZ+9OMf856/eReWbfPAQw9yyqoVtLe1E2oWK1esYcWKVXzj+p9w/HHHcv5Zp/O5L3yOQqHA37/9zTiVMuVKhcd37GGgo4Xethy14ijzB/t47ZWvwMVk+46d7N10B6dceCUtXbO4/8Hfs2zxcZx+0gZuvO02Fs5fwEXnnsVHr/ss7e3tvP2tb+a0DesTt6p3vetd/Md//Mf/9rR8wdSSy+K6LnUkHW2tmKZBxs4gAgffCyiXJtCtLIZlY2iaclVznEQHrNVdLNtHCwwF1gW+4kuKwtPblkmblqfuekyWqyqiHYIgVC8OmiawYkDGMDk0OobrKUuobDaL0BQ44bkO1cAj9Bx0Q7litbS2IYAg8BWhNYJCPkfgeQRA3XEVxUbgs3XrVgqFArlsltbWAkgoV+uYEdl51XHQDUO1MVSW6bZpYgkDnRDPrePUqrhuXbmIBaGKsid0NM3AMC2qdS8CVTOYlq4sxgIPTQNdCDLZLIauAJlarUYoXcJAgqHeN0zDjLW45N0kjA4jPU9Sd131kgjopqGsFaRyofGlxI1AFcMwyOXziiw7DCmWa3i+TxACqCiE2UIr2Y4eKsUijz3+MFa4GSE0xvMtzJ3dxWBvG2FplNHJMUaeG+KxoT2YuTx6Zw9L165noLeL7s4O6l5A3XUplx2QkM1kME0L3VDcToHrEgQhhiGpVOsUS2VyWZuMpYBnTVOuk3W3jpSKg2uyWMT3PEAyq79PcXeFobIaExqtbQGWnUk4yDRNgKbhRQGlTKExq68fx3UZGxujWHMIJPT1difcY2HgI5E4rqtkrulooaRScyJgNcS2bfp6ev53JuaLTUd16KM69FEdOiXLP0yHfgnAkypWSqk2s/h7jIjF1ZlhJEwHBjSmuqqluXRIz81YoDJumHp444ShEaHscM9PwAmZKkdOFVKD10jGz00DVqIBmoVhgAxDAs9BBi6BW8etlyM3uhqBVycMXGTgAcr1TBoGoaY4kzJWHt3IYOba0a0cmmljZloQuoVmWGi6ApviUyKEQItAPRBoEZE4EFksqXYJkWorAiljFzglX4OpqLaM7m8sHzEYGEoFTAkkht2ClALf9XCrNTy/hgxMTDLktAAR1NDRMXSLQGpIX6c8WSYMAuxsiXxnJ2amFYvYmqgBYoIk4lJv9ETcIIkiEU/3Y+SKKFNlNQbO1P5vWD2FySlEU4EojDPu+/ifSEDUBrSsZqiSZ3R6Q7T9NBd5xKb0iI/HeJJmPByYeqGxPL/QZvlCJaXT8xgeq/+fZ8NM8igM8qWBgI1V/LA/zVTx561OUz75IjbOhlVdY0GfMqbjT9GGKZuvHrbcUPqYwlKWHX2LCSshmdzjVOqTVB2HEV9iChfTK+H7dXXq3AKl8QNYTp5ZA8fTN+9EBo5ZRs1RYZFjsFjGu7WYPnDS46wRMUQkggtl2qS6Aeo3HTgcrl2p/19SmnZKo+Tc2LxFKqLMkZkuuOACAISmseHCV3DisuNZfsx8vvnjXzI8NsbbrrwMXTfYvX+Is045JQJhHMLQRwiBlWvBDUapVmuMHFSn9qCx7LhjGDp0iD37DnDg4CFMw+Dy885i1/4hdgnBSevXsX9kjD0bN7N66SJ6BuZSDk26urs4OD7Jj+98kPPWLmdgVjfFqoNTLVOemODeBx9hYFY/g7P6KU5OMDirj/e//Y0YQrJv/0GWrRxg9/79TE4WOfv09RRyOTKZDCsXL1Qn5KbF7NlzGBkZ4T+/+R3WrFrBscuW8ZOf38TswT5OXreO2+75PV0d7axZcQKbntpGrVyhzxbM7e/luGOPwdQFcxcsYO6ChWQLebKt7fQPDtLX34emRRYPUjA2fog//7O3cPXVr+Hqq6/mT//0z9jy9FZ27dzLX75tJy2FHEjJ5Zdfzpo1a1i9ejUbNz/NV755Pf9z630Yptqzn376aQAuuugiENDf38/XvvZ1Xv2qV7Nh/Xp6+/p58J47+e6X/p2/+uA/4/oBb3nNq3jL29/BytVr2PPUY5x10mqOP/54WltauO223/KVL/07V86WLF52AlJeQP3gcwxt3cJ3f3UPp5y4jDWnnMc/vOevOen0s3jLX/wlXa02mzdv5j3vfhdv+4t3sGTZcu548GGWzJ/L3P4eNj76CD1dXZywfCkTk0UqAezcsZPF82ajLZhLeXKclcuXsGDebG659S7a2gq84+1vZ8tze7Bti3Wr17Bz917GxossXXIcz2zbytDwMBecdRr79h/g37/yVebNW0BXZwcH9u1lsljCcVzabYO2llbMXJ6f/PSnFKt1PDSWLpxPSXRwr9dG8YHNdLTv5cT5A9gRYLB+9RrsyK3syisuJ2NbaELwoQ99iJGREb74xS/yjne8g0suueR/cXa+uOS7Dr7r4TmOOoAMbchlFWG6JWht6yQUGkLoCMNAhBJ0E9d1CUKJbZmEvocjQ3zfV65jhkG1VkUSIoTE91TejKERhurwTpGLe/iRm1oI+CFkslnlMqXp2JaNJsDuFIgwQAPyhTxEOqhy13KpViqUKlUF3mhaYrVvZbKYuoGwLI499jjl/pXJJtHYbMtM6C0KuQxeIPHCAB0Jvkfdc6h4DkLKyPJFAgaGnVfcVkKDKBqa43rYtoWu62RzOcWVGoaEQo/0V/C8ACnVoaUiz1ZkwMp6R1NcUzFwEARKFw4VL5YZuaH5UVQ8GeuPUpHD65qOERGLA/iRtZeIdFoNEfFeATLEc106e2dhaAaB61McPkClOEmxXGTnbo+x0TH6DJegWqPTAkwDM5thdn8Hs7o76WhrpV6vM1FSss9kMgRBQC1yMVSBhwSGpmPoWhQQwUbXFBjpeS4T42NYtuKJbW9ro+Z6uJ5PS2sruhAYugKTqtUqk5NFCnnFHSiEoFKrU3M08tkMXuAShpKujg4ytkXGthLPAdvOkEVLrK60SGfWNeVyWK07KtJmEOLUHDw/wPd9SqViFBHxyA7Wc1SHPkyljurQR3Xol6BDv3jgKX75jr41Xsgb3xtATfSKH1UiMSBJBNgASaZ2vvqt8b1JPE0I8syCEyLGCJrLTAdRPNzdcU2mYFRAg1A6DNTgkUGgXOg8R0VviDmcgmgDigjBhTQQSETs6y0lRrYdw8ph5TsV8GTYaGZGKRsJibkiZycBjlIC0BJ6cEIkaQvMOF/MFZXcFVmVNfvMEkF5InlOA+BrWEdphoVu5TCz7QSBjhZqmHYB25VIH7yqC6Eg9EJCXxIELlW9hJAByIB8Z1c0O1KAjUxji81E49MnYdqAtLFsJN9lo9+n35+2DEsBkCm0qLm0hqzjMpmKTMe/w5RrR35q6v9IFoddoGacYlPXgBl321Tuqb9Nf1pjgxJTrk7t65mr05Tjxe5oU57eBL4+X+7D/Ngk1+ivmHJ9Wr7DyLfJgnSGMtO1biTR/Ecorg0pA0KvThD6aJZJ+8AcXNMgLE4yOlbF1kNszcfKGREZbEimPU+utZP2vrmYtuJkCAMvWgNT8klPYtFo0LQ+k42J1piLUQtnGnzxhGa6/OJWN8lBTlnTZ1T+4rGUrnAj89R950hMt9xyCwC6YbD6nAsRCCrVGpOlMvW6y9yBWYxPlqjUqhSsHEEQMDZZpCWrIgbVHS9R7g+NHsK2smSzedpbC4xPTuI66vQ5n83T393B/tEJ6p6PbmXwgpBarY7rS0w7Q0dnJ9lcFq1YpuY4TJaKZE0N084ThiG1ep2xsTFa8lmc9laKkyUsw2TFsiVMjI0jpcT1ParVKtVajVl9PbiuR7FUobO7m8likce3buXYYxaSzWYVQa4EzbSp1uoEgcQwbeqOQ7Xu4Lg+1ZpDvV7HFTqtrS109vZSKpUINZ1Q09n27LOEvhe5Oyn3uvHxcSYmJnju2We5++67WLBgPkuWLOGJJ55gYmKcwZ5WKuUitWoZKVXY+kqlwuYtW3jy6a08vW0HT2/bQS6fp6Ojk2q1hus63HrbbQAMDAywceNGMrZNa2sbuqHjOi6jI8OYlkWIy8iBvYSBr1zSPMVv1d6SV31Wr3No5BAH5SSdWZPS04/z3HNPsm3HdjTLpqO3k77ZPTz4lf/CtkxGzj6D/aPD7HxuG3t3PYeOpK2lgOf7aqwUy9GLvUbWsqjn8jiOw+j4OPNmzyZj22x99llm9fVxzIJ5PPHkdnrtLhYuXMADm58il8nQ093NQ49uYmx8ghOWHY/reVRrVWYP9DMyMsKu3XtZsXwZne1tTEyM4wXKgjz0AxX9NgTHVxYsuqbhOHUCCa3ds/BDqNXrCsBAWWbnspmIa0PS3t6mLHaEYHRkmL1797H70CSD8xeyZMmS/73J+SJTLSJsVmG1FYk2NFYhoSuC8TBU0djifxJFGm4aOoHvR6TYjcjEoQzx/QDP8/BcBxBoukms+erRW1cYhjier07EhYZhmEhJxI2krIZ0PYsMfISUGKaV6Gu1Wh3HdXFcF9/30SKLrMD3QYYYlq1AGd2gra098WIIw7BpTRdCoGs6QegrL4aIosLzfQLPS9bimFdV6BqGYWAYJgjl0ud5AYapnmUbOp4MCZSQkufJUCZcs8olTbVZi8EmokjOQosIksOkfokHRqSzK7eyxl6h6VqURx3uyrARgVrXdDAEBA3u1TDwyWZzyI5OOmfPR+oGZPPk0JAioOqGuAICdGXt1tpOvqOdrs4ObMtEhCFO3cHzlOzjw9F4rRVRf2YzNrpmQjRe9Ih/K/AFYRhEURXVHiL8EE2T2Jksli4S0CcIQ9UXQQCRd0AolRwcz8P3w9SBvIh4omRyaK9rWgKtxIe5cV/4QaBc9qQisQ/CBn9WKCWBPLJd7eCoDj1jARzVoY/q0C9eh37R5OIbH31MLXaaaPDipOtAyhUsAt2EaETYSFe0cXu0WEenBA0sQBDKMBKyTBbZGAlI7kuQg+jelKBnFHYDmUiqDyTudOpzDPqEjUEgZRTdIcB3HQiV4hB49WjTDBGRH7uyxFFKhZRhE8imTmxMDCuPZpjoZqYJqUzXO5QhYRCiR5tBbM7ZAFaUsGQQJpt0ehA2XNeiTSI1otKiaZCLRxNNxnmUrBQ3ANFGHuB5Dr7rUhw9RHV8jOrEGId2b8OplnArJdy6pxQZXad79iDtfX0cs/4UMq3dWLl2hFAR99Rzp4CM0QYfD5VkOZYQRyFJRtKU+9L/0v7ksWVbwzKuoVQ0yohOulJySD0pkX84Zfw0xqC6dsqZJ3Mkpy1PPDl904zSTGavL+xnPXWRmWmBm+mewyxOTRtg+r7pkS9TlZpp63iBJJpAytia8XAlJFOOZhmkl92ZNs3mJ8b3h42ymD7OFJSc3iIbTxFSJAF0w6Z8oMm0lZ4am4aVx6mOUxrdza7Hb8TO2Cw/9TKKQ9s5NLyPX/7uEXKaS6sVMjg4h5GxSbbv2MsVl7+SvsH55LrmsPfZzdRrVeYtPhXNzIJuKmvO1FyILU5jOSS1F9HZnoyIW2WsEDTcsNOHE+mDibRo0sOu6SQoAoTlYYZHo1/SSkhz/8aKsRatL6eeuWHmwo6AFK9LlmXzyCMP0z84h6ee3cWShXOxTJMnd+5hdk8nrbbBnTf+jEpo4WU7eNkpa6mVyzz68EZOPfN0hG5w/U9+xvFLlrBg/jwWzB7gmWeeZtOmx7jokkvI5/O4joNt20yWq/zmnodZfexcZvd0sum5/XS3ZJjd1YKZa0XXNUwh+cjnvkK17nDdP/09t/3+YZ5+bgdLZ3USuC5OtY5E0trZxdxjjqO3VZ3Wb90zhKEJMpbJ4mMXsfnJZ3j8iS288opLuPnmm3jd617Hrbfeymmnnkq9WmHz09sZmyhy7lmnseWZbWza8hRXXHAuQ6MT3HzfI1xy+nr6OtvwPJ98IY9t2wShZMvBCR7esZ8PXn0xhw7sQwjBHXfcwfx58/jB977Hj376EzZueizhf8lkbN7y5jdzwvLlrF+/joWLFpHL5QGJpuns3r2blStXUiqV1H6jG6xevYqrXvUKvvilr7Br9+6mfoutIlpaWnj8sccYnD2oXgA1jcCpUjq4m3zPIFauFZD80z99iK985Sts2rSJWf39eJ7LVRe9HO/pjfxdr8bH9rrsbevhtu9/CmtsGxO7nuS8D9/IfOHzqllZvrq3zqwly/jCtR9hYNEJFDp68YOAx7ds4bkdO7ng3LOoOS77Do5w7IK5lCs17nvkMU5ZuwohQ97+ng/wuldeyhUXvZwQjXq1THlijJ/deiftHe38yZWv5K/e/ffs3L2b//7Bd6lEYFxPTw9bn9vF7x99ggtOXwuhz1NPP83qNeuws3lu/O2d9HR20NvVwZLjjqU4Mca+3bu47ZEtdHV18ZqLX06lWmWyWOLRzU+yZMEcBns6eXTTYwzOnsuSZcv59o9+RmtLgVddfAEHd21j18FRvvHYOK85ZSnnLp9/xIPHP/n1zbQVcnS1t6KheIiy+QL1CPR1XJdSuULdcenp7MTzfeqOQ19PN4IQp1phYmKCMAzp6O6hWnNwfZ+2QgFD19A1QblSQhOa4gcTAl1TY9pxPRzXZ7RYwTANLMsm1vWCMFCk5rpOxjIh9JFBiB/4CaBw8OAwYRAoriDdSA5JhYgojTWdXC5HPp9HE4Ig8BWnF2qv86TAMhS4JQMf13NxHJcgAkSCMFSR5KIofGGo6uYHIXbGxrZtZGTp5TgO2YzSn70oyE0QBGjRfWEYKssfodwLDbMRyc7z/MSFzjRNDNOKLKaUjh/4rgJKpDqWbdpHZPTaGK/Fth1F6Yv0cE1gWXbCJxUGLoHn4tZrOK568QwRhKGP53kcPDhEaWKUanEcSgeZLFY4OF5i5YbT6OnpZrCrlWKxSCAF3fOPR8/kEKYd8S2pqIEHD42qSH+5LC25HBnLpiWfpVSuUK3VaCkUFBikKdfAIJRU6g5eEACCXDar6o/ENg1c16NaqyFliOt6TJbK5PM5dE2jUqlgGgaWYZKN+AMLUX9XazX2Dw2hG4oU3jRNLMvE0HUqZUW+HvcHUrn5VevKYkvXdMJIppecd/b/3Un5EtJRHbqR66gOfVSHjuv4UnXoF23xpBB19fyYsLBRkag5KaCI6CVfRCYmad6c6EYS165kQY8glfg3msmdm6ZU8vzGT7Er4Iw+olGvNICbxu/pPIr4SypXuth8NwjUYA8bG6wQBkLTG3LQ9CmdJKd0T3SCohloutoEVZXiqAPJrExAl5iLqAEINUCspOVRdA51PdUnMYASRhtnslmKaQukiApWfyVSxtxWEkEDuJJCQ9cthK3T0tFNJpun0NlNtq2VWmmC8vgIk6MjyCAgY5u09fWQb2/HqVcRZgU0C9PKq2elxkVz+0Rc22gsiMjnXCZyapDQN0AfpozDlFAUUJpSSEMZqtC3qUnbVERcamoWq76SiSyaXEPlTJvDkZdeDMacuM6mFsTnT+mtY0o5z/OUWHDPX6XD/DjT+H1JKW5b9C29WD9Pign5G8+fue1a05UpW3pCQimm3D1lM5jh/qazqxgQFpC4fqYA5tgdVRM6lpnBK9eoDI/yaP3OiE/EZXbrAGF1FFErYfhZsrpGe6ugNO6Ctxe5aye16iS6ZWNYWdD0BpCdrmFqo0wdxCRKUAyYT1c30ptlYyykV/2p63XzNzn9YloRpDF+o5WPmOpNaKm5L0gOOo70dM4553DVVa+hvaMDQp++9gIPb3wMLwg49piFICV1L+CYpavAsNAzBTK5PJZls2rtavaPTlCt11k0fzadLVnw6mza8iSmobN23Tq2bttGNptlcGAWY4eGcP2ADScsxqtV2LP/AIvmzGJifIzHnt7OmlUrGS9WeeyZbZy8bg26pvHg48/Q3dHB6WtaGdnxHJ2dnfQs7qVUrqAZJsiQiVKV8bExfnvb7Zx52ikM9s/n/nvuxc5mWbt6BeMTRebOW8gXvvAFZs+dT7laozw6Sm9XJx3tbTzx6KMYmQzrV53Itr1DCKFxzkmrVHSwjI1hhlz/gx/y8MMPEwY+Y1WH4VKVybExdYoPXHfddaxcuZLLL72U3919N0HwKKD24zAMOf64RSycN5dCNsPunTvYv3+In//ylwCUSiWq1WoyD6SU7N61m//5+S8YHRub1mdBdIhVqVT4wAc/wHnnncef/Mmf8OzWrTi1CllD8t2ffY2Dh8Z4+1vfRHlygmqtzgc+8AFyuRxShjy+9VmCSYd/c8DTDfrCGp/8j+8xP+PSr9e48pg8wxM1fjlU47Tjejh+9Tz6Fy5FGBbDw8Pcfu89zJ41wIoTlvG7u+6jq7ODYxbO56mt21V7F84lqFcIg5A/f+PrWDhngGq5xK9+cyODgwOsW7uW9SuW40vB5h17OWndataceDyaprN567M88dTTnHDMfLK5PCetXMa9j2wil8mw5oQT2bL1OWqOx8rlS7FNA8vQqZRKuK6Hlc0za1Y/+WyWickJhkZGcF2PE49fwsT4IR57+hkWHruYyUqVm+64m+VLjqNYLPK5L32Z8047hblz5/G6lgEeves2fvrFh/nKV77yf2km/mGpra0VTUCxUkVHkfMbpoVbr0VE4gGWoWPqWXQNDFtFt8tmMpEOGlDI55EyJGtZyFCRilumckssl0vYtoWZscnn8ujRS77neQghsCyTjraWiGTcJAgU2FUs1/D9ANMwME0jonZQ98auavl8PiL59nEdB4TAtBRHWxhK2trb8SVU6w4ZQ+mQtm3h+WpOhb6P47vIMMCt1xJtVTNMhKZefmIOHGWdHxJIqVzCgpCa4yHiF2gpQWjJYaIiPdfw/CBx59PNyKUuioaNVOBW/NJmRMTjugZCCsJof5aaRkiIJiGUzbu0ECjLq6g8LdJl9cgiDxRgFcqQmA5CaDqWnSGI9x/dRBBiBz5ShrS1tuI6/TilfnLFEtqhcequz/joKJYzDghMO082Y2NkM2hWhjAMlftl4JO1LaQQZCwL01DREWUYRu9U6pmu41B36gpoMwxydoZASoJQUq1W8D3lrWFbVhLNrr21BcswyJhGdCAvCNEwLZuMbeF5LuUgoF6vk8tk8AMfwzDxJIhQkLMUQKZpAsu2qddqVKpVcrlsYi2WsS31Mh0ECgY4wvfgozp0cwFHdeijOnT840vRoV8a8JRUsHmwN36KJBBZlMSLsrolNTJlLBZFzpwMGvl8kzSeaET3qbOIqZaFCe9TCrlMOi8pp7m42OpKQuIOp6LTecrs2feJuzLe4ITQ0DWjAW5oGpIGSbUgZe0loyuJT7mWPCvNdRXnjbs5Jr6OCcQaTY1BwMOY2YnGxEvLX0vAkhmuJbVWk7PBddUAggTKFFyZU5vYuTxhGJBtbaFanMAqtCANndB3yWUs8u3t2Pksbr2KbuXQzSyGERNYzjwV1HVlVRdLUgiBFM2gYhqgai4oLaU4z5RlKCapj5Sr9PBFNCZ6cjH6GCYzX2WM/f4PZ2F3pKWmE4loHkoxVTqxVBttTM+7w60sjVHPYfM0fkuXI1PXpj7jhco5/JVp2068/KSmQPPYmVqvRkmpkaa+J5vt9EUwjnuQ3JNabhrlp9oqUmF3X2DVju9O+CaAeAFM/5b8JEM0XcO2swgPKmNF9u95hFy2BcvK0JZppRqYODVJUJPogUnebGPy4ASVQ6P47iEKnW0UMv3olq1OoKMIS0jZtLYcbvjL1L9GK5IiGhvl4e6faZ+J1lM1s6MSpy5jSX9He5AkmasIlC96anlWVphH/hw+5phjuPzyyylXq3ieT2dLjjv27aNcrbH6hKUEYUgtCBiYtwhQY9AwLYRp0dNvsXPLVkqlErP7ejB1DadaZv/QKHMGBxgYHGTrs8+SzWbo7+tjZGQYgeSEVcfwzDNbGRsbZ9nS4ylOjLHnwEGWLKkzXiyzddd+Ljh1Hflshvs2Ps2q449hVncb47t2USi00DcwQKFSpVZ3mCyVqQU+I6Pj7N65E3f9WkzDZPfOnSxctIjZA/0MjUzQ3z+Lt771rRQrNcqVCuVikY7ePnTTYuvjj7Pw2GM59pgF3PrgJnKWydzufqrVCtVKGQncfPPN/OSnP0VGru8IQXd3N7apMzk5yS9+8QuGh0f40Ic+xPwFC+jr6wMhqJTLBEHA/LlzGJzVR9a2OTB0kK1bn+HnP/85ExMTuK5Ld3c3lUqFSqWClJLhkWGGhw/O2GdC08jnlHXA9df/ANd1Of/l57N7106capVCPsudd9/Nrl27ed0VF+M6Dq7n893vfndaWXtrsK7HpDN0+OEvbueUhT2cNLeDEzstHhMGv69Jrj7hGJYfPx/MHI7rMTk5wWObN9Pb08PgwAA33HgbnueyeNF89h4YwjIMjps7m3KpSBiEnHbSWjQZUKtWePyxTQghyLW0Mtjfx2S1zsHxIosXH0urrVx6hkZGefrZHbTbOgvmzWPu3NnccPt+2ttaOb+njzvuf5TxiSKnn7RWRW4LfGrVKnXHxZfQ09WJoWuMTYwzPjEBQnDsMQsZHh5iaGSU1avWcmhyB089s41XXXIhbr3G3b+/n5UrVjJrTpbju3S+9/Dv+eY3v3nEA08thTyO41Kv19Aiq5us5+FHLmtSSizDQNMVgGAYJqZloRs6YagAjmw2A1JiGga2JdH0AMMw8IOAcsT/YxgGlm2hCxVFr1KrJ9xGucj9StcNfJ8o4pvi2vGDgHw2gyFAQwE1IiKZti0rOfRzHEfRRpgWXuRCKXQDKZVFkYVAMwwM3YwiqCnQzPNcAs+jWimjGyamZaILCxCJ/UHjXUEt0n4QEgTK/UtIFS3OMI1oK1WLuK7rCBlF54sspXRNU5Y+EaF5GB0iI5Rubhh6wy1MvWFFUZ/VBhFKdUibPmwU8bPiw89of9Gi6H/Kaj9IolwHofJ60E0TPYwsLkwbjRCkD4FHLpclDNqo5FvRC2XCTCtOtUi9XqPou+TyBeyssuA0LBthmgpIRL1DWJaZAGnxHuf7SuaxHu/50diwbbIZGyufJ4yuT7gurlOPwKcgAZ46WlvQNWWlJiOQCqGh6QaGaVJ36riR5YYW7caarhP6Sqc0TBNdqFd6y7RwajUcp042YytZIxL5S1IBp47gdFSHPqpDH9Wh/8916Bftarfp0SdSDYmAENE8NOOiYjQ7Bl6U6WuQEnKjpTF3UkJMFTW46cU/qW0MVqkBocZfc/VjIaUtotKIX4JoxhtJCnWQUkY8F5GfvFSmoaZpqjqhXA3jImIAKr4Wl69pjY5qyKwxcWTTFIpkFvMfpWdyagOOgZZENrFpXmrUpV3IIixNoathjNymQ5qKZJNM+i0GmyI5KsuvRvhEmapTjNrKMLaICpEyoFycwK1XqJXGCOplZOAgREhb33xau+eQaelGEJHLTxm0jefGE/FwQzMGjKb4yqbkGReclKsYLqOFTDaKiT4o8aqxqEUgYlxGmNRlCtdWIwsgOfvc0w5T3yMjPfHYluhTNA+jCJGCxjRqbP4ylTf2u5c0m+w2Vp7m05nmZXLmFI3+ac+Kzzpe4P4ZxsZhN82ZFt44f1N7077pMgmgCSBFfNaaPkmYwQhaNktFAdohCibXU3WJMiIjU1r13/O2Ol66ovo22qIBsatuY8xrhk4mm6WltYWnbvof9mx+lAdu+DFOmCPEJp/LomUMNEtHuhV0YWAKi/37DqBbFrOXHMP5b/tr5q9YR6Ua4FQqePUa0eKfrO8zbpqJkBruu9Oa03Rp5t5Lrw0Nr+2GoiCERNea70lunHJpWv2ioRwKZZUipeSsc47cOSyEIJMtkG/toO+4ZZx1+qlc94/vZfTgAcLAp39wDtv27OPQxCTrlh7HbXf/nh//+mY++YH3MDlZ4r9+/D/8yVVXMGdWH7t27eDxJzYzcmiUt7z5zTy17Tnue3gjF555Kt1dHbS2tHDnPXdQLJVZeNyJhPUiWuiz7MRVDA0N8eyOHTyx+xCzerp5+SmruOW+h/H9gMvPOY2nn9vJ2MQkp65ZyTPPbOWxJzZzxaUXcWDoIL/89Y0snDtIf38fq1av4aGNTzB0cIQLzz2VJ5/ZzqbNT/GaV14KQmfvgRFKEyPoMmBWZzs7x2tUfMHZ65ZjWRH5bxDw85//nLf/xV80JrdU1kWu6yayy2az3HfffTz44IO87W1vA+Dkk0/mnnvuoVqtJnmv+/Sn+dKXvszGRx5m7rx5xG7wvu9Tq9V429vexgMPPMB9993HF77wBa677rrD9JXiUxSaIF9o4b3veTdvftObOPmUUzg0MkKhUOADf/debNvmxz//Je99z7s544wzKOTz/NM//ROfvPbauCSlX6RIQw01/fBD+KtXnMyrz1jOGz/2Q8675BV86jP/RsbUee7pzXz9Ux/mjMtfx4KlK2nr6WNkeJji5ARrV6/iocee4Ic//xVXXXYRrYUCw8OjrD5hKaah87Vvf49zzjyNU05aR7laSw4RP/O1/6K1pcBfvukaNj61lXKlyurj5hOE6qXU1AUPPb6Fm+68lz997ashDLjn/vuZ3ddHNpNhrFxn3pxBBvp7aSm0sPmpp7nn9w9ywZkbCITgiWd3cfLKE7EMnR//4lecdvIGli4+jnvuvZdcxqaro50b7nmE7q5OrrrkfH5+x/08/OhGrv/36yiXSziOc8S/uD69bRtxuPmxiZICJnSDFkvD1EDIQB3uabriAJNqbRovVdUaFYa05zPYhoFp6MjUYabrutScOvkojL0bKvAlDEMmShUsU4FZ5ckJ5S5lWZi2jR8EVGo1JksqepxlWeRt5XZXKVewI6uriYkJMrZNT1cX1Wol4ebRTVtxcOkmGcska5kqmnMQEEQudTKUGLrAc/1oLinrG9OycNFVOwFLk2hCgTs5y8I0dHzPT/TBSq2qAA6tYYmjIdEMAykE5UoVAA1B1lZuXoapIzTlmlav1RIretOyieJFR0TvMuIdizmgIJCKjsL3vIQjybKs5F0EoWguDEMn8BV4GPjKugwhqFWraLqBmVEWT0Ioviot9AidKgeeexrPdQh8D+w8upXBzOQwTYswcKlOjlFoaSPf2sq845bhOC41x6FcLicBc7yI26tSrSZR5EQQkMvlyeSymHYGz/epOXVaclk0IPA9vCAklOALgyDwo7GVxfd96nUn4sILqTt1RidL+GFIb3d3pLqF+J6LhsDQBNlsDoSKUKibJoZp0lrIK41KvYhQr9eoVCu0tbZRq9fZtXc/mgDT1Olqb8MwdDRNY8NJRy5lxVEd+qgOfVSHThXxB+rQL9HiKT24479TB32j1ukBMs2SSTZfbzLZk3LG4ZMyUkEmYe1Tv0f1bLJ2Ip4KSoFs/CaT58mI3DAMQwLfQ4ZBtIDHPuJ6AljFgF7T5KLZsiuFa6SeEbWoadLO0MaoRDWpRDKykjYnMovBpfj3eBCnwD1otDc1meJnx2hnGt4UTf+LSN7xd5nqqMi6S4vlriOERa5FnYIFQUjF9fC9AEMHIUw03Uiw77gMGdelac1tfJkK9CjMLZHsFMFFm1x6IU8Pu2jIhOl2psuPgLdkW0jqFz+Xwy8AzzdBj5DUNC5j5niYvuAxVb7PtwI9/+Y2Q08dNley0Ux7VGNuRR+et7TnTen5+zzFNGZSfJ9Mjd2pa9mUgmYgeJxeialr5otv03QrxykWqLFCrJnUy5OURp4j0Gq0DXSx+vyLGNo3xGSxzHhNkrElVgYyZidu3adcqjN4/AJaOjqZvfgEXKfK0K5t6HYHQipX20D60545Y5KHUQPk9NYefsuc1vrkT7zeN900w1aUvqT6Xcb6DKDW9PTJ0ZGc6vUqXhBwzekbOOGEZWzbN8T+Z7dhCMms2XMxwgDqVbY9+xwZ2+KcUzcwMT6O5/uctHoFHW1tGKZJW1s7s/p6yUZuNZap01bI0tbWyvjEJDfeehtzBvtZOL+XztY8WosNYcDePXtACObNnYvIttHWokKmz+7tZLJU5tGnnkHTNDra2wnCkEI+x9yBWbiuSyaTYfWqFRi6jh9I7v39fWSyBebMnsVd9z2IZdksXbKYnfuGMQWY0qO7ow2ERhWDjo4M3YZJJmPz0EMPc8+994EM2LRpE+Pj45GEGvtLS0sLb3rTm9QLtmkyd+5cwjDkPe95D1JK5s9XwFI+rwjRv/3tb/Poo4/iug7f/Pa36WhvB+Dqq69mYGCATCbDFVdcwcKFC/nBD37Apk2bDttPyYm3BM91eeihhxKuk0WLFnHhhReyas1aTNPAEzqLFy+mra1NtUDTmkqK1xPF1ZNRfECRy+CmZw8gEYxUHB5/8mm++a1vcdqSfuoTI7SbAW0teVrb2rAMja6ONnIZm23btuI5dU5avZJ8NoNp6PT1dGPoKkJZobUN07JxXZdf33QLswcHOGnNalYevwjLsnH9gJ3PPcvExARrjz+GjZuf4Nkdu3j1ZRfTls/SXbBpyWWo1BwOFWssW9JJT2c7zu69jE+MU65UmD/Qj21oHLtwHtsPTmDbFovmzaHmuNTqkhOXL2NkZJjb9++jp7sb27ZA6CxfvAhNCJ55agsdGZ25PYrAPHahPNLT6MgI2VyefKEFyzLxQ2XpEUiJJgW2YUYvWOplw3VdavU6yIjrQxMEQYgvVPQ116vj+QGarkU6ihYNF3WQ68ZjRSprHyGV1b5hmli2jWlZGBFAhRT4QYCm6eQyduS2pdz4LMvA9zxMXUNIxZ8k0NGEJJPLYpg2bqh0RN91cGtVJKnDUF3p0Xr0xmGZFpquLKkM3YAoYh2hh5RhEk0OwDQMYhdYXVNk4IZpRnWWCpiKXLVc18EwzIjTSZBYJGkCInqFGDTSNAVaEXGxIgS6rkUk28oCS9FrCEItIAzUe0IQBMmhMxJCLSSUKoKgcrNT1miGaUY6v0DTNbxaldAPcMMALXDx6hVGh/ZRr1XxXQctk8PI5LDzLXT29GIYJplCKz4alZrL2Ogomq4TE6THnGCarmg+wkiWWvwOFB+IC3WYahgRz5VQHKxu3cX1fQUY2ja2ZSaRB4PAp1Kpo2sa2Xyegh8QhKGKKBm9Z7i6hud61B0XhINuGBiWpd4TQsWZVa87eJ5HxrKoOx7VmkMu5wOCfDaTEKDHbnyxy9ORmo7q0I2KHNWhj+rQf6gO/Ye52qWuhWHsKqaqlbaEiomr0/cra51I4LJZyYqtUUIZpjDRlOBjrCkiNJSxiVwCJMU8RTTPvZQFVFyGjFAEKWPi8Oi0wnMjs1UDXTeUpUwEWsUmvDMtILG1UHM704CJTPV3sjw0gVPNpabApxm+CxrWN8oyWCQWTaFMQSsiPRhST4wGjjLFbSi3TTMy6ssGB1bKQiwEtIhIPsqj6xqZbEFNVscjKJZwpa/CVmsWmmaQqOQyZUkVzjC1ZOxeGFmwJfVPja8pozwut1mQU/oq7vfkF20K6p3yk436Wk6Z5FNPVY90QtOpKTFfjTfOKe2Lx1XzuJm5pMNvpiJ+UvQt7V0dbxrx2FKnDTNtJs2nOcywQTU/8XA1mVZV2WwVqVTmRpa0PV18vWGY2hg/ie6ROvFpVCsCpZOqT2HwkxC70yJo8JjFdZhpzU3VdaoMkiVOxCerNuOH9rD3mXvIWtA2u4vjTzmdJx+6kz27djC8q0LGrJDJ1OnumcPYWJGDO/ex9tSV9M+eT9/8VezZ+TQjB3cxeOxasvlO7Ewrges3P3qmfXHqSVbTF9F06YXUsaYlKbUcNik2qQ162hCRaTgiGmVRxFC1ZsQEsoepyJGUZIgmff7sta+irbefex57iqce3UTO1Dj19DMwpI/p1Xliyz4WH7uIc047hfsf+D3ZbI7LLzgXx/Xww4DWtnYWzZ9LvacDz3PJWiZz+3tpa21h+3PP8bVvfZvrPvqvLF+6jCDwMU0LPwi46447mTN3LscvPZ65czz1sqZpHDunn/0HR/jF3Q9x8qoVzJk1i1q1Rmshz5LjFuLU6+RzOc4843R279nHjp07+Z+f/5LXv+61LDnuGN73T9dz3tln8qqzT+dnN9xJTg9ZOaeDzlkLCXSbbQcmGOzM05FXnDK//d3v+OjHPo703QR0MFMvm0jo7e3lYx/7GIVCIRFfW1sby5YtQ4bqHsdxME2T8fFxPvCBD1CpVAD42Mc+DtFsX7NmDd3d3QC8+tWvZt26dWzYsIFKtYplWXieN93SRkpl2aDryDDgphtv5De//jUAl156KR/96EeTrOs2nKysqg/X5ZHLjGVZ9HR3Mj5RpFqr4Xkedz++k7sf3wnAgw8+yEMPPci/vGY98/s6WNDfyay+Xjo6uikVx+hqb8fqtfj2977DwMAgl51/Hvv37UUIwcDsQbTQo+7UmTNnHoV8gXKlwn9++7846/TTOPWkkzh7/Sq8UFKsuWx95knGDg2jveoK7n3gIX55w81ceuHL6WzJs3igGw2oez4lF9o6e5g10Mvk5ATP7T3AofFJMoS0tbWy5sSlfOe2h+lsK3DWupVsemorjutxzumn863v/Bd33X0nH/nHDxFIGB2b4NR1qxkeOsCvf/ULzjj9VHKL5vxR7b8H9u+nu7eXQksLGcvCDxWBdxj4+AiyhkUQSkKp9BvHcSiVSuQLLQm4FIQBjicRmk65UqVWq2EYBmZkwRQEEk1XYFLZVS/+QjOQMiAMFO+SbWfIZnMYpooeSGhhGTq+H+BLyNo2pmnSks+jaRq6rqGjuHik76ELFdnNNizy+RxWJkul7uLUq9RrVaqVMpqmrAViV704UI6GQFoovVHT0C1T0TeYBk4dfF8RbwdRJDXbMJChIBQoayRNx7YspTX4AY7n4wU+fhhQdz2yWQ1h2yndVe2HkXEYqEcr4IoQEcYBfETUVl1tGMm7TZgErAnCEPwgigynLPdFGLnxJdYSyrXOzmbRLAsZWX4F1TJOrYJbLYPn4tYqHNyzi2qlhFuvYmQyGJkcVr4Vy9AotHWQaemkWCxRqZVh/z5a29rJt7Rg6Bp1J6BSrpDL55Xlm26gm7YCB4MQEUf4Q1leGoah1HYUr5brl6jWHTQ9oJDLKRJylGWS6zhMjE+QyWbo6e1VkfEi4Mk0TXRdp1rTKUZlhFJi2xnsbJYw8JGEhL5HpVKmUqnR2dFOrV6nWKnR0uKha4K2Qg7dUKCjG4GiU13WjtR0VIfmqA59VIf+g3XoF+1q9/im2NWu0YIYeEowFhExNyXYRmxV09gA4hROnQw0plkTwRfpqHaNnGlXvASICIJks2lEa4srQxOgpQAnX0Vqc5yIjE81RBNacoogiRoUCzauTwrMijcsIYTyg05db9Q3bHyOAZRYLlGPTu2J2KIpAWkkSf3iFCulMZ9WLEPla9kwG4zN/uP2xy52SRhYSEBAEU3gaFmjIfrmhTABcFIufvVahVqlzKGhA4wc2EelOIn0Hdo7u2jr7KZ7cB5WJoeVzUWbeXSyFK03SfQ6mV5A0stZerFt9EHsDtfMAZV2jWv8FkcQVPk0pgzNaAxH4yS1zsWbTWNBkOkhybkvO4MjOT2+acsMV5u2S/V/ilusOYkp+RtlpDyFo9S8QUzfNOPyXsymGd82w7NTETQPm+T0Woc0OLoOF/xVRM+c+quqRvquKHwz8YlOPD8bFoVySlum7eHRAtCsvDQ3qnFaRfNfEa+b8TM1NDSMXAulQ88x/Ozv2b/lCVxHIlrmI/0x/MBhvN6GP7kbKgdZsGQVo5U6zx4YYdlxc2nJWdjSo1gaQbezrLn4rzCMDKAR+OoEXopI/DNtmqn6qAtT2pLeRxoSiL5PvZJSZtKnM9E+ocWb31QlLfoSptbeNNtAeqTJ6GDh3POP3Dkct900Te743W9ZcvxSdCvLxMQ4Y5MlHty+hxUL57Cgt4PJg7sJhYE0MuRy2QQE2fjUdsaKZQwrw5I5fQx0tjI2PkG+pYX2jk6EplGv1xkbn6CztUDd87j3iWdYs3Qx/d1dfP/Xt7L0mPmcdMIS/uWT1zKrv58/f8tbuO3ue6jW6px20jqu/9UtPPXsTj7993/F7+55gF/e+Fs+8r53sm//fr7x7e/xV3/xpyyYP49SqcT2555jYmKSlStOZPfwBDuGRjl7zTIsQ6NardPT3YFlWfhByIc/9E/88hc/B+DKK6/kmmuuASm54cYbec9738t3v/Md1q5dq4QlJYZpsGDBwuSlEeDXv/41f/d3f5eSqca1136SE088keXLlyfAUzrNnTuXbDZL7Abe29vDF77wBTKZDNVqlUsuuYQDBw409ZNp6Hzy2mu58MKLkGHIF/793xP+odbWVgYGBpKDDaFpfObT13HhhRcC8MEPfpBPfOITTXVYPruTdetO4gPXfp4gDNm5cyeXX3EFTr0+rb7drRnWrT+Jaz/3ZWYPDmAYOg899BB1R/GxrFpxIofGxti6dTuOU0EIDTuTZ2L4IKahc8Ell7B3aISDh0aZN9BHxjIwdcHtv7uTQksrl1xyCbc9+BiHxsc5edEgUtMJpaBULGPbJrmszWe//j1aWwv8+euv4omntzI2MYllGXQWcnQUcnT3z2b40BjP7dnLutWrsCyTyWKJnvZWDF1jZGQM09SwLJPBwdnc9Ns7+db3f8yVl72Mwf5eeru6qDkuz2zbxhvf8CZ83yO9xx+p6aZbbqWlpZWOzg5s2wZUmHvHcZS7UxBiZzJYlglSJiCM0A28IKBcrZOxjIg0nITqwDINZXFimJSrVXRdp5DLKRcyqSyP4meo+SRxA4lhKOumzrYWZBhSdxz2Dw1H3ESCzvYOFeY+CMlZuopGV6siTFO5AxrK8kdKyfjEOPV6DadexzQtDMsik81RdVSk45xtokf6XT1yCzN0DTOTUcCTYeD4Pn7E52TrGoYu0IUWLfeSyVIJXTfI5PKYmk7oB5SLRRzPxfU9ao5DNpsnn8+TjSKqGYYeRbsLqVYq6j1FaOTyuWgPCfE9HwSR7q92iVCCHygLJ8/zFPea62FlbHRdyduP+FoM00wiXzv1Gtlcjkw2SwD4Th2nPMnIzq1UxkeZGNqHWy7iVCsMHTyI1DWEYdDa2UHZ9TlUqtHX10dLaxtdfYPUfYkfSAKnRltbG+3tbcxZuAjDyoBuUndd9epimFimmUQFHBsfZ7JUorWlQD6fp7W1hd279+D7PhnbJpPNKhfBUJLPKQ6psbFD1KpVapUyLS1tZHJZWtvacTzlimcZunLXkZLhsQlGxycZPjRGT1c7hmEiNZ2OlhwZy8TQBYEfEEpJZ0cnjudRqdYwCKlWq+w/cICOru4oEmKBIPAJg4CTT1r/vzQ7Xzgd1aHTtx3VoY/q0KmiXoIO/aItnhop3d3xy32DjDr+tYmjZ+p8ir9GQEoyqkWzwJon7VTwofG38fLfmGjpe2OrHhEBQApwCZKNIkyZaWuxya8QDfAlBodIE6YLlFd6M9DWdKFpYDTKaLoWNSM9IRKxIBpjTkJSDaZPZJqux0BLWnZqlEsxrSsSGaWrl0hYpoZWyrQUVIUEoEdk4UITEPgErotbreBWK3i1KoFTp6rpaDLEzmSx8y3YvoedyaEZyrJspko9z1LWlKOp1SKRapNF2DRQL323TPVF9GOz1VP8NNlYgGVKJoev7B9RarS/abFrStOvvYBH9YvKN/O7wgtsln+IvONNKV5zUt0305x4oWo93z4d5zhcNVPSnrYHNqrbvIYdtiJN0zKa+1HD7EyBjt757HlkE8XhMSZ3VrCyEt3UkCJEluvIuqQyOobnBth+yKFd+5kUAbpfpnvubNq7Z5PLFwh8FR1ppiqk65uA5Kn1v7FGziQNOeXbTOOssa/EFi3xRAxS4zVeCZoJItOlpPI17Rd/PFM4DEPuuOMOarU655x7HuVyGU03aMna1Oo1RsY1eju7mCxXGZks0tXdheM4PPfss8jAp5C10QwDx3WZKFWwM1nqdYfde/YmUY8y2Sy+VNw9Ha2tjI+PUy2X6O7qRNMEQweH6enuprurCyGgtaUV27bJGRrdrXn6u9oxTYOO9jbmzRkkm81QKOQZHBxACwP8elW9LCMxCOnt7qLmCyarDm2tKvx3KDV+//v7KU5OIAQ88vBDPPPMM4kMFi8+DhCMHDrEFZdfwapVq1i8ePHzyq5YLCZlACAExWKRXC7HpZdeyqZNm3j66aeb7tm9e3ecGVAWAYsWLSKfz1MulzGMhhp1xhln0NXVhaFrrFu3ngULFrB5y5N4no+uaczr7aDquM3PEBq33347juMAsHP3btq6ujl5/ToODg2xadMmTjrlNE499TSOOWYhCI3WlhYuv+wyNm7cxLZtW5vb6Gk4Wo7ugblkczaEPq1tbWilEvVajT379hP4Ph0d7ezcV0XTBD2FAsWxMUIEWcvENFQ0KqHraBGfUKG1DT8IuP/hR8llciyYMxvH8+jt6yKXy/PdO37InNmDrFu7moH+HjK2ReB75LIZQinJZbPooU+1WufgwYN4gaS7q4taeZLAtslmM+w/METg+3S2dzA6oSIwDg7OpqOthYVzB+hob8cwLUYmS7S1tJDPF9LEFUd8Miwb3TDUIaXvE4YhjusQhopvs1aroRmGAqUEaIZAR0RWPWFyn9QU92h8COn7nnId00SibgtB4v6VHGKGUSQ2DUR06BhK8Hz10hpKZRkjPS9RcWL9VAV5UfkNoSE0xQEUhspiy3McRZIeBFiWSF5cwrBh5Z7wZUTLuKZp6JpyhdM1EVFbiEbQG6k8IDQRU19E0aEjMA2dqN0auqY4ghAkFkihbDx7KgggY/Ok+Dg/erGP6WNDZCK/+LAxtsJvJJG6N7pPKq6oIFRR+XzfxXdqeE4Nr17FqZSpFiepVyvUHUfNMSnxPQ+n7lIqVdDECLVqDSF0fKkTIhThvyYx8Zk81Eam0EKm0KpkpeuYtq3I230fM5eLoh2aKlKhYWDoBoaug1SHF7msOpCo1WqEYYDnOgloLm2bbC6LYdl4fqD6MRqHtqlHxO0CQ4/4rYIQoYUYhqnGt6ZRrlTU82OXQ9QBfdx3lmVH/aW8JQT6FKjljy0d1aFf1COO6tAzViFd3//XdeiXBDw1WZNECGGCVggtikQWL9LPU4XktoYbVWxJFEsnflYa+Dgc6BILVNO0yB1ObTqR/U5yP8gksoXvOsovPBKYSFk6IVLuVSJub4TDajqxeBO8KkLRkv0rGiVaZBUVb9pxJyUWXJDUNd3OhjvfFPQ2KlfVTSabd6N/onzTZnNjcIgkQwP1TAjJY+L0qPFxXyq8KeXah9pclbu9FoWsFehCUPZcglqZ2sQobmkCr1Qi9ByqnoNfKRK6LlahFbu9i47eWWRyeXL5lsQaK3afSxQVpi8YU0nt4ybF0fDSJPZqX0tvCLLRDhGRtk6xYIvLlbI5RKSMXBhj3/40Uve8pwVHZGos1Qmn2LTfVDpc06Yudc+fe+YSlcynntRwuNX1sOkl5ZaxFSUkYHey3jzvbc+TGobFjQjM8cBhyjyOL0+R8+FOZ5jSvvhlIN1tUzYJKQOEDCh09NPdO4enbriByr4DbNv0LFZHJ2YuT2fORLcshGGy+4lNaJpF3sjz9IPPUq9V0LWAq/7un1i67lzau7qYHB+nVi0nloqNVWqqoOIXn7Rq0Nz29F1yxt+nyyG9Dyt5oZQDOUW68eKdPgCQ8S4z9ckQv3D8EQS1A5S16gf/8UNceumlnHPueezas49ytcp5KxfzwGNP8NRTW3jTla9i0htiZGI/yzNZDh0a5aZbbuUVl17C3Nmz8V2HbTt3s2X/Xi562ct46OFHueXW37Jo0QIVRSlfYM6cOXS2t3HehjX85qabeWrrVv7kmtdzcPggDz/2GG9+w+tpKRSQUrJ2xQk49RrD+3Zy+solnHPSKmzL4tT1qzh5zYnohkF7exsf+Lu/ZeeWJ9jx5JNUJORMSeesDjzHYcGsbo6bP4AXqMOh9tYc//KRf+buu+9KtV4k63U8Wk477TROO+0PJIWPxk5PTw/XX389H/nIR/jIRz5yuMypj2Fyb5pO4JOf/CQbNmxIso0cOsQXv/x1HnnkUWzb4pL1x7Pj4Bi/euDJprI+85nP8JnPfAaAroFBjlm6nG9/+9v85te/5s/+7M9423s+yNq1a5Ghj9AE/bNm8cMf/pD3v//9XJsQkavU1tVPV28//e25qNY6J564gsnxEQ4ND/HvX/02q1et4o2vfx3P/vq3aJrG2lUrsDMF5bpVrdCat6Gvm7sefIRj58/jrJPXc/qZZ/Lo45v55+v+jY/8/btZffxytu7chdRVRLX//Na3OO+csznj9FN555tey6HxcTY+8TRrV51Ib083EsGDDz/K5i1PUylNsHrVSl527jn857e+SUtLC1e/+ko+8bP/4eDwIT71zx/gJ7+5iRtuv4tfffdrrFuxjGXHDNLW1c+2nXv49o9/xpuufCUL5s1PwIY/BuTYzOQwbRvDMCiXilSrVSYnJ8nnC0hg+NAohmmRy+XVC3sYghRMTJRBhmRti3q1hIYkl+0i5m4anxynpdBCJmNjmXpi5Vet1fECH9s0E/7SMLQVd49tKLcyYKJcUUumlOTzOeU+GiiibQ0QhgIIQinxpcSMyq9UqwQR2OG4Ln4QIoWG0BTxuR9KxakpVdkyssQXqENexamkI3Stcagb6Z7K0ioiKI7cu/RIPw+CAC0TufAZBmb0MmVJFUQniCyVNAEy1JCxfpdaN4IgoPEtfj+AMDpQlgiCiPs15ofVdF0BnVF5IgokFFtDhhEBfBCE+H5AEPp49RpetUToOoS+R+B51B2HSt2hGoAWBuhhiFWtUq06VCoVSqUKuYwNrguGhW4qN1vcGk7JY8/2p8i3d9LRO0Bb7yws28bK5RjbN0a9VsPs6yWbscnlsti2hWVamIZBe3s7UkqymQz5fA6BoF6r4tRq1CXk81lkJkOQ9zHsDEEoKZYraLqBlDKKdpenkMtgWxaFXAbXzeO6LpomaM13kM1kCIOAoeFDdHd20m5nqDkurucpV0hTx8pk6evvV4CargMK8NSMmIT7jyEd1aGP6tBHdej495eiQ78EjietcWoip5iAAQ1G+AZmrYAaVfHEJQ8SsAnUJhG1p8HZEwEvzWNINimb8WnF9HaqexPXMwEyDFVECt8n9JXJaOyWp2tqk0wApgSQETQs9EViFZNGJDVNS4E0USdKZTrffCoST8iZJkmUMx2IoMliqiGLWDFISknmesotLv6WPGvmpS0uPc1JFQbpiRemsJVmH1uZ9JWGJtRJne/6hL5HcXSEydFDVMdHCWoV8B2EkPjSQ7qSkZEh5Ngo4f795PbvJ9/axuDsubR1dJHJZKcQq0ayjyURt3XKJGqYZ8YYYPqUS2sCMeOxO9XcUIZhav1JLXYRWCc0DSFTdYv7bgrB/R9HaiwdU6HNxl+Z+j59LMkk39Rx/lLl8Yfck0pi+t2NmjfXTUzNdLgayaToZC4mgGz8WJGWT2PeKRUgvfk3HtZ4/uEVi8PD61PqGPdR6k/yJE2dRrv1KpMHh5k8uJ15a1YwsGQhy88cYtu27RwcGWN/yaOzIOhoFfgyT63iUZkcZdlJqyi0tZLv6sLMhOx97jE8IdD0DJadJwzqyUFx0+hp6B4zjqqpLXghWRyu5cgQopN+kUT8iMts9Etyoh0rRom2MbWGat3+PxqH/xeTYRh8+ctfZv6CBdxx973MnTuXY1vmYVkma1esYNni49iy5UkKhQInrVrJyKFD6LrOa698NYODs3H9gFsfeYTjF85j7THHcNf9D1DI5Xj9Na8lm7XRdR1NN3jy6acZHR6ir6uDdWtWs+z449WLjGmStxUn0eZtz/GjG2/jjVdcxPzBWcyaPR80jVK5ygc/8RlOWbea8886g1/fcjf5fI5VJy5BmCaZlhbsXCumCLEMDSuTRTeVOmLoGg8+/Chf+vo32bp9+5TWq7X++h/8gAceeCC5KoTg05/+NCeccAIA1eI4B/bt5d3/8EFqdYeMbfP1r399ujBnOjEQgrbufs484zT+8s//lL/927/lySefRLkURbyVEWFMNpvle9/7HuVSEa9eY/FxxyXFfOITn+CWW25h2/ZnecUrXsHH/vWf+fD73sOSpcu45V8/B0C5WGTrk1u4/ic/4fEnNqtrk5Mc3LuXIAg4//zzuemmmzhu8WK1D+sGH/3ox3j22Wf56le/ylvf+lY2bNjAn/7pnzI6OoqmaXzsnz9INpfnsle9hn9477s5ecN6NE3Q0tqBncnxznf8BSPDw/z0pz9mxXHHk8/nGTk0xvy5sxifmOQ9H/kEF513Nmeffirnn3EqDzzwAK9/45v50D9+gOMWzOPNV72Cgb5eXM+n7nrcc9edjA8P8elrP05fXx8SeHL3ATQhOPXk9VRKRXbu2EHN9Xhi+y62DY3xttdcxu6DI/zLF7/FZWduoDWf4aknn+DMDWsxomhnr3nFJZx16kkUD+7lNw88ws9v/i2fvfZjdHW0cfZJ65gcH2PP7l2Evv+SX7L+t1KpXKFarTI2PkFrPoNpmrS1tZHJ5pASqq5PzQs4OD5JS6FApeYwWanSks2oeaILDuybwPd9WlvbANX0fL5AJpvDsiwsK+I30jQKBRkBMJIwUEFystks5WqVYmkSQzewLJNcPg9AEPhMjI9Rq9XwPY+WQgue7+P5PnNnD0bPk9QqZcIwxHWcRF/PZPMK4Il0NoSKGec7LiAJTR3DUmCXgCY3OESDHkPThFqPNVUGYcMjQY9c5jzPw3XdBPSxbAsLi1yhgON6uK5HEITq8NdoRG9WNBxqd/X9QHFXRVGMZSij9xT1LhNHFIzfaTRDR0NXh8/RuqGs/eP3jIAwDNB1A01XYKjv1gncGoFbj4AvDWHaBGYWzwpxnRBbA8MQmBrkLZ3ulgytGRvb0MnJOo7jELoaFc0nyGTxMhk8UaFcrVGt1KhWK2QLbbR296IBuWwW07Iol8tUq1Wy2SxhEOJF0fZMw0QgEgtLyzQJDTV/8vk89Xqdaq3GgeFDSCHI5gpIPIQmyGYzBEFAcbLIrp07sTMZejrbKVWqSKBcqWBbBoauKW49IajVXfI5ZW2VtW1Gx0bRhKC1pYAMwsjFs06lWKRWrSRr+JGdjurQR3Xoozp0U6kvQYd+8RZPaYkcri2xdQ8kgzkhEosBmqbeTYNYqXJIDfoY7DrcY2X8hHiwpeqrMijQKQjUiU/Q2EjizVmLolhE2VPdOfMwb4Acqn5qw4yuCJL2T5s7SX1FIof0s2RyXwMomdbew8oh3eSUafNM5cxQSJy/ATBFvSBSfRF1ToOsTjbk6/t4tRrVUolqqUitUlZE7SiuDWHoCE3DCzx838et16j7PvV6DduyFNFjGGJnc2rSi5lln26PJN1fDS6w9GhJrM2eR27TBJP8kYlg4wX0j0S/fZFpKs3f9I2gOfdMaerG+jxPe7HCO0y+w9+e6vGk71KgbXJ9Chzc1N3T29G8+U5dZGNItHFrMitk47nTTmSmXGv2wW7UbvqcnfI9WWSnCyXhtgtD6tVJxvY/S//suWRbC+QKOUbKk5RCDy908e0AaYRYuTbqVKkWa3QM9tHd1097Xz/lyiEmR/fQ1r8IO29iGlnC4HAbzEwtbl77mq/PvHHONCdnXgmnKnlTqpIKQarMprXmDfMFRHwkpu6eHubNm8fyFatob+9g566dtBby5LNZntm2jcGBAfq7u/n9fb/nmIULOXbRMUxMTGIaJnMHB5ms1hidLBHIxsh2XJeuzg5mzeplbHQUQ9fp7uzA970kRL2mmxhW9CInQ3zfJwwlnu9TKlcjqwDJeKVOW0sB07Iolcs4jnLfqNbqyoVHguN5BGFIR2sbGiGGJiL3I3VIsGfPHjZv3sydd97JxMTENBlIVJ79+w/gOnXa2tpYsGABnudRrVbZtn07XS05fN9jdHSUWq1OJpONiHanp127drFx40YQggNDQ4AiTs5msnR3d7F06fFYlpVEt+3q6mTz5s3MmzeP3t5eOjo6yFgmTq2KYRhUKhW2bdvGXXfdxZ133glAX28PZ555FqMVFzeAY2bPYmD+QlzXZaCnm9vuuDOqjcBzXMrFSTZv3sySxYs577zzACiXy2zfvp277rqLnTt3EoYhixYtoqenJ+ILUimXURYtY2NjuK6r2iOE4t0xTZYsXowAtm3fRkdrAaHpbNu6nRUnLKO9rYVKtY4EspkMra02lmkyNjEBCNpbW1m2+Fhcp87w8DCWaVGvOxRLRdavXYsfhowcGsX1Awxdp+p4eH5AEAb4vjrsM0wToWu4fkCpUqW3txdN+mzctJETli6lu6ubyVKZlkKBjG3jTx7CcV2KlRrFUgXbzjCrtwfXqaPrOitXrvijiWqnRYTPTuChteQxdE1Fe9M1Qgm5XA4pNDw/wA8CxYtTq9PZkse2DMzooEtZ1PiR6xlYdgZN0/F8H8tSY8EPQgUiawJdgIcCUoQWkZRHgJ0QKJ5TJIHv43senqvc5hzHwPMDPN/H971kV/MjN8G0VbphmkihESISdxIZ6YdIiRQquptuGCBV5Ghd1xpeD1J5KcRtIorApng/Y6BHiw5JFRgWu95pmobQBJppEoQS1/WjNSmyao8PiVPvI2GoSMNjsCwkdtFTIFUQRgfmyAgDE4mlApGumUSSlo23HcM0G54TgTqQDX2XMAhV9CehEWg6gWYQoKm9SRBFH5RYukZrzsbWNfQgIES57Emvjq+BlCHVQMPzQ4TQsTIZZBhimCYYpnLnjFzqAt8n8AM836Neq2PbNkZkveS4HhJJLpNRa6NUAJ1yTxTU6nWkEJgZZTmpodzkXNcjcF1Fam8aWKaBEGpMIr3E0syIeHL9QM1/LeL0CvyAMNqyfd9XrqCA4zrUZ+CsO7LTUR26cctRHfqoDj3tITOmFw08hUGY1FFZf6QaLWlET0BEkeDUDw2Sa6mspiTJQgMqKkXcSpHy1Y9FlRb0VMUxGfQy/YyUuW4EhPlOXQFPEUmjEFriFx5HrZPp8oh84dMASLTRCOLoGBEIETYiyKlsEfARxpY1cd7IBzKUCW+amNLpYiqY+CKAzCawKQJIwjAG9MJEZvHmTNxvsnmpTA+gRBYinvwNN7sk+F20+UpA+gFuvUa1NMnYyDDjIwcZHT6IbZvYtkVHTwe6baKZBq7r4Xo+tbrLeGmC0fIEo8NDTM5bQHd3H3MWHotpZ9AtkwTIi5nPaLZWiiMYxPWLrdzCoOHqGcsnPXa0lKIzTZ7ELocyaq/C3hvgIhFSHS+nMrLSehGddUSlF7/Z/X+ekuOQ/29k1rwONMZHdDUG7F9SWenvjU135hTSOKFpjCnZ1L4X/fwpa176l0YSzR9Ta4VI8krMbBYZBhQP7aPuamiGOgk3O3vpybYw1qHD6HYmi/tYsuQUmCiy13kOY6CfXG8XrW05Dux+jlq1wrwTzlYHJFqYnNS8pDRVrqTkNEWZmUnYTdtiykrz8A8TzTfJeA0R0f1NftIpMP3ITle+5mo+9slr+c5Pf0l3exuvvfTlAGzbvp2/eMdf8Lfv+mvOPvscvvvT/+ail53H+rVryBVaMA2DTC7H1/77BorlCu/702u466472PjgPbzhmjdSKhXZtvUpfvjD65k/fyFvf/s7aWsp4NomuoCb7ryHx57ayvve9iYmJibYuXsf69d5nHjcIj77D+8CIdg/fIgv/fDnXHHu6axbtpjPf/RDxGv4ZS8/DU3TsDMZHtx3AM/zWbZ6TbIf6ZGlq+t6/Ou//AuPPvoou7emiFybjgIlbR1ddPX1s+OZJ3n5y1/O97//fXRd56GHH+bc817Gl7/0Ra553Wu5886Gm17sVtSUpORDH/oQH/7whwG1dyIl40P7+PH13+VnP7qe2269hZM3nIwWcTnt2rWL1atX8973vpe/+Zu/4bLLLmP37t0IIbj77rvxfZ+zzz57BjBEUshleOKBu3jv6y7hE//1Pxx3wkrWnXY6XT09STtD32NydIRLL38Fb3rjG/nKl/4DgEceeYTzzjuPMAw55phjZhwfYRjyxje+kbPPPps7b7upWYehodgvPPY4BhcuYv/oBI8//jhf/Py/8eH3/wOnnXwyP/zmVyLrj4Dh8UlOO/10Lr34IgU+eD5z587nhz/+CePjE/ztX/8VfR2tlMtl7EyGp7Y8zc133M1bXvtqDo6M8o/XfZG/fstrWbl0CVJKujvb2bN3D//+pS9z8knrufbv3kGtWuPBRzfx+W9cz6f++YMMzM5zy+/uZmSyiBuE/PnVr+Qti5fxxje9mfsefYxDE0VmdXcwd7CfFcuXctlll73wxDlC0uxZfQrY8Ty6OtsRQLVep1QqI6VkVm8PjqcIti1DRxcSLQwoZEyytoUmYKC/n1q9TrVaIWNZWJYVRSGscmhsnPaIELxUrdPR1krWtshmLKquT6XugeEjNJ18voAQ4NTr7NuzizAI0Q2drs4uNCS+52Ibiqg6sCyq5bLikJIRT5SuYxiKBF2geIOcIMTzfOquiyY0bNNI9HJN1zFMC8s08WSArimPA03XFJdSGKo8QkWVVmq8RDcM5ZmAwDB0RX8QhtTrdYSmYWnK/S2OSBePeT8IFCASkd4Ckc4aBUUiUKTmaKhI2wpgk6ECX/yw4dmhCTCFkYBg8aG1rutIGeK5KtKfbppkCwWCCMQJnDperUq9UsGNosW5YYgjBXWp4QUBGsqdsFx31fwUAss0FIm8lJgocAxdp+65lGpVDlUDCq3tGHaGfKWM9D1qpSIdPX3Y7R1kTBMvlwMhyNg2YRiSz+UUKbpuYNkWNT/E9X3cShW/XiXwHCbKCtjNZLNkcnn8UOKHkLEMBILxiUk8p0bgueRbWrDsDI7rcWh0DBB0dHYQeB6EAV5kkSY1jXqthmVZZGyLlkKeIAhUEIuJIn4Y0NnehmlatLa1/S/NzD8kHdWhn6+s9PejOvRRHTqdXjzwFEWEa+LCiTsrBgci9HDmxjSsRmLQQ5UbbUpihmmc6hwBzf6Y6UEiRPpSdCISEAZ+k3tdMoijTSMWqhQxSBUBRQg0I3KXSx4cVym5QbmbpcAlIOWyFWG5qXsFRCZ8EZgTEe3FfE1xpjQ3VHJvaqDE+SUqNGoiH5medI2Z1Ijuly6DBggVmQqTyFo06pj6rQHmROVF18NAbTK1aoVKqUilVKJaqWJZrRiWSWt7G1Yui2nb+GGA7/k4jkt7zcHzAup1F2plSsMBo4ZBS1c3ufYOjEw2edZMshCamBKKM+ne1GgQTffE7Y/zx1kj6K+pL2KJybivifs69ouMxm9kIn6kp5lPBpqWoxlTHIFyZnI+OeV7A5RLpxldEtObZ6r/ZPIfSd9MeUTTBYECIZO+lDNmnFqjma82VyV6gmxMsGlPVo+aWlo8bp53VEzZB6evm3LmjOlr0bwUqVukDECGZAoZOnpnMWfBKh797W+ZHJvAkRbZQhbdMmkNDJyyQ1DVGd+xB98N6ApNtj3wOLs0iS09+ubPomf2cjoHBvHcAKdeT8ZRHEcllsuMtZdN31K/NcafmNL3Mj0uUuVPSzPIa9qhVhJdJrkSr8wkUWSkQBDM0IIjL911x+/4+/e8myuvfh2uL/nIZ77E+WduoKOtwHvf/R5OOOEEcrkcf/Vnb6Xihnz/ht9x9toTGC1V+dndG1k0fx79na3oms6zu/fx4GNP8brXhriBpORILr74Crq6OpFSMm/uvORl8KSVJ7Jw7mw8p0pPVwenblhPIZ/jqa3b+MFP/5s3X/Na+vv7uPyc05g/0M9ksci//OtHOeP007j4oov43H98mcGBWbzhmteydPmyhOTYcV1GR0f51Keu5YwzzuCSiy/mmte/ngsuvJDR0VEAdu7cybWf+lTT/DjjtFN5zdVXU5yYYHT0EH/5l38JwMjICPV6nW9+81vcfZcCnS666KLnBScOZwm1ZvVq3vD6a1i0aBGGZRJHXNV1Hd/3+cUvfsGOHTsYGRlRfDGpfTu2Xuhoa+Wv/uyNnHXqSQDUHJfRiQqO41J1PbZt28ZnP/sZHn744eipjTXVc+r4npvUR0YvswDDw8O8853vRNd1XNdtsgwLgoAgsuZoshwW4FRrfOQjH2HpCSdw9euuoac1z3Hz53DhBRfSP2uAQ2NjXPeZz3LhBRewft06rv34x1i1ciVvfMPrueGmWzANndM3rOXkk9ZRdzw8z6WQVxFqP/6p65g1a4ALzj6dBzc9QRhK3nzV5cwbHGB4eJiPf/zjnH/+y1m/fj1Xv/pVjE6W+NaPfsbZp5zEwKw+3vHmN1Cu1dmy7VlWLj+euutRqlb4/Je+wsoTl3P+uecwPjaCaZh0HruQ//zmt6iUS/zjP32IEA0vDP+QaDn/V5NlGhHPj8P+ffswTZOW1jYsyyQMJa5TZ3KySK1WZ2DWLPKWidbRgobEdWq4Tp18Lks+lyUI/OgQVSA0BQJZth1ZFEmsyJI8CENGx8YoV+u4fkhLPo/nB1QdT1mlCI1cLofveRiGQa5QwM7YhEGATki97lCvO4S+C9GhbczKoOtaopP6vo+USifNWjaGoZOxLaqVMr7vUS6XMU0jsu6SiBAEIQRqRU4OgyXoWsSvJCV+zEOhKWoO5aJnUHN9EAIjo6MLZbHkVqv4no8KeKRAIs8PIkoNLbKsDAhDQRARkAdhmMzb5leMxoGrFgVQ0tRRo+KD1XR0TRAGEPoepmmiG8pNFM/D9z18p4ZbrVArFakVJ6lWq1SrVWqOg+u5IEMCP6RGyGS1jmWatOSzCYm77/m4ocSXEKBhGhpZQ6cjK7BNiR46WLaBbho4fki5VCQMfCzTwAnADVEk8H6QWAgKTaPmONQ8H4mgrSVPoIH0TQxbuemZUUABEYToQiZWlIHvoRESGKoPLEuNuWw2i+f5yrrUNKN+1pW1XBCSzQj80KXu+ZQqdYSAXMYil80ikWRsm2qljFM7si2ejurQTTWa+epRHfqoDv0C6UXv0zMhoU3cOhE6ISPwqQFUNFvMTC84upwCMqY8mNiypgEyxJM+BR5Es0vKiK8nCAh9D9/zGuZiMZCCSNoxk5gS6yBmBiSIrIvSCF9cXhimvVMFUjRkRLRxJacmTCUXay4rDSDFSq0ixJYJeCRFahikB19qkMyYUiNazJCvATrF/do8RmOrIIkkDH18z1UEhdUqTq2K6zpIQDcNsvkcmXweK5tFSmX+67kuLQX1t1yqUC3VcMsOxWETXdcwLQvdNJHCnL5oiriG8Wc5pT1pVDIWvWiMyRTwmQYjk3ErpsskuU8K1MF5ZMF2mAXjjyPFbonPs7S/SBT7hUyAm36eujNN36WaP6e7c+oaMWXTmIr7Ty/4hQHCmTZOpTTEi3J6fqbqNu35DfC46anJGpqWwQy1Pdzmn1JA4pHcdCIVzUvdEGTzBTq651AZGmJk926Kvk1ndw+5QoFM1iB0XKSvUzl4EClMCqHO8LO7cetlZLVI9+AraeuaR661ldJEicCvKsvV1Ax54REy4ypLujOTT1Nk2nRnfDKQype+J63TxWOiSYbRAGrcqSkFL2rAkQ8dw5bNm9n6zDP8zTvfyXilzm/veYCli+bS07mEKy6/nEq1Rs1xuOC8c7n70c3ccM+DvGzDKip1h9sf3sw/vukKVh47D4BKzWFsskK1VqPuuHi+5KS167EMnfGJCTraOxCaxmSpyrzZAxwzbzZD+3eTy+Zo7+jCNC1GDo1y6+/u4vKLL2DunEHm9XTSkrUpFkvceONNdHZ0cN45Z3Pf7x9gyeJjkVKSzxfwPJehoSFM06RUKnLDDTfQ3d3NJRdfzFlnnonrB5Sr6mT9iccf4zvf+Q7j4+PUajUA5s4e5IzTTgXg5ptv5vOf/3wEVAl6enp56qkn2fzE4xw6dIje3l4uu/RSRg4dSgCazs5OLMuaJt/YxSljmaxZs5q3vPlNZPMFfM9ndGyM9vZ2dF2nv7+fp59+hkceeWRaGZZlMau/X1mw9Pfy2ldfQaFrFgcPDlOvO7hSw7FbCYXO0NAQX/3q1xo3p/fwMKBaKTM0NERXV1fTM4rFIt/4xjcOP1Ciw5WJyQl8P6C7uwsQ+L7PLbfcQhCGXHPN62nLZaCvlw0bTqazq4vS5CQ333ILSxYvZs3q1dx7z91kbQvP89i6bTsZ22Ld6hOZO3cOUsL4+DjtHZ3YmQx33n0PZ55+OscuXMD9jz5BLpvh7FPWI8OQfXt2c8MNN7JixQo6u7pZYtrc/+gmHnl8M2tOWEpPZyenrF/Llm3PcXBklOXHLsQ0DMqVCp988CFs2+as005lYnycfD5PPpfjkUcfZWhoiA9KyXhxkvFiiSUL5r6IWfS/l5RrmTqsGx8bJ5PN0NLahq4bCBHiez7VSoVyuQL9vWQsA9vU0YTE93xq1SqdXd2YloXreYQRdxEo4MaIIoppKYv9MAwolcqRiyv4nofredQcl4xtYwhNueoJRfCcyWQIQ0tZefuOIg4nRAYgNUUWHrtjCS1aPGXEj0QUoU5XwEXGthBCRd2rViX5fB7bspND0lCivAYiXTOOZqdrgiCAIFROcAJ1IKus2pWLXhAESJR6H2vZjuMQxJbwkQ4fRNEAdRQnk/pRRO5lNA55U++oQqbedUTyFhPfSsIPG29HYYCmWZiGivjmC9Uu33Vwa1VqlTL1sooqWavVcF0Xz/PRUMCXFwSUai4FodMRuR2HEtwgoO6H+KEkEDqmmcG2LdACdF1A4CrwDokfhtQisndDE4SGTahbmLYCEb0o4iBCKGBMKis00zDQsQgji1RlFaWi1cV7paFpmIaOaeggTTRNYNo2lmGoMWPbCFTUOz8F9AWeAsFV5M+QEKi5LoamKWs9W4GjGduiVgHPT0X8+qNIR3XomdJRHfqoDv18ScgX6TS6aeMTKSACZCgJUqR/Mfl4XLdQKne1tPtcUtdUPgWmqG8iNZjSbU37ksdJAUNqs4utczRN4Hsugefh1WsJcCOiUKxC0xPib6FF16Yg0GFsUQSJ/zikhS/UJonAD3xiUnVd16J8jYmlxZtc0vXxxtXwE4+vaaLRThEBaDHRobqnGVyKSb7TEfKSYZYGVlKDq5FPJqbHmiaaBmLczjh/QpwoY3ez2MxYJBEC66UJJkdHGNm7mx1Pb6E8OUm1XKJ3Vh/tne3MXjAbO6ssnkCZJodBOgqDpF4q41RrFIcnyORbyRTa6Dn2eKxCC1a+JSWrptU3aX/aiikGKptOJ1JWUw2LvbQlU6oMoSQlYuUkfQ+NcSsj8QpNRWQ57/wzOJLTY5s2v/SbkvnwQlxZU5eRqXmnboyHX3bklA/Pe0iUHuszPHXmktVYmrkKjU2oOaXXIHGYPFNLOvymqcZOcwHTmjnT6U18KXYHjWWU3n81HYSGXxunMrqHid1bEE4Nt1xhZN9Btj27m0NjEzhAb0+BzvYsxUPjuLUAtxrQ2tlOJt9CS9cgC1atpmv2HLrmLkAKE4mBDPymLS+ZC9Nr21znpt+0REZCNsB5iVJPZ/TVn0HgUzdakvU6tR7Eq1m07qryApS/erxuq/XoZReeOb2yR0iK559pmjy6cSPHHXcc1VqdTKS8Syn5zg9+yMMbN3LdR/8V287g+T4Zy+K53Xv4xc2/5YIzTmbOYD+5fCuu51KpVPjdHbfT3pJjdm83gwsW89Qz2/jat/+Ld7/zLykU2vjQv32ZN736Ms4+eS2u53P3xi389oFN/O3rX0F7S45qtUYhn2Pzli28/Pzz+eynP8PrXvdaJieLTAzvZ3J4H7MXn0g230I2l+WKyy/nnnvuAeBT117LVVddSSghk7HJZLIA3P3IFj75nz9mx8O/Y8FAN9/91n/yrne9i+uvvx4AOzplB7jkkkv4/Oc+xyWXXorrutx0043oms6+/fs5/YwzeNe73sX7/v7vOfnkk9m+fTu1Wo3f/OY3TdHn4vT49j08uXM/l566ko62Armscld54IEHuOiii/jqV7/KK1/5SkqlEh//+Me57rrrmvrn3nvvZd26dZRKJUDpKYV8jk9+8lo+/ZnPUCwWueqqq/jSl75ES0sL9913H2eemR5zzXucZVkUCgVuvfVWJicnOeecc2bMl6oESMnZZ5/Nb3/7W970pjexZcuT3HPP3di2jZSSUqmkLFtyUdQ7qSy0XF9F4/LqVaUfaRpCKl6aMISMbbJ/vMiNj26lq7qPoDTKfY9v5czzXs76k06hM6uzZftu7npkC1e9/BSq1Rq/+d291IvjtBWyXPOaKymWihw4eJAPfPijvPzcs3n3O9/B3l272Pbcc/zqltt56+uvZlZ/H7+8+XZOWHIsi+bPI9/SyqFDh9i9aze/uesB+nq6edOVlyIioKWzs5P3ve8f+NrXvsbExPhLnVb/V9Nzu3ZTr9epVcpMTk6iGyZtHZ2UqzVkKGlryVMsFnHqDvPmzkYIQSAltmXieS7FYhErm8cwTExdw6vXCH0XK5OlUnMoVmsUCi2EoaRcrdHeWkDXBJVymUq5RL1exw9CvAB8KRic1Y9haEjfAxlgmSZ9fX2Uy2Vq1SpetYznuni+RyFfAKG4o2quRyhR5OSmiWnokaubgWYoIulYF927bx/FUolSucycOXPp7u4il82pU3oZEvgeSl/WME0DIQR+GFJ1XBw/wPUDLF0nY+gYmgKc6q7LZKmMBFpaWshlMuhCMDpyKHK70xXnlAwJ/YCMrfjNYq43KRVBeRwkgEiXDT1XufIBCI3YFlIQuRcKEEJXkfTi8gMfp1ZFj4jSNcMiCHw8t87uLY8yObSPsd07KI0fouZ4jLoBNT/AD0MyWki57lKpO9R8SW9HK8cM9tJi6RAGVGtVaqFA6iYtPYMqcmE2w8jQAXzPQfoempXDzhfo6JuDHwQKBAtcMrk8mVyBvrkLMe0MmmkpXTl+5zAiYnQkdUdFJJw9ew4aktD3maxUqDsOpUoVW0gMTZDJ5SlXqziOQ2t7B6amYWgCp+7g+QE116O9rQVd1xmdmFC0H6Ek8D0My8Sys1HEwRDXdeloayWfzdDZ3sL42DilUonzz3/5/8LMfHHpqA59VIc+qkP/n+vQf5Bl8kxAUBOiFDVZxiZKIv3i3/AXlSkgK21Z0zwLxIyTNQZiGnxOoSKx8zxC3wMZmw1qyT9NU1E2YhCjCUhLOr5R5+ZR3AAtVN2Tmkyx5moGO6bcrvJJiM23Equx2KWsIYVpumV6kKbLTWCi2CRumrSmTshGwXFfNOQZtSn1gBk9EaQ6tfM9l2q5RKU4SWliHKdWI/B9dCMiWNQ0PN9HuB4hKMVEgBYRKsbPMWwDKS3srEXoO9QmRike2EO2Xbl9mNk8QtcbANy06kzpn1hOM6yiM6nsSe/FKFsKqCIll0Ro6f6Wfzyh2A+Xpi/g8UlO80ah8qbzxTmmHnG8kEDiO59v3rw4oT7PVq7+TzUhKXnKQjPzycjUUxkx7bep98iGNGaoSeNhz9eyw54FyNQfKZvHZ2rT0TQdNJ3y2D5KI7soju5m4Jg1ZDoDxstl2mb3E7S1sX+ihsz4aLrP7MVLmCzW2T80RutAF109fSxcup5qdYSx/U+i2Tr5jgGyhW68IEBGHvkzbgORAESy/osp8k3Zq8oY4I6llrIQlc8ji3Sauj9M2zDjy43x3Cj2j2/iSmDbjp3kW9uYN3uQn/30p5TLZa655hqWLllMPp/D0HUee/wJ7v39/Vz5isvJ2Rarlx9Pa2sLlUqFBx+4nyXHL6WvbxaLjlmk1lXLRCLo7u7inDPPIJsroJsm5512ErNn9eJ6Hnffey/1QHDyiuPJZiz2HTzEbfc+wkVnbaC7q5u3vPktzB7oZ2LsEDVhYxba6DY02to7MCwLJFxw/vm0FAr88Ec/4oYbb+DgwYNYts2GDRs4/fTTASiNj/DUQ3cxuvtZvOII3/jGN9i6dWsiA8dxkqhMTzzxBP/5jW8wNDSkyL7bO7j5llu47777cByH++67j3/7t39jz549VKtVhBC0tLTQ3t4+TbYH99/HnTffwOi2jdhRlL22zh527NzB+Ph4FDZco62tjXPPPTcZn1u2bOHGG2/i+9//Pjt37uTqq69uKnftunW88Y1v5Jvf/Cbbtm3jP//zP1mycB6O6/De976X0PcYHx/nu9+/Ht/3k/va29s57thj+dl//3fietgYBc3phBNO5PwLzgep3Kw+/elPs3HjRup1J8kjhKC1tTUqQnLnL3/K/qEh9pYcLrr4Erp7+vjFDbdw4rLFHDNvDj/77/9m7py5nHzyydxw6624oeDERUvJuVnC+izsjn4WzptHxhDseO45JkZHabUhl8lgGgbzB2dhzu7DMnWe2rGHjpYcvV3dvPKyS7AzWX59yx3M7m2npaWFs04/lX0HDzE8XmL50iUEaDy56wC18lbaW/LMmtXPiccfS1trK3Ymw4033sSePXvQNMF9993L5OTEi51C/2tpfHxcHSpKgYz1UhHzjUI2m1UHqH6AZVuKkNr3UQuqhtAMReKMj4aBFwT4XkBIDd/zlZWN50bk4150KGpQKBQQSHRdp1ypYVoGummpiGI1l2q1QlshH7lleQSehwx8BQZZFobRcJGTUh3QhiGgK0BGiw7fIsUQtIZFv2mayrpQShynTqVSJZfLR7q7IAzdCMAJ0CKuJpGUGeIF6iVKj8r0gpC6q9zENCGS1y9QFmVEB6NEh99hbFEFKhBO9P6iRdHsIHKFkrEeLZItJIwi3BG5rmqawIzWhVCqaNlSSjTDwPM8pOtiWNGhqpT4rovvOsryqV7HcT08T6ILMHRB1jSou4q0vTVn05K1yVqKfD2QIQEC3cpgZAsMzF1IvtCCZVt4oXLFDT3Fo2SYJlZQI5fJgWZTKXlI3yWolSmPHiTX2k6hswdhZgjCkFqtioWKIBq/ByXAGuoQP7ZW8/wA6dYJwpAgUNxctmUp97sIuAo8X71/BT6GrmPZyo1OiwjiixPjhL5PPayRjUDCINApVao4jouhawr8Oozb8x9DOqpDz/S8ozr0UR16enpJwFNiMRIqBDd2/Ur/lpBr05h400z3ZHxVJuaw6YbEIJAgJoIWiVymDROhqcU/DAhcN4oeEVliCbVZN0AmLXlGbC7bzFnVEHa8nTW1W8ppC0baamlaEnEtBTI6OxFxebLhvhciEUInBrEUCDtlEWsCQmJZN2TJTHJOy0rE7Yg24FQfTcudWrTCsMGBkVg7RX0c+h6eU6cyOUFpfIzJsVHq1SqB7ytXOUOdXrmujxQOgQyxrQB0oaK5RBMlBHRTQ2KSac1SGy9RLxUZ3x3i1WpohokwTHQsNN1I4T+pCIrRIqKuqb4LZRih2AK0dNS7uHWNBS4B3mIAcobTh4a7XtS30eeZF9w/7tQYfzNvlo186R/TG0k6s2j627QJifQCmhrXMzwzufwiRT3zejvTHJla3zjfTG1If5Yz5EtVcSZ5NWVvXs2mjbm0TKcuoQlZalySTIrTNB2hG5TH9lEc2cXk8G7mr72MEI3guSdomzsH3YOhXaPIYAjBJAtOWMmBsRIHtOdomdtB/9z5rDjtNH5/4zcZ2bsdI9+GnevA6szgOzW1LqTW0mkpDpU7g3hk6v+Yll8gErdhEaba1FTmFMVsJnvuKcpEs+Bi68X0mh3XZup9R26SUvLk1mdpae9k3uxBvvOd7zA0NMTrX/961q9Zw9pVqxEC7rv/Qf71E9exYe1qjjt2EWtXqDDVQ0P7uPnGX5LNZhkYmMOqFSsZmShxYHQSKTQGZg1w1StfwUSlTiglr730guiFtcwtt9zMhg0buPyS0wml5Jnn9vBv//VTli9eyIYVx/Ov//IvjB7cx6GDQ4wZbfS2FRgY7CaQEjzFg/Knf/pWVq1cwc9/8Qt++ctf8fOf/wKA97///QnwVJsc5cCW+wHYWxrjQx/6EKAsgFzPa+r3xx57jMceewxQUf8c1+UHP/gB3//+97Esi9/dfju33Xrri5Ltkxsf4kff+DI/So29ecctJx4nnufh1OsgBGeeeWZirfTDH/6Q22+/nS996Us89thjXH31a/D9IOFkOvfccznllJP57//+bzZu2sSWLVt49flncfIpp/CpT30K36mybetWfvCjHyfAk2VZzJs7l7PPOpNv/td/sX///uet+/r16/jUtdfieR633347F154IaZpcuyxxyYgXZxiEuZf/dfXuP+hh7lv3yRz5sxhxeq1fP7r3+Ev3/I65s3q5TOf/Rznv/xlnH7qqXzvhz+mu6uLr19xMa47m1DC+oyt3MOqFR56+EEM02CwqwshJLlslpVLF9PVXqBSq/GdX97CGetWsnbZEv76HW/jVzffzpe//QPeds0rOO6YBZy8YQP/8a0fMDo+wYff/Xbue2Irjz25jcceeIAzN6xm7SsvxrQtTNMkm83xwx//mJtvvhm3XntRfXskpEMjI1h2hkw2R4CGHoFORtQf+XyOfD6KIiYU2T6+n6yWQjejyGuK8NpJIs65KmKdRAEdQahoJlDRxTK5HLpQrnReIMlkMuRzeYpl5Wo7Oj5JIZ9F0zQ8xyH0HAg8zEiHE5GeHQZBTHEKkeapRSThSjlS1uxSiwAgocitfd9H03XqdYdyuUxPT4/iO5XKnS4MAghDVY6hIyJ3MxUJWbna6ZpAR3E21Rw/Akg01KNlAnLFM1eBY2FiqY8QBFEUNQXI6Q19PIrqpvQ6FWkuDCVBEEaW/T66rqPrOqal9o4wCAmi+3TDVBZiroMtFaADIaHnE3gegefiug6u4+J6kMuYWIZB1tIp64r3tbMlR1s+Q8bQ8BxXRZgDjGyefHsXc45ZTDavrN0cP8St1xTwFLhooY/hV2ktdKJZWQK3DoFH6FYojuxHEFJo70AzLfyI3wsAaWBbBroQoCvO2Rj0y9oxR5ikFngEvopIres6lmmRz+bUm00Q4OkqgrXvueiGTsa2KeQDLNNC0wS10iQ1x6VedyjksghNJwgloxNFwjBUrpOeqyIt/j+SjurQR3Xoozr0zOlFA09NoINsdNBUa6Q0SR9CJOTX6vQhJIY+Gi5ccsb74+ao79Gpg2h4RUpiZvgQ33EIA3VCAyA0QRA0gAaikKmhlGpATbV0OqyQG5dk2HBtS+6jAVrEFlsQuxzGIMUM5pVRe5rC0UagiqYbke+5SGZenLdRnRRoFUUNREAgY1PgGO5SA3tKDwGKHDHdfw0QsQEoxnM2bZUWu+aFrke9UqY8McbQrh2MDQ8xvG8vvu9hmCaFtgJ2LoNhmfhhiPQ9QkJ0zQcpEKEgkOoZQSjxow1ez5hYrTnQNWqjY/i1KvXxUToXLSHT3km2szcyEVZyjsdILEsJ6CK2nJMxOocMSfi2RDTZmriy0uMrdU1LgNE06NhYyASHswD8fyy9wBSZnl5UJiXruCNT11J//r9L6X39RWZ+cXU43Mb5Aje/KJm+yEqnNmIZqDDTC5efy4jZSX3nMLd85UuUqg6lusfA4CC5QoG5fkgwKZmshYw8sx8v0OjR2tj/1DAHntjLxt/cQa4A7X29LF59DlJYOLWqOgV+gWbIEFSkoBgUn0ERi77Ga3CYKuQF59PhNKsXkFFjZ2mWaThtHzhSk0DTDM4+5SSWL19GEEq++KUvKStTXeebP/ofHnj0cT7zob/jNVe+ktNPP5WFc+dQqVZ5avNTLF2ymIHBufz9P3yYkYrDw1t30G4Z1MYOUB3Zg951Nk/u2Mk3rv8Jb3/T68nlsnzg4//GG155MSevWcFFV1zJ5Ogw3//+d9j45A5mz5nDr7/6Cfp7Otm9bz+f/o+v8qpLLmT9mpXM0Q2+9Y1v8IXPfw6ACy64gM997nOYls3K1WvYuHEjH/zgB/nZz37W1MLQ93jZueckYFI6DQ0NcfHFF1OpVGaUzhOPP86qVasYGhqir6+P3/zmN3znO9/h81/4wguOExnGfDnN+fbtaFhavf/97+cTn/iE6onUC/lZZ53JIw8/xDWvf0PST//wD//Ar3/9awD++q//mje84Q3opsUrXvFKPvbRf6Uln0vcBQ0rq6x6o3FdKBT4zW9+w0MPPcQnPvEJJicnVYCU503KNfy1r30tDz74IADXfvLjnHDCCbzswouplkt4rgNSctVVV/HPH/4wDx0osmm4DMB73vMelixZwk+/+VX6e3so5HP86pe/wDJ0nHqNf7/uk5iWRRDCJ667jud27eZv3vdBhOOA53DFZVdwoFjjmaFxvv7Ff6ens52Lr3o937n+eiYmJ/ird7yTnc89yy233IylKZeub/zbx2hvb+Xpbdv583e/n2tefQWd7a28+33/wPkvezmvv/AMXnHKCh7d8gx/94l/56/+5NW0t2Y4dPAAn7nuU/zZW9/CK1/5yiYrsSM5SSEIZIjne7iui65pmKZGXtgK1DAMfN8n8D0cp4am6WQzFppuKssWXYNQkcyPT5QRuolmZtDxyeiKgyeUAs/3MXQNQ0icWpW9u3YoK3RNR+o2AQZOIDFNk9ZCQUUby2YwCakUJ/BcV4W913WErgAgP4hpJXQKMTgGySGiYVoRGBOosRqRhbe1tpLL5bBsm1q9ThAETE4WsW0by7QIQ/D9AK9eBxliWCaG0JCajjA0TMOJLGvUzPRDSdXxyGdMDMPA1HUViQ7I53NIlN5bKVcQSGWlZBhIJGPj4wSBsl7q6+tV9/khvgwiXVDgR9GgXT/AdxUY4vseZsRJlI3eJULfVzQLmo5u6EiE4pfSdMVKJSUtHZ341RKVTAbfD3BdF/yQbMEka+kEKBBK6Do9rTlsQ8OpVnF8jwBBaGTo7ptD98BcBuYuQAgVPKB/YDa+5xEGCtgicMEpU2jrwLKz9MwawCmO4ZTGGR4+SPngbioTo7TOXoRu5zF0i3K1hhCCzvZ2hBDoMuTAvj20FAp0dnYiQokwdchlyVimoseISJches8KJV4oyRYKaKaJGwRYpqGs08KAiVKZquMzVqwkAZ7GxsfJZjJ0dnaiazpBGJKxbTwNgqnULP8vpaM69POkozr01Gb8v6xDv2RycZLHHWagxA9PQKKpGUjcqqeWm5Scsu5pdiuLLKXizoj8q8NAhUAVSREaQkRR7BJQSMSwYPOzp1QyhU2DbJCDKxc92fiNRjnNUePCVB/GE6/RSRLZsNDy3chUF6QM0KWJhknagim2Y1JjL4XQJqjXFOESg04NiG4auCwav0/txsTaagooSmSKGwMxru/h1qpUi5MUx8eolIp4roNl29hZm0w2i2mZaIYeuVxKVKQAFQXEDyHw1OmY5wX4gUz6I/B8AhkSEuK5dZgMqY6OIEOJkc1jZnPohkniDifllEl8mMEvG79NBzwhts+LZu3MZcwgs/jS/9+lw8hoBmOxaacR09eTGe5P+lUkIONLWSCbOyoGWA93w/ROnXkRFU2f4kW4sRi/mHrNcHmm9S5904z3CRrTW8aDGClDwtDH0C10K4udLUB9N7JSRfgmMhWiewABAABJREFU1bExgkoVnRARBEjNYHRoL740kC74pRJevcpEeZwFJx5PoXM2mUI7Tt3DdWoQHyw0Kp9UT0Z1iqdQw/U1PSsbIHcikilzOAbdp4ktOdGbeY6+kIl1Irfm6v9RJSklDz30EFKGrF+3nuGxSVzXZd68eXS1tzFnoB+AXC7HrFn9KnS242AYOsgQ3/cpOz5O3cF3XaxCBzXTpqplGB05iF8rM3dwALdeRfoefT3dyj1C05gzOEjW0NACj1mz6swdHGDB7H7uf+Rx9uw/wOyBWbS1tWJZNoauUSpOJi5yJ554IgD33nsvIyMjgHI9mpqEELS0ttLa3sHdd99NEAScddZZSZs0TWPx4sUsXboUgL179/LQQw8BUK/X2bp1K2vWrGbJkuPZtm0bw8PDSf/bmaziJrEsxsbGuPPOO5ONXEbWSZdeeim33XZbQmSejiw3NDTE0NAQAEuXLmXJ8UuQoaRQKPDkk0+yfv16Zc0B7N+/n71793LeeefR09ODYRicf/75LF+2jOOOO66pzQ89/DAPP/xwYiGlaRrHLFzItu3bp7jYzZCEaPBXCsHChQsJg4AVJ57ImtWr6e3tZeszz1CplAl8Hxn43H///fz8F79g8Qkn0jM4GynhgQce4Omnn+axRx9GW7Wa1kWLaO8boFL5/7H33/GWFVXeP/6uHU8+N3YOdCA1OQkKShQVsyCKmBVRZ8YZdWbMihgw6ziI2UfFOKOizjiICJIRJOfcgY63bz5pp6r6/VF773PO7duIzzzPM/j7dr1e3fecs2vXrrzW/tRan9Viy8QMk+M7qFUqjAwPMzI8TBhFlHwfhEYJTRKF+LZg4WCdiQULKfgekxMTDAwMUEotbkqlIoMDg1gIWq0W99x7D8c+4+nUa3VWrVzOsiWLGKiUGRmsMduY5bENG1mxaJSBepXRoUFuu+sBFo0Os9+aFWzbvoPp2SYvfvGLuf3223nssceeuJ+eAqlWMxElbcdGa43nuqlsVCiVktsnhqDZRJkD2zFWTkkcGxcp1wHMQa7tZJZRMt3HBLZt5XxJlgCpFGEY4iMQbspbmnoCVMsllJJEgYWlJTI2Fiw6PdA00ec05JyiFpZt5S5UWSQss88bFzcbK9UhjU5n2TauZVGtVrFsmyiKCcKwR3fL9FqRHiKa5xqHNYFr29jCWDxlbngZoJS5v0VRjFbKcLJBzh8lICVcN0F5sr61LMtYQplXFSwEMj10lUlCohRJotID3+xZGdCsUrc0kZNoG3c3z7TJdowI1IJCuYpXLOZRtIUwIBiYA1cpwHcdPFdQcEzMvChOiJVC2y5uqUp9eJTBkQX4xaKx2FKaYrGM9BIDkIUBKvHAcXAKFRy/gFcsYWWg28wMUaJI4oCwOYOnFcXaMDhOfiAv0oBMYRDgex5SmvmXRf2LY/Msz07dEDFcX4mUhHGMcgytRqVSQamUMypJiBOVuhX1EJnbtol46LmEbkQijdWcJQTq/2uK9B4deo8ObSr9/ykd+kkDTzJFAA05N/O+fOfuTulpR+6+1FvddPPtvSf7a0CNXS2hMlBHKZlbE4kUwJFRgJYRaONnnQ2nyAzQ0lNJ+p4JZuBIEZ1uYzI3MoMVaUQa4iwDXPosj9LNoNeCijT0a69bnMYI7GzHVjJCJhFx0DAEgVrh+hUcr4Dj+ViOlyqSDoa4y/jR68yyRvdEE5wjtJnT4znWJEROOGaswHrGbe6izCZ9+nsmWK00HC1KEQcdWtOTTI1tZ2L7VjrtFkpJKrUKpUqZ6kAV1/ewXTutQFo3rVCphVO72SEOE4JOlJo0m0oYAS8QroOMEuLZWcSm9UTNBm6hgDWyEKtkgWWjU7Nz8nbS/Wz1j/ku3Fh6rjVaz6RO58Z8PE86+6KzsRXmxOEpnnbxQd9dlbXuz9D7Xc+ZK3/mGeZHdovMaboba6+P9a4CbJ4bd3ctTVYuOHe5ZZdvuZDt29x0z0UxN3P+WfUIhH4seBd1gN4dMdur5rOy6N6h563u3GflK0CA0hKZSMIwQKIoDw+zdHGNekkwNaMZ2/44YRgyPFSjWC3h1YtseuQOkAJPlLAcH5EoonbA8JJ1LNnnaVhOAa1DpAwxanp3tLoCrafHMlfi3rr1tkt3r+0CFOveMdVzG2k+zmf9Mc8k6WL1Iq13r5A2Y6HT+v61wMdJEvPP730vp512Gj/90Q/56v/6IeOTU/zsOxfywmefwPNPfhaJVEzPzjIxNUO5WKRYLLBi6RIcSzA5McFl193MXguHWLpgmGWLFhC6RSaiEsE9t7J4dJT3veOt/PGG65lpt/nbN7yKgUoRxxKsWrKAlYsXoA89hFOUcfcRQvCZr3ybmdkmv/vpN7GyQBvMP6s//OEPc9VVV/X91rsPC9vpy9vpdLjhhht6rE/h9NNP5+Mf/zhozU9++lNe9apX9ZX3t3/7d5x00okccMCBNJvN/PeBoWHWHXokpXKVBx98kDPOOANEFv1L8ZEPf4gf/uBiDjzoYDZt2jSn5v1Kz5lnvpwPf+hDICwuvvhiXvHKs7j+uus45ulPz9u0cOFCfvSjH+VE3hf965fn3Xe/8IUv8NOf/rTvtz/7kpDpHcLCcT2s1C3qM5/5jCGinpqiXKmwceNGwnbTHNx4BeKgxe9//3v+8Ic/cNNNf+Tww4/I+/SSSy7hVWedxQWf/jTveOe7eGSyyc7xKca27uBH3/gia1cu42v/8kVe/YozUUoyPLqAKIpptzvcdvN1jIyMcuTafdj3lWczPj7O3XfcznNOOYWhoSHuvv8hli9ZxAH774eUku//6Cec/6nPcukvf866/fblo+95FwBREPDGV5zBz664nv+45sf8zateyrJFC3nDmWs5++3vY8miUS769Af58te+xc6dO/ndf/6Sf3z3u7jwwgt331dPkbRyxQq0VujUTUspAzTFcYzW0OoExEliAMgoRiMQjkTHCc1mk51jY4yMDON5JoKaYxldeLwdYAtwHZtquYRtWXiua17m6eqAlmUhlAGrHNti4egwWibMTk3QmJ5KSaD9fF4psr1WYDmOAbQcx4DYQBInpg1S4pJ6FNg2URihhQQEjmXjOA6DpTKFYolOEDA+PmFIy6OQUqGQ65YaAxApqZEWSCx818URGgeN5dg4toVrCxzbTjmdLIIgJI5jPL8AuutiZ9sWfsE3gJGWKU9RglLCAHspN5VliZRE31glJSn5ty1IeZ18HNfFdV1kEiNsG9d1uwegSlMsV/BLZUJl5LzQmtrgEK3JMSSAZeO6Dq7nESOIowTbdaiXClSKPiqRREliIowKG9f3qQ4vYvHyVSxathLP8wik4agqpPsJmAiXMpFQrCCKJbTrobwCju1jF+sUZluIoIMVBcSNCRwdUxkaplwso4RtLLsSw48bRhFhFBGEEa12O+fHajSaZr3XDXG9QkMYEsUJnTBMXfN8FixYyMTkJEGnY6yxtI0lLDzPw3MdSgUfy7Io+D6Fgk+73TYAqlAkWpFZUz1V0x4dejcF5F/36NB7dOg/n568q132wq0zFzbyRaUh533qXu+3eJqPDyprZwZGmc96l7bnQBEib6zxB45JwsBEk7AyT0dTWys9YQCRg2V5vXqeB1m9RL4piHTy7TIEugdQykEIA7T1RvUje1aPi5rIB0ehZIyM2kStSaKwYYCoQi0Fngq4hTKWU8Dxy9hOCRMIltSyS/X0NTlBYhfAM5Mwt93ZxZWOXYGmtD29LmuZT3wGbxmlxUagkTKmPTPJ7MQ4M+NjqDikWPAYHKqxYMki/GIBt+Dn3oKWrXFsQw6ppEzBppDpiVnCTkSnFSJlD6gmjGLkuw62Flga9MwMUWzIMgejkNLQCIXB0e4+lw/SHIDoCRHd+cxAs2XV5dvqjmtWJvlc3wVl/mtP8y+++a/tcutf3hP9r3J5SfOUm62lbp7ezbhXaHXHaN79dt667l7QqXl+69YgE3dPoBfMuSf7f3dCuL98U4U5SsyuBabXAWEsH5Axj999KToJcUYrHLzPqwgaUzx082/w9lrAVACPrX+clSXN8oWatSuOYedkm/WP72SvYZe9lizh0GNPJUw6RJ3HuPvqLdQXrKY6tCx/ptYKRX+b5h/PJ5sy//HehoknVrr+7JzTXT1vnv7Ld8rdnP48FZPjuJz/yU9xxOGHEUUhpx5/DO1OgJKSO++9ly3btvHck05maKBOuVhkw/13YDsuC5auxC8WKRRLvOCUZ1H0XGSS8J2LL2bx0uUcst863OGngVI89tAD7LVqFZ0w5LrrruLwQw5hsFbjzW8+h9NOex6vf8Mbec9nvsXyRaP84xtfxkf/6W9JZJKDTtk+3Nvj11xzDc9+9rN3caEbGRnh29/6FuvWrUNrI0uvvvpqPv7xT3DnXXehpOTUU08lIwX/yY9/zD777mtu7jv0gf32248vf/nLHHDAAfO6Xx12yEF8/BPnsWrlCu66a8pUVamuRbFWuI7DG159FjfedDO/u+IPPXfPIzRTl/VnP/vZXHbZZXzt61/np//2b3zhC1/g/e97HzOzsxQKhfx+YVn87ne/64uGB/DiF7+Y0047jXPOOYcoMtEGzzrrrHmtnT70oQ+xZs0a3vKWc43rDpJEB/zm17/mOY88zIUXXsjatWupDQ5ywac+zf33P8All1yC63q02i3e8Po3MDmZldvtu/POO48XvehFvOUtb8ESAt+22XfBAGuGKqi9FnHkyo/y+LYdvO+zF/KK5z+bWsHl7/7+H3jZGWdyyqnP4eDDjqLdbrN+02baCfiex8knnsjdd91OEAQ845nHc8+DD3PVTX/ipc85hec951T223df9lqxnO1bN3P1FZexw17ATCdh6+1Xcuxxz+Rd57yGX/3yVxx28MGc9rxT+fx57zZh3S3Ne9/990RxwnSrQyf66wjDvmPbtjSql6RULiGlotVqUa1W8HzPEDQrE6zEtl2EbbiOpDb8OmEQEAYhWkOUaLRO0mAtAtdzKRRSgMS28VyX8YkJwjCkXKkglSaKYzzXQsiQqB2y9fEOWibEQcuAF8LC0haO7+IKYaxZUkoCK9UHpZIIlUah81ziWCClAWwcx7i/paq6AdBSLqdEmchnOn1BjWNDYu47No7t4BeLhqBcGD1RSY3UGI4kAUpAwXZwbYtywaPoZ8+yDADSCSlHEWhjvaN0gmcXKJVKpj+1plarE0WGB7bVbFIoFCj4PrbjGFe4TkBrdhapJLbrUCgW8X2PUqVC1qiw0wEhcNKocDoFrFzbUHoEQZTqzxDGMa0gYKrZplAt4+ki0nLYOj5NEMWsGKlRcGzKrk0zkajUdY1ikWJtiBVr9mFgyACNrWZqsagVrmd4s6IownJcbMfD8wsonboizjSMN0gSowpDxHKWZjvBERLZaMCmR6iPLqZQrlEq1ogdm8RxGRyo47qG20lg5pXjuvieQ5KQAlMxiVQUtZW7D1qpVVqn0yGJY+PCNzREO4gIopiSM2C4wGybRqNhAEutmZ01HE+O6yG1Rj61cacnl/bo0HNy7tGh9+jQ/ekv4nhKn9LXgLnmfpoMdJk/j/meFfQEiPGcvHnDzS6PTDJOJ4UlHEQWsS6tSQYm5U9OhWYGSvQu19SBj5w7KW9vb711z99dUdisjnOvdV3wsnZotEoM+BS3kWEDmYRYWqITHx0XQMc4XtmEhLV9hJURj3dRXgF5ZD2xG4Rcs5t11jdm3beD3UEoGVBnWcK4CMYxQbNJ2G4SBW1s26JQ9KkP1qnWa7i+B5aFTP3mhaWwLbAFyFgShRHtZodWo0MYRISd0Lyo5KCgWT6OEKnlnGVOBNttWpPjFOoDWLaDW6kZxcyy59Z4l9H58xua2M3nbkf2dXMPCNkLwv41pe46FL0/zM3wZ8qYT8DR9zI4X77eNL9g20XMPakq6p5Pu65eMSfHPKnHmnCeS7utV3f9Z8/ZTdK9H+YhQ5w375zvAmOJ2f9TCkCDJWyEA0mngYwjEr+M9iqIgsT2HcrlQaLIIdw0RiIUCE1teAEN1STZGUBB4VXLjC5fxuZH76I1tZOEAuX6YmzHM3uv3rV3e9vdZxbc229zTwB78vccrey+7b0/zdd1PfvernNF94DpXWXsrwNu6iZhCY468ijW7b8fAGtXrcxBlk6nw+zsLEEUImyHMFG5NUUUJxTLhix2YucYixctplAsEgQhlkqoe4KxtiKJQog7FCpVwwmjZL7fzc7OEAQBQkC7ExCkpNUH7b9PPvwb1m9gfHwnlmUhk4TDDjuU++67n7GxMa644opd2yMEtXqdqekpbr/tNg448KA87z777oMlBFdeeSV77bUX+++/P8cffzylcnnevqnX65x80klsenwz991/X5+FMsDQ4CCHH3Jw32+rVu3F0NAQAIuXLAEhKBQKeK477zM8z+OAAw5gyZIl+W+u6zIwMECn08FN7zvgwAOJoog777wTpWQ+MW+88cZd+uHNb34zRx55JLadHjIpxYYH76VcrXHE4Ydz/wMP0G63TV8fdBCHHnpoCvKl+6LSbNmymW3btnLTTTehtWafffYhCEKkUpx44ol4nkez2eSoo45kfHwcyxJs3LgxX8urV6/G8zxjFYM5/KkXPSzh4QjB0tEB/OIjXPL7a5BKoYVg6/ZttNotBDDTaBHFERrYtn071XKJvRaPkiQxQRCYl9Q4oROEbNi8ldGhQY59+jFs2ryVHdu2EnQ6dJyQdmQimVXLZRaPjuCmYIbveVQKJrqaaxtXnSAIuPXWWxnbMTbvWD3VUqfdMnxGKSebVIp2u02lUgYhiOPIgD+WwMLoPmA4S5XWXWtCrZFaY6eAUMH38DyPgl9AyxiVKlJhYNZopVIlkTEykbiuAqlIVEI7DgyxtkytqzLdK+VnEokEofLNVKfPVplVT3ro2z20VLkM1eg0wItx5VJKGUsiqbBsy/Bu6jQisCXyYDTG3U2iVILWmihKSAQkAkN2Dviei+sat63M7Q0w4JlWaC1zSybbEmhpPCp8z0OgSZKUaFzKnkNZjZSGX0sphefaOVjiOm7exkzf775taETazlwIC9NbURQShCGdOKbougggkppWZIAylEJohWUUYBQGOPIcD7dQpFypmkiDMkHFWYCiVPZr0r50sCwby/WQUUwiE8IoTME7he2V8KTGiyXEbTSSTnOGcrmCSt3zhLCwHMe4JQqIkzgHA6SUOLbp9yhOCKKIOE4Qjpf3iW3ZKGWiFuZ7bvYOpVXqHmp4YMIoyq/HiTR9b2XRx/+69Og9OvQ8aY8OvUeH/jPpSQNPlmXTN+G0NicfqbAywofcZL2vomRgVO/y6G6ec/eauQOSWxppY22j4ggtY0DjuC6Wbaedkfkfm5PIXeZ4z/N7F4BWGmEZ/3ShrVzJzlwFs3qaIqye4nomSSZ0RO9DNRnZuDlMNdZO5l+IjDvIsIGKmoSdCeNeZzt45TpusU5RLjKCzymB5XUtnVIwywBO/T68INJIgN029NY3d4eka9mV3m0Woy36+kxjxj73pe8EBM0Zpndupz07hYoC6vUqtcE6o0sWUq7XwLIIw5hExqAltiVNtDilaLYCGjMtJsdnmZ1sIBOJJaBYLOB5Dr7vmnEQRvFFAUoTRyY8cDwzg3h8I2FjFrdYxKvWcYqVfGx7rZOyHwRd/qjuFdG/sHQGiut8rgohjMDPdqO8R3qmFKQEkxZ/NWmX3eb/zKv3fAJgV5fZuY+fe8/uBU7vfbsCw3OeRaYe9n/f3ZP7t/1e/+uMryLLt2sbBeQRDueWK+YVtPOV8ER5nqQUAXSSYKc8aIuXH8W2h+/n0Wv/xH03b0JqCZ2EwWUFRvwyo+UBRLvJ9OMxw0MFyrbLUA064Rhbt85w8xV/YMejtyLjgIOfdzalgVG8UoX27CRKy932R7d+uwrT/iyZIqR78gsyd+XdNVf3/dAPEvfv1+k+2bfOdf6U3t3zrwd9Mor8woEKCwZraK056IADQIPt2KxduYKhWoXHt2xjeyNk80zIaUccShKF3P/oBg49oMy2rVt43otfyofe917OesUr+Ntz30Kz0WBiYpyvX/wTKtUKp518PI/fdjsl3+MlL3ihcSuxLH7/+98DZv194/y/T2skTHQnDA/LBRd8ku98538hLIt/fNc7uerKKzn8yKN49NFH523Rzp07OfnkkwETTv7OO+/M5fNXL7qIYrHIcccdxwc/+EFe//rX/9m9VgOfuOBTXPyDHxKmYM0TpfPOO4+zzz47b1e73ebr3/keGzdunDf/4sWLueqqq6hUKvlvl156KW984xu56qqrOOaYY/K9buvWrRx//PE5aARP/AKRJd91eMfpJ/O0E07l6S99Hcceeyy33HLLnIZ2y7FsO38JfP3rX89JJ53E7373Oz7x8Y/RpTHokpajNYlMOPbY47j99tsB+OlPfsy6/ffve4Q3h+x3xaIR/u7M09hr2WI8v8AFF3yaFcuXI1TC+Z/6HE8/+ije/LpX85Of/4Iw6DC9bSNHHHU0hVKFS6++kSMO2p+jDjmQd3zkUzzjiEN5w5kv5RNf+iqjw4N8/H3vwrxIKILO8/nTnfdy5fU38U/v+nuKhQJSSt7yN+9g2bIl/OTi7/He932ASy+9FLR8Un36VEiJlESxie7lej5KKWNFEoYorWl3AgbqA5TLJZLIcPSAJohiEBZDwyOGkF4IZBRg+S4F32O4UsZxHBzLYv1jj4KGarVCJwiI48TwPMUxcZTgOLaxhokjbM/FsW3cQolYakOKna7nrs5kACTDxWNh2zaxNG5rlm2bf5ZFFEU5R5nZYA1flLAkWihiqWl3OsRJQqFQxLItE8XOslC2Y1xFMaCrlBE6BYYazZA4pWJwtMT3XCqlAp5fMK6ESlEpl3BsmziO88NL3/dwbBsZh1iWY3AN10YoGxtFotPIyjJBC3OoqpXCtgSO7VCplM17jZLEUZTr/hk4HEcxtmMAOFtGxJ2OiSzoVgwtCYrG9CSNxgztMMDzisRSsWOmxcRMkygICAcKRI5FaFsgbBQWsYJqsYxfKCETyczkBO3MOqtYwvMLRJFxiwuCkEq9jmXZxFIZN73UG0QrM5q1eh17eAjb3ovxHVvoNKZpT22nM70THbVwtYVVKGM5Xh7EQGkolctIKWk0GoyMjmLZJTZs2pyCyDFhovBcF9/3KRYKaDST07P4rgGvdoyNEcUJUiqq5RJxktAJIqamZoxro9I4no/n+xSKZSPanuKudnnao0Pv8uQ9OvQeHfrJpicNPO1SqiA/aTATOGtov0vdLhHdmIvkZpYj/aDQ3DxoUtNRcyJhgAkL23ZyIMYgJyIHA7QG1Tubc3CG9MSm5wlad0OqklWnW69uxLesDfRbumidhjJMeyF/pkJrkbrEabSWaQS+GK1ihIpAhsRhMwWEQMYtVNTGFmbRWW4Z4VYQlgfCwXK8fDwyXiQzMUTP801ZSum8inmUv5412AXYskh2RtnIxkQIQwpo5HNCuzFDY2qCxvQEUdBBoClXK5RrFUrVCo7nozXYtsK2UkJKrUlSpafV6NBstGk12igpsW1BqehTqaYmzeUCtmNh26nrotZoqWk3QqJIEoQJrXabBHA3PUZ14RJKQxq3XM25qPrmTTYzLKs7ZmnfoEmJz00YSktr04dpGSrlNhApqbwlyPukO6PS3/5a3lz/AgV9V4GXbXLz599tUIA55fUtsTnr7Ik32m6Z3U1xN3Wft9TufADjv67SbUOjSTnw+wRuL+Xf7lKWP/vbyznWU9mesua2da5CQH++uTIz29J6bsqeKGwLJWOisGlOuDsN5NQWZsMdxEqgEHRm78eybQbjBEcoImmx/p47SKSgEmoECbOTs9z40GaGhkqMLFnO4rWH4RbrxCkn3W6FpYaMFtbEdM3kQneffMJezGVJjwFyz5wSpKS2+RwS8xTdP892+R0zRkKI1H0kixL617KGzZ+77ryTC7/yFd7xd+9gaHiIL1/0NZ590okcfujBtIOQcq3O8iUW2zdvxHFs9t5rOY4lGB4c4rOf/ASrVy5nx7Yt/Pr+9SyoldhrpMaZzz+VYrnMiqWLCReOmJdS1+WHP/whd915J+effz7X3Xgzv/rPS/nw+/6RLZs3c9FXL+Kd73wn+++/vzn00IZ/EaW49Le/Zfv27ewcG+OII47grW99K5/73OcIw5D3ve99JOmpvO97/Pa3v+W3v70MDRx11JF885vfZP/998e2bb7xjW/wzGc+sw90iqKI8847jz/deht+ucbZL3kuTz/maIQQJHFEHBqXmBc8//m8+MUvRmvF2jVr8/vXrFnDN775Te677z7OPffc/PckSRgfH8ctlCgPjPA3b349K1csA+Bb3/oW27fvyEmOs3TMMcdw0UUX8fNfXML1N97IP737XXzzm9/iiiuuIAiMFYDv+3zkg+9leHgU4XhccMEFrF+/Pi9jwYIFfOUrX+Hf//3fufaaqzn6+a9gn3UH4TgOH/jA+7nuuuv4/Oe/wNe+9jX2339//uVf/iXvj0yGK6n45AUXcN9993HOOecAsHDhQs77yEdwXJdOp8OHPvQhDjn4YF519qt6rDjgq1/7Wu6qePTRT6PdavG5L32ZifGdBO0WH/zgB1m4cCErVq3hloc2MDXTYGlJgJIUi0Ve/+qzqFUrjE9O8vxTT0UIWDw6wpXXXMtMs8WzT3k269dv4MY/3sRZL3oeC4YGmNy5g5c99wSq1SpCCH516eXsGNvJEQfuy1C9Sq26L1/48oWMLljAvvvsy9vPPYfB4SEmWwFveeu5vPhFL0QI+PGPf8yVV175f3ad/V9IjuuhMftwqVw2elpq+ZHIDmEYEUQhlmPTbDTxXOM+1+m0DfeTUjiOi+04+ImmWCxRKPhYKaF1LCWtdhuBoFAs4hUrOAXwS1W05RJ5MY4tzBZrQcH3DVeU4yJiQ1yduZ1qRGoBY+a5TPVjG3Jy8TCKcB0HSxiiba0Ngbc54Ez3WiUBCwuwbQutDVjl+z6e5xFJE+EpUgpHK1ASlEx1QEHRV4goMZH6HAfXdVL+qu4rVqVUwvc8JianTF0cm0KxBEoRttv4pRICgYoDtIwRaGNlphRaJigMgGU7dmr1J3A8nygMiaKEONG4rofrughh3i2iKMYDBBohDUimtMa1LeKwQ9xp0BzfStyYxBeS8akZmkHM5okGrXaIrRSddkhYLBBLjeXb+J6inDjYSOJOix3btlAbHKJUruA6DnFsAMgwTtBgCMcVRElCu9NBJzFaGmsvnfHSaoXQNhaCcnXARJKLAoKwSRQGFLVFdWQJxYFhtO0QSQOE+oUCUiZEYUgYBDiuZyL7eeb9Y2JyGpH2PRgruFgqXNfo/GEQpiCe2Y+jKCEIQ0aGh3MC/DCRxiJXSZI4Mm6MT/W0R4feo0Pv0aH/Wzr0k49qRw/QkoXTFIa4u/ddvxc02mXhaE1f5vkapLtgSI6yaVKlSqJTniMrDfEqLKs7icgwqCxyR4aiprUX9Dxf5ROtb/KmeUXf0snuyQbWfO6zeKJ3kXRLSqV4ftVwNCUolYCSCC0RKkaGTRJpIkdojPmt63qAjeW2EW6E7VWw3GIKPInuYk/rloMfPbOl+/h+48det0Lm+T0bKjO+ZuLLKKLTatKanabTmCWJQ4TQ+KUChVIRr1BA2DZa6dRH3NynEkxEkTih0w4J2iFhJ0wJLm2KJY9yuUCh6FGulnBdB8e1u8CT0ti2RacdESWKKImQLUVjbIfhxPKLuMWSIRMXgswHsa+9QuREuOYkSKeLz4BOQpOe9tEDvPWAdmAssegCeF058lfC8/SEm8L8G3j3Nz1P3t0LrSfzyL4105O3i+X++V7NLCPmFqLTguY+I8uauaf2Qoa9gu8vGdPd1bOPS02nVoZzAOxdGiN2demc1/x8V4kAAizLQcoIlSREQROVdPCsBBG2kYkg0gWixjSW0NTqdbAdlBBMjW3FFja+5aOEQ9AJ2bZlG/WBQyjUFlIeGCWRmjgO0kfNs3/oXkVDd2Wg6K1u2gfzKmSC7nGAoGck5/Tp/PMuI9ic+1v3Od35ojEHJ5YQPUcmfy3J1HRsbIzf/va3nPXKs3A9j6uuuZYjDz+MWm2AqZlNVCtVhoYGuWXTQ/iFAgtWD9JstbEchxc+/zSmJ8cZHx/nnoceY59lC1g+WOLwg9aZiKSOw8QEqRuFxb333ssVV1zBBz/0IdZv2MjlV1zFu9/xdnbs2M5vL72UFzz/BQwMDCCgx7pHc9ddd3HX3XezYHSUww8/nDe96U1cdtllTE9P87znPY8ojkkSSaVc4rH16/ntZb9DAKtWreJNb3pT3uI3vvGNTE9Ps3XbtnzPDYOAK664gvUbH8d2PQ45cH/W7bOGbdu20WoajhMhBGvXruW0005jdHSEOIrZtm0rw8MjLFiwgDe98Y285jWv4Yc//GH+LCEEo6OjLBwcYXDRCs4480wOPsBYAv3hD39gy5YtbN++g4ULF+RWT2vXrmXN6tW87IyXs3HTJrSGO+64g+uuu44FCxaQxDEF3+OsV7yc4ZEFzLRCvvrVr+J5HsPDwwRBQKfT4fWvex3bt2/nkUceobZ0DdKvsG3bNp72tKNzd8rbbzecSZ/73OeIoohGo5HXXSnNVy66iLvuvItvf/vbAOy999588IMfpN3psHXrVn7wgx+w/ZRTOPHEE82LbJquvPIPbNmylc9//gtYAqYmJ7n66qt46KEH2b5lCy9/+csplcoMjS5g7Ob72LxtO8v3XkSz0cBxPY57+tHsHB/nsfUbOHDdOlzXpdlq8ciGDYyN7eTMl76UWyYmuO/Bh3nJ859LHAZs276Ng/ffB8/zmZyc4t4HHmLz1m2sXDzM8uUrKBVL3HjTzeZzpcaxRx9NuVqlEyUcdthhuEcczvDoAu64886/CuDJ6G02lu3g+b4BD6REJV1rISklYRTTbLVNNEnHWPJIpbCEZYAn18FxEhzPxfE8lJSAAXzjODFR27TGdn1sy8bxfByl0cJCqNhYLgkH3zMgluO4KEBKRSJVuh1r7JTGQAMyiroacbpnJ1IaXS8FEqSUSGXAZBCpq65GiLTulo1wDTDkOCnRdmR0+kQmCJ0gMoDLsrAcm4KXeT0oHNcQmzu21Re+2/cNt5VWEyjLwtLguh4yjgiiCK9QACHM4bVKAIFf8JFRRBImOQWMZZuIg8IyyFySSOIoJpFGPlm2IXRXykR0M9HYwFISpY0+adsWYRwQNKbpTI8jOw1cFM1Wh+l2xGwrQGiNaxluqihRJFrj2wJX2xRdB6ES4jBgemoC23ENWFST6R4gSKTCdlxczyNMNHEcEwYhFspgij2WMVJqEBJhWbgp+XpYqtEOWkRRBzEzQblSw5I1HMcmkSlvbMYnqzVxnKBTknA3dcfbsXMCrXUOEIo0RKCwDMiIVggtsIRFEsc5IFmrVbEtizAMCRMTQVEplUZTlP/XV+B/K+3Roffo0Ht06LyG/7s6tNBP0kb5jtvuyq2blM4sg3SP61kPCJMLhLQj0lO17P7eU8uMzLqX8Ll3jgghjJWTTEjCdvpMkbt/OY7dJabOQBLRJRanb3CzDtJomfoWk1ltkdc1A1zMRCcf9HwRpBjWXF/cDDTrfV7WZtt2SOKQqNOgM7udJJghbm1HtSeQQYPm1HaiKCROErxSFc8vUarUEMID4YJTxa8txqsMU12wBmGbkxcpkxwMyTcMnbnTYforg6ZEL0TVX/dsLLqfjXm+ZZvTMJlENCbH2PbYw0zv2MaWh+/HdgSO57B41XKqAwMMDI8YLgIpSaIQWySgE6IgoNlo05hts2XjDjrtgE4roFYtUCz6DA1XqQ2UKZZ8qgNlPM/D8Rwsy3Sq1oqoE9JpBoxtm2ZqOiSMFI7lUh8aojo4xMJ1h+KVKzjFUo7kW2kI3WzO5FNCKzLOqnyha/IFK1M+gmx8LZFG2oOe8bRNP6bzXGs47qRj5107T5V0x213PcHVJxaa3WtzN7tdf+/P/8R1yqzJTN5dTzH+XFl9z9W6f6vtcYvt5kl3hR7hmq1x0fPovwRK7K1DJsPz0rNN+ok7tb/J2USde89chD+buNlly8Yr12hNbaU5sZFHb/4RtYERVqw9nJlt40yOj/HAA3fQUDWC2GZm52YWj3gsGPKxvGFmGjE7xlrUaDA4OMA+hzyN0kgdu+Ax02pSGVxOZWAZ9ZEVqTIa9LY6Vbz7+65vb8ysM6152pb1WFpGfgJDz9pLI2KakxbDfaJ110W2r/t6yuxaOvbKFt212LVN5bXWnHDqCbsMz1MlZX3pui633347++yzD61Wi04YoTWUi8Ztodlq8aa3vZ3jjz+B173u9VRcmygKmZya4u5HNrF9bCcbH32QE5/1TA4+4EAKvkckJZ0oYeOWLdTLRQ5Ys4qXvvSlTE5OcuWVVxKlvB52oWgsBJKYcuqK0W63efXZZ3Pd9dfnwFMOaAhBsVjiuuuuZd999qFUKtFqtbjtttt4yUtekr9sCyEM15QluOuuu1izZs0u7f/bv/1bfvijH+Vzp1Ao8Lvf/Y5bb72VN59zDgXPM5wvtt1XB9/3GRwc5I9//CM33XQT5557LpdeeilHH300AK997Wv5wQ9+kD+nVCrxxz/+kRUrViAsi1LJRAkDePWrX81PfvJT6iMLed8//yP/+K5/6Ktjq9UCoFwu0+l0UvJvePS+O9j0yAM852Wv4pe//g/e9va/odVscvTRR/Ob3/yGv/u7v+Oee+7hhhuuBwQT4+OcfMop7NixA4BidZA4iZnYvoXvfve7vOxlL6NSqfDRj36UL33pS2lfW2A5NGemkLJLrL733ntz1513csGnPsWXvvQlGs0mruNQKBRotlopaGF4c/bfbz9uvOlmHl//MJvWP8LAwACX/Oo3fOIzn6c2MMAppzybf/vpT4lTNyiVRHzsExfws19cwpVXXM6ll17Geed/jN9d+p80OhHvOu8C3v/3b2f5kkV85ssX8fIXncYJxz6dG26/hwceeYx77nuI55/yDGanp/nP31zKu9/xtxx2yEEoKfnGD/6dK6+/ic9+4F0sGBnGLxb4h/M/z+jwIB9+x1t47WtezcbHN/Pj/7yMT3zwfXzvm197Ui9a/5PpF7+5zISql5K9V68CIZiZmaFccCl4LvX6AK1OSKsT8PiWbQwO1Fg4OkK708F1bGqVCrbjECeSreNT1MolCq7D2I5teJ5PsVRittHEcWxq1Spjkw1iqahXy7RbTcIgwEoCSr5HpVSkWPCwbQfbcYkSQ3oexwbcEKnlUBa1N4wipDJ5nMwtTso8upzvusSpBUsnCAGjJ9kpTYNr29ieh7AdJCKNMKeQ0pBqayWxVIzQBvByHEOjoYUwlpFKMTI0YCzoo5CgE6A1eMUSxVIRgeCxxzYYHd62WbRkEXEUMTM1zdBgHUsIOs0ZwtCQs48sWIBOFDJJCBMzJnEc0ZidJYxiOlGCjcaxLSrVWko07iN0QhxLgjDCdSzsDHyyHSzbwS8WGN/8KDs3PcKme/5EY2aK2ZlpdnYSIiy0U0IlEp0kJM1ZRodrjA7VGK6Vcre+qQiUU8Crj7Bs5WoGhkaoDY7kzyhWa1i2A5bD9EzDWA0lBty2bQuZGCL5WMrcOtOywHMcXNumVPCYnthBa3aKyW0bKFdrVGqDrDnwCLAcIilpNluAsZybbbaQSjE4UCMMI8IoZHJ6Bt/zqJWKDAwMgLAIk4RSsYgtLOKgzeYtWxjbuROlNJVqjaGhIWrVKnEcMzE5Sa1Ww/NclJLYKbfZM55+zP/oGn2itEeHZo8OvUeHzq/97+rQf4GrXRfp6m1w1yWrJ2MOzMy9X/f97eYXu+bvmbxKGjJu8+JvpYBIl3ixiyhkczTjL0o7rRfDE2BMXKwuqkj6W8/AzV24Ir1Pi948u7at755dmiNSUMz4tWe/ZxZGSpkTpygMzSmRUsa4TDhYXoDllLDdIlpJQ6jduynMD//mfdgTn85UQ8/PA5W1pddUUUpJFIY0pqdpTk/TnJ1JQ8o6CFtgOTYiPQWSiTm5QBvLLbRGSkUcJcRhTBzFKKlwbAu/4FEseRSKHoWSR6Hk4xc8HMfGdro4utbgehaq6FIbKBInCqsdEXQiglYDC2ju3EYpGaHkuGDZxhxa9fdLZgo6d4MU6QBnc1BgwoRnU8Is2GwOmA9aKfQc4OmvP80VFX/+NCYHZ+e/9CRu390z5grxFPbvbgxPKNgyYLiL3+v8ytwn9s6F3ZS02+fMm7t3fomu6/BuSSN72tT769wa9AoTMfdiWo5UEsfxKBRryNCmOZ2wbWuD9mxAO9R4pSpldxEicdg5PoZMQMSKgUWLSTyJiGZpTbcpCpvS4AhR0CBuTtNqtShXFuMXSqmAUfkYZEOo+0akKyzNX73b6bSL0tHXPoGdCjeUBsusRcs2lq5KA3L+sjJha6XHMRqwRXY62yOPsnrPdyr2FE1SStZv3MRvfvs7nn3yiQwNDXPrvQ9SsEHohNOecyr77rMvniX491//F5VyiWcecySDJRcxWGHh4YexdPFihCW47No/smzJIvZbs4rFI0O4jkMrSnjeac8nSF0fbrzjAdY/vo0zX3gyDz66kVvvup8zX3AKY9u3cskvfsGDDz7I7MzMrhXVxs36xz/6EcPDwwCcddZZrFq1inPPPZffX3ElGzdt4uyzXoHv+biex+DgAA888AC/+tWveOUrzsRxHH74ox9z0003oaTkzW9+szl5d12WLl3KffcZEvF2p8OSJUt49atfjRCCRqPBt771LcIwZGJigosuuohyucxb3/pWFi1alFfxBS94AUuXLs2/e57HsmXLqNVq+W9btmzmhz/8EWvWrOGf/vmfsByPIw4/bJfmlntIz4vFouHjAVasWkOlXEYhGB4a5KRnHs3K1ftQqdb52te+xqpVqzj44IOxLAvP9RgZHeF1r3sd1113HZdeeintMGbFihW8+XXv4fDDD88trYIgYCbvd4GwbV776lezaNFCAH75y18yPj7O5z7/ea666ipmZ2cB46aYgWIrV67kla98Ja5jMzo6iuPY3H7n3Vx26W+o1we4/6GHKZQrtJot7rn7Lj7z6U9z+ukvY+3atYRCcPTRR+N5PpVymQMPPIA3v+kN2GhKnsOZLzqN1SuW4Lku5XKJ8YlxHnroQUbqFQ7cexULhwZYs3IFreEhTjj2GUTNKe69/RbWb91JteTzgpOfxeBAnU2bt3DP/Q9w1EH7s3TxImzb4jnPeQ4PPvww37zwX7j7jtv/ovXzP5VGRkZSfp4Y23GxLEGtWsUWyoCmloWTRqSrV8sUPM9Y9gjj4pFImesdpYKPYwuUkszOTFMslnLrqOwgdbBeBSEoeC6WjLBVjOUWKPoevu+DEMYhI4/6ZJnv6cl3GtYGS1jGpU6lPKGq6zFgDpZ7iLeFQOmUF0oZ1zPbtnFtO7fGMYemEpmklv9KoZUkTIyVYtnzUVoj45hEShzXwfdNtDWllIl2p42GaEjLEzSGoDyWmljBVMtE0FO2R6KFYZoRNpbj5e8SShgdQaayRGOD7YKt0SS5V0VG5K9UYjihtE5J+M1BaxQnaXQ5heuZ4AK24xBpi0gLYi1YODKA7RdwS3VmZlq0Wm3GO01CqWgGkeFGwlBLKKnBVni2ZeQfGGsg28nrpLSJ+KdkguFSTWWugiTVT7Oo12idM4kIS2C7LuVaHdtxCIMWWiY0mw2mdm7D9org+ExNTaGFoJSoFEg05OJxGnlxoD6Qu2Jnrp5SaWMxZ6WxzCwH2y1gazO/s8N527apVSsUCj4CmJ2dwXc9XPcveiV9CqY9OvRuStrtc+bNvUeHzmv4/4869F+4ys3m1d+8nsnYM6C7dgO5Jc7cSZO9+Hfz94BASuXcTpYQWLaVWzt1n2c+KPOQHsuWDDkQfbPMGDqJfBPMpm1f/TM53ANqZdZsvRND0M3cNYHrQj7mf5EhGghhGRJxYRtAluxfijxKkEGEjBJkEKCTBGE5OIUYrzSEW6yjVYJWDog8vt2cbsumQXeV7dLvwtR+LmA2F40XAmQSE3Y6zE5PMTs9RWtmBikTHOEYE2vbRKNQypgC6zRShwFkzKlWEieEQUQcmuuua1MseBSLPoWST7HkUyx5+AWna52ETvvWmPP6BYf6YJE4irCQdFohYbuFihOK27cgAL9aw/aKaCttpO6dWpl5YP+8ydue/59avSFysCrf8DCgkxTdfv1zG/hTJ/XWcVdYdJcsvTnmkYBPdALxxALzz/dVP/g7V/Dtvr97c+renClgmBsF94CK2Q7QOx96P+u5O9qf0wZ0fz/n+0qP4MytPrUhdM31gjlDlIGe3bp0/883up77VBLjeAVKlWFISsw2YyZntpLoEIhwvCrF6gJQLlKYKDi6ralVF9JxNHanRGNqIwUlwC8zs2MjrdkJsBwEFsVy3VgDpi8eil7QVXfrpPvnl+gdGa3Ih1fM6c+evVoAFiIVdKCEhS2UEaQZh18OLpv7pJLZVostBLbdfa5GGFcPYU6olTKnP4numSN/JSmRkgceeoRPfvaLHHzgAQwNDXP59TcxVBAsHCjz2rPOwvd9oijm4p/+gpUrlvH8U09iQbXIUMFm9X4HYdkWs40WP/vtlZz8jKM48oB98IcGiBW0ooRXvfo1uKn78uXX/onLr7+V05/7LO6450H+9bv/xrOedgh33n4773//+01ErUJht/W98MILjRxIYg4//HBOOOEEPvnJT5K87/1cfc01nPeRj1Ct1XIL6t///gre9773cdThh1IsFnn/+9+PbdusWLGC8847j2q1mpdt2zYF3weMy9sFF1yAEIItWzbz7//+70xNTRHHMZ/7zGd41dmv4vsX/6Cvbi996Ut50YteBGAImh2HMAyJ4xjXNdGsNm7cyEc/+lG+/e1v84ozz0xd/PUceUnPC7zI14ht29SHF1KqDpJIyYplS3jNWadzwqkv5p77HuT444/ne9/7Hi8/4wySKEIg8P0C73rnOxkdHeUPf/gDQsDa1XtxwQUX9NU9i/amdDeq2DnnmAh5nufxyCOP8POf/5wPfehDfffZ6QsjwH777cdHPvIRPM9YUYdhyI03/YnvfP9HAPjFEuVqnQDYtHET55//UfbZZ2+WLV+BcBxOPfVUTj75JBzb5sjDD+Poo47kofvvpey7/P2bX0u7OcuOnTtZsmQhE+Pj3HZbixc+/3nss2oZnuthOy5JHLNm2TJuvvb33PHYo9x0/ybOOvN0TjnpBIIw5t77H+DiH/8bX/vy51mxbBlhGPKqV72K++67l2OPPS53Q3yqp4ULFxKEEa1OB9txcB2bcrFA2Gnn88m2LXzPZTgN1KKUQgsLqSGMExylEZZFuVhAYCgQmo0GaE2xWCSKIjLOr+HBGp7rGtAi7mCpCMfy8TwX3/OM5Zom9QAwngIyVbuETvd2y7y0eI5Loqwu0KN1zuuklDKW4qmeaaKzGWsmrR1cQGsn3ZdT/UqbQ2VbJ9mpK1EsEbZD1fVIwpAkMhERK9UKvuumpNSmjkp0nx1GxrrR8TyiUBLGmqAZ49pQtDxiqbGFAZ4cN43YJwwPinEx1EhlyhSOh6VAWDGWnVpt2TYClfKzSkDgOBZCSaRUdDodhC1xXEmxaCJDup5PIlwiHGIEK0cHqFZrFOsjPL51nHHLYmLMIowlM+3ARGu0LBP9WWlcrSk4No4FltCpVZCxrDLAnSIKTXRvoVUuE2V62Isw0blMdGnMu1H6DmLZDuVqnUI6X2YmdtBpTLFz6+N45RpeZZCJyUkUgnJsdBTHcYii2HCNaRgZHDBjrTSW7ZDIzGosQVkWSiqE4+EVywidYDuusXJTCtdxqNfqCCEI44hmo4ksFvGV/z+0Mp9s2qND79Gh9+jQ/10d+kkDT1mEt7leiZmi1fWeS5E8RB7pzrzIC7IJrLTx984mUea+pHvmglLGtDaJAtASE/zCTknpDP+PxgBTGZ+TpbMJngEtZhCsLK82z87aI4SJDKdTgCNDVU2TFNkSE+nvZKhhD+iWI37pJMpd9QzKlGbLlEIQlo3teGjHJYu8JzVoYYNwEEIRhxGRkrQSiZdFfSjUcAoVHL9kwCuR8QyJbrt0d6swOkTmq521kRT8En0LuBc4ycAp27JTcE7TbMwyOznO+LatNGemCYOOiUDi2OBYqcuaRsUJWhrAybYFKFBSE4UxnXZIpxUgE4njWJRLPpVqiXK1SKVWolQp4hdc0MqE0pWKjEsMjLKhpEZrh0q1bE6VhKLTksYXftvmlKzcprp4JbZfMKdDaXsyknVLZNxMAtmLEqfzYC5ybvrQ+Lqb28w8mc9V8a8jPQnBabbqvt+F+H/9Xp6ts17hlX34CyuSgYap4MyWwtxy5wrOXXP8JY/sEfhdOZCvWyuzVhQZ7aruWlWmp8V5MADI+SxMMAELy04B1HyYsg8Jjl9EeCVGBley6d67eeTWq6A4iOX6eKUClr0dYVmsUh52B6bChOZVf0Bqi7Ky8EKX+PFZLvny11DhLOVqiRPOfjODi9ZSqA8xMzGWK7b9ik13vzNHKOa3eWdZT5d29YfePa17zqbS6DwalRMZZmbelhB4TnqqKzS2tlMwWPX4nmd5zYO10kRK9o/qHBDhKZ2EwHUc9j/gQN7/8U+zeu99GR4c4G2veSW+I3AEjG19nE6iaUvB589/f+oWp7hr+wytdpvhJTMUPIeCY/H5972DUqFAFEW85MUvYfXq1Xz5wgs5/7PGLesz532Ad735Fbzt1S+hWilxxvNP4plPO4S3nfMmHnn4IUqlIl//+jdy17WMj0UlSRr1yqgZv7/yD7zn/R/iE5/9Ir/7w7V85hMf5Z/f/W7+7u1vp1Ltgk69yXZ9bNe8jJx//vm84hWvMKTAPem5z30ud91lXCAKhUK+Jy9cuIgbb7yRC//1X/nyl/+FY0aK7F/f9cXm/e9/P7/+9a9xXY+/+Zu38/rXv57nPe95HHHEEXz6059m02MbqJeq/PGGG5FhyN233c7SvVaTBG2idgttOalFhpuv0SiS3H3H7TSbDV561iv5+te/zvcv/gG/vOQXrN57P5atWEWpxzrqn//5n/nYx0wEune/+928+tWv5vkvfBEHH3xw3rZSqbRL3d/wmldywtGHcscDj3DDjTdxyS9/xVlnncXxJ5zA97/3vd1OodNPP52Pf/zjgOGiOuSQQ7jwwgtZu3YtL3zhC9m6dWueNwo6KJnw85/9jP322y8fi29845tc8qtf4fs+09Mdnvvi53PKKSfx3n/+Z774g9/gOhZvOP053PvAQwRxzOkvejHVokfBsYnCkFvvfoDbHnyUg/fdh8UjQ+y9fBH37IzZEVb5/Gc+yaObtvMfV9zIolqBdfvuzde//HmKBZ//+u1vef+HzuOiL3+RoYH6X5cMljGuBZWiTxRFJIkAz6XR7qCVwvN9wtQiqt1q4fk+JcdhqF5PrfoCopQLNEokrmNc2fbdf11KAt1heLCO7fjE2qbRCrDooIImcdhGJDFO0cyjOJGEYZRbNTiui9LGqiVJ6SuEELgaPNfo87Zl4Tluysmjcssfy7JIUlcLrRSubYBZJWMSmQCaRLnYSWz0OmHh2xZetYJKDJ9KEkc4hSKW7VAq+ITaHGC2WglRGBB0DPiDsBCOi2d7Ru+OQzrtNlJpiqUSkQ0y0GwY71Ar2Ow17BMEAY7QFDyHYrlkAGWZoMOYJGjRaoZIYYPjU6zWKQuo1WsgDeeU61jIJCaJjcW+63mUi0VkFBBJjUqM7qtkQhx5+MUSQwuXsnDlapxiiUQINk+00RNtlDWJ6rSRYUDVVkw2m2yblAQLRigXPCoFjyiK0FjYcRsvaVGQRQr+KLZXwHI9EzU6SUy0PW3GIY6lkXXCWH4prdJohMbDwHVcfNfFti2CMMK2BQKLweERHNehVSqzddN6KrU2o5bDwiVLkFiEYcTI0CClYpFSsUCrExBGMY4FnTCi2QpxbRvPc1g4PESj2SaKIiwtGR6oMVyvMDa2A8ex8T2bJI67AJZUCEuwZOnSVFv4a5DBe3ToPTr0Hh36v6NDP3mLp3zgs9XTA6nNSbtO9QzvFHk3zjc1e+/R2pjeZnw8IvX/zRaT7nWNy+7PgZ6MFb+H16f3IRlw0LdPiG5ZeR4DOuneyHh992cgRbegrI9yIK2voVl+1bXkUjKN+iEQlo1lu9iujVAKISRuoYJXqlCsjeJXBvGKVayU8DGz4Mn7VxuTvS7wlSK98yhmuaVOD/iUA1MY336lNFJKgk6bTrNJ0GyQhKEJkSuyB4me8exuEMISKKmRShNHCVGUmNMZpbCEjeM5uL6L57v4BQ/Xtc34ZkiwkimoaUqWCahEE4cJSazQUuG6FrqAiZ4nY5JOi2B6kuLACMKycOxdp7cBB7M5RI4a94JOvdBiN1MXvNz1pOCvRfGdb1PoFU79Lpb94iT95cnKj75OnK8Ou6tLf52yERE8QZFPkMx6Nptstsc/URl/1nJtN5d3ua+vsv0KSObi2nv3PKpBPi979zWjV+6ysdBr/ai1QgiHoRVriIIOrZmdtNuBOdUVCSoJ0UJQ8MsIS4NQBJ0ZtLbQ2sEXHo4FiU7wa3XqoyPUFyzFK5bTU+28cj2tMwpJfy/07ovzq5T5XgWInhOe/FPPaUQ+O3R3Wepewa17e0Wk+2MWqTOtpVbpKY9xRejK+UwheWqnvffemyOOOIJ6vU6xVuOIgw9g5+QU7XaLVSuWsWPHGDMzMwxVi/i2BUogOy2CVpMtWyX1colSocDM7Cwtx0XYNrEyrg++67Df/vuxbOlSbEuwZOECWtUKQkClXKRUNK45tUqFgu9x8EEHsnDBKK7rcNihh7J2bRoxTms6nQ6XXvpfrF27NwcfYsCKu++9D5nEPPrIw2iZ8LOf/YyjjjqKRYsW8Z+/uZQ4CsnCaf/xj38E4OprrmHRokWcfvrp2LbNLbfcwi233ML+++/HAQccCEClUsmfPTk5yc9//vO+9TUwOMgZZ5zBAQM+Bx1xFABXXXUVWmtOPPFEKpUKCxcsZPGSJZSLJSbHxtl3330ZHV3A1i3bTUQn22ZgeJjxsTE6nQ7T09NYWoHSRFGACAVhR6BSC4AkTgxA6HnMTM/gez7Lli4jUZrx8Um2btrE/gceABhC4x1jYzmf09TUFLZtc8C6dRx4wAHdfu1JzWaTyy+/nJnJMcJWg4MOOphiqYJtO1xxxZVs3bLlCedRvV7Ly924cSMPP/IIl19+OZs3b+aggw5i3bp1xHHMZZddZqLyScny5cvzew466CAeePBBfvXLSzj00MNYvHgxBxxwAJ5f4NY772bZ4gVUSiZSresX0LbLgqE6Oydn2DrbZPWSUWrVCiMDdQaqFWzbYvuOMZYsXkS5UmH9Y4/RChJ8z6U+UMf3fZJEEoQxhUKRQw4+iGqtht5lz3lqpyAITEQ61wOtjQub6+K5LjKRxElCnHItZRHEMkLnzM0ujiND+m87SGVesMquT6fTodlsGlcOSxEFMbEVYaNwkxABKTeT4b5MVGIskgBzuKdRmpSg3JCZ25ZIwSWBm+3T6Wl59qJh9lOdvo+mVuWWhWNrlLJSL4leBdrst0KbvV+lnJpKKQoFD8fz8DwHLU0fOY6DlJJWs2mizbketucidGpZJWUa8U9TsC1836ZiWRS8GMsyXEdWEiJssHwXrRRRHNOcnUEnsbG0SiTaAss2/SmlotNu4zs2XhqBL7EEcQxSRXQPuM3Lo+e5aGE4UbWShrC9XGF04WI00A46jI2PE0UxipiysPBc17g7BpJIxjieh+16YNuEicK2Y2wV4wmNZwsTbCh1V4siQ0YvZZITgMtULqdaQPryjXEVtGwc28ayu4fnmYuWsGxcr4BXrCAshySOaM1MUqsO4rpubgVqWZkxgbFcTWLjaljwHQMIao0FRHFEFMUUXQffc3Asi2KxgGXZuI5LOwhIpKlbnMSGA6xaJoljZNINdvDUTHt06D069B4d+r+rQ/8FFk89rek1AcsHsiezMi3LzDszS5wsT+Y3mBWXvf13p5YBZbRMEKjUta5rEaV6LHvmAmAWJkqZThSgyCKy5UAMadjhng7KI+CRTv4MrMnNx7Iq9rurdSd+F7Awkc8MIGOskOZuRqZtMglJwoAkMqc9CI1luzi+h13wcxO4cm2YQmWA+uLVlAYX4ZXqWI6L0iIFrNLnpwibQOdtzjomn5gZaKLILXzyPuj5KwS4jkucxCRhTHNmmtmpCVrTEyRBx5hleynoJIwwsoSNJSwsy4yNZWkSTaosRgSdkKATopTCsgS+51IoehRLPuVKwZg/C2PmRxpNQ6aRRASCJFLEgaQ9GxBHIVIlOK6FV7ahLGjOSGTYorFjK6WBYXNSVyyTNrtvL1KpsqRTc8Xsej8+150nmXlyDvNpuvPgr+m0dS4IqrMfdyeOur/nn0T/1d4fdM8HMx3nbKG9Geau3/6cu732hIKz56Luy5fO08w6kV41YK560F/c3DqZLS2dl2L+m7JTlnze9QnqVCFE9d5CdkrRlycD3S0rj/zSWx2VC1Cz72TzU8oIaUlWPO04Fu2zijWHrmLjLVcxPT7OzsmARiCM64HfwfPAsTWTMyFJpJGxxWC5gl/2WbJwGQOrVlFfsoIFq9eiHZ8gJU/OrEXztlk90U/mWIXOjTKpe/rO8Kl193CzLrt93ZtMPvOc1D0ejezZx0R3PWoMcJ2VJXR6gJD1bdfSFsyLk5J/qUr2/z6ddtppfPGLX8zDDT/z4L258OJ/Z6bZ4j3nvIY/3X4Hd957P//4N2+hXCqhleLnP/s5rXaH2kCd4595HOVKldvuuItIOIQaHtu0mQPXruTpB+3PF7/whfzQ5HVnvhTQOJbFZHOWVqfDskULTb/ZDl/80pfmXb0IwdT0NG9+y1t567nncvAhhwAg44j27BTt2Sm2bHiUa//we771rW/x3Oc+lzee81amJydQSUjvyJ933nk87WlP44YbbuDN55zDP7/nPaA173//+/n4xz/G3FX68MMP84pXvKJvrXzwgx/kJz/9t/y71poPfehDaK259ppreN5zn8eRhx/Js048kR2bNrP+gUf44he+yM7xSW655S72WbUUt+Cxfdt2hGXj+EW2b91KrT5AtT5AMDVBEgXEYYdEeADYJCxZuRzX9di4YROHH3YEhx9+BImyuP2WW/n1T37IBz72MSOnXM+ACbJLtFAsFrnoKxfudh5s376ds88+myAIqNfr3HfvvZz6nOfx1re+jWOe/vQnYQW06/XPfe5z7LPPPtx5552pFdM069atY/v27Xm/Zemf/umfeOD++zn0sMP45Ccv4B/e+Q98/WsXccU11/LNH/yI89/7jyxZuJAw6BBpmyCOqRdcfnPHfdxwx4N88f1v46ChQVYtX8rQ4CBjYzu5+uprefYzn0ESx7zrnX/P857/Qp51womsXbWKBx9+lGtu+BOHHnog+687gB9+7zskUnHPPff8BW9y//Npanqaeq1GvVrFcx0sy8L3PNAGTAjDgCiWSK0ZrA/g+x6+5yEtG6mMYI2CDijF0MgIzU5EGCX4tqDZbDE2NkaxVAFH0UgiPGJ8SzHoG+4yx3FJ0gPFJDGWUwhz6Jnti0pKwtBYtcRxQlIqgrAQXipHhcCxHSwhiFKACrquL0JgeJ0E2MK4B2Y6NpZ5lpLGRQOdEIRGB1YyYqBYSKNq2jjCBA8Kw5DG7AyzUw2EJShXaxQrHkoqYi0JksS4dymzp1dLPhXHJ4glUdCh2WiC7mB5Nk61RBB06EQxGzZsoFYuU6+UiZIEYYOLIuh0CIIOWzdvZsnCUYbqdSq1KlEUEQQhUdJEY6GkNFynWlOpVRF2Sp8hI2y3gOf7rFq7N8VKhUjBpskOjaSFBQzXi1RcI8vsQKE6CQMDxi0SrWhPTCO0xtMRBcei5HvYxTKREsSJpNNu59GZMzpoqQ2BuHn30MblLgXuHMfGTedbz5kxWgsSpbEcn0JJUKrWidoNxrdspDq6mEKxSKE6QBgEBGGE73kEnQ6tRgNblykViwwM1lJLsJhEQLPZIohiikMDeG5Kml8byF+rdoxPkEiF5xeJotjMoyii3WoSdNrzL5ynStqjQ/dc26ND79Gh//d06CcNPHXNtnoGt9fSR/fYjPS9k/fmTbs1dcUTGcqBzq2DtDZRJlQSo1NTL2GZiWMMj9JJInom5RwlS2jyKDRA19WM9P4UOOgnO+8BsAT0GjmlpQDG99pky1Zn35AZUKeLpuXoYCbYpUyIoxZx0CQJm6g4MH7jGmzXw7WL+NXFWI6P5foUygN4xQqV4cV45QEct4iUgFQoofrql72MdOvWNbtD9EetM20U+cLM29BD3i6DhObMNBPbtjI7vh3VbqHiCKUkWhoha1sWjm3Md0Gni9g8x3A+ScIgImgHBO0A2wLXsymUDLF4seTi+Q5omVqBpRFONAgclNTEsaI50yFsh7SmmnSaLWQSYVmKSq1EsVKgUvGRSpDIiObYFhNVr1DELhSxHAeNMmaI6VhrelzmssUjerxodc915gl7mY63nrP4ntqpF5BkV9BM7/aLyU7vxrdrmk/I9F3PNsXenLuRj10gNBuBboZuOX1icbd1naf49Pvu2zj/9pntPfNdM3dalm3WukwAlVtw9N4/97vWmUtvV5x3txdt9sv0VDNTFnWPQiIEIFVPiRFCQFCqIeorqJYX4G97kIGBIguHVjEjR2h2JBtvu4SSH1MvWaw6+kW0ZYGJhmbn/b/HrxU56jkvo7ZiH9zqMLF0SJIEmcQ4gMbKBdF8fat71ky2zetdpl4qxIwYzRXouUlpcsvTbP/WmQGwBp3uN2LuqPf0oVF2en9OZ0Badop3P6XTlVdeyU033cTJJ5/CmoMO5cjDDuMtrzubl5zyLKI0MtNhhxzMXitWsGXTJsamG2wen2btmr2pVysMDg0ivCLTnRhnYISlA1Xq5SIHrlnBA49t5sKf/hdnP/8EHrjnbj52/vl86lMXMLJkJed/9iec9ZyjOXCvUU5/2Us59siDOfOFz2X5uiNw/eIu9fzc5z7HL3/5S5rNJj/68Y/44x9vBGDnzp3Mt7qGh4f55c//je9//3t861vfpDfQB8D999/PKaecwgMPPJAP4g9/+ENuvfVWvvOd7/DAAw/w8Y9/nC9+8Yvsv//+/P73v+8r/9prruG0057H17/2NfximY3bd/Le974H17bY8vhmRgbqlHyPP1x9HcuWLGLvgw/g5htvRlgWe61aykyrTaPdYaBWwS+WzEEYCsuy6AQBQmlsLITt4bseWgikchEKtDGRoFKtUCwV2br+IZaMDvKuD3yAdiKxBPzrR95JyxvBKtU5YO+9WLu2G9Hv0ksv5fOf/zxf+cpX2Hffffs7WgjOOeccXvOaVzM8MgKYl/+vXnQRjmNUu/POO48Xv/jFvPlNbyKKTSTC7373uxx44IH9ZaX9+vjjj/Oc5z6Xt7/tbZx66qn5ZSklb3nLWzjhhBP4zGc+A8CKlSu57LLLcIcWcsvmCRLhUFy0kje/5mz++KfbGR4c4Phjj2Ziepap6RmWVyyOO2Qth+2/hhtuuJ7Fixez99o1fObrF1PwHF5y8rFYgOs4fPgjH2VwYADbtvn7936QvdfuzfHPOo4f/fRnLF20gHec+yY+/JEPc+WVf0BKyd/93d/x0pe+dPeL5ymSaikp/OTUtOHZSi2Q4hQEKhWLuK4BUQoFH0sIZJJguQJUQhJ0GNu+DZkkVMpFiKXhAvJKDA4OIoRgwYIF2I7LiNS0ZybQicJxfFy/gON6qKCDUgJSF7lMpzfcHhrXcykknqmXTIiimI5tAGE75SDKqB3slOQ64xjL8CUBOLaFk0anMzt8ag0oJMJ2iaOYIAyZnJwgSQxwUShXkRpcr0AiFVJb+MUSs40GrU5IJYpRzRZBJJmemkJguIbK5TIIw5fkiBhXWCwfLtJqaSYn2iRtSaAVQRgSSk0nimh1QkqlMpZXoFA00YxlHBJ0OnQ6bYJOGy0TLEubNW+7WA7YboRtWzieB8p4LSQYwm5hCWQMzU5I3GgbV7MlK/CqQ1QXLDdRBVWCrwJk2EY+up5FhQHKoyHrDjgIy7EJY8nAwhVUCh57r17G0OLl+JVBAq9GZ7ZFu90iSRJsy8L1XHRq+YXUKTG8QiUKy7bxHQffcw2xukqQ0tCVOLZDFEYkSUIUhuns1IwsWk5zaifTOyJaOzZjxQGVSoXYEiRSMTkxThh00DJhYnqWdicgCAIG6zUc20ZrRb1SopTI1DIqIRKaRrOFEIYnql6toIXAdjziyMUSgnKxgOfYJOXyrovmKZX26ND93/fo0Ht06L9ch37yrnZao0XOepR3TNY1Xde1LkDV/Z+eu7JO7EdK83zKkOjpjLMoDQWaoUF5GcJK79U9CF0X+LKsHmAqn5z0DeTc9vUCD+lD+kbadPyuw5qBDxm0ZebD3EWc1lYpVBIhkxCZRMayS0nQGstycLwChcoATqGM65dxCxUcr4DtFbFszxCTq8z9sGcZ6jmLWc/zY88GJRD9LoSQAygZKBfH5hSi1ZghaDZBJsZaSymsFNTKwuV2ua/MKYxIlROlJEmcGDBRJniucavzPAfPc3BdG9sCmaR9o9LoG8rwOsWxIuwktJsBQSswf5sdZBxhoXAtQ8joVgw/QaISwnYT4XrE7SaW64Jtd+dA9l+mIXUHaI5E0PR1zjwpmw9/HaATfXMU+gVHjr32TqhdCzB/etH0bPPW86yp+coRWb/tKtgyeLgHj+65rb8cASjmuy768mQld4vrLae784g8h+4roZ8UMXMn2FXZ6N3TzLJLI27axjQ9C2PaV/vuZKRPBZhbxR7rxNzitSdPLgzy3xQajcLC8QqGLLRaQTgJ1YULQC9DtGKcootXUJSqDov2WkUjKRNPacY3XI1d8RlZtRfFBSsRfo3JsbE85HVGQjtXmclsd7vLQXT/9NS7f5/U5KPXJ9S6fZUJvd7l2XV1NiI3P5WZk1PoLOgEeZ3TDbCrqGi6/57C6bjjjuO2227j6quvorZwKZ3ARJwr+B6Obdyv69UaruMyM7GDODYWC4NDQwzUqpSLBdqJRipFpVxmZmqS2Z0R+69bx+YdE8SJIZVMkoRWq5lukxatIESkL5zXX3cdBLOsXjTI6Kp1tDohjzz6KGhNqVRi3br9CcOQThCwYNESpqanueqqq3pa0b92NmzYwAMPPMAzjnkajz7yELffdhv33HsPYRDkeZRSNJtNli1bxrJlywDYtm0bV111Fbfcehv33nsPf7jqKmZmZqjVapxwwgmsX7+e2dkZ9lm7lgfuv4/p6WmCTgctbIJOwIpVa/AdmzgISaRGIgiCjnnx9g3Hiud5FIsFZqZnsIQJK94JApJEUiyWkFoh48isfcu42aj05TqOYkgSbFvgeAUjD6VEoPF9j6HBASYaLRzbYvWSBbScQazSACtXLKMxO8stt9yC5TjcdPPNXHXVVTQajbw/Hn30Ue6++260UqxetZLjnnEMWC7j4+Ns2LCBdevW5XxQBxxwALVajaOe9jTCMKRarXDCCcczPDwy7xzrdDpcc/XVHHLwIYyOjhLHxvVFCEGn02HHjh386U9/QghBoVDgWc96Ftff/QC33nob+x58KKO1GguGqzz82AbsRhPLsomDDq3ZaTZusVi5ci+WLh5h+5ZNyCRGK0m700FQwPcLoAzRdLk2iOO6JFFIq9lCKUW5XDEcOnGMVJJOu0OnbU6PPc/LI/09tZNxLUukpGQXQYCUSW595IlMJc+ippHKD53uVYZ7VAhBkkiiMDC6VaUMCBMpz7YN6CMkkdAkZK4dIt2E0xeUdL8TAhOeW+r8gNlxTJQyokyXTl3qtErdNHq4Usk8DcyrjECbwM2YYECOsNEYa3aZcrd6vmuschLj1pckMUpLwjDEdpw0Yl0qm1Nycy0M/2ocJ4RRk4mJSWzbZmRoEM/3sWyb6WabJCU/r1VK4Fl0PJt225Cdh1GCsmws26ZQKOC6LsKyTDS1OCGJIpI4QktJqeDjucZVzJCnd/lhhLDAsrEcByQ5D6xIo1bHiSKI4pSLyqEiHIaHQ3MgqmKS1gyB0BSqNUb8MgMIFi5dhrBsgkhSGQgpFzyGlyymPLQA268QJzZCGEsn2zJRBj3PI8lD8klE9nJtGXdIx7FNtDtldHFtZWNv3OXiKEImcRpR0aZQKhMHbVy/SNBu4XgecaeFFobXq9VsAhrbEoSRpNMJkFFEueijtZsS0xueVykVcZKY7+nBribdK4WF69ioxOp5veYpr0vv0aHn1mePDr1Hh/7LdegnDTypzOJJGLKp9NFkJl85/JRuwBm4keJF3c/0sNFDbqWDMJuhASpiLNEVON12dssVlkUGg2XR8nq7qxd4ygRmFr4wS9lyyRdqT6tMlbogjClLkxGnm+umHVqnJmxpG0wys0QIK7XashBSoJUkiQKSsE0cttFxiJYxAmO+7PlFqoML8CuD+NXBnJRcJgkiClFSI4Sbt0Bn7nZC5/2amdoZ3C71hU1/yyewJbAwlk0q7ZfMJFFYFkEY0pidZXzHdhrjY0TNGTw0cZIQSontQsUSeK5n/L+FQOsEgUQI4z+upAGdok6IihMsrSkVXSpln2rVp1wxUexAp8SNEpkotLJQShC2Y1rNgJmpJrNTDaJOSNjqoMIQkgRHa5qJIm6EeEMJ0vOIXJ+k3UIKC39sq/GbdxxjRpmbd1q5FV02XjnQ2TMFRDqPspStL+ZYy/31gE99yNr81wVdX+70t37h1P03d5+ZP3JEthP29E/PXip6bxDd8np7s1+w9qzxeVrQC3v3Ck2T1Nwaz2lVHhsj31v6n6zn5E+fKMzasYRlLBqTAL9YQdgO2DYyDlEyBhXMqbXu+Sv6+qUrXHbTEU+QlDLC3gc8AUUHqpUygQhBRlhJCy+RDA9UGSw5DNUtlixbxHRYpS2gMjBAuV7Grw4QRQ5JqEiCELQx6VV9o9BN1tyJkrcu6zsjK6zejbm3G3ZJ/X2eyzfRVSKya73j1TcvRd+fXVdAOpRC0+cf/1RMU1NTdNodbNvmXW99EwcdfBAAl199PY1mmzecdTrjnYCpmSYrlq9gzWoX13VoRQmtRpOHH3qIkYULKZfKLFg4wLs++0n+8zf/xa23/IljDtqPZxy8H4mGE046kRtuvNHIEw0//sRbsSyLsZSD6De/v4Yrr/8Tt5/wQu5/4AFe8cqzkTLm8MMO48Ybrud973sfb/+bv+UL37yYa37/W669/L96WtE/2J/4xCf43ve+x913381rX/tazjjjdA455FAee+wxsl1m3bp1XH/99X1RbD55wQV8+MMf5tWve6PhBZlzIPSxj32My393GZf+4t944XOezcte+jLCTgchE/ZZOsJ1960H4Ph1q7nhnscYm2pwylEHEIUhj294lMOPOJQwiNg5MQlxjF8qsnjZUn71i0t4fNMmXn/OOQQzUzQmxtFeyYBOtsN0o0PY6RBMjpE4Dl6xxBGHHMTOHWNsGt/IwUceyZb1j/KrH36fU09/BVbB5zdXXgMT20iigJ8Pr+K2u+/j3vsfpjI4TByFzE0f+MAH+NnPfmZ4caImsj2OXV7Ir3/9a972trdxww03cMQRR+T5ly9fztVXX50r33Yf96Hepe8ALrzwX/nKVy40ViyWhef5fP/iixnbsYOnP/3pIAT777cft956K7/8/rf53ve+zz333sOCBYNorVmxeg2+64BWFOJposnNXHzXg7z0OQVOWryUU085mU5zltmd23jn68+k0WpzzwMPsW7VEoIg4FMX/ZinHbofh6zbm89/4iNMN9ps2b6Tt772FZSKBdqtNp/4+Pncf/9ZPOMZx/KFL3yBL37xS0j51I5uNzUzayLK+R4D9SpCCNrtNnEckUgJaNqtNnGSUC2XcBzHjFcqY2zbYfXqVWitCWPJ2M6dzExPgxC0OgEzsy38QoGCa+NoY82ipKQtQoRt46cHyFKrlBdJ4TgOZc8DJDpRRGGI67oUCj4Ii4w6wnEc49mgZCqfzNwxdTTAhU45SwU65Xly8QsFtIZmq0mr1SJOYgY9H0uA45gIfq5jYzsWnVaDKOjgFSt4haKJhBaFWI5NpVrD9QwoPDPTYOv2HRR8n7V7r6FcLeM4Do9v3UG70yGJEw7cbxUlR7BwoMDjLYcwTphqRYyMDFIvFanV6sg4RsYxRd8DJWlHAUImVIo+a1YsoeA62LZFq9kijCRBZIAUGxslhAmyYwlkYjhJdWrlr1Rqg+D4xFFEsx3QnJ5ERR2qdsLU2BitdkBtYJhVi5cyvGAxixaOoBFEicRG47s2g5Uiwi+jcOjMdnAcF8/18L0SnufhF3ya7Q5RHBOn88cS4HsejmMAyIzgPUkSAyhqTRRFdNJ5ZwuLgu9R8AskiaJUHUBqwcSW9QTRONgPU16wFGyPsfEJhgbq1KoVbDtmenqKrWNj2CS4foEYhygK0UC5VCaMQhzLYnCgjsZQb0zNzABQTed+ZmgQdDqEYfQ/tjafXNqjQ+/Roffo0My9/hfq0H+BxVMmaECJzHA2u9QFj0QGEGXXUkQtE5xdWCe7ReTly9T6x8ry9q0z3QM+ZWCQ7omc11tWL1BkCu9O8x4zPJFdS8EIkeWgr5yuNU8KhOm0RjoDqKxumfRH58vAHJTOI6OZE6b0hDQxJznmERKdhEStCbQKUUmTJInRWiDsAl55GMev4Hi1fl0xb3YGhpjfrKzVKTjSN46K3NQwD08pLLJTidmZWaYmJ5ncOUbUaaPjGMuyCaWiHceUtGMIvF3bjBcqdZEzSLGWIKMEGSXoJMFC4zoWxYJHwXfxPDtl4lfIJEYmBnSSsUZGCXGkmJlq0Wp2mJ1p0Wq0SKKYODCgk0jBniRRWGGCnu0QugltP6GjBB0hsKcncGoDYFl41boZB4Tx9NQ6DYsrUSpBJhEZKGU7ftfKji7QmC9KpfvmZhbS96meeoXdLtd61k7W3q5FXXeN5hey8rSet7xddis990q6S4jsmaTgJz1rbNeSRc+HfDfZ7d6r5/ncow6I7vfd+UTPJyy7s0Gke54BgFvT22g3xghak9RH9sLxfBMowKth2QX8yrBxVU1iZBL0lMku7djltErMGYNdkkCkFoyOYyMsi6g1S2cqYDxoMrEjoDXTYqZ5J4kqohR4kUaKAg1lc+vV19EKLaYbCVU0Vdtj6vHN+MMell/Htq08ilHaYfR0n0lp+NBeE+YsS1/vimyPzOSFudIXEIJMz+quP7SVj5lOuf9sy0Fpo7jqlCNnrujriuz+OuVzSGksjEv3Uzn9wz/8Aw8++CAAzSDisce3sfmmW1m5bAn1WpUkjtiyZQuPb9vOisVP5+H1G7n3gYd59onPolwqUq0P4HseSik2btvBaS94Ic849liqlTKXX345v7zkEj78kY8wNjHFt773Y95+zmvZd+81CMvi4osv5rLf/pZ2u02xXGF4dAG2bXPoIYfwta9eyOc++zmUNK46tm0TxxFX/uaXPPbIQ7u045/+6Z/wfZ9PfOITGPfzdNyEoOAX+NSnPsXs7Cyg+cxnPsv69es599xzEUIwODjIxz72sfxAoNOaRad776c//Wm+l0Zy23vvfTjxpJMo1EeZbnRobxtnaLCGcgtMUWDpYAVXQGK5FB1B3RcMDI3w0EMP8+BDj7Bg4RLanRabNz7Kmr33pVgqsXHD46xauw+Lly3n3jvuYHBggIGhUdqtNrMzM2zfsRNhCzzfY6/VK7H9IsKy2LLhMcqVKqvXrGZi+xiuV+SYU57LRLODTixOO/vN3HLJ91l/z+2MPXgfh4wWOXbFkfz4+vs5aPVSXnz8kfyvb3yVr33NtPnmm2/O5c0vfvVfPPzoBoRT4KGHHs77Mktf+/rXufXWW9FKccbpp/Pc5z0XgGuuuYbvf//7aK3Z1hPBLku6R2fIrJ8/dv75dDqd/Nmbt2zh3HPP5ZZbbqHRmOVd73wnz33e8zjr7LPZa/kyHnvsMd73kY/xnJOeyQknPZsDWwk33XA9/3XJv/P3bz+HBIvx6RZyy06iOKHVCVG2z9DoAK86/TRGhwcplwr85Oe/YuWK5Rx68MH84peXMDgwwOkvfTHf/vZ3uP7660x9LMf8e4qnYtGnVCxSqVQMd5NMA+ikVk2WsLBTN0mlDMl1dnCapPQTWpugLUGUUB8cpl6vU63VKFeqDA0OUSp4CC2RkTRk1xheKNcWWELjeAVD2K00cadNEmsC25BPO45DqVTMrQIcx851Y9u2U5XZNmCBUiZinTY6kePZoC20tk0QGcvCcVyyHd5N3b5s21jiGFDTyE/f96jVqnSas8g4ItINHEtgoei0zOfBgRqFgo/n2Ag0e69Zhev7FEsllFIE7TbBzBjtmSmCdpOJYogtNFEQYIsiFa9EfWSAcrmE49i0Oh2mp6aZnZ5mdGQIgaJS9AiRuK5LsVDAsc3BscRC64REppylUUwUhRRFjGML/GLJuK7FCXEQUCoWqQ8MkEQhO7dv5+EHH2DbxochDhkpu8xMzRDGkuLwYhLh0gwSHt+yJbUAixgqWtTLPnrhEIXBJYhCFSVNvxWLRTzPRGyOU1e5ONWxHce40nmeAcyEJUi0wLXcnCg8W88yPbR2XAchLJTWBFGEFhblSo1ocIQo6LBj2zYWFyqUagMsWbwIpSRBEOI6DoMDdarlIpYFSRyToFKLDoFrW8zMztJpd4gTabi9ANt20Gg6QYjUhofX943O7bre/8zCfJJpjw7dV8IeHXqPDv2/pUM/eY6nnkHtKzo33e11gxP5Quh1TRN5/vnLV6mPedfKZM7CS+8XIoui0d0G8gWQnuiYMrv/Z/XS6BRV7i6E1FiJrNoirU/e0ULQJcEXvbPAlGD1tpe+yZSTpGUAnHmiQXctO3VfzLpFoVVM3JlByxAVN4ljE0HDdk3ECbCw3DLoHjQ5fWgvuCSw5p89+d6ombsARUr6rrSi0ZilMTNNc3oaGYUIJdGOTSQlQZzga9PnJrqJSgnLlZn4qWVYEktknKATicD4/Pueg+eZkxizyJUBnGT6L9ZEgSTqJDRnDPDUarQI2h3jHxsbMkdLg20bwk2ZSGhHxJ4ilJrIcZGWTanVoNxq4Hg+fiUNuywspE5M5DxU6qMfE0dthOWkvvwOArtXanTHPJ07ublm/tNud7OnTBLpGs4tBUXPlNCZ97rYVUZCf/vmzpvsJ9H/G1l5+Wfdsy7SvzrL0yOe/6KuFD0PyzjGsurO2byF6G9GzxjOLy57f0v3ubzc7JTGNoJCKzrNcVpTm2hNb8ERCtfzcTwbt74CtziI446SKAlKIudyBcypgu597Jzm7qa6+XU7PYGeGR+jOT3O9I4tNHa0aM202bFjM2iBY1mM1EuE0iHsWIxtfAAlE9AJSxeU8JRg56bHqcoCfi3C8vz84EDNMxf669vPidZnaq3nXsXs13N4ffJnQTZJckta8wRDcmsJC61ld/7p7hP7P/XPid4wu2Ysn/o8bVdfcw1oWLJkCVEsGZ+c5uHHNnDgvnuzfOkSQ/rabtFozqI1TE7P8tCjGzjxuGMo+mX8YgHPdYgTydj4FAcddBCjwwNEieTBhx7m8ssv593/+G527pzg91dfx5kveyF7rzF9c++993HVVVcRxzHVgSFGFiyi0wlYvXoVr3/d6/jhD37A9PQ0ANPT02zZvJl7bv9Tn4tYlo466igGBgb47ne/i9KaxYsW5dZMtuNwxhlnmIxacfHFF7N+/Xouu+wyMv6at7zlLczOmnKTKKRYLDK4YIRbb701L+OTnzyBF7zgRczMNJiZaTIzNUOtXCTGZVYrqq6Db4GUmqLvoMs+fqFAFEumpmdpdzp0Oh2CTotqtYzvF9k59jgjoyPYjsVtN9xAoVBkxCtgddpEYcjUzp0MDFfxSi61WpVipYpSmu0bHqVarTI0NMijD2+gVCmxbK813PHAY9iW4IhjjuPeP/wHnSjCCiKWLR9k1fKF/O72R9h7yQjPefrBvO1jX+OeRzbRDvujPt16+13cevtdAJRKJZYuXcr09DTj4+OMjIxw55138l//dSnbtm1lyZIlHHHkkQwPD/Pggw/yne98ZzczLdOpBAsXLUqtmTW/+c1vctc7gNmZGX7y03+jXCoxMjLC1Vdfw/DIKM864UQG64NYwLU33MhJJx7P4qXLWeE4/O4/f8XVV1/D2We8EOWU2D4b0ZregW0JqtVBphttLMvm6MMPJooTZmYb3P/Qw5TLJarlIus3Ps5sswUI7rjzLv54059QSjEwPEK1NvC/s6z+nyY/BTQq5bIJea9UTvQtpURpPz9UVWlkY61TNzUpzUuqNhHgpNaUSmUTOcxxcNN/MgpIYkWstImUrEkD2iTIROL6AtuycZyUi1Mr42VgWdiWhecaQExrZSyZRKaviu6+LEkjOEqyg83MEwEslJDpfeSeBrZl47queY5tY1mZdZqxmqqUy8SdFkrGqYVDhJYQRwGFQpFCsYBtmYNOikXKlSqOawjT4ygmClpEzSmi2Z2EjWmmt2ksNEnQobRgJYWiT6ngYVsG1EsSSavdNoTv1Qqea1PwHIR0cFwH13WNm5oQaJmNiSSME+xEo6XAthOE51BIyYtlItFS4rsupXKZyYlxJsa2s+mxh9mx6VGQEWGtRKfZRiqInBIdJZhuB7Ta7ZySYvmAS1QtUqdFpB3sckLsVLEsi0LBx3ZspMzcFBOUNP1trJxsPNfJZZq0zDXLMkCUloZHFwAhsGyj60qt0yhzNn6hQKlaRynFxM4xBpsNCsUig6OLaDabdDodXNehWPBx7CrTkxMkMgZbYAnjKWAJiKOIVqtNudJB2Cbyn53WoR12SBKZg5vGEvOpLYP36NB7dOg9OvR/X4cWej7SonnSbbfcmn92rO6mprVOUbUu+LIL3jHHHSnr+PxULQNldJJ/ltJ0bIba97fH8CggRJfNnYyfyHzulkvemdnpauZylQ2dJXZ1/RPCIot6JiA1UdNkHlmmmjq1XOoh6VI9JF2C9LTIlC+TiDho0Nj5CFFrnGB6I3FnGhkHJgKI7WHbHggX0CgtkXEEWDiFOuXhvSjUFlIcWYPlFrBs43ed9Vk+mbWJbJdZh5nfQM8x+OwFyCxh4RV8ZGL87O+45WYmt21hcvMG3CQAJYmVZuPYTlpRyNJFwyxfPMqSBSMMDdRAG/JBpU09pJS0G22CdofJ7RPIOEYrxaIlQ9QGSgyMlCnXC9iOMAK4I4lDSWcqpD0b0GkGTE7NEISRiagRRSRKIVN+K0sICpZtwudaNhXPRdo2oeMwUythFX3qtSqLR5cwMDDCwtXrsF3PEMI2J5BxhyTuIGViTDvjAMcrYbtFiuUhbLeA7Xj5XNKk4SN7AMTuRmEW4HNOO4mncrr7jrvzTUvRLzRFLjR3Naa1gNyKMP38ZJPu+zDPfZr+cnsn5V8I5vVGmdzdrdkpQXeXylqrmbtz6b7fM6HZHX+jjDskabCAqS33Ec9uIm5sJmhMGvdeS7Bgr8MoDSylvGB/sMoI28f2q8g4RCbh/157d5fVsqhVqxR8j2t//TMeuusO7vjjddSGRo0QdxzilGum7nsEYUwnjJluBSxdVODgfeo4boHpmYi77t5OcXCQgUWLefYZr6Y6OEyhXKHTbphoF3Oqs7tzO93bNr1rLythoYUFuFiAjcYWyrwQqW7kJdcpkR90qASZdIjjpnE/tly8Qg2tU04JzFFIL5dJ3xzMZZaZ38ZqU3Dic49/8mPw/zjNpC4KWmvuvvtuvEKBNXvvS6VUxEIzMz2NXyhgOy6TM00816boe4xv30qUKBLLZdnCYeI45srrb2LNsoXUqxV+8Ic7OXjvlZx0xP5InVrvKonrmxcc33GIo5AtmzfztKc9jZWrVnP0M45jwcgQBx1wAGe+/Aye/exnMz09zU03/ZF3/+N7+P7FFzM9Oc586kWpVOKII47gV7/6lQlkYVm75ec58cQTaTabXH755ViWxbZt2zj55JOZmJggTElxX/LiF/PNr3+VHdt2gLBYsmIFN/3pNrZu3cYR69ZQrg/hVwaYHBsjCgOSsMPNm2ZxLDhpdZXKohV45Srt8TFc38fyXK699kYWLFzAUU8/mnuuvwqhNQcefSyP3ns7zZlJDnzGKUw+voHxxzdQWrqKxswM2zY8xiHHPAOlFLfecCPDC5dQqdUpelb+Ir9g0RLCqW1MPXIXwfLD8Kt1VtRsLvjI+7nv9ps5/52v47u/voafXXETX3jrSwiDkAcf3UyxVmDT+Czfv/z23c6P17zmNfzLv/wLL3rRixgYGODXv/41nU7HcGg94xkML1zCmn334+c/+j6X/OIXnHvuuU843+r1OjfffDNDgwM0Gw2e/8IXcd9993XHsVLlmBOfwxvPfiUveO4pKCm5+AcXc95Hz+eKK//AvvvtR6vV5sf/9lMef3wTh61bx/7r1rFs6VI23nsLY7MdtjQimpM7WL50KS964Yt53TlvZ/2Gjfzgu9/mhlvu5MFHN/DW15xBs9Vm05bt7LV4CM91TDh2LB56+GFe9pIXcf55H+HNb3ojo4uW/JlV9D+b7rjnPiqVCvVaDcd1aDWbPL5pE1u2bCGOYxYsWsJss0UUx6zbZy2ObSOEyK0J0SaimdIav1gmCAPCMGKm2aJWrTA8MICOO4bmIEkMzQAmoqShUbDxPD/XC+M4QSpp/kpjqVIoFLBtxxwA96zfbK3aVnYop4nj2ES2kxKsFLBxHCwMuBGFgQk+4zj4hQIyfV/w/SKtdptmo8H27dspl0osX7oELWOSJKLZaGA5jtHNtYJUjzbgVnqybhkgQwubqbGttKYmmN32MEmngQyahK02tlZ4tmLVQYdRHBhBFYcIYkGibfzaEI3ZWZqzDerVCr7nUvRMVDnbtimVS2lf2ERRzGyjTaPZph1E2BYUXYFHhGU7WKUB4liC0pQLLo7noFBc9dvfsGPLRnZsfJRWx1j+JAqKQuIIiLwqHQWB0sg4pFQqUR8YZN3iCgMll4GSy7SoI/06y9YewMjoAgYGB2m1A8LQEKHLFAw2YJ6FZRsLMit9b4rT8ckAzjzsefoelNOEAO12B891KRcLqCSmOTvNpscewXVdKrUahxxznOG1EgKkpN1u05idYduOHTiOy6LFS8j0r0RKbGEsLGIFWBYIm8bUTpqtJjsmpgliheu6rF6+FCUNgHb2K874f70sn3Tao0Pv0aH36ND/fR36SVs89YIz/b2RdoTo6ZycFLELNmnV7a2+rk1PcAxpYtr1WbsEOchgOHq69xturi7C1oUCcpQpf05m4ZRxHGWATBoZMO1e6B3OzKQ5r0hapgGR8pLTclPCx74ieurSuyCFhbAcQxIuuidIIoepFTIDRFKTQoSFSiSOZyJ3uNWFOMLCsl3QKYinuvXNytJkG6FON6fuYs8tunRXYGml6LRbNGZnmRzbTmd2ClsZvq1Ea2baHdpRRBQnkChkJyJstGhJM2ZSqnwLkkoTdgKiMMr93wUCJRUykagkQUuJwvA5xaEkase0ppu0Zzu0WwFhq0OSGB98mYFaPV0sId/8hTChe32t8JIEEgdQxHFAEDRpzYxjDnYUQWMHSRwg4wCFsTozi9a44skkxLIdtHZTLjFyN8k89e5zGYD615h071zufspkS6/F5587KJi//N4v86Phue1eD7r8l/Zmf4TKJ0g9Jzt/Qen5jX1nCkIgLJskDomCBkq2EUhsyyLstAwZqeMTNibQccj0tk04xRHc0gij+5iQ58IyER37lIcnqkZWiTmDodOjJ8/zSeKIRmeWqR1bkFGb0dFhVu2/D16xSCeImGk1kUnCaLXMls1jNKdnWbx4hJUr6qxcPcLUTJuYkMUrF7BzYprJsW00pyYpVqo4bnYquWttd+EnyE9WdtWZ8r3I6irINtJYICYhYRIgLBvbreL6FYSwSIIOSkUoZUiJg84M7eYEnl/F9cvglVKZauUHAD3VYE4V+uaA3lVnesqlr3zlKxx11FGcdPLJzHRCysKmUiqSpObbxVKJa6+9lkcfW8/LTj+DR9dv5K577+fkY59GpVYmiBRjOyeRSrLv2tUknSbjO3dy6JqlrF62kEqlwuXX3EilXOKYIw4h04ssISgWi1SrhpNm59gO7rr9NjzP5aEHHuDRRx5mw4YNDAwMAHD88c+iUikTBS1uuulmrrn2OgD222+/PPLY0qVLqdeNFWqz2eQLX/gCRxxxBMceeyzf+ta3mJqaAmDTpk3EccxFF12EEILZ2dkcdHIchze84Y0cdcThtJotvGKZWCoe27SFgcEBKtUqDeFiJwo/ahGHAY5jMzi4iCXNBFsIBhcvI4giZnaOkSQSv+JRqVbptAKiKKHg+3TwAI3r+YQJzLYTwk4HHB+/PgrCwXZcSuUq9z3wiCFP9lxsz8NyXRwHOmFIqx1SKk+TxApZHmVocIA4Crj1qqsZsjqsXlDjp7/7I7c9tJFWJ2TL+k0UikXqA3W2Tk1RrA3x3ve+l1gqJicnufh7/4vjjnum4VwCjjzySGrVKp1Oh61bt3LBBRcAMDExgZSSSqVMrVrlK1/5CgJ4z3vew/e+9z22b98+73wTQlCtVhkYHKJUKvGWt7yFG2+8kZ/+9KcAuLbN4pFBhofq1Go1tFIcdeRRnPuWc/iPX/+K++67l5e//EwOP/QQVixbSr1cYXh4mEKxyPW338PgyEIOXHcgmze4FIsltmzbzgnPOo7DDjmYxuwMgwN11q5dxcZH7mfz2BT3b9rOfeUCyxcv5FnHHMWV117PrbfdhtKa666/niSJ+dBHPvp/YeX9n0vGfcu4mcWpXuO4HoODg0gpKaZ8SHFiSNYNK4CJHqe1zCOQGTAqYXZmlmaziV8sYYMxRUp1aSslcRZCIFwvf+GA7lbnOja2tnBsmzCKkFIRRhG2beSYiVacnpynh36JJQ0wJQS2Y+Oken4iNUoqkpTnM45isy5dD8/38EslIxM1uELgpFZBtVqdgu+lLoYSoSw8x4bUI0DKjNA8fQ3SYGmB0hZSKzpxxOxsk05jFqFiXKFwLM3k9CRCSYqexfT4dlpBm47aRqx9bK/MyqER3HqdarmESiS2bYPtYFsWlmXaAyLtx0xPUSYysyPwXAdba7Sw6IQxQtjYjo3r+4Rhm1Zzlq1bNtOansJzbOpLFiMsh0gJ7LCJpRVWfYQwkUQyQQUtqvUBRhctZUnNxlIxszNTbGnsILYbjC5fA+gU2NO4toUo+IhiIT1UT98BhE71bGUI24PA8MHpjAc2oxYBhMBO368EQNHHsSwsFFqA63rUh4Zpz07TaTWZGt9hCOwtC7Sm0WwwNTmF0IZwXMqEzA0oDEM8xwQfagWx4afyfXzfQ+sy9VhTFynliDQRzC3nqe8uu0vao0M/mdJhjw69R4dO05Ne5XYPIXjPo/onqU4JrbPK9iwCpRW2tndTsQy8MRZGXTAoc4Ozegi50rLNA7CEiTjRXQtZrL2s3AxoMd+7lki9eTIupxxK6mlXL3hkQHutU5Iu3bVyEpaVA2Va5fz53falRRkLKce4c6WR+YRIkTuh0UiSOCCJIuIwQKenUDqOCd0iCIti2MRyC2hdMnVQuo/bwfBeGZNJLeyuZRnZvtTlpzJ1MsJVJpJWs8HkzjGmdmxDd1r42pjpJloz2WrTDiOUVJAoknZIYDURrSAHnnTKE6UQxHFiTtLijGxSIOMkJXRMUImps1IWcRgTtkMaUw3ajQ5Bq0MchSakrpImaAegMuAwnS06Q+2EwEHjoPFTYEtoRZIEBGGT5vQYFiGoDkFjGzKJzCmgW0I4BWy/CsKc5MgkNBZP9M+lvjmdzpUslPBferLwP5JywZJhqd15bTZtkW/IGQ76f+ddfH4J0QMV9+ft+23+DftJPTXdGTO+uN4hy9d9/l3M03Yz37JgkBk3XBKFREETrYzQdCybOAyJlEApn6AxSTC9nfHHH8Wvr6A0vIrhNUcgLBfLdvJ1kO9hWef3Sp65Tda7fhVC4HoFwuYkrakxJndsQciY5StXcNjTDsEtFti+Y5ztExMEUciSoQHGpmZohwF7rVzI6tWjrFiziPixzWg3Yk11iIkbbqMxPU5japyhRYuwc6HZPw7zCiY9z3VtetmQGwocy8OyNLal8HSbRHYIkxZhZxbLKVL2B/CLVQQW4ewUcTyDjFugNe3GJNOTW6kNLQegUKgiHM9Yq6b91w8WZ+Fy+2tr8gqe6uDxBz7wAf7mb/6Gpz/9GUy3QrA9PMemFcYorRmulPjDVVfzH7/5T15+xuk88PAjfOPin3DCcU+nVhtAz86yfts2BHD0kYdx9523MbFzJ898+jPwikXa7TY33nwLixcu4NijDkNGkbHyxIxpEARordk5NsZ0CgwB/Od//AoQLFq0CBA8/7Tn8Zxnn0LYbvClL/9rDjwdeOCBfOITn9ilXbOzs5x//vm85dxzOfigg/jsZw2vU5aEEH33GXeTAoVCgX/4h79noFZj42OPUR1eSCeKufPe+zj2aUewdOkSbnxwM24UUlBtkrBDoTDA8MJFrGnMYlkWw8tW8th99zA5tpPC0EK07eB6HkmiiGNJlCgCu2xmuxCE/z/23jvckqM69/5Vddzx5DM5SDMKowwCCQySUEAEgTHJBmySbYKNAzZw/fnaXPvaGK5JzjY2jiRjMBhsQAgQSRIIlDXKk+PJYceOVfX9Ud377BkJGxzulZ9n6nnOzDl77+5dXV1Va/W71npf49DPJd12BxyfysQG4jRBOB6V5gh33LEboxVP2nU6QaWCGwZIE5NminY/obqyhHA81MgmxsfHWD5+gO/e+DnWBZr6dIPf/KevkSn7cPng/XvYum0L287dxZ37j7B5Yiu/8Rv/izjT7N23j3/61D9y7bXX8ou/+IuDsSk5mPbv38+v/dqvDY2yYGJ8nA3rpvmjP/ojXvLiF/Pe976XL3/5y8zNzXOiZDW4rkelUqHk9qlUa/zCL/wC5557Lv/8z/9s1cccyfrxJqHn2pKfLOOJT3wiF1/8RJ5+2eWsX7+Bl/3Yy7j0SU8izzIWFpeoVW2my8133s/Tn9rggnN24RhDr9dnz/4DPP+5zyYMAu65916mpyfZtHUzt3/xkzxyfIn7jrdotzs8+cLzeO61V/OtW7/DV7/2dYzWfOH6L/KF67/43wJ4klIWgUVDrhSu5zM1NWXnmBH4njfg39HKRqtd38doTRpHSM/ucXme026tsrKyyvbTTsN1BJi8sG9FaZwsMoUK/304C14IkNLBLasXgDTNiKLIqlhKy71Tltrpok8Gge/bgKXneXhYBbVcpwXAYb2zJLFlVsrP7R4rLFCUGfAMuJ6H5ziosTGrjuy4GJXahz/HQTsOGkma5ghhSXmF5XSwWfVGkmpo91K63R5xr0fDKBxpEA5ErRZG55jQZWl+BlaWaPVSHL9JdWSS8MInU2lWcT2PpcVllAEhXRzPRWDIs2RgV+3YGYTRuA54BW2E0YJcG+I4Iwhdm93leSStmOXFBWaOH0PkMRM1n23bthFUamQ4pCvzmDylvn4reZ6SZwm6v8rYxBQbtu8kFDbbaGZ+keNzSyTG5bwkRhiD5zoD4CnwQlzfR2tDP4oLdURVlOGl5LklES+JQ8KwYp8/CiVqAThS4BRcVr5nCeKNshxejucyOjFJ1GkR97oszBwrlPKsel+n02FpZZnJ6XW4DuRZinBctIE0TUA7uNKh2+tbFUHf7iue5yNcS2gO0Gl3cKRbAJ2P43bKh+aUD33Kh/6P+tA/ALxsDZYon7YxRabN0EQrNmg1KP9iAHqYwlgM1uoQKFNmOpXgjTGiqGUvUXzQxk5QCuBBFLXX1ihaoMV+74mLT8qiX8buBGW5mSjACmHMoITq5EGTQ8p5JekYMCDQ0hpMIbE60MYrIg4YC7ZJZGHgXQQuwg8sebX0Mcb2SxgwSqNNjlGaPMsxRuC4FXDsUBlRpryVROlrcIg2eqiEcC2DaS07y2DQA1BODl2f61p+AKM1i/NzHD14gJnDB0lWFwkdqNcqrPZj2nHCfKuNyXMCIXHinMz06PYTItbGXQgbpUI65IaibtyCZ0pAtxshHUOlIvEDifRcciPorrbprfRYnVskSywwNWjl5B9s5mUCp0QjUFipXITEMYYwV2RxRrzaJSgVfMQcOllGJ6tk3VkoHG23OoIXNggdB6FDhAkQQ3NyULJpTlRjHJRpyrU02sd7K5ddOYaIR4maAicGA044tnxf/Fc/pD/WuYv1dfKrP3A/hjfykpvue7WTTYE54S9tFFLn+GETgUHFx0jTFpnK8Crj5P2IuLXCI8eOIhHU6jXGRjYzMrUNnaVIVyKEgzAnAsGPIW3yb3ovQtjMFMdzmD12lH2772T5+BxB1aM+NY1Xr+GHVWo1xY6qh9EJUS+2kVwjEGRkWUy726UxOkGlIUgMNEcaxIkm6nbIM8v/8K+5LY96/VGOiV07Ulr564pnyDpHyXozdLoHrRy9EwIjyECAilk5fAdJb5nWwh6yqEOeJchwHOEE+J6PyROypEevu0RYn8BxQwZ3d5Dlak7oVMlIKAoAWxnDfwN9AD7ykY/wla98hY985MNs234680srNBt1pOOw2I35uV/8RV73utcxO7fMky44jw/90Xvod7rcNz/HytI8551/AYHvc/NXv0wmXMKxKZxKnY994h/4sz/7AH/5wQ+yY8cOcm14/etfz3e/+13qoxNE3Tb9bodOp8NP/uRP8iu/8iu2Q0XGspCSILAP1W9/+9v5xCc+gTFmwPv0rzd7b/7ygx/kU//4jxw5cuSEd88//3w++clPDqm2GpaWlllaWiTudliIIvxqnbzXphoEPPdZ13Do0BEOHf4u2ycbHFlq8cBym2t+6FIW5+b4hw9/lGue+yzGRkc4suchYreGv7HJqExZmJ1l34FDPP9F13HLI8tc+xtf4L2vupiNDcEN19/IrnPO5IInXITv+ywePsDK4QMciTyCWoOJ9dv5iVeeh0oTDu7Zj1QJeSvi8OIcoxPT7Nq5hd7qIrMzs+zZc5AgcKj6Llde9yL+9sMf4/DBQ3z6na/FH9tC7Izw67/9PnqdjG2u5Nrzt9FJu/zi61/FU37oMraftpNv3nQzH/7wh7ngggsHY2iM4dixY48aYem63H3XHRw+eIDPf+5z3HbbbTzhCU+gObmBM8+9kIfvu+uEz7/lLb/MG17/eiYnJ054/Yd+6Ie49957eeMb38g999xDvVrh1ltu5uZvfoNPfvozvPCFL+Q3/tev86lPfQojJO005xs33USv2+VFz34mf/Enf8iXvvh53vWe99ONYj71mc9w5plnkRvNbbffRro6j++H3PjAYS48ewc7Nq9nYutOrj73ybxk3UbcLGFhYYn3/eEHedlLX8rzn/1Mnvuc55Dnj281u7LFSYLSmjzP6Xa7xHFMt9Nly6b11CoV0lzhY0m6a9XKwNZGUYzWBt/38YIQISRpGrNl8yY2bdyA7/sWLEkTwrACWEAkieMiKGnwXM9yAEl3ACwN01+EgY/n2kz8snwuyzI8z8P3PKQSlhtJ5ZZUHPA8F89zkJ4ltU6ynCTNaHf7aKXwwwqVMMD3XJJeB+kH+MKhu7yI0AphFI3RSUtcLgRZwfXpSAfXC8gRrMzOE4YV6rUa1UoFo3OyJMbxA5stLwy1sUkaVY9aJyNrRSSdDmM1l15f0W4nHHvwCMLzGBupsOO0SdatG6UWeBacU5rxsRGQDsJx6PZt+WIvypBORJ5lFszRNgtIKUUuhQXQ3AChNZDgFMTe7fYqx48e5sj+R8iiLo3QY2pilO1bt1BrjiL8Cq25Jv1+l56skMQR/U4Ht7dC7glku0Zl3RZyHERjHcLtITINSpElMUm/hyetl2orEe29CAIPjCJTml63S5Yl5FkGwiAdF9fzBsFuKSWeI3EESBQ6j9GF8l35rJYbgRAOYbWGF1ZI44iZvQ/gZBEiT0iNwG+M0hyfIut3cNA49UYxtxxGR8fwCkAryhRhGNAMA+q1ClEU0+n0kIHl92o2GwOA8/HcTvnQJ577lA99yof+9/jQ3zfwpI2xD9hF2Zkxa4TQFKm2ojBka7iSQRfEgvb1olBqeNSLB/tB1k8xuifUmhZoWiHFhuXNlifevPK0Qy+WqaSDARx8YHBIAaaJEzeCAs4ekGeVOWRDEHapGqClGczx4f4UCUyDY4QoASsXxwtwvAAhPUAWAFQJHGnryAsHxw8QwmZGIR382jh+dRTXD4v0wgKwY23oGEyGsq19BjEYDtYIzmVRi5+wtDDPyuI87eVFAkcQeJZou5/ldAslj4qU+FLiaAOZleO1kTB75UI6ICTGcVHSSs4Kx7FZWcbYLKg0sz9ZjoMV4MyTlCxOUWkGBYmmkNK+LwTOCRtWSYq2hqkb1gBNVxuMUqSxVcETUlpZzlxhFOTKlo5Kx0EYDTqDPEZQKCpKp5iEYjCQZbWlBS/NEMA5HEV4fLcTSkqLaJcdsrU4hZ3vj3GwGJ7dxYoy37sO/F+NqZiTjd33Hjtzwi/m5FftXz9wyi+DjeLkbx7e2E+I1xhz0tXb/wv2L4xR5EmMylKUzjFC4voVqk6INpYzo7luM2Nbzqa5brstIzDGrvuTrkoM5tn37v7JL7hF+nuv22V1aZHluVkLPrsOSmiUytG5jZ6Hvoswmqgb4QiJ53oYlZFlCVEcY0QNpEBquzaVhiSOLCHpY3TqscZ/LcBw8hvFHigEQiV0lw8RrR4iac+g0nmEX8GpjOJVqqikR2tuH625fcTdRdJ4vlBhynBrKUFtjNCfxugcrVK0Tge2aM3X+B4z8Xv27fHdpqeneeITn8jU5CRSCg4emWHnts2A4aZv3865O7ezef00s/PLNhihFW41xHWFFVHIFXkeYbSiOTpKpTHCytICtUqFiy68kI3r19HttPjC9V/g7rvuZu/evVTr88RRH1fA85/3PC6//DJ27LBlH+Va/uZNNzE3NwdCoJTinHPO4YtfvIEse2x57JWVFb7yla9gjCGOY573vOexe/duHnjgAZ71rGedwPm0Y8cOdu7caYMX2paZeZ5Hs1FjdWUVbTKk61NxCjufxoSBh6rXQGU0qhU2+BUCz0q3N0ZGWF1aQKURruNSC2sgPbKVWaIopteLqDfqbJw2nL9tjJVWG3oZMu0T+nadffUbNzFR9RkfH2f1gWOM+QHjY00efuRh8jRhvF6nUQsRaObnF9EU6lhJTOC7bNi8mbTfxiNg485zOOu8C3F9lwcPzeMsGZTbYONIgFAZdzx0kO0jAZnSdBeOWtWuqE/gOmzcsJ4zz97F3sPHGG3U2b5xmpWVlQH/FUC90eA5z3kuu3fv5vChQ9y7ezf33X8/+/fv56efdR1xFD0KeJqYmGDT5s18/vNfII5jpBRcc80zGR0dZceOHTzrWc/itO3bOf/887njzju55+57eOSRR1hYWAAEmzdvRhlDlGnk3B6io4e4NRTkacRpp21n7vgRcH1GG3VbViYkG9atp1ar24feuI8vBSP1GnrDRtq9mCMHD3HpBbswStHpdmnUqqybGOGlL30paZY/7jMWASgCnXm+xrfj+x4CC2iUmWSutJknQkqkdPA8tzDBmjIA6boebqEClia2nEoYPci8dyiV8axfA1CWQQ1K18Sa/ySw/qDve4O1JqVV2bM+qBnIxIuhTA+JzZoJfLe4RBu4k8ISivueDW5ijC0HFIYoS2xGZZ5RrY8MKhsMNmhpk8+lLTcsyLO11jiuh1XVMyisnakGHiKXCAVSxZg8RauM0HdBesiqj3SryCBgcrzB2LpNjExOgxBkSYrKc4JKFYMiV5o0ScjzHNezVBZ5npOlKWmaWHEbUfJdWXU/neuBWpXSis7qKgvzc8zNHMfTGYFwcDGYgojddWw5nptnRL2EbrdHp9WmmvZIawE66dmxFbKgotDkWUprZZnRkREatRpBpYJSijRJ0aU/57g2W0nbUktHSoTn2YoGxxlUWUgpcIRBFCI7eZaQZykqz8iVHVUjBFq4CGlASjzfxw0C+ovLiLQHWUwaR6AVYbVC2BzDc9Yy0srMGIpnjEa9hue6ViUQcKWkEvi4RZA8CNyTYInHZzvlQw8de8qHPuVDP2bf/u32/QNPWoGUOEWenNaaNE3IM4U2Bkfa+uayzMsUC8MaN9ZSOyWDjCFb4maZekTxd7mYB5uXKDKCKDKLpERqgXE4aSGxNuPFieTag+VhhkjKhwbIKSRGS6fAHrNmlIfxBVFkWEkhsEzjcvB6cVFr+JksSwULMEhaIrUgrKGzBsKpYISHNsKmthaOPMYgvZCgOoLj1RCOj+NXCUem8Wtj+NUxjPTQpgBoxFopZOk8DDo+NDxSlqV99pOySLHt9nq0V1c5vG8vS8eP0F6cZevUmM2EkpLlKGa51yfOMkYqFeqeh681IlUFp5NaO68oavNdML7ESAfpeVZqNcsRSYafCOLYI0xT3MKRyuMEFccIpXBMcT3SKfpq54Kk3FAsaOacAD6JYjMGzxhQChklJN2ITBuMtGofjtcAt4dwJJ4f4MgESY7J2jhmHFcaHMcrwKcT2yB7r7jP5Rg/3qM0a02vIY8njFnBzCXK0tS1I05WNBAlFidKzrVhqc5hcLBs4lGvPHq/KufpMFz6vQyhOemr/m2DefLmbR7rxaG2Zjj14O9Hf2YN9FR5RBa3iVeWUGkHladoowhqo0yMb6fR7+H4Naa3X8DGsy6gNjbF8twiOsuK/ab8kuLaHsti/uvDQRiGCCnYf+AQs0cOs3DsCM1GExEIoiwh7nUxuSZNYkLPRnZUqvAcl1oYkqcJcb9Ht+vhhA4ID5UL0kwTZ4per0OWpnaaFPuZfoxxNCftOZSfEdhMSCGRIsAXGTpa4eA9n6G9dIyos0StGlBpTlAdzwiDdSTRInMHHmHuyH3E0SrNkQpZoshzTTgSIaSgMroerTKkchAm5yQUvpysa6nX5d0rfScMRSRj7eHscdye+9zn8nu/93sYozl0dIbb772fyZEacdTn937/j/jpV7yY6665gq2bN7Bv/wHuf+BBrr76Kqq1Gmmacf+Dj9Brt5gYH2X9li3UGiN85+av8aSLzuPHX/4yNILPfvYzvPIVLx98Z7e9CsYwuX4dH/yLP2N8Ygqg4ACwAad3vOMd3HjjjQB88IMfHJRltVqPDTzt3buXl7/85Wit2bhxIw888AB/+qd/yjve8Tv8wR/8QQFsndiMgSzNeOjhRxipVRlrNjiSZKRZjpQJ1ckxMJrjex9h4+k7qW7bwsH772Hrxk1cumUbK/PHGWvWuPTpT+e7X78BKSWXPfdHGG3UkBgeONyj148sh6ExXHrmFJecMcUff/hf6K8u86ydI1RcWFxe5ld+7X/x+p98Na//qdfy2Zvvpd6ocNqGcd72lr8kS1N+/3fezvSGDQjXZe/RZVLtEkUxUWeFyakNXHjFE3nw1hvp5y5nXf5sXl0LeWj3XTz3lT9HmmZUA5fffu557D6+yl985hu86OqnsGGkygZf46Ho9Xvc8Z1vc+klT+a6H3kxf/yxz3HRrh286vlXcelTnjJQ+APYsH49f/e3f8Nv/uZv8u73vIefedMvYLRCSskbfvJVrKys8OG//ctHreVut8sb3/hGZmdncRyH2267jYsuugiAt771rYPPfevW73D9DV/CGCulXjZHCOq+ZPPM7XRv+yrv+dSneMVPvZGXvPRXeMdvvZ0nXnwJL/nRH+fOh/fhuB5XPuNKPDSrq6uMyLtZN1Jj68YNbJya5As33MjffewTPOF976I50qDRrJAlMRMbpvjoRz5CqqyK2+O92eh4kSUoJGEQMtZsIIQkShJa7bYlug5dkriP5/n4QUClABoiIenHtgSsUa3gONbfbq8uF6BGUT5VGOqy7Ep6rvU/i+oAq+orC9nuNYsnEIS+TxAEgDhBsEYXDpYs+IFKP10U1xX4vlXX8zy6nS5aW4DBvm5Dh26hZGyyhKTfJe73CRtNgqCC5/sYp+A/NbbvRucIo6BQ5XM8S4zuSZe0HyMNTDV8dK5QSZ92d4ks6pBlCbVaQD0cRY5ugZF1+JUa4+MjjE9MUKnVybSk12kRdzpMrJtGGeglCf0oQToOY2NjmDwlyzK6nQ5JHJNmKWHNKuD5nkvc7ZCmOVleChcpjh07ysED+zm45xEmZEpNuIgsptduY4RL3fGLVHmX5ZUFFhcWaS/OMuFENCoOWdxB6ZzcGDKVk2Upca/D4f17CTyXMAjYtG0bWZ7S7bRR2JJJP6yQZylaKTzXIfDdgtrDwRhbfWC0DfK7wmCyBJWnxN0WaZqQZTnagHRcHM9DuIGtXFAKP6xSUYrV4wcxSYbJMvKlWRydkgQek1NTBGFQPEMptIZc5QgR4gQu01OTVk0vs5ytUhjGR0dItYUnfD8g05Yb9vHdTvnQgyNO+dCnfOiyvz+gD/39czw5BcFeUb0lRCFnn+tBWZxWtja45LwpcSEhpe2kqwegjTYasI5KWZO+pnJXglBrgJUde2uwDRbzocg6KsdIrq3oIklpaBKehMzasbWvrEkbigGZtC35s68LZ2gx6+HltBbZKdEp6cjBrXGK6G+WZcRxB6M1EoMvBEFQozmxiZ7IiR2IO3NgNEJoXM/DDXyCSg0ZjCD9Kn5tgrA5jVdpIv0KGFtiZ4rvd4ZI+QaLvrgPg34W1+dIxxojbeh3uhw9cICF2eMsHDmAoxImmzUaI006UcLM8ipLrQ79OKUZhIwFAaO+T82VuBSOxGBkbfqxEoK8KLfDtUYsy616So6y0sAmt/0y2kaqcoXMDb7jlnMYLQSuKP43BoUhM8WGJQSuEPhFyrAriyyooi+OgRqCOElRxtA2UKlVCasVJrZcgO/b9PFo5QAq7ZJFK0SdKkprnMoUwgmQ7rBq4tCGYIaARlFucI93gwlggVWtsoI42G78QWCd0izN6Pdj0jTD97yCd8EpZo8ZCASUI+K4JRGnnWbmxK/615tdYCd99t83hsNHDUz0YxlKhm9VcSOHYjIDckUxgDLX9jExfB6DwHIcSMcn7q/SWT5Ct3UUoXNbAGoEleYU63Y+mdrEOqTj2qhpkpIvLuIYQErUIHK81p9/zzAEgU+eZ9xz261Exw5R0ylZ6tj1ngkkEtdxcX0fq16bowrCf9d1qVRHqNTqhLUGq60Wxkiq4Si51sRpyuzxo5y2soiK+5YvxBhQP0B5y9A1CaHIESg8jBwnS48TtTvkUUqufKTbo7rexa01Gd16AYmCzsoMq8vHqTSnqY6N4Ds9hGqTLu9lYuuTCOoT+LVJjHAHUtGD+1dMtcKk8FgDbPfM/w5r2LaZmTmE0Vx35dPYc/AIURzze+/6TdZNjKOlx9997ONs27qFy57+Qxx45EGCIGDL1q3sPG0LSm0kifrsP7pAq3OQM3aeTXN0jH6c8sY3voF6rcbXvvY13vrWt9Jqt/nzD3wAKSXdbpefeNVr+JEX/Ahv/Jk3Frwx3z9a9/Wvf50rr7wSgE6nYx1GYHFxkeuuu44rr7yS66//Aps2bRoc8+Y3v5koinnf+9/PzOwMq6stGlWrjrXQajNWC0mSlE4/JggCwjAEt8KRo3O0H9rLgw/ew8UXCyY3beWR2S61asiOLVO0Eut/TIw0eM/7/pDdux/gj3/vXZzue8Rpzoc++3U2r5/k2ssu5keufSrHj8/x5a/dxKW142zatJ4//aPfp1GpcOTgYS679IksLC7xgT//G179Yy9ktFHDJF2OHjlGqgWBI2g06oxNjuE5hl4Uc8/t3+XMsy+g3enyB3/4hzzrqsu58Irr+OINZ9LtdEj7PTaYJZa+dgt85yBX/dBFaKX43T//OK+vV9ii5ggveTHKSBbm5njC9im2TzZIk4ST+ZrSNOXBhx7mRS9+MZdf8Qx+6Tfey8UXnMMbX/USzjzzTPI852tf/SrGaI4cOcJP//Tr+MAHPsBnP/tZlpeXAZuN87rXvY4rr7ySd7/73Sec/2d+5md4/vOfD8Dtd9zJs697Pn/6x3/I6aedBgj+9t4V7vruHM/aNsLx797IZxaO8eLrnomWATff9HU27thFkilu/ta32LJxPc1Gg5e99CWsLC3znVtuZeuWdVxwzpn85q//CvuPHCcMA378pS/m/v3HuOXz3+TrX/kCnaUFok6Lm775jR9sIf1fbkkck+U5eZrhFYFJled4hXpas15HCkGWJmR5Tj+K0QYaRQZgnuU2s8RySAwyzoOCl0hKSxRuEJYbU5sBHUSeq8HWZ4nDS87VYvcr7KLB+jdS2MxwbfRg75RS4HmWo9RxHPzAxy8yWTAaoW0gtF6roJXGEbYcz3EcHNdFY/3tWmMEL6gQ1lOWW108P6XZaFALbflIqYKMgbGxCYx0wfVp9TMcaUl0HcfBl5JqNWR5PqHfWmVpaRGjrIJfbAS12gjT23fghQ0cz8PzPIRbIRchCol0PVzfp9Npo7QhVfYZxZUCRwCOizKQK4NwXPwiqBtHEVG3Q9VzCTyXyXqdNM3odrosHDtMb3kBFfeIpALHhV5KMzM4CirKkGc5GMWmsTqyX0FEIRXXoTY6ysjkBKDQWQJZhKMzdJ5w7OhhJqamWbcpxnFsINV1JL1e33KhtrtUfMub5XseyhiUNmQ6HyQGIHJMnpNGvSLzISFJbFWAdF0C1yoQep6PG9YwQqIQ5LlCxC7KDRHaIDFoL7DgYHeJiudSqdWQ9RFWujFpnlENfJvl5Nr5KF3bZ6VyVKro9SOka4HGNMttidAPYE/+37RTPvQpH/qUD/0f9aF/AFW7InunBHGEBVnK2uxBrbgAWVTEDZA9IYrsn/IHBrWDa1cyeLAvQe/hR/7yr+FtqcymKheIKBAjMXSuteMHIzP84eK1tfdF8Vo5uAP0emh9G8wgle9k+jQx9GEpJAqF1op+v0ueZZg8p1mp4ArwwwZp2EBlEUlvCVOWLRaytZYU0kE6Hl5QwQ0qOH6IlA7GaKQWBdn2GhhTjks5NlD2URSRKuuwGK3J0pTO6iqri/OsLsyjkojAd6iGIVoI4iyn1e2RZRlSa+q+R93zqLrW4LvCDCJrphjGvIhg5GVKNkX0bXC/io1XCMrHFqM0Jrc3XpYbVuH4WMU5e25ZoKz2WsEVEk9acGpQeleCkNjJ7SqNzvJC9jdH5gavOkoQhgSeR9abw6iYLM7J0x7CCVB5jFbq0TvvyW0wh753uuzjqUmGCPrLzVpYo2dVI23ULkszG3F01zK8ygzGcm7bzDoBjizAaLMmDzpYrmLwR0mCX6b3i4I/zX587byPaicb46G9YLgct+jUY96HRxvM4c89+uwnCiYMXcbwEYNlL9B5ispijM5AK2tShVM491baGCHot1dRWuG4FYLKWFGukJ/Q/xM6K9Z+H+xnJ2yAdp04roPSmiiKmD1yiEq/S83zmI8SW0pEYEtLhUCKMkPPRrO11hYQd2wJsOeHGF1IvRbAdq41nXabuN9DZYl9GBHf436V4yfEcPfX+os9rxYS7fiEzU2E7SWyuF/MB48s6qJVjhcGNKeniPpdcELiJKc2vpn6yCSqtxd0TtqbR+cRGI10fJRZmwTlfDVGPLqTJ/cN82+v98dBm5ub47bbbrP8GZ5nHVZtkNJh4/SkVWTJbbADY+wDSJ7TVznzCwtMTa8n8H06nQ5ZnqFUjhdUcFwPbTS33fZdztm1iyuuuIKnPvWprK6ucsUVVyClZHZ2lu9+9zampqZ50pOexHnnn2+BnpPagQMHuPvuu8nznA0bNrBlyxYwhuWVFb7xjUcDA2macsstt3D55Zdz2WWXAbC8vMzevXuZn7Xp7lE/otfr0e/3GKnXC64ZRehIZGgj80magBBU66PMLy7RWlnBC0L6/R7HDx+0D5C5orW6TKM5ipSCOOoSRRFJmuBXKlQqIW6acvDhB6C/nuiC7bj9ZQLVw6uPIFz78HruuedyeP8BHnroYc499xzifpfFmeM87ZInMDk2Qm9lkTRPiHMrupHkOf3Eyp7bLGgLImSpJeV2ghphY4xKpcp4vUIoNIcfblEdm+KSSy7hrHPOJ05TNu44m8np9YyOjuKPjtONUjqrLcaqPi6axcVlzjjjDLrdLo88sgew01przWmnncbZZ+8irPwJnmdJfqWUjI6OcsUVV4AxHDp0iEsuuZR9+/Zyyy23nHCf7rjjDibGxyk3ojiOue+++9i8eTNXXHE5IFheWSX63OfRWtNqtXj44YfZN7/KQgKh0PQWj9MVkk1XXUU/NRxfWKXbj8mVxpGiCFBpJicn6XW6tLKMNM1wvIDRZshqp4c2Bs/z0ULS6vb45k0301mcI+m2/lPX2n9JGwoGOo4c+DIIUUSzBcZoCxjkuS0pM4YkSS0fERSZ3vZ0Sim0yq0fXgBPA05VVWSiS7vfG23QYgiUFAKp5Zr/bUpaC5tdrk8K+ApR2u414EkWQUwpJVqXBkpY3hC3CIo6trxLq7zIkLcZLqXNace2LDjPM4zxB/uwFZQRBKEFiZRwLZenAUdSkFw7eI7EaEWaZSRpikTjOgIlJDgurh/g6AyR5GRJhPQqtows8HA9F1EJifp9VMFX6/meBe8Kbiw7LgIKknaltS1LS2IqThVH+oSVkH6vR6/TptdukacpjhAkuULmVqQAx8XxfLwgIE18nDzFEwppbMBehJ61wWEFITTS5PjS4DlWsbnX65GkqfWFC+DQcVzrdytNnmsCx7EP41qTKWVl34vgvSdcm42kMrIkJk1jVJ5jsCWRruviuRbMcqUdYyMlQri4jlXudMMqoDA6Q/ihna9ZhE776DQufJo16hLrY9i57AiJI4Wd09oUPqMugE6JEc7Af3+8tlM+9Nofp3zoUz70CX37AXzo7z/jyZXliABigOR6nlcsBj0AbYZl+AaAkRCFobXNEpOX3EDlcWWJXgHmImw5WUnQ7ZRKDGuzS+s1pboBDFSASabsr93Z7GQpM7YGQ2avpYz2lAO4Vq87lIVVXpKxYMiwwtlwEwU3kCMlOTZleGl5kW6rRWtlmU2T6xip15gcb1CtT+FKQdxdJE+MTUOVVkI2S2M8N8bxfFzH2EiPBIF1ApDCftca9PSofssCxLIOghzwC/TabTqtVQ7v3cvskYP0O6uM1Hzq9RphJeTYwhLzSyvMLiziZzkjjsO6SoURz6XqSCqOsFGhMmqn7eKKM0VuDJHWCGUlqx3HsaVvWuM50qYp+66t7zaCNFVkqSJNi9INYTkDpCzmhRCWBN7YokxZzCfXKTcCcLEZXVJYMM5gjwk1uMoavl6nRz9VbNjiETgVHD9A+nVEFlk0PWqjlCLsLeP4NdygjtAu5YIalNkVfSrv/X+D51WANUdRlvPbgoNOkaVXKuBIIQuJdssBYIweGBKVm8LWClzPwXGwDilYAI41s1qeXwhBXqSix3GE53k2lV+Ue0r5T7HJDY4f/n+omWF9y0e9+QOPy8m2qNw/7ZnkmoMx9DlTOFbKpKC1VQCqNMmTHjqL8f0AHa2wtOdmVg67KJXSWZ5jYuvFNKbOoDa2FRV10GlkV24hlnDSZX7PyyujZ67n0RgZZWnZEpoeeng3Z6+bZP30Ou68azdNXWNi/UhRfmvA9ECEgCFXmjiK6Xe6KAOO61OpjVCvxeRpXpT/SnIDi0uLdNqrlkS0Ngri5GBNsSc/ltFHQPHIYbSx9eRBDVmbYPNFz2N864X0V4+TdGfoLz5C9/hd5L0FamPr2XDOZVTHN9FdXWBy/iBj06dRq09w8PaP01naS2dxD051gnrcY7IyjfQqtky2mLNmaNBO8jdO+Etrc6Kz9DhtH//4x/mnf/onvv3tbxOGFf7p+ut5wQt+mHqtxic+/g+ce8EFnL5jB6/+8Zcxe+wYd373O5x/0UXMLS7x2Ru+yrOvvJyRRp3777mLM886iwt27WTf4VlwPKYrlRP8tj/4gz8Ahuxc0T760Y/y6U9/mrvuuoszzzyT4kOUc+Bd73rXILjxpje9iXe+850A/OM//iMve9nLvq/rvPHGG3n5y1/OZz/xcS558pNZml/AFYKRZoNWJ8aXEHhWEXWkOcKZmzbx1Ru/gtGGa5/7PGaPHaIaOLzqJ17Jrd/4Ch/6s9/jZ9/2dubn5/nE33+Kl/zoy6lWa9zxnVt50xtew8T0OhZWOnSjBJX0Se7/HO2laY5sl3z1H/+esDHBT//GnxEGHtoY9hye4fM3fIWvfenLfOhDf8GOLdPEO6fxHEk/0yRaUqkEeBoeORAz2zqOEMfZKhfYuO00LrziCv7pLz6AdF3e9ra3IYVg//79XHX1Vbz86ot58RVP4C8/8WWe+szruOWWWwb34Fmv+Dm0gUwplpfbLD3wAIcOHGLD9CgzM7Ps2X+M9/7uu7l39z1c9/wXADaSe+45uwjDkFarxeqRh/jYrV/h43/9x9x666084QlPGNzDbdu3841vfJ1f+ZVf4X3ve9+j7ovBoHOFdBwOHjzI5Zdfzjvf+Tu8+c1vBuCFP/ICXvDDz0cKwQ1f+hLXXXcdl5+3mSefs4UHkj6b4habYgfR3ML2DRt5QrPBO//4rxht1vnZV76UPfv30+50OXD0KOMTY2zevJHVVpd777uPb9/6HX7+Z99AL8n4u098lmddfQUjF57J/z52wJIo/zdonu+BEGjDwIf2fY84zcjSlG6vR+A5eFKQJgmO6xH6Af04xnNdGvUqQttYtzGKPI3Jsgy/IAWXQpAWapRZlltwpggOgwUgtTZIqYuyKzGoKtBaDR6kBn66ym1ATwo8z8P1PMKwWmQ7yoHoTW4MINFoNBAUoKbnumhlycCXFmbx/BAvCGiOT2CzsrQVoVE5qJw8jTGODbYq4ZCBBY6EQBViMlIKqyzn+9bfUzmpFiTaIRMBrrClXNr1SZWht7JENH8cFfVRWUpz6xlUpzYytWMXlXoNb3yUw/sPIDCEnkujWQchiWIbgFRaIR0XZTRKa/pxjMoSdBKh6xVc16FRr7B3zxJHDh9kZWUZIwX1sXFmZo6hM80I0Gw0mJicZGrTNlqLAe2lBY7te4SluXnmF5YIw/Uo6SHdAEdoKq5houEzUgvp9yOWezlaSNwgwHFc8CCs1PD6KYYM17FE3cYIWp0e/TgmyTJGRxqWRFy4JHGPNO4TdVqD54N6o4nnWgBP6gx0jskStM7BC3GrowSBh9ZVJtZvor84Q6wyZHMCofvovMviwfsJ28tUtUPQGCcIQtqtlr33WWaD6EVFgudYgKlSrdLr98nTDD8QOK5AOj+A3tX/g3bKh/7eR5zyoU/50P/pqnYD3iBz4skH98IYm9UEg8iJnWuDu2yNnylqgJX9KfC7AgwSJ1yZAIYJnssMKTMAnxgg62WZrBElECXWwAJtkSxZZPucEOExxgIjg/GzfbdlAGuLpbximyL36KVZgj6lchxFH8rUZ60yOt0WR44eorO4zEi9zo6tW/FkgtAOSoXEaUQSgTYZjuzjOYr6SEalFhMGAa7rYYRBVhyE4yKEs4bwluBagYyXInwD0ElKu2lFfTqrLWYOH6K1vMTMoQMIk1MLfUbHmmRas9KPOHh8ln63h8wzpnyPhucyHXoEjrRgUgEESlnwXQkbTRMK0NapQSm0EOjMkpFLIan5HhU/wHcDMm0Btk4/p51pYg2uEHjl/lH+YIrvLAC2AvRz5BoIZaOBYuAIlUCnKyVKSlIjBrxk8/OzpI06jNSQrocX1tFZjTSJMCpD5zFCq6EyOzF0lxlwHQBFlO/x/8AK9n5hbAWkbaZYj/YaPNeh0ahRrVYoMxFl8QBZroJCK8Di6p5rSxuLBeyUUU9rKQdjJAQ4jkAgCQO/AJBN8cMaz8Sj5DgNCEtoetKrPGawwJx4L4ZoIE/Yw83gneEzln2m2NjtPuC4pTFYA5+FWDtG6RwhHRzXx/c8TGZfCxtNhNAk3UV686voPEGojPaRe0nbi4jKCF7QwAuqZHEflSmUsWo+5dAJIYf6b06+COu4uC5hGLD34Qd45P77mAx9As8jRjCz2obQJQgCW7utM7tnFBENB/AcQeBKfMfguQLPcwh8D2EMaZKjUSij6MYxcRyRpTFB00VpKxwxHJM5Ocq1RtdghpaQ/W4XjdApSbyM32gSNMaIFh10NENbZ0TtRZylWZZmj2BURrXeYGz6EvJMkPUTMmWQbpVKcx391iwGl9rEGVTHtuK6PiqNHusOP4ZNXwOTv3dM5/HR/vqv/xqwa3J0dBTP83jmM6+hFyX0ooQrr7oKv1IhV5pbbr+Xmi/ZsH6K22+/3XLoPO0pHDl2nKNCcMGFFxK1Vzj8yANs3n4md973IH/27e/wS7/8FnbuOB04EXD6l+tv4O577uW9733vINq+fv36tc4Nrb21Em+4/vrrmZ+fB2BycpK/+qu/4j3veTcPPfTw4NDR0VF+53d+h0svvXTwmiwIbRc6ETMrXVA52igQgi0bpkniiDjuMTkxhUCyNLfA9s2bcFyXJEmZW1xkZmaGLEnZvHU7T7niag4etA+XT7v0Eo4eOoyQDhPj4yzMz7O4tIIT1tl7z23su/c2rrzyaawsLPHRD/w165swNeLidnbzDx/6GgcOL/HSn34TV195BRedezYP3P8wruNS33Y+SZwghWDj1m20l5eIem0CR9OsVxipVZCdPqv9lNvvP8jYlp0061UcKfnE3/0lt99yE1edsY6ZmXn+5FNfp5kn3Pvtm/np171uMJ7GwI9cuoPzztjO9CU/wkizwUhzhI2bNtOPU8zSKvfvOUBXubz5d36PbWNVtkxP4Hken/zkJ/nyl7/Mr//a/8e3v/VtPvyhvztpzZrB2A/f+yuuuIJXvvKV/O///b+tf6RTjAzYsGEDH/jAB+gnOX/+Nx/hVS97KZWKVTbstlbpddpobbj2RT/BaZs38L/f/utctmOU7b5g6ZaPsDhxGsnEmVz5lCcSRX0+8vcf59xzzqFeq7P3wGF6o01GajU6nR7rp9fx4hf9CLfefie+H/CcK5/GaqfDI4/sOynQ+fhunU6HNMtJs4zR0bEig8aAUYgiU6dWrVKphATVFCltiZpS1r/2fI+ShjnXoFwXtBpk0YEFkMqIuetaoRQzZMOEsMdrrUmzbKBurAoCb6WULf9xJEFYQWtLqhv1+5ZwG4kXhIU/YZXztNY2KCpsmVepqKzLB24hCMIq2lii7CTq43i+fVCrVsmzjCyJSOLYPowiMW6AkC4aVRD4SgwSrRVxmln/VoBUqS11qdUJqg1M0kHnEaONKuiElUMPEc3PopMYWZCv66TH6MQEgZzGCXybKZqldixNMZ5o+r0OaZpSrdWI+yndfkSubGljc3wCLSS9JCVZWGBu5hgLs8fo9Xo2gwtJL1VUQ0XFgUCnuFlE3m+TRn3SNCmuFRQCJ6zjBnVcvwp5H5FF+EIhiyqBHMvTpJQekIA7XoDr+pRPHZXAtyCFUhijcaXAlwJURtLPSWOr0ielg1eAkoEDKEv2Hvc7ltw5TVDCwwnrhJMgHY9KtcrkuvUsphFZ3KPhu3jGxzMeS+0OoQzx1/UIGmM4rkMYhnYcoshmwBkLfFbCEIFB5VkhgGGIo4gg1HiPc1/6lA9dvn7Khz7lQ//7fegfqNTODF304PWhTpSlToNU3xKkKv3QYvLrIkPqBFWNMrXsMVbE2sWs8UaVXYFhNTr7Y8rFbtb6Uh69BiCKNTSv/KeYl2Vq8QkDWawdUe4Rem3Y1z5SnHPoOKsKYhdClqe02qv0Vlq0K3Vqfkiz5uE7ijRziBNJPzKkmSVUdIVFgk2eU61Vcf0KUkicoIZwZBEdcAbg2pqzKDCmzH6yHddGD2RbVxcXmD92hNbyEq2lecZGG4SVKn4lpNfpstLts7iyCmlKxRhGPZcR32O0VFYRa/dbipI0viD/lgXPkrZlg2iNUQpZRFcCz8N3PBzpkuSGJNO0kpxubsg0VIQtnRtghxQgEyXotFbyOVyWdwJoWXhhsog8OEISALG2c661uoI0GRVPEfoO0vMtaWUSDVKRQT8q7Xc4o8xOa7NmJP4btDXS+bVmCo4IY2w0x3VdymyF4c88ykYNdp/ylzUg2P5lBllhJQ+acGz6bLmwSqNZjrNVd2SwHsu9BEGRUmvP9hhLb5ASKooN2h42/KFy0+BE48NwmWS5P5jB+Qr5n6ELLg9fmwe2JNYtHtgAFI7vWCLCuEt/dR6dp4SuS18dIU/61NpzyDEPv9IkNX1ypchzZcsTivtk/xuac8XmJoovdp0AKSV5lnH04AEOPvIQG2oVXNelk+as9iNG0wxXSFQSk2uNTnPyAaGAdUwDr+C0kPaeuI6Dkg5C5IOsw24U0+v1iXs9wqkS8F8b12GDafdBBu+fiN/adSyxapJJb4ZKfT1eZYygUscLqkjXI4t6RO1lOstzuI7BD3zqo5toLa6QxF1wfJyghpRjrC7NIpwKadyiirGKnyfddkRB5MgJ5guwQPKga4/j9prXvMb+YgyLi4sopVi3bh0HjxxHa8O5u86g149odTrsP3SY0zZOs2PTNm6/ezejo2OcteN0Dh89TpykrN+4iYPtZXqtFUYadVZWV/nuHffwol9/C6dv3zb4zizLmJ+f5777H+CBh/fwSz//s9RrNcCW/XU6HUplusdqu3fvZvfu3QC85CUv4Xd/9//w4Q9/mH379jM9PQ0I1m9Yzytf+Urq9TrGGObm5oiiiE2bN5Eh6cYpddcGDoSU1KpV++Ci7EOzVpokihkdG8P1A/tAnVtZd6VyRkbH2H7aDo7OzFKrVti8YQMPPXwApTRbt6xjpdMjShVuDY4cPMCe++7kOU97KQ91u+y+7Q4mn34uqJiZA/dw5ze/yCN753n563+Os8/aSXj+2Xzun79IUG2w9czT6c8eQGKoNxt0V5fQeYonDfXAZaIREOkGqynMHJnjtKn1jI/WyZKIb3/zG9z8pS/wvKeey90zXR6Y7XDVlMPswix3PHiYuLuKEIKgNsK58gjT2dl4O34ICYyNjdJojIDs4Xe6zC0s4lTqXPuCF7G1KpioWK6RvXv3cvPNN/OmN72JLEn46o1fwfc9kiRhcXGx2PNNEVzTrJuawPVDnvKUp/DqV7+aT3ziE0yMj4ExLC0tkaQZV199Ndd/5evcc9+D5AUvhNGaY0cOs7q8zOYtm9l+1vlMT0+zb7HPk3ZMUKmHHL3nm6RTCyTbXa679tksLS3x1a98ma1btxFWqkRRzIrRxP0IiWR6epKNm9bznTvuplGr8bSnPJn5+/fQ7fXZtGkTSqnHnH+Pt5ZmVs03yzLr7wo58KUcWTy0hAFhpQLCsdkTjlUKthn7Ak8Wj1FpZh9Uy+gvRcBXmwFvqbQ1QAyi18Yg7daPxmavGWmKjAqriKZUDq4lpvY8jzw36DwnTWNylYNwrFiLAcdxyZVC5znGEbiuwClsodYGrXJrdwy2xCxN0EqRxDGBkDiuj1eox+k8JY6t4lKcKoLGKG7ggpA4jsR3JZkyZHlGt9uFOniOg2sK9T/XQzqu5QnSmqrvkMYJq4srxMvzmDTFEeCEFYQjSXstdKMJGMs/pRU6yxElkIchz1KyNMEbaQKQ5VZBSzoelVodlSUkac5qd4nW8iKd1WX7cKk1WZ4TZwqltPVp0z55v020GhB12yRRv7ivllLD80NcL0A6HjpOEXmCiyqAQltOl6YpcRyRJCmO464p1QmJIyWu5+FIaR/gtcLB4AhbXZLlOSq33Fm2WsXFlRIHRZ72UUlE0lkhT2OrLoaHW8tw62O4tRFcL8ALKnQqVaQfUJEeLhIHQXu5hUgS0BmOsACKFJJMF6JC2LIkpUxRFoolhi4qGfKCEJ3hJIDHYTvlQ3PKhz7lQ/+HfejvP69RnMxmVKRWDY1H+bs2elCLWvbEEoqfOAGFsJ8tIdA1bPXk3hckz2Ktfr2c7MaoElhmeAVqXWZcrZG6KZMP0pHLLKc1JNSsAU7YWt6hqcqAx8owKC1cg93WulxOJmM0CmsQAz9kamKCpN9hfrzBgf2HmVmYY3ZhkemRERqVgEAkxHFOFAna/RSjNI7RLK30qVVWaa12GJtuUR+bZOo0SWV0Cj8IwXPRSpPn+SD7yBp9G7nq9/v0ul163S6zhw/TWlpiefY4UWsFaTQTIzXqzSbS9zk0s8DxuQXmFheJe31GfZfNjRobwpCa41BxZVHGVv7YsVWlE4N1BIwU1IT9bOFR2MiL6xK4AQaPbiJYjFJ6ac5SJ0UpbJpqwVUgsCTsZXbTAHkfApvk4H4LTJFmKUowTNoft3i9boQte8TQWlkBnRI4ismxGtLkhQEs5oG2MuR2bukSjRxsXoM5XNxnDGvv/XdrYi29eQ3ALQxVMZ5GnhxFKUyL0idulmKNz8uWwK41WTjN0nUGgDCUa48B0KiNKQji5aBP1nCufY8NtJZ7iN3UtSrvxxqn3KAZw3BQ3C7j0lgObeoMtqIiSmPLNYfvffm/nVYOuAHCDUEGpP0+5ArP8chShcpSkqRHEI7ZKFeuSNKIvNdB6gxZPOQpNLnKSZIEpdzCKfQpOdF0IRxd7pC66M+G6Ql6nR5f/sIN3HPz11k5foAXv/j53L7/CN964GHSPEf1UrpHWxxcvt+WYShwqhWE56KNwRcuo80mnuOCyknjNlmegXBoNEaYnJxidqXHTbffz9YH7mf9aJOnbdyKKz2k46PzpEglXxvbcp8uif7MYIMG4TjIIETkbVR3loV7PkUcd1DasPHsa5F+nenTn04UrZBH88RLD7J8bA9p1CGsjqCFtGVhpz2RpDtLZ/4B3JV5pM4xaYzR5SoXDE/Zk9enXcF6YEENJztZj+MmBM1GnTvuuovf+8M/4W1v+WVOP+10brz5NrZtmGSsETIR9JloBoyt38qPvfwVZLmiFyU88+qryI1hz+wy01t3su3Mc1jqJTzzqit5zlVXcM01V3P22Wfz0Y9+FIAHH3qIq65+Jr/zO+/gr/70D6hWKgAkScJ1113Hnj2WR6jf7/+b3S62UQDOO+88brzxxkEZUL0gT06ShGc/+9lsP+10PvWpz1ALQzzXwXcdVldb9Pp97nvkABvWTbJx0xb+8aMfZcOmTTznBS/g2w8dxPQTnrapwdOefjn9foznBywf2cfcvge56MrrOHJ8jk9+7mv8yAuuo+IJ7vjaFznv0suoTGzk9z91C+ed8xR+8arLmbnxg8iVZX7kuU/h3tvv5xu33MdN7/sn3vbss/lfL7uYZr1C1OnS7fe56qrL8cOQoBLyz3v2ki50qFcfRjkeXmMUf7nLSrfLar/H+bvOQq+0Of7wfppnX4Lnwp5vfY29h4+yqB2ufM5zeOX5T6Wx6Qz+4R1v5tqzzueDP/pTfP0vfwuvUuOq1/8mD9/wNzxw+y285NJLeNv/96u88WfexK133M3q8grt5RU2b5jC9z3y+f285Xf/D3Pz83z7W9/il3/5l3nVq17FlVdeydXXXMPu3bup1WrcdNNN/PAP//AJ9+r1P/5iPveRP+P0J15BpdbAcRw+9al/RAiJE1T5xV/+Ga7/wvVorfjN3/xN3vPbbycMA4zKSPo9XvPTr2Nqeh3333cfr33ta7nhhhvIsowd557BBc+4iJf+8l9x2dPX8XPXTPLgvgM0mmP8r1/7n3zsE5/kjrvu5nWvfRXfuOW73L77QX72p17JvXffxcc/+nf81Bt+htV2h/e89w945StfwTN++pW84VU/9p+0sP7r2/oNG8nSlCRJCAK/AIYETuAVD4k2Ap6kGQuLC4PMv/Gx8UKO3inKqQx5mhZeqilKDYu9rNiPlbEOfskZWm7JFswSeEKQZrlVy+smA+EcqxlQgGJCIhwPx4M4XiJNOiTZIpXGCNVqnXXr1+EHIU5FoPOMPM+Iel38IMAYQa4NrXYPA4yNjiKSiCxJWG2tUskyqkoT59oGF70AI/pEcY+jRw6zYetpjE96VGoNfM8SmM8fOczs7Cx79u7lCU+8mOmpScbGJ5mbnWGp3WV+7jhjTsy4n+P0l5BRihuvEnqgHQ9lHJJcYfoxnV6EHycEeW7tkuNgckvsjpBoZWg06jSbTUYmxgnqTUYmUtrtNq60gV/pSHorK9x15x305o7h9FZJWkvMLLdZaHWpCEVadcmSmCMP7WbGdcmMgbCC8ALCepOR0RGSLGO86lGTGvpt8n4XFfdxTI5QKXkWs7rSYu/DD4HKCX2f8fFJRkbH6XU7ZGlGGAZUqwGe59KoVfFdSZpIorhbKARqgqCC60h8KdBJF5X26bYWiLtt0qiLTntIY8EqrzKCKxRC56Ct+rjn+niBjxdU8EyM71YJggrViktYH2W8WcH1XFKdMzs7QxAEeJ7H8soyrusS+AHLKzGOI6mGIVGSobQZUHb4zn8TGzzcTvnQp3zoUz70D+RDf9/A08kp2Wbo9/JLB2BQGX0xJ6XjFQtAF2mgg4woIQoDWsK2cMJMpkRyzWCRDRC2ogsG7CSkPHbthpWL1Az1VQ+j0YM7Dui173jUGJSvm/La1ibD4NxDKGVZ8mYd6yaT45Ns3bSZzuoqrVabKO6w1NF0I4+KK8jTlCzV9CJrJNAKpXP6sWXPT3KHRi9DuyM0+hm18RwvrNkrN8VlGwvmpWlClmZ0Wqv02m267RaLx48TdTsk3Y4lcBOQKsNKu0NuYGm1Rb/dRqQpY77HWOAzGvgEriV5Gx4SiSW9tNGKojwRC9i5CHwJSlgOAMcRuMKSFmYG0kyh+iltFJFSZACuRBqHTGscY7dMr9y0B9+6RqA+2GXLez2452INtxSD/RgPgY/B1watU9LEpduPqQcKlwSVRjZrzIYVMAa00pQyqZZcc+3Ea8CqGUydx30rFwrmUesLStC0vCax9tmT4O3Buhs6rvhlbehPXr9DXRi8L0SRAry2LstMRWvMhoDdgVoBDMgVLQIJ5XFlFOikb36M7WRwbeXdszuQzXIrsqmL7xy64KJ+tTzKcSRBJSSrNVHJCLnx0DnoPEekMSrL0FlCdWw9wqmg8hy3UsevjVId3YxwA9K4h4PAc11EUJbG2rLSwbAOQfLGGHzfpr23V9scOXiQm7/yRRoebNx5OgkOc50eB+cXGKlUqDouebvLSlsVETRw/BDhumjXJYkSjBC0FttUKpJ8XYjWgixWtJcWEf2MCg6O5zK/uMgDDz3IriccpjY2SVgdod+1ZKeD/diUxqjYs0/YNQSymF7dxUPES/voLc9YUlkhiVaPDZRJsyRCxzFxcjfd1SXSJKK7dAQvrOHXRhBGg7HReWVAapsBYwHjNSM+sEt6zXiboaCCnVJ2vj/Glv+4au985zu55JJLuOaaa0A6rFu/kec/77mEQUDU73H6ts3UQg/HFWzbfibjE9NorXnowfvIshw/rLJ58yZ836fuKHxpZbjrlZDVxePMHd7L8tIiUbSWYq2Vot1qITAD0OnW73yHL91wA4cOH6bT6QDwile8gu3bt3/vzguBIyXvfOc7OXToEBMTEzSbTaSUdDod3ve+95EkCQDPuvZZbN22Dc+RJHGfTEp0tYYX+NSlRMuEbrfL3k6XraedTr1a4fDePUzVGsRxxNc+92m2n3UeY9MbaK2soKRPbd02VK7I4ggVtUn6faqjI2w56zzavZiV/hGedt42Gt2DpId2s9KLyLOcppty/uXXcLrT4EKvxiW71jO5eR1RDsvHjtM6foSLLr+CxcVFHnn4EdZNTuK7EyRZRq+9QhTFJN0WoxOTjE5O0l1apN3qEimohD6tlQX+5u8/STXtcOnWCVbnZwiPHyVzG+zYdS5t4/Kpz93A0UcOMVb1OOOmT1MbW8eGCy4njT5fSJMLHJUx0ayzef003V4fhaFa8bjiiivo9/sI4Oabb+brX/86c3Nz3HH77fzxH/8Jr3n1q9i0aSM///M/BwiWl5f54Ac/yK133oPrefzPS585IJAXRYYZQL/Xo9VaLdaaJgwDAO68826+8IXP8cxnXsu27aeRG0G/HyEdhxf+6Ms48/zTqIyM8bKrz2TjadNkmWLTxkmWWx3++m/+lnXrNzA1OcVn/uVz1OtNzt+1k89/6UZ8Kfihyy7jngf3kuc5F15wHqQR+x68j3/54pe55ppreNKTnvSfu+D+C5rn+VCE1rRWqDwnV4p6vWYzJYwhSQqlMex+r1ROEvcxOsCtVMhzVXA4pWR5Rp7nVnVMWNU5awQLugWjQRu7PxeZMcZQBOfW+E2lUOTGZo0J4Qwy2dM0GzxgVmoN/EARKIXnV/B9W+KljbHfoXLLiaQy8sz6i5mGKLHnqGUKI1ykB7g+Wa7pdzvWljsO0vcJfA9TrzExNY0fhpbXU+XgWptYr1UZHR1hemoK3/ctQIQgrDVojE5QaU5g4kX6cURVWBClXvPJqzW08DF+HX9kEr8xjl9rog30u10wpiDXruE69qHPMTk2cK1ZXW0jPQ/f9xkfG0VgcDD0el3iqM/y0hKh41EdGcPv9NErXeIkoR5KHJ1DFjG/mNqyRt+houo4fkAnSsjjHqE0OHGbvCPoLkuMA4kW9OOUJE7I4pgs6rG8MM8Rz2N51wJhEDA6Okq1EpJIgVIp3U6bxHVxXc9mgGhNmluSecdx8cMqjjCQxST9LlmvTdJaRqURIo/xUEhpyczROSKL0P1VmwXnh3jVJo5RVAIX1clJtUEjiPo5NZkznit8R+JLn2q1Nsi4cV2bzWK0tuTlrovneXT7EWmWU6kEGOmgHO//1dL8/topH/qkDp3yoU/50D+4D/39A08lUGN3krXXh1DTss51LYWsfF8MJrsx2taMF0zwjz2bT2JzN0PHDw8C5ULXxUWbExZuCVQNAwQlaGZOuoa17zNDwJIs8au15TUw5truzuV7w1iVwfZHaxsxEoJGrQETU6i0x8riDI7IOXJ8ntVejsAhdENQGqM0SaItOKct4bbv5CRJShIbOu2IXIT0+ymNKKM2Mo5TpBiDJTJPk5R+v0cSR7SXliz41FqltbREntpabsd17EQtSLfjJKG92kbnGV6umKyGjIU+o2GAL6VVOSlAN3uP7ThZmd58sPlIx8FBWtBIWqTfcRybEu04JNqQpoq+0vQcQ4ZGSYHj2hyzNBNIbZAaqkIOyhaNWdtoMcV+NuDsKjfLE0GncskKsGCYEQQGTJ4XEtwJo36ELxJ0GhVf4oC06do2o08N5q0slRmRrJEFiseyP4/LZkolkeIyv2fHhzacEyIlxnBClh9r4zu4N0VbM8BDnx0CrMsyTYOx3C2D8zgoowrDeLLxLfcB+3mr7mjXX8m9Joa+q+yzPU8ZQRjq0xCQOOBlw6bnFuI5a+8LBvvIsLMQ+h5prYlK+xhZITcddJaDE2PyDKMyKiNTeJUxslzTWLeDysh6quNbSJMeadzFES6+69qICSVbg/2msjy4zPTTxhD4PqOjozx8/0PseeABvvO1L/PiZ13OrjNOZyVVHG+1Oby0xKXbttL0PFSnRy/uY4zGc0E6PsLxUJ5PKqz6z/LCKtWaJO830CYgiTLm981CO6ZqBGEQsLi0xH0PZlx2YC/rhWRsbJqoL9Eqt4YSYRfmYxBX2mF3wBgcbegsHKQ78yBRexkhPaRXIVo5ihvYcgPL99Ennj9Erh1ypUg7i1Sa46ATdBahswSVJygN0liCWlNEZ9f2fDN4+MIUqevDpdxD9/TxDjz9+q//Om9605t42tOeBo7Hpi1beMXLXs6BAwfodTqcefpp9OKYJE3ZvvMcPMchTWLuvvsu8jxn09atNBp1RpoNRj1wjc2KbdaqHHlolrtv/QYCbR/oiiaEoBL6uEMlELfeeiu/++53Ew8BVK94xSu48sorB8cIIQh8nzzPyYoSrE9/+tO88pWvBGBsbIx+v4+Ukrm5WX7rt36LOI5pNprc8KUbmJ6cYmlxnriQ+jauT833qYYhrudx+PgsR4/P8/QnX0QW9zj4yMNc9NSn0VF9Pvkvn+YFY+Ns2LKF46sruF6F5qYJ4jghi3r4JqXX6VJvjLDtnCdw7x13srq8zLXPuZaj37qHg/fdSDt2cZSmoXo88drnM3bauWzevIlYC5LcsLTaY+74DDMPPsA5T3kKx48d5ys3fIU3vOkNTE5McHDfQVaXV+i2VkjTmPqWzWzcsIGDt3+Ldi8jEwGeK1leWuKDH/sEL71wKxdsnWD28EFit8loKtl+1i5u2b2Hv/6nf6C++Aiba4bNYoUnveZ/sWXjBYSei84zoqiPj2F0fIytO07ntrvvJ0tTwkqF6553Hb4fYIzm+uuv533vfz8At99+O3fddTfPvPpKnnjxE3nHb/82CMkjjzzC3/zN33DLd+/ivof384Zf+lVczyqN9VrLuJ5PWB+xwjBGERSlPWW74667eM9738+NX/0qp+88g+Oz9h42R0Z40Y+9nB1jMX7Q4tXP3kXXWUc7yzlz4zoW5hf4kz/7AH/8B7/P9tO28wtv/R+88sdewkVPuoi3/ca7ufxpT+GnXvUyfv13/4haJeTVL34uq7NH2f3A/bz97W/H933OPfdcqtXqf90C/E9ojuuWjxdE/R5ZmhLHMbVaFacgjsnzHkmcrKlk5TlR1AdjqIQhucpReU6aWGLxLM8LXiabpVRSD9hqEI0xlgtTOqJQU4Iyo0lKg+MYXEeicmvjZMHvJKUkzTLKwF6tYQEXmy0gkEV/tdI24z3LLPiUK3KRYjOeIEmt9HycZvi+h/QCpBdaYvS4Ty1wkXhIbdWrXM/D8XyU8KwflmcYVyBdSaNRxwBKa8IgAGPIckVYrdMcn6Ixvo50oU+3s4hregS+R70eknuj4NWRjXVUJzbgN8fwG6NoI+h3OkjPcqh6gY/QVonaUTloY4n82yvUR0ZpjlSoNWqYggi9vZIQ9S0IW50YI6jV8Fc6CGcBlWd4ToCLwiQR8/0EpKDZqOA4GlcFLHdboA2BMJj+Cqmb0fIVwcQ6Ei3p9BOiKCGNIvKox8riPFoplhcXGRkZxWhNo1HDdSWrK326nRgpJPXmiFXNLMqPXNfB8QL8sIo0OVnSI+51iNsrZJ0VHBQuCs8pRXpA6RSR9tGdJdKoh3ZDSxSuUkLPpZWlZBnI3GGplZKQsiHNqArLRVZv1EmThCxLbelf4Ud7no/nWZ9Hq9xya1UCtJDk8vFNLn7Khz7lQ5/yof/jPvT3vcq1LgEmM1gp1ogVQMAAQZVFRxlk/AxQTmPBJq30ACSStiiSAT9SCW6UxlOUC2Uo9bBM7Rk0O8m00RYNpMyUsUZSiHIqmsFnhxe0HpJNLQFgWYAe9vTm0WttCIAr0w5FifqWYJXRqFyjhcDzApoj4wS+R9rvMDk2QujCSrtPL86IkoQ00+SZxmS2NttFkGpJrg1ZpojiDsFKxHIro9KYJWw0aY5N4AWhLbvDyuvG/T5pHJGlKWm/S5bEZGlKlqYoY8i0Jk4zEqXpxgkmiZF5xogw1DyPejVgtBISuA4VR+JK1y5kY6wToDVKZYXKh8Hk+eDeKemihCARDjIIcFyXajUsNkhYjlISYUgdQaURELjWIGUiRaGJtEIYcKDcLrAKdmUkj8FmJ8osrBKUFGugpVXB0whdJKMLTSAFCI+aa6NArU6PMU8TygQn6+JWxvArTWoj6/ArDURBuFkCkbZXDHpGOT//mzRRRJws+Xs5j4c/UIClQxmAg6hIsZ6tEqXNXhAwuP4yg3DYyImhNfJYrayLL1t596wxHDJZQ5ELbcr67TLCUu4tJ37WmJIT5iThgHLNDi59yEMoHGwpHUSZlamtERVCorSt4fddn6Ozs3Q7LdqLc+zacTYbxtbjPPW5zB+4g8WDd+KYLl4o8RvjhKGL9B1ktUl1bB1hc5os6UKe4gqG9iUr1WuKf+08xkq1ui6u5zM5PUW/12f/Q4/wwfe9m87iLC973hVccOETcMMqf/yXH6UVR2yYmmJLY5RJV1IXmrDmF0C9RBmBFhITVqhWK5jAZ2bfIYQHE2Me3tQY7U6HPfc/gOM5NDCcNT3JsVaX3TMLXP+Ff+aJT7qUK0abhGEDx/eIe52hO3uiCVq7ldo67DqnMnEWXmWK6tgWHOkBgpXD3yZpRWid4dS3E4QbENolybqEjsv0k86lM7eP/soxDt/7JRxH48i8kHoOwa2Q5QaRpGRZgi7KAxzHLeZlWZfPYCtZM6zfc5o+rtqHP/xhvvKVr/CZz/4z45NTPLjnAGedvpUsjvj9P/hDrrjici644AJc1+XokSPs37eXq66+FiElrU6HmSP7WHQdLnzCJSy1I/rdDtvDkDPPv5itO3fx7B97A0GR4QKwa9cu7r77biYnJ+0LRvPaV7+aZz/rWVx33XUcOHAAgNe97nVUioyo0XWb2HbaTj70F3/ERz78Yd7z3vcihLC8LEW7//77ufDCCxFYfo9ut8dPvvY1/NzP/RzHZ2Zot9ts2rgJrVfBYDlS8gihYXpyGpVniCwhWlmgOTbGU69+JocOHkTlil96x/v42re+y60f/jiveflL6XXarCwsEOWK0ZFxnveSl/HIYsrxfbNM7n2I0fEpNm3ZAsDtDx7l81+4m5/96edw+KjgH69/kF997Tp8FfOx//EaNl78DMZO20Vty9mc8+Qnc/ElT+SrX/gi41NTvOX/eyv333M/Rw8d4wkXX8jKahsSePZ1T+Omm27mn//l93nJNU/lotNP47LNO7nhX/6FvffdzXN2bSJKU247vIATB1y6xWNjtcHNt3yN0fFR/uh//CR/8fvvp+IqLnjmtcT9RWaOzzA2WuPGz32Gww/dz6++8z202y0+/9lPcc4FT0TrCo88+DC9qIPjOCRJxvJK66TZZApenMfOMuh0Olx55ZUD9bVPffITnHPOOfZNIdg4Nc7/+aUf58lPu3BwzHOedS1b132Yt77lLRw5egylFQsLC2RZxlt/7o380quu5bmXnccrf/3zPPOqZ/C2N1/Dkfllprds50vXf4GvfPVGHnjoQf7s99/Pbbffycc+8Wne8fa3odKMu2+7HdNvUWsENEfHuH8pYZ8ZBwTvete7+NM//VP27dv3711a/1eaIyVGarSUeJ7NcMpVTpokYDSeW9wLAUvLSwhspoocH8cz1v6pLCPLEpI4GqjjBUFYCK0YXNfupwZQeY4uAGZdcNFoTVF+Z22jFILA93DLcqcgIAgruJ5HnqtBRlW1XkcWVAhJ1EflVqwmyzJUnqOiDp7vEfgBTsEX5ijN5Ei14F3KSKMUMIQu5MZFiZCgVsGVtsdZ1EVpg+/6CM9FOB6u0CRRn357Fel6hK7DaZs3cezgfhY7He7r9BidnKRWrbL9vEuYO9BkTvscXTpEU7hsmhzBcxu44QiVdVuY3H4mldFJkswSpsf9PlEU43oeQW7547RWpJElU5eOg5ASR1pRHXqrdFaWmDl6hCMLS7S6fUbHJ4kNtLsxxxeXcdBsmayzc6pOIGCh2y/suaDbj0kV+EHGWHMU6foY4XBwYZ751GXJ1Zw+3aSX9Hn48AIrSy10L2Lcd0lUTqfb5eiRI4SVKpOTk0xt2Eh9pInjCHpdS4be63YGwdFavYYfVAirNQLfQ8URcZKijUA4PmGtiVQJUiWYqENWZK4J6WKEg2mv0M4EsXHoew2kFyCkw+LMPJXQp9losNBWdPOI5rE5RG2aatM+13meh5SC1XYXz3WphAFxv0cSQxz3CcMAPwiIoh5IQZqn/w9W5fffTvnQp3zoUz70f9yH/r6Bp0eDpgWfDhKErf8URR8G4FHZkQJRHfzPYIZbLp4SONJryNla0taJD/YGhgCf4dIrc8JnB6V1xoAcTrQ7qdkTMsh0Kj5nNwozWEuP+g5xYg9N8f7ge4ZAwRKUkY5HUKkzNj6NVorW8qKNRokemVZkyqByu2TA2Pr8AthTSJLcoHSObnXpxRlep0un08XzfXw/HGx6WZKg8xytc6tQoWxELM+1Tb1Vml4RDUmSlFDnhFgS8YbvUvd9qr4lHnQLfgB7g4r7YnQR8TSWNNzoAgw1GGUlX40wSHycYhMywkrupsKgJEhXUPEdHEfaVO3UAnZaFMBqCRaKgpNLWi6QkjtvaNbbcV/LqSxI7tfqecv74iDwhcAXtuQvSzOS3MFxBNIIHK+CFzYJqk1cP0A6litrsKUNLTSxNg3+2zRRWskSzB0YnGJEh9WMzNpcF4VShtYGUaCqw6Wq9kMMrW8ejQubEqstVoo5ccWcUK9eHKKLCMDwCl9bbGuZi8MiBUIMPlmobBbnfwyjfsIGNfyqMYM9bphLsuQPc6SVwI3iHnfvvgfVS9i8fiPrN09Sr0zQr03TWWqRCkOmJNniEn6YUpuYQOYdpKqDrKAdu3/aMbVZoqLcOzEDNUrf9wfy1bNHjzJ77CiP7L4Pn4yN68c58+yzWOh0WTgyQ6fbYcT3GavWmPAc6oWz7Dk2i0UbiDIrYd1XiooQ+I5DniuSNKUXxUyg8YTBQeNhne4x32fFc2klkn3HjjM6dZAzDuxjetcFeEFAnnhFCbUZuqsntYGB0ITNKXSljlRdhE4xeYTnGJIkI49jqhvX4damkeE4raX9CDRTW8/FZBFpf4UsXkVLY8fQ8fDDOpXmJNL1WCv8XeMgWNvTi64MbeUn2pvHd1u/fj1PuvhiqpUKvucy0qhbZScp2bJlM47j0Gq1qIQBUgpGRkc5dvwYYEBrMiNxHJ80SXGlQGL4zD99hp07d3DRRRfRHB0/4ft83+e0004bekUwMjpCWKlYUuCizczMMDY+zjOvuYbm+DTrNm7CkQ4bNmzgyU9+MgLBkSOHmZudBaBWq9nXi/X45CfnXHLJJUxPTdKPIqR00FrjFhxQlh/Ex3dE8b5kdHSEWqOG1pqZwwdxpCRsVAirdaYmJ1Fas7wwhxRQrVVZWI3wNIQqoxG6aF/SlCN4QQBGszx7nFq9wc4LnsDs7AppBmdfcD4ze+5jPk3oHNrDYm2EPO5RaY7gr19PvTlqnWwMjs4YadaJ44QH778PiabZrHP7XbuJ4pRtp22n3YupZxmbGlV237ebYwf2c86FF3H3ffezsrLKEzYLJkebTG/aTOeMc9Bxh6X9D7PU6jLSCHDDGrnJ8EjYuXUjrXafhx5+GKcYH1cKFhYXAYHvOQhRRUjJyuoqZ511Ji984Qu5/vrriQv1sC996Uu0222e8YxncMstt/DQQw/xohe9iLvuuot9+/Zx0UUXcezYMe68804+f/0XWVpe4YpnPAOAoFLlgic9jaMz89z9D/+A7zqsm5pi17nnsLi4yMGDFpQUwiq1nbtjK7Pzq3zh63ey79gqZxyd49C+/YyctREtYHFlhWajgee67Dl4GOG4bNywgf17HxmUiO3ccTrSkXz727cgJrYyOda0IM3SEktLS/9Vy+4/rUVxTJ7npGmGzlLSLCWKIqv0JawKned5eKWKcVHi7zjeACgyhSq0tXvWP/NctwiYglMAiQMqC71m0615sb6bVjkUPpYQtuzFqgXLwY9w7d4oWCNWVloP1NFyXEu5oLXNEE8zSyquLaG9IyXSaKzaFkPusyxIpg2Ume1F2abRCp0ZHOHYvc2zBOZJmkCSEgQBQaNOnvTprC6x/8AhJjptRkbH2bphGhnWcRsTLC3MYDJJLTa4MsFTfej1yOKYIM8snYPnYsKQfrSC0gptTFF+aMiUxq94SM8jSC1o1+92aC8dZ3VxgZkjh1iOcqJcIx2PVmuFbrtNv9MiFIrxZoX1YzWM0vSjBLfIaFFCkCmDThVprmzpm4RelIOnSHLrMweOQ11oxgIHr+qjjaSVG/pZxtzcLLV6nYmpKWpj4wRBSK3ZHPhlnXYHWwRnr7EECcpKEen6uGEVyzIfgUowBThpEAjHQ7o+2ggypen2YrqppmMi3LCK43q0Ox2EqTFSr9FoNAmqdRy/QqfbJ9GWG0wIy98kBbiF0p1ReQF+OPhhBQRoneN7Lt5jkHc/ntopH/qUD33Khy668h/woX8A4GloGMwa6CNLdnd0gfTqIRLxoelo1riTBkz9hZGzE2a4LK64kBKuHFo45XkGMomCtasf7uCgo0N1rkOrr8CVOAGpM2vHFpRSQ0u4QENKBIKhazTYDdzK6Q3Q1zJV2hiD0hpHSrygxsT0Fnw/JOm2cAQEDmS6gzaQaJv1JIwFWZyizA0g05o01/TiLoY2oHFdt4hIujhFmrUjBK5jQR3pSjQ2My3N19R+unGMVhphDLXAZcz32FwLqPk+Fc9Fula0VzNEMldcr8aAVpSsT44AYaxkZ67zAlB0cAQ2iuY4pMYQG0gcg+NJqqHLaMXHLdK5lRTkErQwGAnGsmAihMR1Jb7rFsCT5RTQWAeo2KlPBEOLzV8WETw7Vw2eEDhCEjoOcZaTZSlxXscRHp708avjVBpT1Orj4Nia8zKiIAZShWuLqwSi/ns8sgKm4LCizMor7mdBbOdSrGexZmQK61rudYUhKo2cONFYCV1+zUAGdADYFVNImSFjW1jBMoW3NFaymG9K51aZUDqDvcHOgdLYF3XIpsicLDZLa9DteZ3i3LkxZScHX76205jBPmK3skLRUsiBoT/BSRCSWuiTpn1u+PpX2HPP/ezYsIWf/anXMRKuI5s4g6OHHiZJc5AaL9pLo+Zzhr8V0a6Bo/AmzkRpFyWFHbZy/1P2eoQxuJ6DFwRMTE4Vyl0RX/vC57jvjtu49Wtf5uU/9iOcceZOzth1Du//y7/jW7ffRVUIzqpX2TU+jl8qMzoutcAazSzL6KuUJFcsxjFT1ZCKCTAoEpXRivtsEgbpu4zVq4BDBkwLQadaoW8M9x+dQfgB080Gzz9zF7WRUeJck/Y7aJOecG8Hc6PcSYt7UJvYjCOgFS2Sd4+QxyuEoYNKJP3U0Fh/Fs31ZzOyfhdH77uBPG6zeefFZNEy/d4M/fl5siQlVQZvZAPV5hSTG8+w4L3SSGlsRHfwYCUGfHsnLIlBL+1u93hvz33Oc3j/+98/WFAXnHMG87NzgOFlL3sZ+w/sZ/+B/UyONhkbn+D8C5/Au97zTvK4z7mnbWPjeU8hGJuktbLE6MQUJs94wxtez2tf+1ouuuiif7sD/wrSvuP00/nYxz46eEAG+OEf/uEBcfUnP/lJbrnlFgBOP/10PvaxjxWkx4Z+v09rZZnV5SXOOONM0jRhaWHBEiq7HkEY0hwdwXVd7rt3N5VKlen1GxmfmODIvoe56frP8tyXv5qxqXXMHT/OE87bhRDn8I0vfY7tp+/k9DPPYX9/CdNbJl08wPazLqA+Okat0eTYseOsLC4yM3OAHTtP46ILfp4//NW3sG3HNt7wxp/gb973xyweOMB2T7N459dpH7yfjZum0BUBzVHWbdoMecKRB+/jjAsvZnZhgT95//t5yUtezOYN6/nZt/0mP/GKl/LKV7+aT33o71B+ne3naW78xtfod1u87Lffzjf2HOOR+UO8btLjgtM3cdZFF7Hz/Au45bP/wId++73cc2iV007fSpJKwlAxUZM845IL+Motd7F731GU1jTqdbZv2sRNux/ElQ5PPudMKvUGGsHeg4d5wQtewOtf99Oce955zMzMoLXmf/7ar3HN1VfzjGc8g/e///3cf//93HPPPbz97W/nr/7qr/izP/sz/vmf/5k3vvGN/Oqv/irXXnutBZ6Mwa/UOfPpL+Bv/+f/5Pd/7/eYqoe89nWv57f+z7tPKNd0HJf166Z4+y//DH/6t3/P7//NZwE4fPAwX/zc9bzugitZ6vX527//e177sh+lVq3yC2//HV7/qlfw/OuezWtf/Sq279jBM66+lquvvZZHHn6A9//ub/P233gHF2+ffmwH/XHalldbZFlOmqa25ClNaLVbjIyM4HqefRCXDsL1aDZHbDaRUoRhSOD7ls9F5xiVAwbHkTiuV/iBBVgkHeuD5wrpmAHIA6XdTlG5IleW+0cMgCZR8KMAWP4Pz3Ws2l5hX/M8J0li2itLpGkKXgXHryBcmx2TJgl5t0e1ElKphDQbDdKoj9YGxwtwHBekg85zpAAjrY9p3TjH7sJKEcURfkXh6xAnGEUbQ5Kk9Hs96rUqtUpAFnVpLc6x+647qI9PMTY5TfPyp2O8kOrkRlb3H6ATZaTLKX7WI/S6jCcOfrWBMYbK6BhhEBLWaswvLpKnMVE/wg9sRo/B4IYVwmqV1Aj63S6Ly4scv/d2VhbmmZ89TtqYgqCKG9aZnZtjcfY4/aU5pibrnDbZYMf6MfppzsxqhIPlBk2VJlGaPNes9hJcXyAcQ7eX4gQajK00qPmCHQ3BuKrSrrjIVk662qPTjdm/5xHSNEW4Ls2pdUxPTzM+Pjnwfxfm56y/JwS+76Fyhzx1La8L4NWaCGFQQUCStFGRRiUxJtdIz0cGNbxKjUxp0k6PlW6L5XaPVqLwwxDX81ldbeNLcBlj25Zt+I0RmhNTLK20UcstNm7chOc6hbCQpBr6NOo1fM9DaY0yUK1WLDDgOriuh3Qf36p2p3zoUz70KR/6P+5D/0AFtaIYgRJ30UrZv1l7AB88hIshlLVYEFprq2JXnGwNvS1qZssRHgKEyvynwaUOAAb7p9Z6bVCKG1Ke16rMyjWcCFMod9iFLbHZViXqW/YbcVIK4hC0cHL6YjkuxpQKb2oo28aCJFbeVg02qbA+gkZQn9iCWGqT6S4mz6j5goof0PEUKtXkiSIHXCHwhAQpMEaipaAk9dTGSt3mmRqo2nmuS641JhckkSbThkwbHGPwgFDAaODhSUngOIz6kprrMBb6lovJdTAFTF2Cx6bgO3LEmqxnCcy5wkFrC65ZMAuUMRilCicrIXMkmSNojlTwHEnguaAsf4HKFcJoXAlB4ODmBqGLQJ0UuAVqLRCocg4Ys1bmNrQrDwBRsabwJ6XEdyx3k5IS0rIe2hDlDmGlxtj0BkamthPUxolThSaCYiwpUmJLFcdyEzDlv0Nz4vHcBqm82CwyI+01OIMIAQNHlEIZ0ZKFWiNSKlBhbAmrFBaUtKSEZgAel214/TMEEJegIEUZZAlkgwUTy8xHBAiLS6NVoTZZ1LQbCkNWRHOVUtglUqx/bdPlB/mDpki7LZ0GY2y6dGkwh/qntR44D3Di7VXakOYZzeYYWzdu5ukXn8t9D+5n313HWPkTxcaxGtMNj4WFkFY/ZaHbIlAZNT9mYfUh1m9YZmxqHdsuNjSmt1Ndt5G4H9lxzvMiNd1KaPf7Ef1+n2/d9E2OHzjAzKGDzDzyILXQ50df+Fy2nXEmS1HKx//wgzx0YD9KKS7ZvoWtgc+Ua1CejUbnRqOwss2O7+IpcEUGcUrW75MYGHNDpqt11o1OYLQgSRWJElRcqEnJZr+CIx2aQcA+NN1ely9/+1s0JtZx2s4z2XnRxcTNJqlSdFptMAqMLsa7tAwChOWaMJ1jqHQFs3Q3i8ePsLgwx/JKh9HJ9Ww8/6lMbzsPJ2jQnd9D2lsm6y1z8NZ/pNc5hk9M6gri1BDFKVvOPJvxjWcz1hynF3VJ0hiVGzzXkumWUYYTquaHl6wovcLH9zr+xje+waZNmwZ73cP7D/H3n72elzz7Sjxh+LXfeDsveuGLuezpT8f3XLvfCckrf/xVrCyvcOT4MTavm2RsZAQV9XAch0q1wk/8+Cs4eOAAV1xxBQCXXXYZ73jHOwDYs2cPb3jDG1BaMzE+zoc+9KGBAt3aZ38bsMp0UpwYsf7Yxz7Gn//5nwOwuLj4mNellWJ+ZoZc5UjX48iBvThSEIYBU+s3IhyXpeUVDu1bwGjF6Tt3kKcZSRSxOD9DtTnCc172ah6+7x4cx+FJl13FgeMLtDp9LrnsKr71zW/wob/9O9741l/Dn97K8lKN2ugE+w/s5xff/GZ+/hd/iSuuuAJ30wb+5dP/wBc/8wleeW5ApZFw19e/xriIaawfozE5yeLcEu1+yv6FHuFWzaTnEeeaQEga9QqPPPAAaa558Uteys5dZ1NrNHnLL/8iadTji1+4gaddcw0PPbKHX3jzW3jqpEvLc3nbr/82CzPHCR2Hmczn/m/ewMK9t/L1vXOs37ieN/7Gb3Hgt95Lc2SCsV3PoLfnGySzB6nXAowj6WXWnjl+hWBkHWfttOSsaaZ48L4HibKMC8/dxerMQQ7vvpU0jnje857H2976VhCC0dHRwdxvt1b56N/+JZc//Yd44QtfyMTExPecj4cPH+aZz3wmBw4coF4N+IO3vZTzn3YpruvxF3/x5/R6vYHce5rE7HnkQZbbMfVGg9//0z9n57bNbJwY4Vd+47cZHR3j53/2jazOHefIzDFecu3lnL5pPY7j8nO//D9wfZ96s0l7dYl1kxO8653vpjo6wYGDhwD4hV/4BV70ohf9gCvq/35TqeXgqQQ+EhcpBV6SkmropzlSJkRRnzRJmBgbJcutDyWNRmUpKYYkjsmyFK0N0pT21WbJOK6DHtpuC2cJYyhAKYnvByiVW/61NCkUkHOkcAa2UuWW3wjPs+rAnkeuMoTKkSql0RyxX+EGKAS5UqysdDHaPqgFQYDv+QXgVZTweQ6OH4Dj0u7FNjDpWDutpQTHJayNoMIcJTpkWUqaJMhi/65VAlwBQWiz0TeedgYENbYenefw0WPMze4mWpplshEyXvWoS02rl7B7doFeu4NrDNP1Q5wxt8CGzVs545Kn0ByfojYyxvoNG1AFUbZTBNOVtjxa7dYq9+++h/n5BZYWF0iWZ/Fdh8boKNWRcTpxyoO772Z17jh51OGMiRpbx2tsHqlScSROJQQvpJPaLCqZZugoJk1zVlpdgjC3RO1aIcFKsStFnuZ045QkzjBZzmjgo0YkYRjSjWJWZo9xb5qSKs3GzVs5/4ILrM+dpmgcEBpHUPCwKkSWkWcpWmVkUZe8vYDqtUhX5jBxD5NleLVRCGuISpPU8UmynH7skHo9jG8IVJ/QlbgutLQeqD8HvkOj0WD9lu14lSWyLKUaePSjiG6SUq83yPKMo0eP0Ww2EUWlQ5YmGGNYXlrC84MTsmgfj+2UD33Khz7lQ5eTcmhh/IA+9L+TyW1tkZTpuyeqj53czAAoWVuc5eRd+8wgjUusvTaQE2QN6TvhzCUIW/ZsMPkLY1z8aWAAxq1lXhXphWYNODsBzy1Bp0G2y9rr5fmHu3rSFQ8+bIrrt1mPoiAxrBJURxBuBWVckiRHug6uK6n4DikCrQxagcKyCzlCIovUVSjSkks5TlOiyzYxugT78lyRa4PSFnTypaDuSEY8B99xqAQeNc+l4kjCQt5XSKtGN+i71hhRXJEUdjykHJoDdu8SSFxTlBVqi/hrrcm0RrsCXEngO7b8zhjSJCuY8vUgOuO4ckh+kwLoFMN7GiX6IwcLcQiAgqGMJ5vSaf920EKgDOTF+hBAlhtyPLzaBLhVci1pra4gHRfHcRlpNm3mVOHAFVOHtT8f3w+rw20NNDXYWl2Ghq9IBTa2fHIY1S7J+8vX1s5SMqeVBrNYM8asfUf5mv2GNZCYNYNphoymndf2eCFL4LOI1JTzemjvoZynuvgGudZBo4e1L9fGQIhBR+3eUKKJaxcwdA3l9xed1Va21fdCGvURzjnTEugury7z0KFH6HUn6I+PkvQk7UjQ6ma4WtGPFUZFZJmm342oTB1AEWC8GipTdnwM5Ca161YrWsurtFdXOfTwQ8weOsj8kSOYOMKvhzTHxlhud5ldWmHPvv2oNGE0CNjQqNIQwnKkFSl5wghUWTIqbDTMdxwqjkJqTZ6lVDyP0PXxRchqlNGKctrCIRACVwocRzLmeyAkUaNOJ45ZWFnl/gfuJ0lTRqemCMbGcfyAwPctoKxsfbjFhSXS9e3DkRSkSzNkreOsLhxjeWGRhYU2M0sx1H22NDaANuT9Fquz+0j7K6T9NkcX5zEmQpsIhIMb1Ai9UUYnt1JrTpNlGXmWoVRe7JVyYJdOKPHmxP0ewQnvPV6b7/s2YwDotFt0O23yPKckCc7SjDTLSZWm2ajS7nZZbrVYPzVNrVqzD7ZaoZKIIAg4fPgwi0vLXHzxxczNz3PTTTcBdi1+5zvfYdeuXXS7PW666SaUUoxPTHDrrbfSaDRIC1JkWTzI7tq1C8dx+O53v4sBPNdl586d7Nu7d3De4dbr9fjOd77Dhg0baNTqZElCri1JsRQCpXK6nZigNoIXhDhOkYGrrcQyYEnGj84zMjLCzjN3ct+9d5NFPeJ+z8qD9yOqjc14fmAj7CoD4+N7Hq7rFYBIWjwUONRHx/EqDbT00aZPHvWIoqOMNQJ0o4oZ28BoOI52AoLmBEmaszw/RxCGVDxBUKuieitIBBvXTdHp9ujEGefsOotjRw4zP3OciYlx4jji1m/dwmueehatToe/veVzVKSgOlLDNTlHDx3gwIM9WnHCaE2QygsZq1dpVjzorZL1umRxRNV3cCQkWc6D993Lps1bqTaaiJk5hIGwWsdoQ56meI6g1WmxNDfDObvOZvv2bfiBVaLr9/t85zvfYXl5mSiK+fa3v82PvvwVPPWpTwVgenqaSy+9FICzzz6bYpLQ7/e5+eabAWhUA5CC+YV5Ot/9LlJKavUmQgjOOGMnAlhYWGDnmWeB63PeDz2dLdNTTAQOCIkUsG5shL0P7GZ5eZlzztxJr9vh3vvuY+eZZ9Jut5lbmGesUQdj6EcRYdNQq1W55JJL2LRpE0Hg83hvwhhEUcJQ7jmOZ7lDcqUHKnVKKYIwwDFFcBUsGKJKzqV8rZSONddIDIWAzcBmW6MopC198zwPpSxvl9H2fPYBs+yS9cm0BqWKjHshCuLwDK0sWTVCYhwHnRfcrVoNAp++7+P53hpNgjE2e99xMNKx3EHSIIy2wJKQIKzv6QhBEFYwGFSeobLEnkdIfN/DkYIsjQmrNUYnpti0ZStLKyu0Vlc4fPAA8WiNbKSGAjq9mPmVLu3VNo5WZJ0evh+QZBmVDZuYzvJiDMAgMdJF6QyjcpI4otPt0um0WT52iNXlZVqrLXTUw4QBFRWi45io26O7soDM+tSlZrpRYbTiE7oOWZqTCQeNg/RcHGHH23L92Gt3hcEV4LoS6djZ0Y1Ssl7MUi8njTJUmuN6PjXfBcfBZAl5GrG6OMfB/fuIk5SR0VHqtRqu4xCEYVGCLfCCYGA30tQeF7dXyVaXyXst0lYL8gyBJqx5OMLHkT4Kh9hoEi3QSIyQA14iCh6j8jqsomGONiAdB9d4+J5HkmZIR1Ot1ej1euR5H6WV5cqCtSQGrQfPC4/ndsqHPuVDn/KhbfuP+NDCnEyb/z3anvvvP/G0xQJTRU3isLLJiZ+zpN8qzwrGdJv1ZAEOMQAAhCgk6hnOdLIXVKZ6lZvnYJEWP7JI54MSfLGob3neUh1AKV0Ad4Y8y3GcQjZ2KLupFLJD2ChOuaDX+quLLKYS+WawmAdosBn0fpAtpItFL6UkrFZQWc7c3Cx33nEb+/btYffuOwk9Qa3i02zUUQb6qabXTdGZwdNQ9xwqjkPVcyi3L1VuHEKSFxlWWZ6DUqC1LUcrrnFECuoOjDkwEngErotfCXF9H8d1bW2nKTazQlIRrdB5XpDpaYSx2UmqIBm3fE/2+vIijTjT0NMQuT6p55E3q7g1H69iuaOyJKfXjen3rGRwJXDR0gKBOlfIVONmmhFcao5D3XUHkXQlhsGeQr2gWJTFBBjcV8eRuE4h4yok3VzTU5ojaUqkM2KdIsMqk5NTPOGCC0lSRS+K2XfkEKPNUUZHxzj7zF0WQS+iUKWzN0h9NAzm7LOf/9zvZyn9P2sP3nvPkAUrjFcpvwwDhwgYcKsYY8hVKbNcRFsYmJOTIjRraxIKALAwnKU4QZmBJoUgK75Pa1PwS4AaqCkUxlyUVq1YR1oXYoZicM/NwNjZXoiCWFEX9wuw0qqDPcrYeTuEWg+c7iHQcw08LrtQqowowmoTVwgC1eXrN36S++67nZsePESchWhVZUO1gWsUJouIshSlDSjBCDF1V7Nx0wamtu1gausOJtZvolpvUB8ZZXlxkU67xfFjR1mZPU5vdZnW7AxhEFCrhGzcto1WknJ4aYV77tlN3I8Yq1XZNj7GdL3GWeMVdK6tIdYG3xFUPMlylJHkyhr8IEQ6HimSrs6JtKIpPEZHGqxbN8l3ohUWejFLx7o8wdX/P3v/HW7JUZ3745+q6rTTyWlyHuWcRRKSECCCEBgQ0TYYcOJiMBjjhLkGG2wM+AK2CSJjQFxMlpBAEgLlnGY0MxpNDmdO3menjlW/P6p77zOC+/3hi++98vNMP8+ZcHbo7uqqtVa9613vYkJqsm4QJAmNZnezyYOzc0zPzjJQrfC0007l4suez/rNJzC0ahONTodmu02n08RRtsa+NjiGIoPmDNtu+QaTu7awd3KGRkuw2BY8emiOk049jedcdikDskXYmGLf7vuo9Q2TJIYH7nwIvxxQrpVYvX6Y4WXrGVtzKuuPu5AwgW279lCUH48NDZEW9g9+YZ72DtF9HWN47lN4DUuleNvb3sY/fvjD3HrTjylXKpx53oU0Gw201tT6+rjtgUfYffAwv3HZs9ny8EPc9rObueJFL7DtySv93HvnbSRxzEWXXMYf/OFb+c53vsOjjz7C5z//ed71rj+hGBspJT/60Y8YGRnhnHPPtQwIlga3HLXOb7jhBvr7+7ngggvIsozRkRG+9pUv861vf5t//tdP/dL7EULwB7/3Bzzvsudy/AmbWGwsUl+oc+75FzB5cD83/+h7xKrG0OgEl7/w+XmXvg6333g9azZuZu3mE/jEZ77OyuVjXHXlc3l41yHmZmYI921lbKBErVbGDK5laGiIvv5+vv+z+6iImBOHFOObTsYr9wGGnbv3s9hocfLxGxHCdht71xXPZEzVeeFZE9TWbyLxR9jbWc7JT7+UifWb0ELx2D13svPB+3j2y66iVOsH5ZA2ZohbDRanDnHNj29ncr7Fh/7ufVZzC0Nr+hDXXPNN3vXuP+W7P/oJURzzkhe/AG0My2o+/3zFiXzlgYN8f9sMP3nfi9i6b4F/ue4xTlu/nI3DPpeuMjQmTiYuD+GEs3z2h/fwjZsfZtPEEC9/9Wv5y7/7MB//8P/A9Vxe96Y3cGjHNuqzM8QmYurwARbn57nw0hfwne99nz/7i786aiNklmz6/v7v/553vvOdv/Csi+d25ZVX8t3vfvcXnmfx9/CylUgp6TQbfP3fvsLznvvc7vdExvDjtmGlIzjdtwmshZkjbHvgLr510x3ERvHRD7yP9/zlX3HNN/8n995xG/c9cD9f/dpX+cD7/oZHHnmUK654Cd/73nd5/vOfj9EZf/T2t/PJf/6XvFHMU/fY8sjDJJEVBg/TFCMdZFClXApwHYUrC3FiTQakSUwSRQz193fb0S/WF6zwq4EgCPA8j1LeyMVRijTLY1RDN0MtEHkpntXZwVg2gxWjjojCsNvJTimnm7Az3Z0FuVao7ULmuS4GQTvOCBPbOS0Lm5RKJaqVCoODg7ZEJ0uJU+s9lJKgXDIhqSegshRHJ3h5eVWmDTqNkQJK5QpGZ2RpQmP6YJdJ5ZX7SOKI1uICI8tWgeOyUG9w+6238tjWR7nr9ltxJQSug/JLhElKvRmShB1EllKVmmq5TKVSZvm69WxcvYJ1K5YhygMov4RTqiCymLjTZurIYWZnZ+g0G3ideYwboJ2AOA4Jo4hmq8VUIyYMI7LmAqv6fEYrHqvHh7ryE9P1Ji0NDRTLJgYAmJmr02mFiAxWDA8QlAKU57Fruo5bqdE/NoFfrlKvL/LQfQ9Qbi9S0ikjg304QQnpu3Q6LWYaHfbPN2k5Fcr9Q2w67gROOOEEli9fzoYN663mm2PLLpMkIYpCZg/to7Uww9yhPbTmpoibDdr1OVuu6fn0T6zGK9kyO20McRyxWK/TmJ8jCjuYOCIztrphvhkxMTLIxtXLMJUh3NogteXrAYHneWxYs4rM2Ch9eGSYxmKDmZlpdJZYING15aRSSqanZ3AcB6kcLr342f+3l+WvfByLoY/F0Mdi6O7Tzo//eAz9KzOeignWWzD5KfPFt6Se7ejStiJ7YnoaUORgTC+YsfQRo+2HpSjkDLv3tOQaesDQUer/xR/GCp0XInqIXkmWEEVGKBdS5GgQw2BsaXt3nZoupbGH8FqHYl8uPp0jxQC693C6BXdFJ4T8vTp3xJVKhaHhERYbDUrlPuKozVy9gzZWZNJxHEqBQruGLNYkGNAZTmIIlMR3FIHrIR2FchxibUgzTRSGkMaIzE5zJRVKKmquQ0kJKkoQOLakzvF8pOchlQWeituxoJIVsZQGjNAgMizKb4MAndnXBZax5KDRKLQEpSV4LrgObuDguLbWu9Xo0GyFzC20iKIEV0kGqiVc30E5eYmczBNgiBw0k3l3w/yJLTHeBbupmINCSERBZ5WSBEFmBO1U00hSmmlGM41JTEpqUogiWs0Wh49MMT0zS7PVpNlepBJ4OGoop4va7g5Z0R9UHB2Im96EeUofRcdJMF1nIszRqwDsvWV5CWuRsbSZnCXsOikw3cxtsUwLENCOR88dFeBv7/u16dV8q6K23HDUetVadzMnQloHr4Q6Cnnvlerm5+k6ttw2dbNIPbDYGG1XqzF5uw2667kLVmMwRuTijHRtkh0tQRKFGOXglPpZufYUlPAg1dQjQz2W7DzQII0zVKqZKLm4EjpJhjYBLWE4OLXIkcWtOI8/Ybtdlko2K9hsoZMEoTOESXFMxsDwIFGmmU8ztj28lWaUsNAJGfFdBso+G/sqVMtlAs8hS1KU8nBKJZKoQ5YlNFsdMKB0RhpHZEaTSod5Y8sAqtUKo6WAZqq5e99hFit2rAfGyjTqbUg0475CG4E2UJaSiVKJE4eG2CkFUZbx4BNPEP3oWlY98jDnX/AsBiaWUxsaoRIMEccRnXaHvdu20GrMM3dgJ3u27GB2apYjiwmOcBBCMdxXI2stsu3+uxn2I7Kkzcxshz2HDtGKNHvqCrcRU2kYTj3/mYyvOp7xVSdx/4OP8MTevfz0rls598xzWL9mHetXraHZaRFHHYTJdSPE0nkD3balBYgsntpr2GjN9T/6EYv1Or//u2+hVq1x122305ibJEpTouoYE6MjnHPyCRw8PEmtf4BLL3sebafC1L7D7N/1M47buInRkREsK9b6416Zul1DJ5xwAq951avYsGED/f39XP2Zz/CFL3yBn95yy1F2rzh0nv1eu3YtV3/2s2hjCIKAE04+mdfV+jj9zLP4i7/4C9asWcPv//7v86EPfYht27ZjUAwODjA2NsyhyWlA47oOT+zZjyMFz7j0+WTCdl2bm6vTmD5I3GlwwqlnkMYd9mx5gIuffhYGwwMPPIDrKAa9jPnhZQyuGKOvErBr+2MsTno4fplTN6xGmow0bHDzT27ED0o8/dkX88SdP+bR++/hEzMhL3rxFbzwhS/gZe94L4/c9TPe//2v8ce/fz7DXpWFu+9An3EOUkoOPL6VgaEBznr2pVz/3X9ncHiEU047gwfvvxfXdXjaM5/BC188TCfO8D2X7T/9EVtvuZ6b9s5QHhzhfR/6GN+85hvs3rWLKEm56mnHsXGin/9x+24magG/d+E6PvLdBxmq1XjFM06hPDjO/OIi773uNt70thewct063vtX76c+NctpQwH7FlscnJxicvcuLrr4mSzUF/je17/E8pXr8P2AvbueoFYqsWbtMI0D22hO7TtqgwPwh3/4h5x11lkAnH322Uc94yfrOrz1rX/IS654sXXUQBRFfOkrX2Lf3v0c2H+AxflZBII0jfnHf/xHvvH1rwPwqle/mvMvuIDPves9bFqzloVnPINbf/4zRob6edkLn8dVw6vQWHv7yt94GWeedhoP33cXgefxpje+CeU4rFu/ns9e/VnWrt/Alse28dF//DAbNqznc5/73H/aWvs/dRhjNS8dz8NXDigH5dsmLCbTNMOEarlEKSiTak2ilNXulIo0TWg2FomjsJsEU9KyxfA80BkZNsEK5LETFP63SNIVpTFSShzHsfF5lllhZKmQyrHaUrHNfitH5d32THeTG8WWKdjsRIRJRqZhoFolCHxcz7NzS4Lj+yRZxyaodYbKE4JVV5HqJAdEIsDGa6QJGE2nE+Ln7CZtrGaokJKg2odKEhIDmbB6pgMDAyxfsZx2q8ETj2+zOlNa00ogig1hqnEAz1EEfoB2XFqp5ok9+wgXF5g9dAAC263N9UtINDpLaDcXMWmISWLmG3Wk66PcAJ0lhGHI4uIiOkopS8HocI3lI33USj5NAyZP/pYchUxSCFvUj6QIJagITeBojBKEcYpfUvh+iVVjko42tBZmODQ9RzuMkUGFLI2J4pBWGFJV4DsZfkkh8EkxHGymxI15Ht/+GAJDY7GO7wiGB/ror1Xwfd8mkE1M1FxgcX6WycOTNOfniDpt4k4HPwBfO5hGE9WJEGrRdsWOY5rNBo1GkziKLAMjtwWO4+A4EkcpGmGHtha0zH5cz6dWrWHEKqIoJklTalHNEg9yZk2cpcTtECltZUEcx1YHVz21GU/HYuhjMfSxGPrXj6H/Y8ATvQVRJEKWCqNZQeiliFh3lfRaTC5ZOBakyhdtzrQplNKLMKfLRiq+cynSvORMxb1r9NEBlXnS2HSvu2gLaI4Gt4rrXXLv3cXfhXSXItZHf/fST5ocuBIcdYqusfD9gP7+AYaGR6j2DTA/l9JutVGtkMB3qZQFrqswShBj0KkhyQxJBr4UKAMl17FdUDyXJNOkaUaYJQgkQtjyOkcpXMeh4rl4SuI7eQmaUkjXBvZCKevcC3BRa4y2Rkhn2ZK7yoFDo3qP2IBA2xa9gDQCpMI4ClwH5VpqINp2x6gvtpmrN0lTje8qAs9BOrlGwVFAZg9UEnmdaU/XiS6DTEpR9Ou0P3kXPY0g0hAbw2KS0UhSWmlKqFMyk6JJIVWEUchCfZGp6SO02y1c16CEwXfd7vw+mta+tESUJWj+U/soMqZmyTwu1nHhMLorbcn/u2wykzsfU5D37cOXQvQWGbnrEmLpqu0exRgWjqxwzL3xNUeByl06cG4UZF43b8zRDrNLI156RilsULAEKLZ/9diK9rVcKHIJYFxYnqXGRS55R5YmAGTKY2hsDa6QNA7tYLrVxm9H7DicEpFhMlBS4Cub2c+MItWGhXabeGGBNAkplcq4rovne2RxhiMVA9UyQdnH9VxEUCFOYxpxwp7JI3TilETD5uEqqyrWaQrXw0hJJ00RrtXk0ElkO1nGEUIplNFInWISyERK20j6KgHlwKdcDpipt9g1X2ew3E/JcxC+otMMyUKYEKp4arhS0ue5rJSKltHMttscmZ9l62NbmTp0iMFaHxt0ih/4eNU+TBLTri9wYNdO5mcmObj7MY4cmqLZ7FCPFGUfyi70lUuQhBzZv5coiDE6o9FOOdIMaYQZs6FE6YhOCrgjaDVAnAU8svUxtu7YwhGCrMgAAQAASURBVIMP382GNatZtXw5jushoo7tImOf8FFroZhq8F9g4ebH6LIVzC82uPnmn/K2t70NLwiYnDxMa/YQYZIwW0pZvXyCVeOjPPjoVsZHR9i0cT3bDs6w0Jpi7769nH3W2QyNjHLgwAFc12N8fILDhw+zsLBgTyJgxfLlvOylL0MKQavV4qKLnsUNP/7xL72mUqnEyMgIQRAwPDzM617/+qNen1i2nNPPOIMvf/nLrFu3josvvphPf/rTuK7LyNgEIyPD9PVVmd57iErJp1ItMT+/wNDQEJuOP5mo3aIThhyaWWR2eoq0VWft5pNYmO7QmJ9hw6nrWGy22PH4QVYO9+M5LmG1hlcdxCl56KhFqz5PlEnOXrsOIX0aGPbs3oXrulz4zGfRmjnM4ccf4evX3c3w8DDnnnM2x595LrsPT3Hf4ZgDDch0xOTux1k4vJ/+5atpzR1hYu0mhpev5ptf/RJhq8WmDRuZnDxCuVajNjLBulKNMIqYnDzMtvvu5J4ffZvb6y5nPf1ifuOCp/Glz3+GbVsfpea7nL1+jBNWDvHFW7axdmyAM1eN8J0fbeGENS6XnDZAUh1ishlz42MzvD4YpDa2gkd27GVV4LBpuMb2XbMcOTLNzse2ctrTnsHszDS3/eSHVPtH6HM8Gq02Q0MjDI9NMLfjDkxrlvGBMrONEOW4jI6Ocvnll/O85z2v++y01kxOTlIqlRgcHAQgCkOmZ2a44LzzePZFz0LIvPSz0eAnN99IHCcsjcwMcPttt9HpWM3E008/nbPPOovb//0apo4/keFSmZt+ejMnn3A8v/fmN6GCimXXCdi8eTMT42PcdvMNjE2sYP26DRgDfX19XHzxxQjlsGv3bm7+6U85+ZRTuOTii/8zl9v/kSPNbBZdCInjOjbuUspuyowmihNKpRJCKpzcXxdaqpnWdDqdXFfH5OWjWc7yyv1nzky3CVzobWTpBq1miS6qUgqtHZTjUJS6SeWg47jLkvG0142zihBeZ5o0y/JSuCyXg7Ii54WPVsqCWNYFaytYq6xorS812lg2fZTa9vJCKUhtmVsah1Cp4HkuJr8u4ViNKC0kwiuRaZAGSuUSQ8NDjE2MMzQ8RH2xQaPVIUlt5ymDjRuVEtYvKofEQHthARG1CRfmMX4J6bg4rp+XgRkwKWVlkGTM1xfxXB/PC1EYkigkbbdxMk0l8JjoKzHUV8ELfCYX22gNZIayksjUYHTMdCNGKEl/zUMrQ6ahlSRoY3CUolb2Sdsh7foic01NYgR+uUIWtUizxGps6QTXSDzXQ+MSA/W4xWIUMzs9xeFaFZOljAxUEfEwTjYItQpa21LssGm77jUX6zRbLasXFqdolaGdDNFsI/J4LIpCkjim3e7QaLeJk5Q0MzkrTjJQVd2EfxzFJClgFqjWamSB3+1MGsdxXr5jWT8GO3fDMCSKYhxHW6ZQPuxP5eNYDH0shj4WQxfzsHiY//FF+ysDT0mW2smdt29dejqBFeQr0FwrIN6r6TTGOqgu6JT/YYRtmVrAMkuFSbsg1RLURme6Sx1UjtP9rm6YU5TB5ZSwYvF2u+wZK7BYOGVdvE8sPb/5ZUPcBVi0zoqb7oEgWFYRgty45jTnwsEvRdLIRdyEpaOuXLGSarVKs9lg587HeWLXLmbmZnCUoFb2GBmwztevOERRRppo6lFKkmoibXB8TVlk+FJQ1rYMbsCVSOWijMITlj2llIPrWXaUdFyQhbaCLUPLaTwWOBICXQA4CBCp1cPCCqQbg/1M3gZWAsbYzgcdIEbQkgpd9pCBi+sq4jih04nZc2CaxXZIvdnBcxRl36Xs28yJFAKV066NlCCsIDiOh6Nkt2a9qIXO03YgBKmwwuOpEUSZIdGaTqZpZ4ZYa5ppQqxTYpMR6ig3vLkmQRSRxm0qvqBWqrJu3TrGJtYwMDSOENK2By4yFfnDt4uumONHA45P5UMLgxa6201SILpdNoSUtuUvhXPU3XESFEMtlqwvS+1VQpKZrCusb5mRuYOmqDPXBeJLsailWrJF6dqNnlPrHcIKnQpAgZIOxljqv9ZLnKbQOTAucnajRDgyjyHz78YcbWeKP+yEso4N0w2oyFmYxbsLgF3mJRHh4jyDE6uoDU9w972PMnVwC5OHD3H5mWuZb6Vs3bfI4Zk2vpFsHO4nzlKSLGNRlnArPh4GE0eESUpjbpHhWhXHc2krxb6ZRRbDiKl2RL+jGHIVZw8OUPJcAs9llaupOBLf9zGui5ESoZ2842MHkSW4OsORkAmNVqCCgChv5R0YQ00OMBCUONTRHMkyWkHGRauHKfsuR+Yb7JAZizrGUEIKA0ITC4HvOqwIFKOeRziQsjAyyN2Hp9g+NcWjX/0Sx69bx+Y1azhxw2bisMP87DRP7NrFYrNFvd2hVqtRqQ0wNOSQJFZ8s68U4CiJoySH5yLasWYhhHaK7bQhYrySh/ADfvTzB2l27mR6fo6du3YwMuDzikvP4mnnnMWylZuYrddJkih/ar0gSWuxZB3nD7/7/J/ax+dvupsVFZd1NZeHHtlCnGRc/uIXdxMZUinajUVmjhzitvse4YyTT2DT+rVsmhhi4/ggF519Oq7rsmXLFp71rGfx/ve/n7e//Y941kUXMT01ZU9iDJVqhU3Hb+bKK6/k5ptvBshZCb94XHrppXz1q1+lVCr98os2Bs91ufbaa/n+97/PSSedRKfT4fjjNvPlL16NX6phpMPEYJmh0QlGJpYzd3APeA5TnZT7f/Atmo0Go6c+g76x1cg05utf/gKnnXkWZz/tYn707W8yNDLKxc++lG27DtBoN5jwGuzavoWOljzzohdy+OAB9u56gu9/40usXr+Ji553BaecfDIIgRcEXP47b+fEi6/gaz9/Op/71L/wtS99nve86FyWT4zylb94M3/2mW+x68ARRnzFlve8k5PXrOC3P3k1teFBPN/nj/76A6SZIdHwW6eehqMkynX4ype/xI0/+Qm33XYbG8b7OXn9Gr73tc/z45tv4bKLn04chqwdLPOWpx/H8rKPYwTf/atX8IOHj/C5HbP8/W8/l/seP8Af/Mv3OP+csyjrlIsHPAbikCEd8r3fWM0+M8qubJifHb6BO279Gb/9wL185Qc3cMqpp/LH7/0AP/vxjziwcwunnHwKteEJPL/E9vvv5aS+mH//88t5w8d+wsTG0/ne9777C8+w0Whw0bOfzeXPfz4f++hHQEhuu/12rrzypXzta//G5Zf3KPVpmnLbz2/jRS98IR/+yYeLhw8GXnnVVVx33XVLNi3273vvvJ2tDz/AH7359Zx7nmVavetP38P+Awf44Xe+w+e/+GV+fONP+MwnP863v38dr/3dd/Cj73yDAwf289rf/G2+8LmrefazL+LBBx7kL//qLznxxBNpNBr/sUX1f/k4PDVlO8g5DoPDoxghaXUi+islpFQkScrU9Cwzs3NMjI2QJDHtTogjpY0tdYYlN1g/p/KyG61tbCak1Vgq2EsFG1Hn1QZaCJJI27K7HBhSBmSmu5tVpawWk8yFwYuEnpTKJiK1AVfhCAgqNXQSo7OUOGoTpiFp6OD01VDCkBVC2bngscwyMBFZp0mapOg4xfVLGASZSWk3F0niiCxNMQgCXcIp9eE4CtdRRFFMs91hZqFBxXcoBz5BUGJsfBmO53P40CF27XqCfXv3IknQbkBW9knbTcgyYm0oBR4lz6VW8knCDkfqDcpeOxc9ztDSxfM8Rob6MakmS1P2zzaoOU36XMVYfxlfCfoGKpQcRTnwmBiqsKgN9VZIQoZUdq+hs5SSC8MVhViMMEYwJBzqmSZJDVFmSEOPrAMHFjvMt0Jm6i0qfQOUylUGRsbYr0M6ZNQcGKi49JddZhMr4L5xoI+R4UHmOhnbptvUpw+zOHWY+sFdrFw+zvjYCJW+/nx8NeHCDGnYpuqCVw1IA5ckSUm1IY0jDh86SJykREmaA0SGJMtox1kudJ/hOsqyx1yHdiek1WzRThXSl9QCj7WrVjIyNs5Afz9pmhHHCUkSYbT9rMDNN7N0Y3rbsei/Rhx9LIY+FkMfi6F/vRj6VxcX7wGm+f8L3JIuzc7+2yKkBWpasFUsUmy6iK/9WMEletIVP2nN/CK3qfgO0aNILX3vEtj5qHK+o87zpFK9LoMqx2RNfl1L8K+jvsUcfd0Gk1Mujz5XAZIUY0MXFbYPz/N9+vr6WLtmLVmaWjHuJCYKO9SbEY6SlPyUaiVASnBcQWoksRFoo3GTmFBnxGmCZzQOBtcYXGHQeRtdoRxwbBtbgUIikUIhhMQguug3mm4nOFGMnTEWyRYiFxy3hkUbYcEnmQt2o4m1piEEHSmJXAfHd5COJIpjGo0Oi80OC80O7SgmzjKkFCRZRpxkORVbgZEU5i3Giqo7GkwOcEltxcFtQslghEYLiA2kQGIMsbF6U2GWEeqM1Oic5WT/nekUjLZlkcJSUaWAiYlxKuUyy1espVwdxPWCnEF3tCHvwpKiWIBPlt97ah6WHmvbphpduIil62tp144eo6wrVpj7j6LO25YYFm1fC2Zaz+kWnTV6tF6DeDLNF9DkemJPsgPd78vHv8jwFOty6duPXsv2Qnvv672xuFeRBzlHaVkW1959b3fgCp/aXfwmX+sFEO24LkMTy3ls1+Ns3z9PqVrD9QPWjVY5YCDqpBxYbNHnOwSOZIVfRmO7RMSOa+dYv60x1YCJUwIpkb6P5waMSBhRsMqXBL7CK3kMBJ4N5KSDye/XwQrFap3hOBIjHJCe7XRibJmqAKTKcDoJYRgzu9hg1pU4ZcXxg6OQQdxOkJnB9xSm5NDJUiquS8l1ifPx1NiuF0q5eI5i/WBM2fOYbCzSqS/yxBO7ODI9hxICZTKiVCNdl3LZbmwyYwP9JMusZkSn0x3iMImJUk2oM4QA33WolcskQBt4bN9uJAmOiDn35JWsXLGcc859GsNjy1GuTxSHOc08f15gbdcS1m2XnVsAyE/xmPdbV/8zfZ5itOxx2WXPpd1p88+f+gxXvOiF9A8Mct3P7+HkDatYOTbEeWecwvxCnS9c8x1efNmz6XQ63HX/Azzt3HMYGRnhrW99K+eccw5jY2P83u/+LjfffDM33XgjTzv7FM46+TiklLz0pS9lfHycq6+++kmBRn4IyRNP7OJjH/sYnl9i+fLlvObVV3HttdfywAMP5G+yYyuEYMuWLTSbTa561as444zTUUqRxBEQ4/k+aRJTn5uhVK2RGkM4c4CV6zZgjKC6fIyDO7dRn53mlNPPYGhggIWpw0ysXEO1ViVp1+loQyw8nKDK2HgfsVEcOXQAIWD1uvUEJR9lUh6/5yZGRkfQWvPATT9g9QmnMb5sOX/w1rdyyy23cM9dd3Hzlt0MHZqnb2ieZqRRXkBCxt5GSHvfJM1Pf56zTtjEKRvWciDycP2Avv4+wtlDzC8s8PCug3R2P8xJpQ6lZz2dqmnRJ2O++MXPs2PH41REyvmrB1k/1s+KiRHazSZz8w1u3rtIUClzyakT3PDwblrNDk/fvJLjxko0mh0eSaCNpJkavrZ1EU+luF6bp51yPEfm5jl46BBf+8LVbDvnPK565VWEiabRDpk8dIAk0/T1DzF20nm49b20Fx5HZxrHsR2pAObm5rj66qtty+h2m8nJSW6/4w7+9oMf4o1veANpmtLIRe2XHkEQ8N/e+lZOOumko7oeArz61a9m9Zo1fPYzn+GGG25gcXGR3/mt13HfAw/y05/dyomnnsnmE08F4DmXXsr83Bxp1OLUk44n8F1mZ2cYGx7gFS95AUODg2ijecnLXsry5cvxHBen5KGqY6TV1f/ZS+4//fBcLwdxCr2UvOuuazvclTxFktptm5V4EF0/7CiJ6zqoPI6U2oLNxkAcJ7l4d14uZ4yNccjzc2LJ3g+NMaILShVbYCj2tQLf86woeNHhLW9iIxAoxyUvtLGJu5I9n5RtRF5KpxwHrTXtdqurlSqllWkoEshK2qRohiEzGvMkId0u4KUcDMKCu2GTVqtDu9UikCW0q9BpYvVPan2MLVvO9PQUEoPMIpSw5XXG7SdLM+KoQ4ZB6ozBSkAiNanQDPVbTaN2nBFntnTJlxCFMVESU/YcBkuKsbLLYNUHIcmMpJxvYIMgoJlJMIKyEiidoDKN1BY0EI6i4rukBsJYkyQpWWZwjCaOQxodF/wyTqbwY4MrQJkUmYZ4CrTv4Hsl/FKAX/LpK7koKfFdiVsrUzUKf1QxefAwzcVFosV5DumEubl5pOdbJpsQVFSGIzQutjoiyzRxmtGJEzpxykIrtABTplHKRoFFgzRHSpQnrBaZ4yCUQ6oNzU5EJlxwUkyWIvNO0DOzsyRphue5NBsNi3lISTO0paJB4OdMuNQyuHIG31P5OBZDH4uhj8XQv34M/SsDT123JJ6EdhWTdQnA09OLIAeddM6iKe7BFKuyexytmVMsmCedxojujRU0Rvvi0nPbz2bdWlrT/a5iXHqgcU4j7H1R7zz0GFv2Q6J7IUtrXn/59T/53yb/XP7V+dTItMb1XBxHsXbNGsACINMzM8zMzlJvtJAY4pKL58j8vZJMCOLE1q6TxnRSQQiUsKV1pVz/yVUSIV0y5djsFrlekpG4KCT2XrJMd4Xdpcy7wYniiZtcUykHnYw1lhpA2L5ymYQwEzQN1IUglpLEd3A8hVSC5mLEwmKb2YUm9Vanu0gyKUgzSZym+TXoroHSAqKurdVkWuRleIZYW1H12BjbyheItCbNf5cYTaYNkU5JTUZmNBlpbqKsqKYwBmksvZ28s8qyiWUMDY0wNLYSjYNGWApwVxy+Z5yL9qdC9Iz/U/0wxoAUSKVsF5tiDRnTnd9FMKqERCh5FLXY0udzyj2CokllIT5XCPsbs6Q0sTv/7ZpfKkZYjFq25Lnb7znaASOKGLqXmaH4ao52mIVdKX6jc005UXi9wlwtHRP7Jd3SBFvHXsCLvWvtgt1LbJCdtxlKKcZWrCKWAbsmG5S8KVYvH+KEjSsItWZmIWTf3gXWyjIV12dZKUALO3c7jodwPZxymalmmziMEM1Faq5CBR6eV2GUjFGRMqpSXF+iSi5OrYZRLomRmDTFZBnKGDKd2QYOjpMjt5BGcX79EqUEKpN4YUrYiajToD4UMFKtsn7ZII2pDp04BTSBrxDaodXIqAY+1cCnkWSkOiPTKZ4SuEJREw4bB2G4XMaTivlmk4PzC0y2n6BaLjE22M/44BCeX8L1IUpTksy21c1y/bQwsXYg0xrh2PWVmIyS4+A5Lv3VfmaimHoYcuDQXkZqinVjZS4+/0zWrj+e406/mDBTxKkmbTfzzKFcEjOZX7JQ8/X7XwB4+vyHPwDYkpYrrriCemORT/7rpzjzjNMxyuPrP7yJ33nFCzhx8waecc4A3/zBDXz5m9/j2Reey+z8HN/90Q1sWr+eEzdv4k/+5E/wfR/HcXjPe95DpVLh7rvu4rJnns+5Z5wEwFVXXcXmzZv5/Oc//0s3BEIIdjz+OB/84Aep9A1yxhln8JIrXsT3vvc9vvKVr9jyql9yvOa1r+Ocs89i364d+SZU0N9XJYlDonaLFes3QqdNeHgf6zafSFDpQxvD9ruPcGjvTi67/B0056aYPbiPles24khDe2GaUHtkjof0FOP9gxih2PbAPYyvWMmKtetZvmYdh3Y8xEM3XMMzXvF7pJnmtn+/mtrQCOtPOYc/escfA4YH77+X256YQqg5lHOAwA/oq/VB2OBIBodmW1z7iU9z1QUn4p5/Evc2a/QPj7B5wxp2P3gHO3fv4X/+7F5ee/oyTl+/nFPPuYz5PVuYevwhPvGxjyKMYdVAmcs2T7BqdIBa/wDTk9PsOTTDNw4kvOG5J/OCs1fwsmtuZN1QH1eddzyDQzV2Tmn247KYaWZaEf/6YJ1T/TnOHJjlwkuex55Dhwnnpvjq5z7Do48+ynOe81zCRBOnMHnwABhQxjBxyoW0dkimt9+No1xc16XdbgNw4MAB/ub97ydNEoQQdDod7r33Xh566GFesIThFEVh9zOe51EqlXj3u99Nmqb573sx2VVXXcWZZ57J5z/3Oa677jruuvNOHrzr53zrO9/npltu5bhTzmLNphNot9tc8aIXobOU5vwUZ512CmedcQa33vZzxob7+d03vJZqtYrj+/zOm9/ExMQEYdhBJgmUhggmjv/PWWj/B4+gFHR9o5QSg00Ouq6Lq6DsO4RSkGly/SaRE7sFKJUDVFaCQHXjVEMSx2RKobTT1ckRFKx8gZBL9GLymMr6b9NlPNhXrR9UnofngXQUURgRRSFkBqUcfD/otmZHCnzfw1VFEY0FzJTjkCYp7VYLoZxuCR+5rpySEkcBQhBqg9UT7TUwEIV2J/bf2tgOza1mi1a7TdjpYMouZJnt2uj5lCs1xiaWs2/XLhQgkhDH9fC9Ko5fJcs0C3XIkgSRplSDmk1cKsOKkSEyBM04pR1GoA2egFYcE0cR/SWP8T6P5f0eZd9Ho4i1pOx7+J6LFwQ4qYOjoQyoVCPTFJ0W5UsOpUAQpZpGnFlmlda4UtpStDBGDY/hy4BSJpBphEgTTNTGUyB9jyAAr1TCKwX0u4HtCGhS+gb6IagwUR6kohOOmJj9+2eZbjTpGIhSKzztOYoVI31USh61ko/RNn5pxwmNdkSjEzHf7FiRd8DLyyaVlKh8X+ApmWs7KZTjkmpodSK0KxBuRpaleZUATE3NUKlWCHyP2ZkFPM+lXCoThtYv1Go1dL6Z9zyPKIq65VdP1eNYDH0shj4WQ//CqqBYAv/pwJOl3bJkIbA0hdItW+tO7CVI6VHaOBjI68WPAqgKYOOo7ygcZxexsdivAdLUfkr2AKGi9G1pbW33OpYuwoLFU9xC9xxFZqd33wbbTaAgK4mc+SNYcl9LqJNdhPqoxW1yITkDGqstlJ/DcWwHkeGRETzfZ3x8HCMEe/ft47Ft25mdnaE536beiqhVfALfpRS4eSZIkCnoIAi1IE0si0dq6zRc5eAnAs/J8o4p0oo7SoXr5J0lsJmmbt1xHuS40o6nzIE2oTUUAJW2ba8zY8gMRJkhAjpGogMX4Sm8kkOcJETNhAOH55hfbFNvhcTdrg+23WWSCTpxbOm4jsRzlWUzCZhNIrSOMFriCtm9ngLXT41BCztPiqyZ/bFGI8078xVzqitZr23WQhtBagxenJDECZ5fpVQdBCfAZDYzZzB5maFltNm/rUZDMZfosuWe4kfRkSI1PdptASTnc1kV6zzL7I+2zkMbS+NVwgGk1ZUwReCaFclJurRjabssWgHj9GgnmMesViDVAo5Syfz1vKsP1uYU2Rp03m5S5NkjDNpkRwHUheFbCi4LA0bbeSFF0SHEdAOewm5I7DrXuR2woGK+tp9kTbvlu/nvF+t1HMfl1FNOYWFhDldk/PCGn7B/ps7Og3OcsmkZ60cClg2Mc2imyc5Gg8m5BmuqPmtqAScsW4Hju0hXMSkFoSvJREgJjSczyiWbNXS9CsJRGOmglUPmlBFK4QoQrgtaEyc+Ku4gifLn4SLwyLSwGWWdgQZHCJYPjnAQwYIjWbdqGA9Bc6rBz+/bidaaE9aM4fkuruvQDjvEQnSTAo6SKOmSGkOKIJWK8cFBlgHrq1WaUYfFKOTu2SbzUcRMMyJJZkBCjAbpAhKW1I9ngCOFDW4F+I5Lf7VKxS+hkeysN+mQIp2Up28eYOX4OBvWrudZz3s1QW2EegfisEWWpUgli1nQW/fQI7QuiX+OiuP+ixztTsgZp5/BzddfR//AAMpx+Oz734nvubTbTXY9ei+nrR/nS//0AUZHR5kYG+HD7/0L+vv72L59G1dccQV//dd/zWte82p0pvnN17+eK664worRBgEAb3rTm7jxppv+F1logdEZlzznOfzrv/4zQki279jB6aefzjve8Q7e+MY38pznPOeXlj5tfeg++koOmzadQH1hlk67RRxHBEEZvzbA3t1P2BIAI9n56L0sNNrctn2SS592Dhc+6xIO7t9LX18/a085i93bH7Ni5qUKp6wcJUkSHnvgfiJ1GOH6rFm9kcMH9/Hgffdw7rnnEkYJZmQjwisxMDDExb/310QLMzz+2COs23wiGzeu59nPPBeEYj407F00HN7xKEHa4YyJPkbXHIfxy/z7jT/jtod3cmD3fh5va8qOYlngcjCBFaP9fPzNL+bqG+7i3755F2f+fCdRmtBJIo5zYf3yUS48dT0nnn0q++ZbvO0L1/Kqczdz3pkncor/MD++/T6uuv4ePvaiDRycj/jhXVs478Jnsnz1Zr7/3zfxqW9fwwf3zHLSWedTqh9ib32Kw7f9nPXLBviTK8/jT//n3dx1zz08/cLz+Yd/+Ade+9u/RbMTMjs7y9zsDFP3/Bg1uwff97nmm99k28FZTj75ZIwxpGlKq9nkT//0T3nlK1/Jc57zHGZnZ3EcddTm5K1v/W/8yZ+8GyEEf/7nf84b3/hGAL7+9a/zl3/5V0tssuGzn/0sy5cvXzJ1BF5tCCcog9GEmeamW37G77/5TfzzJz/BmjVreMOb3syb3vDbXPysZ/F3H/4oz7vsMt7xtv/GG9/yu4yPjfPBv/sAv/uW3+WWXPB+frFpBWCf4kffwFB3Y9pXrWAAP3ZsPKmhr1alL2eiZ0lIGrZJOy0S3wGdSwO4LiBIYquHZLTGyUvjhJRW39IIhDa9DlfFDhdjy+jyrnVppknSlCiM0BiUdHCcGlpbTZ5Go0GhI+M4Llprms0GIu985wS+jX+kpK9/oFs5YAEEkzObZM6itzwpIQRuqYpjNI7WhA3LiorimDBOSOKYTqsFJoUsBjRJapk5xgiCSo1VA8PUPIlCEzYWUH4ZpMP46ChrVq+iPrWOe++bZ77eIllocdKJx1OtVhkbG2bfvv0sLixwZGqKUU8yFjjU+gaRnseAkCTz06Rhm6jVpK8/QDkVRseHqboZJZXSiEBruxsNqgHlUonqwBADtUG0VEwf2IduzmGSCL/kkiSKVpQxr2MiLQilsAUIJiNJDbFx0ZTZvHwVjUaTdphwaGoKk2UMdjoM9PdRHehjQGW4wpAaEGmCzlJ0EpGYebTbJvValJImYwG4IxWasaaZaOrtmDgzJEnM5PQ8KmfOFZIpcZISJ5Y1gTFdcCnwXPuMVQE+SQseVcqUyiWqff1gNEmakSYpWaeDbCzSabfwS2U6YYzWGR3XJQwjaz8Cje/7aG0T73EcI4Sgr89DCVvF8JQ+jsXQx2LoYzH0rx1D/4cYTyafmUcxnp4MQnX/ykuytBVTBLpsH9HNrpjubRW0vi5za8lNWPzGdMFWey09kKk4W5fWtOSaKVhMS5C6nga6yP/dYzBps2TVFR8z5qhr7CF8xTX1LrZAqwswoptJ6hqpAryz79daIwBHSdvmlgFWr16DkJJ2J0TrjGazQRJHtMOUNNOkmbYZCCWQpuhsoshkDswBqdHILKOTJDgmw9ESV1qWkxQKR6UWZEJbQUpjut1kpLDAk8izX9LYMSqEK+17LfCUGkOiDVoKtCPxHJsdybSm1YpotUMWmh1aUUycptAdPzuPMm0dV5SkeLHCcxVIG6LEWpNmkGZ2jGWe/SqGO8PC8AYrKl8YdmsQdY7U985nn7khr66zzC0hrAZBzroqgsLuZ4oHlc+T7jTqquD/19mxCmEdUtGWtRjIrgZaPmcLUcMueJoPmEBY9pcoaJU5zXgJgGzISyKlREqD1oIsMz3R+MKEGZvdkYBRSzIuS2xLr0y1l2Ix+bMtrq0QPdV5LbzRJs8mHQ2S99aopmtMu6Bz94zWFuTr2ta5F3YGjq6bL95T6LrZublq5UrOPedctjy2nZnZWY7MLTI4WWKov8zIcI3+ioMSEJmEeaNxwhgvjCmnKYHUlLIEXxoIXMpS4EqJH/hI10O6LsILbDaY3HFnGuXkdycEjlJoqXLdtrx0wWD1OQxIDAobN01nkAQOTsmlLCWtZsiRQ3NM1xsoIWi2IwLHRymJVtZWGl0MmW1eIHUxvvYZKikolXwcVxEEPpuVz3wnZLbVxjOa2GhmdYrJ7KoNHEVqNNqA7yh8pQgcBweTB7sOYZaRmBShMvp9242zudhgsRzT7GiUV8HxSiSNxXyjZdsFU6z3fNZRZONY4s8gj6z+/62ep9YhpSROMw7NLBCUy5QEtDsdsizFUYJq3yBeuYrnuYTtBvWFBXY8voPTzzibOE7Ys2cvjzy6hTvuuocDB/azeeMmTjvNljsdOHCAn33nezz44IMcPnQIgHPPPZeNGzcC8Nhjj/HQww9z+eWXc8nFF7NmzVpuuukm7r7rLvbs3ceDDz1EEARceeWVuV3N+OEPf0iz2QTAcT08P8jFiJVtfuGX6IQxC/UG1VqVLJW02k2UdHH9gOVDFUwas7AwTxZ1MLqCkLaMW0iF9AKShRmiKERrqFRLKN9n6vB+FhcX0EbQ6MRoJ2Bs9QbQGfW5GbY8tpMR3zBQ8dEG1qzfxNMvupRrr72OqBMx7nhU16wgizrM1KfJ5usEVcMzzziR+swMh+bm2DDaTzuM2X1khpHVq6mUy2zZd4SpxQ5RqqkQMdgXoPwa0WLI6tF+lveXePCJg8x0Ys7fPIYWhsOLHY4bCFjZTDjSTqhISZZqZhodajLESRrc/3iduekZvDTi9BM2cGBri8OTB3n6eJWy1ByYb3HmhgkGpxvc88Q+br31VqQwnH3KcVRURlZ2uX/fXsLpg8h6neMxkMXs2bMHsCyEV7ziFVx44YVs3LiRl7/85SwuLuK4LgMDA0xOTgJw/PHHU6vVuO666/jZz3/OyMgoz3vec5mYmOBpT7sQgMOHD3PzzTfTbrfp6+vjqquu4q677uLgwYP8+7e/w7333Q+AEjA0NMQFF15IJ4yYmp7h7LPOYmxkBCHg/PPOY2xslP0H9rF61UqWTSzD93zWrF7JyhXLuO32O4+OSZ/Ch5TKxpF53GeMIU0STGasgK7nUXSvyoxlAmRpShJHFNsA8njYaj6Zru0n735XcA1EXhZhjMkTaSnGaNvExXFsyZyxG8g0S8nSjFSmtkwuj6OSJEHkoEMRummtkSJvOKOL+NGWi9hQwG6AlFL4QdDVlzLa4DgWzCgYHiBwPZ9UGwwxi4uLdNpt4jjGdS04prwSWe5fLQMsL8PLQQAL2tlEdKlcYXRsgrXrN7Jrzz703DydxQb1xQZZpvF8O76WpaXJhKGVanSjhXJjWxkQxwit8RyHoBTglwIGhobRaYdW0sGUA3zHo+b5lB2NqxwMEpEkKJlR8lxi1yV1XIylrqF8hyzSaMfgOZIsjkiyjI4RqKCCX6kS5vpVC40Wc4ttMBrHdRkcVHi+h9ERSZai0xTPxcb+SpEJAzrDJBGeBOE7yIEqVW2b6/SHmjjVRGlGksakWpNq+/8074SNEHiua8vplMwBJ9UDO4QFNE0OMloNMEmSWMaU1toy8NodwtCKkiuVy3kYYwFRo4miqLvxFvk5hYAkji14UgA7T9HjWAwNx2LoYzH0rxtD/+pd7fKZ0wVngG5xZ84A6lFjRZdaaLV7lky27oV3d/BYqaBclb/4vuLOxJLFa+jSjGWOMhcC3gX0VoBN3ar1HBgqrrsArophK4xgAYQcxc7KWUBGG0u3yweiMA+mcO70BMqtkV7yHPLrz7R9kCIX4S6MkM5SjLb34yhFtVbjuONPYGBwMBf7zDhyZIpDhw/TjjJaYYLTinAdgedIRDXF91wCz0M5ypaHZRAW4EuSIlJLf3akQmCzaUVmSi5BpzXF2IKVkRT0ME8QpkfntKCT/VsL8DyHsi8ZdARGGuIwYXpu0ZbY1W1GKzPWoBUzVhvr9KI4pRXGFoBzBI6rEEqQmJRIa6LMdgCx45uz5WT+MIR92l1Rea2XzJcekNmdq3nwlJkc0HIESZoSxzFxFBJHIaUsy59prjdAATgVgBldg9qbt/8FAl9jnYrOdN5+NXdCeXYEcmcnes7UZkSKOE92WWD5FwJLHF6xhorgRJreGqLAc3uOSEknB/B0L3uyBKQ2WWbZkUJ2AWBtNJqs920F7TkPbLXRCKPyQFejRB48SdvW1WDntiwCA4pg3vR+6L3wy+rtuzpy2PdobTBZSrvTYc269axbv559u57g3gcf4uY77+G+dsL4YIVLzlrHqv4APajY7reYrMfsWYyYk/MMkTGWdVhWK1PxFEEloOSVcBwX4zq246SSuKWaXZda02q10cbgYp2kQeBJQSZtOS5ZAtrYjkPKASFQmcZxXNoadndinMGAymgFP9Xsm1rgtkd20YwiKr7HfKPFaKBwAxfj5J0iDXkZRG7zckOnMKQmI0WiAp9ABFSFZHhE0I4iGq0WnWaThThmR5QQtjqITDNW8WmkKW2tmSiXKTsuJcdBZCmhhiMpTHZahCalUlOsHKzQ57t8+8EdzDUUiTvEc8MUp5SSJXmJTw7Aixxs7oayphew9VZzdwIsjdee8ofve0xOz/K5a77L77/mSpaNjvDzex5i7aplrJgYZf0JpzE1O8eu/QcZCeDRRx7mk5/6V/7uQx9FuT5CwO133sXkzBzXXnstb/mdN+bAk+Hee+/lta997ZKzCd7whjfw5je/GYAPf/jDbN26lQ//wz+wefNmAD74wQ9y4003IZXL1Vd/juuuvZYtjz5KX38/YRhy6qmnsnPnToQQjI4vY2xiuW3tLKXtuDowyuTj23hi21ZeeMVLyJKY5sIswegKBnyPE9et4OFtu7hn1w7OOHETOg4J2006SYwfVAhq/Uw9cjthu4VXXc7aVcvxA59rvvgdBoYmGFu+jrlORv9AP8ev3QyLh9m78wm+9Kkv8vIXXcL46SeTxCmnnHU+m046jX/8xNV4nTmetWmEsWdcwlQj4ktf/Tec2e1MDA/wz+9+C9+55R6++7O7ePuFx/PowVn++eACLzrleIyBD/77jQz4ihX9ZU5dM8ry5WMMjQ2xY88cg4FkuCz5s6/dTF9/iX//0xfyiR8+yq2PT3LqyTWe4bqcPhwyO5dwcC5iPopZF8wxP3eEd33xbs5bN8K561fwoqefzlcm93NrvcNfnbCZnbMdvnHvbt7+4nM5stjh3l1H+MQnPs73vvV1/udH/oyx9cfRPzTE1q3b2b//IPMLi2x68AGm5uvdIHLZxASfu/pqmwQTgo9//ONHMZ22bdsGQvCOd7yDzZs38+Mf/5hrrvkmt/zsVu658E4uvfRSLr30UgCuv/56fnrLzxBCsGLFCr7whS/wjne8g3/6p3/iD/7gDzDG4DgOnpKccsopfOmLX+R7P7yW3fv28+EPfZBOs0EYtvnb//4+tu94jJ/fejO/+brXMDIyhtGa1736Kk46fhN33nXPL2hOPVWPvDoOgwVwkjSh1WoCGa7j4OYsMJNvDG1SLCEKQ1SexdYmF32OY5yCTSRtV2KkbdltN6VF/KrRaWrL8dLUCpB7Pl5Q+E5IkyQHBQxxDjaBIEtTC5YpULIXV1mWvEandkOlc4ZGHjnksZyDF5RoLtZJkhidZfh+gOv5tFpNhJAIpShVqhipaLQ6TB45wmJ9gUIXVguFKtVwXQ/X83CEFbsOo4jALSGkxHMcWxoDlGrDrFy3gWqtxp59+xF79rDQaHLw4GFc16VSqxH4DrW+Gn2uJm51ONQOiQ9M4ipFyRH0S03ZlQxWAoZHhqj11fBGlzE5O8eRNoxNrKC/VmFisEzWmCGNE8IwI2nPII2mXPLBD0iThLCVIqXED1xMmCGBWn+JmXqbVpjSEC6jfcMMDY8wNzfP4SPT7D00yZHZun3efolVQuG4PkknIooTTBIxIAS+q/C8EomyzIdUp/iewpcBg31llOcjHI8I1wJPcUJjcZ5WJ2S63mSyHhJnVk+s4nuUfZdSDsyBIM2sZEWaadIiBtYGz1gd2SxLaUcR801bcqucjMRIWo0G1VoftcGRnOkm8DwXrTNarQapkTnw6VD2XTCa2dkFHNcyQ57Sx7EY+lgMfSyG/rVj6P+AuHi+uc8XWDfLsgTp7U6urNcBzHSdKN332A4c9muVFPnN9OZrAd4U3wcc9f12QIoMTA+HzdIeW6XLRiqAII4GiEzxXUuu3S7oYoiLJZ6DJcV3kg+36Cn7F6V25MBbD6TIwQkpMKZXriBFztpZApakwjp4qaBSrjAxvozADygFAbMzM+zbt49Go0knDImjCIPVJoqjNu0kox1F3fpaISHL6/a7VRJdA5BnxpRC5kKQkp5xsNcLyZLx7Zm8HshnkN3vdB2Jkhk6NUzPhSRJSrMVsthoE0YJSZpaEThTlC3mwpn5k4uzjHo7JIpTUp3hugrHkcRGk2obZPUwTmFbfC4F2YtnqXvj2UXX84mVZbo7T2xnQ5vVsQi/DQCjqEMUdkjTuHtthYYTgh5jL2e+ddF78V9DXJwcZFVKdQNbvcRSCEBnmaVrKtUNGqygon1Hz9QcbXxEd2zsd+kss8Zd2GA0y3JNA8fr0m+LMoACVBaIXkkvhiSOLMvMtlpEAMpIpC4A6p7vKjrwdK1BNzPauzlZmM+lxtEsdeZ5p8YlY6KXZGi6JbWm10jAiOLeDc1GgywN8H2f33jVaznh1NMZHR3m5tvv5vDcIj+4YwcrxgZs5mawQt+QS9Tn4Dkp87HmYEtwz9QCLoKhcoVyCXwvo1ZycZE4SMolmQPDmXWKxmBCiacEjrQCggKD8DxEBIhcdFLaFroRiieaEbNaE43XGBmpMlL1ufXuHRyebbDYiZDKErHnGm2GBsooz6UhNKFySbwyo4FtC5vqDFynm3nuZtfzen3lKKqVgKFUk/UPELUapEZzkpIszs1jjGb1+lV0HJe2gcOP76YZGxa0ZNfcJKFJyQKHgUGPEcclDkN27DzAQj1kxdq1nHTSSVx44YUIIei0WyjoMmW7PspeWD5fRNcvPHkimO5M/q9xtMOIdetW8s43v45lo8N4nsvznnU+D953Bz975A7UC16OzjSVao2x8WGePrqMDSeexuo16zh46DAnnXEuM/MLtB55mH98/3s57YwzSJKE3/qt3+LBBx+0Ypsmy9fCLxuXoy3eRz/6Ue666y7e/Ja38CfvehcvfemVVJ4kMn3RRRfxN3/zNwz099kMfZaA44MvIWmxYd1a1q5dx/Yd2ymVSqzZdBL7Dh2m3ekwvnEdK9ZoBoabTKw/gUP79vDIIw9x4pnnk8Yxh7Y/wqqNJ+G4ivmZaR5/fButKOX5L3kV01PTHDkyycbVI3TCBR64Zz86baMch3e+5z30ixCTRDx6x88YW7uBwWXLufSMzWzfsYMfbZkk2Hctmzdv5Eff/jIf/5eruePOe3jnx7/EWVXDn540yNApz+aczR0+tHYj9X17aCw2eP7aQVYsH2f5SI3nboLbt89w44O7OGHdStJqHwtuPx//2D+wUF/ko5/7FMev7uesM8d5YPccOA5Z0MftDx5kdU3y3vOG+cyNj1FasZ7vfePz/OAbX2Pfzh3cdcP38DrznHfSeh5veVTHx3jLiecwe3gvteFRbrn+f/LVj3+cR+67n7e87+O4QYlyqcRlJ02weazC3HyTW677Hv21Ev/2vtfzka//lEd2H+DS51yWxzz2uOKKK3jnO9/Ze5BLo0sheMub38xrX/daBgcHjnre5513Lj+75WZOPOHE7u/e+ta38rKXvQyAb3/7O3zik58EBA8/8ggf/ehHed1rX8u61av48/e+j75AUvIddi1ozjz1JJ532QuY3L+LH9x6C5//yjd533v/kjXrN1m7LX0QT/FNK+B7VkQ/ThMOHjpElgvrCmG6GpfCGCuO7Tj09fVRKldot5o2eaZELnILUjk4joOrFMp1EfnmUScZiLxJTL5pzXKdSoMhS6zGZpQkKNcFY1mIUil0pulEUZf94LsuAg1GkCS2LEoqB53GJKkmiULo67PswyjOGfOAVKRZRtho0mw00FnWBYhUHtdBhjQGY+xmLKj2ceJJp5ClVii9XC4jpeLQkSnCTkicJGzetAHP93H9gCQOSbKU2CQ0OzFhqknmOgzUqoyvXMMzLr6UVbufYGBwgCeesN2gDk9O4XsOrqOYd2UeM8KakT4C18GX0KgvstjRLOiEMMiokpKF02hjUH4VmaY05+d5fHqSdqsBBipeCZFEoFO069IOIzphhAkzAhdqEqq1PlpJyu7pFs04QwuHsWUr6BsYQPkldj62kyNTMxw+MkMYRniuQycMqS8uokxGo7GIMhpXQt9wGVku41bKSOXhGCBO6BhNSkgqDI5wcJRLEFTx0gzfiTBhE5FlhJUKxq8xhMILfCq+R+A5ZFlGJ4pptTt0Gi2iOKEdRqQ5WKKUotHuUAp8KiWfME5pdCKkcimVSnhBmUazib+wgFFFN2qRx38ZOkuItWWstVptBvsqKCEIww6lPDZ9Sh/HYujuOCwdk2Mx9LEY+j8SQ//HGE9P+rsoUYMCtLMzsCs8CD0wgC4HKb8ds+TfS49i4j/pFpZkipb80UPccvZTbyGbJeCB/bzV6BFHfa74KiGWDKFZcsLckRbv6xqNXza+xuT65zmTCtFb2F0wrQduFV0IDORIsLaQmlL4fsBA/wArV6ykVqniuR71+iLtTod2p22NW5ZSr88Tx5ENAExmF4wAqTPbvlbkY58/KwvIZOjUttbV2qLhOZ5jjU1mr9O+fynwZPK2oQJyFFwKgTKaJLVdR6IoIYpTGq2QMIpt5wyTy3rnM1mKgi0kuzPB1u8bVEfgpgrHsWL0Oh8bveSztqtor59EMZY94Mk+n6O0vnIETgpwlEAogVCSJP98lmnSJCHNM3NSyqMnhVlKae8Zz6Pm51P86LIDly4/OOo+nuxE7et0HWPx0e645m8vnEfXBmjLJ+2BvUvGy9Cbk8WXFwul8Lr5lCvKI3u2w55dLjV4vwxm/19C70cHCsU6XdK3YAmevmQsliCdS39vumNi0FlGEltG3tj4BGEUcvbZZ7Pn4CR79x9gdm4e5SiiJEVJMNLqlWXKkElJ7EqakbWraZrhxgmugX6hcZG4SHyd67CRobTVikuNJHDAk4LAdSiq8GVcdDrJ0NjsZSfRTCFoOw79fSUwhsZim4PTCyy0QsiflzaWQp8mGSbTCCVomozpOMFzrRVNNbZOphiLLGdZZtp2XDKQxhnSAFqQSQeNwXEVrueD0bjlEsb3MdimBB2Z0RGCSFkNN88DoxOSyNBqdWzHIb/MSSefzPHHn8DqNeswQBJbTZFiXix1h12HKY7+PeRWrutP/msATwaYmp1n2YqYjWtX8fgTT9DuhIyMjNjSttQmdpSUlFxFp90mKAWcdNKpbNm6lUe3bMEYw2K9TrOul/hNO7cHBwe54ILz2brlURYWFgB44oknuP322xFCsHfv3l+4pl73HOt/0jTl7rvuAiGIoogwDBkaGuKcc85h+sgh0ji2ZURakxmDo5T1KXlgazdAUf7dkji1IFrg+xRl9VIpJJaMrKQAx0W4Ll4pwFFNjI6Znpllanqa6elpOitHSYzCbnkFjnLoG+inrF0IJXFjH2nYBgRnnXUWiTZs3TfFwtQUg4MDOFJQqZSp1GpEcYTRCke67Jpp4JHS7zksZgm+0By/bJDVG9cyONTH/sVthF6NvuXDjI6VKZXKhKrM5v4KNTJucyoESlFV4FSqLEQJ9U5CebCG52WEqaaeuThuhTUrJtBCMV1v8fgTeyj3D7B5/RoSEWKkot93qXdC3ChmsOyxcqDEdM3j7slJ2pEVDD9rZcVusj2XLY/vY3SoykVnrsF1JGHY4Y477mDpWhgZGeFpT3saAFu3bu3+vlQqccH553PBBedz9lln/ZKZKrr+ptPp8NBDD7FmzZrudx2ZmuK+++9H+QGtVpM0zWg3G7QDz9rTPKYzxlCvL7Jnzz5ck6KE3cg5SuH5AX7/CLrZIkue+qwng9VdStKERrMFGEqlgKI0J0liXCHyhJctg3FcBd14o2dvHaVQUtrsubRMep1mpJnVbVGOY+Mlg42GhcxjT221TLOYTNtzWIFzD60sIGXyrr/5frUbA1shck2a2LI9YWyHNsdJ7EZJ5p2O05QwjlhstKzQr4DA82ycnjeX0TnQlprIJhYNDAwM2MguS/F8H2NszBcnMc1Gk2ajSQWoVGtkkb0Wg7BNZrShHXWolQMcx2Vi2QqyLKO5WKfd7uDOznJkeo44SYmimEjZGFQ5tqOVLSeDSEOaahIyvFZEW0tiOnieS+B7xGEHnSaEnTb1VgcQDJQMUicIo4k6Me3YxsEy0ZQ0aJmQOi6d1FDvJBaUcQP8coXMQLPVpr5Qp9FoEIYhaZbZkp98nAo7mWmrq9qINcYzCC1ItCbJNJ1ORBSlpHEGRuNkEicTlGWCyTKyJLF6TAaEdHB9FyUdSqUSJd/Bc5QFy8CyypKUME7oxIl97hhUPl/Abo6jJKMTJfiBAiHxS2UAdJbiOIW0h0F5HmmaEGcZjuNYll1m9yjKEai8AZJST23w+FgMbT9/LIY+FkP/OjG0ML9icfzWBx/s7cF1jypYOMNuyVHOeCouIE0iChDI5Jv2XhlbHnDmKO9SraQCTV4KWJm8tT2mMH7kImu5c31S/ajIBbJ7YEkBPPVK74oApzh7URZo16/oUiSLK1nK5rLfV/wzBzB0cY1LgnFEF3QBW8MJFtEu6t8priD/TFFSZunMKZ12m3a7TRRHtDshSRITxQmTR47QajWp1+vEUQedpWSppVRrnZEVTj6zrJ4sTUiSmDBvaZrlIEsBPhX6Tbp7wbKrp6eN7t6Tkrb9r8wtjBWHTOmESZeiWxiTNOs5TqkEnqMoey6OtMi8zqmr2pgcGJJ5CYY9txB5yd8SdP7JR3e+5OLnRdDrqKI7isYR4Ejoq5ZwXAfpuCxEEuX6DA4OcdzmTYyNj7N89SaUY6mZS41vV59B0NOR0rZjI0Lw/Be96H9xdU+N49EHHrAZyRy5t0upF9yb3NEVtfc20LRBKtjxl106fTHXc+MjbbCc6dR2z9A2kLNDs8QgCdty2D5zq8ug8hbQkA+3toGTKeabFGSieLZ5MFw42SIqxtaop6mlEIviPfSA326GSi8xeQbAaqQhTfdal76nmPNplnavId/7guoJSxpDrgNmKFdrBOUKlf5+vv+tr/Pgg/fzre98h0YnIU7seJZdQTWQnLpxgv5alf5aPy0jiFLDYjulk2iSIiGiHIRwiTPAZEidQZahEUTCIVASVwhU3v1RCiyjxNj772QZYaZZjDOOWzvEypEaZ64a4v6te3lg2wH2TM/jKkmt5NFJYgA85XDK6gnGB6u4FZcDczFT9ZQVlapttY0EpXJ3YxBZAkaT5jZDSGyOyWikTm2WEIi1QcchSsLwsiFE4JJKwSOP70JIKJVcPB3iC0PNEdy/ZT+HZxaZ7yRceME5nHP2mbzmqtfhemWiVDA9dSTPkndNbO/RmtyVilxOMzfOS2aGncuZRmeGF73siv/osvq/dnTp9Urx3/7yAzzt/HN56WUX8Vtv+QO2bNvBy1/5SjZv2sCalSs4edN6srBFqz7L3XfcSt/QCOdd9HxeePnl/PjHNxzlw/xyjT/6b2/l7z7wN7lf1ugs4/mXv4Abb7yxOHsvnjW21O+hhx7qltpddtll3HjjjT178CRKqjHwwhe9gE9/6lOY2OqXSOkwMz9PGCccd/zJPLFzB9u3beFZF13C/Nwcd911G2ef/wz6qlUaU/uZWL2eSrWPfVvuYWB8JUPL1vDInbdQqlRZc9xJ7N6+lThJGVqxjqHBARr1Ba540XPp6x9k5ep1PP1pF7B+43GcfOZ5xPNHmJ6Z4mf3PsCzn/ks1q9czsG7byBYtoHKyuMYqAbc+MPv8YH3vINH9kzSCiMqjmTDyaewZs1KXnDiKHc8sIOf37+NPXMNRjzJSYM+p564mRUj/Zw4UWPFeRdTdyo85zW/zzvf8Xbe/fY/pH3npzg42eTRgxIeu4NaX4UTXvJSbrnmW8zs3cMLrryIf//pw9x4z3Y+/b6r+PH9u/njf/kxb/+tl7FiYoww0Vzzgx+zbeceKqWAV774Mi5/9gVM3/MTZmfnmZxusLKiWAxjbtmzwBmrBxmu+hxspGw/MMOuw/Ps7aRMDPVxwuoxHtpzBINgzbIRduybZH6x9f859+yzNHznO9/hxS9+sdUqyu1vT7zCvvf666/n8ssv57vf/Q4bNmzkzDPP5IMf/CBve9vbut+ljWF/Iwad0S81n/zIh5ifneFvP/wxC4w2GyxbvpxPf/Zq/uwv/pIbr/sBJ598MqVKjbmpQzy2czdv+OtPM7X9bhYPPv7LN1BPoeP+rTuIwg7tZpMjU1N4nsv4+LjtVicEJkuplnwCzyVNYlJtSDJDu7GIFBD4bt7e23YetiwpjVAOSZqSJAlxkpd3+R6e59lYudDn1Jo0toyrOEksM8NxKZXLVCpVpBCEnTZJFJJlKQqDchRKuWQIOmFk9ZK0FRoulQJcx5a71Wo1PFfhKsXi/Az1RpPDM/NUa31UymWWj48isdew0EnohBaQbi8uoKQg8AOWr1qDchxmpo8QlMoox6XRCjk8OcmhQ4cQQjA6Ospxxx2HjtoINK7j2AY3Scr09CzVcpn+apWgFNDptFmYm2b3zsc5fPgQDzz4MDt372Vmbs4CJp5LKQjYtHqCkuvgKkmr2eqyTUTemr0dRQzUKgzWKqzs88m0ph2lHGllZNpQdqFa8lFSMLPYJM40qYFA2QY+jskwUpEaQytMGFu+kr6BASr9AxyZPMKRI0c4vHcPjVaHertDoqEU+KwYG+aUTWsYHezDpCGNZotmJyQzilKlTP9AP41mhzCKaDSa+EqghAV1wMZ6tUoFaTRkGXHYITWCVLlo10coh8B3cKQFIuqLTRqtNguNFvVG286pTOfAkMRzHXzXglRCYGP+OGVoZIzx8XFOOeUUapUyff19nHDqWSSx7VRX6x+g1W6zsFCnWquRpin1ep3BgX481yVJU9stTyme+ayL/t8u0v+P41gMfSyGPhZD//ox9H+Y8URBszI2K1kEJF2NnaXXkr+nW4aW6zMhVBec0dpCssL0QB4QdOes6C1Sk5fVGbEEDxB09aCOYoDRA496/y+yP7q74I3pIa5PRjV0noYRBepBD6k19OoeuwJsS4AoG4f1gCUhlC1vy+tEi3sr1v4vnlejtdXAUI5Lta+PoFzp1vxnWpNlGSMjI9Z5t9uEYcdmFeKlwFMBkFjaZRh2aDXqzE4dptNu0W42KOC41ECU6dxpmrwUTyBETn/VhrQrSpd2kX+Zv6YzgycFbgHQ5GOTpFlX+NtRNkgJPNeOBaILPBmtLfU8N2xRknUXZME4KjruKSlwlcRR1kB07bK0WL6UEs/z8DwXRykcCcKkSDRl34JOQrlEBrSUedAWkyRJccb8GeXP1PQyEYURlTlQ+Mue4VPxUEvonIW4pxQi/70h7cKrhiRJe8YnL1nURkOeRTWQixSaHtOBQhXM9F7PUy5FW2ijsyclUnInhGWkZcWaM3TLPXSXxdZjsOkCZc9M7qDtNagu1ZeukbDG0yzRvugZKCGL2nfdA50lXWDctrwu/p+bWiFB6K7RKEpn9ZK61iiyWdw005xyyhksW7aCZRPL2bPXZm1arWbuaDWHpg9zaL6OKxbwfQchIc3XkzaQYHIgWmEcD8d1cDwXqeyIl0TaBVgzo3KhfY10NIUUoqOgTyrGBj1qjqHTbHDt7ZMcnl5gut6g5CkQ0EnTbno7STMm5xrEScqaFQN4MqEUxBwJU8s2cB37PIwhSSyNHmOQjuqKNyapzaC40uq5GAQaQ5jF6EQze6hJueThuQpPd0jjhFYzZqrRJk4ywtjg+iXWbNzEVeedz3HHn8iatevohBmt9iJRkqK1navaYJMbxmZhlpDGu86ycDyWyFmA6/anW2X9FD2+/OUv8aMfXc83rrmGi849gw0b1rJ9935e9cpXkCYxa9eupVqtgDH8j3/5FCcdv5lnXXAep5x9IY4XdG3w0s15f18f//Dhf+SsnLFibZtls/7pu9/NRRddxHvf+15+8zd/k4svvrj7WaUUy5Yt637Pkxmg/f39fOhDH+LGG2/k29/+Nn/7t3/LaaedilKSucUGOkvpGxql3WqzUF/gwYceAAzLV65m7569uK7LuedeyML0QdpzinWbTiCOE8LpKQZWrMcYwZHDB5lfWMBIm23PpIeRUBIJk7MLNMOEP/+rv6EUBFRrNUZHR3nk0a289fd/n/e8822sXLOeC70K8zNT3HNwLxN9I9z28A62XHsHf/ym13HSGWfx7g/8I1//0md5bPt2Ht62m7179zI7M8Phx33qrZhIefzJb19JFscc3HeY2/ccpjbdwh89j9tvvJN2qnnXG1/FhK7zw0/+PXfcfwe1ch/rV22kIQLmmikzP7+TnfMhLV3ioYd3s3pijFe+eDkf+LfbmW9GnHfSek494wzCKOELV3+VySPTKGXLV44cPMCWBx/gJ7dvZ/VIP08/7QT6qxWE67P+khqzu7eTtBo87cTlnHKWy2IEB/ds54nJeR7cO81oxafk+wz6Ae98+9txK3382Z/92S9oJj0Z0PnoRz/KN7/5TQBe85rX8LznPY8nL6BTT7W6TTff/FM+/enPkCQJUdim3ahTqvZRCPV+5G/ey9DgAO951zt50UuuJI5CpJT84Lofcettt/Nnf/onnH/+efzrJz/Bug0b2fb4E3zyU5/hLW/8LUqlMjPb76Izd+TXX2D/F45Mg+cFlIZ8lBBkOiWNQnynjEDSDkN817FgSmL1d4oNnzY2uBeOzYSD1dnRmWUn6a4/zl9LM1KR5mLRssfidr1cKFqi0wRtDFEco2Sny1pySkFepqe7m06d2NbftXJAoRMqlUOWRESpBXEkPlJY9pGQyoJZyiUzglYnIvCcPLEIriPRrkvqOtYXZmm+kbb7hpmZGZJUU6rUqNWqrFmzhunpaZTjkGljwRABnu/jGIPnpkQlD1cJTJoAtmRneHiEwHVYtmw51Vo/Y8tXcmRmlk4Y2ohFCkQak2UJaRxTJC1NlhKnGUmasdDq0Gq3mZ1foDNUQSkHI13qsY1POklGM0kRGGYWGhRb98BVeYMejRdYZhtSEUYRut5gpt5iZuoIM9PTtNody3RyHBu0CEGzE3FwZp52FFP2hNVKFYpMKDqpIWt2SHMmU6Y1i1GCMIZa2es+89l64ygQINUZzTAkTBfQxlDyLJDkKEGS2AZGUkB/XwUpHTzfp1wu43ke5VKAysOtKE6IUitcvmrVWkbHxli/YQNJp4XruSglyXLWlhA2zo+TXIhcKaqVCqWghDGG6alDFnhyntqMp2Mx9LEY+lgM/evH0P9bq7wocyo24sVhis157zddXaiuvpDM0dscpNJLFoIUObiUdyrrIqLdWy/e2VNVP+rXGCvK1v19wTgyxX+PEqEuxMx7Qme9xWQXiu7el1zy8lHnhi6w1rUG+QMxeU2zzlKEdJDGsQ5N0H2c9vqK/oTFuXPmmCZnFUkrruja1wvDYoyhUimTJFYcOwxDK5QdRd164AKVtx1KItrNBvW5GYg7NCWIqN29pzAxxJC3OjVWUBJrJAS29I2u4GBPs0oJixArRLftsswpkNoYHCm6k9ZREsdReI6DUC4GywYz2mbZk8QaTvvTo9sXAZUrJdKRuRi7wFMCVwmEIRc/zx2BoyiVfILAz3UQwGQJQie4SthWkUrhxZBgz5mmtnyxN9FFd353p1GOchbz8uj5+dQ+ltZX9xgPFlk3CERermgdpM2Ydefy0p8ChCV/Deu4jMyZfQUabHrgrsgXUPH/nuFY2mjAcBRrURRzozB4HI3Eky+5ArymAK+P1owjf8tSdqb9vkIg8Ukb8iV2rKfnVZw0ZyLSo0AX0LgRPYHJLM3QOiLLNGPjyxgeHmGgVmPnzieYOjLF/MICSZYRxQkL7Zh2s0EUtkBoWwoqtC0hMnkdOHkvEZ1ijItRBoSy6wAN2j5DrXORSKNRjh14I1yklLiOor8kMUlEvZny6K5JwigiTVIqZY/MGMI0I/BssKy1od4OybRmdDCwHdNkQj2NUEaRKReZr884sdl2ozWeKyEHn8M4QwksWJwV9s/QihPSNKPejOkLXMqei8lSsigi6oS0WwlRCs1EsXZilDVrVnPRM5/B+LLV9A+OMDMza0uMc92Rgi1aPCa5ZKKYpdnC/B02SdGbB4XrfCofr3nNa5mZmeWaa65haHCASrnC5PQsZ591JiXPZXrqCP2VMlmWsXXbDkaGh3GCMn6lz24Qu2uvdwRBwMteeiWOo9i3bx/jY6O4rodUkksuvYSJZRN8/vOf55JLLuHVr371UZ89dOgQ8/PzGANhGHZ/PzQ0xIYNG3j5K15BkiQ8+OCDvOxlL2PZsgnq9QXCToc0TfFrqWXjpimTk4cZGhxkZGSY6SMzVKtVlq1YweE9OwBwgzKd9gxx2KY6sYK5+Tlmpo50fXgah2RIMiRRu8l0PaGTSS577uVWjyaOqPUPsGXrdu65604OHHo5I2PjbFy/kftuP8D04QOsWH4Os43dbHlsO/X5eUZGhnnGc57H7u0P4TmSybkWi4uL1OcX2KMNQanM4EA/J21cQ7PV4ch8m8nGbmZDze7FjEe37SCKQ/7w9a9gbtc2tj2whVu2TrJyfJSB6hBtXKI4ZuejO5hvazJ8du6bYc2mtaxYMc7PvvlTBvv7eNrpJxBUqswsTrFtx84cSMip/K0mczPTPDHdoFSt4lYqeMNj+JUqw/3DLE5P0gkjqv19DNdGkF6VCbFAGKfcuXuWTUP9lD2PzEhOOvFE+kYnfqGzVLVaZWhoiMOHD+eJGbjllltwHJfly5dx0UXP6r632WwyNzsLQhAEAa957Wu55pvf5Ac/+AFgNxZxFDK7UMcYW5L50H33sHr1KlzHYXxiubUjRnPw0CEefewx2p0Oo6OjDA8O0tc/wOzDj/LDH/6Aq17+G4yPjdGc2kutWqU2uvo/a6n9HzuSTBN4DiXfJUsqhGGHZmORcilAOLalizG2aUsYJ5aN7jjd+Ekb6xNMvjHUmbYxizFFh3UKKQcrQm4hkELH0+rTSDQODrYUo6hSiJMEV2t8z8FzXNudOLUldVrbsjolBCXftfYdW+WQRpo0jUmTlNRxcLRDqsEIhef5aGEFzKMkxXUdHFEw2h17r75vGUYms5tqaTeIrXaHdqeDcj2CIKBWqxF2Ovi+b2N7qWzTHMfFYDfmQd4Jr9hwO46D65SpBD61vj6McpBBhZHZOcIwtMnOLGN6cpK40yLpNEFa0CmNbQI804YMQZakRGmK59hzKjejo6W9N5ESJhbEq7c66DyLHmdOt1N02bExq6MN7U5ImNhmQfNz8zQWF0niBI1ASoWTgxlJljG/2CJOUvqrfg4m2Vg8TTPidoQw2oKMmaYdxhijKQcOUki00dRbbducR0gc1yHJNPV2SLtjqx5KrsqfueqWu/m+TxCU8H2fal8/tVoN3/eplEt292UMzU5EkhlSDWvXrmVoeJjR0TEWZiYpqlW0Nvkco0dMyOei4zhIJcnSjHarieO6T3ng6VgMfSyGPhZD//ox9K9cavfoAw90sZnCiBQChMUM7YqGLUFDoyjMsyY5WCQsfbVYOPnUzMGKHpq8tAXjL171kr9EDxTolazZH5l3xihWmxVjK5g1S0vmrLMuOuUV13DUKfNzdttmshT1Le7B/m27HKSkUYs0apPEVpNJSAfl+Xh+BeV4OF4FIR0EEq3THBVfuoCXdAoU1sHZAKPXsc/JW5bKvMa/axBzcMuWGVo02WQpzfoCs0cOsGvrgyzMTDJzeB/GGFJtmG8lLHRSFqOU2NgAxXbM83NtJU0n7BDFMY1OJwfxoOa7VHyX/sAncC3wpDHdjY7AltCpXMU/M4JUC1LhYPIWwEV3vTAMiZOUOE2JM0tjTjJ7T0oKSp7KF5liqOpSciWBYwMFK16YWtFNz6dS7cMLSkilEEASdciSiDTqgFQI5TLTkYRaEeGyfu0axsfHOeGUM1Cuj1ROd06KPEg2xWTIs4pLdRee9xQvtdvy4IPdfxeAb5GpsXOgp7sAdO3M0rWglEXiHaVI05Q0tTXQT67lto7FzuEsM3kpZ+5MWVIjvqQ5QNc5LcWBDV3qrX27yGnB9jWTFtme/LHIHlhtWxDYbEtqsi6LUi1B8S3IrXsCiKZ3v7ZU0zqhTGswMrcTEqk8ECJvlGCdVJrESwxW4WztvTuOQ7Vq29srKYlyKq7Rmv379lFfrDMzO8fMnA2IO+0mSZyQJAmtKMo7LnaYOnSAVrPJYqOJ73g2wJYQpSna2BbQKm8ckGZpHpgrAs9DYLNHB6frNNuxBWY9B8+RLDRth5vYaFaP9BE4CpMJGu2QJM0IPIe+ske15FHKnaoQkBhbimCMod1skkQhOmkjHQehVM/O2qxETq2GJNakmW3XbYR1ssIp43ol/FKVzZvWs2LZck47+TTKA32UKxWWjU2QxDFJnPRAFEMPLM47ZhqKmC2nlpNr00mJ7opxFt1nJNJguyJpzfOvfMmvspT+nxzGGP7pYx/jj9/5Li77nffwrAvP5Y9ecSmxNmzZsoXnX/Yc/v7v/543vvGNhGGIQKOTmD/78/cwumw5f/hHf8LLXvJibu6Wz8H4+Dhbt27lK1/5Cn/913/Nt7/xb5x44okMjY4jcy2OTr7ZW7opiKKICy64gMcft53qOp123hIZPvGJT/C617+eVpThKkngWqHgZqvFgUOH6MxOEcchHQ2rVq2mr9bH1q1bcE1qu0otW8PhI1Pcfc89bNh0AtVKGRHVWbFqLf19fbQObeOuRx/nnsf28u53vhOfhKknHqbpD1Nvxzy29VHE3AFqjuDl/+0vuONnN3HrTdfz1ne/l2rNdtm74oorEEJwww03sHvrgzTm5zjxvGcQNus05qa4+9b78Mpllq9bw5r1GxBZwuHHHuCv//4jXHfTLbSi1MYZwnZs8h1J2XV4zmmbEcDPH9lBkotA+67L009azbnHr+LOxREOHDzAnsfu59JnXUCSaX7407vYvHk9QwM1FicPMjVXZ2GxzbnHreasC57Gc176Sv7gbX/M5O4nOHHQ59HpJjOdhL7A48rLnsllTz+b2f3beHDHfm6493Fe9NxnEScpP/zJrZx9wjr6qyXufHQXp25czXGrlrFvyyOURycYOf5kRvsrTE5N853rbmJmsUMrjOl0OkfNu9/+7d/mIx/5CM985jN55JFHur/fvHkzd9xxB9VqFddmxfjsZz/L29/+dgAuvfRSvv3tb3PFFVfw/e9/H4CPfOQjvP71r+Pss89lemYaRyn+7drrOe2UU1heLXHVq17F7t27ueG6a3Fca2P9IOAzn/40f/4Xf8GtP/85Iou5+hP/wBv/8F1kwuGss87ib//2b/nd3/1dqk8StH+qHd+/5W76yiUGayUW52ZYXFxg8tBBNm/ezNDQEINDQ7SbTVqtFvsOHsTzfSqVKrrTRElJEPTYRkoq4qhDkiYgik5hblfvyRxle22THJX7NJN3wMukZaSkSYKOQ6SAarlMuVzCdRziTpMksQ1i4lR3u8hJadvCd+KYxUaDOI7p6+unVCoTlErMLizazyWxbZojbWvwarlk2e6yl3hNkpQs7yzseR7KcXH8gMd37mR6egbP81ixbBkrli8jDEM0EqNcsjhEYCj7PnFi/cLCwjx9fX309fcTJZmVnYg6FmwTkkT6JNraUp8sryBI2bfrCVqLddr1OaZnpmm3WtQbDYK8pGxqsU0U22qC+twMnXaLVrOB59rubK7v0enYxjom02hhN7GpzrXIPJ/B4WEkhs7iAmEYkRZaovmzWmi0IE+a9lWrOI7CIGi22qRZRqXsUy0HlAOfwPOweIHdvussIwwjWvkmd6BazjsTwmy9RWYAIXFdC/YlSdLtrqaUwvc9At9nfHSI/lqV4cEBRkdHqFRrDA6NEJQrefLbo3D+2uQAtRD012o4rotyXKYP7bXzYfk6FhetZtXalcsxxhDHCa7nEkURMzMzDA4M4ChFc2Gmu2e58pWv/eWL5ylwHIuh83s4FkMfi6F/jRj6Vy+1K9DqX7KQuu/hKECVAuwputb1AKGCMWWd11H4zZLzQQ9h7p4gN05LsHO6nesKQ5g/oByXoxhdY/IaVbrrkRyntkusYGU9GRl+UqbY5CCXLEoH6S1U+7rOW9jGpEmHNGqS5MwiqSSpX8XxAvzSII5XQSrPTpwnoeL5Cs4DjQLfyzNUBUpuQEptnUB3wZscFRWIbAmCbXrj7zoSz1UEvs2mpZnBiw1eanAzy7ZSSuEomXetk0gkOlNobTOuRXlk4Nm2qNWSa4EnbCatOJSw2koq77YXZ4YwAYHECCtsaXEcTaokWWZL6ZSRGAzSaIwRKCVwlcJ37U/JdSh5At8RVixdG1KhcFwPx/PwfB/P83sZw3wAsjTpPjeVA2JGa9IstWWMaYJUrqV75Q/cZhxyY1tkPZbM9F8Nvv1/f3TXVf7/o2rMc4DTZl+O7kTBk4DhJE1zfY/8OeqlGaA8G5lnegRLXmPJesY6re6/7UeL5WuNbP59XWqy6TnJ/C3ddQwF2Cy6BvUoEPeXjIGBXNRR5Mt+yXd3wfV8dIRApxFR3EZiGXtuudr18NLxbJtpnXavzH6tzUq3Oy2SxGpu9Dp9GPr6+ymVywwMDrMyjEiztNt+WmurFZEmEXGnw6P33c7M5CEOH9hLKSihgcVOSqINSSZQrovneDiOSxLZ7+pE9kfkzMSBks9A4OP7bl5yATozZCbDoOnLQQaNg5COXRNZRpRoUh2z2Db5mpYox9qtLMtQjk+5r4LvL+vp/ZneOBQeQGOZD/YxCKp9VSrVKsPD45QrNWq1AVatWE5/fz/j4+O0kgSDIAxjdJrmpci952dLSMizNaY3j7qzIvfwwrJHbZhUJEHsSza789SutXvf+97HnXfeiZCCS84+kTXLh/nxbfdyygmbGBsd4+3veAeVcok777iVs885H60zosxw0SXPQfkl9s/ME8ZHl1BFUcgN136fhx64j8V6nc998UuMj09Q6R9g2crVrFixguc/5xJ++MMfct9993U/l6Yp+/fvZ9Wqlbzyla8ELAPqs5/9LNdffz2dTofffMPvUC2XUMLwiU98gkqlwgUXXoAflEAI5ufnaDSaCCTDA335nBKkYZuSIzh+wzqGR4cQGGbmWl09i3oEy1et5+KJ9ezY+QQDlYBlKzaQ1puYwHD6Kacys6+MjtokUcTylas5+8KL+NdPfYbNm4/jJVe+hNe85jVESWoFQdspcWbbXB+ZPMK+ndtZtmoFQbWP6uAIs4f340iYWH8cv/Ga3+TUC55JmndJzdKUO2+7jSxsURIJe2cX0VnK2vEhnpiaZ6HZwU9SHtl7hNlWxJQ+gtYpI8tG2XPwMJ0wIk0iFuYXSJKITqPNwOgEKzYMkDan2PLYNg5++d9oz04jspR9dY3j+wx5AVEn5JHH99CJE/r8lI5RnLBpHXMty+Q49fj1LHZCmp2QC05eSxhrtuw5SLlviKkwZed9j7Bx+SCNRpNGO6TZahPGyS/MO9d1qVarRzGhpHKoLzb46Ec/elQnqnvuuYdWy+pEPbplC+/77/+d7dt3dF+//vrrmZycZHp6ilarhZSSr3/x82w753wuefHLuPj5LyRt1hEYbrrpRrY+to1XvvxlbNq4gbe//e3016oszs/QPzjC5KEDNDqhBRE8j0ql8p+xzP6PHpXAx1GCNM3o6+vDc5X1GcbQbrfxgxKJNqAclF+ysQu9JKcxGkRPF9XSICTWr1qfVWwyrT5oRlEuJ1CYXMRfCmltf2Y3yUpKvCCw2X/XxRjLqEmSpFfOZzUnbHfi1Mo4xFFCltkSHG1yllVmWURxHNPptPALwMJ4xHFky0kQXa2cohQHIQjDECkTfCHpq9W6XfvKJZ80jkjDNhqBUS7SpDgSpLFMIuF71AaG8EsBwnEJWx3IUpSUhFFEnBmaWYRwfBvbiiTfGDuMjo8zPDSISZczsdggjOx6qAT2vYudkDiOicKI7Y8+wOyRSY4ciLqb7jSNu5UdfmCFfjWGThSjtSYMQ+Zm52zVRRTiKIHvOZQD31YYpJoosZtc33MY6CvjOK4FFKUgjGKSNKXZ6hBGMWXfltI5SmIFgazu6uDgMMp16cs7DYLA7+/kYIQFyYvOg0paEEAphR/4+IHP+OgotWqVvr4afX19+H5AuVLB9TyrSZMLzwhhKwYK4WonB1Ns0Gbfk2YZpUqZSqWCyrWz5hcWqFQqOI7D+NgYrueB1kR+kO95f8lm8Cl2HIuhj8XQx2LoXy+G/tV5jcZ0J233ingyCFRAPT0h0qWfJwdqLIsn1wXv3dZRJueoBUgP+OpRu/KxKICj/O4Ltk9BLTSG3iITBajDUuSpe/78dL3Xn3wt3XeaJy38AroqQCmT6yvFZElIGrWIW3MYnWJMhhdUcLwypCmmlFjmkxtghLQOq4tOFyO7dMH3FnPRjUjk5XgFvbXIbhVAWrebic5ydNmyh1xH4nsWlFGZwXM1bqJxFaTYYERJieNIq6ckIE0UWaZwusECBL5D2XeolmzmFyzAZIF126LSlbbzUJxpOrHVcjJYnQHlKmRup6XIywulQGqR697ZRVEIjntOD3zyHYHnCNtxILPzwfFcHM/DcV1cz7Ptf/NAzGBIVccGaMKgpOlSHa3wugWeHK8os+wtPVkEf7kB72YQngRMPtUPm0GwayVb4hTUEtFD0517PTZiIaiojSFLbZDUnXuYHAn/RSeL0LmRtG2ZoWc/bI0kdh4vXXN50qhrLwriotbooskA+TKV5AB2z74U99lF57HrpGvDoGsvCopp1/0uAb0z3RPUFwayNKLdmEFocNwAGXjYIlOJcjwyY7t1YbIlUQBondJux0BIUdorpJ3rpaBEpVrFdT085UBOpZf52Duej04T4rCNG86zPwCvNUW1ViXOYN9sm0aSEWuN4/r4fgnf9UmEohV2iMKQTmydZs1zWd5fpeq7CCWtYGKa4QqBRONITSnwQHmkjkfJc9FpSqPZpJNktOKEKIlxpMBXir6SQhhDEsUMTwxS6R9kcGwZaRyTxHE+7vm95tp+aWZdpxQC1wuYWDbK6NgwG9auo7/WT3/fEIP9A0ilSEzG3sOTtr1zq4OSeefZJU5RSFXELb3NV/FI82duHapYwgYw3YQF+dx4qge973vf+wALBDzvglMxbonPf/MHrFo+weZ1q/iLP/9zbrj+Wu65+05OOOlUpFTEGVx0yXNZaIc8fniGaEnnL8/zcJTDTT+5nu3bHifTmi999WsIqXA8n3Oe9gzOOfccnnfpxfzgBz/g05/+9C9c0zOf8Qz+6i//EiElDzzwAN/4xje47rrruO+++/id3/kdfM+h0+nw2c9+lnVr13Lh+efg+Za1kaUpi4uLZJlm+VANoRw0ktnJAwSO4uTjN2GkS6vV4mAUWRsC1BOH5avXcvbKlVzzrX9nfGyME046hcXONjxHsXLNBraXfObn5+m0mqxYtYZlq9fzrj9/L+eeey4vevGLed3rXkcrjNm+b4pmJ0Vklnlx6OBhHnnkMV7+6ldTqvUTGcWunQ/jKMnY057D5S97JZdLiZ8nd5Ik5l//6X/QnJ3EjRb44g9vJo1jXnDmZmYiw1xkcD3FE1OLPLJ/hoqrmFg2yqbj1rN96+M0G01coF5foNlqYpKYNZtP5LgTT+KBn/yAxx9+lF0/uY11gxUCz2HXfJuVE8PUAo/JJGHL43t4eMduTjphDavGRzn5uA08dnAa15GcdfImbrj1PhYbTV7x7NP5+UO7eHDnYU477USOHJ7i3oceo7VhAoA4SfE8D6GcJYwnQblcsmVPrVY3WAXbentufoH3v//9/8v5+sTOnbzvff/dsqaDgDAMuf7667n++uu779Fa8+VPf4qHH3ucZRc+j+dfcSXjgaTTWODGn/yEb337u5x31mkcv/k4Lrn0OSzMTjM7ldA/NMbUkcNMz85ijCGKIprNBrVa3//+Avu/cNTKAWDjjf7BfqqVMq6jaDabtNttHNdHuS4oF8evIIXpBvw2Nu3ZtqJ6QBSxGEvjFWvjsswy6Xs6NDb52QWRMgs0SikJvKCrB6WNJsvFygufT66lpo0hTVK7kYqtALrJE51FeV+mrRZp2Okg82tGB8RRSmxMLlitclApoCj3K0p2tbQaQP19NVwlMVlGEnWI2k2bqZcOJReEI5GOwXVKlilVqiJzrZYojpEYHE8RxwmtKGG2o/GCCq7r4ooQx/VQrsfA4CCe61AKfMLIMrzCKKJWreC5HlESkya2kx1RgwPKkC4csfpKmWYxzRmQOSuNfCxSbYjjmDgKabc7CGGb5wz1VaiWfAZqFeJUE8cpUWplICqBw0DNAk9GWh2rVidken6BdmI7zMV+3E34oq34d6lcZXB0lEq1n+rgkBWbFpKhTkhR0uS7Lq6j8q6WngWMHIUfBPhBwOjoGEGpRKlUxvd8pJIoqbqxr7b6Hxawcl3rcLVljZmctVJM0DTLqNVqlEslSCKiKGRufh6Mpn+gn4mJccsiiyLcHHgqzvNUP47F0Mdi6GMx9P9+DP0fK6jNEbilX70URLKVmia/sFxfyPTWR5HhUFLm5BMrKl5M4O5F5+BWAUYZOOoGKRwZ+eISxWJ88uWa7jX8AliUj3AB7GTGWI2gAsTifwUm9G5o6eIsKI4FwAHa1qvrBJPFpGGd7P/H3n+HS3aU1/74p6p26nTyOZNnpFHOOaCEQBgBQmQUSCZeTLCxDQZzfR1JBhvbMja2ARuTbQwmIxFEEsoBpRnlGY0mhxM77lBVvz+qdncfgb8/uNx7LZ5n6nnOhD7dvfeuXeHd613vWlmLotekJxRSBiwFNaLqBGFllNr0oUTVMaLqKEgvtmj1AJkUA5R7OMPokHXQwjsJWodFujlbIpTKZWZMgdE51uYIYVBKEIVuCChjCXuGIDBIaSDXWGGxGhQBCpdJE1YjMc6ZT7iNNg6dM0YlDokDd266rCnGojBOLV+AcPsWUgmUCEA4GrYD5exg8yqBTnezEAjPTvLZGuEYUNKfhwFPIVXIIESFITKIEEGEDAInmCddWV/WazsxNetqgZW1GO1o4XmWUhQFqihAFX1Qsxzny8YBj2eoPbGbEh4pxwsQDmUt3FAuNwv6AnPLAGc8Mu7r9rU2CGOx5SpWvs8YrBBon8HJ8swLI3ohT5xTh7G6xI8psVZBOYfAWtEHp7UebORGlyi9QAQe5Laiv8nYUhvMGjcXypFkXTmtDPq2ABRFOecHSP1wua3yehNSBvTai2TdJYrOAr2lfWidInfeTnVkmkp9ipn1p6CDCrmOyXttrC0DBZdxVqXrCO5ajLbowlLkrUGg4R8wjDUukYkgimIX3GUpedZzzowjCbVaRC+3hIuCerVCEEOtEpIkIUmkqI+Ps9gMsLqHkM7hcbqesG6qxmgloplmuC1A0IidDloYwKP7u3RyTY5hbLyOEoIdJiM2htxYFtoBtVgxVY84fk2dUGgW5uc5/pwzWXP4CRx56oV020267aYvqRiwLgGMcX8LCVHoREhLWnNRGLppQe/AnLvXGPbv20eaplSmJwiDkEBIpz3Sv1/+gVhYp63hjuitwP24xGD6gpn483D7jBHC9fUTfwq7JgStrODIQ1bxP9/068RKUPS67N27j1NOPZPjTjiZd733vZx91lk859mX8vb3/S1TUxO88VUvYaSW9L/mj/7oj7jiiit4dOtWPv/5z3P9zbcBYI17yHvL61/LRRddNBAl/hlN64Jua4mkVue4447j7rvv5h3veAfXXXdd/z1JHPOf//mftDttlpotQqMJopgjTnkSs489TGt2D43Dz6E1t4fFPdtp6gqBsoilRQptaHa6zOeGXp6h85SuiPjhj69j72Nb+PXX/gZFlvKDb3+Nk05/ElEYsuknt7F6w6GsXbue7379Sxx13Ekcf+oZXHP1NRRZj+0P38/2++8hSiqc8tRnsTQmSTtNss4Sqw49gnhmPSNTK3hs+3Z++OMbuOTpF5FnPf76A+9BrD+V6uRqzq4uIioNqI7yste8htAzD172e64EPQ4D3uoFfwXwlc9/iq9/4XOwtEin0Dxy34PML7RoVCs86YxjuePBLew6MIfEcv0NN3HDjbdQZD1qScSR62dYu+4Qut2U/Xfdw9z8EmNjI/zGS1/Ej2+/i5vv3MTevXPMzy5y//1bqFUCjLHc85N76HSdNfuf/Ms36aXO8Wxu8SaMMVSUYNO2fayanuCKZ57HM694HbIywnOefQlZljMyOsp3v/NtbrrpJk488UR2797dv6dFlv6XY2JZs4b3vOvPWLdmDS/99Vf+lGg5AEGFmcYIlxw2xR0/vIabdu0gj0e44qUv481veQs333gdQRzTGB3jrz/6r4w26vz6q15HHMfc/8ADCPFHvPd97+NDf/d3bNu27eebQ/9Nbd2qGbcfWOPcxwqFHZugEAG9tMfswgKVWp0wiummGUkoqQQhMghc3FNazvu9XIQhgfJrqHycXIUsHFBUMjKUc+pVZSLOGLR/sFFKoaqJ112y5L2MPM8oCjMU37gH1tyLRGttKKwkjGKklA4osa6MqxoqKiN1JkbqLDVbZFnGnj17qNZqSKl4eMtW6rUaY6MjTE6Mk+cZiwsLVGt1LLDrwDbiAOJAMj05QRRXCaMYbWH//n1s3fIIk1XDaDVm7coVJCNThJURovoE1kZYGTIxNoowBcpkqJEaDQNTQdW7OReY5hIUmkKnzC0uEEYRjdFxcivJjaXXS0kqVaJIkKYZYeDAsGoYUg8V45EkqlXILcSppW0kqYZeL6PmmT5TU9Butpg9cIB2x4nmjzRqHLZ2isnRKhUJ80ttlpo5E2snaVQipkYSltopvdzSzjJWTYxgbAOtcxZbXVrdFG3dw2ISxzQiSb1aYdWqNRxy1HFMrVrL2sOOQgQhFsn+A/sdaGEsoZJ9Fk2oFFI5Ex6pAidJIZ10B0K48kttyLOuE40uAUjfpFIoqVCBA7iEdCBVGCVOD6jXZqHbZh6IwgghBGvXrHEln0FAq9Oh5UsDa6MTfSbWE7kdjKEPxtAHY+j+MP/fjqF/8VK7n/G6O0nf+ogQQw/lwx8oP1NqF9n+p/t4qceYHr8GLTuGGHrNMoQt909sGSAwKNdzx7Pip/vI410e7SvP5nHvGjrW4H30r9OWC421aJ2ji4wi76GzLkXao0i7jt6MRMiumzhaE4+sIIiqnq4beMV42R8QZZ3lsmsZOh9Rwt0CVwL3+PNdZscp+qwipTxNW7ha74EwpUGYkm7pWFLunpQ0vMEkV/57gkARKKfs79QM3bAXVgxQefcK1oo+VmiH/ugv4KI85/I+e70r0S8x9+/zd90jswKB9O6BqgzYgtCBWyUQFkWIAkyRO/DKuLMy2tX8m/5iZ/3m8VMjZWhU2MGK/wRvw/avQP/fy8pZfSvHMQwBrMb0sxpyKEIov0NI6cFb+uPu8UA1DM3zstuEK6XEus1aeAvZ4SlbArvL5/kQCIwXOByqSV5erju4nsG1Ds+j5ddfjrXyV8ZYjHWMRWENRncpek2KdAmTNsnbs5BrVDKCiBtE1REUAbpwlOHlI8ZliPoCsSWTQHgBfz+fy02zKBxbURc5AotUEAaKKAoxwhIGCikGYLfEutIDp4bhAFu/acZR0P/JTRkwQBJKQiXcxqkEoRXI0NH5h3cUgQtWlJREgXT17ULQixSVJKFarRAnFYwusHrgfPn4EVCu+mE4sAAujAu0tNUInXtzhoxe09Xsd6oJo2OjxJUKvbTn11mB9loV1icOSruKMgPvxhX9/rbgMyXlqLH9DM6vRLNgigJhDEnoMuLaWpTVpFaQyoTDDj+CyekZCgRHbtzA+NgI1ThECZeRP+ywjRx++OGsWLGC//j8f7D10Uf7X7927Vqe/OQns2vnDq7/8Y+44LxzydOBePixxx7LKaecAsCpp5yMCtyDcBRFrF+/nqc97WlMT08TRZH7gBCMjU8AlqW5AyS1GjII6C7OU6tWGanELCws0mt3KbQlSWKXKaVgqd2lm2aMjo5irKDd7RHYjImxEWKxgS2PPEwSR0xOzXDrbbcjpOTw9WvYs2cPvV7KzKo1LLY73HL77Ry1fgUmkixmkpHJadrtNl//0hc5fEXC1GiFTBiSoMbM5BhWhVRqdTasX4vUPaTusW7dOoJVU4S1Kq19j1ALQqrhOI/cfy+T09McdtSxbNm5CYHg+GOPYXFhjjzPmZ6ZYbRaJcxTJhsJrUKjuzlmepJAheyZm2dicpLq6Bjze3fTbHfp9LrUazXWrBzn+MNW02oVGJszNjnOEStHmBytsX33HiZHapx/ytHc+8h2er2MUElG6uNEAWTdlCNPPIGxyWnC2gitdptup0OgFKESxFLQ04aJ8TFOOu0EpqemafWcbsapp57C6WecwRFHHMEdd9zBY4899jPG4c83Xx588EHm5uaWJ/6kAr8OPutZz+SCCy6gFioefnQHO7Zv57ynXETW67Jr+2OMjI6R5ZpHtmxl3ZrVTE5OUhsZ5ZZbbuW2227DWsv8/Dzz8/O/0DT672iqjFcQ4OMMly9z7sWVCsRRiAoUjWoF5aKl/n40nJzVhe6vylI6PUqlnOSCKaUgfCbb6gGA5PZk7xKsZD/u1UXhkovuAO6BQ4h+XKTzoi8wbP1DcJzE/ZitdFFTUiDCsG8jH3gRcYtbqwttiOOYOI6dppOUGP/Zbrfj3fsK2mlGx2owhnqjQb1WJ+21KbIUgWV+foHuokF2lhgdnaVSqUNtAhtVsWGVcHSSMFAEQUhoXXJVCkFuXCFcoSR5npMV2l27lPR6PQoRgHAJVWs0adpjdm6WaqVCHIbkhdOySxJFvRqRGVjQGUEOGgvGiQFHgSAKJEXo+qSMk5NIUQkVlUASWE2sBJVYUh9JiEI3L7TW6MIlkIsixwBJGJBGAUWh+4lQKaASSmpxQD1RVCNFNQ4YadQRYYwVijRLMYVPtMqyrMf0GThRFHrZEMecczGUochSjC4oshRdOOYbJXtFSqefGoZYIzzbwfrngICiUE7jy1i0FShVuncZ4iRBCCcqHipFEAREUUyn0yEd2meeiO1gDH0whj4YQ//yMfTPDTwN39hlrRxsfiMaRneXiRvi0TFphoCRYXhJ/Mw/hyddX8xbDN4hJP2MjrHWW9yXQNDjmCj9SeA7r/+7/jT2lyeWTdrllzt40ViDQA5qZ4feUy7cWa9L1muT9zoUaQfd7Tn6nDGAwq3lljzrEBQZgS5QYegCDDGY5Nrq4ZPoDzoXBLiDD869DFJc+Zr1nxHgaJ1S+syZy34JKRAGVOAGucXVjwoAo8AUPqMhkKKk4LnjKC+SFypFGDjV/7IjjXeZo6Tf4kAnYy3aOhdPPzAQ7jdIaZHClhpnHpj0x8S/LsRAAK8EqaSjcQqpkGGICiOC2Gk9qSDsO2hI5bQMigxyV4FLoF3ZnSuPLLzmQr/jBuNpKOjrj0W/GP8qMJ7yISdCoA+YWcqN5WdvIiUIWxQFUjmnBRUoP78HjDzh3T3cC+V3eAvQoR3Q+nFaLnTOQlX2x16oVF90U3vXGbfq+YB5gDY7qw2fEbCmdPHpXwSirDkWXt/NWvD9UIKXy9YJiw/YfeZHGydaT1m/7UT2MBkmW6JzYCvpwg6kUOzq3Uht5jBGVh3JmmOfjJRhP7OENUOWxsLZuNqBeGI5n6w3YpZ2sHE73Q4DQqOUY+mFnipvpSWOI0S7h841OQWiErly2bSDzlOw9PUgwtBZuEZhQMU6HQp3htqvoW59iEKFqlUxXrTVaI02zqK2dDJRwuvK4W21jSXNCuYXluh122Tdtr/ljoXZX7WF34cBpYSn8gqMlkhhUcKgRIY1Gaa7SG9xJ81WjySqMjY+TmN0DNtqOnFUY7F56uetQVjZ36LKDbO8r+Uq39+yGL43+ud+kP7vb+6as26bVpYzNjZKGAaMxPDAUosDmeLXX/HraKCZG1575Qu8C5oLeMbGRnnOpZdyyCEbaDabfOAvPrDsof20007jk5/8BBdf/Ax2bn+M//j0J2g3l/q/f+Yzn8kHPvCBoTUSpBywcF/zmtf81BkvNJdYWlokby1SmVmJRfLoffdy4qmnMbNqNbfedCMKQxwmjI82MMbS7nTZv9hFG8Mh69ZSWJhdbFLRbQ4/7ihWrFrHH//Jn7Dx8MN5w5t+i3e/+DLyPOMrX/oSn/jnj3Df5nv5k/e8n29/74d8/Ytf4fWXns34inWoycM56rQN3HPnHbzlpS/jD179NJ5+3knIFafSmF5HbXyELjC9ajUbN6xj6+3fxxY5z3/+C0lqDfKsxw/+8wdMr1rJyok6f/G37+Ko409mw+FH8x9f/jpKSk445ii2PbqVhYV5zp+4kGypSXfPXtYffwipVFRSQ7u+ggOLba6/8Rae+7xLOHT9Wm753nfYOzvP3BKsXTnNaccdwqVPPoEv/ds36HTarDtkPa+66AhW1BQvetcXuPzi8/j1Z57D/3j3R2h2MyqVCvXGCI1YMZNILrvixZx89gUccdyJbNv2GDt27kQFIdVAMBpJUmMQYUI0OsP+rQ/w6P33Yq3l8ssv521ve5sbbT/nvFhutjJoH/nYP//U+8IoxhgXY7znXX/MCSecgAVuuX8bO3bu5h1/cA7/9ul/5boffp+3vO1/su/AAa6/6SauvOwyRsfG6OWav//Hj/Dd736nL2r/q9BskVMyu4XxgE6Rg4AoChmtjvbXryQcJ+126HWabm0qxYX9PlakXax0TBMpItQQ4wmDZxmUsbF2D37CPViVzIkwivrSDlmaUghXCqakRAaKIpPkxpClKZ1e6pZIKRwTKI6o1WtorbHGDOJK6fR/sjyn2+sQhjFBGFMBlppN0jRlxYoV1CoJ1UpCEoUoJajVa+zZvZu8KKiNjDG/2KHb6TA3N8vM5AQzk+O0F+exRcro6Chb7t9G3pxjIVtk1WidRqVCEdcxlTFsbZLpE55EY2yMuDJCKAMnJJ5moHMwBTIIydpdms0lPx6h0+2BCgnDkLGxUdAFrU6LRx99jLGxUUYbDVq9lAJDUouYGK/RKww7lzKUKVBaI01OQEEoDJEUXt/UgU5hIJ2LnLSEtsAWOZGyjFRCVk1W6GWa2cUO7Y5zjDNWsNRyQsCVSGFMhBTQywrHRsBSjRT1SFBTBqV7kHUco04KUG6vtxKkN3kyfp/XeHkLbZFGI4RjRTmTHk3ablHkGXnaJe91HQBgDSoICIKQOFQIJZAEWKuROLe/MAopipx2t01mJUYoGlK6MdRpMxUn4EHIWrXitKykZO++fezbt++/ZV7+vO1gDH0whj4YQ//yMfTPz3hiADYsa31a1uDfroZ12DnOZRpKOliph0T5KD/MksIOlZcNjm6tQ2RLumEfkBKlqOJyUHCA1A5YQ8If8fHHLDM7w214gFsG4NmySWkAYTAeBSm/RhcFpuiRdxfJ2nP0FvfTbS469NIopIxA4WxLqw2S+hi1xgRB7Fzu+mDdEMBhykzD0LVZf1ED6E70r30Amg/YT9ZnoMpJKqVCBo7lZB1q43BiWwJULktDiYYa+kiwA5hcbXKoAgLlNiPlgScjNKJkolo1uOPCYhAUxpLmGRaPIkuDxBApsEZgrSQz2mNvHrjy9bwqEASBZ1gFTrTcCoXF1fRGSUyUJP7H1f4rFXj2kyTslZawBVZKMmsIpFu8jHbOeG5cyH5N8/CEsgwBsR7wU/9F0P1EbaUQpgqCPnBbOiMCLvMyNN+NsR5Jz92tkHLob5c17Wv99QFisexY5QQx2qBNGTgJN+7K94pygfXiedoJ9UsRDDaWIbvYUtDQeaEOXi9Xy5Jdufz1n75Xg0xwWVbpvteB+o5CrqwgzVJaS/vpLs2Sd5qYTJI2uxitXX163sPolKzXRoUV8PPJsbIH4LYLBPz//YouJEir+ptMWa2qPNjqmHwKFbixHIYhWliCIKQwbdI8I5QWnXexGYTSEijcHM8MUkiSICCJApI4pEC5gMBqtCn6cz43ltRYlIbAWqQwBMpSIFzwgu5ngixgJaB8hs1Yl6G1GitAWe0pz4YwjFCBIoojlHRbjy4y8sKiDURJjC0W0L09ZM3doHMUCtGdo7vY5uZH97N/317WrF1LperKO5RQxJUKSgVEYeSyfkP3H3wCZOjOl6B2GbCY0oj8V2gK6zxDSZianOC+u39CnqWccubZ8MiP6G57hO7M89m7fStb77uTC599Obfcex/vfOf/4nWvfRXvefe7mZmZ5l/+5eN885vfZGlpadl3X3fddZx3/gVs3rSJLMt42Wv+B9t37uz//nOf+xw33HDD4ANCcNXf/A2nn376zzxXAdQDia7W6EyuRec5QlhGVq7lwIH9tBfnWLd6Ba3mEkvzC9x3zz1oa0Apjj3qOKIoYveu7YyPT1CtTmCmJ9mzdx93bf4Br3rt/2B2bo6/+9CHeNMb3sD42Chb7ruH88+/gFNOO50/+8N3cMLJp/Pbb3oDf/SHf8Bh69fw6pe+mGu+dTPawn9+7Zt84p8/zH/+ySf4zZO+TVSrYeMKD89rakecyrqLX8JJa48hlpbd+/Yxt38TRZ5z1tNfwE9uu5Xvfe8jvOI3fptmu8snP/FJnnPx05iaGKO3sI9vf/d7PLxtO2c/6Vz2dAvua+X8r4uO4IGdi3znm/excqRDXGhWTTSoFE2KxV3snl2g3csRQUAlgGJpnh2bN7G31WN0osZvPf84Pvftu3lw+ywvOu9Eduzey3s+/iXOOX4Ds0ttHt41x9JSi/pYwtkbJzjwwG38pLfE2o1H0Gy3WFyaZ+VojWY759GlLmtWziB6LRa270SYAuMdNT784Q/z5S9/BSFgz549/3/H48jICJ/5zGcYHx/vj0+EE6p++9vfwfXXXw/Arz35XM590pk8+eLn8LWvf52//du/ZTBX4bd/47XMz81y94+/hQhCjj7ryaxdt46xkREqSpG3F7l/x6N874abee2rXsELnnMJL3/ZyweuPE/wlmtNkTt3NFtk7qHRGnRribwomG9HhMrrMYUJ3U6HdrNJHAYE0klZRGGIFE6Iv7S5Fl77xfqHS6M1Os8wnu1ishSjAnSg0IHbQ5SSDnTwD4JKyL7Gpgs/HdsqCAJEkiDDGHxJHb78pt1ccsLTKiAvcrrdDnmWEYchhS7odVMqtRpxGBJHIaboEQrDxPSkE9YVFnROIGC0XicdbaCNYXR8klq1Spo6vZfReoVqLaHottBpF9lbpG5a5KZJmC9xYO8i+5F0ojEm10VMT6whjmOsEDTbPULpHriVFHTzlE6nw/xiE7DIMEaGUX9/jcKAIJBI7RLE0lrGx0ZRAjrNBWLbJVcaHYUUyvXJ1HTIjt0HSNs9ssxpW4VKUhmtUo8VKydH2H1gESkEdS9JEQUBQRIRFpqs0LRaruwslo6RpQtNK9WEQYCSgty414qicHG4hCiQdAtDqAVZUCEZnaA2PkmBQOcFFI4Va5XwyW4AQZQodOESrb12kzIxXUliAgFCGrKiS95t0Z2fpetBKGsMYWncIzRhnBDECc1uigpjRienkVjiKEBYzeT4OEmtwdLsPldmq5SLa4RzzBbWUKRdFlst8rQ7SFz/CrSDMfTj+uNgDH0whv45Y+ifG3gqQY8+wjX8u3Ik+L/F8OuPf3cfxR38Viz73eCt1pZoav+V5UAK9F0V+h9cduHLmUvLwTgP4ojl57eMICWW34Cflfmz/iRE/xvdhm1NgdUpJu+6MrvM0dqUCHwdtRjUVEvnNDIAwwag1zBc1u/n/mQb6q7HrQvWlv3lz0t4MK3fVWW9sFct609oL8amAkcXDByjq7xbQngBcH9wgfAi5L7e2+tPaTyLyILVtg88SekEvR2g5a7VGg3CgLBeB0wM0VAHBEuBA8RK0XOlJFK5bJJbZkQ/2A28za1jO4VIFXgA0TgtgiBAF24hVB7QwvqaZttHzHy3CAaEwmWjrX9dvwptWUbGb2D/VZa6HAdSSpfRtENzwALSw3zDoHEJ8P70xB3Mc1tSMp2SvBtP0tsPDxYzbbTTSCuPJwazYeiPQbP2v7wTy7fJwb9+Fjjfp/AOzTHH9BNYnaOzDll7gbS9RNHrgIgAjRAQRjFxpU6lPobwIoDDdOXBcQegsluDBvOrvy7a5dmzPiDcvy8ONJY+E16C9v1xXBSgnGZCGCpkbpFIAlkCtgGB1k6LzRiXAhBu59YW8sKQ9lLqqkBhCJUkt9att15Pzr/d9Y+SCKW8/oAvD8ExFKVyGXBXzmrJewYtFdZYJ6js6jdQscRks2SdnRSdvQhjMCKGoovQKVmqWVpcoFJJGDMjrlY9CAnCCCkVSoZDDiq2TBlQ0oZ/+mYPxvSvwiw+99xz2bVrNzt27vSOKYL5dpcsy51QdzcjkJJ6pNi2fSft2VmELvzccTT+Y489tg8Q7du3j9tuc7pOq1evZsOGDdx5553Mzc1x4xCwdOfd9yw7j127drFr165lr91www3uYdrafglfvwm8Ro3A6AJjFEpJ5/5UpOSZpjHSIFDKMbOM7Yv0Gp1htKBaq5FlKbooqNVq9LpdFhbmWbNmNVYXLM7t59BDD2FyYpyH7ryFNRuPoNYYoUi71CoRa1etpD42SVxzx7E+qdGIJKHJIG3SPWDZuVOzLzWMrj/WJRMsLHUzEkVfizBLu+w6ME87zQjCiLhSo5tpMAUj1ZhaHNBuLhHHEbVanV07dyB0l9VTNeZTTaEi1qxeRXv/Xnq9lFBJ2q0mSQhrpkfZeWCJuWaXehIQSuh2eoyMNqjXYtJOh6J067FOh6bVahPPNAiUxBpDpJweYrNXUFeOhbzYbFF48WI8OyVOKmRZhrAGaTWLB/Ywu2c71lq2bdvGjh07OPXUU1m1ahUrV67krrvu6jvWPb4FQcAZZ5zBzMwMAEtz+1lqNtm+e/+ypF6ZxDGeJVPGgvPz82zavJnDjziS0VrMFz/xVeqrDuGQQzeyadMmGtUqq1auZH5+zrmDWeuEnbMMsBx66KGsXLXqf29i/T9s2lhngV0UXo7A9F2jrNHO1S2JXElUGaNab34CSK0hcCz1IFAu3O+zoNzS7PrY9NdhKSyBFE5bUzh5C1EGiV7M2GXPBu542rNeyoc7KRVR4GLVIAgotHNpMjr3SVH33rwoyAsHJDnzG+OOYSTWelMazxiQWDBu7XUaUQG1ahVrHRNGqIC44sZJLYlIkoBeGJBSYDuLyKJNYDPCSJFn2gl5Y5BRQKVeI0kihFLe1co95AXCMUS00XTTlCSOXenXUCVAGHi3OKMRuNcrSQWdZ+gsIxBOKykIYwgrYCVhJLwJjiCOQscaE9aLDUMSOYdoKQRRFBAGgSsxC10xZWEh7WWUDoTGGHKtSbPcAY59RqmPHXx8irUIJZFBQBDHBFGMCiPKaEkI4XS7jFsb8qJAa0Oeps6xK8/otJoOlANEkXgtVSi6TYpum6LXQWddTJG75DWGAkPWWUTnXWQvZLHZI4grBIljsQm/1kvh2De9NHU6ujKgl6YIIahEEVjpE+LarwlPbPbiwRh6+ecOxtAHY+jyfvwiMfTPDTwFSvURzbIJGKCwDM5LSoWyFiv14HT9hO3rO7kPYwqNoxd65zUsxgjHLFqGtNr+78s119/B/veWNONysj9+0PYHXfmdogQUBgr/fVDG/778vvI7yrI6t0jYobVh6MaUouJFB5O30VmLvNd15x+5ASs8RdoYTZ5lpL0OBBVkpEF4Y0IpsEZ4QAVfR/3Tt3/ZGlIuSrb8r8FIkH6Bt3Z4wDvwCwTCf0YIiQoCqkFIHAhqsSKwhQ9snHNHaeBbgoCqnIhhQFDWmwqwXqNK+06yGOJIYIXCCIXtFhR+wyktGEoxM1neG794WL+JllpSYRgQhgFR4IAjpJ8cUhFFEVEU93+U13gSuAU9jhOELUCnICDUGiU9TVIb1xemcButKOmvygn2lWO5PyYdPdUuyxQ8cduw+Ch2qBwWF+yUdf/DbdkG0h9oZebEZdLKhQ8YLMDlO4UYWszwDxw44FI6O1Hpj2NwVu2mcGPC9X0AOMadxcKQ1vFPg8HlDBlsQ4+/dvc5huxYyxfp90PZAj92pBBkvTnS5m56Bx5lafd2jBXUJjdSrWQEgaUxPsHUYSczdejZZEY5mnqvTZlFEkL0AxCBe1hzQpP0x15ffK7sTuHXH+2yna5qVRJGkdssvLiks10OqFUjAinQubO7VgJG6xGd1KKEJJAhQZgQxDGhzZAGlBHY3PY137QRdHs5Cwv7SCYiKrFkpBphegVZWmDQWBkgAkkQKsIAAh0RJjFhEhNJn8cRBiUESZJQq9fZvWsX7WaLpYUFZzGdZmx5bDcjsWE01qyqzVOkTTqdRer1ACEUuQ6xPUktDNm4YTUiCGm12yRxiK0IVBQ7HREtUEQYCizugcH1ozOO6C/R/uaXOgrlhvmrAD396Ec/4qoP/T2//84/ZHRikm4h+M4td3PusetpJCE337WZww85hlVHnsr7rvp7Tjn2KC55+ouo1EY459xz+O73v0v0X6i3XnHFFbz73e/mlFNO4YEHHviFz+133/pWQGCN5iMf+cjjyu0EJqqRFbO0H7uPsSOOI4jqVLM29dERwjBkcXEJaTXjo3WS8Rnq9TorZyb5+le+iDaGF1z+cq655hs8+OD9POnE48jSnJFaQtZeYiSGc07aSBhHLLY77N+5BakUI5MzvOmNvwEyZP7AHj724b/DAO1Oj4vWHsKWTXfyZ6+/ghedt4bfeO2pbN3W42s3b+Nrmxf4yb98mA0bDgEp+Pzn/wOwvPgFL2D1RJ1dOx7jzb//Tq684nJe/ztv5x8+/CHWrl7NlS9+Ptf94Ls81OlyyLpDeMXll4EK+PhHP8Jas48/fPaxvP/f7uLEE47lXW99Da/+/b/kwV17mawnbHp4O6unx/ityy7kc9+9g69edw8bpkeYHm9QVOtcfOFGtu+Z5S1/+XV+50Vn8YKzDuOlH7ya8449hBeceTRX3/kQBxbatDtdDp0ZwQD/etOj/M0LX88FF1zApq3bGAnh0BXT7FtsMzUzxemHHsKPv/89rLUce+zxfPab/8ZN1/3AMX6BRqPBl7/0JVauXEmhC8488yzuuuuu5Tf+cQ9HAFjLtofu4wfX/Zjff9dfkHYHYNV3f3g93/3h9YgPXIXFrYEAN998M5dccglf+cpX2bhxI7//53/P+9/7bi498zROOPEkLr/8Mv7qgx/ks5/+BJVKhVe+/OVcfvkVfPvb38Zay5t/87d4w5ve9AuP2//XLdeG3BgKA1HgRL6LokDENZARrcUlaqM1aqMjjsUtnPtjnvpSJ6OJAveAkFRr/fg2yzOwol96pwChJCqKgBCRVPoPXFEYYAGjC/I0dXuoEOC1fgCyLOszs5RnCNSqVRezWqcpJwwgvU5SnlMYA8aiVAjCJQQrcYjOM4o8pdd1YFm1kmByB0RYa/3DT0AURUxNToCAKKkRVS2FEU77KlQkgUAv7iHb36XY9zCmuR8hoDazEqsUVkqqMmbFIatZfcg6JiZGKKyg3c1Iu12E1QRR0Lcx10VBMjrKxOQk3U4bIdxzThKHSCHQhUaFEaEKqdfrZN0OqcmIlaSIKxSNSUR1HFsYCrsPGYRUkpjpep0kEMSBIMRgvUZqKIUD1yoVKpWEJIkIlCAzFpMVNNuOxZqEkm6a0+5lNDs5cRQSiaBfAqmEIDca7ZlSIyNVJicbTE6OECYRSHe/wihyJVqh9DGq00JbWlxg+2OP0lpcIM96SKOJlCBSUIskoRSEyomLF1pjspxAWGf7LhzrDp3SntuNKTR5nrO3lRPWRrEqIFy1ChUE9LpdOq0WBsmBuQWiOGFkJGbf3r2EYUieZdRrVeIopF6tsjg/T6fV/G+cnT9fOxhDl587GEMfjKH/92LoX6jUrmwDhNbVj/6s5vRyBhOyRIus9fWdDrr1QKOrKxbCeATZDxSWg1sD4Mn2T0hb3QeeynK04eYAHOkP74Eq+pjVAMgpO9YOPlkCOgKJUKK/yBg7qCkF3IIxfO5+8JX17tJnm6w1aJ27jQgHuqnUEnQygvo0CEWQ1AhU6EGXUpnf9s/VneLg+oV/kChR7sH9GdQdO+fcQQ3scA+5z0uP+g4Q+kAGxKETQnSglSbPLSXFusy4uOt1C22gBown68eALQWorKsVjiJIEkG9BlG7oJcVdDo9TJH70kz8Z8qMn8DpaLljOC0p9xOFjpXlkoPCUU2FE5N0ZX/+R4XuHI1FWeNYUCpAK0VoIfCsqfJeGZORdRYosjZSRagwIYyqCO8mg3Djx1rRz1b+KrThuSF9f5WbZgmiGm37tuWDz3lKsFJlDtbpRfhxSQnemoK+1esQzVgFAUIbnwF1i7eUJWhryYtisDELt4mAQCjlNfENQsrlxyo3FgZzsfzRpvALpuiDuOV6A6C9uJiwEgKfAbaOLupq3AeUdLfJgRGiz9YLAuc4YoxB50uO6mxhz6PbWGxa9uzczboTLyQIE5QKKIq8H1AoIZ0LpwfMjR6UAZdrWwlkO3De+uv14Lrw7LwyQ4IhSzOSpIKKq6xd0XAlAjojTbvYQmMLn030ALGbPwFBoJFGYKzsO5+AYe1Mg9FeQbSQIkRGL8sRKFwdtwPDJdLVuUcRUQCRLtx3KuXvsQOYw9CV4WItzcUF9uzezX2bN9PrpeSFpp1ZGolgNBHUVnWRpo3tLTHXMcggIalPMTK5itFkmmTmSOLqCHFSpVKpkPVadJqzBCLHFpp2M6XVOoA2BdX6BGFUIwjjAat1KAExmLJ+/RwsqU/Y9vJX/Dr33/8AmAyd59RDy6lrEqbH6gig0tlLt1lHhCHPu+h8ZmZmSEZG2bp3jk333s3nP/mv/Pab38Ca1av43ve/zwP3b2Z0dJQPfOADnH766URRxF/8xV/wve99j7/5m7/5L8/jkksu4corrwRrufW227jqqqv64xgsH/vYx7jzrrv4wPvfz3evvZYvfvGLvPoVVzI5NsaGo09wFPWix4HZWYy1VCoJ83Oz5HmBMZbDjpggLzLuvHczRxxzAoUu+M53rmHFipUceuhhpK1Fkrpm0mq+/4MfUq/X2XjocRzY/gjaWGaOOInxiSniOGbfjocYHZ9iZGSU71x3A5MT45xy/HHsvO8u9OwjPOf4Ua7btIevb17kbb/5Rl59zCYu3rkZu/9e5miRTK7lrDNPp91scsP3r2bVqtXIMOGSp1/EoWtW0V2a58RjjyEMArZv28aq1esIw4gVq9Zy212bODA7x9OfdQnXf+1z/OC6G3nL297Kzt17+NMPfYpRqbnwxMM57awz6e17lO7SPB/7+k3s2TvH6kZCEdaRYcJEaHl46w7mW13OOv5Q7tu5wJ3bZomkYP9im3t3HGDDqikaSURgcu7asptD1kzw52+4CNp7uP222zjp3KeTd1tk3Tbr1oyxedM9/OtHPsx4NWK0EpI9ejuNRsJhJ56MuP/bXPGiF/G85z2XsbFRvv/97/HP//wvP+UYt3r1at773vcSBAF5nvP7v//7ZJkTJ184sI+9+/aRdjtef2R5s9bytKc9jVe8/GV8+MMfJgoDPvqPf4/EsGvHDj72jx9mZLTB3ffcxV//1QeRQcBXr76a9evXMTkxSRzFPP9ZFzEzEvGZL36dz3z609xyyy382+c++39otv3facpmGFsgbYGzEHcBfBTFhFFMJY6p12oIFXJgfp603SbtdFC+DEbnBiUlWhsizwwU5b5o6btkDeuhun0QSoaGMYZCa/K8oNPtov3eHEeunE8FypcFOYZMoQ1KG5KKRljb1+aUSpEkVbIip8hzet3UHVIIKkkNARidk/pjICRBGCFkQGtp0cVhUUytUkMKJyjungNc8hPtEpPNTo80lFRCiTUFoTTUI9iTF6QaRMcyMRFTqUTE5OjuAnt2biMemUFGFaRSFIVG5ylZt+MAMuHc8urVCqGwBLUqWhdkaYrOBVYFyChmqd2ll+b0Ugc41esNwqRKVOQUxmLjhEz3WFpcAqOpJzGHbVhLKAzS5iwszJMVhqxwgEQUKOIkoVarUa1G5FmK1pY8L6jEIUZrepkmDCOqIsAog7bQyXJqceBAr0BSZJ5JpgtCiWNpefkLYyxFnjkHMB+X4zTLwWqyXoe5/buZP7CftNtBWksoLZGEamCJlCIOFZV6gyBKSOojBLGLZZDSsS2LnO7SPJ1eh6WFBZqppSICrCnQWvefCXw0yPT0DEEYEscRQeBkMQrjWC4qUNSqVaYmJ4jDX8xo/f91OxhDH4yhD8bQv3wM/Qu52i0/zBBg04cV+292yvjWUEI95WAQ/dI2ywDxdb8rKXqls1q5oTK0b7oLtkMnMOiAZeco+pDSACASJeo8AGuGP++uxStQiVJHygM3/lNGCN/Bg2OVBW3YAaLdZ3HJISDNM2kK7TIQeZYjCwg1ZJ0lipEe1hR9sG15v/QvzKG7Q/eivxaa4ev1nVX2HfRd5ET5Pf5H+msasNf8AuRL3qSV/Wvs43dYD2bRB6ukGiD9yv/eEZlclkRgiSOXkUMqtMgJuoI8y0mL3FEW7VA/loAjjsashOw7CwRKeaDLg3qAFe57lQqcq50MHNKunN2rVAZrApQHnZRn8SnpUOU+bdMUFJmGHF9jbB1rSqk+INq/848bi0/ktmx+SOk3CvqryGDMLQdhlRrMbfce+jW/bjP1Tjrldw0O2N/I+uxB9yVu07ZujTD90sbh8/TllkNZICHon9cy2vJQc7jgYO6U1qp9S1j/2VJnrvy9G28ShNs4y/XD9F0r3BiUvg5bKDcPddFFEFBYy8KBWdo9S7uTsuqYM32Q7Z0irQOsZXl+/twtyx2LNIPMTtlh5fv8stQHt0vbY2OMNwkIqVUqoCUmh16WYa32Yvm2f9+lkn1g3NXEC4rSstbC9ERMLbOkRpG2c7Jcu42PUkPEa7v1N2DhdSjKa3X9q4Tqsw2xDqDP0pS5uTmazZYrEQsSsq4gjSVLDU1MiixyOmmGiiCqGqr1MZKxlYyvPZQ4qRJFMVJCcy6lO9/F2NwZFmhBe2kv2hQoqZD++G5S26Eh9rgxg1g23p+o7bOf/RxYQxgGWGsI0IyFBbrI0VZQDSxGF2SF5tjDDyWu1lBBwHyzxaOP7eCmG29g7ooXMT5aZ8uWh1laWiIMQ84880zWr1+PlJJnP/vZRFHEl7/85Z86fjmGzjnnHF7ykpcAlkqlwlVXXcVw59188y1s37GDd7/rXezcsZObbryJFz37aUw06jQmVqDTFkWW0my1iaMITEGe53S6KWnuHGW0zplfWGTV0Ueji5y777mLyclpGiNjLkmiU0zRY/fefcxYQW1sil1334qxlsNOOY8okKBzet0eYxOCpFpl5569pHnGYRvW0W0toXSXI2YqfH3zAe5fKigaKzl04zxHTB7g0S2baXY0h4zMMD4+iQQevms3QZRQGxnj5BOOZ3ykRnPuAOvWrKHVarJz+zYOPeIo4kqNhU6Pnbv3Mjc/z3Oe9XRuSBrsmE859rhjaXZ63HH3fRw5VWfdzARnnXYSO+5usyNv8v2H9kLaoxYpVBgTJxVG6wEHtuylk2YctmaSh3buZ99Cm7WrptBCsGN2kZMOX43JMvYqyWKzgy5GOOHwGR5cyJifX6AaBXR1hC5y6vUai/OzXP/Dazn+iI1M1UKK7T0mDj+J9dUJhPgOp5x8Mi964QsRUrFnz15uuPHGnyqzGxkd5YorriCKIubm5njHO97RFwdevXo1YRiybs1q9u3bR7fbXfZZFYQcceRRPPf5L+D9H/gLxsdGef1rXsW2x3bS7XY57/zzePTRLew/sJ/zzj2Hh7Zu5ZY77uDSiy5kYnyCVrvFyScciyhSPvuf3+SOO27njjtuf8IDT7bI0UVOkacIEZev+thJEScxQRQhhKTbS8mylKLIkcrthboo3EMmJQNc9R8oh2NFYV2FwHCS1h3KorEUnqmSZY7VoosCWzjx6zAKEdKt907r1O1dhdbIcp8vk5RCoKwrlcpyX3aHgNERV1prnc6KNhalBEK48+12u0Sxda5PQQjWUGQ9zxhxMajFyUP0ej1MLtAKQqORwrGChIWiMDR7mloBsQVhctrNBVr5bqbWtYhqEoJKvwzQZD2foJTUqlWiUCGsJopjstTQ05pCCC+ULWi1e7Q6HZQKqEQBlSh0mlZBiAxCrNeQzdIUaw1hEDA22iBAY4uUZnMJIZ3+TllOGEcRSZKQJLF7QPcxVRwqcjwIVUlQRiBCQ7vdIS8KZBKgpNP2cqlZ6zSyXIbasw6EY7zkuUuuSoEMJKVQijXWM9269Dotuu0WpigIMAQYUmWIAkUlChFBRKIikjAmrjbcuJQBOs/Is5TW4iJpVtBqtekZSVjkfqu1fYDEWldaVKnWUD5ekFKQFwW9XupjSBeL1KoV7/r4xG0HY+iDMfTBGHpoYJdj5heMoX9+VzutBwO/PLoHJwQ+6+IHZKELSvX7YYjHAS9uAOMXzz4o1D9j6+l7QwCV3ztLoGsYdS5R5hL46R9nqBdKETchHHCALdXaS/bU0KAsARZrsMYjpmYwGd0E8gtM+f1DC4PoC3QLEMofU6LCALTG6JLGbMh6KVFFIFXUB2aGQSEh3YJljPCC7e789JBLXMkJEh6BssN95c+x7OES4hZiYO0q/UCX1iJVgCF1m0KWUeQSjCJSblgVXhzPWIsVFunPTzqvSVDKIewCrHYT24niuQ1SScFoPSIMFWEUIlXKQqBodTI6XUFWuFK7Eit3qv/eOU9KQiWJA+V+QuXK+5RfXN3qjZCuXjUIQkTgACghg36NvACCMMIUMSZwtcWBsq6mH8e8s0VKrjOszgniuqv1l4ooCB0w5heqZRvE0Jh8ojY7PN6HaLsMBUVlG+hOuFpnY33NuP+Q9JRvIWRfQ0BJ6S1T/fzC/Z1lmaNsG+MFReXQ/BFugZMugOv1sn62TLoVHWud/pc/2WUbZcmwKzPtQjg6O14g1Y1c690byjLTgV6CKQqvG+bGkUZgi1J837PufPlCmIwQhDUQAZVKQh7kGJtzYF+TbjtH5z2mR1cyNjVFHNeQKnJ0fSWxgn4/IlywUgaKoQe2sWU5MTglfQ/eWk+ZZnBeUrlsplCKqFqhu7dJu9dkX9ijGodEoUIbhbYSgyUMLGEIVgoIFCIMCLVBa1fWLJWbY0kAGzdMkmkI4zYPPNyh1eoxUnEZmEgplN8wa3FIHEVEgSAzBhFEWBGQawtIrAoIotAJOaqAY48/nnXr17Nq1Soe3fIo+w8cYPuuXSy2UxbaOYmMGU0k45WQKMidNbjuUkkS6o1RRmqjzO7ewsK+x2jObSFrz5Eu7UcEEQQhRFXCMEYFMT0VunEVBMi4ilvhdXnbH9dK8conOPI05GyqgpB9802++p3ryZL7GZ9awYsveTq9NKOXpsy3NZV8iWq3SZQ1ecaF5/C6l9xDksRIIXnn/zqGXXvnuP0nd3HuuefyW7/1W7z3Pe8BARdd9FTuvffe//I0BuuEGFr3+mkcBnsNvOY1r+blL38Zs/v3szQ/y8Ob70bGVVJtmG9l6OYWGhEccvLZzB44wL7du7jnwa1MT01xwZPO5K677sYKwSte8Vp+921v5brrruOH3/8+9953HzfechfPu/Q5RIGiOXeA+7duJ4orXHjJSh6461b273yM0ZE6cVShWhvhuU+7gNvv2sTv/fF7eedv/QYTU6v55tVf4mVnrUUXOb/7P97E5OQo05MjfPHGb/Hs572Qj37s+Xzo4/8OwBtf/mo++7nPsnXL9bz5TW9m+wN38pO7ruOpL3od9917N9/68ud5wzv+lEe37+ZZz3kBf/+3f8Vrf/1KHrn3do6f0Ky5+Cj+8Pfexsx4g3e/8un8+b/9gOb2OV4xUueHS5advZD3/+4V/Mc1N3H1j+7k8JkKGw8/lA1HHI148LPIdI5VIwHZQsD6sRle8uY38M+f/Rr/8aVvc/xUlaWFJo8caPOqsw8lN5oLXv/PfPwTn+SiJ1/I1770BY4+8nAO23gIu/fsY3ykxosufSo/vv52dmxrMhkJ3vySt9FYtR7153+PUAEyiAC47PLLefall3L++edzzz1Del/2Z8+XIAj44he/yAnHH48FLrvsMq6++ur+74VUTG04iiyos+nhx+hlOTfceBNnnnsBn/vsZzjymGO47NVv4M2vfSXPvOjJvOP3f4+x8XGOPeY4xsYmmJuf56uf/jQvfMGLOHN8NUL+Wd9l6YneZheWWGq1mFto0hgddzpglQhhcwJlqcUVlJc1qMUBoY3JrAZdYKzbP/JCuz1WFwShW19VGFKuY2V20FoHSpeuUuDjRaUGWlP+7yLPsVlBoQTCVklqESqK3fHynDzXdLo9gjAiilwpisUZ6VSSKklSZd++A8zNz7O0tMTY2ChRFFNYiQgTklgwUq/jWFs5rU6PChIVFRRZD6sLuu2We56QUDTbyCD0WlCwtNRkX6fN6ppCqwSZNJhoVAhaHfbP7WfLwgIGQZZ2SNVuTLKDZOowamOTyKTu9ljjnNRanQ5aO+FrtEULixWj9NKUdrvtytOEJDVtHtu5i263xwnHH0cjCUikoREJcnIW2wuknQ55ljNai9jV7dLJMuZbPZQwCFsg4wo1FRIkFfLCEMcxE+MjjE1OUq9VoFkhNU44nLRLrCSNJGJ0eoZCBOxrpjz4yGMsLabovKDINVlhCJSkHoesqCW0FttYIuKJlPqqkJpKaLXadDsdp6UXhp4Zp9BaU6lU2LB+PZUoYHFhgZ07dtDu9NBZjw4FSehKBmUto1AamQNaEmiFxMUVuZF0M02n5xIGNqqiVEicJI7FkuX00h5xnlHonFY3I4pCZBLTabfo9VKWWi1G6jWiMGR2bhalFEGc/HdNzZ+rHYyhD8bQB2NofukY+ufnNXq6UbmvlWGm7JfN+bOxA6BDQB9g6oNPuAkpjVz+OQYgVMlsArssthkAWUNo5tC/S+TTHU0MABhP++mDY8MgDAPQqYRDS/Cnz9Ly39FHVhFe0HoISaVEfB3YUhQFWZY5Mb/+zXDXrIIIV5oHYRSgAoHVKbZIMUXms1X+u+SQrlX599A14vuz3xv+Gvu93kerh3rDL3Z9LSVRAlcwEF7M0FoCijhwbicY4zUKHN3aMZEGYt8lS2oAKApHZ7TCM5WEF2VzQovGOspmSUXOtRPCHEiRezxJ4AEox3ZSyjGfpF9AlLeS9EhdX7BdCCfaXiLmQiqEsgipPBMqQBrrF+gSHMUJHBqnpyDxIp3WDGUevOWpLRfiX402cLQYUIEd9dT1d1EUvj5deMCz3PzcfZGBQnu2XV8EXjgNCpd10RiP5vfB0P4x6G9O7nW3cbshonzHC+QQOKwL3b/H+DFshjIP/sspxfCHWYhlFslqO5TxKUHsQVks4OvDB3MqDMKhThuAu91Wk26nTZ4XICVSBUBEnLgVMe1mSFJ0b5G0OU9clwRJHXSG0VAYMNpZwlroU6kH2TFfOoGj4pbnQ7kW+IyRm7uyP+8QklwXdLIes03opIo4lFBo93rhkgaBlMRhMMiS+4ydxIHCYSCIY6cl0csN880e7VTTKyyxNhhcaXSkFLFShEp64FkRBJHrD69bZ3Tu6Phd60pYlXLOTGHEmjXrKLQhqVZJC81YnqN1QcV2MdKyaGusiZvEQYZNm+zf/Siziyl79ndp7n+Y1uyjLM3tIpCGJPRjSQbYuM7YxCon+igswhYYUzhqths9eMW8cpnEf3rZ+vir0ApjCIVERlWOOHQDjUaDe2+9gf1LbXqF5vwzzyQQmjzrMT05ybbtO/n3z3+Jl115GYdtPIQoinjuc5/L2rVrATjrzDMxWjvHFxVQrbrQYM+ePfzTP/0Tz372sznttNP+P87Isnr1al73utfxta99jQcfeog/f/8HeNpFT+WpT30KD80fIO20qTZGQSkCbZiaaKCKCCGh00sxCOJanfHJcYwx3Hn3vdTrdarVKouLCzzlwgs54vDDmd27m5FalbNOP4N9+/dTS2ImxxqsXLWaQhu2PXwfyICJVeup1Bvcdu8DPPDVb/PSy17AhrVrOPe0E9l+321Usnk2HrmOG+98mMf2tTj13AuoNPcRLOziqOk6cW+e27/3NY45xI2prXfeyEQ1wqxdzTev+Sarp8bZePwZ3HjzzRRpylOe+RzmFxbRRc7bfvctTM6sZOf+eaZWrWHzrYIb79vPxZdcSnNpgZvvv4dOmtM9MMsnvvANmvP70HnGtTfew2O79pNEIVOr12JQ3LdpM6edeCQHZuf48e13ccLGNcxMjnHHDTexc9t2tLVEo+OEPRc3FHGDlWMJb1yZsPehn3BtnnHciSezZ/dO7r/mOxyy8Siqo9Mce8aFPLztAM29OxnP5vnW175EW9WcltBQC4KARqPBm970Jq6//no+9alPUbKDi7TLtd/9DjffcitvfOMbufXWW/nWt75FpVKhWqv1Pz/cKpWEN73uVZx00kmsmp4kDJwAdKfToddcoBpYXvmSy5iohWy57y4uvvgZbNu+k1vvvJunPvUigihyltGBG6tP/JTPoAkVooKYKM5ceVmestRrIT2gM1KJQEnvWiYpyqS9lEgUYRgRhqGPt9yKpY1Be2F/U2b0fQRY6jdJqQaxrXTC10IKKsQUhSKXAmGcGLQRisJa0E4fRgVhX1Rc4DLuFhf7J3FMGDqdlckpV9460mhQTWLCMAIR0w0CrHFubIEvb6nUqu73QJ5nCEBFCdpCN8vZs3sHjXqDSiWhUa+ibIHIu3Sb+9GdJoW1tHJoaYUJa9SShFBJeouargjIJGSteaqVhGpjBGE0Bo3WOdIaCmNYWFykVkmoVWKa7a7TxRESoZzWVWQl01NTaGNIKgkqVEBB1whyERJU6kSVOrLTZefO3bR7Ge1uxsOP7iCJJHEgkBQUhaGXFeTaUJFOW8YKgbGWKAqp1qpoo5ndnxIFgmoSE0hBXuR0mk3SNCXXBiMCjNQDZn8YUalWmRyLqTZiajKj15xnMYgYn1qJtpYiK5idnXPi8FFMEChkGDM+sxojJGFSo9Xu0gsUeUcQ5l2UMNg8pTl/gG63y1K7Q5A4qQkhnTGD1TnZ4ixZp43CElWrVGo1oqTqAJYiB6NRwjG5VjamXFRvDIFsEAQhnTQj165vpDAIrfvPLU/UdjCGPhhDH4yhf/kY+hdytfspcfE+ALIczClfA6e2X57a8CTyGvA/tcz02UseZHn8Ma0/bjnRnaj44JuWiYf3P8AQmDTASZe9h5JWSB+k6rOm/KUNgDExALusd0JjUB/r6lYL8tQJNBpTipe53wdRgLJ45zVFEEo3sYoMk2f9TKLwoA041pOlBMIGYJ/1fe4WJvm4a3ZAkHNpG7y37L9y8rnzch8qKdVpnlNogTESHSpP8XUPPI75hKdOl0CQ7KPaAhwrzgNuUjhWlFKCIPBudN69KNeGNDdkhSXTzn0FMeBplSBWCT4FUhJ4PaZ+KaCSKAFWKM96kh5oGvoRyrmoWNsvv5NKIbVm2EXP4rXCjEZY7QAnSpCSZcCTtcIvgPbnnW//ra20ehX9jW5oqbBeKDCwICSBdG4Pfbtm4TIjZbArwG+aLutprPFEXEcZlkNIb+nU4u6Vn50WPxf9uPbTUknVX8AK7ex33eaEyxw9Dugry3ODIOiDwP25JoV3m/ATeAh0Lu+j8F/nnLTcKYcq8CUC1hPc/KbZbtFrt8ny3B1VBkgiKjVJlEQolaNkTtFbJG3No8IqcW0clyUwiMIt3MYYrJBIix9HAE74X8mAMsMkhpb2PqjrN05XeuqddBDkOqeXpcy1bF/YdCQJyLSmk7s7pqQi8Zsmfl44fqbX31CSMA4QQlIUmvmlHp1eQVpYV4JgLcI7+pQ/yv+UzpFCSrTVrpykyJzFbLkuVipEYcjUzAqyoiCKE1rdHqEsUOTM7ttFLxe0TUScFMRCY7ttDux+lI6dI2MP+eIW8uZ2lhbmGBmpMz0ziSl6IANslsH4CkIVePts49zLpOzrngjrKdm2HD/ln/0MwxO6haETunWW1Ir66DhHHb6ROBD84CvXsm1uiZ5VXHz+OaCh1SlYtXKCO++6l7/50D/wpDNPZ+3qleSF5oILLuDJT34y1WqFrJeyuLRIEEZOm1A5k4bdu3fz7ne/m4mJCY4++mhq1Wo/8fH4tmLFCn7nd36HrVu3cscdd/CBv/gLijznjDPO4MCBvUgEM1MrwWqM0YShopcVFMbQancwFiq1BlMTY+w7MMfdm+7n155yPhPj48zNznLhk59MHMfcf+dtTK9ew5FHHs3V13yDRrXCmpXTrFqzlna7xWNbHmR69SGMrVhLVB/lzq9fy8f/9RO8+AXPY93aNTw1gBu/8q/Y9h6edPQq/uHbm7n5wRZ/9cqL4L6b6Ny1ncWNq6mqlLt//B0uefXvEAQh13/pk0xvPIax8TE++qnP8OxLLuWscy/k6x/+e9atW8ezL7mU2269hSAIeec7fo/b772P7Xv2cfiZJ7GrK/n+gwd46wcv5Sd33c3nv/4demlOp9fiU/95NacftZrp0Srfvf4uOt2MOApoTM6Qtps8/MADPPOZF7Bz3xj/9B/f45yzT2bD+hm+8IXvsGPbfgwCWRtBJj2UFKRBjekV41x5xlo+evM9bHp0L89+7gu474EHufYHP+YFEytYsWo1qw89kjW33s68Tantn+cH13yVrQspSaWCtZZWqwXgNS1CXvayl7FixQo+9alPUalUqNWqFFmP73/vWv79P77IrbfewtTUFN/61rfodDr9zxePA7KSOOZllz2fqakpiqJwgT9ujUs7S1SU4XWveCm3X/89tjxwL895yev4+re+w1e/fS3tbkagFPV6lTzL6HQ6P1Uq8kRuQRgRxYak0ARKUuQp7aUFgjjBJBWMHgXpbM+DMiFmcfGMcmt4GHoRcGs9i8JQaMcEsD6RJnxCUHpmRCkT0C+JwMn+KKXQOiBTEq0LsBYtBIW2WKEdSCUlgRCEgaLQhjTLnBht4MqjwsA5CE9NTtKo1UjTHpUkIfAC10JKZ6CTdl32XApqtbpPXLqyMKkCZBiTa0s3z9j62C5mpqeYHB9jZmqSwOSItElrdoGi3SQ3mqXc0ioUolZnZHSEehTQ1TltFF0VYXptRO7KVvOsIC8MtsiRHgRYai4hpSSpVGh3uj5+kAjl9kiJZMXMNEIFRFHo2PVW0DOKQkWEtQb10XFQTTJj6fRyFlptett20KhFNCoR1TjwwFNOrl0UKbyovDaGKAyoVisYa9izf9aJm1crCGExWUp7abEPPBVCopEYoUBYVBiSVBLWTNWp1ioQFvTaSxQiYmJmNcYYskKzd98BlJJUkirjE+NEUcTo5AxWSMIocaLewpIKi+jkUOTYIqO1MIeRS+i5OYz0ZYVCuP7DEumMQBgCAdVqlWq1RphU0VnqGHRGI4UlChTTM9MUWUq33ULWqgRhxGK7S26gl+eEkiHzoyduOxhDH4yhD8bQv3wM/QsBTyWoUFINjTH9B+9yIjgU1g6AGn/fjfEsHmxfEJvyuxi8X3hwqJwcjwd5+jfAA1LG+JI4OaAbOnE07VBjMdQtQ3XH1pZOdkOTTOBKstxFlnO+X5YHbuILDzwIDzYpWYpO+yDBX7TRZT2/+3FfEVCfmCSs1IiTGrpwFqoqirFCUOgCrZ3OkzFQeAtTrAei/GB3115eh5vgZW1reQ5CCIQR/fsgfOZLlTRMD96Ui8cA3PEBihUURlKYgdB3YQXaGnLtvksrV4calJPIB5HDfaYCi1IglejjpdoKtHEMea2ds3ChccKVHpnPtXGlfVpjA+nvE84+tpywgRc0N9YDT06ILQhdsOAoispnaixgPJ3b01rlQJeqxMqs1egiw+QpBREhMVpmqESjREAQCAQS+hkMLwD/K9BKIDcIBxmJku1VaENR5OgsQzqXagfUWXf/jbWuZNSD0KIsp5Ugca6BhXbfn5fpCUch8+Ces/3ts/Css212ltjSB6LKC/ibgWMF3qVjyD2kBFKFECAtYeA/N7SpWm0ocrehl7RhEIRhSAnWuuDBrzPl9JFlBkgRJYkbr4X2x9RgemS9nrfznuPQky5gYvVh6DxjaXYXrfl9aCzaFBRFjyLrujGsDVEQIkOXYSkfFHKdYfyibfOsv4aXa5kRrv479BauZY28DBRSumBaGYuyAm1DtFUYKyms2zR7hSTrFs7NB4ikIJaSHn4dkwIhNFZaenmORmI9S9AYQZ7DYk9QaE2hNZ1uSq8RgpIE3l0ywDiRxDBy/WrxmT3HX5TCsLiUIwUsSYk2mtHxcS546lMQ3d3o5i4e6d2OETGiMk0sJxFFgjFddMuw1Glx364mMSkxDepBj3ZP0901y+honWolYCwW2CKj2+uRiyqjjYgkqdEYGXcrsi4cuO/tm4uicAK62jinWp7YQS/AFVdeyTvf+T+p1BrEUchlz7uUOzY/TJrlXP7qN7rymTxn/4H9oHOUNbSW5jnr9JO585bruO3WW3n/X/wlH/+Xf8EYw9TkJFd/6bN84ctf5/1/9SEA1q/fwIVPfSqvfMUr+sf9kz/9Uz75yU9y7bXXMjIyAtDfe8q2adMmTjjhBObm5tzvdcFHP/oRvvzlL/GeP38fK6emWDiwj7CSEEQRo2Pj9HbtoLMwx4KWrFqzmjXr1nP3T25lZHSMK1/8fG675QYeFYILn/Ysrv3ONTy27VEuv+IlLBzYy903/YDTTj6Zxx57jH/66Md47vNfyOGHHUG31+OuW29gYe7HXPbrr+e8p1wEY6tpjIwRV2ImV2/g7Kc8je333cnffeyfOSmwPOWs1UzaA6x97uWs+O0/4+SHNhPVRphaexhJpcIj2/fw7w8JXn30OCcfsYbXv/JV7Nu1nS9+4h95xctfwT2bNvPGN7+ZF198AavXrmfTw9uJW3tYL7pYC5ecvpFj83O47+bvo2f38T/OXM1f7t3DYielUYvYv9ilMILTj9nI/Y/uZuvOfXzx81/krDNO4qWveDH/9PEv0F2c5Q9feDKbHtnKA/dt4bxzT+aAuYf7dt/PV753E2nu2NV6YQ/dZsz2+Eyec9kJ5PE4n//SV9iwdi3v+L3f5boffI/9u7YyNjrCqRun2Rl0+Pymzbz8Zc/lxJNPYvrES/iHf/wnjjvuOACecv6TeMUVL+RP/vyveeChRwC46qqreNaznkVjfJp3/sEf8ptv+W1k3qOzOEdRFLzghS8k8nvM/v37l43hhYUFzj//fFfqYC179uyhmkSsmh5n1YbDGVl1GHPtHqsOP5Hp9UchVMDFT7uIJ511Jn/+T59menyM33nVa3jjm97Mtdde+1PA1hO5jTQaRFFEGEVoXaBEjRVTU32muC5yCqx3V4uxRg+5z5UxoPCJO/ed7nnQlzoAfb6T9S5bwj/Eum28H8uXmpxGG6SSdNttp/ekNcZYlNZUKtU+wzxN3VgOlezf23arCVjCKHYOVP5HyrpLDhc5kQQRSLIUFpeW0Lroi/+HUUSn1STrdsmLJnF9lDBOaEzOUB0dJanXqVRrREpQjRV2cQcLzTlmZ1vYbkYFxfREg7WHHsro+BTWnkqvMKQGVh56OJXGONWxCbZu30O7XVBkgsmRUcajgEpzCSx0mktElTq9LGep5RyjojBgamqKOIkJI4WyKYmKCYOQtdOjtGNNr61RqoBAs6oRMVuL6aYprU7XuyIXRKoOQCglaZbR7XbZt3c/9SSkkoQUBrq9lE67zVji9I/SNCVQikJrksgBFVmh2bfYIsucxldVCa/xBLXGOKPjY1QnVpLGU5ioQZYXbhxIxeTkpNMBLAqai/MEQUClmiBNQTUOWLdiglZs6VQUs3udA2CaF4SxEzauVWJk6B6IQTjGiS7IOq7UzErFSKNOvV7zYKjxxkKWXpqx1O7S6GXO0W9kjCRJaIwa6qPj7JldoJflqCSm1Zqn2279P56Rv3g7GEMfjKEPxtC/XAz985falSycEl0tXx6ajDBAwZYBRqXeu/WIWOl0xvJSumXCbP9FFmvZpCk/LyzY4dI6f7q2rIAd0PB++ntL6M4DTyXCvOygJcrrgAmJwRhfblXCTCUwNVTC5j7onAocmi+QwvqsV4W41iDPUozWqKiCCmNUEPljGaeHZUqtrAH1suQCSQG+atUvTmXfDKiY/XNH9M+tD5K5TncTUAriMKCWhIxU4/69U0oSldRRIZC+1M5SECmnyt8ve8P92LJXpENHJcoDgJ6sZy3Sn6ocEgs3gdfOKllnOBp5gXPtKJ07lFJu4SiZTX0kW7pjygH7rPyR0gFdJeQp8IuF14dy6LunbRrjLIDTDjqXiMyiUujkzpUljGJCz9pyjLGfOVSfcM34TcUJ6T0uA2r9sPAIvhdjo38z8GCisY6RZp2LRV9FzPeBo+oPkyL8ffFgotZ6aG0YnmV+1Egcou7u0GBIl84hpXNlee7WZXGKohiAyn5K94FKP0eknzzSC4L26bl+HTE+ewSeYmydvkUQxkRRTBxFdKQg9yKo1riNWamIMEr8PK4S1Saojs4QJjXyLHMb83CWSZQz2P2hAuVEKo3uJw36YChu3QC1DLBHOMFWISUTIzXWTueM1CoEcYRCoASEShFFhiiOaYUZjUrojuX71t1/l0xwQoIWIQyFdqB2EkhqSQTGEiSRc6wxmlgJRqoxcRS6uSNEf4Mf3MvyXx6E9w9BLjFlkCp0NfGBoNueo7P/UXR3CRlWCOMKKhzFGElWWOr1BrLRwI5NIXWK0F1k81F0npIXOUY4QNyanCJro1Esti2tniCa79JY7BGGAVHgXDH7dsd+nYjDEAgGzh1P0Pbyl7+c1atXc/311/PUi54GNmDf/gMkodO8m291qFWrxEmFTrtFFIYktSpBGLNv/wFuvOVWbr3lVh56+GEee+wxrLUsLizw71/4T+YWW1x44YUA9Ho9brzxRuq1Ko16nZe+9KVYaxkdHSMIAjZv3sztt9+OtYbbb7u9f35ZlrF9+3YAKpUKz3nOc5weTBAwNTlFo9FAFTHtNCPLC3KtUUFIUq0zktRI4pi012N8YhKlFHt2bqfeGAEh2PbIAyRxxMpVq9n6yCOEgaQxNuky6FjWrttAHCdIKQmjmImpGYSA22+5CauqnHbckVx99dWsXb2SM886i6Q2RrUxzkQtYm6hTVNoLthwNI/Ntrjhwe8zu+tRjjj6WDaecCY3bX6U3fsXOP3k4wglLC7Ms2rVamzWxfSa7N67D4PgpJNOIqiN0s0KejseYmY0ZqQ+RpH1WFxqsXf/IjNj+yFtYWTE0y++mB2zS9xxy42smZlg9fQYG1aM0eqmpNqyduU4usi47e77WblqiqwRs2dxL9MrVzATRhxYaDJRr3DmMYewYs0aFhcW2L19O4duWEWtUeeezVs5IllDbbJCHCrSXpeFeU29WiWMIqojI2S79iBNwZEzNQ7ZeCTrjzyZ6fXrOfnkk3h061a+8tWvcudddzM11uCBBx9i/4FZAO69916mp6d59rOfzfj4ONVKhc9+8uPcdsdPANize3d/XJx52ilUqxV++OMb+8nCnTt3LhvbUgT00pTv/eCH7Np7AGsMG9avZcX0FJv3PUalWqfeGOPojRuYGB+jVqtz0skns7i4yDe+8Y1fGdZTqQ0psQjlgAYZDNjYRZF5fRWJLRkVxvaTvS5WoZ94Ba+FqQL/8OrKMgY7qN9PlOqHKcZaRLkWC5fQK9fEUpMlCBQqcCUjZelQyVLHJ5DLvbLInQNWye7HWtI0xfgHvfIcZbnnCEUUx8RxQhRF5Gnq4pJM0+t2yDU06lUwhk67w+zsLJVQEoURceLWs5KAgRQESQUbJmQyZH6p49zmhESEFYyKaeWCnhEUKIIwJoxC4jikbusUWYbOs6HkrgLlHMB0UaDzFCUsSTyIcwUGYQrIewggtAVjjTprVkJYHWHXvgMkgaAaKUbrFVdKpQ1CKZIoQklLUeSkaYYIXAmkCoJ+bBtFEQIIQkschYw3agRBRFSpkKZO2DuRMFJNSOKYwgiyAmIrXYlTFPb1hywOUBDWYHXhnyucQ5fAlQclUYCOQkwcEkcB6ABrImq1KnGlQm1khDCOXewgpAMXs5zFWeeiiLVEcUQUKCdP4eOBNE3Zu3cv+2YXWFxaolat0qjXqFQSEJLCqaATCIjCgFqlSjgc4zwB28EY+mAMfTCG/uVj6F/M1a5EWY3t94sn/VHiP4Nx4TpyGa2vpCVa48fN8OARAybV0Kb6+KlVnssg0BhM6j6w5CdXH2waoDWDa/EgzmDBKCl4g0WkBLYsQ8ezrsrR4Trl5JZoP5ll4DJJgVKubM+67IDRBoEEBaEHnqKkDkKhtSFMRvxPzeGbQxadvnsGi5y1feAE4xeXof4ZYEvCM4/ceQ8E5/rTpt+HUgpqlZiJQqOkpFHN3T0tWVx+BdLWCYxXIucuUuo29a1Ty+/uW3CWAYcBjAN/BGjh6qIDKUmigCKOCKTnafpbqgPpaeSaJApIYo8Ml6i1Z3+VCyi+5rbP5IJ+wFSCduCZd3IIHPX3XHntJ2M0RdYh7SzQznvktCjEEjKeR4URSSUhiROiMKRSqThxT6V4ojftMx7a+BpdWWY8B5Cts95VQzofQ+PeOkcUKDOpJcA6GHPK3wYNbrz7xVkbjbGGNM/7umCD8ed0zEqXRKmEs2l123ffdrZvWCAHYKM1bvMo8tRt38JbpJagox+X7nx92QG+CtSUJgFujhdFKVAbuE1eWLqtHiOjIbXaCLV6lVYgybotMAnCKoQNsNqi85x2cxYrAipja5hYfQRFoVk8sNtleADVZyr64/jzi1WMNposK+v1BUEQorVzehyQn2V/UxVC9i2aD109zfRYjbQoKIAi0+S5JsvdGhEEirmljit1jQIPrpZl0AZhJUqGSGlQypLmmqLQNGLJ1EiVRhJTSQIXLKHpZhljjSq1WgWLxBhQQdB/IFK4Uobhyl8Xj/iHJgFRHKOUIu0ssefR+9j/4PXo7hJxteb0NZIqFkM7LVixegX1qUM5Z+O5tFsd2s0l9m+9g05ziVazxcL8LnLdIdcdRGcO3emwff4A3WIHmY2ojk/QqNcYG2kwOTFFkiTUanUqtSpRHFFNYqebQVkW/sRsn/jEJ7jqqqt44xt+gzt/8hPCQHL9zbdw7hmnUq1WuemeTWxYu4bJsVHaS4uEE1NUx6aoNEbZfN0NvPo1r3X6df09RdBstXjL7/0v3vrWt/KJT3wCgC9/+cu84AUv4PvXfpdTTjmFm2++edn69s1vfpO3v/0dDO/MwxlYay1jY2P8wz/8A2Njo1gLO3ftAGOohCEPPbKFbreHDLoElTrj9TE2rFvN/NwsBw7s4+hjT2D3rh386Pvf5lnPv4IwDLjmS5/j3Kc8g1NP38BH/+FvOe2Mszn3gqdww7VfJ6nUeOYll5LnOb1eD6UURx9/Eq3mEu9/95/y9Gc+m6dfciknv/olPOmsMzjvSWdigyrVkTGedNw6/vrqe9myp83/OuMZfOGDH+TP/vRPscDLXvYyLnn+i/n3H20GDH/9+mdw943XseXBhzjjKc+kEgomRxO+ed2POezww3nb297GD2+6jbnd2wn3/IRDn/Z8pjceRWv/LjY9uJ1v3fAAr127ik6m2dmRvOMPfp89B+Z5xZVXcMaxh3DcYasJdAphRGNimovOO4F7H97OVR/5HH/7vreRZRl/9J4P8ztvuJDDD1nNe9/zIdavnOHcE47knF/7NbY88AA/+uY3OfvsU2m2u3z1y1eTEbPxmC6HHHI8Wx95mE07HuPUE0+kPjZBZXyCG++5HdNa5LnHT3LoESeSrD0Fi+Cyyy7n6U+/mB/+6Efcvel+7t50/7KxeNVVV/Gtb32LZzzjGURRRLvT4Z1//Gfs27v3p8bty654EevWruGGm2/rC9g+vmVZwb79C7z//X9BqCTrJ2pcfvkLOf/8c7jltluZmFnNIYefwMuf+3RqtTp5UfDbb3kLv/Zrv8Y113zL2W3/CrQs65HnBUYXrgxNCPfw4zYp0jQlihOECsh1Sp47x0djtI85XUwthHQPkJ7lL5WizNb152r/wdbty2WFgi60exbWBuez5AIiqQICH0uFHjAOw7D/AKxUgBDGa8S4PUgGgWM6ZWlfz9QCrVaLKIqoVqsEJbtA4LL5oaCSVIiTxAmQe8ZEt9OhubiAQTI5Ms78/BytxS5pe5HVM5OsmpkkqTZIKlUCpZyIsQiQlQZdQro9zd0PP4ZUiiRJWH98SG4UrVZBRwegYkYrAXEUEoeKSpLQbbfodgwdXWCBOEmQxCgBeZGjOi2kDokbMwSeEaKzjKLbIWsuIisZoYWZyQkqU2tYkxrC+x5A6pRYatbOjDvATlvixY4rT0xC8jyj1WkTVaoI5cr9il6bKAyp1WsUeYEV7qF17cw4hZVUGyN02k40PNBuDx5pVOlkGtPOELWMsRHHRuvaghLjUEqCEU4UGeufS3zplxBEgUKHChu5xHMgDFEAE1MT1BoNxqenqdbrrsRTSXrdHt1Oh+0Cut0evV5GJQ6JQok1OUEQUBSKVqvNjj37mJ1foBLHTE9NsnbNairVxD0DVerURidIKjVqsStNFGL8//GM/MXawRj6YAx9MIb+5WPoXwh4KkEggQNxSxCknBh2yNKxDEA9crOMqSSwgxK9krFiLXoI3CmjWG0HTm8lI2rQRH9TxLqa6dLdpE8hLDEnu7zkzA4BMuV7y8lsrcUIA9azb/xrfQDKOhRVWOVppQULC4vkeYEElG5B3kJnXazOEBiCMERYiRABvdYSRZ7TbS2R+1rXpKGRYZ2oOkYUVDzzp5wsZR86LanhPneLgAO0jHZFvtKLmLsQYuC8IKWjHDqb3fIeDRhBI7WEJAoZH6mReQE6W6Kspi/ZhEWgPZUToFEJSWLnnNGHA0tE3Uq3dIrS4UDitJEgDiX1SsD0aIVGJXLZkyGk31jtKYfW07sDRuoJlSR0QUCJ1vczCiXCb/vjzy1QAqQvy/SC4GUW0foDKjWwthRorO5h8rYTHwcsinbTlzKYskyTfnD2eAHVJ2JbRrOFQXbD06JdAtGPK+WCLCcs6DKAUThYGEvkvfy/xAvAK4UTqHcBqpCSOK6Qe6Q/72ZuDFp8TTmAc8wo5+ZgM/XnoxROF8aNO+GZZlJKDI7WXZSOX5ZljLd+SW5hQDrmoBEuY6Sks0Mtwc4szZzxgZTESUKRF/zghh+gDCRKsWG0Tbq439GHq1WkiADFvq13s+vhO8iyzG1yMiAI64zObGBkxaH0ukvowltNl+sZpUhijlKB6zPtXC+sv1elq4kr67UeNHAzHKHcZqUE1WpEtZb4hU77On4wWL+mKbI89SCuBSVJjUEqP3eMz9oIx8g02s23NStGWDXjyqoCjwkjQQiXqVdSYouM3Dr6uDGOZo4qM9+DeTJkqIIBulnPPbgQEY5uYGRtRhInCJNjiy7zO+6jKLpYERCNraQ6fQiV6ghFew5j5znxSRdhtCLtGe675Wt0lnZAthujO0iRsmJsmsVU0coEC/t2sG9HRpqmWOvGaFKpMD42Sq1WZWJimiCMUSrk3Kde8H920v3faH7/ssYgdU4YRtRqdQ5ZOU1oC1pz+1jYvwuJoTHi3KVOP+NMfvSD7w9lSl2bm5vjyiuv7P/f5KnTQRGCv/6bv+HCC5/czxwub8vTQVdd9TecfvoZALzvfe/jmmuu4eKLL+aVr3wlr3/969m9axdaaxr1BpPj46S1lEd27mJEGSrSsmluNzOr1nLE0cfz7//5BSbGx3nuZS/n7nvuwRrDs17wUh7esoUHt/yI57/wxRBEbNu5i+nVG9B5xvZtDxMndZKkwsTEBDpPSQLJW3//f6GimAPzi3z205/klltu5vwnX8hrn3osa0dDOjbiLVeejqyGXP2x97CivZ0/e8m57CmqnHbmCQjgrS8+n/s23cuLLn0Wr3/jmznlzPO44Ttfo96oMzI2zqUXX8QDDz/Cb//u73DF5Vdy7NFHcSAu+MF1PyK/7npe/OLLOfrwtaSnHcquXoC1gvUranzr3z7CUiflSScewbrRiKC7xA2bd3DEkRs55cSj+fI3fsjkxAi/89Kn84l/+yZ5r8tFx65kz123M3ff3Rx3xFrq9RFsEPDJf/0sE6NVzjz/DO6+fwtFlnHemSdw2PGnML72cOYWmzTbKZ1CMT61gu27dnLT1d/kWRddRHPfTj71d3/OS1d/lsnN1/CHn72LV73mdfza0y8GGbgszc+jvfJfsI7+6u/+kaOOPIrvfve7fO7zX+Cb13yLZqvVT64tzR3AmgKhJH/4plewYmqcd77vw3ziC9/gP7/9I0y3jQgiZFzl6FWTGCHZ3Sl41zt/k3o1+amx+ERuuiiwWiOxVOIYIbzLcdp1ZXZZjyKvUIQhYRj6vwMno2BdvFzqiSZJBRUGfUHafiK3n/zzQsTg2FRaowuN6fV8yYfTV6P8pH9Yi8KAMIx8SYpy+701aBxIprV2OpkCpAww2jGzpC/fC4XTdBJSoaLYcyVcjFmtVpBB6B/c3HclSaWvc2Ln5tHGUqvFZJ2QvNdhx2OPsbh/F7u2RoyZJnlrkUY1ZHK6gVYhKrJ0m3P0csO+R+8niKvURscp8pS4UicKFDbvYNIuWVFQhA0KFWHzHCEc2KQLgdAGnWmCwLGbKoHEZl3SbofZhSWSxDHd80KT5QVZliODAFRAUompVEcYtZL2wiRKp8SiYHqsirWCTFtqjQZCCmKFEw1u634S28W5Lg6tJxFda7CBolGNmZqoEkYxSa1OnvbI0x46S1GBIo5ier3U7evhPPHIFDKqEFZiumlGt5fRaTUJlaKSxNRqNaSSaCDvGTQFhQgRQUwYxYxVE2wEthCMjVWpNOqMjY+R1EcJohipArK0S9btYNtN2q0WnXabOAoJgtAJ0eOfpZRkaqxBNVbs3T/Hrt272bVnb9+oRyrFSK1GHMWopMLMzDSj42OcffY5/x1T8+dqB2PogzH0wRj6l4+hf6Gn5RJ0Gp507i+7/KVyMvYZTgNwp+w4W844z+ezYmiq9Ik4wgmbPf53nqHk3iJKXKZEUobOZ3DGJQPI9sv8+gV49Ge/fVzsVB7D/yEQyxhcJYBljKHVbtHpdCjSlESkBLZDkfV8psotwlivnp92neaTaDl7TSSIkLg6StFrEVdHkTJwAE8pDP441FxgsVb0HwqG2UvlufZPvP+b5Q8ddvlvnEikUkRR4MGVEqH3C89Qv5ei6sZYXwbn7Df7NDJhvQiZ6+8SzR+cpyVQkjhU1KoRcWQGOmCifIcZIMDSldmVmRWlvHNBeduH79XwWDAWg3HDzAzsQB+frQ888BQoF8BZqzEmJ1C4TGBQQWlJXhh6aUae52hvQ5xnKeoJThEuWwmwlm353F1eQluCrUNvHzAKPQBrhAOhB8BfeSD6zDPhSy6Hj7+8rLacv/hsrt84xZA4oM/OSDyjrTyWoK97Yf08sUPnN1yqMMQC7l+jHGLZSSlxZh1eaNFYWs0lFmfn6LWaNI4eQRWtgTC9VAgRsLQwR7vVwuG+BUJCd/YxqvUGUXwUeRa4TOnjgpZSy86xAW0/AAVfkuFBUelLSsHNOaztZ54EXlxfKd/Pst+nLvvlrHejyOkPdFONwDlKOsYkLCs1lgIhLFJCHAdeD04g+y4m0mVmrHtoyArfkUJhbQkELxtEQHk+g7432rjSkLBCWJ2gMr6GSuQeEHRXkHWXKHRGNLqSsDqGSup0FvfTmd9Jd2k3Y9MrkTIhCgIao2NI0aXX6qA7+7E2ozaaENYnGBE14rl5Wu02S80W7U4XrXM67QJhMjrNiHazBcI/YD+B249//GO2bNkC1tJsd6jW6qyYnqbQbk2aGB11DwW9nFq9QaVSJQgUi/NzhGHACcceTbXeQA05zszPz3Peeedx6KGHDg7k79MxxxzDCSecCFgefvhhDuzfx6FrZmgvzP7UuR1zzLEcf/zx3HXnnRjjdKZuvfVWjjzySE444QT3XGwti/NzTE9OEQShK8tQbgx3uj1arTZJs4mUijiOqdfrhEGANppatUYQhFig2e4iRBeAJE6wQN5rU6kKtC7Ys2s7IyMjhGHI/NIScRRRqVQ45thj2fLQAzx23108tArM6nFWjVUwGIo0pbtnE7pbOKHnHLrNefZvuZe1qzfSWzVBEIbUR8cYmZwmQ9JOc2S7zaHHzHBgbh6lnNbJxOQEureOZKmH7vbQWdc95AtJmMQoIahEiv3zc9jCcOzh6yiKDnvnmoyMOCe4ZrtDlFSIohgB9NptbJEzvmYCvObPaL1CtZYQxhHYAovBSEUcJwgEhSnQFvLCMje/iNWaWhKy1OmQa0OtVsOmHUyRk4xNseXRbTy85SFuvPEnHHn0sYyNT3DKKafQPOwwtM6566676LTbP3NshkHAWWedxebNm3nkkUeW/a5aazC9YiVnn30223bsYqnVptlqYXSBLgraS4vMze7ngfvu46ijj+boIzZy+lk/IcsLtNZ05veRpT16i/vZl82y1Mu5d88SN914OtOT449LRj7Bm18H+wlX4bL42sc9pXhxqaFRVgeUrw8Fx55p7VgoZSa83xdlHCXKfdmJ2grp3ADdMSS51m6Ptxbl9wH3sOMeUqVSfcZEluV91oP05RbGsydKEfRyye9LGJSvgWNnKeUAJmudmDnuwU9JSRzFLkGrDaGSVCsJRZGxr8iYP7DAUtHFVDVB0UZKS6USUAiF1F3HuOoWmKyDkQKdV7B5j8AWBJEkEoYcB/o50CMgzTqUQUEcx4hCU5gMKaXXQYrJcXqfvcy9LkLXH4hBUlpILyTtNL8Zq8VIDYF1RjgW504dBbHr3sIBCNZqitwx9axPcEpAWoPCEiqoxCHVqitTUoEkJMQEoKNS0lj2hcqtKdVgfNK+0I4FmqYQRVRE4phxQnjHbY3RFhVVEBXn9pe35tFWY4rca+o4TRdbZFjli8JMgbSGUEIcSIwHnaQKkFJhtcb6UrTR0REaIw2sjOimGb00I+t20EVO1u0gsy4dIehq6LQWGRkb+78+BX/ZdjCGHroWDsbQB2PoXzyG/vkZT4AogSQGA3JY5LsPKZTMEmvBDwytNYG3IJRCgHRInhg60YHI81AgoYYuRIDwbB7pN1RXd278cYYBrwHw8fjv7b9n+P0eWXSAqLvzJeJrxYBZpYcAqyAInBi4MRw4cIADB/axf/cuxhJDPTSMxy1snnraYghIrBF0WovkWU6vlwIOHc47S0irCSU0xmcIVIhVIaY3EOrrgz7GiW5ba53F7QCpoVxgBuCoHCj5S9dnfbZX2akAwrmWiOEFzXVWHzWGEs13/y6Bp0K7CV7WISNwbnzWzUeJ9LWvtr+0CiCOJEqFxFE4BCQO0Oxyg2cIMBPCjUP8Fjus7SWsAxadNpZ3b9AForTetNoj3p4m690MlJRU45A4iagkzoXF+GxcrZZQGZ2iNnkIBFUKbeh0u7RaLdK0R7vVJPcuHk/0VpYmDhh/7r5K5eeS8ffUGnRRAnSg/IJd5Plg4TcW79VIFEX9+uQi95RYoYgSN560MY6irLXTL/BBcZ4VfQpwWRqpC02ZtQmCoF8eAC5wjYKBeH3umRlSSqIodsfx2VejDRj6c8d9xo076a+/MIblBZLeIVMKgjBCSsXkaJX77v0Jt956E6uTM5isC5IgwuC+W+uCdi5oFzGgqMge9SBHdHagspUksSLtRS57ovXyow2NY3de5YOAATQqiFAqREUxgbIo68wKrNEoqfqWrtoal41yt2VIkBAEug/+WgvC17mXFGrQYAu/3oFSEATafYeAwhqEtkgneQtI0AYpDILc7TPCZY9c4OmKNwY/y8UssaU5glszVNKgPrnGUXXbOxChhDCg0D20CEimN1IZX4tQCfdd/0WW9j9Cr7mX2Z2bUGENoWqMrjqS6kid5mKNxzbtJu+2mNkwzZrDT2dy9eHkOqPTbrO01GT//n20WkvM7t/L/OwBWs0ltj68mYVml1Y3/WWm1//19uQLn4K1hkApHnhkK/XRMZ7+jGdw20/uZfe+ec4+/Xjm5w7QailOPPspVJKYOAq49tvfwBY5a1bOsPGYk6mPTvS/c3x8nG984xv9/8swRqhw2ZoPgg9+8IP8+2c/zQd/5yU8/JPNjzszN3cfeOABLnzKU9BD4/wzn/kMX/ziF/nxj39ELY64+7abCYOIuFJhshFTq9QJgohOs8Mjj27jlptv5MqXvwprCrZsvpvTTj0VIQSP3HsHhx1+NBsPO5zfffvbOeXIdTz5tONIVx2HDGJGGqNMTa9gbvYAX/jMx7n0xS9lZvV6XvXq1/C8iy/klVc8n/31UUZiwfNOXMNNm7exZc8B3v7CU/jjz93OnQ/v5QuvPoEv78z57KYue7Zt5ex77mFy/+085Tf/iqOOOZb/+No1SCHItOGwC57Hjs23snXL3Zz8pKfwpHPO50nnnEe5e02tWM0xpz6JIu2yZ/P13Ln5Qb59927eddH5qKjOrkWYXLlIEipWzUzywY9/hUce28U//vFL+dTXbuJfvvZj/vkD7+D+Bx7ho5/7Klc+61xGRkfZ0Tasm46ph5ptD29jvB4zMTXOiSc8k4e37uTHN9/NC1/wbBbml/i7v/8X7MThrFrsce+uJQ5fUeOwdWPceMvtHHvCibz97X/AR99yJba3yFtefxnv/OCn+N5N99DJNR/6u7/n05/5LJs2bWJqeoZumnHeOWdzz913/8yx2RgZ4Stf+Qof/vCHefOb37zsd+973/u49NJLAXjpFS/mpZe/GIsl7/XodTvURsb49ne+wyWXXEJ11TGccOElfPspL6TIc9rtJl/+j0+wtOtR0t3b0L0WD+44wH17N/G+D34Ya1k23p7wzYMeUlryvHBM6zBAkGB0hE0qbt/TDpDTukBY41kQ1peNuFgrCCMvNYAXBTdD+i/ucHII4CrjqiSKKVSAzHPSdsuzsAoi4QK2XoZz1lOK+sgYhbHkhWZ2YYEwCJmYGKcSO6ZZs9miXqsRxRF5XtBLM3pZ6oSKgSztEXidpyCKXexaFBQqp8gzrLVEXrjaOTyHCOmi7JUrppmemmBuz0627niExx64h9Z0hfFawPRIRDWWGDR2aSc2A5FZxqsBhJJQGmx7lspolZmxabr7JS0jsdoQV+vE9TrzS0suPsSyYvUK0rzA0ERrQxxHTK9YSbtZodftML+wiJIChSIIpHOmjmPCStUxiLSh112kKAwzIzE6B50Lstwzv8IIoQTGQqaN00kRkPZ6pFlOUWgmKpIIg+60UNaSKEE0VkcFESBothY9w0QSVytkuabXyxzwFUYk3lVORhW6maGX5vR6GUWh0SFYoci9+cSBuTmsKQiUYtXkDEKPo9Mu80stljqapcVFmvoAtWaLXtqmVq+70p4gRBcaXRR0WksYKwiTKiqpoeKqA/TSHrrISZIKM6tWMz45hQgS0iyj0+2yb9d2OktzLO7dSdFp0m632b5zD7t27aAYfrJ+AraDMfTBGPpgDP3Lx9C/WH1Qn40yzBYa6CpRbniiBDh8hwnRB53KetA+EqlkP1OCv7lYBg56QwNMyAGFsGSuGFO+SyClxzytFzmzg89iccwXHidgbssSOpfVcYDY0LWVl95HpL3Qt79OISRKKgIlwGrmF2fJ2zmd0BCOGgKRo6zvMavRGtLMkGaWNBfeRQ5MllL02mSdJUzexYYRKogJghAj5aCmFWeDizADZNv/9PWpoN9PQ0Rq79i2XD/LBSYeDS4/Pww2+Yno8Sz3ff3uEX3w0MNA/b4RwgkNeoTSI+/uHkrlXO6ULoUyoU8PH4wsJMqj9CUy7UsP+6J9AyCxD1BRlhHaAcPJI/lOayt3dHNdLsaCUCkatYSoGhPFUX9RNdaClARRTLXWIKyNYZGMauciURQFvW7bAU+/AhoTjh1o+46Dw2MHwGL6FOBybEnpqLZiaE4IfPbS1VAC9EFfXRT9DErhdbRynynFQhgHfUH2ojBgCowpELisQOidQixei8LPTze2zYBVh7/b3hbVZR6d80eeetcFq52+l1j+U9Kl+7RpO1hfyjWs2+kiEJx07Am0mgu0u3PMtlMEsHZUoXWOMRl5z9BqWZotRbUe0isMRsPu/R1oLDJxYD9xUiOu19A26Y/LPMuQ2mX0ozAkUK68QXsYVVjXP0Wu6SwtYgIXTMPQfUO58V7OMSyg/DLqHG8sZTbNuXVKM6Sw35/XPlAILHEoUIHEaBDSIEzZ10C/hNdv8gSUdfNSSG8ioBxoa0pmpuvPYRZqKW4pEai8jUz3o9vb2fXQXWRZB130qE2uoTKyglWHnMnsY9tZXLiTLfdcj6RASsuubY+glCIMI8ZWHeoo/j5AMlhynZMWOWmhKYxAJTXG4yqjE5MUuSs/6HXbdNottj7yEDt372N2fvH/xrT7P9as0Tzj4ot5+ctfyllnn8HC4iJX/d2HOP/c85iaGuPTX7mak446jLUrprjuxhsYb9RZu2Ka1YccQRLHTI+PEkQJRVH8f5QGl+PocQkgIYgrNU6/+HIebn0Frr5+2Wfe+973EkW+XPrx32gte2fnmZ6cYHRqBWnqSn1UPAIqINeabVsfYmJ0hDNOO419s3PEUciq9YdwzTVXY4zh4qc/nbTbpdnczwVPOoPDDz2UtUcfSbPdJctSer0ud99zF8bCM55/JWm3w9b77+E973oXJu+y+ZEdnLPxZE484xxG/+CDvOMP/oidrRbZ9HFccvIs56wZI3ny69k49TAXxfcyctwo84st/vbqe7i5/X7Wr1nNCWvHWcgURdTgkHOfxfoNGzlq/Rr27tpNFM9SrVb5q6v+ll3btzFdCZnrFQRhwBUXHMcxh69n/bqX8r0b73RaV1HCaDVksd3j7x7Yxckbpzn1yJX861dupZpUefVzL+Ab37wWawqefPqRTK5YhdGa9va7CcYPo96oMRIrtu+Z5/Yts7Tbd7Fu1TjPetqpfPM7P0SqgDe+8SWsO/5CkvE1rNi5j7Q1R6/X4szTDkXpLjd99RNsefQx2t0Oc9++medd/nKe9nx429vfwWWXXcbzn/98xsbG+OEPf8RHPvZxtj+2fdl93bVrF694xSuQUlKv1/nLv/xLLnrKhXz8o/9EWKlyzz338v73v58P/tVfcd2Pf8z73vtelFK02i3e9ra3ceYZp/OSK6/gf/7B/2T7Q5u4/JzDWTtZY8+ePbz3z9/P85/7HM4/71yedMHF6F4Hsg66KNiweTNbuv/CSBLR66Vce/M9y8fqE7i12i2MB4mSatUxmbAEArCGdrtDJUmIo9C5QRUFusjJs8w/9AzW0UIXmNz0S0qG9+1BMniQZFSepRTHidtTpbMTxzsbh9JpMRljKYxjJGVz894VWDI1MeldziqetQQNz0oMhCCInRtTURTs3bsXJWGkVmFkZJTg/8fee8dblpVl/t+11k4n3XNz5VwdqnNumu4GGlCaJCOKAUdFQBFxhjGggoqOA5jGPCoMgkCDKKDASI7ddDedc6oO1ZWrbr4nn53WWr8/1t7n3m7wN8zgzLSfT+3+VNete9I+e6+13nc97/M+jx+AUG5/hcsVkjgmjocjl2WhfI4cPkyWZcxOTzA5PUsQRkxNNFkda7BcqTDf6pHlAdWKx0pn4K5j4IMMSbVgsZeiTYJc7fLw3bfRWponTTMipYjG60ghCcMQKxTh2DQ6GWCyGOX51IKIqFqnPxhijWG11S5aH51DXJ7EDNOcQZwQ5wYtnXuyK0BbpHQOx37g0esZ4izHSucMF0Y+rX4Kws2VPEsdSGihUXVgY6gg8iWVSEGx+c8NSN8HqVC+jzbaSYoISRD6BFGNdquNtoLeYEilP0DLiH4GcZKg84yKr/CEJUtjl0tLyeTUFEJnCJ2RdVbRSZ88HuBLqFYrYCeQaFILK+0evWFxn5TTM8q1pduLCatNahMTENaxKnAsKqMR1lCLfKLAx/cDWoOYIAiYnpllcqKJTmPSXps8HtDvdQkffISVVote79szKp8px6kc+lQOfSqH/u5z6P9FYZpvRaO/Nd6XF6n4U7xKjASfSw3/ksFSsGRGb+QorKM+WUpgwT23wB2xT/3EETBU4kO2oL+tAS12JMQ9OvECWFr7VmvaQE9PZOwI+CgxjgKEEo4qHQQ+vqfIdUqsY8hy4kgReQapHFhiDBgDWW7Ic8h1OQidM0iWJKTxgCyJkX4F5VfXRLuL740FK9cBTOtAJ76F2UXB6nILlix0jsoJJorXl6DNuqtASesudZRKwG098Mrau4zOr1yApShx6LXrWH5UeapCOmaUK9o5euLaG68hykLIgsEnEHYNgLN2HYhZ/hkh02uMNoqfjXbWxFbr0YIphEB5imrk4YcBvq9GyZ0tAFDpeXiBc1QRyk0ZB2pp0qRBniX/JiydBUW/9vqrVpZGsaP7vh6YLOffUwItjrJb3Dh3HW3JfCxBRoHR7r3L4Pf04FUOOxcU3bkopUagsVnXNy+KJ2uzRu11VdwSjHbJsyzdE4v5ttbS8D8PnFK4gGONJUszJJItm7eyZ/cellbn6C8eYZAajFEY3Bgy2mCNAOESLJMZBpkhXxoiqitMHjvG+OwG/KjiaPrlNYIR1VgqOUruRaFBlmU5g/6AeBDTXl5irFalXg1HFU8h1sZ8Sal2y0O5rhbzqVhPS9E/N49suaAUj69RhJUsEiJbLCeWgkq8Bk4LKNik4BioonCa9JBCOVehouqnpGTNZbOgNUsB0nNnFLfRvUWS1gnmjx9xoASG7Xt2Ux/bgq/GOXn0buZPHqTdWqBWrRNVaq7SS44nNHnSQwUVdOEy5CpYltxoUp2jrcBTHkHp2mMMzeY4RufE8QCBxY/q1Bor/9pT7l/92LhxA5dddhmbNszS6bR5/InHee6Vz6YSehw6doLdWzdhLRw7fox0coJmJaQxs4lGo8H41JQDy+OYpaUlwAlabtm8mV6vx/LyMlhLr9tj165dVCqV0efOTE+zfedOqE1h/cq3nNfXv/71f/GcLZBmORZBbazpnKSMIaiPObOKLCMe9AimJ5manqEzHCKwTI5NcPz4MbQ21MbGHR2/0+KsM89gfHoDJhonTDPyZMCw12NxYYGoVufSSy/nkXtuo728wHNe+FKePPAEjz26n6X5OarVGjvOvZSpLTvpLM9zrO8xUaswo5oE28+mttBnpnGAZ593Lt988Ek+fMN+cns9x2bGSHbOMB976MoEla1nsnFmkmisymMPPeS0WRp1PvvP/8yRA49x9oYxVomIGmNcuTVi085dbN62ldtuvxuRDZmupsg8YKE14KEn53juedvYu3WGm/evcOFpk5y1fZq/+9TXmJ4c45Lz9lJrNIj7fQKb0ev18TxBvRoyXO5wdL7L6uIizZrH1ESd+ZUuYaXC1h1bCGp1hB+yY+tGFhclqyuupXz55EkO3XczRxeWGCQZq48e5EU/8rOMz27iV9/6NrZv386ll16K7/scOHCAT3zi49j8qdXMTqfDxz72MQAmJyd5xzvewd69e9i+ZRPL7S5Z5mLiN77xDZaWlnjnO97hxFCThE9+8pN4nseP//iP84UvfIHe/GF+8PI9hJ5g0Otx+x13cMlFFzmx+LBGoznJ+FjdbcaDGpdcdDfj1ZDVVpuv3f7gvxngKc8duyXPM5TvdDHdxkk5F7dCHN9TDmgo43OWZlDoPFFshox2rVS51q5oWMRgQcG6yPVa8dc6drxSri2qPKQUYAtXpiK30TYnN3lhv57i+z5BEFIbqxH4TgPKaGexPmJTiULvUuUoKRkMB3gCIk9gTd3lVKJsI3EixGmWkSRJEfslQmX0+j3yNGVY8cmb4wRBQKNep9FoUGuMsTTfxU8NiRYMYldADFSAUD5WSVIjydMEYYYcO/wkuc7xKw0mpjcQRhU83ydNYtAW4QUFI95pd/qeJPICBoMhcRLTabXAOJZ8lqXkUuPb1ImoW4GVPgZRaJ86QEcWRVAjBBrHbhPKQ3oe2qYILMrzinzR4HmKahQSRRHG5Hi+xA8V0kjHOMlyin2ra5HUZUh2OYPyAqTvF7mwKPYYxkndWgc2hJ5CKjFqVfKVolqtILIYkxj6yy2Sfods2AeT43uKaq1OlsVYoxmkGXGWuo1ysbczFoZZoS/rV0D5WKHIizY7gcWTRV4gJFmWEwTue/peFWkNTE6Azhj0+7SHGfXFBVqtZ3bx51QOfSqHPpVDf/c59HcMPJWTq2xBKkEQKNrepGI0/8DZmYp1DaEFWOMu2poQ4vo2uPLPSLG/iGilCOUI0WINlHr6ZBiBXbK0vXTWoaZ4nRwNtrVJXFIc1/fMlq4F5XcuAS0ppdMTKoA1KQS+57N5w0ZCT9JuL9Jvz5MPO/RTF2h8abE2x2iLzix5Lsi1wuKh0RhjafchlUMGepWgeZL6REZjEoIoQijn4lYuaqYQh3PXfk3jSYyupXFJg9Ykg6ETr0xTIl9idYJOk2JwFa8pJoRbFx0ibNduL6OJyVMBpxFmVVKiYO15jsbk7rcQeAqUJ/B9l+woJVCqwHpHjFQxGirlu43ySQNrnCrpFglhysG2DgBzlr+ipJ3LQiTe2pGNrNbu2mAtvufhS0ml4uFHEUJK8rQDRruFwA+xUpFqjdQaVbpMAAiFH1XwwujfRuIrHUJe6pSVyWue5yOtBoGjBY/cFGwJOLrFXqmSalyE2QLcc0uAwC/aFI0xJIljgclirBos/d7AiZBKR8WX0rUaeMovqiUuyOrMuYcgXIC2a7F95AIkRZEECGcqsJZkiwLVNBicwLy0FqWUc3EJQrQuE+s11qAs3ICMNSRxHyEkG3eeyRWNMfadcQ5//5E/x/QWWe6kNKrCJap1SVSrY0VIVAk4NtfhyPE2j95+hOjeOW679X52bd/KWLPJxPQstlLBq1TYtn07k9OzjE1MsbS4TLvfYtBt0VpcptVuc+DIEZZPHqfXWiaeP8HlV1zOpVdcxtRUE9/T9ActEBpwGiDGCooG0tEc1ZTXSRYhs0iXhKP7GpsX88iVArS1pJmlUnGB0AcyawqBxbVCmUukQGunGeKHiuZklfpYnaBWo9sbjsaA8kqHJUEQVAn8gFqtaCeJu8zf9w2OPHYfxw89zm2PDxFeQK1RY9/ZZ6B7gi987J/4xhOPMLApr/ye51GPfCI/oDK+jf7qUdonHuLoY3e4dSgfOvvbxhR+WCHNc7q9LsqLiG2M7bi2aMpxFwRI6bN179ls3H5aUdl+Zh8f/sjf8clPfZrPfeFL7Nt3Jn/0+3/IwSf2016a4xd+4od48vAh7rz3HnZt3camjRvZum0bd955G+PjE2ycuRqlJE88/jjPfd7zEFKxcfNmbr35Zj70oQ/xtre9DbC8+MUv5oH77yeKotHn/sZv/Aavfe1rufLKK0eg1Xd6SCE4bddONs3OsHTyKCsrbZIsIx106A76mDznissuY3GlzS33PMDVV1wGecqBB+7mpS9+Mcr3OfroAyy3WmTacumzn8tN9+/nYzd+np9/1ctI0pTH7r+DHfsupDk+QefE49QiHyYnueXmG9i953Re+n3fz7Oe9SxCkfPCKy7g997xn5lbWuWlL3kxSim2b2zy2Zd+igdvuo2/+fS9vPHOO+jcdBP8w/Vslwlea4k//vQBeqlBCrjnxuuZG2Sc6GfUfEluLMPcUBOas7ZM8B//3RWc/8qfw5/axm++9gd4+PgnmU8EN3z1y9Q8zclH7+b6W+5kdirgs2/8GT79iU/zlVsO8Ad//Ofc/MVP8pWvfIZLz9rJ+MxmJrfuoSq6TMw02PtjP8bb/ugDPHbgMB99x0+Q1lapNlY57dnbefjJOX7tv3yQ3/+bjzK/vMr3/PCrSLVl48aN/PV/fRe7zjibPaefwdVXX8XJEyfROseXgg1jEVdPVPBMOkq6//hP/oQPf+Qj3HH77WA1No+/o3ut/BAPyQ9+74u577773C/LjdjTYqQrLDk3tkOLXf70c/dz0Q8d5Zpr9vKhv/1b5o4d5tP/+A/82X/7Sy696Hx++PtfzmQIE1MbeNcfvZtMax588CH+4gP/+BTtzWfyMd4cJ00T0iTG94rCnLHEwyE6z0cbzBJIAunam4pWG2tylOdCXJZlxMMBWZq4tUx5xabTQpH76sIRzxqL9n08zxRi5O4+K88bOQSrYjOZJimDeEiWZlSjEN/3qFQiwjDE93x8T9LquRappeUVZmZmaI6NFaCCIvQE0xMTKE/RHBuj1migpCRNEgaxYygOEud+FoQVPAnWuDxk5/btjnGVp6SZRsYJEzMb2XJahvEjVm+/lVwZ+qrGeN0QeorJjVtI/DpDI9mTB5gsxqYx+w+d4LGjC9z94OPs2bKBeq3qhMzrU/iNCTbuOYtKGBAGHvNz85RuZfv372fu5An2P3g/Fc9JUIS1MTZM1JgdrzPRrBFEERpYbPVAZ/hFnpHmmuOrfcJAEQWKarWKRdBPBeP1GlZruq2WY6Z4ipnpKcIgwFeK9uqyY1NY95gGev2c5X5MP9VkuaZRj2hUI6KKxyDJabcG1GsVao0GGzZvpzm7Ha/SZJBZknhIliRu7gpAODDTU4qK1GRZn6zbYu7Ao3RXl4j7XWoTTSq1Go1mg5waWW4YxAlJ6hhaWEPke4S+R2MyIgirhJ4oQBOnM1XqH/WGCdUkJcpzKpHLuZaXFmm1VvGUZLI5xkSjSmOsyWVXPJsky8nyZ3jb7Kkc+lQODadyaL67HPo713gqwJ+ns4HEU57kkomCIPMtj5fMJTmakRQtc+7p65MTU1Rx1kAIigTGPXsNolgDgUonv/I1JRSx/vMLLgvl0x2A8JRv8bRXPf3hglYp3Lkb4RTva/UxLJbt23eyNCfotxU2WUIbTZ4bh4Li+l+jUOL5EmNV0eNqGAwz4k5Me7iKDQ5SH2vRnFylUqvj+T4q8BGFy4gfhK565XnkxoEoeZZj8gytNUmaEA9jF+A7XfI0wWQZU5NNAl8QeO47jVBfUd6B9ZRR3OKzDnAa6UyNUPK1QWApEVw5ur4ORS6BR8cYEyVoWCDr5WQc3f/y7hWolhid27fe07KtcvT7EoykAMIKSiYUbhRaj4QPoQBMi8VXKuW0CIQgThM3PrwIL6qj/CpC+m6hKBhjo97iAgz9NwA7jbQwyqooFIGzBHxhdP9K5NHdQ0ZAcKkp9hR3QFyvutZ2bYwgR0Y7UjrR3/XsO2sFyhMo6bmKXXFeWVaIWgJSqm/5DiNw2ZYuiwZRWMiurR8lKLrGFizHgh5VaBgxAtcuRjGSrHAVSGu548678KzFt4ZzzziHzvIxlo4/SlZoQyjPwwn7AgamxkICNUVuFINBRrvd4dDBg4RBQFQ5hAoD/Chi5fhxquMTRI0mJ44dZ9hrE7dX6bU7pGlKnMbUhGFLxWP6kguY3ThLP4k5triC0Sm+FzkhfOGqLW5Yrrl+usJAabFdMAWL9bmMfL7vFTRrQ5omgEuckzTBWom1pUvHqDC3NteL9SPLBHGiSRc6+M02dVEnCioYX41cKYUAiUAnQ/q9LsvzMfmwT9xrceSBhzl27ATz830GuSJQCm0VDz1ygN4w4db9jzOshIxPbWDH7rMh7WF1xqYdZ7IgNCvH9xMPOm5tMblz56k0CcdmUGENhKIQfStil6Hs13dUb4lXVJpC8cx3pszznMFwSBj4HDt6hE99+tN87/OvYXp6invvf4CxZpOtW7Zy/fXX4/seu3ftYtPmrSAVTx47zhc/+xnuvvNO+v0+QvkMBjFguezyy3jLW36Zv/zLv+TBBx7g937/9/jJn/xJ9uzZCzgNiiiKGA6HZFmGUoo3velNTE9Pf9vzTLOMex58jMf3P8STj+/nv/3FX3DRBRdwzXOvJKpWkImkn8T4SmGAw8dOUqlW2bNjK3ghuTYYL2R1eQkQeEGIX6kTAHff+g2ECHjW2afTT3MyPDZu3UkQBMTDIY+cPMrW7buYqE/w6Q+8H5Ds2nMab3zjG3n4gXv5xm03Ef/1e6hVAn702mdx072PM7fc4S8/9k1OnFjhvE01/vqv/hKb9nnty5/Fk/sPYrXk2udeQbfbpt/vcfDoEtMbN3HWxlm2+H3C8VmCzfu46667Ydjm9ocO8Uj6MbKgwX2H5+n3h4RW8N7//t+Zrno0shb1MGA47PPfPvAJto1XOOP0nXz1s/9Ed3GODZu2MblphkGSc9c993H85HG0NdTHmpx/8RVcefXzOfTQI5zsZCz1cloLQ6Tn8YIrL+QfP/Fxjs8tUhGaOM1YXFjkuo9+jG3btzMxPs4OP4WK4MnVnHN3zVILA/YvDekmhnp5/5KUfr//LxZUXv2jP8rU9BR/9Vd//W00lixxHJMkjiG1cWaKbZtmAcvnP/c5brrpJq695mouueBcyti+bcsWXnbtC9m7dy+DOOVD113HReefwznnnMfrXvfTbN28iW27T+OD7303GzZv4+cvfC4f/dB1PP7447z97W/ns5/9HLfdduv//sT6v3S0Ox2yNCGJYyYnJ4pi4Vph05i80OxxOmtaOz0dM8ox1kTES7aA1gapDQjnnOU2RnLE1hZGOkBAuvwmy7O1ODDqQhCFTpRG51nBzCjb89QoFltrMLqIoaVRi3WarlmaYnSOENBoNrEIUjxSK/FsqV+TkgwHGAvS9wh8hcSgrQBr8D0f10YW0O31WFxcYtDvjl4zu2kredxjrtVGt7tUAoUc66N9S2olmYVqfZxKGCCOr5LGQzqLCxzLY/wgwEgfWWngVxrML63iBwHKU5g8c+CcMRw9doxOa5XeygL1qSZj1QaNyXGEzVlZbbG0sozyA4JKlYmxKTxhIR0wjIcIcsaaHp6EQAnCqIpUPlYF6EGb3CRILFEQEkUh1UoV31euayKqkGYp8+0hY5FCCQhCHxUbpNBIqzFZRpqA8HyM8PGrEZmAfmqYX16lb6uEtZRKtYHvKQKvitG+AynTlEGng8kzltIBSWeZYafN8bk5+p02yaBPNdNE1ZjqMMWLKgjlIVSACgPH5rLGGUK4riNMnpL1u1Rn3L4ut67PQSlFozlOtdYgiCqsLq0ilST0ParVKl7R4rPa7gKWaq1BZizPdNzpVA59Koc+lUN/9zn0d5xpm/XAE+s3+WJtIq4DaNbhBU8ZlJY1ZhKsa4UaDdoiqCJGryspcetZVkKOyIFrYFQJ6ZbI0yhnWvtFQcRxkw4HPq1N9AJUEXYNMFn3fHcu5TsKtNFuYgrr+vU9xZYt2yGPUeQMltoY62xspXA3S0mIIoWxHkifLNMkmSbp5iTDhEznJPowtdoy4+NL1MfG8IMQvxLhRxFeGNJojhNGFYIwIs1c/38yHJIMBg5s6vfp9XrEwyGDdgubpaBzZLqZer2KbFbdQrOu/XHtu60Bh+4+rcGz66me6+GfItMpgKLy/UrGWHld7QjHKqmdBaBeLKp2DUAcsdnWDZ7193LdPRilY+teI8CZDFizZnNa/FysLs6Ss8TFivNWSgEWnScgFCqo4EdjqLCKUP4IKHUMujXw6t8C6ARPtYL9dq4c5TVcq7ay9lzhqlqqqGjo3BTtiwWwZ11vvwuSzrlGFs6DPGU+uf5hYQye8J1Ti+c5e+c8JytE2gWgpMKyTm+sHFtFx4EV5YCxSFk8Z+Sk6N6j/J5Wm1GVylVo5DqnoLXrUAbYqFIhy3Nuv+N26mGF6bEmZ+84jYVQMX/yIGmegXHWrUmeYmyGJ6BRrTI90SCXihNzHR57bJ5BpwVGI4xxyWAQsHhyDlmtYYOIk0ePkPY6ZJ1V0izDU5Kp8QYbN25gy9QMZ192MT1jaQ0G7H/iCLXIY9vGiaJdVeDkHYs1VaxVHKyWRVIkEOhiHhftvRI8X+IJgUKiM1fJSI0hSZ1rh7UhJc1aFsxBcAFZSoHnSYYpxHFGd2mVaGwJISqMb9qKr3wQAVmWOcAdy6DTodtpc2J+ju7yHL3WCoeeeIy51S6rvYRGbQxfelgUDz7yBIudLnccPsaZl17E7LYdbNt+Gt2V4wx7LaY3bKPfmkMbgU57YDVCCiqVJkFtinBsFj9qIJWPE3402KJ6VUYTrTWu4mXxhDdi3z7TDwFEYcCx48f5q79+N1c++9nsak5w7xe/xNVXXsXWLds4ceIEszMzSCnZsHEzveGAo3Nz/O0HPsidt90KCJRy99ICF190Eaft3cvf/d3f8ehjj/GOd7yTq6+6mj27d4OQJElCv9/DWovv+zSbTX7+53+evXv3fttz7PUHvOcj/0SW5zz2yIO8+93v5tprX8Tzn/88oihEChjEQwLfR0vJ/sNHOWPPbnbv2EaiAvI0Q0uf1cWT5NpQndnKhplJAgm33/hlTj/7Ai655Czmuwm5lWzctpMs13S7PQ4cPsLWPWfSmJzm3nvuYefu09Ba83NvehOf+Ng/8OHrruOuB9/DGTs38Ye/+GqOzC1z+PgCH/jMPZy3uck5Gxr8zXv+mkvO3skv/ujz+dWHDpNZxWuuuJje8gnmFxe56/AqF+zaxYuuupRtyZOMb9/H9GWv4E+14PGHH+CbD9zGwm2P0U01vVQzFUgmfMmH/ua9bGpWOX/zBM95/pWsdof89w9+mt9+84+zc/sm3v+Rj7N7x0727tpFONbk+KHD3HHXPdzy0JMMhgmNis9f/c3f8uxLLuQD//GVLJuAtqhw6Og8F+zbxb+7+hxe9zvv4/jJRU6frZPkhla/x9//4yeZnRhjw3iDiyckKq9yvJdx5qYJtJB89cAKy90+Y4VrXRgGVCsVBoM+cfytbKeXvfxl7N27l/e8578X7muWXq/H2NiYM+uoVqnXHYy1cXaaTTNTANzwjRu47kMf4o//829wxtn76HZ7RFHExtP38rOv+wm2nbaXkwsrfOzjH2fXjm2cdc457D7jLHzPQ0rBl755D9u2LvLGPOMz//w/OHb8ODd+4wY6nQ4PP/x00ftn3tHtuE1RmiRMTIwji12IlNK1VxWMEaUUJteugp5nxcYW3K5ljflu7Jr7sLC2CLUuXktVVBjNU3M3nWdrwJTwXEi1FlO0AOqCDa6kGLlPjdj0hZ6ULfQ7VanFagxpod0GUK83SLWlk+QEhZZnIKXTq0pi8AKUcM7G0tpRLBeAVJIgrDK/sMT8/Dwnjx2mEoZUqxWmZjawuqI4Mj9PZ7FL1Rc0pprIIMGgSDJDY7xOfXIKL3yMeDBg0GkxnwywQtLTAuEFKD9kfm4O4flOPsHmBU4gWFltkSdDZNIhnK7TrPpMTo7TXllmZaXN4vIKlUaD6Y1b2LBxE1VfkfVWSDUImzIWeQirUdYQhFW8IMKPanTTASZL8YQgCkOiqIIfhCjl9iEqCEnSnMVuijEe1UAxVgnwvMy54wmLzTPSxGJ9A4GPX20wGPYYDFJW+4tUBlCp9di6dSv1Wo2oEmGMj7FDsv6Q1ZUV4n6XfmuRQWuJuNdleW6B4aBPmiREiSasDKn0Y+rjE4SVKvWxCl7ghOyt0UgHkaB1islitE1QRU6QG5fHKyVpTkxSazQIo4gkTQh8HxkGVKs1PCXxAp+lxQXSNGVGBWgD+hmeTJ/KoU/l0Kdy6O8+hxb2O+wRuuvWWxkhErjqhNZmpMU0op0UfzmBtWIisTboHfhS2hWu7w9dJ6Ql11qsXCBSrLXBlW9VgBejCW6fNgHMU8AsZzmqR+hzcfcLsEKMJnr5XKP16PPK5zhsZR1AVTw315re0FGTs2GfYWeRpL9Ca/4J8mELHbcJZOaExIXA4APK9aVbidaw0knp9HO6vYz+UCNxWgxhwW7yw5CwUsGPIsampvGjCiqMGA4GpMMhg16HpNcjy1LSOC4ChKHmKaqViEolYmrTRrzQR/geadLHmBxF7qwei4WxiBvYkrleXl8LpYbTU3ho6xIiR7WUxfpowBbuAlYjcCr+vrJ4SuD7DunNNSQphUufe52U5f1dG8RPAdRtiSqW4JFAlnaunof0wuLnCCFd8mW0weQpRmdkwx7WONq68JyLgPQCKo0xhIDlhSNIL0QFNSa27COsNAkqYyOnvDzP1gA0wWgsf98P/fB3MpX+nx133XJL0caqCsF1O9o0WGudlcO6wFkG0fUOVyXSnZctAcVDzuFQj6jGZcVUlAlwcdgiMS6BPmfjKknTtKDupsUmQxXVnaLyUFxno81a26yUqMJwoLRmLkeKpQymqnh83ToEa+KP5VwurofAnVet1qA/GPCb7/otjh09wcrSKi971mXMNkKmQ8ty6zj9eMjSIGOxnZKkhm3TVSYaIRONiLASsNxKOXC0ixI+npTUA0WonMXswfkl+sMeWTbgrC0bmRprMDM5QW1mA0EQEkiPJM5IcsOCkjxx7BhPHj3G4tIqs80GZ2/fzMRUkzAICP0QIyVWCkLPbVyEBF/5zjXJUyAcndhTCiUkWaY5dGyewaBPmsZs3TBDo+YzPqYI/QysIElDtJFYKzDSjNZbIyyB5xH5AXc+dISDxxa55d5HOWPHVrbMznDWvn3MbNrC1IYNbN2+k+X5OQ7sf4Qbrv8aS8tLdHs9sjzDAl4UEQYhke/TCD2ENpg859jKKqtpyvEs5Udf8kIu2ncal5x5FkvzB1ldPoHOBb32Cq3lEwy7x0GAqjTZce7zmdh0Ghu27aNaaeD7AQtzJ0iSmCRL8P1gNK61cWMmCALK8t1LfuBV/wdm3r/OUSaDQRBw9113sXPnThYWF5iZnkFKwfETxxF+5KjWyo3vLNMcPPAY9UaDfWefwyte8e/46le/NnrPDRs38tADD/CJf/wE73jHO5mbmxvp1X32f3ySF77whfhRjbe+9a1cd911nDx5kp/5mZ/h13/919m4ceO/KFI+NzfH5Vc8m8WFeeLhEIAXfe/38Cd/9Ickwz7WWPwwIB30MbmmvmGbc4jNcrZu2cjCyRPcfss3OfPMM/CDgIPHT7Jzyyammk3SNOXgk49x8MB+tp52PvVKhXqkUPVpwMDqQZa7KRk+51x0BYcee4AnH3mAS1/8w5iFR1i5+f38wrtvYP+xFrVahbO3b2Tr1BhbmyF3PHGcO584wdlbJhhmhuOdmPM3NQHBvXM9AgVYy8mVLq973ev40R/5Ef7Dz76OVqtFpVJjsd1zgr7kBJ5iqhHx+uedw0NLMQ8vDPje2oClOOee1RQjFJsaHt9/eoNP7m/z6GrG1pkxTqvAZs/wvsfadOIMnWWctmMzu6arvHB3jQtf9HLSsMkPvO6tjAvNhK94tJsyWfHZO15BmZztm6Z45Usv579+7GZufvgonSTHV5JKGPDS517MVCRp2oRP3PkkKgx54WVn8s3ogQJSAAEAAElEQVSHT3B4bpW5uTne9ra38WM/9mO8+tWv5siRI6yurq4fiExPTeF5HnNzc4ADTjZu3MhrXvMa3vGO/8L8/MJoA/SGN7yBkydOcOtttzEYDOj3+0w0x/i7j/497/rd3+Vv3v9+ztq3j8nxJmlh1tHu9IiTISsrK/zCW3+Lyy86j3//gy+nNjaJMBlZb5H6hj1Um9Ns2riR1uoq3W6X7Tt2/OtOun/l45ZbbnVgkTHMzExjgf5gOBLrzpIhQRDge96I8ZTnOelw6OJjlo0csKxl1OqiCjZ86dJUylVY4xje63VYsvUMqkK0x7nNZU8pqrkdsCKKKlSqVSbGx8Fq0uHAtQbqnFxbx8gvNxxFsdAIQaqhl1kajTECXxGi6S7PM+x3kcrpVwkpiMIAbSxJmjE3P49UHntOO4OV1RYryyvcevM36LRbDPo9xicmsXlC2l/lwKGjZGnCRCNgLAoIfI8496mNT1JvTjBszdNvt1ldXMQPKyjPJ6xE9IcxcZIxzCyNsQbNsQZTVUkQVghqYyz1c4bDIZ3Fk0xWPKphgNecYWllheWlJVaWlqhUqkzNbuD0PTtp1iIangbpGCSd2G18A08y3mwipYeVHmmvDSbHU4LcCnJtnDlC7oxqVFhB+iEqrDETWSKREeo+K92YYeI6GsCBY1TGEZUmojrJgQMHWFxc5ODBg0g/pFKtceF557Jzxw62bNlMc2KSlZUVjh45wj133cnKygqtVossSzB5js0zpHUtxGPVkCgMqFVCxppjVGs1xieniWoNlOehjSEe9EnjIWmvTegp6lHEviuuIaw3yaxE2YzA95jesoOwUkN5rkgiCuHr+cVlBNCoVcgzJ0dSq0RO0N5YXvqKH/i/PCu/8+NUDn0qhz6VQ3/3OfR3zHgq25LKPX9JFRsJq60Dc8w6EMiOaCwF2GrXD91y0772WiscpcwJg7tFdr1Ydvm3KN577bGCgliey3oQivLXYhQYR68fnYcTUlt7LztaFNZ6Y9cBLjhAzOY5SZqwuLjIYDAgGw5ReojINRIf8DHWcyKQWFIsucmxGJSyKOUhkAS+IgoMaaToDRKy3JKlkCUJSikC3ycZDlB+wDBOUEGA8HyyNMakKXk8RKfJSNNKCdcrHCmf0PPwg4BhmqKzlFRrsjRGCkM1UASBh1f0HbvrXQrAlzelvC4l6LbWZifW/TBq0yvvhTVr96HAJo11rDOXCBWiaawtxrCmHbVWT1i77mJ0G9Z+V74v1qm3l+JyWF3ca4kUGoQZLR7ufAoQrUiASgQ/rDRQQQ0vbGDxiZOcQdopbEeFq9IVovhm/Vh5ph+2BI1hPUttfbVm3UWnZCKu188oBQ2ldPR9Q0m5Z4TsUwCIa/N1HSo9+nfxt4G8SI6xrkIDhdOlLceDuz/rWZel3tfa2BgNRGwhQF8+Snm+o/EoRoHbtQaXrQNrgV5rB7Lu2TxJ0l6gtdDl4YNPstios61ZgzQnzizLvZzWwJDkhmo3p58alnsJtUrAMLGkxuIr955GCbqFjoHyPTY3phirbGLT+BhhECCCkF5myLOYwSCm1enTjxPa2tGNdb9PQwr8LKO3vILIMwLfxy+CppCS0JejyeP5vkuA/UJ8sdB0swjSNOfoiUX6/T5JmqBkiJQ1Ns00EFaQpJrV5R6ZLqo9ShZzxF1PTykCldBp9+n3XfvVyeVlBmlMbg2zS0vMzM2S9fq0V5eZP3qYXqdNMhyONAHACbCWxQisc1LK0oRelmOkYMtUg401SVOmrMwfZXVxkZXlFY6eWACT4sucKKoT1eo0N+xmcnYntcY0g96QxcVV4iRBkhP4PlEYYcppUK5vArQumQP/NnRijDF88Ws3cOklPa649GIeeeQR4jhmz+5dHDx6jOXVFufvO43lxQUOHz7Eho2baNTrJIMuL3j+NVQrVT7z2c9irbN3fvLJJzj45JMcP36cc845l5nZGbZu2cLDj+zn5Nw8QaWGUoqrrrqKT33qUxw5coTrr7+e7/u+72NsbOzbnqO1MIidTkt5SKkIowpJv4vJc0TgrJ5zrTFpH9+PCGs1uqvLxP0ujWqFaq2GFYJ+ZwWxdTN+VGW13UZ6AeNTG/CVJIoiJqanWFldIUsTlA2oNRugAk7MzZGmGRMT40RBQDCzmbELrmHP9gO0exnzrT6tbp/Ak8TDPoGE87aM00lyBpmr6vaMR24s3WHCRN3p2AA8ceAAX/na11le7dBudTArbbbUQybHI3Zs3cIjx5ZIc83GUPOYSen0h/RVRj/O6ScZu8YlUwEc7RrS/pBKHNOkSp7BQqbpdXtk2unYjFUjkB73Hlll9ea7yb3Isbc956y1KXDM58fmUzbVAirdIXc+McfmsYir9s5weKlPO84YasuTJ5dpR4qZwGClQhs4NrfMaaedwZnnNwGIoojrb7iBQ4cO0W63n3Zz+RadL2MMJ06cKAAqwYYNGzhx4gRf+cpXOHnyJAuLi3z4wx/mzDP3sWPHTqJqjV27d/O85z2P1dYyd99zF8sLS8SDHr4S7Nu9ncbULOOTUzzrsks5c+8uxsan2P/o4wgMm6brPH7v/fTibORCC5bXvOan/tXm2f+Jw+Da11QQjABeVQiMW2OQ4Fxy05SoEjlGkafQSjmNSuvawcrOAVmATJ6nCrFpb2SPrqTCGlm05OmCqWQwViIKx6RRrls435QbaYpYHvo+QRgQhhFCKkxuyAv9TJ07fdIM0FLh+Z4jZmBJ4yG5FSgU6AwjLTkGoTz8IAQh0QXQnEtZrMtFHEaTZynVKMJOjDM92STpt1jptZgbDvCkJRDauYRZGA5SZK7xlSTJJUlu6A+GhCJ1zn9Com3JspcFQ8yQWUEQVWiOTxCK2Il3u109xkKcG1Y6fTqih+ilTk8rHiKMwWQpcafFysnjpJWQYSgJogCpJP1Bgu97ZMX1QLhcyTM5QlgSqejFKcMkY3m1TZqlaKMZb47RnJxharZJJFJs0mNpuU17kBGnOVmeOwdBT+GplDRt0V8dsLq0QLfVIhv2iXsDer0+Txx4kjiOaa2uMjk9xbDXY2Vxnri1TNptMex2GWbOKS1QglBJB1RCIdeRMRwMsRY8P8AYi+d7aK0ZDgbEwwGDXo/I97FGkGUZvnH6YSYzxEnMseMnHMAoFVZnRJUqfqVC4Psuhys+zxj3/CzX5N/GFfUZdZzKoU/l0Kdy6O86h/6OgSclC9FCzFqbkSxogKOJsDbJyra4tU25RZrihq7bo5dfwI3yUj/JXdD1LJeRQFv5C7EWQBhNQjMCt9zbFehi0Y9KARyMDuOE3cozKBHcp5+Xm0zlexUItHQ2lMYYhsMhh48cZmVllWG3x2QtdMisVVjtYbRHnrrWvFxbhmmGsQJPKapR4KxzA5+KVVgB7Y4gzjVpmpNZV5TKPIXsu2pWvryMEQ57UdbgYQkFo+TDIanOfaRZreLVqqhKhdYwoTscstLpYvKUQElmx+vUqhFh4OH5PiBHQFvZ91sOLuyaOPv69XXEgioWIGsdmk/BdhvpOMnyPS2qpHoigNJhgHIdf9p9LE+geLxYKI0phPGMBbRzEbACRI5VIKRECUC6Hlyk+1Api4VAlJ8tnQuB8lCeT31sBi9qIoM6gwz6wy7d/oAoCqhEIRPj40+pAti1KPSMPsrKhwsect3v3T3z1DpXRLsGqj2FXixlIWbouwRV43q1hRy54lgKU4ECAXdVETm6hevfyzmwFAChkCjPOea4KlIxFoqAMAIozRqb0S105bx2oKkx+VqCIIu5qwRGy+LcnB7BmmGCHmmtle+RaY2Sihddfi5N2cf0jnP3wccJVYUt4xOcOVZDClga5gwNaKtY7mviVkycZUQeBJ5PFIaEviWwCpn7zLV7xEnOjulJLtq3hwtO28XiSo/VbpcTK8scOzrPcq/PgZNzLK6uMhwMqVrN5vExNjfHGJ8cw+YZ8dICutVCKAXScw4XUuJ7AVq4irMIPDwlCH1ZbBwkGYLUSoZpyoEnjzIYDkmzDGN9qpUZ6tUxkp6l00s5+OQKaW4wFoIgKswIQJUes8ayurhKNhgyVg9Z6Hc53mlx+MRxpmp1phsNFvaehtE5g37PWSzXKtTkmNtAWUMnLVyNrCbLLHmakMRD+pkhqgWctXWKLTVDPV/l0P6jtFp9VltdbrjrfsbHInZtneCMvVuY3bSDXec8j6C+kVx7PHngSe5/dD9HTp7ggvPOYPuWrWyYnqbV6xdOL64dwApIcz3qpf+3cORa8wd/8de85EXfy1VXXM5XvvY1Wq02v/G2X+P44UPcf/99bGhWeOjB+7j1pht562//LrValeOHHuc//PybuPbFL+Vzn/98wd7MufnmmzhwwFnrft8rXsEVz3oWL3nJi7n22mv56le/Rlip8Gd/+ie86U1v4ktf+hKf//zn+drXvsZll132LcDTqKVHSqrjM/QHMXHXOZ14vk99rEl3aR6dxuRKkqQZaZKiTxxidutONmzazIN3fROdpWzfuolafYzeoE9naQ6pLiBqNHny9luYnJzh3EvOoNdZpjk+ydY9Z3D8ix9ndWUFO7GT88/bR71e54//7M84/8zdPPviS5mYbCLkJPn0Ti489zZEGnPHI0c4sdzi4MIKnV7MKy/cxquu2M2vfPJepB9wxvaNHOkJhmlOvdFg41Sdiq+YW+lyw/XXc8PXv85sPaQSeLSGKZdsqHHujhmuee5F/M7Hv8mDB08SxasMV9ucmGvz0EAxNJZBYnnu+TNYqfjwwx22Aec3AyY9TUuGHLER1cCnag210GO8FrE6SPnILfvZdNshxqKAmXrIRKNKsxJyWqB5opNy40rKMI851E356sEV3vy8vbzk9N3csn+ehxZ6PLbc5477HsVXkvGKz+Ytm8i15qu3PMgHP/p2Xvp9/w6AX/nVX+Xtv/VbozX3qXPjX54nawU7y/33389P/dQaEPT6n/5pXvtTr+eVr/xBpqYmeP7zn8/znvc8fvlX/xN33H4Ht3/zDrSxTI03eO3Ln8vLf+ynedYLXsLv/pf/XLSnCN7y62+nWqnwn/7Tf+BP/+IPuOXW24qNvWsPe6YDT2nmhJajMGQwGCCEJAwDhoMYnWcFADok15pqZZNjkCuJ8VOskY6ZpDXGgqe8EfAU+B6eciCkK6A5VoYxzuFK506/qdywlHpOrhBoEdaMWBZpmoN08XyiUqFWq1Or17FINDlpbkjTjDzLHHhWOLeNBSECizU5w14bKyR+VIE8wFqfFOt0QKJKAV7l5HlGJp3GirVrOUQ6HDA2PsHYWJ29u7YxbC9w/ECbI/MtosBndrKJLwXCU5gsY5A7Vv0wTjGtFkjFzOSYW+OsMwgy2uDlmlQbMmOxKqAxPsmmrdtIV0+S5ZphnJAkhmGc0OoNyfptTOpaTWuhTzXwaEQewhp0r8Xy4Q4dTxFUIsbGGgShKxB7QYgfhvS6PbevSFOmGzWE9OhZyUKrS6c/YH5xmTx3Wjc7N6eMN8fZumEaM+jQigccOrJAP8kdmJZqxuoVGrUKDfosdwYcml9l2O+TZSkVaegPEnq9Hg8Ohhw9eoSxep3Z6UkCDJ7JEP0VgnSIzIbkiSazlrASEvqKauhYJRZIsgwGA9Iscw5hcezEjHXGcBgTxwmdfkwUhWgkcZISak0U+QyTHt1ej0ePPE6WZghg32m7mJndyPjEOPV6DWMMnpIM+o4tMjQO7Mqe4e7Qp3LoUzn0qRz6u8+hv2PgKcsyR+krQAa7bgKsZ3yUPeZlX6prF3eTxxY2hKVzR4mSloFyPVJcCq6tAVBPQTpG1EFJAXaU/BXx1ESpXABGSjzlXCrZPaJ83E3C9a1764/yfEuU2xhRTHhDnmX0OyssLxznyOHDVDyfyPeZqUUEIse3OXmmSfKcfprTGbrefU9KalFK6EsqkV8wgSC3FqskMgjwlHMb8aREF1RUrXN8TxIqxVilQuB5zjI1CEEqrPLQ2qCNZX6Ykg1TUrvKar/PMEno9wd4WCLfQ/edK0YYBPhBAEJBof0kJY6GKUtk21EOlZIFQ6pE7gstKHCBO83o9fvoIqDWKiG1qk818ogCzzncKYs1pQ2lQFmBFZKyh3Qd2lVc8rXPErh7lOmcrEC/c73GkCvdXZwNsO/siT3hxMyLxMityIxoqp7nu3uaQa8PcbtNnK1ydH6RXr9PbzBg9+6dzExPMznRXBtIT/v/M/lQygWpJHfJhBQSz3O0UcfeMiMTgZGoYEnnHX0990OWZ0XF06z7bem+oQoprWLeGzNilI3mpXGJp7sHpfCic+rIbWHprBMHKmaOyimK8y0rtK566943CIJRgE+SHGttUVFy64er5j1982RwtqwCzwsRIh+dX54nKCnZsucSLhxqqjqj2XicY62YJ5b7DPKMscBjUyMgziHTltRoPCWoeAFGQ24gTlKGaYa1cNxo4iwFBItJlduePMbD8y0OHD1KdzCg3e8DAiUEdU+wbSxCNSOmhKLhezQCiWdTpLLIeojAAa+pTcBmCC2QOkZbg8EgYqff4ZiWbr3TRrKSawbW4IU+05WIQHp4JifvD+gtdZlf7rGw1OPQoTl8qwvQWI1GvC89FKAAz+ZMGEPQrLKQRnQzw0oSs5hmrKys0n7wQSbrNTaMN9m1aTPaGJa7Pbr9LuiUaQUKg8whEDlagIwipmSI7yu8Idx770EekLDUTRgMHWNkWVfIhwp/IeX0PZtI4wkOPrrAydVHmF9Z5sa77qK92gJreNbFZxCFftHa7MaNEAJdWvJKgdVP31w/cw9PKf70nb/FhRdcgNaaV/3AK0mSmIWFBS68+GLOv+AC4vYyl17yLJ515fPo9QdkWcbWHXsQXkSSuyT1LW95C89//vN5yy//MsdPnEBKybUv+l7OPvtsAP70T/+UdqeDFJJ/+NjHePe730O32/0Xz2v//v287nWv49d+7de49toX86m//xDvf9/f8Jf/7S8AuPmW2/m+V/04r3v1D3Danl2IoMZgaZGs32XnBZew/5FH+NQ/fZKX/btXMux3efieO8gefoTG+ATf90M/ya03fp0bvvolXvbKH+bJw0e5/uZbePm1L6S1usKHP/BeGlMbELUNDA89yGN6QHVsgrP3bmfLjt3I8S3c+ZX/QW1snO37LuBHfv7XOP2uu/jn17yO51+0hx0bmtxx/5Psn+9y/7GH2DFRYyzwmDZDHltu4yvBS06f4dYjqxyJc/7TC85lerJBVAt558du5tzNdX7q6r184Z5jfO1wm89+6AZettvnh3Zv5Ne/cpjnnrOF//bje7nhtifpZZZpz+e2Yz0Ca7iqmnOCCkeM5JHFmOecM821e2fZOFhm//KAu9sJZ6iAakWxpRHw4hdezY4dWzm61ObxRx7j3icOUpGwZyLiN86c5pGkgskNG/MOBw8t8cCBRR5ZHnDadI2XnzlLL57g5CDn8W7OuQ1De5jxYKLJzFMrgo16nY9+9KPceOON/P4f/MGowPf/d3zyk5/knnvuAeDMM8/kmzffDEJw8OBBfuInfoJ//udPc/PNNzI2NsYP/dCrePOb38ydt9/LA/c9jLU4l73ZDfzUL/02jxxf5s8/8Pds6j7CI4fnufXxed70hjcSBD633P0Av/Gbbyeqj/FwK+bj7/kLbvjMp/6359T/rSMMQ9dK5/vkeVa4IjuXsFxYFNa5SQqBHwROtFU6jTUpc5Ry7Cihtctpyw2lcDIHSnnOdZkCzBFFbiZlIXy8lkfpIh+wxmCUROcaz1q8sILyfZTnU6nW8AOnU2J0Tp7E9HuucCmASrVCnOWYQrpA+T5BWCGrNYjjIf3WCsPBAM8LqFRrBJ5jZSEMwgZ4ojBrkRIlfWZmZh3QkQxIYuekt2fHFmTSomp6tG+6h05vyIHDJ6lFAaGvqIc+GI3Rroyp85xUZxyd1ygp8aQk0Rnautxa5xqDRYU1FlsdooUVThw+TrfTYbXVcvkCllAYAmURlYA0y9lQD9jYrNDPBVmuyeKUGhpjMrrdHPKUSuAxFgjieEBbG3qZY8hXfQntFZLccribsjxIiDONpyRj1YCxashsVVIxffoLhzmx1GJ+YZkHDi9ArjHaMMw1i4WjXLMSOPAmzdg5XsX3K6AmeOz4CovtAcu9AUtpzMrKKktLi9RDn2YlYLLi0WzWiaoR3TgjK+RSIl8ReM7hWlvIjKWbWmyWsZJ0CDpDPCnx0K59U2vagxSZatoZ7G338evjTM5WWFk6wdzcHDdefwMIQaVSZfOmjURjKZWh04VK4pj5dps401gEYRigUVj5zM6jT+XQp3LoUzn0d59D/y+52oHAylKx3w28p3xM+esSMCpoMcKuwThriLFdQ1TXgQzuOaWIuS2INiOuE+X0dBO7fLkY4QAlO6Z8t293IRwduNDnecoJitH7PoWJNfp+a22BDqx0/1BSEvmSQFnydEBnaOkhMUmNqhJECsg1iXZCo91Eow0oacm0JfAkg1SPqHNJbjAFKGMKYCa1BcXaOlGywPepRQHVSogqql5aCAyQaeMqyVnOYJi41jqtGSZDsixHpylSgNY5iRRIbcj9FM8PEMoFH6mUY3UVwBNFYuN7nut59d3jZXXbFve21x8yTFI6nR65dtWOLNcIUcH3HEtMSnfJjTHoHLLUYEdmlYyALsdTdsdI98mt5FjrdKHS3JKkhjjN0NoWNqFOsyvwfcLAx/MUUejhewJPCSTlQr++1U66ZCLXLC53GKQZgyRlYWGOJHWUbVtQpctxbdeN9n8LRykQWkxCNw+NHVkrY9e4W24OWDB29Lr1rZQjVqMoKh+jGff0xWcdeLju9+vBYSEstmi5tI4WtxZkRREctRkJAbopXp7L2rmWZ7/207rAve5vUU5wW65T0om5rhOiNzpH4FGpTjA1u40dO0/n5PISmW0zN+iTGEPfaOLMoIQTalZAJgS5EMTGtRxn1rEtjbWFtob7vr0kJWt1WO4MmVtpMUxiBmlCTSlCz2M8ivA9ia8E40IRSkFYzEMlBL6QaOOCvi3esyixIdAYjCP4AdaakXCnNcKJIAKiVsPzPELlU/UMJjMsLcccWRqwtDqkE2eMSU2ARQvXJoIVWOGCpidwgK4E5UsyK/GkRWPIdE6uDSv9PgbHdqlVqq4tREkqvkcoDMpop3dhihZchOuz9x3YniWa+TjGGE0nzkgyS5IbhPTRVjCILSuthEG6Svd4j8X2AivdVdqtEwSeR7M+RqPewPdDcq2LRHBtXCDKQon9NzGRt2zZwhlnnMElF57PzOwMTx4+gijWWWMM3W6HJB4yVglRQQUZVhisLhMP+/T7PaY3bKYSRVx99VU8+9nP5vzzz+fY8eOsrq4ShCHT09OMj48DDjgoj/f/7fu5++67C1Hhbz0eeOABbrvtNm677TYWFhbwfY8Lzz+XrVs2j56zurrKXXfdxb//wZfjhwE6z/A8HxlVioqhRSpFv98ji2OUHwAST3mYzDmkqaICGscxJ+fmGAxj0iwn1ZawUsdDk5gMKdwmoVEJUNIlr1lu6Pe6LBw9yO4zz2Hb7g5TjQpSOEbE3k3jPHBkmYPLA15y7iQelnZnQIAmEJI4TZkdr9C0bu5lWuMby2kbx9g4HpFpw3gjIhOSpdjpL2TateR7CAJj8AVUJdQVHO7mRMKytyE5FlsG2tDwIc8ylrtDtsxMMBAeJ7MO3W4fIWDzVJOJptOlMVZzUAk6g5gNs3UaFQ9PChQWJaEeBqz2c/qpph56BEU7zcZ6QIIkjAXDJGUwTMiNxT5t/CvlcdFFF6G15uqrr+buu+6iX4iP/0vH/Py8A0AvvJCZ6Wkuf9blgGDjxo085znPcZIDec6dd97J1q1buOiiizh54iQ2GbJvpkJ9yx5OO/t8tu05g2O9h5EnF/D8ED9wgE3gKacX5HuuXSrPyNLk2zjrPTMP3y8YPUWbE8Jpq+jcuRP7vucYXEKQ5/kowS83p1Iq5yRUFG2VKKUK3KZzbXdrC+bC+sJwGW9dvlP6XTn/GAvKZWGe8vH8AOX5+H6pJ+U0oHSeYXK33kjp2BUiy5yWaxFbS0Hy0u6dQvagnJNKSrIsHRm/SKkQUoHykNbFGaHF6PmV5gQzMxsYbNnGZPNJ0kzT63cIPOm6AaRA4lrvfClca4sx6CxHSoXxXE5dztkyaZB5zrDfp7WywkqrTa/bpdPuUPEEFU9SrwUEgbOo7w8MVV9Q9XCtLQaMKL+bxeQWcoGQBpRCp5oszclSi/AUFp9UC4aZodcd0B9mpMbSqFVQ0hV04zSj0+kyNzfH/EqPpZU23TjDK0SVdaZJsoxUSvI4RglQwiJshC8FQegzXg3Is5w0ddo2ea4ZDgxC+ygMjahO4HlUlLvmudboQqdHF3mKQWCExAr3s9YWYx1I6mGKz3RjKss12dABA2muEQLnKDYckA46RNWGMyqoNwijKkhVjFnrnLi1LYrPblPwTA/Bp3LoUzn0qRz6u8+h/5dc7YQVozceAUNlsCsCWzkv3E0URfARhci4G+WmrKyNTrhgLRX0P7eel+9fgAMjgGod8kPR7rdGkVmbl0KMkOf1QFmJTgmKRWQNZXJ/jcCdAmgrBmL5uLWGUuvISIOSkrFahV2bZ6gwpD1/kJNLLVrdISvtDhXlU/V96kpgsCTGMNTWuTdYyyDRBYjhKg+lcJ0ULkB7xlGg84IWLYVkpjlGc7zJVLOBxNFi24MBrV6fOMvpJSm9YUycJPQHA4QxKGsZCzwipWh6Cl8IlM4x3Y4TC5QSpFdQMl3bWZmgmHKkSYnvO+ApCBwtUSiFFQJtBbmF7mDgaMrtjqMQC5ho1tE6RynL7ITnICZjiAcZcWLo9TTGOktfIQsnBylRhVC5KNT/HTNJIYWjLsaJpT/MGcQpnd6QOM2Jk8xNDiEcEyzwCQOP8UaFWjWgEvlUQyfCqYr7L4REKo9We8BKu89d9z1KnCfkJgUbU6tWmWyOMzPZYHys4aqKrJsLpcXpM/wQShW2lwqULoA/jTBr1rBSiFHVyRiDyTWlloTne6NE1hhbJJeukmq0a9vJniJAWAKIskicyyRTFsl0VrRJWrRbxpEqx1PKVZFURJ7n5Fle0NHFt7gmlIHcCdlanHaaE14VVjjs0tiCBlq+qgigxmmslaKsTpxRF64+BjyDiepMbNtHZWIj8ydOUPVOMllZYf+qod3XPLjYY/d4yEzFZyZUDA30NeTGkFnIrHKVQgGh76GtRVvLcq+HZ7p4Fsb9gHHfw1Bl1pM0PMlsoIqFvKBEF36sFh9PgA8kOsEAvlKUl8VdZa9YKiXSFpsKY8iLZKkuJcpARxsykSGxnD45gUkEdz3U5p5Wi0GWUfEDxj1DTbjrp4uk1Pl1OIfOsPjc3MKGwDKNZFulzkBr+rnmQHfIyX6fo70uC/0+45UKs406G8fGCLEMBl2W4pSe0QxQhV+OIVJgrWap5wB7dxWc+KOIBBOAtBDnglvvvJ/2cMj9c/M0pyImmiEX7W1y/jnnsXfPmWzYfSbaSrr9ngPVJeSZ09lDuOAv143aZ/Lxgz/4g/zJn/wJ1mgefuxxPvCxT2C6bTZMTfCGN7yBD77vPXzj+q/zvus+yuGjx7jtzru56qJzWVxa4HNf/gqv/cnXcuaZZ/K1r34VhGB+fv47+lxXHf2XN/e/9Eu/xFe+8pX///fQKXl/hQ0zk2yameL4wcfZsHErYVTjgXtuY/vu03n2c1/AP374vVSqNc6/8HKmt2yj117l8x95N5e/6JU8/6Wv5OQTDzN34ijz83PcfcddbNi6nee87FVUh0uknWUOrM5y2tnnMTG7mRs+9w905o+ihwO2X/QcFg89ys2fuo7pn/llpmoRr7hwJ19+8Ai3PHSYd/341cQWnljocPlZW3hirs0/3XeUZ+2exVq47q6j/MFPv5CL9m7i5W//KMMkpxp4XPez13DPkWXe8MFb+asfu4Tzds5QmRznbdfdzN2Pz/FnrziHu55c4s8+cTd7mwE1ARUM2kTkoU9lPGTwxAp6kPLjl8zwyQPHeO83nuD3X/9StgzanP/EY/zJ3fsxYZVXXHku/X6Pg08c4JLNPvfKhEwIXnP+FAdXE667f5Ga0VSigN6GaTZO1Nha8dgzprjtWIebjra5YlMVsFR8wdcOrNCL02+9WWJNs/HlL38ZL772Wi697DLuu+++/+lYUUrxvve9j/PPP48yL9uxY8dofCwvL3P22efwyU99ik9+8pMAXLipxq8/dzun/ezvM33ecwijiKsvPoerzj8Dv+Lc8fI8422/+PNUKiE//pOv4T/84q/yjZu+SRIn/9NzeqYcURQy6PdZXu4Q+U6PaTjAtVEA1dnZwghF0261yLWLfWEQAqA8jzzPnMOUzkGpgulUGPBAoRvjYofW+YjdUNphC1HoqBb5lTWgrUHg3sOPIrwgdMBTEGKNJk8SkkGXLB4irSaIIhc7PR9r+44BVeTzttBUQvlUak1838fzfaq1Gr5y1tzt5QXSLCPXhsbEFEr5IBUrrQ7WamYmxqhWa1RrNcJgkg14yKDBvkMLRIcOMxweINeaLM/p9g2NQFH1BGORhzaWQapdvEUy0GLE6qgFhSMVFmEzBstzHO8s0e70MDqn6llmqh7N0GfzeI2o5tprTixpKkpj0iEYic3dtR1k7voqJan7gpovGKaaJM3JU00Niy8EPhYjFUZaFIbAbQ+JPJeHZkbw8NEVvJNtKgfnMQiyTGOlK/B61lCxhjTLidOU+Z5rVYt8hWoPqKWacWBDPWAqUsxWPVqDlM4wo5W4tqtOnBImhqpQjFcCxgMfrKE7TGkPU3pJTmYsvu8RRQFhFBSu15KsaNNMtSCSEt8TVC30M0svThjGCXGSkKcxcb+HTYacPjvGxl1nsHHX6ZxzwcUEYYQVgoQci6VWr6OSFGMtUeAziHWRPz5zj1M5dPmqUzn0qRz6fz+H/s7FxeUauCPWJSUFJIMbm2uaSWti0WvsIFn2rYqScVSCSYzAnzUkdh39sAC5rBEjRpP7f/nitWOt53TtEqwhtTidH1wgkuVHjT7eTWBRoNDW2oIMVX7v4n+2/M4F+ygImZqaRVrDaTvmCX2fxXCVudaQOM8YxjmJctVITwp84S68WXdtjC2/sUUKjRCmuM4Z1jrnPApQyk8S8k6PTpqTpClxkjjAJ00dK8pYp69kDVXpqkA+gjFPEihBpARKFPPQgsA4wUSrQZdouSrOZq2tEiHJlUBLQS6dm4IVEo1z6UitpZfmpDonyXIw7vqkSUY8TBj2PdI4wEi3IHfaQ/r9jNVWUizG66plSqI8VVTQCvFM6Vr8yoUzTnOGSUacZgwGCUmWjf7tXFuc9kHgewyTlIlmlaau4HsVR01dN3ysheV2h5OLq8ytzBNFHtWqz9aNm5mYmGJmeiMbNmwmqtZHwKUth+IadvmMPnSWra0Mdg2dFoVeWenSMRIYLco2lsJ1MNNFS6woAN8SuCuouDix/aIGUtynAqQtaL1a51DkFiNG5Pp5bAzaOlcJ6ft4no8SijRNXLBeV7l17+H+uN7yUjRRjpLgsi2ztHmmqBZAOcZt0Q/vqrZCCMIwHAHa/V6HwPepNqfZc9E16MceZP83v8ZEJKj5Hv1KjdVuwvJqyvZqhUagmPEEFSHJrSXThr52Ab/pe8Q6J7OGsdCnIiU1Kagql3hIDCEWT0BQsv2kQgFaSLR0Yq0CF8R8pVxigxOllQIMa1RsgcUIS17g7aoYtaF0lSTPGpq+x3i1iuf7zPeHPLLcZmZzEyFg0Okz7HSxScZE6LmUxFoUIIUFIcnKoCzARxAAQhgiYakLMLWAQe7YHMnQ0f87gx6rtRqh55GmKcPMrRlC+YUbqkWW+nIKPOlsxlNtiiReECrBMMvpxCkncwsKdu6YYu/2SbZsmORZF17I5OwuGuObiTODMTlG5656L6xb04oYVeowfGs0eeYdn//851laWuK3fvu3mZme5tXf/wpsmpAmMV+//qtceMllXPmca5iamiZNUs49fTebtu1AKMGmsYi7H3yI2x54mJu++hWstYRhyJ/92Z/h+75zJtswy+233caf/Omf8ra3vY1Go8Gv//qvc/vtt3/b87njjjv44z/+Yx544IGn/H51dZVf/uVf5q677hr97vLLL+fNb34zZ+zdCcbQ3LCNTrtFvrTIWRdeTtJv8/i9t/Ks57wAk+fE3VV6yyFZrtmy7xIefOgh7r3/AfbtO5vT9+5h29bNbJiYREU19LDP7TfdgLKaK15wLe2VRU4efpxjx46z58xz2LpzDwceuZPA83ju9/84jz94L1prXvO23+dFqz2OnZzjuvf8EcfnVwgF/OOtT6CVz849O9k0ExEPHbjxyW8+xq2PzrF98yYiNDWped+Nj5Nqy6V7N/PPDy/xuUdXSLVh01iF7790N391y2EmJibYe/457NItGsowFsJW6bEYG750fMAlZ25kLBT89Z1HufC8HfzBS7Zy+JHHObzQ4qFjS7zw8n0EUcRCZ8DBk8dBeew788WcsTchtIYH2paxKOK1l29m/1yCQbJxPOTgSp9DCym3aMOm6XEuPn0rtx84TjfO6GaGRq3CBRdewE+98c3ceOONfOxjHwPgvvvuK2vsuLXyqbPjl37pl7jkkku+7Ziw1vLf3/s+2u0WunDi2rp1K7/3e7/HRz7yET7/+c/z/Be+gMcfe4y77ryTMAyYPu08LnrT26jvOpvO6jy/+4d/iRqbQkR1Hrv/Hi6/6AJefu33MD67mfHJSWY37+Q//uJbuPJ59/Bffuvt/2YYT3Jda5xj/biYKITA831nXZ3HBQsqo9fr0mm3qY+NO+kA33dvVMRcWUgFUDIoCo2ctTzZbbwoGAgjEeOCDaELQDnP8lH8c2CUxiiPNEmK3FmTpyl55lhPw4FxxUHfte8EQUiv1yOOY5TnO9YMkjg3eKHTT9FaMxgMSNOUQZqTpxk6S/G8rvvufujkEJSHH9XIspReOyP2FBbJ2PRG9p5zAcavcGJpFfIhwmowhizNGOaauGBGNgKFkpZY5ySpoepLPCmIfAlF+910vUIYeChPcUxqhNVECiYiD09KhsaikxRPwqaaJM8Nw0wTVXxqgcdMLaDTjUlzQ4Yg05Z+opHGIK1FSUFsJVpIJILpesSYNXgm54SwdNMy43f7kUxbpCfxgohqrYqxliCKGHY6ZHGMNg7gqilBtSKLVkpFlhmGpPgYxkKPiifwawGBFERKEniKzFhSa+h3uwwHkq6nCJVjlRkLiXbKPUZIcgtp5tzVPBS+j3Pms3akR+VYJ4LIcwViqXOSQY+5uTl6gyEyCLnokkvZtPtMprbsIBn26fa6xGlGMugigVqtjqWH1sY5NSqPKHpmF3BP5dCcyqFP5dDfdQ79HQNPDnld9691iM06zIZSRb9sk1v/ojVwpxjp5Vtg188Dno6bjeCr4jOEeOqjtpjca79eA73KibT2OWIEKtkRiLTufZ7+clF+ppv8paKU+z7uxirlU6s1sVnGxtlZ4niA1RmtQUrfauLcsZZCK4mERAk5wq908dU0zkmjBKJKxlgpoJ4bXdAZLf00Q9shwzSnPxwSpwn94XAUFHzhKIW+BE8JAuH+VJUDngJVgG4Ug7+8h8ZQwl+sq26L8lrhWv8QYIRjKBkEOYLMQmJhqB0qrI11lFoLVlvyTJMlGWmSkQvH4Or2Y3q9lHZniNWO07gGPKl1wJMstA7ESPMA4cTrkiwnyTRZkjq9pzQjSTK0MeTGkniqEN6UhIFH6Puj60zJ1hMOXOsPh7R7XZJ0SK1ep14L2bRxA5OTs0zPbKI+1kSq4Nujuv8Gdq06X+dUIUqdtLJd0lUDSuq4KMaEEKIk/BV6bGoEwDo2ICONxTJpHbUvinKUrU2p9SxEqbxiRq2tLdZYEBYjRBEIhKvqFiKKFvOU5WFtnpiCkWhHAW/kdmRs0dbgzq00CBCFppirPrkqk5ACr2D7WZxQn+95eH7I7I4zmGt1SI2PJCNUEIwF9IYpvcTQyQ2BhKqUVIvXG4mzKkYwrgRDIDPgSUXNU9SVpFq0x0hcFlheHyPchfWKqqMVAk84lFNj8YTASEHmOjYoJPSKldcFHmtdQjmqRhTViUAIfGupKEXV94i1oac1HZNx1mQd35Mcz3OyTheTa6ZD35UNRGEHUKy32hYJknBArio+VwGBgunAY6As/dzSTmOy1FVsEWvimk4fxKCkLURgLVKumRK4VmKJMRQ+oThxV6NJteu1r/o+m2bqnL5jCzu2bGLvaechoxms16DX72KNdm6XthgTozZeMWKMP9OJ/rt37SLPM+648076/SHjE5M0azVmd2yn3W7xhS99jpe85OVcfPFlHD9+HGNytm3eSJrlWAMbZ6cZJAmHTyzwsY99DGMM09PTvPnNb2bHjh1MTk5i8oyVlWVuu/VW2u02Skpuv/12FhbWmFHNZpNNmzbh+z7Hjh3jH/7hH77lXIfDIf/0T/9Eu91GCMHWrVu5+OJL+OEf/mEeuOMWTp48SXN2M/1Bn3jQZddZ55P22/TbK+w883yS4YBjKwv0Oy2sVDSmNnLw8BGWl+bZt+8cJppjbJqZoF6tk+SwMujTXl11jk+1cXqHn2Rp/qQTPpY+CEnSXcUfn6K+YTsHHt8P1nLaBZdz+sQkK6ur/NW73wNBzGTD8vDRZepjY2zZPomUFqQgDHweO7bCieUBu7dtpkKKlyfcf7JDvRKwa2aMJ1cGtAcJq60uP3L5TjZN1PiH2w5ydmOKreNNRD/GqhztWyYCRSfPeGQl4aozp5hp+twxP+T8MOTsnVPc+JX7ONTOWA4abJiZwFOSR0+c4MjcIgbFcixoNsY4c9ssdzx+gh1jknNmI070JUnumBWtQcLRdkwrMzQnx9leCTjWTTFI6rUGJouZnJzg0ksv5XOf/zw333wzx48fx1o7arl0x1MD3NVXX833fd/3AbCyvEy312Pr1q0opcjznP/6J3/Gfffeiy6AgL179/L617+e66+/nk9/+tO89vU/zfj4BADbtm9n91nnseXya1ldXmJl/ij7H3oAObERqk3uuf026oHk4nNOZ3rDZhrNJq1Ol0suvYzm+CTv+O3fYmpqimaz+a874f4PHOXmEdzGNM9z0iSmUq26Njqji/YPTZ5lpEnCcDjAj6ognB5UGZfLUrAAx7guNGGEFEWeW3QRFG5DpbsdgLCyCPeuBUfrHKOdOY9RCkjReU5WOFNJIbDGtQM6R7vcreHWsbCU8ojjmCzPUSoniCqOlZ7mRBWLshatDXGSEscxuXH6IEZrdFawpaQq1nuB9DzyzEkcpFjXahlVmd20lZVWm0ajgYktmMy1xBqngZRmmoqvqAYKrS3KGoTJ8awilIqq72QkfM+jWXEGPMpzQvsSj6ovaASu6NpLzGhDVfEEfQN5bqlJQaAUkRRkcbHhtQWwYCwRLt5L4ToBJGCFJfAlCslkNWQQZ0DOoChartnbK3w/oFGvU25948GQ3CZIa/GVA3t8X6GRJNbpCJlcoxOD8FxxOlSSiifJA4UBUu3aa4Y6J88tWSJIlJPoUJ4qcg0xiuvGuPslEU5vVq4VoB3Bxrq4LCWBVJjctdd1uz7aQlCpsWP7Nma27WBsapaTi8sM4pje0Ok7hb5HNQrx1FqOH3g+wTM8kT6VQ5/KoU/l0N99Dv2/ADytAUflxp/RJFiHUo9QobJv0iHBVkoXrCxF+53G2mKyjhhNdvQWZSufFYUtJMU3Kyd58TmmUNEXwjr0VZTooQu6I6e6YhKtB5WeIoxegqNPWffcP1zL15pbgSn6Qo1xVQErFWFtAqkCtu/OkNKnUamRac1KL2a1nzJILENjydKcuqcIpOsjt8WiMTRO0C8rAph5Cj4nUdJdA20sncGAPkOH22rnJiC1piIc6DSmJFVPEipBIF0/a/mntNqVuGuocNpRxlqkXWOZlc4FQEHRc4+Ut9pYhwLbgklmjEWbsr9UojyfwPPxlaTieSgDeZyztDggxxJnGUsrfQaDlF5riGc0qqgSFVkIFFpPru2wYDwVwc5RuoWjXWJBG6QxeFoTYMjLK2sMNtckSUaSarLc4nkBnu8qXVL5SM9DSI84HZLnQ7ZvarJj+3a2bN7Krj37CCsN/LCOLiZcmTgaC7oE6J7Z8RJ46ngXgqJ10Vs3lzRGux5tz1Mj62bJ2rjXJh9hkyUQrNc5NYShjy3HsCmpxqU2VuGCYN38Wd8iW5D/AWfRjDXkNh61RNpRhl1WitwwMYXYflnJcUHStXtIpciyGINBKUHpbJOlWeEsohDCFhRoH+UV4LNhJMSK56GzhF6WsmX7dhbaLSobT+fWW2+FfMAV52zm/F2TGCSPHOuw0EtIlxJOrwc0fcVk4LGl4uEr10IqjY8w1jEOJUgFYx7OklgrjAKNa8k1QjnKvXVBKgQEGVIJKtIjTzOMoai+lC3NFiE0Uhg8UbRf2MJFshizgRDuXqkAi6AV5zx4fJHp6TrPu3g3zz99B0mS8eV2j8NCkBY0clWEFefn6G6ILiofTjmtaJW2bmMjkEx4ginfiR/2dI3YQEtbVtOEXjzAl2uukjbPMcaSW4s0jvKd24yJsEbFc1XmJBswTGMeX02QgU/UqHDRdMhELWDzRJUrnvVCNm47A1uZYTjokHZWoXRsEsK1qQDl4ipglCA+048HHri/iK+uovjlr36Nn3jt6/jQe9/Npg0z/P3ff5y9e/exc+ceXvC938sP/9AP8Zu//jZ+9g0/zfT0DG/+hV9iYmKC/Y88wp///rvAGJaWl7nqqqt585v/I+9617uQyuN5z30u37zh60zMzKI8j9u/eRO/+JZf4YMfug6A17zmNbzrne8kqlS49957/6fnHYYhn/nnf+b0009HCMGvvP13OH7kEO/6zbeQ4ZFZy/Wf/RR7zzyb85/zYm772uewWCamN3JyYZ48y1BWsHfPbs48ax/bt2zgiUcf5vFHHuIHfvKNiEGf9qN38P3//rW0un3e8a7f5aILz+f0vefwgldexC03fp0Pv++v+cnXv5EnDh3md971Ln75F95M3GnzIy9+Pr/5e3/E977sFdx22+1883P/wA3/46P8xSdvJO516Rw6wOf7KX4Ycs7pO9DDPhUpuOa0GR45scwjx/s854LTaHUHPHpkjqsv3ofvezxyaJ4vPHyS4WDANWduZr7f5wu33IuUiv4gZmm1zUTVibmuDDL+8mt9Kr5HzZd89EsP8tEvPUQ3yfiBlz2PD731Z/iB1/8mD+1/kkgJ+qmrmn/sgx/g4vPPZu+eXdzx5fv5am/A+4Xg7K1TGGs5sNAhjEIalYirT5/lwMllvrn/GBVPctnll/GKV34/b3/HH/Lxz3yZT3/pPD74wQ/yS7/0S1x++eUkSdG+9h1Qef/gD/+QD3/kI9xz993MzMwAkKfxCHQCOHDgABdeeKFr+8hz/vu7/9qJI3se7//bD3L+eeehhOXDH3w/CwvzvPtDH+PY8eMsLi6w482v4+77HuADH/8Uv/Irb+XQwSf5oVe+jD/6k79grOnAq7e+9a288Y1v/F+bUP8PjtWVVfIsdW5fVpMkCa1Wi0qtAVJx5MgxqtUKge+x0moDlvGJKcJqDd/z8D1vBCCtxfOCNeWSX9ZrPWVpWoBdTqDaWgNSOWBESue0nOckgwFKCjzPuRsPhjHDOGZxcZFKpUq9XqdSici1Js0y0ixDFFqgge8MXLIsQyk72iwnacri0jLGGKqVCmONOlZ6eGGFSqWCHkpyZalWQjw/xAsj8izGoknj2K3ZBuJe2+l1hiFTE+Ns3jDLzs0bOHYsIc9gLHJiyZ6SrHQGVKKA8WrIiZUeubUESqCNQVtJtRoy3qiglOLIXBsh3KZ0YzNC4DSLUmOpBB6nTzdItCHJchaXVpFW4iuJyQxJaki1xstylLFEQM+4IqwMJMo4sM1DE1pJxcJqd0Dg+4yN1dmmPKaSjGOdmDhLGGhNs16h0agzPdlkatK5hVZ8WF1eJrNOHy4MJOORRz30yFEMjURY8LBUhSaNMwbDlE5mSLSLpc3IJ1SSyJPEmSbRhk6S08ksibakuSb0BYEnCQMfC+TGEqcpmYXB0DkrUvxeWosnBZvHXeukUj7LS4ukeU5UrTC1cRv15jg7zzyLJB6y3OrQWl0hyTLiTDPs94gl5EnfMfnCiCTNqdcjokr1/8Gs/M6PUzn0qRz6VA793efQ37m4OGuucSUIVAa9NSbT2hSwrDGZ1sQN19hLtqjIYMt/r32GQ/7XvVtxU1jHAnLgyPp2PTECkKwrARW32BavX3diogSbirMpQZ7R+TH63PVX4NtcFPdaaxHKQwUVas0ZJmb6WCSTK6vktu3sFHGuGzaHxBqMAZlb/MK1riohFw55HXXaWkeXdGuaRBffybGaCmEyIcAqV+nAUQyr0rXT+cK19okC+S4RdCFkIWYHgqKlr7imQjz1a5eIvfuHe7C8l6U4pQQ8CT4Wr7ifpVy4EoLAU0gkOoflTkZiNH2d0441Wer6eKPicnsFqm5FUcHDiabbYgHQQowYY0KIUbuiwAX60LqfcwG5dJUEKRzCqwqQ1k15WehJKRCSTBvyLMXmKaEfUKs2qY9N40dNpBdikCPhPMHafV8bKs985GkE2IqiKlLOpVGlRFM2gDpByaJFtpxPpoyWBQXYrTiM7sAoWDpRS3CgsVg3+ZTnYY1EiIJmbh1CL0rLVvc0B2bmjqosFGulhqeh7GBH30usux/WWiekr93vpHIV3qIrwQmjqpJSKzC6oCAX39OU86QQVjVW0+v1mRhr8qJrno/NMk6cOMr+w3NMjoVUIp/pmkcahGSNgBxLy0JPG+b7RdLoFa5BQKQkoaeILJgCCEaJp1RUCjlKUgMYg7BmJOgvEfjSOsqrdU40OW49dqNblqMcBQihiztrCZXT4OhoSyuO6ciMzZsabJpssLlR4+DhRZI0paaUs0vONAOdu0p0eTOLG6XK8UBR+QJkseaWcplSCCSKyLP4FkIP6tKSGqcjYEVBRcdiBBgrUMKtdIlR+Eaj04QVkzDQGbGxjE/UqVY8GjWffNhlNY3JcsW5iSS3Hjpx7SolaC4LAHskIOkGSTGG3Z9nOvj0jne8g2dfeRUvfelLAdi7Zzdv+cVfYNfu3dSqFd7w0z/DvjPPJAgC/sPP/Rz79u3DaM2LX/IyOt0uX/3ql3nhC174VI0HaxkOB4W+AyAEQRgyMT3j3KykoNEc51U/9EOcdvoZJIMeV151FWEUcvPNN5OmGe985zu58cabyLKMa6553lNasJ7znOfw0pe+lC1btxKGTqfmJ37iJ1hdWWbDtj30Bn2SNKUxuwEwHHriURrNCYZxzIm5E9SrDcKoRqItY40qgaf45h130ahWOOfiZ3Hsycfwg4BdZ57FkccfZjCM+Z7v+R46c4c5/NDdnHveBcxMjnP23u2QdvHjFTaJNu12h6jW5PU//5+45/4HuH//47z5zW/m9PMvJYwqjJ/3Qh586GG+/rWv8/offwXG5PzTx/+emaqPUh7XP3iQxc6Ape6A+6wlTjOW2n3u2n/ItXbHGVtnJ4n8GbQy9NIhrX7CWTs2YycFsxumOXL0BEHgc82FF7I4d4IkSTn3nIvpry4z7Kxw6eaNeELw1x/4JINWi7FAoaIIrVK0NpxsD1icn2cmEmybHSeebCCEIM9SAk9y2RlbeOJki25/wKG5FcbGGly+eSNjkzNcdOnlXHjZs/mlt/wKd919D+9///tRSrF161Z+5z//Z3Kt8X2fA0dOkGjL1k0b1vIA4LrrruO2224D4Prrr2dleYV3vvOd1GrOKn3u5ElOO+00XvOa13Ddddexf/9+4jgevT7PcwJP0aiFVAPFkUMH+Pgn/pHdO3ewa/cevvC5z7B58ybGG3X+7uOfojk+zrUvejFf+NKXyLOMn/nZN/HE3Con7n0Uay1f/OIXWV5e5l3vetf/kbn3r3WsOV6B7/mOTVOpopRy8bPQp1Seh9MslkjPJ4oqKOm0Uj3PwyqFKITHRw5VRZ5dxu1ca/LCQdoVHF1rjFAKKxWmWLGFEK7VtmCelJb2nudRbzSQQqLzjGToYnalWqOmPEo3ap1nZGmM7/l4QTDShbJGo5x4jYtfUhEEyu0Z4h7SUwTVKpVqFYREG9deaCleU+QYspB9yPMMa6BRr7P39NOpjDUZ9HoMOkuYQU6Sx6TaMEg1UuWkQiF8RTUQDkQxltYwRXg+gQ/D3CCsxZPQi936l2nDUApiDdJL0daSG4MWHnnBZMlzx5qIpKQSgmctSlgCK0isY7cIafEVNKxBCuem5ysJngLP3QMptdOacT1ChIGHFM4ZejAY4nuSqq+oRz5ZJaAaaMZDRd2XpNqQakusQQmn25L5sjBigqqwRNbl4b5ybYYIqAaK0DgATSROb3agLYEUBdPEnS8ShjjdmczaYkPsiuSu80C6tk8hSRHoJCXKNWEQMtZsUm2M0Wq3SeKYLE1cm2gYMqYULeXAFKUUxjrzoTRNQSpS/cyOwqdy6FM59Kkc+rvPob9zxpMtL5QYgUnGmrXN97pPFAWCY0egU0Hhe/objl5qv+X1gsIpzZi1yc5a/6wtP2eEHDory/Ln9fjbt4ACFkfHKy/U066WWPe68qGnAmeUYN/apZEK5YdUGpM0J2NA0jxxnGHm2uEya8lySyYsWapdK5p1wIwnnY2wLyAQkLrTI8cBOuXAy+3afQ4EBBIiqQpqnkJZ4+h5wr2fKl5XfiFTXENRDH7XZSdGSOYIgxUuUSmvzWiZKpMcIdbdW4GyFmvALwAehCUrgrESjpYskWgt6HQzhkbTM5phYnDSVRLPlnhz8YGFIJzDdwRWrHPeKMA4WaKFwtEUhVjTrtI4d4QS5fdwQJlz4yjurnCIvhHO0U5nKVZnRFGVqNKgWptE+XWQclS5AEfnfHrlg6ePsWfgUdKBhRBo65ha1hjHKnT/wAUhlwA7SmWxepcBxYoR6LcG1K4BuCXDMM9zlFQj6nA5H+Wo8lI49RTrA4WLo1w3p5xOm8Gsu7YlMG2fNnFL8UZ3Ho4m7gL32v1RRV+6No5ZJ4u+ZyzovGBY4qrHUiiksATKL9Yb54jVrNe55tnPpr2yzH0PRnzmS4dIk4TxmsfmTVNQ8TEoVgcZg9QwTHLMMEdZqPs5Pg4QrvsedSuoIUmUA4g9UdCbpeu/9rBILDp390ZYgyddrQQrRgFAIMkFKGvJlS0EIUvrVjcnhHWrmcatOUII0szQMjkrQnDmxmk2NOo0/YAHHjtMludMTtSIooA0z+kP+tSEwi82SGU2NAKfhav22tGnugVSjZYfSVBU7MaEoKmceGSiTcFadAluOeaUdHN9KBRJnpNoSyc39IFMSLaP1xirSJoVwdHVIQPj0Qf6mSTVApMP0TZbS+qK8p4QRdZUCk5a1iqBz/A5/Jd/9dcYCy996Uvp9Xps3LCBX3jzfyQeDNB5zk/91E85FqbO+ZnXv448z4kHA773RS/moYcf5P3vew8XXXghQgjGxsbodXvkeUa9Xh+BQgBSeYRVj8FgQF5sQq+66mqufPaVdFYWaDTHMcZy4403MT09zZve9CbCqEKapvzqr7wFIQRzJ0/SqEVc89zn8Ja3vOUp3+PVr341aZpy8uQc3sIJhoMemzduYmlhnhOHn2TL9p3ktFk5dpRmY4KgUiPJDbVGAx/DfQ/t59KLL2bvvnO59+avMTY5w9mnnc3937werXO+90dezxf+/v0ceXI/cb/HZLPB2Wfsprsyj+4ssCPKaK+uEI3P8po3/gd++qd/mm9+85v83M/9HLPb9tCc3coV19b57Je/yu37D/GTr3s9yaDHdR/+CNunmtSrEXccnB8lqIcW2oUtteXA8RU8JamHkj1bZ9kwMcaBI8fIkAgvYKbZIKpEmMDn+MlFokqVyy88h9tvH7K02uH0cy9g5diTdOYkV1ywj0cPHuE9H/oUEx6MVXx0JcII6QxFhglLS0ssewmbpxpYqVCe5OCB43hScN7uWVZ6MYM4Y6mXsmvPDOfv20Nj0y72nnUem7fv4WfecD433XQTn/jEJ/A8j4mJcd70c2904AHwqS9+HW0tY7VKoQHijn/8x38c/RxGEYHv8xd/8RejPAngwgsv5K1vfSu33norjz32GLVabQReWWupVwKmx2tYnfDkgSO892/+hve+5z3sO/MM/vB338m1134Ps9Nn8enPfYGXvPjFvOY1L+ANP//zbJid5V2/8zv84Qc/zjfufgBjLV/+8pf58pe//MwHnopNWum6K6UkzzVKFTtDQSHU69ztKMCiMAwRWJKhc4IUQhQuuwKsXWNAFc5teW5IsszFtwLk8nzfVfClVxQQ3UdKIZCBP8qTXRudwPN8xsbGyNKULEtI0xzf96lUa1SqdYSQpMmQbntIEg8IqmN4hRNeksRgDYFXuJgV30tKJy6e9DOUFPhBRBhV0FqTDQcj4KmcW6VLnsWic421hlq1wq7de6lOzLC62uLQE/uxyx1SI8i1ZZBptMjJhCJQkoqviHNNqg2tQYb0MkJtSY1wbnHa0I2dLX1uXO471JZcpKPdhBSKHNdqFVunneT7ktCDUBgCaVHWdS4sJwYhXJdCgCDXxmmrKMccMqLUZ3JxzlcC5TkpCGst/WEBOkXOpa4eBZhqSF0b6r6g4gkGvZQ016SZxVMKlCLz/dHGtuK5PF7gvpMFtBVEvrvLoSfJhUFmliw1eNKxpkKcBoynXD6fGYi1JUOgASvXgCepFLkVJBpklqONIQxDGo0GQaXCaqtFnqYYo6lVKkRRRKVaweROFqPI9t29zzKsSP5tAE+ncuhTOfSpHPq7yqGFfapv47943HbDN9ZQUVGirGbU9mQKlNZaRihoWYVxm/Z8pMqv1jnRjdzu1iHHshg8JdCxfmKUk4IyKK2bKGadLtEaewpKK9qnA1Blb2qJqY2ALCGeAtiM3t+6IDUKiEKOzklIOfp9POzT77a5++5bOXT4SQ4fOURv2MMxoyRpapz2d+4YOr6AisAt+GJNf8kKS1DYj0qBYzxZiy9lUaGQTigcB6qsiajb0Riw5SIjXBtcOXBKUqajbOriHpX9y849z12jNdAN68A6YyGzFFpJxf21ltxYBlaQIcilTzWqEAY+jShCC1f1WYgTrCcQgYdUrlUyG8T4cYKX5VR0XjC53EcaGAmFF5y7UW9sKQ4vyrFRLsYFdmWEs4UVUuKFEdV6jWq9ysymKer1KvVmjWq9TpIbFlp9Ht7/GN1enw2btrNj12ls2ryNsfEJEGX/sylCpRhdZ631aA58/4+8+juZSv/PjjtuvGkkRpqmWTFfrQtuRfWibKPNs2wErLmkeG3OYynEZs0oGK61XLr5oZQ3EkbUxokOlp8npXTVTuW7RDnNRnaztphjxthRgl0Gh/Iz1h9r9q12bS6u+7vcLLnEt5ivds1/YRj3cdTjQizfGpI8xRo32qpRpVh4DVZD4AfUanWkEKyurnDTzTfy9ZtvZP/jj7OytELoQTWAmekGYRgSRlXXgmrBCie2mmuLZ9x8yY2z2JYIlIWSR2itpiosHpY0zQkFhAoaShVVEEEgHLgbSvCFwcMSSYlBoguGpMAxD7V19NtYW04kOW1taPkBu7ZMsmNjk6b0ODi3yh2PHSdJMqYaVa48azsraUJ3GLN8aIGNocdM6JFaB+QGUiCFE7vV6BGQL/FGwUractYK0gKsD6SryBhj6efOGcNVxIyrsGroZppBbljONH0hwFdsmW0wFnlUfEFreZVOL2G1m7LztHPYuXMXV191FZOTswRhyCAerO2sRmC2XVsnRluKNVMHLLzq1f/+X2Oq/R85jh87Rq1ep1qt8qIXvYgdO3bwvve9j/e++y/ptDv8p19+C3//4b/ltm/eyKt/9NW0e31OLC7y/d//wyzMneQfPvy3/Puf+hm279zN/MICb3vrW/nCF77A9ddfz9atWxkbG3vK57361a/mG9+4EZd4lo5Zhje+8Y285S1v4dnPfjaHDh2iWq3y3ve+lyuvvJJG3Zkv6LTHsdvex9iWC5nY/Zxv+S5GZwx7bY4dOcLS4iLdxZNs2bWXrbtP58bPfYJac4J9lz6Hxx6+H53n7DntDDqLJ0mHAzbsOYsH7r6NB+6+lZ98wy9w+OQ8f//Jz/DaH/1BNkyNc+SJ/dTGp/E8n9YTtzO57Qyqm/bw8pe8mNM3VnnLT3wPOmhQm97GvqtfxUMPPUyr1eLyyy/jz//8z3n3u9/NP//zZ5ndMEucJDTGmlhraa0sFxbugiTL0cat/ytHn2R1YY4TRw9z9pXP5+Tx4/zer/wcsVUMteX4wio/96Y38u9/7NW84t/9IEvLS1SigMnQOdfmQrHa7SOM5tKdMxxe6XN0dUA9CsjynH6cFG3srhp+xrYZpsaq6DRjqdVjpTtABf4ob5j0BakxHOtl/Pqbf5qrnv0sok37EDbH5gmr8ye5/qZvct3HPslnPvMZTj/9dJaXl5mcnGB1aZFfe8OP86rX/Awve9WPMYxjPvrRj/L23/xNFhcX15hx6463v/3tvOpVr+Kaa65haWkJAOUHvOh7X8Rn/vnTvOIVr2D//v188YtfJAhce2GWDB3AIhX/9PnPUQ1DXnjVs/naFz9La2WJK694FrI6DkEF252nUm3QaE4R1Jv028scfehWdp5/NccWW7zgmmtGAOl3mM7+PztuuOEGojCkWq24Nrgir0iTBGvdxl15HkIo4iSh027Taq2ybfsOpJAMB328wkHK9zyMzrClc511uVKaFhqXhWiz53lEUTjK3UWRKzvWiWO/K6Vcm5B1luWllqYTny7kGAqXYiUVYVQBIUmzjNbqCr1el1anQxCEVKpVJiYm3SbVWmrVKp4XoIKIXq/HcNCntXCcsFKlUmvgeRKdpQwHPbR1QtbVeqMoQpYO0MUFzNPiu1nGJqdJ0pRHH32Uh++/h2OHD3L44JN0BzGDOKVSiQh9Rc1X9OOETBsybWhUQqqhz3i9islzcu3c3MriuFJOskMj0HmOtIapiiLJnIaU9EOqgcd4JaBhEnw0yuYYIDGWQ52MwFeEvqLqQz/RLA0yztg5Q+Qp4n5Cq6+JtUVGFSqhR+ArWv2EziBlpTukMTbG5FiDM3ZuJuu3yeMBw9YqymZ4VlNVkOWWYWbJtNt3BAXAlmlLqnXhkI1juOH0WBVO+Fxi6eUuH1hdp2XlQDSIShOiwknaSqcp1c5dq2+cW4IwwAqJlR7bt21l8+bNXHjRBQS1JlYqWqstQt8n8N1mO6pUqNZqLK8sI6RkrNEk06X2WIYMKkgv4KXXXvv/boL+T45TOfSpHPpUDv3d59DfeavduoFZjMl1tEOH24rR38VJSXcVpcXhjiMAwz38dBhIjM79qTOjfN3TgajydSV66P5aA5JsidJRIsxydCGfgvYWr7Hl0yku5NrL3ecXwNLov3WgxxoLy1WKgkqVamOCsNbEC+uY/hBrNb60+J7ASNACtHZsIYzFSAewhMU1VjgApmQOecUXKxlNjvEkUAUia4wdAUHrr2pJw1tjNK0D2qwDpExR6VkP2T0NEB9tPhAFFRAcml8i7KIQLRsBc+71sXaaSzn/H3vvHSfZUZ77f6vqpA7Tk2ejtKvVKucsQCBAgZyNhcFkbIONsbGEMQZjDL7GNsEJG5OjbYwAkUFCKEsoZ6Es7a42zk6eDidV1e+PqtM9i7Avvtzftfz57NFnWXamu0/1qfTW8z7v81gIBFEcUKvHhIFEl5q2MeiiQGtBUVhH5cSh1tLavgj8ynaLFW3r00sZ/N5N3spW2CKNhrJE5wV5WpDHJbo0IFz2oNDQbI0S1YaZWr2OVmuEKIr9WDEDkU4GAOYTPcj9eZcx1tHgV7S91BphDODo833Q1z+7qpa8cras9NdcP7isy0pHS6p1gcG6UIHEVWbWaFd+CvgMkntrJQpYvV0I+qKI/hUMRBAH5QXVe/vgOCvGgn+N0fuuX9Yv6Hig2VjTF/lUSiGFcgXk1vTHnzGGXq9LktSo1eocccSRpGXB6jVr2fLIVrJemyLrIlTpqPDLKcJ/TyNc9joQjuUopUAhsdJ9n8qJBD/PMutq04tAUUrIBfQMfr1ymUkJSFP214qmtK6s19f5u3JXb+FqoWcESzLARIoDVw0xOVwjkZKHd8zx2MwC8+0ugRBkZcHccpcgUTTjkN1ByLIFVbh1LpQQWXDkXryVLz7A1VSU4SrZIBAU/sFL1ykYCz1Trli/3cZeGEspBDpSxElIFEiEEkhbkHZzMmPo5IL68ARTB4xzzHGnsmb1GibGJxFKonVBRXfHZ/zdHdyYwWeuBgsJj1/snoDXQi/jvoce5tGHHuSoo47i4M2byfOcAw/cwNLSEtu2bWVkdIwjjz6ObTt3o4KQ0ZExHn7wfnRZctIpp/Poww8yNzvDSac+mUajgVKKNWvWPA50ApiZmWHPnl2Mtpq0uylplgNw7XXXMfWFL7Bz507m5+eZn5/nxz/+MTt37qS/uZuccs+dHHf6Gk7d6BywtmzdyhVXXEVSr2GNZml2moM3b2ZyfJyyu4QuNYvzczRbI1ihePSRR6nVm+RZynXXXsMBa1Yz0mqx7dGHAcGGgw/jjjvvIi0NRx95GI16nbn5Bb757e/yrBe8hM2bN7NlegdCWGzR5YynPBndW+B719zFM46dpCmW+elPLmW53XUHB2DDAQfw5FNPYXrHVorOAiqQzO94mCCMGJlaz+49u2m329SThCxzZSSbN2ygVq+z1Ouxdt160Jo4ikiimERbHt6xl62PPsqtN17PcruNEjA21CDrdpwTkHXlJtZatk7Po6M6k1OTTE/PMNYIOXL9CPfsWCAQcOy6JrMpzC/3GK5FlAgyA+ubMcZY0lwzNTFMIGC8ucyaiQlaIxMISkpTkmtDmmYsLCyyc+dOiqIgjmPWrl3LZZddxm233Mwd9z3IM+YWyPOcb33zm1x5xRW+b3/+NTw8zMaNG3nVq17FjTfeyPXXX8+LXvhCTjj+eO658w5OO/VUDjxwA5ddfgUCiKKQF73g+a7ECkFkS2IZMjUxRhS4Q+q6DQdz/W138eCj2/i1F53L9N4Zbrv2Wp71nOfR7Xb5ziWX84bNJ9FqOE2Y008/nSOOOOL/9pT7v34VRUHonenKsqTSR83Snhf4LlFB6ESDhQMmw0BhtUYEgjhJ+nsoPu50rkzgAjOFDJywcRDSB57iKBzsldZL5VqL1cZpjBjjy78ksQrAJ9mETxSrIHCSB9aAMe5QLYSz1LYghJs/0u+lSlRlLtYLCwdOdFgKB0LUm1gh6WU5InOlSGFcI5aOZZClPccIE4I8y704syAOA8oyY7ndJmoMIVXA2vUHUKYdhpt1FIY9c4vMzC+BNc5SPo4IUVCW2Cx1grvuCVDiGEHabxXGWIxw65WQ0u2bRtDOnVu0QVCUruRGW+ihkda5CWrrDG3mU0OkIdLQLSAtDe1SML2YESlJnhYQJoRJRGN4iDzLWOqlzC11afcyltop2ro9cm6hSV06y/pSBnTTAp2XDIcuRiitjy6sxZSaTu40nHqF9iChIIklQeC0iMqqnUVJr7RkxpJrL0hsLaU1ZMKSSlfKFCpDYkAFbq8UtpLocGVYKggJAkGrUWe4NUSrNYyWTmC8NdREGI3AEkUBYOmlKUEQuPhKQhJEGGPptlOEKZGVyvYT+NofQ++PoffH0L9cDP0LA0+DQTsAnJRSCKH86Bywipy4oAUhfWlT1Rg3AfuD1b++Aoyqa+WEdvWhdp/J0QdA+gAS+0wcN+4HT2PQXtlnZVEp+3twpGJmyRUTvGJgOTaT+1vhOrwCAoVwg0Abh1xrbZBBQJzUGR6bojm3SNKcp5ydx2qHoyaxAiHIFWS5Ji8teWmc04cAqQShw2i89pIrPHSbpXOoC3H6Tn3xcLxIGd4hQ1RDwFm1Vj+vFhIpbL+vjAebPKnST+BKP8lSbQXOLEUgrBuSfVKg9Qi5hNi6hUBJVxtrLCznBYUALSxhI2KoETPeqpNEAXlegC5ZzjKKoqRnDBLpFhUcU8ta59AgVnbrPkhTNS7xwY8fsxakD7REUWLzAi0VWS8nimOKwplouu+umFx9AGFUY926A6jV68Rx7Kayd5kx2ng8tdoUBpmBJ/aR1V9CePFDs88zcwHwAFhWHjh0C5sGW7EUA6QaWKs6y9XBRmixXmywKkXs4+B9ZqKwriTWaE1ujNOw6DMgbb9NFdpfaZKJyl3CGMBlyZwWxYCFKfdFifF8OSokXmu3mAcq8u1yAV3FcNSldgE4kjBMCAN3QLBaY60L4rQu6fa6dDod4jjhiCOO4eBNm+h2l7n7rnt4dNt2tmzfwYNbHmZxYYG52Rlieijh1BZHm3VqcUgYBoRhSBAqeqXxmRvjNggpEUqR60rMM6AUghxBu5P5ANc4611jybMCa10OZ0jiLKZxtf0Sv44IZ+vcs4rGcI3RkRqnHrEW3SvpLKVcefcWulmGEJY4jii1YdvMIoesG6WeRJRRxGyuWSw0NeWBb2EprFN/MP4ZWyvIbOmyMRYy40UrcQ4jxgpKK5F+tcnx1GAEUlo0hsJahhoR9SRgfChhOAmQxjC9Zy97Fzosdwri8TUce9ghPP2pZ3DyCacRhhELS0v0em2KsnDBkqlKwUV/4ajGKaxkTjorhX7Q9wS9fvyTm7ji4u/z3Qu/wq233MLmQw6l3e3yjLPOod1Z5seXXcoJx5/Emc98Fn//sb/noA0bOem4Y7j0h99j1Zo1vOxXX8kH3/dulhYXOfGU0704qOxnUVdq+FRXHIVsOnAtW7bv7gNPl1x8MT+65BJgkHT5yEc+8nPb/IfvGOfkp70YJUNuvfU2fut3fpfxVVMIa9mz7VH+6q8/zK/8ysuIhGFpaZGH7r2HAzZsYufuaS770cW87OW/Srfb5dOf+hRv+Z23sv6gQ/j6pz/BKU96Ms96wct55zvfwSGHHsYfnH8B0zu3c+dt9/LXf/dPbDj8WA4//DBmpneSzWyh2HYL73vPu/jW9y/lTb/xJk5850mMZaP8+NLbqA2PMLp6HSc/9WzOPfuZnHb80Vx7+SU80F6mKHPifIlGa4SNp5zDlVdfxdat21i/apLFhVnSbpt3f+BDxEbQi7aioogoDonqNdatmgApueX+bVz+40u584Zr6HWWWTMxylEb13DZLffS6aVMteoIqchLw117Ohx75HoO37SBS6++kQOmhnj56RuZv+w+hmPB28/ZxAe//yD3bF/k8AOnMEIQRQGHrh0hLQ17FnM2bTyA1XXFAWKBVaMjLGWCfMddlEFEKUPmZufodDqP66uPf/zjXHTRRUilmG2ntNtt3v72t7Nnz56f07Puqtb1Wq3GRz7yET7+8Y9z00038SfveTcjQ02+eeFX+bXzziMtCk465TSytMvoyAhnn30WjeYQxhpW1RVRaEm7bYabTaIwYNWGQ7nh01/iqxdeyOt+/ZVsvfNevviVr3D8iSfw4CNb+NgXLuIZL3gl69evA+AVr3gFb33r7/zXJtR/w5WmKUGgKMuYNO2hjUYKWFpaosgzJ9Ydx0RRTKPeQEmoJQlGlxAENJtDdJaX0N7B2Nmra4wX+hYqcNIGPt6NwtAzpFySTxuNNVUKEvIsdTGBMdQaQ4RRSJzUKNIuunAsLBUqgjByxje6cALxWc+J2HrBcuXbHScxSRI7kxirKfIMIYa9QQ9EoULYiCCcYmFpmYWlZYwuaNTrTE5MEEURRZGxZ/tjqKEhZBTS7XbQxsWe8fgUeTdlenoaIxStkREOOuggpkaaLM9vpJFEPPrYTrbs2MPszAxKKeJGA5v2CPIUaTVJoAilAGsoSu01oVRfF0sBQSCoxwHGWApbspiVvspAkJcl3bxk1mZESmGNIc0KisIxYFAhQQ6BMi4hbAUlkof3dFzZjBCsXz/G8Ogwk5OjbN22i51zM+ydXaSXFaR5SS8vybOcZqhYNzFMPQ7IRMhs2mFpKWM4gkgpwkD5hLo7EC6nJb3SiYdX55gxGTIUSGpRSMdAryyY65bkpfGVCoPqBa39nmm97pMSNCJDPfZi2dIxK0MpKIwhEJZGqJgYbTE1Mcb41GqWOh20NkyNDdNeWiTtdmnU6vTygsXlDiOtJoFycWOzVsday8JMj8g4B8In9LU/ht4fQ++PoX/pGPr/GHiqUFspVyCrgBVVCZ6z9TQVoor1Fq7GiWyv+DKiAoD8RB3cg35QvBJ0cg/EfdGVYmi+3zzK7D/D0q/JtZb+ZK70oKQQDm/0yOfK7+Y+UziMauVD98BTBYioFQ1wIJr7/mtWrUYAzXqDSCnm5meZndlN2cmRwhIEkki5xd2GAdZCz1oyC8JYhHY0QYUrx1P+XomxREoSGqh5kEYJqFwNXNbJPc4Ah4pW7RXVHzkAchQWK1zNrvWgksTVjJr+EPPIvF1R5ub7u/p39fyEFZTW0i0KSm0oAkkQB4RxwNRInaFazGg9IZKCFEEvjiiiEFOUpD3pQDXr2l59n2qMCFb8LQdMJ+t/YftPYQVSD56OmqMtBJ0eUS3BWFBhQr2WsL4+SVJrEoRRn+lkjLMOrkaVyxQKEF7QjUEm4+ec2Z5wlxMqFaAgzzNPr3bOQtI7I+iypCzyAcLngxpXSlvR0V2Pm4oWiMBa3Q+i3e8GvMUKGRc+6FJC9UtDrbXosnD38XMviCIvWqopdI7OvVOIL+eVyj3/PCtcRlMpoijqf8+q7FfrwaYarnAeqYBDIQSldiXAuUfxlQpJgoiiN0/a7mGFQkVNgqiJtgaDc0K01pCmKdt3PEYSx4RhzAknnsIxx51AUeTsnt7NwsIiu6f3smt6muXlZWZnp8mzlLLISdMu7Tyj6GSY0gX+hdZI0cWNPePKE1RArRYTB+7wUK8phAgcBV66DE87CzBW9p91lb1EDjQkLI4GvipWrBquUwsVDzywg+17l9g120YIQ7MWeecSSEvNnoUO442IsWbCptVNtsy02bqQUbOKSEEUSFQo+s/c493EkfDor0Aap1sh8Q4hfvKWpdOEiGwVLFkChRsbAqwu0L0e00tzTBtABET1MTYdcRRr1qzhpJNPZnRsnNGRMWYXF5wegS5wJ5QVg74fQzkquMEFQH1WqLWAcWVTK/eSJ+D14mc+ldlH7uebZckb3vRGzjrrLN7//g/w4x9dys7HtmA7O7lb52wdX8vLXvh8fnLDTbzvA3/O7//OW8izHh983x/z9LOexYEbNwFw/gXv4MUveSkve9nLeMlLXsLv/d7vPe6eGzYcxKe/8G984H/9Ly688GsAvOpVr+Jtb3sbAJdffjnvfOcf8R9B70IqVOB4sM94+tO59srLeNvvvY1et8dFX7mOL37xS7z611/J77zptbQadWpxhJURE1OredoZT+aKKy4nz3Pe/Nu/zdrVU3SXF/iVV/463c4yt996Pb/z1t9l+2OP8d53vYMTnvRUxqfWcvVVVzHcqLG4dxerDz2VybXrmVyzjqs+8X7GmmNc+oNv8w9//WcUe27ldUdO0qsdRlFMseXhh7jvzlu5765becmr3kTaa/PIfXdwxHGnEMU19k7v5bAD17NhaoJjTn0KJYLlbpdff81rOeGEEzj/ggu45JqbmX7sEc5+8ol875rbmVnu8JW/vYCLLrmeb116Pc8/43hmFttcdsu9JMJywNoxnnTcIVx220M8tGMGawxrhgJOWt9gdvNqyl6Xb1z7AKcOQ5hE/Ov9mqje4oi1kkd3znLSxlEOP2aSb9z8GKWV1Os1Hn1kC8utBtmBa5kI6rTCmKXS2cvLUHD2C17MbK+ACy/ap6/+4i/+F++44HykCrjooos455xzmJub+w/H48aNG/mXf/kXvv3tb3P66U8CLNPT067fhWDNuvW84jWvY2RsjEceecSVhVWyB0Jy10/v4errruaMk05kdnoPf/reP+W8V72GDcMj/MYbX8MZT3sG3/z61wiE5aAD1vHq836FZq3O8Ucfybf/7TMcf8LR7N7r2vePH/t7vvmNC7n8ymt+4fn033E1Gg1qtTpxnLBs59FFTlbkLtGV1Gh3OnR7Gd1ehvFC40IIsjRFCElzqOUOv9Z6xzoXn5giB+u0ekKlBg51gXKu0lT8JYmVoLWhKEranQ66LP0hVBNGEbU8d6yUMAEMRZ7RabedDo9fI7V1TH3tDxphFDIajfmEp6DTSz3wFZHnOdZCGMV9QKzXaRMHkrGRFktzs1BkpMsLNKdWkYQ1zFgLaw0672CX94KQSBVRqx9IGMcEUcwjW7Ywu7BIFNcYaTVZNTTMyXGDTYvLzC4scc9P7yOOY1ZNTbJ753YW5mbZ8ehDRMrFqt28xIgSFbjDsjUaS4mWAmMlNreY0u0nI0ONPtAnpSVAEAhFErgke5AkLLU7mEIzMtLq90FelKgoJmkMUWZdJJZ6qAjDiF5acN+DW5mZmWd+foksL9weJAVZUbDUMTy2yxDaguFGgi41uYaukXR7GiU0oTQE0rWhNJZeUR3ABUkUEEcBGsFyVroSubwgKzXttATp9L7CWtg/H+DHlNGazLpKgDy39DBEWtBMYDgJSAKFFZJavU5ruMXqqUmGh0ewQhIFAZqCbrsNCKKkxlK3R6eXstTpMTQ0BAZ63TbVOTXNC5ABQj2x9+D9MfT+GHp/DP3Lx9C/uLh4H37wjRAVmGGwtqIQ+m6zHoH7uY34eSd06wED98H/cQmT+/nKz7b+PX1AwlY/q9q5L2BkPDPJfZ0VrBVLX7CtKqPrI3t2cPu+3aSnuUnpgJYB88WAdQtNvVZjbHQUayzz83OEYUiRZ/S6C5jSgTIVbcqBOG5AGTd/cQJ2rpmFcOydSmQ8MJYQR5VVdiBC7sA0Rw2UOMDKVpPIOH6PwhJ4eMYJbruvJ20fOquWQveI7KBv9+lFAcIP+orvVgEy2jpNpwKDVU70NIkUSRgQCgHaUJYWXXiKo3Q6AyjHwNL0Mcg+sFndV6xoi6jGDCu7aTBWKwFD8EJ7WvdReSkkQoWoKKGhXOCnlAMAXd2zK7FDDOikfaCLFTf8H3JVgLBUYgXIK/rMB3DPzn23yiFD9gdIBT67d/ln3mfRrVwD8EDvwPGyvzRWAPKKnhyMXOGcBqVCSkFhSy88mXvk3b/WDu7RL/f112Cer2BWisFr+11W/dsO2lVptklhMUWHortAXpbE9VHAILwwaxDVKPIeRmvKMve2swG1ekLi6YFSCYZbIwyPjDE+sZpOt8vs7DSdTps0Tel0l0nTHmnao0xzdFlSlAUWN+7KoqDIMhfE5DloCUoBLrgwUmK8Hq3EJQCq/hO4eSkDQagkcagwOL2OUDmLbZ1Zdk0vMb3QZr7dIwoDlyxQ0gXY1pIWBQvtHgJLUg+JI0EtUW7tkAIC6dxSAKu9Da21GMqKWY021TgzWOklLq0TxnXGEZXdihN0lFISSkFp3FoQipAoqhHHdSbXHMSGAw9k3dq1HHjABneQkQF515WpWCyyMkuodvBqoVoxchHWr1uDy2L/k33niXGtmhjjiMMP5cwzz6RWq6GkZHF2BqwlSRIaySRzy8vsXXqUdWsmqdUSRkZGaQy13CEwjplcvZbm8Ai33HITBxy4kSOPOpK77rqLNWvXcvJPfsKJxx9Pp9Ph7rvv5sADD+Sggw7iyKOP4ZSTT2Hrli3ccuttrF69uu9c1+v1eNpTz+DOu+6i3ekyPrmKpYU5et0VjBo/P0dHRzj5pBNJoogyzzn55JO58sor2bZtK3FjiDAOkdIlO6SAWhRSFhlZlrn1yQfY8wuLlEWG0SWNJKZZrxEnCaFS1JOIg9ZO0Z6bJl1eZmzNBnoi4oFd8+zZvYNopEB1utSmNjNUH2HNYWN0pjZhxtaStZexxhDXGnQ6bZSSrFm/kTwZwwQhQ62MtevW0+32eOjhRzjgoIPZsPFgWq0WUggW5xe8ropkKc1JhGY0guFGnXocESpFXroDQCwtU6MtRobqdHo5eeGyms1aQp7n7J1doDE0Qg9Bb77L8FhMlMQsG9N315ocigmVoJeV7tBjnPhxHNScAPTUAZRWkPa6EEaQ54giZWxikk2bD+GUk0/h3nvvZWlpCYCjjjyCzQcfjJCKr371q9x22237jL+TTz6ZZrPZ//eGDRs45ZRTuP3220mSmBtuuIGiKAgCF1ZGccyqNWsAqNfrnPm0p3HvvffS6XSYmZ2h3V4GwIgAESY0mkN0ez13oE0SV2JmDbt370JJyWGHHcYj2x6jWa9xyimn8Mhj27nj7nuxwNat29i5Y/v/L/Pu/+alvd26MS62MLqkyDNU5FJ5QshB7OFjPymcy52QktKDRI6dUmK9lksV6YgV+7HwBxdjnTB3dUA0xlIUuRcNL7wIsqUoCxCCIMgHrG5biQyXFEXu419f1SC8mLGPH4LAmbQUZenctAARhn2hZCucjpT2LKlABQShIosdi8aV9xmUkERRyNLiEp3OMml7kSCKiBNLgCaMI9TICHEU+0oD50ZnEVgZMDwyRnN4jLTQDnianKTZqLMwN0sSSBQufl9Oc9derTFFTlkW5FnmSoN8e9qLc5RZz/WddcygWqOJUAFSBRS9juuTKoaRbv4Ln/k1QCik0+PKJcIaEIIsL0iznNn5RZaXO6RZ7s1rRH+ts9aS5jmdbo8Ag5XO9UoqiTbOQMcl4L2pkpRe3sZrcuF0nYx1r7NYx1qzwrU/CFBBSKPR6Md/eZZRFDl5lnsXwap0B6RxjJVaqGhGAUZIaklEo5aQJAkqDCmM8bGVpCgKhAc90yyjKPWKsSlRKvAGVRDHMWEY9bWQnqjX/hh6fwy9P4b+5WPo/wLwNBigjxNKc8Okzxaq0EZj8GJjAwRxHyqWwLGJrHekW2nzvOKrVkivY5dUkMiK11jbtxHFU/6qSS+lE0czVVv9g5H9mlhfgufb5lBrN8n69Enw7XYC4/4nrv7TukGsKjFuUxWuCZI4ZmpikrGRURr1Grv37GZkeJhHHn2IhcUFFhbmsboAawhDQRAol6EKFFjZZx+BoACq9EDXzXLQBmVLJw5ZAWa+n1xpniXym6ww7t8B3n1OuOA+EBInpTZwfnPsJS/07p9pdXtfHttf5hBeI8p64TULuYUuhkJKbCCo1wNa9YhmLSKWAp2XzHUy8rTAWkefjAKFTiJ6WYTxwUBhq/JCBpS+FWO9ur9dMSmsb6cQg3aDGIB6+OwAEEYRKqwRxnXieKgvolmWpduoPfDkyghtvz7bbRi2v/BWm8YT/cpzV18fRSFKuQ3K6GrMuzkjg8AJ6ZWGqjwV3LMoy6K/wYoVJToIJ4QYyBBTuiytVBI0fSFFY51GgmOQ4QM0p/sgpVcG8yKnrswVyrLr3XR6CAKUVERR6IJeQCWDNacSUxxsys6pwm37np8ncIAxBmnBIPtBvJTOSUhgMUWXvDNDd2EX89PbaI5O0hpfTVRbRdiYImmtJdd70DoFTx3O/AaotemX3YZhxPp1GzjuqFGiMMCi6fS6ZFlG2ktJ84xenrE4v0CWZWS9nnPO0Ya01+O+u25m52OPsnXLFizSBcTCUfcL65xllHeYEcrXuwvn7BEJSagEiQhpBgHaQqE1naWUR2bbLHYyFrslzSSkEcdkpgQf9Mehy7b18oKHpxeI5xSHrR1lKlGsHmqwnHqgWYC0LtPRzS1l6XQHbGeZoiwptPabp/sv90KZ1vcXFmQQOEcYH7CEQUgZJYhoiFq9yfpVqzn04ENYs3oNRx11DLUkIggUMzML9NpdiqJwYxk/M6vo7Gc2TLeGm0p4hP4PAZCeOfvEBp6iKOa8887jvPNegbWG6Z07uP6KH3HyU57G+OTTyXod/uXCr3PdjTdQFD1OOOEkPvbyV3D7HXdQGxrh9975p8wtLHLn3ffwh2/7Lf7gD/+YJz/16Vjgm9/+LldcdwNX//gS7r7rbl760pdw8cUXc845ZwOC337zb/L855zLk5565j5tevKTTud73/kWL3jRS7jzp/dz1gtewY1XXcxD9975H3yLFc/YWt7xjnfwB+efz97FNnM7tzG381FMmdHrtNm7YxsHH7SBucUlfvi9b/HCF72EZrPJB9//Jzz9GWfx/Be8iNuuu5rV6w7g3e/9ALO7tzM/s5vrf/xthkNoNetsPuMlfOkbF/GFr/wrLzlmNffd9TBf+svzuOqqq3jyk58yOLhmKVtuv47jTzqZJ539PD7zd3/BQYcczste/Rt88pKbAMFvnnsSRhse3bKF5514Ihe84x285z3v4Stf+Qq33nobn/jUp/mdt7yZ2dUt3vDhP+U5h46ycWI1//6tK9k9PcPBU8N895o7OHC8wXOOXU991QHsWujypR/9xPVvGHDwAau4/7FpbrxvG6ef83xGh0Zo1TVyOKGRKM6qGz527wKPzHR567OO5vJ7dnDJ1Y/wrFMPptvNeGzXAsccvomNmzaz4ZSnMTe/xI5tj7Jmw4GUMzugM4+whjPPfDqbNx/Geee9nJ/+9B7AOdW95CUv+bm9ppTik5/8JMcff/zjfveWt7yF8847jyOPPLLPeOJnAtANGzZw8cUX8/a3v53PfOYzXHX91Rx56GG89LnP5/pbb2Oo2eT9H/xrPvY3H2JmZi9/9/cf4+Of+Gf+6J3nc84zn86JJ57Mqac9mde+5XdYs3o1f/dXf8X73nI+P/jhDx3LwBry4glepgPMz82giyGUAF0W6KIgS7uUPQd4JEniY1VLre7KkIzWDI+OY3EleUa7A0epSw8aGcJKMNeX5rggVlFqV4qXpj3KokCXriSs1KUrmauEg6XXmdElpiwphHAgmdFYo5HSgaZlqSm1JklqBEFIEDoxdKUksQLT7dEtSheqCgFCOuDKFOSZb68xJCogjCLCKEKYUTAlCgNFD6MVqJDte6bZvXMnKp1hamyY0bolKueI4lFGJibobdqI1obRkRGm906zuLDI9PQ0GzZsZMPGjUxMThKFIY1Gnd7mTWRpytLCHLr0h3FdiTBrim6brNels7SEDEO0sXQ6Xe65/SZ2bd9Gu73s3aMkh286gHq9QRzH3H7bbSwtd9Fe5F0BeZr2D+K61AitqQWQdVOMMaQ992zzomBmdsGXP1pfHuQOuYH05urWsrjcpsh6JHGEQNKoReDLs8qiBK0JA0mrWaNXGtJCs3exR2ksaaH7pZZKKYIoREUQGksUxURxzNSqVSRJQhCG9HquxHZxYYGlpSXyPKfIM3eukoJmKGlFimYSUBAQxRFhXEPFdawK6fRSoiDESuimRV9ou9PtIpViqNkgClwc16wn9NIMay1r166jcnN7Il/7Y2j2x9D7Y+jB9X8YQ//CwFOVxVp5ucmhPGlnUCdaZVCAPiomhcQKixXGl34NBrhd2dg+ilwhawNkd5AFsv17VlpMK9s0uKxjD3mGUgVM/exl8ci0ckjwgMlVtdGDDPTnnW+HQ70r2pn7ZLHP50rpsjdTk1MkSUK9VmN4uMXCwgLTe6fdhpam5HnXlXaZ0lmNWrfhV/1e1dBW2QJRASnCCaGVdgA6rRTbTlcgdB57d+CS7pM9vcoR+zheBDgNqUAIRKVZbweQn1zxHEsLhRXkFnoISinRYUC9ERPFIUONxNGBS83u5QWyrKTXc64HkZK0GjFI58qRJJHTYiosWVF6oEy4GtsVz9YjjgzyBgPQcyUzyZXjCYzAZyokYeg3zCQBGaJR6KKkGo0rnxcrxvWKmcjPjqInOlsCvF4aTsjWAcUWpbyLxs9kPSpgVliLsaUvmXU2zSD664HLsNDfSF0yQRCGAalO3XjOir57jhCVw6L1W5mrey/LAmzpbE9xY03iHDACFewz3ysasHPlGdTDV4BxvxSWyoXDUZqNcfNUSoHLj3qxeCFRgUIgsaYgS5f7mztFh2yuw2JnO7Xh1cRDa0HnKFVDBAEEbv3TxlL60kyjDWEYYrSm3W1T5hlKKmQonOOQ/2wpAxpJiBp1GQslBdoDm6ES1MtFJqOCWjrraPEqwFhYTEt2LWf9jGahDUXp1sZQSae5ZqFcdgFMIJV3hhyUCTeTiFY9BlxGdCktqAWCeiSJZOAzqgK0e0YPTy+RxG5DzY2gNJaiNP1yWOGfppSS1vBaZF8g1/VBECqS2DEKlQz6gXCYxATK6ZDEUUgcxSRJQnO4Rb3eZGR0klqtSRSGCJ3SXe6hjSXLnTCvqzLwc69aBoCK+rpyVRaIfubXWM949K8VGJQduKI+Ea9fe/VreO6zn82rf/1VCCFZWO5w4133cchxpxDFy1z6vYs4aP06jj7qjSzu3kojlCwuLvDDH3yP1vAwrWaDO26+geWlJT7wwQ+xafOhFIXTbXr2uefwxje9idWrV3P3XXcB8Od//udceumlfPCDHySu1Vl34EY+//kvsGnTpn6bpApIag3+9H3v47bbbufv/+kT7N2za592F0XB+eefz+7duwG45557KMuS817xCl79a7/K4Ycfxnve/0Ge+bQn8+LnPYv77ruPbrtNZmCyNczI6BitF7yIgw7aRKs1zG+9+S2sXnsAw+NTrD/4UIqsx1WXfodyaZYwijjkpKex/eH72LIwT/joIxyzNub8lx7PP3/+h6zdcAhf/tKX+M7X/p3rrvgx57/rT/jYxz7GPffczQfe+24e/Ond3Pudb/H0Z7+IIAy58borObQZYbTmsou/z5HHHM/q1av5whe/wB133MFrXvMazv/j91IbGuGFz38u+cxWxOw2fuNZx3HV7Q9z285dvO01R/HNKxe59s551k6OsnZqhOb4FNfd/TC75hzr55QjD2K81eDGe7fwghe+mDOf8Uz++qN/w8i6IV78vDP4x69chi5ynnvyweQiQBvD1j0LLHYytLE8uG3GZXGVYiyxjMYGYwRBXMOWBXu2P8r1113P7bffxad+eCNPf8ZZvOY1r+GjH/0I1157LR/4wAcA2LVrFxdccAG33HLL48bff5Ra+eIXv8gll1zChz/8Ya688ko++9nPcsE73sHTn/50/viP/3if177mta/lKWc8lSOPOpzbb72Fz/zzJ3nZi5+Hygzf/8a/c/KppzM8Okaedjj7GU/nsEMP4YF77+aeu+/i/gcf4tfPO49YWn500Rd542t+jde+5tXIIHwc0PVEvSbGxlBBgNElo2PjZFmKsZZ2z4EVSRwxNDSEUiF5nhFFEfV6g263Q5ZlLC8v0xoaIggCJ0buy2Gq2FYYSend6UpjKXKX8c+zdB+XaSEEQRiiwkoLKvIZe4kSLk4wRqPL3DOzNFGcEEb0mf5SKFTgdIaUkkhTUotjlAppd9rosmBubpbGUAshAzq5duV/ShEkEZ1Oh/beGZrNISIVEEpNujSLNZpSBAijkSpgOS0JF+cJbZtWTVDWRjDxBDIzBGGNWigYqiWYsqSzFGHyHkuze8AaCiXIlxRhVENYkFLRK3rkee6BAneAnpyawhpDnmdIFaK1pr28xPT2R+gszFIWKUXPlaktLiyQpRlxFNLpdsnynEDSZ7EttzsOPLTuGWZ5RplnGOFUWYrSOA0ZaxiqhWSFIC81UeBYY1GokDLox1+51uS9EtsrHatpBciBMU4qwwiWu4KoVqeVNBidWIVUAVIqQuUE6uNQEcfO5aw0FoTT7hodGyep1YjjBGstvV6P5eUlpn150969M+gsxeIS+LmBVIOWEiFCShUj4hpWBvQ6XWwSE0hJqzXkWXaW9evWkuUFvV6Pmdm9BEFAo9Ggl7oyTGuMPwc93jXziXTtj6H3x9D7Y+hfPob+hYEnKSvUdgU25BtSIWDVnKuAHtdJFVjimSIVVW8fuuAKUKEfQIif+XtwrQwxBpNkhRUkeCe0xyNwg4Vhxe/6GJekYjP9PEHzx10e/Nm3XSvKsfoTWVKv11FKEnir1pGRUer1BgsL83Q6HZaXF8nylCxPSem5zBMOAEN49pF04FOfGOYXH7dAeP0h69HpFUgl4Er3KghvxSCrrCIFjkqLdb+PhCDAEgr67nTWv7Yq5as+v7TOHSS3glxJbKAI4oCkFlGLQ+phQFlqikIzv9ihkxZ0ehkKQS0KiEJJHIfOwSUKKI3GGEnl3Kw8nbU/vlZ22uBR9GGo/msrBp7vpuoZhmHgg64IKxXWCkwF8vl+7X9ev4//o7C739n/+e+fAFfFKHQOhtIDa3af+dOffVI4YwAGjn7uvV5W3hqE/4w+KGehz3wUFfXSuwEagVUuK1KtDfTnmhvnrg9Mv+7d2TkrF6jvkwnzI6Df7sEcdUxFPZiLwlNa+90j+u81duX7HL3dbcZ+5xYCTEbW6ZAvpVjdQ2c9rJaEwxuQ8RAyaWAKfwDwG7m1jg5rrMHkJWWWucxXqPoZrkAFfgNRJHHiMsZxiLaOql+LQ6bGRshmh5gfSpzjUBBQarAiZ283JzcDmnOp/YEC4fYLa+kV5YAuLbzDTRBQiwLCQJFEiqK0ZFoTa0kSKhqxAhRSQ6QtSFcWspwW5FoSRxIrJEVpSbOSREGkHP3e4ux7J1etJ6k3CeMEhHMWisKQpFYnCEJCFRGG7rASJU6AMgwCkigkiiKSOGFkdMQB9Y2my8SVOenyNEVuyEuLFmF/TldMUFv9zwpQulq3qn6uEgkuaLP9TWsAKT9xr69//RusW7uWV/Mq5uYXmF9aIjeW+YUFrCmZ2TvNQYceycGHHcb9nRmiQFJkGfML8xRFwcz0HhZm9iCE4PTTT0eokOm9ewHYfPAmnv/c5+xzv6uvvprZ2Vne8IY3sGbNGhqNJsceeyxaax5++GEOPPBAwjBEhSFnnnkmzWaTCy44f5+5Oj8/z4MPPsidd97JAw880Aef3Pf5OpsOXEuedvn+d7/DwRvWMTYxSda7jW6vi7GWWuJKsMZGhomTGlJKTj75NPJSs7S0RBTHZGmHvbt2EJRdGs0WYZSQi4h2KWm3l5kaTlh/xIG847E9jK7dzNOfdAqXXPh5djxiefjhh7jssh9z++138NGPfpS9MzPcdP11PP+Vr2dubpaf/Oj7POVJT0aEcNOtd1CrJaxev5GTTjyRO265kVuuu5y5vb/J2OgIURiQ9+awWYdVw3V6WjCbGjZMJMQBzHdSNqyZpFFL6GrB0nKbTrdLmNQYbTUZH67T6fYYG5/gqKOOIuv1sCZhdLTFbCcnzzJK5SzMjYG5doaUgrGhhJnFLkkU0mokBKJECY1SIRZXwhMISzvX7F5K2X3X3axdt569e6c588wzfUbegU533303X//618nzHCklBx54oNcACYjieJ/xURQF27Zt48orr+SHP/whH/3oR1leXuYzn/kMl156KVmW8au/+qusWbOGKAzZ9thjbNiwgaOOOpq9u3fQWW7z4EMPkaddCgUz07tYf/BhjE+txmjN2OgoKgjZu2sH27ZvZ+u99/OOc55N3lniexdezItf9VscePDhLHV6NBsNasm+7XsiXlGcOOaDLmlGTcAShBFB6XQz4jCkVqujwohOt0MQhCgV0O12yH3ZiJBOSLzo71eD3RSc9gdCIErtxMPLkrLM+4lShHTsbX+IVUq5Uiel/GG5Yj/5PU077ZkgiDxjwLFtwAErxgi/lrpzQhg6FoEpjSuTDXOEcuu2VAFCKaxQdHopM7NzxLWGu7cQpL02pswRUY1ICZIoZN5IemnKkm3TmVUE8RJl2MWETVTDojBEYUAtjqhFIcKW5N024PRytADZAisCrNEURUGe54SBc1oTWIIwREpFVKsRRLFjKglBvV6nVosJlwPCwFAYS5a6+DxLFaUvYRKeYVLFANUBvSi9tIPWJPWGcwLUBmk1SliGaiHKS/M0IuXYQGFAYWV/P0tLB1YUWqO8Ho9LGrvKhMAdeChLTV0F1Os1JletQYUxKogAQRhIklBSTxzwVGjjZDykYqg1QlKvuzgkUGRpxlBrCCEEURTR6fTo6hJ04aEGd6C20jHTRJigQsfC6vV6zrgoDKnFEaJwgMLI8AjdXpeyLFlabJP7fTfXLmbJckmWZeR5/v9yOv6Xr/0xtG8n+2Po/TH0/3kM/QsDTytd49ykcQPMOb4JAuXq8T183X99lV2RFQBgBw3H4vTQqgG64l4Dlf7B5KgAhQGo4Gvm/YSSfUSGPjPIXZV15MrvYn1t/OD1fac7cG2tmC7W0xztCkEtHCXPsYsqlz63mVeLgtaGwqyoZw9CxsYnGB4epiwLOp0Oi0tLdDpd9s7N0G63WW4vMzc3R5b1SHtdsrSL1iVaF75+3/TZWMZahNYD0TrfeNN/SPjgwtt7Kp/JsgKt/bJlB4NF28pW1ulFuPI7gewznky/9C3wfeDYRBIrJShJrRFTSwLGhhOacUggBGlaMr/UZX65x+75ZdK8JCtKYqWoxyFhKBkREEcB9SQkE5ZcCLK8dOKV1hIxKLmz+wxvPx6rn/YZSq7/ta0QefrWxM1Wk6TZRCUNx/eylsqnTwgxcGL0m0alcWX9rKygRQvYasHmf8LlSbMeCAYXOFbzpp+hEG4+V9lUt0EKlzXB9OeRlKKvO4HfVJVSGKNJu94RRyniZkTfTVL4vrKCSqdCa4MuC/96MRjHXqzQWjc3B6wz/GY4WPSklP3fGV8+I6Ub89LTioPQlQgXhXfmKUvCMPCBg6bIXdlrlLTIe0tYGZKXGd2FBXoLC0S79yDEnQi+x+rDnsHQ6sOZPPxsunlJXpZYtEtIBhJLOVhvPAauM+1p0K6MN88Lv9YJVCDRtiTLC1dSbAxzC4t0ehlBkiClIAgc9VrlBlTQL6tQytWiA8SB6ycpFN08Jy81vVwz3owYTgLWt2K0cUxQTQXIWoRIPKit2LlYkllDMwlJwgiBpZ2WGL8ZKaHIpMFayYEjIaM1ydphRa4tSWucZ7z0FYxMrqHRGqHbXqCvYSCdMKIUyu8RhsLoPmpcFNo5cFpJkNQpyw6z2+8ipIswOTrrgGqh1BBaDLkjg/8u4Fi1PmLwc1euAKldBlr7UmnvIeKgdAFWqH32oCfiVWY9V56jNf/w2c8z2mryxxf8Pp/7/Ododzr8wQXv4qf33c+V1/6EyVgQqJBaLeZ3f/8Cpvfs5vbbbuapTzuLoWadm6+8hMOOPYlmfWhFquTx17333ssJJ5zAP/zDP/D85z+fM854KvML88RRxI033sghhxzyn7b5s5/9LF/96le55ppruP322/n1X//1fX7/N//wcaSUDuhQEUEyRL0ek+c92mlJUm+Q1OosLS8xs3ULusjYfNzpXPvjb3LJt/6dZzz7ORyw4SBOPvXJJGOrmd+zk2/+/Z+w5shTmNpwCONTk+i8yd75BlpEPHTLtXz6/FfyypMOZMdCj+OPP548z1m3fj0WuH/7Hr5/4z28qyi59fY7eccfvZcfX3YZB69qEW25jnd/7tPcsW2OQw/ZxAtO3cy//MmrGTMP8Z2v38K7Pvw5fvzjSynHmrz6o2/l9150Cr/x7BO4+/bH2LnT6T8dNJIwvbDIl257gN869xiCWpPvPGK44aEH6C3OMNqI+bcvf44LL/wKJz39XMqFad7/11/mkLEh1o6NcthQQTNw+/SSljzpyANZN9bgQxfdRCAsh03U2TG9gBrucMba1Wy5/jp6aY/X/NbbeOF5b3SHFhxL6YQTTuTKK6/oxzxvf/vb+30B0Gq1+PGll7J69WqElMQrxGcBHnnkEU477TQ6nQ7Dw8OP6/trr72WY489lq997UI2bTqY008/nT//8z/nDW94Hf/6uX/kkMOP5nvf+wH/+IlPMDoywm++5Q/4w3f9Ebt37+YLn/sCn/rcF7j44h/w5X+9kBtvupG7HvgyneUF9u6d4fI7HuWM53eIZ2b56Ke+xEufczZPO/2U/80M+u+/FtptdwjVLrMvcNUEqyYnCYKAJJAYoSh0ycLCAr2oQ552EEZTTxLWrdmElYo8L1icmwVrkB4gqEpslpcW+3GxlG5ND+MEVWXQfRK5YsyAhbKgKJzWSqPVIgxdXy/MZOgyxxQ5MkyQKkAFEWVZkGUpe3fvIfSHoqnJSbIso5v23P4bRDSihL2zcxgLo2PjNGsJSRIzNzvD9p072bZtG43WMDQSwtiSp12Ezmgoy7rROiP1mF6nTW9pN9v3zFDO7yZWIWHQIJo8gMb4Glqj4ygR0kxCxkeG3L6PoddZJlASGccUWUZhUhbnl2h32hRFydDwsBPE1ZoHHn6UKI4Zag0zMhZjraCdZgRhQKNRJ44j4lqCkJJ2L2W5vchyu+uc32oh1lqKwmINJGEIwrEg9i51yI0hM5qDVw2RxJHTlMp6BJSsH45o93J6ac7q4dhpByG4b0+HXu6AiRJvI+/L8OJQoY0rg1JC0IpD5zhtNK0kYmxkmFNPOp7RiVUMjYyhZewO8GWJ1Rm6dOWdeV449koQejZbTBCElEVBmvZQSpEkNTrtDrrIKTOQYUQURdTiCJU0aY6NM7J2PUmtTqE1e/fsphxpUa8lCNNABRFRHNMcGnLaXMqBf+1Ohx07dzE1tYp6LcEUGfVaTGuo8d82N3+xa38MDftj6P0x9C8XQ/+XGE+PKydagXRVG9nKmtU+w6aPg4g+jbD/VawHePa514Dd0mc0+XfYPgjgv/zKmtQVbKqKUlhpA1U3qJBLj3v1278PqCDo/91nE/nX9y0tAYynIRuNUYGfyCErsT8H9EBRentTIV25VxTTUiFxnJAN5wy1huj2unS7XRYWl0izlF63S6fbpshz8jxFlwXGaMqy8H9KirxAG4MuNcY6q8s+6mytF9KuBolHc4XwLnj02T3gJrs0bnD5BJZ/NtV3kW4BwJWuVX2MlK5WNlDUk5A4UkggzQqsNiwup8wv91jsZHSzgtLrEmgrKLSmmxWEHu2t1UJnERtbsp5jSvW0IbQQASH7ju3BsPJtrJJ6HnySHhZEKWQYIMOIoFZDRZGnLFdjtxqPK2Etu8//s/3XDTIb1XjaFwx7ol4Wx57zEwC8BpoLUnVpUEGV9bQOFLYCjBcSxdGDHbbssqDC6n4NOlTCmF6PDbephmGE9q8vS+0XTtHfSK0pfZ/5e/umYi3a+lICCRJHLdVelF9K2X/qFdUZGAhUCpyTBxprNVVdu9PwMg6urFwrsW5RtwJJiTQ9KJYo0y5B3KK5aoq8O48UhjgUhEOrULURR2/G0VWNpV8Gq41ekZVywUq1YQpwFHRP2Q2FclbX2rVx4BhikdIQxQolnaOGLgzKf4b0WTGlhCuTFZYkdIxIKSArB2WikfLZmCR02U7jgGaJ03qLlCu4LY3E4t11sI6lKQV1Kym0pbSCAIEWot+mIJBEgcJKCAJFUZakaYpQXdJe5nXx8M8Bz8isNjLP1MQ56DjdOdDzO9G9ObpzD6CEHx8ywkQWG0qoNfG7nTf/8DR3n6Aw1ccK17d9cFl4EV/nJOF6x7rMsf0fMIWvveYa3vve93LCaU9ibHSYh7ds46ijj0MqydLiPA/eexcP3H8fL3nB8zFC8Ni2LbRaLUYaMYcceig/uuwysJZnn30Wi8ttlnfv5ffOv4BTTz4JrTV/93d/x3XXXde/n7WWNE375fO9tEfa61HkOR/9m7/hqU99Kq/8tV/7D9tb+rEQRdE+rjkrf19dl19xBX/87vewZ9d21q9dzdPOeArbHn2IKE5Yv/FgVBCgixwjJOPDDQ5bO8qeh+9jqFZj7MnP5J47b6a7vMhTnnceC/Oz5PM7idjA8tIe2jse4mlrIkxaMrN3jt58k8lGk99/zXMpSktrdIJAKZ721KdRS2rMb3+UVSMN3vdnf4bqzrC4d5kTn/9aslXXcdx99/ONH9/Gj67vsX3nHp76NMvQ+Gre+973MjFcJ+8u8rbXPJekPcf9D+7g2JNPYPzBWUaSrTwyvcBybiCI+eljsyRxm1qqGIkgbtYpLRyzcQ2Hb1xDN58jbAQceNJJxN1p8l6PL13zCIW2bJhsMd/T3LNjgW0zy6wZrlMLJJ1cM3LAIQyt2cjC0jK33HEPi0uLvPG3BUkcIZWztz7ttNP4kz95D2vXrGFudhagb62NkDznOc/m3HPOYXJqilq9xs9LrUxMTPCe97zHHayM5e/+7m+55ZZbkVLy1re+lTVeWPzQQw9jdHSU97znPZxy8knoomBsfIrFxQWuufJHbN6wjjTL+edPfIJDNm/myCOO4Jvf/hbjExP86q++gjvve5D7Hn6UdqdLFCesmpri1BOPo9WsU08invvMp7Fl21Zuv+N2fu/Nv/l/Mq3+n11SuuBcSKeLKYUkjBPyvKAsSmqtBmEQEISSifFxjN9HjPVJaWswGrQuKbRBeTa81u5AFgSB36tdkjRQIUEQEic1hL93leK3+HjdaLfHCoAQow2FUxV1+5EMEMp4nZ6AMHYJ5jwvWG4vU0sS952Ucn+kdGUxyglI1xsNiqKk1+sipSBNY6QKmJiYJI5iJkaHveh3SdQcw+qCUgqy9jxZu81QEmKKIYqiZL43QytSTCYuqx+GIWVZkhXugFjkuTMaiBNkoHx76wRRjDSGYeMOhnlREESJOxQqxdK2bZgsR3a71Jq5X/ec/pASLvnaqCUOhGr3WBCCbrdHEjnHqU4vc9IUkWKonqCtpfRyFsbvpUkoaCQBQoT0pMYWgqLQxFjiSFILA4wQ5NaV9ihhKbQmkI6VFinVTyJr4Q6JQaCo12LiQFKTlpFWjZFmTLOW0KjXqNfrICPf1xZr6xijyfOmY9BpTVmWLjbyGrhOHiRyVvVBVcIEKEkQOlFyqUKSWo3G0BAjo6MI/5rh4WFUEFAaSAtNmXawdFFhRFHkdDsdjJAgAwqv+2usY9cFoRgIuz9hr/0xNOyPoffH0L9cDP0LA08/q3pP1aYBxoLt/0cf4NhHDLoCk6TsU+n6kKb/woM62er9EuMVyPvcFkufBaUrwXAhkH1mlOfB2ArNtf0/ot/WigY5uDceTe5TH33TjN+kXZsklXeB0bnbJIsMoUKEDJBBtcFLhFBUNrbaF95KIYhkRBAE1JKQWq2GMYbh4RZplpFlKe1OjzTL6HZTpwGVZ/R6XfIspfCZpjzP3J/Ubx5FgTbaC9C5zUSXJalxjCnjwZ4KkEMMALSqDytGkfHPx6N4feCpzwATolIdBz95qomTxAGhEmAMvawgy0tmFjosdjPavZysKPxzdn1YGtMHngRQTwInrBgG0Bd0s0QGB3ZJUFivMVWNtJVg1GChEP02iz7NUoQhKomRYeifgeshy75Oift+5r7XSk2yARPP/vwXP6GuCj6rAFafFTHGb5wWhbMBdkXO+MXIj3hLn+ade0edqsTTPboV4LRHACUSFQRY7ThlxhS+Tt2zET1D0m02/g+48WEcqdtaDUZgVfUa218c++skg7lfbaYW+g46xuaA29ArwXgpRJ/x57Imyj2S0mCLDiZbRGc9oqH1xCMbWNq7nUBaGrWIeGQdqjHuXTSMG0qVWqB3Jho8c/dj6Z+d9YFANc9CVN/KNElq7vlbH7goSxw7S2ylFIUtfVYU757h6L9CuMAvCpwMRPXzav0NlSAOJUkcIEtnuay9PoQSUAuECxZL+uurEC6bHihBLfQgswYl3GcriaOTe7FM5bNjWZ6hOl1KLcnTngssq53BOpBYVjW7/UtgUITCoGRBOfsAeXs3nZkHnMaAigjrq6AWI2yCTOhnNASDMmuoEhV+D/F9UP0nhfI/Eysm+P8M2Hh4eJi7776bO+64g6uvvpqJiQnuuucejj/2GFpDQ8zsnWbH1kfY9tD9NIZfTa/bYXrPHhqhpBbFrFu3nk9/9nN0uz1e94Y3cfddd7Jr5w7e8Bu/SRIFzM3N8S//8mXuu+/+n3t/KQStoSHSXo80Tfn0pz/D7t17eN5znwtAu91+3HuiKKLVapGnPfK097jf12q1PiB12223cf311xM3W5z99Kfx0he+kFtvuQGEZMPBhznhUuXswcdHmhy+YRU33X4fnTXraY6Os+2BuyiLnJe/8Q+49Ypvs2frA9iiS7E8Qz67hSetitkzn7NlocPS7DwbWk1+6+Vnk9kAEbcIAsXxxx/HYYdu5u6rf8TE2ARvfvObefDqb7GcCQ478yWsWT/Kifev5Ws/upWbfrqVG+9+hObkak5/ytN56WtfRTa7hSLP+M2Xn81XvvA1Hnh0J0978YGMjj/CUKTYOruMVRHNRpMHdyxQCwQjzQRiQazq7FlOOXTDap7zpCO49OrbiVtjrN50BPKxgke29fjOrY9x1AHjrB6ps22pZK69hC5LjpoaAiArDKPrD2J49QF0eyl33/8Qu/fsob204ACImgOejjvuOI477jjabVfuB9BoNAmjyAGTz342v/vWt/6n43F8fJwLLriANO2xe/duTjv1NPbOzBAEAW94wxs49thj93n9BRdcQHt5kaWFBSZWrWXnjm08cN1VPO95L2DHrmk+//kv8s53vIMDDjiAf/70p3nWuedw4vEn8K3LrmH7rj2AQEjFyOgIp510HFGgMGXBaccdxd/+87V87dvffeIDT0q5PRGfnJWSMAzpdjpgDbSavpwqZHxslG63R7fTdmx0n+QcJBpdGFYdYgV+f/ZOYhaBDAKCKPIlfm5dd3tTlWlz7KuyyFFSob0dfAU0V2V90oSk7WWQkkhbpFJ9zZ6qVM85aTlHLSc4rgjCkEa9TpZlLC0tYa0hz3NGxsYYnxhnamKcVj1CGIMpUoLGKFoXZGmPTrtNd2GWWNUI4waiJumlOXUlqdWHSOpDhEkdrV1JX5blFGVBRI0gDEnqDQhiiOpOPNhopzUqJGmakVtBXGuQ1Ovw2HZKbcjSjKJwLIq8qFyjQFlDMw4ZG26AkBSFc5IMA8dqwRhC5Q6RzVpMoQ2pF7uvYslQCpJAEsURtizJraUoetSlpR5K4kCRIzHa6W4pKcgKQxwo4kDSjB0jIteDM5OSTtelGQWMJZKRZsxQPSIJQ+IwIopcv/jTj3PGs4a4rDtb+rIg7XadE6E31BECVBAQBM5yXnjwzYlZO1cyoQKiWp16c4ihkWEMTl+n1WqSF05jLC00aZpSFCUqdEyqLE2J6w1QAcbHja6SxIt+iP8BwNP+GHp/DL0/huaXiaF/ceCpYucap7qOb5LyPWSs9oNXeGG8FeiZZ+BUk1SKaqFxm2+/lK4CkPpopcAK25/UK9k51aVWMLH20Xnyn1t6mmOV4ekjhlI6J7z+5HNIhVjxMPsgmgfA+qCULbG6oOjNU2Qdsu4iCIlUIXG9hQrrSBUT1EYdJc7X17rJ65wNKmZYJfBWlhohFHFSp9EYdswoqRyN0pTkeeZECovSOU3okrIs6HV7nvmUO+DJOLvlXqdN2u2we/sWFhfmWF5aIE0zSirgz7nRad9nDg1dIdYl+n9R1SFXVtFK4VhJFWIlXJ8Kq+n1enSNJcsKOmlOlhUsdTNKXw7oBPKqEkW3zvTyAtERFKUmCSRxFBAqSVILSZWkQLBQapS2RNoQS0EgnP5UIEBJN5Cr9toKAfb9aYVw5YdhjK3XiRpDBHGEk6GrwKlqw6vGYn/kVz/2//QgZh8cHUzNJ/oVqIG1cRi6A4hBO2BXQBCEzgTAumfYd6CsHoFxQaO1lrIs3eIsBUr6DKsPjKVwAu7VXKwyh67sVvqt2/jB5T+7QtP7N3SBTiCcRakri3WZpT5Y7V8rvSNP4S2RqzLdlWKPzv7ZAcJKOeBSCrdRVHeMkgRdZszP7mXvtntY2nUvvYU5RtYcw9rDTyU49UV+U80IhyawCLL2AtqUGKv7jpfWSK/HJlEq8qwOB+TmpTs4FFoSBAFhqAglGC2ce4VVaAOYAiENKhAEQeyCeBXQLVIsGRpDq+4cYmoSekWONiWRMDgqtyWWYJQgDyRJHJFEMXGYIIRBGYshdwcW49x6XNmBIQykmy8SjMkpi4I4ipyWW3VeEQYrTH/kWwRShQRBhPKBbgWEg0UxWCtMFan4y/ixEcYJur2b9uxD7Lr7e2TtWXSZkzSGievDDK9fjRQxqDpCBbggyH9fwFkl+KSIcNtwv3XCBbYVC5dqHPqs1P8Ec4B77rmHT3/607zvfe/jBS94Aeeeew4f/8d/5HvfupBut8NLfu0NvPClL+eMp53Jg488wtq1azn9KU9j99693Pvg/fzoB9/ht9/yFsbGxvjKFz7F0cefzJOfcgZxYPn85z/L3/7dP/DZj/8t9z/wIL/9exf071t11cTkBD/5yXV8/OP/zP/6iw+iy5KLf/gDjjrqKADyPP8ZHQl40xtezwV/8Pt84QPv5Ka77n3cd/rABz7AK17xCgA+9rGP8Zd/+ZdknWXiMGDz4Uew2OkwO7OX66++jNWrVzM8OsaehTY6arBq42bOePRORuUSMzOzRJMHsrzrMT7/oT/igM1HMLbhSH503Y1sPmAVRz/tuey+41buXcy4bMcMh6xaQOaa7sLXGDvnTQwf8mSEDPinf/oH/vnjH+fiH3yfm26+mRe+8mj+7Uufp1av8fLzfpULfv9tPPVZb+GWW1/Nhz/8Yf75n/6BZ65a4t6rv8LR7/kgf/+6Ezj4gFVMq3XEwyOs2aSIk5hUw952jqw3OWbTep7zpGP47hU3oYuckw9by5V3b2XP/DJTI3UCndJbmOXoqYgbH3qEz3zrSj76ztdw5qGHsLSwxHVb5tk20+aco9cSyDqhUhx8yGZ02qM7N8NEVLB6tM7x5z6HT3/+y9xw402ceMpTePd73sNv//Zv95+9MYaXv/zl3HzzzQD87d98lOd6ELHVavVfV3oHriSO9zEVqa6/+qu/5hOf+ASzc3P/2zH8L//6r1xy8cX88bvexfoNmzhkbpaHHnqI0bEJLvzaN/j4x/6GH/7wu7zvff+Li77xNf7sWxfxx+96F41nPx1tLN+96EKGR0Z43gtfxl995ENcd/1PuPfu+1hebtNL0//t/f+7Lyf2G3oR2AitNb1uh7TbwVpLYSyidAeuJArIepY8z5mZm6Neq1FrNJ2bXBSyao3TR9NFRhh4JytdOh1RwAYBYRAipQOTKomGPutduTgLa7E69kx0S6e9jFRO1ytJasggQgQFSVaSes24qsRldHSU4VaLRr3u1mKBFy8u3eHWSJr1mhMdl4IgdEyaZhKirEGaAtIlhFREYcRSVjK/1OOhB+8jn91J1l5kvmdIWuM0RyY59uTTGWs1mRxpkhkX2wVhRFgrKYqC+YVFSqNZXFhk8oCN5IQsZjAUS2phyNiqFmlpWez0uOvue1izdi3rDjiAo446mqLI6bQ7hBIwhqmRBtPSIsqUyQRq5JB2yLopWS8lzzLyLCNSkqlhD6BLxXJasNjNWer0AFfek0QRC+0emYZ6UyHCGlEQEWaWWmBoBpY4ChAaUu0OsqEU1CNFM1YkodNoyrsF3ayknRtC5bSflhWQRNSCOg0RoGVI7t3tZFpgyw6VO6EIAhcHKeVBCUEQOJcz0wc03XlLYolCRaOR0F4KSMuCxV7u9d4kcWuEqNlCxTWEF4XOsx5BEGItLCwuEoYhcRyRpqnT3anXXdWBsdRqDaLYCSEPjY32IZ0n8rU/ht4fQ++PoX/5GPq/pPFk+7Q3238Avk0MyuH8j63tN2qgB+WRNf+lsP4B9hHeAeOkuqeUK5goFdNqn8mwQjNK9B/JijabFQ+mwgs8ymetA58GrXZARf8DVjyACnTCYo3G6BxdpJRZlyJdAqMdq8am2KjpwacIVAQiHIBaFq/HZKBwtajVQl8Ba5U+kct6hBirPB3PlZ4lNd0HrNJ66imGFe3QobBpt02vs4zpLhKYHFn0CK1/jZBoA6Wx9EqL9n0lTTWYHeDnwCacWKDAidtZiTXOHa8PPGHRQI7FauMyR1lJmhcUHhmuHAEqVwbpxeoEbgzkpQtUOlkOWEQUEEhBFEhMFLjsEJZSa0rjBm4sLKEUrvxOgfIL6MoZWYFOWgXEcURYqxFGIUEQrGj/YCAPijofPwiqyul9Meb/GaATDMpa3DhcwU4U+4Kt1ZjsZ0V9lgP6qRG/MVW97659hPuFe1rWusC5Wg/6JgVeo6AarxUbz6L2yeYMGGWi/29jdH8tqg5CzuHHLdISX87gM01uvAFUpQZOOHGwpHoxUC+KWGYdil6HMk1JmmMEUYywBYFy7S5N6RdkBStWD7mCLema5fQjjHW/U0HgdNasdbXyRQeRdjFREytCVBC5FcY4MVJwtdzuEOD+WO9DSX9uuj6rgGMhTJWL8wY4rj1KOmODMHCWtBiDtsqzOX3X+qmglEJ5LblqCBjjvlNFh3Zr++Aerv+9TbCSfshY73xC/xm5seEEcd165wVuRTUmFUbVQCb+j0KqyLt7WFQQouJ6f9PDVlumoB+2isoQoeplixPs9NmT/tZpV4z7wf7yRL3WrF5Na8iJvh5+yCY2H7SRWr3OqtVr6Xa7KCzDrRZRIEnaPXbv3sNtt93B6U96MuPjExy08SCGhkepD42w4aCDWW53uP+BBzj2qCPYdNBBnHP22dx+593cf/8D+9zXAtdeew1KuYA6iiLe+MY39AWGhRD84Ic/ZMaXbK28mkNDrF27Fpm2sb3lx/3+rrvuYs2aNbz0JS/mjKc8hde97nV8/etfZ8uWrXz5X7/CxFBMqJy+UBjXQAbseeReau3tJO0Zti6m7HrwUZa+/zUIBMPNGrmeIKo3iWp1Vq9ZT295nntueZRGLGjUI0pjGZoaRzcivn/bFp5x4C2MDEWIdS/gkM2HcPZZZ3HX9VezPLfAs571LBpDw9gyZX2toB5K0qzkkksuoV5LeMWvvIxyeRe1zjwnj/awqk5XjdAcnSLTgrnFNnv2zNAM4LiNk2w88ihGh+poXXLMprVkaY92u8eRG1Zx4JoJ7tmyGykUSRQxrwLWTrV49ikH8NOHtpFg2DjVop3mLPZKhkdGaYSCeigZaQ2ho4CoTLnp7gfYa5uc/qIa555zDmEY8t3vfIdeb8A4u//++7nqqqu49957mfX9NjY21i+PW3kJz6z42Z0uz3Me3bKVLVu37iMab4zhoosu4qabbqbaHYZbLZ79rHNoRCFrJ8dJooDZuXke3bKF9WvXoI3l29/+NiOj44yNjXPDtddg0g6HbFjHUKPJ9N693HvvfUxOrcYKwQ8vvpjxsTGOPPwILv/RFY8DPJ+oV7fTRtRr1OIIazRSCleKlg/394rCH6yE8GLV1jDUHCKKYzfn/OE2iRWmyNDFQCDXIgjDEKncwUW6wA3jGfdCOCfqfvLP+v1GDHRbrfHMBeGZ4oA0xrGGBOiypMgzL8QbeADDkmUZ7U7Hld/V68RRhAgjMG7HajQaBKpywNNY47RLy7yHVCGhUBhTYnROnrZZ6nTodVKMqoNQrjxRSAesqBp75mYw1jA6POxYW15zRimFCiPyPKfEIIykSDOUVuSBRQUBtVqdJEno9brs3rmDAw7cgFKKWr3mnJm0JlCaegi1UJL6vURiCKTzwiq1cYwgKajFEUZISmNppzlp4fRJG7W4H7tHtSZRvU5Qa2LLAmlLhqIGkS2wlFghkNISqUqyxBAH0rlsIWinpRPjFsI5CfpDlJSOyRFEMTKqQRi7A66pWHKOLGB06S0JNUI7YfV+1YgfGypQKOtK+JIkJoljksg5Hpa5u6dSASqMiOpNrFR0Ol0ajbrTKtKl1yhiAMxoDUq5fdoaknqdQNUQdpQoDMC6crA8LygqjaQn6LU/ht4fQ++PoX/5GPq/DDytRErFihtVLJGK9VRNjAr5dS4A7lduw3OdZCr0dQWWZQUDpNiuAJ7c6BuAMxUrylYDZTBpK9poX3PKWt/JshppVDBTtWhUoFOlaD+oaxQrGmcxuqAsUsq8S5ktU3QXMEUPISwir2FqLYJoyDG/wiY2qCNl4DZ34ZHnUlMyUMyv2FrSC81JWdVbu++kvPWmUspR3XybBwvSgO1lLORph7S9hOjMkdiMqOywJDzQhSDThrS0ZLqgMNYhxBUa6AeiA2xXiqiDVA7csdqseP5u4Su1Ic1LBzzlul9/219Lq1VWVNjfYCGsUOyljpuVwkIYKmQkkUpQWkteaNdubVFAIiDBEguBtB7dl7I/tqxwdbRGSIrQBRtxc4g48Y4AUlZIpEORK6FNu8KZQlRj3fcRLrjrU1J/Tgb4iXrleeaynEHoRQf9ciIkVrqw1VgD/U2z+n7Gza2KwktF6V8xdhE+yHV1vtX7tSlJ047/LEmt1vAbn0VIFzCXZYH2LhihdWj/SqOAATjolmFtyn65gJe9pyhy+tRQ5Zw8pNea6Jde+r4qSzNYJAX9TFJZlpR5js6XnfNGqRlZs4EoTih6swTdGFNq0k7ba0jUQEqkFYN790FxNyfy0iBQiEASRTEqsAjpAst8dhf58lZ0cyMiahHGTYwusF6QEiOQBEilCALlLV0l1jqJf4EFq8m1dmRt4Utofb8qv9QJIPBlAUnkhE+F1pRAYXBGA657EVISKCitcM4+VoIVlNp9qJIC4yng1gqUEgTKBww+AFaBcM0QFu2fjLRVda4FSmfnjCAUkROAldKJrqoE01hNNHQAQtTIsy5hPSSsxQihCWMX8KbWiyt6i+fBOPFri69BsWZFxqbaZf1rRbWmSwHGuKzlE/jK87Qf2L/uVedx4sknI6Ti2BNOoShyKDPiUJGMjHDAxkP4+Cc/yQf+/M+57EeXcMjBm2nVEnIV0S0MZ571bL5x0de5666rOPKwzZx77jmcdc65nHTiidx//+NL7b70pS/zpS99GSklF5x/Pp/8xCf6h1mL4NnPeS67du3G6UCsSAxJ52A1VgudCK5UKyj08MUvfonLLvsxzzrnLJ797GfxjGc+k2uvvZbb77iDt/3+H/C+t72eY48+gslVm6g3R7BItt5yFZN2hlXMc82ODuUDtzF1w00847WvZ/XBhxEfdDgCZ91+0glHce23/5VrLvoizz16kolWQhJI1h96EIU2/NPnbmLt2Dc40t6HPvkcnv+C53Pu2Wfx+y95BocdfzL/9I//yK6d25nf8TAvPH4dq5uK3Tu387a3/S5vffNv8sEP/Cnf/cPXMKZ7/NHT1zK76lCWRw7ikI0H0E4vZsu2XTz04KNMxJYXnHQQz/u1F/LI9r388PLrefoJm+m0O3z1+9fx8uecxsTECL/9t99CqpBWs8kDJuTIQ9fz+pdM8dL3fJ28m3HBc4/iwDpkuWZLaxVjMYzFkDQaFIFClBn/9M2fsHlnzm//Ebz5LW/m3HPP4dprrnJlQf5gd+WVV/DmN7/l546zlSCOW0MlKpKP+3273eaqa65l+/Ydj3v/+9//fh/UunKtww7ZzKknHM2m9WtoPuU0Igk7t2/l6muu4n1/+n5++tP7+K3f+i2+9c1vctSRR/DmN7yalz7/XF76nLMIo4ibbryJf/ynj/Hlf/13du/Zw9vf/jY++uEPc+YZZ/DJf/50n0XwRL8W5mZRjDE81KQocqIoZnRsjCSOyYucNCso8gILBEr2D+KrVq92zKXCJeakdJpdWc8d3IyPsQGiKK6OD5RF7lzptHZsDKUIg7C/JxpdOJFcz+IwuhIkd2UoUiqsBSU1QeBKQazXGdVaY8qcotFAlzGdss3c7Ax7Z/aydu16FzfWnBCxlILhVsslMa2lyHuURUFZ5OS9LkEQksgQq3OkThHlMsvdDkvtlInVqwiiCGEty+0OqAAb17nvkW0YXXLY5oNRGNAlaa9HY6hFUm/QbbexUhGokKLIMFKgyhSlQlqtISYnJ9i7d5o9O3dQbzQYHh5heHgYmXewBWgyWhEsJ4pdpaFmDUoZktASSOcyFwTuIJokCe2soJcXLCz3PHAoGGu5A15pBUOj49QaTcK4RtpZROmMsZGIMu054wg0QkCinGaXNoZm4vZHYy3Ty5nfXxWNQFRII2HgSh2TehNVa0LcoPB27aXXbDXGuXZROR5K3cdAjNZUboZREPUFr/O0S9br0qjFJHGEKXJiKYiimKhWJ24No5HMzy/QbLUIleoTCYS01Go1er0eeZ4RR6ErLyxLpibGCaOYseEh2stLlEVJmmYsd7pPeNbi/hh6fwy9P4b+5WPo/zrjyVaYmHNWQbuG9EWZhVdcXwECVd+nGrx9UKcaHP4LDErsXB0y4JHcFcDMCsCp/1m2GvgDcbQBUOZv7z+3WmA9lLBPE6t2WiqbSH8fuaI0TLt6WesnrjElpszIu/NYnZMvGcKkThDViZbnUfEIKhkhaq1GhjVUVPf0OevE06oR3kd4HYAjtKAsC5dREdUgdc9CW9v/PlWpo0NSHcXaWIu0MVIn1JOIZi0mryco40TKEIJubujkmm5p0WhXP+qBw/49ACsrMNFnR/IKG80GYJSkj1LjJ0cSqv7CZCyUxlBaN8BdYCP6Am/WOIvZUhsWuxl5qWlnBUO1iDBQBKGinihkIMgxZLkLslJjSRAkQGktNQQN4R338BtvqCCKiEdGaLSGGGokhLRRSKRsuOcqoC9Wb/dFbR2zy4P8voTPjR5ZDZYB4+4JfkVR5OaWlNiqrpoVWHL1HPzYdCCtRAm3TGht0cZR7JX3AO5TeP3G0y8dt4KiLDDaIPBio9JlYowHo4vCieVbTH8sAU6UVCr6VtHedtY1UQyAauh3UBjHDnzHlTI4vbUIrTM3V/VKBJTBF/aArbUCK6TLxnSWQRcEYcjIuk0YrVna9RAPXHshxhjCqM6GY86mOb6BZPIQsszNVQdOOvahxZUTGxQRJYHuwPKjFJ15TNYm6yxQ5G3KIqMRDSFsiigXCKIhl9WldJkjXfoAIOwLK7qN0JAXJaV22Z9IWZSyPuvohE1La/ultNLTjINAEViNlQK0gsAgrcvi5kKAEaRFSVZohC0JpOmD39ZvQgKFFPiS24AodGxCopAoChz4YLXPDuMMGKzub+gVg8KtwYLSGoRfV4NAEQ1PERz7HKwukEbT2Xod+eJ2Zh+7kyGRUA/qBK1NGCMwWuPNvF2wT4VvV4G5F0L05cI+hUGfWmytE8asspNP4OspZzyN6elpjDF8++IfMbO4xJq167nm8kspypKXvvL1XHThv3Hn7bfwh+/5AM9+znPZdNiRLEzv4uF77+T2u+9h43iDOAy4pCs49oSTOOXkk7n7Jz9m3UGHsf7QY//T+4+Pj3PhhRdyyObNAEgVcPnll/POd/4RDzxwP9YDSu9+97t50YteBMDFF1/MU576VGa2PsxpT3oKN3zmG7z5zW/mlltuAeA973k3L3vZyxgeGUMqRRJLvvrVr5J7++R1qyeZm53ls5/5LM9+znPYsH4t2+68CcZjRtaPcvZJm5EqotEcob3lHoKszVlvfhG3Xn8F07u2s27DZo458XgmmzlX/9u/k0UtXv/rr+Sya24gVoZPvutV3HzDrbz9kz9h77+eyeve9Ju87vWv5x1/9zlu+Ml1vOz55/I7v/kGNm8+mNN//Y/467/9R26/7Sb+/f0vZs/0Y3zmz97BhsSwbS7g36/cy6atl7Jx08EcOPlS6qPjjBxwEDaoMb5qDWpyjAv++vNsWjvKi558KN+79l6yLOdFzziOxekZ5nZO8+5Xno0oM26762E+c8mtFFoz1Ig4/zdfQFPBDRdfQ1fGWFljdGkXdmiYtmzy2EMP88COGa6/7zH2LHQ4ZJDtYd36A/j+D37IhRd+jdNOPx2AmZmZx3ewtWzbupVfe+UryfOcoaEhLrzwQsbHx/svueGGG/jd332be7kQaBmyY+ujP+ejBnPpwx/6EGc98xk0m0Ps2DPN3T+9j9POei6nnf5kDli3mpuvv5IwrvGT665l1eQEEnjHH76TqakpZLPBhV/+LBOr1/OZz36Rm6/8AVFc4/Of/QLd2cfozjzGNddczYc+9GG++tWv/u8n0X/ztWbVJENDLZrNBrosUSpAAmHoRKrbvYyZmVm6nQ6bNm4giWJkq9XXQbPG0Ol0USp1Qrf1GnEUMj87i9Gp0xvFHX7CIACtEdbZuYswREnphMmLgiLPKIvCyWT4tVMKgRKBEwmWEq0L8ix1hgJZihIwMtwiDAOnzaI1jUadZrPptUoESVJjctUa4jj27nhtyjJnYW4v6AJhNWEYOV3UMCHrZhRaYPOSeqSQzZjxVpMt5U6W2l02RoqayImyGXY8MEMpIsqgwYMPP0qtXmPVqlUUaY8iz8jSlHEVEdSHeOjBB6nXa6xbswbRW6TX7fDo9F56RpJpS9broHvLxEUP2d5NN19gYTpwSU8JrciynBnauaFWS2jWYlpJxFI7ReIAtCRUBErRTgvyssAaTS2JKI0D5MMwRBuLLQ3NoSFaw6Mk9QZ78w5a92g0miwUBcsFzKYFUSCpxyHax6/dtCAOHaCz1C0IAu1t0wNX6oSgXosZHqqzemqM5uQUcXOEKI7RZUm3s+wF7QEZ9EFjawaZfuHjPOljYedyF9ManaCXFRRG0ss1WaGZGK7TGhlmdGoVq9eswwpBXpQkkStBy7KMKIoxxjIzM8vQ0BCjo+Pk3TZRKGkN1UlCRVFkTM/O9xO37U4HiyWQPxujPbGu/TH0/hh6fwwNv2wM/V8CnqrBKirQxnq8tAKjVgz8FW/sD899fmdX/t5SKaXvw6paya7qg04Dkkr1AAag2M986T5I5logxIqWeJCkT2jqM7fwAEQFsAyYVBV7a6UItTWOwqqLDF2kXmy8IAh76MIS1HMirQlqwwgVVLftgzJ9wo0YNM250FXoov/u3gWFCukWwjGsVjzzAZDmXmdXvDcIJFGo/OIgKKwgNI7BJEr3WT+Dv/WftUPh8eJmeBrpgBEVCuGV9D1IVz0v35TSuIGJdgiulF6XyQvYGWHdAmOgMAZRuJJAJQWxtSTStSGQgjBwdGY0FHZABwysQFpQFmK/OGopEXGEShKSep04UkTKQtHGlgHWDg8Goq2+tWXlk+gPj33+Lfrr7/8kjRjpXRcqrTEYgMH9IMR/F1kJFVbPpEK6q7/7QPKA9TaYTO6qHCcr2j4MprTwWaBq0xrQa4WvHZcgrNd4c5sRVKKHKxgVK9kV/Y6qwMFqfgkQHsDGfbYbNv6z8ZkO68tovbiom985pswpszZF2kWXOWWvTXtmK1KGxBOb/GSRWFv21yG/fDu2AIAuSJd3k8/toGjPkbfnHWs5VJTtaVQ8hAgbSBViRYj0QodKDai0fVci/yBLbRDeglIJxyg1QmGMA45NtQbgHT69sKqQ3uvR+A1RuQyNLkFKizbuswMsMvA/s76O3JtaSEAJt64EgXIHpyBwdsErF+j+uFihv1f1jhi4kFb7h+tHg4pjJAmBiuipBGMsZdahzLvoIiVYOZ78cq6k7N/LWtt33RjM6cH4NWJFZqbK0j7Bgadbb70VcHNgYnIVSa3Bjh2PgRDESUK320MFIfXmEL0sJwgUU+Mj7HzwpywuLdIYaqExzrI3qdMrNPPLPYIwxlpLnnY49dRTWLt2LQC33347RVFwyimnIIRgdGyMk08+mWazibWWG264gauvvoabb7l5n72658XHTz/9dC699FJuvfU2AE5NGpx00kkMDQ3t89rl5WXKIkeIGISgvbxMq9Xi6GOO5vbbbuenP72Xu++9j8lVq1iY2c0QXZIgxoYJxiwQhJJWs8bSTI/uwgzdPY8SYKnVm8xM78IWGY2hYWaXc0Q9Z31o2ZGm1GM4ak2Ny9OSu7Yv0jF3cesN17Np0ybGaxFLe3cx8/C9SCyFEdx23xamd2wln91Op7eRnTt2cd9Pt5ONh2ybT7l3usfBmyNqtQRrDY04YKQWEguD9tbPURCCNizMLRJHAQbY28kIDURBQL2WsDTfZX6pywEbNjK/sMjy3Ay2KLFI0hLCVg0VRtjeIt1Oj3ZP8/CuvTy8a55tM0sAzM3Ncdlllw3WZtx6V6/XueGGGxxT+meuu+66i+XlZW6++WaKoqDZbHLFFVcwOjraf80tt9zCzbfczLHHHMuq1asZGp2gvTDL3t07/8Nxu76lOGDIsmPnTlQQMrlqDVu2PMJIa4iNGzdx+x230Wy22PCUdUzv3kWW9li3ZjVGSJbaHeKkRpIkRLFzAUZKlpcXEcbQaDQ45sSTmJqa+j+cVf9vr4qhr8vSu0hpiqIgz3KKsiTw7sgWXDmbccYxea/rDwa2b9luygIlvQmLT2YaL4obKIVVzlkOKyr5YqwxlNq5v2WZ+3x8krFKykql+kndoijI85w8c9buUkrnBCeEFyA31Ot14iRx6y/OgU1JidGa3KTe9dDAioNJ9TNbOFdmPPvciVo7Jz6rDWWWobuLSKOIIkuvl9MpJPN5QGd5gUC5vc34OFNbvLV8Sa/XI5ACYUqkLaFMaS/MMNPJ6WQlushJREE9sOjeEmWe0i4EQZg4we6khhYKIxzLIQ4D5yzn9zYhQFjH8OukOcLHtvUkIi0dE6LQBq0NRaHJeilZ3CMIQ/cUpKQoDYVPuprqgCu9aDOQa1fiCPT/LrWhKDVKujI8KfDixa5EN44jJ0ZtLWVRIP1hWinpdVytB56qM5xPoA6waoQUhHGNMEqcTbo/eMZxTL3RoNlqkdRrzlbeVmVjwgEWPo6Mooh6rUazUadrHIBWSyJ/ZvJgZ1Cxcowrw3yCA0/7Y+j9MfT+GNqN318mhv6FgSeHiok++8YNeV9O51+zcsmw/oFVda7uOa48vldfoqpgNFTuafuASNbXoArRr23tfwS+ltYMyuIqTLcPSBm3iPZRlP5Er1hVtr8OmKo0zyNSwtGI+sDUoJZ20MHGOiX9LMscXTbLEKKNEIIwnKPWmqQ23CNsjCFkgI2HBt/BL/AVoFYNIPfRroONcfaQ1aQeMKUGT1t44Ef4gMRaS5FlZGnmxNWxSCUIQoW1rq44N4JAW78ZOcs4Yd2EcPQ51w7VR1bBWIUotd/4nP1lIAWNSDmrycAvsn4RrupY89KQliW5dshsIAVx4Nhawr9OoB1DqXTldLnfjJMooFGGNJKIUMJQ7BDrTBu6mSY1UPhnUBpBqSHC08SjiOGRYerNJkPDwzRjQyI6lMvTSJGj4iZBNAYygJULcQVY+vabqrurnVmuHO3VgvDEPrSC2zS1HuiBSSERUnnKr/s+pS4RQiMDhdUGU2o0vjSm2ihRSAaaH1JIjHCUzcoKFUCJgUCg9gGYG8/CU/hdFkbIwH989Z/7jDAIoSz6GVo3pyKk8tRcaxFi5Ybs1gGtnU6FKEsnIh+6jaQorNceCLxhgRPqF0I6NyddYMscXRRo7QK85d33IFUNRI2pTafSW55jadeDTD9yB93lBZrrj8HKCKTE5JrK3hYkKlDEYYASkC+X7H74YZa3/pR0bic6XWJoaozW1Djt4jaC5irisYNBNRCBm5dJoqgnIb1lgRAVddpRq42G1BifNdFIazElmGjAHjS4dVhKQeAddxxaHOCsaUu/vkIYgJGG0DoadmlKAukyMko52+dSO7vWSLp1IZSCOFLEcUgYRZgwIQhjt/Gj0EaiC42Q1gs7hmCFY7raatNaoYMQ1jFlF9pzmN40QoXI1nq/xjtg2Xoqd2QFjo7pMkBKSd+vtl82UtnqlniDCTSKah01gyQGDLKM/wMupRRvf/sFJEnEd771dV7wwpcyNbWK+++/jzOefhYvfNl5PPTYDrY/eC+P/vQ2Fjop6zcezGve+Epuu+s+tDacfcYp/P1n/42rL/wBn/mrP4G8w9zOrXziE58gjBIAnv3sZzE7M8Mll1wysFf2V57nvO51r+OBBx54XPs+8pGP8G//9m/cc89Pocqq/AcP98Mf/jD/8i//wk+uvIyp1WuwKuR1r389J510El/5ylf4g/PP58orrwTgR5ddzlQr4UtvOo1wfIJefYTr7rmZsZriKTJHB4ql5Tmu/eS7OeqFb+bgo5/Jdy78PHWR05QFi5mhbO8mv/HHHDqZsHo0prZwH/PtefbmhlPWtLjsW1/lS1/+Ek9ZM8S6kRrnHjzK5kOOZNtCl+c873n87rlH86TTDuY3/uI7DAcwkSi+fkeX0lgCITjl6edw7JGHIaVkVVhA1GNCLPPQ9mm27lrgj970Sn760wf45y9+gz/4nfOYTzVv+fC/c/55Z3LE5vV86/pHCbNlhkPLp/7mz9jz6ENc/a2vceFXfoy2liMPWs2xG6do1mtc/1PDzM497J3ey6XbFkn14BnffvvtnH32OQxSJvCXf/mXfOtb3+Koo45i165dj+uL9/3Zn+3z73a7zctf/vKf22/vf/+f8cIXvhCA888/n7+5/76f+zqA3Vd9kXv2XM5l3UM497kv5JznvpDfe8vrOPX0J/Pq172J6ZkFduzYw3D9Rzzw4AMYq3n22Wexfc80i+0uL/6113HbrTfzuc98grf9/jt48IH7+Y03vYGPfuRvOPbU0/rr//+Ea3Fp0TGN8pQgDFEqoJemzvENwdSadWhjqCURiwtzZGlKlqWE0jEMZVin2Rp27kxZjyBKEEJSFi7Ocy5kDkxyws41pIAiyzwQkdHp9RzjqSgJw6gvuqs8Ez3w2jxaO0vvLO2R9noEUUwYRST1hitJk27NjaPYgUVhSL1RkuU5e3btJM8yiiKnliSEUUi9XndC1sDS3Ay97iJpt0NQH3Kfk8SuxCQv0CbG5CW6vcTcI/dQn2jQnGhQlLDcLpne0yNpDDM6VGO4NeR0q3oxSBd7F1nqwDQs0pbEgUAHQNll747H2DUzz3K7y5qxIdZPDNOen8aoiHapqA9PEUQRKmkg4hoqShhtJAwlMXEQYq0DnxRe76os6RSG8aGERi2i0awz1y2Z75bMLM5jTQnGsHXLwzSaTUYnJp0osorZM9um6KVQlrRiRRxK6qEgUu5c0M1LB3iFiolWjU7mxcV7mihQiDh0Qu62JBYFibJEgUBGjnVVliW2LJ02jogIoxCsRXt9WUdWEPi6HqRx4KTVhjipEdUayDAmjGKEKRkeHmJicoLJ1aucRlZWoG2GlIogDJhKIubn57DCctCGA6jXnNZX2ay7s46ULC8vobVmuNXEevMnp+MXEoa/8JH0v+XaH0Pvj6H3x9C/fAz9X5jlHrTxlEwAaQ3aI7XSI2X2Z94ipVqBgrm/HaAzyMwY74jQr7Gssgkr0GAEWDtA2Kr/X2k4VWiyRfRBANsHUAaC1n2ryaodSA/6eJR1hf6E8AFzHwgznt1lDZgSdAo6w5YZUoWosIlQQ25hwBImMUFtjLA+iowaiCAaPJ+KreR7zqy4j1eaGrRB7AN69oE2GCCUxlai7QPkWnjRMqfqL7FRQKWHFegSpV1fSul0nKwaoPcCN5kGiLFzwLMeRNTWC3srSSMJqYWSRuitLnFgTQU8Of0nSWnMoF5VOIV8YyEvXV9JbTwQ5b5saS1ZqbGp+5xASYJAUleSWAkiWVFOBcoz5kopieIAFYY0Gi4oqdVrhBJCk6KKLsakmCJHlwWBGzE+6+M1+1XV74Nx1h9jAjCmegf9zMUvPpH+264yLxFYAiEhEH1RSndV4K13P9ECJUNkreay40KggtBlOY1B2NJ9Z2v7mc+fvSoBfKTrOxkGINzPK9FUqGT88E4eYT+7Uxal2wBxG77AUZKVp/S7e7h7BcpvvkLRW9xBujxNNvMw44c8hWhokiBqIJXLtBV5RqkLyrLobypSWEzexhTLEFpKK0kz2LtrjrjRJG5YhJYYBNHwGiY2Hkd9dC2FASEsShik22FwoGsJ1rlNmihG1CcZP+JZ1IfW0Nv7CLvvvY68W9LePUM8FhHYGB0tkdTGiIKQRhxTT+pkSZ3SThPissKy+u5SUPpxKHGOGiCgrKjVot8HeaHRVmOERQYSaa3bgGSADCwYiGLQQmNz90y1thRCkJaKwApKo31GxWXdq6A1UgFxoAiUc/9QSoJRWJ8OVspnQL1rSn899RlAtw64xSpAQzaPnX+Iha03gjUkw+sQWJLhETrZLBgJWvuEBf15a3zA7JpoAUc/1zinE5elcgEZ1iK8c0yVVNBWOyr5E/i68MIL+d73vscXv/hF/uwvP8SJxx3L888+ix3bt7F7104OP/JoHrn/Hm77yRUccszJbNp0MOvXruGqH32HnQ/cwac/eBPPfPGrOPCwQ1FS8ryzzuDU44+ilsRcdf21fPc73+Rd73kfk1OrKYzhPe/5E8oi72tFWGNYnJ0mDEPCKOTv/vZvuOzyK/jIRz/qnW7d85MqYGm5zWtf+xoeeeSRfjTyk5/8hF/5lV/hnnvu4eCDD+Yv/uIvkFJSSxImVq/lu9//AV/7+td597v+iCOOOOLnPoPFbs4Hf3A/Tzq8y6mHpqxpJTQbCTJusHpqkiiwjOtd3Pi9f2M2/yYbjzmSZtIiomSptKxtKV5wcouPX7aL9t0FOx+tM2UFzzxonMVSEkaWoZrlwcWUbZ2cO2c63PrOP6abu/Xu4ju3ccvDezh8KCBIEuJ6jfeduYmRjUfTOOpc7vvJ5Vx7zbVML7Y54YQTOODU5yCWHuagQw5j9SER//SNK5gcHeYNv/MWrr33booi572vey6yM8+2Bx7kGccfzPYt29i+bTt/+oGPMDkUsXl0jGc9qUba7bF39yyX3XQ/nUyjul22LHTYttAlNz9v7D7+Z41Gg0996lN85zvf4ROf+MR/Ot4ajQZ/+7d/y0033cQnP/nJn/nowWe/9rWv5dhjj+X3f//3WVxc7P/8yImQt54yzMSqVfSGN/MrL3gl191wA1+/6CJe/frfIs1SvvHNb3DSqU+mWUuYGB5iw+ZD3V6jQjZsHMKYkntuvpay0Dzpqc/gc5/9FEkc86EPfZT77r+XR7c8wm+8+W288Y1v5Mwzz/xPv88T4QqiGBmEWCGp1Zsor7uEUP0YVBcZRdql024jlaLebFFvNAnDiCCu0e5l6BKGWw0qyYrh4WF6vS69XhcqsxofoyglKb3Ok9YlZVEgEMRxTBwn3sRmhdCxtaRZhtaaNHWuyaWxjk2T1KjXG1QaLNYY8iylyDKSRpM8z+l2O+x49EHSXhdrNZOr1tAaHqU+OYkunT6UOwCHyHoNpCESmkhoKHJI24TpAhMyQ0cakbbRXYvuWlaPjTM2MsL6DUPEw1MMT6xm/drVdLOCNMtZnJsl8FqfB65fSxxIImlRYYNGEHHY0ZKo2WJi9x5uvP0B9sx3mF1YRsYJYxOTjK1az+SqcRq1hJHYsHHVMEN2it2PLCFUhA1iGq0WSTsDIVjOCgyCEkU788+psBhtia2hUKCRGAGNWDFSV6xuqj6bIzQJkbAQSUKTgTV0ehlQaeJKhFKEYchws8ZyL6fdy9m72HN9i3UxTZHT63VIsi5h0STwDDIroSy1jwNydyYQLoaQfg92LBUXk8lAYkuBVV6Wo8iIpKGZBGiZUKvXCWWJypfodZYpUago8g52AY1GgzwvnX5ZltIuC3rSOYIJf/6K4piy1HSzzJVllZql5WWi8IkPPO2PoffH0Ptj6F8+hv6FZ/lKraMqEDWW/uJVUUOpaHqewSM9+6WPyK34PISj0VmjsbYEqwCLwXggYQC8OJRyXwCrAmPs4Mb+b1E1g4rJIrxgnr97//UVYjf4DN/OlVk0f5MKzsIarCmxZYYpU6zOETJARRFK1r3oqiWsJUT1EYLaCDKsIVToP2EF4wvhwawVAJdnPFUMs31L16pBRz+ZXL1f9JvuNjW/b3nwSWK1xBjRX4Qqeqxc0acDcpjxVEWBZ/girEB7YbS+TpMSRIGze63FQdV0T1N07TJWYKx0jLKq7RbHUDKVFaSb9Mbi3AZ9XXLpONSovCQKXF2sq18WiFBicHXAgZBIpLPfjCPCOCKp14iTmDiKUNKiyBEmBVNitdsc9uly393VRBZU9b37Di8rVv6gGmZPfOipKu2UQjoKvgc+V5bLCumAX13koNyiHAQKpHIC90K4Z1dq6C9+FUg3YCr+bBa6EqnVfS2twesqJ8KfdeJwWSW3K1asO6gAZFhZ5iilRAYhQoXodIl0YTuLj91Ba+0RhPURVDIEtvClBm7DdBpqoQ8BwZgUTIYKJVYElFqRL/UorETLACktQgYE9RbNqU3UhldjRWVy2kfLHbDq2ZNaG7QBpRJq4wchdYYKI+LdW6E3T9FdRtbaEC4j00VMtggBBESEShEEMZVtrpD9O/U3HndL2acQV2YI1eO31uvk4RM1lV5dP/h0dOwgECgNfTq1tc790kqEkQjhBB2lnwAV9K184CU9O9QlGlQ1STw1GQ8oF/0xU13CAkI6d1GjMekyxeJO0rnHnH5e0SMeWYMKQqwMsAysiv037G/A1dm70vKz/gZSqBV944F5/7wEYEW/EOWXmF3//18ve9nL2L59O9ZaHtmylQPXr2PtmrVMT++lp3vU6g2ytMvs3t1sWJpleHyKqVUHMTkxwfzuHdx41eWc86yzacn1PPTgLE0J4+MNlmf3sHd6Nzv37CXtdZ2mizY86clPIlQBQkCn3aaX9rBZxuLCPJ1uh4MOOoijpvdyyKGHYbUrbXnsscdYvXo1zaEhvvv/sfff0ZYd5Z0//KmqnU68ue/trFbOQkJCgBAGhMhgg8GkMQaDwQMzNuPxOICNDZ6xjT3OJhqMTQ42wYAxYJJICiggtUJL6lbn2zeee0/aqcL7R+1zumU8M8ziN6/ltVRrtbp1wzlnh6p69vf5hs997kFG1ceOHeOTn/wkALt37+Z5z3seSimM1hw8dJDv3nADn/mHf+BVr3w5U1NT3HfffczMzLBz506OHDkCQK4t375vlXoUsb0ZMNsKCKKAlX7BTNt3JEMpWTl4D4eXU846bw+NeIZarc3ERI1WzUvs+kXJ2qBkteeYiiJqIXx3OSdUkpkkYKlfkDqHCeDb3/omWMe2ZkihHRu547KtM8jWFMHEFI88UzFx+k6C8y/gCx99P3fu3cvhlXV2nHkBO0+fZnNpH/VWk0atxf4ji0RJjV2n7+Gr37keypwnXHYue285QWdzk7MvvIDlQNIb5nzrlus5a+c8W648n9NnGqQhHDqQcnypR6efU7cli0PHifyH6zSurq5y8OBBzjrrLC644ALOOussDh8+TJ7nP/Czk1NTbN+2nQsvuuhfZUetLp/gxLEjLGzfycUXX8zu3bt517vexf79+1lZWQF8hP2FW2IGM9tQM6cxO7eFXq/H/gP3MznzUlaWT7B0YpEzdu1iamKCRhJiUBjrKIscZxzOlBx54F4m53dyxpnn85V/+kcmpyY565xzue3Wm1g8fpT77ruP3bt3c8nF/3uPsofEEAqkX6+DMPLpulISRZU6wFmE8zVmmWcEUUQYRtTqdaK4RhjXSItKpicDdJFhdEmcxGhdkg49WwHn2S5Ga0BV+6kHn7AOGSiCCkBWciRx8uu+Z0OVlGVBXpm2u+qhOQjDcVqZcw5tC8+2cpao5n2rdFEw2FwnHfZxRjPRbmMaDcIwQpcD/7CKT5dTAowpkVhEVVM7nRHanKayZKEjzQp0rigyxVyVXDk3MUcyu4PG1BZarSbIDIckDgOEc0jhfBJmVTYYJAQREzNzbNOGIIq5+4Fl1ldX2ez22ex2qdfrKGcIMIRoImuYqAe4dp1VFfj4cRUSJQlBJSkrtT83QRRgEZTGocoSAUTCKwKomAVJpGhGiqmaJNdVypUMUHLE9NLkhWWQlVVima/LHRInPCPIe89Yz04TVa1qLUYb8rzwZvK6GEutlBOUeKDDOYuuQMYReaDiAIyDgPxDrcUZQ1FqynyIM6VPn5MQxSGhBOV8/WSEz/orihxjvTeUbxz7Z0NrNM4AUeib5s74GkH6OkVbHyyU5YWXJFapcQ/V8XAN/XAN/XAN/aPX0D808BRF/xI0qRY9J8EZTFkwkoTJYKRRZGyahrP+w1WsopHhGZWEzIsjg9ErVxf1pHBu/M7VojaieZ28QU4Fph78dank+EZxI+f18WH4G89VaJ/wB1Ylx8kKXR6xk7zyzpiCMuuSdpfI+usUgx5hY46gNkltcidCenPGOE4Iay3CWguVTDCKLzyZtmcxZgRxuJOL2SnH4RFFP1l81CUg5BggUlWqgbNy/GsjTTF4iZ2qNKSYcLzAKeWQ0vokOKVwwhFK5VNHcFhnEMKOda/gk++0hMB5htRIix4oUbn9e7q2B5V8IeUBsZOozejWtE74VD3to1RHUaCymvheC+vpnsY5+plGSk2USxpxSBR6CqUKgpNU8ervWq1GFEbUkhphGPuuuhwQiZzAlRgRAOoUwM9HgQr8Iq6qz4EUWOx4gRqBmFLI8fXBncJce4iPIAzH5vzgZ1RpSqQYwW4hUTIBSJYO3IAZdiEfcOYVTyFMIopiHS0URkpyQvLcG/tFYexfzTqKMgdBZcLn/SpCJSnLkjwvquSHKrZXeqlBGEWAL4wH/T7W+EhXZ7WnpAcRglGSI1WsuyXNhxhtcA5P049iVJyQrx9h49BdHLv9epo7H4kL6zTrM+RFSpkPfLdG+7kX1quYZmfB5SilabUmWKvPQJSz2T1GN+0iVzdA57Rn59l+1kU0JueotecoXQA2x9mSQmt82oKhFQxxKqAMGqTpEI1ENiGY3UNjehenbbmA7r3fon//txGD4wiGqGhAoQ/ialOE+QUYIxBRRVFXHuTVBvLCMswKWq0mUeDPcxIKAgGm9KbMTggGma6WOEMYRARhhAgUQjswDilstdaFxIEcf37vN2GJQuXN/aUiViGl0Whj0E5iS7DaoqT/vlQKocLKo8N3a6yzIB2Oah5bD8jLiu46cj8QSuFkgO5t0F89xsYDd0A8i5IKI0LyjUWcM1ihcGEMYYxzZbXelzgkxrsAoIKo6volSHxkrxIRWheUZYYz2j/0RY0qCcaM19KHuL1ENRxBEPBXf/7HLCzMc+fdd3PxpZeT1Orcv/8AZ134SC6+9Ao+87Y3s/2sizjvsdfy9J98Ge3pL/OxD36Y5a//Eb0bAp71OzfwE3Mhj95SJ7vs0Vz65OfwoQ9+hOMP7OPgfXtJrWL7rj20mm0accBXvvIV7rn7bv7zL/4iH3znO3nDG96AEIJnPetZ3HbLzTjnuPWWW7j68Y/nN974Bp76tKdx6SMeQbfb/V8eyWgdWlpe5rGPvYpOp4PWmmc957njNfWzn/0sr3/963nCE54wBrFKrfmn24/wzX3H+eQvXMl9yz3+x0dv4/Fba+yabXH6BWewc9sMexYKFq//PJOPfwZ7Lnsab3jZFfzzjffy8vfeza8+dTfnnTbP1DkXc+M/38AddxzgrmOrXDQZ8YjphBsCxflnzPOiHzuf9/3jrZAO+enzJ5m95HJq23aR6pCtFzyK2TMu5F2/9Xpu+9pn+fbdb6c3zCiNwVjH3d/+Ium9N3BkM0OUOZEzvOjxV9IbZvzNO9/Bzi3TFDrmrz7+z1hjiAKJuGEv+050uHetYKAdtx44zt5DS7zwwnkk8K39q1wxV+PcZo133dHH1mYJJycpOg94Fvb/Zvzpn/4pf/mXfwnAy172M9x666087nGP47bbbvuBn335y1/Bc3/y+fzkT/4ky0tLP/D9P3nLb/CNT3+M9376iwRhyMTEBF/72td417vexetf/3qUFNy1onnFZ1Z5xwuezfmXXMZf/OHv8aSnPp0XvuCneMazn8O1T7yaX3n96/jKJ/6KE6HkkY/5Md79zvexvrLMG1//Ir7wz9dz/c13s/Ps83j0E2Y575yzefNbfofrb7iBl/zMT/Om//JaWo06V1xxOb/7P/4Hr3n1q4mS2g85j/5tRpoVRFFEnCQ+wMVaQikosz5Ga2r1Js16QiAmWTn6AIPOkPWyYH6qQS1RSEK21L1PjsmHLC0v0x8M2LPnDMI4pl5vMExTP3+UT94Sxj9IeA8mv4+qICAIQ6IwGO/VWnvAKU2H3jqiLDHWVYlQAVEUexmeEJV0w1IWBbosAf+QJYRAYWmHFuky+oMuLp3H5W2MMXQ31ul3N/w5iCKiJGHY66DLgl6vSyhKnCmZrEdMNSLyWsjixgDZywgkzE32iMM6zVDS2rKVeHIBEcQcOXaAxeOL5MMBzWadRr3OffsP0G41OH33Tjorq1jnaDbrzO86h217LqAIZ7jnzr0cuO8u2gwx60c4PFhjcX+DyVadS/bMYrUgEI4gSQiSGkGSoDJbsdYUKvLMse1bZry8SGt0nnpZjhTkhWeSSQcT9YjZdsyuqYRuPyXNNUMXEqqEUMaUPc1gWHJwdcAg93VNLQ7JjaNIS3JtfXKUhVqovOepFBjryApDZ5AT9gcQD2g446+bkNjMnPK8oX3driRRGKFUgAoCz95wrnrm8Q3go0cOsXRikZXlFZIkptFs0KpF1Os1knoTE8YMhjmrmz0m2m3vXbe5ST2JiVtNJlutMaAVKFmx7Qqy4QCLII5iev0+aZohpfIMnsL8n6bQv+l4uIZ+uIZ+uIb+0Wvo/ztzcUbwz+hrHrCxxlAMN72eWgiSZtsjh1gwroIb1Jjpciq7x1ZOWzKIKrmYrZC0BwNOo7f16NpJdsq/JFONf1b8K9ibG3WVTr6/46RBtXMn2UKjdxZOPAhYsFajiyH5cJO0t06Z9rC6JAhj4lqLxuQsMki8tlJIgqhGEDcQge8EOKMrYGmEVleAB2L8bzs+Bn81R8wkhNfXWmPAlj4a1QUIoUAEjF7pVHjQgykezZWyQjoBr+s1HrGUPqMtqHTlAle528uK+VSdPuFQAmwFeI08AUZ007E5oAOExTpvwofzd4BgBFaKSornr0EgPSVRiBH67D+Pkz4hwTrn4yqdo9AWKTylWQhJaAVhCJFSyOpamspkEhlUHR1D4AYIM8C5DGQM0k9yhwdFRyj4CGCTVVfIs5/c+F5wzlZMqdH18x1Mxw854/4NxyhZAeEQSEaJg1WsH7rYRBUZAkkUJfQ3jtFf2sfKvTEIS3/jhGc3BnWS+fMhaqHCGiODwXFioVI+zaaagB41r2S6IxBYivHa4Y2F/SLrP6P0pnbypK+bMQUIf59pXfmsWTeOerXW67GVCJAyIorrNNqTBEkTpyKG6RBbFtXDqxqz+qyzniknlTcDLU0V6asJQw/OemA1RCWKVqNOsxYRkiHsEEcdnGGklXemAJtSluvIqImqTRGGow7LqMuoqE/MYrfsQqQr5EslSIEpJEVvkaA2pN7ahXNNhAqQQlZdF0etFjI7Wef0hanK0FVVQLQH+HUw6maAtgqHwjoIpSQQkkB60FpKNwb9pai6XVXjII5DnPD+Ajivt9cu9O+jQFlfSEaBIgzVuJs3it5VypvZYgXlqPGAreTY/o446QWHF9vjIEkIJraSLFyICiRKWCJRMli5lzIfIOtbqTVnaU1u8/KF6rxL4RCiRJYZyvqN2JQleTH0RURQpyxyirRPFMcEcYOkMomVEs+4rQrzh/JwIyDeWt77vvdx2WWXcu0Tn8hd99yLsZbzzj2HzvIih9eX2HnaDsxghTu+8GEC60g7x3jV03bRzgbo9YLnzzlKW3Ljpuaxu86lPrMVISVHljeQSrJ95y7qSczK0iL//R1vZ9++fRR5zmtf9zquuuoq3vzmN4NznH322cRxDMDpZ5zO7//+77O4eIK/evdf8eu//usPAuTvuOMOPvShD/HqV7+aq6666mTx7hx5nnP11Vfz1Kc+FXDcfvvtfPjDH6keeKMfOBfWOdLC8J5vHKQzKFnvp9yxbNm0krndKXGkCdDUi5QHbruF/cc6bDxwP7mo8bKfeiZ777+D248dpHb3gBmXsWPHNC+vJ9TCGs1ak5ddfi3z0YB5fT9Pu+oShAjYsaVOa/fp6KjG177wDfq3HmCYTPK9m+6it7lJI3BkStCMIs7d0kSWOceXVqE0dAvNsDTccOvdGK3pdvvkw5TSOk6sbFIYH2t9YqNPEEhmaoratlmkM0RYNnOLKEp25Dn3Lxu6CDSCp13zeJ705Kdi0g1uvPEGPvnJT/Kf/tN/woUNPnnd91nffytZ5wQA1157LVdddRXf/e4NdLtd3vKWt/CCF7yAyy+/nPe85z0POr/f/va3WF1dpbO+Xnk9CH7hF36Bfr/Pe9/7Xk5s9Dm81n1Qsy+OY6IoREnBlkhy9tln8YKXvZxhd4Pbb/gW5599Bgfu28fd9+zjlT/7s3Q31vm9P/wT1h/Yy86JiNPpcW47Z9EF/Mn7PstkUPKIPdOc8+jLWF4+zlve/Nu88PnPY/u2bbz6Z3+Wew4cosgLfuONv8GjH/MYzyZ4iI9Wq0m9VieKfOKbrCRRUoCzmnxzBRVExNLRqsXYwTpp5zjdB26mKyPW+hBZRxhENObnUWHCRLvtgYQogkZj7FOqggAn5CjIHRWGBPj0MSklUqlq//Beot5IvEq6M2YcIDNyjSnyrKp/nH/QHXc6q8Zo1VYUWOqRglAi0NSFIcKzrUpjKLShLLroMETHEU546ZkuDVYYMLaqFRQiUKQWcicohWRjkJHJTbriBLvm1giiGmJyjlBJoigk7ZUUwwFCl9SShFqtQRTXUG4NYTTKeZlXaQRFUdJqNdi9YwfTQQdpcsxgDWFyCDSFnvHeM4FEO0leGpwokPjggG0zLVRSJ45jZiZblBXjKB1UxsM4Mm3JtE+EU3hpXCQdibJYaVjtZoRhQBSGTLTbFFYw1c8oyx659pJJFfh62OhKPun8vaEqRpWX+kmsinHSyziN0chKxilw/rml1NjAe6Qq6xvrXmEx8mb1NZopc4p+ytKxI6ytd8ZN9CiOKVyADRuI2iSl9vtvFAT0uj2UEjSTkCw3OCXIdJ80y8iLkjBU3iQ/z9EIgrhBa3YrrWaLOE5YW1vDGv0gq5OH4ni4hn64hn64hv7Ra+gfHniq/usf1N2IxOQd7E1JmXYRrkQBcexBBOcMXs0U4FQNR8XeqUzNXJWIgJCoIMKVBWMqkvNAB+4kJHAqknRqQXsq6DT66rgeOuULlopGWjFxrD1JhxvDTRWzacyzwzGiU4KnjuoypUh75INNdJ5irUUFMVFcJ2lMoCo/J6sNKoxRoU+GEMb8ABg2el9xClQ4pvpVQJgUXvcphMUKz/ZyJseaDIhBRshAjT2VqhlanYQRcObBJ+F8aTBKERzxo6QQFQV3pBeWUJUsIxjO/xwoMZLkiYqSN/pzMpWicmuqMDaLdP7dRgwt6wTGeQplIEfxlielmaICwJwcSfYM1nqzukxbjPOGcKNr7kLnkWGHNz5X+IksQGFQLgWTYl0OKqnigsPq9934PvGnTfsF0PlFw5t1VrHEzmH1ST22CmNwJ2mZD/0xAlirOVZdC2c0ZbaJcQJRSSlN0WOw9gAr9w8wRcb60lGkcETNaeaTFvH0mQTJFLZIx0CuCjzrLAxDry13nj1HpQ1WgRrfUdp53bQrDEJ5NqBPe/Abuqj818ChrR6zDk+liaoxoDq6+QVKBoRhTKPVRsUJTgbkeY60uuKSetqrlCPWpTdszqyjKA3pMAV8dLGUzrP54pggkCRJTCQF6D6uTCAMqw9U0eKNxeoUXW6ghCJsBgShqNYj5+nVOOIkojYxjduyE91bBlNgSkG6tk5YLzBFipMND5BWXmjaOZJayIytgzWe+o/AOO/hoa1FmwBrqiKGAClLhIAo8B1SxSkAr5TV48JoLvsggXocerNE6c+REF5OIKVCIZH2JDsxjgKCsEq9qa6FkMIbVwpwxj8E+Y1aVeC5Ly7FOEzCx8CKuE7Q3kJt4TwCm6JcTmi69JY1usxI4jZxY5pac5Z+XlRyXIGSDmyByzerzpChLDLSfpc8G+LCpo/aTge02lPEjYKo1oQwqs6t9Z+BhzjwNFp/jOEzn/0sRVHyip95OV/71nfpdbs8+vJLOXT3CQ7vv4eLz9zJ8X13sv+m69l84ADzcxFP/7EdLN+xSLHU42nzEV/uRtwfTvHsMy+mPj1PnuesdofUazUajSZxELCxvsY73/lOBoMhs7MzaGN41KMexaMe9SicNRhjGQyH1JKE+fkFfvmXf5lf/MXX86UvfYkvf/lLD0qw+/SnP82HPvQhnvWsZ3H14x5Ht9ulVjvJUHnEIx7Ba17zGpy1fPrTn+LDH/4I/X5/nOIF/j5ttdsUeU6WZXzshmPj751oNAnKgPXNAbU6BIElLAv233M3992wl/U054KLzud5z34Mv/adW9l33xEicYRnXbGbi3ZP84xtbZbLhDUxwZOf9eMEq/cy+Ob3ufKiy1D1CQKhEK0J+v0h373xVu5e7vLARkaoJBO1kK3thNJYJuKAi7e2uX+5x1p3wHwk2SgcG7nllr33ESvP2u32h2gH/ULTLwypNnTTgrO3TnPmwhSz7Uli4ai7kqXNlCBznFFv8Pn1PvdnJUIqrn7so/il//QqAD7wgQ/wta9/nVe84hUU0STfWPoA/aVDY+Dpyiuv5JWvfCUOybe/9S0+8YmPc8MNN9DpdHjPe95DvZZ4GZWQ3P7973PTjTeOz62Ukhe+6EV01tf5u7/7O6yUZPKkZ6Vzjl6vR5ZmBFIwF0su3LObn37lq/jM+9/LfUcP8dgnPIEvfeOb3HXvfv7sbe/ik3//9/zhH/wBs7WAi7YkXCWOsn3XHoSIeNvffpMXXH02j7nyXC695Hw+/rmv8b6//lueePVVnHPOOfzU857Hb77lLayur/M373mff0j7d7AJN6oEuCCMkCqo6hxQ+KZm3lsnrjdRQUQ9kAxNiu2doH+4yzCz3Hc0paki6o0mC/YipnaeTrPdqmo37+2ii+rhUPo91QLCeaZkEATe7BpO1rrOoSv2UlkUaF2elMhWrH/nHFmWobX2CgA5YlAxriW97YF/x1qo/NOF0MROE1gvwfOgj8GkA0wYYk1J3GjjhKS03jtVlD7ZqnL9pUCghcJKxeawoG96iEIxvWuZuFbDljuIQs907+PQRY4tMmq1BvV6nShOCKWXHSlryLOc0hVk6YBGEtPcOs9kP8UOM7JsEyscoggorIAgBBX4h7TS+IasczTikK0zbeoTk0RxTCOJKbKcsijoScYgikZ4M/Cs8DWuc4QSYgVaGIp04I3UhWB+epKWsUy3amz2ht7g2FoUDuVlGeN9t16Lxq/nZTYKF8Q45ZlYxhikOwmUWGspywLrgvF1E1r7xxvp5W/SX2iKPCfdWGP1xAm6gwFSKQ+UxgklASao48IGZeolgWEQsNntInEoG1GWfQoMYZbQ7fUZDlOCKKjSG3Nk0qTWnqY+OUuj3iC2CRubGxhdVNLQh/p4uIZ+uIZ+uIb+UWroHxp4klJ6RNRYrM59GoEpsbrElBllf5lysILNugxPBOiyoCxyVFQnqE8ST59G2FpABjXfC7DeFC1QCilDpBQUgLEGY0rKkYQJxtTGMSoPjGaP9ZFo4++p6qJ57MpP5JFx2yjFzo8xz2h8w4x0z65iDY29kkasF2so8z7FsEsx2MAUOQJBXJvwppESTN7F6hQhFEYbVFhHxQ1k1PDHPQKDqN6vAlxORh57YzOoNNzOeiMzoxGmwJmSMuthigEUQ1w0gQwbSDmBEBGVgtRPBjF6L4/CKqWqxWWkBa50pZwaDzo6+tE59QCU/x1vNu6clxyelPtVjKcgIKrQdSF9+oJFVKb7lWnZ+Dp6NDhQliiQ5MZL7owZAY/OezkxmsyeUlxqHztbWuilJcNCE8iSXHtTWxloWq0QGfnPVQsttdAQGYfR3lwzSlqEtUnC2iTI8OQRW42zGpsPvKWaszhTYiots64WI2NsRYeMSFpTBHEdKeMfdir9m40iy06Ckkp5FF4bRDnA6SFltoQZdtHDPmvHD2PzDgE5J/ZdTzrI2egUxO1JmnN15p0iDGLiuEZpCkQQjDs1zjl0VUCMNjNVmWQao8dkPlkVtNY5TO7p+iMDvREwPX6NUXFbfU0gCMLY39tSEteb3pgw75N1DlJsHoZ8DbuxH2oJrZ270UWELjIGg7XxfRsFCXEUU4trLA1Kup0em6vHIVsloEduArRoUMg6g/VNjq8t8cCRVc48scTcttPYc+WzMGoCQ+xB6GEfVw4Zbi5jjUK1wIkAa0t0b4Vy+R5sd5GN4TH/4BFEhNPbsEWGzbo0Wi2SeoNWHJFp6YF7KzDaUQpDMwlp10J2zrYotDfz09bLj4yxaOfGxoWl8fMlyy2TjYAkVGTa07ilUoBECoNPlIQgkEw3Ay6ar5HriAyFDHwkdyS8f46qwGafQqNo1gKk8GlJkVCgQgrrKtDZjaWzOE7x+xn5uTlwurruVbRsrUljZhvZsRvIequsrK+TpQFhsoMzzr2KHpOcOLGKFpq4VqfRnKDoLtNdPsTB275KmfaQWCYm22jjKI1lM82pNSdpz2yhKCL/9h1FbWIeFdVGfY6H/JDK+8GEYciH/vZvueiii3AOnvPkx7K+dJTPve8POOfyJ/HEZ7+Ig7d/h+2XXcuFT/lp/vZVL+CL39nPr3zhINskNCSEUchP/+qv8KaffAmz01N01tbYv+9envi4x7C2coIvfubjXPmYq5ieavM3H/oI7/jLP+f2fyHJElJx2/fv4M/f+W5+7b/8Iuefew4Ab3nLm3nVq17JNddcQ7/fH/98mqYAvPzlLx+zpP7oj/6Iq6++GoB3v/vdfPSjHwXnqo6pN64edWMBFhYW+PrXv85f//Vf89a3vvVBn+fdf/VearWYFz//eTzuzDnO3NIicwl7Zus885wa9x9aZd+BA7z4dW8hHaZEUcS22Qn+6c5lPnHzEc/6lZJABXzyutsY5jkrnQ1++bmS+Xad+w8t8ZV7T3DvUpder0cUBmyZaPAfrtjFwbUBn997nN+8ah7rHL/77cPsboZsb0U86vQZVBxTCMU7v3kfiZRcOFtj32ZBMwp45tkzHFgfsjIsWc8dLgg50ctpa6g1Gtj2NDfe/X3Ov+Ai3vvRj3Hw1a/h/s997pSIej+e//znc+211zIzM8O3v/Nd7vnk/0QX6fj7f/RHfzQGEYviB32d/udbfpWnPeVJxLNn8N//+//gHe94x/h71lr+/C/exqOuuIK77rrLr99SovMUKaA/GPJjP/ZjHDl8CGMdWxcm6XaO8Zu//Asc/P6tDPsDbjy4xPOe95P87Gt/ic99/rOYrMNv/5eX8+EPf5q7Fzd4Uyejo5fYMpXwiV+4gts361x31LDj2AM86bGP5LFXX8NpZ13A0olFPvy37+LlL3kxO3bvIRv2od4YpzE+lMdmt4uxPmq+3x+glKARRxTZAJ31cdkmG0uHyPs9uosHUXmHOdbRR45R9ApYzFhvLTBwitmkRdSaojkxzTArfQ0WB7QnvEfWcDgc+2zqUp/SJFSeJaFLsiyrwn10BTppsrzwzAqpiCPvHVXkGb1uRhCE1BtNjDGEQeCbdsqDM8Msx2UpNh+irEbZElek9FaXSQvNwAWUOEIgqnvWVxTH1JtthFQ4BGuH7iFbP0F2bD9l2iMKBM1mg3q7Ttiqs5prim5Ksdqllig2Vxbp2Zja1AJ7TjuNhrRsrK3S2+ww2WrQaiRECuanJynylN4wY3H5Xja6PbqLDzDdajLdbBKnCi0qZoiUSBSbmaKZ1JGxoCSgyIZYXTDbrrOlXWO6tkA8MQUyoNQanQeYMqIdS7I0oygKdi3M0M9LljdT4lChVEAQ+ASrGoI9W33CdOkcqxs9KHOmGhHFREw/FawNCpq1gDgKqUVqzMSvNxq+arWOotREUYhQiiBKUHEN6yyl0cjypG+N1j7ZTClFTIKUAQYLRQmu8Ebxgy6D9RU2lo7S7W5gELTak579j2RqfgeldiydOIHBe7QWTlCv1eh1N/ne9/ZSrC8Sm4wL5ms4KTBCsDwoieOIVqPG9tPPwbmcB+7fx9zWnTSabU7btZuVlWU2Njf+bSfo/2E8XEM/XEM/XEP/6DX0Dw08aa29rtxoXJnjTIEtU8psgM6HpN0Vyt4SJtsgrWidZVkSt2aInSSa8IZ7UkqsE4xsck6alntqrcOhiwIq0ENIWbGsqi+NZlyFDlvnJWGjlLgxc6UCnXBuTAEb+QgxYgBRveao88OpJ+8k48nT+zwKaMocU2aY0hfGUgUESR0pBNYUZL2Vsa+VdRAlE0T1SWKpEDJCCjWmP1eiuvFnPZWoNCIu27JAUIIZYMshVufotIfR/hoob++OkwEisCA8oVd4L/rxUVRK0HFX8MHHXAF01p6UMYpTz4KofurkqXlQb1GcBPBU5UTuEwq94bnFnaIfxHumudHCKcayPSUF2p6EvcbvJTxT6mRcqTcvN9bhjGeApaVBOUEofLRpqCSBMCgswhYUhcZZgSNCqgZORGgDwtqxab61BlvmpN1Vj5br3ANR1mCNpjQVLCcUUVLHRQlhnCBOiVJ9KA8VVL5W1pFlg/EiFgmHCAKsCkFKtDN0l49giy7oPv2VHtqADGNmT7uIye1n0pg9jSCqgSmrVA9/fxRFXhkCGm9gX1FPR3eQ0boqaj2Ya6z1KTsVoGysq1B4V72up3KOgeIx8OyPSUjlAUch0L0V8o1FBqsHyQcboBLStUWciFDxNMSTIJPK0NP7kikVABJjHWEYEAYSzBBMhjM5AslGL6efGxama0hpyU3JPfcdZWldU9+yn+bMacTNaWq1OkUuKHRG1lsjkE0i55AywJUpZecAunM/preIzXvIIEKGMUq2AEuJZH0okRrceoZNyur8jcQOFYgrfSfEsxgrEXOgUFIS+n6Fl7JaMFbQSHyHNVDgfWcraceIzUmVNBIoarEgsgGFlqQuIohClJIEjJJLRAViS6JAeiDaelmGE/gkjqpD55sLHsx2zo4BZxgxCUfU8spslxJpeoh0meHGCmurq9x7ZI2pZoNWq8ny8oDjvQ3WcsfZ55/l1wwhPas0bhA2plhfXyUfdhkMh96PQQXew6CmqxAFD5qL0d7gvI+ek6MI338fY2ZmhlxbPv/1b3PZ2TuIak32HzzC7otLoijizhuv5/RzTmdhock9vYIN7XjsQsz8ztOJWzMUjQV2nnsxE5NT3Hn33UjnSELJxsoixbDPtq0LHD58iDBOOHPPbu/h8a+scZsbG3z/lpv52Ec/yo7t205+fXOTo0ePjsEmgD179vD8F7yAz3/uc2PD6n/6p3/iyJEjFEVBlmUMBoMHvf76+vr4349//OO58MIL+epXv8o999wz/vrpp5/ONddcw4EHHmBlZYVuWnD/co9hYZhp1qkrH188Pz8NjSZZXGffwROUpSEOJe048N4OMvD1jTb0Nzto62UkN913nHYckG12WV3tUAwzLphvVTHkgtWNITGWH9vdRgURw9wwEUAzDojDgEFakGWGrhE0AkktlBgEifKSnIPdgtJCoiQWQyggkLC43uXcbbt5wlOeynf3PoCVARMLW3n6s55FrdXiS1/5OnGtPj4PtVptzCCzRlOmvQedy9P37OH888+j3mhy77338q1vfYtPfepTDIdDAG65/S7ak1O88OWP5UlPehKDwYBPfOITpGmKc3Dn3r1smZtj69atAAyGQ75z/fWsra5yYvE4J44cYtjr4hws9nK6do1geAfrx5eo1xs87dGPoRGHLB89yLatWwm3biEW5/Kt797GZnOJrXXB0dUesRIcWPFJwTuaoBqz9FLN4soD9LSiyAYszEywsrqEFooLz7/Ad4L/HYxWq02tlhCGAWXWxxWWwuae9RSEuCBCCIk1hvWVVfJsk7LsExQlZSlwcZPJHafRXNjJxNwCcb2Jj3P3LABTSW6gWper8JZSl2QZvvEWSN/g1YayYjeNpHY+rt03hFW1r/rXsuMmblEUBHmGtSFxFPk62xiKfhfSDeivkw16DAYDOv2UkFWCtKQpI6JWi7DmlQFBGKKCiJH8JwhDoiCglF52Zww4FM1mCxUoCk11rCCl5diJVdaGluNuL7vOckzOzlNrtEiHQwb9Hp3VFWxZ0KxFFciiWOtssrqyRL+3SUIKmSXVGWW/TzFI6aeGwuZEIiXsD4jrLWQYVemDAc4Y74mERQnI8hIntGdCCOcfyMDXFiKkXiU9m6ZnicVhSFEaBpkmK7yH1ghA6A8ylNHEwFQjoh4IIglhzXtrJXE0rpNr9dq4aZylKVIFhM4npWF1tb/6/VdV11IFAdaYcaNdnPIcZK3BFAWbayt0O6t0OhuVtFCQDoeUIqXIUuJ6o4pBczSnZ4hqdRqNBg7QeUqoJN0sZzjsccQOkKEHS6wUPuJeJEShQsQhDRlVHmMSJbyPcC15aIPHD9fQkw/X0A/X0D9yDf1DA09lnnvwxmicTnE6w+ab5Jtr/kOuHKYcrKLTDcpBF60d2gqaRuLCBu1qEgQqxFRUvREQUa2ffuN1FmuqSVRRBkfsJcFJ0OLUFIARO2m8SY7BJi8NHJlcV/xIJOJBhcoINR69pjiJz1RgkIUKfNB5is6H6HyIQKAC7+0kJJgyJe2vo7MhxhRIGVFrzeEmFoiSBjISXlLoocvx4jD+zG7EN8KDRk5jy02cHkC6ism62GJImfb8a0hPzRMVdVo4jVARVsUV8FQxmCpwjVPAtrEzv39zz+QR1kvkBChhx+dhhI/b8WdkzAZjBG+NaIZKjq+ntqdQARHja8L4K/7chwJC5ZPvyipicnxOqg8hZQWdCQnCe4cVI7N143CFJkIiAkiikHoUEAuNsjnYnOEwr8zbY0TQwrqYLLcESqNCQRSG1eab0ls9RtZboxj2KtZYJeGzIFRIWGvg3CS4JrrwwNO/h+ENCAXWQtY5htUloQoIWpMEKgTTRJQ5WvXYWDpEOezhipxepySs15jZPc3pj3o6s3seQTS5jaLXQad9n1ZjfQd1MOxjqvjeMAoJgoA4GiWd+MScIAiQIsDi0zGyfEgSJSBEBXB74DEIoqpD++DggNHctBaEChBhhLCGdOUAnfu/Q/f43VhjCWtT9BYPkm0sQ9kn2X4FauI0VBgTBZIkVOMo3LzQ1JIYV4/YsENK7UFeJRKW1gbct5jxE9dcSBTAYNjnplv2E0crtJsLnHEhbNmpaE/PQE+Q5QMG64vEskUDixIBVucUJ76PXr8Hm64hRJtq5SJsFFgXol3AfeuSEsdmvcuO7Q1qcTz2UZNCYo1Fm/FqeMqaJQmCCtAXJ1mdnhgcjKn/pSt9r0Se4krmvEy3kQim2xEbbkheOprC+1copcBahDiFRlt1z4wxXmKB3zQRDmFdxVzV42SMEa17LN0dr8mADFFBSOiGiGwZu7GPjRNHOHi0w7f3rvPI8y/Aqhb33HWYuxaPsTToce6FZxBVsbZB0iSZ2MLkzvM4eOQwqxtD3GqXyXaTVtNLLQLhN9ggVGMqe3XwPkWkCnx4KA9jdFWI+M7X/YeO8Cfv+wi/98uvZb7VYN/BRS7vD7Flztf//mMUT3gE550V8q3VHltDyX9//BaSxz0Vu+1CjrUuZc+OLRRZyj987vOcd/YZXP2oy7nnjptpNJpc9shH8uGPfoI0y3jVKy+i3WyggvAHPlN3o8MdN9/EHTff9H/8/I985CN597vexZOe9KQx8PT+978fYOwT6BwP8vkYJ+hay8te9jKe/OQnc9FFF9Hr9cbfv/LKK3nnO9/JNddcwze/+U0QkntOdHlgpceP7Z4hH2YcXx/wkmc8krPaDR6vQt728W9wZKlDUiX7hUqSRU02+wO6vT7OWKJA0UhivnL7QUypOXsiwpSWrc2I55w3z0q/4Nhmxq0HlrlwocGrHznP91YcJ9KM8ydi6q2EOAo4ttLn8FBzNNXMRopGrOgbRzOU9ErHdYe7nDUR0QoFw9Iwm0RMJCHfO3CCK67Zxct//hf4qw98bPzg/8pXvpKnPPVp7PsPL6c1MfWvnmu/Fz94X3rm05/Gz7/m1WzduZu/+Zu/4Tvf+Q6///tvHbeU3vOBT3DdDd/nJ178Kn7iJ36CJzzhCXzxi1+swEPHHbffxsL83Fj62NnY4COf/Cw3fOsb3HP7bcxEkpoUDIzjzhM9pOgRiBMYB+ecu8DPv/rn+c5XPs+3v/x5XvLq/0y9PQlCccHXrkOvHuKxW+COfUdYXO/z9zeucM1Fgit2TVGbO527b76FL332M7TOuITd2+Z58iXn8alv3EzOXi677Arf8BoVbw/hsWV+ASV9IEvR8/KH4bCgVm8QxnVc0kDFKag+i8dX2Bz06BUZsYyIak2aUwvsuPgK5nadzpZdpxGGIQJBFAaUeU6ep4SB8gnCuqwenCxFUVIWXu7VSLzPkzZefjWqk0tdhf4giJWqXtsP7/ckxw/GUgqsiYnjuHpI1qS9DqK/iugv0d9YZX1jwxuDd3PiuMNMmTO7cxf1OGCiPYFTo4Ql711STxLqtQQdxxgHpZUYFzA52cLpnDTLmWjGREFIoELuO7JKatYQh4dcUSpOP9tx2s7tRIM+Iog4fP8+ZmammWzVSRotUiM5vLjC+onD6GGHPXMJxaDH+iBHDrsM05zOoGAoBtRzRW2qQ7M9QSKVT2szGgGEYYxwhtI51jo9nHPMtGso4SU12hjCwHtuxRKCSBEFdZyQBEoyzErWexmDPCcMIagYEf3hkAhLFMCWVoxoBMzWFEVQxwYRKo49EKUESa0xfthMA18fBZQIneN07p8FnPESyzAktI7QmDEwqap6YpSUZguDLlJWTxyn0+mw3tnAKu+7Oxx2PDgiJWlWUFRJh6dfeAlb6i2mpmfQZQ6mYGqyxcoRQXeYc193SBBKoihg90KLSCSEgSSOI8J6nThokjRqyDDA6oI4UNCo/29mz7/9eLiGfriGfriG/tFr6B8aeMrTTZSU3n1dCqyEwmrKtEu2uczasQcwaRdTpJjSEtRaxO1ppk97BI2Z7TRm9xDETa9xVF5SZ63vuOBOAj4OQZzUxgaJQopTTjRjMswYAJEn0cwxuAQnqYYjgEMKhAgYG+lxKqdplKQGI5BBUCU8ACBxzksLTT7AFhmYgiAMPJoZhjhdYExJurlOkfYwZe67LEXmF6f6JGHDEQTJmNV0EoKpGPNjjaikyh+h6A0wwzWy1UOUvVVM3seWQ1QUEsQRWFBxH1XkBE2LCOsQSQSVtjb0iXaBUhgrx8c72nB8t6NiO1VyOiGrSSUqd63q8xrrmUZjYAhfkHiCl//FsdRRAMZ5vTPe88l7UFVm40IgFQRCEAaO2HkgckxzrN7H+jc5ecUqlFopKlmfP2dBGNGq15meaNGOAxqBoS5LeusdsixldWNILWmQJDHrZQcb5ph4g12nn0Gz1fI65iDGBAlOJQyykm5ng2zYQwqP7AdR5Cdg6DteUnoDSdypyX0P3WGdJQgSojghCQOMK4EcESisc3RXDmHzHmW6QRhZAlknUFPMX3wxtakFprefTmvhHERQJ+9t4LT3GcnyIUWZkxe51yzHIVFcq/wgLEWRnXJ+bBXxWiU0OEhiT/uWQhHHDVTg57TWI4ksY7mN0SUIh1QBUaOFyTOyziqL93wBPVjHZJtM7job33yUyHgKaw2dw3fTLA31uSUmzn6KX1OqjR5hkVKRxBE2CrB5n42eptuHtWHJwpaE03a02DGTg3UMMOzeOUe3X/JP//zPbL19L9PTc2w/52KasaER5ky1WjTbAVNqFSs1KX3W8pLUTpFTo1vM0O/1GHR7dEyPYa7ZHJRsrPWZaE2wa0+CsM775kkP6PqOpfdLw4EZbY5utChSeeqNlklRMUFLRnGyoQgrH7XK4w4LwntIWGfJ8tJ3foTAWUVRGBxmzDpUEhC26glVrMnqa0op4ihhenqOQhcUZU6R51jrKczOnlznkV42Fkch9aRJqBSdu7/P6tF9HN9/O/edMKwPFGF9gqVOl+WNPnceW2VqfpqFnQvMz8yhVMRgmKEiRaM1wWnnPJJBf0h7egeLR/cRxDEiDonCkkBoZDkgjk4jqk0QJC1kGMMonti4U1VLD8lx5ZWPZnl5GWMMv/Fbv8EVj7qSd7z5V9i2ZYbNow+w7ejdBPs+Q16/h0ckOd/98nd5xz/dxoXddc7cPc/q7kdx4aXPYmL3+exUdXorR1g7scilu6fYOtsgVo5zzr+Eg0eO8Wfv+hse/ehHMzszzV333MPP/dyreN1//gXf3XYjGfr/N2Nubo6/+7u/o9FokOc5L3zhCzl69CgA73jHO4jjmFe84hX8zu/8Dn/6p386ZkXFccLHP/4xZrbv5p9uvZff+59/QogHRX77t3+bm7/3PX7/Q5/ks3//MT7413/Fbe/9CrUoYKIWccb8NJectYte6Rj2uvSzjDzvsiWCc+frFNo3h5TVPPbiGYZWcsNmyNN3TrCtHeEGfbbPxOycn+Jxl51Jd6PHP+5d5KyJiFhZjkYB84mgHcNQhZzbjDlXSQ5ultQCyZZawAO9kloAz59XLFnBQIRccvZWnvzjL+BxT3k2vbTgm9/6Fo9+9KPZt28fKgh43NWPR+uSLXNz/PXb/owd27f/q+f08ssv54YbbjjlK46F+QXm5maRAn78Oc/h0ksvBeDGG2/ita97LQCHjxzh6sc/HoHAGM3a2tqDXvf666/nyiuvBKAsS46fWGJeFVy5rcnelSHNdoPT56aIAkVvmHH/4SUefcY8l1+wgyCQNCZnaM5u5eabrufYof3cu/c2XvCK17FlfoGadDzwZ2+ht/Idbj+wxNH1Ll/a1+FXz91LvRZx2ROezlWPfyKLx47w1ne8m2uufSrnnHuB9wWpWDvBQ1zyvrrZG3eNVWEos4zu+jITrTYYzYkDd2Os9jVLWpCEEadNN5k9/ULiqQWS+TPYceY51Jotuv0+tcgn0wlnMGWJ0wWdXgoOoihGGe9LVGpDnmfVQ6keNx7NyU4iQeA9oqIoIgxDpJSU1R4/Nm6v6tM4rhFGEc5J0u4m6aDLcOkQYbFJWGySp32cNST1GrU4Jg4jYlEisj5ukFCLIwyS3FjKwqshdBQQJxFJLUETMiwcg8wQN533sdEFk2GIdo6u0Sxv9On0C1jLECrkyKGD7F/Ygh320INNXJEiGjHWwb77DrC2tsKx/fdghhu4csjt64Y8zSnSAlMU5MYyLC1Ts22SuM3U3Dz1eoMwCmhFkkgLtHMEtkAbQ1lo6rEHZ8q8xFUbcxiFGGMYaoMUligImUhirJBoa9nsDVneSOkM/J9mPaLViDhj1wKJdIS6oNzsYsqSMPYR904FqDgiDpR/4E9iz1JRAZHAp+npEj3skUswrSahkoRRiIprRIEijiO09qyFOAx9Y9k5KHPSwQa99TUWl5boDVMGuUZIR5bnrK2tUxQ5zjqCaJGpqSlmZ2ZZ2Lqdyck2kYSJ6SkmWk3azTqxlHSWF2FziXw4oCxShsOSKC7BaJQKQSryQjNY74BUhBJKXT7Iz++hOB6uoR+uoR+uoX/0GvqHNxfXOU4pECE4gzMaW+aYwrN/dDbAaoN1Cpm0iFoz1KfmaUxvozaxxSe7jVlGrvIysuMO7qnXXkqFtRVV1FqQqqKzjYYYeR5yypdOeW04ydPhwbTSMVPn5M/j/pUEvH95/Nb4pA9dYk2JNbr6XQtOe1qeLk8ymazD2BJT5OjcO8NLXaKsOUlHc+OjOXlciLGeWox0nNZTj8u8QA9TbNEn0CHYmDLsYa3EiRgRtZAiQAReZicFFWXaJyEY7SfWqedCCG/a+gw5rwABAABJREFU5qzDCHASpKWaEo6R7fpomjhOPbP8AIhGxTyzlYRSWrzJpXMIKyqAyv+oFPikPCkIJFgFgak8pawP1RTwL67NKewnjzxWky+iFkc04ohIWqS1lFlOrz+kP0jp9EoyXRKXJS7vIpIS1TBYZ8ZMKqkCVBAR1pqouIEIa2jb92kHxiKtwVmDcKbyu/Ly0FEyzUN9OFvd51KCKbBFH1sOyKTE6pL+8gFM3kdnPVyWE9Xb1Ke2suXcS6lNbqU+tQ0ZNdBao4usmrC+4+KTFh0yDAhUSBhGWAvO6XGnUIyYhiMWm1Bj9p1HFE8a1YtqYR+tE6MgAOuM77wKkEKRDTqk68cYrh1GSgjiGioIvTG/sciogdEaGcSYYYeiE6BcgZAxVoQ4533ahFDgtF/XdEmhITcSFwS0GgEzjQB05osvaWk3Q0pjWVkb4JZO0Ov3GWpot2LarZBw1kEvhcXDDM0ag+4mi2spvb5hmEEnzxn2C9JBSWotzoLSioXGBNMTk8w0Gigh0EaPzR9HsuSRf9+Idlstm+O5IhjNczi5hVZg7ylmk777Ik6C9cZRFCUjg0TrJKbaXL3Z4UmA3AkvBvZ6dUcUhhitSYcpy0tLBKHywLJSOCUJlKqaDKBkWJkygrSGctAjL0qOHznC8rFlji71WemFpFoQhiFpWVKUhqXNDaa2zzE9NUUcxfiMoMKj08Jr4ecWdhEldeJmHZcPcWUG6XGc9dJwz3oMkWHCScm2raKHH9rg8S233AJ4lk+j0fCyBKvJVg/RW7yPY2ub3HLHPWyUPXbtSFjrNzg0mGa2GDA9N0djz6UIm5MuPcB9iz1CCiQFCwvzCKU4vHiChflt1BtNWu02Uegp4lEUEccRSRL+L5e5R1xyCUEQ8L1bbuG8c89l2zYvuzt48CD79+8HYHl5ma985St0Op0H/W4YhlxyySWsr69z1113YYxhy5YtXHTRRVz5qEcRxTFPfvKT2bt3L/fddx9XX301R48e5ejRo2xubtIrHmDv4RO8+qeew2nbvQzs6quvptVqcfZFl3DBAw/wiLvupldaQiVpxQG6v0yZF5QEvpmgFFl/iHGCEghDRVk4+oVmOgmJQsVp820mGjEqUGyUDiUtodNsqYcUfcVGqrET3uTaSEXuBKmF1AkiBEHFDPZUbsmenVNMNFtcsm0X/3TLXSwtr9OqZzQmZzjtrHP57nev5/Dhw9x6662oMEJow80334wxmq0LCxw/dpTJiTYzM9M/cD1arRaXXXYZAFlecMfd93ovjCgGZ8mLfHwd+n3PHrv4oovZsmUO8CuGLssx4wwAIej1++P7sF6v86jLL8OsHSdbW8I5x2Szzjk7t7C6vkmW+ql59nnnc/GljwQEE5OTzC/Ms/+uO1g6cA9r++4gXT2Bm2zRWJijWzo20pJtTUUUgtQlhx+4n9aW3ew58xzWVpbprK8zMT3LcDBgfW0FgH333svhQ4d46tOe/n8xo/7/PwbDIVEYkkQhVpeU6ZC0s0pic9AlG0vHKYCsKLHWUWvW2DI3zdbT9hBNb0XN7KLeaqKUxPQyrAKnfKPUGkOhNaU2fh9VQdU4dARKopXyhrnWjb2ewnCUzOXXPlnJ3vx+I8e16ohB5/8OCMOIIPDMqTwdkHY7ZN01nBmiXIbAEQSKei2mniSEQYASDqdzb2NQpDgZ+hrXOYwuSYcDdOlBnUJbisquIzE50pY4p1HOnxenNVprilKDGbJyYpE8y0g31ghMTqAzaknEoN+n09nkyLHjrK8us766SmBThCnYHOboQmNKjRQOKxQyjokabaJ6A2RAVmq0sUjhZTSBC1DC16bOQRR64MkUeZXKLQijkDK1ZNpRCyVO+gdebd3YpzQIIuJEEJb+/BoNcRR4hpR05EJikBgpfPiRoEoNP0WtIKoGcuiZqNZoTFmQp0PSvpchqSAkCCKEkiCCcYiPkoAucbqkHPYYbHbY7HToDzOyQqMtOFNSFAV5UZDnBcb4ZM3JyUmSWsLk1CT1JEFgwXhP1EAqZubmqEUBaqrB2vIim+urDNIhalAQ9zOyXBMGo6AkhzUWU5Zoox/ywNPDNfTDNfTDNfSPXkP/XwBPQ3ABDo02JTrrkw82KNNNdN7DmRwVJURhncaWM2lMb6U1t53J7ecRxHVEEPsbsjIP19W/rXVjDbKpgCgnRJUg5mV3SgiEDB5UBCkxop+5U9hN/+LmGS/OJz14xAixOkVaN6Iwjm/FilVzktnjacumyNBFhi58eoVwJQhBmW4iZQhOoKI6oRMIFWPyoac0lzm6zJG6wOjSJ1CMODzi5N8jaZvfHASIABE0EWFRycM6aCMohxlOF6ALnAtQhSG0AS5qEaAIowZSSAIliKOQIgzJlaIU1ZmpJp+QYhwzqW3lvO/ASW9R7pwHikZg3UjaeBLYE6dMySrJbrRJSoGqkg9Edb5R/pwLGE92SWVQp/wETkIojKA0FkaLfPW+1dUhDAKQoprMXp880WrSThJacUhIjskzVtc7LHaG9IaabuZQ/SFSFfRNh9b0JHNb/eIQhl6vTBAhaoKp+d0YK3AqoXDSU5dtiZTWdyqdIZBeNhqENVQQIYMfjPx+qA2rHVo6nLLk3WXyzWMUm8fYsFBkA9YP3kzZ76LTlHwd2ufuZvv5j+b8Jz+foDbFcFiysXycweYmZdZDBgIVeHDUIQijmCiMvXmmijDKI5JGFyAUQiqi6FS5TgVeVusADrQpK/adN3HXxvhNuiyRUhDGoQ8jECEYQffIHWwcvhU77NCc20lr4XRstumNwAq/aas4ZGrXI+if2Ev/+J3M9Y7galsx4SzWeiankopB2mc42EDnBdqAlRHN2UkmY810WLC8tA5SENdipicUMghY7E/RLzS9jS5Hj34TGSeE9TrDR+yhFue4249weD2nn2r6/YLNQcogK+gMHiCUkkhJdjZrbJ9oce7OOc5bWGBisk2yY4FDgw3W0pQoiHDS8wZHaarWWJTw/m5CmUpvTeX5xlju6ueZO5XeifeBAyHLKhXH4aygKAwmL2nVIwLpqcPaVkCvFF426zwcbiU46TfPQCkaScTSxoDF5T637Ftn967t7NixwK7TzySMEqQK6fa9LCEMQyIcwpSkq0ssHjnGiWPHue3Wm+j0h2xkYKRBKUktUgyNYWBKiGDbwhwXnHE6gQqxSMI4xhYZZT4g6y1x2pnn0ph4LCqqcfiem1m8/3YO7j1IkRnKyPu4IQJk3MKaAme1X9+NN5n89zCUCnjDr74BJxVvf9/f8owtSwzXjvPBAz3M/dczNxHyvT+5kqdc+DzsmS/lT//TS2lu28lFT38F61/8fW6/9Xr+2/u/z/Nf8mKe8OQnc8YFV3Dz3ru47utf5aXPeQa7d+7gl664gs9/7jOsLx/jOc/5CT758Q9x197v82u//QfUGz9YNvzu//gdJicmuPoJT+KXfumXeOUrXwnAW9/6Vn79138dgOuuu45rr732f3lcH/nIR3jjG98IwAte8AI+9rGPjb/3xS9+kZ/92Z/ly1/+Mv/wmc/wF3/xF/zGb/4mL3vZy6qfEDz98vPHwNN/+2//bfy7z33hi3nuC188/n/nHD/+lGu44/ab2b19gQtP38ZUq8bg7v2cSAsO9DSnT9bYzEr2r2R858SQPVta/OLT5/nGvmXuPNpHOUM2zDB5zmQILi2oJyEbQcLQQl8Z9megcu9zqE2JNpZYCayQbNqA1z/3Ys68+HJaV/03/v7FL+a66z8GB5Z57HNWGQwGvPglL+bYUZ/aV29P4Zyjv74MwPHjx3nmM5/J7/3e7/Grv/qr/9v7ZXl1jde94Xd57c+8kJe/8MdBSL7whX/i1a9+9YN+7rd+600897nPHf//xsYG559/PidO+FQ8FYRjkABg547tfOaTH+O3fvt3+Mu3vZN6IDhzYZpnPOp8PvjJrzBY72Cc45oX/RxPf8YzMA7OOOM0FqYSPvBHb6HRW+PM2PLpP/stTjv/bP7DzzyP2+7dz/1LPX798VtJahEmCPnKl7/EVU99Ls97xgt4wQuex5bZGf7kD36fN7zxDXz5S1/iiU95Nm9/+zv4y7/8ywfJSR6Ko7O6zMz0FM32HIPlHsX6CXqH7yGeTLC6YHX/3axmjl7hqAELc1s454Lz2HX5o1DNGbKgjc6HFHkfl/cQkUCiEEJRGktvmFWSkRAVJ9hsCNJLYsKggbGONBuigpAkSQjDqJLi5eiyGHcSPYhiq3rNe6DIwPsEhVGNeqOJEJJs0GPYWWVz6Sh6/QQidMSxty4IVEC9XieJEwSQZSmmSMn7GwyWjxA0J5G1CYQQ5HlGd30TO1hn0NlgszdgMBiQDwdEqvBx5VjIwZSGrFegnCWSYJ1m+dgRjh89wv0SmqGkFQUsbF2grwWbLmbvvvvodtbQm0s0I0kgoNNNUUoSBorpdkzSaFGfmmNybhuNeoNemtMdZuAs0griKCaKFMLkvpwNoJ7UMRb6xj/QK+Fo1GJ6mWEjy2g1aoRBiA0Cer2MsjQ4J9i6dZ7tUUI/K+hvdsgGXWyhsUpgkWRGUBhJiURZgcIRlAVOgJXCsx+wIKyvgQOH1Io0y7BZQWFhqvDhTxOhr8ekDH2NbwyuLDDDLmU6YGNlkaMn1jm+usHGMPMsOCHJ05SyLAhDSaml92p1MD3Z5rQdW9m5fTvGaDY762ysLZNnKYONdRbm56nv2UMrluy77Wb233Mnh+7aRyc1dDLL5GkdJlxEPNEkiusYB5vrfcoyf8in2j1cQz9cQz9cQ//oNfQPDTwVm8cpK4aPyYeUWY9sY5FhZ5UyHRLKkPrUVmrTC0zvuZS4OUXcmAIZUmqDKwfeL8f5KMBRulsQnEx6cEXpUXBrPb3UGsqi8B0aZXwErZBjcy6P5p48UDcyxxYnwZJTJ6eogJdTGVGMQJ5qjEAsj2aO+D6uSvDLsTqvUs60N1i3npejggREgCXAiQARCAIVEzenSdpzqPokMqx5hk7F3nKnsLSUrJYeUaGjwmtLVW0KoWIvNxMKFddxxoDNMEUBKsURQJAg0y4IgYoTD4ZUIE2gAu+fUR2vrFhJXuN9EvE11lWxir6jMzotoqIjnurxBIzPk3UOM5LcCTzqXr2mG5knSv+LTo50qg6kP/fer08i5Mj3zSOvwvgEO+s8hW+EIivlGUY5liAMiMKIyVpMLMFkKRtFn7LI6PUHdFNDri2lFWSmwFCSS0VLSdrtFvVajTj0oNEIqZcCJqZmqdUbTEzPUgx7ZP0ORXcRicaarIokdkgVIVSEkD/0VPo3G8aA0AWOko3jdzNYOcBw7VBlVCipN6eRk7tB1igHGZM7zqQxOc/K/bdidE5v7ThBcx4ZNgmiNk5YrHMoGVRd0pEhqcQ5gzFFpVGuzC2rTqr3hPDdAld1vJRUOOEoimwMTgZhWMkSJGHoaaVBEIFMcEAxXKfsL2OGK0RRHVeWZGuLCGvHncAyyz2YT4CjhrElK3d+lfr2S6nvuBTyLi6IsVG92iRgUGrqkaQeS5K2RKeOtY4h7QPSUZY5vSxhM4NcSworsULSaLfILGzmJV+6db+fPs6xkWuMdcTAbByyNQ65dGEHE60Wk60mW+sNWvUa0+02caAYas29d+7jnvVVNoqMPVunSJKYOI7ISw1YVFWoeHmxHZuaChSMok09la9iLYJzAisgDKQHWnEY4zDG+5f565NQWD+3c228zEIInPSb74ifOgKNcb5rFsYxtdDQ7/a588Yb2Lc3JmnVOe/cc1jYspVd23Yys7AFnKVzfIXlI0fobXTYWF5ieX2d9c1NesMB1gmSOKSnLRIIEf6BHcn0zAQ7ti9w2q6dJHGdoshQesDKobsZdlcYbBxBp+s0JueptRfYWD7GoN+l1twCNiXNhvR6q7ioTm1mJ1b7e48qyEGKH27T/Lcffu/cOjfDC669mu3BMQ7uvw/EP/Lix2zh6nOm+NvPLVL71mdob7mLH3vGNeS9AR/+1f/Id+7Ziy42ecPTFpjWd5J8r0/7UT/GIx/xCHbv3s2urQtY5zh0+Ajnnn8Ry0vL/Mqv/TqPfMQlPPt5LyIMw0pqByC48sor+fu/+zsuvewywjDiE5/4xFjCBRBEMbVmm2zQH3sUvPnNb+bCCy8E4O3veCff+e71/PRP//SYGQUnGzJvetObuPPOOwF4zGMewzXXXMPPvfrV7N279wfOyQ8DOnzzm9/kT//0z/je7Xvp9lL6hxZ53ktexpOveSLP2OyRDbv0Ntf4vd/7nzgNF597BsM0wxnN+75+D7OTTbZO1rn/6ApJIGlMNPnn/WtkhWaQFty9maMd9EpHEvpu9GJngHWOOE74iz//Mxa2bCFUgne/8w85/rEPEMxcz003jTyyfPepXq/zV+9+99icPYhi9u7dyxt//df+t/eFs5ZBdxMhJI2JSQDKPOPw3hvYXLn6QXfQaFx08cX89m/91lhC968NIQTP/fHnMDs3h5SKm753M5ubHX7uZ3+O9Qfu46LJiHu6JTXT5SxziJV+nxMD74XxF3/2p3zyEx+jFQekRYEzBU/eE3LXkZiP3rWGPnaM+qEuX717kWuf9VO8+KUtjn/2L7jl7g7HMsmvveV3MSrhs5//PK973S9QDDf5xPvfzTOe+WxSLXjxi1/Mrbfe+n+89g+F0azXkCZjsHaYpSP3cuLoIfbeuY/dW2q0awHbtk9Q13X6OkYN+0xu3U40tYXO4iEyc5i1gWFieoYoqdFsNDAOBllBq9mi1mgiw5jhcOiTkKxPJLJaY8rcN2+FJI5igsA3Y+uN+jiy3TOOSqQqvdROKawuxr4dfh8PCcLI15NGk22ukXaWyTeWiV3pfWeEop+lGO3rAwkoJbFYrCkwuSNdPYzKh8hmSeaUl4kVQ5wu0drXbIGyqNjRjA0bg5L1fkk28EbsWjsmQoVIBJuFZ6NjLVlhMUaQloZseY1gc0h4Yo2NTgdTFgRWo1VEECoWpidJajVq9YQd0xHN9gSt2a0MZItBWnDHXfeSZj7B6rTdu5hp+gdiVQ4IA0sthMXNjNJCGNaJQonE0h30CJRiy2STWqgIBWA1ceh37azw5yRSkq0zkwyUZRhY+p0e/ZHKwxiUUtTiuHoWcDhdYrT2NRMSITTIsqqPq8Rx47Boet0u1kGWZ1XaYQ0Z1cjzkiJLSTfWGGyukw4HLK1t0BnkdDPfSLfa+DqszKlJ2DLT5PiqZZgLwsYEC9t3sXPPmURJQp4OcLZkcf89DDtrDDurFDt3056aRmzdwqAoyJxguh4SBoK6MmSb60RxnebsDtKipNTG+9wY//D6UB4P19AP19AP19A/eg39wwNPvVWcLXGmpMz6mHxA3lujTPvYUhOECUlzgsbkFppTcwRJExnWvJeT80ZpUlWAy4i9MgISpBo7z4+Gl+UJBDnOaIzzGlIUCKGQI1rTaIz8nNyI7TRiR50CPgnhi99Tfk+M+FEVZWzEhAJ30qvIWZwtsabAWk979PTQkdlrhookUjnvlg8gFCpKCOoTRI0pVNRABDEPkgyKk75UQviFQogqkaCi88kwQQpF1JrDFD59phhs4rINXOGlf6LMsUWKKfrIQGHLOkrUK2rtiN100mhUjME5RlxCfworUM6JEYOJkx5rnAI6VddvbN5eeTLZkVZSeG2wFRUVcSR1lKIyuTvJTJPSoVxlgy4gtFWKYfV+HtASuCq1MJACofyCIayPvo7DkEhJhNE+HWmYkhc53UFJqr03FQJKaymsxUQSFQY0GvVKTqLAGUyZoatzGYWKKGoTJQlZv0ZfCnr5Ok47j/Da6tpLhZCScUzjQ3yYMsPmKXl/jbS7Rq+zTBgIwiihPncaYWsrKpnGFENqk1MILBuH7yIfdhisH2Ji5yVEE9uI6pO4aqWWMjwpO6zOgzfi0zhn/HyVJ+f3iGUoMfg6y1ZsRm+oR0VZ9+xDD5I6qfx8rPIgndHk3UV03sXZAhVOggObD8GAVQJjc4zDzwNARS2sgcGJ+wkas9TmTsNmm7iwgUqmxvezdoJIQagcrdCy3rd0BwZjFNI5RGnJB5YiF0g3oikqCCS2NGhjWOwM/P1hHaWzBFKS1CIm44CtrRpnz88yPTXF1MQEM7W6T80JQzaHQ9aGKfcdOc79a2v0dMnMRB0RBITRg4iZ+O3QeSmr8JNKOsVoEpsRcDzmEo/d8qolcDRf/ZwVUqFCcdI/wFkCFFJ5qe2pa4WomKFyJNdFYIyjLEqGnQ5Zx2ADgdAFvfk1TD9FCIvAsnr8CAfvu4/O6irdTofOoE83yxBxQhCEPunDOgIhiIHceg+1KAmIkpAoCsnylHy4Sbq5RG/1EIONZfobxwjCkLS/QX1ySDro4hAk9QmKzJKnffJ8QFJm40Sg6lRW99j/ixn3/24I4YMZajM7aA1KFhoh584mXDCX8J6b10iie1mYOsZFV1zAcL3DgW99if1ZQHMi5pLtdRaPL3Gi0+cCV7Jldoa5uTnWV5bIsowsy5ianKZX63HgwH6uvvpqzjz7PPrdDnFSp95ogYBt27byEz/x4xw9doyNzS7nn38+eZ5z7733ArC2toYMAsY0ZOC0007jggsuAGByaposy/jsZz/7oGPr9Xrce++9fPGLXxyDMs9+9rN58jXX8Md//McsLS2Nf7bVarFt27Yq0a26p//FcM5x8OBBbrzxJj71qU+NP8yw6FPImKA1y3RjislGSCQN73r/3xE4zUVn7+aufffS7Q/ouSZNwGnNxjCnVYsQQcC+lQG1eoOtO7bTzUryYUrvxCKzW+ZptVsU9T7LKyt0i4IrHv8kduzYiXOOP3zn+7jtgfs5ct2nTrmo/tMHQcDTnvY0ut0uJ06cYPeuXczPzfK355xzyiIAxhjuvXcfIGi3W2yZm6OzvoZUwRh4CpRkfqo5NpU+ePAgWZpy1plncvjIEZqNBhdccAH9fn983WZnZ0cnrrrXBI+87DK2zM9zYmmZe+69j9WVZT73+S9wVjtiWyNirbREJmdjbYXNYY6Lapx9xg4662usLS/SW11iWBgCJXnqj+8hak+g59sInbOZphz+9q284lX/mUvPO4NPfyGkk2qWerBr925WNgbce+h+Lr34Qrpry9xz0zc455FTiNzwpc9/lubEJGefffb/1fz5txj1WoIyKSbt0e+u0+mssbiyRl0lMJkws3WelmgSugYiiYjrDbQV9JeOMcxy1rsZoT0NNTVLY3KaTINGIoOAOBCEYYzWGmM0RVmijfd4UWN5DoggGCf5el8nSxAEjMzrbVWgKWsrw5OqNq3keSoIEM5hdEHe30APN3H5gDDybH3rBGmuMdpbPtgkQkkqWwIfmlMOOpRO4kpBoRJ8o1dXpbifv4ESiABCZbHOkJaavnWEQhAKSS1QlFbQLR1KgAJ0VS9qHFlRQKnRvT7SlCgB9VpEPYlpJDGTjTr1Zotas8F825E0mtSaNYapIM1yjh4/QX+YIqVicmaOJAyoJyHWOIwDJyTDvKS00IqqdGMsWaEJlWeZBcJL0JzWhCrAWUnmHGVZIJTyD8OBREQhneFgLDeLA290HIe+dvIPsd7nxViHoWQk27VUtXiVNodzaJ0j5QDnHMN2hyjJUXFBmhWkgyGbK0t0N9YZDFOWu0NSDYXFv541lHlG6EqiQDFVD1lVgkwKojgmiBNUlNDr9cmHPQbdTTaXj9FfW2WwtgpKkWUpKvZSRRHEtBsJCkMgHKb0ViVSBbjSS8yEG4UNPfQ34Ydr6IdraHi4hv5RaugfGnhaP3IHtswwxYCR8bYUIUHcRCQRYdKiNb1ArTWByTbQacf7NEUtCBJE2MA6/5CuZDDWXKpKBucqnSAVeCGVQih/MHnap8wzHOJBkbMjaRquciByFcIwYiuNZWx4BKVanEf33aknruLnjDXGotJdCgCb40yK00OMzih1SaEtOjeARuWWMHHIIESqEiFDZBARNadJ2vMkU9tRtQmkCkF4nNVVG4QXfBoU2kvsBFghfSqJMQgVIkJfGNdURNhegLBB0TmC7hxFFKsIPYTM4QYCY7poN0DUp5FBvTL7EggVjBMB/Ryq0uhGNCiorsloPxtJ/8QY1KOi2o4liBV7LdclhVaU1mCcQyFRSozeAek8rdADTao6ZouCsaG71yv7nwmVQFsIZeUt5UYRlP6apRZKK1BBQLOe0K4l6OGAbDik1++R5QXaOvRIqocgFB5dlkJSb9eZmppgy+w0cRQinaHIBgxWj5MNN8n669SabeJak1prBhEnmFqdPK6jseiyT5YNEFGfujVI9+9jw0Q6hqtH6B+/C4VChRMUpoUUGYGTBEmNZGKWaGIbSpTk3RMs7/sSS3fejNUpUSwR+RqNhbNoze4kqM2hoibOeH2vdQZciS4LiswbAMuquB114+1IGmstxo06qeBciXM+HSFUyi9io4VaBghbYsqMfNCn3pjCDDss3fJ3OGdJWvOEzUnP7pOKzcXD5IMNht0ltl34OJL2LE7G1KZ3YY3h2PV/Q3BiL0EMvZ5GNReoB9M4XSCBWtKmHPbJ8pxI9ul0Nce7JVu2TBJLR8tkDBYz6pllVxySyYDcwXq/TyNQTDdr1HZsQ1qNzIZMJwntpMb2uTm2t5pM1xImGk1UVENGCbmwrA2HHD2xxO0Hj3B8vcO9x4+zqQ1WKXSUsHO2zfapJq16zcc5BwEKb9CfBApbTWUpAiAEZ7HaJxfpKpZ3lGzZH+TkpcbYgkYSUYtDImVJImg0oNe3mNJWD8CVDNpZRkmjSjpvOukEYajQ1rG8MeC+Ix02NzIefcmFFKYgLzPuP3SExQMH+dZ132TXrq1EYYDOCzb7PbTWtOpNjIoImzEDZyhw5LpkaxRSl4KmhI4xdIuSnsnYf/wgyb6I5qG7KDonyJYO0CyH6LJkY5DTWb8JJSXN9hRbz3wkO/acw+ZySGe5YGP9KGVZYKxFEFYxwA6sRgQn5dj/HobDcf33buOlL38Nn/jQe7n0jEfz24/bxv3713n/jYtcMBWwa6bOrvmCX//lt9ASjhftiHnJi56Jajf59t9/iY/fsc6+wSZfO3grk9vOwtQW+L03/CI7dmznF371jXzvhpvIs5IPvu+vCZMaeZ7z9x94B+ddcgWPecLTEULhjMEUQ179cz/H179x3Q98TlPR/E8dr3rVq8ay+bIsH+TzCP4B98tf/jKXXHIJRVE86Htb5uf59re+yVv/4A9485vfAsDTnvY03v/+9xNViUP/2kiHQ57+9Kdz4MABHtyxgje84Y385m/+JgC/8cY38sbfeCOf+uw/+s8CPPFJT0QEbf75y//MK1/5s7zvYx8b+7mMDFtf8tJn8d73vAeAb3/n2zz5ydfy1l9+Iz/1wp/COc/y8lKw6hiF4AMf+ADfvO46rn3KU065sA9mbn3qU5/ita99Lddddx2XX34537/ttgd99je/+c1ccskjAHjFK17O2972dr59w01EUcTzdu8BYNeuXdx4440EQUCv1+Oaa67h2mueyA3fvo4nXvs0brjhBi655JIHv+5vvYn/8NKXPKhJeO1TnsLKygqvec3PI5xnrWvrsPU67fk2v31WzndODHnu3+6j1JYnX/t4Pv2Zf6CzdJg7936f5/3Uy6hJqAvHL/79/bziVa/m5k/8IYPVB7jnu9fxwd/4Nda+8SH23jfNuVvrnDuxBVsW3PTRP2LPo5/By1/+s/z5776RyekZ/uvvvoMXvOD5XPfPX+aCmYhfeNNv8tyXvfJfvfYPpbFtfo5ysE622cNK0DhKXWIL0EPLylqX2mSDdrNJ2J4mGw65+7bbWFo+TOgKZhOHMeuIYg9TZ12ADhuYICYKKmDJgTaajY0Njh09RqOe0KjX2LJ1O2l/kyIdUlJ5pvqNtzIzTmg0W6ggJMsyjNZYNKHy8h7vCaMQyjPMy2GPdHONzuF9yOEaLVUw0Z6gtDAsDaubQ4S1NOIAhCCIIuKkThxYAmFw+Sad9Q7rg/tJpuZpTk4wM78FqWoIUzA5UaOUETbLKa0lCBTtRsxss0UoBMpaerpHWuaUpaYuHK1IomNFUoup1RNm2wlFUbLRTVmo1ZhsJGzdtoXG5DRxvUnSmCRuTxE1J9g88QAbG5vce9f9HFxNWdvsc+jwUbTWXoo30aTYbNJv1bFlyshrpygdQilcGVI4n+xU5iVhEhAGIboo0c5S4mhPTRFJ6GE5cuQYw1wTJAmzrYTpesR0u47RJXleYI3x8kZniVSAEBJdGrK8pChKHIVPfK4KdodAW1eZF0vqcYAtcnKjWT56mCCMkVHCWi9lMBiytrJCZ5B6RkYYEUUxtTgg7Q+wwwF5Z41WK6DpQtoonC7ICosrNPsPHqafZtx0880InUExoN4/TjYccnw95f71ATJO2HLwCAvzW9m26zRkoun1unS6vUoNM+HvpajyqbIZuOgUFchDdDxcQz9cQz9cQ//INfQPz3hKhz6xLu/5lLSohqrXCeI2UsVIFeJsRt49wbBzpAKDHMnUDsLGNPFkggwShPSL6KkCyhHoNI4LPBVJqwyfnXXoIq82Sokdob+nHOcYaMIDFSN0cRQ5OFrURkijH6P3difBL0YG1raKCCwqWV1RyQTBOkmp/WsL7bseUhZImRHVGoQyIIwTolqduNZAhvGYdeRc5V/kAAw4g6CoKLWyAmekpzeKir2lIlTSQqiQ2tQQaXMKnWK6Q8Abupms7yVgziCcQMYG5+oVkCRPsq1GUrvK6T+ojMtEFbsphTf7lsL/oUoYdM6bIwrnsMaNGVKlseM/ZsQ8Ez660o00d6OzLUeMM39+VcUu82Bh9dksqIr5OAanhWeSaQdYXzQ1oxqxlEhdMhgMGKYpw6ygsCfBw7CiSUqgGN1xSmDQDIuUtc4SSjjKwQbp+gmKtEc+2CAbdAjjGrXeJg6BNYYwSsBp8tJ3psqyPEWa+dAfovIgi9tzWGfQViIPHfBRui5j0Fml1BBuLCJd7s9Dd42gsQVnDcbm9NeWsU4xc0aHIJyAEIr+4rhjYZ1CG01Rmso7y6dgGuOwruq0jDqpnPRpG7n9BUpVhZT3HfPyae/xZkyfsrtEnnUp+2tsLh6gPb+H2uQ8cWsWWwwosy5Bs4ULFE55ZqRwBTKsewTUOWoz28BZhksPIIIGyrYJpKEsU6QtaDWbbGQpmU4pypJ6oti2pc7MlgaxgKiMmBoq4kFJkhbkDoyQzG+bp9Vq0G43aE/NIMoC2+3SFgG1MGJqcop6HBGHChtFDHTJIM040ulwYnOTA8srHFxdYzPL2LSOKAyIgoBikLFmDabbp91oVJumT9ZQShAnASoYPSCokXcxcRAihKyM/n23KxSClc4qy+tdljc2OW1hil3zk8xPNogjRyg0YSCwVpJnkkL7+egQVaKGpTDam14aCANFoTXrm33uPbZMp5syVW/SikPqYcCehQV0qSm0xhmL0RnWaG9eGUZESUIQBP7zZSnKOSJgNvCA93pakOKotVs864rHEtVjut0he++5E5cNUPmQWamphwETk/O+a4ajzAfofIBOO+isgzU5UoXEcYMoTHDOAP6hSwXhD7A/H+rDGsNZZ5zOb73xVzjzjDPQeZfV5QHbzjqDHZdPcd03v8fxTVhvSJ5yRp2pua3svuwqmhc9FiE0u7ZfzxVrA7ZuOgLd5e4bv85ttx/kHE4wPNbhTW/6HZ729Gdw+jnnkzRafPf67/DA/vu56PLH0Wi1OXjgXrZvmycMY2SYeHlMngPw/Oc/n0c96lEAfO1rX+MLX/gCABdeeCEvftGLeM9738sDDzwAeC+nK664YnxcZVnyx3/yJ+zYvp2XvvSlABw+fJi3ve1tfPzjH+fYsWP81//6S1Uh7oeUkjiOede73oXWmte+9rV84hOf4Hvf+x5CKpyzlEXBiRMnxiDYf/yP/xEhBG9/+9u9zKfCxkqtyfOCP/7jP2bPnj286EUv4rWvfR2HDh3iN9/0Jm697fsYO+p1nuzCSCmJYp+odvbZ5/DWt76Vy6+4gijyX3vmM5/J1NQUb3/727n00kv5qZ/6KaIo4pxzz+UP/uAP+NCHPsT3v/99QPC1675FKf4ng401bv/+bWRZxp/92Z9x1VVX8ZrXvIYPfvCD3H777SAE11133fi833/gIJ/53D/ymc9+njQdcv0NN/LTP/3TXHTRRcTVZ0uShF/5lV/h9D2nUW+1vZzK2vFrqCBkZn4737z+JjZ6ff7LL/0SN954I5/5zGdQUnJaU/Ha0wNWN6FXwlKS8LhzWpy/o8EXvtvh3vUMra33zgkD4jjmmzfv5TvfvYGiSmjKJQxLy4Hvf49/fufvc8PhJVaOHmGldHzhe/cxOVHj2jnL9xe7HMsE//F5z2XytAtYzS1XXfMM+hsrfPpD72T5yAHmZqd57a/8Vy57zOOI4+T/q+n1/2xsbvYps4w8dTSbU8xOdNhWj6hpC/2CYb4OucD0h5iwjisKbJ7STEICIHApa2sdMtlgtr+JanoAd3VlzcdpRxEYQ6QkrWaDVrNJksQ4Ki/VIGTQHzAyPEiqqG+BT4kUQmKNqRqwzpvRS4kQiiCMCJTElBmbK4tkG8uIYYdEalTNM8dzXVJkBcI5lJLEcYQKI2QQE0QRSpRIZ8mKAp0V2FTjajHkEqknqDVqBNRYmGmwomO6RUaWF4RhxLaaYmqijbAOnRbUuim1UtNKApphQBwGqMYEzVZCqxkzk0BRaDqtnG3NiIlmja3bFhBJA6sierllkOZ0TY/jy5usr62xeGKJxc6A3tCzPkPpH5Ly3gZdm2OHPYqy8M8QUhAlPt2v6ENJVdvrknSgyYYZZe6N1kMpcGGCdY5hrukOvX+U7g4wRQOnG2ybrJFEIbVQMhxkaGPo9YbIsPTA09hw3YP5DrwfblUzISV2bKkhCQLvf2PyjCLLKWyPpQ1/bOsbXTLrcELSiCvT+aKkGA4ITM50BIkzmMJxdM3iwhpTc03OPO9Cf00FHNh/PzobQpmyvSlJak12nHMGha2AkWxAqDMSlxBGEhsJigDqgaMWCupJBPhEQxHFDIb+Wj+Ux8M19MM19MM19I9eQ//QwJMuSnSeodMUEr+RqDAhrLe8vxEGU/oPmW6ueHqgBCEcUljU5FYvaVJRxZoZAQ4jDx9TFXGuYiL5gxDCb5bOWfJBH/CsGSmVpyWOGE7wIDq/OMWI3I6YVI6xE3ylmj7JgnJ+Uo/8KwR48Mx5LyfnSi+vGnkZOeHN04zFYZDaVGbdAhlEhLEliGLCKCGOE1wQ4oT0IJepOrwjxpMzCEpwckypdE4iKvf7EaVWRjVkEEJ7Fooe5F3ydBVnMrDe/NyaEmyBUok3SQvj6nyM0MgRbdp3RkIlCQNJZPyk8yZo0kvaqEzGpRkDcwifjiCsB+icc2jjvQS08Qi8HXfURql2J2V+TkqPAI4WUOFQeC+nEZXRJ8Z55pSnQ/rXMs4XrAiJIKCRxITO4MqSNE3J8pxMl5XJOURSEkmBApzxpFYhBSpQGCzDfMhKZwlpCnRvFd1dxeRDirSPGnjD8Gw4IIwbREmTIIiwJsIJ4Tv5Rp/Srf938NDqIIgaJBMLEITkw9Rrj0tHqTWDjXWKYdd7aJkMXZQUpWVix+U4Jxh2l0m7h3DGovsbBPUhIqiRbR7xTMawhlVttJWYiuY5Bn8r4NLPNQ+2IvzyM5p7QghCKceyTVvRXQUCJQO01ZT9ZUBQdFcZdpZoL5xJ1Jwlas2Rb2jKIkPV6ogwRqrYA8c6I5ACizfBS6YWKAebpJ0TxBNzSDtAiQKtUwJb0G416W10fEyy1iRRQL0R056ICYRAliGTOcTdjGipoCwNSMH0/BzTc1PMzE4yMTEFWY7ubFDTEMqAuNGmFD49MhOwmqUsd3vccegIx9Y3uX95hU4+RDtQYcRE6Atqlxf0sowMx6CeooKgWugFMpAkdd+xVEEAwtN6VSCZaMgq0VLgpCSwEEhY3xhweHGd+44uIZxjoh6zc6ZJHDgCaQiUoBSCooqPFsIDuVYbjLH08oxSO0rtiJSiKAtW1zc4utJhtZey3tJsa7dYaDXYPTWNqjp1S6srZGX1WnGMU4oojqmFIZFSmFITOEuCYzIQDEvDWlpQhjHtyQmufezV7F88xv5jR9h77z0IC42oTpo4trRjtk3OIsIaxhg2FvdTZn2KwRpFuoHROUKGxEmDKEoQwuvfvbGjRNsSYx7axqaTU1PkWTZOxNlxxun8/KteThiGLO7b4NjKgEc/djvbLj6P9990gL41qFTxrNMiZs/YRfOx1xDuvBAz6NCeTLh4S8Ke2MBwnXtvvonPf/Tz/OITFrhnechffvAbPP4J1zA3Pw8q4J677+Lmm2/ix5//IjorJzh4/z1M1aE5MU3QmKfVbtNqtej1elx99dX8zM/8DK1WC631GHg666yz+C//5fV8+zvfGSeqPfnJT+aFL3wh7XYbgDRN+eu//mvOOeccfvmXfxmAW265mQ9/+MN89atf5Y477uB1r3vtGOxvt9s0Gg0APv/5z1MUBa997Wv5xje+wYc+/GH6g9Qn0J6S8yuE9wUKw5CPfOQj9AcDylOYVUWe8653vYvHP/7xvOhFL+IlL3kJN9xwA894xjNwzjE5OcmD13tHvV4HoN/v02g0eNWrXjX+XABXXXUVl1xyCY94xCM4duwYT6lYTs1mk1e96lV897vf5Y477qA9McE99+3n0Ik11o4dIBsOcc7xwQ9+kGPHjvKa17yGf/iHf+CTn/wk7fYExlpqjSZZOuTo0WN84Ytf4ns338Lq6gpf+uKXeOxjH8MFF1xAkecEYUgURbz0pS/FWktvkNJoNKrj8SMII6bmFrj19ju5/Y47uOm732Z+yxa+8Y1vMBwO2WJzXnZ2m31HBhzvW+6o1XnEthrnbo94w4mUzkAjpZ9Tzlo2Nzb41o238LVv3UCprWexS0ktlqw+cDff/Ogh/v5AD+Pg3KmEAweXqCl41CXT3Hy4x/f7Eb9+9qNRzUkW1zc466LLuP+Om/jIX/0RnaXjTM9t52kv+A8EYcjGxgZTU1M/+kT7fzh6gwE6LygLaDQnmW5NslCPCXUGqSbt5QhtsemANGwSArGwTMxMoFyBGmSsdbsM5TrD/gaxDBGRYe34Ye+n1mgR1ZoEStBuNWk0m4RBgLWV10gYYMrc12oI8iwjjCLCICSOIqSUFHnmmffWEUSJr5mFJAwjcIYyG9JfO0HWOYEsesRxQBgFuMr0uigKBI5AKqIwRKgQVICUAQIN1qLLEltmUBaIvA95DDonChpEtYiZiYTNjRgjQ4baMF0PmW5GtNp1jLZkQBIr6mXAZN0xkSTUkhr1LVuZaCVMtGKmVUpRGqZamoVWjXazxpaFLaQEpBpWuhsMc8fQpRxeWmd9bZ2lE6usdwc+zU5ranFAJCw67TPQGeUgIC/1mEk/OzPlu/3GyxudddWDpCXXhmGWo6Tw0pdoiBOCQaHpZwXdQcYgy5HOIgVsaSfEkaQeKHSWo0vLYJBjZOHrf6m8b5YxFEUx9lwlDJDKSyBVxcJEehuKKJSUeUFWaPppwdp6j25asDHIEWGECv3rOmu8F1ieEruSRiJxVpPlmrVeDpNtJmbmOO/88+n3umx01jh27BhZv4crM6LdW1lozrD7tDM9WycdsnL/PcgiRZURsTSUEmoBJMqRBJIkjnx6HuB0SF726Pb6/4az84cYD9fQD9fQD9fQP3IN/UMDT3F9BmegMAPKrAQ3QAWrWJ17ra7JMYVPbTOlrUCaEiHux5UFtfZWVFBHIjxiV7ForIq9gXRlQi2qONfxZLIWGQREUlDmGVoXDLMh9fYMQRhCEI51lwLnOwB442xExUhypzBnOMmMokLmtSnHrCg5nucOawqwJdgc6UrkKDoRhXUB2oIxHjRT0ni2UBiMI6iTOCIOJYFy6MoEDkeFenqkxerCG4W7vgfYwgQVBUgUxvnkNmcNzhofp+oMYSBxtTquNY0ZepTalQOcLnC6IE9TVNBEyAgRTHEy2U+O1k7CUFGvhcxM1FFKkhYlxlUMNDE+m35DqvSq1lpUFQlrnEE5g3Vec64tlNZRWkfkqthJIUF6OzUf+1m9v/XJHpU4HSEhwOIc3u9Jep8AVxHjpPCRsrnx5n5hFBAhiZ2hTFPSLMVZS6gCWomk1BoJ1CUkwr/HhrOESUJQq7F923aiWsTqxjr7D9+LzlPcsEsTTSKhXasRGJAYzOY6tUbhDdBdCc4z3qTyMbVBEBAo5bsMD/FRmpKkPc/k9nNZPnATKjmOVODiSWxZsnF8hUarQZJE5JsbNLaex8J5V3L2tT/DcOMY+776btJskTLXbCwf4v/H3n+H23bV9f74a5RZVtv17FOTk15JKKGDhA6KAqEpiIpXFEXlXhGFe7ni14KFJnoBy0UURKQIikjovQkkJBDST+/77L7qLKN9/xhz75NguVz5/TTf58l4nk0W+6y91ppzzTHGZ74/7xKWD+FdQf/wF9E6I23NMn3xD5DO7qW37XxsNcRaQ11NSJKERElcvYEzFc5WqKyLStok+XRkjzlLWZax0JUSRQIyBgm0pmbxk1XK00dZXTqCMxXdPZeRTm0HlVAN1+mfPsT6iVuY3XUhOtEkmWPt+J2gUuYu7CBkErHNtEsicnQ2R6hP4weHMEuCZLRGHizbdi2Ad5xuteivrmEqg3Oe1ZUJ3U7CjrkWe8/tYesux1GEYUkiFBefs4t2npErRTi9gqkdobLQzglZCi3F+njC6rjgpqPHObq8wrGVVU5vDKiDxwrB9l6HXClSNNPS0xaBmdRSuUBpA3a0gW2Er0nDDB1IRUDGDTPNtxicpBlJmpK3WlEmIUApGIxqUp2QJ5KljYpvHlwnkYE98wl7d2jqSrDWt9xyYLgFjgtnmmjfgKtrvPNY61Ayguk+GHbmml7SYdXC4fU19q8uc3OesbPX4/zZOS4/9zw6MpDWBacGQ/p1xbqpSYInUYpuEn06EmDs4UTpuH5lyCMechb3u/IyHvH4x5Nf/02qiUfaFv1JxZKv8R1JkknUdJdFYyhciawKlk4dZLB6DCEkZV1RVp7OVJfZuSkWZnuYMqOua4aTDa674+vcfvQOnvVjL/5PnaP/1rj1llt461vfym//9m9x/BvX0j98PTecMjzjqU9jbDzvXXUsrK1yXznhHz7yUezBzzD5xtv5g/ccYPvBr/PTcgV91dM40oefeus3ef5FLR59VouvveNtfOPABgc2KibdeVLTZu/sMh967Ss4cO19eNb/fD3PevYPc82zn8eNh05y6Kuf4NAXPkj1sPtxzn0exGVP+Ane9ra3cd111/GUpzyFV73qVbztbW/jk5/4xN1kdkop8laLv/qrv6Kua4L3/Parf4c/+99v5XOf/QzdbnfruXdlkV555X255eab+aWXvpTPf+5znDi0j/7aMnme8/GPf5xLL7kEgLe//e1A3N9/93d/lxe+8IU8+jGPYTz65110IQRXXXUVt9xyCy95yUv4wAc+sPV7uckguMvYfO6/NlqtFiEEnve85/GNb3wDgD/+4z/mmmuu2XqOVorHPeb7uO32O7j88svv9vcbGxucffbZfPazn40glpB4Z3nPu9/NL7/sZfQyTTeN5ZoAzjnnHD7zmc9w67Elrr91P2/47y9h/523c/zYEf7uAx9ganqG933g79izaxcnjx7kr//qHTz6cU/kPve9P1dffTVLS8sorXjHX7yNSy+7LB4zgkOHDvOUpz6NyWhIr9vFh8AP/8iP8MQnPYkff/7zmQoDfv+nns/Ul7/KyX1H+eA/LfLlI2tsyyTndjPmWxkrVjApK772tX/iMY96KEkxRFUlqRI8/9Hn8ZQH7CYLjgFdVpjjT54+oNtOaM0uUJ8+RjEccWwj46G9DXauDHnyEx7Hlefv4HEPOJef+ei3WF7rE8ox/aLm4PKQ+95FJnjq1Kl/9Tu6J4y52bkmYWoWsezx7Snme9PUvkdtLcONDaR1qGrMVKqZ27GHhbPPo7dzB8VgjdO3fgO1MsZNhmwcv4NhcSvjScXo1CGsauFaM1x0v4cyu7CD8887n9PLSwxHQ4J3dNttWt0es6aimEwoi/KMHUJzs6qkpNPpxLoTaLW7W4bGrpww2ljn9JF91IsHENWAThKQUuADVKMx9bjElgWtRCGUZGIs1doArUa0UkWuPVp6MJ5UCeY6Cm/HMNFM1lfwzuKcYWMwxuucfGobhShZLyYsnxojTldkWtJLBLNTObO9nLM9hKyHbk2z45L708sE3cSj+0cj80O3ydIMqRNM1mJ1bcDSWp+vfuNmloYla5OaSVHgrQVXo/B0EsFUkjDbSmgnisRbXGmZhNisrj0ULjCuarRSZEn0wJFSkKUplfNU1jOu4/qnpGRjUkdgz3lGlaXygUltObU2pD8uCcaw0MvYPZVRlTVVWTMcTRhWjtpFFUGqFEkD6sb4cg86poOlrZyOVqRKkuiENMtJswj8VZSYwuCFQCcJU1MJaZaSKEVHeXw5JhQTZls2hiYkGd8+VrE8tpyYeC7a0WV++w4uuuRSDhw8yPJ6n6J2FLXF1ZaTayNE0uec9SUqa6nKgmoy5NjhEcsnJHtaHuMDhYNK5Pi0SzY1h1UFfjxmZfEEhw7s5/ix4/+Z0/P/OO6toe+toe+tob/3Gvq7Bp5U1kYVY4TQeFdja0s9HhGsbRg6Hqnz6Nbf7uDqEbbs4+oSUwypR+sgM4ROcdWgoYMqVGsOVBZ/tiR4myNqByHSCrWSBAcuOEw5xruUJGtFvwhxFwMjsSmvC1socRx3MQbbXLjvIrOLclix9d7Bu/j+3myBP977JuXjjDxMSIFSUausdQQhlJLRB8HHNDySFIEGKSNQ56PpY0TFHN7GIiBe+PGzxgNxMVGvnhBchfcG6iGuHkKoo1GkT5uUNYfwAYlBhoatJDaJYPHYN5PnpIyJgu1WivOBtNGZ+hBLkcjq8jgnsTL6WHjncTKynbSPpt2RqRQphL4J5DiTbtfY2wkJ+Pj1hkZA5yPbKUb2NpkBmwbrEJlsalMSKbBe4BpQLBUShSC1lmAN3lpSIvIalIpG9ASyRiZoQ6AKgbzVoj03y+5du7HBMiomrPfHlMUIV46pE0E31XS7KT7RoCSurpB1iZ4MIVisrSINXUQjQKVUI1W853s8bcpZffDYqiQ4T9qeojOzAwKsHwGVaZwS2DBEJCl5p40zBaYcYosBSkddbzE8hSn62GJAPSywKrIhu5MV6M7FLmutCMKDknhXYU1FKFfZlMuKYBANi3CT7ab0GYA0xnY3oGMxpJoMMJO4dsg0J+8tkORdpEqYDE7iQyDpLMTr0cVjVe05gtBUow1UmiGljIaMkkglrgXO1Aw31jl1chWcZ/fcDK3WHDu3T9EfwUp/wOLKkFRreu2EsQnMVgK8YL325Coll5r1wZBxUaKlgklFlqR0Ol2SXo9awIH1DY4sx03y9pOLbIwnDKoKLyUJkrYSTEtJLmN+yCZw2myJxEvsTCCBpkm/DOAanzvtYjql8x5jDaFOoK6oQ4hUX6WazqwnzzK8D4zGJUvLG/SSNuyYRhLw1jLuD1HN+iFchSfObe0d+ID0ITbdBGgR6KjIMJRKUmpB5T2186xNCkRYQwXHbJqwoCWtvE2apHTqktparK8a35y4Zq9WgQ3jUFmCSgOWCXccvJ2jJ4+yvL6KFAmdXNDTmoWOoJMKhsMNHBZhahId2ZsQsLXFuoBDcXx5hQktjJwC5ymrkoMn9rH/2CGOnr5n37Tu3LmTXq+HQNBb2MvC7rM4t2VotzukWvPcn/wpKI7ytRsO8vxnbeP4wTY3Hy0pC0/dkayFLge+dhNHVwvOb0lODiyfOzZhdyewZ36WpzzpYs5+yGNxh46x/bP7yIZrDA/t48Mf+FsecOUF7N2zg6mgcf1lTh8+hnrguSgbDWanp6e49NJLedGLXsTnPvc5jhw5wjve8Q6sMbzoRS8CYHZ2lv/9v9+6dTzBe2769k0cOniQt73tbbRaLeq6ZtDv3+24kyRhx86dtFotJpMJ7/3bDyCV5qd/+oVccMEFTDeMnS9/+cs457jmmmuYnp7mvPPO44U/9VOUDUvsfe97Hzt37uRxj3scX/va17aApGPHjtHtdnnOc57DAx/4QJIk4fk/+qNceOGFW5+hPxzzua99k6K/Sp5InvOc56D1mfJp3759vOc97+HWW29lcXERgLJJpNscPgROL69xanFp6zk7d+7iaU97KgBZlvGxj31sy/8K4MZvfhMhBE99+jVccMEFvP0d7+DwkSOMx2M+/OEPc2J9xKGTyxhTY61lMh4zOzvL3Pw8nXZOohVVWfHlf/oaF1xyHy6/8n4sL68wMzPN1Vdfze133on1YYuBJaXkBT/+Y9RVhZSCv/+7v0NrjXOOQwcPklLyvi/fTnV4jaqWPOPJD6MdDNpUfOaG/VRe0G5lPPEJj2c8nvCFL36RjgxMt1Oe9djLmZ9JObBcMR6O6NsJq3bIcLYiTRVVMsAPVvF1jRE9jiwNOb4y5PTpJbJQkvsJ49EAYyrKsiYQ153UjLj8/g9i7wX3fHPxRHpUqtA6ZyI0RiQYndLudWhLiZyaJrcDUl+iZYgMmHaKSlO80Iwqj/IWZQomSydYG5QMRiW6WGPsFaOwwfTcDqT3bJubQwQf/ZmkoKxKTGmxxQDpHKkMuKqMzT8hG7/NyHpzDZvGuRhgg3cUGytMNpapN5ZQdoLENrViiAyO2uCdafy/PFXtqUqDpCCRkl6usLkiTwVpk4KkCVhbY4sxw7U1NoYFxllG6yOsTFFpCy89w2rMxnoJQDtVmE7CVKbQUuC8wBqHkIZ8NKEuPWNhSUZjskTT6WVMygobagZrY06sbLC01ufEyjr9Sc2wMmQSlAhIFTvPWgh6qSRVkYFfWxeBJaCVSHQ0g4l7l7GYqiZRMenKWofxgdoFKuO29k3jowR10yw8UYosTRCAsY7+qCDB0ZWeYB1VbagbWZ210dDcSYlt3mfz/kY6AdLH2l+csc+QKrKfHILaBSYm1q1KCzIhowxJSaaUxwiHCQbrPdZBIWBsofTRc7Y2hvFoxPFjR1k8cZzVpdNIHL2WptVtsa2X0Es9brIBwaNdzXRXI3EoEQ3rKwcjI1hcG1JmK8jpY0yKkvFoxOFDhzl27BinTt6z9+B7a+h7a+h7a+jvvYb+roGnJOtg0hFSJbjK4JyhMhvYZiFFJrTmp0i7O2jN7aEaLlGseVw1wIz7lBuL2LoAAWa8hFQJMslIZi9AtWZR7TPAU4gznM00ObyJi5mWeBf9eqrJAKkzAoKkmQyBmJIWL6y7+DZtXlybqEaI8jvvXewYbIJUW8DTJhDVgE7ONEl2MakjeEfAAR4pwhaIo5UiTTOSJEFLGf/OlPh6DKqFVPE8SQHBS1xwCOEJGLwpmjQRHf2fNsEzZwm2xE/WCFWfYCaEehCN3m0VkzSSNKZCBBMPLgi0AC3AbflobR58BIki/VfRa2doKTDGUVuPC5FtZF0z8ZzD2EihttIhm8nivNgCqQJRfuh8wAZiCgKb5uSbBuKyAcICjYIOTyB4ATQzL2zBbXEBbfTqPkBtofaCIBS5kKQEWlWNsAbhHVqceT+QiGZRGblA7QMTYHqqw8LOBc4/91w2hkPKEyfoDyYMRiOqqsK2UxyaHWmOTBNQAlsViKpAuApBNFO31oGU0VMhaRhP8p4PPHnvcKbCFCPqUR9nDPnUArsueyBJkiJcTVlVVHWJVQNkqslzGJ7ex3DpMNXaSdp5LIJHG4cpVo5jhhuk+R4IBWVYYW60CNMLaGLaDiKBPMUNNjCTJWR5CpV2SFozjXdaEudV462WJhkQ2XWlGTdiT4mphhQbS5jxBrrVQmUdWr2dpK1plNaM+8cRqk1vxyWE8VoslmUg33YBAcF49RB5p02apiQKvBD4RvZR1Zb+yjpfvPU0ZR140HmKKy+6gO07prjzlOPYYD/X79tgptem10qY3zB02hMSqVBeM9/q0lMp1cnTUR8uFImx7FyYY9tZO1HTcwwnBdffvo9bDx7l5MoqS/0BOo3pEnm7RSagR2BOQkKUJ2dSkDTafohgsWr832TwMSEIaCOofFzTcupoLhgCti4JlcBMJGNbYYTAyRydpiAlnXYLawOTccHJkyNmW3OEMIPCI2zNZH2dPNUkSoAzWCLFOZVNMIOUbCpNlYyAMAKmpcLKhBrF/tU+6+MJx9fXOD0asdDpcNm2BS7odZnXgqTqszocsDEpGTmFE+AInBgbNnxgaqoNiWF9ssSnvvARTp5Y4/TiGlonTHVy5qcyzu5ApjyryyfRGdFDIE9Jmw5hNRljg8DKlJsPHaG7NmZt7MnThEk55vM3fIFT68usjwb/STPzux+bMoqFix7CRZdexlnW0800Sgj+4A/eyGt/9Zd474c+yLN+3bLvVM0HrxuSeUjzaY63L+W97/kI66dO8oxzu3z4yJiPHSl48YWe+z7uKu73tKey/apnEr7yFc7+679lpzSYxeO85XW/xwue9iCe8Ij7sPvKJ3LzaJXlw4tMZZ62rhmuLjG9fTd79+7lj//4j/nZF72It/3Fn/PyV7yCV7ziFfzpn/4pAO9///v54R/+4a1jUXdhif7yL/9yY5cUYmErxVbQB7AliR8Mh7z691/HK1/5Sl7zutdzV8nbG97wBqq65ulPfzpCCGZnZ/nDP/xDACaTCZ/+9Gd48IMexJvf9CYe89jH8pWvfGXrb/fu3csb3/jGCOwJwe/8zu/c7bwfOX6SV/3+mzm9/5vM91Ke/vSnoxp/JICvfOUrvPjF39Hp+w71tfeem27dx9GjJ4G49lx66SVb5+fgwYPc//73Zzwe343xJaXkJS99GVVd8+xnP4fBoE9dVfzSL/0SKslQSdLIo868YfAOZwpC8BRlyee++BUe/fgILulEc/XVV/OmP3ojT73mWczMzvCkJz0J7z3z8/O84fWvAyIL6wEPuIpTp07inUPLeG/z/7z1I1zQ0Vxx3i7e9JvPRrkJ62srvOer+3AhsGeuzUv/689z9PhJPvLxTzMIgVavwyt+4lF88PN38qGvHeTOI4tUTZT6Qq4xPrBYWEKATqZ58EXbOXR6yMm1MRA4tLjB4cUNLrt4L1krZ/9wTKIlvTzlPntm+LkX/gRPfe5P/rP5ck8bWphoN6FyNoRmIjQTnbN9107a3S4zXmCXD+H6i0jjSVSglYaGHeNYHdX0XEUWakbHD7KyNmFtXLF7SjMeG04PDHnahqpgx47tBKEjcCgk4/Ul6uE6mR3ELn7aZlyMEMbgiQ1RoRQqiXYY3gfqYoytCmwxpn/yMPVwFbt+kpaq0TJQIxEuAA5TVQRrkMFhnGNUWZaHNdpZUgmmneCm2rh2isoESfBoPM4Y6toxGVtWqxhBXpmauR07SNttrKhZmziOroyR3tFrJRibU7fj+u6DoJIKXwgmJ08ig0W6mrbtM9PJ2Y3G2MgyOrQy4ujyBiv9EceWNjBNit/8TCvWcEHgrKWl4Kyupl8HCuuYVJ5cCVpaMp0pPILcCxaHZQMOOdpJbEKWtYkgEWBsZPqUNtCflGil6OQpeaZppQpBirXRU2tjNEE6Qyu4eL6cpzTNPYfzVMZhEVRC0MqSJrFaxjrAB2QIaClJlIqGxk1D3jhPYR2DykJjr6FUVGZkEua0o5CeAseqC1QuQO0Z2UAZJEpLiqJgdWWZG6//OstLp1ldWSEVlrmplD2zGVOthDwJ2PEKQgVSCVPbcoI1zT1MoDKejTowPLFEd+wYlIayMozGY+687TZOnTrF2urqf/YU/TfHvTX0vTX0vTX0915Df9fAEzIhafVoz+0CZ/GmwhQDvKvxHrRukXXm6cztJpmaw5kRmwCQqUYMVg41QJLFlUOU0ug0pxc02WwgzXsgNQERzTttQXAVou5DA29ImZEmCqV6TEZjvLWUgzXoTqOSFK2Thi0Dm+I60QAa0Pg6NUwn5+xWMkAEpzjjp0QjFXQ1wVbYqqSuCkxVYE2Bc1UExPCRYCU1AYUNkmACYlxQOwH6NMY4vHN00y5KaYTWhBCpstJXeBzOVdhqhHcBERJ0yyNkXERcNcSXfWz/KG68jK+GUVbXHBFohAgIpbFCN4CaQjtBsCCaNpYUosHymi5J0xHRKqGVRHPB2roIOLlA3Xg2GeepjcI6H5P8mt+BRAiLEBLjYufLOo+1HusCNkR9ckz/EI20chPYi9GVmx5g3osI5DVu6o3SkSAkLoANgtIHjAMZAspFHWsb6KQJQklqU+N8jOF0eBwRcBo6z9AH6kQRUhCpY1D0GUxGjItJBOlkgkqhnerI/HIV3hiECwhXYwnUFgix61T5wMa4oFID5MoSeT4hTVvf9VT6zxqmLpFKkSQpM7vPJ9gJi7euMTy1j+7sdi68+hkcvPFzDPbfBGnKeOM0i9/+Atn8Ecb9NdZOr1O2FWkiyPLT5J09TJ1zGTMXP4aN4zexvO8LrB75NqOVo6wdup7Z8x5Ea/5cZnc9kFMnvsbG4a+T6YrOwoW0ZvZQ1NGk31sXZZkhUBTVGX26TEiSnDRtoTCEwRRoja9r8AGbrbB2bBHnaib9ZWZ2nMPc9gVWj/dxTiBUi22z03gzYuO2W6HdxeZtkiTHO4e3jjyUoHKSFFZGNYdOj7n+lhNcvvckO2anGVcV66OSNE8RiWZkA/21Er8SkAjyNEGqEUIIUrG5xUOHwI7hgMNAv9rH6mDIN++4k5Gx1N7T6naYThRTWtJLFCp4pHNkUqClQAuJFnHdK3ygCaekq/WW/9zEOnwApSRKRs80S1wttRS0k/h3LkAuEnQIlN4yqT1BKra1201XtaasDJPKUtQxmjoRIL0jeIEXklaqSJrvJULuAiVEjLxuri/dGPnXzpEFQVcGLusmrNeCpUoxqmqGVc3xjQ1unZlmW7vNJbM9FqYWOG92AV+NGNU1q0WNU6AzzXk7erQ7GeOq4tNf/SxSKVKlePhlU/SQdB0Yb7AeygLcRIAUyExiKoMJnqFIGaLY8IqD+49g3WGyG75NpxMp1SdOL8bQC9n+j5+U/45hjeHnf/LHeNwTnsirfu+1jPrr3HnHHfzCf/0lVk4chfGAt7/wGi56+PfxP974J/Rv+hidud2c8+jncWzfMU7eVtPeNc0v/8SPkpx9Bf/j5/4Ly9+6k7mpjzB7yZOY0nDfTuDWfiBrK97y3Dk+ees+fv0rdyBmv8SsqLj8st20t5/DvoMn+Ic//Vle/Krf5+Ir74/A8Ks/tIunTN+HH3vz7f/qMVx++eW84x3vQErJaDzhbe/5B2664Tr233YTf/POd3Dy5Mktg3KITZijR49+x6t8B7IDZzT1/8r42Mc/zkMe+lD27dt3t9+fOrXI1Vdfzc///M9vMbTuOurJkBO3fpW6GDHf2w3An/3Zn/HWt0YG19ra2r/wbnf5fCE2LbwpCS4GifzlX/4lD3vYw7aectZZZ/HFL36R//W//hd/+Zd/ufV77z0veMELeOADH8inPvVJfvVXfoXbb7+d973vfY2hdmDcX+UfP/wR3vBHb4rHs3iat7/jXfzdB/6Bc/aezac/8xnOPfdcut0u1157LdNTU+g0581vftOWTPzlL385n/3sZ7fe1znHytJp2jLQTRUbJuBCoKXgZOlYO3iaH3nZm3jIBQucv9Dl3Nk2u2dy7n/uHC//5ZdR1pYnXHkWS2sjSmP5L7/1d1STClsZLtw1Q563yLOcr91ykAvO3cEf/fTT+cI/3cDhY4scP7HC/a68nMft2s1Nt9/O4uIKJ08scWppHedjjTHfi1H0X953mqdvTP7tL/4eMgICKXX0H9m5m9oZ8mPnYlRGUG3OOfdsFs2I1cEG/WEft7yBT4+xXBxnfW2D4ydXaYWKXAnmakFrZp5zFnay++y9pCdPUx08wujQ7RxfP40drbPz/PNoT8+Q96YZntjP+uJJemLMtt1nMb/3QoRJqYxjuLaESjIQAu8MSZYjpWK0vsJkY5Xx2jLl2iJJqJlKHDpNYzPXRuDIWYuzsQYLOE73R6yPKk6vF3QUtBKFVh0yY8mswsuA8xa8pa4MpTWMmuS02gWqAIun17BywJHT66xvDCiNI9eSUe2ZrE44srrpbQPRPEyRn1hufHAc0y3FwlSLwaikqmqGRc2+xQ2WhwWjsiZ4R6YEiVLMtRKSxtc0OEFLwc5eSrFeMrCeSe1Ic0WmJbONkbqTitp5+qVhYONrZQ1LIW0a8jOppHSBQeUY1jb6U1WBViJJE0W729q6D1HOopWgqC1BEmttEz1hCIFuora8VKuqRmtNmsr43yQhawzW0yQywaytqeqKxZU+a5OKfmFopRol4poyKUuGzoEypFKRzM2yZ3qKoqoZDMckG6v0Ms3O2Tmm5+ZRUnHLt28CW6GwXH7uHJ1E0k4EpraMasd6VdBOIdGCJNV4ExUJ3sGgsKyMLUunb0YoTa/bwQO1sZxeXmc8nlCW1X/2FP03x7019L019L019PdeQ3/XwJOQujHNbsVOn6lBCOrJgOAsZ6hE0aDOViXWVGAb/6TxeqNOCzElzUUjbDNeRWUdbD6FagMyie77tiKYMaLqR6NwqWIkpNRImcRNEoOtyzNpd1I1srtNQ7VNQVxABAEiNIZ8m4ymTURq84tvWFFbbCuH9zZSgU2NMTXe1QRvCI3XTwRRdPRHcjHSNJQG60t0OkTIFKlz8pkKITOU9kipIzomRTSJ8wZvKiBBKncGKAuBYCb4aoAr1nDFGqEeRemeiEbkyJzNuD4XoiStsgJRB2ztyJy7i2H6GcrXZrLfZgc9hMiCsi6ahatmg9POowRY71HSU1uHkmILpQ0NuCg4Q090LhqQBxXN1jffRwQanycfk1I2r4dGIUmDPm8W7JuSPxsELvj42sYytjZ6SUlBS0YT8UxLggs4ET9/7aHyHhMEBoFMFE44aley2l9hNJpQlCMSBZ1UoUL8b65ERPqb60VvepERpYQ2QOUF9aRkzBC7vEQrH5M0Ju735NHKM7LmJ5FzVL1ptITR8iKuskyffR/SvEPemSL4Flm7g271qIar2GJE0ppCZglBOKrBClk3IevOM73nYsrxCkHmlIMNXDnBVmPyqW1IAaYzR7lyhMnqcdR0G1cXBFujkmmEypEqide6d9i6jtcroKVCB4NyoCjRVCRaUo9GOCPwWYpzNc4ZMBWhHOHGK4yGfcZlYGhqbNohExVK5fF6M3UEt63DGUMRLEEJYML2tmTUTbhj1XB4eZ3VUUGiJJOqJk0UUsYNqLYB53xjVi9x1uEJaOJcUQIqwAyGlMdOMi5rJkVJWZWRoSkl06lmSgmmZKDbSEy9EA21P6ZKqrh4sZkxkAhIGxzdbrENNxnWYisFUoit5WXrPlwLSYTXXdNpgUwJghJ4J0lk7IxLJXHe4p1v6MnxXQQSKeLGWG6lejXJlwCCxtgUdAAVPCJATwlCIjFeYUKg8nGzX54UlN6RKIHptAh5ylzeJpMJPTStJBC0Ik8SpFP40jDeGNNqZeTtnJZSaOsxlWVsLLX1FJXH2hDp1FMKIR0ezzAkjLxg7AVV7SirmqEbMZrEOVsUFiU32bL3/BFC4JZbb6XTm+Kzn/4Ug/4G+/fv55s33sgF8ynn7Mi57bZbmNu1k/tv3Jf96yNGcsD8+jK7d82jJmexMthgj63oUpLiGWwM2XfwGNPf+hrFyiK7zzuL/bedjA2WIOlqx3xaI9oVOzuac7ot1k8sMdjYYGpygNu+8WVG/TXus0szXj6JsZLHPvaxJEnCpz/9aR7xiIezY8cOnvSkJ3HdddfTbnd4wAMegJSS8aTgjqPLzE+1Oe+sHTzoQQ/izjvvZGFhgeuuu27LiFwISavd4eEPeygXXXTRPzsvD37wgxmNRhw9coRtCwtb5t4HDx7klltuoSwL1tfXWV9f58EPfjBCCL7+9a9zxRVXsHt3BJNarZzQGDE3JxuEYHqqx6Mf+VCC9+zYsR2lFEtLS9x8880YY9i1axdPfOITtz6LIEojN8f+A/u5+ds3UxQTdu/axZVXXsmDH/zgux2Hc46VlWUmkzMgyu5du7j00ku47vpvcMstt7B46hSXXHIJe/bs4QH3v3+TpBcohn1W1/vcdOvtTE1NoScF973yvtx4ww0457jvfe9LnsfUtyvuc5+t17/wggu2Hk9PT7OwsABAcWQfkxNHENYz20m4eDbj+qUCFyR7einHB/FG9tb9x9CmZH1tGmMdlXFsjEr27z+KRzB9zjZcCBSV5ejaCimQa8nZrRzReEtKFT0ojYfKeIrKsDGumZ2UtIoC7z2tVsaOHXPUZUWet3jA/fZy/t49tPMWi/2CnbvP+nfMpP/4UdWOTAdSrZFK44WmDIqNYYG3nh27PELn6NY0STtA2qYmYbCxymQ4QgmB1x2MEoxqz2ySMj3VY2b7biaFo9daYrS2TBksGycOkudgilmqYp7hyiKT9RVaLYerJjhTImWGkpGN7kwdax1bgTNIIfBFv/kZgC2QKqATjVCbpsY1zvnIysHjvKOyjo1xxca4YlzWyCTuHcbHlC3rHNZGBmNsZAZcEEgRSEVkxdcuMB5PmHjBYDimatLOorIhxCZo45UatyOPwGKsbQQMAVwaLReUxFaGSVnTH4yoK4Nwnl4WI+e1kiiiQiD6I2lyFRUB8dzQ7OtRdnemOg1b+59o/l0LgRWRvaCVINeSxPlosuwkNpyBowWglUSoCBhIJ9AigrvW0yRI03hXBJQWkWUios+qbBQaWuvox6MVSoqmFo8R8LV1jCuDcU2qoYzvVdYVG8MYoW6kZaqT02tn9NotglSUtSVNE5TQzHRbtLNoyVFOxmgsSkGqFQiY1J6ydBgXqLxjUkGqBd2ewtYxVt4Yz8R4SgfjssK6kvF4DELivGc8LjDG3I3peU8c99bQ3FtD31tDf8819Hfv8ZRmiGCQoU2rOxPNnDvTbCwepS5HODx10UdtSOzGEkV/icnGGoroFeBMiUqnkEmLtLMTW2xQ1xMmq8eiUVo9obNwIbo1jW7P4qp+BFtGJ9B5D511kEkHROwYZd2ZaDZuDPVkhFU6yvdENFK76wWzZeTtRIQQNoEn4hWmGnpbhGaif1Mg+jM5azBVSVWOqYoRzhQ4WzeG24KAIoQkmoyHgHOOoi5QKjr1V7WnNoK8t4vcKXLZJm2lMfFNCpyPcjxbjhBBE7QhbTY4gscVa9jRImZwjFD2CaZoZpEiCIlQliAUHk3loDCCjZFgJB2ZM8xmhkBMqZMySu6CF435t4gbVYNHaRmTFLwPMfWkKQzqJG4OlWnovs6jlaM0iqTejFRsOjQ2glO18ZG6LAVRhbY5pYmfIYjI/AoBSdSeh00EqvlAtYuFSuVjh8Yay3AwZFxUUXbRypnPU2bThOk0QweH9o7KGMbWMbAeKyVOCPJ2hg0168NVVkfrGOMwlWG6FUhbKR0R0zaUCPiixDfHJGT8SB6oXASdhl4wWBtg1ibIpWGUV94l3vueOs7auQvVaiPbHTAzMF5kutfl4I234/0ButvPotVqs+ei+2Prgs78HqZ2nsfhL70XKQW7Lr4/XvWoxyNWbvwk3Z2avNdl4fxLKTZOItNtTNYPonVMZewfvp7y9G2Mj1zH8pE7Ga4tkaeXY8ZjqsFp2ueeh0y6CCS+nmAqg3UFSjQdAzQU8ZqXbJAWJ+m2JCunl7BVScsP0EmGlhopAnb1EKsr+ziyWHNgzfHVY44rz9vDeQtTXH3R/Qj1GsGOoDH6rx2MS4ESNa16le+/aBtLe7q8P1EcPLXBwZN9ulLQzSS9vGFTCiCR0BTT6WbMrY8VZaIkWilMgCNrQ75+4ATtNP79uXNT1A7wgp2Zph0MebBIb/FCYZUmVTHGVcKW3METdeotBbl01F5Q+AY0FgED6GZTgxAZfyEW814Q15qGWmwxtNKURGu0dM0akDA3kzMz06HbTTm9WjLZ9L1oYmWtg0xJUgFWbqalBKTcLMjPFOVKyLjOekcLgVKBNBekac7Ew8BBWReM+iOOrq6xc3qWXdMzPOacnUylsK1l2TlZYsM5fO2hDypopusumUjJQ8qQwEpRMOwPqYzCOCgN9MsKpQKX7EqRuSAkgg08tRNULtDNu6SqZjgZUZeB4CELLUajMaUp/5Nm5v/FaPat9crxyS9+hS889QepTbyxUQKefb9tPOmSWV7+wcPkn/oEe67/OL9/LDC1azs/fMfN3Oeq+zO9a54/euNfcGz1HSx0Mh7fKlkaWz54w3FOHP9V9p57Npc/7Sksb/w9J46c4K/+qeCHrprhx54wRee+VzHpT9g4ucZH/vqDbJ8OvOyx8/zcH/0G/cLzv593Nn/2kVP801KLL9z0Bf74T/+Upz71qdx000086lGP4mMf+xiPe9zjGI3OpBd12i1e+NynIcTTN7XS7Ny5k6uvvprHPvaxfP7znwdiSs3OPWfx93//9/R6vX92al73utdxevEUf/vud/OEJ38/lzYG3u9+97v59V//9a09XwjBH/zBHyCE4FGPehQvf/nL+bEf+zEgemLYqiTJ28SawSG15vLLL+ejH7n2bu+X5zlT09Osr63xhMc/nne84+13+VexdSwAf/VX7+TVr341AD/xEy/g7W//S75znDx5kqc97ekUm95QQvKEJzyeN7/xD3jME5/MDTfeyPf/wA/wvve+l2c/+1mx4RdiymurN8PTrnkmT7vmmVuv95EP/yPPfs5z+Pa3v/1/uqoAeNWrXrX1+MgbX8mdf/FGXrCv5rL5nBdcOce+z59CKMUPXb6df7h1iYOrEzCWr99xki/ffoJepjm8MuSrB5ZJE42UgpuPrbE+KjHG0daCkfUMbSBr5xxf6vPNfSe4cHuP0WjE7/7VJzly6CijwQgh4MhXv4UQNzHVTTn3vF086Kr78tlPXs95Z+/hla/4rzzwEU9kYef/NwCnzbHRHzGrc2ZmM5bqmsFozKmVPm59mU4imcpbCFJ628+hO7uDpN1Bt6eoDp1GOMeO+RlMbwcWycbSSba3u8zPTLPz7PPxlWN04iTlsQO40YjJySHHJ4uodhfZ20E5HOHrioU9M1TjAeunT5Lv6JGkCT3RZTQcUBuDD55yPABTkpoRLTNAygLTihKupB3Z3c7G+HRjYp0sRaCyltVRyYm1EaMiSui0TNEBLALjHHUtKBoz0OADxseE6k4rIc88pXHUg5Jhf8jqxNAfTCAEEiVIE7UVzqOVjH1sYro0wRNsTPZSQlIby0rfsTEs0D4yh8qypqUkM6lmz3QL60MEvmyMpm9pxUI3JVUSj0TLmkwpumnc/5QQFJUlCEFNjLwPPpCIyJBIlMARth7PtRJqH8iURQlB6QJV2EyD9mTE0IFESZKgED4m6Djv8EGQEEN7fAMkJCqmk42Ni71RKcnznCxLyPJNGw9HURnGlWFcWca1B6mY6WYkwlMUFStrfY4vrTEqKlICOxdm2Lltmu1KkeUpXdei184iq6OTEHQEhXMNuHhPNS4MtbEMRxWl8U3jOcqV0kRzzlltqhqqyjOZFCATSDJkBr6sWBmMoxcu8TvUWt/NN++eOO6toe+toe+tob/3Gvq7nuWtTpeyHlOMBwgPMklJ8g55bxqVaKQApVOCc5hyiKsrkBneR1lZqCxpt0fWnae94wImq0cpB0sUGyvYqsBM+mBLkvYMaW+ByeoxTNEnVGvk09sRCFRHIJQi6IQkSKTIkGGKYrCONyX1cA3Zm45dkUY2t5mutun1dFfGU4Q3ok46jsaQO3hCsHhb40xJXU2oyzGmHG8BT845jIv68uA2Ua4I4lgfsN5RrI4YV5pJqWn1VugZgZI5SsaizNsabyp8XeJNhUqiPl4LF2WBwSLMBF+PqcsCXxu8DQSvG3d8T5A1LkgMlsHEMKkcGyNHV1paWPLSoJvvR0rR0P7i5w3QTPbYJfFbWJy4m8EpRDqnkp5Eywg8aUVaO1IdgSfv483PXcGnVMtGUysbj63otRWCx3uBD5FCLIiATyRAxe/OB0FlIwpra4cvJriyopiMmdSR8VQ5R7+u6Caa7XnGVKKYSTIynZBbR5ualnRYQOkETKAe14yqMk5uIE80aRAo66nraBxvbLMoEOhkAq1ikkEZFFUQDJ2kXxtKW1G7EVLIxoTtnj3+/K/eTndqhqnZOQ4dPspo9Rjjw8vMGENHlRy+7uPsPP8+TG3fw/rqqHG8y8i27SWpJ6SJIps7i7qq2Ti+m8Gojz1wE9nX/5FquMLCWWfRr1dQStHubmOyvspgaZng9pG2Osxu20kiA9XaEeq1IzFqV6dRM1+W8aavKKhshbc11lbYusJVFVVdUNuaSTWh9B2syFlbhSqUmACllxgbgdGTA8/qJAKF+06usTIoKK1CCYcWKdt7jrZqUg+7LWrjWB6V5OM+ImgeddY0Z3U0pwYFdx5fpwoCawQ7ckUiAoooBYg+DqHpWioU0dfBBsiVpNXrsNDrknhLimcuBLQSKB1IvKGTKlppSmk83tN4NDRAsPPYEP3WeolES0hEYOICtinwMh1RUeObjkrT+d3sAkvB1kZahsh8zIUiQSGRTCxYHze5c3f22LOtRSdX9PsF6xsTrAskIjTeLgJPoGpo0EKI5lGzaISYXCmEwDXpn5K49qogSAMsKIHTEiM0Q+0prGKtjib/+8uKsprQ0QmdRLM0HFE6SzEYsNGwT4raMhk5hCxYUUOcc1hjEaitz5Mo0FpSyBQtEkRQjNZKagO1FUxtV+QdSXsuY7Tq8LVktjXNZRc+mLP37PzOKXOPGtdccw0HDx5EK8XrX/catk+lDA5/AyNSVvoFf//ZG7ng+3+Yyx7/fbzmhyZ85SP/yGve83Z+9CELbJtK6a4c5OiXNyiN5+ppx0I+ZqbjmH721ZTVmNFgHbc0YPnESd765x/krMxz0RV7uOCiKU4MBe+6CU5/4Yss9wsWNwp0pZFDy/v/5hQ3Hy8xDn7uAye4/VTBWlnwo89/PscOHyLfYgmcGfv37+eZz3oWL/nFX+Txj398UwCeedaXv/xlXve613HzzTdv/e4nf/xHefCDH8zP/7df5qlP+QF++NkRZPnSl77E61//eiCmvf3XX/xF3vO+93LwDa/nNb/zaqpi8m900sXdvJHe97fv591/8zdNyhucoePG8eKf+SkuufhifvcP/5hvXPd1hoMB3ns++7nPcc0znnm3V37Zy17Gox71qH/2jp/97GfulnYH8Cu/8ivs2rXr7k8MHqk0Wad7Zj8Ogde+9rV84hOf4Nd/7df48LXX8sUvfYk3velNzM3NfcehCV7xilcwGAxI04T3vu/9fOozn+GXXvwz7Nq1i+m5bbz8FS/nwIGDAPzYIy9i53SLt3ziZs5bvJNdXvPovS2EVnz6SMHTducUQXDT0oRdEmanU5aSnHO2T7F9qs237jzBelGzUTnOOe9sBIGl0ys84KI9ZFpz25FFOg0b5LYjS0zKmk4r46K9C9Qu8M0jJ3DGMNNtcb+LzuZRj3kk5114Pr/6a6/j2Ik1JrWjP6m4bd8hfvs1b2J67r2kWWRx/czP/Aw/+IM/+K98x/ec8elPfZK5+W3s2LmTgwcPsHTyBIf33cqCMuR5wul9mtmZHp1Oi4kIaARpqllYmKUYJVTjMXknx3oYOcva8grS1bR626jW1+hkkOcZznky6Un9BFk7QiXp6oBKQNYTypVTVP1V3NIaSatLpzdNMejjvIf2HHmWo1s5DAxGqAjsEFk4k9IwqUyMip9MkMFBiH6gpwcVR1fHDCbRGJsAKEWQGgcUtUN4j9eRaeADKKnIpIp+mRpk4pkRCqNTsnYEwqx1eOfpJDFZSgSFFwpPrLedjdYZMoR4E9eYb/vgscazqcno5hlTLU0n1ezoplgPtQ8UxpJIQSsR5Co2aisbyKSgraNnaKajNKYy0Tx87CKTz/mwZUIOkWkBYFxgUMdGthCCTEuEaHxNm1q5Mo7NOxGdqMazSeKirW0Mr5EeXPRg1ToGF+kgUEmCSBK6vRZ5lqKUQASPsxFwGlSOsfFkaWyK+uCpRyPK8QQ3HpAGS1vFe6D1wZhhWVNbG8EtAuNJCUKwuHiawsko86trjLFY5xiXTVpogE47RymFDdGGA6lQaQrW4QKMSotKNvfnCG4FPM56pJQs9KaYm52l1zuTbHpPHPfW0PfW0PfW0N97Df1dA08uCIy1VEVBcIIkb5GnGUmaNywjgUrySMF1duv/B5+AMzjjQCTIJCdtz1CN1pCqT12VMZHNGaosx1cjvCmpNk5hqxG4CTpro5IWOIOQFhEsIUgQDlSgCjE5zroam2ikVIisHQGluxpuNgbim9y6IDZT1za/+0CMW3PRi8oZnKnjxDXxx1vTRL5u0mHBNTI1IUELFQ3onGcyqbGhIDBiNBiiVE6Wj5A6RWoZ/aPqCmdjEogMvkGqPQKHD5bgDMGaeIE48E7iXPRcci7gsJggqb1nMDYUtWMwcYjMI5IIAknlkUqeKe7FJll4s4EeOHNaIgIsGpRXNY5ZPoQz37NsIDshEDKaFxrrMNZFOVoDPlkXUCrS9oSIkbICjw8RzZUhpiHG1k1kQTk2U/Uag3PrCdYg6grqRrrpPcFDYQw+OEprkSLSmKOPlsJLgVA+oskhIL3Am4BxjmpSIhtzdYQkBBE3UxM/c9kwCOJJkmgNOhFMAtQBJi5QGE9lLUUVZZ73bIJwHLfcdivT0zPMzM5z0223UY0HJCYwMztPntSMVk9RLuyi3ZvGFgNsNcTXY5J2Fy891EMUNVp6dKuNsxOKjSXWD92AThTtXFFmaewACIGrK+rJCFMMSZIMpRNsXWHLEaYconX0daurCXVV450jGN90USvKqoiFTh0LXYPCqBQvEqyTjMY1E+eonKdGUtaBonb0K0nlYmxwYTyMDQdXCyQBLT3jyjGXeeZbga5W2AAmKDLnSKVgb1fjQoZUgaPLisoS/duIpv1tKdDNplkHT8xYlGgRk2ts8HSkIE8SOq0cqhrpDJmpaKlYmDrryNOMdivHUUdfu+BBNGEHWze80RyxCdvBhhgAIET8LEDsyDTz2G/+KY15IUQycYg3DqmIDsHBB+xWoSzotlKyRBF87AqXlWkSMcUWezSI0DABN0W7jZw5hLt82i2VanyGFCgv0M25i4m1giRoxiIW/cPKMTGGo+ueLElppymhSY8sjaVq3imWK02iDM1a3hT6SkqkpHksqLzCGEkwgmJcg5ckUpEmEpkL0kRTDQPOS7Ik4Zxdu7j/pZf8/30Ofi/jQx/6ELOzs1x62WU8+clPZvuU5sg3BXl7ipV+wcH1wNyF90PtvYrvu6LH0dOrbHzhK+ycN3QxLC6tsOL6WA+zWuBNzWQSaHU7oBxZIVgsLceWx1y3f4C+z27a0110KjjSd9x0wnDoziOsTAwrpeOCsxcoK8HRk2MyKcgSxf6+ZK0WDMuST338YyQEemnKkYMHaLda7Nqzh3PO2cvi6dPs27ePfr/fyNniMYYQOHz4MNdffx0f+tCHgMgsOvfcc3nUIx/Jgx70QP7s7e/iQVddRQiBgwcP8vWvf33ruQ996EM574LzGY8nHDxwEGtq5ufmuOSSSzh48GCUcwBHjhxukn8CJ0+e5MCBA5x//vnceeedfPjauzKbtooDAB5wxaWUkxEf+ejHWF9Zoq7jzdfx48c5fvzuUeA/8iM/8i9+j8eOHePYsWN3+93znve8fw48AYPBgH0HDlJWZ7xPTp06xfT0NMZYbrn1Nq79yEf42Z/9WbZvXzjzUZvzeekll0R2mBAcOnyYL335KzzmoQ9kZe9e5rfv4OMf+ziHjxxh79693JwtcyLxfPRD1/GIuQQ1lzHdSqmlopSSs3JLJQQrKkONJmRB0pprsWu6xUw3Z6ab44TESEuapk1zzjM/1aHbyrjt6BKzU5FJcWptRPCBTEuUkgRjGA1HzM/0mOm26HVy9uxa4IJzz8IHKMYlXira7Rxb13z9+m9GBVJzuFdccQUXXHABl1122b94zu8p4+TxY0xGQyajAYcPH2awvkpVjMlmM1qppBiPaGmBDpZaS5I0IZgWrSwh1Jp6EkiDRQVIRcCWE0Z9R3/xKLaqEMGiEoUUmkR5tHBIDM4XSKFQIhpFh9EI6z2T9YKk1WN6bhvlaIhDomYkanaOpN1CZ23qtEDo6OkSHNhgGU+qGN9eWRIV96ZR7egXlvVRTW0dzodmXZZIFU10a+uQIbIHPAKPIEsEumk4aiWRWtNTCUYmCF2zMSyoaoM1LsrfGimOlypaMfiAkxCcQzTMTyUF+MjCqXzAE+Pls1Qz3U7oZZperuPe70IEdAikMvrOxLCeRn4nBU4JUilQki1FgLF+S02hm9oYEROZHfF5hfVbkh0tBF4KVNhsssbXkdJHWSNJNDsWRHqEDAglm7j1gNncZ6VA65ignSSaPEvJsgQIBBfwzmOMxbiA9YKWapr/1uKrAuoS7QwtBQqJD4HCWoracmo5ruO5VtR1XCtr45hYj/OgZMD6eOyjoo7BSkrRasU6w/uwpaCoGxCjMlGGJ7RAah3BwRBIUg3BoqSi2+kwv22e+bn5/7S5+d2Me2voe2voe2vo772G/q6Bp33HTlOvr1Atr9NiiXa7zayryDpdVLeHSFrorBX9mbxHe08rgPMSU4yZrJ7EWoupC4IrUUqRZC0qL/C1xfgJw1OHGrBIEnwEr5I8p5bLYCoSnSHTLjLtNMZmFldX6MmQUFeUkxI72UC3Z5jaeQ4yyRA6iXTcxtxzC2gJm4ou0bCfQtwuXI0zBVURY6LrYkQ16WPKAbYeYeqKuraNF0HUqtYOep2MTCt0KjFlRWUsaxsFeSmoKuh2TjIZl5RFTWumH7WgokKUGwhbkCpBlgryDHJRE5BYX4OtcdZhnabybYyHSa2bC7tmXBtqZyhtYDQx2EZPLROHTiM4FXxAarb8ls6Abo2w0EfoafPcCMIW8CIb8E6GgJcxbtZ7iVKe1AXyRCOEoKwtk8riQ2i0oiZKCUPs9iRKobRENAbhojnvEUCMiYQuQF0HChsoG+2pqCvyYkJdTBA2aonbKqEOUDhH7SxjU3OwMrTTlBOTjO3tPG7yLhY61nvcwDV4W8DUkY5tVcDKaGoezTFp0vniQiAklF6TpIokk0ysp/ae0gi8DighabVVTCWx/rudSv9po9VK8L5kuHEKWw6QWtNeuJz7Pe5h7OgI9n3+nZzYdweHv3Ed0zMKu3YEMTpBa2qOwm5w+sDXsLd/GdB08tlYJHrL2jc/TGeqy9TsHPNtjzWGcvl22jqjNd2mnupirGXl9CnKqsKHCCzecOunmNSeYR2og8IhqdDRzM/D0IALMt7MeB09QGyNFNE8cWJCBGN9IBFRU+28J0szZrodLt2zQKJzfAiMij5r/RGjScVXyprt3ZTd0xkXbTPsmEk5b0ePXkujvKdaG7BmHaPgOHfnFIPCMSwt6xOD04LplmC7UiQNCDv2ktrTfHIgCHpK0s0Uc21NJQLGQBEq8lyjtKIyhunpLtPT04j+EIdAaM1o6TTBGtIkQXoRqeveb4HkHolWgo6U4C0xsRMQsYgfmbippVJsRbc6HxAyoIl04hVjqYxjttMmSQSZEowngeWVEjBUozHCWrROSKQiQWCICWMi9kZQEhLhGxkAGGJXRhG7Jj7E6Nm0Sf1UWsWuUghkwZDIQC+RZCQUaUrpoV95alOzUU/izYoQJDomWQaiR5wPIIIgFWKreEc00mg8omG7jkee9fGYUWlQoubs7T0u3jvHajqgDJ5JDUJqvAgcX1pjcXWVlfV7dqIOwHOf+1x+//d/n3a7zbG1IV/LHsb3X3E+D5vpcP/H/QhfvfFb/P1HPsbzn3UNP/qjz+cZz3gmP/1Dj+Xbt93GkX7FxTMZ0+2UZHqKO0+uc2ptleyT748hDn6zExcLg1u+eowgOCNpCTEevJcnbOum8fwRbzDnplrcZ+8cv/Hjj+T3338d1153iF0zbTq1oVXV/PjTn84PPPOZ/Pm7/oa3vvXPt9LgJAFn68azEaqy4DnPfiZ33HHn1jFfeeWVfP7znydNEqra8Juv+jXOP+9cyrLkh37ohzhw4MDdzpEQkt/6rd+KdgBpwi/+t1/iBT/1Qh7wgAdw5MgRCIGf/Mn/AsTr53/+z//JW9/6Vm688cZ/4YzfvaXw6te8AdmkwH7nv33nuCuT6t87PvjBD/Lha6/FNAAXREnhs571LLTWzC8s4IXmyU9+8r/I6nrXO9/BNU9/OirJOO/cc7j/fa/g51/6MsqiQAiBMYbHPOYxfPSjH+VFz38ef/K+f6DtPbVKOKlyvrhU89jLd/CLjzmPF/zZV9i1rcW7X/YQXvDGf2LfgVX+7BELvO3607zjG4f4wYdewqVpBkg+ef3trA0n1M6zXsQbnsX1IQ97wKV831WXcODOA+w/coqb7zzGJ68/sOV987ynPJJtc1P85lv+lk9ddxtKSYqyptXpkLfbPO2RF7O+MeSDn7ghBsU0Sbqvec1reP3rX09V3bPNieen2+DGbJxax4wHtFPBjksu4kGXns9UO+fUiWWWTxzm+KH9tNowNdXDz04TVAKTAre+jB+tkirJBbMah8HbmsXbvoFBUYXoMaKSjDSHrJMhE41JFIOJZVJa+stDnDF4V7NSHMQikDKJci6dkc2dxX0uv4xzztnL3vMuRE5vh94Kx++8BVtNkL5iPJpgrUWLACoG5hzfGHJqo2RtUCEDKK1QWtNu5WSZxlhHGcBLME7hieBTDxdrxEoyM5XTzhKm8pxOYZgaV6wPJhSlpKwtmY6tUIFvmpQxIUpr1ew/kckugVz4yFYQglWnCUoz3W0x11K0tUR7u9WIlWmCs9G0uxiNkM7SkpDjsSrgg6DVeDZ57xvf2fi3NipmYj3U1Niu8UodGoOS8e9Uw57YutFs/K4214k0TUAopNYE19ygeE+agXYKby1CRfp9N9PkrZxur023k6O1oqwNiVB4CcIE2q2UTKUIazFlgd9YR5djus7SbiuKTFJ5GNnAoLSMawfOY4jSxcG4woaAlyr6PUmJcwGlNUprbIi3ykEIRpUhBKhqw1Q7w1vLnYdOUpQRhJzutOj0uiwszHNqaQVrI1MsNN+PVAqtU3R6z/ZKvbeGvreGvreG/t5r6O8aeDpwcoXE1mSySzutQUnqyQARHCpJUXkd5XZphtIKjMO5GhEUAouQYMohYBmf3h81p3ZCoje7C9HwMIRoUC1k1H0H4uJcTsZMCovQOaisSXtwWGO2WENlWUO6gsqn2OGhPTVLqzcT/anuRqmP6IvYpNEFB8E28roSZ0psHSV2pprgTYG3FcHWWOswxlObwKSMHQUXojQt0mDvQswXMRK6KivW1lapKkNVGTrjCUmWkCaQ+iGJKEmSuFIEa6iLIc4LqrJiPC4YTwzDMlDUUJvAsHRUpaOqHKVxd9GpA16QCE0iNYnQaCEbqRtbskMvwz+T0n2HoiCyeDaBqGYzFQFEaOjCm38kApmNuntrPbW1mOCY1AKpIqAkpcDpQOLV3SRpjcQVj6Sy0WRyVEX2lDMOURbIukbUFapBm1tSkDSAWVsqCgmlg8IFrDUMfez4bG7wY2sw3uPucnjGNWmEIhrYxSLAR98pgBARahmgdgJroAqbTKh4Y5MqgdDgEkldB+z/B6R2T/3+pzS+Co77Xb5KQJK1pzjvggtopxL3yB9m7dCtDE8dZryyn8FgiDt6O1mnhzUG51v44ACJcdEA1HuoaTGaSFbthNoKahsYlxKDxwTP2MRzV7uAcGBDNH/fGCcxCdELXIO8SyFwQja+DZAIQSJk7BIAuYROYx5odIjdU0AFgfHxPVqtjDyT9FxE/IOQzKYpvW1z1D5wcmOAJjAwcOvpkuN9w6m+4QEXzbHQSZibaeFX+qyvTji6NGJmqsW5cx3WEk1d1RwYluxOY5rGzjxhRgTQ4IPbosbiHcLWlIVnMi5QScLuC84lGEtwlk45BmAwKdG9LipAsJ5Mp/EaozE6bMwYN0m5eTMXlYg84MZ3FBc2WYl3n6+bIHtLSXyAOgQy0WjKgU4i6aWaauI5UTsObjiGfYutPZmOnRzVbFCbk0bKKD1wW8crcMh4IxAaN7cG5CXEdUaqSIEOAUwAKSQpga6GNvHzT+k0yh6co+8cDnCb3SUa1qRQaEFTsIOQEs0mqC4x3lO6wHhjQCfP2DXXYvfcPCIJrJQTlvoltY+At4/tKiyGG++4naOnT/IL/+M/Yib++8Yb3vAG7n//+9Nut3GmpFw5zvCmT7O/4ynOOpsLds5z0fnns7BtnuGgz5F9t3HrN/6Jxz9oB9umKv73R2/lxKhmwwS2Z44r90zz0L1T7F+rGZaGUWm4cL7DsDTcemqDK89dQCvJN/af5sn33cklu3q898tH2DXd5uId07Sqknwmp/uA+/LxG4+xuDriwLf2c0EueMYVu7hkV5vBsGZ5tWT1yCoHv3UDf/Tff4VnvejFnHV+NLW++ds3sbKyzPc96tF8/vOf50Mf+geOHTtBdReg5dixY7zyla9ECEGn0+FZz3gG3/zGdfzpn7yFxcVFrLUA/MIv/AKPfOQjEULw/ve/n3379vHyl7+cL3zhC/zjP/7jlkk5wM/93M8hhOBNb3oT1lpOnz7N/3jlK5mfm+P3fu/3eO1rX8v555/P8573PN785jdz+PBhIAJ/V111FcFZPv6JT/DJT336X/2+3vnOd3LgwAFe/vKX/x+/23e+853ccMMN/PZv/zZCCKra8OZ3fIDV0yeoN07x1O9/MsYaPvrJT/Oud72L6667DoC5+W383u/8NqYq+epXv8r73ve+u73u29/xV3zpy19BSsVFF1/Es555DZ/4+McwxgCwLZG0Thzijt/9n/QO38aFvYQibbHqPf3VCY/e2SYpxrz9c/vpBE/LOL7wtRO4cc1sItnYKNnb0TzurB57zZATgz63blh+4NI5UjFDf2QYhRph4SXffwVLRcHHPn8Dy2vrDIcT6iB4+EU7GNeObx5Z5cZv30knzzDWcdZ0xnw74duLNXVdM94Y8NUb9yMInL1jisXVEZMyHodzsR68p48HP/zh2LrElGOG4zJaHaDYfcF5dNst8h0bnGx3WDuW4QfHGYzGjCdllKoZSz0uKFW8CVHdDj44vLOUo5qxCYzquDfkqWAqaExVUYea9WLIqDSUlYvWBc7hnGVYGqRUdFuN7CV4yuFxQDDY6KOVJkkTRNqmM78TWwzxxYApIfGbTH2tsR7SZEI7TZnKNJWKFhY6TcgTRariLR9Ni7eyIQbrIDASjGyMt5VCaI1HYGxMddNKkSYJMWYd8B7vYtdeEO1ichnNf6OZcADvSZrOvdaKmpSgEjqtNN5zyICxoWHiR1NxC3grKX3Ax00XJaJVhBS+sY0QW/cSSsX9J9o+xP1NNXWgC7F+VA2YH7xHKNmAZpsMB48IkSHhXDxeoYmKDSnj3iklOtUIH9CJRCWaJNHR3DpNSLMkshe8wEuJSLL4mTHUpknFG2zgiwKqMiZoKY3Q0T/KAqkNJFrSrh15O8WJGFIUmmZETfwcQoAMkixNSHWsJ7RW5GnSWFQ4TG2iH6uNnlCJVrSylG6nRaeV08pjGqL3gbIypCreT6yvr1GUFUePnfgPn5P/N+PeGvreGvreGvp7r6G/a+Dp9PqIqVQwm0+j2wYlDLYuIrVVa7QzKKWiq7kIgCW4kuAl+AoE2GpCMCVj4WICg4gyrNDQbqxpvJOsQSYZUiUYD6Eo416yMSYITUBT1hbXUD59Y8ZX1Qav2qi0i8w6zFqDVIqWilGrgk1JV9xUIq0tELwlBAO+boCnKoJPVYGtI+jkbY13BmujB5CxgbL2Mc2uoRLHSMbGlDqECPJ4T1VXbGxsUJU1VVVRVjVpltFqaVq6IteGjozG5M7U2MmI2sZYzOG4ZDKpGRaBSeUpTWBYeOrKUteW2rqmGw3CCySSRGlylZApjVZqi9a3KZXb/O8m6+g7QafINIzgXGDTcT9uEJtokdoCpQKpVjgXGsPx2MkJtW0owhF48iGmdWRas8ladA3Sa72gsFCZwLj2BGPB1KRliTAGjGlYUoAUZM0kzhEkBBKilt94R+k8VdNFEoALLprLhVj0EESDqW/KC0MTrNdQrJvzExq+cOOdTrBgG+PKNAmRXp6ATKNJOptI/T14POphj8Qai60rqqpsaNsa2ZoBqUi7s6TtGXRnirX1Rapxn8lghSzPQGVYNYVv0hx9HWJh6AImtLG1wwxqCispnWBcSwobN7F+5ZrH0BIJJkDlA4VLEMQkGIJHAS0hsFIShCQjkAAdARWRQp8qwWwSqbM+eDIV6blYqLyi9LErJZUEV1F5Q1CaPO+QtVugNEIJRkXFqKhZ7tekA8NSv2bnjmmyNGE+T3BOUE4sq2tjZlop29oa7wUr3rG44dDB44JiPlF0VUzKsHgSqWJqRQgEb6iqmrKa0E57LOzZRTkYYYsCJT0D4xmVFd3ZaYQPuElFonWU6obNJMpNB4j4k2w+YJOyublpRjNEKc9MZcmmb1vTvQmBynlSGSm7MgTaSjKdKsrSsWIsx6uKtnVkPtDTTTCAiGkbcSeU0TOPSL3XsLVJO98UsqLxcyNEDnOM34kyhRBZoimxSG/LhgFJYFolVB7GzmPKmtJDLRSEKKGAxoBUKqCOVhJSkhE3TISkrA2lM/QnBbO9nB2zLc7fM8fyZMTB9TVWNmp8gETF2GkhAOXZd/wIN+2/Z7MlXvrSl249XllcZbB4hHDiZg7s383IwgW7tjE/O007Szl98gQ3X/dlvnzte/ivz38orbbi7Z+4jbXSMfGSnUJy8fYO585kVHIYE6iKiqvOnuF0v+DgUp+Ldk6TJpobDyzxkPNmeMLl2/nct05xwbYuDz5njuLAUXbO93jIYy/lxoPLnDi5xrE7j7HQ7bJn7wxXndPm2HrN7XnJtxf7LB3cz7v/1x9y1aMeTW92Fh/gpm9/myNHDvPwRzySb3/72/z1X7+Luq6RSke5CbC4uMgf/uEfAtF0/EeeeQ033HA9b3rTmwBItKbdbvODP/iDPOIRjwDgS1/6Il/4whd56Utfyk033cS73vWuLUNzIQTPeOYzEULw5je/mRACw+GQN7/5Lbz85b/KC1/4Qt7ylrdw/vnn84IXvID3vve9W8DTD/zAD/Dc5/4I66srnFpc/DeBp49+9KPccsst/ORP/uQZw/B/ZXzkIx/hjjvu4KabbqLVajGaFHzshmOo5Fv03YiHPfiBjCcTPvrJz3DttddybSMH/L3f+z1+/ud+ln6/j5TynwFP137ko1uPX/Vrv8aTn/gEti8s4KsKX4w5uyXprhzn5j/7Q7TQ7GknjKZ7HFgZsDao+JkrZrh1teL9317ifttypgR84RunkMaxvaU5uVqwPVPM7ungx2MOb1QcWyz5bw+/jIVWwsmlEZ8+OqSqHD/wgIt4+2du44vXH8IEaGUpM90Ol581x8a44qZjaxw5epIs0UzPzHD+jhZnTWluXRpjjKEKnlv3T5jt5Vx27jb644qysggCWRbNXu/p4/Ir7ktdTSjHw7h/2kBhAtvOOptWq0Vn+4SinFCYktHoFOPxmPG4xAsV/UuCJ0gQWiN1RvAWby39jTH9iWWjcLTbKe1cU0oYGse49pxamzCpLMY6sizD+8hsKEtHnoDWMeK7toblwRgdHPVoyK6FOWa2LdCbm6c1M4/NMqwIpFoQbGRNISPw1MpzenlBnScUNkrbdJaSJ9EzSfjQyD3ijTXE/c1YgdEe68FLGZPbfKAylspYtJSERCNVTMLyBIJrbhKJsrtEClIJMoiohmheWwlBoiRtnYBOyNNoouxDrE2kjJWfJMrq7NaNaKOKkLF+3WRGxWZ1I0kREcCqXcCFGKYT+7kC5WM6lxZNldkw+jb39DNkybDVbLeuMSpWm68dnYkloqmNFEmWkqQJrVbWAEgaLxqDdaEgbUXwzlS4uqCqKkx/gDAVylaknSxaXzT+NkGAdvH9WkrQ6SZUXjC2cZ2sfWzs2hBVEEoK8lSTZwnWB7I0odPOoh9UCI25uceGgLWOVpbSaefkWRpTzYTYalJXtSVrZwgRGA4HrKyuR1+we/C4t4a+t4a+t4b+3mvo73qnvuzSK5jqtJmdnmKhDVQDiqVDjJePUw4HiI1FquESSZYTBJiqoC5GWBvBhWio57AhUBV9dBIZTc6FBsjx1D76JtVOUHuDCwbvJ7jm95N6LT7XRXmbD9F7ajMS0foADFBSc+T0mLMbP4mzz7+ArN0habUJIgEhkSLamAUcwRUEbwiupq7GzWcfUhcDTDmKP1VJXZlGAxvZTqPSoZRmqqdpZZJWChKPkuFMp6W2VFVNXVWkyYhx08FKs4y8ldLJPK0MpJOktUSPPYUvKGrHcFSyvrJMMRkzGJSxY2UcRRU7VsE7EinIlKKVJMy0cnKdMJ23mJ6fpdPr0E0Tgowbo2z09t77LeurKDnc1H/GDTk0Urit0YA4sQvjGxQ47l4BSLTEe4X1CePKUFvLqKwoakuqFd06I9GKVEvSREOIqG3t4sSrG68s7zyiKtFlgaorQl3G4iLEAmJz8m5iZUmIKR9tqWgpifHRg6nyYit2MoSYaBBERI036Zabx3Qm3TAi5KJZBALR4K4uLELKaPaXKZJEkrckVjls8FRF9IXy7p7PeKobI7xaSFS7h3eeqqzIzBidpswv7KGcjBm7hOFN3+L4huT4SmwJCiERosKG2Jks6wk+ROM+5wXGS4yLYKXEowXM5zmpUmSAkI5cBGaynFR6EuHReFpKMp/rrc0hFZLaR9P+jjJkwpHhKJ2O/QqpKZvkHS2iPNZ7z2Lt0VozoxOc83GzTRW6myC0wgpHqEaA5H7bZhkZS78ynB6PmVSGwbjk3V88TKYC5813ufysvTziQReT7TzJseVVvnrLCc7bPcPuqZSzZ3dycHXE4bJm/8qEhUQwrSW725qODrR1oKOTJg7V0pufIe900FVJ4mwEfqdmaA8GyGpENplQ1TWT/kb0I9MS7zwagQyQBB9XqhBwm6W7iL4VFtkkcMT1MGk6IhBIZJQheASVjwV7BiAlTkRBQqoS2knK8argeGXYP6qZDYEZCdMJ1N4TQkwaicAtCO+b7zl2aBTQUoFKhKZrLlFIYoaoazBZsbXmJDIQo3EECQkOhwuOFiWJkKRSorKEKsCYqCsHKIIk05pEaYToxIaBM1QuMDKOxdGEOjjSRPLIy86inackieZbS6dZGVacWi9IQoy5TvK4aySpZH57j5PLDr9h/gNn479/GGP4Lz/zInYuzPPaV/86v/DffpWl1XXu+86/4Y1veD0f/MDfMq8CP3DlNC95zHby8x7HrD/ONVfeyOf2r9BqZbzy6VfwD18/yJ9+8RDLw4oHzaf84M4WMy3H/TLJkx88w1eXT3OigvvtnccfX+Po2jrzSnL/c3o85WE7+PHrDnD+VM7jzr6Clz30CKPFhLTV4q9v3+D6xWUe9m3BeVOKvT3Nrrk2q5OE0bDg//nZn8KphH2Vp6xrFrZv5xd/4SW86Gd+huc85zm86U1v4vrrr+czn/kMeauFgC3gZmlpicc+6fvvBuQ88uEP5ZW/+lJe/buvpt2d4tprr+XVv/WbVGVJp9PhxT/3czz72c/m6quv5tixY4QQ+PCnvoAQd1n/AYLnLW9+M3/5F3/B6uoa//iP/8jnP//5uzGlAE6cOMmjr76apeXl/+N3dfzECa666qoYHf5/MTqtFn/3Z7/DyRMnuf22W/nd3/lt9u3fx78k7xuNRjzmMY/h0KFD/+Zr/sEb38jfvPvdfPCDH6T64ie45bdewWUXZRwz8KbbDXcWBpkGfuk+ObtVzaHE4bpzDDY2WC5X+fGnXM6wsLzyb7/Nf/++Hezual5y7VF+5NJZHnPOFH98suaSnTO87ZEdDrgW1x0Z86nrj7BSOmof+Mr+JYraYgOcO53zuKsfwrOf+WR+5dV/wtETp+lkCb/6wsfzfQ+9itkH/jjFykFOH7mDj7/wldjgmds2w8UX7WR+eoqz57chwzc4feo0orI87zlP5LFXP+j/6hz/Z4wqaEpyCiXYtWcnaZKipcRYS3COTqfN/I7tmOJsThy9g8NLJQePT5DE+PpeO4vJu8EwPL3ceGl6EqIMdlI78hqENLBcMNNOUFJgjSWT0M4SFtpRjiekoF+mZFqy0EnpphofPEvtglwZ0vEyN3/liyyctZed557HrnMvIG+38VNT2OEarhpjJwOkisa0F2vNei9jra0ZlDVBRGaWd9GUNzjNJiHJ+bjfK9GE8YSYerc2rmBiGJeG0aSmqi1pkqCS2NEvyzoahbvoxepDiPIhYi2iBFQ2UBpHcLH+7ATFbEejU40nMChqjLWYqkY0N+uC0PhCNQ1JKTEqGmobGSiwsc4xbEnmpIhSGCSNKXhkN0gR90ATPF19pqbcrDFTJXE2YEOUzYSmc2xsbJhqr0gahlFwEuMcXsDsVIfZ6S7dbpuJ8TilCFqTtFtYFJMSqpDhSs/iqRX6axsx/KAck6nIzMikwArBxHk6qYxMpyxaaeQyMJ8GxsYjTKDXSrDA2AZkc+Nae0GSgFYwNdcGqREqslisjLUAPt4XiBDIE0U71awPhqyv9wmHjrI+KqJCo7lxzhIdnWecxdT2P2difpfj3hr63hr63hr6e6+hv2vg6cLzzqOVt+h0OvQyiS+HaKmojcVuKMYbYyaDMUJOQCqsNREZdg3wFBrNovf44BAyIITH+NjYNDZuPptARGnjhdAEn+E9lDZEloyP9MSA2EROgKjPVASEd5jRkOHqMitK0M1TOlNTdGZmQOuGvaPY9DMKoW4YTxZTFZi6xJQFtiqxdTRRrGsXqasWjIXKQggCpSStPCHVEY2k2VDPIKmRyYQHISy1qZFFgXEW6yqCFTgr6KQpiS2RVWBkSialZTCq6PfHlEXJcBzN4WobtaWi6fYkQqKEJFeaXpbSzTLmOm167Zy8lZNojREuMn426YN3+V63AKbQ/HBGkhg487vvfL6UccHcTMsT8gyTKoQoZ/MhYFyUuSVakihFom1cgIm6000tMtYirEOWRTQSt6bpkJ1Bq7cMqtgUSzadoRBBs1RAFiCTYIJg4qAMsVuz6QfQHMUWwnzmxmOzG0ezGcRFChFIpSBLJK1cI5u43MJ4THDU3hHCJpJ9zx7LK0vxgZS0W22UUrR6HUYb61Tra5TlCfrLhxiuHWduvsfypGK8XFNMDIkQTGcSEUAFaAUgRKhO6ljQ2aaI0kAmYHs7AoJCSConsT4yxVIhSYUgF4JMSXqJbGBPgUGRNuSxtooU0IRID3VILJqQCJx3BG+wLgKErU4HpVRk2Yl4rbXTlDRPowG+sRFkDh7laoJ3BAw+0xRK0tEJa0rhvGWpCMwOC5xM2DU/Q20MRVkymRiM8bRanulc0dI5ZUMzH4RAXTha0tNSjlmlSEUgxTOVKbwLrK6soaGxUZSo4MkJMBmTOEdXQBCx62JDaJ7F1nUY43HD5mRoiIqbqZDNXNzanM7QckMQzTVK07GNr6eVYGwMx0ee5boibaXcb36acX+IrEo2ijEdLUmEbKSqMfVTNGuuEJHe7YlzbHP+W9swCQX4iFITAlsbqRQCHxoqOJFFqIVqggai708uYqcuwzeMSxHPlY8brpCayhhGVcV6ZXEC2m3NTJKRSEExqVAKZAa7trWYn2mxd2GKg8fXKStLVTp0KuJ2kHqytqDjk/+Qefj/i+FGGzDdoT29jTRJGGys8dfvfAff+sZ1VKMBVz/jh9iR9Tl8YpELlvejyiGdbTtQR6Pk5vO3nqRlS75vR0K/G7h41wznnzPP5+9cZlp6HrGtw+h0n9J6HrY7weHZP/JcOpfREYITa4aHX7TAwmxK/9ABbjvVpxgYHr6tx55c0G9LHnzVbpaXh3zxxDo9NHNTmu7CFEdOT1gaGFbGFoEgEfDnf/7nPOKRj+QBD7g/x48fp9vt8uIXv5g0TVlaWuLd7343EL0aVlZW7nYuelPTXHL5fSirmqPHb+dP/uRPuPyySzj7rD0seM9tt93Gl7785buBP9d/7Z+2iri7jsgwic8rS0dZ3j0e+FOf+hQHDx7k5KlT1HVNkiQ897nP5cSJE3zmM5/5F74pgREJUwu72JaknDi8H2fPFGc7d+7kqT/4gxw4dAjnPX/znvcSvNvydOr3+5w6tcjJxUXG4wkAeapRUm6lSm2ek+Fw+K9eL0IqWirQdmNu/fTHkPtvpsg1/9SHQZJz7iVnMbu6gvQ1xgX6tWO18mSdnHMXejz6vFn2LY7pT2qmE8nBtYqlkaHycMd6hZQjFoclEktbOQ5XFacHFcuFod3OaAnB6Y0J97twFxfu2cZobKis48tf/Ra7O4q9972AS656CBec3SL1JeXi7YyO72Nw6E68j+m2w+GETEpMWfOt2w6zsjEi785wzfOeykMedAVnXbz3Xz3+e8rory5TGUtZG7Isp91q02u32Vhfoy4nUA4oN5ZQbsT83DTL/THoDYoqIh460SQi1ibCeJKGwTCVaiotaUmQicIBlfNMp5JcS/IQ0EqRKMlspknThCRL6JcG4T15cLSFBwm+rclE7OiPJyPWTy9SWY/UKZ1el3a3Q9KeIm21CZ0eeAOuRouA8hVJqMlGRfSMEmBqg3Oxdq4dGA9SxvpVcsZH1COYVBbrA8NJ3dhpeLRSNMShCPAoiU503HsaI+I6RJ8aJQSFC0ysx5hAHgIiDcw3oFDpPJX1lLXDmpiwJwmUtd0yII6+LgKDxDYsDEOTCE1kRm2CZqL5LuJeFrcnLSPLQcloCLxpLr4Zfh3BqWheHvfw+D+hYRV57/GNG3FsxMfX8jpDpBkqzajqEoJANYmBodlPzWiCKUrKtTX8ZIJy9ZaZcaIE1jqCiIFAzslYCziPDPFakiGQC5hNoMThECSZpKWiefn6JAIWwVmkTqjqmrEpmZQ1IcBUr4MIHu8dFkueqChvzFsE5wnOUFvPuKqpzaYaIdDKUrzzscF8Dx731tD31tD31tDfew39XQNPV1x2OUpplE4RSmKrgqQ9xaSqqIJitLJIUYwxpgKpmtOrML5BdINvpFUB40TDRHHULgJPzhNPZIgLbeVi3GEkmsbFyIdGMkaz6LNpJCi3AJFUxEkrywmTFc/p8Yi28EzPz4LdjsoShIwX0aaROXji1uGwpo66+GIUQaiqpK4qqtpSVYHaCioTZWEISZIoeu2ENBFoBc75uwE7PkSPKqRAOBc7W+UEaRRlpXBWYY2ilYIqHciKQeEZl5b1UcVoVFBXhnFRUxmDbWSFWjQJIAgSqWhrzXQrZ7rVYsdUj3a3jW7nhEQz9pEhJrY4Pc1oOjD/3JR0sztDY7xO838a4KpJDIl+UTGRY8u4vJnGxnkqC+AoaovWCq3iYhZTThRp1oqpAR6SukaaGjUZIbxHOB835+b7Fnf5aHd9KBENpfkMdmaJRnWpkoxcoA5QN+BU/EPR0KVjqtFmMolvpH9VI81zzXWWJIJOS9PtpDgCQ1MzLiyldVv0Y/Wdnln3wHHs2GGSNCPLWsiZQLvXpTczw/Ejhzl94iSH99+Bqk+Q+HXO3jPH0sRjj1VsbPTpyMDOVEb2GYE8kcgQ5ZvdVkI0p4tgsULQEoIdbUUniRtk4SSlg4n1cVOVkraIFN9NKrsNgvUgSaRH4cmE2uSgkWqJDQrjFVorpLdMqpqJD9ggmJmbideJDySdDK0TUpU0BoMeNx7isLEgqicE51DWkqUtfJ7hZMZyr0e/rDm+usbB1T4bZcXDLrswGn06zx3HToL0tI1m10yPNEkwSE6NK9YLw8HVIWmj/96RpbQldDTsbgvapWUwWGS+16aTZ2inkM6hRaAaDkmkpJ0oSlNT4Rk3oK5AxNSPhmabRQSbgGrkACEyLNkEP2NkwFYqCiI2Rhr/Mtl0JaUItBWslTXrtWVDOS6en+JR99nLDftOsLKywen1Dc5pp3QSmAAqwrLRk09IELoxVo1yg1zHTd7iI8uQu2DFTbG1mYoZY3SjFDaTsSNjG3N/QiDDIYkbpyOu/R6Y2EDlAZ1QloblccmJcUWrnXLR9nkWOh2Eh1sPnMRpi+7B/c/dxVQrp51k/PUnbuHE8oj1oSWbkqRa4JUh7wpCkv4Hz8j/u2GtbfwxHPOZZDZPCLrFth3bEbffyu/+xm/Q1oI927fx0l/9ZW7/0if57Dv/jJ17vwS+hd65F5kdZ3VtyJ984hZ+6aoZfujyLoNBTeecnbQvOJdXffYwu1J4/MW72RBjKgxP2JHwlRXL/lLwlN0JlYNvHhjzow85G1lXnLr+q3zk1kVMgCdcuYMreordIuVHn3Ef3vLRO3n3F4/xwvM6XDrX5n4XzPL+G1aYeEjLeKNRjYb8yq/8Ci9/xSu4/PLL+epXv8qDHvhA3vKWt+Cc4+tf/zrvfe97twzJ7zqkVHR6U+w8+3zSLOfw4cO85CUv4ed+9md48pOexO49Z/Phaz/Mb/7mb8Vo8kaO9cVPf/zf9R28/e1v33oshKDVbvMbv/EbfP7zn/8XgSelE7bvvYDtO3cxMz3N8qljFHcBns4/7zxe99rf5+/+4UN89evX8Ru//Wo21lYZD/rf8Uqb7ZfAdKdNnmpqO4heEdDYHMh/8RyBQGnNWfNTXLTQ5W9f8xv0VGC+nfKxE5bZhRYveNKV9I7eiuuvcUPhODqyHBoZ8k6LK1oJZ7cEf3XTafqTmvN7KV85MmZkPe1Uc+NyyTcWJ4gQOL4W+MLBM/WEFILz53rkqWK5X/CYqy7gmquv5CM3LvKtWw7w4U9+hZ9+9IU86BEP5ode8j84+oX3snZsP6v738fg8AGWjx7D1TVF5SiKGkrL6vqYT/3TLbRSzZVX3IdfffVrokVDfc9nLC6fOIJxfiuApdudYtf2bZw8foxxfxW7fpLcrKHdkLN2z7M2KmifWGUS0Qd67YxERI+jyngyIcmlYKGdUBnDpBTUIsplhrVjdyehmypGiSTLEtJE0wbanRadbptRbSgnJZO1DbIAQkiyVkJbxfX+yFrB+uJJjp1aInjPtl27OOv888lnZ8myjCRR2NEavhwitKOlHd1MkK8PsdYQrKWqwBjHuIryIhcCWsrmZg+UblLvBEyKmso4BuMq1nZSkOikuV+I3qRCaKSMHjmB2LQOAUxTB45dYNR44rSERLtYsyoJto4pyIVxWOPBO6R3jEtFrmVMsPPxbqAmgk9GQB2iB5Tx8bzIzZ+m7nQB7F3qYxWi2bgi3o8kIrApQkmloJRiK8QmAlPNDa6Psjvno29q4aIUUyqJS3N80sLrjLEpmnQwRUDFpGgfKDf6lBvr1MtLSBk9UYOK9VM7kRgTVScmgLMBGXw0iW+AJ5wnl4JOJlgpLV5Kslwx3U4BQV1bxjZaWqRaMJnULG5MQCjarYyd22ZxdRmb9b6gnSdMd3Omt+2K9ZmtI0jVHzGuxxjrSBJFu5ehlaSd3bObP/fW0PfW0PfW0N97Df1dA0/tbo/NwqcqK+o6dsZIMsg7FOkMp/qwOojxmzE+tKGiBt+wnRoXdVRE9hvwTRIBpE6i0ULQ0xIjG3PrpvOiG6QylVFrmapNCCV2SkDEkyw8mkAiGk8gbyhOnsL1NyjX1+ktTJPkGqSN6CA0BmNxwTcmdkLqusZUI5ytqEtDWUVDcdOgzi5At5Mw1c3odTK0ctGnykXplWs06JsyLy9kTG0zlto0aRpK4l2KtSlZGoELFwJrI8Oktgwnlroy0fvJ2nhcSpKkmjRJyBPNdJ7RTRNm8pyZbpdeltHKM1KtUSKaxeE8zvotrpCUUX+/CdRE6doZJlFEYcOZf4fYcZJnZGgRmWqcoEKkThvnY3pAiDG6ojm/mxI/pWI8cKIT0jRrdmsDkxFJVSCtQXrTfO9nrj3fsJ62GFmbV6LYNECPnysCVAGFR0sRF2cElqib3ZRkunggCCnwSJz3VNZSNtr0QIyrTSS0EkUr13TbmrQVrzWfpBF08jApDULHT3lPH2vrKwTncdbxsf0HCVIxtbCd0wduwxcb7N2mmZvVzHS7dHsJZ+3ocOV58+yvCrStmaImb7TYLa2aDqFAijLOTwEbNpZliYqg88QEgvKoEOgIYmcnREN+KxxORD8t2XwnudjUK3uM10gkUkCqLDJEg8+iMJR1zcZog97sDNPdDp12Tj0uqSYlnZmpGNHtLHJYxtCDdo4hwzpHvbpBKgTdVKLbCZUP9KuYitFrKc6+8Hwm5ZiqrvnKbfsj9C0VO6a7TGrDYGI4Uo/IEsm2Xs42DbNdSSdkBKFBaibWUhBYJ3BofYJGMJMkqGKMZIhwlpbWtBNNHgK59HQVSJHEzpUIqGbjmNZqi62YyKZv4uMmZEWMP7UhxHUw/L/s/Xe4Zedd3w1/7rLabqefmTOjGY006rIs25Kr3HHBxjbNYBuDgRRIAtgYSEwMeRIIJZQrGPIkhBYIBmxThA3uuBt3W5JlFatL09spu65yt+ePe+0zUkLe17x+n0Rcl5auc2lmzp6z16y91v373d/ft8RzRcb72LmAwZMoSNp/x5JO8Ajuncw4ZyzjEHjypRew2isYb47oCE+RCEaAbZ+alBgR3SCi7wWRwvxwuLWxUcKbizhRCiI27kLGpI4UMQ8CQrRadd8Cx0oQ+fvzOGgkjiiXNR6MD2w3hqlxsRmXDUor0m7BUw6u0cs03VwznAaMD1x11QaPu2SVwxcssjFIkTKmD20sdSiNYUxF1omJH/U0YONo+1F9XH/99Vx66WGufeLjeeF3/wAXHbqIIs/5iTf9FK/6lm/mHT/3eq586g0cvuoK5M2/zd4QePY3vZiP3nora4cW+Fc//hqEq7jv9ru4rLCIVPKe44G/uHWTlzY9vu9gyU9ct85oZ8Zn7zjHq69ZZuwCP/+ZE3zr0w7x3EPLfPxzD7JYzFgXgT963/1UQqMXl7i8l5GnCR+p9nOsLrHVNuXE4OooH7nk8DpTD7/0hW0uX17khtVlnmFqrnnFq+kcvIx/8cNv5O1v/e+8773v5dixY1x/fZRN/eAP/iCf+OQn/05AJUkS/tVP/EtGoxFPfvKTd9PtQghcfdXVXHbZ5bzgBS/kgQcfJM9zbrzxRvbt20cIge///u/nlltu+bo+j2/6jtfyom9+Jd/zfd/P0QcfANo+KcBsGtlHtql46I6befnzb+C7X/tavviRd1NOJ/EBCJ5bvvxlnvmc5zIcjZjNSibTGdY0f8e7nQdzfvLf/Fte9MIXYqxj78YGvX6f97///fzpn/4pP/MzP/N3/l1rGr56/Bwnz+3w/desc3Sn4k+P7PCNV+5hsZdz5x1f5bN3n+TkzoQ0zzm4d5VvvuQgv/q+rzCrGipjCUhcCBw3lsp60izhussPcM/xcxw9s8NqN2XvQp+11SVCvsByL+Hxe1O2QodR5Ug7PT5z60N87Av3cHZcM53VzFzgsosWSZoz/Oef/3d0HvoqC7Li+hddzVtvGvOe20bUNrBnzwr7D2xwdGzwdcPjLljh+NYkGjKrlDxVpNk/gBq8tYPSGpkkfOWmL+CcJ89zzh4/Bs2Mi1cS9vcDC4Wg01tmfWmBC9ZXqBrbpqqBtha8Y492rHRT+nkSB4GJQmaB4xNLFaCXCgprSYNnARgUCZ1uhkWQZRlZnpIrgROe2qbRwNj5WLO1QIuAMwblArmrOXvvnYxOHePUkYc4fPXVLK2vs7axH1EsIrI+quij0m203CSdNiQClIae9Ngk+nEKEUUHkXQQ+7q8k6MShUoSTGkoG0tZG4okQUtJY2NfZnxAq2i6LaUHGZlUtQfX1hgbPCYIrJAEqfFS44RkZqLvk3FzT882xbPdY8xa42YlYNJEf5jEw8wFaheHkRCZS6qtifN9S9wVxQ1l2ySTJBKVCEwNMnh0CMzdi1IhyWNJp25ZTvNB7nwjXFmHsY5hGfcKRZrQXVpDdnJMqkl60XRdpTmbWxOaWYnd2YJySlLXpAlkSZTSjZroy1QUKXncQ2OIF6EJPvoqRVoHJybR8LvQiokLaA0LmefB7Zqp8Rw5N6NupZHJSJOlCatLfYo8p1PkrC4tMhmPcN5z4MIDXHpghQs3lljfdzF13TAeDjl2+iyNdQyrhsWFLv1uTr9bMBOz1sbj0Xs81kM/1kM/1kN//T301ww81U0T0xe8YzoaYeoZ9XQHZyqE8Og8x6mMKhhmTd0isq1zPBG4mF/gKMcS0SSQ6A6vBfSVJJGCREZwJxBROi3ihc1FiJ5GMtJGIYIJcyd41bKdFCGCXu17uKammS/w0pF2UtJCI7WIMjFU1CV7h60rjLE0VYM1Nc7FJDu/q7FUSCVIEk+WJeSZRmsZ9eY+YG3AubDL7mr/wS3CGrDeRcqpALyisRJtJVVtWqNtz6Rs2uJrsSaaWYkQ0AKUlBRpQp6mFGnSopAJ3TyjSDOyNI1odtSR4azDOouzFu/PAzWBR6I7c1BViIcxg3jYS1o549yYvf0hu6CT8z4aP7bsISXnJEdIEkWiNVprUp2glUIDwdSEpkHUFcI0CN8aoIXzbzxHfFtr8PNfuyfMrswtNjIRgIzwpthlwNn25R4wweNDXHjg/JRpfu5JolAqavYzLclTRZ4rBr1IObWhZbYFKCtD9MZ6lFdMwDkTjefTnLIuGY4nHDlxjI4d0k8d/e4CeSpRWiGEp5tL1pdzTuQJobT44EhEBH4zGb0KdGtQmAhBJiW5jyCrkOc/CRvigi0FaESkrYfzQGAIc4ZdQIv4twSRYhpCBHmjtDRO6LwUBK3QeYHWGiVky7qbN4aRgRakiMw5KUn6fYQPSOfoNI5UK9JEI3WCNBYTPI03WAIag1QCmSiq0qISTZpqTBONFQ0KH+LzVDWGVCu0FKx0C5oQaHyIzEaiWWplWj8LH2LMiI+BCAWKQgk6SBIXGLaNrxTtZCN4VPB0VQSRlRCkOgKshGji78P5p1W0VOL5A2JDi2/PC1ULttoQqHxgaBzomMihhGA8qxiOJqSJJNWSJEtpgNJ5cj1fOCJLcA4Az5mnoX0e26CQaM7/8HVCtAU4zL35Wgk1c5lC9OpwzkdGAAFLoHKt/0eAUiqslqACiVJkqaKTJhSpRoo4fU2VpF9o9m/02DPIWEgEmWjXZONjupAIKB3NbnEB7wWmgqp5dD/Dt956K6PRDrWp+OHXP4f9+/cz2znD8aNHOHfmNJftW+CiPT32LCScu/MhQm+DPQcv5fipE3Q7BbKacMn+JcRkndHRI5QmGul284TRtOYr951lY2WA94LPPzTk0qv2USjJrD5K1umxsLLC0dn9VK6howWaOMXcHpYcShQL3ZQilVgpGDs4c3LEIHiu399n3HiMSlhYXaF0Bh0EF23sYW1pge7SgGc98xk8dO+9HLvnDrreMzpzig984AMIIbhg/37wntNnzuzKyS6++GKuuuoqnv70p/OlL32JW2+99RHX6r7776fX7/PlW29lNptRFAVLiwtoJTly9BhN83eBO1/bkec5z7zhBp51wzN4/NVX8vP33svpkycAYjrqw18sBGmq2dk6xwP33sMNz3gGk1bK99nPfIbhcMhtt92++1opJeF/wVpaXl7m+uuvR+mEI8eOQwj0B33W19e58soredrTnsaLXvQiPvvZzzIajeY/creS1o1l2zmOTw0nS8tm49gsDbUP7FRTTswsm06xYAPTxjKpDNuzmHZYGsvyoBelB1Kx2IneLGVtkSHQTVS0NMgS0jRhai1lFRhOA5uNZ1w7rLGc3hqzOZzSWRiA1kgpuO/slO2pZWfnBCdPn6GfS66pLUrEDTPE3jGVsDWaIayhn+ooc5hO+eAH/watoofFN77kJf8/f67/Ow6tE5IsQ6cZ9WzKbDplx1pMOSaXnk6aoYh+T8Jb8kyzsNgnO7ONDHEo2hWeRAU6mWS5m9AtMsbTGKKeCEmu4wZLB7EbV65pa3bLztYChHM0tcEbCyIG4yQi0NXR4Dq0tUwS/0zYCjsNDH3g3OkVPJB3++g0RStFnnSQhUd7UMMhoZ6hXMVcGpInnrodYM4Z4kJAp5MilCK0rL05L38uO5lL2ELLyIpFpO1HESAVSEEQ4Fxo+w/V9vcSj4gbOkS06AjnwaLY8QmMb60VQqCysRe0AerW+sP6eU/CbjqYaGvX/BlTgXZgGxUAUkpMu9cJu2Py+Hot47/LtrSG87XwfNiNJ6oysjSl0ylI87ztPyRBaKwPlGXDdDjCTKeE8YhUeLQM5KlGy/O12AuJEzKm8oVo/1EbF2tt7Xbfc1xHj9pUehoE2gW88owtlDZghIzm9u3AP0k0/W6B1glKSpqmpkgUaZKyZ2OVjeUeK92MQeIY1w1jUxKsIQS3e42EiDKuuokS1Efz8VgP/VgP/VgP/fX30F8z8HTq9CmMNZi6YufMCWw1gXqbVEyQvmFhsUs+NMhJwI5cZJ2o0MacRiR3ju4mSra0wojaRuBJsJip+EAqscuGajy7hSgX8WdpGRHeOejk2kUzyu5US4GN5cEHQeUdpiopZ1Om0zFpp2B5/wbdhS5pnpGkGucM2lZUkxGurqhnJY1p8M4SvAU0SirSNKVDQEhPt5NR5BolBcG2SQ0mfhnrHwY+xbsnSrks1ph4oycJqdEo7RiVDdbFSNKdWUPVRImacLHIFVKQa02mNYNOTifPKLKcpSKnSBJ6aRrjeJOEJElBiMjkqWoq11Bag/FRn3veh4pdFDhw3mB8fqPHB1Fw/u5vv9UCQyFEVldjI3W8tvHnSwGJFkgZG4kiz0mShCTR0dTdWqgrxGgb0TTQNO1jQxwY7cJg5xlX7dnE6E8RXxNE6x8m4uSp/dPoGRWizjVtF96knTi5QOs7FumGRkhMCJQ+EKRAKhmlkzomAobg6HUSFgcpF270KTJNlmi+mipObE7ZmZR44Xd1uI/mI5Gwsb7KBRcc4NjZM9x+22184WN/w3e86Fouv3gP+w6sMpvW1LVBNQ2dTHBwb4d7egUT5xhXhoGWJFKihSTTCq0EpRMoGQ3rBtJigUZKUqla1l1AtAVWRF5pbNBEy14LQHAIogGfbA0dhLRUXlB5QS8oRAgk3kDeQeoeq+kqTEtCZXCZR2rIOxKcR6QZSb+ArEInCZ19F+AaizeW5dU1VJaispTpeIqczRDDbYQ9S11OKcdb9PvL9LpdBr0BItGIROOUIGks/cbRlFMqU7M9nZGpQJEkHNq3xGg2YmcyxDYlKI3SBSpL2kJhke3GrVIKm6RUOmGCxFpLVdW05nVIiHHV3jJQDYVKKGRCL4uT6EQ4MmITokX0jJAikKq47sVmJYLVSSJbPp4AGXhwWnOuiWaSl6wscuH6gJPbU06c3eH+Y2f55qdeSj/P2LO6zHhzm6pquHwgSITGCYVr30ETNfC0E7e4GYiHF/F5C21RdyFQtedUeqAdBJgAE+uZucDUBqz3uOB3NxuGQBDR3H91ocsgURRa0s90BOIFbM0azsxqNrfHPP/aNS7d1+Gqi5cjg+TMGfSgy6yB7YlnZzilrBqU1LgKjPWoVDHdCYz+1xY5j5rjwQePcPz4SX7x53+ZvYsFR279OG968y9z8sj9/KfvfSpJdZrTd21x723bHHr8hVxz/UUc2J9y9tQZPvaOP+MJhw+w1r+M7/2rz3HZUs5lSzk/8dQ9fOHohF/605v5+R94IWPX4U+P3svTklUOLeRcs3APvcE6O8VBbtr6NHuUw9SGFz9+D+eGFR+6+QTJgRWWFguesjbjTOE5YQJf+tQDXLqU8QsvPMQvfuA+9h/Y4Idf+XR+6b9/iO2p5aInP5O7HzxCZ3uHX3vLr/Cpt/8x7/uv/4m7x5Z7P/cpXvKSl/DRj36USy+5hN//vd/hxne+i5tv+TIAr371q/m5n/s5AMbTyf90nX7tLb/e/irek845/vbjH+Gee+/nt3/v97+uz2DPnj3ceOONZGnKzs52axoaj3L2SBPxJEk5fPmVvOf9H+Adb387d9xxBxdccAEhBJ7xjGfwuc997vyLQ8C7vzvVSUjBtU+4lve+9z286lWv4vWvfz0QU+3e9KY3AfDiF7+YF77whTz1qU/lS1/6Unx/JVEipoS5ELAu8Me3nkSLyBr/y9tPAVGWvr62xP5+n8Q13H38HJ+7+zjXHd6LMYadyYz+2hpZqukIy/6lHOss7/zMvawVmouXchYGPaxK2JlU3PPgfZRVw4dC2B0cJjpK4NEJ119/LcPTZzh219285T13cWlP8k8O5fzFacc07/C4Y4aD/Q4vu3KV245uU00mDE+cYDJrSJSk142BJSeOH+XlL3/5wy7ho7sOr63vIclykiyjkyim1ZjtU8e56OAGe1aWuPzivVTbZyinQ7TcIUsFG/v3cP+Jc5jplPF4xgWLiqVUoHXKYLlLWuRsVxZaCU8nT0h93CikmY6R9zLWCWE8RSbBGlxTc+LsFB8CmVZ0tGCQSDYGCVMEI+MYHhuxnCg2OhojBDNj2dze5Og9d7O1uYkj0B0sUnR7rK/vQfYL8u4KaeVwsxGi3EbKEVJWdF1kqec+UBRRuoWAbr8bzbyDYDitscZTJ5pER0lQ7eazyOipGkKsEz4QAbMsjZu3EGhsCUKidZTDaCUJQjCtLcZF8+T5BpL2ZyIElQu7fqyVcQQfe3wTorzO2HDex7Td/DHfc7T7Eisig8GF6L0qpcC3P9+ECNTMAahExqG3b/11bPAEJ/Gy3TMIhVS0gU59Br0uRZ5jvacyDhME9ayiHI8ZnziOr0tEcCwtDiiKlBUFsyYqJ6YhXlu8oCtizduc1AzLGFZkjItJgkLQuGgNYqyNfj9Kk86iB5FSkt6gh1QKKSTOWRb7BXuW+mxPGqZVzbmzm1x70SoX7Fnk8ssvJPclqSmpTt7N1uaIo8c32T57ltkkCg+d9dS1ZbwzYTwpmZXV//jIPKqOx3rox3rox3ror7+H/pqBp89//nMEb/C2JvMTMuXoZw6dBYTyDDqalYWMqrb4yQztDHnw9GSUx+Utm0kJ0DLMP0JMaI2e5fxhnPv2tGwoKc7T30SEHyOuEAERKeaYcIsahjlYEQuEmlPWApjgCGWFcRZ5WuMag+336C0vodIeWbHIku5QlxPS4RbTafSsaupyd2ohVdR4aqVIkniexnhMExfwaeWomhZ8MhbvQqstjRps3zrcBzGf6MTzbayjsXEKUdaW2jpqY1EhkIhI79MtA6eTJnTSlG6e0sszch1/nyYJWuvdKU+MaXV46yM9tHVqnxuN7d7iMhreeT+/eA8zGP8fGrk52GTbAl01lknVUDVRQugJCAmZTsmyFK0TiqKImlbvseMRoamhKlFNE/2cdlEudinYDz/mUkraa+UQ8XyJX2H+cLW/tj4+pDEtJXo1WR+wxKZgThU2RMNHISVJIsnS6EPVSWMCX6Ilg37G4iBjbSlnY6kg0YoQoJ8qOokkSWMai/gHADxd99Sno4RGBcXehQHpJRscyp/ExReu0+8XTCcV1lp88NR1IJGStb5mY2+fUarwWxIfairvyZNYDD1Q6AJBoAkBrWUEJucGWUIiRGgnbgKpYnOsQmQRKhmnqxKxS123SFwQNM4hlKZINFPjMNYwMxVL+w6SLy5RLC1SnjyBGQ3pdDqofA2Z53jjUElC1u8idZtZYzzCGKT35Av9GNtM/OxllpItLLKoNb6psVVFKOIm6txwhq0q/NRzaLCAkIogBWeGm8yqmn4Zp0AiBGZNzeriEof37cdXMaL99NnTzEKFF4KQF7Em+oDxDi8szoH1EuE9iRIkeRrXBe8xLgYyGBFTUCY+cLKOtHhBaN83UrDTtvnNdfS8i75356fGJkSz2aGxGJWg0pTrL1xCBM/WcMq9x88yLRt0mnB6Z8pSz3NgucOd4xnnKk9eB1LpYpqGOL/OwjwNs9WQB6hbs1cTRJQJt9MWJ+P9YplHUrfeaEIgEkGqA8IJvG1rgRR0EkWaxk1Ikeh2UgWnNqc01mG8Y2xtjG/WirOVobszobj7QZqqwtmGZKPDZiV5aCg5dq5iWHt0HkdizsJsaqlnHt88uqU673rXu4B2mTzyKT70kQf43Rs/ypOSLS586gVc8OTncd/NN3HqwftYuvrpJAtdNo/czWc+fyu9fpenPP9pHL/vQSZnznBJP+XxF+3n4Poy/+32B0hF4Op9S3zsY18hSTU/+fxLWBqe5vRZx7GgGe2cIz0Hr7mow2Cxy/LaIr9/00OsdjSvfNHlvPVzx7h9Z8qzDwT2UDEdaC4/tMBXztX82W0jnnnZKnWS8Lsfu5fX/Mib2FhfQ2/fz0M3fYFz99zKn4xLmsmEQ89/ES+79iqGx49w+4ffx+rpv+XMzi188v3v5lXf/m38u5/5WQAuvfTS3evyrGc9i3e96528+c0/xe233/7IiyYE3/md38n3vPa1XHHF5bz3ve/7uj+HM2fO8KpXvxqlFNY6zm1u8rznPY83vOENvOlNb0IpxS/8ws8jRPQy7A8G/Lff+z3+8sYbH3Zagl/5lV/hb//2b3nzm9/Mj//o67nkksO84cf+Ja961at46Utfyg/98A/zpCc+kR/5kR9BCMHKygpSSn7yJ3+S173udQBceeWVzGYzfuiHfoitrS1CCNx777277/Ndz72C/ctdfu2dN/Oky/Zz2cF1/uwjt7DY73HZof1Mzp0lBI/u9jh6Zpvt0ZTnPOEw1+o4UJs1gYdOnuPMyW2ecM0AHwK33nOUB09ZrLEkIvCKlz2Xlz3/yYyOP8jnbnuAd3/6Tqx1JFqx0s140hOvptPJ+MwnvoDTGpEkHL3zLqaTGePa8W3PfRKHVzqs9xu+dXuExHJYneTDOzNuPlVx0eEDjCclp0djpmUdgb4QKPKULNXkYcLhQcq+3qPbHwbg0OHD0RDbGC7at8Za5mj6jo29Swx6GR3G6G5Cky5j8Sx3UoqllK2zm4y2tqm3NhmaQGkDCMt6alhAsaeXUZeCcuZZGeTUzrM1s6S9LolWWOMwjUNUFelM0Pjoo1rXDq0VaZpRC4EBqD1OCbQPDIqEVCtsmlCjQMFSKlhZXaS3vEiv26WuKsrpjHq0Q5YmMaVMgu50UJ0M7VfAObKyxGxtYcYTalPv9sXORQldN0vpd3JCEDRNvH9Ea9kgfOy14+sdzsXBtWiHwSJ4cG63pmsp2v1DvO61jWt7S4xrvZnOD1qND60Behyieh+Bpvlg24eAaJn1slUFiLaPn4NikYYvcT6gvEcQPWudB+PPmwh7FY3OEyFIiSoJ6+JOOdcJg36XhX4vMlGUIklSpNacm0QT71lVcfbMGUJVIuopk+EYgqeTSPy0RFaK4bSKcj0X0FlG1QQmtqau44C7tB7b+u8GJEpGJYcS0XtX+kCRZyRJTCrVOgKYg0JHiZcPjCcTNocztkcllQ147xCmZjybMRpKTtxzF9JUKG9YWS3Y2SnZHE2ZtcmWeZZGcoFxOOcQwaPF+Y33o/F4rId+rId+rIf++nvorxl4On3qOHiD9DUrHU+SCVSuW/8eQZZKuoVm0E0YphppHMq6mLohIJcxfSNqEefpagIdRIy6F3LXVX7u1wORWutaSmGLP+0GiJ1nxM03/W162ZyztvszaHV+McnOe09TVjRphZKarGMRKkWLjKwYIKVuHfuhrqNTfGhlZHPHeyUFUkWtpvOexniaxlM1HmMD3kUaXzy/lkJP/LM5N1fICLiJ+UTShdYjymFbvyQRIMjozq9EW7CUjDRHFSVsqVYkOqYRzE3m5iBOmHOUOX9JxBx0mjOedq/mw7lF5wvAw2tBTN0IGOupjaNqIgBVW4f15z2dkjQhTVMSnSCFBGfBGKhKqGtCXc5d0NhlVIWHn8H5ou4exhqb86AC50EnT9htDhyR0eRCwLSeTY7zyXYesEJGNDkQqaRSohLVGqDH66Ak5AksdROWOpqlQtNLIireuLmGOrT01EeIEx+1x/LyGrPxlOHWEO1rlrqafZduUHQzEJLJrGm9VDzOxelOnkoWBhnBeGaTBlcbTJuQ6ImTFiVVm8hi0TIaJgYbpa6hvceCEDii6aEMAeVF28xFYDUm3ISH0c4FHoWW8R6vRYJTKiYv9Pv0FhYolpbRTUWjBamQqE4X1e1hqgqlNWmRI/OM4AP19iTe7i2XODiHtTaa50uJyjKUgGAyvFa4NMWiyGXAGIu1lp6UyESDVsw6BVorOkmgqRqMNQxnI/qdHt2iz9KgyzgvUHVJbSZxkNHLd5N6mjpQB0EdAmVwWBkwBJRqQV8BSBUp0kLFpBvnKb1vgXhw3kGQSO9IZWuEb+aeeXGSIlqvOxPiZmPbBrqpIk8TFrsp26MZ2+MZw2mF8wGtFTvTuLnbs9wjyRJ8ajlnLLnypKINFaCVr84/r3aN9kDpW5+N9hsOopmp9+0zHZMwohRWksiAlrFJUx6kDmgh0VJSaBnXtnlTHKKMeVI3Efh2jgoXn+NEs1M7zk5qVlyJb+qYVFo6qkoznipmjce4QI4keLDOU5cB1/iISj+KjzmzwzvLh3/7Tdx5y80cvfervOJZl3L1xRcwNJrxtKGaTDm4vkxwJSePHuX4sTNs7F9nebHDce/BevYvd+l1CrxOOFU69hWK5U7Cyc0ZexcLnnHxMpOzm2wOyzhNbEpUNWJ/P0V1UkSacGRYIyQsLebY4KlmJZubY1KpWB106GYSpxOGMrC+JBiGhPHMcvDCgxza2MPRm+9HBw91xZG772BldYW9F+5j4+A+9hSS1a2rGZ16gLOVJanO8cQr9vPc5z+F+49u40PgzjvvBGAwGPDyl7+C3/+D/85wOKLf7wHRjP2++x9geWmJw4cPc/DCQ+zd2KDf7zObzWLa7Nd4dDodLrzwQgCMMbz//e8HIkN20C3Y2LPO4UsuIc9z+v0+L3/5y6MsqD0+9MEP4rzn7rvvRkrJvn37eOYzn7nrXbVnzzoHDxxACMEVV1zBS17yEoo8ZzAYcMkll+yeA8B1113H46+5hvvuvx9jDLfddhvvfe97OXv27P9w1oKVfs7GcpdBN2O532Ftsc/epR6dbpdut6CosvhMFVlkC7sYBNLrZBRpwmRz1jbcMeLbec9wWkWPSB/F9P1Bj/WNdS7ql2yPtlm7VXNmK/Y8e5Z6rC73ybKMPNU4rQlaM93eIc1SLjq4lysPrHJguaDftawspygzYzzepmksUgbyPGUyq5nWBplEuXtpPR0VLQW0FBw+sI8nXrj37/tI/W8/OkVOOZtR1TNyBbrQJCsdlnuaPBNI35AkKSLVYAwqScl1xvpSF2UqTu8oKmeJQtFAp7JoZVhMNY1UGCSDLAEXkHWIMjitKX2DbSy+sXgVmS2lY7dH1Uq2/VGgMR6FIAE6qSJRGq80qLxdlxUL/W6UfylFXdeYumE4GVHkKa7IyNMoFQpS41WC0D6agk9LVN3QTOtdY+7aOJxQBB1iryzE+T627fLFPAIuRGaS99GoYy5rA3EeBCLW+d10qofVjUeCRDAfaO4yAn38CrEJafvMNv3qYa3qbgPd/qj55hTR+q74OPQW0IJXbb/Zvk7JuKkVux4SAq00eRaVC4uDbjR1lhqLwHiYlDWjyZTRZMbZzW1oKhJTMaubeC2lxtaGgGWzjOmADhhkAuHBu8CotJEtRlQkCNleDxV9XyWBVMb9RafIkEojlNq9XnMFRIBW4WGojcMLhcSjvGNWNUymJSNxDkyDCJZO4anqhsaa1rO1NUh2UTYVbAQD5KMbd3qsh+axHvqxHvrr76G/ZuCJZoQKNUkoWekv0CsSOt2UuV14qgML3QTncnbO5dgZUAaU9GgJiZSkKmqMZasnFW1xc8TFWbX67tAWESEiXTZ4dv2g5iihkm0Uq5iTV+eyq9A+cLKlxIaYoJakqLwTwZ4QkMbgq5LaWYbWknb7ZP0B3dUVkqJgsbNI1t2kqWZMxzuUszGmqSM8I2KShHHsyuNmlaWqLNPZvJmNBVogEEKikzTeXEk8H09ApZos1aSJBvxuLYxYUevC1BY4Ieb6W4mS7ZdSJEpFzySlYiERbQZcC9YoISM7SwSsmHPF5sJyHob57Jbs3fdsf/sI8zPnA4117ExrJrVlVsdkBOfPR9/qJKHb7e4upjvnthDlFFmXpMZAiAbkjjkIFnbZTPPTmrOYdqdEIUrxvGA3vtbNX8ucrhwjNBsf5XaRbtgWTCmQKno35amOXgfi/MQrhEBtHLMmFo19ixmdNGWjFyi0QZeG2k9xQTBuBFvbE4ajCmtbmd2jfFIDcO74GR647y5uu/Um7OSrLPUT9l56kLKsMKZByPi8BA/WOlIlSIVifTnFW8fZMwmJ1MggUEqfhyZ9aBf5BKE0wnugwoSADxKpdPysQyAlSmWVFhE1BzIiKOvbG1KE6E8hsg6JFuhE0Fnfi00yOkrT6xZkicbVDQsb+1D7N9h+4Cimaaibc2SLi8gkI0hFMIHgHARD0isQSjE5cxIzjoacyfpeRJIgpEJkBUFpjDEY6/HBsdJLCanE15Jz507FiGWd0O/3WOwuEPoJx7e32RkOuem+kxw5W7H/TMO3PPfpHN7Y4AmXX0oyO4kUM5JeyWxWMisbTpxqmJQwqTyjMGZcO85NYLu20feBQNo+zzqVSB395Twp83lM7T0+eDyxGLkAs8qdL2RE3zofPEmSkGnJgeU+G72CXEvuO77J8a0RZ0YzFrIUKQEROLo9ZdpY9i10uGxPj/3LXT5x10ls5fAumlMGOK9JFxKlErQKu2tHIkArQTeNEmWtFN475nPm6EERJzLGOXxwdNKMQkM3CXihmZjAsaFltDXGOIvu0QY7hGjQm0oKmbKQxxoytZ57Ng3nRp6LruqSZJoUh9ABnUg6HUneUwQn6PcDox1PXXqa2u+e2z+EwznPf3jrx1moT/I7r3scl732Fzhnu/yLb30xz7xmH0+6Yi9X9+7l87ee5v2ffIgbnnSY9Y7n2Mc+TNLdz8aFF3HDM2o+dNN93H/zPfyrGw4yndac2pqxes0T6GvPdHiKrxwZc2Jck4SEXINKJJ+YFpy87yybZ7/KDZesokLgv//1Hbx8T4pc6fFrnx3x+CdcxYWH13jo7pu57upLeenLr+IdN36SvXsX+C/f9CTefeNv8OHjQ0ovuOz6p3H4mqezcscnWOvXrHZP8wv//t1c8ZTn8JO//Bf80+99LbMzd/M7b3oe3dW7OPqpu7jh1b/JZFbvho9853d8B29961v57te+lle/6lV8y7d8C0IIjh49yhOe8AR++3d+h7e//e3cfPPN7Nm7l+d/wzfwyU98gq2tra/5ml977bV85CMfQUrBgw8+xBOf+ERmsxkSybe/5PmcOHOc66+7nqapueGGGx4xuJkfs+mUl7zkJXzP93wPv/u7v/uI7/3rn/63SBm9Th5+vPOd7+Td7343AXjuc57DBz4QAa8jR4/ytKc9jbIsgQiGCWJfFMJ8ghr4zffeymI357lXH+CuE1t8/s4jvPEVT+Ku49v81edv54lrOSHAXce3WeplqCLh/X97K5VxNM5H7w0l6RcpH//iV3E+MGssL//G57C00Odtf/Ye/ssf/BVv/8sP8pFffwkvekKXy5eu40d/69OYIHnedRfzoS/cyqnNMRvLXUrjqRpDkiR8xzc9nX/5g6/gg7//J/jtLRb2HuSCKy/g3KjkB375KN/1xD6vf3bGt/7XuxjOLFoKnvTUJ2Gc4567H+DY1oimiTHuT/7uH+aHfuhf/D2fpP/9x+axezl1/BgP3ncPzeZx+mngovUevpxQ1pImK+guFHQ6BbqeRnsGX7NnMaee5Xy18fSEJJeBvg7sjGpGE4NbHTCzgjEJfZniCSRJIEkLlNa4OtBg8Ngo75GejvTUBBIVKJSNxtM+UFUNBZpEC9Y6KUZonEoZrO1FpgUy6dAZFORZimxm9BJNJiVnHzgeN5tFTqXbOX6IaU0BgU4UmkDeTZnVCusE1kmqrZpADXKMNRZjLLPaoFVMcwsRGSJ4T90G+BjrWk9RsMa0G+522j4HrOYz2N3ftyAW5/Gj8wCS2N3cI8SuD9QcwFLta+Z9uBBzi5DIkkhVfJ1sr2GQgI+etCGAC9H2Q8pYExMVdRo7xiK0Js80e5cHLA867FkekGU5SEkTFKNJyaSs2RnucPrcNpvbQ8oyMmuctdHSQsDIOoTwIOJwNdMJaaLwbYKzFIIkc9H7RmmyLImKEht9bJ1zpGnGYq9gz1IXY6Ka4djmhNG0wjhHJ89IU42UitFoHPtzKen2CgQeWzpODxu88Qxsgw8epGA6q8F6+klcS0wwjKoGU9VAIBG0oUSP7j76sR76sR76sR766++hv2bgaf9KgRaKRGgG3RijKiBOIGJpoEijP85gkFMRaJwnuKaVREXJnAzR+G/OuplLzUI4Xxwi8PSwIjFPT/OhRftaxOQR8qZWoCXmiWWqfRBBphm6KEgGiyit4jnPppEhpBQ6TeOC5wy2KiFN0WlK2llBZQNE0kFnQ2xd4r1B6hSpUxBJZDvVDWk+oaoMnZlDICFAUzc46/BurugE7z21aQh4tBb0OilpqnDeI0TUo2eNbwEkiWo1pvPvRUPCmCBnrKMytm04IxAFKhofylgktZKk6F0mmPOO4GxEeufHwy6jEPPPdE6ciktjPG/HpLJUjWVr2lAbS2NdTFRQCTqJIJcUAmctzlc4axlPx1DV0NQk3j2y8M/fdJftFKduPkAT5hOn0FKCI1jl5/dMC8jN+4ro+8VunK0ID2s2WkpilEnOXaQCtXUxkc87jPfROFLC2FqKWjCZzPAanPIIE7Xy41oympZMSoO1UVr4CHTuUXp85lMfpR6fQTUnWFvt0SkS6srgfZwIiCiKJuAQMjZKxgYGmWaYKko8iYopGUGo3RQNExxKSBIhwXpk8HSVwMdvo9uJYggBL+ZPami9usA7t0vSEwQyHRfaEo/zAmMVi1lG3ukyKLqIlq3m64ppNQMfU2hEkqB1nKgIEQimwRqLdw5rK3wt4wTEBoRKSAuB7nQRShKcp5nN8NaikgxacFME8NoSkgZd1wjv0Vh0XYFpsHi6eNY7OU+4+CKsBxsMH/7Cl+jlOUvdDmtFoJtaFmc1ylmEDyz0MgYdB8Hh6TFuBKcnihPDktK4uK64gPUw8xXT2lMaoAWetRK7094IOscLmGZql4UqQ8CHGAiRtIEDgsCZ4ZjGWDYnFd46VoqExUJHsNfHVM6Z8dx+Yoe9S12yTHPF3gG1Da13XfRy88HjQgS6hVS7aT+xh/JtcVTzFaQ19W+h3uCQREnDtLE01nPhUs6BhZSrllO885yaWM7UljZvlsFqHtmMLWvUtudTzyfZSnL5BQvs76WsLsToXCkCnilaBnqJp5eCqWA8DdQ1ODcPmBD/w6L06Dw+8YmP85d/+ZdccslBLuxukC9LPvmR9zGh4B//4Dczvvc+jtx9nCwFPyp54t6M7XNDbNMjuWCNhUKwXiguvvgi1h44x8nT24zyJY4Pt7hra5PnNNskJnD/9oRLnvp0Lteaq7/yWY4e3+L2YztMRpbL1gsOXn0Zn77rNCvdlOc97SJOHN9hPGvYs5SyN6np15v89UNjri7O8pTlUzz5hS/j9PY2//EdX+ApVz2Oi67qYqodpKxwm3cz29nmy6cdYy952Wu+BycSfvPXf5XrDy8Q9l/G7737Dq65csbiQo9XP2GDLIVOLvmjjz3AHV/6Im984xtZGAw4dOgQaZrytre9jY985CM0TcMzn/EMXvjCF7KwsMBwZ4fbbruN2Wz297ruUsoo6RGCJEmY3yzOez7/lbsZT6bUddxE3X///bzxx34MleSsrK7xE2/8kd2fkxUdbrn1Vn7sx36MN7z+R3Y3y1E+FF/znve8h2PHjrGzsxPZ2a0R+p133skb3/hjAEyGQ3qmJASLRfDiy5c5NWm4+cSEQxvLSCnYGk6jmTBwx5GznBtHqc77v/QAfRV4waE+DwwblhZyfvz5F/POzxzj7uMjtFYooZAuYExN1u2xsr7G6WPHME1NEILb7ryPPEuQxLjrJeWZHD/LPacq/vpL58iLnEHeYeZzaitwztPPUp5z/V4uO7SE29mkZpvf/N2/4tB0xJ59G2xc+1xuvulTnD11ju97zh6aacUH75jQ2IBQCqE1D9x/hEwJ9uTQKFjd2OCNP/bjPOe5z0XpR7/U7t5bP890NMRsb7LcSemkEofCW4uQAdXVzMqSWVVhTE2eJRRFRq5jVHgvz9Ctt8fUNdHHyHsmU4OSgqVUoYzBGMesMiyYhlR6FpNAmSlqmTC2rjWwjTXaest0NqOTJTGWO4uABVKgchBCg07oLCxQ9BdZWFwjsVMwDbPhFlbG7KhuvyBLM7I8Q3mHC57Ge6SIa3bdmOjR4j1aCbxQEOIwsKwN28MJZVnHIBznyJI2uU1Fw33fGvdHdUD0kRWAcCYyZdrdovdxGKhE9ISKCoFonfAIJtXD9iBKCJASdEB4hZftz5aSIKIccA5maXk+RSoV0a8p13J3cjq3e5g/2/MYdx9EmyYtcFKBVPQGBTrLSbOMXicjTROaICnLhsZ6hrOareGYuqnpKEtCQ6GhGBQxXayx0UgdSPDtQDbWb6UkaaLpd/KoqghQNjZufNvr5X2gbGIwUAgwWCjYu2eZyw+tU0/HbO5MGE5nlFXco3WLaKGhlKKpSoyLFhbSW9JE0Vvuc8FKj/VewsZSgsAicGQqsioIrg3v8dg2kKndeQOP/hL8WA/9WA/9WA/99ffQXzPwtLaYkUhFqhKSRLWkmpaSGqJmOksk3VzT62ZgPL60EFzEYUWb7iAiA2i+0Eh5nsVEy3YSop1yzEk3IiK9cRmfw07hYf/GFqxCEPWwAqE1oQVrZJGTdrp0BgN0mkDwWC1buRTINEEogfAOX9c4BFJn6LSPJiBUitIptpnhTI1OUnSWo9MO3ntMXaOzMXVl6JYuLkBBYBqLaRqaZo7+epxzZKYCHEp6ukVCmkiMdbvgUl6fB57w7YSiBeRcIDrWO4e2lmo+6RQC3V5MSUCLaACoZfTW8iJqfq2LkbPxxm916uwSpHZZUOfLQCtbc4FZZRiX0bBwXDW7krak1aJrHZ3xg3fUdY2wNdYaqqrENTE9RYc2EeRh4JHfRZ3a96ONfA2PTOHz7Z/PjbyFlOcTGFoASrZNxPz85/OtQPTmirJHWv+rCDwZ76mdw7aFWwnJzDomjWBaAtojpCMJgiYIyloxqwxlHTXWLcfsUX/c+ZUv0s8aljs1q0t70UpTV4YoEW4TYObVS7VUUAvdVFNkCicDQSkIkkAsQEIInLco4nULzqEIJEpSCdpI0/j5hdbwThCf5/ki7r2DlgWpESQqSkcbGzDEa661oshSim6HsWkwxhBsg5lV+CYmaCidIPPohyC8J9Q1rqzwzuGkx5kGITQhSIRO0UmKyrLYzLoaZwzBeZIshXZtCEGC0ohEocdDpIleBNJZvA0YV9HROXmesHDBXs6Op5wejfnyPfeSpBmLi8scXFtkIRfsySr6ytFRsNJNKJJAkXi6qmBiEgZFihKBaW0wzjOtI7Bsq4adxjOcxXVBK0GWxGKppSIBZGglz0pEY1WtSIlpKTZEOYr3UBnHmdGUUVlTN46FXDPIEwZ5TMmpjGCq4pT6gXNTEi1YJeOCxQ6NE9EXxDR476J/XJDtui5RPtLljQ+tf4SLG4wQNwrGt4EL0HpoRG+NobGUJrA3ge5Ac3hvgbQNWRr4whmB8pER211MMCZgDaCitDmUDmvi/dtJFJfu7XHRUsFybiMdnIAfV0jh6OgYcTuuYWcaoslbiJsTIcQjjB0frcedd36Vt/3J2/jn3/ctXLyeQXaW227+LDYp+NHXfzsf/cMzfPmWOzAqZ7UruHgp5TPHxsycYml/zgKGIhMcvPAAKwt3kWvFJjknjeLIxKBmO3gCR7ZmXHfF5Wws9Th74ov8yd1DPnuq4prFjAsvXuAZj9/P+796ml6iuezwOnecKjlnPRevduiLhjCrub3U6K2a/cfP8pTnvprtO+7j3X/wVzzr2S/kskv3I8rjPHTnXZw+fRLv4NiO4Z6h5zU/+lzuv+ce3vbWX+KN3/VctOzy8791C54+jzuU8PzL19lYLVhbzvnIF49zz7138+tfvYvv/NZvZanXwU52eP973s1b/+Rt0ErXvvkVL6NpGk6ePMl9rQeS1prBYADEwcrOzs7/8rpba9nc3EQI0b4u7P692+5+kBDOT/vOnDnDW9/6VnTe48CFF/G67341ZVkihCDrdLn3vvu5+Utf4sUvesHfma736U9/mk9/+tMI2DX/NB6OHzvGb/z6r5MnklxJ9qWKRCVYCdfv73Pn2Rm3nJqxvtSL0ilrSVT0nLnv1M5uvf30V49z3b4+r7hilXuGhqKb8s1PP8CHvnySnVnNcq9ACYmSYEyDzjK6Syv44ydwCNI05b6HjhGcp5solrsZBxY7lJsT7rlvhw9+6RgX7l+hKHJ2yrg2FFnCnuUuT71qL8+6boPyKLz7syd42/tu4UefeQF50SXbcyn3nvg4m0d3+O4bFnn352s+98AM6yFJEvJOwdkz5+inksvWepyWgtXVVV7/Iz+CTh79oBPA0XtvR3qP8p6F5T2kqYq2CtbtgiJlWdI0Bu8tWnRJullM10003TzFWh9Nma0lbcGXsrL0c00/U0gbDYCrxsSapwMdFQiJxKGZ1g5FTAkUIoKns9JQKIFKE/IsAaVwUqBzDVKhdELR7dJfWGB9zxrNlqN2BjsdY6TES0Wnk5OmGVmWI62hcY7G2GhF4BzGzAN3INEK5yXCK7RM8I1jXBpG4xLvXOxZA6TKk+oIPIXgW0uFOIRWxASqEBxqPnhuwRQXQCiJUDE5LEsic2+utHg46CSIvaEUMlrq+DjopFVLBCEi84T4/My9ahMRYsK2hELL3fetHbvePfOeM3rVthdcKYJKkDqhVxR0ux2KothlQVQ2MC5rZlXD2Z0ROzs7ONNwYDlDBUumBVmWYb2nSS0BGeVWIXrBxH42ApFSCtI0ARFj4efDWTgvV6xbTysp4rO9sNDlgo0l7FSQas/9xxRDLQBJp0hJ0wg8ZYlGSofyMQ2xk0jWl/tsrPZZ72esrSTo0CB8w2w6RrbAk1LxvOb3AvMBMuGRXIJH4fFYD/1YD/1YD/3199BfM/CUqYo0UeRZGnWG7QLvWw8hJWMyisig101oKss4TXAuGk4jIEi5C0CJOUDUordijuIx93ya/wMiOh+9lFrElyi/IrCr45YtYuhVfJhlp0DkBaIokEWBThLSPEepiB5mWuPqGm8tvk0zU6mORdJUNMM6Lug6QXcGdAb748NIpMIHAWl3EaVTpNKsmaadykRtWAgCZwPOOpy1TKdT6mpGOd6hKXcIrkKFGVkSi5IJiklpGM8MKpkyqw3TWY2pTSy63lN6MMbSTEsyY8mrhnFZk2tFN0lY7BQUiWaQZxRZRpJoRFKQaAla4oJBWkkIPmqtd2Ob5xyksHvZ49TG01jH1rhkVlu2p3WLIEftcZImFLo1n7SGuq44t7VN3dTUVc1iJ6VIFL1CM5MwE4JpY88j9yG2wjHoNn7mj2DatkMoJeM1inyu87JA3U6wosY/nruUgsVCU2jJIFXULlCawMmxobKGxrtWYtd6QyWt1ZRvWWOxC8FISRUkRiqClshUIbWL+lnp0TqgE9Cm9b362u1C/o8dG70tlpcG7F3fT+Ukpm4I5RDXTBAikC2sImSOVDmmMfgQ51WLvZTGBS49uMy5IzuMy4YFHchVIFECneYIRETulUeHQA5ULhq7h6Tl+wmYekgIpLSJg4BBkOgEpRSF1lgPjReIpUWKVEVvkKpkZh1VWeGVRipJJ0sjGKkVk6bGB49wDpXmuFnJ7Nw2wRuE0qilpfjsC0XWXY8THGNoRmN802DrGUm3D0rjbaCppxhT4b0lLbpkRZc86yNVQ+YNvdVFghCMRkPqmcE2M7yRDDoZBxb3cvHGXuqmYTarOHv2LEeN4WZr6KYZHa3Z23EsFA0LHcPj96/iRWz0ZapIZCAPgsUu4APrTUqyVVP5msr63WZZt4aqE1NR2fhcijnAD+RS7RpPWut2td2JgpVCsbSYk+sYL9sO2si1ovSB0nga4bnvzIgHzwk2FnrkaZyEO2db4/5ATwsSGchEaAsknAuercaxXXmCN5FBGVwrCYjPMo1HKMh6OiZ0poIHHhpTzCqW7YwnrmQMksCBfQKqnIlx2NqxuWkZTzwXrWWsdXOWVjOStGAhFRzuBdZ6Cd2OJls9wHRnzGw0YlqVeA+5TNBG4EvBZORZWlTkuYix2zXI5tFPW3zd617HK17+cv7xa76NL+8c4bVX9Hj+i74VvbDCh9/61wxm53jaVcv81Ece4ILFLk+4YIFz05oVdxb1QMlff7IkWVnnh37qDbzzEzexNa345KdvYq2b8YwL1/jAHadonAepeM6tH6MpEn7pKyVPXenyo9cNGCjBnVsT/sNf3cH/9V2P556TY179Xz7Nd+1Led7ePo97+gX89ieOcOs5xzve9Yfc+qWb+PgHP8zsj3+LA5ce5m/+4jf49V/4v/mz33uIaw+v8e5bHuJkpfjw+/+Kl023OXv0Pt72H3+Blb7mP77+ZXzwk3ewsz3mu55+MVc942l01/fxG2+5heuvO8AzHncdOv8iaVIhnePExz7AvXd/mrvOvJvRl++JFywE3vpHf8Rf3HgjKkmpq/OpSU+49lreeeOfo5OUYydO8uxnP/t/ZkIJCcFz0003cfXVVwORnfTw13lTPuKvXHfddbzrXe9CSMmJEyd47je8kDOnThJCYOvMKeY+Na/5ru/+X37OAljOFQdzyeO6ko+dM+zYQCLhHz3zEJdsLPLBo55LupZ9WcOvf+o4pRPsW13kniOnSZRidbHPky9eJtOS3/nwDntWFlld6vPgkVOcqTwfPlnzmku7OAk//nu3cnYM+9cWOXJ6mxBC9GhaW8HYhnu/fAurHU1vzz4WL76Cu798C9tnzzK1jm98yXP5rpc8nc7OVzg8OcrLL53w7rvPslOfIlX38ayrDnDtsy7lB/7xs/jTd3yKf/SGP+f27SpueF3gIyc9Xxregf/YG3jZtX2uuDDnB3/vPvZmsK8TvTkuv3Avz3nK1Rw5fYZzZ7e4764jTCr7iCjsfwiHMDNWl5fYv3cPvlihnE7ZPHYfC7ohT8ANGybDimlp6BQFBodRgYVOTrO8wN59Ffc9dIaqadiTKWTrs6WKLjKJfWkdohdMrgPGGMbBcc4KprWhNI7aGDIZk4f7Mg79jIWJS7AhZSAStFJkqebQ3hUsEoNApw2qOsfw6ATvLHjPwvKAupxgzQxX1ZTOMXWS7mCZupyyNTrGYkfSSzUri4tx02Md1XSCrypcVRHsjEVlyVYLzqSSsrHUtQUiY8E5sytx88T/J6qtbwJAtImNnoq4QXPWtRHuksUibkiFEEyb6N3qA621R+xBCy3QQpJITall9FeFdsguSWtHbT3GtzVPBFIhSOU81S5QEutrZT2uTU7OkziQTbQmzwqSLKO3MCDLMnQawdSozogs+tlsxnA44sETpxlPS4bTWSujDUymOZmOqoJpbckTxaBIsCaqKryzsV8SccBcNQ2TWcXp7UkExXzYHegrEUFzIQS9fo+0leKdPH2OTNQsqimPu7DP/gW4aL0DIkqaennCZFYxrBqKRLDUy+h0EgadnKV+h8MX7GFZeXqpZH3vIs43GFtxfFxRC0eRgrQ1vmmo64ZOr4tOEpSAqqxozP8MxD+ajsd66Md66Md66K+/h/6agafIvA0E73cprXCeqLJLWZOSPFUkqUSoOAnxLePpETpq5kwmsftA7SK58Mif33YWYvf3AeYyKhF9j8ScKislXkmE1qg0IckzZJ7HCNBdetUc7Y/yLKFUNNCTguCiWZq3vv2exiNQJkPpBJ1qhE4QOkWoHKHir7XKmEsOd10OfXTUD96T90tsNaXqaaqxxzcaYT1pqlFKE3SXbuPpVQ6Zj5hOS8ajMdPpbFf3TuuLVHuPMzEe1jlHpRRNYgjBUyaaxhjSqkbrBGU9skgReQpJ1ArrNEWZhtAWa9F+LvP/w1zOB7VtkVcESZKidOu55OIEKtiGsjZYY6jrmABYN4ayMWgJ1ik6eYKUkKWqpfwGnJ9TBkMLRMZJ1DwxJIR2ajU/pTkgNWdoAS6+Ei/i9ES07CedSnq5Ym9PU5nApPFsGYMxgAORzu+jGH8rARn5qwgpSLViqUhZKRIGvZRuEsh1QFFHHyvpSFR8JkIA79pEwEf5sbZckGWKxhhQRcuqCzTlGO8MIYAsFhBpZ5eVGA3vPGkiWF/K2D4lMZXAoqJOODhESxX1AEJiCTS+pQbjsd7vssLmfgs+ko1bFlv8biCmfNQIvFT0B32Ejp1daOL9LUQbC+0DdjprUyJjckto6cimavDWQZoibIyhlYjW2N/h0TjnscYRbPQck1rvsjid9wgJWsdpp5Qi0oe1RAmNbsHxACiZkGlHEjyOgPANobZ0QkIqochTpO9SGUdpbMvGC5yrLCMDZ0vFoBfI04BSMdEkRRF86yshA9I7pDS7BSfOyqJ/hGqn5HPTe+vjdNb6gNSSXAu6mcLYFpwlJvsoIehqhVagZNhlIEoZeYJSxmLqhEQAlTFY71GNxIU4dXEh0O0pEinopYKkDYLY8a3PBLQbA4AWJJZxUODna2QQeBeDFcrSYVyKSlOQAm8ddW0iqBsUPjiQAaUDe3PF3n7GxkqHnUahnGWyPaXrKpJgWb5A02iAdkgSxG7IgCcOSoSIA4L4/tF48tF+FEVBmmiuv6DPiVry3ru2eN03pqwv9dnMFUdPO86dbbjh4i5Lgz57lxdYS1KapuHW00M2rryahZVVbv/cF7h4rcMrXvAkPvTxL7dDAFhQkPUKFtdW2dmZUk3gqRcOWJSBsfec2ZmhujnX7iu49/5NRrXnGx63QTHc5tTWjGO3n2VrVNELcO6WL7B51z2MTp5mqro89MBRHvrA39IvEvID63gUV1+4h0NB8am/+QDVbMpw5xwbBy5AhoYv3nmM/sKAXrcHdcl9R04gN6c86anX0wT40Gdv5ZrLL+SyS/ZjtGJ070M03nLu7DmSpmZJCXZcYNWUXFjWVFazaTzD9lpubm7y539xI1Jp6qbhZS99Cbfddjt3fPWr5y94e12MMX+HeXdk4rzmNa+h3+8TQuAvbryRJElYX18Dorz7W7/5m6mrGVVZ8ra3vY3JZALAznD0//Gzdgh6meKSlYy/3bF0lOKafQNOjRumbocDvQWaxnD/pOTQngXOThpO7VRUjSMtFBuLBad3ZljnuGBlgEwk07ImSxOKNKGjBbedLel2Mq65cJ3N8UmM8ywv9KNHqJSs7VljNBwxGo5pvGZa1piTJ2iqikRJ9i93OLBvnb0X7MeUNzM1Ffdslqz2Mg5u9Lj8kgt54uFFVhYy/vojt/OZO07w0GbJ5Wsd+plkIZfsyRySmkZInIUk1zzryhUeOLrN3acmOA+jacUDJzc5eXoTbxouPrBKc2ybna0tfvM3f5PnPe95XHPNNV/v4/X/+tHJsyhjCxbvG4R0dAuNm00pa0NjDKY00DhqJGWqqSqDSDOyPGFpaYHk1A5l1VAHoE0Dy2xDjUQHSa/Xj5NzJTEmbvArF2VeeSoRSre1o+2vvEcho6RNCGZeIL1EB81iVoBKCELTeE8SoNDtGu59HIyGgEfSBI1SKTrNqOuSpilRWOrSgdWkaY70cdPR6RTIJEXmXaS3WGPIqgrLjKqJsei+lddZa+OU359nPCFjn0Egpt0R/y3d1iTZqjiY7KWSPFGkbS1XNqClxKuA1yom5oVAkSgyLSmSGF9vnSM4T64jIGNstG+oQyBvE+kSye77QpTjaiAJkiBDTBzLc5Ispcgz0k6fJMvo9LooHfcjQkiaxlDVDeOdIWU5o5pMKKdT6tqgCNH4mzjkr01MvjYuYBIF3tPVUfKHFgy6CUJJKudj6I+xmNbz14cQE/JErIWu9WSpGxv9Ywlo7xDOIqzBzCqq0jCrDCFEj1QfWm9eJVhfLBj0Epb7aWSAqcB4NKabK3KR4WROYz2ViVIEFwSV8VRNPP8IYrRMJx/lZSI8uvvox3rox3rox3ror7+H/nsAT/Gie2t3N/67mqzWnyleEEmR6WhAlyiCUgQv2zQ60VI955reSHdVoY2AfBjAsEubbW+Q+V+ZUzHny5NE7sYKBinxcxBJR4Aly3NUnrf+SIFgHcE5vLGtZ1Sk1Ik21SE0BmcttmniKENKaGqkSpAqIe0tkHT66CQFofG0tEOVItrzmCdzCKnbSEaBDA3eTHFTzXSrwVaSUNakeQed5qjeHhorqZpAp7/NZDRk+9xZtrcFVVUzKWtq4zEu6jFrYxAhUJto2j7TCuMsqVYMVTT/U0qRNQ1Fv0cBFDqmVKRSUNdNvPEbEwE5IVAtrXhX++mhNgEXJFJJup0YuwrQmJrZdEZZzpiMh/GaWYOtbUwcsI5RGagaiZSQak030+RpTPCzPpoZzmV+81QQSSzYPgSq+feZf+bxQfVz8GluyBeiLE8EgUKiM0Gvq7hgOaFsHMMajlaC2kBjQaUCEeLCK+erRYh3o5KCfp6wMcjZ08tYW8jIVCARDpqAagyJcmQqUtW9i1Tav0dA0v+xY2N9wKxyjCczeks9lNZ4KahnY0w5wc4q8iVL2nfIvE8sbtFPLNGBjZWM+3PJdCpwaKw3KCxB6Pn6R5Bx4XTeY32MN8Z5kpYGrAQgIrVUMU8njAXTB5h5TyU1QWlWFhciEOk8ptqJn69OSEQsYrPhOMaGJBrdW8CZ2MDW41lcmooCYVsqfWgXRgIoha0bzLRCBRt9v/I8Uum9xXmPkoJEJZBqnPHYukYpEWOFlW6bAkBoUp1EyUJwuLIilDWJLsiSjKToMugWGB+Y1Y7KVFRNw4ntmtpIXEjJO571vmPvgiTTUSJb21hcgw84EWXDkYwXmX+SQKYEmRbkqSTTjsoGpkYRjMMFR5FKFnPNWjfFuDjlybTEtnTd+OF45qkdLoh2iBCfxzSRyDR6VxjnKBuD9eDEPAAB9nYSUqUYZCmplFgvSKxHCI8XkKn4rIUAut2wzG8WIQQEgW2iOWHVeJCa7qAPSYmpHONRSS1yrJBoEVAJFIXg4p7m4FLGhes9bj1ZMZwYHjy5jVgTSFdzsQ6MpScEG8FuBI2LGwcnAlkaG2jvwBuPrWNCyz+EQwrBy67Zw4cmx/m//voEL6kDl3cz1tb7fPTLni8/MOPnXraBKBaY6CUW9qxz5/Ed/tudW/zbf/p89q/0+cNf+AWe+YKn8fxnvIAbP3orO6OSWWP4hrWMfXsXOXj1YR68814SV/Ha6zf47INT7jgx44GjY571+IJvvGaFt7zrLjbWBvzoN13Lh/7qi9z+0DYfuP9+rlnKODxI+OIf/wHHtkumWzOa1Yu45457edfbPs7/9f0v5aLHHeLu+47xTZfvJ9eBX3/Lr3K2clQ64z/+4k9x/PhJfu8P3sa/eM0LWVno85mb7uW+m27HBPjpn/4xbnz3h3n7jX/Nm7/vpVy4sczqaoff/IP3MzxzhtOTQEdI9ueKaeV4XEfyjT3FyVTxlSk80JKVHnjwQX70x34ciKlyf/R7v8vb/vTPHgk8/X/h02RZzs/+7M9y8OBBQgjceuutKKUwJt53g8GAX/i5nwVgPB7zvve9bxd4kkpB4O9s1gLghKDbSTi8p4M+UtJPUp5/1V7e/qVjnB5V/OsXdvji6QlfOTHiZU+/lDuP73DnkU1SLclSxYHVLh+77RhnRyVPu3yDY5sTTm6P6RUZi52UvR3NX9825qK9il//toN86d4zTMuGQ/vXqYPACMXeC/YilOTkidNMjGdUj6hPniEAgzzhCYdWuWBjjd7KMvUDM85ORnzyoR1ecs1+nnjVxbzyW1/M6mLJsVOnefkP/xHjypAo+OHHr3NwQbOnA/cemzD1kqozoLEaHxL+yQsO8PN/PuZzXxjhA5zeHDL5yv1snd3kwGqPlz/zCs6MKo6cPs1P/MRP8Ja3vOUfBPDU73XRStDUM5xMUHiWBwXnts8ynU4JrX2AQDBzsd5keU03TcnzlNW1ZbIHT8O0Yuo9zlqwjlxVhETh04S1xQU0gW4CD56cMZ5VGA9Lix26RUqJPq8S8B7hYiKS1jGJbuwheIX2CYu6QGYdVJIz296hUIq8yBDW4hpPOZ7hgsSJhFrkdJKCrNNl+9wpQjMjE47ZdEYjBJ0sQxKZRWl/kZSEjASNwzU11WSMVOM4wCxLrHMY55hUDWVjKRuLMb7ddElk68mZijaBSggGqUYE38rkJGmmyXVkHQVAKR8VAARUiOnVeE8vT+mkin6eIAM0xmIbQ1dHGweniWx3ERO6tYySu7lVhSeglUJoidWC4CF4QdofUBQ5vV6P3sICSZq0QUMtqNY0TCbTCO6eO41pKmxT01Q1wUORJbvJg0pC3dhd4/9ECaq6obuQkSWSJJGsL2SoVDGsLMNpQ2MdtWvrtRDoTIGSLVjo8N4zrepdAHOtl5EJQU5gNi4ZThq2RhXGaUBiHSgl6aqEA3sGrC9m7F1OGQ8njKcNJ4+PyVcGaASVz5g1FbNZ9NtyHkaVZ1I7GgdpmsR73Tukt8gQJWaP5uOxHvqxHvqxHvrr76G/9lS7lt3impIQXDS0S3OQSUx5EwJaX4BBN6GqM2aVZVhZnHUYQjROk5FVgpj7MgV2s+xC1LAGGRGoOSV2blD28DUpCEloGU5BqviVpqg8QyVJ9G2S4E0TdbQtuCLaQiOC342pbDNFIx21bvDW4KxBpOkucgme4AzVcJN6vI2QGpV3UFlB0huQ9ZfQaUZIsl1deLBzNCKgMAjXIJRA5xlCdrHKIzvLyHxAOtggEZpOkHQWtqnG5xgvKsZbUJczprMZlQFjBZUJOOujaXkILSso3o0GSxMsro7v3VM1PrVoE+iKBKVThC7InEDoKi5wrvWnkAqpFEIqCiXIskDRCXSqmroxjCdTxqMhVVUxnkzwxuCdRePQxGTDEATSSmoXUe/Se86NPHkS0/sSFYEr35qkCQGZig9XImJBr12g9oGRjVTr2oWWahhvgfmESTiQKlIcURIcGBcYTg09FbBWkOuokR4MwDQSZ8BZCDbgTIiyvFSxUKTI1g9rKRWs91OWOwkrSz0IkWFWmxIIMco0gPTgTFw8H+WDGgCOHLekqSTPcxaWBuAapmZEbRImo0Az3WIwsnSXpgwuvjKCtT7Q1B6lBBuDgj1rfQSK8lwV9b4AxuCkICiB8BkiCDyaTEV/t8rVFFqRS4kTYFA0KJI0gHPYxtLoBKUS0m7BolIx6dEYaIuFyhO8dZTnNhmbmiBAdgrSwSI678TpoTQgBLPhGOE9aQjIRCIThUwFtg44C9LMGXsOVWSEEDDW4ScjBIG8NwChCVLgZIaQBiUjgBtXAkGwLc01TTGVxpgGLyBRKQtJQjNrcL7GWhDOo4KgCIpekRO6XfrdLtOyZlbVVKVkmijMQopUlkREwFURGZOiOY/IK6L5PVIQXyXoSoWTEKRnho3MPynp55pBoVkoNJWJCUASQAmEDBBcDHUIklTFt2hCu5aECPSqdiOUKI/1Kho/EougD5AmCaqN8RZC4mS7YHviuCYGiCCICaDQRtXK+LnaOjCdNdSN5cqLV7n20ALXHOhTblaMKzh9Ek5MZxgEh/YmXNTPWVtPuXJPwaQyfPrW49x5ZkZtA1oXrFiPHlre9+GbyLKULNXs6Q84MzacHhqGlcUIWFhOSfN4DtOJQwPha6+G/0cPFwJ/8MWznL5vyPfsL/ivv/4H/FZR8NS9GftlzeMuKXjw/hFqrYfa12fr2A79osO/+effwt2f/gS3jYc8+Yp1VnoZto7T7mdcsY/vvP4QRx48yYObM97xl5/ija99Kcu9nH//jnczKg2JVvz0P3oKNz005N+95wH+yVP38tBOzSvf8hF+4pXP5ZXP73DwMzezd+8S3W7BHfec5uIbruPFT3g8733P++ktZLzplQf5wmdu4Y5Owg++9gZ+7z238KU7jvHKJ13I6qFL6F94Cbd97AMUmeJNr3sBX/jKAzx4cosv3nOMV7z4+Vx2+BA/+wu/wUULkje//HHsS0pu+fJt/Mmn7uFHvvdbWSxS/uad7+WGl76Ab9+7QiecYqHTI0+6fPe/fztnRmMO5IqtxmNDTFOqAmxtbvGDP/x6toc7X/Pn0F9aZe8FB9GtqbUQgt///d/n5ptv5slPfnL0v3zYEbzHb59lQQuGNuCdjabAc78T2PU/LPKUX/2BF/DA8XP8/Mdv459929PIteRzNz/AlR3J4/KcLaMxaZfOgoom0yJQpJpvePq1OO951+fu4KIL9rBv7yqfu/toayAcOFs1FKLDcJDxa//0qUwbx0/9yRc5vTOjl2vuevAESRLZ3cOzZzFNnGgP8jR6XkrHVuNZ37vOT/38v+Pmz3yeX/zpX+LZ+y0nThgAbj855qHhV/nwbUf5Z8/aSy+BSdnwjIsWeNpFSzz7mRfx4S+f4s033sN//tevIhOBj37sZjYuvAArBd/2Sx/n1NYMLaD2gUzCSgbrl+zHGMtffPQ2tkYVBw5dxNvf/nYOHrzw/y/P1v/bx5H7j7C82EetL7O8mCCdwYxm2KZmVtZs1YFunlJkCV46ptMZ3llKp5B5h36vT7/fYTSZce70Jto7dPCcNQ15qunkKevDLZSE2axECuiniozWTdM5BoMc4wKN9ZTThkzAQq6ZBrAoRH+V/qBPnmWc2dwh79Tk3S5ZojB1zX33nsM2JdYHZj5h7/4DLCwukzc13jQ0O2fp+Bku1BjryKRGJwky7VPVNdY49HjKeNYwmjXINCcvChYHa6ws7MX5wHgyYzabUlcVbjohtYa+bWiqBk805xZSQ/CYuqRqanAm2iUQ2vtUUDlBObGkjSDRklxL0ixBpgpcW/QE5FmCVpKgJDqNO+1UtGl1AooUKhf7xmET281ESzIdzcuzNInm9kqTpzlJXpDmBf1+BCeUUtTGUtUNp89uEpoZwhly4XB1Q9I09KVhhGO78Rgfe1lfG/pFGv29MsXOrCaUBumBlpVRuUCWwGoa+5LaQ+NinyKkRPhAohVJEpUHeAfOUuQZQkqMD7i6QvrAxYf2c9XFazzxig0mZ48zbXaQzmEqhxWKhV7OnqVFlgc5q0s549GUW+44zfZwgmmij5e2gfHUMLV30cs8qXYMJ4bNseHM0FCbmKi11h+QJtGdqxyPcc5h7aN7gvtYD/1YD/1YD/3199B/r1Y7eIe3Db6pQEqU95FSqAJBaFpYgEQL8kzSKTTjRII/b2Q3twQPD/vyxCjSuXHa3JTsYWSUeMzZVQLmZuJBSHwLQokkQaUpMk0RLUU2eA+tkTaCXalggPPSP1qjrtZ3KLTsl/P/tf9+oglkaCk3rqmRaYmzDcFaVJqh8w4qyaIflNLxpIUA2VIlZYJIO62RoUZkC5D28arYZUhlHYMIDb5ZRLgZJlNkKTQGrAvUzZzWFp3747mJXd+tEALWRClcnsZ0kDTxMU0i0YgkI80j0GSdx5ommo1LGTXGDhprI7XZWpqqoqlr6nJKU04xdY1vKoJ3bUJJ2GWqaRmLspJi91rOvaLgvCTNE89TSxBS7hb5tJWIRigsamDNHBrevQ1aY0gfQSUhRPw1keZpXMB5QAqEaNFo5vfUebqkFoJBIulnmuVOggsCCeQ40uBIgkWrOLnyrfHjXGX6MLXpw4C/R/cx227wHY1E4ENrXg9tSAAgNUEmBJHEiZ0gsg4D7fQCBj3NrNRsn41LdvsT4lebDRrahke3i2s82gUzCJRokxqJRvNpvOWAOI1J24aOqsa3EyPvI0PRt4BmEOCsRTSGIA2JEBBiYiIhPvNCgBQaKaJPA5JIgXcOQvuT27UheHfeX8z7aBBJjGH1TuAk8T6SCqVSnG9iYctSrG9Fwt4hpEVJSZLo2HBmKVQV1jlwDk2CkIJ+ohHOIYIj0xlJGkHh4Ms4lWkpwcLHgulDwIZobzpPAI1bCdokG3D+kfemlNEPIk3k7vcJAoWH4JlbvImWCi1bz7VYECOD8BHsVBHl1vMVMa5nYneQcH59blme0VOyZX+KuCa5+BmKEEBEbzQhoSgUh/f12buYkXjLpG2eayvJgI4SrCaaPXnCWqGZ1Y7NccPxnZqO9nRTRZYnJFnAScFwZhhIRZpETXxt4NzEUtYeEwQdEenSUkJWCHwD4VFOeHr/+97HoUOHuPTSSxjkijLXFDPFQn+BkKbUW+dwHXAZHJnCWq9in5jy0NaUvGNYWR6Q2hnO1zResrM1xE0aHr+vx3JHc3pccXJqqITg0MYC06qmqg2ntkvWO4o9fcnpiaGyjn4qqa2PxqqzkqTTpbOyzAUb6xS9HJVolvasEbTm3NYOtmnoZZK9Sz0+PZ1R1QpkQq/bYaHfY1Ra8mlJMhpx7MQp9m+sc+iii/jkzfczrQ179+0jBBgPh/TClNBotsZQ5BNsY1kddJhOJoQqxofvPXCQQ4cPcufnH0KlHfJ+wv6ljJVCsLbY4ytHt2PqVyLQOlL+j584Qm2jt8seLbABRj5wIIsMgfvrRwJJafCkTcXHP/ZRLtyzykZHM64sk+NHOHnnbRACqRZcvJZyZGg5MrLsyaJnhBSBTsumoPUWDCEwqm071RZYH0jTlPXVBVTwuMYRfPSZqWzgoa0pvX6Hx68ucGY0ZXtSIwXMqrjhn9U2MqOlYFoasiROgye1oUgl+5cLJqVhZgKrg5ztSYUWsJorSu+pqgbTNGRpytLyAs7EFJ1uliBNgxSB9aSkW55Dbp6gWVvH+lgRxmXDrDYcPzdi67CkGKRs9FMSKZkZj1ApBIkpLQ+dHrG2mHPRpavUAU5vzrj/xBjnoxxnqZeTJwpTN3ilqY1jXEWjVWMMx48f59Sp0wgheMlLXvK//8H8exyT8QytE/KuYTEECJ6mMVgX++M8ERR5Qp7nUaIhFSZIvEyi4TuOhV7GpF9w6lRAtH3rvAeRUmKtaQtzZB2gZJSUiTjlV4Q29Y045A3QuMDMtVN+F2ncQUqq6aztMx2VSKJSoIlpzdYHrI+M/GQWJZ3CW4S30ey49QlDRNZ8ZRw2SLyAWdXQNDXBRhTHG0lTlSRaI0JMY86LDjrNKHo9nDU4Y5hNJlgX13CUjr18nuLrkuAMwju0iKb8kigPaYKMqc4+1lMdQAYekXpcuSila3ygCVHGFITaZYY5AT56QuMQraIiISly0kST52n0sJUKkeYkWUaSZkgdgZVgappJTO2b7IzAlEhv8TLW4hh0FBn4SisQEcANzBOrYy81Nyq37aY2+IcpAsR8cz23rZBIqdAadKJJ0zTuw7zDtr6xCIF3DiUleSJZXV5gZWmBhYU+0624aTfWR+ZdkrJnucf6Us5iL6WsG0aTiq1hCdaTCuikkkwGZLA0ZWTwqVYFYn1g2jgq67HCk7T7LUlAKYnWCv0ol7s/1kM/1kM/1kN//T303wN4iguUbSqa0Va8wdOSdOAj8ynr7vpEaCUocsVCL2Uri0Znto43u+N8skIQAiciXdWHuDDNwSvVspDELsgU0csgWjPn+QIrokROaE2S58hOhyTLdum2hIBw8daKwEwr39I6XrU2KlXg4kMUACmRYi6/ExGWlHExcNYRrCU4C9U03iw7kmmSIXVK0u2T9RdIiw5pbxGhNagEkWYEkUYwKteILCa8CZ0TZErtFCJE2aDQBaJYJFuID7Krx3Q7WXxPHxlk80TBOU0/BLHrm0TwEQwLDqUUeS9+Fb0MoTsEXSB0jrEWneWUZYlpGqrGRGqusWzv7GDqClvNaGYTjDFUddWmiwSyVtMqVPQKmIM+ykUqqBRRBx5BvBhJWRlPaExcCEMsspmOOtlUKToJ5EqCjVTE0C4INgTmlmVzQ3ra+ye+SJw3LG8pzghJkmq8abDO09QOY8A6wAdSKchSwf5uwlKRsNJP2Z456sZhqoo6SCqv8Yu9uDjNF9cQF6jGB0wLZkaD86/9Sfo/dZSnSppCMptqOnsMiXRREhIsaSLoLSyTLa6TdBeom4CSrk1aaQtXsKwsJVifcuxBh2lBVUl81LyPNDAh47OT+AgO1lJGurH3cTIvJYkKuCam6+RpwpkQjflWlSbRccH1wxHGWhrnINWgNSLLkWmO955qNKOZNUit6WUJMs0QSUoKCC1RWqCT+Mw5nxB0IEiHL0vwBi08dhopxUoKdFEQEDFy2INQkuWFuDI0DhrTkGQ5RbeIDTiger0YvVrVhMmkXXICSb+Lygt0f0CzdYZqNmO7LJFKIENGAXglIM9YWlhksavpdSXjZrzrbaaUQqq4/ljrqU3UzSdKkLRF0wbBxHmmJlCaKEFwzsfJiIgMxiTRGO8RDkAgsa2cgPMFLrqNEoiAsw9x6uKCmPP0W58NdgcIgQgaSyWjQaaU7dqqkKlH+0BaxMmwVpKqtDS1p64crs0IsiHQXdAsLec879oNVqiYnNtmVllqJ/BJwqWLkpVccXg5pV8okkRw04NDzpWes1XgO68dsNKNoP0QzcxLpBGkGWQ6YBvL5qjhnpMVw5EjSEGuBXmh0Klk0NXIqUGUf/dz82g5XvpN38Qb3vAG/uOv/gqvunadW8Mp/vxTI/7p976GfcuLfPpX/y2nTjm+amFHpTx7aZPnKMvnjlTMajhz99085ZmPRxcrfOhTXyU//lU6wvATzz3Iu287w797580MEslzHn+A3/i+Z/PLf/gJbrv3FIW3vPTwgKv2dHjDn3+F51yyyL94yjrv+OwJaAz/+LIBmQ9s1pr+xVezc/YUdjrjhhueyMc/82X+6E/+iusOr9Ldsxxrl1JUQXLPUcPzr3scz3zcpfzMb/w5yc0PsZBr6qJHsn4h3UPXoLtfYGOv5Hte8jLe9+73cNvnPsVPf9d1vOvzD/GW932FVz75Mq66ZD+/+M+u51d/612cO7PJs67Y4IKLLiU/cBk/9P3/hhdeucZ3PvkQP/LEBXqriyxfcZjf+tMvcvb0kEv6mstWEnIFb/3cae4cWx4sHc/uSnYc3FR5vmtVYwL8h+PnjW8FkE220bNtvu97vpvHr+S86vCALxwdMywt13fjc7XaVbz5G9f4v28a8p+/NMK2/UyiJAe7MZhjIjVreUzZ/dyxYetBAW//2N1cf2iRN7/8cfzh39zOeFpx0VqPm2eeIzsVi8Nj/MC3PplvfvaVfM+/fycnz40Q3vGxz99GoiUrvZzjp7Zo2vj0fh5Nlo0PHF7v8fLHr/OGd9zK0kKX//yDz+Jn/uTz7OxM+cYr9nDz8R2+cmpMbSyr66tccfnFfPZzXybYhsW1AW5qqMfbDD/9xxye7rBnP0fJ1/IAAHcLSURBVLiFLjofxtj2siIEIvvi3BYdCl5w6RpfOjHmT285w7Ouu5wVL3nZesof/eEHefz1B/nln38Zv/87X+CzXzhGVwkaJSFJuPqSg2xuDzly/DTN2TFpmrC0NMBu7vDQQw/xild88+7n8j+yzB5tx2ha0ciUmZqxsr9Be8POtKGyDqUkl651yHoDVNFl4hWlE5ROkg8WUSLgZyMOrvXINNx75BShihuRQabpFCndXoFzcTPfSQRNonDAtDZ0hUAroDYoIcmERBc5TeM4M2kYB4dUnkJuRcNwpZg1DZOxJGxJjMrI04SVbopKYsgQs4at40c4c0yiO10WBz0WB11mkxgZk2UFU1NhTWC2PabXjz5HO2fOkAjPQiZIc4dphmwfO00hAkppZGeRwdIqaW+FlfV1auMpq4azp09TVzV1XSFkVFh0tQdTEmxD3RiUUiRKIZzFGsusNmxNKyrjGFUW5T0qeKR3OCHxSIRoUCL6NkV1RUyB1j5uDp1U1MrhMo1QKUmWUfS6LK2ukOc5eZ7hnSWECOZEUC6wPRpDXSKqCeOtLWZVzXbZkIr4GU0C9PKEIovSI6k1iz3NmUmD9R6tFEpF4GZYGZwLsZZay3w/K6UkCMksCHIVLTa0kiSJIksTUhVBsizLqMoK08R+wvsqAkLWsdQvWF3ocuH+dfasLdDpZhjvmDaGUe1YXe6zujTg+isvIE8CwRs++LljjEcz6mnJNRsdFnJJLxGkOo1+UBgymZJpRb9IEFIyrB3D0mBxNGJKkigSJSIrL01adcmj93ish36sh36sh/76e+ivPdUuT8FqLIKqtHgXi1SQGbojSJIO0eg5LtR5oljsJfR6KWUA17iWpRJNs7wQBOERIqbMSUSbNta6t4u5BC9qC4OIJuK+hfg9EVzwKiL5KtFkWqFFRB3DnMcWPKaKV8OHGGUplEbpJJqKC4GzluBi+pxwLcrbej5Fc7hAcNHkLTgXiwvtzeMcGI8wBq8UrikxsxEySVFpjpTx/bJuD5Vk6Dw//95KIxwI72J4jjMt46tlVSUdksEGyizRZIvgDMFbhKnBxWlRsFV8LZ4gdfSZ0ilBRChSpAUy6SDTApsN8EQN6aSqqauK6WjMaLTDbDbl7PYOk7JmUtWYuiIVga6OIJPGkytJUC2zqpVFQtS9zz8TKeODvcsuEpFZRHvFnGf+uJ0ng7WGabJ9AKWfpw60EswW+d0tSaGFJ0P8OaFN7FBKUKSS9cWcPYspg07KcGRpTGA89MxMNExf6Cp6qWQx0yymkiR4dnZKhqWNE2/vSRUoaQlnRyglkVLGSMogKY1g2gRmJiAUKC3jovMoP1w9o6yg2oakc5Qid2RskilB2s3JugmqkyGKArIsmq4TwVrvHGVV088ktp+Q9nN8iHrfxFfET1WhfQRxkYHKS6SHrAWIg4iT1YRAJh2hO4AsJXQ77GcOWEbz00jRLQlaI6TCSgU+EMoJuujEM9M6mlriUDrHe4ctZ9H3TYLUAhdiZGvtBVJ4RHAwG8cpbggIHc02JcSJZYBUR5q+lIFmdoambGjKJrIrwwzPCIlGqARjpjFBVCt8VSGdQSlwWRblome3yIEszdlYyagbQ2NKqqZCCU0qEux0iJUZdAukUqiQxGlJi+iqJCaQCALGiTjxbTw2E6QKaicom3hvOyGwIRYjQryeSiUkyiHlnIEYGRyCebKoQKsYuSraBsd5D1K1PzM24659zkp3/rmPzbpESd0WzYA1BteOjrTUeOuZzpoI6EuBzmSUujooy4ZLDi7wuAuX2Zc6lDGUzmJUgRGSqt5hmioS7TnbKLJMUATB6YnBCsnqQkqQglnjmE1KBntX6RU5K86i7QxpSo4Max4aNZyYtGs7YGvH9rmA1IKiI5nMPLP60U3znx8uBH7z00c5df9ZFgYd9PZdlE3GTTOBRFHkklde3edMHfhPH9nmiYdWOTus+ZtbTnLfZsnG3mWe+rzryc0Q2Uw4u2Op0gnGeZ58eI1V73j3n/8tL75uL896wh7+9P13c/8sod4U/MAVfe6f1vzchx7k7KjhovVFrr/6MA89eITk6DGuu6DDXQ+c5NjWlCdc1GdvUvGEC5d5wbe/EiE8Z4/cz/f8k+9lUhr+6i9uhCwlzVO+40VPIuksojqLZJ2UE5tD3vDmX+IbnnQJF6wu8o4/+mMG2nPRvlV++Z1f4eCBDX78dd+ErqfMqpoPfeAzrBQZh574eF782lfx1a/cxpmPfJC3/PNnkNUNblrya587y3KyyTPvOMfn7zpL2sn5rhuu5t7TNcNG8r1veAXTk/czPvUA+658JpOdLZ5z15f57FdPk6SK3/5Hj+NLt55kc6fkeU+7mE/ccZpP3nGab7u4y0Ubi2xcskGzcz+DtYzve9mT+O1338StJzcp1w9y9cXbvI4JL/9nP8CXb7+H3//vf8a3PfNCeqnmtge2WV/ukRcZ11ytuPXIJg+eG/NPXnYND53c4t/eeAsvvGwN6wIfufsML37SBXTzhP/0vju56a5TFFLztL0FR7LAXZspT714mZXFPgt7NvjyHfezuTVko6s4NnXsWMmv/NANnDi1xS++9y6+84lrpGnC777vDu49MWSnbHj/V08zMY4gYhR7PZtx/MGHAPBITm5N+Mff9lyuu2QN6e7ng/dP+PQ9Q370YkUn1+Ra0LhYt4tcc4/rY5oCEs+3P3OFPasFd993HDOtWNlY5DsWNVuu5Nt/5EZ2To4ZDiu2a8tg0KPbKbjz/mM0xuKE5JorL6IxhnseOE6whkREacM/lCMYTz0usc057tCSXDqycoiqaxIREC6uy1IqUpmgUk1Hanw5RgSHdhWDRGE6mpVeRlooMjwdEUBJps7TzzrY4NmaThhODcE7VvoZIpE4KVF4rPFULlB0BqSdhAtWNWXTQAgUaYJKc1AJEkFjGuqmJrhokjkNDQsLBQKYzEpSqejqhG6hSbG4ckKvSKmbhu3RjHPjioBkcbFgOpmg8GR2SieRdBLNTlnhhSTvd1GmBYC0J/MjMlOjd8ZUlaWaWqphiReKPMvQaWQb9TsZiVJICbWJSVvGGERTkvrI4BqENnHOWGxdR8Ny5/FSRWYTkaUjnYkKCaLsMDaa0bO1HzcGZJ0OaZqRFXmUxjjLznjM9vYOk+mUreGYsm5ojGXPYsYglSzlElSgKDQHeymzcUlTx0Gv9xobZIyl99GHNksShAxkeY71Dts4XIDa+mi+XhuEiNYUqZb0Own717p4ISlNoGpsNH52Fuui90pd1dGew3u0ipJEgUeKwOpij4P71lgfFISq4sjd25w+PeLcdsVOabDbE2aNY/E+xWpXUqhAOZqQE1hfKdi33kMi2BrXrC/2yYqc/4e9/462LDvLe+HfDCvtcGLlqq6u6pxbrVbOCEkIJCERhA0GLLCtQDRBsrF1wSbI1yaYKFsgjE2GKwRGAZAQSkjqVuiWWp1zdcVTJ+64wkz3j7n2PiXsz/T3aYxPzRi9xjhVp+qcndaa4V3P+wStBDqR1ATuO7vFw2sTzm5XNI7InHGWoCIoMaocdWVozBObdvxkDf1kDf1kDf3l19CPG3gSMp7gEKK201mP921sqZvpnObrNFoK8lSR5wpbS1wL6cZugmdGc5v5K9EyWQQtRS0qlOeU0XiJY7dQiJY1JSUohdQKpeNFEyFACw6FlvHk3cyALT5OiFb21hYsIrRSwNZgT8yYVKI1Qw/Mny/MmFRcwMfzLRjlZ7GmMX5SyHGrm5WEZopOC1zRRWcFQifIJENIFTe2lvIc2xjt3z4gRBpt7bUHGRlPQqQEq0Go+D5Day2nkvZ8pASZgNB4lWHQGKOwpsa6gLGW8WhIU5VMRzuMhjtMphPWNrcZTivGZY0Mjm4qSQtNnsWkD6FmBnYBFzyhNTyTRHZg9KdoDd1m46YdD/N/zdwYd0fWfOLOzvmM1bRLHw/Ry2l2Wlrp3Vzu1soUtJR0c81yL2Gxk5DpCHFZJ2iaQDCRYt0Rkr5WLKUKFcBZz6T2GBMBvxmDy3rBtDRo3XaPfOwoVAYqE6iNbxHrSJ57oh/OO4wN1CZQD8dIY5FqBN6jhCSGX4RoatdS8+OMi+fDWE+eKHqZptNNoW5ZbLFUps29iF8hFkoBSSZpgwVok1zaOZ7l0CkQ/T4db9E+su0QEcR0IQLZyEh7D6FlGnofF2ClUN4ifXwPoU3B0UkWgUAZmXA+tCaseESwYJqWcRkLfAGIGdgrBGmWEDMTHaaZ0jQ1ddOg0gRvA27q0LqDCBk0khCydm1z8w6kUzIaFDY1aIlSilRJnDG4YNHekIj4+ZQB6QSCPHZPWl+GGTirlaKTaRaLhNK2Y342TkVMnZzFJNNeq1nIYvSok0gVTRZDCG06ycy7TrT0fbkbTe0DNpI8Y3empQfPp23bTdLtOq/bdB4lJY5W7usDwUFw4GygqSw6SxBEoNZ5Dy6GBfRSzf5eSuFrgjdUBIyXNE7QWMe4DggR6DeO/S6OM+cDMoEiEfggMNZR1oYFH81mUw3GWOqm4fTQcn7iGJsWxBbgbZQQIOO6UpWe5u9IqZ6Ix9bWFnfddTd3n9qi3qk4ur9DNThPqDSqk6JcTNzMU0E9cpzZNDz32oKiDkynNY+cOE9tHF9VpBQ6RagUO42dzm6esNzJcI3l9nvOc9l1++kv5CRa4bMCWxQcouTRKmUzZBgsTil8XrD92GMoWzPtLdPUUxpjOHF6jboq2buQIzs9cA2JcKzuWSGZGuq6YTKeohLNM648RG95iWxxLzZYTpw+x/1f+AIvvfEYnW5BOdrm4P5lep2Cz69NuKLocdWRVdY2JFvnNzh/5hx79+xj9dB+fGeR9bOnOXv/nVz5smtxO47hoOHEoGHLWvZXFU0T6Cxo0k5Bk6eYNOfaG65gK5uyUZ/j6OUXsbWWMD6V4rsZMk+4ZE+HndUOK1px0yUHODUw3Ls25tKVgv1LHWSvy8JyBJCW9i6ytH+Z9cbyaKnIi5wbD0suP3aI6WTMVUf3sLRQ0E8VVx1ajDcpacrhpWVGpWE8rejmCiFhp7GxAyohSMVyN2PvYs6xIyvUxnH/iXVWOynGw9hLju1d4OC+FQ5fdhHn19Yx0ykrXYUvuiwnBUf3L7C9M+H82HJwMUeqhM+dt9gQ64mTO1N6vS5LSwWj4QhrGsY7g2iFECJ75tIj+7jxiqPIM2tUac4oqZBpgtKxVkgyHQtkKVmvBXoqqI3n4EqP644t84FHNymNxQjFc44f5L7zEz781/ewkKiY6dJG0Cc6JvFFP0hBr1tQlgJT18Rmd85lxy/h3LlzbG1tfaWn5997SGLz1RvLeDjBCkdophTBEJTAWk/iImDg2+AcJcA3VUwkwqAVZDL6UwoL0kW5CzIy9L1UWBsY1dHiQOJROibWOcC7mGZsTCBXCUlesNgryMqS4KPsKugEL6PRtvQOLUWU1viAMTMpkJg3PUVrDu1dwARHr9fBOk9tPca1UhbnwTZ4b9CuRqgEFWSrKBCtLC9+hixL0MKBnWLHY2xpcROLn1pQKYjWuiOkqDyJzWet8TLgUQgvkIlva2NPrhQeyJ2nriqMsRjH3KpDBI8KFuXqlt1Oa/4c94S0tYRAKnRexAQvpanrirqq2NkZsLG9zXA45vzmDuOqpjGGTCyR9DKW0jwyl6QkTzSNFDTMDKRBI0jTFKzFWNfmGgm0VtS1w7l4X2CdxzqHDx7VAmKpjkniRaapLAha71eirNI6j3MxEVC2tbWUEhFcvL5K0MsTlnsZPe2RTclouM102lDWjso4/DQmOp9f12SNRmUCYSxJquhmmiJPcS5Q2xorFEFrklzhgqduHGuDms1xw7i2cyAv+Jj47YLAhpjCZ8wTu/nzZA39ZA39ZA395dfQjxt4qiuDaSzB+8gAERKZdpFpF3QRNZOtTBMV5XZSSRYXEvCOciTwpk2WmwEsxAsjRdQ5akTLnNl1gpJzMEbMdZRaKazSCK2ROiFJUhIdPad8FQ2zTfBRitWm3UGr5axrECai/lrHTRZiLJn3EeWVAtl2QuLG1PpEOYdwpmVT+fb9hRbhbD9R6ynVcuxicpt3+HIQ2V1SzwEikgxmvC7vI9tHaVRRzKmWcgbGeRdlfwicU3ifE0SCLpZQSqGSZC6/q42N6QTWMhid5/xgzPmdMWe3BtRNg2lqvK2iHj4YrHVY5xjX0dXf+GhS2knayZ5olJgtQHHBkyFSKX2rzRXzK9qCfCEwU2u30GI74cTu5JuBTDO2k2zNECWRbqokSsTuTKJFex4CtgmtP6Kfg51pLlnuJxzZ1+XSfR32FBLtDdZCbUGg6CfRyPVoJ6GbSrpaMJwYKuuZNJ59fUUvVfRyjUoixdJIRZBE+aLzlLXj/NCyNbIMpp6GaG7+RKcIA5QIZKpZzDULhUBSU21uYqpIHjVhSh7WSc2YoAq8kiitSDqLOCS11fQyje4oLj/S48ypkrPjhgWv6KpAT7toxonHW4sJCQhJkUJjI8V0f79gYBybtaXT7ZH1uvR6Pez2eUxTIYWkaWJ8clU1cVxoBYlqq9eYWKGkIMsklIHQWKrKIBOFzlLSxT4BgWk8ARf9JsombmDWgDOIrEBn3WiIZ03rERFI8pTlwwcYDNeZTseUZUNZN1S2pl/UOGsoRyWNT0lkwp6iixQLKJEh8gxPFk2CTUOOp9sRuAacsew0DutiUbCYd8lMQ2NK8izQTTKyImNSTedFvW2B1YUi59rDikv39ZhUltoEShMoG4Pxjsp4jLUY6xnVjqqdFJKYQplISa1mHh8grIq+FTo6qUkBnUTRODAOxg1UNqBEDHqQQiBU3LylEnSyKJHtJLCYp+SpAg1SS1QbBODrgJl4po3FOUdTO7K+RCeKNFNU1uNFQGYpKQ1ZvUN1zpCmml6W8fB2ydqwYth4NncMmRTgFYdzSdKVHF9NmNqAsYbKJG19IRis71ANRuztKrbGNeeGjg/c3zCo466SyFlzg3nRUFWBphFY+8Sfw7/3e7/HH//RH/Lcgz2uWdRclxtuv+sseT/jR77mIHc+OODukxPe+oHzPPdIwXdf0+eM3EuST/iOK87x8XXDzrTmo+/5G/rSUSSS/PKrObx3iRdcc5izo5KNYcm9ayVn/p87WMkUpjI89xlP47obLubbf/S3+aoXPZd3vvnr+Kvf+S12Nje567YvMhyUGBf4w52apz3lMi69cZE3vOMvecbBPi+9bJV/99O/zNVH+vzQS4/z9l/9NUzS561v/k4eueMOHn7wEX7lf97KDUf38MxL9vHHH7uTfUngh29c4Z7bbqO7/yA//ePfyxdvu4P18xv80re+ljP33sV9t95K77Ib6fUWuWgp5frnP4WNyvP61/9LXnzZIvsWMr75J97Pq65c4rXXrfDqyxY5OzR8YVDzjU89QJEmvOuv7uCmp97ADZfsJ2/O8+eff5TffM+9/O7Sx7nt0U1+4n/ew29929VkUvJ9v/FZnnXlES4+eIS/Xlvimks0L71ihQ9/4SxnKtg4OeTVNx1iezTlLf/pz/je73g+b3zNTfzTn3kPX3v5Il9zxSL/6gf+DddffZRf+9FX860/+S40lt/43hfwXz7wEPc9tMm/eOl+nnmo4LBJ+f5feD8ve9Yl/NXPfhPf8u/eRz2p+cGXXsXvfOIhdqznvb/2nbzrvV/gzz5wF4cPHeDgapdvPWK4awS5lbzyyj389S2ac6Oa+85M+P7XvYTXfM3NvOL1v8INh5f4+dc9lz/5+P2oXp9//O1fz1/85Qe4654H+PxDZ7np+qu46qrL+J0//HOmZY1yjqaysQuM4OHHznJoucNTr34eb7hqize5AadOWazcwArJC646gvSeR0+fZ21tm531bYKxrCz3cXqJFz3lIH9xxxrv/PhpXv7G7+HoYMh1nzpFaX306FpYpJxMqauSw4f3Mx1PGO4MeOjEWYJ3LGSaiXEcvfRSbrnlVt7ylrfw9re//Ss9Pf/eY7GToYsuWXeBPcuLuHLMcGON0hmUFlgtWZSBwk7ZrhRSRdPqbi/HS8HUOfAVqjFctpLy8Pmac6MKfODAcsJFywXOlpTTmp2dEXsyT6HB1U2sgwU0zuNdAC/oJppekdNdXEInaWT9y8iqcNaxvTkgSxTdPMEhMNYzaRzOK7RWLC70GY8mTEYlY7OBTjOSPKezsgcpMtLcsJR0cdZRjQd0lUEKy7BsMMbSGE+v18G4wGgwQEtF0u2y9+BhtkYDBpMxm9tnkaZGNjW9sqa0gYERjKaORGnYu0TW7SPTjB2f4aUCqejl+VyxoHQrX0oUOitQKRRC0BiHsZYEQaY03aTAmibW0kiqqiRYw6qu2Zo2bE4aTo4c47JmMJnipmOCNREo9C7ecDY2pni5QN1YrI+gWEJM055OSipjKZ1n23g61uN94Phqj+3RlLXtMVXdYNwFnVUCTRMb2yIEullCnip6ecK+xYxephmNa5I0JdWSXqYJxqKcZFjHRMBJ4+j3uygVvat8HUHDfpGxmAWWVUl/cprQNPjJNPr0+MgiG00NQwndUNOvc/qLGat5TA+3QdI0bZhS2bC1sUNZ1xw5vsrOTsPmdsmJcyM2xw0uSHqd9ro4R9PYlhQAjfVY+8T2eHqyhn6yhn6yhv7ya+jHDTxNhyN8PcU3NVoJ0AqVpyRpEo20WxRWIFqdfVxOikxS55okj+bj3ooWWJoxWMLct6kF9Vv6WgtWiPY32y4YWhN0gk50q/FWKB0lc75lw/iZFKxlwgiYp+6F1gMptJuLV6p9jWjiJxVRwtf6J3kR2VCYJjKp3C4V9ML3NyMseQKSCKk6ayIDyjt8iGlxUkrwGTgNzkYJn/OEqowXXkpIszkTTM2pZDPjcE/TUhxdgDRLSDNNkSf4EDc/a21kpTnHznjK5s6E9Z0JGzsTjI2DWAaHFJ5E+Dn9z/jQPu9ugpwUERRSLW1JhFk6imjZY2JurB3Zbo5ZrOcMcI7yuni4EMErGyBpHyVbRFm1X5GKJuZnWYjQdtaI0bItE0oI0ZrWQ5EolgrNwYWUlVzQ1ZHqaDw0PmrulYgDPo6xCGqWxlHbOPASJciSaHCutUQmmlxJBA7hHZPaslNa1ieWce3jRkCIvh3+iX/TqoJHK03SSVCpQlhwTQMhj9JM67GNIUhF2kkx05JJVZEtBZJOl/7iEt42OOdZWcg4l0yZ+JrcQYbHCxsLZQFaSJSSICUNILRABnhwZ9Ky8jTSN8gKgq0JtcF7gZGipSV7vG0gjUb9SgsICmQHEcTct611zkRlMaZYpwlmPGkNA6N/QbAeTDWPJdb9BZTU0RuhjsEAznnyIictMoLyBGnx0lB5S2kaplXJtDY4a6nrBlSgk2lEv48SKVJIrJYIT9tJCTgXN7LJeIT3HplpsixBqRy8QE4cylTkaUqapAilWkagjx2J2RxUUAhFpjN6SYILgcaDcb7tMvpYQDtPaTyjyjBtLMu9lCyRsbPbRq8qQaS5h7hZCiFRQs6ZqplWHFzM8SHQz6LuXEnQSqKFnFP7tRSkbadUtR0PqSQycpNbqrGb+/YpLfHWY9tGQt0mhKwuFuxZKFjt5YzLktwFMiSNFZjgcQn4JALSS5kmkfG87Om25rta0UuivNqnGVpCcI5z25b712se3jZsjmLnUH+JF9tuaMSsvRXcE5vx9Iu/+IsABO+47Q9/ndHOOp/ZdHzVV91Id7HLr//5+ziawNEFzZV7OqxqQbldgnmUjVHNF09PObqcsWdPnyufdg23f/5B7jpxnmfu2WKJhiv3dkgO9JlUhkv39Xh0bYgxjm9/9kFOnTrHvae3eM4VB/Hjbf7kPR/gpsv2cn5B8zeffpibr72UNEn4/L0nmIzGdBL41puPsKDiPnHz5YfZt9zhbF1w49FVDIov3PUQd957hpNnhlx97DCX7O+y0kvpdnLSTg5HjvC0S67H513++tb7WXFTVnPPO/7gvRztSS4/vJ+Lnvp07r33Ad7z/g+z2bmbIs949mX7ePqLX8zK/gNc84X/zEKqGIwNDw4dBy69ju99xat57x/9DnZni69+6iWs1zW33Pkod957P9X5DV5ybAWtU667bD8/+d3PYnNcIkTKd3/rq1hJLblvOH/qYUQXTF9y7XVXtMWlZ1zW2E7O177suZzdKNkcnuFHf/A7yNYfY+PsCUo0D53Z4d0fuJ1veOF11Mbyzr+6h6qEy1cLutR8fmfKp89OeNGxJTpNw2/++R18zU1HGU1r3vW5kzzlmotYXOzw0+/8GHuLjFe/8Gp21geMpxW3nS05vrdD3gx41/s+Tb25xRXLGZc88wpOn93hl37nI3z71z8fX9d89P4tTg1q9ogRve372Flf48zmCB9gfX2DVEWmR3dliYP793DvQ48hrWOxV3D6xGk+NRnxmS/cR2nGlE3JdBx48OwAKQRXHNlDcI6z6zscPXaYlW5OOjrPeDLho194mI808Ub0cC/lt//4LxlNSh7bLjl89CKyPGf93FlG04qyNnREStMYfAgx5c1HJo0P4Kox63f8NV/7wqdzxRW/+JWcno/rGDaOhcyxoD2pMjTCUrdrsRSRWV9WDcaDCwmjcc20diws9eh2cpZXemTSkWWSYVUgt0qMhySAbwx2WtHppogUpl1NpmJaeiph4gKlDQxrR6oVnTSJHe2yZLITaOom7r0zH80AnUzT6Xbo9bsgooQybQLTusSNK6q6RmtNupBS9BYIUuGlZH1zB4j7hmxiUnQwNZXzKBnodHsUqaZIkmi86RwqeLq9RfJOh2o6wZVjaMZkwjFtGqajkuGopLGeygm80EgtkDqWy0LCgrZ41+Cdo7CGqq4ZDYZY5xFK0OlmOBtr0DRLGU5qBpOangoREOhlDKcxXasoMobjKc4YsiLWEZ0QOLS8xKiTkCYCp2qEg1zqec1rkAyqCPQsdTOKTIOMMrkZ80glmlxKVvOYCm5DoKkNwnn6qWK1m4KQLPQKsjwDBOe3hhhjcNah84x+J2V1MSfXIGVAC98qPKA2nmnjGTc2jiURiQD+gghm5z2pkuzfs8RF+5Y4uq+PcTWVsQxdtCWRWsX0LBEbybWDkRUMraTXScjyhF4veup65yl0NBcXxvDgiU02dio2dyp2pg2N8yitcD463FjnydI0AgTOtfc4T2zg6cka+ska+skaejYb/n+voR8/42k8AVtCq8GWSqGSCPpE7eTuDf0ceBKBLFXkmSLJdNQkeovzEgnM1UkhzOAVaEEcwUyiJeZInNAJIk0hz9GJZpYpIFvgYwY4ee+jL1TLvpHBx98UtHS+iHyE1lMqej219DwZ6YyeuDB7iA7+1oIzkdF0gfF5BMXE3NeofSTBO5ytcC3wFJC7r+EdSB07Co3DG4cbD+OGIAJep62MLaBmsRUhTkLnIn3aEDe4vMjIiwTXS3EtTdi1rCznApNpzWQwZTIqmU6qmJ4SQMkIxKAiMORDmG+cMwld/Iwtu02J+N4CiCDxXuLFjHa3CzzxJdciXl4XxHx8zOVxMxqjiMkDqgW45AxonP1OICYDhAgwzVLxZlK80I6fTEt6mWJPR9NPoi+VNWEOPBkfgUgtaQ3Yo6m9sR7rA1KrqElXbWKEjMkqOpGENuZ1XBsGpWW7dJQmYGxk4lk83j3xgSfpHVIJdJYgtWjTEWZjUxFs/JzeOjIRME3NZHuHINNoUp+nlMMa7wOL3RSVgpUOa2Q8B8IS0BGIJaazBCmpvSeVcbafnY7p5hnLWYr0BtG4aJCKxguJ8cwTMrxz7SKsUCK0UgKNNC1VGEfQKUFphFbxS2rMeDvO/SzFVpGpKF0ddx+t0d0uyoNyHuPiz32AJEvRWYIPBqQD6WhcTIaq6oaqKXE20sGzPCPREqF7ra4++p+EmS5bSIKTGOupqxLvHLkuSJKCJMtoXEDWGiUhSxN0ksznDrTrSlsgihYIVUhkEmm7XhCDRwI0JtC42GE1LjCpG6aNjaRKpWLntN0kpJAEERNN4iba0ntDlDQXieTAQooQ0EslqW43TSlJ2s5PlrbzVUisn1GSQ5uiE81VA5GeHWXT0XgxuLiR+hAwxiOkYKmXsdLLWepkVONYdKrEYZ3CEfXjOpGkStJPIqXbuGiUrBNNVqRoFws5laTRl817zg8tD21Y7lk3jEtPoiDLxDz5Z9bMEK30V4QZUv7EPX7gB34AAGsMb/6rP+aRzfNsOcnhyy6mu9DnQ/cNePXxDpcc6HDliqZna9a3SnR9jnLsuHdkuelQwZV7Cg4fP8Kn71/jTLVBPRzSV5pi3wKdTo5pLBcvZNyzNsT4wPNuOMh/++hJPvXADt/+rMu499wOH737Ib7uDS/AB8fZUcP+w/tY6Xd46NQa5WTKSDheceNFbGyNObsx5obLLyJJU85Vgov3eKy13PnQSb742Abntyd8zXMu50BPopRnaaHHwvIS+sglXHzN9Uwax4dv/XNeeEnBcjfhQ5/4JC++8Rg3X3YdSwcOY06s88X1iuUHT3JkpcdVh5a5/IabWTp6Gcf3vpOeqhlPLY+NHEf3H+FV3/It/Jff+SPGWxXfd9lBTn/+DPef2GL7/BqXrxQ87+JlGi84uG+Bp910iP/+7rswIedVz38q4/OnmWyep3nofpzXbPqCS59xBKHAlCM+c986XqU86+bL+fjHP8dgPOSHX/8cHvyk4M4TJyHJWNue8rFb7+X7/vkrGdeGH3//Z3jGZYc4fKBLU07ZqAynGsFL9vc4PzV84NZH+dHX3sygsvzRpx7ja160l+MHFvjut/1P/vGLr+NFN1zMg9MBD04cjw0MNx6w+HrMJ+87T9cZDvdzXnzz5fzeh77Ah25/mHf94g/w8Ik13vUXtzBpPCumQm49ys7WJhvDCUJJtre2sdU0Gv/2uyzv3Ut26hxaWVYWuqyd22DzzDlOjQ3r04adypK06VVKSZb7HZx1CKVYWl1h/3KPIptw26kRd61t8MjGkP39nMv29PjLv/kUw8pSGsfhok/a61I+eoJxWTNpLCKpcM5Gs/I6yu5q69vglSnr993CM5/19bzitc/6Cs/Qv/+YGkfHe7T0aGGxwkX/j7bT6r2jahzSG6QSlNOajZ0yMpBCYGXvAmkS7xWLTo7UGi8E0keGUjWtWOgqMhXoZppUSTSQYPEmUDsYGOhJSSZVBJ6Ygqnm4TQW0d4sCVJdkGUZRaeLUgLjBcIKzp+eUE4rrDV0Ozl5ntPv92h8oLaOnZ0BiVIsdgsUDh+iFM/5KM9Z6hQUSUKeKJrxGOE8CYG8iPtjOZ1gygmhmaCIvk2jac3OsMK6mFaXdKP3p1QCoeO4K3TA+hrrKjIXqMsx041zVE2DlAK1WGBN3A91r0M5mDIclCgNqpPSsV3GkxovJNIVlOMKYwzTEJBIcqFI+xl5Hj2YLBOUF/QTgQsxY8yrlIXSMKwi+yBLVPTm8WFevyodEya7qWJqArWPshbhPd1EstJJUVqxd7lLt98DIbFNg20k3juyfo/FXs7e5QIzmSKcRRNDl6IHDdQuyri8VCCiSXnwPiZGh2iZglYsL3bZt9Jn/3IPO6yoQ6BEElSIDAwVz60ETBBMrWBkBZ0iYaGbsbKQY6Y1NgS0jnu18Z6TZ4es7VRsDSN46oVAKTW/T7POk8uYZudbQCM8wYGnJ2voJ2voJ2voL7+GfvypduUYZ0pcNUURYsRfUkE9Bt8QbBoHpZQxxU0KpFD0MkHownjRMWgCtQ0Y48hFIBOQqJnfUrywUohoRt2CT1LKmIImIhNIFTmqKGKUZIiAUPQbihryGQMmxAxCZq2bGUAipYisnRYBCUQQLSbYqTgYQ5SQWRsvgDcmxsQGj1S6LRIkWDNPUUk6KUIJbLA0TY2xDdNqiptFy9aRkheCIE06KJWS6S74SH8UUsULCFHU6dsFzfm5mbd3rdTRRoNAfEALg5IZ5ET9ro+dh4jZBLJEsaefU7RdlMYGGuvnRYYLcbJZ50mMp7KexnkSpdBSthI4FSl1IiDmXlexC+JETDOAFjcTkoDHh91rONOiR++GljklBEUi6aSSfpaQJTqyjKREysgdcyYmERgX5tLGmKK7K9ETUkAQdFNBX3kWqEnqBiHBWJjUjlFl2Z5a8IFECpYyRYJiMY0m48YHgmpZax4a7wihwRuHSCRVYxmVDfevNayNHOfGntpGUFOEQHCCJ3gKLADltKHIcjKlcc0ITAkk8Zo5z/bONosX9Sl6q4jOCnYqmdoR7GyDa8jyQNNIhExYXV3i6IElPIrBQzvULjCyAS0juKeBpZ5Gas142sSxISWHDh0kwZEFg7QWJyXTdt0IgUhdb6+zzqJ5p28qXO3bpMk0shRlROobobCAqCoYjaBpkDsDZJahlpdRIYYCAKg8R2U5qUrwocF4Q2UqpE4olvYybSyMKtLxkKQrWMwy1twO1lTYpkGrlCxRJH3FQvcAeb6AyPpIFdmDoTQ005pmPAUlsMbQlCX9NEGhcHVJmCqsc6g0J+0voLp9Uu2R3mAnE0QQKKnBh7nvW4s7Y0OIHRoiY3AG9/q21aK0JE2hkyuCj5II37IZpWy72HFCAhLtddzohMSGQJZIDqcJSculDW3nKK6trQeBiOuAI6Y7SuINChK00m1sb3ToY3ZTQFzShGi7OM7RGEumJYf6CUf6KYd6GacHWVv8dFBO0Peay4sGWQQyCTjHztBhK0gzzWJXUnQEpYnnp6MhzwumBu4fTHls0LAx9nR6oNpYzOB395kL4PJYqTdPbH+J2RGABwcNi8td/t03XM8HP3wL00nJb758hXvKHvfUGc85MOAvHzL83N0jfvFlPZ5/fJVnvWg/n7ntBB+4b4cw+AQvf83L+c7v+ee88yfexhXXXMqzn/90/vSvbqccbrFgGvoEkrxLdfSZnJVjHtg4xT233o2UgqcqwdnP3cmdGxWfXptw3Ydv5WlXHOTNP/LN/Of/8SE+dPsJfv91r+JTn7yL++/+DN/3z17CzrjiAx/+DNXps6TBcPySwxzopeQ+49oVySfuO8OH7jzJm171TK6+8Uauf/HLeetbfpLt0yd43UuvJTv+FPTyAf7gJ/Zw8syALz50nn//Bz/ApUf28N/e+m2o4XnOre/we594lNUrP8Llo/s4ubZDvxsQSjMpK0598VPc8qs/yOrOY3SE597717lKDji6Z8IvPzTl5isPcMNTj/Ff3/cFsqLDVZcd5ak3XYcpS373v/w3zo0akk6Hf/3938Yfvv+TvOuvbuE3n3EVo1LxifvGfOFTd5P7muXtx3jO1VdSJgXP+drv4QWX7+MFV+7n6tUJrnToUvAvf/ZddFLF665fZpBoTg5KfuuTD/BPv+G5/OEbv5lv+Ze/xhV7u/zgy6/hP7/7dlb37+VDv/Vj/Ltf/mN+/d238ivf8Qw+cOcZ3vTz7+U7n3Mplx1a4qmXrPBHtzxGv9/h+77tefzuB+/invMjnr21xZE88KwDBZ//1O30tePbru8zNguMDXzs0bivIRXHjhxgY3OHh89ssby8wNrmgEdOfYajexdYKHqsdlPuPDFkcziNzRmtWOxkTKtoTo1z/NKffSoym53j3MduQ0vBYFrhWgDFuEBlYjNHSkWqY41z9xfvJC9yLrnkOHLtHHJzk+BimpdBspTHSHhropTEIxFZF1TylZ6Wj+vInUWbmlCVuI4gUZbDqxmDUU1tHOtDy0o/YUFLUCm5tHSCpxqNGeLYLDRlGuseFzQL3YIDy45yVDKoDduTis2yIWvj1DvLy6RpwmRSk3YzlmTCorf4usLXU4aDIaOWdZ53clCSqQfTRNZQJ6+YlBXjyZi9/QwnFI1PWO4mdHXB+saUcgpVY9FSMp5WDMdTMmfQnQKVK/Yu9xECbFXEG1yp6OlAohOk0pjpFJ0I8k5CWZUMp1NsOWE0GdHUJZ1QYRuDcI4aTVCSRCs6WUKeaCyaTl6QdwqMqZhOLJNJyaoSGF9jhGOhG6UxZe3I05QsSVnodukkisP9BNfY1itWstrPcAEqa1lcLEB2mdQNOY6cgB3vkCrNgZ5iHLrgUnIZa95ArI+6WcJ+azm7NcI3DmMERTfFGsVgWJKoeH2ybs5ynqITzXBripSSxW7BUiclSTQLiz0Wlvp4ITm/sY1JIrPi+KUHEQKctRR5hnAJOEvaWUShWR4LJhZGtWdhYSHeqFrHZDTGOTuvCxLdtv9Vish6dPcrdNOgy4rxmREoQ79TsNKL/jXSO6YmsDG2rKDIspSAwglBieSsSznc3wdSs3PmBKMyUDaeLM/mzWjjI8AkoLUi8VgT1SEzoOCJejxZQz9ZQz9ZQ3/5NfTjBp6CtwRr8da1dBOPMhZnm8gaauVZCIHMOugkiSySIEiVJM8VAy1wAvCQyDCX3MnZdZyxXeTuxzG+RSYFJDPG0gyECD4mmoXWpM75luO0S5kSM30lbUIa7f+LmZ9QNLQmRAmDb6WC3vv4eX00boygVYwqhfgZfCvjm/lCCRUHmcNhvKG2BmsN1pkICgUgSEJISXWkQce3KRBa7dKBvJubnTtj53JEIURkZxFnjSCQtIuUkrvgh2jPnSCalnVSHbtXSmJdi+y2kkTnfdRWt4VgbSONXauoE09Vy0ISM9ZStHj3MsoWgwy7jCcR3fkzHc3zpIyXMlEzRpOYg1BKCjItybWkk2lSrSKNr+2aRrA6doic9S0wGVcK3+KJ3u8m3nVSTZFIUhHaMQreS6z3GB8ws3M729tC7Ch00ohUCy3JVIznFW1igbOOqXUMSsv6yLI2cGyVntq0zK/22v1DOUJwCBGiH5pqAV0n0EUOKERbbJrJkLrylKMp1ipUFlMmnROE1gDeNYZuEos0s9Qhtwk9n4K3UeKqJJVtDfdRTJwH71ldzGN6YxPmEkwhQqTi+zA3UBQClNYxlUIpvDG7JLjgCQ7wHqt8TOpxDuqaUFck3Q4iyQgtmCuiSRcYiw8VXhHXgCTFCYmxjmY4JhAZb53eAkJZbKhoTIMgUCQp3cUeOokMz8RJkuAQ1mCch+AoRxN804CIqTQ6gJAerWKXRKQdVJYhkgR8TE8UwUeKsNZ4uUtdnc03KWjpwi0rVFzAGtzlEc7phH7W7QptT0IQAVoR2o0wguZChigtFjOGafw7Un53geTQnjvZXnfaTfNL3mf7RiNcHK9bmiZkmcc7236O+AjVvk6eKBKtMI3j3FbN/RI2twMeT1AVJzZhUHoWpKJIIVWR5itak01PTOEIwzpKU5yntB6dWCoLa8MGD/SLBKRDMJuz8X344Ft3vd1TyD8A8Hh27NQWVzUMtiZsndliazjl00sWQslCaDhdGbpa8PxDBStHLyLvF3gvONST0Dj+9pGzLN36Rba2hhy55ChFt8P6uTXK7U1EPWW1n3D80BKNSLj9zoe5/NKL2LN/D5c9dicPbky5d6vmFZcc45pDhm+cCi5dykjShC/c8Qj7l5d4/tP6eNVHqIxECe647Q7wjj12B79vuV1nA1dfeggTAp996Bwqz3nJc65jOJpw2x338YVNz0UX7efYgQXWa8HmPQ/RiJNc2huQLezjipuvZelzD7CYCPbs28utD55gZ6r46ld9I/0+bJ5bxzSWR62jto6X3LiPpX6Hex85z75egkkFp0+tUVVjrBC8+hu/DlEO+Mhdp9FlSd1YvvjwWQ4UkItAN89YqhqEq3j4gRMU5ZinriSsP7aG7i9z5bE93Pk5RVlJdvQCg1Pb1GLAy28+xjX7Mg4twJ9vDOmnmhuOHuDrrtnDpKz47L33UWqHzHO+/sXXkEvPpz9zD1fu7XNoMWNUGqa1JR+XjE6fZG+RcGz/CsFajqwu8JTLU75wesj+hZTL9/W4/KIVkIpb7zrFgnQcW9TccvdJChG47vhePv/wOY7v6/O0S/bzyVsewIfADZfspUjAWsdwNGHvyiIXH9rLI6fP462hkAHhYyrTybLCBmLHOtGxHvOR9r/USTm42MG30vRTg5iALJAs5OncTuFQV2F8YG1c89xLlxmUlo89sI6xho4ouOGaK7i9qVg/v0Ei4v6fSFha6NEYy85oihAwHE/5o7+6hZV7BvT2forv//7v/0pPzf/jEVr2gUhTRFYQTDT81lIQlKB2AWktopY4X+ONAQIdLSjaxtykjrWkV9BLFXsXckolqKqGsmqYNDGVrV/oCDg4R+PaelsE+p0EIyy1VzgbQSet5Nw6IdMCFWITVgmQtA1HZ0F4pHNt3LijNh6VBHQIeNtK6pyj2+tSdHtxL9UKgkelmrL18QlKI5OUJO9QsY21DdJUeO0RStPpL1AHsEFQDyd463Fe0F3Zi1AJSaKRNrLzhIBpWVLWhqYucU0FzpHIQCdXrCx3SdqmaKZyMilJpCDBk2oBMoFuAUohlKI2FuMDBIlMFChJUnRJbIOyDdujChMEXimUFEiZ4Hw0BQ/e0cl1tOgQYV6r+MYgixStJXmeAvHeJEliIzuEQDdPwMaOqXMBLUAFi6lqLJASyPIEpTWhZelnWQ4BLIaqsvRC9JWRRNaIm93LEK9j0qZ7eecRLpqYl2XF2vqAFI9UhtoYplXNqfNjtoY1WkkWioxESeqqIc0SdBqlhaPSYDcmlFVFaTzbpSdsTghSsj0x1F4gdBb9d63FWIsNtKnYgcYYBGI3ZfAJDjw9WUM/WUM/WUN/+TX042c8ORvpdNaBUAg8zhhoaqRvNyMb6XYpLT1TZhAg0ZJOrhFaYGUcBKkPeOGJAdCgiVrWmYYqEFlblYvmXPHNBggOYZv5RXXezxdX72wLKskvMa2egU6yxaRAEKSKBt+z1/Q+prbQmmg7307kCGaJVEd5oYratODb5IiZREwTtYPe4bFYb6lNQ20aTNNE+RsCgULKTkw+CK1MTQiCiNK74D2ypdJ563BNC+xpSZKmSKUILpqOa2vIdez+aCWxQcxBmZlNUtJqSfNEsZBpXADbIrg+BKwPXwo8meghFQKkWpImem5qrqIJQZQAekGQ0dl/ZtAeAmRaRskeu3rQVAu0jI/XraldogSJmuldZxt4BJFmrzfz2XLOx+KnHYoeImIc4sRPdDQE7ySKRAScsVEiKXRMAWnpxSKI6F8QxHwi99LIjNNak6koPwyzTdt7xpVnbWR4bNtwescxMZ7GzYfp7qT7B3E4lIQ0VWitMVLhDGSLcZNRQeJtRb2zzmiyhXEK7zWJ8mgpcSQIHQ0V6mlNRwv2L+RM90HHOhasY7y5DnhkljGuXQwTSHJGpsYRuDRPqY1gZGPXW4SAlh7bxGJaaI2Q0cdLa9XqzzV1qx1WMnbJfIjArE8UQUm0sYS6ItQV6eH9oBOMD0gZ2mQbcFWDLyu8Eog8R2QFRgxpqopmOiQtCopeh2xhP40b0NSWqq5QQdLLcw4dWEElCi+hWjNga0QzjVpx6xhvD0kSyBJBN5N4JEkt8CKA1qRFD5GlkVk5mYJtCMGQZV3IEoyOiRUihOgHR7vGBfAh3kz8L1Ti9rt4W+Gxrs03mDUCmCVvRGpwBOXbTbNl+UmxC/wToh9aTPiY+fVFSvB882U29sUcfJUqRsj6EEjShDz3dDyUAxM35fYGQQiBApJco5VkPDE8cGbK5lZNYzwTYxnUNZPKk0jBnjxhKZekGqz3KKVixK8QDCvH5qihNI5x41gbNXhiksfawJGmmj0LGTv1roxE0+4ts1SX2cls7Q7+oRxDG5gOKu65/zzbZzY5N2r4wrmEly5WXNcJfLpOONxR/LOrFzhw+eU0PjB++FEuWRR0TOC3Pn+Os+c/yP7VBd7yvd9MOdjmgS/eTbl2isVcsf+iPVx36X7Ojy0f+djneO13fgPPePp1PPp7mzzwuTPccqJk5ak3cE0WuGw1Yzi0rG2XvPe9t/JVL3om11x3BdM6xfuEXpHwofd/gP09zTOO9OlefgMuyTn36GPceP1xisUu//zHf4evf/FNfMernsuv/fqfcudn7uOzp97P7//qW7n40D5+748/wD13f5bNjU1uuOIYX/WKG3nBy17Ox977PvYudUm6C3z0/i1EZ5lf+48/wP0f/hPu/9wnEN7xwKjhiwPBu771KDtTwfs+N+LwSpfQVJx87Cx3jBws7+HPv/+7+O3f/VPe+c5P8bIl2K5rPr854ajZ5MBilwP7D7IgDPVkwmf+9tMcEA3fcHGX0/ee5uAVKc9+0bX85Qc7rAfJdu8wd915F6EZ87YffjXJaJ3R2mnuPL3FJYf2cPFlF/Odr/lq7j25wSte92mKdMxlR1Z4x+uexx/86Wf4vT/8JK962nGEkpw4P0IrRahKvviJT3PZSpejy8dZ21zj8iMHue66FX7kHX/FSiehdpKvufkwW8OSd7z/Tl597R4uW9X82t8+yCuefpxnXHOYf/dnd2GTlOfvO8xf3fMJFhLHd77gAP0cGmNZW9/m2suOcONVx3ngD/8S6Sx7uhnBWgZTx+mdKXuXeywvdBFJip1OMVWFB1Z6Bdcf3UMeLOeGJWvjmkIr+plmz2KH0sbu7wsPZtx1fsKHT+zw1uv2sTlu+NuHNnHORZ+um67l1MlT3OE8qi3mtZKsrCwwLRv82Q20gK2dET/3P94HvA/gCQ88OUSMNy86iE4PVwpqyzze3juPbCwheKzx+MYSQmAhVxS5Rqcpg0G8ge+mgcVM00sVVSdjPK0ZjktOrg+RypPnGussjfNRvqcbdAgs5B2qoAhWYwQopSiyBNM27PqZxmvwTuGCbOs0Gf1dgiWxLib71tHHqKtjCpI3NcFZhIDF1RU6vUWKpRXKqiS4Bp1IRlVN1Vh6SQeSlKS7wDgkVHVNqCZ0ckvR7bKydx9WJng0o/VzsaksJIsHDqHzDkprxmsn8L5BShgMRpSNxVQlHS1aiQukaUqaL9LUgNDoYgHtDdJZwnQcmSVaky8vE6TEIRiMS6QNaKFjIpiS8efVFDeZMDh7hspYXBDs37uASjRNE42KvXV004QQondq8IFgHb5ukHmC1grRUy1jXqDTJIJ4jWOlk4J12CowLaPCQpiGqXU0HlIRKIqUvJMzbSyF1HS7HZoQbbImZkrHGaR04Ay+teawxrR7eyDL0thwdh5lDEoERqMJj56ybG7uYEWgtpayadgc1EQ1nqLfyckTxQBBXqTkWUKwFdvjmpPbJZO6jvcVQbJRbmIRrA9LdJqhshRpGryNLA0/q+29xzW+7bW7Nq3viQ08PVlDP1lDP1lDf/k1tAjh8c30X/6WY7imwVY1IbRm0KkiX1xCppFuWZclzjR0eh3SToes1yMIhfOC2gkePTNiMKwpN6bkzpIFx4IWsfugJEmSzBf/GXjRhBmAJCjyFK1Vm8qgWuAp+kbNfKVmLCaZJMwMqIVQ84scWrTPtfGFQgikjebROEdI0tb7CYKLtDGhFUkWNdeSgDcW15pdxgGjSLKAkB4vK0bTMZOyYnNrQGMs1tgWCFNomdHvrlCkBQvd/hwkso3BGxu/nMVbg20agm3iwNQSnWXxcyGhBaiyIkVlCbKTUpoG61zsvLQTLk6UlmvYIpYzttNMkulmaXUtIOW8x7ZQupwhvu3kik8TEwBcy8xSLf8wEM3aZgl/u+BMaFFh0dISo+Z1l0k1u06RObY5NWxMGu5ZGzOpo/eDosV32s8UiO81TzW9XPOsS5e4aFFxyZJE2RoXoA6a+zcd58aOe9amiBBZc5csxom40pGkiUJrSZElCGJn1YeIjFsfeGzTcHpgeGSzZqM0mJm5+RzpjZ9dCNg4u/X4Zt1X6Pj+p1zEwtISK3v3URQjfDNkunmKpX0HkDplc2OHuqlx3lFkKxEc1IFJNUIWfYpDl7Gy3CVNJLapUIkGKVkb1ISyQUxqTj1yBi0Fq0t9NrYayspTG8nyQk4n11TTAYTYZS2KHKU1MlMtGBgZehDTI1zWR3a66E6X8cY6wZoY2TrvVMSEBykF0hqUTlBpRrpvL95Z7HAANqBUQnd1iXo0wFQlQWkMEhMkVWXwtiE0U6TSZJ0O+y+5mLI8x2Syzp1fuINEZnTSHocPHyAEqOqa8faYRCccOn6Ura1tpuMJdlBR9AryXkFZ7pAERYcclRZxDfIeY6KBa1Jo7GSMn07Zd+QiVL9DWCjYWNvAGINUum0gBIyddWsC3saYVhtCu35BEDGlyPtdv7bATBIb5aO03RoQrVzW4VyzO7eJHeEWkgViV4z2VMuWGSpEfPzsBxfO20RDZT2fenjAuVHD9sSQRsJwnOuyZZ3OKNAi0nat820DoV2zfJiD1WkSzRcTJXA2UpkTJXASJpVlOLYE4mNrDz0h0MSGhVcx1nmxWzCpa7anU7RSEIipTmH3s01HU+qy4XFuh1+RY/begnfc+Z5/zy23fI63//Ynec0zrmBvP+cL953gnrM7DCYlP/NVq0yM4tRIUAbN4f0FL3r6Ku/7yEnWdgyHLjnEfQ+uceLsgMd0l0UN+xLP4ZUug9py9/kJ/+KrLuZAR3Prpx5mU3UZiZRyuMNTrj/C028+zi++6/N0s5SX3HiM229/AFFXvOTKvdx6esIjOw17F3tcfOwIxy+9GDdY59z5LW6/7zGuuuQijhzax9Of8xQ+dssdPPrwYzxzqeTu7cAdO5I3ve41dGXN8NS9vOfW06xtTujaihe87EVced01JEWPWz/zRT556+084+IlnAucG9VccfFepFQ8eHpINdhEViOu7U6ZyIyhyNmjG1ZXOxw9vodf+JO7CLrgzf/sa9ne3mJnZ8Qd92xw6bVXcdEVl/E9b/5PLJgJLzrc4wOnJ0y94MrVLuulI800P/LyK/jQ3Wt85N4NfuZ1z+Xs0PDeL6xx7tRZchm44egenv+cS+ktdfjx//ZJDnYUx5dzbrrpWk6vbXPL7Q+wf/8yRw6t8KLnXUtVS9Y2x/zc776fr376dTz7+sv4mf/6J6wWmmddvp/Lr7mcc9tT3vlnH+dHv/U5HDuwxPf8/Hv5uqcc5aU3HmWYLnD3w+f46KfvpSFweCHhNVct8df3b3N+4njeNUe4+8wOj+1U/NgbX8Ppk+f4+Mdv42XPOML2pOa3PnQ/JzYmjEpLouLanGUp0hnqxjJtLC+84TjBe+575CyVj541pfFce3CBY6s9zlaewbhiezDh2gOLHNvT4xlX7OF3P/kIo8rwk699Kn/+2cf42N1n6Sq4uKO4sq/42EYDUnDZQsbHTw05X3lWV5e5eN8Sy72cv/nsPdSNxYfA0soSIgSa0Yjah3kT7e/OkSfq8cbnHmdluc+B/SutMW+J3VpHh+i5M5rU1DbegF+yfwEjJJUX8QYzL9B79pJ0+5EZPhmStXXp9rBiMpowHox46NwORZFy6ZFVBqWJidRbAxICqRIcObTAxHoGlaVpAv1OztEDy4yMxyLIs4QiiVYLo6kj7XTJez1GW1u4psY3FaULVNazMy4jKJFqauvI85yi2+XgsUsiI2Y0RbkaraDX7VBVE4xpkEDlFKWT1NUU5RtyX2O9IC06HDx2jLXzG2xvbnP+vrsjKCEky8cuI0lTtFLsnF9DB8uR5Q7b44ppbTEIFnJNP9cEpUiyhE63gxKq9TxtYnOXwEInZTotmVYVlxzbD0pTOsGjJ9awxrLYzUmKDLRmxyuUbZC25tzadmSXlTVpt4h2IN6BjawAneekeYbOEqqqwdYNtiwpOhkqSSDLyYocKSSjwQDpXYyRR5JK6KhWgtZK03SWERBsDSv63ZxOkbE5LOl0claWF8iwWGPY2RkjlKQ0js8+vM65QcXWxKAT1TIv2vsjIviQyniznEqBa1lsjQ/Ytv631qOkpJsn9IsMrSRlY+mm0ZvLNjWlsUxqi/MeJQXdNMGEmIq4XRqSNEOnKd0ip65rJpMptWnmIVCyfT+zZG3nfGS/PEGPJ2voJ2voJ2voL7+GfvxSuzA7SZLQ8k+8j75KwcY3bY3DmeiJ5G0EUGhPdqIERa6xxuPyBN16jwUR8C3tyyFmaqj4PSC1amVutDS4gBB+BuBfQIsL0eB7ZuANEaQIAWT0VhIi/j0DLQQOGQLB2tb3af5B53Kv2fSccxTFLh3OtXorKTzSi7nDfTxf8T1JIUi0jqCV1CiRkiiNjPF5BB8NxJyNlPTgXRzlIaLMsn0fUu6ab88QWCUi00lcQC+cv9/2mzD75oLPfiFNJ25CrYBOBpSPxo1KitZoPPydJ45IrpBRrzoDeWfYcSqiFFHMPKHi2ZiDS7Kd6FLsvgPRIsMzNFfMWGuth5OYXewLPxvs+kYRJ0FjApM64JuA9VB5T1kHrIFCKVQrTZSiNZSzASEDiMj6CjNzzTZ5xHjYLj2j2lNb8GGm8b3gnMxYdE/sehcApZNIyy6j70FwIdI7TUVwBnwNRBS76PdIpEOLmkkNjfE02yW5TqGTkOUZKonXJs8k1kqcFiRFxMOt8hSLGUkHymlMchXOtrLVNrGjHQcI2SYnSpRShNCa5zmLtgZh6jnIJ4KMawGCIBQyBFQICK1RSYJOU3xTtyk5rZmn8HgRk12cjN0Kbx3WmgiEag2qE/3l0mga6Zyhruso85QOIy0hqFgMNh4pAgjHpBzhfINUgbyfIxOJ8YZBOSGTKWme7WrDY3znlxho7gLDu3MlHhcMqtk6NPNNu+BXZh2YINrfE7vzMSLAYQ4CMz+H8ecztuXuUjd7gtmv7v7vl6wZsycLF2yaYiZpjmuZM/FLpmr+uWKiKPO/CdEDpjKx2PRCIEPs5vi2S9XYwLh28Rx6qG1AySi3rY3H2Ah8awGpknSIkoJAoAwOayGRmiKNhca0qdt1OXaX4Il/s/q/OwaDKa5qOLqcMWoM1U5gfdJwrnTs1IEdq6iCYiKiee/aRsOnHhRsl44kSbjk4AIPnNhkfWJ4eLzBYqqYdhOuuuQAmTGsD8ac25owGgrOjRvOTCtGDq7an7OgA4m15JMhoUpZ25xQTSpSbxBJysr+LuOu5957HiDNM47uW8bXNaZumNaWje0hvYUe/aVlbGOZDiccf/rlDE6NOGkGFIkiRZIg2NzYYTRquP66S5E6YWswYsF4EuHYs5TT7fdoGktWWYaTKsog/IQkF6BTzo6H9HopB7oKU0u2x4bxqW2G45qgBXee3OJIx7GSS04+dppLL7uIY6spV11+EXJnEyUrFjsZeYCFVNCgkYlmY2KpQox+X77oUsr1If10k+V9GdIZqumUSWnQXdi/usRqoekuZDTWoZXk4J4+KwcuIut3ObM+5PCBw+wTBePtCcPBhPG04tD+VXIsZdVwdnPEcFpxaDFlfWtE8J4jKwXGGB46s0W6qtAycNG+PudHNUmSYHRO0lugl8DBPYuc2Jwg/ZiL9i2wdvY8953c4Pk3HkRKxWKnINU1SjoWOhllY5hMK/YudVnopOzrJmQi7qnWB47t7ZNoxV0ntzDWM64NBZJaBBQBYS11VbM2KFlRgU4Cj5wfYRrDYqqo64ZJE9iq4eSgYiFPOHCoT6YleIMfD6i6CXWqueaqK1lb3+Tk6bNMpxVKQKIk+NkNFFxzzTUcO3bsKzonH9chYwfc1bHLHEyNMtHKAR8iE162JrXdnFxKUg+DYUVtLeNhST/pkKYJqY52FlJJQoh7UqoFnVyTpZogNUmmEEKT5CWuriMLBoFONF2lUMKQJW2gilZIpck7HbIkdrLDdNraHbhdyZZSpBKEiqzzREmCaGt1rRBSUhnXqhb8/DpNagtBILVGqwQ/NdRVHROeSEh8QIgUnRdIKSILxjSUjUPIgNaClAblPViBdBa8o64bfKCVnhUEPJVxTMc1SZZivKSXJgQfaMoK7x0C6KYKayNo44wFBCFoysbRNIZUK4JSCOJ70ViUiHJFIUApSZomICV1HbDeztOXUyXRqUYZR1ASL2Vs8DoP1tMRIsq1IErqhKRyIVqkuBhuI+bKj7iHKxHw3mEag8KDszR1Q561dhgy3uh651pGS+RwzOxBXJt0LQTRvjoWUlTGxkQv67EzJpKLN7txb43AlHeeuonWH9YpvLXUNiaBKQIyCAierL2fUPg27CgCkkKAMYbGtF5wIRoux0Ty0KasPbGPJ2voJ2voJ2voL7+GfvxSuwC0xnlCxIe54DBVg2gcjZP4mRm3tXhrcdaj0sia0TK6rydSEQyoukE1FppI0TYiAjlBCGyIunchJYWOUYMRLIieTgHfAimzDxxaxFAhtURK3crAWkDKe2YDa8YCcsIjWx8lYV0bN5nMgTIhZwMj0oKEc3HMa4VrQbLauigNVRKZpGilUSJEYK4FjrJERz+nIm8RW4lGRVpe8BhjcdZiygqJRwaPCi0MJ2KqBFIikyj1E1KCDygRB08SDZ6ixA52QZx2cM/OUUysi4BKBOvEfHqGC2ahkCBDjO0UIeD87uQNLegURLw2ihD1yhcMk91JJOeze0Y1FOwitruIDTCbcIIWbIr6aa012gak9AgfgUHRbmqz66lbhHk0sWgf8LWgNg7joLSeYRlBowUZqYaJio93HioLDo+wAVnHLo9x0VDOeEHj4NzQMa49Ngi0lnNDdhHmWNgF3zyxj6Qo8M4z3dqJRnfKI6Sm3NlCeNcWpAVZVrDn6AGCmWAnm2SNpppYzj60jhs5Vlf7XHH9QSwNjTfxeoR4TpdWOjTOMHI1l1x6iE5aMNlxrD+2xnhrxNJSDy2Jm04rd/UqI0kik1HphLr1ApiOxiRNSVoqtMoRSiFlMguVjGPRVmA9amERpTRKCcqzZ6J8oNOj8QaHZTyZUDYG5yBPEryxiKYkzwtEkiKyRTSQppo0DTTVlPFgiLOegI0FhUxRzqG8Z7GfYZzl5IkTLC4u0O136C+sMBhss729xdntAd0sI8tSFqwgEQkI1c4vSTCA0Ig0i/JSPN7EAIJdhmL8VrZpknGvm81R5os+zHT9AqGI3RgELrQFcmzF7G587bRTUs1lrdAO49DyFQVzcLl9hflbm62NgQtCAyAC0SEmJdnG4BoDiYzNheBjUEL7CfFy9k0sOHRkoCoEyUw5LuLPqyY+LpWSxvv2nECmBQvdhK5QFEqykMTOc+Md55tAPTXUxiJE7NisLC9y56OPYK2jlxbzdJ0QQlwDL1zInsCHdZ7/8PYPsTg9zb9/6cW85S8e5ZbHRtTWkSlBP9P8xVnNSjdjqUjZKwz3bEz5vz5yD9//tAPcfLzPvr0Fp63nlo0KLWPU946FN11+lItyx8v3G/79h89wx1pJLgXdLOFAP+ENT+vzwPYO73nvJv/oeIcdK7n10dPsl5YiT7i/Sfmqb3glK0cu5gXf8D1w5/0sr52gynJKF+h5y+m1TcgKnEjo4dmbCBae9nJecN0Wz9w4yYMPPsCZtW3ue/AUtQkcv+RivuN738A7/vu7uOVdH+IZx1Z47oueyTe85bv467/4BD3vuPKqi/mF3/lLQgj8+Bu/HtmMOL+5yev+47284EiXV13h2XdwD598ZJtf+cMv8syVlBAGfOdP/Db/+pXX88xL9zB0MN48hT+l+Onv/mruvPsE733vx3jFdftZ6qRkUjKpLIPa8b4vrLNnoeDVNx3j4I1fzYHJFoe6ipWtOzlzfod3fnrCX37iBEt7lvn5H/omQl0x2B7w1nd+gKsuWuZ7vvlZHHrRd3HbA6d5xTf9E/7N93wHT7vqOC++bB/rj53kDx87zQ/+k5dy5vR5Pvrx2/jtv/0bLlrJ+blvvoZf+tCDnNgq+YVvvY4P3LXB73/yIab1fTzzyoO87mU3sLZTsjZs+OszE6658mr2L3ZZUFNuODLh4sKT+Jrtacm92zXvuvU0Vx1a4l+95qn8pz+7jc8/usGx/cusbY/ZHE2xKuXqvQUvOtLhs48NWN8pOTOq+d5X3MBl+xf4j+++jdM7JQ+eH3LTcspynrL3QJ8lU3Pq1Jjf+dxjfO+VC+ztKn7kd2/lGUeWeMq+LqfWDI8Maj5wcsRCJ2NvmrDYSdFSUiSa51+8wm1ntrn3zDb/+Wfeyi2fuY3f/oN3UZclWkmyPCE0u9KcN77xjXzf933fV3hm/v2HC4G6rBgFx+awQnhHV1j6SpAIUCHQLxLSPGNp3wqSgDMNzWTKeDrl0Y2KlSbQ73c5uNzBhhDB2/EEbEOmA/sWC4LUNMazvLJMoiSqIzi3vs1oUuI6Bf1OxsEiYbw5BB8Z9yrtkGY5iyt7CC4CMtNqG9kY6ukEjSNRiqTooXUEm0prGYzLKJ9b6OF9oKwqRmfXyPKUpV5B0wSssZwflPQ7KZ0io7+6j8pvI0cli3kGQmNsQt5bJc0ypNSYqmIyGrJRGpZ6CYvdhAVV4p1gMrEktsL7wObAofp9kqJLb3WV0eYWa+vrDDd3kEqRdUYcXuqQKklVNnPwpdTgq4qkqWlGY2RREPIetXVMaofH0AmC1DrSTNHTnlwGzuJRWlLogv0HVglCcm5rGBlkxnAwT8mKlE6eUI9LNKDTKHVyzmKaiqUiJVPQSzWZVKQisFEFJrVhc9qw0tFkOiaCNyYygRI8VVkxmVYsdDK8d2wNJ6TLXbyHqfUo4bHetFI/j/eBXreAEM3FR8MIWotE4azHArVxMemubQqr9v4hUXEuLncSfJteZlsPL6uiRYZWip6Q9PQslQz2LGQIITDWMmm9wFaWF6mqDEKgnJZ4YiplliUoJaES+PZ3n8jHkzX0kzX0kzX0l19DP26p3S9907E2Sc0hVIL3ISLXUiKQIJL5CU9yTdLtkS0skXU60YBLCkoTqI1nMGzw0wpfNZjhGBEi2ue9xHmJcS27R0Wjw5kpuJIigjyqTVmbo4ct4KFUnAA6iSwqG32nZhBLCLQMuBhNKHw06FZSIdMUmSStoVg7CJSMLCtr5wl5TulIC7UOU1VApIt2F3voVIKu2d4+z2g0YLQzJs8yiqwgKzKCB2ccWqRIqUnSnKZuYkJLY1pjsmjiKQNIL9qBHRP35pBrcMjgUMHTWehBmuCzlGlTYe3u4h2EaIGmXSPxCEC1ANJsyrWIrve7YJ5rQbtZzON84sy+847WnS5eA2aobwt/CTH//ZkX1ixZMM6H+SqwCzy1dlubE8PG1HD/+SmTOhqryjZudUZrnI1vLSVaCRZzTaogk1Hu1zaWmAHjiY5jKVER2dVKkEbnzJi0YVt6sY9RzbOYzXEdaDw0nti5IlKR50aIFwBQ2+d3Hs9U+oodb3n2VXNDvu5SBycsEzsiC2My5VhZTDEWXJAs7N2LxCJszXBSM60k26MC43NEkrJweAmZBqQOSFOiQ+x6TU2NtRZT16RFhyRJ6GQpqpLIGsx2Hdl60VxhnrYSTRA1Ic3jwhrAhwa8A+/QQqFVQprkhDSa9QlrCFUTZadLi3FTFZJqczNSXJXGJRleJ4RuB+EsMngSIXEmGvfrPI2gc5JFr7FUohYkjz50F+trp5kMa1KdUKQZB/YdxNmG0WibID0ySFLXJclT0iylt3eRyWTMcDDg4VOncT6gZMqC1nTShKWVBZKQoNAImRDqCkxFvtRDFx10f4HBzgbWxjV2xpp0hDn918yB5F0QOHABO3HW4AlxnM7B+bZLCyJKiINHBjdfU76k19gyFdWsmxPAtWuwALRq9eshgsQSiCEeinHt+Ot7z3J+WLIzbejnacs09XNzxRmDUYS4Cnmi4WamZJybItBREiUEChE74gIyJI1388+VKUknaU0DiR3h2apWezhXGbaMpSRhsd9jz9Iij62tMa0rStOQpxlSKqyxlNOKumoI9okLIs+2amMMz3naU1muz/FTX381O5d/DffvBN781p8keIcSgtVeRpEoikSxksCotty/MeXixYzFbkp/pccDZ4ac3yk5slzwVV/zdbzym76F03/6Kzz86GP87SPrrGYJh44c4jVvegN/9Ud/xh2fvJVDe3P2aMGqFHzwzJTjlxzgda95Br/8B5/k7NqAp1+yl87yHmSacvqOL3J4T5/jR/Zy5OnP4+HT53nPX3yYf/yKmyg6OX/yicd4ybV7OLa3w//z2XW2B0PKyZjvfuFVrOzdi95zhPvufojT69t89rFNvvp5N3HxgRX+7J2/T50XyJVV/tmrn8fauQ3e98FbWd/c4fCRg/zYv/4BPv/xv+G+L36RD956P1/99OO89BmX8JN/+Bn2HzrAK7/m2Wye3uDhE2v85ns+zvG9ffb3My4uJBtOMBCKH//253P7/Wf5v3//k7zs+CJpmnDHIPAtz7uSi/b0+A9/9Ele+qwreemzruT3Pv4YdjJhyY148Ow5llZWee03voZzn7+VnbNn2OqtMq0bjDE876aLefjcDh/83KNcdNFxRtOaj976OS4+coheJ+f0yVP0tKSfKYo9e7j80ArPvvwA2eGLWdsa8oH3f4iDiwWJEtxzZpvL9vY5ttrHSM36qOLExoir93bpa0HhGi674QpEp8Pvf/AOrr9ohcsOLPEX95xj354lbrziCPbE/ZzdGPLXj4xZ2xozLhsm1rNnqc/ehS5XpTXrk4b7d2pECBxczHjR1fu47fSYM4Oa9e0xNxxe5NhKh/feuRbl7yoW7N0s4eiePuNxSaolz7/xIu48scX9ZwcMxhXPvO4Qr3j+pfz73/40w2HFJcsFL3rapeRZyn//4BfZntTULnD55ZdyzeXHuOnay/m13/ojzq1vEkLblQ1R8jdjPL3vfe/7Cs/S//PxA197HdJ5pHVYGzDGMJ2U9KWjq+HQgkboWIuuHlgm05BIz+mzQ3Yqx5lSMPEKLxVpt0OuAqkICNO0PiyeItMQBM6ByLuxkWdKjIsJ0Olin0xrcq1w4ynBxuYrWQFJRsh7JDr6o9i6wpkGa6LfaV7kLK0s0+nm+BDYGWxTTUuMscjuIml7ozit65iW7EXs2gtJ0evT63VIswwXJNVoSDUakqXxxswGSIp+bCC7ip1zpxlvb7O9s0O/k7DYy1hd7lCZwNbIRG8srVlZWcCrBFRC0l1kPJ4wHIw4cf/DeGPQMpCmSWSEyMgS0UpwcKWHsRZjPRdfFD2lhk7y4Ilz1I2hX2SsLHcpioTae3Rw6OAYlu21c7C4sohKNF5K6tpgrMMFP7+RrMYxzcuUJUWRRXZUEHQzTZZI8kTR1DW2sfR6HSobGJRxTBBiIyEVUWNSNw4v4l6p05S8U9Bd6KOCwxvDdDqmrBuG05rbHtlia2IY147lxX60yQiBqizRQtAvYty794Fx1bR7sCCVMSAoVQIPJFLQT6NHm1YC08p6fICVfk7ZWIaTmsQ7tIBEBNIsIQjYHBu2a8/EC/YfPAgEnLVsbO1Q1Q1lY6KcV0qssdRNgzGWyjxxwacna+gna+gna+gvv4Z+3IyneYoXkQ4cRDTjxsfEtUTNTmkEOIQLiAZ0FmVTSgjSNLKDjPOYoLF4bCnbxDIRETw/Ay7iawU/cwwKIFTLiwu7vzOXZonWbV60oEr77/aYaTXxUXInwkzuJVGJjqCVUgjn5gNPtlRU72eeSa3peOuJFMQFMrEYbRclhy1y79uLK4RERuJpPF/Std5KDc6baHomfDRQE4EQbBwsSrcLgZrTUeeC0+Dn+tE5IDM/JzAjHe7+rD1X8zEhvuSvMAejZpNxng9ImJ3zOfDF7gScQ00z+uCFsr+/AwzOJuHsJxegx/P3P7vaob32kdw2/wxRajibwLPxBsPSzMenmwNoEaxUQpAHiQ8C61sasIw+U0GAcyF2lXykldr2NQkB58L81XRroo4Q7fuj7bhegK4/kQ8XC1OBpzGBaYC1WtIRil4Ke3XSyj0DzWQUaf9ECaISgiJx7AymTMY1p4yl29MUuWQlbUhUIFGB0kZPM9sYJmaM0oqwVLCQ9EhVht2uoV0kgdZ8M9L/CQJHEwtPMTOt9y19Pcp2pZaEmbTA2zm4KVoZgMPPwVbnG0izWbsigtlBtFG+Yv468aceqZJIB28amiYCwlmWkumULE3Am0gfdpamaUhEwkKeRnZfCDhnECiypEue5EzqhnFZI5Oooc5tEw0CpYpgt9YQUkyIzEQRXfO5YNliF8q9YICJWbZkRGojKd7Hjo2bAbSz2bFLE27PVDt5L1xnaX8zzsAg5i/D/CFcOG/ja8zX13Z++xCBbufjDBWzuRraJI5WQhKNamO8pBQCjwQhyZVEi4AGOlqQCIFGRcBYQoGKcoTWuDGV8TEO3zIRQ6uzF+RS0k88NniG05q6TtqbiSjjmLZprDNQfL5w/gM4hBAcPn4pi2aZ/ODlPO3Zz+NQpbju2j/BtsEQCBDTHcR4i+TIZehxidh4kMcGNQwbWC85sP8A1190KcdWuzz3Oc/hZS97Ge/++J8iNhvGS32ecbTPjVdfwotf+tWsP3SS8caQLRRpV3KoA/feeztu0BC05kzleXhQc3B9yPT0NtY5Lk09DsE2mmde+xTcygYH7j9LsdDHh8DmFBYPXsShYyvc8s6P41XB4soq3dUDFEtLjKXGCknjYGNkOHT0Ym689jh/NHkn959a54w7xdc+9zrGlcOoHkePrXDs2FF6+y5mbeh49MwO1199NZdfcxl7Lz/G/esfQy40HNy3xMrKIVxxCvXev8Wki9j+Cscu7vPgXY/y0ftO8S2PnuXhc1ucGtU8ujVFac09OwG5cpC9xw+yNfkwg8owbCx/e+vtuKriUC/l9nMjLjra5R8VXQ4ePMSiVpw8N+HhM9uc39zhhTdfzGBS8fE7T3LgkbXYTAuBxglGjeDUoGJPJvFWcffmKQCeduVhjqwuMWw8d6zVLPcK+p2ccXGA1SMHueHSPdzz6Al21gbc9vB5rr74ZlZXehzRjsMXHaFJM0R/jVqn7DSBT935GDdfI3jZs65h7bHAcFLyuUfWWUgj2DCY1Cz1e6RaU1AyrRru35iwmmsuPrDCi591Ex/8vY9z+6MbLGWao4cP8tzrLuEL9iSmsWQiUCHZ08949sWrvPsTX2A0GfON/YzVAwdYTvdTGMv1Tz3Gy190LX96e8nJ8yPyTPPUp97EUjfhzz5/hsX9GVKnNB4OHDrMC5//PP7HH7+XcH4T4zyXH7+YhX6f2sOZM2e4++67v6Lz8vEcaapwdcD4mNhWOtisHI20NKnggIjmuPjAaFxRJ4I0adc2Keimkq3tklETMKOabioptGA1l/P9mhCNwJvKYpro65NLR5JJUp1gnKfxFm88wfgIOhlDkmQE55hMyii9kIJeInEh4IyhcT42Z6VEpSmyTTXKE02qJS7RFHlKp5PjbcXUGKYTi5KKNFGkaRLTrpWirgxCQJrENGcXolGytAYvLNRTvDGo4OjnCb0soZPq1iw4YLzHopBSkXXyuAcKiSBE4+uFLmmeYbzDm5qJ80gpydIErWL9UVuL9eCEgjTHB0HTWAQRABAhJpHFSPbIdrchkKYKqQLCBZTS6CT6rOZ5gfOOwXCKMQ2NsQQhCULiWykUUiI9WGsRITZDjfPUxtKH1pNFMybiBSJ4tKa1wpCtQXG8zxBSUuQpk9Ek+rqGMGftG+vbRG6PaUyU2RBIRGy+5m0IkMOTadnu5bGuSLWIoGSIPkKECEDlWtGRsUnrQmCx0CgCdSXjuQoxnMfaCJAVWjK1gSYEmrJEqRgsVOQ5QsrYGA7R22zWxH3C78BP1tBP1tBP1tBfdg39uBlP//FVx5DBoGii1jiEGP2aFiid0u31Ca4hOMOotDjZwas+i8uLFJ2U3mIOKtLFJtOGelLRTGumw/E8OS5LC0SQeCtxpSFYB9bMXeO1jkAMWiN17GDoCw3EvI9pdS37Kbqshy8dcO0AUSJGFkql0ekuMsrcqFIg84wgY9RnCL7Vuvs5mszMyFwKin6BUJ6q2WH9/BlGgx3KSU0n79Lt9OjkBcE7bFPNB5nQmpnBOUHQmIa6qWnqikRqemlBoYuWfhcn+0zLL1pDwt5iH5GlhDxru0wuGoPH4Ypr2UwhtKbiPsRFhRbgEbsgzcwvK9LnPDMd9myIzCdeCBBcC3ztmqTJFjW6ENvaBaTiE0gh5pN09l308NoFndZGFeeHFfeeG1MZR2MDem6dv3stBbuv571vL3d8Xoloi6f4/ErtamhnVOLZAhCfIMbXSkSrUY+A0tQ5Kg9TD2leRLadVoyrisYaTNudEQi21nYez1T6ih0/+oxLKZSkpxQPTywnSsOntqfsKwQHu4KvOybJZCy6mkZgQvS5SrWNwKpI+NTpmkd3HF8823DZgQUu3tvlpmM5zhuqpmYyKjFNpHYmMnpOrPQSFjuLdJMO6ai9K5aKZpZYqRQksYNqqgmJStBSgQwoJDJIXCjRnQ75vv3QxELZDTZBJ6A0SkZAu3GOJii8FAQF3YVFdNpGrTofv4xHOINyFqUEQSm8Tsi6HYSExo44/dh9jHY22LOygghx/hVZxrgyrO1MOLd5njxRPO2KSwgEHJ5RY+kW++lmezm79ijbkx3WdjZYyTpkWqE1dNKEPElZXtwfKbgBnFLIVKFzRTXaiYWL1Pgg2uWoTe6Emc0gIFFCMftnlNEGrPFzGa1xFusjRV5duCd4F4snYeedWSUCBIH3qi3i4+vKFhz2YeZhRwTH56MqbryJjJvfsDS8/4unmdaWxngyJSiUoK9FG88tKJTEed/KkWNalRYCfHwfejYkhKRAUjkLBBbShMp5GudJkwRHwARPX0cPi8rsmpU6b+c3NPcNS0YOpl7y3BuuxXjHPScfYzAaYZ2jUxRMxiXVtCaYJ67PxIVbtbVtxK6c+S5GQ9qZHwHAxl//D86+++e58sf/jA989i6+6Zu++Uue71d/9Vd5/etfH9dCGW+MvLPtsn+BL5+S7U3MrBkRaOqam556Mw88+ABKzq5nG0Ax6xi2fxRFwe23f55LL70E5yxf+/KvZTyZ8NGPfgydaM6eOcN1113PG9/0Rn7qJ38SJeFd7/oT/sm3fychBJ72tKfx0Y9+FK0Cg7VT/F9f+0JuPb3J57YblJJ8y2tfy//47d+Z7zVSSn7g9f+Mj3/kw3zkM7fR7/epq5KXP/Nm7n/kUbYs/M2H/gYEvOAFL+S3/tt/49v+yT9BAj/5Uz/FT/7UT6GkaDvGsUDMlGC1SPjl3/gtbnrGM7n+hhspp1OkFPP9drZ/JUqy2iv4tXf8Bl//9V9HeeZWfvo//3d+9tf+IHonEov6C4/f/d3f5eabb+amm26iqqr5/wuxG8KRd7rsv+gizp8+zYG9e/jUJz5Gv7/IZFpyw403cubMGYSUfPITn+Dmm29up3BNwONFzlv/7b/l53/+52MTsX3eWd3zd97O/LUF8zIAgJe+5MX8xXvezTe89tt4z3vfD8DP/ezP8i//5Q9e8Bxh1htECsFrvuEbee9734uSgp/92Z/j+9rkOSloz9/ui0sBbrrN+mf/mN4lz6Zz6Pr5mDN1xTOe/VzuuusuhIA//ZN38fKXvxyhEn7oh36It7/97f9fe038//v4N6+6FufAWs9jO4atSc3ZzSFdHVjMJTcd7JFIhRICaw1GRBuKPUVGmiWk3YJP3HueU1slp4cNKwsdVvsFz7hkhSRYpK3ZmtSUjWdUOqrGkYjAseWEPUsdukXKYGqpHdRO4KxHC0FHS5YPHSSkOaeGDdOdHUJVcuneBYxzVI1la1pF4/DDB9i3fxUtBNtraywtdimKlImNseZpmrB+fp2twZST6yP2HzhAp9MhyfPddONUIb1H+Ngpn1Y1W8MJC92cLJF0VOD82nlGwxGJa1jIE/qdlG3jGZSGc8Oa2gqyLOX4RXvoKkiVwMmUhcU+/X6HBx48xXBrwHB9E0u8QUtbM2chY2CQzHJ00eWG66/CGcNga5PBuZPUZUVpoLPYJ+0U6E43vndgWtZzv6v+6gGCTBhUDUmbaj3cGbG9vcNoGGVRioBwlqaJjDMXIJUOhUcoSXCO4DzIpG2A68jma9lFmY6+PSLJyFRkRkzLiv5Cjz37Vrj3kXOUZYVyMe27bCy3PbwRmVO1JRCtL5QS7O0kdBJFL9NMGocNgSxVJCreh6ztTFv2hSS6+UZmYT/VpFqQ6JgcrQCRZ9SNY1I1UcLY1uCli/P6UD9lu3IMjccFgUyicfXC6h6sC2ztDNnY3qaq6pgS3koDp439Cs3Ov/94soZ+soYGnqyhv8wa+nEznoyN9BDRLppCRLqqkPEDCukRwc8ZIM5Y6rpCiJS6cRgBMokXomkarDV4HGjmBttex4urExkHlIFQR+BItuhqdNAjFtgtTuRblpOnlYDBvBsjiHK1tiqFVoYm2QU8Quv15K1t0UqBFyr+btvpiLWUmLN9ZOu7JORMVyvxOIxpolG497u+RRAX1hC/YiUlwQZ0KlFagxDRnJBAZSxGRLmX04FEaTKd7KKKREZSpNhF7GQmr9zFG8X8zwtLsSDincEueekChHIXfCX2jtpHz1DXC54sMrliJ0jICx48e5SYMcq+FAGdA8Bi9/0xP0/x/IZZskC7EYUQF4J5FTz/XLtvSIjZNY3sOimiM38ixTxFb/b/agaQhdm4AqUEmvizVIionw4hfgYXTRdDGx+phSJRKnaTsF9y1p/Ih3AGmeSIImenrhkIi3WWQQ3BCz55UtDRgUzFc1NamFhYziVKBgKWjYnHOTi6lHHZgT7HDiyQZpayNNjaknmJlnED0MKTSVhykmQKXjm81MyN+wOtYSFxIQ9EKnzwaB9Ii5xZkIFrUrwTmNEU7VoNpUrwMsofp1XTUvs9IomLjUhTqnKKqmvybg9b1bjGELyNctwkoQkOYS1YS57n0Vesm6ITFTcH36BkB6UKrI+x1yv9hMY5nDM8ur5Bv8hIlGI8rqHeQeSShX6GFRlbpUAJTyI0vaxPpuPY8dYhMo1Ks3ad8EhnyLQCKUHqNgK2Te4METBunMe50MZkG2wI1C7GFBvnmNbR8NN6z76FgjzVFGlCu2gS2YwtSBBHxRwhCKJN/ZwtGDOGH+3D5+tP/F/frglRVhs71xLIBO0GGVhOVGR1COjrCOh678hkjCYIoe2WtV1sIQS+NUE0tMza9n0OnScVgm6io548xCJiBjbnSlHPujZiVjgH9mYJsrY01rAxGpFnGZfs388DxjKcTGNAhg8XfPAn/qG15vzpE9z24ffzmftOkvYWefOb34yUkvF4zM/8zM+wcc9nqR/d4v82AqXiVv+mN72Jq6++GoAXvOAFaCUx400+8ref4i8++BHe8sPfx3LqGT78OX7vb+7i4XM7gOAf/+N/xHOe85z21QOijegOgTnwcuTIEX7oh36IP/7jP+bWW28lAC/56pfwyle+kv/6jv/Ktddey3e97rvajl6I7AcpWVpe4T/+p//E9ddfh040ILjpqU/j53/hF/iVX/kVfIhhIkJqOkv7+JYf+2leMK44NSr5D//hP8TkJ/2lpcw3ffPX86xnXken20UqTZoV/OC//jG2hyNKL7nk0ksRQvBLv/RLPPNZz5o/fma4+yVJacCRY8f5sR/5YW586k0s9zLe+m3PQa1eili9lLe97W1sb2/P58rFx4/zlh/+YW586tNQaYdi79W8+rX/lD0X38Tb3vY2dnZ2/pfrqVSM5xZC8MpXvpLnP//5vO1tb2MwGODamqosSzbOnaMqS86vr/Nv3voTJEmKsZbtnUE0WA4gVWyoAdAyHaTQfP2rX8Pqnr3z5931t/jfH3le8G//7b9lYWGhPRGBi45ehEw7HOrlXNRPOTlq4jlzljPv/w1ue3Sdj54Y8eY3v5lDhw4B8IY3vIGXvexlADz/+c//X67Vhf/89V//db74+c9SnX+QZPGT6O5qO1afzze85jX82I/9GB//+Md5xzvewTt/87e46+57+Ff/+sdIsgKVd/+Pn+eJcDS1oVN0WF3ucR4DbsTIDGisp3aBB7YNHe1IpMAZQ+k8E+sZLQbyzJFWgY2pYWIDRadg34GDHNq7TK/rMdMR03rCtAl4nbF4YAk9GiNMg7FTymlNMJZJ5SFJSNIML+LN5nZlSWqLwiKdQzlL8Db67yiNTzIS51GJBOkZT6doIdCJZFhbdhpPYwwLHctCyEmzgqIj6HU9jmicHZxjMpriTUPeLegUGd08pbGWSVmzPRiz0O+R5hl5EplIlY3x342QTINgQrSVWFzpsbE1YVpb7nv0fDTvTxUqSbDO4r2JCWCZpvRtHSglKkmivEspRo2nlyT0ujmDSY2tKyaTktp4vFB0+l0SqZDWI4whSImNxTw+eBrr8eOK2tec2RzhnYnAvWmYDEdMJxO8D3TyhIVORn8hIxBTq1w5jj4utWWm0Ui0bAUNIUpkREy4y7Qk0ZKin7fpb5ZOliAIjCcVSRq/V42nrC3O+SjFkqJNytKkKoKL3SQyIprGoFv2Uz/X2DYhstBRgaIlVE2seyUwwdI4SdZKaVMlUO1e6zygFYnSFJ0UM6wj8yoIet2cjpRsTxoqGxhPK/IFR5KmHNi3iveOoRozHIx2PXiewMeTNfSTNfSTNfSXX0M/buDJeknwERiQIaBUpIW27NGIfMhdzaFrExc8FcYHfKrRGQjh8a1BnceDiqZU3gWC9JFOqqK/EUISrNwFVFq4MCBaiV/LzhEzfopopXk+AlAyytRmHcPIrYuPlcx8hwDvCdYSjAEZabFOidiFoAVZ5uBOiNI5KSL7pS0YZx1S60z0/2kHwIwqF+bSOM9MnRUHmYw+Tlogmyh1M85hgyO4aPTtg0friM4K0erDhG+HxN89xHyM7/47fMn//d3HhN2HMaMD+gueZw6riN3v51I+MZO/tbKzOaDUnt8L388FzKn53Jv/frwWF6oJfeszNZNJzh8y//uCTzkDrkRM4VAimnXOgCfdbuRSxK5Va1HfpkMIsguAp6i1jd1gT3TyL0XLqGsp76r1C9h9A0/0LROEc/GapCkTaZkKiQ+OsgFr4M4G+pmgk0SvsbEJ7NRwqJeiZWRUjKp4Lfb3U46sdjmyp4fxI6oSvPFkXpAITZKkKOHJCfQ9WAdOOHw33QVjRbyCDqLGHIGWCuUdikCeRKmNCSCsjoDktGp7FYDUcToTmNS2ZepBqmN3E51gRlMckCQ5rqywTQ0YhOzhVY4zDuEcyrm24BKoIqZyBAHeG4QUKJljvEEqSb+jmFrDuJxwbmcDQp9ullJOKpQdo51i5eAClU/jvPUBLQRF2iFtkymddchCIvI0dg9dA9bGboMUCBFDDHwA40D4aLBvfFwrm8YxMY7aOsaNoawbamMZVg2T2lBbFztlsmAhT+dF3fx8xxHBBbOVQMuEFLNZ1gYJzIHq2Xo282+b/bkLUgsgFWDb9J8FHYMP6hAoVGxcTK0jkZEu7NtCm5ZpGbHlmJjqRZQ2aOL8rpwnTTSFUlQh+uAp4u8qEbs7VYhGqReG2i6lmso5tirLYDpFKMXFq0ucOr/OeFrO1+t/aMfO+jk+/cE/53c+9Dm6ew7xIz/yIzHWdjrlN37jN9ja2iJNU/5Ns/vZXv3qV89BAAC8w053+Nwtn+Ttb387/+I7v4lux7Bz14d51++/j0/efRqA6667dhd4mrGD/06RsW/fPt70xjdx5513cuuttwJw88038/p/8S+44cYbeeyxk3zXd333//I5ut0ur3/962m7ASAEl11+Od9/2WW8+93vZjoZ450Brcm6C7zgW78LgLIsefvb3/6/PTcveOGzCfYpyCQBIrv5G7/1W2PDR6bz33u8htT7DxzkdW94EwKHG6/zHV99Hf1rXoo49jx+5Vd+he3t7fnvHjhwkH/+xjfN/636R3j2C45w/VOfwy//8i//b4GnC49nP/vZvOENb+CXfumXGAwG8/931jLY2gJg0DT8+m+88+9/4yLudgDPec5zuPbaa+PzDod/b5GYZRnf/d3fzYEDB/6Xn60UCfuLhFOjyLLwpmHtb/+Uv731AX7t1jW+67u+i0OHDiGAV7ziFX//+2yP97znPf8ffZq++Ztfy7d927extLTEO97xDt77vvfx6IkT/Oib34LQCSotHvfrfKWOpnEs9jXLiwtkU4MYW0oXaIKn8YIzI0MvVdEny1jGjWNYx30hbzypDQxqS+UCeSdjeWWVfQf2k7stbDWlNo7KBpI0pbeySkDiyjG2nFBXhmAsZR1IpSJJFBKP8YFJ4+g1jlRahHcoHxPjoq9qgpMaVZbRV0YEyqpGS0FXS8aNY2oMztRoEehqSZJkZDkUhcUSa2nlPJPxBFNOMSGQJAqhcox1VHXDeFKCVOg0J0sDHknjAp1EYkX0RqrQiCSh183YGtZUZcP25gjTz1gsNHma0IoiyJIEnShqT5tmLGJqX56ilGa7LlE6ygMnZYOpaqqyjpJCIel0ughrEc4jjMUrSWij6p33NNZRlzWTJnBuY0BdlThnySXU0wl1OUUpiRQdFnsFnaKIBaexTOspzgWq2rR2EJDIQBAuJndLgVLRsyWTkOr/t7276UkYiKIAeukXlQjR//8jDQGF0im4KBsTEyWmiYtz1rOfm5v3ZqrsNl0OpyHjlPRtnWuSj/MlbVOnSZv6dsl5GHO93r5M93dNnU1TZddVWVfzJNVQpnn9sa6yaeucxilluqW7bx7Mb+7Oz6ZUq/kjnnKfeK0zT1fMq0r3PFHNv/g9757ydp4yDiVjVtn2bfp1l9NlyrmMOQ1jxlKy7vu8vmxzPL6nlJL9/vDtnfLfyNAytAz99wz961U7AAAAAHhE9fMRAAAAAHic4gkAAACARSieAAAAAFiE4gkAAACARSieAAAAAFiE4gkAAACARSieAAAAAFiE4gkAAACARSieAAAAAFjEJ8sky56d0CwQAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAADyCAYAAAAMag/YAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOydd5weVdn3v2fq3bYmmx5SgRACggFCLwkQITSlKEpVAQULKAhYqD4iigIWQGxI8RECiPgi1dCLSu8klFTSs/VuU855/zhnZneTAAk18szv81nIzs4995mZc67rOr+rCaWUIkOGDBkyZMiQIUOGDBkyZMiQIUOG9xnWRz2ADBkyZMiQIUOGDBkyZMiQIUOGDB9PZMRThgwZMmTIkCFDhgwZMmTIkCFDhg8EGfGUIUOGDBkyZMiQIUOGDBkyZMiQ4QNBRjxlyJAhQ4YMGTJkyJAhQ4YMGTJk+ECQEU8ZMmTIkCFDhgwZMmTIkCFDhgwZPhBkxFOGDBkyZMiQIUOGDBkyZMiQIUOGDwQZ8ZQhQ4YMGTJkyJAhQ4YMGTJkyJDhA0FGPGXIkCFDhgwZMmTIkCFDhgwZMmT4QJARTxkyZMiQIUOGDBkyZMiQIUOGDBk+EGxwxJMQgnPOOWedzh09ejTHHHPMen/H3LlzEUJw1VVXrfdnP2xsqGM95phjGD169Duet/vuu7P77rt/4OPJkCFDhgwbBs455xyEEB/1MD40rI/dkiFDhv54t7b8B4mrrroKIQRz58592/P+r8m6DBk2VKzrvjTDR4v3nXhKhPXjjz/+vlzvkUce4ZxzzqGjo+N9uV6GDBn++/B+y5X3ikqlwjnnnMN99923Tue/+OKLnHPOOe9oxL4f+NGPfsQtt9zygX9Phv8bSNZe8pPL5Rg2bBjTp0/nF7/4Bd3d3e/L97z55pucc845PP300+/L9VbHn//8Zy655JIP5Nrrgg/6/vrisssu2+CcVRk+eqy+lh3HYfjw4RxzzDEsWrToox5ehgwZPgD0XfNv97Ou9uyHhWz///GE81EPYHVUq1Ucp3dYjzzyCOeeey7HHHMMzc3N/c595ZVXsKwNLmgrQx/cddddH/UQMmR431GpVDj33HMB1imi78UXX+Tcc89l9913/8A9Mj/60Y845JBDOOiggz7Q78nwfwvnnXceY8aMIQxDlixZwn333cfJJ5/Mz3/+c2699Va23HLL9Nzvf//7nHHGGet1/TfffJNzzz2X0aNHs9VWW73Po9fE0/PPP8/JJ5/8vl97XfBB319fXHbZZQwcOHCDiyLJsGEgWcu1Wo3HHnuMq666ioceeojnn3+eXC73UQ/vvwrvRtZlyPBh4pprrun3+9VXX83dd9+9xvHNNtvswxzWO+Lt9v9rw29/+1uklB/8wDK8J2xwxNP6KD3f9z/Akawd5XKZYrH4oX/v+4UPe/ye531o35UhQ4YPBlJKgiDINiX/h7HPPvuwzTbbpL+feeaZzJo1i/32248DDjiAl156iXw+D4DjOP0cSB8l/tt19oYCpRS1Wi19xxn+e9F3LX/5y19m4MCBXHjhhdx6660cdthhH/Ho3huiKEJK+aHZnhuSrMuQYW044ogj+v3+2GOPcffdd69x/N1gQ9ILrut+1EPIsA74UMKFjjnmGEqlEosWLeKggw6iVCrR1tbGqaeeShzH/c7tWyvhnHPO4bTTTgNgzJgxaThgkq6yel74qlWrOPXUU9liiy0olUo0Njayzz778Mwzz7yrcSdhyffffz8nnngigwYNYsSIEenfb7/9dnbZZReKxSINDQ3MmDGDF1544V3fe0dHB8cccwxNTU00Nzdz9NFHv2WI4csvv8whhxxCa2sruVyObbbZhltvvfV9Hz/ALbfcwqRJk8jlckyaNIm//vWv6/wMV6/xdN999yGE4IYbbuDcc89l+PDhNDQ0cMghh9DZ2Um9Xufkk09m0KBBlEoljj32WOr1er9r/vGPf2Tq1KkMGjQI3/eZOHEil19++RrfLaXknHPOYdiwYRQKBfbYYw9efPHFtdYT6Ojo4OSTT2bkyJH4vs/48eO58MILM/Z8A8a6rq2kTtpFF13ExRdfzKhRo8jn8+y22248//zz/a75VjXJ+uaOz507l7a2NgDOPffcVC69VY2Xq666ikMPPRSAPfbYY61hze+0FmfNmoVlWZx11ln9rv3nP/8ZIUQ6/4UQlMtl/vSnP6Xfk8z1t8p/X1uNCiEEX/va17juuuvYfPPN8X2fO+64A4BFixbxxS9+kcGDB+P7Pptvvjl/+MMf1nrvGT7emDp1Kj/4wQ+YN28e1157bXp8bXPq7rvvZuedd6a5uZlSqcSmm27Kd7/7XUDrhW233RaAY489Np27fdPFZs6cyeTJk8nn8wwcOJAjjjhijfSgRCa89tpr7LvvvjQ0NPCFL3yB3Xffndtuu4158+al1+67Fur1OmeffTbjx4/H931GjhzJd77znTV0T71e55RTTqGtrY2GhgYOOOAAFi5c+I7PaV3u71//+hef+tSnaGpqolAosNtuu/Hwww+nf0+IvaOOOqrftR966CFs2+b0008HtF30wgsvcP/996ffk8i0t6pHs7Z6NqNHj2a//fbjzjvvZJtttiGfz/Ob3/wGyPTlxw277LILAK+99lq/4+tjZz788MN861vfoq2tjWKxyKc//WmWL1/e71ylFD/84Q8ZMWJEapOtzeaEdZtjfXX7JZdcwrhx4/B9nxdffHGdxw/wwgsvMHXqVPL5PCNGjOCHP/zhOs/lt9OfM2fOZOLEieTzeXbYYQeee+45AH7zm98wfvx4crkcu++++xop+A8++CCHHnooG220USqPTjnlFKrV6hrfn3xHX/t8bbpeSskll1zC5ptvTi6XY/DgwZxwwgm0t7ev031m+HhjXfdVb6cX5s2bxwEHHECxWGTQoEGccsop3HnnnWtN43snffdO+/+1YfV531c+/PrXv2bs2LEUCgX23ntvFixYgFKK888/nxEjRpDP5znwwANZtWpVv2v+7W9/Y8aMGQwbNgzf9xk3bhznn3/+Gvt3IP2OfD7Pdtttx4MPPrjWPcW62hsfV3xoNH0cx0yfPp0pU6Zw0UUXcc899/Czn/2McePG8dWvfnWtn/nMZz7D7Nmz+d///V8uvvhiBg4cCJBu+lbH66+/zi233MKhhx7KmDFjWLp0Kb/5zW/YbbfdePHFFxk2bNi7GvuJJ55IW1sbZ511FuVyGdChi0cffTTTp0/nwgsvpFKpcPnll7Pzzjvz1FNP9Zv863LvSikOPPBAHnroIb7yla+w2Wab8de//pWjjz56jfG88MIL7LTTTgwfPpwzzjiDYrHIDTfcwEEHHcRNN93Epz/96fdt/HfddRcHH3wwEydO5IILLmDlypUce+yx/Qisd4MLLriAfD7PGWecwauvvsovf/lLXNfFsiza29s555xz0hDwMWPG9NtwX3755Wy++eYccMABOI7D3//+d0488USklJx00knpeWeeeSY/+clP2H///Zk+fTrPPPMM06dPp1ar9RtLpVJht912Y9GiRZxwwglstNFGPPLII5x55pksXrz4I60LkuHtsT5y5eqrr6a7u5uTTjqJWq3GpZdeytSpU3nuuecYPHjwOn9nW1sbl19+OV/96lf59Kc/zWc+8xmAfqlGfbHrrrvyjW98g1/84hd897vfTcOZk/+vy1qcOnUqJ554IhdccAEHHXQQn/zkJ1m8eDFf//rX2XPPPfnKV76SXuvLX/4y2223HccffzwA48aNW7+HajBr1ixuuOEGvva1rzFw4EBGjx7N0qVL2X777VPDuq2tjdtvv50vfelLdHV1fWRpTBk+Ohx55JF897vf5a677uK4445b6zkvvPAC++23H1tuuSXnnXcevu/z6quvpobmZpttxnnnncdZZ53F8ccfn26Ed9xxR0Bvbo899li23XZbLrjgApYuXcqll17Kww8/zFNPPdUvDD+KIqZPn87OO+/MRRddRKFQYMiQIXR2drJw4UIuvvhiAEqlEqA3ZAcccAAPPfQQxx9/PJttthnPPfccF198MbNnz+5XL+3LX/4y1157LZ///OfZcccdmTVrFjNmzHjHZ/RO9zdr1iz22WcfJk+ezNlnn41lWelG4MEHH2S77bZjs8024/zzz+e0007jkEMO4YADDqBcLnPMMccwYcIEzjvvPAAuueQSvv71r1Mqlfje974HsF7yrS9eeeUVDj/8cE444QSOO+44Nt1000xffgyRbOZaWlrSY+trZ37961+npaWFs88+m7lz53LJJZfwta99jeuvvz4956yzzuKHP/wh++67L/vuuy9PPvkke++9N0EQ9LvW+s6xP/7xj9RqNY4//nh836e1tXWdx79kyRL22GMPoihKz7vyyivfcwTHgw8+yK233prapBdccAH77bcf3/nOd7jssss48cQTaW9v5yc/+Qlf/OIXmTVrVvrZmTNnUqlU+OpXv8qAAQP497//zS9/+UsWLlzIzJkz0/Nuu+02PvvZz7LFFltwwQUX0N7ezpe+9CWGDx++xnhOOOGEVI5+4xvf4I033uBXv/oVTz31FA8//HAWLfJ/HOu6r4K164VyuczUqVNZvHgx3/zmNxkyZAh//vOfuffee9f4rnXRd+u7/387XHfddQRBwNe//nVWrVrFT37yEw477DCmTp3Kfffdx+mnn57uQ0899dR+jtSrrrqKUqnEt771LUqlErNmzeKss86iq6uLn/70p/2e39e+9jV22WUXTjnlFObOnctBBx1ES0tLv/3y+tgbH1uo9xl//OMfFaD+85//pMeOPvpoBajzzjuv37lbb721mjx5cr9jgDr77LPT33/6058qQL3xxhtrfNeoUaPU0Ucfnf5eq9VUHMf9znnjjTeU7/v9vvuNN95QgPrjH/+4Tvey8847qyiK0uPd3d2qublZHXfccf3OX7JkiWpqaup3fF3v/ZZbblGA+slPfpIei6JI7bLLLmuMddq0aWqLLbZQtVotPSalVDvuuKPaeOON39fxb7XVVmro0KGqo6MjPXbXXXcpQI0aNeotn12C3XbbTe22227p7/fee68C1KRJk1QQBOnxww8/XAkh1D777NPv8zvssMMa31OpVNb4nunTp6uxY8f2uxfHcdRBBx3U77xzzjlHAf3mzfnnn6+KxaKaPXt2v3PPOOMMZdu2mj9//jveZ4YPFu9FriTrPZ/Pq4ULF6bH//WvfylAnXLKKemx1edr3+/qOw+XL1++hqx6O8ycOVMB6t577+13fH3WYrlcVuPHj1ebb765qtVqasaMGaqxsVHNmzev32eLxWK/+f1W95Dg7LPPVqurAkBZlqVeeOGFfse/9KUvqaFDh6oVK1b0O/65z31ONTU1rXVtZvjvxtrW3upoampSW2+9dfr76nPq4osvVoBavnz5W17jP//5z1r1chAEatCgQWrSpEmqWq2mx//f//t/ClBnnXVWeiyRCWecccYa158xY8Za5/8111yjLMtSDz74YL/jV1xxhQLUww8/rJRS6umnn1aAOvHEE/ud9/nPf36dZMFb3Z+UUm288cZq+vTpSkqZHq9UKmrMmDFqr732So/Fcax23nlnNXjwYLVixQp10kknKcdx1ng3m2+++Vrl2NrWulK977ivnTVq1CgFqDvuuKPfuZm+/O9F8p7vuecetXz5crVgwQJ14403qra2NuX7vlqwYEF67vramXvuuWe/+XvKKaco27ZT23HZsmXK8zw1Y8aMfud997vffdc2WaLbGxsb1bJly/qdu67jP/nkkxWg/vWvf6XHli1bppqamt5y79EXb6U/fd/v99nf/OY3ClBDhgxRXV1d6fEzzzxzje9Zmx694IILlBCin77fYost1IgRI1R3d3d67L777lvDPn/wwQcVoK677rp+17zjjjvWejzDxxsnnXTSGnN2XfZVSr21XvjZz36mAHXLLbekx6rVqpowYUI/23d99N3b7f/XhtVt3EQ+tLW19dvDJmvuE5/4hArDMD1++OGHK8/z+smMtT2XE044QRUKhfS8er2uBgwYoLbddtt+17vqqqsU0E8Xr6u98XHGh1qZO/HKJ9hll114/fXX37fr+76fFhuP45iVK1emIf1PPvnku77ucccdh23b6e933303HR0dHH744axYsSL9sW2bKVOmrJXhfad7/8c//oHjOP2iNGzb5utf/3q/z61atYpZs2Zx2GGH0d3dnX73ypUrmT59OnPmzFkj/eDdjn/x4sU8/fTTHH300TQ1NaWf32uvvZg4ceL6PMI1cNRRR/XzsEyZMgWlFF/84hf7nTdlyhQWLFhAFEXpsb6eqM7OTlasWMFuu+3G66+/TmdnJwD//Oc/iaKIE088sd/1Vn+eoL1Lu+yyCy0tLf2ex5577kkcxzzwwAPv6V4zfLBYV7ly0EEH9fMEbrfddkyZMoV//OMfH/gY3wrrI0sKhQJXXXUVL730Ervuuiu33XYbF198MRtttNEHMrbddtut3zpXSnHTTTex//77o5TqN97p06fT2dn5nuRshv9elEqlt+1ul0Qk/e1vf1vvdKzHH3+cZcuWceKJJ/arMTZjxgwmTJjAbbfdtsZn3iqKem2YOXMmm222GRMmTOg3p6dOnQqQrsFETnzjG9/o9/n3GuX39NNPM2fOHD7/+c+zcuXK9PvL5TLTpk3jgQceSJ+ZZVlcddVV9PT0sM8++3DZZZdx5pln9qu99X5izJgxTJ8+vd+xTF/+92PPPfekra2NkSNHcsghh1AsFrn11ltTz/y7sTOPP/74filnu+yyC3EcM2/ePADuueeeNOqg73lrWz/rO8cOPvjgfpEQ6zP+f/zjH2y//fZst9126efb2tr4whe+8C6frsa0adP6ZT5MmTIlHWtDQ8Max/vaLH1t3HK5zIoVK9hxxx1RSvHUU08BulnBc889x1FHHZVGb4LW21tssUW/scycOZOmpib22muvfs9z8uTJlEqlte5ZMvzfwrrsqxKsTS/ccccdDB8+nAMOOCA9lsvl1oiCXh99937h0EMP7beHTdbcEUcc0a8+25QpUwiCoJ9s6/tcElmyyy67UKlUePnllwFto6xcuZLjjjuu3/W+8IUv9IsihXW3Nz7O+NBS7XK53Bohci0tLe9rfrGUkksvvZTLLruMN954o18O5oABA971dceMGdPv9zlz5gCkE2V1NDY29vt9Xe593rx5DB06tJ8CAdh00037/f7qq6+ilOIHP/gBP/jBD9b6/cuWLeu3wX63408Mho033niNc94rmbf6ZjkRCiNHjlzjuJSSzs7O9B0+/PDDnH322Tz66KNUKpV+53d2dtLU1JSOffz48f3+3trauoYgmDNnDs8+++xbhnAuW7ZsPe8uw4eF9ZEra5vHm2yyCTfccMMHNr53wvrKkp122omvfvWr/PrXv2b69OlrELXvJ1aXG8uXL6ejo4Mrr7ySK6+8cq2fydbK/0309PQwaNCgt/z7Zz/7WX73u9/x5S9/mTPOOINp06bxmc98hkMOOeQdO9Mmsnx1XQgwYcIEHnrooX7HHMdZr1TwOXPm8NJLL72j/J83bx6WZa2Rurq2ca0PEhmwtrT6BJ2dnaneGjduXFr/YtKkSW9pB7wfWF0GQKYvPw749a9/zSabbEJnZyd/+MMfeOCBB/o163k3dubqNl0yXxNd/Fb2ZFtb23u2yVafp+sz/nnz5qUb0b54r+t6fWxcoJ/NMn/+fM466yxuvfXWNWyZhAR4Kxs3OdbXPp8zZw6dnZ1vKaOzNZthXfZVCdamF+bNm8e4cePWqHe2+vxcX333fuC9rMUXXniB73//+8yaNYuurq41xglvvRYdx1mj1tq62hsfZ3xoxFPfiJsPCj/60Y/4wQ9+wBe/+EXOP/98WltbsSyLk08++T0xqKvneifXuuaaaxgyZMga56/e4eL9vPfku0899dQ1GOcEq0/+9zr+DwJv9Uze6rhSCtDFL6dNm8aECRP4+c9/zsiRI/E8j3/84x9cfPHF7+o9SynZa6+9+M53vrPWv2+yySbrfc0MHw7eb7kihEjnWl+srZDg+4H1XYv1ej0t0vjaa69RqVQoFArr9F1rKyoMb31vbyU3jjjiiLc0Gt6qzlWGjy8WLlxIZ2fnWjdACfL5PA888AD33nsvt912G3fccQfXX389U6dO5a677npf13HfyOd1gZSSLbbYgp///Odr/fvqxun7jWRd/fSnP2WrrbZa6zmrO6TuuusuQEc9rFy5cq2yY214rzIgGW+mL/+7sd1226VRcgcddBA777wzn//853nllVcolUrvys58J9ttfbC+c+ytdNX6jP/9xru1ceM4Zq+99mLVqlWcfvrpTJgwgWKxyKJFizjmmGPetY07aNAgrrvuurX+/d3Uzcnw8cH67qveS/2zd6Pv3ive7Vrs6Ohgt912o7GxkfPOO49x48aRy+V48sknOf3009/1Wvwo7Y0NARt8D9C3MpTWhhtvvJE99tiD3//+9/2Od3R0pIXJ3g8kHs9Bgwax5557vi/XHDVqFP/85z/p6enpt+heeeWVfueNHTsW0G0j3+13r+v4R40aBfQy1H2x+rg+LPz973+nXq9z66239mOxVw9PTMb+6quv9mPnV65cuYYHady4cfT09Lxv7zLDhom1zePZs2f380i0tLSsNU0v8WgkWB+59Hbnr68sOfvss3nppZe46KKLOP300znjjDP4xS9+sU7f1dLSstYumavf21sh6eQVx3G2VjKkuOaaawDecoOXwLIspk2bxrRp0/j5z3/Oj370I773ve9x7733sueee77lvE1k+SuvvLJGZOArr7yS/v2d8HZr8JlnnmHatGlvu65HjRqFlJLXXnutXzTEuurCd5IBjY2N67SurrjiCu6++27+53/+hwsuuIATTjiBv/3tb+v0XYkXuaOjo19B9nWVAcl4M3358YFt21xwwQXsscce/OpXv+KMM854X+zM1dHXnkyuDzqS9v22ydZn/KNGjdqgbNznnnuO2bNn86c//alfB8u7776733l9bdzVsfqxcePGcc8997DTTjttEG3vM2xYWNd91dth1KhRvPjiiyil+umftc1FWDd9t7529vuN++67j5UrV3LzzTez6667psffeOONfuf1XYt77LFHejyKIubOndvPIbuu9sbHGR9qjad3g2KxCLDWDdPqsG17De/KzJkz18hFf6+YPn06jY2N/OhHPyIMwzX+vnoL2XXBvvvuSxRF/dpXxnHML3/5y37nDRo0iN13353f/OY3LF68+F1997qOf+jQoWy11Vb86U9/6pfje/fdd6ftaj9sJAx13/fc2dnJH//4x37nTZs2Dcdx1mgH+qtf/WqNax522GE8+uij3HnnnWv8raOjo199qQz/vbjlllv6yYJ///vf/Otf/2KfffZJj40bN46XX3653zp65pln+rV5BdIoo3WRS/DWcmx9ZMm//vUvLrroIk4++WS+/e1vc9ppp/GrX/2K+++/f43vWtu4xo0bR2dnJ88++2x6bPHixfz1r39dp3uwbZuDDz6Ym266ieeff/5tx5rh/wZmzZrF+eefz5gxY962JsrqLYqB1NuZtBB+qzWyzTbbMGjQIK644op+7YZvv/12XnrppXXqKpdcf/VaFaDl/6JFi/jtb3+7xt+q1WraCTaRE6sTvevaxe2t7m/y5MmMGzeOiy66iJ6enjU+13ddvfHGG5x22mkcfPDBfPe73+Wiiy7i1ltv5eqrr17ju95KBgD9auSUy2X+9Kc/rdM9QKYvP47Yfffd2W677bjkkkuo1Wrvi525Ovbcc09c1+WXv/xlP/ttbevnvc6x9Rn/vvvuy2OPPca///3vfn9/q+igDxprs3GVUlx66aX9zhs2bBiTJk3i6quv7ic37r//fp577rl+5x522GHEccz555+/xvdFUbTOdkyGjyfWdV/1dpg+fTqLFi3i1ltvTY/VarU19Or66Lv12f9/EFjbcwmCgMsuu6zfedtssw0DBgzgt7/9bT/ZdN11161Bqq+rvfFxxgYf8TR58mQAvve97/G5z30O13XZf//90wnZF/vttx/nnXcexx57LDvuuCPPPfcc1113XT/vyvuBxsZGLr/8co488kg++clP8rnPfY62tjbmz5/Pbbfdxk477bRWguPtsP/++7PTTjtxxhlnMHfuXCZOnMjNN9+8VkP517/+NTvvvDNbbLEFxx13HGPHjmXp0qU8+uijLFy4kGeeeeZ9G/8FF1zAjBkz2HnnnfniF7/IqlWr+OUvf8nmm2++VqHxQWPvvffG8zz2339/TjjhBHp6evjtb3/LoEGD+hkYgwcP5pvf/CY/+9nPOOCAA/jUpz7FM888w+23387AgQP7Mc2nnXYat956K/vttx/HHHMMkydPplwu89xzz3HjjTcyd+7c9zViLsNHg/Hjx7Pzzjvz1a9+lXq9ziWXXMKAAQP6hfN/8Ytf5Oc//znTp0/nS1/6EsuWLeOKK65g880375ffnc/nmThxItdffz2bbLIJra2tTJo0iUmTJq31u7faaits2+bCCy+ks7MT3/eZOnUqgwYNWqe1WKvVOProo9l44435n//5HwDOPfdc/v73v3Psscfy3HPPpTJx8uTJ3HPPPfz85z9n2LBhjBkzhilTpvC5z32O008/nU9/+tN84xvfoFKpcPnll7PJJpusc722H//4x9x7771MmTKF4447jokTJ7Jq1SqefPJJ7rnnnrUSDBk+Hrj99tt5+eWXiaKIpUuXMmvWLO6++25GjRrFrbfe2q/w9+o477zzeOCBB5gxYwajRo1i2bJlXHbZZYwYMYKdd94Z0KRIc3MzV1xxBQ0NDRSLRaZMmcKYMWO48MILOfbYY9ltt904/PDDWbp0KZdeeimjR4/mlFNOWafxT548meuvv55vfetbbLvttpRKJfbff3+OPPJIbrjhBr7yla9w7733stNOOxHHMS+//DI33HADd955J9tssw1bbbUVhx9+OJdddhmdnZ3suOOO/POf/1xrxMHa8Hb397vf/Y599tmHzTffnGOPPZbhw4ezaNEi7r33XhobG/n73/+eNt/I5/OpQ+WEE07gpptu4pvf/CZ77rknw4YNS+/18ssv54c//CHjx49n0KBBTJ06lb333puNNtqIL33pS5x22mnYts0f/vCHVOasCzJ9+fHEaaedxqGHHspVV13FV77ylfdsZ66OtrY2Tj31VC644AL2228/9t13X5566qnUJlt9LO91jq3r+L/zne9wzTXX8KlPfYpvfvObFItFrrzySkaNGtXPSfNhYcKECYwbN45TTz2VRYsW0djYyE033bTWupU/+tGPOPDAA9lpp5049thjaW9v51e/+hWTJk3qZ5/vtttunHDCCVxwwQU8/fTT7L333riuy5w5c5g5cyaXXnophxxyyId5mxk2IKzrvurtcMIJJ/CrX/2Kww8/nG9+85sMHTqU6667LrULkj2XZVnrpO9g/fb/HwR23HFHWlpaOProo/nGN76BEIJrrrlmjQAXz/M455xz+PrXv87UqVM57LDDmDt3LlddddUada/W1d74WOP9bpP3Vm3Pi8XiGue+VRvS1dsSn3/++Wr48OHKsqx+rRVHjRrVrwVrrVZT3/72t9XQoUNVPp9XO+20k3r00UfXaJGetFhcva3xutxLX9x7771q+vTpqqmpSeVyOTVu3Dh1zDHHqMcff/xd3fvKlSvVkUceqRobG1VTU5M68sgj1VNPPbXWsb722mvqqKOOUkOGDFGu66rhw4er/fbbT914443v6/iVUuqmm25Sm222mfJ9X02cOFHdfPPNb9mafXWs/uzvvfdeBaiZM2f2O++txpo8p75tuG+99Va15ZZbqlwup0aPHq0uvPBC9Yc//GGNtptRFKkf/OAHasiQISqfz6upU6eql156SQ0YMEB95Stf6fc93d3d6swzz1Tjx49XnuepgQMHqh133FFddNFFKgiCd7zPDB8s3otcSdb7T3/6U/Wzn/1MjRw5Uvm+r3bZZRf1zDPPrPH5a6+9Vo0dO1Z5nqe22mordeedd651vj/yyCNq8uTJyvO8dWqn/tvf/laNHTtW2bbdr72sUu+8FpPW1H1bPiul1OOPP64cx1Ff/epX02Mvv/yy2nXXXVU+n1+jTfVdd92lJk2apDzPU5tuuqm69tpr31IOn3TSSWu9j6VLl6qTTjpJjRw5Urmuq4YMGaKmTZumrrzyyre9/wz/nUjWXvLjeZ4aMmSI2muvvdSll17arzV4gtXn1D//+U914IEHqmHDhinP89SwYcPU4Ycfvka79L/97W9q4sSJynGcNfTe9ddfr7beemvl+75qbW1VX/jCF9TChQv7ff6tZIJSSvX09KjPf/7zqrm5eY1240EQqAsvvFBtvvnmyvd91dLSoiZPnqzOPfdc1dnZmZ5XrVbVN77xDTVgwABVLBbV/vvvrxYsWLBO6/+d7u+pp55Sn/nMZ9SAAQOU7/tq1KhR6rDDDlP//Oc/lVJKXXrppQpQN910U79rzp8/XzU2Nqp99903PbZkyRI1Y8YM1dDQsEY75yeeeEJNmTJFeZ6nNtpoI/Xzn/88fcd99eeoUaPUjBkz1nofmb7878Tb2YRxHKtx48apcePGqSiKlFLvzc5MbL2+ei6OY3XuueemNvruu++unn/++TVseaXWbY711e1rw7qMXymlnn32WbXbbrupXC6nhg8frs4//3z1+9//fp1aua+r/nyrsa7NJn7xxRfVnnvuqUqlkho4cKA67rjj1DPPPLPWvcBf/vIXNWHCBOX7vpo0aZK69dZb1cEHH6wmTJiwxlivvPJKNXnyZJXP51VDQ4PaYost1He+8x315ptvvu09Zvh44aSTTlpjzq7rvurt9MLrr7+uZsyYofL5vGpra1Pf/va31U033aQA9dhjj/U79530XYK32v+vDavb6euz5pRauyx7+OGH1fbbb6/y+bwaNmyY+s53vqPuvPPONWSbUkr94he/UKNGjVK+76vttttOPfzww2ry5MnqU5/6VL/z1tXe+LhCKPUuKv9lyPBfio6ODlpaWvjhD3/I9773vY96OBk+BMydO5cxY8bw05/+lFNPPfWjHk6GDBkyZMiQIcMHgq222oq2trY16kJlyPBh45JLLuGUU05h4cKF/bpg/l+AlJK2tjY+85nPrDW17v8qNvgaTxkyvFtUq9U1jiX1BHbfffcPdzAZMmTIkCFDhgwZMrwPCMNwjXpX9913H88880xm42b40LH6nqtWq/Gb3/yGjTfe+GNPOtVqtTVS8K6++mpWrVqVrcXVsMHXeMqQ4d3i+uuv56qrrmLfffelVCrx0EMP8b//+7/svffe7LTTTh/18DJkyJAhQ4YMGTJkWG8sWrSIPffckyOOOIJhw4bx8ssvc8UVVzBkyBC+8pWvfNTDy/B/DJ/5zGfYaKON2Gqrrejs7OTaa6/l5Zdf/sgK9X+YeOyxxzjllFM49NBDGTBgAE8++SS///3vmTRpEoceeuhHPbwNChnxlOFjiy233BLHcfjJT35CV1dXWnD8hz/84Uc9tAwZMmTIkCFDhgwZ3hVaWlqYPHkyv/vd71i+fDnFYpEZM2bw4x//mAEDBnzUw8vwfwzTp0/nd7/7Hddddx1xHDNx4kT+8pe/8NnPfvajHtoHjtGjRzNy5Eh+8YtfsGrVKlpbWznqqKP48Y9/jOd5H/XwNihkNZ4yZMiQIUOGDBkyZMiQIUOGDBkyfCDIajxlyJAhQ4YMGTJkyJAhQ4YMGTJk+ECQEU8ZMmTIkCFDhgwZMmTIkCFDhgwZPhBkxFOGDBkyZMiQIUOGDBkyZMiQIUOGDwTrXFx80JA2UIr+BaEElhAIIbAtgWVbCPO7QOhTFCipiKVCyhilFEpJ82kQwgJzvrAEIBBC/1UBCKFPRF8XhD5mac5MKPT1lETJGCWVHqfSX64A2wLHEuRcQaPvUHBtWooexZxDzrXJew4gkEAtiKiHMd3VkI5KQDWI6aiG1CNJKKW+fv9H0A8q/U/y7eYe+pxs7qz37wqUEvp31e9Ka/5u/iXS6/ZeW/8qEMJCCBth2Vh+DuF6WJ6P7fk4jovneuRcB8cSuAJsFSOkwpISIRVCKZASqSRSxoQyRimQAhzXxXYccn4Oz3VxHZec72PbNo7jYNsWFmAJpeeEJXBdD2Hr8UgsIqkIpSQIQ8IoolarU63XCIOASqVMENSJwoAoCJBxhIojiGV657bjYFk2jufrf9s2jutiWbb5sfT8M89dCRBYSARKKcI4JopCwiikWq0QRyFhGGC7Do7r0djSSmNjMw0NjbQ2t5LL5cjncniOrZ9NFBIHNWQUEtTKhEGNKAy47A9XsSGjbWArQL81LETvBNbPSc8j23KwLIGwLGzL6p1mUq8tJSVxHCNlbD6s0ue92pLo/U5hvkMl8sE2g5DIviNTsncNmwUlhMAyY2nMCYqezaCST0vRp5RzaS442JaFsCxqkaQWhnRXa6zsDumpSVb0RFTDmHosiU1ZO5Hev5ExSq9JiUrXYlICL6mEJ96mJN6aS3Ut5yrznemyFel7EFikck5YCNsC20EUSlheDsvNISxHj0EpLBVjoXCEwkZiKYkVRThK4CLwPA/bc7F9D8u2sISFLSwsCywBrg3C0s/V830tF7wctuWhgEDp5xhGEeVaQC2oUQ/q1Go1oigiiiJkGCGlRMahXqNKmltLnqEFSqCUAGLzLqUR60LPJxRKKWTyI6X+UZJISmQco1RyTOuTXtlp/m8JsAV2oYCXzzN08DAGtgykuamF1pY2PN/F8xxsBEpKZBBQ7ekiqNeolnsIwjpRHHLDLX9/y/f7USNZq67rcs+dd1AqlXjwkUdRSjFgwAA+97nPYdt6TdXKPVxxxeX86Ec/4sGHH8X1PG677f/R1b6KAa0DOOGkr3HvrHuZ8+ocjjnmGB555BFu/dstbLTRKGr1OgsWLOCkk75GQ0MDv/jFpQgBjaUGvvLlY5nz2uv858mnQFhUKhWWL1/OzTffzIIFCxACpk2dxpgxY7jlrzexzTbbsvfe0znq6KNZsWIFt99xO0uWLGXQoDa++c2TEULQ09PDNddcw8bjxvLJLbegaeAgbEebJnvssQevv/46X/va15k5cyavvjqH008/Hd/302dSLpdZvnw5N954I47j8M1vfpO5r7+OUpILf3oRuVxuzYepFG/Mncsvf/lLvvCFL7Dx+PFceeWVdHR2EkURp59+Oi0tLat9RHHkkUdy6623su+M/Rg1aiNGjxrFEUccQUNDA6A7qVqWxaGHHkoQRnR0dDDzhuuJwpBavc6FF17IxhtvzOc/fzhLliylXq+jlGLw4MEUi0XiOOa2227jwQcf5KijjmLatGlrFGY97LDDuPHGG9PfPc/jqKOOYvCQIbS0tHDpJZewYMECADaZMJFCscgzTz3BjH33Zccdd+THP/4xXV1d/eeWZXHUkUexyy67cNRRR/KPf/yDO+64g6uvvprJn/wkhx/+OX50wY9ZuHAhAMcccwybbLwJb76pu2p9cuut+H//uJ1Zs2Zx8803I6Vkq6224nvf/S5vvPEGruty7Be/xHe/+13+8pf/5cUXX+SFZ5/h2quv4pb/dzvtHR0A/PqSnzNi+DAOPvwIoihCCIHnOigFliX45skn09LSSvuqdl5+7ikcoTj6iCP47dXX8vc77l6jnfWGhuFDBiON7oxirTtt2zZ2MEipcF0Hx3ZQgGXZek0raWxnhTDyMgxDZHqM1PaWSiJjSRjFqR4TAmxby3/b0raulFqKWkLgWIm9JJDC0tdDIeJI/x+IFQjbwnE9Svkcec+m1bdoyTsUXRscF2FZWEIg6zViBKGwaa8EdNcCFrd3U48kUazvwTE2Y68Nou9FSUUYRQRhRBzHxEriWBaObWNZ2oaTUqYmh2M7OI6NJQRBGOlLCbAQKCWJE30ite3nGF2IEOkzdWxb/w54to0Q6D0LICybpqYW/EIJL1egp1JJn7kl0PaKjNP7iKIQx7ZxHZuGhgatW/28NjFUjAzqOLaFEFAPI3w/Ry6XY/DgwTieh+24+LkcUaTlh1QglSIKArq7e+jp6aG7u8s8A4USFjKOqdeqqDhCypggCMjn8+RzOeJYEsuYKIpwHT2v4kg/W5naN/o5xLHZo0lJGEXpetL2l8C2bTN/JbVaTf/NEkSRRAiB4zi4fh4/l6OtbRADBrbR3NJC64ABFIsFGooFqtUqQRBQrVRAGhvGsYnCABmF/OrK33+ga/C9ILOhMxs6s6Hfuw29zsSTbRShXjHJIuglnizbwjbEk97464eizMQTsSSOhVZ2Mk7JJcuyNFFiWebfIiUNlOglD5IJJixLTyjLTs9V0jzUOELFMhWc+qUpLEM8OY6F7TlYro1wDBni6ImJGa/l2FgqwnYFtqOwpMC2YyypsJRAit7FoJKZL+g37vR9pryQ6COcRH/iyQgHKY3S7ctc9SOizCdU3/Um+vxZE1dCoYWOpSeXjAI9JAGWbYNlIZQ0xoTAQhNNAmWO9xd6ybOMlUIqQFgoBJETY9sODgISksu2zX3qSR3LGJkYPcrBshSW6+HaVjpf3NjR792Cum0Rx2H63VJpYSmFQFhxSlQ6jovlOLiej+U42LaNbTvG6LGwbAdLCD0eyzZzSxtFYBFKTTwFUYBXqRCGIUFQx/U08dTU1ExjYxPFYolisYjvefieh2NZCCmRKGQAMo6JwoAwDIjCYJ3W0YaG1FAXvbNSazeFUsIQu73zMDFI5WrKIyVDWauq6HdcK87eI71crkAhe+c3yXIS5jwFShLFgiDSJHHNdXBtmzDW17WVHolAyxWtaBWuENQFWCgifeN6/SilRYzqVfjaQOwz3j6/rNO2JuHc1WqHVruG6PPX5B6tPkpcGTlnuTkc85O8G4ixhY0twLOtVGmKIMCKJXbca1BKKTWpbyxloUUoCozcjLFivR6lkni2/l7PsvHcmFBKbC/AD3xq9TqWcPSaCQMiEerNgRBIAlRs5Ht6R8oMWc+ZXrljZL3V+6IVetMhpSSKY6SUWCImUkLLEvOkkhfU14mBshCWg+sXyBcaKDQ0k29oIldswPPzuK6N61ip0aOERSgEkYCYmFj1bgQ3ZFiWheu6LF4wn4VvvskZ3z+LWEomTZrEQQcdhOu6oBTlnm5UHFHMeURhwAvPP8+p3/42sVRsueWWHHvc8cy8cSa33HILn/70p9lx++3Zasst2W333Rk9ejS//vVlFEtFPM/jggsu0OtQQRTUeeiR6zj77LMJo5gDDjyQ66+/nmeffZYFCxZgWxYHH3IIe++1FzfMnMntd97Fvfc/wF57782zzz7Lqd8+ldtvv51dd9stNY5WrFjBd797Jiccfzy77LKL3gBFoSYbBLy5aCFnnHF6KqvOPPPMfs/k0EMP5dprruGJJ57goYce4lvf+hZnf++7fPrAAwAIQ61T+sonJSXDhw3jxz/+MUII5s+fz3nnn88pp5zCOeeck27sUyjtPFNSUimXmXn9X0AISg0lpu+9NznfRyrFJZdcguM4HHjggQgh6Gxfxemnn061WjWXUTzx+OM88/TTzJo1i2232w4hBEcffTQ33ngjkdnsNTY2ctZZZzF06DDCMOzVq4mNaFlGdglKpRJnn302d955J1/56ldRUqZ/32rytgweMpTnn3ma2267jdtuu41kE9Ir/wS243LNNdfw6KMPc8jBn+FT06ez/fbbc8stt/D44//hlZdfoL2zO/3Mn666ik023ZQH7r+fKAxZsngxP/jBD2hvb8e2LZSSzJ8/n8svu4zTv/Mdtt1uO3K+l9qIURSx1ZaTGHHyN3jkX/9JiacRY8YxevRobUcKgW1bNJRK1IOAnnKFn/3s5+kG2bIsmksF/KDM7NlvfACr7f1HLON04ySM8xTR1z5U2oaxLEM86b8lc0/KWG9ik+sZOek4dq8taYgK0LJU28C2/hsKC6E3UI4moFCaSMCyUltRxjEoiW8bpzAKKXtt+iAKsYXCyvvYhpRQQiClJIwlRDExECJRSmIJTeiEkf49mX+WsfEtc41006QUVhzrfVisiNEbJstKlCvasSkEltDPIVKKKIrTZ5rzXKS0INUcikgqYhVjCamJLPO9kJAvIIUEQzxh7Fovl8f1cziejxdrJ7qMI3K+p8mnODLkgiCMIiwUtiGlojBEKkG+UMDCIrYivfdAEYZVHNdFAdVaFSeKsF0Xx9E2bLFQJEbvDyLXI5YgEcRKy7V6UCcMI+JYEw+x1KSjflaarNPqUqZOVyklQRCA0cWO66X61Eo2lQgsSxpiMrFlFGEYpe8O875VZN6XsMG28QtFCsUShVIDnp/Ddlw8P4efy5MvFFMZF3suUT1GxRIZm+f/wSy7DxSZDZ3Z0JkNvX429Dp3tdt04qSUFU8nkdncW5aF5djYjo1tGFWRkC1KIaUmIaIw0EIxjlPhZdtasNup96OXiOq7kDXnoUkETXI4RkHbJtJJEkUBcRQj45g4jpCqV+k5loVnW5R8H9+1acy5FHwHz7XwXTsluOqB9rSUawGd5QrVekBXpUotCAnDuNcjQPIIdISR7WivlW05vYZE+mMhrD6RYH2eYxIFFkUhUqpeL8ZqKyxZ4PQRNsmi0BNSmpXed6UKsG0sx0U4Ln5ebyRyfh7fdbQXSaAXm5JYsfm8YUhjKYniiMgQSEpgiB4HP5fDc308z6OQz5tIKhfb0my/UBJUBEpqA0Xod+f6OYTtIBwXZVlIBWEUUa/XCcKQcrms/x0E1Go1ZKwVvGUWoW1Z2I6rySbHRViGTEsfCJpoMp4510R5+X7BfM4hVmY+xiHValVHPwUBtqPnYLFUolAokM/lKRVL2jNn6wWnZEwc1KmVuwnqVao9nYRBjTAM+d01163TovuoMGBgC7C6N6WXPFUi9RfoNW28NXreakWnzOZHxsoYM7KXkE4Y+DWQzGbR5+sEYBnl1GfeKgXouSyU6FWaQqHMv/MO5BxBS86huZijIecxoNHHdx08xyZWEEQx5XqNjp6QSi2mvSzpCmKqUUwgo0SWp96aZGMH2sspU2+Rop+IVH3+scat9j/Q93NCrXaaeVaaPDYKW2hiVQmBEpoctxyPXEMrtudjuZ75nMISkHNsHEvgCWHWsMKOYzA/wnjQlC20oWJZuK6H57nYtln7RlZ5nodtO7iuS973jcfWBctGWYJAQT2MCcKInmqZoB5Qq9WpVWtEUUgtrJkIxRBZq4GKQeooxb6boWRuJVGLruumOgSsVGlq+R0jkURRRCxj6mGoPbVRRBwGxDLSnhwhsD0Pv7GZ1rahNDQ2M2zIUBobGikWihRzeWzj0SKKUDKGMKBc7qJWq9DR02kM+JBbb7t7LfN3w4AQgs8edihfO/FELrzwQt5443WWLVtOEAS4nsvo0aMJIy2387k8K1esYMmSxYweM5YgCFi4cAGlQoGWlhZ22H5HnnjqSebNn892225DIZ/HdRzufeABSsUi2229NUtWrKBWryOBYqGA5zi0d3ZS6emm0t3FslWdlBobGT9uHC+/8gpRUGez0SOJLZdIWIRRTHv7KjraV7H9JyaB0iSTW2pi4IABTNtpOx57+nlenzcfr9rBxHGj2XKz8TiFJmRQo96xgmq1h1VdZR6ZvYjFq7rpqQW0tjRTrVToKZcJo5jBgway5cTNePaFl+js7kYoRVNzM8VSiYEDBmCsLEa0NqAUlOshrm0RRBGLV3YwvG0gOc/h6RdeYtTIEYwaMYJnZ78GSlLM57DQ0RWRlFQ7VhHUqoTCobOnTHe1xqbjx+G4LlLBkiVLcWyL0RuNJIp15MHipSvwfA/P81myspN8LkdbazOOY1MsNTB67MY8eP8/WbRgHsOGDqGnXEYp+MPvr2LBwgXc+ve/MaTkY6HoqlQpNA1ECYvXX36ecWPHMG78OLbebieksOmpVHnsoQeYN28uTz33HNtstRVNDSUeevgh/FweP5cnrnYzYNAwRo6fyFNP/gtHxUwcO4pHn3qWrnKFvfbYnSXLV7BsxQpq5R6aGxsYNnggXeUq7Z1dvPr6XEYMHUxrcxPDho+gq7ubzq5uFsyfT6VWo1oPUEoyaOBApkz+JEtXrKRcrRJLRa1SJggCBg4ahANYcciLr82lFgS4tsU3TjmNtrZBnHfeWRRyPgMHDuRbp3+f5597jjtuv40jD/8cy5Yt43d//D2f3msPGkpF/nzzrZRrdYIwYh3N2Y8MLU2NRrdq8ijd1Bg5LCwL13GwLZsojo1O0A5bwDgX9b8ty9IbFhORblsiJaViKTUhYSKDLEMqgV4NSbSREppoiKMQyzbRR5ZNHEUoQzy5tiYwpNTRNTp63cKxoGALhjXnaS3lGdraSBBJamGEFYfIWMvuN7trdNcjOqoh5XpILYyIYmmIJ22bO46D53rUw5AojtOxS9U/y8Bx7DRqwzxBAKJYZzukJBJJpJzSm0LLIpaScj3QG2U0MZU8kzCK04AT33UN2SdxPB/H9WgZ0IbjF7C9HFGsCcA4jmksFfFdh7xrIyyBkoruchmhYiwl8Rxtb4ZRrAkmpQjrdU3quy5xHFEwkUn5fI5cLk+hVMI2ZFQURQSBfhaWsMxmNaQe6n1KrV6nUqtTr9Xo6VyFjEJkHGmdYOxWJWPqQUClWjPzTkfF2ba25YulUr8AgDiOCIKQSrlHn2fZaTaLlDKN1Ojp7k6JT8/zcFwPP1+kbdhImppbGDa4jUKhSC6XM4RHDDKmoVREoAjqNYJKmaBep6urU0f+SMlf/nrrB7gC3xsyGzqzoTMb+r3b0Osc8VRqaNThWYZISqBTnSxNSDg2tmU26WhvhOZCNPumiae4H/HkJBErjoOThuraadqdEr2TLxGMwrKxHc8oIDv1BIVRQGSIpygKNRMpYxNBJnBtm6IhnvK+h+/rRea5Fn00ECKMkF6d0M5hBQHSqeDUA8IkNM4w2Am5ZBnFqcOiNXmGIaSwTOqb1WdxmsUoDVMqZUwYBtprYbw9q3O6AtF7rI+gkcaToQkr2X+RG0NG2A6W4+Ln83iuqyN4DElkC7CUiXoypJOKtcdZSAmxjVAmekxYaWqb5+dwXa1sbNfDdvV3WIZ4spQEaYFRwKmHz/zftm2E46AQOIZIck1ovet6BEGgjfk4RhkDzEIbULZtoqRsWy80SOdm8l4s2xgznofreuTyeZ0maGtiUCod5up5HnEUEYVhGoWVy+fJ5fLkfB/fc7WRI3SkmASUlZClDpbtYjlSR35t6EiEaP+DfUi7JL2V1Hva9+zE69X391TpoYxS1RcQ/R6Hmb0iUZoiJa4TpZh4M/QcBtLA4ZTzhz7/lkoRm5DvKNZGYGQJLAuUslKSVqCMMko8BcnF+oQhC1BCpR6k1AjoQ7L3+uKSG1udBBbp30QfmdWXPxYq8TSkVDrCzN++7yN9L1JCHKPiABkbWWIMGUtYOLaFYwlsQEitmG1h6X9YoJQOpZexJFbao63M2sCQ/ljaWWDZnvGya4NbmzRgu2Bh49k6HdmyLKSKcWwt64UQhKFtnp8iEqCcCJVEjxtiPfGOCSGMrjApsp6nlaZtYwknnXeRDM0zVDpUWCqcMNQpuFFIvVbFikKiKETYNm4uR7GhmYaGZhpKOloxnyvge76WzSpGmHmi4ggZ6evEcWQcFzFKbdgRT4MHtaGk5I25c1n05iLaOzrwXO05q9XqvPrqa2kUbCx1+kix1MCbb76JZVm0tAzAsfVm9elnnqbc00Mxn+Pll17C9Tw8Ey1Vr9V48eWX6Ojqph4E1IOAfC6H4zh095Qp+B6lvE+pmCcK6rz44ouAIp/LIaVk2cpl9NTqDBk2HN91Kfg+r7/+Oo5j4zguSxcuZMWKFTT4NgsXLiLo6mSLEc3YQQ8vv/QSza0DUPUalZXLKA0YgLAdmop5Oit1glhiWxae61LM+diuh1CKOXPmgJI0FPLYlkWl3ENXZycrli9P51FXaxOxlHRVaniOTRTFLO/sptLeRkOxQBiGLFr0JqtWrGDhkmUos3EUSq+fWhjRUiyQ81wCGRJLHRa/aMECFIogVjQV84jYYs7s2TpVBWhqbqHU2ES+2MiyVV24rktDUyuzX34eBESRJKjXKRi94zgOAsFj/3qMVe3tdPeUUeUuhIoJwhDLK+Dl8uTyBUqNTZQam3jxpRcpNjQxoG0QAMVSA5/Y6pPkcz5BEDBg4CDCSKfhFBuasF2Xnp4ujI+U7p4e4wi0WLZ0KUuWLmX5ypWMGDoU3/ep1AK9Bh2b5qZGPNcjCEKef/75VA4jIOf7uEZvW0KwbPlyli1bTndPD53d3TQ2lCjk88yZMwfXssi5DlIpisUiA1oHsGDBQnrKFXbYaVeaGoq0NDbQ3t6OZVtsvPHGxFFIsZBn9912p6m5mVqlQme5qiN7/gsg+ivGXsIpccQmpQIsgYokKOPRpjeVItE0MrHLEEgZax+4UHrD2ydqSn9PEiVl9Jr+l7bRLUs7KBNnr9ENSml9oxBpak06brRuDmJJZEL7HVs7Eh1l47q2ngP1hFwz+k5ociyKjWce1Zu2I7Rs0hE7so8O77NZl3pTLczMTe4nSRuzMZkQIjnXnJV8R2pP02/OaJ1n9JOVRAOK9FmHQR1l2TqtTSWmlLYxXdfF9+w04ishxWwsHMdGRZqcCcNQj9WQgUpo56hl2zqF0ex/pJTUK3pOKxnrqCtD0nmei+s4uJ4kiGIcz8f1A6quS1AtE6OTcaSj9wZBFGGZFBulJGEkDbnp4np6reZzeRMAYKGERSwVbk7v0aSSWLZjUgM1pVIPtGM4SYWUcUw+n8Pz8xQam2loaqHU1ExjU7MuUeF5SKUIgzpBrUq9VtXPIQw0+VSv6agwk7myQSOzoTMbOrOh37MNve41ntqGagZTaiGvJ4dIiSfbc9PoJScVlIlXR+cYh0GgPQVRL/Hkuq42SF1Xp1AlKVt9mN0kCki/NB3t5LqeJnosy9Qi0jWDolgLwygMjLdEM4aWENrQ8Tw8xyFvSAXHtnFcndONEHhhSBRFePUAp1ojCANylUoakdObV08apmsZQW7bmjxDJCFwJvXMMs/CCIxk2UmlCZ44jqnXq9p7FcdaYRoBk7LJyX/16tNkm2HLpamflUZLKanFg2F/k/fieT6OY+M5Dp4J5bVNFJYwgjIhBsMw1AJJRka+6WfvOA6WY+O6OhfddhxzXZ1nL4QWAxZgSR2uTRylwkkkEW6Og+P5aTpcLGPiWJLPFwmCQIcR1+upwhTpGJJ5JYzgVCZ0ONTnxhJh6bRC39eEk+f55At5TZQ5ro5O07drCD8dIQcgLD0nXc/DNV44PZeFjgSzBCjtCVNC4MURluuln9+QkRq9ybpEgZC9yoO492/KhOTrD/TqOnNuH9Wh33Hvt/T7jlR5mjWh+qyBhLgVltX7OSWRMgIZ66ISidfE/F2H0WoPkQRiI1uiONJGt1CAhYqlnodC1xtDxPoH2avrVJJDrW+s7z2pVOYkz6nfk0zOSu9RmWsoklzsxOBItKZKvzcxoi0htBGbXNPSKSraO2bIYBkTVARWHCBiH9vRxqLt5LXSFGadyVgrWWU6RggLJRQyjgjDgDCOUQisKEZh4SmBa7tYtofj+ni+8f4qSWjWQxhKfJXDcV1cz8GyHTwbHMciimICP8T1PYKgju1YVAQEgY7MjKOQOAoh0PJXKIwccnB8X9dkM+mytnE+OJaXplvrRA2BJRwkFhLtlQ6COkFYp9zTrf8d1HB9j3yhQGvbYAa2tlEqlWhpaiHn64hMVwhUBDIKicOAKKwT1MrUahWCsJ5GyaoNPNVuu09uzQvPP88NN97EyOHDdHpXGBJGOsS5WCzS3NSE7/u8PHsOjQPb2GjkSJYuX4rn5Rg0ZDgrly+hu7uLl2fPZuTwoYwYNpQXZ89JPeqDBrQQx5L5by6mpaWFBt8n7uggDHRKceJdkwiGtA2kWqvz5rLlDBnUhmc7LF62HFyfYqmBnu4efBuGDGhm+aoO6pUatTCiqbGRIIq56+F/M2XT0Ww/fjOmtAmeXrCKx+YuYZIAEQV0d3Yzu0cR2S6NxTzFniq1MKYWhPiOQ2OLjrhJxtDc2IDnOOR8n+6ebsqVKiu7uk3EhGJFT416GNLZ2YXr2Kk8DOOYar3O0hUrTWi6YPSwISgl6alUiSUEkaS7UieI9ca+Uq3iWDa+69Da1EgkJd3VOq0FXXtqWRQZHSzIuzZNzQMpDRxK/PwzUMxTaB6AEBDVq/R0LKch71PIteF4OQa1tdFQzHPFFb9m1Jjx7LL7nixaMA8VBYws+bz22qt0dHaRb2qhJ1Qs76ry6CMPkc/nGTZ0KLPnzGHQ4KEc/cXjePj+e1m4YB4jx03gtdkvsfjN+Wy25WSWt6/i348/TmNDA7GM9XxpbKK5qYm2QW3YrkdjYxOtzc2saG9nziuvUvRd8rkcY0aOpL2zkxXtHSxdvpzhQ4cyuK2N+W++SSnv09zUSFCv0V2u8OjjTzJxk/EMaGlmzhtzcW0bjFFuux5esUROlGltHcjkbbbnlVdeptTYyP9cdCmDWxtRQY39DtifjcdvzN57T+ev11/L6DFj+NlFP+OnF/yQR5542th4/x1wHKdXF6B1oGvqHInUjtT2aL1eR5goJmUcknGsU+0UIMM4VbCxSakDyDsOiUq1TR0nIazUMYeSacSVnURjuHpTpDekAssVqT6II+2l16ltUqfWObp+jSYctRPQQteRcoVFsVBARhE1qwdJmVAqYrQOcIWu8yljaWoJSaJY/0Cqmknj/lOfqzIRXhARk9S7gl4SKbY04W7bdhoJppTUpJA5P6kTVQ+CfsScbetn7RrbOCDCFgpkSHdnO34Y4eVj/XyM/Wrbtokes80Y9HfYlpVGikWxNI5wQw9Ypt6osFK9irDw8gWUUnSXK6xqbyeKIhyhaB0wkFy+gEDhuy6u6xDEilBCIdYEU7mnh2pPJzWlx+AIi1qtSlAP8W0dMSeAIAiwHZdiqYFSqZFcLmei+nWWQCj1+CzboVpq0Gm7yabWtnBdn0qlQqVSRlgOURwhpaKYz1EolRgweDgNzQMolkoMGtSGa7IICsUi1UqZro52Fi+aTxzUsNEp4YnTd43ImA0QmQ2d2dCZDf3ebeh1Jp7aBg7qV7Qqyeu0k7BbU3Q6EcSWsNIQtCQyJ4xCU0QrNotFb/JtUxzQMalTtmUns4ukIFYS0ZIQTynhZSUKVRKEEZFJNYiTuk8mfM5CkyyeKdzoGw+v7TjYblIvijSENowiiibKqbFep14PCCNdJEyZmZ7UK7AtXeBQE2G9qXapUFiNREqWZhK2Gsd6MkgTtqp5J9Ebppl+JmG3SY2IJFUvIWj656NqUskyUVeOo4vHOY6Nm+S3p4LUMOFSGwNBGKbPMfm7ba6REEeW7aRKSecCJ8LQ5AnLWEdLJYXBFTol03b0fDHenqQgrlKKfC5MC29qJjVJIzTPxHjklFLmfet3HtSDdG5aAizbSokn1/Pw8wUc20TXpd4/8Bwr9SQmj0FHPiVpo6T3pKPXbPBcoJAWgkw8dBs6iqUmfa9GTKcpnWY+S0gN4DSk3bYMK5/4I/TzCiMdVajrqmkBpyPN7H5hoGnBPzMfVR83jrBtrVxtG8d29buVijg2142SonsSqYyhKRSerdNmC/kcOd/B82zckovrCGxH6PBiCTKWeHad2AvxVRlP1IhESBTEJG5LhQ4/liafPYmWE0KvO6kSEth4SpJU4MTjouLUSI6juE+ttkRhJu4g0B4ilZKeiWpN1nSslPbdGO9GbNaQqkmEjLHiCKdg5iYSYoESJh88UZqyj3yJTRhtIrMBFWuyVQgIbAdhOdh2jMI1a9jW36liIhlCUCWK6sRRpNer4+K7hpT1XCzHIggcHVVqCep1F2E72qsSBgjH0aHnAlzHw3YcXN/HcpK17xgyWa+tRB5YRr44Tj51MsRAPawTRAE93d2EQUAQ1PFyHn7Op6m5hebGZgr5PI3FBjxPOzUsqYhQBKGV1mUL6lXCoE4UhiiTpsEGvoRPPeO7zJx5Iy+8/Aor29vxHAffdWlq1uu6q6uLWr2Obdnk83mq1Qqvvv4qtm1TrlRYtWqVafhgMWzYcKIoZPmKFQwbPJhKpUJ3uUw9jLAsQVOpQLm7m9ikrwQm9aWxIUcUx3R01egpl/FzOUaPGsWqVator9exlCTnF7Btl472lXoTJmDM0IHEsaS9q4dcsYSw9WZkaWeZ7nKFuXMVQwYNZPdtJzFn4TIIJY0NRcZ4PqESrKwG5B2LBt9laWcPNSHoEYLOyqtmkydwnAKRVLy2YCE5TxtgQRiR8zzyOZ+u7h5832P0yBFUKmUcSzCwuZFl7Z10dPcwemgb3ZUa3ZUqWBZhEFOp12kqFvA9l7qps4NSjB46KNW1i1esSuX/vLouuBtLie3myBdKjN50SzordRYuXMAntt+Dro6VPPOfh5i29wwsFP95aBZbbLMDxcYW/nHrTJqKPgOahzJ+zFhaBgwgqleY88qLeLbFmO23w8+XyEWK0cOGIaIayxfOZesttmDQ4CGMGjuWHXbYkeXLl3Pdn/7AJhtvzOYTJ/H4k0+w6cQt2HrbHXjyP49iuT5bbr879c5lyChk2LCNWLFiGUFQhyhg1crlzFu0mBUNDeTzOcaO2ohFixbR2d1DLEE4Lg3NAxi50WhWrlzB/EWL8P0ctSDgjfkLKRbzWJbF8KFDWNnezrIVK5BK0VWupPZcHFcIgoAxE7cml8sxf97rbLP9zpQaGvjR+ecwYuhghg5u4/vf+wFvLn6TZ559mp133pmenjInfe0kNh4xhB222ZqXXn0doNeW2YDheV5aMNx2XGNYKKM3tG0cGfvacnWxWt/3jQrSEWlRGJri4VEahR/HmiBwXZdiYzNC6BpAnu+b9CmTehHrtLqkFmtDQ6OxY8F2PB11pNC2VxxjW4JKtUq5XNbnCF0v1fdz2m4TQL5EzcmxMva0XZfzEKUSloyx3SIDIh+nXCVe1anT6KKYIJIgpK7BFOsi6FEca+egbVMoeqZGidbRVhqNZKWb94Rss0yUkFIS0af0htZ5EplEb2Cciq6OYg/CSJeSiEzBXrR9EkplNsI6hQ9TM0nRQxRFFEqNuELhW5LGnIPn2kizN5BSUsjliGOdMpjYy57nUy6XUWYOSCmJo4iaUsQKpLCoh7rcRj0IcE3koJAhYVAHpSgWCtreiAWlUiNBFFGp1imWGinmc9SrFbq7u6lWq3R1denUUysiMFFTTq5A0c2Ry+cZNGQY+Xwex3ZASbMXsqn1lLWdZ+lITcdxcD1jR7senp+jq6uLnnIPg4cOIwwj6oEm6HL5PK1tg3H9nMk00HrIN5tXGYf4nqtlaRwS1mvazpcS23GIZNS/rt4GiMyGzmzozIZ+7zb0OhNPhUKBJGQ2KZCI0ORLskiclHhy+hBPln6BSgtaacigZCL2JZ6SFCpdCNFMnuSFm1CxpIi17egOFwnxJJXSefGOPj9WvdE/Cd1jIfBM5zXf8w1ZZpv6TCaU0RBdrtRhrFEU4+ZCgkBHU0VhZBhrZarca4NHh0gLbNFbLyrpVCIShloYzxMqNVoT4ikM/DRqKYlUSmsBpFFPb008JXWe0nSztKaUuZaJWLIsYcILk0LwffNjTZcPqY2a2DxHM3pNxCQ1vfoU7k6LZJrFIdDpe5ic7V6PpOpTz8vFdlxD8jgpQenYTr+UQ00eqnQMOpVE9Qkb1IaXbTt9iCc9FzxPdwfRObleGsaeGqhKoSzjM0ulWEL4JQuZdOyJt8O2bVQSIi3sNOpsQ0ex1KTnmJKpoJdKQmzC2FEmzN/C8Vz9vBwbN5krZjIrBWEUEgVamMo41uSoELiuCf80EYDC6lVGpN4aIz6SOWQ7uI6nI9kURJHuZqiVskRGRoCb1ALf1sSpNmocfNfGLbg4Ljj9lKbCs2rEboAf2+SEg7TqSBGmG0h9Ra3MLaHnh+MahY9lGgTosSfPRlg2Qldl7UP46lB6GSdddJKoUIVSveujn1cv+b/AyFXjl1Am5DqZe8nzF3rturaFa1kmVVZgo7BMioFl0euJMsUitcI3ho9l0piFDqtPDRlzX5YJJRYKJHYqD+MoNLXTbBxzjm1kkWPbpril0msDQWDbRI6DFUdpZKjneoZ09hCO09sgQvX6vxJd4vo5XTfOK5Lz89iOo/Pk45AwCvA8vzcKx9NRlw2NDZSKJXK+b1J+tBNDxTHSfFdqyiTeMyF656hlfzAL732CMOsJIAyj1MNYNF3blJSEQUBkWXier+eVKeQqpURGkYlM1WnX1are1AwckMd1te4OowjXtsm5LnXLRJEaXd8re01ofhRhO7oQrg7Zj/Xc6mMgxjImxhRMtgU518U268n3PcqVMt09IVaDx3DHYVhLA68vXgnKIee75CyohhFzKzVQ4Lm2cWTpEqpBuYzn2Nj5nDY0paS7XEGYTWayWbWERRRH+HjkfY96rYZlge86RFFEtR7gmpSSZCObyEnHttF6wUo3u46tbRRtyOloBse2zDzTERieIQIkIn0+fi6H7XqEsaJQLOE5Ns0tzZQaGskVilhC4Dk6ssh1HJSS1CplapUy0nWoRxLH9cjnCzQ2NFCvVQjrNdoGDtTRS7E06S0u1UoZSwhyOZ/GhhItra2UGltoam3FdnM0tA5ieaUDJXQR456eLsKgTk+5TBSFWAI6uzoRAlqamtI147geju/rNdfQSC0ICWIJcYiIdQq96+VSR1d3Tw+h0TGhcRSVigVAIBE0tAykWCxg17sYMGAAXi5PR/sqonqV7s4OdtxhJzo7O+ju6qQ4YijdnZ08//xzjB7UTN73ABg+bBhtgwZ96GtyfZGkN3mej+v7YOaGNNHu9VpFRxEphee65PJ5CoUiFjpKyXNdakldylinaIahLhTtuC6+n6OhqRlLCMKwTi5fMOtaR7FHppFKYhc2NrfotW8JXC+noxmFTVCtEoaBjlx3PKTQUVeWAFdAPp8zpIqDXyrh5H0i18LJ5XDzeUTON+e7lJotlFuhK9B2pR1FOkUvTu47SvWi72nyKl8o6LIZUkfv22YD7zi6w6E0jkdQuI6T2s5SQWzSR6QhrqSuXJ1GiPi+pyOvPEk9CNNC24m9bdmu3uMnda1Ub5F2ZIxr67qwujO0jo6IUoc8OK4DqLQpj0Lo+lnGoZ7W0iLZVhvCy0SAxVLqzasQeoUY+8kWvW5r27ZxEfieXu+2ZVFq0DXsLNsxpJruCGgpaeSvJgJyhTyNjU14vq/rRtWraepQAiEgl8vh53IUSw0UCkVcz8MxP/lCAdvSZFmtFiAjXWewWCxiOa6Z49q57xmizzbP1zZOepVEt5g10DfqbUNFZkNnNnRmQ793G3rdiadcoQ/ZkeSWq5SISGs1WbqgVkJ2JI9DKYX0DEmSTEQT8WSZKClhWalnQ5m2girt5qHDbFM22U7S44w+QE8IG90OVqo4nXQiCUtE4JqoF8/1tMJ1bCN0k/mZPFhJQekQ1SSVITEe00mpZ75+DkaoJDWcjK2uzxBJBJMm1frWZYrCyNSkSiK0lE4VsyxDlNjpPSdX7EvExHGUElkpQyx6u6H0Ek9WqvBM8I5+BcaDJEi+Qw8+NoJVpveJiZ4yEVgiPQj0tqVNCCRd1FEXqEw7DKLDypNC8r1sfq+3Mi3enj5AkyctEgbPVOc3LXeT3OQkNVDK2NSCEiYX3jPpgL0hiJgoqkTJ995GLwGXmAVJmobh2EnqMNieXmC+r9KWxhs6Rowah4xNYTnjVZVxbwvdlOy0bdy8j3A0a+4m+dAi8TYqHf0X1InDkKhP6mzO93Q6pym0pwVxEgWo51VqBFomYs7x8GxfE6MCXastjqgHQdpuNorq6TxyLC0vCp5PznXwXYdiTnddsF1bezmlwoskVrWCHwSIxh6dMlurUa70pOtZSn3f2gOt/+97eZP260BC/Cb15YRA2FYyNXUmaRwhZaQ9ACZVN5Z90gTMvLLo7QghwHigjCfazMW0UYKUxvA0LbUdB9t1KRSLOtLFcXujFgErvaZEhjEyigirIKTEclwKfWrpub7xmjg5vT48D+H52oixLWyUaTbgpeSxVKaFbhzj2ALb1cRxvlAkjiWFUp1qtYEgCCiXK0TmOWhZJkztv0RJ6k6VCl3fJjbnKhmnz8z3tXc1l89TKBZxXV2rLSGX63VdkDEyHb9s28bL+eRyeVPcMadlshBEKKRjY5t7dZC4cYSyPew4QtVrKDdGROsWJvxRYeoeu6cpJdr7rahUKwRRiGPZFPM5cr6v6/Ss6mDY4MGM2Wgjnnr+eTzHZqORI1i4dBnd5TJLli/Hc11cx2bJ8uU4jks+n6ejo1N7qv0mRg8fShxLXnljPsWCrg/Y0dWN4zrkC0UsGREGdea89hptzc005nPUqhUIq8i4zoBBg1FhQFyv8sLcRbiOTUupSPfKlQhh0dzcTLUW4FiKnbbclME5yHUvZYuhTYRGj1vLFtHd2cm/Zy9lxKABNJUKNJUKSGGBsHFlQBTHVOoBTrkHpXSHmkqtBvU6DcUCURjR1d1N3tX1mlasWkVXTxkpJZ1d3SgpcQS8umhJWg+yVq2AEBTyOd3qO4qJggAhdCew1xctwXNsfMchn8vpaBBgwugRAMyZv4jmxgKOI3jo3jsYM2ErxozfjAfvuJnWYWPY+aBjuf32v9BS9Dnm6GO5595ZzJu/gC233JohAwfgujmee+klGhsaUVIycshgIiz+PWchg0suQweVKDQ04ORyxHFMoVjiuRdf5J5778UVik03ncBpp32Hu+74B7NffoGD9pvB448/wQtPPcYxJ3yDNxcu4F8P3ceSpcsgDhk5qJWW1gHUo5gnXniFTUePYNL4sdzx4COsXLWKnnIZgaJ1QBtbT96eWncHlXI3byxcwOQddmXsxhO56rKf0jpwEOM22QxkQLlcZv6iJWy2xSYI4F+PPYQQFp5rMX7sWKRwqEaQa2xh00034fD99uIvN9xA56IF/PRnl3DvPXfyn8ce5ZKLL6K5ociQ1mYeffBeFII9dt2F+fMXsHLFCpRSfOtb3+LEE0/8qJbmOqPU3EqxUKSxsZFiSRMF1XrdkMZ1li9bqjdowsIvNtDY1EJr6wCiuo44cl2P9vaVBPUA27J0CkgQ0F3uJp8vUmpoZMTw4VgCarUqhXwBy9aFyqvVGvV6nc7OzjRqYKNRo8jn8+R9T8tZz8fLFVi5ciXd3V1Ue3qo1qqUK1XK1RpCSTxLUsrndWOZYonmlhby+TxRWKOhUKCxVKSzu0dHTOViWkutFOsBFFuo1QOCMKC5WiUMdFOXoFbFtgW+56OUwnYcmppb0n2GENqe8D2PnOfplJFY6jWsoFDIo6TWeT09PdTrdR0lhNLpLvV6al+GsTTROC65XI5yWaeNea7eCkkwXf90UfXQRN9XKxVcz8fP+bS2NJHL5Sjk84RhQBAEuqtbn72F43rEcY6u7m6t14Wg1NRk6pu6WofaNvlCQddL9TxNPCkFwkrtUkvYNDa3UMjnkEFN12u1XYIwwvU8Ws07sxyHUlMLXq5AYxBQKBTo7umhWq2S9zUBYtuWcRRoQlN3voSaY1Gr1ahXdIe9JCIvl8vR3NzMyFGjNWFuCMy2gQMBTeAFQZ1KpUq5p4cw1PUAbdfDz+UYMKBVO56VbhWvYt1syPN9XQy+HuD6CqyA7p4eoljqToIbMDIbOrOhMxv6vdvQ60w8iaSiHkpHs5hXb5sXZin9IxQ6rzKlK/oUOktzoEVKdiQhYgjMhDKsTZJeZ7wAmsHU11JKt7RPyAEplcl/742UkWmRK81GCrQyl4aEkpH2xCoZa+LJtEpMujck5L8QSUod2MpCprnI9EZlYUKBk7FD799F0lmg7+ROomz0M0OBIwQKnVNq2SItwJ0UH+ubN6wfRxKCbOgvgSneTZqil6TSJR3lksiipPuAFlwiJWSEIZH0fRsCzjDJpPfa66lJ50YfT0nvvcfEsb1a7SltVCSEWpKKKVa7lg557nXAqOQ7+hBD0tKRYbatc+sdpzfiSShlIrtsE1Gna4gJM+diIfV0VJAUV02ingxvmBJJso8HJqlbpmyRssvJe4X+z2BDxOBBQ5FSK810nUhdw0Eq2UssWhZuTgtW7a1J0g7tNJohMt6UKAqJI5m+H9/zsB0bz/ewbVcXZbcchKmaKKXpPKQgCQu1XBfP8YwsIDX2giBMUwS0t0bPQduysIWOnvBdXWwzl8un0Ysp0R3H5Ot1gigi11ijWqtSrweUK2WTzmnyuc1csS3jSXR8PfYkms/cmzAEct8Iv0RpxnFMUNeeaF1njjRKpHd9WenzAyPHjDdEGg+PlDpkNU5IXLOGhfEW+r6Ha9t4jo3bZz0nq0jKmCiMiMMQt95AEhTu2E4asej6OifccbXBalsOtmOlZLVNb3cPkaTFyKjXoPJ0zrouaqhVSD6MyOcLhGFEQ6luaj9oJWglxHfathoCE/lQrwfEbpw2WbBtC9d1KBZLeL6Pny/gm8LWru0Y+a/wHMt4xoxXzNL1Bj2z3m3byNrk/ToO5HJI2YQb5HG8PK7poGTXa3im09KGjCjqrSPnOboeTKlYpB7oWniO5xFEMSoMGTCgDSybN5cupV4PqKNYuHQptqNr91hCUCqW8D2PZSuWIyxdm9G2beJYsqqzm2qtjm3bNDU16vkdRbQObCMOA11sV0EhX2Dg4CaCWhWpJI0trQSxIool5e5uWhtLDGgbQLRoiZb/nkte6s3fyOHDmb/oTbq7u/jPq4vYbMRA3OEDeWrO6zQ2N7PlpInEhSLNpVVstCzEtm2qQUgu59NTqdFTLWMbAzky6TC2bVMs6JQ7KSWVag3H0ZuocrUCUUw9jHBdFwAZRzo6WAlkGJErFCgW8kRRRBhEVOu6XTmA69gUfA/bsmjvLqNQ1KIIYt2a3Xcd5i5ZhpKKSj3Aq1ZxnRAUdKxYgkDRNHAoFoqFzz3MgTP2xUZyxx23MWTIMAa1tfHII4/gEtNc3IhddtxJb/rLZbq7OnD9HCNGtdFQKmIBTzz1FJMmbcGmEybywnPPUotitt95V1T3KmzH5uabbyTnugxqG8TsF59nyJBBDB81mrv+318ZPnwYnzvsMP5U7mLVqlV4DS1Uurt1XZggZOGS5XR09aRrIo5jdtp1KiB46qnH2XbyZEZuNArluHR3tvPSC8+ww8576C5cYUhPuUZjUysH77Q7L7/8CsuXL2PMuPEoO4eyHNpXLmLsJpux1ZRdWLx8JT1dHdx9912MGTuWXL7AG6+/TkOpgS233JL/PPogQkkKvseSVR00lhrYfpNx3LdkMe2VOkopbr75ZmbPns3ll1/+YS/L9cLoMePI53IUi8XUdqkFQZp65edyZnMInp+jUGygobEBz24klhHVWp3GpmaiKMJCF5u2LYuunh4s29V1M02H4aam5lQHCcumUA8I6nW9ObZ1d6ZiSXu38/kcTc3NeJ5O4UBJ8jmPat7X9YgQdJUrWCh8C/K+jiYMwoh8sYFcoUCpOARLxaBiGpubdT0Tz2fFihVYtRqD/SKVekAY6syHerVKvVohDup4nktjg950CSEoFIook7dhO7ojpOf72EKn7oSxpNDdg1SKvO/rbsMyothdNLpaO0OjoE6tognpWCpqYWQcnzYNjc3UazXqtaqOTFTayWyjC+O7rotSusB2UK/pOi2uHovruni+r+WHwJA5BSzboVKpaKerlDS1DkgjYxzbMdcKyOd8XM8jXyjqTbhlk/dcgrqOOHSMfEJG+IUStmsThSGu6+N6OaRlE0tFtVbHzxfI5wu0tbXR09VJGNRpaW6ks6OT7p5uCjk/tdELpQadkWLb1IxsE0JHSbm+T7FY0vaOUgwZMoRCsah/ldqR73uOyZzQEXCubVPIedQrIBwb3ysQKwuBpL29nVJBp9rV63Vsx6ahsZEgDHWaqWUT1KoE9TqR1NGAjut9JOtyXZHZ0JkNndnQ792GXi/iSZgbTkhpIcBSJtIH0p+UaFKm84TSKVMkxJHVm4LXO/t6N/86xM1EOkW9YXgkBAEmb9REHiXERtynG0Zf4ikhbpSlC2wJpZDCIlIWViywnKTbGihlpwUdk5pMOqpOYClQwkpJpSQyJylilhRYS6LBku4CwpBqQiaUk0p6I6bd5KyEsErJIhMWaCWL1ErDO8HUJFLSdJzDsLoiJZKSlDI7Df+zU+IpKa6YLGrbsL7puxa9VfsRECeeGNknuqeXY+uNrupTwDKW+piUVlq7Stfo6l2c6VwRvURPMrH6kNwpMZnOMEsilGXmkkIpLSz7Ek9CiLRlcFJ3rHeq6ZfSN1ea5FjfOah6i1YqpcCyQfQqiL6BX/8FvBMtzS3oGmZR+j6k0umeCbmYzB3XS+qfOcYrYDoRqkQGxMYroetGKDTx6Xo6jD3x1liWDgXG1FpL6nYpqYzStLBNwcykI6KOYlOmjbDptqF6w+VtMCkpWkg6toNrPHKWqTuh12OMH4ZEscQPQmr1OkEYUKxU0rDuxLvp2LpWmyUEruObaDwTtZm869WVplnrURSv1iAgQsZohWeJtA5eGken0HnlSWRg4hVMw/VN96K0Tpsh6QU6zNa0uE6UphbEprtjnKRURHhhqDtlWAJX6DWuUwyMQeRq408IG5DpfLaNTLJlbx5/HEWpbPGMgZiE3QsE+BLPzxFHsen8GRuDoJewTdjaWClqtRpBGCJE1dy3jpB0bAvXtSkUCtr7bmpLOLatvYWYy7hG1kijFYyMdhIPVtphxcg4R8t1qcDxctheDscobsurEUa6ucGGjEGDBlGpVOjp6dGd3TyXXL6IXdPpybbjUK/VkCYCJgxqrGxv195zIagEES2Fkk7h8T0KOd0Brr2rC2Hb2sCxLeJY6VpPtoMrdCRVrFl2CsUSQa2GJSCOIrxcngEtA+jp6SKWMb7nUfAKRErQ/fps8vk8Q4cNY0lnWW+WXRtfKfK+R3NjIys7OqnU6yzuDmitQZv0WFqJEQ0OueY2qsImh8+YEV0sa++kp1qjWCxSrtapVGv4rotC6/5KrY7nurS2NJmUm5hytYpv58gX8lTrAZhNYlLQGVS6ScR2046m3T3dhFJSj2KkquvaiLZFIZfDcx1qaUtzvdEWgHIcVnaVdVt3oYtDx7Fu5V7uaiesVxkwYhPieg/t819mqyM/R71e53//fA2f/vQYhg4bzl133Ul3j25RvOnGG7N46VJefOkleipVSsKi5OsUjCCMWLRkCRMmTqKxqZk3ly6lsbmV8ZtMJFy5kFUrV/LkE4+zw5QpNDc1Mv+12Ww9ZUfGbDKRa6+7hoHNjWyzzWTuuuP/IZWi0DiA9u5ugjBA2DbtPWU6unvw/FwaHbPpZlvQ09PDfbPuZueddqZt8BCWrljKslUdLFuxkl132Z1ydxdvvrkA4bg0tw5kuyk7sGjJMlZ2dDJu402QTolAOczuXE5r22Ambbk1lf/8m57Olbz22hz2+tR+tA0ewiuvvIznuQwdMkRHKwuBimOqQUQRQWtjA4FU9NRDXMfhkYcf5qGHHtrgiachw4bpyB3f11ETcUwuidyW0ni/dVOWpKZOLp+nsVQgCENke4fuPia17dfY0KDTobp7dK0gLP3ZnEdzsyaoFDo90jf1PIJQPzM/lyNnuo75uTz5QhHf87UdVCzg2oKcY+muxV6OhnIVC4lvg2fsrc6ubi2j/TwtA9sIalVqZd0t0/d9CqUGqkGAcD1ywiFn6qZatkO9UtakUByR832amxoIajWU0mmD2gYUuH5Opyh6vrYhpO7o5vp5pJTkPIekNmvOdFt2XQ+pYsJ6nWq5W0csxpJK0Ovdb24ZYAr4BgjL0To8CHBMAXXP84zDV6DiME0R0tFNpiYt2mbK53wKpUYs22HlypU6wkdKCsVSWi7DsXVab7mni0KhiO/r2qNJE4KGQp5KtaI7THmaLJJxhOfq71HCwnI8XD9HqEjTFJOi9E2uB3FE5Lk0lBp0mpvnUsiZd6qgqaUF23ZQStHV3UO9XjMRKDZuFNPS2qr1fRzT2tqK5/upI1Yp3XjBM2nZ9VpN20yuSVEWCttxCWOtzyvlMjnXJeebSDaTIlQMAizHRSGoO/pYGOtnlcvnP9oF+g7IbOjMhs5s6PduQwu1jjlCZ37z+4ZsMOlJhjDQbL2luzyYek1JRXlNCmmjLjatfLV1a2G5mgm2XTetE6QjpjTBoWKZEjNJClkamQLoXocYwilOu7wlJyS1jzTzkxBLvQXbdDpgsggwE0+TUEmOqk7/E0ZoJ2RLL8VmONdeNk67VTRRYwgLwxTp65gFqllypSdXrCemMC9dCMwYhMmHts13iTR6KEq79+mikonisJ3eels631IrO2EZoWc6kWjWtbc9qm1rNlWTVAlRZ4YvTPtX40GWcdJFrze9TF/XtO9VKu18mHTI04vIRGiJpH6S1YfFFubdabInqcmRRMWJhOVNH2fyLozgQQtaTXKaZyj0fSXenaROB4mQM2mTURSa1EWV5ssq6E3FC3traOlUStL3KehbnB2++fXj1mnRfVT4/pk/TMNR02RZhQnFlUhiHZKdRNs5JqzUdnvTPtOJoet/Sak7H2II0pxRXknqrIYAsyaUjFCxMiHVfSL7XEvnViOJY51bHoZJeKr2tiWks610OoyOaPNwXAff0/XChK0J0GTGSLM+4xhTjDWmFtTTLkFCJWeajjdCmPpn9KHTDQmazFu7txi+QhKFidKMej0uSqUK0zGpx0l9N5QpeqgSvlOmZLY0BHvymJOIOv15u9ejYuk2sELoWojJexHQ64lDE9k631xLLiu5J6GLKvbmZat07QrjJJBSGy0qqV1h68YMSdqqlRTNNOsirYehktmVjMh4oNHrO1aknSsrlUoqv5WMEUK/23yxiGO8yikxnub+mxQM8z4SzrdvpGoakkgvyW2hUymkMu1lTWpuGARaaUrJOd/71ntdZh8YVq5cyRVXXMH3v/99Wga0YVmCKKwzZbudaGpuZcHy5TQ3NeHaNg/c8w9AkfNy5FoGMWzERmw3ZWceuf8O4rDOQYcczv333M4rL73ArlP3Ye4br/LcM0+AUjQ1tTB67Hhm7LMvcRzxP/9zHsd/5US2m7I93zn1FEaMGMWkLT7BU888TWdHOz2dKzn1zLMplYr87Pzvc/zXv8XkKTvygx+cxbBhIxi/8SbceN3vqIUxjYOGE3S3E9UqBOUOJkzcgrFjN2ba1Kn8895/cued/+D3v/4l1XrAXfc/zLy5c2lqKHLUIQdx9cy/8p9nnmPzCZswf/585r7xBptstgVRUGfV0oW0d/UgLMGQtjZahwwnX2xgxeKFOH4Bv1CiKOoMHjKMTTffmmuvu4paELHnjIOZ/fwTdK1azhbb7MQLzz7J808/TqlUolAo0tDUQq1rFUFQp7sW0DZQd3zxLUV7V5n27jJFERJJRS2WDB85Bt+1iTpXsGD5SrqrdQYOGEC1WiUIQ/aeOg1LQE9PF0GtThCFdNfqCKUolRqYsd+nuf+B+3j0sUfYeLMt6O5sZ8G819l5971xXZe5r82mu7OdXD7PYUd9kace/zcvP/8cB3z6YNrbV/HySy9Q8l3a2gayzTbbUetcRVCvUo0tIiwsz2efPfdkybJlPPnMs8xduBjP89l03DjuvudOFr35JiPGbkK9axWy1sNW2+/KiqVLmPPSs+zxqQPJ+z4rlyygp1yms7OTp599mrGbbM7Q4aN46enH2HzLrdjrU/szfuxoustlnnjqGZSCUqnIzjtuz1PPPMvrr89lm22346UXnuX+WXez6eSd2HLzzTjigL24/Hd/YOmyFZxw3Je54X+v5cH772XqtL2ZPfsVHn3kQfbZc0/K5TKzHniArq5uAEYPHcT8JctYtrKddTRnPzKcdc75JLK2Wq0ihNCFpytloljiebqQuG1ZtLa0EIYhtXrAwLY24ljS0dlBFIaAwvV09I1j21QqFcJYEhrD33MdGkwtH2FZdHR2EtRrxGGY1pPSUZK+rlVqWZSKBRzHQSh0FzYZ47kuYRRRDyPyxRJISVivIaNAkzfNzXSVq9QjyZBhw7UcjyMGD2zBsiyiWEejx1HEqlWrqIQx9SimUgt0rSTHdH4L61R6uij4uitkuVol5+dMnc48UmkbuKWliSgM6enuSiNAXdehp6dMGOmOmWGoa7JKJXFsi5zr0N7RST2MiCQmlUnbhcVikUKhwLLlywnqmphrbWowtWBts7ETDB06lOUrV7JixUqdUmclKUUuttHJSYMly/GoVKvUanWdxpgvmLRKvTGMghq1Wk03xpHQ0NREQ0MDtiUIgiAt5i5NRFGl3ENQrxMEAYWGRgrFkiaKTJRlpVZHCJ2qiAy1I9tx6ezqpqenhzis45lopsZm/V6SiJ0wDFm2fLlOq6xWaWpqMuVTBEOGDCVnumcl9cG6urtoamyiWCwShoFp/qN/enp6WLhoEY2NurOql3S5tiwamhrTcim2ZRHUa7SvWqlrsypNYAaBTjm75Kc/+ohW5zsjs6EzGzqzod+7Db3OEU+qT7t4oXoXnEhmVJ8fYVkkHdZipdPZ0urwShNBOu/XRsbShOOZcDiFTutLiA1p0vZEUmdHkz99i2tLU1Fde+ZMGpSK03zWxKOAIUZsW/ZZDoDoE5JnlLCKYmRSdFyYtyCApHi4SIrxJcSTJmeIpWkTq3qjnxICLHmXydjjKE0/tIUJf7SEbmGJwEZgmTrsmnySIBSRHSNFTCwk0jL9FYRZEsrCko6O5pEWQtpg2ShhI5WDsmyUZYNyzGcESH3MchwdtSV6aT5JbyfDOI6JI2kWR+8zSWo7pcSTUshImneui6olkVIyYaCFMMW5e8OiQZl/2yihzHn0CjZFP4KKVPAr49XvXSQJw24lEUqWTULf9kak9Yng0rxjP3ZcCQthKbOgFZEpUpm26xQ6BPK/BdKkx/TKs+T5Kp0umBC/KmlDCpZUWFZCrKaTETCRegmZmBCKSbRdn1BanRuqU21VbNa0lLoGm1TpGpUCdL42hr1PvBcxMnl3yqTMmu47FpEu4mdZxiOk35m+PxBWUpdLoJykOHOvpyR5Fsrcj0B7g/rwm71C2cwty8wR3aIZbDPHYqHnjDK5x7qziZM2TRDCTmWCTg/GjKE3LzqtS2cl36eViGU5COGkctKyjAJMefAkSrCP8jQKU0HadQV604SVKVibFK5MjxvvURyHRmmq1GNpm/TVhBxOOGptJOgbEKqXuO5di4nMNvLdFBxF9KZIE/cqzTQ02EQ7aONA6G7FgtT5ofrMSf0OzZRT0oyjT/SqsNIxOkKgLAsljRfLiful1W6IaG1tpVAoIIRg4KDBFEsl8jmfjTfZFM/3WbB0MQ2lIk2NTQwZNpJcPk9LSytvLlmivW+ex7ix4wjrVd5csoR8QzMbjd2EVSs1YbXLrruz6M038XJ5WgcNZfHy5bi2xb4z9qder/P000+x/0EHU63W6OruxnYcho8YyUY77MjSpUvo7PA45HOfJ19sYMGiN9l///1YumQJc197hRkz9qOzXGP2wqXkWhoo5VzGjRnFsmXL6ezqZHlnNxuN3ZhPH3o4y1d10NXTA0oxZccdcSyLex54iGJrG9vttBtdnasYOW5TRo2fwNIliyESNLYMYMouu6MUPPX4vxk3fryOILptASNGjmDjCZNYtuBVcvkC9SBg0tbbUqnWaV+1ggmbTcRzLOa8PpeWlhZ22nUPWloH0NXZwYJ5b7DR6LFYtk1HuUYcBTiOy2af2JpXZ79C96uz2XTzLYmkYlV3D4R1AAYMH01p6GhqQciiua8yZtx4hgwbSVdPF82trWy21Xb8+7GHEY7PzrvuxJtLllGt1pgz5xUaGpvYYadd6OzuYdjwEUzcbDNqgU7LGDl6DM0NW+DnfBYsXMSw4SPYaMQIli9biuN6bD15OxbMfQ3HLzJo2EheWb6Urs4uho/ZlHI9pBqEPP7kExRLDXziE58AN0e1UqGrfTmf2GILxo8bz+xXX2XTcWMYNmQQz740h9bWFg4+9LPMeX0ujuMyetRYXnj+OSIp2XW3qToVKw74xFafZNjwkURRyOtz52JZFmNHb0RsaoDMnz+fhmKBCRuP5ZUXn0OomGlT92BVVbJsyZvc/c9ZDBsyhLaBA7n//vtoampi2rQ9Wbh4McJx2XrbHVi2chXdPT0UGprZepspuLbN448+yA477MiY8Rt/xCv0nVGrVnRXYcftLT5t9JAttHOxkM+TMwRMYleFYQhCUCgUiIJAb2hiXRcqSssqaCvRNakzoMWwbVmUikW644ioXgclcR0bYenC96Dld71WIxA6UjBx3gkBQRBRr9cp9/To6wlTcN+FoB4QhyFIiWMJYgWRUtTruutTFEnyhRygi+/nRG/JB9vSG1SUJqcKhSK+Y5muyo6JcuhNTQKoVisIwPdcmpsatZ2hJBZQq9ewVIzv2viuTbVaBRUThxGeDbawkEpg2wqBbv2tQoc4EPiWwnIFDg6WihBK1wj1HJ1Sk/dd8p6OFHVsm1zOp1Qs9dmcaatSCAsvl+tnWziOTUOpaBzNEbFjma56AT21INXZtiEBcmZzlWy+87KA7TjESkdrOq6uxyfQujpxTut0GA8BRFLh53SDiWqZtOSEMoSJLmBupYXck4Lmfi6nN8eOPjeKY91xztQ0KpUacD2dDhcEoe7Y57pEcWy6XLspIagiSzvEbVtvuh3HpC9KwKexsam3RAqWLmC8gRPHmQ2d2dCZDc17tqHXnXiKwpQwMBK2l7gwrKtmAEHYlnnQ9OZeRrEhWpSpG2SDJbAjO829TJg3ocxLxiywlISwSKpHJVE3SWQNZgEkD1ilXS5MNSiBLnJmJgVK9VkZKn3BCQspQyet92RZmPuzIOksZMgy/XCUYaNVH1a6z/dgCp5hSAt6F4tQugubY0k8LDxLYIkYC6XDIU14pRZIWsvJhBhSeuGlNa5ksngcIimQShDFtibLLBsZe1qROy5IzSBLBMrU9nCSBQZITO4sKmXzoygiMsQTfboWpkXfEwJJKVSk37mKY+1lMwyusnrzfS0TUSYQKfmnBa4iLTyeXrdP1JVMijCSLhatsEQvAWbGkrDTji3TuQq9zLg0xF8S/ZVEPAksPe+shEDUbL8yecS9siqlLzd4RNUKCk1CqmT92gLipIaaUYzahQBCQmzp/wtl2qUmAtGsG6UQSOjDmidKKTmNOEprtamoNywWobTikRboBjU6jFmS5s5LFWvBnZDdaBLRsiyU7SBiPdccodOELMcibf9iCWzV22bUsYXxODmpIkjEgB6rXmvEfTuWJFpVgbBNDbvemaSkSI85mKoU5rnqLjy2qRHXp/ujUsRxQpybjjmiV/6ItKuiPuZYFpblYlmujjA1GwzoE4Fnzk28X0nTAKlvKyXypSnMrwnXOJW7lulGIVWvRySKrDTaUStNHYbtmTQli95U6kThKEMep3IzUZhGb+g07Rjh2Di2he3qVt/SzA8LTIcl03nIFH1FQZyw8GnLXdPx0tx7r3Ggn2uyPi3b0QrS0o4JvUETWh/YJn9dJrJgw0VC8Nu2zbCRoxgydBjDhw9j9IgROv3tX49QyudoGziQcZtsRnPrAAYPGU7HnX9DxQG1IGSzCZsR1is8+PhTDB48lLahw3n8wVl84hOfYOddduWBRx4liBXFpgG8OHs2DYU8xxxzLH/53z/zyCMP85s/XM1jjz7CLTffhG0JxowdxyGHfZ7f/+aXCCQ/v/hSbrvzHp5+9jlOPvF4br7xBu676za+9dvfs7S9iz/8780MLVmMGj6Uzx7+ea684jIefvgRXnljPjtsP4XDjziCq397Od2dHeQ9h/1m7EdnVxeHf+4wDj/meHbYehtmzvwLEyZsxhaTtuS3l12MBFoHDeWzhx+BlDFPPvUEEyZsxsTNJnLPP/7GmDFjmLbnXtw3S1Eu99De0c4nd9iNcrnCrDv+xm47H85GG23EPaedwic+sTVTtt+JliHDePHZJ5n/2iuM32QCpcYWVnSXmf/6bKIoZMsdp1INYxYtnMeW2+1CpGDR0iW89vRjKGDg6AkMHTIEZMzM+a8xcdIn2Gn3vfjNry+moW0Im2+zE0899wI532XvT83gmVde4/U35vHoP//GzrvswZ7T9+GWW25i9OgxTJu2N3/4/ZUE9Rpbb7Mdk7feCtd1+emlv+Tggw5krz1259Rvn8zoseOYuten+PstN+H7OZoGDqGrWmdFeydb7zicrnKFle0d/L9/3Mauu+7GQZ/+DIGymD/3DV5//kmm73cghWIjPzznu2w+YQ923W03rr/xSPbcazrHnfBVjj36SCKp2GnXPXj2+edRlsPBhx7O4/9+lDmvvMS0Aw9Bypj2zk7mzp/HoLZB7LfPdMq1gI7OTh599BE++Ykt2Xj0xlz/v9eww/Y7cORRR3H1X25k3uuv8q8HZvG9M77DoLY2vnHKtzjyC19g5wMP5CsnnsTIUaOZtus0rvrtryj3lBkyYhSfPvizuI7N3//+N742bU+OP/74j3iFvjN6ujopFAr4Jcd0nYqpK4XreghLEIcBXmMDxWKBWq2OlDp1p1qt6a5hhSKhbREGAV3VTl3LTEGxkNf6S8a4Tg7H1k7AOI6wHYvGhhK1Sg8VGSOjEDfn4+dzVOtBqqtr1SpxHBHU62kBboUmGGq1KksXv4ktLBpKRRoam0AIyuUyYRTq1CILkIpAxpTLZZLyF0Io7VAVSW06C9tJaqVKglqIJQTFUgkRh8gownd19AUIojgymy7o6qziey4NpSJtA1pxXYd6tYqKI2yhO0DmTAphWO0mDOtU63Vc01lMCYjjgFgqojimFgfEgYelFB4Kx1FEtSrKCch5NrmcrlFkoXTqoWvjOjaNpQKDBw2kWqubItM6AkEpRd53DWkkqdZ0YfNCIW/SoAXKNiRR4FAOdDZAFMf4vu6y7eJii7yueRMEOEUHP85Rr4c4roPrOJrICkPKPWWTqWDSu1xHk4XVOr6Xw/N8VBSZzTGmA6LedHqej2UKnCtI0y9dVxNEsYwhDHFdx3T+g7a2NrPdianW6+RyurhyVAt0ZzU/pwtbhwGhENiuh+t5xFLheQ75nE+tWsVywW1qoloPiKJIpxyZbtsbMjIbOrOhMxv6vdvQ65xqd/IXT0BX7HdQwpAvjovtuZrVdnU1d53qpb05MpbEQR0ZRchaHRmZIooyTh9mEpaYMLy9hb7S9UdSSDupdYQQaU6jJp40EdE7mQ3ZYxZe0kXPsuy0a4Nl8pyVERTJ//UE1KmDwoQ6WkKnslm2hXD7HLd7x4tJmUsJKKlMsTmdRuc4YFsKxwaPAJsYR9URKsBSMbYldWE2C2QUavYaS7djxCIWDsJ2wXLAzenW2raLlaQMoiCq68i0sE5Ur+qUvKBObCZRjAWWDgW2HB8lbGIchO1hWQ6OlzfpZrYxaLRHLnnGug6B8exYjk7RMy0mSRePYXfjGBUZYRmFvbW3QBN4loXl2Pr/pj1lsuiT1ox2EhFliZTIiyJtmCTzSCUMtDAhg0Zo6P9buv2k8TAm6Y6RqamQeHFQmgx1DJtv244W0ErXMYki3To8qNeJo5g4Cg2j3VtEXwAX/PjsdVp0HxVOPv7bOu3SdnES4St6i/PLODYeDnT3AtMBxenzjpXSJGQcBfrdKsCx9fpwbWxjzFi2hYNWKKQkpDRRj1KTrqaOmMIy0l3pc0zBQBBpymPSEhkEuuqd9tZp+WGbmi2AJVCWJr8tx+TZ27oGQiJU4sgoYQkqKQ1vWShTl0GGsVEyhiBG33svsWm8Lsq0UTbRnDKKtPyxBMI17Z9tHV6ta8wZj6NJPdaFJSPduULoHGrb1XNXp8iaEH5Tn82yXRzHSr1iygj/JG3VMmSubWSTzkY2abEyeW/SeEeMYWMKzTq2nToSkpTeMAj12lfaeDEuBhzHNsUObWPIJC2rATOeVJknacz0hkgnz1T7F3Qnm8SASbqKuZ6W024ip1GmboHWK0EYaDIaZXSSGUfSFTNKZLrSIe52b2259MsTGEJfofjGiV9+n1fd+wcpJbffegvX/P5KWkdtyqAhQ5k0cTOuv+EG6kHAGad/h5tmzuSJJ57gqC+dwPPPPcOD99/LeeeeS0d7B1dffTVHHn0MTS2t3PzXm/Fdh5zv0zZ0OMVCnmI+x3PPPI3l5Ri00Them/0itpLssv0UlLCp1APuuvtuRg0fxsRNN+aN+Yvo6mynfflSJm2zA47r8szjj7L39E8xZsxYLr/8MiZv9Ql23XlHfv+739E8cDB77HsgncuWsGLpYh55+AGm7b4bo0eP5m933c/gYcPZaPRoFs97g0EDmpn8iUnMW7SUMIoZ0NrEwgULWLFyFStrumh4rVZjowGNNLe00DZsBDdd+wdUHHL4Eccwa9Y/Wfzmm5x4/Jd4Y8GbvPzqXDYaNYoRw4ey+abjOef8H1Kr1fjq8ccz86YbeeONuZz4ta/x6uw5vPj883TXAiZO2IT9P7Unf/zT1cxbsIi6tBk1fCilYp65Cxax3bbbsNUnPsE1f76ezs4OZBxxzBc+S6mQ5/EnnuTV115DSsnXTjqRf9xxJ3ff80+O/dLxLFywgLvvuoNvfv1rWBZcd+21HH7E0YwaM4Y/Xn0tI4cPZ+Tw4dTDkEhCFENrU4GwVmHe668SKwsvX2DLrT9JtdJDtVzGdlwWLV7Mi6+8wp677Uq9VuWeu+9i6JAhNDc10zx4GKvaOyhXykzdcQpLl6/gmRdfZstJkxAyYt4rL7LFNlMQjsevfnEJ22y9FZMmbsYLr81nk403Ztedd+T6mTPxHJdpe+zO+T88j9ffeINvfft0/v3vR5nz6mzOOO10VnV08OIrr7D31D1YunQJv//DH9l99z0YtdFGNBYLvD53HstWLGfy1p/kySef4Pbbb+PIL3+VUqHAsvlvUK3X8fN5Jm+zLc8+/wILFi7iU3vuwdNPPckdd9zOiV/5Ku0dnVx1zbW0DmyjVq1y199vZmBbGy0tLbz00ksf9TJ9W5x00km6ppKfo7u7G9uyKBSLugiwkaENjQ0UC0XypQaCIKRSrYHQ5R/y+Tz1cjdRUKderVCuVKmFAb7nUyiVKJUaqNV16pXneoShJj4aSiW6u7v1pl+Ycga2ndqyjm3T2dmlI5vKZfK5HH4uR3NTE+X/z95/h1l2VOce8K9qp5M69+QkjUajnCOIbJAIkpABC66NTTAGDBhnY18b+14bB0y4GINxwLKJBoPBZBBBIJBACQnlrMnTM9P5pJ2q6vtj1d7dwv6+q3u5nxHPM/t5WjPq6T7n7NpVtVa9613v69sq+91lojBgpN2hNTpOGImY8VinTavZoNNpY6wIfx88dJhAC+BlykJYV502wzSjKEvCpOFb4nKfd0mcHHYXCBSsmZoizQuK0vgWjmrvL2g2EsZHR3FGXPGWlhZZWlpi0O/T6/XqvH7Q763KG+SS1NxRSXQoL9hr7YqLs/baoM1ms2aPCcNIDuNxGNJqNZkYGyNJYn+YDAm9DtXk9FpyIzpUvcFQnl0Y+TYzRbuRMBj0yfKCgW8xctYyMS7adFlZUqYDcNIyN0wzytJIYdgfEEdHR7FGmGhRnFDpSFWu21EY1Lb0RZZSFAVFkdMZHZW2JV3pVVmG/T7Ly0sMh0PWrttAkiQkSQIeEEuzjCgMCcOQ0dGR+ty1vLxM5Wi+3O2RpinLvT6NKABrWV5eFDAqitm8ZQvNRoNmIyHPM8nnPXNEKWHyLS8t0u/1+PU3vv7HuEL/f19Hc2gZh6M59NEc+kfJoR8z46k0OUoFwsAJNIpHi4Y5Vuhlcmh3Nconk70aGIO1JRXSKHRELQJdgUeJfTsW4N3HBBASZE6cAyrGUy1cbSvkuFJhsnWAkWfpmS7WC4iplXa96nNXavhK69pCsQJBtHVoK1aOKpAFr11QC3iLHpUgfzoIKuaen+AQakugLKEyhE5eR9sAZ8SdovSgFc6SZwWltZQGSgsWRekCVBBDEEKYosJYhAYbDRFLCwMiHRHokDCOcAQonRMAFDnO5tgiExArT1FB5FH7SF4riFC2ROkQdIhBYa2ImIljUCXeLoi58ouo0lSqqlemEmo1Blca+dNUDhD+mcjAoK0APW7VBsEq8MnaoE4MKraTKXLKohBUvyz9VIeqz1brABt6ND+U3lnnKxDK60aVpXd5KMs64ZD5K0lHxdV0KL9I5b2qr8LrJDhPf602k8f7Za311FJDvXSrNehW1Mtkba6qMKyi1laOkaYoBVx0DmyICq2vVShcEIj7ow+aqvRovB9LmdEW4fSpeuxdDVzamt1Rr0/v5OEcQjvWvjoUONAWvDMDipp1qYNAWl+DACJLpc1njLAgnVMrm3rFpKv+9HTmRwVNX8WyqqwrAqU1YoBgLc6IQ6ZGo603T1DWfyAP/pZVQMrEirnIKQsjgTKKCI0Aui40VDptVgcEgSUIDM4FKzRszxZ0KoBKD0BV9gWrnpddsZuVXnoZb8Dvdboeb6WUfEZjMLk4Vkg/+IpZQ9UerZWp935hAXrdOL2yfXtCtVSOKpB3FbW3bsH1hQOnVeXRUAe2R7Fsq3vzr6mQ9mjnZ5R2+GLDyuviA7+wK1ceZ3VVFbCfgCXMps2bedJTnsr9+4+QDfsMu0vCZsgyHrj/fpTWrN+wgSOHZwgDzQkn7CTLMtEuGR9nOBwSJn3WrV2LdpbAG2nkuTjVTU1OkRvL7KEDrJmeJgo0+/btY8fOE1m7fgOddhsFDHo9okDRbjXR09Ok6RCVpbQ7HZYXF9i3ZxdRGJJlGYcPH6HZklaTB+65k1jBoN+j1xWNnigMWZidYWJinCSOyY3BOEiShLm5OVCaC847h8MHD5AN+hxzzE4OzhziwKDHxk2biOOYbneZyalJQgVJJJXH0lriprSR9LtLdDodTGl44P77WL92jRykOi02rF9PnudkwwHjoyOccMJODs3NE4UBDz/8MFu2bGFiaprSBWzasJ5mI6nbDNdt3MzJJ5/AsN9HK5idnaWXxByzbZsXe9XsPOEEvvPd75HlOROjHdiwlpNOOF50IAwcs20rg+UFjhyMOf3001mYm+Xee+/hyU99Gg5FtzcgxJCEip3H7+Cu+x9icWmJ0dFRAtnQiBotpqZytm3eJHFMabZt3YJ1iry0dEZGUVrTaTdFR8i7YgVa0UiabNm6lTTLKYY5Z5x5JmEUs2//AU495RTiOOL2O+5g3dq1xHHM/NISGzdvQYUhR44cZnRsjBNOOJHde3YThCFbN29meXmJXq/P9NQU7VYLrRVHZmcx1tDpjDA5OUVndAwVNVheXCRwls7ICN1histygjCk1WoxOjqC0pqJiQlO2LkT46v1mzdvZnrNGpSCmMu4/fbbuffee398C/MxXoGWboA8y+ocUdqlZA8SOQNDXhS0qqq3AhVKrMzznLwoRKgWJG8tSwrAlgkKeabWWrJ0SFHk8j7OkmeZ7NMewMAprAFlLUWlk2or7cuSoMgpcp9vGTEOiMKQKBY2jCsLb88txbhBr4sKQtABg36fMAxpNxs+VhpSb3ygcJgil4O03/8rQxhrbFU9BiR2ie13SVEW5GnKoKcZ9rpk6ZA8S+n6uZZlKcPhsM7n8yyrtVYrkMM4V+uHVjEQn3/IuV3Y9lprepEcuAPtHcZ8Z0AUBjSShOWlRdpNYQglsdiQJ40GkcYXdZWIsSgxNTLGYJUiVcKer4qfVQ4phVXDcJjiSmFPkRfkRQkOwmaDSnsmTYe1lqoqpOUtCEPKosQ5Sxw26zNNFeyqmCqgj5yjnM8NpKC6ql1pFUvFGoOKo9qFsTrT1TkworPlXEKS5wSCbNJstX2RWuJL1Y1SFgUKcQsXvTJF6V38wvAxH0l/LNfRHPpoDn00h155nNX1f5pDP+ZVnhcpSgUoHRIpERFHC2paM5CcR2Kp2qc0uhYJpwadjMlX/YwT7SVt0YSCtjpqkEDmaqUX5V9bgXPKT0IJlM4/jErUvBpeECC4atfSCghs/a/VQhVngRJTWgFGdEQQ+5avQKON134qcnSgUIEiikRk0AYhgUdMgygmTmLCWBwlgkATBAptMrA5qhhSFjLJChOSmpDClAyygizPyfKCXlcqQaJan0svvzEeFNJYxN0iiGMaI6PEjSbNkREmJiZpNltMdDpESU5gcvRwATdYRg+WKbM+ZVFKy5iS1sEgjKVyFUaQtFBBhAoirE4wTlE6jXWVk5+Mu1PKUw/B6aqDUdoJazaQEZtp/IZXIcCmpmCKhasKhIW2AmAiG6JSKC+SLn38shjKLKMsMkG786ye+9qLiOtARO6lahXgjKH0QVkWjVAfK+eAaoO2zhJ4cXwbWZl/4JODgiIvyLNc/u7/dMbgrKktJx/vlzUFGoNSBkUIHqatCLhaIQCwZwTqMECFAVqHgMOZElMBgGWJLQpJFAODDgO0CaQy41lqtoLjDL5H3eFcCd4lokL3rTU1KGmNVHUkiFe0Wou1hW8ndb7NVbQgXGiwWuNVBepESClNoEOsp6/bKKj3BAsCdgYhYbyyU1aVR0wVCF21SSClnXIliPsqSGkMpnQ4I3WfMI5QcYQK/B5UeiAe2YeKQgDPLB2QpkPR1SgrO+MGSSMkDLXX4KjYf8rTjQOiWA6zYRBK0FAKpQPiMIYgkKChjQgAYjBO9o6yKDCloSjKWpSyEnnUWlPWLl9gCuNZqrk856qYoKtSXlUxWg23WtHu0BqCqP5s2OonViq71hhfIanGxdVBTAcBLghQqoTAEXggurokGbB14NXBCjPSOLBKigagMbm0VBjf5qxY9Tz9JTTilbbfx/OllOK0s85h58mn8mu/8ZvM7N9LuTzLky68kO5gyK/96ht42St+iSteeCVv/8s/42lPewa//hu/zd/9zXtwDs57wpN48KEHAdi58yTKPCUbDrjnvnsprIMg5EkXXsj+/fv48r99klf/8hsYH5/gIx/8J9atX8/xO3Zw2WWXcucPbuWaa77O1k0b2XLsds553uW8773vZjAY8MZf+w0++6lPcN/dd/KyV/wSd9xxO297xzv5lV/7Te679x7e/Kbf4JJnPIP169axdcsWFhcWueP2O7j71hs5ZssmTti+le9efx0mzziwbx27HnmEuNEgDAP6/R695SWeceLxNCNN2l9i7bq17N27hy9+6Uu85pWvYHykzbVf/TJJHLN1+3Hcesc9zB4+hHIFI50W9917Nx//8Ad42zvexZYtm7nz1u/znEsuAR3yrne8leddeimve91reWT3Xr78xS/wy699NZ/+zOc5+5xzKcuSvCgoipInP+UpLPRT5gcZv/xLr6QRRzjnePKTn0xZGj760X/h4jXPodNuEQQBY5PTrNu8jf7sQU7acRyXX/pc/uqv/gqtFL/2xl/lvX/9Vzyyaxdvf8/f8t73vpePfOQjvPjKF7F27VqMMfz7pz9Ns9HgxS++kj1/93723v8ABw4dYv2aKdavW8Mtt9/J+rVruPhpT+aqD3yIJEn4lde/gb99/1Xs2r2Hpz/7ucQabJlz+x134pTmlJNPItRKdMLOPodv3nAzS90+r/iFX+BLX/4yN998Ey/52f/GLbfexvuv+mde84uvIAhjvvndG7joac8g1Jovfe4zPOkpT+HEE0/iT9/yxzzhwgt4xcteztv+17uIoohXvuKVBEHA/MIi//rJT/Gkiy7i/PPPpzcYsGbDFp7zgv/GHbdcT6uRcMYZZzG5Zi0OxW23384JO47jvLNO5+pvXMPxx23nD37/D3jrX72XPM952tOeypOe+AQ2bdxAu9ngV3/1V3nPe97zY16h//srDgPKsmSYFiSJaOWkwz6dzigqCOj3B1KJxjFixiWnVdCIY0pj6PZ6lNkQZwxx4E8X1lBkBUUWU+YZSRyTpRnzC3Ni365g2Fv27H2N1YpYxQRRRJrnlKW4OFWmQM6K6DTO0nVigoO1jI2MEEURSRKz2BtgUYyPRQz6fdJ+F2tKWp0Rmu0R+r1l4igibzcZ6QgAsbC4QKfdJooiuv2h2IqHIcZalJZ8Da0FbPKAS14ULC8vk2VpLUidZ5kI5g8GFEVBNhzWYtmqkmxQ1DkH4Bn88pXECaHXb63ieV2vd0iO41zdLoOrNGAr6Q0tdvdRRKfVoBFHjLabjLQaNBsNFqamSBri9Jd0xogbbaL2CMaKs97CYCBtldbS64kDYLvVJAg0g3RId3lJXANNSbfbpZEkJHFMErYwTgTbe72edxILSItCgNp2h9J3lQTtJgZbF32Vwusr4fNfSxhKZiLAouTCykl8FqBInLSVEk2vIJC5K4Y6ljRN0YEmUcJQK8oSrRVplgOOzWvWyHPLc2njLEvRe7WGIAhoNxKG/Z7Ph4Y0Wy3Gxid+PAvzMV5Hc2j5maM59NEcurr+b3Lox9xq98orX+Q33pCkOUYQJUTNDioKfKWmEECgyLGm9GheQKQDmfrWUhSp9LXbQpA9NKEO60qC3Dx+wKv7k0G2TgAm/7HlMVlh4RgPHjhXUdXcf2CgyEMWdXztaXfV+JnSu8SVhXdH06ACdJR4OnK4Iv6mLEEogac90iZKEpJmmzhpEEYRSaslwmHBCtvGWUM+7FHkKdmgR3dpkXQ4ZHl5iUGvS5qm4kriVerTNKU0JWVR1uKTAsbJ4DiqxaLFlSQMCZOE9tg4jWaL0YkpRjodGo0GY60msbLElASDBWzWpxwsk6feghElThxBSJw00UHkN8xYRN6UxqoIh6Z0gW/9kz8FiNR10JYqSFkj15XInrMe2LO+LdIK4CeOgdR/Oifod8VQ06F8liAQW1tnpVImriqFB56cX2xhvdmHUSzAk+9V197xr6pAVCCWIOfyftaJFay0jUY1+6oohM6d5zn5cCiVtyz381zYXFWL5z//6z8/pkX347pe9wu/iFJCwwxqq1N5niiFC0J0HKMjsYDVYYAORfASpFJW5N4ZpzcQkNHIHMX3VAdKnBNlTXsAsfoAvtpWfcPpymmQWhyvKHP8ji+uHh6HN0Y279Iz18SuVua+1kE9//AVlwoI1JEHJKOQ2ow11AJqhhFhEvt+cAnCWIvLy7pl1lm78mUKAc5tKcHHGIrC4GsGxFFElMSESUzs2xCCqsLgkODlqcHDQZ8sTSUxK53M2ySh1WoSRuJ6UTMAlVBdw0ATRt4ppq6KyL4mlriyv1UVsMKWq9wbRYy29MB6ZcEslR8ZF4vX5MsLMVfICqFO133gIiZIoOvgWbXJ1q0bSqj3Wq0YRlSJRpHnvjpuvIachLIVbT0J4JX4YuiFS6tgXhrjK8UlRS6ag2glGhxV64BnyBaZ7KWmLDFFWTs5UTmesFKtDGrQOuAPfu/X//+5BH+k65JLLqFqH9+1ezc7d+7k1b/0Gj72sY+xuLjA85//fPbu28/hI4fJBkM2btzIscceyzAvvC6AYve+/egw4EkXPYmDex5h7vBByjSlO8xYGqZ0GgljE+NsOWY7t//gdgAuvvhibrj+Og7s38vr3/BGvn3tt/jMv3+aV7/qVSwsLfHFr1zNC1/4QkY6Hb7+9a/TaDbRWrP3kYfZeeJJnHr66dx9553Mzs6yf/8BQlcwPjbGBU9+BvsPHKTX73HGicczOTnB+NgYB4/MMbewxL6DMxx3zDacKbn1+zfyzGc9iy1btvKPV13FzhNP5tTTz+SLX/wc4+PjXHDeBTzwyG56S4vY5cOceOoZjE1Occ03r+WEE0/ghBNP4n1/93ds2rCeS5/7HE486SQajSb97jJJs8Xhw4d59iUX8+pXv5rXvPa1vPIXf5F77r6bXY88zNnnnsvoiLhlnX7aqZywcycv+bmX8qGPfJQPfujDjLQafu2F3HDjjVhjOPnkk4njmE2bNvF3f/d3HDp8hAMHDnLMlo1EUQQqYH5+jsEwZXG5T6QdURgwuWYdd959Dw88+CAnnXQyh4/Mcvc993L5cy9GO8P3vn0tx5x4KnG7w3e+ewMbp8bZsGaK9vqtzB06wK57bufs859Ibiw33no768ZHicKAfTMznHbyyWw/9hi+8MUvMTU1zUknn8wDDz6ItZbp6WkGvT7WGkZGxxj2lhn0ltk3c5ht27Zx9llncv0NNxGEIaeccirf/uY3mD1ymB07T6TZ6ZA0miRaDu2FtRw8cIBOu80pJ5/E/OISg+GQ7tIS01NTtFptvnvjDQyzgsLCKcduZmlhnu9cfx3rtxzD2nXrufD88ynzlDLPQWufIw1FVL/dYmJ0hA9/8J8Z9nv8yZ/8CYcPH2Jubo5LLrnkx7pG/3fXK3/hpXWLWaPRIIoiGo2GyB8EAUEgLkRhJCLSYSg26f1hKmxzFZAP+5gix+TD+hDS7/doNJq0Ox201gIeZKkU+LQ4ZVVuvkmS1NX0rPBsdGO9PpCuWVTOWRpxTJrlpGnmRaUlxyuM5EtTk5PYMgdraLVaEo+DkLyq+JcFIyMjhGFIYR3Kyh5cGOs5G4pmq+WFp2P6XXHfS4cDusvLDAZ9lpeWhOleCshUeta5MNlXGBYVM6HusqikM1aNv8O3ufiCeXVeCCpJDbXiOm1Wve6Klk0VO3TNfgq0Jgw0SRyRRBFTk+OMj3YYHekwNjZO3GiQNFoYFVIYJ6w+LVIZSXu0jntxGGCsJS9K+t1l0a0KNNa7GDabbbLSUBhDEicrelzJyjlFIbG01YipRI+jMCLLM/r9AUmjWWvX9LpdDwxlkpdDzVIy1tFpt6nF2/3htNUS7bE8z72MRUgUhTSbLay19AbDWvcqiSPfkeLngpGOAa01zhqKPBN2lD/T6EByud/9rV/7L1mL/zfX0Rz6aA59NIf+0XPox8x4qiiwSstGovxEwmqcEspnmeeSLBQZWknPowoT6Zt0eADJUwtxNU2korQ5tyJMVW3ytnLE8w/f1cie8u1fpg42dtXvrwaelOcOak871TqgagnEOXkQZUFZFp49JdQ7bS0qCAlWTa4w1B7s09IvjsIqDVGEThKCRlPoxkq0hAQhzen3BqTDPr3lZRbn5xkO+iwuzIlVapoyHA5Ek6lq5aroiiu3+2iKm///qldbBQHLy8vEzSZL3S4jYxO02iMMJiZpxyHNOKBNhFZeJwqplImzigAoRikIS5SLhFKpNE6L/JlFeepjiEWDk5Y8XCAC5c6T97zQu6vE4VemKM5VXDznN1CZwCsiZ5bCFPU9B76dMAidsL2c85TgEuPtXfFVKh1YDzzJHAhsUE0igsBgja4XMs5/XuNbQ33y4SpQSq3QLcu88FpZnnZeljLPixxnSlzVk/xYF9KP8bJWKM5OOawNVgTxlBedrxBfn5g4rLRb2hLf7LyKvqmoKJ/WGtlxtd96lZZ2VLeqhbL+ED6IeBonylNdffJrjJHqjlN1LUljfUVH1rhWniZqDRhdV0NqUTxTep01qeChA2mVrTZop2uw0GlVa9Mp57wIhK1/v6YN28o61NZ6X2VpyAtT94cHgUZbi7Yyl5XVnvLqRR7LEuPFU02ZY02ONYUAsQqcCfyeuorG6+/VaYe1GoO4f1j/CPAJkLYW551ocPLvpZVAYapA5YF6F4jAo1ZVFUr55+jHORcKuC0LqHr2ra1tZamo40Eg4LAPpFWbsnNCo9fOmxdY6eHPvd5fWRpMVflCEejQg8MSNK1PlpwN/R7ng2ZpKXyRoCzLel8Ry92QIPSuInbFOMBWCUMpQL7zMUD5sRWxbuvB95VWg8fjdfXVVwOSKJ14wk5G2h0KYxmmoue3ZnqaAwcOkA4HrJleQ1kUPPTg/Zx2zvkURcmeXbtJGg3iJKHX79Pt9RgMBkx2OgzznHTQp+gv02632Lx5C7fecgtpmhKFIb1el0MzM8wenqHIM0ZGRrFWDrfDQZ84ConjiEGvS5I00GHA4dlZtpclE2PjzM/OMuj3WbNmDTbt0mo2sSj6acYgzTjmmGPoLy+x++EH2Lr9eHr9PrffdRcn7NhOnEQcmpkhHQ7BObJhvy4+ZMMhptMhjmMGgyELS0uUC/OMjY2weeNGDuzfy5q1a8jynLvuuB1T5F5ANxJGrA44ePAADz30EAcOHuSBBx/kB7fdxoMPPEC322X9xs30e33SobT7dJeX6HaXuf+++7j91u9z4/XfQSlFu91mamqK4XBAluVcd911OGDTxo3cdttt3jLZMjm9BoWiP+iz/bjj6Pb6zN56B8fv2MHk+Bgzhw8zNTVJUR5LaQyDwYDl7jJRnKBsSbe7DEpsmfvdJfJOA2cNi0tLLC4u0e12KcqCYVZw4OAMW9dNMzEywn0PPsjCwjyzIx0BGHAM+z2UUuRlyZ59+9m6YR1xFHH/w7tYNzXBurVr+e5N32fd2rVs3bKZL1z9NZKkweYN61mYn2Xf3j1c8ISL6KcZy90uZ596MgdmDnH/PfexYd0aWs0WS0vLlEZYEkkSk/lWsbIsJa4aQ6PRJG+1pGpcFPVhOB0OydOUZrNZf9/ZkijQjI6OMj8/z4H9+7n11ts4bvsxnHPWmT/W9flYrkG/v3IA9zEsCqXtUYcRYRjX7RCS30hYNWUpOVio61zZeGkGKc6WlKUU5aSg6uOjj69hoEWawFnvOiYxpizLWvzXWmHnR2EoNu9G4mm1BxdFXrsUq6rKX+QSJ7wZjTBsDGEYk5uS4XAoay2KRFjZigOecU70y5xYphdak6oBg16PNB2wtDDP8tISw0GfQb8n9+/HzVpbzynlx6duM7Le/Eb6ieTfoc5BlJK80zp8m40/8vrKf+gd2KQI6mUW/Nnjh120rHPkXvhcAWkqQJSMsQBlUaCxZS4yFkEscT3PcTqCsES7FrYwlM6Bd4sDfFwWBoj1xfd02CctSopSOjesMZRF7tM2jVOB16QKKAt/CA0g8WwHa0ppvfRjMRxIe6Kx1cFfSYy2jqI0ckj3TAhtFMZrAaXDoWhzBQHKKEog09nKGcynkZW7Hf58UImla60wZcmg3yOJff6AwrqVQvLj9TqaQx/NoY/m0D96Dv3YXe2q3mun5NCtNLrMZeCVosxz8nRIkQ4ohr0aeHJJs+6ZNr4Vz+Fb3jyqWCnFO4Qqiw8OVUA1ZgVtq7R+qsnovIK8e9SW9R+hAOUXTBjIZhHU4uII6GQ8+OSDknUI00mHRHFCo9EgbMS0R8bRUQRRREpAaqCXFYw1FQ0XoF2AywXhH3RFkLG3vMjszH56S4vMzx5maXGePE1Js+EKaFbRKFnFYqs3m+pP9+i7ciu0SBTSY681cwf3EyVNoiShOTpBuzNCuzPC2rEOnRDGwpiGjgSkMRnKGJTTaKPQQUKAIgqEfkgQCgBoSlSZShC2ClQMQQN0QmlDqv2megjKVZ/f1W16oKQ6oP3zsqUXMK/GviTN0npMorhBGCaESUkQNgDlq2gVc2oFnFsRiixk4wxCrHHYUnp/A1U5HqoV90S1Mi+cUihjwSH6Vn6Dzr3GQZ5l5GlKWUirnS2kykflcPcTgDyJtppfXy6n6u0NQ4UmIAhidBQTRGKGakyJLaQyhRdUpLQos9I6a2xBXmYoRAtB4zBa4Sods0A21wpvpAKUncPK1o9WWrT5vbtGBUjm1ta98+ABahzWW6qasvDrIUCAYKEZF0WKtYayNOiigQojtGNFfN5auY+iQJtMKpZhQIBCOYXyuheqAvb95muNwhhNWWqyzFCU0h6rPWNTx7Fow1VrGk9XrcTwyxxTFr5XPMW6HFRJECpP/RUNEIUPQOAXjpFcQ4ErV8YBJKBEQSQunL7HXflUw9hVwpLO1GsQ34FQ4nBK7HzrdlhXYgsxBRB9tkIYi6bAmMrJA7QOCcIE1RCatvI94k4piAJfvZcKrC0lQc7TAaYoBDSwpQeMQ3QYEQSRVAd9ZbVMpJpaJHGdmJrSCQOxLGuDAeccRZkQRTHNpCXz3FlZp37tZsMhZVFS5gVFmYH1zh/eVjgMxYBAbKkf/1cYBvzJm/+Qbq/LX/zp/+R1r3sDI50Ob/kfb+Y5l17G8y97Pvc+8BAP3H8P9997N0+7+HksLMzzve9+h1e+6tWMjk/wzx/6MEmoabeanHzSsSz27+LIgT3sPG4H2pbce+cPePpTnsziwiJv+q1f47nPu4wrX/zf+P3f/W3OPPtcXnzli/nQVX/L8SecyD/+w/t54xvfwOzsLP/jf/wxn/r0p7jhe9dz1vkXMb+wyEc/cBVT6zYwFoT0lha47HmXooOAD//bZ1i7fiNr1qxhzyOPcNutt3DrrTfz3vd/kIf37uPLn/kkz7jwPM4680ze9Lu/x8c/9i988hP/yt//w/v58tVf5e///m/5vTe9iYce2cWf/Pmf88qXv5JN66Z5z9s+zU89+3mMTk5y00038fVvfguD4vDB/Xz/lpv5+Mf+hW9+85scu/04PvGpz/DRD32AW26+EWMNV111FR/5yEd49atexZZtx7Bp6zE85UlPYHJiAuccYRiyd+9ezjrrLHq9HiAtLCeccAKXXnopV111Ffv27xc9FOc4ePAgT3nKUwDodDrcdtttohmVTGCtpdVscOYpOxkZHSVpNDj2mG08vHsXDzz8AD9zxQu44Nxz+JkXXMFnv/xVmo0Gf/iWP+PNf/Z2brn1Nq54+oWcec65bNm2nZe95nWcdeYZ/PKv/ia/89u/RZHnXPkzV1KmKUWecenzLuWmm27khk9+kle98lU88shDfPrTn+QVr/wl+oMB//RPV3HR63+ZTRs28MEPfYDzzz2XtaedzllnnkUYRnzta9eQphmTExOsnZ7AOBjkBSPNBoHWpEXB0lKXhbk5FucO88ynP4WiNFz7neu49JJn0mo0eMdfvZuxsTHWrFnLq1/5Cvbu3cdNN9/CD+69j43r1/OXb38nt958E/v27ePrX/86Z5x+Gls3b+ErX/0KT7zgfH7+v13Ji1/yEjqdEX7nd97Ea173Rh544AFe9vJf4PJnP4snX3g+v/Srv/XjXJr/22tpeYk4imjEMdpZbJGT9iFotgm1uA9XkgsjnTbDwYD54ZDJ6TWAYphlFLmYyDQbDRYX5+n3uihnCDSUgRZNIERvtN0WUDaoCohlwezCQi0WLG1uPh+2ouGhWcmTB8NUGFNJwuzsLABxHNNsNNBa011eotVqksQxaZoRxxFJkrC4MEeWF2RZXjs5pWnG2GiHZhILa9wLh8/PzZKlQ/q9Hv3eMkWWkQ4Gdd5fdQ04ax+VaFkPzpQVG8mJHmlV2I4C7TVYVw7uFSjnnKlBgyAIiJOEOI4lz/cMAVOWon1XdSGUpT+DeNkIa6jTb6XJrSUvCvrDlPnlHq3mEuiQiVFhkyXO0NCadifE6QCDY2nhILlxlE6hJ9eQlZbeMGOkmYBW9LtLEv+sY2lpgcI4jHPkaZ8kTmi2WiwuLWKsI0qaxHEk7ZBRyKCfkhcFdnSELMsYDvqki4tCEigKnBWdnSAMPRhsGBuf8EVZQzro13pY7U4HpTSzc3O1tu+R2SP14T5pNEGJJmriGTBZlpNE0qbVXVqiErfOsqxmXHSXl1DA6EhHWqjM47v4czSHPppDH82hf/Qc+jG32r38iisqjAsdJdJq12ihPYWwzFPytEeRDSnTQY1gxnFDGDla4z3NQMmgayXUYl2xeZTXaMLVlL3VwFNZFjUF1v/UowTEqxsRQtBqJMD/n1KixeT/lDnpfO+1bHqFf22UJmk0ieOY9sgoUZIQRBE2jDEoSqUJmy2SZouRsXE67Q6B1hRZTr+7RDroszh7iH53if7yEksLc6SDAf1elzQdeqc4U3OCataNZzNVn9k96g4qBFetAqlqVMej35VjiddPShoSkBpNpsbHGW1GTLcipuKCRBkiKyKXWivCOCGIYsIwJm6NSNtdlIAW5f2KblhR/YQWFWBUQmk1hdWURntm04rtpfOK/rgVGnRFEbdekLw0Av7leVb3KkdRQhg1iJMWQZiAU4I85ynWFBR5Su0sADVdMYobQrsMPQVZrfTSVi50elWVi6qNMvS6ZUEgbn7WkufCdsozYQSYsqDIMtlQnEXjBPXF8ZHPf/qxLKUf2/WqK6+s0DYBOn0AjeIOYdgkaU+hGxE60jhbUhYZZZZSloUEmzAmUgGBA1WU5MWQwqQUpiRQmkBHRDpa0UEIAkRsX9fzvHJ4cL76UjEYnZWgV4ljypr2oJ5DAolf75WjZBzFdessSixFjSnJskHtRqjDBBVEBEmrNgqQ0pJURKMYT0cNxXkEvQJMrqpOicuDrIG8LBimYiOdZikisChimo1Gg2YzoVlRV5Wqk9WyyCnKHFPmpFkqlYfSYJ1QVaO4QbPREdqqEoq77AnWU1oVojfpedRKBCzDQLTJtA/+UnXTWKuoxAFXhdnaClhXLcSAdRUlXrTLavTdyvMoylySmqqS5NdaEHknD+conexnTleBKEbpqG5rLbIBtsgp0kE9/yqHGB2EBN6BMghD4iQhCKVdVgdeQNPKYaBiDFjPVqzcY6JYWkiscyIWnQpzIk9TCZi57BlYi3ZSvQuUJo5F5y4MA975d+/8L12T/yeXUopzzz6Ln3raU5mcWsP83Cy33nIja9ZvotFsgi0Zm5yi0WwzMzPD1PQaNm7azJ59++h0Opy4cyf33ncf3f6QzuQaTDqgzAYszc/SbrUYGxnh3nvvIWk2OXb7cVL5LnIW544QhBFBGIkjU5rRTzNOO+kE0izjoUd20RkZxVrLzMED7Nx5AuPjE1zzja9x7LatnHTCTr5z3XdBB6xdv4GRRkS/3+P6m2/lSU9+Ktu2HcPN3/kG09PTbNi4iX6agg6IGk2WZo8QBgHHbT+WhX7KIM2Iix5ORxgdM8gyRsdGOWbbVrYdcxxFUXDDdd9mZuYgMwcP8LnPfU4OX1CLDVtrueKKKzjzzDO54qdfyB/8/n/nC1/4PJXmSxzH/M8/+iO2bN3G1Jq1hIFibm6Ob33rW1hn6S53+dd//VfRwUGAp8nJSbZu3co999xDv98nCILaMdUvD8Iw5Morr+SZz3wmv/ALv8CDDz5EfzAAB1//+teYm5vlFa94JZ/69Kf4/Be+wNYtW4n8IfiR3XsJw4Djtx/DCaedyfTa9TgcxaBHmQ4JGm3m52fZv/sRjt2+A5xlZs/DbN22nUarw0P7DjA9NcnYyCi33XoL4xMTHHPsdmYXFrDG0UgiGpGYlKgwoeHBijvuvpu1a9dyws4TufOuuxgOB8QhHJlfxBjL9i2bmFvusdwfsn7tGlrNJq1Wk127dtFutznzjDN44IH76Xa7TE6toXLB2rJ5E2mWs7i8zD0PPEyr2eT0U0/iwQcepN/vMTExweLCAoNBnw3rN9DvLrIwe4iNm7eS5yV79+/njDPPZjgY8Ae/82tsWL+ONdPTfOu67/54F+n/5nrBcy8WJ1+laSQi2BzoABU30FFCa3SCJEkIw1AYhWlKOhzS6XRAUTNRpOXFCmu+10VXGiIoRkfHSBoJ7XabTmcErfWjpBwGg369jw58W5SxUFt4K0UjSYjCULSftOTyeZZ5a3BLu9MhjLyjm5bD3sjoqDD285x0KO83HA6JkiZhFBE3mjQaCYHWLCwu0h8MGAwG9HrdWs4AK3pSooUjBcaiXCk8r9YQUX5tBf4zA+QVy0YpGkksrTOBmADJ+dfWBz8B30IvmB4LYNNo0GgK+845Jzqrec5wMJCOiNL4Q6S0rBSVQDoVoCUaSlX+s2njBqanJtm8YR0To20BwzBEUYIKAgoLZWkorUOFCYOsYLE3RIcxYRTRbLaotFOXFuaFHRFGJLGwp4wpWVxexlpHEEUizqw1UxOTlMZSWkun0yEvCgb9PoNhinOGQCHtmsZQmOrMo2i32l7XNmBycqrWdYq8ht3CwiLNZpMkSej1e9KBYCwjo2MoHYiQspFnkDQSKvHyfq/v5590C5iyJC9ylDUydzpt6TgA/uZ97/svW4//p9fRHPpoDn00h/7Rc+jHbiHgZ49ziA0kwnQKvUOdKTJMngkTxIh4tbWaUuW1CLnyiKNMSofTotMkryXCYwpBZ51nNzkPPBnPSJIgaTEekakAKFeDNz/EEloF4oCwWWSwlMdxRLTcWEPpKcD4CRUGEEUBSSNERyFOa4ZlSekUJZpWQ5HoUFxicBR5xuLcLPOzh+kuLTB/aD+DbpdBf5lBrye9/VkmKCMrgf5Rw7zqDlz9H6FVVrez4jhR/ZYHpdwK+8cU0r+ZDYeosIsOY8osJWs3UWNtWmMBOoRYC1qrnAJnpQfflihTCMXThX5TkskcaIU1itLmKFeAA6sdhQ7Aa0AZp4CwfraVkJnzyDGuYrlVLZSlB+KspzOvsMAqABLjF33VlmdXvpx1NXup2phBYbWnEGvvvlDBk9YK6KQUgQt8f7JCWw9MqWrDsDKXvZZT9YXXKVC4usf1J4DwJO4kSjbUlcBk0bpEaQOekmqd9IsXeUE+HJKnfZRSRFGMiho4LQJ8lW6Xc16Q3wfhSosMqoTMM9ycw7jCVz7KGjSs6KLOeucXa5DfMMJIQ6OcOFxYZyWwodFe1V270AdNoY/meSpB0xiUsaigFFtaHXoNB0lusQYTWqIwgDjGBVEtHFr11a+0hyrP6vPVV7cyr41xYJS3htaYUmNCEeWvnHqsNf7z5ZRl7gNp9fpVEHfgSpyR1tYqsEjQ9BXbAE8nlO9VGmu4qlVU5rw841UV3no/9AUAJVVU6/cgg09kjKw1nPOd0B6g/+FJbh3WFTik3dWUhsIU3gBCE8YNwihBhQ2fjDuMZwoWWS5jCPL5A4PSAZF1WBMirlwKa4I6kZb7D7yumsH5dhEAWxic9X6mSuZbnhVkaUaepeSpVGuKLKfIhr5asxI0sUIfdib6f7/o/h9fmzdt5MkXPZHPfulqlubnmBgd4Z677iCIYq64/DIOHDrCgYMzmDxn+/bjOO30s7jmmmvYtGkjZ155Jd+45hoOzBziuT99Ov2FWZbnM3bv3sUJx+9k27Zj+P73byHLM4osZd+BA2jg9JN2cs999zO3sMCLf+bF3HbHHdzygx/wMy98AQ8//DBf+cqXed3rf4VWq8UXP/9Zzj3nXM468wy+/Nl/oxkFbNm0SQSRg5AoSXhk1yMsLS5Q5ilxoGmEAXv27Gb9hg2cdMqpXPWPf8+xxx3Py698Ce951zs5MnOQVhKxdtvxTKxt8vkP/g07TjqNk04/l89e/RVOPGEn551zDku9IdY5TjnzHL701j/jq1/5Uj1uSinWrVtHnufMz8/z7//+7xw+fJg3v/nNHHPMVtavX49Sil5PxG7XrVvH2rVrGBnp8NDDD3Pffffyuc99jrm5ObIsY2pqyh+axb59dnaWQ4cO1e+1mpmRJA0Sz6j42Mc+RlEUXHLJJezes4d+r4/Smm9961vs27eXyy67nIcfeoibb7yB67797fr1Ktvma6OYd/yvMzn15JO4+a77OXBwhqVDB3jpK3+Jm773XT7xnW/zU898FgGWW6+7hjVr1qKCgHvvvYenPOlJbD92Gx/50FWcdNIpPO3pz+Dm799GGIVc8lM/xc033cBwMOSKK1/C8sIC80eO0O0uMzU1xejYGHEUMHt4idseuI+dJ57MmukJFhcXOTI3z8JyH2tKjtm6lQ3r13P11V9hzfQUV1z6XL7ylS9zcOYQr3j5K2rTlJmZQ4RxTLszwujYGMYYdu3eSz/N0FHM+nXrOHhgP3v27OH0085g9yMP8fnPfpZ3vONdLHV7fPqzn2FqetofdBwPPfwI99z/4H/pWvy/ueIokPjqD39SRPQi1j6fqURyB72uF94t6PeW/eHGEY+MEIUB1lhCrcVV2Vgvfl8yOTlFs9lkZGSUkZERAAbDgejFEOLiiNQLkufpgKKswIeqdU1hyyZxFMnB0x9SAy0H19yzDrQWAV9pAwStA0yZMuj3KPNMDinZkKIsCeOEKI4ZDoXRPjc/T7e7TLfbZdDriRuys8KQ0YpQUbfyVKCTMUbyVH8pZ73Atnw2pRTG08+V0iRR5LWjQg8k4YERid9BIJoycRQRxcIOCMNQwDEvl1FpOVljCAKNCcSFriy9OyCVsZKrtWaNteSlsBEOzS3gdEh7dJxGq41TisAYgqAk0tCMIowWse+sGKDzDJUNybIQ12gyOjomZkQ+XxUNnCZRGJBnGYMso8gyjDXoMicbDsFBiANVnbtE9iPNcobDAThLEkjrZFmWsuYqu3kgjGLiWADCIBAmTellJoaDHqFWhFp59kNBWRgazRZKW0pjyIYDwBHHEXmWerbVoHYdtGVet1oFGqIgINBIq45+nLvaHc2hj+bQR3PoHzmHfsyMp5c977krPX9CqxG2kg58cCiwpQiLO2P8IGtcENZ9jSJepQl1RBDEHmEMUcoCBmwmrUvWyIOzAkAZz4bJSqm4FMZ6cMMPVI3AeBV/Dzb5W/QDWd+wBFe38mPWSeseShE3xRK1MzpCmDSwStMrLMPcUDhFY3SS0fFJRicmGR1p40xJPuwxO3OA3tIihw/up7u0QNrvMxx0a3SxLKsecbFzFSX44FHgEjXza2V2Vo9H+X+sF8jqh+P89lRBy+CpgcLmkqFUxI0mI60maydG2bG2w0QrZLoBYSB05CBKRM8qjIjjZk3hS5LEC7MpTzMWu99K40qHsWDfDnqpJTeKoQkojKY04kIggnLyLOuNsgrUNehkPQtM7i+IYqIwJo6bREET/EZSFENKk3uxehnXqtdUaU0UNQT9Dv39eGdC2UW8cB6SYGmvMak00vOvFDpcEZ7Ps3Kl1S5Pa+ZdNb8qJxiF5UOfeXwznn7h8st9pSOU2ocT0FUFDYKoSWdsGt1ooKKIssjJBssMewsMl+ZQzhKHEa1mh9Brb5W2wNoCaZHVaBUS6cRTXnUVayQYeyHQssgFaCxKcb3wgLFDWm2NsfI3vzCU0quCsKzfyl0m1FKhF3FH5a2oC9LqOVnrDUw1KoiEZakDtKqox45IVdWahGYsFYIo1nXW66zfx1SAQTb/0pRkw5SyKBmmaQ14R3EklZpmQhxLAiUMP3HqKXOxtReBPr2yyWPq1uQkSjy9XXlxU7dSWWNlzmoFQaS9iH4iPd5KE6rAB1WHVXbV018lQmmr1gQvbKgCnPb7jA+U/if97wr9WpiKThxLrMG4gsIWGFOQ5RmpT1acsSSNNnGjRdIeAxWCCjCpJJ1lNvBVu4py7Om6cUIQxp51Ga7cq//kWgl9XYFPqIWerMIIpzQlAaZyIUlT8jSrHZDKvMDkBTZPJcY4hw4UgdbESUCUNIjimPd+4B//Xy65/6eXUoo4jmgkDXSg2bxxI0970hPpLS5QFjlhILHKRQ0ue/4LufnGG7j66i/ztre/g0MzM7zznW/nda9/I5s2b+Xb37uRwwf3kQ16XPyMZ3DXXXdw3XXf4dgtG1m3di3Hbd/BjbfcwvzCAs0kZtOWrUxOTRPZkvlun8OLS9x3z11s3LCRSy6+hK989Wq01rzm1a/l0//+ae67717e+IZf43vfvZ6vff0r/O6b/jsHDhzgAx/6ACfsPIGN6zdw+umn86WvfIm9e/bwP//wD/n2dd/h6q9ezZ/+8R9z4OBBPvChj7Bu87Fs3LiRpz/pAj7+yX/j4Ycf4V1/8RY+94Uv8Il/+xT//NF/5fY7budNv/1b/iAIpjQMh4OakQTQarW47rrruPHGG3nta1+Lc44nPOEJfOc732EwGJDnYl/+nve+l6v+6Z+45mtfY/OWLZL0eo2XNE15zWtew4033sh1113Hu9/9bt72trf9h+ekg4BWq0me50RRzHnnX8DP/reXcMnFF/PEJz6R2dlZ2u02b3z962i321x73Xf45de+jguf8AQ6nQ5vfvObeetb3wpAFMc0m036vR7NsUl2nPtkjjx4J725w5TG8KY3vYmXveIV/M4fv5XTTzqBV1z50/zOb7yRfr/PMy55LrsfvJ/lpQWizhgzBw7QX17md970e9x2+w/40Ec+wgte8lKazSa7H7yfpz71abRbbf76b97LZc+5hIsuuIA/fetbWbdxM+ddeBHvfvufs3HjBt72trfzZ3/6Fh586EF+/hWvYXlpke7yEoEOOHzkMHv37eVFL3oxTsEtt97G5s2biYKA++6927uXRUxPTrG4vMyh2TmuuPQ5dLtdPv+lL3HFZZcxOjrCBz/0Qc498yy2H3ssX/zq1UxOTnPMMdv5zKc+xoZ163jNq17Fu/76r7n5llvYv29fnSc9xnT2x3b97POfI2BIHGPRlMaQZhmNVoek0WJy7QaSZosoSXDW0FtaZGHuCEcOHcSakiAI2LJlG51OR+zoc9njjhyaqQ8sGzZuFIHyMGJyagoH7Nm9W+QGEBezfq/L8vISvf5AmIwjozhEl2fQ69KIY8JAHJeTOCZJEoqiIApDRloN0tJIHEHRSiKiICA1VsAKpTg8N4cDoigmabZwSjEcpmKoM+jT63allaMQVz2tRPS7kcQiOO2oW+XyLBVRYV9QVAr5Gd/uEQVapCGUorCIKLtvm4tC7y4dirRGmgkgZq0h8KyoJIklfwmEOTA+MSFi0FozHAxIs4zu0mItaqwQ5r2wnfzB1DqGWUZeiFyE8W15YZQwNj7Oug0b2LHjOEbaTVra0ghFziKKozrvtWbF+Tkrpf0uJyLNS6yDkc4IToumar+7LGZIZcni4iJ5kVOUhuGgjzGGZhwzMTXN2NgEQaPpGRqaMkspsiHdxXlC376VFyVZnmGNYcOGjcRepkPOV6Jp0+91vWaVZ2egxI26Kud685/SlIRhSBCGNJtND6YalhaXGA5Fy9bk4lC4vLxEHIUkccTkxLgHABQf+Jd//TGtzv/9dTSHPppDw9Ec+kfNoR8zvFyWec00MRZ5qLqoKa7Y0guSGc90UcJ6CoTO5rSiUtK3AYRWYa0jDEGQR7PCJjElytPUnLVe9LugLHJKK33cxlWg02rgaQWgkQAllccKnJJ14unv1tWMoyAKiGKpejTaLXQYUaIYpAWlg0HpIEwI4gYj45M0W0KZ7S/Okw169BbnmDs8Q7+7zOLcLMNBzz+s1ANAdlUv+MrnevTlwP0QIvrDSVQNOPlo92hu1H/yc9QgcDXxracJV2wicR9khbmzmoWlVu17qtJIcjhlcS4XIMk6FAanRGw8VBarHJErPBItfbDGlOSluLlYPyZ4d7sV5pJnOFXsJeWxeh14tF55enGx0oJZ/R6efeRkMQnC7UUVtfXC6BIosEK7tEoROH+flVOEAu17Z3F4PakS5wqUbJso5apRqYGnRz+4x+dVGiNbp141XxzSm1xmFPmAUDsCZ7BFji0yXCl06IqFWBQ51jov/rdal03jtPK2ntYniZZ6JloJmsbTrCuxOuvnqmXFIGBV7YJKg6v6rHL5CoPKMTr0rhcSNEsrAprGCc3cVEw5z9jTWgRAZS5DqcA5rx9hS8IgwJrAi+sDzkszKoVRyrf6GmF4FiXW5HXQNKWlyAzKFZRF4AFvBU75oJl71qZB4ynLStWgp8FSKPy81fU6Nbasb11amCXxDpz0VDuncdqbJmhbj7tTq3XjfLXJyrhIMF7V8uxFCUMt1r8y/t4+1VeHnKctW28E4KwTwNjTh6sHJyC0D/bGobRbpcnnPCXZ1oxIhXx+0fHwGhpGMgNXgeqAcsbvVYqAQKoH1qGcJMOBkn1EWVvHDox3aPJsRdnLZMy1lrWgnEWZAorH96EVkNbfouRJ55/NyMgIe/fto9loEEcxjcBBGFMGMXfeeScqjHjK057BI4/sYm5ulvXr1rO8MC+Hz2GXidEOwbhYn2fpkDBQTI2PYoqc62+8kTXTU2zcsIEwDFm/YQOdzggP3n8vzUbMcVs3ky3P02m36C3M4sqcfpbzrWu/xeHDM2At99x1O1k64Nit27j55hsxxnLW6aez3O1ycOYA7U6bzZs3s27tOr72jW8QxTHPfu6lXH/DjWTDIScdfxxpmrE4s4cvfHGORqPJ+Rc+gU3bjiWMGxw6MssnPvFx9u7dy8LCwkpF08fNkZERXv7ylxP7NpotmzdjjOE3fuM3KIqCY7YdA0C73cYYwz//8z9z80030et2+cAHP8jY2BjOOV7ykpewceNGms0mV1xxBdu3b+djH/sYt912GyAtdFUBxX8AOdwaS0nB/v37+eY3v8XhQ4fo9/vs2LGDZz/72Zx3/vkkcUJndIwdx+9gbGysbrGoqPeVFEAQhoy0W2zftI4j9/+ApaVFAK6//npQijtvuZHlQ/sI8z47TjyZKIqI45iyEEbEuq1TjHU62LLg1ttuZWZmhk0b1tFbmKU37zh8YC9HDu4nHRklS1Pm5+bZt/8AR+bmQAfs2/0w2zauI4oDPv1vn2BpeZlmq8PCkRl27d7N7Owsz33upQRhwOzcEVrNBsvdLg/efw8b162hMzJFHMf0+30GvR7r1q5jdGycIE649fvfJwg0p59+Jnv27KYsciYmptl/4CCHDx/CmZLu4gIP3n8PnUaMsiU33XwTY2Pj7DhuB/v37fuvXII/0uWQgmMSx6SF7EeBUuLapgOJK2GAVpDEIc4UZIMersjAWZSGQb+LNZJ7C3hTkBWFsHMiReYtsAMtObuxluWlBXyYIYlCAg3tRkKaDsEZimzoGRMVA96infVHLcmZ8izFmpAk1HVblLOG4SBnaC1pURInDZJGgzBO6mr8YDCgKEt59v2+tMh4oKOqnFdkAGuFjRFq5cWtNQExUdXpUBUNRV0b5SDUK65SAaLDFkeRNxAIPespEt2S0mADbzKk8DFPi8an8iK7nuGF17PRFRMFn/V55zGlg/pA70CMeIJCwBotujQqkLwzL3JhR5oSE2uGWAJNrSeloNZcqbSjHAqnDcpKHlQUOXlpyT3bxXiB/jAIsDYgzTLv1OVqx7thOqQVN3DKil6O3xu11mRF7sWMlR8D7dkxcmJKs1SYY42GOGM5hzUFYSi6TXEsjLg8z8UdOwjotFs1S6zdajIcDCjySghetGLFPUx7R0CZ/9LhsvqQ//i8jubQR3Poozn0j55DP3bgqdLesRZjqxevWtjkjSv6XMWEsUpjA1OruK8GnmwAYVBt5haU9EZiPPDkqpY7WzvO5bkAT8Y6rKvUehSrb3WFGeSBC5/ECTpZPRiZANr3rreSUHriR9o02h0KB8uZYWkoNo2lChkZHyMZGWdiei2hElvYuUP76S7Os3D4IEvzc6TpkH6/V7u1GFOu+mS6BlKUrvSlfniUHc4pVsU5f0+rf8StgjlWM5/8NP//+tz9b1Ti7E4Wl7CveNSXVivsqspRoer9lzjqwKVi2+k1nwgaEGoCLBEG4/L6+Wi0COgVOf3hUFBoL+TtqHpeZdNUTiiCSiuqBmGl8MrlFZW0wNgKePLPEyv36DdQoZP6RMqL21fAk7QtyP3YivGkVjb4lQMMdSIgQowGpVYE8FdWgKrF+x7Pl7iMKAJtZceQ3U0qLs6S531Zi2WBKXJsNsQVOdrJs7JG7DxLbVBlKZu98lbEGhwSOI2zGEpw3vLY4mm5DlcUtZh/UWaelUe1PUtyVGHZTq3aYVaBe374NUi/vD+kVS2zuStrW29jqs0ZwiiUnvlGA+fXfkVGLl2OLTy1vAzFytavV6ukblEqVc+fMs9E76wsPWCssBTkVoujTFhph2kfXKT33trSA77KV46kx9tZsVl1zlN4nfbz27tP+FvXuhJM1QQmJAhCrFXYwBLoABsIDdhRtbdWba3eSagsKUzpe/n92lAhjUicvkhigtC7fliq8g1aGb/GHAbRGJCAWbmXyDp3BDiPZDsngK63kJA55Dxl2gdNqcg5lNOIW2qJNoGvjnmatU/EnDWig6C0N6eQCj9OaOtKV8mXlfetxB2LEkrfPox3YAlAY6RyZw2qRPRFfgIupRVPueBs0izni9d8h+07jmdyfJR2IyAJYlKrue7663jiRU/i+T/9Qj74gX8iHfQ5/bTTmTmwl4P7duFwbNy0hbGxCfbv2U2eDpkYG2Pt+Dj7Zg7x1Wu+ya+97rWcdOKJoEPGx8fQSnHb7bexfs00x23dSpOSXq/H/l0PEWLJ0wGf+MTHWb92LWOjI1z37WvYsnkrZ51xBv/2759m06ZNvOgFL+Kzn/t39hzYx8LSIpdf9ny2bNnK61/3Gn72pb/AL77iVbz4Z17A9MQ4L3vJlXzvW1/loYd38Z07H+BVr34dz7rk2YxNryFoNBnmBe/5678WLSUEANI+tgKsXbuWP/3TPxV9HGQvP31sjFNOOYVh5ZCXZURRxMLCAr//+79Pvy8tEX/2538m69Y5zjnnHKampgB40YtexHnnnccTnvAE+v2+2BAH2mudCPDk/DqrhDb37HqEhx98oP73Sy+9lLe85S2iF4PjwosuIvaOVpVLkVZicOGspSxKms0WUxPjnLh1PQ+MdTgSxxRFwdVXf4WvfvWrmLLg7ls1X//KF/n4Jz7Fxo0buPXG72FLkS+Ynl7D5g3rGW23eOe730271eTUk05i/vABesvLzB7Yx+4H72N0bII4ipibX+C++x9gbl7EiHc/eB+nnXg8M4cO8Z53/xU7Tj6NtevWcWjfLu66/Tb2HjjIa3/59cSNmEOHZlA4+t0l9jz8AMU55xCvmWZ8bJR+d5l+b5m4kTDeHmF9lPCRf/o71q5dy2vf8Gt86J/fz/59e3nSU57JTTdez4P338uTnvgE5mcPsW/PHs489USMsXz+i1/g/POfyPSatVx77bce90yn6rJOWtLiOCYvSrSSlq+yyMmdo8yGcjBwllbcwRYZw94yyuQEShGqiH53mWG/JwBn5XBkrbSLqYBBmhHogkA5lpcXKYqC5aUlcI5AK6bHRwlDTdJu0u12yYuCtN8DD6QESgAchSXQCo0ATFmaUnowKEqaoIWFMOz3KLKUrDA0OyM4rYkbLcTdrWC5u8xwKOLhZVHU+iICuvGo/NJZ6T7QWtzZolDY6hY5V+TeyVgrcEbWl2i5VAcwS+hBkSgMa72TChwuwpKyFNt3rajbyayj/gxaV22FqgbEFDwKtEFpQiVgS3XCtkqjgkAO44HGFFq+p8ShcGlpkTxLKBoxzhSeMSCgWBCGIpzsWyYDJcBbEicoHaGUZjgcMkgzhllOo9kUl7o89056Ig4fhnKINkVOlmWofp+kMw7K+rap0p99ArKsT1kUNL1BQBgEK3mDtaRpShhGjI2NYssGWkGvOySJY9GES2IGdsigyHBoorDJ2OgIxsjZarTToUhT+kVOqL3CkDU0mm3CMCAKJ8CKXXu/t4yVQ9qPZV0+1utoDn00hz6aQ//oOfRjBp6W+t3/sCfUm7ET5XwRkRZQyHpqnQu8CLWfJEppTOAIA0sYlNIr6sWZrSnASf+hMN0cWENZCMiQF6VHYL0dKtVi82DDKhhGqhdBLWwOXljQiAWhDjQj7RatVpPpqQmCOEYFEUe6QwalpV9Y4tYo7dEmYxPTdDodkiTBDpZY6i0xWFrg8IE9DLrLdJcWGA6GFGVBnhe+YmFXJUOqJjg9WtPpP9tkPfIpP7yK0+TpccqDHP51VI3GVi+3que3+jckoQ08fTMKFHEAUeBpeHqFqqd99Uh7AKpysKjZYxUrqxaPM7ish2VISZfCagwaqyLZrKwjpoTAEcaOIlcMU8vA21NX1rcVEhyA7yEPUMZgwxxTpORBiIB3QX1vVS+ziOzZR81Jo6W3NQgKtArqNowauPNU0yD0jC/tv4cWsM2PWYVKy4Kv4qLohElVmlqX6vF+maJEu1VMRGfBFL5qAkWekgeRbL6mlPVYZmhvu2mVFhBOaXFhUDJvoiAmCFZE+RwG51JsmaJMibYGZRTK958bk1OajGGRCe3WVk9+ZbbLyq5SPrU6XvpeeNmQ8yqAKoV4YEgrrgRjb3/sf88AWEcWGAJtCfWqd/CBJVCg0oAwCLE6QAWy0RsstrS1q2JmCkprKLxehHwgmT9oTRBFQt0Pw/oAW5bGr23n++VlX9BhiA5DqX6GXp/MKW8hLVVh/BwNVCDBVYn4qS0NrjTkUoagNnBwqyB5621hrSUrC4rCu8pYoScHKqCVjBB5bYc49tasOqwWFMZKe4KtevM9gG18pdJZ6VG3zmI1aGNQusRUGiFYbJ5jTEFhvCCkkTVfGtkXQ2eIrPGfXSjQLghwzvhYUAVsg7WFZ186VNZDBaIr4JwkKS4tIU9RJiMgA1XighKlYtnLdBU1xLLaFWkNYDzeL2sdN/zgHiZGWpy9Yxtrt27EqIAbbvsBE2NjTIyPc/EznoELQr7xzWs48+xzyAY9Du56mHvvu5f5+XnydMCTnvRUOie1SZoNTjrxBM4783Su/upXKU3JC557MVEY8NDDD3PrHXfx/Msv5/gdO/jWtd/mogvO49wzTueq797AsN9n4/QkBw7OMD45xbve+hd84KP/wi3f/z4/85xLuP+RXXztm9/ixZc9m+X+gL9+39/wnCdfwBPPOIld+2b47Kc+ySDL+NPf+RXueOARXvnyl/K6n7+SXXv28Xv/8y2kgz47TziB737ve7zjnf+LX3rVy2k1m7zwhS/kpptuQinF1Vdfze/9/u/zj+9/P+ecfTYg+0wYBLRarXrctNZ88Ytf5Ld/+7cBmXNRFPHHf/zHnHLKKY8aY1OuuCu97OUvo+UFh621rFmzhm984xskScJgMODyyy/nwIED9WuuXbuWn3rms3jBT1/BySefTJ7nvO997+P9738/1lq++rWv8axnP4eFuVlMWRKGAW9961/y7Gc/W95wVaJVWU+/733v46yzzmJycoJXvPTneODBB3jRC19ImqbeqhuctRRZxq/88muYnJxg+7YtPPG8c9mwfgPzueM73/k2h/bt4llPfTKP7N7NV7/6VU49/XSs0uyfOUx06y1s2LCBK579LHYfOMgd993HG371Nzkys5/7bv8+N+56mOk1a3jLW/6Mf/n4x7j7tluYftJFPOtZFzM6PsUnP/4R2iOjbNq8hXe96x20mg1e+fM/zw/uvJObb7mJdRs20mm1mByf4ND+Axw+coi9e3fz5Cc/GQdc9Q/v47RTTuH0U07h29d+i4mxCZ7ylGdw4KG7OHjoMPtmDtFqxKxbM82FZ57GA/fezv6Dh35iQCcQV7sizzBFLuCJNViv11EWmtmZ/XTaLRpJQndW0V9eQuUDmkoOPemgT7PpcFozSDMv4WBptuR32p0RCmPJ8hKTD6UloyxweS6GKUrRXZZ8y5SG5eWub1ux4mKsFNbB0LMZtNLyew6SWNzK0ixndnEZY0QYOoki4kaLiQ2TGAd5aZk9fEj0fYZDhpmwmxRyv74KLKyDqiitvQGMB0AaSUyr2aARR0TeAMYBS92uz+EtLqhMZcK6Xa002aMOitrquuugilmV5IXUM23dMqhXPSdx1KK2p6+7BJzzgs8rrlPVZ4uMxVWaUEksztZZDkqRZhmLi4t0teaIswz6fWkzNFYYREHgreUL0iwTllYY0moIgyxOEsYmJol8C002HFDkGflwKKwQFEkcU+Q5zloiDXk2pCgKJtduoNFokMRtDu7fJ+2Dgz7OlGgFRZ5R+DXUHw5pNJq0Ox2aLXFEdNaSpUPSdIhGXMDToaPIc/r9PotLS4yPjlGmjsMH9tFoJCRJQp6EYAsiDXErIVSWUBmUCjDW0O31mBwbod1sEGrH8nKXwXD4X7wi/8+uozk0R3Poozn0j5xDP2bgKc0rvQRVH8xlsvnWtYo65tlOTrla5wltUS4QCpeC0pU+9lgBnfyDEVaJ1+CpGE/+YRtjhe1kbI30VUurRnpX5R9aK7F/9J/TIYmZ8uBLs9lgZHSEdrtFa6SDRZMbyAyUThPECZ2RUZqtNmOdDmGgUSZn2F2kv7xIb3GeQXeJ4aBPlg5rdf36s7kV9pHgE9UmIN//D6LiK1jSo75ZbRCrwer/8AuuAm/89rDq/1c+h6pR3jDQRFoR+t7PCmASwGmF4bTC6qk+gP/TVf/v/HMzHnB0WKcxBB54DGUyBxFRaKF0tEX9kaI0ddJkjKjr42TTclrowoFWVOJzygqKrVRN/vbzrUoqvIgcoIwCaynw1G1PIV4FS3oKtZdHU4ogUCtth07X1YGKXrkC4K2MhvJzuNK9erxfZVVl1IrAAlisKTBFKWL9xmB1LmCjF5l3VTsjihKFC0VMz/qqgVIKFyjCUFBzmS1iKerKEmyJLku00z5oegfDQhx2JGgqxGXC7yoehKxaJQW4rbQEqp3HgZU9Ac+SWxF2dDVIWIGvQpiTZ6eNWAwYpaUN3c8fa8T9KgwCiBwEwpqraLFlXvjkMCcri5qKXK0759tBUZow9o4/vtJqfYswVcJbV3pBm0jsaVcBmg6oRCexpmZBOu3nnO+Xt0rVzEr5FHalmqUq0URq84TcCHPUrAqaWmk0EaXX0Sht5e5RCQU6SpN7IUxbjyue/eo8M9X5IEhQOZ8oijAjUAatwhUbXM8GlTXrq3nVAQQPgKsAa0PR+8P6uLCqudoByjMdlbQL6LJy7vAtsjZHDCsMWlmcxrsirbBKHfLZTVmA+clgPAHsPTBDsGk95596AotpySAbMj05SZZlzM/Pc0oSsTxIObK4xMk7j2dRWW6dOUCRDoiVpTXSod/vsm/fPmyZk/dDelHIIMvF7SmKWepKsSnSsG/vHobDAZFWLC0ucc999zPRaTPWjJkYG2HvwYMU2ZCFhXlMkROHAc0oIFKAM3TabbK8YOC1ZaJQewepJsY5lhYWmDs0w5H9e9m1ey+79x/g4MwMDphdWOTue+5l165dtZ6Pc44TTzwRpRQLCws8//LLOeusszjhhBMA6kPiD8fZ5eVl7rvvvjrGBUHA8vIy7VaLSy+9lB/84Afce9+9rJR8YM/uPVQtcNYzAbZv30673a4d7KrE+SlPeQrH7djBBRdcwBlnnMnmzZu47dZbUQpGx8Y46cST6PX73HXXXXQXF+TwHgR84xvfIEszHI69e/cyNT3Nueeey6GZGX7wgx+wbetWtm8/ljAImJqcpNlscPnll3Prrbdy33331Z9VhM6P0Gm3OPW002i12vT7A3btO0ie54yOT7K4tIQCtm3ZzNLSEqYs2bxlK0WRMj83R2GkWKiDgLnZw5RFzvT0NIcPH6LX63Pg4EHGRjrY9evo9Xoc02iwbs0037zmENPGsWGDtE9qBXPefn2k3WJybATrY8Ds/CyBVhy/4ziv+6nZumWLsMa7XcZGRsiKnMU0ZXJikiCKSNptxkfaBDjm5uaJtKLTTOr87ifhKvKcQivyUBMFWjRLy6JOKLJhnySAEEOWl+TDPq70Bw3rRMMoqFyKquKY5MXOOQKlyHwuFAQhhRPwxNXFYUWeCdOgKAqydFiDMToIqByRvbwulhW91iSJAQFRsiwDB0mnRbvTptFoorQmG2b0+gN6XXGqK/KULC/qwqfEs8rdeCXPrOJUlbuCk7a3wLsyeXHcwXBIibAfnJL7Wf07VMyE0qC18eFYoUtdj1Ml7aAUnrUg54KKbViNqbTSGAEK/Pqui7z+qgqy1lE7hSnE8coGhsA7xpmyJEszwFHmBcPhQNqmjRGt20D2lrwoSdNM7jsMSbOcJM2I4hjjFK1WS1zlGg1xPowjur2+FHGdgEFYSysWLSgVOFyZ48oA63WxcCvu4TgrqZ6/x8A6yjCkLAphRDhLlqaYssCWJUVe1AVckJyyzHPSdFjfh3IGW4q5UZnn4CxFnlEWOdYYojiUw62z4mJdSsuowhIFP3wIenxdR3Poozn00Rz6R8+hHzPw1E9TKjX/IAg8IwaU9ZvYakqaU6CFLib6PArlVsCC0hm0KSm0prRlTWetFoswqGRkpHdWhPrKVe4WxgMqQsGtKIYrm5ZWmiBwBK7qj5QA1Ww2aDUbrFs3zdj4GM1Wizhu0Btm5P0hudPoOGFybIr169fTajSJNfSWFxj2l1mYnaHf69LvLtNdXiRPxbWhNPZRQU2SXj/l3AroVEXZ1Umx80BO1WYni1Ctmh313KX+Bc98Wp1wOVf1o7p6Yq/obUkQj8KARhSQRJo48FRiVbGdgpqGqFZ9Vffg/CJWbjUFkbpNzjpfoXWWUiloNFFRC520CWxBYkqSZkprkBJFMWVpMTYjz3y73irgyWnp/TdBQGACCIyID3rWHErVmlBVMlMlHsbKxo4xNbOpAo9Q1AJ5gQ7RVg4UkRM6Nlqj8UkdKyw+ARRVnTBV41w5LdifgENr6jUasCWhBpzxbYvWs3iV39RFtLOiZhoPJhdoXFgIMOj3AqUUJoQodLgIX323QI4zBZVmW+Apv8ZItaBKSKWFuWoGf/R6AKhaZusvb2aAE72A0gd1qPQZFKyuXVZzE+mZVs6hypB663PIvC5zdJnJfhEE/v0jEV100pOe5gVZntNPh2QmFxcb/1mc7/eW2Cz2ooHWUvny92R8gqyUVAiq9RVGMWEc41BE4N+/GgO/s/lEWVmDQ2OUlTZXwNRMU1cHZaUUURA+av0aaylNSZ5JwmudRSnr3SuH6CJDZwFBtlLNlV+3FGXm99/quXjgFeqqTeCDdRSFkhyFubSS6AhNKEmqN1ooy8KDtbZO+C2iQ+eqg5Cq2KpVBoR3oMTThB3OGVwt4Kjqn12ddChlpNJV7R1UhxUF1lGWBS7zjqw/AZdzjnsfeJDRkQ7nP/FJfPgT/8bc/AKXPuun+MZ3rue+hx7m/HMX6Xf7zB+eY/OacbLlWW68+UZ2blzD5o1r2HLscdy3ay8PPPwwm8ZHWFjucmh+kY2bNqGjhIPzS8x2h3SaDc7YuZ0bvnc9j+zdz45jtjB75BAf/MiH+aUrn0+n3WZ5mLJn714OHznCB//5Kkrr2LJhLRQDJkdanLj9WCpxzzXjo9x6x110Oh1OPvMczj3/PBTwsX/9CDjLZCPgnX/7frKi9O1mcO/9D/CiF73It80EULMOZJ1fdNFFXHTRRY8aI600TnnWg5JCg6sTXOp1W5YlSinWb9jAhz/8Yf7kT/6EP/7jP66LLqvja2WxDnKQXA1uVV9//ud/zoUXXlj/zpEjh/n7v/0bHtmzl23btvH7f/Bmbrjhe7zlLX8ilVjkMPOOd7yDd7zjHQBs2ryZk089hX/+p3/i85//PK95zWsIw4BA67qFb+PGjXz0ox/l937v92oh8uqampri7HPO4Q//xx/zwX/8R264/nq+d/NNPOfSy7nwoufyV+94Kycct51XvvTn+KM/fytKa372JS/hG1/9MgdnZrjr/ocYGZtg7dr1fOKjH+DEE07gkmdezMzMQXbv2cP/+ut38/MvvpILzzuPL33tqxzX7xFgmVvuEjebuCLl5S9/Jbt3PczfvOddPPc5z+O47ccxMdrm/oce5uHde3jkkV08/enP4Od+7qW87V3vYmJigte/7pf5/f/+uzxw//387Itfyhe+9Dluu+1W3vSbv0Wz2aQ0hvm9D7Bn336+8Z3rueyZT2fbpo188/obRaLhJ+DK0pQQS6EltzHWiTZSKHttlmY0AohcybAvFvS2zFnuD+WAojTGivNYs9WS3KSENM9pFCXOif5PoDXNkRGKPJVDVenjDU5Aj0wssodZhjGOwjrCSNrT2q2gzslNWRIlCXGjwdjYGMM0Y+7QYay1xEnC1NQ0a9ZM02g0eGj3XmZnZ5mdncOUuY9FjjwvsE5aCutCsLMCPuB8Ac9J2LbiTFd64W6lVM3+CcKAZBADjqw6KHrdJim0Sj5YliWoTA7ANvQAksSFysnNGINVEOiyPiAqLYcuI+iouJKVpT+AeYkGVmKpQxGEzh+sZV/QSqPDCEL5uWHhD6Jej8eUpbCdSt+qA2iVU+lLFYXkGUoVfr0X9PoDtNYsL/cYGx9jbHyc7cduRzVblEWLg4dn6Xa79Pt9/+wVG6fGZdxwlMMeqcnJdIDCEocBLgyxZUFhBFgTpz9L2AzQ1kgroDWYQroTrJe16Pa6NJsNXNJAB2FttrOwsODnTosyTwFFeeQII+02zUbC0nKXLM9Js5zp6ZYXcVYsLS5iygJlcpI4otNM/usX5f/BdTSHPppDH82hf/Qc+jEDT7mprAfx9oG+P9vKIqsmZwVGrCi7yyBbVhg41tOxlBJ3iAq1BFcvCFUNlDU1Xa40KzRZa6UL01gZMgGhVhZZUOnwKEFfkzii02kzNTVBq9lgZKRNp9WkkSSoKMGogFxFrGtOECUNOiNjtJsNtDMMlhZZnj9Mb3mJ5aV50uHAi+b5HlW3qq2uWtzVOKh6K/CbgRWACaTHrb7Uqp/BP/zV/7wCqq2uOMhfXQ0EVZWfipponRO3Nq1J4ohWEtFOIhrhihOIUmqFnYYXVVQrmlxaKwKlfC+nxblyVRKvQIdAhA5itEoIdYQKWwStMXTSImyPiQuEVtgiIx0MGF9eptGZodvtMjs7R7fXFbcCz3bDWrRfiLaaF9aKkNlqFphPKFQFWgKW0s+HqjpTgU6CloZhTKBDwsASWC8kiQMVEriKVeXfwnpwrcaJhYVlPOBVmqIW+3u8X91Bl1AHxKEWgA8PVqqVeah8NUxZD7r5oOnQGB1Lj7mf48rrtjmr6kNYTIxSDuckyRKLTekr1ihsUVKUlrzEA4+VZpwfW7Tgen6cq3keRDHKu2ngwc4yLyltiXEG61ZYe3EYecS/ql76qoK1KCNaXSYIKXVIzVgrc1SZE+AwUYjFENuEyCZYB8ZahnlGWuQMipy0KOpks9qqSlb2tSKHQIlIag3QOlBVv7deYRhWY2nKQqrO1eHYt5GaIvNunF5E0Kc1FpG7L52rx78aL6Ug0KFUMdQKoF1pSJgKIFeySZnSrqz3bEWPznl3j0rI39rKLcWzXqvXtYYIR6gU2iYoU6LCkNQUMr+URqlIkgcfzKr5tbJuZZzzqjKjA+l5t17o0VdylFaEUYA4WfpUo6JoY6tXoqpcl0bml4yJAqcwSKuuKwvcoC9Cl+VPBvCklOK8U0+kk0S8+++v4ph1k0xvXse3rr2Whis4e9tavnfTTYy1m2wcbfPpT36c7vISO9ZNcfy6cZRSfPkb3+ak47bxhJN2cOPd94ODdZMTdKKQsfExNmzbzv5Dh+l3u1x3w82EynLc2nHMsEsSaqanp7n73vtY7g244+F9rB1rsXHNJIM0pdVsoXTAp6+5nqmRNmvHR/jsV75KXpQoZzj3rDMIwohrvvlNRtttwkBzaH6Jwhh0GPHX73kPB2cO8ZF/+Si7d++h3x8A1FoIcRzz8Y9/nO9973uPGpO3v/3tnHbaaQAsLC6wd+8+/uAPfp88z2m1Wrzvfe9bFTucd0CVNhelVG3JrpRiZGSEpz71qbz+9a/nN3/zN7n3vnsJo1BmoVIEYUigNa1Wiw996EMsLS7SXV7m+B076s/0F3/xF3zlK1/hgQfu58orX8xll1/O2972do49Zhtf/tKXAJg5eJAvf+GzXH/DTezZuw+lFP1+n8MzhzDGcPHFF/PFL36RncfvRCGH8Lf+5V/yyCOP8Nfvfje/+Iu/yIUXXsirXvUq5ubnCbTmj/7oj2i327z0pT/Hsy9+Ns949nP43Fe+zOc++xm+993r2LZmnLTf5WOf/jRPuuiJZFnG1V/5MmvG2kyOdPjOt7/Jxc9+Lueffx6dSPHggw/w7ve8mxOPO5Zjt26mMzrCoQP7OXxgH4sLi3z/Bz9g38GDnLBtK5u3bmPzMcfysX/5EEWec/nzLmVhYYHvf/9mNm7Zwt133cX+/fu4/LnP5fDsHL/+a2/k1J3HMt0K+fa132RspM3JO49nopNw7mknsWasxSO7djFz6BC79uzm11/9CjZt3cbM7Cx333sPy71+nU/+JFyNRkJelszMLvi2Gol1oQeejJHq/CAKwBrSLGeYZrV4trWWbm+ACjLQmryUvFgB6bBPd0k0nhzQXdak/R5lkaOxJHFMFAQ0ggBlLXmaUpQCsFhAuwDlDGWRSQ7kD7LDLGeQlxJzPOg7MjJCo9kgiUO6y4sszBv27tnDcrdHr98nCSsdFR/Hravb6SQu65rFVBsU+ctZAavyoiCOI2Jj0dqCwRf7nDjK+fa3Ii9WsjPnKPOcLC+JCuOFxkNy7yBdFKWXeLCsTiNj5EAeOmFVWEqKQlhhZVVU9L+QFwUVA1J5nYbcWO/ebFdyK+R5VgfBwgtCF2WJQ6GCUPLcIJAuhCgkCo1vuQrrfKbwOqppNsTOG3q9HulwyNjYOFPT02w7dju9Xo89e/YwPzdLnmYMhylhGFIay7C3JJ+xNOS+y8AaU7fFRGHotXycdz3M6C0X2FVsrOEwpShLQq2xpSG1QxaXlkRXKgjIC5mHwzyn1WyKs51S5GVJ0S1QWtNIGiRxQlkWaK0ZGRlhochIi4Le4rwUE4KAx/N1NIc+mkMfzaF/9Bz6MQNPNaLvH0xlFqg9iiaI5QqFFpwggVaodtXg1u4vq9DZFWZNNQkrtNgznmrrwR/WLfKByFXsp5UWwLqHVYkFdQ02tVs0GjGxB17EvEJaCxIiAp1INanRIMBhy4Js2CPt90gHPfJ0SJFJ1aSiMNfoBjz6/VdVV0WXaeUz1//jf6taTBWW88PXqtGpr9X/76pnUKEsyr+uVjL5QrEtTeKQRhQQag8cVq9eoZjVs1hVxa0WXcVsw62+bw0qROkIwgR0E4IElXQIW6OEjTbJyLjYVYYhmJxGe0ij2RbdgEZzBTnWiixNJWB7cFHmkEIp32qHffRNe5BT1+O/mqXk50Y1Pj5RUCqQKpUXfhTcVBawQvukRNXz3tbzbgU4rSiTRZGLYOZPAPCUF7m4rVhd1zNkWAKfSCHr1bn6GdcbpRLhyQpJrYBipwTtZmUqy1rHSO+0lZ5sqyQ5dtZSGu+WYW3dOrvy9CoHDFYAasBpI33Evi/bGUNuDKU1lM7gfNAMnEZrR6CsiJ/6Kqix/rM7i8sdRhu0LiQJcMY7j5QYBRpL4K1slQrroFklbpkxdQ+8RzQBcW9EVaC7uDuubgWo1rbyszigcp3wbbLWB/AKaPUun9YLkfpJLMHSKUonldbSJwb16/hLe9fRCjwGsKbSRhPNEOc/s1HG79O6nvvOCyNKsu9fX/J/+VmkECHBSTQMnFaYQAoOyjlyVyJuLZpAO/+MV4DylcTICWPVUQPaQppWKwdLLySpvN2t0l4nRMcovKWt860h1kkC5mwtsKn868NKb70tS2yRi2OqKXi8XwoJ/I0kwRrD3n17OX7DJK0kZN/MDMetn2JqdIR77z9Asn6K8bWj3LXrIco8Z7LTxBpDmucsLi1S5hsIlJLDhYI4irx4KkyMjLB/5jCFMYRJgi4zlCmItMxdoxSz8wvMLSxx4MABplpbUY2EXn9AFMfEQcBSr08nDtGuzZHZWZIkYfvWLURxQpbnzM/OsrywQBhoRjstotYI7YkpduzYgTCrQ1bnCEAd/w8cOMihQ4fo9XqMjo5y7LHHUhQFw+GQhx9+mEajQVkUzM3Nkec5aZr+pwCFUordu3fXDnUzMzOAJLWNRoPp6WlOPPFEkiSh0WhQFAUTExPcddddbNu2jbVr1zI1NUUUii11GIb0+30eeOABrr32Wq699loAJqemOP+88xgMBrQ7IzzlqU8lCkMOHtjP8vws9z/0CHv27UdrTZ7nLC0tceedd3LCzp381E/9FAC9Xo8HH3yQb3/72+zZswdrLTt27GDNmjUkyQpToOkPfgsLC0ytmWbTxk3sPOEEDuzfz3333s26kbMZZMvsn53nyRc9EWstu3bvZu1pJ9FpNektL2LLnEYc0Go0CLUmz6TdptFoMDUxzvLCHOlwSBJH9LpLGFNyxsmn0m42WFxcZGlxAeUcYRAyGA7I85zpfD1pmjIcDFDO0e8us2f3I5y6fTNpv8sdt99OM44ZmZ5kbvYQ1hpG2m20Eme0QzMH6A3FKbiTRCyXJY2kwZlnnrG6Dvc4vwRI6A9TwlD7Q4AW4Wcl2ppZDtZoQuVE8yfPacaxtG/5WASrWUEaa0qyLKene+SFtF1hBURwVkTCA188DlR1sKpLoiv6R0Z5xpDzBx3ESdo64sS3gEWRuECHAc4a0kyAjm63y3AwJM9yAgSYrQ89ztX7uapyU7U69+dRxVTjGUe1HENZ4ryluvE5hDOSsxWlQeNqXVJjHbk19SGsMhLCiSuZ8Ux5GW9hPAZRJAdJP77WrQi3l6tsy3HS6oSPq0Eh8a3wrCY5iOIPtj6v9HtW1a1R56JU5yTqPNv6LpHIA5FVjuuc6L+kNiX3rYvWOhrNBiOj47TabUbHxkjTIdlASX4iGQlZOgSlKa0jK4xnf1l/MK7SExknU9+H3G/gHQHTVDRZdRDU99AfDKQt27dCOZCOhCCUL0UNcEVhIDmIUuSFFK7DOKrfL8urA+t/cvh5HF1Hc+ijOfTRHFrm7Y+SQz92Vzvr6oFXfnJXuBjOYcuq7clPfWkbxCBIpG8Y9midp6YpUY9XFTLIyuRRfiAF7ZX+UGpUV2j0VUuZ51Ph6qXn6XdhSLPZYNP6tbTaLTojbZlyNqccDEhdiTVNorBF3Ggw3kkwKpKNokwZpkOydMDywhyD3jLpcOBBJ6G41VBTHUBX0e7dyudT/hPKhFhhGIlNKqBUHXPV6r9TYUiqvrf6cm7lZ6qIWF1aJpy0GIRe7CxhfKTNeDtirBkSB8oj9gqUTLhaiL1iPHnXAu2TFU3FdjKrnkWAjlu4IMEFTXLVxIQNaE0Sj04SNNs0x8al2hZ5oUhrcaZkYu1GestLTEzv4cC+vSwszHPw4AFMXgi11wkNWzu8oJzXcqo3IUulExD6JElBjUQX1lOkq1kRBCg0wWowyf/dWIMqC1zltOgrGAIweeDT/70sy9pVIs/S2qnl8X4VZUkJ5GpltojOSSR080ChrEU7Wd3OA42SOInoXqBCtA4JdCi90kCWpWQqZ5AOvQtLBcBKy2xdjcThTOHHz/hqq9dwwydXThwypFojiZFWECvQVpwXquQxzVNJCu2KQ2WgA6AkUBBqj8h77bl6hRTUlQ3nqjAtQKxWSKVJGSKbU7pIkkZrpUqTF6R5SWn8XuU3YefHtKKwVkC98vsh+Gnr93+fe8tGrlcFKlOC3xdcWYrNsCk8yxOMBeOgsFAYz2rE1slyBZCCZwr6oBn6RLduYQbM6l2lRraVvIH/meqo7ur9RoEKQVWB2PiKjvHCmQpNQWwsUWDAhBAEEECgRGjVKXDG7yHW1mxFaT2Q8Uiz1MdSqcZLhSYhUDGBCilK0IEiDBXNpCm21crTgJ1PO/zYaB3V+6UIORpKW8jazXOKNKUwGeVPgKtdGAYkUcgP7nuQ9VPjnHfidlSZMT/fZ3FYYpIO4fgUC4t3sW3tOOumJrl/1x5CV7ButM1XbrmH5UHGhSdvZ/eBGe7etZ9nPuEc5roD9hye5/D+gwyN5eTjdzB7cB9BHPMrv/rrXPVP/8R1132Hy556AYdn55nZux/TbhM6y1kbx5hfWGBfWrBnbpmdxrJpzSRPOft00mGfpW6X7RumOfmkk7nyZ67kf7ztnTzw4MOsmxhl/5F5nLO89uefz4WXXM5ZT38ef/RHb+amm27izjvvAqTFLfKgmDHirrV1506OP34n3/zmNVx88cV8+MMfJggCbrvtNl70ohfy1rf+JS94wQv41re+BVCvg+pSvpKbpilvfvOb+aM/+qO6qOCcY3FxiU9+8pN8+tOf5rOf/SwXXvgERkbEHW/37t2cffbZ/NZv/Ra//uu/zkuu/Bke2bWLNMu59tprMcbwjGc8o3axU1rKdEmS8Lt/+D9pt1ocnl1g7fQEGzZu4tWv/xWu/e4N3PL9W1FBQJamHDxwgJ/+6Z/mZS/7Bd7znvcC8P3vf59nPetZWGs57rjjVpLkahE72e9+8Rd/kac//Wl88Ytfqu/5a1//Bm//y7/g7//2b/nCNd8RPUpneeCBhwg8YDZ7+BB6cozTjtuKGixx983f5d+/8EXOOv103vUXf8Y73vUu9u7byzHbtnJkboHSlDz1gnOl1ac/4JQTd3LrHXfyD1f9I7/xhtczvzDPO//6PVxwztlsP/YYth97LIPuMkU65N1/+3ecdvLJvOzFV/L9H9zGgVtv576Hd/HLL/s5picnecff/C2gGRkd5bd/43dYv2aKIOvyd+9/PwGWNc2QSy+9lFPOOIsnPPunvV7j4x996vb6ZHlGmuWEZbXvS+IS6IDRdtO35lhKaxikOf1MqvjKt9mJk2JAXlqa7Q5RHLM4P8dyr8/C4pKY4FhDmmY040hcprQmzaX9rREAzkkxMokhLxgMM1yei0RFWcrhVI6plL6ANzo2RhRHtJpNiiInHQ5wuTitDYYZg/6ANM+9ZpUh0IoyWCnkKadrFkUVH+XQLsHTuOodpaUly0VvLolCikIK28NhKkBX6kXEreg5VcftKAjkYFsaskKs3YuoaglaKVJLrFaUxnimZQw6JDSmBkHSNCVL07q46F+EPC+oirqVMHlWSouj8/FMmBSqBgkVXjPFWIIw8uML+DzXWsswzRCreUvstX6sEZcx40FDCZUlWZ4xGAxYWphj05atjI6Nc+JJJ7F27Tq6S0vs3fUQLivQWU5reZlmq02r3SHNe9LyZ8qaZTccZD6XtiwuLcseaC1RPKjPAdZaOcMgY2Y96BeGEUmSoIKIZtJkYmoNWssZpixyoiQi1Lpm7lhTUmQpxhi6XcNSt0s2HEpOk+d14ePxeh3NoauBOJpDH82h/+9z6McMPPkCCjh8cJD/WE+/kypCBbQICKOxQFkzaGDVQ/V0L+esR+C88JmtwAWvV1SzqDy4Q1Wp8R9GOXAeHVROAqfWtFstRjotRkc6tNtNgkCJE0Q2FODEWZJGTtxIaRtFkLQIkhZEDayTalKa9smHqQi4VcrzqyaP1rq2lMRZcSWsZ6Cu+8rrqekXqkWhvDuc8/f0n465X1myZa36qRq5rUbBv2sQeIHDAB1GqCAkjBs0koRWEjM11mA8UbQTRait/33lV7quaZ+qcuzQ8qVV1U5Z4rxYnqvQUK1xQUypIlKrGShNWYJNC3LVJUrFuUNEEVt02i1BkIOQ9ugYcZIQJTHN9ghLiwskjRZLC/P0lpcwaVoDQ8p61NjZ+jkIQ8kDmDqoKZFSZbJ1talKEiqnwyAIJVCEce2K4BzSNmdL6Tn3CeHK65S1i54xxjuSGLI88/36j3+NiWJVElStI+WrBRVz0RN1URXQ55w4JyhAlUIPV1ZEK6EWDaw2KWVytF2ZrSuek6CU9JQb4zXbbGUuigdlWQmgfg3J7yrPLgTnxAmjNFaqjL6aJCak8jOFEuFBaypwst4tVp3RVtZQNSYGGQdbgHGGolQYN/D36RjmuSQexoqQ5KpArOoX9u/jZF1aL+YHfq/0MLJG1VVC6w8Z2hRYJ+KVAs4av7eWtdijMZKg53blQFAFTOuqKoi8d56JLp8OQqJYnCjUKgcGw8rf/dkHVgX2Hz7GVSL9OpB6k7UapTzNV1XkXCicQ1ct2NqsjItvk3U4z+Z16CpQI3u/xck9Vi2u1koWEmgiFJEGtCT2AbJflWUplS8vBOmc9OwbX12Se3KeRVlibElR5OTpEOOp34UpMT8BBgHGWApled5PXYQpC268+14mR9tEYUgndBw5dIju0iJrx0c5srDEZ775XdaONBgUJdfe8QAbJ8c4dn1EVhi6vQGLg5TZ+UVml5Y5fPgI460mSaA5MDNDlg7Ju8t89MMfZmbvbsZbDXYfmqeZRJx4/A5ik3F4bp7bHllmrNOklURsnhplut2goRzfv/s+1k9NsGXtGr57+9307rgboz/NzKHDUrixlrNOP4XOyAif+fb3KaePZd3Os7jsssu56KIn86KfeTFaa/bu3cu73vWuR43D2Wedzc//ws/z01c8n9nZWX7lV96AcyJmvbCwyPvf/36+9rWvAfDc5z6Xyy+/XH6xDsX+L6piu9pHfx849dRTueL5V7D92O00EhE6BQHCjDF89rOfZdeuXezbv59hmkq8969hvFPP5OQkv/Xbv83TnvpUiqLgIx/4J3q9LuNjY/zB7/93rDG84x3v4JZbbgF4VNU1y1J/yOU/vO7hw4f5lV/5FcIwJM9zFhcX6wS5LEuGgwHzRw4zOj5B0mgQBAHPfs7zWLt2Hb/7e7/HwsKi7BFFQWidHDZ0QGnh4X0zbNq4kbYuOThziCS+n3XT13N4bk5Ya9t3MDs7y+LiIsu9AaFWtKKQj3/qU0yMj/GiSy/hW9/+FlmW87SLnsDkxCR5lvORj/4Lk2Md1q2ZRp12BtYavnbtt9mwYQMnnjTFSaecyj0PPowz93PZc55DlufkecEXv/Il1k5O8LRnPJPPf+mLdJcX6aU5n7n6Gu7YNcMTnv3TfOpT/8a1136L9/7N+/6frrf/11dvMFhhKDhX624GQeAZAoq8lPxXQR3fhlkhPxPGtFttgjCkP0zJff5Rid0aYwhKOTyOdNq0vCD4IB1K8c5ZCAJhDZWWopTXDwO9Am45yIsS4xzNRoN2u0Gr1WRifFS0lrSmyK0UYHPHIM08aCLOdWEQ1C0wWqmV4nSV2/t8y1r8Qdzn8877SfklWJSliGtHoRyejGE4HHqdmGKFQWCs6M0irydxUSr2BkupTBVhfA6wwkYQQEda6rTWZEHg9Y6c6GB5MMSURf0aRVF65oUiL+TomfnWP5x8FgKff1dsIH94t1aY+5Iz+cufoypgUCtVA001Q6o6eq8KysYYhmnK7OHD9Pt90ixnZHSU6bVrCEPN0vw8ve4SaV7iVIpFMxwOJYcpCprNJlEYEsdRrfdSloYsy0nznLxyYnNIG7InC+gg8N0LokWTJDFx0iSKY/IsE4FxXwWumCFxGJIOC/q9Pr1eT+aKUqRpSp7n5IV3LX+8A09Hc+ijOfTRHPpHzqEfe6udX0yrJ0Q1max/gK7CgvyUt7aS+66iQgV2iL4CVq8MpkfJZZF6+0MPPMkrqJqqWb2kPFXfk+iRTwnkIe12k9GRDuNjIyRJjDEl2XDAcNAXZXgHSW6IsxynApJmSWKtV6VS2NKIK0eRiXr8oxaYonLEcc4RePtC/IStnPycFz2v2E8rs6dawAK61TmwWrWOFRXy9Kjvy6SQBV8PAQJg6SBEBQFBHBMmDcIoodGU5KOdxIx3FCOhpRkaDyZVz2YVPbDqu6+ExrXntznnQSdP/XQeeFIBTkeUBGRWk1rIrcO4jMxYojBlpQ9VqnWRB8iSRos4SUiaDaI4pjM6Vttg4xzdsgS/ISg/trXLiK2cSTxVO3Bic+qdUyotMGeFyhrgQTkdiN6Ut99UfnCd8850TjbEioUnm5EEhrpH10jgLktDURSykf4nbRyPt8uswj8DnExT+U4Nbmona1pXwG+dLImThXMG62TN1RXHet4rtPEacI/ahV3d1lkFTLvKIKBiH9SBzTlfaYCqidI6K6YdiBWrsRXV2O9D1iJtn5bSVl3KzjMnkWSXVSLzuEetKfD37b9vnZWqkMq8lrwj91UmY3z16ocQY7ldX5dadT9+FAQEVX6k3cr3rF8fpSlwxlcZfMDEVcL9kmCUpWz+4nD0Qy2l9WvJ98uilETR+TZkz8SsrlWpb10tUri6wLAa7pZWACfVEC0tqZ7QLT+sqrRfqsBGOfl5Z8F6FqernqmTrMatTq78wdpaSudbKawEPRdKtRzvGhRQ7VdVgC3BVMC5H79V47Ga1ViUudjg5qm4OxU5w7KoK4CP98s6R2kNJxy7lbnFJXYdPMxyv0OnmbBmrMPCwgKltWxYM83s4jIP7N7PxWefSFGW3Lv3EM859xSmxjo8fGjRA+Yl80vL9PpDTGloxiFYw8HDhzBlwbDf45vfvIbxdpORZoMji13WT0+yfnqccLjI/KJmPi0Z6UAj1IzohGak0daw++Ah2s0mjUaL+e6AI0s9ut0+C8td8Otp+7HHsnHzZv7h9nvYd2SRpaUlzjv/AqwxzM3NEYQh99xzDx/7+Mc4cvgIvV4PgLVr13DG6adz1plncvXVV/NXf/VXzM/PA7Bu/XruvPNObrvtNubn51m3fj2XXXaZgCVLiwBMTk4S+0TSVQFZwXAwJE1TxsbGOOOMM3jxS17MunXrMNYyMzPD+Pg4QRCwbt067rvvPm655ZY6N6jYRXEcs37DBpy1bNq0iZ9/6c+TJDEzhw5xzdeuZnFpienpad74hjfQ63X5h3/4h+rtV+fxlKWh1+8zMzPD1NRU/X2lFMvLy1x11VWPmhuBPxAWeU5ZlPS7y+RlSZw0mJqa4owzz2T7ccfxnr95H3HSAOeYn58TcWHnyEvDMC+YX+4yHPSxubQnHpmd5dbbbyfPCzqdEZqtttjcK1ju9Ql8pn3LrT/gvLPO4KcuupAvffXrKK151tOfRpblzM4tcMONN3Lemaez7sSdrF/f5uChGXbt3s0x249j3dq1rJ2e5jOf+yzLy8s842nPIE2HLC0t8W9f+BLRaadx4fnnkjQSestQGsvdd9zNgYUeMwcP8vWvf40PfOADj3vgKc2ETaNYFZ+UkmJhINojhZFcI9C6PhjlZUmIIog1URwThgHd/gCTZfI7XgdV2qUsQRCIpk4S4ayjN/BaWM5iXeWmJ4dP56jZDg7lD6QSQ8Ioot1uMT42xogvGoqbksEUJblv8ava+ySF1HXbW3Vglhi9wjIHP9etE7c1+Y7/pnQElMagCgGZ8ALYWSbaT3khGivViTtQvoBonRdy9m/gLMp4IyS1ErCrZSZC4iLwL5oxmrKQVrbCs7eqfMVHdsqixFZ5RNXaVxqwwjMJAk2gNEEYEgaB18eReGal98Zr3la5veQ7RV74To3A51yKFTt7HyurxAHJhfMclpYWGaYpRWlptdu0OyOsWSeAozGGMk9xeYFxQ4a+Zc6UpejbaU0chR64k/HPlTBiCs+KLI0l9lp4WgckgQClCgjDiDiKaSQJOhDx45DQz6eKHeGIQnH8GqQp/cGgbv+sxrgwpp53j+fraA59NIc+mkP/6Dm0cqsRlf8f145tW4SGF4j2ggyRq/uaS1NWO7HfxGSVrHTC+sGq0Sn/ECtwQ3u4yvkFsPLk/IarpCpTu5T5gVh1szrQjI+NMNpps2n9WuI4JopCyiJnMOizMD9Pr9+vUfUoDIjDgJF2m87oKO3RCVpT6yGMMSqk2+2Spyn97jLZcEiep6TDIaVf+JXwoCR6hW/Dkvauqhfd+o1lNQ3c+KhVbRj+BvlP8FE/GdXq71CxwepVrzUEAVGrRRAnJK0Ojc4oSbPF2MgYI3HASKxZFwxIyGiYAdpKoA2imChpEIQRUdzwTKCQOG6K4GEYEFKgbIHN+5R5Km4YhcXqBiZIGIYj9EzAfKFZMpqsFJq0RhEEmna7w8jYOCMjY6xdv5FG0qDRaHiNLUUYKAFzyoLe0hJHDs1w5NAM9915O73lJQbdrl9A/nmbst4cqopD6MXLA12FATz6KmMYRdJuGMYJzc6oCIxHiTwbI+JzRT4QO9Ay9/3AAuhVLD3r57rxQbk0hrQoZPN2jnsffPixLKUf23XCsdt8nrbiKQjoYgABAABJREFU2qBDcXQRiq1Y4TprKbOsHnP8PA10AFEIgWxgOKF6ls6hvDBk7ME8pbQXxZS2Sm/SiSlXBOs01AmPtYKwl2WJwdW0bq00gao0DxRoxTArKExJWhbgVL1qpCVUEfpkQKN9FcXhtPT+ykrSrNSQqJed89C+BtmXlEYHK9WtKmBVuVGtI7fySjVTTin/GbSEkuo9lKoCkBft90KilfBq4GOQBD7jn1U1pxWlEx2K0joKrz1R+uSjAmZ7gz7DLGfnKWeJU6MpOXxwD0WRE4ZxhXrXrdM/fNlV2H5VLVu5L/nMFYm1MobQ3u000JooCEnCgNhrPVQJS50A2NIHTEUYRN64AJ+gi+ZAXkpVWaEhDFCBJgpjGnGDOIxRQcVgVERRjNYhoY6pjAGMzSlt6asznqVYFhRZRlkW0kaRSRKelpkEeut4eNfe/8NV9V93rT44HbNhDY0kIY4ilPMGHWHE7OIygzTjxC0bmBrrMDXaYX5+jrnugEdml9kwOUocBMwudjl26xYmxye45d77Of3Ms3nCRU/hg//4dxyZPUJelJxz+qmEQcC1N9zIKcfvYOO6teyfmWFuYZG5xSW2TI8zPT7CMRvW8tDuvRyeX+KBmXk2TIwy3m6i46SuJva7PdK8oJflpLkcUrVS/NZv/iaXXXYZJ5x0Eo1GgyRJCMOQz3/+c7zul38ZrTWnnnYaH/jAB/nVX/1VPvrRjwLQaDRoNps453je857HO9/xTp5/xfPJ85wvfP4LhFHI4cOHef5PX8EvveqXeMPrX88TnvAEHnroIQaDAV/4whe44IILHn0YdY6PfvQjfOpT/x/23jzstqOq8/9U1Z7O+J53vGNu5jkBDGGyQcIggiDNpCIidBsQ5Pd0263dLQEBFQVRkSGAQCMgQqARBDQoEEICYTABQhISQuab4c73Hc+0p6r6/VG19znvTYIgdnt5nrvzvLnvcM4+e9euWmvVd33Xd/0df/muv2T7jh00Gg2klFxzzTU8/elP593vfjfPec5z2NjY4E//9E9581+8mcKzkqSUfPWrX+X888+vATIpJe12h/e89z2853//b26+8Uae+9zn8s53vpNut8vXv/51nvCEJ7jNuN90al/KAg7EarfbXHbZZayvr/OkJz3Jl1pJxqNxvf6MscRJQrPdYWN1lcc97rF8/nOf48KXvISbb76Zq666ijiOsdaysbFBxZ56xs8/leuvv4Gi1ASBotNs8B8eeibjUmOE4nnPeQ43fu/7fOaz/8jz/+Mz6A+HfPQzn+Xc005iptNm/+oGw8EAXeT89HkPY8/BQ9xwy+085uEPw1i4fffdDIdjlFKccfKJZEXBKM244+57ueCCJ/CrL3ghV37ly+y5717uuOM2fuWXf5m53izv/8BfsTDbY26mR7fTZs++/dxyxx1Yq2nGEdvnZti3/yD90YhhCStr6/SHI37IcPbf7TjtxF01+OI6BDkbqzzwFAUheZFTlr5UrSwdK00pkiRmrtdzzDRt2Oj36/NW5WvGWBqtFqFPwGpdUhYlG8OB83oCIqUcsFCUVEliKfAsBMfeaTSaNJsNTjlhF1EUEKiAdjPxrKMR+w4eZjROPQDk1vh6f+hlDixe3gUJlJ4hj4AkConCwHdacr57E0DlgRnp4wkhJVGg6uY2aZqR5QXDNHPsE0stiFyDZ7U/tLUfDlUlPTHZpk10YKERR57hLz2rYlLJUXW6qq4zL3W9WfXYGaUvdxFA3EhotNo0mi3iOKYocsdAXF4lLwsMst7/RIHyXe804zRzXafjqAaxSz3ZOYh6xGydWK3saAU09ubm6c7McMJJpzjfj+Wu229lY22N1dUVV5YjQAnhRMDDEBUEXkfX6fIURcE4dR3TtAeDIg92hlFMs9EkTuJaPiOOQoIgJFABURzT7XYRUrKyusp45PTdwjAkyzL/c4YuS/Ii94wyX0FQuH3VbXcfvT74WAx9LIY+FkP/+DH0jyAu7h+8EeCpq5UmQq0G78ETMwHvPH5H/bcJ+IQz5lSZj8qsVsypCehUaybZinnlSxv94nOglKLdbjLb7dDtNEniyHWGUJJ0lFPkGXme+jpsx77RhXGLD+01jCBsdpCJRUQuW6GDwGUuItfG1WiNLCWldEioMgFKBRRB7v5WFL79qkFqh2RvEjUVAukzPxU1v8aP6x+PgJEroK76Ww3sCcdQCgJUFJF0ZogaDRqdHq3ODEmjwUyzSVtZWlIT6xGh5zdWSHJF/av/9awgpSq2k/GldQW6LDBVBshKtJBoEZBbSWaF+/KU2Ww8cjW/SnkAygl6J40WeZKRF659ahgooijwrTEljWaL3tw8Ukr6a6usLDc4DAzWNxyiWrXC9XXTbm64UZJGYKSsJ5/7eyXiWBl+WXfPkMqJzFVzt2Lb6bKo598EeZ8wnnTpkPxSmxr4rLszHMVHlUFwP7j/GTv9e4ExbhOTG1NTLAVMWh5rDwoL7QFQX/tfMdCsrQVTa9tQi/BPz3mcR6n8lnB6XY7qOXFpdTeJ6XsQ4BT5qG2PmAIcnZ0A8Gkb4b6dgLyWyf+nx2MS2glEPSabVqn1fxFTy9Mf05tYB1pOxrc6e/V/W2VF/PhIf33aOl0zt4nwYzzlvrR/nzaOvm2mnqGxltFoRNzs0Ns6w46TTiUfj1jev8eXRE9q6gVTZqaOHWqjXd9vlUCognig3kQ4jq+s79UKF+oYadBGUApDID2Ay6Srh9Yu2BF+sxRU5cpYR++tfcqE4q+kIohiVBijgsjXe7t5VZQ5ggJNNnGauAyYtdq3sHU0/rIqTSnymmaujR9Ps2lGHNVHf5RiLERRyPpgjLWWpfl5ZtquW2uz3aafFhxa3UO7mYAKiJUkzwsKoSmMpdXpsrC4RHL7HRzav49vXnM1Rpe0mw1UEHJ4ZYU4jHjkwx7K/EyXOAwZZzntZoP5TotOM8EYw82795D7TdOuhR7dTosoiji42q+zYGWeE0jJ9l6H0x5yHoWxXHb55VzzzW8xGo/ZsXMnj3nMY3jc4x4HQJZlHDp0GCEFt95yK3/1V3/FrbfeWjNcsywjTVMAvvvd7/L+D7yfAwcOsLi4yNzcHF+8/ItcffXVrK+t85Uvf5kiz7nvvvsYDodUXetmZ2fvN6661OzZs4ePXHIJnU4HBMy029y1ezerq6ukYzfWvV6PJz7xiTWA873vfY/Pfe5zXHLJJezevZvnP//59TmttZxz9tk851nP4i133sltt93G+9//fn7uqU+j0WzxO7/zO+R5zsrKCh//249vKjeZmZnh5JNP5tOf/nTN6KrKVzaDLJYzzzyTZ/zCM0lHQwKleMtb38r1119PlmWbbNDMzEx9Xc/7xV9m+85dfPrTn6YsNaM04849B5ifm6U32+Gfv3Uthw4dot1s8L1bbycIQx59/nmEwhApxbmnn8J99+3h4KHD7Dl4mPX+kCiKWNvo1/5013E7iaOIlfV1Op0OW5cW2bptO3EY8MXLHaAWhSHnnnMOd9x+B/dEIY997M+w+647uPOeu2k1mlij2bowz/5Dh8iynNX1Piv9ARuDERuj1DFOfgKOChQBz0CoUv7CxRg5hYsrPBPBxRdOBFZrl9CrWFDSl4VV2Xnt4/EgzymFYGQdE6iSJ8g9IypD1IykqrNcNTukhWYY0+vN0O20mek0a1/hKh68v/XrsPbf1k59GWC6nTm1DzHGdY0LhXRBBaK2u5Xfhyo+djFDqjXK6+dYDxjVuw2B23CqKf0ofIRb+cXq+vzlTJgJk0vUnh2gqQTJbe1Tq/2IEJV4eVWyZCf7EM/sEVKQSFeW47r+uX1DOtkQYa3rZKd8PFpp7CgPXLhOYpNrrhmVdXzhpEym47IKiBqPXQfQgwcP0J2ZodlsMbuwhJABeVGysb6KLpx+j5Ku5FJVWnS4jbSZ9oU1QcBVVMRJQtJs0mg2CZUiCgOiKHKdx42hLIq6PKnMUtCuk+lwkHqbPXZzoCwZj8fkeeE7dPlk/VEeRx+LoY/F0Mdi6B8/hv7hgSdfrzoZTmdAtZ7QsMTUXydTTtT/1r+vZrbAg0CThTH1pxoplP7JVs7ElTZ6xhMO3AjjiLneDAuzHTrtJkEUoqRDBB0lbEyZZ2AdHbaiOJbakpYpwmiE0cSdHpEQxHGTIAg83dghnNIbAqkKZCGRyjn80BrC3JXzqSyrkftSa6TRE0qwd/QV5XhTAGldSZitF8nUopxenQKE9ZkbATIIUVFE2GzR7s2StDp05hZod2ZoJAm9OKBpUhomJRyC0M7AubUjvGPx4IyQXiPLoa5KgLCuI4DVObp0mQoHtCgMCi0CUiNIjQOf8qIgy3IHPHnHirU+EwVhlJAmCXGW0mw2XcdBEztmlZRESYOekjSaTbJsTJQkFHnOsD9Em8zpbVU6GNWyNjhRR++05ZQBlcplytwUmmTFXDZNuRabxriOMT5zp7V29EZrsdbpkDl2XVEHTtXXdHeDo/2odUyYAnTrUkZHyXQGxFDUwZXLgAg8+FxOB2wGi8uCIAyOn2t99tG1L7Z+PDGVdptH92sdACeAWC94D0xL/3MV9CDwtcumSoHgnLxjBwShqO2Hs+midhDVDUs5yXtsdpni/out7kwx0QBzmROXYazCjFrvrr5+UXskV59eD5bzM3hngQ9EjMVYXWe+a9q2Z03aqli8cuiCidM0zg5afKZLawajMbt2nMDxp57BCaedweF9eziw914XIBv3ee4yRe0IrX8mP+iY/HlSKuEGurLqph57IzRaCIQwSFP5CuvtotPTqJ6tsQYTBEgra322qvuPEAIjLKF0ZQtRnBCECSqI/Ka2dAzFYgzGzTH3hD0A7aO+0oPlWvvy6bIkK3JX0mLM1Nj84DE4mo5cG8LS+a/ljSHWWrYvLTLX7RCGIZ3uDHfcfS833noHj3zYOUgVEksoisKB7VKRtDp0Z2dpRiF77tnNd2+6iW1LC8z2Zuh1unzv9juIo4gXPffZDPobrK6tMUozdi3Nceau7Yzzgt17D3D1927npKU5ZtsNts/NIOIGmRXceOd9VO3FS23YMtPm9B1b+JVffC5jDVd97Wt85aqvcMWVVwBw0UUX1cCTnyBY4L49e/j93/99wJVql77MoJqHN9xwAzfccANCwOLiIkVZ8H8+/nE+esklSCn5/Oc/z2c/+9l/cUyttayurXHbbbfz+j/6o+oq2LVja70BTLOM4WBIFEc87nGP43GPexzWWv7P//k/XHHFFbzrXe/i+uuv55d/+ZdrMXRrDI9+9KN52MMexl+9731cd/113HzzzSxs2cajHvUo3vSmN9HvD7jlllv4xCc/6YJSHNvpuOOO43GPexwf/vCH2bdvH0IIt36mrrlajj/1sIfxutf8HnmWccUVV/D0ZzyDKI45/bTTKXwL+GrMgsDpz7zwxf+Z7buO51Of+hQI13Hqxjvu5tHdGeZ7PT7z+ctoNRKO27LIP197HTt2bOfCF/4K3/n2txkNBzzyIWcRS9c567a77yUMQxbm5jh0eBmsJQwUZ552Go1mg09f+o/Mzs5y/HE7Ofvsh3DNt7/Nxz56Ceeffz4nHH88P/Wwh/GBD36A0WjExW9/Jx/+yN/wtW98A2MMJ+86jnPPOI3DKysMh0Oy8Yj9K+sMxhNQ7SfhcD7Y2dtKx0c4yhoWMdkwGGfPram0R6DQmvE4JStdl6NWq0Xu/YdLyLmNgpQKYy1ZltNIYtf+GldOlvs5mYShY/koBcIJYQthUVLSbDZYnJ9lttel00xqSQGBqTfKskrged1L5xfMRKPV66FZ7+/wG8GqtC1UajIOPqntNsnU89R65lFROpHwMFAo72Otd7oV26cCbYQLVMAY15q9Bgfs1H7Zx84V4OaBo6o8rygntmXSFdnWmlUVS8P6TXvVWcyBBr6DdJy4+DZQWK0ZTgF0xkIgQCnPfPBCzYG/D+Fj0eq510n4KSyvKuGRwldQuLsiG4+9jXdxXBBGzC9tIQgjyrJkfX2doiwptEEKQWhClNYEQeCkQ6prNKYGLVyVi2tA0Gi2aHe6NFsthLVEYUAcRQz6GxityXPNeOjGukjHYC3KGoYba6ReO0pJRVGW9Icjd63WTjrjHeVL+VgMfSyGPhZD//gx9A8NPLmTO7aOE8NywJO11UBCRT2x9Syaxjrd6yZPYcJUOfJwGI2oF7YzssI/cHfeiWi0ZHFhjplOm+2LPedkLaSjIZgCqwvS/hq2KGhGAVaEzolPdaGw2glljQYbxKsHMbokiBKiqIEKFNZYiiJ3GhiNZq39VFTie3hBa61rQULtdX9Mlbnyq6eaGFYbf87CtxQtaiM0EVlzBmRCx6sWsRcDVwFBq0nc6tCenWdh+y5a3VlmF7fSaSQkStIsNlCjZcRwSGZytC5clsMDL1IF7l/fwrVyfkElDm8KTJmiy8x3o3CCaDpQlCKgECEpMbkQlOAWRpE7HSjfucP4ySpVytraqmOQBS57EsYRrVaLTqtFkiTMtFvIMKYZhOw8/iS6Mz16c3MEQcjhQwfZd999NeNpUvcO2gqkNp5uKacycl6rqQ4QfGtSrTGiRJcGU5ZTAvI+m4eiMnTaGzFtnShdYWxdXqfrrNhR7jGBoizqFSilQnqHaI3FYChEMTEwZnNmRwjHXRQcqdsmauF3KCmtrimvxgeIlcj+dHcOayyB8ufxLTu9lF417V35rXSCdyDRuiTNMoJGkyiJaXR6jIZ9J3CnS4x1z08R1lbe4LI7EoExntoPbl7UVcDTkLmzK+4TXSno5M+yBomNN8jWMsliCKa9Sx30uo/w7lC6NrfeTPmPnFSK68rhal9bPXVdVU28iwVsFY8CMByOMMDJpz+Uh53/CM46+xyyQ3eRZ6vMBoZ+FLv324nQ6ub7lvVPR8De9U/TtzcJnNxDtUy6SVa2sFBuLgkX8bhWxMZlTqoNiTaGoCy9fsQkw6dx4pESQSADIhXSSJoEccN1IDIWnecUGWTjvgPFi7HLyiGwMvADZdBlhtEuyEiLgsK34C7sVDbtJ2D9VocQgtNOOgFrDHv27eO0E48nCkMOHj5Mfzim0CWn7NqJEq40YGNtjbLUDHPNOB3RbTV5+mMfwU133cXXr7mGNE2Z7XY459QtFGXJxmDIzbffxWMf82iSOOEv/+YSn4mHYZoxGg7ZvWc/4ywjVIozTziOTjOhKDXX3L6HIHCtpa3fkGVeA/HcRz6Gd7z97fTm57EI/sPjH8+rX/1q/u7v/m7T/ZVFyZOe+CSuv+76yTr2tv3AgQM84xnPYDAcTi28Sdxxww03cN5553HgwAEWFhe59B/+gQ996ENcfPHF3vA88JgaY1jzpSHTttwCe/cfqn9+7Wtfy5/92Z+5ErpOh2arxeGDB3n0ox7FFy+7jJe9/OX1+y+66CIuvfRSAH7rt/4rL3zhr9FsNfnF5/0iv//7v8/WrVtJkgYAzWbDdc3z722323z2s5/lm9/6Jm984xvpb/Sd/f4BGcVqw/7CX3sh11zzTQDe+MY/4afOezgX/n//jX337mb5wD6MNfzSL/4Sf/AHf8CnLv0sX//612q9Sle+Djfecht33XMvvU6bViNBSMGZx+8AIfjEJ/+OvYcOM0ozrv3eLYRhQBgEHL91geW1De68+26O27GDIAgoioIvf/0bNBoNnvKkJzIYDLhj9918+/rvcupJJ/OHr7qI43bt4s677+ad7343Z5x8EnEc8d9++7eY63Z45MMeSrfX45777uNTn/siO7dvpzcb0e/3OeG448jzglvu2v0vrpmj5Si1rktECv99HDn9HMfIFnXMWGqDkIpAeAZFUdb6TUr5jmfadWUrq7I5AbrIPQunREknLK+1dglaD8BUJWdREPpuRpJ2u00cR3TbDdrNBlEYsNEf1DqWVVIvCAJ63TZJErO6tsHYpBT+vJXGiNS6LoFzDWuqDZoTsE5F4TPxklqL01qiQNUlbaXWVNPdbchcxGdq0Akvs+BAKSklCp8YxGLMlA/zSWq0dewoKQnCkJrZZCYi3kYIF+uVZZ1Un2Z5hd6+Vffr7lkjZEAYx8wvLrEwP0+v18XkKbYsag0qBFhtPINLUclFVHF3NUe0x8wq3yQA7YKDen9UHdPjigChNesrh8Ea0tGQHSecTKs7w1mLS6ggYPnQQfbeczdpllOU2guEx4BjU+ZevzSKI4SQWCGI44RGs8FxO3YQNZoEYexAujxjnI7RReFYTzonH7rEwCjNyIuSoigZjIb1xjXz+lxl6eKEervD0R9HH4uhj8XQx2LoHz+G/hG62rkHZ7yYlfsIU39WhfpVz6Bio0yW3uaLmv7LAz2g6VfXHCDjz+PRhiBQNBoJ3XaTTishChS6LCm0o4NZXTi2jilcKV0UuoXpZ1vpsGaw0tV8liXZeIgMY8p0SBhEKBUSxpGnNTtIrygKyjwn90aoKtcyxhBmGaGvgXTMrCrTY73xEQ6U0dq1IazrnVOfxfXC6uARdN+foGImCYGQASIIEGFI3O3R6M4ws7DI3OISrU6Pudl5moEgoiTUBmudQ7C6pGJU1d3rpKrr6StBcSV9Ba/VWFNQdbIzRnuEGM92cownI924Cm2oqLkV7bm6bosL7ovcjU0uJXmRE2SRc5gIqlbBsQfAGs0WFatucavLOm+srzMY9NF5zjTtVXjgUxgn2jcZL4sTy9MoXSLLkqLMHaZrLaY0LltYTrqkOIE9SyWyJozECtcFwN179WXr/x50R3MUHdMtjDEu6yH9vLUVyLapdFDUOLyHfpnUKlOlMLzInzeexo+rFXXQWIH6ldGV3uEan/0A48sEHJA3IS2LKQHBSdeJKPL6XHgGm5KAcnPTX38VJE+ZJKjv0puQSpjvSIMj/BWIyrH4DJN0Ns5a10nC2Tt7pPmqTzjtltyvJy7HT9cpd+he7Ie0nmebbfnUTPPe2hqXEZZKEUUx23bupNtuEdgCrTPakWRpfo6D6wMKoymz3Ld3v396RtSI97RrnAQSE6+5+d6qYLEOGq2rmXfimj7BYJzWx4Qd6KMNPSmrcOK2/jyC+tkJPF1cuj67onpdbVds7bCFcSxFjJsz1mp0UWB8JrLU5RQNuQo8psq7f0KO4WiMFIIoDN1GQbuW21EUEtiQ4TitN0Z5XtSbOBUEIASHVtdZWVtnMByyc/t2BJaN4dBt+IoCYQ39fp/xeMza+jqL83N02i3ywiUuRlnGaJzSbTaY67bZGI0pSs3S0hKra2sMh8N6U1YNa9Josv34E/jG17/O4eVlhBCsr6+DEE7o1rMkENDpdujN9rjqqqvQWjtmkXH3J4Tg9NNO46yzz8ZoVxr3rW99C3At0G+99VYe/vCHc8YZZ3Dbbbdx8OBBt3FE0Gw2mZ+fI45jVlZW+MpXvlIDNv2NDaRS/MIv/AKXX345o5ErWylK15lXKsWBAwfYv38/AA9/+MM57dRTWVpYoN3ucMstt/DIRz6SrVu3ArB3717uu+8+nvzkJ7OwsIhSiide8ATOPuccTjvttE3P89vf/jbf+ta36u6oUkpOOukkbr/9dlaWV6gC9OlD1P5V1AwUgJNOOpk8LzjhhBM599xz2b5tGzd+9wYO7dvDxtoyZVFy9dVX8+lPf5ooUJx1xuk869nP5p+/8Q327t0LFidWXBSoIHDsm6IgUr55i/+8JI5ZnJ8jzTIPTrgMazOKalZxACxuXaTZapFmGc1Wm3a3S57nZHnGfXv3Yqxm+eAhGoGknTiJhOH6GoFn1wipGPSHDEYj1vt9J4FgQRdOaLrSN/pJOZy9mdhft7H0MYuPT+sqAu8YJrpFE5aU66jr1n1ptNd78Qxvb0O1dhuvspwk1ZS3/1XSLBCSKIpIYvcVBwprNHluGAxHrglBqZ0GldcECoMQa6nPhZ2U9Ag8M0TKupTQ/X6il6krUfPKB07ZigkY5HxFEAR1l7zKA9ZNAaoRrZJ/lZsSE0aTqN2YSx4iK8FkMfX+yWZUVzF7dc6pzWn1vCr/VcUlIAjC0Mlb9GbpznTpdjqkA804DAgC321alP7zKsFpd1+hQxA8YFixrJj64ImveoAJBXjwy8cYWpeMBgOEEMz0nV1rtNrMLiwC0F9fI0/HlFWZnah0c6k7Z0oha50tFbhu0GEY+oZI7v61MU53K029DpGhLFyHxTTNKL0W6qQ7ufWsHcd6MdMAGsK3lT96j2Mx9LEY+lgM/ePH0D9CqZ0HQ4SoVd0tE8c4fbg/+4lTW8/NF1TPH7v5F0d2nqhRQmu90r87VBCQJAlbFhdZnOv4trGQZ2OydIzOR16bqETh2yGGERoxZRQsJZWjcwZyvLEOFqKkSZA0USqg0Wh4VM/VSRqvNZTlmTPUfgyMtZR5QZaOKcuiRpqtkBgrJuvLuM5wZZY6419kpOMBZeFEyqnqUq1FF3lliZDSl4cFMTKKkXFCe3GJdm+OuS3b2bbjeFqtDr12l7AYIPMhuhyS5wN0OvDgigWhXIme7+ymgtB9KVfuFgiBtNqznTL/lbt6WCPRQlAKRSlCChVB2EIUBmlyAhVggwAbhn6yK4IwcrRR61rUWuvqUC0CGQQMGyPK0pC2C8IowjQSmklM3GiigpAoTijyjFanw3g8Zs999/gsn+8QYwVS4kFRR3cVwmfYRNXToXCO0lrkKEQFBTII3T15cXGjXRc9WYFWuDI7NxEVFo0REo2uxfseMBA4Sg+jHcBnPf1S4Tq+AK6Hpw8IJ5pkk7szNWDJAxtc9/KJ4akaPfqfKxDSOUyJRHjxdx8YV1leP++dnak6GbrzGqNBOjZAEMasra+710pJGAYUeYEuDbkpvUCfFzD1hsRYQ1XyKy3II20QFYAORlRBrMsaCCRSTQJGYaAqVa2toZ22dEd6YqijcmxdOj/5m629hLVVObHYZEupNhT+cFoQmvFoRLM3R29hidPPOpMEzereu2ibEXPdNt3eAvetrJMVOdloHSUihAyYDgimL3HanlcfZ/DraCrono5ITNWZw+KyUVogSkEuitpp1qul+gzhHJmSld6IK/uo6tErTYRqI+GcurMd4DoDObq0C2xFdT8Axmmylab0dfGV03Tttp0PmNJmmxLYPNoPay233rmbmXaLE3ds4c49+8nygm0L82xfWqTVbHHH3fe4xh/WIG2lTwLddhtj4Z++/m2CQNFuNXn8Yx7NDd+7mS9/42q2Lc4Th4qtvS7fvfFG8qIkCgNOP/lEdm3fztevuYasKNDGdWFqJjGLs11uuWcPQgY87xk/x1e+8U1uXl13gU+1SfRJAmMMr33d67jqqqsIw7AGdVrtNmHk6N/Kq5Faa3nta1/LaDTi61/7GlmWMh4MAXjuc5/LH73+j0izlL/9+N/y4v/04k1j9IpXvIInPOEJPPShD6XvRZittSwuzPPY//DTzHS73HLLLfziL/4iQejKTIwxXPTKi/jQhz7Ewx72MO6+++76fEI4Ac6iyF3bdOAZz3gGv/d7vwcWPvzhD/PrF/46V111FY95zGPq923ZsoVLLrnExRDG8IY3vIEwCO/3TN/61rfysY997H7PeRKQ3n8eSA+GKaWI45goCsFa3vSmN7G6usa137mOs846k/W1Ve6+9XtYa0nihKEe8sUvfpEvfelLfO1rX+O8X/lllPrvPO95z+NTn/6UDyBdd7N9BydsrziKWJqf4xEP2UWz0SCKY556wc9wzXeu47vf+z4HVjdIwpATdmwlx7FC4maTX3jms5mZ6fGOt7+ZJz3xSZx/3sO55aYb+PZ113Pxe97LcUtzbF9a5LHnPYSyKEjTMSdsX+SuPQe45c67aDcbGGOJwog7776HKIrYsrjIocOHGadjl1E3k03h0XxUOj2VKLQQrgmKz9lhvBRDtUEU3k9VcbS1Aq1dDDtOUyoaTVF4cFS40ig88JLlOWApihIlJ4wla11JWV5qgiik2WrSiEPiUKJsSTrKyIqS1Y2BB7U1cRzTbCQkSewEwrEoNdlYKSVRRmLERIKjYga5hOTEQealRkrj9EQraYSpe7bW1vpwURQRKEWgVB3zSSnrZG5Zag+CWaQSNcg8Ee0VvgSw6mLnBrteXzXQNynB0V5KYRLvTCVRa5/hNmxVi/dms0Vvdo6t27YzO9Oh00zY0BlZMiQKXaOjotSI0rEFjLEu5vZC8EVZYErPsJoCxSpSiQM3/Dya6tlUMzcqZgRgrWHQ3yBLx8SNFqXWhEmTbTuOY2ZmBlvm3L17N/2N9ZrRFgQ52ljPxnKsvEApgihC+VI8IZychs4LgjBinOZsDIYM11dRwtJtJq7rYJ474N6DqRUoLqz1nf6sb2ruxr7SlhJTgOzReByLoY/F0Mdi6B8/hv4RGU/3/74atU2/OiIb4QZz83s2/+gmRTXNNmGFfgG503rVeqlYXFig22mzNN8jiV1ZVDoako4HFOkIXWRI61o7BlGEUoIwcG0EtRGUYVBfROmdEuAc9XBAsHqIqNkmBoL2nKOdyYAgCGtQovTtLDXC1bQLN8nL3IMYjguMkAptpupldQlGY8qMIh07uupwgyJLybMUnWe+1tJS5GNfg1sivMJ90GgTNNtEzTaz27bT6c0yt7CVhdl5kkAR6xQ9PEQ5WCE9dA/pYJ1stEFRlCC80LcKEEGIDCJkEKPCEKncOFpTeKApwxRjtC8zLH0JsgOeArSKsGFC1OxgSo2WGbqVUYQBhQp8sCEJw9jPCeG6/3nDY4VnSSFZk+uMsxxjBd1Om06rxdxMGyUUSaPFwtbtREkDiyCMYw4d2M/evffVGkvCCialns4AWaF9pxFBITVZWaJU7oIw5UTj644NvhWuAAIv2CeECyxKiy+rY6q8zncsPPpj3fqYNtKuC4YDXo2uzL6u72ey5mB6KZv6TDUPcRNY/EDH9MbT0Vyr1sLu5HWHGOuMmTjifRXtFOHozeV4hEnH6MEKLWUJIojCkCKMyZMmuTHkRc4wHRKqcKLl4D7NO3OB1hNnPslAeX9g/CutC/LkJCrYpHQ3/fgt1CUDXtJ0YsatxQn5TRwjTFs95xQrnFNPvUaYKTfmPYgQgvFwjEXQmpnlzHMeytbt24mKAUkoaUSCWCsKA6kuajFZjrC7E6HVSag7scLTd2ixxtGU3Zyw3t5NAt3qna71bJXF87bdTp+3OqXwY+0cnbKeMekFMvHrrDAa6cVfjTYISorcOJHDPPNMVIGUISpw5zLaEvimMaVfsyWGEtBi4p0mcdNP0EIGx0yIIoRUNBsNwjAiaTRYXl3jwOFllnpdwsglF+7Zsw8EdNst1tb7aK3ZsjBHHLhN3+e+dAVCSk4/5STGo6Fbj0pyys5taGO4c+9BDi6vUBQF9x08zPxMlx2L83x3fYON4ZiV/ojzTj+FvCj5x8u/7BhSC/O8811/yaWf/Swf+OAHAPjqV7/K0572NK6//nrHfvVaRYsLC7z//e/n5JNPZjQc0mg2ueorV/GGN7yBG2+6EaMNT/v5p6FLTavd4qMf/Sinn346CKeDFISTMOaMM87gbW97G2effXbNHpo+zjrrbP7XKy9ix86dHF5edhvwoqAsSypGRiNp8Orf+z2uvPJKPnrJJfUGtcg36wlVTCNjDE/+2SfzuX/6J97znvfwtx//OH/+5jfzqle9io2NjbqbnLWWVqvFFy+/nLe85S0TUAn4j898Jk972tN46UtfWm/aXvjCF7K8vLzp84Ig4KKLLuKkE0/kN1/xCrIs86X6JZ/5zN9z66238fa3v50TTzyR837qobz3f7+PO++8k0996lOEYchoNOI//+f/XJ9XVa3RheB1r3sdz3zmM/mNl72M//yf/hM//7Sn8ZKXvIT19TUiJdmxOIuQgq996zqacUgUhfz1Jz5Nvz8gTccct3UJFcUQRBzev5/tW7fyrGc8nVtuvZmstFz4G/8f133nW7z7ve9hS6/DwkyLFz/vmeSDddb6A668+ptsbAxI85yiyNk6N8vDTj2e7921h9hreCaRSyDOz/bQZUGWN2i22iyvLLOx0edoP6qyMu11XJyejyu9ssKVmVZGyRpn+CuPWG1C81JjsZtKwbQ2dWe3UKm6lK4oHCu/7nqnNUENuuAa04SRK/eTjq2xkRauSUxZMkqzOrtd+nK/LM9pJkndvTpQsi53AwcKZbn73FJrJ31gpzfWfiyMY+kYZWt2RTU+eFmEqhJBTMVj4PRtHGhhfELUUAqBDSohJGrQSfl71/79FtfJKlNO3gLjgPkqDil8SaOxxov2unVX7XlL7TqRVb4jDAPajSZbtywxNz9Pt9WgEUgCShpJSKfdZm5+jv44w9o+Q88OFULQbbdcWZXANyXyW24P2MmpZzXpKEb9u4o3UV1bJX9irSE3hqLUHDqwH20sQZQQbttO1Gxzwqlnggw4fOgg+/fc52IOYwhUUJcBOpCuhMJdiy4K+oMBhd94Suk6hhvPtLLWMBpnIEAFoU9yODAkKzRKGa99lLrKlLrKwM9Te/994tF2HIuhj8XQx2LoHz+G/qGBp/o+7ebBdQbxiEVjpy/C8i9dTzUfHXZgnXiftVOPzn3nWiv6lp0dJyKeRCFYjdYFWTqiyFPKMseWJVW5VJXtrRyl6y4o0R5519o9IGsdmCSLnHTkAKwgSojwkKIKHFDjO79J4+rGSwsiCL1mkqpL2qpaciElThvO1ppSGI0tc4rMMZ4ajYQ8HTsGVJZ64MmQZ2OMduVhDngKCdtdolaXuN1ldmELne4Ms71ZOklMaDUqHZKO17HDVfLROnk6JM9yp4Pk23gKqVzJngpd2Z4KPA/S6V4ZnWPLHF3mk84pBge+AAaJlSEyiAnjBka5rF2RJJ4WLeunK1UwEck0utYwcN0XDGWpyTzoNBgMvbF0rXfjKCAOnaghFha3pqyvr2GsYWV1hTRNMUVez7eJ36ro7N4xG4Pw2gNVVj1Qk2ACbE3nFgRY6ep1jV+4DnCaphdaqtahPymb1iprUQG6+KDX+hyGsWZqKctJvsFClfWwHkS2005zuqXo1FBscqZVGoSJ8xbefmwC8aydepaVeJ+oaeRCSIosI5CWmJJ2qEhCSRwKCqvITchIwyCFYTau0fiapl9v9iqvJSfZgKlxqrQetbSuo4iY0PttZayqOVb5W2t9HGtdhxGos5V+0KnI1kw5lHrQrKuhtuDbsQrvSzdTp91z8G2rw5DZ+UUWFxdYnOsR5hskIqQRBERCgAZpJuUZk14n95sdbh7U5tr6+5t+oJufb3XNdvrf6tprZ+rOUzvlTedw4zFNGwc37rUIr9GOFSNd62VpQShDkWt0njlbX7eOcRsuictiYSaMUyu0t1v1dHZvqa/kJ+tIfEfQvNQ+m+zuJC9ctxFrq7a71fOh3pBUma1KC+/Q4UO0221mezMM/IbL5VJkXcI1HqdgJ8K7UkrXsUkI1vpDts31AMt9+/aDhUazxUxvhuOPP56HnHsu37/lVg4ePMjBgwfrezBT87LZbLK8vMzB/fs5/5GP5ODBg3zpS5dz2mmnI4TgS1+6gl27dnHmmWfy+Mc/nlarBRzRmctaZmZmeOITn8i9997L9773vfuBTzO9Hmeffc6m3x2/63jm5+cRQrBt+3aEFLS85iBMBf1+fkZRxFlnncX27dupyrHDMGSm12M8HtMPHaPp7LPPpigKbrjhBsc+M06f55prruHyyy/fdM6XXHgh559/fs0MsNayvLxMFMecd9553HzzzYzHY4QQnHvuuTzkIQ+Zah3vmBP79u1j3759XHPNNQCcdtppTsfSGi644AKiyGkjnX/++Rw+fBghBPfcc89kHI4/nkAFSCE45ZRTeMITnsj5j3gEd9x2Kwf27kEKQVlqVjf6hL0uUsA9e/e5piCBYzQHKiBqNp2tk6574HA4ZDDOSZotilKzuraGSYfs3LaFnVsWOTTcIM8LVlfXXOmYcckoqRyIEgSOERJ51oX0YsfSsynkg5Q9HI2HQPguSgaBmvgjn5TURm+SKXB/o7avlb+0thIfr9g6BlBeM7japFDPLyGFV3Cwk0YsShLHsS+xC1G4+KzQvmzH+6iqoYoxTvun0gAKlBP7llISBoqirATDXflfXVlgq81ydZ8u1qo0OivtptobWly86G1XWTpNFVH9EWp2l8XZ9npspnR1qvBDSoGVVaVGNV62ls7AGoSQVOLnLpnpYzyvwSynAgTjnbQQEChFFMf0ZrrMz/WYm50hVqDQCGNc7JrEtFot4siJuTt9o6osztbPdnN51uaYpJo71hvzKhaztoq/RD2+02WZFhgNh8SNPoP1dfTiEmGjQbs3y9ziEhZYWV52yWWtUbKKcCblkJW917pkNBySl66jswpCrNGYsqwiQUqjfWmkm19l6WoD3M5/qsTH2hp0AnwpHhztnvhYDH0shj4WQ//4MfQPz3jyn8Nk7k9+aetv8EvhAc7wwwUG1QPY9C6/PqWSNFstFuYX2Lq0SBQIrC4YDvsU2ZhBf7UuU1O2rDNKLmfk2E9CCaQVmDDwzkM4Jwm+RhZMXqA3NmisryKkotGdQ0YNRBCCDDBCYh165a9RQBAig5BGq03oNwVONNJ129CFK88rigJTFk5Nvsicorwund5TllKkY8o0ddpOVpPnLjuQZakr3VMBUadHo9Oj0Z1lbmkLjSSh3Uho5ANEtkG5cjflyh6y9RXS/jpp7qi0wiPXQkr3fRCjoiYySiAI3GwtS7AlphhhCic2Zq3EGKfBVBhLKSwWSRAlBK0ZZLdHVJYEQYgSgrLIKXJfmmcNReHE263XB5kEBwJ8HXNRlGgrsBt9xmnG+saALMvotlvM9jq0k4QgDAnCEKUC5heXSNOUA/v3sbqy4hhmFoSoAjRRO+bKUdcZq7zw3fuknyMgfJZHSYkNTd39zrU1dkFeRTnXWvssmwef7I+26P5dj3oheyMProNf7aiqjZah6kYDwttA64zRJgMAVtv7r25ROTz3/grmr2qPjahCTX8mM3FoVdBXH3ISmJelQZY5rUiyazZmoR3RSRRRCKWGTGsOpxErUUJmBIP+BoUuiEO1CSCvvjNe7lH6gsxJdOkGyhjjQOupaxWSyRj4lrTV9bkMn28SQHXb/k5raz3luKyd/qc26s4nu7HWVIG508xwmf6UKG4yt7DEeec/mvmOoi2GtEWfVtCkFTUIgZEWoCSB3EwHnjy/iYusF8nUbD6S6VqBwke+f/o32EkWp77jKe80fR1y05Dben7owiKERmpBWhQEKiArS6IoIQxDn7lx2myYwm9EwLVEcDR4jURbSWGgNJbSljjXOQkd7PRF/oQsYgHMz3QQQnDg0GHCMCSQgsGgT5I0aDYb3LlnH2mWk+U58zNdhBDsGQyZ67QgCLh7337arRaNOKbXapBmKXffs0FelAgpiaKY9f4IKSWdlm+okWfMdzuU2nDP/oOccvxxDEZjbtl9LzffdU8tJm6tZd+Bgzzzmc/kFS9/GZd+5tP8zBOexF27d9/vXqy1HDhwgJ/92Z8FoNFocN111wHODrz1LW+h0WhwwROewKtf9Spe/OIXE4STUrWKjXHkOf/o9a/nbz78N47lywQ8OvJ11lp+//d/nxe84AWA20SPRiNe+5rXsHv37nrOT79/27ZtfOnyy+l0uwCUZcFnL72Ul7385Xzp8i/x6Mc8ugaQ9u7dywUXXMBwONx0HdOg0wMdzWaT93/gg5x44ol0O20e+9jH8u1vf3uTJkvVjUdKyfzCAmmasra6yq//+q/zhCc8gc9//vNcdNFF9cYRoNPpcOmll2Kta2n+2Mc+luuuuw4pJe99z3s59bRT6+vqdDv8wz/8A3/9gffz27/1X9m97xBBEDA702XblkUacYRYXqPTSGhEIbfdu5fjtm/jobt2snx4hnGa84Wrvsbc/CKNluUv3/0uHnrOuTzr2c/j3X95MXfdcw+33nob9x1eIQwUxy3M8tAzz6DT7bDn0Arfu/0OvnPbbk7Y7ph3w3HK4dU1ojCkmSQsr67RHw7h0KEHG8aj7ghUgLWl96OAt1uVRowDEZ1+aShkLR5elJPnXmnIOG3MyaYwDCRxGKBEBURYAl8qI6QA62KWstQ0mzGdToftWxboNGN6zYTheExWgAxC4ightFBYyWg8pizHFGla2+jBcEQchvQ6LYLAicvjgcmK5VSWTki62hBr39QFa2n6bntCSMZ5gZEGK1R93XlZ1n5mnGakPpnZasQ1KBco5eN6VeupOuFd54OVFFjly8aEA58C6cSyK4fsNrpu7I21vlNx1QlLeHAKSqXrCKD0zwIB3W6b2V6PU085me3bt9NutRhtrCKMRGhJu9UCKckMhGEIQpBlRc1Qq7peIhyzy3pgQIoKlpscE6B5UnZXg2K435k6Hp0AUOl4zMbqKlJItu88jjhpEDSaHHfiycwvLDIY9Dmwbx9rqytevF66pKws6/3dTNeBQwfSfWR5QaENnXbbJ/MtUVB14xOuLE9K38DHJWzTfCLKXfrnY63TkUKA1tUm/d94wf3fOI7F0DAZgmMx9LEYenKRP+T6/ZEYT7a66X/5VT/CCanLHB/orW7qOkHEmd4sCwvzbFlaJA6dAGKWZvT7fdJ0RDYeo4R1WRhlPfggHSpvBMYo353H1a6awGlJlDogxxnuAmcES10wHI6Q0YB2NiZOmkgcZU0bV3aGVK7LmXZCYEIFNNKCRjMhjiM6rSZh6DJ1lY6EUgpTBhhTYkLlF4brrGby3Il45RlVJqbqfJdlKVoIkIqoO0uzM0uj06PVnSGSENkSPVjG9A+RH76bdG2VdDQkK7SfME67yTk2hVQOKCOIsUGMDZSrMdUlhhz0pDWuRWGtcxi5kZTCokSAjBKiRouw2SKsuqYEAaWv8c5zJzqq7RBK4TWR8MaTiWaV77hgraOau89ypW+ZF2oXC7NEQUDSaNCbm0cpxUmnnl6L5a4uH/bMLOux4YnjrWeSN9yuzM85Z1GL4zlAydG9nfZARS+d7oh3JOjkqNE/IQ6zOo7cgE1973MQ9cuqeu4KdX+wN276y5GZD/8KUTsamHaZ1fkr+2LsxNYArra5eqtwxDwlQGHdnIhjojjAYmlYg7YpgRCosMleqRmMnRCyVI59qKrPZMp5bnIEUxfvO4qaqZsSRwxY5RBNncWrOJrOdUr/96kQwa+DylNWV+Lnrah+N3FoVUKs8IF9qS0nHbeTrVuW2NaNaDIiLnPagaEZQiOSGBuiBISlo1ErFVJqTRBMgoDK2U9ECJ3o4/2eKZNgdtJ6ZCq7PP06v7bqu7K2Lr+v6v2rJJel0juhpmVPT09bWqQsEcKB52EQ1qyM6goDD+5XcxUcIFEaTWn0VDawun47ubnKgx/hzI/2Q6oQrTX90ZjFuQZKSQ6vrDKLoNlIiIKAbrNBq5GwNhhhgZkkpjCua+r2xQVK43RMVgYjN49Fxfi0oEuX/QsDBqMx/XFKWWp2bF2iPxiysr5Bt91i7DsXgWPMvPKii/ibD32Iq776VbI85/OXfZH79u7j8PJhHv7wh/Oyl72Mt7zlL0izjFf+7iu58467WFtb42E/9VAuv/yLXHbZFwE4//zzee9738vZ55yDUor3vOc9PO6xj3X23h95nvO6172O6667jtm5OV7wKy/gkY98ZG3DjTEkScxTn/pUnv70Z2Ct5eSTT66Dw5NPPpn3vve9fO973+PlL395fd6yLDl48CCNRsL8wgL/6cX/iZ07dwLwvve9jwMH9jt9RA/mBGHET//0f+Ad73gHX7j8i9xw04289MIL+cAHPsAVV1zBeDz215Lwute9jrm5OYQQ/Mmf/Al33nln/blLS0u8853v5G//9m/56le/Sm+mS7vtNvavfOUr+drXvsZb3/pW/vIv/5IzzzyTt77lLfU1xHGMNoY8y3jTm97EzTffzEtf+lKEECwtLfHa17yWMApJ05S/ePvFnHH66TzrF54B+A2rMXzggx/gtNNO5+KLL+bhDz+ftfV1PvjBD3LVV75M6p9xWZb0B0N279HEUUgUuTbthZRsW1oELDfffgcmT2k3ExZ7M+zevZtRmnHKiSewf+993Hnb9zn/3LPq+OKEk08ilILAaG695z6GaYa2MDMzy+LiErfdeRd5nlNqw7bFBYy1HFxeYW6mwyknHM+Tn/IULr/ySq79znX/V9bav+WhrakZS8Y4QEgg/O/wAI3Blk69oWIMVYClrmOPKpHmNvxh6BqySKUozYRJoaRECOoyHCEFrWaLmZkuc7M9tizM0m4kzLQSxOo6YpyS68xpaJamThQa40r8HNvHXagxhjAM6LQaxHFEECiyvCQr3CamUC6eyorSlYNOJR0rUfMgkMhiEmdV69tSlRa5z8aAFpqiUD4p6LvaCdc1y3HnLUVWdUwrXaLWWkopfTv7Sv9KgE88OiFm4UAxOwFE3Ph6BpS1TiLUj2ol4hsGAb1uh4W5HkvzPWZaCXGkMKEkDJxmjvKgl8SS5XltL6tnV2pd82Kqjau7ZwemTzSy3KjU/tEDGkJQv9ZMxQz+VFTsrixL2Vhf4/DB/Vhvi0AQxgknnHSKi8WFoL+x7hPGJeCTskKQ5U7XLy9K16jCGHSZEwYBcRhSKlk/D22c1pTW7nlKL7tR+mYApS+xq3x4NZe1rwj5iTiOxdDHYuhjMbS/8B89hv4RNJ42nf8I8ElsnuTc7wUPcMKpl0/W0v0eFLj2pyoI6M7M0JuZodftIrXTAcizjOFoRJaOKIucUApQDg22XgjQeGdvjEZ5FFoK4bNB1PXMpXbZEFcPa0izlHA8psxTIl0irMFYTV5oslxjpHLGWGsXfAtJmhfkRYtGw20GYhNirUGphhP8CgKHKhqJkSDxdF8vyE1Zgo7d77CeAluSpSkagfXAU6Pbo9HuEScNpCmQWUYxWqfsL5NtHCIbjchTF6xpL/rlhNx8qZ0v2xMqwKoAIwM0BisVzlLg6tgtbkysRzyNpZQCKQNUEBPGCXGcEBiDFC5TUpYlYZYjxkMQKdKLYLrF4OdKxbzyZX+VI9XGYHygYjzQY7G0Wg1Es0GUxLTabaSUbNuxk9FwyHg0cl06jHUdA6lYTxNnPj27ank8y9QKtbUzdFlHTdVFsDKGlZ5UJf7pNPx+cOb6aDoqQ26nDIaofz8Zn01Ga9O/R5rIB77vCSXcvbQqz7VMBdHUM6F2YNOftWlIvSMV1dm945S47JwKI4IoxklzabLxmEBB2FCMsxiLpT8cO6F5MaHuTutYbtJumfwSl4wUE+8vmOhVIEBUgnxMBa1mcn7r7nsSJNRP4UHGcHPEYP2HVa8qjcbgNBSWlhbYtmWeXgJhnhOalCSQxD7oLYzrUAHabVAQ9abFHGmw6yUymR8PcGWbf3fkPKkiZOuFJadOW8fNYvP31Rp1+S0/NhafuZ2mrguKPCdUAYFUbrOhBEIqbBxhrdrESnFO01DW5bFTXXWqQMHaTffzE7KMQYBUgRMSLbVbx8IxDLQuncislDQbCQu9LsPcNZVI4pCN4QgsLHQ69MdjsrxgmGWEyjF0hcD7RkEziQmDgMFwhC4d8yKOIwajMXlRMBqNSXPHYhVC0O12eepTn8oVV1wBuI5aN3z3Rr57400sLi5y3nnnceGFF/LFL17G2to6T33qU7n22u+wf/8Bfu7nfpb77ruPL33pSwCceOKJXHjhhfUtX3jhhaytrbFv3776Oadpype+9CX27d/PTK/HIx7xCB7ykHPZv28fo9EYcKyI0049jZ//+Z9nYWGBPM/Zs3cvi4uLbNmyhQsvvJBf+7Vf4yMf+chkeIVgcXGRhYUFdh2/i1/6pV/izDPPBOCKK65g7969HDhwAHAMIqUUp51+GiedfDIvf8Ur2LdvP0ZrrrvuOr761a+ytLSEMZZms8mv/MoLmJubZW1tjXe/+93Eccz8/DxpmjIej3nxi1/M/v37uf322xkMBiz7krhHnH9+rYPyne98hzRN+bM/+zPyPKff7zvdBh9Zv/vd7+aGG27gr97/fgBOPeUUXvWqVzHeGLN//wE+8Xef4rE//Rge+fDzvH6Oi3muv+G7lFpz8cVvxxjL8soq37j6am659TZyrYm8NME4zRinGWEYsGNpnrwowEJ3ZobBaMi9h5ZZ7LWJpNtwH9i/j/5oxMknncR9d9/Fvffs5qmPfyxFUbK6scEJx+1AAf21VZbvvIcDy6tEYcjps3NsWVzguptuJs9zhBC0mw2KsuTQ8ipznTZbFxd49CMfyfdu/v7/7VX3b3JUekTGWISwSOOqGYx3eg7YcBZxWtdlE1OOSixWTrF/HMghhBOFB89yq2J2Xz4rpaTZatJpt5jptul1WjQTJxoe9EdIWWCsFx4vSsqynDCstHHxld9AW2tJs5x2s4FSikaSEAQ5MnXzSXhQtO6A5GOPClixqEkJm990TvyI33h5QKiyzYXWBNaClQhV7fR8t2eL08/yrKVqI1R6oAg8O8g3/RFSeIHjiUaOA8YmG3jrNVNKPfFjFYAXhiHddotep8VMu0kSKkIFcSAJAuVKzoRnSVinJVcUrj16xYjU2viSoOkYxDjtHoFvnCPqYMVOeeFqPza9IRRMxnN6vhRFDiNYW1khimIWtmx1oF0YsrhlC8PBgPF4xHAwcCChrngjLumfF6XTasqyGhjIstz5jEZSVwgEgXKgn4/lEwRB4OZuqTV5nvvu3VWcOAU0eZDsaD6OxdDHYuhjMfSPH0P/K8TF/fKqR2IKjZq6hAm6WoFS05NyslweaIFOH0IImq023W6Xk046yYlaKsE4LRiORhxeXWU4HKHLHOWH3QAOr5cIJGUpvFN3nyClF+mWEincoDvRMEuWqbozwHA0Bhkw6K+jkiZCKgqjWN8YsLLWJ9NOWNwgyAsn9ChVQKvdptFsMjc3S5K4GvqZmRnCICQKQwKfgZHgRK1NAfkYZTTKlnXAJoVFiBKrS0qhMUJhlUS1I8JGRBCHWAymSNGDFfL1Q+QbK4zTjKw05FZgRODuWgJCgQwQMvSgUwgqwsoQLd1GBmKEKJAi8WWJktIICqvJtaUUCqNCRNIiaLaJWx2azSYW0I2Gy34WpWun7Z+pHA1dbbcQCBV4pFi4cj+pqATYZdUF0BgKbUjHY8bjMYPBACFgpttl29ICSZzQjSJ2mONRKnDaGqMRa2urbKyvT4l++wCpmn8V+OUNnbVyAqaaSunf0bwdOCnr4M1C7XA36zxtnu9H+1EZsemfN/1+2mDWCYof7eamP2MTMO6/Kq2J6QDKVt/Ux2YYusqmSAGRkiShIAxcLXSOQAZtJ3AqBYuLgjwd0eqvwWxCJ26wPjKM0zF5WtBMwvr6qkuZfLK3E1XGsQZKqZMr03X304KKNc21vn8v/DflON17jnwKm8dj8+EdsrYYU1AAvV6PnVuXOGn7HPOdiKZeJww0gQwJG22C9iyq1aEcDcmGA1bW1lleW6c/GBHI0H/akUFC9RAq/ZHJXyo7/wBk8PvdwfQ5H8jpgm/+wmYdEiF8ls5Wz8RscmqVsKP2AolFdU5hXcAQKJI4du2fhcAa69q+al1nWK12CYUqGJ8kDytS9w++v6PnECRhQCMK2b60QH84QEnFw848lbWNPhvDIev9IWsbfXbv2c+5p51MqTX37D/oMtdas7YxcBtRIei1nfZOlhdIKWm1WpywfQvfv+seRmnG4myPU3btoJXEfOeWO5hpNXjIScfx/Xv2kuaFK6uwhu/eeCPnnnsu4/EYcM+12uh+7nOf47TTTkMIwV+976/49rXX8rCHPYw8z7HW8ru/Gzj9ATnVNYrNwexrXvMaPvrRj9bBURzHfP7zn+fOu+/hT978Fl75qlcxGg7A2pplNByNefvFF/M3H/4w3/jGN7j66qt52ctexj/+4z/y6Ec/2o3mEWm6ZrPJZZddxvG7drk25I3Gpr/v2bOHRz3qUbzyla/kf/7P/1mfIwwD3v62tyKAKI758z//c974xjditGGt32cwHLFt21Y+8YlP8IpXvILBcMCjHvkoLr30Un7rt36Liy9+O1/5ylX81//6X3nBC17AU57yFA4cOOBioGajFmN/y1vewrOf/WziOOZNb3oTb33rWyczQwjne61vV+4DeCklb3nLW3jb295GmqbcetN3+fAHP8BgMKgZE6963R/wtKf9PEEQcmhllbVhyh/84R/z8Y99lN9/7e8RNRpgYTweTdlyy/7DqwzTlG1Li4zGKavrG5x0/C4G44z3/80lNDwb5rP/8GlOOfF4HvPwn+Ka629kMBwyHI+5d/8BrLWsrK1zwaMeSbfT4evXXsf3b7+Da75zHbPdDkuzM7QbCbfefR9CCLZvWWDPwcPctWcv377xJvq+2+HRfgzGYxe4456VAWyJYwz5co6qVCzzneoqEXspJUpWwr4wHT878NDWGzcQvvRV1/FPnCQ0koTFhXm67SbtRuI6BhvLfYdWuHvPftY3+qzVnexMDTpV4JHxHZDcdRmyoiAvSoyFhbkeeVEyGqeY5VVk5ta2Ezu2lIVAC6etNMpcUrT0pXdU1+8BDzPtT/0NWyDLckrfda3SoMvLqgzOuo5ruqJ3uPON0xwiz1D0SVSsxZaastBeV8xDOo7iA9aJ6VaMo8k5IYkCOq0mi/M9dmxdZLbXJUBTjPoYJWm3G15DVVJoV82gS9ex2hhDFIX+Wbp9Q6Ut6h7T1D27B4sw0wVVVVAm6+evta7BCKncytR2EqsKoLQarVP27bmPUmvmt2xjZmaGKHYdI7fu3EW726UsSvob6wz6/dr2WmCcpp5dJmt7WRaFS4pnGa1mgzgKiUNVdxsUQtAfDsmL0gkY+/vSxtTaZIGqSvRM3aXzaD+OxdDHYmj3acdi6H9tDP2jldpZ98A3Y0zTS+KB3nP/iTBNQ/xBhxCCKHKgzfz8PFHgOHtFoRkM+gwHA9KxE98W1rgSOzwd0TpjpoFSloD1tFGJlBZlLVYoKqkyB/SITaKORelow+loSHM8IgwjpEqweUo+HrIxSh0DCGptCyxkI6e1obMxURITJzHjNCVJElrNFu1mk0gFREo4kXFdIvIRlBmYHCkd6KSEQeoUTElQlhA0sCJB6hGyDJG5pDQWOx6gh6sU6ZAizyiMoLTuq653BQfwCM8y8gi01iWikFSKbE4DMEREbdARRkaUWUZhXb2/CSIIE1TcREUJQRRPWqUy+bAwdOWFQeE6K6kwItAGK8p6cQgPOiEqLNttKCqGkTGGsrSkWNbXN7DGksQRs90OcahImk1mZmcxWrN95y6kCkjTlCzNPPZrN63c2pHWU3by95oC6ayfc4bCIiuUnooOb6e6Ltg6IPpRHcu/x2GPXKr2CD+16XBGdBOe/QNsij3yh8qXTNmJiVvYbLArhzlxKmIqQ+GekazEKYUiChVxKIhCJ1hYGm+GrUUbMFqhceL5iSjpKFjsJCwLGGY5WVEQKBdE1QClmFznxJpPrntyW9PuYCrrYjfbuirY3zx4dvMY2iO/tff7fTWF87Kk0JqluR7bFjqcum2GXgQNCgIglAoVKETcwAQRBYFrCW1cd5uqNXXt46ecuz3SxR353KvLEpN31AHPdHQ1PZYPdqt2+l4rec1KkHGS4WcqE1rZKuuTGKa6DL9mi7Jw3ZGs9R26HLRdNQPQxtTlsabK2FRO007Ny58U3Mla+sMRFqe1Uh37D6+QZjlFWdDrtOrXHlpdw1pHFY+jyJVepFk9R9O8QArhy8NbKCk5uLLqO8Y5+73aH7DeH9BoJJTGcmB1o86C+9OgtWZ9ff2IS7UUecEll1xSC3g///nP56STTuJlL3sZ37nuOg4eOsTPPPZxRL50q9Nuc9NNN3HppZfy3Oc+lyAI+PjHP87VV1+N1pqXvOQl7tqCgO3bt7P77nvYe+/drK2uMDc7y6/+6q+6TU+/z/ve9z7SNOXw4cO8613votVq8fKXv5xt27bV1/iMZzyDnTt31msiiiJ27thBp9utY4GDhw7z+csv55xzH8L/PO44AM4777z77UKCqY1Ts9msxyCMY5rNEXfcfjtZlnP+o3+aM087hZlul/e8+92ccMIJnHvuuYArm1tcXOTFL34xX/3qV/nc5z7nusYdt4tf//ULOe+88+h0OgCkabppzKWUvOhFL2Lr1q0AfOpTn2J5eZk3v/nNfPnLX2Z9Yx0pJLYoGI/c3Dn++ON5/vOfz3949KPYvnUJKQXXXP3PXPHlr9Butbjllu+zbfsO+v0NijKvzZrWho3hiDAMmWs0XAcxKUmiiKEXo+91O7QasRvDlVUOHT6MLl08Nteb4bhtS+R5QZYXREHAodU11ocjVtfWUEoyO9PFGsNonJJmOc0k9p0ELWGgKLVibX2j1r462g9nQivx6Im/cwL5clLS4H/vzFXF0Z5mV7vW2VUWurLtE2bUVKmWcK9tNhp02m3iUBEqV652eHWdNMtYXd/g0PIqo3HKOM2otCvdLsaABzCqc1VbYGt9nJzntWB2EkeEoWO+gysBUUrSSCJELihK7ctdDOQlKlAuLypccx93n9ObmwmDXVTgEYCumGNTqex6eKYaAghBoQ3K4hOg7iVWO3Cpijknn+M2cBUrrXJoUggCKei2Gsx222yd79FOQmIJOhsjlEIYhY1Ddy7tS/h0idEaIVzpYxSGVUjpk5jC6fVMBWPTunWyYnTJeitO5fumN+qySqziwEGXbGdTkJfnGePhkLXlZZIkcRUYQUAYxSSNJktbtyKkA6+LvKyfuWNAgRJONFwISRRFuK6C2rExfZwhcPeigpCiLOvGCg5Q1ZvKCGt/7IHyI5MAR9txLIY+FkMfi6F//Bj6R2I81aJYD3ByMTXI03NF3G/xUCOY0+e+3/m8M46ThNnZORYXF1ESTFlQFjnr6xuMRgPG6RhlSxTG6TvhQCS84yg9Elg9RHdeDxIJXwtvneNSwl2bAKx3gnmeMxoOaY2HRFGESiSUKTobMVhfIys1hZk4RlMUjKKEKI7JxkPCJCFMYgbjMa12h9leiZIBIoZQBlhtoCwQ6QBZDKEcI2TpwDGhUeUQYUqnRB93EbSwRRMysNYZdTvqU/aXKcdDJ+yNpLQCbambdjqDIxFCIcSkc44pcjdBtSuxE9YiCZFRF3SBVRlFvkaOpUBhVYwMm6ikRRA3CMKIQCnquk/lHnYQBO4rDAiiiNBnlQwSYRz90nW1c4JvVKi2nWhL1Z30tHbBZVkShoHvDtIgThp0Z3ooqdh1/AkYY1hZWXZZ9HJi6o60XRXlVNgJxXPTQjLOcDrtBevHDiqGU005rOf1/efv0XhsWsPuN1WycdqP8kDmbvo2H8y2HHneB3yN/3+V4fPR8mRtegNcd4+YMnKu44LrcphEgigoAFMLdFrrMgG6FBgTYFVEzJC2gi0zXUoEWijW18dYq5DhZCxqJ+I/cprU6z5/orVgN/GL7/fN/cakfl81dhbqjglTr7ObbKhFiKpUQZOVJUVZsnW2zQlLXU7b2iVSmgBLKEICD+6KqIGWEdqq2mmWfmPisjAemDfVmG5+mnV3i6kHXv/fKUJOfYFCgjiCWnyEw9z0GYLJ8/Qf4846Nd7eatlpT1Y5TOGxasA1JrB1u+2iLF3tumcHVDa50kWpuhFZO/Vc7dSoP9ikPcoOC6z1B2ijWe8PmJ3pIgTcs+8AQaCIw5Ct83NOXNdabr93L1JKluZnSRoJAsEgGNbdqg6vrpJEEc04Zr7XY5Sm3LNnL1uXFonjiKIoObSyxmg85oSd21jvD9i3vOpjJVcyXXUymtjFaj255/eOd7zDJRK05rzzzuOCCy7gDW94A3/1wQ/y3e/eyOte8xqazSZKCoqi4AuXXcZFF13E2WefQ6OR8KpXvYogCNi1axevec1r6Hphb4B0POLgHseEOfnkk3nDG96AlJL77ruPT3ziE6yurlKWJW9729t4/vN/hQ984P2bxvPZz342z3zmMwHcOlKKNE3Js4wgCDDWsmfPHv73+z/IRb/z33niBY/HeD3Aosg9SODudTQYuPnUanm/IQiDgEC6Test378ZIRXPeu4v8txnPp1bv38zT3jCE/jgBz/Ic5/7XNI0QwhJkiT8t//231hcXOTKK69ESskpp5zCG9/4xk3XHgQBcZxgK30aY3jJS17Cwx/+cKIo4rbbbuOTn/wkr3nNa+r3GGucb44iAM444wxe+9rXEkURQgiyLOPKL13O29/2NhrNFrPzc+w4bid33n47RmtUoijy3M+/IVu3LDE/O8tw0CcKA9rNBhuDIZFn5EVhSF4W7Dt0mP0HD7O8usZx27aydWGOE47bxi233gnG0G012XPAsfIOLy+zdWmR2W6XPfv2M8gysjznuC2LTgA+TYlj11VxZW0z2Hk0H9Pd0SpQqJJ+QLisfAWGVCCSY624DVoNtEgHYjgijvHlW06/dJqRrXz2WgUBrVaL3kyHSLkyC6xl38HDbAyGHF5eZZymdZlUpdcTSB88e98hBU6qoWIG4TRT0iwnzXOiMHQAchhQFKq+50ApQt+JMJOlKwv2G5qGlFjlNJvKUk+BEXgQaGKX6w6WWKdlZX1JYQ3ATOKJSoAbLIXQGGVRVACO9c2EfJWEmcR/lTxHVUJcOQ0VuC6LvU6TxdkO2xZmaSchkTCU6QgRRQjrtPes9ee3Aq0d8CKE05iKo9ALgTv7i2dHVIwsMXU9bi/i/iar1ukAdpKgnQQWE7DN6OkuXPhRcCyl0WjI8uFDzMzNEScNlApRYUgYx2zdtp2yKDiw/wBaj+t5WOqynnsurg/pNJuu8ZFJfQOhEj1OCb0NTRIvNl+WNfuuKCsRYwd8ajth6Ekp6pLIo/U4FkMfi6GPxdA/fgz9IzKepkemGoCp74/47GmAaTPQ9C9/llKKRqPJcbuOZ35ulmYSY/MRo+GAjY0+yyuHKXPXFS6QFiUtobQo4bvXYcFWtcV4GrLTKFJSEiiNFI5xo42rA9elxhrXccQaQ1kWkAo21tccXRzNfKSYTSTMtRiPh2yMSsbjkXMy2lBmKbkcoFRAmaXIOEJFMasbfTrdGbK8pJE0CYKAlgoQ2mePiiFitAzpCtYMsDbH2DEU665jgoxQyQIinkHpMSaIMSqCdIzJUsrhiGI8pihKBzoZjTaOdmxRIFQdCEshsLp0zrXw+ku40rcgjJFBhAgbWBlhZEgeFOQ6pIxjVHsO1eoRzywQtbqESeLa1XrwTSgJOL2QopFgBbSLAqlCVBDBaFzX4N+v1TfGC4RX3eNKD2hp+mVGNh5R5BnWaGZ7PbZtWSRKGkilOOGUUwnjGCngxu/ewGDQr0sT6rkrhG+r6X9npjqHVEbL4rNc3jTU/6v+bmsA6sEM5U/iMTGDk2OzI/23O6rzTgItifJi7pVwqHPksn69thZkgAxikqYgjgxRIFBCIa0lG26gVIhUEULFvsRUEpeaQOYo0afb6LJWdrjxLk2WjhmPM+I42pRlq4KIysHV41L5jGlHd8RdPWgwMXXfFd35QZI2m5yVK3OwDDLNYq/Jtvkmjz6+xWxb0TIjVJCglCQJJWGokIH0mYkSQ0amnS2QYUIQR6hQkVmDtLbuP1JRdKcDnQe1z9N6DP7QR46CmHZ+1fvsxG9OSzr4gahpw5veNT3Ofs0ZDxgjUGKSKTMeTdba2WwhhWNh+g/VvhFAxVQ88jPsT9g6dmCGRGq3qWsmCWEYMM5ytiws0u122FhfZTQeMxqnbN+2DWMM/X6fQ6tuk95qNurNzpmnnMJgMGBlbY3v33EXcRyxY+sWDq+ukRcFcRQy222zZWGOvQcOOk0f4cZ46/btPPwRj+Q3Lvx1TvHC3RsbG4xHI/I8d7qMs7MAXH755bz61a/mne98J9dcczWvfOVF/OJznsMzn/EMut1OfX9x4rquALRazbrU7Q/+4A/4pV/6Jdrtdv1aay0/93M/xw3X3wDCsYX8H9i6dStf+9rXeN/7P8AH/+bDvO+97+WsM87YPJgWLrroIi79h3+g22rw0pe9jF994Yv4+ac/nfl2zLN+9rHs3neYNC944kNP5spL/5Yv/N0lZMMBc70uszNd9h9aptOdYeeuXaS5Y2Pfd+et9EcprXaH3/7t3+bjn/57Lv3cZbz/A3/N0pYtICSddotb/T38r//1v3j961+PMZbf+Z3f5oUvfCHPfOYzechDzuX6668HuF/JH8CFL3kpT37KU7lz9918+cor+MiHPsALXvACHv/4x/PBD37QTxjuZ8Sf85zn8Ed/9EcA3HjTTTzhSU/mT974Bo7ftYtn/sf/yN49e7DWMh4NybOUteVlPvaxj3H66acD8IpXvILLL/8iwhoOHT7M6uoaRVky0+2wOD/HvXv3obWmkSS+JEqxML/g/XvJ4cOHObS8zHdu+j7NRkKn3WHHjp1cd+NNDAYDzjnlRA4sr3DLHXeipKDZaLBlfo7haMw4y1jb6HPSzq0EnRara+s/MSu4CubxwX4Vk5W6dCk4z2qpABdXHuF8ovFir5We0dh3RqvATYsDFV3pq/UamQalAhYXF5jrdem0GhijWV7bYDQ+xPLauutS5rWH6jI9v4GVykkgBEpC4QQskBKlAqQHU6215HnBgcMrJHFEEkWEStGII8oiYWjHTtA6imjEoevQZy1ZUZL7L2UkIgzqqgNjjHcV0xs3UZeBYJ0OVZUErACkMIp85t/WIt6hUp6tYImEQOFsaAUeu79nlKVx7/EewZpKMQWSKKSdRPRaDXYs9NgyP8O2uQ6myLC5i1cDKSBQnhXgu7apEBCUxjLOcs9I1fVzk0LUYsdRFE3KYTzDLAhDwjCsOyzXEg9mOg51A1RWz2/a34IHvZx4sDWG8XDAvbvvIIxCxuMRO3adgC5Lcq/btrC4yJkCbr7pJkajEUVZ+u7crkyumqBhGPp4uSr7c88hTVNAkGZ5rfOV54Vf+6YG8yu9JyHc+hZiM8j4k3Yci6H9vR6LoY/F0P/C8SMBT/c7/gUw6V9rQ4QQxEmDVrtNrzfrBOysrsXE07HTdLJG1yBTNcQO9a1AQbcCjLFYYerLNdL6rI4vqbLuNVVWp5LirgSlizwjS8ekowiTjwkFtOOATiOkLAv6wreJNS6oEtYgrEEXuVenF5ixo6SPxyMn2OjRWKkCRBCCVAhhESaHYghmjDVDTLGOtAYrE6xKnPh3tg65KxM06RBblJCW2BKsF4A0xmlDWeOtgKfOYa1jE5X+2qx3rgJkEE0QXB/4GyswIsQogQlDgriNStqEcZMgjLwSfhUWuOlXUauDICCKQuI48cKNkBcaITSW0nXRqzNNzmG6LE61SLygmdGgDbnVjAawsd5CCUGv2yEKFGEU0Wp3mJubZ7RjJ3v23Ie1hrW1tc2LpEbdJ4DXA03o+i3CI2LefE4jvNWrH8xQHq3HkezCKntTZ9LcqzbtVSYgmzjiddPnvf+5H+iomAHuX+mdpBO7E1LWTlNKgfRZEWG901QBMopQAcjAIBx3HmMhyzOCwBIgCFTs15YrCxVArIe0hJvzS7MtVtcta+WkrfF0pu1IfP3BHeWPEFD4Qd4873yQX89/Q5XpNdZQGrDCtbPfNtfmxMUW3YYiCdz1OIgXlPSZ4LpLpEVg6rKNUtu6OxGVdauct5h+bpsD2SNuffPg+DdXYK37UfxQc8C95UHDhiM+zm5+nTVg5f26d9Sr1FrfAclMHHjtMM3U2p7cy08SiHzC8bs447TTue3W7zMYDGkmCaUH6MMgpNSlYy5oDQiCIKxLHYwxxKETEC/95k8IwThN0V57xFjr2pRLWW8CpfAlMHnuQCegmSRc8KQncfzxJ3D6WWdxzjnnsHPHDgCGgwHra2v80z/9E+ecey6nnHIKWMuNN95IWRbccustFGXBJz/5SR7xiEewZcsWLr300lrvSQjB1VdfDcBXvvIVtm7bxnOf+1yUUnz729/m29/+NmeccQZnn302AO12m/YpDoxaWVnhk5/8JDCZjzMzXZ71zGdyzjlns2VxEYArr7ySMs94xE89hOHaYUYbK8g84vs3XMeXPr/A6r57yKKAq7+ZsNofIYRgrtfj0PIK/cGAPE3pddrMdNsM04KZ4RCpFMM0Zzjos3fvXsZZRrKxwTXXXM2ee+5GZ2Nuv+0W1jfWSRoNTj7pZKRStNptVlZWOHjwINZa1tbWUEpx9llncfbZ57jxO+IYDAZcdtll9AcDsrzk3Ic8FGE148EGV1xxBfv27Zu8+AGmdrfb5aQTT0RIyX179nDLLbdw2Rcu49RTT+Gcc87mzDPOIM9zvvCFL/iNJOzYsYOTTz4ZIQRPfvKTkVJy+eWXe1F7N9/KsiTNcpfc8gBCWWrCSLBlaQsrK8tsbKS0kpisKBmlKUopgjRlbX0DKV0Jz3CcMk5zirKk3e2ipCLLc/LSgZ69bgdrcdqaP/aq+n94COqGLVU8Afg4DZzuZGW3POdF2LqzHDABp0wl3GsRihqIqP8OhGFIo5Ew1+vSSByw0fcdqgajMWmWuy5l0w6ByZe7LMeWl9XfPNAlldMpQjhAYpxmtZ1JwpAwUDSTiLL0gtrSlekpKV35pZgIj4NrWqOkmsTw9v5T125yULaOx7Rnayhz/7LECpSqKh2c6K5j4yjlyvfqjsUe2HOf4DrmBUoy23ad/3qtBo1IEUiwusDqEqypY17lOwtifPc75XYoZak9K8h1iJKomk1lfcxb3Xc9VTy7qGKtbQKe7CRmttVcsROHOO2LnU1188tYgy5L0tGQ/vo6UZwwtzAiyzJn27XrVDc/v8BMbxaEYNDv12wa5dll2leDVBpi9YbUTpUtao2Cmgk7iSf9M/NAVKXxdLSX2VXHsRj6WAx9LIauXzx1Sz+8J/7xgKcf4Zi++X/JwAghmOn1mJubZ2nLEjYbovMxWZoyHg8Zj/oIo1HCIITTQ6o+o6qhnNb81xUlThu0ZzyV2iCF9lkmuUl4zX1ZjLYYSvI0ZTToEwhL1mkQJg16jZjFTgOMpj9QDiH1gJO7FoE1JRgFuqQYj8mCkPFwRFEWzsEpiZIxUlpImsgscA6iGGH1AKs3oNhwQYEqEEHDZRDG7vO0ztCjPsZIMCHYJmgBZY4tckyRYzVOJNw7dKzB6Lym+FpdAA5NDaIYMCBB6BBjQVsoZYgOQqwKUM1ZwvYMcbNDWOk7+QUvBE4LQFhX8hFHCCkoS+OAL6EoSo3wrVmFtq7jgPXBgakWus9kmdJ1UTGlqz8tYVhkrChJmWe0223mZmfotFu0Oh2kFDQaDQ7u34eSko2NDa+9VUHEU65gE3gkHhhBspu/ObKMZNNLfgKOB3aY04Zj6rUPfIYfGkx+sPLZyfcSqRRKhcThpCsKUrgWy0ISTAmUldYglCKIE1RoIbDYIEQL160yTUfEsSYRrsxTSUUQJOjYYmRAkG/QNBuEBJyxcxd3BpJ+mrnuHVK6so0jrnviWJyTP1LQ8X5j+YPGw5/wftmMqvOE1hjtNvXGGHKtyYwkCGNOPXEL52xvctaWBEmGkI7uHIErL5aAlFgVIFWIkAJJ6catNKRZSZa5Vqr4DNn9bvJ+d3W/yOEBbmrzHx8sW7mZmv7g5/9BH1WVV1hA+Gz4REbAPxMxOc/mtsyTbOyDfdgP5eyPguOCn/kZfve3/zsvuvBCRqMR87MzLK+tU2rNTKfD2vo6B5eXme20ieOYdrvNgUOHMcYQBorti4soKblzz75as2B1Y4OZToe52Rlm/AY3K0qaSUQjDhBC0R8Ma4AqSRLmej3e+hd/wckPAIq02m3WNzb4vde9jpe+9KU86tGPBgtFUbCx0Wdj4/t8//vf53P/9Dne+9738nNPeQoXXvjrrK2t12VC1fEHf/AHPPKRj+TrX/86v/Ebv8ErL3olRhsuuugiXv+Hf+g2ebaaA3Dbbbfxghe8wAMhgBD83qtfzV++4+31Oa21vOY1r2G4vsJfX/ynbOuGPPKckxHGcN03ruTKf/p7jptrszHO+PsvfIWl+R6hUtyc53WbaisEqxt94oMhW3bsZFxaDq1tsLa64jrQioCkGQKWD37oQywuLPCo8x7Cxz76YRqtFvOLW3jZb/wmQRCwZetWlg8fZjgcev0jaDaavOOd76yv98iYaf/+/bzwhS9kPB4z0+tx04038uhHnMeLXvirPO5xj6s3qw90VBvBoigIowhdlgw21nnTn/4Jp516Gtdeey1JHLO6tsbZZ5/N/v37682hNRahBL/zO7/Dzz/t5zn/Ea7bnkQ4NktRcHB5mZlWEykdYDkYjpFScPppp/Gd66/j3j172bl1K2mWY1kHXbKxvs6h5RUWFxZpt9rcdvdux/hQiqX5edb6ffYePEgcx3TbbU7YuZ179uxlbaP/r1xJ/16H2BSwTwMHWDDoupzMvwBjXQkEOPaTUgqBoERPWtvryQYmDIN6Q9Fut5jrzbBr2xJ5npGmmWM7pSlpmtWscylcuZu/DKoyncJYlHDMppqtBcRRSBAGDrQpHHg1Go3rzm1xr0scBDS6rvQsywus0U5bKhCIjpsfRhv649SXDFqSyDM2JulBz3By16U9Q0ZOze3Sd2GzgCjKSSc5nC3Lja1BM9dExnVVy/Lc7QWkIPfdOY0x9fhLKUnikGYccsKWWbrNhE4jIlECUxQMNvpEgRM5d5qmIWEUEUaxq5bQJUo5Jlqa56S+XNQYC8rvUiqwwVoCJabTokipiGNfUWAdq8yaqlJguixwkqitKxrsVLc7JvGH8SVVWpesrRzGYun2Zp1ER55RpkM67TbbFhZYXV0hikIG/X79HJRSTrepKOj3N2pAUuuy+hB/TYDWPjFdEQJcWXY1zmXp9LyEEORl4Zh9Rzn4dCyGPhZDH4uhH/jDfpQY+l/R1e5fBo6ODJSOvKAj9R+mjzAMabTabNu+g16vR5mNsXmGzgvGwz4mT4mEQYUCayTWODqy8A5aW4cEVp1W8SV2xjoAqlBVqZ1CekRPCYnwdPBmIyE2kDQsaeZoegIosoyxtPTXItqdLq1Oh4V2hLIN8rTFfl0w0pZS4DJBSvmWqk6wrLAWtEbnGaZ0lFilFAECJWNs1EBEDUQUw8iALV23O1v6DEGBNSNsKdCZdoylMkcUGcIGYBOstphSoLMUWxYIY1AopC8/xJSYsqQwUJrcC5s7kbhAScIQAhMRmACTCgptSQtNWkIpQmwUoeIGUdIiSRpEYUQgpXNmWFwLYDdeQaBIcPpPWOdwhHBtWfEZoFJrKJ3AudEOdHJAk683NqX78uLxAEZrxv0N0CUH9zeQuHFsxIlv5xpy5jkPodXpsLK6wvraOnme+TlXzUMx9f/JpuWB0KfJ3J2AVkeur6PcVx51R8X0i+IGgQoJg7j+m7EGowHhsxXWoeylLqGU5EYz1+qi4gCVWLIsJSsN/VFGQzsYMZQhxgugOjFLSRnNUKZjyrIkMgfZ0gxQu7Zy2z0HKPKcNE3vp1MDPgjflKHw//NZWiEm2UdjnH6EEJs3DtUbhVS1gReeSi+t66ApwpCgPUuzO0PUaNGcXWK20aAbSU6MNuiI1JXuRgmBignCCBNGlEFILhsoGaNEQCg0OhtT5hmisJR5wWCYMuxvkI+GxIH6fzJfNyXQ/43OJ4SdtFDh/k5201PbFPxMyhJ+ktfql770Jb721a/y4pe+jDvu3I0xGqUCojBEKccIkVKSRCGD0Rg7HGGBIAiJY0UzDtl/eIXCax0s9GZoNxssb/QpipL9Bw7RbjUptaY/GLE410OJkP2HD1cPAGMsT3zSz/Jrv/YiFpeW7g/GW8ub/+Iv+MxnPsPG+hqXfOQjfP1rX8Nay6FDhyaBunVrvchz2u02n/rUp/nwhz/MX73//W4zPvV188038+QnP5lbbrnFMUOASy65hGuvvZb3v//9fP/73+eP//iP+Yu/+AvOOvMsLrvssvpaLHDVVVfxs09+Mo84+1TyomTf4WW2tENUe4l3vfNd3HHvfRxeWWNcONYyxnD3WoqxlqTRYDBKUVLQiIK6cMFKiS41I21YO7CP1QP7KErjdCgt5KWmESqUEKyNUjbWN7j33vsYa0sUKNpRwGt33+UAvhDSOGD70vG85W0Xc8YZZ9Su6HOf+xxvfvObecc73lGXuUHFhgh52ctexK/+6q+ysLAAOADh4osvJghcaPe6172OZz/nOfyPV76KtZVlAgEf+MAHOOecc4iiqF4QFeB3zz338LSnPY3f/M3f5ClPeUr9eWVZ8vKXv5wLLriAN77xjQghOPGkE/n85z/Pu971Lj75iU8wznKnwaiU2/T6RmCuZG/Mt679NmVRsG3LEnv2HwDhdIpWNgYIIWk2G6ytr4G1NLx4vFKK3fftcaLFnp2Htew/eIjV9T6j1HVQ/C//5b/w7Gc/+996yf2bHxPxbw+GCFGzWcDW+hpCOPaYcQiCYwJ5pkPhOyhPur7ZOlsN7lkFQUC73eK4HduY680QRRFrG32WVzfYGAwpy7IWZK902hwbw2+MRcV4sl402k51qXKHUopWs0k6lo4xk47AuljTGIOKIzrNBlIKsixnMBxhfGzXSqKa2Z6V2jGCSo212f1Epo2d6nKXT9qqWz/BxGSiUeSuTKQq17NeDFdJCUgvfu3WaKk1Rhu0ABkExGFE0mzR6/WI45hGkpAEkASCxdgSeTmPigkFgkZnhjiOSZpNojhCBQEGTWFKB7YVmuFwyHAwwJSla2KkJtdfzYMwkAT+GRhrCQMHfGldUpbWAzXFRL9rOlb1976ZKTeZb9V41qwo//vRsA/WsOfuyFUvKIUunK5dluccf/wJtJotVlZWSccjjNZEUejnSUlZlNWH+G53AJIgcABlVVYXho51K7yuVcWCqplO/j9Xznf0d7U7Go5jMfSxGPpfc76jJYb+ERhPE9dWG6+pC3V0s6lXP0CW7l86hBAEYUS706HZbpEkMaZIMWWJKQtMmSOsJlICbSRWWoyedHLwPhoqszyJhZ2QqnFldM7Ji0kbUwnKukxUECgCoQiRCOnAEe1rycuyJMvGJHGELWMaYUKRRPSaDfrDkUNZyxKkQqqq/a2jI2sNwrrWqpXzdZWVvrRPBYgKbWWyNoWnWls02BxrJKa02HICyAgrnfMtnai2LfN6USopagYXXrXeag06r8GtAIUQAQqNsgXSFBSloxfmuaa0Adorr0ulXJe6QE3ELNFTz9BduJISAvdM48iJKBpticLQU5wdHV9TZW20DxR0/VVtAlzHvQnSqoucIpWMBn1Gow6tcYtGHKGCkCixLCxtIU3HzM8vkKUpZZljdLWKp6iqR8zu6pvJ99NA0w+P5v6kHP9eLI8qm6hk4EpNpcKtX4M1E2p8FfS6tVdgEI7pZ9qARAUKmxeUBrJCI2VJmBc0Yx9Qew03oUIELURhkTpFlmNaQRuiBod6XQaDEcP+GpWxrbIzm655kn91WUk5cYrSB4za+PXqXla/U0ydowrohfSy+kIgg4Co06E1v0RvcRuNdpfZ+SXmA0OHnNnRGNKUMjOEscQK13XCygCrAowMHXgOSO0aH5h0jLANTKnJ88xlM8uCJFSIze5l0/FvMScmGMREIPfHO7ynqVM0P5pfqRzmv3Qd/07L4Yc+Tti1iy9lGdd861u0mk2iKNz0/KY3s5VGiJjKOANkhcvahWGIVNJvGhSFdb+v2pG7cm0L0gUclT+1/pxBGAGC1dVV7rzzTowxNJtNzjzzTIaDAWurq8RxzN69e9m9e/fmZNNU4HDXXXdx880385jHPIY777yT71x3HTfddJMr7/LvMcYwGAzYsWMHO3w53759+7jyyiv51re+xfe+9z2uvPJK1tbW6D6kywUXXMBdd93F8vIyURCwvrrMt675Z8RgmbwsObC8ymknHY8MFbfdcSeH1wcM0ozCWEKliAJF6du+SCXRfqNvja3lFQKlXFmRdpomZakZpRlh4DZOuQHtgSfXTrxgKEaOfYFlw2pWRhkqDOm0mowGQ+IwYH5hnpXVFQ4eOkSz2eTaa6/lyi9/mX5/wuy54447+O53v4uxhhNPPJGf/umfRkrJ4cOH2b17N2eddVbdUe+cs89mdm6ORz7qUaweOojE8vjHP74GqjaV7QCj0YivfOUrPPShD2VxcdGxmXzZfJqmHDhwgG9+85tEUUSz2eRnfuZn+Ie//3vP2jE1c7kCPxpJQpplFIXTdWokDUIvNl4nAH0nQNepzm1gs4w6fiq8OHNle40xvkRPEocRZTmu2X1H+6FNVQpS+Q23JqpW8w8W1Tt/4Y5aVBrqNSLqNVWV2ylarRbdTodWq0VRlozSjOHYCUFroyf2UEy/f6rLlP9VtXFlqhyssjVxHGG0Y6ZnKbUodwWkhWFAu5EQBY6ln2Y5hbcnYaBoxDGtpgNp0jT3shgumVgDc8Y4wFcIKhldN1TSiazjNGpstafy/lsCVljslNC28H+XgkkVgBAkSYNWu0Nvfp6tW7bRbDZoNxNCSpQtCdM1hM4RusB65o8MFHHSoNFs0Gh3aiH2PEsxhWuCZIWiLHLKovCAkBd7qPdQ1r9v0hnalbSJGpiptJGMt8kOGHR+sGJ2iXp8Ns2aOtaFKs62blysdWCBkAw21kkaTaI4donpPCfLUjrtDt2ZGWbnZjl0oCAtS6yvbKjWpfV+2TWycE3VpYfnsRP7Uo//1M71fkLiP4Fx9rEY+lgMfSyGnn7dD3e+H57xVCNgk2zE5qB38+s3UwI3//3BAKkgDOl0uxx3wok04hhhHEOozEboPCXAEAQCZIhRBqMlxjhxPm18BsMHh1pMhtZYgbZeZNw7IY0gVJJAug4h0t9RGIaEYUSYtGiXlqLQjEYjjHbZhvF4TBQGxFFAq5sw04xhaQGNYH04Qqp1tBUYBFFYATQK7TtXGOPAJ10WlHmGRIN1XeukDJFBA6EChAmQ1us/2RIrNFYPMaRQBhgbYAkgaIGRUIAtRthCYwqNEC5j6HSbvLK/LtCmpNQF6BSJJhIGKUMCLLHUSFtAMWI0LEgLzTAvyYMmNm6ikjZSWA+muVp9pZyxmLgQHyz4oNEoZ7yEkAQq8PR6l5WrasSxthYVN2XhSxQ1GFc/jw88BLjOg2WBEZbR2irrcYySLlsaKIUKQrZs304YRQwHfcoiR5cFeTaunZ9Uqm5RWy2oWlsKv8Gwxrlz88ArSdT/4yeGRvGDmIb/rw43/hMthKrrhMv+GSwlRVltYMq6u6E2LiM6ygoWZ5q0Y0WcNBnnGVYIxhVV3loazRZx4JggYaj8c24TBE3ydMzG8n20opJeW9B46NnsPbjMTTfdhDAagalLSCvKvmtUYOpOPwLpekYYyLWm0WwShhEgKfOCIs8pdIYQFiUFCm8AdUEQKteO2kps4FiEM8ftYmnnCZx01sPYtusMOs0mPZkj7r6W4uCd3HdonaIsMUYSSTd3QSJkgFARKkwIKAn0GDteQ49GlGlO0NqOLQsGwwFZnlKWBda6zFjt8qen94NNi2lUdioYeMDXVQ6TCjT4AQmICtg9Yn5UL7dTn7uZcTt1Bf4HIUT9/bTWxfRHVV+bL8ce8e/Re/zR77+Gm26+BYDF+XmCQKHznI3caeF0Wq06ix+FATOdLnO9Ge66915G45w0SwnDkFazSa/bZv+hZe7de4BWs0EYBMy0W/RHY6JAsX2hx8ZojDGGpdkZ+qMx4zQD4B/+/jNc9oXPc+2113LzzTf70raSn/qp8/ja177GK37zN3n6057K777yd7n9jju5b8/e+h7qhJTfvP7Zn/85H/3Yx/jud7/Lr/7qr/Ks//gsHn7+w7nzrjtrQd2zzjqLr371q/VGxVrLn/zJn/Da176WF734RejSt+ieesCvf/3rueQjH2HXtkU6jYRzTz6OvQcOEoYRiwvz3HDLHUghOHHnNjLdJ80K5mY7xHFMFEVEuiTNC9ZGbswkUBYlqQGkYttsC126Tk5pWWCFImh1GA4GtabW+tDd68JMG2OdcKfOUwZZQX+c8eiTT2V2dpYwDMnGYw4fOsiLX/wiDh9eZnVtnYc89KGsra3VQEV1vPrVr+YTn/gExhivPTmk0Wrz93//97ziFa/g61//Ouedd557sRBs37adT370I7WAdAVKAbUmz5GaMBdffHHdibDVbrOwsMBHPvIR9u7Zw+Me9zi6vR5nn3MOX/z852twwiXYNMNxSlYUzPZ6nHD88Zjdd7O2scFgOCTLMsIgoNdxYvIG2LVjO2mWsXf/AU475SEkccJX//kblFoTxzFbFpcYjUesb6zT7bRdNzetOWHndrBw3c3f581vfjNvectbnGD3UXwMRyMPuDn9S1VtvoWLTbXWlP45BMo3nvExlzWGwrOUpP+5AkKldEBo6ePbOEnYtnUrM70egVLcvWcfyyvr9AfDSczjwatqXflGd55JJOrA3Vjjui/75J8U1HFbM0kIpCAOA7LxyMdyhjzPKaIQay3dVgNrE0IlObTWJx+OGIzGhGHI7EyH7kyX4Tjl0Mo6w5HrpBZ5jSgpJVle1ElZ69lUxhhCz/RMQlfSai1ozxgy1lBmmU9gVt2oIAzkpNNf5CQgpAxY2rKFpa3bOOnU0zj11NPotlu0I0naX2PcX+WOG69l3Nfk+Zh2q0mcNGi2O7RnejTbLbozM+h0SJmNGfRXycYFWV4i4wZlUVAWlc6eBXRdMhh6nSwpBIV27e6lVEglwLoudKauAJgwuMD7SimPdKCe5VRF5FNsEmuRFqx02+bCa+oNN1wDI4lr+jMcAtbSajbpdjucfc5D+Pb4GkbjEcPhiCgKCYMAvE0rjfaSFpaiLGvhdCUlaZaS53kdA0gp6xK7aXtujCY3GgqO6uNYDH0shj4WQ//4MfQPDTyFYTTJ+plKx8h6Vk59C5PvPEhlj7iYBxtAISXdmR4zs7P0ej2kLjBFDrpEWlfCFcYxWAVGUwqcrpJ2aKh21BlfVuf+dRnaiqYr0B5gQFhs4USybAABcgI8GAc4KBUQRhHWOieepSMnFm4NRakZpxlRswQV02om9Ga6yCCk8PoYhfaTxTOMKrTQGFOLpBfZGGlLMAWqKJyzlzEyaDlKbiCQJkHYEkFJJWdvkUgZYkWMInZC5VaDdoCNFAIVRhDEyLDp7t3gEFsjyLUBbVFYAuUyU0pYpNWYMkOXJcPBgDQvGeUlJilcSZspEJhJhsw/5kpRq54DTlG9pvhGoagnciOJMUZTFAVpmnokXlKWQCUk7rWd0JV4vAec/L8Sg9AlZT5m1F9HKUl3ZoZms0mz0UAKQavT5YSTTubgvj0oYVk/fKimYIsgcMZaSA86uUxk6QMDrUsvNmnqVrCbtUemF7AfjJ8A7Mn4wLHKOlX//b8AzkQVjHiWnMv6GSeCbwzWOtHNqpOhnRLShEm2zhhDlqWkWYRQPcIwJIoaRFHsGxAU9AcD0jQjCgPCKECpgDjpgExQUYBo9CitpRxuMNteItoyR6PxcJYPHCDPMpSUdVAbKEkQxQRxTBBM5m7c7qLCGBskNJKEMAgJpaDMU4pszHjUp8wyitRt5K3RpKN1l6VVkqA5Q9ieIez02HHqqSxt2cHxJ5xGQxcwPkh+73dZ33Mr49VDpAVIFRFGEhnEqDAhjBLiMCQKFA1poEzRxZhssEJZWLQWIBRaheggIoqdyCtS1HXdAFVphUssHJmlsli/lutSVVHZVf9jlQKnymNV3025ox+QBpmUBUzJ/rudbH0NiKlWwUJSJcoqQck6EzP1oVVPhanwgEkGuPrs6XGQD+7cj5Ljqq//M6vr6wCsrq/Vm9Ekjmm3WjSTiPX+kLwoSJKEUZoy3DsijmLCICQrCp+Z1qyubwCua1wUBJRlyTjL6LSaWGM5vD5wOoC4dul5Wbr25cDs3BzH7dyJEIJzzj6bi9/+dv7iLW9xYrFaE/ryirvvuZfV1bX73cf/+B//gziO+eM//uPaJ1ZHEAa84Q1vYDAYAPCnf/qn7N69m5e//OUIIZidneUP//AP62c1Go3q8rs3/emf8tcf+hAAt9x4HTsXZ4hDRZrnjNOUVhxRaMOeA4eYm50hVJJBv49UiqTZJM9ysqwEOaIbh16MVdEIXCY0LyRlnlOagv5w7FnYBUEYOo2bbETpO2klcYxSbk6lWe7Z1TBMc8Io4bjFJR56/qOZm+kwPHgv++/p0O/3WV9dodtKWJrtsOfeewiU5NQTjuPP/+zP6HS7SKX45re+WY/ZZz7z99xxx52oIOC2226b6kzmjg9f8lGuu/561pYP8+xnPYun/NzPIYTgK1/5Ch/60Iew1rJ375QQORMNqErvpiwK1lZXef3rX+90qLRmOBhw2y238LKXvYxvfetbwHS3Ibch7Q8G3HbnnURBwEJvhjTLGI7HDMdjGo2EoixJ04yiLNF+rh3wOk6zvRnCIERKxfrGOkop5ufm6ff7lAKaScyBQ4d9eRaAneh6HcVHnfDCug24rNg9EpRAe2YMuJikYqxIITBSOiZ7BRCBL3Ga7CKUlPRmZ5mfn2NxcZ5xmpFlGcurq4zHY9cEB8+swWnzWONSk7W20RGJZVedMWE+OtF4LyhvNFGgUEREYeDnnyHPS0ZjJxg/DgOUdMnYVqtNECVYu1rb9FaSeKApYH0wojSWJE5oNGICFTBKM4IoIYoTvy9zNr/V6RJGMUnScPo2ShGEEdZqdFmysbqMLnJMWVIWGVhD5OVZLIJRYQniBlHS5OSTTmTLli3s2rWLRhRiyowD9+wlH22QDfukwwFl4SQbrJAYITFCOU2rNKUIJeVog3w8ZLy2Ql64sqGk2SGKYsKkgQpjZFCgiwk4I4Xw+xVDmmsPPGnCMPB6XtLpzYopjkXli6nioioEdQnhih1X+8apZ1n5V2MMphL9ttaB6FnmShGtJVCSbDwijhPm5+dYWFqiKEtWDh+qr7uaL4Hv5FfNV/zcUlI6eRNTTPn5yR6wAt+qdVH7/qP4OBZDH4uhj8XQP34M/UMDT1EUU3V5o/QTezPnqfr4ByWhPSjo5NHxTrdLtztDs9GgGDqk37FdjBNMU6EHnkqE0RgpnUGeYhNZ8CQZW9eGVyidAbSfBMYat5C1e01FP63r5hGEUYSUrmuaFJBLgdUZWru2q0VRomREEIU0kgRtoZVmCJEhS02p8VkpQcUJEgJXt13k6KJA2xxhCo8US4SMEEEDhHXtbG2MQCNthvXlccYKEBFCxlgbIIXThMI6pyGlQkUhMkyQYcOVDWiDLUq0LSmNxWr3/Ixwi0FgwGq0hlwXpKMBaV6Q5yUIhVKRZyDZOmhxj7iCnDwTbtNc9/RaJTGBwZiAOI4odUmcR0RRgDElea5cFg0L1pchGl3rOkmBGwvhCMnSurp+W+Tk4yGjQDEcDlFBQKPZREpF0miwsGUrW7ZuQ2cpMk/dgpESoQIQ0hkV6xx/aWwttluJJ5a6RGZZvaHS2mAxR8DLm5Hio/lQSlF1J6jxdPv/JntTzY9p42SM9tZC14Ly1capWoP4K52G/PI8Jy9yF2iroGYpmjLDmIJ0nFIEOXkuicuIMEoI4hlQIUJYRNKhTIfoLKVnc5JWh/b8IqFUjEcj0JrEt3RXgSJqtolaHaK45YRSs5TOwhJh0kTFbad1phSxdIyGMhsz7K+TjYaMN9aJowCrSwb9FVeCICVxb5HG3BLNuSWOP+00FmYX2Da/Bb33FrKNfQz2fI+N/XsYDAbYsEMcKlQYIoMIFcYEUUIYKgIpCE1BUY7RxYhsPMIYhSV0wGoQohotkkYDrV3A66RbqTPa1gPytnYsE1uOEVXSHTAOtLcTUH8z+9VrT0xnUybRJtMLx97v95M31S63CqiFC7qqjkhKTPQqXNA+ceq2PnnVaWYaJK6+NjtShCs3q7pBHa3HMM2QUjLTaXnQ3g3QfK9HI46JwsBrF7p1lmYpw9GILfMLSKnIS+3aogP94ZggDEniGGEtuXXtx+MwpChLhmleByeZhZkZp2Vy8OBBup0OO4/byXg0YteuXfzai17ERz/2MdbX1zHW0h/0WV5e5tDhZYaj0f3u4xGPeAS9Xo+//uu/xhjD1q1bvSCuy4I/73nPqxk4H/rQh7jrrrv4whe+AEKwtLjIS1/60rr0rMgL1wktDLjsC5+vs3HHLc7S6zTRSPIiZ5zldJsJaalZ7w/YsjjnyvCGQ6SQrgQ8LSiNpjSWSLgNtrWu7EUCpZS1jcoLlxgzRYFUynVzG6cgnF6iUpLYxw2r49QF315HsjvT5cQTT2THjp3MtBIGxRpzszOsrG+wtvcgs50W87Mz3LNnP512m/neDF/4/OcYjBxrV3uGUhD+/+z9d7SlWV3nj792etI556a6Fbs60ZluQpNpkgQVRMH8FTOGQcDwNc3IoI4RnBEmCiM6OgroDCigGECQViQJDXSim246h0q3bjzhiTv8/tjPOVWN8/suZtBZ7Vq917pdXXXvrVvnOTt89vvzDoYbb7qJ62+4gRACxWDAkXPOYXd3l83NTdbX17n187fxoWv/hpuv/wxHjhzhyU95Cuvr63zhC1/gd3/3d/+Xe7846704fPjw4mf++V/8BV3b9s+95fTGBv/zHe9gUBQcOXKEEAJlWTLe28MHT900nNo4zdFDBynymIxU1c0i4rrrLGVVxaJYxNj7vfEeRmvyNEXKmNxb1TWDvCBPM/b2xvRVPONpSdP/e0a9pOzhPrTRZ3XKPd73ddJZ7Tv6i0Ssa2WPEp25OMRtK/QgxRnmthASqWF5ZZmV5WUGxYCNzS3GkwnTaTSuj546Z07T2E2PtaoWLM6G8EUXn/jPOnMxmUvAQvCRad7vPSEEnAs472jbjllZ0WmF1po0y0mzFJMKyrJaNPW0Uhgda0NlEqyHLC8YjYakiWFWRbDWpBnhrJpyaWWNNM1JiwFK6Qgg51mUCduOrZPHsW2Dsy1d04C3GNwCrJk6SVqMyIfLXHLZJayvrXLowH5me9tMZxU7Gyew9QzblHRNtPwgEBOolUYoE+vFrqUuPXY2oS1ntOUM5wVB6B4MMyRpTpJlmOahKWBSCZyLVhNunmxIQMMi0jwIERP5hED4CHrM06XmYOC8to3JXPNz/cx8esg4+/f95cg7i+16TykpcDaha1uMMQyHI1ZWVqjKivHONkYpjNHx5/Sj6xwIcF4uaj0pJdb1wUBnxbCrubQ2hB7Aimc7D7nkPjzHIzX0IzX0IzX0l19Df8nA08FD52K7lratqaoSa2N6RaSBnu0T8EW38v+PMX9UJkkoBgMedfGljIYDjPAIrfBB47qAUgaJ6qM8I+VUSY2zHa5roueE6uJmZx2di6Zqc+qx9XP99xln+H7Z4n0g0XNQSNJah6PDMmMkDEmakWUZgqhXr0qwQTBrLJQ12gqkVbR9rGiamNi9C4G2rghIkJI8H5AkikFmkL2pt7cWLzwhCIJM8LqIh0i2n+ArhKiRIkTGk62QrgLfInwAYfDC4DpPoEUQLxVBCqQqUPkQkQzAjCL7qnPQemznqa3ENx6NwwQXZW8KyrqmaR1V65hNdmn7Zyl1CqbAWxcnMmfiJEMIvWRUoFAxpW4+C/rFJWQEFhOjGY0KtI6Ho3MWrRS263Bt3FjiQujfY+LBpAQYEQGoyHyKvljBtrTlFO8c25unQQjyYkieJegkZbS8yqVXXMX+ffu4L02gByiD1HghcUFiQ/SZcoh+3rgY29y2dF1HU07pmtg1bOoqUuFdTGiZb+VSyN6c8+E9Dh86l7ZraJqKqikjs6t14M5sfnOw8J9ixAIpdrZ8cISm7u8QHtsX2z5who4r5aKjpEScW0YJqq5j2jQ4G+N6M6VZHuS0TcA2Ha6t8FZilUKmKUIlNGaINAMQGq1TuvE2rdti4+7bGK3t48BFj2bf1Y/HCRPTwtYPMRguEYLAJRk+zVnedwBjYmd3OMyjGagLVFVJ1zS0TYnARzN/YaLPQzVDEItE7wPT6Zi2a9HLq6zsO8jKvoNkeQGzLco7P8X0M++m3D7FZikYN45GZBjhCRKQClOsoooBDEZ4W2FtSb17kraeYF1LIKG1nsZ12Najl/dz0f4rKGcVOxvHmWxtkOYDdJKgVBIZot7T2Mjy67xdrHElFVJEmrVUfWEoiP4gPfXf2xgMYF0XQwK8pydFIs46DD1zwW+/Z8i+4WDMopjSUvTPLrIaJWD6jqpUCpUmRM8BhbV+wVKM/nEuJvNYG/+89+U5e+6d/SsASvXx7SlZVmCSlIfzuOWWW7jluo/zsQ/8Gb/xB+9mY2sH7z2z2Yy2bUmShKWlJdb37ePeBx5ASsnKaMisnC460gfWDiClZGdvQpokGK3Y3N4lS1MO7NtH08V01pWlIbOywjlPahS/+Iu/wFd91Vfz1Kc+laWlJY4eOcK73v1urrrqMXzrt37LAnxXSvEf//N/5u1vexvl/wJ0Avje7/1envjEJ3LDDTcsZC/D0WgBdnzx/vOYxzyGD37wgwghOHHiBM973vPY3t5efH5tacjl5x/l1PYOXe/BMC5r7tvYYVAUpEazNCg4ub0HQrA8GnD7XfdjtOL8I4dwTYNwjkNrK6AUTkhObGwtzgC9tkKWaAqjCEWOC4HlYUFdCargmdTdwgg6UZGFdmprl9EgJ9E6XsD77v5XP+vJPOZxj+OZX/F8/uwdb+dEU/GUpz6BZz7z6Vx46RX86Z/8GSc2trjj3mM86bGX07Qtx06cZGVlhSwvOLWxAUCSplx85WPZOnWS7Y2TdF3HN33jN/If/+N/5KUvfSkrKyu8973v5edf+xq+9Zu+kac//Wm84x3v4HO33MJ/++3f/gfvydlrZc6mWlpe5tprr8VozYP3388P/It/wR133rn4+qIYcM0zn8n3fs938zUvfCF7u7u89W1v4+f/zb+ZbxVIITi9s8v2Xlz9wzxjdWlI5xxWCowxdG1LkWecc/Qg9xw7wfbumDxN+vh4GA1y2q7l/mPH2Le6jPee3cmELM1IkoTt3T1e/apX87KXffv/6dL6vzbOOXI0Mt7bJloNWEvTtme1bedm2qEH3uKFJbK54p4cZaWR3SR7k2trLUmakuc5F190MUli2N7b4+SpU0yn09jodH6RVLSQ5fSX6HlTWUqBVroPgxGLc1gS+u+NoI21Dms7bNuS5ilSyQWjHClIdGwmtk0LwRAQJAiMSZFas7qyzN54zN54wmy7ZXk45JzDBzh4+CjCpJjhCuvr64xGI7I0paxbZlWDVHLh55UWA7SJKXJV3dL1KWpaBrQIHD2wRnDRrkFJGT1Omxlt02C9xyUjBkurDJfXOHRgHzhLOxtz8t47mGydYrpxf2xweocMEfgJUpLkQwYra+w7eJjgWsqm4vi9x9BdiXItiYSuL5AtGlMss36k4JxpS7Gzw+bGqdgkkFFp0VmPdQ6ZxjuEEII8SzE6AjzWRuAmWxhOQNerL3wICPqayllcfyc7m0X6ENuT/vdnwo90fE+txYZ45upgMBK6pqbu78CHDx9mNFqiq2fkiSFLDJ2LTdqm7Wg6i1t4BLreDN2CiDJQcNGudQ5eQu+ZF2VXWZ7HwKI+Ge3hOh6poR+poR+poc8a/4c19JcMPK3vP9hLxGpmswldFw3obL/RWDvfcFyfcsbZkNyZh/XFm6CU5EXB2to6g0FBmhikj8aUgYBKTZSdMTc4DYu/V/YvGnqNe4AgOoJwKB9w/Sp0ISwYUHO0+AxLReC8QIX4U4TQBARdF+V0zkcKsg8hLmKpI0PGgWg6pJdgobWBzvWmisEhgkP5mDKkhKZIIU0leapIjcQoiej//dH4W4EUeAEyWcI7FQ3JcQihog9VEIABIuvJexYdhRBCBHSIdGORJGAMXhscHuElSEVAYn2g6zwuOBoslY6oresN5pouGqBDr8MWiiAUUZwnFohs3PzmErQzzKewQHfp0dcQCxqhSENMM8mto8gLQgjRnLVtCN7iW4kIEoJE9ZpgJUDJOfNpsXZjZ6vrsAiqyYQyyylHMxKtEEoipGJpZRVJYLp5mtC1EdySBofEcTbwBNZHentjLV1vCFmXBW1dU1cVZTmN1Oq51ref7/8c2E4AB/cfoukaqrpiVs2iiWRd0XXtQl4476SJ/j0+s17/d1+jeMh3LaiZPQrvnVtg1Ivu3WKfmCP+frHtihDTL7SSUfrTWtrOogUkWpAZjfSSzimEiWsgHQ5JixE6LVBZRug76NEnQeCCovESJjP8vXeyfsmIZGkfat8BSHJqL7BIZuMZs2aXzb2SvMhZGo2YTnuKbprFTrJ18Zl5h/ctopuigiMlyptE8ChfMzIVVnlErigyTW40vmvpJrtUp+6lrFsqL+mEjiEFhFjwCg1SI3QCKsGplFYapFDYsBkDA2yHUAWtrZk1HaKzpMs5R4+cx+Tiy1laWuJ0niOljp0PlSwO88ZZrPN0rmc1ipgQqZRBKoVJzOIyEjv1Dt/7tNmui14zVdnHaTeRlbjo4dDv4QtiekywUZIiz9BKo6UiMfGyEjvvof9/geoPTWEMQWg8EuvAhUDXH5wxsrulaRts19HVFV3b9Z5HfWwzZ4pxFsW3Ji8GDIZLZNkZ75uH43jzm9/MuQfXueb5L+Stf/E3jGcVidYL7x5nLZNpnxCW53TWRkl4YtBSoIBpWSGFYDgYIERMF82zlDRJSIxir656VkRcd4cOHeS7v/t7eOpTn8bSaIQQgtOnN7jhxhtJs5wvfOEL3HXXndx3332srK4C8JznfAXD4ZDJZMp1113Hxz/+cQAuv+wyvr5PHjt69CgrKysIIZhOp/yX3/gNHv+4x/HUpz6V3/3d32VnZweA+++/n67rePOb34yUkvF4zNbWFk0T/aYSHS/iW3sTbN9cGpc1eZoyLBRb4xlKFQySHD8tI4vExS67D4GdvfEiZGRcNQsgrGlaCJ4iMcyqmrZTrBUpLsTGU9tFD6iybqMPYz+fup5inSZJbHq5Buc9o0HB8tKQC88/l0GieeCOWzmwbwUhlvEIikQzSBW70xll3WBdL0PrmbcxvTBK1sqmwQfY2jjJU570RB571ZV473niE5/IaDikqiqOHz/O61//egC2trbw3rN+4BDnnHcB//W//lecc/yrn/kZ3vr7v8/Jkyf/l/NNEJlES6MRSZLwQz/0Q3zquuv4n//zfwJxDe9bW2NlZYWl5WUArrnmGn7qJ3+St73tbWxubgLwqKOHKfKcB06ciqnBxjDe2saHQJGluN6XaG86QwpBlphY/3UdLniU1lgXPUpmZUWSGPbt20dZVrQ94+lT112HdZZff9yv/6OuuX/scd4FF1KVM6aTSUyTahomkyh7JcR6zocALjZ0hYwt6znDfM7I93Omio8daaUkg6JgbX0dk0RW+c7OLnXdLICLh0gv+i79mRGBJRcE4OL+3dfIi/KuZ1sFwhlrghAwPRCxNMipe2nfGYgk+jWlaUqRZzRdS1dXNE1NcA4loKpbZrJibzxl/cgq+XBEvrwCQlLVTc+kq5mVFbI39U8SA1ItQA7fX9QiGyHaRmg8Ukbz7iRJECFglcPqPjluuMRgaUQxzNGuoZyM2Tp1gr3Nk9STXZSY+2xJGmMI1uEDKBMZE8okNF1HawNVB6kX6CDABZrOUVqPrVpENmRtfYWLvGB3d4+iKAg+qhOU1ri+KVA30WPHOUdiYjqYUhIfesuKJIuyTClj0z/ExrntYr1aTsc0VRVNpBe13Jm5AnOwUvbG/zlpYhgWefS7VRIlIE0NmRIE12FbqIGkGDIaDTl0+Aiyr8u1SWitpWpaQES5cVXFQJ+uo+4T0Jx1NG0TLTJCWCTXhQBpkqKNIc0yVlZXGfbebw/X8UgN/UgN/UgNfWZC/p/W0F8y8LR//+G+U1OTTQrapqaqyz41rKOpa7qupbMdlmhatzD8PLufM+fC9wtJSclgMGTf/v0UWUaiJb6zKKMIEoJPFwyXmM8b3wYhBF7FuF0EyE6fRS3s0C4CKUL4heeT9aAUvZ5dxX+AFPggIpYoVC/DUlgfqJsW50NEC2Vk7qAUzvoIMrWW0AW87HBBxq6yjYlswlu0b0mkIlWB5QTSTJBlisLE5BwpFdJEeprwjiAVSIlPl/CtwPoOQosM8kzChzQE3+BCTNyL/giWQKQsa2kgTfHGELShUzr6AkgHQi0mXNs5rLeYYDEyUjYXsbb93yekRAqNVwb6yRrmwBKceY/7U18QkSGx2C3nO2VA9dTblLD4vrbtgEBdVdimBm9xtep11AHZJwApiN8vQPafm1OJfehN3ydj0ixnOp0yHAx6HatguLxCYgyzQ1vYcoZrm8XCc0g6euBJRADSB+h6+rS1HU05pKkrqnKGmSS0TUNdTmmbGtd7B4SwICg+rMfhQ0eom5ZZXUWzvKainE2YzfZ6zXcd2Ys9Q1AIQJ4FFi8Os/k4+zdnrWse+jWynxtnzNzPKoLPogQvttm+oyP8nDDaI/39oWmdp2ktTdNhUk1iBHmqUUGjvEKplHQwZLRvPybJQaV4k2L74sjbDu8CLiisMDTTkp3TG4wOnEc+GJGvrDMtG5ppTSsVm1tbbJ7eAm0YjUYcOLCfLBFkacK+fftIlImbvpZRftPM8NMtUuHJEoHRGhU60mY7vl5pCHo/UloEHZOyotndoDx1L5UV1KKgUwKUjzJaAKER0iCkJkiDlQarEkAhRE4SJNIH0IbWlkyrmqzrWMlyDp5zLs10j+XVNZIkpWs6vPMooSJQjKBxDusdrY3FoZASYzJMmqK0JsuzCPQrhQi9D5rtqKqKpmmYjSeMxzs0dUlVTsD7KJVdMCADivjz4uUyGleujgoyk5KYeHlRUkSQJMx9RwTKKISMlGcbFDZIrJc4ApZ+vTofvXyqGW1T00zG1FVFUzc0bfSSi03ovmnRd/aNSciLIcPRMsXg4Z2K9drXvpYf/uEf5iXf/P+wtn6A8XhKkUbGR9u1eGeZzGZY5zl6+CCTacleNSHLsv4CBZPpDCEEa6trVFVJ27bkeU6iFLq/0FjnUP1aPnToED/9L/8lxhg2erbN6dOb7O7uLdbze9/7XpRSHOplWS960Yt4/vOfz/bWNm/+r29eAE9XPeYx/Mqv/MpDOsMAk8mE1//a63n5976cR19xBW94wxu4++575ocMUkp+9Vd/Nc49osxL9OdLlhiC95zc3qEoCryHnUnJJStLrAwKHtzYosgzlNYEEQ2cbYjpdT54tvfGjIqcxGh26hYjBVpC07akRjHIEjb2ZggpGGXRw7ELUDUtZd1SNi2Z7M2KtaapmwjYFAllVdNZS6IE+1ZGXHDuYc479whdU3Pb9Z/i0kdfQZbnzJoOIyGVnp29KW0XE98ms9mCvaCCx2jNaN8qW7tjZlXFxrEHefIP/gA/8ZM/CcS5PZvN8M5x991389rXvnbxnJXWnHPueVxy2aN5/S/9HC99yUt4wxvewF9/8INsbGw8xB8pAEbryPQWgmIwIC8K/t8f/3E+9KEP8ad/+qc0TQTp1lZWMDqylrqu44lPfCJPe9rT+NsPf5i98R7BOS4+7yjra6vM6hqjNUII2s5htGKQ55H9ZC1be2OMUlGWJ2QEFEL0QBIyzrVpWbGkNAf27+f4yVPUbXQjvvbaD3HttR/i13/94Q08Xfioixjv7bG9tUnT1syms+irIyIDZC6hnft2LHKgIuaDd75v9sXLpuhBCa0Vw9GIAwcOoFSUu2xv79D0VgHRu7Tfi8MZOYUgHuvAAqAIsACe5ibVZ1c3IdADJPH9SRPDcJCzMhoyEUSbBHHmu9LEUOQpgyJntrXDZDrDtTXeWbSMsh8fAmpHs//oBeTFgKWl5SgRnM0wSjErK6azEm0MdZFDCCRZE2VsSYZKMpQ2SK0Q3kZbCtug8GRSkqk0Au1e4UWMQx8t5xTDhCxX7O6NKXc2OH3sXvY2T+LammEaWfqCGHzkkAgfkDpB9nYNrfM0NtB6hQwacAQXKBvHtLPosmaUr7C+/yCjlXUm0yl5XlCWM6ztyNN0UfdMy5qu6xZg6vx+opRBa8NotBQlSVrT2a5nqQWqckZZztjq3x/ZSlz/ee8dwfbzKwi0jnemJEkYFDlZlrE8LNAyXla1il+TGIG3HZ2PDY18OCJJCw6fcy5tU+G6juFwGIGnusWkGdY5JpMJ0+mEpq5R00ncF9oW6xxBxvug1mpR/mV5TpqkZGnGysoq+/q0zYfreKSGfqSGfqSG/vJr6C8ZeFpZXes3OstotBIZT20dASfbUlcldV3Rtk3cVLuWrmvo2vYMC6pfJ/M1KKVitLTE+vo6R845B+laEIosH8SN03V0Llmg91JE/wopBFKZiIzaBCE1zrS9f0+N7NrYuRGWAHSR+oQLMZIXqdBJSpqYqFdW8eBWxpAXS2hjUDpl7g4fvO1Ny33PCIofoSsJQkbASKjFJiBtTRoaCjVjmCYsFSmrI48eBFTu0akkSTTaJOg0Q2kVkUTbEWyNa2d41+LbGltvI7yNpoEICB7bTrG2pbNtBIl6urRUBiEjqu2Di+brvu3tn3y/IQmC0jgRJ9+scTjvSGpBYhRKxW6wTrMo5RMpwQxBF6AS6CMn6YHA4CN6Sy+pW+hZkQu0FgJCKpQUIHS/kUagTiuFd5HKnGiFcDYWJV0Llpi2EfoFGAIhuDP62BDweIL0VOUEtZegsozlpWWEiEkrQkh0mrHvnKNMt05T7e0Sgozvm9AYFVFxtCbMkxZ6artzjrapaJuGpiojxbOuqWZT6umUtqmYzcY0bTRIfbiPw4eO0FpL3XW01vYG7yV7u5tUVclkNo6m9230ROi6lrbrsLZdsBUFZzT8/39HDxLOF3oETeOn5oaH8FCwbm4QLAAvfM+oi4fm2X+XED1I2nZs7U5I14aMRhkHH/UoqtmEyXiX05sbtOUue+2YLMsxSUYx3Edoozy42tymcyA8VNbStJ6y8hyZTElnU1ak5bobP80dd91DJ/o5QWC2tUmaZqyurhOyBJWm5CtrXHXFYzj3yFGOrC3HuOUwQ27cgmj3CH6GF1OCnWKn95IW52PyA8jZJuH0EJ/k2M3jdGVDV7Z0Zkjna5rxcdqQ4IMm0RqpEpTO6JoSupow2QKdIZUhHV1IWDpCsBWzU/dReUEXBEk2QOcDhoOCK664ivrCi7josis5dt+9bG+dZuPB+5mnTWo9iN0hqfriVJOYlCRLF15ASql+H4qd+bZtqaqSpqnZ29sjLTLK2ZRymkcw2nt8sD17JgY2SBnZnqt5yiAzHFodUGQpWZKSaLMwXY1WagKCIOgIyDuR4BC4IGjoPfuEwPtoYlpbS12XdG1DW04ppzOqqmRvbzsepE2NbeuFZESJaBIZKd4NWpt/tLX2TzGEELz97W/nAx/4AK969Y+xNx7z7nf9MY897wJs13H9TTeSpSlSwMmN00gpGQ0L6jr62ymlWF9dQSnJTu/HFOh9eVxsOqwuDbHWsjOZEgLcceddfPt3ficbJ0+ytbXFbDbj5S9/OT/90z+NQNDZjqqqKYqCwaBAKcXP//zP8853vhOEYLdnLs3HP4zQjqbQdVnxlre8hT/6o3eyub3D0toaaVawt3WaKy6/jHe+851IKTm9cYrv+eavp24bdJKyb20FIWIhfWpzm7puEELx4MYOp5Mp5x0+yKxuuPfYSVITm02tjUCHSRLOOXqI7e0dpuMpS4OCum1pOsuRw4eYlhV3ntjgyP4VpJDce3Kbg/tWGRYpG9t7LA8KDq6tcPv9x3DOY1SMevc+cGxaYpRkkCU8+bLzeMLjruDKyy/mthuuByEYDIfs7ewwHo+p64o0H6BE4PxzDtJ2HcF5tnbHaKXIszQyym1H10kGg4zhIGc6q/jt33rLwlA9Ps7AsWPHHvKIs6Lgic94Lp+//QvcfOP1vPtd7+K6667j6quvpshTLjj/XO66+95+ksVm4E/+5E/yAz/wA6ytri5S7wCe/vSnc+ONN/KqV72KG2+8kf371/jsZ6/juk9/ij965x/x9V//9fzcz/0c73rXu/iba6/llT/0Cj71uds4cvgw3/O9388nP/1pbr/jTn7oVT/MAw8+yPU3XM9qmlDXNRsnT/aX0sDe3h66N6lvmobgA1macuSccxFCcOr0Jj/5U/+S0dIyr/yhf/HPwlgcYHVtlaLIWVpeRipJVVUc2NjAGINzjtMbG0wmY8oyFv/zYJOubWPilHeLpppUut+7FVkxYH19nUOHDrO9tcnu7i51XdE07cIOIzKnOMsWIyoO5p5B82bh2ZfbmJv3RYa5QmCdp7XxHNbasDQaMUg0O7t7bG1tc+L0NsH3a8JZFB6jBMu5JgmaXRcI1tMFj/CWuox+UIfP3SXLclaWlzl9/H6OnzjJiRMnqap4qZdSRUlhMcCkGdokZMWAy664kqPnnsvhSy+hLSdUe1MeuPN2ZDtjIJqYZg1IEVgqErIsgZ0HqXrAanc8pW5a0qYh0zBrAw+e3GKQpxitaazv7w2apqnZ2TrNZHcHZzuU1qwf2I/xHaGr2TzesddFCe7Awr58wNFzz6MYDKnqhpW1fWxsbDAe77G3vY110VcuHQxJAhTBY11AKkWS5Swtr1AUBavLy/ECrhRNbwTedZbpZEJVliyvrLK3s0k5nbC7dZqua7CdJTG9IXbPUEiThJXlJfbvW2M4yFkuoqm0CNEsfg4qTqoGFwRSJ0z2dsmKAUfPOz/W/cFTV1XkQAjZM+XgcM9KrauKqpzSlCV1VbHTG727rkOIKNWs6prRoE8zE5KyrPCbWzycxyM19CM19CM19JdfQ3/JwFN8MRIhDEmaIrVCaoXWBussxiSkWU7bNpgkpWsbui5e2K3tzbR7WmxcgLEQXlpephgU0bXetYQgkTqmxPggsH13JTgfYxWlQAuxYCyJEFDGxILJObSPhDBtHSbQM5ZiUp3z0ZRQSoXSJrraJ4ZUK4ySmN4I0OhoGC57SpxrLS6c2ZDnH9Z1CKmQGoSKBDgZHEZYtLRkxjIykqVEM9AepTxChkj/FX7B/hK9DjT0QJczGUHqSH9rSoRtUH3sI708wtouPlPf68I5owZdONV7T+i11fGZK6ROMGlOl7X4VuJaSzvXlQpBKjVK9tG1woBICdJEiqKIz26eehP6gsXPGU8+Lo+4aXrOrlZEOJOKonqqb2IMPnXkeU7bFBA8XZ1jRURhA73JuCcm9vXUYs7q+HlE/Pltr7suS+q2wSQJqTEgJVJp8sGIZjalLmd0VUMg+mEJZSIoZhLEnEbKmZhpo9UicUUKaJOURGkSEenX3kXW1kN7gg/PkSRJNMXUBtObEKZZFmNv64o0LyKQ3DbU/WZY1XVMdPRRVhgWBuvzg/PsX1n8Xsp52kcseM7utp7960PGosvb/3ZBMxUPebpzvxrr+0NZCtI0i7JMJZnOJr0M2BLSuCZUL65UwZGZCIJ2SjCdlbgQcEIxK2eU0zGqnTLUgWGqeHBzJ+qYlaQpJ9C1VMaAy6FpmbWW2fllZIlojUoypBsgtUS2HTR7+LCLsGN8uYPWq0hdINsxvt3DhQ6/dQJ8ihAreOvxXY1vmxgOKQJSJAgCwVtsM4uXde8Q2qCTAnQKSUqQilblWGPxWYoerKKyAVoJRBo7IULqGPnuHVunT/U+Cz0luP8wOhrFmiRGy2tjyLKYMBRTc2LhqFU8PoQQkSFSxgty1yT0mw7Bx+6ORGCMRElJqjVLuWGUJ6wOU/IsI0sSEp30VGTZr+/IRnV9ipATvUQ2xFQOL6N82AeJ95D6aGjZ2ZYuy8iynKoskUrQ1BVNVdLMZlgXqcyRMu4je3c2wbuHP3i8/8ABrr76ai659FIefPABnHdcdsWjUUpx822f5+D+/SwvjTi9uU1ZTimn0zPScgRt1yFt7FrOjSad82RJgi403kcAKvi4+qqq4tZbb2VrcxPbdbz4xS/mWc96FhdddBGhB43atuWTn/wkm5ubCCFwznHllVfygQ98YGH+/MVje3ubD33oQ4QQqKqKr/mar+GWW27htttv52te/LUsr6yQpBnTvV0uOP88Lr74Yq7/7Ge57dZb8QEOrO/j8KEDjGcVTdfhu47lYU6WGLbHsz4lqsX2Ka+pVosEqSghimKg+e+lEJHBamPkdGdjsqpWkrazi0uCDx7Xd/lTrUiUpOuj0hUqJuEFMFpx4cEV9i8PWC5SsB3T3V2Ct7H4FB6pTdyPKTFJgnGCuo0ymfklMYTovThnrLm2i3WGlOg+VGNre4embbjgggt44hOfyM7OzkKKCFAUBV/5/OfyNx/8ANd/+g5uuukmbrnlFu6++26+93u+m7quufue+x5ymVlbW+Occ87hL//yff2FX/KVX/mVrKyscNFFF/GVL3gB559/Ho95zGO4/oYbufGmm7jjzjsWc+Dcc8/l8VdfzTd+0zcjpCRJEnZ3d1laXuHiSy/DIVhaXePRj3kck/GYuipJswzbtjR1zWQyJUtT8ixFKkVdN7Rdx4F9+3DeM97bpW461rOCb/qmb+bGG67n7rvv/qdcev9oQ2lDVtAnP8X9NQSixMI6srygaWrK2SQ2cNuW6TQyZNqu6y8hcczNbEejEcPRiKIo2DztF14h8eMsA2p6w1jOqljm53ZfQC44F4LF184ldnPFQfQUcrSd7f2oJKPl5d6jjZhO13W9T2cMg/G2RQtPogVGCloRa1QRYn3fOc9sOmE2HdDVM6R3aBEZPdPplFlZoZTCpCmddaSDgNJRTtxUJXgXwxJsS5ckJGmK72bYcopra0TwGAnWZzibYoXDimg/UU1LGuvjR1nSlBV1WSKDxxqDFxLRqyWaqqQTopcTxrRtb0fIxCC0QhZLCKcQtAyWlhmMlsiLAVleIJRmaXmFuu0ICCa7e3gb1QtKJSitou+pcwipSPIck8aL6/wNE0KQZinaBbSJ9xIhJZ1taZsK7yxpmvSMhK5//+N7lxhNlqUsjwYsjwqGecYw0xA8IkS1hrXRGD7WHJ7WdlBXBKFik9okfVBClAF6BGHeGO9tSRKTkKUpTTGga2JjoqnLPh2wo22bhSLG2Q7nA1MhqM/atx6O45Ea+pEa+pEa+suvob9k4Mn5aG6IiLRTqWOSRZJlsQC1o17Pa6nqkq6Nsrxystcvwhl1Uy30yELEuMWDhw5H74gQJWNSx7QIT0PnA3XnsV1k72ilMAqCkRjZp/foPi9OSvSc26gUaQgx9hRInY+SO2LXQiqDSVLyYkiR5xRZghICJQJGK7TRJElEDoN3VF21OByib8MZSZpUilRKjO6lYD6QSUcmO5ZUxzATjBJJoS1CWYKM5Lb5Jh/6JD6pDXgVNbTpEKfTaPg1G0M7i5rSbITQpvfUijS90HsMiX7j930BEZwjCIun69FM4utOJbkwoAxdXdLsOep2hvQepSARGm0yhE7xwuBDQpAJQUaARuvYZYv+Ao652fuZIqbvmM3fnzlrLAphkfO4VyH65JoIHAVnMUoSrKUpJa2S2MoTbAc2JqV4HxaGbHPAy4VIsupqCTpBZmNmZYkxCYOiiFRDLRksLVNOJ4jplNn2TuwEyIS0pzFHllvU4J69nzubxu5FmpFqjW1b2qygTFLqchbN3sU/D+BJaoXRCumjJ0kAXIBhMaLrWqqmpmki7bOcjanqktlsxmRvl7ataZoZdV3i+wjrCERHMHLuBxELXIGWkc4+/zln0iLn0oEzoOTiAH0Ijbj/HDFKGCEXOKbr16ETke4eZZiK4WiZpZUVJrM9JuMZe3sl2oxiZ1RrrA8YYG1lldYGmtZyensnXhZNwu7ODpkxmNlpLj60zDBVHN/YwOMQQiNwCCwiWDTgXMfe5iwWU7bDJBppRpDmuNE+lJ8gyoZgp7iuxFlQ3iJoUK7CTU/STY7jJjuE9CBqeQmqbfysxNd1pKZrjyqWIruzLenqmK7jumi0GvIBJBr0PrxMqNMV2rCEzSTp+nmkS2tIBb7xGCFYHgyo9u8HKTh24kGaqqZr+2KyN2o1SqGUxGiN6f1WjNHxMO07J9oFjI4yJwJUaU2SptH0UStEiJ10nEKGKBXKNBglyI1gLZMs5ZL1gSHNNEmqMTrtgW2NI567zgWaEH0CHAaHwtF742mDTJIIIofIVGxti3WWrqnjIVnXFMOCpqxoZjNmuzvUdclktktV93LatqGpy2j++DAeIQRe9MIX8sY3vpGTG1vs7u5Ql1Oe8/wXsLK6xp/82Xu56nFXc9lll3P/vfdy+223cvPNN5L3kqkQAtu7exFQ71NsjI4S9fXVFQ6u7+P6Wz7PrK4Xu1nXdTz4wAN47zmw/wBvetObWV/fx9wfSghBURS8/vWv59prrwXgt37rt/jRH/1RrrzySuq6/gevAeCuu+7iZS97Gd57zjnnHG655Rbe8pa38Gv/9tf49X/7azzqUY/6B6//v/+33+Z//MHbkVrxhKuv4nlPfyLv+cCHmcxKJpMpl5x/DgC33v0A0yqyUHfHU5aKggMrK+xOxlgRL0dBxzNoNp1GP4Q0oaoq2t5wc3t7By0F66OczUk0SV8b5jhrmVrLtKxwXUM1mdB2tu/8xUh0pRQHV4d85dUXc8mRfdx870lOHT/O6RMnOP+cQyRGIoKlWFpFGoPvSobLK1jTcPL0Fkoq8jxnbalgMqs4tbnDgf3rKCmom4q2T/LL84zhcMBoOGRjc5MXvOAF/MZvvImnPe1pfOYzn1k8t7WVFX76R17JbGuDD1/7QX74h3+YEKIv0Kte9Wp2dnd5xzv/6Mx71IfFTCcTXvmqV3Ly5EmUUlx33XU8/vGPRwjBT/zET8S/Q2s+/olP8r6/fF88j88yNX7sYx/LW9/2dnb3xtx515381I/9ME++5lk8+Zpn8+fv+ysuuPACXvqNX8HH//6T1OWMIpFsnDjJ1uZptnZ2WF0asjwaIFTC5tY2e+MJFxw9h7ptufvee7juM9djg+Stb30rr/3Xr+G3f/stX/4i+yceTdPGmjGNdXNeDDhy9FwmkyllVcULTO8ztrt9mrq/yG1ubVNVFbPZLFor9HWQtRGg2Ld/P6urawyGg56l7xdsqRD8wg9Vxk9Gp45FoROB17nkTvQXXSF6Bl8Iizkxv9iKPgW4qmvazhIQrK3vYzgasrK8xHQyoyxLbNdgpADv6KoZIjgSKUi0pKI3TfexweisY3drk0TC/pUhRSLZv7LE3VLgraWpKpSODHUXQJgMpKQqpwTXoYWnyDMkDuc6Dhw6Qr3pmU1OoZsx0nUYJYAMZxMsMbW5baJPUe0C006wO6mo6pZ6NiNYi0kMJsuh3++6qqQ354hpW13GzCTkBw+R5EPydUFmJrRlzeGj57F+8BDFcIiQGuUDw9FSDO1RmhPHj2Hrhrq15Ek0X88HA5y1IAQ6iRdJax27e7tkiSFNEwaDIdLEO5gPAak11lqq6QTbNmR5jjHmIfVy8I4iTRgWBQf3rbC2VJCnCamCCE3Eur5tWwQBJaD1nrptaB00nWcwHrO8vEKaDRhmeUz1c54kzfumuCUEsFkHgV7y5zBaM93bYef0KSa7O5RlGS0yqroHXC1hPP6/vRz/t8cjNfQjNfQjNfSXX0N/ycBTXVf9JI5skCjb6heOlKRZQdpP6qFfxvXASFNXdG0TdcizSZTizaYxbjhN2X/wEMJbpns7DEYrKJMhVYJUKVKFaALWdrTWU1ax85cYTZGm6F7LKIQEqVHaLPTrxjmcB+sCxkSTRqFB6RSlDYPhiNFgQJ5lDLI0OsETsLbBO0tddbGv4x1tXUUDwBA340QppBEkwqG1JE8kaSbi4g2QWI/xjtxZNPHQdrZCdinSNoS2ApMTnO1liJ4utHHDCR7nBTYIOi/pmo7Q1CgRUEIiQ07stajeUN33G0rvv9SDTo4OJwRBRRd7ZZJo5IckRTJoatq6ZJJkNOPNqKkVHTaYaC4nNV3vgRSEirTBLOsXkcS7jsi26ze5RVdd9mi9j0aIQvTyihi3KvsNUwkZjeSV6FHdaBgpQqA0ikor6uCxrexNLEVfAEX3fR88nXWRwikEQjqE7VBNw2Q2RSdJNEXVmr5+ohgt4Zzj1PHjvfdBTSENSQCSlIQYR6yk7NMgQAmDEgIjZdwok45OGQyQaEnTTLB9IfhwH7P2LO+1vrOCUHgRkEaRyBSdGnLvGI5Gi/Sd2WxG1zXUdUk13aNtasrpmLaXGFrrCEH0BatkboQqY+xCX9/GYjecRfc/e5w5Q8VZBXE/wrzHGueO8yGa+NkG9AiRZOyUDbrpMAoGgxWMLsiLhq6pmU0n7G5vxpCBACEoms5SNR1VOaXt4ppryhmTnU3uu+NzrB04zEUHCh573kGOb25zamcHnRh0mqOT2DF0AabTCtV3hSUeXIdvKlS6jNAF3jWY4OP6TUCGXXzT0mxt4hxYIFm9EOc0du8Y9e4enfUkWU4iIxCqupKuc7TBYtspGkciAkujIblKKKioto9Rd4Gy9XR6iBgsUQyXKPKCTClmhH6v6RgNMpTez2VXPIbTG6fZ3t4hJmtGpqPo2+HWOWhtb2Ab5Uyqk0gVWTK2s8zqirIsmU6mlNMJ9WyMrUtEcEgfMAQUkQWadoHEwyAIssbE11d1wIAQCkIS8FITpKbtuqg57xwzB22A1kuEjAkr6XAZ2QPGUpseWBFkPsN7R9fmNGlGW1ekWmGbDls3TPIB09kecsvh/B6ujjJw7x2i+ydaeP+II3hHW5X8+3/3a7TO8zM/94t88AN/Rds2/Pob/j3TWcX27pjjn/oUF172aJ771V/LbbfcSFvNUMFy2x13sbO7R9fWVFVFGWBY5Ozsjdnc2aFsGp7+9Gv4hV/4BV7zmtcwHo9585vejNKK6XTK937v9/DSl76UV7ziFSjVB3X0630uJZizbb94fPjDH+Z5z3seEH2d5nvA5uYmX/u1X8tznvMc3vXH7+LQwYOLz/34j/84N990E4nR3HXXnQilOHpoPxtbO7z/w3/PobUlCqO4xzuauiZPDU+/6lF89vb7eWBjC+scbdOyN5n2zIyYsDqrGnyIMkPnov/NUqIwIvaGJ7OqL/6jKTvA7qxm5APGKJaHOd45Gh84//zzuOiyK3jas57L5RddQJEo2vEmN3/8Wm645x6WBtFLJc9zLnj0VTH+PcnQzS7T2YSNvZqye5DJdEZuYrR8nqpFWg7AUp4QQuD0Zs15R89hOBhEENFFBnmRZ1x/3XX8xI+8mgfuv/8hz302m/He9/4Zj7nyCv7Tr/8av/irr+cZz3wmP/7jP8Gll12GtZZrr72Wruu4//77eeUrX8lb3vIW/vRP/3SRHui95wd/8Ad57nOfy7/7d/9uUWAKIfihH/ohXvziFxO857PXX8+LXvQi3vSmN3HhhRfivef1r/sVvnDHnfzsL/4KN9x0M5+9/rO89CVfx2RW8rlbP8+oKCjSlLrrWD1wiPVDR3j+i76OWz77Se75wudZWlqOBrG25e+v+1QEt5zjczdcx91fuJW/+eBfcPdddzErHwpyPhzHrKwWbLUkSajqmllZLgr/pZWVPmXOUYxWYuR3VrC07wC26yhnswWTYm93J7JY0pRHPepilleWKYoBSmno2X1zj7AQQKtAkPFMlkBYMNfj+frFF9kQeoll/3m/ADGiYsE5GdMcXWRVtX0wTd1ZVpeHDDKFbZJ4ZtuO8U4Zg1uso24trY0eT0HGGgQck709tICdfSusrK0zGAw459CBCIh0HdKkFKNlVtcPko+WCN4zbUu8s7RNtPnomhpnW/LUIBODVwKdaESIbA6kwLsY205nUbZDB4/oHK5s8WWDsJ5BakhThdSS1nbxtfchDlIKjNGsFSPyNJCJina8ST017E4bEIbl5SXW9h8gH4yoWst0HEMRyrIizTIOZAVZmnDy1Ck2Tm8yrVtMmpJkBcH3FhohYNsWS38rJNbaJulASFwI7O3uMptN2T69QTnZo21rlFQE6fuQIB8j441hdalgWOQs55rcCBIZjcLlfB/3Mf0rU2BEoPaWum5xdYuoahxRbZIXA8aTXdI0oxiNcNYjpWCQ5xHYdAmDQbFIBnU2GskbpRgUBZPxOAYjWdd73Vi63t7i4TweqaEfqaEfqaG//Br6SwaerLMPOYAiSiKRMvo2CCkXiQv0FNqYPpFiu44kyTBJQtPUGBMRwCRNSLMUW8cYTqVNTIzQBm1i+pnWKZ3qEMLhfNtvxl2MldUSkNFua876kQqpouP83MgrHsQgkCiTok0SqWnpPM1HI/AQPLYL/SbYRfDMO1x3xuxPCo2RoLWM0ZRakhtITZ+85kETUC4ilDEK10YaoXMI56J7fg9WzGNsFxL7EHotv4hG4GHegeyi3MzZ3tgw+iSFXjIwp1CHvjvlRVhsNMgIJBmTo6RGS4NKcpRJ6Zoa3zVYAsGW+CAj/dKBFXFRR2RUY5KkN1oXuN65f244Nn/+9J4AUsafraRcdM/jxhglHkIRPZ9QOGNiVx5oixrnYkpT19TRX0K1vSdTZLC50JvF91K70D835SMY1XbdIvVjTlMlCHSSkhUDpNb4uqFuG1RTE6TCtJGFp0OIdOkQQEYBoxSAlCRa4wLIxOESg7dmIcOLsbQP79HYdmF8OOfVC6EWZNwgAkKJfo5okjQl8zlpnmM7G2nDeaRMp8ZQViV1E33eznREOatYPSMJ+OJxRipwpnOz8J2Yn6Ahymbnn4vvRjz4fAgxrheBUJqq88i2RYYOHWIaTZZqqllMV5lWZT8BBXgVkxycI0sTpAq0NgK2bVMx2dtmdXWFIs84emCdznbMypJGROqs0VGi5H0fcuB9LKBsC02Fr6ZImYBKCUIjdIZUoKRDag3YmLAocoQeoNIRsurw9R7eVhAUSZYiVQJC4Wygc5bONtimJhEeoyGRnkR6VGhppiWzqqMJCldoRLYU91OpF8b8rt+XjdEMpGD/+n6s9bTWM5tGvzofOJNb4X3cr+Kbgu0LbkE8UNuuYzqbUlcVs9k0JnI0Nd62/d7n0dKjhSPBkhBIQ/wwXqGcgS7tIziiVwRSE4Skrlta65g1HTMnaHz8UDpH6QyZDhCJRyPQSvbF2vwi1bMtg0cBwnu87nA6JXQNIVim0/g+NrKfX2f5Jjycx8mTp7juuut48NhxsmJAYhKatqVtWgaDgrLuCCEwXFpmdW2d/QcOsbu7zWy8SzPd4dDhI+SDEac3Tp1lOjw3laxxzrO2tsYzn/EMnvrUpzKZTHj2c56NUnLxs/fv388Tn/BEHvu4x5JnGSE8FGS65557uP6GG3DOcfjwYY4ePQpEed2HP/zhxdfN13nTNHz0Yx/lGddcwzOuuQalNdvb29x5553cfMP13HTjDbSdJcszisEArRRlWVHXNeesX0SiVfRmqio6G9lH+1ZG2ADbexO8c9Rty8rSCAh0nV2ksLVNTZFmGJOyNioWe4RTJhr9VjMSKfDBUzctK4OM1ChmrccGAVLz+MddxWVXPpYnPfXprKWgXEMlYzDJZFazsjSMndAsFtxZXjAYjRjf+wDNeJdqNiU3MspdmEuiItsMYJj3MgECxphF8t6czUKISVGnT5/m4x/7GL43La562UoIAWsd5593HpdfchFplqG1Ic9zpJSsrq7y7Gc/m66z3HfffTzlKU/hrrvuWpjCz8dnPvMZ1tbW+ou3om5qPve5z3HOOefwrGc9CwHs7O5SVTEZcXd3l9tuu40bbriBB48dxzofJQd5HiVTWpGlKZXtMIlhdX0/e9ubSCE47/wL2Dh2PzunT7G0tIy1lm2zzXQ2jabWPrCztcnm6Q1uueVzZ7EBHt7jTApbb0UQ4nwMPSNBLaQXEmUMiRBobTBGEbynW+mix2RdYbSJbJIkYWV1lSzPkUpHuYrSPWOpP4uDj6z30PvF8FDGxNm6uzOSuljLLUgWYd54jjVR6GvVechN3bSUZc1kOkOKmDipMdRNS9dZyllJ07kIMPRnu5KKYjBAJQ7VRKaN7Vqq2YzllVWMzlheWmJW1VRNi5c6GlKnafQHJVp2QDyT6rrGtTW2DyBQSpJohfIGiUQqheNMfaEISAlWghYhmvgLj9ACmUa5nlCKro2x57GZ3kQAi4CRgVQGdGiZTfconWRcWkwxIk9zlE5gnoTdJ7wJohRNJwlpYmidp7aeanObgMA6i+7Tr7x3ERjvfVStdXTSLkzorXNMxrtMp1Omkz26usJ1va9Xn0alCBglyIyiSBOK1JAahZH9nYUzCVhRNBRjhIKPoFDbtFgkdA4hx5RlGX1Nuy4maAuJVBEkkVKQJhEkT4zpZxQ0ISzWvu8abNeSpWm8TyzqPf+wb+A+UkM/UkM/UkN/+TX0l3xb7rpuQeGLEfL0G46OLu0yuqYrKTFaLRgwPh/gvWNgLUttjNlsqhlJmmCMivQ35/BCkBaj6IifD9DK0CUdUii0SjCmiqbPXUvddbhQxcIlMaRaooVEaY0IEYoQSiOVR2tPkvRsIGlIshyTJAyHQ/LEkBhNokR06Hc2srPqmvFsxqwscbaD4CMlNTExAUL1nlBCY7QkyyRJErXsWIeQHjqPtT4ypTpJaB1aeUI0rUL6KP1zzhHoYG4A6R2ubgk24GWOlSlBanANKjgIDimi7E2EqM0OELWs/cbtgseJgJcQhELqFJ0UqHyJoAxBpSTO07UNQfRxsZMMO96kDQ7XBoR3OCmwIpDrBJ3m5MMh2miECDT1rO/M9QBNz7oSUi2oo8q5PhI2yuviwRRQKnbMpJQIJaOPgxCYxPRgkQCpsLbv6jiPsJbQ9oZs84IniBiTGQQiCKQPaGfjRaxHe9OemucC6CSjGAlGq2s0XUe1vYWXirRrCRBN9IzBJLqPnY3dcRHiwaxFQMmA0gKrBc5IUmNIjaE1D29jYoDxbAphcQwxnzjxlz7NpjfHy0xOkkaGW2SlxY2lrSrapmUy3mM63aMsJ4x3N+nqOprP1W1E8vuC6YxnREx64Iv2pS8+MOOfnfU/Pdjd/4t7RmOM1q7rEhcgyITaNpR729S7p1lbHmKUQOGZ7G0xKSsmrV9o5m0XSLKULM+5/Oj5tDawu1sxGW9ju5ZpOWN3ZwuB5PFXXcXqvv2srB7j1PYu1sV8kKqsqH3Aa03VNkynY6bbCbLcIcx2ECZF6RGqOIhK92NULHJpt8HO8L5GqzWCXsVbSe1qXDONBbtJyVf2oZMBAcXW3pim9FRdDS6CtgjHIBHkyuGbKVunj7O5u4fzHn3gQpIk7oX9rQOpJYrIPFRSYHTC0SMHY8z1YMTtd9xF17aUTUOqdT/3+2TNtoOq6ju+nrYPjajbhrJPwJjt7dHOxngb9ylJLOAHsiOVnlQ7cuVIpKdQjiSA9ho6FffLYPG2pQshSh5mFWXTsTtrmTlDFxQtGp0OMNkAlwwopAZjkcag9VmeCKEHjEOkPGdS47oOm8TwBoJlOh2QTWeLWGHv+9jph/n4oz/+Y/7kT/+Un37tL1POpvzCz/0M//K1v8C+fev83M++losuuYzzLngUX/N138gD99/DJ//+I5x30RV0wXDT57/A87/iORRFzt98+O8YZgkqeD76sb+L8oq+k+qcoyxL3viGN6L7WG9nO2zv1/SHf/iHvOc97+H666/n4osvjvv0WWynX/u3vxZl397zqle9ite97nU453jXu97Ft3/7t8cX0u//c89HAggp0SZ23q699lpe9u3fzouefjVf8cSr+NgNt3DuuecwWlri7jvuoEgNK6MBg9GIo8OcJ1x6Lu/7xE08eHKTu+55kOd9xTW86Og5/Plf/x2buxMmZcVTHns5e9OSW++6l+c99/lkRcEX7ryNSy6/igOHj1KsHWIwKBgOCi665BJOnzzGzdd9HCkEtqnZPX2Kw0spqZbceGyPdPUQKweO8mPf/c2sLA0RAv7Nj3wf993xedZXlwltQ6HAOU9pA10TOHX/3Rzav8Lh/CC33XYLm5tbdG3gwHnPxO8/QNU5Wt/vMU3D6iDnogsOc9/GHgHBxecdZXs8YXtnB7yLbGcpEVKzO5mwsbnJxecdpbOWW++6F4DhcMg3fMNLydKU3b090izjL/7iL/jzP/9zPvGJT3D11VcDYIzmoosexd/+7d/yr/7Vv+KNb3wj0DeepOi9LR3lbEaW59xzzz085znP4Zd/6Zf40R/9UZQxfOM3fiNf//VfTwiBD3zgA7zkJS/h0ssupxgM+O7v+DZ++Md/iu/4zu/mF//Nz/GExz+eb/6mb+K//OZvsba2ynd+yzfwvve/n/sffJB7772b1X37edLTnoOk4/Ofv5U77r6LQwcOUFYVd9/3QJQswEPkfQ/3IaWMF462pSzL6MOjDePJOIKm2jAYDGOiYAgURUGe5ygpSNOUpaUlmqqkbRrGe3s0dUUInrX9B6JJf92QDUYUw5Isj9LQjrCQ1gB9gzjWY5HZHQEw1zNs/ENkdb09sRDxaz0EHAGB9xHQLOua8WQKwbO1tc3G6dOsj1IyLciUZLeqmMxqTu/Nor1ECCRao9OUJMu55Pwj+BD95Ka72+A9k50t8jzHOcehQwfJBiPW9h9ka2+KD5EZ4dsqms4nhgC0nWU83sM3FbaekrYNghAB1kRESwSTIPuwIi0cSaIxWGTtEaojhOiD5KVGDEaoJMULiZ80TMdjqqpmMisxSsVnE3z0vmlKNjbGbEwatuvAyoHD7JOGcdWiCsdAKJZGQ3zhovdVkiKUQS0vRRmMStmexPTk6XiPtfX9GGN68PCMLKuzFm8tk90d2rahqiq2traikXxVInsLj7YucV1HcJalQUaeGJaHGSuDjCJPyRONURLVp9mJ/rWEYHG+I9iWtol//3Q6wwlFEIq2bdnaPI1JEkZLywQhqJuW5eWl2DhuGkbDAUIIJpNJlHP5M55jEJvRiTEsDQZMx2Patj0TA/8wl7s/UkM/UkM/UkN/+TX0lww8iV4fOjeInlNzRf+meOfxKlI7fehR0XCG8aeUQqQZpjedU1oi8GxvHIMQMGmOMklPU5MkSYbWCVJIjEnJmhqlVFyYbY13HUIEbBAoD0iQSiNUQAYWwJOUDqUgCInUKUmakZgIOAkB3nVUXUfbNNQ94NS0HXXT4nykzikCUkm0DGTSkipPogSpFhglSTQYxVk6eUEQkqpVODReGpwqQBWg8uiuLzQ60ANPESmeI94+QBAaTIFIBwhfo7rI8orxtnL+gonokofgEKi4SUkDKiOonKBzgk4IyuDFmbjNIAQojcoGmMEy3oGtSlxX4WwDOIJS0U8ry0mLgiyPiUnetosI3BBYgE2iN/KOUju18BXQOhqqSSVRIXaKRE/3FiIuTmMiiysvih4Fl9i2Q8qYcuOCw0vVd9dFZIxZt0CXpVSxQED0kZaRRefTpJ+7IhqNa83a+gHqumJz4yR1GTXxwXu6LFuYnmsl479LyYWkU/bAYLAddDOwJcE1BN97bT3Mh+ofXex49Mw4F9MaA5GOv4j7FIogQShFsvBT04i8iEmMaUq+NKRtapaXV2KqQV1TVdHfra5q2rbG2o66jpHRzsX3S/T04flFdz7EnJ/6kD8DzhzziNi3RARB1cQLXWk9zXSPcrzNbHcLXINWMhqT1i1N6xiXFtXrq/MkhhFY26F0wvJgwL71nI1TD9LWJa3tmFQWkobZ9jazJsY251nKrKzZ3Zug04Qsybjg0AGGiUa4Dq01Mh1AAKcU+AYxPJcga4ICYVKoBtBNMcHiRYoXCU2zhw8dxhjW8gGkQ/TyMl4V2KBJnWTaWqpuRjvtcMYxFIG6bel8YG+rZG/nNPV0itCaUE4RsxnWxsJlbngs+85WiJsERklWRkOUVGxtbbGzu8fuzg62i8ahRoo+GdPRNg3eRR+OtmkiSN91dG0di0rbxC6tTtC+JSF2k1IlSBXk/WFpVCDVIZo1EnBdS0cZu7Oyit1f55hOGsrGMp51lD7BokHnMUxACMrZeNGZ97aNvnxGo3TP/nQxEUSGEEFkJRDKo7VA63imGJ1gVIsSMqZj/l9Zhf/n43d+53eAeGbcePPnadqWr/6al/LJj38UIeAFX/lCTm+e5p677uDOL9zOgUOHufzRj+Xmm64ny3Je+g3fxLH77mYynfD93/8D3HvXHWyeOsHjnvBkPv3pT/HRv/tbfv4XfoEnPelJDAaDvskQzcLf9/73c+ONN/GGN7xh0Uw4dOgQUsRI3bm3BPQM3f5pvu9972NjY4MQAvv27eM3f/M3+Q//4T9w++23L0Cn1dVVfuVXfoWnPOUpiyI6KwYcOvdCju1MEc4ihGR1eZn9+/exeewBhIgRwPc/cIwTMkp5Lrn0ci54lOP6z3yaL9z7IPef3OR5T3sCJ8c1J8YtT33ec1leXiLPMu5+cAOk5Cu+8ivJRyskecFoMOD4xhYnTm+zefwBtG95/OWX4L0jSVIOHDzExr23Mdnd5vCVT2HfwXNYP3CIWTnjc9dfx0f/+n2spIH9V11CnudsnN5iOi3ZnVZc9qgruOTKx1FPtrn/2AP89Uf/kieeO+LQoXV27z3JrANVDLjmOV/BfXffzcnjD3L4wD68ddxzcptxGdlLTWfJ85RBnmKbhqYv+hITPWeSJGFzZ4/OWqQQvPJVr+K5z30uSZLw7ve8hw996EP869f8az7xiU/w1re+9SGXFeciKKC1fggb5tnPfjbf9V3fxS//yq9E0ELFJuORI0f4zd/8TbY3T/Of/sMbeeWrf4TBcIiUko1TG+zu7CKV4lu/9Vs4fOgwP/mTP8E99z3AHXffy7d928vY293l3e/9M17w3OfQdR2/99a3sbyywv79B7nrnrsYJAmp1mxubGCk4NEXPYo77ruftm0599B+dsbTBavrn8tIEkNoAk3PRgF6n6bYOLV9UpaSMjKY+rk9WonG3bPZlMQkJKlA6hlZUSAEtG3Xd9Ulw9ES1lpmsxm6Nz2u6xprXS+9c730Q/Rm4GLhbbloLPfTQvb+Mmeazr1ZuepvwyKaC2/u7FJVJbs7u+ztjqE1JEaRJ5qdWUNZtZRNF+V7c+aU1KAdQkjyLGE4yCm0oG0a2j7lqbGOfHmd4WhEPlpGmk0m4zHbW5ukaUKSJKwsjxgWOWmS0HUWiUCZlEGRQqrwoiM0Uwgu+rv5qG5IhcP4Gu0ahK1RXpDkgqRQBK0hG+F0ihOatdTTOtie1OyWlkRFv6fdvRlNFY2yt/YqxmXHpPGIyQxZTCnrhpG1KCnIB4P+/bZYH/DEAIGl0RCPYOPUBjvBU8+m0fNGR2Zj3bTRkLuuUT0jqa0i66iqasqqigAFgUTF5n+epojEoERgKU/IU8MgS0iT2DSXhJhk50CInt3kPXVdU9Ytk7JmUtWUTRs9bYMniLg/TMZ75EXBoSPnxATUrU26tsGYqACYTadIEa1HPJ4QHMM8oxWeqgs4SZQwK7m4I9A/C/XFqacPs/FIDf1IDf1IDf3l19D/W8DTHDAIUWBKEH2h2R9W0SxbntUtOWsNCFBaIdBolUHwONfSVGX0H0oz5kkzIYSYrCYVIosghjEpBKhNiaoNbVPigyPgcHOpmVSgIjAWQSiPVA7pAaGinrF3nZdCEkKUwNm2pKxqyrJiXFZY6+l86NNnNErGN9mo+UTwZEqQqYjQGykxKgJZkYEj8ShabfDBgEwJKsfrAqdyULHbEQ90T/BRcx49pUJPlzOgM4SORt/CaYSYA0+if1YaIWL+25nnLCJ4pzNQOUGleJkQhCYgCULgCRF4kgqVZKh0gMotQmfRDNA1kUYqBVJqTJqRpCmJMQg8vmeG+TmwOJc4Son0IQJQ0qO8PxOffXYjQwiEd2fAICF66rIgS7OeWgxNET0brHO0tov6cmf7DpwCukX6EkpFIK7XL7u5hHFOPZ0/G6kYLi9TbA/QWlFPZ9i2iZ4FXRMN9IzGKIGWEq/Aq8hJ1v28984Suhmhq/G2wbuO4B/+iViqX5N+7sNyVqE59xOYc+qts0gXWWtBy4WuXBoTYU+TkGQpznbkWY5tYnxsXU2j18I0ero1TYX3Hb5x0Qtr0UU9a0JEYfuCNXH2iHvI/D2MgLbs6b6tE7Re0gZBW89oy1k0fCdS7JUI1K2lsZ6qi9JXEwRFJhfzxLrI6FtdW6NtZsymksl4h7LzhLol7O5Rty2BEE1fg6erZuQGCp2yvjpkmCqUCEhlUGlB1PwTX3d+AG+3ccKhVAG6RQQDoYPew6W1DS7EtKusyBFpAWlKK1J80JjUgjR0XjCrLMo52iRQNi20lu29+NxdV6NE2rNTuofKOvpnGOW58fkpIRlkMeJ1ZWWJpm3Y2Q40bYsEvBYxAtl11GXZ+/ZFzxw/L4JslD8LPLoHxrXwJEQjRiMFRkAiwPRpnkr2F49ATE0JdaRZI3vZgaUqO6rGUZWW2ndYNCol+pJIQVVNFzLaOfXZpToaf/Zdm8jljF07cAThkP3PV1KipULNQWnxDxqJD7vx8pe/HO8DXddy87/6GbyznH/Bo/ng+99LXVd887d8O3t7e0zGe9x//32YJOGyK66inIzJEsOFF17IsfvvwXvPZZddirctRmsuvfxKptMp9959J8961rO47LLLSNIUiB3sEydOcOutn+eOO+/kx37sxxgOh4QQ2NjYiF5N8JAUtbPHzTffzM033wzAi1/8NfzEj/0ob/393ydJEvbv348QgkOHDvGd3/mdjEYjQgicOnWKyWTK8uoa29uncE2FEJIiz1geDmICbs+Y2t7eAaCzjsseu4IxhvW1FW679zh11/E1z3oyw/0ZqzZh/egFHDl0kIvPO8qDf/5+rPVcdvmjqW0sLJeyhM3erLee7FFoGCSKRCkGwxGPuvBC7O4J6GYcueAoh46cw/71dW743K3cedvn+Pu/+QBfdc3jOLBvlTTLmJY1VWuxZUM+XGb/4aOc6Fq2S8eNdxzjCRdcRZaZaKo8a0gLeOKTnwIhMB2P2bdvH7OyYlxbdBKZPVXbsbQ0IM/S6IEYBNbHxFfRy++ndVxPSkke97jHcc011yCljPK5T3yCV7ziFTRNw4eu/RDGJDRNw+bmZmS1+4BJDIL4viileMpTnsJ3fdd38a53vYvV1VWU0uxsb9N2HS94wQt41x+9g89cdz2djWdgCIH77ruPra0tzjvvPB59xRWsr6/TdR0nT57knvvu4yuf80w+97nPcfsnPslXPe8r2Nsb897Pf54nPfFJjEajyMBxFhssbVOTKMn66iq33nkX1jnWloaUdQNCsL7/wD/94vtHGlopuj5cJfQFsvcRfJHzM8NZvNdRQhYiW0SrKOdpmwZj0rPsJCIbresiOzwgopSz61hdXcN1bS9FC7RtR9cJOhvVCzGqOyBFtKsIfWpwZKb0F1op5jSJ/nNnSxrj62i7KKPxXfSyKasSnCYxiiYxTKu293SK0l4BCClARfsJHzxKSoaDAuktdamoq5KqqrBBoAcrZEVGnhXMZjOa2YSumpKrnDSRrAxzijTaQHgf/y6tUpI8QWjwvqGbKrxtAbdIo5O+Rdj+bJAxtc6kEpMkCG2wSUYrUgSawkhkMqYTirJzOAe5lkymFY1RdM5R1ZbORsP3pu2oeuZK6FMFjYlJ2Vprms7iQkAqwSDPEFKxsrxMW1fsSRl9qjqBUCoCEE3LbLKHCg6Fj5f7tqNpGpouGpEbrWPSuJIoRbQEkVCkmrQ3NlYyzjP6NOwg6JUX0WeoLGtmdRv3rqalbS3OOVwQPbASqKqS2XTagwiOqpwRgidNUhgMsMFF1kmSEKwF7zCJxssY4BQjkOI8kPMznPjrF9d/D7fxSA39SA39SA395dfQXzrwhDgDLsj5IWUj9bOnUUaTOqJeEBa0/TnJT8qYGJfnOeV0LyL7TYdGIZ1gMpnRNo6macnSDK00iUnIiwGFgKIY0LZNjJotJ3Rds1iUAk9QAqkSRHDoIAmqAWUIdYwuRZmo9/SBsirp2hrbNVTlJJqkNS2tizI9naQUoxGpMeRGkouOTFoGuiGTjlQ6tLBIoVEItMwj4CNTXAdOabRXIHOkHiJWzkVkyzDYhxysoNI8Fg49a0xrGcEkIQiJxsuAdyU+Wca3DTbMkEETvERp1X9vnKwRHbEonSN0js9GeLOMVwNaNcBLg5cahyT4GAktlCZojcpzkm5EAOp8GA+grkMIjTYFyXCZwdISg+GARENwLZ2NvlXOE9ltIoDwPePJ93NE9pTTGK8aTDzkZAhRGtdPZBlit0CIyDDKswwpJIlOkFJSlgNMliOTlLquELMBopwhu47QNMgQQSqlDTpJoklaTx33kZ8MvcRv3i0YLUfjyrV9B9jZuo2ua+naZsF0SqRAiyitS6UlUb3ZolZE2V6grBvqpqMeT2nKhqZ++DsTZw6cACsFHkVQIJVAur4LKM6KGvcRYHRdSytjcqIPsVsSEyklSku0ycjSAaI35ZUhmm/WVclsMqEuS7a3T7G1dZrxeJfx3l7s6toOvsgb7n9VdPzD/k3cbL2QhHyEGKwgiiWatorBAMGxNytjdkYQtBY6L2hD3AckLQMjSfMck+Tccts9DIebnHtuyXCgyYdDNvdmuAb2QsPuiTsjYItCuQ7d7LKfUzzh8EWsrGj0qIa1DL1vBWlyVLGE0oqunhKSlE5lTO5+P3J2Eu0rdHYQKVOavQdou4rGNtgQaebGCIxyeCxlXdH5gA0a5aMrhROCSVXTVi2usuxVDqUE3nfkuaYYLtOIFWy2hpMD2q6JB3IfYIAPoPoLhYDgInU6Tw0XX3Qew2GBEIL777mHup7R+haJAB8QtkMGhxCeoGLhpaVA6gQBqBD9Q0TwKA/KgfaBCHd7QhC0XfTSaD1I4ZDSY+oSIds+qUhgPXQOJhVUnWdWOxrbRjp4XaGaGarO6bqOKiuo8iF5MUCpWHAnSqGlJM8MiZYRQBYymrXaDlnvItspuL6YC1Ga7EP4Z8B5oje1NXzXd383n/j7T/Ibb3oTz3j2C0jThP/073+NJz/9GTzlmmdx9OIrOfnAPbz9v72JH/np17K5cYpf/8XX8Lp/+waWV1b5/u/5Tl72XS/nCU++htf81I/yjd/w9Xzkox/jhS/8aq644gr+4A/+AIDbbr+d5z//+fzqr/4Kb37Tm8jzHIC2bXnxi1/MXXfdhVSayeT/O5FICLjlhs/y2h99BXffcTtXXnklH/zgB2OHU0oGPRugaRpe+MIXcvz4MZaGQ9oySngGWYYJHTRTNnbHnHdonYvPPcTx09scPXyIZz71SbzlHe9lb3eP5zzmQjZGGcc2G/7db/0h3/E9L+e7v/Pb+OEf+RFOnjiO7RomkykE+K1/X2BdlA5lywd4yTd8A1/30q9nKC2f/cTf8fa3/Bde+uQL0AJef9P9PPWKczjv0Cp33P4JToyWKIoht9x+N8v71vnF1/wwv/32d/PJW+7myY9+FJu7E2onuPSqq9je3uT9f/rHTE4f5/D5F/GaX34dt/7VO7n9zvs4vjPjxo9+iqVzNnnTm/8rt99+Bzd/7mb+9u/+jrXlZR596cXc+cCD7Ozucer4SRAeZztOnjrNSES28cnj99FUFU1TsbZvH1JEpsu//Omf4s1vfjMf//jH+bEf/TG+/du/nRe84AU8//nP56Ybb2IwGPCRj3yEl7zkJf37FFkwr3zlq/jrv/4Qhw8fIssylFS84x3vQAhBlmf84L/4Ad7//r8izTJe8zM/w2/9zu+R5TkhRIDjx/7fH2N9fZ3PfuYzfN/3fR9/9Vd/Rdd13H3b5+iqKZ/+5Me5/PIr+OZv/hb+++/9Puv79vHz//o1/PEf/xEnHryPV/3gD/Ln73kn133iI3zV817A7Xfcwd997DYOHzrErCy5//gJjh7cz5VXXsmbf/f3Fz4/D/fhupYs0eTZKmVVAQKdGLa3trBdixJ9uIkQbO9s93YWCrW1vUiiLMsKiImCtmt6U+89dJLELnSSsbyqyYsBS8srzKYTtjZP9cbkNdPpJHbauw5rHRYLXX8pFSwAMSFA+t5drPeDmScXSjUPFYoKAqNklIeEmFI3nc4im11Jys7HhGbnInAFOBsQ2pM4x+bmFvWojWyKNMMEQSv2iKhR4NixY2RZTppluK5DdBVZaDlveZm11YIDh5aQmUQGC0ozGA1ZHhTMpnuoZESyz7C9N6WelnSzXYo8QStBtbONcTXGNdRohDaYQUaaZQQhabtAU1e0LmCFjklzStOpBO86dmc1uQwkRtOZlOHSgJHRmEmDHhZkec7+1WWGRYbtWk5XkQlk0ow0TUmVRgkoMs3KSNJedCFLRYYKnuMP3EvZNiA1dV3TNA2zyR5aglEypnEXUdK2txflQVIqijwj0ZpU+nheB4fsz7euiwbs2HgQq6j9wjlH1bRUTce0ikBW3VrKuqPpohl856MSQwpJOZsxyyckSUoIgdEgZzoe03hHuSNIdS9Isi1pb2fSiGi3oRGU0zGz6Yy2LrFdh7NRYSJlZEk9nMcjNfQjNfQjNfSXX0N/ycCT67pIH9QmdiuIvjrBxZhOhAevEd5hOINe276r0lsBLQh/bVNTzqa4ALhA03RxMzJRW9xmDVobsiwjMUnvEyQxSRqBFyXpuhaTJHRdQ/AWOdfA4jFEaZ1MMkTS9sh03BBCcDH+r4rRl7NZRec81geESqKpY1aQFUOy1DAwikxYUmFJZI0WNpqc4RFSEVSC0wOC0og+6tWhIDUIPUAmS8jBGiIbIYsRJi1QSXKG5kyfZiD7DUsKRJIishE2XybYBt9MsNIQpEGoQfwaGQCF8BZc17OjMqTJkWmB1AOUHkV2kFD0qY39f+LPVlqi04zgHNloOf47evaQKQbkS6vkxYA0TeMGNu94CYnoUdGA6H2dZG8u3xudQ5T2hXnCSug35mhKh4xfJ4JAqThfjFIEE8Ej3zOmAmCDRycp9ObxTdsiTb1ApKVU6CQhSdIo7VP6LBPNwAIJRSCVJisGrO5bR+l4sNd1RbAdrn+uQUQ2nRRtZM7JEOnXQkRUuXHRKLNrH6JffziPtp7ihcJJSTBJLz2M9Ob4aGLny7n4uiBEueHcaA76REFL5+i9RSSpiUafUZ6YxlCBNCVJMrphTZImZFnO0vIyu8Nd6l7WWjVl7KZZu0gzmcc4L+SR/Z/F+Of5IRrZgVJIhFAIYUjSETZvcG1D6BzOBhoXmDYO6yEIhdYJRklciKDqaGmNdBg7y8E2VFVH03WUjcW7KagaqRPmPzWnJjUNg6WO9axjkFgw4IRD+FjEK6UQKJK0IEhNEIomgK9Kwu4xkjWNypbpgsb6aNIfCASpCFJFcDhW5ogQDfzr1iFUQjFaY98RcOWYcnaaMKvJEsXq8pAkUQhp8GGIEzGidZ5Us4hTDgEZegZiiKRrEeJzHuYZ+1ZXaFrL3s42411HtTftjRVljGYOsQPfMe8CxaJWBBAhxL3XE/eGENd95yD4uGYW6Wci9A26gBYORCBgsUh8iMVO1QravsvWWRdBZC8iAxWFVNWZ7ruP0hQtoAW0DIQEnI5sRacM3kfPhGo8piprmnJC29a0tut16ZGA/nAer3vd63jyk5/M8573PP722mvZ3NriW7/5W3jw+An2yjFf+5JvYFZV3H3nF9jZ2SXPcx7/pKdy843XU1U15136GG68+RaKIuMJT34aIQTuv+9ern7y0zly3oWUrWUynVKW5eJneueYTCaRcVQUAHzyk5/kgx/8IPfffz/j8RghJS/7tm/jvPPOi/4lPZjkvX9IF/v4A/fzmU98lMms5KhSjEYj5l4gb3zjG6N82znK6RjTG49CPEc67xmNhhw+uJ/LzztI0znueuAky6lCBce4qrjq3H3sjhQndibgLEMNxyctW6eOc/yuz/Gocw7g6hm33v4FnO2QQtIazfLBoyRZwckH7iVTcO7h/Zw8cZx9h4/ytd/wTYhjN9LNdnjsoYzcVdS7gbUjh6h3t9g7eQpZjdk52fLJSU27u4NoG05tnMYJjZaKzZMnCb2XpWgrJtunuevzn+Po5Y+l2H+Ez33wwxw+/0LOvfhShNIsraxy9LwLuOqxY06fPMFHP/YxzNIaCM3K2hp1H1n+6HMuZHVpmWFecP/99zCbzZhOpjxw9+3UZbz4W+vYPH2a3/yN/4wLsDeZcvLkST796U/zpje9ie/4ju/g4MGDvPrVr+4ZZNv8zu/8Dh//+MdQSvJTP/VT0UAeegl8nBezWcnu7i7GxLWV93Pj05/+NO973/t4wQteQJHnvPdP3sM9d9+ND4GnX/MMptMJJ489yGMe+1hcNeHvP/IhDi4XqNDynj9+B8ZWHBwZPvj+v0AJeOLVV3P9TTcym04599B+brvnfibTGQhB03UcP3GCN73pTbzwhS/kSU960v+1tfh/Ok6fOkGSZmTFAI/orQQgLwaRZRgCznnquqLtbG8WbrDOxUhurWMimO0iY7uuaNsW6zxJmpFmObo/0/MemBiMRpg0YTqZUM1m6MTQVFVf98QaKjblAvOcgJ48gfNuYZche4Z63C37r+slgiZJKDTYNtbv5axPa+4sdWP7RGixkGkmaUZe5IxGBavr+0izFCEF0+mUclZR1TWd8yiTkA+GKDw6WEQzYeAqDqYwko4sdEhbI20Dto21i/O0PqCTFBUU2msaC7OqoRmPkaEgNZqubXFdQ9c1eBPr0CC7GJIj4zkuRKxiG+tIiyH7D2U0FtrpGDveoXYBLwMmUygh0EKQGIMysa6Y14dSKVwXw+RlmBu2B5ouSmq0SVhbWcbbjrYume5tMR6HmL5pLSK4yEQg1kNJb9CslST04UUIGaUyAoK1WG8JLqbjKSGwSuBdFxPupICFp5ej7aI9Rd1G1lbTRYZa5/xCUhZvVh5nLdZahDjjO7Z16iS2rckTFR3AgoeuwRpNozXKGKIvGEx3tinLKgKhdU3bdmdka4uZ9fAcj9TQj9TQj9TQX34N/aWn2nUtKpheCy4X9NtFQSUEwjmkj/Qw1Uuo2r4A7fpJrnq2VF1HF3cXBMEFQtMS/KT32Emo+/S7rivIsyKmA6RpNDsVCVobrO1I05SqLnE20tkIEXxSJsE7h7YW1bYLY0xnHbZraTtLWffmebMqUm2lIcnS2JEoBmSDAXmaMkh1BJ2wJCHBSIcSkbKLkHhhsKZASIPUEXX0QRNSEGaIzFZQgxVkOkQWI3SaR/Csj80Uoj/UhYjgk1SIkCHyEbJYjYBIOcap6OskzagHngRCGITvkLZF6AShM4IpEMkAmQxRyRICgQsC11mEj7rNuSmpkhKTxkS5bHk1emOZlCAk6WDAYHmVfDAkydKektcn8M1lf6I39xZzvXbsPEbq7JyCFw9a7z09nzy+VucJMkRj8D4ZQ0sJJlKCI4NK9dRWSNIMlEJojW5bZJ3gOovr5XfaJGRZSpIkkXas5KJQFlIg/PwZx6Jsbf8BtDGEEKirmqAVRoCUjiA6AhYpKoToDeO1BilxaJqu7wRYFtLAh/to6ilBKLwwgESa3kNNG2TkX1M3M2zX0bW2Z+IpZL+hCAGd7/DO0XrXJ0iq2OESMfVP9eAc5ORZges6BsWA4WjEbDZhtLTLrJwxnU7Z3j5JXVdUpV3IIqNcRIGMc+yho/eOCdGjAQIiSCSGtFjBd9EU081mdN7RecesbbEO8lRj0rw3Ig2YbMRoeR+j1X3YumS8eZLZzFG1HVVrqcuGgOTgwUOx3xBgIGpW0ppDWcdK2mK0JWhBGzq8i8EJRkmElpisAJ3ipWEWJG1d0W0cJ9VDFBIvUwJVH5HsCULihOwPJtH72nR9ceqQJme0HIHgydYpTldTbLVHCIFz8gFCJ3hhcLaIoLfzKBH34Lk3x5waHo0DY0qHCB4poicEKwplEk6dOBFlE1unECZ6nKU66d+CeLzFDpBd7LfM/c9kwDkR5cNe0PpA50F4ifOx8OxC6Cn2vUlscD24HJM8vVB0LtK4O+sXkfHCdSg0OkiEqqOc1juEbdAi0uBl6FA4UDVeQ1ACrTMsgi4EyumMqu5oypqmben6Q1MgH/b+Ej/7sz/Lq1/9ap7ylKfw5+/9Ew4cOMgvv+7f8rpf/SV2N7d4xQ+9ive8+4+46cbrqadjHv+kp/Lka57N/3jrb6PTgquveT6f+syn0AJe/PXfwrH77uELn7+Va579PI4cOcTG9i7GJKS9zA5iYZzn+UNSOz/5yU/y62/4dWbTWZxTzvGyl72M5zz72VTljLQP8FBKnUltDYH3vOc9/N7b3g7Es6AsS0IIHD92nF/+5V9mNp2ileT8o0dYGg6oO7c4XzrrGC2NOOfwQR538bnceMf93HTXgzzj0nOQ3nJ6e4erLzrA3l7Oe/7+DrTtGKhYG26ceIDbb/gkV116IcFZbrrl1qgk14qsKDjnossZruzj5F23MEoVR/avcdd997P/nHN50mMfzZ/9h5+l3jnFMy47wPGNPcrxhOGjjrKxs8fmsdMMhhkbmzt8+t5bGApHqhSbp7dYXlvDpJKNB++PUeIS1kYFs+0NPrc75ru//xWs1C2Tv/ksT770Ch7zmMdQNR06SVlb389Vj7+aj/zNNtf+zd/ymKc9m7V966yurcKsBWW48vGP59xDhziwusJ9Dz7IZDxld2ePPz15jNl0ghQxYaoqZ/zHN/w6u7OSSRnTsD796U9zww038IxnPJMnPOFqfukXfwmlFXfccQf//b//dz784Q9z44038vKXv3zx3u/tjTFGMxwOFp4/84Q9AEIEnn7t9a/n2muvpa4r/s1rX8P9991LURRc88xn8bGPfJg7br+NS849h3vuuZuPfuTDfO+3fTO7u3v83u/9N77vW1/KgfU13v6ed/Kir/oqnnD1E/jjd7+H9ZVlrrzkIj55w83sTqbkWUbVtNx97338/M//PEVRcOWVVy7A0Yfr2Dh5nGIwYrRiyYphdHZ2jqIYxKZdcOzs7FBXFZ11KGMwISwulYlRlGVMQRoMB5RllKTVdUOW5xSDlrxnBxWD2Mn23pEVA6bj3TgvlKScTplNJ/FMbzuatsXb3raBeZOWhXcQ9H5QZ8nsINZ4SkcmVp6pyPCwHa5taUJLU3e0bYcLkCUmsppMQl4UDEYDlpdHHDwYJbd10zKZTJlMplRVhWg7jLEsLy9HnxMcXTsl8SVLWWAgLMa3hKYEWyNci7MRMKk7R5GkaAwqGFrrKauGcm9CpkBl8f4Qmmj8q1ExgboXgQllkEkPFghorScfLlGsDVAqYXdzg9NttUg5y3RkXEiicbrQ8TLe1DVdF0Eai4IAmtiInZvBCxF9UFeXR0gRCN6yceI4trOMxxPwFhl8rF36RPE0TUiNJtEqBgE5hwtRQoj3dK7DdvEj9OetElCLsFCm+D7QyM8lliHgXKDzMaWrsT1TrVcPzBvO1rkoyyWQJClLS8vUVUlbTtG5prUxgVvaOvq/KhWN7n2gtY7J7hZV3TCr2gg89emdsdHw8C6kH6mhH6mhH6mhv/wa+ksGntrZBKk1rknwxvQApgfboULAaE2hJAOjWUoUqk+567TGhhAfVJIQJFjbLqRvgRbnQpTtNd2C6m2MQWlFlmZkWaSmFj3zJkszkiTGkZo0Jc3yGPvZG7F57+JE9FEOqJoGZzu6tqWtK5yNKX1101BVDXVrMWlOmuQMRjGWthiOGIyG5GnCaJCR9dpK4+re6d4RlAERU+KcSvrNwmG9wjuJ76q42/sASoM2ERySupfVyYVePvqj91RLKSBJQWvC2lE6k+N9wLkugqHFGkEbglIoWyFcA13VG4YbfLoE2QiVjMiKFTwx1U11fVqCtX0KYexApVlkPBWDIU01o6kqrHUkaUoxGpKPlkiNjj5MQkWgSJvYnegjgOdJdnPTOwLRf0BIpOono4iFyrxr5kMguP7Ve3DKE/oZKRGkRiNFjtExcrdpG/KiYFYOaZqWsowbvOuBT2MiQ251eZlBkTMsMpIkFgDe2QVC7F3ApBmr6wdYWl6lnJVsb29jZbwcoC1edgRpMbLFS0dQHh9isoeTKd5F7bBUBp0Ikn8GTP9ZNYnsMxTCdqg0IyWawSJ7enTn6dqOro0bkTSGIoARAq0VLY7OCuqOSPNV0RheqTiXm6bpKfYCpTRKZZjUkI+GWOc4dK6g7VqapubUifuZ7O2ydfoks9lkIaPtejCxs10ECvuuw3xoKZB4Jns7VHWFC1CsHGBurGgdWFoy32CUBBH19OsHz2Hf2j6GiULQa6u7afQ0w+NDZM6traxSz2bgLOetmEj/DoGssuiupW0btqe7JE6yJNdwehsXDO7ARTTW4qYdsqwJ1uLqksYbWjmgBEIzJqkV6eAgQicEl+IRBKEIQVM3DaHXUvtsDUzGyqFzENkQ0gEeyWRnk8HKAbbvugnRlexMHToVoCSTtkYNChKjWRqNSLSinI3p2th9ix3nuF6NTqK3BwFpBZlSpCvLXH75payujHB1hZvuQNeSGoEgPkurYiKnDR4f7MJMei7JcC52aWwHdW1j8ITzWAfOC5yPTMi5yUSck6EPZoh769zMMdDvJyLS8HXboW2UPmjn0N5D05LgyWSLokHQYsOMVsZDXCcpDkWHpmwkVQuNjUVZYiRKpZw1vR7W421vexvv+8u/RNiGU8ce4P/5lq/nWc/5Ko6cexGv/9Vf4vxHXcKLv/HbOPfgfm6+6Xp+7y3/mXMvvASlNffc+lkOHTnK+r41Rqni8zffwHXXfYrbP38L3/ANL+Urn/WdvP99fxlZLC4aHl9++eV85jOfYX19fVF8fdd3fRdf9VVfxYtf/GLuueceAF7xileQ5znWWlZXVzn//PN461vfxh/+4R/yxje+EaUVk/Fk8TpuueUWnvCEJwDRbHc6nZIlhiJL2RlPo4F5zwiWQtC1LU3TIVXCV3/dSznw2c+ykn+Kg4cOooOjvOdW/mo7GmtecWDAZ+4a88DmmMIo7r3rbt4/nfDTr/nXLK2scNvnb+WuB45jihGPf/pzSfKCrq0QwPHTW3z283ewe+xu2ukud013GNQ7LOeKPWdgaR/GBY7de4wCx0X7U6bZEgc9PHZpl3K4n2xQcOHhVa6/5zQnTu9w6cBz/7jjVOV4+VXnsjzMkUbzJ7/3ZnZrx5VHV7j80ks4fP7F3HDbndx96408ePcdPOUFX8dXvuglvPhFX8Nv/bffpm5rLnzM89g8dhfVZI+NE8e47/bP01YzHv/Yx5ClGeuH1/nW73slJx64j4/81Z9Eg+ampewie2FhAN+/l3meUeTRoHrRpenHeDzmec97HlprtNb8wR/8AY9+9KMB0FpzyaWX8od/+D8499xz4zcIeOxVV/JD3/9yXvWqV7JxepPtrS3aNsqo/uQ976apouH1L7/u9Tzt6iv5/m/5Ov7Hn/wZWeh4xXOv5CMf/xi1F3zbc5/Mxz71Ef7nH/wBRwrJbLzDX3/sk9R1g9EaYwy74yltF5MWX//61/PmN7+Zu+66659w9X35Y5glCBz1dEzXtOgkJR8OF1IZY0xkeXtPU1forgFjaFMVAZMwYGmQkap4CYgggO3r3yaum37NtE1FMRiSZhl5z/Du2oZ9+w8ym0yYTqJJd12WTKcTprNZrJG7PjI+RHncHGSce8sAhBDryLKsqNoRAy9Il1Yj8ykx4B1705JJ6wkyXszSwZCDB/azsrLC+v51urqiqaZsnT7dM0EswjYUOpCtDqNth1bszwUSC87SVROka8kkKAK269jY2mYpW2NQOBKtmU6nbO3sMUg0RaJYzjUheCQB2hpXKTwJgzynDZ7OWpqmxTctlir6niYp2UiCTjGpoUgzTLFEUoxYW/v/sfff0ZZed30//trlqafdPl2j3rsty7JcZcvGBRvjAsbYX0oIfCkBjEkIgRBCQsAGkkBIAsYGY0wLJTZuuMjdKpZkFVvFKiNp+tw7t53y1L3374+9z5kRyfot52uSiLX0eF3P6M4t5zzPLp/9/rzLIpvrK3S6XQ4deMRLlJqWUviad9RIOl3PBoqiiKIoeOLgIfJeHyElk8mYk8aglWDH4gI4R13XVK7FCEV/cYmLL76IY0f6bG+cpLYNxgniJAkMf4PGgHEY2yBsixaQRP59GuOogkyqccKPj7albepTCaR+B/a1mpQzNYCxjtZ6hkTVtBhraUI6twv+RpPJGKU0hw8fYWl5mYX5ef/5omCyOWIu08QSiqqchQqVxYQo0iRRhBKePVI2LUjvqdWJouCH9dRWDjxdQz9dQz9dQ3/zNfQ3DDzZtgbnkw+wbZDNeeRUCoiEIpaOOJjaSRWSMsL3Owcy0jgpvAmY9hTiUzfPBoM2f4+MMUglQwxsSx1YS3Vd0zQNeZ7PCiIChdf/PAfGO8k7bAB2vRzQmRbbNti2xpom/D4/kHQUESUpadYhzXOyTo80zUmSyEdiSoeWDmXjgBY7hI5BeiNvK/ytdLbCqSFOSLzZU40w/t5Nt23rHMJ6c3bBKU396Ru8FN49X2VdnGlp8nlMU3m6X9zFRYkHn0yCaytQSVDQKZz2BuYo32ESXmWKEwJpDFJN0R1/38IT8n9XGlSMbFviOCbJc6IkJdKeSizC5uNBNw8iaRWdiuYNLC4EAYjyzKyZaEJMlz8x+73OOkxQh04le57VLYm0p4FKpVBKzuR3SVyjpaRtPfCklCKOItI0od/rkqXeDN2nspy6rzh//2WQbXZ6fdJsPVCHLU44amtQukUpgw0LmKdZTqWaBMaYN6xXQqDVU//kasJ7cM5BU/n7rfxmqbX2PqJNgzAG7QSx8HHIqRLEWnoKPzFaelq3UwqpNWmaeYYjElOVwYgP0EFmEya1UhqpNFpHxHFMXS4RRzFSCPJRL8QDTyiKCXVdUpSTUwlZ0zmC88Z6zjKZjBmPx4yLCfNxhI5TdJyhkxxlQZaeERmh6Q7mGfT7DLpd8khQlb5TfPToiKauKMcj4ixHK00SS/p4OupC6s0wnTEkxpsMVtbRtH6dqaymQfm5EIo+Z/w6Zk2LqWqs7kDcQ8axH8ezEkAihMaToC3WViC079zIFEQMMviWRTEiipFI4qxLNrdM0l/BTDYp64JIGrAtTSuIooSs10dHCud856ltfcdc6Wnap/ZyVim9iSQCqUAJxdygj2kblnfuYvtYSzPeBjs19RcoYUAYJN4YFjdNPAJj/EfTQtU6Jq1PPDXG0hqHtQJjA10YIFD4p9JcAqEfEQxuHQR9gb9LwmJsi6srWufQzqGExAmLUjVCVjjRADXOGS8nMA5HhAWcS/BBE5I4caC9vMTNNu2n9jU3GHDuWWcy2d7w+0SUsLG+SlFM6GYZzhovlZPCr2+dDmVZBCmAYby1TqIE2JZuljDXzXj8sUfY3FgnieMZiDDtnCZJwtlnnz37/UII5ubmyLKMKIpmnz9y9CgL8/PccMMN9Pt9duzYgdaaHTt2cNWVVxDFCQcPPsHhw4cB6HQ6XHPNNZ7pUJYMt7fBGh/zHhoVxprp5ggC0iQmjiPue/gAZVmyf9cSZduwPZ6wcXKDcWVwQjBWKWedfTZ7zlasHT1MLB2uLnjowfsZlw2XX3kVveXdlI1ltLGGGnka+a49e8nzDkVRsr21RYRlYWkH5cISskrorOzBFiW6acm1oEtJ5kq2xxIdRSzN92jm5og6XZL+Ajt3x+h8yBMHvs5m0WINTKoWLQukNTx04Am2KsvePbs4urqOXthkYWGe3bt2kklHJBxZGrMwv8zyvjNZO7nBwQMPkUaKvDdgXBRYHFLHNK0FbRESqrqmtZZer48QkqqqKIsJZ551NvOLi3z+85+nLD3z6VOf+hTj8ZgXvOAF3HzzzTzwwAO87nWv48477+SRRx7hyiuv5MiRI3zlK1/hYx/7GBsbG7z4xS9mmn53zjnn8PUHH+Qzn76Jiy+9FKk0z77uOv76Qx8+9ax7Pebn5rnqyiv5+oMP8PiBR9kejTl67DiHjh5lKZNIIzm8PiQSFqEkjx46hsZwxnKX8XBM2RoaY0hSX+foOCaKa6yz1E3LyZMnOXny5P+BGfhNXs55U1lbYayXOUkl0SpEdxtvLN3WFdIZlBDEWpDGmiRSKAl5lqGUYms08V13JX1ojlRBIucw1sx8nACiWM6Spbu9gWcpxQlSerle1umSDrep64qyKD1ryRia2qcvmSDVsIFdYAPLZjyZMJ4UZFmKxYfiyCjsc8onYCVJjNIRC4uLLCwtMRj0iaOIqhgzKSrvB4VDCxC28R6bcYQW3i82k943yrgWJfGZXEKj4hjiBCNiUBFCRWitPNuiKKjGLVUSoaz3Hpsaa7vg16IzhdUKqyR145PmGgtO+T2jdQJQOKnR2huAG+tIkpSs22duaYXVEyconWVSN34uSkVtNT0pSZKELE1ACopiQpwkSKVoG894sUZSNw3GWkTTYHUCeKler9ejnvdrwfraGpPJeCaTk0qjAzjZmJaqLBFCkIajlLV+r22N9bLDpg1piS1t42vZQNtACB+iMzUHNtZLPVvrv9d7cokZMO3Cv9dNzcbGBlneYW5unjTvMN7e5OTqEG1iUi3BtKAtOIkRNgT2RF5SFozQYyTK+UO09xB7aqdDP11DP11DP11Df/M19DcMPNFW2FbgRIVVwR9I+gO3UopURqQSEuUBGiFBKOkT2jxE5TcKCRbjk9LSHNjywBAioPkueEPUIITvcEUlkdaUZUEcJ6RpQlX1SZKYLMu9/E4KpPabt3AO2/qOTFtXtFXhIwerCU05oSn9xu6MgUAXTbKcrNOlM5gj7XTp9vrkaUISaZI0DgZbnpU0SxXQqfe8ijIMHhRxzQTGG36xbia+qyA9COVsi3EWOaVEMtXj+ls8pcMhfJqF1BqdDxBC0dQ1rpx4el7eR8appyGaCkyNawpfuAgBOgadeuAppJ+48DOdY6bdxzFjPSEEKg4JenGGqmviOCLrZKRZSqQUWrjZ4HYqmknr/IJ7CnSastYImxkBRfeTI0yw8F6nnlEmbHIQYlWVQgfUX6uI2EFiNJHSpElK09SM49jfD2uII78Qp0lMN8/RWnm/KOsXPDejSQZgTyqiRLGwtMz29iataXyHAIuKLNJapLY44eWATLt9LkghVYQkRsnE6+yf2gxhIDw3ggFcU/pQgLbFVeUsytYFWncmFF0dMRfH9GNFFCtUFNG0Ea0FGbeIKEJGEb1+D/AFdV2VtLalNi3SeqkMwatF4M1GlZIonTK/uEyn26PbHVCVNU1dMxmP2N5eZzzeZm31mPevaGsPEocFVUmBMZbtrU1Orq8yGHRZ2rcLnSTotEPcbYicQIwKup0eOslZ3rmXlfkB/U5GKlvWK0NRTPjaA1+nrEqg5aKz97PQ7zIXQ7+fkMWKLG99kdg0JMIyNo5xC7QR1sQ4OgjdRUW5n9+Bhl7XwYi1bUmSBUR3hbjTIUlSYh2DMd6YX8YIKpypoS1RcQ4qoU0XcboDKsUKcM4D5zjPakzmVsiXz6TaPMH42ENElAjdUtuU+U6P+R27iGKJabwpqUUghPdB01GCUhpj7WyuRdpvQEIIFucGpElC21gecw2bJyxucw0nplPaIYQBzGzDNC20RmCMo24FRQ1l7RjXvoNqjD94OwfGx6L6j0Bd9kPEM0Yl3lNN4NdbjH/b2CDpRdBYULpG1xFOSlppEVGDjBuUMqAMQngw2b/wkM+hUqTQxDIiiyAO0ZzGGixP7W4rwHOvezY/8SP/L3/+J++naVv27z+LP/2rv2Y0Kfn+7/8B7n/kUe679y4iYYjihKufcS2f+8LnkFj279nFEw/dz3q3y7OfcQXn7d9HbCr+4M//kuPHj83Wxtn6HS532uI2/fzpJqbTwviss87ij973PnQUzf79Fd/yLbz4RS8k63T5q7/6Kz73uc8DcM455/D+978fpRTHjx3jW176Uk6eXKUqC/IswxgPoLVtg8BLxhYGfTpZwi//5p/zjPP38vwrzubmW+/miRNbfO3YNhcuJKSR5rENx1u/61u55KIL+OM/+VOqzXXseJs//aP3cd6lV/Gq138XJ7fGPProw/zR7/wWOuuQ9wY885nPYvfuPdimZnVtjTP27uWa572Ie4eHacbr7Dr3XPTxY1RFwe49u0nKE6jRcb7+1ePIOGbnGTvoLa9g4i4nxDyX77+I8aTkZ266jWXt2NuNeez4FrFrMVsb3PvoCYatpaoqJnfcy/4y5m1vfR3XXHw+kVZ8/gufpy2GjPOMc696DvaB+7jpT9/N81/x7ezefzbjA/czP79I1pujbC1t2RAZxwNfu5fh1joLSyvMzy/QNBXHjhzh27/9tdx440t51atfTVVVOOf4uZ/7OV784hfzghe8gP/4m7/Jfffdx5dvu42f//mf593vfjf/5b/8Fz74wQ/yQz/0Q/zcz/0cL33pS3nxi19M23oWRRxp/viP38/v/u7v8rP/8l/x7Gddwytf81r+7a++czY2duzczYUXXcw//emf5j/8h3/PPffcA8BDBx5nPNzmh195LRujgnf97e18+3UXMcgT3v3Rz/PdL7uO177wGfzL3/sAdevBSqGj4KEp0UpSlRWTovzfOuf+Pq+2bb2kyYFUDU1T0TSNj55vY5w1FMMtqsmIOFLkUUw3S1jsdz3YqyRzgwFl3bA1mvi1O4rRUYwKJsPgD2xVWSKAJopI2hYd+Zqt0+2RpBndXp9uf84fGosJo+E2VVUyHg2pypK6rhgPt6mrkrqqPHBhTGAIeabV5taWB5akpN631x+chfdlkUqRxTE6kaR5l7POPpvFhQWyLGV99QSj0YT1zS2G20O09AmSy/2cLI3o5jGx8l5EiagxWBpa4iTyYTo4ok4fkgxFx9tSJB2SKGLkCupywvr6Bp00xrUDf/7QygfEBPBPae1lcZFmXDW0xtEY5y0ZkNROI9AIERElGZWBZlKikpyo02dxd8TRY8dorWFj9Rhpo3xqofaKgG63w6DXpaxrNjfH1JPIq0aC56lzjtFkMqsdO4M5Ih0RaU2v00GtrHD55ZfzwP33ceLYUdZXT5BnKXnm/Z2qqmEyHjMaDb2/quh5KZyFynh5UVV7NpdpjZ+zxgQm26kEtmmjF8QswctMAScpZw1kh8O13pumrmqOHT9OmndYWtnB/OISk9GQE+ubmDKmEysGqUZajdDKs95iTaSkr9UtJI0nLLgg4/Rm90/tdOina+ina+ina+hvvob+hoEnHRgpzvqH7RFwUM6H7UmjccZHgFZN7FE2JA2E8EyvK1Za08/mKIpQMDiP0E+BAb8KW6bphVPjtFpK6roOyR4RRVF6oCFLSTNvqKgjHZIzWsrxiKoYUU5GVKMtTF3RBADKtIamLBECkiQl6g7IenPk/Xl6i8ukeU6n2yOPIyIp0fo02n/wHhJKIqPES9Z05HWVxmAqhUw7mCrzZtTaexIJFWGF8sglHvBy6pQ59wyIssIniQgB1iJ1hEtzosESIm9w1qKSFK0DijuNUratZ3UFvbaTGqTGWIcQDiEkcZwwTVwwIca2nVKprUdbbdCIqijyUrs8p5PnaCV9Al0Y7kxT65Qi0lGgchJ8n5iZggMhXe60xTt0ztqwiWHEbPM1gWrr8AlOU0M+CWjl0wO0EhgbkadeMysEnqoeKOZKeg+yaWdpKisIv3xGOxRSsLRjJ6PRkCTLKYbbNG2LdjZoXR219BRtLQDrjbvZpCMAAQAASURBVN+t81piQwBWp5PhKX5J/4DQUvr5ZVts1dI0Ba3wRvNSOKSETtalow157FCRQygXJrDXjispkZE3jdQ68sWcEKhI0zpDWxuaEEfa1g1tYzyVmgC2Sph23JRSdPpdz6ZYnGepWqKqSpYWlimLCWVRYEWLtS3GNjNjVLe2xomjR6irkh2DLtI04fkAQhHHHTpd343bsTxPTEMxPsl9jz/O5nDC5rhksLKHRSnQwrDQcQxUyYLcRtUtohXE6R6ETCDrQj0hspDNSeTyRcjuLlg8Gz0YEGW5T3zAywOiSPs5qGKadh0zWaOuE+pGI5RAaIGKElSsaYsWqRIinaLzOdpojq1siVJktCKiReEahzU1UmuslsS9LvniMs62bB6ExllE5JBzA7qDAUvzPdrJNk3TUkzGXrMuJKqqkbryEttgxK+1Js2yWSSwdo5ESfbu2UldjdFZzuHhEKoJsq2xEtrWd1KbxndhfPKJ3yCrpqKqvf67DtJnYz2dGPCGbbMNs/Xrn5B+Q9cZOvKdcgE467x82hhvIuksxvmOmJcEtDglaBW+y4hDRX6qzsgyIvLMVBkjXIxyMdrFxK1PaLJtizAhofMpfP3xf/kNzjr/Ys69+FKsMTz09Yf46Kc/x/nnnM2+JOF9738f55xzLufs3UtiGx56+GHuuucezti9kzRJUMLy+te+mn6/z6P33csznnUtN77ilSQLKxw8eJAXvehFADz3uc/l3/ybfwPAQw89xA/+4A9irWVhcYE/fO8f0ul0sMFz5nnPex6/9Eu/BEC32w2NDT+vnXP82X/7b/zOf/2vSKVYW1ubvRd/rIH/+tv/iY995MOsnjiGcxAlmTczl4o4zamH20gBvV7OXfd/nYPHjtOOhzz62GGKomBts2JUO7rKcbyw6Lol14Y//W9/TWdugbe+9mV85d77uO2Ou7niqmewNS75d7/8b3nxDTdQFBPWtie8+vKzufy8M8h3LDOZDLn9qw/w2te+nu2tTT78iU9x2blXU24c54/f+wdcfsXFLC7O8amPf5oFO2ZBVBR6gd5gwK6VOdYmhu1hydHj92F2rFAbRxRpNpqGYrvm7MeeYILisVryhpdczbCoeP8n7+KV33Mh17/gWu65735iYX0UeneeNInpx5IbrrqQM+ZyHvnqV1k/epDx2mGi7jyHHnyAzZMn2dlPGA2HHDtxwlPolaSXak6urtI2NWfuWmbz0Ne5/VMTqmLCK1/5St7+9rfPGGxTg+nNzU3+5I/fzwue/3y+7du+jYWFBYDZ85xeOvKH7pe+9KUcOHCAOI55+ctu5Mwz9pOkKb/2a++kKAr6gzmyvENd19z8pS/NWFBCCOq6ZXVjm9/+4BeZzyKet6/P5sl1NjY0zzxnDxjDQ08cZS5PqVE+MCVpiKOYpYV5Hn7k4Vn094/92I/x2te+9n/vBPz7uJyPFE+0D0hpyobxcEgxGaKkB1RM671KFxaW6HQ6dDs5kfKVok+JlrTGUpYlbdsG9tmUSRI8VYOhbBPM/qOoDKbjKpxjQw3WeH8O7yu24o+lQbbX1BXDzQ0m4xGT0dCzjqxv6J7c2KAoCi+1K0o2t7Y5ubFBqiWxwHtTxYY4MXSynE63y6Dn/aa2trb5+sOPMB5PKMvCg2ZKILWXGjljUPjmZG0h1pIkieh0MnqdHAEoIUgWdyM7A5bmdiPSPjJKmRQFWazZu2OZ3TtWAtsdNtePUTlNrTOyJEKk2jOzMoMWloHSs1S3tNMh6c7R372fYW0pWsdW0WBlhJMaMy6RziGtZXnnLqI4ZlRUFE2FcrC8tMLS8jJLC/MI16KwdJIIa7zfkoq8V1PbtBw/Mfam8VFMlGbenxZHnGY+LKfTY1K3xHnX77flhM3NbbIk8nPWemaWbQz1xhbG+hp6UjbUdUVdNyF8yQVViZ0x4qZdZH8AZnY2EMrXdVGSoSOfFi2CKsW0XuoaJ6lnOmU5DsGOnbtoyiKY2wemWhxRtZaqrOnlCW1ds745BJ2QphFzKsNJjXVQFoVnccXR/5/J83//erqGfrqGfrqG/uZr6G8YeJJMDeb8f7vph/U0LGsa2qamURIR14BACE0rAoiCP+hr7T2FvPmoDki7O0X/nHHG3PS++hjAELdhQ/wneF100zY0bUsUaaLEy+CcNZRlQVlMKMZDytEQ01S0ZeHldtZhWuOpuVFE3u2T9fpkvQFp3iXJMuI0DQbgAqHkLLZSKO2ZPmFxnn7OOoFVBmENNskgyTFJBxFliDj3sjylPeooTkMqZ3eTmUTNf2pKlxNeTxpnSBmFjStGKI1QyndkcEj8IugCV89NPzsFRQJoNgXOkAKMRQS6t5nRaj3go2REEsekiTfr9mCORU7pfOFnSaXCAA/Ex6meWIhZd4ApEhvQXhfAMGfdTHY3ddf3yK1DhM6Lf91TUqVnaAmtsM5HUYrTft8UOfZ/+u8/3aNgennZocM5Qd7pknd7ZFlOMR4FjXv4MNZv5AFhlk6AE1gXwELhJzvSJzw+1S8xZTOIYC4pQjESDpGezeWQSqBoUfhUCGMbnJUIa2mQ4X64MNZa2qYB3Cxq2VpDawxV5WWxdVnR1KeScwLuh9K+QxvFMbFUaKWJosR3ItMUZ6xPnixLhLI4Z7CmYTIeUUzG2NbQOueNUicTEg1a6bBpSqSKiJOMOEkRzjIpx5STISc2NplUhtI4dvQHZHFEIiy5HpGomjTx98SPE+1ZgDqlNRkuVqhuhurvRHRXEN15oiwnShKfTBHur4o82OyiGJf3cfk8LpqjIUY4TaRzpBIgHK5pkHgjQx13IO4gsy5S5PjwAA/EW+sZd0IpT7XudGiKHlFngHUGtCbrzZF1OmRphKkr3+W01ndIBFjbIh2+k4YH/a1z6CgOc/hUlzPPUgbzC9SN4US3T21aqqrAzJJvjPd/MI6q9aakxlrqtqZuGpq2mTESbUgE8cv9dEfzncNpMEGUZERJTJymRFoDAmsssiqDEaxfvwmmqA6HM4I67BkxjqaFVjha7TdO67ypp5t+CBnWRYmULmyUwfPiKU5bjKOINMvo9Pren7AsvLFtEhNFms31NYZLS4z7PagmbKydYLS1weC8M+l2O0il6HVy8tSnZw1HYzrjMddccw0f/vBxPve5zwF+DN96661ceOGFjEYjvvCFL2CMYWFhgVtuuYVut+vlW6Xv8iZJwkUXXohUii9/+Tb/LKOIXTt3cv/99/PFL33pf3gv49GYW2/7MrfcfDN33HE7xtgQXBL2gWBK7qPbg8dfVbK57run4/GE1TXBemkwTUuiBMPaEEeCXXMdtqygblrKYHQ6qY2X4FQ1dTlhuHYM21Ts6ShWMslCIlGqpTAlRVGgkgyVVEipyOaWKScTHjvwBGeduYe5XsZ4OEQ2Y5yrEcvzOOeomtY35YAIw9b2NrWTXHb5FRw/eoTN1eNsbI9p4hSX9FnspiRaBnmCQOFl5FujMVVZcO5Fe9DCUUwmLO0YsHfHEldcfgWP338HG6urLCQ9xsMh62snSNrMG/wWE4zQEEeQejBCOc2gk2LLMZurx9i7Ms+OxTniOEFKwWQy4dZbb2P95DqTyYSbb76F17/h9TznuutACFZ27ODaa6/FOceFF14IgNYRddPwhS98AYB+v8/Rw4epiiI06BSDwRxz8/OceeaZGGN44P77OPvssxmNRtx7zz20IcZ9XCgGsWSxl3Nwq6RxFWfsmGc0njAsa1YW5xk1ju0GFud7SAF1VTHodsmShH1nnsPu3XueZIr/VL2sszOTYWsNbdNQlZ71JIMUTEk8M8caz+AXLkSze5aRN9v3nqXG+Lp5xoKQytdywbrCOosM7DQd0iZVaAo655t/vuoTnu2gfChL0tS0TYMUPkHNpxr7eenZQhGj8RghN5BS0pqWsqzQWUwUKaIk9b5EBrIsJUlirDUzX9WNrW1MawAf9BJrSaYEWht0pEiSiLYNLHXpWSFxHEPsGTpaRSTzi6jOPHJ+GSMTnPTm3VL5mjFOMlprKasapxOsSjA6ppGaVmisjlH4mjVCUeNzymWUotOctDdHVbY0tUELQ2N9HWim+7yOyLo9WmPpLyxTjocIZxnML9LrD8g7nSB3rDFNE7xdPXBX1w2tMd5zKU3RWntWkjQhAcsrFWIZ0Z9fomoMvePH2TppKIoCqsoDc01DFaR00/rKOmjbaf3lazCc3+OmTCs77ezja7FpUJCKYpSO0XFCmnfRUUwUJ3gfVotrS5I4Ic1SOt0eaZp60KPbo9vrk2Y50pXgApMKX39r4c8Cxtmw30sivC+Psaexrp7idfTTNfTTNfTTNfQ3X0N/w8CTsGbKzcEhA6MJnPG617osvHazrtFGINMOMpWI2AM3SgriOCbLMrJO1zONohitdaArTllPU+zFb4Z+gvm/O2cxQe8426hH3pxOaU2URCjpv74pRlSTIcVoi2q45VPv6gqs9XIwqUmSnDjvMbe8i3wwT9afJ+8PiKKIOI5QU6BESi+p0xoVJQF4UrNEFyGEB36cT2Oju0gbgB8RpYg4R3XncCpGyuCVJIQf6BYPrghfccjgou8BmrAIgZe2yShgOB7scPgFXEqfijGjztpT0rK29Qv96QDNFCEHQWsMpvYxlq318ddRFNPLE7p5xny/RxLpUChNB5WYsZqmH+ALGTndN2YDhBkbasaEEh5YQiucU6hQAE315Q4/poQxPgURMQO0pPRUQRBYKWZglTHtLEFplj7wd1MyAtDn0wT968m6PQbzCyyt7GA43KIqC9qpRl44GutQxstKhfSLihVgJFghvM8TEi2e2olYAKKp0EqjRIIncAkajWclOh+VK6zBOnBtQVNCoRwNQNxCIqiQISFxmv8C49EomCsKqrKgaRqqqmI4GlJVNcWk8OZ4DqZ8Nm+iHwzotSaO/HrQ6XRJkgQdZ8yv7PZz1UGepX6OOMdktElZjNhYPczBI4fZGg05sbHO4qDHQq+DZR3rlDd+j1Kskxw7eoTV1eNsDbcZtYKs02VhMMfCrl10k4iugrzZJJOGTldTNi2tgZHuo9MuKs0oygaTxci5BdTKOch8jqQ3T5L6rsfU+w0E2ptR4DBkK/vRcUax+hjF6CSlbRn0zsZJ5QsXPY9oS6QpcOkCpPPE/WVUtoBRKU01YTKeYIoCpbxfhk4TxMKiX/skjLeHGOtYOfMsFpaXSNOYanuIQaJ0jHM+VWQ6JaxxtKaijSyR9R1zayxtGzZRrUnShF0rO+l35xmPxxx6+D7WR9tMNrZ8/LJxtBCSM0zYIP2hx4TDjgtdXjeFoZ0v3mbSVSQ69bLr3uIu4qxDknWIE89mtMZ3m+qyoNw6iakmmLr04ymsj8Y6WuNQ1hELC9YRCQ+Se1Dbp3o2TlADNV7qYlozS2GybevTNp/C1xt+4J/w4z/+4/zq1dfyxPFV8l6Pt7/h9Xzys5/jyKFDXHXheTz0+GPcfseX6WUpg0GPc87Yxd4diywszLG8uMCdX74F4wQvfPEr+f33vpd7v/ZV7r77bo4cOcyf/dmfYa3lc5/7HM997nP56Ec/ytLSElr7dLqTJ0/yLd/yLbPXY63l4MGDXH/99Xz84x9nMBhww4tfjLWWwWDA29/2E9xz913/4xsRggcefJAXvPAF5ElMGkd0e30mkwmj4ZCFwYCqrllbW/Os5H6Pnbt2s29OkwvDV7Q3L9bFiEPHRiSRZt98h6OrW3S7XS654jKuuvY6uoN5fvnfvZNyMsa2LX/+wY9x9VVX8FP/5Ef43Af+HLd+mJ+9biePFpvc99UJe8+uyPddwmDxDP76k5/ngrP2891v+g4OP/EYhx6t2Z7UrB0+TE/UXHj2bjaOr7J6Yo09lExWh9xy/4NcdNlFrAwGLC1dwCe+8gibrea//v77+PCfvpcP/NF7+NrxNfbuTLjh4j089ughSqd46fOfzdfuf4DVYcm/+mc/xZfufZAH73+El5+xh6PHjvLFO+/jcqFYXlzkX7/9B/n5f/VLfOHQYTqTMVo6ep2U0il2n3keL3zJOXz2MzdRlhWDhR2cvWcXmXaoZkwaR8SR4sfe9HK+eNcDPPe513ujVJgdRp1z/N673815553HS15yIwL4tte8hte8+tVPat74BLUOxWTiQczhkNd827fNDrP7zz7bpyEqxX/49/+eFzzv+Xz/938/3/u938va2hqXX345a6urOOd4/XVXM9fNOTGuOXDwcdq65kXnLfPRrz3OPUeH/PwPfTePHl3j8/c8xIuefTlHjh3j997/J/w/b/x2rr/u2bzxe3+Qn/mZf8Zzn/fPseapPYebup7Jmeqqom4a6qqcsRiSSCNjDcKxtrZGXde+2ahiZGtoiwYRxVR1HRLqfApWGseoUD82beM9itqGuvbm6yr46ky9MME/86qqZgenvNsjSVLybo9YRUSJRccJ/XkPaujAQJcCL8MbT3j8sQNsbpykrkrKqiJLYqIkY24poapr1HBMEvsxduLYUdY3hwzHE4bjkizP6Ha77Nu3hyzR3nuuHJIoWF7usz0qKevQyE0jVBohTI2KU+LOgLm956HyPpVIQekQmCMpy5Kyqkm6EdpBhCDrzeFMS7F1km3bUDSSNJ4nTR0JBqe2sIxpSoFJurhsQDRYptNTxE4yL7X3EVtfJ0tT3wRIEowT6LTL3PJONlaP0dYlZ5x1NssrO+jPL7C5ucFoPGFre8juvWcgHWxvbTMcjTCmZX7gg3u6eU5VN6Hh6UjDaatsLXPLO8l6A8qq4TGpGZY1m5tr1AH8H04mNE1L09TEUeSftVI0dTUDLsLGO+vpwymbD6W8aiOKEzqDeeK0Q5J3yDr94GejQyy9RdmGbrdDt9tlx+7dDAYD8jwnkjmT0ZDlHbsYrx6irAsAEuV9jhKtUHGMiFOGRoD15xdjvexv+sLcN3hw/b91PV1DP11DP11Df/M19DcMPLWt38A8Y8ej40JInBAY5yjqGtEaRFUhG4HOLFErSXqKCK9bTtKYNE2JIs800lFEnHhdO8YE46rTfITCx4z946aQlDd4s9YijKBtjfcqKqUHJnDYpqAuJtRFSV3XwVTcgPXooNYKFackeZdOf+AZT52uN2qTEmccDT4tzUXevwjhGVDWOURAQU/5GflurTGWWsS0uovJHTKKUHHqE+2UIpL+Z4AHlqyzHnmU/rVPDZ+mHakpmNLW/ve50EmYAk7SeMTbWIcM3ltCaaQW05VyFpUqAvtHnvbzPe3WmxQa62UBcRTR63bp5t4cUYZvEMGsDKZUz9PYRhDeV2AtBQBp9l6EX/ymGlDBKW8rKQRSBpaSOPVNzlqskJ5pFDomLniAOTulDfsv9saEgeX0d8z0AoY5e79WWIQNUkGpSbOc5ZUdnDh2hKYsiIUmiiGOBHEmiJREaeElk1KDStE6B5VC3MPJCCuf+rF2dV1jlENbiZqqA51hmnjhAVQPojZVQ+HAtBZlFDIxiDxGpClOCp/IUFWYpsW5bQ+YSolrfVemCp3cqm5OdS4dmJlY03lfCwPYlroeI0TBaDwmjhNiHZGENMs0TYjTeOZ/0OlkmLZhbm6B3uJuRuMRQhlUEtGomP6uM8iNpVe3ICKqqmDtxJCN7RHjSclgaQ+d/oBOf44s69PtpCx2M1TdQ9mWiWih00GqlFb2qCMJCqq1I7hijBgNsd15nzZk55CtRWBQUob52gbffd8BiJIc0R3Q2XMxo+OP0xRDCt0lzrpEcQbjDNsWmHqCi3KcykFFxFECUernnZDoIJVVWqPjiCxLMXPzdPoDNk+u0zQN/ZUV0l4HqRJU3CCFQkUJsfA0YS2nUb0CY62XaISABuM8+1EYhcMg64ZIJ/TyhLPPPhewWB1xoLybejiimIwoWm+qipC+I2otRTn2f3dutkHCqbVd+MUEIQQ6zUi6PdJuj87cgCTJSdMOcRSH7pLxnZw4wpmaRvq1oykKX0j7UzPTRJWpP4W1jsZ4oNo1BictRhpsoLtLKYlVjHPeZ8C2rXd0fApfzjn+9m//lpMnT7J9cg2B4yOf+CRV04CSfO3hR0nimDP37UFJQR5HpEpyy+1fIY5jFhcXuPrqZ6CjmPe977088MD94VCrZlIqIQQry0tcffmlLMzPsWf3bn7j13+DP/mTP+ELX/ziKcnyaa9p+ueZZ57Ju971LgDiOOKSiy/hmmuv4zXf9lp+/ud/njPOOIMf/uEf5h3veAf3P/CA92BUklrA1vY21lqUVoFJIZifG/gEJenNk3VvnjyLuP7CDY6tb3N0fTRj3TY64c1vfhN5mvDQV7/C8DOfJUkSzljqotQAHUVccfaYubmUYw/cjim2KWvDrUdqdp+1l13dHp+461Fesu9qnvuMq/mbz9zMF7/0JT71sY/ysuc/C2VbrrhgH6KcsHboKHsuu5w8G2FjwWMnhiC8+fnjxzaItmr68wtcctHFtFHOn7733awsLfGPf/rn+cVf/EVWhyUPP3aYfp5SNi233HEPP/RjN3Dplc/gHb/525x/wYW84MqL+J33/QnL8wOuuORi0kizsbXN149v8cKX3MjFF17Ar77znezdvYsLzzmLRx97nLoYMdlc46w9u2jaFqs04+EGo7rwc8M5lGvpzKW4ppoBTdPrR3/0R2dJg1deeSVN0zzJQH4qowf4/u/7Pl720pdSV95fqWlbPvOFm3nw/vu45647WV87iVQSZx2/9mu/xh+///1IKXn961/PFVdcMfuZ1jk+de8Bds33uHD3IlcuZVgTc6KWXHvZ+VxzVcxnbrsLpxPO2ruXW+64A2NaXvL86znw+BM8fvgIn/nyXVxwwQW8593v+fufdH/PV1WVxC728zOJSLQkkVA2LdZBHGk6aUISRZShbm3ritFwiE5Sok6ftqmpQ1Lz1LcoSSIEAuvsbD5Pw3mm1gYuNDHN1EwavxNba6nblmZjAyEl6uTarK6bJgVneU6WpjP7g/koojUteafD2vFjjEbbdLKUrNsh7nRnPm2duZJyPKQoJmye3GRrNKYsa/qDOTq9Pr1+H5nkEEmEFiSp93aqVES2vExXJ6g0RwQf0/HJo9TjIdVmxa5sB3lfEHUVrjU4IbEID+bVDe3Glm9iWkfS7fs0RNcw3N7CtA2F6pJ0c+IsxrqjyKiimy6SdAeIvMeoMiS9PlGUMi4bst6AZR2RZiHYKPJ7Z1NXlGUBAtq2IV9YQWVdjPDMr56KiNMOo9EEISVZltPtdrzyQECSZp4d0ckxFqq6YWs0xjlvWJ1lKUkcs2vvPu8po2Meua+gLiq2hmOGo6Gf78aQJlPpj6JpGn9wtaHmcsxqZgtE2qs34iQlzTvEWU53sECc5sRZTpp1go+rpG0qnGnRKLJOj25/gLPOAyRlSdTJiNOMheVlNlePUZQN6+MKFdIElW5QViKd8pJHaykbh4oSUBqdpLPX+FS+nq6hn66hn66hv/ka+hsGnoyZ6oCZap5A+cLBAba1WLzWECOJrCARETJJvJZVRkTBiV8GmlsU6LO2bX1sIqfMpq0LQMMMP/CUxuCEhHNixmBxzgXTLoEMjCdnKpq6pm1amsbgjE+ywIJUoIVGxgk6zYizDnGaEYXUCQEzEEMIQGlkePjCnDIDE5xi/QjpTQtNa2icoJUxNu6ideQN5ERIahPMgCfDKXBp2nWcXeEe2NARaNtm5onkNwMRgCb/+5X20j+l1Cw5wjO7DAQUFYdHMMXUV8ofIoxznm1kLbEQRFqTpYmX2YWIVv/a5BTD8ZtmGA9TAMnL3U4BPKf4Rh4M9OZm4evC5wIX80kA1uwWcArVnWFI1rv7u5nk0l9te5q/1ZO6JlPmlTgVEQwEGyi09Bvv3MICed5hMtxGC0OcSKJIEqfeL0NriVI6GIvHuKiD1Ckq7YKKvRb5KX61psU6iXMtTgo/T4Snu4vA3prSnf1Yc9Rti3Qa1YCWHZI4nqVVtq2hqSqapkQKz/qS1rPVWmNom5CGY09JSqdjzuE8oBg+17SnggXiyK8VnV4Pi0VFyi/M0huExlEHgCzvkXYGTMoJm1urSOFwSpLP97HOg5HluKBuKu9FUdbUjaXTHdDtzdPpz5OlHdIsp9PvQp34BMm6QncWkEkXIbtYYbGu9lTbpkRPtqCZ+EXcOrQxSEDFMrwHgw0GqJJAI08yksU9lEVJKxPauIvO5iDr+xjUtsTFE1opETpFyyDp1YrIxQip0HGCDZIkHSmiNANApzk1EXVVkvXniLMYFWl01Hr5QZwitKfuJyoOa6Z/Tj6uV/nYXcJBJKwHTdN6Y3+tWVleZlRMmDSGQ4eegLql2Rp60EMKkizxHnChaJp2ruSsi+Cm/pinDBalIk5Tkiwn7XRJspwkzkiTjCjWs4OUxSKkoC4zny/bGtqqRliHkHa2fkgpQrImID2Yb1FYp2YUYSFVSIWJEYHS6pw3TeUpnqgD8MQTT7C9tcXuuQ4CWNvcZNeunUSRZjIZ0+92mBsMqJuaThrTz2IeeOQxHIJxUfD8578QpSK+dMuXSLKcnbt2c+zYMba2tgD/XBYXFnjOs6+lriqGoxHPue46Pv3pT4e1+smvJ8sylpeXSdOUxcVF3vqWt5zaEMJVliXve9/7OOuss7jhhhv43d/93SDhiWcR0mVZ+LGoFVVV+fmfZlRlAc5RNw3EOUm/x77lOYZVQ3FygtaaTrfLwo5dXHbpJUgcX/jMTRw9dgItBOftXSLr5GRZyrzsYK1ldPwJImGoI82J7Yr9nR6DxQVWy+NYnTE/N48WjtXjx7nzjq9wxUVns5LBytIc1doq5aRARp6p5SLF49sNWkrSLGJce9NQWbbs2LOASLp85OOf5MUvfTkXP/M6Bss7GJ04zMFj65y1bwdFYzixts6eXbs4/5yz+M3f+V1271hh59zl3Hv/A1xwzlk8/7pnsb21yVbRcHi75boLzuWsXcuI1ieAdbOUJFIIZ6iLMb08wdiYyjk2NiqK8ZjGCRIFkWvpyi62behlCZOqJooTlpeXefnLX863vOxb/AE6JKKtrq6RZSlzc3MgoCor1tbWeMbVV3H9c57jaxnho9SPntyiqio210/6miE0zb7w+c979ouSXHbZZVx55ZWzseEcPHhknUnZcM5Sn7lYgFNsFoYLdw1YWhjwiTsfpjuYZ9++Bb6+ukaaxFx6wXncee/XOHr8BJ/90q38wi/8wsyj7Kl8NU3rC/bIG1trAcpFM8PxOETOJ3HkjZat9XWsHZFYiLtzmLbxnh3WepmY1r5Om3atp36kSiGFP8i1eNNmd1rtOmWiO3x9X9d18Ei1s9o263SQUpJ3u16GJf33ZJ2OB6a0JtKK0XYXa1qSNEUlOVmvD86RZhVrTY2dFIzCHty0hvluj/5gjt7cPHEaoxUoJYhjhVaCVkl6g0XSvIdKu7TFkGa0SdkeZVTUbJYF2coIqzN6aReLb4K3zoOgjWmpW38esQ4WOpmvj21N7TwrykQdRDZA9TswLNFRS6frUHGG0DG1gUx776VRA0nW8TVxkgZ2lUALR1NXCClp2pa2NSQdH/7jpA7pi5K8qzh85BhYR5aldHs9dBRRVBU6BPQkURxYIobR2KeRZWlCGkeoOGZ+YZGqrjHWcujxR2E4pDaGqvHMCAFPktKdzpIID39Wl8M0DVF7YCLLSfMuaafrg5+S3Kfwhf3UmSYkaYVDexRhgkSsrmvo5ERxTH9uAVREbQW18361CkdtQVlQ1mEQGDz4lUReraKf4mzj6fV0Df10Df10Df3N19Df8Gm5aurATBEzqZhznsninE9Jq+raL75uQpSOScdjrGthMMdg0JkxnZyQ5J2cufl5JqNlitGQYjSiLkof3WpMiG+1tAFk8CCMmdFEbXjwU3aLB6u8dxACpLC41mFROBTGGkxjgy5RksQZujMg7nt9qYo96GSn2se2xVjvldSGASSlpK1Kb1Be176TILzTfZJ4Xa2XDpoZfVQ5H6up3CTQnb13ktfaC6zxi4ZpvDgPwGk9A2GauqFtGn9/qtojwcrL1axztE0LeE+FOPObRTc46iulPF2vaWmbdiax01ZDWPimwKHvDPkFTSlJrBVaetlfa/39FzJEMwa20rSTJuUpj6WpHE9KjZnRJv3lfZAEU2cnOwOppml+zH6Ol8oF6qoA442+vPa5bQPAdIqBZUNXxzlCCkeYoKcjxbOxasN7lehMk+Ud9p1xFocOHMDWDTJEjedpTK+b+0IwipEq3DetsVGK0zGkXYT2nltP9csQPNKsofVtEoQzKOm7WkInPoZUwMQa2rqkaWqKk9tEWZ+5WrIYxaS58nHGSuOUxjUKjAXXYp2ZbRw4n6yglJhRvKVQAX0FIdQMTMT5VMGyLJiM/LPc2t4Iko6czfU1kjgiS2K6nR5pktHrz7OwvMKy1iyNV5gUYybFmCSOaMox7WSVZrRGtb1BORkRx5qkk7O0dx+DpRX6i8vMpwmJkqAUstNFSEmkIlSaIaOYPMmwVni/C9nizBBVnyDSEUbnbNeNN2TUkkh3ce6UFtsYf2iIkxIlJcncIr0oIW1qlI6Jk4woTmm6XYQALSVNMfRz1jhc0yJdhU4isk6XKIopgqFs09TY1ncmqspQtZbWQZZm9LtdBp2MIs69v572666SikjpU505dcoDrrHtTHLRVN7Qsqi8h0gURXQ7Pc7dv5+dO3ZgBDzy4ANsjG9HKkW31+fCiy9F4tM3DzxyP+V4m7oYUw9HPprbGk/ZVxKpNFmWk2QZc8s7iNLcx/hKn47pBCFt08cLpyJHaY01TfDkwK/PpsW6lkgKYiXppRELnYg8kQwyRSQUSnjfFCs1RseodA4Xd3D5HFGcIpVPGvIF41NbLisEvPENb+Cfvv2nect3v4litM1zrrqMsjYkkeLbnnkBt3/9cR44eIzHjqzy3Ksv4+UveDbWGJIk4apLL+SeL9/C44ePMRwX/MK//je8+tWv5kUvehGrQfbkEJxz3vm87Z//HN/xHd/JZz/7WZz1XiKhffCk1/TiG27gve/9A3q9/qkXedpljO8Gf/hDH+JvPvQhLrnkEoqioNvtcs2zrmFj9QTbmxusrW/6b3eOPImp25ZjJ1aRUlC3hi9+8Wb27NzBWWecwR3HRlSVYf9cxsluznXXP5ef/Imf5F/+7D/jq/feS9G0DIsK4RzLkaHJE5o0pkxTBlnM7kHC8mUXIKwl3jjGZH6FduEM/uPv/SwPPvAgv/277+bG5z+bF159KfJ738T9h05y/xOP8uDREZfu282uhS6qHaNiiBYHPHNnytr6kMceP8aNb3410WCBex86yCduuZutyvCSb30z9z54Hx/+5L/ih7/vzXz5zrv47Xe9lwObJSvLi7zxNS9DK8vWxio/96Pfx30PHeA9f/iH/MyP/mPW1jf5wMdvYjIasmvnCq/71m/lti9/me2tLb74pS/xG+/8Vd7ze+/iO7791cRxTFnV3HzbrSSR5gXXX4spFzEqpd3e5MGDq9wx3GbnQo+lXsabX3Qlf/nFr3LJVdfwgQ98gCxN8SNAoCPv4fOqV38rN77kJfy7f/vLSC25+eabecMb38j73vc+Xn6a7LIsCt712/+RV73yVXzlzjue1Px505vexEc/+lGAmXQMfPNKKUU3jWms47YDxzl8chus4bq9I95338OsNYJvveH5fP2xg/zV3/wNP/iPf4jReMxf/ve/5tte/Wr6nS5/9Ie/z2/8+q/xzne+k+Fw+Pc97f5+L2dpm4aJc7g4QuAwbYsS3tep3+34pqGUzM8NKKqa1ZPrjIqGxZUd7Dr7POqNDZy1RFqSZyndTk4ceQ+lqUWDwzP7baR957ptZqWYCoCUlKFD7wBqnPXm5XVVBkmgYTQahr876tJ79zR1RZympGnKwsICZ55zHlpKjh47OmOeSx2DNUhRMZ4UbG4PWd8a4pxARwkrO3awvGMnSzt2EicJzhrqcuLrEaXIO12i7hwqy4nSDlGnT9odsHlyjapY4/jJ46yUNVnb4kwbPHOglRG1hcYKUh0OsabF4o2I84WduKRL0zTk3R4qial1RL58BkpHpHnuTdlb7xPrEFhj0FqR5X3SWGOcPw+UpZdIei8cTVm3VHXDTuXNt9MsxZmEPE3p9/sonQCOpcVFuv0eUZzgjeAbmqZlY3tM1XjvlzSO/H7cNpRlCTgW5+fpJJodC3OMtrfo9AYgFHl3A+E8oKV1BEJQh3SzYjLxUs7ApJjWejqK6HQ7pElKbzDwzJE0Q8UZUmsv4cIiwtmkLsY0dUVbl+D8GBnMLfixKyWDuQFplrP/zDM5+sQBEq3YtXcXxXjsD/PdHKEUVki6aRcrFV0UO3btIc1yJlXjx6V8au/BT9fQT9fQT9fQ33wN/Q2flq31aKlw0i/GwXeHmb+PmnUXmqYKLBpL3u3Q6WQkcTzb8KyAKI7J8pzBYI5YR8RRTJX4+GTPVGr8oGuaYLZ2mt+R88URjtOYUaGTI/0NV1LgogjXxgjnaITEtM1soxBKIVSEVDFI7V+7dQE08ki+aVs/ASanzKrL8Yi2rjB15c0RhQTpHe2jyDOFdFiEpjGLjVKoOkJH2jO+BCilkcKzcLCnJGTGGoTxCKI1hqYqaevGD8CqwrQtTYjabIKBoKfjCbLcm6KXxZA0y4OHVjRl0SFkiHFF4Ak6njkmCMbpgb2lpAwMrWmSjZiBYoGaFRhns094EDCARcCs03L6OeR0k+9pkt+MESVAOGZSxmm3xtopyGVnnZwp6GSDSTk8OXFHSE97nb0S52Z/usAi89StAFRpTR7MEUfdHqYqvaFelpF0+6RxSpKkyMjLJdEaESjCxAmo8Pmn+OWsxYkWEeaMwKHElLQb6PdCYoXAhi5V1RomVY1qLUiNVJDlOXEc44wv+qSz+OxKFwrecHgJPw8VaKSEBS/8Tv8YPCCopQLlcHESDOH9866bGjtyNLVnFWgp6OQd0jRlbjyh3x+QZVlgsPnNeu34CcrRJqOTx6gnI8qiQAKDhRXS/jy9pR105hbIez3fTQyvR8YJSkdEaeaZj0rhpMQ5b9razu+h1TE2m0PN70L15shF5LXQApqmno21qReZkjL4v3mjelSMEgolNQiJsSZ0kkMUtpRI0yKaBicUCOGLGgQ464Ft53CtDN1PD0BnaYIQMYshcl5H3rNhutYprWcyiWlHXMgp8xGU9L/HOYewjlZOCx3hY6abmkhK+mnKmXv2QdNSlwUKbyx83nkX0LaOsqrRWcrWiaMM11fZVCf8BhhFRFrNPOzyTpckTcn7Ax8vjS9MmralLSfUkZyZVDsEzjhv6BhMFFXki2NnBYn2LIEsz0i7KWka0+nmRDpGKy8VskpilcZlPU+9zrroKA2y5MiD1U9xuaxzcO+99/Ke338PgywiMgn3PPgo870OSaS4afU4m6Mx0hqe+8zLkULy0c/fxsrKCk3b8oU7v8qRY6usb24jhDf9XVyY58bnXcedd9/DvQ88xKu/7dt50QtfQJpmvO51r2Pnzp28+93vhinXNTQGwDcJHj1wgN/6rf9ElqXs3r2b73rzd/PhD3+Yu+66CziVWCuV4r6vfY3RaMQ1113Pnj372H/WfjZWVxlubbG+cTIUiy1ba8fBQRQnPHHoMJOioG1bTqyucuhIj4W5Lqttw+a44Mx9exGm4m8/9hEeeewgm6OC5ZUlzr9gJ71ORnH4UfYtLXLOGTu4/d5HQEXsmduJNg1KCnpnX8zyGZehFnZz9MhhBoM+z372tRzf2GbSwq49e8jShEGvx8q+s1mdrLNdbnLxlWcRqRwZdX3qjajZKFvI+qjuEk025pnX7cM6wV1fvpkdy0u88IU38NChg4i0xxu+67s5eN9XGAx6XPWs55CmKSeOH+PWW29l154zuOYZV/PZL3yJoiyoypLdO3fQ6XT54p330s+7zM/Pc2RzzBkXXs4rXvedPPjw18gTn/bWHczhrOPhx49wclgwLismwxFVY3BSs7o98Q09JHXrDc2zLEMAW1tbfOJTn+LE8eMcPXKEg088wc0338xv/If/wP/z1rfQti1bm5s0wTtoeqVpyo/88A9zySWX0O12g1muZ8286U3fyRlnnMF73vMePvnJTzIcDvlH/+gfceedd/LJT34SLSV79uzhW1/xLXzkbz/B9uYGlz3nevKjJzi2sU02v8wOG3E5iU8mHI2555HDXHbVNSwOejz6yEPc89WvcuCxx//PTcb/j5cKzTyc97WUEr8+4xOfo9h7x3jZBr7paRwGEDqi0+kyGg6R0rONVGDSw6wpHhq1vkaa/psOTP6p8bsMe4AxXj7h9wPP6k6nZtfGN3qrqmJj/SSj4TbOWdqm9mbGcUIxGTM3mCPLPAvI4Q2zTxw/jmkq6mLC2tpJhsMRSmm6/QH9/oC9+86gPzdPp9f3qdfGoBFo6V9r0umikwyp/Z7ssFjTIvM+Sc8wWLL++zu9U/sWAhnFmLqhMY48zz2gVVW+SrUOg0RGKZHyh1YnoG4NOs2IosQf4IQgsYY0TbEIjPHhBZH0iXPGGtqmYjweUxfjAOhI4sifcfodL6XLs5y6KolCo3lhYd43S4X3qXXWEOmIpvbsQvBN3yyJsZEKYJHxhzohZ9HtWZ6xZ+9eVLDWME1NEmuWFhawwjOvjh8/zonjx1hfW6OpisBg8+u3D4TwYFiaZWR5BycUFkHZNJi2oREVpo4gAKNVMaFtatqm9PVS26CVP+9EWvsQAxHT6fbpdHuUxYQ465JknpmbJ3GoqTSN0N5TKvHkgzhJ6TgRar7/o9Pxf/l6uoZ+uoZ+uob+5mvobxh48hNOBS9sGVA1eQrh8vorzxBqGmhbmqaiKvrYdkCS+EV5qs2Koogsz+nPzRMnPjWjTFPauqYqCuq6DukPVTCeNjTT1AY7nfL+F0/XKudc8D4S6Eh7iZlpkM57V/iOjQ0JdSokw0U4oXBOeLlZ6wGnJsTJmralqapZvOx4azOAQRVN0JUL5TslSRzRy1PyLCONY+Ik9Q9DKVQUE0UxLvMdHaddMAS3pz6sTwLwkl1DW1fe7LquA/Dk0fNJMWFS1UzqmqKocMYn2eWdjCRNKMfzZJ0eSZrR6c+jlB8USqqwUAlvhj3DjjxrS0mHkipII8Vss/67m4GXvU0PH6fuvQd0RPgnx8xpXExZg0FKOf0hpzR6sz+EFDM6m3UOKRwGN2NBzdz9p1RiF+iu4RkzBURnwNP09T35dZ5izjmfmtTt0e326Xb7TKwgSjrESYckXyBJPbKs09QvppGP4hVSevApdCif6pe1BsR0gwuG7TIkFoQNzoWF1DhJ6wS1gbKcIEIqAs6Q5V063a73vpLSLyLhobpwQFUhclYIEVI+/KKkpZjRgZvGP0uDL7ikjMIYNcF3oqFtfRdxNBqDs7jgY5CmCaPxhIViTK/Xoz83oGkbWtNw/MhjjDfXGK0eRdgpC04yt7STwc599Jd30ul0yfKMKJKIMC5l1kXHCUmn41cV5zDOAAoU1PN7IZ2j6hd+08z6SNPggpl/0zZPkt9KeSoowOuljd8Igwmq915rZ8kwWmlEFKGcRYS1x1nn19ow9pVSKOs7C1VVeOaeVH7NSSIW5wZo5Q8jkXWA34y9LV8oPKWcFS9TkFcGtqGXX2hkK31SZ5Dg1k1NlsQksWb/7t1ESiG0opOm9Ls9zty3n3FZMykr4l6fE48POJlmvnhKYrL+gFhJpANlDZ2e7/jKKKEoS4qyoimGNG1N29SA9aa5eY6OUkCGjqDv5Cvtu37SKtIoIYljsrxH0u36Dt9ggSTJiaIEI4Uf11Kgs44PikhipA7SauXZjP8Q5vDtd9zBnXfeyWuefw06T/nc3Q9w4b6dRFpz3+NH2DHI2b04x/OuuYqbv/JVPnzTF/iJ7/1O1reGfObLn6epKlrTzsIa0jTlja9+OVpJDhw6ypu+681cfvnlCATf+R3fyfnnn8/v//7vz5Jkp2ml4Mf5Qw8/xDve+U4GvQ5XXnklr3nNt/GhD32I9/3RH1EWxZMaAtPr2uc8nwsuupgojthcX2c8HDIeblJXBWVR8Mj995Joza6dK4wnE8yaoSwrjq+tkecJ5y7Nsz2pmKxtc+benUwmI/7bn/4Jjx06ghOShYVFrnnGlexaXuJDf32UxZ07uOTS8/n8Vx5G2xjm9yBOPu6f+e7z2HvJM0nndvDBD32Iq66+miuvvJLff/+fkRctvaWdJJFibtDjjPMu4q5bv8jWxib7r9tBL19Ad8dMThxnJEeMRUytcnTcg+4Kz37ONeSx4v1/9F5e/8Y38S0vfyX/6hd/kZ07VnjzW17Df//DgiiKuPQZz6YcbXLi+FE+9slP89a3vJVrnvEM/uCnfoYkklx83n72776S2kk+e/vdvO6lL2D/nl187t6H2Xv+pZxxzgX8yFvfQCdWpLGmP7fAeFJy36OPY6wvesfjIYlW6Dhmc3OLsjaMG0fdGkzbMtzaQkjJ0WPHeN/738/XH3iAQ088QVEU3H777Xz9oYd4+be8LHShDWVZMh6PZz5AeZbxT//pP6VtWyaTCeVkAjh0FPEdb/wOrr76GfzRH72Pv/3bv+XWW2/lrrvu4i/+4i/427/9W5QU7Nm9h29/43dy+NAhDh18gsuufxHzjx/g2LGj2P4iu3pL7Nx/HhdefAlb44qrjg658NIrWegmXHvtszmxtsZjjz/xf3Iq/n+6tAoWBeE+giSOfWjMVMI09eQ0xtAYR2sBqdBRTN7tztLpIq2C/+ZpaWWh4TtN9FWhNonUFGw6lWwshA+XUW040EpfB2oVh+htP++qqvLmxmFfNqYNcecx49GQydKEfq9Pp9/3+3bdcPLYEapiQlmM2djYoG5aojhhaWmZlR072XfGGURJhtAR47JGCOnlqrFXDURJio69ikAphXU+hU5mfdKBZFElDOYX6PR6oQntfFUTxzTGIYQlyzIfQhA8cWxgjDgVIbVPcDNNQ922dLsdr3qIE+Io9iVp3rI93KaqamKtUIHdMpUSTcYjhsNt73nV73s/VCEYdDt0e12yLGcUamnnYG5uDmMM29tbtG3jk/eiyPv5VPVMuhhH07Aizxg14A/YbYsUkiRO2LtnL2maEac5aaTodnL27dlN1VrGZckDDzyIUNonMzc1SkqiKAr+Noosy5mfnyfNMnQUU5QVRVkyHq97OZm11Mofov0ZqPQmwk2NaxuaqiBJUwaD/sy0XihFp+tToieTCVGW0+12ydPUg5paE0URo6pFRTH9wbw3wdYaFSde3dG2/xdm5Td+PV1DP11DP11Df/M19DcMPDXGetM0IX0HE4GS3qhaIMKk0EhpAhLr36DWiiRN6HR7viPiHEIqv+DFCUqqAPLU1GXpNcNVSV35GMO6Kr1RYOs3iGnEsnUBAAsJczIsrFp7n4g4jgMZxzLaOMn2xkmOH3yc0fYmJkwka3wUs6lbmsB4aqog92sb2qamqUq2T66yvb5GMdxmtLXpTVHblgbPdhJRQpwmaCVJhGG+36fbyZmfX/BIrPLIaRQnmLqDswYdJ8RZ5plFUqIC+GLC4t42NU1RMBlt01YldTGmmIwpiwlHT5xgWFaMqwaDBtNCW5PLlkRLtno+CjbpzrFy1iXk3T5Z3kNrrxf1sjkdntkpbafWMUkAAaepdyYYoMOUUSj+x8ERvAKEUB4UCsunCKbgZmqMFwzLBCJErYbvFVOG0lSEZwIuFfD/UOw4N5XbhY5eMHefpvZ5yeEp4OvUn1PWlv/f1M3fAU3ToJU3gez0B3R6Www3N0H4uFyddtCdDnGnR9LJTvPSmprJ2WAS+T+5L0+xq6p8l9p7E/jFW0UxRipskBF6maIglgkChXCKuqqpm4rh9kmqakKcJMzPz5GmKXEUowPFUqDQUe6TdlRMLHziRKIhyXLiNCGPUuqiohpP2NzcojKGqqn9OJCSNE6CBNTiqgLbNNi2pqnq2XObRgW3tWFrc4s4jskHXc9+sw2HDz1GPRlh6gpbNygV0V/cycoZZ7Gy/1zywQLCGlzdsDapiJKEXm+ASDOslAxHQ+JQEEkZUzcNZVWxrhaRnUWShYRGSqwpUIhQ0EkmhU+XqeuaOPGJnUJpmsZLQ01j2FrfoCxKoiyYPSYxZVX5NSzy8y+KIvrzi1STiffZGY6CTHbquSFIs4T1zU3KyhtLn7l7J0vzA3p5QmNamhCfHfbJ0BgIf4S/T+ejsQ6EBxW8kbMHqYWQlLVnntatQYgaYw2DTkL3zL2cuW9XqOSnCDaAI08zuoN5rDHsv+gS0iwn6/QYHj+MqytiLFGWg1SMywI1HCKsYbsaMd7aYHt9DWOsj/VO05A6IrHI2RiwpvWOcwIQ8czoMI37pFmPrL9CknvvPpknSK0QSqJl5OWyQoDya2+sY//3fwBzGHyhc8tXv87Ze3fx0299HZ+65U5aY3jH23+I27/6AA89fpAPf/YWzjxzP//yn72Nv/mbvyHPO/zEP/5H/NFf/CWPHHjMp5i0BiEU5139HP7p1dfzM7/4yywvr/hOLI4f+Mc/wE033eQ9X6a6fzctvvwef+ONN/Kf//N/Bud48MEHufKqq3jb297Gp2+6iRtvvPF/Kn0aDrc4cfwI480NNjY3adqWiy67GtM2VFXBYGkncRwxGPR56evezOqxo7zjl3+R5bl5luaXGJx7Ac8823FV03D04MM8ceIoX7n/ES656CIWllaY27Ofex45wtcefpxXvu6NHDlymPd9+gF+5Jd+k3Ftuefrj2APH+TE4cf42J/exAte9ggXXHoFF55/AQ8feJzP3XY7+3bvYjye8OGPfBiVz7FrxzKve+N3M7ewyNcffIBbHzzEy174PJ777Gv41V/5d+y56Dp+8W2/xB/8yZ8Tp0f48R/7Md7zgU/xyMGj/OEfvp8HHj/KX9/0Jf7Fz/w0x48d5ebbvsz+K68jybs8ullTrZ4gdobff8/v82d/8Ve84bvewm//h1+naFru/frDPHLwCIsL8/zk93wHH/j4Z/irj93EReedy2Blmbm5Pt/70/+ar97+Jb708Q+wvrVN3bRYazhr3x66WcqJY0MK6buyICmqmqqqUEpy111f4epnPAMCELGxvs5P/dRP8brXvY4bb7yROMu55IqryfLO7Bn+k3/yT/iZn/kZAH7u536O7/u+7wPn+NM//VN+4Rd+wTeKwte+613vYvfu3aHu8p+Ngh8lwNr2mM/dfhc/8LZ/zpve+AZesLDIH//FX3LNM57B1S9+Fu//qw/wrGdczbd/6yv4lXe8k+WVFX7hJ3+Cn/nnP8sXPv95Th4/wmQy+Z+CnE+1azQpiYKPk9a+dkVK6qYF2xJNilkB37Q+XCVOU/qdHgtLSyRJ6g9odU1TVVShpm7NKXnOLFwF/CEpsJyiKEKFjjn4Gk0pgRQO4VrP5DcWF0VYa4LioGLmqxpq5LqusS7COsFoUmBX1xgNRyy1/meUkzGHDz7BZDRkMh5jnCNJUnbv281Z557Pnn1nsLxrD8PRhM3tbTa2R2gd0et1iZIEaw1Hjh5l0O+T5zkKx7iYMBqNqUVEOlhkbmU3Mk5pnfBqCqlwwLicYMsSqorhdji4Ihj0OkgERTHhyPE1huMJaZox3+8y6OYcP3HC21UkKbt3rpBlvolrTA7AsSOHyTtd8m43JECd8j211lKUBWeddSbLi4ssLC56k2i/SFLVFePxiLrxVhnD0dAzx9qWsm7Z2Nxiezhix8oKWkdIpXw6cxjPNlDZrLX+oCgE8wtzdDo5y8vL/skEQKkeTigahxGKztwSe2TE7t27fJp4lrG5ueHj1ZWk1+2ilGI8GlE3qzRVSTHaOs2U3IMXbdNgTevZWs5SKUWhfAKZEtDJczrdnjdBz3IWllYQQpJ2O76m7nZJ0mzmJVW3LQifRt623sJkcX5+xnh9Kl9P19BP19BP19DffA39jQNPwchQGQsBhMJ4DyQRoL+g6PIvCJDKA0xpmqEjrz0Oir1AoRPEiTcYnTrDm7YlThKa2i/STd14BK81NG0zQw8dU8AkGGtL79oeBfQ9SuIASjg6mU9nM3Xl9c9VhZMyLObG+yaFrs8UMPM/N8Ia4yVxTU1bjmnKEU1raI2lQYGKwDqfJiKhtjXSGUxTEUcRcZISx0koCIx/33EMQqDjGBT4rVFMedKeddUEyWFgWtVVQTEeMhmP2NpYZ1Q1TBqDUzHSWaRpiESF0tDKkkZ5Sq21BhABHJnKIqdsITfN5px1W6JIBzpfgIJm0jhOsZymkotTarZTrCgRnEDcFDRi1ombSt0IDKUpYHXqZ576uwinnOn3mdlGf8o40ZtrSoSwAXyapjna2QRwbkpBf7I7ydSvxFmHUyCkIslS4iyhbmqquiJpKlrrQTCUDAw5PQM7EeDM9BY89Yvepm1P3VvFrDCS4UNY75k1LdZ8kqMMQKLv5vjN0YN3beMNLdvwtQJFZGWIeDZBhy5RQns0PcvpZV0qMULUNZHwmnk1HRfOgvTzxFhvqD+N6Jx2lgRyNjZ9JLVfG0rToIRPxqjLmqZusY3FGC9RyOaXSDo9opCeYozBNn5zEVLTWsv2cAvbtlTD4ewZaxV7E38pqKvgc6cUdmKQShApjUyFLxiFp/ZNzV/Bj7M2FFR1WfiPosC6lqqaBMO/Gqm8zKIzN0ea5x7UDOEIVV2HDVDM1j7rHAiFkL5AVVISTcHccE0lp393L3D4jc7aqcebC95tBPmqmBESZ1PcWqz1sarKeVp0olUwtLQ0bZBU4T/f7/eJI8380iJSKrCOOkpACGIJKk5xQqCq2nfL2pZ6MvZJpFXpx6iTNBXY4C84HYu4YJgYlqG69h3duq39e5HCBzrEMSqJ0aEbJpX0/giBVDndNHUUzRJB/6FcTWvYHk947MhxpJLESvLw44dY3xrSWMjwEc1Hjh5FBlnwya0tTGtma+vBg4f4yl1f4bHHn+D8887jqquuBODQoUN8/vOf5+677+bIkSMIIXjWNddw3nnnAXD//fdz99138/JXvZwbbriBM888k09+8pPc9uUv88Tjj3P33XeTZRmvfe1rw9g3fOQjH5mBUJsb63TyDFNXlEVBVTc8+vCDXtpuWs4693y0VlRlSdU05L0+3/rq11AWJQ2StNNHO4utCtbWNzm5sUVV13R7PVZWVthz1llMtgeYumB9VKI78+w5d4HVcYOTmsUduzDbZzEsa9a37qLT7bGyvML66nG0kOzasYOtokGriHPOPIPVzTG2Ljmytglpn4U9Z7KcD3BC87WHH+ecCy9lcXmFJumxvHsvOMeBxx9n0Ek5Z69PmIu0openHDx0iLIoWF5e4e57v0re63P1tc/hse0TmNLR689x5v4zufzSS+j1eqTWsX/fPlxdobXyrC4E3TynHA8ZDhO0Vlx12cXY8QYP3XMHJ7cf8IdHY9gejqjrhmCYiHOCxhpUkGot7TqDqq55/InHAOj1erziFa/gmmuu4dxzz+UNb3gDKk7Yf9Y5dLvdGbP4ggsuoN/v87GPfYxbbr6ZvXt28/wXvJBdu3bxnOuvB+c4duwYn/3sZymKgsFgwHe88Y3ceuutHDx0iL/+67/mjjvuAHy61uLCAs985jMpq4q19XUuv+IKdu7eQ9bp8oyrrmBlZZkTJzdY3rmLPbt2Mt/vccH553Ps2DEeefC+fxCgE0BRVT4NGREUAJa6aama1rOeJgVKR2G90lgHxliyvEOaZmEPML5GNG1okra07dinHxvPgBCh5otjb7eglUJphXKKU7HGfn33gTcEVrmhqb0pvLWGtvFsJBHkeS4YUqtQBzkHdV3hrGF7a9PXrVXhm8nBeHraGM7yjk9PS3PGRcVoPGE0GoGz3k8Ix8bGJmVZsHbiONubG2RJSncwAIRPYgspi03bUpYV1kGkI5T0Ng3CWjANtBXWtITijqZucM4yGm4zGQ0pJxOUEAy3GqrxFidW1xBSkiQptinpdjv0en1/m6z3hq0tuNp5ZomO6XQ6tK2/R3Vdo5Xy6WFxFHyimhl7SAhBExLmoihGqgikorW+ER9FEcZYhLTeCwlm7MLpvmSnDXP8vqe1Is8STGsCo8LXM9Y6sixncXGBfrfD0vLyDOidTCY0TYMQflwZaymKCcVkQllMaIKqYhblPm36Tn3DcD6oSRnGwyFbGxusrp5gZfc+pJSkqWfltU3tWXFJ4hUtWU4cJ+g4wYTiQkpJnHjyAcL7ykXRU9sr9eka+ukaGp6uob/ZGvobNxc3BuVAAa4RyHD499JT/4ZMSMTwzGBPDe72B3R6faI49jc/AAkisFOmPkRx4mibGGv8pmfCgm0C5Xe6EU6BBDF7ouIU2BS6SEoqdOTpyFJJivEiW/PzM9PG7e1tnxrhCH5OVRgc2rNopESriIgErRRlmqClQ9oK6jHWOForaIX3TxIOcIbGWVxTYOuScjIiihSdTs/HStY1pmlwxqESDzxFaeafuhQ+mjOwc9qmnoFNbTD0q8sJo+1NtrY2WVs9QdE6KgsyzlACYmFxqkQ4gywnyDRBtLmXzk1ZOuHAMfufs0zTAaWAJPZJPUmg5Hos7JShrHVed+uejDmdkrGF5+KECFTyqddAAIROk9dZF9z6AeFd8mYTVwjf1THBz8laX1DN0vJsMJy3NkgIJSKgzUJI/0zCxub4OywpCD5jFuHczMROSEXW6ZJ2OozLMVIJhIK5ZpnY5KdJEn3H2L9uD1/Z01hhT+Wrqk1A7yXG+YRDLSSRVCiHB4+1Q6KQKowRAS1ghUTHKWnWDT5lXhJQBeNRFxiIUdMGDwlFkqY+1YWYNE7pZh3m5+eZCHDFhJECIxwxAmO8kbw1HmhuTEPVeENUgSBWCqH9cqUgeKjJsGC3TLY2ERiEMDS1wbSOtm4xKHSc0dt9Jkm3j5CCpiowjaGt/eGsES1lVbNx4ijFcJvhiWOewmwdcZKysLjAwuIiVemTR2w1lVcqdBwh5wQy894UVZi/VVV6EBtBXRb+c5MJ9WREW1aYdsKkKhgVE06eWEcKSZZkLO4/k85gQFlWRNLPo7KsSFOBjmK/OTlorfWyDPym4XdA48MKQmV6CsCdXlPgljAnntRk8WAu4Knk/ppSh910LjqfMOas9d4PwYuvtQLr/NdlWpGvLCNjTbc3x3h7m5PHjqMgpHB43by1DonANg11WTDa3qQYj2jbljRJ/fw1lrqqfEElCHIRNT034YRniba2JYoj5tt5nOsiIo2II0QSzdLTVFgPPPbtQJ3Sunv/wX84wFOsFSdObvDHH/001195CVkS8zt/9kEWFuZZnJ/jnLk+R48c4Yu3fJlnPfvZNK3hM7fcyvZwSKQkxjruuON2JsWYO+7+Kt/x+tdz1VVX4pzj9jvu4K1vfWsYv34MfN/3fR8/8AM/AMCv/dqv8dWvfpV3vvOdnH/++TjneMc73sFNN92E1or3vOc9fOQjH+GrX/0qg8GAoii48sor/SETOHLoIKZpWFyYpzWGophw50c/iGlbokhz4cWXInA8cfBx1jc22bvvDH7p372T9/zBe7n9zjvJ8w6uHFE0Yx458DhHj51ACkl/MGD37l0866orSLOMsiz4/d9/D9c953qe/4IX8b6//ggrK8vc8Lzn0PQFNukhP3ATl195Fdc95zn8+3f8Ctc+93lc+9wX8o4/+EvO2beT173ihdz0iY9zfPUkn/ril+kP+qycfQmvetFz+OjHP8kf/dlf8vP/7G1MWrjrkUNce/3zGW1t8uf//UN826tewZln7ONjH/84Kzt3cfn5+/m9d/0eZ+3fz6te+XJ+53d+l/m5Ab/6Cz/LR9bXOHjkGKvrm7zg+c/j5S99CUdOnCBNU66+5GLmujmPHTrCb7//L7nmiss4c98e7r/nKxxrWyZlzWtvfC5d2XLg4GFOrq1hmoaiLDm2ehIpBf1OB+XV9UwmE9I0pdPtcs7l1zAZjzl26Amcs+zYsYPf+a//1aduac1v/dZvzcaACXuwEIKf/Imf5LzzzuWTn/wkH/rQB/naV+/hgx/6CC95yUt4yUtegnOOT3ziE9x8yy1Ipdizezfvec97eNvb3sZ//M3/yI/+6I/OwKJ+J+cZV17Or/zSL/Kz/+JfcOToUX7rN/8TBx5/guMnVvnB73krX3vwYT71xVu48aUvZ/eOZeqm5S1vfStXXnU1n/zoh57yEp3ptT0uSOIW47wMUVhH09aUrWd0N03jgaIoZmFxAdf4Pbbb7dLpeMaZabwxbtO2RKFWHo/GVAEA8YEv/jCQZaelkwWpXRSY5Fgf1S3xprxKekZBFdQGxlgvy1Xa1+gq8UlPSnhD2SCFaZuGtippKg9AWdNiT0t/nqoROt3g+aNjjhxfZTTcZjwasjg/R6wEwrYcOPAoGxsbbJ5cA2cCu2eJxeVllpZXWJybo6pKNjY2qJo2yGOScCASSAzCNNCUCGsCKx22RyOaqmR99TjDLS9166Yxa+tbbG9ucPDwYRDe6+zE0Z30B3127NjJ4tISaZajsw6l02xXjkGuSRLNUpYi8AD/+sm1GUgkhKRpSsaTCWVZIBBorSiCnK7X66OiBCEVddOSpBlKaerGm6RbIb18qm2pyoJYa5T0Ndu06aoD80lLQet8+tm4KKmqCmsNC/Pz6MUFL9eKYpq6pphMPEhZe9ZFVVYY07J5co3tjXVG25veRLxpgsdu4xkdzp46jE/VDa2YMWGtkOzadxZSKZIkpt8foKWkrgqSADzleScYIyuM9UmlQgp6vTl0pKnrmixNSOLo/87E/Aavp2vop2vop2vob76G/oaBp9pary10ns2irJcv2QAmOOdNCOvGI4xRHKN05CmYeQcpvXmdN/WaxkFyikUjBFJppHJo4lMgw4ydM2Xf+K+fph9MkX8pTteDen2sDObeeRqTp0kAVCTr6yc5cvQYKo4wWFrTILVCCU2UJEGq583FbNughUU0IxLZ4OoR46rBVZbG4NF/Y31sqIBEOmhrmtKyvbUNzqPXaSKhbaEqSaoyJM7VCNwp/e6UATQFYKRC6gjRNNR1QzEeUgy3EG2FtD6qtK0LD/xFAi0dcaRIk4i8N0c2v0R3ME/e7ZEGvfuUPdQaO9PuOjygFGtJFD5UkOBNb/mp5+GL15DiGZ7hk00BXdggjT0FPE2f37TbPvUlkFLODOqnD9TTRN0McGzbJlCPvW/Bab941rmbJusFUBfhREg5JGjl7QxkmoFIeONIKQQmsiRZTpZ3mJQT6rpgNN4iyTIa0yCCHjaKE+LY0YYOoW0rbFvjbPONTqX/a5cvzf3C0DiQxqFEQ+xAtYYosqhWhXRHaNqGsq58pw7fWcyynDROibWmtQ3Gei+3KegsxBjw4yOJvWFnp1sRxQolvaFxURVUdYGjRsuWLHI0wvkkmaKiKkvqtsYKbwQY65g4MCad8wma1lmqYuJ92ZzDmMYzHpMULZYptzYZbm6S9PohraWDUxmGiHK86SW8ZUE5HlGMR2yePMn2+ipVMaGZDKmIsComn58nfdSQiZYLzjufKE5xwpvpRXFCf26eoYSySknSFAQkSeI92qiRAortDcrxiI214ygctq154rEDrI4mnJyUxGkfMxlRnzzKzocXSPOcOO+z69zLmFveTa87oKobWutILUFTLWaFSpKmJGlCFMWBnj+djDMa4mmjwOHsKTmqmG6k4cu9fDVIR6eMUoLBrWk9xU9474m28c0BhCCKlN/MnCDWi1h8J64pCxSWufkerp9jmobJaEQx3KKajNlaP8nq8cOcXD3OZDzEWOsPSloyjTQQWoNzqBm46ztWXmLiE9fKsmQ82caYiu3xBmm/D8qzS9vGeABdhcLAGi9ndr6jmKQd9DS18h/IVTYtWRJz1u6dNK0hSxXf9cobue/AExw8vsod994PAvIsJYs0qVas9Hsck4I4zbnimZeyubXFXXfdxY/96I9z6cUX0zQN3/M938Pdd989Mx+edt2tPd1H79T+C37v/ve/8Rvcettt/NAP/RA//dM/zWtf+9rZQXlaeD3rWdfywz/yo9xy25fZ2t6i1+lQVC2oiMuuuJKqaiirmo/+zV9jWh/vLiR0Oh0evv9r7Nq7jyuuvIL3v+d3qYMk/vCRY+zes5fXvv47eeUrX0mS5Xzh9q9w6Ngaxlne/lNv58ATB/nYJz7B//O6V9EYy+MHD3LzZz+PaWp+8Z3/EaETbrn1yzz7hS/BOPjcF7/E7g5QbPOpL95K5SR79u3j8osv4pY77uLB++/jC7fcxrOvvISf+OF/zCe/cCu9Xo/zzzqT5fk+zeIcOk644/bb+PynP8GrXvkKnjh6gq/cdRfduQWGRclNn/4M//YXf4GFhXkefvwgF553Nmfv38sD99/P7j17WVxe4uMf/xjnnXMOL3/Zy3nvn/8FbWv4/je8hs2tLeq65tnXPYfN0YThpOCLt9+NUorvfuPryJKENFJ8+7fcwPGtMU8cPsx/+vVfZbS1QV1MmJ8b0O32WFhcIIkjLr7oGfzyv/hJ/uXP/zy3f/nLvPJVr5o9f4TgNa9+NW9/+9tDfSXDgVPMmCxvfvNbeMtb3sJgMHjSmHjWs57FJz/xCS688MJZw+nHfuzHeN3rXocQgg/+zd/wn//zf2ZYFNxy2+38vz/yo9x440tZXFrid9/7/pn/54//5Nu49NJLecVLbqQwjjvuvpd/86vv4Md+8B8x3+/8g2IqKuXlF9bCpPRSR6nUjNkNgij2chHTmhljsNMNnjBxhFAeQJrGeE8lZEVRUBSF944SnlGVBplFORmTdzqkiZeQTaUWXllgkK4l1QphFcW4pirLYHgdmAjO4rScNTI9G6qhnYwCG8an8inpa8ck72AcuEnh6/7wvqJIo6RgNPLSMyng5NpxivGY9ZMnOXzkCJPxhKoqSRP/9dubmxw/cogsz1lZXEBrbxGhdEySZpTjIVGSopSmDezCNM0pxiPPgkhSNtZWmYyGbJ08jm1b2rbh8BNPsLW5yfbWJk3TBIBMs3rsMGmasri0zL4z9jO/uEx/eRcyVuSRpJ8lniHWNlgUKk7YuWMlPLOWoiwoq4q68QqNONZ0shytI6qm4eTmNmkABHudLm0U0bQto8nEg3yRnqUKlsWENkhSx6VPHgTopPFMseHCGSxLE9I0sCCknCXZlWXlG9vWsLy0RFWWDIdbbG1uMh4PWV89xmh7K0gjR0wDIab1g5JTOwtgxv4Q/r0WBdubm5RlSVXXXuKLoGpaHnnoIfafdTZplmOc82O5bhgOh1jjU7xNVRJFMa0xtHlOnST/Zyfk/+L1dA39dA39dA39zdfQ/wupduCEA3z8oBCnfHIQPh2jCfQ4Yww6FKlRAHD8ozkFGJyGUxCgiFOm0KcVErPoXcGTwA2ppmik8+jwk2RaUwpx6AroCLKMwWCeuYUFWmtZ39rGzfTxLXqKBqpTaXRTF/ss79DpDbDliPFGjqGkMTVlkJHhLMr5BIJYha6EaanKiiqpSeuWJJlq5K2nxpoW2xqsVAhhmbFohAjpcoGppCOEVJ4W27bYtiGWjum24FyL9Pg6kVZEkSLOuqSdPll3QBxkjkp5pHJaNE672da6QJGbvm8ZIiJPf/qnoUzu9P904TW42fyc/rc9Dd11px67p4c5L3ETwUFR+tk/feCBjUUwkvcAlpl6FwQp5PRVBdIkjhAhKbwM1AkHzo8FD2TZYJQ+fR9u9jqnZpxRFBPFCc75ZIGmrhgOt4iSlLzTJY597K+YdoCcxTYFri3APDnl56l42dka6m+KxeGMp7mDQQWvKoenFPuY32ZWyAKBpis9Sw0xA/U8QNjif6r/f2td0PArysIb1k0TKz0FvQ1dzWlOpsE2Xmbati0i8uaKaeRpxkJ4oLtqa98dEBahFVpKcpWT5jlpniHNIttJwmhjzVNUCe/XWNrGH2ibpqE1BmNbivE2a4cOMNrcoK5LmqalUQlWxxitGVUjZD1iaW5A3u2RpDmgaGNvyCe0wgnfYQZ/KJ+lUtYl1WRCGRJwpDM0VcGxI4dYG1ds1i3dOYGdDKm3NxjoCS6NmMRdBjv3k8/v9NR7B65psIlDSDfz6ZDSe1zEwd9uaqB6+jw9fS6706YxnPr7TAY7Bb2Z7punOj7OBS2788k+3hwXprp2GTTtSinaAG63zh+usiwFIamrmklZU9U14/GQzfVVhpsbjEfbXoIixMwjYfaCp4D8bBvFMxydpzdbYzFY6qZkY2sdIWB7e50oTdFJilbar0dah+fSYKoxbVMCFlGNsVHqI8D/gVxNa0gTQb/bYVLWOMbshVmxY6wly1K63a7vaNaND6o4zTtka2uTrU1HVZYzbw3nHHNzc1x77bU88MADbG5uAvDoo49w8803A/DEE/+jifPUrHi6r7Rty2233Qb4bmJVVd7XYmGBTienriuSOAb82jHo95CyoDWOk2sbYY7WpEmCMZaHHnqI3twc8/ECq8eOMilCMpt19AdznHvhxWS9AVXTcPToMayT5HlO6wTrGxscOHCA9RPHaCysra4io5g4zej0B0xGY4qqYe+evQwnEybb26h6jFMwLips63eZLEkYb2+wevQwExd5meBkyD333sPSwjzznQQan2I1ZXNtDkdstYqi9bHuu3fvYrS9zaOPPsprXvEyVlaWeeLIcTp5Rqw14BhPxogNFdY8yfZ4wtb2CCUlvTxjOBqBkMRpQtZ6NnBR1vR7HZaWFrn0sss8KHnueUTr21RCk/fm6PXnSCLvqdnv9VheWaGwxh9Id+6h0+vTWsutt976JOna0uIi119/Pc457rv/vtnn8zzn2mc/m2decw2XX3HF/3ScThtWk8mEe+65h/3793P99dcDsHbyJHfeeSd3fPk2Tq6f5Ct33M6LbnixT8UqS7LWmxA3bctouM3xo4eRUUI5HoJzFGO/nv5DulRoMBprKesapRRxHFa3qd+n9PXn6Wx/7xEah73XXyLsM8YY75Fae4sAa/wclMFOwhiDVj55TIamrDFhf6/LGZghnEU6541+jfHm5FqjlGfseDNzrxqoQ9S7c3bmeZkmCUns/aucbdne2mJSnFpbTt9HqmBWjYCqrNje2uLYkcNsrK150KttsVlGHEdUZcV46IE2U03o5DmDQY+68jYUcRyR5l2fCCiV9zETGhtYZCIwJupyEhQE3jD92NEjbG9vMRqNiJRCK0mrNcV4RJkkSARzc/OkeZeec+H+GCLl96NWCJzwlhzdJPOqDiFpGm/FYa2bseQ9UKaQQQ5pTIs1PlVKaRUOnvEpwDfw6afjxTqLCcbAU/BgFpQDSOFBPx3HvuYRBAmmQemWyMVh/Hn/mcl4SF0VTEZDxqMhxWRMVRY++dtNm/ti9lqkDK9JnAKerPVjpG5qX8+ZqXrA1ybD4ZBiUtDU3jDaGENVe/9a09SYukTbhiiKQWmEbTH1Uxt4erqGfrqGfrqG/uZr6G8YeDLWBR04WGUxzsvtpiBC3TRUle+SGGs8lVBKn1oQUETrAiCk/w56GICA0ztXs8UvUFenWkumoJIKQnXnZmCGtTbI3vzIsLLFKoXWCi01c3PzrOzYhdIxG9tDRsWEum2p6hIVaWKXIFUSCmif9iIExHmXueWdpEmEKUeo9Q0cW9SmpA1AXKYliYJOBGVtaVrDZDxBRSk6yenPaY8GSumNyauapi7DJikQTs3YWloHGrPWXi9a195osm1RtmUhU1QWSgPD2qCUI40kWZ6Tdzt0l3cy2HUW+cJO72gfCtoZqIWgrn0nrWlb0jTxhpdxRKw1OoBUXtZ2ChD0Xk0WYf1GagNrKZBvEQFYc2GTPJW0Mp2GeM+n8LNlgIiNtcF+ypt12/B7pqZtHnQ7lf6HA08W99AT0wkfNnh72vSaigun0cAEFt009WX62ow1JGlG3u2hdMxkPKauCrLjRzCmQeCNFdM0o0lSpDMI10I9QjRjhKm+0an0f+069Rykb6cAGEc7Re21gyCVraqSqqwoioKmqLypnI6o69Ib0kWxp/U6R2v9OJpqsqeTtGgLKuGDAqIkRmlNrzdHVdWh6PU+bg6w1vu72KbENr54TvOcbpbT7/XoBFmqsZZhWdBYi1ERnf6ArNNleWGB3mBAdzAgy1MOHXgYW9esrR2nrWva8YhyewuMZTIez8z0dX+eyeZJ6pNHaCcjWmupVQ74ItPVJaPtLcZbJ5Hia+zcuZPzzjuHYlSAUJi6YVErVJLMAhiEEyjlY45HwzFb62vUVYGUsLm6yvraKl+7/wEaGePijKaVxNKRdwfMqQ1SN6Y0LVkckXXnybtdqtLrtqUkxCj79S9SyhsidnLSOKJpmmBGOu3IMMW0Z9fpm6b1j9z7LoSlVE2HCYT00iBPtQbnDHB6RzTEywpFpCOkkLTW4myNsS1pFCGk1/i3KJwqcdtjtkcj1k4c5cCD91IUJXXTeOnJ1P/AwTQW/FSOWlj8CaEWoU/hhKIxjrpuOX78BMPtId1el6atMKahbZfRoajAgWtrXLmBHR6HZkLrWmTSR0Ud4E1/P5Ptf/M1KSuyNKXb6fK1Rw6wORxy5/1fZ8fKCouLC+xfWQrzYY5DR49x7PhxHnzg60zKktZYbr35Zr8GK8U//+c/ww/94A9y+WX/gve///0Y4wvL1772tdz06U8D8Ou//uv8xm/8xuz3J2n6pNfzkz/5k3zqU5/CWss73vEO3vnOd868TRDev8M4+O3f/k+cuW8P870eeTfHNBXjrXWyKGZ7a4vNjTX2nX0Rk9GQg48+wJ6zL6DT6eKKdR5/9ACPP3qAleUFNtYFW5tbLKwss3PPHpb2nc0nPn8Lx48f5bGHHuDHf/SHufTSS3nrD/8ETTFEm5rv+74PsHvvGVz3/Bfx5u/8Dspiwq/8yi9z3QtezNnnnEc13mJ5foH9+/bw57d9moUdezjnmuu46ytfYWtzEyklt37pCxw/eohf/KVf4dOf+jhve9dv8fATh1lYXOTeO25leccO9uzZy0te/BIuuuRyls44j//yma9zxc6cqy+4gOWVndx626185qZPsrq2Rq/XI0kiHnrkESbjMeedex4HDh3k4cce43ve8lZObk/4wt33c/mll2Gahi/ecjuD5WWiJOGRAweY63VZmeuh45S6rlldXeVlL7iOre0hf/bBj3Jia8zJjS0Gy7t5+StewfXPfR433fQJep0O+/fu413/5be45Uuf4/j6FodWNxks7eDkkYNPerYf/OAH+eAHP/ikzwkh2L9/P5/4+MefVFSf/u+33norr3jFK/jv//2/c+6553LDDTf8/9j783DLrrrOH3+tted9pjvfW1OqKjOZICFhJiEBCUOEpkVGEX382Wrbigo2ra1tA2qrNNqNLU6AjXaLMiODhBkCISQhEyEhc1Wl5juecc9r/f5Ya+9zC/z+ftjot+Pz1Oa5VKVu1bnn7L2Gz3p/3gP/5b/8F173utehleK6F76Q5117LVdccQWPPPQg481VPvu5z3Pe0ZO8+NrncHKzT3+S8l9+67f4yIc/xE//zE/x069+GZc+8Ym86w9/n5u+dhO3fuPWprj/l+DzFPgBZVWR5gV5UeI4DlFUEcchnjsNx5HSIc0ykiwnzQuCKLJzTjeWAUJIK61TjCdjsjSjyKfM6/pQo5Qi8H2qMkBXBhQqi5wsMR5LWiscqxioqgqUaaw5jqQVx4RRTBzHhFFkZCKZ8QBCSrxWm9mFJTq9WRasp1Cv3UIKOHrkMFp8nRPHj6GFaHyDiiJnPBrhOIZhVFaKJElYXz1JOh4akLw0gGiRm4OoSZUumAw3WVleYmGmQ5KlpFnK8SxjbnGJdrdHpzeL0poky3Fcl7IoGA8GqCLFFZpW6HNsc521tTUeevABcsv4akURge8iAg8HjdYlOm/jOg5BEOK5LqgCnebIKjap2MJ68XgecwsmYc8LPJLU1uuYJq5GkmW5Td1yCDwXBw3KABPCvsZMz6UoK5K8QAvDEFuYn7dhRhVCWmsPYQ7KaIWykjmNOVyGYYjjukzGE/LcKCUcxzUKDreHVhX9rU1WTxxjsLXJ2onjbKyetInZBQLdSLBqTxygOXvJbWcxZRl6VVWhK1ubA77v4fkGmB8PBwwHWywvLVEUKaPNTaQu0dmE0foJ8rUK33Npzy6ROw6I7y2O/f/WdbqGPl1Dw+ka+vutof8RjCeFFiZOr1SVQXprZopSdiLkBmUVNMaGjucZHXClGoNCKaa3wZhdTWnGp/w8C0bVbKYaUDIMFiO5Ulg5ngUSGjaMthpWWVGVlgJsI2DDKKLTbpEXuekUJcZoUArjM+Q4trNjf65RQ7p4YZfe0h6k38ENN3HCLXKLLEeuxpUQiAqkQpSQSx8hXUAipdHJ190ArTSqqNCeQrjadqIcmzRn6OyOW5JOEsBB4eB6EUHUIXKMQV+hIc6NGaHr+7RnjKwumN+J255Dhi2r1a4QuWy6FgZoUQbksYeDuhMipGi6lKewz8S2jpV9CPWkVBbB1eabjbSu1i2bIuk7YGP7W2V4n0YvaoGr7X5MCGtEpypQYjrbmyFhY3KtobhAIupkPWuyeep71tuYVBUC3TDApOvg+QFxHDMZD1GJJpmMGQ2M91XoSMowRIUhri5wdIlTDJFVYvy/HuNXaRcg0bDNbFdFKioElZg+jywzGuskSSirEkc49tlUDU23VCVlVZJlU5qw47r1ttyMgzwvKAuFqkA6Hlpr8iIjScaUZWH8wMrCBAioAi8OCIKIpTP20+vN0Ov1TCQv5v1lZWE4bl5Ay0Z/znS7BGFAGATE7Zh26CLylK/f9DUmSYp2BVpqkIogCk1caKtl2IGeJDn+AKuHHmQ4ycgIDJuiyBBqg1Ao2jMdssmYQb/P+saAVtxCSpdJMqGdJARxgh8EKJtO4ToeINAKvDBGui5CRRw7+BD9jZPMtDxS7ZIKQTIZIH2HoO3gCI3nRYQ7zmF2eRcz8/NEoTTdLIExEK2M2anAyBtC30UKjdJV3cugXig1mPADUX9nOr/NPDDzp9omVtcCm2BqisDtHRulTQeu7nbW6ZcmdrlCCdsAAFzHpaxKy4YtGWcVoyRlYzLh5OYG62vGW8LoxC0wbzdvpavmPQqtkUJbRqMwmnZtkk3N1m0ktY7jAqZLtLG+ShCEphNZFoYN6khkVSCrFCffQCabUCboIqPyAirnsc14+su//Euuv/56/vqv/5onPf4i0JqHDx/F932WFxbwXYf5+VniOOKeBx+m3W4xPzvHzp07yK0UorIt23pv7XW7/Jff/i0ufcITANt5cxyCIOD1r38Dz3jGM3jTm9/Ej732x7j66qubFCLP89ixsqN5b9M9w+zds7Oz/M7v/A6f//zn+fCHP8ybfuM3qJTittu+QavTM+lGWYbnSALf5cTRA01neOvEYVzPY9+ZZ1OM+6xunWRrfbVpyFTphFGSMcoKutrQ8lcW57l1PCTPUi695EI+9tEP85d/8S4evutWqtIcqJYW5iiSEZ/+xEc59tC9tOOIuZbHPd/4Gg/dcxdPfcpTuOPe+zh2co2nXfE0xpOET3/sw1x6+ZMYj4a864//kLP2rLDzwvP5nd/+LY4eeZQTx4+xPDcHquDb37yDe+52mJubY7h2guX959GaW+apZ/TYNdsiboV85RvfZDLJ+cHnPw9VlWxsrOOGcdMEclyH3SsrzPZ6/N1nv0y322Xvzp3osmA0npCtbzI70yUKQx749rcos4QiT3nkyCqB5zLfbXP76gm0hl3LS/jhkKX5GZ5x6QUUZcU377iNww8/RBCGbG1ukCdj0v4G3/r6F3n5y15Gr9flDb/4C1ZmNX2233n9wR/8AR/4wAcQUvLKV7yCa6+9dluH1fxy8cUX8573vIcvfvGL/Pk730me5/T7fY4fO87Cwrypdezr5UXB+mafvTuWedyZZzAZD7nhi5/j9jtu59GnXUHaX+elz7qcbrHJ3Td+ng9+4tPM+5phf6vxnvqXcDlWVldLMKQjDRjhmwQnZUHfqqpIs5yq0rh1UpNr9s4wCAnDiPFgQGoToIu8QAOe75vVX+uGyV2nMCu7xruOSyVNslhmmQuqLJu6XGtF3Irx/ICVXbtptTu02h2bUFVbFFjPTekQtzoEccxsb4ZOO6bTio1BbhgyHk9wHIc0zRhNEsZpRlAqolaHIPCJwoBOq4XvuaTjESePHWY8GlEMRhTWZ8p3JY7WCEcYywlrTB7ELcswMml6ZZYZtpW9193eDMl4zHg4tMlhAlVkjMcTNjc2EarEte3LosiNHM13CUKfuBUzN7/A4vIK80vLVDjWZLtibWsECHNw15rQ8wlbbfwoxnUdyAoLQ5gmaFkZaYovDMMl8H2rqHCsZNmwIQf9PpXWKMz6Kh2j5HCFBIyBfOMXo03aXJompoEgHTxhTJi11vieZyQ/wGA4NvW7NJ9ha3OL1fUN1jc22er3mSSJSa1TCtf6uNSG9AhzVqmrd3MeM4d219FGxuV5eK5hjEkBruualDIpmEzGbK6tstltMxmP2Fxfo8rGqCKnTCcIqagk9DfWzH7+GJ/Gp2vo0zX06Rr6+6+hv3fgSRskUilpXOHrQ7wyN6k2O1SqMnIta27oOC7SStoacGe7Jt9SwLQQ3wES1CbW4rsAj/rhme6PmoIVVdmAUwIM7dH+bG0BHYP+m3QAbzhECox5tzVKdKWzLbFDNa/jCYF0Q+LuPFq44LhUSNuJyfAdhYPC1SXK0UYMrENczzfdEfvluI75nHoqGxNYWaC0dDtrLuhIYam3EiFc3CBG6Iq2b2C/Co1XaLR0kZ5P2JnFb3VwWjPIIALpTQtIIWwHwwJb2/yOmp8rrSa0uc36O57V9LdNoaexZt80rKPtflDTVLyaortt8mKYSzWLqn7d7YeY+mfWpuXNDz3lfdRvWFoArP7ZlvtkqcH196h/hgU3lXSsUbnp8gRBiCMN2yzPctJkwmQ0YBL46DxA5gE+JQ4FXjnAURmofwlSO7NpSn3qPDILkKDUBgDUCrI8I8uNZxu6QmqbAmn/fqUMLbioCqNftwOgHsuifvZaU2ljNmpSCM18LPKcJJ1QFYUJLLDIvPQdgk6HoDPD0u4z6PVm6PZ6hL41vLcFNdKkQsaRieltxVFTNLXaLVwB6nEX8MCDD6M2Nii1QlGhUXhhQBhHRK0WcXcWlSyytHsX2dYxlFZsZQJdVFRlhaYgjFw6kc/J9SGJlb202z1cz2cySSgKswboqgSbUNlsNNLEYavKo8oz0wEbjehFLl7lIBSkSYpwXQI3xvECvLhLZ2kvrd4cURwhMYlWSvkUlUKXRnYqXdOZ9D3XMAAbwJWmG9cArnYMGHC4lplON85mrmpAKrQS1nttKgGupbqF9R1RVYmPQIrKSqwUQuhGuiGlRFSmiDBykIIsz5nkBaMkYTQxKTpuEJgGxbbUzeY9ao20jQm9bS2q32q9aU4BagN4j0dDRoNNQs8lcj1816GS4FYprkqQxSYUI0SVofPExCHL72hrPcauV7/61aytrfHe976XhVnT9RwlCZ122ySoug6tOCKOIwbjCWVVIYGdKysIaAIatl9hGPKD112H4zgcOniQufl5PM/D8zyuvvpZLC8t8Z73vIdrrrmGV73qVRTbUqqOHTvG5tYmAGmaNq85NzfH/v37ePY1V9Pf2uL222/nRT/4Ik6cOM7tt92KsMkqyXiMIyD0XE70N9CY/TlPhrhOh3Z73hxExyOSNCfwTHd8ZnaBJCvJ1reotMZxHNpxxGQ8Ik0Tdu0+jxtv+DK33XoLUmvTPUSwd+cy/cGQB+5/kBMHHmTH8iLPec6z+PYDjzCcZJxzztkcPnKUA4eP8rxrnkVenuT40UdxxBUIVXHwoQe4YP9OZjoxn/nM9VRlhec57FxaoMgz+qur9Mcpg411di0tEM7tIJ5ZYDGomI1doijm4NHj9FohF190EY50SNMU14aUSLsPtVst4ijiC1+/g107ljn/zH1khcQrK8I4MkllthlT2MPn8dVVOnFMO/DY3FjDcz1Wdu5mQRoPoXPP3M+373uAI0eOQFkyHg4YT8bkqTFr3Vg7ye6VRfbu23/qng+0223m5uY4fvy4MWEFvvSlL+H5Prt37+bKK6+sG7cMh0M2NjYAiKKIV7/61bz//e/n4x/7GGBkl6PxiCSZmO77NqBlkiQmHEVXDDbWOXrwIR66505WQsVCr8WexVncrM/Jo6t86iv38NRzduBJgVaa2dlZOp3OP8Os+ye+bB2jbVPPpM8JHCuFy6w8pyxLkjRDSONR5HmG7QCGCeP7xgc1z3N7sDXG1m7tIaUV2qZEKoWxwLD1+VSBYczMsyyjsKlGjuPghyGdbpdWp8sOCzzFrTZg5prveU0SmUYgXQ/H9eh22rTiiFYcoZVmpijYuXs3q6sn6ff75iCeF+RFZSQ9QUArChFRhFAV4x07yScj0JpxYpiZlSpBukhhWAplWZJmBsSKujO4rktZVtY0O7PyMCN3iqLIAGpS4HkuVWn6/GmakSQTPCmQjsARBiAyoIkB3aM4pt3t0u50ieI2m0lhJLdKMRhNqLS23noBQoR4foDjTpOdtifRKVtzGkDB1uHW7N2UpQpVKcajobmfXoDnutuUHoA0RsK2pEBbQDHLsunBlSnLzbOG5FLKhsEhnMrev5wkzYwnkzWH1rZ5PJV7ysbHrxKqCf6pG9d1I9pxJK79cqxMsJaKSiFIkwn9zXX6G22yZEIyWCcf9VFlAVWJ64FEM0yN/071GEeeTtfQp2vo0zX0919Df8/Ak6F6CqRQKJTtqpgFs+6q1FRLxzUu52EU4QfG4wm7SBm96LZLG2OtOoXMPGATbThNMfsOwKD5Ug1zxSTglc3ocGU9eK0ST2F9fDziKGZhbo50MqJIEzY3N6myjGw8pswyXM83evp6IQUq18WVDl48SzdoEfcWaM0uGtAqSw3woA3ltFUJSiXJK7ORe47XFOvScQ2zSUokFnCiWc4N0OUYaZx2XDzHxXM9wriD7/sIKnodQ7PVuiIvTYekEi4yiJGeT+XGJHlFVo1gPGk2kyiKcVwX1/Nt4QPSlbie7VBY1LVmQQnzkFEW/LXYjQVwRDOo6+6X2hbs9g/tHw1wWHdt2D5ZlaUj1lZtBkFWNs3QTGyzsDYzxvpyCUtV1ChE7btlqY1T4NqOH/P2m4UfIRBVSVkYRNdxXdqdjk1hFBRFSTKZMBQaVxnqZh64hLLEEyUhKS4lkse+10RZL2yqsv5nNpWmMp27XJXoyszpLMss0l6ZIsiOXy00hSrJJlnj56brB283NXODgfp7uqQsEoo8AQ1FljHqb3LyxDFQijhq0Z6dp9XpsnPnHhZ37mVmfpm5pZ24rkQ6ovHykJjNsjYxrWmrVZFT5hqUoshSPNdl374z2X/OOchHD3F8/SRuEOAGAcvzC6bDuLVBkiQ40uWsy67BKUpOHj5I/4GDCKWppGB5JmbG13TcgrWyYDQYcejRY5yx90za3S6VcMiynOFmnzhqEYQhvh+YlJPAwfUDpCNIxhMeeeAhhqOcMqs4byFkUmmGueZwVRIGkplA0NlzCbMrZ3DGpc/Cb3dRxYSt8bBZk6q8IskShoMhvZkuMg6JosA8l6oAXa+v9aSlmWf14G9AYmqgFwsgG5NJocwm6SEw8n7LdK0UaVYwmUyMD4hSCC1MOpLMkE5pQfLpaiakRGqNo13asWuAAgR4IYRt4pl5UBVCg7AJmo3M1yzalgo8HVZmbRCNKaaB4c1nrpmqeVoy3NrCqUq8MiNyJaELoRrj6Qz0BM9RSGnA9bJKKIrH9hxuumxK8akv38j87AyPv+hCHj54iNX1DYbjMd3ZWfYvrfDCZy8YYGoy4VNf+CKDoenSfydoX/s9vec97+E//+f/zH/9vd/jogsv4tzzziVutbjo4ou44447CKzpq2PlF3mec9111/Hwww/j+T6DwQAw4+Y3fuM3uO6FL+CNv/Tz/MC1L+CWW24hDCMOHniEb9/9TbSVd6+fPM7SwgI75no89GCFVjk4kh1n7SdJEu795m0kScrM/CIv+pGfZLEbszjX43nPfQ7v+B9/yFt/93eo8pI8M2DGgQcfYDgcwTOuImp16LVbhI5mMMkYJDkHDh5GVSUt32OUZFTS5SmXP5E0zXnowCFuu/EGrnnu8/nZn/5pfv9tv8fuM/bxs7/4Rv7rW34NRyve9zd/zbv+7E943wc+bAJFHFNj3P6tb7NjrsvFZ+1iMhqzsvcsXvaTP2+S9ZKET370g/zAD/wAj3vW1exYmCWIItzZFZZ3LZGlCTd+4y727NzB3MIyR0+u4jkOnuPw/CufTJalPPLQvbizO5np9XjJc87hM1+/kxMbfa577g/QHwzY7A+46qnLpjAtCvbs3cckmXDfffdx4UUXE7da/P3nvsjOHTt4+tOfwXXPfz53fONm/u5D72PtxDGSyZggDPml17+eLMsbcKm+XvrSl/Jf3/pWnnX11dx9993Nn5+5fz9f/epX6XQ6JuAE+Nu//Vt+6Zd+CYDnPOc5fPCDHzzltebn55mZmeEpT30KqydXUcrIrOqe1B+8/e0szM3y8udfzVPP3cELnvhavv75z/CNm77J1x44xs8/+wJWZmd47XVX0i2HrG8Y4PNXfuVX+Kmf+ql/qqn2z3aNk7RZ32p2Sl4bzGLsDiZJSpJmrG5sMjM7x465eeJWiziO8X3fyN7CkLIsSJIJ4/HYNHYdx7CSHMfEcgtBZj2iksmkYUw5jmMOL5MJw9GEoijQWtHr9eh0Opyxdx+7du9hbnGRuYVlNIYh3+/3cVyHTrtNt9uzrBZJfzAgTVK0qsizFF2V9AdDyrJgdmGJHbt24/kBR48dYzgcErS6LC6t4EjD5XcFhP4Out0uYeBz8sRxlHAYD4fkeUboGl8qAWxOcrb6Ax45eJj5HXuI2j0c1yfLUvqDAePJhJmZWfP+XJdWu8XO3bvJsoxhv8/Jzb55BkqzY37GeGiVFSIwUsZ2u0W706PV7TK7tAMtHIajMUdPbhFGxrz75HqfJEmZjIbs3bWE75o6UymFktgDvimHRpPE2E5UlQGmpKRQomG0OLlJ1c6zjMFggJAOYaSMEbTWKCkpqoqiKKnAghomCa0oSyqlUaqwjVMjf5OOS5rldi4bKZ/vuni+j6pMLP38whLDwQDX9Vk/KcmSCWWRN2lqCCuls3VB00C29T4YwMXXGtcxvl6+BcuMpNAAX+snjrH6aEpYTQg8B09Ano4okokxGY98Amu+XmqT6vVYvk7X0Kdr6NM19PdfQ/8jPJ7MDdLSULTALIBK1XSuafSyYdFIKy2bprUZOZlBxGoplVJ6SqSZPkn7qyW8GEoUWAaOtv8eO/GRNEiutglr9RhR2j5YrRCVAVNcxyGKIqIgJLRa6aowXRPP99HaAC81tVgBlYkwQJqhhOMFxJ0ZVGX08ljpn0RQaWkM3NICZReOmvlVdwIai8hmQVdN58EVNF2bmoUTxzGO08bxHHqzHfNzy4IszSmVoqwM7RnpWEO2HGQJ1ICXg+f6FtU08jwpHFwp8FzXJAPW7CqkRUyNSbeogZt6klEDOFMpXe33tB0ZrgWkp7CSaiS/eehTVFkrbTyzGrCpsnTxGmTU1mBRTbsDwna4pJy+kjYomRZmItb391Tgsl7fp8Cpa4HGMIyMllWYgquwXbbJxEEVDrpwKWSFKysychxDsv1ep9L/tUsp8x61HX9SGJ2vRhvGWWnvfaUoy8L8uRCNPFQp0512rBS0BnybAADsYRbMpmOp6apKyZIBk3HIZNynKDKE49KeXcD1A+YXVphZXCZqd+ksLdPtzRLHbXzXAsfbDOWNmWO95hiT1EqVqMKAzhJQZUXleYCk3W7T63Y5duIY2XjE2HXpe4H51EqhhkM8xyH2PXo7z8aJZ8mcFoPRhLzImYnB0yWqKmgvxGgnxI+7aC2oo2Id4dhOlRnbKG0LEhN3LATkUlDmBUF7ls7SHqJ5ia81sVL48+D4AVGrTbSyH2d2gawsyfpbaNvp8IMS36/QOChdUaoS13PwPM+sqaqy3bhaXiqauaqsBX+9KNbmiXpbl6aes9vLPiOvxhSh1sRUWJlVVQoUhp5fVYqiKJHapGNKYf0v7D1AOCCl2WxEzL6dK7jVJWws7eB4p81w7QSTrU2KPDfv1677EhpqsFlK5Lau03YQ2a45QhjLN6CwVPeJmzAcDShcSeFAKQ1QnFPgSoW0EuCyqqge40bFb37zm7npppsAmJvp4nsejx45SpZleJ7L8uICo9GI+x96mNAVpFnOOElO8X35zqvIc77xjdt46KGHGAwGfPgjH+FrN93E8vIye8/Yw+49u7n2eS/gE5/4BN/4xjeaf1dVFY8++ig7d+3i5S97GQDHjh3jne98J5/5zGfY3Njg+de9mAsuvBCtFH/0R/+Db951J1VVEUchYRhyOE05fuIEAEJX7N67nzPPOZfZ+XkcIbn0sisoqhI/jNmzfw9z7RYznRZZXnD+4y7gla98FTd+9Susbw1Y3Rqz5+zzQCn27NzBk57yNOZmetxz61dJCgVJznA0phU47J5vc3BtyOZmn49/6rN0F3dw3iWXcc83bubBB++nMzfP/v1nmQOz67CwtEJVZGz0hxxb3WB1fZPlbmiKTKXYLM0YzCsYlIIFN+SsfWfwtTvu5fDxVS65/Mkc3Up5z0c+y2Q4YDmKiMKIUmsUgvluCyEgywuyvMKNfRw/ZDAaIaUk7s4yM9MhSSZ8+GOfoDW7xJ7lBQ6fWCXwPTqdLnfefS9xFLG8uMCBA49QliVLi0uGDVOWXHjeufT7Ax548EF27trFwcNHePCBB0iSBIAg8NnsD81/b8cnBfi+T6fbtcwKc/m+z3g85r/9t/92yp/feuutjEYjAO6++27e8pa3cP/99zff//SnP82JEyc4efIk49F4uncIQV5V7J/vsWd5jsjRfPPbD7I1HDGjYOd8lyulxg1CkgqTwFVkrI3NnHVdj/A7fMcei1cjUbNrpbCsr8FwZLw1lSLLLTMoL2w9EjbSK6U1Ydyi3e3R7nTtvR7bxqthPUm7J9fSHaUUpZiyY5IkMYwHIIxCojgiDCN27NjBzMwMO3btZnZ+gU6nSxBGpva3MlDDxtcUZdF0+kejMclkQhH4VnLlsL6+AUI0zWc/CFBVyai/ieO6xFFgLBHKEokyDVrXZX5pGel6jCcJozgmSxOkMtHjSmt6vpHc1BKvIAwIfY809dGA53mANrYfVYnrusz0ZhgnE/I8p1QaLwhodzqsLMw0/kmt7gxBGBLFMa1OlyBq0e50DTg3SUknGUIVxudJgaDEEcp46RSGqVGWDhLZ1OxGOqbtzygorKeX0qBKY0Zdsx5UWRJFUdOUVZUBmrTrNHuv5wdWEleRWaaSEJKqMobg5szgIJUizwuK0ry+6zpIK4NDSqIwZGVlBVRJr9NGKAMgjEcjBKbOLotyqhRofhFNHVY3LcqyJM8z+oMBYdyi1ekCRkURhiHZSJJVJZPRkFSYGrJMxuiqwHPMwTcrKgoySm19ch7D1+ka+nQNfbqG/v5r6H+Ux5NZd4SdHdZXSdUQD9skcQY4cTx3mtKgp3Iy80JqmzeQNahu0AgLHujtsjw9XQMtncx0BMy/lRbOU5Uwg8SyWtAC1HY8zyB6RicfEgYBEpPCU1YVfhharaOJrtTaPChl+g1UQpi0O9clCqMp2IVGYME2Ydhak9HQpmmkSNf4Nzk2ga8GyqiZOEqjldlskMZnQ9quge95tFotgjjGjyI6i/OUeU6eZzijMaU1mSuqqpEelsrqzG3srlQmvU9WhqYpLajleS6eN008qQGv2gTcgETf3SWvB+x2EEc1gJB9boYyZZ9D/eyElVUanldD+7avV9lJuD1trknIs8VVAyJZeZyUGqkkCIlxLBcN+lwbhDXMOftmp+9bNckx9eYdhCGOa/TFldIWeAJXQlk4qEKSS4UrFZ4okXoaPftYvrSuUNoCtwhz3wClTTqktp4KSlXNhmnmrxkLZVVCniHtprn9qs1dp+i/fR1VUJUpWTpiMg4ZT/oUqsQJQnpLO4g7M+w44yzml3cQtzrEnY5JmJECwVTSW/sMmE3AUFiVFBRlTlkWlHmOxBj0VbKiqsyMNJtmB6EU2XiIUBUOJonGcRzSZIzv+dDu0l3eT2thJyII6W+skY5H+CIhtyaRvbAD+HiObzafSuMHAUIppBZN1x5tghikdJCuBKFxhKQqSuLuPF4QE805OFIhhGKGgEqGVG6LYHEnIgyZpAl5mlFVCtfzKUuTlOP7oZkXGB8H3zdmhFob83whphug6XpMixpt/6+uQVSlpiB+8yDNJoKwtPJm3TdAv7ASagHG609pNBW6LHEwLBBHmGknpMDxjY+LUBrHEQSBR6sd0+nMsDUY4XguR++/hyzJyJKJGTtimsBRr5UNwMy29QeoywRTME0/R6kUWVHgJOBJQe4KCldQuAWerMjsvK1DCmoA+rF8vfnNbwbM/VicnSUvCg4cPkK7FRNFIcsLi2z0tzh+4gSB65KXBVlW4EiTbPOdLnS+7+N5PrfdfjuHDh2iqio+/olPIB2z5zzlSZfzpCuu4LnXPp9PfOIT/Omf/ul0j7dj5ulPfzq//IY3EIQhd911F3/zt3/L9ddfz2233cbdd99N4PtsbmzwJ3/yJ6yeOM7ywhztVosg8EmynI2NDcq8IIxjzjr3PJ5+9XPJ0gndTpszdu+xYRwVG/0+M+0WURhwYnWNffvP5BWvfBU33vhVNvoDjq9tsf/cC2lFPguzM1x2xZPZsXMXRx+8h2GS44wSkjSh48fsmG1zop+wubXFRz/5GV770z/L+RdcyNe/8FkefOABlONz+RVPZm5uniJL2b13H8lkzMGjxzm2ukF/OOai3fMUWUGSZhSE+L5PoQWJDFF+i5X5GR5+9Dh3P3iIX/63P8InP38T13/xy1xz6T4WF+aJwoC8NHvZ8nyPpNQkWUaaV0Sxi+uHbB07RtRqszS/xFw75uD6Kh/95N/zype/gt1LZ3DXvd9m58oy8zMzHDh0mOWFOfbu3sEjjzyM4zg8+clPZWNzE4DLLrmYr339Fh584CFyLTnw6GEeOXCAOPBMDHsQNE3B2kgYsA0vA1Zsnx+e7zMYDvit3/qtZiw03Xp7PfTQQ7zlLW+x8vWALM+4/vrruf7667+TfIfWRrq0b3mec/es4Dlw1733c8e3H+JfX3kpOxd6XLyjw1D7DLKK/mDIUEk2RsZYN00T+v0+i4uL/zST7Z/pUlXVdKPrJqSqKoajka2np/VIWZYIKafAk7WNiOIWnV5Bp9djY2PD7L1KNa0vsS3NrrJd9bI0YEyWO2RZZrrojkOr1SYIAmZnZznz7LOZnZ1jbmGRIIobeZ+wNZdro7JrT1chCvKiYDgckEwmlHmAa5ORNzY38f0AP4zwgoAg8NFVyWiwiapKup22MWEuc9CaMAyZmZlldn4RP4gYDoe04pgsmZCnYyNJKisip3ZlEni+R+gH1szapBEbppAiz1KUNjLRXq+LcBwmk6QBw1yh2bF7j0keywvzmYMAPwyJWl0cL0B4AWsbW0b2h4PUJegS4Qa4QuM7IFSJLgu0Mkl1JRLfWo04jnlelTKHyqIsmz2rsOBErq3PKJo4bhnfn6quc80BTQEIgR8E5DmUmUmHMxu+SUQzM7MwvmlKkiYJdaJ0EHr23GX2jjAIWFlZIfAcep02o/4mqirsOSJDq4qiMqqWugaUcpp0PVWimKTtPEvp97eI2x0WGyBZGh8yR5KqitFohKpK8jw3yYBS0PIkhdLkqqLME0r92Pd4Ol1Dn66hT9fQ338N/Y/yeIIaK7EPprnZwlKtDdigNQjp4Hq+ZQ1JhNDWS8iuXhYfqA27DFBg0eTtr2uxR4R5zeZy5ClgR6VMtLKyEcsmltK8T8eyrqSs5XwaIR2TYtZqE4aRARiKgirPqYRAOdJ4ZNSsKtdFOIYu6bgeru8ThGGzKNeTsN4AtdJEsXHST5MJRZYBFvARVlKmlaVlVs1nqJQx/JKOg+dps3H7AZ3eDF4Y4gUBUbdLWRTkeUYSGXO50mpGK6XI8oI0M1TcvCybQSfFVH/uSEPLjsIQ3zWafaUUSggUcloUat3Q6JsBa9HRmo1kUhWmgI6579ICfjSmloCN3QYhVDN8muhMbZ+BUo3xWt0NqOzGXhR58zPq7kC9UAu5XcpZ0xTFtMbVU6mKqhdhuyirOmZcCKI4bswRjR63sub1JZ4UJK7EkyCFtgkoU/D1sX5N6/2aRUajqxfKLLx62zgxrC8soJmTF2UDWtZfdeGLNrIBbX+QJ00nut1epDOzRLs3jxe3aC8ss+u8i22samj05DVADaBKVKVtEevgOJ4xzcO8jyIvTJcmryhK+/uqxHc9pJVL1qmXK4tLOFpzfxTS39pksLaKVpqw1SaMWwRRgKwUk81VqolZxLtLe4lnd1CVBVmeEnghQRDhOC6jQZ+Thx/F8Vy0FAR+AEWBIwSeI3Eds8YlyQTX84hkjBcGJiq5KFiamyNstTnnKZczHo4Ybm0x3twkT1PSNGGycQKNYAOJ4wdIx8PzfFTLdGEc10iXu70u7U6LKAopK202bV2bw9asxKqZY+YZauv5YZ677RDYr1PHidb1YLGAvpqaYha5STWqqgpX2g6ZUlBnO0iFdgTaJp/W483MOYHGodIVFRU4IUp6VEJSVoVpDDie3aCN/4awmn8HSwvW2voN2I/QjGoB0szrCkhysy4WeY7nCAJH4ktlijFlvwAttQXd/6ln2z/PpbXmoUcP044jztu/13j9VCWHjx5BOkY23R+OCDyPbitmrT9o9sPt2MCv//qv89If+iG+9MUvmMOPLXxVpchUzs/87M/x7Gue3RTOUsqp1Nle4+GQh+//NvvOPpcLL7yQu+68kze+8Y3ccMMNDWs4brV4zWt+hLvvvINbvv41tvp9AO5/4CGWl5fYe+aZ/Oqvv4kgblMo+PT1n8LzXNIsY+/efUyShM9+9nM8/sLzme91+ZsPfIh9Z5/LOedfwK6VRXSV8fUvfYoXvuhfkyUTfu6nfpwXveRlXHTJ43nxj/4k3/7mXdxz1530TxymqkqO9FNwJJ1WTK/XY6HXYbHX4ezzzmf5jH2csf8s2lHAkcMHuf6zn+bHX/0qhJD81Qc/wihJabfbPP2qKzly5ChHjp3gJ3/ohxDSYXNrwNUvfAlpUfEffvXXcMM2e9sBn/zg31A4EU+/7ByOfvsWum6FuvQJDLYSQs9h/759HF3f4uTGFo8ceIRsxwqIHbTnlsjynAcfPsCdWxu0opBffcPruf1b9/GFr9zI8571TO4/eJi77r+dpz71yRRZxsMHD3HO4y4iz1Lu+MbNnHX+RYStNn/zkY/T6fa45LInsnPXDrLxgAeeciWP3HOnSc4JI8LAJ8syssLUDL1ej+uvv56bbrqJSx7/eI4fO9Y898l4vK0p2AzM7xqnVVXxhtf/EivLK/zyG99oxyGnNqKawyp844GD3PvoMYpK8eSzVviZay/nY7c/ROx7LHVbfPvoGqHrcN5yj0wJiompq9761rfyx3/8xxw6dOifbJ79c1xlVeJanyTpmLqnrKrGa2dqUGvuied6RFGE4xgvEg3Mzs0ThqExbd7YYDgY2LrRyqC2sapMSSNxPZ9Wu0O322PX7t34QYjn+5RKEQQhvZkZ9u3bR6vdRkiHSZIymkxO2ed7vZ45tCplEvQKa3ifpVRVSV5IKlUhK4der0er1WJ5eRFRZlCWCClYP3GM48WjDDY3WF5ZYWVlBcdxydKEBx9YZXllB47ns7hzN8u79iDQVHlmD+CK3swsg8GAQ4cOGSAO6HZnaLXMvlblKUVmOv6zs/P4rgH34jBgptthz65ddKIQVMUTnngZSWqMytM0o1IVaakYbo0oqz65TderFLhRi6jdIo5bSN83e0ccsjQ/S6/Xsw1nQVUpNocDczZBGMBQSHx7DjKm8VnjgxTHbQNYFQWj8chYgcSxNZMuyPOcTreL63mM0ow0TUnynMl4bDy7qtL4MTnmXog0wZGS0HPA1nGlVXQonRtCgBREUUzR7lAWOWFgIu09z6XMMyO/sSES07VfbKv1pt66Ve0zlyRkaYKqKiMHBBzfZ2uccfTEGutbfVqBRzf0yKraOsNOCiGaA++/hCr6dA19uoY+XUN/fzX09ww8GWRoOuFOWSEaJK35mwjHJMg1k0prq2kU1u/IvENHy+341bYXsNDBNqanlNs/lXlNoW0EbP1gK2s0WBb2IWmbpFdTYI1+UQuB43nGuDEIcHLTD66KglIISinBVcZE0XHQ0jHSTyEs+OTi+QGua9LqjJG6g3Rds/AoZQzZHbMpTDTG/LyqDPppkU9pX8t1XagUJpiTBoiSjoPwPDzXww8DXM/HD2p9rgF3ytK3HSGTXlIpkGVlkFa2+WfVTEE9ReJrI3UpLUvI3sfmAWuQetrMbICaurBh+itsGxZ6Sk2skfYGUZU072v7mGnM2lTtHbZdGjdlLNWsJYQ1a9OGmUXz3s0kEkKCnai1RHP7JWyvCbCodu1R5jWJI/WfGZRbUSKQFWgtcASYfhVs0w4+hi/TOdhGYKM20+OU/xcWIBT2Hpn7XdWLoKWN1vTN2lQSW+B6no8fxbSjEN93aYURrd4src4Mc0vLRHGbMDZJGq7j4nougm1SSIMoTjdlOV3QhDagra2GwHaNazC8rIxvl7LjRTqO9cVoMRgMKYsCrUp0VaDKHKUd8/cqKxVuAHMPlCZsdQnDmChqoasSKSTZZGwkxPXPdkxxlqemoBSeT5amVJUyQKg1HJ1fWsQLQoI4pt3pIqWLRCJKRRGGhEVsqOhKkWalGVv2npjNxLARXUvl91y36Zij6z4wdnneDqzaDXMbi7BmJtYAbb2Bim1LewMQoy1tX1FLmWt5KlIjHW0TcOy8Q4Mw87BsurzmcSkEhdakeUaaZ8Z4VUqE6zVzsf7Z9YYu7bYopi2aaRev/szN3mFjC7RGVZpSQaoqKkdQOZJCYEZ0/RqAltj3/S9hDpurPrAmWWoi2B2HXqfFJMtJMyPRUdp0rDzXdMzywrBgwzDgzDP3c/bZZ7O8ssKdd97Jo48+2rz27t27uepKA6x85atf5aqrriLL8mbdveCCC7j00ksp8oLzzj2HOh3G933OOOMMnvOc57C4tNjIgzzPMx1PG/0+GPRxXY+lpSWueNKTedzjLiAtSorxGKU08/PzTdrX0aNHGY7GaFUxGU9wpcQPAubnZtmzawU/jOj3Bzz60H3ccuOXieOYyy57Ilub69x5+zc469xz6M0t0J6d45yz9tPf2uShRx7m6sufSlFV3Hzzzdb70WX33v305uaJfIfDjx6iVIpdO3ZQD7pdK8uGIdBuc/bFTySa30Ewd4TcsbI7N+CBhx5ikmT0+wM6ToAThLhegB+3aPkxYmGBbrdjPCylpCgrVldXSTLTdOu026YQB0ajsU2acuh2ujiO4NjJVbqdFq044sFHDlApza6lebTjkpZj+oMhrZaiKgsqBJPxiKqqcNB4jsRzJVubm/R6PZ5zzTV8dP0Y/fU1xuMJYRCiu7C2scWll17KFVdcwTlnn81tt93GoYMHv2v81R3c/3/XgQMH6PcH2xqKRhJV//e1115LMpnwpS99keEkIc0LHAEnt4am0ZOX5IVpAHmuDxKObo5IK804K0DD5uYmm5bd9Vi+akuCRoIDDdOsXsvqJq4rDHARBEFTKxn/D+O1FrfadHuzjMcThOPa5uPUpLhp0AlJGAb0ZmaZmZ1jecdOK4ELycsK6bqEYYRwPCPRUOa9OdaovPYbUbamrT1+HMeEGThSUBTutKGnKzzPHC3yPDcJ14FPr9szAEWWmfrQ1uq1NURRlGR5ju8HtNudJm5cB8Zs2/Vcwsj4mE7SFK2MP9h4MjZdfQywJx0Xx3GNgbjrkLVaIM15ZHZunjiKkFKwsLSDwXCIkh6On5kauighTRFlaSLGdUapKyM90yYBq8gzBIYB32rFRFFMpUwinBBi2tTE2HrUDdLaMkKK2u9WNOy2Shm5oQbSrGjmluM4BtSw91xKgWsBAaVKijwD3zf1GuYcJqVZc019LBrZnEQ0dXxRGlP5LMtN0x5sDUczFuFUxlNtxaGFAiUQomr2zBpIac56mEZwpRRpXpjnrSrzhbDzwN4fYc5LdXrXY/s6XUOfrqFP19Dfbw39jwKevqOhZT/cNvf5bZfjOA0jSEBDRTXj3KDuTv09vY3apjXaejZZSADsgmmwk3oCGTSwUoqqNLTPsihsIkhBmmUNMl8be7uOi9IudYyt4wcEcYswbjWpPLU5olQKfB/tuAg/QLsuGoPQCtfB8X2CKMb3A8IwwvNMUkUNhCilEI7Es/TdqigpsoS8LACjt5aWOeX5IUEYIcsSUUgrXzS0bNf3cT2PVrtNEIaWQeZQOQ6lawCjsqysHCxH5DlpbqJya8BFSMei11NXfQPkSUvJtCAW5j6qbc/SPJ9mOqIxdNhKTVPxTn1+5m+ZzyCaiVsP9HpwOs6U/QRAtY2NVE0ldrqRdE6BIZqFxLwaSqOFRitDdwWzaUthO34Yhtt0Nag32em4bQoDjIzAcT2rw5ZIUTMFzOtVysgqdfPv/2UcWHXN9ps+rVPmdJO0Iww4bP/QLsL1c9SAKSJqgNJzDONP+gFh3KbVnWF+eRdLS0u04ph2HBO3WoRxzOLSkvF88LwGzKuq0qyx9Y+zrQKBZVIK0Loy36xMOmYdOavwUEqRYOSyWZ41CT9SCELfxfF8ujMzrG9soMcThNZQlag8JSsMuOz7IU4Q4IWB7U4aWWy9PoRRzLC/ZUFjGA2HaFWZeeQ4CKEZDQe4rksYx0wmY6RjjAArZWQVZ17wOEsddolcFz+OaDkST5UmVcd10VpQFAUbW1sMhkMy6/PhuI4JPHAEnusR+AG+4yJtYelIYYuH7aNRNOO6sn40qlLUMavmkvWuwfRfThmSCtNJT/O86TprzPzPC8MOdRzXslHtzcHo2o1sAKzI3BTRWpNWitF4yGgyolSlWU+D0HjU1aC3LciEkNQrFxrz7GwMrK7/u/6stpYyJotYuruioqIQpmD3hNPEQWth/o22Hct/aH97rF6+Z8b90ZNrzM/N0W23OGvXMvc/cpj1zT6tKKIoSybphJlum6qsyO0BpNfr8cIXPJ+9Z5xBmqb8zfvef8qh/bLLLuMv/uIveP4LXsDRI0f527/9WwOC2Bv0/Oc/n9/93d+lv7VFmqZMxuPpegH8xE/8xCnv1fN9HnzgQR49dBCtFOtra3S6XS677FJ+7Md+nEufeAV//O7/SRQEzM30OP+CC5BCUGYpX/nazfQHfeZnOkzShEIpHnfBBVz+hEt40qUX8/aoTf/Rw/QfeoA7brmZCy95PH/ztx/kP/36r/Lxv/sIv/U7/5W4O0M4u8iLX/NaDj3yEFsf+Bt+8ZffyGg04voX/SBpmuI4LuddeCmSAqqMG269mbPOPocf/MGXsLZ2Aq0VT73sCXzjS58lHfZ54tUvYM/aGjsOHuKW2+5AlSWx5/L373w3qlJccMFFZEpAJbh431mU0iVXgh0XX8ryjhV8z0XqkPFwwAPf/jbduWWCuM3+fXuNxMlxOHH0CK1Wm127drJjaZ7VtTU++PFP8KMvfQk7V5b57bf/KT9w5dO56smX86lvfIuNrQH9/oD+xrphM7d7rJ88gSNg99I80nVR+YRvP/gw5561nxf91E9y7x238K0kYXX1OEtLy3R6PdY2tnj5y1/OG17/+inA9P90bftenYL1nX//fe//wPTP7brcarUalvZv/dZvcfTIEW748peZpBmuLFiZaXPXgZPc/OAxVuZnSfOc1a0BT7roPNIs5477HiYrShPZ/X82hf6vXObAoSkrheuaGsi1a7cAC/ZMmRJRGBDHMTXzv2bNCCFod3ssruxAuh7+6uoU3LXgU/33XcchjlssLS8zv7DA/rPOIW61CeKYUZI29WNeVpSTxNSErmvBCwMemAS1tAFKPM8nCALm5uYYj8ckSUp/0G/Muj3PoyhL1je3UJXCD0J27tzJZDymyHParRjHEeRpQlFabxUhmCQJGsHc3BxpklAUBW4QmEj4mRkmaWZSqzyPY0ePsLW1iSoLotA0gUulaLW7RHHI1uYmZVEQBAFxp4vnByzv2Inv+wSBz9LSEsJbI600catNWVVkRUmYZpaFVKI3NqnGE9I0RegK3xEMN/tmL4kjup0urXabPC8IXBfH2cY6oU6SFqjKAjAY0NWk1kGaZY25dBCEZEXJ5nBMHEX4vksUhWRlRVoU5mc6Eu17TKSg0IqiyBoLD2F9dT3PJQxDW3sodFHacWaUDGVVMhonbPYHbG31ybMcValpLVsDFJYxIS1rxqTdOcY3V2mElYIKKfF936QdOpLSsjZM/QN5USG0oiwrxmlOFPjNParDlrKiYpwYpcZj+TpdQ5+uoU/X0N9/Df2PAJ62+fHUr74deNDTDo6wG5fv+5alZAANo6GUWHUsQgg812H6chZ80LW+uH7wFuRQU9pb2QAVmiwvjLFVVdqfYw3fpEDiWAmWAbum6L2D50cEkabV7pGmKd5oTDoaUGYpRZIQhhG+b7pNru+ZwWCZMTURT+t6AbH8mRqxFCY5oL5PruehKqPB9gKDaIetNn4UGwQ3inGrCq80OuiaUSQd4w2FlBZAck9FKy0SW9kUhSRJGQwGJElCURYGuVYKpUxnyfV8VFgRRlHTXTNgmdGWi3rCQLPwTMdS3bU59atuo9SMpJryPaXTNjuZcecHhCOs/dL0e1MAU09pfBZ4qkW1Ugiz+FODkNLOlOmGv91fqt5Ia5TZbBQW5bXdG61t3LA1yg8C4/0VBgHS93CkwHNNAefYye9I2XR56g7Hv4xLNM/LzOmp5NFctmtjOwQCqCpjkq+qsjFE9QKfsNXBC1vMzq/Q6vZoz8wyv7JCt9NlaX6RbquN4wiKdNwYbkb1mqBKi6xjElDsSmSK4GnEr5A0ckmB6Qx5lrYukWRlQVaWjEYj0jQly1IDHFopqe620Y7L4o7dnFxdYzAYsLV2kjhq0YpbhiLveVS4lGh816M9t0gctQiDgLgVG1qqqmiJGeJej4WVXRw58BDj/haTwabZaIOA3twCM7PzdHszKBxKG1+dZimu59Obn6PT6RKGAWhJ5RWUvo90XcrKzL9+v0+S5QyHI+Oz4DhE7Q5ISZKkBFrixcYzpV5bDeNToEQtp7U3a1unxoC2dTfRgsy6psra6Fc79x3XdF6EI1CVjX/N6k2zamjZpmNn1vOiKNFIHKeOZN0WS2tHlagqpJS0XI8zFpZY7M3iCI9qMiIbDxkc81BFTqUqXOk2U0pRf5aKUitK+3n09JXNyBaYJBQpCBzHNjcEnmOaHG5ToBvzRmP/p0jrhKDHfLd1ejmOpBXHzM3MsLaxyer6BlVZUFaKXrdD6LnEcUSr1TJynNEEpRS//wd/wNOf/nQWFxf4i7/4n3zqU59iOBye8tpf+cpXeNbVV3PPPfeQZRk/+tof5fDhw8333/ve93LjjTeeYl78jne8gyc96Un/4HvVWrO5scp4OMT1Al7+6teyZ99+Hl3d4OGjJzi2/mkef+EFVBrDADp5gmSS0O8PePrTnoIjHb517z0NG7bXaXP3t+/jznvv4wXXXstdy0v89V//b175I69haWmZ33zTr+FIyTOvvJpPfeYznH3WWfzwi17Mn/zRH3Lm/v38pzf9Jjd845tMJiPe9ra38bnPf4Ebv/pVfuw1r+DhAwc5cOAgL37Zqzh44AC/+Lp/x+t/+d+ztLKT+x95hOe8+Ie4Lgg4d/9ejh09wsOPPMIPPf85bA7GfPPBA/y71/0iRZ5z86138sBDDyGl4Kd/5KV8+MMf4pOf/CR/9RfvpsDhlju/xTMuu4hOOMfJ4116MzNEcczm5gYbm1uMk4w9u3YShgFB4PGVr99K4Hn8mx95FZ//+u1sfPkWfua1r+Tg8XU+9Lmvcuaencx4S2z4kvvu+SZCSOYXl0H5eI5kcXmJk+ubrG8Nedy5ZzEYjXjn/34/J0+eRKvSsLYFpmsOvOMd7+Cjf/d3tLs9Dh9+9B98rtuvbrfL//pf/4u5uTkANtY3kFIyMzvDf/gP/4GvfOUrADzjGc/kiic/mRe98IV84hMf57//9/8+rSXQ+K5LGHjMzs5Qbg1QScqlexdZG0x46PiG9b50cDyPnd02aM3Dx9f+j+bQ/40r8P3mQJ8Vla2hzUnHdOCdBnwqirJh1Gu7zpdKmUNTEDIzO4dG0urO0J2dN0lned4wkqQQxv/I88zhtd0mbrUIImPQbf6OxHUts8qrPacM8ycvClzPs807UyNJIWm3YoIgbDynTNoy9Lc2mIyGjEYjZufmLINH0LLsqpUduzhx4gT9wYCNjQ0jixmNaHd7+EFEt9PG9YyFRXdmhl6vZ/Z81yFqtYjiFlGeUxQF3ZlZ8rJiNNhiMh4wGg+R0qUzt8hCp8vy8kpj4bDZH5CVylhWdLu02208PyAtKhzPZ3ZmpjnHVEqztbHBZDxm2O/jSkk7jui1YxwUg401BMYnpt3pooVJqlIoBgPD7KnlpFoIAnsu8n3PerppU5c0TVZz8EaaZDQhzP2Sno+WDkllmEoSzXg4JJmMSZMJSTKmKox/32Q8JHM8AKLQgHKl0g2rKAyCRs6ntUZKh8W5WXwJnShgsLFqbCzKkjQ1oINS2kh9DCxgpWNGvmdYDpVtQmsLpBoQuT5Qa60Jg8DImbttHAGeBTPbgfGUdaxvWaU0FSN8q0547F+na+jTNfTpGvr7qaH/UcBT/fHrI705x9tjd43ySsPy8XzzVXdypmCCjRCU9VM1AELNQtEarI938/PQ2x+w+TdVWaFUDbqUTddAW6PnhjElmPowOdLoHS1a57guru/jh1GjeU/RqLKk0KWlP4Jf+lSlT1W5qLIwNPaiMPGTQCEFGtX8HL2d/SVq+uv0yywSxqDcRNXqpnMnZJ0sZyBHA6xskzEaxMloRS3YZijCBVmakqYTszllKWVpUjS0U6Iqp/GSclzXGG+jMUZq5vXAdt4aep7ZPHVtkd+AXVbbrLfB+Nt/a0GoGqSqF2oLKVnAzqKtFmEU9l7ZD9kAkHVXoDbJbPwgMGBTw1oSdvrUCwb1609R2FMp6Ew7U9pQCutIU88z3Zsg8HEB13XwXQfPc3GETSaU9XP9bgnfY/ZquiA0wJzW2wBltU06aQumWt1aA6Ce7xsfgk6HqDND0Oowv7ybTneGzsws80sLdFot5ro9AtcFVTEqUwPWWUmQ+dHKUMh13SUyY6MsSyqbxmKQdwF6mu7gSGmZj3VyT2m00payr5tibtqpQDpErW5jmJpNJkilkUoRx62G9l43G4xnm3m/QkqEMu/F8Yz0wJUOvueTOS5KmflUg8deEOL5gemCZpmZh1UteZUmZMD1oDJBCE23R5ukmyRJGU8mTJKkkeKqqqSwBa1nZTiOY6Wz2kShouzcldsnAA2A3RhWNpdoCu2mQYLpXkr7CtuZrPWcn37VILv5vtq+LtgC1KhPba9FmC6LABwhcAMf6bgEQYjr+QZct+tOI93VDUl9CmjbX5sPWH8aYTdI18FzHWI/wPMcKy8yXVXHMj/rfUrZjrBIU5yibA5sj9XraU97GseOHeORRx4x0hPpoJRlcwrF1nDUMBzq1CrHcayppnkmj3vc47j88ssBWF1d5dZbb0Vrzc6dOznjjDO4+1t30+/3ufFrX2v29jvuuOOU93H06FGOHj16yp/dcuutaKAsCiPhW14+5fvS9Wl1e3S7PXbu3sPSjp0MlaRKJ+R50cg4kA5rq8epyop2u0UUhriex8LCIo8+eojhYMDeM/bQHwxY3+rzrCc+npMnjjcNmSxNOHTwEfaddT4zswscOHoYz/dZXFqk1+0wMzvDwtIKnv8AoVbsO/tsoq/fQp7nnDx+hBOrq6z1x+zctZtkMkFIyfrGJsL1ydKM3Wecwfz8PJv9ISBYmJ2l3e2CF7A7yfFclzLP8Xyf+ZkuUsCxw4cos5TZbocKk9wkBQz6feNr4QUm0SbLaEURo3FKnhe0Wi2kFMYouFLgYTqjtiaQQQxOH6WUYY6kCUWe4bkOVVWxvrbG0uI8cbttfqbjEvg+6Ole6vk+rvWlFFI2CXUHDx7kyNGjPPOqZ7GyvEKv3eauu+5iPB6f8lzr9cF1XS6//HKWl5cRQnDgwAHG4zGj7/CCqveXOkZ8+6W1Zn6mRysKKSrF4sIiuwKfstLMzM5yydJupMrReclMt4urTUIUMK1bHuOX0zDPRdM119ZgFjE1o61BE+OT5kz3s3pflhLP92m126aO9XwK6/WpKlsDY56L6zhEoQnTCYLAMursOKJe66frfQ0e1ObmtVzIbZQDVh6lFXlRUBui14equlGohTRZUFIihUMQGaNxx3GYTMb2IF6ZP/eDRm4kbdJyHffuWHN6z/NRWtv92SWMIvI0IR3ZDyAlfhDh+6G9N53GfqIoS2ORIU0dI6QkSzMExmy7KCsqbZgoxgQ7YzQyYJYjHZPAVhZMyoIwbuEHAVHcRog6nUxTqNIc9DHvR0hzKJNWUeBYRYTxgrL3a1sKd2UPodJxjBTLbPDW/0gbRluWkmVZ4w8zlQgZ3xWllAGObH2kNTjS1PBVpextEgSBTxxFFHmGHxgLD8dxmwJ6WqebMSd1bWNB02wwFhfa1mFq6rNr634jz4rotNtIYaTYURgSOCbUKIxim5BYUihlPu+2s85j8jpdQ5+uoZvrdA39f1pDf8/AU81EQU/1qlrZqMAa5fN9/CBkZnae3twCnW7PSsMwVKyynN44xzNvXBkEXjYUVSNrUnV6mUUja8d0pQ3Vraxqt36sr5F9KMK44TtOjfAKGydqYl6l44KQKASu6xMEkrjbI80SkmRCMtgkL0sTVylAqRLpmA20Kg1lT1cVlCVSGcpxERhplnScZgCYw4C0C3JlEELp4DrWG8o3esxJmkGak+Ulrufiuo4xaLRpdE3yiTVMrw3J8yKjyDMmE1O4p0nGYHOD8XjM1vo6RWH8NDw78aW00sKohXS8ZtNDm422tJNOCsPkEXbzaxBRy1xSFvRSDQiom42zAaaa5M56wtUDXFPHOTYSulrmV09O7ORQlfkMtktgxo55N/UhRTYV0z+0WdVd1BryVc3i0SQtCtAl1o/LHM4kENnuYK/TIXCNvjm0YKojHVzHa/69ENMF4zF/1e9xO2NsG+atsdG+lTGMFDZdMe708KOYVmeWucUl2t0ey7v20OnN0mp36MzOEwUBrSAkDjxcCa7UpMnEplmMabU6BJ5n6N4IKiUoi8xGDZfTkADDK0UAYejjSGMMGHi+NbhU5HlqDS0LUhsbLDDdZN83qZKO4+D7rkmrQBD35ujMzNPe2uTo2gnS0Yih47K8YweO7xKGAa7JkSWZDKEqyF2PUd/B8z28IEAKULoiqexhx873zswc7ZkecauH4/tUQG9unixNEf2+2TSlJM9yJuOEqlBm081zsiwhSXKyLGc8mXDs6FGGo6FJ9YkifM9jkE6M/NVxabV7YM7naFt4mIOswLEAt8ast/Ujr2OdG7DYFk6qgqKoKMsKsPJj10Fo02NFSBzXauIdhxJFZdcMKQSeY+J266hgrY2GvSgLarV8EEYNKFxLYoEmYEFVFWVeUKSFORBj0OhKaYQwaSCVXecrS3fW39VUMUxI33FoxzFR6DPX6xGGAb7v47qh6WIhaNjM0KQHZZkx/CzLxzbj6Utf+hJvf/vbecMbXk+vFZMXJfc88ABnnXUOruvxwP3fptNuEQQBm1tbDIZjNje32ByMjG/Dd1w1uC+lwyte8Qre9KY3cfWzn829997DeDj6f3wfdTG1PcHkP/3GbyCkZHNtjT/7sz87RW4nhGR579nsOvN8nv60p4J0OXb0GFQV5519Ft1Wi89/+UvMzc6xtLzC1uYGu3bu5AeueQ6f+vwXyLKMZz7tadx84w3cfPNN/PDLXkU2mVClE3oLS8wtrTA3P8vf/s17abdbXHP1VczNz9GdXeD8Xo9Wb4ZhVvDH7/gjjq+u85Vbbue6H7gaLQSfu/kOnvXc5/PkJ13B+97zZ1TtJeKV/fQ6ba565jN5wqVP5E///M+YTBJ+4Jpns9RtEfkO7/nIp7j8wnP58Ve9nI9++evM9zr84DXP5HWv+3mOnzjJU668hh9+8QuJAo//+Gv/kR9+5av5o3e9h09+9ovsWJjnmZddzMc+/XmyvOAJF1/IwcOHUVpx3bOfhRCSJC/w4zbD/iaPHjzAZZdczCTNeO9HPslLnv9slpaWePtHvshTH7eP5z3tMj7099ezsbbGYHOTC88/m35/wN///d/xo6/5UXasrHDXfQ+xMj/LzqUFvvzVGzlz315e89IXcfyR+8iLkiOPHkL6IV4QUvu0tFst3vPud7GyvExZljzlqU/lrrvuOmUceJ7XSL8a4EJrjh0/xo1fvZHfe+tb6VszeYCv3nADX73hBt7+B78PYNPaZDPnn3Lpxcx22/zlRz/Fv3nta7j6mU/nJ3/hDbzohS/gP7zh9fz7X/lViknG5Refzw233MGxk+sA+L6H7/0j+qj/ly4p6pRkLNvDrL81SyTT+fTAIh20MKl2dX2sK2UPR4a13+l0aHe7LNb33wJWqjLWE8br1BRkvmfYT3Gr1QBMYMxyq0IhKmMqX1ZVoyLQCHzPxfU8et1ucyhNJ2OKoiTJMsqiMIfWoiDwPLxejyiKrMWFsdxAQ5pmeIEBmU6cOI7vukyikFarZcDyKAQUuvTY1to2LHNhPDVRJvAnCEKTmhcEBGFEq9MjbLWYXVwhio3MeH5xiaqqyPOMycSAt1mWoYVAOinDSUI7DIijiPWtvtmP05TVE8fZ3FjnyOHDzM4tEMctdGFMnwul2bewTHtmnvmlZaQjKSuTjKeUkTL5gW8P4tPkMgFEod/U8WWRU1ZlI+EpK02SpriuAQk1EiE1Di6eo0EpRuMReZZSFjm6UhR5TjIZMzMzQxiGxHHUAFOKaXPUkaI5N/m+AZj8IMDxPGsi7U7PLLYirO00AHuWmHp9aQs6mVrNgGhZnhvGnU1SBJMouDg/j85TpGuSubvdLnlmwK65uXnSLCVNU8L4JP3BkMlk8v/STPw/vE7X0Kdr6NM19PddQ3/PO3XtryMQjSGYK43Xket7xK0ucbtDHLeYm19keXmZdrfX+DhRI/A2MUErw+ZRGoQoqMGr+jKLuJW0NaDBNG7W6Cwt0FGphm4jseycGmUW4LnSTjhhgZIKrQ3Q4roOcbtDnpuUjvHWhmHmVIbiVxSa8WREUeSknm8042FEHkVUWYbn+/hBYDo5rocfRrjWSV+4Bs2dIvn1IMlNF2acMEkyirIk8APiKCSOjC+W5xokU1iJnSn0K7SuKLOMPEsospRsPCbLcpIkIRlukYzH5JMBRVGY+1ZvKq6DL6XR1ArdFBBVVVnDb2k9qhTmLk7/t42z9l1sIb1tbOgaWxW68XuowSimj9aAXQqUUEgMwa02basX0bI0ho4mQcAs5M3P1cK+Q+xGMDUU1wibqlGjYdPxux0cEhYw3S4N1Mosbr5nkmRarRahb7wMosjQyx3HRUp32+e3EkMe24dW2PYctLlfGtNdNZ1K0/lQjgO+T3tmlrjVod3tsbSyh1a7S29unk63RxhHzM7MGkaY6+J5Lq4UOKJAV4pKW82zcJCuAaOlYyS1eZY3KHlNNUUbzTlC4PnSgrQmLtmx/gKmE2kW2CSZWHPM0i6iGiGmnda4Zei/vu9TWFm7H8b0FhZJ0gmbRw5RlSUCTZKOUZuKPM/pzswSxjE6y8jCEN/zcQIfzwvMnHY9EA5auiClAYqlxHOMweHBw0dN91FIdqwsgVakaUocx7hWX66qynhllDl5NiFNE4b9IWmaMh6N6a8dYzQakk4SdBLiOg4KjRu2CFqdqexUVZSllSRjvNq0I0znxg7z+t4apt/UK82MezN1jNGpOSAIKYxcXWmUUA3TUWtNpc09yrOUMk8Asxc4rm9ludgGgSYvq+YQZLpghgVad4FKZQ1WXYdWHOMHPjiSsqxQpfEh0tJscqru3thCWNdFXgN2W786IQg8l3Yc04pjOr0ZoigmDAM8P7abpty2DmkrzzZFc1GUtnh47F4/+qM/yn333QcI4/vXatOZmWU4GpOoEWfu3U1/MGI0Gjesl/5oQqlUE1M9GAw5cXKV9a0BG1t9et0ev/d7v8cTn/hEwiDgzf/5P/P5L3yB33/b207p2m5fO1/wghfwyle+EqUUt956K29/+9sZjwxQpbXmXe96F3fddSe/819+l89+7rN84AMf4GlX/wBRFFHmOfM7FwDYePhhDh48aPyOPMM6GPa3ePIVT2I8HvHRv/tIU2z+1V/+BWft388lF19EqaDb67F3714ePb7G5ijljH1nodWDaFXx6KOPIh2PZDRgqz+gHVxGvG8fv/2bb2HPGWfw3Odfx99ffz2VUlx51dX81bv/nHvvvouXveb/w8KOXfTmFvnyDTcQt9rsPGM/P/SvXsJkMub+A4cRDx0gCkM6oUOZTTh+4jhpf4OHTx7l0P33kk5GtKKAwHX5+Mf+jtGwzxOe/Ey03+aOe+7n2U+9nK3BgM/feDPnnLkP3/fRGs49cz8Iwee/ehPLi4tceM5+HnjwQSSCnTtWuO+RQ6RpzuzsDLfceTdBEPCEs3bhUnH/gUOkacr83ByPO/tMvvTFLxCGIb/8C6/j4JGj3HjT12h35zl24gRHjymWV3YStrocW99kPJmYA5LjMBoOcMYjtNa84hWv4MX/6l8xOzvLF7/0Jd797nefkhgnhGDXrl389m//No7jkOc5v/Irv9IwkNbW1lhdXWXQ71MWxXeNZaUUz77m2bzq1a/ij/7ojzh08AA7lxc5ePQEOZLff9vv8+jBA3zyc1/g9a9/A1VZ8pfv/VsuuOQJCK2QqiTRLocOH+Gub95N8S+AsQgGICuVaR6W1hpC2gRlpRSO6+C6Po7nEYRGzhVG8TQdWmkye4+rqjJsJ8fFC/wmQMcw2E3UfZqmxl+0yKdd71rCoQx4UZaliXlXXpOQ5gcBXt1c1qYR7Ac+ldbkZdH4L5VF0UhuawmP4zi0e13LBjLNxkorpOfRm51nMUnY3FijKgryLKO/uUGRZ+Rpgh+EZO0OM72ObSgbc/1Ob4Zur8c4zXBdjyiOrSwoAylptVp0ul1EVbB6ok+STJhfXLaWCX7T3MyKkrwc231Ak6cVlBnpqM9wNGZzc5OTx48xGvYpsoTh1gbJeISuKrwoNtIoL8B1HLSqKMocrRR5qQh8668UBA0zJS9MjVNUpsYXQlHklTEJxyFTFXlZkhUlCEFRVuTDEV5gGtFhGJHkJVVpzkhoM3fy3LCehLAKCscBrSkKYxZeVpbt5roI32/GQy5ASEFeVuYwKhyj+Agj/DA0DBVh7E2qUtt9GLSaEgNMzWzGn7CHdNc1srnCMuDAgAph3KIzM8f8woKR89q0NMNulUStLmHcJggjeuNx47X7WL1O19Cna+jTNXQzG/6Pa+jvvUUkTOdSWN2ndFxjsN1q4Qchvdk52p0ZWq02c3MLzMz0TFKG4eRa2BBjtNVIpsQpbBlEbYYlrJ+T7Xo0QELNtrGMmwaFNN+r74e0dD9BjQpasprW1PGISgGOa2mnIVHcJuukhHHLSO3ShEoZzaLKDFjm5DlobWV2BUIpXN+nyEOCMsbz/YYG7yAaDXzN/tFoVFU1C8c4L+gPR2R5QeB7dNptilbLdO98HxB4QYDrTot/rRRFkVLmKUWWUKQTijQjTxLyZEyRTiizFFVa/ahboZWDxDtlgNWTSVUVqr7nNUPo1MgGe0Pt79kGPG07jOgaBNRmWAspkOYRo2uW3La/i9JoqRtqeVXZRdF+1TJC1VC4zXs3jCmNkhqhlV2cddOBQDfT6pTD0vbufP3+DZV0u4G5Zcu5Lr7nE4YhYWAo6lEcEwaxNUN0t33m2mT9sc940koZGuY2EFDYsSkkOI6PF4Q4YcjM/CK9mTlm5hbZsXMf7U6X3uwcURzh+x6dODJJMsaBDiseMNNVaZRdNIWltmtbqORFbhdhbf+NbvzXhO1qCsdunK7b6K2VjQ6uyswCt4X1UpDGCE+A2TIUnmNjWYWg0Ea77Xoe7e4MvfkJYRyTJwlVmZPlKUVVkiYpKE2RplApyijCC3yCuEUZFLhlietHCNdDuGZREVIibDpPnuUcO3GCPMtQpcJzhZU5FfieSb30XLdhDOZlSpZMyJMx6ahPmqQkI/P7bDymSFNklVM5DpWA0HHxdatZS7UyhWNN5dZOrTnfPs+2bZhan/pn9fOXEqcGigUNnVcr0TBaK8s0LS0TtMgz20l1kM50/a20ajq6xj/AFGJQmxCaZ1yqCg8jwQgD38h9rJeI2ahrpmK97gH2MCW2bXr1GiZE3WAwRX8Ux0RxmziOjU9fGCPMimzuEQBTeYibFeRFYencj93rve99L4CVuRh6eqvVZn1jgyzLWJrbafeTnFYUIDwH7XgEwtDrA9+wcpMkpT8ckecFnufxpCuuYPeePQgpee5zn4uUkg996ENNw+c7gaenPfVpvPIVr0BriKKIt//hH1LkefN3vv71r3P48GHe/Oa3cOTIEb7+9Zt51Y//JEEQ8uD999nocZN4NaxK0+WP24AyB8a5s8mzjAMHD7B75y6qouDwo4fYv3cvZ555FsdX13Ac431zcjBGCcnuM/axduIY49GArc1NOq3jlNmEza0Bk/37UXnK1772NSbjMS/6wR/k4MGDaASz3Rab62scPnyYfWedy66dK7TbLT78gb+h1ekhghZPOO8set0ODz56nLWNLaQUdEKPKk9ZW11FZWM2T65x+MgRqjLHd1xjGn7/t9na3OKFL38KjheyNRjSawWMhnB8dZ3zztxHpxWzNRgyNzuDEIKbb7+D+dlZeu0Wk9GIKArpdha5/9Ax8qJkcW6Gw0ePUlaKZ+zeQzIZcWIwQMopM7ffH+BIh3POPosHDxzi5Ooqvh8b2ZFSLM7PozQMxgkI2cRsZ2nSNFSe8IRLeekPvRQh4MSJE9x4442nyuyEoNvr8bKXvQzf99nY2OCNb3wjJ0+eBGDnzp14vs/Kygqrq6vfxWSQUrLnjD1c/axn8da3vtUAT0uLKOnihm2uuOIKTp48yYm1DV76isu45557+drXb+b5L3gBge+zeuwIZ599LnGrzTfv/pY5hD22p+/00jQHmIaBbZnfYRgZKVcYEbdadHozNqTHaZ5NURbNWulgai3XcZvXwTZrhRC4tgEpSrOeGi/PygJQdQK08RupLBPclfVBVVDkGUYaWaI81wISJjW6sv4rQhjfGO0YFpbrukRBCEKQFwVFZT6n47h0Ol2yuXmiqEWiR+RpYpIXLQsoCCOqsmC4tdmsydKRjcSwtOcFv6rPAebQjFboqmScTFhbX2djc5OiUnRabXpdA2w4jvFWygsDFvmeQ6kKdAFZMiYZ9elvrjPsbzKZjKnynESDkClCa9rW9L82DK+K3KR6KVBCIoRvVQ3m7ziui9I0JvqNKYPWSCHNpiVU0/h0HaOQyC1IqJRnmGCW8a/BsCGKktwmxbmu8XHRaiqxKpWiKEzj3gwZD60qy36rEMKkaSoMq84PwuZLWn8xVZ/ZtKay63+999a1/vZznHSNObKqKlsPGkZfEMW0uz1mZufNoVyD5wdUqiJJUgPSOdIwcsKI4h8AqR9L1+ka+nQNfbqG/v5r6O8ZePLitk1oi+n0ZgmjmHZvlu7MDFHcYnZmltiyQnzXJfQkkW+jRJXVIkuB0IJC2VHeoIYWgDjlJ1qimf3Dhs6oja5YaIsmKmV4cJaZI2xnQ2IoxyiNKozjvW4M9zSlBun5CNcjCiMDFvkBk0Efz/OpipzJaEBR5JR5ZvEWQTIeE/gBQRCQtIxJYRibxTWIDDAhrEO960uU0KArlDbdpclwaGmpBZuTCYPRiDQ3FOWZbo+ZXpcoCgnDmLybm86T6+EIgdYVlSopJmPyZEw+GZONhmRZRpqkFMmYKs8QVYlUJUJrHG06IobCGxAEhkrpOKaTUdXUbWoNvzglbU7bIqn5j+1PqAb+tt1X3QCIJrpSIIzhWOMJZYEppqATmENIUZSkSWZMcktrhqgqlP0sCGEXRpC1RtaOjqmnV92VMaCQGUk0k0twqjl5VU0pqjXQ6TguQRjaiRcZs/EwIggii2q7Vk5YA22qQcgfy1eZZ403mJAC4Xq4UUxndpGo1WF+ZQcz80t0ZubYs2sXrbhNHLcIHBeJRgqFEAohKkSR2g1YWDahKZx9K6EVQlAamJc0zVFlAhridst2YCSxjYL1Xc/SwrGLqo0s1ZhOdlGQTUam0y3Noi4Bz3YtEQLhuVTSMAqFqiizlDxJSMsSLV0C12VpeSdxZ5bVQwfYPH6Y/sljDIfDZg0aDwaEQcDszBxBHOOHEXNLy7S6M7S6Lk7oIBwXXBccj7LSDNY2mIwTcg233HsPo9GYPC9QWULgG0lrumcv8wuLzC/sRImKUuUMTq6TDrZIh32SQZ80y0mTFFFkuKqkqnIoFGiPuN0mikLiOMbzXUCTJhmONHM2ijw7X+uNpZ6803G5HTywtgAIx1CLBQKttnk3CBPO4KLIc+Mfl0xy8txQac3rKDRGO6+VQpVQWbNC1/WMTFiaBJhKldaA1WxsjusY9qAriQOf2dlZFldWONnukIwGZMkE6U6DBoBmbtZL0PbN30irHcIooNXt0un26M7MEkWxKai9ECEkGmm83LRG6QrPznvHy/HLfxmMCTDr7rGTqwjWyGwEuNKKu+6xHk+ug+8HXHz5k3nylc8hlwE7luZ55hMu4Owz99LttNm9eydLC3Osr6/z9Gc8g5/6qZ/i13/t1wiCgGc+4xnccfvtpzCQt1+uPVDVchK0Nmaa2OhfPfUD+Ymf+Ale/eof4c77HmJ9fQ2tFffdf5+VwBTs3ncGy4uLtLozHDlyhEMHD3D99Z9iYX6ef/2iF/GVG7+K7wf88R/9Mb/267/Gn7/zz/ngBz7MV2/8Kh//2Md5wXX/il1LF3P++efx0AP3sbG+TpllPPjAgyCg22lz/13foBpt8bznv5DDR4/wwy9/Gf/pP/8mCys7ed+nvsBlT38mlzzh8fzJH76V/mDIcJTw4IMPsXPXLlaPHeFNX7mBs88+mw996CN88GOf4IGHHuLKKy5l9eQxDt5/N7PtmI2sz8EH7qEbOAyGff7iz97BS37whZxzzdXcdf9dXHzudTznyiv42Z/7Wc47/3H85E/+FNd/4ctIKXnulU/nxNYWWVnxr1/wPA4dPsJNt93JWWefi4lcL2lFIe1YsHf3DnzPpT8ccusttxBELaJWm4svejxfveFL/Pab38wfv+OPSLOUF/yrf83P/dt/x3OuvIqPfOyjPP2pT+Piiy7if/zhf2f3vrN4xrOv5YLHPxEN3P71rxL6fsOckFJYPyJ4yUtewtVXXcW1z38+3/rWt8wYVGpaF/wD4+P9738/F114ERrNK1/5Sv7+7/+++b4Qgm63w73f+ib/9Xd+k9WTJ5kkKQ8dOsyf/vqbOHP/fl79I6/mNa95Lb/8xl/lz971Loo8Z2l5ieWFeU6cOMlHP/FJfvF1ryOOIj744Y98V2PpsXqtbWzaOG7rqeW6BGFEd6ZDFMfs2XMGS7v2MDu/SNxqM9drszjba/w0tNYUeUGljERWlJU5jOQ524u2uqlYG74qrVGlkYQU1mRaad0w1ISQ+H5A4PsmeEYaE+lhWZJlCVmaMh4NzZ4jJaHvo1yXLM9ot9p4nsf6+gaj8ZhBv8/M7AxoyJKJSSoT0piI797NzOwMx48eZs0eMgeDIUIMkVLafc7ErgdxC9cLqIBJmjEYjTn3cRfi+gEKQavboyxLNtdPcPKuY6RJwmA4YpKkZHnGzqPH8H0jTbrk8Y9ncWmZHbvPYHNzkyRLIFfmUK0qRpsbjLb6DNdOkIy2yJKULEkRjovn+azs2Em726XdjmkFDpQpm2sTsjQzHnRLK+asUJU40nDwPbAyFVN/T8YTlNa2qWwSq4pKEXiuaUvrurnukOcZeZ6TZrkBl4CqVPQHQ7Y21lFVQa/TYXFhga2tLfrlECEF3U7XmIvrCke4eFLgO5JxVjDob1JVmrAVE7VaSMckjs3ML5Fmxhx49cQxksnEsHe0tgfd2vbkO05olkYrHUkQGv+uBrBC4/sBC0srzM7OkWWpsTYJQxOElJb0BwPzfByHrCiI4hYzQfDPPge/n+t0DX26hobTNfT3W0N/z8DTyr6zGmZQ1wJPrU6XVqtlZGJxhO+aRUQKcK2jmq4N9FSFxoBCGqwBt5iCF1o3D9v8fy3t06f8Ol2ca6+nsmE/IQyCL6Tc1lXSVEXZbMSV1ScrAY5SxiAtNHTEIIxo9WaoqpJkPKQsDfqu8syCE4qiyO3PN1Q4vypBaJNgJyVhUeCUJdKpqCqzwWtVURUpeZYwmYwYj40vU5Zl6CLHVQoHCbpAVQWq8lDK0GtVmaPKDFWkaF3ZQVpAVZpUA2swqCyAgu2gSWEered5Bg0NjFbT993GHLJBd+uJpWtmU42aKrPxMJ2E3zVoa/BFWxM6eylUE++53ZzNzFYNWjQTwSC8laHqFbYDVxaUeYFSJVqbblHjewCmG2BTQATbZZqNlRqnSPwssi1EDaTZUVZ7XWHosqqq5YLyFN17rXlXWiC18T5A8x2xmo/tqxQmcjPwA9qzPaJWm+7cAnPzK7TaXebmF6xcNmam024MjFFGM47WCMeOh+0Ao6zNFYVB7CsDCNadviYFEEHgG/8DR0rDQFQVVWm6DfUzNJum0V1XRe2BYTdLpRBWcltkmVmoNbhBQJ3BMhknZq6XFbkqjeTVcRFhhyCMmdu123RqJmOqZNxIDZIsMck9UhJVOWGZE0QhjufhRzEhhhFnmsolVZUxngxJ+lukRWkSbAIP5TmoKkNVpqCvbJdJ5WMqKipVoIsMUeU4qkSVhfGhSBOziNvOt2c9OaJO23y1W9a7Ttu/Z83+oJmzGtUcQBpg1IKwtdS5noZaK0udnW6apTKpGQLR+IRkWU6aZBR5SlWkaJUbGUWlUI7poAptzQ+F9TER0mjq62epdMO0VJaaTmWIw1JKHM+zdP3tzMXpJmn/cPo7Xe8Lokn7lK6HsMaxCNFIdyED4SAwZtzGR65qOl9QR8E/xo1Nt111RHClFNJxaEVtzj73PApcHD/kuVc+haWde1jctZdut8vaiWP8xbvfyc/89E/xuPPPw3UcXvSiF7Fr1y4ALrnkEoqiIIoi4+0gTLLK8ePH+bM/+zNe+MIXcvnll5uiDPGdZxCU0uzcuYOf+Imf4GMf+xgPPPAAv/d7v8c1z342z7rqWQyGQyaTFNcPcYTx8Ks0JEnKidU1yuMnmUwmKA292XnyouDmm79Ot2sOUp/65N9x/nnnsveMM/jylz5Pnhc8+fLLuf/b97C8YyeXP+lJnH3e4yjLkuH6SWoW6trGJnnxIMdOrjG/vBMvDLngwotZ2+qDF3LRWXu54/ZbeeSB+zl65CjS9QiCgE6njee5TCZjlhbmmJ+d4eTaGr1um+WFeb7y1RtYWZhjz44lPve5LzIcDVmebbO+vonjuFx7zVV4QcDGcMxzrrmaLM/5xKc/x/OufR5BFHP73feye9cutFbcfPudLO/YQbvT5cTaOptbW0xGQwor/98aDNi1vMgkmfC1m26m3Wnjeb55Vr6P0oobvvh5hsMBz/qBa7n7m3cR+B4/8spXceL4UdZOnuCyJ1zGYDjis1/8En6rhxe1yLLE2ABII9WZMhhOvYIgYHZujn/3sz/LjV/7Gn/1V3/FJZddzmVPfCJlWfLZz36Wm2++mZ/5mZ/hlltu4dOf/jRxHNPutC3TxTnl9aIo4ud//ufZs2sXC/PzfPLTnzcx3Vrz4H3fxpOCF7/oxQRBwL333stlj7+E+++/jzvuuIOrnvY043GjlUkoa7X/2ebYP8fleF4TcBO1WsRxm7mFBeJ2l067zZln7mducZlO1yS6eY4xgzbrmPFVMx12ARgwiko18jtz2eZb7ecBpi5uCj2svMQcNmqwoLSsmqKqmoNklmUmLdruGUVZkVcZtUmI4zhGrlfkOFLQiiPCICBLjJREokFVVLpkMh4RxzG9Xo/llZ0GGMszkvHQMPnLkmo8IcsKKqWNzDBu0e7OEEZmX8uyDG1/rmFLDVlfWyMZj818KSt0VSDRpnaWgOeaQKCyBFVZVknFcNDHcyWeFIxHIybWQ0lbVoAxwG4ZFloU0e52mJnpNeC6IwWtdgvX9Q0Qb+WQkyTDtwmcoTQspiIvyCwrVNi6VGsas2dHCLYGAyO51Kb5WbOPitIAB1tra0zGYys/9FBKMRmPCEMTDlAUJRNr5h/HLVODVSWr6+ukacY4MdYg9qnQ/J8w6gxpz07bvdpqew2ta/ZEPYBMzWdCm6ZsPKVBV5U1PzcstqooCDwf4UhUZTy6aov9PM8b2w9guv8/Rq/TNfTpGvp0Df3919DfM/C0c9/ZhGFEq9VmpjeLHxj0sJ4EnhRNgp2uKqSYAkQN4wmLGkLNZzKghL0fwkq8aikBWrP9b9dIOlpPPYqKkkpVjeFXvfiDbMCpqiibSVRWhXkYUuJqgQt4lsni+Q6x7aLUqKHWRkdbam2108bgu1ImFlNpg3z7YWQiHQtDiy2dEscWSFpVFFlCno5JJkNGg2FDQZaY1AlPaBytbESmBmVMv1WRoQoHXbjmc6oKqhKhSiM1w7KJ6o6fsJ1KbUzCfc9vEgYD3zPsKaf23dJNAbGtJqFGRTXagFE2inNKNaTZlE51/N82wutBz5S223xXW/We0oaGWH2nt1NBWZpiRqvS+lKZBchx63Fgxo+wRZwUctt7m3Y/G+Aamg11+5nJ3DczzpRSVEJNNwRrYq5twWdSXkzCR21oXtkEmX8J0JPwQrxWm7g3x/IZe+jNzrGycydL8ztotTp0Oz08z8F1BK6eAppFVZgNSUoEdaqSaDbNRraITTjQgDL6X1WZIsqVEteRZr2wvgFKmbmrRYmj3eaeljYhpdLSpHOUNr1DKQtCmrlf+7IprWm5DmizKI9HJmq4LHIqUSE8D+WERIFhKM7t2Ek2HjHa2qQsC4Q2Bqt5kVOUBUhQGD+1ybiFH7WIcuNdILXpBukyo8wTRpMBG5tDkiw3Rq9eYGjOugBcXNdHq5KyyKjSASWVWUPKDKlKXAwlvlIlaZ6DMAWs5/nW6NGn3eoQttuErdgY6tt1VVpJRH2/tTRdVLGdB94UjgaE3z6H0cryBw2wqqzkFW02I6W0pfXnpKnRpasyQWA3SmnS08zTd0Boa9BoY5expqbaABPSHkC1Nik4NTJdp2k5ril+7btu1qR/6DDcrABC2nAKI/+uQx20NrHCWuc2ptpBStfuE0ZyAjVN3q4tzmO76AWoI5VLVeE6LnGrhdaCmbk5nvzUpzEoXUTQ4kde+6NUCAaThDN3LvOl1SP8xbvfyfOvfS779u4FNFdeeSVXXXUVcRyztbnF2tqa6c57HlJAGMUcP36c3/zN32R2dpbzzz/fGB1Lu97q6bNRSrG4uMjrXvc6HnnkEW6//Xbe9ra3UZYllz/xiWz1+yRpSuAH+E491jTjSUJ/OGJ9fY0gCGnFLWZm5zh5/Ci33/YNrn3eC3Ck4OMf/RCv/tEf5/zHXchvvvk/cfHFj+eKK57E//iTP0Vrzc6VZc4573Ekacpd66uNn+NWf4uTa5uUSnPmGauc+7gLecaTn8bxk2vkRck1T7uCL3xmlbu+eTdra+ssLi0x0+sxWZgjjmOqsmD/3j3sWFnkwUcO0I4jdi4v8PEPv4+rn/5kHn/+WXzzW/fgupILztnHo0eO02p1ePazruT2bz/IxnDEs668kk9/8ct86as38Pu/+RscW13jk5//Mi9+wfMpy4IPffTvuHpunqXFkEcefZR+v0+RpaTJmEmSsra+zll797C6rvjGHbdzwfnns7S0RLvdRUuXLC/42le+zBn7zuRZz3ken//4+1hemON1v/gGfvd3f4eHHnqYNz3vBXz+hhv42s23cO7jLiGMO2Q2LUhrE1mvtDkUtNoGMBpZ3y7XNWbEr/nR17Jj507+6q/+ikuveDJPf+aVVJXiC1/4Au973/u46aabmJ+f59Of/jRJkjAej+1cP7ULGoYhr33tj7GwsEBZFLTaU/Do2/d+i9BzedF1P8gtt93GnXfdyUtf/CI2Vk9w6OABNjc2KMrSGFK7XlMg/0u5wqiFdI1MdHZujpnZOXafsY/u7BydbpdzztxPp9sjCEOyyZg8nZAlxsi7btrWNU9dHVeVYc7UNZasG7iNxMKAyKaexjQQLfgkpQSlqbRhRxVlZRkdtqa0LHFhz8lVVZGlCVhPp1a7bf1WSnPAC43X6XAwsOCNZw/GFXlR0mq3iKOYpZUdZFnKeDyiyFOKPLfm3zkTnTAcT5iZTel2e0StjvkM0iFJEpSqCH2PdDxiNOizsb5GkaZUVYnv+0g0nmNkKo4wv6+sxKUqC8P60IrRaEgceMjAI00S0iy1jWWjAnA9j3bbgINhZAJnur0eeQ082eQ81/XIlcazqWXj0Qhla2jP9ynLytT724CnOpxG2shyKWA0HlujftkYwDuOQ5FmJGnK+vpac45yXBelFOPxiKWlZQN4TSZsbm5SlhWtVgutNWVRsr6xYYx/K0XXD6ndgU9pFm+rd7cnbUF9wNbN2U3UfYeGpVO/nvl7ZTlNSStyoxgJuz37vQLPdRtj5CLPUWU5Bbj+uSfg93mdrqFP19Cna+jvv4b+noGnCy+6FM91CFzPmHXbyYKuDOumVGg5/XM7pwyttyqpqgLf860ZnTHc1vZh1aDF9nh7A4hom7RmNlFpEWEhaMzVirI0KQ42frA2+NJaWFRQU2S5nXyF1eiC47t4WlBpICjA9UA6+FFM1MlpzcxRFTnpOMCz5plVadz/60fWhNZKB+24IB1KpUiTlDIvyAab6DKjKlIGG6uMhn1GW2tkSYJWGl9KPNczVEkPfEfjC03ou3gSyFPyrTVk6uPkLfNzrE5aSqOLbrW6OH6B8CO0M8RNUxPFWlZgDdylsMlxWNPAojCdHa1w7PccURttg7TWSfXwFNppNh9tn48xtqvsPZ42T+rva2gAwTq2t76EMPeuluaVyqQUltu6JEWWkaUTy5irzObsOA1KbcaRsBulnr7fGjCzbT3dbKzT753yPpQB7rQ2XRqJMIQszBgqSoXSJUoLSgVSVnaMmejKerPdjiQ/Vq8rX/wK2p0eMzPzzMzNEAUB3SjEE6YDUqkElVRkSpFZP7C6QKIB9pS11HLNc660mRP2mZtITjOufdcB1yHwbCGjochyxnlOlmUUVYEUJlrX9X0rzTRMMymETXewX1kOqkToktC35u7SJUnHhmI/GFl/C0k6nhgAuMjxfYkbRLgtRVFkZt4EIZ2FRZaKnMBzKFIjJUiytIkFFq6P8CLCXg8ZRuSV4vjBg4gyQxZDhptrDIdbbK49iu+6xC2XlpvhuB6u59ByBK12m9mVPWTrJ8hODOkzpPJ8tOPiBDGu7+PKDivRLL08pzsZsbq2SjJJmAzG5FmBriDsmI6pSBPKyjAQWlVM4DpWm+40o0/UY3F7xwZNqXTjDyEsNRghUdoWKBaANbupTeTEyKKLUqGrwsgmJgNQhW08tBsQ32zmpkMyHmyipWPAfS803RQpESLAAdtdlc3ByAROVOgmyfT/96WxqVB2jwldj9D18ZwAtKSqNEmSIaXpvNXJPY7jNV5wGruvUCeZON+1Tj0Wr0uecCnPuPJZfPb6v+fMc87jdf/+P/K+97+fqsj5tV95I8fXNlhd3+SWO+5EAoHnEAhNb26B173ul3jo4Ye54447ePe734VSivn5eT7ykY/yoQ99iLe+9fdwHIf9+/fz/Guv5eWvfAVg5vRb3vIW/tf//t985tOfptfrAZCkCXmeN/v2Pffcw+Mf/3g2NzfR2nSz//RP/5QPfvCD/Pi//QWWl1fwPYdjR4+RJAlaQxiFeJ5Lu9OjFUXEUciNN36NHStL/Nt/+/N84UtfZDwa8tznXMsH3/9+jhx7Oz/0w6/kyMGH+dN3vJ1du89knOb85tv+kEsffzHLO3ZQjrfo9/ukacLK3AxrW1tsjRJ+7pf+PWlRcfvd9xIHDg/ePeB/veNttHTKQpFxUiu8dEh7Irj8zCW6s/Ms7NyLlg4nTq7xUz/2I7z+F/4dT33Kk3jFK17BoQMP894PfZR3/s+/4o477+J/vOOPmFtcpshz/vhd7+aFL/4hzjnvcXzko3/H/OIir3rpS/jARz/GGXt2829e/XI++ZVbUBpe/cpXcvjwYe574H4uOu9cNucX2OgPOXTgAVaWlnju1Vfx0U99Fg284Rd+gS/d8BUeOXCIJz/lqSRFRVbBc178wzxy/7f4k7e9hR9+5Y/Q6/X4y7/+a86/6PGcde75/Nqvvp5LLn8K1133g9x5x+3kaZdut4cuMvLUBJTM9rqcd+65vONP38mfv/OdXHjhhQD8q5f8a17/79/Iz//8z3PXHXcAcO2znsF1172AVhTzq7/6q/zcz/0cSZKysbFJWZa87OUvx/c8KqU4eeIEdiAZMHBri6uuusoYYWvN8ePHqeOZ9+/eTTv0+YVf+gX2nrGblaVF/ugP/xuPv/Qy/vp//w2/9mu/yuLSEr/3u2/lt3/7t7jpppv+QfPyx+r1rB94nmkEhhGB5zLT67F//74mgEZIwyBCVVSlaVxKKSksE6aqlDGydRwcz0i2tKYJRzHgoWWt2IahFBiDXSsDyW0CW2X9NLU9LNXWCDUbRwhwHdes8UozSSc2US7CdYwEZDKeUJU5VVky6Pet5QK4nmc69VVJmuUm/sULWV3bwA8TurPzrJSFkRhp4+2WJQlFnlFVFUWl6fVmWFhaZmXHToTrkucFRx89gCpyynTC6tFHGfQ3ybbWG3lMK3TwQx8vCJidNYdk1/NZO3GM4WCLPJmwsDBPOwoYxzGqKpmkOTvP2EdvPCZorfLooUOUkwm6LMnLCq+qaHU6uJ5vwnhqhooUlrUk6cYxaVmRF5XxSpJmby0Kw0wNw4A8LyiKnCRNiEITVFOWJWmWkaYZM72eSeZKJvaAa1lUTol0XKJ2l/GwTzoeUWYTWnFE1OsaSZzWSMfFD0Ig49jRI8bfx/GQXoDvS2SlzJgQU6zWgBfKAiQ2PdwessGeH6wEbHs0PFijYg1NNLslDFRKUZVmvGZpymQ0ZHNzE1HLwC0LZWFhkdFoSFFWxHFMkqaMH+Opdqdr6NM19Oka+vuvob9n4KkVhQ3iasMGDdpXltQGzY7jIhwHx3Mb8Kle0FS9KdqFquaJKPucDLtm222paWA1I/GUmzZ1lK/9JCqlGid5hEEalR0oeZZZ88ICMP4FvgAn2ObtoxRKWGBCGFM21wvw/YLKN7rjSgqEUzUAi+cbp37Xbm7SglfGgFFR5RN0nqDyCeWkT5mYDaOy5oZSOggqJC5O5SBKlypzyCZjlGd0sJUPytGo0muSAEzqnADHxQk8fMejEg5pXphNvyhQQhrzSdezvlOWDqu3GbRXlQF2rPGZQXotDZdTPZNgippO77u2nTE9/TfNZKV55hbJsc+zppY6zYalLS1ZNUw2te39GcYTjrSbfIVAIG23r3Ywr00Ot40g+1+iGVu2+desKQ1IVo+B7e9ROuCYDoJukGdLsxSW9QTbOkSP/Wvv3n1ElrUYBj6e4+AKwIJ7hkGYN3NFOhLX8wgiwwg01F7qO285ZzWV3/pmSdGYGU7HW90lMAVNUeRMkgl5Yeimge8j86IxUnRdq21WFZWCsrLdCSFwpDvt3m6js6nSfIZKw3iSUBYFRZ7RIUJ62koKFKrMyXNj7u+4Hp4XNHJVpLBFHEStDmGrQxB3DCPS9SgnY0jH6MkGJFvoZEiRpejKRTkOYZnhBQEeIcV4wFBpsqIkKFKcyMd15lCYSFNdaYPuSh8/aqPynEiD5w8oihIvDPAd1zAUXc9sMMp2tWu2Z/2lFAiJ1FgJs9k8azZibV5qmIUVjqyLIUulrSpKVdUcQhzn1H+jVIWuSuunZ+drZUxmHWHXFStvVkqTpYl5H9J0SBwpG/qv0ttNSTWupYzXEbb1uv9dV71WNL2JaVFcR2r7QYTj+QjHQwvHAPDYAsF2p4S2YHXTJJFNhO5jHXh6zWteQ16UPHroINdcczU79uwjLUqWV3ZSZAn3fPs+JmnOJM0ZDUc4AgpXcvjQQY4dO8ojjzzMwYMPs7W1Zcy1LQjwwQ9+gM3NLZ797GcDpll0401fw/E84jjm1a9+NVprer0ejuPwrbu/xW2330aWZdx2221oNN3eDFJKjh47hqoqoijiRS96kWEgOA5zszMEvtv4AlXKJNilWUwQRszPzeO4kqos2LtvL3EYcvjYMXzPp/ADDj36KEEYsrS0zL333sPq8aOsrq6x74JLEV4ISc7W5ib5ZEQQhniTCWWRIx3J3Pwis4uS++67j7mFRa647AkcfuQ+RKrYtdAl2SoYpxVCKQbjCboqaOcl8TBjfVQYP0jH45qrr6bdbrGxsc7m2kkQgt78EoeOnSCvFBddeCGrJ47jei6Pf8JltFttsjSlLHMya6Lc7XaRQnLs+HGWZ3tkRcED999HUZaWyaZYPXGcA4cepR1HDEcT7rzrm8zPdEE4HDl6jCgMWVyYZzgek6QZySShmAxxgd7MHIOtLbIsY31rQKczg+cZb06lNFmWsry0gOd5HDl6HDcIiFttHEc2kci79+zmoosu5olPfIBPfervufXWW/nA+97Ht775TY4dOwrA12+6iTiKuO6665idnSWKIv7if/5P7rzrTgCOHTsGgFaKpzz1abRaLT732c808//w4cOnjO3Z+QUuuOSJrG72GQxHzC6sML+0g7nFBdY3B4ySjCPHjrG4sMDszAwbm32T2FaV/y/Nvn+aa+++/XZdcpAo/CC0bCYJQjUMiUxAkWUIajNYU+OUlZHMOEqZuk5Iy0rCsCegAZxq0Gl7Q1db1v7/l73/DrPsKs+84d9aO51YqaM6SK0sklBCAglEsgFjE21sAx5sD+AZh5fXJHscsY3B9mBjYBiYMQYPeAgmB4MAkWRAIAHKCaVWt9S5uqpO2nmt9f3xrL2rZHuujxlm5hXX1VsUanVX1zln7xWedT93EEuDiqqq2jVe5F3a+4sErY9MUyOFYeS9QELf/JW9RywS5CBcez8pl2WSolaIT1IQxfS6EcY6yqpGQA3xoks6Hb/HGB+37kicJHI1Uq7IeyXNJhmmzKiyMaaYYcscZyrfmYcslYTA2Fqi6ZQwKonihLjbJ3EIYGYN1jehpezT6DAmSqzIpAYDUIqyKL3Jbo8ojMA5ap8Aqe06iCBeo5Iq5rQSD67mnBGtS1/yXBhVztt0BLWXMFrbGsPrQACHJi2urqQWs3W1HpDkzzvyZ4Y0zVtZXhCGhNaSpjOUMQShpZd00CogCBxRKIBEI9001gNpgQcr/L7YXI3ypKmom9PARoVDIxXTHmDxw1XuYW3IitKflwJ04M9ISkt+tm/gKh1IQ/whDiKfqKFP1NAnaugfvob+gYGnbhSsS+kasMIY6qpogaU4SdAqJtCxMFRAqIIenGokV8ats10ak66GydSATn7dooEPHMoPCPnz1szag1DWiIdTw2qpjTByqtpIgVJLqoNCuj8qCAmtLKbWy+GMd523vnsQxQmYGlsWgh4HAWGDJipNGEsSRNIdEHV6hEkXHYSicTYVdjbGFVNsPqGerlLPUqp8RlVW4ITN5WyIMgE6EL+h2i++cRTjOgmmo3GRkontPKCGLFIqDAmDGGUsLkzo1DVOa4qqxAayEUehpAEEQbQOCjUyPu21s0Yc9E0j19Paa7AbIEnu+8YNR56dTDhTe8qd90VqBnVjorlRZ6q19puNQ/k/axz/G92qgE71BtCyJnAaAoethcHlPNrcbIqNn5MgwOuLqX9Y679sWnn+1+3n8R0z0eYGbacILSmFVgkNVXnEyuGTEr3s5EcBfDrrtNPE4NBJMqIzJXVlMU5YXwqo8oy6zJnNUqJEjEaHw34bl1t7Y1Ll6ehaK0Do1sGGjqlFZBvGOIqyap9PqKCsS6azMXkh3ZrCm4VKARKSxBFhqImaMYdGBVKAduKQMNSykGeZf90QakNRy9wZT2cUZUGZ54RRSNSDKIl9nGnBbDqhzAuc78xaExPUFVEn8cVfRHewSKc/pDu3iThOCMMI4wyuziBbJaqmhHVKVRTkeYnCEaqcqNcl6PeZFDXT6iArWcHZu3bSPWk73bk5bGWpjSMvjSThhBHd+QWSoiCpa6IoJkpqCEL6SVdYoh48xjkCJQ4NzgrdWBtNWVfEhCi0FHX4LrhdB9brWtbCsijlWQYNJVt+TuWjmbUO0aEjUBZXlRhTUZsKY2TNCrTGon3xU6G175yFspYbZ8lmqczvQIu0BJHruKZoqiuMNQROnmccyxrl/LiRVV2uFuze8N/NhquUT1DqyWGhO5gj7PTRSSIMVk9nbwJzYb1IDsJQtP1KE6qAH4Hpy3vf+17e8pa38Nu//dt877rrCOIu7//EFWxZWqKuCv7mPe9lfmkz8wsLbN20Ca0gx3Dogf3ccdutfOxjH2mT6lDiIzCdTfmt3/otXvnKV/Le974XgE9/+tO84Gd/ls9+7grOe/SjueaaayS1CmFWfPaz/8h/+J3fedB7275jF1Ecs/fuOynznIWFBd7xjnewsLCAc46rrr6GtdGI2TQlThKCPOPY4YMESY/eYMipe/a04MyPPfWp3L9/P5/59Kd47MWPodft8qEP/Xee9VPPYffuU/it//BaOnHE1s1b6C1sYXFpE9045htf/yrHjx0RWUIgKT+5UezetYtdJ23nfe/9O37iJ57Ju9/zHv7unW9lRWU8+dwn8vmvfJOb1yZgDYdWZnw/K4FDhN6YtzCWSx77OL78pQ/wza9/hdtuuYnvfvtqHv7oCzjvwov40Mc/zc5tW/i55z+H97z3fegw5KUvfTnXfe96Dty/j23btjJaW+HIkcP85E89m9XVNb5y1dd58c88l7XRmD/5i7/isssu5bTTT2N1MuPmG6/ju9dczYt++d+zf//9fOWrX+ZP/+B3sU7xn9799zzhsY/htFP3cP3376GYjqlmE8aHHyDudLnoksdz9x23Yhws7NzDaDylm0Q84tEXUFvH/n17ufiii1gZTbj+hps5+ZTdLG3dRieOGU+mHDu+gjWW5z33uVx66aVcffXVfOvqb/Ktb139oIL2rW99K1/84hd5xjOeQRzHZFnGn//5n3P40CGZcxvkdS97+a9wyimncNVVX3tQ+uHGa8fJp/Jvfu3VvOPP/5AjB/fzG6/6bebn5kiikJKI5eVlPvzRj3HpxY8hiGK+8k/fYDAYcuYZZ3D8+Mq/+jMfitdZZ5/NLM0ZTSV1yTrLkaNHiRKJ/Q6DAIXUo+l0SieJxRA36eCco6prnHUCUMSxlCdKt4d+7ZpQF7kaxoVC6jVjxFxcYr0LsjT1Fg6WMIoJw4j+ICBOEgFNNtTkYdjI9Zx4Jpl1BlVRFNLg9ez1yWRCUeRksxnzS5voD+dZ7PZwKpDDWyXMJq01nSSRM4URuZ5SSsCiKPY1vaPXSZgbDjCzFXAl1khilbJlm4hV1YaiEB+jOI6ZZhVhJOynPaeeTrfbYX5uDrAUeUpVFpJsHUQYpdFxh8FwgcXFKUnSIUtTFhaX6Pf7kqZlDUWe+/uuPSDgmf/GiNROKSbpzB/qoJMkaM+sH49WqeqaOIopilIsOiIB5qNQJLNaByRJggpCHJBlGXmWUhW52GtYI/48RmRsWZZRVBVBGNHtdglDSdauagNKPGyHgWcs6IAoEhPqPJdULWONb7JLkrYwG3yynZXK2VqHUg6tXaPEehDwpP2hV7cHUZHRKR1SVDXjNKfXH9CJu3SHQzlNOEtWyPsOfaCRsWKc/1C+TtTQJ2roEzX0D19D/8DAk3KeaaI1Kggg0BBoAiw2EMp0GIlxdaBVu2BZj/gp5VpgQqGkM2KbpDHaD9UAUFrpFnxqkN+G3WSNN6I24gtkjbCdnG1ABOcBnJqyqpimqfcPqgi0INBBEhNZS+gc2gMkNY6qLKlKMcRrTMuVDsT3IgiI1fojVUG4bqxnwRlLXRYoU4EpceUMVc1QJiOiIlQ12hnyXDbJAEsdB5ShFhouATUhqtNlOBzS2bIZHShUEFBZS1WX1E5hnEZ7FDeOAkEkI4fSQodLkg4ulncZhaFMhMaczuvJG3O/Jta3idZVDfXQyWDTVrWT0HrpnIBKri08ag/4KWXblDoH3pBdNhmPCrWblkj1CqwVY8wiz6iqkqKQRbuuq3YhD5SY6uGEQVe5QsaHjxmVhS7wgJJqX6vRTW+ky0kdtS4ZfLAHmR+joSLsdIh7gxbBXh+LQrFuJJ3Ky+70j8DJ1ZUptRV2ojECwgaBJtRaFiAVEGmN8VToIBTwVTnAic9WFMnICaCV1RrrF0PfValrQ16WIqe1IrkRE01FN5bFLIxiXF5RW4PNc6zzzy2MsM4SOUmCCaPQj2ExpkynE6qqpKoq0plsWqaqCZUmz3ImacrK2gplVWGNJUk7uKTDXFXhrMg68zSlzFKqNKMuZbPoDuYIQ9kM0ixlNl4hn83AOOIkJoxDXHYcVU7RrqDbCXAuYXHQ497DI0aznGI+ZOoq+tWMA8vHIAzpDPps3b2Dpe3bWZ7MmKY5RVUDITpKCKIOaT+nKHImWSrvJekwGIYESrVSY4fBWU0UCusUhY/G1cLMC+S5tM+a9aK4NuIxYWrjgWbjWZ0yZ3QQEOG90rzJaFXXjEdrTCYjiiyjnI2xVQXGCHPFWep8RpXP0DogTBKizgAdhAzmN8laZWT91WGEUk4Kai2GilVRgoOw0yXpJgyGA5JOjyycSDJQC3pvZCMKaKyVotPt0+0NGcwvsrBlG91en/5gSNKRzngUBE0+BTKv5fZoX4A3enbt2aPG1v/DlK6H4nX8+Bp5tcxt11/LEy67jKWFBU4740yGwwGDwYDNm7cwG6+xdvwYC5u38vgnn8STnvJj7Dl5F4NBn0bavrKywotf/OKWfVrVNXGnw6lnnMFrX/UqHnPRRax7e4jnSNOZ3Xi95pX/L495zGPIs4w/+7M/4/Of/zzPeMYz+KVf+iVe/iu/wn0PHOLIkcOMV5Y57fQzmZ9fIK0sJy312bxpCXTIoN9nEIf8zTvfTqDg1B3b+OLnPwfA8579PL597TV89KMf4czTTifLc9Ky4P5772Q2PYlN23Zi6opQOfrdmGBpkbnhkDhOOHLkKHd+/w6e8dSnkk0nPOmJT2TbMCYOHN+9JufUzQOe+ug9fPiqKT0HURzR6/XJi5K10ZhH7tnOObs2c/j4Clde+SVuvv56fuYXfom77/o+H/+H/84zn/9Cjhw+zNvf9R4ecc45xFHIJz/6IVZGEyrriPpDFpc2cdJwyKf/8bNs2bqN8y96DLfdez/jyZhHnnsuZ591Fgvzc3z2is+ybetWfv4XfpnDhw8zGA74hV94CZ/+/JewKB536aX0B13SvEChyLOMyeoKx1ZXWVxwLG129Ac9jDEk1YT9dx8FFbDl5DNYPrCf1ePH2HPyqagoZvtJ28mzksl4Rm0MZ51xGjt27ORNb/tPXPDIR7Bz62ZhG8O/2kVdDxWRhl1ZFsKkaPZXf73h9X/C2eeczZeuvJIPfuhDfP4LX5AaxUnHd//+fdx31x28+Y9ew7Oe/Ry2bN3Gt75zPavLh8FU/MHr/pjbbr+dL155JSef8ygOHzzIJ9/zd7z2ta9lbjDgO7/wYs/geOhfVZFT5ilVNiOOY5QS5rccFEOSOBZflRp6/T6xBwR0EMg6XpQoBYELsca2tUmgm7qHdq1sWOnONbYI4ssReGYLqJaFU1UVSadLkiRiWu+tHDTWIw0WYw1VWZGlM/JMampb1xSFeDQZY2QcVDXLx46JZ1JZEnZ7hJ0eDmFTOWBl+QjZdEw2mxIGEgmu6a8nI+P9f6zl2JFDFNmUfNJntraCqTIwFf1OiKsT+t2YrKwojaEqKlReoXSGXpuIFGpuwPyjH83mzZvodLscPXKY6WSMRYO2KG1wQUzjRybPBfq9Hp1OhyCQpMooikXOFEVoYymriizLxfQ3COl0EjSOPE0JwkC8nwrx0JnNZmTpDOdEJlMb0x5m5RAryW5hENLr9ShrSf0cj8dkk5Gki01H4BxJKGoIaw1rK8e94iKiKkviKEQh+2Nt5ZmPx2N63R7DuSHdbg+0JvXv2zoHQUjc6dEdDOl0e8RJIuxLz+aSAB6HUmZDI1r+FYQhnW6XuNMlCKN1Pze/d/cGQ5ZQ1J65cmx5hd27dxGEIUVZEodSS6ytrIBSdHq9/8sz8n/uOlFDn6ihT9TQP3wN/QMDT4GSBAbtaYDghA3SJIE5K6BTk5jmmge3gVXSUDNpfKA2yuvWr4bjBEJJM81+6hp6XO0HgVCGGwDENnI7Xwg1nZ2iLFvz6jAQ+lhZG/EWspbAWgzeN6qusbXZoJds6KRa3PDXDeMF3HB4I/AKU0n8pTIl2BKqHFWXYCqUd7Vquh91baisgE/GBtQmp3Ka2mliwHQTPJ6FcZairKiMZ4sRoC2SsGZkcxCKs/xa+yJE2HsaHaynJgi2zgbAbx18kujIjR/Qs+v8fzegnrDNbFskNHRc17RDVPuT25+xEVxspI0NcFgUhRidVhV1VVDXlbDkPC2yvZyVlAMraXs6kA1AvCJsi1I2KQNaB0IrdOtILRvGFp7p1khF119KoYOQMIrX2XfNn7TdHO318ht7iw/tq9H/Wk8J1VoT+eQ+pTWRDjDaYf1YCb3ctNES45FuBd7TrgF5ayzCxLNWurJS2KiWbhr6eO5ABzJuA+n+GNOkbTihukILIFprwYp23hlDXZVk6Uy07XVNkYkxpQCihqLp5JalgKEoyrqmqCSWOIj9LDQiETa1mI2ixMuiKdoFnBSj/zqf4eqMKldQjlFViipKdOCorSWOBGh3KDKjoXQUdcW0KOhoKajDKMICo9GIWSbJO1HYIbTgnCadzSiKnDRNfTfMoOqGFqsI4gTQSARukyzj2nm3kW23MQp2Y8fjQdOoOTAaWqPohu0XBEHbiZlMJ6SzGVWRYaoSVTdUYY2kQEqiqFXChtFBhHJI0paS9+5sQzeugQRFA2T79cRvhEpr8PeRZj1p37D8q5ESBEFIvz+kN5xnML9Ib26BTqdL0usRRUJLDrwXHk1nxw+rxh+uAcEtXnpcldiHuGznG9/4Jnv37sU5x513302n2+PknSdRl2JEfcbpp9Gkf8ZRiB4MiLUjrUQmd/YZp3HGaacwNxi0i/Lq6iqXXXYZp+7Zs/5CTvbdhz3sYZx77rkYY7jnnntYWVnh0eed9y/YJUopTt2zh9NPO40bbrgBYwxlWfKd73yHs846i0c84hHkuaTkZFnG8tEjOKVY2rSZbrcrLIHZFMock05EVqI1VZlLYR+GdJKYPMsYra0xNzdPfzikp+ZZOX4cHSXMb94uEpS6YpKmJElCEiekWYYONN1eT+Rk2YzDD+xjuHsbpVYcOXqMgd7KwqDDlvk+oyhkVoiRcxxHLC4scOqu7Sz0E6695tvsvfsu8YuZTiirGqUDJivHOXboAPftvY9Hnn0mrrbccdttbNq6lYWFTXQ6ItUvSolGj+OYTpJw/Phxqtqw5+STsc4xGk8Y9nskcYLT4oUSBgHOGtbGY9ABJ4eB1DNVxWy8RpFKmlcSCzulSGfSzQVsXUlt4hxrx5fRSrG4sMhkMqE7nGNuMCBNC79/wtKWbcxv2sw1376Gcjrm9JN3c/7553P//fvZv38/WZ6vmxH/sysMQy5+zMXcdttt3HPPPQ/6sySJWVpc5JJLLmHf/v1MplPiOJFGU5axe9dOjh1b5o47bgf7LAb9AcoZSW4LArIsJQxDtm7bhnFQ1tLpTtPUN8l+NNhOgCSrOUuoFWGgvCFs2Mrb4igkwFFrRaU0YSR/3oC9xnh/EWVauUWzdjcLfstI8R5L1grA1wJTrDfkWn8S7/XU1LXIt4H162NdUZQFVVmSZym5b+YKoCWspLquKXJJliqKQuoC51p5SlWVbYNQGrwFdSUecWEQQBJjTHPY86CHqUmnE7CVqAVmI1xdindqXaNwxFFAFApbrDQeTDFGGspRSKiQJEErZtzj0RqT8YROfyiGptqiisKzt/I2tU5MySvquqI2YuzbHJgcrj2QBt5ftn0ejel2IIqCqqooq7IF79frYOQcY62kNTdMVK1xThrrRZ7JoTVPKYtcWHFhKOcII36tspcJe8bWoZfcrCeGF3lBGITrLESnvLLAe7pqLfWuH4ONf0zjwdbK7xrFSzualZdBdrylR/Cgs56pBagKwxBlXMusw4/XKJLXE2WKzIuNP/2heJ2ooU/U0Ov/faKG/l+toX9g4CmOonbQyyYoG5v2L+qs85KuUKhZzraLcV2L63xtas9OUZLsAN5QCxy2BbQEQJKCyfqNTfyE6laTWXmHfFtLl8X5v+P8RpnnOXlRkjWD0es4ozCkxhKWJVFRQlKiqlrS1axtN0RT5tRl2foxSeID6EBtYAlZLBVVkaJxmCCg0oCtULZCVVMxUjNFy6iJQkFVjYO8tlQOwsqhndd7K8XmbhcdaOIkFlPJPKeeZfjgEnQQE0QJQVxjlKT3VXUlpubN+1V4UK9GaRDLucYdyk8+Dys1yXvNRJN6Yx1waSZnoy1tKNutztRtSLdrf8h6WoN4Wfn/9ptZbQyzWUpZFmSeSmzqirrMcXWNMwasQSOAJ1aU0Ja6nUXa60xl0nnmmdLemV/7sajbxVB7sKidlF5y2IJqHoCyyKIeJV1ZJADlhPaKB57aIs+u35OH+uVc07lSJFFMFIZ0kqj1/1JKY2qJHo6jqNVvuyYlU0PQMM88xb6qamZpitlA76zrmllWChXW37fAsyWMePsTJl2ipEJVAh4HoRgqht4YNNABdT4DU+FKqKqCLM8Yj8fUtWciErTvJc9mZHlOluc4UxMoJYkyxpBmBWujEXMLS4RxTABgKmyRUuZTv14lUDrfPY7EJyaKCIKSMksp0hmUsnlURUbogeRQK7Yu9OgkISuZZZrKejTf77O0aYk9p5xMnqYcLQpms5TagtOa4dwiibHE1jE9kJIXOePpFMoCW1eYIiWOpAO+adtJEPk47AYsRdEyAv3zc87hjGnnndIabcVov+lwR7FaTzxp2KgoOeDokDAKmaU5k8mU48ePY0q5n6HzSZrWUhZmHXT1m48pSyo7wUUF0dISQRCjbIzJ5bAymzp0GEnKZhS378fUMo7yoqCsfCfJNy021qBaK6IopNsf0O322bJ9F73BPL35RfqDOcLQdxh1O1Rb48QGjGl8B0HWt8bfpCwy6iLHVBsjyR9611Oe+lS/11re9e5385QnP5k/+9M/4c/+/M/Zv38vf/r613PXPffywAMHKPMZp+zezRmnn8aHP/lpqrpk87aTiL1focxVxeLiIp/5zGfk95wTyUeecc9dd5JuSCX7y7/8Sz7zmc/wzau/TV6s36eWBaUU3//+93nyk5/8oBSz97///Xz0ox/lbe/4r+zcvo3ZZMIXr/hHkiThl3/tN7l/790sHzvC0dGMA3vv5Mi+u/jT17+Bo0eP8JEPf5Cn/+RziZMO37jqy2zdspmF+XmuveFGzj3vAs6/8DF89jOfpqwNZ5zzCFRdMVsbcccdt/LYC89ny9Y5vn7Nd3jMYy7mJ571XN7xtjezbWmOl73wWezbfz9Hjh7n+GjGx79xC2GgeekzLmLvSs7thybcc8+9bN+6mcdfeB5PePTpjEYjfu0XX8yOxQGDXsI73vJXPOWZz+Enf+4l/MVv/T9ksymDuXkO3n0bWZ5z9dXf5hW//qtceunjyF3ATbd/n7v37uOVr/h/McZw3/796CBky+ICe045mU9+7gscO36c173mFXz0U5/l45/8NL/x717OXXfdxYfe//dcctnldDpd7r7tJrrDeax13Hvb9URK04kiHn7GaUwmY+7fd7d0OoOQCQEn7z4FjeNzn/woT3/Oz3DZk5/OF6/8Aput4ZQd28iHA9aOLeBQbD/9HJa2bOWjf/nnXPHpT7K4uMgtt9zC1V+/ijf8yR/x/Xv3keVFu9ZsHAMLCwt88pOf5J3vfCe/8Ru/8aBx+8Y3vpFnPetZKKV40QtfyAt//uepqkqSFI8d49TTTuOrX/sqz3rWs/jql65k7113ccGjHsmWHU+g2x/w9//t3Zx62un8xNN+nNtuvonJLOXpz/5p3vN3f8f99937L1LzHspXVZVEYcDi/FBYaZ2OpPt5iwecQ3UTnHWsTSZEQUAcxy1oUVVl67HUsIysnH4AX9o0h9m6pqpKn+hcEYYRYRTS7fZaQKGJ0Y5iJT4fcUSoNdbJYZi68ODHjNXVFUldc6IMqOuaNM8ZDgbEUcR4PGZldZWVlRWpv6KQOOxhHeRFzurKcQZzC0RRTF0WVEVBVeQESs4OnSQhy+VAXBvbGlpPRqusHS+xdUWk5cBblQX9WFQRvThiri/MJDIvAXSObpKwONdj59ZFbDHj+JFD7Nu3j9GqsDm2797j75vG1JY8z1hbWwVrCALNoNdlPBlTVzULmzbT7XVJkhgdBi1oFCVyzgnDkLKSZzEcznngRp5XE1rT6fbWGREecJlMp5Ik6BzzC4vCZnCOPBeZYjadkKUz6iKjrksUEYFCajYcSlkwJdbWFHVF0dTAcUcOhVbAO4UkDIZRhyCKPXPVnwAsaBWgmi8/LqIokmRsn1zeGBk3Zx9jLZ1uV4zX4wSlwxb0NMaQpjPyNKUqS/q9HmHUJYwiap8cGCcdb9dSkZcV2WxKUeT/X03NH+g6UUOfqKFP1NDy836YGvoHBp6aRahh0zSLi0SU1lgjLVSJ3Gse8AYjLGsoMumCiLEZ8v16nQVjaBIW6pa91IBNstBJtKS1RswEvbyuAb6cT+qwngZb1cKKEvqXW2eqKCXUuboiKCvCukLiA2XQuVrM/GxdYKsCU5froAXeAE4pAs8kChQ4U4pG2RiR2VmZlJgK6hKMRNU660jiQDomyMaQGwE2ojAgiSJJ+gnEbG82GYOSVBOHBhWQdPuEDgIHVS360qIsKNIZxgho0zCswiAQvXzSEbqeR3sb9loDLklq4LpXkbMCW7deYZ6e55xD2QZ18QcYrVC2kdatU6Xx/2p8nRTaJ51Y6roiS1OPUk8lwcUYXF2CMesovRLPJqcb7Nm2c8kq57skCqWt7+Ip+fxaQyiRlS0y24LabgNQKd8ThGHLypJum4xlvFeZMJ3WWWKNEXpdVW3n76F+JUmEQp5x5M0Hm+6cgI1GuplZSpnlJN0e/cEcUZyIzrwqxNzSOWwtXSqhnlq0hlArwHjPNI/sO/EFGE2nFEUhNNLBgPm5OTHk1yFhKGi+A6rK4FyFUjXlaESoDJG2qEA06VEUEYaNr5vFGYtBFsM4Ft11S38NZWsLwoiqKKh9AperCmyZY+qcUHsPMiMmpEEgMazOWeoyoyhzGSPOYayiNoqygsIImO6wRKFm2IsprWHmgdz5QZ9+EoOpyMZroBTTPKMyjalqlyDqEDhYPXqIbDYhnazQGcwLUw8ofVpnXlUSQ+9ptkHoTVmTDlEUsx67CuDEClBJEaJCSZCsjWdcao3yrIXKU6mds0R1RFlWZEXBkcOSwLl29DDKVWhnSDRE3hyzrvwcVKo1I4y7XaEtW0O1uuwDDSI6SU88JGJJBCpV1RqKBoEWz4/aURQ1aZpTlhVYYZgqLV58cRwTRzH9wYD+YI5eb8Dilm0knR5xr0+cdAh0IB03D6aLJ4WWIr1droTRakxNWZRkqaSyzWYTbCkHm4fyZeqKpz/96bz4xS9mOL9EVpT8l/e8l3PPOx+c5c/+45t47CWXcNqpp/Klr36NldVV9u+/jxu/dy27dp+MvfQyJpMZZRIx7K9LGtYDIZrOmoBbpZedB2HI1u0nceoZZ9LvS0ds42Wt5Y1vfCNRFEmH9Z/9XGstX/vKlcJw6nQZ9Ps4pbjlppsoi5SyrFibrLFt6xbOPuUkvvTlK5lfWOD5P/ti7r53L3mWcdqe09j3wP1M1kZs276TtdVVvvWNf2JuOGDT0hKdOOL4ynFG4zV279jOdDblgUM1555zFitHD/Pxj3yYc0/bRV6UfOaL/8TK2ph+v8fTf/wpHHpgH+O1VW689zC5C+hFisW5PkWe890bbyVQMm4IAi6+/MmcduoevnL1t4ltTnbgTk4/fQ+xhl3bNvPtG2+n05/jda9/A9df9z1ueNffcdnll7O0uMTlu07h2u99z6c+ObZu28KBQ4f4xKc+zWWXPo6Lz380//iVb5D0Bjz3p57JDbfeTlFWXPKEJ0FdYuqCU08/g6oSCv/KwftRiGfE/XvvZNu2rZx5+hl845vfJIwiHvPYxzFaPkJZljzpx59JURR89YufZbiwld5wnrQs2bf/IEePHmX3KSfz5Msey9Zt23nXmxUvetGLeN7znsfCwgKTWca+A4dkbrLOMDp48CC/+Iu/iNaawWDAm970Jp785Kfwt3/7bpIk4ZZbbuYv/uIveNvb3sY111zDH//xHxOGIdPplFe/+tWcd955/PTzn88fvu4PuXvvfVx8+Y/zc89/Lps3LfKpz3yG8+OYU/o9NI4qzxktH+ebV32VvMjZvutkTFkIU+ZH6IqTji/kFdoDApPJWPYcHJPxuF2jprOU4XBAEi8CyptVx+KjVNeSKlmIvDGIIpqgE6WkrjQeeDKe6WBt2jbZmtq7YeBpHdDEyqRZSuYlfcV0jHIG7SxzwyHOGsqiIAgUziYM5uZRvvmstSaOIjqdDmVtCKOY/mCufW/pbEbS6aK1EjPyLGU6nRAHmigMSZK4BeB6vV5r0uzqglCBTkLqsqC2jso4Vqa5JHeGmiSKUEFIaqAoRbXQ63UY9PsMh0NWV45T22XG01RYDzpgdeU4w7l5esMhq8ePkk6nTEarwjoLAqpsRlUbdBDQiSI6UUQSCXNIhZo4ihn2+8RxTFWVNOe8MBCD86qyBIEm6SR0uh1WVtcwpqbTjShSYYVlaYryke5N87VQitHKCulsynhlGVsVOGuItCLA4mxFUeWtgXUQRQSBMBkacCibjiWFKoxYWtok5uxRTFlVhEA36hH6lHFjHFWRUCRSY0SReD0pJyl0vV6fKArRPsGrrgQsKatSApiSDo2pcGOt0pjRz83Pg3O+9pP0tSLPPdutYjIakWYpK8ePt+eBh/J1ooYsAzmXAAEAAElEQVQ+UUOfqKF/+Br6B5faaZHQKcW6I3xdyWCsa6zXOcvXujlXawJujHRJjFDRGpBAUjPkAzVMp7pu/JWaD2nWjar9v42n/zhHa5hqjW0L5wcxchRohIYmyL32RbZs4KY2KO35gVaYNs5UOFNhbY2zNZbALzi0yHZDn1TKCdDkrAAodYUzNaaQB+FMJZJEz+KKAo0NQ6IactfQJP2gbPW4ClNX5JkM0LIy4D2cgjAGFQBaOkdVSZ5LFK1raFFOqKAuFPMvE4btw26Kk/WvdXYSngfl4XBaPyv/9+yG72so22qdXrWeVNcWOCDwuBJlpsXL6+Q953lOkWdYf48wgggrZ9F4qqFS7fsQWmFDYmrMxZVfnOW9WOdQrvEI0+2ssS0CvA46AR45Dta/rxk3zb1CQCfxcfJmfb7TWFWVGFs+xNM4AOIwbBejUAdy25Rr509dS9xnNpswm6b0rROacCCx2EVeQjMvG0DYeKai8gRQa2Xs+WfYoISF77QUZUm1abPITeJE5Kuwbi5vTEtpzbOMUNVYbYk7YpoZhaGnpSPpMc7RqCyDwCc/NNGoWkw2lVLtYhmaAOoabA3OEATe0M+uR98qpWQDqCrKLEU3TE/fEXQEGFu1LLkgCEiUJgmhqDRaQxKGBFphqlp07spRVpKQpXTUyglMXZOnE4rZiGq6Juk5UUwD7jcac8AXlgIaB0FAGDZeHQ8Ge51nyMqzZsM61cxXAWut9+RoqcXW4uqatbUVpqM1svEamppAOYIoIIiT1sehJTzEXTEXDGMqJ9KOKs3QUUIYWXS3RxgGBGHUEA39e9sATDhJXanqJl1EWJI6igiimG53QJJ0mFtYpD8Y0usP6A/n21TRIAxb0Lx9X83a5gvClv5vau9TkjGdTsQjZzLGVaWkjjyEL+cc27Zt45JLLiFKutxz3z6+/u1rufC8c4mikPe9/wOcc/bZAKyurjHCMVpZ5sD+ffS7HQIla29VVxw/dpRGBrFjxw4mk4l052rDeDzmlFNOIYljrLVEWrNr1y7OOvtsjh45zHg0etB7AvjKV77yr79pJd9z5NAhFI7+zl30+n3K2nDo0EGiZv7XFf3FIVu3LHHd9d/jZKW57PLTufZ717G2usIjzzyDIs+ZzqYMhwusrR7nwP37OeOss+l2pWgqfRT7jq1N4lvO7p27GI1GHDxwP2c86kyqqubg0RWm0xlKB2zesgVd5/RjzV37DmF1ADpk81yf0TTlgUOH2bp5iSSKmBsOWNq6nc07drNp052YYsaR/fewbetmOlHAwqDDytqYhbDLo887j29+8xvcedfdPOr885lf2sLS4hJ33n0X1kGcdCmKkvF4zL177+UnnvZUdu/YzjU33c4Ze3Zz8o5TuPPLV5F0Ouw6eQ9H778XrRyDfp9jR4+SjtewVSNRL0nTnEGvS6/bFc+dWordssioa8O2k3Zw6NBBlo8cZs/SdlnT0Rw+fIi1lRUWN21mrt+jH0cA7Dn1VB77uMcRxzFFWbI6mvyLRzsej/nwhz8MwNLSEn/6+tdz+umns2PnTkZra+LTCHz9G99gZXWV173udTjP5vjUpz5FGIS85CUv4Ytf/CJHlle46LKncNoZZzA/N+TQ0aPsWVtj65YtGGNJZynLx47ywP37qSphUJi6ou1H/YhcYp4NTT3krEihQOqO6XQqjPuqIs0yiVOfX2gZimEUUufeGzPPRdJW18SsmzyDatPrWoVAVXmQqqLIczHgj2MWFjeJGW8sLCRrDHleYF0uLIjJKpFWJGHAwvwQCKV56eWZUZIIc6l07b4UxTGVLVtv1CYERg5pppXEVpUYnCvPRIijUGovhIFgK8BJsjFaTJcbb1h0IPHoiGxRBwGRVoRBSK0tRpmWWaSDQMzOy4pZmtPrdggSTZGn9Pt9AqUo0hlFOqHKUzAeeKorwkiYI3JIcW3UemP2G3rvnNpL3kAO87UHYMKwQxgGvqYPsE7kS428zBhD5NlRbbCOc6SzKbPpmHQ6EkNxIIi9n4rzEkCfJqh0ICwFL4mz/v4qFCoM6XZ909l7SzXfF4fCdqu0FaliGHhWVOiBJ2GiSdpVLBIvb7COKjHWEkaRgA06kHW8CZ7yDYhGTpflWUsmKEsvayxK1tZWSWczppMxeZZSFMX/zen4P32dqKFP1NAnaugfvob+wc3FNW3KWJln1GVBnqVMp2OqqsI5xWBe0LoefRpTulbjXVSoWszV2g+k8BNOXqNJx2sZTM57CbU+UbQ3Ra2PkQaFEJmU//tSVAegYlQYtB9CeeBJ6UAMuqpaqLCBmGpT17i6xNaFSOZcjWoNFjUQtRt8E3XpTEldVwJktEwaizEyP03t/GIgnyMKApTSwknKG4RbjMCTSGiMtixJJ2MP/kBlHUGYoKOYMO5KHKmDLJ1SFhn5bNJ+7iCM1gEh603AoogE1tF5D5zJ5ikdF+cHl/g4OPGR8h3VVr/qJ13gEwGbyzkwHnwyngnUHEqamF6lNEVVUeQFs+mM8dpxMdssUjSyyAY0tFI8ai1g1zpbiZa1pnwaRsPbkn8EVMRYjK3axWKjs7/QLGUwBV6q1yzuFucjsKVIknntwSal2nFdlt40cjL5kejUAMRhvA5dK5kvxlSUs5S6KCnSKdPpiFk6ZWV1jbmFTRhfaDlnKdPUzy9ZzFXjBYDF1YayqnE+7SawttWah6EgjmWesvfO2xhv2U6ZZuzYdYr4INQFSssclWTHAmtq6rpAe0A4ikI/jiLiWOj74/GI1BiMMwRBJN5sVro+tTHkaUZRSDc4HAzB1igXEmDpxCFBv0uuFXVtMKWhKEpcLofXQIkclbqSpM5Qk/S6uE5EvxNQFiF1VZPnlfiuWQva0FhtTKa5qDSVIsYShgGdXp/uYJ6o26c3P0ddl4zWjhCGin6vS08tMRkdo9aKwcJmOoMF4k5PQgEA7QsEWWZESiHjUuaKUhKr2qD+pvGoc7TeGs56ZqBrQAMHWKIo8P4pNenqcdLVZaq14zhXoDVEw3lClKRXOC9zVU1Ci8W5GqV80VTWrQnlLI3oAP2kR9LpSYc9ks6stYbSVDgUYZTQ6fawZU5VGzqDOeJOh/5wyNxwkW63x9zcIkm3S9xJSLo9SdTQ3tHGSfplM1dpEks9WGysdASzNCXPc8ZrI9ZWj5NlKdPJxHu9OR7q1/vf/34+9rGP88KX/DIXX3wxb/zD3+ULX/4q09mM//zWt/KPn/ssb3nb2+h3e2xeWmDYm2OytkqV52zbuhnrHDfffDM//tSn0Ol02L17N1/60pd43/vex+/93u9hreUZz3gGN9xwA71ujyAUCvq//aVf5BlPfxqXXnopy8eOPeg9/Y/uWzP2VKD4iac/jc2bN4u0uqwZT1OsNSwvH8PVJRc99lIe2HcfV1z3PZ74xCeCM3zkA/+NBw4vMx6PueW6a5hMU6yD8y54DOlkxP5997Fl63am05SsLNmydRvDbszJ27Zw6223ceToUY6vjXjMBRfxcz/9Av7gT9/AjpO28yu/8jIO33Yd9x84wF++4z2ce+FFnLL7FJ66qc+3br2P73x/H7/6E5ew79gqn/jWGqNjR9i5bRMv+MknceWVX+TvP/gPvOg5P873br6dG267m1e9/EXcs+8B/ua/f5xLL3gkvU7A77/y13jqU57Es3/s3xMs7uS7N9zCJ6/4Em96/R8RhBEPHDnK1ddcy/xwyIff93d85Wtf4wtf+AJPvvhiVkZj7tq7l4vPP5dZmrG8ssIZp59Ols649frv8sXPfYblo4f56Z9+Hrfdcit33XUXl178GKq65sovf4mHnb6H8WTKu/7mXbzkZb/Cyafs4aPvfx+Pu/wp/NRzX8An/vEz7DnjLM561Lncc8ffsXzkMEtbtvEHf/hHrBw7TFmWvOc97+ZrX/san/jEJ2jkAPyz5/zP91Z8Q8tZwwte8DPcdNNNABL0UhYCOmWZzDcnyWxJkqCUYvnIIb74qQ/RjzQn7dhJqEPu3rufg8dWObQy4uDRZW6743a27tiNMzWTleOy92YP/X1349VJEn8I01S1JJOl6YxDhw618qraex/leU4SBZjNm316sCGOYrI0o8hz8iyV0JggJPTeIjoIpI5WDu0lOtZ3qdPZlHQ2YzRaJY4Tur0+vf6wDWcpS/Ezyouy9YaKlUUyoAQUSxJhORnfQByNxq0dwUa/qiiWJXhtbU1M05OExcHAx8lb8kzi2rUStr8AXpkEE1nHeG2VwBmUM2AM41lKmhU4HP1ejy2bt4AVZUI2m5KXNWVdEwUKF2qU06ytjcSvppJ9IQoj5hYX2bxlC71ej+lshrYV1WyNXqyIBh36sWI0mVLXNVrHbN20hW6vx6HDR5ikOXNZzradu9v0vdF4JOcKf2izxnB85TjD/oDhcEC32xGpYVWzsLhIXddMpikEIVGny5xn2muN+J7VNXmWk09HzFZXWD1ysLWDCINAwiP6AzH/rkvGoxELi+JxFQUKWwuzZNjryVkhjKjKAm0tKogI48S/3+YQLQmFwvyHOEnodnv0BwOctcRxTH9+nk6nSxAE1HWNCqY4nWKcotsfML+wKEzYMJBzSCV2JasrK5JgGkasrI7aM1nmn31V5swmE8pCzpJFnlGWD3Xg6UQNfaKGPlFD/7A19A8MPNWe9lpXFWUm7Joim5GnM2F7qEA+dJK0bJt1uZ10X7CNbnLdqEp77yRYZy6tP0wpboJgXb/ePGynG5DEIoShdUSqiftzBITyIvJ3aFyNWPdp8swVpfBG1LJwB4ANNDiNs8K4EXaVw+BNGOU3pCvjNwfVMGM8aizMHfGVctaKPld5GptyBFrofM3m7bxfk1bei6lJEdJhCxqB87RKh6k9vc3WApp52nMQhj51L26BJtX+4y8H63daFkaLQrdsp/bbwN9rzw9sgS2tNc66FgluHlTzbABJDTEOlG03mXQ6JptOqMscU2a00kCtCLUGrQlC5ymQGy+FDuT3RQTnQG9goOkGZNwIi9GChAowSjzGNgDc7V3AOYkRLQqqqmCd2+XxTWupjXQNy7JkOp2QprMfCeAJ3z3x26DQNitf7BYFdZmTZTOy2YSyyDF1KR0N7T0AujHT6QxTVRSlIUok/cBq3w2pS6hFPhBrTeUpqFVVE0aafr/H0tImOp0Opq7I0ilBoLGm9sBkk7joCLFEcUioIQy8BtparKvRgWzcRVkxnkyYzaaUhUhdjXWoUPwTiqIizwt0HNEr5v3nicRoFIWzUBnjaePGG2sqKSqdgMgWAcPrqoKgbr2+BECXDcdaWQe6oSLsxvQj331VNaZMMUoTqFi6C96bYba2ivMLfTmbSAc1CImTWJ6VNSJtDgLCSN4XTrrKqi14jD/srRe+bVFJ48cgwH/zs1QQYI2kSmqlcUqDcmTZlDwvmE0mFJNV6mxKVaSgLDpQknoUr89EY2qsK1EmQFdS+MRNzHSzoHuGqqnFbDqMEvDSGPk+TVEUQkleWcaYCh2GxMMhg3kxOxwMh/R7Q+K44yUAsh5aHwqgDG3ktvN6fZT3tPNsxUayXdWlP6ymjEZrEkec5xRV3voDPtQv45kMF5x3Lt0k5m1veytnP/wRbNuyma9d9TVm0ynbt25l//59uCpHlSJn2bt3Lx/56EfYd98+7r33HrIswzrHLE1xznHxxRfz6te8hv/89rdzyy238B//43/kJS95CWecfgYqkDmRxDFZmlJVFWEY8mu/9mts3rxZ3pcROXvgn2+WZVxxxec4dOgwy8vLXPmlL7Fr1y5OPfVUZuMRVVnR7fYZzs2jbSUylLpivp9w4w3XYX0hWjRejipk5ymn0+n1GY1WPVNrJwceuB8dxWw/5VSSTgdTdLj73nspspROqFnNcvbetxdblzzqrNOpreOrV32d6bHDJEnMC3/uZ7nrvn3cecf36e/qs3XLZi4fzHHDfYcYLm7i5b/4Ir7x9W8wLWp2nnQSp+8+TBxqHjgqTJAzT1rg4H33YmYpF561ix3btxLEMYQxToesjGccPHAb27dv45GPeATfu+lmobkvLbJ18yYciq9+72ZqQrZs3c5olglbazaj3+1RZBmz8YjlMGR1+Rg3fPcabJEy14k59MD9BMqyc/tmJrMZw7l5Hv7wh3PbrbegdcDzfvpnyGYpd9x+O3vOehhFWXLnHbdw4YUXEiRd7rrrLpH3VAXLRw7w4z/2VJIo5D+9/e2MR2MOHTqIqaWW6Pb6FFna7ukvetGL2LR5M+985zu9cbUfn8ZQ5uKr2bAXLrzoIi688ELqsuTKK6/kG9/8Jk972tO48IIL2oZcrz9g9yl72LxlK0mnw8rxY+zevZtT95zC6rFDlE7MSw8eOogCFocDiqpiYXGRV776NXzhC1/gmmuu+b86F/9XrjxPaRj+SZxgjAca8pw8y8jSGVWRU5fiV9LpdpibF18ki2r9i4wxTCZjkjghShKKImyTdY2p1y0omsOTESNu7VlB4iUk87Q2xpuBez+o1pqiYYM3c7FAaU1SG8q6Js8L1tZWcabGmprJeEyaF+R5jkNjavFajeIYax0LbV2vCMKAJEnQtgdWzI3TTNYVpQP6vS5VnmNqi0UTe6ZAVeRoBWleeLZCRNLtYl2Gc45A1fSTkEEcsJaVOGtI04xhv0sUaBSOdDbziV2GqsiZjPFG4jVlWVEUJcZCEkQU+YxAw6DXod/tkHQSyrLCoUmCkGGvjw4CqlpYZcY65oZDet0unSQRywjlzdN9jRlF4oMbWoMzgWfAWPIsZTadsra6ynS0Jq+taC1DiCIvcysBAesUjrLIBTSKYyJvEC4sDT8e6hrrFMopVBgJwwWFcWIAPp1MGI/HIvM06/NdOUkjmxsO6XS68jkrAamssyil6Q8GDOfmSOLI1yVeduUaK5YaY6EoCp94rnFWpJ/pdOprN5HdNaEJD+nrRA19ooY+UUP/0DX0Dww8iZlgRVWWQt8uC8oip8wzqrpC6VBAEOvTCZQAT80iVLdsJ6EYK9WwYRpJlKBqgnm4DVSydcd456lzLRvKCljhDDRLgTyuBogQejLesM/YRs7nsMigCzyLS4MAGFb8kbT2EbVaY7X2cZf+NV1DrZQkOGWNdAzwJmXN5wm9ASAyqYxnNqHEFFBr7d3jXQtkWStu+MrDsmEUSeJEJ1x3zMd5LagsVM7K9ytPXbS2JtAdmXA+aVDotQ/GWRpAqQGKWrDIm5655vsakMZucP9vOiZNN7R9hv7HbwAQnVVCRwXKsvBU1CnFbEpd5tgql/uhnIB1QYgKA+/r5EGwdjz712rGkJIPEngWWxCsS+b8m1//nM37tOIdpZphw/rPd07AsarMqYpCxmCLwDkvryvJsoyyyJlOxqSZJI489K/1Z2ydj8DOc7IspS5LtK2EPZfPMGXpvcIcgYYo1MRhTDqRjlZRVDJOtCzQdV1RFSXaGMJAk8QBhRJwt6wNURj6TXOz0HytIc9mNImE0gWWNK5QQaRAxxFaFLJysPXgpVMlxjiyvGA8mTAer1FkORZwShPFicyjQuQKQRWRZ6lsmrbTPlPnJD6+rGuqqvZAqujTralx1KC0dEZcCVYMHsNmXPr1DSxKWXqRRsUaRUxZlygsri5wYYRSImeQwssyW1tBaQGfy8mqeCX0F4iThCb1USnkvnjprfLJNU2BZ60FY9HaErj19bKdlxvmdFuUoNCBQddGClEkXWM2mzAdjVhbPkY+XaPOU+qqQAUK0FRVLQb6St6HtTVFVbS0/brUBGoOFW3oCDrbrmllWdHprFPwm/dZViXT6YjR2jLG1OgwIOp26M/N0+30GA6GJHFHgis8zd154L0B/m1dC2juRJsP8pyatcIaS12XFGXBZDwiy1LGkzVms/VYYbnnD33gSWtNFMc85oLzOXDwIP/1b/6Gt7zlrWzbvJkP/8M/cNqpp7Bj+3a+//07JNiinJKlKQ888ACf+9wVfPUrX+bI4cOEkcSaG/88zj//fM444ww+8P73c+edd/LGN75R0u5OPRWllRQ30ynOOeI4Zm5ujt/4jd/gjDPOAMTrAAeRl2qtrKywb999VFXF0aNH+eKVX+KMM89kMLdAOh1jnGIQxgznpXt65NgykSlYGHT45nduwKmAhU3b6Pc6ckhLeuzcczqLS5u55utXEkUxO3bs4Hvf/Q4qCDn16FHZK8OQvfv2MYhCklAOSvv37+PY4YM8/qIL2HfwMFdcdTXWOs4+60ye++xn8Y7/8l+47b572TF3Fqds38zDlub5m49dyYVbT+bnnvcsvnv9jeRFxtz8PKft3kEcaO45tMzmRPGI3VvYf+89DAc9HvvwUzFzm7BBTHewiNERR1ZH3HrPAV7wsIfzk894Gm9489tZWJjn4osuYuvmzaxOZnzt2ht57CPO5KStWzi0skaeZiK1SjPSVECowgUcOniI7992M5uHPebm+jywfx/zcwN2bN/CkZUpS5u38vCHP5wvXPllFhYXefZznsfHP/EJ7n/gAJc+6akcOXg/d33/Vn7hZb/OkeVVrr3hJh+lXTJdGfGkJ17O7t0n8453vtMHrVRMpxOqqqbT68ke58fLTz3rWZxx+un81//yX6j9OjOdTonCkKqq6Ha7DIdDAM4773wuuugiTF3y9W98nQ/9w4f5i7/4C845+2xG4xHWWvqDAWed8wi2btsOwHS8xrDX4eSdJ3Hr9dICr3AcPniAIAgY9k+nqgzbT1rid37nd5nNZtx2223/l2fj//xV5rlnL9WECwsiE8mllqjKQhq6eUqZZ0zGY3q9Pmurawzn5lBaOupNqtZsOsF1BSQqw6CtT0wtQTbgUF7m5qwRJnkQEEUxqgGI84yqkhRJSSQSX4+wqRl9DVXXDqhQSpMkJVlRkKYZq2tr3hO1Zjqbem9VQxR3qKuKdDYlqhJQksJmreyYYRhBkhApS5lnFHlNnmXESYc40fS7PaY+OMgqTZRE9MKQDItxkBUlseoShQG9pCPgijVESpFEAZ0opPAp0GVZEM71iL2kbzqbwkzTSSKKoqAsC7YsLmCsofAp2M5BbBLKbEaoYG5hnm6/R9LpUFYVTgdE1tHtdgnDkKwo5fdxzM3Nk8QRcRTKuUALI8lYYaFFkcjerLM4E+JMhakr1qZTRivHOXroIGU2w9QlQSCSpboqCT04UddVy3bQCpmXzhHHCeEglIN521V1rRKCWqE9sGhAQAZjmEwnjMcjJqORZ3pput0eWkkiZb/fl/RRL2euy1IA6SCi1x8wGA6J48iDyLaVIxprwRiUFTN6FUfgovbzZOlMQMBSApGqUvxSH9rXiRr6RA19oob+YWvoHxh4KrNMqFZ1jVYCgIRBQBxqNKI/jENBKYPG7wfr3eK1T5STzSwIvVcSrr2/DVSwzuqR323SybQOANXqNauyokb8mWpTywJQVq23U21My4SSiErruxJiXthIuJyCXl0QqAilArzbjxiAefBFOkxNqpvbMDCdGGBbK8gkDZNLEJ5Agw4VgQoQmZ5fsPz3hRq6cUAcKoyRRSPUFlsX1E6jbSCa2zCUToanKVd5SpPAZkpBGrUzPrFNPnOAI1COKI7ky0ckihl6A7o0ckaH8p107QLfOYpwKJ98sc6S2hgr2TCexIdOAaJXdsoDgN5s3DjraXqGdDwinUzIx6uU0xGmKjBVLownrSCOUXGMJsYFEWhkYrt2SGCN9eZuCu0CdCBG7doZsAEqEJ+D5jkolKRO+Am+UX9skUmsQ1lFrbHk6ZQ8nZHneWtO3xR0xtRtEl9ZlsymU9mMH+LGxABBFMpmWJVt3HFRSkpO2AsZdGIwBaGp6EZdFoYDBt2OLJK1mP4bb35nnaDfDkvVLjiKKAyIA0UnMBArShei6khM5ata4kKbBbNIaVFFj7TXYUDU7xMkMcYZsllOlqc+VABqC7lPAimynDSbUpa5SDfCiCDUmKqWzm1VoqzBVjBaWaXXn8M66VAYFHVt0dYROIOmQrkArPa6bZ/UGSZgpctXVpJOY5SWTmsnJI477VzU3nMkUBBEA2HfBSFxp08QxURJh+lkLJTyPCcII/GIsBV1UTIqZ8SDRcKkS5z0BHz1seIiIQ3ASQhAGAggrZVE21auwJiapCNG/mKoBirQhDQdDkteFsymk1bWYWxNbSoO3b+P8fIxVg49QCeJ0VrR6XVo0nmCULcpHDrQ1LXDVAUqiqTjozUqEA17HEWUlXiPJHEi4Qadjkgq6sZ8VKEJiIOQWAdEShHHHV/sCt2/k3QIfcx0XdcYl6GqxgvB+mRUKxukb9M0XZe6Xjf9r6uSspRO/Gw6oSzFX66uqpYV8KMgswPpTJU+veSss8/hTW96M8Nel0MP7GPH9q2MJxOyouA//PZvs/fO2/nut77Ozu1beNgjz+WVv/0H/NIv7ufwoUNtKMJ0PKaua/7u7/6ON7zhDRw+fLh9rSIvyLOc/qDP61//ev77+9/PZDLh5S9/Ob/3e7/H9u3b2+8NwweXEkVR8JWvfJXjx4+397bXH3LyaWeC0pRlwVw/IVSWMpvxvW98hW6nw+LCAo+97Ankec6hAwdYnOsTRjG9uU3kkzUOj46RJB3yomQ8XabbiRkO+gx7ffbeuZcynfCoh5/NgUNHGI8nnL5jK1Gnh447fPLL/8Su7Vt51b97Cfv33ceR5RV+5dd+g2c+/jx++2U/zXSccu2td/HJr17Lr/7iz/PAoaO86OW/wc8/9ydRCv74r/4L5z7iHIbDAbfcfC0XP+wUtu4+mSu+831OP2UnlzxuD1/8zvexOuSxF12ISgYEUcJPXb6D/ffeyRv/8mZ++lnPYjSectNNN3LGGWeya8cOTt59MkEYkpua8eoqZ562h907dvAPn72SIIrZeeYj+ebnPkw+XePZP/VTHD+8n7XVFe68/yg66pB0I6bTCbN0Sl5UXHT+udR1xZev+BQPf9jZXPCYi7n/6Aqbduxh2yln8Y1/+jrGWrrKcd/eezDFjIse/Uj+5I9ex/LKKmVZ8ju/8zu86EUv4gUveAH3338/o9FI6owgIEo6vPI3fxNJ7ZJ9bzQacfnll/OSl7yEP/6jP+JTn/qUyHKU4hWveAV/+6538cKf+zl+9/d+n1e+6tUsLi7ywQ9+kJ/+mZ/h6NEjLC4socqc1eVj9Pt9fuppT+O+++7mmqv/ib333UcYhPS6XU7atg2lNZPZjCBQdJIYpeC1r30tL3/5r/xfmIE/3LUwP+/Xnxxraso8YzoZEwYhydwcmxbmOX70ECNbs7Qwz/z8HIPhoDWsLorKWyFIc9WYiqoAEwXtQSn0/iVxFEv95hyFt1MIoxLX2Ih7r9PKe5K6ukJrRa/fJ9DCnBiPRmIh4SzdXp80zVhZWSXNcjmETCZiFl2VCBs98B4mtW9CO/I8w1jL0aNH0WHE0IPXri6pCzEALoqcssgpyoqoyInDEOdEXlNUFVleMrMZGEen22O4KD5ueVlhbUESRcxHIvMDYb+ffdZO8rJibW3EcDCk24np9TqsjmZkRcasLiQCvCrJxl6tYC0L/Q46iEj6Q6IoAgWdbg+0pqhq5hYXSDpdet0ehWc5xXFMp9OhqgyEMUZpKqeI2gMkFEWOtY7QM1RMLQbdZSHJgXvvuZPV5aMsHzlMEovXa6eTEIcBgYrpdrvEsTBkGvkP0NbwDh/HHoYUsxSUItABi5s2gw4xKApvOF8biwqEEDAZj1hZPsbaynGKPJV57s8b6ICirEEVbUx8EIZ0ul26QUS318M5qKu6NZBugndsXYuUJ9B04pC6zFmdjVk+dow8zyRt3PvjoJRPM3xoh/ScqKFP1NAnaugfvob+gYEnEUY6r2zyB/kkxlVdASyCmDiUh2hN7SlqgjiqFt2kpZ0q3YAZntrV/Dl4zWFjgN2wdQRMsJ4VZT1NrvQLQFVVlGUpZmNWvhpir0PeS+3psNY6rFIEVUxQhdIt0RqroJXsNUwf5zw9cR100nqjtKwxvvaUNCdQhnaNmbUwdpRPkQsCQRtl4RBWlXMKZ306glLEoRixhWFAGIrRoVZKDMqdw7oKaICnApw3PfSDRyvtfZBkwLdphO3YUrTjjA1g0gbmk3OSpPAvhoEHttqfg2qBpvY5+k2x8UMyvsNRVSXZdETh42GNTwy0dQXKoZ0AcNYE2EBAK9USlbzPkh/czikw+AVL+y6gj6q1QcvEaroJygVo57CN7NIz2HAW5+We0oGqRUaXC5tPxlTddppMbaQrWeRUVUVRyOT7UUi1a6Sswgy0yNyz7TgMAkkw0dbQM9Dt9wm0xlQVtbM+BlcKpySKBDX398RZeVZJIsEBCk/5dZKC2Jjw5XkmXVcVE1oZ18rK+NFKQNFGbpplM2azGelsgjBBFQZN6YsVZyxKa8IoweLEp00HPpFRFncBTsXANc8LOmVB2LAn/RqjFYQeCBfar0/m8gvx+kSR/xPfM8+qDGk3fe0TELWCKE5QYYgKI3QUo5Si8jGvWCMeZs7gjDyXhiGq/IGiofs2VFea+dmuoxuZoK7t8FhTY9UGBmnLGHSt/531YLnDUJU5eZ6RjceU6czLHkR7Lv4hfk6pDeub/wLZwBuduDGOuraEnQhtLQHyuoqGkejn44b3UxaFFKh+01S+WSHrdUWJAl15uXED+GsCJQeFAIfzLNOmADZ+DldV0bJ0hcpftGa8xnd4nKOdEz8K2JMEbhiuvPKLPOxhD+dh55zNzTdez2i0xtlnn81tt9/O0SNHSNOMLBeA6rInXM5JO09m+dhRHn/Z4xkMBnzh85/3XbSSW2+7jTvvvJMDBw5wyq4dbNt+Emc/7OHc8f07OLZ8jM2bN5MkCZddeikf//jH2b9/P1+76iqe/axnMTc39z/1/i2KsqqEaZCn5FVBnqYszA+Jo5gkScBZ4ihk06YlTF1JVLDRVLYCU5LnJUUhhSdKk+cph+6/j507d2GqnH2330AcaBbn+symM+bihH4SSQx8VTGdpWR5TqDg7D0noXAcObbK/oPH0FrzsNNOZt/9B1lZW2OxnzCdzWi8GWt/UOwNBqylBXfsP8IpO7fSSSKuv30vw36X4dwcm+YH3HHfIYra8difeQ75HXez9/A93PX971Maue84R1FkHD18mM3bThLJlD+QTWYzjh8/zqZNm9i+ZYnpeI3lQweYTabE2hIlPZYWF+j3OkSh1Ayj1VVuuulGdBCShCFr4wnd5WU6WUE6njG3sER3MCBOlqhreQ+9TkJapqysrXHOOefQH8rz7PV6fPPqq7lv3z5Ga2vt81NOgmKOLS9v2E+kOXfw4EFGoxFBGLJ9+3YOHjzIl7/8Zfbt28eRI0f44Ic+xM6TtrN1y2a2bdvGqaeeypOe9CQ+97nPUdc1K2ur5HfcRhiFhK5ivLZGXeQ+0j2i1+sLwKEUOoyojWF5+Th///d/D0hH/6yzzvzfM9H+D13i6yIR9Y20LQqjdl1PkoSuN06fj2LmF5fodbseXKh9A0wOA1oH/ku3CVu6Odh4/86mfm0bjXa9dqP1yATnvDWE8tKSusYgVg51XWPrmsKzGq0TwKIx0JZAGS0R7oHUq0WegRMfr6oofRz4hCzLiJOkTbs2VhrH1ofiWGcwtSLPcxTyfvFAhmmUCcqbmAca7TSh0pIwDQShBa3ROiROOqADev2aIAyFJr9OfKfISwIMoRbWUBDIPYuTWA7gUeiN1xNhmPgDvlZKgDmt29oHJftkFDXSm0D2cO+dKmchjVKW2tj2/pVlSZam3n9rSplnElNfS8O2Cppnui6vCQIxNTfGUBtLr9el0xNfJpT47aC0pJMFoU89VIRhTBDHhFGC8qCxgF7r6pUy98x9RSvpyYsSCY9qEsEtTokvWEMGqI1BjODFvqSuKiaTsXxmrSnTqZjJlwWz2ZSqLD1Lzbb1uLWiPnkoXydq6BM19Ika+oevof8ngKdmmAkVVwcRnSggDgTddCqQjUcrqrKUhcSts4PWHzZC+fJAjHRT1il3jXdQM2qVT2/DT/Umja6qDWVZkaYpaTqjLKs21cZah/Gvjd7gzVQbqlqAJ6cUOgpRgaauS1k0vLHXuuxMXss0EaGyp3ngxj/8xmdINWCLTDrn/6SBpbTSPt2NdtA4p1taqmqYOX6ya7+5RLFEmwYKL2V0no4qPlHGm/EppdFRJAM8jFotauN3pfU6a6il4Sr1oIHi/PsVQKaB7Pz3tk/IDy6lWnmidRZl/eS1zZf1KYM1eT4T88AsZbJynCrPhUFXStfPmsqzgmUjN4FPJfRjbgNCtr5R4VB2Q7KgDlq2XBCE/vdkwsvvBzgdeLaTbY3yQdheyi/Wxhqy2Yx0NhXfhTT1VELxQDB+U63qygOfzea5HiP+UL3quhbds0+CcQHUftwqZJbNzc0zN+hjncJp8SIosswnEeYoLZ3UMFJkWUZRlpS5UKVxln7U90AgKCtf1iALYJkzmawSxTFd+nQ6HQFFlSJQmlBrklCSbfK84vjqCpPRiMloLLNJBRBKh1trRRTH0tXQCkMDmFpMVaHRKBVJF81aysxvDnmPQaxbOaks6AoVapyyOCdAaTPHxXTPA8stEOuQFESRgDRU5oBYihAgjLvoKIQowvg5K8aSFUo5kjj07M1SNhYlRa9Wys9Pv85qn6aJk8KO9RjWxh9PEj4txjmqsmpBX+W98Zp5Y42RQgNfgytHnqdMVldJV9cwRUYcaXAW6xQBgTe/FG8GYWzWVLUUvEppL+UN0TqmqgyGimQuJIhAhwGmNu1hK9gg+7VOxuNkPKEuS4l47ve93EMOxaauqVROawjgjR/loCW/DrXGBeE6W9FLJ2aTCUWR+tjmQtai2tCIUB7MCG7Gzv/Z+fe/66rrije/+a94+tOfwbv/9m/5yEf+geXlY7z2Na/lvr33cP9993LrrbexfPQg0zzn13/pZeRZwec/fwUvevGLeOZPPpMvXXklIBK5L3zhi9x22+1orbn4wvN44pOezL/7jd/kmc98Jt/85jc5ec8pvO4P/pCXv/zlfOELX+Dzn/88X/3q17j4hutb4En8/1wb/KC1ZmFxkTTLqMZjcI7aGNK8YG00Jk+nBFoxXlulyHPOPvssYQ0by2Q0otvrccrJp3DrrTezNhpRuUAKW+cYTaaYMpf9w8FoZYVbvns1r/rdPwTgc5/4KBeccyqbtyzxhav3cXIUsXVpgaWFIXVdc9NtdzBeXWHrpkVe9vPP4sqvfYuvfPsGbrv3AM9+ymP5mWc8ht9583tYmhvw1Mc+itvv209ZVZy5ZxeBNcwmY3afcjIHDxzktnvu5xU//zTuO7TMBz/7T/zmS3+OM0/fw+LSAp/63Bc5dGyNN77xz1jJ4dZ77ueTn/w4S5u2cPrDHgXOsra8zJe+8Fke/6QfY8euk8lmUw4fOUKa5Rw+cIClYY9TT9rEZDTizrvu4fDRYzz2ksewe+dOzhjOE2iHwjDsRBw7dIDrbriRJz35qQznhkzzjDtuvxXloL+4lW4UEM73OfnhF5KlGccOHWL7ti0cKmfccdc9/Pbvvo6f/KmfAuD3/+APedWrX02epmw0ELfWUm00AG6Kev9roD1I3nTTTfzbf/tv22/99V//dR538YU89qILOOPsc3jyk5/ME57wBB57ySXcdc+97D94kKOHvkuZZwwHPXZs387SwgJZXjAYDFlc2sRtt9+GtZaFxUXKsuLevXt52cte1r7Gr/zKy/9PTLn/bVdRFoRhSKfTYTWdYa1lMOgxmU4FhIoiBsM5kjhm85atxJ0ucdLxXkxy2BHD7Mp3+yU5rtvpEEWhMHTcepO39I1W4w8hdS2+R2g53AZBKMtroIWt4PcK6WTXbXJ1UeRM09yTMjRRFLW1l8R+hwzmFtomaZ5nOIQJ2fhIjccj5qcT4iTG1bWYq1eSzma8HKwxGp+lU0ItviyNM6tzFqs0zh8wu5GAZdpFXvYjjA1hbcQSI64D5pQGZzAOqlpS5bTSpFnGIAlI4oDpbEYcRSRxRK+boMOEKohIuj3iTgerhCmh2nOQDPeqFmNf65z4z0QBpU/d02Eoe6Ax1HXVgkVpXlJU8tnTLGcyHjMerYgxd12ShBpra2p/wE38GcD49TWMojYZtKxqNg0GzM3Ns3nTZtbGY/KyRIcRYRQTRhGzNKXT7dCPE+aXltBBROVgOhNQIstSb+6dkmcZIACX8c+4qmvyQNKxxWBZziqB/9y1l0TSNJl9cuKxo0fE98pIzSksr4rZbNY28deTshog86ENPJ2ooU/U0Cdq6B++hv6BgSdj5GFoD6gEShEFURvfWVuBjaraPqgTFgQRkY/cFMzGT5JANJeWhrUi6Kv1CFqjBQfPCEIGR1XV0iXwUqc0nZFms1Y60N4M311owJWmY2I2AE9VWaCCgCzNPFgSY5zDtriL/EL7yWjxABIeWBEECYdCIwZjtLQzuQeNtKvpTgVhSCNBU96jSjTAugVKtNeA6yD0ZtkKaytsVXpkXPyknFIon0BgwQ8ukUGqwINPGxaHjQbg8hxkogZaaIQCFvqVDkXgPBAYNEC1a9lSuikHmkLFSEJLUcgCWxa5B2xKJqMV0umEfDZhNloTWrcVU3atxMhON0BRIDRAz2tqx1+LPVuD8aZo/oN45LoBA2VzVEq3SLPS6www2exou3/iNyYLUJHnlEXJyvIxZlMPPLVjq/Smnd6U3k+yxvvL8QPOuP8PrzQvsFVFXXqWmV/gtTNoK0WV0xqnQtKswrkS0Bif1qgIiILYd70M1jiqoibNSx8+ID+3E4cMujEoi7GOMnfYqkY7Ra/XB8AZS7/ToxPHdMJATFWrivFkRl16dlw2pSorgiDEEhFGEZ2+dPiVUpRGobR0Mm1VUhW50NlrkQbgHFmRY50jTEKhDtcVdProICTw1HyR3GqMU03/inYENgdqAvEga7offhNTPvnR4jBaNaguVZmjyg1ALlKgQwAWHztqfTczbud+iCNAOh1YPOW1FAquko2hLEpqO10v/H0xqoMQa3OquiRQmjhJ2nEP+LUhotsfEkQJ4+mY2XjM8cOHKLIpYNBBtN4AcBB637S6KslTJxtcRzrwtTFkeUEcw9zcEB110VFCEEQQhIBrTRiLPPXR1rLpWRxFVXHk6BGOHnqA5UP7qfLcH2QCSlf4tdcD4kpCBxoGqAvlZ1UeULfGkJcFWSrBF1k6w5hKElo8sKza1dYv7R5El+7cj8Yc1kFA0unwW7/3R+zYuZOP/eMXueRxl+Gs4YrPf4ELLryIpz71x7n5+u9y7iMfwfOe+zw+9rGPkyQxF154If/5P/0nbr75ZpxzvPa1r+VJT3oSr3rVqzh06DBBEPCyX/1/eNSjHoVWire85S1MJhOSJOFDH/oQf/3Xf81kMvHv5MHsWK01d9xxBy9/+cv5rd/6LX7iJ36CD37wg7zn3e/m7W9/Ow7Ye89dvPsdb2XHjp30BwMqp6nTCYGrOWlpN3v3P8Cd99zHRZc8jrIsuOGG65jMMoqiYjpZodfvE0YhVS4HptksZTgYUOQpD0xG/Ke//kuWFhe5/ImXs7p8lHsOHues0/YwnUy57sZbOOmkbeAgL3L2bF2gtpa3/LePc8bOrVx2waN4ykXncOf9R3nTuz/KEy56JIu9iB4lhw4eQAchT3zi+Xz5mls4fHyNFz/zMqILTqEylk9/9TucvHsXf/W6V3LfgWNcf8c+dHSIl/27X2c4v8DP/PTz+LGnPYN/++IXcvOtN1NUNU6HfO6KK4ijiOc8/wUcPHKMm265hShOyPOSTpTxkhe+gP377uPNb/4r9t23l24S8uTHXcSWzYuEruSuu/Zx8p49bNu+nXu/fR2nn3EWL/7ll3HHHXcQRgnnXngJd9x6M6srx1Gh5sixY6yMJ5z2sHO5/Zbv8eH3vZuLH3cpi1tP4h8/8VEq76/inKMqC6Ig4B8+9Sm+8Y1v8Jd/+Zdtws+/oNQ3zR/gk5/8JNdffz3OOc4++2z+6aqrUFqz7759/NIv/xLX33gzd92zl69881p+9md/lle84hWyPhQ5a8ePsWXzZknsqUtWV9c4fPQY2086idFkwr7772fQ62Gs4fDhQ3SigM7cgNE09fvxQ3/+pnlFFIF1sh/EiSbpdIjjGKwlikIWlzYJw90Hq5Rl6Z+NI4kFSMBLnlAKax15UaybOfvnZK2V+PG6Js9zH5giHqyBDgk90CI+o2B8qMra6gpFllFVJZGPEtdByGA4lITqum4PP2EYUjeZM9ZQm8ozXkpvfyGHHwciN/IWB6EWNr8wiiKUEsZDhNSBSadDluVURU0chQx6HTrJHGmagjNMR8eZ6yVEseynaV5Q1aaBhADHyvFlAfm6XbHhqA2TusSiWhBcuRBlA2qnUU6RVRZV1EQEJEmPOJYEqbKsGA7FqLeuxftsNkvF+8invQVBSByGRE72cKyhLH1St6npdfqUVSV1GOCUhA/l0xHjY4fFpqTTwYaKNM28ckN2Y6d0mw5ZFDH9/oBOkrC4uCCm6c5gTcXccMicDjAEnnkl5zMdRVjEQN1YR1nVZNMp6VQ8APNM2E5FNpMSR+HraOX3bc+uC0I/HoLW5D4IQ/H5tQaNJFeOxiOOHDksqWHWSlO/aWardcP6uhbQsfY2Fg91xtOJGvpEDX2ihv7ha+gfHHiqvVFX8xue9aL8IR/nUUTPEvJPCRU2LJSgBWVsK3PSDbbjmTxmnYLbGBE6WiCoqoVtUlYVud8YC7+ZmjaNowFW1mGLB8nH/As6nJ9EYooWhLWnJsM/5/ooDxZq3Mbb/mB0z3dr/vltd807aoARQDyLnERH+q0yaECnIECFkQdLhN4rHUTj2WE+Yhb/Ads34ZlTzYD3IMyGfuQ63ZAH/aK5SX7QKHAKpy3WqnW5pKcdttCV/Of6ffWsn4ZqK0VQKbr9NKNIU4o0pS4yGcQIToYHwHRDu2zv0f9oALuWVQbe7FxJJ0zurwf8tAIX4LQ3c9sAPLVjBIR1hjDOqrL0ySIT0tmMwifwGVNjfEG1Pn7WJ59IKv8Hb/chdJWVpSpriqxA2ZpAQRJq38VDxphWWLRkDPrP1HhKaB20YGNVCz1eTPuFal1XNbO8oLbiNxYFDXQMoVJEQUgSJ0KrV4ooCIjDkCQOmE0ryjJdp2FXcs9BEUUxBvEq68QxUSh0/6KuW5C39t3TsizBd4YlPaWSqRbWVL6wdv2eeMeFUkRhlYwf59Zni/NjsLkJftDLkG0CA/w3+rXPM2eludOkXHqQWHm/hIb7uc6Qc+1c1zrYwJL0UOsGBiVa5rNzVsw6lTAdo9BHqzphmQa+q9GAsA34in8fgdLoUO5Zns1IpyOquhAWahi0zYGGuq21pnZO7mVtiBLRrcdR5G/PRh61gO9KN90sod/XtXTQnY38Z5CiVcyTp+SzMa4W+QhhKC0+3wRoWBXa04dVEGBsgPHrR1PA5oWkQ9VVJcWTEzaifJusMaDbNd46ua+yltgfhSnMzp07edjDH875519AVRu+etVVPOqcM+nEEcvLy2zdtoUlhU+CFVmEpEwpaqc4euwY0+mUxz/+8TzucY/jvPPO4+jRo4xGa8RxzK7dJ7Nt20mg4Jxzzmlf97/+1//Kddd973/Ykb7lllu45ppr+Pa3v82xY8eIoohHn3suO3bsaL8nS1Me2L+PrVu3EngZkLUWbE2aZsxmKWkqDaUm/bQsSy+PrynKgsonaNVVTVlVbex7WZQcPngAV5c87OzTWTm+TF5WbF6cp8gLHMqnQEnTpJ+EVMZiTEaaFeSdhDNO28Kd9x/l/sPHeMpjHk6gHIeWlxkkwj4+vjqh3+uwjQWmkymdbleYyYEi0HjwQ/bLME6wDqpKGjLZbEI6WaXX7WDJGc+kQRPHCb3+gNHanSwfP87ZD38UVW04vrrGwx/xCI4cvJ+D9+8jS1PiQLFlaQGFoywLkiShqg3jiSTazc3P0+v1CKMYtBxUwzAiSTpyr51BeTPcfDZhNl7l9NPPYG1tzR/8TDtfUIowDLnggguw1vKEJzyB73znO0yn03/l6bdVDkeOHOHIkSOcf/75bNmyhUse+1iUUpy0fTuPf/zjheFS11x33XXs3r2bCy64gNlsJkxzf0ht9lg5kIp/Z2Nc3KyHVVUR6w0mrD8iV+3r1KIQyYhS0nSUZqFuwRytA6q69nVwAyjZ9TAeaJloxhjKQmR7YRiKzYSvzWrvB9I0chtAIWgkIA0jXiFNVytJb03jUEchyjPpwzAUyZXv3ENT/0njs/H7MLWwmOqq8jYENeCNsb1kozfs4+qI2qdgaa0IvQF3U2863+B1dj1lryEgaAVayXyrqqq9rzoIfT1QYeoShcPUYQtsmLrGebCuYQ1UXkaGUmK47RwRiiQKiUJhKuRFDQqiKMLUUu+IrxVSRwSRhAIpkbAFoUTXKy02EMbXxPL3Kn+Altqh8fkyZYH4rcgYUNaKGXMQiCwJ8V3J84wsyzCmJowkzEGYiCVxR+6ngFVSywVh0L4XY+Wwbzzj33l5myRWyVoFMiadlz7hpJaySqO0AGw6DInjBFCoQLf1FghoLQmNaev/EvppqhQEoa8BaFgktgWdWonWQ/Q6UUOfqKFP1NA/fA39AwNPRVF682s5xDu0AExa4zSyyHkQYgPuROho6aFVLmyV0hsRutC7pZvaf9DC01JrkTAZPxlNU2x4gMlPkMY/yBiDBf+glKfQBR4gAJQTem6zoSn/PmsDpUy0IAwJQ+OFc+3WLhu1wps0+p/lLE5EoDSSO7Xh7zTDaGPKW0spbNlHgFsvIrRW7QCn0U7jFzJrpUhxkvzmZIVrmTaNpjUQcmQL6sjrqxZ5bToO1voCcwO7TGF9M0KtU2CtFXTbheumaNq1qF6TEOh8odN8cIfFmIoiS8nTGelkTDGbSFJHWdACRg191+tbG4CyoT82k1BolC0QvmGTw4NKqn1xh8IZJ89HS3qH3P7GUE06iQ1tWKnQE7k0aTpjvLbGyvFjXt9aiabYp8g4166d7fOWyfejwJWAtDTMpgWT8ZQYQycKCAcJAYj/SVGK0Z0OIIjRgdwv4/cOpzVZVVHXFbN0KpupUsiCI6mRk6wgrwy10ww7migMiGJB2OPQkfbm5MBY10RKEykIsEwnK6ytrbK2uoZCFupOp0Mcd4jjHoaQKNL0OgGairI2FHmGdTnGQp7OvAShFAq4MVLkGoNTUBtLsCreEgtzA68hjym1xikprvA6ebE2cA/aLwP/C7/stk9ftjah6Von3TyFxmJkw3RGxrN1ks6BXycRxh34AALt5QvKScmimvdgqUxNpJR4TsQhVW0pixyHFM+Kro9IFup/GISEQSgRsFoOzYE/PAQ6wCkZs7PphPHaCmvHjxIGUlSHYYdAS6Er6R3+QISjLgqq2jIYztNJOkSDIVlR4oCyqsAYdFWgQ02UdAiiuF0vTVVJMs8GE2pjDbPZmHQyIhuPCJGkTxeE7YatglC07UqBuI5grcaW8vcrY8i9CWLlu+yiw9/AfgWUsui2yJGDkrE+ZaQJiPgRuJ7/vOfx5je/maMrY77+9a/zuU9/jK9+acDi4iJPvPRirrzyi0wmE575jGdyx5138enPfo6ffNZzMCi+deNtbNu1h0c+6jx+//f+A0EQcPTo0Q0sFvegPWXj1bApHiybbzpgjte89rV85ctfbqXQDTsWeBATxTnH4tImtm3dgnY1K1XKdJrznZtuoyxykihk7713E0cRC3NzjMcPUOUFnU7CZDIRj4kkatfcNMtk7wtDtizOsXlxDqcCObwB1tRs3bqZk3aexI3X3UAchWzbupkkCti6NMd5F5zHR674J6658TYeccYL6HT7DAd95pOAvYeW+djXbuL//Zkn4pzjLR/5Mq996U/z8DNO5lf/6B2UtaGTRLz6557MvqNr/PFfv5tffP7TeOQZp7LnrEfy9ne9l3v2PcA73/42vv5PX+PP3/BHXHb5k6gMHFsdceFFF5J0utx+1918/5YbyGdTnvfc53PdTTdz2+13cN6jH4W2FZs6gd/vFUkccPDoMpWBSy6+hFvv+D7XXnstz332s5ilKVd8/nNsP/lMrLV87cufZ9eOHWxemuf4yojh4hLDxU0cOnIYFUVceMljee5zfor79t7HW/7juueLrLsJ3b501p/5zJ/k6U9/OhdffDE33ngjbeIPjcQSwLUJiWEY8q53vYtHP/rR7fedsmcPV155Jc45jh8/zgUXXsinP/1pPv7xjwMQRyHdJOLo0cPUtWHY7zI36LM4HLCyvMzc3JCHnXkGd967l6IQM+m0rFpPzx+Vq6oNk8mE1ZUVup2YKNDC6On3iOOIMAhEUmckyUpiymtMVaK1ImlsKvz0lHj7GlMVhKEcLIMwEu+SQKOCEK00EUjdE4gEJgiF/RAoOdhZZ32Sb05dFjjT1JuaMBAJX9zpoMDLeCQNL8tSauMPNz4dqTY1s1nqG49Fa0CfzRTTyRpJHLF71w6myomnET7pKo6YpBnOQWzkUO8CjTE1WWqpikICebod5ufnKPKCNC84vrpGHEmAThKFpFnOLMuZ63ewrhavIX//Qw2VtSgHc8M+tq6pbM1cV5gNxoFDE4YRi/NDgjAWX7oip65kT4mTDibLSdMJ08mEMIoYLiy1zM/ZdCJmwElCpzfwZ41KfHeqmiLP6HQ6BAqoS6bjEUcPHyKdzeh0EhbmhnQ7XQHDEG85cNRlQZFJElyaZiRJQqfbEwChqhiNR3QrAaOc9owJHdIfzhNGEWEcizLFOWoje23opZG2NpR5TjqdEASaJI4IdUKAsESMqQQgcYiPVxgTzs179kSINTXK1ihnSdOZN4BO5UzhD1HNztGAfmJvYbAtuOF4qFtWnKihT9TQJ2roH76G/sGBp7ISnyGtIIoARRCKB5NWCh1aXJMoZz0S5hxG6RZhqz1Nr65rqliQ89pPQjGe8x463gRcigrpZFgrFLnWf8kXtjqMUJ7atpHoZX3xKwkL6/rD1tjLOjAGfCdCGFOCrDami1prnBbks2EeWY9grROHBI2wzht8yzSQByWQr3Sa3HqHyM80mRQ0f1+hDWjrBOndUPpvBDV8Kf+g4h8auqA3Esebcrt1tLd5Hs3CLulzNS7PW0ptS6vVgRw+PGsqMMZ3pTwopBvJ2gYKpJbNOggrdF1JNG2ekc9mFOlUABzTHFzaflmDXbeHmPbzWR/36O+ZdPfWJZwCfq2/R0Fim4MQ7d9r750VlphTnhemxUjTWW9M7hzTyZi1tRVm04l0zIzhX3Xsb1qHzTNRG1/1oXulaYqzhm4nIbTSETx8ZMSw16MTJwwGSeuRoCJ8B8ZQVDI3rIWqljlqnDfZ9NKfJgBAexpnEIWU1lJXEPj5XFV1Cy47ZxmPVkkDATOzLCVQll2bhx7Mg7Ry7XgJArnfVWWwpqQoK/IsxzmFdUITxVm0QmQH3pui2fxMUVIjeuyFXoduFJAE0q1TRkz7gqZ72zAx/KaoAdy6LPafnckBGXm6nZO0smLZeeVniR5WNiPbFGSIt1ygfShAmECYoOKEMEkI49h3RwKZs0YSKDpNZCzyGqY2cp/Qwjp1NaUqCEMDyrUBDwooTU2epWSzCa6uiANNHMvmGuqmUyNroHUOjPOpkAFOCz04sJYQRafbQ1xmxLjZmQI3m5I4S+w2+Pxp23alUYqqMpRFRZEXWGPQKCne5Om3TQKN8YizFBtVkXsPEjlwVsZQVGULRrfr4oOgE7fua6ebP0VCLhDPisCbPz7UryuuuILDhw8TdfrMLSzyyy/992xanKfIU6766pdZmp/j7NNO47zzHs2mTUt+r7HgFAvz81xz1T189+hh7rj9FpRSJEnCX7/5zeIlGARsWlrimm9fw9+8+2959StfSa/X4/d///e59tprgXUQqVkTv/Pd7/CWt76VW7x8D+S5ra6t8ZrXvIbvfe977Xu/4PwLeNnLXsr+ffexurrKocNHmY7XyNIUkKKt1+1K6k1dM6sqtA5BlRw/vooOpIGVzlIc0O926XfF+Bcdcnx1jbKsmF9YYuv2kzhp505uuv57RGFKEscMhkO6oWIQWO4+vIo9tMpw/zF2LXQ5eWkPV11/O7ouueycndx/+ChpaXjUI86mQjNNU5yD2+66jzLPedKFD6MTR3Q6MdfdfZi40+V5T78cGyTcse8I3/3+/Tz5qT/Os4ZzvP0d72Tnzl087ZnP4YH772PT5q08+YlPpCprJtMJRw7s59HnPhrlHG/9yz/j8sufxEtf9ALuvOturv/Od7n62u+ya9MccRRw3/4H6C9sot/pcuCB/SwtzLP5ogvZv/ceFhYWuOj88ykMqCDilD2nsnLsCOPRGkcPH2Bp60ns2n0qtXXs3LmbPbt2cdNtdxMo+MAHPsC3vvVtPvGJTxDFCTfddCO5fy5aK6zdMJuc49WvfjUXXnhhuzf/87Hx3ve9j9HaGlmWobRm186dvPGNb+QDH/gAn/vc57j0cZdy9913cf311wNyGJ2lGXO9Lkpr8rJiNJ0xms6o/GF6lqYoIAoFYIii0CcVP/QTZZtrbW0NU9eS6uakoTsZj2RvUX2GgyFFWVJVNVEUU9aWvCwp0hlRGBB6g+cgCIii0IM9/vClJVEuihMab9UKscgw1okdgr9XgfculeVB6vKmRuv3Otgk8vYUnvUCUk9Dy7CSdKeUyvuqNrYb1hoBpsrSJ7kJjcFYy8ryMlVRkCTi5WLrWlLwwINrss+l3mtI+bU5UKC9fKYuS1ZHY5HrBQHbNy1QVpKINhpPCUPNwqBDHCiKqqbMy1ZSKGbNIhvZMu8lS9Yyy3KCUJITF+bnSDod8qIm1jFhHLNj5yK1sSwfW2YwP08Uxew46STSLPP+WTWrWYa1lk4SY7zMMR+traeAhxVaazYvLUqIwGzG/fv3cXz5GHmWEWlFEgbEoZckNXYdsXjySLaT1Om9fo8oSnxqdSLMkzAkzTJcmmIRw+gwTjybo0ecxPSGQ5QWVlwwmaC0ZjA3RzqdoyxSymzSgkHW1IinrwCdzj974/fSBryMohBXVFhTUxUFs+mU6XQqa4OvUdbXDwe+HRzHsX/Gat27dWOd/RC8TtTQJ2roEzV086f/6zX0Dww81Z5VZJW8WNA8MM8wUlrjajHnqv2GZazFaW+ErbV0VeqaykqyQxAE3lywkm6bN29eNwH3P8N7D60zTjxs6mNT5basU90FbKpb1k7rQO8BJ+uBLKxFee+nlubp2SxNCp3zi4FT6yl5/2LWeJCrcZ9XNBNi4yLqPGDR/LIBUGSiKoe8htdCNz+nYUr9qzMVcZdq7n9jMtdQDduXbcC3DcCccw5nDA7RZgt4o2XhCNw68ITI7pTWhKEHgaxDi93+OqKtdKv/RglaLulvGWVRYHyCS4N4b7wtzadrFhEagNAXRjTP3G28/82fKP//ap3R5B70o9vP2yygbsPz2bjZFXlOls6oa/9e/cbwz+n87XNh/c8e2tulXGUhVNA4CtHGUdYVszQnDmOCIPJFjTDBAuc827CmMrUHgw21R7ibIamVamUzOAh8hDNKUZXC1tOIYZ9snGV7v9N0ilIO56TjFWrF4jChto7KOvJx5YeD0OxxIh2oSknYkW6vk0aLXZdiVHXZAtrNoKkdmJmAmdPRiGDQI+51aFJXVPucHcoj+M3zVzQFVDNR5X7KOtysg+sskXaj9cNG2ITKd/98YqcHL5VSUlT7TUJpAdLREg6gg5AglO6FrQ02rFG+G+P83G6Ypg4JJmjZiv4jtfRapXBIskpR5OSzGbauCDVEQUgYBISeNdr6oVmHUz5VwVOdPT8Sh2p9Rpy1uKqSjawqCaoIHYbtvdE0xaXcg6qsfBztlKoocMbSitG9lFjAfg+gI91RMcgV7wxjxVuwNrLHBApPj5YY6Zb0vcH8E280SSPv9YB643X3UL5OPfVUqqri2muvZX5pM2ee9TAee9kTOfv0PYxHq/zDP3yI7Vs2s33bNqy1dLtddpy0g9lkQmXljmoFo9EaH/7IteAcmzdv5hWveAWnnHIKmzZtIp3NOL5ynGuvvZa1tRHWWq655hqOHTtGs3nNzc2xbds2ojDigQce4CMf/vA608lfWZbx8Y9/nNFohFKK7du3ce65j+J5z3se733P33L44AGKLCPPM/I8l4LNf4k0xYmszu8xRVEQJwlBIGa9OggIo5A4iiQ5SodMxxIFfvTwEeYXFukN54U94mRuJklMpB3OVGRFTZoXHD18jIsfvoetm+b5+l1H2LXQY9fmeW7ddxgVdzlt90lMsorxrGDL0gJrowkHQs3Zp5xEFErz4tt3zNjUjzllx1ZWMstomrHvwEGe+OSnsWv3bt7xjnewZfsOdp68h8OHDhAEIb1Ol1G+SplljFaWOf3k3XTimPvuvYenPPFyTjt5J1/44pfYd99eJpMxna1zdOKYtbymMYmtqpqF4RyDwZD79h5vfV8CCzruMFjaxNHDh5hMpPETRRGDuXlmWcaw32Pz0iLf+ta3mR/0ed4zn8rnrriCa665hsNHjlDXNXPD4f/wMHjZZZfx7Gc/B3CsrKwwmUzYtWuXeFnUNe985zu54YYbmE7FR+OMM8/kpS99KVdddRWf/vSn+YVf+DetMX0QBHS6HTZv2kws5QM1mtFoTJqlLG3eQhyFVHXNjh07vLwgZTgcSBz8nXextLTE/Pz8/52J+ENceZbKehNF4gFUCcjSmDA38jlrLdq5NsCkrGSNsxvTq4IAFwSYZs/S6+u2NEdFUtaoCKpqHXgy1hL6PbOp1ZwHGjpxhLUNAJS3Y6A1Hq5F5loWJXlRiEWGtbL3+Pq6qoQ5UZYiR1N+/U+nE4yp6R87Sreb0Ilj76tisc4nWjtHXVY0MeRS19J6y1pnKYoS4og4DBn2OkyzDJMb8qJgGHToxhHOVJ6FUYP1pthK+zQtAXm0lvud5gVaK+IoIo5j710lB0OlA7q9HuPJhDRNiTsC5nS7ibyXqiYrSvI8xxhDJ0nk81QVRSly106nQ11VRHHMoNejyjPqMmd15Tiz6ZS6Kkk6CWGgWxPipnaXG7hR5hPQ7fZaSWbjTROEEWUxo6pKjIXIWixOEvuiEGetDysSL9ssFVA4CEKSJKHX7TLtJJiqkgOoc6yrC/xx1hjQoKx4hIVhRKAD6qbmMOLrVde1Tyj1ZxndJE+71iA5jmPZ7p0j8Kb4D/U6+kQNfaKGPlFD//A19A8MPFknHYvSGsIwQmlL5MQg2ynxMshLWWjzomo9AxJjCANNHAvjqfHN0VrS6hpzuSYtrIlYbbS+LcZEM6i8V49PKMObRVvnJFWhFhCpLEuvYRaEs9k0K/9grXMEyN8vi9yngwgNDyXFkAkCnG0YQKwzp2jmQAvjeFS2SbtQLdIvWtaNQNAGWUOThOenVqOcl5Q1mYS6lQ/qdcaP9VpKh0jg/Oah9bpHEu1rylejxZSPrNr3XDfdQj/QjEfbN4ItgWdBhUHUSuHE+Hx9cimPNjtUaxaaTifMxiPy2cRPBCceBQ1Y2QJlisb1X3lNuTVQFTmmcfxvJ2CTkkD7TK3V66b9/xxxbQEmAbP8U5FCRmt/P4SiWRYZRZbS63ZoDOfahLwWAMQ/a/8fep0t9lC/ymwmCSmdLmHSRemQnpOFw6KoqxodSoE2ns1Is4JpmmOcJJukaS4brhZPk6KWuRTGMSqMiYLQe7wZ78OWismhp9sbI8aWjafDqPCpC2XBloUe870emxa7jCYZdVrgCHBOxgN1IUVtLcVlWUnEZ+VZklpralNR1hV5mraAdSPJVDrAmoIyNxw8cD/1ls0EwWbxWrAWowLZuZwDYwVYd95g8UFwsx+DzSYKgPMdGg96+nGmkVQMaw1gfTfAbZifzQFCe/26glDeh61LnIll40ZhqxpTemPWOCbq9kFt3MD8eolnBlo5vKtAE+K8ZNYRxCF5mjNdG7F8cB/1ZA1tasJAiinpxPswB3//rHNyqIkSgkgR9/rSpVaKsijQOiBOEuK4g3UOHUQoFbRR2zr0CZteThzGHY4fOsKBB/az97brqMYjTJ5h48gnejaRr+JVFLSMCt/QcBalpQESBQHdzjxRFJEkCXHSkQ0wjNp5K00zf5esZ3EGEToKPYARE3o68kP5uvHGG4X+7g0pv/q1q/jNX3sp/+H3/oht23dQuJAtO/ewddcp/PyLXsRTn/Qk/s2LX8Rb3/FOprOMrdt38Fuv/S2KPOMnn/kM6rrm+PHjXH755bziFa/gDW94A51ulyc84XI+/tGPsXXLFsIw5Ktfu4rf//3f54Mf+iCmqnjhz7+Q3/3d32H7STu48aab/v92q+M45m/e8Z955KPOZcvWrVz51au44frruPTiCymLkvFkSrfbJc9zRkB/OAQcphSD6aquWViYZzQaMy0KNi0tShR5VTNLhRmBgrl+H2Ms3/7Od7n7vn0sLS7yyLNPxwG1qVg5sI/xZMY94xnPvugMrLF84Ou3Yp1jLom49JzdWOsoqprv3X2QM0/ezk9cuo13fORLBFHM61/5y1xzzXc5duwYu849m+tuv4ebvn8fv/xLv8Cxw0f48he/xGVP/Ql2nLWLh519Fh//2EcYTyb84X94Dffuf4Crv/F1nv+Cn+fb37qal7/s3/IzP/vzDPpd1o4e4J++fIRNm7fy9x/+OLfdfANve9tb+fCHPsipJ23mFb/wXN79sc/T7Q95+S+/hPf/w8c4dOQOXvPa3+am66/l6qu/yROe/mz23nM3b3rzW/h3v/abxBg+++G/5/jyUQAuuvgy+sMBaTrl9NNOYzpa5a5bb+S/v+vtHDzwAH/42wHvfe97efWrXsUll1zSmvwWRUld1f+i79Wm+jp405vexAc+8AG++93vsnXLFgCm06kYQSP79N13380FF1xAbcRC4b/9t79rx8v8cMBjLn4sv/e6P+F97/tvHDt6lBf+/Iv4wheu4JZbbub3X/cnfOfaa/jYRz/Me977XlbHM97wV2/lN176EpJA8fyffj6/8zu/w6/+6q/+b51v/ycuU1eEHWHW6ECTzQJGoxFiXSEgng4CnHMcPHhQDq5WTMXDIPBMbDEIT+KIyCdYVYVI1IpSEtMa/488z8UXKBPPJmPq9YOxDkROUdeYMieONEkU0o07ZHlOWZWMRiOSTpduX6HDkLosmUwmTKZTyrJso7UbVlNTk5VFQVmW5EW5IWBHYa3U5sfjiE2bluhu2kQYxVKng3iehCGB1t4PzOCUIYwC4ihg0InEaBvNaJZTqJJeModSAaH3TdJKDlDLkxSlYKGXkFcGayxhkDA/7KO15oEjy/4QB8Nesm6MHUzo9Xps2TIgCAOsNRw4cECar4Emn02piozpZCSm3U5R15Y4jlC6gw5DYUNkGXVV0xsM6PV6zLKcxFrmhgOwNXWRMTp+jDwVltGw3yFJYkJN61erdEBRGVAGFcb0koRut8u2bdtwQFkJYywIIzrdnvydIqfIBTCs64rxeORN5i3D+QU5Z1jL2vJhVpePsXLssDDdhkNOUjspfKhOkediOJwX7fpe14Yw6RDGmuH8Ar1ejyhQVKYSOaGThnW32+NR557XBvKEYURRlqRZymAwpJHZzc3NEYYRlTG0h5qH8HWihj5RQ5+ooX/4GvoHZzy59UdtPEuoKktvYOdIi5KiqHzEp22/B8BFAVEoJDrrHGVZoZQ3HPT+TdanlQlCCjrUHnhRHgPZAKO45ibKgG2keILkyeSsq0poddZ4iZ50diT5zra0VeugyDKJFQw0ie62VFxhOq2//vqAb2gz7ZtgHXzyOGOL1K6DThtEYA/6fgGomu8FGr+lFpVajzNuDMybt6Q80tuYcyuPqor8IFhPtmt9kPzreANC1RwYHMK4aqi07QsI4Ka19W/ZCkgEaBegNQKK+X9sc5+rUmIYyxxjSg/I+c/KOuik2i/5BsHG/aT348IaI2kngUaknRqnHev2ErJQK6cFzFPav33VAoLNA1M4zw7zbDndGHpGdHo9BnNzOLdTALZAipkHpRpseP7tUvojAjxZK5uZdQJzGiNdjzDShFZTlzm1kTm9NpmRlSV5UaECiTMVs1cZb5WVA7B1YsTZUGjrovQpOkVryF6bupXMenKgzGEl4ycMLM5pihqOTwpGk4w0K8lKRRg5Ij92nQ8gKKtSCuw8a41nUQpjhW7fesz4uSP/8+BjE8vqQwo62kfMKolpBuebi1povbZhOvpCsOnKtfXRxrneTJwNc01ptF4/lLdLSQOSKuXXM+VfV75PN8EAfs4JU1Ney2iFqkqcltRL0Z4LHd/UEmdclTLnAp8q1O32ZIZWAdPxiPHqcap0gq1ylFs3GbXWeQdXRSCCbg/0PribLptfgskLT9N2Yu7omZQY470AHTiB1OMkIYwiyqpmefno/4+9/w63LKvr/PHXWjuedGPlqu7qnCMdgCaKCBgAnSEJOqRxdKTnq4I4CGbEBDrO4HwHFBgRUIdsgCbT0LSd6ZxDdVeuuvncE3Zaa/3++Ky9z60Gn4f5ovOreZ7aPJeqvnXDOXuv8Fnvzztw5OB+hmtLaGMIwoCo1ZJI8DgiDGN0IMmUgTegFZ82XbegCIKQMIxptVsShZ20iL1kTIchSvngC1zTyXM+JUg5JZ1bzxw4/mcvvOtd7+KpT30qL/ihH2LP4/vJC8NFlz2N/mBEeWA/M90Wq6ur7D90lJe/7OUkoeZb3/yGFJZVyeHDB/nSF79A5iUhIKDAeDymKIqGGdRKU7Zt3UqSJmilmZ+b4xWveDnnnXsuw9GIK6+4gtnZOW6+8QaqquB3f/d3ue2226jKkiuuvLKRYAE8+9nP5kd+5Ec474ILmd+0Ga01r3/967njkku49qtfAmB2ZppOu81wNGIwGGD6a+DES6ZO9CqrCq01rVbKYDjyTQHtDX0hDELyohAJSRBgPRX+0cf20G636HRa7Nx1Eq2VFVYHe3j44DKdNOKHLj6dpf6I61cf55IzdzEa54yGY644dTMq1Fx72/087dxdKB3w5W/dSi8wbN88x60PH6C0mjNOO5k9jz6Ks5YzzzqLhx/bQ7j/ADu3zLF1boodWzdhTMXi4iKPPfYYj95/J+1Y829f/gr2PPoImIId8z12nHwq3elZ/v4Tf83jjz3G3sf3sG2uRyuJeOLIEldcdhkozZ133oFWjtmZKfY8+iDOVGzbvp2VowdpJTFPf+ZzcOWILLfMTHVZOHoY6xQnnX4WW7bvZHpunr17HiXSim1bNnP11W/ivnvv5UMf+hBaa3bt3MVv//ZvU1UVCvi7z36aCy+8iGc/+zlehi/WCR/5yEe46aabALj22mtZWlri937v92i321hrOXToEGeccQavfd3r+OhHPsL9D9wvsrumAHacf/FTeObzfoid81NoHfDFr3yV8y+4iDiO2LPvAGedez5nnnMON936bZQKeNnLX8mXvvQlVBDywh94Nrff/m0OHdiHtZYvfvGLzWs4nq8oSjDG0l8f+GaX7LeVseSFpJYpJKBn8eiCsJlUQK/TwYUyrnPvN+R8WpLydXQdR1+z+suqoihyTGW8Ma2XbvmUYmsdzlRYIzWz9ubAw/GY8Tgjz3OKspB6KZROtvHm/vWHqSam0KZOpbZOPm9rU9q6Tq2Tm5X3ZxW/1jgMII5JqpTKszm0DlBKxqDynqrWQlZ4xoMO0M6gUGR54WsLRysSc+GyqrDK1/RJzLgYUVYG45R4a4UBkWeZSEM7OIa54YC8LAlUiAogTmJ/jy3Wlei6ee3wEr0UpaVJ2dQkPgyoyjMG/VXa7Y5nrhSMR0OGg3XKfIyyhiiQwCFn5TmqoGYzxd7j1pEmMWkrJU0TMTb3rHtjHa6qJIXKVnL2DutmuWe1eT/cosgBWVvz0YDRsM/66jJRGBKGAdOz894gvpLXVxRk47EkrllDZCyt3jSdqRl6UzMkSdI8a60VaavFtu07mJ0riGopHSIDLSrxkAsj+byzhnYrJQhDqSGexJo9Hq8TNfSJGvpEDf3919Dfe6qdq2+coPFlVaFxYlVlhaqal1WzuFuPFsqgirA2asZxVZUbJo8MyLpTIhuUOiZxA8/iMU42S2NdkyQmRCdhSdXUQFNVDXtKjLlNQwM1fqILSwq0tccAT60oIFQ1zU8dw/w5dmLUk7KWyvn36twGltZGm/L6+zfON+ffmzcIr3++p6c2lERXT/wJ3lX/tI3gja4HtQ4EfPIo8AQ42fidvmOplDxb/z7EdBy/gHgYTHmk2UnBGATumPsiKRree8vf57IoqMqcqiywppLXqb2Z+ga2k6q9mWrwxoPz8rMMyoDTRgwNVdgUCM47jdedGOOcTH6tBQxr3utksarBqPq11MCi0AQj2u0uxhjana6gt6F8iFFncMxC2XiIWU8P/b/g5Gq9QV1eVHKPsVS2JAkCKqMpCktpDaWxrPWHAiIbQxQnktBhrbemk0jQytPjDZ5BpiDPxkIBHWdoTTMm6oRKGScCCCotRTPGYqwiKyyFKRkMcsZZTuXExC8IJO5TopzlMJoXOUWeNUb50l3wYLdzk7miNsw8/8zq9aEohN4OWqKH8RuiUkKJVchEcJOxVs/7DVj0MUPtmPntf7eqgVA2yFeVn/s1bVip5gcqVRse+jlnnd/QDFYpqDTKy5A0EOmEMJYkzMqbuxZ5Jlr2MMSYiiiK5IBjc9b7a/RXl6nGQzAlGgvG4AKJ7tWBp88qr6P3IH29wdTvKQwjClX5ZyzNAoCyymXj1Bp0fd8gjhORA5QlK8vLLC4eociHpJF0WdJelyRJaKUpSdr2m59QeOuuSu1locNEDG+jWLquUUwSp0L9D7RPFgnl2dZpWM407FdT+YOBjGwv9Ti+i97/8T/+B1VV8UPPfz4PP/Ioa+sjnvK0Z7I+HLO8vMyW2Sn66332HTzMy1/8Ym6/7Sa+/IXPEbV6RGHIkcUFrvvmNxkNh5MiTim6XZFoySfwviERw+GQqpIG0bOe+Uye+YxnsLLWZ6rXI22l3HDD9czPb+JNb3oTn/n0pyirije8/g044NChQ/R6PZ773Ofy1re+tf7RALz61a/mwgsu4B8++xmmprp0Om06rXaTTjUejfw8rFkPFaWx9LpdoihkcXGJJEkIg1SSrJTCaUfuwbM4jqSwL3Iee3yJTXMzbNuyiTN27xJPk4OHePTIClunO7zyGRfyka/fzoMHFrns1K0UoyH9lT6XnLyJJ5YGfOOeR3jry5+Jc/CHH7+OH3nqeWzdNM/Nd+zltB2bOH3XVh58+DFmZ+c46+yz+bsvf5NsnBHmJ3HqWecwv3Ub6+vrrK2tsbKywoN3387Jp57Bj734xbzjV97KcG2Ji170XE479VSCpMV7/8t7WFpaYTzOuPKis0AH7Dm4yHOe9Syy8ZhrvvgFWt0ptvR6HNj7GL1ej+3btrO4eJi5Lds594JnMFzYTzYe0mu1CYOQyinmtu5g0+atdHtd7rvrdmZ7PbacegpvfMMbueOO2/nkJz9JFEbMzs3y5re8BQUM1td5w+tfy3g85pJLL5VDutZgLZ/61Kea8ZMkMhff+973HjOuLr30Un71bW/jxhtu4MEHH6TT7UyAJ+CSy6/gdT93Ndt7Cffdczd/8J4/4a1v/iV27drF+z70lzzrqqs48/TT+J13/R4XX3QhP/rDP8pv/ebbmZ2Z4eo3Xc0f/8mfcMstN2Ot5ctf/jJf/vKXj3vgKQwjsjwX9kscC3tJaUpr0WWFKcbilVOWLK8sAWKcn4QB1oRoLXKfqqpwKOIkbeSnRZGTZ7mX95jGxkLYRK459CjlsN4DxNZpYsZQIcAHQ0nCzP0BWOkSlXvWi28G1unFtqp8g1CMs+ua2/jDa81Crxt9Qe2dam2zD6dxjAohSVJJncM2YTZQ18TCgs+MbaQdgQ9tz/0BEaAVByjlKEu5r4E3RrfOy54sDSCWxlGzfdfepVrXCgdFXhoCSoJI0el1ybJcjN6tI2gAq4ogCGgliU/Ug7WsjzWVWHk4iylzhuuOTrstNVKeMRwMRAKd5yhniQPl60kBnqIwRgcBcRxhsgKcJUlS0iQmiWMB3INQJEWI8XNZloicWjUm9WL+75UaVsyiFbInl3lGMR4xHvRRnS5x3GFqZs5L+DT9tVWy8YhBf41sPPRnKsfUzBzTc5voTU8LIOfPV1prWknCth2JHG20gFlBEDQeQlVV+bOkjKUo1N5oXDepmsfzdaKGPlFDn6ihv/8a+nsGnkZZLm7xyqFtRQGMELaRsY68KKmMeDyhhCrsgNyUOFMReRAkCAU8EDf6GqSRzTDwCQuBpxEqP4gEbLI+5U4+TDMJBaGsGVg1uFR5iqc1ViJdrWySjSwAcKW8ptIYQaqLjNAZkiggjSQVr6Yl12CVzJUa9PLUPOeo3fkn8ZH1Rz1563k1mVkbWVETtlQ9d2rPKDESa2SxTjUASiNVq+9XEKB8koUKQpHDNRpXj0hah62qprsTaEE1HfWaIrHLdepEbeptnUSJRlicC5uFQuFBbb+x59mYbDwiHw2xZYFyhlBr/0w1Yb3B10CU14nWv1s1crvazF2ooVoXKAdRGHkk1oNiHvAyG+SUph5bzd3fsHgq5dNC5DXHcUKcpqTtDttPPo3NVdUUSVqL/rb2v3L1a2qQbQE7J8/7+L6y0RjrZKQGTayrYZRbCgUjK0k6tYGdAqIgwFXCXAzBF5qG0SgTOa1zRGUu2uYwpCwl/tpUFRXyM8JQKPwKhakBYUGRcU4WrtE4A2T+lMZhXODTeqBwAjSbylAWJcPRxBOjTmYpTTUZL6aWxNbPHkB7YFZhyoLR+jqrAFNT3vNBQ4BIh43PdPVdAeUUziopF5w3PaxvqsIb+dfyagdqA3G3AYRrkLieM1qKxiCSr9GKEAjwXZEwEXlzZcXvrpbZVo4oUCglQGhVFqwXBUks/je2qtDGEAJ5Wcj6YYR6XJYFSwsHOfD4g6wuHJY115shBqEwGbKsQFWGMA5pd9oETjeAc21+WYxHKCcskyiJfccoJk5jFI71xaMU2ZBs6AjbKbGCkJQwTtBRRGktabvF/OYttC5/Jp1Ol1a7Q296ljhJSdKUJEnkEKDqOOmAOJLiPtAhOqwNW0NZEzyAXLNNlXYN2G5NXbhJJ9dUpS8qxAOkJkYe7w4Td911F71ejyiO+a9/+m7ipMPPXP1LfOYTf0teZPzSL72Fb11/PXffcxfv+oPfpywLrIHXvOLHWV5Z4bP/8A/87BvfiHKO1732pyirivn5ea79+tfZuWtX45dYXz/zMz/DddddByAJK2FEmY/5D//hP/CWN7+Zv/lfn2D//v38wXv+mP/+3j/jaU+9Ukwzg4Bt27Zx44030ukI2JCPRyitJRHKGLZv387v//4f8pnPfJJv33oLh6qKJAqZ73Y4UuSSmIvz35Mwk7Yar8ZNc3Mi28jGbJufJ8tzjiwts2lujigKyfO86dQXZcnBwwscPLLILXc9wIXnnMFPvvLf8vkvfpVqPORIf525qRZnunkKFfHg0QG3PbyfTrfFdCfhxZeewrW3PkhlLM85cyvVaMCRI5Y3vOipLK2ssbC0zFSkCU3O0uEDXH7aVvI8Z3WwxvLSEqO8ZO/+G3jhj76UX3rLr/ATL30JcXQ9T7nkDi4+5zS63YvYfc75fOOb3+TQoUOcuXsnaRhw6MgCSytrBEEIWvO1r30Fg0KlXc678FJ27thOJ1Esr66xsjZgbtNmkihgfXEf1sDhhVX+4fPX8OM//hPs2rWLj77vT7ni6c/g0suv5LJLn8J13/g6f/Cu3+aaa67hqU99Kvfeey8zMzNkWc7ewwtsnpthdnqaP//Ah/jEJz7BRRddxMLCAqaqjhkjzjl+5Vd+hZe//OU873nPY3FxEYdjaqpHt9ttvu7000/ni1/8IpGPf8+KklarTbvb5b+9/4PEUcR7//S/cPt9D/HYzXfwg899HgcPH+GRx7/Bf3rTmzCmYv/BQ/zWb78TYxxHl9f4lbf9Kgf37eUVr3i5B0iP/2t9MMQhkfJFkaMUdNod2TfLCmVLRsMBeZ7T6XRFrpblrK2tNc1YpYR5MRoOSZKUIIrIi5I8LxhnwlSy/gBZAz1hFE1qmiDwC54lN75mqhUMzqsEPIAUaKkbbVWR+9rZmEmNUHlJUFVNQlhq4Anw67MAGcGGNKbBQMDvsixRW7f51KgYp3294YGdMNBgKqw1lM6ITMRYqsqwbW6KNIlwgVdTWEdlNOOiJCsNvekpAVCzkiCMSYOIUCuwkhK9bV484IrKYHWE8j4lsfedqgwYZQip76M0iYMoJklSOt0uddrxYH2dIBB/uv7qsn/9kIQe9Cpy2nGAxnD4wD72Pv4YRw8fIh8PCZVIKbVnI1h0U6cBdDptAdeRQ7IzIt8L44QgSqSOUPL1eZZJ5P1AfN2MMSRJiySOaXe6AmxVwqSYmpkBBdaUtFst2u0227bvIG21SNM2WZ6T5xn9tT5rK8uMx0OGwyG92U30ZuaZ3bRZXk9VoNKUOAqZnZsjabVBadbXB9Ig8DK7+vBclgVaadIkEqNjX8cJAHJ878EnaugTNfSJGvr7r6G/d48n3zVxypJbz+zxCJd1Qt8z3gMJVRt9i/RKOUueC8oXBIK8ial2/SIFuBFXelWDfNTMEvGAkgWzBp5q9Nd65K0BAzxqPqH/GkpT4oxt9MaCGCOUM6uhzClyYVnl4wRlYyIVT968Zz5NgJgNIJFz4BcH/EStY0Mn6jbPitow0WSyqYbJ1CDAHtGtv2/yp8DCNTuq+TFqwiCqDelq5lANvij/nfiuh6kqD8B4Nk99txXNz25+r0eLa6RMDNYM1gZoJehxbXpWM53KIqcsMmwlXR+Nk2QPXwRNQCd1DHOquZ0b7jk1SOjcZOGA5nuD5stt0xloFswGLKzHZS3zq4EnKwa1Xteqw5habjJJ+atjKJUfc64ZX84ayrLwRnrH94YJiNGnErlinfDiUBLZbA2UZfM2atNNmWM16AmlmcRuWq8/rpQDb943AVBd00VxiDxSK4VVQrW1RjZX5wzOVeLv1Yw91YzrutA1znrJQNV81OkOChpfuHqdOgb4daDqlBjPliyynIF/nXEc00pjArVh9HuTf608jXdDZ6aRzvoJqOrvc1CrxR21NFV501cfge03Tk3gmYmBaLLreevHqjOVzFVTgpZEDK2Eji8pOiUqDNGI/KEcG0q83LgsMKWkGWknB4fxuhxmVo8eJF9fwebDxrhVqL/+o74DTvmGgPcw83NYKeVTQCusrQjjxHdeldzf2jTTWun6ukQOHf7gE3jgecumedJQUc3PkKQtMTft9gijmDiOJYnHNx/CRg4be+ND7ym3oYPe3LtmD5rMx/o/le8oojVRFKACwHfN/2+4Ht93kNWVZY4ePsTpp5+FRXHHrTcxMzOD1orbbr2Z4WCdXrfHnQ/cS5qmTM/McP9991KWBfNTXR556EGRhZ15FgcPHiQIArbv2PFdjZmXlpZY6/e59LIreHzPYxw8eBBrKv7p+uvZtGmeQ4cOsbS8zPpgwJe/8mX27d9HGIZNWAfAeeedxyUXX4xCsXfvXq7/pxvodLpkWcY9d93J3n37GAyHtJK4kdQFQYhD0m2TuAYqcr9G0MgTtNIMx2PPEJCEr6osGWdZU6AGQdBIj7TWrK0PuPv+Rzj11NPQtuDwyiJJu8N81KI/GNJrp5x9yg6MCsidJtQKFSbEsWLz3BSDvGRgYM+Bo6wPR6wPx8x0OuTGsufAEWZbcnBY6g+ZynJckPHonid47NFH2H3SLmanuxIUna2zsjbEoAiilLX1dQ4fOYoppgmihK1bt9Jf75NEhqluh3FRECcpp59yMoP1Pnv2ZGzbPEt/fZ3hcMT83BxFkXNg/37iuEVR5GzZvJnRoM/SwhG2b9tKr9tFa0230wbnWFhcFDPkNGXnzp185Stf4ZFHH2V5bcDznvtsnnLJxXz5y1/mhhtu4ODBg98xPuo6ZXp6mt27d/Oa17yGm26+mZtuvJEf/pEf4ZKLL+auO27nyiuu4OSTT+brX/86IJ5fP/ril5AkKdZapqamSOKEbqfLoL/G+uoaV1x0Lg8+eD8P3v8AP/yDz2F1dZWjCwucsvsk+uvLfPOb1/LjP/bD9LxB+VOf+jTOO+/cf41p9y96FUUme7CW5qzUu5osz6jKgmI0ENaPs7Q7YtwcepkEDipTESeyV9WSNVe6xlPVesCmXhPDUA4ckT+01vuXdTJHTVk04T7WHzypWScKAl/EWmv9Idc1EjlTmWbfbRp+dcN0Q6NPLs+mqhuGznnvIIjjVZIkJkmk/tKBltrYBVgcZUWjJIgDTQUe2PIsgBp40o6qmLCG6oQsZ40PAlDEYUAYTJq31tc3NSMg8AAIRqNDf8axIjtTSpHGMU5rD/6J7URVVaytrVEbo4+HAznsaU3cFeAtSUMPhBccOXiAQX8FU4xpp4l46DhHlKSgBXgqjUEFAWGUbLh/TtgxzjHOcmIHqQ6JowS0FimXZ7rleeaNo6UeCQItIJA3Ilda0+70pL4xFUkcTZI/W21a7TY96yiKgjRJATk0j0bjRuYsa67BlFbeaxzT6/VQYYxDMaW0r90VcRxTFKWERPgkvDRJSKIIa8X7N1Thcb8Xn6ihT9TQJ2povu8a+nsGnuqUA4sVNpETalnNSnLgtX8yeuo4xcpU2KoErERQhpKGYK1rktbq+L9A+8QOP+Cdc56xJLrToqiE7bQReLKuof46z0Kp6cD15KoX4Prf5EY6aq2jKxyFfx3jOBLqa6gJPBDTuNOrjQ9j4tIvmlVbU4ZqZdwxoErNshLT8NqEfAJGTe4cPkkNz/qZPHBgAlRtBJw2gE5s8HNqdLrNM6wT//zEtlYKIIVfTD1EVf+CegJ7wEcpsEaKfxsYzIYXJebwlafvjsnHQ2yVg63QTHyoQs9oqnWu1HfDOQ9w1UWPgroD7yYAp3VONLAO38HzSLh/nfUhQ/5um46UV6VSm1yCdA2jOCFNZaMNgkieszuW7lvLCKvKTAzmrXQGoyj0dMPjH3jKs0J0wJFEXyq/IYxGhZiBZhlJHBFHIYk3tqvKCqv8DLWOLBuL3tzI2FKAcQblrHijeRgz0FBWMm4CF8mG5DdM0UKXFPlIqJsYWkmbQMty5OFBkUI6J34N3hOirEr5MGLK6DxQW2+idkPR7DZ0z6w11BGnxhjGlRETzTyTjqKeIYliv4l4YN0X0EpJ4eCZxE/GSv2axYZ/sNQ+baDAKL8nSQoWWqNUiAtC0VlHUTOnJXpVzF6dtX6KOJKkRRBFPs66woxHtLu+cLSGfCzx1UU5koOLNbQ70ygiAhSrRxcZDtZY2P8oxfoyqhzLXGw2TIl6DQJ5BlLkSFRqnQSkPd25zEcYU2JMSSsWE0JjDa4SP4IAR+UMyla+4RWIYWGgiQLpvp+2+2TMzh3eP04OSlEU+cSbUJ6BX381E2bn5NYfa1jpqDvxbrIG4DasA/LvzloUQvEPtKa2BFBPYvscj9dH/tenuOeO27jtxm/xkb/+JEtLi/zR7/8Ob/y5X2Bqepr//l//iKdd9Wx2n3I6X1s4ytzcPFs2b+Gzn/kks1M9rrj0Uv7hs58kK0qe+Yxncd23rmNpeWmDLObJTQDH/Pwm/v3P/Twf/sCfs++Jx1FK8YUvfoEvfelLWNEaUOQ5f/ye9xBGEVOzcyLN8MbS/+nqqznj1FOZmp3ljjvv5ud//ufZfdrpKBQPPXAfYaBJ45DZnTsYjMasDIbMzUyjgoCiGjGVJhhr2X94gW6nTRyFDEYjojAgDkMWlleIwpCpbgdjDWVZsdpfp9fpiFFvIGlOOMvMzDQrq2t87NOf50/e9WvMdFt85H/+JZu2bWOm3WJhzyPs2raZp1x4Og89fpD1UvwOp+fmaLdSNm2aIV9cY3V1nTtvvJM4jml32pxy7qkcXFzhjof3cs6OOQD2L/bZvDMDHXH/g4+Rxl+mv7Cf887cjbKGwBpufnwvvZkBT3+2ZjjKWF5e4ejyGmedfiqn797N1755Pb1WzObZGXILU1NTXHnJhfzd57/E4/sOcPGFF+BshXKWndu3s7a6xn33Pcj83AyttMUVl13C3sf3cPjAE7z8Va9hetNWkjRtPG6e3Cx5//vfz2c/+1miKCL93d/lzNNP481vfjOHDx/+jrFY1x01eyZNEt797nfzvve9j1tuvplffvMv0+t1+NTH/xeveMUrKSvDU5/6VMbjMTMzMzznB54n8k5nOf/cc7HWsj4Y0F9aIBsNOWnHNlYWDnHnLf9EpK8myzKe2L+P008/jYceeoiP/OUHuPjcs5ifl/v9kz/5k7zp6jf9a0y7f9ErH4/FK8t3musm2Gg4ZLC+ztLCEVqtlFarRbuDMH7iiDiKqNPiailUWYjMqSoLylLAFofyP1fWyyiMPKPByyWsxVQltqooy5w884CXZ0mBPNvAd+ZrewTnlQ1SVwvLSRgTtqmJjJmkEG9kT7oNDAqlJqa3WZYx8qzEVqvFVK9LO03E5sCbLxsFeSY1s8bRTpImqbJmZaWhAqWx1jGsm4KmQnlTZGcq0rRFGIakcSgSFucoK2GnFJWh3Y2a15wXJQSONErFC7UqWF5aYGZmhunpabJCzj95ntFpdzDGcOTIEfwpGe2qBpjpdLqkaUKnN83K0iKrK8vsefQhTDYCUzI71WU4zoUB2OlirCPLJepe6ZCk1aHIx96jy+E0WKsYr66RttsoHZG2uyilKY0kbY1GI88ok/OZ2GOEpGmLxMfKO6WYmpmh2+0yNdVDISBjr9uVsdduE8cxVVXR7XYay4xDh6om8TkMhcljbEWgRbo4MzPDuBAWT7fTZX0wZJxlJFFMNs7o99fYumULSSyH4yTu4qxlcXGB2JvlH8/XiRr6RA19oob+/mvo732W+0O9s4YiF/2hM5W/mdKRsJ6BZFEN46ksJRbVmIpuu0UYRyRp2tAJBcX3gJAHRFTzu8RLqiyNp/R6FpO1x2x4tWt8PbGsNQ2qXPnOTA3CNHRgaiKrarTHusjJ8oxAa9IkRoVaXPYFOqHmAzY251oQYJxCWQVqQk2sF5kGmqlBUOeaCdIMAFczjSavSb5GN5/bqLOVzlWt1w+OQVlrQEt4TP7zXt86Ac0E0NKhxemNqHHotameXu1Ey1uWuTdqt03RFFcJYZQQxREWRVmUjMdjRoMB4+E6xXCdKh9jy9wj2bJgqnryedTWoXC2PvS4Y2th5Y3SlfMSwoAatnPNTVUTxNyJv1PNdqrHg3MT7alS8ryVpx62O13anQ5J7KMglaI2oasXbOcX42Kjb5jffHHGbwjf80z6/9vV6XSo2WN5XgkQGIayuThQ1kFVYG3B+nqBNeKnZgLtwUFFUQodP9Ry8At8Ao+zFlPkksjjN65Qy/TAe31VTlJ9xPsrp6pyaulpVZZYJcCebIgSAlBf1o9hMRsufIdXfOQEFKyaub3RSL9myAloPjkwiUeXhVzimauqIvGduHYrIQ40oQ4IN3Remk7wk9D9BlT2m+UkRMDPRw9KC/Aphw0XyAbqsLiykHEehjgnKUO2yBowoFSKwGkCFaGTkMoZ8nFOmY3FzyEMPcU+YzRcFepvGKGUYzxcZ2XhKIcOHCAbDzH5EI1FqwAdJBPwV4mZqQ616LyDiCiIm8LEWEuYxMRxClHoQWjZIJWtqIYjhoO+j3WtPMMxIEpi0laHVmeaOE5Jo5gkDplO06bb33TVEFajsYYax5eb6P/iJuu4tRU1o7Ee0/JPMhbrVCWJH/ZmkWUhh/5A04ojoij20dVqIvE9jq+X/ZufILAlN1//DX7j197GJZc+hT973wf5yIf/J4ePLvCyn/4P7H3sQe68/Sbe+ra3c+cdt3Pt17/Ks668nMoYbrvrLp521bPoTc1yeGkFdEh/bZUXvvCF/NRP/RT/6eqrpWhSk/1mqtflhT/wbL52zT82r+M1r34NV199NQDf+Ma1vO1tv9rMweF6X3xElCJOU7pTU8zMzxMEAc973g9w7bXX8ua3vIXxeMz111/P7//e7/H5z3+OoyurnsWkWF8f+CLIcmhhWQoy3303lWkMjavKsG3bdqGVt1qsrSzR7gRcdukl7N+/j6XlFbI8954wmsWlFdIk4oyTtvH/fuDDzE1Pc9Vll/Hgo4/z+IEjTAWahVFJvjzijN07KSysjitaCJP3rvsfJWmlzHRSnv+0S3h070EeeeIgf733AKfu3MqrX3AVf/f1m1hdH7Jlfobb7rgbay0/ePk5DCq48Y4HOO+kzRxdWuXuh5/gbb/+mwRBwF/+xfvYf/AQa+sDqsqwf29AMeyLJ4t1rGU5nU6H8Sjj03//Oc45/0IuuewKbrvlRjbNTDM9PcUnP/13WGtI44i1fh8NJHHEuWefzbbt2xhnOeXCUYajEc+96mls27blO8bX7/zO7/ALv/CLJHHEZz77WV7wghewtLwsa8QGYLJeZ0855RQ++tGP8vd///c845nPxDnH0YUFAIIw4OSTd/PaN/x7ZufmeOyxxzaknwmg8uAjj3L9Tbdy+im7GQ4HfOKb3+DpV16OBn7+P/4sl1xyKb/y1rfyyb/9qBg5hxEP33sXYRjy67/261x2+eX011YBePzIEjc+8ATPPP+0f6XZ9y9zpUks9gDWiSTOTewgwkDT6bRF+rG2isnHjUQizzKRQQTiRxlFEdpZ8nxMkeeMxzkaiENNFMYNg6A+aDgr8ghTVbI2lpJmNfI+bqVPN5bvEVYRHlhsDHwb5YHUemUpDMV63cVN6l9rJ01MUwNapvZSkgQw42v58XgkLIMiZxhHxHFEr9OmlUTE3qy+yDOyPCcpxApjy3SHlcGYcS5N5dhbSWhT0gmhFYTk4xFJHLKpmzIuS2xeMswVaRIThgGjQgIL0iSgzMceDIy87DBnZW1NXkfaYnp2llYcSvJdlomxclFhZmfQWrN1y2YOHTzAoN8nDWF2doaZqS6BdqwuLfD4o49w5PAhxqMh+WhAEgXCvopbzLQ6UsdrRZnl5EWOdaqpd+SwJ/e2rn3zyqDykizLaWXi07O0uMjy8hKj0ZAsy+h0urS7XdI0JY4koSqOIs96CsAJk0m5GX9A9YdNpcjy0gONtmnkgiOKItqtFp12m1F/BVsWVNmIXqdFGEUEQUgSB02yta0KlClZH/YZDgbkw3XWVwOyKCIMI58AZllZXqbX69Fpt/7PTsj/zetEDX2ihj5RQ3//NfT3znjyg2zSaTA4YzYQgCzWerACTy30g1krhfaLGkinpzJC8XN+E5aOiGeOWEnHsFZMAstSAISqmlAB68W4ZvDU3kTGCP3XVMbLobwTu9zZBnTyL7r5s/aDqv2hKlMRevTYwcRs+xiEwW+uKPl376xfdz42/oaGRPQdN3byF/WkTzeSL/xBoPlhnlKoJ6yhGqyqQadGxtYMJIfoZuWFCHXaoZ0Fp6kpfs4pkY4pv+I5YZ1tlDFqrwvWOsCaABDaaJ6PKbIxpe+iWc+MU75wlRez4WbU9MonJRc2d2Mjale/15oN1kz2Gtuf3N/J76uHprynenGzzhIgkZNRFBNGob9n9eT0Y8JZnPFdAGOkU+glm9bT4TUOgqChpB/PV+S7pqYpJmROSjdROl4KT6n3hwTZOHUzOiXKWVoWWkEk7odU1uCMw+Gp96ZCWZHZqhqjc97M1CdY1sUMaE8FlgTKytYJHhPfDudoaOSmkRXQzO+NppSNhNdt+Gae9ClkuFTG4AoBKcswJAxDrLO0k5gkCghC3cy3uvmyAUU+5qc2I0CBcnoDuLxh3VAb/u4va00Tcex8l8lWflNQGluVzaFBJXG9S1D6hJoqCChzicsuy4JAy2GlKgvGoxGrK8usry5Q5jkaK54bYUjDctzwUbMYgrBOj6RJl0SBDgOSoDXZD/xeUOZjxsMBRZahFLLxRrF8xDFRlHiZtdDTo0A21aBO80E84qy1vtvkBOfXUopIJ9nH+m5Yyzd678kYs56i7D39qjp9qaQscmxVECqF9jG7NvAeboH4EBzP1yknn8RFF17As5/zHMbjjCAIKMuCJE2ZmZlmx86d7H/8Edb6fYoiJ45C5mdnicKQoihYHwzIs4wkzRlnmRRs1nHH7bdz4UUXcf9DD3Pm6aezvt7n3nvv5eSTT+aUU05h09wc55xzNpdeeil333M3W7du5YrLLwelWO/3ueiC83j0sccZjUaEWIwSOQCelRr6Lvbs7CyXXXaZvB6tueyyy7jqGc9gcWmJB+67R7ruQUCSpjjwRrSgXEC7LTKQOIpZXFokbbXpdLtsnp8HpcjKkjRJicKANImJIomfVzicBeOsL9DkwLu2vEpVVqysDRgMR2RZRm+6g9UhldMQxgTGEuqKcSY1SBSGRN6Hsj+Ug3egoD8Qyd04yyXgpCzJ8pIiHzdrRFkUjEYFRxc1hdVs23UyURgyGg544oknGI7F16rdblGWJUsrqyglr3U4Ftmcc7Cyusp4PEbrkLLIWR8MqSrDyuqqj0buko3HBFqRRgHdbpfp6RmcEilMt92m3W7R63SY7nW54/bb6ff7AJx11tmcdtrpRFHIxz/xCW6//fYGbFJKcfnll9Ptdpv1dffu3Vx++eXccccdJEnCTTfdRFmWchBzksCzfccOQA5sz3rWs7j/fkm3K8qKcZaxvt5nbXWZsqzotFvyjBx0O11in4q12u/T7XTYNDPN/n37mJ2f48qnPp1Dhw6xZ89jREnK448/zre++Y3jHngSw1thxcvapZqiHwVJkoA1lKYSuUclvhvSGJQ1sarERy2MIqqq8NIJ52vxideoArBy6LOV1C+1xEfkdfJnve7qGmByk/AUY0xz0DQ+IVp+hm/qGkOzy6mJVyf+/agNe6Ws4xZtvZfGxt/hYOzZWGXp2R04AUrCaKJq8K8liWSMGevkLOF/VlFWkmQXBthK6g+NBV+fWBTKhWgVEvq6TWsl9RxOZHROvt4UGVWoqby3k/EpgcLGErndcL0vzdgw8pI5Q6BDwkDYAEWWMVzvs7q0wMrSIkWeoZ0hVDFWy+E98h5ceVFIHeNE+heGAeATtn2dVVf7cSRrnNYKa2TNKfOMIh9T5Jn4dXUQw+C0RRQn3ujbp1x5oE7hpTO+Ppd0U/z5TJiiDlBajJDbnS5Jq0UUReSjEc6UuLJA6y5KqSbxzVjrpUrCOCmLHFOVKAREtFVFFZaUZd4UZaKKOL6Zxydq6BM19Ika+vuvof83PJ4msitVQ2Q4XFVhnPXG3aI/roEn8WfyG5qpKLJMblgUCaDkB0xljBimVSU1HRg3iYSVDc56hpRtmDi1tEpAgtoLyjQSv4m0rAacNgz0+v44mkForcWUfkEsCgLnZCFx4JzydEl17Ozw/kjKs5/8c/UPcaOkzgNHyk/XDfcQh4+B9P/EZLI1Zmp+U5dPT1hK6EkEbKBqemUDxciiaC0o46lw8vqdlzrWJt5Yi3HeA6tmI1kntGQr7DZTd8W0gDZBGKBtQFlVjEcjBv1VBmsrjNbXqIoMZyrZeNDNBLO2NkuXhVpteH80t8N36XyKoixW4osgBmCT944/5Gwc7lJAOQKviXa6BitlwbbG+W5LQpKmRJF0XazxmLuZAJxVWXhPA5+a6CNpqyLHWUOolKRABcc3RRgkYtdajTIWg2eCGSkGggCCJETZEmUhDhVlpXDGospKADsFthTE3DiHCiNCJfLJwvmNpxSD/6os0D45p64xa6N4Y0oqZzxGKw+4KAqsj3q1Tjo1hY9WrgXytXy2MB7kRj7Hk6SRG5ol3/WqZaPgtd2lbNhShGmS9YTpqSm6nRZbZqbQyqGUaTYYSdHYsFJDA6YKWBxMwGE/Mh1gVEDg2ZMypuXnmcqI35jX1DpnMVXRcJODqhDPNBWQJDHae3aMsqEYiWYZ1no9u7XoVkCSpJKktbzA4f1PUOWZFLRRBFoTGomCrpMvQTaowEd0B0GdDilMz1GRE9kUqxy93qzvnEmsd1XmDPurrK8tkecZQZQQxAmtJCVp9UjSDlGaEsYROtBYJwk8VlV4PbPvIBZkec5oPJJCQmuSKGkOMgonQQWBzH1X3/4Nj8B5pizGyI8OZXNWTlMVkI+HFNZSjgNanYo4TiTpIwqbtJHj9dq1bTNvfP1r+dl//3ruuOs+brrxBn7jV3+ZN/3ir3DGWWezf/9ekiQmr+C//el/4SkXX8SrXvZv+eIXr2FlZRVtLV/9yhcJwojdZ5yFKSWRJi9LbrrtDt793vfxh7/1Dm6+6Ub+zb/9t1zz+Wt4/vOfj9aK1772tVx11TN48Yt/DJjsUeefew7v+s1f4x2//S7uv/9+5jsJq0oxzCWdp/J7RsM03tA9Ncbwlre8hVe/+tVcdOGFmKpkKk055dTTsM6x2l/HVhVBGDIzv4nTzjib3tQ0N91wPSedegann3M+oRlz9PBh7rn7HubnZjFVyWN792LKik67jSlyRkVFVhpO2rWD0XjMI3sP8ZQLziXQiv/12c+xc8s887NTpL0pOr0uvU6bQ/0SyjF6vMYDR0ekacpzLz2HpZU1jiyu8Ndfuo7dW+c4ZftmAq1YXVvnf/7d19g932VLL+WR/Yc595RtzHRb3Hr/48z2Wkx3Ur5xyz0867k/wDt/6c188H3v5f7772dheQ2AVivl/HPP5uChwxw6fISZmRkqY1lcWuFplz+FXrfD9NQU37rhRo4sLHL26afy4CN7WFxe4eRdOwi19vuto5OmnH3qSczMTBElLYL2FLtPO50zTjuFMAyZn5niorNP55d+8RdYH4os8lOf+hQ/8RM/AWzYj+VhoYOA97///Vxy8cXfUfT/3M/9HC9/+cu54IILOHr0KFB35UsfzqE4+eST+fznP89b3vIWPvLRj7Kwuo7WIafu2sE9dwuY+bqfeg1/97lrGAwH/I/3vY8PfvCDfOyvP8ZVz3oOu086iVN27uR3f/932XXSybzmp/8d//7fv5HrrruO6U1b+PI//h2f/Zu/4m3/8fX/WtPvX+RSyskaG4YEG3xKV5dznLVM9XqMNeSBwpal1FblmChpYVHk2YgwCmm3UqanugQ6EIlFoCgrYSOZxuy1Pti4BnSq0+/KovTd7AkrQhJ85dnWTJvatN35Wr42p66NiY21jWFuGIb+UC71k3IK52swlPJWGOCUJVCB7DdKEu5KYymKnBECPgxHI9qtlFaasnXzHO2oh+p0MdkAHYgfaxgGYAQYGeYlRVkxHOdMtRNaiYAyDsdgmPmwAgRsUhIv3+20Zf+vKjJTinICCJVCaYsNHK7MKLBk4xFZXoAO2LJ9F04piqLioQcfoCwKZmZmUKakk8bMzkwRxwllVbGwsMhgsM7aiq+Lq5I40JTesws9pqWELTAajzHGEkQR09PTJElMoCGqk+uqyq+7jpnNmwQIj0JcmQtTxhm0E3mTqSqCMKLV7jI9O0en2/Ppkx5w82wRaSxXTZPeVlVzEK3LKIsmjBNa3R7bT0potVpEUczSkYNoZ4kCRRTHoDQrq6ts/GYdaOIoEj8dRJKbZ2MKFFEkfoBBELJ582ZRHtTpqsfpdaKG9v98ooY+UUN/HzX0935a9qhcfXh31kfpOStaaufpoNZT+nyHQyabgANFngutLYllY7Q1+ipyOFubhDc+Tc5vllVjaFgDAtZsSNHwwNPGTU9YWccWuxsHuKpZQn721JK9qiwknUApXCou96FHGAVEqpGQjT8LAXDqn9cgRxPgaSNY5X/zMfyeukOE74LJz639kOoPD8roALRIz5QOGn1nzY4S2aLBGagQA8ogFB2paPYlpa9GNSfIl8UYMDWoaOuY3MIzfiqvHQWcgHTOZaLVHwxYX11mtL5CPh7I+FAepNKTiSmRi/LrNN7cbAMizoZJ0NyxuuOj1LHP3N/c+r7Uz9d6wI96A3XOs5Vk/KgwJIpi0labOBFPAVNVxyxyNaQY6gCNajpwgUbGfVU2KLaplCxwx/mVZ6NmqNVzpSyEdm+rCldVBBgCZ8BVPg3CyTRH9jcV+E1Dayrn5YfKUVYlVVVgK1kTQtUguphmbjqMszjlCLwRZw281gVV/RjruV9LG5WbzPEJPF/vVRPD/2aus2HKfZerQfrthpRLJx521uYoBpRFSRQEtKKAJAwJAp/GoTTOGTlE+LEswK9fI/z7ano4fuzWMc2W2qjeIiELCmccpSlwfkM1VvmfY6mGfYLKEhiHiyJPA5bEEluVjEfrMpeCkO7UHEEYk2cVRw8fYL2/Sj7OfEEgK05VCpU3DDVB2CIIJd2jjjWuKdcqUgRhhA4iEiO0XluVVFXu14OCMh9TFbl0P6sK7XxyRxQTJC1UmKLCROJba3PovKC0FcpJugi+oMoziQm3ZSmHCwXaGWo/QOsslZZNNwi0dFUrnx6jVJOepENNu92WtRDn2T8xcRiSBLoxv44TKaDjJBVD2+D47rb+7H/8OV70ghfw6p98FWsrqywvLbOytsa999zN0aNHufuu24njhLNOO5XpbhuHGI4/sW8/1lrmZmYY5TkOyMZjlNIkaQvWBzzl4gu5+mdez+zMNDXV+l3v+l2++tWv8Pu///vMzMxw7rnn8OEPf5hTTz21eU1TM7Nc+JQr+YM/+iPuvONO3vnbv0nuI8frqyxL3vKWt3Do0CEA7r33Xqqq4tWvfjVveMMbOf2MMzDW8oIXvYhXveon+cSnP8soL9l+xgynnLSTQCsO7N9Pt9shDjUXnH8+xloOPHo/h/c9zmAwYK0/oJUK66C/PiL08eSldXTaKbNxzOLiEgCbZ6c4dPQoU50uP/TsZ/DAo3t4bP8RokCzcHSRvLLs3DKPUlAUJbt3bUMrxa33PUqiZS8555QdDEYZdz+2n7KqCIOAqW6blVFBoBWn75hnqT9kYXXAqTs3sbw25PEjKzzvuc9iy5ZZvvmVa7j/gYc4eHgBrTW7d+2k02nz8COPEWrFptlpVvoDet02O7Zs4p9uvg2tAzqdNkVZEkUh/cE6eZ77BVOk9ArHKTu2MT09xfzW7aSdKXScEoUhX7jm8zz+2CNM9Xqcf965/Po7f4+VtXVuv+MO3vWudwFw8OBB3vrWt3LbbbcBx66ndVNPP6m4/Ou//mu++tWv8sd//Mdce+21fOhDH+Jtv/p2nvOc5/Br73hHA1RprZnq9ZibmebRhx5iMB6z54m9XPKUy4nCkC9/7VrOOesMpns9Du7fx2VPeQqnnHIKhxcWWFle5tCB/TzvOc9hdtNmHnl8P69/wxt5zatfzfT0tCQaV+W//KT7V7hKb4A/MzePtY7BYCDx5pkkKytr0ApW1/sCEFUV47yU+64DTJmTddp02imV31fLsvK+S1VT09bAAriGqV1VhiIvmmcZRWHToQ/9cy3LEq2U7NsbmnDGN3Fr7w+ldWNaW/uHCAMAker52quu3TYyKpQ61tKgLkyc82yZkQBceVHSaqVMdTvi29Zro0xFVYyJ0xahtehAEaI88ygkiTRWB3jnWwDSRLrySisqpynzipEZNGBaKEgdRZZLxH3dhKZClYZwfUheGcrK4FQgIE4c46oCU2aMB2ty77UkbRXGkhUjDh89SuGT5qIo9iqBiqKcGDtXxjAajXFapH5pkgpQFMe00kgUB9Yzj5TUHwojTM5SJDHj0ZiV1TWyvMA66E1NkyYJSik5oFpLGAQkkSSACStKfL1qqwgFDfAkxulKpHNJyvTsPEmry3A0Ek+xIqdmM9WJhUprSSlEgMF2u+3NlGH3ybsZjYb0+30GwyE4ke2NRkPAocOwSUc8nq8TNfTkOlFDn6ih/7/W0P8bjCczcWI3E+BJO9MAFI1huHETIhFIUoMTGmcQaKLUo9qOYyRc5kl/Omsb4MmaDSymDTTHmmK2sSNzDMvpu0ym+lLNn/7neIpaCeT+AUdhAHG0IU712O/d+MOUpwO6msWk+M6vV9/xbbJQ1CtHfdecsHbUxp+j/MautWf+1KCOdEwm9EVP64MJdc4XChqFCuoOtCycspn5++TRTtcAeF5iVn9eKeHEWiuJKFXFeLDOeLhONuxTZiOqMgNrPXJNw8iqExacQO8C/yvQbEwkEICnfloTw/OaBfUkMLG5ixPUd+PVSDk9qOmcI1CKIJQ0u8Cb1dUpTEpNIiVRTJIrtKzm8rUVNgjEi8yIx9d3GV7H3VXmuQB1qIl/V57LxmfE2C7EYLEoxPzQGMB6ZLzx2hKJozGG0jqcslSmxJoJVbwuekXbbHwggMXUW4mSn0H9LJ1t5nFtbFevCxOW5WSzrNH7+j83pk3W10Z8WKbmBGSWP6GO720M7n3XKctzrHMMRhm0UqG4qhCn8L5vttmIVLAh6hW/aXp5r9D3xVxQa6Egy1aIf2+TMW2sEW8HZHpoJewFV5QEVhFYIBQPDOIIW5WeZl+IIWugaLW6mKoiyzLWVlcYD4eUZUUYhBDI3FJm4lMmnStPafa04fqAYHTlGQtiWlibMJaFbJpVKbH1VSH0ZGeFq6ib8ADddMerohBfQN/5LssC5yqsp5k7B3mWU8u4dRA1kbv1kmlsnZ6ksNZ785UVxnkWgdYEgcxfkVlNRoJW0iPTSOe4KEuiOBa/lDhunuHxfH3u89dw0kkn4Zzj4MGDLK+s0Jua4fChQ6yurvLEE3s4edduNm3azKbNW8kHKywtLTAajUSuA6RpC4eiyHK6nTZRoFhaWmL71i1cedmlx/y+6667jqWlJd7whjewfft2ZmdnueiiizDG8Oijj3LyySeTpClbd+xkx0knMzc3z6++/e3HHDBXVlZ4+OGHueuuu3jooYeOMar+9Kc/zbnnnd+sJaeddgYveOGL+MLXr8MORsxs2sKOXSejFayt9ptu2sz0NEtLiywfPcyhgweoqgoVhBgrCXbCsg6aPTMMApI4ZDgaEYUhvekuw7ykTA1zszOUxrLSHzIcDFkd5qyMMtqxeCcOS8f2bbL/HFpaoxM6QgUzUz0G45zV9SFxLJ4pWiuqSuKcW0nI6jCjMI65Xofl/oj+qOCCC86jyDLuvftOlpaWyPOCNE3pdDt0Wi2GozG9dkorSYVt4iRq/eE9e7HASTt3UFnrD3liYtxKE29pEEik+ew0M9MzJK02KohwSpOmKf1+n8cee4xAa7Zv387Ok0/hyp076fZ6ABw6dIh7772XT33qUxRFgdaaXbt2SdxyVPuxTNbYoijYt28f1113HV/80pf4gz/8Q/r9Ph/84Af56le/SlEUvOpVr2L79u1EUcTevXtppSlnnXkmK6srDMcZ4yyn3emAcyyvrHD6KSfRTmOGwyEzMzNMzcySlyX71tfZf+Agz3r6lbS7Uxw8coRLLryITXMzOOfodtq00vRfZ+L9C17WSCMvL4pJY6/IG9+yojJEGrDOp6BJ/VuUFToICWOfaKfw1hM++dk3BstSVAN1k9TveDjrvKGxMB4alpMft2EQNilcdbO0rreamtxNGFp1bQcbUp2Y1KliP7Fhz67/VTVf1RxUNx6eJxK/SQjQcJTRSlNUENBqJ9gyZ1wWYihsZE8IAqnVwjiayOf8e3FOCVPAp6zllSRjm6qglk214xAcVNZRVDUz3lBacNoSj8aMc3luqTff7nQ6Avh6mYxxikBFOKUENMsz1tb6VGUBzsmepBS5lXRuYy1hKCC9CirSVocgCInjeEMjuXmCxzRynWebWZSAlnnujdqFodZqtQnDSFgQ2ZgiTQWY9fda4tBzjKkmkkOlJiCClRpdBY4gCEjTNioIqazDVqWPmd+YoOgP+5URQ3zEXF3qIk2r2yGMQox/72JUrRsPsdqQ+Um8m+PuOlFDn6ihT9TQ338N/T0DT9l45DctYSgJNaZEY3ycvJU12ImxoMUf1kVAjHWW0XCIrSpanQ5aCSruauCpquQG+IjImvVUlsUEAPGGzvVGVW+CG1kwxyCwGxHeemp4Vk0zvVyN7Dishdw5Kh1QFgV5IpGErVZK7GlkUa2n97hqDZX4bXoDsPRkz6bJhG8mV/0JNhiW+08pBdqjtaJ19eBLIzXbwBJishg4LBgfjYvysrgQG8Zinh0qH+Urz8vkmWgz1YaNx4hppfG6Tnxcog5CHx/qKEYjykoSEgZrK2TjAeP1NapxH1dVKOWagkR5ZpbSGqc0NdfLWofoGOtOmZ5ovN0xd62ZQI2xN2B1IGboSompmQfrJmNE4odNWZJno8ZkNvS693an57W1mUz4mrbuN/5AKwIf5w1C0zamItKKOAgwlaH0TKnj/dAKMBwMBM0OtKfMy+JqPGCsygqtDVoZxvkY6yONdSieK8Y5Ag8oWizjsmJsLBESV4p2VBsC/mrWYV3oimmhbja4JzMYG0+3SqjGzlRNEUw9b22d1LARZPzu9146Mr7AVsd26Sed1o2XbhIPjbFkWc6RxWWyqWkqQqbbMQEQuMqDpeC8zlo8z+rl1IGrfIfJykqgNCqKwVTijYf4vuRFiXFgcBgHeSld6TzLSeKIIFCYskDpdXQQ0ltZJooikiQiTBKckuSiOGmTpG16vSkOHzrAwYP7OXr0KKYy4gfjLIGFWGmwsiznlUMZh7KuSUwJdNAUL3lRCs0+DEmTVO5nZVhePCpU77JoOn91zLAO5XBkTMlwfZXV/jpJmrLY7RGeezadTocojKiqXOamn7LKOsqibNarMEwIQtGNBx4orzJDVvtX1NIIY4iSFnGcQJJQJ4vIWuEpw1Zkt0kUEwXi0VAZKQh0EJKkrWOB++P0UnELdEhZlvz5n/93oqTFO37r9/jYhz/Aww/fz/kXXMrCwhEOHj7EmWeeQW9+jmTzLMP1ddb6fQ4fPcoVT30maavFbbfeyAue8xxO272bX33nu/7Z33n/A/dz6aWX8t73vpcf+7Ef4wee9zyWl5YIw5AbbriBM888kyiKvmtjB+BDH/oQH//4x7nuuuu48447+amf/qnJ+1GKP/rDP0BrTe6NLEfDEe12j7X+kIN7HuHQw/eilSOIY7rTmwjjlIWDT9BfW6O/vsbMlh200oSpbpvHH99LmY3Zsnme0WhMkRd0ez1GoxFLq30JJKFieX3ImWeehXWOj3z6cxh/CDq8NmaU5QzHGU8cXCArSpbXBhw5eIDpXpetu3Zx78N7WF1b57QzTqfd6XDGDsXMps0srfZ5aM8+nnX+aTjnuP7+PTztorPZtXWe0WAo/ijdHs993vO59dbb+OJf/CVbZ6fYvWMLvfnN7N27n3GWceGFF3L40CEOHjnMzOw0zjoe2bOXqqqE+dFpsbi4RFmUtLd02bFtK+0k4sbb72Gq2+bUXTvozm8hSFusrg0odIuZqMVlp57G83/guZy0YytKKT7ykY9wxZVX8pUvf1m64Urx5je/GaXkIKuUYmp6ir//+79n165dtNttojA6xjx0z549PO1pT2M4HDI9Pf0kkAGuv/56LrroIj7+8Y9z2mmn8YxnPIPf+I3f4GN/+3H+4cvXMjcfctkF5/CxT3yC7du28wtXX82v//o7OHzoEP/jf7yfv/vc57nl1tv4uTe+Hq0C9h88Snd6nrwqufuuOzlp22ayLONvPvlpXvKiF/CMp13x/U2w/wNXv9+nKCVWfjgc4fzaGUYRSZygseTjAfloyHA0BOQQEITeuBak1q4qxuOx319qdoOhKgryIhemUc0Uh0ZmVzMT6vq73lOLKm8ac7XMQsp379emJAQGmByKXO1d4gCpg2q2TG2Bgd/ThBnj2flqEj7EBgCrbrTilPRVlZgWLy4ve+BF0043gwqxYYKtwNiKqixJk4g4EkYgyFAsjBxsA1WfQRxFZTEKjJL9bZwVZHlBPxCD4SSOKEoB8AajEQY5/I0K23jrVEVOq5XS7XVR1hAHiizPids9oqRFUVkG6wP6/TUWFpcpPRNv8/wcobeJEKaiJU0TAuTe9Lpdf0hFUvKco9WSJCuRFoYkvlm63u83DDbnIM8L8rygsoYwiOj1uiILKzL2PfYwK70p1leX2X3q6SStljCRZPMmy/NGGhSFcjjWgfci894/SmsCHYqMryyo8jFREBCGAVEcC5hUSD0XtNsTYFwLqBCFbXrdrq9dUobDEcvLy3S8l1vt2Zce5+DxiRp6cp2ooU/U0P9fa+jvGXgylUSnWv+BteLgjzeltqLftk5hnfZm2w6sGG9bayk83a/Ixii8VtIvbm4DuFSzqqzz0juP9Hpok/pH1x2TekLWm95GIGrDFJL/bzY7Aa5kS6r/7gGchsLnPZIUGCPAU+W7A4FWRD7Rb4Lg1swX/3vV5K+OjZiUO+Y1HQMpU3ebVIM2OyVoYwM0bXi40t1SOKuocw0lxa3G1FTjmWXKBFBorxl3vvNRU9S1Ly6cs1RFLhOjKhspn9CEBdkvy6FsdkXOaH2NssgosxGu8rGgHmCSBU9go8YfywNS2ifcybtVzefrrtmxQJy/N07eszNglO/gBMHEL6r+Lv+Xmg7r8FG+gUzKwH9UZeVZSw4dOFwQEDTsJ33MM6snIEihoELVOPnXHb/j+crzTCI+A/lwOIJAqNBOuSalMlCKNAqpjKOsTf+VQmNxldzLSkzcUM5ilG3AvrKyDSW4pvbWBWsNHNbMxLLwckUf4+qc9V0dg3PGz1/VdGeaOe7RfbehAzsBoye/zylEexwERFHiCyk3WcsaivCGTpC/6nlcFAXj8ZgoCokCYTsEzhJq5w3lZX0LnCJSHpRWgBNwV1nR+Dv861QaFSiv07cURckwLzBOOjhVJZ53eVFSlDL3asNKrUsCJ2lVGulgqiBARSlpu03S6jAcDVhZXWZxaYHcewnU5GTjwJXGm2BqDDTJNSDj3YZOcgWcaPddwQZvPSlu1gcDL48uhWKMB5EdWGVRRYlzA6HjqwCbR1TjdRanW5QzM8xt2oJSmjCICOrFXDnCWDdAtVMKa0Fhm8Ou8msKfjTpICSMJCVEe3+RsiioPCPAVsbLGkrP4vQGt75zF/hI8zAMN4D4x+81Xl/lG1/7Cr+Zjzhpxw4qY/jc332KKAzZtm07hw48QVEZOdiMx5jMMabi8ssvY2FxkZtuuY1HH32YVqvFKbt2snffPvY88QRVVXHLTTfye+/8HYZZzoMPPgjQNGmyLGs8XYbDgWdQaf7sz/6MZz7zmbzyla/8Z19zXZjHcUy0AcQHmb91mhbA9dd/i9/93Xdy8223056a4ZzzL2L56CHybESWFVRmEYClxQUK3zGMAjHZ1Dqk1W4RBJokjmn3ZlA4zHhAYRyFlcZBUeQMhwN6s/NgLdvmp+m0U4Ig4PDCMmGgmZ/uURpDGARs2zSNrSr6wxHVgUPEAcxNtVk4elQaLLaiCmIUjjN2bmFUVKAVZ5+yk6mpLgQhmXGcd+HFXLV1F1+45gs8+NDDOOfo9br0el3arZjdJ+2gMhYVBKSthOmpLmVeEEUhnV7Py38c+w8dIUkT0jRlfbBOFECoO5yycxuVMSwsr6Cf2Eu73aHbm2bPwXuZmTvE61/3OrZu3kSrJalRV155Jb/2jnewY8cOVlZWmmel/Nx40YtexA/90A+xc+dOer3eBFx0AnAEWjM/P8/b3/72Rlbwp3/6p3z7299Ga83VV1/N9u3bATj77LOZmZnh7W9/O6ecehoPPfwIo/U1xjiG/VVO2X0qpir5iz9/P51Ol927T+Uv/vx9DEcZ3TThEx//X6yPxqwORszNz2GMoRVH5FlGt93m+c99NvsPHuQDH/4oP/O6n/6Xm3D/Cld9r3QgSXXGe64YK+OtlcQkcUyA+D2VZUlZWaJQ5CFREJBGYl49Hg0FqEC8dAJfi1jPhlEIo0mICJNUQllyLVXpJqm/pg6XkWfcKAdqpk19UmVSZ1lkLNR1ttbas6Ns83V1uID2Zug1w0JTs620eGZWlRy8/J4OvjsPBNoyGo1ZUiuEWhGHAVGgyApfuxpLYB3aaVxt7K0UlBsP5bapE7RSBLpmeFjKqmQ0rogjWZ/kUGUZZSLbQSkqYwkDTaiVNyT2Ej3f5bcEdLpTtDodqqpifX2do0ckRdIYiaEfDUeEYdAARgCVcU3ztCgKAmPRQUgURuLRkxdUWvbrKAqbg+VoJJHvVVURBML01FoRKQH3RsMBcRQT1il2OExVkGcjAq1IWm1arQRrY5HiGTlrTdYAnyjtx43UNFb8XTKRBoVaEUcpU1NTJEmC0tof+MXg3PjkRGsqRkORNRZFRZbnTaOh3W4TxYkkcfmz3/F8naihT9TQJ2povu8a+nsHnsxEeuU8qlHrJ4USZ72huI+7bzAVGZQOKCtQzpKPx+gobtJu8OBRvfhN5HwbqYIbB7ZqBno9SewGAGoyEWrOzJNR2RoG8ptcg2/4ialsA57JgBK3+FBrjN/0wzBARQEBXkKm3IbHuYGrozb8yg3/OfnCY19bQ492x3yb/3KZpE28LVJANGQ6p/z9phkkTtU6VwEPlQ4ETAv8AmKMB14sNWwjTLPcM54KgjAEJGHDVDLJhoMh4/GYfDwmGw0EkKpKasmeoN7el+kYbtiEoaQ8y6mmFCt0MzEm49dN7l39OU9NtaaiBtqU/30bB77DNZTpuvCqu4eBL4ZMLRv1v0A1YKN0+urED+fli9bT+rRSEueptZdZHP/AU5FnHvALiNPYLxzegF1ZjNZoZQVUjUJyDKWtcBhwAoVaL3s1xjZGpCaYzMPau6CqKhpI0XdOPZLbGHqWmY9FN2Uzd7FgsYhSXGZ6LWVsNkg7meO22TxdUzhLgqM86zhJJNklbslGbC1FDlr7pExjjp1kfq74fRpTGvI8ZzwKSKKAUCsCLLEv9PGpFSgIG2DVL/DOz0MPlpqm+Fc4J5TzoqwYDMfSMfMUXWMtRVWRI8V8GkcetnVoa8ElRKECcoIwJo3bxGmLKG2xtrrCytoKyytLlJWhNnFUzqL92hAoH2ft72ddnEvHOkIj31MniSqlqKqyaQys9/u+02aIk8h3sqXLo1BQKEwlUcNxFGMLRTXWrBxtoUzB1NQ0OhLpRFA3HrQjFPQYpYINa75FE/jnqZs1wynx9IiiiMh7WVhnG+NOjfOpUJVnzfomhd8s4yRuAhKOd1Px+koDxR3fvo1bbrqB//SzP8tgOOQfrrmGq575HGamp7ntlhtJe9O0Oj3ybEyJJcBy7tPPZvrQNLd9+w4O7t9Lq9Xi3GdcxR333c+jjz+Bc5Y7br+dh+6/j6wyjVxjkozqmjW60+4wHAzJ85wPf/jDLCws8KIXvQjnxKvmyVeSJExNTTUd2idfrVarSS+7++67ueWWWwjCkAsvvZzdp51OZUrWVpbJ8hWK4ZCqLOj3+8JMDUPSWOKbQZOm4jeQJG3a3TZxFFKuLUKcQtyinYinyJGjC8xt2YYrC/JN08zNTqO1Zt/Bo3TaKVPdFstrA9I4YG6qw9HlPuOsYG1wlG3z0/R6LR7dv0BZifwoiCNmux12bplnoT8gUJozTt5O0unidIDRIeecfwGXXHkVv/G2t3Dk8GGR/E1NMT0lXf652Vmc0hxd7tNutdAz0xw8fJQoCmm127IGjcccPrrAybt20Wm32X/ggMSyRwHbt8yzvNrn8QOHUEHA1HRJ3JnmkUcfoXO4w0yvTZpMgL+LL76Yiy++mH6/z2g08kBYjziOMMbyohe+kDddfbUADB4grItLa+VwOj8/zy//8i8zGo04dOgQV111FYuLi4RhyOtf/3ouvvjiY571m9/yFm6++TbuvvsesuGAvCwpKsOpu0/h4IH9fPoTf8sP/8iL6XW7/O3H/pILL7yYk07azTVf+DxJp8uWnSfRbrdQCqZ6HcajEXmnw1MuPJ8PfuRjfP6LXz7ugSdjKg+maIoy9+lS/gAXhnRakmAUh5rpqR7D0RgzHIvcMQyJwoAoDNA4hsOhN3r2a3AgjPGNDVjY0LTzB4Na4leVFWVVNv/t3KRmbsKEpAvoG2vesgHf+LUeuGJS127cS2rvnzhJ5fXHccOqChUkcUwcRwwGykeZF81B2KF8k0/28ywTE16ceLbN9DpkuazvWlkiKxJXOZSKgbYBqlL2+GoDO0MphfYbvDXicTIYjkmSiiiUxnJlDFle+i6woigLWnFEkMTeesJQFCVpkhCGEUGa0up06HZ7LC4ssN7vs7i4yHg8BgdBoBmPxz6pTu6vUorKWiKkXiiKAh1YgtARJSnWWsbDoRwcFVgTNSl+NfBkjABmOghECqQFBBkPh7i0ApfSaiVy8LaWqiio4piWgihOUEp8mQQIEsln3ZjH17Z1SW2tJRsNxZOmLAh9emi70xVzceSeDodjn/xcMlhfJ8vGZOOxsHG8WX1lDEVZEviDr5xFKory+K6jT9TQJ2roEzX0919Df+/m4q7WY2pJcLMaHQjCrpySLkcNQNVggaMBqqwfMM6WrC4vMj03T9LuEEWRPAAnrvS1v5Dxfk7HFKtKNZOj7shMDMUnwJOM/e8scjd+/rv9e+0uJAwihyuF4lhWYraotPhFhGFAFIZ0WilxGJLGIZEW1pMU2BNDcPm5+J9bb9CTDVA29AmaDapZjMBLyJTCqQBXC85qtEzhkWlPnXTyOevwgIr3WfL3scwzAQeVJlQInU6Bs1WDvtb+Xcb41EBnRYftwFSVbFB5zurKMvl4RJ6Nm7Q7rSAMQv9zg2PZQH4DV545JYNVjMyCIPJab93gcM6pY1heG2N5nZ9othRDerTCmMqPzZru53xqgMgOVRCgfOxtd2qaVrtLGMUNuyrQ0pHTul4wqskYtKaZfMYXKn4nIIwi4kAfI0E4Xq/R+hpBGInJpU/X0V4y6IwFLFGgSUNNoDQWA0WBs5UfvZrKG1XiwIXyjKs6rrk0VLaOkLU4z2gLGjM6S5GPJIq5KKmDNBx4KhvNJxwK46z/nGvWAuvk/jdMR9+JDbT2Gu2AKG2TtjpMTc3R7nalq1qWlNlYNNVZTFWVlFUpdGhjm9f3ncuCEh+z8ZjYF6UaiEPRQJfGEldOaO34okNZKTCdn4u+c2uLAlAY61gfjciynHFZimlpKcalQaDw7H6005IM1HSfHOO8wFiwaNIkoZVGTM/OoVTIYH3Et7/9bdbWVhkOxt5TwmGd8QcSJR1WDaGztG0lz9aGTZeorEqJs7fSZa58V3U8Hjebq/iA+ISMsZ/DYYByIs/oxilhu0XSarNp6xY/rwKqYsSov0o26DO7tUfS7mCdoSplvdG1AaIVo806bSUMYw/uhgRRTKQgG1VUxmFshVNlw0KtvFdKnmdUZSFxuOMhRVlr0lOSVsrM7ByJbRE65X1Xcqrj3Jz43nvv5QMf+AC/9Vu/xQc+/FecccaZ/OzP/Efue+gBDhzcT296BmUNdrjKiiu5/OILedZTL+cTn/wk+/YfYJwXvPgFP0grbXHN169Fa822LZsZj8f0B0PWhmM++ld/xZ7HH+et//k/EycJcZLQm56m0+2xefNmrrvuOj7wgQ/wnve8h/F4zD/+4z9ywQUX4JzzqTrHunS8/vWv51d+5VeI4oS1/nrDiqivd77znbzqVa/COcd//7M/4w/+6A8xVcXObVt41Y//KNfdvJ1DRxfp9/ukaQtrDTfecANTU1Nsmp9nfssW+ssL7LnvTnRnlrTd5bQzz5HuZFmxb99+5jfNs2l+jtv+6Vo2b9/JT7z41eyYn2Fh/x4+ePfN3PnAHsZ5ydx0j/5wzGP7j7Bppsc4L7hvzxq7Ns/SSmOOrKyztDag20p4yQ9cxf2P7eXBx/fz3CsuYHGlz013PcyPPe9pdDttHj+0xObNu5idn+d0pTj9jDOZ6nUpKku73ebUXds57axzmZ3fzNzm7dx/712sLB5l8+wU0eZZtII4epDF5VUeeXQPJ+/aSbfTRWnN0YUFlFLs3L6NPM84eHiBA+aIpPoEmp/86Tew++ST6Eaa5aOH+fYdd3LppZfyjne8g5//+Z9v7r21lle+8pXceuutAPzxH/8xP/zDPwzQgIUAe/fu4+677+G5z3kWU1NTRNGxzLX3vOc9vP/972d5efmfHbvOib/RjTfdwD9+7nO88tWvYWu3SxyGHDx8lF27dvGJT3yCd73r9/j24cN86H/+FTfcehsPPfwo7/6T/8LM7CztdoePfuxj9LpdXvqSl/DXH/8Ut99xO7dc/w0GgwFZln9/E+z/wJWNBvizoQ93kUTgKI5xcURZREx1WrSSNq0kYnFxmfF4jCkzMAHKRiwvL1GWFU4pdu7axdzcPGEYYSNv+BrF2MD62gtwNBYZdapdHafuSyzxJ/NAUl5W1MqAuh6qm5QNY8L4Oh9RLtRd79pjLW21SJKUbq9Hy0u7iqqkzDOqskQ58QISSwPdmJtbYzFYqaEDAdOKyhA6wCnGHqBaX19HeYPcbrsFOsCpgKy0lKYi0xVVnlEaS1Ya0jgiDDVxoFkbDBkMMw4urDRKCqUgL0qOLq8S+HOGdlZYKUAriXHWkue5pNspBUpjeoqp6Q67Tz0VYwyLC0d56MEHObqwwNpaHxxEcUQrTQVMyOW+a/+e86Kk3W6TpqkwKKyjyHNRjlhLlmfi6+JVBIPhiOF4TFkU3pvL22Ro5eU8CVEU0Wm3US4i0NDrdun0puhNzZAksfdgomErpGlCu93GGMNoNKIoCoqiEKarMegwYjQaMRoOWFkUCaBWijiKcCB1greqUEoRRnKsXFleIs9zMdMfDalVDVUlCdthnEjqXRyRxDHGGrLR6P/wjPzfu07U0Cdq6BM19PdfQ3/PwFONOtbsj9pkqtY1Ootnu4gcqUY7rakahFVrjcWRFzllWRCZhCiOKMqi6bQI2LGR3TS5Gj8na8XZ34NNG0GoDa/4GBT2uwFNT+4INaCTn6j1z7ONAbfCaE1VBVSh+ELYWLoRKgwIGvCpNlqc0JO9tZw3C/fcJY0ffBzD5qpBGvlPz+LxCCXNrdkIoE2Avvo+GeuTDJS8JksJZYH1TB2CABWIdtv5lMKqTq8zFXgmlaTgCSBUVRV5NvYdDKHclrmYmWmpXjBK/q5czQBTx4BHGz+0nhQeuganJk9POmm+nVbfSwGnxETPOM9ksohXmK69snycppkYitdspzCMSFptoiQRhLlG05mg/tjJ34V9J6BcWRSSAmAMtcm7DgL/PI5/4CnUAaEOiHSAdtL5LKsKawTMC2qDeRDzS0+Zl/k8MTGtizVJcfUswWYxpelS1MlWgREvN2csVeEXQ1zzvCdDWB6EqYvbDUzHmnnocD6GOSCME8IoIggjkiSR4jeKiNMOSdKi3ZkCpSR5pKq8z5ikO/peKlEVUVHJm7ZgtWveB9QYpswn443/HJa8lHtXWkNVWcIwRDnlTU4dof9ahWxUMmatB4Uto3FOVhRkRSX32nd6LV7q79l2WtVzwOGcJA1V1lJUhs5USpS2CeKE9fV1+v0B/bVVijyfEC3roqPuZntPNetc03XEd4mkKJRur/VdVZFYVYzHWdMh0z4iWyHAvNaKINQkgciZ2qEiTSKSdkq73W7SNMd+fSnGGaYSE1wpwB3KhVhXYT3ds15vncMbRjoUEzZsM15ULRHROGnPN++tLu7CKEYHEVGSejAlJUlSkQ57Nkctdzmer9m5eVrtDiDd6jRNxVQ5iWmnMZHqEIWhT7uxrK6scOsddxEHis1zM6goZnltjWg05pyzz+XAwQOsrqwwPzcHSpHlBTffcjNHjhwFpHkhh4YR3/zmN7zPoyWKIl73utcyHmcAhGHIF77whe8AHpRSTE1NsXPHTlbW+vI8n/Se7r7nHrZ/4xu89KUv5apnPIPXvfZ1fPrTn+bA/n189lOfYMvJp7Nz+zaqytDr9QgCze5TT2fT3Axbt2xiXEnzZevJp1GpmKTdZtfO7eK/V5agNZ1ul26vxzOecRV5UfHoA/eRzU+xcuQgy/0BOgjodSPiMKAVhxgbN8bNaRxKPWL8YSsMCXTAgaOLBBp2b59nOBxTlhVz0x0kayJk+44doDXDcca2LVsZjDKe2LuPAEen3WZ20xYuuPAi4qTFo488QqfdJty6ncFwnU2z88zPTHHXXfdgTEUriRmNx7IOGSuH6CCgqkpmZ6bptLdR5jntTpfp+S3s37+fKAx46Y+8iB//iZ/g3PMv5PDSCpu3bmtqngcffJDrrruOBx54gKUlSfubm5tjx44dk4fju7uddpvt27cRhgI41WtLlmc8+MADPPrII8eYxjvn+NznPsedd97ZSCm73R5Pfcaz6HSnOPOss9m2dRtZlnF4YZFOu002GvG5f/wc3W6P005rc/+DD5KmKRdceAHbt29nda3PI4/uYdvWrQRBwF333MO2bVs456wz+YdP/a/G9/F4v6yxBGEgUipjMEp5aY5P+aVe+1WTOBz5FF6ZP25iIg4UnqlSgzjaR3nX9ZW1xh9MKqqqbIxq6/AerbVvEMu+VH/UpWvD3Ec166V2AjKESguo4tOBoyiWQ5YxdLpTpK2UbrdH4OV/djDABkHjI1rXUtbXczUTXlvvX4r3kbEWq5SkwDULiBLD9UoR+fdbGUtpDJFnUjjPLkMprIPKWm/KW1EZeZ0i77IU5USWFDQhQr4OUDQJdMrvnUhJThwLOK+A4UC89FZWVxsQNI4FlNNaIWW13SDLkWSumvEW6ElM+nCcNyAhtYTKWm9vUfi6VXv2meyXzliJSteKUGviOKaVps2eIKwpaaJWZYkJQwE1tBZ5otbYJGnqclWWPmhHUWQZ2WiIqSrCUJq0cZIKU6ssidPWxPsLMWqPoriZ/0mcNEqDKIzQYUAUxURRKCwQK8wQ86TGxfF2naihT9TQJ2ro77+G/t5T7ara2BtZCL0OU2uFRuG0dyVyEvMpsjsx0pr4LQUy4DJLno29wVdCnucyKb0GsjZMrDeNugBq/t1T6WpwoNGjuyctWk+qcv85FtR3fovzm7F/Hc42/6JrAMNTyyoTA4LghoF0VITZVLN0XNNRqSmTzd/1xDT7WKBtAj41DB7PBqoBkvplNq7+ftb7GpmaMikAV4k2FqsytHNUnpKsw0hQZiM6TqHVSWdMKUl+C1QEaKyFsswZDYeMRwNGg/WGhqcUOKVxns4nVF0rLvcgnTdqad1G4Ek1Rn3av+fmudcgo5JFBO2LEiWTQ7SmNdwvHThdL7B+TNTIrcM1HaE4SWh3eiRJSxBkP7GM9UkFTmJKa1lpHdNsqlIYTzXw5CV7kUuoR/fxfrWT1He5YpzvQmSZdJi0UsSJTxaxEiNeVdYraZ0v3Aym8pJbPPhsazN4h8MSeAaf88h/U2R5XzhrxQNFhzKerUNSMD2gaq31m+ZGma3vzvqFNI5T4jilNzPvC9w23V6PyBeBcdoSI/wgZG11lfFoJDpsB04J603eqSMOLRpN6UoPOtrmtQBiyodnEPq0DOUgy3OcswQ6IIkSojDEVoYw1ISBIgwDYdGFodfsG0+JluJ4MMoYFyVZWeIqD+o3ck2/nug6MUgg8bpIMTgKY4i7PdLeNDqMWTi6j8OHDjNYWxMj0DCgOSI6vOzWLyBawNLSS6pKv/HJ25fi25iK4XAo9GAj3g8g9z8MIpm/MlpQCoIQ4lZMFCqm2yGtbou016PT6UiKC4piMMQZyIZDinxM1EpIkpbo0bWisgY8RTzUCqM0Viuqsvb6q5oi3PniX97eZP7VfSRj6q55SKfV8vG5EXGaEAQhUZQ0+0dR5tjGD+H4vVb7A8ZZLmyXXTvZumUL2IqpTgvlprBFTnd6ljRtk60u8PDje7jmK1/jNT/6PHbv3M5KbvjK174JKK7++Tfx2b//e57Yu4/zzjkHpTX9fp/3/Ml/aeZsWYhHx3g45AN/8Rd88AMfQCnFW97yFt773j8jG49R/oDz4hf/GEePHqEsNxwgfTdYaT8fAklNMTXAD3z0Ix/h61/7Gs/9gefxghe+kB/8wR/k+uuv56477+Stb/klPvBXf80ZZ5/HgQOH6bRS2u0W515wATu2zLNryzy33Psw6ICp2XnCOCKJI7bM9MiKkqKs2L51E7lxGDQveckLuP5b1/Hb7/wdds72yMYjDhxd4ZzTd7Npdoq1pUXCTkqnlXBoaY0oDNg83ZXC1sqY7HVSoiDgprvu59xTdnDJGSfx0L7DRGHAWSdvpT/K0EmHiy++gAf3PMHC4hK7TtrNwaNHWVl9hEhDp9tjfttOnvWc5zIerPO5T36Mi654JlNzW/jWjTcwM7+Fs888jdWP/g15XrB5bpqDR5coq4ooCNi6ZY52mrCw2ue8s0/nwvPOJR8N2LrzFE4//ym87Vf/M/v2nsxv/Mavc/HlVzAcZ1z/7bs5bdf2xmPo2muvPYb9tPHaKNMKgoAtWzazZctm+Ud/gADor/X5/Of+gccee5SNUkpjDO9+97uxzrLeX0cHAaeccip/9hd/yc6TT2Xbzl2cduop3Hvf/dx7/4O88HnP5aEH7udX3/Yr/OEfvoczzzqLD37wA7ziVa/ih57/AmxVcNMtt/LxT32G3/zV/0x/vc+f/+Vf8UtXv4nLL76QP333H1A8mR1/nF7OWaJQUgzLIscGiiQKxdhZi/eQ9qBPNhphjRHPsnYHay2jLG9qQPEAEglmt9uVZljggSetRM5X+LQ8zzypTCWMbX9pJfKUOvWuMrWZtGpqOTwQVterzjnP+ojodHtMz8zQbneJkpiiKCmKgunZeZJU5msxHpGNR+IN5709jREvlrIqvYerH29ao73My9iapWGxdpIUpbWkNw6HI38At2RF2TB44kg+tFZEUUSrlYpHWmUxRS4m3F7+UlSGLC8o/T3RWvZvrZR40fj7UPqvDwLtgR4J+en2erTbLco8Y2lxkcXFJZaXlkWCGwR02q3m8LexNq3PNpLcLcz8QAtzpigKji4Kq02LlEHkhnnR1EBy/qgTB8VA2hlDFGriMCCOIzrtFr2eGHorVSdYFR40EzNxEBlgbS7eaqVEsSRYRkXhy4WAbDxiuL4uzz4ISOKYVrtD5Vlg0zOB/z0aa8QDTnU7VGVJWZRMz8yQpClJ2mJudlb8vrRmvd9vwKn/G4CnEzX0iRr6RA39/dfQ37vHU5H7RVPouVrJgCqtGIZXpmwQMmtr3aOgZvWb1IFDWdlV+2trlGXB/JbtxFHkDfJMExsp30OD1FpXS+q8UaCd0H7dho+6U/LdrkkUpB9J3+WqUU3bIJyuQZFBPq+Uj3v1tNH66+IohCRqDP68ZZh/lF73rrxc0bN3NMhG0EDWtXmXB3C8BA0UqjZRtw7jLHWUrnPOLwquoSXWqSK1AkwphS4qgjAmjCXCMfSxko10sSpkUTRGDOV0RByngKaqSoaDIev9Ncajoddsy0KoAy3okLXgKpz271nXIJPESW5A3Z580xuPrFq/q+oukwOr5P4FCPUaf2eVqWMkN4CODhpndWebyR3oQBbXqWmiOBGmkkfUUTSFlXTHfDyxMRtij50stt63IIrjRp9e62aP96vVEpAUJcVCWZWYSlgLVilypymc9eCxZxECBtXE3DolH9ZZobC6ySIlRnoekS+LRvpaS1epFzrt2XHeL6wyPqrZWunK+vQYlBKGWtKm250iTdt0elN0p6aIk5R2p0fg0xrdhBqHc5Y8G5HnY1ZX1siyjCzLqGNlnTFe4y4mfDp0BM5S2cq/J9/L8a9J/LsmCYo1E85YS4n1qT2K/thTlcMAnMQnx1FMzfOwTrwmjHXkpZHN1EiaplKSJFNHZSucL3A0cRRT+TkOEKcpnW6PubnNBDrkwN69HNr/OMvLS6RJSK3hlpvhp4LasCU4hTUwznLyovDyV+8BYF1TGFVVCR501z5aVSk5rNQQcaAgCBRJENBrpfQ6LdJ2iyRtEccpyikpvBAzzcqWrPXXSFZ8cT4b1F2KhrUQBP49GENRlU0ik1KOOIqI/D3Wun4ewkotypLRcEheFIxGowbwn05iOq0209PTxEmKcxI7m9fSMOcaA83j+frhF/4QiwsLgGM8GrK8usTj+/ayb+/jFHnOzq1befSRR1kdDLjqskuJooQiG3PznfcSRRFZWXH6qbsBxfv+4v2csn0zL33eMzmy2me2m3LRGadw870PMfoukiWlFPPz83z84x/njDPOEN+EVotrr72Wt73tbTz88MMi/3GOd7zjHbz0pS9FKcUXvvAFnv70p2OM4bLLLuOGG27g537u57jtttsAePvb387LXvYyNs3PS6GpFL/7m78GSrNz96mcedbZ7D9wgM9+5H089Tkv4OQzzmbvvn2sHp1iYX6WdtIiG/d59KH7GBuI4pjd2zazstZnnOW005T29Czp1Czv+9D/ZLi6xNMuPp+jB/cxKDLxbcFQ5RmPHVqiFUd00pheKwalKCxkZYVWMNttsdIf0mq3+KNf+wVuv+tebr39bs467STQIePKcfrZ59Jutzly9Ajbdp3KSe0eKghYOvQYjz10P/sPHWH7VkfiSm6+9duMxmMqJSlUu3Zs4Qef9XT2PvYwf3vTdaz1+5RlRVaU/MyrXsrsdJf9Bw+y78gyhYEffNEPi99PGHLmpZdQqoj7Di6RFcca9LaShKdedB5/8efv42//5m9QSrG4uNg09erLWsvje/bw0//u35EXBb1ul49//OPMz81TM1JuvvVW3vzmNzcHGlMW7D9w4DtAn6GXzCitefcf/RHPfs5zidrT3HvPnezb+wTTvR47tm3lZS/5UW67815KFfJn/+8HWF1Z4t577+XH/83L2LptOwcPHuCee+6m0+nwll/4f7jhpptot9v88i/+AnlRUVaGb33rW7z73e/m4x//+L/shPtXuJIkIY5DokDTikOiANqJSPwVUGQZRwfrOGfppjFJLMyCoixRStPtdqnKksSbvduqZNhfo9VKGxmHxLwbSpNTlRv2U5yw31VtWeEovE+Z9Qwkh/O+TEmTQFY3PrUHteI4Jk5Soiim1W7T7U2RpuLjVMu0UApTlawsrjNYWyXPM4ajUQMkGSOAS1XVtQYCcHlpn3WTJL4oDJomrEV8kVxRMszyhr1T15Zaa+IoIo5CHMI46rVbPoXMNUEJVWWx3oRXQJewMV3WHnCKw8CzsRStVkQaRyRRyCiv0FFM3O6ybds2wihk4egCi4uLrK6uorQi1rJHhaE8p9rbqGlIe59S5xz9fp9+f12S5HxzdjTOPKA08R0dZ7n3+AoJPLCmlSJQ8vc4DOm2W7TbLVpJ7NlWUWNpUd9TW+/zppJ0rE6HJEnFg8s5b1pekmdj8ceqLMsLR1jvCxifxDGtVsqmLdtQHiDs9bpYa1lfH1CWFXmWcejgfqJQxpB1kKQtNm/ZwlRvirIsWVxaEhN8LTKyKI5Ij/M9+EQNfaKGrh/iiRr6/3sN/b0znozoTiV6WJ6HcTIBcRv0nbZGXieAQN2dwQ8Oh5i0gRitaS0F4zHG0K4GgeougduwsU4SKo4Bnepv3PBzvuOqQb4NHTr/6aYIa16/B5zcMV/k74eVRA+FIg9KIm+8GYUhKtCETlBW5WrCsqLWOONBGKUnIMtG4KmRizH5WpkANXDmwSdjqIxrpHU1vbLuWiGNo2awq8oShIbQp7iZMMKZWOpP8CbcQrOuu9U6DDGVadKJsiwny3OP9NboL94I0jagUk3lrrW1QMMEe/Izts55KWLNjpp8tdAjawmmgEJ1kRboUF6vcwijdYLZ1s9Se4CvNrlMWh209pPS003l/dZGd8rT010Dglr/O0LPckpSoRlKZ7GW2h3/lzRSPFXVlhgjFNAaC6zQYI2AicjdnBi/Oy+fnHxIGqXMBaFwl1hPBXW+uwLyOyfAcNOWobJ1AVr6oSTPNtKyFoRJQpK2aLU6TE3PkbZadDpTtNotoQdHEbVpovWeZDJODGVZkI3HFEVGVZU01F+Fn1fKm2eKaFh7uWfN5JQvVRL1GgjSLxuHE1p1M3YnnfbSKgJt0GXgOzmaODK+aypfb3xHxPiUHflFNUNEN91urZQvXEPiNEF7U1FQngLdJQhCjDEM+muUpcQzx16SIfWDmPo766i8nKEG8x1+/fIdMKVV09WpqeCSmDmh7DbrCDWN2knQQqBJIomiTppi1xvuN+C9jCeJD88ZD0cEYUy7PSVybflx1IbWSiuJ2zV6spkpJ2mUYUgYhTRpO9ZhFGhjJmulL6Dqua38s1ZKN14HqunkS5zv8Q483XXnHYDco81zs7SThEOHDlF4cHxldY3+ep/hcMTSyip5WZAmMStr/YbF2e32UEoxXFthPNUhSxNGwyHKWaIwmLBRlUhbut0uV1xxRQM8XX755XS7csi4+eab+da3vsVtt912zF5a+3pcccUVfOUrX+H222/HWssZZ5zBZZddRq/Xa752PB7T7/cZj0eSnGaFnr558xYuu+xy7rvvXm7/9rfZ+/hjnH7hMpvykpleB5xlaXmZXm9aTKazjNX1oUzrfEBeSTLV2nLFdF4yZWHf/gOUgzXscECejbGmYqrboiwrBqMRnVYir78ypFGIDmW9r0op4svK0O11mZ6elgJWB4RxSlk5knbMzPQM3W6XKAzJxiOSNKE7NcV0p83jD93H0sJRiqIkSVvs2LmL1eVFlldXGRcla2trdJcW6K8ss7JwlJXFo5x71hnkubCMO62UVhLTbbfZtDnAENDtdqWl5WD/wcOs5yULfQn9WFlZ4etf/3pzn51zrC4v0263ufnmmwUceNJ19913s76+zq233kpRFHS7Xb7+9a8zNzfXzJdvf/vb3HrrrVxw/vls2bKFmekpBqMRR44uHPOzTFXRm57hlDPP5pLLLuess87mpm/fhdaa+bk5lldXmZuZZtu2reS33g6IX9FoPKQoCrZt34ExlqNHj1KWJQpFFEe02x3iOKLIC4x1tFotLr3oPLZs2fIvONP+FS/nPPNETL2pJTcNYFR6eUaBdl0PCrnm0BAY8UYiCpu6qCpy8XvxdSPIobYy0sh1NWOCSWncyH78WmhsbQgekMSy78ZJTJq2pfnpTYbjOKbVajWHjDCKabckirs+xCiEzVCVuTQps4yyLDbU3aph/EhD0qG1HMxqc+Da6qEGnGTNjwWkcI6qqOSgbi1lRXOoV37dqowALGUpHf7QA3VZXlB682ZU4Pdg2Wu1k3058MBTGARUvlGeJglpLEwqQ0AQp6Ttrni5OMdgMBSD9LIUOW4oqclKy6ExCIJmP8V7Mde+WbU3jNLaMwnCSeiPb1TTPNljLwUifQsC0iSmlSaNz5MATsoXwWLVUZ8urBOJD86RZVLD1mOgqirKomA4WBevp7xgNJSErVbSJUliWq02aavt77chisQ4Po59Sp5zoCZNWpHVyUf9+51z3mJDzmxxJN5Jx/N1oobmRA19oob+vmvo7xl4KsuxBzyMUOUUWAXKehmavzEN2eQYUKimy3pAxTlGlSQpDNfX0EHE9PQ06/01cchX5WRAWtcwneoIyTqlrP6d+MldD976hjSXn5CTqx4AasNnPPhiJz9jIxg1Wfb9wPODznlEWylNZR06iLCI431YTwAQfyYUCqHoykCtEcf6RXqjw3qBcTRLlLjQQ80EMz59KCtLSbqo0XXrKKsJYBLo+iDBBk+lkDKReMskiSWSV/vXpQN0IB2vMJLEjjzLyfKM/nqfwUCKdimEPFrqzdbEo8Cg/XPWgfxcVwPpDdvJF0cNrbYCLZNMo5uv0Vo1fl/GVL77BFEkDCYdBuAEGccoaubWxmcq+ldNmqZ0etNMzcxJUeCpxnUEsWjglS9O6oJG7nHtKRV4LXS73SFttYWlZ4Si3mi5j+PL2LJhDJZV7lFwDyAC1ii0EhAwqtF+QCkZW6UzBM6gPLvM+o5F3VWtqgpbluB8eqCWTqUxFaWzVN7osKbWl8ZTZ6tSCqggoNPp0e1N0+p06W3aRmdqms7UNN3etPw8lDDzyoLhcI08K/zB0OGcj5B1IrPM88IXBY4oCvycCqiwOCuGeFr5tcJYjOTiYHA+kFGho1rX3CKKQ6wpKHO/2dRbh5uwDp2rfGdKijjxd/ASU62F/+jEH0906AE69BR/PdmYajA+TmI6va7vdDisgU53ipm5zVRlxXA4YGVlgSgImJ6a9k9aWJlhEOEcVNaRl4UcRKoatBdKrj8BNM+6kRVv3Cihhs3rslWel1a04oAkCumkEd1WSitJ0UGEUtLdsZWFQOE8K9C6ijzPWFtdpawMaatDEteFspfqKuXXAUUcKQLtTWt9B6uOL8Y3IMIwQLsJCByGos93TmJtpetsGY/HZGOh9VsnngJBEKFV0BzE/m+4tNY876qnMxyP+ew1X+CS888larX41s23Mjc9Rafd4vobb6LVSjlp104Wjx5FWUMrDrn33vsIw4BLTj+Zux/bxzdvvYOTt8yRpkmTLhQFEt2d5SVnnHEGX/ziFycJtP4qi5LXv/71PPjgg9/x+v7be/8bn/nsZ7n1llua1JSi9Ia8T7rHf/Inf8LHPvYxPvPpz7Bpfg6tHL/9e3/IlVdeyQ+/5Md526/+Kt/85jfJs4yjawNOdgE/9gPP5sGHH+GOe+7nwOEFnLXEvTmyowsM1lZ44qEVTj71TLq9ae655x7mtiyyZfsaJs84dPAgd9/yT2zZNEM7TTh91xYe2XeUYZbz/MvPYc+hJR49uESv12G6nTLXSzkSalbXxzxxdJkfe8FzOXnXdv7b//w4u3du58Lzz+OmO+5m9ymn8bxnX0nWX8aUBUnaIVKWbuR45jOezkP33sn+g4cIA8Upp57GC17yb/j8p/6GQ48+wuLyCrfeegv33Bny0IMPMD/VZufmOf6fX/ol1lZXuOv227jvwUcY5wVJK+Xip1zBzOwcd999N3Nbd9KamuXP/vSPWV/3PlrWsbJ4lBe+8AXU6WQA73rXu/j0pz7FxZdcwqFDh77juf3O7/zOMf+9vr7OK17xiu86Bn/913+dl77kpTgcv/zLv8yDDz50zL875zjt7PP49f/yfs48cxer/TU++3ef5aU/+sP8yAuez/s//FGKnTvZtWsXSdpiNBzwxN7H2bR9B512l3anw2N7HmNxYYGnXnYpB48c4Utf+zr/4XX/jsNHjvBf//v7+Hc/9RrOPOO07wyhOY6vvMgoy5xsPKIq8iYVaqPUrL8+YDQaMh4O5fARBARhBM4xHg1Io4g4DsXItiwxZcVgvU/o11E5nDhhAnlgS4vTrt/pDcYKC8cY27RFkyQmjmN6U9O0Oh3iJCVOW4RRQhAnzM3N0263mZ7qNR30Is8nXXPv46oUjAbrjMdjhsOBrxU1rXZbQB+f5qRCSYg2vg4IgkBkV8ZgnCGMFAHiZ5a02rTbbRTStB6sr4M/ZFcbmP9KCXMkV1LLa60YDAYkaeqZNZJ2Za2T+tQfDCN/YLKBJUCApySOJAFLa2amez7xThOmAVGrTWdmHh3GjEdDllZWGWcZOMf0VBelA1CaLM9RQUArTRtgKs8LzwBRjLPcBxhVPrI+8syJyRkgiIRNEbQ1NZNEjOE1Kgw82CSgdLvTEZDMpx028em+4a384V8HcqCtqoqiv8Y4GnkFROy9XDMO7H2C4XDAYH2ANZVnjsww1ZtibtNm2p221HyZqGDiKGJudtabEFds2bodhXjj9aanSdMWwvBaw1pHmqaNFUYYho1X2PF8naihT9TQJ2ro77+G/p6Bp8obWTVRqQgBR7BOofCCB1nwm4A1KD+IsRtYSlZc4isUS0cO05meoTM1K5RMv5lN6L8eObRuQjVshsY/f02+7Lt91aQzBMrXw55xU9fGGyZF81Pc5Ovld3jJHRV5IHroKAxxNsSEotlvTNg1WG+u7rREv06GIjQu2v731F0BVb8uasRTqMalNzXLssL/9+T+GiNIuPMTN/CUXEGDFYGuUM5iqhCc8RM7QEcRYZz6hLcYFQRUxjDKRrIBDQdkeU5RVWC9l4fSoCzKaQLnGaDKgXUE1qE8LTJozhy191X9p0e97cRgUusApaVLpJ1Qw2vfCWNKwGG0j4895ikd6x8FuvF2avemSdtd4qRFEEaTJJVQT1BbDzxFVgA8HJjENIVtGIboYGKmZo1tcOtaL388X1XpAV1jqQpJKMjzXJBsJabzkfc0aBZIN+mq2NJvjNaSl6Xv1timi6NxWCXctcpZjNjC+e6jbYBk8SUwWK0JoohWd4rp6Wk67S7zW7bR6UyRpG102hI9rw6orKM0JbaqKPMxpizIx1mT3lj7fjnfUXbWoVVAHEtHUpI3Ky/RrXDayeJrNYQRNoqJk5Z0jIKQsDbDjGPiVDbNYrDKeLDGeND3nQUmfyKbYANY+0/WkpRmjDatIN8hCpT3tVAE/u9BoInimCRNiOOEJO2QBCEoTWXEqHdmZhNHjxxgrb/G+mhIHMnr7HYmbBLrJl4eg+GQvCzF4LD2ztjATp28QHlDvgnZzI0gCpvnHDoxww0UaGtQTgtInXYJ2h2qMPUHEUNbq4Y56fyzCqOU3tQ0vekZATyCyBv9i8eBbGBSWJnKe7VZhwFUHON05JNzZLMLfAcmcI4oCsWfw/ucaK2JY9nmqsoCpXQEvb9gENRa/fK4Nyj+xCc+wec+9zk+/OEP85nPf4Ft27bxwhe8kPvvvYfBep/zzzyNUZZTlCU7t24Sc/B8TBRqkjhh09ws5YFDmKJkdWWFSMHcVJc4DBhlOaP+kJM2zzEuCg4vr/GOX3sHz3rms5ouljGGw4cOkyQJaSvlT/7kT/jGN77Bf/2v/7UxLAaY3bSFVneK173u9Tz66CO+sw433nADL3/FK7j33ns57bTTeOfvvNObE7c49bRTuebzn+czn/k0v/Zrv8Z5550n3fdSQh0A7rz+axza8yD9x5/Flq3bOfP0U3l87z46rRYn79zG7l07MKai1+uy0h+QlxVXPO1pJHFKnKRsnp9h0F9l/54f4y8/+Ocsryyye+fpnJekVGXRHD6NMSwu9wHF/PwcM5tiVDLi8NqAwipGFfRaKWVZsNLv88LnP5/VtT7/8OlP0k4jTt59Ki/76Tdw7Zeu4eEH7uescy4gbaWcfsYZ3P/AQ9xxxx383jt/h4P792Grgp0zLTqRo9OJeOVLni9rmVPcfuc90tms4LwLLkAFEZUKya3i6Oo6p513MYcOH+GRu++iLMqm1NHe56JuhtS1jTWGJEl4//vfzzXXXMNffOADmKraUPuoY76+0+nwp3/6p9xyyy38+Z//+TFjsW4Maq157Wtfy0UXXcQv/uIvsra21nzNTCflyjN3ce89d7PeX+O1r3kV99x7H3/8327kmVddxcrqKp/9u8/SaXfZMrdLWHzdHsZaHnrgPnpTU5xzztkM8wqCiE2btvCNf7qRJI555ctexmOP7+Pg4aO8+t++hDe+8Y0897nP/Zecbv8ql0aeQ1nkmFLYN3meN4wdrZT3vBFZWF23oXRjlJsNrTeK9cwRYFyJoXdvepq6n25s7fHiASrPhC8r0yRB6yAgjiLanQ5z8/O0Wm1anS5Oye8Mk5b3fUnp9KZI4giUEv+3smwkgIAH1MaMR0MGwwFVWaGUJk2jxn8py8XmAUXz3mQfdeAP4dbVx7J6P3UkifgD2TKnyEZESoqLyhiGo8zbc7gmXVgBUSinEWsdo3HW1IUK2b/knsj+rINAZGRR6A26NWEUkngj7Y5P9tI6YG56nrjVodWd4ujhQ6ysLLO2toYCWq2UXk+YFDoIKCojeyyTGrwqC2pv1obR5dcekelU/uAsB8cwChuJXZ2QVZYlSkGEN4OOE9J2m9Qz1cIoQvnaSZhOTO6no2GoKAUOkStWRdH4vBZ5TpGNqfIcZyviKGyArKTVot3teiaiyEeNFQBJWBqq8dqqZVOttAVKMxqN/biVGrAG2qrKSGJhdXzvwSdq6BM19Ika+vuvob93jydTNQCBVmLSJZPL4dRkANXsJ7zUCh/nV6c51JpPYwwOGPpOTac75dH2simcagCrYU01bKN6/G1kOX23V/2kf6uZY2oCftSfa77DbXwv8h6PpRge+7V196GqDFpV3hAQIBADOA/OOf//KAFj0K5BQnXzUpX/HcfKFf2/eNN256nEAjYVlRhClpURthl+UdqoDfb608A5byRpKf0PDD0iFARWNirETLD+e1mVZFnG2MvsCt/pwnmJoBaQSddpDkrhtEM7SVbQG97HPwcUCmvMop1unjVOwCcBj/zEds57FdB0t+r/HfNk/Oe1ZzKFYUTa6hDFiac/TxLphDo4YcApV+uCA5wNvfzD+a5M1BQIdeGglTdH38iwO04v4xdKa2QhMp4ZFwBO1/eeZszLcLRNDHPlCzXp0BTUMsdA1UJJz3rEF8Teh22jz5vy41wHIbE3m+xMz7JpbhPd3hRzm7eRph3CKKEESiNpGmUpr8FUBWWWyebpqeL1b64LAuulpEp5KSUe1/VjSOlQCLRKUjllWjpia6XYjhKiJCWIIsIkJknbxGnKmqsoC+lqeiHusZf/hNqwWDj/ezd+tVKqcZDVPsI0aMaqFOhJKgaPURQTRq3/H3v/HW3LVZ75wr85K6+808lBRxkllCUUkJAQiBxFssFGgIHG7Ta2MbYxGGM+bK6bYJIFmNQ0UWAQwchEWUQhlHOWTo47rFh53j/eWbW3oLsH38W+93iMU2Ns7aMd1q5VVXPOdz7vE3B9D+16lKWi2WwRNZpkecEkTkjTFN8Xj4Zmq2PBYEjTmMq4MC8K0Jo8yzF5jrGy1eV5hpppqOq3U6+cNgJXoY3BxQLqyoAp6muKG2DcgNQokYfkBVG1CGPnUQWeFxA1mkTNpiSZoCyzdZldKLJqeQ3xKzASYFC6UqCtWCOWO07ChFQuNU1ZO5WZrczR1U2qihOttaV9m5p1cLAez3vu89i2bRvGGHbt2UPUbDIzM0tpxAOmGUW2iCzotZuMRmOS8chKR4TR6mpNYUoW+0OUgmYUUqXOYgzNKJAxXBq2HLaFI486CqUUo5FIuOJ4wtLSIkmasmXLFvbv388xxxwjkrDxmG3bt7N+/QbWrFvHN7/xNbtBko3P9u3b2b59OwCbNm3i2c95NkEQUJYlDzzwADffcgv/+u3v8Nr/8jqmpqa477776PV6rF+/nm3btrFn+8Ms7NtFM/Q5/sTH0m616XVaNMKQwNWsmptFOw6dTht272Mcxxy+5fA6PabTbtIMfQLPBe0QxykGTbfVQJmAcSxdvlboM0lSsrwE7aIdhef7dFpNsqJkNE5oNELCQIraLVuO4P4H7mf7tq2sWjXH2sIwu2Y9KM1wOKQ/HOJ6AbOrVuPe/yALC/PcfOMNlMbQbTVYvXktKEUUuGzZuI5xWjKcZOzdf8AylxWruj38sEGhQxaWlkiyjNAoDswvsPWRR2zX3R52OfxlFtD+/ft56KGHOPqoo9i6dStHH300Dz74IPFkUv9eNU4bjQazs7Mcf/zx7Ny581eexcSaWjebTU466SQ2b97Mhz/8YR548EH27d3Lpk2b2LhhA+3AYdBfYnFpibNPP5Xrf3EDDz70MOc97mySyZg9e/ZwzDFTtFtNWs0m2nUoEjFBDoKATrvDvvkFtOOyetUqtu/YTrvZ5ITjHsO9Dz7M/OIC991/Pxs3buL440/4Dxl3/66Hwda/ZZ00Jwl1y+CfsT6qeZ5bsELSz7QCT2smqbDcdWXgicJkhdQ5jYbYFWhVj+PCSkwqH6fSsuaVUgRBQKPRYHpmhrlVq4miBo7nk+Ri4+D4AZ79cGyNkKcpaZqQpZmswXb9TyYTJpMxk9GYJEmFlaBlA+g6Lq7rLANEStd1lmPlNxT5sr+pdpdre4UAT0FIOhoQayjjEcaU6EwxUcomOVVXw362zU6DqQEN1wJM2noTFXatqYAe13Hsh8a3DDDX8wjCyNaLLr3pGfywgR81eOjB+1myfrVRGBKGAU27rmnHIc2KFddfmDFZ6pGmK0yjVZVAWNYSSSXI3IpGqhYGlv1aluV1g1pZU3nX9dCuGEJbw9JloKmqQ+yH2FssH1WatYQMib9TJbGqamLP8yzI5eP7gSg+7PmXFbBi35NjAc0q1c9xXEwplh3VRrUoDVXruChLTJZbKdTBexyqoQ/V0Idq6N+8hv71GU9Wt2vsgqesuZmVNVpgwL7hvKgpxEWeL8emVnp2U4ENhkGWgaUTd3rT+L5PEic1CluwYiKSJ5CVLCWZ9Kqv/+pRF1818lglfjh1h09+TiZNrVeCXfZRL5dvzqPhheX3kueSLJEkCZIg4JArJUZnWklcqaNxSwfPKBxtKFlOMalCRLRSNpXOGqGZskbCKibTJMlI0owkz0kyMdjMssLS3FacpP1cllV3DIwyskgbeT2lFL4BD3BRtRYXNEmaMhgOOTA/z3A4YDgaCQC5gu2kLFVPK0NRGbsZjdIGXRpUWeKWZT34csCxI3SlHLTSu0ux4qAdg4MYq2tLNzVliclNvUgWRV7riqvYV7CXSymU0YRRg7DRojczhx+GFjgt6kVda8c+S2X9PDiOJDW5tktXXUvHWUH3LA1KlTXa7ri/9lD6/+zIsmVz/iROKcsCV1MXYqaU5JfMLijyTBqGw6GNIC5EMlqPD4FNCyRJsSgNifUcE6DZSmRz6YZJoRvRavfodKdZv/kw2t0uvdkZiYtGk2XyLI/jhP6oT5ol1sMGATsNVPHLWknhqhWkWUqaFWRZgipK+7jpeuEqykK6PaXB8SLxHfB93MgmNDjLhoKO68pk62gCzyeImnhBBGVGkSXMIx3MCng29X9/9VieYlbOHJKO47mawNP4rieFruvg+j6O5xE0OzQabTwvQGufIIrEWyyKbCcnxChNYSDLDY4XEja7dGdW47o+Wjv0F/dRFhmmzNHKIcoyAs+nP5B0tDRbLjqQtyKfqhXUkfcpZ6zwbfKSq4RmXJiCIlPkpUOpQhJc8gwGgyWiMCSKIhqdAtek5ErMI/0gYnr1anrTszRaLTDlcnraeCxAvNZ19G5eSrGulJbiX8v6I5sqK7uupDZlJbfQdkMjMtq0qIxkTf117ao6QKDIDUVh+OXZ/WA7Ki8ErTXPvvQS8qLgy//8JS48+3Q890i+/I1vccymtRyxZpbCi0jSVCQcRU5/Ycy9D++gHUkSyf17Fti8bhVTnSb3b93J4etXc/aWjfzsjvtZGAwxxvCa176WU045hR/+8If88Ic/5L777uOVr3wlV1xxBW9605tQSvH0pz+dn/3sZwDceOONXHDhBbzyd3+HJ1/6ZE7+3ndkU/2/6Aoppeq0pb179/L4xz+ehYUFiqKojcmVUnz1q18lCAIuuugiylJSvH7+o3/j+p/8kEbU4Kvf/BY7d+zgHz/wD5x8yqk4WnH7TT/jxFPOYNXaDfzzF35KtxHSjgL+x2c+T5LEtBoRS/0BZVly3Y23sWHNLGHgc8OdD3D8lrU8+czH8NO7txEG0ul94KGtKO1wximPZWH+AA/t3826jZs45uijOeKII9k/zol6M5z5uHM4+vjH0ulN86Mf/4STzjibcy68iFy5eM0OM6s3MDvVptVosGXLZjDQbrc56thjObBzG8OlRX5+692gPZQXsGHdOpIsZ3Ew4o4HthJGDTYedgQbN21mOBzwtr9+K2mS1A1BsGP3l/duFoj6wAc/yBUf/jAAv/M7v8PPr7uO8x9/PjffdDMVE72ap88862wee/LJPP0Zz2DQ7y/v4u3xwAMPcsedd3HG6aehlKLb7fKDH/yAD3/4w/zJn/wJn/38F1i9fiP/cu1POfGYY6HIeM/7PsD5553Lnz3+9bzq1a/mzDPO4Hde9lLuvO8B+tYjZ9fe/fhByPOe81zufeBBHtq6jX27d3Li8cfx+HPP4Qff/S533H03b/7i5/kvr3ktoedx5hln8Kd/+mf81m+/lMO3bPoPGXv/XkeVfuT7PslkjCkNge9SowiAKnJZULVl6ChNFk/ITUmulGW3U29yZPPlMBmPUNqh0+uhlCZJEmG9WZPhajOLUniei+u6bNy0mdm5OTYftoVGq01p4MDiEownkGYoLUlTcT4iHQ0wpqC0rJvSGKmFjDW/Hg1JkpgkFv9W13WJwoAgFBa9ATw/QLliWeBbJpXne1DKplzSzhyU1uS5MB2707M0Gg2iMGLf9oc4sGcn/fl9jCZJzUApyuXo+sq3JMsNjpJ0LGUVE1mW47sugecx1W0wiRMmScJ0t11L3JTSeIHP3Ow02ASvZlcUGWEYsnrteomTV5osy0nTlND3mZqaotPpMLdqNdoRSdNg0Leb/gzfc8jSFN91GAwGJElKacRYWGuHzEp50jQnCIVJ4LmOzHtpZhlEGs8JlvdCBrGEyEtSA24JqjSoJKUwirwE43h4BmsCndfXK3ccy/Rf9sxJxiMmYwkR6i8uIWyzQIy/o4i51WuJmm2UdnBdGI3G9PsDgsDHYEiTFNfzCAOPbqcjYJjWjMdjmfN9YU0ZA0bp2spCgW2eH9zNn0M19KEa+lAN/ZvX0L++ubj1cqqoY8qisaV9HgpMjcimaSogiUV2K1PwGhWEOkEiL0uhX7qLNDs9XNchakRkWSoMFyMDoNJ1VlXUyn/LOH4066VKOTNUxlhWM+u4aLXCbMuOKgGdllNBaoNDg0C9Rv1vBwb23Cr6Y1FUumrEsEspylJMvgpHHPglltWyIJUFoCqtfFGZqQttTl4fMntN4zQlyXLSNCcrSmuyuIwIK8vikilN1cl2y+e6zJzKihLHiPRPua41ktSkacpkPGEwGDAcDZlMJmS51d5SWaXbIVUiCR2AsWl+eVnglCW6XJZnVsCOApS2SXGaZVM2+5zVQCbYQWJBJQvwVABmffswFlyrkHvR7TuOJoiahNZETtXPRZUqCMvgoSQWsgK1FTqh9GRQ1DTu+tGzH8Y++wf7YUpTm7BpJdpdrRSeI89IWRbkebq8OCLvTXTeJXbdApQdGqYGkJc7qxlVEAAISBc0IvywgReEtLvTtDpdOt0p5lavJozEDLMssQtsZrstBa5WlFpjHC3SAFNS5CVZWViAXsxWFULzL4qcEvWooILqtrjKx3PbaNfFjzr1oqlcC24q15rLY29wgVaKVrOF4/ko7VjAc0VxVK2IdbfArPjMr8zBxnYOHa0JAg/fFpZhKN1k11JqHdfDDwIazRZB2AAtxqqu7xM2moAiSTNiu7HodadYPbeG3tQM7e6UdLiyDO37kvxYOHYhkc6zpEHlttvGowD4+lAGGSeq9obTutKGG8pSkReKHE1RakZpTjK/CLbI7PWmcL1gmVpfFELZDSMarXbttyGsSZH2BmFZd1BNLlHDvgptx0XjeULd1tp2zu3CijF2sZUuIMj6VBoDhf2eEhp8lUBZGttMsUXdignhoD0mcWLvm+GWO+9m7eo5nnzheWzfvpMsS3nOpRezbfsOHti+Gz8ImcSxjOXCgHaY6cizY4B1q6ZRStEfjUEploYTHtq5l6WhyKkB2lHAcHGeP//zP+ehhx4iy8TX6dxzz+Wtb30rRVFwzDHHEFqD3cMPP5y/fcffsnv3Tv7pox/lz//8z5fnfKW49bbb+Mxn/ievfMUrOfecc+Re2C5ekiScf/75XHrppRhjuPXWW/nc5z4nkg3/0YazVZrqZDLmn674RwaDAQ8+cD8zMzN02k26rRY7Hn6A7Q8/xL75edxqbJkCT0OeJvRaIRjZiFbJNNOdJllesm3fIpPxhDTN2IVIngyKBx56GG1KwjBgdtVa+qOYW++4C+N4DAfiadNfmEeZgp7JuG/3IxRFwdpNW9i/azuDhX2ccNLJ4ucQ+QShyL7nFxYZF4oiaNHpzBKEIg2MogivKPEi8aeYnZ3jvPPO46tf+Qo33ngDaZLwpCc9iQsvvBBjDL+44Rdc9dWr+L3fexVxHPOJT3ziUTXXJZdcwjnnnMO3vvUtdu7cwdve9jae/7znc/ppp/PRj360vr7GGB568AFGoyGDwUDmEq35r//1DxiOhnzsYx/jpz/9KQbDaaeeUtdSQRBw7nnn8Vdv+xs2bd5MGDU4bN1aDhw4QBJPOPW009m9ew8PPvAgz3vOc3D8kJ/ccCvtZkSv12Xt6tU4ns9gMOAb//ItZudWsWnDBtbOzbK4uMDHP/0ZPFMSBAFnnnY6t916K67j8KY3vYlzzz2P6anuf/gY/E0P8X+RzX7gexQa8iy1NY41eMZuOoucipCQ5lkd1KJ0FYIiviuO1qR5ISbeJbQ6XbR28Hxf2OmAU/luWllXEIY0mk3WbdjA1PQMnd4URSlzYprltp5UywuoqbxW7UbDekNVG5XCsu5B4/mhfYZ9ms1mzZRKkkQS2FA02hLhHoYiKSmKQkAZK93QWtkk7cL6TEl6cJHnpGlGnGT2HMB1NGWp7TlWadj2gqsVn9TyWlfV666jaYYBvisMoWXZnSssLy8QawbXs2twiNIOhTGkaQIYPNel1WoxMzNDb2qamdk5slxkWF6S1OyjwPcxUUEUBLa+HTIaT+pTdV0XVZRkplIVLBsQo0SCaaw/S+B7te/tJI7J7Xnnuchpw6DEtzUZjmuBSpvi5xq0I/fU2KZ2aU2t48mY0XBIv98nzzNh0YUhjUaTZrtNb3qGhmVZjIax9e8SPzitlfWGFZZTWZYixUTYE5XpcW6fycD3SGLxgxoMBva5PrgtKw7V0Idq6EM19G9eQ//awJOp6KhK/J2qxbGgopiZmiqapqlF28ra3LJcUQBVQEFhhL42iWMKYE1RoB2HKGqQxDGmlHQK+8TVRtPCQLIyv0dhQcuglLEPcEWh1TYyVRB4eXCXQaeiRqsLVVjD9Mpo3NSMI3vy9Sq2spNbeR4UFg0vUeTKyukUFKUwYwoLbDmFAwacUrSepbPsDl8t5hUIVlHYsrwgKwqSNCfJslpmV5QrzRVBVTI4qlhJHkWrNYgMDlOZkkv3QTuuZRdpkiQVc8jBkPFIUoPk4YJflraV1ZUvxfPIAKoQppNTAU9aocoVwFNZpcVpsaOzL1kaYUkZZaxhuPxG5U+lLFPNmOXEPAHNy/qMTFnIANIOvmU81QbqmNrPSV5nxXWx10Q6MDKIHEcvFyyqQv6rpAL7GnDQd2qAWr+NKamiPx0MrgUQTVlQ5uLdUKiqk2lIU+luoh1M9SDZe1Vin6GKflxJco2RSdr1ido9Wt0polaH3sxqmq02zU6XdqeF6yg0Estd5DmFLbCNMTha4zkOyrikdpIsTVEnOKKk0ITKz0SDq3HCSO5XKWNbIewKP2rihRGNzgye79mkG2wlIIxEmeBTjPUSi1pdKazznDyNKfLUdo3tNGCoN88y3/wq6l+xJSu2ius5BL6H5zh4jkMQ+PW8iiO0dN/3CaOIqNHEOLYL7Dj4QSQGpZMJcZxQFiXddpeZmTmmZ2ZxGy3xYstSHM/HOA4UrjVJLPGDgP5wyDh2lsF7s3K9eHTFLqC9Y1mFIlGVkgJyY0hRFEYzilPKSVz7n4Vhg1ZeMB6PhWKfZkzNzuKHoV34ZdGsFmNtTRGNhY1LnaNRVurg2sXaqQY7me24V2xOWXyrhoKitD4KJcZKa60k11Lay9KQZplQ5bNMFmP34E61S9KsDrR44OGttFoNzj7lJD56+50MhgN++zlP4UvfnOfhXfvoRL6dm6Tr7WiHbhgwTnNQilazweJgSH8oRU1/PJYI3TilKKS4m5uZgbLkPe99L2VRsnr1qjqt7vTTTxfWQ1EyGo0IgoDVq1fzJ3/yJ7z+9a/nO9/5Dt/61rfqBDulFFdddRWf/cxneNpTn8Z5551Hv9+n0WjU7+/kk0/mVa96FQBf+cpX+OznPsdoOKw3zyDPY7vdlrSlOOZzn/2f9ff6Sws0QpfZmRkefOA+9u7dR1ZCmmbkeSZ/KxAGR6chKVxpVjCaxCRpzmynSVEadh4YkGY5KsvYn6X1Rnvb9h30Oi1c16PR6rBnzx527d7FVK9LlmYMBgMGi/NokxOognvuvJP+oM+ZrsPi/t2MB4ucfPqZaAzxcJFGqyt+UgcOkKPRQYvO3CqajZBG4As7Qyla2iXJC9at38A5Z5/N+977Hv7tmmtQSnHBBY/nDW94AwCf+cxn+PGPfsTvvOx3mJ+f51Of/KTMk/Y466yzuPzyy9m2dSs33nQT//Iv3+K6665jYWGBj370ozSbTZGWG8Pu3bt55JFH6t9VSvGiF7+IhYUFvvzlL/PgQw8QNcKa6W2MYTQec9TRx3D0cSfgOVJDrJructsdOxgOxxx99NFc/a1/4dZbb+Gtb/5L7nrgIb71gx9ywVmn0el0Wbt+I3GckCUJ3/nBD7jg8Rdw+OGH0223+N411/DVr3+TCx93JnOzszz2xA1861+vRinNh97/DwS+978u/g+yo2K3aws85QpMkUtqE1JfVI2sIi/Ira2CsMFlzfU8jUZquECJPCxOc7IkpUxl3hPANhBZiJHNJYiNQhAEtFptur0ec6tWi09Io0V/OCTNJFClnlerk8J6hhhjLR2q7GVlmZhSf2nLPGh3e4RRRKvVqtf1vDTgadAu7alZkYo0GtYcOSe15vmu4+A5kCcxRZFRVia7hfhhJUlCkmb1+uVYT6aqZq6UCssgk1x7ZfcD0qiWa+y5ksbk6jpX2Up1JGHNDyMczwdXZDra9TDKehJNJphS5srQbzI1LaBTd2qa0WiMGY7w/IAqmTrwXPnbjYjxZEyWpgyGI7t/klQ3KGqzdVNKneHYc8vyol7rPNelKAR8rJgXFZNI1ghVM2hWAk+OKxJGT0FZFXOmpMwzCgs8TcYjxsOhhA35PkEQEjWbtNodOr0p8WVi2SNLKZiMx+LlFDVEWue68qzkopQJw0DWYaUxuTA3HEf2cGWeMegv4Vjj84P5OFRDH6qhD9XQv3kN/WsDT662xs8YFJaaVeRkRV6tljUCXw0y6+1uGSUWHMFYoKSsUd28LEmLnIWFBdqdDrNzc2JIikjXSlVFvVoqowJtPZMqpolSlq5XU8WUpfq5+EGI67p4NqWt1saXNm3PUs1KI7GUZVmiipyytLpJZTWvlMutk+oRs6vaSnneMigu51eWRY2KVp5DjtYkniO6T6tN1XUcpLVor5lipRjD2dhV8Z8Q3W6eVwutWjZWtPRZbRetiklVjYxqgUVrjNIoz8PxA9wgwmiHLMtZXJin3++zMD9PPB7VnXZlU+eMvec1qmXAKKGOVtc/twuMvyJuVCj9yww40Xu71khx5XXEyjplsqz0po7r4ChBZCvpZ30PKmpqkeM4AY1Wh3ZvhlanS7PZlt+1g7S6HnWhVxqqhAKRZC6n3Mk1qxho2Gusl0GnskpsPLgPk08QA8OShltSFIY8yxmnE0l7sb4DxhiwaHqWF5QrgN6ykI6iTEjSQUkquqlRdXpF1O4xPbuGqNmm1ZuWAs73JU0ny9h74AAH9u/DczRR4OJrp/bJkohwhUF8vlxP4zgeJRCUqu7WKO3apEEX7blChQ8iwrBpx7ixi3AJRuF4Aary+FLCtnOqboVyiBqSDBEGAQpNnhc88sC9LOx+hIVdj7B3+4NMxmPyzNTdLEqhiTu6kv/KnGEZyrLAFOJhlhtoBT6NKKQTBbhKxr7n2GcR6TY4jo/ny1gsUDhBgLLeDYXjMhmN2L9/L+NBnzJL6U7PEgUBnufiNQKcNEZpTaPVFiC1FNPAKiZX7z8gc3BZsf/UcpMKQNlkTaXwlaRgKu2QlYa0zClSYV6mRUGBAlUwTiW1zPM81qxdRxBGZGnOQw88iOtqwsBnzYbNRK0u+BGFQgp/pW2hoC3tWYDnyAtwHYcokI6z+Jwss2czK92W+Gt7PzTL49o+v0Vh8PwqPAC7qZI5P8us0Waa2ujpg7vo7XVaRGGA42j+4OUvJo0n/P273stpJ5+AH6znb9//Efr9IaqU+xJoTeBqhnHBcBzz0M4Bq6Z7eJ7Ljr3zjCYTkiTDdUTykDg5Rx95FH4YUWiXMy68FNcPMd/6Gjsfub8+jwpw932f66//Oe95z3v4i794EyecIB47b33rW7n88st54hOfyHA4rH8vjsXg9xWvfEVtSvl//f3fc9655wLwkY98hM9//vMATCYTMIbfvfzyeqMIsHr1aq655ho+/vGP8853vvNR1+eP/+iPecyxR/GT71/NsVvWszR/gF0LA0b9JUaDPpO0oNXpsG7tOu67524cSk45/ih2759ncWkoaUtW7n30pjWkRclokuIr8ehYGMbs6494cMcuHv7UJ+tGhbdCjn36Y0+gKHPe+/4PoRX0uh3OPv00ZqZ6eEFEonwpjhvT7F84QOC5HHfssSz1+6RZRq8Vsdjvs3fXkFa7Q7fbY2p6hg996ANs3ryZl/3Wix8FsNTNPGN4znOew8UXX8xUr8cPf/SjX/FLede73sUVV1xhZR8ZVVJQdfzd3/0dlz75yTSaTd7+9rfzj//4j/X3yrLkE5/4BKeffjp33HGHJLqWJdseeYTQ94gnE57zghfylKc9jb/+m7ezNJrw4P3385Uvf5HnPe/5hBs38Cdv+FMuvvhiXvvqV3PzHXeyMH+ATTMtVq9bjw4ibrrjbrY+8hAaePOf/xnX/PCHfOp/fIqnP+UprJ6d4SXPfy4b1m9gsd/nFzffwgtf8EIO27SJcZyilKSQHexH4Lm1F0lKge8oGoHH3v37GU9im5aVWauK5bjwSrqlQYyKy5I8s/4yjkOcZpSWHZHlBX4QMjU9bUEBbec4YbN3e1M02x1a3S5pAUuDMUujmMkkJs2sT6nj4HuycYNKppZIDVSWdp0S5lSlbhgMhni+TxiGzMzM4AUipZuMhmRpQtgeoV0f1w+YmZ0lCAICP6gBjDzP0Z6H77p02w2KeMxkNOCmG28gHg1IxiN279jOaDQgzTLajRCtFVmS4jnaNqKdugnrOg6wvLFWth52XRc/8Gm1mtgtlpTGSotMLGoQRg28sEHUauF5AanRaNenVA6D0YTxaMT8gf1MxuI11Wi2mZmdY9XqNTQbTdI4JovHtK1ZfpLluI7C1ZrQc1hYWKQ/GFKlVGOE0VTJqUUlUFLkBtf367Eqfj0FiUrrn0uyXDaebiLrdF6QFSV+kuL5Pkma4wcBQRyT5TmB7xM1GlZipTBFThpPSOMJ+/bsJklT8rJgqtezSXM+69dvYHp2Fd1ulyxNSRJh9SRJyng8pt3tgNKMkgwvbOB6Pr1Oh/F4zGQy4cCBefwgoNlq0Ww2JTVv5y6yOKYocjzPq432D+bjUA19qIY+VEP/5jX0rw086YoNUlEDy7L22amYJ5XkK7M0XGGC2GerAp5qAMoORMdDuw6u61OgMcrBC0KiRoMizxkOq8nZoI2hVIKILt9glgFG+0WllH1ND88PCIIQx3YwJJ4S+zAJ4KSAUikoqS+cYwQZLFWJrhg5PJohs/LPq1/+omXHVCh2acGYip0kGsxl4KnS8mvrP1W9H1N1mWzna+WHsMlWcI+UqmncyrJ09ApAqwKeStth0Y4kIriej+sFaMdGLhYJk/GIeDImS2NBvI0whZYZTysOCzpVF6ICn0oLBOVFQW0EruUBr7wGKuDQsQ76mGV0u7QLsiqXQTNdapRj/60URiOUVftclWUhaHcY0uxO0Wi2iKKm+AxUNEGWRXl5UQjeZJZRX211yiKRXNHlMyvfsr32hanP92A/VJ5CNX6rGNZMKKNVyo0d5uRVt7WUtAtAuh+WJlvUVF2FHzRtbGlEo9nGDxqErS6tTtca9gWAIs8sUy9NSOIEU2S4jkMa+jR8v+40aq2t75sndGZMHU+Mdi3YKQCu63l14oPn+ZJM4QUWKJT0oGXKspgKa10lBBkpPC3TUHwv5BzKrKBMExb37aR/YDfjxf1kyZgyz8TXzg58U80lVOPDshblSlMYxDhfaXzPEdp61KDVCNCIZEhppLvoeKKdDyI8PxJqMgrf9awE1gWtyQqhpseTMRRFraXX1hi16iKWjoPWDq7j4ypFWebE8ZAsS8myFBmC1dJOLcnVtvPhOvZDY3XuAs6XxbL/nACvkOdGaPauSxiG5FlGfzxmMFii1W7RnZoiarXxwobQyY14rSmt0boaP1YWbI1JXcepZRcVmF6W0hxI07QGI6qf0TVNX4oPXcq4rRKAQMISSssgkAKwtD4l5qBPtRsOBtbTB/bt3ct4PGbnvgNs3D9PGAbs2b9AtxnSa/VYGMUo1yUKAvYuDknzgmYUCuM2zRhP4rpb5voBjXaPdm+G2Y1bZHPQ7tBfWiRNElrNBp7ngcl/5ZyWlvrceuutfPGLX+SnP/0pIB2+paUltm/fLgCSPbYcvoXLLruMb3zjG+zcuROtNf969dVs27q1ZjCNRqNHvf78gQP1v8895xyOO+44vve973HPPffUXz/88MO56KKLuPfee7nv3nu4+7abGC7NU+YZmw4/im6nSxaP2LlzF77noTDMzEwLLd8N6HR6eL7IeZIkJkszomaTpoJuW6R2ZVnS7XZodSZMEvFbSdOMJMvAEcBD5lVhAG1Yt4Z2q0W73WL+wD7cUDZcCwf24ShNGLh0uz0812E4noB28HzNcDSiip6/8847Oe644zn33HMl9nko3lsXX3wxnudxzb/9G41Gs74OjYZEzleNn18+1m/YwJFHHsXqVXPcd999/PgnP+Eb3/hGfc1vvvlmut0uL37xi7noCU9gNBpx5ZVX1vfwlltuZmqqx9q1a+29X+J73/su/cVFBv0+5513HieccCLGGH72059w4MA8hx1xFHv3z2PKkmOPOYZVq1YRhBG9bhetwNWa/Xv30mq1mZubY/++JqPhkNtvvw1TlmxYv57de/aitSJsNLn73nsAxdFHHsFgNGL7rt2sW7+ubgId7JwnbcSnMsN6odrEuThOakPuqt6tWBBFKePUWABWpHCyYZDkMvDDBtoVOUnQaOE3GgSBjz8eC6BjfSml7pMNmNKuWDZYY9hqQyEpRmKcHzUaVGwnL/NrNpHn+bWZeVVDOL4112406HZ7aLcyucamJLtWsuYR2bVCzHWtNYKVLSklyZJZlkrCdZqQTsZMhrLm5anUMdgaLKvT8Ixl+CuM3ZCWdoGS2k6as77vi6H6VI8sTUiTBIwk/LmeR9hoEkYRQRhJk9h1CZxAUqc8nyJPSeKYwdKSZT0t+6tVaWVZlpEXOZHn4ikHP4QyT8GuX3leUOQ2WdCeq+NoSmM3sKWsha4jbCztaDxXNpdVXVqBdY5lO4ihsvhQBUEoz4wRmWbl7+U4Ti3ZMTa9yhQZ8XjEeCQSO2MMyq69nu/TaLYIGwJAJXFsU/XEiqOwSZlhGIl1SpLWDX9s/VIaqSdMWZLEiQRcWAN1pTXaODb0x6mZeQfrcaiGPlRDH6qhf/Ma+tcHnlhGyooaKSusplouYlGu9CbCAk8rwCr7b1n/dK1L9PwQL4xA+2CRymarhTElS0uLNfiCXfQwpmY4KaMwVP5RRoARpfA830awSvfCcdxlA+h60tAYVdFXrRbeMTX9r6YAlsuF3DLIUP8AFTOwkmdVxc9K+V3VdUEpsrwytlaW/qZXAB42xlAtG6gbYyhMdW1LsqJija1gL9W/XzF2LKW7YgnZv2Ow9Ful7MIS4AcRfhDiOC5JnDCJJwwHfSbjEWkS24XbqQusFgABAABJREFUPIo1VT3kFYupPqwXVuUhpW36Q3VNVLl8jsaUFIVj36Nb0xArEKdO/Vh+cVSp6gKiRpk1Ni1F2E5h2KLRbDE1a2nkUYPQLsQVi6kqEvKirM/XqZhiVo9rb0D97NbnoOxzvSLatCo+DuZDZXE9VvPMkJcFcZaRV1G41ougBJI8t8Z0xt5yg7HJLEUpKQnK8XDcgHZnmnZvmu70LL3eDK4f4vqRJOuYkjSJSeIJeZ4zScToME1T8iyTbm0SkLcaBH5ApCU6uAKNq1QFzxM/FM8aXbqOSxhEovd2pCjXFVPNGPJCTD8TlBQEClASK+s5rsSYKnCUlUw6uk7GMSUk4zHDxXn2br2XydJ+0uGCFI7G4OrleGKUtkkSNibVkQhhU8o4U2VJiaXaRxGtZpNOq0mvFWGylCJLyPIC7Xp4UQM37OAGEWGjKSkpKDzXtxRtSSZLs5ylpUXGwwGutl0Ku2h6jgNlQZFOKBwP5Xs4QQNPOxRZTNafr7ub2PkSZex8YWNfbUc+8D08VwoMMaoV74mqKNBgvf4MaVrSaMg4C4OQxcE+Fg8cIEkmRM0G3ekZWlMzhM22NdnMbZfLwVXSqQEZ057WBDZFqWKnVhuyokhtotYYR0sIQBXJvPJwXFdSNTGMR+OaZVmZdeZZUYcFOK4r/gsHeaLOnl27GfT7GFNyw403Eqc5B0YJ9zzwML7n0B/HbFk7x4a5KX58x/00w4BGI2JxNEEpxfq5aRb6I8aJGOp6rkcQeITNFqs2HsHGo05kamaa6akemzau5yv/82Ps3bmdw7YcTuC5FPlyAEN1DAYD7rzzLu688+3116omQvFL0dinnXoaV1xxBRdddBE7d+6kLEs+9alP1b9TeQX9srQOZC144QtfyAWPfzznnX8+g+GwbqyceeaZfOhDH+KSSy7hRz/6Uf3z3W6XPzvrAtoNH4eceGTlhIMl1q1bh+u6DJOUqDNFa0rjNVv0+wMGgyF+GNIIXHqNgIf3LqEoOWymxSiVDuW6uSn2L/TZv9gncyORSGQZeTLB930uOOds5lavwnVdbv7Fdaxav5nZ3jR33XknnqtZNTPFkYefBkpz7733MDU9g+cF7N29k7m5VcxNTfGJj3+CudlZzjzjdKIwkNfPMl5x+eVceumlvPzyy5ma6v0K0FRdF9d1azDGYLjwwifwkt96KWecdjKf/vSn+clPfsJ73vsPVEmxH//4x/nRj3/Ec5/7XJ717Gfz+Asu4Nvf/jZxHANw3XU/p9Pp1vdnaWmJr33t69xyyy0sLCxwy623MT07S5Km/POXrqTRavOHf/JG/uUb3+TA/n1c9vznkxsYJymbN25kNJxmf6vDTbfcxKq5VZx75qnMzy/ywGDI5z//OS66+BLOedw5XPNv1xI1GkzPTPPd732fjRvW80evfz1f/MpVTCZ3c/7jzhQ5Umkkn/pgPqyJdpZloBVpmrE0GDIcT4SFZudgaYpZmV1Z4rrUtVtiU+0AdAlaufQ6PYJGg6jRojU1Rxj4BJ4mHI8o8lykT1ZFIBswB6MdxnECqJqlUYFOjUaTsNEgiiI5bWPNu5XYHQRhiOf5NBpN0lSkRc04odmM6LSaRFGDwhgmSSZd/CCXlCvHwXEdQl9kK2WeUqRxXV8ZrSlyw2iYMRksMRksYfKUMo3J4hF5GsvGFcucR66HsXsORym0s8zwr+LFtaqYmpowCul02qxdPcfiUp+FhUVZ1216XbPVIWxENFotqScch6DZwgtCXNdnaX4/yWTM0vx+RsNhrcTILHie2qSsLMvxPVuzeAHDwRJJPGE0HDGJY5JUZLzalc2678k1yXNpjWql8FwBC5TWBIFvkzQ90iSxXlfiIeW4wlZpd7o0Gk1837OKiELSzHIBOEF8WTSGMvBxLPA07C8x6C+xsLAgyV7ttiTTBYGtoZtox6XfX5KmcFkyGPQJwpBup4sf+GS5gCIiuXEpELlfbgy+71MUOePxSMrqssT3PfFFsl5dvlK/sr4cbMehGvpQDX2ohv7Na+hfG3jKknQZRLF09KobUxojruf2aytZOJVZdGlAuRJHGoYNiVcMQqJGuwY/gqgpqHqhaHenCcOIeDKhv7TEZDwWhI7cektZj6caEEFoir6P50kkYhCKi73jelQaUjE2K1c89IKuKmPQWgy/hHkkYIMgxQplEWtlHzRL2Klfw9GyoLqOxKgqrWoZWGkBCnu2WPhKuk+5pUdhDbuVRR9VRYO3zLH6wQFjrz+GZYQYoRFX2FDFonI9D9ei0I7jWhM76s5XGDUIwgjPD+zimYi0rlrglUG7y/r3GgayrCY5t2XgqQbdSlMXqDoVyp6TF3XHRmmNYzsvRVHgekUd2Wqv9KMlBRiMqbiXZrmwtsBQnmdgxNugMzNHb3qW3swczWbTJtS59n4pMdArRUud58upS8sGcNpSSRWlo1AUUNoORSXPtJ+LKonjl6lwB+ExGA0pDWIiWsqYtJEBdTGRl9JpTXP7zJYluZGY4xKN44Y4gU/U7BC2OpIY2JshiCLCqAEa0qJguDgvslVTopTG9X1cz2eq0aqBQ1kMXcIwIoxCa+gp41cWSL/2b3D0ska7AlEd7Vi/OWrAWcBckYFkecrSYs54krG0sCCGqUYoveS5aPGTcd3NwQtwPHlvS3t2MZzfR9pfRJUFfhQSJxM8SikGLdDoaM0kNWRFQVGCH3i0ohDfd0iynP4oJi8MynFptdo0mw3CMFieQ5XGeD7KD3D8iO70NH4Q4XohuQLlSBez0W4TNZokac78vt0MRwOKIsV3PcLQw/MkInVp3z768wcYDvrMtadwXAHXB4sHSEd9hvu20nVzgpkGGF1vTD1fFnvf9fArL4qyEA13UVI2u8txyp4Y9VOWDK3fxmAUozwXbVIW9+8mzzIazZCNh29hzbqNbDj8aLywgbEac9/OyXmeMy4KtI7l9a0HnzTCq66/LHZZJsV2UeQ0GxGe5xH4vsh1MXXUMVQyYyVM1pqhW9TjtjQlppBOjaPcg93TFIDnXvZ8Dhw4gDFwz459tMKA4w9bJxu/vOCw9asZJyn3bt1FHKdsH8ds27Mf3w8Aw+75JeI4pd2b4lkvfgWTNCPJC4zj0Wz3aHWmuPVH32LUXyBNU2bWH876o0+ixHDx057Lls0byY0izXJ879Glw0qASMy/f6khseKopHrKMl/nZme58sorRYKRJLzoRS9i+44daKX473//9wSBz3/9g//Gf3/Xu7jiwx9mPJnguC7NRoNPf/rTHNi/j6c/9VJ+/3Wv413vehcA7//QFdx599284CUvkRj2LKO7/igevOdObv7ZD3GDEa7nkZVQ6ILSZNxzz/34vkcYBmI6mufkWc7qbkScpFx354PMTE/TbrdYikvaM6uZXreZrY88QhhFzK5aQ6hlzYtzpLguC9auXYvnu6TjAScd/5ja/HRhYRHtuGzYeBgP3n8Pi/PzBGGD8887n4suuphLnngJ1157Leeccw733HMPrutwwQWPJy9KVq1axXve/W42bNhAFWe+7FtoOO200+q0weq+zM2tYmZmBlA8/enP4NRTT8VxHK6//nr+y+teh+d5HDgwz1Oe+lRJyJlM7PO2fB+vu+46zjrrLADSNGXHjh28+jWv4YUveCG9qR4PP7KVm2+7nSc88VLSNOHqb36NxxxzLDOPO4vI93l42zZ27dnDAw8+IF3jNOGkE09ift8e/vh1r+LsS57F3LoNHHPqOWzfO8+u73+PY48+hocffIB//eaPed1rXs1gNOStb387xx57HMcdewxuxdz49xpo/4HH9h07yQsBAzxPDJgnSYqrFY7vkWQ5FZs6zfNaMZDlto5Go70ARzv4YYN2b4Zmu8vUzAxhGBJGEVmaMp7EJLEhajTxXI8kiRmNxtK5RuQ8zXYXY2zTLkvFENwPaHe6tNotwjDC9/0V9edyo9P3fenM201sUZS024YoDGg2QmEiZRnKFGSTMXE8YTgcyG9rxTjw6jk5nsS2aawImm2U0mRpwnDpAJPBEv3FBSajAUk8EYaFVhi9bOXQDIPa7xTE/6hKgMuLkiTVIkdzHDrdLq1WmyAI2b/QJ00zlOuRZzlau2g/pNHuEEWR1Ixa2Duh79FsNYkaTVSR0l/Yz3g8tl4sIZ1OlyAIUBgW5g+wuLhAfzikORzQKAp0A5LxkOGgz77du0gmIzH+9X1C36MRhRy5eQOeK43Y/mBAkuUkqQB3Wjs0mk3arSbNRgOlBECK40SS61DgeLQ7XQFpp2fI85w8S1lYFOZqkqbEkwllnqNNSZF6skZmKUuLCywuLZGXJZHn0+50aLTatDpdpmfnGI5GDMdjwjCqm60zM7OEYUir3UJrXSeYFmnKpCzxHYeyFG+ypaUltG2qT8YTDIY8KxiPJ5RFQRiFuM7B7/F0qIY+VEMfqqF/8xr61waecrvBFvDJ+vBYllNh2S3lo1g4MhiNNdZTysH15aEMm23CRpMgiIiaLTFQswMF7ZDmBUHk4YfQbnfI0lToqUWONppSaVBl/YeWC1ldR7SGjSa+H0h8q9L2fIuarFQtomblv+XVll9P/q+m6dadxRp1qmRtGsdza1aVsgCQWfHilfSw9jACoBTpoAXFZPCLYWDVtbSnaz9MRSOrf1bV718W9Bp1rXyjbCe5ogwvs9C0NWCrXO51DcbIAiK691qaaK9N9VneWmX4vvz+qhOugEkoa0Nc+bDgjv1/vdKjyRgLnunq8j7qeyUGZUqhIxtFlbQoP1PWVOlmq0PUahP4ls5t70f1OrUJpe30Kqi7AhUrqv6woKPSCooKMV4efHmx/N4O9iMtCmt2qCiMWvZgswNC2HRWypnb7xpEB+4I3dQJWrheSNjqETbb+FED7YdiYAlCJbbgrOM4OEoovGEkQHMjaloqroPjOXVqlW8nP8d1cRzPgpBu7XmmbcQy9v/rlMSVGkg7BqoOhLDxSvI8ZTQaSCRtUcqiWRZQFKR20SwNOEFkO00hSTwhjsfkeYp4QNi/p5UwHC3g7TmaRCsoVJ2oo5UitBtz6VhK4oNvCwLXdckS8QpAu2hHdPMo8eLAKMoSHCsPNYheXOQIwoYsyqK+e4JPFxR5xmBpiWQysYzOnCwuiEcZ+WCRIh6h8phm4BC5EaqKHFBILK7j4rlSsBsMeZ7juo5cG1fo3p7vEXhu3amJ4oQky4iihAIoUWjHQ1lfvbXrNjKzag3tTlfmRtvhlHlvOdnSQeHh1e+pKHKoWgu2U4OpwHVXFtiVLFbsHG1/Pi9ym+yC9ZEzKz4q1qMweat5Xh/k6NMdd9xR/7sZRYSBL4CDI9cgywvGaUKeZuK1mGUkaU6nIzHHJYYNhx/JzNwavLDBJOtTFgXt7jRaK+LRElGjQeQ7NAKXcGYdYavLXK/Fxg0bWL9+LaD+l0EKJ554Iq7rctNNN3HMMcewbt06AB555BHuv1/8ofbu3cv3vvc9FhYW7FohY9f3fR772MeysLDAnXfeSVmWrF61ipNOOomzzz4L3/e5+OKLueOOO3jwwQc5//zz2blrF7t27aLf77Nt2zZ+ccMNvGXdOk499VQAzj33XKZnZ1izdh2e55NkOUccdQyuo8nGA5LxgNFoxLZdu+l0e7bL35FupaOJolB8bfIMpYUZ3OxO0Wh1CKKQJCtouLLWNJsNXNcT2nxVS1RR4UCz08NYo1kv8CVVV2vmVq2i0WzRane46/Zb2bp1K41WB1MaZmZmuO+++9i2bRs33XQTjuOQpnDjjTdRlAVr165j+7btdLtdCyY9+mi32/W1iCcTbr7lFlzXodVq2gj4hIWFBUA2hRjDiSeewOrVa1BKkaapbKRXNH9c12U0HnPjjTcCIu0788wzOfnkUzjuxBNt/SCgysaNGxmORtx+x+22FlHs27cXDUx1u2zbuRPf85idmabyR6zYVEWes379RkZLB4jHfQ7s30eaJnTaLQaDJcaTmGajCXaOUsC9997Ltm3buOSSS/4fja3/t47hSNabwlpVlAjDTznaNtCKqg9pk+XsZtAa5npBKFIXxyVotGh1Z2i02naj5aGVEmaSKcFR+GFDpGXNVl2HKdu0C8OQPC9QKqfIlfig+j5hFMpGNgzxLPBkzLJvaWkMvufV1gVaSS2hKo+WquFaFOIDm8Yk8ZjJaCiBMkDhufW8HidpzVgqEYZRlqbE4wnxZEIcx+IplGc4UpSCEYBCK4XvWyPrUoJfpKmq8X0Px7JpskLqQz8QDxrlOIwmsX0NB8fTaEf2H6UF44qikJh217OKBIXraIJAvGKXaz6Ftk3QPMsYDwdMxgK2jYYDa/icMuz3GY+GZGlM5Pu4HXktR4vxeLfdxPdc2zSGOEkZTRKwadytdptWs0HDGrBXSYAFGoOmVFbB4Ad4ntQaJgzJspyxUpYBlaMwZKmDo0oKpciSiTCwkhTX9QjCkChq0On2aLc7BGHIcDSmKEp82/T1HIfAmhYr7dTeVOIjU2CykvFwQJZbP7KirJvk2DSw1DK+xGe3JCNHH+TKgUM19KEa+lAN/ZvX0L828LTciXm0V1OVqpYWZX0iKCm80ArHDdCOjxOEhA1ZIJsdiVINAqHrrmSipNYYLwh8Ai9i1eo18gCUJXmWyzguS8pSkDiJ4BRvpiAUfWwYNqSItAOtKAqMTaZZaa61zEgyy+eOZRCpRwMQMmlqjOX3iIbTLrzWKV8MzD2Ukcl0JRzzy0bVFXBTTVjV95SyCKOqHORZQa2SQ6OEUlyDJNT0PlXR/BxH0HDfE+2w5+H6PhUNFAs8hVETz5XEiSSeWApvjEL05SpY+bcrbFeAp8pUO690qytANakvZBLJVE5RKnRhGU9aP0pTqgvLiCocFMoyxxyU0aCqa1S9nsIYLQVMsVJ6qeT+d3pMr1pLq93B96XIl06ElcZZdlRhYz0dm363DFD9Et1QS0yv0Q4Z6aNQX9HK5v9pgKfYSHtG2QWzNJKMU9h7l9kOv2h3jVC8HZdWq4cfNgmaUzhhG+0F+GETbRP/RskYnUqscRRIl7TRbtNsRMK283yazRZhFNHt9vAt4q+dCtxFJnClhMprNdPLoGr1PQtgO/KclIhHV1EseywURUEaiy9ZkeeMJhOGoyEL+/eRxRPKPMN3HSnMXB8rEacwJY4nFOBmGDJpNognkU2SyXF0ld1oJ9ZCFlLPk/FojLAcgqwkTQv8tgZcwtCjHCaSYmS9F1zXZX5pHt+X//eChvjzFyW7tz0CKKJ2j9WbNhE2G6STEcMiIx2PCDszMgZYlpuWuX3PecnundspEdloOlxiMlxiYe9OQicncBXNQDws3ErSatl9kr4jby1NU9s9dgibHRw/ImpP1eaBgRJJg6sUmanCIcTLTdJSIGy0iVodVm86nKDRIIgioU5b6UiaCYNWIpglLchxJa2pzHPGWQqIfNi18a9BEFlwWK243+Xy3ImA9rmNstbWp03WGfHDiOMEY72KyqIAIymilUz5P8OhleKsxx7PaDzh2htu4cgtm/Fcl1vvFN8jpaAVibTYcx2SNLMs4DYveeV/pTe3hk9/4mPM73yQfNznrMdfwnDQZ//8fi586vM45cTjedbF5/Dpf/4XhuMJL3ve09ixd57+aCwFp53jV16ut/zlX9Ltdnnq05/GH//RH/Hyyy9HKcU73/lO/uIv/gIDXPvDax8FDKycMpVSfP7zn+dNb3oTxhguu+wyvvCFL9Tfv/rqq3nFK17Bd7/7Xb761a/ywQ9+kLf81V/xspe9rG4IVYEkAK98+e886po1Ao/TTz6R008+kec997n8y5X/k+t+9jN++IV/5vDDD2fjho2cc/6F7Nuzm727d3Ls0UczGI14ZNt2+rlDq9Xl0iedySSOiSdjdjzyIGUpCTdr1qxlaWmRhx+8n46NQDaOL40y7bBu4ybiOGUyidm/NMZXJe0AnvqUy9m4+TAcrfnylV/k+htuAuBJT3oS4/GY3/7t32L79h0ARKF4boxGE7TW7Nq1i2c88xn87d/+LW984xvrJlV1LesLrBR79u7lda97La973e9z+eWvwPNcvv3tb/PqV7/a/pjciDf8yRt4znOeU7/G0uIixx1/PLt370YpRaPZoCwNw4EwVzZu3MRXr/oa2gsYJbKhbTbbHH3kkaxevYr5/oDtC0P27t3D7q0Pccedd3HpU57CueeczZe+/k0O27SRM089hY987GO0223+7t3v58tf+yZ7tj/CRRc8HtdRTEYj/uZtb+Wkk07iJS9+CX/2Z29k/fr1/N0738nnrvxn7rn3PowxfPCDH+QDH/jAQb8OD0ZjAeKUWja91po0zymKkuEkts3bZUsKrTRBo0Wz3WVm1VqJJnc8vKiJHwroOekfYDJKmJQ5pXKlq+6GtLoz4i+S53YDLF5BURjSbbWIE/GWKrLU2lMERFFEFEWEkfieVRNjlslGJM9zPFsvGWPI0owks/5FaUqWxEhcd06eJIwHfYaDPouLC8IwL0s8reqk6cx6XYknjmzghFAhksThaEQyGZMlCYHr4Loyr0n9puk0AluHGpK8wEcaiVEYioWC65EWxjL8xaAZpVkajAgDnygMaQSRTYVyGPQHxN6EdqtJ1BSWRJbnkhqWpUTWR0nkKaJuKI1IaUxZsnhgH/1+X0DGPLOpeYrJeARlgacMG9euImo0UNphPB6RxDHNKCTwPQLfw3Ud4iTDG8W4Fkjq9XqyqXUtoGD3COKn5ILjMRpPyPOCNEtpNltE9jyXFhfJ89wGKGR4jkKZHGUMg/4Sw+GIOM2YXb2a3tQUvalpNm05nGarg+MHeFkhgBEQRiGNMMR3PZI0tSEVicixitImu+Us7N2N12jj+BE4PkVZUFgfsSIXz7owEF+iNEvJJsWjZNYH43Gohj5UQx+qoX/zGvrXl9pZDbhItcraw6corOTOVINMzEq16+N4AY7XwPF83KCBH0lXxg0DtOeD44CzLG/ycGtQwm8I+h80I5JELmASx6CW0/Nse6VmGjWaLZrNVm0KWIEjEvtswYIKfLIRsHWLEgs26RKsmbW2D5ZWjmUTGcC1D6uu0wBcPyAIQ1lIFRRpQp4l/HINZBtZdcFegSas+BpG0gBZwYCqf78CozR2AhEqXO3lpGUguTXq7eAH4TK9zw/EYE5rKuApipq2gJAORGI/DEj0pDWqq5heFXRW+U0VpUHlGUWpLLC37O9V+yjlywyuolD2HheCPFsz9eUkD4VXehjX4NuUGllcK9R+GRzKi8JKH8V4tNHp0Z2RBd33xQizyPMVQB4WV9RoDa5roy7V8kCsbklt6l6YupvjaAecijUFYnK/HOF7sB+mlOdZGIoyfvM8lxSdyu9Ku6BFK+0HEX7UoNmdIggiwqiNdkVKGoah9Q5z0G6HwPcJwwDfCwks/brVDHBdTZkbGSeuQxiEwsRTFWNNnn3XtUCqo2svOHnMlWVrUIPPY5uoMslS0iwX1llZMeOwclpDaQomkxFZmtNst0kchzxNJa656px4gcwfnnSA/TCk15um2YiYmZ5i/yN3Eg/7TMZjwMVxJEFDaYODIXAMyhSUpRRUaa6ZZA5xboSZp1x8X0xVhdJqTTSdgDBq0273aPempC+Rp4wGS+RFged6dNo9ur0ZRqMR8XBIP9nPpt4MjUaDqek59m99iMlwwiNbt7Fv/wEc7bC0tIjre3i+RzpeRBUZDaek02rieS6+F+BobxmQpZCiqbBjVDkYr4EbiEbc9SO04wq9V9mQBRspXSgJcQi0Q8P1bVfckBvwwgg/bBBGEQpIRyOGS0t1l99vNHEDn6jRrHXxRV6CNrYz6FjgxHactbbdN5saWlYF6qMlzZk1+kzS1P6udAbLzM77hcQNF1YWgC0ksXP6f4ajNIYb7ri7LhZ379lXrxNhIOOwNzVD1O7S7M7wxIsvptFsEec5t954HaY0vPy3X0TDdwh9h97ULNK/MaxZt5E9+/bz3993Bbv3HSDPC9676xGiQFKKTjpiozwHpUjQzzrrLK688kpOO/0MPN/jC5//Aiefcko9RzebTVatXsWB/QcEGFKKt7z5zRx//PEopfjwFVfw05/9jJe+9KU88MADKwogOd7ylrfUTK+zzz6bJzzhCfze7/0ed9xxhzAqlrlTIi3Jc9wVHbwqkrw6nx//+Me8/wMfYMfDD3LgwAFGccrTn/VcnvzkJ9Ht9UjimP7SIh+54kOUec6quVnQEn6yf2HAYLBEGk/wm136wwlL9z/AaDwhjJqsP/JElOthkCjizYcfgXYc/scnP85oOMLRAsTNzc7gKMN73vsPbN+xA4zh+uuvl6aRK53qRqPBFVd8uDb2dh2H2++4nb/8yzc/aq2p1h+tNUUunhw7tj6C63kcdsSRgGzgt2/fwcACRvVhC5KTTjqJt7zlLZx91ln1dXqUn6N8gXPPOYeZ6Rlc12Xbjh1MT8/K5tvVxIMhr//D/8app57GS37rJfzdO99JbhTnPfFp3HvHrRRZwtOf/VxuufkmvnX11bzwRS/h/gce4C/e/GaOO+UMCuDd7/8Ap558Cps3buAnP/ohjzzyEItLC7z61b/Hww89xD995B956Ut/G88P+fJVXyf0XEwKL3zhi7j55pv+nw+o/xcPz/NkjixLK98vSbLEms5KMA/W/zQIA1l3G01Wrd9IEDbw/JCiyFFK02xKnatdh+6aNYSBRxR4TNISz/Not1rMzkzhKOi2G1Kf7t0jTWFTUuQZqmKR5xl5lpJl1qvDYDdm2rKXSjH6LgrKsiBV1Al6cbzsT1XkGXkmbKQ8z0niWEA1WxSaimlua3bPDwmiZWZ+tzdtzYMj0ngN8XhIOwrYvXM7u3fuQDsKz3HwPQdTh95Q16dVGmBeGGGGKYWLxg9y26TWdl9gJXk2hW96do6iKBlPJiwuLtR14ZzrETSaJNZIPM9z2XR6Hp1uj/mFBZIk4eGHHmLf3j24jsNo0MeYwk5KqZg2ux5+M0QrYXDMTPdotdo0mg0G/QHD4YAiyxhNYgl+MIB26Ha7uH6A68p5upXBuGVBuTYcSDsurhcQNVtkWc7SUt8agWdiFh0IqFjkGVlZ4DkaU+ZQlvRHY/LS4AehpGjOzDK7ag2rVq0hajTF50VLAyNOEtIkhaIgsWC362jyiv3m+6RJTA40W22UG6Bch163Q1nklHnGoL8oBvGmIIljtBaLlKopfTAfh2roQzX0oRr6N6+hf32pnaXAGevzVNYDzwINyqnTMryggeOHeH6EEzTFQDxs4AWBsFk8F9ez1EPXUohtJ6Py7gmjBr7n0nAVrc6QPEuZnz8gC4uT4xT2DRolE7DrC8jiS/KEUsKKqWL/aqaTBZyWGU4VxbAquHRNM9RKg8YCI9qCm9qakAkt2fF8/CDADyOZNMuCtCwoi4yKZllPWiv+Wx3qV75CDUbVp6dWAFNKgJiKCKU1lrqvaiOx+rq6ywuT63q4riSLaNehAp78IKSirOc2FrewBb0wgTzrj1QhpPbaWfBP22cBVdTPx0oGl4FaOlhR9GpmlAO6Snso5G1rq9sX3wpX3PotJbOmakJ9DtgBF0QNwmaLRqttO1HagnhGpHIrWGQVCKYsU27la1byj2VgzYJKhvr35HeL5fOozuUgP8qS2pctswZxRV4lwoB2fHQQor2AZnuKoCHXNIxaEoXbaFs2mhhdep4tHoMA3/cJ/AClxeSy2+vQbgW4jiJPrampUriuBBgrA1SXTKm66BC/teW5ppZrFoXt5OVMJjFZlhPnkiqV51XHRsZFaQeOsSxi7bg0my0cFJkrPgKeZxMvw4ZQX8NIUoB8n2azSbMREQWSEBSPR5Y1ImZ9jqPxlIODwdeKwFUkhcLJAAUFhszWnaVR9cStMJatqXE8v5YaN9sdKAuydILjeRhd4gehpJl4Aa6XWi8Muwn1PBrNFqUROv7i0hLj8QitNFmeEJUhmpDCZASOIgo9Wo1IYpndCIWLQsBmyhzKnNIUlgYtNG3lugRRJGmX1owRuawYJVGrRmscP8TxPMKgiUAXYiaqXA/H9WpJa5YkxOOhbJI9F61lEQ/CQAoeO9YUGq1LtKWmO45elnCYKrmykvGyvJCWtuu4YryuBByE6ZjbRCH5kG+40sQoqUGM/wzHnv0Lck0AZaXqM3Mhs9M9et0OvZk5Wr0ZenNrOPWsc2m122RFwX133MpkMuIxxx5Nt9Oh0YhoR2Hd3cQU7EwnbNuxo6ZT79y5i5lui0DDaDyxFG0HjWLt2rU861nPYtvWbQzmBzzmuONIkoR7770XgIWFBXzPr89bAYdt3sxxxx2HUore1BRxHPP1r3+9/hnHcRhPJtx33318+9vf5uc//zkAT3va07j44ot573vfy+7du2umU7vTZu3atURh9CsNACOVIYUp2Lp1Kz+//nq++tWrJJHGztnNdpvpmTmyPGfN2vUcfuRRBFETjWHjxk1s3bGTtChY1e6yc9dO5g/sp91pE8cx8WTCOE7ZeNjhbDr8aAoDw9GIhx+4n9lVa+j2epRGsW+/RK8fe8zRbNiwAWMMe/bs4YZf/IKtW7fKtVEikUeJ7OnSSy+l3++zZ88eNm7cyKrVqznmmP+5vLbajfa999yL0opms0mv22XH9m0EQVgDT47jsmbNWprNFkVR8PDDDzOZTDjqyKPYtm0brVaLE044geFoxH333QfA9PR0/Teq+3b8ccczNzfL4uISnZ6wIgaTGK0Ui4uL3HvP3czNzdHvD3j44YcJoia9dhOUpkAzt2Yd4/hnbN22jbnZGR548AEefvhhzrzgieRZxsNbt3HWGafTbkbs3r2T7Tt2MBj0mZ2d5b577ub2227l6c98FmlWcMMPruHIzRspspQ77rgdx3U5+uij/x1H2H/MYaxUNTcGjCIvzPLcqhSOtZxwPY9WuyPS12abmbnVYhuhHcosRWtNp9eVNCotEsoo8IlCn6VhjOO6dNotOt2u+EdRMOwvkSYxw+FIfGeyzM6PEo5S2pTq0ohpdzWSjK0TsjSVzYox5Fo2UZVxdVmWoOz+IBcf1SIvSNMUEHaTZ82kjSkIfN+aHIdWGuYRBAGdbpcwCGk1G2RpRDJu0J8/wOLCPLK+SHPV9zwoxdQ7z7PlJqwdP7XvDsvjqcpnL0tDqUv7N0VW1mq365TKLJMatDDiK+N4Pto2R/NC7Docm+jnuh5pmrK4uEA8GeM4DkWeEnjiC+VQ4mqD5yhCPxD5k+PSiCKiMKTZaAiAXub0+3mtylBWThlGDbEosfV8peKovu/YcCYB8QJcPyDLMsbjCXmRUySF9esROVGe5wJQuwmmdDBlSZpmdh8T0mq3abc7tNodXCunVBZ4Ujq3rJ6Mssgkbc8m6mmtbDNW1dddkgytp5DnUmBIC4lfL4ocU4EbSrxoV9b3B+txqIY+VEMfqqF/8xr61wae0iy3J2w341ipm+OhHRffj/DCCC8IiRotvCCyaWmRnRT9ZbDJc23somtjW32CMKAZBfWF8jwPRzt4jibwXVqtFoNBH60dO/kbHHsunideTkFgjcSVkkm3kMjS3MZelqV8rqVRShZ/0bLaG4O4+6MEyDHGULrGsqHE4M1xfWEQRfIgekGIH4iBax5PGBlB9u3Qrdk/FQ5VQTKPBp0exYNacVS/Z32cqMzfFK6j8F3Hsp0ktlFrLWCTHwhCHDXwXAGenAqAsguC41idf5FDkljTPNEoGwOuFsZUGEay8FAh4YXQaSvwyYnJ8hylMiAT1lO5nDRYrSVKQVlqlCopradUFfNbFQPygEunWlhIAiI5Ky5HWZZ2sJS2YxYxvXo9jXaHVqdru3Q25lFplBZ/igp0ogbBykex0iowsiyrzplMxtWC6Ni0waIQjXpZCKW4AjQP9qM/jsnyjCSVKFDxR/BpdqYJGx16q9daz4gOU7MzksjiuSwtLeEHPrOzs0z1emIo6nmChjsuynGYJCmjyZiFxSWZgMlx8fCVSxj49VO97AGn0BUK77h4rq6L4KJQ5KVhMkmZTMaMxyOW+ktkeU6Wl1a/7uKHYe13lqapRfldMcVzPYLAp9vt4DiKZDxiMhpZc1Vtu0cujWaEHwRS4NkCUysBwZvNiE2HP4YHsoK9e/fjmxzluziBSycKCRzwtaLRCojzgh3zY0pclPaJS01R5EySVNIlHIelpQXSNCHwpbPY7k7R7vZwPJ9JErM4Seit3YjrevSmVpOVhsFwSKs7RVYacuWQ5AWlkk1mGEZkyYQ4TchtrG672aDVaNBsNJidatMIXJqhi+eJ5FmHLQwOpVHkWSq0cAs4aEdAf1yRIpQYPNezdFvxfsvyjKQs8WyKjt/q2nAISQ5VSlNoGA+HDMcj5uf3AcKOaTSbhEFDUnIaTTw/IIoa1nsiI5lMwGi0tn/fQJymFPnYNhEMWknwQmUoLKRXoSenNjbcdxwaYSgbIQVZkpDEMePRkNFgQJampGmCF0a4rkHHKckklljt/ySH74mvSZykPOlZL+CIo49DO5pzzjyF444+kjDw7WbA8M0f34iJY8447ije/w/vZTwec+3Pb+K6W+9mkma87NmX8rOf/ZyrvvEvbH3kAc48/TT++9vfwo2330WW5Zx1yonMLyyyuNTnZ7fexZGb1nPiMUcs0/KThNf+l9fyb9deKye3YlKtfH/qZooxvOa1r62LmSzL6q4tSJEzNzfL9b+4njPPOpPhcPSo761evZrvfe97vOtd7+Id73gH2nF4ylOfyic/8YnlhsOKQ2tNPIlZmJ/n0ksv5ZFHHqnTnarjTW96E295y1swxvCmN72Jv3zTm7jiI/9Uf//iJz4RpRT/17vewyte8Qq+9q1/BSsJdxyHNEl5yYZNvPLlLwWl+MmPf8yb3/hHXHDe2TzxGZdywXf/lb9+29v44AopmFKKT33qU1x77bVceuml9VqZWlPzClT76le/yu///u/zve9+l1NPPbX2V6pe46//+q859bRTMcbwu7/7u3zwAx/gxltuJgxDzjrvfJRSbN68mZ///Oc4jsNgMOCSSy7hoosu4ofXXsuTL72Un//855xyyimPAu3e+MY/47LLXlCfh+M4PPe5z2X/gQNc9oLL+OxnP8c5j7+Qf77mF6TDRdwi48tfuYprfvgTXvXf3sDb3/pmNq1fSzEZsfmZT2FxMOLr3/4u557/eF79ylewY/8SZz3uXJ56yRO5/+FHKA2cf+Yb+dlPfsitt97M9NQMZ//WOXR7PV7zqpfjOJpVq9bwl3/+RsajEcl4xNfihCOPOoZrf/wToiDAdQ5utgTA0nBUgyKV56ZyfRqNiCAIaLa79KZn6fSmWL9xE47jglIk1nNrZnqGdqtBFAZ0O10b1KLwg4jRZEK/P6A/2k2epYwGAwIHWs0mW7ZswXM13W6XW2+5mTxLGfSXaLZadmwasjRFOY5sQnPZpGISsjQlSWLGwyFKgev5GHRdZ4WBh1IeSZKQZiLRSNNMWBiOpt1u02m36HU7dd0fhCFFKcyRTqtFGAa0mw0BtJUEB40GBUUSIx4zBUmWYXKDKVw8+7eLvGA0mYjkrimMIGXBkEq2EidZ3YjFFORpgjIuvV6PqakppqamaXanmMQxaWGYmhWwZnpuDa4fUSqHVq8nAUJWjueFEa1Ol2azSVnkJPGEssjQlPieR6sZ0W5ERKGP77lEYcD0VBfP9SitJ1OcZmRLAwHBlUOj1RJgw0iEvHZcokYT3yYyx3FMUWSQy/3GgCoh9AIcz0O5Hp5SuH7AGscVg/N+nz27dzEejRj0+wz6fbE0iSeykdeS8tXudOlNT7N+42a6vSla7Q6PPPwQruvR7fbYvW8fcZLJdcqF8dRuNShyWTenZ2bIi5L98/MoW9e5StHwPHzPYzQaMRwMWFpaJPA9NDBJYir/MgHcKouSg/c4VEMfqqEP1dC/eQ39/wfjqbBSOgffj1Cui+OHojH3fMJGCy8QtpEXiO4yCCOiqCExpb5fm1hrG8GHEoptRTFsNQIcRy8j6dYDSHW6OFozMzsnxVmaWK8dMc/S1mupYtXUkjoLNhk7oa0srNSj/mFlWCjrzF59lsNYHbV2HIlU9Xxc38cP5d/VZ1MWJKbEcVcWwGr5szJVBMKv4oI1CvWrHKiqSF9pGi6LoK7pdBXopB0tiLplOwU2AlbouF4NAgqlX5B20sSaWso9EdTWdlRcX8BDx7VSOZEt5nlCWRY4Ns1QihDqrlBZsYdgxaYDjFqO5K4myZWdDqeUBUike1XqXYlTlFTxC1VXy/N8Gq0OzU6Xdk+orI7j1qiuseAeSCRplTxRn4sxK85l+SmopXQW5AORM4rvgnQ40iStC7L/LFK7rChwg4hGZ5qw1SSMItqdHt2pVUTNNt3eDFFDUg5bnbYAxK7LZDzGcR1azSaNKMJzXQFlkSJpkojxf1mWtJsNAs+lFYV4joerrZ5cyXUsrCl8rYfPU9LJuB6neZHVEdJ5Lt21zEo/XdfD9R1CP7QmmIHtPhUSgWq7odifjcKQZiipHj6GwPPEyFXZLp3r4vuhHS/SWYgnYw7s28Xigd0MFufZtX0bw8GQEsUkzSzoaSgzg6fB1xrlOhTGARzyEvIiI8mH1vwzEdNH60nhup7o91sNUIbReEhgFGmeYVBM4gzPVYA1+88yJnEiHmleSJJk5HmO42rm5mboNANrAmulta5HK4poRhGdZoDnKFwN2hXzRWNNWZUxeI6DRlM6rhR8dn6pYlmFmCvyBNcPKVHWeNXglAqUK6+pHQpTYgrZMI8m4lmRpilh1MDzXLzAk8LElfhghejCVWlwlUa7HnhFDWbESbLc/ZTBKDJhU41PG+1tN14aVQcTaC0dssJ28OOJMFMm45jhYEQcT5iMRxhLQXccV879IPeXqA6lNGefdwEbN23imKOOZNNRx9HpTdNuNVgaDPjxz28gywtcR+N7DqH2WNqzk49d+69gDJ1uj3MvuoQsz9i7f56lpT6u77P58C2cftpjWbN2HffvOsDszAxZEvPjn1xHf5KQlYbDNm3kvnvv5QffuZqXvfS3mOr1LOXew9Ga8XjM85//fM4880zKsuSaa67h6quvBuDII4/kKU95Cl/96lfZvn07lZfTGaefXjOOsyzjwx/+MOvWr+Oyy15Akeds3bqVD37wg1x55ZXs2LGDP/zDP8T3hUVlrDw7CAI++clPkBcFr7j8FXzpS1/ihhtuqF9zMpmwZ8+eGnS63HpQffzjH5di0H79wL693H/3nVz5las48qijuOyyy3jta1/Lww8/zJvf/GZuueWW2i+wYnVUviSu44KCI444gne84x2cfPLJUsT5Pk99ylOY6vX4xKf+ByeddCLPfuYz8X2fY485lne+85189rOf5ZZbbkEpxQ9+8AOSNGEynnDbbbcxHo95/wc+wLnnnMOrX/MaPv/5z3Pb7beTZxnXXnstcSwmyXffdRef/vSn+ME1/0aeF+zYtZcXv/jFHH/88QRBAEAYhrzhDW/gsMMOo9kSmX1RlhT2NTzPY8OGDdx5551c+aUr+aM/+iN+/vOf87WvfQ0/CDjuuON4+9+8nRNOOAFHKcbze9i8bjVzU10+8L730ex0eemLX8CuXbsYD/psXD3LNddey2J/wOMueALDScp3fvRzvvsvV3H2mWdw2fOey/U33UJeGo4/7nge2baDfXt2M9Ob4nvf+Vf279vHwvx+QDEajXnCBY8nyzJuu/12Hnfe+Zxw4kl02m08VwCLg/0wSuMHIUHUYHpmDj8MCIOQ6ekeDcu8abS7RM02nalpO6cZRv0BjufS7vQIw4DA9+l1O4xHI+I4ZjyZxxgBpGemetKUcx1ajYgokvp0ZnYVjuOy9ZFHSLOMyWREo9kQOYYfiFdnsdJGo6ibjUXln2ZlgNp1cR2HwHfBdskTu+lQiDem5zpEYUAU+Chd1XOVX6oYfqu8oMhSUpMzzBP5d5IwP3+AwdISo+GAndu3Mb9/n9QBysgGr2JXFQIsNUJhYbpOWZuDJ1ZOFCcpfhDg2g22YxlQQRjheD4GJV5XqXimSHNW6mcBaWIcLfW3MZq8EJ8q13FpNBpgChqh7GE86/MqJuARvqus3MmQ5yWlyUE58j6UAExFIZ4u2vXxnCp92tbirhihG8TAXPxFRWki0WoFk8kENy+IGstWFK7rEAQ+UeCzZ9eQxcVF5ucPEMcTy24rxPvV9+l027R7UwJ4Ts+KdMdxLYiYUyDAc6vl0+20bNhTjuvb/YTnEUUNK80y4jelxP9FIVLfeDKu9239/hLxZMLC/AHbzJUaI7fMoYP5OFRDH6qhD9XQv3kN/WsDT6XSlo3kEUQtXGsWHrU6eGFIs9W2yXRy84TCGtFsNmoabeUmb5Sq5XrGgO97EsPaDHEdjVMDEfLhqDau4zI1PUOaJIyGw3qRMyavFzNlAYayVI8yES+rFD5TybZqy29LbFtmE2HsX62lXfLQVBRoP4zqWEsBnDz8IEK7jhiYZ8n/wqTagk7/G2xC/e//sfwzSvT22tIUXQvQOa5Tx2Xq+vtOLbPzrDGh6waW5eTJ/9sEBM/zZSLRy+ZzKAetjKXyenh+iGeBqryQKEYSRJOrC3wjC3plvG2ojMeXqfrC3Fy+AKYUV34QBtRKOl8tcysKtJZI1rorrkHZZDzP92m02rR707TaXRxXFjFjxDi+NLWNnaUVChi1sqmiVz5rFvMT/E+uhUZXbO1atpnnkgqUWhS4WgQO9kN7Ho12l97MHDNr1tPqdJmZW0VvZhWNqEkrauF7Qmn1Ql98F7R4KWilpFtpF0AFJGladzilSDW0Ww1C3xdzYyo/L5fKn0yVihzLPizFBHM0GorBqe0kFaUkhygLIpqyrGWfXiBGoJ7nEvq+aO2LAo2kAFX3wfNcGoFP4HoWzIYgCKRbpCo/NwelZQosCkMymTDsL7L1gXt4+P47mN+3C114jEdDwLI+C/HmyFyDq8DTDkEoHmSFUWRFSVIY8iyRIj7PKUojk3hZEEYRJYYwCsVTYjSkxKEw4qMxmSTkrrwnp9AUCkajkcTJare+To4DM7PTlGmTKAjxAnmfxiiaQUgzDIl88fIwZQHawyhX1h9BXWWecpVdDK1ElpWzItLuQKM9TximhQWWSynCDeIdkJUFyggoPRoskdkEpbAxQxiJZ4EfhDKfGr0815bGyoRdjOdLhH2ek6eZgMx23dH2fmFBXpujhMwfVbiCY+dIZSUPGWWe2QVzwng8pt+XxKHRcImsyK3cyuBqjat/dd49mI5Op0OapmRZxulnn8Ppp5/ORRecx8JgTFGWdFsNvv+j67j5jrsYjCYEnkMrCjj9lFPY01/gX7/5NYbjCZu3HM5lL34J8wf2k46H9Ad9tOeyYdMmzj3jNHKjuPvhHZx65AZU7vDT664n0y5+1OS4I7fw8MMPcdVVX+Mpl15Kq9kiDAJmZ2eZnZtl6yNbOf/883nZS19GFIXkWV4DT4dtPozfednvcMcddzAajymLgosvvpgXvvCFdDodlFKMx2M+/vGPs2njJl7/h39IWZbceOONfPazn+X73/8+t99+O6973evq9aLVatGIIgC+/e1vk6YZl7/8cq699lo+97nP0R8Maql9dSileP7zno/neXzlK19hOBxaSRCMBn12bnuEj3zkI1x08cVcdtllvPjFL+a6667jaU97GgBT09Niqgm2oFOyAVUwGAxoNpu84hWvoNlsyo+UJeeecw4nn3wyFz/5KezZu5cLzj8fjKHVbvHKV76Sn/3sZ9x22230ej3uvuduHnroIRYWFojt+vLVq65icWmJV7/mNXzzW9/iqq9ehec51iNFmNkPP/wgX/7Sldx1930MRiN+fsMNnHnmmRx77LG191UQBLzkJS+hKAqGwxGNRoNet1tfmyAIWL9+rcjgtm3lG1ddxapVq7j22mvxfJ8thx/O6//oj0jTjL379jPYt5OZY7Zw+Kb1fPnLV3LJky/lla96FZ/54pVoY+iEJ3PjDdfTHwz43Ze/nJ/cdCfX3XwHX/3SF9FFxiVPfCJ33/8AeWnodKfZu28/8wfmcTD89Mc/4vbbbqUVBRgUaZZz6sknCzsgL3jWc57L8ccfTzweE1tm+VSv9x85BH/jww9Dmq0O3akZNhx2OK12m163w6q5WZGnNJt4ocirtB8KN8YU9MMA7ThErY5lN3g0mk3G4wlJmtLv9wnDkGarxdRUV2ZGhZgQ+xKj3u508XyP3lSPhYVFBsOh9WoTcDS3hsLiw7QidKeac20NqmwYi++5NBuhnbMzli0glAW9XZqNiEYknjR5WYKRsZhlmeX9GNJkQhaXxKZgMhoyHAx46KEH6S8tMR6NGA6WGI/HFHkmd9mUaEVdJ6Z5TmRE6aCtRK4sxbM0ywuSJJW60JW0P9/zwIiJuVKarCjIJjFplpLnRV2zOFoLEGZ9U6s9RJbb2tSmXzoWDGtE4qfqe55IJMMQjdQAeRqT5gXaFqWqaqKaqm5RuI6L64sXE9rFIFJMlCRNacelMGBKqSkoSygKJvEEryhFaudKIp62JvK+5zIZjxgMlkSuWKUKlpKG6qFotlp0uj26U9M0u9N4rsTK59ZIPi0MnXabKIroNBvENrDCsT+njLH2JuA4mtLaaSSJGM0nScJkMqnZnEuLixJmsXcvvu9LsFGSiIF7fnA3fw7V0Idq6EM19G9eQ//awNOmox6DH0SEUZN2Z4ogjGi2OoTNphj0RVEdr2qM6Kd936dhv+46joBNpSG1xlV5kaNQ+FYPHfm+mJZZ5BU7ELBazo2HHy1eStY8bTweMR6NrHaxpMhSGWTaRl5W9M1SwBBl2U3AMgJYgU520dLatYifFuaS4+JY7bTjetanypp121hVLwjBlORpAlRyxOJRtHoqL6OacvPLV1jVkjT5tqmRycpbyHUdG2PqCfDkaBtrqy1SacEppwKdfMIwsr5XgtZqx5H34flWm63rqGfRgVdpBa5o35sdokZL2GqOi2sljEopMQssMnutnNovKbPpg1mRQ7EClBF9nIBLK4Cm5W+ywvRd11+r2EkVKKhtx6o7s4qZVWuZml1Fq90GlEW401qPWhqz3Am1k70MOgssVuw7mUcEoDIyWLVbmbHJOcUWaBoOBvSXlognMePxsE65O9iPpz7/JbQ6PXrTc0zNrBZpilOBthLHWdHnDxzYz2Q0YjIaMzs3S7PdZmpmWlhfZUGapPT7A8aTGOV4dNptpnpd2lGAQqI8B5OYJMsYDAfEaUKaZsRJbCc4jTJi/h7HEysl1bRa7XoeUY62MlVoROKh5ihFnlkpCrl0IxyNVg1JxilKTCESTo0hzVM0Lk4QYfKSMs1Y3Leb8WjAZDRkMlgkmYyZ9BdZWjjAeDRgfu9uJuM+WZqgHQ+tXSLt4jhQmoIkLcgzhTJyLViyF7jyL7MPqkYKzEkslHIv9ySdIs8YT4YCYmYZo+GAOE4YDEc4lrq9e0fB7KrVBGHE7ofuw/VDvLBBNmqSJ2O8LGXV9BSmKGp/DlNIMYlW5FpRuIFIU3MbWU2C1tabAUVe5hgjnVXPC1HKRSlnWaetFIWBLDcUVViC4+EFEUo7JEVB3l/CIB2zlckZ7U6AFwQ02h1AURaGySjGdV3arQaBF9ShAqYwNZPRuI50s+0cU3WgHMsgNQowJWEVHlCWJKkYA3iuh7Jym0mSMBoOGI+G7N+zj/mFBfbt28vuXTtknjYFge/i+R7tTpfpqRla7S4H8/GNr3+DK6+8kis+fAXPeOql5Gj++C3/P0467jEo7XD1D67lGZc+iRc955msmu7UXdVb732IU888i+c96+nEWc7iYMQ3rvkZR25cy5mnn8ZdD25l5+69bN+1mztv+yRxnDCcJHzLl4SUPMs48bjjmJtu8YY/fj1nPO5c/uod7+Tqa3/G5gce4blPfSLvec97uP4Xv+BpT30qf/VXf8VHPvIRPnLFFezbu6c+/26vy4knncgXvvAFS9se8ffvehcf+9jH+N73vkez2VxuVNhiuMhzHnPssdx+++28/vWv59prr2Xnrj30+wPCMORfr76ao485hrIs+Yf3vheDbLre/va38/KXv5wLn3Aho+FI5rUVc3Sz1eTMM87gtttu4w/+4A/48pe/DMCaDZs46YzHoR3nUQlLp5xyCrfffvuj7keexORpTNDs0Gg0MGXJS17ykppp9aEPfYhnPvOZDAeDOur6RS94Ptdffz3HH3/8o15rcXGRjRs38v3vf5/IAmlFUfCFL3yBN/zpn/L373kfZ511FiDr32GHbebrX/saH/unj/KpT35C7t+OXew/MM9XvvIVOp0On//c52g2Gtx3z9389Cc/5rQzzuSwLYdz4YUXsm/fXjzX4wPvfz/HHnssQRgKG2b7Nl7yWy9hcWGBwA8oy5IXvuAFPOUpT6HTmyLJJLXpq1//Jr+44Qb++UtfZNv2HTz+CRfzla9/k7vufZC3/f0/cPctP8d1HO679x4ue/FvMzM9zXs/eAXnnn0Wr/2t53Lx6Sdwy02/4Pdf/Qr+9E1/hQG+/Z3vsnHtGnrNBl/6/P/kpFNO5wmXPJkbbryBM884g6c/9Wn819e9lpnZWf7szX/NP7z7v3P77bfRaDYlRSjLuP/uO/89htp/2PGMZz+Pbq/HzNwqZletxQ/EvyfL89oIX9jlingyYtRfZLBwAEdrabJ1p4gt+OxoWBoOWRpNUI5L0GjRnZ6hGUWURc54OGIcJ8RZAeMJaTwhS2M2bzmCRnMPu3fvRvj8hsD3SZJYkumyFGVBqygMySz7J05SmZNdl067SeB5+K5mZGtC18afKwWu1niuxjEF8WggdVmeMRr0SeIJRZHVKoLBUp8sSynSmNGgz3A44JFHtoo5dpaJeTiGZugJwxHIc8uqNwbXcUgzScOOk7Q2fdbKMh7ygmElIak8T/2QOMkYTRZECsxy41RbBmUjDCiy2DI5R7IvcBya7Q6T8Zg0HtPtdtG9LoHv2c2fss13m/pXFiKtKw1JaRUPuhQAQjs4nm9j6UvivCQzGbmBMKrYRK7IkYsCo128wMXzsXYj4quUJOJLlWUp3W6XwPcpiox0MmQyWiIeDSjSGFdDFLVQWpMXJd3eFJ1ul82HHc7qdeuZnlstQJAxEiOfpgKqN5s0mk0C36NIJowHAyZxzPTcGvKiZBIn7Nx5L1EYsnnTRpaGI9Iswxjx+OsvLdBfXGQyHjMcDHjw/vuYjEekacr6dWvl9cMQL/BxXf9/O3YOhuNQDX2ohj5UQ//mNfSvDTxt2HIUvh8I4NTs4FtTPs8WVMrRdbqE4zji2xSIWZq2iL3JxLhQIhQ9kYM5Qsn1rf+TUhX9sLTggRSLpTE4vk/UatOdnmVpcREQXWqVVJfnGa6s3HZStj5DNY1lWf6l1DLLSYCnCuWz4IwjnkjaJm/UBn++b/Xiy8CT6wcUNrqwMs4rrdxsheDsUUclC/xlMz2Lgdi4zmXARlmmU2VM5zormE6W3qeUpcmpSqpo6ZD2Q1Xxr9bwT2kBd2p5Yrns5xBYz6woEu8B7Yg5Y27ZQY7rLT9EtotiSmMXcVUblBf29QUJVvXVsF+qgSjDSlaaXAhtTdGqcxRASuEFAWGjRac3TaPZxvelM2Co5IjavqYASUZZ8M6+bi2vY9l/CniUZE5ZyaGhtBHCFvWdTBgOhgz6fSYToRsWtkt4sB/rN22paf5V58W1unBlSXlKKUwJntYUrkPpu3YyVLVfiymF4m4sHTzLUuIkZjT2MHmGMQVJmjBOktpfLS8kOaMwZS2NDTwpJD3Pt6wyje9HNVCYl8uhALLQygKpSm0XzeWxJfJL68FlKWpGSXJDmRYkkwnxcEAyGrFv5yNMhn3GowHj4ZJ05cYDknhCnma4piDyfAJHWICOdnEdl7J0bJpJKQUGxnYt5BzKcoVxvqYOYFCpJFWWRclkNAYDe4K9eJatmCQZaZoSj2N6vTZh4OC5iixLyPOcA3t20mh3aXYKijSjzBLSOMZVStJDHRe9YpZRjsYoRWqNBlEa7fp23nWsOeOKtEkU2M6LUcrGeCNzhhJ/NVOWy3OZrlJ1auc1QCTPnufTarYtDd9bASTI67mu9RCwi2CWSwhDdfZVt7o6qs61tvdY5mhdAwNFUTLs9ymNkchXX56l8WTMaDhkPJSxOh4OSeMYz3Hwoogg9GhEYmzbbLZpt7tEjea/53D7dz+OOuooZudmAek86hLKImf17Ay9Xpfx5HSO3LKJqV4HV2uGoxGL/QH79h+gLHIW9+/BKIe0kE3l1m3b2b61oDszR7Mh0hCdSTLsrOsx1W7iOIr+cMJhWw5j1ew0Z551FieccDxbNm5g7+7dpFnGT667geMfczTHHH00r3rVq7jmmmvYunUr//yVr6Adh9/7vd8DoNfr8YlPfAKw9zWJuf3223nwwQf5+Mc/ThAEpGnK0tJS/dxorWUdajSIoojxeMwXvvAFAH73d3+Xw484gl6vBwZ+/JOfUhYFz3nuc+l2u2zZsoXLX345SSLj6Itf/CKrV6/moic8geuvv5477xSQYvv27bTbbS677DLOPPNMGs0mL37xiznyyCPra7+4uMDVV3+LPC9oNptcdtllUjTnGW4Ycd999/H5L3yBu+66y27oYTKZyJjzxYw1y3Puvece7r/vvvpn1q5dyzOe8Yz6nl599dX1+gVw8803o4CNG9YT+h5XXXUV27ZuZWlxkW984xvcd9991ghWgKo4TpiammZ6eppub4pGo0GWF3z/Bz9gdtVqNh+2hf3799FqNjn7zDPZsWMbjUbE4y98gvWHdHnhC17IeDzGGMM11/6Qo446ihNOPJG8KNm+fQff+fa3aba7nHjCCWTJhNlVa5jft4dr/20PC4MhWilOPOFE4smY3bt3c/c997J27VoO27SJHdseYdfWh2j2ZnHCBuu3HMUjW7exsDDP9T/7Cc1mC6UUa9ZtZO369axdt46NBw4wt3otjXaHDZs20elO4fghnakZNmzczKmnPFY2+P8JpLJbjjiCMGzQsNHoWjuUiKylaoA6ln1e5LmVbrmyBln/UjEXFvClKK2/cGmYxAnzi0skk1i8UYZD8esE4slEutdlQdho0p2awRgxwq8TrIqC0uQMB30azbZYZYS2wy7FsjX2dvFdB8dRy6AIkrxIpSowhfhITUa2riqtr9QCyWQsAJKW9WVxcYEsFXbMZDyU9LgshVIkdZ6ja1BHmsxSa5alWKBXzUiUJNU5ljUvLHX53SoESTyfEpQecWB+gaKQBKeqIQmGMAiFwV/kjAYDirJgaXERx6bgeZ5HWeTigxMEuI5ICpUF8bTjUNk2FJSSZuX4dn8kNXylIHA9F1UUKF1SpCmFgSTL0a7sZbxA2GqSYGZsnV9JeaTGqGpY2YSnUgsUGWkSk8YTMQE2RvZbrit7CU/TarfodrtMz8zg+b74tuRLeK5D4MmcVRpDHCfkaYrjaJqhmJeb0lgZjtQScRxTFjkL8wdICkl3y7LckgPGK+rlMQbwg4BWu02zJUwq8bgRq5aD+ThUQx+qoQ/V0L95Df1rA0/HHH8yrvUHCnwx8fNdr0ZvkySumSRRFBGGoY3/dKgiHBOTWXqgqZNxokDYO441m5ao2eVJLc0yixkZcByiVpuZVasZLi2CUozHI0tHFy2ovClPYFJj6ai/JIOqiE8C0lBL2LTj1NGQ7qNYTpF4JLmuNRS1BolBaA3WfOI8s0khCUUmju8r5X3L4j6oVs9Hg06m/q+qHyMjlEaUNQ93VxQiQmtzKrRdKetcvxJ0qlIwHHDEDE4AJwGeJFrWRoJa1o5CKL9hGNGIGjSbYhSPthGdmZyjtsCTvIWKsifsIG3vpVz2vJ74Khri8vs1YFR9nepoRpYBTKH+qXrQKschjFq0u9NMz62h0WgR+P6K35Okuup9Cf1Rkgmx11I+2+wNtXy9q2dTWeaW+BKU5EVOnEwYjYaMhyMWFhZYXJhnMhkTj0cYfvUZOxiPjYcdIXrvLCVPY3AcPB3W3mvVc2lQREEgpn+BGJ86nieJGDZS2bFgput5DCdj8rIgjmNcrSnKnDiN69QDSepQtmh28V2h+LYabcu4Wx4PrutTFtJ5HI1H5LYTbMoClEG7Ej9KxYionhtLKdVKY0xOqaDUEq9apCnDA/uZ37OLwfx+9jxyH5PRgHg8ZJJORDJaZPiexBZ3Gy3QyhaqKQ4aV2mcillZFrgKFCWmdO2TrEhzkRDnpaGkrI36Xa3Ic0OcGwZLfYaDIfE4Fm+FdovRcECR55RZTrS6R7sV0mhGQlEfx+zevpWZuVW4SjFhKEzDLCaMIrmWrS6hZYvmeUKapaR5RlJId9ixKSnia+EzmYwp0oQchWtDEzAyIiqavOi2PVuoKlQpPhRlRdu2qZ6FscxO6/0XBCG9qen6+k0mE8tCcfB9kSG4rgeWmpymSX3/MAhlGSzl2Zr8pxmUpSQDNUJcN0RpkTbnRcb8gf3keUEQRTRbTZTW9Ad9xkPpNi4uLDAejyiylHa7TRgGdKe6tNptm3oS4jreLxUBB9+xes1qOp0OIEWM73qsmu5x0vHHcNQRh3PR+Y8jTjPiNGdx4QAPbt3GXfc/RJYb5g/s5967bsVvdJiemeNJT7qEH3z/+zz44AP8/mtfKx35JMGfE4+K3uwcR2xah+M43P3Qdo7cuJbV0122HHEEzSii3Wpw3NFHcf+DD/H5f/4Gv/+ql3HMUYfzwQ9+kNe85jV8/OMf5z3/8A/86RvewLve/W6MMXzpS1/ihS98obyZaoNtj9e//vXyvjC1JL/Ic7S9J1kqUoSlpSXe/jd/zRvf+Ebe/e53S4feTuLve9/7SJKEZz/nOSilmJqa4r3vfS8A4/GY73//+5xxxhn8w/vex8UXX8xPfvKT+u9v3ryZd73rXXTabZRlTMEy4/jBBx/i9X/4h4wnE9av38Azn/lMoigS5m9Z8tOf/pTXvva1v3LPlFJEDWFyTeKYq7/1LbZt2wZIet8xxxzDP/7jP6KU4oEHHuCUU05hNBrVf9dYOv90u8lgcZ53v+c93HXXnRzYf4DXv/71YpAaRWgrBar/rvXtiRoNkep97Rs89pTTePwFF+J7HmefeQZvffObeOvfvJ2777mHCy+6GGMM09PT/M3b3gbAYDjkpS+/nLPOfhyHH/MYyqLgjrvu4s//4i/46Ec/yiVPfBrPesbTue666/jFL37BJz7xMY44+jFc9OSn8rjTTmbnju189J8+ytXf/jYbNmzkj/7gD7jig+/j61/7Kk95/kvYfPiRXPC05/BvV3+du2+/jWu+9x0AZmbn+O3f/T02H7aRmdlpjjjyaDq9aZYGI8497/E4fkB/NOHYE07khBNP5HWverllnBz85uJHHH2szGm51DNpnpGmOc1mQ4yIa4NgoCggitBFh1IpYdYrTeDLmEgyidVGOWRFTtIfML/Ux3e0GF5PJsJs1wplSuv/6TIzM8OMH9DpdLj/3ruZ5Bl5lpFnIk3LD+wnarQk5azVWm6glgbtKELfw3cdlILRZGJ9eUSOJiAQZElGMhnTX5y3bPKSIksYLM0TT8bSmS8FCFpcXBTrgjghTWOKvEBZjyqFg+dqPEeL/5GrbYPT2jqUy6apAn65tolJ3awUaV9BXpYkecloPCFOM8ZJRlEWtZdVBfxN9Xo4GkyR0x8MGI1G7Nu/X6SMjQa9TqcG2lxf5HVRo4EpZJ0SwKtK0VaU2gFX1ylxvu/XG2atVB1kk9pU6TTJQCf4RuHaPYZjZINZpRgqXdjnSJhcCvmbWZpgihxVZsSTEZPxSPYiUKscxIbDp9vrMT0zy+zcamHVDAaM45h2q8X09DSu55Harw8HS5iiYHZmWprRYShNfyv5y7OMNJ6wI08JG8KqGgzFUHw8GrEwP2+ljxlBGBIEAatWrcK3HlHNdlv2XO6vvSX9/+Q4VEMfqqEP1dC/eQ39a4/yuVWrbQyiY/WCAnKURU6eQ1qBPICYDdo0OSNRrVmWkaUZWV6QVRQwW7SlhZh/J1lmnderSdumplnAwHU0fiQpeRu25DTaHUxRsG/fPuJ4QlHk6EIWP8eRt6aVsYmTy4BG9Vk0j0KN1Ta60Asi+eyHyzGlNi2vig11XEFvXU/AlzxNGPcXmQwWGS0tEI9HZIlMypXXUMV3rBa4uk1RF4uqPksLsdifFVBOfLJ8As8j8iV1QAPaUbUUDy2JHo7r4briSYV2QFtRecV0clxhhRmJV63MVYs8t1TmCugSZNUPfJR2BBAsS1RZyuvY9+MASsmCCArHsegU9ryMqYGtYgUQWCcL1rdH1Ykkju0aGWMo81yKJs+jNTXDqvWb6E7N0G536wddkuZYZstVl7au4QrKQgwyXQs0Cr1U0PbCmjTKQu5atpUmTRPiOGYyHrFwYJ7xaER/cUEW9CzDcbWYvR3km1YAV4HjOvhadNqu49h0Db8GC7M0JjMZXiDJE57A9uRAnqRoRIJYYCgU5JQMBoM61WHV3Br8wBc/CSsNbYURvicGheM0EX3weETiJniej+8Hy8ChEeNBrYUu6zoOpSfGfRJ9mqOxmHJRkuTSBTKOpE74no+LEbrv/l3M79jGpL/IaP9e4ngsMgKjCIOQKIxollkNHApzzVDkZe2hFiofVys8rfEc6dyWRS5GgEaAU6xJpEkydFHimJLIlW5hVqUjloa8VIyTjDgrGA8WiccD9u9zbUoIklK5y6M5GNEZJ+zbJ8bPu3fsIi1BaZ+pmTmCqIHT7eEHEtzghCG4DqWyhvqlwTWid3ccBz9wCV1JG1EoGo0mUSRd97JOMJKF3igFWqFcjRv6NFstPM8jz3Mm44mA/AqC0Kfb6UmksB27nif3K8tymZf0CoYjRgBzxyHNJb63LAqKIpO5VDtkeUlW5KRZKoWS/d0qRMHxKim3Yd/+fXWkaxRFUtDlOYsLknqya+dOK4dI8XyXTrfL6jWrrVGjhx/4Fpi3QH0FSh/kRwUuJEXJlk3reMXv/Db75vt88apv8uH3v4dmu8vUzAwXXPQk9uzcxgP33s1Tn/18zj71JF7x4ueye2HA0lCYKBedfy6XXnwh3/jONWxcv5YTjj2KIzeuIwwDlOvxw+tvIctznnbB2fzi1jv40U9/RpLETIYDJsM+s7OrOHDgAA/dfxc7du1mZnaG2akuf/EXf8Hznvc8nv/859fn/ctR2ccfdxyf/OQn0UqxuLTI373j7WzfuYvF/ogrPvRBduzYwePOOWe5kDeGrVu31q9VbeBWegP+n65ZxWa9+uqredzjHsd99933qJ/ZtWsXF154Ia95zWv4vVe9yrKBl+uFspQN60r53Uc++lE++pGPoJTiwPyB/+N9S5OE0aBfy7KVUvzTP/0Tj3vc4+q/sWHDBq699lre//7384lPfGIZfMLw8ssv5/TTT+ejH/kIr3/967nzzjv53Oc+V4Nf8/OLXP2vV/PBD34QpTW7d+3ik5/8BJ/73GdZv24d3/3udznssMNotVp87evfoNVssmbNav7qbX9TM2ne8IY38IMf/KB+381Wizf/zTvYvHkzGvjIpz9PHMd8/FOf4Yuf+RR//3fvYM269Tztac/g2c99Lmeccy5T3S4b1q5hx74DrNEuf/CHf8zMdI8knvDe93+Ao48+lr999we48+572L31Ye679Sa+96//wsz0NH/3jndwYGmI4wc87nGPAyRpLY8n3HzTDXz/mh9w4eMvYN++vfz1m/6UF73kt+i02zz+/PP4kz/+Y170ohf9H+/BwXJkWc54MmGqN4XjaIrQsGp2ljAMwJSMRhNG8YQ4TckN6CAU/w7t0B+N68Rk1w/EigKxN6jGmOd5qMAnjBp02y0816HIUqJI0qe8ICCexExGQ1avWcvSwgK7d++ktABUnCTM799Laf5v9t472q6rPPf+zTlX2/1UVUuWewMbVwzGYEwxNgZCCy2EBAKkkVATQkIKgeQGQnJvSEhuQgrd1IRisMEGGxswxoB7lyxZXafuvvr8/njn2kdOuYP7kXvjO4aWh4YsnaN99l5rlnc+71Ms9UYTVGVbkWNLlzjnwNEkzSZsDyFMKAyKxeUl+r1VlhYXiaJQDpxFRpbElFnKcDQSf5s0JY6TtfrMWjytqDXrhBUQURYYJX8/1W5i3T2M42RSv1b7jPY8HJdd5qo75FXnjmGcSR1rLUU6XmuKgrDs3ZnGlgJ+xaMR/V6ffn8gzBLPUOQpvh9Qq9fBCCMpswqlPNAFNs+EXWIMNc+XZnpRijes8YTZYyozfEnn9soSZWSfTbNsrWGMAA0VU6qo2Cuu3qyMwgWwV2TJmBxLmaUMBgMGwxFJlpM5A/PAJVVPz8wyN7+ezvQ0WV5IHRaGiKSnZHl5RXy1yopTJofpgwsLzEzP0NYGBn3SNHXG2aIUibOCuLtKlqQ8vGsno9GIJEnwjEdnepqp6WkBZWo15ubm6He75HlOENWkyfsoT7U7UkMfqaGP1NA/eQ39YwNPQeBPktSMrg7ZMmi0o++VlbGUO8xLsacc4GApHNKZ55mrJ0uHv0hnInMbT3VV4BAIQCForkRQtqdmsKVl2OsSxzFKSVeTqstRLWBWtqHDy9Kqs6G0ckwnAZ2MHzjUXXybPAc8VcwnYw4z73b3oMxzsnhEMuwTD/uk4xF5mjwCCPnXYrtHPBqlJgwsi+Awcgsc+KTUpEvhe76L5zSifXU0W6Wd6aMRo7fKj0k7o7DKIH3yuwOiqs5QlWAy6SBZu8aiUky0wlpZF79aAUR28uzkI1jXsZAJkudibJfn+QQIUoiTvsWZVT7imbjn4ja6CQtK4RIY6jTbU9SbLaJ6Y7L5lhPaqtznwk24imMmNOpyMha069ZZ1tIh8lzAtzzLQeXuHglFPY7HjIYjMUhMU2xZOg21UBariOBH+xUE/uQQlxfyzPIsF4014uWSZSl5kaH0GjsOY1DWDVARCFPYArREijfqDcoyR1krndsgwAQegS+bZi2IxLBSKcapFJlpmgoj0pSPTCM6bP5rpdx7UE4mIH4NFS2+KEpJ4rF24ueQpimj1SV6q0sc2reL7sJB0tGAbNQXCWwp/mEG10EII7fOID4TRUGh8ok/jlEKo8AonMShpDQa7TZxO+lygDJgtMVgqYUBUAGuhdtAZX4EaY5vtKMcI35nbuzHSYpVQ9Ae8WhEkaZEoaSbKCAMArwwQvshxhNAuLSQFy4pxD1XTdUkkM1f5mlBmZcYXzwojOeRpRlKZaRFigC/Cu26s2Etwg+kY5MXshF6nkFrT96H76Gs5wBePaH/Fm7h08g9q75uXWEi5ocS31oWGWVRkimRQ1QAgUgKjIunNZN0J6wU24kzLU2ShMAL0AZsmtLrrTIaDel3VymcOWOt1qJer1Ov1wlCSXPxgzVKf4VPq3+1Tj/arjRJJ7KY7910E8vLy8zNr+fOu+9m98MP056aptPpMDUlHoyzs7OoY7YxNdXBeD7dXo/xWJJSSivFsPECmo06ZZGzuLDASdu2UBQ5i4cOkqYJWZZx3733MBz0qUWS8FIkMUMLzWYD39Pkp5zE/gMHCMOA6XPPYsuWLTQaDZ7+jGfgeR7XXHMNT3ziE1m/fj3PfOYzueWWW6jX65x55pkopeh1uzzpggs4cGiR/ijmnHPOodVqMb9uHbd8//ssLy8DYDyPZqvF2WedxXHHHfcIIEsB55xzDt1ulztuu5WtR29jemYGgH37D/Dg9u0kSSJs1dVVzjnnHJRSE7+ljRs3opQi8H3i8ZioXgeYMI46nQ5Pe5qwgtavX48xhl6vy+49u1lZXmH9+vU84xnPmABgCsWGDRsm72/79u386Ic/JI5jNm3axGMf+1jOO+88TjjhhMn3FEXB4uKi1DHIvrt+/XqOP/54br31Vu6880527drF8ccfz4YNG3jc4x43Savr9wd0e13uu/8+2u02o9GIU085he9///ukScJjH/vYCUhV+UtZa9m27ZjJz+90OszPz8v7V4pmq8Wxxx1Hu9ViMBhwx2234vs+F13wBLqDIQcXljj1tMfiB1JUz87O0Wm1qNXrHDp4N0maMTM1RRqP6fd6eEHIaDTm0MGDLB08wKGDBziwbw+tdoeNm49iw+atEC6hjMfM3By7HtrBnt0Py1gsSmq1iHXr15NnKWk8RuUpoYZ18/Ni7v7/wBUGgZMpiYysLArX3BqjrLB3RqMRo/FYDoMW6Uwr7Q6K4mlircU6O4AgCPB1S5qoxojvjLNmaNZqIolLRCbm+bJeF0VBmuVEtTpFntMetYnHsWPfZBRZQhoLk8HzPIzvkWeyj2TZGpu/LMtHJCLJASxj0O8y6PeF3aSsk/esGdGWRYYtMmyZO9UBWGdya7QmjMTmwfc8iizDKIvR0HDPOXNMnzzPSRI9AY88359IAw8PGApLkX8ZT4Cn0vlp5U5qUlSNTyVSQt8YlBIwx/MM9VpEFIZO2iSAlvEMhTvr5EVB5UwrLyVWEZ7xpD7R5QScEfa923eUct6omiCQWl9pg0Wa57KHizxOlwpbeYFNGruKIhfTdKnlwZZi0j4cDgUsd7ofY+S+1htNpqZnqNWbeH7IOIkJykA8ZP1qv8aFFMm/SUOfPEsZDocCElhLmmYksaRdaQewpWlKMh6JyXS/T5pJA77TmaLTmWJmZpbcScP8ICSs1dFZJmcCpVjzwn10Xkdq6CM19JEa+ievoX/s03Il6/IqSiHuAyowRhHVItmMkIFu3aJeRdOX1k60nXESO7BIUY+iCbJXATuBYxQpJVSyPJeJ7TmJm2c8arUa9WaTwBegY3lpkYMHDh7WwcgratEaEqwqSENNHNy1MWIY7kCnoNbA8wP8oCZMJ8ds8jxhwfieJ0wppUhGA5LRgOHqIr2lA4wGXYa9VZI4psgciDYZQBUUchjgouS9VH+uwF+RlQk4M5H1BRLXWgsDar5xEkIHFCkBnUwgBuImqAzFg0nnpJISqoqqKy5voLWL3cxkYSoKx2Sq7pXoQpXWGM1asp7nYR1wVwCq0JQoPCssLevYXlpr8V6oOtPIoq2snVBHK8Cpuq/VgSLPc4lJNj6N9hTt6VnmN22l2ZkiiKIJe0oW0HwyVvNCJl45mQ6ALSdsM4nGFT1x6kC3JI5Jkpg8y12agICkg35fGE/DEWmSSNcr8IlqkXhhRaFsEv6a59Wj9Wq2RKZDKbr9OI7pdVcZJwOyLCEejx11X9NsTRFENcKoRhSIiZ1BkzrWYpKXeJ6h0QiY78zgez6h72M8kWRmWYap2HhAbkVuu9rtMhgM6A8G1Gt1Qi/Ac0WHdD/KtQVMyUJpUBITmxdSHFcdy7KYANFRrcZ4NKTX77L9tltYOXSAQ3t2EdZCeV7NNr4zGO4uLpEnMWVRsG7dOsLAx/cMcSwUaEIIPPGGKLNsElCgtY9yscqVp5gtIU2dv4g2eEbhe5pOq44W/jsgxW2cprTyghKLF4YkcUYcZ/TGKXlZktlCOrP9EckoIQpCZjttNq3bQFSrUavVmJnqoExAWsq8K12XoixlzCqbEShFoI34c2ApkbTNspQiI6CBH4TUa02UzrA6pUykY+4bQ1gTL7+2S4gqCrnvWitqjRqNWh3jWIGeFjNFMV6VjTHJhPForaJWq0/8OHIXVy1dmqrwyUidB482hiiKqDfq1GpSfIW1Oho5cA17XZe6UpDGKb1uj+WVFTZvPgqlFSUl+/buZmV5GVsUtFotWq0WmzdvxvN9tGcoC5Fj1KI6VVpmUbpi/lF+dVdXpJDKc976xl9j07ZjedIlP8XdP7qZ+dkpPvmJj1MLpFjbv9Sl06wx327yowd3cfvtd/DPn7mCzux6ZubmOfvxT+Cehx5mNBjwvMuewQ9+8EO+8KUvMz8/x7Df5Rtfv4qnXXI5hW9482/+Fr/0+tdx+SWXQFGwvNplYWWVY7YdTatRp9OI+M3f/l1uuPEGzjzjsQS+z/TMDJ/77Gf5kz/5E5773Ody++23c+GFF3LVVVdx8cUXMxgMJp+r2Wrxxje/zXlICpCyceNGnvKUp3DxxRdz/fXXA1CvN9h2zDY++pGPMDc398iboxTvfe97efCB+/n9d/wGr/uVX+PJF10MwDXfvI6//Yd/Ynll1X2r4s/e/2corbnoqRfxtre9jVe8/OVoY1hdWWbh4EE2bd2KUoo0TQnDkNNOO42vfvWrj/iRRx11FOeecw7XXXc9T33qU/nHf/zHyQG4YmVV1xWf+hTvec97sNbyqle9in/4h394BHAGwrp63vOex3g8BiRV6KKLLuIPfu/3eeGLX8Rtt93GZZddxic/8Qle8MIXTthTxhja7RbPe+5zeN5zxS/KliWf+cxneOlLX8odd9wxKUb/rafk2p/f+c53PuJrFuiNU5ZXu+zdu5+br/saxvM584zT6cxv4MKnbeKv/uLP+N4tt/CtG2+k3mgxv34Dm4/ayjev+TrWlpx19tlce/WVxHHM69/4W/zNX7yff/nMFZx04vGsrnbZf/AQ73z3+9iwcROHekMOLC4RhAFBvcV3bvoeV135RdbNTvOEJ17Is5/7U5xwwgmsm25z8UUXUQxWCDsRX/7ylyd+F4/2a3qqQ5blJEnipPsDDh48SHdlWepO32cwHJGmKa3OlPM1UmTOO1NpM2m0ZWVMPYroNJvMTXfwXANs7NhPvudJ0nKRMzLCVEgda6/X69Fd7TI3M0W9VmOq06bIc9TyMnZoUaVIUbQtiQLZX8s8Jc9zScNzY8n3fYyVgioMA9JkxKDX5eCB/YxHI4qiwPcMeAZPCXMJrTDKEjqvKBvhit/CHZgMYRRJwp/vk8RjOYBpRbPVRIGwdIKQNMvxHFO9tGsWHmsyE2E7+cYd9suqrpDzRpLmJGlG4oj4JVCPIpdWB61mgyDwmZ7uEHg+frB2TwM/kKatlb2tks95LkXK8zxqUeQO+7kAEFqhKCkyaZR6XgUSitG4by1BUTg/Jy1p4I7xVBTSwMVaslzOF0YbYUwUOUVZYBTkecaBgwfpdnv0B0PK0roI+pD5+XmmpmfYtPUYjC9pkcvLK85n12dmZkaa7J7n7FJqrF+/gcQx/w8ePDCZa0kcMx7HDEdjrErEpDiOObhvD+PREE8rPD8grEccve0Y2p0O7U6b1VVJ7Or2+4Suqd/t9Zxk+tENPB2poY/U0Edq6J+8hv6xgSfj9NtFnslC5yielQk4DtiYUEQd6GMryZy1Ao74zrxPidSuXq+jjXbdAb0m8XLUuzTLKPJCDJ5tIQwoo/C9gGazjX+UbMTtqWmshcFAgIIsy5zrIjCBUUR36UhWh7GJXNKFHwqa54f4YV0SR6qEOLeheZ5HWRYSWzkeMh50GawuMuqvEI8G5GmCdRRfATqqHsga8DKhBavKHFw7kE06MbIBWkrUZAPzfW/CrPEmyImiUIUDnrwJa8sPowmYJl5OsqALJU7YUEobSsc+Kp0peJ7nlHmOcqBLJXfEMauM1i7S0qCc5KD6fFbrNWBPqYn5GkqR5/lkQ6n0rZMiuAIHq/tTsZwQo8havU6z1Wbdpi002x1qDdGfFoVERpZF6V6vmAD91fAXlpYwvLTyJqh85Z1RFIWLcc2Ix7HookvpJMTjMXEyZtDrkWdiGB8EIZ4XCgXc6fUnoOT/A4Xv7l0PTTamyrAwS1PQGmMCOh1HxQ8ConrTaZUl0QENxpNN0Gih0/vK4GkP3/hoIMsyknQNbMYXQ0WLJcszARJ9n3arTbMhEabGGNIsmzyTLM+QlAhXZBflpOCqfEvKNAVHzR+ORuRpSrK9y2jQY9Trsrq4AGXBUZs3U5QSj1yv14gCD60sYS6pQHle0HQRqlpB6ViDkUuVKm3JIOk6VqdBe4GYLVaJMghF2As8NBCIBQdaQVqUUiwr0MpgPEPT8yd+GFG9SdmylAWkKHIgczR3rSR9J/CDiQ+AjMGCdDzC83J8L8S6mNm8kI3YIpu9pKwIJVhrg6d9SpVhKfCs6PyLPKff71O6AiSMJH008H0arQbG8yjzXFKCioKoXndpPRqFXgOgjYQyeJ4H2smakI6zFMtrzNPKzFJrD1sWZHlGd2WZvMgBy8ZNm2m32kxNTaGN6P7zvJTuv5NlVN4F8Vi6fkYrHth+L6PRkOWlJXzj0W632bJlK00XAV2r18myjDgeMxz38Ywh8DVhVAOlGA4lESjP0//bU/J/63rVz/0cO3ftwngef/TH/40TTjyZdRs30+teTpqlXP/dW/CVJdCa6ZkZvvfd7dx599089/LncNzWLTz72c+hNxxj/IC5qRbHbz6LyDcsLa+wbctmfvZlP41R0O8PGacl993/AHNzc/z+77yDH97yfd71e7/DhU+7lL379vLg9u086/KfQmvDgf37uODJTyUeD/mN3/5dNmw9ns1bjuYFz3oKz3ne8yeMImBSnDy4/UFe9KIX8cu//MtcfPHFcsA6DKj59re/zfve9z7uvvvuCTX8smddwhmnn87bfuNtPO95z+OlL30ZADfeeCN/+v4/RaHYuGEDv/irb+Sqr32Nf/zwR/mtt/8WOx64jwfuvsMxrZVj4WZSd7hDXyWt+9KXr+RjH/0otXpd1q5q3Cppvrzuta/lxBNP5M/e/6fceddd3P/AA6RpyvXXX88LX/hCR+uVvewtb3kLT77wwrWmi9ugvvGNb/D8F7zA7avytTe96U2Te1RdWZYTBAHrN0h6Egi7973vex//8oUvcMkznsbdd9/Lw3v28IEPfIDp6enJHBPGhOE3f+M36fV6hEHAVVddxU3f+x6XXXoZGzduZP36dbzjHe/goYcewngeb33rWznvvPOk86sUeZbxtau/xt133s4Pv/89XvVzr6bRbhMnY172oudTrzf4zJevRinF/PrNzE13ePjhXVx3zdXMr1vPxo0bOf30Mwh9n4WFBb59/XUcf8LJ/NKvvYVbb/0hBR5xklILPdLxgAfuvo3lpQUajSarSws89/LLeMoTz+Ntb3kLN3zrOvr9Hr3BkKOPPpqXvfzl/NX/+DM+/8Uv8akvfZVfePVruPTSZ/0fmHX/udeOh3bKoa8oWVlZIs8k2jsqGyJFCUI6zq+r1mxR5DlpmqCKQvw+taxbtiyJUznQ5XlK4Iu3URqPGbm10Za566DLAS/LxIDXaE0UhpjpqQljanZmGrAsLS1x//33gdKUWUJ3ZQlhsAdEUUSaZozHI1LXWM2LgtB5U8WjjJWlRQ7s38eg3xfQyRdbCE9DLQjBN1B4BGrNaLcoxH/GOtY9gPHlIOt7BlOruXOBlnRmpdABWO2hHIMJI7Wg8WSv9Y3U+UVZokyBcYcBw1qwURgEZA6YGqUCXJVWUYtCAt8n9D1Ms05p65IIraVhHY9H8n5tiS3kUDkejbFhQBCIX5EYT3vinwPO7kIUDbhGacU+qUy/g1BCcjzPo3BzsGo8VzW10QZrHOvM1edGKyghzVKGsRh4Hzp4iNgBHEEYUm806HSmOP7Ek4nqDUplGMdiXJ1nBYPBEFsWTM/MENVqNFstsZDwRBo4jscURUmn3SZNEqmR05RxHDMajej3e8TjmH6/hzGGqFZn08aN+IFI+NZv3EhZlvS6XRYOHpCao1aj3Wrhez79Xpciz+Ts9Ci+jtTQR2roIzX0T15D//j6IMdWsmVJXmQTpAsA5eR3WoOTZeFohY7jg0WAD+V5qBCh32kj6TzaAU+exkzAGEmlyyeJE65wsxULR6Ndot703Dq01nRXVuStltZ1QCo/Ie34Q2vsJ3nfFdVVT+RsxgswXuAW3cAZqleGXkKTzVIr6GoSk4yHJOOBpEekiejDHWV6TUbmwJnqViK1qHZgjnEDsChLCuVc/N27Ns5nyfM8YWhpl/RWygsouyajq2i5njMf08abAC9CI14rtHGpGEoLF6ssq2Q70bZX6G9ljq44jO2kXbqd1sLmctRg3IIMltK9Z2utA+tKqrjaEiY+Fzhp3eEglHKa0SAMqdUbtDrTtKamqTWaE18tAYnc6xWCplcPVVXjyb1OBTBqd9+xQi0lF5BJfAbiCXU8SWJG4yHxaEQcj+UzugItCAKiWu0RNOgquvTRfnVXV9x4Fxo4CFtRxryY51UMLu2F5HlB4opbrIXD2I6em6PanbME9S4mElPpLuayoGo96c77vswl7Z65LIz5YQfCnGr0+4E3AQirZMpK4mrLnCJLiIcD4uGQ/uI+4tGAZDiALCcKA6Y6bWLHHmhEEbXQw2gomjXSzBMzPd+lF1pJz1FKWI2lBeW8FBQGpUF5gVtHtADEIPRwo1GIhl0pi0I6UxYmhpMaJeCxo8zWwogqLSPXQtnPlIZSKM9hEOC7TdPaktFozHg0pshSFOAbD1UWqKIUfr0CpRW+8SV1yDUKsJZKdayVxniawgqTNEtzef8uCcUzZgJuK6WcL59Q5YOoJmuQMY7pqt16WrE7hLVaWpFVVN3j0rrVX4EtqpRR5cIjcgdKi4yq5jpStagmByUn20iTRN6HK/KyNBPAOE3J84zFhYP0+n1WlpfZuH4TYa3G3Pw8tXqdMIrcGjCWjTFLKHNFEotnntE+yjVIinyNNflovK66+mqazSZbjtrC0572dDZu2sTiwgLbtpxGnOZ87cabyMZjtC1oNeosLy/zwI6dDIdDWq0WW47exuLysozdPMdTltDTpElCo9Gg02mz8+G9xGlKe2pm4q2wZctWvn71Vdz6ox9x4plPYGm1x8rqKrv3HUAbw+KhJc48XRLOdl9xBalpkJmIXbv3sH5+npNOOB6QeayUYuvWrRw8eJAHHniA1dXVCWtHOYDpwMGD3H7HHXzxi1/EGEO9XmfLli2cd955nHbKKXzkox/h7LPOpixLHnroIW6++Wa++IUvAnDuuefyvve9jy9e+RW2b99OHMeEQcC62Rn6q8uk7mCzc+fOyVq2b/9+duzYwTHbtrFjxw6+fs01QpefFH6Vh4rh9Mc+ltFoxFev+ipLS8sMhiPKomDPnj3s2bNn8qyUUrz0pS89nHM7uXbv3s2ePXvWZHlK8eIXv5j169c/4vvKUrw/Ht69mzSVgs5ay/79+/GMYfmsx3Hb7bfx/Vt+wJ133sn83BxVmheuCXTiSSfSbEpS3J69e7nllh+wft16tmzZwlFHbebqq69m9+7dHHPssQwGAyfXKemurrK4sMCPfnALO7c/yOLBA2zctJGpmVkWV1ZYNz9PEIbcdu92DJbA95ib7pAmCavLi5x62mOYmZllMOizfsMmPD/iO9/9LMcffwInnXwKBw4epBaFzM5MMez3GLnYZluIz0m322Pzhnlm2i1qjSbdbo87b7uV1EKj2aQzNY3VHosrXW750W2cduqpbNt2NKeeeup//sT7T7xWVlZFVoRiOBqjsERBOKktgiAAK2V5FIbEriYpylIOaFVT1tpJopk03krXQBszjlOKPKfIUgeyGIIgmtgpeMYQhAFhEJAk8YT1PzUzi1Ka/fv3i+9SmTMa9AQ8iGoT039rrTSD3cbiG01ZQpqIvKq3ujoxRTaVUsIYwsBDiWOxAEEKtxe4etP5G1krAS9GSY3hBcHEX1ZpMeo1SqFNga78RkvH0q/Y/a4+QSl8C2WxNtekkRtQq0UEJeSlRcUJhRMoRGEocjvfw/flWRk/kHtt5XPK3uo21rJwcheNLY1rFgu4laWpm+drq4C1zvu1KKX5K2+MAGdroTXgVAKTf6ZYk+a5dD8EsKv2+SxLGQ4GDIZDSSt0tUYQhjQbYhg+PTOL8QNWen3yXA7ikrxVGRJXjfZgIqHK84w0zSYsr9yBXnlekGYit+t1u4yGQ/q9LrPz66jVarTabfHLdebr8XhMlqb0+12ROgKUJVorfM9gi4y8fHTvwUdq6CM19JEa+ievoX9s4Gk46AvTx0U6gkiwPD/AeM5fyNHFqih6nMROOSAl8D2MVgRN6QZUmsOK5WLMWiylMKoEeLJWPIc8d8CvBkMFGk3NzlNrtPD8kL27drBw6AAHDux38qkENaE+uQGunHdUWbF5tNNrBvi+MIWqBdP3faJa6JL8DEWek4xHxMM+w+4So94y4/4qWTwizxKh6sGa5la5LcPKu6jeSSX1C1wkp+9p8qLSs1rnfi/dGd8VJDKgDTgQzVoF2gNtBNAzPsb3xX0/CAXxdAi0dl0V44uTvtJmAtxU4FPhmFy2KBx66SiSE5RVu5RCQ5K6wtzFR9rCgVtucooEznVOi3xCapKFVbkmcCW1q+6/maQFNhsN1m3cRGdmjrl1G2lURuJWkGbr2GF5lpHlGWkcC4Vba1rtNmHg02g0qCJ7UYrSbbR5motXQl4wGo5Ikpj+YECWSerGcDAgTaV4q0c1arWIer0hG6mRwqfyOTBGEzgN76P9ikd9Go02nfY0U7OzQsP0fFn8raJUarKQdXsDkiQmTmIpiMMQFdWJwmrTFEP2MstIlaROxUmMHwSUpSR39HurWFsyOztHo14niiJ8P3BpLGL2WTojvNLJcpUxzn9BoUuPvCjI8pwsTlBKjNyLVDzVuosHGPd6pKMho94yvjFMNyKmp6YIfUPoQ3dVxkq70xJJL5ZwbgrrNvHBeOSSC0uCmmyWg0FfmIHaMD07i9WaUim0lbVHW0jSlKzIGWXxRFJc1z6mLFG2QCNy2bS0lJkcrE3gE0bhYb4P4vlQHSysLcBqSiUxuKGWoiYeFxM9d+4kFwSlpGkYjdJWNOWez/zsOuqReFEcPLSL0WjIcDig1qgThSHtZps8lyjuNB6h3bybmuoAirwoGA1GFIVIEIwvhah2yZJ5ad3m6CJ+VYFnPbzAFylCJUNOUqFYKzWRUhe5gLyDwcD5G2imZufoTE3TakqXWFlLt9ujLAuyLGc8HpOkqRRcniFLM0ajESvdLsNBn35/lZVDC6RZRuBHNFpt6s2WzO3RmCTNaDaaGOPTarZZ2L+X4WhIb2mBzUcdTb3Rdoca/f8EePykJ1/Ez/78L7Bx0yZu+f73+eVf+RV+87d/j8edeTZnPeYUfnDbHezdt8RTZ6Z4xkVP4YnnP4Ef3H0fWbGPerPJhtk5iizl+zffzO2338by8jJv/Y3f5FB/xO3bH+bhXQ+zYf08P/tzP8dwHLNn717e+PZ3Uq/XOeHM89ly4smcce55NMOAT336M2xYv46fe8WLObjUJfBDPv6Pf8+ehRV27TvAH777j3j6RU/mxS94HnmWEYYBnU6Hv/u7v5uALkkcM+wPaE91wEIcx/zBH76HH/7wB4AUU6efcQZXX3UVYRjS7/W47JJnctKJxxPHMZdffjnbt2+f3B+tNbV6nXe/+92UhXT7Tzn1VH7xF3+Rs88+m127dgHwute/HpCC/bff8Q7+9n/+T75/880TfwdbWgosqNLxpcWs+I/+6I/cYSyffIZ/fVVy8erX4Szef++ybk8r3J5y+PWFL3yBr3zlKxPgCeC9730vL3zhCzHGUCjDQw/v4bJnP3uyLx5+/f2HPsRznvMcoqjG/Nw8W7ds4Xfe+TuMnY9UnudcdNFFfOUrXxFJj/t3V3zyE3zy4x9jz+7dPPenns8nPv05Xv/617J+/Xr+/kP/wFve+S52PryHD33gz3jPu9/Fhz/8YV79i7/KWWc+jt/7vXdRWLj55pt46a+8jje/7R3Mzs3z5S98jrMedwZnnPFYnnvZJWw75hiOOeYYnn3pJSR5yU+/4ueZm27jBwH371ngc//yL+zf+SC/9rZ3cOst3+OrX/g8f/+Rj5MXlj94z3/j1a95La969Wt41tMu4o//+I9575/8CUmS/C/nz3/1FY9HIqkLRfZUr9WYnZunXovQWktXOUkkiUxpxknK0kqXvISwVqPZ6hAFHp7WdJp1OTxkGUsrK/R6PVaWlwhC8fJStsAWOZ5nmJ6ZEzY7iiCqT4Cn7soKWZZwYGFRjIWbUxx30mnsfXgny0sLHNq3m363y8rSEnMbNkmT0VkzlKUYCGMttshZOHSQpcUFer2uSPBcbdSoRdRCn1YtRJU5lAVF6En6kq3kNiVlnjNyKVxlUTqivpo0p5XWFEq7PBpFkuUkSUaSrs2bqolaKGGXGK1RHqyOhbFjPA/jW4yvwPgEoU9kPJQ3cgdhS6PewPcNoWecBw3Y6rAOBEEgwEBZ4mmREYaB78JqcN6fkhw3juMJGGyUkfeX5wICKOXmvPyMIiwmjd2K8SI2I3KmyKp0MiuePha57xQZeTqmt7rCwUMLDAZDRrFIhKMoYt26dWzctJltxx6H8eQ9DVZX8IKQyAGOUShJc41mE7D0+kNsr0+WpfR6PXDAeyXJzDKx5UjGMavdVRYXDpHEMVmWMj09w9z8OvLSMh70sVjWbdhAWRZorVhdWZZ6cTwiCnza7TbTUx0GPRiXj27G05Ea+kgNfaSG/slr6B/7tDwxqtIaP6g8fzTG850Rs5BZbSmmadpJyIS9JOCTRsyyhHRSTlztK2ZNlq1JuqruQpVeU3k+GceuyZ2cTVLwpEPS6Ewzt/Eo/DASGtygz2AwIImTCUPL5o5po41M1KIQAKpck8ZNjMeNJEkI6CNa7Hg0IhkPGQ16JKMe6XhAniUUxRpN1DUcHehUSbuAUqi8lfSu2mR8Y2QDd2Q/KRrWpICVxK+SA5SOVSQ/RDsDceOYVWpyT3GAnTCI3DNz5pPGURaLvFhLZas2M1tMumOFWxBw4JMwtMwjurgSJSnG41Zp0KWwq4zBWOtYW4bC/a6AwoFnSmk8XzpQvu/TbrfodKZodzrMrd9IvdkmjGpuPFTjpfJ1KiaU5SoJzw98ojAiCAN8z5fPZEW2kDuqapFm5EVOnuUkTqc9Ho8YDPokScJoNBKjRc+n0WxSr9dpNOR36cpLfGxR5GR5LsCmffR7PG3esk1YfH6IUrI5pa6rYBHQPy/EuI6yxDOicY6cz0DlKaYUhL5HDhRKuTEinSujtWjJ04TxSLwg8qkp6WSi6PX6E0ab8nxKNKXVlErmvhjGC7MyGUnhkyYxw25v4j/W7S2RxiPS4QBfKcJ6ROTNoJHkm0bNQywdCqJaTYo6W1IWMiG18SjRKArCsD4BMUVXX6BICDyL5ytCX4Pxsdp1TkorBVeRURbSjdYorII4TYg8Q2A85jpTlECcl4zSjKK0DNKSXFt8LEZJxDWF3HccGO77Pp7W+EZhygJy6+axdn4QwoAU+q0b855H6dIhl5YX6CqF1pCmQ/G9COtoE1FYj8Ewo2qj1mt1vECYnUWWSXSti15GKcIonIQW2NKuJZoeJkGqNt1SGeK0wNqcJIknwQfWlqSJGG6OBn05sGQZUbNFWGvQmZkldDHhQ/f1PMsm0ei2tM58Vk1YjiJJzrGUaK3ZsGGjfCbtEQQhRZYTj4dEtboUKKWd7Ccgcb2j0ZDBcIDSHlFDopyVeXSDx+9///s55tjjOPW0x1KWJc3ONJc89wU89PDD9IdDnvD48zlmy2Y2rZvjzvseoNlq05mZ4cxTT2LfgYN8++Zb0KedRrPZYsvWrWw9aiNGQRwn9PoDRqMxxx+zDW08br7tHs4+7UROPHYbz3r25aybblOPAu74/vcIfUOrFvHEs88gCHzuuvWHfOOb1zEaDjjncaezZ+9euv0+F11wPt2lBd73J39MEseceupp/PRLX0ajXsf4cpC76447OHjwABc//Rl86/rr+dKXv8wdt9/G4sIhAIo8Z9fOnbzzne8U35Ew5PFPuIAdD+3imt/6LQ4cOCAdP+BXfuVXuOCCC1BK8bnPfY4HH3iAt73tN/jWDd/iS1/6MiuOEQ3w+te/HqUUf/mXf0mWZRw6dIjf/b3fY2Zmhj/6oz/ife97H8ceeywvf/nL+cAHPsDOnTsBeMlLXsJZZ51FUZR87etf45prrnkki5o1Sd3HPvYxtm/fztve9raJpO5ff091ffKTn+TW227j3X/4hyitieOY973vfXS7XdI04fLLn0Oe51x11VV88pOf5JZbbgFgw4YN/Mbb3kp3dZXvfve7fOYzn3nE637s4x/npptuwngeJ598Mpdccgmf/exnSdMUrTVv+LVf44lPeCJBEPCVK7/Cvffdy/79+7nt1ltZXl7hZ17187TaHT712c9yymPOpNVu8ZWrr6EsSmamOtx66220OjNc9LRncsETn8DCoYN84C/+O6effga97irnnXkmg94qYeDzznf+LtMz00S1Ojff9B0evP9ejt66lZe85KUsLC3zg5tu4PkvfBGtVptP/e3f8dhTT+Gsy5/DVV/6FzrT07zytb/E5z/3WZTx2brtGG749ndYXjgoTbQsfdQzFgE2bdxA5Q1dazTR2hCnmTMbFyuA8TgmzVLqSsxrm+2OgCbGUBY5WZJTaC11sasLkySlsGBc41RhsQWsrqzIAcQ6j0/tkXV7RFEkHiCRxLwrpUnSjLwo8GsNpufm8X2Pg/v3k6cx/dVlvEAMoT3PJ0tjqfU9jY6CSY0XRRHNZpMiz1CIOXfgGYJK/qYMaNy+qVG6YnCVYuORyf6Uk7vmtcyT0gKFAMHS/y+Jk5QkSSUBytW4uCZjVdNUXmuS8GydT4kk0VmrJpHmgQN4KjCtYndpx8oS6QtgxS+pshdBV3viYWoCt7+uMZ1cGrRTCBSVjAoByi3CUsmdXEofFt5UFIWT1cnvWotZs8aSFxlZPMLm4i00Go3I8oISsTBptdu02x02bz6KWr3BYDAgc3Ijz2jarSa1eoOpqc6kQTsajRwbIqZer8nnNdIY1lq7YApQ2tDvyeF2qjOFUUqMpfMc3/dIkzFZZkBJ3RAnCQrw/IBarU6RD+iurlKr1cnznDCKUEYSxB/N15Ea+kgNfaSG/slr6B/f48kzVHbTxtEFqyg9ixJD56KgsCXOOB3lCfh0OHCh3Ay1tpJcOUDIig5VOWaT55mJNMz3fKxxptTugVcTtXRG3GhNrdFi2paEYciwtyLvzdG/sswCVfdAXqXMC0pTTGRl1W5QgU/CSpKfX3lc5WlCMh4SD3uk4yFZMhbTMfd+HJFHfkYFPCFAy8RE3H2G6vWN87eyWAp72D9CNqG1wSqwXUVTVe5zo5zM0Y0MAdRKrF4z1K58pIS1JAisKS1ZkOP5zvdJrW2YZVlQlLmLlhVATLt/X+l5rXvOWmmsS7xTWmGtSC611li3GVf/rvLxqOiCWov7v3TgQlqtNlPTM0zNzDA9My9+VUEIVN5QLsHOWhexKffdOB+sIAwfARTK0JMOXZZmExP1PMudnlpc/ZN4zHDQZxyPiccxjUaTMAip1evUGw3qjYYkCCkZN8p1m7I8E2roozwGFmB+/SZy52lQ4uSKzoLdWsFfK/q1UFFFrxxF4qtQlFLUaC0GeqqU7kWcpIB1pp6GMneMsjRxQGZJlucUJZNuaBjVCD1/0vUEjciaHQBbFsSjPlkSkyYxg5Ul8jSlyFIGg2XyLEUXllqrKTHUUQC2QFmh/mJL8swShBEWSHNn+msh8HygwFqFH/iTOZJmOZDie4owNASBxvMU1hjQAcb3pBC01rEXrQDEWoFVjIuEwBMgdbotm2Y/zShGMXGWMxrHqMJSGgj8w1iBUoJjjPhO+FoRKAeq5wW21KJxNzgphqIomXhOeL7v0kJzVrorE7lKFElnPYzqKBNQWhiOcjxPkjVq9Rp+KIeXoUtRyvLcJXga6bxJ9U7lc+NpgzayTpSlS4g00nTIc3kPaZLiuzUtzzOSNGY0GjDsd7FlQaA1oT9DvSaAbkXTFaZhTJol4qNmPKGUKyYFjaz3bj3SQr2enpnBc7HW/eEAWxQkcUIQhG5JtBNzxqoJkGYZ4zjG82OCRlP2ND/g0Xy96U1vAuTz3Ld9J35Y4+JLns03vv5VDh06xKknn8LGDeuoRRFXf/NbzM2XNKdnOO6o9SSjPgf37WHdho0oz2fTxo1sO2oDnWadr914i0jGSsu2LVvoDod8/877OO/0k1g/N8PjzjqTTdMtvDLjU1d8mjJPaddrXPDrv0Ycx3zrhhu45sp/YXlpiYN7HmbPwzuxRc6z/+R9XHPN1/jUFZ9g0B/w1Isv5uKnPQ1vw0ZCFVHakgceuJ8H7r+PJ1/0VG6/4w4+/vGP05nqEI/Gk/3owIED/I//8T8wnseGDRu54pOf5Fs3fpu/+qu/BMDzPOr1Os9+9rN54hOfiELx7W9/mxtuuIFff+Mbuf222/jEJz4+MTRXSnH5s5+N0gI8AfT7ff76b/6Gt771rbzmNa/hgx/8IMceeyw/+7M/y6c+9akJ8HTppZfykpe8hKWlZQ4ePMC111zDv8dlstbyla98hbvuuotXvepVE8Pw/+i66uqreeDBB7n9ttuo1ev0+30+dcUV7Ea8Wx7/+PMYj2O+9rWvceWVV06Aq/e85z288md+hp4z5/3XwNPVV1/N1e7/3/GOd3DRRRcxPz8HSBH8yp95JaeeeiorKytcc+01XH/d9ezduxulNK1Om0svfw533X03V1xxBS//mZ/D83yuve56giBi/fw8P/zhj2i02jzpKRdx4vHHsXPHg3zpS19EY5mZnuLMx53BoNfF9zx+8fWvo9sfsu/gIa74+EfYqWDv7p38/C/8Ert37+bqr15JGAS0Wk3uu+0WnvyEczn33HP5wJ+/nwuf+nQuvuTZvPH1P09Yq/Mzv/DLfOu6a9i1Yzuzs3PkWUpZPPqBp9mZadI0E5PcVouitHT7Q9JE2Ei1MJCDYpoRRDlae9TrDRekUlLmGalr7AroJPYP6XCMReGHEUEYSmfdWkaO9W+9UGKwA0uc5ZLspjTT7ZbYPGQZg1FMlud4XkCrPUXgGZYXD5EkKeN4jHEpZI1me5KsV2Qi5anquCiq0Wg2SeMx2AJK8RCRhqWzVCirdGWDdmu8LUsKLQz/NYagmtQmUi9aJ0+xkwN/6oAUCarRE1lOZe8hta8oM7TFNV29SXKc3EeRLuWu0apc4xtYs4JgDcjyPGFbgJp4qIoFhEuXPozlqA57v9adfUpHo7IISFC4c1OWS5qy53kCoFmpebNUjIOzNJFmqmcwWGyeyfkjjUnGY8ZxLP5s2hBFNZciN8PMzCxFWdLvif+t1pp6o069VqPZbFCv1ykKia0fj8UjajQcukQ/b9KsVgrxQnX7aDweYYym02nTqNfkLOfk2WmaiHzQBe8kSSrJhkp8YcbjmNHqCv1eD20M87m8bxOE/xXT8se+jtTQR2roIzX0T15DK/u/4oAfdl3x5WsmgIqDkETD6CZZmmUTMEgWK08O/0qWbPHhcWyVsmKu4FLrRAc5Gg0ECQ5D6vWGgCN6rYOAEv3jRMfqgKdJN9Fa6ZqkCUv799BbXmR1eZGFhQXG4zGD4ZAkEWd6ZXEsm4B6e4qo2SZqtml0ZmTzjgRwCMKQdqsjg6TIObhnJ92lg3QXD9Bb2EMaD0lGA6GelhJpWm1V4hEh7z4vCvKyJM0LCZNTiigIqEcBoe8RhR5pXpBkOd1hQl5CYTVTUx1qtYhOu4XRFo0VjarbZLUnyXVaexOqm9aSkGH8gLDeEPAmigjrTYJQiocwFA1oHCfsefghFg8eYPu9d5AOB+TJmOnpaVqtDtOzc0zPzhNFNcJ6g8IBPr1ul8xFOgqYJAOzSBPKPCdPE4o8oShymQipmNGN48RF9hbS7TIeUa3G9PQ0zVaLjZu30pmeodnqPCKuUYCwgiJLyTIxSEMpvCDED0IazfYk8VDolpZKmCuGe9KFqPwEsjSTRIpelzgeMxj0SMYj5w0GUa1OrVZjfm7Omas1iKKa68KVdFeWGI+G9HurMo48n/f+6ft+rEn3X3V9+AtfI06E3eUZfzK2jVFgIU0yJz8t8bwK/VQTcK+0azRoXVHQLaR5QeAHLjQAUqfj7/VWsLZkamaG0go4fWDhEI1Wi870tBj25QXpOMH3pUuTjoT2m8UjeisLMp6ylGQkyTVZlhGE0jlRSk3oxbUoQikLOLBVm4n2WAj4uchaPUlkzHNHQx2NCTyPVr2OcskbRZHIxqBgNEwYjAsG4wJrIE5iur0+ypOx2whr4PpdWZERBj61IKBTawjTrihIrfi25WUVUWyoR+Fk09RVwapFRmCAmge5S9DoDnNKa7A45qN7MkWRycaqSrJM2HeD0dCFJYTMTs3hBz5+4BOnOUUu9O1mq04Y+GglHhGlLfACSeGoN1pYrV33rqQ6VVuc55xWBGE4Aa/zPCcrc+I0ET29Nvg6YDweMRqPWFg6MPGhaDdb1KIanXZbOobakJSlrBtlQb+7LJ+pzJmZmiMMJexhaWmR8XhMkZWTMIs8S51prcZXVTsCkTbYEr9WpzM9Q6PVIkszxqMxw/6APHc69zybRB17UUjg0nX+4O1v/r8xFf9/XdVWneU5v/abv8vs7Axv/KXX8cCeg+w7eIgf3PRdlla7WOANr/8F5mY61MOAP/vzP6PRbHHZ5c/jbz7096yudnndz72Kb97wbe6851466zbw2FNO4tzHnU692aQeBUw36zywez933XU3/+133ootpBBeWlmhHga0GzUyq/F9j06jRrvRkM52XvDQw7tZXlllqtPhpBNP4JRTTuKB+x8gjEKO2ryZV/zsq9mweQv7Flb42w/+BffefQfXXnMtxhi63S7/+I//xM3fv5mrrrqK447ZhlJw3/0PAjJ/pqenGY/HEu0NXHDBBbzpTW/iz//8z2m323zpS1+a7Plbt25lOBgKq+ppT2PPnj0opTjzjMcC8MNbb3/EPe5MTdFutzlwYD+e8Wi1WqysrDgmhrCYLrzwQp7ylKewsLAweQ//7qUk/WV6ZobRcPi//l7guOOO47bbbqPmjFkXFha4587buO6aq7nic19kz779/+Y1/viP/5hf+qVf4slPfjIPPfQQ/X7/P3z9ZrPJhg0b+Od//mfm5+cBmJ6e5vs338yrXvkzLC6v0Jma5g/e9W46s7NEtQaHDh7gxm9dz+c++yk++tFPEMdj/ug97+Ydv/07rFu3jpe85MW87nW/yOWXP4c//5M/4ISTT+Ppz/4pFhYWiJOUOCu58vNXkKUx7/3vH+TKK7/MD75/M7/6i6+lu7zMg/fdx3du+T61eoPznnABnWaTRqPB5qO28JkrPsFNN32XN7/j93ng/vu44bpv8LwX/jS+5/Hwzu1s3XYs69at47EnHCPzA8vGDRv+l/f4v/r6+Kc/x0q3x+LSMps2babeaNJqtcic70ijYlUDg+GIYRwzHMXUahG2LEnjsbCJlKLRniJ3RuVZlslhNAyZ6rRIk5ilxQUJR8lzSW12htehL4ezMAwZjYZkaSpAEcJEGo9jATaKjIP799Dv9xn0+5iwTtho0Zlb7zxJC0aDPp2Wi9quRQz7PXqry6wsHqTIUihzGlFA6BuaUSApVUBSKqmbgpAoCLAu1GUwGJAkEu7iXFkFSEOJBxNyBijcIavIxW/I9z0Jo6mJ8XrhPHUq017jhaIe8LyJMbhWinq9Qa1elzOI8ysC5/XiACqUrqqKyVGkAo5sZRLs/D4n6gPHvrJWWJuVd1W151vHZvA8X+roLHcG46GwKHwfsKRpxnAoTPwsiamFAVHgkcVjknjMeDhgOBozjBMWVnr4QYjvB7Q7HWZmZ2m326ysrJJm4uuyecsWwjBCaUOz2cQPQowfuiZuibYlw+GQbrfLli1bROaocIfhhP0H9tNoNIlqNUbDAb7nEYYBZSFgaC0MObiwIBKdLGd2bp5Wu8NqX55VmWeMhkNJWHTga1SrOasUsax4x5vf8H91Tv7vXEdq6CM19JEa+ievoX9sxpPD9x0SL39XgUBYMQtXxmCtM7nWckCvWgdCLbPi8F8xi7TCWE0xAaeE8VRpZC2Q2cwt5hrj+w5VrjoIbhF3/1/mGXmWkqcpWKEmR2FIq9EQiZdj7GSpbDKlY1kVjgVTFvm/88uI3r4sybOUJB6TJWPydEyRp85M/DAGUsV2gjXG04TBdPj9dOAdaw987XsVqMOkf66LIv9OADvlpI9KV7+cDM/J54rSYorSAVD+5F6VhWjpSy+XrpOqkjOEgljRlMtKxlb9KoUiWjGXPN+XAqAQtN8NEFk+qj3ascYqGvJa6p3GaAgjSYBotzvMzM3SbLVpTU0T1RoY10ES+rPTlJe562zK4u37Pr7nOT8BD1xHIUuTSXFhHEusMg6XRMLcSfQKcKhv4PsY6o7dpcQc0pi17tthv0van9C/y9K6JJZ/9YAfhZdCCdAXhAJcOnq0dAMUnpNjiiDWToDdYuJJIPNYugVrC5iMVxfnqhCzPa3xjE+WJSwfPMRoPCLNEpTvMyYnT8aM+31sUaAqspgtwWbg5mN/dRmKAu2SW0wgrDZtDFglKR/O6NL3vMl7lk6mxfO0xCIb4wpeSYrUymB8H+2LRtzTmiAMIE8pCkgzS+ISYQajmFFSMEoLhHusaLbEh0Q2CE1pZaz51kOhKKxilObSeXKMT6Uh9M2ki1H3fVecKopcfPOSNIFSQGllxZcN46E9hc3FIDWNx6AEgE6rNcwKiKuVptOZcnIImfcoNZElKw1+IPepKApJN8BJqI10WUvXvdZKo42dmBlKkEQpHb2iWKOWu7kYBqF0yNKYhaW9jMYj4iQmLws840ucsBegjY9Fk+cFJQVxkjjar2z8Is/wwFryrCAvxyRZRuo8cMTw1afjYrUpS4pqvpdWmLmldnIF9Yi5Wzq5g1YK33kEWHDmjBrvx2rB/NdfWilOPfUUrLXcc8897F3uMUpSTjzpREmoyXN27XqIA/t8jNZs23YMpYXb7riDqNFiNqhxYHGJTRvX0+m0iJrisTEcDnno4YeJfI/Nc9Nce923uOfuuxn2VkkTifGdnZmhEYU0agElmsDzaNYCVnsiCZibmeYxp5xCaS3L+x8mHfV54MEdbN22jXaryez0FN+58Qas0ozSgqM2b2LzxvV89KMf5dxzz+XMM89kx0M7iMKQX3z961m3bp6FQ4e4/4HtVPLq5eVlDu+XdTodTjv1VNI05b777uPv/+EfOGbbNjas30Ce59xzz93ceOONjJyvkbWW3YcZgR9+9ft9ORgVa/4Ih1/XXnstO3fuZN/+/aRJgu/7vPSlL2Xfvn1ce+21j2ANKzf+xqMRUS2i1W6zcOjQZM4AzM/P8/SnPY29e/dijOHKK68kjuMJO2v/3t3cfdc9HFpYYDQaYTyPx55+Bs1mi+/c+C0pOIuChYWF/xB0UkoK3XXrN3DUlqP5/ne+jR8GxEmK5/s8tGMHWZpw4ZMv5LjjT2Rmfh179+3j4KFDHL1lC8ceeyzPee5PseOhh8jznMedfS7aGEajESeccCK1RpPhOGZ2/Sa6/SHXXXsN5z3xAupNzfaduzj2+BMZD/t89tNXoJXizMedwerKClobth1/Infcdx/1ZpOjNm9h964dLC0tMDM7y5ajt1GiGGU5pfHpzK2nMzVNURT044wgqtOZmmJ+3fzE7+RRf2mD5wdEtTpJmqHM2HkG2Yk0wvOkntMjiy0K8iwhVmJzEAQBhaul0zTFOk/VRqMuptme1ERFpmXNLiUGvLu6PGH7z0x1nPGuz8GDB0jiMfF4/IixG/pyqFpZXhJ5lfNL0TYnHQ+oNVoEnoeNahRlwXg8InKH2SiK5KjqGFrxuKDMNMYW+J7nJH/+YWx+TYmE1FT1bFVTWuVqLHeAnEjeUK7uM9iywJ/4g4ZydsgURZmD29uiWm2SPpylKUWRg6sVAGE2uYI9z3Mo3N7oyiErBa3UUJ7BafAc61/8VqXp7N6e+wDKhfsYrUWC43yksJUMj4kvVJUUXpQFunQyGSfNwoX+2CKjSAsG/Z6whkZDkqwgy0uCMCKq1SassfF4LAf3LMfzfOr1Jkob8d11B3ldlKT52DHKQJViPj/V6QDCtqqUKGVZTMaoQmS+gGNa9MCWFEVGEMjPL5FghygMMAM7qSHFyzfEcwfV0kozZaLaeBRfR2roIzX0kRr6J6+hf2zgKSvkEK8Nk8O4LXHxyGI8VwG8VXyrfMMa+0fkoQ6hrBLanL51jZ5aTnTNeVGQZjnGc5vHxI1/LWFPIk0FHMniMVkyEmpqGqORDbTTahKFAWEYoJRibOIJAi1eP0I/FJ+AFG00Re5R5AGFltSfIs+czG5AGg/JkzGlM+Ke5NUpQTQnwBNr8rrDdrgJiLcGOU32UrcBQuXXVA3gtdcRk3LtFiYxV3ODxMkWszRB5znay4XtFIYT2q6AN5loto2RxdITA3PtjLMtlrzIKQonTXPu+bYsJskiYRBIhyTP14DEwwZdBfKBQReV6fwa/dk4/6RGs8n8/Dpm5tfRaLZpTs04B309AQazLCVJxgJIZplQgI0h8CQuMwjEfLJ0KYjj0VCKDmvX4jSV6KZLd6CYmDY66nQtqmFqtckzETqiTMoJQ8/9XZ6J+WVVdBSlLMeP9ksrTRSE1IKA3Gl943g0iS2uBZGLEGXCYMyzjMwVHtrzUMqT4iwrJQbZlhjPxyrt6PuW3JZizIsmT3L27drO4uIB4mTIiac9lqS/ymg0Zs+OB1G2pFFvEI/FFLbZqEknQWuGgx6e0oSex/R0RxiQfkCa5mKQl47JUvE/CBz9XTZzhTYlvm9ptltEUYQxPnGckmcFymqCwMP3DfWoLrp2ZcljGW/jcUx/EDMap/TjMam1ZFiU8mg1Wqybm6dWqwOWZDymKKQwN0qTphlpljPIswnrsyxBG00UBtQ88LUm8j1M4KM849iYGcOBsBm0NhRlSM0L3dzUlGVOmWbE4z5QoLUlTkRTXlio15tEtZD59evxgwjPC+j2+zKP8wyN+Mjp0JPDTJGhlL+WhOkFoBRpnhF6wcRbrlCp8wVgAvZnbpPPnKeK7/k0a01Gwx6D4YB77/khcZqSFyUbNm7BbwSEYQ3PBIAmTtfYqnE8nmyaRZHjex6BH1AWliJPGDsDWfl5CWEkZrXr122gLHKSOGbQWyHPpHMngQoWpYzb1AVIVrji3krykXTshAGZFTmWfJJ89Gi98iyfFFqXPesSdu7cxTeu+yaro4T29DSvfPnLiHyPNIn56Ec/Qn84oijhl1/78+zdt5+/+tu/54zznsTU9Aw79uzj4ieey2NOOp7uYMTDe/Zx/46d3PCdm1BlwdZ103z8n/6B3Q/vZN3stByUlOKEE06gHgXUQp+5afGEKNKYq6//DuM45qRjtvCYM89l/YYN3PGtq7j5zvv51o3f4Xff+dtsO3or87NTvOc9/437H3iATmeK33vXuznv/Cdw7tln84u/+HpOO+00bvjWtzj77LP5i7/4C4qi4Oabb+aDf/03E7Dp8KektabVbLLtmGMIw5Bdu3bxtre9jZe/7GU85clP4agtR/HlK6/k3e9+9yS2HGBxaeUR4FV1lUUxaWz8e9dHPvIRKnNxEHb27//+73P99ddz7bXXTsw1i6JwhyzD1PQUs7NztNttVldWHgE8bd26lXf81tu5/rrruOfee/mrv/4gD+14iD27d2M8T9gbrj6q5EzPuORSjt62jR/ccjMo+VnVoXqSNHzYpbSmXq9z+hlncuaZZ/F3H/wLFhaXWOz2J3HJGzes57WvfR1nnn0ed9xzP9+96bt867pv8nu/+/uce97juezZz+HP//ufYTyfy5//YpJhl+7qfp72zGfR7Myw+8AijznrfL5z4/V89MP/xGe++BWanSl+cNuPOOf8JzLodnnbG3+F3/jNt/PiF/w0//yZT7Fpy9E89qxzOe7++wj8gLnZOW65+bssLh4iqtc59bGnc+FTn86V3/w2aQ4nnHE2vh8wjvt0k4JcaZSR7nWSZoySlGbt0e0RY7yAelNj/FCiuEfjSfMMz3cAjIS4aFtCkZElCUmaUYtC2tPTFLlPXuT0hjFBGOGHHtNTU46X4M5CDnDKkjGjfo/dO3cyHkkC4zFHb3WHPs32Bx9gOBxMQFljDI1Gk2ajge8Z9u/fO0mAC32DpiTpd2nU646h0aHfW2WUxDSbDZTWLgVJTXyJsjgj0QqKnFqthh+GeJ40Iz1X30o4s8jv0HotyclKMzHNS9I8x+LsN5ysD2spihzPyD0Tr5OUvOoMaoM24itUJSKvnTMcI561etsiSVACejnfKA2Vd5RIZQKqgCJhi4hvkxIJB/qwU5UCdwD1sFnq6kq7Vu+7M4LRmrwoJ/ugADwCPNqykEa6sjIe8pLV1VWGozH94RhlPLTn02zKXNbGMByO6K526eo+7XaHdrPF/Lr1DIdD8qJEO6CsLK0kG7qzWJnn1Bt1Ou02o9GAJB4xGo2p1+toY6jVanIe04qtR28jyzJ6vR6joXgJFVnqEsA9itIShr788jQGQ6Egd1JCPwwniV9FXqB0zqN7Bz5SQx+poY/U0P8ZNfSPDTwVZTlBeI2n18AUayZ0t9Id0Cfm1zhgH9yNkeN5pe02zhPIKwu8QmjCVbpLP47dgLBo1yUZDHqCHjo/KfFlKrB5RumM9rIkFopv7hgtZSEIaSSU3igMiZOE5dWuxHtmOXmekiZjtDEEkRQu2hjyTHTNJjFkaUIaj0VWF4/Is9hR2hwSChwOJx3+a/L5J4yvtb+XjUlx+H+CoIqReuXvJIluzjDcSes8F3lqHPBU5ClFlgn1zuYT5lJF61VY53mVUeSCiGIkuS8II4IoIo0l8S7LJG4xcfpgYzyKqEAbia8Nw9BBLcp1xA5D7t1nEEZQOYkBLUsIgpCwVqPV7rBu/QYXjTxDrdGUtD2FmLXn0m3O84w0Sye0ad+TgsP3fYKohlKaPMvEXNNNvDQZg5XEudKBlbktSJKENEvJ08rEUdFqNuU+lMWEIlvkIgUsbDlJNvR8393PUhICLGKqVm/xCAr2o/kqiwklXKuCogAKKN3G6DtAr/Jlk06jA3mtxeY5Yagwnk9YbwjgaHFmiAL6Hdq/i/17H+bOW28hHgzJktRRq0dYCnqLCyg0thQmgNaaYRRNfubyYi5pGoHP5k0bxCjeD7FakxaWMk8oMtFB53lOq9WiVototVvEacpoNKbXHWBLMCgGvT6j0Rjth4RhHT+qo5QDECU6kvFoxMryIuP+QIo+JXGvJgxpeh5xlhHnGUUp7zuLE2e4KVr0eqPuPOAsSRwTj2N67rWEVQgUJeOkRJU+hS7p95eku6UVxkSkGZSEFKV0ryw5JWOMSUlT8SBLkwSDwvND/KhJvRU4ll9ObqX7kqUFgWcJtGZ6ZorcluRlwXg4lm6qglqzie95GG2EAVlINLInWDZZLumOKEVYRcMaTVEZE4IcOmp1kjQmSUYs7NjJvj276HVXSdOCTZuPYt36TbSm5idygzzLibMUmyXu52vqtfra/lHkkr7pewyHfbIsJ0kL1m3YSBhFjMY9yMRzrj9YlfRMFGG9gclzkjjFVy7QwBOKeFmUKCPj1QSSBlOUJVlRUqu3XHhE5e/x6AaPzzn3HB5z5rk84SlPgyJlZqrN8y5/NtrzSLOcO2+/Da0lDONVr3gZaVbQG465+rpv02k1+ZM/+B0++8Wr2L/zfp71jGdw5Ze+yB++87vs2vUw55//BJ55ybM455TjOLhvL7fd8h0uvOCJ+BdfjA5Ctm7ZSr0W8fEP/z312jo2bTmW+XXr2PPwLr5+7Td53KknEPg+d93/IHc+sJNmq8VrXvYi9o/gpru3c+UX/pn5uRnWrZvjRT/1HIwx3HHb7Xz+kx/jHz/0txx30kl8/Rvf4Gtf/zr79u3jnHPOAeCXf/mXueGGGx4JqLiiwhjDU570RBYOHeDxj38827dvn0hwTjrxJE459VR+/hdex9133kEURXz+859n48aN2NLy6te8mltvvfXfv9FianDYHxVVFPXh7yMKA3yjeO5zn0OvJ2yjdrMBWFa6fVkrsozFhUUuvugiLr3kEt5w990kSYLWEiN/991386KffglJklC4xk6v16VKuju8jLPWkiUJp518Ipdddinnn3UGGzdtYmpqiq9+9at8+tOf5l3vete/+Tilk8Z/49qvcfNN32Fdp86xJ53MRcefxKWXPpvp6WnKomBUwDdvuplvXn0VWzZv4S1vfTu63ubhQ8s88PA+thxzAs16jXqg+O63bmFpYYFzz3wc3/rG1dx+5108/eKncuYZj+NFP/0y/ul/fpDO9DQve9UvcP1132Tfvn289pffwNTcem676142HX0ct952K//jrz7IW97yVoaDHr//O2/lBT/9Cp705KeSZSk//NGtHDx0iJe//BUsLS3y4AP3E6cJSsGJm2Y5cetGtmxcDyjqUUgUPPoDPtI0xfd96lMdjB84CwFQRYnS4h2ZJjFpXEoDLc/xPUNvMMIWBaMwdIlyYtwdBR5R6FNkCRrAFjy4fTf79+3l7jtuZfHgQeLRkCRNXHqyYbiy4OwwNMN+37G/rTPgVvSSMcPVJbTRBFGNRqNOu92SRLOyZDAY0V3Yj+cHNKfnCAKRcwyHI1crRcxu3EI87NNfXWb54H5GaUyWZTSLklpR0lAGTytyo6Thay15LpLB3B3YPSPng7woSdOUcZyiXNhQGEZEtQitFGkS43lrITx5IXWOtrgUO3/ixVTkuTtYyxTP8hyVJLIHFu5ZGGHboz2sruRzLtJdK0mRruR16LWkLFugtTToPU+8pPJSmBUGF2NvhQl2uBdUZYAOOP9U5bxVC/IkRpc5gYagFpFmKUlSMM5KSu1TbwdyOA8CWs0WcTwmyzKM57F+w0bm5tdRb7Yc6O4LWOK8pGSNK2m3mhM1RD+JpclsS0aDAVYhkr2pabQ2LCwuMBoO6PcHPPTQDkknN5qNGzZibUkSJywuL5HnBevWr6cWRXhac9RRRxE7u5PWzCxFaUmynGknOaoawMYz//HkeTRcR2roIzX0kRr6J66h/7difCqqVWXgZxxlUGRywvsp7RpVTy75emX2B6wtuqgJuylNEpI4IU8TUhdBWZYyEIwnG0cFOpVFBRLIwokDmGRCZRIh64AATSUBtGhtqdkArRR5M8czhjRNSdIUyoI8FZBFaS2mYK77OZFn5Tmlk+RJJ+IwquSk37R2HZ5kYytarnX8YfWvvsf9dhgxikm6XmXK6Ci98vdG3PkdKKe1mMHZsnQ05zUp4howtvYMy0kXtTIPXEssEbS4mDCMcpcIV+S5bOROOucZD98v18AlmCwE4ECnUr6OEgO3WhBSb7bEQHx6hlqtTq3ecOaFyskZY4khjccTB35jPDTC8JIEDkklERrymtG4yANL0Spb5Q4KQmudLP6IUbrnjP8ERC3dsy3RShYMZa1LNzGOcXYYQ02JpNTzgwll8tF+lUXuWHiO7ovG9wxF7kDishRtslrjjFusY7QJbRwkDSFPnLeaVeSFGF8m8ZgDux7i0P7drCwcJE+dMX1Z4vsBWiPztyzkGaGwpSWNE8IwcIxKjSoLiswSj2M87RMGEmBQFiVplqKVke5HLSSsRfiByEaG4zGD4QilNUEQ0mg2iNOYNE5Ih2Nq9ZwwiAgDb6JlHw0HDIcDVpaWKNIUoxRTreYEJPY9X3zZihKljCsqhRmotMbThiCM8DyPxPlkKCy+Z7BIVKvRsjbkRUGqFIXSLv1TgHXf8ymtwvMCykwor0maOqYD5HkGWLzAoxbW0V6E9mso7cautqR5ShXRLI3XtfeLVni+R2k0ViuCKML3fNfhdAwPK6aqElxQUnV/S89glHLGgxZdWtI0IU3GpPGIwahPkowZ9pdJ0wRjDPPr1jE7u56pqVkwvvP+A2U02q7FQRutCXxfAPzcglYTcDzPMpcM4+aq51GrNUgZkScJSZK68WImHWXjW1RZyt7gJMMgUmJjDF7guw55SZLn8vda5Nh5KZvpo/m6/fbbiQvAjzj/nDNpNprMzM6ye+8+un3xAfG8AK2lI5YXErUs0ndNURQ06xHj0ZA7b/shO3fs4NDCIkYr4njMwYMHSOOY1ZUldu3axXHH+kyHoXj81WooZUmShOFwRK/XY9u2owmDgNFwSFHk6MAXJixSUGI85ubnOPXE4ymylOUl8cXbtuVoWq0W9Shk4dABDiwscf7FlzDo91leWuSCJ13I3Pw8V199NSjF5s2bsRYOHNhPr9fDAscdeywnnXQSjz/3bO6//wG+cd23JvepKAp2PLSD9g/a3HbrrSwuHkIpRbvdQWvDnn27SdP0/9czsNYSRRFnn302vpYD4s0/+BFxIt3mitFQXcYYOp0OcRyzb99+nnTBBZLwpBTf/e53WV1d5b777pv4m9TrNdIknfysw1+n3W5zysknsby4wC3f/z55ntPudNiwYQOnnnoqT3jCE3jmM5/JTTfd5CLQcYxpmT8z09Os37Cek48/jum5eeY2bCbNcsZJQqczzf1338P+gwdpNptYaxkO+sxu3EygtEiklKUoMuLxmFa7TZqm7Nj+IL1uF88TpkwQSPMwqNXJ8oL77rkLrRXr169n3cZNdFeWOXTbrTz2sY9lamaGdevWceDgAfI0Yf36DeSlZbU/IBsPRN4VRvT7fZE1GkM8GqO1YtP6dXjGsLK6yq23fG9ieXDppZf+/3qu/7cuqeVkew0CH6w/CWsxWmwmClfHiQF35RW6VlNhLRppBFMWErEdjymLjDJLObBvD4f272dlaYnhoEeapCJjMZKIVgWjFAUUjoWDAt8Ek/ouz8SPJ89lnwiCAKOV66JnFGlKnqXisRnW0L47pFgre1pYE6C2KOitrpAXOeMkxXjioSTjyVXNDggqSiugWiEWCJX8qCxKF9deYNz+VoUOyS3w5LBv9ET6oVizeNC6qhVx9ah136coSkuW5ZNatSiZJLxpUyV2ayeZq1j8VXGkJjPdWjFKplybt6q615NaXva/0q7Ny8oHtmpeVozJyuJCPKzkvGONprSKEoXxQzDVflWF/kgd73k+Ub3J7Nw8U9MzEgbozmz1RkMaqw58UkoTBL4EMLn9r8gL4jghzTIkwj13KgVDGEWkSUKapPR6PUnPa4o/k3jvSkp2adWkpi9tSVTZpAB4obCu4oR6vSaskEJ8uoz36E6WPVJDH6mhj9TQP3kN/WPPcg3YMidLMpQvC73xfcd6Ui6hrpzE21eyMZHdaXc4d4uvFmS2KEvi8ZDhoE+/u0pvZZl4NKS/usJo2KMsc5kUfoDSmlF/MAGDJiwhhYs/VfieaKk9rTFBiPGEDmatS4IrCnwj8aC1KCROM5I0Y2l5WQwNRwOU8SgL6RiEYeQ05IIklnk2YRUVzlS9LCqPqTV+k/vok89ZOrCjYjtVm9UExnAD3VI1Wt1nc2kgldxOJoWegE7GuHQ6xx7LsWBLtDFryRkTxMv9LEdNzrIUay2+8fH9QAz+6g3iYR/t++RjSVaJEwGBjOeJhM/FxZrAJwh892dBY7M0Q3li3F4gnZMsTcWA3BeN6roNG2m1O0xNz9JotieSP+uMw4eDLv1eV9DaPMfzA8KoThhEblMNAENpIc1zd8Mq/6bSaffthD2W59KSyIsSqyQG1MPiaYnQbNTrgvrakjSOxWRSKzAluizRZi0dD71GMfStRRcGjPeI2/tovtIswZQaz3piYGl8AmPWjPFLKf4sOG8DRalkXhtjqNdrlGVJniasLK8I4q40/W6XQXeF3soid//we8TjEb4xNNsSsRmFLrrZD6DMGY1GDIdD6TimMu8Cz6Nei5jtNOkP+4zGY/buPsDsbI7WIWEUCAtuMKA91SaIIsJoCq00eZ7zwIM76PX7DIYjTj3lVKZm5ti4YRM7d26n119i34F9hFFEGNZYv36900OnbN/xIPF4RJbFTNXrTLVazMzM0O8PiOMEPwjoj0aMxmMaTUlfbHZarkg0TobQQGnFyuoSWTwmTxMajToojXUAZ1GU9Ad9hi4YoFGrOV16TpEW+H5As16jP5AFXWKNXfdRKabn5pidm2N6fhNFqRjGKWWWoRWEUUDoTB21lQTNOE0lMcVIlGsURbL2+gFBKHT8oszxK4lAkZHnOUmaYjxN5QJblAXaaupRkxDp2K7E+1lePMC+PTtYWl7AArXGFOs2bGBqeo7jjnsMpZUAiH0H9082o2azKf4OVmKGjdaEvkc8SshzOZDkucgW8jTBlhZfG9IkRhsjRXOak9iUbBxLPK4xYsipDX7kERclZSrj2XMDOQwDkQd4RhJSLUI1d94GnmcITeTYmo/u6/67bueh++/hlS+5mhNOPAm04eOf+wL7Dxzi537mZTQaDbTWfOUbN1CkCcYWXHjhkyQl7Z+/wGNOO50wDPjFn38lZ51zHo957BlcdOGT2Ll7N9ff+B3KNGb/vr384Ie3sfvh3WzcfBTPesE27rjtRyzu281oNGQ8GrK8uMAFZ5/OfLtGJ/LYsWMnzWaTx5x0PLMbNtJoT7H3wEGO27aFM049gW/c+F0OHDjIzl27OXTo87RaLU454VjyPKNer/Oyl72CmdlZ6o0G6+dn+fIXvsBll13Gtddey4knnsgnP/lJPv3pT3PLLbeAtbzkJS/h3e9+NwCf+tSn+Pgnr1h7ftZO0uoqVoHn+1xz7Td56KEdfPQj//TvStIm17+S4P1rSd7s7Cx/88G/Yjzos3f3Ll7/hjcSLwjw1O0PJt+ntSaqRZx9ztncetvtfPWqq7nzzjvZsmULZVlywQUX8L3vfQ/ANXgE1JlcqvJEFI+mxzzmND7w/j/lrW9/B29+y1sA+KM/+iN+8zd/E4BLLrmEZzzjGZx//vlynxAfxDAIaLfbvOCFL+A5z3kuW449gcWlFR54YDt//w9/g1Kap1/6XL79za+TxmPe+vbf4TOf/iSf/+wV/Mn7P8DRR29lfn6WH333Og6NxnRaHS666On0+11e8eLn88QLn8LzX/QSHve4M7n37rv48l//Jb/wK29m797dvO3Nv86f/Y+/5PFPfBIP7TnIJz/8d3z3hm/yx3/2Vzzjksv4mVe8gle96meZn5vnT//0z/mf//QRrv/uTaxrhZx3/oU88YKT+JevXk2r0eCo9etZXlpkZnqKx5xxOou9ITf/6E7e+EuvJhmN5JD+78gnH01XLQondgB+FBFFNWampyUUJ0vprq6IHAMIazVyCyrJ3MHMuA66QVmRe+bxiHRsWVpaZjTsM+x32bVjO4NBnyJNaLfbAgiVBbUoJApDZqufl8QksbDKsZZGvUajXmeq02J1ZYV+f8DKYECr1SQMArGzSGLGwz4ClGiyJKHWmiJsNGlNz1GWJUmSEfgBtVZAo9liNB7DsmHp4H7yfMBoNIayII0lZl4UEvJ6Ik8Ss+AKcKsYRbmTgVSG4b6TE1WpWAoBkaquu6QpO9uG0mJtQZYVLmBGxkllqi2MJTmjBGGI9jyM58Jt3FnDTMAtOeyWRbFW01vnXauZWIBULIQKQ6vMnHVZyn6klFPxOSsSWx3HStJkLOeMLHHqjsrnCkrl0Z6aJs8y0jRhPI6lOVyUNFttGs0mx51wEsYPsErz0I4dYvxdr7N+gzA+l5eXqHzFgiBiXAwpC2FcpmnG4vIyeSqBCmm6RFir0Wi2qNcbslblBaurUgM2Gw1K58ubFiW1RpPQNcDzIqe05cTPNaw3wATkZUmUJIQuQGg0GuEHgYCxj+LrSA19pIY+UkP/5DX0jw08eUa7tAiRuRXWcnh4beEYJ+WEBSR/L79L94YK8c4L2fSSMUuH9rO6vMTy0iH6q6sOTY/JsxSFJYpCt3ko0jiZoL+yqVTATGW86Au1M5AEC9lwcH5Olir2FaUIHC03CgK0VsRxQpwkJHlBkYwZ91YJgkCQVz8ALMooZyCmHJqrJr/WGjRrHS2owKRK1S03pep0TDoy6rDYWNY05xXoVJkeKmmdOFBKuhWVQaPWGl2YyeuVOP+rSgLH2ns7vDaTz+dicBstxoM+4+GAIhmTFyXj0ZjRaAgofD/EAkFR4FuLdYWxUSKrq1hjeSrSRaXEQHx6bp6aSw/pTM0KNTsIxQPAaWXTZEyWJQyHffIsAwud9jR+GBFGdTFVc50nq2RiURZrJm4yytBWr918LHmWSJHhUHU/8J0EU5hyuUuI0UoWF08piezNCygKcJ4D4EAno4iMoQhlrOcupfD/hUukjAq0Ii8LFI4Np7VbVKQIkCInR7sFaTwYEA8H9JYO0V1eIhnHpHFGvV4jCHzSNGHQ69FdWYYgoFFvMDe/jqhWR6EYjUaUeUmeFWxcP8dg0EWTko5HhEFJ00RYVQjjDEOt3sILayTpMmmWsLq6TOgbgsBjut0gL1IGvZh9+xKmpjqSglmrEYYh83Oa2ZkNhFGNwTij0ZkmqNfpzMywf/9+VlZW2Lt3H77vEThWYxRFtFtN4tGIxdU+o3vuo93qEEY1hoOYxZU+BxdXOLY9RVSLmJ7qUGQiT8jLgvGoR5HnjJxERilFs90U0BoYjyXJ0WgjcaZWNPT1eoswDEjihNF4xP6DC+RFjkIThDX8IEQbTWdunnq9QRjViJOMEosx1gXIyvqGkm4Ipeu82pLIC6WbbrTTYFuULcnT8aQT6bkgiErbnxdOLqAMnhdQCyKUVuw/uJuVxQW6K8uoPEfZksDzOO74UwiiOrXGDNqlnfSHkqSUpjmj4UjkX6EcQozRZMlI1kTXRc2LnOFoSK/XE/24MrTaLYIoIIhqJElMkqbOfNYjqjcZ9FYnnXCczx3GSB6LcdG6nnRQ8yLHKovB4nm+K3gAJGVmHGcT5uij+frCF74ACNvyhBNOIM5y7t++m+de9ixC3zA1NcUPf3Qrd999N9+78TqOOeYYzjjjTL797RtpNBo89tRTuefO2xiNRvzl33yIh7Y/wN49e/jbv/2fUhwZj+c89/kc2LeHXTse4LLLn8Ps3Bz33/EDTjv1VM4/9xye2u/y0EM7uP++e/nwFZ+m06jxrGc+jaXekOm5eV75qtfwvZtv4t5772H7vfeIeSeKpz/jGczu28+Oh/fyy695PUdv3cLeXQ9x8aXPI2q2ueO2H3Bg/34WDh7ksqdeSCeq8eEPf5jPXPFJ9u7Zw649e3j+81/AO9/5TgBOOOGEyX150gUX8PnPfY7f+/3f46677xb2tZuHWite+IIX8dKXvYxTTjmVr171VT784f/1gl2BVYf/GdYAqKWlJd7wa7+O1nL47/b6PPWpT+XXf/3Xefvb347Wmnf/4R9iPIPn+czMzPB3f/d3fPazn528plaK9773vdx444389m//Nm9+85s57rjjeNOb3sRLXvISLrvsMn71V3+VM888kze84Q3iFdXpcPRxJ/AH73oXv/prvwbAKaecwmg04g1veAPLy2Ig/cADD1B5Qr3wBS/g+BNPZM+BBU49/Uyieou3v+0tRGHEtm3H8PSLn0aj2WL95q18M4k5ePAAcZJw6aWXceGTLuCbV3+JOEmxCi540pPpdXtc+aV/5pqvfYUgjHj+K1/H1o3rmJ1q8bWvfIE4zZndsIVvf/sGiqLgmc95ESv9EXfffS9btmzmxBNOYjAYMh4n3HXfA3zvR0Ne8YqfIc9SrvjUFWzZuIHTTjqBE4/Zyu133s1VX7kSryiZaW9g41Fb2PHDW8m9MWhDLQw45cTj+NQnPiHhJ49y0Amg1ZSkJltaxmmKLQr6/b4cJoBOu0Pq/E2LoiQKQzxjyBYWSeMRC/1VVhYPkcRjyjynMzVNvd4gzVL6K0ssLRyCsqDlPH2iMKIscw4d2I9CLCSarTbxeESarqUaeZ54mSoFrVaTWr2J9gJ68QH63VUeLnKmOm0C32d2qiOHyjSlP5RmrfEM6bCH8X18L8DzA8eKVxx19LHMzMwRhSHd5UVGwyF2aYUoCqmF4cQk3PM8qdGVNDYl3U+axpUUKwgCl0btT2q/Sp5V+aGtzX3jPEmlaVuW1qUWrykySmf8m7uAGKWNGLZrT2r9ySX7ied5ZHk2YUipSR1fpVe5vbQoUCpztaFrSFfMNbXWnBbGvqKACUO1zFNwDfyytFhlsEqYTlIv5+KS4XnUfd8xUutMz8zQbLYIwpBSaUaDoWNiKkkPrDXw/JCyLPFd/Q2WLBfAe9Dvs7y8NAkMWr9+PUEgqdm9bpfhYEit0QALNWfWbvyAlW4X3/fJs4zVbtcFOUGRZ4RRTVQBVoyc8zih0fYIjMaEweTc06xFNBp1ojD8Pz4Hf5LrSA19pIY+UkP/5DX0jw08GWf4J8o6gfhLWwjVz64l3FW6VhzhvCyqboaT5blOwXg0YDwcsLp4iNXlJVaXRDsskjYx01MaSedAWCy5Q+GstVinD9Wehy2h1IpCWQrPozRV+h2iRS3XgLBK5meMYxAZiMJwQv9jNJL3nacUSUxuDFk6doBXMaH/Vql0uM8vq436N4hfleQH1b5USeWkKNbu/6uvT15Lrb3XSuZlK+zqsE5oZTwum58SKudhsr01xtPhPlSTdyfP1hj8wCes1Rw4E5JoD0sVo5riGfF7kjQE9wa1oNGFo2UXeSZdmiJDgUj3Al+Ko0aTWr1Bo96Sz2shT1OKMhf9bTImy1KyNEEpje8H1OtN9xoRuDSTSnJY3eYKwHPtKmwldHBjcuJfoLSjI0uRUxY5ReYWCaXE3FI5CaORqNPS3etJ4eAKHYzBw58ULELd/nFn0n/dVRnrooRiLlxEd88KRVamk4RISzExy8yShGQ8Yjzqs7KwQDwaY0vI01iSLGzJcNin1+9RakMU1Wh2pqlFdWwp3g1xIfrowPcIfEPoa2wi1GMvDMgKK+b2xsPXPsYWAjorRZbGlBkoIvx2gzwVs/skSSadpFariSRLCIhqjHg9GOM5IFikCXmes7q6SlSLaDQaRIF4eEVhQJFb8ixjGGc02xrtBdgkJ80KxnEqVFctnU+bF1gcyy5LyXLxIUOJtFc7XzYFjJGNTKGxVsajLcXzwfcCEhWT5ynj8QDPD/F8j0ajJdp1z9CempGYVeORjUegxN9DuYK7xDratwIlG6YF2RCNQRs16dIezgpQWqGshzLGyQzWRELVqM+SlLzIWDi0n6WFA3RXV5iKmtRqNeqNNlMz84RRg6jeIc1SirJgOBxMpBFVCoakAUkUb5l7ZHk6keimmXSJBsORjAcvdMxCSRXJxzFFaYnjGD8IJokj0nnN8W0JCF1YaY0qjZvrzjNCPVJiDEgnulonnfRC2Ue31O45lz/HfRY4tNJlsLRKnKYct20T9dBn7/4DHNi/j717HqZIxeswTRMOLBxifm6e4445huWlBZI44ZmXXMbK0iI7H9rB6uoqvu/RbDbwfY92u82xx2zj5FNOpd5o8MPv30zke6yfn2cQBQz6PZYWZrjrnu+ybctmTjntaTy0ey+1Zouw2aawivE4Ic9Lkqwgt5Z6o8nc/DqOOf4Ejjv+eDZv2kh/ZYkNGzdRb3e44+676K6usLx4iP17drHxqK0cc/wp/PVffoD77r2H9Rs3cfrpp/OsSy9l18MPU2Q599xzD9ZaWq0Wl19+OR/56EdZXe3SbDapDMB37tzJ1PQ0xx17LMccs42jNm9mdnaWXrdLlmX/9ib/Bx27er3O0UcfDYhPz/Xf+ha+HxBEIevWreeYY4/lhBNOIIoims0ml19+OcZ5l1hrufLKKymtgELGGDZt2sSTnvSkScDFunXr2Lp1K1prTj75ZJ71rGdRq0XyLI49FqWUyFo6HR5//vlkWcaOHTtI05S77rqLr371q/T7A5qtFnlRTOLUj962jW1Hb8Ort/D8gMXFRfbuflgO8FrzpKc8hVa7QxrHtNtt0iTm0MEDbN60gbmZab70+c+w/8BBuv0+z3zWsymtZf++vRjPY3p2nguf9XyI+ySDFQb9LiaQCObBYEAYhJx48qkUhWV5ZZktmzdSbzaZmpljZXmRNC/ojYY89fxzGQ0HPHTjDZx44kls3rSJZj0Ca4njEe32FJ1Wi5mZaYrS0h/02bNnN3lh8TzD8SecwLr5eaanOv8np99/yhVFkdQLRckoSSjKHJuw1kBVyjEnqkapIvA9tJXkoX6vy9LCAuPRUOwBytI1aWHY79PrrqKUIgoCWu0O9VqNIs9E7ubGu4TRrJnFamWIwgCrZd9CaRc2I2a+ZVEwHPTxjYFGnWa9wdjTmFwWI5G9iRm6eBkJ+0gradQ2Wm183yceDYjHY+I4ZhQn4n1TlDTqCINcH2bg7XkCOlUgkjF4VhL/qkYrSO2iXFPXcljSNhXQU3kpre0Bh+OTa2nH0hzX1R6uqnQyJnT2SVx7BSDB5GdP/lztNe4QWoXpKFefCzClRGbovgckqTrPU7HzyBKMO2coLQfB0kJeSLJfUVqCMJyAdY1mizCqObZTC2MM3f6A8XgsfnKHNbndm0ZrLYdta8mznDQVT9fRcISl8pHVrn5SxEmCtQkohV+xb0Lxi+oPhrTbbQrXOC8c26mSPVrHWhPgT2xLMML4yh2TI3T+u7VHeTjAkRr6SA19pIb+yWvo/y3GU6lkU6k6EBbRPzu7dkpEc5nnmWPbFKRxMtEUGyWGdmmS0FtdZtDvcmDPLpIkJstSamGIqon0SWvRo4eBT56l5HnGeDSShdmlPvieoRYJIlkh6sk4ocjsRJMo0Z1uEzJ6srmVFuIkJUkkVSGq1ZiemhFkMMsYjcfkox55PCQZ9dGTRD3RRhs/EBPCEtHzuoFYARBarRmKVybpIGCTrw2+kVhIYwR8cuvTf6BRdy2Sco0RVYF5le5cO/mddkwoa8XzoCwKYaO5waIQfKy6lFL4vhgoTk3PkMQjYZw5k/YszxmNxpSlxGbmaY4X+NIxcZ8vScYOMJTn7nke07MztDvTRLU6tYZowI3nYQtLlgpSPxr2yHI5HCkjHaZGc8qlCzQIw5po8PNcTCCVJgglLlg7za9x7LEyLynzXKiVZTG5n+5DUuley7KQBBlEG52nqeuyFXhG7gNGwEznm+8YaU5H7xBg3/fcfWaSkvdov3xfuklCz03E2D/w6HZ7DPoD9u7eS+CiNluNGhQFNsvoD/qkeerSInORriroxwk2Tgg8zcLiEnt276LeahGVkKUlRlepgT7GjMnzlIVDB1BlSqgUxgvRnk/YbBM2G2jPp8jB5hmUOcds2yJF6mhEb2WFssio1Wt4YY1mq8nUzAY6U1M0Gg2JUc4K0iSj1x9iy4Jas8ahgyusrq7y8MN7MMZQqzfZenRILRJZQRiEFEXJOE447oStBL6PVorAMxgNyXjIcDxiablLkZXEwzHdlUWyWKKRte85qULJ/OwGMluQFAVLK6sYbQi9kCQVE8rCgi0Qal5hGfaHDPoDVlcPiA9CLWDjxmNoNDs0OlPgNrtBr+881lLqoXbJmeD5IUorykknVTmfBZECh1HgTGQNKteMxzGrS8vSjcV1LQPx9bCuIEaJGavFMhp1eXjH/SwtHuLQwiE6MzPMzM1x+imPo95oE9aaLC4vipFif5mytGRFzvLyKrV6nVqtRrvdpLI7KJIxqvQJfJ/xaECSxPR7PUfvTsmtoR7VRB7iBWQWsnFKXsg6trS4xMzsHJ2pBus2bKa3uszCoQM0vBZhFBLW6kL/VhlRGBHVI0ky1S6SO7cMh5J6Iim9Hl4QENY8ZIY/ytHjyeZv2XlgEa0UTznrNG7+7re57/77+crVX2fd/CxHHbWZ97zrs9xx5x1cc+21FFmKrxQ7t29HlznxqM8HP/hX9FaXUcry3j/9c5YXD7H9/nv45D/9HVu2bOEtb3kb1g9ZWlqmGfks7rqfHy7u5vNXXs0JJ57ImWeeyfLSAscefyKPe8qzyK+/hnvuupOnXXQhJ590Mscddxyvfv0vMzc3S7vV5G//9q857viT+MIXr+Tv/+aDfOPrVzPdqvGpz3yapdUev//f/pwX//TLWD8/x9VXfoEbb7yRj/3amxknCSeffAr/9E8fYevRW1lcXOL5L3kFB/Y8TH9lCYAXv/jFfPSjH+WnXvBCLn/u8/iZl78MgN27d3P22WfzoQ99iCuuuIJbb72VY487np97zWu54uMfZe+ePXJbD2c0WftvRoG1ltNPP51vfOMbKKXYtWsXZ511lpOH+Py39/0p995zD09+8pPpdrucf/75k85f1b0FGPQHXHrppbzyla/kQx/60CN+xu/8zu+gtSbLcxcAIqyGL3zhC1x55ZVYa3nyhU/my1d+Ga0UDz30EOeffz5xHLs9KOXs887np170Uq7/5teYnp7mlT//Wv7lio/yw1u+x9Oe+Wyu/eqX2LXrIf7uQ3/P9266ib/4i//O9PqNWGu59Zbv8Uu/+uts3ryJd/3Wm/GiBlGzw4YNGylQdLtd7rj9drQxnHDSSTz9Wc/h+BNPYtvRW/jYP/0D37z267z97b9NfzRm+67dHHfcsXjaMOx1yR07+q4HHmLfwUOsrK7wja9+gZNPPJHHn3cuu/fuo9Vu87OvehVz01McPHCQ1/7SL/ELr341v/W2t/LtH9zG3OwsR29az5ZmwF133cnb/vGvCTtzlEpzaP8+/uC3f5NXveJl/6dm3n/a1WpP0RsM6PVX6fYGKK1oNhosLy0xGo/ora7QcGtnZ2rKyVky8ixhPBxwcP/eiQ9I4EcTyY3RmqXFBQ4ePCRyHgvNNCUzYiPQqNUYOOuD7soytsgxqiT0ffzAZ2ZmlvbUlFgqZJmztNBsOWoTo3EshsP9AUVpaTSa1Gp1olqDqfmA+Q2baHWmUEg9laUJyTgFz8eounh0BiFHHXM8yngEtQZ7dm4nT0WaFdZqeEqDFqsMY4x4hbmDXBhFeKV05pV2/nFW6kiwE4kYVKzECik6PCG66r9WDXIm31/9ec3R5LAG8qRpbCdqC4VLlTZ60njXpfuXao0xKaCyeKj4vnjLlmVBoaycbW0ptXYuIEAejybrRVRv4vmypw2HQ/I4EdaLBaUNxx5/AlFUw/N94iQlTVOWlpYZjMZYC/v27aVRb1Bv1AkCD2ULxoMejVooQJ7NGY2H5HmO1oZxHJPkBSWaRqPO9PQ01iLgVV6ITxYwOLTAtmOOZcOmTQxHYxYOHmD//gO0OtM02y2mZmY5dGAfaZIw7UzE86IUuw5nb7GysiLph07e43k+U506UVSTSPlH8XWkhj5SQx+poX/yGvrHBp5Kt1LLzS0nRZpSQjUsimKSSJfGY9mAsoRRX1hMeS4He5E/pfS6qwz7PdIsQxuPehhNaIW2tM78GsLAw9NQGLCZptAGW1SRs+Jx5DsUugICJF1Bki58z+CHAjRU2m6lhVEjhokGi5jmRWGNIIiI8owoDEmznLwsSNMxaSnO9UkyJktieX+VMZdd03WXVfHqGEaFdfJCZC8zSuF5WpL2jHadLkH+LWsbYsViOrxrM5HZuSdxeLdG68Mkde6X0IsL54YvxYQyMmIqYzddgXFa0Wi2aLenSJ3Je5bEFEkiUZ8okjTFAjpLUeOxDDylJjJHvx45xpRQAoOwhnEJIUkckxc5yVgifSkkwcUzHn4zwPghxvj4YYTnB4ASvX5ZkuWOPm3Wnrs2CutMKEtbONRXPKnSNAMkujQIBOVW2ggN21GPhXbuo4yTjpalGL9ZBDWUNpWYfhrxddIuZeXwpngl5zBG/7hT6b/s0kpNCikdhJRWDPhWFhborawyWlqgrEXYMGSUJpSFAMZZmYnRntEo30OVljxJJ0RGlOj8j9q0mUazRVSr0axH+J5IIOs6wJQ+ozJlHI/xtSL0IlozHcIopN5pkgNpXtIdjiWV0pa0gpAg8FE2oh5uwg8D6q0mQVifUMetUsRJLusIgoHXAk2cJhzYu8j+AwcZjcZieNiRDTYIfAJH1y+s0GzrWU6r2RAfDWvJYgHDA9+wcf0cQeCTFQWj4Yg9e/aBGxf1Wm3it2a1j1Ehka/IC/EXS2OZe9YZ/NVqkawLRcI4GRMnMfV6QL3RoDM1g9E1oGQ46mFCkQxHjQZGK0n5oXAVdEngR5OxmReFrD0K4rEkYo1GQwFJA5/MMUmVA/S1EumsjGsPiyWNx3R7XXrLsrvbIiGORxjP59hjT6LV7tBst1HGI04TRnHCeDyitIWjI3v4ypfo7cDH9wyNWijeNaMRCwf343mGqFZnHI9J04Rut0+pNNoLqbcCPM+QW0uZpAKoGwF4jSfyB6XEINN3enPj+2RZjueVBEFAs9VyX/cIAt+tFZosk6IjGY/QxtBoNQmiOkpp4tGINEknjIBH8/WtG27gX/7lX+gOYzZu2sTFF13E9ddfx8ryMi/56Rdz+60/5IF77uZv//oDGC+gWW+wsjRkeWmB2/tdth17HOvWb+Sb3/gGc/PraHU6/MvnPkWeiRHni1/6Mhq1iIP793DH3fcSxzHnnH2WsJP7fTbOz3HM0Vs56eST2blrJ8N+l8984qPcf8/djMdjnvH0p3Pm2edx9LZtZElMv98jzxLOOvcJDIYj3v/+97N+us0555zD5i1bWb/tRPYfOMh1117tpPwFi/v2sLi0xOatW3jyUy7mqKOO4tbbbmXfgf34QchPPedytC0JPC0x62nCm970JjrTMxx99NH4vs8nP/lJvvnNb1IUBWedfTbnn/8EGo0G99xzD9d/41q6q6uTe/q/kmhV7IZK5gNrXW/rmmif/PjHWFxcpN/vi7H5jh285S1vQWvF7Mwsb3nrWycHyvl167j/gQd4y1vewq/+6q8Cjn3gmkPWWr7y1a+yZ88eut2uMAVcc+Te++7lbW99Kygx+3zjm9/KHXfdxfbtO3jqky8kTmJu/u4NDFeXiYzmofvv5uitR7FhfpbBcEi322NxYZGPfeTDTE3P8JpfeB03fvu71Go1fv7Vr2HfwUPcff8DTK/bTLc/YGl5WdZDL2TLCY/h5pu/x9T0DGec9yQe3r2b/fv303vc49iweSuXPPt53HnXXRxaOMTDD+9mdnYWypJ7b/8hs5uPxvgBex56gOOPO44nnvM4VJlRrzVkPVlepcwSHrzvXr58z92srq7ytIsv5sCBA3z0Yx+jF2eMB5KQdvddd9NoNvmpF7yYzIQYP+ComSbnnHXm/7lJ9594lYjPZBhFtFsNsixlOOixcOgAg0Gf8XBI2myS1OsCqHji45ElCVrB7MwsqyvL7jA5dONK0263abWa2HIdU1NT+EGA51LvPGOoB+tZXQ0YDAYMBn08Ywh9j/UbNhBGIa3OlDt0WEZLi2TOmNfzA5rNgHqjhUXRarXYvHGjmLkDpZHueeX/ZBSEnnbSjphBv0et3kAbLeE0xtBsNpmdXy9pe/GY/nBMmubU8pzANfWqpDNjtKT2uXSwNJUm9Gg0lP2wqr/0Wr0s3rgW7Sw/qjms3feKJ+0aK0prjREqhmMsuZpQZZNqu3TWDOIhWq4pEZQAXZXhdPW9lS+T0hqv9CdyHluKR6115tBiAJy5cB6pxz3fR3k+ubWMez1G4zFFUVCrN/BcCJDxfJIkYXV1VcIKEG8qz3iUVlg4IgGwNBriyzQej9i5/UGU1tTqNWE6ZRmrq6uuDvBZt3EjnjuTpFkqViUotFkL09HGIy9EYuS5xOc4TlBaE0UhrXYHWxbu6yK/8ZQkCCZJhrIlRnvU63XiVNLgVrpd0kQMsh/N15Ea+kgNfaSG/slr6B8beJp0C7CTB2RLO5F9iTm0SK3S8Vg2nvGIQbfrUtEKPN9zAyZn2O8xGg7Ii4IwikSG1ZBo+jzLBE127BmjSgpVUviaUoN1XkvaeJO4+wpuyV2qWZYmYA0KjyDwpFtcSudNO2+kMNDYAJTy8H3xHUJZ8iLH9zRxHJOmKVk8pkxTMXNME0pnxqi1xhqDtkrkgKXC2sLpQ6WD8m+ov4hRWhUlaZzcTm5yRRg+HHhao/ZapVCVjgwc1bqgLPXE48A6qqLbQR01TthIE1N2s0Yl1o4+bCxEtRr1ZotWkpCOR6RBQObHjjatKawlzXN0KRpb4yiTYaNOGAbU6nUazbaYCNYagDDRMrfpxcmI4aCPBnxtxJzP9wmiGl4QoV2inlVOL5tn0vUqpHMknSbZnI3WFLacmM1nRe6iI4UyDIrAQhBEa1G6hZiMaye3q8wnrZUkjzW2mnTflF2jixvPm/hnVfPBPWSUEvr6/xuXjE1jNEWWMxqP6a2s0FteJh8NKJXT7CYpeVmSFQXK1zJmtHhEKFNgbYnGpUZaaNYbtOo16vXmJBbX2BKNxTOGPDCUmaEbj6VD4Ie0p2ap1ULqnYj+OKYYJxR5SVHIgxBQ1Mc3hnq9jfZ8lG8IQ/ENqDdaDEdjSaW0GZ5WeFqhVUmWjDh08ACryysURUmr1WG606EzNUWz0ZS0Qq0ZpBJjHpUl9VB8KcqiIIulExlFhtmZKdqdNjsf3kPqzFX9SIwwjVEEQQ1lFCVCU/a0Qen/j73/jrbzLs+10evtZdZVtbTUJatZ7hQDrrjQ2RAgtJCQQiCEBAgJIUBIJSEhhBDSSEIvoZpqTLEBY2Mb9ypZlqxeVl9r1reX88fzm1PO3ufs7e9wzoe/MTTHUOKR2NLSnPN9f897P/d93QkFCVEifyedEtfSVRsIdDsBYdgjCAPGxtczMjLKqqk1tFo94iQlDHrYlFiOg+dKBMoyDYpcXIWUObZti3BrWsJPKORQTBOJXsRJjK5akgbffbEua4pJYA3h/kWZkWUJvW6LIoqgyNC1jDwvcVyftWs34PlVYYaUkEYRkeLAydfKwjDlnuZ6nhLVwbFMyiwlSxO63Q6arlOtNygQEGyr3car1HErHo5tyXBfyKCh6wYWmmralJiswGYzSkRMNi1bKmrzHFM3qPgV+e48VrjXNTTESZImiQzDuo5ly7mRJglh0CeO4p/LFfl/5bV3714+97nPQVmwY+eZbNywngcffJCyLPj9iy7m+OGD3HPn7ex96H7OPOtcnvK0i1maywiCHktBwNnnni8MkLjPSKPO2MQkX/zstdiOw/jEKn7jN99AGof8+Ibv8OB9d6NpGldc9DQOHTnCSqfHujWrWbNaarrXrJnm0KFDXP+da2l1Q8YnJnnZyy/nzLPPZXxyivvvvp1er0en3WLHrnN4aPduPvf5L/LGX38tGzduZO2WHfgjE6w6cZyPfeSfOXL0KDMzs6yeGKcxMsK2HTt57vOeR7Va47vfuY7ZuQUazSYXP+1pjI+NMjY6QlJoXHfdtbz9bW/l9b/1xiH76fvXX89nPv1pHNdl8+YtXHb55URRxJHDh7nrzjsAEZBqtZp6WC1ot9v/TYQansG6Rl7kLC2Jw2plZWX476VpynXXXSvRbhUbmZ+f57Of/Sy6rrNu3Vp+5bWvJQxDNF1jZHSEY8eOcdutt3L11VeTpKk6r4emaW699VZ++tOfUm80GBsdBWT2CoKAz/7XfxFHEdOrp/nCV76KV2uQFRrPfd7zuf++e7j55h/TrPgUacyBfXvYuW07nl/hznsfJAgj0izjxh//iMufeSUveNGL+fZ110FZcOlll/Gv//lxHtz9MOtWTxHls/TDiHa3S7Uxzqr109z2g28TJwnP3byNG6+/juXFeSzbYeu27WzfuYtrvvhZZk4cZ252huXlFco848SxI1j1USzH49ihAzzjqU/i0oueTpFndPshS60OWrFE2O1wYmmRH9xwA1EU8Za3/h4/vf12Htqzh1pjlJNHj/DIngcJw4gnPeWpXPXs5zCz3MG2bV542VOHrpYn+mtwvxxEU4osodft0FpeotvtCt+nVI63osB1BSycJjEaUKvVCPo9kiRWjh85J03ToFqp4FgWY+PjlGVJGAbYhtSqWxWPshDRpN1u4TkOpucyOtIUYLAnbok0TYdu8bIEy3GGTWmmZVOr1ZiYnJRFZlGS6wZxKpDZNI7RLAPbNMnTmCiM6PYDKf6xbWFK6Tqu59MYGQEgimOCMFbNcjm5bVEUlkoyqJnLMsgVtDmJ4yHSYdBkZ5smpXKgD0fpYdu0gmLI8KiKYgr0QmZMXZem6OFVr2nSkJ2rCJ2Kp+V5QVloaLlqeNN19YCNLOCVGAVyH8iUkGwYgqzQdX2I6xg0ZMuyPlUO/QJ0A8200C2HUjPIspxur0eSZGi6RrPp4Xo+jutRlhKbabVWiONYAZo9DF2Bh02JKFHIA2aeSvPhyZMn0HWDiVWr0Q2DLMtYWVmh3mhSbVQYHRunyBKSoE+eJ/I90KVEyLRsHMV8ytJMYprqDE6SBN3QsSyTSqWimhFjHNcVIHaZE4YhSZyoRmkdx5GCpyRJRYR0HBzriQ0Xl9fpGfr0DH16hv5ZZmitfJxExv/65vfFDpqltJbkZhdHEaZhDpXEwQ01jAKyVOyfYT8QxTfNTrGM8oxer0sUBgB4ni+NCV5F3fcz4rBPnqVoZT78RZoqBc/Acj3QdQp0ygIkG1VQFnKAJXGiNiEGlVoNw7IwLFvlPy08z1c5d408U9woIMlSoigSa2QUUYIMCKVsKHr9HkEQEAQBYRSRqRhhrjYYeZ6pbYdsSAYHYKk+SNMwcG0by9BxbXnvNA3CNCVKc6IkJ0wKTMvC932ajQauK+C3Ik+HCrpl2Vi2jaPo+rphUOYCl5OGAcmh2q6P41dw/SqVZhPDsjFMC8fz5SDxfNnXlKU0+4UBURDQay2r9j6pcxVwYzq00hm65LJt28b3KyLMmBYFqrlDN0iTiDSJWVlaJE0TsjzD83x8v0Kj3sD3a2i6PszFyq9yeGijyec3uNB1XRehUdWGFqVYeIURlZAq0akoCqH9Ow6262IYJmj60FJtO660RPg+IIyEfq83rLR2XFdl0gt0TVcQPQfTUg1++SmI5UC40zSN1//yKx7XRffzen3u2uuJo4gwCOh1u0RhSLfdxsgzTF2nUauoSuOchfkF4jQjSTOqjSoaBWkSQgGGplNxXHRk4EriAtuxcF0by7HJi4ww6pMHbYo4JgsiHF+g/zG6ahQ0MB2XJMvo9PoUBRi6Ra02QqXiYNs6UdiTf9eyMVTsMkkyNXxmpFmBX/EFbFi16XXbrKwssmfPfsJYtnW7zjqL8fEJJiYmabfbqlFHxEUNneWwR1ZK42HN97AMHb0siPt9skicjY5nY7s2c/OzhEFE0A9pjDRkM0kpuXjNxLQ84kR4CbohdbHoOpQZWlli6fJ9jWMZAEdGR5kYn2B67XoMw6QoodfrSe46z9A1C003KS1L1lA6+BVpGPJdB5OSMs8J44gszykB23XJ0ow8FQE8y2XwScIY0zCpN5ryUJPnFAUMOq27/Q5pEpGEIUkcK8emTqMxgus4aAzy3LIJ1dW2s9DESRqFMfVmUzhxrk2/2yHs9TCQ+FCcJLS7bYG7FgX1xgi241IAlVoDv1rDNHWiOCLo9bBMe2jNt2xbtkGgmiV1GaCUIzHq9zEMnVqtTq3RUM4Ucb0mcczy0pKKaBgMxGJd1wj6AWEYsjS/gKZi4//y4ff/3K7P/9NLHiZDVlZWeO2v/Tq26/HKX/pl7rvnLpaXFjC1ku3bz6TZHOFDH3w/O8/cxSWXPpNbb/0JY+PjXHnVs/n8Zz7ByuICz736Ko7NztHqdNm1cyf9bovF+Tnuf2gPURxjGga/8eu/QbXi8x//9k9c9eznce5552OnfXbv3ct9D+3hHX/6VzzwwIO85c1v4vf/4I847/zzWTs9zb/9+0e47/77+a/PfY7bbr2Fb193Lb/xW29matUqar7LBz/wfh544AHm5udZWlrGNAz++G1vZs+ePdx5991c8dzns3PXWTzjokv5hw9+gOPHj7Nl63Zcy0ArC06cOC4O2jTjqZdfzeHDh/jm177CR//zozz5yU/G81x+/dd+nU9/5tPouo5j2wJP9X2iKGJ5eRmA888/ny98/vO4nsfc3BxXXnUlvW5vKCrJg5QMVoZhUPF9QIpUHis+DV6DiM2FF144BMHPnDzJq1/zS8zMzNBaaWENa8czFWcpabVb8D9NYbVajRt+dCPTq1djGjpBlCjEAXz2ox/hrttvY+/Bw0RRRJqkuL7PeRc8mee84EVs3rSR40cP85EP/z3PvOJqKtUa//DhD/P0iy/j6RdfxjMvvYjdux/i29++liuufh6tlRU+98n/YMOWHTTHV1EdW8W55+xi84a1XPPFL4MG9UaTc885hyAIuOOnP2VqegrTNHh0/wEuv/RinnTBeaysSDygVqvz4X/6MCMjI7zpTW9icWmFNE0YrXo8sHsvux/eyzVf+AzVapU1a9dx8uhBGo0GT3nq07jsiqsAePc7386lVzyLnbvO5j8+8q/s2L6Dq664EiyX0fExztq1i/f88btoryzxja98aehCe6ILUN/8/o+Gi8BjRw7R7XZZabWH+IiRZpMojkmSlKLIcRX0NwxDojim2+2RplKIUq9WybKEIsuAEt/zhNOmhKpuawUDWTz2ul05rwyJVVmWjeN6eK5DHMcsL6/geBVcz2NyYoJqpYLt2MLdTDPSPMevVIU9VOTEcUyapvTCmGq9get5aJT0Om3aK8vse/SAWjbbnLlrF/V6A13XaLdW6Pd7dDttup0u7U6bfrcLZYGulbiWiWtbjDXruK4Cj5v2kPfU6nRJUxErTNVa7ToOrprzBhXqeVHK/Oc4AhW2HdBQNeaROodyiTCZpsIwKCaosC7EJaDEr1PUhlM8VV3TFO9k0GImcZsgisnU7yesHGnaztOYPBdmaq7Oa9M0h2KSCEE5SZLQ7Qv8vR/0mZhcRcX3KLN06F7odNq4rkuj0SAII1XqBK7ryUxeqRD0ewT9Pu12S70nBb1uTx5ca3WqtZokFCyb0bFx6g35jMJ+j05rBdO0hM9UQk1xurI0xTBFiErTlDgOiYIAz7HwPY+xsTEc1xOXiKkP0xYnT55UTg0PzbCHM/PszCydTofl5SWVxND5p7/765/X5fl/fJ2eoU/P0Kdn6J99hn7cjqcsy0iTWCy+vS5JHJPGMbmqNzWUXXxQsZirVoZTxITyVPQaDceyMPDRDQPHcXAdG8tQ7qlSXE1ZqZFlBboGumZgedbQ3qnbFgUaWQ5ZmkOpo2mF/OVLiXANRCrb9YYbG2m8E4VS3CslmiaRtCzLhgd8HEVKwDBUvtZF08C2HSWehPT6PVHr40hZgHPSVKPUdQWIVFuO8pRIYQz+XOXqGWxM8qJUkOr/NWdeKlsgww2O/J6FEgL1IkfP5QtRloVSIiWuNoi+Gcr+WCpBpcgLck1uQAPRRxxR4FgWpe/LNibLhoJXkZtDS7FlmqpdxMZ2XQa1l2mSCFC+KMjSmEw5rQbvo+9X8VxPNeSdysKLl04pq9pgM6XiibrEL8s8I1LKr6bYXXEiAqfE8ko0w0Rah6WdTtj2Jbou08TAdYbG4E8cHniDl66sl4PMvkAchZ8ltbxKeCqKISTxsf/9E/U1PzOj3IRS25ylKUWWEccRlAVJEuG6rhriCzRydDL0IpMYaZoJ70orSOIAW7W8VBs+piENNmHYI8tSkjTGRJODxQXLdrFtG9e21XWSsrLckuiBbuL7Hq7jMjY+imnKZqhQMQJ0g1T6BqDUcGyb3NBJ0z79Xod+t83CXEYUBoRhgFup4tcMLMel3hzB9X3J4ls2tlOQxLGyuGcq8ol8d9MMCgPPNrAtGwMIo4g0LynijEZ9lFo1F0BmIa7PIi+E36Ab4ngoMygzseLqOrqp0e9H8uelCWUp/61XrQ5hoFmRUyqRtVarkuc5YRCQxVL3mhcJpWGgmSa2KdugMi9pd6QFtB8F1Op1HM+T6LBeggmeIy2UBdAqWuRZTtDryf1U/IMinBcZURBS5BmU8l0ewgI1ATialkWSpCRJQqfXxbZtKrUqluOg6zpZKu9HmmXkMURxqmz1mnD/ylIOulIjz2OyosQowXFd0CBLEyxLGA96TZe2oUIadzRdpyyFF6ANf3JpmPFcD8dxQd1nw16XUIcsT0njhDQRR4Fu6Ji2PEhlajtTKoivaRjSXqk98a9hz5MHi4svvZwTJ0/wg+u/x6aNGxkfHeXE0UMsLszT7XS44sqr0DSdwwcfJU0TVpaWue2Wn9CoN6hXKswvrTA1vZYt26qsLC+xsLjMyRMnyLMEz5EHEdOy8Ks1nnn1c6l4HjNHD1IzS9IowLEMrvv2tzly9Bi2ZTM2Lv/+ddddS5pmbN5yBstLS/iVKmefez67H7yfPQ9K09HDDz/MzMmTLCwtsn7detauWYvhV5lYt4GzShGK5ufmuPFHP8BxXaZWT1PmGUvtFYo8Y/MZ25ibnWFm5iRhr02zXuWKK6/myJEjFEXB1q3beMqFF5LmOdd8+Uvs2rWLpzzlqeiGzr59+7j++98HYHl5ma9//RsSAUgznvWsZ7P7oYfYu3evvNmllKPoutjMFxYW/pfPw7IsXvnKV1Kr1QD46le/im3bTExMSETPMHjR/3iRLKrCkC984Qv0ej10Xafb7cp89P9m9VeUJQtLK4xPTDK1apLPf+GLLMzPY1sWu/fsYWZ+Ab3M2bBhI2OTU+i6TqM5wqGDB3BsgyzPedrFl9MPIzr9gOf/jxdj2i7HTxxn7yOPMDe/gGG5PHD/vZRFwTnnXQCGha6VVByTmaOHWD55VIkYEa3FORYW5gmDgOWlBc6/4DyaIyMcPnwU05TYxejYKO1Oj0f2H2DHjp1oZc5NN3xXRQkLWisr7D9wkIOHj7IwP8fY6Ag7d2xn65ZNVKo1Nm7aTLfTIYoinvLkp1IWBfv3PcLmbTsZn5omSHMeefAuxsfHmRwbY8eOHSzOz/ORj3yEyy67jLPPPvv/b9fd/69eRw4fVN78kpXlZZIkwTR0ev1Q2nZLcXeXQBLHUMimX1w1JUWWDp5ziMKAohBkQa1Ww7El0hX0uuRZxgDwjeIiea6D5Ti4nkeaSqlLGIayYDOkVKBSq9McHcN1bEzDIEktjDRDTzOyNKfUhd1iOy6aYaJFKb1el263QxyGRFEoVfCWjetbVKt11Yymqzr5iiwTH7NNF0ZnRllk6JQUQBDFpHmu4L6KvalpkjYoctVUXlKqZuIk0TD0TAqABlGzIqfMhY9lqLmSshy+/4amCYrDFjE4z3OyVDXcKUe7qZ+aHRVb4hRWoSxlNhbwEoYlDciarrqytHLoaory9BTcXTklNIWN0HRDWKnKLaA9Jnqraxq6+pltxxGObRwPY72O4+A40lTXD6OhOyHNcuIkk3M4yVQyopDPTNNJspw0KzCsEse0FMs1oFKROJ9frRFHkYgTeTF01+WZNPXpRUGeJTiWSXVsBMvQh+zVJIkhiQjLgigMiaOIfr+rWFJy9ue5CGwrS8vESYxtO1iO8HKeyK/TM/TpGfr0DP2zz9CPW3hKkpgoCOn3uvQ7HYmcpSm5ISR01EaiKEtyFK1+QDjXxO0z2EXpuo7p+WheqRg8horUPYaKbmgSYcsQO6eu47seli0wxFI5ZeIkpyxSJeyUmIZwlLRBRMoQ+JVumCI8mbY62MvBVQhlLtnFKKLX6RAnCWGcYFsOumlgmg6e6wo0zdCIE2l4a3VahGFEr9+j3w9I04Qo0oYCXJENbvg6ZZFL9athgC6+IYGOi/iV5WKPLBW4XdPk61GqoUO4WoVYeimgyCgyyBhE5oxTTSWGWAp1w8R2PExb7NIgLCoBjgt8fKDyitQljCPDNNB9jyKzyLOULNVVJt0cZult28EwbdWiYFGUBWmeEUURWZKQJZFwAFRrj2ML/6lWqyvQuKXeG6nTlB9Bw9StIVS9KHKJ86moQ5ZlhFE45F2ZliUcriwjVfBz03KG78MAfk4ujSWGep9EJBIxS0LN2jCOV6rttqU2YZSnPo+BJ6tQ8FdpQgG9NP4b9+mJ+jp64KC8NxqsLC9haBq1apVut0MUheRpztTUJI1GA0MvMLWcUssx1HBVphmaaVCWJb04oFKtYlg+jbEq5Bl5EtNrLZGkKSUa9aqPbbvgaLJ1MQyqdY9Ot0en1+PYyQVsx2PN9BqaI6PUalVWTY2firgWmgAFVRsDhbTmVH2HsjAJgy7Lyyt0Oh1mZxcAYbFsP2sH1XqDWr0+rF0OolCAlq4rIL8oJgr66IZLqUtVcZJkYJZUXQfT1ShNkzjPSZKMLIrZsHYax7WxHZOjx44TBiGUJbYtg0bQD9C1AtMoMI1MRWlhqd+hHwT0eoHawtqMjk/SaDbxazXCMMK2LPxKhWajSVmWLGsaYRqRJAFlpoHto5kWnuOiA1mSsjA3T6/XpRcGbNm2jVrTlQNVZUZr9ZraGJskYUKv02VlaRHfk3uZYVjEcSQbkn4wjBCIH7ygyHIV4c1xnApJmhOnGa12B8/3cXwPzzIBnaKQzWiaSBtoHESkcSYQVRWPNh0PDBlk80IjL8R9KENCH9excR2Xer1Bu90hiaXtskTaRSzLQEcOT13BSWv1pggDcUhneZ72yhJxEhGlkcRn85w0lu2SYdt0e1363S5LJ05Qq9XxKxUmptcMK6v/n/DSdZ3nv+CF/OCGG3jPu/6Qv37f37Jz55mkUciePbtptVZ4z5/8OXfdeTvf+vo1VGtNZhaX+PGNP+QNr389qyZX8Z0bfsCrnn4x559/Pn//9+/n0IEDHD98gM0b1zM6NsGa9ZuIkpRSN3ndm97Kd77yWe776c1MjdQpDZNVYyN86B8+SBQnTIw1qVar9Lpd/vmf/pEX/sLLefrFl/Povn2MTq7iymc9l/f/1Z/zyN697Nv/KM1aVRyrWc7Fz7iICy98GithwsS6LazetJ1j+3az+/77eGD3bl7y8ldzxtYRHtnzALOzM6Rpxste9Roe2fswYRxTxAHTq1bz9KdfzDe+9hVuv/12XvaLr+DZz3k+l172TL7z7Wt59rOfzR+/50/IsowvfelL/PAHP6AoCo4ePcofvfOPAJicnOQjH/kIX/nKNUPhadCga/3PD0PaqVyc4zj82Z/9GRvWr6cEHnzwQQzlBtA0jVq9zl/8+Z9TAt1Oh+9ffz1hKN9pyzIl1pSf4jOapjk8X+64+150w2BqYox/+scP8cB991GveoRJhmmaXLBrOxdcdAm7LrgQz7bZs/sBfnD9d+m0lti4aTMvfdWv8KlP/Cdzs7P8+fs+wDe+eg3f++51LM6dxK/WmVi9jm9/9fNMTU3xh+/6E2655SfMz8/RdHXuu/t2Ht2/j8ue91KSOGT+xBE13Gb0em3Wr1/H2vUbuO2223FdWW55ps++A4f43g0/4vW/9lrmjh/m/X/6DnZs345pWlx/0y1ESUKWFTi2yeaNG3nWVVezbvMWdNMiiiK+/fVrWFla5BWv/CW+8a1vcMtPbuLFr/o18rzgyMw8X/ni51izejVbNm7giiuuZG5+jl9++Uv4wN/93f8jhKdH9uwWB7Vl0+/3sEyTRrPB0twsvX6P9soKjeYInucTRyFlLrXbrusp/kohm/2ioN1alrIay2J6eloiemlCa2kRTQPfczFME7PUKT2XWk2g4KVusLS8zEqrxUqrjeN4rFq1ismp1TQaTeqNhvBJlFChWzl6mrG0sKAKferYloOZSVxycWGedrvFwvw8hqFjmRYj4xPU6g3GJyblIVy54CvVGpVKRRgmjottO9iWOQSox5HMjb0wRgsjhVcQsWcQrdM0DcvQKZBFapYkIkbpMuMNxCytSCnSkgSgLMU5r2nKXSX3Ucs0cW1b5vEsJS7l6bxUD4yWDoYxaIsW4Uk3DNVMmKvI4eB9sk+JSspdn8bisIrCvjjATJNavYHtuliWLDeLsiROUrq9PpZlU/F9de+RunVhxWR4lTpxkhAEId1ejzyXqNDUdAOAIIxldtd1ekFIL4zoRwk5Aj3OCzBsT67jvCQrpCWv1HR6/T5BGOCoa9lxHGZPnpBkS5piGCa2QowYZoFumpCn1Oo1xsdGpVyqFCxGGPRJkkT4XZ0OQRgoN4os2Du9PlEY0ut2iKMY27bZvvNMas0RvErt53ZtPp7X6Rn69Ax9eob+2Wfoxx21e+/f/7O0kcUReSTcH9MwFEeoJAwj1chWohkag6rXIpONjIG4oga5QREwTmWuyzKnzBLIMyHyD8xASiQYWF9R/B10HV0z0HVTqaUaul4Mo2CaZojApCJWlAMhQv4+0oom0bx+v0cYRoRhRFaUcvOvVqlWa1imiaZJxArFtcqKnCzPSbJYKX4ZSRqTJrL96QeBVJOG4bDRL0nioWtJH3w2RT4cYiVeJocBmiEMAM+l4vvYtoXvOeiUsv0qMsmYahooWBiqPWNw8BmmhW6amKaNbsoFog04RQokOBBwBgO2NnBVlQW5OmQUfkJtUqS6UjdMTMNS6qZSY3N5D6J+nyyT7c6AyTSw/9qW/DelEm8E1q0L+LsQ+55lu0OIdxKr91dFGEV4Ept0WZbDv6OIiw6mbWPbjsrti216gGM31Obsse4lwzDQH1N5zUAkcyRCaJrm0N2Uq0YYyfkq4U65nwavd/7+Wx7XRffzev327/6BAPcti6JI0ZGNfL/fExU7LajVanieS5IlyuWWkgYxRS7XeX2khuNYmDpK6c8Jk4QiyyHLaVZ9bBWHFHechm3qxGFCnub4FYduv89yt0uKjVepsmpyEoocTddwPVcNjzpFwRBeuby4RKfdZmF2jiSSWtlyUP2pQ0FGo1an2Ryh0qhToBMnqmGzKDBkAQklJGmCbZo4lklRijOu1HVs1yHLMxYXFxRUXqfRaECpibVYXetZng43jvJ9spQFVSdVUNXWyjxhFNHvBxiWi2WrzZFjY1kmrudgWZLjj/uRtFZo0pACkCr4n2VbNMfG0E0H3bDIopBOa5mZk8dZWmpRllCt1Tlj21bq9TpHDx+AMscwNDZu3gSluAKjMCdNc/r9mDSNiaKQ4ycO0+v1CMOAaq2J7bq4vseaNWultch26HZ7JLHAjdNMIhcYOq7nUq3WMAzZrARhRLvXJ05SaTSxbCzTwlLbWHHBFjLMW5ZsXXRpLS2RuILvV2k0RxifWEUQBERRSLu9jKEZGLqB68jGz7RM+mFf3LdhnyJLKLKYJGqjayaGYeFVRrAtAS3maUoYR/RCuS8XWU6ZZCri4DIyPoami/D87j944l7Dg6M6yzJe8YpXkJfwvOe9gO997zscP3aELA6ZXjXJ+Ngok1OrmZud5ciRIzz9kiuxHIdOt8fJ40exLZMrr7qKR3Y/yJFDBzl8cpZLLrmUF77gBYRBnzDNaEc5RtSlvbLEjTfdRHtpAUuH97zrj7jj7nv47vU38PrfeRsP793Ln/3pn/C3f/t+tmzewh23/oSuasC6/bZb8Cs+9Xqdw0cOo+sGjeYoz37W1Zxxxhmcfc55/Pgnt/LogYOsm57CNGTJ4PkVXMehWqlw+OhR2t0enSBm84Z1VFyHb3ztK2zatImdO3cxtXqa2dkZ7rjzdp773Bfg+T733nsPQb+PbhhcddWzWFmc48Sxw1z73euZnJzk0osu5nvf+w4nT56g1VphcbklAtrEJK1Wi5YCj8tZqkop1ODw2HGpVquxemqKG37wA9asWYMGHDh4kHvvvZf3vve9/0sUz3Ec3v7Od3PnHXfwgb99H7ZtMTIyynnnX8D9992HYRh89vNf4DOf+iTXfPlLvONtb6bd7XL/Q3to+B6u61Ct17nsiqtZu34jnW6Xm266ifvuu5cXvezVHNj/CDd891u89BdfheU4PPDQg5xz7gU4jsuXP/8ZNMPC9ipsP+tslhfmObzvYV716l8i7Pf4r898knOfejGNkTEeeegetu86lw1btnH80YdBN7C9CtPjTcbHxti6fTv/+ZF/5eE9uxkfHaMxOkpzZIStW7aw/+AhbrvjLlwDwn6X40ePsGvHNrZt28Yv/cZvYVviypmZnePmm37MN7/xdX73LW/FdhwefGg3l112KbZl85GPfYLLL7uMM8/cxX994fNMr17NOWedjeM49Pt9jh47yq5zz2dyYoIRR2N6epqxsbEnfNTudb/12ziOg+f7ZEmMoet4nktPOb16vS6VShXHdQnDEFttpOMoQCtLEXZsB9CI45Cg3xu683VdxJnp6Wm5x5aFnMWmjmebEsvMMnTHZ7nVZmFxCU03aTabbNq8RRoSEVdlvVbFtm3a3S6maWHZNrMnT9JaWWbm5EnCKAZKXMel4rtYhohZlUqFWqPBxKrVFEVBry9N1CUl1jBlAHEcqSWgQT/oSWStyMUln6aE/R5ZIo75KIqH5T360J/PkFFqmSa2ZWGawk6Vlzh/ZO9YoumKB2XbmLq0XVuWJQiFgYMkS8W5oulK7JI4k6Gidkmak2RSXS6Ne9JwZ9sOzdExHL+CYdoSy4ljkjgm6PcAVAGPrSriTYo8J0lijh89IgmLJAXdwPN8YbuNjeO6Lr7v0m23SZIY0zTpdHv0+gGOV6FerzMxMU4cxyRpShgK9yvLxemkmzaGZdNs1MRhFMfESYKhG/gVaQ8fwNk19d0ZGxtjpNlkcmKMfr9PGEa0O23lxioZHWlimhaarhH1+/R6PVqtFrOzJ9GAWr2OromAPtIcwVJut/n5ebI8JytKOt0+UGJbpyLQGzZukuV7kfPm1//a/41X5P+11+kZmtMz9OkZ+meeoR+34yno9ZT7JaFIkqGDSR7aFeRabQp0lJhUiDtHR5MvoT7YXJgqIy0QQAFwF0O3039rczONYQQtzgrQCig1LMPAMOXgcF0HwxgIWOIQQjXcFaVEyAolhGWZciM9hgcVKTEDXce2LBzXlcpY38c0DMpCuA5FXlCUmTr3NGlsM0FHeEu5k2GaBo7jkiQxXhipjHxKGIbkuVDxB+9NnmsiiGmlik2WGEpcO3Vo5uS5WG9RTp7B/wTEHqcBmsTVilIcPVqhg3JE6SrOphe5iFNFgW7kDAS9sjgliGnqc9W1UrVYiDUX0WVE0JOcmlJyIc1TxfFKlFXy1Gdo6HKTNk1ToITKQpzlGaZtYSCHlFZK8K0Y/H1K1UKYZcqhVQzrdTNl7yvIsXQD3VCWTE2y94YpEPvBZlC204Oq21Pf6UJZ0eXQNSnzTAmpuXzP1fdjIB6mSXzq58jl/5cmA1Dd49Jvf66vMs8pNCiGQPuSLEmlxcSysXSBX0ZhKK0IuYpZliW6oeN5jmq0MKHIoIzl30kTiqykLEQ4dFROPUti9LLA1TJSMuIio9XN6Pb79PoBtZGKOkQsoiChyOT6HwD/srwQkTEMWFleptNu02q3SNX9x1ftH5ZtY1pQqVSo1KrohqkOefmeiFicMVCdNbXVsR1HHZryyzQNSkR81E357luOS5HlZHFKEkeAAEkd25FoBFCUBUlaQKGRJilpkqr7jNicXdfDccQG7XmuNII4AtEsi0Ky5Mr9ZxbWEAipWzam42C7PgLql2raNI7QKKQBRtPxfU8Ohn6POOiR5ylQ0O+MCqeh1CSSkKYCAIxDojgkjkPhtmkaXqWC7bjYroemi2hvqBpZ3TDI8kzFSnUwRNAXO7808sRxQpLIfcDQNArDoMQkUxZ/xV1WbklLBpGBs1MTWGRRKIBjlqrNudjQy1yGn04cSUWvoZOkMf1+j1anRZ4lGFqJ6xg4vovteHheZRinztJsmGayLRvNBN3RFBvPFBF7mF9/4r6+853vsHHjRrZu3crq1avJi4JKtUq/26bfabNp0yZqvouuabSWFqhVqzzpyU9FNzRs22brtm2E/Q5pkiiuyxKLiwts27aDkZFROp2utLjYLlOrJtl95wFOHDtCrx8wuXoNY6MjHDx6gjAtWLNhM2EY4joOT7/oEubn5omCgJVWi+WVFVZWVlhcnGfKnMav1Ni6fSeu6zEyOsbYxCS26xHHsYrCuwRhhOfamK5Dt9vFMk0mJifZvWc3y4uL5Ajrz6/WWL16Gs/zCKOQnhpeR0ZG6AcBQSgOjDxNcV3hH3R7febm5lQ0JqfbaaNRYpsmvuOwc/t2LNcnL6QFq9vtcvEll2DbDnGa4domnXab22+/ffhZ6JrGGWds4YILnsTtt99OtVJB13XWrN9Ipd6kWm/I+WkY2LbFiRMnmZmbl6p4S66r8847n9HRURq1CmeeuZN6c4SzzjqL6enVuI7FoYMHiJOULEnY9dSnMjo2huU4aLrB4sICy+0OSRLj2jaddgvPczn3vAvQTZN+ENJuyzbbdV2SLGdyYorJqWmCfp+iyGmOjBD0+0RhQL3ewDJNHNtix47tVKtV4jBgavUUlu1ieTXmjz5KGoesXbuWY0ePcPzYUc7edRYY0mK2b+/DnJybJ44CVk2vZnR0lObYBGdu3cLatWukdVYxP/xKBdNxidKcR/fvZ3RsjFWTEwJj1nTWrl2LpmksLy/hOw4V18VzbLq9Dt1ul6Df5/ixY8RJwtSTnsS+g0do3XEHz3ve835+F+jjeBXFINKVqodDiCOJSNmK66kpZEE6iGZp8mBi6DqWaeO4LhoaWSbLvbKQ2NKgaMdTFeeaBqXicuoa6gxISLKSfhAQRjHNkQqO62GaJnEck+U5um6QuBmabhDFMYViCC0tLdFaWWFpaYlUuXd8z8dxhBWVl6USS3wRa1RE7FQCIBXWjMIoSIObTUWrDoUlVBmO5/lEYZ8kjjHMvnJEpcpFn6uWuQJdP1XeUxQ56TBZMRCe5GG/hCEUeyBSDSDgepKQZjKTpkmqziU5D1zHwjTkHCpKhrE63dDRDDANU5Xp+IptZGEqQarM8yGXtKKa/bIsp9frSqNcEhGFoTyIliWe64l70LLkZ1COhMQVHEaWZmi6ie244jjSJFIXhBFpmhIpbk+h3m9dYBbDmfyxRUWG2iiLsDFIA+jDWntLtXhmWQZoMuvnGf1OS83yOr1en1a7zcLCIkuLi+Iec10qlQqu6+K4nri6NJnJ86KUOKWaKVzPlwikQpMYuoZuPLHh4qdn6NMz9OkZ+mefoR+38NRtrwxbGdI4FrurZeE6jroAczQlqMhzeKnib5pyIZVDdo/tKEBVUZBE8dBWamiauHQ0S4j5moZpGcRpSpymhHECmoFuangVyarXqhUcV1wuWSYE+QEvKcsyijRTtliJmEXRANoXPKYy1pL6ynoNryKbHtf1sAxVPViIOIYSHOT3Lyg0XQJqhi6xPBdqlaoS03J1GEREYUSnKxG+KIqHPCgBYUuuU1NbIUqJ4GmaWHCTVLl7DB3LMCgH1bED4anMh5pHWRSgqcpXPRnGDQe/pPZR1OXBZlDEQ4afp2FaaoAR+GSlWqMoIE1zut0+RZbLRa7JF1mgZ/FjgODyexmmKVl+VZOpKzU0SVP5lcR4mo+tadiGHJFFCUkmEcKyLElj2RiUuRLVKEVZ1ySDW6CBZgwvcpT12lIuKN0wJIuc5SqbXqAVmnJEyc1T13VhVDhSCVxkGUnUJw4F7plmqWJiiQA1+C4kaSq1vt0uZV6o2OYT/FUWFFlBWuSYpk6e5URBQrXi4dkWhgHtdpd+PyRXQLs0SxgdaeLXqkxMjFPzfXStpNtaxNDESlwzDXJDpyhN3GoVyxZrLlGElsX4RY8gK0nSgkMnOwRBjyjqsbMxiqkBeUHUj+X69Qu5pqySfr9Hu9VmebnFzMlZuW6KXMoIKhVGxsdpNpr4vo9pCUckzXLiSPEMAN+xKYucMJBNYFmWVKt1HNfBcl1VUFCSFwXkwpgYadSVFV7KCDqtFdqdFkUcUPF8RsYmKGvSfhkEPdrtDmEYEfRlQysHkYHv1xgdnVBWVoMwTkUo9zwcx5EDNo6J44w0SwdJtXgAAHx/SURBVEnzlJolYD/HE7irYdkUhU4chcRhQGtxDl0vmRgfZXTMEEqZZtDtrLCyGJNnMd1umzDo41gWzeY4Y+Or6SQrdNotDh88SF6mlJQ4jrSaWLbL2k3bVPwV4n6HfhZIfa1p4ZkWBShrfkm33yOLEoJwAMGV735ZlpjKzapRkOcx/aiPho6hW5imagMyNAxdCdrIYG4aJlGWEIYCMqxVfDRKLNOiF/UIel1OHD2InicYFDQbNcIoEthsnlFvjLBm+1lMTU/j+VXyQhtydfqhCMamYePXpHEHoN/rkRXC9avoBrb5xB56n//85/OWt7yFf/iHf+DP/vKv2Pvww3z5y1/GLFPOPGMTv/Gmt/HTW27i4T0P0ag4XHTJJbzgF17OO97+NsIo4JLLLmWsUWV+bo5bbr6JXr/H2NQ073zXH/OjH93A37zvvVSrNc4//3xe95uv598+8CMOHjrMC1/yCp519VWsmZ7ixc9/DpdfeRWv/Y3f4l1/+Da2bN3GJz/zOX7vTW/gjttupR+EjIw0qfg+q8ZGuPiyy3n2/3gJzWZDhr4k4e477uCnd97Dl77wBS58xiU86fwLuPPe+7ArNaqjk9z8g++yanKSNdNrOHniOLMzM1Rdm5ONBobl8id//l5+fNONfO+71zFaq7LpjK28+pd/jX/7t3/j+LFjTIw12bZ5E/VanY9+8pPUfY/xZp1f/9Vf5YH77+fvP/B+Go0Gtm3hGDq/9Opf4umXXIpXqfPP//SPfOLjH+PjH/s4teYoR07Os23jGu6/924uu+yy4WdhmQa/8OJf4E2/+2bOP/88Zk6cwHUsfuWNv8eus87hgx/+V+r1GlXfZ2pilE999nP81xe/xA+//10OHzqI7zm8813vplb1+c9/+RCvfvWr2XXOBVJn7LvUqx5f+uo3eNKTLuCVv/hynvmc51NrNOkGIX/yR2/nxz/6IX6txiUXX8qVV17J/oOH2LHzTF7zy6/lU5/+FDMzM4yMTfKD679PHEc8+0UvZeOmzYw0R/iXv/9rplav4fKrn8dnP/rP1Gs13vDbb+Hhh/egaQXv+pM/5T//49/55jWf468+8GE836fX7fOxf/4AvU6be++5jwMHDuB6FZ774pfSbbeYn53lM5/4D+I0x/GrvPX3/5Cp6TUsdvqcsW6KXnuFP/qjd3D82DF6vR4vffkryUqdZz7nhdxx912cd845fODv/p4vf/VrrLTbvO8v/4IP/+M/8vnPfIrX/cbraTTq5HnKv3zoAwBcevmV3HrTjeSmw75Wzvc+95/cccO3/heX2RPtpWuQpSlBljE6OkKRZbTbK+JwsCxWNVaxvLREp9MmToTN0Td6jI+OYjvCaKrVG1CWtDtt5RIp8BwHv1KlWm9Qb4zgeSJiLM4eJwl69MKEKI6J4oSZlS6tbp9Ot8/4xCS6pinA8wp5kWNZDkEgBTWddof5+TlmZ2ZorazIGZ1lVGs1fN9nctUUtXpD4MRj4xTK7b6ysoym6Zi2IzXcCkjuOC6260r0wzSlBa1aHTKWPNcVhlJZ0mmtyKwwLPTp0+/3RTyLE3FipDlamknzmybPAIN59lS6QpfzHdSyWrb4hmGQK2EqU8vtIWdVuSfq9Rqe51Or1yg0A80y8G1HinkcZ1jF7no+tuMOQeUD4SkMTarVGlOrV9PvdlleXuLgo4+KkFMIQsP3ffxKlVVr1gu/VjdorSyT5xmVio9freP4VRYXFuTzNQwWFpdod3vDpsoslVKhSqUiDXe2SoqUGe3lRTXkq+eusiAM+0PEie+7qjLdHBYKFUrMDKOITrdLkUSkcciRR46Jy8QwJcqn3K1lUeA2m4yNjrJm3XqqtZrMPIHE6qqVKn0tJMn6+NUahikFT+3lRcIwxLEsJlatotEY+TlenY/jdXqGPj1Dn56hf+YZ+nFH7X7vbe8YOnWSJAFKdE22eZquDSHSZVFAcUpkchxb8oSaqJqirSiW0eBNVnWwutrMGBqUuQhXeVkSJQlJlhGmBYZlYzse1WpV3EmOVDIOmicKJTolaUYchvKmdbunNgHKFSXijqiHlepAqXSl0lRZbQfmGAFbK0C4BmpPQKEsNLpq9CsKsVUOctY6kKdSsZipyslBjWqW59LIlqakafaYNo5i2Eg31JbVz2koW6xYlk+5k9RPKdZltSnRlNXStKSBwtANZfM95WIS4cVQxHtRNgvVxOd5Lq7nUalUyfOSNM3p9QLiKFGtIpECsUsVp6bLATyoT/UrvhxmmkDWBtHJKEkU26oYQvhsx1aMq4IwTofizilflzaMJMrnJ/8nAZY/Jj6nNsx+VYmHni+bMtX0J64ygYUbumytSsR1l+XC+SrznCKP5fPXdGFYIdn+wWeXZAKIy7OMNE7Efgr8279++HFddD+v1++86W1omsQ1Wx1pOtFKjXq1gmNbuI5FHKekWU6JRabel0rVw3EdqhWfPE4oC2mZdB3ZOjTqNcUQ0Oj2+sRpQhiF6HmGXeaMmimhZhKh0+onBP2Afj9gfHwS1/XwFc8ijhPa3Q6JGlQd21UNGAEjY6O4votfrQwHvhJNxUF16r6v3GwlufqOlGWJo/gscRwTJ5HiLFhSaOA6GIY1PDSzLCNLM4IwUvFdnSiMiKOAJArxbA1DXTehasbJM8U1y1IodWr1OvV6HU0T1luSJqCuM6msFgBfmqXEkXDzFubn0S0Tr1Zh1eRqeWiw7WFRQKNRo9fr0Ot1KNNE8RRywiimLMGyHKIopCgLRkfHaa8s01pZptftUq/XmVq9hrQoSLOMfhDiub5EODyfII6JkgTb89F1uV7DoAeU8qBjSRlDCacWAGE0hKwmSSox2DRV14Ew82xbCdiOqyKuJqYppQSe64mjMStod6QlJY5jbNfB9yXmoWslaZLQ6nRZWWkThAFR2Gak5tOoVdm84Qx006bQDFbaLZJEHkbGJiaoVKvUGw25P4Ux/TBUrkRUrayGbkAchApsaeE4sml++++96ed1ef4fX5qm8Za3vIUPfOAD/OV7/5JDBw+xvLTIVVddTaNR567bb5N7sOOwcf162h3ZRvvVOmmW0W632brjTPxKlU67xYb162k06vz0lpvoRRlhVtKZPYZGgee6XHjRJVRrdR49dJgkDMizlIbvMre4xLGZWZZbbQxdp+Z7HHh0P57v84uvfI1yJmvs2roZzbTJNZ1DjzzE7MmTPLJ/P5deejnNkTEWO30e3bubbmuZZ179HKKgT3tlkSMHH5XWrLxQP2OT0fFxVlZatNsdjh87zJp161m/fgM/+dH1UvXcaDJ34hhFkTM+sYptZ57FmvUb2bZ1Kw89cD9333kHex5+mB07tvPSl76MldYKYRDQXVliZmaGOIk5++zzpBnGcbj5hzcwPrmKJ114MT/6wffoddpMjo8ThCFZnlGxLXJdftUbTfbt3cMN3/020+s3sHbNGq646Onc/cBDtDodnvPMSzl06CDHjh/jN17/2+zZ/RCf/cwneeWrXk2zOcLsiWPUx1dToHPbzTeyb98jzM7O8md/8V6OHD7Mtd/6Jq/+pddgWha33nYbF118MY3mCNd881o2rFvP5k2bOPPMMzlx4jj33H03Y1Nr0Q2doNfjwP699Hs9Nm/bycLsSbrtFV760pexuLTIAw8+xI5tW0mikAfuvYcLnvp0avU6N9/4Q7bt3MWGzWew58EH6HXbBN0Ot956C2ds3cpf/vXfsjA3SxSGmI7LT266kQfuv48N6zewbcdOzn/yU6iOruLokcNc81+fZLTZwHUcCt2gOTKK57rccfttjE1MsWnrdsJ+j363zfyJYzzz2c+jUq3x1S98jmqtgef5HD12BA1hYp2xZSsrrRVuveVmfvetv8/Y5CTv+7u/Z/bIIVqLc0944el33vxWtb3O6Xc7w/KWiu9J05LvE0YxaZphOq5yqQjnxLKkOSxJpFGuHwRUq1UqvkfFlzY723VBtTr3uh167RUoc8Ya1WE7XZRrdHp92p0uo2Nj+J5Po15nbn6eMAyVy0VGrqIUd1S/38dzpTVvYnxC3CqGQYGAik3LwjJk+TfgYgoaISZUDU+u4wzh36Zh4LiuuPGUy0hXjUllIfBiU8GqiyyltbLCysoSSZwo900+xFcYQ6YnRLFwSXI164tz6TEMVE3YoKYhTU8D3MRgXj7VflwqhpKFZVpUKpUhysLxfLW41YbtdCUaSSrvW6PZFHRH0Of40SP4vsfk5CRpkpKoBmXfr2A7joCRBymAUmrPLcdhZWkRTdcYHR0biotJIo7BKI4Iwni4RM5SmVc9x5ZnsLJEM0XAMgxdzf+mcl/oijWr4TmysA+DQFhM6vtUr9doNpsq1tdnfn4BTXGmwl6H0dERmo0GY5NTMhfnBd1uV9i4Ycj0mjXUanU83x86IBYWFklVciFKUtUSWqHIBemh6zq1RhO/UuF1r3nitkOfnqFPz9CnZ+iffYZ+3I6nAZ9IQyJzqDdIstna0I5XFCVayRAy6Ng2ug4ahXIk5UNmglYihHm1+ZBYXolBQV7mZHlJmuWkmVRSool7xrIsDNVqJrayQUOGPnQjJUlMFEtrR78fqBtyIa4fXRfLrymCl+dXlNXQJlduraIoh4dkWRQMAm6GaQ6HgWJ4aGnKziqgPpTII90WcqN3TBMo1e8t70EUR8RxorLlSpDJi1MuGwUoBNnC6MpWZxmGaDFKgFEfkIhLA7jiMNPuqCy8pqJoyg6nIT+bYQwdQpTFsOq3yE2KTFmbc7Fpi+MrJU0TBVSTFpM0y1TFqrSP6CoGObDkZsp1lheFwMd05RTTNHIgzdQNKy9IVFyvLAYwSF3xuFA5OTk0B6B2Xf2d4THClIpMDJgH0hQjolqurNy5pmEYmrJbK9eWakwwNOF8WaaFZtpijdR0Ck2ingPeB5qm2iu0ofj0RH7ZtkWpLNNpklCWhbLkS7OjYejYjo1plpSaKPQFGrZjYJgGRV4QxSLOebaFbtjYtotXrcn7U0Cn1ydNM6IkwTUNCsMiQqPQTQxdp1q1JAusm3J4pCndrDvcsHW7XaJIRNqRpsB3TdNmZHSUaq1CrVnHNC2KsqQXBKSP2RZomkRgKDQKpM4YFETPdSl10NNseM3KwCj3LWlZEXtvluXohlzziRKEB8Julkl7RT8MKIpCbKwMGitle1iv19A0AQwHYSiRCN0Q63ohjsQ4TtQmuCBOUykNSKxh3GfQvqhRqnbJlCJPsU1TrpU4UewMEVJzxYvzaw2yrCRJCmZmZinKEtf3cPwqpm0xWqniO/6wkVLr9ym1PnlZopW5DOCGOAKzXByUkm6We6vAJ2WrIQJ3hlZow1jF4DWMKqiHEhn2xa1paJoSmsV6HUUBURxhGBpprBEZGlkq8YEwiIiikCzNsGwH169SqTVwK3Us28OwHTBtut0O3e4s/X5IiYbreeqhoJTK2jwXu3cmtmgT9YBBSZFl5HqK9t/+Bk/M1/LyMrt37+auO++k3W6zbu1aRsfH8X2fbqdNo9nEsW0sx6MfzHLs6BHOf/LTiJOEEyeOs7KyQqnpjE+sYnrtWmoVnz0PPYhTG2Fi7Waq1QorSws8svdhrnrO81i7bh0HDh6k1+0ShyHrVu9g34GD3HP3XZx9wVOIFdB8ZGSEtevWs3bdelrdgDTPaY6N0+31WVpaZm5mhoX5OXqdNmkcYZkGmzZv4fihR1mIQmzTJKYkS1M8v0qa5bSW5tmwfj1+pcK69ZtYWrqL2ZPHueP227nE9Tn33AuwLJswaDM7M4PvCqjYNE1S9YDj2Bau6+C4LgsL82zZsplNmzdTXVggCPr06jX273uE48eOsmnDJqamp1m9dj2f+Mi/MDc7S60xyoFH92NZJpc84xmkuSywbK3gzvsf4v6H9/OaX/11wrBPo9kgT2I6K0scOfgoJ44dZaXd5q677sB3XTauW8uatWtYWpynUa1w8MCjNBtN6rUq8/OzLC63+NEPb8BxfVZNTbNu/XranQ5pXrL34T3kec4jex7iuc9/ATt3nc2ZBw5DUdJqd0SwCEN2797NBZU69UaDRr1GszmCruv0u1363TZxr8PU1BRRFEkjYKNBK8/Yt3c3T37qhfiex+49u9m8bSerV6/hC5/5JEWW0KhVmF6zhnUbNlJrNDANjX63y759++i0VsiShHUbNrF+w0amp6dZ7EYsLy9z5NBB5hyHWr3OBRc+nenVq/F9n+CHPVyvSxpHVPwKraVFfnr77Vxy5bNxHJe9jzzCk598IdNr1rF7z0OEYUBZ5DzpyU+lKEuCfoBtmVRdBzsN0Iv0531pPq6X49gqtp9LK12eY5mGzCS5lLjYtjCVLMdTc5xBmsTDOSiKBOFgGKY4FxSw23FdLMelvbxEGIW0Ox3yTApaCs2g1AEk6umVSLFNCUmSDKvhwyAYti1qmkalWkXTNBzXle9Uo8HkqlVYtkOhQNFDRIKhfPjKPT/gbA74U67rqpRBJnOipql9YkGpYiNDjmaayJlhO2CaWE4wZFsVRUGZS0RHo8Sx5XzRNI0wDFVkRVrYNF0bzsXyKofRF9t2hpxRXTcYLDgHaYCiKIauINd11fypDR1UA7SELC8RFhVQbzRlmZll9LpdsjTBUWegYRhMTkzi+j6WY+O6PlEUE8YReZRIc5gpD3GAKlBKyXKJEaWZuLsGs/ZgOa1r4npIS5l7DF3YNpY5SDsIn9WyLShL8jSR5zhKsiQmDPr0e11cx6bf65KmCZ2OuFD6/R6OZaJrGqZt4zgunl8RV5Mh75tpWbSVa67b6VKWUlLkqhinYZqUmoamFRgqSiSzgHBU4zghDINhq/cT9XV6hj49Q5+eoX/2GfpxO55++41vFuuqpmGZYoXNC4Ft5co+NgAt+8rm6/senmMhsOqYNImlCSLLAXmYr/gVDNPAMHVIY/QixS4TojQjTnOWewn9MCLJMjy/QqUiFYqWIQdblmcYpjEUV5JYtgrtlsAa41jsh7qC+1WqNRxHmiNMSzYAhlIjyxLygc1WfVkLlZE1VVbS8zwRRHSdAoZvfKKEo8GXWNM00jghS2PyJME2Tok+RZGpTKcovoNWm8FGZmAV5n/+NfikdE24Q4N4m/oIxS4rvCJj+PP6cmMo5YApBnHJLFOZUV2JVZBlAo9PkwhD11WUsYFpu7LV6MlQEsUxeS6Kel4U6Iaosl6lNqzFNAxhFuj6gLWlnGgDV5caHMpy0BKXDzP3osAr9pPKnjMAIWqasvpK89ypL7o2/F+242DbFhUVe8zzjH5fLL9RFBL1u9KcoGnYlklRFkRxTKaaB+v1BrV6A79Sw/UqKraZ0w96pKrOdtg8qGnDn/0Df/OXj+ui+3m93vfev6LfD+m0+/T7HRzHZHKiKUOCblCtVCQTnpekWYllOcMGiyyTG1xZampbNeAylJiOQDhNy2RxboE0S8kpGZ0YxzBN+q0OeZJQZhmaKZWiYZxAkdLvB8zPL2A5DmgaWZpSq1WpVqqsX78eyxTHnmnJNVdqGnFaiEiZpeqeBK6hSdQ3z5QjL6XfD9EtAc43x0cBEYc1JZAXuYihSZrSjyJWWi2yLMdxHUZGRoS3keckcUiiaqL7vS4riwsURYHjuExPT+P7HpZlEccyLFuWhabLwVKUYFm2MOpiFbmNI4pS3m/f9zhw8FGWWy3ml5dZt3Y9I80ma6dW4fsSO+j1uwK+L4VLEwR9lpaXpRHUNLFthyCKQDfYunUXaZwS9ANuvul76FpJo15l286zGRmfZHx6Pf1Ol7DfZ252higRMKnjupi2hWU7pEVJnuUkcUSr1SVOUgzHoV6rUa1WcEyXNEvl4aa9TKbcf5pyEVZcF8d15IFAcQA8z8cwLJIkZnlxnq6qsS1K8H0f1/dxHY8oDMRh0e9gmCbN5iiOV8O0XRyvJjwD06TbXiZOY+IsoV5rkuc5nXZ76GgcGWnKcsGwKCjodTq0lpYIeh31IOXIoaru954vrte/+5u/+Lleo/+718BFbJomO7Zv46KLL+EP3vEu/v5v/pL52Rl+8w2/zd133sa+vXvoJiVPu/BpXHXV1dxyy03Uag0ufPoz+MDf/BWzszO8/DW/Tmt5nsX5OX74g+vJ0gzTMLnysksIoph7dz9M1Tao+B7T6zfxwv/xYtZv2MhVz7yU5ZUVNE3nrX/4Tmr1BsvLy5x73nn0Oh0+9LfvJYwiojjh5MwsW7fv5KzzzmNq9Rp27tjB85/zbP7iPe+k1+vyznf9MYVm0O72+fgnP8H06tVs2byZxU6fWsVn4+pJPvYf/0qeZfzuW97GZz79SW6/7VYajQbbdpzJjrPOYXrVuMR3HBfDsOj2utx33z2srLRYXl7ixzf+iBe9+CW8/BWv4MSjD/PI3r3ceNNNrF29itGxMTaesZ3l+RkMXee1r3sj37zuO3zjW9fywqsuY9/+A3zxa9/gk5/6NJMTE1zzpc+xadNmGvUaM4f3sf/gUQ4ePcn4+i24loGv5zzl0qvIspwfX/8dXv/G32bjxk385ut+jV98+Sv5xVe8igcefIC7b7+Vb3/lC+w5cBTT0Dln+2ZmF1foBiF5lvHK17yWZz33hfzem9/IFVdcyV+/72942UtexPLSEr/w4hfTTqHWGOH33/QGPv2Zz/Dlr3yFrZs3UeomUVbyyH13MDE+zite86vsPXSE2flFjh87xite+mKuvOwS3vt3H8TWYd2qMb70xS+wtLiAY+r84qtfy/YzzybFYGVhlvmTJ/jYJz7GL7z0Zfzt332AbhDzwAMP8KEPfoCFk0fJooANqyd5zgtfwoUXX87JpRb333sPN934Q17+iy/Dr1SZXVgkCgM0TWP1uo3MnTjKysIMum5x+NBBHnzwflZPjlNrjDA2vYGnPOWprFo1hWnZ9Hp9gjDE0EpmTh7n0IH9tJaXqFZrbNu+g+u+fS2ua3PtN7/J29/+dv71X//1Ce94+uv3/S29Xof2ygpJFGCaBr5fIQ4DdF1jfHwcv1rDdlyWWx1h5lSrhEEgrcu9nhKd9CFANlYlLM2REcbGxjhx/LjMOXHK1NQqbMuk12kJn7IUIQPl6A6DgH6vx+L8nFp0yqK1MTJCvdFg45Ztw1arU/fLkjRNlUggPFJxz0MaR6RxRKPRII4jlpeWKEqZJSZWTeF6Lqahn6qiz3M8v0KaZnT7PXrdLpQl9VoNvyIPenEcq5hMSBSGxHFE0O+RJgmWZTIxMcGaNeuo1ev0g4But0O/11PNYiI4BX2Z3dIkHs6XlnVqWTp4iI3jGNd1sR2Her2hHAs29XqNlVabVqtFnKT0+31aKys0Rpp4riA/SjQs22bjlq0szM8xN3OSu+64Hcs0GR0dZeu27YxPTLB2/QaWV1ZodzocOniQJBVxbmx8HM/zh4vwNMtotTqstFoEynVmuy6O69Jsjg6d/NI4nVOkicxhpkm13qRWq+J7Hv0gGPJm6o0mYRhw+MCjJHFEkWUK6yHL2XXrNxCFIa2VZZaWljBMk9HxSdasXUe1WqUocxxTEhcnT84QJyLy2Y5LkmYsLa/gWAa+77Fj23Zcz8O0bKI4pt1qsbi4SJ7nWKZFtVal3VqRhrteD8fzsRyHD3/gb3++F+n/5nV6hj49Q5+eoX/2GfpxO56SOJShVzewDLGomroucO3CQC+GrCuJbpliscwyqSel0LBtVwQFw6CUclgB9pUFWZKi5RlGWaKjUWoGmqFhOWAX5dBFVJYC2SsyaUAYqKmlguSJo6UgTTMM06RiCcFdV5sLcUuZGAp4LXWNp0Qk/ZSZRTZFRaGK9IzHtLCpXwO1Ly+H7qRB3K8cHM4qgpeVp4SWIZg6TYfur6GVzjKVWPPYqJ2GZphDbaUoSnJNVOo4VrZoQ8d0bAzLwnVd1eJmqM1UPtwyaUMglPyPkmKYf5fDyQY0ojAgz0OSJMev1NR2RayDhqXYV6X8vfNSsvOW44hzikF8rZD3U1OYQ02j1EqBqaPJn15Cnhdqo1Mod5liT6nopWlI5E1XsUxLxesMXTYIYsc85RLL84w8taDIReTLcoFphqFYsZMI25KNkOt6aLqO61WJVcQRzSQvIM1y7EKxpQBNM9B0qTNGxRwNQ1XsDshvT+BXGEbkeYFl24y5Y9i2geu6Ao4rS4JAGl0KIEkzNF3DxsRzbcrSJndtlSmW+GmiwPmtTohwvQwsQ23rdJ0sSUmjmLDXVRHcgqjXJ4xTacUp5aZVqdelttVxlGVTYIkYOkmRkacxSTtB03X5jpm2OOfUNSLZ6VKqS7OMJJbrSjcMKhUXw7QIgr5sN4oCz3HJ1MGaJDFJJtslGf51Km6DRr1OpVKh3VohTlJ63QDPcxibcJlavYqg21PAV0NtfaBSqw0jrGEUy/Vk2wRRRJbnpGmCY5s4doU4kqrYAhgZHaPUdPqhuO6Cfo9WyyYIBMRaFCWWqWNbhmJYaHLQuJ44ME2pci6Kkrn5GVaWWqwsr+C6FTzXYaRZl9bRxSWSXKPM5R7p+RV0y8JUjkXTkgMu6nTVQJmiGQaWo9yJuUQ4ilyaJilyfNsl1w3iOKIsczQKyiIhSwrKPMFxXBGUM9lQRVFIe2VRtfw4TE2tVfdnARQnsU5RatQaI/iVClOrV1Mi7IF2u0MSGRi6JgJ5npGkKV2tC0hUoyxysjxlaWlRWX9t0jQh6PXodlaIel3KsqRvyLZQ7jRyH3piP7LChz70oeE/e77ArH/0g+9x9tnn0N+8ha99/Wts27aVq57zAm75yU1YeknQbbMyN8PcyRMst9qs37CJDRs3EQZ9Dhw4yPGjR1g1uQrfr1CvN9m4dSdHjx1l9sRxarUa69dv4DnPfT6zC0vcff9DxEkiPMRanXPPOZtur89Pbv4xrYVZijyjMTpKODNDniact2sHU2vW0qhWmD9xlDzsk8ch513wZIoi5/vf/z62X6FAOVPzjKCzwrH9j2KZJu3ZcTZtWE8cRXz5S19k0+Yt7Nx1Nvfe/wCT02sYaTZoNJq0Wys89OADrF6zFtu2WbtuHWWW0m8voSEPnXMzM9x9731UKj6ve91vcs1Xr2F2735KdBYXF8iLnGuu+TL9MOJJ551DkiRsOeMM3v3ud/Pw7oc45Lo8/eLLOH7oAMeOHOHMs59MbWItk2uO89CevdQmJ9l57pM59Og+up0OZZmzZ88egjDijb/9JhZmZ/mnD76fRw8dZn52lvnlNq/55V/B81wO7nuYC55xGWPjE1i2w9zcHF/8r8/w3Oc+H891+Od//CDPfs7z6HQ63HHX3Zz/1KfRrHi8+93vYmlxkZrvUQJhv8fS8grnPflCPM/lvvvuZmqdsK4euf9Ovvutr3P/nbdhZRlZnvHogRaO67LjzLN49rOfA4bFsZMn2P3QQ+zcsZOzznsSL39Nybr167nrvt3c8dOfMD8/z/jEJJdfchHNeo3lxUXml1t8/RtfZ2RyNa12G8evcOzwQWq1OqZXYe7kcYJ+j06rxfzMcVorS0yt3czI+AQXXXIZ6zdsIM1yjpyY4f777qVZr/Pkp17IvXf9lL1797Jr1y6KosD1KkyvrxMGfX7609tYs34jGzdtxLIsXvaLv8i2bdt+Xpfm434tLAjk3nZsahVZCuZZhqPYRrphKDyAcCXjOKYoxcFiOy4jtjNkIEVxJCJvFJMlEVmaEPa6WLZNtVrFr4hYnSrHeRCE0hKlYh6aphFHEpXwq1X8an3YPlxvNKhUq1QqFdIkIQz7Ik6bJp5Xkfulisg4rivNR1mq/l0p0ilLFD9VIldB0Kfb7UBZYFqmANTjmH4QiAsiDEnTVC1QDRy1wC7LkjAQEVIq032mp9eQJjFlKRyaLEsJwwDP9wENw7QEOlyKG6fUTTQDXM8cCmUawnZK85LCsInChOVWB9MKhTVl2gSRRNriOB4iRkZHmjiORZGn6EgaQNcFv5HnOUcOHWJ+fo7FhXkq1Squ61Gp1en1++KAKSGKZe5ojIwShpHcV10BlDuuK01YqTidTEtiTUHQpyxyBUHuYlsmjWqFOI7Is4xMEydTWuSURUakOLYCV5dZvdNqEYYBy4sLeJ6H53lMTU3JM0multJqrhsbH6dSrTG1Zi2u51MUJQsnZ9A1cWbEyimjaTrdboe8kO+1ruJ3J06epNGUc7zdatHr9ej1esSxiH9LSwuyeM5zgiBQz2hP7IKP0zP06Rn69Az9s8/Qj1t4yrJUBCOVAdUV20jTdIwS8kKT1jVdx7JNFefSyLJcCQjaMFLnuq4IEUA/CMmSnCTL0IuSUgNTE1VWM3RMW8fMSwpNR9fNoaBDiUSkYonUiZ1XNa4pd5DtOrie1BuKS0m+4BpiHRTmkXL8lEKNH1iMB06boij+W/uZpmtKFVFtfooXJY0NhbJLKodRlgkbqsjJEMB5roa+QSSsGNgCddm8mKYtIo9yAg3sv4b6kEtK8jKnJKcsdZJUMuZaAS4GmmFj2h6mIUKZbhqUGWhFPnTpDES2gVNqYG8Vl5Q4lnq9PkkSE0ZyIzVtG92wsF1H2FHKJSZtg9KAohmK6VSWYjFU76mmyUU3kJNAR9OUWEc+FLAGDXSa4mihIS11hjEUCcV5Js0AGpp6fwuxaBfSPKhRUuQpZZEOmwSDULLxcZKglRmWKZ+/7bhie9QNTAV9l0ioANWzQtr/Ssrh91vTdQWflO+BrmkUgzjgE/glg5Ou3GAepqlhShKRPMulatc0BRZY5BRlTllmWJarXGcOuibw+35Xmh+SJKLTasn7o2msXrVaMsCmSZYmpGlMHAZKICwIooQ4TonUEGc7DpV6jXqziet5+NXK0BafJcK6SJKEbrsrTSh+TrUqtmWxxJfK0loqAHxBnGRI9FTHdRw0XZMGqDgVkbdhkKaJcMqCkDST+0+ZZ+i6hevYuI6N7dhDtkIYxtRqFer1KmMTI7QXl4nCkH63L383PafiOKKxFyVxnMjwbNlE8QDKKFW4tmGgFQElJWme41drxGlGxe9QlhIT7vd7RJGULNiWg6FZYA02k9Kcadm2WK4NA1uTA3VxcZ7ZmTmWFpeYnpqiVqtRrzeJ4oQ46RBEKY4tW9xKrYpuWxhZRlmgygdMZeeXTaamHJQy8wh/rsgzuZLLEscyyTXIk2h4/VJCkRWUhSwqclWk0Ol1SdS2ul6r47oukxNTck8rctIkGcaEq7UGtUad0fEJ0iQhCiMW5uYHtyxpCMrVtRoEIrJbNkUp99go7OO6HrblSOw66EtLUhRKW2YJuiHxjBJZljzRh943v/nNw38+PjPHvkf2ct23vsaVV1xNURR85ZqvsOusc9h51rns2/MgFDmzMyeJ+l2W2x32HTzCJRdfzOjoKPNLy7RaLZZXWmzdsomxsXHGxyepNscwZuYIel38WgOnUmPbjh184ctf5cYf30S9VsPxfEbGJ9iwfgMHDx5g/96HWTpxlIrvsWbtOvo9AQCftXMbXq2JaducWF6ktbTAyZMn+JXX/iqe6/L5z30Gw3YxLAvblFbRfrvN4sxR0HSioMfWTRvo9/t89Rvf5HWv/y0ueMqFtMKEuu+pdhaDMAw5fPggnu8zOjrG5MQkwcoS/VaFSsWnLHIRp/bs4bxzz+WZV1zJl776deYWlxibnaXT75NkGbfc8hPOPHMX5+7ayeGDB1m7YSNXPut5/OVf/Bl5kfOs5z6Pg3sfZvbkSa583otwq3Uc12P3gw9gmyarptez+4H7aa0s4vse+/fto9sLeN2v/xqf/Oi/88XPfYaFlbZsj0dGuPTSy6jVavT7fZ72jIs5Y+s2LMflM5/8OHf89Fbe8c4/5uCB/Xz9q1/hL//mA0RRzLeu/RZP0cCk4LOf/jRbzjiDbdu2Ypk2QRGQhD22bNtBUeTcetMPWbN+E816nSLqce/dd/DTOOHlL3kxMRozyy1qjSYbN5/B5Vc/h1tuu40DR47y4H13s27desZWTfH0S59Jv9/n3vsf5MYf/RANOOe8J/GMiy9l9dQUu/c8zI9v/BEPPnAf517wFNI0Y2R0nNmTJ+hWWkyt30S3tUKrtULU77O8vEiv18NrTLB27Vq2bN7ExKrVLC0vc/jEDIcPHcC1LLZv28ahA/t54N67qFYqVKrSvjY+Psn83CyPHniUS694Fps2b6UELrv0Ui5/DPz9ifpqt1p4nketWqVWrZDnGb1uB8O0hzNqluXSnjyIiChX0GBR5rkOWZrSOrIikckoJk8ikiik12mzdv0GHEcA2GmayrxZFPSDPp1ulyBOh27tNImxLItqtSb8Ld/H83zq9Zo8UGfZ0G2UZzma46JXxD0zWPIN5umsPLUEjBNhNHmuR6VSATSWl5fp9XpkWcrE5CRZJg89cSTCSZpKPM5QC94BuNs0THlITxJ8z6NarTE5OSmQ8SSm224pLqo4AQcL4G6nIxXrpiW18YaJ/VhMR5qSxClxlqIZFkle0u2HGIa03NVqkVo4SgTQ0AXNUW80MExDGiGjkCxLBEmh6eR5xuzsHItLi7RXVhgbH8evVKhUa4RRTJwIVkNTOIrm6Bi62UcLQgzLHqJA+kFfKtg1JcorJg+ltHRncYhjVqj4rtTTlwXkOkmWynNInhMXEcRgWjZZLkv6frdDHEn0plLxcT2X8YmJoWi4vLws+BRgZGSUxsgIq1ZNEaeSGlhZWRY+EeBVKiIS6DpBEKh4TkUEvTxnYWEBVKlQu90miiKSOCFU4Po4jqj4vkqqxGSeN/yzn6iv0zP06Rn69Az9s8/Qjztq97tv/G1MQ8eyTBwFo5ZcpKbeJ31Yk8lAvxzE1jSGN21D1zFtU4lDJf1+IDWmWY7tWBiArhxQeZGTFaKsp8qOmg/eqLxQgoVYFQ3dwK/4OLYArkxT4IG2Y2PaNmgaucpIl6X4rSxDspJaeer3zTLJaBqmiWFaaDpDur+mstQDV1OcJlIRrOxuuq7juZ4cbEAcBGRZQp4mspHKUtI4GUbupI1PBC7JX9vYtq3cYAxdVANRZsB+yvNTQs1Ka4U4jgmSmHq9ge95jDWbuI6DaRpomrCqBo2EuQJjD6t6DRkg0DQct4KuyeE2O3OSKJIv2ujoKH6lSmNsAJW01M0pli9kksgG7THVilku72WeFySpiF6ojK6uC/dKIOsy2CSJ1IqWpYAnDUNX0EqpdbXtUw0iwqGSDdmAGzZwhg0YV4WqDi5LgcgbptRmokm00rZMHMfGVAdjoRTboiiIokhZxzUqlYr6rpvqIk2JglBdfDkDvakE/kk17jxRX3/8zj/Dc6U1KQjDIZxP4PwGpqEra7lkyAUmVxCrOKvn+kRhQhLHtFtLIvYpR5+0+pWMNscxLRsMC89zKPKc+ZkZHty9m9m5Oc4662zq9TqVWpWMAk03sCyHleVlYTNoBb7r4zguVVeuB8u2xNlXlhhlychoE8u2lEU+lfbIKMY0DCzDJOh0SJKEKI4YGREL6ZGjx0gzEae3nLEZ1zYwDY0w6InYmBZYagsUZzn9WOK9lmlDnkGW0fA1NE1aM3XTksNaAUOl6aNBXkrWfWl5GcO08as16iPNYc2wkceQxrRaLeZbXRY7PUzble9uCWkSC7C5UqXRGMFxXOIkxjZ1HFunVq3QD/osLi5y+Ohh0jSlWqko52VOu9vHcyv4XoXx8clhLNXQdbVZa2O5Do7vs2HrDvKsIIlS5mdPSEFEUdCPhDEQx2KhNy0bz6vIgVWCbUnDpmXqdFrL9LsdFmdOomkatmOzduMmPF/gi51ulzTPSfIcr+Lj+1VWTawmDEKSOCHotU99hwqEIeH5WKqpVNMKWUQUBd1eV4ajEhzXkUbNSFhzUk+dyiaqkMZNv1LB8yWLn2cZaRKTJzFpIoDXQcS5KCTDb7sOn/nUx37el+n/x9fgqM7znPd/6J+pVCq86AXP4xP/8a/0Oh3e+vY/4r8++2l+eustvOLlr+C2n/6Ub3/nO/zbf3yUPEu57ptf49jxE2iGyZOedhEXPe1C1q1Zw8c/+TGCXo80irn5Jz9hZHSMiy97Jlc961mEYcg73vo7LCwt43o+3/zWt2mOjKDpOvfcczc3/fjH/OM/fJB3v+c9PO1pT2fXrl3cfNNN7H9kL2NOyaOHDrN3/0E2nbGdhcVF7rjzDjZs3MTW7Tt5/W//Lt+45ss89MB97DrrbIIood0PGG022Lh+Pc946lO46bbb6HS7TE9OcOMPr2dpcYF/++gnuf671/GVL36BLdt3sHHjZp70pCcxNirxk4MH9jM1vRbDtPjif32Gbdt2sG37Tt74xjeQZylbt2zmjJ1n4XsuZW+ZS5/1fFav38iNN3yPdWvXsnbtWm768Y+wHZc1a9dx6MBBSk1n4/ad3Pi9bzNz7AgveNaV7DlwmIcPHuXKZ15Jp9th3769XPrMqxgZGSVPY772pS/w4AP3E2cFeZZSFjnTk2NcesVV/Oob3szb3vI7mIbO+973N9x+2094dP8+Htm/nxf/wku59NLLeenLXsr46AjPvPxSfnrHnayaXMXv/s7v8P6/+zsefngvv/WG1xPmJUGS0/A9arU6zdFRfvSjH7K8tEgWhxzYv48kTbnq2c/Hr0pr71k7tjE+McHkqim+de13eGTvw9x12404nkejOcJFl17NLTf9iPvuuZOzzr0A3TQpNI23//7vs2H9BjzX4d3v/EP27NnNq177OkEUZDnEPaZWr2bDps389Xv/nHarzYYtW3nWc57PyOgoN3zv20yumqZaq/Pda7/K057+DF728lfxF+95F2le8LTLr2Zp9hhhT+7JF11yCWds285nP/s5Du7fy6H9e7no8quYXrOOTZs28cmP/jsaJTfeeKO0K+un+DxP1Nfb//AP8T0RY9I4Gp6dURQJyNf1qNVE9JFGY5ktWq0WpmXRaI6SqRrsfXsfFi6IpjPSqCueaY9ms0m1WmN8YpJqvUGWpex/5BEOHz7M8soKGzafMXQzSdRHlqCtVmuIpvArVRGgmk0cx8a1HTzXlmVfWTA6PoFumLQ7HSLVrGZbporoJJSZlLokUShuhLLk2LFjdNptsjzjjK3bqfg+rhLRSko0NKI4IkmE6zJYKI80m6rJGaIwQNfBMoWXVJYCIpeHJovxVdP0+n06nQ7ddkuYKrrB1NSUgJB1MHUdjZKw32NhaYXFlTaa5cgiOUtxPV9mUF2j2RzBdcVtVKlUqFWrNEfHWFqYZ/++Rzh54gRZllHxPTRNF1dRL8B2HFzXZWJyFY7j4DiOYhnFLC4s0GiOUGs02LB5K3mekcQxJ44fpyxLLMtiYXFJKtF1g9HxcRzHod3rE0fS+rVmahWmQnp0Oi3Cfp/lxQWiUB4gz9i2A0ud3UVZ0uv1WFleolqtUq3VmJ5eQ6/fI4pigl6XIo0pc3HeOa6H61cpdXmILIoSx3EoioKTJ4/LclcTllWRZyRJzMrSsnoeSIbRLt00WTW1mtHRMXRNVzNFTBCIYNfrtoegjCIvhomOT3/iiXsGn56hT8/Qp2fon32GftyOJ2EbaZiqOWwA2NZ1KEtNlHnTUI1ug6fxcpj/k4iZCDxxmjCYDwauHgFRG+JeyYUeL8JEQZrmpIOmikKiYZoulYOWisAZhoHnediWPWxSQMHHNWUHFXFCR4yF8nMXAMXgZxOYms6pVosyF4HHUDDEArHYZXlOlCTDg1bXDXS1TZHNxCAqh8AWbWcY9aMsBQaoDk/d0LEstdFAewxgT5w2A4CbLuQ3cUgpYURgawVakoj1UdeJogjKUoDtmliKB7E1GOTxBTBumIYCYw9A28KOEoFOw7RsdAWxE4CcQPQAlUe1MMxSweZ0NMMQF1cmYMTB76dpOpoSdkSEGoDslCipaeSaijaWhfqZ5J8plWhGeSqimGUkSYSmYhq27Qzt49KOIJ/xoPXO833QpMVB4Is6ZalJ+0SpWhw0AbyJ2JeTFxCGofo9zOHFOKjlzNKUU+bCJ/bAC1CtVSQ+qtx4RV6opgQLwzSGYF5D08RWWgpIXbMMikIjycTZJ3XDAsgzDAOKgjSJSeKYMIxw0ampKFCSJCwstUiyHMt2qDXrVKo1PN9npdOmSHOyVLLFYRiSlRlas4leFqS6um8oN6OuG1iaJhb6LKPUNBE4VSQhNwxKU+zNA/Dh4O/hui5WUaIbphqMdHQDXMelsApyu0TTLWFgFJEwFYIAz/XkwDI0ygKyXJowUnWzLTLZ0ImYHA7Vf8ex0Qw52C3TkuvIMEnjgDxOhYOmS/NlGieYlin2anUyxWlKXhZohkatViFNIoIwZGF+jiAM6PR6JGmOYZi4rj9s9qw1xoaMN91QcVYlnAPYlkVRyufVabfEuhvIP0sDiLQ3lnkORY5Wlhga2JYp4NYoItELLEO2fkkiURDbqwjbz3OHMbA0F+adrhs4hoXjeBimTZSm0nBT5qCV6IamNqdyTytLEXjLsiBLElzbGtqKy0Tiy0mSSEtQHFEql6Oha6BbCMRS/sZpmmCoAdowTDRLII+2cmRSyiEsDSrZ/70X5P+Xr7Is2bP7QTzX44JzzmJ0YhWm7XLdtVInf/Y553L85EnqjQZXP+vZHDl4gKLIGRkdZ9XqtUpIMNj/6KOcPHaEqN+n0xZ+SZIIY2FychX33XsvszMnmZtf4NzzL+Cc885n1dQUBw4e4O6772HVqknWrlnLs5/zXMbHJuh2u/z4hzcQJynjY2Psvfd2FldaoJtU6g2qjRFGJ1YxO3OSsN9n757dTE1N4bkXsufhPayammbXmTtZWlxkbn6OH/zoh9TqdSqTk2RZSnN0HM0w2fPgAxRZxtlnn43pePiVCrV6gzvuuIOV5UXioM+jjx6gBIIgYGZ2hlI3eMlLX0q7tcLywjyGBq7jMLXmTI4dP8HxmTmmp1aztLTEoUMHmZhcxfLyCj/8wQ9xXXmQ6PV7jI6PMzI6ypHjJ+l2Ojh6ycLcDGgaU5OreHj3QzKIZRnHjh8ny3POPfc8Vq9ezcTEOGVZMDY+waOP7OHpT7uQIAj4xje+wczxoyRJxBVXXIVtWdx3792YFLi2jWW7jI6OMjIygmk5rFm7jjhOMCyLqNtiaWmZQ60VRsfGWb9xE0WeoQNhEDA2PoHr+6zbtIV+r0u3tcJNP76R9Rs2cs655/HQg/fRbrW48OkXc/DoUbr9kAfuu5t6vc4lz7wSy6sxOtJkzfQq/GqNkzMz3PXTW7EdlzO27mR+Zoa169bRnJzk3rtup6KWX5dcchknZ2aYmZsnTyPIUxq1GnkaE3RWeOqFT8OyLK7/3nfYvmMnSZpJK2GeYtkOjYbHoQMHOHb0KBMTEziWyarJScZHmkS9DrfdcjMjI6NYlsm/f+Qjiqv5312BT8TX2NiYMDtMU7F5ZObxPB8oh0BZQ9eFMaqEpwE3NMtSut0u/X4PQB4qLRu/UpVFX1HSD0Is2xUgrHIbdHs9iW2ZJmNjoziuMFV6nY7E4oqCMAgIw4AkjtHKEq0sJEKXOuROimU2hvNUHMeAPEBLMYvUqGdpSpamwyZrTROxqESWeKgYlqOEGd/3CAeNw2rha1kJcZIQhQFRGGFb4qCwLQtNG7ghYoIgoBicUYNFs9cmTTM0SjzXVckJad4GgSwXSgS2XRfX8/GjhCARkcerVFVhDOSZzHe6YVCrN6AoRMBptWm1VlhaWsYwLWzHpVKtYOgGmq7RGBmDxxT5DFwlhiGL15qCcmdZRr/XJY4iwjCg3++hAalpUWTScGWZEn3J8wzHtkmiiCwWl5elWDh5qpz9RYFfqUrNvS1OkzQKhxDkemMEv1qV9wVNSn3yXJpQLRNdGzBrNUFXkKtoUITnukO8SqrYskG/p8RFmbFM08K2HRE0NJ00K4aw61q1NoxDJoo1a1q2hHTKkqJQiYUnOLLi9Ax9eoY+PUP/7DP04xaeKpWKOkg09cFqQ/EIJSCYpo5pmcppIwycQtHuszQliROx1yYJ4oHVcGx32HqAppFTkqa5WOtScc2kShTK8nz4fG+7Qnm3HbnRGYYhFZHqh0pVE0SWF5TqgtPUcIIks4Xdo774eVaQZ4VyyKjfQ6mXWZopi64hbp5UKcRxrCysqUTQMBUQWxuKbqUSdTzfY5DSy1KxK0qmVw5y+zEWwywTur6uGzJ4DIcPDQNdMqBIttVxPfKilJx/mhGDtEMUOVZqDd1Dpq6pL6cIRAZIhM+00JWrStT7hCiKiZNEgHOOL/E7zSBLMzRdMuO6JuKjaZkUw2ic/JIInmocVIeUppfq+yDvr6G2Tjoalq5T6jpaoZGJNKRsiDllIXG6TEsBTdk2Y9VSkOE6IjZWqzU0NKnIDORNMwwTW9k9G43GUHQKg2gINB/Y0DPVaDCIaQ5cYnmWYhryuRbqsw+DPlG/N4RjloOL4An+aozUSeOEKAhIkgzQBMxrm5iWjmNbMgjkBb1OGzGSGVRHalBqJEmmeAHCHLNMEX9JU3ppRhJndLUA3bTwfY8kS4mThOOzCxQYNEdHGZ8Yw3ZddMMinF8gTRL0sqS9sqyaixJcS8c1dVJThjM9TqhUaximtOXkWSZON4TRkGU5URxjaJApp5yuIrR9BbZtNOuUKq5rOw7iRJbDdGA1TkuDNCvQkow4ium1BehYq7o4FYes0AS42Atoh32yTL4jvufh2A6mobhxpkG1WgVNmkcsS9plAMIwJgkjPEs2S45p0gli5Qg1Fa9CDuYkTfHKgnqjyfJSRKfT5sH77yNKEgpNY9WqKSqVOiONUWqNOq7nYdkucRwQxSHtdpciz9EwKDSJF/ieRz8OSJKIxbkZeqqWN40C1d7jUJSa2tTJXcbUSizToJfG9LotijzEMg0c2wJks1cbGWdsbFTeC9cmCEPCOKIYVETbLrbjU2oaK50OZZ7Jg41tDi3HFFLukGUJZZ6SZzlREFJWPBzHwatUVfNlStgPSJOYOJYHE13TZOmg2o2yVNpCkyTGNKSJdNDAY+mKy6aAfkUBcRQJePb/Aa+yLNn70IOUZcn2LVs4Y8dO2p02f/6ut/P61/8Wz33eC/noRz/CeeddwCtf/cv86z9+gKKEXec/mUsvuQTTsvnat7/LLbf8hIWTx1g9NcVKq83s/DxepUpzZIRGo84nP/5R9u97hKIseeGLfoFffOWrsEydm2++mQ9+8IP8w99/kLPOOouNm7fQ67Q5cugg3/raV7j6Wc9l48ZN3HbnPTiez9jkFH5thA0bN3H2uefw5c99iuPHjnLjDd/nhS9+CU+/6GKu+epXmV6zlouediHf+e732L/vEe69527+6O1/wPT0au669z42bNkKaNzw3e+wefNmrr7qah45cJB6rY6mG3z1q9dw+OCjnLFhHcdPzhCEAWeedQ4r7TaHjh7jA+//O2ZnT/L1a77M0tIyeZ6x7dwn87lPfYKDj+7jPe96N/fffy/X33ADf/EX72VxcZlvfvObXHDBefiuS3tpjv/xil9h/eYz+MKnPoaWp4xWXPY9/CCrp9dy9rkX8JGP/BtHjx2V5hnTYmJigle/6lWcd8EFbNu+g937D/DQ/ffy/eu+yVve+jZOzszyCy95CevXTnPmmTt5/W+9ka9f8xW++PnPMTnaZGJ8lAKdHdt30Gg2WW53Oeuss5menqbTDViYneHEsSPcefc9jE+uYtfZ5zDSaOJ7DjPHe5x59rlMr9vAus1bePi+uzly4BFuvvlmtu/YSRiE/PiG7zE1vYa3vf0P+eTnPs/dd9/NDd/7Nr/8a7/JC178Mu68fzdbNq7jkqeez/7Dx7jjzrt475/+Mb/ztnfwjK3b+fEPvsemjRtYMz3FNcdO4lfrUMJLX/ZyHj3wKB/9+MdpLy/g6CVjzSazM8dZ6nd55a++gZ/c9GM++dF/5+8/9M+EYch//ue/M75qNaMjY2zauJFvfP2r3HPP3bznL97HmWfuwnU9jjzyEA89+ABf+MLnee2v/yaN5ghvf/sfDB9Yn+jC0+TkKuU8zyjyjDTTybIMt+KgK+aSoYSKJI7UQ6qmlog6SRLT7rQJ+30sy8L3K3ieR6Val1a1UtgovmowStKMXhDS7nRB06hWa6yeWg26RpqkLEXCVdKVQBQFEqVwbTnfg74hrUmmhee66JqGY3v0ez3SLJMHSMXX1ClUvCTGHwgVhiGCim7QbI5QqdUpQUX6hDGUpgllKeKa63nYiTBasiSm1+3g+R6UvlBh1XIyTVLm5+dJk2QoDFu2sGsGiQevXhfuim0PAd6WZdGPQ/I0pdFsUqvJIjuaX8A0LGq1ulSbZxlJLsmKEo3RkVGWlxZZXFziyJEjBIoZunbdOmrVGvV6DcsyxZXWGCEIwyEQvCzFQWCZJqbjYI9PiECQpqwsLdLtdISRlOciDFjy4GeYBo7ryvckKbEdD4qMOOqzMB/ieS61alWQHoU8GzVHR6nWaliOS9TtEgQB9UYT23GoNprYqi2vH0aEkfwMtUoF33OxLZN2q02cpgSqrTDLMsKgT+Law4fxNE3I05ROGJGoM9jxKriuS7PZFKZWCSudDlEUk8QJrm0ThgGddksYO6q9TxrBS+IkUS1dT+yo3ekZ+vQMfXqG/tln6Mcdtfvz9/yperQWt46mGE+6bgwVysEX1VCHpGSjZQMSRyFxFItdK0sUy0fD96tSHWs5aLqqdu10WFxcJI4iNF1uvpLF1EFFqVCRt5ISw5IcuOe6wjZ6DCOpLEQ5tRQZXkQRgY8zyFMqESJPJd6naRqmZRIEIWmWkaaZ1NU6Nq5tqliegNWKQjhGg3YMzTROReOiGL3M0SnxPWso1KVpNoRin6p2dYdCTZIJ1M2yHTlMDV0A24iCGgShwOXSjERVVyaJVHTquo7nOPj+oO7RwtSlgtE0NeXYiej1ZQMGqOyxQCgTJfYZmmxnBi4yXfGtCkS4sj1PXFy2TZJkpCojnuXiVAvjiDRJlTvNwDAsEdl0A12Tn0fXgVyU47DfJY0T8jxVYpGDX6nIe6rp5OUpCJ6pQOOmYkrpasAZgArTLBPrtq6r3KmJ69oiBBalgl/KwPHYGGOuKmvLUlxtg9pewzQwlZOuLERBTtShnahGmaIs+co1X3xcF93P6/UPH/oXRVYrSONE3RQNuUmVA3W+UHyykjDOCOMUS1nFa40GlYqNoWuEQUhrZYVeryfARcUqW7t+Gl3TCIOI48fmiJOMxkidqdUTNJt1NF2j1WqztLRMv9/FdR1WTSrGQBzSWpghiBLSrMD3mxSlNmy18Cs+4+Pjalgp6AZ9BoKfZKhzyjyn4vnCbtN0+mGPosgxbRPfr2CbNmGcyv2HEsc0KEuJoHoVX33GMD+/QLvdpdcLKIqMssiI4wzd0LEdE90U0L1rufiuWGJd22JQMJukOWgGmilWd82QOtqlhXnCXg/PMSnQyMuSmbllbMehOdLEMW1KSnXorRCGAVEUUeQpeZ4S9vrU6nVWr17DmrUbcGxHLLGebLCzIRw0od+T/zYMAgx1eFdrNQVKjWm12tiui+066KZJOeDJmZawRzodklju2Tkllj34PSpYpo1tOtQbo5SaTjcICcM+eSa1tmmckCYJaBLDLjWdxogwCGqNOpZaAqRpTBwEpFEsLZX6KXG8LAoKBa/UNI36yIg0qGY5vW5XQXhTPM8dLhZKTTL8YRhK3XWW4dqefD6uQ6lcmEmSEMdS01vmhYBt45ivfv2an+cl+r99DY7qsizZt/9R7rrrLj76n//OMy+9hOk1a3FrI9zyk5s58Og+rrrsYtqdDnMLCzzlqU9nw4aNnH3uuXzy4x/l6NGjrN+4iTN3nUWj0eTP/vRPuPiSS3jpS1/GV75yDYcOPsq+vXt47vNeyNZt2zjzzDMpdYt2t8v7/vRdnH3OuVx2xVUcmZ3H0DXGqy7333cPaZJy3nnn49aaFOjc/KMfcvL4UWZnTrBuzTS2I7W927ZuY3x8nOnpNTy892GWlpZ4xjOewZ13/JRbf/ITXveGN7JmzRrGxkb5/vU3EKcpl1z2TCbHRjF1+NbXv86+R/ZwYP8+xsfGiOKYhcVltSRK6fV7XHTRM9i16yyecekzueO2W7jt1pt5ySt+mdWrVzM5Mc7b3/YWFuZmeN6VV2I3x4kLuP7ar7Fx/QbWb9jIdd/7Pps3beRFL3g+P7ntNmZmZ5mbnQU0RkZH+d23/j7Xf++7XPftbxIHgbBgDJN+r6sA5xt47a/+Glu3beNLX/oCrutRr9XZuf0MZk6e5O677+JVr/4lplZPU5QaywtznDx+jH/76MdJwh6WrvHyX30druuTphmuZTA7c5JvX/st3vjbv8OatWv5/bf9Hs96znO55NLL+NbXv0qcJFiOw3lPegpTU6vZvGEDn/rEx7j33nvo9/sUeY7j2Lzjj/+MIM549PBx1k2Ns7Qwx3euuxbTqzC5aorf/a03cMedd/LgQw9x1tnncWD/I9x60w94xiVXsGHjRs46+2xsX5g1P/nxDzn3rDNZv2YN//hPH2bdhk084+JLuPOmH9DrdtB1g4OHD+H7Pn/4jnfx7Wu/wc033YhtOaxes5bNW7Zy9113EEYhruNw4sQJirLkvPOfRL/Tot9pcWxmHtuxqVQqLM7PMToyyoUXXsijhw4zMzPLfffcpSrjTeIw+Lleo/+n10c/8Sl0uSPS73WHyIgsTchVRXuWSVnOyIgIGN1ujxIN23ao1hsYOmRZxvLSAolqYwuCUG3GdcYnJtF1jTRNWVqS62J8fIyR0VHqtTrNkRHm5+c5fvw43XaLSqXCunVrCYKQOAppLc4L9qAoCFOZiSSxZlCpVplcNYXreuRFweLignjoNYF4i4tdY3xsFA2NNEvp9bqK9SrCiOd59DodQV5oGrV6feiAGpTvhEHAyZMnaXc6eJ4nMZA0ob2yjKbpOI5DHEeYhs5Is4nrV6TN2LKwLBPLNGXG1zQ03aDb60GJgK5XlkjiiGajTq8f0gsCsrwcztymqXARaUyn3SaOYwxDmrCCfo+g36daq7FqajXVWh3bdvA9V6J8hiHiiRr2W60WQV+a9ioVXwSgak3NWDnLy8tD3qxpC6TdMi3Fis0FBt/tKLaQKjnSJc5Vq1YZU0JTkqbSMqeaspNEWraFfWsqR5iD4/lKIKpTr1YxDYNet0Mci4BoWtJUJRBnmwFnbH5ujiSOqdYbeJ6HZdt0O23SLCNLM9CkWWv16ml6vR5RHBNEsVqy59SrVYnf6Tq9fp8oiuh2OtJ6pzhe/X6fMAr52pc+/3O7Pv9Pr9Mz9OkZ+vQM/bPP0I/b8YQ4A9HQFXhboM8CMRP7bFkIc0kzSnRNYMynwNEq3MjA+TJohMtVk1kp0be8HGYjkzTDdvShjbbU5L8exODyIifNUsxMqaS6TqkcRAPX0sB5pWkMhTMNFPNI2SBLERuE3VQoS7MIKJJhlB99EFHTQJodygGHSQQZqXuMBQ5ZCLHe1OS9yFL5swvFmSqKQtk0DfXzSiNfrmj5aPL7abqOrsDaWiE/t9hTxSopLq1SbhqaACMHDhxN08UipxXkZUEWqdaRKCSMFJDd0JVtUj5PqxxYHi2xN5oiqKEsznmZQ6GhpfIlJZMWljRNpF1DfS55mikLt7ijdDWQFKqBsNBKTEOHolA3JXmTDd3AVFbOQfSwRNm+FMPJVM2ElimxxbJQImOpHGug1FmTQYNElmaoRaJ8J4Zp0FMVwqUSIgcVp6jvrqZsqQO3n1jCLQbxxKIo0J7gFmGAKIxksLENLMtUbr+CopQGnTLLlL1OYP6arqEP4rOGDkVOWQrUXtflmo/jlCCKVeWnXKNREjO/tESSF1iOw9T0asbGRvArHq1OW7gLZYnveXiei+O4GK5DZlskQZdesEQYhFimj2lJRl3y8iXh/6u9Mw+6rKzv/Ofs5567vWv32930QoMKdNPNroCYqIFSFEQcNMRMrBiIidFyHBUzVLaRQTEaNTouQQ2ZmGgStwSVZERHBQ2uERRRtqaBXt/9Lmc/5znzx++5p3GSmjBlOWLV+VZ1VW/v+9577nPO83t+v++SJPJz9HsSjwuEeVcaKL3+DdPEcz0qU0z3FEpTRxVlntZyVUcnXmR5TjkeS4hABWVRYOliWuQQJg5yn9iuBCg4tk3gt3EsR9PsxWVSaK4FShWoJKeoFIZl1pRdTJNcU+MLJd4GkzCCMpMGaJrGDNbXCMNQPDcCn067y1S3T7vdZkr7uJmmSRoXpEZCWeSY2tzPNExhZmYZaZrSbjuYtoVhmbqRbWFp5qFtyb2sKpHHPhYTXz1VKeyWTxC0cRwP07D0NF6a/5UBhRKJdFUU5GlKkeV6/Zg1K9W2LFzLFslEJTKQvCgplcLT8oSamWqYVK7QdydGtlTCV0UfWkTabNdF7UQ6DZMoA6MeLijtBWcaBo5tkyYiicqznCxJydOfD8YTAIZJ0G6zY8cO1tfXKcqSha0y3XQch6npWWzXo9TP8/XBOnfdeafEWRcl8/MbGI/HDIYjNm/bgeW4PPLoIziOzdzcHNbJp3Dc1m3MzM5RlCWHDhzk8OEjzMzKQQeg0+kQjobcf9+9FEWJ7bjEcYLhpCgMVtfXCDodTtm1mzyNxWMxy1laXgJg69ZtDNbXWDx6mE67zdzcHJs2b8Z1bGEMWRajcUiSplRFweGDB4ijMaurq7iuz9ZtO1hePCx7GRXtTgfX9djaanHyKaeyY+dODh54lHA8wncdlpYWKcuSMBwzO7+BIi+4+wc/4LRzn8Hs7BylqpiZm+fkk0/mK7fdRicImJ+fZ3p6miTNUGXFgUf3c+RQxP6HHuLo0aOMRiGmKnRQCZxz9jl4LZ/xOGQcjjl65DDxaICnfSIe3v8QSZKwceMCo8G6TGcrk2i4ShiOabVa9LtiPB0EbbI8Z2lxkTSJiMIxx23bTprlrA0GHLd1G0G7S15WTM/OMx4NSZKII4cOksYxVZ6ztHiEaDykFXTw/Bb9qSk2blzg4UcP8ujDDzHdcTEM2LhxIxs2H8fGhQUqbQ3gt1o88tCDDNdXmZ6eYcP8HC3f5/Chg+w48cl0Ajk0rqysUhY5CxsXcF2HAwcO4AdtMEyiOGLjwiY8z+VHP/oh43FIK2hz5NAhTNum3emx78EHqKg4/vgTxNxWSYKPsMoz1leX6XR7BO02/ZlZOt0eeZYxHA4ZDAdUVcWuU05h5wkn/AxvyMeH8Xgs0jHXqROdS/2eZeiln6eaKW9Z4nGJadUMEdMysfTgttDJcqPRSKendTFNi7zIWFtdoyhyPM9nYWEznW5HsxOMWiGgOh3ttSQBPJ7jUKYx4XhEEsfCHLdtHO1xOfHA9DwxS3YdRxplmmE+qbOVqsSn0/NFtZDLIcrUNSpInVVoKVtVQZIkpIl4oU68UmxLIuBtR3yD0lYge75pigeK4xB0OnVIjKXlISI7LCXSPC+I4gi0VqDQPq9xFMuhNI4xdRqzGJZnmlWViil2nOC35P12u13a7TadTpfpmRl9HSS0KNX7h2kaEkNu27VpepZltHxf9i9jogxRdeiS7ThUoO0+UlzXl9OSvheKPAfDoBW4+L4YcmMYZLn2VzVMfWY4JmWSfbvC96QeUlUlfrKOTaD9YwCyPCfLxUfX8Xwsc5IgbWCZFl6nzXgkSVZKrwff90mTpPaoNfT7KLVPa33GqiZ+MQVmpWqiwkR2aFuWTsErdLLeE5vx1NTQTQ3d1NA/eQ39uBtPqgLLMDEt7eWkLzzatycrjkmObO39ZFpGTSoCQ7yCbHkTeSmLI89ySWxzjy2cME5Js4JSVXR8n1Y7wG+1SLO8bgglWiscxxGO6+C4LqiyNhd3nGMG6LZm2VApvXCr+mGoSoU1aWwwaWBUUOgmlGngWmJybWlJoGXYmIZL6Za6eDBIc4mTHI9CoaKWJb4r79e0pHtdlqUYpU+YRoaJo/2DxDvJ0KmBk4hCnQRoO9i2SZnK9GnSHFFlKXp2Q6h49sTbCmqNue3YFEVGnqWsrSxLBG+ciL+TJRuQaLPdevOr9GdKNVl60lybNGhUVaHShEIpTDuTVANNsZ5QLpVmH0mrUsmUr1KkeSreBiqvO7aVquT1OI4UZb4vVE7b0g268tj7cT1c38eytO+SltyVeaE78LLxi/+UTpYoC3KlsLS5vWnIwxX9GstSGmXodSA9U6M2VwS5YSebrO24WKaFUiWm3myVemJvmADDtSF+4NExW5KkUJQkWVrLDStZzCJJNCoM1yEIfHrdLkZVUWQpcSiJOChE25xmjMOIXq9DO/AZDQesrQ95cP8BnvSkk1hY2MSu3U8hjGLCOGZtGFGWiiBoMd3v6PRLaUxadoXtd4iSI6yuDXCdgJlOVw6JFeS5HLimpqdwHEn4ER2zxPjKs0hep02F67sEvTalUqyPhtIgLRLyJESSFS0q16EsFXGcs7p6SBhsZYllOZi2g+0H+EFLR9R6KFWQprFOWHRoB12hk+tnE1WJUgXhSIw7x+MIy3VxPI+8LHBsm3a3QxILvX44HOJ4U6hKEY7HrCwtkcQxaRYTxRGVUszNzbF1y3a2b9vG1HSfosgkHSjPyNOM8WCdClnf8xs3ygHAshiNBhLVnGbMbVjAD1pizKpsTMNgenpWHjUmZGVBoZTQ3ZXe0PXk1nZkSjMzPUd/aprROKx9KZJMJlgKxCizLFGFfs6lKb7ZohO0mN+4EUd73Hm2LTHgacryyiq2AY5OrJykgkhECBgu9QGryDIMTKnrlJjR1kamehiC3shlUCDpmSaSypoXeS3D8FyHcaUockn6SaKYPMt/pvfn44VSik98+u/xPI83vOGNvOtP38Ud3/oSSfyPPP3pF3DppZcxu3GBUzdtYsvmBT72P27iS1+4lS/d/lUue8FlnH7m2Zz5tPN519v/mK98+X/xzg/8OV/98hd51St/m4uf8xye9rRz+dVf+zVuv+Mb3P/Ag3z843/H8tFDWAa8493v5Tv/8l1u/txnuPrqV/DAfffyof/+d1zxkpfS609xyz/9E3v37GWqP8Xnb7mZl1z5Un77d17NzTd/ljiO8FyXmz/9cVRZ0u32WFtdIQnHPHDvD9mzZy+XXX4FX//ql/nend9ldRiytLSEY1vsu+cuPv+FL/DDH/2ImelpLn/RFVx2+Yt41SteTrvb5+nPehqHDx+k3+/zwsuvoNNpMxys81sv/49sPW4LJ590EktHDvG9u+7ku3fdxdWv+B2iMOSa176a2W07OXPjBp567nmcffY5nH3mmQxXlyhKxaEjiyxsXGB6aposTaBI2Pfgg/zBtdfUvgbzU5KytfOEE3nDtb9PXhT8tzf9ATd96EbC0Yjn/MK5nL7rZE457SxuePN1bNq0mQsvvIgjj+znm3fcwU0f/RuO37LAzh3b+d3f/V2KCsIkZf999/LIIw9zzz338P3vf59du3dz01/+NR/7m7/hrnvu4Zr/8nvcc++93H7H1+l2pyiVIlpf4ZZPf5y1tXXWh2M2bZhl85bNXPrLL6PTE2bI8vIK3//ut/nyLZ/kB9/ewJ69p/OHf3Qd3V6PwWjEe9/zHnaduoeLLnoOr3/1b3He+edzw9veycLCAt/4+tf4tZdeyfs/cCOnn3EWKsv41re/RRiOufyFL+LQoUN85xtf55WvehXjMOSvPvbX/Op/fBmebfNrL/1lTjv9DE4+ZTdhlHD//Q/wxS98gaDlMzM7S1EqpmZmcF2HmZkZHtr3IPfd+yPmp3rs2Hkip5x+Nlu3b+Pwow/zD3/3USzXr1mAV131G7zqVa/6Gd+Z/z4effRRpvp95ufmSHMxa02TBNd1tPeliee0ME1pIruuR7vdkSayUsRppiOzE6IwZDgaEoYhw+EYy5Ym1Wg0JAzHHDl8iB3H72Rh02ZO3nUK62sSaZ8XIZZls2nTZoo8wwAdlCJNCb/VZm1tndE4wm216XZ69KamyXIxQo6jkH6/j+d6zM3Ns7a+RpKkdDodzZbJGY7HBH6LmZlpLMuSyO7RiLIoSOMY2zBQljRsbNsmTVKWl5dYXjwq95kxCYuxwDDp9np0u11mZmaIo5C1tTWtQhB2/0QtQGUQR2IVYVkWYSjPkEmzw/N9Op0utuczGA4Ix2PCMJSGiy32HWtrA5JUPGrSJAZga2crm7dsYdOmTfhBqz6riGl2ztraGmurYha9ceMGGeIaNuPRkDiOqVQp1iCagd/udDANkyRO6kH+yuoqSZqSJClTU9OYE/ZUJX4rjuvT60/R6falMZikjEZDJlHpw8FQW10YZDoVrMxzOp0uraBNq9NlemqKbrfLpk0LDNbXCccj1tbWAGGGGYY0E23HIY1jPN9j86YFlKoYDAYMhgNcx5ZkxXaLLLOwMol8r6qK1eVlPN/HtkxUkdfEgqpSJHFKmqa0gja+L2EIRZaSZykrKyvC0iqe2HV0U0M3NXRTQ//kNfTjltpd/1+vZxLBKgSYqm4aqFLiFwslDQq3JVGDjuci0fYFWZLUuuY0kSZMBQTtQBuz2SRJJokWUSxdUdui0+vUUr4oimomSqVKyjzT1DShejqOLybdtoNlC2PHcV2Clk6aMw3xHFJitqa0OZYwmAxMRJepdJce7Wll246epkhqgWmCZVA3GyoMylJS7lZX1+V9FmJwKEyf6lj3X9rEMi2yxTDRtmwcx0Z+oDSyDNPCtB3dZBHD9iyOKLKMIk9J8pw0KwiTDMMw60abQaWpvugmjJgkFnnOeDRAKfncuv0pfM+nHcjmLSmAjm4aKdI0Ic+lk6mUNHQs02IS45aXEzcm6fBWmjWm26xU+iaaNPImFOFKrxvTBMeZXFNXfw/0tZF1VhTHkgylkWTj+j5eqyWbuOMwSWQpMjFIE0aYoSeD9jFGUylFgmkasqErJRGgaVpLJ0VOaOr1Jkwr8S+QyZmtpYKOLZTyqqKezpVlwYdvfP/j3b9+Jnjzm94qUyzbxLUt8rxgNBxRlDKxNC1brxmT3nQPx3OxXYfB+rAuTA39WWdFSWWInng8GIgnVqXIc4XlOLQ6Hebm5vF9D8MwGUexUNZtsFBYVYWpJ2hlVdVSySiKePC+B1lcXKTX6dCfnmZ6dhbH83VRVdUecmgGHQr8lq+NVh2KMhcjPceh2+3KJKeqOHLoIOurqwxX17BMMYTMc0Wa5URxxGB9DYC52Wk63S6e71GqAsuRTW9hYYE4EkbBeDTCMEymZ+fI8kL8wpIU01Byv5clSmmjflWhAGVY9DpdWi2fdsvm6NGjHD5yhKXVsY54hTIvMA2DwA+YnpnRdPppup027U6A47k6tjfHMkwqVZIloZYIQ9Bqs7q6yuraGlE+Obh06XR7ct0QWUeR5wxHYZ1EajkOWS6eHb2pHp7vEwQBWZqRJglHjx6h0gWVo5v7nufhtwIqKqIk0ZHWSjaySVqn4+C6Dn7LQxXCIC206WgFtLsdXNeR16afM6aWaFeVojLkOZJnGevrazi2FO6mZVGUMo0SlqNMZytDoorHYSjs0zzDtZ36QDTZuNudDuurK8RRRBKNJkNKvnT7V36Gd+j/HZOtOs9znnfJpQzWVjnj1FM4afde+tOzFKZNr9vFBD7+t3+N77nMzcyQJxHTs/OcvOcMOr0p1tfX+duP/RWnnXkWx+88gdFgQK8TMDvVx3ZdFheX+Jfv/gvDtVWm+n2ufOmv8sCD+3jo4Yf5+tdu56lPexrPevaFvOud76DTDrjw2c/m45/4JEcWF9m6bbtExXd7nHb6aYSjIesry6wOhhw9epQf/fCHXHnllUxNT/PNb3+Xc592Nhs3zPNnN96IZVr0ez1eePnl2LbL0uoaf/fRv+TwwYO0O12ed8kl7N27F8O02L9/P/v3P8Q5Z52F5bhEScYdd3yN1eUlSCNa7Q5+0GJqepYN8/NMT03x539xEzt3nsAvX/kr3Pr5/8ni0grYLqbKKLOE/Q/tA8PCawX89stfxoMPPcTHPvEpPEsSWIfjkCQKKfIMx/N57vOez0XPvZjRKOSB++7lq7d9GctxyfOM5aOHOe+889m8eTMPP3gfjh8Q9Po8/fwL+OEPf8inPvlJzj/vXCzT5O57fsDFz7+ETZu28Lcf/zjPfNazOfucp/K7r/tP2LbNzhOfxJ49e0mzjG988xvMzUxjGAbfu+t77Nh5Alu3bWd58SirK0scOXSQ51x6OQsLC/Q6AaPhkMH6Ot++805UlqKKjKXVdTzXo9ftct4zfoGiKPjWt75JX0t2vvylLzMzM82mTQu87GUv4777H+DWW7/IC158JXOzM1hFyq23fp71wZCLL38J/U4bA8VHbvoQlu0wOzuHaVukScLK0lGJhVclrmUxGI0Yh2OiKGLP3tP4xV94Jjd+6IMURcmpe/YyMyVspq9+7aucfva5bN2xk7/4wLvpdTvs2L6DTdt3sry8xO1f+iLHbdlMqztF2lng5BN3sm3LAu9603/52d6k/w6u/b3flzQj/VwsipJxGEKlMA2OJUbbNu12G78V0AoChsMhWS7pz6osSNOEw4cOCSPdMBgMR7WnkgwT5Tm3actxBEGAAQxHQ9IkJeh065oyGg2lPixygqANGIxGYw48+jBrqyuYpkW7I/uH47m6XrPoT/WxbYeiLCTVLs8AQ4xxWwG2LcNeYSa169p0NFgnHI9ZW1mW2qksMS0x3V1dXSXSjImZmWlmZmcJ2nLoDYIO7U6HmZlZxuMRhw4cYDwaYhjQn5rWU/+CIktl2KhlS2K5UTIOx5qZn9PrTdEKAnzPZ3l5keXFRaIoAkOYVWEUoZSYRm/YuIF+r8/MzAy9fl/SxNptsQQZDen1etqM3GB1ZZkoCsmznDhJSFM587ieT7vbox2IdYQqC1zPw9b1aRiFxHGMYZrEUcxwOJDnl+8zNTWtB8wZR48e1dINkyLLaAUt+n3xzSpVxWg40IfDgnGU4HsunufR7/W0FYiNgcK2bTpBoCUgwqCbpP1M/FVBZIKu67J50yZWFo8yGg1ZWVkmCLQJsu/VfycBRFplgkGpStYHg9r/a6o/RZ5nxFEkB3HboRW0xUC/lGStiSbmM//w9/+/b8vHjaaGbmropob+yWvox814sm17Ql3SkiZJvRD2UFV7HSnNKJo0iCzLgEo0zBXyhiZO7ZMJT6l9c5JUjKtt16PdadUXe7JhmPpGMU0D23QoHQvTUMSRmJTlWYrEvQKVoRsQJqUSeRfaUX/y+iYdN3n+ammaIc2RUrOdTNPAtiYPVfl7QDSykyYY0qyhUnVcqzImCWkVZSXNRy2Ar5lYjuPVTCXLMqmf+OUxGWKR59p0UJImJn+upWWqAlNLBTUrqSgKiiLTzb2J87zSyQYirWv5LXy/Jf5ZWp4o2vYJfc8ELWmU+FSZPpkTjZqq6iQNJkZjelNESyIncseyKFBGqSVqVn1DSSNIblhj8tqVfD6lNpCUFMNSplGG0tLGql6LhtbUHrt4EymdWcvphByqGU5KaNqPpRtOvlf9uvRarZMNJ1JQJcl3UNXffxLp+zj7tz9TuI4tzc+yJNVsw8nDyzBEPigSWvFQmLD8ikI+Z8exNIOsIi9KvKCF69iiR85kmlUhxqHzGzYQBC0wYDQMSeKELM/peT62aWMDeZzV8s1JkVhVJrbj4fttST0xTJRe77JGrVq+K/5eJoY1aYhLs9q0jUlNhabtYVsOpaqkQM0KSlPCBKJYCrUsy6kq+fpWIIdW13XI0lIv6UozHi0s0yLVzyqvFWuJbkWWZ9imgW1NPMzk/1dFTlYo0jghtmygwnMCkZNkOcORyEVs2xJjQccjCNr0uj39q4vr2lBRszQrVVGZsi4t28Ss9POpyEmSmCgKsfw2rufjt9r1c4HJWtXr3NDNVttxqTAoSlV7ynmeJ/e5bgAniURt9/q2RET7EgxRKkmhtEwTDFPST1xX+6vJRo2OvZbNS+5jOSS1cF1Za3mSiO+eblZXVSX3myH69qJQGGaJUZmYhk5AzSWZY0INxjAoK0WsjQ6LshAqsI49NjHwPE/8B3U4QKnDHCSw++cD7ZZPPLaIwhE7jz+e4098MsrxKLKc0WAdKkWaxIyGAxY2bGDDhg3Mzc0ximLW1td59MABnveCy7jgGc/gy5//J47fvo0zzziD5ZU1iuL7LC4uYlclncBn755TaXd7+O0O//iZfyDwW+w+5RS+d9edzM3O8qLLLuORR/azf/8jzMzMMhoNCQYDLrzoIpaOHObO736Hk3ftZrrfw/ddpqenmZ6do9vrcOKJT+K447awb99DBL6HsWULs7Nz5EXJ+oP7WDxymJXlJdq9Pk9+ylM4/+lPJysU+x56iK/fcQfnnnsus7NzzJoWjz66FbNSHHhgSdakZXLGWWcx1Z/CsR2JCvc8ut2uHjgpuv0pynhEhhyOfnTffex/5AAvuvR5HDx8hO/ffTdd38N2HGzXZ+P8HC3f48jiIp1uj4WFTZjOGobtsLSyIml6qmTrpo086UlP4tRT95CnKQ/uf4j79z3EM37hmYzGId+587sct/U4pvp9fM/jySedwubjtvK9P/wDtm3fwfbt29m370H6/Sm2H7+Tufk5VlfXuPsH97D75KfQbbcZj0cELZ8tmzZy3z13s7h4lJW1NXbv2cspu3axcWaKI0eOcPDgQe69/34eOXKQw48+zIHFFTZvOY65U/fQ8lssLS/xjTv+mW67jaoUBw88zNLRQywfPczMa/8zaXI3X7/jaxx3wpN46tnncOV/eCF//Vcf4V/uvJNn/NLFPHnnDjYtbOCjJnTbLbZv28ZD+/ehypzNGzfwxS/+L9bWVrng/KcTBDIEnJ+b47S9e/mlCy/km9/5DmEYcuKJJ7Bxfo40jvne9+7ipJNOZu+ZZ3P7F/4R26jotn2OHD7EaBwyM7/Ajh3HMzO/EWvzyRzY/wD33fcj4IndePJcB1WWJJpJU+qDFarE0vWRsLl1cjRSnuS5MP0N45hhhWnZdTqdDD9LVFnia9PunmYJmabJ2uoqSSz+P0ysEya1oq4rlS+1kSTB2Zi2i2WJl2pe5HXtZmlp3GQoaGsriCzNcB2HdtDSdYN4FAWGHJ5sy2Q00JP3otA+KWKpMZELqrLEc11Jm2uL3DSMQib1l+OK/6freRTrshdmaaoDiEqdMG1gGiZZmWNbFq1WWx+g5GeGYShpbpZNluXEScpoNBJPUEckSBMpSTto0+11xcDctmqbC1UWYr+AJCTbmqlflpP3lRKGkR7oerSCdn3WydJUGgAOssdiUqqKludRuPK6lJadmaaBZQp7ocilVimVMKACQwzaJxYdpmVpCaZJu23RaQcEQaBZJmLxkemDpFnJtbQdF99vaVsKgzjSEelKvGMNIxdPVKUeU8/npJmw4/JM/3s5GahbWpVSiBJC1w6e64rNRxSSZTmW40jatVYZTIgIT/Qyuqmhmxq6qaF/8hr6cTOe3n7D25gkgYlOUFhHVLIsFQaVIebfE+2ubVvYlvjgZGnG2rrQ1qIownYdHNvC9T2yTLT8pungtwJmZ6Zpd2VKkmapyOqSBFVkWLYlRuGOI0yqNGbx6FGiMCQMk9rLoNXuYGrdoqsd+i3L0p1pxUTGZmrp1aRL6Lri7o7JMdldpSi0bhTtmWGZljBdikLHg5ZavldSlJVukKAbWvXVxqDS0w4Lx3YxkQaGqTdWpUqhyCpFUVagDdxtV96vUgpVZKSZ0ImTTGGgmyW6EMjSmCRJ6q51u92mo385jvhl+X4L0zDl5tPMLddza7lfqL01ovDYhCJot+XGAL2BSQynYcvNV2kdeaXXhBhlivZT1r6pkxWkuBL5pYnj+rXfQZwm2ruqoEizuqHTCgIc15VJVcvX8kOrTs3L0kSmhpVEDJuGZi8hD85JfGhZljLh0XLAVN/IpSrrLrBlWXUDNU6EvVbm+TEjc71uDM2gmqyDD7z/vz+um+5nhT95y9vJi5wkSxkOxtoUrtBU7IDp+XnZdEyDLMlI0pQ4SYgLoa23fJ8k1t4ByHqxHQfHpG5cBkGAUhVJnNb3hWlSGyf6nktVymeRJ5kkS5oG4zAiy3KyKNd+X9Dt+pjao0vpwsawDCrTpNKfbK/TllABW0/sTAPX86VALAviNCbPS9KsYn11jTiKcB1FGsekcYzrdLBdF9/38Vsunu8xMz1FkoxJ05goDMlzRV5WdLo9mRQbJg8+sE+08q6YfHqeS1Xk+L6L77koJVHMBpBkGXGSsbI6kIe5Ng+MoogoilgZivHohg0bOOkpJ9FuBeRpwdrqCmmS0Ot2CNoy+fZ9tzb/lMZsQVlmtHwPyzQJo4SyMqgMg+7MRsq8JI5iwtFIdPqGYnp2Tu4nS9JNKqVwWhI9XVUwXFkkSxKSNCMch3I4UJUuol1dELVpd3qMxyItLooM13W0cWJPN3EtWoFLHEWsr66xsrqKadpMT8/S68s0bMImNS0LVYhXXKYPJIZhyHNemxnKhAygIopGxGFEOA4JxxFZlulJtQQLOI5s7I4j0c5ZnpPECUkY4rouc/NzOsIc1peX6ufZbV//2v/v2/Jx47FbdVFIbK0BOmlk8if5P5N0oMlh4bOf/SxXXHEFGAZbtx/P7735bZx3xl6esnNb7WtoPGZYMkkJm0hUKu1DoHSARZbnnLZ3L/fff39tqCteEZNuv3gfVFWF57r889e+yoknPgnbdbn44osJw5DbbrsN27Y5fPgwp556Kq94xSt405vehGlZfPITn+BXfuVXUEpx1llncdttt+nPUmTtf/zWG/ivf/RHWJbFi1/8Yj7ykY8cK7SqijiVlKR+J6jf16Eji3z605/imte/jltvvRWAZz3rWXz4wx/myiuvBOC6667juuuuqxNsJ9dm+/btvOLqq7n4ec8jCAJOO/10Eu1x8thrVlUV01N9nnrmabz+jdfyjF98JnlecN1/u44/futbxUNB+wJOBmlVVfHRj36Us846iz179pCmKaYpaWeTz8U0TeYXtnDBcy7lO1/7Eq4Jt956K/1ejzSJ2bt3L4cOHcKyLP75n+/grLPOrNfM5LVde+21/Mmf/ImsF/339WGyLOvfP3adTYyWS/25X3jRRXzus5/j8stfyM0334xl2bzt7W/jP73mNeR5/ph1BDKgMbjixS/mc5/7HGVR8La3vY1Xv/rVwLFBz2PXzuSzKopJ8IocmpI0ZTgcc/mLX4zd6nDVa67hF884mS1zMximwWtf+1re9973PeEl7+/603eTxDFhOGI0GmsfT0szSHw2bJgXmX9VMR6NSLNMJvOWJZP3Xo/19XWpWyowJslJBrR8n3ZbnsuTtLDRaECWZpRFrhOgPYJujzgKGQ0HDNfXoKpwHZeg3QEMBsOh7HtFxvTUFFmWEccJWX6sDuj1+liWSRxFzMzM0NZBMBOT8LwoGI1Cji4eZWZ6Wsy+s5TRUGRsvusxHg0ZDAZEcSx1IwbT09P0+3127Nih7RsSjh4+XJtjt7t9OcClCUtHjpBlGbZl0un1pcFSFrRbLYJWi/W1VWzHod3usLi0xGg0YnHxKMPBgCzLaHf7jMdjxuMRZZ7hei7dbo/t23fguC5xHNeHZM+x6Pen6PR6MmjXLPl+r4dhGIRRTByFwljQSoAKA89vAVL/rK6siDzPNJmf31CH50wkRrbrkqUp4XjIeDCQgat+thdFwfLSIq7n47UC5uY30J+aZn5unkcPHCBJEipV0u/3CYKAbn9KBqxAHMeEozHr66uosiRoBWzesqVWddi2g6/DiI4ePapZSBLSYxgGritm2JUqGQwGtV3FeDRkPB4zHA7EZ7AQr9YwDFGqpNPtyrDZNOl2e2S5pMEN1texbJv+9Az9qWkcx6mlo0kS89Xbb/8Z3Z3/Ppoauqmhmxr6J6+hHzfjaeIpJPIn6a4awCS9znFEEymHfQMMMSSrlDRwilJhWJaeHLrChDIMneAh/j7toIvfauEHAWK2XdWddtuxwTLEzGsyDTItDE0hrQxLGj7i1HXMLMuyHkuGkU3dsGq2ysS5X8hIhhh4mWIGVyp5v0kkC6fIc9E9GtJ0SNNUm3VH+lpMIkLlYWtqyrQUb6pOLamUmGsX5YSNVOkCQiYN4hEl+lClGyi2KrEtudaGJcVrmqbEcV43Kid6alWW8vBwXIIgoNft0u106HQ79fudHCbKPEc7X1Gpom4ApZr2p3RRYmvdt2lwrEg0DYxKiuK6u1bxmGvboqpk4UqXWZuulwZVVeoHolA9FUI5nRS9hmFiu67+XExpNjkOro6OVGVJpgt4pZlcBtrszbLrop7HNACFmVZRZFk9WVGT30zYXUqbzut/K/VEMM/y2nkr0wcB0xRN7aSh9UTH8soSeSkSQyopKFpep+6qJ1FYN2HztEAhExHfb0lTMEnkXnf1WrDkOviOSGVtyyKLYybG+kYlsoBwHOG6Hs7EbDPVclvdYM2VopAPiaDj47muTBcryHKZpBSlmMNbmLi2mMtjWlBJ1902HZ3GAKura6RJRjiKKAp5za2gI/TcdgvTLCmzjCLLaOsGtWHJBKZQivXBAKUyPXUEw7BwLANVyJq1XBu/5WMY1GmTZZYSRmPywqUoPIKWpMOkScraQDbLUZgwHI9katXp0JuaYmHTJhaSVIoSzydPM0aFMElNXcjX7D49girLkjCKapp6kWfYho3p2Xh+gOm4mLaDqiqSJGZtbRXLtjEcG9u1KIE0y0nyRD/LFR1HmrhJHJOMRlSqwvNaYNr4qqzTJGVKLIVTkiRkmRQHjmNLSENZkozHQu3NMyzL0IlTElVtmTa+5+I4WnoxXNdNZAe/1QLjmNbdNAwcy6QqFSrPiUZD0izRiSOpNjQUKSyGgeO6KCXPct/3xIvNtkiSDKXkczQMeXbGYShDBtMiLxWJnlz+vECMXEuSNOOmm/6McDzmDW94A6ZpMh6Puf7662XAY9tcc801TDT+r3zlKzn7nKfy1NP3sHF+BhBD26985cvccsstvPGNb2TDBvEo+cAHPsC9995LVVW85CUv4bzzzsO07dofcdLUmDTBZmemufiiC7njm9/mgX37KJTi2c9+Ns9//vP585v+gt27d/MbV11VP7MnISD9fp8bbriB3aeeqmUrsOfUU3nz9dfzZzfeKI0PpbArbdxrWzznOc+h027zlre8pW6a1E0voGWYqEr2hQmmp/pc8PTzeesNN3DCzp0Ypsk73vEOzjnnnPrnTv7/Y5/nVVUx1e9z4UUXcdxxx2HZdv1zi6LgzW9+s/ZJEWzatJnf+p1X85STTqoDWC655BJmZ2a4/vrrGY1DvKCDoYShkqXJj322z33uc7ngggt4y1vewmAwqBtH62srfPeO21g6In5bf/gHv4/ruBRFzvr6ev15POYy/Fjj6rLLLmN+fp53/umfsrqy+q9+7v85gwyCgGuvvZZeryefQVGwbds2TNPgN37jKk7ZtYu3v/3t9fPJcRxuv/12PvWpT/GGN7yBzZs3A3D1VVfxS89+NkopLrjggvpaT2BZx7wpb7zxRu6+++5/td7PP//pXHLppbzuNa/hh/fdz8c++F5un5/mxJ07uOaaa3AcG9d1/tXXPdFw8OABPXSUhCjDsnA9H8eRhN7BYCiTfgOiSHxUbEcGsgDj0ZiyVFi2Q+D7GJXCqOT5O2Frj8cjLEuSzwRiGWBrM+loPCKOI9I4lsNCUTAoRrS1wbFhGLTbAYbR1iwePT1XCkObnYsaQCLP01SGoEEQiMmuYZCmGePxiKWjR4nGI3zPo6/jyn0txXN9n063R6ZTmcMownXk+TIaDSURu8glWEhV8nwejzB1sIztuBINXhREkUSDF3mOoZkPvu+TZhmHDh9mbV0OzOE4ZDwey4Eeg063y4aNG7F0yldR5KKSKEuJGVcO2OLVWmqWk+t5ZJWYKa8PBqhSMQ7HgDB+gk5H0vEcSVIeh2PW9fPBdV3Z50xDDqN1ErTCBzmA5gVFqeVCQVsOfoDveXVDCyricMyRPJPmIRVBEOimpSKNI8ZhqK+LPoDaNtj6PjHE9LmqFOPRkCxLcRxJXitMgzRNSOKYqlJkqQx5q0oRhmM03Y31tTVJ/EpiSeg2LfzAF2VGUUiTzHVxHFs8gi0bP+gQRhGGrvsnz+wwDBmPRiRP8FTKpoZuauimhv7Ja+jH33jSxc/kcC4folnruC3bxnJsTMuUpDXN3pEo1ol0TTdiHFs3aiZ+RHKAbwUt/FYL13PrKNBSVSJPsy1MpYuoSVPBMDAMGwwLsH5MQjdhOBmWFJIT/bBh6pQ7zbaxtPfQ5FvaulFkOxKHaACR3pDyLEPcvw3AJNIbdxRFNUUxCMTA2rJMMcv2JFFAlaUwgPJcGj6qAkNRldobSZXHJHGFMInyQhYrpkQcmoaLbWtz7EqK/yRNdRKG0H/RTSHfE1ZQuxXQDtp0Oh26nS6GiWY56QmtIfJIadCI75VQllNhhyGpI/YkLVCzhwz5AHUDUK7JZCpuYNZyQpDJd5qkZJVuuqGgMqgsQxuZTRhimiqlZXqWfayYmlAJbZ0+Iql+UhApxH/KMg197a1j0/vJp18dazzleXFsXSOvuQItqUPLJ3V6YiE0wqKQggb9Hk1tdu65rk7keOKn2g2GQ4qyolAVnaCNbUs06KQxm6Wp0DSrijJVmI6N5XtYrkNeiD7f83xsx6HV8mXdVpVMxCyZDEbjIZWejlMpqlKmBbZhYtg2qpD7II4T0AVKWhQYjshZPN+l12njuS5JlOrms6xFU5S52BOfLdsWr7eiAFfot6qC4WjMaBiyurQOVY7r2MxvsOlPT9EKWkABRUFVlnR7HTANClWRrwrbME0TLJ1GqZSW4NpWnYJpalYnlcICjKqiLHOiKERVBVAStFyUEknFcH1AlCSkRVlvmq1Wi3anw8LGjRSF3HeqkDTPtErBEj85R/uigT5EIkkoSZqiyhxVSAFQ+iWVa+B4Hq7fwvE8BsMxWZowHg/pTk1jOzam51JiUOUFRRTXDAG/25Zp62hIGceYpo3f8TA9T6eZyj1mYLK2vkqWZURRSKWQQ4TTRmiEJXlSEo5kaq6qkna3x/TcBtqBNL4dR0uLqYjCsXjduS5+INNhpenQpgFV6cheUhTE4ZhxOCJOIpHNlhVVWYFOynFcB1WKB5/n+SLhNU1UlD6mWS4MlTSJUWVXGjJKkZcl6c9R4wlkAhonKX//6b9neXmJ173udZimSRRFfPCDH2R1bRXf87n66qvlCwyDS1/wAi668MIf/z5lwbe//R3e//7385u/+Zts2LABVVX8w80384UvfAFVluzatYvzzjtP1wF6aPJ/oNftcuEzf5FHDxzkgX37ADjzzDO56qqrOO200zh0+DBXXX31jzWIANrt9rHXqHHCCSfwiquv5ubPfEYXZ5LWZyFDnXPOPptTd+/mfe973795beyJbwnURWfL9zh19y52nXySliAYj9uQut3pcPoZZ9T7ylVXXYVt2yRJwnve854fazzNzM5yyQteWL9PwzA492lPY/euXbz73e8mTFJcP8BQBWWe/XgDyIBzzz2Xq6++mne/+90MBoP6n+JwzP0/uKv+84c/9KF/9Tr/LQL7ZO2fd9557N69m5v+x18yHAzJ/p0AGs/zePnLX87CwgIAqT40AVx88cXsOP543vXOd/7Y19x99928973v5dd//dfrxtNzn/vc//sPegw+85nP8LnPfe7f/LeXvPgKrvgPl3PLLbfwR79/LVQVu3fv5vWvf72k3P4cNJ6Wl5bodjpMT0+JzMJ1aQWdOtlrbXUZR6clpUmC7Xp4no/vt8iLguFoLINI2yZotaTxBHieWzeE4ygUhpA9qbMNCl0bQkUSS3pcnqU6FS9lHIaURYnn+3Q7HS31EPZ/khxj9dXDVT0QbXku64OB7JmWMLcMDPK8kCn9+hpROKYdtGh32nWammGYckjq9lAYRHGMsbpCmWVUSmmWhFgtOLYjsd9ZTlnF+nqIGbhh5ZSZ7Nl5ZpDnmTQDWj4tzyOOY1ZWlhmNxIw7TmKSRLxyTMtmfn6ezVs243s+cSysAgyjjguvU/jUMUWCZdsYeUGel3rKnzMaj6XRMmGVtTt4rRZpkjAajxmPhgTtDo7j0GoFco0KqRkmTBbbceqmk1IK07ZFNql9XlutFolmwFEpkjhiPBwSRyG27eD0urJnKkWWJgzW1lhdE5ZTp91mZmZa1BOOLcN+y0IpSDRTy3FzelPTQEWuTb+LosC2C/maSpHESS0zHA7WdRqemFNbri0skPGYqqrEvLrVwnNdxmEoh2fHwrZd8TNSquboxrEYLcfRE7vx1NTQTQ3d1NA/eQ39uKV2DRo0aNCgQYMGDRo0aNCgQYMGDRr8v+Dnx021QYMGDRo0aNCgQYMGDRo0aNCgwc8VmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58KmsZTgwYNGjRo0KBBgwYNGjRo0KBBg58K/jdj4unrUyrVNgAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAADyCAYAAAAMag/YAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOydd7hdRdW435ndTr+9pTdIBcFQBIJAAkSqKEWxUFQEsYEfCuon/QeiSLEAdhRQaYr4IVU6KkgvIb0nN7ff03ef3x/73GtuEiChi/vlycNz5s7Ze/Y+M7PWrFlrjVBKKWJiYmJiYmJiYmJiYmJiYmJiYt5k5DvdgJiYmJiYmJiYmJiYmJiYmJiY9yax4SkmJiYmJiYmJiYmJiYmJiYm5i0hNjzFxMTExMTExMTExMTExMTExLwlxIanmJiYmJiYmJiYmJiYmJiYmJi3hNjwFBMTExMTExMTExMTExMTExPzlhAbnmJiYmJiYmJiYmJiYmJiYmJi3hJiw1NMTExMTExMTExMTExMTExMzFtCbHiKiYmJiYmJiYmJiYmJiYmJiXlLiA1PMTExMTExMTExMTExMTExMTFvCe86w5MQgnPPPXer6k6YMIETTjhhm++xcuVKhBBce+212/zdt5t3a1tPOOEEJkyY8Jr19t13X/bdd9+3vD0xMTExMe8Ozj33XIQQ73Qz3ja2RW+JiYkZyevV5d9Krr32WoQQrFy58lXr/bfNdTEx71a2dl0a887yphuehibrJ5988k253t///nfOPfdcBgcH35TrxcTE/OfxZs8rb5RKpcK5557Lgw8+uFX1FyxYwLnnnvuaSuybwUUXXcRtt932lt8n5r+DobE39C+RSDBq1Cjmz5/PD3/4Q4rF4ptyn/Xr13Puuefy7LPPvinX25Tf/e53XHHFFW/JtbeGt/r5Nuaqq656121WxbzzbDqWdV1n9OjRnHDCCaxbt+6dbl5MTMxbwMZj/tX+ba0++3YRr//fm+jvdAM2pVqtouv/btbf//53zjvvPE444QTq6+tH1F20aBFSvuuctmI24p577nmnmxAT86ZTqVQ477zzALbKo2/BggWcd9557Lvvvm/5jsxFF13EUUcdxRFHHPGW3ifmv4vzzz+fiRMn4nkeGzZs4MEHH+S0007jsssu4/bbb2fHHXccrvu///u/nHXWWdt0/fXr13PeeecxYcIEdtpppze59ZHh6cUXX+S0005706+9NbzVz7cxV111Fc3Nze86L5KYdwdDY9m2bf75z39y7bXX8uijj/Liiy+SSCTe6eb9R/F65rqYmLeT6667bsTn3/72t9x7772blU+fPv3tbNZr8mrr/y3x85//nDAM3/qGxbwh3nWGp20RepZlvYUt2TLlcpl0Ov223/fN4u1uv2mab9u9YmJi3hrCMMR13XhR8l/MQQcdxC677DL8+Zvf/Cb3338/hx56KIcffjgvv/wyyWQSAF3XR2wgvZP8p8vsdwtKKWzbHv6NY/5z2Xgsf+5zn6O5uZlLLrmE22+/nWOOOeYdbt0bw/d9wjB823TPd9NcFxOzJT71qU+N+PzPf/6Te++9d7Py18O7SS4YhvFONyFmK3hb3IVOOOEEMpkM69at44gjjiCTydDS0sIZZ5xBEAQj6m6cK+Hcc8/l61//OgATJ04cdgccClfZNC68v7+fM844gx122IFMJkMul+Oggw7iueeee13tHnJLfuihhzj11FNpbW1lzJgxw3+/88472XvvvUmn02SzWQ455BBeeuml1/3sg4ODnHDCCdTV1VFfX8/xxx//ii6GCxcu5KijjqKxsZFEIsEuu+zC7bff/qa3H+C2225j1qxZJBIJZs2axZ/+9Ketfoeb5nh68MEHEUJw0003cd555zF69Giy2SxHHXUU+Xwex3E47bTTaG1tJZPJcOKJJ+I4zohr/vrXv2bu3Lm0trZiWRYzZszg6quv3uzeYRhy7rnnMmrUKFKpFPvttx8LFizYYj6BwcFBTjvtNMaOHYtlWUyZMoVLLrkktp6/i9nasTWUJ+3SSy/l8ssvZ/z48SSTSfbZZx9efPHFEdd8pZxkG8eOr1y5kpaWFgDOO++84XnplXK8XHvttRx99NEA7Lffflt0a36tsXj//fcjpeTss88ece3f/e53CCGG+78QgnK5zG9+85vh+wz19VeKf99SjgohBF/60pe44YYbmDlzJpZlcddddwGwbt06PvOZz9DW1oZlWcycOZNf/epXW3z2mPc2c+fO5Tvf+Q6rVq3i+uuvHy7fUp+69957mTNnDvX19WQyGaZOncq3vvUtIJILu+66KwAnnnjicN/dOFzs5ptvZvbs2SSTSZqbm/nUpz61WXjQ0JywbNkyDj74YLLZLJ/85CfZd999ueOOO1i1atXwtTceC47jcM455zBlyhQsy2Ls2LF84xvf2Ez2OI7D6aefTktLC9lslsMPP5y1a9e+5nvamud7/PHH+dCHPkRdXR2pVIp99tmHxx57bPjvQ4a94447bsS1H330UTRN48wzzwQiveill17ioYceGr7P0Jz2SvlotpTPZsKECRx66KHcfffd7LLLLiSTSX76058Csbx8r7H33nsDsGzZshHl26JnPvbYY3zta1+jpaWFdDrNRz7yEXp6ekbUVUpx4YUXMmbMmGGdbEs6J2xdH9tYtl9xxRVMnjwZy7JYsGDBVrcf4KWXXmLu3Lkkk0nGjBnDhRdeuNV9+dXk580338yMGTNIJpPssccevPDCCwD89Kc/ZcqUKSQSCfbdd9/NQvAfeeQRjj76aMaNGzc8H51++ulUq9XN7j90j4318y3J+jAMueKKK5g5cyaJRIK2tjZOPvlkBgYGtuo5Y97bbO266tXkwqpVqzj88MNJp9O0trZy+umnc/fdd28xjO+15N1rrf+3xKb9fuP54Sc/+QmTJk0ilUpx4IEHsmbNGpRSXHDBBYwZM4ZkMsmHP/xh+vv7R1zzz3/+M4cccgijRo3CsiwmT57MBRdcsNn6HRi+RzKZZLfdduORRx7Z4ppia/WN9ypvm5k+CALmz5/P7rvvzqWXXsp9993HD37wAyZPnswXvvCFLX7nox/9KIsXL+b3v/89l19+Oc3NzQDDi75NWb58ObfddhtHH300EydOpKuri5/+9Kfss88+LFiwgFGjRr2utp966qm0tLRw9tlnUy6Xgch18fjjj2f+/PlccsklVCoVrr76aubMmcMzzzwzovNvzbMrpfjwhz/Mo48+yimnnML06dP505/+xPHHH79Ze1566SX22msvRo8ezVlnnUU6neamm27iiCOO4NZbb+UjH/nIm9b+e+65hyOPPJIZM2Zw8cUX09fXx4knnjjCgPV6uPjii0kmk5x11lksXbqUH/3oRxiGgZSSgYEBzj333GEX8IkTJ45YcF999dXMnDmTww8/HF3X+ctf/sKpp55KGIZ88YtfHK73zW9+k+9973scdthhzJ8/n+eee4758+dj2/aItlQqFfbZZx/WrVvHySefzLhx4/j73//ON7/5TTo7O9/RvCAxr862zCu//e1vKRaLfPGLX8S2ba688krmzp3LCy+8QFtb21bfs6WlhauvvpovfOELfOQjH+GjH/0owIhQo4354Ac/yFe+8hV++MMf8q1vfWvYnXno/1szFufOncupp57KxRdfzBFHHMH73/9+Ojs7+fKXv8z+++/PKaecMnytz33uc+y22258/vOfB2Dy5Mnb9lJr3H///dx000186Utform5mQkTJtDV1cUHPvCBYcW6paWFO++8k89+9rMUCoV3LIwp5p3j05/+NN/61re45557OOmkk7ZY56WXXuLQQw9lxx135Pzzz8eyLJYuXTqsaE6fPp3zzz+fs88+m89//vPDC+E999wTiBa3J554IrvuuisXX3wxXV1dXHnllTz22GM888wzI9zwfd9n/vz5zJkzh0svvZRUKkV7ezv5fJ61a9dy+eWXA5DJZIBoQXb44Yfz6KOP8vnPf57p06fzwgsvcPnll7N48eIR+dI+97nPcf311/OJT3yCPffck/vvv59DDjnkNd/Raz3f/fffz0EHHcTs2bM555xzkFIOLwQeeeQRdtttN6ZPn84FF1zA17/+dY466igOP/xwyuUyJ5xwAtOmTeP8888H4IorruDLX/4ymUyGb3/72wDbNL9tzKJFizj22GM5+eSTOemkk5g6dWosL9+DDC3mGhoahsu2Vc/88pe/TENDA+eccw4rV67kiiuu4Etf+hI33njjcJ2zzz6bCy+8kIMPPpiDDz6Yp59+mgMPPBDXdUdca1v72K9//Wts2+bzn/88lmXR2Ni41e3fsGED++23H77vD9f72c9+9oY9OB555BFuv/32YZ304osv5tBDD+Ub3/gGV111FaeeeioDAwN873vf4zOf+Qz333//8HdvvvlmKpUKX/jCF2hqauKJJ57gRz/6EWvXruXmm28ernfHHXfwsY99jB122IGLL76YgYEBPvvZzzJ69OjN2nPyyScPz6Nf+cpXWLFiBT/+8Y955plneOyxx2Jvkf9ytnZdBVuWC+Vymblz59LZ2clXv/pV2tvb+d3vfscDDzyw2b22Rt5t6/r/1bjhhhtwXZcvf/nL9Pf3873vfY9jjjmGuXPn8uCDD3LmmWcOr0PPOOOMERup1157LZlMhq997WtkMhnuv/9+zj77bAqFAt///vdHvL8vfelL7L333px++umsXLmSI444goaGhhHr5W3RN96zqDeZX//61wpQ//rXv4bLjj/+eAWo888/f0TdnXfeWc2ePXtEGaDOOeec4c/f//73FaBWrFix2b3Gjx+vjj/++OHPtm2rIAhG1FmxYoWyLGvEvVesWKEA9etf/3qrnmXOnDnK9/3h8mKxqOrr69VJJ500ov6GDRtUXV3diPKtffbbbrtNAep73/vecJnv+2rvvfferK3z5s1TO+ywg7Jte7gsDEO15557qu222+5Nbf9OO+2kOjo61ODg4HDZPffcowA1fvz4V3x3Q+yzzz5qn332Gf78wAMPKEDNmjVLua47XH7ssccqIYQ66KCDRnx/jz322Ow+lUpls/vMnz9fTZo0acSz6LqujjjiiBH1zj33XAWM6DcXXHCBSqfTavHixSPqnnXWWUrTNLV69erXfM6Yt5Y3Mq8MjfdkMqnWrl07XP74448rQJ1++unDZZv2143vtXE/7Onp2WyuejVuvvlmBagHHnhgRPm2jMVyuaymTJmiZs6cqWzbVocccojK5XJq1apVI76bTqdH9O9XeoYhzjnnHLWpKACUlFK99NJLI8o/+9nPqo6ODtXb2zui/OMf/7iqq6vb4tiM+c9mS2NvU+rq6tTOO+88/HnTPnX55ZcrQPX09LziNf71r39tUS67rqtaW1vVrFmzVLVaHS7/v//7PwWos88+e7hsaE4466yzNrv+IYccssX+f9111ykppXrkkUdGlF9zzTUKUI899phSSqlnn31WAerUU08dUe8Tn/jEVs0Fr/R8YRiq7bbbTs2fP1+FYThcXqlU1MSJE9UBBxwwXBYEgZozZ45qa2tTvb296otf/KLSdX2z32bmzJlbnMe2NNaV+vdvvLGeNX78eAWou+66a0TdWF7+5zL0O993332qp6dHrVmzRt1yyy2qpaVFWZal1qxZM1x3W/XM/ffff0T/Pf3005WmacO6Y3d3tzJNUx1yyCEj6n3rW9963TrZkGzP5XKqu7t7RN2tbf9pp52mAPX4448Pl3V3d6u6urpXXHtszCvJT8uyRnz3pz/9qQJUe3u7KhQKw+Xf/OY3N7vPluToxRdfrIQQI+T9DjvsoMaMGaOKxeJw2YMPPriZfv7II48oQN1www0jrnnXXXdtsTzmvc0Xv/jFzfrs1qyrlHplufCDH/xAAeq2224bLqtWq2ratGkjdN9tkXevtv7fEpvquEPzQ0tLy4g17NCYe9/73qc8zxsuP/bYY5VpmiPmjC29l5NPPlmlUqnheo7jqKamJrXrrruOuN61116rgBGyeGv1jfcyb2tm7qFd+SH23ntvli9f/qZd37Ks4WTjQRDQ19c37NL/9NNPv+7rnnTSSWiaNvz53nvvZXBwkGOPPZbe3t7hf5qmsfvuu2/Rwvtaz/7Xv/4VXddHeGlomsaXv/zlEd/r7+/n/vvv55hjjqFYLA7fu6+vj/nz57NkyZLNwg9eb/s7Ozt59tlnOf7446mrqxv+/gEHHMCMGTO25RVuxnHHHTdih2X33XdHKcVnPvOZEfV233131qxZg+/7w2Ub70Tl83l6e3vZZ599WL58Ofl8HoC//e1v+L7PqaeeOuJ6m75PiHaX9t57bxoaGka8j/33358gCHj44Yff0LPGvLVs7bxyxBFHjNgJ3G233dh9993561//+pa38ZXYlrkklUpx7bXX8vLLL/PBD36QO+64g8svv5xx48a9JW3bZ599RoxzpRS33norhx12GEqpEe2dP38++Xz+Dc2zMf+5ZDKZVz3dbsgj6c9//vM2h2M9+eSTdHd3c+qpp47IMXbIIYcwbdo07rjjjs2+80pe1Fvi5ptvZvr06UybNm1En547dy7A8Bgcmie+8pWvjPj+G/Xye/bZZ1myZAmf+MQn6OvrG75/uVxm3rx5PPzww8PvTErJtddeS6lU4qCDDuKqq67im9/85ojcW28mEydOZP78+SPKYnn5n8/+++9PS0sLY8eO5aijjiKdTnP77bcP78y/Hj3z85///IiQs7333psgCFi1ahUA991337DXwcb1tjR+trWPHXnkkSM8Ibal/X/961/5wAc+wG677Tb8/ZaWFj75yU++zrcbMW/evBGRD7vvvvtwW7PZ7GblG+ssG+u45XKZ3t5e9txzT5RSPPPMM0B0WMELL7zAcccdN+y9CZHc3mGHHUa05eabb6auro4DDjhgxPucPXs2mUxmi2uWmP8utmZdNcSW5MJdd93F6NGjOfzww4fLEonEZl7Q2yLv3iyOPvroEWvYoTH3qU99akR+tt133x3XdUfMbRu/l6G5ZO+996ZSqbBw4UIg0lH6+vo46aSTRlzvk5/85AgvUth6feO9zNsWapdIJDZzkWtoaHhT44vDMOTKK6/kqquuYsWKFSNiMJuaml73dSdOnDji85IlSwCGO8qm5HK5EZ+35tlXrVpFR0fHCAECMHXq1BGfly5dilKK73znO3znO9/Z4v27u7tHLLBfb/uHFIbttttuszpv1Ji36WJ5aFIYO3bsZuVhGJLP54d/w8cee4xzzjmHf/zjH1QqlRH18/k8dXV1w22fMmXKiL83NjZuNhEsWbKE559//hVdOLu7u7fx6WLeLrZlXtlSP95+++256aab3rL2vRbbOpfstddefOELX+AnP/kJ8+fP38xQ+2ay6bzR09PD4OAgP/vZz/jZz362xe/EY+W/k1KpRGtr6yv+/WMf+xi/+MUv+NznPsdZZ53FvHnz+OhHP8pRRx31mifTDs3lm8pCgGnTpvHoo4+OKNN1fZtCwZcsWcLLL7/8mvP/qlWrkFJuFrq6pXZtC0NzwJbC6ofI5/PDcmvy5MnD+S9mzZr1inrAm8GmcwDE8vK9wE9+8hO233578vk8v/rVr3j44YdHHNbzevTMTXW6of46JItfSZ9saWl5wzrZpv10W9q/atWq4YXoxrzRcb0tOi4wQmdZvXo1Z599NrfffvtmusyQEeCVdNyhso318yVLlpDP519xjo7HbMzWrKuG2JJcWLVqFZMnT94s39mm/XNb5d2bwRsZiy+99BL/+7//y/3330+hUNisnfDKY1HX9c1yrW2tvvFe5m0zPG3scfNWcdFFF/Gd73yHz3zmM1xwwQU0NjYipeS00057QxbUTWO9h6513XXX0d7evln9TU+4eDOffejeZ5xxxmYW5yE27fxvtP1vBa/0Tl6pXCkFRMkv582bx7Rp07jssssYO3Yspmny17/+lcsvv/x1/c5hGHLAAQfwjW98Y4t/33777bf5mjFvD2/2vCKEGO5rG7OlRIJvBts6Fh3HGU7SuGzZMiqVCqlUaqvutaWkwvDKz/ZK88anPvWpV1QaXinPVcx7l7Vr15LP57e4ABoimUzy8MMP88ADD3DHHXdw1113ceONNzJ37lzuueeeN3Ucb+z5vDWEYcgOO+zAZZddtsW/b6qcvtkMjavvf//77LTTTluss+mG1D333ANEXg99fX1bnDu2xBudA4baG8vL/2x22223YS+5I444gjlz5vCJT3yCRYsWkclkXpee+Vq627awrX3slWTVtrT/zeb16rhBEHDAAQfQ39/PmWeeybRp00in06xbt44TTjjhdeu4ra2t3HDDDVv8++vJmxPz3mFb11VvJP/Z65F3b5TXOxYHBwfZZ599yOVynH/++UyePJlEIsHTTz/NmWee+brH4jupb7wbeNefAfpKitKWuOWWW9hvv/345S9/OaJ8cHBwODHZm8HQjmdrayv777//m3LN8ePH87e//Y1SqTRi0C1atGhEvUmTJgHRsZGv995b2/7x48cD/7ZQb8ym7Xq7+Mtf/oLjONx+++0jrNibuicOtX3p0qUjrPN9fX2b7SBNnjyZUqn0pv2WMe9OttSPFy9ePGJHoqGhYYthekM7GkNsy7z0avW3dS4555xzePnll7n00ks588wzOeuss/jhD3+4VfdqaGjY4imZmz7bKzF0klcQBPFYiRnmuuuuA3jFBd4QUkrmzZvHvHnzuOyyy7jooov49re/zQMPPMD+++//iv12aC5ftGjRZp6BixYtGv77a/FqY/C5555j3rx5rzqux48fTxiGLFu2bIQ3xNbKwteaA3K53FaNq2uuuYZ7772X//f//h8XX3wxJ598Mn/+85+36l5Du8iDg4MjErJv7Rww1N5YXr530DSNiy++mP32248f//jHnHXWWW+KnrkpG+uTQ9eHyJP2zdbJtqX948ePf1fpuC+88AKLFy/mN7/5zYgTLO+9994R9TbWcTdl07LJkydz3333sddee70rjr2PeXexteuqV2P8+PEsWLAApdQI+bOlvghbJ++2Vc9+s3nwwQfp6+vjj3/8Ix/84AeHy1esWDGi3sZjcb/99hsu932flStXjtiQ3Vp9473M25rj6fWQTqcBtrhg2hRN0zbbXbn55ps3i0V/o8yfP59cLsdFF12E53mb/X3TI2S3hoMPPhjf90ccXxkEAT/60Y9G1GttbWXfffflpz/9KZ2dna/r3lvb/o6ODnbaaSd+85vfjIjxvffee4ePq327GbJQb/w75/N5fv3rX4+oN2/ePHRd3+w40B//+MebXfOYY47hH//4B3ffffdmfxscHByRXyrmP5fbbrttxFzwxBNP8Pjjj3PQQQcNl02ePJmFCxeOGEfPPffciGNegWEvo62Zl+CV57FtmUsef/xxLr30Uk477TT+53/+h69//ev8+Mc/5qGHHtrsXltq1+TJk8nn8zz//PPDZZ2dnfzpT3/aqmfQNI0jjzySW2+9lRdffPFV2xrz38H999/PBRdcwMSJE181J8qmRxQDw7udQ0cIv9IY2WWXXWhtbeWaa64ZcdzwnXfeycsvv7xVp8oNXX/TXBUQzf/r1q3j5z//+WZ/q1arwyfBDs0Tmxp6t/YUt1d6vtmzZzN58mQuvfRSSqXSZt/beFytWLGCr3/96xx55JF861vf4tJLL+X222/nt7/97Wb3eqU5ABiRI6dcLvOb3/xmq54BYnn5XmTfffdlt91244orrsC27TdFz9yU/fffH8Mw+NGPfjRCf9vS+HmjfWxb2n/wwQfzz3/+kyeeeGLE31/JO+itZks6rlKKK6+8ckS9UaNGMWvWLH7729+OmDceeughXnjhhRF1jznmGIIg4IILLtjsfr7vb7UeE/PeZGvXVa/G/PnzWbduHbfffvtwmW3bm8nVbZF327L+fyvY0ntxXZerrrpqRL1ddtmFpqYmfv7zn4+Ym2644YbNjOpbq2+8l3nXezzNnj0bgG9/+9t8/OMfxzAMDjvssOEOuTGHHnoo559/PieeeCJ77rknL7zwAjfccMOI3ZU3g1wux9VXX82nP/1p3v/+9/Pxj3+clpYWVq9ezR133MFee+21RQPHq3HYYYex1157cdZZZ7Fy5UpmzJjBH//4xy0qyj/5yU+YM2cOO+ywAyeddBKTJk2iq6uLf/zjH6xdu5bnnnvuTWv/xRdfzCGHHMKcOXP4zGc+Q39/Pz/60Y+YOXPmFieNt5oDDzwQ0zQ57LDDOPnkkymVSvz85z+ntbV1hILR1tbGV7/6VX7wgx9w+OGH86EPfYjnnnuOO++8k+bm5hGW5q9//evcfvvtHHrooZxwwgnMnj2bcrnMCy+8wC233MLKlSvfVI+5mHeGKVOmMGfOHL7whS/gOA5XXHEFTU1NI9z5P/OZz3DZZZcxf/58PvvZz9Ld3c0111zDzJkzR8R3J5NJZsyYwY033sj2229PY2Mjs2bNYtasWVu890477YSmaVxyySXk83ksy2Lu3Lm0trZu1Vi0bZvjjz+e7bbbjv/3//4fAOeddx5/+ctfOPHEE3nhhReG58TZs2dz3333cdlllzFq1CgmTpzI7rvvzsc//nHOPPNMPvKRj/CVr3yFSqXC1Vdfzfbbb7/V+dq++93v8sADD7D77rtz0kknMWPGDPr7+3n66ae57777tmhgiHlvcOedd7Jw4UJ836erq4v777+fe++9l/Hjx3P77bePSPy9Keeffz4PP/wwhxxyCOPHj6e7u5urrrqKMWPGMGfOHCAyitTX13PNNdeQzWZJp9PsvvvuTJw4kUsuuYQTTzyRffbZh2OPPZauri6uvPJKJkyYwOmnn75V7Z89ezY33ngjX/va19h1113JZDIcdthhfPrTn+amm27ilFNO4YEHHmCvvfYiCAIWLlzITTfdxN13380uu+zCTjvtxLHHHstVV11FPp9nzz335G9/+9sWPQ62xKs93y9+8QsOOuggZs6cyYknnsjo0aNZt24dDzzwALlcjr/85S/Dh28kk8nhDZWTTz6ZW2+9la9+9avsv//+jBo1avhZr776ai688EKmTJlCa2src+fO5cADD2TcuHF89rOf5etf/zqapvGrX/1qeM7ZGmJ5+d7k61//OkcffTTXXnstp5xyyhvWMzelpaWFM844g4svvphDDz2Ugw8+mGeeeWZYJ9u0LW+0j21t+7/xjW9w3XXX8aEPfYivfvWrpNNpfvaznzF+/PgRmzRvF9OmTWPy5MmcccYZrFu3jlwux6233rrFvJUXXXQRH/7wh9lrr7048cQTGRgY4Mc//jGzZs0aoZ/vs88+nHzyyVx88cU8++yzHHjggRiGwZIlS7j55pu58sorOeqoo97Ox4x5F7G166pX4+STT+bHP/4xxx57LF/96lfp6OjghhtuGNYLhtZcUsqtknewbev/t4I999yThoYGjj/+eL7yla8ghOC6667bzMHFNE3OPfdcvvzlLzN37lyOOeYYVq5cybXXXrtZ3qut1Tfe07zZx+S90rHn6XR6s7qvdAzppscSX3DBBWr06NFKSjniaMXx48ePOILVtm31P//zP6qjo0Mlk0m11157qX/84x+bHZE+dMTipscab82zbMwDDzyg5s+fr+rq6lQikVCTJ09WJ5xwgnryySdf17P39fWpT3/60yqXy6m6ujr16U9/Wj3zzDNbbOuyZcvUcccdp9rb25VhGGr06NHq0EMPVbfccsub2n6llLr11lvV9OnTlWVZasaMGeqPf/zjKx7NvimbvvsHHnhAAermm28eUe+V2jr0njY+hvv2229XO+64o0okEmrChAnqkksuUb/61a82O3bT9331ne98R7W3t6tkMqnmzp2rXn75ZdXU1KROOeWUEfcpFovqm9/8ppoyZYoyTVM1NzerPffcU1166aXKdd3XfM6Yt5Y3Mq8Mjffvf//76gc/+IEaO3assixL7b333uq5557b7PvXX3+9mjRpkjJNU+20007q7rvv3mJ///vf/65mz56tTNPcquPUf/7zn6tJkyYpTdNGHC+r1GuPxaGjqTc+8lkppZ588kml67r6whe+MFy2cOFC9cEPflAlk8nNjqm+55571KxZs5Rpmmrq1Knq+uuvf8V5+Itf/OIWn6Orq0t98YtfVGPHjlWGYaj29nY1b9489bOf/exVnz/mP5OhsTf0zzRN1d7erg444AB15ZVXjjgafIhN+9Tf/vY39eEPf1iNGjVKmaapRo0apY499tjNjkv/85//rGbMmKF0Xd9M7t14441q5513VpZlqcbGRvXJT35SrV27dsT3X2lOUEqpUqmkPvGJT6j6+vrNjht3XVddcsklaubMmcqyLNXQ0KBmz56tzjvvPJXP54frVatV9ZWvfEU1NTWpdDqtDjvsMLVmzZqtGv+v9XzPPPOM+uhHP6qampqUZVlq/Pjx6phjjlF/+9vflFJKXXnllQpQt95664hrrl69WuVyOXXwwQcPl23YsEEdcsghKpvNbnac81NPPaV23313ZZqmGjdunLrsssuGf+ON5ef48ePVIYccssXniOXlfyavphMGQaAmT56sJk+erHzfV0q9MT1zSNfbWM4FQaDOO++8YR193333VS+++OJmurxSW9fHNpbtW2Jr2q+UUs8//7zaZ599VCKRUKNHj1YXXHCB+uUvf7lVR7lvrfx8pbZuSSdesGCB2n///VUmk1HNzc3qpJNOUs8999wW1wJ/+MMf1LRp05RlWWrWrFnq9ttvV0ceeaSaNm3aZm392c9+pmbPnq2SyaTKZrNqhx12UN/4xjfU+vXrX/UZY95bfPGLX9ysz27tuurV5MLy5cvVIYccopLJpGppaVH/8z//o2699VYFqH/+858j6r6WvBvildb/W2JTPX1bxpxSW57LHnvsMfWBD3xAJZNJNWrUKPWNb3xD3X333ZvNbUop9cMf/lCNHz9eWZaldtttN/XYY4+p2bNnqw996EMj6m2tvvFeRSj1OjL/xcT8hzI4OEhDQwMXXngh3/72t9/p5sS8DaxcuZKJEyfy/e9/nzPOOOOdbk5MTExMTExMzFvCTjvtREtLy2Z5oWJi3m6uuOIKTj/9dNauXTviFMz/BsIwpKWlhY9+9KNbDK37b+Vdn+MpJub1Uq1WNysbyiew7777vr2NiYmJiYmJiYmJiXkT8Dxvs3xXDz74IM8991ys48a87Wy65rJtm5/+9Kdst91273mjk23bm4Xg/fa3v6W/vz8ei5vwrs/xFBPzernxxhu59tprOfjgg8lkMjz66KP8/ve/58ADD2SvvfZ6p5sXExMTExMTExMTs82sW7eO/fffn0996lOMGjWKhQsXcs0119De3s4pp5zyTjcv5r+Mj370o4wbN46ddtqJfD7P9ddfz8KFC9+xRP1vJ//85z85/fTTOfroo2lqauLpp5/ml7/8JbNmzeLoo49+p5v3riI2PMW8Z9lxxx3RdZ3vfe97FAqF4YTjF1544TvdtJiYmJiYmJiYmJjXRUNDA7Nnz+YXv/gFPT09pNNpDjnkEL773e/S1NT0Tjcv5r+M+fPn84tf/IIbbriBIAiYMWMGf/jDH/jYxz72TjftLWfChAmMHTuWH/7wh/T399PY2Mhxxx3Hd7/7XUzTfKeb964izvEUExMTExMTExMTExMTExMTE/OWEOd4iomJiYmJiYmJiYmJiYmJiYl5S4gNTzExMTExMTExMTExMTExMTExbwmx4SkmJiYmJiYmJiYmJiYmJiYm5i1hq5OLbzexDV0KTE3SkFDUWYLRWUHS0NGkRAiJoQkCFE+ssxm0Awp2SC6lIQQEgB8oQqUQQmBIDVOTjEobZHRFRofA8wiDEN8PGNXeTHt7Ex/Yexea2upIZSwGu7oJVYZQNpEduzO2bdOzZhlrnv4HXqVM6/jJNHa0k8rl8ColzHQ9RraRztUrWLNsCc889iBKCurq6th9j11pa28ll8ugh3kUgiCUrN1QYvXaLp567iUWreukaNsIFKPqMrQ31POBOfsxauJkOsZPRIqAwHNwKkV81yH0PXy7jKYbaIZFurEdzTSRuoFXraDCEBUokvWtGMkMRraBMAgIgwC3UkZKDalrGKkMQjeQukHg2AR2Bbt3A1LX0U2LVOtokBpKasPHNwohhn8rIQRKqeF/GyOlREiJCsOhyijfx6sW6Xr+73QtfoGuFQtZuaYT23FxXZ8po7O0NmWYMrkD25NUXcX6DRXMTA4rU0dzWytKBXiezQNPPceKzh6eX74O3w/QpGRcayO7TZ/AzlPHMfV9u1HxNboHHe67927WrV3N6tUrGD+qmdFtjewzZxf6Bot09Q7yfw89TddAie6CDUJDSoGuCdqSggZLsF1WUmcKsoYkmdCphoKCDyv6XdxAoWkSI2kQSEFnyaXshjheSBiKqC/rkpQhMFAYoYcENAGmQdSfDYvdd5lNUzZFY8qkc9li7EoZz7EpB4KiF7K0v0Le9im7AU+83P2GB+RbycSxLXTUG4xvNnlseRmUYHTOIiQkqSmm5RSj6k1ySZ2l/QETGkxmtCT4/cICy/pdFnU7jG42MAxJb0ERKA9dD9l9epJ2U6dN6ixeVsAPwEoYCCAMQoqFKrOmjWe7qRM44ORPUVi9gfXPLOTun99C23YzOPTM/yU9egq9nZ1c+63TSDq9NNQl+cRPbsHI1KPQEIVu+lcsYMnDf+Hq6++hL19m3z3fx4dO+BTTd9mZDQ/dhzQ1jLSFFbosX7KS++5+mD8u7KSn7NCeMpiUMxjflOPwIz9GpqkNq66R/OAAyquiBWWMVBZpJtFT9Ug7jwgcRCqJNNNIMw2eg5mqI9k8Dqu+FaEbBL4PKEAgRPRPwfD4EkIgpMR3bIrrViM1iWYYZDrGARAOjc/Xm2pPCBASXZP4pTwLbvsl6xY+z4YVi1hRCKk6Lk61wsTRTYzffjvmHXscycZmqq7Hnb+/hZwpaUgZNGaTPL90NX/9+9P0OyFh6GOFZWSintbGRk47ci8SmXr0dD2ZSbPxqiXK3Wu48fe30NO1AV2V+cQJxzJm7Fj+/Kf7WLVmNWs3dPJSZz/VQOApAy8QBCG4YciotKI9CXPbDUzDwDB0EmkLz3apFKo80ePR6YSscBQtKQNTk+TtAEuXWLogpekEnodn2yRSKZrrMuw4oYOXFixAGjqf+9IXEcU+vP4eFj7zJLnmJtrGT+CJ55ZQKBZx7QpN6QRSSjqLLksGKqwrOixbPvBGh9lbhhA6QtNJJJPc95frqW9s5KkXl1MY6Kcul+HYjx2B1CwQOqiAcn8vxZ4umidNQ9M1QqfCnQ8+ge0GHHn4fB64/16WLlnCcSecwD8f/xd/+b+7mDhpEtK3sTes4kMHzUGaFj+/+WEmj21lwtgODjjkMKTycUp5bv7LA6zf0ENPbx9//OOfGBjoZ+cddmCPOXOZNGV7in1rkWaSRLqeY485FCk11nf2YA+WSFgmU983FZRPqVTkuhtu5n07zmLPPXYHoYHyUH6ZuQcczj8e/xdto1vp7xlEFyFnnDqPQn+J7s4i0/c4Aj+U9PT2cMvNt6LrGl/96pe58+7/Y6C/h/vvuZNMthGkBcoHovECipUrVvLDH/2YT37iY2y/3RR++5tr6e3LU3V8zjzzDBoaGqL6gApd/GovJ3zua9x4619IpRPM3W8OB87bl09/6jiyuTpA48abbkZKwdFHfZTOxf+ia90KHn2xmyBU2I7LJd+/gsMOns8vrrmCn/zst6xesxalfMZNnEaurp7SQCd33PFXHn74EY477jjmzduPj31s6EQcBcrnmI99kltu+RND845pWRx33KdJqQp+3zJufuBFegZLgKCpqQnDNNmwYQOHHnIQe+6xO9+95AcUCoXh7w+x5w5j2XXHiVz03VO555Fl3P3QIn573S3sMGs7PvLhA7jyx7+hszOScR/YaSJjRjXT2DKOSWPqGNWaoz8czaOPPcEtf/wThAHTZ0znS186ha7O1aQsyYkf+zBnX/Qjbv7zvSx48SkWvvwiN914Azfechd9AwUQOn/8/TVMGD+a3T94OLqVIJFKIaWO5/sEgc+XTv4s9WmLgQ3L0M00bR2jOeULn+drX/8OP7n6lyg18mj5dxsfmN6Bpkl0KVndX0UpyCRNUpogoUNzUjGxJUlz1mDtgEdzzqKjMclDL/exftBh9YBDS0MGTZP05qsQhphSsfPYDC1JjaaEZHG3jeMGiCBEBQFeCH2+YI89ZrDDDtvxwbkHsnZ1Ny+/tJyXF7xAXVMz79tjHyaMaseuVrjrzjsoBwZmpp7PfeZE6hsaSaYy2L0rWbtiMU8+dj+33v138sUqO8+czp777MvkyZOpbFhGwlSkExrKkCxbvpp7732ER55fRW++ghSCmR0NTBnVzEGHHUS2pY1kfRN9/YPI0CUhPLL19WiGRSh0yvkBPLtCwrKQhoXQLHwMEpk6GttG0dDagW6YOI4biUFAN3SUisRpEBK9a0OnWqlgl0v0rF+DoWuYhkGuuR0lNBQCw9BBhYSBj2makZzWNFAKhRqhU1crNgCapuEHASDQdB18Gzvfz3N3/5H1yxfSvWY5G8oO+YpLb9FhxtTJTJg4gQ/Om0dFpCiWHZ586G6a0hpNGRORbWLBsjXc//dnKFZsVBhgSoWVStPS0sSJRx9IUzZLLp0m2TaZQqlM54YN/O2uOykP9pHVFO/fcx/qmlp58bkXWLV8EevWrGRZX5miq8i7RGuGUBF4HqNTkuaEZFaTSXNapyFp0JQzKfoh3bbPA0vy9FQC8q4gm7LQdYnj+piawJASEfh4foDjBWTTSZpyKaaPa6Wz6GEkUxwybw/M6gBhqZ+nnltCpr6OllHtLFixjsHBAv3dfUwbnSOdNOgue6wesOkpOvzjpfXv6Bh9NWIdOtahYx36jevQW2148sOagQOFH0IYAkrgBeCHoFB4oSJAYQeKQIEmBaYmEAK8UGGHCl+BroFSIUGoKPoSTROkpERqAoEgDCUCBWGA8G2UZxIGIboVooQATUM3BKYSpLOC+hYTr+KTzBgEXpXygEthwzpSTR2k0UnXNdDU1saY0R0UCkUMAYWeXrKmjiUCtBSEoSLwfFK6pCFtMrq5js6BfhzPo1B1KVZdEkaFfH8v9U1NeNUKiZSF1HR0M4FQIQEhoYj6MYSEYYBUkRFDCEHge7iVCkpIDNcmpWuEvk/o+TiFQaSuoRkGQoJmJkHIyHAkJNJMIjWJ0IyaMUnUVEZBpJCq6P8AyH8PYKUIwxCl/i08xdAArQlrpUIIAkLPI/A8fNfDDwLCUCGEQtc1dENH6hp+xcepeFRLVQItQWgFOJ6PJqPrh7W+4vohQVAzbkXTSCTwfD8aGKUSoeciVIhl6GhSRP3J86lUHQZLVQZLNiXbw/ODqG8IiSkFGUOQM6P/pwyBZQhMQ6fqC2xfMeBBxVMIEZDRJFKThEPNGFK0RdQvhRAIFJoUaChk7Z2goj6NAIRCESJEZJhSUqIChR8oSk5AwQ4oucHWDqV3jIQhSegSS8pIoAFKRL+Xv/GkLYY6cfSuMoZGWhNooUddziKdMtEsCCsCGfhUbB1baASmIPADglAQKtCEQDE8ICKUJEQnEBblakClEk18QoBmmCSSWQhtfJkEI4PUEigUgdJwKi4D6zsZ9FxKmsRIppBWFvQcgdAJnCqhX6KhJUEyESJRhKECIcilU0g9wAlcOjvXMaGxg/b2iQz09VItDOAMrkVPZzHSddS3J0iaWUyjHpXQEEKiVIhT6EYFHkamiYQKkUIQCmrvSQwbf2sjchgpJYFdoeulZzBMHSubJTdqfDSXBZv2m43eFa8tSAUgpEQQje3AqSKlwkwmySgd3XIwTYnTs55KUuJtWEmysREjnSGVSKFpIYGQJExB2lSkzYCiL/BUNMeHCjylCOwiWl0jiWw9Ml1PvqubpU8/zbJly3HcKlMmtCNDDdyQhCYJw4CK41CyXQIMpK4RqEg+IBQtKUlHSlCxQ6QuMHQN1wtx7Gh+2a4lRdpVdHa7AARBGM0tSiFCQVoHUxdYCR1PhZTKBZavHKRQKJLO1SNCiVDRPOiraJGQTRm05BKIwKWrWkXTQAnF2qJHfzWk4r32GHpnUeiGQSKVpnv9ChYtfJHLf/knVixZxMRxY/jIEYdiGBpCBKjQxUzpNI9pRikPt1omKPZw7XW30FdwOGT+Ptx48238+c+38+GPfJg99/gAu+66GwcefAStKYezT9gT1fV3zPoOvnvReZE8VgGh8vCqRexCH9//wZXMnLUDv7vuFzz/3DMsWexz5Ic/zNz996a+sY5ZO3+NqivJNbRz4Ly9MAyT555fxL777EZLcwOe56FCj97eXs4550JO/vyJ7LH7LghNgtAQWgZNRsrRmuXrht/BuZf8X9TnpST86wscc8zR3HD9b3jh+Rd45NHHOPOsbzJlSgczZk4mcAsEXgJp6AipMzy+lMeE8WO57NJLQAjWrFnHBZdcw1e+fDLnnHs6ChlNjkPVAxev2IkkQDdM3GqVO+98gEcefYbDDj+KbF0DKgy56ic/QdM1jjryI3RsvwuO2czZR32AcqUKgEBDAoHj8ZUvnYLUozad/q3v8eef3cjaRf8gCDyy2TTf+fZZjBo9Ct/z0HQdIaLfQBBNqZqUCKmTy9Xxv9/+FnfddRdf+MLvEIJoblIweswostk0/b3d3H3X3dx9970gBIauo0KfQEUyUNN1/rlgA72OxYXm9hx86M7s8cEyt912J/966kWeem4hvuvWfgPBv55byWAp4J7vnsd9D9zP3Q89yq1/fRrbCRCaBipk6dIlfPt/v8NPL/9fDpj7QVJN22GmGwDwQ8kHdtuZ989s5aFHn6R/II8mA4xkHUayCVRIrqGexvYOpGbRv2EdnSuW8oPvXYIimg+kEMycMY0TPnMc4dBG2rscUxMYusTQNXQparp0iI8gkAJdkyRMjVRCJ2H4JE3ImJA2IKmDISCXNLAsHRUqlO+hE2Jokax1Q4lCogmFJUOqfqT/+aFG4PuEnodQCk3XMJMWqbRFMmmRMHWkCCH0CH0XIXWklOiGidR1hBSo0EcFDsqrQOiDCpECNKkhdQOhWwRekaoziJbN4XkBbiAIlUAKgWVouEFAoWIz2D9AprGZXDZLtWrjVRzsYh+B76BbCcxMA5quo2cyJFIZHMenYruUy4OkPY90NkcYBChdoRT4QQhKoenG8OaqXtOfw1BhV6rkBwfoXLWChKWTTKZI1zVipdIYVhLfcwnD6F2FKoQAwiBACoGUAqFFS6VIhazJ2iAgDMOafi+HtFx8BYahk81YuLpECUHJ9kiFFUxnEHegC9KtaEDS1NFE1J9T+GQNRUtax/ckjhcSBAFB4BN4DqFTRtZl0RNJglDRP1hg8dLlLFm9AdwqO41rIm0ZpE0NQ5d4gaJoBxTtgGoAoRKoIESgMCRkTUldQkPXJKECxw9xXBfXD/G9gIaUho+gEoQgogV+ECqUjCZFQ4/eb+AH4DlUSz5r1riURJKs1BGaCUJHKUlN7COBxpSOdA28hIbnh5SqHuWqR9n2KNvvbsNxrEPHOnSsQ79xHXqrDU+BEvi+oqoCDAmmlLiBjHQzEU24sha4JwVIDTQgm4w8m4QQ9JQ8Kl6IE4SEWmSkKQowkCSVRrqmMOmaxNDAEAHSHiAoVvF8HccuIqwALZHCs/tRfpWE7KGtPSBUJommRhwvSbWi6OzJY1VD0lWX8TN3pmPSdiQsyUDnWuxyiWqxTG9nJ065wKjtJ+JVqtiFIqFdJiM9Jo9rYv1AP34Y0l92qfohRdujt2s9mUyabDpJy5jRkZAjpFQYxKmUcasljEQS3UwQagWsUGEJCZpOoKBSKVEuDaIbBkG1HxCoMMQtFyODkyYRysXINmJZidpgAN/zwQ2R0kVLptFMC2mYKCQqDAh9jzAMEFJiWEmElCDEsEImhIjaOqS1omoG4pDAtfGqZexSnkq5RKVSxfMClAoxNUHC0jFNHSE0EAqhCYxsPaVQ0jtQpFC1yaUtmupTw0bnUKlhIa1pkTVZ0wSVfB89/SWWr+wkP9CH69iYhoEm9ai9no/yQ2SoqEuZSAGZZAJfRcpUSvq0JKDJgowBKUNiGTqeZlHyFD1uQNEDz1eYOngBaEKBioyaomZQUioyjoahQsmoz5q1/ytqAkVFn1GKMAyGvce0qJAARdVX2L7C8d/9h0MWbZ/WjEZKFyQMHddXuF6kVCgJHtEE6deUE02CrkfeAaECNxDkSyGe71N1oM0UpKXG8lU2+WSCgbTJuKZ6At+nv+IhZKRU276PEwR4ng/FEnVJHX37Vnb+wHQSTWNx3GiCFkohHQfpB2iq9isENgQOWq6RVPs4OibPpKV+IdX1nTz7/L94/4r3o01qpvV9e2J3LsTufBFkgmRDI6NmvJ+mFfdTLVcYdF0Spk4ilPSsWULTqPEESMbusCtOqY9S93JK+UECP6DQ20U+8NGkpG38BIxUBj2RIqzzkLqF71bwqkW0MKyNwWgSlJo2LPKU61EbAQiiec00JbopMQxZmzPfBIRAyMjgGygFyo2EqG5SqVZBBeQsk9nTptIxqoW0HGTD849TqEJWOhhWEjOZwjITZLJ1tLQ20bNmENtVuEogPB/XdZFSkKqrJ9vSQfdAkecXLObPd97HsnXrqEsn2DGZxEgIhOEjVZn+UpkVvRU8LBSS0PfxlMLUYLQFExKSVlMSoghDn8AN6S+HWEBd2qS5OY1mK+pLIYHr4wYKUVNeo+GsECISYH4YRh3Y0PGlxFcC33awlELXNJyyTfe6DbiOQ7FQxXM90GBJv0vJDekq2theiPZm/B5vMQd/cBonfmwfLrvqV6zrGsR2XaQG67o2sP9Bh9OWS5KzdIq9vUxqSjOjo4E/LdhAR1OOT86ZSar/edZu6GefefNYvXotg4UC8w48lETCwjAMVqxcTfMYE3Pxo/z2mTJLBxTq+/9HoxFiEfLP9SU+fviefOm4+dz0y+/TuXARV39iHmtfXEhjx0SOPe6TeP1rWffSkwhlc8yH9uXkTx1DR0s9umkxf94uWMLh+X89zOe+fAau41KXq+fOO/5I2utiyX0/Z8IeH0UTLt7gEs7Y02Jvs4ML7+8iDCFr6Xx211G8b98DmDpnf372458xY1IrfqWXn3zvO5RLJaSu8cwjD7B2ySKu+saXmTxlMttPn870A47FTGYBhZAanuvR391Lti5NS2OWv/3f72lubSHwbBa9uJR0JsnY8aNA6gihk2icxne/9wO+dXYZFQYsWbyUVStXk03qBHaZMBT8/MeXRrI3jHY825sbefj+vxJ4LmHgEzgujS0tmOkkXmUw2kxJZ/nq8Ydz5B7b8bcrVvHQqgGe73X589c/RkEmea5icdH3L2PydtuB0mhvzrHb9FGcNHc7xu8yj9zk9/OFkz9Lb28375sxntljshTKDn9+ag2nnHg0c2ZP54lbf82oWXNon7E7RrqO7hceZundv+K6Z/K0TZ7JeedfyNe+8S2Wvfgky35/AX94oovbnu5CaIqW9iZCzaBSKOK5Lr7j8cVd6tmhXXDjRefS0ZbjiO0bufM+HccNIPSZOaGJVMIETfLDn/yWK6/5PcWyR09PD45rc/Ahh/Gxj36I0075BFLq7DR1LN/89P6M6/orXQvz6LrGgZOS7LmdxZX3vowou3Q0ZfnucdPoHHD4zu8Xc+D72mjIwR5zDqRzQw9v0oz6llL1wFcQIFBCQ0hFKGp6tJSYpo7UDZRm4AsfJU2kYaFJDaHA83wKZZuEb2DoEqSOCkJe3mDTmDZpzUnqmnOEfkC1UCbwA3xfRYu+iku1WAXXpymdYPr4FtzBRvRUBqSGkUiQCAMS6RS+p0ebzG4FzzbRhEAkMhi5FhIt41Dmy1QClxXd/exQGkCEFTrGT8TpX4/db5NKZmlvbef9s2awprcMog/Pc6kGAb3lKosWLkZL1dHYMYnx280gcIpUejL09eepVj2KhXX4jg1K0TxmMsqwkKkkZhBG8jOoYpcL+L5PgIHn+SgVomsS3TAwhIg2HGsGosD3cW2b/OAAQTqBlNHfpYw2HsMgMnhYpomoeUT6noemaSglCVUwvPY3DYMwDAh9H03XEFLHtExst0TguQSBT6gifVEjpM4Cs8FkWkeKxkYDxy4wWKhScQKyJtTX11PXUEcmk8KuVpnalqFStRkMoOqD63o4to1nlyLDQl0LeRdWd/bx6JMLWLJ6AzlTwsQ20A18zWBDJWBDJaC7EqAZBrpQSE/h+QGWJmjJmHTkDFqSGtmkQNMEDooFPQ7lQFEMIJsyQVcUPRcPRRCA1DQCBbYfUvaDyEgShKRMieeFrO2voCyJTLoo30ETAVKHquvh9/UR2mWk8pCuS8GDyoBNECr6yh4DTkDJfXcbkGMdOtahYx36jevQW214kiISmF6ocHyo+oqKB0kBhhYNMCkkCNAimwdhrdtICUlNktIlKgQnCCNXWAW+CvFC8GqWQVmzfkoBUoSIwEV4gKahAgcCmzCs4pUG8O0Sld4evEoZoRtouo4mEmghYEhCfMKgipGwsFIJpBiPUCHFvh429A1QKkWeLK1KEggNJXVAYRiSulya+lyawbKDrhUiq2UQ4thV7EoJu1JC+T5K1xAqxHVs7GoV13YIhYZCojs2ummhwjAKbxMQqIDAqaB8iV8x/r2TEtgQKIJA4LsVNDeNCiLjjwpDfN8F30NKCKolCIPourpBGAT4rhN91jR0w6p59ETGln8bzCOvIxX6kXuiihQSz67gVcu4lQqu4+B6PkGoEERGFk2TkcU5VNFOsJSYSY2i41NxPALHRhMhDVmr5nklRng9ShF9XwpJtVIinx+gp7ubSrWC53nDrpUAUmqkUkkaGwLGtTdScX3cAMquIvQ8pF0krfskNYUpI2MaUtZC3xQFJ8QLwpr7pYj+H4qaBxP/dhCj5o6tauGfMprYpIgMUsP+Y0OT95DBqjY5+WFt90dFXlK63NjK/u6kLqmTMKJ+CKrmxcDwbooieiYvVIRh5M1o+yElN6Tqh4AkdBWBDAl9RYXo1fq1nTWhfFqNaCc3YYb4QTh8eRUqwiAAL0A3IFVvMWpKG1qqsXb7qA26pqFqu2RBZZDKYAm3v5PshPdhJRM0TppGS12GwR4YGCjRu24tfWtWUD/2fXiaQCgf9ASJjEnbWJ2OxjrsSomSCrF9KLkBfX0D5AcHqJby1HWMQpMhXrkuumfgg9KxS3lUEO0OCyGRmhF5ISqFX8njFtIYqQCrsTV6dwrccjnq51IipFYrj3q21DTMdAbdNDCSmeh5/93JhsfrMKF6DaEqhhVhAbVxHaACLzJEI/DDEI0QQwoam3LU1acJA5e+ld0M5F0MyyKVSJDO5TAsMby77Xg+FddDhSGGDIeN11LTkaZFUHKpVsr05wt4QVAbFSHISHblKzaDFYe87RFqFrUOhwAsCa1JQVoXWBJ0TWDq0a5yrx0ilCIpBY1e5CFrSqgKNRwUJIWIFkFSIFUkW7SwlqxwqJKI5rV/v8EQFfgEtoPnB1S9gP6qT96GqhfWQiiIdmbfxew4c3symQyr1nSxfNU6fMdh1vh6XnIERdth9YqlhA1pqgmdZSvWk53SQKqljQ2rV2JW6zCqaYRfoFousHRlF825JBM76li6bDlCCExDY+fxOcbXSTZ0DrJibYE1Az5tiT4KIkAFAavXlBnoHoP0e5kyeW8KnZ088cLLTBrdyPgdJtHY3ERP92LsgQ2gQlpaGpkxcyqmaSA1QSZpUlr1Mn1Ln+all16mNSFoHTeaqdtvR9eCbpYseIn6UVNJZUw0VWHADul3IApnkRiGRr0GY5rqmLH9BPbc4/1YyTRPP/4Y7VmDpqYE2dZReAMzqEsY9Kx6kYSlowKP/nXLkUaKQEmaR41FyCh8GxS6JtluysTIAykMsRImhmEQ3Rl8P6BSLJJLGtSnGzESaRKGQXNjI5Zl4XkelXKFcePHoelGNAYDH00Kpm2/fSRzA5/CQB4zmQKgVCwjpKAxlaGlIY3WXkeTJZnWliVRB88tXsaAr7HKT9C97Fla0pDtmEJLUxNjR4+iMZ1kdEOaxuYUy5Yto1yp0NyUizwWwpCkZdDakGJcWz394zoYu91ERk+fivKrlJcadBZcxtVbTBndwLTtJzO1vY7KUsWTLyzl+QVdLFvWx+gxLfhKUql59OYsjTF1Gi0Zi6Sukc/3km2AhkyatCmpGBp+qEilEhi6ZLBkI5w+wlBRLZYxVZSmYdnSJaxaOJr+hc8QOFUaG3Ls9P6dyS95nP71nUzJasyYOIrpsybj3fE8SRnQkTMZVZdCojOxNY0S0F+o8PLC1TV9490vg9OJKDWF1ORweJgmohQChhalskBEOoYXRJu0VT/yrK54YeRZ4Qd4UuAjCIOQMAipOAFK+AhdI5VLRdEGSQPL1QgJMRRIFaB8DxV4WDrUZRN0tNQhEllymSSJRAKlAtLpNEE12kX37AoVwC6XUSLEUxqpumaydXUUylUq1QqlfD/lgW7qEqPRNNB0HcO0yGSytHW009xYR7FcpWfAxQtCbNenb7BAPl+kXC7TZBgYIoXK5Ei5CqlXsUtFgqqPCgIIAzSpoVsJlJdAkwLPjjZKdT/ATNcjCFFhQLVUxDQNlGliJFORlhOC1CSGYZBKp0ilUyRTKTQt8jZUKsSveTdpQ4sXFcnsIe+poQ1bQeR9AQolIi/8aA4RhEPeSaFPEAT4tbQhSiksQ5DLJkinTYLQo1woUqp46FKgWxZGMotmWWiGhdB0HC+g6nhU3ICkEFH0QKgQUkczLLyyTaVaYbBQwHNdVG3eCgIfz/Mo2i6FqkfB9pG6rHlBAgp0AfWWRp0lyVmSdFIDGXk1dPe7lH1FNYSmrI4mFQlDw/Oi9ZkmJTIyE+BT87wUoqY7g1QKvxaBIUTNGUFGa0ICH79axVEhxapH3om8N4Mw6t+OH+ne72ZiHTrWoWMd+o3r0FtteDJ0QeApAqUoeSCFos8Maaot/pO1uEEhwDIEJV/hBiGOH2JpkqSlUW8pdBFQdELcICBUCt9XeCLEQRHoovaCa2FQKKTvIL0AqUlQLiqsorw81fxKSv2DdC9fDKKCla0j1S7QkymSlkmmKYOmgZXwsTJJEqkcdc1t6EIipc6yl16mUq1QrNqM9SXSSKNnDYKggiUhnUzS0daC7cOyzj4E4PoBdrVa85gaJPAdpDAg9LErVcrlMo5tk1A1V3DNxDAtVMpHMxLRTiiK0KsS+CFBFXQzGXVGGeV6Cn3w7QrSrGB4DoQQ+g5etYhyqwhCDKnQEhlkIo2WzBIEAa5tRzs+uoGZSA0P2mgAR+8z8DxCz8V37Sj8rjaROYU+qoO9lPL9VMplbNcjVAznQdJ1DSkEnq8I0BCaRrIuA/15qoUKxVIRQyqCpizhsNFmKL+UQsooXl6TkoH+PjZ0bmDFqpUUSpXoPSEIVWQsMpMJ2nM52jpaSScj5StE0tnvUBosMLBmFfVhmZQMsbSo73lCo8sO2VDx6S65eEEQCUehRa6ORLsBaiODUoiqGZAkOpHX05Bw9msTllKgwkjxiR4sJAhDHF9h+wG2H4XfJXTxH2F4mt6ewjTADkPCWr4TXUTejJH3ZoATRDtjrqdRchQ9ZZc1BYeeSoCOjnRBqBBFwOqSwA0E7fWCihfQP1ClQU/TnNJpywp6ijaOF2JqkVLkux7KC5BJsLIa2+8xET9sJDA0pIwESzKdxnZdAl/D6VlGYdGTdD/9MDt86uskm8cybs5BbP/nm7A7V/LUGpvFz71Eg6GYc/g4NL+KwAeznmxLlmnpBDs/9S8s3+bJ/gJFN8D3Q1Y63TSsXk3H2mW0jB+PJI1mpmke3YiuaWhSo3/tEqrFAaRQkVKl6ehWGr+Sx+nfQFixsepbSTZ3RMZI3ye/dh26aWKkUmSamyNDs+dFxnfDJNM+Ft0w0K1EJCBVCGpIsRC1sBtARWG60V7sFkSn2MKHwEe5LkHVxvM83CDADQMSIkRHUNeYJV2fplx1WPn0M3SvG2CHuXNpqqujdewYRGUQYRo4CvpKVfKlKlJCvYyM34QhSmigGYRuEeV5CBRp0yCha7hOBaUpPAnLugusGyzTV3HIZpJIERmidaHIGYIpOUlGA11CYxKshEag6SyuegxUQkpVn5maHXlWagqbaMxKIdDkkPekhkaIFoJRU6ZFEI1fIVUtPDb6T9ckCV0jbej4gcdAxeflbnvYaJy1NKq+wH+XR8t+6TPHcN/Dj/PVc69HMw12mVDPyXu1c9FfyuQLNk1NCdrSkmxS45FKQK5RMG83gz88ZdCe9di+cT1hWCFf8bHLNrNnT2DmpFauvOUpKlUb5bl8Zb/tSYSKfzzfw+ruaH4+YHyGnjJ0VxTtSY0sRaisQh99AD0k+Uunx4/O/CB77/WBSE4UurF7V6JUiFXXQN24yQihEXg+XqVC9z//RNe/nsBzffbavpF572vG1DXWrO7i0QefpM7w6Jg0ibZZs7nuhSqPPltGIbBMk4SpU+gZxCkVMfSAT57wcR7/5xNc9v/O52P7TmP77SeR2ftQdtpzN3baa0/s7oXY1YBKNWThP++lYofYQYp9PnwUjW1tNDRkaw7AIagAFQqEJpk0dRKRYhspzU6pyLIXn8ESHqap0TB6Ou0tzUycNAEhJYN9vaxbs5LJU2diWUl8t0ro+VH4j2khNROkTk++h7QvSWd91nf1IjWNxtYOlF/BdwoUizb7TWujY0Ibn7jqcXzPYUxdyMoHbyBbWMrMo85k8uQpuMUBVnetpGHVCnRNUanaFCo+oebyWO8AgpD6jIF08wSVfjKNbSQy9Uhdp3/RP3j0iX9x4V9XcO6Bk9i9wySwS+zVqpNstbjmkQ1syNtYCZO6XIZ8oUK+dwBNk0xpMjh1hxzdgcHKssEu7Qla9BJauY/WtI4XCoq+Qk8kqdguLy3vZs6s0YxpSpHyEwyUHAbKDs90lhhY+CQvX78KZ7Cb1KQJTPzAAfzluUWsWufzkbEWH5yzG1P23ZfKd//MBCvkgLEJyoMgfIP5O7Zw74vdrOopD6ce+E9gbFOSUEU6xtr+aMPV0CUpS5I2BUkDBAGuryg5HmY50p3X5B26Sx5OEOL5HqiQgWqIUwv5V0DFVxTckKaWDLmERtZIYOFhVwUuPpYMkIGN8stYiQRJy2L6dqMQVo5kWwuJbD2aodPU1IhRtAmVRmWwn7zXRaViY9Q1o1A0tk9gwvixEHqsX7ee3rVL6Uw6NCYlIgywkmnMZIqcmWK8mWTiy0uw7Sqdvf04fkjZ8ejsz9Pa08uorg2MmjARU9exMo20JjL4jk25t5NBv4pd9TGEj2lq6Jk0hlCEbpVify+O7ZHM1tOezSK0EC/wGOxej2kYJJIJ0g2tCD0K9zJNk1xdPeMmTIpCC5NJrEQChYjyFLl+FG0gNQwZeV7ohjG8oI9kxdBCtZa6QmpIGYURhWGI73t4rovneTiuh+26lKoOUtQMT00ZMg1pBvAZ6OmkUCjT0dGOnkghU/Uo08CRSfKuoCtfpa9QwQ0UTUJEqU6EVssfa+JUerBLBZxyEUuGWFIReg5utQS6wUC+QG++TE+hSmN9GoWIvG+EIqVJRqU12pKCxpSgqSGBIzVKgWTN8iplJ8APQyzLQghJOiEoel5kUDY1DBFdR9RScQgRLcwTuiCjQ1ETWLWFsCaj/DwZSyN0Awg81hd8uss+6wZdpFA1Qyv4CKL8e+9eYh061qFjHfqN69BbbXiCWs4mPfJ8KXmKdUWfAKgPFWlTDCsAQ3HRUgrKTpTgkMCrfV8jl1AUHah6AU4Y4qYkgSHB0CLPwCBySySM8hGJ2oTkKg3PcfCq/Th9efI9Bdas6iUMAlI5jczoPLm2BGbaoqVRR9N1zGQaQx8SECZCSxAKg7LtUq5UEPkKk3sGaWhpIdfaQqA5CEI006Kjw8dVJk2r1pMvVqh6HgMVh1y+QK63l0q+QCKdQtd1NCHRpY6v6cjagAjdCqGbIvRsqIUypDIZAukjlI80DJBRDLjUdBBaFFbnBwjHwSkVUb6HVy1TLfRB4CBR6EKhOTbSriIcJ7LMBlF8u9CiHQRZC61Ttbh1FQbY+YEohtepDOc3QtPBc8BzUa4bhewFwUY7cZIgUDieomgLhJnBSFokMDCK5WgXRUSeRZ4f4PqRxxFKkTU0spZBS0LHCBWVis2GvkE6e/oZKJaiXZyay18QhoQohGFR19hAJpOiIe0RhAGBgtbOCoM9JuvLPYiygx4qTNOgKg3Koc7KgstAxaPsumg1ZcEJIrc6WZt6oumnNpRUlKQtEJHbexgKlBbVCNSwgRlNhEgVgAqpeB6DVZfufJUeO9qB1IUim9IiwfAuJ2XoCBHtytkuuIEioYWUvIC0AZlWHYGG7Ul6bY9kQtHq6tiuQClBJq1obTRIW5KCowiVR8EJkFLH0BUq4bEmLOMpnZaEhWVLCCSBaWJooCsHUViJ6whs4THYtww9FVI3uh6ph2QbXD54pEWxu5XAy2Lm2hkMsizpCVhz/R8Ys8Mu7Hrkcew4Z2+aW+qYsHIl6VQ93Z1Flj14Fw1jGslNnM7qFxag/JCEafK+aaNIZyQL73qYoqdTETptlk5n1wYWP/M4bePGYyUsLMPAdT0qTpFSz1o0AjTdoFy1MWUZEw0zmUSzUvjJOnq616EN9iKsKOGzCkIq3asRoYMkwBs9ETPXTKJxDEN7FaHSCNwQaglwpaZFYyeIvBqDaoWhnRupW5GweoUtm9qwizz1gCD0Ub6DVypQKZUpVhw0FWJo0UaAkbCQuolXDahrbMUjwxpP0L1sDek13ez9/omYukTUPE8VAlODpKmRNHWEJhGeTVDo44VnnqZr7Qoa00k0DdKpJBhp/HyFktvNky8tZW1PEbcakHcLCF1HmDrTWyxGpSWNiSihv6VDYypByUiTx6IQ2FSDABR4YRjtyAACGYW7qiiEN0QRqmh3y9TB1BW6piID89D7ESEQEKqg9u6j2PaK51NyA4q2QtcjIVsthzh+LZfCu5jpE5t58aVopy/0Q7oKHvcvqeBJg3QmQW85oOCUMaRg+3qTrEyztreeqitxQpMqbezeUUWrhFzfXaBSqVItV9hrVhua72Mpnx//bR1jG5IcOLWd0RWdwaJNTzXg8S6bxQMurpCUbJNKMUPWh+1bUnxz/iT+774n+cfSMj/c8wSkJtANGckyx8YtDmLVtdUMMDpNU2fSmC8C/+KhFXk66eVox2aHvfalY/x4ev9xE6X+Am2Bx4cnmLT2Wlz/fInxTRbtdUkeLjg4jz5FpVJm/5PPYsZOe/K1sxqQnU/S1d3LnT+5nqnjGmnKJVjdWWS7mTsyecZMHrv5Lloac8zbdybpjFVTVE2WLl9LoVjmfTtsH3lqhyESSRgEeI6NmUzR39fPX269mbaGJG1trXxo1p4Ypknoe/Ru2AACxowdC75DeaBCPj9IJpPGshKRAlzbIR8zpoXAdcn3dDJm7GgMM1r86pYFiSTLfItWzWRK2mTfSTkyMmRGi0mzLsD1IKyS8fppcHtB+OjpLLnWUZy65yhW9JVZaZs0GFkGS1UeXdjF4NrF2OMtWqftSqKuicJAH1+64Fe8uGgZqJD2iRNomzgBzUqw3E+y0E7QmLDpyyts22PdhkFAkcsmabAEuZTBCltneU8Jg4C92+q5c5HDC/0eX5rbyqPLSvz28T7schlT15g2sY01/Q5r+hyaMkYUYlR1mNGcZP2gx3fuW09X0Wd8ucyGxQsZnapSbZZceH8V+be/4w92c+7+jby0vso9az3CbBf9FZfbX+whkBrZTALHCWoe3O/k6Nw6EgZQy9tSl9LJV336ClUCU6ISEpmxcMsuvi0plz0SUlCxJK6vUAgSCZOWXIKUpZG1A7oLDvlKgB+l6aTqKLr6SoQZg9H1OjJhRSkSHBfd1DBNUE4fjivxfJ9KuYqpdJKhB6GLKXzG1hs4aQMlTCSKnq4uli9bjp+so7WtlR1mTmXXXXZmdEcrTz3zHH6oWL2uE9NK0NTSRlNzCwNd6/A9F9dxmNSaBqeVpWt7KFYcSq6LYVTYsGEdG5a9yMSxbaSyWaShE7o2TqVIb29X5MkjNELfpVIqErgKM5HFJ8B2AvoHVpFIbCBhQCgknh8wsH4VuohyfjqtYzEzDVh1kUeFkBLNMNF0PZK9RLv0YRh5YQkUge+RtMxhr60hIicoORyWo4noGkLqkR4thiIDFJ4KKIcheR8CoWEYkkzKROoJBDq671GX0BCeSbFcpbiuC23AYfy4MZSqPnYQhbooIk84Xddri22LIPCoFPtZu2IRxb615AwXM2eQS5poEgKvimfrhIFDEHh4QUihZENtAV5vajQnNUanBSkt0ooLSsMONUo+9NkBrusjlcLxgijBOrV0GbWwm6GlfF1aogUamk+0gFUQBFHOHqVq+k6gEEGArgm0lEXC0gmrJWwCSq4/nEBa16MQvuD1Joh+m4h16FiHjnXoN65Db32Op5oXiKwlmvICRdFVpN3ohwnCqM5QKJOsuQ8rovC8ihuQNKNOYmgSDYEIqeXZESgpo3A6FAEBQVgLeVK10/D8kEE7oOpWqTou/gAUB0rki1VUIAmEj12qkKovYVo+SUuhGRpGwhx2MVWA0E00w0IzLexCCc/3GBwokKprQBoW0kpGhifDJFffQIMdUJ9OUak6OJ5H2XEplCsU8gVKpXLk+po10TQTTTeRnhcZypRC+S6h70SGJ5VDSolpJQjCJEJ5SK1m/CFy2RXy38pTGARRvLhjR6FwTgVCDykUrmOgKYEMQSJQUicQUfLUMIxO5lChjgojN+LQj3JA+Y5N6Noo144EihYlhZRSoulaLd6dWghezYhY24AIkfjCxDJTSCOB6/koarmPiBLQRYanIDI8EYVX5gyNnK4hgoBy2aZnoMBAoUzVcWtuuzUxVnOVV0Ki60aUcyQTKe2BUri5AN22cFIGrq+j/BDNMPBDnXIgGLR9yl60UyOhlvAvsuQOnUzyb6NT5PEkaoNpY511yBsqmpRq8f9hgOcLyk7AoO3TXXbpd0LcILKVGpogZby7d2oAinaIoYXouooS0waKshe5AYvaOAxrHoeeUlGSTWqu1DJ6e5YpSCeivG3lmuei54MSIUIPqApBBXDCaLdQlyI6rVGKKHlpdYDAEzihS6UyQMJoRWgCv5IndPuor6+Q0HMEqg4tmSMw66hoObqXLsJoaAEhaZ88lWRCI1ufpLe7SrXksmHpIsz699HUMJXC4AKolhAJRXtzKw4hOVOnaIMdKDyhU6lUyPd0Uh7oRWuox7IM/IqHY1fo3bCebDaDlUwSOjZoBkIzSaQzKN0Ew6JUyiNUSH1vA5phAYLQyRO6JfCraKlElHC1edyw+28YKlQQKVuBa0dhtiIKQQ2UT+A4KAKkpqOZCWpZF0cQKcA1t+7an5VS+I6NVynh2jaO6+H4kfTThMA0BIZpImQUq51IZ0mTYkMo6OnuB9tmzvvG1ca/GB4pouZCr2kCwzAJAxe7MMCKZUvo7e2OTtLw/SgPBhLlBYSaj1KKpKnTmBZohomPxBWCehMaDEhqAkmU4NSyTPqUQb+rUfEij0JDRoJbhNRcFDfKzVZ73iCMnl/KKOGuqH1naCwLaq7CNaEphIgOBqh5OtpB5I6sxJCSQJS8+V1Md08vxVKZoR1411f0lhWBihYGChEli1Zg6RJN0wmEiRsofCXBSKFr0Y41KPJFm67+EpapkzAFCSV5eGmegg27TRGMaq8jm0mwvr8HJwjRNUXRU1SrHtXBKukgpDGbYPdpo3n27+spVj1QCt2yMNMZgJrrukvg2kjdRBomydbxpNs2kDQkPRUf2VPG7l9FQ+sY6t+3G92P/AHX8RB6ipnbTaRcqMDzfegiCtkootHZ1cPSFzz2DTQamlvJZtKs/ddaSrZHsVSk0NeDXhGsX1Vg9MTtsTJ1yEQGM5mkLmPgVksodJLpLH4Q5ekIw7Am//59KEZY6xxhEFAuFnAS4Ps+uhHJzTDw8F0H07LIZDIEno8fhgS+X4s6j3I4Eq1NSVgmbuhTLnnUN1roVgIg8pSwbTRDxw8UFdvBlNCa0ZnVkSTTkCMUsHjBi3j5XtJaQKpjFKmGFsx0HVPbM7i+x6pqiJSRAui4Pm6lEOWtnDIW3UxSrNr8/ZlFbOjujkJjdAOpmwhNp9dRrKsEZGSAZRrUZyWVqoumRRuOHbkEbanI+zlpCjQhGbB9FvW6PLXB4xN7WrTmPOqTepRzh2h8l+0qrhcwWBUM2gGOG9KQNOivBqwYcKLUC2GA71RI6oqEJRn0oWvterrSHqOyOosMjVUlm3WDFQbKLmv7bdpasySMyBgwuqOdpsaGt3tIbjNlx0fXZc3LSafqhdheQFmFGEJiO1GyaU1TBLXFlFBBbRc6CpnSNIllaFiGxPECPC+g6NTyVoYhjuvjuOD7kV4tdB1dD6J0GMonrObxlMJ2fBxfICwXFXh4dhnfqWDgYVgJhJFAN02CIKRcLlMqu6TTKRKJJGPGjSORTNDbP4gqdVOqlFnX1YdM1pFrsaiUNhC4VULPpiGXorW5nkw6SdH2sB0Pxw+oVkqUBnqwS3lM08Ay6yJdy3WiUxdVNIe5nkegbIJAksg2IQIfXwlKhUG8iqQ6UI8wrMhwYRej06Ml2IkkQmqYmabowAIgVCG+7yNdB9+1ayFJQ/I5xHM8NAEGCs0whxVDKaMN0khDFsN6ZBD4w3Iy9BxCzyHwHTzfw/YDPD/ENHSkYRKgRcnkXQ9L10laJn2uoloo45cD2lpboyTpUg7LsVABUkNoBtJI4AcBlXKB7q5OyoVBLC2EWjJxP4jmsEhP00kmE6RTKQzj3+uClCHJGoKcIbD0yJnAUyLylnMUVS/KCWaKyJNOSFVLk1FbCwgQRGF1SUtHD0CTPgRR//Nr67awZjgLFVHeoVpS/WTaAr1KWAsfjA4wiuoEYSTX383EOnSsQ8c69BvXobfa8FRxai+RyLYUKii5Ib3lyOjUngnxw6ET7MLIipfUSEkdQoHjKVw72vlTtVw6ei2sKaSWfFsaBCrECUOqQZRHygmgWvawSyH/XNFHb8Glv+BRp+voXoDAJaElCKTCLg5gD7rooY4Mi2jSQNcTKD/AVzah70QuwC2tjN1+KgXnJQobuli6eCloBplsPVkiYSfNFK2jm8HKMWH0Eiq2TdWu0lOqoOjBdWyyLR20dcCoXAuJXDPoFr7nR2FeYYjwXMJqAc/QMDP1SE0nma7DlyrKVxW6wzGVQgikqkVPGxpCgue5eJUyXqWEZ1dA1N5fRaJ5AbrnogcumplCS+YYOvXGt0tI5aI0PfKGcj18z4sGqgrRTQs9mUQaJkYyi5lIYpgm2cYmEj1dSCD0HBASTZjouo6RSGHkWknUtSA0g4HO1ZSrVUqlIiYCz/colaoMliqUqg5CQHPSZFQmyeiEiV+qsrLi8fzKtQyUylQch0zCAhl5S0lNokmJ53hUSmW00CcsFKJcVkAqDBGGIqizKJHEc3WCRIpKVdFXM0p6fkjkqF4T2EOhfjVr6NAJJ6rmFhuKKJ5WDRmaapNRqMDUooz/IvSoOAGFcsDS/ipdgzZr+x3sEEDQmNIw/KHcZO9u7l4wwJgGg8mtFuOb0vSXPZZ2l/FCUIFgVSFgVJ1OXQLqEtGJJ3WWZFSdRpWAVf0OEwOTZs1kh5YsaSlYKeD5zip6ClJ1gtaMRCrF2g1lmoxIQVEKhKahGRpUBlChS2iXKZb6cfU+ssUNFF5aQ7VnKfmFf6d5xz2onzIFs66J3KSZtO1aZPDen+K5XYjAYfTs/Rj9vg8wvW85zzz4CMuff4FnX3gKfdJExteNomrU4+RLFPvXssN2kzDr00wdN5rS2j6qRRuhJSO3V3uQ3s416IagpWMynlNmoFpm8ZKVNLc2k63LkU7ZBI6LCqChrT2KvjF0Bvt7CKsFGs0qZrYePZHCTCbwCQgCFyffhZmqQ69ZblUY4nkOQakfEfqYSQM9kUFLpDDrGghDH7c4QOCHaFYCK1Mf9c0wrC1gVc2LVK8ZR2uniYYhgWczsH4Fg6uX0p/PU3I8HCUJAzCkIJfSSebSIDXWrVpPpnkiZluONX15Fi5bQeey5XzywNkIP4zCfmti0w4EVT/AU4KW1nbKdpnVG17g3r/dB0BrcwN+UMXzAzzfBlOnrqmBj+y/B/mBXqqVEg0dE+kcqPLymh7aqmuoUx4JLYMeBpgyOqRg9QaPJzeUGRyskjWhOatBKPCVIPAlEICMBFqoQvwQbNfF0ELQBVbt8AonjFzeAyUQYUjouwSejZCSpGnQmDLJWhqGJrCDEEtKErqgMQ15D8rv7gN1OObU/xcZQgjRNI2UpTOmIc0zK3qpOj5Tx9Uzrb2OhpTJbx9YxJ6JgElTQyrKwxYh2XaT/1tR4IEX+glDxdPLenh+1QDSsDAMiWlISp5gYXeF8+5YzC+/dSD1GZOPnflnPjs9wezWDJ+/p5/C+pX0PPsgjbt9jExjE9vtujuX79+E0TAKKQV1Y8bT5pWQmoamCXQdiuuXoSczZNvHkRi3N/WDWbZruZLVA1UCp0T3Pf8PY7ejyO7wUSqlQcy6RszW97Pnl3ZCf/JpxK2HsGhDifV5h0OnN6OHIav7CoRCoCXSaFaKtmm707rdzuz5scl0vvQ4PcsXsH7xIiy/gKGbfOXLJ1HuXUvfimfpXtRJsr6dXeZ+iOnTJxP4PgPrVmEkElipFLpKIaVGImkhJDQ2NXLEkUfR2JQlV1dH6HkQ+gigdVRblJBYGljJLGYYYiWT0WlggGN7wx7gpVIZgSKZq6NaLKDbNpmmVtYuXsSGBU9x4FidfKGPR/7ezR+fXsuBM+o4fk4DLft/gBdXFfjMYUdwyF7T2HnHqex//Olouo5vl6nqKVb0dXLfE6uGkyYbukBKC2nmyHVsh1ut4BfWR7vAtbCEFYtX0NYyiulIVncN8Nzy9YShYq/Z27HvdqP53R1PUqk4OALm7NLO9jnJeFWgfa9xlDSDS/9vA4t6AvIVh6sfd6m3TD76/jbuW1ahv+DgOD57b99IY0rnpZV9hCa4Uie0LCZkYMe2BLe+1IeZMGmd0EL3gjR+kODQKfU0eSVWLKzwcEFndcEhX6qwsqjj+JJMJkkul43yQwa9/M9XT+bUUz77Do/Q1+bBBb0055J0NKepyyZRQmP9gMOgG1D1Qxb2OYyqN6lP6ug6pJOS5jqDppyFHboMVB02FHwCNHablCNj6tQnNF5cWyQ6ElwjYUjCEDp7bbIpEykEGVNiBi6iUqDauRQ7EBRdkNkWRKJC4A7S37eOUn6QteuW09AyjrpMHQ1to2hzAgpVh9Vr1mJKiZVIM2n79zFuoktbazvPPvEQK5Yu4onl/VSSY0iPSmAXIbQdhDNIXfsE/EQj4zrWUam6eLZD0hQQuFRKBWy7TEY0kW5oor+ap1SxWbmum1SmjkQyjT+QR0/4mEloaMhRrRoUCwOUinkqfpXBlE+moRkjmSKX0vHtKr7j4Oa7Ma0Ehh6dOOb7HsX8IEW/ihQK33NJZutJpuuoy0aJvYuFEn7gY/oWupUk9KOwOsOI8r8KAUEQ4LkudrVCqVIBBcmkRbVrLaWulaiBdQSlQVzboafg4SqdTH2Cgg2ecikXKuhWhnRdhnV9Dj35KoVqmWmTKxgE1KdMpIxSW5Rdn3p0hJFCy7ZQqroMDq7mqRcWUikVMLTIEK98QVfBZbJIkM00MGnSBHQz8s7UDZNSsURfby9NXp4WS5Gu5dvTTJ2SkvQNOKwcsKk6NU8SXcNTEqkkRu1wIE+FeK6PYekkTZ36lI4WCoQHmmdT9aJk5o6EpAIltcihQAp0XWAlddIZA9McOjxKIWuG41BIAoZWye9eYh061qFjHfqN69BbbXiKrGeRtUyX0T9TjxQcXymKboBXMzzZXogHhEKQsnQMIRAm5G0fxw/xwhC/lkVOCIEKFb4T4skAGQJCUHBCtJLPqj4bRwWUXJfnlwzQV3QZKPk0WhpZTdCkgW5GwqZn9RoCN4HTYNDQLDCMECspCbwqfqVKtVBENyM32tFTplIoVTB0Seh7VAcHyG9YR7Kx5hFlZbC0OjK+RntrKxt6eikWCxRsn4FSlTAIWLNuHUq3qB81Hi1dj6FZ+P2D+G4ZEdiEOJGhA0GiyWHo2GKp6dEpGQSRgaRmGR3yUpO6AbqJMBIIwwXdRqkg8lgKfBzNwUxmMJFYdU3oVhLNMKLjbj2fwC/juQaBpqGEgR+EBIGKnkvTMEwDYRjRADGs4eTeqZZRJHv6SfblMW0fw1BYhk4iaZFIJUhlMkhdx/MDevt66e3ro3dgkNZcDscLKVZdChWbih09qx0qSn5An+3iuSEVJegvVig7Ts3gGLk4ajWrje8H9PX2E3oeXiZBwnOiuHRNi47t1SVWwsC1DXylKPiK/qpPb8nD833CUNVcJqPr6kMJD2uW0mFrb+140OjVD/XDaGIa2mFIWQbZpEGlWqXshvQUHVb12eQrPhVfDB9DXXTACwIK2rt8qwaQuqDgKlb0+tSlQzQZUp/RqHpR11vaH+ILnzalSOhRzG8QRsnrDCnQQ0FXf0BoO1hhtPPdUZegq6KoBgFeIaDoB2iWoDkpIjN6SHSqThhGRkQ7wEhoZOrSdDSNRjdSpN2VdK1byfrlq/nXQzaT+3sY272WxqkV0rpDe51P4v2jaZ7QQOiXEGYuCpsNDXq7ulm+fAkrNhQZ2zmA6uph3M67YPe2Yy/3MVIZkqZkxoyZrC0/w0AhT3epQp0lsL0EfrmIVy7jOS6hWwXfAWkidTPyqPM9HLschepKDU1XSBHS3NKMclOYmSyalUToFlLoKCNZczPXcR2P8uAAiWSCwKlg53sIqgOI0MPp0fGTObRkDswEju1QLDtoUmIZte2DmhegkICITq+o9PUSOBVCNzpFS0iJYeh4g314xUHKVQfXC1FKRkkHTZ1kKklfbwGkgaclSGQzyGSGxMAApmGgJ1JRngoh8ZF4YbTbbkkwZSSUDN2kMthPz4YeitXoJMroCOnIzdm1S2AmybSOYt8D9sPpX0pQ6sQavzvLl28gET5PuHI1idBHhj6ZpAW6wePdNgt6KqwfqFCf1tGFouwp8IPa6UI1d2jx71cSqig3iicEXljLmwd4YVAzM2toeKjQj+L2CemtOPRtKLK4p0K+6jGxXmdUxogWZFrIqkKIW353j+Eg+PcJpXts384O43PMnWXx6EJY1+fTPVilWvXJGhpHbJ9ljAp56p9d5IsBfabNwn+tpZi3UVJgJi32ndbA5JYkv3uiF8f28Vxoyibwg5BCqcrPb3ueiW1pvnHEBNasLnDj0jJ1KYvWUS00T52CJgqE/gCG6KVa1vH1ehoESD1FKlXP4dPb2GF0MxgZHvvrtazrzbPaM/nsZ0+mo72F//nSUfzi1kd4dsFK/vDQanYv3c8uhUEm7TIHK2lRWnwXWqqepmAdZxw4gbsX9LGkp8qLvS6h6yJDxVP33MKUabMYPXUnuteuJfBdWmUGp38NqtTF2O12JGUZ5Ncu4MmlJdIGTGyfyuqn/4VX6qfUtR1WrhU/FDz31N9J6VCXthg3axdCLUHZljQ116NpkoaWFjLZNFY6hdS1miLssmDJarLpJBPGtFAtlxFCkkj+O0xHNzSGjs9IphLRBkgQkEglokTkClrHjce2C/zk53neP7meGdMa2XHRIOOaMxjZLAKLXDLNHjM6GN9RhyYCbv3DTey0625M2n47FvSGrClGrvVjm9MoYH1/NTr2PnBQgUOxcxHdC58m9D1G50xmdaRpaswitYDK+ufwKoORZ3uoWLaqm4F8Bdt2SJkGLXVpJppVvErATxYXOGXqWBrqMqyxO+l3QhwvoN1wkZpBPrSw3TwpQ2PWxA4GKxW6iw5VLUlzUpBWDku7SkxtMJjRbmJIge/65LsHMYIKlnTpdhUTOuoZ05xi/aMb6K/6gGJxZwkpBZmUzsBAEdeNPMv+eNsdLF66gquv+cU7MDK3nqoPBTvAKLhkPEXVDTFNE8+PPMf7qiGa5uN4ipQpsITAUIKMpZMyAlDRdwoVn96ij6bpNOeStOQCSk7k9b2h36Y+oTE6Z+K70WLedfyaN0nkvZIwJcoQOFqI51bp7+1iXWcf3T39PPPsSsZOtBjlpBk1E1IJk7aGDGEpRXMugWUYmFYi8sIwUpQcQXfepWfAoa9QoVBx6Bg7ATMoIivr0LL16JbDjImjGcwXqVZtSrZPX9kjU3TpHiiiZyvkXB/Xi05J06XEsiwSiUS0VnBdpFZBUz6WDrlMAruxDuGZGIk0PhqhF+Vd0q0EmmGgmWZ0WpXv4XsBTqVIcbAfr1pAhD4q8MnUNZHKlcFI4rjRpqeRSBIiyYagm0bkmS+jpMmu42CX89iVMsX8IIOlKkJKGhoa8CslqpUqnQNVBqs+nhK01ifJ5hIk0waeChCBjqunaahvJmVYpO1ejKoPTojSTTyhUfEibypdQl1Coz6hk7U0PNuhUBxkoK+X9V19uI6DLkOKtk/SkARINDNFJtfA+2clmDCqhXy+iDBS9HT3sHLZctTaRaRxQTfwjCi304aiR2feZsOgTUgUkWIZGpapo2mSai2LuCYiTy/HD/FDD12EmESnnWqhIEBgagKfEAIPv1oE6aJZMOCH5MsOhSAyUrtBFAGTTVnouqTqKcq2R9V7dydajHXoWIeOdeg3rkNvteEpyliuhnP/DO1kimhcUPWjACUpozA8n6g8sohJTCkouwG2UjheOBzLK4gMAb4XEuhhrZMISm6IqvisG7Apey6FqsuKdSX6Sx75ik85JWm0NBJZkzo9CkvL93SjCQt8k4amBjQtwDDB922cskOpp5NkQzOamaR59Dg6envAdxjs7MQpFyl0/3/2/jtasyy968M/O5zw5vfmW7m6OofpHk2UJioMI2kUYIQkhDCWsQUI2wJjg4UJQsI2FsHItowIMggBAgmEGAlppJnRzPTkmc65u6q6ct0c3nziDv5jv7eqsX9raVj6LU+zVp9Zd6rq9o3n3c/Zz/4+37DDcucEMYHxFMVtGkawvLRMr92iGUcczDKmhcWYmu29XRrdBbKipLPYQ8sYrxJqM8EVJcZMbyXB9aoKpeNAl56bEnqvEDi8D78zHBWJChRCFQUPJqkCSlmXmKrCiQovI2RiQnHrCKUUxtR4Y7GuRJgSrxROJlgvcQh03EDN2U5IFczOpZzLNDzpwgrNxVVai4ekkympqokSiOKIKEmIGykOgbWG0WjMaDxmNJ2y2G5TWcusqJnlVdDLC0HlPFPjGBQ1NY7ceaZFSM1zR3I+EczPnfdUdc3h4RDhLNgmShuEloFKKYPJeZxEoZGvJZPMMSqC75KxFnyIyD2iOUoBimCEHxYxc9mduCW9vHWJ239EUtKIw1RnlhfsTytuHOTsTSvy0mLsvIqB0nhq+5rv8Tq+tJYUBnYnljjyCOVpNxQIqI1nc2JJEoFUnpMdjRTBNwJC05FIyTR3eGNoqZyVbkK3oVlqJxxMK/KJZVZbGm2J6mlkLMGAsSHZReLBeJTUxM0osAmcwo5vkh9scri1xwsvG4SeEOkBrspIREa/UdA7t0x7tRfSH10HnAJistmMw8N9rh0W7O4OmG1us/Lm91D2GgyGF1BxQhLFnLvzHpYvXKQhLYO8ZFwm5JWjGI8opxPKosKbGuFdkM1GMVJprAlMQTM3FhUyUGf7i4tgmkRNhdBJ8HpAIlWMSiSukhhjA6sBgymmVNMBth4jvKGexNjaIGoLnQXKypCXwV/CvYYSCyEgwM6p6NnwEJuNIB/ihQry3k4XX+b4sqQqq3l8tprTexVpkjAcZqBSRNIhabXRzZQIR6QVOmnMfdrCZmTmTvxtJehFik6kMc4zGs/Y3tknrw1S6UAp9mCdw5gSooS0t8D9vQU4rPETizh3J6lUTC9dZntTIiqP9JZGo0OlYl7cqLg+zBjMZpzrJljryKoabTxKzXVjR/fC+1ubpndgBFg3lz0QptpBDCHQwmK9BRc85w5Lw+HYcH1Y4r3jREdzph/TjiXWGfbzGv06r+HV1WWyLCebZZxd7XDnWouTi7DUVjRjxWBcsFPnpErwB9+9SNc5rr06Jisss2nFzrVDysIghCSKNfce7/D2s20+8dKA/UnFrLA0F5tUtWdgLJ9/+iYHJ9v88A/fy8/tVjwzymkmml6/TXd9Bao96tkuxeyATLaIovwWTztRivfdvcRda33QTa6+8iJPvHCeT1zc4UPf8d2cfesDfPj3fzNfOb/D5Y0hz16d0oqfY8lt8eCH/xyuHHFw/lPECydIyoo/9J67Ob9f8eLWjCujCl/XaGu4+uTnaPuClRNnmIwm2Lqg29tltLfJeLjH2l3vQ2vJ4cZFLl2DY2srPHTvOaajj2HrgsnWq4DEipjN66/S8iVFKllYWcQni0xsj14/MGuSRpMoSVBzmZ11IU58Y3fIYrfk+HKLoqhROqLZbga5mXNoLedTV0eSJjjnqCpD3GghlcI7S2ehR3NpiWf2Cs7coWkvdjmzkLLabSJbXUzlSRC86Y5lVpe6ODyf/MTv0Fte44577mMvDwwWIWCxnWC9Z+OwmPcb4Oqcg81LXH/lCTqpYDlJuWclJW0mgKUeXsfV2Zwk7NneH7F7OME5R6uVcmKhxZou2ZlWfH6r4ntdRDtO2MuD34O1ngYVxisKF+Oso9HQnFrt8NzFGYeTmm6vxyKWBVtzflhStSCWR/uMo8gqMCXCV2Re0Fxos3ZykWG1wbQKPcPWMCeJNavLLQa7E4qiJkljvvSVJ/j8Fx973QNPxoVD9jA3c08bQRRp7NxTbFwaIhnWTS+JiURgnSRKhsQ7Qn+d147DqaWbKhpJTL+dUruCUW44HFcoF6F6Kbi5DULtQsDKkWRCSxIEE2OwsxlZvcvmxi4b2we8fHmXOl6F5gRjDLES9JsRpp3Qa0RoJdFKh5SzKKG2iqzwjCY5g/GMwWTG3WfuoC1bRFmJ022kTrjj5DEuXttiZ3/INJuFIW5eczAc0+pPKPICYzxuLrGLopgoiqmrMkh2TYXwhkgGMKzX7eBrjUrSMKU3jjiSoc8W4NB4IXDWUJcFZTYlm46oZiO8q9GKefqcRcTtkCJY1jipkVFYb0qpOdtJBNPwsiSbjMhnY2bDQ6ZZhdIRrWYjAFzWMiwsWRVYBWv9hHY7odmI8IAVEtI2SbePihLieBCCk4TACUXlJVkdPMsiJWjFmoVmRCeRlNmM/b19Nm5ucDgYY50jiTV55VDS46VCRTGNZou11S7r/SZ5liPiDludlLicMBheQdcWFUe4KKEUkoOsYH9Wczirgxplbgoefi5J6ez87Bf22doGm4mp9DSkBwnpXMmipAiG495i6xwfG5z0DKsgP1ZZOMtVxhJrRb8dk0SKcWFDH/E619q90UO/0UO/0UP/3nvo/zDGE6GxSWJPGkErlZQ2gFG18yTzaFEhHK72lHPvhIYSdBLFckuTKEFZ14H66gKY5YzD1RadSBId0MfdzDIqcoZ5jbGG0liGU0NW+ZCcUgd/nYmFWjqsqiidJS8tceawZq5NlDV5MWNwMODmhfP0Vsa0l9Y4/fDbuPsRWDt+nOc+8ymy2ZSLFy7SX12E1iJJ3EVGDdKm5PjZuzi5s0s2y9gaX6e2lqo23NzeRsUpq+uXuKu3RNxo0V4+xs50zGhSMN3bptVs0O1O6By7g46UJI0UIRVeKpyVc2+n4Il1BMU558FafFVi6gJTF3Naf0hRQ8d4HeNUQllbHBWR8wgVIXSMVnF4+CNQKkIKhRMSqWOQwfBPijnzx1msEHgZ0zlxJyejFp1jp1i8fB47O4TZLlalVFZgjAVfYKucPJsxy/IANHkBtaecFreAJSUlw9oycyWFymnGEZEKyQtCiuDqLcLvr5RiMM0ZZyWH05q7zx7nnFxldSUmidW8sFOSRKKqHrPJhMrMuL6bsTkx7OdhEhhIY55IQCQETQ1H1ku3Tc/mgjpxpGJ9jZYeUErQaqakSQIy4sbuiNGsYjzJSXBoDVYdpZuIOeD0+j6wHl3N6Ohh7Lg2MGgpaSWaRIJSjn3reHm34spA8Pvva4coWOuYzCwIOHM6puVjbAlP38g4veJZ7cYsdzXW1kwmlqyCWkW013ukIqKaGg6nG0gB3WaCTCWFcwxHFR/57CbDUY2deu4/uYQ9IfCrkubpZfpn1xHmOj5/FTO5QDHpIJt9LBF2WiKEIlk9w5ve9lZiO+W3XvgNPvfY84hiyg/c/40kqo2uK+rCojsd3vSeBzh/6TyT3Zs8vlezk5ecH8wQj3+Jc+Mx7bVztDvH6LoG652LNOOIWIeGU7sMmY+oszFCp+ioS3/1FN5k2OpwvorsHHiXSBmD9HgMs8kh5c416umQ2cE2UbeJbrapk1ZIcplOOHj8Y8hmj3j5LLrRQqVt/FwrHiSgYGYz8smIfO8GkYJ2p0XUX0U1OkTdpTB1wdJ0GVOvQKRE0pMoT1M7RrkgXlzm9FveR4cpVTZiNp3hrCGKJaIsyCdTtg9GDMuafqz5rjvXuXtlkX6vw2cfv8BXXrrAMxcuI2NBkiqwNZWtkEoT6TZSaqwxHG5sUu1tUo+20ZOXiEYT3nKiwcW9BYosJOUki8vkIuH8c5cpSktDaaRW5HPZbL8dPAKNAOtd8DvxMjRxMjRxSI/wYRBSAzPjqa0FLAuJZFYKMgUXBhnXRiXXp2EIsNjULLV0eH2lonIO91WaIn4trxee+Qz/4Of+GX/lr/4NfuWLl/jIY4q//hHN//CDb+XD3xjzoz/zuRDDLuCvfmqT73/7Gn/ifSdJvrDF0ormvR9c5e+/PITdiiiS/MrTIz5zueSf/Oib+bdf2uTv/Polrtwc0G7FnDu7xB95z3FSBd/1Pz/On/jQ/fzMH7+D/+pnvsBgc4PJy48zuXqR8xs5//azm3z4wyvcue6x+ZBy44uw/Swf+OY76N67ho4T/vCf/2s0f+O3+cX/9i+Tjw4xtSc++QH+x596F3/pL+0zefIf8Au/+Sw/8H88xaN/8BjjvTH//O99jH6nzam77+EH/oe/Sf+ln8A9/etMRlMePrXA288tcULs0S63wA65+63vx5mM7Oqj/PJnn+eZ85v84//tB7j8ysu8/PxzfPhP/hj9leMkzQ6/c2nG4Pp5Gtkmp+9/kIVjx/nAux9guDdgsL3PU7/6T1h/4O28+cM/gooSBgcHvHThCutdz2KvQbO3jFQBYPq2D7yb0cEer756gTvuOE2rkyKjlK2rF5lNJtz74L0hwbcy6LSD1gIVhb3cW4Mzjo3HP8b0/Jf4uT+wxr96fp//4v+4xn1Rzb3n7sCufj03nn6c8WBEV0ZkapW9WvPRJ3+TM/c9z0NnjvPhR1ZIigOeePkaL23O0FrRbiV073w77bvfiR2+xC/+5qf5hV/6LX72T76FJy8P+Qcfv8rvdzvozhrNY3eh0laoAilYXuzQ6zTZ2Blwsqt577pGYbhrucM/+SOnqEvJU88O2bi5SxIr2u2Uf32+4N5lzztPwo2VLnvTmt/4wkXuP9HnvrtXeeddC1y4ccjWruInvsHy+G7FTz02YZIZHu4tcupt38zzj36ay9cnfNPJBg+cXmDl5DL9hmIysUxmOcu9FKU10yxMZrv9Hu97/1t54bmLXL5082tcob/7FTcSvBQUVuDzI3+gkIpWW09ReRQW4R3t9RZKaqa14nBSMysMSRTRazeJtOTVvYJmokgjRafZoDAwyQ2VsXip6PTa9GMwteFgVpF5mHqJ1TGT3LEzrPjcixtkFUidEOOpy5LYWUSZYSZDxhuvQjHCj3dIKIkxOFNQZmO8h4VOm7tOn6SeDLh49Qu8evEC0yzj7Ikl9EJEs7OIbCygehH3J+tc2M3ZGxUcXnw1DEptweWXn6ecjom0ZmV9hfbiMrRXKEWCsIK1fgctgpesNBlGxFjVRHZW8SanVpaqrICahcVlIPjNjqcOKktaVYwG+4wO9xgPd+m1YhpJA6ElWZExqwzG7hInTdq9fug3lcSZCmclToIXksloyOH+LjY7QAno9josn1gmSpu0Ox3KQUTaiOgdP8HUeLJJTjvRrLYijvVi2p02SWeJxrF78EIxmWZsbO4xGBcUFUyyjP3hmGvbhzjn6LcSHjrZ484THRZ6iusXX+SlK9tcuL5HluV0mzFrnYhta0liTbffJU0Uylfk+4dM97bJRwN6K8dYNhOSvmV7KQGv6awtkemUg8KydWnAqAgJ5EJISuOo6uBFpuegWFHUIaXcQiOJSOKIKJKAw3jLejdmVhpujCpoSFoyQsUph7OSybDm0mYWevy8xsxNjXUU0e8ldBuK5rSiNuaW1O/1er3RQ7/RQ7/RQ//ee+ivnvE0P1zPrW1QElJ9dNifJ6BJQawF6dzorjSeylgqIzDOBdpaNH+YGYeZm3m+1phKinD4VwqE8cwKQ20NtbG3zbR0iOtME0m7LVlYTllspXTaLZqtiEZL46XFuJy6HlGXbapiTDabErdykk6F1Jq42SRpt0Fp8sowGU2YTDLSbk67rDDVDGMsabtPb3GJxaUlGje2sIWnMIZJVjAcT9jf2+VknhGnDXpLy2TjQ+qqYnS4T147mGZMxqO57rSH8wKHwqHnTJtgqn3kNGSdwFYGU0/JZhlVXpI5jRMpTjtE1IK4hYibeKlDosfc+0NKAptpPtmSc1cuj8DbYNQtrUNZO6f5zV9ZFyIpdRLT6HRoLyxQSUtlZtROQA1RVqCkwNYlQoowTcJTWYcwNrDc5gBQrBT4I/qeC+9nnrZ3xC4ScyM2L5jlFc57Sis5UVRY624BSd4Hw0U5N1k80ubWNpiJWxdApKOHTKQEsfCkCpS4baZ2yzRtfs+P7v0RLHXUBAqlyQ1MasP+uKIoaypzW5InOYrWDevxNSrJ1/VlLCgVaL86hLpQ1+7W69FNFYUJeuhJ6RjkNVpacmMpraOqPGtNTRIp1LqktI7NUUGnqamMI4kVprbgoMxcmEoUBhkrDnLPtUHNO4Rm42DCM5sHfPGpXUaTGld5smlOW8CJlT7KOYY7B1z+4lfQep+4UaKFptEEITXZ7hWcMbjVNXrHz3LmLYYHz3yRVFiube4wuXoBEdVEjS7OK6TQpEvHWF9b4/TqIi/s3cTUNQdZzdVygmhusHL5Ive//V00Vjq0j99JNh0y2x+yvtSHymDKMdVkgG710UmKqSVeSISI5q99MNkL8a7BmFSkKarVD/Rc5/FKUBUFdVVRTWYI3UBGTRaW14maPXS3izUl1aRkVh2EiZEO6UJFllNmGWl/mTiJgtyn2Q1SWamJugs0lo/RWT3Ozo09hrt7tFOQXtJuRUSLi8SLy3R6C8y2dtnb2uKVS1fIZgXNNGI0LdkfZ+yOJigpiCJJ7jzlPBji6vYhN/aG7AwnRIkKpqTO4nFEWtLvdZgOR2xf32B8sAvjKTKziKoOqV5zwDmONZ1el0MDN/OCyTRHA2kUJomlAeclkfJE0lPNTUs9QQJ09MzReh7lLIM/HNZRlTVLnZS1fspoMuLFa/u8cm2X84eOUSGobJjgzirB9aHnIKtR0lBYy9bUMS6/NnX51V6Li8u0Wi0gMC0r5yic4+r2hG4rRsUxSRTkEZPhmBuDiievTygtuNpT7GecXmxy5zHPla0BdR0mqFd2LEutBn/wbet84qVDKuMYT0ueujSiEwnu6MZc3Rwzzi1rqaQbRVQ2QVWGhY7kG75+hdXVFmnkMKOLPPqlZ3nx2SdpuIq3tg75hocN7cUVTh1f493nlug14yDT0Q3abY03Jf/yS9d46tV9xnmFc57FY6f5+u/6w+iDZ+gvxnhjeWityfvP9fj81RFFZRjOKh694nhkxXJ30iRutpiNSl69cIO2dNy51gERMRhnXLu5g6tKhKvxtubNdywySlZpd1s0+8vE7UUODsY47+ksdvDFEo1Wk7osglGphE4q2d64ycbVgmkBze4Szc4iq2fuxDnLeDTj6sYuvX7N2XOLdLod4jiaD1c0xJLp8IDpeMhgf5uDaUmz2eLhB+9j7+Yml89f55mLM5Ca99zV4+bWlDJWpB3HF28cUuY1p8/dSXT8OGpqKMoamSQ0F5cYVpKZCTVW1yENllgh4g5eNrj5wmfZ27jJYFrw2fNjru3lWDzGWiwa1VjhOz74Pk4fX0ZGHTrdLlIpfubv/WNSb1mh5JWhp9uR3Hcs5pOXD3hpJ6fdSkJKjhd83ekevVRxaCQWG3xglhvUzrMxLHjs1QOkrWmnmsd2S6ZG8JZjKY9drygnYzZffILlJUNxrsOvfmbE2bzghCjIijBJXW9HtFpNai8YZjWNRNFqaqx1vP997+a7v6P/tS3Qr+Ky1iJQeCWDo43zGGtwNsRtKxk8KgsnOMgdKIMTFeO8pqgdWisW2ilJrBhPC2pjKCuDs5a8MhydsqzzTAuLcuCsw3hBVsE4d+xPPAeTmut7GedvDJgWBoSmnWgi4YmVIKqnMN5h88JzJJRok6F0F+ENpsgoZ5OQkCQ0vYVFjp86y/Fjr4JU+LpgPBrRjZp02hCnEqk0zXaD1cU+J5Z6XL0WkVeWzcOM2h1QyAad1S1aC4sImZB2FqnLDDOb0ZERsQKrBdPpFJV2aDRbKL+MswXKFQgd7C+sCGbDSBARWBGRFTW1BSs0Km1TejAV4CBKFZFOSRsNoiRFxSm1sZAXzKYTnK3ROgKpyPKcoqxRIiZOYpqdDo3uElGcECcp1AukZUl/9SR7hxlmf0xWBkZVLD2tVpu016e1sMTuwSH7owmv3tihcgIRJRR5xizLGWUFpfUoKai8oHaOoqo4mBywczhmNM2IlUD4cD5ynuDpFimKfMp4dIDPh9TTCa6YoUxOIgwukaSppjZQeTjIKnamNbvjklllb7GdnA3J4sY6tBRE8siM2M/PDOHfeWVpqHAeQ8rw2ktFM41IYsnh4YCD/UN29wfsDHOyylBZP7epCH/ujQommSQvTFCS+Nd3J/1GD/1GD/1GD/1776G/auDpKELTzzWTSkBDE6LrffDpiZUkVYJm5KkMZFgq4yiMpTQyuMOrkOjhy9sJPEfAE4Q9I3wtgXGeSWlCcoc1RNLjVIAYWomk25QsLmjWj7dZXuiyuLyKigRKO7w6xLgpZXlAXTYpiwl5NqNZltS1QSiJTmKiNMVLzay07A1nDEdjGp0p/SynNAVOSOJ2n/7SKivjIa30IkVtMJVnkpUMRhN2d3fIZxO6vT4LK2sUeYb1gp3NTapiQj3NGQ9HRGmT1kJIvXNCYYQC5sVHSPwTQlJZqGxFYSom4wlVWVDZCIRGaIiTNj7pItM26DgkRDg/X5weJ1UAdW5RX4Ojvavr+WtJ2EyPNhEX2GHCVgghiJKYRrsNdUE1aVLYmrr0yFlGogV1XSGkAilxQlAYixMGNTfzVjKk4ARg8dbKQYoj4Enccvs/oidO8orSGBpGMCsrrHNz0GmubRZivrFpjBdz3yo3Nwu/DTsJIYglJErQ0ME83HDbqT8gT7fZe+F+hL9IESiZSMW4cIwLy96wxB8l5d0Cq0LBKiFIVKiB/xjMxWvrEFKSSEkSheaiqtxcXihYbmuGpaWyjmFhUDIkWGa1pTCeaWVpdjSrzZSzC00evzrk+n5Ov4pQQtCIFZUPSRDZ0FC40FBHzZitmcXtVFRec2l7xm8/doPPPH7ANLegBKO9A870Et59Yg1ZVuxd3eSF8S7HH0g5+XCDtFmTdB1SRUw2XqaaTfA8SOfkOdJjZ3nXQ/+Ca9e32dw95PDlp4lWuqSdJbyIcCImXjjG8WMnuPP4Op2XLlPWmsOspswOqGVM/6XnuOfdv4/W0hrdswN2n/oC4509Tq0sUNcl5WhAOdxHqIh0qUc1Dc29EkGqAj6AsS5EveqoiW60iHormEaPWirQimo2oy5y8nxK0u7R6C9z7s1vJ2508CgGOxuU2Rgz2ydud5BJE6O6VJWhto6106eJmw2itPnvvbZRb5GGMyyevgt/c8hwa5d4tYGkQacd01lfIVpYo9PusjkccvXqFZ588WXWFxc5u7bKwShn+3DC1mBErCWRVuwVNUuFIaficn7IzYMh+5MppxtLSCGpnEEITxIrlvpthjt71LOCysxoVjMaDuL5pmcFeOGJEs3K6iKvbOVc3M+YTDIWWwmNNGZWeSorABnqSnm8CdGvt9IovQ8JHZELgwrpUUogbDBxvvtUh5NLLbYP9vj8y5s8+uI2h2NHpIIczRMkSecPLIrgJ1F5QWkDk/b1fAkRIYRGa4UjeBNIpXj61f0whU4bNNsNokgzm8y4dlDw8RcOKS340jG4NubcUoux0bx8eQepDDPh+NxLMx5cT/nhbzzF0zczbhwW7B1kfHRYsd6O+KGHOnz66oALT+7wTWuKhUaTWvSQVBxfb3D/u9bI6zaOmmr/BX7tdx7nl37zMY4vpPzxY1u889sq4maLM2uLfPebjrHSbYZ4YKXwOKaF5e9+5EX2Dg5BKsoi59Sdd/I9/9WPMfniX8fmA+rRIe883iB9eJUvXR0xzkquH0x5bDMlP+X4vihFRjFlbXnxheusNTVnlldxTjMY59zY2mU2GtLp9JBK840PrZIfsyjdpnPsHFFngY1nP8/ScpvltQWa6R3E/UXyyRQdJyjhWWhKXr6xyebNG4x2rrJ8/E6Wjt9Nb2WNsigYTzJ2JhWLSxVnzpxjcXmJo1CLsF96htcvs3ntVc6/8ASvbE5YXT/Og3cdY3djm5df2eDvPznkB9++yn/ylkX+59/Zpmoo0lbGM9cHCNHk3R98E62lBZL9Ed45Gp0e/RMnuTHx7Gfh+Y6twUucEqBSjFWc//LnOdy4QVV7/uWX9hAYInU0NYyQ6Tp/9Ps/hPv970Y0TqIaXSaZ4ed/4Zdp+CHLPuOjg5SuV9ylNJ9+eYcnr084sdZlOC0xteUD9y6xV3ie3SkobU0r0dy/2uLpm1OuHuY8d7Xknafb3LWU8JELJW9ajfnWu1q8sjMjGx5w6Ysf565ThrixyKf+2XkeGU64v04YZSUaON1P8J0O49KxNx6w1Fa0U8l0nPFHf+Cb+O7v+NDXuEJ/9yuEz4DXwf7AOkde1iG9jhBo4oWgcJKtqaV2FcY4hrOa3HiiKGapm9JKIzSO7UHNeFaQl/NUM8IArbZwOK2xIdYXi2BWeg6njo2BY/Ow4tXNGa/cOGQ8K7Ee+q2UfiPi3uWYqJoghjXXX8joNRT9pqZ97F6EN1TZhOnwIISw9NboLS5zUsXcde4i4+mEqqoYDg5o65qFKEE1QUSKZrPF8aU+w7VFnm2kjIqS/d1pkPk6TWfpBsfP3U2r06PZX+Vg8xrFZELTSpJIksQRw+GI9kJCv79Kq6lxtsKUE0Q0pa5qKh8hVbCykKnGyZisqKm8xKmEqLVIls2oiwovPd0ophu36SyvoFQIA5jNcuq6RgkXfJSikBidZTlVbWgkTVSzTXNhmWa7h9ZhgOxafZLasXT8Dm7ujPBbB0zKCUVl0MLTbHdo9hZpLSxxdWuH7f1DXrq8QbvdYnGhP1cRzBjPCkoLUsG49oyrGic9V3dydg/GTGYFx7oxHhhmdeh/hUBpmEwGKFHhioK4nJDUBdqXaGmRiQzJY4RebmtYcGNYsDUI5xWQ4fkxH+aGREVBrNRcDgRSS/AhkW5WO1Qi6cYKKxROgtAR7VZKK1Fsbe1wZWOf69sDtoc5zCXeIfU6gN4393MEnto4ArXg9b0Hv9FDv9FDv9FD/9576K8aeDq1EDGrwmHcWo+1AukFsRS3GFABKBDzB2EAkDxhOns4M4Cgdn7OignsJus8xVw6NzHg5PxmEUCoOFJAYOeUFSAhAk62JSeXYx66o8N9966zsLhIs79CZUbUZkI5nWCNx2SCWLbptgrWT0F3WdBZBOEtSmniRotjJ09SFTnldMD0cI9RHNPrLlIaj4wbdE+dZXFlHWtqji29gHGOWVlTOc+sKDg42GU6PGBhcYnVU3dw/I6I3vIxlIoZ7m8xGewwtRI/qzGHU4SO8AiMUQE88TXCV2h1lCChgmTCOLIsGHzOZqE5kVLSVZ5UKKSO0XEwB7fW4qoKZw2mrkKs6lzPOXfODulxIkRzRlGEEMHUzJkaW5dkh9tMB7tMB/vsbW5QFTmmLOj3erRakBY5XjiKsmKUlczKmryqGU8nJHFMEscoKYmUAg/WBL12JAILKVJzXHvOjku0QklF7Ty1h9J6YubsJGfx1oDSc0Q8eCNcO8i5sF+wfVgxMcEjQUlBbf2taEwhBUqGNenmjmr+tW+vWddHpmvB7iqAZKNZwf7MMcgcB7O5tvq2rRMQwCYlIDP/8TCepIKi9kwLRzpPy1BaILwjjTynFiU6kwwrybSytFMNkcYKR1l7Jpln1La0pWF9OeLO5YRUw42DGi/CJMg5qCtDPs1ZbcQ0U80dC30ev5nzzMYmDVmyNy3ZO3Q4GaMbnrShOKwdeqo5qCTCjPBVyfVXh1T+FEtL5+jd2SXp9JBRh82tLQY3L9G8fJH7PvB9rN3zCH/kv/9fuPzs41x88st87mP/jjPnzvIt3/1tqLVzyE6g3588dw8iH3LmiWfZyAR7tSFutDnIZzz79Bd4+8VvJZGS5bse5Pqll8lvXuGLjz+OnY7wxZTk1CYrUZPu8TPkgnkGiwRxxFVUAITQRI2tDUwHIZ1yNsTmI1RdIITFdRdp9pZp9lfJspo8P8AVGSrtEC80iHtd8HPauVCoOKKhNEorBBJvwc3/u1QCJzWivcSZD3w/0bm3ctd7rzDdvkRHTtkdTlk8AYnwaJ9h8yH5ZMDB4ZTl/jJRs83VUc71gyn7h2POrS2jpeArWwOulYKFTptzayv0GjHtRpg81XOj2l6nj1SCZy9d5alXd+l2+vyh73wXrRqSWqObKaKp6XUkZv86u3sDHn32Kp/ZLrk+tSy0YuJIYLxFokgkpNE8kNYLBJKQpXokjD2KaZa3WLhZVSOAs0sd7jqxRruZ8JnHXmF/e8KiyFhaiAEZYo7F3FjxKE7Wg8az0hSk0eu8ir3lXW86wU/+8ffz85+4wDCrSRoNXr5xgBaOh86tsz0yHExKojRlY1qzd/GQ//Ltfe49tUS+cidXnn2Fy1cPUXHC0kKbTjPmI09c4UuLbU4f6/Phdz3I9d0h//oL53HWkSYp733/Izy0P2BzZ8jf+thlTlUVC8cEVJLxzPPioxU//4l/g0Hz3//Qd3JXKvjgHW0evVkyNRKVpBR75zHD6yQiHOi8NeTjAVGjxUK3x1/9Q+/h1z7/HB/5ygV+6If/OB/6tm/jJ3/iJ1HL9yHrCenSAo98/3/Jwjd8L9HHv5ftYcakqPmpP/YNtKJt/uFf+DP8/j/94ywfW+db/sC38a9/7VGevX7A95w+w0P3ncNtnSW1OwjbRzfO8OgrNeXU8z3fdgdf/srT7O2Pef+77qezdIy4tchnvvwRVs+0eedbeow2LvDq+Vf4e3///+Lb3vsmvuFDb0c3l2kvLJC02vzz//N/pdXpct+D93Pq/q+j1e0HMcbcr0THKZfPv8LVi6+w3hzTUnDfvQ/xjX/grbS6C8g45i3v/zq6SzX//PLvYErHZFDwV77vrWgJT//2M3zre95KZ/0O1h7+Rg7OP8bB5Ytz2brEWM+zFy5x5eYW3jl+6N13cGqxTafV4sTsRV7+/CX+/L94ip3DGYkW/OT3nOPpSwf8o0+8QtS7m7QfALLR5Wc5vPIsjz99wIPv+DpO332WP/tQg6iyJL2YH/6mt2OihO3hkNwFTyKtFDhPXlR87Pwu0xq2x5bVpqXMDb/5xC5xp81yv8G3vH2Nl26MefTymL/2jUs8u5Xz05/f4zA3PLS6wpu//bu59qXf5uIr+7Qj+L9++zI///ErtFopxsKGE/xv33eG0bTiZ/5NzvXDGbuDnKsbI1698OP8xE/+TV5++ZWvbY3+Lle/nVIZQ57llLfy6UPKV6wES+0YS6BReylwCJxzaBzeOWZZyXCSE0vHw8cSUlFzw1t2xlWYhkcRNTXOBgZ/vxeHgJ9+k0lec3B9wPa4JitrRrOSfM5CqYwDSpy1jBqChiqwxjG1HruQ0o6bYeofCbLJmFeefoLxeILqHePcQ2/m+Ok7+PCH/wCb189z88rLvPTicwzX1+h1H6ERL5A0O3gbcfyOOzHec/zyTeqtPQa7h0x9wcbOAf7Z85y4803cca7Lgw+/mWerkuFozFMvvIzWmiRtcNL26S87VkuNcwZrDWVR4GyI/O60YhqNBo00Jek2QSi8kNRVGdjsQlGXNWVRkDaDP1av16PV6uCdpSpylAjWDXVZ4oxByDlIaD1KxxivmBUGsz8knRbBJsM7vKuxpubcnfeSRglnjq3hN1+go2qK3DIa19i0omFqimzGbDomK0qazSZxFI5iR+qRRqJxznFpa8Q0r+i3Elb7HZppRKQVk9KSxIJmqmnFCuEsT75whZev7dPv93jvO95E2l6kqdqIRhPlHVEas7zcxuwPeenGDs9sF2yMa4rKhATSOeiUKEG7GdFOgi/V7tSS1WHPd6XBKIdWkmYkiPDEzrI7Mlgky/0Wx1e7xHHE85e32DucMBhnSClpJJpOMyEra5x3SOHnfq/QSDSplkT69b0Hv9FDv9FDv9FD/9576K8aeDreixnlNkTT+6DFrG2gxh0dvCsbULXKBkNDOfcuAjBzqqZxzKVRRyKnYJY4qz3j0uG8QMtgXmcct4ATOfePUnMQQBI+2ViP9R4vHFo7HBbvDZWY2/hYgZQVUVTR7FoaLUucGGxV4GqL8Ir+8irZdIzJJ6SNBlIprDHY2oHSSCFottv0FxZZ6HYZTjMSNaVwgUabFzmz2YRsNqEsA/3ZeI+IE1TaRDU6VChk7VCzHKEtiDChMtbNgQ1JrAVGQ1Pr4LSvIIoragtelMGQ284Ry1taWHnrXgohkD4AN/g58HRkZT9vhL0QYQIrAtPHeR+AJ1NTW0ttfXibg0G1l1gh8UIhgbquyYuCSV6Sl/PPqesgtRSB/gvhNbY2TAICXTeATUd6WyVlSAsRYepn5yl3wW/Jh/fNGU0QGE55adibFOxOK/YzQxUYqbfW0XxJ3L4XYTiD8Ld8xUOhefHvffxrXZqOEoecdbfAOzf/XPmaevBe4MT/G8h6PV9nF1MOZobtcU1lAwNRq7n0UUIj8rST+ezBB0ZaqiWtRJHVBPpvbclrg3WadqJYacfsjB2lsZR1qF9BWAdKeLT0xJEiUkH0eWlnQlYZitLQTCTaEVA/5QNCqQ3dTkSqIvJug8ZCH+tijJ2i/QREzmgwYn9nQCctKfOgj148cZz9G4vEUcLFm7uIVhdjPEpGeCfI9neI230WztzDsZVlRrtTdkYVJlJktWV3f8D2zet0FlZYvP84S+vHyYZ7bF15mcm4oBiNONjdprm4jHBuzmDQeGduJUcEK3sX/pwD8NaG2nKuRgqP0CBdSPL0SITUFPkE6T3UOUmzh4gSvIiQ2FA/IsKLEATgnKeuKkzt8GKeciYDa9J5T2f1GMeUprWwwN5LDj/dpshKJrnFTQta00O0hDRNAI8TAicVmfUUxmKMIYkUWgpGwMxaYmPRhGYz0voWgIsQaKmoasPV7QGeglUjaKQJ2mswYE1FnGiSbpd2M2GsJbYqyYqarHIhxhVxC9yNlCCVkkiEAcVR7Xkflsn/8/Lzg1kSabqdDjMjmIxrru9Oqaqa9nxC4wgNnZC3QeIjpq0S0E8Frfj/xzd4PV1Ss37sOG99x9v5xc9cwU7KEPWdxCgc01lOUbiwNrzH2LC37mWexZllfVaxOy45mNVorTiz2uXYUptHD6fsTkpKP+ZMrxGMMeeSd4TgoJBklaeoLVML09IzmTlazS57+zmffmqDZy5sYb3gk195hY3DGTpJeespTbvY5cpTX6BtblIfXEcrPR941GSHO7SWjqGjiDe95Z08tzml/9wVLl26zI2bG+At1gSZoDM5ae8EC3XK3b2Y66ZgXDk2Bxm+Mly4uMO7tm/QX2yxfPJuXPIko3yHwfYNEgWnz5zBFRPqbIy3huX1dUyR0ugt0e1uUZcFaaNBHDm0nNLuNFBxzGRWIXRKo9VkfbnBylKDTjviwsYO5eYeFYJGu8Hy6jJLa8e4fmObOB5wzx0rqCgNvop4JpMxuzs7nH5wjThp0RYd1o4dJ06b2Lqis3aG/nCA4BPcHOQ8dd3y++82xLGilhGLZ+6ivXaGuJHwwqWbPPb0hSCfNyUmH7O5P2I4K1Ba41VEs5Xy4B09rt7c4Nqg5PrelG4iOb3YYmeYsz8psNZx4vgy6yttqvFNbt7YYOfyJn64h52cxOaLnO5pZrOIodXcu9LlsPI8/sQBw6wO8h4dUr88nhsHGa004nQvYpKFIA4rJK1Y0Yokw6xmWjkMkjPLTS4OanZnNa1GTBpJzHTAMxd3ePrlPYrShMOuh4WODoEsSvLq1oTprAqyMq3ptTq8/c1v5sWXXuaVVy58rSv0d72OLbUZT3MOajNnfgBSoUPqfNiPQ4uClBBpSTNVtFNF6WBah8FfWUoSndKMFc1EI2SNJ5jaesB6qIKr8fy5KqnyiknpqP0Uax21sSgR0tNK5moDJUjTmE6nRb/ToNVt0GprojgCFQx6TVmxdzBgMBgS15pTtSFOUlZWVsgGm+wrweDgkCSOGc0KVoxHWSjLkqjRpL24TLvbIxlMkFJQGcs0L9kfjBmMJqxm2RxoapI2O+hmH6kUIknJK4ecZoj9g3nfF4aUR4BNXdVopdEqChI/PV87OkJIDXKeiIRHOoN0NdJWeFPgncOZEm9NeH7OAaXgwxrsK7S6rRKo6/pW4JJzFucs3lq8UDRaHZZW1qjrQ6J6Su0zpkWNnxU0p9k8hCcMNbUKCgElmduVSLSIqGvDNDfklSWNHc0keOZIKSiNJYpCsrj3nqKu2Z9lpIWjdAIrI4wS1EpSzs3pUy3QaQJak1XBT6mo7Nzseb7+jtQCStDUgShQG3c7DGiuD5Bz9sTR++LgkUKaxFhjmNSOw3FGXQdz+kSroHaZq1mklDRTQZaHs0Iz0nQbilas/r8uyf+g640e+o0e+o0e+vfeQ3/VwNObjrfYm9a044rdUQnehxSVObgUK+aMGsuksNi5YVVg8IQfs7KWyoRUBO+DlMo5yCuCLtZBJ/EYF6jBzge9O57gkyAVwofFUtae0dRwY6dgcXUCkaTdi8BOUC5HiRhFA+UbCCqSuKC7WNHslERxTjUeYKzCOcGxc3fTaiWsLjZxBqK4iZMqoKU+6O57/UWSOOLk+jqTWc7+YERlHbUzTLIZhwd7NNtdmkvbTLOcLM8ZZRkVCtHsUiGwpaUaDEMzKmRI4nDghCRJUmqviaWmEXeIk4Q0TTAyRU2m5IWh9jneWXAeCSilkFLe2vwiJfAyRDcbF4oWeftBXlX1LZTEWRukfYTXzQmJbHSIraehYpq1Q2VTmE3RjSYqjomUYjqrGE1n7A5GjLOMqq6pqxKFD5PsOeBV1yEaV0tIdUg2THRgQkkhAvA0j2etjMV4h52jRs45jLGUtUepMAUoiprDacHl3THXDnIOhyUohZmr8AJCHhh3HEn5JByFsx79XN7Pi2eORnl3m6Xnj1Aka4jwJNIHb4G5HPQIRPVBiIx1UHMb9X29Xx+8b4GnN8bszjKKWiGFJEGhVQCQY+1YSCCRkGWKhtYspRHHO4AX7E8sWV0zzD3jQtGOFY1IcW1kycaOg8zQmkfwJpFCKIcXlsI41jopWsXcOJxgbPAgOdZWzAzs5Z5mR9LuehqtjHvvO83JE6uwdhaKCp9NGc8uYrM2DTbZ2dpj4+qQlaWEspjrdVPITc3BYMpXro4oWyNmkymqqnBmzO7lF1l54CGWHz7Bg/ffx6G5wMW9a5Rpn6o0jIYZLz77FCqKOPf293DfI29heWWF/b0Bg+u73Ly+x6kLL5O0u5x7Uw0iDgCyL+dTGgF+Lvr3HlDztWYxtsI5SxJHiNjjrKHay4haFbV3TAdboSGb6zWdTih1QpokKKVQuMAAdI6iyHB1hqlq0Pr2hi2Cd97i4iL91RW8u5dNCg5upGxemjLcr2iWh0RUpGnM8to6SaJASQoEGZ4Kh/COZixJYk1lEpJIokRo0iMJcRxxOy1EgodxVvHspW0W+wvotEErjTGFJytLGI9QSwu0F5Zppwm9RLGShMQe/5pJDF4Qa+gpwbKSKAW5C8lA1nq8e+2j7AhJDnUoHDTihJMnVnnq2pjNw4z93RlrvYSVbsJhZnHOI5QjloJUQTeSQdsuINGw1NR0XudNr1ANTtz1JhZXV/B/898wGY0xHu45s4rC8/hTF4iSGB1HmMqEA0Uc889eynnToaAX3+TKXsbm1NFuRrznvnXefvdxzm+M2d4bcunqFk0K8tohpaaRamokH3thyPhgn+FggFCayURw+bLlrrec4aXDK/zUr3wBay14+LGf/VVOrS9zx1qXH/+WJoeDp/iNv/0k73tzl7yAOG4hpcZUGQeXn0Spt9JZu4MHP/RDPLRbct9jj/PklUOyLMPbgnwwxGSHqN4GiV6iEWk+fLbJp6j4zE7Nz3zsUkhEy0u++9JzrK02OPnm70C3P0lZvsDzn/wIx0+e5t63fQOzvcsIvUljdciHPvj1CGqEMLzzXZ46HzObJgi7R2yGPPzIWaZ+hUuX97nvgbPc2+/xI/YikVaMJjP+1a99lGcubnFjb8Zjn/m3nD57FzJZ4qf/9E9gizF/+c98iN7aHSTdRbxTTMYjdnYPWfyu76K3sIiKmzhTgfdEaQPWHyGZplTVT/OZVyd87oLlnXe3uevuU5x+5B6aD349ur2IFIf8k49+nl/9d58mbaS4ckR2cI3zNw7YH1fEzQYvHFrSRc8fuqfDn/v55/j409sURcl7z63xtjsW+ZnfvsRoGhLvvv5td/PwvYtMr32OLz1xno3Lm3znOUdXltRZyVJfM64iLg4jvr4ZszsY8nc/8hRISSOJaTZT0lmOzgSXN0e8+64F/uDDy/z0JycMS8+J9T7rnQSc59ee2KbfTji+2KS12CNuht9/bWWRlqi48oXf4h//u8/zhRdv4j30Frr0Wg12d4d02xHLC03+yj99kap2SCVZWV/k4Tc9wK/80i/w5/78X+b//Nl/+LUu0d/1ess961zfPKTOCw5mNcYFo+IoCQlsIJA4hPdoGdFpatYWG6xPK7woOcgKZlnJRHuMiUgjRb+VkkxColNeBXmPkpC7QMuWSmC8o6ot07xmWtQkOgAcrUQF4MI4Gqmm20k5tr7A3afXOLmyQG+hhXYlypZYoSiNJctKNg7G7O8P6PqYoqqQStFsd4ikps4r9vb28VKxtbvP6vEMh2Y0GCN0Qntpnf7SMu3DEXFywGSSUWcVhgk7e3ssLi1yJstImy1Wjp0kaXZCOqNQlFXFeJIxGE1Ik4Q40nRaKZGSCAU2r6l9hfI1zWYDFUfEjQZZUSLKGidjpIrQUiFdCcUYN42pZWDeGGMxxuK8oLaWWEdorUh06LWFVOH8gsdbQ1EHTzpjLVVVYa3F1uH7tBZWERGY6SH5YIvppGTsB9jOHvujknEOSmnSSNFKVTAy1oJ2omhHiqKsyYvqFvDVbyc0U42SkryoaCWedqzYm5QMs4ob+xN6HRPsN2RK7g3OSFwl6KWSZlNDo4GLEwon8Ui0DL2aJIBJzUjS1IJuJFhKYFbDxq0BMMQq7JeRCkN/48AiWWtr4jjCJQkX9ifszyp2hzmLzYhet4GYFCgVeolEC1oNxenVmMGkoq49nUhzYiFhuR1/Tevzd7ve6KHf6KHf6KF/7z30Vw08lbWjGUnOLiZ0YsWstAyKmiwPMZjRraQvz6y+7dPkXJBAeRkO747AUArPsfkimRsgjlyg/HqgGatg3oYgkgqpBFJoijrIu3amNePKMqtqFlZaRCmcvbNPnMSAQogIbAvhGrg6wZaCepJRo/GVBXtIVVq8FyyeOsPSyXN0l9dxTuCMxVY17mAHTE1xuEPSbKKl4PipUwzzgsF0RlRDo9lmdWUFm3QZ5DXVqxfnjJkQQ6iVQiYN8qKgykumWU6so1AMShM328RpQmdpmThJiJOETrs9j6yVJElCXVVorXFSBooqgTGkVdiEvHN44fHCAwHQm69nkGK+aUu01nMZ223DbeccWoevI4FIadJGi2a7izU1xtRofChcKkzpqFWNFQqEQkpBbQ2yBjGng+MdxlokjlhKlhqKZqLmQJlA+sBeM85inCevKrwPIFM03+C5hU47yqrk5t6YG7tDLm8NGGcl1nni6LVsphADGfyebsvnhAOODMZf++bDxzh/xCAD7+brcy4HhcCcikRIx2uoI6DudsE6L6hcYOe93q+GMNy3oOjf0+bayHGQOa4NDaWFSEoSH6E0pNJTlA4hHEpw5PWHlB6tAmB6aS8PBolChqhxLWlGEucMmVHs14puUyG0IlIhr8LiObvSYZzlHE5nVMYReeh6wftOxzxwtskH3nOGztKDJJ0TVBFMx68yHlxiPNxHxNswvMSp04qm6tBsKprd+ahJapZXV7j/vns58Zkv48bbfOXTH+OtukeUdrn+wpM0j51gsXuO03fdz4ndIctXrjFDhIjjSLN/sMv+7ia+nNHs9Fk92+ADH/5PuOfB57n6yrMcXH+B6zdvcuzSyyytrZE2UopqMjdIPNJiBumEAKSOkK1e8IaoHLVPaXSW0RL04QXMdJ+ZrYhXlpDtPo3OGl4mmNpSTvep5vdfySjsyUCezwIQLxWaRnguRgnV7JDJ9JCXP/0UVT6hzGdcffUqCk+rkdCqK1SVQe45HGZsD0pqoRjPZuzu7rCQplRlyepij1hrnPGMxhWNKJ1rxUNtVMaRRpJUSbpJzKQy1B6sDJPyViMBVyNdhfYVSbtHEqW4suJL1ybc3JixMwWpJL0EstLPvejg1hxFyltFfLtePd7J24xGNY9tBtrNCIvjhWt7XNzM2Z9UZHXEbATJ1Lxmkyf4v0noJoLSBNDYArG2aO34yf8vC/I/8Pq2b//uuZyj4MaNIKsyZcmlV2+iteLYqeNMxlNsWfANZ3tYHVGIiMGkoJlKRtN5VHBVMXWGr1zcY1IJfvQ9C3zuvOPXn865tp/Tbia89f7jXLqxRzaZ4feusyhgebHNPXedZGeQ8Vd+6ct8z17Jla0B1jqSRgMhJXVZkRUle4MJX3y55uKg4vmDik5HcmyhwX13Nmm1UsppxoVP/jpf/Pgn8Z11fvC/+wk+8J3fw70PvZntl36NC1f3+M4P/wA//qf+AA/c+w2ozklkukSqPe/6/j/Mweef5MoXnmVnWNCKBXeup/yzf/soz16Z8Nff/J183/d9H2/5ukf4O3/zr3Nn92nuW0r5xKv7vPP9H+TH3vX9wALzWR+qucJg8yY//Bf+O77vw9/E9334m/kzf+FvsbU3pSal3WkhXEUxvMEHv/l9PPjg/fyZv/Q3+Yf/+Bd56Rd+if/sT/wYjVYXmXS4cP4qzpa89Mpj6KTJ8RMn+Yf/4O/y4COPcPL0aToLK6goDJ6kjm8xk3Wjz8k7H+Sf/Nzf57HPfIpXnvgiTaUYHpQMXhjwyAMRkTdMrz6NzUbheePBe4X3GrxHKkXcaHN9+5DDwYBXLm9yz+nj/OA3LvCPfvMJNsYlyfaUxU6Dh453eWQ95e/98qMYqWk3Uz78offz3ve9Dffkr9Fc6NJeW6Nx8k7OpZuc6O7w13/uE7yyF4JF0iQiiTUH44xpVmEdvPWedYwU/MunBnipSGPP3jBnOAqhJCv9Jg8tKs60HX/to9fYHpf0Ow1+7I99I1VV82f/4ac5f/MgsL2jmBP9Bqv9Bk9NZlS1Z/cgC75CsaLVajA5HPHUE8/xA//Fj/Ker38nv/3bH/0aV+jvfsWzESvawGqTjUlFVjlmZfDbakWS070I5WskjloJolRhU02GpEIRxRFRpLFOcH5rSmmgMJ5IKSrlECYwtfGSOJJMrUBYQSeGVgR1IpFxYOE57ynnbJZOqjl3vMuZYwu84533cPbEKZYXl4i1YHq4y3hvh8nBEN1wNBdizi3HrKdtukstVtuaVINWCZ3FVdZP303y4k2mk5xnnn2FdmeFXrfLYG+P5dVjxGnKm+85hatmTEYDGmmLKE7o93pY6xkMx2xsbJLEMcePrbPY6wT2uXPkZUFZVWRZQRzHpEnM0kKPuiqoq5KD4Yg4LkjTEhU3abqQ2CelJI4j2q0mKX1cSyOKMbIcMdseY7OFkDjZ7hPFSRh6+zCwtMZRu2rO1veMixozVwV02i2iKCLRESKSGOGpvAoDVKmQvWNErSXUwomQ5u08V7ZG3NgesLU3xHkR2F4HI/Z2dxmNhlTGUIjAcPNz39cwYGY+uA1GwokO7zeAmZ/VG4milypaqqKraprC0G52UEoyrj3ndypu7pYMsqAViLVkVtlb5wRPAJQK7yl0sLDQIhyoAwFAh4G7hUakSCJFp5mgE01hPRu7U24cZAyzmllpMHVgf2SVCYoVGYKjCiuprCMrDNZ5IlGzM65oRF8dY+Jrdb3RQ7/RQ7/RQ//ee+ivGnga5oZYhuLopuHBOirtPLXOU8kg3/JAaYNeXRIO5FIw1729FiQ4kkWJW+yT2jmkkWRVoKQFL6Bg+KyERGuQzuFE0Bwb54ilIy9KKlMgtEFpjRAaVwl8neDrCGsauNpjspRaa/ACGdXURTFHATVR0iftLOCsD8ZloyFSSlxdUU3HCAloTaPTo7uwzOLKBG0VSaNFb3EJdExpHGY8Qc3TIZIonlMmwRqLMTXWWpR3CKtQkUPhiZQkTRKStEGcpkRxgprTX7WO5sCQCgCSC7pGMf8eQtz+N0frzvt/799ChE1Fz2V2bs5McnOdmlAyJFqI4NGko4ik0cA5h3UWZ+pgWFrnyGaBLgztbp9ZZamdDwtezE3h5kiq945IQlNLunFIcUBI4iNdpjiS1HmcD9IOSdiY5FyCp2SgPpqyZO9wxPbBiMNJFuKCXyPxPFpYYU35W7dh/mPxmg/595hJt5z+/e3idP4IIL0todMSUgUdHday90fLOTC2cgPlfwTA0+GsQnrPibYmTSRbE8uw8owzS20clREINV8vwuII7MTSeIz1aMUteWRWWyo7Bxt9WKuRnKdtWcewCsaYSnli7amdpXKeJIqJtUIJgfNButtSgn4sWWhqegtNGr02utlCujGFzkGNsUZiC4fPDuktGIQXpA2IIoMtS4xzpM0e62fu4NyJJZQrGR4eUs4ycJpsPMDUgVK8cuI0y4sXWEwicnyQTGrNZDpmPDykzibItEuj0+fknQlRJEnTmCcON6itZ7C3xeLqMpFOKI6e4mEBz5uzsOiEVKgoCWmSdUmZl8TtPlonJEkMWEQ1Q/p+mIhIialyjPfU2QjrDdJ79JwhiRCU+Sw0olrjrUFHCUpLqmzMaH+b5596jHI6os5n3Nwd0en2OHnyBF0BWnhsWTKczDgYzzBAWdfkeU42m2GNIU1ivBfUxlKUBkF4lmsVGl9jHDqRxFqSRophUYe0EXFUtzI069ZirSWOE6RUlGXFxb0ZN/eLkLqBJNGeWeluT34gsBXlEaH/NkX46O8wr8ujuhaglcR4zyQrKMuS2lgMklkdDmVa3/48Yz2VFPPfHYwLhohCepCvb9rixz/+CSCwNe+56wTGem7ujBhXJVpp1np9pAjk8kaisUpjfaDoR0qitaLfUPRSyTC33NyfksQRf+T+LjcPGnSaDcZZibGB2i+VwlWW4XjKqYUmi50GVSvl0vaYF28ccsf5m0zzguVOQil0YJ9KSWUsWV4xLWJqoVEtTe0VUmt6/QY6ipiUNa9evMzlgcG1VvgB5zl28gxrx45xo/wy165c5RO/82n+7A9/N1FnEZIF6tpiTc3pN72NpSt7RPqFcJARIXnp5VdvIpsreGs4e8dZkjRha/eQemfK7Kbjy5dnyKVLPP/SBe66+07iOGFweMjgcMDlS1t89rEXOH3nOe59cMAr1w7Z3tmjrivW11ZJkhjvGpRqARcv41QDi6auLZ//yjM0W20WFlc4HI6pioKrVyaA4MSJ6zz97AuksUbgOQ5zvns4jYRxCaATWp2Y973v/eh8QpoPSKLrFIXlcHPIA0VOo6HxcyazlIJOMyGJdfh63tNONKeW2ly7OWFrWrE7KHj7fec4sdRBSsEwr9kcFaz1uqx3IrppzLPP3eBgVtNpxPzhH/gwp+++iy9/1tNwioU0IV3okdgR0mmeu7jNqwNLpxkTKtSDsyHFVivuWkrZmtQ8v5PRikMjPMlM2EC1JJEhjCORsH2QgVbcc7xPr51wY6fgyUs7LDZjjvVbHBTBH2WpFSEFdFqK1Z7m4o2SJNbcfbzNZODIq5xPPfo53vcNX8873vbI16o0v+prOsnw1tFNJeiUrHaMMkNZWSIlkMITCVB4nAwWFdMjfx0h0Eqh5+tnnJn584sAZMowrLwltXWeaeVBOtrxvJ+UYb9zfm6H4ML6O5IDtRuadjuh02vS7bfQwlNncWBNlSVS5UQuZ6mt6OiETjemEYH0FucESdqkv7zG0sICRVlSZjnFLCNWiul4RKe3QJTELC70Wez36He7WFmjo5hms4k1hjLPKLIJzW6HRhwjI0ldOypnqauSIi/IZjOEbxBJUDgqU2Oqksl0RpJYrBdUVU1Uh8S/IGNUxHGEtglOGJyZ4qqcoi6wXhBbTxo1EBFAGHo67xE+xLrPnVEwVbATqaynlUbhzK7CPQg8Ig8qBD8QReAbqEYbqhJflhSDIcYLhIro9vrEicJ6wWgyY5oVwSRe3z4gHnm/Mu87BaHe4kgSzYGaIymcnB9ApavQ0hJLi1aaysGsqLh+ULA5KBgXJiRcz88L/96Gip8TBOZDVm7vi57bIIrX3J7yejDWMckr8nkglLGBSWc91C7EtksfFGHGOSoTWHhH3rPT0vE6t3h6o4d+o4d+o4f+/0MP/VUDT1+5PKHf1Kx2ItZ7MW2haJWa3UnNrJqbLxOIINYH9//KglaWNJI0kzkbZT5JcPNDv5TB+ipWIgAQwLRyaBV+gWZTB0QYGaRNTlJ7SW0FWoaijNKauFEi0xwVt5EixluFLZtY0cTWi1RFg9leCbaFbTeJuimmmuHqGo9EJS2itIk3JVJANR2iRNBXjne2kLMZPmlgm4ssnWvx4NqdOKFx3mHrCmMqamuxUtNottFxiGctszFFMSKfjpE4Eq1polHCI6wlMjXa1ETez/XPweQv3BeI45gkTogiTTWPQZyvrfAxAryUKKWwzgQw6QiVOZrReAFeBJ26DzI974Kj/dEIRSiBQOHjaM6E8tTWUlU1Rpu5L1SfhdYSzbUcOitsbW+xs7vN/tYmpirxVYUQDkTwdlpuxKy2Ys50myA0lYUlJZk4R+481s3pqVFE5d08FjZssnGkaMSKIs/ZHwx44dUNbuxP2B2MaajgWWDn9yNYWoWv5V6DNIkjepI/Kj5xS253VHTO34aqnAhyOis81oc0Cuc9kYRuLFhPAtqLCwkWIRRIMKhgYl7fh1aAf/nkPncuxTyynvKdD68yM3D26oSPPr3PwaTi0tCTpJIoAik1uRFsTg0b45pZ5WjooOFtJhqBZJQZZpWlcuCcCVMZK8krwat7hvHMsNRQfN06DLKaw9wRR56qdjBnL8ZCcKyrubZnmdkc29zhgQcaHD92iMv3sPkeOjdE6YNEcpVqf8DisW06x0Z0+w1iscf02jUOp4beyinOfeB+/rPxRcZ7+4zGAq81FYak1UBphU5i7n77+9nZ2mLzxafZ386wHmSjwf7+NpvXWuxfuUjn7H0kiy1accS5hbdw5oE3oZVksrfB1tVLnL33XEjPcQYvjnwjuD1lEAKERqkGykwwk212Lr2ItYL28jprp84gqgJsSbPXQihPMdmmLC5jbY0zBmxoeoN/QABuq6oIklABSreIG23S4ycZ3LzIqxcv8Au/8ltIYUmiENd9bG0V3Wry0L130W+lTMYDLty4yYs3tiirCmsMzhh8NQVbIaVmlhuKsmJSFEQSOklEJ9EIB0Vh6S4ndBsJzUgxLSqmZY3QitIa8iokXE0zy2wCx+KUyhr2hgM+88oOWzsD1hY62Cj42DllQt3O2YOIYPSIEHOa9W0I2LvbLbBzDkuYtBgbmv0F6TnVEXRjyfZ0zrSdHxe8D+mZFk9pPHtViBqXhMOY9R5reZ1fYVKgo4h/8bM/yuXre/yhH/kZpAx81M0b28RJTNRIeWorx9iM2jgS7bij0+O+s2t8N4KXt8f8iyf32dg5oMpn6A8+yNpil/vOaq5ubTPJSr7y4k1WljroZsonb874kRNdHj6R8Jc/s0FdG04stfnYE5c4sZDyh99zBx957CYbg5ykGVPVhkJ5HjzT4zvuu5v1e++m2roEwqMabUSUcDAs+GfPDdgZF7QXoTaG1BpMWfGJj3yGx598GVMbXDnCmzFR5xQ3Lr7MdDTigXd9O9FXLrF5+Kssry1S5CVPXDtAa8nJ0QAz2yNqL9OMU75lXfOFiwW/cH6M9/Brv/6b/OZHP8anP/1Jzp49w7/8F7/IL/+rX+XpZ57Deck/+qe/xj//pd/ij/3nP4SSnoP9bX7sz/4Id991Fyrto3TC9RsbvPnr3sF0OsV7SDorPPjQfXzXt76fn/tH/4wb0xEq7uK9ZWvnkPe9/4OAp91u8czjj3Lq9BmEbmCKQwB0Y3k+RZHo5iIPvv2bObZ+jtlj/ydXrm3ywsXzvPXmc7QbD9F/+HuIer9JGj3Pex46yZljPXQcEma/7mSHH/ngGf7yvzpkdyK488QiZ9faLLZjtJbsDAtGmeEvffgsL22M+amPv0pdhufJdFZQ6UWG8hg/9eiQH1ob8733Zyyup2RqgZF1iHhEv2t56M5lnr+4S5YVvOl4k45KqUzMt645vmJrvlLWNOZyAuccD53s0EoUn3n5gKfqBlu9hD92b8Kp0+us332WP/UzH+XaYUa70+Q/ffed9BoRf+0jz9CIBAutCFNVfPu71virf+ROvvUvPkE/Tfgb33snDRxXdqf8wN99iuce/wwf7xn+0A/9ua9phf5u1+cv7LLciTm+2OA99y2jtGZYeJ569YC9YcH5nRlNDakWdDuwdVhy87CmrD1SKpI4BO5EWqBtGP6OS0utErRWdCPJeOIojWNjUDDMHd1GRKoCyFXWjsNpBkepwj4cilqRoJjkHOwOePXVq/RTwUKSEzeaNFRGt+mQviLSGU0/YL0vcCYl7raJhaGajaicJEmbnD53H7/vPUNm4xFllrHSaaC0RHmDqQrKMkWkPbpLxzl+ukTsD6mqiqIsyaYDqqagaVdQ0xlu5pkdDhnOCgbTguevbDCeZkymM+46tc7qQpe4XCcrKvKiYmOU0+31WETfGmpaU8+TlhWNNKEwMa6uKL2mqqHKLTY7IJpkNKcZzVY7+Lx6SVEHRUci7BF+imovEWuN0AolHMKWuGyGrSqsdegoJUoaqDgNPqTzxOlmq03TGIROcTJmaWWdY8eOB5Px2ZRre1uMhlNqY1BNSYwjkp6Fhma5GaGdvcWQbDQTOp2UhV7MjcMp3llqY4N/UGXIsgmNRBBHEmUk28OMCzf3+PQLG+zvH1JVNWkSCARahn7feIeIVPAV0wKpgpqifs1gtjS3k6lz45kWluG0oOMCg4na0IyCobuTFhWiolFCBOm3VNR18K2qKsPcYQcVBdam96/vCe4bPfQbPfQbPfTvvYf+qoGnUeEw3lC7QPdzPiBtxs59cxC3IuXlXOZVO8+sDHIqUHMqGLdAKgAlA+MnAE8ipLm5QAFGQMvqW95Bw9yQ15a8tgEZVAKkpygqptMZk+GARssRxy28iJGxQ2iHr0uMKCjKEl1ZhAUvFM6BsRZbldg4QeoYP5eXGWMorKOwjsw4qskMMy2Y1ZZZXjLNCgaTCWVVzTXuGhXHtDt9llWCTpp0+33qJKIRR7jZCFsVYAylLwGBcY6sNMSzHN1ozeVmmihJEczN1KW6FQ8bJHNzg+454ylQcMMCct7fQjf//aS1UHxz9Swej/UW74MRe/iQMOnwc1qQJBheEoUUAD+ffGitieOEU6cV/YVFTp48zcHeDtlkzHg4gI0NprMpAji+2ORUJ2W10cDUjryqWfbgrWNWW4xUeClCXO3cqNHY+ZQJT13XjGc5G3sjtg4mHI4z8KClDPrWI9bRLQaduAXliqP1KOAoRjJc4uiWALeldn4eiffaD7tlQe7D36WYq2llAKC0CN8jVp7odR7FDpAZzbWhZ1YVtHsTFloR9ywlVPctsDuu2ZlVTGaW2js0kqqyjDLYm4ZmoBmpEC4wb1LCAw6sdXOJY9Ace+/BGQ4nUFeOG20NUrHQUMyyklYcs7S4gI5iyqpmUJdsbRsahyVFWbC01OPE8S7N5RV0oYnzmHLUIJIRrpbkh32KSiIzhVyu8PGQg1eeQfsH6K8+wtoD72WxthjVIdIR5XREoiPK/U0m1xJa/R4rx47z0Jsf4dnf+SLW1JS6wfZ4SnN3wO7VV6itI9nbYbi7ExgjQrBz7QrlbABVhqsM3vrAn8UFvbCMgCPWnQv/8xYVpTRbfdZPnWHh5HEa/RUwGcLV4CxSN4DAGNSRDNOZRoMwRmJunho2kqjZvMXQE1KRJCmNRDMcDNnZ3idpd3jzww/y8JseCIxOa8AY4iRCKo/WnrysmWbhcKikwDrDYDyiKGsSJfCuxtiKwhp6iWStpdE6sCIN0EhinPfsTWZzn7eKTiMhjSO0UpTG4WV4HtbllOv7Qx6/cI3hrEIIwUpDcuihcsHjL5j0hwqWc7NOL0HI28xY95paZD6NxQeWpHee2nsmlaW0UDtB7aGlBA0d1qWdy2EloeY7QGnAuPA7CREkBa/vS/L1b3+ED33gPTzzqSeYDQ74L999gt+5POXGsCIvgtxEo3nXwyc5ltSs6ox/8vQYmUjOPrjIL7+wydObBXEccXa1y7F+g5/55E08kiWt2Gk0KIyAaclkmtNrRnzTfQsMXMwXdzwfuivlpZ2MZzctP/D+u8nLms++skPlPO1mDErxPR+8k3e/+RRvve9tdFdP0l45zsBXXL92k8cee4U/8MBlGirhWx46g7QTFhb7RPNJmYoiHnnPt7BlW6gnP8rf++e/zdMXdvlv/sx9PPfs01y7fIl73vGNvOOeNf7r73yIX/zMeSbjDIHHGsPlK9f4b//iT/Cud3+Qfn+Zz14Zc31Y49HIuBEOaHXB3/7bP80jjzzMd3/Xt/Po5x7HP3cx7KU27EMP3nma5aUu3t7D/u4Bly5v8qkvvYCtC8ajAXleztkA4J3nxo0NfuM3P8bh4T44C8rhbQV4VGsZW86YZQV/6cf/Oh/4lm/kP/2jP8jLL75MnuW0Oj0+/ukvsbd/yA9937fy+cde4ouPPc/01WcZjcbsjwou/2+/SKu/iGou8PQzz1Ebx7OXtnn3jQ3yvRtoCbszy6cvTigsiDnDKTOSjtM451lsKlY7MVf3CoaFZ2mhze5uSTuJePjcKn2V0Sh3+P77NQ+e6KM7x6npcWF7m899+QZ3rXXpZ4aL1w9xKFrtJlZIpkXJeFbx3E7MsPScWYjYHZdIKTm90mJrWOCso9fUnFlqcG65hVqKeH7o+cinXmXrcEJZGJxz/M7zN4MnhhJc3hmzP8rpdxu8dLPir/7iNUYFZGXJ3/mNV4m1ZFpaZNriK0++xM2N7dc98HRYOAw1lYeV3SkL7YReq8GppTZpHHN1d8ykNoxKx8zVeBki5o2x4RlmPYkStCIFSqNLh5QOJYIHR+2CX6cVwddDGI8vLRsTG4bRStFpiFssmkhCWQV/qO1BRlEZVroJp5c6LDU0ybpCSUcz1UgkKI1DkZdgaodLa6JshosHZFlG2u6Tthe4476HqYqCMs+IGg3qukJHEaPhIYfDITv7h+zuHlAWM+oiMAWwhkQ6Eg1SeLwpsdZgixnT8YTt/THXbm5SVTVaQitR9NopnXaHZkdjkXTWPc1mk1a7TbfXJUnScJ61AbTRMvipahlSlutWh7rMMcYE6U0Uh5RoY8mKjEleUBtLK42JI00caVLnkVoQRzE6iudDZEORZ8yyjOGsJG20SBpNlIqojSUvawQCYwzT2YTD4ZhZXjCb5cRxQqvVot9fYDIesb+3w2y0Rz3LiGTGcjvmeL9Bt9ui3cpoNXOWujGxlhyOS4bTkllRI+Z+TY1Yk0YxSSxIIijzEaPhmM3tHYbjKVVt6DZjoiikZx9Mw3NKSnGr19UiWEs4L+ZsCBf8aJ0LNiGBKkVtHbPKMVDMw6OCEsXMN2gtReiPVdjjjTekkccqQSkVxTyZ2s+ZVoLXdx/9Rg/9Rg/9Rg/9e++hv2rgKa89FofxHqXDY6Koj4yVxW1pphAceeo478lNYLIoIWjEMjB1jmRSc3AkVtBMgqyqth5TWWrnwASNsSUg8tOiprKOynpiKVHSg3BhEcxKZtMJSsVIqZFCISODFDVC53hRUNsqGJe7IwDG4b3FlCUqKhFS42xFVVUBUKoNWW2ZGkuW1xTWkRfBw2Ka5Wzs7JAVBVlZEDVapI0mi17S7i7QBRrNFolWJEoyazQprKUoKqq6xDlPWdeovCTOc9oLS0RJStpq3+LDiXlq3a03MU87uHX/5rpsO0cz/dHiAxC35XaA8H4Ox4T7GeLxDN6Z19Bl/S3kRUiJQgRzSiFvfW0hIvCQNhr0egvUVcnSwgLj0ZD93R3GZRXkjt6y2u9wrJvST2IKU4L1tL1nZD22ttSRRUSaWAcPKu8t1s3VpMJTG8skK9gZTDkYZ0zyUHTRHHgy/lYVvUZqx9FCPCIa3vr/1/x6t4CoMI0Sc2nd/3vT86/5iyBIGIUPHmZaME/zA/W6P7RC7RT7mWU/s6xvZpxbSnjziRYPHW9x2LM8+uqQcV4zLgzNSJNXnkEWQgQiJWlpGR5yzmO9AxGSK6333J5TSYR3SOfITajb3Zml34xoxZL9vCRKFQutJrmDocg5KHK2RxbtLB0zYjqboSJD0l1CNwRRKvEzjRIK71PKcY98BlGuaLZBRiWTmy/RX1sE8WZ6px9C6ATVXWR08wqmqoh1TDXcYxoJ4uYDdBeXOHf//XQ++xWmZUkuBIPcsDuasnvzKkrGNEcjrr/80nzSKdm8fhVvS9qJDzGvFtBJ2Px8mEAhwEvmBwaPcwalU9JWj6UTp+msrpN0FiimUwTu1jPQO4e0BqFlsDfTKcGoTQSp69Hd1RG3vMzmRoVJkjKZZBwcjmi0Wtz3pof5lm/7VqrRkMPdHW5evYqOFEJ6lBZUdaAAh4QcsM4yyzMqO2cSGoO1FuEd/USx0tBz77VQH5FWOGBclBRVhXWWNNbEWgX/AucRShPFMcVszMb2Hk+8fJ1ZZUiUpBNLxgZwt4HyUJuhvrQAK25X42upwtx6XxAphceWwLpA66+dxHgwPrBouxHEAmoXJOChrRF44TlEkBmoLUGe8Pq2lwAEZ04d55vf9w7+9f/6N4iKId9w1zKXJx4jFJMMJrMSZ2rOLjW5r1NyV1rzqy8KdCygE7GVOzYmlijSrPVbHFto8rGnr3CyF3PvWgOtU6LYkUSSsqyxGs6tNLg+FtyYWf7TB2IG04IvlJZHzi1zfXfCL376Iu1mRCNRaKV52wOrfNv772Tx+COo5joiXSC73mdmN3jh4jbftLfJ6lKfd9y1Qk+lLPTaKBzWGpzz3Pnw27hjZ8pi7zN86SvPkxfwp/9ry/WrV3jpheewxnLfmVXS9z7IP//E82SzHKkkznp2dvf5x//0l5hkCefuvJfntzPK0iKkZnXtJFWVM9zf5iO/9u/Y3d3lx//KX+COc3exfuwCUsJkPMRUOXecOsaZU8doNyOef+Ua5y9c5dd/85Ps71yjzCYsr6wxm06ZzgLbYG93j60bV8HPE3qEAD+XoTUXiFtNlMv4pX/1q1R1xe/7wPu5fvUG2XRCs9Xg0U9/mhsbW3z7u+7l8Sef4l9/9HPM9q/gvUUIyVPXP3t7FaiwX17ZHHDj5ha7mzfx3jEuPRf3yyBrkaEprU14c87TihVL7YhZFVgMrUYcUpdixbn1PqnPiKpD3n5ccWKxjUwX2Z9Izm/mfOalXe6/5xReKp66vEej1SJOIowXVCZ4tVwfW0oP/VSxsW+IYk2/HXFlM2dWGNYWUhZbEWvdGNFqc31/wO+8sEVeGoR31JXh+ZuDIDlJIvbGJXujgpPrHa7sVjxxcUojCWazv/707tzsWSJ0woVL13n55dd/qt3MeGwRLAo2DzK89fTSmIV2gpearVHBrHLMyprShYAAhMCYwCJXQiDxaBmGp2ruBRqsE0LP5MU8oYnQK/vKsZ8ZuomkGSlaOrBaYqXmB17PMKuYlTV1bdnfHzEejMknLdxKP9hGJBESiZURlUoojKSswJeGqCjw+YzJ8AAZJbQX11g5cRZT1+TZlPF4iClLHJ7peEhWlBwcDMlnGdIblK9xzuCcQXgLzlKXJQqLsjXOlGTZjMPhiN39Q/CefishjTWtZoNWt4tKWggdsyD0XCUQpHtShbAdfOjwlJKIOMFpTRLHmLrCVCV1Xd3aaKRw+NpgTE1ZFJS1RWsVEAIlUMahZZBEHm3g3nuKomA8HrO1N6DVatNut0njhLysGI4zauswxlCVGeNpRl5WFMbT7/Vopw26vQUazRY6irhelZSVI00SFloJy+2UViul0YhJEk2rEWOsZZRVZIWhrN1cLRCM0KM4Jo4h0p7xbMxweMju/j5ZUQb2VdpASkllw3lofmwD5gwG4ed9T7C8OFJHeOdB+Vsfb+ckgVkdzntH6eVheBwGtE0taMogxauMI46Cx1EuFR5POT/QHtmGvJ6vN3roN3roN3po+L320F818BTpIC2yHka5wXuoak9tww8hREhVUyr8wNbf1pDn3gY9tJXh60hJpAJC5qwj0YJOLBFKUFqHFZ6i8pTGcDgNh3w8ZLW5BRq1kohEh+LdGVp0o+KuYU2jaWkJC2RIWSLVmCjSJKmj1bUkTU2UShBjdDRF2JzpwRbTwSFexvhYM51O2N68wWw4wFQFti6ZzjKyvOBwkjGYZhxOZ+yNp1R1TWUMOtI0Gg28taz2+/iFfojDbTRJkpS0t0JeWgaTXcbTCVVdUpYlSRTTaDRp9RZI0gat7kIwZIegQ1U6xMNqjVQSIcXcPHI+I5hru60NBcj8Xh2xfY4Q0OCTBdZbnKkwJmz2YdITwCWtNVKEpjZIGz3O+vAQFBIVRyilETJMhNT8a/a7fVqNJstLi6ysrTKdjNnd3uR0VLEkDY0yZ1rNGE0z9gvDYWkYVBadOLR0wYjNeawNdD2EQCjJqKjZHGa8sjlkZxy07wuNiMWmpqEluQ26/1l92/jsCNk9Apm8n6vtXvM253bhPFQmFNURG1HM5XZy/kDDB0TZWm6ZqEkxj5YE5JydJfl/VPXr8GpEAuM0tfM8+sqYL0fwsfaA733zMicWUt573xKfePGAywcTlppH8tnwu+YWrpeG2kl6DcVqLzQt3nqqOphtOh8M4qUU83TGMNG5cVjinGC5HXN6pYe1gp1xjnEaR0SNoCkV/abi7W9KOH2fo31mSjFtohoJSfsko+vXsSqF7tsx44xyd5uxKli89xTx6h2YvMKUBu8EqruENzV2tIudHiJMRnehw3hrk8MbN5hOShZOneCBb/1ezv2736a4dpONcUblBDvTgke/8jgf1BG94yUHrzzDC9ev89LNTfYqx9pChzefXSebFfRXmzSO30NdTHEmpLYEFqHDCQ0qwZYZUbtH1GzTPHaaKO0hdELUyVFSoVXE7W4rPC+PKOdH9PT5gAwP2PkGKmQIHoi0RiUJhyXsDoesLTQ4ceYOTj/4Drh2kaHStMsZpagpgF5/AUuItnYivIZFZYnSLl45kqhiLy8RzvHmXoNHVrrcu7LAvktZTSJOxiJE7GpJFCcsddtMy5LDYkasFc0koZFEtHUDlTb48gsv8eiLG/zWl15ltRvTSVIOXWg2nQc13z8sEqvE3NTf3/Ky4DU031C38/vg3Px9EifnElsdEnysC7r0Tuw50xWsRWFjzGpYSRRKQA08ceDYzDxjC03paXzVu+HX6nL829/4BL/1ic9QlWVo7J/Z52//4D288747Uaun+Z9+4cv88qfO8y++cBFvHd5Y/uh7zzAuHe//bz7F++9e5Du/bp2Pv7jPzsxQUfGhe7pcOiz56Mtjkp5ksRXzvofP8MT5TfbGOT/3qavEjQaLnZTZPasUBrIs5y/+wmMoJeh1UibTgrSp+cNft8Sv/Nvn+PlffYF/8+NX6SyeheZpYnedO9c83/fee+mWN1Hjbd72kOZwsEQtF/CuYufmHttbOzzwyFt5/zc3+NnxJrtXr9JfPYZwFf1mg7V+H6UVKw+8j8aJN9H86d9BDqbYqkY3FkFIymLMv/6VX0YqRVVXIBWNZovf/nf/kudeusp//1f/dw5uPhNkHd7zv/xPf5Gf/PE/j3cVP/P3foF/9E//Ffe95es5dfI4QgjW734b3/Qhw5/4Uz/Mn/yRP81jjz/JFz73Sf6Pn/lZ/tbf/mnqbAhHwxxvETolbS1QAnhDpxPxo3/iP+cHv/c7edd7P8iv/8Yn+NSnP8/P/tRf5NSJ45y/tMn//D/+OCfPnKHd7vHRL77MdP8SeIFO+ySdFfLhNs4UCGxI5/GB0/6rn3qaL7x4jd2DMe+8b40/+K5lLly+jLGOd5xdpVGMmGUHeOc4qCS6TvkrH7qDzz63xe88+SrGGA6ngo+9uMe3797keN/y6NWY907bNF3Kj/7vH+HajQ2Gk5IXh9fptyPec1+f56/POBwU9Bs9ljsJJ3sxx5bbXNjLeG5zQr+T4hG8fGNCt9UgbQq2BxmRmDCdFXzn+gErueGBjsSfPMmotFy8eciJtR6Rlly+OWD92ArdbpOLF25grAUEswziNGb9zAoHW3sUWY532f+7q36dXlGSYJ1jXDmeuDKmlcxY3ZiytrpAs5nywLlVXr52QLY7YVyGHkQJQTFPJNZScGNY0EojmmmMjmMWI83OMKO2IY5dRRolg1+MdQ7nLINJQTdt0mnGJElMXlmGec3+zJCVlsIKvAPrXUhtoiT1FZ4EGSVo1USmKS7qoJtrVJtjhtmAm3uGkz3oJIIbezOOpzWNlZCkN57MuHn9KjeuXWE6HjId7qNcTSTh7tUF9PE2UsK1qwl7gwnXtwdc39hle2/E3t4B9xxfYLXXxOuIUVmzPZoymWVoKWglGtXo0Vo5yan734qbR6FXeYYUoXfxtsY6E06XPvhmxZFGxBFCSKLoKGzHYUwdQnqcQ+AwdU0yHpPOZtS1IUlTjoCX8XRGZcaUtWVhoUcaa5ras7l3yN7+AXuDMcdVRK/bpchm3Nzc5rmXLnIwmuC9o5lGIbnZeSbzKHsdxSwsLNFopDQbTY6fvhPpakQ55WzXstTwNJuG/5u9/462NDvrO/HP3vuNJ958K3dXZ7VyS62AEBJBCAEiWhgYG4dh+JkxgzE4ATaYAZtgwBgbg4dkkzEIJCQBEkISEoqt1FJ3q1N1VVe88eQ37zB/7PfcKsnL6ycvrTU0a/Xb61RV33jOe3Z49vf5hjTUOGe4OirBWZzWpHF7kKZpgSJFGA+Iu45AVtz/kYd48PweH39kh9hp4iQgkoJFYym099O1LQMkCSRpJEkSyUJ7jzBrDE2jabSX3tSN96lJAkEUKgYhBDhq56hbD9pAQlfCmZWQ4/2QBKirhqKoObGiKA08uXA8MdHoyltbBK2K4Kl8PV1DP11DP11Df+419Gddat8YJd9oD3j4v28UdF0/2PtHC4sLDwZULXspUktwxA8Kj5R5k2ptaV3oAee1xF6n2FLK3HUwAeETHxrtqGpBWQmMVQgR4JxHlp21ONMghSNKHEJUNPWcg705rpyB0dh8RtUI8tqipcTUJU2eEWJQwlLZBmlqpGkI8AZ4oZBLKy9PIW00tawpsgVlkVNXpe+eBBKhFEGcIMIIg6Csa6qqpKpKnDFIIairgqapsUZfZy2190csO3tLxhMt2+mGRVpKCa1j/RI7Fy3raflw7cZprW0fS7aQaElCspX1BWA9imuNJi9ynHMEYUhvMCQKEoIkPDI311p7PSmObtr1LCAcPVEjTU02O2SiKg7J2NWOQ+PInSO1DtFG0Zp20XUOT00uG+basCg1RW3b2GEPQsaBJG31t4G0R5Opxdna8eHasdJOsxuoS0cfaseQE8vXz9J/rv1jaTzujhatG8e517+29/+znUh/hVcYgLKgnKBBoq3jYGF5YCdjv6hBBtTaEMrlOPILlhSulV875pVPIYnDgEAKOuH1NEvrHEIYH0DQC1vzRE/FXlQGpTQb/QStDVlZs184St3gXEAQGFTgyLRgvD/l8JIiSiU2HGBVn3gYEySKcKUkq6dMF1PSyJuIShWT15KqbNDFgrC74hl0vg2CcxanQoI4RgYaZ2qECgk6a5w4doyD2YJouoOMI4yQPHZll3tnU9he586bT3BpNmX+5FUWtaZTeGPByWjEYG1Mv79FrQtMlbfGeq4dc8LLecUMIfxm0DQNTW2RYYcgTdv0xuvjUAiJbQp0XVHlC5z13YvOcAWpvInw7HAfaOnua1tIB5UTzOYLsrzg2OY6idCUBxf56Ic/QD2fQLlguBoSCElTu3aNsRgExvlHEoXe2LW0lNqxGke8+JYNTg4HDFSALjQ3A2UYcGme46IIlUSkSeQ13/M5ZWOoG00oLKZpyBYlD1zY4/LBDCcEsQoIpfQsVivacANxnanZrveBFNTOfBpovJTPunYu+zkp2n2AlpF4nbwJ14Fm63zDxNCm6rQNlOV8TwJHogTJU9xcHBx17Rm5KvKx01WhecdDIyaF40tfkPKim9fgFc/gHZ+4RKYd2gge2smpDFgnuDgqURLK2rCVKm5ZjwjqCKSmMY7jiSN0DU/u5DgZEHc6NHWNAkrjeP+VhsMKzqwldAZdBknAiX7AR5+cUFWaj12ccX5UYYTkicdGnL51jfUzBVKFJLFks1sRx5LGKs5dKomkotOr0EVGPbpIeflBmjtup7eyybNe/uXM7z4kTrsIFXPmxBqx3kJKyf0PPsb73vd+plM/T0Bgdb1cvKmqkn6/z3f8w/8fURQThRGnTx1Dqohv/9//JtPd53LqxBYI6HY6GDPnv/7ab/PhD99HNp/xX3/jvzPs93BW841/83WcOLFNGod8zdd8Fbfcciu/87t/wMfvfwCEJO2tYXRNnU9AKJyFppzjTANYssk+H3jfezHljGwx49ZbzvCaV38Jt999N2srK6jOKsdPHGM47CFk2EpeLLSSC2sMMojodrucPnWcyxefYDadADCaLigb30C6cjDnHR95kllesdqJed7JHhubm2S1QSrFM8+scM8d27zto1f45BOH/pAThKRpxKmVhDRKCIKErZWU2E6pxufZH8+YZhXWOV54+xaBgiuHU4rGIoQgCRVZ3pDXDSc7lnFHEoUhcRygjaOal4QDiENJJwlonGNUGB7PQmaNRAWCvVnOvHEEgSIvayIpONUV6KpgPGroJAE4709ZWF9PlXlJEAYkSUSR5Vyf/U/tKwm8MbhAUdUNtrLYaYWLCnq1pdOJqRuDg+tsHRxKKX+YAp8W5hzaCdJQEsilPMfL7aQ13rcpURSNl0MVtWFRNCSBYjuN23oQ8qqhbIzvfMu2sekcxvj0THSGaJ+HkAkIgXGSomrIi4ZKhCADwighihOyLOPixYvkRcl8NmV/9wpXr1whzxYUixkbvYikF7Pa7xLFMSoImI4WZIUHfsbzOZYFdVXQCb3P0NZ2jzCJiaKgbbZ65pC2DuskMkrQjabRDUVVEwWCUMkb6miHaFvxQogj64owStpuv0Ppxq8jzsehN0FN1DR02no0ThLviWI0Rd1gG0PVaOq6AWux0jKaLhhNFwghfOJeknJ1PGU0nTOazgiEIE4iNlcH1MbvlXVjfIpd0zBXiiIPmYUzklDRiQI2+zEiUdgYSpPRGOmT/7ISJfx4GvY7JIlB28yz4ywYArKyomhKLl09ZHd/yiIr2E49sBQKh9be1J72fLA0Jg+VIAkkVWsMLqSvTYS0CK5bfFigtpA3jkg4sBAIi3DLU4iksVBrx2rsTbdrCR0JkRRsJILDWKKtxTaOVAo+yzT2v7Lr6Rr66Rr66Rr6c6+hP2vg6Qg5s9C0T0Qbz/qgpWrdyChpcSP/OZbAk6Wx4Kz07v6eO3yU4KbahxQ+pQbnddjaXNcpLm+CBxb8AmiMo2kkZSUxNgAiX7Bpd9T1FXjgyZBTlSWHhyNCqQkDRRNOmCwaDic5tTFEEoaBoKMcKId1DYFrCNCkSlKFAVUcEimFNpYK70+gm4ZisaDMFlR5hsC2MjkPPMkoxkpFrTVFVVOVvmuhlKIqS5q6xhhz1L3zPkXXpXaewr8EnY7elNbvSYKSOPvpBl/e0M8PRuusf7RdMG86trwkQiikDFFBgDUOtEU3htl4gjENYRiSJAlJmhKnnXYz9+kh1oJoDHEYE0rJIE3AaGgqZo1jFBXsiRlXLUysI7OO0DmUtTSNbTtzfgDVtSbLK1CGRdlQGnfENFLKA09JqNCuZcMtJ0n78K+znZTtJ5af+7R/cyNISrtwtX9znRm1BJ9uvI4mbfvTlv5mT+UrDtwR8q1VQKUd08LxkSsLBiM4PogpatsWx37TRAgCBQjvEbaoNEVlCJVkux/QTbxxpBZ+vktnSEPJibWIg0XDovJy1XmlaSzccUygrWFRFlw8rHBC0E8johhUaDnILdcujthIM07eEWBDi5YhyXpC2JWEq2OyZp/JYp+mG2GcQ8mQolaURU2TzVBxr10QBeClBFZExJ0uUliEMCACRDjgzOkzHIwndC5cQScdjBM8cnWPg/EIo0/wvLtv5aHRFPvoJZpyTN5oDmcZBwf7DNfWWDl+EldN0cUCK8zR0Ue0nVRjDUHSwVooZgtclCGTAWudsy1QqrGmNd4MFKbKqLM504Nd6tKzNY4FkijpIIOQ8c4lnPV68zRJEdZiKJlNPb36+N03kbiC6aWHePOf/SmhgJu21nl+b4swCKlL3R6IjY9hbjfOJA4onaFsfNe8O+jyiuec5UTcIXUSmy+41Xla8oPTjCbRxEpxopdgHRS196srmoZYGvKqZH8856Pndrk48Z5CaeA7rdZarPHz07UHINduJFJ4qnHdxnwbcz11EiEQ1o9Mv/7fCLG3e4+4Pp+thdpAJX2BvOwQCeHZuO2eTTeEVEKi/hpMYgAEQeT3uFqX/M4H9vjQo1Pu7hhedNMtPPfOm/nIuX20K8FY3ntuRhoHrA0THt3LKCpN0xhO9iTP24558FoFsiJQgu2uY55XfPz8Aatbm3T6Kdki86kvzvFn5ys2Y8Fdx3v01tc41o94zkbMYWF55NqMP3/kEIRktRPy6CMzkmHO5lmNDTvE0YLVNCftxEyrmE88WnHbcUevE9DkGeX+eYonP0A1+xJ6m6e58xVfC+B9mYoFN51aZyOeoXXDe9/3If7Df/xl5vMcKTxtXaGRQkEcg3NsbW3wb374B+j1ev62Oc1g0Of22/425XQHD+Q1hKFgPB7z/f/yh8iKGqFifvQn/gPOaGyT84J7nsf6+goAf+Prv457X/RiXvqyLyJbLEiSDp2VY9TFjLqYgFB+XjcLnz4mJOXsgDf/0Rt54x+8HrB85Zd/MT/yQ993tKdsn/GJg975c7l5t2uw0Zi6JI47bGxtcu9LPp+6KimLgrrRLOY5i3kGOJ64MuaJK2OEVNy01uXe013UsZNcyT2Ice/t63ztS07xzT/xTg5mpfeQDEIGnYQ7tzsMuj2ipM9t2x06Zp/51U+yyHLqRhOHki993ilmRcNPP3gNhyKNFZ04YG+kmc1yTqYrHHQE3U5EEgcUVYPRmlBa0ihgkHoD4XnleCgPERaclFzemVFZSDoxi0VJKh3PXZc8ejhnb244e2q1TQbWjE1IpS3zaUa3431uiqw4mhdP9SsJvMGylIJpY8i1IatrrMroFg39siErGxwQhuqIhROFqq25LVmtKVvPJ9KIJFRHtZhzDqd9XbveCZgVkqxyzBrNZFHhHGyt9dqGsCOrGmrtWt+eAKm8pKJuGuq6AD1HuMAH08ieX3MaQ56X5HmFTVNUEBEnKWmasJjPubZzwLXdXYp8QTafcHA49v5zVUUvXCMapqwOesRpFxXGHAwmjKY5xjrGkxlZ3XA4Dhj2U+JOyombEpJOQrcT+0hy4xlKdaNpjAUV0JQ1RVWzyDI6cYhMotYaoo0MbxuJHmDxYTxhFHlARYBs/NgUgtYzJiCqKiyS0FiSNEVrTdPUyLwEqTHWUje+9i91zcFoxuF4xtb6KmmSkHY6jKYZh5M509mcM8c3WF8ZcNOpbfKqIStK8qJmtsipq4psPsNYR60NaahYHfQ4vnoTNu5RR5Iiq6mNwlrBaFYQhwrZSzi50kVrS1bWID3Y0zjFdKGpZhlPXj5kd39GXtQkgw7dWBEph24aqsoAbYq08gqGUHlAeVxa790rFVI5b73RgqBSSm8XYmFeG7rKH2lDrD/aOh8PX2iY15bTqcS0Td1YQiJhM5HsxYLGeqVLGgg6T3HW8dM19NM19NM19OdeQ3/W09z6Ez3LYeFBoKMh4jdBDVbCsCOOfJxmtY/bM+66KVVpLYHx1Mo0vA44ebTdez4564GGbtym2WlYlEuzMUveNK2+PWAYRwyjCGFi6jJmkUVMxiVVllNlOSHCo/CBZTZfMJkbHnliRNrrESUdzLXH8d6Gll4UYIXASNjTJVbXVOUC4TyzJo0DamMpG0coLQqDxMIS3NEN2WzC9HCfMlsQBgFRHNPp9Um7feJOF6TyE7mNTPRacs+SamqvwXbtu3vEbLrx/VwivO4IqPRXC1jJ5UB0Fi+W5Ybvdy2Ysnz4KEUplC8+lEJJhWk0eV6yu7fPxQvn0U1FN00QQlBXNcP1Deqqoiq92arRBnsD4tVUDc42/g1f2yKVMWv9NbYaiZiM0aORR6fbYkq0SCrOMJ1OuXzF0gthPPVsK6Vku6FdfxyxudqCi5aZZFqTeos4ktwtb49tb0UgPSqchN7YvtBAaVESqsa1MZLi05hOy3sPXnaHcO3v/mxn0V/ttdF3dAJHN4RzI1C1IJCKjZ4kCuDKqCGv/ALUGOgljkFHUFpBrYX3HIgAB5fGFVmt6aeStW5I3ihmhTfRBOiHAtELSGNB6QxFZcmqmk9cGBO0HTSEQwlBJCVn13soabn/ypTj1yyDDbitu4Y1gqI8RKg5otwhnJ1nc2NKUKdEwTNIOoowOeRZzxUE/Zz9i1eZ3PcxBhsbnH3es1EyIQg6RN0YXWiaqmbxxBVUskZnbZN7Pv/liDjm0cfPcaGRzBpD5Qwfe/QxZFPw9S9+Pqc3N3jVvffyJx+6D1Pm7B1O2Lt6lY21dcIgxKqIWiYo5f2/cCCEp/paa4jSIRiLmPvkS6Fr4jQmikJCpTiCmQX04oCm7JMmAdf2DikbTX+4RtLtEEQho41jSCzdXsLq1hZSBuTjOVVZoJuSO245QyAEF85f4m0f/AQBmrtOrvB5d7+GrdUuewuDDUKMFIRtZHNpLJenU4q6oakKBqlka7XDLWdOkI4XNNOch69c49JkwaVacKAdCbCmWoaicdSVRkqIk5Du+gpXd67y8JURH7kwonaSfr/DZidkLZFsdSX3H1TkmTmS1krh0zKMs+08vQ71WueZmkJZzzK0MM8cCQ6TgERijzzWvGbWtcCz0Q6rPNvHHa0XHuAOccTC++GkypE+5WmL1zeBIIq9D18UUecFl8Yl/+B3z9Ed7rG1scJ/+b6v5E1/+Rg/+3v3IQOBbCxZ0ZDnFXXtGarvPj/hwVGNSrpsrw74huMd3v7wiEVl2Noc0OnFWCcYFxWRipAODnZ3ecHzjvO1L76Vn33bJT5xYcrHu/D4fkXRwOljQ0bTglAaXnxrziDVjPZDhiefgWALu2tJbnolcdzjlaND3vTOj/HGR0b8zLec4mP7Ab/19l3+yzetEHf7OKMRKkDIgLAz5Of/6H5e//u/T/gDb+B1X/9VvOX3/wt1lfEnb3sn/+Jf/Ri//Mv/hXtfeI9nHZmaIJB0un3fkgMQij/547fwT//Z9wISoSKi7ho/9M/+Pnffcfp6+w7QVea/Rqb8vf/jH5GmKVIKrK7Y3FjjHX/2ZuI4Is8yvvrrvpHx+ErLcI555l138G+/7x9z7OazdAd9ytkev/Arv8sv//ofYHXB299zP6/5pu/m4NKnMEYT97f50X/9Pbz6iz+fo81aKHAGa2pMNeMH//E/4p57nsdzXngv2fzvcO7cOV73t7+LPJtimxKWISE4nDWYsqI6GHPLTTsksR/zf/7AmAuTgHvPDNiZxTx+WJEVNXVVsZguIN6kt30rd7zkND//hvv4zT8/x3Sec8t6l+efHPCG+y5RW8ezbl7lwm5OUVuujCtuXu+wdbLDHz0J49wwlJpLV2d+6x9E7I4LzEGBsZZ7T3a5ezMmsjUXFpYHMsHZ7T55rXliL+N7vugkt22kvOfRnI1kQWxKvv7FKX9+vuIXP1JjXI2Qgk4aIVuLgc8ocJ7SVyAhDryvVuBCGqNojCMOFdY5ruwvaI4OEJAkIWko0cZQa8OisMRhgBBQac28cNRasT1MKNOAeVkzXZQo51koaSBw1tc6RW1oTMXj16ZoYynrhrLSKCXpp4FnCgnH+YOGB6/miDhh82ZNoiKkiGm0xrBANbAVa7orimC1T6AzRjuXeeTBB7m2P2bnYAIYb6GRSISpCDF0ewlr/YTVXgzGEAYBSX/AyVtvpY47XJoVnB9nzKqG8aLgws4IgpC77rqJXifi9LEVumlMkRdUVc1kPGIyHlHXdVsPSrQ26EBirD1SabDkjbllwpNn+RjTZjo5hzF+/vgSVB95tFhrj5hTyzOPEMqHAEURKggwWnNwMGY0npJlGStnjiFMw2w84pHHzrF/cIBtak5srHDz6ZM897nPIas0s0UO3M/u/gGj8ZhAQpaXVFmG1WBUQzUOyRhik5iyhrS3ztmbOxDtEghLP4G6blgUNfO8pt8fEKcpIkrYPRxz5cqCJ/Yy8lLTS0MIAoSSdELJWidACcHVzHoTYuuYlJZQGgaBYD2CWAoWRlEavyMHUvj4dG2oG4sIIBGCQRwAgryxvtHtBE1jyCuYS4UMBKETxEahohDjHGVpUNKDsd1IeebeU1xq93QN/XQN/XQN/bnX0P9r+HILiS1TxJYfvM40uU7TCpXfZGsDdYuy2fYLLd5Mzcu5xJG/jhLiCIBaUg+F8JuBvOFj7obnIKQjUH4AKKVAKIxVlIUlXzQU84JOKFESlGoXTWOoGhCV8HGCdYEz3m9qWvg3yViD1hXWNjhTeD1zIOkkKUIaAmmRGATWv4tCAj421XckM6rSR7MKIbzZXxwTxUnbMVBHgMmSLaW1j4C8vtn5G3pdYNe+Ce3NX26IR7S4Gz529Ikj0Ep4uuT/ID1rGVQtfVYI3znT2lCUJZPZjOl8jtUNCkdVFNRFRpUlZHnOIsvY2bnm5XbOkiiJdBbR1G331nnKuFREcczq2gpI34WyTdVKIW0rLxAo4bBae1DL+C6nJ6teR2T/ZzjPjay4G///M/+tpCBu6cRBa5xYG3+vJf7ftfaU5Rtvpb/1/mYvx/oSe31qb5f+8kEAXL+fwt8Laz2rsKy90bqULf1y2UG1y6LN06W9wZ7zxUjliAK/WSShpG6kZ385dySfFQhCKQi9b6BPPnF4PzG8OS1CoqSXICwKx+HcIkSEVIogcAinvJS0cYShIe060rTPdHSN4rFdsmqfnjuBUoJ8OiKKA5xuEFiUgjCSYCRYhVIWYStcs6C/ucHGsS1Ora9wbT9H1AahAnYnc85d22dvviBQitPrq3STlFlVMitqJtMZs/kc6yQiSJGxQgjrB4QTONH6sDkDKgYshB3CqIuIEmaHh964tCqIk6TtyApsU6ObksVszN7hmKrWdDp94k5KEIZc2dlBCejOI2qrEEgWoylNXZEmMcN+j6woORjPGM9zOoGlqmtAolRMmCpkELUHW4dUPrXGGEujNVXTMOxEDAJIrSVAUDi4VDU8UWkuVoYSQdgu+E1j0Nq0Zz+/F5Rlw6LUzErv7WdauXWgPNA7iAMCWfM/8ghbg1JrP32SX0fWfSfV3TCWhWtl2X7fWDJm/abpOzrcUMwuEy6dcyjhPSUq544MVf+6XKZpiOOQ1WHKodaUpePyTBNXC+a149LejPG8xFpHL42RUlCUDUpKosh7gsyKhtJkrKwoVqMIFcbUGj8fnaCuayKleMaxDpPaMq81ptEczkrO7WacPdZjf5JzaXdEVhgP6gchQlYI4QglSFNiywnCJGAyhCmRYUwtInb3x4xmBfPCemPg9XXO3nIzYRT6+eAcf/ne93N4OMIBH33wHBd2FsAMay233noTzhoOJwu+5qtfyz33PJ8777zLv9+2wTmDaA+WS5+X2WzOI488jpCBlwoke8zmC7rdHl/xZV/M/Q88yqOPP9l+jx+fTz75pI+yT7vUxZyiyLn17Gm6vR6LLEe13X+E5Ate/jJeeM/zeM7znsvGiRMEccwTj+asrm9x6swt3HV2g+mi4sEHHmR87XGs0YTdQ97xjndRLCYAnH/yMoPVDT7vRc9jd3efT3zyQW6/7SzPuPMWtjYGiI0+nU6X1772y/johz/MI596kOstKEF3uMbK+oDVNUnajJnnGmcNe+MM4yTbkWE46PLiY1u8/xMXfIhHpTEiwriQa5cOuXBxj3MX9xA4Bp2QW7Y6PPDo3LMbQkcaBwQBzPOawVrKzRsR9+9oFo1DKUEQKN9wNN5INQgElbYUBg4LS1/4lLFB4Gi09eBLEjEuLaNcc7wjuJI7ZrVjgGU7Ftw0jNjJapoWcDrekygnmYzkX5vmj8+oax83sNetA2sctbYI5WvZZc3nSzhfeXhbCtEmHvtautYWYyxSQhIp8kARhpIwCAiMRimfWOYbtQpt/D2vmzZBuK1BJQopBBpJbiQLI3EqwgURIojaeWUQJicOHSb0aWfFfEI9XzA6OODwYMzB4ZReJyZMQ0KZeFkGeICn0TRlRbWYE8cxcZrSTUNW+h021wb00pjZPGeRl8wWBaPpgiwvkRKG/ZQ0iairGl3XFEVBXuQ0dY0QkiAMkCr4NFndsgYWeDNcr5jwpp26ro7qb2t9S92rXI2XNFcVjfZ+tkZ7MEob/zD2Ok/AWkeWFzS6AefoJBHWGGazOaPJhDzPUcInWXU7HQbDFWxWtTJID+I0WoMEY4xP0UIgTINoSgKbEDmBk5JBEiBESt2s4qxG0bA7mlNUmqr2LLBaG+qmIStrZkVN0Vga6wgDSRwJOolitaPIa0OtfQMc6/dGbTlKpktDiNp5tWSO+bNR66OzZJBJ2aaaOyIlURrAq02w/uxXNJ6BURtvQI5bnhyvX1GoSKKnNuXp6Rr66Rr66Rr6c6+hP3uPp1a751yLs3D9EL58YdeBD89m6nj7c2oDhRaU2k8WJ/zfxjmkFqTGv0glBYGDUApKPI1Lu+un/2X2GPibJaV/BAGEgSSJFVIFWCRFacmyiny+QCSKKFTEcYwlwMkQlaxiRAw6JHS1B3yahicnC+ZVzbgoEcIgpSEJDMNuQD8JORmBE5YgMEhhEGifDkeAEwZjDGWesZhNyWdTer0+ghWSJKHT6dLp9YnjhDLMkMqDPMZa6rqiqWuapsEa4wEZ18aLHuFH4vp74JY62BuGww3fcyQZa3WvQghvSnrkon0d0JLSs5yUCryu10FZVkxnc67t7jKezpA4OnFEVeSUiwiBY380Yv9wxEOPPkZTVwhnOLG6QjcK6QY+clVJgQgDTN2gsJw+vsXGSp/jG0N2dndb8ConDCQ4RyQd0mpsXWGdxGndJvItx59bssTxd+/TQaV2oFz/2BKUc0uulwecepGkH0tqvTRN84DTslNRG4c2y3Hmzy1Liafwxxk/5ttNQf41OLTOCzCNV0Bq47t3OMgK/xrqRraFhB9pxkJRQWMt2oKzXoCvAsFKAlnlmFQO2zQMUsVKR6KNJAygMY1ni1mH0ZJeIEkCyUonYpQ3HMxqAqkw1jHNG+ZVTD+RbPdi8rzkyn6N0SFRnCCDAFtESJdg63WUGhOnNRsnOjz0yQ9w9eAJlH6Muwc3c2ZzwJOfLGiqBaZagK1R0pB0JIEIMcohaUjjBlVNiLY32DxzkmfdcpqHJk8wyhqiuMOl0YK8rHnRziErvRXObq6w0ukyXyzYrxqu7O6xsXdAZQJkukacCFxT4JzEovCro0WioU3PdJ01emubSBXy6Mc+wuMPP8T5c4+zfeoEgQrACSqr0VZT1SVl6dMvn3jsEYIoRgYBe4cTlHB0Y8XmygZSSObzOVWRsbG+xupgwMcePseHHniEum4YxDHdNMXYECNS0uEqKun6WGxtiSJJL468Ea0xzIuas8OQTWmJR3OsDShFyP3a8WDecH5R0e0GdADdOLKmIi9rpFI4J2hqy+7VQw4nJfNaEichtfXruGgPpGkUeBkSYlnFtSC8j2yudAvo3ugf2M5f43xx7IT3IwkCiEL/8TiUhLVPmDTt/mJd27hof45u10xj/YYZSqhrQPmQgaf2dX21K+cz+kGXu05u8InK0Fjp2bmNZvdgxg//6nuYLUqwhq3tFepac+nCNVbXhkRR6H0jZguyeUZIw4FcRQVrOBFgTM1oXhAXNSdWU775C07zRx/f474nJjgcH3zskI8/OeNXvueVXNid8QP/9aK/zyogNylGeBrzrAiIyilp9ThiuoeYzRHZk6AzJrOGt7zlvUwrw+raFkIIXnbPXTzr2Fcz7IRYo5Eq4Ad+8Ef4i3f/Jc4aVNIjSPo4Z5BhglQhhCmveOUX8Yov+lJgaRDiQCqEE9h6gVARQkb405VDyBB/MNI0xQwZJBw/fRu//is/yw//2M/yIz/2swgR4KwBV4AIkCql119lbhp8cZvhTAQIRNBBqgRszb/9kR/gJS95kW+6CMF8NufdH/gkWqZ8/iu+mH/z3d/AW9/+Lr79e34I2xTgLNVsl3/34z9Oa1zAyvZNnL7jmfzqr/4if/yWP+Xbvv0fceaWmzhx+jhNNibsrnLi1Bl+81f/E9/7fT/Ij3/qwevjQwhO3PJMbrlrwF3Pb6jPXaV6YoRtGg4ODxmNJ5xPunzZS07wD7/uRTx2YYdrBzN2SkPlFHlu+NPfu48nHhu1P1Ky1ot45qkub31sxLV5waV5yd23HaeTxnzisR3W0g53H+/wsUtjb5AbBKytD8mrhv2DObeeWqGbRuxnhgt5w+OTgjsHgvUEnr3i+OPHcyoZsnV8jTd+asFmOOOfP7/D/Zdq3n+l5HVXC7ZUxFc/Y8BbnphxbdZwMKt4/k1dBpHioSvKAwF/DdAngTd01cZ73zTWr2dF44EoJwRREBCEiqo2vjbUoLXBGuuZDoCSkm4nIcsrqqphtChJ44C0TTzrhJJOJ6F2FaXx4EAviekkIXEU+gZsu476fb4hUXjD3TDEBQm16uKSASJNkWGIagzUFtdkJLGg1pJxtqCaeBnX3rWrHIwXjKY5nXjDp1pFEbFSGKGpq5rZZMahqRgqi7QNkWjorW+yNYy49eQ6D631yLPMH/pmC4JAsT+asjbssrHaZzjoUJUV47xgvliwmM2oyoK02ycNI5I0IWy9R498UUXrkdqCK77JbChM45M022avbA9ctgWeFvOpP5wJ7zWltaGuG4qiPJLYecmJB5ms1kRKMux1WRQVB5MF+/ue7dRPQ+I4Ik4S4k4fUzjyBq4eTDkYzZlOM5JAoHWD0cY3gq0m1DUDoRkGBh0J+qFkNYnZGJxkUVaM53Mu7kx9qndeMZnndKcLZrMpszxjVpZU1u+PyjmGXcX2IOSmlZhyyeq3zdFWa5AY5zDOECvhx8jyQCwkddNgrK+DlfCgchyF5BYi6RgkMGkMwraST+dInGR37sGSurGUld93Y+HBqUb7OdDpxKwN0r/K6fn/93q6hn66hn66hv7ca+jPGniKghaxdb57YVtqiYeZODrgW+dYVPaIydSLBYPYL/6zylFox7S2NMbfoOXGa5zXvzrpgadA+g3R2aXfjiMOPRVeSEsSCeJAoISh0RW1FlhXI2VNEDR0Eo0aCNIgJpAhVS24eigYLRR5KVHOEmpNgCF0hqyqyYqSyTxjVmumlfaotLRUoaF2NYvam62FIkA6T62MAt95Ms62qLehqEqybMF4dEh3sMJwrUEFAXGS0O32SNOUqkhoqsJ3WaT3ZrLGm3l7AKllJx11xeR1Ws0NoNL1EXW96PLwimwBKHkDYOVY0uhE+6Z5/yjPeHLte2qtZTqbM55MGU+mWGsJQx9TGygJzjAZH3Lx4iWeuHSZRx57jEA4+klEp87QUYgO1PJpQhCihUA7WGQ5jbUIB6ePH6NpGkaTCePJmLquiJVAO8m8dlSNZl5pauPa7sHSMLwFoPyHWLLolthPS066TmE0vrMkEIQKurH/2+HIa4t1Pva1H0sCCUVjyRtHKRzKQqz8Q94wxl0LCHqWnqe7PtUvJSHXMKsljV6azjmKyrGcyctRJIGigVkJp1clnUiQRpILE8O8dAjhiKSkFwhKbTGFIa8dnViQtr5tkROYwNGJapy1NE6xPQyJlMAZ2Jk3OGcJQ8u12YzKBLz4tiGDbsSqVBRFTFak5GXAgx99CGUFG70NnJij+pa5eQcf+cRjfPLBPZ5zR5/TZ+aQP06/n9DtdZAqQJuaPFtweHGPbuQIREO+8zg2P6Qa77B+cptuNuKeu85w/9Ux2joeOZzTOI2UksuznDTus5kGnFnpUZUZo2zOpZ19eisX2du/Sm/9JGnapawXRywLIVtjYAu188xOpKQqMvIs58/e/ic89MijPP7EBXqpl005aE30fRfSy3sdUoQ4IbBC4mgTORAEMiQOAzZWUrZW+mxvrpHnhp39GRcu77GxJdgaKAZDiVOecbDIS3SjPW1ZSOIgoBOHXJtnYOHM6oDnrqXckoRkhxkrz7iFjW7K86uSg7Lmws4hqQoJpKDBIY0fN700JhCWbDHlT9/1QYqyYJrlrHRTFo2PDzfGYIw3lnZStMC7X+eMtSjnO6dHLFrXpk223eqq8ZKRbig4tRIRCMdBbjHtz8gqx7wQZHUryxW+VSGlRLQq4FJDIMB6F0IcjvqGFNG/LtfqICGOQq4eFNy5FaFXJB88V/Lc2zY5udHjfQ/u4IRgbX3A/t6Ufhryec86jVOOvGx44PERJ48NGPbXeOyJPfLqkMNZzte88ATTouYvHtphMi/J8prHL44JsZzZSLgyqbDWG+7+1Os/TlbUNLVBBpJBJ+Dld2/y0BOWRT0O2AABAABJREFUnYMp3/W7l/iGV8K3vHqI7N5KU2eMA83w4AKRgZffsYbqDehsnfTx7qsniToDwjji4pWrvOeDD7Czu49zGnDYOsfpChUE/PZv/w4feO+7j6ioQgh+8if/Hc9+9rMARzW+ys6VC3zn9/0kDQnd4RY/91P/yh+gWiZuECZ0104RJn2EignSNWSQIoCk3+cLX/5SvvPb/y7f889+gMfOPYlAo+IhQWcbGfnvSVPHr/3qf6bI5tgm5647b8dv2pIf/bF/x9vf/g52dvd43ev+Bt/5bX+Df/KDP82pk9v86Zt+C4CmKpjtXuE//tJv8v4P3w9CUpY108MRRtd86atewZ+86Xe4/fZbECog6m3wYz/9C5y/cImf+w8/yv/+9/8OL3nxvXzrt/2fHB6OkFLxvd/1raSR5O/90s8RlhXFws8/5yAM4Tu+4g6mheUHf+nPuXa4YNDrcM/dt7O6OmRuJL/2wIhr85JASV54+yaFc/zH9+zywpNdblmJeNNDllmhKbSX6X/4SsVBOefeFc2+DXlMJzx04QCB49lnV9mfN+xPK8pa44ylG8Dffu4aD+yW/NGnZpzaHlAZuLwzpptEdLsRt5xOuH3ccNAIjp/d4D0XFvz2R3e5+6YBgyRgWhQ8cOBNWK01n9F5eupecaSoG0uWaWrr1zshJEVj2wM+CG2Ogla0tj4peRiRhopuJNkZF+S1IcsrisqzVnRuiLUjbSymMSTSETpNRzlM6IiVr3miQHBmPWFRSrqRB5waY6m0pZsoVrsh6/2YXhq1xr0BZeVYLGquXLpCWTTUleNgWnnVgLIEEhQ+5SyUjgBzVBMp5WuqUDiwDbq0ZKJhPPXgWhQJwiQgMoatfsTJtS7ZvMvFnTFN4+Vo1/YmpHHI6rDL6rDHYlGwdzBhOp1xOBozGR/S6XTpdhLc+jqYxst0l7Wz9FIcp72JetNUmKbBNiW6rtBN5Zn1wke+O2ep6ob98QSEQgYhWINuGQ1FUeCAIAhQwoHVlGVOHIXEQUycJOyM5lzdO6QsCpJQMux1WF1Zodfvo63j8tUdHj9/kfMXL1OWBbqpsZEiwB+Iz6x1WOtG9OKQ8TRnMi+oXGuMHgR0egPWuhGrg2OEQcDeaEaSXCYvG6bjEecf+DjTeUY2XdDrhDRaIJwlwvuqVo1j0TgWGlTgGZvOOQJatqsWjGtJZQVpJJhVFq0txrSAk/RgaKNhUYHWPtkuFI5x6cgaR+NE6zcFvVh6Zp2CaWmJAkE3DUhjiLShyg2LouapbrP4dA39dA39dA39udfQnzXwFLSMD9FONJzX/PFpmIf/5bX2lGKJoBt6iVsn9CBHpB2V9XRE24I1HmGnHQxtnL3wL1ogPD1ZCiIlcVickCShIwkhCSFUrjU8s0hhCaQlChwuFLhA0WhFUQnGc8c8c1S1BW28oTkOhUWaxsevth2HWmtEm7YnpIPGYDHMyoo0sCQy9JRytXR49wu3cYamaSiriixbUJYFRjdIGRG04FMcxcRRRBlGCGcJWlq1AM9IaoGk61K6/8lq3H78OtPsf/gC/6OO2FLuhm9tOWst6LSkfC9T74qioCgKqqpEIgiUIgrDNu7SMp/PORyP2N3bYzqdkgaSjuigy5DGNjQ3pIo4FUAQYKVE6BqF18n30g42NlhraJqKQnqPAYfw4I/RFI2h0h4cklxHbf9n1w2vEFo6oW5Zh0rSsrD8V9TGJy0KIA4FSeD9xXC0lGP/ddfphzf+DteOzRYNfopvmOBfQ+38ZngE0glPm3bOy1lb6BxYGss5pJTEoWC1A7sLqNoO1RHCJ/xib60lDlo6MR48Dp0lUFBbrz1WEsLAg8bL5MFAgDYNxkEn8WkunSDECUVjAooyYH9vgWg0DGC4URNH4MSEssopCkMcDJDOocsRusnRTYmuC0xd0ZQVxaKkESXO5OxfuEJ3uGCY5wSiJBKwtbnOyfUh+4uSh/enGPxr353OOTFYQSnYHPY4yBaog4jxImP/cML4YJ/OyjZhGNEE4VHCllS+E2WdlyBZAShFU5bkszEH155kfrhDvRhTFH4uGry3mwOEFISBlz4UpcE4i3GOIASE8PRkJ6lChapTtoa3kyQJxuC7pqak2xWkiUO4ZrmwYvEgt3O+WyulH8PToqYfKbaGHW5e6XKim/pueBRi4hCppJc0t4k0Snw6ABuHilA6MA2jwxEOi9XeQFO1B5sjluZnTN/lnF76qbnPmEu2/ZwA0kDSjSTDRFE2lkVpad0SKWtHqX2xu6QLL9mPy1+krV/7JF46gFjyTJbJMk/lSyBVgAwClPKvzWhNpBQq9J2vOArppDFlpUnSmEG/w+5BhokUvW5MXhVY4/1LpBTEcUCvm1DWmvE8J5DQTwK21zrkZePLChEgZeNDQKQkDhVJGHDu2py60Tcwa9sDaOi/5uHdmv1SEnR7iKCLTBTh2jrYnEA3nFwJ6JzYoHfiJEoqZJCgooQ8m3Hl6jXe9/77mM5mCAQqjDw7wVRI6bhy9Sq7u7tkiwUrwz4333wTTeMT/3b3R3TcAt3UjMYzaldR2eQzwjTa+ykFFy9d4eP3Pwg4dvcO/GcExEnMxsY6z7jzVjqdlOHaMYomYDBY4YEHH+Gmm05z7NgxXvzCexgd7nHpyXOEgSLLFjz22OO85z3v5Z3vejeeAe54xh03c+78RTbWV3nJC59Dp7eC0TWTaxf43Tf9WdtUUxjdkC+mPPjQI9x5+y188Re9EmdqFlnOuQvnec9ffoAnL17BGs1tt51lc2ONOIpZLtxxGKLiDrPoLGm8Ab2c54rjXLl6jfl0TDcSXN7P+OjDl6nLmkE3OWIHa+d4ct5Q1j70JAq8j4jGcmoYEyuffFvUhsZ6IGVcWhjXfPntYCqoJz5yQwlf5DaNpag0utGkoaSXKOJQEgWSSEmiUNE4Q5FXbPcC+hFcKwyVdcSBIAwlxjpmRRtigp/fSa9DvxPzvNXTSx78/yez8HO5VCvBKRvr66F27hjj10dfX9FKmZZ1pSWQ0gMYacB8ITDaMdceDNFtY8610jlpLToAbYz3lFI+pMd7ZFqiAOLAe00d1TTW+YNuIOnGilh5w2MhAoyRFKVhf39OlleUNYxznyg36AiiWBEH0In9cwyEr2O9V+kShHI4YXEWdAN5WZOXJWWeY6oC6SSdSLHaS1npJUSBpLEeAJrOc6pao6SimybEcYRDkJcVWZaRzaaYzRLhusRhgHYGbZYonjgyXhfS761Ga5q6os7nNFVBUxZorZHSswkEjqpuyOZzRBAShCFpEnvGu3UtC14RhYH3snXOr8NRQCeJkSqkbkEzay2BCul1Unq9HnGcUNWa0XjCzt4B09kcazywrgSoAKJAstKNGXYiolCRlZqyMcxqgwoUYRiwgiJOU5JOyMqgB0IwXeTsHk5w1pCN9qnLCldVxIEAJzCm3SqtZ30Zu0ym8vWHa8eHaw+vjYOlc5y1rvXN8uMpkJAZWmN14+Phha/lSt3WzkvWmWzVD05A4AErZZfWHn78WwdGG3+gfwpfT9fQT9fQT9fQn3sN/VkDT7HyAJFuX5hoyTPXaznXMma8Ebg2UNRetz5MHL2h4OTAe0tESrAza5ho13ouWSptqI1on74vWpCCUAiSQKGkp3UVjaHQms2eYLUrOLEKa0PJal+RBIo49BMyCgWFhaywXDlwzOdwOHK4psRpi20aVKhQgSIIFUkg6EcBg0jRaIMwBm38oHIqwEiosUzyCh05XNRqko0lDiW6thjntZp5WaLUgt3dPYZrm2zmOd1+TBhFdLs9er0eti49X9P5RSmKIpSULVPHG6i7GwrlJbvHtRXi0X9CHH3P8u7ZlinloJ3Ero2pvP6zlt2gZWLe0t/JtlG109mUxWJOU1cMOgndTsKg3yWKAqw1XLhymfOXLnLxymWk1aRhwkoakSoIMWCsZ3A5cLJB2ZAwDNnqJDTWUWlLKAQujFHrWyAURZGhbMN4ljGaZxzMMiy+0jTO+xQsUdylMfoN88FvdM4/lmOzaXX0UaBI2rGhtaHQvrtQNY4kEKylil7UFmP4ZJclzViJ6x5jSyYV7T1UwhEKcE/5KHbfpaoFIGz73kMQgNX+Xhm7BCn9pRQkArLGEYUe+Lt54ChSwV6hGBeWaWVY6/u1oTGWvbnDmpBTg4Aw9uCxRGGcozawsyioa+uLQ92gnaf3b/UDhqlkd17RHwj6K5LuRoTIImQekAYW4woqVdMUXSL6DIZned6z1tjerHjZs04w7KfMdw85/9BDDNc3WR3EFJmlLiqsUNz3wGNcOP8EVz74KHfeusozn7nFzv5pjp08zbPufg733DVCBYoPnr+KaGPR73vgEYZxyC2ntrjrttNUgeTBnUN2D/eRaodHPvYx1o/dzPapm3Et9RZtCUJFrRuaIvdeB86iAsPk8nkm1y5w0o05eTwg2D7OIImxtqKqZginkQLCICDurSBUxOhwjG1KnKnQViBUhIpSVjsphdZ8amefjrBYpwjDlO1Vye2nNE8cKFTdMLp2gEQRpz3SeA2nJI1pIJAYayirkr3DCSsn13jWrdu84vQm250ONu5ybZFxYWePd73/QQ7mOWtrHQaxT78xBj8xlKQXQDeCQSq5eX1AVZXMs9x75RmLD+v0OvBISqRrKeTtvBZSHkW72nYMSukfnrFoWUkDbl6LON4PuDq1lLVlf2GpWxufsvFFigM6se/uyzaNo2k9BhsrWo+3pd+KbRsM/6uGh38FlwxIhut017eYXH4cQcNdxxyPH5SMM4218KnLM544qGiMY7ufcvb0OrOsodSWR/dm7Fwdec+DQY+r+xkHo5yvf/U9PHJhjw/ef4Gf/9OHOLvd59X33sQ8axBC8IIX3sUT73mUJ5+YEUaKO06u89ybtvjI5RGjeYERC5y1TLOG17/jU9x+vM9dxwdEkeDsHXeS3PYyTJEx3ISNW29DFwnFfskgXbB+y2kGtz0fGQQgA5yVPPzQE7zz7e/iF3/hZ/3BNUoYbpxkMd6hyqfouuLkmTu5+fY7+dB7/oJXvfrV/OZ/+0Wkkly4tMO/+8+/x7e87lW85J5X8K53vhxa30LVFldC+nfa6Ibxtcf4vu/9fr6/ld8ZXeGcJZ8c8obX/yFvfuMf8dY3/BIvfcmLCHonAMGTT17knhd+Hv/kn3w33/+9/5z9izv83h/8Pv/0X30f7373OzHG8oVf/JrWsNghVYQQAiUdX/jyF7Pei/jEe97Bsz//i+ivrLFx5nbitIOzBhnE6GrB6NqYr/6Gb+Xv/K2/yc//7I8iVMLH3v8xvuRVr8Zaya233oLVGU5bnK09i8tZrHF82//1/bzylV/A29/wqyxXc2crvv9f/RA//e9/lh/+zft8J9n4vXX3cMrr/+w+vvabrrG62mGlGzLBUmnHXz60w//2yuP822+5m3e+64DRuQVCBswXNWEgOHusT14bGqO582TClfMlH31kxC1nt2gazYcf2WE47NLrhBSV4LZjA06upPzkfXOet6H4V6/Y4ifum3FxUmN1w0uGDWuB41t/3/t4DQPH6MldjjvBV92xwpsvZMxrS6Is3/ra5/KKlz6fm77kH4B4ys9eAFy7z9bGp4ctG2FG+FZWEHgpjq/a2vQi7RlmAkc3gPVU0lWKYtR4SZNzHuwwlrLWhMIhnGR3Ltjsh3QTxSBVZLVhsjDsjCSNNmRlW3/iU3mN1phGIhpNIhxdpZCqQ20lua65sl8yneUsSkdRG6JA0QsF/WGPbhpS5F2qqmIylRTZgkhostghbUUiDTb0DWXtLNO8IpyXRFHOYGVBEMV04pATm0OyomLQTRgvSoqy5sruiBPb61gkKysDeuMFTkhmi4z9w0OuXrrASi8lRIOQ1HVNVXuVQRhGxC17S0hvmFvXFUW2IB/vUS5mlPkcay1KeVa/UsoDR9MZQRQTRTGdJCIIE4IwZtDvEwQBaRLjdEUuDM5qhitDhoMehAlZpRlNZ8RtOt2J41tsb2/T7Q/YPZxw7sJFHj/3BIvFAtUekCtriFBEScj6IGG1G5NGATtZw+684rGdGbXxTdhh94BBr8PG6oATW2sMeykvfvZtXLx2QJYtUPWcWNf0XUOEoXG+yVpVBh0qgq4jlo5ItQbOzu+PRaXpBQFSKaJI0TSOed5Q1gZrHCtJwFqq6IaCC2NLrS2LoiGUy7AfSY3CtkSBXidmOAgx0vtqCQeJ8kbiVePr71r7uiB0htQ+tevop2vop2vop2voz72G/qx3ayH8C1b45DrPv/IvzutQ/YRbgnHOgXYwrzyqF0iLCjxIs5pIMAEdJZhUHsGtNeSV75QV2lG2BnVGWeJA0YmUZwaJBm0tceDoxoKNgWRjJWA4DOimAomhrhrGE8e1XcvVq5bFQtNUYEvn09e0pWkanFUYo0hUTCAE3VAxjAIqbYlkjdHWI61WgPVaq0ZbKqkJpCSWilBJkkhRaoc13pS8bjRFVTGZTplMp8xmM5LuAKkUaadLr9vDViWYxg8Opeh2u8RJQhCGR3GlbXBny9yXbWeZI9TT3SCxEyxRzqXHkx8JQqgj1ERIiXStkXgbrygEyKWZpRCt0bmmKkusboiUpJsm9Dsp3U6Kc468rLi2t8d0NqOpK9Y6MYMkphuHxIEilALpPDNNIgjjiE43pZOmdHtdHBLtwIqAxjqyxlDXFdY5inzuP+cc2hic8JPq6HJLt353HY274ZPuMz4SKkEihO+oS/81ee2pxmXTos0tLdHgAS7T3lAp/EazZDwtf/Cy47pkQSnx1+DQih8f1oExkjRuuzPS+Y1S8GlotXPt61eOrKI1JBUc60o2uoIzayGXZoa9zDCubJt6CVKBUI4GS7dlA8ZKoKVAO4F0qgVQDSvdgNpA2QKDgRLkRc50phn3S6StUc6i0GxthMTJOifObHH14RH5xNIPGrZjQXc7Ik06GBczLxSByJH6kHp6nmxSk+eGybhhmuXkxrFxdpvV0xt0N7fR0QqFixkvatZ7XW7eWOG27VWuTAumRc2V/Sk7k4xJVXNmY53DSUYvCMiEYl5VXDz/GCcfeQDT1Ozu7GC1RhiLMZp0MGR4/BSdlVWUiNC6QilFL4153h3bxCYnFjWBSnBhB5uu+I1C+DFnixmmKanOnESEMSKM0C4EXSGaBX2lqYxg7dZnEKydJu6tUzULZsWC0SJjf6Q5vbrOs+48y+DULaiVLcpJ1RqRGqTw/nJlo5FYUilYjUIcIZkWzJqct1+6xgP7Iy6O5kglWOnGvpuNX/PTyJtNylARqJDGBjy4l6GcPlo/wUPlrt0UFb4Ak4BB4HvM/gCkhCAQ3g8wbyzz0nepokCyPQhQyjGrNecOapSE433J6RWFtY6DrGHRCKrWoy0NIFFtt3bZvXWeiRstfRik8M/HuaMO5lP2cpY6m4FteN5tq1ijefjyjLmWWKE4dmKDsmooioq4kzLLax557CpxFKAbw/7uhNtPrXB8NeWFZ4f86Ucuc/+FCR/85AVmixoVRARJRGYkH3z8kFlesRJL7P41NlXN2bWQi1PNLC/Ym834unvXeeLajN/4833CJEEFATbUvPiZWzzrphV+8U8eZ3d/hJnvoO02l8/v8qH7PshW1GG1l3DLPS8gS9a4ev6QX/vZ7+YZd93OvS94LseO38xrXvMlrK93kEHClZ1D/p9fe6Pf0xyA497n3sU3f/PrOPyaL+HgcMJ3fNc/x9mGxaLggUcvs3v+42yuryBkwJe/5lW89itf0+6VHqi5fjQQGN2w5JF7GZ5fDM/edJKXf97zOXHyJsJ0iFQBCM86M9bxR296C5cvXyWbjHniwpNYIuC6PMA5WF8d8s+/+zv4gld+PtbCRz76YYrFnPs+fB8/dsfz2Tmc8VM/9TN8+CP3swz2WLoX1vkUXS3ANiBDz6huU9z29nb4zu/6FwRKUTcNs3mBCBKkiqjyKeVsnyYbEaV9LxUSAV//tV/DyROn+KEf+QkmkxFQ+f3UOupG87E//SNGH18lqwzHjq2yutLlEw9cZD4qufTYnHeey3l0r2FtmFBWGmsdo3nBiX7AVqr4+Q/NEHHCV7zgGB99csY018RpQhSAcoYyz9kfC6zRaF3x8L5jb+IYVwKhFEEU8fFDy6mB4bu+YI3dg4qDSc0vfarmjhMdXvW8Pn+xs8uiARWF/M47PsXDe45/80UNb37bO3jvhz7OT//4T/5/PCn/166iZTpI6T1xQuWIQolwPvgG5yUi1nnZgveIFUyymrISVKVkLZGESnDTesRBZplVlly7dtw5UI44lmytJ5xajXEOxpVFlYZa+1pFt4eWbqwA5ZlokfJrb2Moa1/D7h1OGc8aru1nLApNURsWecU096nSg1Qy7Cgi5YgDRT8JWO/FBHFMv5uw0o0Y65rK+hQ07QTCWGTdsCgqkqwkywo6QpJ0U7Y2VllUlrWVPlltaMqa+Txnscgpcp+s3OukRHFEWWtm84y9nWtsr/YJbYU2jkVZk5WatNuj2+uyurpG2u0hhDyqrZX0sfXSNkhTE0YpYZyS9voEQUhjDLVM/F6sJN04Iu72iDo9rAg8WKRgPqmQWIJA0uv36A+G1MZR1A1lWTHsd9naWOPUiRP0V1ZxMuLq7lX29g8ZT6ZH42KZch2qgNVezEovoRsHVI1hlleMFiXzsvbSTCnIa41ZFBSNYVrUpFHYMqQCkpUhrlYU9YxpWZNXPuK90Z4dVxtLXpsjNQFCIhQo50OhlPK7c1ZZZqVlljeAJAyVT/HD12zW+eZ7L5Bsdr0R8bhw5FZirLegCJUf550IqgoW2tfXMYLQenuVUHirC4FDm89kpT61rqdr6Kdr6Kdr6M+9hv7sz8vuiGnmkx+kv2mydUO3N/CxxBH45AEkBwTS0k/9LUwDgUukZ1Ghj6jFReOBp0p7bx4QaOOBqTT0wEFjLHntqevLuNZhVzHoKpLIJ6IVtmI0MewdWK7tWWxlwIKwto1JtdRNjXOBB1rigFB6ZlU3CujWhkQJ/9ztMpFAgvMeTk2r9U4in9YSBYpAaAy0DC5NVdfMs4U3QMwWrBvj6ZZJTJok6DSFpvQ0VKVI0w5xFHvdeAsCLT204DpDiaV8jusPXJuQshSBtW/UkamiuE5pXYJXogVzvKyx/Zzz1FndUpGxpk3yi+mkCUkSU9U1eVlwOJ6Q5TnWGjpxRCeJSMPAp1qI5djw5mVpJ2bQ6zDod1ldGbaae0nVePrgrNJMstzHBec5liUo5o5eO0tZJ9fBzeX/3zhGl1/Q2rITtAM2VArjfHpO2TjqxtEY35Hw39ZOLLd0wfK/N2jTGW/EvmR7324Enp7qZ1ZYGsVJnBP+MCAd2gmshCUEtzSasG6ZKOnncK2hbARriQfzTg+Vl+qEkvFuhfUNd5T0WmLjDAr/NYH09FLRbpoST+vvJwGFtjSlIY0kaQQ4nyRTVQ7pNApNKCt6Pclw2OHMmW0OHivIqgY7rekL3VJhBUUNpbZoU2EaaBb7lJOMPLMs5qGf81Kydmqd3tY64WCNJuzQWMUsrximKcdXh9y8ucqo1OwvShaLksN5weGi4NbTG2z0ugyThL0goDSGnZ2rXL3wOMI0PHn+CZ8CYgxVWbJ+8gxJr09/dR0RhDhb+7meRNx20zYpc1JR0tgEetvIjTuRQdjed0Nx9WH0YoRI1wh666jeKtrFuGKCm10i1TNqEZGGNyHiFawMmE32mWUZo3lJUUrSziq33/4MehvHEXGX7Nolysqn3yjlffRqa0kDQTcQ9JRgWlmyumavrvjw+at8YueASVGy2k9Jo5BFWbKUAgf4FKswiUmjBCFDzh1kJMoRSteOoza5qT2MXz9as4TWgesfDxC+e9/4PSFQkjQU9GOBwTEpDTvzho2u4tRQcaK/9KgQ2AKcDxcilHjqcrtm2tYXTuIIb5i/wQ0dyqf25dBVjm1ybtq+nVlW89GH91BRRJIohis9mv0JWdXQHfaoyorZZM7J05ttylLG+p3b3H5qlc+/fcjD5w949KLj8Sf3QfpEqCQNqJ3j0atznNYMlGCyP6InNadWIi5OfHT3wWzBXce2oSkxTU2YJL6xoQSnt7rcdWbIPGsosgxbzLDRrYwOr/HR9z3ChtQcP7nB8Rd+FYd5wMWdCW95yx8zn76Ik9tDnvGse9jYXOP49oAwHfLI4xf5o7e+38/nxRiwHNtc4QXPuh0Vd/mzP38PP/tzv8zh/g7gOH78BB+6dp5Ga0bTgu3tbb7yK17Nwf4Bk8kUrGZtfZ0oikGoT7vDWZaR5znra+vc/Yw7ec2rXsHa5jG0DRjt7rIyXCUIAra3j/HII4/zkY9+AqczECEy7AKCKAo5dvw41tScOrHN3/nmryPtrTKfL3j8sccYjSdc3tkgKyoWi4xf/OVfw8e0t6Vke3qxuiCbT7h27Robm8faZ+i7ffP5gl/51d/kyONKRUgVI6MUXUzQ5ZymyljkFciQ9fVVXvSie7nrGc/gv/3m69ndSbBNzuHhCG001hquPPhR7KUY4WCl3+H49pAHHhLkWcPulYLzo4bdwpJECueg1v5QfLYvWY0V736i4daTHV56W5/3f2qfxaIh7iT0I4lyht2mYZaXaOcIMVxZGB4qDEm3h5QKGQbsVtAxipfdnHIhFJxz8BuPLFjbkty8nfoOrPDNuo8/cpV5FbCzc413vvu9/Nbr//gpDzxVmjaNyvshRdKRKGiUaA+1rrU7cMvCB+cgKzWVhKYRxCpkoBQbvRAnLCpwuKyhtO4ojCdQgl43ZKUf4hykkaIxfj8P2oNCIPzHAynoRpJOqIhakx1tDGXdsH84ZW9UcmlnTlU2VLUhL2omWYWSgskiYJHHpKGX8iWhYpCGJJ2YXiein0ZkuaJpBMY6dLvW1o3/+VlRUZQ1URyjlGA47LNW+NTFvfGCRVGRFSVZXlIUJWkU0UlikjiiyEvyomQ8OmB8MCQRmqY2jPOaadHQW1ljtVklSVKipOOZ/crLvqQQKCwKg3KaJI6Iu126g1WCKPIMA+kZTRJLGoeknZSkP0CGERJvjl7M/GEvUIo0TUg7HZ8qVzc0TcNar8P62grbW5uknT6LSrN3MGIynZJl2RFQ4T1LvbnvSi+mm4aESjLJKuZFzSyvKGqNUAqFotKWWvvPLYGnapByfGOFOIkobELpchZaUDWWpk0+1K3fadUmSeojbxbR1rvqiDlRVoa8MlSNJYiCI9Cusf5nWedZTf004PhAoa2lsRqnJY31nlJK+D09lFAJb7OiEMj2XKVwBMIDXp7E8NSupJ+uoZ+uoZ+uoT/3GvqzBp4qs5xE193NhXBYIZAttcu1dE0h2hdg8dRWCwe5oTSWTijZ7ivWO4rjg4D1XsC0NIxyw7wwRzGRTStINMYySAJ6kWOrmyLxBl9VU1M2AoMkSRWdVCCpuXR5zN54yofu1zSFw1USqSufjNZ2FTzw5GNHSyXpRQH9OCSNAjY7sdeEaoO2Obm21I0HjaTwb3CjLYXUDGRCHCqG3ZiiMlin25hajbGwf3jAyv4uqzubbB07RRRGRHFCp5Pi6g6BqYnihDCKiDs9+oMBcZIgA9UynGhBFNdqed3RwnxEdlrqG3HLGtQDSUqBUMhWVvBp7CjhKWuCNrENPE3fWXTdUJUFtikJhGWlm7K5tkK/1ydJUnZHI67s7nF1Z4+mKumEIeu9LitpRC8KCaWfTI2zhGFIHEWsr/ZZGfQZ9rp0kujo+XQCiRMB26pLL1bsTXu8v8gp64ZSG44Jj3o3xjAq7BHoZK3DGIdxSxCuZX8Jr1m3LUoqlSButeULbZlVhqwyFPVSj92m7omW/q59F6cy/vvjAFIlSKWgI0G1NGAHR6hyKLx3gPpMUe1T8JpX/r6nEQxanXNhBChPlRQOrPHz9jqzDmIpsE7Q1HDfRU0nhMkcXnbbkC+5I+UNDx7yyE7FIzslUSxJAi+JnVce0PTx2g7Rmoyu9CLSlYTHD3MiqUlDzfNOhxxfkfQ6kv4wZWW9h3Ih/U6POAh5+P33kY3n9Dp9TmyeRPQc6nCXJ568zO7hgqqfMQ8iplKxe23GqfUNtrd7ZIc7ZIsFs1xyciXk1No2Io5Ahlya15zoNYSioqDi2E2niVdWeNW84SD/ODuTBXUac+7aLm9/732c/eKAQap45Quew9w5RvM5D1/do/vRDzA+/wDZ/hUft2wN1XyOzZ7P2TvvwIo7kSrGNQdEYUSwusHJrZci631cfcjB1CHW7yK87csg7vqbbzS1+QNq+TjD2+4lOXY78dZZT2ydXsHsPEAz2SHqrHHrM7+CjqspRnv83i/+Rz7+0D4ffaDki1/2HL7gxS/iS179WsKNTfYPRzzw4Ce5trtDlhdsrq9T1oZKG156yxa3DDt0swU/df9Vri4qDosCS4UUjtObfUTbCMgbUMLirGZez9lc6XPv8+8miRImi5JfeMO7cGFIGIds94MjbzXtLLU11BhYMhndci3z3QyJJBCS6bxkVjkg4tknUwap4IlrM8a5Y14CUqKUn7vaGpbRrtZYtPZ0YNOuA96rxBfYRx5vwpEqx0A55gqip77BE7Sm2M4JJtcmlAbibkoYhYSBIp/Pva+Htax2Q1wvxKx1sCJAY1FhwocfP+CBixPe+mHFF9+c8C9ffYofffeYrNJYW9JNN2hqzXQ0ZzCImTnJT35wwivuXOGZN/X52E7FaF5yMMn5wd8uaYyl000xVtM0npL/tvdd4InH93ndXV3uOb6Bkcfp3fJcnr865ObB43zLj7yL+/7yAcI3nudVX/qFvPjFL+B9730H3W6PKIqI4h5ve+d7+ac/+OOsDFe5+45beOebf4Xv/Mffy2/99u/jTMEv/erv8hu/+yZwhq/88lfzyY+8g9d+9TdQ5gv+8Ld+jnTlBAezhtd+4/9JZ7BKWZR86Zd9LY8//hhCwG/8+q/ykhe/CLjeYXe24Wd/4df4pV//7/zp63+dM2dOEUcxYRTzoQ99mK/4yq/jF37+3/N1X/tVfPhDf8FP/swv8u//0y9TTi76BDxTgjPc8/x7eODj7wd886XfH/Ded72Hd739nSzmc776tV/Gz/3Hn2Iw3OB9H/gQ4A2QhQiQQYSzFc75WJo/+IM38LY/ezt/9ta3tA0mSdRdQ6qIcr6HDLvIsIvVBSoICeMEUwpvQDxY4Tu//Z/x0MNP8O53vJk4lvS7Ce946+s9e8o6XvXqL+f++z+Bs47nPOM495wZcnWu+djOmHc8sUuURqgwYr7QfMfLVvnE1QX/95vO0xv2USqgLA0fuzTn4kjyy3//Lv7i0Rk/80ePoJKYKIkoFgVf+qyTHBvE/D/asSgNo3lNU9Ws9CJuO9HjoPTMDrThm19+lq1BzLf89uPcOgi4dRDy71425PzC8RNv2WV35jAtq+y7X7rBetrw+V/2zYwPx+TzxV/JtPxfuQoDCkESKjqhrz+sMR68EKACRXHEbPMmML5JqHACSuDKTDMpLEEYcXJ7ndvShPH+iJ1JxpVRxrzWlGXD/qRAtTnuk6xpZRSCUCo6XcVWN2J/UVNqQ6kNwzRkaxhw03bKTFsOpnPe/YGHabSgri2uqZkXNdemBfuzEnBY3WC1YTxIwTkabRmkEZvrA5I0ptuJmWYFVaOptD3q2ithqKqaxUIymSxQKqA/NKyurlLLhJvPnGRvmjPNS6bTBaODEYe7+2ytr3B8pcvNxzd44tIOZVVx8eIlhqFFT/dwxnFtUrAzK+msbnLi+DGSKKTb6/t0LykJVEAcKoI0JNYhHRuxcuIk3bVt+ts3IZXCWkOeLSjGu+hiQRAGdIYD0pU1wijC6RpdztkxDdY0xHFIEkWEUnBtb49sMUc4yy1nTnLbLWe55bbbkHHKfHzAufMXGI3H1HVJFKjWC9WxMYg5vdnnrtPrxJFillV88skDHr824WBRohH+gCdglrcdfWfp1A0mClBOsyhKgiAgiRPKJkCHPawqsdorCPJaUzUSGSiSJKRjBHbaeE8xB0ZJSg2TwrbG87CShgz7CUIqdiY547qhbrz5cxxL0ihis6sQzhEhGRtFph3jeUXdaCa5JZbgtCXG0QskUkDeWJQQdAJBP5L0IkEaPLX34adr6Kdr6Kdr6M+9hv6sgadat1LEFtyAVqbllibg7Ta5RPBbN+ilTZHD6weNtUfJBdpCN5aEUhArwRzRGt5dTy8rnWNaGiLZ0I9jAilYSUKcNMSBBxeEFNQanrzWcGHHcu1QMp6B0o7Q4o3EW2BGuBtoeM7hrPeXSgKFcRC1rKe1NGJSNjg0mbYYI2gEhFKirUUajcUSKkU3iejEDcYJSmOOZGJ5UTCbz5lMJxRFgRSSKPAMJ991Wb6JvluE82l29sZUu1YKJuR1SPFGI3HnPj1ZUCCw7fux5H6KJVh1ZAJ7HSv1jC7bYvVLQ0j/ujpJAklEt9cnThOsg9kiZzSZURQFkYROHNIJvb9WKJcLrV91kzjypqy9Lr0kJg4UGG8mbrSn6vvXFhDoihjDSppQV37DqmyD0xJJA6LxdGSWCK/4H0zWXMtWWhqsSeEZaNp4t35PL7ZHbKYlS+zIXLHF8Jz1XQohfZpd2LKajgbyktl3/d1B/jXgPNVGHpmha+u7NaHy90i6JVNuyay7Edz090lJgUTSWMeTE83GQUUlYLMjcRshPSW4mBsQMM0tofAGxvPS+nhP59BW0wkDjg0SriwaCm2Z55pA+rVgvS9Je4puRyHkgrJwzMcp28eeQSQNsRac350yGdUcXD1ANpIg7rOaOCbTCVdGGbvzjOHqNsMTJ5lPDqjmNXuHexilMFLSOEsaJfSThJt7fZI4IBmu0agIZzXH+wmnhh0uD7qcmyw4nBU8rPe4dDij0+lycn2VY6sr1FqzOx4zni1YixWrwz6VbiibhhBL2ukQhB5o9SaCHtytGs0Tu1OkKZFIumunEJ1NTFMfjW209n8HMdr4It0sCoSzPp9Xg1EdkCk0jtpoiqJmf7wgKyuchJvOnOLYsWPEaQ9jHHmWc/naNfKyxIlWNu28Rvzs9jqnOxHDKGJa1ezlJZO8Ytj1hySEQBvn02ukwhpL0ZR00oBep8PN25vMphOm9YIkFIhQEEbyiEm5HEtLJuwRZo47YjPSAsjaOYJAMJCKtJ8QK6hqwzi3lI0A50MdhGh9EVw7tgBaL51U+HTUdl/27EfhOzhBCzaHAg8cY68zQp/S1/U1ZmdhMEISRwFN0xA6w+ntlNCGjKX36jDG0NQNMoyxztHpJhhjyIqaqoRHuqBdzFc9e8gjuwWfvLygyAu0schAUteawSDidZ93its2YlIJ4kOCYyspJ1cT0hAO5zUXG8OJrQG9WBFrLxMpjOThWcNd2QJpxwgVEa/czNozvoJXf8WQ/vHHefPb/pIHHnyULC+pSsvnv+zzePnLXwZY8sWUy+cf4zBJKSY7/NIvJzzyyCNeCicDyrqmrGpwhk8+8CC//Cu/zu7+mI31VTaPneKd7/skH/rYp5gd7vDud70DXYy5dPkyWZ4jEPR7PVZWVjjihjsHVhMGkmw25Xd+9/UMhwME8LIXv5AL559kPBlR5XOwFSvDPl/4ipficDT5IQ8++Cn+9G3v5Dd/67c5f+E83/SNf7M9eQBYjp88xnPueQ5RnPDYuSf5lf/2uzzv+c+nqmr+yfd8J1U2ZXQ44vfe/Bdoa47e75WVFW677Tbe+MfvYDQag1CYpsKa2tcKpvJ1g224++5bec1rvhRdl4RK8NM/8/N87P4HqepWPtj+ORz0QXhWw1d96ReyNezyZ3/xXt736CGXDgs+tZsxqyGKAsqyxlpHGCne+/iERw9K0o5vliml6HYjtjqSY92A955b8MDlnKLWfr+PQvqdDk/ONXt5Q1Zq4jBgvZ/wstMDrs01D+02BGGACCUyUeyPcxI0r3tBl3PXGj41qtlKY+JA8qw1xUd2wGkYhIKPXSuQLmd/p6Spaw/+PcUv53wdRtvEXKb1gmccuJYloVq2uG/mtoWr8HtDqQ3WWfbmGhVrhDKkoWSzHxKqhMuTCgfsjCqs9h6iRWMpah/pPik0G/2Y1UGCVgXjrGJ0WHtfECVBKcpSktWCJPIBQMI5SuNoLEceaV6iaShrQ9lYQiVBKgKpCKOQKAyJgpBuktA0higMAItp12u/PtWURUVZVNRVTdwLSNOU9dUVBp0OaRRidENZFCxmM06t91lNQ85srTIaz8jLmsNZxsFkQRwErA2HhJEhSRxS+GLOm3fj758DYy3GG6YQKImMY5IkIYySVpYqEUjiKMZGMdLUNNpQlBV6saDf7eBMja5LqqqiaZo2IMhhTcN8Nkc3DUGgWFsZMOh3CYKQ6WzOaDxmPJmgdeNZV608QAGbg5SNfsKgEzHPK/anOVfHCxZljbaWKAoRyjf2tfGgTSglvTigk4SspAG1sei6ZlyZo/EVhZFXbVgvhfEJ2rY1DL9uVny0QrT7dBx403gnFVLg5Yfa+O8RgkBJQqWIA4U2fowY65BYIunTzFdiySAWmMagtaWpDUjfHDcOTCv/M8ahDWjJU/p6uoZ+uoZ+uob+3Gvo/wXGE0jrf6GSfvGT4npttTzML8Vhtr0fy8nnJy3UxlJr/0ZVjeNMECIRxIFsgZcWtMIzVyoD40LjrGCjo1FSsJqEaKFJI0cQCpyU5DU8clXz2GXD7kjgdEAKPu3OmNZ9Xh6BM0ELIDn85lmHlsY6QiXpRgEb3ZjDokZbx7zWaCNASJQRaOFAGIwzJGFAP4yY5xrjJIuqojKeVZW1wNNoPCLLMqIwJIl6SOUlCQKLlP4+YjXWaozRHpyz15PcvOWEX5HdDffzSFzXrmzXwafl91z/93UinPd9Eq3E0XtemBbIMR40whFHvisURhG9/oAgDGh0w2S+4HA8oSx9AdqLYzphQKx8mom2HjATUpCmCYNeh5VBjyQMiJSiLkt03dDUFc60XRshcbUl0IaVNKKoUsrGUDc1AomwAoRpwbjPmIC4z7gv10FLIZZeUY555chqTzEOpPBmaKKlMLbTSrT30rXgpFAQBRDi9e/Lce3c9fPKEsx8qh9ZAbT1xumB9KkaUeCIQkctWsYi/jX7+yiwti3UWgaYCiCxEm0dF6YarubsFA33Hg9ZTyJuW4t52/mCRbvARX6tZZK1vhYC6qYhCVOOr6T0DmvGhWaUGaz1gQArPUnUVXRSQE7I5jV7VypOnHw+oc1Q+Tkeu7DHY5cXPPDkAffcvM3tW0NODBVP7s259uRl9mTELSJk4+abuXrxMuXejGv7h2RCUSKY5wXbgy6nVgcEJ1OSJCJd3aIChNMc78fctNLj2mqf8/OSw3nJ+DDjycMZNwUJJ1ZXObG2yjQveOTCZcaLnHKlyx2ntymamkVVofMug9U1wjj1Y9R6vzJjLVVZc+6RayhpiJOAe87ehkwGlPMxTnrtp7DGJ+ioiKYqqSZjbB0SOgjqCUHRoG2I1Qo7mVE3GfPRmL3xgrxuCELJzbecYfv4NjJIqGtDPs948upV8rpEKA+WWmcxOG45tsGJMGCoNZUxzOuavDGsq4QkCjDWj5mmcd4IVRuysmR7uM6gN+CmzQ0+dbBDsxh7z48oIIpDz15t59T1M5Y7MjNd8oZdC4Rb52isIwklnSBgOEyYFyXTomGU+Y0wULJl33pflGWUa+M8RV1JQUctzQ+XhzsIhCSWfrOUwndoIsF1POevwyTG37LLC+tl3nFImRXg4OxahHMWA0xKTZmXVHlO1O0RRyG9bsJikVPXPqDj49cEe5Xjx7/yBO98RPHEQUmeZd4zIAwoi5LeRsR3fe1ZTFGze1AgEJze6PKKuzeYTRecE45Pas3pjS4n1lI2ZcVCB8wqwccPxrxgMkWX16hqQ9A7ReeuO/nmv3U7t9/5Ed7+ng/z6KPn+NRDD/PHb3kb3/sv/gkvf/nLcLZBVxn5eIccx+HVc3zyo+8HhI+j1wpntUcggPvvf4D7P/EgMuiwuX0CF/b5vTe8ld/6729E6gVv+5OL/PGb3gjyM8odAb50XC7ogqasmB7s829/9Cdb6YTlB7/nO9vDmaUqFxTzMSpd5fNf+gJe/nn3YnXJ7/z3P+Ad7/xL/vPP/xfuv/8TfOM3fgO60VijcbbmprOn2Dq+Sdrpcf8nH+ZTj/4k3/Z//F1e8uIX8uM/+iNMdx/nkYce4PVv+vMWQPGSvdOnT/EFr3gFv/l7b+batR0Qgfd9csbvm03uu5LAPc++jR/+/u9Au4B3vusvec1XfB1R0uP2O+6gqhvAmyAjJEEQEgQRr/uqL2Nr2OVt73wPb/n4NQIlmWYNa6t9Bv2U2STDGkuYKP74gRGX54beoIsKI6QURDLm1s2EM4OQ1394zP68BGf9ISiN2Fhb44HDfbIsZ7qoObOdcvN2j3/4RUP+5IEJ7z23y9ZGigwlkQh44tqMoAn4139jlZ9465h3PZ5TE/L5JyWvuTnkzecFroSVSPDO8wtmeU1z5Avz1J/A1vl1y7XeILR19I2HBoFPglbSyziw1wt/EFTar8V2WqOiEiEkG8qx0QvZGEhK6xhnmiujkqp2hIGkNLCoLI2xHCxqVgYdVlZ62EBSWciqKdo5jBCUVpHVkkUpSYJ2DcWfATSSMAwIlEQ7i7a2TQcGFYZHZ4IgDAnCgDAM6HYStPVytbppsMbX3R54chR5SZGWVEVFRyrSOGBzfZVhv0MnDplWFUVRMpvOiZxhtRNy9tgal3YOsXbO4TRjd7wgimI2tk7QIWJFVWjhn6ez9simwjifqtY0Gmnb5MYkIY4TgiDw/j2tnkUFAWEU4pqQrKwpshxXOwJhEbZBlzll6ZukQRAgnME0NbPphKapiYKA1ZUh3W4HhGA0HrG/v89kPMZo3aZie5PgSDqOr3bYHCT04oDLe1OujTKujjKy2mBxRJHyYFKbfqaUJAwUw07EIA1Z70UcLkrmjWa8yImi6Eh1ACCcRbYNVmtca1hsj6Q7R2fG9tzQiRWBkqhAMS288qNu/GFetr/bJ5xKL+WzlrKxOOmDoFZiyXpXMowEh1NNXVmfKB60SdoWrLbo1mA8VD7s6Kl8PV1DP11DP11Df+419GcNPBkrsMKzkVQbtaeOQCh/iD8CoKSfhNaKozhOiXf/FwhqA6PcMi0tmfZmWFJwlJhnnUC37BbrYFZpv6A5WEkUq4lic+gYJpCEgot7gnEh+eg5WBSCqhakNIStA3QShATCtUCDfz5REFA3xuuSm5qikgRSMUhCIqVYTSKO9RKUEIyLqjXmswgpUQ6Ms5S6oRuHDLsxjVZEYUNeC1xZU1pNWVdMZ1P29nc5ODzwHcJOt40YlWhTo3UAAmpdIYuEoOzQNDUyCJDO+s6XuJ7mRtsRW95ra73VvDUO4TxSLpQ4ev8d1jOe2oXQ80EVUvrEAZzxhYA1CKUQ0pt8Hjt5EhWEpN0eYRRRVRWjq1c4GI05HE1IlGKQRKx1Y1IlCHFYY2i0QQWSfq/D+sqAlX6PNAhwjabMC/LFgqauaeoa28YBF41mP6+ZVA3npwWTqmFRG7RQGBVBKElihzMagYZlV6GNVl6iwcCnoa6mjYDVbScGvLwuUDdssr4FiXDuyKztiCLbSkWXZZ9tN23XSvxwy693fw1KXr9YWAeNEUxqS2QcXQcCSShBWudjN3FIJXBSXJfO2jaOUyq/6KQB18aaq4cNl/YD7t5OeP7JlL/57AFXZzV/+UTGlbFBW+hEAtPq+z+xUxOFEWdWa7741k0e3Il58OqEx3Z9VPDZ0ymDgaC/otF7OfvnJzzyUMW7J1PyypJXU9724XMcThcMOwEvuTvh1IlNTgwjnlELSqPonLmFs3feTjRI2ZlNuTQaURjPDumEAevDPlIoZjrgI3sF/cVFhteucvvJs6z3+2yfOc5tO4eMFxlvfeACt53c4Lm3nuS5d50hMjC9epm+0ayGChErdrOMYdbjtS/6QoKog3UBk4MrdFe36K9vttHSDUEQMVnMOdy5xsOfeoTBxnE2T95ENDjBpYsX+PM//RO2j59kc2ubZz/3OUxtSmVXWAv6fOxD9/GJhx7nRS94LhtrK2yuDXjvuz7AdJajVj7IYjojWyyYLHKqymBq0IXDBj3U8Zupzz/MfDJm99oe0kE3SalMg3CajoTtMKaoaj55dcRBoTFO0AtDOnFIHAeUNTSmpmw0cSyJY4UUKZ/3zDvZ6sd88oGP8NaPnuPC3ox+p8/ZVclWT/Leq8YnvSznjvVeybYda8tmhXWW2kqMsCgl6CUBlRFcPsi5NCmZVZpA+bkbKAvOm0IY6yhqXxBOSohC6MawlUgSB4H11OHrLEjpJbIIUgmx9Gk/tfV+F0/tqzVUBGQgcQKKrOKZN63SiSQffGLM4ayiaiwveMZxRouEy4cx/uRqyfNWhpHG9Icx44MZj12c8g9+I+e1X3Qvv//vv5kPvfGNfOTxHX7nkyOEFDyxk/Fl3/deTg5COqEkK2o+8eSYJw8yvvD249y+tcbzX5Xyhw8c8InHdwmV4h9/0SZf9uwBwd+9mz983wEv/ntvQKYf4NVf+ir+/U/+3xy7+U5edexmPvqCl/L9P/Aj/MEfvsm/PBGACCmnl3nl5z2fj3/kvT4cA4fVOUKG7O4d8BWv/XqyrAEZtcRd6xs3Ouf+j32Ee+59Jbt7h2wMe7z5j97Mr//W7/Offv5XcFZ7UMcZhAzxoFN7OYuuFlhdtc0Hf88clv/0y//Vf4mz/Mt//RP8xE/9PEKFHD99O5snbuZTH38PL3reXfzFW/4b3/p/fd/Re/W93/t9vOWP34qKh3zHt/89/tY3fR0bNz+bL3rNbfyL7/q7rKyskaYpCOitbDHcOn30/vb6A97y5jfw4Y/cz4/+xM8wm8/RddX6SSmQIUKGngHWJtoJGeBEwDf/rW/jvg9/DCEDvu2bXsVtt5zmK77um8kWGVVRYOoF3/C6r+Nf/+sf4PVv+xAf+OAnUGGPoq7BaYQULFpPGakEe/OK9z98yA//b8/i3GHFD/3+o+hmjjMWqeD+suFCN+bmroBGcDAT/L3Pv42s0vz6ex5BNz7dNkxiMiO5MrH8wQfmxAK++6Vr7KarPDkq+YuPTtg43uNSLvgbv3CV2zqKf3B3h2cfj7n/oOF73zPjjrWUY9ry8f2K7/7CY/RDxz/+w4seoPlrsAurtpbTFhbGA3S+G+6ODrRSyKMGVyB9995afw+184CDdY6s0py7OuLy7pitjmRjJWZ7LeG2M+tM8gZ5Ze7lr40/iFgAKZiVDfOqodCGm08MGfQjKqPJnOL8SHI1s8RBQCgVh9OcadEwzmuME0RhQL8Tc2prBeEcobB0el3CTpe1zXWcNZim8XHc2jNkuklEIAXN9gqjSUZWlFTaeOBJaDrznCAIGU7m9LY1YZhyenuLmzZWyA8Puag1YRih8alzvTAkjRIubK5gjeVTkznXphWyY3jRiVvYTmPCUJItFiRJh9WVFaI4xgnBPCvYPZyQTQ6JqzmDTsSgM2CR59R5RXZlh6KxhEHI5toKoTA4AvZnBfN8QtFo5C2niBQ4XWOMRQUBg34PqzXzomBv/5BFlqOtYTpfEB0c4oTi/KUdrlzdJcsWSCxJFBAKxyCOWEkDzm726acBs3nB41dGXDyYM81rwkgRB4FPl2p8414Jn8Y8SBRCCirj2JtXlJXGaEMaeNaCxAPUQRgRqIDemmTQlayshsSZRi7TsFuGHc4SS8FqKljpKGrtuDqruTatWdQWggAlZWuuLhE4dNNglaNuLKNCE4eKKJD0IgnWUdT2/2Xvv4M0Tet6f/x1hTs9qXNPT57Znc27LCywgGRBgqiIERUjInCO6ZhQFDhG9CiiGMAAepQvBkRBUPISdgkLy+6yu2ze2ckz3dPxSXe6wu+P6356hvrVr4rzo+p7xqq5q3pqpqf7Cfdzhc/1/rwDZR2kPLEWDCy0pWCxGzGUlrqwnC5rPMHO5EK+LtbQF2voizX0119Df83AkzovLn4iaWqS7re9nyZI+cSIWTSGaxMaZzCQE00kX+igbBVum0Vl7LlUMdmYaUkRbnDtHJtFHWRoztFtQV5K+mPBSi5YH8PWKCzM1goi4bBIrCQAPQR+kGxejBQC3+gGjfUYayjqmlasA4VVhZSPolZkWmFrG26sFdsYTm0s1gadZRZHGCPI4jiwdRpQpaorxvmY4WhAN+9RG4MTEiskpXVgajThvsR1TV0bjDFIY1A2UHC/SlpH8+TbDJ1zoMsEDT0fdsI5zv1283uiMRyXPpgbce49Ka2Ik5jedDBZTLMOzgVAqazC63PW0koiskiTadXI0IIhphA05m8pWRKTxBq8w5qauizDV1VRlRVlHbTiW0XNyrBgozSsDXOGtSM3Dq9k04iWgY4vBcr57a7INgDnfaAtS0GsghEfgmYyhCLPNz+vms/+HFdqMmkFpmmc1vYcwmtUU/x9FWtscicn5uICvrb59n/1SrSndqFjOnmvKiSCbrPjJu8p4HFNl8Y33ZwJEiyC14Ah0DRXR47jmzXtWHDZQkiI7KWarTyMCdlIESUwsrAyrHloZcS1OzO6keKqhU7Q9gtHtyvRsaQ2gkcP54wGll7bcuT0WZY3ao6sDFkf1VROkEYS7R3CGqxIafd67N4jsbFGlCVrZ1bY2OrTzwsqoellKZ00oVSCygpqKzixOiDTlm5UcWDHblSkIcroZhkLnYylTswV+3Zy4/XXMDM7Q90f4UxFJ4noJjHOOkZFySCvyXqLqDgNJq79dYSKmKRcITxRFIFUCKmZmppibnaGxbkZbDHE5UMiX6NdjTQFrhwEJp0MNHnlLYkv0L5C+hDTrvHEwpJQMahGFOMB6/0trDW004i8v8b62VMcP/4I68cfZWV5uTEC1CjpKK0l1ZKpSNHxjpXKcHpUUtQG7zxJpALwjaCubVjDdUjPUFISpQolYVSU3Hd6mdNbJaWBK7qS+UzS1qJJw/ANTboB0M+T/QBhmSL4+jkvmhTJsIlt5I5hFWjmmRZoSbNXnLeqebbB9ZCk0xh/Nl2Pic9CWB8na+C5MV/74A33X2AKN5enriqU0ugkoahD0yHWkjQKxs/DcUVRBSZrSwdZVV43xYsL0bzOSwyS5aHl0eU+9x8+TV5ZFqYTXnjDAl863Gd1UHNkeUxMm4VeQpJE1Max1i85tj6is3eKJzz2EO9/YIvBaIjSmlY7Ys+uLu39M8hbBzx8YgQ8yrXXHMeUIz7/pXtZW98CAZtbfYQQxFkPHWdAiIbvTWXM75zi5ls+h7WGZzztyThTEYdwWa644hBXX30N3hacPHGKL37pDvBQ5GMefOhhHnf9NVxxxWU89PBhVlZW8K7GO8vM9DT79++j3W6zvrHJLZ+9LTQzvKUux0il+ZYXPY+P3/QpxuMxeFhd3wQhkDpheWWVM8srIBSLO/dycO8ijC+l025x/0OPcOONT2Bp5x4EnlOnT3HixAme98LHszA/i1aS5zzjSVx5+UEuv+zSACA1s+BLd36F2267DWtr8A4pBZdccoCHHznC+vr6OdDsvBmk4g7eljhXh4aLigHBJQf3Mx6N6HUSLtm3g/npFg/cdz/jog5sj/E6t37hNt773n+n2+vw2MdeR7uT8vnPfY6TJ08iZDCXtt6Bcwgb2Mgn13JObQSJn1ISoSRShHUi1ZLCGmbaCY8/kNIfl6wNSsoy+N9IqaicYCrT7OhFjCvPyFryumbkS7CGnV3F1Usx3UTxmfscWwLOCijzGlUbOs6yldchGcs6Tvdr+pFAxQmuNiFy+wK/2nFg3dQhXT7UJc3Huk04EQTZDmxTq6WcNNJCE2xy2DAWvHOsj22oZ5Vgfj5GiMBMKk2NmUiqmge3HsalYX1QMN2NQAjarZSyAuMksQlrvJWOUVmyOa7ZHFcIKWkBPRFSjiMpEN4Qx+Hz1XECPrCIbF0GGZ6stuvDNI7IkghrLWMTFAbGeYalIatqyqrGGouOBb1Om9lOxlwnZWOYkCYpKsnQaYdICZwt6KQR3VZCp5URJQkySoiyNlknI0saz6EkJUlilFQYH6w8qtpQlDWuMrTbLWTaxguJqQ35qArJg1FMXbeJEo3QYd/2QjSse4f3oYZO0wwnJMiIusjJ8xCBXhQltTX0h0N0FCGEZHNjndFwEIzJm2IrVWFOLHQTOokGD5ujgvVBwWBcBzmPCl4sbmI67zytSNKOFe1YhTTo2mKKEJ6E9ySRJksVSaSxHqpaUBlBJRSVkDgZTOXjhmDkvEc48DI06CMVyADOe8aVCWca61FKb4cReRr2Se0pVAh+Co3ZcChRgsbzyDcKBBG8UZUk1pIslkSlC2bacI7BcQFfF2voizX0xRr666+hv2bgKdXnFgYb6hEsbMuStDrHFhGi6c2en63nA/Akw0jA1QFo2szDQqekRzcP4D0kUdAgKgVFHei8a0XNqDT0x5IsUZRek8uIY5uCfikYl8GoEecwIngyVU4FG+2GuCLwSB+oZEIJlJAMjaGqDc5DFkekWpFFiukkwjvPTKoprSWvHFUt0R5AUpSWOg0oRTuJkWimWpa8MmHgeUdRFQyGfdY312m1O+TlIkZIaqEY1obCg1I1SRShqgpdlRRFiZcaKTUyUlhjz/tEJ8KwsJBv33CCaaNoABIfzAEC44nwM6HwkI35eIR38qtkayDQcYxOE2aS+RCvHacM+5sMx2PGRYGxBilhppMxnSV0Io0mGLcb75CRJkliprttOq2ULIpwdUWdF5R5TpmPqauasqzYHJcMy5ozg5JTw4LNsma5KMmNo3KOOEmItCaJYtIkQTqLsiClCywj30QI+yCRTCNJJ9UkMkzNQemoXACShGjYeZwDrM5DnrDOU5iw2Y4a9Nf7YAooVTAa57yJFaSbgRIv+Kre+QV7TWWOURU2DO8EtRMYG96bVpBqse1l5Wxj0i4DsOqcQFq2tcAKaKcK5xWbY8tdp3LuOjngW6+dpp1odnRiNnIYFmGx1QK8cggVcXi95OR6Toxmvh3xPY9Z4lSxxlTbsHuXYKOKWB0ovnBLnysuybjumjbHzhzn8Mkht907pDMzw1I3Y2/PE5uS8cYmG+2EdG6WS3fu4yu338PK4QJXlpw6dYb1wZhCx8zMTLOz1+LE1gDjPaWxHD98BmFGtOSAZz75qSTdHoXL6LVa7J1p88T9c3zjE6/nRd/8fPpry2zY0wjh2DHdYaussGXJoC/Y7BVE7QWMd4yqIYPhCK8z6sogEhfMPHWLJOvQ7s3y2Osfw46lRRZ3LLB1+hF00efaQ/totadIsohq4yTKe9I4gdqwZ65D+6o9LM13SDONxnLJrlls3aEzO8/DCRym5iO3nkQDO2dbrJ+6nwcZsLZ5mq1Ta2xs9Om2WqHbXTuGVcWlUwmXTbeYMoZTecnxQc6o8XVptdMg97Ce4bigFSvaWUTuaqIoppe22BxssjXK+dAdJ8nilIV2h6csCWpg0CTo1DbEyzuClMPKCWmx2Qtc2NSMCyzZWApKV1NWjuVhkGhLKUh0SKEUArxx4EWIJSfsN7EICRx6ksLRrIMWt2286CaFcbM3eaBwIajgwr/O7aeDzRFZp838rgUePXmamJpnXL3AahqxPqq598gaDolUmh3zGdZLCi+w1RhTVeSlB6FI2x20Mnzitvv40Kfu4OmH5nnGdXO8/ScO8AN/cAc3fyUwn2amWywtdDhVKTb7OYP+iM89fIbZXdM8+8XP4I8++gj+yDoCRzLXobVnEdFdQmRbCJ3iTY6rc4rhGq973eu55XN3opIeth4hpGRq8QBpewq8JW7PhIONULz+Db9Onud89rO3UGydZbh+Cu/hO1/ybfzWb/waZnSKf37PB3jZy+8MN6bZC1/5Yy/lmU+7kRu/8fsZ9DfBVSAklxy8jh/7sZezY2kHDz70KC/94Z9CUyKFpfYxv/JzP8Hfv+NPuP6J38SxY0cD2CMFUkVE6RR1sYmvg4n4Nz71en7ttS/He8873/VufvSV/4ObP/khnvLkG8Eb8I7FhVn+/h1/TCtL8M7wO7/yCkQjBQgVlAChefNb/pJ/+ud3h1YmPrCYXA0+1BF+Enk00XEoQdKdx5RDbDVExS1U3ELg+b03voFjR47wrnf+DQf2zVGMxww21xBRi6TVwZRDPvrxT3HTTZ/kczd/kMff8FiESvjO7/lB/u3fTuOtxTXsabynIzz7E8nv//sjnMwtUkJvuksca7wpOTiTstSO+NLRgsftn+Kbr1vk1//9AY6t5Tgks7M94jji+Ok+h+YSHn+gixmNuePYiI/dv8GBxZIdHc0zL+nw0hu6zCQC1oZ85kzJZ07miFHJUir59nnBmx/qs2FhpqX5m1vXqLwk6Uzhh0NqO/5/eT7+n19LHcWo8myVjlxIjPWUDfNJS9C+ObE2RwvR+DvJJvWrNi58D9BKomWQ/myMS/plwZmtiqt1AgRriaAeCB40wYs1pG1tDAsePemItUcqTStr4ZxFOJiNJKULnihntgqGRc2wNF/FJp+batNKIrAm1KNSILQmUhIpUjbP5tSVpSpL0kghhSCNNJ1WgpSCvDDkxlNVHlFYojyAQdbUJHhmp3rsmukxmunQz0t6vR5Jb5Z0ehFtS8rRmKlEs9jNGCwt0Jmeozc1Q5y1iNOEJFaYNCdOEtIsRSrZTDfRJBtbTGmxKiFqzwTlQJ1j6gprBUoqvHNIFSGVJM3aOOS2dC2wfTRz85puZRiMC04cO87WYMTG1oCyDp6kZ1bXGBcFg8GAs+tbDAcjUi2wlccJTy9RLPVS9s216cSKzXHJibNDlrdyNvOqkdMFuVtZu6BswDPfjuikEb0s4uzYMqws66MajSPRkkvaCYu9hOlOjJABPFwdOjYrhYwVi1YTaUUrDlJE2zRnkQJJaLyXFkaVY2tsKIzDuiZMR4Sa11pLWcHQe2IvGnJBKK6982jvES6EIyEkUgZ/mF6m6MWSTiKJx2EPnxys7QWOPF2soS/W0Bdr6K+/hv6agafpmO1OTeVC58C4BojyYH1D7RQBYJpspBNjKtvEAAZULHgA6Qb0EAR5XR0EiyBgNlZ0E8VMS7FVGAalY3lQU1mPMY7lccLAR6y6mLHRVC54FDnncNYyMI7aiJDgIGIyBW0JcaPP0j4sgkoIjA7SPmMMw6LExhFaBkOwaR+xu5s1FLKKsfNYCyAoSsc4N4zGJZ0kJtOamVbGsKgojaGoJdZaiqJgs9+n3emzORhSWE/lJWMncHmFAGamImLniY0LtF/rqSuD7LXx1m4j6ZOvCeAUigvfZNQ12lYvwo0WNuDkQjY/PtFPh8GKOIfIn0MMJVKq4OGgdMPsMpi6xpiaOFJ0s4QscnS0JBIEFFKG19JuZXQ7LaZ7XWKlwDmqvKAqwleRF4zLisG45MRWzkZRc6KfszIuGdWGojG2EkLgrcECpQ9mbJIQJZp7gbAe4R2OMKG6UQAL24lqqP0e62giY/kqKNafv7eJIPEcmcDA80BeNZ0XAd3Yk4hzYN/kmhjUB78o8dX/eYFe8wqSCMAzqsIcdj4g4bUVWBPQeN3M3yDsEU29JsLmqRrKpfPMJp5WJEiVZFRFjGvNbScrYl0RSXBItIZxDWPrqL0jjYINu/WCDz28yo5WxDULCTsXHLt6Ch0rbG4xlWPPYsrSTMJ0FpF2E1pTjulpmO0mzHVSrtk/w0Zp+eLRPmNrWdi5yPQOxfpowDhf48TyWVoSOmnER+59lCTLsGkHEaUMNtY4vnyWbhKzY34XV+xaIpMtiv6Ike3TamccOLCfbyoMBxbmqGvPuKwxQpLOTDFrBZemGd/xwm9l58I8O2Zn2Th9nP5owPrmBsOVk9SVY3bHBp3eDDoKEt7KQH9UMFpepjvdI0ozVHuWmfYM83sOBp81a7DlmPZUC2SEd5Ydu/awtLSAjFvh4Cole6+8Dq0k7U6HhT2Xs+f0KjffeZjCriP0iKI15N7j93P883ezY2onSZzQ7rUYnV1hYzwgTTMOzc/x1N2zLHRbnK4d3ak26uQGOIcTUBqLlB6kJE0CBX9PFDOoBWdHOR+/f0BVO2SUcu1CxMGeoqcEJSLMzWZe2O213jcbX1jrrfHbc6kbS7QS5DZ0AoWSdJNQaDsvtjtFE5mr8KAcNLcDGtas8OC0hKYp4nxIlAm/F4B4Jc69Bo1DbIfT/le4JLoxd6YukEpQW8n9ZytGRUhWfdyBaWokIxvSTaRw7OzFVFWICi+MC518IelvlRgDQmnuPj3gxKjis8eGfPtzr+FbnyP45T/7LA8vjzi5WXB2bUirk7FrzwKnjp9l9fQad9z8ZX7+u67kW56yyGvf9gUq26IQO+nufyly5l/A3QZC85lbv8yLv/dV3P2VYBJuqyEIzdzCEu/4k9dz5eWX4OocGaV8+pYv8Nu/9xbuuf8Yzlle8C3fgy22aKWKd/3dn3PllVeFrmFrBzKZDfsZjiuvuIw//sM3cvXVV2GMBRfYTM1piN075/mWFzyD2ZkpHn30GCbf3E5ucb7C1gVxpPjNX/1Zbvr0rfzdP74Pb0NSYJ1v4JxhotMWOkFGHVw95pue+xw+/MH38Rd/+Q7++d3v4U2/9+u89pd/gf5gTJLE2/6JMmrx0Y9/kj/4w7dA0zgBz4tf/G188zc/n1f8+CuoqppxbviBH/sfrK2ebd6DQQiFinu89pd+kksu2c9/+9k3UI/7gfVUj/mP97+PRx/6Cm/5o99j795dfN8P/DB/8ta/5fCRY7z3Pe8iThLGecGPvvwnWVtdARxSZwjdAuANr/sVvu1bXshPvPpn+JEf+n6++YXP5RWv/O/subLLc3/4GuLPn+aLD23yF584TpxlGC8Yrg8QeU7Ri3nNc+a4f7niDz74EGfWx0RaM7swTVkZyrpix2KHB5aHnFjZ4uXXd9nTESzMpDxmZ4tWpBgYye/ftMq4qFnbqnjy7pTvuqrDvz9Ske1s8ZxrprjWrHF0q2KrsPzok+fpJJq/umNE3czlC/2ajz3SOcalxcpgRWFdSCt0wNics7HQTQP3fAWBiIJR+MTvJW7AHmtdk1pmefBEf5tFYk0w4w1BOue61lujiryoqZF0soSpTpvFdkokBKYq0dLjNLRiRW0teS2ojWWYF5xc3SRLY+a6LRan2zgbxnZ/q0+aJqRJHFQNVc1gPAqm402dVVlH7Rw6jhFOYoxgtfBEhaVfGapyTFqnpFnE0nyXerTIal4St4KnmE5TdB3M12c6LVQU01ncRdKept2dItGCqhiTD0pGgz6drqUzNY1SklRret0uvW4HW3QwLidpTZFNL5LEmm5d05krqJ1ESkkrjUmSBKUke/dqjAkerN0sCXuSM7SlxlhPNhyzsdEn2hyQpinWB7XDyvoWW4MxK9EWWni8MXQSRTl2WGeZb2fMtmI6ScTmKCQGHl0dMigt1kOWRggpsc5jTJDXtSPNUi8AeNY5hnnJsLRUlUVHkkh4Um9IbU1mBfumY6YyRSuVDErBxshyx9GKMjeMi2A0rqREK0mnFaO0ZFx7ausYVR6kItIC4SGo51yQjTmLVxKtFVGiG7N5g21M6Hd2BLEIbJ1Uy23FgfdQ147hsMKUFowLPjLuwgeeLtbQF2voizX0119Df83AU6bDxqFcoAabhkFkGgqWQ4ATeOkbRlC4EUlDBbEuoG7Wh8eRTRSg9OeAAOea1+2DHCpSgm6imn9bBoWlEsEVvnAabzVVqbAE8GVC8cT7EMdYg3eCUSRAS6LonCdVSA8JN08ribMT2qhBCkGpFakSJEoynUZsFJrchAQP78P7MRZqE8zJiT1aBMldGmlirQN44gKglRcF4yJnNB7jjMN6gUVhrAEcjkAFrp0LSTI+LPS2lW6n0k3YTr4R04nzACOP3GaYBVJmU2GI8FsesV0whxveGK1LFR5PANsSPNlUOaLxOgqAngDSKKKVxGTSEAu2pYACiVSKNInJ0oQsiYOfQaP5nwBXVV0zLms284rVUcl6XnF2VLJVVuTG4qVAI5u0j+a5ETgmQFno3EvvUE6AkEQqOPjrxgLFN2MhjDEmgTCICRPfN2zB5l46AkgVPJwEtQ3/P3FUmeQG+u17d25+icaf7MJPxIK2Cu+xQmAt1MJjfJh33nvqCYwO2x3Wc+xFQDbMLhfQd6U8sYYsEhgvqRxs5A4lPan2tOJwX0o38YOTRDoA1qWFlXFIi+kIz9y0Q0mNjnx4/DqMvbr2jMeelS3PxhicCNLONFLM9Xr0+wV1bQODsCiwa+s4byirktFowPzMFJEQWGtYHxW0+zlzqcB5h8KRpTFZ1iJNO1SlIc8L4lgTRTGiBbtmpomEZGOjT1mGdBmhFbEUzCUtnrh4BXPTU3SzhDIfUuUjXFWGZoBzmLpCIJBSIZUOALv1FMbhVIxudVF1SLpsZQmmLrB1RSk0KmsjVISpK2IVJAbGB6myw5N0E6IoIkszopahljGLO6ZZH40YmyH9qmR1K+fYiS0S0aPbFbTjiMoYKlMzH3XoxBGtKGatNGzVYf5NmJSWQNVVBAltFkmmW5qlluRk33J8s2K5n6OFYE83ZV9PsacraemQtuOtQIjqvDnkmy4NIJoOp/UkiaSVBOmAFNAvfBNEQUPN57x44vOOl83YLZ0IDREziQuHKg6hAIHd2Mzd5m9hkw5sgUj54M0g/FcD0hfwJQTsnkmJ4oja1Wglqb1mI7dUVejwaCXxXiBtYIYKPDhLGkmMhHFVo7zcpkonsUanEVvDnK1izPGNmhc9UzDViYm0CtKgMvgcIgQ60kgl2Rzk3HbXMS6/ZpalxWke95irGJmU2x8aMNUtcHqGxz7mau69/wHOrq7zqbMrNJ0FvDMIFfbJLJGsnl1mffUs111/A8srq9z0iU9x+WWXIIXgpps+yb7d81x1+UGe+Yyn0e50QwEkkyAxEyGcZKrX4dnPeirjcc3hR48HM20mhQW0sozdu5dARgR/w5IDB/YzNzeH97BzaQdCKNrtNlmaNvugBG9wtgYgjmOuufoKdu3a1fgsOaJIMzXVI8/HRE0k+DXXXENtHHd9+S6srQKDQmd8/tbb+PhNn24M0j3g+PGX/xhPeMLjUercvru5vk4aR9zw2Ou47/77yIsKpOa6667j+uuuAlvibUhzkyri9Ollzpw+xRe++CUALr/sctrTi7SnSp79rKcTxxGD4ZAnPOEGVs8uI3zN0WMnGwEH7Nu1gHzs1UghuOzQpXzjs5/FE5/weK66SrPzigNcfnTAmZVh6IBahyfI760N8ejtRFFbx/GNgsq4wHBXCkEDugFFZahNxeowwTjHbEuH/cUHQ+JRbtnKDVbK0ORKFb22ppNpkkShldhOxEqUINPgTI2fxCdf4FdXeUrpSWWoybQMEn/fNLdsQ2qT2wVGWHsnIzhSQTLlxWQ9ndgbCKwPne9BXiOlJGrY2JOyeOLN4wFrgxH0qHTEEaRK0Yk1WsCgPv/4MPG1DPVxVRuG45yt4ZhIKeanuwgZEr2qotheaSdAWFVVmGbdLp2ndDReURE6FsReMiprcusZVYaiLMmqgihr0WklzM506LVTnJY4W4c1o/Ew6XZaRC1JrzWLTNrEaYZwlroqqIoxVVViTIVzNhzelCRNItIkIokjiCKiOCVO26RZTGQtMsqwqAYkEWitQmNTR9syu0hKnLMYUxHFaQBLZEynN0Wn26fdalGbmrquGYwKxrJCy5zpdjLhEAQJq3e0IhVYQhC8tEYV66OK2gaGWvDzYptlkChFJ2kMvR1NomCwwpA4Mq3oxsHQu6M9LenxDQLiZARaUFSW4dhSGUnlJFopIh3kb7EONWBeOSpjKUxoamsdTNCD9UlIxAueRQ2TTkkcQZlSW49rkt62lTDNqUXQJDU28iF8WH0ice5sdiFfF2voizX0xRr666+hv2bgqRs1HQsHWgYWSSSbpAt3zhfH2bDZyWbHa0VN/B6eYS0oLA1IFOAQ12yKE7KTbwZEWTlKFaidC+2YuVZ4o4PKM6wEOmuB1sGA2gRgxJtglicFWDy1tdS1Y90bqlgjWzEyCsug8J6ICf0sdEud9+RlSW0MtbUstBMiKVlsJxQmbF55v6BwjtpJjIWqDtHVPnVE2tNLYzppzKiq0SpotmtjGY7GbG71WVldD55RVpDELbz1OG+RUYoTmrIGMxiRlDU2M0x3240D/fk66AYKOV9qJ2VDyxaIySjzvvFzar7fFLTOi+D8j0LqePsz9gQwUEjJJO4Wb/Au6LCzLGW21yW2FXJgUaZukgNAaUEcx0x1O0x127TTBFsWmKqiLHKqMsTl9sclZ4cFxzZzHl4fslnWrBdVADABTTMzbPC5EM3m5GjYWErTd57cOTIcUkM3E9uL0XhkgnGj9kxngtKGJIHCgKGp88+PpPMwQTvDESBspFGTaJcqT9y8ju0IS8Jn4Lxo4mNFQLQv8KsbhffUiiaGcFBZ0cgRBUUNRQUFkMYQ6fDzYZEI8LgUHiOhQJJb8CVIGRaeSIJvDOscjmEZ5lSF4KodKUtdzfHNnLWRZSv39NqavPDc9MCIdht6c5qknSBJqEaKex8esLJWc3S55u0f3GB5vcYaiKVgOkvoxj32XbqTTidheqHLHffczxc+/TmeeOVeFIJT62P0KMcDz7hkgUc31vn8yjo3XL6bqXbKrkN7qGVCVdZ86YH76bTgkr27eNzjHsfq6VPkgzE6zjhxapm1E6scOjgPZU5ZjolRLO7axTO/99WM1pcZba5w7J4v0u31mFvcienPo7JWiKeWUTggC8XEGDiZ3km6cIB06QqyeANnDTUOkjCv07kI2QQDJM3YR0ikozHCdyAkVipyneH1GtHMgOufOMM9h1d56ITj7kdH+ELSbc+StVtIrdjcGpGXBhxc2osxleErZ/q8vz9gYAxbpkZohQasNYEsAmjhWexEXLnY5tq5mC8dH3L7sSHCK3Z3I37ouhbTOrBK52KJzGLGUuO+Msb40PmZdFg0bNOCi8pyyWLGpYsZzljWBhV3nQ4sHgjqCC1lCKzwE8P/QGt3wjFycGIzdME2xoKBCZ3GVINOPKnyOBfWFNUc0LQOiTzdlqRSjunEEDUmoBf2FQBwKeBVT1lgaOCf79qglSVULuxDk7r9i48OsKbGW8N1+6YpjOfhU30O7eqQaFhfH6O0IooU01MZC1MdFqc6fPbLhxnlJdbW/MqffYYkiZjrpfS6GXGiWWnFVLVjbW1A1u1weLPiNe/8Ap1em8c/9mpuev87+KlffCOv/7l/JJm6mZ955Q/wsf94F0982vM4fPhIeHHiXLqDtwUrp4/xvBd+DwhBlrW48/bPgne4esRbfu+XSbOEZz7n23ntL72eH/7BlxJlc4GFZPPwGM5s3x7vLd6MuPVTt3Lr5+6grnJANECTaVp7CdCYcjvDG371f/D93/fdCBEOnOPRmF98/e9x5MgxnK2RSjds4hLw7Fya5xMfex/d3iwQTMk/8O/v41U//St8/EPv4clPfhIq7oBQnDp1lGd+4zcxHufQJMr6JuADXxJMP5rJEW4OeEcri3nnn/8W+w/sJ263eNqzv5Uv3XFPiIZv1hDvQhNMyIjuwn7qfMBo/SQ/8vKf5Buf/Sw+8uEP8Ou/+nOhCdOgO91Ohw+87x+bhlDBU5/xTdz55XsQKuZPfuunOXRgF96Vge3bm+Hf3/se/PgoZuNOTq3cwdnVEWmWYo3FGIuQkit3T/OYvVP8xsc2SbTniZfO8IWHNxiWljOn1tm/c5pYSx54dJnH7Omwb26KP/7CBru7mmt3ZHz68JC5VPAdl7X53qf0SGPFTUcdnz025CNH+vzVc2dwVc2Dd53irsN9TheeLNW85ZPHMY2vzH+VazH26EYmMPQEfyCl6DceHHnlEELiRZBa6OagUVuLFIJENXIJ53DWYetgJu08aK1QcQjNcT4cOoTwDdnPszCTMd1NMcYxymuG45qFqS5L0y2u3NHF2vCZFonelsJtjGuGeUUeurgYZ8ltzfEzawzGJZ1Om7l2QhbHDAcDiqIA+kTS46oaZ23wCLWOzbwO4LiXXLJvJ1OtiDmlOHpqlcp6Tm/l7FjfxAuIk5ipboISsyyeWWVjXDHaXGW8cRKZaFotze7ubkg66Nnd1MYEs/LRJmWZUxZjIiXQ3uDrIrQuJaSxopVoykQj0oS01SZpd4mTOEgNdYVUwZNJ4KlNY4odaSKt0VqBd9R1TVkWREmGkIpsSnLAQtLqcvLESY6d9FRVwdrWMDRtvUctTKGlYDQugkefd6RKYI1ja1TxyNqY5a2c5UEZGDJSYr2gqgPQkyrJVCtmoRPjEAyKmtNbBf1xUE1MJ5pLp2N2diOuWUzJYoXWkkcK6GYR09MJB5KUQe545OSQ9a0xXkYsTAXz6kSLAEhWhq2yDOPOC4yTZIlGSkFZBp/dqg5Ab2lgZDxTzlMaz0Zusd4TS8nZwtPTYQ/OK4sSglhLrJI4KRBakMSSFp5u6km0IFby/+fcuRCuizX0xRr6Yg399dfQXzPwFDWd0YlayzS0SS1Dl6aWAZiyzVdlAzaWKE+mIYoCa0rLibeaByu2D/DCgZXnbuyoCnKp4+sl062ILFHMtFN0IlC1RMdRAACsxdWh66edDZp3CVEkMEZQe09e1eAaHb2Ig2m1CgwY1Wj9JobiQSLnKOoajacVa1pxRC+NsHjWSgOVaeRcCufD5jBJl9FCETUm15LwQVtjcdZijaWuK9pRCx3HTE9NUyahgGy1u6godFjLKpiFprHGWoNANfeJbeCDyULW/EvIcx5PwR+jYT3RMJLOA1wETOhSgd00qdy8m6AqWFOH/oSASCnSOGaq3SbvtNFVTjnawhGicVWk0E1sbred0U4TlGgMSusaU5uwUVc16+OKs6OKM42n06gOHgGqyeFVImjMRXjhTefJo4QL+JqQICVOSCrv8VIgvWBchM8trxydOEy4SIWJYJtOipg4dm4Tv8I/lAhjU4hz0tFYh++1dIi6DT5ZNPdPbLPeKhsAKeUu8FYNYcGIXOiedjUkEgoJhRPUKsznygbD0tJIaieojCONIFbQ1p40CqDyuPbkhgZIDt2cJBbUxk+a+NDcp8o4lIepWHHVoVnuW8657cSQYW4CQ0M5FncssXP3DGruIKN7lzlzfI2b715DKUGWaVpCsW9WEylBFDtWRwP+8dO3861Pv4En7F5i12VL3H38BKujitseOEkWx+ya6/DwxggpBDdesoPo5CZHN3MeOr3JtXsWuGzXAg8fO8VgNGYwHrMyHNPrDynXlhFVjVYJojXN+qllHjh9liz2TGcRvake0gviNMaXQzbXzrC+cprROCd2AeAcbK2R1DW91jSizpF1hHcKX+d4UyIbtN07u2187H1IzQzsORNAUHwA0134vnTNd73DiQQRS7JWzJFHj3P06N3cf/9dVAPDkugxSmty5xmMYa0yYDxbgzEewUwr5eBsj/VhyZH1AYf7Y6SCLFYgfWAcNga4SgimM8WejuJAW/DI8ojjGyWFgd0dxe62QFhDp50w3425dH+P5X7F+nqJsaFoliKsywhPZSzDMhRtu+YipjOJBo5sVuAsu3qK2lsqB4NyEjpxbv8REoQT1B6GZVgDrWU7EjZM9nMHed/cMyE8sQrSFCUlLekpHERa4psO4oV/hTWsvz5is3Isr4+Ym2qTRYL+5pipbkYri9kaW7K4RSfTrBclsRBcv6fDVmmpBXzDFfOc2CxZHRr6/RyNJJKK6V5KnGhGpUHFMShJYR3j1T7eWSonMMZiaku7k4GzWBcS8/LCEXX3gm4F/4/hOv/5n//JiaMPcnZ1ncc//gZe+Yof481/+nbKsuI1P/dKbv/sJ1k+eZznfefL+ORn7uDjn/4iQiqe8PjH8ZdvewtXX/c4lFL85V/8OU/7hiei4zYgcCYn7y/zW3/wDu64+wE6Mzv47hd+A096wvWoqMMX7nqAD3/mNp70rG/juqsP8dhrLsUMDnPo8quZSO8uvfQAf/nWP+Lee+/jVa/+6VDQAqY2rCyfIskSZhYO8OM/9FL27VnC25q/fvvfsLx8JnhVhkWOqDXH9dddxc//+Dfzrn94N5/5/O383E//BH/zzvfwyU9/jqKocQ6SJOJ1r/lp5haWUGmX333j73L48GEa6jGLiwv82Z++mXf/y79yyy2fpTU1TdqdQsUpv/baX+SWz9zKH/7xW3nrW9/KVVdexh/94W+H/ZBwcPE++K688ff/hHvvf4hX/MSrAdixOM/rX/vzRHFCUdb87pv+gmuuOsR3vvj5IBMcGkzN37/7g1x+aD9/8sdv5urL93P0/tv4u/fdzNryUQbLD+POrnJ6LbBYhLEkseaaS3ZSese9p7a4rOfYLD1H1w0iiplJBUtTCVvjgq3akqURG7lDb9X81PP3c2w15/bDfaI0ptfVZO2E9z+cs5UbvFNcOx/xlN0Jf39/zhyOXdJx44EZjo0Md50a8K3XL9JJNP/05TXqssYZ8/89XS6wS0tBqgRdLVAIjBAYAZUI65OKQgHsBeS1x9DAkj5I75SATiQQSIraU/vQUZcTRrsUTRJeczWWCgJPmkR0WglaKVqpIYsNC1NtZtoxaayIowjvIapSdCmIKjAty2Z/yMZWn0F/EGpc6TF1xXA44sjJFeziNHPdFkJKqrIiL0qEMygcMZZOFiOkIGmllKsj6twwLCqSJKbTzphqp1hrWe+POXpmnbwyZJEm1hBFilYrZXVYsrE14NjJM8xPd1mY6pH1pomyHtHUVAivqUvWiyEST6IVnXYapGq2wtUVIPB1gXQVWljSRBNFCqkUlQm1alkURJFDKk0Ux1hvQxCDCHtx6O1KjA9ftrIIGRqvSRzTzhKSKDQHAusryNKkEGz0x+A94zxHO0sWSTSevKwZlJaVfvB1CmE4IvjoluEcpISgk0bEWuGEYHVUszWu6ec1kRC0Y8WBmYQrFjJ29WL2z6eNdxKkFQwqy2ZuiNtBT7NnrkUiBcMkYlOBxiC8oazqwBCTkGiJdlD6wHAQBMmNEIJISyrjqK1nVDpObQSWVl67xnw5JG2niWAqEhR4TMOGWkolvUjSjgWZ94zxJCrI1sb2wt6EL9bQF2voizX0119Df+2pduedq10DHspmI3QysKBqG+hauRXb/k+5CR2bVJ1z/k9Uk+rhAvIrnMdJEWICCSBJaYKG+CzBO0gqRZJFWK2wOqTxWOdwzuAb5k0kPLFQKClwQlJ6h7dQ1jbID0pBSwcqWiQlovETUg3AopourLGW0liyKEQ5t5OYLFJYH9ONS0rrGNcW3+geJ8Z8okGzI0mTCjGRqrnmy+KtRUlJrDRJr0eVRDjnyFodvIqwUuNM8Kna/r3J4zChsp37+4SFExhNE1Rl0kFtTMaBbbjK0wyg8GEIzhmvA9uPb41pZGRBlxxpRZYmtNMUlyRYKah8oN1qodFaB4ldmpDEUaCWWoszBmcMdW0oa8NWUbORV6znFcPKUDUUedk8VzCwZPs1B1qhR4qgK5UEiaSXgtpphAwGhpWpQ7pG7WgFl/oAYolm05w85vn4UAOAKhGAJkWggY9lGKuRmviANXdUiPPubtDfWu+R7vxJeuFeUgoUEHlPdt58xDUSWib3yZPXIW3DusZEvZkf3Rgi5Wkpz2ohtuWziICgWxcQdSbjclJAWYdwnkNzLcaV5/hGRV7nDbhomZ6eZXZhN7JzNQ6oipzlTUdRWYSo2Lc0RxxLpDD0TcUgL7jn6ApPuO5KrNT05qdJWhmV9Rw+s8nidJuluR6by1skWnH50jRrec2wMnzp1JCDi/PEWTskTxpDaS2ro5zuVp+Ns2dAJigZQRQzKCrOnF1lebZHtDDNrt1zWGNRGsr+KqOtdUaDrWY+htjXqq4QdSh4fTHEa3Ba4esR1HlTabjwZS3e1DhrgjSlmQdOKLwAb6ugoPaC0L8Ic9hJhbQKgWEwWGd19TSry2eJfYuO7CJjgascfWEZ1QbjLWujghgRdPmdjDNbY45s9Dk+KmlFih2dpAFpRcMgCSO+m+lgCKo8t67lLPdrHIL5VDKbCLyxtLOI2ZkWO/ZMsXV0i/psjm0SbZDnkphq4xpfE8F8V5NoQV07VoeW6cSzNCUpjGVce8aVpPYTG7lmRAmBF006qp+kPYVxKJt5q2TQnE/WsyDTbdaZMDyJZPCskCLMZXPhT+Hm8hTjkrpyaFOTSotSio72dFJJlmmGFWRZwvRUytFhhYxgqZewenqI87BnrkW/Cokn5bgkzyu24kCRR0ms0ttdptp58nFgrAqlyRJNtxtjmtQzfPAjHI0rzqwV5EXYb2094stf/jJ33XUnCwuL3HDD43j5y3+Yj336i2xubvGC5z8bv3WCw6ri+d/0bJY3Sj71hftACA4e3M/LD/xQw46CH3v5j7K5sc7p5XWEjDDjFYbrx7nppk9y/MwmcdbhMddexVVXHOL02U3ufvARvvzgI7zo27+Pxz/xRp7/rBuYUSepXcypUyeZn59jcWGeH/vRl/FDP/LjvPP/+SdgwgyWLM7PML2wxK6DV/Ld3/USrrnqEHjLJz75aU6eOsXp02fYgaY3FaPiNgcO7Oc7vvkZ/Mqb3sOZ1T62yrnz9tu5+eZbWFxcIM8LtNZ8z3d+Kws7djGsJG9769uIk5T5uXnKsqYoa37oB1/K6VMneOiB+9kajknWNpEq5ulPfxpSKt705rdwx+1fosgH/P7v/SZVVTMYDqlHq0gVI+IOf/6Xf89dd9/D29/+twBcdugSXvtLP0VeFJxZWeOf3v1envn0J/GUG6/HWI+QGmcMt931AMPS8da/+n5Wjj/EIw/cw4c/9gmOHD7C6WOPcvUlcxjrQlx7LOhEkn2LU5xd22B1dcQTd8T0c8fKwJCkEZ1EMduNWN0aMxzVpGnEsPao3PH4gz0K4zg+qJnqpMhIUQjFfWs1y/2K3ankirkOhxYSPnp4zP7IsdAT7J7JqHXNvacGXLGjzWwn4T339jH1hX1gnVyuqTWTxg6jxpMTGrvIwK62hFU+9x7rm0YtAiZAghahEexDym8twFu/bbUQlu4gbtoufBobBaUUnSxFS0ckLb1WQjvVKCWD8beSKCORJiKxmqRWtNY30EphqhJbV0hvscZQeM/K+iadLCaOFL1EYawlL0qqsiCRgl4SOuNJomkrzfqoYlRZ8qKi7rjgpZRoxoVjVFScWR9grWOplzIz1UIqSZzGWO/oj3JOrqwDgqmpGXppi6TVIoqDrMJEgi2lEFEEWtJpt4niKLDybY0XEmcqsDXSm3B4atQEdR2kcXUVmD7Ke7TW2760zjgg2D5IKRoQJYDUQjoSH251pFWoqzjPLNuHz2SYlwG8L0qmUxWAJxGa7IM6JAeOKotrxonzAbjSjcQqjTRSBondZm4YFoaytkylmqlUsbuXsHc6Ydd0wsJU0gTmOFJpGFhPMXagQgrhTCfGmiAbrK3DVTl2W7IXUq2ySFA5gWzYTUGeFPbLxvki7MEWNo3FugAsxY3EUyKIpCBVE5+YIL+LRNh3IyWJtCe2Dq0Epg739EK+LtbQF2voizX0119Df+3AU7NhCgAZ2DfKBRR3ctXOU3uQVUC+SgtruWAgPcMKOvEk2S68YKfCQd81i5IU4XGtCDepdrA6MpROsFYIFudSVCSJI00xLjB1ja1rYm+IhKetJYmeRIEqKg2FFqyNHLV1bAwLBJCbCFoxmZIkwMQESAoROgreU1Q1W3lJZR2tLCFSkulUsrudgHOUlcEZj7ECiyaOE5IogtqTRMFML1GS0gYTwQhHIj3tRDLXa9FppXSThbCIE4zAxpVhXFX0h2MirYiVQIlACRTOgrN43zCtXHhc12gVJwwhCNrriYmRb/SLAUE/54MgZBB8ShkOF4HBE5JzQoqOaxZRiXeBzq1c0HxGBKqic8EoshVHtFop09NdOq2UWElsXWGrClOVmLpmXFSsj0qOb405Myw4Oy4orcMLtqWEYXr6c75JjXG3aDZygQ00IyUQXoGKwubvoXIS20gFJ1GSk6LB+MYQsekeNNNouyBQAmIVPLpMCEUMMspmXHo4LxUxeFHEMnwpKVHqHGh5QV9iksDnSWSIeFXCI20oXlMlMFGgbw4rS20DfTivQnxsaSGOHLMKDnRgLgl+EEf6UFhPYUGrQAm1ToILWuRuJHlgJefwak6/8BxabPHKp+3mS6f6PHiqz813n6E3dZCpmceCfDZXP/Fy9u07wc7d9zEqa4raUZdjTpw5wxfvuhuvQjyqEZ7PPnCcQiTs27OLBZHylENLfOLRs6yieGirYE+3x1I348DSHBuVxQKfeegU9x47SWEdly/0mJ7uUuQVdz1yhi8fPsZ9Z+7gudddxqHFRfJ1SV3mGBXzxXsfor7iIE987LVsbayTDza4/yN/z/SuAxzcMU+0bxYpAl+v2rUTZ2pclZMfu4M6kkzNtPBn7seeXaWUs+FAoSJ8XVFurTNcP4NKQoqOFJJsehEZZ2xunMVUBmccOorRWhHHijjzFPkWq4fvZUqnXL3rOq7f+0yOnHqUM2sn6eyaRdSANKh8iPKWKT8iTTSzWcpslKFRVBbm2mHeSiFDLLkDFCityTLN7vkWK6Xh448Oed+9fZJIcmA6YmcGU9JR5I69B3dy2YE5hC4wtaUcjFHNmJscoCrj2MwNu3oJU10BSvLISsHJ9SG1D/4Us60QChFJ2MgDMO7waOUbjbqnqqEXw3yLZk2H5Vyyt+OYTjy7UoGywQ9QR2CdwCHolxZjHGUZCuxx7RmMINbiq/ayC/M611CY6sZc09U860DGO+4ZsekEv/Hd13DLw5vceXzAYH2L/jqcOiWZnp9hBNx8ZIhucp4/cPsZkkTTTRRXzndZG9acOLOGsZ5uN+Pg3nkOP3KKvKyZWVxgfncPqQQnHjnBy77tCfziK57NC37sbTxydNhIsyVf+cr9XPeYJ5Dn4wBaeY+KUtrdaT70wX/j8ssuRUjN29/2h9x++x089oanUZYl1jre9m+3UNUWKTXO1IDDN0l0QkiQMb/2ht/lH/7xPei0h63HxMry4Q++jzvuvJtX/eQv8Ib/9Zeh6LcleWkwxvFv7/wT3v+Pkl6vw+c/8zFuvfU2Xvnqn+WD//k+nvSkG8P9lHGIXLY5eEGr3eGjH/0Q+/btQ0pFlsrgp4QHbzh18hQ3Pv3b+ZVf+hl+8ed/EqEUszsvY3rxAP/2tO9HCE/abvMHf/DbvPGNr8eZmvf+503cdPOtTC9dwn9+9GP8t//+swxHY5504xP5j/e/h9e84Y/463f+O+//u1/j1T/8Ir7rhU/kW7/vR1hZGyJ1xrd864vJxwPwhje/6Xd5yUteTJKm/N7/ejN/9Md/hveuWd8lw7wKHjJS45uUPBn3ePMfvZk//pO3khcVx489zD//wzsZjgucDXK/Jz7l6TzxiY9HeMPNX7qfD37sFp5145XcmVhOHXmQh1fO1QcvfOwSBxY7rG4OeXRrwIOn+hxb08FY2Di+4Yr9FJXl5i+fpNXJSLOU0bii244oPbz8L++mrC1l5chHBatrmgfOFLz2qW32d9r87S1rvO/eTYZe8aZnzrHQlqSR59Uf3WC9cNy4t8v//swJNnJD6YLnzvlc8Av1emi9DvWa98Ta4iwMyop2EqFiBUpjnKd2Hu0shRXkTgRmNSCQJDIcerMm8UwIwcmBYWRg9FUJyOFgFlj3jjNnBwwGJVfsXSBLYqZnW3RSFcykvWCp16HXbbOrNYXuzCHTHj6dYWVllZMnTvK5z9/K2dU1ls+u4QkeTmubA5QUDMcFV+1fbOp5xZnNMco7eqmm3UnpdDIO7ptHSEEr6fPAiXWqomBja8hcJ228lCRHTq1zZnULX425bP8OZqa7xFlCYT2nN0YM7z7GJfsc0fReWgsKasvWyaNMz82RtNrsueSKbTa/psZWJdV4iLMW4SvMeEA93KIebSF1hG8ao1VRUJc5dT5E1AVWKmwxRiYttIzIq4rRqKY2NYgQcW6MYzAaAZ5uFiOqEcVgM9S8psZah5QqfGpKYPKSCMfuqYh90y1mWjEtJVgbFpzpl2yOKgwBHCzrUNsroJfGtBJNHEcMa8daXrPeL8F7Uq04OJOybzrhxn099i91mW4nJLFknFcIWzOjQuMhzSSVDGAaZcFsKuhFEe24zck1x0puMF7SiwnzLZYMK8d64RkVBuNFo0wI5AAtINMhSdpC40tl6MSSqUSyp6vBWdbHFqklmQK8YFQHf6fCeqQWtCJJJAU6/S9g8nSxhr5YQ1+sob/uGvprBp4mylsvPMpvr+1MFEiiOcBrD5We2F83c5Wggx3WoE2QVZlGZzihcIrmSc4njngfugtShwxABzhjscZh6hrhHKmElOAFlUiIhEfjA2InJEpAWWsKYxlVhryRdiVahQxBVJB+Tm6IEGgpiXW4g9Z5xlVNK4rQUtKJNd1Y04kkhZcoIRFCE8cpWRIhpCGNNGmkyGKNqG1A+b0h9jWxr4hFTSwiEhUMWoUIlDdrHUZYYgzSOYQBV4zwQmCKIbbK8abCe9UYaNOkSzhMbYL/w7YPUbixUjXRzT4kavimQ+0aiaGQCqX1tuTOWdMYJ9qm0BF4W1MXOXVZ4o0NvksN+okQJElMmiZkabrN8nKmxhqDrQ1VbRiUNRvjkrVxyVZRURiLE2yPk/CY5206zaDwDfiDc9sSN3yFkCqYynoBMujvw+M4dJOkQdN1mnRqJvdsMmiDLLFBkyYjIJzLMC7IRWvbJDSKiTniObBKicDGEl812i/ca6K/nTDHAum66Z7KQNsXTWdGRmB0eP/9OoB3eQ0rQ0FRgeiEOZZqmG42T+tDmolokHk7Yej54P1mLDxwakRlQiToocU2beUZrG0x3U4piopbPnEziRsSC8NlT34SxmsqA4/cdgunVs6yvlnhexFCKOJWxqm1deQDD/PZO3azub5OITPGFsqyZlQP2d/J8N6RVyUdJdjTiblh7ywbtefRU2fZ1dsbaN54BmXNqCoYHzNctmeVuZ5HiGmsNxQG+v2cs/0xg+GAVhaRpAlnS43LZnFJF+stzgcrfCNjnI7wMgVfIyKJbrWQ2RQyKaEOTEisBRm0yCKJESEqIgxrFWKUrUiohKIWFuE1CRopNO1IU3nHxrig207wIqXV7oBW5NZA4cjrwP7U3tKN4JrZHs5rMhWhqgAma6moCFEWoumkTxwIu1lErxUzKB2nRzWDUYXWil4qWEw9KZaWVuyey2glOrRLak8kBK2kCVhoaPZlDS4WpLEkFoJRDac2a/p5s0bqpjNqA6U/kHtdAKUbhsDEow4PSnqyaKJ3b0DjpkGiBU3neNKhFUgntr/nVSNHcRBrj5Jc+EXvedeoFhzrOx5dy5nW0BWeT9+/yvH1AltVXL3UQmmFjDRHNgqqYBoCMjB+Wx3NFdOSxQzuWi4wzjPfS6itR2rJVj8nyxLiOEJ4Sz4c4axDRxFfeWSZv/vXL/Cip1/Lg3tX+MAn7wYRkpe2trY4d/L1TYc/513v+ifm5uYQMuKl3/sdHDx4kFe+6pV87FOf5+jRY7z4GVeQtTKyTodO4vjK3V/mA//5Ub7nO16I1hH/8C8f5NZbb8Wakpe/7DuJtERLz+7du7nv/gepqxFVKdm1c4nvf+nLkFLTHwz56796O+PxiLou+fO3vp12p8OrXvUKlpZ2bN/Lb3nRC9izexfeBg+nOI7ZvWuRXrcVGFeu4szyMu/9wE1cedVV/MLP/yTe1txw/RVA46UoJUomSL+KqwryepOkPUurPYt3nkMHdnN2eTcf/OhHuO2220HCD77spezetYu3/cVfs2fnNFceeibj9dN0pmZZ2nOQH3rZd/HZz9/Jhz7+Oe66+x5279rBa37pF3jcDY+n25sGoChrtrb62/dcCMkP/dD3N+9P8N73vp+1tXXe9KY/4lOf/BT9zY1gtuoMuQ3yo/379/HS7/0uDl56KXv27EHphNOnV7jrzrtZ3bmL9c2KxT2XsrU1wNQ1IHl4ecjGqGJrVDEsDbO9hG99zAzH1iu+eHTIma0K66A31aabRQhgNJqkqgmSOEJpTZyEpk8n1uzpJdgKljcdR0eebqrZ34qwec3JSrBhBd+wv83poeGBlZz5bkav5XhgefhVTbUL+ZowuiWhqRYJz5SXaB3WqKoBpbT3dCKJViCMQDUepEXl2MBTKOglsmGOCFpR2DO8CBIe533zXBLpPV4GD6g4imjHmlhLNJZ+bhiVgmGp6PVKahSxiWiJNqnMmJtvo5Wi02qxsb5Gq5WRlyVbwxF1bTHeMsxLhJSs9cch/dEF5rk1hrys6W2MkUpxwFqmWhFmJuPUap+8rji7vkWqA/MoTSKWNwcMx5YHfI1O4iBDaqos6z0b/Zz1/oit4Qjngg+oVDokF9eOUV1Sm8AUikUwP47QeC8nBSsQzK2rsg4SOzfxmg22GMa5piErkbHfNtQuqyAj3PZVJextUhBMwBsLCCdUWGdlAJHC5x4kOL1Iccl8xp6pFt1EUxTh+cZlHeQ00oWDtw+gUxorullEFmus95S1Y1wZnPdkSjCTKPZPx+ydTliYSmmlETpSWIKJtJOeKNJkzmG9p1IOJwVGOkalxVjPVBpRdVMEghVbE0mD8I6itBRVuJe1aaxUxKQ2CMnkgRklkVJQ1Ja89A3LAyDYUFjvibSkto3hsZTEKoz53Ib3VBuHUHLbl+ZCvS7W0Bdr6Is19NdfQ3/NwJMQIbnCc+4FTQAb0dCvdOPwX/mwJIezfyNH855RqHOIJ547nHP7n3xYk4k9oRjGShPFQcqFp4l2DXGJgeUkyIQi2H/6oIPHhw1ZSGIpqBONFFCYkABhnCeJNEpKpISYkK4n8dteT4nWgYLqHKOyRjeJIBPgaSrW+NoHyZ6MSJMWWRYhZUGWRLRKTTuOkdRU1pIQQKfEF0SURGiUUGgRikW8R2PQ1ES+RFgBlcXkfQDqcR9bjXGmwrskMHi8D+kQxlKXFcaE5Bzvm6QJIYmThMlOYMsSb10wYbMNsKQ0SZqidaDxGhMS6KrKbBu/YytMGQzCnTEBBDrPtDxJE9IsJU3T0P22BlMbbAM+FZWhn1esjkvOjkv6ZU1hLbFW26CjJ4BPXkxKg0mCX2P43RQGzjpc7fBCoiOB1hFSRuGAJDzCW7S0KHEO/HQenGtkhw0ZbII1iUai6LfHXHguYxtttQ0MLydBNtiYpAGfmtceCHMXfrfVOQJrS4TExLBpBvah9OBtk0wgoBVP2GLBZ2JcC/o1VEPYVIGsutSGqQRm0sCsy43H+WCMqiCMOQ/SCzQKZ+HB0zlbpWPTOv77pftYTAXFWou5Tkw+HHLLJz7BwmybHUuLvPj530WcdLFGsvLoV0BpNrcsrcwjIknSbnFmY4P1jXVu+kKPOI5wMmFYeTbHFcOqYmaPpKwjNodjWsKzr5PwtEsXueXwGvcdOctVe3fSTRTSGvLKsja2PDoquXF9jb0LhrZOsMKQG1gdVaxuDVnfWOeyvTsQaZf1ah7XnqPSKeVgFVwNGGqlECpBJS2iGFQs0d0U1V1Ftg1+sw9N7CtKI+IE3W4jJklXIgDuSkc41aLWNQUWRyhsExkTxzHWWbYqi0ok+IioFeMjQe4t9dhiaoVDoLxhLol46r4ZRrXGGYkqLcoJlFJBsuz9uXEcJiRT7ZjpdsLaYMzRtYozWxV7OpqFlmcpdejK0daK/QsZSazCGKsciZLhwNkYGhrrqUzo4rVihbSeynqOnK2pbTB+TaLQUZ2wGI3zWAJPfbKdOS9wNry2YIDoSZAE6z0XGKhusqaEUAIp5PY+4wEnBFIH81jpHWl8jtr+X+HywGYJR/uGf713wI9c0aYbw5/ddppuIpnJNI/ZP03WSpFpwpGbH6WuPa2pHgiJVJLpdsxjdngOtgw3PbRFtx2zdy5jaD3DwnF2bcDsdBulJMNxybA/oixr2lNdPv/lY3zutof58F/+NA8fXOUjn3kApZNQ7DXMkwDyW4RQCG/40z97Gx6J9RE33PA4nvWMb+B3fue3sP/zTXzikzfz8694MXML06TdLiqDj33pNl77a7/JDVfvI8sSXvurr0cpxb59e3jdL/8U3W6XsIA30nnhEEpxyYG9/M5v/U+kVJw4eZJ3v/tf2NwInoV/+Oa38H3f97387799+3l3El7y4hfx4m99QUi68g7vLUURQjHitIV3lhMnl3nL297J7/7Pn+FFz/sGbL6GjDtsm3H4UNWNNlcxxRaJrlBxC530EFqxd+cixRW7+av3fIDTp1fYuWsHP/PTr2Jrs8+zn/Mi/vYdf86Lv+U5HL/zI6ikw8LeS/m5n30lO/7hvXzi5i/w6JHD7N2zxBt/5zdDkc3E2yl41Hhn8YRDz4//6PfxhMffQJxkPPzwYd7zb+/nda97w3mH5WA2GqcpAFdecYjX/9ovEjWsk8oITp48xd1fvpuHjmwwPTvL0v7LqB+6h8LXINt85cRwe82Y7WbsmmvxY09d5JbDQx5cqzm2WqAixdx8l67y2NpykuBJoIRkejoLhvgWOhEsZYobF1MGw5Jjo5pjhecZ8xGPX0zZ7FecKAQPFpLvu3GGRzZKPvxQn2+6fJaWljx4ps+ED3ShX1o1HpYiyHZiIFE+eD0BZe0QzqG8D+bQzVqnCGBOv7JY48l0SFeShHq6pSdFdGMtAefkHoSEyzSOaacJnTT8nnWGtVG9bUze6eSMa4hix5SNmfKaXfs1nc4CSzuWGG5tEscRZ1fX6Y8rahdAm0FeYaxnZWNAHCm0lJTWk5eWsqrI1obBmLoo6WWaWLaY6yScWB9zdmvEVLdFJ0topxFlWdEf5WxuDUhbGRbJ/Nx0c/ckW6MRm4MRW/0+1hmEEkRJFhLBSstqf8xoXDAuKlqxopvGzPdaOGRz3wNc4LxgXFZUtcG4MHa8D56xxjbAk9REDYDnnA2JzEWBFxIpFZEOZwitJFEUUdUaJzRGaHwzL6Vy2x6rnUQz39FctmuKnZ2MRAmOLg8xtvGhRSBRoXHqw57YTTVTWUQcKdbGhqK2jMsa4T3tSLKjE3FwJmHPTMr8VEKaRkitAvgmFE6BjjSJs3hniaXDCCjwrJdB0bFzOkL0UtI4Zjwu0LYAVzIuDeM6MLus9Y33FE1t0DCVlCDTgiSSKByrzgXfW9eATk3yXaSC3KesHUZLnJZEWtAvHWXpKI1HC4+6wEN6LtbQF2voizX0119Df83A08QUPBhmsy1bmtxkJYNsTgGxC4+spafdPEPtoN/QDcfVBKxim/o1YZFIMfH7ASElvXZKN0tI44iyrqlNQDhnIklLS3qxRvsQTWrthNET/JSkCJ2U6Swm1govBFtFTe1gI6/xQmEIGvJEBkBNWIviXLqC855RXiIhdAeyhJksAe9pVZ4kTekmMWnS+Btpxag0WOuYbZUUUURlbZABCouoc6rRJqN6RDGQ2wwv4xy1sdTWYopAo3XAsIjx3jMYDBkPS0oLrU6bSdHsrKEqCwb9AePRCGtDNySKIrTWdKe6zSLpqYsxrq4xdcWoqAJ4GCd0nCNNU9IkxhmLqSrG4wprXUj6sCW+LsFVSAUqUqg4QpmICE+v26XTbpMmCdIb8A7pgpl6Udac7o84tjniyMaItbykdj50g6Rs0g+/qom0zXQyzp0z2HMT4Kkp9JFUpiSKfFMAaJIoUF0TSmLpiCXbPk/hOp/pdN5zNlNs8vRSCGoXKIajWqA8xBEkDVCFCB0zQ2NxIrY/jgv6mrxVT5DOgsfg0Ux8IdhGrKOG4ugIC+koCpLI0oTN9NiW4Ow4GLDPpuC8JFOhoJ50D2UssQ6MaRYsCXOzGWNjufPwFr+4/gBLcc21yYBFPUJFGfevOh549GHm2kd40UtXiXsWqRO+4Zufz/zOJcRoxEfvOcxKf8RUq8X8ri4tLfjc/fdReUntFUVtcC4Ym35lZZXjW5scXevzbdfs5/pdC+yYnyc3iiNrI+45cpi5TsZlC7Psne/QHmnuPVmxtuE5smZYam8x8kFPnbVTzm4N+PebbuWlL/wGdh+cZd9jHs/G5iZnl8/wwb/9Gzb764zKIXPTU1x61WN56vO+ndb8EjpNMQpsNIOLh3gxxONAGITwaKVJkjZh9QbwaBUFTbp3SB9o3Vp4osaXzAlFlPXYc8k1FP011gfHufvIlxmUq8xOR3hfMaokAyupfIWXEdNzcxwQKdpJNtaHqL7GaqBqjBcl1NYAkuluh32zHWbbivHmOlPKQAseOyeZSwRzMSwtRnRjSTGoyAc5eTuhu6ON2BripcDYwAiJlaCVgNKe9crywHLJib4jN4JWIkkjFcxopUfR0NKdwCJw1uMsGCGb7nKTDCVCd1CKxiPBw6AQaMA1t9I3aZaRCD6Dc4kmVgHkTiIFUrLUMZwcOtbyC5014QMDRyruXa+Ihef62RjdyTBacKBXcOO+LvvnMt73aEU/36QoK557yRS1kDww8Bxf6dMvDcN+zD8tO3qR5yXXzXBoJuJgT/ErHz3NWinoTXdYWx9gjCPJYhYWZ0hizbETZzFNWtUP/9o/8LjrruVdb30Ll1x7DZ2pKbyrGG2tkg82OXPmDPM797Nz32XgHZ/63B38xpvezl+889/44l338Zqf/lF+8Sd/hJ98+UvZMdtGCosQFqFa6LSD946oPUeUZSAkv/Hrv8b3fvd30G63wu1ozDVe8Pzn8OU7bwUgTWJwBYiUpaWdfO6Wm/jnf/0Y7/63j/P0a3s85alPYTshxVu8GfIrv/wGbrv9y/zn+99Lq90lL0u++Vu+g6suu4Rf+rn/zsbZFeqq5q9+7+fodlocfegwew4eQugERISfxM3gaE8t4XuLpK0uCIU1HqVh194rmJ3fw2VXPQaPRMZddu7ax61fuA3vDb/0y7/Gb/zmGzHlkF/4hZ/jR370Ml79mr/ksoO7+fLtn0EAWZZ+9VgADl12gGc/56nc+8gZhltbDDfW+YEf/Vme+Yyn8rd//RbOgTGTLpIAV/Ed3/ld/NZvvgHw3P2VB3na876P3/+tX+bg/t1820u+n1Mnj4OrKfsnODtapr9yhH/6h7/hissvB+C//bef4mM3fRyBZ29Xc2lX8yNvfwCpNTOtlI3lEbWDMtcsOxGsAazh0pmIS3d0uWfDMtwas7beZ9TpsBBLHjvn+cvbBmyWln/6wb287+4+//LQgAPzXS7vSV6wKPjAl9d5aKOkKCquWkqYa0e8+0v8l9h/AdrNxiq8p2wO8l4IRpXDIZiJQtfZOvDO0ZKCKBbYWDOuHNYFFowAjm7VnBxYIiWY6yYoBZ2mDq8bz46ykeh1spReu0W3nTIYV00ITzhgWAeVsxw/O2BlM8d7SE9t0umcpiJm1+497Nq9h2uufwy9uTmMl5Tudk6vnGV9q09tHM7XPHJqjVaiyeIo1IIyHNjObBXU1nPfkWUu2TnNXDfjCVftJj6yRr88y7HlDVppzMJ0h06mUSLm7OaY06tbjY+IwFY1WaxYM5bBYMjJEyfY2LgkpOrtvoK1jT5n1zf55M2f4eSp0yyfXeXAvj1cfuklfMOTb8TrDBXHpFKjehuY3LCyfpJe4Vi0ECWt4F8mhlhbo6QiijNklKB0jFQVSIVDYqwn0ZI0S+ik3ZAmqDQb/SEr/YIzG0M2BwXjsqYsQy2Ct0x3JK1Wwt49O1hoxUjvOdmv8EpQW0ekdOhiOosSjlak2TPbopvFeCE4vTnCGINwlrmWZv9UzLWLKZctZsx2EiIlGsaWp0KRW0FuwtgqSsM4LxmVlqFxLJeelXFN7TybA8PexWku3dEmLyvKcUSdS1IPxluEFCgdal3nzqVICqXwgDWGNFZYGdQG1lpq4xlVkpjACNocBs/YlhJMp4JEQV5bSuNwDmZSzVZlGRT1/52J+TVeF2voizX0xRr666+h/4/MxScGcZLJBNv+IwAIDbtMNjQtpCDT4eeNDxucJLBIHI0xc0OMmoAPUgQQS2tFpCNmuu3QJWoeW4lA6WpFiraWtGPd+B9JajwWGo8ij5eBtqxE2LxSrRgrh8NTOc+4tiAkHe0QWqLPo3lOAAia11kbh5IGayOUELQjjROeKNZkWhEpjVYaISGLY1pxTSuOkFISO0+aZGgd45CMi5KyqnAmdC7wHjNhL4WxEAytlcDb5v3YEmcrnJXn3t/EeLwxLjfWYIxpUgNl473RgHlSnEMwXdDnWw9KBQp3aGKECRoS+GqMCSaS0hVgQ5xuSIIOdLuJeaXWepsxhQ0LJs5R1oZRk2S3WVT0qxrTPJfc9nRqvMNk+DsTmXeD1nofwD/X6OWc8yghkcKjpUPiUPjQrSWYx8UusJ6kdHwtFek23iUmY3DyvEFyZ/12k2f7NZ9/eRrq4gV+qfOYXX7SdW06xcIHcBnCOAibZkC7YxlSKyPpyeLgtpWb8PkMq1BYTKSHk/s0keYKGdhixgYgtdeK8Bas8QzHFSQpS/t20F1cwugWpq7xZU2lPd7X2HKEy8dk7Yylfbu44WmP4+H1TTi5wpY3xCohihTjTcvYWkpr6aSaOJK0Ik1hQ0dzdVQytI5KClIp2d3NuHZHj6+sDxiVNVuFJY5jOg5accTGwHH0TEmyM6esA8AuBIzKkiPLJadXt2gvFCy1W2z1B9TGstkfsNHvMyqGxEJSjPMAhAuFkKopWEL65Pbn4GE73xTCzyHCIkDjk4NBC4MXFikUsRBoERiLSEWcdRhsrdLPc06vr+LMGCk8whKkuNaQaMiUIo5TWjJFGzhtDZWz2x3fyZdzPhxiUo0isBXy0iC9o6Whpz0L7Zj9Mxm9VBLhcHWN1BKVKIgUTkosAmM8iZL02oECPbaeUwPDoGiMSBuaPgJE42kRTUwUPfgJU5HJnjNpVJxbm4U85wtXWU9uwqYrHGwDypNmRkN5tM0EVx7aIlDlL/wpLLhk3xzXXb6b+uwKsq6ZmU1YKz2i8jxmMUUKOD2omY4gslBMGhvWU1vHnqmIykiOblkqa8lLWB7WRAJq49g5ldJzkiiLGI1KrIOpVoTEU1Ym+AcKgdIR11z/eB73+MfxmBsex+6DB8k6bbwzFMM5NtfO8rkv3snM0gEOHboEvOW+h45Qjje5/957KIeb/Nv+XTzhhsewuDjPhz/5Wap8iDM5ILn1C7cBnk/d/HmWdi7xnd/xEqK4xR13389tt9/JlVdewbXXXA1Ap93m0KUHwTvW19d5z7/+O0JGIDTg6bQzXviCZ/PYS1pccugS8I5PfvLTODPm6Y/fy5lTj/LA/Q/wqY9/hKuuvZ6lPfu5+qqr2LNzAVdXKK1pRwnTM7P0+322tvqIo0fCHllXCCHRShHHmtPLKyAUO3btwdrACMlrS6fVIotjbr/jHuZ7La677CCfuulBbr39HlSUcnatz8rqJt5U9Ac5UioOXXKAyw/t49CllzbFdFMkec9wNOKjH/04d955F+NxwfOf+2ycsYz7W3z6c3ewstpHNCl9506KwS/Le0ev1+HSS/YjhOD4yTM8+MBDfPRjn+DyQwe49porueqKS6mqgo985OMUZUkF7Fqa59KDexAq4rnPeQZSWD520ydIhWdKw85MMbAwyGukEigCW2LCYk/ThNx6NkYlV80lHDaClbMO0RS/yyPHTKqIFTx4tuL0wJA7z+W7E3ao0GSzJsjop9oxxzdL1kb1Ofn8f4FrwpRWMjAhQrEf/EUnpUpDUkJ6j5bBoDk3rglBkbQb+YUxltqFWjYqbKjfCGujEkGmoxu5V6+dBXNqIbDu3PdbSdjPpVJIqaitp2g8YfKy5vjxEwipSJKE6ekpet0Oe3bvYm7+CMO8YGsw3K6Lyjp0/I1xTLVT4kjTaaXkRcmospxYG9Ftp2gd0W1nTHVSptoJJ9ZznPPEkaIdSZSI6I81tbEMRjmjwQhbV+FMARRFxcraJqfPrpN1Z5jZo6ispygrNje32NhYZ2N9lfmZHnmRN95DEqE0Usd4FeNkRGUbRoBzqCYhSMjGmFgpvFCBISqDNDSOIiKtsGXVGHCrwLRHkJc1a1sDltc32egPGYxzxkVFWQX2hcShVUocRWRZRpIGJMeLxky+qTfxoZ5UUpBoSS/TRFpiXOMLJjw6EsxnioWWYrGjaccypItbi3MCKzyVkBRVkNNtjWtGRcVoXDOuDLn1jCtPWTkq51kbVsz2amY6lrluwlh5hiIYRjsjEMIElTZh+XENs2HC/BeE81FtGsmiC3tNZTxSBfsS4UPSdysODAbjPFUZmFQCSFQgLZwLQ7owr4s19MUa+mIN/fXX0F8740mJiWTxHKC4DWU0g6rZ/FXzAgQBzdXN35WAcU2gWBtP5UDY89hPjZF0qiFJY7IsY/eOGfrDMeO8RBBSPxItmU4UrUjTSSK8lVgbAIiaABYYa7flWYiQHtHSkiLWYAJleVAaCuNJpII0IlYKfFhAaAArIQJaWJuwgRRRhEQEnXwkUXFMFgePIR1FJCqik1XUtaWbJqQOnJB0ejPErQ61TFkbFNi6JB9sIr1F4LFBkApS0261yeIIrSKUCgNfiJB1ElLygneGc7aptxxCBOWlax6rsQZHNlRgJZtEACeplcAQZJEBBQq0YCVloMfWNaaqMHVNXVcoXyK9QYugqRdKho2yGZJKRSg1AZ4CkOacY1hWrI1KTvRHLI8KNopqG+DSzcQIlHO2Nc1IsQ36VLXD2LBJuQn640ICXaQgiyGRnkR50liilEbLFF1DRIUUVXNf/PZw/SoJqg+TaPI6Jr5osvkZ50NK48Spfxt4av6YbJHunD7wgr4iFRZE58GJkHujGpBPEQDFyfsLwYABuMxdYC/GyrG76VZtGTg9EmyUcHoY5nk3cqDOYy8SihOrJEWzaS72ImZjzXTsOHxyxP6dO3nCNz6P2asfy+ZwTGRylJK0khShPGa0RbXRp7VriR0HdvH8S1/C6ZPH6FFw69FVvNVUVuFFinWh2JlKY+baml1TmjNbOXntqLxn3RqWTc2CFxyazehcucTR28aMasfxrYpLFnv0OjFzUwNOrJRs9CvasWJUKCIpwVsGecnaeMh9R5aJpndzSaQCC9R5fJqgTTtQz9MOsU6Q3iFc6FIiJd4GMDespWGOehv82Zx1KBWFOFiltuWhiSyRsiJWFkFCLDxxM1cdCplkDCrDytaAR04vM5V4ZrMIHNjaU5vQbZ1JIyKdEcsYnGFtPGJQlJTGBgAY0YC7jjiSzLYVVVmzPracHZRoKelGggzLnumEJ121xHBkKPOS4eYmaS+hNZOC8jihMF5RVJZeO+GapQ5b45LV0nBkoyKvw8FnKlFU1lFah7LBI7ClgxdguK808zQUEmGDBOEnjNRQmGnliZWkNI4hns1S0JaQNtXbhEFrbEg6tQISGuNOJJl0xPpCn8SC5z31Cn79Z1/Am3/rH+ivbrDQSvnXB0cY63ntk6Z41719Pn9qyMuumUbLmNpFfGW1YrWAtRK+/ZopEgV//blVrBfkteU/79siijRpGvHjT14i1pJT/Zq1oWVYOQ4stnnk1IAz6/m2p0qSJPzRm97IZZdddo5BBAihSLtzuH7Bb7/5f/PKVwie9Y3PxTtHMdxg5fCXWXlUc98dCR/92C287Y9/g+d+41P5iZ96Lesrp6nzzYZqHwq5X//N3+XGG2/ks5/5JD/5c6/nDW/8U0brx3nta/4Hv/kbr9sGUrwz4A0PPvgA3/eDP4Gzdvv1/Oqvvobf+p+vI3RFwDnL617/esxomY+98+dxxRpbW1v89ut+iZe/+mf4kVf9NH/yx28mH2yysXySpV37EEpjnKDY6LOxvsGDd36ezbOn6K+dQaiYTitjfqbHZ+4+DDrhxifdSG0cRWV45PQ6V11+iP17dvNTv/DrPPHADK/7/mfwC3/4Xu49sUHcng8Scmsxbh2EIEsTXv8LLw831btz97ipJs+cPs0PvOyHKYqSqelp3v0P/8CuXTtxzvFNL345SacDMm4+FdccoCOE0jgbDK5dXSB1hDMV+XCD//X7b+byQ5dwx22fIk0TNja3uObaGzizvAZCYqsBthqg0yl+4X+8ihc9/xk8/sk3E3vHrHT8tyfM8YmjY97x5U1mZ9skCEZ5HQI/lKTTbXO8P+bU+gZ/+h17uEUp7jziaaWC3Hk+ebzmKTtbeGv5lQ+epR0JdvU0P/HULsdPldxyR8l8ovBK0o9jPvzAFoNxFfwqt4v+C/uSPthApNLTVEM4IGnS7CobYriVEKQuNPpQkJd+u8M820lCSIC19AvDuHac7lfbB4O5TozE46wlTWOyNGXn3BTGGLy1gEZNUopbEh2FROKtccW4NJSmZFSMYTDGuvsZjUZUxZjrrr2GLIm47LKDPHTkGFVVs7yygpLheY11jI1lDEy1U1ppzEy3xcnVLXJjuPdkH6EjCiu59tA0c1Mdds7mHF0ZUJQ1xlqu2jtF3IopTHj9g8GIzXVFNQ7G3BIYjQseOb7MPQ8dpxItdl1myIuKPC8Zj0eUxRhncoQPKVdlZcJvymDePtmbjJNYC9Y4alPijEVr3XieqobHEmQmnU6bytRUZUlVjFFek+iQ2FfVluX1TQ4fO8XhR49yenmVjc0+g8G4SaXzgYmv22RpTNbKiBKJq2tsI7GsvQ/mvT5I1DIV0v5m2zGl9djSooUniSWxkBzoaQ5MReyZ0iRRKOKKoqYWYFBUQtAfVfTHFcfXRwzymq08MJyCiEA2ayGs9Eum2jlZrNgz22HU0pyNNOuFpa4LhPLb5zcpZACTrQskAMIhd1BYRrWjcgLhHcoLCtOcF2SQ43UTxUymGFeOvHaUhUVLiRSCTDZJdxf4FL5YQ1+soS/W0F9/Df01A09Rcxr3nu3YViZA1OSHGjZLAJ4CkKCk2GZLZQ27qWfDbzgDxk2iNyeIekit271jgXa7hVaqYet4WtKh8cQCZGNx5X1jMCjC4JVKoq2jqKrtOFLrA7vHueABFcng41RZT2UNy8Mi3Ezvacugx54wbfzkhjdMoUFekihFrEMcahQpEi2belCACEytoKePsEi8ipjfsZOkO03Sm2Lt7DLjwrC8uoU3ZZg0QhClLZJWh9bMErrTpj3VodOWeFeTe0VkRtSla+53iDTUSgZ0NItwPsVYh0ETqQCGRVEUgCcl8C5BRgqVxPg4C+w1FdFqZcRx3IDEBuFKtM2Dn1SRU9sy3G8FeVkwzHMGeY6rLRpJFMdEOkZLFYwlK8Pq1ogj6wNOrPc51h+zWVZUPsSmCoIOdUL3nhgK+qabYqzHWEdRBXpm+NwkSgjiSDYbvqATCTqJpJ1IkkQ2XTuNi9tgNKZ2WF9vd1y31QbNJc7/akDG88ElsY1SeXzob2yb4VsfYiiHxgem3YVPlyCREis8RoQxNPFVF8081tuawUkYcwAZlQ2SRYWgHQdPjpZztJSgXwmO9gMIOTLQlkF7WPom8U/CTAIRgsJ4VoY5JgaRwhOWUq68Zi9PfN7z6M4vMTh6HFGMwhyNIijWuf+eh/jiLbdTJl0uObCD5z/jauaUY6kds5BoSu8ZV4bCeWINrSiA1wZB5WOk9lhT8ujqgPd86VFufWSFF1+1n8sWp3j6viW+sDLi/pU+955dpptK2q2YnTt6jPMRztY8cDKiqGpKO2ZcGPCQdto8cGYDcXSZ6za2EFIxPTXNoZ1LRNEeslaLLGuxsGc/relpEMFPwxHh8I3hXzhPNoFSKAUyEnglQGpElOJFFDbNOEZKj7GgpCSKI+Isw5YVJ04f513v/xARBmfGPPnq6zm5ssrxsxsMB0M0gkxJ9i7sYtf8dHgc6RDKM5VEtCJFJERImHRhFc7SCOs8953Y4PL5DlOp4sBci2Jc4OuKqy69gssOzLDr4CwP338SIT1TMy2iWIMX+Eqx3Bc8vOHZv5DikKyPKgYjQ0t5HrsQc3QIG6Vns/SUJoDL7UygI0mkFAL7VXNx0gWcHC6FcM1BSyAb5qwSjsoHRm2/gjgJxZxwsmFRenIb5LidSBJFgtLBWuEYVWDMhT2Hb/rYf/C5z3yC73j1O1hZGbCoLU9fEHzDgmZk4e/v2WS11uyc7TDMDadGhoe3ap42pzk0qxnFCYdPD1gfG3CGb3viXq7cM81bP3w/46ImH1e87551cI7RKOfA0hSyG3H3wyugFN2Opr854iUvei4v/8HvZteOeRpKLuC2C4E3/eFbeP8HPsjC/E4+8tFPc+sXvgTOcHZtA5XO4OoC52rq0TLVaJ1epviXd/4Zf/f3/8Bf//XfhM9aKqRKcKbg/vvv57nf9EIefPgIRf8seMf/865/4ku33847/vovuP/Bh/ntN76JP/xfv87V11zHxz7ygea1eLyrufmWz/GC57+An3vmbo5ulPzjnas8+Mhhrjy4hBXztLvztHo97juxye2f+xRXzHpWjp/igVPrfOqB03zXC7+RKy6/nOtvfBrr66ukacKlu+fYcmsMasE1L3kVWW+WONJc/exVRhsrbD78JXZf/1Q6i3vpD4ZoO8KMN3jMlfu5+tqr2f+s7yX565tJ1Qb7eoaXvPDZPObaa1i86slceunBbdDoQx/+OG9685/yp3/8Rq64/FBTJQLCI3XMK17xMl72A9/L/NwsNJKON/3Oa9AqmKK/4XW/yIu/7QW8+mdeRzEekKURf/PXf8W1116NitvbY8uZHLzj+PFjvOjbX8Yrf+JHed5zngUiAgS2Lnj1T/0Kz3z6k/mdX38NOuly4NKr+PCHPsA//e938N7/+Hc+dGyISlKuu3QHJzZrrPf0uhHDYUlVO+qy5rK5mMU05o9uWWd1bIjTlLW1Id1uxFWLHT5xsmRQWF66V3PJUou5qZhf+rcz6MLQqwxl1kIpwZO7lo0Vw3plAPipn/rvvOQlL/l/bS7+/3vtnIqpTOh+CyFIZEhALkxgQDkpSROFVoLxsGqabZ40UlgBynnKvERIz67Uk0lJvxasjEyjIhCMa4dSiiSNWZqbpZ0lJJFCqlDbGmtZG+Qsb+XsXZqn1+pwcPciq/0RW6OCynrGeUlV12z2B4jjx8nHQyJhmJ7q0ev12DGdMVqY4tF2imjMgIWQwYOoMmyOCipr6bVSEi3BCzZHFY+c6TMsHQuz0wgPO2c67JlusTkuGZQVw8ISxwIvI6ypwFmG4xHj3FCUVfDMsZZikHP01BqtqXVq48jabWbn5lhamCcSltlOypWXHWTP7iVaWYJqrDPONW6bUACCGkBaA7jg2RTFCKkRommoNmeQREdkSUSdxKRJRKIFpizY3BrwwP33s3LmJNV4wJ6lOYQ3lEWOt5ZOrNjRSzi40GZHJyEfjomMDiE+AFIitab2AaTRAlpReF1nNnMmtiY7uikpjkx6dnRisiRi7DTLQxfsJBx46bBIcgtnByVrw5JjGznDyjKqgixTS0kSQaQVQkviNIBwm8Oa+awgFYKlbkxZ94gjzWq/wDfnozjRTYNeYmvTGB57erFEIViXkFvJ2AlWKziYKebaklEh8RJyK2gpSaeJNi+tZ2w8m2NPjsZE0f+1ufm1XBdr6Is19MUa+uuvof8PpHai+agnKGN4/YHyFo7l51z+J3KlcylgUogG8YVMQamC75NtJu6EtqmVIs0ypnodWlnGaFwgfWBNKQGq2SyMc9TWUlsZDL4Fgd1DQPa0UsGh3dkGoQ7mV6JBplWj53LekxvLuLaMaouOgqcP5wFPk/cKUBuLpJHCxVF4b4REuto6lAoJHEpKkkhhhQId0Wp3SLo94u4Muj/AqxF5ZTBFiTV1kCXKGJmCStvE7Smy3jRpS+BMiR6VqKFFWHPuxRDAEaUCWNfKEqz3GK+RUqFkoE8HNlGQRwilkFFER8cNU0cSRxFKKQQmFBAYpDcIV4GtsHWF9Q4nPYPRiMFwxCgviIQgjjSRjrbjcG0DPK2PCs4Oc86OcvpVTdmYmavJQBcBfJIybLCuQTGdD9Tn2gQztYkxY6QksQpyyTQKf29HgnYUNulEBiQX6XEiwgmPtVGg1DXL1FeReP1X3cYANHIutWLynxMq5wSwmpit1Y3HU26hJIBQF/oVKYFwYc5a6RE+GJ16589blM7NaSkaJqMIPlmSABbGKshdfTOXzkbnGIy2ST2wDQtMEea7igUtDZUPCSb93JG2UrpZzNTMNCrtIXU7sA0FgeNZ5ww21zl+7Dinc6Aa4q/fSYwnizXtWGM8eBcW2FgK2jp0DYvasT4ygfknFB7BytaYujSs7a84gKCVZezttf4/7P13tHVZWeYN/2ZYcYezT35S5UhVUZECSUUQxUiLqbsNr21qFbO2+tnYom3O2tpmbUVtIwgYEJRQhIICCorK6aknpxN3XmmG94+5znno8Y1vfPTLGG29Y9SqcThVnLT3WjPc87qvwM604ElhmVU1Qkt6vZjGlNTeMinCPYkV4Eyg32vNheGE3uYOO8MhkU5Jk4Q8UfS6XQZLyzgfpCVCqzBmfFjo9oF67y+CoPsFcKBUexlMg/e+T0qNVBZJKDADuxSsNRSzCeePP8nKYp9eJ+Wmq66jqAQnzo2pGkuSKFa6Cd0s0Pxr66j25alyPzQBs0fDDetJ4yzDaYVd7pDFmkGSMfQNpavJsow4SZFRhI4V2iiEdTSNo5obtA5pPdPK0kk0s8YznDfUtSNLBINEcqF0qBrqJnQPpRAoJT7FDNfuW9LsbZ7hXrWfP4UuLPf2nuDyjyfsLc77/U13D2De+3EFlC4AxzsNlF7g/xc65DPvuvWma/jQPR/kg/c9zZHVAbqv6CjPvC0G6saxmEiUjtguSmoEC90YsETCs5opLux6mtoRR5okCs2T5UwRi1C8nB1WwY/HWK5WIR53UhjSTBBFCu/CHpelCULAcDTm6eNncKYmzxKe85zrKGYzppMxi4trnDt3hk/cfx/euZCgGmVtt93hTMWxY0/z2GOP81kveAlPPfE4H7/vYzz88CPUjW0p80FCMp1OOXxglcMHV/Hece7sWd579/v56Mfv55FHHue9d3+A0XjKwsIiL3/ZXRw7dpzdnR2WejEfpWL7xKNUQ8m5k7u8/4MPh6Qb65jtzji4tMC1lx3ivoef4ujxk3z0Ix9hpdunKubMZxOK2ZSmKomShNo4ZvMKWcyJo4jl5WV6/T4kKdPasLyySi8W2LMZVd3AvOTQ6oDZTsHOzoy15UUWl5YQ+QIoTSdLuOmqQ3zWbTfy3FtuZkf32djcZmNzCxUl3PvR+7j77g8wGU/Yk9sdfeo4Dz70MM45rrzycl764s8CIdna2uL48ePccMON5HkO3nDjjc9hYWGBO++8ndlohyyGl931YlZW1wiJfQG42dvk5vMZd7/vg9x8042sLi+FekcFNndVWzY2t/noRz9G0l0j7w2466Uv4R//8e2cmjQ471leiDjcbUNifEjfqbTEN566McQyopsoju6UFI1HKklVeUrjKIzHS4mOg+HpQqIYpJrhbkPiHN2IEGEuAws8UpI4UlSVJUlSut3ev9bU/LSvJFKhmQYtU6itzdqGJyp4w+zJbkKwimitE8IaF3lHjKeng3qgcRArQe3aNF7jSaSgkyR085Q8iXEuMGbAUVoXpHRN2LPREZ1eDyM1MorZnRatj6vHNA3FvGBXeDY3LiBsTTdVdJMQUNDJYjANAkESacZFkOxWjUFKQRoZIgU4QY1nWtRoOWd3NEXLcHhZ6SXgHWXdUDdm/8iOCIBL1Visd6GpHClM7anqhtF0zmgyp6gqlFSkaUq328XWBbH0rK2sMBgshKZq2zgO4TthHu193juj7Nk8iNY8XCiNUBIhRUjaEuHQGkeaSAVj3aYx1GXBdDwCF7yO1pYXmUym7OyMkN7RTSMWOgmdOCJRAlM3GL2nxgjGxHEUkseUCM9S6fDsR0VNGmlirVjsJCTekhDSRY1QjI0ktqBw4TAnQs0zrR2jWcXurGJUGorGURhL4oMszwNGCJwQiEiGxDzjKMqGNFKkkWIhTygaSxZryqbChkHRWp8IqkAqxbugRDGy3WPbWrpua0ElQu2552Qi2rGvFRTOU3uYGE8lFE5+mnns/0rXszX0szX0szV0uD6TGvrTBp5ka2n+qW8gNGP2InJpKSvss0L2vk/QLj6tcLUXh0kaSVCtl5wQEClFv5tz6NAh1ldXUFKwsblL5MLmZUyI5mysY2ItpZLUxpLHmkhKYqVQKphWC6A2BiHANKHLYVv5nUAQSYlt17jaWiZ1AwKc0yQSYgG+NfVSSiJF+N11EwzMrbEorUEapDFM5iWVhTSOsSZQ2/M0xgiJ1zFpN6czGNBZPdh6PFkMEfMGTGVRWpAgiZKUxbVDLC+vsrS6Qi9ymKogLgVqppButt8B2UNJlAqmhf1+iheSxulAh3XgUXjRJiMkSavtl6g2W9GaYGrpvcc3NVpYYmmpqFGuRtoaVxfUdc20nHPizDl2R0PK0Zi1hQWWOjl5lpHECUpKZmXDxmTOo+e3eXxzyIXxjGFV77Oc9gBGJUDpi/5O3gWtaW1c0J43Dmdbb65IMsh0iKNNwmEpUYJUCxIliJVD0AQKprOorIv1mjmga4dqQkcuAFvh+Yt2Q4BQJFcGrAyMqyB+DN/buCBJtF7sb6jWe4o2GnZmofaC5hmuTYdQ9MrWbFTIvUVb0NgAzir8/s5pfCishA8FjRYQy1CEeSnACVLtUcJzoAObBZyfC6aNbItmhxfhkJAKuHyg6MeCnRrODQtObs9YEpaFzR0mp47TvWIpdPmTnLoZM29mUEwR1iJlzANPPh06QWcuD8khUU43z6nLisY19KOQGtNPNKd2G7aGFcNixHVHFuhlETcdXGIymiCsYV7WnNqdg4q5dpASuT61MzyxUzKpGrJskUgKVAxeNCwkml4UM9yuKKynNIKjp89QeckjDz/C9dffSJ5nmGKI6EbECZw5fgyrYbl+DomOkToA43vFtHN7XgEimBM7H2Kv26AE4W27cXiQMdJLFBpfjbDGUBmPFwmJEly/lnPZZZdy4MABbrrxWqx7C08ePUW+lHDZUp87Ll0naQrmVcOFaUUVCxJCSEAUhWjjAtN274KZg/We+cyw3u/wnCMLHE4bTp52nNts2B7OOJdrlhYieis9krlm88w2F07PGe96DvY1ZjzD1yUCybhoOLlbsZTFdKMAMjtrsI1jWsBCV9HLNVHr0NlYqK2g3pcFXCxovQfXbqRKhEZGJNn3/1BCotuucRCvhLkvRdgXEhlSKr31PDUxnKvgsYqQxrTnBvoMvd731j/h6EMfRQr43Ct7XLeouKlf81P3TtguHD9yRw+HZlQLfvr+ms+/ZYVvfukhvu9/PkYzM9weGW5ay7liGcodyds/cZa3ffApXnPtAk3SYagS7n3kHF5qFg8dZGxqqAxJJ/hG1FWFR/LXb3knf/dPd/OJj32AJ46d4T982w8zH21xy03X8cG738H3fec38VVf9rn8+K/+CbP5Dv54CSJQ5I0zCJ0FZmpt+Llf/i3+7C/fyoMPfJSv+fdfxmu/6LO5/QWv5NjxU61/YcMNz7mJD37gXfsdN4TgZ372F/jRN/wEX/V134o1Dc4U7WFVAZ6f+Mmf4s1/8zd89Re+jM+6ZpE/ff1rWb/tFYze90n67z/JeHfEeOM8T77vnbz2tiu468Yr+Lf/5Xd4zyePce8T57nvnvfxxR3JVx97kKKJSHuL6CjixNktHnzgCaqTH+P2227m1ue/gI+9+20cO7PJJ4+d4/Nf+XKOHDzAgRtfzK/90V/w5NMn+Pkf+iZ2trY5e/Y8q+srRNLw9Cc+TF3MufzSw7zhP30rh5/7Erbn8KqXvILZZIJzjoX1y2jKOd5VeG/3x8Hrf+TH+Js3vwVnDb4pcKZCRjlv+7t/4tu+/bv40Afew+133AYET6dLLrmUf/67P6EYb1EXYwbLS4QK3uJdBd4io27Lempw9Zj/9mu/zK//+q/ivKSzsMLywcv4sz/7Lc6ePsnLPu8ryBfWuOHGG7n77X+GMYa6tnS6SZACPHmWLMvIs5hunKJ7MUVlOb895Yx2CGL+/fUdHtxq+KcTJXGes+Xhz56u+a+vXOJAR/Mtb73AlZXl6oWa770xZbeRPD2TXJEaTswsbzzpyHtdLsktT53c4pd/5df5lf/225hq8q80Oz+9q0ZQe4Hxkm6iaDzsNoJY2GDeSpAg1R4yAQ2C2kODxOGIcRzIFP0INK5NL7Msp5JJ5RgbQ1FL4iRlZWmJhU6GloLxuMDaGu8MRWWpWwPzae2Z+wifDTg4WGW5DnN8Y3uX0WTKeDID75jNC86dOYurZvQiw0JkOLgQcWgxx1YFwhmWuimbE4HAsTWtsdYgcax3Y6I4IleOadEw3K15+uhpDix2WB10uP5gj81coVwdEulkg4z3atWIqTHIJGIpjyikbo27DaPJjM2dIWfOb7C2ukqUpAwWBmg8vSzlsksvY7C0QrebY40JTWjTht/gsbbBOQPCEyUaUzualmSGFMRZgtQaD5RFiakbcJAk4Z7apqGuSkxdoXEcWl1Gri0jRUjAGw3H5HGPXqJYynWwj6gNtm5wsQIhiOKEbidjcaHBjAsiKcjjkFJZGsdwOufKAwsMugmXLuY0taGpDbsodqtgHLQkLZn09CIQGKwL939jUnN+1jCuQmiRtQ5jwhkotJiDHKmTeRKVkkWeU9sFi6livRux0u2hlWY0qylObVHWFbUJTYs0VsiWfyJwaCGC/5FzhHUnHL7L2jGaWpaSsC9HCmam9XXScL7ybFWeMwXoWIb08mfw9WwN/WwN/WwN/ZnX0J8+8NQiTgKCITYXka89yyfZfl9Adtsasf1akCkFqVsiBF0dwJ1Msd/diPMOyyuLXHnZYUxVUswrIu9QEoQWNE5hrcA6ibFhgS1bIEgrSR5rYqXRMkjgvAg8l6Y17fbC4mwAr5zzF4E0ERgs09ogCN2iXEFEeL2qHd7ee2TL/DLOUdQNVkioG9x0jqoMWsdoLNKHBdo7qL1lPp8jOyWpdaRZTm9hgaWVNTp5hq0rIuHo9hfodXskcYyOWp25EHihkCoGqQhRsK3htg/3TkqFFBFSS7yQKCeBEGVqLfsPQSodwB8l903N9/VnLkxWKXzoaOxJK52hLOZMi4ILw102dneZTqck3qMjTZqlSCWxzjEra87sjDm9OeTo5i7nxzOGReiURG13TxHuoZQXvZS8p32tnqZx+/GtsZTksaSfaFa6EZ04AFB5JIlb003RMqLqJjDgrGnwVuGVIlYJWsVoZZHYfYRXEGKnW7sMGgszHzTZ4bVcZD7VFiobPhetxLR2bafGwdzuMf6e+ZeUwcAxQuJNiN/Gt+kbUiCRLctvTzkdGIth1O3Nf4fwAi0ETYuWdyMXOq/eM67D34qVIBYgnOdCYUkjSCPFjSspVw5iJgd6bG+VNLXDVBO8myFFRZ4EDXHsDcSCvJewvNJD47HzOZONTaQSRHlKI2PWu5IjImJYG6ZWMLYwN6E7udaLuW4hYTmPiSUUCzHGOkbjCU83hq3dCVctd1hfUtzpFZvzLbZKw/mtKWks0CqiEiMuWV7jOetrjKaKzUnFhWmBwzKvZzx5/CjrBw+jl5YZqoyd7THHxyUrvZxGRuyOJvjdCZ08Y3D5kTYGkXB3RZCZWnyIeHUxXrY+c+0BABGKQykEwkmsyfA+aM5F7BmsLvPq17yWwco6cZKxu3OerZ0JO9tjbr/2Ci5fHnCg32d7q8J6QTfL6GhJZA0VIaTAuU8BY2W7mrfIa91YvBfcfNVhBnlCv9fh8VMbxLHl2sv7RFpjvGZ71HBqtEvWKbjkxQc5fCDh+iLlbx/ZZKf0KK3oJ4JuDHhPZQU1ksFAEsmwntWVxydBury3EQoCKB1SXkQbQhDMVwFqI6gjMCK8hz3AuB3deGRYewhrzIXa7Rcr56xk6EMBSWPCxH4GX7/+x2/j5NkNpIA7L8/x3vN7D4+5fjlBK8nfb2qm8wbbGL7mypj5fM6vv/M4n7UkaBrF9njO0zJl6gSiqrhjNeZgEnHjasQnt0sePTmmk2oaB5OtHXwE4KmLBtdKLUCwdugSrrjmOiSWG64+wq/+zA/z87/wq6Gx4ww6CvKU++/7KGdOnw0v3rd8eAT/6XtfR5rE/ORP/hTeheRUENh6jiuH/OSP/QCT0ZCmGvNrv/VnHDt+gm/5tu9G4FlcHPAT//VHka1xdjWfhQ5jlPPzv/DL/PEfvxGA4eknuOuGg3TLHaod2NiIOZCtsr6wyAsGgpMLh7jy6iu58mVfytH7PsK5p4/xBS+8Cac7pN0lhJlx8vgWH/rAR7jltjvpJRE4x+HDB6mKGQ+d+DhZf52VK57LVT5i/eqGG1+kWEgj8iwh6y/wxZ/32YxGY/LuEh6NSjLWr3wOWxsXeN9HPsFkXjIr4W3vuYfrzk0wXhNHinRpgThSbO5ucvu163z5y27njb//W/z270QIqfnIxz4RfBuE4k1v+UeePHoCIRVPPHk0eFrsV12SP3jjX/KJ+x+gHG/ymi94BZ/zihcjhOZ977+HN77xTwE4e+483jXgw3OQOsf7cFCXStPUNcOtDX78J36W2WSEs4ZyNubpJx/nW7/tu/nYfR/He09VhTFinadpLDMazjvB5etd1hcFzluKuuH4xpTtgWJSGOqqQekYEDTA8bNzRF/xb67OOZILlhLBOzccR7pw27rgrx4pOTH3NGhWFpcQHo6e2g6MFHcRnHumXmVp8MaRCk8iPamSdDPZpsuFppskFCaVCQqAfqKorUQ3UNeh3jY+SByySLKuJZGRJNohpEQlOb1uh16WoHB4E9hEkfAoqVjpagySBk2SpjgUw7khTnPiTsKll15CJ88YjUZc2NyiKErKqmZelkynmslkTJ5oVrqKaw71mU0kTVXRSzSNMUxLyXAaDuGx8Cx2U7pphPRdNnbGFEVFU5bM55JJJJFRRK8Tc+lqj6e35kybhsYLZKJRUjG3jrXlLutrC6Qbc05fGLEznDOZzjl/YYtPPPQoK8sbxJHm6dNnqWYTbF1x/PR5epOS7u6Y3sISaZrS73ZACnQcE8Vx8HMSgjjWSOExjcY4i2tqfDFDYvFat15FEi8VdVVjCPVqHCcsLS9z6623EkUa5xznzp6h3z9Dr5tzxWoXhQNTUzd1YKNFMUrHWASlgbJxlFVDVVQ0Amwjsa0dSaQki72YA0sZywsJ07lkMhdMpg7rg5Nrt6ND8p9wmLqVSBY18yaYHsu2xjfWYfxFlUTwWfWUdc1wGlhkC7HEGol0ltU4IVdwcNDlwu4seHg1hqIWLXFAkmpJP4Io1ihvkapBI9BK0EskzhtGVUjVQwQ9hVbBjtt4z2YFU9MGTZk2AfAZfD1bQz9bQz9bQ3/mNfT/BuMpgBn7gK4PL963FK9AyRIXqVu+NV9rfXOAduL5YCAnIQay4OCNF4Ksn7O80Gd5cYFTp2bMZkWLFoebJLXCS4n1jrKyQZZlLZV3GCf3qctSBA8n7VVAoduEMyEEHheQUifwXiJaOqPxwcxQNNC0Bte59CAhaoEesQc8eY/zgU7spUI3DXVRBW6aNKQSEgW9RIF3WOcoqhJdVRhrieOELO/QHwxokhjXVMTCkWU5eZYTRxFSqpbyJsLkkYpgNSf2GU+unXwIEdI4lCKQ5gRSeSD8bT71ubQfogXS9r05fEjG2zPL22MEee+oqpLZfMbOaMRkPqesarIkgGNxHAVanrVUjWFzPOXccMK50ZRhUTFvmWTQ0k0R+9LLPdqea32crG09udqIjyQS5JGilyoGmdrvHOU6TAQFAUg0DupgeEjtcFQQRagsI1IRWhmkrJAtmiRa0GtP92pd6y21Bzz5i8hw4y5+VC4UfXPrKV2Q1zW+TYj59BiG/6pXuO9BC9160Qd6ajtBJSGp4OIRESQSKVx7r1qwtt1EJaFwSRV0NTRxkB4KwvjXhHs4rh3jRtCzkkEmWVMRXkR8eNe2cZ0V+BIhKlINjfTEeBAerSVpGoWEpKpmvDMM7Mg0RicJa6lmUTuGRcnJuWNn5qidI1aS9V7EFf2ElTxIDWoRUzvY3pmy01jG85Ijyz3yNOXKRcFyNmZcG3bHBQvdhCSRlKIgiQUHFnusLzpqO+bCZA7CU5uGc5sX2B2PyfMulc4Yj3YpyzFLy9djZMRwPMVWDbaq8JccvBjQsLdptrTW0IPVIBTC+2ACG0iJCK1buazEqQRcYPYJAVmvx6FDh4g6CxjreOjsKeZFg6ktB/pd1nod+nHCFgIvJN0sI8OghA3zm0/dxy+uB3s2fo0J8clHVgc4Fw5D9zx8irVphrUO7yOMFUzmlo1iRlIanPb0OpLVvmZaGIpGINKYTgydKHgVOARWQJ5KnA1gs7S0VP6L0uq9Ls3eWrcH8UohcC5smpWCes/7xoMXPpi1thutbKU5tfPsNo7SBVrwGEXlBVo4UuFIeGYfXB89vgHecujAKoeXUs6OKu49b/jGG3IWc82fnpTMZo7YGf7tFSkf36z52Kkx33BDF6fhwtAylDBxAlvXXLaScdNyRCQNwjQUkxlrqwsUjWN3OMHoVupmLAsLC6RpysbGDoOlFa685jkUxZxLDh/iq7/yi3njH/8Jw1GQg83Lmt3RjBPHjjGZzAgPZq8gcdx5+80MBgscOXwI5ywHDqyHsW0bsBVf/tovxJmKanKBv/ibf+L4qUd55z+/C7xnbW2V/3jqDOPJlMDYbejkOcsrK9x374cwTZAKvviGQ1x9YIAvp1TzjNmswYuEQZ5x82qOcQNW1g+wcuUNPPrhDzPb2eZFt9+EzAbofJFyssP5c6c5fvI0Nzz35taL17O00KdYW+YxrUm7A7orR1gu56yqiLS7xM7mOZw1iCjllptuROCoqwahNHGWs37oMh566GHuvfejKKmomop7H3yM0XhOHMUs9rJwuJGC2WjEtQdyvuyua/niH/hTPvnUBYRMkFISRQnOOz5x/0N8/BMP4r2l0+ly+PBhhsMhW1vbrKws8eDDj/NP/3w3xx77JAfXl3nB859HsgBPPPEkf/hHfxLS/wgNpr1WolAab0Mi1cFD6wgRjNX//u/fTlOX4B2mLtnZPM+f/+Xf0O3kHDp0EO8F8/mM0WS0n5pbW4nWkm4ewIVR0wQT5NbL0TYGIYMnZTfVnN2piCq4canDYuzReJ6aQJ5AN/E8PLacnkOSQhwlrWUC9DpZkBc+w6+mca3BuEAHe07SVFBYQWUltQmrnHTQAEoJskiStV3sUMEGUwTrA+M7lwIjJRZJ42XwB80z4ki3BtvBZNtriRSSTqxwKsLKGBnHCKmY1YbaSSIVMxgsIpxtPYwKRgKctZR1w6womUymdOIunQiOLOXsCkMx90QSMi1IlUALH8ywlaCfJQw6CZmW2KpiZBu8NVRVzazQpEoRR4q1xYyzo4J57ZjXTZCzSUnjBEmWsr6yQOMks3mNloKyqtgdjzl24jSTWUmWxOyOp5iqxJuandGU0vp9NUKv1yPLUhCBWbMXiCNauZt3wXTdGB/8l5oaG6l9U20pgwTPeRFYFXgyrYnTjLy3SJQkGGMZT+fknQ55mrC+2MWZhunE4quwH8V7wJMLrPnaOOrGUjeh8e2spLFtomEWk8aKTqrIM4XxjtI5yrHB2sAucyLBK4HBBMlqZZhWlqrdu0ULPFkX/J+UgEjL1j4F5sYw9Z6yMSgfEwlFrgVLTUOkNIM8YSFPmFUN06rBWEdjgt+qkgKtwUkRmvBCIls5bKTAWihMkPnVDiov6MYK50MdPXXBy0gKQSQ8sXxmt3CfraGfraGfraE/8xr600+10+pTGDJunyizh47tTTJBYI4IEYzWYilQgXmGb5PvpIREgFct+0QHbfnBq65AphlbO2NOn9tiNp3SkQ4dhSS7pSxDS1AIJkVJ2RimZUNpDLU1YUFMHFnkWMgSdCSRKg5SKSFQ1uPaLkDdWGovsF5ildpnBTlrqZynNFBrQaqCXC3xFi09Waz2QYmqqbGAiCKMkzQopsaTSMi05MqVPlUbT+nGE8im9KqKKI7Juz0W1w/g6gqsIcMRRxFxHBPrKMTeWosVHutsKxO86FXk95BJ5wKIIyUIvU9D9ISoVo9Heot0lgiPlIER5Vr9qyCk6ThjsPM5tgyUYtEyq+qmZmO4y9ZwyNntbZTU9PsLLPe6dHt9VBwzms2wzjEtCx4/t8mpzW3OjadUxuG8RyP3qZFC74Ffe5PBt54AgTZelxZJMN1cziMWc81qL+JwP6aXKJYzTaaD+aZqEzYa4xlHlnlpmGKYlDWutggHHRUhUsGGLjHeYLHovc2DkEjnPPsJiwGI8vuMJ+9D/HDjYdQE2d3MCSLpiZRgvaNYymP6yTObIgytN4YAZ4PBpMPvb5ytChbRvl+39/8JUFK1C6y7OO5o57qArAU68wQOpHtpf55p44IHllOcnQk2Csd2MeayQc4VA0knTeimKVJF4OdINyH3FSJLGPRS5O6UydlNzhw/jRGOSdXw+NEt5KDPwX7GC597CUdUQx/DyQtDio0ZxycThG9Yy1NedlmHV129ivCCN99/Ei8DM/LS9SXw4Tl/4sQ51rsZtx5c5aVXrrG2OeZND56kwZE0mk6kKUaG0eaU69bW0DLm5GiEswneKYbTkgcffYrz54ccWDpEimIsdugtXUrhFMcfO8aBQU6iCR1TEXzfDOC8C7R/rfACvHbhXiBAtevs/kIbgGKVD0CEhds2Fc56xkVFyhTngsHrpUcOcuetN7KeahJTMRkZENDpdrji8iOY4TbVZIKUMUJIvPAY7zA+pFXugbIIMMZQVYaiUXiviaUmTYK3XV0axsYxnNaMGkFtHH5e8uRD59mdlJzfrVlZiDEV7DrBYiw4lEmuXIh4shTs4jAO5nNHURqWslCKaelJtCRRILEEFrVHS9A67C/OwayGWeXISrG/B+mW4nx2ChnQkYAL0tix9ex4xdTAxsyTUpFJx+HUcsuRHlcuPbMPrg8/+FFsuUs1Psf/eMMb2Di5zRcfjoisxRSOLxoIbrmjy9Ig5lvfssmd6zE/8coBP3HPkEQpPu/yZV683mWrsvziO7aZrSXMneDXPzLizrWYn3jpOsdszlO7NbuFpSgqrHUgBG/40R/m81/9Obzgha+gm0oODBLe8g/v5obnXM+Xfdlr2U+WE/Cnb76bv/vH91A2EmQUmDT7Y9nyH77hm7jj9tu4/xMfRqnAOOh2EvAxcd5H6hzwRN0DqKTHzc+9iX/+539ECsm58+d5xau+kO3tXRDBv+pz7rqZ3/657+LJ++5nZ2OD7Z0NHnjiAsfOjXl8aHntwYy7Ll1meuYxVjuWr/r6f8PRP3kfxdknmT7yNlYXofviF3DLV3wv091z7Jw5yjvf/Fcs9DK+4lXPw9Y7zDcT1LW3IqtddLHBZZessrjYA6nYGk4xTYOUuxy65BKMg6PHT3NwbZmFXo+llYzxcIifjIkHB3neXUe45UWvRL/+B3jgwQd49PgFPvjxp8gixete+2Le9dHH+NADR/mhf3MHl6/1eOITT1GVdTi42ILDh26g211kd7rFbD6nKAqacsKXfelr+JVf/ln+zZd8BYPBgLe95a/5mR/7fr7u330xL3rJK/ibt72Lx07u8ju//nPtiJIIGfatADyFIsiaGgH0Fwa8+5/+Eong6adP8Lrv/iGOPn08/KirSdKM226/g//4TV/Pa77oC9g+8wR/+udv4sd/9tewpkFpj44jPvn0NpGSrA0ynndpn6sWFrnt8jWqp3YQJ6c403D5WsJ/vOsQf/je47zz6SkvXyt5uhLsOsk3XZvx+Njyre8xHF5fIaoMj57a4cOPHG09e+Drv/LVfOkXvuz/6Hz8f3JJ3doNeEmtNU6HBLvShkPAYqbYmRnmtWMpViQKIuGpakdlQvO09pJESA50FHMTJFmVsaRRxKE8J15cASEpywpn5ygsa7nACoUTilFtUYkgimOWB33ybgfn4fzOiEgFYCqRmoWFASkNW7sRsfSc3BhSVg2zsqSuF1nMIy5dyVmMPZOp5ujZIfPKUteGPJJ005hLljoc7Cf0s5YxkWtko8njIOLYnJRMJ4aVQcb1ly5ypLSI7RlnT+wynlcopen1MpwRaCdZSmJ2s4h+qplUhmI258LmFr1ej4VuzrVXXYG3Dd5ZFpdXsB7GRU3HOHIX6l8pFEKosNcKjUdSGfBeIuOMLGmbvt6hdQBShIAkiUAqlNatnMeEPdx5kiQmTfOQrh0lpEka/LVcDa4mEg1JL2ep32VhsAyRwlQNZWMpy4ayqKgqE1QAkce0PkJlYzm7O0NKz1LP08khTT1PXSgBRRKndLsxWni2xwUbo4pZUbcSm+DR11hHZT2Vg+VeQjfVrHRiSmMpGsdsWFNUNd4LFrMYnSZ0l7psTEukaMiSmMuWe3SSiHlZIrREKkHlJdulZWdukQQwuRaS2gdblFM7JQczwWIsGRoYG8duZXHz0PxvrCOPJVmsuGQh58hSzmo3+dedoP9/rmdr6Gdr6Gdr6M+8hv70gSfZUri9CzPP+/1Du2wnmPcgXWss3v6cbFPtgryp/Sb2PwECGUeovItXinnVcG5nm53xjKossRokGi0CW0pLSaIkkpg0ChGN40pQtRtw2RhcazyppAzGbwJEi8YH4qnDtmie9Q7rZCu9CtpJ4wOgI4DGyWC4pS++xz22V8CvHdZanPJYEQqA0lnmAlY6Mbb9fTQGY4LOOoljdByTZB18FIGzpHi0VERao3SElLKdK5/CTMLvSwP3aGTOOZwAaz3CBmaU94GB5lz4WW8N3jY4YxBK4LTGyQhL6Eg4G4At42x4pkIjIo8XktoYyqqiMYZYxyz0FsiThFTJdlOvULtDKmOZzAs2x1NG85Jmj120h+jtjYdPYcA55/YldtZ6nA1dgERLskgyyALTaTHVLGWabhykDIlWLU1QYHX4Wa00eazJIoOetB1V6Yla4/R+nuHmBdY5IhUklFoEmV3Dp1IRW2R4H3jy+2DUHrKaa0E/U3RjxaF+xnI3pZ89s9M4IBg6Ohe6ZEqqMK4VFxNeWmKCaFl97Z4KhPuVqUCvVu0iBkHmqIQglSEKtw2PwRNQ+VyFaOAqkNE4PTJMy4KNkWHBhY07jjXSG5ypmNYWX9d4b9l5+iS7F7aZzA3Oh9TCKBI8vjlhZIL/xeH1jDyP2aiCOWZXCp67lLPUiUmloiIUkXESsTuZYqzhwOoSkZJIB5OdEdrD+YWarlYc6sRcuZgztFA1hoUkQ6JwzuBEjcCQaMm4aTDG0MtS+nnMYj9lcfFKmvoQTVOxsHaI8byiNJt0kogk0kEKYhuwTWBe7rEO2/VUONvO7VDp7o1DZ5pPeYZ72lnR7qce19Q07ZwaLC1y9eWXUU/HJFun8Y1lbh1ZErwkkiSmQQRvEGP3qe2BmRo+wn+HPyElCG+Zjob4ckYqGnqdFKUk09mcQ2sL0EnodmK2pyVFbRkPS6SEXjcJiZXO4ksHLkYKRRxrvGtoahuSMJxHKhG6z/Liyur9xRhnJCgV1mTaTqNr52pt27nbjjyB2P+aw7PdBDr/sAEvLdrDgRQOd2JWcs01qxlXrPU4sPjMBp5+87d+lztuvZ6XvvC5PDEyVLOaO5c1Dw8tXgo+57ouR0c1Hz5X8uorU5xx3H18yg19yUIsWY8tj12YcnZmOdiRFE5yvpLcdWmH9UwxdpJHN+aMGs+1qzlHL1iy/oCv/aqv5IUvuJN+v4cQcP7cWT5y74eJlOSRRx7jiSef5MSJUwwWB4DgtpuvJ9KKGy7N+Oh9n+RDH/kECMX1113Dl/ybLwIBRw4fCcwKoZhOZ/zab76R226+nhc+/xb+8Pd/l93hCLzl5MnTNMbwm7/5uyyvX0bZeHZ3dqnKOVorvvFrv5SrDy/x4fd9mI0TJ9neGfHgqS0uP3yAOw8cYvODD3F2e8K/PHyeu/RT9LsJg/UVpo1lc3PI/3jbh7jzeS/kyBVX8Oi976U/6DFYXuHWF72cPEs5eGiV0088TF2W4GG+u8X0wmmEqRHt3ClmE3xTkycxu2dPIKOUtZUl5vM5k8mEOImo64amqjmx+UkW+x0uX18i045YCUaTkiiO0FrzgU8e5cS5bZwNzaKtUcHJ3ZJZHQ63S/0E62YMxzWz2ZgXvegF3HHHbThTc8ftt9DrZBTzOWfPnuNnfvYXQEi2t3ew1jGaTjl+4iS/9mu/gVKSH/rB7+FP/uebOX/+QjvC9gr0NrEJ6PWX6eYxSsK3fes38dH77ucv/+KvAI/WmoOHDrG8ssLCQh/KZV7y4hfyn76n4Y3/86/Z2tnF1DUrg5w0jWm8YqOwWFtzodji5LCi202pjGC3cLz3sR2O5JIDBzN2rWTuLIVxfHjLcnbasDWpQY4CGz2C563nxMLz9scLPvHQk1hredlrv/1fZW5+ulevEwewzFpEFCRHRRP8TaUCrNs/yJQuMCgiIcliaLxgUlsumr+61oPS00sELorwURo8oYyhKEqsb4iEQ0aCBhuY/R5MYzCiYj6fI5QmzYIPUolnWNco3yC9ITIz5vPAInTOUdaGWVkhvGWQxxxaiJEuGBDvJfsqAf1E088iFrOITHqUbSiKmnlZURhLr5uglSISip2JCWwf61jrJwjvubAzZ2duKKqaJIloGos1nkgq0kiTJxFFU4W+v23opxHri30OLveDt4uzJN0+86Jia3dEJj2xb6Cc0cynVPMZztr9+q4xtvVudahIhbpVSIQI4TzOBAmzqQ12L/QGF5hkxlCbi4yCNI4Y9HusLC8xr7ZxVU1TNXT7C2S9Hmmvh2lKtLCs5JqVbsywlzKvgidtGkuK2uIczEvDzqQmSzUiDh4qyoWzVKIFix1JmjiaxrI5q9guLUXtibXE+MBQKE145rFWdBNFFgUma209ZRN8VRsbWtqTsqFbW0obUtG898yqhizRLIuMlX7OrAphQUIJjAuKAy3lvvWHJ5ytisZTxILUCaYmMJxqFwy640jSzTSHBylLnZhL1xZYX+6y2Mv+dSbmp3k9W0M/W0M/W0N/5jX0p59qtye1QwYHfw/CeZzcQ8raSL72Te5BT3uIr0Ts077YpxyCExKVJuhuF+MFo1nJsdMbzOdzvDU0rfFVLAXOaYQOuudEReQuaBkBpqKhaGqqxlIbF5IDdEiD2McRxB49rbXMcj58bmWCrX96YLhYh3VQt+746lPSVITw7SITfrN1gYkUmDOOoqzAWXbncQBIpEQaExhMzgYdfhQTZznYGOEdifchblNKpNKh+NgDnvbewR53bw94EgLvLI7gqyCkCoZ3qP1CwTuPMwZvSqyvgmQvijDKYYXEuJDI51qJm0PiZISKgp69MoayrjHWkSUpK4uLdLMOdTGndoZ6NqcwhrJuGM4LtsZTRkWJ3bunInQABHsyuwA8eRc059aF9Dpng05WiUAt76eaxUyxlGmW2s+dWLOQalSr193zuvJAngrq1NNJLUpIysYxbzwu0kRCsJhn4b00hlhZItnqsts5uOfttAeI+v1JGJ5BkNwH4DNPJAe7MYudiMtXeiz3cvp5/OlOpX+1SykV0mGE3N/chARr2KeOC78HFPr9/xUiJHB0tCSWgaLtvGkXe9AiFEKCNl1QhC8lEkyrsR43nnHteGDXcX5Y8JSb8cL1DtY74jhC+BprKsaVo5lV1IVj48lj7J6bMi4s3iu0UmSZ5onj25yZNHS05rlLMUmccLawlNYziARXLHTCRoxmbEKXJMtSzm0PGc8KmtYTTmtBMSvxVnBiVHA4FRzoxDxnrccnt6ZM5gYtOyipEcJjTAGuIdWKpm5IjGExz1jup6wvdbh6fSkYj0YJu/MpG9s7zGdDuklEqiTeVPimxDdV6Hz5MObxAm893tYI70AofMtI9N5j67BpipYpKKQEZNvBcdgmFL9SChaXlrjm8svJrOHoPeep6prKOpYWBvQ6OZGOsE60nmjBUyFIiOX/F0iMACU9Est0dxfvajLV0O9maCUZT2dce2SZREh6nTh0T+c182lNfyllqZOAFEECWzm8T/ZlDtZ6qsoynXu0FmgtUVq2BdtFwF2w5y/oUcohnQjOiO0ZOch5QuHh2uaWgFZCHbqO28YzrAXDWrAcNfQ0rHQUtx7MuGSxw01XrtIfdMm7z+yi9/U/8l/59m//Bj7rRXfy9MSQ1ZYrBwn/cNZQSPiWS7v8w90XeP8TI/70yw/xrqdm/OF9E153Y48DuSRRlodOzzg2tVzeU8yd5Gyl+JKr+2yVhqMjw4MXZuSJ5s5L+1wYzVk7sM4P/8D3ECUZG5s7AFw4f56d7a0wTr3jLX/7ZmTc4cDBgyDg+XfcxK03Xc35513C7yj2gaebbnouP/2TP9YWAS0bChhP5/zkz/0m3/R/fSk3XX85v/CLv8SxYyfCm24lLj/1Uz/DVc+9i4XlwyitSGJFEkm+85u/kt1zZ3jjb/4umIbNacXbH93ih7/pOp5/81U8+MCjnN0cc2zYcHnmuOKKQyzfeB2TxvLYqS3++5s+xC89/zXcevUt3P0bP8tznvd8DrzoLm5/6Q3BYxGBf/IpTGXw3lEMt5lunsXM52Ff9VDNpkhbIWXCztYFku6Aq5/3Eh555FEubGxg8URRipSa+x5+mMvWF1mW16J9gxKe6azi0IElkkjzjg89gsCTxwpT1JyZNTy4XTNrPFmWcPjggBNnR4wmJa6ueckLbuV7vvc7wv30lvlsjHOWp59+mtf/yBtARqHphqcoCs6eP8sv/fKv8jVf9ZX84i/8DO+5+8Nsbm7ijL/YVfOeKNIhUUildLpdstjzfd/znbzrPe/jbW/9O6q6QuuIgwcPk6YZTdNgUdx55x288EWfxXvf/yGGozF1VbHYW6DXyzi96zk9bTjZVOwMh6RZQq+XY+eWrbnhrfdv8C03dTm81uXNJxsa4fHO8O7zwQuqLkvOVRVZolkZZHz+1QM6WvCOJ3d5/70P8P577+c3/sf/+Xn5v3Mt9GKaxlLXYc2rjGdSWlY6EZESFEVDSLALiUHaSzIpyeJgSq4K2XpjhhTKpq1h+6nExREmykIDtm6YzEucNCTKo4Wk9p7GS4SSYAyNK5lMJiAknU4XEDTGsL2zQ1NXeNuwEINwDd4EL9WyatidFoxnBf1UU673WOlEpFq0YGWwuci0YJBpllId5BdNw3gyZVKUzBuDjHLiOEjb3LDCNAbbNKz3EjIluLCUMasmjOcNVW1a4MkRqQA8ddKIcRHmj3YNgyzmwFKf6644gsTjvcWg2RlNKIo5mbDEtsLNRpSTIfPWqywk27VyGGuw1oBUCAlBoxPkOdbU1FVFVdXUNliDCCFwpg7epKYMXqZakyURi4MF1ldX2Ty6QTOvsXXDoSwj7fdI+z2KYYn2hpWOYq0fM55nbE1rpIA8UVhXUdaWWWXYnlZkuUYmETrWOBfSIAPwJEgiQ1kbLswqdgtLYzxLkQqSPOOZm2CfkUaSPFbEOgBGRe2Y1Zaqrf09MCxqOkXDtLEsZRHeWqZFzVIvIU0i1he6nNudUFQ1SoZzRm08IgrH1XCFs1BpPYUVJFYwNSF5tfEhybCTKBbzmBsO9zi0mHPNkWUGS306vWd28+fZGvrZGvrZGvozr6H/NxhP4S4KAUi5/8DFPmrWeiBJjzC+jZwMKG+kBImS+3/MOxseOIK6deF3SZfj53cYzoogo6sanLXMCKycWWmo6oZOHJgmi1lMqhULWUKkFL3ahMlZ1JTGsDuriHVDrIMmu3Ge2gbJlPGtRl60D0a28YrtAwPwQuybvTV1SH5rfJBYxTL4VO2l93kfVh/ZoqizuqGoSp7etORJTJ4mKGsxxmCMoakbnLP7XUX2WDZCgFAY75HOo51DuNY009mWVu5DJ0a2G5/z2LqmqUuEnoUIahW1GFVQEtu6wdUNs2oOiABsRUkwXNNxC8lKiDNUnKLxUBX48YTSerzQKB2TyYjaeIbzgo2trZAmZA1aKUoTJG470zlFbUKnaA8vI3hjqRaJDRu1pWnBJtdGvGoZvBsWM81iqljLNYu5YjXTLCSaNFJoJaltoBfWzu2brCsR/AvSXLMaBZ1+UTsmVhI7OLLUBxwKi3clQoSo09Ls3afwIPafyaeApNYH/WskBZmWXDpIuWqty3I/48DKIp00Jo2f+YwnKTSqNVqXXraLsmuRYtmmQID3ggi1j29GJgCbNYAM80X5EIcrpN8PGwCB9eHXJQIO91OSSOGVZG4thfXccLDLzs6M7a0pWVWiTEOcacToFH7zBE05pa4bZhKOn9llY1TRGMdyrlkf5KyvL+KfGLNblBwdjrh5OWZJOg4f6HNouYu2lqv6CcYLdirY2hxTG0sXw/ryIlmvz6lzQ1Z7MWu9hMFCh515yXsffJQXX3c5y52M5x1cZlTUVEXFvISlwQFuec61PHLsOP2qYb3TwSwPyLOExfkpFqse3cJy4cQZfAviVs5SliXZdEK5VbF9VvDYxv2cevoMW8MZ2fIlAQgXMJ+MGY9G7G5tB8NQIYgjzcrBdbI8Y7yzia1KbFWxNZ2RZDkLyyssLvQBz2gyojYS7wVZKhltD2lmFWmWMC8LtsZjbnju1Rw+sNLKSz0Wj44kiVakUjGTLnifyYsx37jW9B9HmiriKKfrU5JkivCWZlowPXee3cLy8RM73HdhitKCH7xxBZVqxo2nKC3GQdzRxKlCakVhBGXlqRtHkiikCmuDbceRlHsbuAgmru3wihB0E8i0p7SCSQXFXLSmiHyKh0LwBHRtx3deQUcL1geSaxcTDi5kXH94nUvX+vTyFBFHeKWZu2e4XFYo/vTP3sQ/v/Pd/NfXHsbNL+ef3neMr3n+KkpLfvrNx7jt6hVe9cVr/N3jY8om5vOvX+ZvLzR0I8EtKxFfdscic+v5w3sv0GvAlw1Pnyv55HbFPRcqfvyzV2lqz3sfH1LPax5/4hiv/vJvYTbcYjbZpTKKb/zGr+f7vvubEVIz2jrLsYc+zNW3vZyVA5ehVMKPvuFH+cu/+hucdYzGY8ImoMLetB+XvVegObxrsMUWv/f7f8Cb3vS3nD67CSpGEOQuN95wLf/zD3+JzuAwOu4w2/laHrz3A9z/gbv5bz/3y2jXsJQpXv2q5zMtG87+1t/z5295N2/5l4/yw1/z2fzjPQ/xV+/6ON/52BN8/otv4g2Hj5AkMSqOubA9Zefox7DX5nz59/w4Fza2uPe+p/gvP/MtbG/vgPf8/m/+GjfdeAPnzlzg0ptfSPfQlfzwj/4I+U1DbpWShUPXMtk+z+nzx1k9cgWdwRJNbfBS4nXEtHJ0k4henvK5L7qDwWDAwoFD+MER1GCXy9Y3cVGCEZIbLlngpVcv8/zLF6nHhntPDrnnoXMsrSzigUeOjbDOs9jr8I0vuJKP/ONfcssf/xm0ZuveO86cOUdrbtCylzxSaaajIdIZ/vHNf8DH73+E25/3Ej735S/lmkvW+LO//tvwO4RExV2+/3u/hW/6+n/P8iDH2xJvazzwwhd+Fp/8+Ad53Xf+EA88+DArgy4fu/fDfPiDH+St7/ggr/miz+X1P/A63vSmv+Zd734P3/jN38ZTJ3bI0wnXXLrMue2G8azhtqtXGReWc6MKLYIXg/Gej+3CozPLYxvz0DgDHDVaeLrdhO9/0RpXHl5h7epruPw5BzkznCL+4Un2mqLP9KtswkG9tIJMBTCosKEW1gJS5elEoa7uKkEShRjyE7sVk9ohnWUlkXRjiSWin4QI7XMzsCLF6YwIT2QsCMluGYJuqlSy1E1ZzhOWBl2sh8Z6RuWQSTVjPNoly3KUlJi6YjwcMZ3NeKooW08bwXI3o5/F9NKYjdGMrXFF3ViuWOux0k3I4ojlnqOjoKOCf2u3LpiWnrlxnJ43eBXR6ydYqWgc2MaynApi13DuwpCDSx06SnLDoQXK0iCcw3iLVip4KaUxC6Wl382paovWMauJJ3FzfDFkshsHAMlUFGXFdDKj2d6iHAY/lKFznNoZMywafNZHOtMmbjuKqmA83GJ3PKOxIFXKpUcOsNDrUE6GbO/ssr07ZHM0Q+qIPO9y+OA6SiqmsxlNXRNFwYv0krVFci5j+/Qx6tpQNxaV58SdjDgWzGxDWRbsTip2Zw3DwlHZcGaqrGFWmMCocCB1TJTmdAbLGOOYz2tqCzjDzmTGmW3H7qzhqfNTlIrQSlMQM3PBYLxpQ5QQgs1pHcBy6ylMkPQJpYOHi4eicZzZmTKeV1y13qObRGSRom4alJRceWBpP/FqXDsq56htkBkJIdoApHBJKdE6+HdFkSPNEg6lMc+/JONAP+HIao+1tUU6eUwmQGqNFM9sn8Vna+hna+hna+jPvIb+30q1E3tAiwirlBQtmusD0ATt9i/2mE4iMI+kJFHBpA/vccLvM0oandAIRd04xvOSeVntdyFo6V6VdcgG4tLQWEdjLFIImtjvG3EmUWDE1MZhfDAdN3aP5Cj2Kcl7QIVt/74XYZJLGWSBe0BSIFP6/b8/M+H9d/Y6O1KEd9uCbjiHJdArrQsJa7vzgto5DIK8qkmrmllRBMDIWmbTafB4coZECLSO0FGMmBekPrw3K1qTtJbK6b3br9n3mFzWg7EuIO7CIaPWyB0JIph4No2lLJr2zTXECUHuJ+PWYFEidDALFIC0FqGDpl1qjWgMtXXsTKYY59gajaE1I9cqMKNmZU3dGKx1LervP8XUHBCtiXdrqhgYimGMKBUYcR0t6MeSXizJI0muJVmkiNvXZpynsmGzq0zw67Lt81Jt3KMioIJpqqjrAFxmSDpJRJEmzMoa792+y/++nxMXj0N7oKJuzemMbxcRH1hpSaRJ44gkjogiHTzQnuGXFHLfHNHv0XxFGMvee6QXrXFmYIGF5EGPkr4F4IIMQEmBQiFp40v3biDhPikBsQzRrFmsaaQAK9DOs5qmHMwSJv0FXOFZ7Hbw5QRhR/hiSuMc1oNzgqKsqWsTomq9xwuB1Hs+aBpvLUVlmJSGsnF0VACkZSwR1iOakLRY1A21M1g0KopQTdjYyqpBKUmkFArYnRcoKTnQSVnJEiadGp+l9POcLOvQyzN684ZuHLHW75HlOWlngVll2NjZZT6dBKDYO6aNwXuBFArtbehyUYGrcK7eZySGORR06s5bqqZlRCrVPrM2BUaAwTErK6zUZMaERB7vaKqKeQXGgq0MpqmIIkGSd4jmczzQ7XbI85zGNOBc67ko27UwjAXvw9y8+DQF3oeJq7VqO3ueeW2ZO4MzHsOYYel4ereisLCYKvI0wimFry1JrIgqj2nXRt/uG0KCVCLIGBBB8tsi1ZEIzEchBNaJMM4E5BrSCGIVNk1oZdTh1e8D3Z62MPBgWjrjIJFcvhRzxUrKSr/DytICnU5GHGvqvbXy4ht/hl6e1aWcW69f51BPcX7ueXLseEWiyBPFybHjmjowdFcywTYwbgSrEfRjz2Lk2ZrW7FSBmXxJB4504cxMkHUSXnB1woW5Y3dSc2pchbQlX/HE408yn2wjveGLvvDVvPTFz+fqq67CNgWznqYXGY6e3+SJY+cR4j6s89x44428453voq6r9qX7T9nXPTs7u7zrPR8IseFFwRd+wefy0MOP8+jjT/E5r3o53U5nH0y56opLuOba6xmdP83w1FM8cOwsk/GYlaU+H3zwKZxpWO3GfI6pWe1GvOy2K/inT57h5PktHjm9jRCO51424JEzY85ujjhx7DSxgF4aMx1NePCxoxxcW+LzbnoN5vwO5y9sce7saWazCYu9DrOiYl5ZkiTBGkcjNLWRWBdqgXI2Be9ZWFnDiYimCfL2hX4f6z2bTx4Pa2HSY2WxQ+MlT5y+wNHTFzhzYYeiMlhThjqlbFha6nPj9Zdx8qkNovMT5mXFER3W5XNlzdqgw2o/ZbsWnNkacuzENkonXHbpEW67+WaG4xl1MwxJdUCv2+XzPu/zeOihhzlx8iQPPfw4Dz/6FMdOnOe6665lOp0G74z2+XhvWVoacPjQAf7x7e+gmI3xruLzvvDLGCwucdXVV/E5r3o5l112hOfe+Bw+fv+D3P/AozzxxJNsbd2OkJpLLrmEgwcPAmEvSNrGpW8PVtPSUFtQWu0neEkVmCydSNIYh47CuL51NQ5JgXnObbceYm2hg4og1bC42OfLvuQLue8TD/HU0eP/JybhZ3RJF4jr3oe6DKAbh9o4GM8Gi9xUExqMSqO0RosG2bLrbas4iLQgbetfLyOcjHBCoaTdTyYOS7snlYFpMkhkYLJIgfECISoK45hUc+bWhDrKW6StiGmY25rahRqzm0R0VEw/T5iWNWUdgLTGhloqTzQRlhRLLjwRwc6gaP07y8YRKxVSkL0Ike644KPqHcNJGVQKkUILwUIWsdJNqLymmyYkSU6SRME/KVLQz0nSnEMH1tFaM5kVPHnsJLapsE1F3ZjgXWoaFpMuQkt8U9MYQ13XiCiE73jvkK2Xk3fB89Q7kJpQ37sAGgQFgcMYg0TQWLtvTt7UNaYug2F8HiFNRa5g0M3ANUy9JYo0SoWThbXBTHw4rxkVhlkVJHyubeib1mdUtA1bLQXCgq0sVdFgakNtLbaB0bxhXBjmlaXXiYm0Cvt1I/e3NOOhMp7a2pCK6Ah7MoHRteeCInwYX1VjGM2Dx59LY/DB7DpONHka0c1TJs2cvbrBOQ9StGN772QSmBQz40AK+nnMweUeV6zlrPVjDizmdLpJMMFvapy1mGd6qt2zNfSzNfSzNfRnXEN/+lI7IVv09uJvDqSaNpEMu/+ipRD7YE6iFJmW5JHel4pZK1qKl2Aed5g7zXBaM5zOqOsGSfCUcgRmVePA1RZnLVMlyLSgto5uojHOMcgSYq0YdJJ9ZG9c+ta42mIJC29jaYGK1q29pbUo1caLqvDwAvuxBZG8p2pjehsX4m+dF0gdUH/RbuzWWBoBxgX/KOMcm9OKWWOZWUjmBWI6Jd0dUswLrGnY2TxPPQ/+EJnWJFlOkneYC0W300Hg6aDA1OBCvLFvzdL2bOq8UDghabzAm+Cyr0W4d0I4hJLUxjGvHbuTKtCLnafXgzQDlXbRIgrFjbyYDNhYg4wSZJSg4wwqy2Q6ZXM8YVKUTOfTAL5oTaQ1jbXMq5rK2OCH1IJBwVhvL8VO0LSgUdn4FpgMiHHWGrkPEhmAp0jQjyT9WNNLgmQSQszntDZUxjGrDY31+wk5exTBfhqRxxGDbkaCxxrIhGQhT7B45tUsoNAudHz2vJ0CqNqOdxkmbhKFZ1z7YM6YWIHxEqRGq4hIK5QOxdQz/VJCYltJqfVNQLj34vh8MDzdYzVaCDR22SYkGk/dUokj2W40IuQsOnORL+YIpu2JUnSzhDTWzHDoWiK94Pr1Lp10iSRZ5vT5gsUDC9Q7Z4mZ4WYTShcosB5BXQeWY20aZrWlNNCIiF6es9itmexCaR2bc8O53YrLF3MWBylj21BbR20axmXJuKgZVQaVZeg4YtBJEM4ynDWoKKYbxxxc6HFhOGVeGQ4O+ly60KGnFE1ngbWFLiqKWV0cUNWes8mMweoq2cIi2cHrODsbU2xcYPPkk2Ecx4qzo5Ks02dt/QiHl/rEvZjl5Zj0/A5y3mBaQ39vTDhAJJKso6kKDUIS5xlRFBPpiG43o1QerxzVdjAPtEjSNANraMqa6cxQ1YbKj0mkpduLKZcWmVUl0eYmC4NFOp0eRTkG16BxeCSNg9I4wGKdpDQCZ33wZCQkaYIk1jr4uBWWzWnFqKiorMWcmDJrPGemjpVEstKJiYViZgRlJVjoxYwtFIXDNiHaO5YQxQIdh025rKExnlSA9IFqHu+tQ96TCEiVYCn1KO3xApp5kMbu4f97gHFw3gjsibA2eLT3HOlpXnRZl7XVFdK8S9Yf4KSl9g5jQEaBrfuMvrzl815+Mz/3I1/FU3/1x3xia8rHRzCzglxKdoh5cuhI0orXXKZ4/ynLB840fMW6Yz2Dha7jp+7f4vGR4dKu4qXrcNu65Mfui3nl9T3+7R19vvJ3H+ep8zOqsiY0Lgyj7fPgDOuri/zmL/0QS6tHQMZUk1PEccw1t72Mb//8L+dd73kfIPm93/0Nvus7v4Mbb7qVuirY8w3Cm8B2xnP0qSf59//+a3DOc/jwIR5+6BP81u/8D376536JX/2ln+SqK68IxtdiT8JsefIDv8vH/uUt/MjbnuZlz3sOr/6sG3n07Ijt0RQpJZ9/+wnuvO4A3/7vXsbx0b/w2D1P8OtvvofPv/UAr3vNzbzhLx9gdzThnvd/hMwb1vsZ5y4I3vSuj/PwySGv/OofYjgac+r0abqp4tDyKrfddBXbGxucPHGGF77kBRw9+gTnNzbpxV0SneC9Z/vEU/QXB1xz+2088fAJzHDO+nrNJYcPsrKyzMc//CF0L2IxP8BgsMRjJ8/xj/fcz7s+8FHOnjoZDItVSIurJmPUwhLX3PZcnH2Iwfkx3loGuvWlbGquWV9nbbHLPzwxYTy2qCgm73T5vM97Fb/8s2/gJa/6d9z38fuxdTAMP3DgAH/8R7/Hj/34T/ELv/grfMf3vQGhO8TZCi9+2UvZ3dlGqBhMhfcG1xR4WzOdTvjW130P589voLTmox95IbcuLiNkzPd/z7finUVGCffc9xDvfO+9mGIXU87Ya3iFHd+z1ovp5Slzo7FokJInzozI8oz+Qo/JeIrHo+KE61ZyFlPBu57wdPOEg0sdfvjlXZZX14hXj7B+02HmoylPve9hsr5k+ZLL+ZM//HW+94d+nKd++4/+lSbmp38lbeNTtkBALCUHuwqcozaO3cKQK0EeCSZOo3WMTGP6SU1tLBeMZ1J7tPSsx4LEOaQXCJ3hZYxDkeiwpqnWTiAGVjLFeiZZyiRLuUYnMTKK6KYRu7MKsz1jazjBWE+uJbly9FLQRrA9b9gpLdMiMLuXeim1MUwKxXA6D7WTgEEnxkVgI09k7b6PCE1gB9TWo9tmX23bLqRz9BXMK8PGuGZSOrIkYn0hZ7mTkGnN3ErW+j26nQWSWNNN5yymmvV+l/7iMjc89yaGRcX54ZjHHn+CqiwwdUWkNb1el7XVVY4cWSbOU1Rdwm5BM23wJtxzYx06TULjV2myOMYLSdbtBQmTkHgUWsekaUqW1qDamjlOwHnqqqQqpoEZmAi0rYjrgstW+3QTwXklSGMdGpm2xlhDUVvODks2xhU707qVuwQPFuvCXialIFaSRAiY11TTktloTlnUTIuGeWUYzmpqE/yTlvuKbhbRSTRV0zBvT6iNC/6zxoaHpbRCtamBQuxpNVpPMRUawTuTMvyN3LGUx3QSWIghSxOW+rAxmkELgvqW3YEPxuHCe7wUjKrg05YnipVBzi1XrHD94YxBFpL6vBI45zB1Q22hceL/9+R5BlzP1tDP1tDP1tCfeQ39aQNPFoGx4aAOgUqWRRKtfHCPVzIALtaTKL8fL59HEZkO4AIiACZeCmqvMCjGPmFYO3aKOaZpwFuUdERJkGoJwNmAbBoXbnpjAwg0riyzOnykOrBitBLkLSBlrd1HRQUBlZZStqZaAbiBgDYLuWc7vgfr7D8F8KEDYKxACU8ZS2onGWiJ9BZ8RWGgRjG3HmManHMUjcEiqJF0RmOsziDbIFYKU1fsbJylGO1gqoJUSfLeAnlvgW5Zs7QYPB8W4w7SE7yXWnaV88EUUQgBSiGJidK2uBchuQP26GgBERUysIHw4V3qOCZKUnSaoXWEVCGCco/JFbpqAiFjLIrSenamc7bHE2ZlkKrFBGqtQwRgz4VNfO9+SxUSW5QKnWHjPFXTosouLC5ZJFnMFL0oxPAuRKGLlylBphSpVqSRaqnhjknZMGmBp7Kx2LYbV9WB4WaMpa403TaGVsqgaadqSLSmm2XIKKWxNfO6Ca+n9XbaazpIGeIoY+WJdLitph1zpfPMTdBdeyFRSraeAs/sTg0AAqT0RB6ElwgRTPj3omAdICxgwVbNntA3PMu2A5MrTVfpdj6HX9uoi0WkIjAHpZJI7ZGRJxMRuo0DUV5xbjTjfFGzWSWs+obkI2Mu6UdUozkiToLZvTc4PI13lM5SNJbpvGK4M8JWc2JhWF/KGSx2iTo5991/jtmkIGsq5EKOkooo67C6IolnFVvndzmxNWRuHNcfWWM1SVhONJvjMRbo5Al+XmLrhifPbdFVkoODDnRyemlCLTRaZyTxjE4CWafL8pFLeP7nfhGnTx7nzMnj3PvBDyK8I1KSRjguH6xzzW0v4tIjhxnkEUtJQXe3Q2LO0ZQ13rp9M9l+L2VlYYmCDtYrvPUIGVE3DpUkZGlCtrTIC9cvwbcdNbSmaQqod+g6R2wNW9sbLPZysm5KJSQz4xjPKprah7kCdOIYryMe3RxzbDhlY16w1AvR5NYEkN61IyLIEALCPi1LticzDnUVmYoZ1obTOw2NgZVUcElHcjCXTKaGWmmsl1SVoyos9dQhBxFaBumIIJh0FpVDIILfmpJUHsZVu3Y6TxpBPwrpPIVt9ekiSIjD0uyR7Rh1hPGsBfTywI48X3hGlWW7FgxrzcAIEiCOPdIJvJMh0lYavHimz2GBTFfQgxt58pwkqgT/+bMGfODxEZUTfN3ty1za0+Ta85/fs8sNA8F33qB568mIBd3lVZcc4Qunx7hhY8zbTje840TDUyPBSw+kLExnfOx9Q6ajkhe+4E5+5D//IP+fH/15xuMZv/lrP4nSMdPpnK/5xh/ki7/w1XzzN/xfJL1VhIoQMmJP1oUgSLPMLLTkwjEKENx99/t55au+ABBMJtPWXNWxtbnJF73my3nZS57PW//iNzl0YL39Wc33fO/3s3Hscb7qzkO8+f2f5N4nLhDlOZ88epZj53Z45e1Xszkq+MgTZ/mt9zzNPSdn/Mg3XsuNlx1gc2vGvU9f4OzOAk/sSIQMSTJlPefouW3OjBryhR6jWcHZjV2899z43BtZXV3mkY9/hMsuPci//Xevpbd6OUnWY7i9TSIEC2nK7mSTopwigNUDy1gHp54+xWBlkTTvkPUW2bhwnvFoxI033MRCPydScObEU9z7/o/wZ3/w53zdl7yM+XzGr/zuX+MaWOokfP+X3c5a5PmX9z7AZYuaJA339tQ83F6c5YZDPS5bX+A9D50CL1jud/iO5y1x56Ex9el3Y+bncU3R3nvBzs4uP/XTP8X111zC3/7F7/Mjv/D73H7LzXzj1/47rr32OoxpePc7/55y9ylOHnuS7/jh3+B3fu+PeOvb/p6dnVGQM1jLN//H1/Hyl72UX/i5H0eoGKEEQmq+9Ru/mi969cvwzvH0qU2++/W/yA9+59dyx2038U9/+wf89M/9Og8+8AjXXJIx8gZnPf1eDkIymxWBmeIcOMM7nhySRIJBJ+LLX34Dn337VSzWJ4lihWbEiUcUNCXLCw1nd+EjZ87wP37+a3n8iafY90l4Bl9z46g9eCnopzpE2rfeGsIL+mkcbB0AZR22aZjNPTUCEWn6qWMxjxikKkgsWpaTsx0aC1VZULmaqqoxTUU3luRakSch6amqLaPRlDRNSNOYhVgREeFtijWGSVEzK2p0GoysB3mQ3JRNyawo0UqwMwmHzkw6jLRQl5Qzx24jaRpDUzXkwhNrRZ4m5HGGqw39qmE0r9iZlvQXOixkEb0s5cLuhLoOoEhVNwHMVYpOGr7uhGIpVei6QPuILo5D/RSR9uitLHHgyCWY7SFTt8toVlLMpjRVQZzmZAvLLB26nJUrnkOvk1FOx6TDGlVJJrWlcYS1RijiJGNhsEK3H/ZknaQkSYKUkiTNkSoi6/ZJurMQGi4U/U6OtzVLOYzLktrMEToODXOpOD+asbU75cLujCtlik96yGwBJzaxHvIo+GElWlAqgUChVMs2aEGdWEKCIzEVi8qSdAQ3HuowmjXsTGpOec+8dtQu2FQspBolPXG718YSKhcOkY6w99KGLYHAt/U6IpiS54mim2okgck0nJXkUWBd7UxLlNbkeQ5S44UNXkXWtU384D2lpWSQR1SNpTEusDrLCl3NES7DoTEyAefwzgYGl/E05l9rZn6a17M19LM1NM/W0J9pDf3pA08eKgfzxmNcQHGtF2gZQCbddriCvlGyZzUYa0WkZaC67f0jBKBxPqJqFJW11E0Aa/YM2nSL1inACoFzMlDYfUDiisa1bBWPEJI8dnRjjWmpK1qF12ADgQzfMrGQF13nAfbd8L1vMWLYg54uUkYDQ8pZz9xYlGjN+qQIfkjeUrmG0lsqF1hPrmVLNdZBY8KmPZ+RTidESmHqmul0ynwypinnlFJQtyklLu2SJCmNCWkhUrTeGOIidXp/HRQtqKT1/msVn/p9/iLVMI4VrjXBi+NoP0kn6EHD+w7eW34/plgIGaRxxjKvSsq6pm4akrYTJNWegdtFry+/Rz8VYv/s4cP6sG/gLYUgadlrnUjS0ZAqSAXEQqAJnZ5IhbFTtx5dRUvZrk0wUdyTThprMSZ8NBqMVftG7lII8BYtFIlSaBWDcDS2Cebq7Qa/d+1RaaVspdvCBw8K21Lk99lygQYtBP+vKHr3XuGe59bePHA+sBm1ki1w6XFGtt2aQBWWAqK2+xYrRSwVXu4BtGFsgkDh9gHePR+ySCn2+mlxpCjmhjOjglOziMlccFBJkqUOw3kDQpBGiq6EOFZIHdITTQs8NrXB2UCt1VoSRxGxjihrx6xsGM9rvNYkUcxCooljTWIsUkkq6xhXDRvzhlRqBrHCubYYc8G4FO8ZTefEnZQ0UsRa0RjL7rTE1w6Q9PIYtETFmqw/oL+4wmQyRegE4Rwq0ihR08lz+ovLdAbLZFlEJOeopIeIhviyCfPGhfUw0hHdTBHJLtZJ6jKAos57dBSHDqVW9JXGNJaibFM6vCeNAp3TUePriroUTIXjzOYWO6Nx6EAKGQwelaayIVb3xGjOsKrbgF/RbmRub5AEaWxbADfGgRDEseaS5Q69oiGbNZSVZF4bjLekErRvUyplWEXrVmbhnGvZj2K/w+JDnRVSJlWYT7UTjOqwx0g8mQ5fEzIwVvde2B5T8X8d24JIhU051QQpiIXCegoDhWmZoIQx7V34CFJp+7/+wmfodWFrzH0PHGM0KrHGkeiLIRSreUQ/DnNwXDpqq0giReGCVH23gn4WtVHaNbMG5kZwRAsi7zBVjTWWQb/PC++8hRfceQeTWcFdd70YpWLOX9jgIx97gKXFJW67+UZufd4LyJKk3SfbyzuOHTvGJ+6/H2stBw8e4MjhdfCOnZ0hd9/9AfYMe1WU4kxNVVd84IP38OIX3MJLXvR8VJSzszPk6NOn2NrapigKTFlwdlhwfLtkebHHvKjZHs6449rD9DsJy92Y45tTVBRx7tw2K52E5166zNEzFyiKiqfPTVjq58TacGp3ztpaH9l1PH12HLqQ04Injh4ny1LqxmCMw6OIki7zYs68btCzlEQ6kiSALh7Ae7q9DkVRURQFUacHwmGsoWlTe9K8iweK2RxrDEmkWF8a8Lzbb2F3d4h3jsPrSxxe7pFGESf2wX4AAQAASURBVHVZM9wZc+lgmTSNWBp0wgHZw/JCRmPDAaIbS5SQ9BPNzesJB9WM2enHue5Ij+lkmSeObYS913vquuKyS49w8403kOV/SRTHpEkwbh8sLnLXXS+m2lnj+OEVnv/8D3H0qae45557ETpF6gypJB//+P0sLS7grEFITVnVPPzwAxw+tMpdL74ThMLfcz8feeAotikRUpClKY0TzCpDVVU469p9oa2yXGDMR1Kw0I3YKS2u8HQ0rOaaKxdjzG6G0wIvFM2swJsS4T2zacn5jQnv+8CHMcbw/wKtbDv22x54++/GQdWE+6CVwkmJQyC8DdIs6fEStApgVT+P6KaaLJE0XtF4jXWaxgV2gzc1TdPgrEPFoX7aC2NprKeszX6lm2UxEY5cCxIFhQiJeI0VGCVJtUYrQ6QkhbWYpsE2NQoLwqG8o6lrZsJhjArG6Y2lUYJcKGIhUUkIeBFSUlrDtLaI0qK1JomhsmDawxBtE884C0RIKYi0hlaSK61FeEcvT6miGB3FxFlGnDVEWYWKU6KmRnpHnCTknS6DxWW6g2WyLA1nlrSDjFN8PWffhAdQbbqfVCoY8suLRr1Ka4SSRHGMEyrU+C7UTN5DEgliYfC+wdQhOKesG7bHM8bzEmMtUseIKKUiYlxZhkXdNrTdxfJRtONCysA7cB4tPJHwRN6RxIJUaY4s53STmkQppkWDlpZ544lkqO+8c61cSxIpQWPFvj8sn1L7tZtHqPvYY/oHxQkeLJ6qsZSNRUuDdIJMqsD20hopQx3i92oIHw6usRZEWu4rIBoXanPbNPvpdwgVyAHGBruMtkn9TL6eraGfraGfraE/8xr60waeKufZrSwbM8P2PHgsLcSKXiLIIsEglWRK7E8sWrZLHmtiJQPrZQ/UAKzPKXzMrBSUJngyBW+ggL5p6dvkseA67Z2nVqL1eHKUxlFYy6S2jGtHqiWDNKRrREqitEArjfAKYx2V8xjjArInBFLItoXoUXiUd2jXglR7TKgWfNpTF3pg3tggv7MO5VtWjIKprykdjI3HWIPzYfGwzuHqmtF4hBUSopQ0SfHWUBQFZVnSFAWlM5TGMq8NNumQ5TmNc6CiwMBJcoSK4FPS7vboccHET4dFsB2Qge3lEVjiSBOJhFT0WkDJkfY6RElGFKmQKGctzjStt5EHawIDCpiXJePZjOF0QtXUeEKUsm43fmsdXth282zjG2XoDAgRtMbGgjFBv66lJFaCpVzTjQRLMWR7ngA2DEotgjwzjTRaKcZ1zaQyDIuGomU34T3Oh+Q+by0SH4zstSSShEhqEZhc1ho0kEtJnuZMK09pSswehW9v2omLHmWiBVSVat+LCx0LT0g1QYYkgT2g6pl+XQR+IVIRxnvGjaGxoai9dCFqmYqeqRJIwsFmo5wSy8Bk7MYx3aQ1UpceL3xglDmPtx5jwxjSSqCRKIJxbO0Cxru62uXYdJuTm+f55wc2ONBJyG88wLmFDnPjoW64fDHjsoWYQ+sDzpgxbrNsx5ZEihi8xBjPaNYgLHSjiMuWO3RimFjL8eM7LOQJ168vIlUoBhbzhIXaM5cNnzw9ZL5sWylljK1qdrfHHF5fQkrB+c0R3oREmbW8x/GNbZ7aKViOJJ1YcPXhg3zy7AWKnS2OHXuabpJwcP0AN996B3kSsZBnmN3zDA4dIlYwn0/AaDqpaNN5LF4E4N54gfcSJxNslOCcxLZ9Se9NkGUkXZTWKKmw1Sj8vHO4piZWcMnBZU6d3aUoKxYUbO9ssTEe82d//3aW4ohbDx0kz7t08x7aWD64M+WB4+e5+/QG1sNSLwX2vM4EkQ4yaBTMjGWnbNgZ16ys9rj0sjVuuapmOCk5tzXl/M6cjUnJQ2eGjMYF25OGKNEY6bGNYTyvmBsDiSSKIFKt7bFxeGOJI0mStH+zhOHc87iEgYZMw3oKO41j3gi0UNQGGgNFHcBiycUYayGgl7ngj4LACU/jPZX1zNpEGKEUSmlwUDcV1ji8D7Lpva7lM/dy/OVfvY2/ffPf80ufc4jdRvDfHyz5uS9e48rFmP95b8FOLlhO4Dtu6fPoRPDfn1bcpsfI+TYfed822cFlRnEfmHL7quZFh2Leearh9kMRt1+fEj0wZj4bsXXqEX7uJ/4TaWcRqSJsU2CrCeD5i795K2/9+3/iE5/4GNdc1cNWY/b8aLwp+dmf/zWEkDhned23fgM//ZNvwFYj3vTmv+Orvu514D0ySumvXsVs9wz1fAdsiVAanS6AkLz7vR/gq776P/DP73w7d73kRbh6yj+c/0/ox09z2XKPzUnBeee5++GTHOgoXnpZxrsem3P2zBZ//kd/yyvuupk7XnE1errJh04Mecu7z/G6r3gJpzdGvPHuh/mnP/pmhJS8+uvfiHWC3fGUH/ivv9DGFBve//4Pc+TpE+x6ja1m9PoL3PSCl3Db9VeRLfQ5sH6ITt7BGsPy6iLjyZx6d865MyfQSmPWlsl6C8TpGp94+DjVdAjNnJe85E6+9mueyze/7rsRQvD+D3wQ8PzHr/hsrr/yMF/3g7/OV77gcr7ihVdSV7CyOOBVL3oO9z16mkjC8265hnfdf5KdccEXPO9aembOwJUcWta43fMc/ecdfvUHvoiPPrXNF33zbwawanmJN/yX15OlGePJhM0L5/mTj32EP/n93+ZDH3wXt912KwhBMriMa2+7hPe++1X80A/9Z37pV/4bUb5GnPVIOz2GZx7E2xpTjtBJnxPHj3HXy17JT/3kf+F7vut1CKl4+Yvv4GUvuo16fJZ3/svdfOlXfxdChibkAyd3yfKMLEvYHc7IUk2vl1IWjpVexufefgnveegcp7embMxqzjz+BCfVFtnhK0h6A7J4kYE4xXxccvIclO4MbjukH4cN4pk+f6HfjamsozCW0thwCHee06Ma5+DqtZw8jYhjhW8sSoHWsFk1dKTgcD/hwEqPThaRZ4JTE81wrpgWgnllmM0L5kWJdxaFxzq5H46ibdivm8qG1N+ipjsP4ErkPRmWQjgaY5jXAfySOkJIHUCEukQZSMwMLQW1d9RVxVZdsS0FOtLUTlBbyCPFoCPwiWOQhoPKXEZMnGNoYDxqGFee8bxhIdYkUmGVCgwdLYP5bV1TNI4018yHY7amFSuDPkmkWFpf5+SoZu4ElRMknR5LRFxx1dVQz1C2JIpiDhy+hCsvv5TFxUW0VlRVGVj+SYqumjYhOZwvtNLEvZQ074CHophTVxXGmGDFIUPatIxirDEY0+BtjTU1aSJpIgDD5vaY86MZF4Yznjh+jliGPXaw0CPOOpweWz5xaszTx7Y4enbIcNYwLg3Gs59mtpeahwjnoGA6L+h3Y9JEs7LYYTxr2BpVaDxb44qNUYUxltG8Cu8Lz0KqqBuNdZ5Z5ffrWyWC11Q4goZGupKCSAA46ib4pzbWURrL7qx9FrHHCkUSCxZ6HWrjGE6LAGa1vyuPJbGWWGMxjaU2gXlTNJZJZaldOLxK6ZlXDU1jUCoi68RE0TM7pOfZGvrZGvrZGvozr6H/N6R2QWpUGM924bAOdqQjjwSJhn4azAtTBXhPphW9ODBWIhWM+6wD5wVWakobMXURRV3uG1J7G0ThQnq8DQZp0rv9zlCsw4KpZGua3dJHJ5VjWjvGpSWLAm21GysSFYzNtVKBpeQFUgY0WrasJYknV4JY+4DyieDhUykoZPj9lQkMpj242zpPCYxqS6w8iYYKSeWgalp5n/dIoXA+IJVVMSeKYppiRi9LiXRMMhhQaUFTdWjqCqkjVJQQRRGR0kihwgaixL4B+EXWU7jPzhicNTRNebHsEjKY/flA2cQHt32ldZhszmFNQItdO1m8B0zT+jGF+6Ja87La1JRNRdUE43fZoiy+fW+mlTR69lhlHtmG6jgP1rrgneUg0ZJMS3qJYiEWZBIiF56984BUREqQRYos1mglaZxnWhnGRUDjjXE479rcnr0Xv9cpCpta5QTDyqGdxfqgNY+VQClY7qTUjWVnUjB3dfhdYg8sC4bikQr+CKmESIBupaaho9TSlfdQPv5XxtQz9brYaZJoBbUJYPKTOzWV8Vw6aujHkjwWpNqzmAoWEkEv1oRFSZDFmiSOaFqZDG3xopRHx57GhKjYRAvOjg3DuuapSYMWkMeSXidid2bQKgU0SkXkWcJWbdmeN5zanTNoAe2deaCKLiSKsRLEwmOdbTsIUFeW3dGMbSVQWPqdjAMrXU5Odikqy/ntKcY31NYwmodUpixS9FPLvGl4cnvKUgIxjk6qmJcVWilWB11mRclwPqdblsxrGPuGo7MZlww6vOCKAxRFjVEzhuMJ2UpCnGV019fppRkLnQ421nT7K2ip2uRGH7yShcUL13azAsfSuwbpFVoKjFBIFFZZvHRgDcn0AkqFLqNLEiCECTTFnKqc0Gxt4axERzHTcsqTp0/y2JmzLC2tcKCbs7y2ivWGSTGnLgo+euwcH33qNJOmoRNF5LEC44I0VqtQ4AAIwbz2zKqQEjKeO6bO0MslTik6eYS9UBPZhmsGEceNJYoUhXU40aY0xZq48NTGo2jnVARxBFEU1rVYemLhcZGjtJITQyg64Xu9CJtkZWDeerlZt98zwNOasLbztnEgHKTCs6A9fekpq9BtND6sD0qFcTyrBQZH0zi8Vzj7zPZp+4Pf+w1sOaSZbTC/7/3k9ZTXvzLl46dK7jtV8cprUt771IQPHq94zdV9rj2S8ZwbMo49HdGJPC85FPHHHx+xOW34nucP6PYX2el2ee1dDY+fnvDzH57wXd/3XVx343NZOnw9SdYLQRim4B3v/iAPPPw4v/gLP4uUEqU0B9YPIIRC6gx8kEwgNH7v34G3v/0dbFy4gHcNK0t9fu83foJf/G9/xBNHTzLbPYWpCwYLC/z467+dz3rRS2m1euADV/lNf/5GTj36MV79ohuR5TYr3ZhXP2fAh49aTl7YpUvMZSsDXv6862jqjzObTMl7Pd7+ybOIx7f5klfdwvADR/n4uSf45488iUWwujpg98wcLeDy5ZhzW5KGsDbeduNzuOOGa3nFc69gaXmF59x0C++656PEScKL77iNRHhGOzvMK4vx4WB+4tyUKIo4fOkVGBsCN2IVvE68bbj2qksQ/jDCW06fPUe8PaI7mHH48MEgW+n1MTubkDW85PIBV64ukaXLZKurjM8VfPSh02ztjpF4PlTVbE8qennKa150hFOnh5w6M+Yvj0UsacMRNWP6/gd54twEqSTf9q3fwite/jKSJOWtf/9O3v3eD/L6H/hO7rnnHt74x3/yKWy1vV2tZVuIwAQ3xRZ3vfBmvu4//F/8l9f/CFKnqCg0wQ4eOsxv//Z/J0pS/v4d7+dzXvHCwAYDzp7d4MLGNl5ovvN138Da6hI/9uM/RVOHdbjTzfDeMZmUXH2gS6wV9z6xwWhWhdaf93gdQ9YjyrskypDWZzl6coRUkkuuO0jVCKrOGHjoX2M6/j+6ahFhfIMzIUq9Mp6dwnJyVFM2jnHj6GeaTqJYzSN6maaXRAxSQd2EhmcsHZn2yJbtNHeaqq4w1iB9MNuVPjREKxNqM4Wnnzg6kSSLPVYKjBQ4S0h09p6mqjG1CawlETxM8o7Ca4uJYOYs1kBV1chIYhrHzryhth6HYKn1F1rpJUFeZeHYdkGvMBjrg6G8cVjrmRtDYyxFJZD9mFgJtJDoKDQlEyXYntcUpqGjM2xdY1zDTu3od3PWlgfslnMSHdLrvIzRSUpvaYVMLNLRniwS9AfhIGytaWn3DRpLoiDP4mBsLaBpapyTRDicC5HgjTGUZRmMhoXZZ/V7ocL4dJbRuMCaGuc1Oumg45qN7bMcP7fF6c1dBI5OmrDcz0kUmKbmwnDG0xeGHL0wYWPa0FiPl4qsZRsp6XFOBma9d7S+yVS1pzKBJZJkEQtSoZVgsx+hjGE+Dc/IS8naICeJNFIK5nabwoQ6LahPFFmiYK/N7sNnQahTQn1tWoWCx3nBrLZUNrAfrJDkHnp5Rlk1IbSnMa3SITA+vPVkGoxyeOkvnh1LT2EtVkCcZTCrsS4kfidpRJQ8s8HjZ2voZ2voZ2voz7yG/rSBp70X1ziY1p7KhIUq1eGQPmkE3Siwnzo6TLAuKiQyqDYtToQpZoWmRlM6SWNMQB+ta7XGHtEalgdkpE0924snVLRO7YHS2DhHZR3WOibekzbBK8h5Rx4pgpdloDFKsZewFiSB0vv99IBYeOLA/myTy0S7kLa+Vta1GGoLprgQEWt8638FNPuLdniiUoXl3HtLU1eYusLXFYkUpEmM1JJKCZo6oyqLlkWjSaLWtLr1ZpIt/UZ8Ci14D3ty1mKamqaYs6cqBdVuIyHOVIgwyqzzOBuAImFLhDJoG+R0AMIavLooHxMisKn2NgZjLKGvuAc8hUVsz0sLWtl4i5z6tptnrdiz/yBRMiyeiSTXYcESxuJNAJ5EJNFCkGhFpFVIDLGOWWWZV4b/m73/jrYsO8t74d8MK+10cuWq7uqgjlK3WgkklJEQQSAhA0KAbTAm+4KNzecLxphgQAaDr8lZAoHAgMGWMCAhhFBqdUvdrc6pqrpy1ck7rjDT/WOufarxd8e44moMqz1Gzx6nq2rUqb33WWvNOd/5vE+Y1baNw7viI0Y7wUMr4WhCTA4wlSPzsXM3s56AIxeCQV4wzhqKNKVqDPjIatJPA550bDKgRQSe0pYmq+Zxd7SsqBb4Cv8bIE9zer0g3idPlI6eHTXsVp5JHVguJAuZZKUnkTImDAohSKTc89tKExWBYh8gREP6RAYS6WOqoBBkKrA5azg9arjrcklXB5YLxc0bU3bLgJQJQiqEkigtGZeWrcqwNWvYnFkGhWNrajDW09FEHwTVUkxbsNQYx7SsGU0VITjSRNHrFig9xhnHpDSUtqRxlqnxeK/bDo2kdo71aY0PkoGGIlUYY8HD4mLOtCypjaFpLKVomHjPqfUtZHCYo2vUjcXWJha9xITIYmGRTqdDt9vHmIas00cpPceIuRIZ4eODNvdZ8BZvPd4YvFR7QHD8dx5R7SKUQmgNyUoLPEfZg6lqymmFSAckqWRSTrm8s8W5jXWuOXwN+7odil6Hsq4QExiNJjyxvsMT69sYHymTiYzrqlICnUiCa2m7yDYIIILKo9JSlSB1Ek1ItYyd9eBYziXrbexv4z3CKwSgpYoRyW0KyNNlrDKmt0cDXBHwKjBpAsMSihQyDVoIjA2xS9NumN63G1d7Pfe6uHK+NoPS0IvLP+daMN2FuKgpFT+7EGEPPHf2mU9b/Mf/6Oux08uUWyf59SceJpkYXnoUPnxqxE4Z+KqbCzbKhnsuTXnxkQWuTxTXrKWcvljQ6Uluvr4L925jm5rb93fYSDtUWZdbrzKc2LXcN7F86wufzw033kJ38QAATVNz+eJ5Hnn8JE88dYF/9uP/mm6vR0Cwvr7JaDwCb6nqaI6NUFcqGgQPPPAgDzzwIAjJW77i9fz4D3037/qDP+PkU+dYW0gQsmD//v287a1vZnH5ICEELl++xO7uLkWecd8n7ySMzvOy4wl9WXF0ueDqpYRHMwHesdpRHF7scM2hNY4sZIyoWV7u8bGHN9moA9/3dS/imtM7rA0yHntqnaKTs7a2SDlsSCXsW8jYGUlsHRDOcPWBfbzyRc/nlqMLFL0B+w5fzb2PnQICRxY7bFzeYLS1iXXRt0ooyXBc0+tKsjxHuVgzZNozHe5i64ZusYhOEoSUnDt3Ej8uGU4cy0sLaK04dtVR6umU7Qszji8X7F9apLOwis47OCTTcUlVNjjvaRqLDZKlvuLAcsas7LAxdXziMhxOHGnXUD12hsvbJUorbrvtubzspZ+HlIoTp87w8bvu4Zu/8W3UszF//YHDJElCXVVsbg8JroXfZCwL96+toJOEO553LV/zptfyrt9+B6srK0idM57WNBa+8HWv51P3PsCp02dxLmrRvfeceuosGxu7HDl6hJe85EXsW1sGiJI4IcmLAtMY6sax0EnwIXDy0jiuNa38p0IzIWVZa7LEkKmazZ2SvMi59sYBvaAZkXDkyEHsnoTgmT1ckHgf2Q0CgXOBUe3ZKi2TKjL4FwrNII8ep15KVDoHJOJBV7f+PSZImqCovYysklaGJgkoEcikpLIe60CEeQ0Ya6p5TW2JcgyJx5pYi1vnaYxFC48OmlQ4ChX/vbVQ1gZFTJCeNo6pCbggyDvQk9GbaVpbauMYzwyliez7somyMuc9lQlYAU0TWExjTVikCillTGoCGuOYNYE0CGrnmTWOncYzdQLV6TOqDJ3E0FgLWY7Wkk53wCCFxVzRTQJZ0UUJsXdthHco4WNzUeu9UJgoTYx+R2lWE4SgaRqapsGZGkQTlQE+oJIswgUhUFY1zllSlUbgKW8Yz2p2hmO2dnY5sNQlzxLyNCE4G+fazpD14ZT1UcW4iQdoJSV5cqUZPhMe9zQ5nHeBWeXRWQANeRElVypXLGWKKolN3NpHNs5KPyfPU6SSpJeH0YtUxMZvqiVFKvfqVt/aaswVC9E31bdEgXiqqK2n8QEHJIlFa81Ct0ORpxRZspeaJtvCX4RoblwoEIlg3PrjzGwMXvKASiIY4z04Ywn49vzwzB3P1tDP1tDP1tCffQ39GQNPkW0ToA0R9K3ca2oCwsC4jpGRWsJKIWj60EkVUhJTEto40BAUlegws5qZg7ppsLYheEvSdl6Cix5OvtUOahXBqyKJCL+WgiITJF6gtETWjsaKyIqpHWMClbV0U0k31SwVERn1xAV+LuOLNzIuus5FUC0JASUVhdKRYpyAF5F66rxH4FspVkTua++ZOY+UKm5GPsoGQwgkaAgCgUT4qNHuyMD+fkG/1ydRirpeiIaMJk4+IQSd/gIL/S6ZEggf9c/OxvefX5P5cKbCTEdMd9bxTdnqbTWIBKESisGAxlpqa9jYGVJWDdNZiZaCLE1ZXl5i0C3IE40MDp0odKJJiwyVKHSWEITEw15iYJTPWYyB4G2LoM4N3OOG5nxMaohnkJgGmGnBWk/TSyULmUI2hmA85dSgfCAVkjxX9PKEQSdFJ5LaeyalYWM4ZVobyqpBq7gwKx0ZYJ7oEWA9ND6maFgsVlgWCkuiJY2Lsb5aOK5a69L0ciYrPRpbYazf07bLVuvepp8SvMAJaFoKtBBRQjr3nhKivTfOfaZT6XM3JK2nRhu32hqiW6+YNPDIzCKFR8pAJxMsFoKVIm4q/URxsJNSJJpuIvHB07i4QCVZgiQ+83micD5SMk8OK07s1mxOHTaLm8UHH9kiTxNUotG9BKMDZ7aGNEJRGsdMSD65MeHhnRl1UyOEwwXHgZ7k6HLGVfsHFGenIGtKY6msoTQNm5OKxU7B7rhhdZBBgI6QMPWYSjCcjtmtGmYWmqQgSSOD8txwRq4VO92ca7sJqRRMR2NSDTqJsoi0k7KcdfnwY09Q25LF3GNdoJfnFFkan0cp6XUXGHQ6LHQ7bBc9ZKdP3u9jbSx4fd0QrIkgOxKlFWmmaWYNk3rG+sWL6N4CQiqkdZDEzuvlnUlMTtQpfrKHxyNVis9yWLuWhV6fajbhxPlzeBM4vnaEb3nLW1jf2OTOe+7hzvsfIQjBxrjkxNY2UxzLRYfgotxhsdMC3XERIxB3Jo/DOMN4UnJqe4sLo5KX37xKphTBCfIspzKB05u7XC4dSZpgXGQWugCzytM0gI1+BZbAdhWTmSobWCoC/TRSe3fK2O0tEsiTKN3dmEhGNTjv6STsHZNcCzxrFcjT2C1MZEybySQczCEXEuEhU1Ea7trISiECSlqssZjGEennDsUz29lU6C66d5huOuD2O57LfffC9/zhvbzphh79gyk/9uGSR883jGYNP/uRUyglSRPJlx8vUIfXeGDnGP/iZTtcWN/hW957iX/xWskbb3U89qkpr37pi/mG738Fr3/zv+XGm57P7/7ObyBkymNPnuH1b/w6fvQH/wU/95M/QFFESnnTGL70jW/hySdPAoHpZNx+yrnkqS0IW2Be6gKhuyA7gODWm6/nfe95JzpfQiVdut0OQiqqquENX/ImRsMdXvaS21hKAv1cwuwS//Clh3jDNSk//d8e5OLulP39hLe9+g4WZM3JOz/Anz9wkU4v53v/8VEe3C25/MQulx4+xRuuWeCV3/Ma3vaf/ppLwwlVbRis5CwNOiys7ifdmCKrEb0L95PvPgdlbyetNylH53nizEOkT30YO9zizsf/lHvXJ5ydGFbTLr001iuHFgWXN07xZ+/9MPc/vM7q6n6+459+A1uXL3Lh7FN87P7HmJkAKuObv+4tbO9OuPu+B+gXgoOLfd7/X36Lf/l//hDveM/fcOuhRT7/2uu54fWv4f4/fifPH1T87ve8ku9+56fYntZ8wU0r3PnIOuc3JrzpR/+Kf/WVR/mON+7ngz/xENuLazTX34LZehwxG7G82OP7vu9f8Yu/8At8/GN/y3d92z/mrf/gy3jtF30lr33NK7n/3o/T7fb48Ic/ype/6S0IqRFCI3TBN771S/mT3/01rrvlVjqdHOFL/vD3fhWpUoTO+OV3/BF/+7FP8elPf4rv/95v49v+ydeRaIE3FeVkyPf/yM+yb98+HvjkB/imb/4O/vJ9H8AYg5AKExp2d0YUecrSYod7T25xoKv48ut7vP+JEWdnBqkEd1+yTLIZ33/oNAuHb6J3/LX0H/hNmsmQkyenPOc5CS9+8WE+/U/+FkQaQc9n+LBViRSBItc0TpAEQaYd1sO48WxWgXRiSSSc3a7oZJpOpuklgYVCc2S5Q6E1WkguV5phHQ/11jTRf8laBmlUHgwSycWJY1I7zk0tGxNJpiUrnYRuqqIqQLdtxBAYN57SeIxxVI1hUsFqFg872sfm7tBBtW3oFwIfApWXMcJbxnSnSe1IpjWDXNPRikECk0kd07VmNU3tMSY2I1GRYXdqc0ovU6z1MzqJQiHYrm0bQKM5tm+JiYlyr089doaT5y7z8IkzrCwucjgt0EpFtYDQdLOEIoU8jQCW1DGtToroP6RwJK2VR920KVbGYiYTgjMEb9jd2QAhqGpHkmikCMwmOy34JxE+yuJqD1Jr0jxjqZsRFhZIekski6dZnNZY77nmyBrGOc6PZiRPnkEIwcWtIePRGOs9SZ6jZTTj7iYRAMR7RG1aYMhTNZ7hzPLEhSnZVkmaSg4tSDoq0BEOVVWk1pAESz/RpF3N9YeXcAhmjcPYKEXtZJp9g5ws1WSJomoiA60y0VMmrtUtiz+0aXWtCbPxAemJda+Mey5S0u3kHF5dJN3ZwVgb2Yw6qmByLVjOJRrPmaFhMQt0pUMTgVDbVDRNTd1UeFMzmwmE+szMiT9n49ka+tka+tka+rOuoT9zxlNoT95c8cEJzFkfEV10Pvo41S6aWLn2m/c8lWREzCZOMm0ss9rh2nhlJQUqCLwPNG3M6Rx5165lIPmYupDqeAMIkb2kdXRoT52MyQ0+0PiAMG0CHE3cMKSKcaKhNS+Xso2tvCIva3/YuEmJaLKX6migLb0AD0LEzdi0NDXj422MXKC5S9S8kxCuXKf5e5iG0JQY5J4BqXO2va6CVHgSEbtWLRdu/snazyf2OhTSO0SwaN9gbU1wjuAlQWWI4PHOUjcNk7bTMp7OGI2jRr9T5OgkoUiiLFFKh3eOJhisjx5UTWOi0ZmnRV6uMJmsc62xWMu1avesKK8Le6mEmZYxvSMRdBNBJkA4jzeeYDzBRkPCIlEsdjJ6eUKeqdac3VEZSzScn4OZrekjAtOajk+Np7YRsJxZgUMQZDSgL9Josuucx+Kx1pIqwWqvYGeko2yidQ7fQ8nb59uG2NmKOthYpCUKXHDUjWFjVFJWDVVjecVnOpk+x6MVJraMNhVN/IVA6QgwC2IhMiqhajyjNLBaBBYLDSICwVmbwGJ9QAnZGvPHTkNlPTuzhpnxWB89t5SMgO1SV6O0wogIrUfA19EIjw0h0mrDPF3S0niYGsFoalkdN1wc1ygZGOSSlV5Kt8hI8hzvFWVtGI6nzNoEw7yTIiuNF5bSR08KG4ioImIP6K09bFSOhcTjEslKIqPnmSCuGSHqyhOlmDWGhy+s0+8NMLVhZzSKhaMQXLxwls3gyQXkScrYGMYqYaXfQ2YSLy3WNDhnQCTspWcmKd4aGtuAtdFPLLBnCHt5YqmbGdZaFheWKbpduoNB2zUBqTOSPKVxFpl16XYl2gY+cv9DbGxv8+i5c0zqZYSQbE5KjPXkaTYnDiIRaKUQBKy10cyw9uDiRpRqGb0ImMuHiL+3sQtjXWC3DowbRyFkvB5KoluKqFQR6N+oLGoMUGM9dBNJoqJMo/bQuNjMSHRMLvUtmNxNJUJCrgPTugWQVZyHqZakKuyZLdKuRcaKPdwjGrUK8J48jd3nVAkU0RtuXBumdU1tzDN6Dv/4v/9JXvSi23jNK1/C40+cZbq9yWtvXmDiBONScMfBlK0dybktaEgQPtDUnvsv15yrtnlk+iRLYQec4RXPWeXAYg8XEnRT88QjZ/jo6E4uXtriquN1y3oJONsw2t0BiElGwCfuuof3f+BDnDlzltFoCMDbvvarufqqY1EmN2/Ue9+ar8b0Myk8P/kff4EzZ8+xtNBDUaP9lNlwzC//ynt44QtfxMte9jK+9qvexHjjPIUb87EHTvKpJ8ao/+G4djElF4FcS44vdykUsHGR05XhngsVz7v+AEWuefeHz7KWwWuv7fH7d57mhiPLXHdwmVsOLrDWqZgaGOy7JsrCZn/BDatd8iOrfOVb38bYGH7+He9mvHkJ56K8RivNgaWjHHnxrZy659NcPn2OrY0Zszr+rGnRI8t7dFTOTc+5hsWllbifyJS06HPkwD4uD0tGtafTGzAc10wnE06fOc1oK2VZGO44tkTnpbeyvTtB+gY7vIRWgqeGNZ88O2RUWWobeOLilElp8MFTWpD9FbpHrkEmT7DSFzzvmOe9T9Zc3HHcvJrx8PkZ5WyMnZzmzk89xoc++mkuXTzHJz/5KX7hl3+Tr/uqL2X/Spfv/NZ/hEw67OxO+PXfehd3ffIetHB8/x0vpuj2CMExu3AKmWR0egucPvkojzxwN9vrl7FNSZpoCI577nuA//He9/L6172aw4cOsb2xwXA4ZlrW6KzA++jFeGSlgwkwM5ZjyxndRHJi13H7wYIbVxP+6sSEA4XjOQNPabvMJiV68wTj0iB8YDmfoeUim1tj/ssv/Qave90beOELX/S/flL+Pcdw1pBoQZZKlEoQEpog8EISZDQQdkQmxLAJTK1Fl45eJqgdLPYClfUoG9iqBbulZTKLQJGzDu8C3SxaW/i5ZDFE0KhqPXsgMDOKaaMoknhYUgIqG6h9/He1jf/2/NiRtOxvi0C2+0E315GVZD0zE0NxABrrmJRhj2ExyBWJVejg2Wrfv3EBITSqNb52DkoL21NDN1UMUskgFXsBPd67qExIYkBRWTdMZjVK5/SmDTuTEqp4bjhz+jS58nQTQbfbJS+6dMYVSEUnT1sVQTw3zGtqIQRJmmGtoKkttXWt5FQgpSIEz85oGk2PBSwta3SaUXQKcpXsdf+npqR2kbmhdYKQgkvbI8rasDueUhmHlIJJWVE1Bjk/pAKx2hGI0CZNtf/fO094z7RqmDa0LJoUmUKqA6YFwaY24GRAhUBwlsp4xrOGqjY459r0NSBEo+PGeozzV8J1WkbJnC1iw5zxdIXFIIKPViaZJEhPohV5p0M6HqNE9FhVbZKXFnOpXjz3CRHrgiTTqEThQvTenRnP9k6NnxhQY178v2Iifpbj2Rr62Rr62Rr6/3sN/RkDT08HPwSRGUL70M0nYkwYExjXJn+1tCzRLvYBgXWSsRWMG8u0bvCtvK4NA8D5uOlFw/EI3kgpIgXMx3g/HyIARQtoaSlAQ+pjp9US2u+Lm1ztGrRUJMpH7yHiw6BF7DQUybzr05psRapLNDkXLR1ORFZN8BGUEmFOSY1IomcOsBFT0Jgnw4VWABffQwaPNxWmDDE+1tqWIeWjjEsJdHAkIury51vQlSsvrtAOQ0AEjwoOLRwhNOAt1hA/owC8w5jIctrc2WU4GrM9HJFIyaDbZaHXZ6XfQRQJSgaMsxEIqwTT6ZS6rLEmFjRh3g0hPtzOeTxhD32M+u4oq3MWFBG46ySSXirpppKOIiYBWo9vPMF6hA9kqaSbaRZ7GZ1OQrYHPMUEOyVC9OxSCb5dTGoXTc9mJrA9tcyMZ1p7pjaiujKJXYmu86wqifGe4KExDYlOWe13WC8S8JaxdVfuPwEh2QO25PzZIP6oiYopepO6od6x7E4qxvOEhGfwCL4FDfdkmzJ6tLSbZqpbnywC1gaqGoYuME4dnsBh5+KmKSHVCiEDKoAIAolqJbDRJH971lDaSMEvEkUiY5fxwEJCg2Joo7+EszHu1YSYVpmo6IumZUBKT2MkQyM5O7L0ug2ndspomtl2SAe9IrIwhKKuLcPJlKl1yCInTbsgFQ7FzIkowRSxIyBEfE5jUgfsVJZBqgkCllKN9yYmYooYTlA6S55opmXFwxeGHDucEWYNWzu7VNMpOMPp0ydpRruEcsp119+AnE6x44pbrz5GPsjxOuBMg7UGmcjohUMgpDnBObwxuBAgOIJQ0ZvCw+WZZ3d7zGwy5tqjKStJwULeA6n21j+lAqKuSLsDuiJF14a/uPNudiYjhqMdGmvQSrE1nmGFoEhy6tK20b2Rzuu8pbGGpgbbeIRtzfpTiWh926QUiCCiB59tcM5RW8+wgWkTk08SFSW6SojWWy4glOBS5Zg5z7h2GBfNUpVq/QOtoLEAAS09jRV7lOCFriRLRFyfvIsdtESQttRx3aLh1vl2HxJUVmBlwIvQPuMg8WRJQpbEYiN4jzGW7VHFud0JG5Pqczk9/1/Hv/nBf8t3fsc385IXPY8HHjxJt77M13zBQd59z4yd0vPmWzMePKO4F4FKc/CO4Bvu22hgvYYndxBCcnS54F+/4RgHF3MaJymE4c6Hn+JPP3iJuvZkWQYyAW8QeLJEopRqZXSOT9z1KX7qZ36O6WgrLipC8LavfSuvftXLCW6GVClSKrSMhxrjoh/Kn/zpe/iH/+ibAejdch1b6+dJdM76xpAf+dF/z3d91z/jla98Jd/yj7+OrdOP8NQn3sdf3vkQD59Z51OPnuHLX3QNNx1ZZqmbsr/QHOmlNBfOcWLX877Lih/4iqvJFfzMf3uIb3zxKs+5psu3/8ETvPxGSyozbju8xPZCxeVRzWDleDwIzUbcsm+Zq48f52u++Vv5T7/8a/zsr/8K5Xgam1qp4vVf/Eb23XQTx9/wdTxepZyfwvrJh5jUkeWqix6dzgLLvWVuuPkqOv0BjbGIpKAzWObGaxPUxU389oSiO0DpXeqy5MzZp9gWlnG1wwuvWuLWw7fz7r95AGFL6s3zpJnm9E7Nuz56BmNjStlDZ8Z4E/caqRLUwhp6/3F0lrPSh5sOVvzIZs32ruX11/Q4v50ghMfsPsGf//c/4md+5U/B19x9993cd/+jfMELruf5t93MD//gv0Lnizxx8gy/9Vvv4KN33sVDjz7Gd3zP95IVfbwXXDr9OFneZfXYDZw//TinH/80WacPvomAI3DvfQ/wM//5l3n/X/w3Dh3Yx4P33cdkPEVKTdbp0VQzhGs4ttZhe2oYbZYcX+1hPTx0qeaf3lawkAQ+8OSYw4XnuYueyveZjEsSHmJYOjoJLKYTnB3w1KUtfujf/RpZscQtt95Gp5t/TubmZzqGs4Y8UwSZ0M8EwgpMkAQRWflKKoJ3uBDrGO8d3nnGtcQFyf7KMTUeVGCzFuzOasbTmqpNqiLEg7CQARfaGN5WTmXbDqhxnql25Imim+o9H1Yf4sEl/hpr5wtj16YLx253IqNMa6HQbXo1jKpYezmiPA5nMbmgqzSDTJNYhfCRzWFc9CrRaQtCaIkNgtp76pmlo2tCoRgk8VDpfIgm3kKio9iCxlpGk4q0M6A7rdjYneDClLquOXHiSVSwZAqWV1bJOz06gxG9bo+VxQFLhXxaWti8iS5QeQGNoDYNxrkoS0sTlNZY69gelQRrUHg6/QWSoku310cl0S9G2IbGlcyMRydJTHsOcObSNtOyZjgt2R5O9pKnqsbEw5wPbVUPpm3su3DF5iMmaEdlRtU01C4mbB9akKRIChEByaoFnoSOJvJNY5jOGnZHFbOqwTnfJovH1G1nPZWJssoYQnTF48m35xrr986hKHEl8TvXgn4W7StSrfC5Jk0UQTq6aTStxkcfXeNiY94G4j3UEp0lCC1pvGNmPMPKc3qrZKdsmDSW7/hfPCf/PuPZGvrZGvrZGvqzr6E/Y+DJz/XAwB6VBVrLoQhIaCFQItBLBf1UtnG/878X1CRMUQydZGY9jTVtDGHssjQ2bnYzHxcr1y6Cwkc0LgSicXfr/ySkABEXYu/jZCaJyKPfo4oSN+rgEcKS6Zi8100Fi52cfq45tNyJjCxEy7ZylI1hY9xgGkdT28igEYIk0RCiplS2i3bwcRIqKehmOl6nAGUdkU/nWt8CBFIrTEuJ3trd3dPBahlpxUWesbKy2nZhUmTbed7bJVsfo9i4iICdzhKyQRefB5ypKauSoOLdFblGTD2mKqlHm5jxCKYjZJohU4/ysRDq9TI6qWE6mjGejdjaGLG1O+HS+g67wxHTWYXzofV/EnvA15wdRMv+sraNWAxQZIpOItnX1RQKcgXSWIINGOPRLqAR5J2U1UHOoJexvNJBJRKpBbWz5IlkqaPpph1q6xk1np3SMTGejYllVFrGlWNnZuMm5wJBRhRTtiBlaRRKQJYoMq3YLg2DjmKxyFnudQghMCnrtvMz32BByIAIV7o9PkSt+/ak4ZHzuygpGdaGcWmYNY4f/Uwn0+dwhBA19cFCcPP5HFl8Yu8xE2gdJbLdIJg6hXGx8EWqSKvHIbQgEYHGwKyOXdc8C1jh0Ql0tKCjBVMXWWkzE0i1JqARThDquGD6IJnZaD6plUUgKLSM8z9Ef4jJTHBiveI9D52lpwUyBNIsZ99in4MLPZb7FxmkkiJN2B7WDMtp7DRWjmHtGJuYgqFSwVIvwVmwhj1D1hTH2eGUrZnCiZwDKsbRnlu/xFTlzGSKDJF5N7WOrUlJ2NllcOYUwXlMVXHygQeY7W7QTHbZHe2SDJYRC/u55uB+ZLZMvrKI6pxB6F3wFmctpjHoRNPVfQaDwd4z6NoKRwXDNfsXmXagnqWsHj1EZ7BI2uthyooQHKCo6pqyauh2VtidrHN+OOTk+fMxpaLTj9H1BOrgaeoIJCsZN55UC2obGajbM+gmmk4OmVbs7ypWM2LqpxAkUqMTTVVXXN4tOXFmxLRxLKSSfLFLL0/YGpdMfcNGFUiVY7mAPIXdyjOu4eLYM8hj5LL3baPCtfILIdpNLzYktI7pO3iBs54DeeBYB6oAMxv9BmU7Z5UQaAVImISAb+ZR7YHFjuToSkpjS05vzPj4kxMeOLnNxZ2S05uGrallVDl+6XM4N//fR+B33vUH/OVfvI8vXGlYt55v+L2z/PNXrrLaK/jZO8c8uW5JEkV3oYupa+qZY3m1j7OO0XBMCIGtqeG3P73F1x8XHD+iWPvi49xw7Iv5xqu/mqaeRWaTt4Dkxhtv4JMffS+r+/aDN5jJRb7+q7+I17/uVXzpG9/CqZMnwTu+5du/m06ngzdTrrv5dm685bn8xL/9Xt717j/hP/7nX4dgmQy3iBI8wWNPnuO1b/puBDGBdTqrwBmqyS7f9M++j1MnTzAd7fK2V97Kq289xi/8+b10ux0OLndZvnYB0RhoHJOrb+DQaMJXpud45188yMJij5/91pfzO3/1MO+66ym+4fn7OT9teMdHH+efvOpmtBRsj2ZsfvpOtIA33naEk2XCtohg2/Frb+Q1r/sSFupz7AwnnLo04tu/6Ru47Xm3IWRKb/9xBsfGTD70SRrTAFCOJ/QXV7j6xuexvX4J7x1CSYpulyzLOXTVS1g59RTnzp6lyHOOrGZ80W1dnnj4JJ3uAi9581fxjne+iw9//C4+9vBZbrnjBSze8grWT57iurUO3/B5h/njT55lWhuuO9Dh7KZgXFoS6dl54gInP5CQ2Jr337vLe+86z+VhTbdT8KjpMw4j8smYB/7gnaw//Ch4E+9BcHgzphjso7N0uK0rYtJSaP2AJpMJ3/DtP0xTjRlunOJ3fulHue7GWwCBUJqDB/bz7//VN/HiL7ijLQQlX/XmN/LS59/IP//+H+fEqdPU1YydnV2yvMOtt72CC6cfZv3iCe5+9AK3X73Cd772av7Lx8/QkZ633djjzx8fc2Zo0VnK+tjx2KWKl7xhQCcVhLrh+DWCk+e3+aHff5xHdx5ifWywHn7iJ/8Dv/iLv8yJE09+bqbmZzjSRJFKQeI9aarpaslqSMm3a1TlsH5u5RALXqlUlCe2FgK7jeOyTchtyqUShpWlqqP/l1aSRCm6RUKhBbkKNEEgVENpXQsAR++dVBCtLYieO42PzVrnAyhJlmoSoFMUJFqhlcJNpjjhKZsYBpRIESVDTiERVEGQt0ynsjJMZg2nNmYEqWPdZAUNEqkhzVKgDe6h9Un1kotjw6R2SBnodzMGWcLm7pBxE9itHLMmmvp7IdmdzAiXNrn7vofRWuKs4amnTlLNZpi6YmV1jW5/wMLKKgcPHCTLU9aWVvZS7aQy7fWNYJQKoLMQwREZlRUhBIKw9BbX8M4iCQxWD9Ltdun1elRVE03Ia4/xEUCsG8P2cMK5y1ucW99pVR2CQSdDKoW1DtPENLc0SehliiJVTGY1xjka5+hmApVptAscWVAc7AtWOjAxiioosjzHycBWZTk7sayXjlopcq0JUnB2a8bWpGJrVFE2DuMj2yJ60lxpYMPeUa5VrYS2mU5r6REb5lq1zf/G0JQV9USQZ9E/1SNROqNxnu3xLDYqBIxqH8OkEASdkA16LBzcR6M7nBs5Tj16mRNnt9ncmXJhc8yoNMyaZ7bcHZ6toZ+toZ+toT/bGvoz93i6Mu2eRlG98jcBEZPiZJRTdZPIdJHzvxeCJpLro0lduGIi6UI0Fq9d3Bw9ofXTufLG0WMoIufaixaln/sNtXKv9uLNN+7QMlhsuzh4FyH8oAUdFHmWsNAvOHpoH0mSoJSmNlFCNZlVmAs7+EnFzqzEBYETEdSSRPBHiej/NB9z8z45f28XTQGN8xFVTRLSvAM6xXnLpKwYjidUdYVWgm6Rxy4PEKRCKN16Jvl2wZvTzuYU6hbwUgqZ56BtPC+ECi8hKAhaxbS24EiCJRMOpzypDuRzql2iyNKEPA1U0oOtmQ6HTIYTJpMJ1sbEij3T8fgR4kcRYa8L4EOU4EU5mqRIosQuV9GgW7qW4eQCyntSKUmkIE8laa5Ic41IFEJdYVApKUh0pGoG76h8YGSiIedO6RhXkeVU2Zb8qqLxWatrxIWwZ4I5p/pWzlG0tv5FmpKnBiUEUsWnNdUSLaJJZ/I0uaNrGXfDKhrtAYxrS2NdS2F/Zo/Immw7NYQWyL0SDxvvbcv+a5mM8XrEhJKOlvE1Qny1GAQAXgR2asv53ZokCQg83sa/0zIyAo2Nm7JSEhlklGwi9mSxdbuxPn2lSbUiDZComPBgfGBWW6RXeB+4NDI8tT3F+mieuNBJWBl0SHdKrHPMqhoTFF6AbcMIEKBaUNv6gA0RnFTQxoZ61meGPNOgFSYEZrZht00CkVKSpgl1XTMZj9nZWifPu8gQKLIMOl00rfShrkmsASEjOyFJkUoT2k6Rb9e/4Bzeu3geJBa7+MiYFCHQ6+YUegHfzSm6GTqR4CzBW4L3OGcQIcZnZ2lK1dRs7m7jvUNrjdYJOklb6a9ogWHfJma2VOk29cJYyDuaQgsKqRgkMWpbShUBbyEwNpr9b88MZeOojaPRCiFix+7SdsnIwkYVKfeJEnFeSlAIchGNNCEmfjgXwyKsj1JkKeNnkjKaHSYikIuoWx+kkiKBy1VoqcSBuTQ6qv6jRj1SgyPdOgQw1jOuLA+d3WFmLKe2JpzdmLIzNWxOPNMaaiN4po8D+/fx/Ntvwa8/giinHO8aqtIySRKee/0qO2XN5WGJMyYavGqFsxYfAnlRUFcVjfVcHFY0SR/6OX/5wC7PWVS84MiRFpiAdgEmSzOOHz+GkCkRcMhYXMzpDjSJVnvfevHiRZaXlnjNK1/M0Wtu4KqrjyGl5sC+FV7wvOcgpOTM6VNcOPMkIOj1+nze578UIcDUFY996mOMNy/wvve/D3YvwHSXyzsTSuPoZgkHOgppSnZ3h5y6NKUg0NOCwwc71DhGTjGyjmbmefDMLlppDq0M2DXQKzQ3dBNOXNohzTLSLOXjDz7GoNvhjtvv4MFPPMblyzs4Z9FZRndphWOdHgeqGQcODskSTd00BO/wziC8ZXGhS56nEMA0NWmeU/R6dMoB1WzG9tY2qbAkSrC1uYVWkoP7V7l04TzVZAef9VhINdVswp9/6E7ufvgEZy9v89zDAw6uLkLe5+Mnt3nq7DbntiY0xrUs3yhd0LplHDcN2lR8/nULnLykeeLClA0qtBTs6+eczlPKcsb773mKy7szlhYLxpWOqba+4a8++BEmZcMrX/5SPnbn3Tz22BN85Vd+Bffecy+nnjrDTTdcw8knH+OeO0/yvg9+lOHM8NovOgbBk2UJz739Ns5duMBDT57hhbffzqCXc82117C+sc5Tp09D8OTdAWv7D/CFL38hHzSbXDr3BLWxbE9qzm3N6OSKJAjODmtMkOhEE6qafYdXue7WYxif8MT5EY+fusSpMzPOXR7y4IUJp3cbxnVk9WxtbrG1ufm5mZR/j5HqeXBNy+B3ob23c2mVIKbMxTVs7qWa6Gi+vdjReJ1SkWJaWYXAzzdlRMvS1h5SFWunItP0i3SP3aJFrM9SLSiSKPAxAYzzMempTalDxBS0LNFkicaZJFoxOMfuzJAoh7GOxkbAqpelZEn0kbLG4L2jri0V0X6jdoCIfq2ZjnVtCNFgPYRYq5U2VsBbU4FOE3QSKGc1O6Vja2YxNraq00TjvaOpKna2t1kYdNBasjjoMQ6OmbNxX3WRMQZRAiVVrKuRMYAnpnt5TF1Fo+G6RpLilYjSt7Zq6nS6cY8m4JA01lNWDeUs2lFMqpj4LKTCuEBZG8azmsZahBDRCFzrGNYTLM77tlZuawDvMa2PKwF6uabQ0FeKQaHJkuidmqsYdKNdTB+cVQ3bpWHceBASpaIcsjGWpnE01v2des/4tsIS4e88l/Mmvds7S0GsRuJz1NXx1+j35QjGkGaOOsSDb5IkWGuinDBqnBCENjU7KhRmjWNrWnPy8oiyMpw4u825yyOGk4qdqaE0nsY9s/fgZ2voZ2voZ2voz76G/syBpxZ0mE+kp4+59CtOEsFyoVgpNEt51I9DRL0rkVKiaFzT3sAoMXM+bmAzEyM8Q4jUNdrJfUVzLFAtBdT7uAggItXQhojUt/VyfN8QN/iY5hYT8KxzOC8Y5IJuJ2Pf6gI333QNvW6XvOjQGEdZVuwOR5hwAi5tc3FrgjEe40GrPOqYhUYpiw8gRWusjaBINKlSrews3lRjHYlOyPKC7sISulNQlSWjsmJzOGQ6m5IoyaDfjYsDCq8SpM6QUhO829sYfPCtpNG3E00i05Q075GEgDcC6UdYIiXSJYpExYe0qx06C3TQqFTTLRRFKskzTZanFClMBQRTM9zaZGc4Y7g7jXG8QpDquNkH4qQTIi6wzreyQz/Xukbm1yCTdBNBLtlLrgu1QwZiNy0RpIkkzzVZodG5wmvRWklFUE2qmHLnnKMMMY710jQynDbHtp20sUuYJoJOqkiTyF6b+z811jMq7V7CIsJS2CgpLLKMrrFkiUJJhZaKfpEgg41SFdvsgXzGQOMCl0cNtfW4EAuuTLVsu2f4kESynm4ZinFuhVYuydNYdfH7QwvmDrLAUg5rhUK19Hc1X5wAJxynJw0fOTPFExikcPVCpItrGSgbT1U7jIoFo/WKaJYmcXimxlOauGiHENM1gvf0ihR0YOoj/XQe91lZ2C09Hz89ZtY0XLWYMsgEhxYLrt63xMMbU0azkrquodCIoPBB472NRYIxWBdiF9j7SHMWMb7WBTgzrBDdjDKHIs+YVob1WUk3AaUU/V6H8e4Eax3r585w9Opr6A8WSY4cxTZrmKZie3uXIDRplqJ0gtQJWuuWnh3Xr9AeKmxdY0yNtTVpliFEy50VcR0c9DvkS30ypWisxQRLVY5xNuCdxTclRZ7RkYIiT5jMRpy9eIY0laRpik5S0rxoU6diwSJkIEk8SioQMC2hqgXOChYLzWpXc7gDXQKp9wiVxA6xNMxKw87YcGEnUvhdgK3K0U81ygYeOzNkuzFs1TZulFK21GRBIQWHMsGui/LW7SkxvSNIPHEeZQJyLdvUDk9HOgYSjhQJi11NniomtmHaRPCY1uzTOIMMGhUkWsVGiFew28DOzHFiY8aphy+zOTGc3qmj54WUaK2RUsekn2fyEJIv+eIv5O0/8UN8+z/5x+QbJ/ie6xPef7rkzFjzr7/1FiZlyQOnNpmNpuSZolMk7GwPUUnK0soq2xsbWNOwNSxh9Qju2Arf+b1/xTfZC9zxxWHvfYRMaNs9IGRbbEt0d188MFaz2PLFI0T09zl+1SHe9c5fRqddhEoByZe8/mV80Sufi876/PGfvIePfOgDgODaa6/ld3/n11FKMtza4D9911t54PF7+bd3fZJ/cF3Bqu/w1PaMJy+PWCk0z12W+PEWj023+J1PDblqueDWwwNe+nkpY5dx9yhFLXaZGscP//49fOurruU1N+7jp973OF9+6xJvee4K3/yb96B7Czz/tpv4wMfv5OqrjvAPv/vb+KWP/TSfeOhxmrrGSwWdAUdvuZ793cCBfMrZzU2mTeCVL34ezXgLN93i2mMHWF7oE4CmnJHlOQJYWF7BB8GT993P9ceWyQrNXR97kGuvv4arrznGB973fpogSBbWOLy0yMOPPM63/Niv453jwELBD37TK3juDQcxKuPnP3iC02fOUU1LVJIhlebCMDZJskwxHZcoYVnqBr799Vdx6sKMux7a5ec/dJIilbz4SIezlwsemtb81PtPcWCl4OpjqzxxKaeejbHTdf7Nv/tJXvuaV/HKV7yM/+vnf5WHH3mMT37sL/nBH/pRfuM33skP/+tv5b+/5z184M//mH/z7/4Dr3/9F/LaL/pygmtIU8lNL3gp3/9vfphf/4138ss/9eM87/m38ZxbbyYm6UZ21eLaIW645Vb+5be+id3Lj/Gxj34IgCcujjm1VfL62/dT1p4/emiTl12/woFlxfsemHL7S27gTV/zUj794TP86Ycv8svv+TimTUjz3sW9qj0g/+8yOpmMYEsQNDbGbG8NS2pjCeGKz4YQoLXaY8v3Ms1aP+W6fR1E3qEMKS6UzG0qJLQHhMC0tjgnUCiSRNFX0WPEtX4+3nu0gFRED6YQYtpYWVusc5TGR5mpEqRK0ssjcCVDBDqGE8vZnYrgY+hOnkR/zkNLnbiWKkUZIhskCY6tyjG1gcr5WIuqqDigTfizziDaRvTMRqsN72qSLEEoxahp2BgbNsYGR2ws9joZVW2xzYzR5jpL3UMsDgasXn8V25vbbG9ug1DknZxeUZClKYlOkCqJJvpSRzaO8xhjGG1uYk2Dtw2i38VrRQ1RdaA0i4uLbZ3rmdWWunHMpiXldEZdN+xOS5aXF9EqobGeSdUwnJYEIE00vV5BlkfDZlfWe/HwBKIpt4tpgUIIkkSy2s9Y6SiO9uOhVYWYaNhLAr00kNYluzPDhWHFpd2KmQ3oVLd+LRJr52nTDq1iOJDxV/yaRBCtCiPseTz5p4EoIsRaK5GBrlKs5pJCS0Tw5MER6ppOL6cKMUSoU8T6oqwdKnjQgixRrc9QlHdujkoePr3NyXNDpmXD2Us7TMo6golCgtQE9cwOCHi2hn62hn62hv7sa+i/R6rdFfrRfMGi7YrM2S9zdLaXRolVrmMcoCNGv06cYGwDdVXjjEF6T6YEiVAkEhqrMLSU4HZRljIwNzWHKKMKEpAtmiciPcwH9qINRYSCY+eoffBUCEgZ2TmeuIgbJ3BoeoNlVtZWWVheAamoZjN2tzY5fWnIaNYgxQbWWmoTEc6QKEhaeq4WaNgDvZwPKB1Tz3pp0gJyksWlBZZW11g5eAQZAg1DjBeUdfRfUkqgtCbPHRaNFwnI2JmJlKK4UcxT8+YRqEJHPbnWCl/XWF9TNW3qoAyQBfIkYbHfxR46QN1UNMZggyLJctI8iyaXQiO1xsmM2msmTbwPaZpyYHmJfpGjhWdSzmiMiQumiPGpQgq0AC8FmdZkWrKQKzoykHiPLS3KB5QPdFNFriSdRJFEL00aHOPGUklBMyz3AK09MrCA7dKwW1k2ZyZ6CjSW2nkcUfvazxWdVNLLJFkSmUs2wLSJyRGND5QuoGxAJ9HDYFQb+kVBlmhSCXmqSbWil0mqckZVzphOfUtXFagmFk+j2oOIMtC5bDNXz+xODcR5OBcSShVBvdg9ISap7KFn8co3LqL3N62lXLuccsNqgZZRz50kEh8im69sHGXjmTawO3asy8ClsSR4TycRvPJ4jwP9lLV+yq2Hejy2WfPYZrkHohoT9gBnEaLZqAmBWRXNTkOQkFhE0iL+QpPJAMawNY2RnguZAjWlCZJOJsl1gQo5p2aW0loEjpVc0k9hJXNInRBkwaWZY1JZdiYNSYjA+UKqGDaGcWNZ9lCaQBJgMq6jPKJfMGaGCrCcKm45sMbhw4cYri7ECGZjCN5G/XiSkQuHrafYphs37Za9J6VCpznleIdyd4Nm9wJOZPigqG3C2qEDpJ2CRx8/x3BaMykNdjpmMOiz//BBVrsFMnim4yFXXX8NneUBg+VFVJrR2BC7uiHgXM1ovBtDApxDtQWIUoK6CTSNo6rj3Dy61OFYX9LXnsw4nJUxohmiOaJymNaTLpMQEokhPgPT8YylIuFNtx3Eahg5x6MfPM+sDlgrECHGPW+FwMQLTFCsLCiaGpomGmomOtArIFXzA5VgX6YZ6Aikr1ceUwXWp4ZJ4/DO0iv6dPOM1cUOmBJsg20qIK6DudOsTyxndofMGocQgX0LOWudGEO7UwtmdYy8fSaPv/ng+zi0fwnhSv7hzYr7HoAf+diQN7/kKnrdjK/78Q/y5PldlISl1R51WTHcHXHwwCrWw87OLkjJ8QML/OCXXcNNRzSpK/mOb/5GnrpwgVe/5g1A4Au+4GX82I/9MITAE0+e5Nu/45/hXGBpaZl3/tYv0e91wEd6+stf/gX86A//IAhJr5MTTElQMeY5uJJ3//4f8qu/9lsIqdjc3CIWDD7KuYTkl37h5/nE3/41X/m8aynlWU5tPsXpZpkN40h9zR29KamS/OyJXZIsYbFX8ANvuY0Hzw65++QWP/BHDyO940hSc3IYD2C9Xsp77zvDxx7TfMlzD+Gd5913bXJspcs11x7li1/1Qu5/7CkeO3GGL3vb9yBdwx3XH0KnKcv9Ba7Zf4BjKxrpDBd2PFffcIyFhSWqsmK1n3NwuceffmiHrVFMkX305BkWupdJVc2Dj53GB8m1117HcOMpti6NuPXaw9T1kMfv+xSu02Ol1+G6/Uv0b/wKtgefxv/cH/NdX/el3HrdUd751x/njQv383IB090dpJSsHtpPqjRd6Tkqpzw5S9iqAyFMGe42XLjY0L9qP/uOw5dedZiN3TEnLs/4vU+cIQsNz1lM+PSsYloLwiRQD8/xhi96Ld/7Pd+G0F0WFwYEMyW4mmo64tFPfJCvfuPreNNXfBnLSz3m/k3zgxYEhMo4e2GT13/xmzn11FmSJOf2Fz6Po1ddjU4Lfu6nfoRZWVEsrJLmPZxz/NlffYwTT10guj/Gtd8ay8cf3mClULzheIdt6zldenSi+bX/cifv/eDD7G5O2NydUtfRF0clCUXeI+/0o3T0wjm+61u/gTe/8XWfi2n59xq1aaOvJYi6gdLiZiWuiV6fXqg2iEe0bJFoL9FNFINMsphrNpxkYgBnyFVApZJUqNYzSbEzqRjOHOvBodtmcK5jM7BbKHqpjkyfOcPJeirnsCH6CzkfYn0gBN5ZgpVgYaWbsFRo1voZdRV9pdaHZUzSMo58e4ZONFJp8kSRpRkHOjmz7RJXGSamjmE0BIJpopwv04TgmQkw1sR09PbnPr9Tsj6uQSXUNq7Nc8uEQa9AipIs0RxaTLj+8DKHDu6n1+0wm06Yjif4oDAeKgPdNEF4z2w6pZpOqcuy9a6SaBEI9YhmPGQ63GIso8Qx63ToLx9A6pyTZ9fZ3h2xM5xgTM3CoMfhg/s5uLqCM5btC2coEtBpRt4pyIqCNMvwIZCkCVmWMa0anHVMyhrrAwFJ4zy1iXHk1noGHc2BpYyrVgt6qQDbYJoYtKRSAVIjtEbSkMrAgoalNEpnt2aGIk0otGSQpJQqkIq5OXkM/PG41teKK4biLWaiiECTJAYrpTKynPppYJBAJ4GOUkRvXUiEI5eCQknSbofFjuZwx5JgwDsmpWOn9tRNIFFQzirOzioaG/Au/rz7+wmJkkwbz9jAzD6z9+Bna+hna+hna+jPvob+zFPt5l9hDkA9DXzam2rtAtYarc2TI3yIBoq1j4bQxthW9hZNvoOQkQ4mBcFLPA7/tPedN7YCkZLohcAL9gzepIwm+4IWAWUOjs3B5yu/30srczHVoTERbVdpTt7tI5MUqVOaqibL0jZONb6wDzHJTc0BLxXx6nmKAUTasPW+Bb4DqZL4TNPrduj3+nQHi3hjSOoGlSQt/W5OJZOx26ySlg58BT0MXPGsCmGelheN22JytdqjtTo3z8IgJnFIQZElLC70qU1GZQy1BaVTdJJESp2IqX+IhCDj+ydpSodID06kYDZLcaaC6GEZzcZEnHwtR4lMR6p1rgQ6eKT3YGMKoKJ10E8kaapQIl5THDTOYRuBmdZ71NzIUIo0w3HtmNaOqnFtGkdoN+/4/kUaTS87qSRvgSfX4lbKBqyJ1NBozhhovKeyjr6UFCphedCNbCkVfQomvkZYSaMlstW9Jzp2jHIdgVjfPr+dJPoaPNNHmBcbzBszT/vM886x2JsthPZw0E0V/VTRTVRbnAaStuPgAu29iK/dtJ4NjYjUzUQKrl7KuHatw8GFgoUiI5EG6zxSgWoTJfdWlT1mX0v99y0Vf6+rHankUkZJQty4YVgH1KihCVMUjlQpOkkKZaTGCjyJlGQS8B4VFFoGulkSkzZrjwwBJaN55qyJiSsTY1v6avSicU4QWpRZtF4ZufAUOEZt+k6iFEIFtFLkmY5suJahOF+X5jdBCEkwDZgZspnQ2ArrFY1L8XYZ5xI2todc2h6zvjuhGe+yb3WFpOiynGmUCNRNSVWXBCWQSsd5jNzrBgXvou9bu6jGQ4WMa5WNjFEtoZdJ9vVTOsqhnKMuDZlKkancSwcxLlBaS+Oi9Kd0ULZS5to5SiexSLRW5K3soLEe19LKHdE+yAkQCnqppPS+NVmNVOBOcuWZkCH+3hNNVBvnadripp+ndIuC5cEig07OwZUek90t6tIzCW0iEZKeB+M9lbF4IFOChVyy0okS4NIGKvH0EIdn5sjSFK01ICOT1gUqF2OrcxHYuLRLOYu+Q/OJHkI8qDvjaJoGrRWdTHHb/oSd8YxLI8MLXvB8zv/lR/jbj94Zb44QfOITd3HjDdcznc742F0P0lQzlhb7fOITd9HrdWnqhqqqUFKRZSk33XQTUgjuvudOZNIhTXOOrOY8/vCDfOSjn9iTHcQRgyvuuuuT3H/vfZx49BGS570UEaJRZSI8Wni889R1g5GCrdJQoEnyyMQYdDT7BxnjcQnekghLU8cGweIgZXt3yu6k4fOsJ1hHVdu4dqea/QsF/V5Bc3GDj3/qQW46foiDhw4zrgzD0Yid9cs8lWwjhaAxEjG4TG08y4MeWkXvl3nICUCS5TgCO7sjppMxad5hcXGRMyembK1fplMM8EHiPSytrLLUyVjoFFS6hy8GHNm3wqDbAal47OKYo4+eotABgidNE3SSoEQ0eO5kGbIK+KipZzRznNtsKLIZa4uaIyuKq/oJwx3BPZdHvOiaFTqp5v4LI6wPNCbgXIXEkaYpQifMZjM+cdfdbG1tUc6mfOITd/P5r34dL3zhSwDYt2+Nl7zkRRAsN95wA9F7KKGqHR/56J2AZLAw4OSZswxnNTIp8AgGC4usHjjAocOHsdZx5qmTHLvqKl5wx+18+oEH6KWCtUFOIjwLmWKpk3BhFBjXnoVOwvmLO5w6s4ltTbMRgqtXCzyS9TKa2uZZyrGbr+LgvsXWN+iZPtoiFEFjImPI2Wg1EXyIG01L5Z/7qko8eSLI09hgbBqojCe4mBCYKoGWGqUi+LQVQrSMMLYFnsBmCqUUqnXCFSHK+owN1EFQ+SspZhBZSdFyAIJz1A1kSRJlY0rilcS2fp/Wg/WBSW2Q1iOVx5OiMk2SpejEoE0MCZIiAht4hwzx9VMtsa1nlIM99npjQ0yYS2T7udgrEOY2HVKEGNuORwZH8C4GBmUp1kuUa19PxtQw0zTUTUPTmL3XEASkN0hXIc2U4A1BRbNsYZfxQrO9vcWFSxusb25T1yVrqyt0i5RDq0ukGlIM0hvwMXU5Xmu995l9iBfYtdK/OYvetoSDEEAr6KSSxY6ik0W/3EllyVwgbZ8d6+N+1SHsrUHzoJ9Z7Zg1lkQrKuP2LCCiFUmbXkdba7UHUiEgaYEkIUSbrBZ/TWQ8VKr5Xkysxe2ewiEGMBUapFakaUY/HyDMDGsMwdfUIRpeCxkDeaxz2CYqOOI+rMh1BGBmNlwpUJ+h49ka+tkaGp6toT/bGvrvATyJva/5wyugXbivMAyljA+4D9ETx4UokZsGzdTCtHbMyhrvLCIE8lRFQCh46kSjhUMEMC6mAEQf8baIJuCCbB38I7gQ3eij8bfyc3ZKpDLOacthD4QTSKGAiMwNpzVboynD0Yz+ssEESaILvIqsIxciLVrI9kFzUfJVExf6JNHxwZcSFV+eqYkPVIyHDGilWcpzDq4ss39tldXVfTR1DUKwuLTEbDZCitgB7nZ7FL0+RbdPmhcRTAq+ZTdFeRshFhzBxy8f2uhM71sHe0kgiyukE9i6RstAv5PSzZZpnKM0lnHZRCpynqGUbkmfET3OOn2WVvfRrQ3eBcrpmMlE42Y7SJMwDZa6vb4xXjcaNAopSaREA0XwCGPBeXSAPJHkiaLTSaLcTUmCjwVlCtGYzVp2JjW7dWBqAkWq6eeK5Y5m1kRjybKJOn/XbrpaxiKpn8fUvF6mKJIYGxt8pBtWDkTlqV1g2lg6qUYKixCSZecoMk1noUshLQqHaxqEMwRnY7JegMbHTn2qYUmLiLi3C3yuYnfof4cRiEwtgCCuUKz/nxYMQZSR6pbt2Dgiwyw4jBN7C2LVxOuQppDmUXKJEGADqRDctJZz46EB+xd6XJ4IAiXBB4qOpJtAp5A0NVTeY7xDIFvNtKU0gVntY9fVKTyKID0kDllAv9As5ClnJ45ToynTp3a5YVVzoN/h6pVlUp1SJAElLdYFpnVgd+JIdUOe1PRXVkjSApkVTGcT8IaucoQ21WFYN7SPK0niCd4yHc0QUqHShIBj48JTNLuXePTMhUjJTTOqyRarS4tcf/zaeDDQmsbbqIdHRM+coHAOMlGT5ZJsdZHtUUVjoVCCLBV4YDiacfHyZc5cuszOzhZXlSX7lg8wuO4weQbDmePc+dNYJ2hmNcJL0qRg2lQoFwjOMxpN4/zMEpSA4D27Y4MMkTZ+YEFxYCHl+ErOdGvCaNywfWHMDceWWVjWdNKExgo2J45cz6hqy8R5Hh45Gu/p5wG0YOICf35yxiCLgP353ZrKxYOEDwrrYWrgQDewqGFf5pjhqaSPTAAVffLGDVgHwQfWq3hgMd6jhCdRcN3SgLXVVQ4dPMTiUpduJlnK4f5Hay5vNuzIlDzPSJKEfDhlXHtGAxUBdyHoaDjQiQXihUlAyPbQ9wweL/2CV/Pd/8d38vaf+FF+6uMNesPxL1+yyPbWDrse/vlLlvjd+4f8zVNTtjZ2SLOC3tIqO1ODaT2KQlAEa7G7m/ziBy/z4UsJ99/zWk5eGqH+6C9xzZC//duP8LKXv5a/+B//lX0HjpKv3YzbeJKtrXXe8CVfufd5vPecOXuOl738C3nfX/4PFpdWef2bvxPTTFnsKH78W17HE/c8SuQYt6WGECA0jz52gpe/4nV8/q3HufmqIzx29308eX7G5YnhJb0dHq8q/rQM/MGjJUpJVKI5fqDPUq/gR//wHt76kiP8h6+8jtMPnOWjZ4b88gMjEAn9IuOafQs8pRI2RzW/8oEnefNzl/ny567wf773MnKwzWTzHPvXehye7WNaOp4aOuqzEz518iJ/9ld/zbt/+500422OHjvKiz/v83jg3X/CDddfxx/8ys9Tec+krjl6YIGFboaSgpe/6pVc3h5y8uImN952B4u9HovLKzxwcpu7P/kQn374JK981at42ctfSW9xhaacMtm8zN/cdS/rF8/zLW95PX/813fx4KnziCTjV/74b/jVP7TceNPVZE1gc6dk4ixVnpIuHWCydRFbz4DAk1s173tsl40PP8pzD6Z86S09uqZmfxI46EZ89Wtezf5Da/zxJ56MTrCJQqqE9/yP9/Ge9/4FMukAAu9tBD4IfMcP/DRv/8kFnvvCzweheNOb3sxXfPlXELxp9VwWnRYkeQ/XTAAYjae86Wu+hflOMljZx/7VVZ5/0/X8y+/7F9zxgtt561u/mq/5qq9gc+Myz33+F3DHQc03vfIa9uU1T23X/N4nh1weT6mc5wXHBzx+bsSZ9Yq8mwESKSTf+/rjXB6W/Lv/+ijWNBy+7jB/9DP/jB/7hT/l3/zof259eJ65I5cKh6B0kt3aMawClYsJx34OPLVKAtMYJJ5UwkpP0+8kNCpnVAdGM4Np6rgeaslir4sQEQxIdiUlUDZzz6DAsJTslI4iVaw2nkxHdtTMCCoD4xpmLvoapVqyWCT0c0WhJaWxXN6tCQiUkqRaxbRk67EILBITQuyeB4sLFVNTUPcKil4XkgSdBvLEoIND4VGuITiwVpFoRU5kWhkbAai1QcJwZpk2jlkTpX9SCvCOqnSUZRPvdYC6rjhz9izrmxuUVQTblBSUjWfQ63HowAEy5UlEYFbWjCYVu+OKygqaxhGcpxCONIPuQopy0UZCJ440lVRSsru9zsXzZzh77jzWGrAVRw+tMuimDHJNzywQCsHU1jjX+onqpG2yO4R3LPZzpAAtA3XjaFyUWyVakemEldSyf6C5alEig2U4Mzx+bsQNizlFJ0HImBxWl5YmNdHEfNKwPqnZnDnWp5ZGKLbrwHYDs9owraJhd2NjctacGCBV9J3KlGQxkzEaXQqsE1jvsT6CI4KYgjezMe1KSUFtfUxPmxmyQnOgp9hykGUpx1YOUo22qWZTrHHkmWTNB4aNRwpNIgOXhvFcUSjBvn4EM0e1Q+II7n8Dc/Fna+hna+hna+jPqob+e6TaXUF6wx7jCf7Ob8UVxpNs/+CCoPGCSVBMa8usivpo7xwieFJxxSjb+0gTTGQEDubGinOsNrQMGyFb02hHi4JGVtVcZvd0nfzehwvx76LndOwmjcuGzd0pp89dIChJEJD3l6jKku3LG4zGE+q6JlWSTqoRwuN8BN6Cj6aQQgqkinp8KQQ2RNodwZPKQCcTpClkiSZPE/IsJU0SvLOsru3Dmposy7HW0usPWFhcptfvk+cFUraIq2+lCczN08WenLBpDK4xNKFENDXOOBw6GqsBjWkIwcaknZadlShNpiPVVyFwTUM1m0XDORfI84LVlRWm0ymT0ZhhNaMpp+jg6WiNyLIIKonordTNJKqNA6Y1D8c6lPckQDeLmtIsiWYEloCzlpRodJnpuAA7G9idObaqwLgJLPciy8h6hfFh72ueviIEJK1BZq7jV6ZiaqFAQGQFk6j4fAwbz8xESqNAoISkbAwISJBM6inBNkhrqOp6z/TT+ohSOxc7bFqBF6I1XAstuPqZzqTP3YhbX9yQ5qCu9RFcbW1NW1g5UlmFCCjFXresdq25vIydC2Pjz28jvrjHTpyzDNMEUt0mAY4NhIrKacraMjWOyjukF8xc2EPvizQChvFRiQch76OOunKBU1slWgYq59CJIss13Y5mSShE+1lHTcCMararHbSOVNnVTsrBnmKQKWobq4QAbIxnlE4y9Yo0S5FC423c1GnZcf1OylI3oWl9MIZTQz0ryZSmP1gkHyyBVjx16TJKadI0JTRj0m6PdGmVJO+1scuybUV5AtHQ0JoaKTX5wgIrCyskl07S1CXWN6QLHcrQY7p1gWRykTW7xVJh2J81dERNb7FLvyMwE8e5MxfY3Zxw4sIuF9fXGc1mMTBBtE4CbTci+EBtIs29MY6VTsJqN+XIgiITMN6ZUI4afOVZSBUHFzvsWyi4NK5YH07Y2hmRhQwH1CEQZKCygZ2xZ1yCEB6RTrjjSJ9rlnNuP7TA5syx23jGdZw/3RQGWaCXCFa0YF+iEQh264bKBWbG0/g4v9R8LQe6KjJhtIzFHKHBuzGT4Yyxd5ydlVzc3GU0q9ltAraxuOAxJrJUVzqSxoq9EASt4i4pRWSoPo28+4wcwQf+8i//ip3tbZ4nLpGsKB4ep1woY+E+PLvLk9sVBEeSddCJRghLM6uwJgILz1lLuO2qLvtu2Ed+z4hwySGTAiEUwRtk0uGaY4d4w2s+j8P7l1hb7fIff+Ab+J3f/S/87UeGeDMlUmxbCbgQ+CAJ3nLV0f38ys//ON57Ui15wQ2HuP7l67zmzaf5wR/5Wa46dhXf8e3fzNt/6v/i0UcfIwRLj5p+KHlyHLg0tUxnFb/9wIzGOo4upbz2OYv08pRHepKLVeDibs1Ljw84vzXh37/nMQZFh7NTjXeepdUBaaJ54twWPkkpOilNnXPvxYqd6jLf8MprmFrBT//xnZzYLhnOIu0/mIrtjUv8+q/9HmZ2mRe+4Dnc/bF72Fzf5K6PfYz91zyHQ4cOobRmsLyPwdohLm1/gnHZ4EPg7k/dT17k3HL8Kkw1YzKrqS+c5Qte+iLueP5t9LtJTNXq9Hni/geoncfIhFuecz1JcPzkr/4K5zZ2QQhcNePW649x3VUH+fh9j1C7gNYptx1ZwnnHwydOR2/GlYJz52dct+h49THHO3d62P6AhWP7cOefYkjNyYnn0uVNUizeew4s5hzdt8CjoWE0KRmOZgQTm2DBe77rO7+VF7zgdkBwx+0345tR69UVJ8fcOBfg277pq/nS17+U4D0IRVnV/Owv/gbrly8z2t6mnE65ZA2fmI35qf/8mxw4fAydpnz5F30BN19/BIDF1RWuf96tvOf9d7O5XXK8H7hl/4AmCO69WPKqGxfY94JF3vmJHY70NHccyHns7JDzo4b+oItDcP7SNt/39t/n1ud/Hr/562/93EzMv8eYM0s0gkE3QaSSiYB06lDOgIx7plIC7wQqiLgXCqid4OJUsD1pGM4s42lDqiJjqN8TNMYxq2PCbt120ANxQ/ZCtMwKmDXRrzRxIj6L7u92qufMcG1BSEHpaL2XXASfZGvaHQLGgtKaLJMsdgTWemrrKKsG06ZDz2pLCLBQpBzopyzlip60jAxs13Bp3FAaS1lbQsvaH5WOyoaYYBcCnUwz6KQsdhKmleHS1oQQBFqnLK8diIdSa3ni5GmCjwx7LxQHDxxgZe0QQufoNMd6i0diHczKmsbE4IWi20PmCjHoIsohWIM3jiAiu7QqZ3S048higiRh31LGQp7Q6XTIi4y6v8Spi5ucX9/hxImTbGxsUlVVrNdl/CqrZu/6CilRITJaOolkoZPwnCVNrgOmNpzbnFHWDoJgYZCzupBjkYzGDbvTBjfzVMYxKh27tWdiIoN/d9ZQuijvG/QzDq52GE1rhpOarWFJFQ9NKGCgBf1McqA7dywKDGtBTXxWCNFv1SOY2VYlMLdBAXqNJ0s9HSXYaByzWrA+dUx2a+pZxWjaRCIAkWmZJhKpJCudJMqlrG8JCldkYs/0TfjZGvrZGvrZGvqzr6E/c8ZT+5D9z+frOe60R+ITLTDSgiM+xI5IhaRsLFVjMTZuXARPLeOLu+Bbd/U5sCJbWdwc1QoIOQeXrryv8XMJWmhpd1yZvSH8HZAsgjaypSNG2thoVnFpfQudRq+kzkJFXdXsrG8ymUxpmoZECfJEgZBRjx2iYVwEz+IiJEWCFALnI7PGOYeTgURHLacUrQRRxk5Ip9NhMFhgNpuAEBhj6HR7dHo90jwnaWnNXIHd5nfiaYsbrYlgQ9OUSGcIzsXIznbhc861cZqRIeV8lALi2btHzlqaukGGaC6odUK318NaxyQMqauSpi5bTy5FSBIa79vLHMi0RItIJbQ2UsyEczE6UghyHQ2/k0RhadMMvSe0dN9USWRbyMwax7T2TJpAL9cxIrJlsM03qHl3QQiBltHQLm1NKxMZwbQ5BXbuA+ZSSeMCxgoa66JBq3LUNpruBSWYzGpsU5I6j/O2NfZkz1srhPgzz/XxgbgpuxD+55CQZ+iYHyBkK9ecX0tx5e/2vjfsbYDxWQq4EEFdGWi1zrR0b/G0js98lYtsNK0iaDetHUoYlIpzxPmAJQKJpQk0RF5EomNahRZXmIsuRGad9bA9s0jhcd4jRNTX60RSeEFtHVWjMN5TV46t2YyVTkaRCBbyhKOrffYv5NRetVJby/rJTeraUDaSLO+gtCK4yIiTIYYSpEqykKcEJEPZMJoZvLGIAP3FFdLuAO8d67u7CCHJ0gTta/YZiyx6yDSLpqYtWBwp/pE27KxBKk3WSemt9THTszRqhrUWmSdYlxHMlIKKJLOItiuRSktWZHS6iuWu5qnxDrsX17m0PmU6m7XraFybQpiXQjHZs2kc1sbEmm6qWOlqFjOJayzlpMJVAeWhVySsDDIW+hnjOnZYgzWUtcIJQRVCNCCUgt1pYLeM86I/qUH02NdPuGFfl+6wgd2axhog0Euh0JBJ6EjoJDKmTVpB04LLT2dTR5o3pLKNAm9ZjiEYymbKrPSY2jDenTKpayrrqD1MGxc173h6eZQxaBGjZ2vvr8i/Wsqu+Aw3zc/VEEpz9tw5psNt/o/nZaR5wuMzzZaT7DrBei2ZOICAVBqtBZnyzLxrGw+BfV3NvkHCSCV0l1fYv19yaWOX3dGE4C0yKdh/4ABf/LpX4Z1hPNzi8267mve/bxEhdbzBc4ozgaIoWF3bT5alrCwv8PVf++ZYVbfryXV2youmW7zr99/L8ePHefWrX8Gv/tpvwVxMbxtcU3GxDIwaj3eO+7diN3whlxwYJCwWKcNBxnbTMA2O46tdHj4/4t4zmxw6foxZGfeCXidDKcn6Tk3e06hEoZKEs6OKi8MZX/vq5/D4pQkfevAMQmUorVjoF4zHJdVkxEP33c+N16/w/OfdwIVT55lNpphqxmK/x/LCAkIpkqwgyTvRiNnGmuXMU6dZW13i1uuv4vzWBGMaslRw8MBBim4/zj8Bu6MJ2+vrjBvHkJRXvPAWttaXeODJs9AmXulEsm91kePHDvJXH70H6wP9xYTVXkJZBXa2dli6aoV+N8OMUg724UDXkeUZuijQnR5DL9ixUCHZ3B6Rt8m7nVSx1E3pdzKssZRaYrwjTXL2ra3yJW/4Qt7whtcBAm9mODNj/dIl8jxncWERqVOqxrC5tcOLX3Arr3jpHai0C0IyHE14xx/+d6zzLPR6iLZmsc7zoY/eRZD3kxYFN11/FTffcDzee50Sij6PrFsmOzXXLjiuWS6wQnDn6QmHlzo873DOnz804VBfce2i4oGtmstjS5Il+MYznlR84KMP8KKXv4FXv/qV/2sn5P+X0cqapAh0Uo3Tgo71aC1b6UuUxmkV2SXxyBOYsyV2KsG4aphUhmltsK1Myfp4OJ3Wlsb5uC8zD2qBeIyNXy6ACpEJEPb27bbB29YExkeTb6Vo5RkxcW6evhdNdmNCVVdrilSRp2CkJRDTj2rrmNYG56Mv09pCh8OrAw4v5izowMWJJQwNlyY7WGepjUMqDcSawPgrB5xUS/pFwsHlLtujko2tMUEqkjRjYWkFay3TyZTLG9tYayF4dJrT6S3gUEidopIUbwIQpXuNiTUeCPKigyZFS4eXHl/NMG6GmddG3tPPFP3FAilgsZeRJ5I0zUiyAl302Bqe4uyFi61kNTIS53YUgvh+gQiIRblTrE27iWSpUKx1Bd4ZJqVha7fCOugmil4nY6GfU1qHmgWct2w1ntp6ZibQhNZ7KEBlHE4IbPAsdFMOLheMxopCg2sahsHjXfxcXQ0LiWA5E9gQzcenBoyPptZza13XnguMj8+FElFpElysITIZz1PGekaVZzKzVFNDWTsCUTZmXPw3EkE3jab5lX/ayUY87esZPZ6toZ+toZ+toT/bGvozBp7m0ib/P6NP4X/6lSh9i7Ge4JDUQTL1kkllmMwqZpXBuei6b61nroh13u1tgnP9cZx40QSwSBVaxT/XNkquZo3FhNjd8fMPIefTX7T6zPinuWmeRCCkorGBnUnN3Y+e4cnzGyw9cpJOUcR4ytqwPRxRVjVZlqB0oOM8s9Ls6XFrG1FXGQSJIDKUiIuQ9bGLKBsHZc3m7oh0YZfV3V0GC0torRksLFI3NSpJqBtDluXk3W5c1J52UfdMtkNcqOXckwmBaQymqqjHY4SrI0quRHT1lxKUpqoMs7JmfWOLum6oakO306HTKdi31sU0FhFKqqmLMZUxkJGmrtnZ3mZnZ5u6jAi2kopUCxLrcCEWGYmIWn3po6eTCCHSp9v7ppIIIjbeIYg6YBkChZB7kb/CRd2qDbEwCqHdqNozjA0BQ9S1eglBQpII8jQ+F0US3y9tfbFC2z1QMoJ9mY4qAS3g8szRiLjIjitDkJqskzGqPVVpWNKi9UAAJQKJiKh0HbFNXLsBGx87QVqB+t8AeIq9LiAERNhrMV1ZNJ72vYFWf+4h1ZpOqhmkkpkVOB83XocjCI/S8awZfFs3zF9IxnmmpMR6R+0M3SSjnyUcGuQ8cknTGMuZHRMNR0VMb0hTSSoFG7WnclC1MketYxqGCIqqMZjdTSbThh0FpRco7VkaKARZK6U1nNsdMcgk1167wpd/yUv5/BfeREgWwRmaasrbf/GPuPex8zxx5iLGLtHr5uwfFCRdS5Ua1jcnGBuTGI8t99nJDJUB5xqWD+zjea94LcONdS6fO8/6pW0cFpkpBlqzb1QzqhOETGLnRGkQChcE3nmMszhvUd0lZEeAztgZC2ZDj7OBQd+ic8FtN1xL445gguP8xoQ876A6Gm8FhILOyvWc3X2AB546x3ajOLC8wuriMp8++SjWGQiKLFU4D8OJwwdBIhXXHljkQAdW8sB0d4aZWczUsC/XDHoJ+/cvsP/oIoOFDnY45HlHBty4r+DkruH8bsW5zTE3HuwyszBqaia13fOUWOll3HBwwGIqefzikE+eKDmXOmYWGhcZkhJBbQMz72iC4/wsUpYHKoCkPWhBwBAU9HLFoJOxWKQs93I2K8NdT0bjxa7WXNXrIqQn0bCgHYkI1NITPKQyFg/Deh4sAWltQYQ9X5Fnuk1bb+UAX//mV/O93/wmfvBf/xjJ9gZvOK6oG0c+KHj+F72KH3vX/bz7AyeZjYas7OtyzYE+jwnJpIwdRrznsVNDPv+7P8SP/+Tb+Vc//Ua+8EvfxuVLFwjB482M1eVFXvuGL+YfvPWb+NDffpTgDY0V0WO6PTTN9euvfc0r+Z13/hrd3uAKC8pH/xQhZDTiFCl/9t4/5b3v/XNufe4LKMsaBKgk467LNQ+PdlnrpQSluGr/gBc/9zoubY354Ccf5T++72Q8tFUVb33xVTzv2AE+uSU5thi4Vpb8yekLNFKyttJlVVX0spSbn3eU+568zPnz26T9BUBQm8B3v+MeBv2C6685wIlTl+kkBW98/Qv4m488yO72lP/fV9/O7S96Cc+59Tb+4RteR6ITFlb388vv+O+oyhKcZeP8WS4/dYLrj6yysthD4MnqC5y7/35+95PvZ6ces3rgIG9+yz/ivX/2FzzwyAnOXtrEu4o8FfzM23+ce+++j5//qbdzy2/9Ct3FFY5dfZT1jW0CgZe+7IWcO7/NXX/yUXS3R0crOmnK++45TWMdaX8RnXQ5vFjwc28+yocfG/Pzd014y7Ud+mzx8IfWecfHLzENgq9+8RGe2Gq4+8IWnSLl9MaYc1tTOp2cxV7OkYHmoXMjXvx5L+K//bf/SpEn8d4KhVAJk5HhNV/01bzuNZ/P23/4eymWjvHxu+7nq972T/id3/wFvviLXts+mQFnDWcee4wv/7Iv4ad/6t9HWV4LmHzt1/9T/uIv/wqCZ7z9RggxKfF9H3uEBx5+ikO9hMp6/vBixfSeLWQIXLuY8Md3Gf5Yp3z7i/fxydMjfuyDl/nal1/D/tTwkSe2KAY9jqz1+KZX38D7/uvv8WM/8TOMx6PPwcz8zIctUoSxKNPQU1FeZl0s4KWKvh6y9U5K0wScBR8wXlFaRVMKRjPDtKwoa4N3kuAlZVVTmRjLbX3rDSUiuCRa2k2aaLp5wsGlLr0ioZ8lbI1LhrOKC2WFs7ExiRCUNtB4S+likpsJAq1jHLiUMrJ3gqdINMv9jE6mmZYV1glcUPS7isp4RqXB+UCepRw8sMZtz7+RG68+wtrqPjYnDed3Z4QPfpynzp5n+4mT6CT6BUmZxBoF9lKVO60/mwiBItOIrMvK6gpXXX0NVVWzvb1DZRzTtmG8uKTwQpH3F8lb+wrvDFrFQ5qQ8TCutGawsB8tHDIYxrMxjgbjBUpKOjrhmsP7yMUChTSsb+0i8z4eCSojJB1MusDFrQlnL24w6HXRSrHQ73Hi1Ml4OPY+mmoDoQXdtZQc6GmOLSkO9gXjacmkjCbNqYelPOGa1S5HVgbsX+5QZIFBL2Ghr7nrxCT6wGSag1qzaCxJEvdgKT2rheTG/R1uOrLIeJiy2decSQJnt2aUjaMxnrVc0ktBERlupY0BPFULMkVPqHjmE+05rFskLOYJg0yxkih6qSJToHE0QVJbgXSW3Buk9OzWjokJCJ2QBYlARf8xC6MGjg40HSVZbBwT45maZ3Yh/WwN/WwN/WwN/dnX0H8vxtMV6RvzmuIK9YgI9kgRF2vVmn45IbFBYkKM1LTW7Znhzc3pZPth5/GiEPAtUhxjnCO9LGrgI7MmkYqg2JuQe2M+a6WgJfbEzg9tAht/l5UFgsksRhpOZxVpksSXCIG6sa1RuETJyDTKEoeWcTNWou0iyYguI+Z+V9F4DKIsrGo8O6MJ6c6Q5a0tIinIMytn1HWFNYa5w2DwgclsRpKkFFlOT2d7Fzo8De2NgJrfuzfOgzcOEQJBK3SqUSohzQqkdbhQsT2aMp2WTGcVaysCqRKkivG3QmmCVG0jO6ZOmKahnE5omkibluIKvhjvmUQISFX0dVIi0MgIkzkHtkX6VYsC6RC/RwnQLVtJtbK4QDSZD1d4ppHhhsC1xpeuNeLzED29VEwPzFSU2GkZr9QcIJ2n0UVmVNTWFzqanAcfoslam+wS75uKUbsiavRFEKjWQ0vhEd5fediJPUIT4s8q/DP81DofIXqBhTa1dt7ljP97+s8wB27ZMyKc63dDiHNq77/5HH7aejAnRsRun2gp1dEvoNCCA72UWw522Z4aNsYWQYx47mSaynimTUuXJzImk0SQJaBF7KJJ0TLVgsDbwKx28ZkRgkRFPbnSoFx8nmaVAdUh667C0jGoJ8jRFt7H4j/I2EVqWhakVJIgFN0iwwvBsDJcHE5orKdQnqNrKxw6dJC1/YfBeKajMcvLgxgNrQS5Tuj1F1hYXkYotWcCumdo6n1k/XkfPywebyoQCULm6NBgqoogZuxb6RNEHycFddhAyhgrS5CEINFZh6K/wMLyKktpHxECxhounH+CWePwQpCKAEqQdOI8T7RiuZBIZ5iMDG7akEnJ8lLB/m6CUoKNacVgVFJJifIixsGmkqfGFWd3DGe2LbcdTUlTwXLHsTUxGOvRUmCMZzIzGOtYyDS3HOjjLo/ZnFku1JDogAwwM3EOmQBZC3mLALadaj0Ni0XGINccP9BjrZcxyJMIGrfxzbPGo5HRZLNNFJjLLaQI1ID0MdHS+tjZLQPURG8+2UqG1TPc46mZTbjv0w/zG78reOGtq4y3JO958CyvuLpL6hy/9edP8vBTuwgBKysLeAHn1kt0UpA5z2xkqZxgZSHjn37xtdxxw37W1tb4pq/7Mv7mQx/hg3/zYW6/5QZues4xkjTjLV/5Jg4cPMRv/tZvI3QXmaatT1RkK+tiwOlz6/znn/sVvupNb+Tqq68m7/d475+9n/vuuw+IqVjeGXTW46GHHmEymcYfpt30rx4kHFjIeWSjjLHMUiBMyf6u4uW3HsNWFeOy4YHzNQ9eGLFdWs6WmhvXCq698QYWR2fZLRvK2nHJTOkXhu5Cj7WlLlJJLg4bDi6kHBj0ePDsLqXxTOtY2M3KigceOcfucIrzlguXL7H5oQ/zgTs/zYIy1MazU1oKAUfXegTn2B2XXN6ZMS09pj0k9bAUg5TFpRW2zs3odyW9wTIEw3S8yeOPPUqWwupyD601Vx8Y8IYXHqafOMrSsrSyxu5wxmQ65qlT50mk4Kq1gtMXt3Emym1UnqGNpS4rXnr9QW460uMP776Mm1oOq8BQDVDasMaEFx/qcG7iePD8iBdeU3Csn3CimzGzsVliXCyMnJC4ENN+u5kguJLJpOTe+09y4sTjPPHE41y6dIlP3H0fP/1z7+Bbv/07saZhuL1JPV3H11vIbAUQFEWH7/6uf8ott9xMr9ch2LrdwzVve+tbuOrYUX7jne/mrz7wt4yGQ77x676SBx94iDs/fid3LA3o9CSHBjlPrMPUBNJ+l5t6GQuF5s4zEy6MLatLXW4+lHFxNx6Is0QRhODeU+uc3di98mw9g0eWxKae97L1RyICfXOVQOuVGbvHASFETBhLNFprvFB7lhaJEiRtY6yrAyoEnAoUqq1H/BUmhmxjr1u0Ba0UWZbQMZba2DbWPaBEoMiSvfeIhtCxRpIyxnMnUmAkBB/ZWBqPxuNs+73eo9UVAI1WjaC1ptMfMFhZZenwceSkRHR2WVvss7WV7dWeEbSmPUuAlCpK4yrL1rBkPK0JQbA06LO6vMjS0gKj8YxZ2dDp9uJ1buoYj17k9PsdijwlTxNMCUkbEBDBp1ivVtajcUhvop1DywASzqK15/C+ZVJlSYRj1ICTWQxNMg3OGrTWLC4ssH9tjeAt49GIkRZs5Zq6iXIzJ2MqlRCxUZ0q6KiA8g7beEwdGSKDPCGR0XQbBLszg9A1qwPdspE0ExN9ovCeQaEpipQjecLl3RJjI9rhKoOd1QykR+YCsZAwnSl2Q8BaH5ky1uNxlC6ae5c2/uxBROaMFJJUC7q5ppMpDiwV9HJNoRXV1KIShdSKXvSgxvqACSKmI4YQjd4TMLTqBCUYl63lhQtUThCkQCiF1p5U+//nifNMGs/W0M/W0M/W0J9VDf2ZezzxtJv+dyhPcaJcAXQiGBRZOQInVfToCVH/bZ0nmoRH8MkwT1Rop3ALrOxRFNvJR/BYJdEyIg8xOW8OcEWGyh4a1n4YL9r0BVowSEZqnGgnl5IROClrS1U37IYIUWkZDRSVTuLPISVSRqJypiVehitURmISh5IxcQ/YM0IMQeI8lMaxPZ6gdnYZbGzgQtzkx+Mx5XRKU1VIqfDa4ZxjNJ6gVUK3KPCdpPWbfBrVz4en+T7FlcoHMCaaj/sgEalG6ZwkL5C1waMZjSuGowmj8YSi6NLpenSSonSC0skeFduHmLBiGkM5m2HaqN/QTn5CZI3JFgRMlSIhMp68kljipgYR/NGtEfmcwaaISRqJjKgtQkaTPsIV4EnG6wi08sCADa2jf/v4aRkldln7pecpDa0xom2NyUSkLqFEIFMR/AohYGzAWLeXmiOlahMNIosNYtqix0fKe/sZn65lNS2z6pndp4lDhDlr0ROhtHny3///p3/69imFmAcu8neEn21x+PREDdqXCy1rcZ6SQohdHhM8qRasdhJuPtDj7G7N5ck0Pg8KFvOEy7ahtHGdkO3cS1NJqkBjsAEEHqVVzHlwgapyCCnRGlLlkcKjlCdJYlE/mhoap/Gyh1g4DNNt3KymNj4eeFPVxtJaht5RFDlKa/qdDAjsVoaybkikoNCCtbV9HD10iJWV/TTTKdPRLvsOrGDqGnxA6pTB0jLLq2tIpSKbMwjmAQEyeESIczgIgfMOW9cgU6TqoAg0VYVnwupiL5owas2wqjE2SnsjVi1QOqW/uMzagYOsLqziTU01G/NIptgNklIoEhxKCpI8QSQJWisWU0E5sozHFalxLAxy9q922d9NmBnDyQsT0p0p0wD78gSlFY2QnNg1nN0xXNhxaJ1QZIqloiGR8RlTQlA1jt1Jw6SydBLFzfv7rI8rqibQWEtPCRSBWeNpWmC5l0RkO8orBFpALxMcWsxZGxQ879gqK92Ebqo4tTEiGVVt8pHHak+iBVVDPLw4Dy2t3QYQDlTr0WdCLJKboEgEseiTz3zgqZ6O+Pidn+KTn7yHD/zCP+DcesJP/8lD3H60i2ocv/QXj1M1URyyvLrAeDTjzMaIw0e7pFrijKEOMFgo+D/edD0rxxfpdAv++be9lUw23HXXXXz+C2/huTddh5CKt771H/CcG27gHb/9BwhdIHWBa0rwNQRHkg84cfoSb/+p/8Tzrr+OfUtLeKV575+9j99517spqxnthh4XD8Lepv5/s/ff8Zadd30v/n7KarucNnOmF5VRsS3Jli0H94IL1QZsCBDgdwk3hBQIoQQCIZcWQiBACCWhmWCTQGy6wcYducuSbfWuGY2mn777Xms97f7xrL3PyOT3+5nrm0S8XrP8OvJIc84+e6/1lO/z+X6KFPHgfN1KxrV7cj5xegeHJE819XjE6lKbEzcdZbS1yfmtIQ9cGnPfhSH3XxyA0hzbfwOr15xg+Yke1daQ3mDCZjWhrA2HjGdlqU27lXFh8zwHFzq84NoVnlgfUfnAYGxQSlLXlk/ffYrgazqtlDNrGzz8iXt4+OR5Xvm8G9nsj7j7sdP8yHd8M8f3d/HO0p9UbPRLdgaGsnYIoKsCncUuN9x8HRfrSySdjM7iHpR0mHKHtYtPsbTQYrGIjZarDy/z5lffSCEr6ukoMqCTi9S15YnHnuI51+7nmiN7OPXUpVg3Ieh226S2xo8HvOS6ghuPtnn9287xJYcKXnO0y3nfQYiKI9mUFx/pcN+lKf/p7g1ef8NebtxX8OEihTowtgJra+oAw6Y540zNsLdO8DXb2z3e/94P8eGPfpRP3/0ZyumEz977EA88eoav/tpvIASHMxMm/YsMd86SLLRI05SiaPED3/+dWOeZjEd4M21YPBlf/3ffzPOf/wJ+9x3v4j3vv51PfuLj3Pmhd/Anf/5e3vPBj7CaeI4saPKOJgMuTsB0utxyNOfEouT7//w0eZpwbN8CJ/Yn6EZukqUKGzwfe/gC/f60GWPP7CtPYhO2trJhdwsaNILYyJsFtQiEsI1FA6Q6IdEJVZOCrGS0KEilJ5eBro6NPaehUMTkYcm8npJKNRHg0e9JSIXWmiJNGCcm1sdEhvhSSzfNTE9/XONdTN4TSiKFmjPcvYh1rMSjQqxdbSPzS7S+rLkbLykkaV6Qd5dorx5CFENQkpWFnG6eoBowenbGmIXXKBUNdYdTy9rWiElt8QGWFjqsriyyvLiA84LhuKK7sEiaKFxdkuYt2u0WC52CVpGSpZqJEA3wFBMABQLvA+PKorxBuTJ+hgB1EChn0cFyaHUZpWJz+exOSeUEHoGpK5zJSJRiz54V6rpC2JqdRJD5iou5ZhIsUxswQjRNc0GuIJdQSA/WU5Vga0eiFN1WRt6kaTsf2BxWTBxIlTOqItthWHnGpcVZR1EkdDPN/k5GZTyjaY03jnJSMRlMOdSCLBPki5rzO5FxNChjupUPgomLcsrKB+qGIqdkHKuZlnQzxepCxmIr4fj+NlmikVJw8tyYoOPG2c1BWsFO7amDwBGZsYmOfmZDJ5smsZiDIlMXQWYvIEiFVI5Eq//1k/JvcF2poa/U0Fdq6C+8hv68gSeaFK9dVtLnzKyGUaSkIJWyAXUkRiRUQTKpLJUxWGtjt0bHQ/2uOO3pEzeCXLsRr1ZEbfOkciQqAkY+RJd222iFlWzAECkQSqJcwOARQcwBkibkI6YSiPgzmdJY5zA2MK4iFbedSzqyYS55MU/LQ0i0CkgFmWqAICRGhij5C40XUIiLxgylmJYVmzs7+NNPcu7iRYKzTHY28XX0TlpcWMDXccN4yp9lPJmSJgn7F4qYONFs4L5BYq01eGdjJHLIcHWLYGq8swShEGmBytqorE1eeBa6lkP7V1jsZEwmbQ4d2s/y8jLdhUXyPEMnKUlWELzDGsOW0nMqH02x4p2dI/u5jl2jNJGstLIomzSWXmUZOxjUjkxALgWZlBRaksnYvVMigk+iKYoiKy0adnshQQakit0+HyKtb1p7JsZR1TFNJYTYectkLLSSJm7TOJjaOCZqtxsfmygxJ+dpETfZcR2ldkmisdaRpGn8DhfHqCSQqaShwwcIJS44pPR4u+uDYFyDLj/DrxlIJpTEI3HBYVw0np13a2ZzOgSE8CgZ6fSZThFoDI4qBKQxkanmJd66OK8ui/YIIRYvaaLoZBmLRUKeSHaM5cG1ER8/PaC0lmntscbRTiV7cs0Lji1Ruvis7z8/YFhaRlVMIAze0bOGRKoYjd5StDsx+XBgFLVzsZMnHMYH6hoSmRCC5/TWkFNPPMpTB3KOr+xh+/xFzj9+kl5vh0R4rt2/xLh0NM1CesMpQgr2ryzjgqd2jlNbfQrlOdARHFSBTAdcPWZlcZHk2HFuuuWLqE2NC57xdMrBY8fZv7qHyWRKVVXYIsagBzwSgVYJaZJz9tIpqIdc8kN0moAuqP2YyXiEKQ29akiapiRpxnLWxiYS4zVbGxcZ9RTUPY4fu4rVfYd5/OGHOXX6cZ568gkOLS3TrQyXJiW2kfocWSmiuWxtGVwak3hYkJIbrlkhaMFEeB7rT0hD4Ja9Bad7Ax5d63PnmuXWwx1uWC3QwZIloFoJpbME4yidm3UdmLrA+rDm9GZJgqWbajpFSmlirO+eItIEqzqgnKVopbQKzVKRkqiYjLmYJ3Qyxf5uSqdIEUqxNTXcc2HIuX7J5mBMbWu8M6QqIUsSZKoQlUIG6OZtJsYijEHUU1Il6OaKMjjKGoalIAw8Cqir6EERnulzuKH1exd4+9s+yYlDHX7vH9/Mnfeu0asl7/ulN/Nzv3cXf3L745y/0GPvcovnPuco672SunYoJblpUdEZT3jl93+IH/uJV/J1e5/N/fd+hte++sW86Wu/hoWFFfKiBQG+45/+C/7qrz6KszUiDPG2jIdiVSAoqKdjXv/aV/Grv/Qz7NuzxOOPP86bX/16vvd7v4e/+tB7eN3rvoThcMTTCoUQEEpxeE+H73jtjXzmTJ8/Pz1BJQm37G9z88E273pgjUl9KUp7EJF5oDJedqLDoQXNH955nts/8wiffugkg9JzeLnN6247xou7fXbGJT/1qTM4ZwFBd89eHtuseOT8U2SLi/i6ZmdtnZ/+J6+FEPgXv/QehJQsLu3hB3743/Ibv/073Hn3r/HBux7EOU9VV/T0YYbZMZTWrK7uZ//+Azz+57ezubmFkIIjN95Me2mF5WffytmPfxI/KkmKNnfd9wR3f/YBfu8Hv5xT57Y5vT4mS3OKhWvZe9vX8AM/+fN85r4HefyJM9SmJtWS6689xM72gA/e8Qh7Dh1kOqnY3twhL9o899Ai//ob9vOrHznHj/23AdYFrj6xym0vOMCvvu2z7C8EO0fb/Pf7Nzg/qHEm8LZ7d2g/PuH0ue3YpReSPZ0EHwRTI8nzlPseeIDn/Z3XAgHnHaNRyT//7u/il3/l53jd67+C0gr2Hb6aJEnnQOL3/Mt/z7/6iV9F6DY/8sM/wLd927cQXM3v/94f8WM/+e/nupEQLL/1G/+ZQ4cP46ox3tYIkdHeexVZdy8+BH7nkWFkPgvBy65ZYl9H8eePXOCoWmGJNuW0AhGY2Iwf+8seOpG8/LbjPPj4JufWewRnG3/QZ377ZzQskVKg04Q0z0iUR4xio8/7hn0tY61d1ZakiTAXaUFQEVgIITTsJNjTSlgpNC0ZMMHhTY3yjkR4hAKtBYlSFPks2EaTCChrw3rfM60Mg9LiQmRjtVPJsw60cC5QGsf9U4OTEq0EiY6nimllYkBQCFgn6E8ktfNoFWEoIeJBxriAkgKvJM57Lm7u8MCjp6hqy9bIMRn26G+tMVh7Cln1OLCQsD2Nddtmf0KaJiSJZrFTIICp8TxyfofgA0FIOq2ClW6HhXaBEylO5dxw002EeoJ0JcPSsf/gAdrdLmmWo9MEnaRIqeIh3liqqmI0nrB24RzC1SQY9hQShWYqUsrRBCY15WSAbFTGiAa40pJJbxPMFJ0mXHvsEKvLC9x7111UvU2qjfMc6UjGScZO5XAjgxSB1ZYmFx6Fx1YVpRWgBYe7GWmaoLOMOghq6xnWNecuDjEMeeRShvGRnbU1cUwrjzEWPTAM6sDQCLZGTYBT5VECxmVNcbwglQGpibVVw2xyIZAoQZFLFtuaPNcsdTNyLSkSSSdRscZWYu5D40Jgc1CyM3U8eHFMlqUsdR3Hltt0UsnABnzewieKbl7gK4OrHNWoxiMYO4kVEhs8o8pycqNCKYnUgtoS2X7P4OtKDX2lhr5SQ3/hNfTfgPHE55gRzhmB82vOFGyogQBORLaTsQ4ffARmGqBJXjZHZ6+1C0DtosI+zL48Roh5LGj8u0hjFYBS8eciI6eZxH6XrjjrqPgwWxTie1UymqAL2XSggsCF2H2SoknYaxYF72PXY1euFz+rm+t7n27qFe+HmANG4/GE6WSKt4ayv0MaDKkMYBKcFNSAEZqylWHqCd6WEeV1JcEbgrcIkvnNFsE3b841iX8SmaiGVh27OVJGs7bV5QW6RUpZtVhe6tJptyIdcn7Xm+ItRId6rRVZnpNmWXz/dTV/4OncUFKRao2xDhMcYxsYGs/A+AaRbdhmQqCbtMKZtHL29Gdrrb/sz7D7fTMfBOeiUV5ogEZJQDGTYUbTd+NCY64ZDTHn47fxPADmtHI3k9tZT20dUmqSxEcjqeZ+iMbgTxLN2IRvgLIQKYczDbf3l8+EZ+YV7RsuSycKoonQnj2J3RkdGo8rSfQi0PPxHb+nmULxT08DoHeZeXMGZEPbFc3cndSeQWkZTKL/gyDez8oG1gcVaRorPO9ACUkrgcVWEr0uahNN4pt5XznP1MS0REkD0DbsSUGUdAohqYPksbPrdO95hAuhQ39jh/VzF5lai04UK1ojfUVtXfQYa8aTlkAQjZRS4JFUQbDRH5Fv7dDb3iLTCUopilaBNBrr46YtpKKsaoL3TzPdm5NAmvvrvcNUhmo6JSsiVTaQofMCpVPWdgz9tT7DcUmeJCx0F1jdtw9rolFhPa3R7RypoLe9yaDfZzqe0l5cQieCTFmsi+9fS4HyDm8tCkErkbQShZcCh49hBNahlGAhSwhVxbi2bA4rhlWO8b4ZM3FO1z5SSq33TdiZwLoQu5qVJROOVqJIU0U7U3QzxcQ5pI5s1cW8oNNOaRUx7UiJRgrbrBm9OrBV11QucLZveapXsjasEMGQSE+qY3LqbMx5AkJCt5WS1NHnYDApSVQMIQDwDmoTmLrob+GaZEr/TAeemh0xIHA2+i88dHFKZ7GFShI+8+g6GzuTOWPYNp6E5bSmrqOxrVEJYxRnNqY8+Pg5jt/9MB//2D3cdttt3HLbCaRMOHv+Au/8i/dxz933cP7CeRCKF952K9eduBaE5OGHH+W+++/ny770dXzxq17OVceP8aG/+ih33vVZtoaOBx85SVG0+JqveSPWRH+Td7/ng9F/J3ikimyPs72SXumpm8WkdIF+DQaJFeBRVGWNUoqrDy7j8WxPDPuW2owrw/a4wjnB0mKHF912M8892GVcwxtWe3zyjrt46swZdFVSaEneKRgbi22SqrJG9gLQ7rRY2bPM3v0HaLU6+BAYT6bM1pCl5UUWlxZw1hCcRQRPq53FTnCApQNHSLMMTMnUeiQeZyqeddUheMFNXH3tdZztPcrWUwOcs8ikQ750gHMX15hMpnzVV7yeT971GS5dWqOubfRXEZq6ivHVUqe84GDKsSXBZ8+MuLhVYkvLc/YWHFrp0l1e4qXXtRmMLA9sWxY7BQbFYGPEZm+ECZ4vfdFVPHF2hycvDKiMpZslHOsmnO8pxlXFU2fOAYFup83rX/Nybn3eczhx4lq+7uveTGU9S3v20W2pCD6qhBtvvIFup817PvBxLl64QG9jk+5CxsGDB3jJi78I72ouXrzEhz92B5PphIVuh7/7dW/kU3d8ivPnzvPOd3+Iu+99CIBKKA7s7fBFzz1A2J4wGVUcW8nxKuFSrVju5hhge1BSCUmeKaRqvE+UoqqrZn4InunXtHSkqUKp2AyTgDEW5z3eRzm/cwIvBd4FnAhYAQaFD9EM3vmmsSkgTxTtVGGco6pjMlxp4rjxIfp9ahFoJ4JOJsnT6LdpnGVcG/qTmlFZUxqHCh6jYFJZvIfa+thwIzaK80THfdo4pAQRou+PDVDZqBSQMsr1ahvruZj6HIG0/mjK2QvreOeZ1oHpZMRosMNoNEQEw55OwtQaQvDR9LthNORJ0wANkuEQrIt1WX84Ybs/ojcYY4h7cKfdxifE2PgEkqzAWE9VG6QUMfWvqilrQ5ZEFo4AqqrGlhOkmSDrJIJoQpOrDCEV/UnFZDphWk7pT2ryvMXycobxntrUTMsqymiEZDiZMppMGU9LlFKoRKCsQEmLJtBWcd/BB+oQ0CLaRSRKQoC6tjgE+KgMmNaWQe3ol65JJxSX1cwxEbpq0ppru9uIn9XTrglqklLQzRRVEf1vZsbSnVbCYjel005Z7qaNKiFE39IAlXEMy6ggGBlPr4zvZWdUk9Se2sFykUSLv6DQaRpri1aU0TlhmJYxsXBqYqN25iHljEO4gHLRj/eZnvBxpYa+UkNfqaG/8Br6bwY8hV2Z0//oigCPmAMyQQgMijpAZer5hhka07oInoTL6IVzAuLT5qFv2E9149Tu/Sxdg4aOG78SL9HeR6aOjx2Z4EOjn42eQDSyPHfZ71IqTjHnFV5EwMkLjZSRjqsIjRwrAiCegJeBpAEkVAOwyPlND5cBW/F+EMAax3gywVQVri6xox0W0kCSSZTTuNJEqq7zVK0EV/bxVRuvBa4eEMwEnEHIdiNzkwRnCc4QTIUSHjQkWdw4BXGRkQJaecrxQ/uw1mCsRWUdZJI1n9uDMdGM0llc3ZiUpyndxSWG5RQP1FWFCJFS18oSOnlCO9PkWmI9TBxsV55B6RhW0SAuE023TM02+TC/RYh43+eMJyL1P/p6zde+OePIOt8kCUXgcZb4IkKI/mE+miSWJsry7NzjIIJQqnkWqnlt52NE8NRYSmNQWsfo00rsSkqDRyLRUpBrGV/fOWoXmVjW/a1otALx/kpANZR+iLLEGF8i5uwwuBz8i9RwLWb+BM24DrteWqHRUT79NsQiQsiAUg7QOB+jnEsTO7tb/TjmFrsa4wM7U8OnnuxxZKVgIddUJaSJZKmluOFQm8oELmyVnB9UTKzFYulNBbWNTESlIYlLLsKDFpGSDILa5Xz8gae4/+QZDn/s/vjca4dTkqzIWVKaxFvKKi6mEL0OdIx/jF4FafS+KIPgkXPr9H3OTU+d5sDq/rhOJAoVHMGBTmK88/rmDsvtPMp2uXxxj8U43iOlwDjHZFiSTGJChyo6HFleIc1S7n/4ce669yT3PXKKI6t7uPlZJ3j9Vcdx1mOcYzQKFMpT1iVnTp2kt7WDdwLTxOMWiWZYyybwQEBlkLWhk2qWWimdXLPT+MwlWLIQaEtFp0iQExOp8M7HkkGB8zE1RRFlxDYQffYUSB0L4alxjCpDjWepldBuaQ4spgQc1ntyrWhnCdcf3Uu7yMhzzaIKBOewpubUTsXmxHF6o+TcYMrOxHB2p2JaOawLnFjVdPO4rtS2KbAtOBxCBVYXMkyZMNWazeGQTAvyVOB9HC9VJUC6ZrSAD4Jn/hU3GCEEe/d02Cg9b3vXOX7179/Eno7mzb/wYepGatcqYsH21GCCsR5nLd4F1kVBITUguOPuR1kfS979l+/nH4oVvuQrFgje8pnP3s83f+s/imkPQqKyLt/297+Jb/+2bwah+Lmf+0UeuO+z/Oy//VGuv/4EEPjZn/81Pv6pezh04vn8/h++i3f+2Z/xwL2fZHFhgWlZ8rzbXs1o9BiBGqU0/crz9k+fZ99iQSvVeO85P7QMgiFvF+RCIXXGxQtr5FrwspsO8akHn+L8Rp8XXn+Q8zsTTq8PMWbKwYP7eeNXfzkrz3o1urXMi0c9vv07v4cnT59muL3F0asOcOPxA7zvMyeZmph2tb42IHiHkJrVfXs4euwgaZohdQpCE2wZGblKc/WxvRw/vEw9mVCNh7hqwtGj+1joFoTgWb3qOvy0R715ikFlECGlGvT4xi99KeVLriNpt1n77Dp3X3qMaVmxIhXF0irD4YQD+1Z5y6/9B77tH38Pf/LOd3NpfYckL+iuLLO9PUCohLyzxDc/t8VoUvJPf/8JrlrMuG6l4DVXL3H9/hXyhb38+Juv5U/v3uYn3r3ON928n9G04uTGkFG/z7624Be/66v4rT+7l7e+634uDCzXLqR8xdUt/uCRKVU9OywF9u/bw3/+Dz/Gwt6jJK0Wv/zL/wGCg+AwwwvcV/URKue7v+s7uO6aY3zg9jewvbbGmcee4Fm33cLrXvdaXve611IN13jfBz/Mx+64GwEcPrSP//Kb/5Hv/b4f5pd+5df5nh/4MWw9BiHpLrR4yQuO8pafei3f/WO3c/c9F3nds/ayE3IeLTVXHVrk/OaIJ9fGLCwKjBWMJwGZZnQXNdV08r9tRv5Nr9HU0gayVJIokHgmkwprLN55kL6pf5q6TARqIRh7hXaCylrqJk0xEYF2qujmCTvjkv60pjepGEzqptEGmRKoRNLRgj25pJMrKhfYGhsGw5ILO9FsujQOJWLj7szmNMq8GtBBa0WWxI57bR2V8TEQRghSHeVGpYO2kpEVFMBbN1chzCRJm/0R7onTnDt/gSeeONUkaBkWkppEeI6sZAymBlwMkiE4hBe0E0GWJCgp2ewn1M5gjOepCxsElXP9uUt0l1ZARq+jWlqcCbSKNjIr6E8qesMxZVWzOZiw2Z/QH09ZaKUUmSbRCu8C5aSk6m8xHUiSPKezvI8iX0AnmvX+Sc6cO8/5i5cwQXJg/35u7K5gQ5SObW9v0253qGvD+k6fzf6YwaRkuZ1FDaSOB9ZUBDo6RHPeptbNE8VykSClorSeQVlRaIVWik6iqY1ne2zYKafRGF0rlNKRKeSiv46xnrK0DTM/smTyVJNnKag0JkgHz6FuTlcrVhLLtPFXWlzMWV0pWF5MKXKNMY5paRmMaialozc2bI8No8qxOa5jgpqLNblSiv7YsJRrstzjtCbNUhKdstSOJ2AnA+OJYmpgWHum1sef90TPQKJcKkk0+hkutbtSQ1+poa/U0F94Df038njyRI8diLOrsWvYZUDNGCohol8WQYmg9IHK2piYMZtSDdy7i/aG+Qm+wWma79tFg4VokE7RULrEPJQ5/nvwWCfiwxWzQN/QsL7F3HtJCiiS2AlSImBx1HhqPF5ETb2SMcUj0QotAzZEJ3vZvE/votbRN4uJEQIbRMPoaso4Ed+/DwEZIiWt0JrFVKK8QhQVLV2TKUeRTaiDofYlBZakMpTrNWfdeSSB7Z0+272KykpWV1ZJkxylM+xwg2q4zXTrHLgpSkky18WbDkHn1GkX4QzC1VANmVYl/dGEgVOIJGdheS/tLCWRgvGwh6krrKka6NKzZ+8eRtMpPsC4P4gUbyDTkemUaI0PcSOZmGgaWNpovieIgODlnkhzzX9oQCERx1btZvTs+KtliJI8QQM0+tAY64GNHnhzVlNpo0TAhfjvtY9Fk2uexeyKa3uI3SQROwi180yNZVDWLHZbJFLPkyt840OGjKwxraKBW13BqAqM6vh7lIT0mc0QBqKZpZYSLVX04cIx9c2cbnT9XDb3IAKrNngsHi+jKSYybrZezswObZwfzevM5rKSsSNaZClTI5hOLVuDCVVtSLVAJ7ubNTICkFXtefxijDL1QpI7gfeSC9sVNgSGxtFKNcutjKv2tVnrT+lPKyrvEFIhlGBaBXAherB5j5aKvd0CiWVSW+45tUYnT1lo5SRZiguSgfOoJKGjFUt4liuajoujtoLouxjBSy01VgWGZckn7rmbbpYjrOWx++8ilZoiKzh45Ai9zW3+4oMf5LUvewn5wf1kWRupc4LQWDOmriZU1ZjlvatkWpNYw3Bnm4BkYXkfWXsPSaLZv3eVY/svMem3OX70AMcO76O7sBR9NHTK6rVdzGTMzvpF7HiMtTVGBmpTYa3DO0c3jbruPUXGIp66MlycOoa1RdWG/TlkWpBpSaEFLa0wTkYqsw4gqzjfTECmEp1LVA2lEVgLtRHUZcDXnsVOyp52wt6FjPFgRJolLKyu8OrFJXZ6Ix55/AwTL/BSkRQJl8YVvY0ha72Kce0YVY71SezCjys7Z6weXZBkKHIBe7tQExiH3ShiR2R9Oud44vwGuUpIpGSpnVE7y4V+zcYIxkZQaFhqRc/A3iTMJdjP7KspukLg7NaUbir5mmtSltyERVHwQ2++kXfdeY5PP7FFvzem1W6xtLzIdDrG1IISx30n18jzghM33Up/UvP44yf55je+nBc/7wSmnvKt3/Yd3HPvg6gkB6Kfgqv6eDONbFsJUufo1ipCqvn7+vmf/b+469N3813f84N893f+Q77qDV9Ku1XEwlmoyMhVAp230EnKweUO3/DS6/jgvad56OwmrU6bVAV8OWSzN6VbpFyzX7KTKJQQJONtQl1SG8dwEteQGHEcsFXFYHuLRWux/Q0e/6v/yuD8YwghaK/s5Xy/Yv3ek6zuW6R2kt5E8LYPPYQ3Fd5bXvPCm3jtK19CmiSsHDrO9S98Ba+6YYlL69t84r4nOLh/lX2re8hSzXVXH8VORvzG29/DTm+MDfBL//l3OLxvmS971YvYd+PzGI3GfOyD7yZxE/IEbrh5D6+47Tns7S5w9qHPMl1/ir379vJLP//TXDx/jn//r/4l7fXH+PJru4y85szQcmk85eajKywIR9dP+JX390lk4FuevcT1J47SauXc8eAZHr/jFO0HL/G1LzzIpYFmWpb80T0XuGq1xc/+gxfztg8+Rn9Ycfaes/ydjuTIK47y3z59kZU8GiMvtTJaqebgkRZ3Xig5d3GLr/y734HWGUIlIBRf9cav5Pu/75+j8jYqSfBmhNI5Kl9ACMnqwVWuefY16CRv1n9P0t7LS1/+Gm5//5/wrGc/m5iGCN/1nf+IN7/5q5E650/f+W5+6Vd+nbKq+fR9l/hHP/gBbkonnLgh4W3392knQzIBD1waIJOEQweWsMZS1Yb+aMJzrj9Cmiq21jaaRtEz/yoyQSsVtBPojw39iUHM2mNNnTRrWEJck6KZazyo1NZhjUV4x2KhyVON0Irt0rE9teyUjlEdA3yUECTKIaWgrA3eaqSXtJVghEc6G5k+LpBI2YBJcKFfzRnmxkMhJInftdmITKuERCvaRcqkMlQm+hjFw/PsEB0wLoCIDdxukcY4bixnL21Qh2h6PG0lpFKSikArS2inkr0p9K1k4gSjacVoWsUmKTH1LpGSwWTKmYtr/NUn7qIoCqQUrF04C3ikEqSdvQz6I3pb2yzkmv2re1jsdNiz1KEctRj0tzHGREbl1ccpR0uMtwrKyRSkJskXaXUWyfOUAwcOMJlOmUxLlvbs4/Dhwzz72c/iwOoelJR0F5bw3tPr96ltZKOsjy1OKKSITIHFThZlKTrBYLBYytqzVjp6JtDJAwWBNp4DSfTrqVVkHAghI9Aj4/mkncoIFjhBJ9MUiaKVKqZlTUWgnaUUWUqWpkx9glSCJBEcOaAYlZawNWV7u2RQWtZMyZmRIU1lTPQ2jrKKX9Y1aXxN818AhRR0m4a8UBKpBOW0orbgsgTpMkoRGG0O2JsFFjR02zn1yDAal+yMairncQGKLAJozrtoz/LMxp2u1NBXaugrNfT/CzX0559qN6MG8vTD/NOvy9HISN8yPk4651xkOl3GNAoz1OoycGn2AgEaYOpzUDRBNBJvWCtzZgyXSeiIxofxJcKcUi+sJ0uit9TMN2n2vY6AJRBE89ozOZ3cTSSYMbkgotXMQCYfGVCR/hrm73P2SX3wCB8azyDoZgpNglAJCRYlHAHTSBEteIEpPcN+QJgewQd6gzGTWiBkQSIDWkWNv/MG7BTMCOGmCCcIiY/JQ64mBEWwNZgSO95hOJmw1RuxVQtEmuNQhHZBImH9wgXKaoI1Nd1OByUVaZaRpGlMABDNs+IyL63Gh8k1LDLnI+g4G4DiaahT/Pc5mChm94c5Q8m5MC8iRTMQZt/jQwSlfPPjvgGhahvwKoJAs0SS+J5mz6NJNYRIjW0mmiCaBFrvqWyEVNUMKZvpSufgapi/3whwxe5gCGI+Tp7pV7MnNs8kGg9admfj516fMyXn3xdlss1mJ3YZiJe/wizOWYk4VoyLPl3G7coEpNwFAKXcfc5VHYvePI9mirUNbI0sPgQm1s9p6Z00YVtV0DDfpBRILXGlQwlBnipsI43USqLRBA+9iUVITSsX5CJ2Y411qAbs1FJQpIrUB+o4aBrQPJo8RkBV4XxgfXOTDWvxZcnapUustFsUiwu4qmRSWtarHaqqRODQ0iFCTAULzT2aHTpmJqo6TZFJRpK38MTY2MWFDkcP7kW4MQcPHmb/vr2kaY5QkiTNaC8uMvWWRGvSNEMnFdK7xgcuvn43S+nmmk6WMqgNRji26hrlAxmBI4Umk01nrqEAR1p5pOMLFeXI1s0ioYkGuKGhjwcxC+ak8RtFyfgZgxAgNWku0ZmhDtFUtMYxGpSs9yu2hhXndipK26TdmOibELwn14JcC/bkirYUFFLQyQN9GxjUfg4S29CkUyLmYQhCxkKgtDCqPGMjqR2kOn5J2WRq/m0gPAGzFe1Cv+aqlZRbj7Xojy19UzUhFPG7ZilZM7btrBXbG05J68DBJcGg32MyGuFvPNi8dGQILy12ue3Wm3js5FkG/T54z6lTT/LJT34KpOapM+cQ8umlg8ATfM10uIN3saN2512fBiS1cUynjXRNxIZOkaccXOmipMBay40H2vTHJZu9ScNi9dR1I7vxgu1hiZaChUIzKmNkfJpInNH0RhM+88ATjDsPRMbWXZ8h9WOuO9DikonhIcOqpL3UpZNnLHfbnDq1xWQyRiCoKsN0GlPYFhYXOXL0KIcOtSHJ2L9Z4hBUtaEocnqjio3+mIUiIU+jCfOp02epx0Mu3XAV/VpQk6GUYntngqknjAisb46aNcQzGPTo97c5cdMLEN7yn+/8DAczw6GlFhdKiRqPccZwtK3QzlIOayYTy2KuObGnRa4ltQepFBd7U4abU67Z1+WprXg4vzSsaLXSuJZISVU77nl8g6u7gWcfyEiUoLSO9bGJARwienMqlWCmljs/fT/z/UAm7N27l5e+9FN40+fhR09CsCAl7VaHL3rhrVx11VHa3Xazr8TNf5aYO+vhTydT7r3vAY4fP8ZLX/IiEIr19Q3u+sw9PHT/nfR6U+57eINnPbvFciuj0xXYyYT+tGJUOjIkeRHoFimpkpTTEjELc9FJ9PR65mtlSRLZMOxhVDomlYs1D2K+t8SrWZNmTIpZU9M7BD5KtlKNkpHxMjWe0sUGXmycxTtvQog10VwlEEEmLaNEYlaTq8s8nEYmspoioyUG5BjvKWs3T6N2IUqxYl3WpAjD3LdzVtb7sNvIzVNFoiVSBMbTCoPEC02WaJwi1iJCkAhJrgM10cB7XDuMi43HECK7QeloZDwtKy6ubZCmGklg3NsgTRRZmuBIcVVJqMaMhz2qTs5ip4XCx4CZRkEhRHy9RCuyRCHyjCA1SZIwcwbtdtqsLC1SllNWVveyd88yi90OWZIiBGRpgjU1WgQyPQsXijK5REmyRLKQJ01NpKiswwRBaWMiVR08Hd3UFr6RuhEPaHFuzpIOL0sOl55ZgraYJRaK2Q4INGoC6yPA56VEZSnCC4ysGNlAr/KYYEnK6OPkfJThGevjetXU8krGWi7XglxJUgkJIXr+6Vh/ucbnVeks7jvWI9PIqGilgoGKKeG1jc9TqJgsmOgIqjV9hGf0daWGvlJDX6mhv/Aa+vMGnqQIIJpj/OcuEM3siQ2R+NtdENReUIpAaT21jTr2mR52JtKcgU9hhiYQX4vgdyepmKG6M6kBzBiZEfyI3zlD3HbZVM1DcyAa759Exs1vudDEBLeIABsCVfCR8igDXAYGEVQDLsTFmQAiSJqAPaz3OKL2uglDQzSfyc6AmiaKdSlxrHZTEqkwVUJZ1dTWMqoNxhtcEAgqTNVnONjAOqLJaWVZaHdZ7C5RiBG5mJKKCiEqkBVOlXg3Au9x0zG+noBuoUgxkxFmPGD74lk2egNOr2+zbjRJq8M1LmCXF0hF4OFHHmE0GlLWFddcfRWLi4ssLy6TaE2i9PzeCzFbgGddOcF8+otmWbkMENx9frOFthlAIh6jTIgeAaX1GBuR0xnG5UIsjOxloJbz8TfbxtxbCo9yDdjJ5dr2yyDOwO6/eYnDNR3zmIZQGouS0TC9khLhBcI3rCsBAR+BQd/ESTpB7eLWg7jct+qZezXnHoTwSOnjnJ4BZrsY27zYgN0DLDSa/IZ5JqREhChzDHOoO/6C0MxULWNyoXOSaWUYlQYpVTQ5DKJJzRA0xAicj7LXPBUQJGkax8fEei5eqgFIEsFySyNxnN+aMKpiimM7hTSNxeJ0XJMmktXFgkt9izGe0tQc6eQUKuUJOaIipxIF+7TGOsu0Noysi886i4y+rAlJGNkInM8+oxCR+i+EoN/rcfHceQY72+jJDitX7WVfJ2Xt3GlGPmUgcqQZk4UxqfcIswPVEGRCmmXkecr5M2cpxwOcq1k6sB+dtUizjOFojCBw+NB+rj2yQiZfQEiWMGhKLzF1jXSejNhNyxLFoePXwOYaYWeL8fomQkqyPOPonjYLecpKkXJ6e8ypfs1n1sfszxSHCs1SkZMqcMFhHZjmoIMAoQQyVTiiweukclS1J9goP01k41eiY+VjQqNPb4wmq8rR75c82XecXO/z3keGDMooGXHWYGw0JqyBIpF0c8m1LU2hFK1EkGuPlpDJ2P1NBIQUyqmnauago/Fp85JcKJZWUhINUgaqnRLnAoNSsTMFZGCp0+wZLpp7iqbZ8My+mvUrwMfOjckWND/6miP88J/1+MTJHhfWNzA2RiTv2buAdYHBcMxkXOGcJViLd466rHn8gXuJY1nymxfXaa0c4Sve8Eb+23/9L5TjPtuXnuSb/+G/5KOf+DSolJ/7xV/j53/x1+LbkAl50WnA+Lgffs/3/RAf/NDt+AD//j/8Gj//S2/BTreYIV6zddhbz8LiIirPOT/2lF6y3Mn4V192jD/5zBpv+ciAaw8uUBrHvWcHOFsjpeQDT1XctFpw1b42H3lySisVHFxOWFOKu5+4wLf9+G/yxTe9FyUF73/gPP/sNYd4483X8o/e8gA2aFSScvbsOrddf5j/47XX8R/f2efUBYGzht9710f5+ANP8eZv/S6OHtjLbTddx1b/JGphgRe96jU8eX4bqU7x8r9zM//1PXfwwY98gjd/8c3cdO0BQvBgFedOPsm7fv8kl3yXw9dcz3d/09fzm7/1m3zwo5/knX/xXpJ2l70HD/GRb/x7nDl1irf+zu/yD/9Bm/NrG7z//tN81a1H2LNnhdG2o6QEU/O8Yswj2xV/eXrCv3jRAa5aLsiylN+55yxnBjX/+EVX88FTOzxwboeH//wBVJKRFh2sdZzerPjxP3yM8WCMN4Yf/vOH+N5X7uFrb1ngoZ5hWnv29A1DKzDO83BdQ76HvKMZ99a4fBN45zv/gne+853MB1+zsx87eoj3/tlb0VkbIRKCK4FmvwiCT33qLr78DV/Ln/7x73Pttdfwxa/7Kv7dv/0x/tl3RRnnG7/itXz5l7yKV7zs5Zw++TheBO7tFxxJunzXmw7yBx9+mA9+9ilUnlLWhtG5Tb7sZc9BKsGTa5rN/pRpHdDFApSjmLj4DL+yToL3MKwD6/2anYllNLU4T1M7zSqlWF/FpCA1n2c4Sy49hYom1THVKHoATWxkc0ulZzhz9FhFYommzl4oslSRJ9GfU8soWdFKUGQaIaLMwwXweLRWuACj0tIflcxCfya1RylLv4x1PUBRZEgV/UVL45pkJUg05FrSKaJ5dghQuQEuOBAeazXOQek9wQZ08AhrUVKhRVzzK+sZG4/3jjTRtIuEykfvoq3eNgSH9JbcjlhYKFhptVjbuYhXirRIcaMt7CRjMlBM+ztUwwGZzklUfD8b62u4SQ9GW6wsLZPkBS5PqCYDzDSwp9uiuPYqjh45hE5TilaLVHjMdESwlmo0QGBI7IijSxnlYk7VT9kZjsm0JJUpx1Y7JErSn1iG08CosmyMa9qFYjFJOH6ojTCOyaCibx2Jj43qNE0ocklWOrSWCKUIUkUVSogyR2eg9nF/NtYxbuqtUZlQe0cSBKUQTKxgs4ZTQ8dTg5qdUYU3lqxh7ed6lj4naWU62mRISarigbqTCAoVQ32Ci3uN0oqREAxmbBoREyf35jmLGtoK0lwxqiwQLVNcCBRKkCeSJFFUhpis5Z7Z4PGVGvpKDX2lhuYLrqE/f8bTDKJjF5VtmLfzf78ckAhC4oSisp7KWowxBN/0YhqGiL/8h5sJOgeL5r/46aUrPB2f+lxu16xJJGZvcE62CcgQNe+FVnSzJMaHOo+tLMYFjN1FTmUCQfqI5LoouXIuevpI+B90l+PnV4jYRQy7huSEgPcO7yq8GVGVmlp4RpOScWkojaP2fk5nLZWbdyyMbZDvAEqV5OmISf8sg9yTMUbVQ4IZk6XgZIILntIJfJCIoGgrhfeOspyw09tma7vP1vYOA9EiF5raWKwxgGcwGtEbDJlUJavTirQwdGdIfJgVQ/H57n5m2fSleNpgEJf9b7dDE83FZ6Dg7vNmDliF0FD2gEntIuIrmBdDzJ5PHEmYEL21xGUSR9eMUn8ZEPq0sRxCA5ZFY/LoZxA3PCkEaZLgfE2w0Xh89rqli4Z3NONXydhNEuF/9FueeZfz4EXABU+i4jOVs2c3Y6aFGeNsNgIjzRskdpbgFwKJitLb+BoKERQiSERwuwzDEIvlqmoKihChQYfDBB9zKQJzA9OZVl42C4lUEYUXIUSDUQFZE6w0LB298YimXsckAlWCko7golba+UgVFjqQJYFKWGoPvtmsM63ptFrUtmZsamyTTmIqjzcSKSUhUxjnm25xA7QKT1U7Ep2z2F5iz1UKdXiFtDzD3gXJYmvEVl2xolKOt3LKMx/lZL/NpcTz2P2n6G1NufZZr6Ho7sXrRer+GuONM4w2nuTQoQPIoo3pLVCnewkqw1VbKF8TbMWnTl5CtxbYc/AoB5e6BFNx14ffQ5YolBRcdc1V+ERTWk/v4iUSFIVWpEmKVIrSWgaVY1h5gmvSPrXAB0cgdta8b8D+Jvo3ZheEBnAHN/NZCx7nDCIIjA/zPSKOlujssbeTE5zjibPrvP3uddYGFVVZs1rE5NBCZVQ2As9eQa6gnQi6OvqqKQVaKJSMa3cqY/d1JAKhjB5tSXOAEsHjvCUQGDdmqNZ7RrXDBMiS2NWb1XjN00Q0lePl0d/PxOttb30L733vB/jvb38H/+KNR+nmmp/7yzVWEHzZ1Qmjqw5x5+kBj69P2NkakGcJrSKlXXQpy4rtzYr5Ih08CMnC4iI/97M/ygtuvQWCR0hNmrdZ3neUH/y+f8yrX3kPP/nvfpn/41u+kVe+/MVsnX+IorvK4upxDu5fbW5kLLBiso/FmzGLnT389C/8Ch/80F/xx3/8p3z93/1yNre2ed/7P8qLjy+x2Ml49ycf5MLWiLIK/Pt3n+TsdokgcGTvAuPS0BtV3HjNYRItOb05YGMM21PJQq6wzrI9cgiVc3Al57qVRc5u9Bhbwb5Dh/j0muKJXsnRg8tcvyi4YUnyh6c7XBrV/M5ffor+1NDq5AhyqtKwtdPnO3/oJ7l0/gznTp8CKlqLe1k5fD2nHryf51x3Da948a183Ze9nOsPLfLW//LrHL72Zl76qoRv/ba/R7lzCbdzlvueKllaOEAIgec+6waULTn35BN80cteySte/RoWOwtce90NfNs/+iccO36E7VE0xn5wbcpmpdjb0ezvpkgWecQuM0orbjosuGNtwqc3SpzIuCrxvOig5qiu6KgAUlPXJXsyz5ElxeMTQTtVvPi6RT712JTRFN5821FWV9pcKDO+/voFtieOoZW87O8cJNeSzQsDDr7q7zFIVvjBH/iXGBMPKbEBGObPedZk/MVf/FX+8A//lOAM3/j1X8OXvP41qLTd9JQ8CMXNt9zEW3/7V7j99g/zm2/5Heq6ZLB5lo3TD7B84BBSZ+ChNpaje1N+8GuPMVqbYqcDhk/VjLZ2mE5rgpSsdDMOHl1iozdkUhnOrw8o2m0SJbDTId6Z/y1z8m96SSEJwROsp6sCVkOm4+E7QSK1apj1AtfIbBKdIIhR1i3t6aYJHa1ZyhUjG+O0TeNnOWPGzK4ZE8aJWKUFIdAqMnuKVKOkJLjo1SKkQ8hYUyElSRLBhxCitcTEOpAS3XTBPTE1zYeGxaAUSvrIzqgtIgSKBDIVUDgmZUltXWwoekeqFa0sJmqJELDWo7TEO+iVkdkgcDgdP5NUCm8t3jusdfHwmmn2718h06CCw/UFS+2EhSKhNx7HBqLzrF86z3Q6wYYnOX/mDNPxhBtueBYLrYxUQT1Yww42EMM1Jm6IzDqUeRmtNgSoasrYWEbGMShLirxgZXmJTtGirkrOnj5FmgikCCwvLbG6d8R4UtEfjpHBk4lAN4l+sBMdmUVTG1lqRYj1ceY9MsRNtmj2v0RLCuWb5OZAqiRZosnThOAjI0aGaNAdgkPiyZRgX1tzeEFzdFGzr62onGN9p+KRtRHb45qNfomwhsVm/OUSssZ8vNCSVhqle1rOPIpiinRbR9BJS6isxAuJl9G/x1sBVTSBTrVkfydD1FNcXTOceuqyJhHR8N42LMsQPNYEpqWJhuPP8N7PlRr6Sg19pYb+wmvov4HU7jJA9v/HNQNgEAIvFMZH42fn3FxmJ0QsZHbfY5j/7Oz1P/fXzMEtIhAx+/Pn/v3uf7/s9UOUWSkRF89UReqYsx7jI1XZuSjzkojoY6EAEfDCg48TMBbXzU2YsVxmIFfDcpp9/oivhDkDy/s4wKyZUlaRJtyfVIxKS2UdLkT6JCFgVQRFXKMHFURUtLaW2pSMBuvkCahQkQuHxpBiQIH3gtLEmymJE9+HmLwxnIwZTcaMpxMqrVE2xhA7Fzf5sq6YVBWTsqKys2SUGRA4u59ihj7NwafZjf7/JsL8a/911tlr/v9yg/lA460UIgNqJmGLHbhdSdvsrUR53e5gmHUKwpzlNHvLu6Pl8mE8k0/O0xabwiwIgSUaKM5ALNN0KwQ8LZ1P8PSx+Ey9ZqAuoUmamMkJ2e3U/PVn1dy70HRrGiq/vuy742Ypmmkhnv4qIc4rmoKKJtkyUv+JyS6zlMoQuzTM5pD0iMbPK1EiIvZaRJ209fRGdWPSKiIDUcS54mV8n5VxJCqQqrhg1kSJDo18VktIkkhqVypKcEWj0bQN7S5ov+sV1kxsHzzGerT3LGQpexYWaIsUMd5BqxJkRZCGVBv2ZI7epUcYrksmZcW5i9uULmGhlZCn0chYmBFhuoXpnyMsOIJtYUQLt6DwSZfxxgVsNWE6HXPHXQ/QWt7HCQsL8hDVsMddn/goKytLLK8s85znPJ+F/pA824prlQqkDeiLkBgfE02qZhOchTPE42XcPi7fPFyz9l2+Ic4DIkLAONfIQOajIZ5PQzQMbeUpznu2eiPueXKDwdRyYk/BairYU0i6iaS0gcoB2pMKQSFj4SpElEFLEdfuVMW1W0ooXZPcFgK5YC4d8UQpyLSOHdTaxeQgHwKpjq8TGkrz5d4q4m/BJP6mb/w6Njc3ecc7/oCbj7WZVvDuO7d4+cGUvQuanSTn0Y0KpWu8qREEUi3RqcY7u9spAmZ/yPOcN33Vl6KU4syZs+zft48kURTtLq959cs5sH+V3/39P+M1X/wq/u7XvpELj32czsphlvZfx8WLF9ne2UEIRVmWzACt5aUOV191kC/78i9jMBzwqTs+yfXXHyd7KgEhuHo5J08V//3JSyRJilKKDz28hQC0liRKkSiHloHVpTapVlzY2mFiY8ewlcSGzKTytDuKlW7OiUMd7ju9w3bpOb56iHPDknM7hnYr48hi4Fl7YO9OzvmdCZ89uU5rYYE0S2nlGf0AZWV453s+SNlbp+qtsX91iaryGLXAxqmHKChBSK45tIe6t49zF7bo98cIITl89CBVR1Fnho2yJuss0N/ZZv/KElx3Dbfe8ixe8aLbeN0rXoLwjm6ny8033YQMcf1a7hT0Ske9M2ElL1huaVp5l+1Q4AUst1JObgyxCBYXE25pS64qAl1hKBToJMFWUxIpWCpiAZknkuMrBfenmso4rt3XQacF25XmRccXObtT8cCG5TlHF+hmiovBc/VN17GT7rvMuytenU6bleVFLl7awNQGEHz4Ix8jSRIOHjrMK17+4uj/JRTD0ZDtzQ2QCUWe8k3f+HX8wR/+GX/xrvcCAlOOmQy2GNUWZILzgklZcSiXvOhEh3v6Qy71J2z3RriqIk8kE+PJtGR5IWejN6U3qugNKrJWO8qDTMXy0gLdbvt/1VT8Ai4RC1hPPOw3lglKRgmeUmqXEC5ASkmSRCaSBBLpWSwU3SSaUg+NpbKNDI24ds/SmyH+vJCz5OLY6JMNoJWqeDCBKJMpjUNIiQuxoShlTDYO3s89bBBRzoKYhbPEE4gAauNQMiClx9k4f1MZZVlKBKyNEtyZZ6eWglaqaScRjDNAKiRGQm8Sg3MIAaXigTU2KiPA7awlKImSgpWFFu1ck+AY2gFFGgNthDcEBM7A+sYGO4MR/VHFcGcHJQLtXJNpgQoWZYZ400fWPeox+LpiXCvaWYaXErezyU5l6VWWS/0BrVaLqirZs7jIZDzm0cefIM81RZ5x9NBh2t0unW63qXE9WgRS2Uha5UwC5+cBOFJIlA/oEPAiHhC1lEgl0dKTiGjVMfP8SZTENH61Ivh49vDNgVVGD9t2KuimgpYOlLWjPyp5an3IYGpw1tFSglRLCiHIRASelnJFK5F0svj/qtl/tYiH1UILdDxPMxECSwSRUIJJY18RmXqCLFHUVaCqa6ZThzUOLSOLZ2aiErzHCUFtomrEP8M34Ss19JUa+koN/YXX0J+/uXiQu+yRmUQOdlEgmjch4pcXAiNVk37g8c43kEBz95uFtAGId319xGVI2uxBNH8XQvx1oum6zUGQGSLmd9+XbFICZqCQloI8iVTSTEk08cZZGzAmxgF6B1I1rztbbYWMvkJEzbN3s7qh+fwyzvP522nAoxAiUjLTkVtrmZaBrYFnUCpcCPRGhqqJm051RDglAXQEPmKHKoIjOlHY4BhNJzz85BO0Lp6jnecsFSndPGWlW6Dz6Nk0MJosXyBTGi8Spg52asdWbek7Ty0FOtWkiY40buJGiIyO+jJRSKVBKoJQc+OxWYEhm4Jo9hUhmvgMG4LX7HFgPXMNaR0iDTCVzDXGgWhwplWke0sZ/bZK59maWLSKzzI0kztLZuMtSjtNiM9wl+Y3AzdnMkx2/8xs+Eb9vQsxlUVrNS+4XAhkWY6vpxgExrv5uJt5JGgRos+WjGwrKWZ47zP7UtDEUEc83UNTsDqC8ERXgbjx7W57IXYxVQAVKaDOBzIffSGkFIQKghBzFcbuoutBeLIEjJdYNP3KYgyUFZhJ1TxriUSihCTXsbCSInYFZ+NJRLf5+CEIaA1L7RSdxHFR1zSbdsAawbiybI5Knnu0w2KR4JziUlWyYwxapyjlCIwZTeM9EEKSpQqRCgqpqCqLcZ6RqfFCkRSR2uw9lHWgNI6Wr7i22GKp7ZHCcN+GoV85hiZgvCWTht5oTO/xi0yrQG8UWC4kB5daHOYRFs0yerrA0f0Fe7N9jDoVpSsZmTHTasCePdeQFCmnzz3O2oWLXLi4zh0PXGTP4WMki6s8a1+Xrc1N/vh9d3LkyF6OHzvINdc/l+A9WjiUloinsVEkUigyHaUWyAYYdwLXaOHDTFItI3NwVDsGpSO4mNwZ56PEecm48qwNLHnS/J2M5ppBBsbGsTWuaavon5FmCQuLBXu7jq+5KmNfOyHXkoGJxpouOIRSECQhSLyMa3nANwcyyBON8rGwGVYxHCLBkQtFS2kWspS+dVTOM6wsSsb363w0BQ3Ebp9oGN+KmNA5k5A/05EnO7mAr3oYa/lnv/UYL7xqmR/68hM88sgFHjvb57fuO4kq2hTtFtddczVlWdMfTDh3rgEMntaNatbKpoh+69t+nx//iZ/mL/7LT3Djs26ks/8qVNLm5ufeyj2f/jBZVqC05tCJFyBVRm0sX/mGr+aJU2eQSZvJsBdfVqb86I/8AG/6mq/kre/4E64+tMwf/e7P8Pe+/Yd46uyl6HdgK6SISVLXHVtgdbHFxx++gFCaJE35wN1P4lzsCN7+4HmUUljnOX6wzUKn4MmLO0ytwDnB8a5nZaGg1z6OlU8RTJ964zzddo5UikfPD3n0KcN/C54vubbF/n1tHt33bC48+hiynnDjies4vZkzqARHrl5l7WxF3435pf/z5Txwdoef+dOP8A9ecRUv/qJD4C2/+iu/zO0f+AD/nzd9I7c99wVMy5Iv+bI3cmJJ8c/f+EJe/iXfwMBIfv1X/iMveu6zufqqo/zsz/8Sjz10D+/547dyw7NeyGhrnXMP38Ott17NynTM973xRXzi3kc5eXGTv3pszDfcdoSvvOkA77rnLPfv9PjUqS28d7z4xhXe8UMv4J//xgP8xUPb/OslR5rnHNzf4pKvsCpl02TYAIMaPrWh2a5gOK3573dd5PnHlnjesSW+5NXP5exnL/DHd97Pn/7yZ/HOYWqD+L1vxyOoawdCNWu54uu+9k383E//a1712jdw/wMPNeNHcc3VV/Pxj32AbrdLkqQA/Pe3/xHf+30/iBCK13zxK/jjd7zlsiFnWT5wnM6hZ/OSL34T65cuYKsR0+kItS/nT959ht/51BpP9SpuObrIkUMrfNN1B/m9j57m4taYC+s9nn/tXlRbs5Zm6MavE+AHv+87+Pa//w3/k2fgF35NaxHNXdPY+ARBaT3ImD6XZVnDQrfUtSXRKUWeo3U0cdVBUCSKIon1TO1h6mgO7HK+985Aq5iAFmt3a+NzxoD2UbKXa8HUwNR7TF2BlAipEUoipGqSxxomimhef/4Vpbo+xATp2rh40AVsVYMCoRSLrTZZFuvJrf6E0aTCWIuUKVmakKcK4eN+00kUzkuMCUxrQe0DJgisi6wO5wXWeaqqRCeOLI2+KyudnEQE+hdhY1hTW0d/GpO0t8dTTt95N8Z6RpOKvd0WB1YWkOUWbtim3oHr90nkYhsmyzx6fkB/OGabmmuOHSdPUh577CEeOHOJhy9ssFZ6jhw+zAtuvQXrYHunx+2ffpAkTVheWuRNx69HtJdIFqY4EYPdlYgx8gKFlKFp2kZjnoAkNL6uWgRaSrHc1kglMVISth2mrjF19KCZG8E0X6qxAFENUOUcbE4cRa9CBNAhsD2pubg1ZTIuyQRcu5pxbDGlk0jKicVZh7eexSwaI7eTyLCa+dvOgEuPwDZ1dyWauk9I2llCpRTdMtbclQk8uW4wkwpblkCURbZyTZoonHHU1pHoxjtXxhPyM107cKWGvlJDX6mhv/Aa+vMGniJVMKIrc1Pw+Ul+9o+I1DZbX/Q9cj4mg81RpGZTnE2smZfTLqZFEA2A0YBMc9M5+Tn/ftnPCXYNxYFo2iUiewkaeZbaBRCMc/OvGeglhWCGXXgf5Wq++TkkTazljKVDc7MbY0XvcUE0BohhXtPPPpO/zJ9Ii8YFTsy60AFF0w1pAJa5XNA3YBzRz4gAZeXRI0eiSpYKHeN0RzlpqglSYUhYXpJIBM7VTI2jXzl2ahhaQYVCCdVsejN6ZohAnWyM0BpqqA8S3wA1l91ddk0OIyV8l/21CyB6oPaencpR+UDhAkso2krGNIbZs5y/bDNhm0FsfPx/TZw0QjRMNESDGIv58JOi6f4I0WzszDfN3fEW5Xw+RMNM72ajdTe+2DSsNxuigfjEhDkS7RvU1/hGJjqfEc/0I2u8pJzdgd3iMczsEp82h3kaM0IJ36Q5xsjMyOqV84cXhI/PTO7KHedjRAqkFoQ6dlms9ay2U247mrLeTai9x8hAWceI4Uk1Wyo9M4xxlqQZQmikp8yUQs1/F3OWYeSxxu0/EYKVVka3SFgfW6raU05dBHJTSdqReHzUY5tAWftIc06a+acFSSJJvEC52e/yeEejp7esba2xseOx3nFyrcLh8MJjKkulBCaVjGuFac5yea5JU8Xjpx9h4hxb2xcIg0sUyrO0kDKdSqoaekazJ+mQJgljaxjZmokzpKkgTTVKp80a45HaESRY0YCnPnYs5klPzSFkt5iZLU67a3quJbmKN7FuKMMRsJfoxotgUjt2pmY+L6UQTG2zpspAkgicEExrOD801M7TL11D29esZJIFJdjT1iwUkdY8tIZEQSIkaRLNF00AG0dc7KTJuLnJGbgsINUpRSJoJZ5UQaLYBamJgRbBRyA7NIzXpOn6yKa5EY07Zzua2F2wn6HXT/70L3Pnp+9FSsEbbtvHYivnT+7b5oZOxonje/mypOCBC2PO90t2+iNMbSmnFUmWgAhUU/v0FwwBU1d85s5PcfKxR+n3d/it3/sLDh+5m70Hj7Hn4DH2HzjIF7/ipbzr3e/lM5+9m1mcrHWOs2fPc2j/Hr7mq76cNG9zaX2T33rL23j/Bz/MYDjmthe/lP1LKYuZxdQWZy15npEVOUkz1oaVQ04tQid0i5TFTsZTkwlJqlnsthiXNXVVQwj0hlMq4xiNpnQzwZG9CdujitL3MOE0dV3TKTJefMNBzm6NGE1r3nTLCo+slTxwacrDG1NCJjHtEp2lBO948uwWOxNH3urwzV/5ah655x4e+EzFgxeHnO9NObiUcnqnYvLZx3nsp36aD3/yLjb7I44dyFjqahIt+ZbXPotF16Prt/jTP/lTbLGH59/6XIYnH+aOz97Jyex2Lpw/S297g3910wtZ2+7xjvd/jE888iiHDx7g5V/5tXzm/G8zPL3GtUsFmbds7AwZk1CjcT7QarcxVvHJT5zjkK3J92rSNKGbwF7luOQcRSI5tNzmzDmBcIbCDFHe0kokr7i6xfWHCg4ta976wce596kexhj2p1Dkknypy6mNIb2pAZmxu6MJkjSnu7gHqXaZUEIl7AxG/OIv/ipqHoEuuOuuTzMeDUFIHnzwIX7ip36BRx97Yr7evPcDt3NpY4e1SxcZDft4U0JwrA9r3vXAJrdeVfDyvANGc3Y45bGLQ6wPdDspS0WLMkimLqATzbScSU/AVSPsaON/8gz8wq9ZjSKkZHGhhdWW5VKwU01xxlIimsTkWBdH8Eg3chpPWTl6ImATiW5pEBKtAokUWEmU1Im4zysZzZu1Ug2TqtnnfdxbO6liTycjSTSdliPTsR6aWJhYEfdmB8FHb8uZBYbzcfMNczAqEAvVv/55hRAUuaaVpwip6A3LudG59Z7aOayXCB+9ifomHvCEc3RSRZCSSdC4KkrTghAQoq9rCJ66rtjc3GI6jEb257eGGBcDY7ypY4NbCmoDxkZ2v7cGU01ZO/cUphyxs3GB1XxMK4V2liKzFokQtENClmfoNKOSgrF1DMuKcekpjY3J3T7aQJS1ibYcjW2FaJrr1geMjPuZVBqtFWkTQS5D052dddq1avZxj9cKqaOxtFKhachH1lhlHFoZahtT0GyIBsWxNpOYENguHXoY5WvBBaa1ZTSuaYmYiHegrdnX0rS0YOg9tQGnBFoLghTUIb6uDAIVokSTBnhyNF6qQmCJiYtZiPVkJ1OUIjI8+lVA+3j/Y+R6oDaRrSOFIEkVUqp5AR2e+VvwlRr6Sg09f6ZXauj/5zX03wB4mlFdd298mCNAf33HiawgiXV1AzzRSM+aaTp7874Z6M0rzdbiuEzFl45+PE97N0//NznHTeafO6bRRQAqEP14hIpopA1NsoKNcaGzdX8GhgUPzsUFIiAJcsZhBaXFXH+LCHNQyeKxROBpJk/7a+BTiPdECBVBrAYsiV5DEenUMgInARHpic1i4L2najbPqnKEYCAEFjJBN1fsjFLSJNJhdZKQyJRMaawpmdaGQeXpGRg7QRUkhWjApRD9jYKPzvly7sXUqExDTEWYfS4xN5gXu2l/kYE4p9rNEgE90Th8p7JMnCS3kb4tUmhp0eibxa40jkaGKXY3bSFAhV064+W+UHa+QkcQbOa7pFUDNqld4Glm24mIRmjBxQcyY2cJEc3Kax+7isYLKhcYm4YmGZijunNmFw2tmF3Z3TP5EpeNb6FlUzSqOeMwzoM4n+PHjc8hfr6GGj1nv8nLJlwDFs723tnAbzpZSsVi2IbIflxtZxzdW7CxnDG1jqnzbI4M/anj3PYUG6KRu5w9LwGBOE/n/oTEZxqatWK2aUbAMaAI5FqyXGS0Cs25ZtOsSodGk6SStKVx0yinNMZTlg6Cj7JcLZBKkiaS2gpUA856H8MKJDGN6+LWOuPaM6kD57cDRSZo54J6ZKm1xLYUJiQEIE2h1cpIUsEjpx5ja2edvWcfopCaQ6srrJ44jjEpE6fpsUDQbbROGTrL2DumeIpCUxQJSZLP198kB5kqhNLzNEd3GfVw1v2WUiH8LthNmNE1GxNLJed+arONdkbrJ4TYARuLWMwKUEpQuqazIwOJjkXppAqc95aNqWVrVLNcaPa1U/ZkgtVMstTStLKm4Jw4dCMfKFKJDQHRdJY8AoSMTFAREGL3cJNqTZ5AK41sUa3CPC3KhRjdm8i4dtiGEqxElHwIaGjlAjVbb57hBS/Av/mZXwUgUZI33LaP9ZHnX//BGb7/VQe58UCLxaOr9D98ipMXB2xu9gAIzpNmkY1STWbmy/EmpllCkijuvusuzpx+EmcNv/2O99DpdDh88BDPev4LueW5t/DqV7ycd737vfz6b/42QqbgLcHXEDwveuEt/MB3fgud1eM88PBJ3v72P+I977udz979AA/+039MJg076+egKVLyIiPNs0gmBnpTS4lBKk2nlbK6kHN+Paaprq4uMzm3jjEWIQQ7wymDScVoNOFAUXB8JeMzZ6aMyj7VuEdd1+xb6vCC6w7Sn5xmOhnzhmevkiRjHuvBE9sjknxKiwlJmmJrw6mzm4QARw4lfM0XfxF3yAnu4knufHKHaVWxf6ng8c0pd595lIt//jG89+xbWeDAUqBIDMHWfPsbnke1dprxxbP82dv/nHz/tXzrt/w93n37e7jj/e/jLWeGlNbTKgp+9IcVG4Mhf3L7neg05eUvfTHf8yM/jXrHX9KvP8OLFhOUN1zcHjEhxUgNBIp2i8oqPvKxcxzO4Dn7EopWSmdcs0iNt45cSw4tF1E+ZQ0dN0Lj0KniZcdbHF4tSHPNP3nrowymhnaqOFoo9rRT9u9dZDStmNaWOkBoGBmtokCphEnpLguNiwbW270B/+bf/ixP20Rnfw6eJ06e4id+6heQTefYOXjv+z7E+95/ezxBhNlxCDZHNe99ZJtfeeE13Ha8w72PTHnowhZ3PzlApimLnYKrD3Q4s1UztpY00Uwrh7PR0XGwtcGF04+z74bX/8+cgl/wpWbFv5IsdXNC6lgeB+TWFGsMwc18A3b9RrWOY8A6z7hyKO+oU0knT0BIUhVIJdimCehDrHuVFFG2qhVaqd1mr/ckEtqpYqWTU+Qe4x3tNNbnG2PL+jhQVxEcCjObiWavdc7Hmrs5GMfCT86O48yYlbMasUgT2s17FTIenmfAk/UO12TK19bF2tZ7EgKtXJOkGuETps7SmC3Ma8wQAsYYNjc36UmJ954Lm8P4PgUUyqKbg29snjY1vneYasr5M2fY3lwnL3KuOpCzstJl//59uCRHCUkhUtI8QyYZpVRMiSbNtfVYH5i5+7imka29xPuZN1Wsaq0POAEOiVBJlDjKuln/opQmggQBryRWRmaU0xKtQMkoSdQy7mE2+m8ghMA0flkNcQ4JWAQmCHbK6NUyqjymduBi4lxHwUom2d9SrBSKTAm89WghqJtmvRdQ0qRteVDEBGuaJ+AbACrI+LtL3xzhGuDJisigmxpoecibIeGb9GjvA0IK8iyJyg4/P+3xTN+Ir9TQV2roKzX0F15Df/6pdlLMTQ9nGyOf80+aA75oaKWhAS5mxv+y2aRmb3ZOsWwO8bOOSmQQMf/zXKQ3B6BCw8hpBkWzKCNANBuMkiICD2pXT2yDZ2zj5EXGFA0rPEJH827tm1rIQzABZxttu2wEgnMwY1e65XzAm8gTnnk0xVEa0V7ZPA/ZvJ8gPD7Y5sEHvItRpy6AtwEzm/mEmQoCQfy+snkWzs1YPDCygmriGdYlCksiA+1UkqsMFRwrS/uYlGMq56mCbr4U2kfqsncWY+NkijWPROsEISTOeyZlRX86pT8tGRpDriSioQqHBoisnMeGuPtoHdANS0s13QEXoPLgXWBkIgo/lVFa6IGRj9I6GwKyifX1BJSQjR+XIE93GU3Wx/ER/Zfi75BKNN29+OznbPAZFYvmvjZInhChiR8NMbnQeypjY8SplAxqz2DqWBu5aAboBVrNpKRQ2jgZJQ3Y97cAeJppksHTzuIip6Ripj+fQ8qfs4DsssLihiRCBOiKhuI9RxybRXzWsxEADU1eEDXEQsLOtGYyit24VAv25JKOTJgWiqUMLg1L+mWNDszn34xxJyVzrXRojBUJAe9cnJNSIhNJngj2dBS2MoxqS29Y4hwkUhOcp65hPJFkRYoQBqoJbXSc+8FRW4t3nqlNqWjGbx3Ax/La1AYpFHVYYnEpY0HA2tYZEjS51KzuS+P4l1C5aP46NRIfaiY1nOnllOdHGNPj6KJkdeE8n370NP1qhE5zDu+7DnnNIUJR8OlLjn5PMDUJOm+TJnnsELuARZK1WrSyhCLRINugWggVpQdagBBRTpokgsR5gogbCyEQhMcg+Mj5MYu5YrWrOZondBNFIRTdTNLJBUF71qeWsQ0UhaDIooZ8aGFkPUJG9kEqoA6KqRGUFnAerTyHOoETXc1yLtApiCzOw06hm45QnMPONmsqcn6GdT6uB6RR8xF8oAoWIQOdQtLSmkTCpWHN6Z2K7bFlezKTH0R2TqIDWQKVi+tFQlRSSxlNIWcHp2f2Fd+f9fDjv/cItxzu8BtfvZ9iocPIJ9x7zrFdRuPf/vaAbidnabHFxbUepm7YTiJKq4XU/F8/8kN87Zu+kk9+5HaSLEfoFsFVjEdDTp16gp/6Nz/Cq7/4VbHgStrofAlXDpqmR0QhlNLkRRulMp5z0y3cd++n+Zc/9KN89GOfACHwrsJVPYSI6UxLnRZU04Zp7Oj3BoxGU5ZWlxmZwOOXRggpsdZyYX0HdEZWaOrJkCxLSbOEYa/Pk+tD1vtTfuafvpYnzu3wi3/wKbI8YWA9v/KBx7m66zm0kPC9f/w4+zPJq1c017/42ZzacfzlI0Nc5dACVle7TCvHznjMV37zd9Pf6dHb7pEurmBNTTnoce2xBRYLuKQzVAh4F3jy4x/k8Ts/iUkKvuIFLVaPXcvhF34F/6D+U0i6iKTF4nVH2bN2De6p+0AmqLTAkeKJ9F2VpIhgqTYfxVcDpsZz+9kxX7nvALdefYzRyacYa8+9wKA/5vrlBb7tTc/mv31yjfv7FT/8rA4f2lznY6e2KY1nOK05s97HWEuqEuiu0up6toZj/sVfnOVrblzmpUc7EAKvObHIP3nRPu58eAftHS9YrXn54gKnh21+7JM9TICFhQ7v+8s/5I477uSW5z6fi5cuMav9XD1hd19t/hH1HCCTSCcmELzlxS+9jU6nxfve/1G8s02vSIJQCJU1YItHSMm/+ct18mSLybjm5hMrfMNr9vJHHz2H9wJUznavTyBwaE+L7YllMg1UwK/913fzu3/8V5y/9E//F83F/2dXPS4pWilL7ZgeRa2wMouR99bj8aiZTMbFkBmtFVIKnIvJRaWExAuE0rRTRyYDo0yQIRg3B14lJGmi6OSKPNUsFAl5VGGwVc8SgcELhdIxsWylBRCoA/RLg5oBPRIIAi/F/LwlQrSFECICK7OGHMS/S1PNQqE5tFIgvKM/mHCxN2VzVDOtY1T7cktxbE/KQpEwmtScG0bDYqSkto7tyhFqKIOnttGMGaFwFkxt556t+5cKEi2x1nPuUgzykQT2LSZILTFoSDQhRBPtNBhCsNx9eq3xDhWsLmUsdVusrpynsqDSgj0HjyMWSoqW4sH1KefHgTEZOhekeU6SJvNzkZZRAtnJYgK0FAqBpJUoOjqwlAkSDMFJShvDhFyI+8+kdqwNKj55qseeluZgJ2VZJyRJ9GNZbWlqFzjfLxlbx6j01A0I7IVgUpvIjNISqRSZUjEp23nGE0t/alhKJau55MhiwZ6WppMmWB8PwD0rKL3EBkEmBKmICXe6UTLMGA67nqzxdzsgWJj4CHgFKWilgqGNTImRkZzZNAwHI4pEkSQSnSikinttIDK6pIy+Q9gAnmf0daWGvlJDX6mhv/Aa+m/g8TRz6v//A2sJ5oDEnHoVLk9EiwvZjNkzM1Rrxn4DNkW5U4wLjWwbAbuyrKdp7SKSPPvdM3O6OQLdMKpmG6NxcbMsfcACTjCX0TWwPYSowbU2Uma9it4/s8hBGSJQJZl5Gl32fuaAB41NQnw/qpHseUKToNYg4Q0zy4Xw1xYrGgRaCtF0bEIziBqGTdM9mn1WEaL/UPCO4bSmNSmZljECN00S2kUL7zzGmAZADMw8t4QQpDF7E+89Wmm8D4zLksFkzKCcMrERWfUNSu5c7GBMjaG0Fhtc85nifVcybpyFjmaPWkYqYtS7R1NwL2IRtAvs7ZosKiHQOhZQmY4g5czofD4WRdMtETNAqXn+NB05v3svaZD9OStOBESIkz2EmBphnEfBXDLpfTzo1U1qhGzGy0xqpxuKYvJ5z6T/fZdr6PKEmCYSLh9wT1svLgeS43xGiHkqoWxo7g3kd9mPPH3RiWzACDhqIcgTTTtP2RnWXBhWTCqHkoJOHvXpIUTDw1lKzrzTIATJXDu9u07E9WS2JgWUkiSpxBGQCiyBiY1goveRHpwoibGe4CLQG+YAKiRaRjamChgrsQ688/g5vVbMFzGhLh+PcZ0oUomW8T4b1/hiuNCY0gPBM4lJ6YyNxNi4tg0MMDZ4BpRmRCsr2dO6RD3Zok4LRnVgZKF0AhtUs5lEmXDtovccM8C/Wbdq66mcBxnXKKUUSsbEICkFSsduqmqYwhtTy8QHrILVJuWm8qJ5fR/HdzNXJZE+nyioq3hDksajBGA0FZQmrrWFDCRCslJocuNpJZAlEtH4jmitouxAiDiXEGRBgm/MFoPfXZtDw6QUsDW19KtofilDfFaVDWg8uQrULoLDQkAnjfd/bKB2ollXZrT53bH0jMedLrsWFWAdD2+U3JjkyEQi81bUIoe4jgbAGMd8UwJAkBcF1524jhMnTrD/wAHuvu9hzpw9z0xGd/jwIV75ipdw9swZPnL7h3nRF30Rk1GP4GpCsDz7xuu59dZbqCYjbn7WtWxvrrG3tUrWbnHs2FFe+9pXs7q6lzRJUaFF1tmLkDFmPUtTdPAkMnDNwT2stiFP4L5Ngw9x1s+kGHGcx7mldMJMaiKEYN9SzrG9HU6e2+b0pQFeKKz1LLQCt13Torc9ZGNY08k0LjjWxzUrE8e4diTCovMEETx1VWEtpGnKdQfbPFqOOVc50vGUxQyuOlDgpaIOir2rOW1haCvPZ59cZ+oEFYJglzmyJrh2usIDT66zsCLRWcGZoeXhrRLVWkD4yDxTSRr9E4Wgm0YT3yCiZEpJwYFOSlsLgndMqhg8AnGfGVWWDz2+Q+VhqZWwvVOzkimee6TDp0/vMK0MG/1xlMRJyVp/RO0CQSoGteehjSl4z75EcCCXLKSSlZbCmnj4TNKUbhE7b8+/9VZeeNsLuO7EtXz2s3dz5syZy0afmHeCd8eWuAyAIv5d8z293oCqqnfrGwEqySLwJDVf8iWvYDIZcftHPsbmoEarCJj0Jha5PcWHaFw9GJUcWMowzjMpa0ztG8YT9IcT+sPJ/7wJ9//SZYyjqh3TyiKSaLY98w2+/F4GMZPZyHiwbQ7/s5oqbcCoeQp7c81rbBm71YWWFFrSnvlhCZj4QGlgUgd6U4NxDoLD2ri/D6sQ5VtCzqU6ANY1wBO7qgXRMDYiRLXL0hING6i0AUlMugrOMqPNSSVBKhr4CkFzAG/YMN0iofJQ+UBV28jqgXndJ1WUroQQ/16g8D4mptU+7oPGxS6/k7NQII/zYIJH+MvYSy7ub8ZFqdK0DqStGr0wZVpVSK2Z1DbOpRn4EjzBGYK3QDywq0bS6J3D2eib5JqzRDQX9qDi92mlo0k7sfavnWdQRjAtlzAuYjiQD9Fcf2oiy8p7cZkqhEYNEg8EqZKoZqP23mNsZMekCoSU5HlCt53TKRRpquL+4AMTL6h9lNbpZn+dK4jYPSXM0pvj2S5QN5IxIWLqnZTxXEQj0fEhRscPS09AokMgaeRLSkav3VRHD6zaxFou7NIqn5HXlRr6Sg19pYb+wmvoz/u47Jz76+CI4GkMq8t/Z5ixnhq6mhTMzcQTNTPRirj3TIL3tBS4BkRyPm5yzov5AugunzTNhixgblA3syyKTbcZDzS+SyPiIJdaElSkNqICwe16C/mGzlgaGz2Z9K5Jm/UOQUD6gAoidoIaJpaYUdBUaNhdEdCRRABFaYETntrHDRHRsLUkeBMa9/vdIk4KGjQ8YonzRajZnPHEiS2aSenjEmZtYGdk0UnFoWmFEJpuq8Xq8hKJkjhrANVgNb4paBTddgebRR5mmkQn/dFwwFqvx2A4oKoNuZYUIqYSVNZivKM3LRlWFZWrCcIhGj1pKgUtLTnUSWK6UtNB0UTwyoQmla553kLESaSD32U8JYo809GAkoalFWIKYESVdhf4CHo2TZPmkc8KpdmkuByWUjIgcJEl59wckFMNdVYQQVJCwHoR41ObITWjbedJNK3P/jYATy4+N0/AukhND76Jy2Z2n+IdmhWws38IIefJOzIEPI4gZEMgC8xsHmiKSCGjIZ/zHmc9WVNsWQSnhoYndsZc3JxEOaWWLOUpRaJYyBSlC7ggkMIjREATi2YPESyGeZqIVM2DttEssVVILNEnYmQcO8aiJQThSXSsqHwpojleHV8jNAC31oI0EeRtQTkWTEsXnVtFACmahR6QASUUMondF2MMUgSW2im18/FrTgiQc+BdK9ge+Gb+KrJE02olOC3oGUdvs0I4x2I+5XDrDOP+UyglqCxMnWBsY8fbOI/whsoYytpQ1o6ZjZ4xhrKuGFcVQ+tx0rPgfZxXWjKt4ufMU0GShKjpRrBeWrTx9J3nWAZaaLyAYW2ZGkeexFpUA4nw0VhfS1wVu3idXJO3mrUMGNeGUWlZSCTtRHF8oWAyNhRpoF1IKjTWC5RyiKYYzTRNMopEWhFlCs6jZFzDjWPuSXBmULFTRh+JUjcGq9KzlEBbCM70AhMTwe3DXZhY2K5iBynTkbLdsJ+b5/S5qP8z95IEXna4xdBL/uPHN/mhV8C1B5ZY2nOYNEsJ3pN3WgRgOK4QWqOIKUpCSJYXF/mqr/hSrr7qONPS8Ltv/zN2drabTVXxguc/n9/57d/gS7/8jTx1+jS//kv/ju21p3DlDuD5si99LT/z736SjXNP0N9a44nHHqS992qy9hIA3/b3vzm+0RCAFl3VRkgdgaeiIMWzlCtefvM1vPwqx0pW8c2/dZKgUtrtAtekraSJxk5KgvMkWY6xjro2CKV43tWrvP65h/g37/gs21OHLnKq0YiVLPADbzjMT/z+I9xxfsSbb13lgQsj7joz4KLaRgroJgbRXqSuLWunN5FpxnKnzXd/3Uv5vffewyNPbVGNJxxcLnjTC1b540cspU05cWKVI2qAqsf84Z3no+yFwPseuMDVq0/x4hMP8r77L3LjLbfyve0udzzZ58/vXSdb2Y8w01gwFgU6TRFCsNpSrLYzRLoHZEqhJS852uVA7pkMe1wYlOyUBgh0cs3FQc33vf0Rvv3Fh3n+wTYPPtLnmsWC//PFXR46t8NoUnJuo0eSZQTveeSpi4QkR6iEIvV8em3Kp86Ped2i4FACvYllsaXoV4K7B5IjiwkTYQnB8fVf99V8//d9D82Rk6dVeTNvg8vnjBAIEZ1cZmy4OK88Dzz0OLN1cCa3SttLzR4q+amf/NecO3eW2z/yMWxtSLLAsQNLnNsYc88T26g0YVIaLq7t8IqbD9Kf1Hzgngsx8GZ+UP3bMX/LyhO8wbrAXplS1TPPJECKKOWYNdGkQio1P1ggYxpzN1d0M02iFFPrqH0ETSIw4SMLh+j7VGhBO5UsZComkIUY9jI0nt7EcWFnQlkbqtpQ5AlaKXxjKi6UIpvVzgF8oqJna1O/zuvTpl6O7G+FVgIbJJWDjUHFUhaNqnMZSARNElaCRzE2glRHNUOeqMiGUoL9yxm9qWVYOtaGhlh1R/8rEOhEg7U479gZTGjnCUpCO1MQYiJTf+rQSUAmEuMtwYPxDi3i+6+FoAyNR5P1uHHFaFLTn1qKdk1375DJZEiiaZKnm2Rn7wiuxtUTgi0R3kQwKdFIpairav5VWY8OgalxTdKfJM9T0iwlSeu51My4wMQ4RPAEa9lXCJyPBsbro5pLQ8O49jihmk1QzhuwEfgRdPKEPM9BCEpjsdYRfEBniiJPWOwWLC0VdDNJlkJpPLX3jJuaxYVAQZRlCRHrwTi7RDwfEWt0FwIWwXTmVSRicp4VgZGLjW/v498ZF5MP8yCwJkpFEynIFCzkmiKV+BAYT2umwc9tWZ6p15Ua+koNfaWG/sJr6M/7uFw73/ghzQ76cXKEy35ZiGNwjlJa6xpUNwrvonl2jPDUqjnUN5taYAY67QJQnoZx4sJ8UNgG6rcNMiBF3MxklIk3b0I0Qr/4oKOGuMF1mwQQa2frQaNlRjRIoMARqL0jWI+amevN0+lmaIZHzn4OSVC7bCsaVFwrQdpozFUz4bxoIjUhyuxcAyY1bv/BNfX/ZcZBYoao0HQFXDSIMzD3hlJKAApCoAqe7bFF64rJdEzeWqLT6tLKMobjMfsWF+Imk+cc2bdCKy9ih9mDtzYi2yphOK0YTSb0RmOGkwnBWpzM50YFs0E9LC1T6/FBkChNIMxZTLPNeiaFnNrGpNvvds2CiuCdmmtRI0CVKBG/ZFyoI5joCN4hgyPXs5vVBBAGAe7ybtBlA1OIedNfyl3AUkmQOHAGY+oGeMwY11DaGEmba8FCU3/7ENlPWsaxt5BF4ClVnyfU+7/xUkqAE41fmKMyEYmHWFCIqD3kcw8Uzjtc44UWx2EsjKvaUgWDcZENKNW8YQuBCECqgIy7FnhBHQLGC4xXtNKURMFSW6GbpI1pFc3bBbB3Kf6c93GdsSFQOpjaWEAHH6WdSoHRCdbBaOxQSQwM8C6wU3uSVKK6Cjc0GBO7g9Z5xmWFHNi4/ijFtqnAeHITEEYRbKSuSxkLVdXyDdgsaRcKqWGEw1rQIqAzQTAQbGBaCUKIqLKUUUKQKxW1+iFQTmu8kDgB3nqUCGilqU3OzhQeuAiHLk05qmued/0Jev1FdnobfPKzjzCeTvGupDYlWituuPparjp8mL0re7mwfon7nzzJZx99CFk7DmY57UwxGpf0g+PCzibbkyHGVzHNRAgSIXnTdYtIGdeUtpQ4BLWL0c5SCzrtPHZ6gmB1JcaW19axNS7jPEoTXBBYA+PKIISik0muXy1YLjSbo+gPoBJJt8hoCU3twEzr2BUOjs2pZGwsgzJ2YSsfGNeOiYmHnVQ6DnejN8WRtqSrA73Esz6xMQQAqE0sjFbbgSKNOvXSxyK9o2FPDgsFHN8jqQ2MqgBezovtZ/Y1K24lp8eBpZbkjde22Nqu2Opt8Ei5TW9rC6EUQme0WjmtImdzc4PKW4K3/MIv/Dwve+lL2b9vP7/9tt/nPe/5AMPh4GkMlo9+7BO88ou/gocefoyqqvhnP/CTXLx4sblBmt9/+x/xiU9+ClNNcdZg6prffMstfNHqobiBsbtGRDapRSUJhxYyvvx4zgMTx/qlkrsfP83H70/IM01rcYGWgq724AvK2rKz3Wf/SgtQXNgYsnexoNVJ2UpSPnNmyGMXHuZl17RZH1ruODNldXUJ0WrzG7f3aScJLz+xwAcf6/Oy65f41lce4d++8yQTL1la7rK5sUUIcOiaI/Q2dtja3uHH3/oRqCa85MQC954veXLH8ZaPrNHes0CK5cH7H+WxUJOqwE037mdtY8zG9pjX3LKP0cTwvvsvMqgdUOMGj2PGW9hywkIYM5kM6TvLZPMk9XCNEGBAwnZp6Z19jHo8YGwcH3hqxKukYn+heN6NV+GyNR640GNcxa7zUifhLx/a4IFzPX7qS4/wzkcG/MUjfSYOUIrKK9zEksrAnnbG4UP70EnCnY+epa5qUuF5yQuvZ18hqEzN7ZsKjeBV++IaW1VxP/hP//k3+bN3vguEZG1tnejJNAMh3F8blgsLHf7r236TlZU9gOTJh+9CJwlHT9zMD/7Qj/LxT9wBwEtuu5nbnvds3vi1b+bd7/kQv/yffhtvq8iGCbF5KJVCJQVSVaRa8vrruxw7tJdjRw5yx/0nWVsf4bzg8IEuWgpOnprytD3rGXy1iiTWpM6z0x+zXXl2dirq2kQgTiVIFVkR3seaWdIkjPlYEy0USQyVyQTGxEac9b4Jy4l1KUDqPXWANIBXCi0EmuYeBw9OsakERkb2kdYJWiscAuMczjlqEZnnSkZgSKaKREZWvPOeSe0aW4XmNOBdNKUVitpDbQKgSLUkUQonqoZJHhhOLZ4KYxIUAZRmYh3BeNJRZEkJIE/iYce6gAyx6ZpoRael0VJQG8O0jAl2pjaxkSkVO1ODrDxpEkjThFQrWkWOVpFlUY2ms+4utZfR5iFRpA6k8Ax3tpn2NllMBbfedAMr5y5y9vwlNjY2Yr3nLFoE2nnKscP72bdnmcVuh0ub25y5sMZT5y8i8eSppl2kVB7K0nJhNKU3qZhaj5SKdqbo5oqb9hdkMqBcPKhOjMdLTxUUWSooUotOkqheaOVU1jEqa5wxsVluHd7WsZZzhnYiSfLIDO2kCqEF26XDEf2zsjwCUMEJpnVkp5UepjWs+VhzCwKqUVPMYBUTIjtq7CMjL1ESrQVeBEY2UNce7ySJhE4q8bkiUTFFGjwrLcVyO+XqAx2GpWUwNdQmrjtay/8t8/Lzva7U0Fdq6Cs19BdeQ3/+Uju/y0aav7aYTaLP2fTDnHAyRyqbhg6IaJSnG4nZXNM6c/cPoZH1NVK2mfyNgBIBL+ICFwlDYc5KmclkZ3rzmS5ZRug+vi7x94Vmwj29mbf7OQLgCAgff5+7jD1jfWhYXNG/SYiZZCt2CthV0c2jCBMt5iim97vyvMhgiubdwUd5Wpi9Jw/RIKoBhBpkcUaznX1vmMU5EsG12e+ujKM0htrUFECWpiyqlDRJ5+BQlqYsdbukSQoIFhd83MScpbYOUda45s+1jYiODSGaKc4AQB9BphDEvNsVQsAJhwtQ+8DUeSxRQje18WeMm/kjxc3GzhqiIcw9wbQIKHy8t430bQY6gUfKMB+G8c+Bz40xnX3DTJ8uBHNaopJil3kWoime9x4TYkxx7WAhEQ1bjybpLt7v2cIeOxICK3Z/6zP1kkLgJRAi+DlLlwHmXZq/ds1wVpp52cxmwex5PJ0FGS77www7FVI2FPFYcAogkYpUazIdaKXxTe2+pzguWrqZcw4cTXILsVPpQ8AGGp8HEELGJ+/DPMIjeDCWGOucioYRF/3hbPBUziFrH0FXBFMXu1fWBZSLVH6SXTA/NOB5pgVZEr0vquCwDcvSBTHLs5lTzYHLfMbEnAFJA2IHT+xIqfh9lVUYAr2Joz+eslpOOLpvD4v/N3v/HWVbdtX34p8VdjjnVL753r6du9UtqVGOiCSSQIBNsBBPGAtjbGPAET/M44exjYnm2WSwbMDkJPEQYAkkkEASit1Sd6uDOt+cKtdJO6zw+2OufU5d2W8M8TSGfTXG3Rqlrlt16pwd1pprru/8zu+3p1npWc4e2eTQgRUOLPXpFQUqRm45eSPH1g4wGAyYVlN2RyM2h0OWMkU0wrYMMVK1js3xFBdERyS3ck4+RFZLERAdO6lyTF0k14GIJPlKSwuqAYpMnLbqNrEGk8lC20qFM4YobR6F5vhSyVKhaEOk9hEXpCo+dULDr13AEDBEzo8Dm9PA5VGgRvQnxq1nXMuiuVRElgrDWg+WcpWAa8X5YWDURFkgM6mmHuhrFpImSlRQO4g+ztcKZJyFWYXx2j9e+YqXceHiJc6eOcvKWo/FwrKxNZEqdIhs7IyomhaFmq3Xc9sa+Xr23Xfx4he/CFBcubLOR+79KMF5jh8/wo0nT/Dgw0+yvbPH+z/4YUgtAA8/+vi+hUlx4cIlLly4BLHTjdJ86L778Wiib7n99ts4cuTI7PXdkRktrW9TGHtY3xlT+QG9nkHl0lwfQiQzGp0bSmUwic2bWSXx2XsymzOcNGxVFZ91fA2bK2IYk1lNG+Chs2NOFJrlQcHWZMS4CaCkiOBbReuiAB1Ko61lbbEgtppHTm9yIPesZh6bi2va2e2ak31p/9J4irKgyASEUcZg8hLQKGPIywzVBprplIvPPMaJIwd4wfOey+bWFWoCzjna6RgdHYuLfW6/9WYOHTzAg488xs7uEAUUhUUpTe0iu04caY21uBBZ7hnuOb7A1vaYGDxP7TZsVh4XhevfLzIOrQzY3BtDcLgQKFOsahvHci/n0EJOYwzeKAqbkdtGNjNolO9a1xSnT5/h3PkLvOB5z+XwgSUOrNzDQ488zmQmUA9pYQUMNst5yYtewJGjR4nKMlB7jCe1AFYpB+sWkxjnBS5AmFLJdv74QsZCaRhPG4yCxb7Yxw9yzfGVkuGkZXfqyLLkk5XYVSL8em1vWgF6PYt3gdAKSNS0PrWSdUYnqRCbcFullFSwlSQhVmsKqykzTS+Dwggo1YlZdzmQTvmv1QJWlVYlgWgpwLlMU1tNmRnJx0JMznc6FU5lLTRmX2ufNbP3FaBMzVqP0unNZnvXdeADNEE2zMpootIoLa1AjQtQeworIEWmFJWXHHln6maFaemOiJgg98VoKV6XmbSnNj7SOCftPyF9tpKfm7RhyTKLUmAzi9GKGKTtLiBtQm0A46VQLO2DgWoyphqNcEsDDq+t0dQt3ol4+NrKCgsLC/TKHkppDh1Y4/CBVfq9gt3RlN3hiN3hiBhTIdUYQtqIDmuHizJmy9ySW7nHi6UlIxDbwPakFSYbasZykjVbWFD93KCI1DqJTyeQ3/s0p2Igs0bGSW4TUyVSOY9tAjsV9I3YoVsleysNTNrAxMHYSTviTMsrbT4i0EYBLSZB9Fh7mWFQST5UeQhedINKY1kpDHlP4k3tI5VTs72gVsL2cz7M9hD6Gl+Ir+fQ13Po6zn0p59Df8rAUzdxOobT/GOunjGC4ShJeBNtWJglskgAWNuJVknlBPRVSNlMTyrKhWmXerVDIDp5KCEhLFIN6kAE6fdERwojE88oaBBwx0XBclSIxA597qhiYd5rK0u4BAnlmaNoUSZD7Pq5EqChDeg0Q0ICJlQ6r8wq8iyBTSGmRV2AFOcUziu8U/hOrzUyE75WITm/KQE3SEHK+0j0nc6SiPN5Lwwx6b+PVI1jWjeMJxP6AyeuQb0FFhYUBw8eIc8MmTH0iiIJdQdQBa5tcE3NcDzCmErudeqvjQEmrSdrHP3KSTIEeAzGaGyWE5SnUp66rZn4QO0jYexmLKbaxRnwZJQwmhZyQ56lh+89JsiNsGi0DwQcbTfEQsAiEzU3zEChxFGlswWVMZoCngIJZzJqjZknZjEBmS3JjSRGPJY6GKZec+NiZDmHxVz6W4c1XIiwWUkPbDuJZFoYUNf6IVRbGecuJpH22Cks7JuA+zG0VOnq1qIoSv6YCEoFQhJcj6S5nL6XRVNhMEQlwnaOQAiO0mgO9gq2PRjl0VGSQO91om7LuS4aWUirCK0pxN41BFwrJ9MSKQ30MsVwIq2dZRZpGulRV1oqJzInFCYYqZACjYo41VI1CbhE0wZN8JrRxKNUQJvIYs8QnYIm0kwiiwtw5ICMd+dha+RwrcEHTTVp5N4FjQoKncBSmwuI2rUQdbFtWkXaRmEzRZHLfN6uNDp6stiyt3uJatTjeXd9Hs4fo2pq7jh5Awv9kuOHDhDMgKaNHFg5hqqHNPWUx6/s0TSOpoZYRHSmyPs5NssIjWNjWLO40GMxtyw2LdG17LWOy5MGpTUTF7k09ngPpYKDKyUruVSVS6Po5xodA03rmE4rlnKhjlZNQ1VJVa9PJC/Fdel5NyyiY2Q0rmgm0jPeBHhys2Zz7DBNw/EBLGZw38Upj6x7HrgcKAuxro0RmqkIQd9wyHB0ELllKXKop1jMYaFVfOC85vwwsjUJLPTg0AA++wZDaSUWXhzD+WHkVA2bE9irI5PGYbXChbkRwbWOPv3lu/6Yn/rpN/Gv/q9/zde95lYubDd8289/nB/8kqMcXsx58xnF2E2I0dNMxgTXMp1WNHUrGieq2xpK5SK6iuAmKG153dd9Nf/u+/45r/jib+QTjz2Br3aZL+hBAARRGUZpi9I5wY3p+o7/5b/6d6A1brLLm970s3zL330jHTChlCU4x6gJnG1yblnWLNLygbzgtuNrHF4d8KHHLzCJ0mq0UCqOr5bcdfQg737oInuV44ZjK1xeH7KxM+HQgUWCgVAU3Lfbp5pWKKOoJxVt4zi/3WBPLnBw0CfLdnjHw1v86UObfPlnHWBj7Pjg02PWFkuUUuxs7PFFzz3MsdWS33j/JTauDPHVmEM3nqBnFK6Zcu7imOWFkhc/9wTPve0keZbxH3/57ZiFFcoDh3nHA2e5++Qqr//C5/Cb7/w46+fP89b/9uu88fXfyj/69n/Mt/zdf0A7rRlGqEYt/bzHPc++nX//T7+FqvH8ix/7RU6fOsVCYXn9S25AR8OlaeRX3nsvIxfJez2auuWOwwN+5vXP4ezpyzx2bpfveMspvvSe43zbF9zOD7/tUW4+uMSXvfAm3vP4Rc5v7nH6whYHl3dYLC1tNeUVz7uTz3nuTfz+ez7OS2/u83dfeZivaaec3Y38+ablVjWmmXZgUWBxoc/v/up/4uDqItPxHl/4Vd/KQ48+wZzRplBGtJq06c3LnRF2hw3v+asP8+9/8r/hqlEaS5733/sg77/vIX72V/4QZTLy3gFMuYzOdiAE/sbtfQ72LD/8gQvceGyRE8cXedvD6+w0cGTZ8Pj6lM1pZHVlwKXL29TTGoiUvZKiLP5XT8m/9rG21mc8btjbrTBK4VFMfMfqlzarTkslhojRhiLPMdqjoiazhiIz9DPNgTISmkBoA6UOOC16pNZAL5OcZa2MrPQjJxYFkvIodmsN0dD6jLXFkjx3ZJmIefgIrfME51E+sFqKSPhSP0cXOW2IDKuWqm6pnYBmokXFDAgyCqap1QetCFrTosVNWBu0EaZ8HZ1oriIte5lWDJtI03o2hjX93IiUQZ5RZsLKqJtIlmkGpaWXdi8htSoGJSLXnrnxTUj5crfhNwmc9EGJU6PSYCzDuk36r9J5QOsYbm+zfeUKy4XlxLNuZNDvc+zIEXZ2b2J5aZGTJ47TL0uqquKuacOB5QHEwFNnH+XK1i7r23uUyqe8SeG1pQmBYRPI8owVayisJriWEDzTxtMS8W3g3J5j4qBVsNQ3qQVTJ6dChVWRLH2VpejqGBWpqpoQAjmeXClyHWnaliwqlI20IbBdR64MK3pGUWjFWiaAWOUi5/ZadurAduWTq5dsMLuit097MuljUZSZZrGwhCAtPjUBMk1hDctlznEKdK9gowlsN5GNKrJXe1ysybIhe1Vg3ASaKIycqzSTrsHjeg59PYe+nkN/+jn0X0NcPMxZTwgww+z7+URLae1MiynEOPuCjiEk6GFwCdCIgQgzu1dF3AceJJDAiKCX1kkXKSTQJ7njdSBIBygYndzGdGr9IwE/qZLUCXXHkICuLkZ0/58uIkrxA7XvBSq9iZqJS81F51IrqwBHWiasC6KvEdJnKfQMtOrOIXYlonSPJE+TvlmQ95qfoDCoVOzuuIDU3T3uWt1qFxnWgaKOmDqQkQBAYwBLiBrfCm3U+cjEQ4yaoDOULdA2QxszO8/WR4aVI0SNNRW5MVijcek8dADvJDh0DiwxQlvNmhBFKyvIM9GpN93HyCBKVStXIWkpCVqsVQILZzdftAushp4RNxHNHAhNMXc+fmYTYb4sWK3T2BEdshbFJEp5MFpNrZNNJFBoqQwtZYjQZlQUVk6oCdL3ajWfEa52IXicDzTeY7UhBD/vT1cxDfYELyehX6UVWmkU4J0TTY0AyiRrUQDt6FpZSS6WpIU4xEjdNhB1apuVxE4rxclDfbx3TKsJPn2GNTJGBPCU99QaitwKSBgDpnJo51HOkWtDaaS1trCwXCj2EBdCF0Q8PoZA3crndi6LJoGXbZ2ShhhmgDDKoDPZf42rpP/mI2WmyCxEAuMqiXe2LcZErDJoDK6N+MZBDFKt1kIddl705UBiT3DJzaWQJMZ7GE3lupWKhOiYVJ7tUcvpnQpByC2HbngWRWaI1uJ8pIktYxcwGJzOZkKSWmmqNnBl2PDIxR2OLEoMXhwscWCxxGjN9nCPYQPDJnLfpkC7zkfGrbSwFtrgs4rCKHqhptCazGuGey0hBjI8i4lqHKMj9mXulYkKDQ0Pnr4sFW2juXHZspBrHrs85W2PjLm41/KiE5bV0nK4b1mymn4WybKYdEpkbsfMoFPlPirRhLNBwHYfpErWWXvnKtJTkZ4ODFKbbigVk0ZxMYtstjBpYNIqSgtGB4lBdLbC1+7xTd/8bTz22BMQIztXpgxC5Gvv6HPxypAzVwwLgwWyHbEtz4qczGpyI8xX30pl4/QTH+c9puX3//xe3vehD7O82OdHf+QHePGLnk+5sMaP/MD/xbv/8q/4iZ/6BYKvZRzrQkR0gzCcvvw1r+YbXv86gpty733381M/+4u4RoSdY3D8t19/M488eYF//33/lD9/17v5rd/+Pa6sb/GcIxmvvjHy2KaCLOOzblzFec+pK3tUU8ezDpY87+iA8uABrgwrPvDYFUaNbIAur484sZKzcKTHk5sObTTLhaYIDdZG1Noi07oFF1now/ntiks7arbRDd7z0VNDBv2cF925wlNnttFa87K7TnB2fZvHTl/m6EoPt7SI832mQdO2Ee8iBw4U5Nbw8BNXuLgxwRiNj4q+gYH1TLKMiztT3v6R0+yMGvJF2N26wl+8+z30D9/E3//mb8BFUCbjtue/jKZY5UXPPk09HrGxs8veZIKPUrn8g49e4JV3HOE5Jw9w4PARbl8oeOFNq7zlfY/y5KUh3/2WTzAZTRlOW3SW8dhmw07YpXKRnfGUT5xf58L6NioGXv3cw5zfmrK+M+E5xxa4sLHDH36o5hVHM8ajmu976zO87GDBXhX42Ok9PkHAJS2br/nKL+LLv/hVhGbKn7zjXn7n99/O2QvJ1S45Ix4/cZwf+sF/R5ZlNE3L93zvv6NpGgCuXDzPlfUN2ukeMTGbUBldhhVcxee/4nl8/dd8OT/9kz/BZP083/iCI9yxpFlbsPynv3Mn73xkyIefGZP1ejy11fAbf3WOYQuZNeQ6csPxQzSt5+yZi9R1g3Of1AJ4DR5lDLQxYGKgaqBuRHi5y3AUpLamkO6bgCFtkKKmD5HWBRqnGDWGYQOjWpgmjY9igqJIG2Jhafv0fZdXEudyFl0epJTCJQYTSNFUK0VpNUVi5KCleBuitFr51FuRWQFDBrlOLm9AauURZnvHmhFmhNYiTiypc8SFgAuKSXpfpQ1lkVo/PcTWY624bFmlE0gF41ra8VwUwe7SWurWCxjnUvKppTWvbR0hiJAuCUQJM6ZWJGphFOxOW5xzIrJdGDZ2hvT7uyyNJ5i8YPXAQQ4dPUKv12d5aYnptCHoyMLiCr1+QfSOoshF70lrhlOH1jV5NsVkuaxTmaVU6Tl4z27TMJq0fPziGBVFW2dYeVwUakEbW3KjGFiweHCR8bgVLb/oybWeickHJaz9SmsxLoqe0NSEaFDGUAfRkro0rMm1GP/cuFTMJCS2poHd2klLXpBseh+ePAOguq2HRyzaxy5iI9QxslQIk26hMCyrjH6RswqcH3mm2469ylNPA83GlIAmxGQ2ZUxitly7x/Uc+noOfT2H/vRz6E+d8RQ6iGn+zvsBp6tem142+4vIjI7bhRURyRYwo2M4dQugVnHWOmdnejxqZl2qlJq91+xLpWmaVPs7ppVO1ZhAnIFHXSAVQH+O5s9Pvru+BAx1gNA+cA2l5gVkEuiT2q90Ar2Uks+dt6PNGTndojv7vMjs5zp9SOzuu4IYugVgLpTdXcgMDOxOXXVObDBpYdxG8iaKoJnRZCk+ah0xzhOCx4dA5aStDQzRWGGs6fnC40OkagPgKLKWMosUmUnaWnItjQu0LiTKZ0p+XJwNlv3gpQJcYgtZLbTxXCfFfyUIt9r3TBQC6gm9XLGQCQXd7BtX3dGhr93PY5w/d9NNSKVwSkm1JSiCUXijaFSn+SUuH1k6txgUhUnspkT72JpCAAEAAElEQVRVrZ3C64i7ttdLINGag8d1FdUYZzqw8njmjMbumMF1ieKbJo38pht/acHs5r38oZ7d8Nb5pLWm8F6qRM4HenmG85FpnehiumNBxtRyq5OTJPPnkZiTKmlKdA6ZSslzyY2SHnCYaRPENAal9UjRseMUipCcCnR3F6IkxsqAMpF66tFpkc0zjTEK52UeOCead4qQWjktMYidqfS0pwXFi1ZdUPvub0xWwkbGng+dswsoJcn4pI0Mq8jm1KGF/8fKoSWi0ky8o21rpo1n4gKFtmCkXUIreWrOw7ByXNiZYHQpWgxZjlZW5lKUOTr2inOCOhNdSBU8ua+LlWMhiwx0IE/AsE+6HqWOrNgMqyXZ6IoDfQOtE0eO7d0RRW5ZGBQs93IyDZeHDY9erDi/13LboT4uJsq+0fRsoMjkOWkUJkZ0YsdqyelwMWKCmsXTLo5Ly4HY3xoNmYrkSoDj0oAxUnGsg/SthyiOP0Um88B9quWa/03Hb/32mwFhB4x3awaZ4sYlw86wZrd1GLM4m5MqzROrSWKvwiId721z+eI57rv/QdY3Nskyw0tf8gJOnDhBCPBlX/r5ZJnlD/7wT4m+IsaANrmAUKElAq98+Yt5/eu+iugdvbLHT/3sLzFb8Il8+N6PcXF9yPd/97dz/vwFPvihj1A1DaXNOdqPPL4l7IPVQcGlUSsgCpGVXHPDQoZZLtmrHFeGzWxzqKJnsShZW8g4s+NF58UoTBRDiLLMGVWOGCO9TLE3balaMagoc4tGcWGn4YjW3HzCcs5IYnZgqeDp0xUXN/Z4zrMW8Vra9YYbLb4VIKPINEpFLm9N2BxOAYXNMqwGExxFYZk0nsfPbuOdp3Wey5s7jM9dYCX2+cLPfwmrK6ssLi7RmD4UCxw/epyIpm09eSaOf62PfPzcDrcdW+HZRlEO+hxY7nHz4UVyqzi30/D2hzdmOUFRZFweO7aaCcuFVHnPrO/iqoqF0nB0pWBja0TlGtZWF9iYVGzuTnjtDYf4+KUJb39ok6MvPEoTAud3JnjsrID2Wc+9i7/5FV/CcG+XCxfX+dB9DzOZVOxnOy0vLfP6130teZGztbXFd3/393DlyhUgcvzYUbLMcuPxg1zZ2GY6rdkvSm6s4fjRg7zshXfzH3/mvxK2L/ENzzvIWuE50DM867Yl7j09ZVIHTGbZmDgublWsrS2RJ9e/pcVlfIRzZy+Kg9hnAPAUXZAvH6T9xc9ZHl3O2pnUwDzN65zRXEiOS61i6gzTNjJ1wiBvg8R8rSX/a738Wxjm0jUQkc+U90tFwO6LRORPmz2T1twY5f3knGMq5IpYcudyVWbSOtPhBhE9k2Poqqsx6nQ9nRyCZA4htSs1qbvAaE2RKZwTEKXx0o5irbS8qARu1a2AAMoYMquxxiT3Yfm7+Z5Ach8fIlXjZ3nybB+hZO0IKb9tW2EHFBqG04bdSU1Vt5RZjyIvWFxcIMtyosmYNFPqNmBsgc0KojEURU6eZRhrqF1gVDm2xjWrlZu13M3yDTph8UC119Jp3PogCasOAaUc0WoOF5K7xBhoG8l9Ci2tycbI90pJrqH9/B5r71AWiJrGw7iJrA9brBbzn+Uin+0Zpk7GU9WGZOIURbeoe5L7cnGl0thKe41ApEX2cbkRIfwFNEvGYBTstJDZgI+KxkUq5ygzk8SQpaVUJ6e/a/W4nkNzPYe+nkN/2jn0X8+LK84BE5UqMSLRtH/ydAFPKmOdtk6MYQaqxFS1aV1g0oSZSHVXLbGpBzQzSlBTKVxgFAQtbXohpAQ7DcxPIjqmeS2U2w6sUSoB0jCni0Y1A75iur4ZoNahI6n3VaojKgEaifLH1cFCazBWYQyg5/22Kk0UjUZFLe16UVBypQMmEyaYkf6vGYMppnNQadDI+cX5NXbnfBV6pnExowo5e43FTiNq0qDqIZ3GVWfr2U1S6KizGUWWYZQFY5JNrEoWuYrGBXz02LqhjYEmGtrWUbeOaSUigd1gRs+pfjG1ZMTAbHx02lmVC5RGkWtYLQ2lgVyDIb1XmAOMWkPPaAqjWNxH7Z7FIubsurB/LMSYEg2V0Gz53itLHRWZV0yNolZwlSmzkvdxgWTpKXdfyeWJhlcCzq71Y+hFGLBpI3mRJgDizBG8x1uDIrWSJtcUT9jHCFRShYhSzQlBUO6mAxl9JM6y14RFhkjbuiSWKovD7rTh9PaY9eGYIlMMesKa6yjCUSsiGqc14wZ2KhhtV/RzzfFlK4ullj5nsPigicrhUFSzvnBJ3HwaOFKTkhFhVCpOeYU2GSppiem0MGudaM8+4tpIYRR5bugtgouBy7sOnQmAWeYFWlup9KgKZQI2j1grlazou3mswFjyQixYg+vmCTL/I0IrToD8+hAujiz5tKQfcqqqYjIec+bKFlorrNFo7VNLQc4Nhw6yUGYsVjU2N7hQkcWCaR2ZthUm3yO3Gte2fOLclEnlUGistfRtjlJe9MqIZMrgI4wbz9bEE3uKuw+XWAI6eJrGpgQGTg5yqZapOGtRVlE0eayGpg00ytBoi9EaH8XGuqOnF1YSdGUU/QyWczhcwDhIchW8QinZUNZO0YSAD1L9cR0IHx1E4Q0QpXrTRJgEaKJY7U6TD0FhkyaggaWeOFW2QSrt1zrjqWt1I8J4a5uzNfz8/UP+6QtXuavQ/OVHzjEdVVKdnFaYfklRlihj0Um89Fn3vIAvfPXn89q/+Tr+yT/7l/zSL/0qr/rc1/ANX/cavuNbX8/td7+Iz//sF3L/h/8E1enzzA753tAQmhGmXENnJURHb/lmlDaMN5+iHW9S7WREAn/3jW/g677mK3jF53wR54d7/P4TGltX1MMJH3p6m+NH1rjh6DK3LkTWa/gvDw+pP7rB4dUBX/SyO/nAg6cweL7mFcd49/2XePTRXb78RTfw+KURD50bog4t4gLsjhvauqbMDat9Td0m/YS84FnHSu44XPLfP3KOK9sT3vHBIV/9shMorfij9z1GVmQsHTxAyA+yO5qyvTdm7/JFjNUsLA24dHmXzGpOHF9lc6uiaSK33XKE7d0Jl69sc8vJNarGsb45oa48l4Ytb/qLU/zCz3wnr3zlK/kH3/+T3HXTYe6++Qh/+M77WFnq8Vl338DBO1/O6s0V33Bxg7e8/S95+PExuq14zyMX+Pi5PerguXDxMn/+kUdxPpIVBb1eQdOKVXtd1bjWsVhYfvjzD/LRC2P+873n+aa7lmlC5Hf/6jT/5uUL3L66yHd8MPKqYz1efCTnzzcKTm9VeO9YbxRtsDQxY7EnOlvTUaC3dJDVE3excszxxqM389ov+2K+6uv/Po8+9nRKpCIxdhY5aZEmQBR2yu/99i/xnLvvxLcT3vDGf8yfvPMvINSgLNoWHLz52Xz4yS3+3v/vZzl3aZNqXPFjf3mG//Slh1jRkdf+2EPccGiBF926zIef2CZi6C32eNVtS4ymDe9++AqDpQF59hmw8O47Tl8ZUTWBae0pM4UKnrZpIIo4bmbnkEQM4tyktKFuWhrnmVQtw1xyo9wodiaevSpQORnvtQuikRJB68D2NBBUpCgiJrkAjyvHXtWyO2lY35sybjzDJlAWOdYaerlOKJRns4lcqVv8rghY59aw0C8Y9Avy3BKCZ7lvGeSaXMtGsnWBxULW9GkbmLYJMPOR1otzWQyyUxWphJCKvAIG51axMjA0raNpPcNJO2NNrS7kOA9704ZJ4wlocpOhYgZeUdc1bdMS2oY8m+8/OvBEpZxEocgzk3JDKciGxHT3IRCAabQMvWXPZ7Q6Y29vwngjMfjSWjGdVGgNqws9in6fflFy5OBBNjZ32NjcYnt7l2nj2BxWmGyEMZpJ66nrltY56qaVVkClSfw2AQxIrJjQYrLIgjE850BB4xxV4xlVnn6mWS4tYwAd6ZnIopE9xvlKz1gMC5mwnRyGnTawUyOdEMmEcuLkvhNl79UzGpcb2hBneln7i9sdYGcTI65v1WzfFKLk7qUR7VtPpPKB80PH1jTivLiVRiXAQy+3FFZRO59cxa/tRfh6Dn09h76eQ3/6OfSnDjx14IdRGKtSS5kkoiHMsCe5bfvAEEXX+qYhhLkmT8d4amVBciHOWuSUkYmDBpP6YYWOCUFHGWBpEe1Eoq2W9+zev9N8skqJcDUdw6gLkAJ8BDrB7yTwnW48+3EcOkG4faAU+75JD0F1n5uYUF2QFkGxNHs7dDFRakkAloBV0roW0YQgiG16MXN+KwIe7f/8LqSlCo/WFpuV2KyHD4qqrhgNd9CmSMu3MIVmoOA+faQmtxTWoGkYj4c07RSjJSGyWjMzC00PVukkChckqeiYXVqp+Tmr7twVs/9XaiYuPnPm04rcaAojDCM7A+zm1UCrRSgzT4wnq5JIYexaOiUwh31/G5HFcz/oZHTq99caGxVea7xWOKTPOhJn97O7v/L+zMA+rRR2H2PrWj+6eeaCJ2BBR4yFPNcpORUqr/egAnQbChHCTxUZVLfWEroxHqRqkudyj1sfaZvunsliGNO9a4MjRKlGdgBhpiO1k8pfm4QprYaehaoVccPh2GOiojCG3ERcEhLMTJQ+ZBWxSlOmKiNAVJ4YDcFLRS52qPP80tKFKkJM+jWpKqVSf2dZCuttVqxXUlnQSautagPWeAG5E8XXZLA4yIlovNdUrpUxFQEfU4VIXY1YkwDlGLDGsnDwOLZYoHWRrYtP03rRYSB241cToxOByKDJQ824sGxtr6NwrC0NcHVayGKkLDIyq6WVBpkvmUmbnOBnwLCOqQ0VsEqTGUVhNMtFRha9zBUr8yeziiMDi1VQOUedquGZ1sRUCVooLdNgaLwRLQAlbp8qKRQqLdVsrcGnhLYwkSYGopL5KItPWh9IWn4xpkq9kqqEDlIg1CqB9FIsiEE2Op2zabfGZFrEKI2RNhYZEJ9ateZ/9xGBjb2WzToynLYMpw25zqFcgnHAascdN6xSB9irAzbLZP5VLfVom2a8zWDtOF/9N76KkydvRKG485ajlEUPbS02y8hygzKWi5eu8KY3/RKvfe1rePGLnk9wDZADOaqj/CpNO93m+InjfNe3fTd/9Mdv54mnnubHf+I/8+rPfyWveOkL0VozsJGbey0f3ZxyervCx8hwPMV7h2mhjhplNHXrqOqWpmrJsoy2jdz31C7HVgpOrmQ8uT6lyC0vv+MAT281+BBZ7meMUwHlyk4NKAYZjKqa85cbquGIxV5Gv8hQEZ6+MkVpzbEja+zsjpiMJuzs7BBiYJAFml5JWWQcWFtiurggrSguklmLip6NjV20Nayt9Nne2sOjyAtRUV1dHPCK5z+LBx96iMefOcuhBc3GlUu87/JF7rhxheFwxHve8wGODvoUVnN5fZvWOXEU85HlhT4nDq/y1KVNWh+oW8fq8gJKwWhSC9NEa7I8RyEFo3PDyFJm+Vu3LXLzgQXyvuXG56xw8dKIs+cbvumeAVf2HO8/O+a2IyWuF3kSRRY9S5nm5YcspyeBrToimpsmaXkZyt6AtQPLfMd3fBsf/PD9/Npv/C5rh49z8OhJprtXeMf7P8y9H32Ab/v7b+Qj936Md7zzXfQHiywsrRBcic2SgGNq0euVBf/oW76eleVFtAr8yNNPcH48ovGR3dZyzJR82Z2Bi7Vhaxo5cWyZvXHDzm5F6/o4L45LRW4o8mubIfHJx6j2tK2wy40R85oss+SZRwdNv8xoE0gTY5y1HvnEWmpcoHae1oGNjlwFciXCsiZ1Csj3Uq0udKRUgZ7y4piUNJr2pi07U8ek8UzbQOMCSjsRetag9jl1+Zg+33ki0PNiLa5T9a3xEd0GilJRZCJoXXvJj/qFRWlpARzVwhLBaGyQQqBLCYJoyED0Yu4yHHfiqtArhRGgtGJUeXmllmcfUvzpcmmtItZoVJbRKzOU0fL7VFzGpV19iHjvkyi9Smug5K7GGIwxLC706S/0sbnl4uVLuKjFeKZpZQ02huCkJagZ76J9Qy+3bG5tM55M8D6kTbgweYwRZmOMYtbTtF7yVK2xQOvcLB3Qad+jZzsXRRMg15peAWuZppcbFvsZrpANZNW0tJUj+MiBnqKNSVy49pigyNEURIrEaNDI+xsChRImyoFc0VeKvtaMXRA2U2TWYhlIubpS9K1ikGmWci0i1kr2dFbP9XW7XL9nFYVcEnlmIHU2ZOm/XZ45ow9do8f1HPp6Dn09h/70c+i/NvCkdAJZOgeCDlNIO/KYAIYZEqmYbfSh6zlMLnBB4RKdzHm5cVELUCO6SvvovgqcgqADPggDR94/LbZpUM80nhQzG1gdIKab3i1nHePRR2ZuAbOB3M2tOL/22UTrhne6NqUSE8rIA+9aBLs/FNxbUWhDZ2vZJNX6EOaAkTEyGTNrCQiqGZ00YMZOFClRNONV5zWfeB0LzRqLzQpMVojWU1WhQkCbQrh8SpxzEnkrAW5y/U2mKYxGxYrJZERdTyUgGkWtRbhO0QFBStwWSC11iTLd3SfV1S/203PTBStItFCVFirRa7JaekpzDbnwy9LzlGeeGUVpkqaAnbfZuRBw6Ry6Z9exxWb4YHo2SpMQb6FuWzStU1RRU0dFFOGx+d+kS5D20KsZTyYK6+kzAXgKfk4VDgk90yaSZSIAmhcyH1GgXES010ICOkXoPpAWyzTGu+dtNOSZEtC4AdXEGVDnE/goY8QREHYjae5kWn7XeFk4cyXPv2dhT0nSO556BtZQGkthpY1AqYYsUUA1iSlpdBKA9KI5FiWwtg2QFsZu3sQQIbl+xM6qBGHlGRvQBno9yQ5U6pdXRiqytpXxMG4jrRcicwjzsdUf5KAsjTf4RuGcIzYO2tTvTjcYw755DMRAZgsOHDyOzfs0zrN14SmiHRDsQFiECCDv2hbnJYG17ZBertgdbhBjw9rSgK3NKT5KxbsscqzRjCdNF5QxKWgG39GmQaluzskcEyBYkpEyIjpxhcYmR48DA3H48lNHndiM2mga53E+cmBgcE7jnZLWJy195jotmlqH1JqcjFQ05BayEBPVP7FqURiVWmvpHGWkRURYoynuzqroauaQ6X1IWnlpzdKiyWZTcky6/de6sKkccsJXhp69JqCjZ2fSoLWmWFjCDCeYuuKW48us7zXsXhlj8yy5dUaGO+vsbFwk5st87ue+is/7/M+j3+uxdeUcV849zbRq8bGW51v2uXTpEv/+h36E1dVl7nrW7ZQ2oG2JzgYE3yYxVEM73WZt4ST/5B//Q545dZqPPfAw/+mn34TznnueczcxRvomcFPf8Y5RxZm9SoCU8ZTJtCIoQ7809AvLbgi41lFNG7LMMG019z21y9e96AC3Hy75qXdd4bknl3jhLcs8sX6JECJrixk+Qt141vca1hYsPavZ2as5P2w46x1333aYQZlTZBkff+oKKM09d99I27Q0dcvu7i6DnmVQGKb9Pgv9goMrC9S2x7RxrF/aJMtkE7y+vs2hQyusrC7wzJOb6CxnsLqC0pqjRw7yFV/82fzKm9/B46cu8DV/80v4xJMbPHnqEt/+TV/GY4+P+ON77+fGJcNCv8fpizvUTYvNDDFGVpcGnDy8ylOXt5OmBiwtlgQf2NzcIy9zrLVYWxC9iLg+vuO4fWD4m7ctMs77rB4qeenLFviOX3qaR85P+dVX5PzX+2o+cH7K59y0zF4hi2OB52AGa2uG9SpwxSsWFhaJKEbjCaDxTUtA8Y1v+D84fsPN/Npv/A5HTtzEDTfdSjXc4M//7B38/h/+KR98759wYG2Vd7zz3Uwrx2TqiN7juzK8kjlY5Bnf+LWv4eDBA7i25Rd+5ue5cP48WsHEW6LOee2zLH/wRMXjO47bblrBru+xt7XHuGqYNh6tILea3Cbwk8+EucusvaT1niZYAoo8s+S5x4RIr7Cy9qrUgpLa0ro2u9bPgacMLcCTnjuTdY5DVkVyLcBToSOlDtSp7W5ct+zVLbtVy9R5GifOYjTMug66vCvP1Mz9vfWi0eS9MISkLVAnp9/AcmnIkyZUNQ4oJVo/qIBqRbdIpVwuWE2MEr+71kKjogBfPrLXBPLMkGeafpmnpTkyqhzKKLLcUPZEM6ltAz44fAgSz60APGVZCPCkjTD1vUd0dyQHcc6RZaCUEZfLCASFMZa8yFlYHNDv98gyw+XLl0Xz1GZM6hajNXlmyYzCO8d4b0ioJxTWsLW9w2g0pnVOWp6NsCIya0FJ4VkYYKnLQyewoZ3vn1SSgzCq03+RNrgyUyxlhqVMUxaWfj/DLlmqGLiwqxjVMraODxR1ECHiK6NAFjxWa3IihQr7XL8FoCxNpNCgc6i0oq+VuAwGGCcxY0/EK2E6ZVqxYBVLmWKt0Ggrml6OTl9X8mOV5nzPanIjxANpl0x6rlp6ZLoWw2uddnw9h76eQ1/Pofm0c+hPGXhq04IQwnw3LyhuFyw6RGL+NQMaQJBArTFAbqDRHWspDWAlaKXE3TkzJTNC94+ACbLRN3rOP4oxJMc4lR78XBdIcGVN7PzeYsdaUYmWuI/a1p1wuoF0YEx6YN31qg5sS/dXrFIFLEkEmhkyHZo4sz69eW15xhg6vztmWLc0k3Z2n4jCtPHeozPpHdUmCbslFNmngeRdEhdXarZod6fZaWERAz60jKdDgq9xLqfIByiToU0uJ59QWTr2kzI41+Jbx3S0xWSyx+7uJtFVGBVkwUiVKlJVTrtApx0qlr8dotwtogmoSTdXJSZaR6nOjGKQKfJEb9qtPFMt/fWLtusVl6pRVLKwNVEonDpV9nQKrD5Kctb4LljKM+5gL5XAxzyhVQbSQhDFNWKfwFqcjxq6EbD/awZwJrZTpj+1Cfe/8zAIsu61gL11G2la6Z3uQNHgEQprctdQWhiOWnczLqRWWZ200wAlugOCinc971Kr8wR8DGglriwdnRx0B7KjhXYoYGyaciZCmRmKLJJlQWi5GWTGYIwsut4Lrb8xMu+JXhwao+g5hAC1D/KZJmC0QaNx0zRmI/uqUl1lA7wD30qbaW9FofMIOjKeQAiOEFpe+5xbObTYpyHywWcucmprD60NWm4be3tTstyQ9zNM06II5FnAqYBzMBwprAWbyVwyCrJMEVWGMYqm2WN9c8yOtRxaXKDsGTKVU01rILHtMouyll7RY286ZnNryLlnPk4TxUggLww+KELwjCcNxmhal+xcDVgdZ4BqBxUD2EIWxIVCs2QDPra864ldDvUyDvUyji5lKOXxMeCcsA5bD5cmgVET8L6hSPM2yy2bVeCZYcOCMSwWGpNJu/GMzQlIhJBEOzMRa4TZGpVKFtyQ8nZiiDTJmCIVcmb6ezEmPb9kyquQKi0xGQCkeJslG3KJUyYtYdf6HI4oY9BZxsPTjGcdsLzpq/v88r3bbG2O+ObPWeFtWY8PP+P4i4+eZm1tmZPHDnL63CW80eS9ko994iKnLv8Zv/wrf48QAwfWVvjD3/7PvOUP3saP/cTPY2zGbbfdxmu//Mv5uq/7GlAZShf8wA//BL/x22/lHW9/C8tljxgcz3ziw1w4/WhixpQ8+vgZnveCV7K1vUsMnunOBX7+p3+S3/zVX+bS5UvoI0u8dzMny3OOLjp2xjXaZrLpqqbcttrjuSeXefP2Dgul4dZDGU9faiAEXnDXUT5wapd3P7rN829aZXsa+L1716m9sAbOb7coLWvUsZUVdnZHjCY1L79jmTPrE05dHjMNikVrOL5S8pjRbA2n3PfAE/zID/4AL3nxi/mmb/2HjMa77IwrYr7IsPE8duYKdSsJtoqRkzcepdcv2R3X7IxqxtMNPufZy2wOPQ+c2WJxZYmzlzb5tz/z27zmZc/mta96Plv0+dwXLfFFL7qdt7/vYW47eZTf/Lkf4tff8qd8/OFTPPXU45D3KAcrHD3Wp3Kex54+zaRyGGs5uDZgc3uC954i1zPmhAotN6+UHB1k/OXpIfdZxYmB5W89f4knN2r+z39/jledWODL7jzE637rMnccXuBv3HOYX3uiYn23AiJ3HCpoAvznh3dYXSz5nBfezE/9wi/xX37xl3nOPS8EYOnAYQ7ecDPnn3iUve0tCJ7/8zvfyGu//DWsrizyr//Nv+Wf/ovvYmf9PFcunsO5lq/9W28gywuUMly5fAGJLxYI7Ozs8Hlf9NVoFYi+5tLlDQ4UmhccWOB5qzXLtPzAe0ecqXN2nOWBx9Z5/hHL13z+QX71I1tMguau2w7x5FMXGY3rlOx2ANS1fRxYzIXR18BUFII5uKAZ1yLuPK4dShmsMQQfZvo3UgATXaY2aOoQqaOmieIqNHMbi3MtqCZIe0TuFSOnaUKkDpJDdcUzo+faqSGmgiiymdBGsdIz8vnAZd9ijUqMdNm0zCU3FKNGdJeMAhelzaiNkUkjwvmt70yDFCGqpCfSPTNhIfVz0TqZ1KkLIiiKXPRUgo9s7NWpdqq451l3Mej3GU+mnD57hq3tLZpWNkhRaaaNBzwhNgJ+Kmmv09YSY2A8muB8hOhYKiT81y5QeQG+x9OGnb0RAIdWFin6GXmvz4oXoK51AW0MZV6wtrjA3u4eV7Z2OXXmHDvDMXvjKTYvyKzB5pbGSStOk7TjTALvYsr9Sfeyy5EzLYyilVJA9I0GKh8ZGrjRapTSFNpwaccxcoHtScQHS1Ca07tOdICiQhlDi2a7EdbZuPZMXWC50PSsYrnUlFaLDlMVGbvAbu2Zio45sdtTkLoUEqvCpX1UGyMLqfDq3bw9LzcKHT3RNeyOWnZGsDuGSZSuhsN9TdN6mtQp4bybMXiu1eN6Dn09h76eQ3/6OfSn7moXSANRaG4hysY7zskhVwNNdBexXwwsJs2lTtRPzdzZdGTOSNm3w4+JPtNd0/6usxkEFucMJvb9LjDXSQpXvUcHmjE7txn4tO9Q6WbPPit2r+0uLv0u7D+vOPs+pA81SrFQZBSZTMTt6ZTKMWNZzV5PxEWflDzizAmAdA1x/rFz0Hl25z8ZjPPE4FN7pFRc8iLHmBxjpU1i/gyEGmiMhejBO9x0V87DOaJ38l7dsyGhpU4ij/N+xt7SaVGajQ2YOfN1ZzoDJlWH8gttuEjOCrmSip21yTFOK6zZp3GlIg6Y+Mh+oLF71i6kZ5/uSuep13X8uRQsdZAKhiMBVUi/9b7B2+H3s7sL8xRXp2vpGHbX+pFZDU7jtZEqSkCE4F2iDytxI4zJ2jbN1DSXEnre6bl14z315fsERDov7yF97jHRT8N88Kr0xOIM3xXHngCdC0hEnkfVxpkzojGKqCLTtqVJoqI6gYVt6M4xue6EeTwIdK2tCTxOKK9SSOdH17YaJAh1TLbu+pxn1vdMCAQfaHwgzw2L/RyTkWxcA9FrogcVFK0P6fMjrpKEwKnU0gsptjFjdnZTRIRFHXU9ob+8yuJggZXVw/R6C+TFAmqWqEeyzGJsRlH2aadjJsNt1k8/QtO00hahMgGVUYynNVornBNxVY0m665TQe27ag3JOSXSti3LK4ss9TL6gxXW8shqFlnJ5PNDDGxOBRjIVGSxyOjlikvDlu3W4+vA6kCcS0LrmTSi+5CpudOoFA3kZusEDAsr9mrVvv2x3qeHO4vpdPF2Ple7ymJEJQOCmFoL5Hp19zO1/zOu7Un8t//2G/jEY49z/wMPcOtBw3JP8eClitWepZcrPnF+yOZehXcOYyyNCwxHE9qmxTtP8IEHH36MIi84feYsMUZ2dnb5vd//72wPx3zhF30xAM55/uoDHwal6fV6vOH/eB0xwvLyEkYFHn7449z30Qe5eOYTPPjQYxAjZX8RFJw7f5EYI71eyVd9xZeSFyU+wB//97eRGc1SKWKyEWkXC6nS2S8zag8XdhqcD0xqx9mNMYpIbmA4acgUmNywPaqZJIKC9wFjDP1BwWgyJYRAP9MMtaZBsT1qUUZzYK3PeFyxrWChLAjGYvIcpeHpU6cpioLMeKJvmYynxMSqLXMYjyoiisXlJaaVzK1emdM6iQebQ8/EKfqLfYL3RO/p9/uMpjVXtneZ9Ep0acisZVBmtK3j6fPr3H3XrfR7lqeffFTcjtBUVUXAMQyOthH6flSBY0slzhvObTbkucUYzXhYcXCpxz03HeD47SdgMibb3UIR2Zs6zm5MKW9e4cBSweVxoL/XYrOGRllCCnIbVSTTcNNAMYqBNihuuOE4Nxxa5PAg8OATl9ncGbO5N2Xj3ClcI4DV/fffz+rKMl/xFV/G6toByl6P//y7v8MDH38MgIuXLiPamJrFlQXKhQE7G5uzotz5c+eI0UNoAM3ycsZLj5Y8sdHgFdy6UjDeU+yNI40PDOvAlYml6JUED3XjqFvZNM2Pa3vTCpL4uyCOSUbJGjmtW1onhV1JhOWavPfJ1EdyoI713a11TUhOdIieS1RCF5AiruQ9AY1H45TGq6QdlGjfHdOmy+u6EiFKGAedXMVsxYkiD9F6j3ECdulZ/tU54knBTsAtYTDUSfcpEqV9Q4kgsSIxrEDMXVIwl1w0vS5Ke6FIN6RcLqrkhp3OOC3QMQiLKSbgyShh0TgvrU5KayJ2ns+nlo0wWzuYdQLElNc2radpHc57bBIo18ZgUKLNFKSJwGYZvX6JT86fIXhZa1VyjXaeaZ3Op3M2I5JpPStmO5cKn+lnRit6mWFtscdSL5PW0ugoosNmsmFqfWRz5Bi3gcpHetpgrGZ7KG07bRCx5Ci3jbGHSQcopfvQFfY7fd4OwJT/zvOVLh/sDh/l/du0eSUBUS5q+QowaQOx8gQv+bdVSKuUSk5aSqV7LrHUhWt7Dl/Poa/n0Ndz6E8/h/6UgScRAI84F2fq9l1PbwfiKDpaqFQH91MoY0JDu0khwENMlp8qbebj3Clu32TswBznAy6IqFYHdMRUPRGgQXVqRbMJ2bmBzANpAhliB0ZdDdrsT17mbgTdj+MsAKPm1x0SgMHs58xa6Tq69KDMGJSWIjNcGo4YtfLCmHiXIUgbIQp0ou3FblTse5ydCGPCp2XCEWeTSea2T20QhswaiqKk1x+wMFjEZjlZVmCNTa4GzNwksjwXanzbEqo9mukIFbwATz5cNaicE6ek1qnE1JJzNilRMTqNj6iuAieZXYfcVK0MZW5ZXizp5RaFxqb0YMF4MoJ8qe7q5uNg1CTAKwrNXMbf/LkJ0tsFcObjqAPEABUCXilqpWiVxiuzD9GTsdeBWN2Y0ASZgAlA68Cxa/3oFUbQ6SBVKhcCdetpGqlGmgAk4fsQpS/bKAFQfZDFLSbBxJDomXI/PW0I1G3EtcwqLjHZsHYTqANPBbSLBJRURIOiDdIbb5Tc6ybCVhUYNwrvUyWDyO60YlRFahex1uJQ0h6JiGm2yWo2RFJCngTvvMargEq0XG3AZJrQ6DRPQ6KGS6VXriNSNykm6YhJSUCddDDIYHlB6PYxREIdUN4Qg6LREZoWNY7gJZl2HXMP0Im1GX03bpQkyMrjncOPHLecuJETx27g+NGbKMqSoihZXV4BZI5bq8jynKXlVdqqYm9zg8uP3sd04wrj8ZCQL6WFWbGzN0IpRZ7J9So0hZVnEaKiSraM2iQdAxdwVc3hu27k9hOH6A+W6PkheTsi7I1ltSfyzic2mVSOQ1ng+ScWWOjl7PqG0xsTLgwrbl4NeBconGd3oqh9pE/EpYAQEos2hG7RVFctmRIDuwxDzZIzxRxc9l2C3K2eSIKio0JHaQ2wKrFI02js2nq79ejqyH9tHr/y336Rn/jJn+Zj932EL3mW4fyu51+8c4vvedVhVkrNd//ZZdqmRhE5duIY06rhzNnLeNcSvCe0Le9+93tlrVCgtWE0rvgX3/dj/PN/9p38yq/8MkTPW//obXzd17+RP/yj/87zn3cPH/rAX0g8Dw5f7fDHf/RWvuf7fhQ6cWllWVo9gDYZzWQP72pWVpb4uZ/5v1lZPUjdRp7/wpeyyC7POpjx8HlDHWWhb5uGGCNHVldYnwSe2txh2rTUreN9j29ydMkyyOCZ87u88ESPwws5b39kh5XFgkMrJTu7LeXAcvLIEp94ZkJoPQMTKAtL5SIPnxtx/PCAW08u8rEHTzMclYx1gbc5vYWMsrD8zpvfgiGytqyJTcVoZwSMWV3pc/DwKrtbuwSVsXzoAOvnL1GNxxw7tkbTeqaV4/5TQwZLAw6dOMzlsxewuuAFz72TM2dO8ejp85y8Z5lhrlk0cPsNBzm/vs1/fcs7eNMPfjvV6E7e/Y4/ZatqmY4b6sleWuMVuQ14L0YsX3LXAdoAp9fH9IqMLLNsbmxz4tAyn/eiO3jxZ9/F8NQpTr33g5weevbGNd45Bv2C5aU+Sime3Kw4tdvy7NtO4NqWzRh5ZMtzQ1/zlScy3ny25dJuRfCOF911jPZLn88TZ9/N3t4Ok71t9u18+Mmf+jne8c538ZrXfAl5YZhWDT/6U7/E5cuX0m4ERNvEcfTGGyn7PXY311OxDWJo971f5HBf85W39fiu921wdhz46S+/Cf3MlK3zFbuN5sIosnOq5ejhVaZ1y9MXtglobF7QTCfMV5Zr+9AmASA6kgHRBzb2aia1l/VVW2LScJE2RdEeyoy0V5gEFgUU06Cpo8EpIwXdVNWWdglNVJqoNVGbtFEWTSmlDFqHZDCjZsXCLtc0SosMgZEc0wUBnFzS+Zg2bg76EGeVcu8lYwox0sakKYWwnVxKAzpNJeel3SvTzFgcjfO4KDlAUVj5vBgYV62w/IwBbQhKHPOG44looboK39YE39JUdboPmqiMnHfjwWTiCpZYXeLWaYhBPqN2AkTFZIgEkuO2ztG0jmnd4G2L045+r5TNqPa4VnSv0IaVlWX6vYJTp06h96QFL2pNDIEYPE0juWqbWhO1gl4SEFZK07RGno82xBjIjGZQWk4eWuTw6oDFpT5hOiFWU4pKQPnKBS7uNIzbQJ5ZVpZyjFZsb9QMa0/lIit9A0bhlWLooEoOiD4BeW1U6DgHnbqtTrfDgsSl2De9YhRGXR1gGiLLSgDQKkIVDUUw5C4ynXjqoaNnNLmGgY0MXcQHxbjRZNagDBjVyobYX9ur8PUc+noOfT2H/vRz6E8ZeDJao1T4H964+7AuKKVhKklH8DN0VvABqYbUJJZMDAl8kovpmDKoMOuDrl2c3ZA6VYVcos0KwHE1VbhbNATxmzNwlKA0XWmHzgazA0Tm6DSgO4FwNQvCswA8exHzJCoK8h0VRD+HZxRSmZm2gUvDMWVlyKxie1yL/oEjNfsyGyBRkYQlmensKdKimNhjqgNhOuS3CwxESMr4besxxtFUDVOmYnUYIMtyijwX4CllGzrRe7Msl/sUAr5tUDGQGZsQ+zmlUCaiT/3pco4dRbZ7htZEOptGH9QMkOvONXpoYyDXGqM0K4Meawt9lvolmQoYPNZVKO/AOdG6itJON6w9devZbDxtsiTuGancFlrRy0TQrbRmVrWLkMTUItPWU/vI2HlsbtBGk+cZmc6w0aKCnvWmd+2kskhIC6GMt47sOm+5u9aPTIMpMsosow6eSWiBOukJSEUkpOIKM+ZaalmNXsaelrmVGRkVLkSmjad1AiIaE8BLUDRaY21GaUtpp/Fh5k5pLagg4nSFURwcyLjfnpLucaqSACjEmQFFLzeMnccrCG1gpVAsZHCRQM9o1nqGykWUD6gQaEMAr/BOzRZFhejLBadxyTJRazVL2mNqISBGgtdz7QyjKFRG1BkfeOICHzsl7h1XtltcZTDeYozoJBQavNf4pkt2QXkl7bOJ8prC5DzRi4qojejnRcvZcxdYX9/gYw88hMkMWW5YHCxCBN96Ik4q1ian1BobA8E78jxnYbDA5tTJ3As6sS0TEzEt3FH5VMlIQS0FrplLaFSEukZXE25ZK5mOpoynQ8bjitqLa8aZoSSMx5b79Po9ityyG2pGAaqgaHRGMEFMI1KJ0AdNNBGVy4ZKK4m/PqirHCyBmfnDfDzKvtZ7SbrEgKKrvEjfviEB8ilezfQm9DyJlp74rugw31Bfy0d0e+AriHD2ciConFffeZiDB5bQCo6u7rE90kxrx3A0ISsKDh4+yPqlS8QIRb/Hj/3Ij/CSF79IAjCKre0dvuENfweCIwbH+ulHGG1dZO3oTfzb7/lOXvGS59LsniIfHMRkA2JsSAtXOqkIeL7/u7+DF7/kxbT1iB/+4f/An/7pO3nNV3w9b/w738g3v/FvE6PnyqjhL57a40RfUa5ZHjtT8ernHOfmQwu8+SOnuWM14zknC377fsWxtT5/48Un+X/uPcfutOVz7ljhzJUhT19peMntB1gf1py5PEQZw7hqefTJ8+gsJ8sLNqpA7SSGHF3LqKY1n3iqYm1tiaZ1XDl9nhffdgRjLQ9fruhlHqMC5y41aJNz9MQxbjk0YNo6Lu2MCOUa3gUuPPkMvdKysliytT3BWDEDuenYIlXjOf/0WUyWMZo2vOPP38t0MsY7x1OnLouGYRrDTdsymdb8/X/y/RitqWyfQ2sKReDM5T0W+xkrCyUv+6znsLGzyyNPPs17HtugdZL0t0ETg0Frw4eevMzWuGbr3Dna8ZiLF4Y8XJUU/WX+4zfewslFBb7l65+zxvLyEotLC1zYGfNoFTmtFF9wVJ7jrz0cqUxBXo34lu/8V3zhy57Ny7/068l/7f0wmvxPBqMnhlbAyLqiHW8Q3RRCmwJaSkej48zjj3Lrrbfy7j97G7/wi7/OW/7g7QyWVgRIUJqdS6d4cqfl335wmy+4dZHVnuX9T+7x8IUJ6zstL7v1ILt15MLIc5uu2YkNDwyn3HPncYrM8uEHnpZc7JqHjsFqw6AwFDaXHCS0BBpCkowAyfV01LRti3Oepm0ln1WpWImAT71cQzRYZdgp7UzQWWuxsh/khoXCsFBoBpmiUVH0RpOEgZnFVHV1vtQV0RQCWPsg+br3qMRK1ykH7RhPIlKd2OCqy03jjCUVQ1eZD0T0rOWui7ny9CRHEB2htF8IkfG0Ft1Sa1goRRfLx8C5c2dTG6BnMpngnSdPc9IajTaKxksiIQ5ikbZuZhu+OYXf4KIHL4wQH0AlDajReIpzjq2dHbK8hy16DHq9pC0qgt4AeZZxeG2RzEgh1mgoMtFpiWkfU+aW3FqWBgVN20oOrULaIMZUjJcicHByP1wAbQz9IuPmA31UBWEC2+tTxk1g2Eb6ZU5ZKpYHOYcHGYrI4YUcqzV7tccYi7aG0iYnLQVNJe59lRPnLZVrtNEsWEUWFX0Uey3UITLx0MSQ2nLUTNtl0Sr6OSxmols78ZHaKyoXKVyktCKGXuZGxKB9oKkdhbLCBItQKo3RkUZFVKax5to2C7ieQ1/Poa/n0J9+Dv0pA08So+eQyv/7a+bgk5phs/L6rhVKKL9pqUnvK+hl18s+/5QObNkPXHUgkWz4O4cy9glfM1tQtZKFMiTwaXY2KU+Z5SvdD2fU4k+6xm6hTIDDVU82vU8MEPX+c5A70PrA9qQmNxprYFw5mlaQKnkbue4ZVTDMv7pTVZFPujH70qy4/z9KxMBCoHWeSVXhQ6RuHXXbYm1GnmcCPAHEBGRpESXvBMXa8ZimadJ9VknhPtG0O/ApnUQnhEgCZDrdpX143dVHAmA7Si8xYrWmsGIPK8CTJjYNodXJQjRtdRK7zUWYBiXAU5BzRCkszAQdM2tEhC0FBXGjEOthsXmN5EGRW02WGTJlsdFKqSCNi+75zB75J49PxSfNjWv30F2A1JrgwRg/2yP8D+efrr0Tt9z/e9EV6/6XWIld0pxuUMfCM2nsdHppXZVV3j1gtWIhE8G62sPmNErfOqLFlSXqrojsilCf2HdK8qiZg35KMQOwu4e0/6pm5wgztuKcA7z/j7rgkP4opkW0A2iVYmdcE0lgqDPSOmEUxka0FQA4ztog0jQIgjMrpCoSr5q33cdJIIhRMZxMGE8n1I3HZBpjNWW+BSHiW7FNkcVG0zOGvjEcX8qxxlDmGXlT06bYqbU4aBS5wabkyBgSLXl/cOmuVRikdd1ST6aYeoxqa6LzVE1LHRVeGQ4s5FitOLTcZ9DLKazhwCCjdoHlXHN0uc9k3DKZRDLlMPsH1/5xF/c/n6R1sW85E4fUeYt2V3HvmLbztYerxqZOY1JMILoEX6632/zM2nWv8eO97/0rnn7mGWKEJzdaDgw0zzueY7OMiYssDTKmrafx0l5SKugXVuj0crO5++5n8fKXvUQAAm3Y3t7lcz77ldxy803QxXeE9n733c/iuc+5m/GVR3nm3CZ7k8gdNwyEVTAPHCiluf22m3jW7Tdz//0fI4RA0zR85N77uPOO27nzztuZTqfgAuvDlpsXFIWRjU+WWcoip24czumZ2K5OGa5LjGWlFS6KO1aIEWsM/bKkiYqmaRmNK1ZWcoxGGBIaBoWB0KJSlY4Ui3KTFlDEYSn4BhcdgzIn6gxlxIVNA4WRxN8Hh6sbYmFAa7xw6VExQGGJ0eGbhqwsCQo2t3dnYzVMJyJi2rb0e0XaUEYeffwZekXGLccP4IPHucCBgUUbNWM8LPUKjh9Y4fz6jsS8KIxfdEBby7huubw9pNo17I0bnt512EXL6iDn2GLOQhGIPvLsE8usrSywMOhxemOX1klfwEA8T2ZtV1VV88EP3cuhxZxBr+BFL3ohp89e4PS5i1TjYaq+S+yWI63fVvOyl76YRx59jKeeeobZAkrk1ptu5IWfdQ8vf/lL+fgjT3B5fYv+wlJiOHgmO4cZb23w8ace41U3DzjaM5zelHEsGiTCnkEpBrmhbnQKIeozYt296ogxicoafAPaBtHr0mrGHJpt7CIzNrlS83WiC5RadVVn0YHqWvH2r9cx5VjCHpLnkWlFrmWzakhyB2gWy4zMyFpduyBi3UgVvTPxsQnUyk3XGpdaO1Le3HU3KKUl9sYuf5J11IdwVV4Y9/2jMwyKzIvCXVuIUgEdFL3MEqKi9lAlpptWEe88SqmU80nhMWiFScXorh0lzD2eZguHdGakvCVKfFFB5vi0rmmdIwSHsQ02q5gU41mbSeucrEFaE1xFmRnatkUTKaywnXyQDhCjxEBo0MvJrcZ7R3TNDGCLKS9GqZQfS5th1bRUdYt2LSrJXjReGEdNVAzKHGs1BxZyVnqSWBxcyDFaU+aeLM8TA86kfCUx5wioKML0IkYdaVRX/O9iZBpH+4deimszEyCjmIbOXEhd1VVilbAlXMqp5gCxXK/VavYa/RmQR1/Poec/u55DX8+h/7/m0J8y8DQDHlDMV8h5AFeRmeDyvFsuzq4mIgibIuATPatDzCIRgpotYF3rktFC9+3Yl0rLhBLEONlPJkX+ztWuUeK8kKW/NVphEnVQ3PTSM4sk9EMeyGy+6PQzJSASQOwEvFNCIK/tmvTmIEX3vh3qa3SyLGw9ZzeGM1ZY2yY3DzpHC+g6vGSB7GivcQbyqH2q87O0OV6tPbS/d7hpAz40tO3GLIoYK7oaxkqPOpEkgNe9g7gIGqVYtEqcUghk1lKgaFI10yeQ0Ci5x1lylpHPT8EsegmmXSyaZ03d0JktuM55QtOgW8uAjFxFLJ5paGm8w7uWqhHRuzZK3/jERaq08IaoKY0mWoWyGpsbMqsp8gQ8pcmnQ0SHiHLigjcOgRAUmTIs9gpaXeK9JY5Fx6ITI+/6WruAPCuUdZN0X7y9lg9hZ4kopQlRxsAnH911xdRLbCOZMVhtEnnTIZw6K1oEJFoxKWGM8z1pR9ef9YpH6OU5Rrephz3S04pbFxTeaLbryGObnj4SmA4UIrhnquS6Ey0LWc4kk0Rw6BuqELEhBXgPozbQBo/z0HoNyogYadIjIwrKr2MkqoAtUkLaRmKUkK6SVsbsPsQgjhwK0BGrwVUQgrx/lil0iahH6FlYkWDcMLfSVMx+2dnoXoXMzkJLxIWWiRcxUo3FhIjynp2dEdF5go8URU5EnLys8wyM4djiUQprWKJERU/lAuMmgjb0ioyTa4uAxKXNSc3eaMpwWqO0R6EJUaO0CDY3GDZ2JlyMjnU7RiU/3K3xlCy3rKz0+YbnH6WfZSxkGZmV6/nKOzQGYSAeXhnw6MURf1mts4TDmECLQQVF9JoQ9IzROmMPKumfpxtTXQO1kvYwo8BHTexACRVmxg6dFaxRkCFAeNNN0k5I8JPud5foXevH53/xV88yi995cJtX3dLn+79wkb+8qDg91hxaLZm6SB2E5l+YyJKtsZkRMdy6IfoWYktwFcoWrK6u8Md/9P9AqsgevvkeFlZPs3H+Sdp6SvCO0d4WP/qjb+JP3nUvv/3zP8TmlS26nnilLTorUErx2GOf4Au+8MvwXjZ3hJbf+I3f5Dd/87dAK46tLdI0LVuVZdhI4vPI5THnx5Fp1fCJLcWFpiXkOedGjje976LIq1rLh89WHOvn3HTQ8JHHr3DHjUf57OfdxGMXd9jcGTGZ1hTKo7zn8vaUO25cZXkh596Hdrjh0AJ33bDAhx67Qr9fcucdN/HE5V3AcfLoKqdO7VJPp3zVq5/PmfUxT57f5cMPnePoSo/n336Y+863hAh5PqBxiqqODHo509GYnZ0xo+kCuVUsL5foXkGIItq6sLZCOejTL3tsXbrMzvoGt996DK9ydmrL9uXzHOnDV93Z578/vMnl3ZpX37HMwxeGPHZxmw9+7H5uOXqIz7vnDs5cvMT5zT0++Pgl6rrCe0fR67HcMxwZaO66qcdHzkb+aivy/S9dYMFq3v/xM7zozoMcWxvwss+6lb6Z4tspHzqzzYWtKaC4ODEc7Rv+1s0Zbz3d8thmzWR0kZ9+7CF+fWWZhx68l/d8+H7+zY//HKcevJd6POSqTYbS6KzP2qEb+IM/eDM//wv/le/4zn/O3BZd8UM/9IN85Vd+OSp6/uHf+0b+wd99Pb6eMN7bY297iyM338a7/uJ9fMXfeB3PXJlShsCJ4wMO1p6yCrz/mR0Ggx5rKwvoxSWsrhn0x5y5tCctaTHymXK03rOQKZZ6mlFUaGspS0veRoISNUqrpVhaKwFqmtaB1bP2G2JMAGAXHyUbnWmxAG2ITF1gt3I0QRFUK4wDIgsWVK7AwYaSwGsyy40HBpS5gJnruxMmlWfJpkgcNZNak2eGgws5mdXULrA9EgfMzOik/yRdCf2exaAhQBsVwUWiF6Y60ZFnVoxfQtJvIpJbJUTMKLIe3SjT6bxtjAJYp51I3ThiDMlp24r5Tdo/ZEr0h0IEbaFtWrlnwYsTldIC6KXPsJksyMGLZXtIDmLTqoYowLfWkjsF59KGTPSeQIDkC+dlU7/aF9bRQi/D6oj3Ijqd5Zp+kXFgeUEAKefY2t1jPG2Y1o7GBbFI1wLgtDGyVzWcvbKLq6YcjGOic/jWcXHY4LUlZjnHVnsslZajSxmlkWtQXgqsjYesyJm0gZ3KcXpDXMG2lbjYDWzkaBlZKiK5UexNYeRhvYax65zquvxODmnkIbUFajKrGbaB1utk2CRj0flA7gM6BNkHaIW2mmrqiTrSMwZrjYiQW0eoP1mz7do7rufQ13Po6zn0p59Df8rAU4evXPWQ6QaCfNsJWslmPRJVxGhx6Mht1+ucfq+76iMztEylG2Y15EaqKrnRuCCIbZaAjUigSZGwQ+06pD2QqjzMgRufqhhR4MEkaJiowKm6MrvMjsrcMYEUc8wwygKv0oWrjoY0u+dzEEoCx/xe7UdExSUiPeDuYekEWqW+X656tuqq950/9//Js0i/CwlJduJXm4AijQoK5btFWPrdO62nECWYGEAXGT2r6ReW3EhXZwiaWombiQtdUNT082yGwouWVqB1Dt/4RCHv0Hw1O0+V6M8igBcYT2uGBiZ5IFhFriOuaXGt9NiLIwgy+XONTeh1knhiIZMFrLSKwex7PRP99iGKdpaPIszohWraRGFPifaARkex7fQh2Rmn+31Vy+Y+8Gx+Sdd+8hsDuA7hj537hZqPXTWvusb5N3SlxxA8PoQkkBjEFTDKGOhETyHOLDilbVPYZYlsLPpjIbAf79RG0yY3EJWqu5hI5T2Nl/O2Vmjwe007E9KMWtNGRe3n4yooCD6gtWFQ9sh6A5yPbGzsSjLbJewhENr/+fxVCvJifs981IQWjJ1TSk0mdNSEoMoHawHXXVrEQ4hgA8rJStpdb4igfDdm0tzoxpdRKBOJNmKRVpRMl9jcYDNNM63wjaOtW8qebPhNFtB1S6bUbBuiiSzkBg00LjBtA5Po2BnVLBWaMtPcvNLjMhHlIxujBqVk03NgqSQS2Z04XIxMg8cp0fYY1R5HRi/LGZQ9tieOqYVs0WIsZFZxZKVP9PLgsuTm4jFSQOiYnIl6L+FJid6GSuMHcS41WokgJrLgeS/97DGkfnMQF5nUDpsyjjQUQkqPtSQ9Mc5dd2efM38mnxFHjDz/7pv43BffxWB4nsl4wr/+k02+5IUD7jxk+L0PbBBtTq/M2N4eM1SgjMW5kDZoih//iZ/mve//AN//vd8tQzc4lE6cdSC2I4IbQ3C4ao/oG1aO3cXSwZMsrp7i2MljLK0szoCFrhX5h374x8msbD67UKhMjixs4g89qh1PrA+58bZVir4BIm1dUxl5j9waFnoZ61uO40s5n3vHEn/+iXVspnnjF9zAnz1wiUfOTlhb6uFczZmLl1jfmOJD5ODqIuNpJc5vmWJjt2Y49Zw8ukzbOj5xdptbblii9Ypzl3cY7g7pFZZevsahI4eYVC33PXaROiiMNdx9y2GcCzxwag9VLNAvFKOdXRaW18jynO31KywOCo4eOsKFjSnGGnoLPba397BaccuRNa5s7zLc2+HmZ9+OWsjx05JLmxNCnOJCJLeaURt56wNXiEQODzQfPT9hrwrkRc7lrTGjqef85ohoLJPaCZNEKdYWCl7/ilu4/6nLfOLsBvc9MaKfwT988RJ/8NGLTNvIUpHzYjdkSTkmCi4NI5f3NDeVilDAqSncc0cf0Pz2u0fcfmLArTdE/uBDI77+61/HV//Nr2R5qcd4Z50LTz5CW0+YM53gwoUL/J03fgtaGxYGA/7Df/hhXvCc2/iX3/Z6nvX8V/DEk8/woz/24/ynn/w5/uoD9/KD/+57sCZjOJ7wL77re3nhZz2b1331a/m+7/8hnnrkIT77xCJ3r1kWbeBND25z9MACX/rcZf7w/svcuAAvP6E5t9dwedjiEEen/bnbZ8IxaURw2tPivMYFR936Wa7hvYcorWgx5bfBiySAyg3L/ZzSCBOpbhzjOjCuhQHTJh2ZrkNAqcCkCQQ8tvLkWlqFcpViJmrmgOeJjNtAi2dUOca1Z9J4doyatdXVQbRidiqP0cmJLIoOjEkghNKSW01rj7GKosgxmab1gThpaNtW9EBjIPqA91IsNFoKmJLXSxtSl8tLMVcTtGFU+1Q8tcKKjGJOY4yIAE9r0SP10YubnFKJXaQTUyKCMin6p/Mg0LSd2Y606JH2CmjRfNLWYK3FGktTVSIjEhKbCAUuogQ1o2+kMyOESEibaKJi2jrGYcrm9i4LZU5mDSuDvuTOWjNx0xnLLbciXNyz0kJJFJl4acyMOCXsi8W+JkNsnOsa+n1LmRuOrQ0Sw18+f2PcsDv1jOuWUQK5vJ7runQueguZpvWRysn+TXScFB5m+6uAgIljD2WU8VHoSMhgxWYs9zIWSksRPbmKGCLDJuIQE4nCSXvTci6270opWjRNEJ2ka/m4nkNfz6Gv59B82jn0pww8dQ/j//Xoxm0agHK63YVrrNa0OqGYaSNvEGZSisyA0FFnTmZa/k7AIWE4+RllUc0W2A4Z7Raq7kyl+hPnlDIShR9575gWndgJb6UBrGYBI11X6ln/H+5w96OO4pX+Zvb81ByXC3H+Rwp54nrfa0L6+zjrB1TzD5k/hPSffWjf7CQ71DEml4QuAUmUObH+SM58UYQPgyz+WncOIqBCxIRIqyHXFoWZPYPSJjk7390nuZrMCL3ZpsDpU2Bq2i4oJGHyBD4J8DjXi3I+UDeOqlbUlcJkCmVE3NE5odp3AJpWkcJoCqUosm74Knqpra5IVHCrVWI7yeFCQLlA1JHcQeYVpu3umUpBS85RXPpCemeZXDPGkzyk9HzjvoB77R++S2SZt67+j8fVlMlZYImi1dD9nSdNizTHZRrHq/9u3zSK8hYJ0GNGCe3mbxukakiaahGofcSloJimLY0PtCnhlWenZ88ugNSSQkRZRZYber1cRB+NIgZNmJ1UFNdIlfrSZ3RhUFHovkor2haih+jlZ50LpRaRB4kvbaIcqyguiUmDTmjIs4lCF0UBYugor7PbDsi86AabSRMlM5a8yMgziwrQ0hIdWJOhtCIQ0H4ezLvZnyXxP63SfW+TO5jUf1jpFfQyQ2HNVW0TC2WyuHfybBofCEr0HqZtJCoDyoLSbE9rShs4OMgJUaOVZqGXi7ijc1jTaYbo1PbBzHRhHhu4ii6sYKYTV1i5Jx0Vv3uNTveuG1f7x1S3IMo4lOep0qBSablR+xZY+ZPPjFm8sjTgjpuOkF/Y5Ol6ykNXWj7PO3o6sr1X0V80FKUlekfTWsZ1mK17WkXe8973sb6+wTe94Q3YTIpCx48fZzgcsrW1RWhHDPe2ueWmkxSZFBx6S0c4dsNN3HzLWYaTCZOqolt1pfToede7//KTUAAR3xQqryjBND6yOW5EXyZRlDUBK9GE3Ih9ePCevtXcfmjAex7fwCi482ifdz8IOxPHycM9nHesb+3SNgFtLGVZMhxN8S7Q71mqxlM7OHmwx54TceBBf5FxHZnutATvxMC1bcmLAqczLl++gjGWPM85tDZgc7fiwvkRR48vUGSaMSq18Ri8c2SmZNAvyE0tGpja4OsaYzWDwhLqmqqqscFhdcRYTVW3qX3KU+YZLkTOblfcemjAoLQ8vl7hosZmlvGkYtyMWR9OWFlbI0aFTj0RVsHthxd44twmw6ljb+pZLS23Hyh40/svsT4JvOCmFWJsybVlWNcMp7A5jvR0pEjtF4dWMsYtPLbnue2kYqWU97/pppt5yUtfKmDAdMRw4zIzbRwAFHt7Q373d38fUKytrfEDP/D9nDh6iC/47Bdw8z0vwdgcgPe89/1sbO3yA//mXxFUYFpVvPWP3o41mm/6xtfxp+/8c6488xSvPDFgqRQ9kLNbNccOLnF4qRARZgOHy8jZXU/lozgjqs5MpsuHrv053IaAdgFlQmqJ9UnvtNNDSmtQ6hLoXK2s1lhlILfYKK1czgcaF9I6OV9LYyq4tl5a5pQKVK2Xqq5RsgGly0tTmxeysXJRMWk8lfM0TpjlXdx1adPTuGTFnihY0plgUEhbYCTS+kCuI1prMmVAyZz3XgrQzD43tfloPXNjiuk9u/2ogNeSn1atJ7NQZiTgSc2Kht2aG5LITozCLzFatGUkv0v5wv7ELUpupJm3KnYLs3QkaJQxZJklyzKid4S0gesYTyqGpK7e6V7Jl1FIjhHBeUfrA8PxBKtAkcveyFqs9aSmP2IIFNZSZppBJhpIMUjxYL5Apo4RFaQ4GzWNBdXX5NayPMgJUYDIxnuGtcTqxnkRcQ9xBj6iUhuRUfQyReU1/SzSBGH9RyXMJx/nUV+wNMmdrJZ4lCvFgrUMCks/MyIMne5D4wIhiv5WJ5Cf6+7+MFsjrnUc+XoOfT2Hvp5Df/o59F8TeJr/i9kpdd+pWU9hx3qySkT3vPc4k8AehfS4a5XU/j21k8U4pIdmtSLTSSBQaQGClCyOorCfwpkS/lM70/2JiYYraLSM45j6ykX3x2SFuEYoQ1W3NI2jqdPDi5JoEyH6bgIh616X2KQcp3PkUwkkEqHxrqUv/U1CoJQCY/XVty92bxWTAHdHpRRUOnZC6J+MO8UOPLr66XRob5fro2WNlYBm0dqQZ501ZKRV4nTklUcn61oVQbmA7j47LYRGIVTjrNssIPaOXvqEm8ahMqFhl5kBZSiMlqAUYEqYCcBprckzRZFrsfNEJmbVeiY1TGogKrxR1K0sWLUTC2JjFIU1lIVoERhtkraBprCGTMvGoBPNNF0bI7JguFQVLApHv3L0ipYmQGHNjB3WuMhkWknvfrga0dUwo6t3sS2kaaA+9Tn3v+2YepLrQcRHh6fdN6s7fYXZPyXhSpbYKedMrxEBzE6XIjcCTn7yIa20oGIQRmKITFtHGz3aAj5S+cDFkWfqPOMGlPF4FamAnbZgEsQCWuEx2lBmGbr2GDyl8hwqMpZKyzNbLVMX8FXAqVSl8BX1sBWxfjzagFYmOQUBEUKrMVlEZ0kHJoBv0vnb1EeuEHqwkeSoM7CMPtJUKc5oUHkkGKlUaa2EAhsMUXcBPaTFGXBd/qjmhhMRcceMwqbUMaBjJFMVpYoUVhGsIbSBEDVN04ISKvUgRgqdKPAhUnuPCiK+D5qAo2pb9sYt57VUGo+vjHFR0YYOCA6E0HBi8SD93HKwrHDTEVXdEoOlNAbKiIqOqgk8cXHE+a0Ra33DbauKGHtEpWm1wetINFCUOWWRUeSaOE2JF1HuiQaPwwVH4+dxPUSpzC8ayEuZx5lRrGSahVKhO/1R323M0vyW/UyasXJTY4xS+SFi4zxp1p88Zz8D5i/Aez/yCT7wsSfolxmfffsib/7WW/mRd+3ywIWam44ts75bceXKlF6Zo3SgmY4p+n2sgX7u2Fgf8vEHHuT5L3wFS4dOcvLWO3nH7/8Sv/Jrv8P3fu/3EWPgy17zxTz4wIcocosxFmUKvus7v4Vv+Jov4VWf92VsbG7RbQYJkRDGzIKg+CtLku3r2c+1NXQLVL8wmBQPblspuOnAgMfObbGkPSd1zSdUZCdkfHS6gs8vsTWc8I9//TFGo4nQwYuc3b0JOzsTnn/7GpM68vSVPYrckA9KlpYXqaqapmk5dWnIs070eeWzV3nb+0+RD5a5847bGO5eYTwc8eGPPUE+WKbsD7j1psNcvrTB5YsXuOnojTTREdoJNEP6gz4H7riFs2cusHHpMgcOrzEcjrhyZZvbbzzKeFpz9ukzLC8NUEbzwBMXUcagiwEPPXGWyWhCVVXcdftRpk3g4lbFcDTmyMDy2hceRh24CVUOeNHoLPc+s8P954YsLi0lkMrNtArVUo+93RFPnxnxXb/6fo73DS8+3uOrv/A4Z680/PF9W2xPHJPa8+SVKSNzM3W2xMcfeIqVBcPtheKnr1Rsjh2Zhu0LU6YeCuV560cu0bQOHyI/+fO/zO+89V287x2/gVL26oWBmJJmK3pYwUFaK8p+j9UDK3z969/A40+dASD6hugqCI7JcJPtC08RvENnJdngIEoZ1icNf/Rky5GFg9y1WvKPn234s8tDfvGJLaa15xMbsFHDN7/0GJPW8sftiPWpYVSlnO0z5NBayeYqBtaHns2RWJu3rTCIJAYCKrF6jDjVLfQyVNBYZ/CtJxBxvmOs6PlarULSi5Gksm4DEY+tHSo3KDS9fdIIESnKtT6yO6nRWjOtW6aNo3WBuquIIu+ZaVguhHXX+oB3mhMrBSsLOaNpy/puZG/aorRs1OqmFne7IOCJ0QplDW3rEjgEbQKVQGFmAJbHWMnZgzICJDeib6TI0CqjKAtChLp1hNalWK/IM0umDXtjJ1IXafMYlSbS2Q6BD44s08JicqnTQSli9BCC6DSZDG0iVT3FmEiRa3SuaVpN5aBppA3Xe2GhORXZGNUzHSxjhO01cVFAAB+Y1GP2JjWZsZRlkYgLsnfpGBMn1vos9zIWc8Pu3phx49getSyVmtVS03rF9rThke0JWmkWC8OtBwsOL0TKXobNSqqgqZ1i2ASaBJQp71EhpL2JJGi2tPT6GQulYTFAVKk9Scnf1UGApw7gyNI5LuWa5UKznGuGTtrJlpdKjiyVWGM4t7tLdJ4SRakVk1ZYetNGjIkmFpZjoLCK1Z7CBY3n2hYXv55DX8+hr+fQn34O/dcAnmZY5v/wO/VJP44p8dQxzIL8HJ27+sVazRXTCfOLESZZFPplkJ51F+aidSTAZy6meNWnp17jLk0S9KHrXRR5CkHz5YvZK2eYTgKSRCFezfPqDs2O88tQKl4VbOaXt/+mzCtY3YtnAGUSUZsVYbrr6VCThARz1b2L+76T8+1oyR2DbD5AIkZJX61KqFgwQlMO+5BNEgLeaW3tSzlmoFcHXIH0wMcQGNeO1imc8/hg6VzkiHF+jel9tFbkxjDILT5Ij32WfutCSHRxhdfzZx1mdRNJHEJUMtldSNeX6iSpmtJVVNS+caGRqhcq0s9MCnSKUSPU7RjFRaJ1kbZ1+OQesb92MdPYUt1D2fd4ufYP551UABRIWmXmg3D/gKYLPLJUyvOX+69UogCnOd4N55AS2ZkA3b520RACJt280prEjAvpdRpjDCaCNpI0ZwasFleeJkjFNnjRdxsUGWUtgv3T4Gmio4kCkE5bmDTQKzQk4U+Pk/aDKPRSZtNITk5buWzvAS1gcl5CVGl+hNSKGxRBp9gCeMmbCV4JyJsq1ihQRs3aJCBi81S5SfGEkEwS4jyuzmJrGsrRq1mc8b6hVQEdGqIzSSAuUfsjKI/owmlZ0LW2FJmlyEp00zKlpvDS2uxRsyrdbiVszxDFyUJrOZO98ZTgDCZ6tIlkVoD9XmEZFDBpHJvjljO7FTuTGh8zhhNHbhwaxXo7IXgnehoERtOG1ntsqgaLyK2ajTKQcOvpOtGlEt8t6CYX8Lu0YE2KYSkmhrhPrLb746ggGgmGWmyrtQG0mrlvdi1iszZvWSD+P82r/5WHTwPwi55/nAN9zX957xVOLPZYvLnHn3yixUfR8HMuYHNLnmfUjbQq+6rBtU6SqsYx2tthtHWZGAMve+mL+a7v+mf87M/8HA99/GF+5Ef/b/7O3/5b3HbrrRBarAnkNjCdTmmbBmMt3/7t38bBA2sQA6PNU8TgWTx8B8TAeDLmd9/6DjbXr7C3tSnW8K6lqiraoFILC4zayGYdxPbcFlT9FYLaJg8Na+0OpVYMrSWEyIm1AYVVXNqb4nxg0M8ZVqJlorTGeVAq0DYtOnqslpbvyzsNAc3SygAfIxfPnaeuxkDg+LED7I5aqvGInb2MIi+44dgaFy/tYo3hrtuOsbU7YndvjO4t0esXaCXrBNqSFQXDJhBMxvKhg/i6AQ+DQcnhI0cpipLTp86ysLTMwcMH2RmOCVGx1C/pr/QpVOC+Mzu8dOkga33FXz6zResVdx5dYjipmLaKUaNwaWM9rRp6pYXCMKlbtowmrw3nzk+YTj0HShKbIlIasLGlzAJ3P/ck23sVm7sVX3RDyeNbigc3G2Ebt5FJ7WmVxRsNrqWajNnbvkJMel3K5MTQOYIpvvarXs3a6iq//JtvE1ej7lCKiGFa1dR1A2juuec5vPAFzyf4lne+67289z3v5Q1f+5W86pUvoYt+mdWs9AtOrlpWFxTvOOXIBz1etrLIQxf2OLyYc9vBHh96ZovKQ5bnuN2KpcLyrd/02bz7I6f42KMX/5fPx7/uEZXkL60TTZ0stXV1yX+3HCskBnov47lLTNvEcrJJg8iFkICjQJMKZy6xpnQUa/E2yoavtJIrFwZaI60YnXisUSIyrZWwEDWSi2e6OxdoSeLiWZauJRBpaX2gajzTRorInQyDj5GqcXQZo9WSx3eH6gqHqfDpAygtXQ9lbuikMEKIaC2OVL6tCTEynTZELe5oIFkKMch6nTYRM6fAIK1MIILhwYfEaBe3Yh89mtRZEaW1sXsYnYtYiNA6acdxrcOHZDSf2B8+pixIQWk1C72CvtCyqFuPndbUqU+m9Z7WR3z0hMaJYzUqiatHfPBMqwZLxERDjEEcmwtDmRvKTOGHDaPKcXGnErCwn3F4KUtMJnBOcvK6hab1+FauW7K+OHew0lAUmn5fM+gZ9NTQNpGhV+y2ieXW7TKZk0+0VpSZosg0WaZpgjDq+rkUgZUW8XSjI3mmUS3oIO2BZZ6kU6zGhUBsBZDr1uNr+bieQ1/Poa/n0J9+Dv3XAJ7Uvof7ScfV+Ep6TRT6KfsGRtz/XjLItAadACf0fvpXaqPzwmhyIdLGmAJrWljpbADnAEMHkrjEzFF097JjBEX5QgbeTE8pMlsgOwBKBZjZsylkoF6NsO0Dn66ejN1tmV13+sfMrU6BNjNIJ/23Y43JfVQdytspondvEj4Jk+o+I7IPfOquiQ6uSYuN/KHXOtE6VUI45+c8s4LcDxrFfbchsaFCELAo+EijFW0rA1FE3bXQxvcPmJgEy4ymn1tm3L4gHcw+CPgjvdOdUKaSAK+Yg05BQnnjwuzcNQqyucvhjFI4e0DMnCUkH1AiRolMzo7x1HpoWyfVoe6epr9X+766+/JJn3JNHyEG0fgyklqGfdU/OfYP6NlfiYhfAtykepNmcJS5OBM1/aQWRHnHSIgeq6SHvbTiCBFTsBKKt8URML5zppQK5aAwTFq538IkVInW6pkaRRs8VfBkQQmNtY1UjaIoZdEOXkQSRfcieUFEZg9QodDZbAimhAqyArxTSRTUyyoZEL2GFNi9my9w3erWGT4pnRbVNEJsLp8ZgiI0HUsuzjYbHTA+ewSdkEL6ufctbWxRThFUPqMYC385ooOUPkJMLQPGUGaWpX4G04qdpqHMxYXGK5OS3siongVkESJMrNKd8QTnNEuFwRpJHCOKfm7oZ5oLOxP2qoan1ke4EMg1jKaexVwcN4beE7xDhUCmYDRtaJwnT/e+M0HoFs5uHokOXwQNISW9dZCFMppIZuKMxdih6qG7Z7OSV7eRM0TlZCNDxzQAaa1Oa1DsYOX0Ztd2zpsOjTYZX/K8Y1zemfKDv3eGH/maWzm4VPCWB3ZxiEaRazyZUmSZZTqtaZuWtp4SfUApjbYZoZ3STrYheF7wgudx++238Zu/8Zs89vjj/OAP/Rif88oXcNstNxCDYTrZY7i3LZugPGN5aZnv+Ef/kNtvvxWi58qT7yV6x5FnfQHEwPrGJh946DRN69nb3hIx3dZRVzVTD0HJZnPoIlklG0FvC5rBClFpbGhZbnfIjcLaDBUDx9YGLJWWJy6ep8gNC/2c3anHBcgyQ9N4YusFGFMBQ4AQWN9t2BwHbj4+YDyqOH/uPCHCYNDjlhuOUNXrTKcTdvd6HFwuWVvr88DDpziwtsBdtx1k42N7TKYVRd1S9krK3HJlu0ZpS943DGsR+l49fIDLZy8Qg2d10OOG48cYDBZ55tRFFpaXOXxomUcffhxrDKsrPY6sLVBNKx58+DIvuX3IwmLkvqc3edaJNe48vsyTF6VsXHmF9x7vPK5pWVwpyTLN6PKQoVOYWvPEM0N6GawUUmDKNCzmkNGQG8etdxzlgSd32Nnc4fOOl/R15MmhtGmNm8CkDqg8QxtFaDyZgdIGRqM96rpBmYwYHF1i8aWvfgW33HQDv/JbfwxJ4Hs0GpPRgskZDAYsLi6C0jzn2XfzWfc8h+hbPvChj/Hmt76DN//iT3Di5lsYDvcIIVBaww0rJTetGlZKuG/H84rbS551bJHzezUnVguefWzAr73vDFVQ3HjyAG3TcnCp5Du/8XOZ1PD4mZ3/nRPzUzqUkjiNl+p7YRL7CNlkdfkfSv7tvadp2tkmrPFBHOdUYsmExNT2kcbJ711yjlNB4/G4GCmsIxQiKltYRdOqBFCCUhGLIlMCQFUzMEoszUHW31qBVposs2nz6FP7W0Rrz6gWIV4fwaacoG1c6lyQjgdHt7mUtlFrjBT+kM4EHcQpqsiNSCwk3SqlRcCc0BJDpKprEWPXhqzLJRHQKBqh/cdEs1d4rEltAEBwrWg0IRv6GCNZJnmwD5GY2gVRGucSw0JpvI/UdYtzMg8UcV+emXRVFJSZYbGfszToo61hWjcoFRk1nohPBVUBFaMTsfNO7kKYooFx1UAIqGixwWNzRa8wlIXolzoPw8pzea/GWIMH0ejqOidaT9tC00RcK+MohpgcPjunqgQSZIpekYCnXNNqxTDAtpOcJrdJtkIxv16FsLoynbS5HCZCmYx9IgpSi3GeK3SjMVGRoSkyyQ+tka4Hl1qrZq2E1/BxPYe+nkNfz6E//Rz6UweeolQM9ltCdmCJrCNxBiZFhJhmlRcQIFl5oj3BB1mctFRYQIKfNUIb7oAJm3qyfeiQYpUGiVxip/jes4q+lYuulSwmLkRc24Eo3WSXyevbSFSJVtaKe8b/TKFyRjW76h5A1ELWnTFfFLOkIBU9Zv2PXRiNKGJIEyQggI+W95oBhAmB7EAqpUFngOne/6o3nAMisyet5r9LE26GqodkG6kiQSu0Nl2zsrw4pMEagTCTfkt3QWGMxRjIsETtiC5gfUNQkejAOxE4a1qofZi5EXZJA+zD46JUXAolFQ+FBDdDSL2roJQhM5IktT5idKBqAz5G9iqPn0o7QO0EsNJAvZCzUFict0BGZqTtbm4p2VEQVbIcD1SpyhIjtK2n8oFpE2lamfD2qlue2HEJzZyBUImt9z9hyV5zR5ZYBnIJXVOsVGzm/MAUxGeodmK2IXPUB0UMiqYFo4XyKcKTgRA8hn2JsyL1f5vZaxzgoyJEg6Yl13CgVAy9MOAIBh3BRtC0CPobsdbQxsilvQkehc1BlzkXJ57LU0850KgMTBNpWo9uU0+zseLIYSJtJYUOT2pBtRFlfHrABl9Hmd9WwFqlgRBnTEnnmC1MIUjVrqv2CFA7Txakn15hTJzdVYnnna5CnM33aEBZhS41NBKTmhryvkVlFl0M8DEw7YB8FcmyiE62m1obmQ8aRtOaxb5hkFkGWc60bvBNYCUDMkWdw7gJ1C5iokpig9CxE5U2bIwaNkcSy+84UrKyYOmXhtIqLDBxkZ0mcqkWavIkKCof6fUy1hZLetFQ1462cbggm6EmBJqosFEiSwwyuXzQEPY1tKaqexMU40ZxZQJxFClsxLvAwUxxpND4VoQSjZ7Pw9Q5gNYBHx1GSeVeIllM7QOiH5dlkGVSkUsatXO26zV7KCASg+fpj59ioTC88YWHufH4QRplsPoc02mD955bTh5kNGnZ3BkSVYa20DORalIRfMDVU1yjGA33qEfr/NZvvI0f/rGf4tLly7PPaacTmsmYfKHPD/34L/Frv/kWhsMJ3/qt38z3fu/3cPTIEXmtMhy4KbFXdAZRHHQeuff9bG9tpvUnk/jrPY9c2iPPLEVZUFpFqURn8GjW8rxiyP2F5Uqj+OMzniq1WI9GDfef2kJpzaFDK0yrhu1hRds6lvo5Nx1c5NTlPXyEslewubVLM6259diAxiumTeSZU9ssLxT/f/b+O2yS7Czvxz8nVFWHN06e2ZyUV1qtpFUOgAAjm2hyNAaZYIIBiWDsLyYbTLIBgzE4kQVCBIEQEkpIWuVV2Jx3dvLMmztU1UnfP55T3T0Cf38C/S4YrmtKV4925u23u+rE59zP/dw3tz79Ok6e22U8afjoXY9w9IojHL3yCKadcH5zh8ePj7nh+mNMpw1vfdc93PqkK0lK86GHzrF/fY2iqJjsnqK/sk41XGP71OMMDVyzdojNE5FJ27KzV3PnnXfSq0quf9K1XDhzljs/eh9f85Vfwl7dcvdDjzPsaQ6tTnjWYMLUa957vAZtWDeeY2rEm05to7TiwFKJ66+x0rc8Yz3xvpM1j++0gOXpy4mnrrf83O0n0QrWe5rlpT7X7NM874BloAoePet43R++kxsODLl6rcdvPDLlcJX4wVuHvOuxhod2HCk6wriZMbK/6zu+gy//si/ii7/8X3L8+ONScpj7GhLf98O/jLWFlEwBOzu7vORln8FXffkX8QP/7lX82Z8+Bx9B6YJv+dZ/w+++5vf45m/4Gr7v33433/4d386Bfav89mv+iB/6sZ/j1MkT3LRk+dprNQeNYqVX8ttfdTW/8aEdfv3dj7OxO+HshuXBsxO+8cVXsTkN/J8PbeB1Sf/A1Ry+7Zt41b7b+OovuecfaF5+4lc/JYwV9k5fGZrYotVEWBRAYY0w+4Owd1rnGE9rai+xysQJ267UkthVWfR14gT0abNkBUg5hUpgkyRnK6vpl4Z+YahbPwO7rFL0CsO+vkFrhXMabxQqadH1jAmfo8IItLn8ziVFExWndx1KOVnXk2JQWVyUUrsQElrPATXRHerK2gRwsUZL1j0mGhfwHqyxcphNwt5JKeREdEBkFDTBOZISZ7vS6sxqCoQQmdaRQa/IroBRdKW0wlpDisJM8iHLcKSISrl6woqte4zCBCiKkrIqWV5epW0drXMU2tE5HscQ0IDt22xdD0oHrFbCLigUwQMpsT6oGFaRSeOpvbj/deyJmHWvumhzY2/KtlJcsJrDSyV9W1AWJjvyKaYuMXVSSkmAXhEYtVAni6PEqAR4NJGeCvSUp1SB1LHCEPCqbSOTkaftWZLR2CDOz91Ya0IitSFLWIhUhlEi2H6ksui+oewb0Q4zivWBxWqIIXLItBwqEqvWUPQNdpTY2QkStycp2VsurKzvTsCN1l/am/DlGPpyDH05hv7kY+hP3NVO+v2iS/31f7roZyZF0QdSoo/e/SBEofwpZGDLgwvaqDvgSc8nsI7y0F3pVOZLzW6qE2TrtJ1CEmV8rURQzZhMEZ2xa/LAT+n/ev+CWjFDBhN5nCcZtItlXLMGn9+S/GdkJvbYkXvIlEa1+H612JZp9nelpHZVZUBmBkzR4er5/hfQyxlUtvB9XTtK+VgWVf+4USKA8xxFTakDXRSmc/ZQZBcTL1RPk0UTc1vGKH0bU5KFMWdfuqdTuS1CjLTeoxDLSFJEZbHTlJ/baE1hFEbLPbZe2EhT75m4iItRrHkh64JBipFCJSoDyRokI5Xr9lGEJHTuSRtoo4gnduWbDqGBuyjZITOjgc37bva6uOvmouOX+DVnbKnsbLAIjf5ff2thkssYiDqRfJqBpLobvynnYP7aOiFgZkzSjz5rf3WtFkiz+djdhwS4zDZsrWRM1j7gs05GUWi8S7iQKAtFpzXvamHMeWTuKAPGKrTONPwuM9OxC2dIv7w6ZyCVuvvsAghyVmq+LizOt5gD8qTmbQ1CDZ5XGORn7EBrJLDoPlCZzN7zEWsKyqKkKqqcmY2ggkz1pAjeSYZMWwl+icRQZ5p9y7RJ1I3D+0hVCQjbZrakMd1m0onGykMplZ1rE2KnG6X+fWfq8W3EomhcIKQkZ1BlCEmxM2kZN5GlAQwHVux1Y2JtuWB5HOhZQ/KyNpRaoURJVua8ImsQdIzSbs3KQUqQcVd7Revlfsgl0KajpDPvk1mH5L4SdoBkmVVm1XZqH7MID/j/2A0ukUseKMbIR06NuP7QkFtu2sf9ZyecmwSOrVWcDJ7tcWRaO5rWEUKiN7SQFK5uuXZ/H50SD22Kk5ZrHffeez8PPPgwp06f4+abn8rBA/s4dvQw99z/GOe33sD64aupBsu86IUv4A/OPM7x4yd529vezud89mezsrosW1bHDJ7Re/Xs8Dy7dyClyNbEI3KDmr5WLBv5mQ+etmmIQQKsvcbjoxhLxCSH46Iw831La3qloSws2GxNHeVAXhUGlQrGtacoKobDgs2dEa1P7E4CCU1ZlvSy9c5kUhOnY1CKldUlxpMa5yJlv8+oETvwqiwJMRBbOTj5tqEZj9DG0HrP+fObaGPYt7bMk689ymOnzzMdj7jKTJiGKReahn3DioNrSwxLy5Kqafe2eHzDsDmestNESmsoqh6mt0TgLMOy4MiBdbYdKO94fKNm1WjKFcO5ZHAoTtWJJmm8D0zbltuuXmVoFQ/uNDxvacDq4RWOrJaUhWEaoGkjpoD9peLMFE5PpDlf9tIXcdWVV4LS9Ho93v6Od/Poo8fZ2dkhd7L0rdJsbO3mdV3WjZgip06dZndvj7LX40iv4uTpc7zlLe/i+PHjnD93jt/5/T/h2c98Ok+48TpsNeDqq6/ipS9+Hn/yJ2cp9YhDPctHztakLc+LnjIk+MDEefat9DkwtFyxYjm54zg/ydo93rG5sclv/f4bqDcfpd45xfM//+9pKv5dL0VOtGpGTtaywsg6FmcrUF7PcgwcQ8i6TczYMp0YeWGk5MlkyYmkdGaOMGODC1CjLpIhiHSx2jzm6vRTZ3GxVuhc5ooX8WuVEip4KaOJMtdDnuNFoWeHn7bxs3gp5D005uBJCQK1EBdLDEgnOg40flYXkZe9mN8ShbWvuwy8mmuNdLFx/lxjZY+3JmvKpJQrCRQ6aaL3dONZYo8MXiU5wPtWSpm01lhrJMZNYgmvNTmxmb8TKWEsVMKGWphBMbOOnAh694zBKp2ZINBJynZnCW1y+2tZO31K4KJobfnEztgTSo3NoBlJymdQ2T495RIuJaLQQWmCCqjQYo1hWBgO9Awql2bqPL5qF2nbiHNieW9yclghe00bBCzU+axWWU0F9Aqd2zbldpYyOzn7RHopEHxkGqPolalF8XwZ95nkhQsJ7yVhcSlfl2PoyzH05Rj6k4+hP3Hg6SJkpbvU3/zfCVSK6BQwSuoiI4rUAQBRUDSlFaVBEF4lyL+ACHquE5Q3rKhlkGslC53ATB3YJHfmM/DkY6L1mYmShC6cVELFlOdFtjqNnRicmj1ibv4FLShmbKSYpCywK+udlcJFWT27JprF3yxQKBeZP3/TCrWwcc7ZM3PQQ+fPIX/uX/tdzYyNlrrVLEIyZrYehNDVy8fZvXYLHszL/GDBPjWJ8J3JznV5vFLYNluwglOC4ncMJ8lSpYX71bMASDJQnnGdSIXGaihNmi1iEpiprEmQBciV1MSGFNmtHVtTT+0kc6LypitZ9oAmUpocoGBm+gEgi3DjE9vTkF06BCUOQIPKdHXRBVEpzllazCdwyot71+7deqf/pj69xK6Us3QayaiGEEiqy1bMXzNAE+kLsdFUEA1GB9Lsf+SgJwcQ83+dkY87ViQ5oJ06sfJNUeZPJDGJntpr2pBmwvYRxcQr2mzzqpS0e+MCqZRa8V5PMwqJ4CXgKq2mKhRbU4/3SQaqyRuEURLYkbINaw5co8603DSbmyFAUpJJTj6D5ko+T6bWgn5YNx+TsCy7Nb+sJJBVSdH6tDBmUkYqu0HTrXMKogCucm+JsqgY9Pr0e0NiLqtANRilKbDU0wmRhO5V9LTGxkDantK2LRBpmil7U4drA/21HkopdhqXgV0oDLTkdU/Jc2iVwOg5EzAoJk3i1NYUo+R5pq0U5/cLjaLAR825rTEb60sMexWH9lmcj7QxceWRVXZaWO3tsZeFEcvcF5iU17pIjJmhmZR0Wm4ryaQoSJrGQ+MlK1oiq0qhNBIedVn0/NIp2/hKZOJimgcM8tXorK0na+w/ggkMSFsl3vDQiJf1e3zDrYf49v99P3efHPPypx2gcYHtSeDMhT26yvulpRLvPfUo8ZxrVulZzSMfkLI55z1vfstfcd/9j2KKPp//+Z/P857zTD795S/hFZ/7lbzzPR/iuic9jX//6n/NK7/2K3njn/8Zb3jjm3jLW9/KbR++jZWVZUiR2I5l3zF9YdRqQ9lfwo7GuBgghayhYNiYOKyFhGbZJvYVMn/GtePc3gTnHB5N6z3jSSOHHms5sNpjdVDw6Lk9YhSdn/UqYcuSVpdgC7T3KN+yulTiY8nxk1scOdjj6P4lzm/sULvAw6f3WKo0y8M+1155lEceP8Wp8+eYjidcffVhrr7iEB/64D1U/T7HrrqC4+e2iRFW19aYTPZo6xptLO10QjveY7i+n0njuOu+R9h/5AjXXnmAL3npU/n1N76fhx7d4Qn+DFtxzOMpMog11xxc5yVPuxZbn+PeRyy//3bFaG8b3zYsD3qUSyuo1YNY+xhrq8vccP3VPPrIo5zZ2OUvj2/wuU85xDUH+nxYWU5NFfdtwJHlPnvjmrObNc87OqAJiZ949xZftH+Na552jE/d2ub4huf4lqeMkV4EEyKnp5ozjez73/qvv5HP+9x/BsrwPd/3H/iBH/5eCE0+HC6eFiQgmu8SXVAjYGaKkeAnfOSOD/Avv+6VSGLJ8C3f+f/wA6/+Jq74qi9k+dBVvOwlL+BFz38md3zwduzZPVaqgj/4yAVON4nr9q8yqQOFVdx41T6evM9wy37Nz77zAufGgbI0+HrMow/cz9f/q29F2PCR7/qR//UPMy0/wSuphDIKXRh29lrGbaBXaEa1/DxmxyoQQxqlIMaAzxbAMR9GYgYFekZhtaVXSPmHDvPDfcrxnVVIyWongaBEI7OJXQIWIgqXA9c2M3HQGlVUECMJD6pGpYAOLUmbLACsZ/bqhTWzOCjVXuIlpTKzaJ5YNFqJLXsG0aNCXNtizLuhom7jzLxH51NnCiLroLKzY2E7t7ws3byY4J09vxjS1KED6wTwVhpSTPKMyuBjQBtFYS1GJ7wPuNblhKu8rBUXKu8kPu33KqqqkjNJjFQ6YQmkcRDjJO+ZBsd46pjUjiMrckxt20SrMj9Gq+ycpyhMIiZNQDTXRKhYSignTeTkRs1yqekZcN5DBh6tUfQ0FCpiVMDoyGDQQ5cK5RK7raYsYa3nuXa1ZNUKSLXn5ZA6aSLTJtCUGh0iJiVKEjYDB42PtF7iHWvSjNm1WomAehuyqLs19MqCaZSSxyp6sY9PgeGyVDZ4Lw6m1iiGpcQ6PiQmrZSQen9pA0+XY+jLMfTlGPqTj6E/YeAppJA7Pi1iJBddCjXXB0qgUsIqQbaLokSnQMATQ8yDpWO2aAqdC6K6SZ2YsZd0HmcmV4hhspAZMI0J7wSKahIkI/WIuRoVUBlwmY1ROsSgs5ekS7ao2YNkamDKkyBlRHfOBFoAFbkY50szZDbFeXgmonGLv5M7KuaHoyvfmzduyiLhJOY2mwufMatr1Qpl1FwwLHa2pBptymxhamaopoT8CZ2SCIblfk1Jobv7zGuJD0ECi26SZzTKkjMWRmr/fUw0npzJygyt2GXR5uJjMSVqn0i1Z9KKFkXPKvTQ0CtAGZ2BJ0Vp5htTQqyIR21gc+oYZyFLRZrR1NsQZ2Lww8rivIi6KSVClxMnlsFn9sSFxxjDoCyIxtLqgiYkGudpnUOrKKWESc2avVv4hcmVZlpdnyDI+w9+xZQ1DFLEp0DMoux5xrI4OBMStBnVMcbynCTNIN+cNBGwMVu2dmCdzkFsCIndaUtn6qiSLFo2r4tNSGxMAiEkXICyEIeMZCR4iUHsVYXBqFnq99jxnqbxTJxHJ01pDHvbkX4pWgVGWdA50Mz1yDGo2fo067ik83oTCURMmanBWhGdIgWpKRdtt4VZ3rEIU26nEpRFqK/5ISNZ4y5ooa6SrW7zHI+qE5RNqCjge2kgGkBHqiKi/Bg/aRi345mBgm8aUAZT9Hj5yz+Lqj/g/kceJUxH0IwZVJHRZMyorhnpgjoqCisZ25SkTCNF6dthaSh0orTSxiJ9Gam9rCUrA8NqCSWeh882whJMEH2kjpGDlWZfT7FaQIXM06lPNAHO7Tac2Zpw3cEBtfMkIwKxNoPV2kS0iRhtJLAXOdsZI7JbMbolTqmYAXUpzxiUFlxiXAsbpjtwxNi9JIsjB4DcZ0ko0T6BM3Ig6g46iyDzpX3JfLztWJ9B6/jp37mHL37xE/Da8LO/fwc7daTqGVZX1lnuG1Z6ivsf26SNMFxd4V2PjUg+gi549Xd8Ey97yQv4zld9P6dPn0HhePmnvoSnPuVJKF3wsz/94+yNxlT9Pr/7mj/iZ3/uF9nb3ckAhIHoRXA6tphqlXvvf4hXfuNX8z2v/nb+yWe+nD/9w9/mf/zP/8N//cVfpos4o/fsjaZY6wi+5QOnEh81mqQUF1rNXduGoERfYW3QYzKeYoncsL/Pxt6EUxfE/auzE15ZW6J2nsePnyPFgDGKOiqakbhyLQ9KnGs4fX4TVfSpTKRKHo9ia9ywfdeDDHqGA/uXsddcw2R3hzvvfITVg4cpyoLWB5rJVDL//YLJaI+ehld/6UvYmzac2x7x5++5n7WlAc95+g08+fA61x1e5babDnODOcbx444f+dNTfOatR/i2LzjMT/7ZX7BXS9mDVZ5+oXnmlUM+/NAup0eB1o25cl3z6Tcv8+6PDDi7O+HP3n0XKQWWCsUrnnKYC0Fx/GzL2BdUReQaG3j0woSqtNx45T4+MipZUYGvvb6H//B93PH4Kc65gtQ6Dqmap6wZTjfwXx5V9Eu4chC4+4LLB3ZF9FOin7LUt/z2b/4m77z9/fzUz/5XfDPqagq60wMog8pZOqV7/OGfvoUPf+zzSaHhiTddz9vf9AdoW/HY8VN87Su/lV/45V/jNa/9I0xR8IVf8Ll827d+AylB2wY2tmq+59OuwAxLmlFkWnt29xpOXJhw+pznra7h2Vcus10H3vLQDsv794FWbJ46N0cbLvFrc+QYJo0qEsZarM0C2FoL8FHYGXhTO2nrmAQAMFoz7JXUBHQMjBrP+rBk2RrWByK00vqAz5pbAtqonPaT/bsJie06stME9tooTmpaoY2ZWcX7IJUKpYa1EtoAkwhbwNTDuUlEGfBJZYFzmY+7EyeH7FxmoBANI5dNZKpCUVhhzy9WJHSsp4SIzMtn2JnJS9LidlcUmqaV0s6UFLaQ0kAFpJiBmpRmica6jcLCKSwmAUnReAG4Ygh471DaoI2R31cQWllfrYKlfsWwZymsoh5tU1rDwBgmoaVX9FgZ9Ln6qiuoqhLnPDo04GomFzy+bRi1jo2JuBYqlCTAUyJ4j0bi5+VemQ95ioEKWUJCEMEQoNCRJZMoouPB813Boxw+fUysDkpWCs36wLJWaCwiXH9uc8q4CUyaSPCR6MQvzipF32qODAxrUYADnWDURM5rz14r5XsxLmhBpcykycDTioWDPVjRiXETODPyKAoKY9BGM506mklN6VpKC6YQa/kQpYRLqg9g6uZaZd4LaH2pZ3Avx9CXY+jLMfQnH0P/rVzt5ifsjvh38dV98ey9Seq7jRLB0+SldGxR+FkpnSmc6qIpOxcNYzbQBBBKAmgoAUZcQiiPSuht6AxSzUqmhTLYmcLNP4eFDqFj7XXY8hwEUh3UNm+I/LEzWuMCYDtHvZlTA/+GlsrPOH9/13aqA8YWf/fjOjQb4M0fqFvvOtQ8JUE9lQB72thsU5tx+AURP2vmLKeEoKUKydxoJYtjl5UKQRhLMQcSVuXsVQbjdBYhiwsPnHK54fyppd2Evgs+g24umhlVtGOthZSze6kr3xPUtQmJOiRqLwu3iYmxixQmMioCS20EAlYpbJBF38fIqI2M28DO1GOMoSoUVSFBjEdLZi6IRkAy/5fMy0L/L3b3P464V/p/MTibbQSLE+Ci3yC/TzIrXf+khTeEmOn0HT+W2WgSaq/zlGbOqNN53HSlq76jLDL/Mnlft6il2XxMgHOR1kl2xGab8eDzhpMDzNkjaVkzZI4qLrrxxT87cDS3gdyb+hv69aJFbiE/pYT5qGXupQ6YDGkWdJA/M0ZhBKqunRYHlAKjDf3CslJZelZTKKGsuxCZhJaoC4gFB/evs7S0xO7WOWob8EWkYMCoqamdo8mUfZNtnSWu06icrhIttu6rRcNsPn9lc0tRNtqpi0x8ZOpFCLEqDFcMLD2t6OfotCtr7VybGidlUiElQtf0szU3zYKRLmiLSc3KSGbtrKSNVLfgzf8ZFu511huJ2av7rsVBPNtc5124AMhf2kEvwLGjB7nhuiu5iQtMJg0fPb7Hc2+NDPoF25OAS6C0yeNPQHIf5kDNgdU+y4M+N+1/Is9/3m3c8oync/bcBbZ3dqgKw759q6yuLoNSPOmJN+VvTfzK9hYf/OAd+JDLUz7uuvOeB3nv++/gve99P+fOnaOwhltvuZk3XXF04V0pBy6BoMScwkVALyQnFvrX5HHWOcI2LjBtPL2qRBGEAZE6rZKWorQobcQaPYlzE0bWdTdtSbrEGI3VBVMvGWuTIiGAjYalpR6T3R1G45qlffuAxHQ8RRsNCpp6irWWXmVnZSHCvLIYa4iZQbY3qXnw1Abs1UzbyKZTjL0cEE6e2+TCSNgK+9eW2LdUceV6Ymk4YLmF7Z1ddqeOC6OWpeGQkZtQ7zXstp5CGXq9Aad3HbttZK1vCa1o2DQ+YmySBS9GygL2L1WoNjAd1bRKDoSTacskwgUHD07g6CBm/cmIq8c00z2KogBE1P3WZ95MTPCiFz6fD7z33YxGu8wDDpil3fPmce7sec6dPcstT38yBw4e5HnPvQ1lK44eO8kLn/8cnPN47/jgHXdy7Ngxbn3m0xmPxywr0FZTFgZrDdhIaYVZorIuDRGWSosLi8tlt2ktrBmX8NX4iGkjRSO1VgkBbjrQr5M0mOs6zKUErFVUhSU6TUISbzEJE2FQGCZWU2olbJqUtUhz9BpjEvc5Lzbho1a0VrvDsdXZRjzv7VqJ9lOphamiskNczAk8FZH1OrNyuviMlNkdOWifrfAqgxxZRHsWX9PF2fODu0LiVp8D8C7vqRBQq5Ni6PbVji3ViZbPt9NuT5F7Fca6jHVIFAulKp0kRowRa4ww7vsFq8OK0mp2R2MKkpTiKE+lIz0Ly/2Sfr8v3+00oYF2p2DatIwaAQdjLlMrrCUm0bMTqXPR3OruS+c9WBlwVhMUUjpMwgeYttn1OYnGV2U1S6VhWEh1AEDKerriVhloGo9OSsC2lMca0DeKvhWtrFIJA2K7joycxNIuZHZYSl3BBxoBI/tWMbQKQ8L5yG4dMLakMNLerQ80zmNjx4QSlp1ePJkmGZPdYfDSn7nddTmGvhxDX46hP9kY+m+l8fR/PWCri/+zU+pPKVCoIIynsiK5GoLDqjQHc5QEdVIGOgcZpLHJLme5sE4L3VgZ2VR8kgW5+zSV6WdFrv+OOWsgto3doOzqqaWmWv5bHirlyTIHovIM6jph4e+xa/ncMCkuTrLudxZ31u69uZ6y68BsT6mzxeFF4F33nV2jdwtHNwnzP6q8UHT1llp3m72mMAZrrDgDzRBiYQoJfVhqYLUxQofMtfbW1+jQon2D954QoFFCEXQhiGilER2mNgo9V2vJqKQEyWQhOZUppovjKANLDgEIAWqfqD1MXWLcCmgUM0W7ddl+Nm+6LiWamJhmFptBsecSxiTKJlJaTxMSPs3pqo3PWb4msDH19AvL2kCx3K9IKJpkaIMT2/HQsZ3mY1r0E9KckZZfiwDUP4ZLKwXGUJBBw9jm+bOwysw2hG5TyFkPFXA+5n6QOaiUovFeSgHy4icNlrIhZGK3ntKzkhFTSnQBCgvBCUpfKgNZ+NB5RwGgobIJaxJaRawRHZG96ZTt3UAjJ2xMXwQOuzLNqOYlkdoobJmZgMzLa1HybzpnjDqkNAWFimpG8UcnWtdlZmeLAp1OW0IAb6JCewUeSUUpJNuTIC2UPmgDwWmcU0zGbQY+s7goUt5gTEm/X3F0/z5u2N/jUB+ONuc4fX7MyQs153rQqERtYTlN2G81Nx8M7AwKRvWQLeuZbm5xdm8MJlBazaDUlGUBaJYHit16gk8BbeeaOFYnjM5lGVoTothHb05gzyqqqmSv9Yxaz/4BHFvr8+wr1rjvzITWeYJy9KuC5aokUkhmRitCNLioaREGq87PKpuWygGKAjSOiEsSHJD0wvE209u7gwjCkJBa9Ryy5PU6j1Tm4ZbsFypv0POFNQtedoHVP5JZ/M8/99P4yR/6Vt7x8z/M2z/4IK+9b8Tr3vIgw8qiixLlEz4kzp3d4GwSxmZvaQmtAuOdXb7jS57Jp7zgmRz93P+Atn3Ond+is1pNKFJoSdGhdElWKiDFgK93cJNNRAm0WxgNSlsSmld/3w/zl295B8E3pOiECaU0KXnmGyWA7BMiEaO5en+f/cOSt2/vsV5GnrgaefSkJACccxzct4QLiYc2G5IXHYoDa31C6/Bty2atcD6zKYZLgGJvPObwsmFYWU7tieCy9xGrW4p+xeraKm5nTFXCtQf38fBjpzl/botjR/ZTqoQ2ltBMmDYt21sjjl5zDZA4/egjXPvkJ7K0usLPvOYdIiysNdfcdB3T8YR3vedj3LGyIntpCDSTCSpFrrjyCG+4e8Lvvv8eesMlBitDlC153rOfSs9ETjxwF1ddeQVHrzC84z3v4y13b3LnOc3RQ0d40gHPPjXlde97jK2J5+6xpnGKvla87Ijh9hMtd222GGuY+sjx8yO+8irD+qDkPlYojh5mba3H9NQ57jg/4gOnpmyOAyOv2A3CbvBO6hu2zz3Ixok7OXrDc9BFH10MSKHmFZ/xQj7z017AbS/4DD7ysbtRusyHrkR0I1LSKCKxnQJgi4L//ks/wzOe8XR0MYAYuPbaa3nTG/+YGFo2Llzgluf/U/7o9X/O6173B5Aizzk24OBVq/zGx/bYdZHvfuEaR9Z7HD6gOLpiuGq5x/Wrazy+A5suMRj2GW/v4l0uc7nIWerSvVwb2YuOSQu2KvFtYNLG7NSbS+0AkHlcmkRpYKmSMpiCEuVrXBuYOoeLiYRmuV/Q+MCkcTinBLRAXsIyD+zUgTq2onM2bdmphX1itWJQKHo6ZTdoeVmVsNGhQiB6j88xlUPs2RPgQ8yHIGEzdY5JIS78e2EERC4tSRuJi7OrjiZhjRZtKoyA5Ih+krGGCNRNgBjRHkorwGRVFrTO4X2gbVusFVkFa4yUyYVIWZZ4oKkjKY+PbmcwOrG83MvlN5Fp3juc8/RKy8qg4poj+zi2PqBv4dHjDb5pCM4xKBSFLRjoliq1DHXJ8rCPbwNT4zmJYbOOnN9tGU1rqsKwNqjoLw1ICXoTj4nSBkv9irppqOuW3bqhZxUrpWF5oHFRsdfANMI4irulC5EQIgOTGBSGY0slkDBGs+WhLUrSoEfhPKb2pOAh6+21IbLdRLyLDFTiUF/EjhsUu3Xk3CSx1UbGbWSvycyOJFUJNkkiYKlQrJaK9UoA/VEdOT8KXH1Q0Suk1Gtct9R1y0CLkH5VWNCKntWUVmNcB4IIKJUSFCZKovsfQQb3cgx9OYa+HEN/cjH0Jww85XzIHFj5+J8rFqZXJKZACBptAkZZbFHSKC3UXpUImQ7somR9RBsozii3vmO6IBtyUCm7wcnD65wJiYvZr6hmdDqr1AwhFGqkykBBV4cq95F0xgpVV0nWYa8Zx01dNrZr6DRL8HWMpRy3Zxrb/Opqc9UC+phILIyG+XvzQ6Q8KS9q4kXcivn3dg+uNKgowJsCkpHe0hpKHbHKZ2tpZlmdmEAZS2n7HDp4iMFwCR8jbVPjmwZVj8DVpAZa14jtaRJhu5BSdrgQptociFGCsGvJ2hmV+zUs3H1Ki7cuWbAMVvkQGdUOFSNNE6gywhxiZNSIrpOiQ5kVJnYkcoVLmqmHvTZR2kAbwGdgKiG03p1aqMR7bQSdWEX0x4LS+KQkG+sceTovTrtZ23f9cRHRjIuxxUv10kp0E7SCOggVPvj8w4+7/7nCmszLEAOtN/iwsClphbXy0lrl5UoCPFkU5TCrNFitMGgBEn2kaeIsw1eWiTaEWSaoy1LWXoT5IllkXkObUj4Oi66DIhsVKDkmNzl7j5LPLnINtI+amFSH9kLSpCQummhFyNnZCDnjIB9alJoUhFWpNbOgoJvHKq+gKWTAV4nGyZyK3AkjKhoPPRVZ6StuvWKJiYdRm5jUgZhF4PrWstqruG7fEjesa/aVgfHJwLhO7NaKAz1wBibG8/o3v4lkFBUjekWFtSXa9JkGCLqiT8CS8jFCnCLXh+Biw8TJgVyqnkWfwWiNVpEUZH5blXAx0jrFREV2W8XYGQof2W1hu06cnXhU8uxbUULTLhRGJZb6BQdWB1grczQ6ZpnxthPGzHRenyIen+eV2GzTlSnn6SfjkNzzuQxay1KptcpagtKDsj/kMhOFlJ7kMa47rcDZHJ+v25f+0VXx52++nTNnN5gevxfd1nz+E5Z4wROWaVH85aPb2LKg37P011eEDeQV23tTvPcopfhvb36EP7hji+q1p1DKUvX6/OxP/QhFWWGs5cjhQ3zggx/hF//7b/Oqb/96hoOKf/fvf5D3ve9DMsiTns+f2PK+972fn/sv/42PffSjxNDKXSrD9s6IV7363/LBOz4yO2Q+59an8S3/6su5+91v5eHHHueNHz3Fyc0JZ7enmMJydhyZnpiwPMggWtlja3cP7wODsmDf2hL9wjBSFT6MCTSSZCotRg0YTWsgsX/F0gTFeCzCoJpEpUWgNwRDIuKalqnzPNqMSbagv1ry0COnsWXF4SsO0zt0A6PtDdTO3bmEXcZI4zRLDPiMFz6bE2fP8fiZ81w4e44QEkWvLy5vbUvwcuBDG85f2M5iq4pmPObGJ1zPS176Anp4Lpy/wINn9njmyhr7+iUpBG5Y0zznuoLTe3ucOzviA2c28ECvZxlNWq7oJYZW866zkeHSgJc/eYl3PbJNUoqlnmXlqitYK+DQo2cYb+5wIQaO3PgEnqpPotJpXvPRXSZRYazixUcqrr7yKm560Yt4/4fu5M/e/D76K4f4yEc/RvQ1yvRRpkKlppsspNjynd/xLTz7WbeQUgAy+yTJRp8S/Or//l12dv47wTuU0lxxxRX8+I/+B37rt36fP3vDG/i0F9zC/Q8s8f4PfQiASRt54OyE5127hLaWey4kjm+0nN8a0zYlk2lkr4Ezo8ioCfQKRdso/Me7tFzil8rraqWiALxRSoxMZhwpxYypGKMAsN4pvHMUxlCWJUob2U9CYrf2IqyLsIBKq0VrqdOKUrKXNhFog4jLuzBzVlNIrFwqsk5SJAYR03cIm2XiAuPGi2NWrlAImWGUQsDa7EKd2YMxiUtwyJIENpsFKaB1Hh8ghAA6s3qy/tKihIG8L1crGAm4E8J4jy5kYEti+arfB2Qdr1sPSpy4khJDHecDEjVI+w5LzaCsuOrgSmYGeU5vjLKNuubg2jL7lvtcdWCFY6slAxuppiVnthwXdiLrwxJbJgpd8/CjjxGw2KLAECB6xpMJPni0koOn1YqUIssDi9WKvUnFhVHLpHVs7gWC9wQf6GmyyLy0oUeRtCbkpKvLyfikpILEWPleYkCjCD6IC5YPrJSGOCjRMTFtAtonQErxAFSUA6wBdEq0AUYOzk9h4mHSQh26cxmzQ2t3cPVJsT2NuAgrleXgUsWgskycgJr1tGY1IS5cUUTTJSaXs53JmrRt0tncZ85Iu5SvyzH05Rj6cgz9ycfQnzjwNKPCzmbVx115kqWUwQ0Bl1QMaDTGlKQsMi6aSQIGhcwcSiotAE/kGsWMvkIGoQR8mgEtGVqeMYsimamYnQMW7zh1YMfifQrgMXvPDEzo4IwF6Dp/SF535z9ZBJ7+pqbpQLEOqAIBolR+5yKQ1wH+SRCoOcA0/+wZ8JT/ReX3zgEQYX1ZLZt934pooVFhlt3xMRKigEaF0awsL7G6to73num0oJloovbEJhFSS+Ma0XAK8rsxJVkoVUedzgsEGdlWzAApPdvy54+ZZaIAea/O+l4xCrVQxYQzEZsFAGKCxgcR1Mugl9Uq1zx3EJHCJylnmLhETKL7JSL1Qg/faSIjF2g8LOX6dkFsNSFqoY0HP/9ExUXj5+OvReDpH8Ol8pZmtEJn+805K+/icS4LWDdXhE7vgyyy3RxVuZ9VBnHns6v7NvksozVGa6wSJxmpRU+USn6udJRa8DQvr00oyQJnJiGZYhzJX5y/T9xX1YxCHJIA3zIGRXxTaYUP3VqRnzCvU3PqcqeLRvYKkO8w1hBSJHZCiwtjTkQOpY6dJAu5rGHxYrC4owYHhSkT/RKuPlCxMYmkUcw0a0WKgcoo+kYxNNBXgSI5xk1g5GAaNIc0BANJBz740EOMfWDfkuLA8jLLgwErK5qkwJYVZWhQqKzdISDrsNIUU432UqKUcpmHMQajUwaBgxxCFJJBiwnXRiZesq5NVNQhWzqHQKGSaHcgoLbzgUIrlnrFbHzortxZSXlVjCoLF3Zrew50ckD6N+kUdmNjBvzm3dF0LyXUcs3C3FxYO1F5M2Ue/CwM90v+uu7aq3Eu8L4P3MVa0XCop7h+2XL9gYpxlNKxQkFhNb2eIUWNt4qt3fFMp+/RCyOOn9/lxF/dCygOHDjIt33LN3LNNdew/8ABfD1ic3OL97z3A2xv/3OS73P7u2/nwsaW3ESKrCwPOHxwH9YoTpw4we/+3uuQvazb4BTT2vEHf/gn7OzsobXm6OEDPPPpT+aLvuCf8dsn7mbn/GmsUezVHu8jRWmY+MR05Nk/zHoK2og+hlaUpWZYWfplwbiVOCLExNB2OoIWYoMiURhL4xW1kzIhsXOX0sMQIq5tUSmSgmdrt2Zl3xpVWXH+5FlW9xWsr/ehWkYXU2xhicGTYkIZi2sj3iduvOkwras5s7HFeNpgy4qltf3Uo128c1JeY0qMtSz1C6atIzaOnoXVpT5HD+9n59wZ2rZlVAeca6EEYmT/wHDD/orTF/bY3RtzYmPMYGmA1UpKgUhYFFutYnWp4NBSgcohX2E05aBPZSM9IqNxDUXBdfvXWT2/xXKpmbpIi2JYwr4Srlzv84yn3sDb33cfd9z5ICdPvZsYPWsry/nZPTN3FBLEwItecBuf89mvAAWbG1vsjUZceeUxjDZ47/iZn/81PvLRj+HrMUpbbrzxRr7+6/4Fb/+r2/mT17+Rr//KL2ZtZTgbL1EpWhTHlgpsWXD8bMO4DtS1Q2uDVoGoPLY02KSgFpaHtYbWOfbv38fq6srf42z8u11aZ0MVnQgkMs+8w2Zne1znWicE9ECMwhy01qKUaKJ1OjlKeyqxiZQyLi3J3BgT3THCRYg+oUNg2noaF0UDU3WHE2FYeS/aQV1yduJFF7NedODSKidzs/aUkiy/aIvMXymfrnUGq0TfSFzaYs7cp1kJ3PwFKb9HYnit9WxpiYlZsG101jwpbAbphNmo8wEwpo6hMS/mkbjAUmVWk/NBmPvWSFmZFoZOVVhKI31lVGJQyPe5lBgaOaDF0HL2Qs3EAdrQLzSFlfJE2VOF9pFyf3ZlZ/3KYiaOlBJN4wToi4FBKXtlyHt2SLIXkoXI5y6ECqUNShvQGpvjOh0TwQVC69BFRWEUVWFoXMoJ3uz+LE2cYzqFQ3S8ph5GHqZe9ncXc9/Q7Y/ds0hSt/byk+XSstIrKMqCSYBp46hbR7DyLB7Z6zvzIXFBlHEZu7grB9t/k4TLpXRdjqEvx9CXY+hPPob+WwBPXPzJ89VoPj1SzAyVgM/UuZimKANF0Sdqi1dCu+wWMEeQIDIJKEIHXJE3RNSC7k8kJKEpdkwnhZ4tojGQxdzIFDhyjXQ3yeYL+UyWAGZsqEXkaKa4jzCWOqxoznTJQuOzSbjQJN1isNBgaQHhiiBaSp14eB4kScki0G3YKS3UtWbmUMwDXe5lQX0q34fWmqoqWemXDCvLkaWCPp4yOsZ7E6ZtYBQDdYbtBzax1jPsG5YYbairwLQKTAtPU8NUeTZGI6ZOrI3lOxRGG4w1WKspjIjPmyj31FnNin2qBCn5eDADkrJJC0aJDa3Jm8608dT5efzCItr9nsuB98DMaYMyCjRGyYY4agK1E7eOTr995CJjF6lDErqvtSz3S2xZEnWB8pbkW5KrKUzCGtmkLwKfFuZCt1F0d3DpsyXE2lMSCSIqby0UhWRDk5iNzFYlGcKS+Qgx4JOGZKldyMBjVilIIjLcZWg7M4XuMkqzUvXpWRECxTVEIh4otcyhtgm0QeNDLjk1SE156rRqRDgRq+kZS1VIBrNtI0SDifn3kFU44rFKs1RaBr2SCIyaVkoowwLjboGJCIhOhAal5NlIAs4mDdHMN9zOOjgphLmZV0Af2lw6q0AXeU5HtBLhORUCymooDNOgGNWJvZEnmUCvhGFhUATCeMSD9484X3oKHdhsPNNa45SCQtif4+BodEVbFDTVGq4siYVmqWg4vFbR7x2g3muYNFN2J2O8ByyUFrQ2RCzBJWKQxSVCFi2ULCtKyLYVED1s7TjajCD3VIXRCofn4EBhlcZgObk1ZnvastyfMOwVDPsWnRIDazi03GNzKtnb1kFsIDUwcRGXLGhDYXx2qMwByiygWxjDKNok2n5KQd/CoIgMSslK9StNUWa7cBYC2dm6LVuBZHrJh7VPcmL9PV0fff+fMx3vMN4+j3/w9bz1PffxLf/ldq6+co0DKxW9SsqGx7Xj1MkLsj6XBd4LuG5U5Gf+xbWsDzWv+KGPEVLBxvaYl33mF/Ot//rr+NH/8L2YouT5z3kGr/vVH+boVUcwRvOG3/1lfuAnf4nX/NFfAJov/fzP5Pu+/Ws4duUxPnrn/XJzSUrrSZ1FeWc0LJbNv/kL38OTb34m1drV/Pa7HuWv3nU3w9U1qlJRFokmKJZ7muWe4vTGBGMTq6sFn/PMK+kXhnc+tsfjZ7fYHW1xcKVkOnWMas8zrzNsTwN3nJlybH8PReL46THrKz3W+pYJiSZopsGgC0VdO44/eorrrz8Eqs/Dj0Z6laE/0Gz2lxg3gfrUeZr7H6HXLzl4eD8bZ8/hY2K4vp/RzgXidJvpFTeyt7vN3njKk59+M0euup5rnnQLJ+9+D9tbG5zYaPBtZN/KMv/2m7+UP/7zN/P6v3grr3jxszh9boMf/cGfYW2lx6BXcuOxfRzfarn37BRlDKa3Suwd5L2PPABW88ynX8fH7jmOaxqecO1R7j1xDu0d3/SCq7n9dMPrHt2lbhuiD4x3PZMTjzEdlFyIFc1Isaw8L2CTO87t8Tv3tzRohr2CAys9fueuc7QfPoN57Yf43//r1/j+H3gCz33ei2mCRF87j7+fZXUVxXBdUq5dwktbKbOMLT/1c7/Eb/3OH/KB2/+Cgwf3gVL4tiG0bR4akYcefIBbb30OgZLAgF/+368hBiefpTRHDg/5vM++nh/+w1M8fm6H737ugA+dMezbqlheHeJc4PzOhF/7lidz4sKUb/rluzl45ADGaE4+epLv+55/wzd+w7/8+56Sf+trsFTR0xK/KGuYZkewEEVOYq5tmrP+CGBQMKVQFlWsChvQBdCOvVb0mpYHwijBGFSn55kiPh/Ykk8k50kJmlyi5n0gqEQMagbcuCAGLtYaChTbraJxMPVyQLRGWFUqaZEjyAdTo2DcuBlgIhpM+aFVtz8mfJC9XGlDzOCZjuIgXBiFQ9rCZxFqKdWzou2Eys7FUOhE8C7zQwpA2izkrKZSCde00n5GE4Kw5bUxYEtaLI+c2cF7T+sDddZri8lx6sI2Gzsjzm/vMbBgVaQd77DXRMZt4nzjQHkiNefG4JOh6vcw5ZCiKNA4ej2FMZY2GkJwjGrHya2GQa8gFT2Gg4TSmu29KVMfaUPCq4Ko5FCqkpTGDIp84E6R1ocsRC+ATUDTBMVSYeirxJIOmJ0RtW/ZGvRoYwaPXMDEyNAk1kvFNCpGteJ0rYgKWgWjCJMg+6sHHBpHV3KTz2MJJkGz10K/jgx6ipWy4OByxf71FVpdcmFi2Jm2tHVNcbhAFZagNc4FXAZeGpfE8cwErthnGRSaOhnaGGiC+Wtz5lK6LsfQl2PoyzH0Jx9Df8LAUyd6xQJGMzdJk9k2A79Sp9UkDBKUF6KaNpI19JpIJHUld8jGFTPaOxvUqJmLQMgZmZCzKnERKEpyD2KPCt2ON8ugdO2mmOkoXaSnlBZZOAvvVRf/PSX4eBixe5+aLTjMFp6Fd5Fh5dnClBZ+fxH0mrEYu//P/6YSFFphDJRKzzMPYT4obA4MBqVlbVCx2i84smwpAhgXSGPptEDCaln8tW/Y294gBIe1keBavGvxzuODl00oQpsDE52ZTMIqk5r6spAx7mMUYugMpBTwzuT26bC+lBYRcXl2HxINzBfdBO2Mgp1mn6EQa+DCanpdmyELVVfeZztkPwky7KPQhl1SJCUCnYPKsFQVszI7SKQo2V0pI5Tvi938pSv97BbP1DX77HXJX1nE1y9kHVQWd0wf/wQpi3wqZnM5xECGTQHpF5/dE4xWVFZjLbM5q5IEizElxk5q2Lemjqmff4bchc47JaLlEBMmiVWpMaC0OGOELP5uVMJqCEZjrdgpxxSzg6ZmaVBSaLFRJt9LzKKas7SO6rI7ZLReAOwUEqFJQEQphSk0Ra+g7Fc0e80siNC5uD36JHa6WmFtD5Ot5NtxK0C8ygBxTNgYUHYJX/Q4vRsYTzzRtYxamfA7gKKVwFqJI6hSooUWQyQGxTSIyGCDwijDSlWwb22N9aUegwJ2Ro/jsZSFJQ561NETMmVZ0VGjjWTcU6B2QZxmopG5p1Qu3RAnEZugSKB1ROUsdoiBQilW+yXeBWyKLFeGQVXSKwvQMqemDjZ2anbGLa0XBqMmkYzOzieIXl1SdENLyTCl2+W6PWdG9c8jplvbY0pZ/415rjDJnLedRkKaH+i6IaCYhYazjE6XrbtUrx/5iV/gtmc+gU970c1MjGdoPat9K4cpbRkOe4zrBuc8+/evZIaxZjJxhOBxPvD48Sm7vZz2TpEUPZPRDm09ydpMnl6/z9Frn0B/2EcpOHL1DXz5V3wlNz/zNk4++DFe8uLnse/odbznfXfgnONHf+jf887b34tzjpe+6Lk8+1m3QHKQIi958Qv5p6/4DG582vNYOXgEpQv+xdd+Lc++5WY++Bev48GNKefGIhgeY2JvGjm8NsTHxN5ozIMXhpTWcHZzlxC8CP1OPb3CcGxQcGo3MGkk6Bw3slL3emKz7qIimh5VoRkozWhSg4ay12N7e8L+1R5f9enXc8fDFzi1M+XQM24j+ICvG3qjLeJ0xN7OFvsO7iMm2N6e8IIXPp8rjhzmox98J6c3dlFK0bcF0QXOnbvA4ycvUOjEp7/ouXzwI3ezsbnF697wFu6970G8c6iyB7bAx8jeaIL3gXKwRO1EmDxp+VnbNlD0mHrP2Y0xV6wNSCjO7Tp80mg07z4xIWjL0w73+fBjUygMS8OCam0ftgB76gzX3nQNBw/vw6kBtVdMmwaU4uplzUuvMax94Tfy2Lld/sf//HWMThw7up8f+LffToigtOHNb/8gT316w4te8jLR/VIWUsuv/+Zv8973fQBIvPVt72Tjwjl+9Md/iuGgIgTP6dNnuOmmG/iar/pSfuM3f4d77r2P6bRBmYjSBc63s5Pa6kqfjVrxn990hquWItcMSv7koZbHxoqiKtjZq1mvNNeuF/zB7efYmgb271+mrWspbSTxxr/4Sy5sbPDj//Fn/iGn6P/Pa2W5JLlA4wJVdgPUWpNCEP0OpKQk5RjSaEXPKJZtoNKBaQxoo7HWip5RCDJXai/6l1ER0aJ3ksgZdEhOYrMU08wtLsQ4M4fxC6+YJCFYGEWpIeT1V5Kd8v/WaKJOuRRL4nSU3K9VOseJUoonx9msgKM02qRZNcJMaDyv3TGv6bEL8DsNESQOSD4DIfkMoCK41tOlNoteH20KlDEkt5d/T6M6vQel0bbEFCUqOXzui9YviKT7wEQ7JnWLzaUn0TX4JAySkZPviwC2x6DX5+Chg6wOKkqjmO5u5X5NDHuWponUvqVpvThMG4PNbt4mh10hJeogBzKrodKKQkHPQuMVLiyIqXdxf4r0dWKp0LMyPWUsSQRZ5CCfnaCnjWdUe/a8fM9eZjg5YIpod3lEL7XKSd1WS1mXz7QnpSWhYLSI2JcaKiPaN1EbfFLUPlL7QOMDe8GQdKRCmHl1SESlQQVhXyEGEJq55pPWl3gkfTmGvhxDX46hP+kY+m/FePr/PmDPYKd8OI9CBVMOYoEhoY0R4U66KsKEJ2LyJ3d7TQcEJTLolOlkzssmGtLcNUOrrswsCVKqBISQjWiBMZOfoRM21QuU0znYlXJHXfygi9N7Bip9HCg1+3u8+McLWNbswxJZEHwBSUxxDkx1oJNswPJJBkFaK6NZrgy+A1RcnNngdqVzPWtZ6ZWsD0r2DzUmb8xjJQimI1FqiCrifM3u9gaj6RhrxQpSQheLC0EE3Mki7zGiFjjhHfOpLGQTdlFEwJmJx8vz6cVBn0doVJI5kEbKIvFpDkalhGhyZNp2kamAnRuA1bkmOi0AjIujMEl9uo+JNkITIOSO6ReGQWnpV5YJWgCp1AFPTqiG3VBiATyGi8fTRa9LfMMEWRCTjDWdFgZtrtueZy8UHZerK1WMMaE6nQRA5eAwBOlrcW2RDUxFoZeC9HEbIrX31D6wPXVMXZoHnBnAVF2GNMlni3i99LlWdJr34qio8r+bLLIoED9aSTa2Z7PlqFJCbfYxV4p0C/F8VsaFDlVdLblPJJNQRmyVbVlSlD3cxBN8IiaPaN0APpGstJsuhpiyQNmCZrwl36khpSgZzBRRdkC0S5zf2yI1geRbxk4CyeDTLAhPKeKSJiVNYbUEaApOjLvnV6wuGZYqw/rKEitLQ0oVOXN+Sln1KCqLKUu0tbnWvut/jVFiAUsMM/F+cT3ToJjV6CtlhPmXcm2+kv4PIWI0rPREHNekyKBIDMqSXlWCUUSlabxia69lb9Iy9UFqyI0mZiMFERbIh43AbHJ1eyao2dralU8vFnx38z7kTXKWjEgdXVzNMrWzNUJd/NldyEh3kLiEr1/6ld8g/svP5599xrPZmk5Rbc2RZWEDuKQZDEomdYN3nvVDq/ioqNtI00ZiDDgfOHGiZqec706KxHBQURWaFIWxVJQla4f3Mxnv4V0L1TIv+9RP44UvejEffttrufKGJ9NbPcLt730d+/cf4Ju/+esZLA9pneO7vu2bUQROnz7F8vISn/KyF/PqV32HlGspScV++Zd9CY8/88n8/Idez/ndCWdiYFAaXIh4lzh4cMBo2nB2c8QD5ycYo7mwNaJfGapCsz32LPcLDq71eHQz4EOgLGDSyCF32LMoY4nKELWlV2mGhWIyHqGUphwM2NnZ5cDQ8jkvvppHT21y7+MNT3naLdR7U8Zb25jpfsZnjnP+9HGOXXME0Jw/t8stz3gGT3ryE3n9H/8xdV2jjaZfWPCOC+c3OHVmk8P7Vrjt5ifz8KOP8djjj/OGt76L0EzRyF4UdUHVH6B8g48w9mKx7kNAaUvrPKPJFNurcLuB3Y0xt14xJCTFh884Kq3R2vLeU1NuuWKZJx3s87HjYKxhfaWiv28diyM0U647ssxV1x5izxumDrwXraCjQ83zDite/sqv5qPHN/n9P/hDrIG15QHf/A1fQ1FWtG3g2779uwl2lWc8J0qkpjUpwmtf+4eARmlLVZUUheHnf/GX8xiKKNvn1lufyfd976t4z3vfx33338/S0jKogoRmtDsm5QPn0qBip4bfeOc5fuyfrHPlWsF3v3HENICxltHOmCO9kmvXKt7wgQs0GPbtX+L06U3GYxE0f9Ob38qb3vzWSx54GvQtNSKYXSDBqNJysIxBNEdjZneT2fulgSUTMDowiV7KbqzFGp21liLjxmfTmQ7kmcfTKJEeEGAl4n233kdxQctrX8dWAmZlWYVOtBkcmMXaSvZelTpZDNlHuzI/bTKYNktEzvjuKK0FFktzwEnlRT51bPjMEpltRvk7QWKXiLgsd8+YnBfJB20oqj6YkqQtSY0BKTMLs11Do02BKSpMVCRa2qwD1SWf2xhJybM7WXDLg+x2Z4jt3OFvfV/BcDjg8KH9DEqLioHx7o7E+Ar6pSUFT53bPfiANSLC3gmxJ+R764hobSkocr+XOaY3RqoZ6M5DIaJTom9gqRQgyCfRlEudUxFy7xMnpjrbdWDkxKp9N7+mEcYply0qASpKJUluq7TEz6EDMWX/LrQS4CmDFNbKma5NMHUCOjU+MPIGrROJwNhH6kjW+J2X/emUR1/q9vhLPI6+HENfjqEvx9CfdAz9CQNPczaQmk8yFvSVZg2tMniULV2Tx0RHGWoqq3FlQaqNbHpRkOOAWL+SmT5Sl90xemIW14t5gsoDGqMWNHq61pjTQv2s4aCDAbXOCv+aGQI8b+iUOyLNWVKzjXYOFMWUQbjuK+XB0UblWs80A89mTCjFLGXUNZd8XG7U1CHJ8sfsdjogBhlkvULqS/cvFdROHOCSCjM9AHGZg5KICQ7VJtpJIrQ1rm7YbqSuPybJkAQC02bCub0xe0ERtWJQGvqlZXXQx2jhKBlrKMpSKMxIVi5EAAkwBqUASiEZQiNAWIjzdjRanFNMBp9ICXTWIMgbuDDaRGywa7gm6kzPzvaTFgqrGFYFw9KwWsnwjVGsKkW7qmPEyWapfaLICLfLnXdwYFntWUpr2PSaqY/4ZkT0LSmEWSngTOAzSVZvPv67++66TM3HwiV8ee9Fb8FoPDnTMnM0kAeIeVPtLIytNWglTjRtmzC2c6yIFEWkKhSqiAQSTZOwon6JRrHdQFAef3YbF8QKuElGDhRKwF9rxJEqhoTTEBFnjjYm0WhJkcImBn2hgFZ9y3jicT4RXKS/XLE2KIhlJdRno/BOREY3JlN6VpbZXqFxbZqJ5M1fOSjItuBKS504QRODaB/4xlFbEYFNap41ptsIoyYZQ1sto3VCpwC0MpNTQQqeGCPBQVWULA8GVHGXBqhTpF/0KfrLLK3ux6AI3jHa2cZ5R4iBFAO93oCqN6BpWrxr8M2YsqpQxjKpJxQqomPkzEZgOGwZ9mF7PKauG5LXkjHSERUUTevYmza4EKQsoijYaRNtCgyTWD0bBUQJgJMkoNBBoWMSgDnKOrLcL1DRE4IwXKyGgwdWUKYEbShDzemp48J4wqB1FDpRFWZ+GEkJFzyNS0SvZizPeakzOTkgyQZNRCdFWVgp8yBRGQGkpw6aNlJriNEINXuWfcoxTqaJe2ROS6A2D6Iu5euuj72HpaVlUn+Jr/nPd+LPPcZXPHWNR845ztWOdrKLaxraxnPi5KashSEyXBmglSE4w81PWeHAkmHpvecYN5619RXe9pdv5Iorr0AXfYhFjmgSX/8N38ZfveOdpNhKfyqDm+7xTd/0Sr73Kc/id1/zWo6fPMuP/fSv8Is/8//w/NtuIbZ76GLAoSNX8p53v03ABgzbpz6CLQcsH34izd4ppjsnaFzLkZUS2+ux78B+blyF65YTv3rHiPPjiC0s5y5sURrNsbWKcbS4pDl6MDKeNNz96CYvecYVbO42vO/ebY4eXKGsSlpKnnBsnZVBxV997Dht7YhNYDoes7a6zI1XH+KeBxu2G80b7g2cHlvKquLaasIDd3+YMx+8gyc9+zZUCReM5ZEHTqCLiuHBo7zxQ/dyx/GzfN4Ln8BHHjzFPcc3ePr16wz2H6NeuoKlQeLC2bP8wE/8NPsPHuYpT3oiN950M7Y5Sdg7zp+8+R0cvfaJfN2/fhVP2g+nTj7Oz/zab1EaYSuvr1bceWqTh85u89Qr1jhrKz4ynfLh01OMEvv0JxxYZVgZ7tlsOT2NXHh8RBsiVhtGwXLd1QU7e45f/NgWYfkenvz4Ke7YhDtP7KCV4lOfcogLW3t8y+tP8xff2fC85z6Hu+78MGvLFecvbPBTP/dLvOIVn8WnvOxl/Owv/BK/93u/zzNufRHnz2+SvGcmSEQkhYbvftWr+eIv/iI+9TM+h/Pnz0H0rB+9gdXDV8t7U+KG66/ljX/+Z5RFydb2Np/68pdz4cIGpMTpczs899plfuxLruZtd+3xoYcnfPY1FW99dJePnJ9w1aFVdFVwX13wpc8acH7k+MO7djh25SG0Vtxz18MsBFCX9DXamUAURsukFT1Kciws+pW6Cz1nrsspgWs8iQbPmEKJDkDIDHgHjMZeYukk+qgxa3F2l8qJw5jjIzKQ1C8tldUMSsMEP1sLY4z4IC7GIQrTvTRaWAraEL2fs9G1ptSaQVmicma38QK0JOXlgKsVaTZuEtF50R3SahZv+SDrVcqbQKc95VqHNgJqKeSAV8dAUZUoRMC7K68ryznrQmspYfLOEUOQfSBKCaNJifXlPkRH61qSLjBlRTVYEq2a4JmO92jakPXaLCvDPkuDHpPJBOccddOwOuyx3CsxKdDWDu+cMCujR6WYX6I7c2hoGFaaJsh+uDVu2BjV2UhJ9NtQKouRK3xUTJRm0LP0KojKsFN7Jm3AFJaiX9FfGbK2ZLFEppOGGHNJnu5T9g1moOh5xa6HkW85XYs4/04dqVPCJU0TOw0o0YSVSiZxBy+NYljoGZA2MJplC30CjdfopOgZw7iJbLWBc1tjdsdTQutoW4PKztfTNjFpk5xZkHNAYQx1E6lbmNSRmFQuP7t0r8sx9OUY+nIM/cnH0J8w8DSjWi2wdOQQzsLf5w87Q9UUsvgGJ+52xmC0IcUgmYsMo4mbRRbLCnMqrVCCZaDOHOcW4gvVoa1pDvKIUHlHb5QNqUN4rckI9OzW1QxsWtRhWmzGxXBmBhh1qYr8U6UymJUXnY+/1OJnLvy4GyAdWNX921x3qkO28yqjDDFpKWPMbZIywpNSJAZwrWM0TuAMqo0ELxviThOkHjXXj0UFTQzUTui30RSiC5IsIVsxWpUoC6kTVjERYxCkPn9M52rQid8ppSG75nX9MhsiilmpHilzohKomI27k9B6U0aMmyA11T7IwkZQVFEcNcSlQWOUAgMpBXzUAlSqbK0ZZbxqnWiT0MpRin4hdGEpIVT4GFChQcXQwX4L3TSfcAthXP57N27gr9FsL8FrtuiTgdz86gae7sTcAVSazRGjFYUWQVNxmBEQb9RIJmtr7Jk0Yc5YQ1rNxUTtE1Of2091q0I3ZuWrfZzPdynplfkVukyjnguYVsawVMm/TZKntFbKDqK4WrQu4lyS4CsKMN65LDKDrbs7nPd21+Mpz2NReFUiiKgDRke0EUHbouoRMhuv9QllDcoUcniIMbM7VC7nTdmcQzQftFKoJAcDsYwP2GFJbzBgeXWd0NQEZ2B1jRDzMwRPr+pRVhXj0ZhWQRMairJAacVob49UT9ApEEk4F5iolrqV4N+o7P6YwXifgd6InAuNEpHEBhEWrDIrVGXacJeRXrw0OZNlRD9Ix4sXzm497BeWfmXENrmdr1cdQB9SZkd2mcS0uNeo+ZrYHURyv81h4NyPKqFVmokkXrRH5Hfp3P+ztasbBerie79Urzf95dshiVPTNcuB2lfcu9FyzVWrlEPF5D6xAu+VlsbnzT2J4KzRcGClxwMbkZHTfO4zVnnPQyN20Bw9eoTV1VXIDAzy722cP8/5C+c5cvQQW5s7jEYTIPHe99/B//7113Dq9Bk2N7bYHTn+8i1v59SpUxS9JYL3xCDsqac95YncestT0Vrz2OMneN+fvYfY7LFx+nHuPlez6TWtUqwaz2gauXfiaV3I+17WitGKSRuJWjKVdSMLSllazu80jKeOXmnRtiChmOyNOL+pmUxKOXDGgE+BqirkubZ22LfaZ2V5AB6UMmhtMKmlsIayN8gHQRkQK8tLmLKiRrFx6gTTrXPYYszu1JNS4sSZ89jdlj21web2DrvbW2xsbHJgZUDpSh5/+D502CY124zrVkruUsuDj57n9OnTOTmjMcaSVEGbk3GntiY0PrJ/WLCx50gqslJaRm2gDZFKJRoXGTlJrw2s4kDPENpIXxteeNN+Du5fwfQGlEVLZQ29wnDF+hKTacvmJBKSpqr6XHFsyJvf9Od89CMf5QMfupNnPfs5eNfyF296M+++/b2cOnWGhVQnwhyxVMN19h86xjXXXM1XfNkX8973vpf33H47/+TTns+tz3gS991zL8973m1cd/0N3HHnQ9TjHS6cO03bthij0dZAlBhjtVcyDZppVLz4qOEjZyUWHBYKFwLndgLjfRV166nrhsYFEXAGloYV/V7x9zcZ/45X23qMkox5SCIk2411AZnm8ayGDM7oHPgnCuUJRuKzDizQIPt2jLiwEMsyz4mp/IfSibiwNsrvQO3EwMUFKfvxCVRIaBfne0UuC9RaU5Q2x4HpYp3TKBIOAnLJQdPmNXmmF5KyoDKZBaLMHGxT5GqIbs2XMwD5dwur82colM0mA0rKy5IyhKSkvC91sRzSmAq00hRFQdGxxYKAajFB1etRDZZYWtsva6Z3UuYYusoDWF4esrrUR2tN09RoDb2qRJHY2NiC6Ane0zQtHccrhiBsEcRpT2lD2zphWUXReSKzOSQelrIXCyirqQoz2xvjrL2jaO1kNpbWiqzqhXMBlJS89YqSsiwYDiNLLtKvapQSVsLUR5qo8Aj4ZJKUBfkFykLSHUuiY5FIi4ZcRVAWoidmjKaOimkb2J3UeB+wKrFSaUojQGDfQmUSVscsmyFjDFRm5+Tiy0uc8XQ5hr4cQ1+OoT/5GPoTZzx1GZSYNXyyps4cwOlAJzVzsRCMIaEJ4BusLgR4MjaL/eWa14jQjDNKHLzYsnYuGV1Ddhto1hmbbUAZDboIB1vUmRJgJNesZ4X+kJjVrF4EPLEA+nzclfL3pMx6AT1bkLsdfsZA7Hbj2U3ne1wAYsggXVej2bmYoGdfNgv1lNYkbQnK0HhondD7vA9505YRl0Jk7AO+UeyoxIbtyh4TdSufVaBwShbQSRIxQ5c0SvdIpiLZCoxC6YhRnn5VZMV+S9u0hBDEpSCvt9rk2v4OeILZWIGUnTeljboSNmaTQQKhFITW54MIYgYUjZeaeh+EoBpR2KCYBCiC/L3UmkJrSAoXI05pmYh5YdA6UsQoJYNJgqdhYdBKMfaJaZCMmfZTVPLZTrLr8G5ZlfEe06xbpB9Ttr5dmNyX8iVsQKGw+yAlKp0tskYWwJjA65SjRJkXVmsqKwFnTOKQ0/jIXuupQ+DEZsvOJKJmKl4yHl0QWncboCykn1LK9ccpybyPSQLeKCw6Y/RMX8vn4vHSSPGAVZolU1AOCpoY2daGqioxxmK0p2lEy6B15IAeUDImOxeRDluW6ahmC7RSctgDYVMmJ33qQkKZiC4ls2SLkqo3xDWO2idGU6ERa2shBHCO6B1aWxQRpSIEJSUGthCgNMpmWdeeeuop9vXoLy2ztLbO6MJ5FNBfXma2yoVAaUQTgiBOSMSCXq+Hj7BxfpMRLVZHylLRhkQ7cdQNUhev9Syo9THNymeTUpKNBqatFivsmKBMaAum1BJAxcXAQvpXI5R8Y3VmqlpUrjN3LmIQWvBwYFjqFaz0CuopMgI7K+4OaCYfrljYUOm+MDNJVe6/2QY7P6B5JJFgjWQPqyJb/OZ5qVPn1oH87gyUFlq0aDTMn/BSvb7xW15FcA4VW37vXz+N07v7+Z7XHufnnnOMfcOSn39z4NiBAftXepzechijsFbz+KkthpXm6sMrvPk+x9Vr8OOfeYQffP1J3nKcmeuN0mphgZNyk36/4lm33caHP3gHe7sPgzL8xZvexpv+8q9IYYpC49spP/2z/xVTVKwcuoHJ1kma8SakyHd969dy843fTtUf8rG7budffcOrsVUPpTS+dRRVwXI/8rww5t6zDXecaVhfrih1ogUR40VxYa9maQClVWztNqwMCvav9LjzsV20htWVPspWNM6zef48uzs7GFtQ9Pqi7RAD68tDmqblwYcf50XPuoljB9dYzYG4NobgGsrhMsvHrsNFi/Oy4F9z1VFMWXL/Y+fYOv4g55uaU/3hTBz7/R+7j7rxXNiasry+Aij5rHYHdia89e1/BcZiigKlLN43XDj9EG9/+/vY2trGWkNZVlhTMPIlZakwFu547Cz7lyw3HB6yO3bElBhUihPbDc5Hrlo1jNvEzjSgNKz2NDesGCY7gYODgld92nX45YPUusdVZpfjuy1n9qZcc3CFrVGNnMZFlJQU+G+/8j953R+9Hlut8DmffYa93S2+8ztfzZkz58ipzzw2JAgzRZ/1o0+hGqzT7/f4Tz/xg/zSL/0K73vPu/iOV34h+/fv581veRtf8WVfgsfyZV//fTx63x2cP/UQSkPZK+kN+6gQMUXFXmOYYjFV5NnXGt70kMzfQZG4sNdy8kLDQ8Mh48bTNg07u2O0sYBi/3qfIweW/p5n5N/+mtaeylpMaeTQmjIDJ8fSwviR9+oct5rCkIxGGxgoh0990fnqGPlJHOJiiDgXZoeADsjptC+TUpK0zN8Rk9iyOx+ZNuCCgDABRRtFXsHFOJMeMEb2MWsNK1nugJQExPCJpnV0rlo+Blnno7DVjVG0cR5bWaMyI1NiNKUU1uQDUVSEzhUmJbxYR6HR9HtlZvYrmgguaaLqESmIaJz3EBzJO0zKoidJkrfGGAb9Hv2qpCwM0+mEJsezy6sDltbW2XfkqJS9tg290ojAcVJMJjXrq0usLw9QQF1bCqvpVxXee46fOiF6tkSqokQbKUudNh6dEgWapCwBy9Q56qhwSVGUltR4XNYWjUnY+yomDIbBoGASJZaqc1+FEGm9p3Ue5zwKKw5aMVG3gTaA6XmKgWYw6LOeS+ZG4ylniil7TdZiihn8mQW8ihAlRgsRXK4mMTlOMCphlcTMk6BYKkp0UWALSxMU4zawuTsmBM/AwuGlkhikj1eryG4BA52YGomqmyDfaTWYlBYii0v3uhxDX46hL8fQn3wM/YkznvKHaq0wC58dM5KyCHiFJPWpMSqmPuKSY8oUlpepioJ+NRCgwQdSVskPIRG9BMFhIWvToXTSX/PMkAZxhoNZakR+Nhe3lvriXK9spG7VWLnREGJmWV0MOnXjIi3E4CkxA7hSXqgFgc33Y/JkVxpTaKILRC9obP5liGo+KBSgNdqKFoXSWgTZXLYuzqCVZAKEHqd0SVAVLZa9RhxznPPUXkrbYs5HZPmzzAQTtlf3UCm3l1YJU0vbBKUI2qKtZtjvszQcMOz3sSaQQk3talIOOspKhE8DEEKYBRlKiYOdUQarIlELVdlHoZBjJKOLkffOFi2p6MgWkVLX7FPCe6nV9V42Rh+ZPVfjFRMnooR7bSIWiZ5JWRRTJo+AnopKQR9hzGnjmTrJ7rUhEdvESEXaXKdrfD3L/oU0m68LaP4cMVSzP1jIRF2MZl+Kl9J5vsSIiiJwORwYCmeISTIiLoCKyByPEKNi5AIuJZqQODcKjJvIqI1S5qkSe7W8r2+ZL2gIai6C+FKq2pXQppBdKY20dRPBZSabUVL7bzUMSqhdEqDVB0IssNqyf7WPVwmvxkxCZHdUc357KhmI7ruVWAkPqwKSsCS6fTS3BrCwEWiNNXn9QNx3ogJK0IU8g1WJQWVZXxuws7mLtpb1Q8dE0NQa2mlNbFtiU+NOPkKIAWUtbdvQW1rmuqc/i95giImR6dYZSm1ZqXq4XkFVWrS16KqHTjBcXkIBMXg2z26wO9mjmY6hKNFaUS0tY8oC3ziaekpSnmQTyyvLTCaO6SQQmGurtRGKSF7D0lxThGzFrKOIkybFtI5EC70ioZFAxxBm6ypIf2yNaw4sF5RWo3MGPiGCiySDTuCjIkYtf8+fb8jMRw0gAqZtSASlSFrKlnFpoZ/kS2POMAWYaU/UAfbqxG4NrdcUSrKrAcm8J60IPm+eHxfTppTmTjL/CK7VvmaKYjyB737Nw1w1NLzyxoJ33HGeXQqedNV+LuzVPHBqTH/YZzypmYzGKK2pA9x3asSn36RYUY4v+x8neXyrZaeBz/isz+Grv+KL+bZveeUsyOwCtiuOHuXH/sP384M/9OM88vCjaFPwFV/+RXzrN389KSXe9o538b3f/0My72NkureJdw0ojS76FEuH6K1fB0Q+47M+h3e99Yl863f9ANPa8au/8vP8x//4k/zpn72BP73P45WhVxW8+LoVLuw1vOP+MROtsUazPCiIKNqguf7KA+yOppzemnLTkWUmrefxCxPKehtrNMeOHeBpx/axb9jjHY9sMxqNaZ3n1qfdTNKa83tTHnzkEc5c2GX/gXXatmays8ntb3oXxhQUtuKJN1zJ2R6ceegeTCEC7sF70YYpKlbXluhVMvZPPvIIR48d5KWf+kLe/o4PUtctNz/5Rs6cOcuj53a5+TnP5Nzp82xc2OLln/5Sdnf2eNMb38bNt96KD4E73v8eRtNIjA1ts8XBg+usDVepl3q0wMObnkOrFSFGTm02XLN/SK8wPHBqi2P7h9x4rMf77n4c12hcglMPn2I07LFTLrOMQynHaHsH7wJVv8/zn3eAiZnAO7OOTgaVfvDffQff/g1fRrV8iNf90Z/yGZ/1z9nY3MrBnUbbvsQwfgLJc+XRdX7n13+CP/qTP+OFL30Fsd3l3LnzoDS2t8qxq2/kc7/gKKuryzz8yKPc/5G3M97bFhDBGLzzjHdG9AYDTu0lfu+OXV78pIrCFPybPznP47uRA+s9Rl6TbMW+fSX7lksGg8RVVxUoa3FZHPLM+TGbO80/3OT8BC+VhXUbp8CUonVjLYVK6CixTghBAKhc7tY4uLAXGJQtZZGgt4wyFmxF03imLtGGmDVkZF3rhIr7pQBERguw5HzEeSXlEknYBjOouQO8tGgKmSyPIECSAFtKibbQUq+isorWR6a+xXnPpHGZIZFyeR0i0JsPPo2L2U4+EnOyVSkEpMkZZa2MCAMD3nmJM0WIgxihsop9yyVH9w949PyEUShQw8OoaomkLe14TGxqUjPB7VyQEkFbEJOiqvocPnqMA+srFEbzyH13MW09zkd6ZUGvMJiUmDQiOq5UwdrKCtZaTrrz7I0n7O3tUU92UUns5qMSLRZlClKQeNdJ2QMpMxINEaVh2gZh8kcBXZq8mVVW07cFAYULomUrlR5Q1V70qpKwVYyS2D6GgHeetm1JQdy/XAKPhqQpomhVhehwJMYpccFptpxiz4nRjs8MGWOyhIZSlDrJeUnPz3JtSEy9jK0QYS1reO1f7dNf6mP7PfY2E1sTx9ZoSpESfWsYe82ggH4pgGsykLTEIz4J8DJp5bl8txenT1Ql5h/muhxDX46hL8fQ8+vvGkN/wsATCJtJadDd4EsLYHk+gPuYaDJrRanEqJWsSZOgNwigLdYU4nCnDCmFzPbpRBU7sGnhwN99wUITLvTfwi12lFDyPJCNzWo9E6PW80TKRa/Zpy2IpnWkwouaNN9Y6t7bUQoTM9Bjho51d58ncocWp/zjlF3+RAchdFL0GVFOM8xKmFEGlbOTMagMmmXUU0k2RQ4MipRi3rAF1Osazigzp8zGmO8v5QBDY604bmhtBNmP4F3MAIzUeXcikYt9pLr/dbMqt6dsJAkV/yZwZl5/qlXCZKaX6ajjHUiXWVUp5k0+CYrvggRbpVGYDDCmjnUGswyaQhF0ogiRNoCLEZ91DqJXKBsw0QtNOqaZwKYIZs7HCszB1cWnSAuvS/6aDYWMniIUT1QkRclAxmwXKwQ6CYS2m4B1kamPXJhGpi7S+oTREXS37JL7P81AW8Vc/LDrz+6rtVbMqchysEkoQoozlmOhtGTddCd+Kv3uY6fZFWlcwLWBpom5UiiPP0MuaZC/XsRWE7SaXJKOOOdogfUhZ1mQRshzqpuHQtc3GcBV9Ad9bFkJeNx6YiEZsSZEiBGdP9ZoTdHvi1hhEGFZldeJpKXeulf1aMoBMQZA40OL924WAIYERVGhtYTiKUqwuLSySr+A0iSM8YBY1KJkw3OI04w1ml43PxbGRIK526eSfhfjAgF4Q+pMHFLXDPmeZDFL5Mx4nj/dApzSfA6FnI3TzOcReWwkmGVw8kC6eJKp2cCVW56t2yoHSvPPd5GZQwfZ5jtcNDvTHFTOa/FsUF7i2PH+5YrBscMsrx3AbT5KmRraKIc8C6A1rU+Ma48u/MwMIiFz2zlP3TqIijvPtJldkbjjjju46cbruPVZz+BZz7yF8aTmrrvv46orj3Lt1Vdy4w038MxnPI2HHniAD9/5AEcOHxTnOqUZj8fc9syncu/9D+ND4slPvJ7jxx/lwoULyPpiUbYHKbDvwCGevTpkaTgAptz69Cfy/Oc+iwsXznPvfQ8IQ1WJtklEY6y5qEu0Em0M0Z+JeB/pD3po61muGpocgyhtufrQMjcd3U888kTuvuc+7r//foy1Mo98YFw7XAic3q7lwBwisWnpDQyDStFOx/i2EXHr0UScA1Pk4KEDVGXJzs4m1vYYLC3RW1mlWlqh6C/RHw6RfKpC9wZYU6F0QX9phX0Yccwaj9ne3kZrRaE0wfvcF4phr5DDi3dorfE+MJp6+taInmKvzPt7ol9ZpLzGAYnlYcX1V+yj6klM4ELCBXG2euTCHkVV8sRr93H0uidy03iV5z0ncu8997C7uwvAE649yA3XXU05WOf3XvvH3PHhO3PLyzr+7GffytLSkOinkBLXXH0lt9z8BD74gQ9QlZb3vP9jtM5hbYnShrLqcfBgD4B+r+I5tzyZe++9jxMnT+UMuQCcossonsYTlyhikkA8m4fs1YFeWXDFesmodTQRhv1S+rBpAWjaQOsu7UMrdLFMIhCJqosw58Las/eQdSpDovGR0dTjfUTrAHiiMURtiEpn0xSJzU2SuZ5zm9npeEFMtruRbo1mHm93a2AnQtvNN6luyPIKMWWmh1icN16EuX0niZEy+yNJqtAYRadFMpeGYBYXKK0prcknmjkgNpdIF+3SWcI5M5d6vRJjGkwylL0eFCVJG/xUyjdTLGiZHxBRIrKiTJFfnT6sPGtlRVS5LCQGjjHglZKDbw7NRaFCYY1FJU+nN4UyLC2vQmhJMdC6ltYLG0aEnOWwN2lFFyt0iWVk/zI5UerzXtrF2T7BxCcKKw0mOqnzmEq0V3TW1ZJu1VpKEMuywFrRWEpKzmOTCJMgIuaz5GoeJ1p37tNqxpRL+ZAqwKO810e5F2M0vcpirMWhGTU1e9OWunFgEiFqGp/oFwJiBpglyLtZqpXKf89x1qW/BV+OoS/H0Jdj6P8/xNCfMPDUCQEarfEqzhlJcf7lbYCJS1yYehKySI2alIW+FfurMVUfCltiTYXVAZfmgoYd+2jWVguTratMpNsQc8un2DVCnnp5QnbCjEqJMn9HOe7AkBDiX/u+i3qGObj28eDUYm1tStKnQYPOSFH3mflv88Wi+10tEt1RFyRtZ3Xe5Imquu/LM10o1wLYFcYIO0eBUkkcRGyFrgYURU8GYfC4tsV7jw9+dr/WCjillMY5R4qBFD3aGIw1szaNKdKGgG8D9dRjc51qxOC8x4VsCzkbaxmUnI3EeT16yDuXCwmjE8GkWV/MMl5kNlQS20kfEzYq2aJSkqwBYsUaM+jU+Ejto2h2aUWhVW5/mYRaZQ2o3C/aBdH+QjMNieQVQWtWaNGhIQWH95HWQ+ul9rb0ZAG4bmTkOmc17181+/OvDaRL7oo+5bJTSCrlbBZMamGZddRgmM+VsYMHN2sSUmsuWUlNWST6VgBdpYQhK0v9vB1mgKRmtl4oJBCuKskQaC1EcaULGpUYBUeMEZ2gVD2ciZjCo0ygiYnNactujLiUOL07RXmhqEWvsJXClgrXkiefgLAZF5b50oGUKRGDorQWLTxyfD6Ih/wLWmlCEjZidIlUGKIUDuO8HByWSgPJEV0kOrFrT6VmB9FtqIDKWkqlGe/tEkOgJNEzJSMMjU+UKTGsehw6eIQUC6bTKePpiL2dC7RNzWC4Tr+o6K/ux/b7hHZKu7tBMxlRVn2e9Iynsm91CaM8D37knZKttgAGHwMTHzg/agghsbRUZg0Accpc3KBUHhu5Rprt6QxmprAG5byIySpxX+mVQg1uQmB72rKqLcuFzUmF+WHD+0jTBsZtwupEpchaBXIwAvApElMWlpXBMwtupN+6zXa+4yYE8zfdswCNh2kLbSuBQGkUjZJFultSuyup1A2U2WdeytfTrj/AZ33O5/FVX/t1nP6TH+TN77mHb/+NB/mpL1zn4HLBN/7u44ynLdF7tjd3WFnpc/jYfs6c2SE4B8nzoZMTcZ6yFYmWGDwpBV73J3/OX77rQ7z7LX/MXXfdzT//wi/n9a/7P7z80z4FY0u+4V98OZ/54mfz0ld8GSl4UoooZbj16U/hV3/2/+GV3/FDbO5M+NF/92/4xf/xu7zxLe+k2TtNDI3sbSnI+lkMAYhuQrt7gu/8tlfyL77mK/miL/h8jp/e4MJezTsfn6KAleUhOgqANqoD60uaqlA8cuKC9K01pP4+1pc8RwaJO88HdqaejZ0pT7hilS946VP5zs/7fn7sp/4zP/hDP8qjZzcY7Y14+MFH6K8tE3XFX370LPV2Q1EUPPG6K+iXCqsjd7zv/Uzrmqrf4777H0FpxXBthRe/4FaOHjrIf/7ZX8DoK1k5eISn3HYbbRO5494NDlx1NfVkwn33PMotz3oG6/vWefc738s111/LE2++hbe+/o9wrqXqV5w+eRzvPdO9XVBC+3/iE67n/OYup89uishrCDR1w+lYsb7c49abDvChux9jb2/CS2+5jvsfv8DtD52mN+jx9JuO8Y2f92y2Nkfs7Yxwj58i6iEbLbzmw6f46s96Ll/2T57Hsdu+ns+5NfLizzzNP/2Sr+Njd98HKF77+7/L53/+5wERZUpJdKFIKaB15Jd/8Se55RnP4KJ5ouAbX/nVfNEXvIKnPv25nDt/AaWtxBahlc/SJddcfRVveP1r+K5Xfz//5Rf+G9EFykFFtbTMdG/EsvG87MYBv/PRXaat58dfvs5Pv2OT3/rwFG08z7xmnZfetM7/eecj1DFx7bFVTp3aYXdvShcBp0ucLQHM4iFSpCWbvSDuk22IckDMsakPiakL6ElksxDAYmPiOXBkif5gSFEUEkMajzVSqpVMZNyGXF6nZgec1kembaD1MZuiCAsqRuaH3OyK1ZXwgSRtJY5STBpHCJ7dsTgzGa1pnaNuxZFRrgyC5ThcNNpymU6XQSShlRX5BmtYGUjcGhLsTVqJWUOcOSRWZZGTxpqEwWOoY4GLou00qCwxtQQXmU52JJFqNZMkxjTBeXQp6MdO3WLGU/qFYqlXEpysgcOeZmVgWVsqwRjGU8NmPebC5hYpBoyx9Pt9qqpHyRDXjJmOtpm2LUU15IabrmdYKlR0PPLYo1zY3GaysytatkrhleL83oReYSmtzlo7ip06nweMABSgKK2Z6QFtNolVLUyvQWmoXcA6TVlYbK/E9PuY4QCbAnpUUxWaql9w9MAK/WGPslegXY1ThpGH7Tax6xAHPORQXxpJOtv8nQJQXLwbzs5ZKWGtpuoV9AcVjbZsNnBqa8y57RHjaY0qDbVV7DWRQaXoKcXYwzSonPyVsTPolWL2BJhCY4kU6tKOoy/H0Jdj6Msx9Hw+/F1j6E8YeHJRLO9dSLJZdoDTAsjSBslYbU7TDA1rQzdgFa6doo2mHPRk0zEWhUarKB1lhSUTIDdgBpwyqGS1uHgUmToMslmJjloW6rKiNyRocM4m5Vr6zs2jYxIJkJBmk2rx6tDmWbMqFkA9NQOlSIoUICKUNFkYEkoniqJbQtRFDBoZ1UZYSklBSKhO9Btm4JPs4Qat8yat9Ly2N2/ktijQVY9yuExZ5g3cOcpeEGHDDgVNCWtEghCgaWqCd0TfYLLYtvee6XSCa1ts8gTX4FqPySMyRi8uHyGKUn/XVhlci1FcHlzOiHXiYxHJYjcBTOgyPGDodLu6EkAoNHgj4JPRaiYSn5KIGroQZ8BQ7SOFkSyQKXLQpKV/UMI0HLeCnF+YBqGxK03QBcpYtLEMdI2JjvbjWGkxo78xChtP05XxLaDNs+zUXx8/l+IlwKJky+vkmbjIaCrMgZTbuwtUZ5hfEhZhoTWlnWtZGTQmZzHSfDJkCG4xHyBC793Po9KzDI1GUQCVCtQRCqU4uGwZGMXQKnr9iqb14BQhOmoX2RhPYWIEmW89RSEbhM5Z0Y4JGoGghNrcue+Q7yopsQEuraHsF0SVaEOm9YeERQQvdb5nYxJlyUyc3kczyxK7kIhNTXQt7bTGWCsZI5V9bIuCXjEAZTj54AMMlgaURUHlA5OkmVCwv52Qzj/GtJEDY/ARawvqvS2ca+lRU5QDbNEjtSPcZEI72kGbEmssPQM4ccVISbLURZFwbUQlRaEsexPJxlZWEgFWW9ro5gZVWTYwpjhbO8kZPFm/5+MoxITVipW+ZX1Q4ZxhZzxhc9SwV0cGwx79PvR6ioQlKVnDRy5hFSyHeZJBnJjSRZsZQEpamLDylzlLtesTpSXzEzu243yMm27tz+tKZyc8Y5EqiF2dL2q2IatLfBa/565TPPV5U1SxxKlHtzh7YosYIu+8Z4ulUjMZy/hbqgYQAwnF9s6UGKMIetoek6DoAU/Zbzi1q9kYS9b5sz79U/iXX/e1HD1yhLvuuoeUEj/+n36Bt779ffzHn/hxBqv7uOYJT+N//a//znXXXkW34vUHfY5efTU/8sP/nnsfeIQf+8n/xAMPn8BNt+ioDc55vutVr+LMaRGovuuue/Gu4ate+d084clPYjBc4v6HT3DFquW2p6zwjofGTH3EGo33wnwY9Ay1i/gIz7npIBujlnN7LU09ZeJadjZHTFJPspNNzSMnt3n3hx/hN+/6Uf7qfR+m6Pc5/tgJrlgq+PJnXcVjE+gvD/iU51zP7715xH2Pb1ItleztTdjZHnHFFYfY3trm+MMbHDmwhtKajVHLhz96N4+trXDzrbewubnFI3fdyerBI5iiQGvLhZ0JWituevJNnDt1kpOPPsKho4fZ3dzgwycf59h1TyC4hnq8zbmzG3ifqJYOcfjAEv3K8PDDj7G6POC6oys89Ohprjm0yvOfcgN/+t4H2N7a4Z7HwNqCfWsrnN6Zslc7lIJ+VfKhh8/zXb/6VxxZshxZX+JZT7yJOx7b4P7TWzgXeOPtd3L3gyfZ98f38CkveR5f86X/jJ/4ke/hXe/5AD/6k79Eio5TJx7j1d/z7/jQhz5CSiIHLX1tkNoOD7qQf0sAmt/4ndfx5re8nZ/+Tz/K297xLv7n//wNXv29/56XveRF/Nt/+92z8WuKIdpWKG3EEjoE6r09ysKy6zV/fv+IFx6N9K3iVz/mueALnnJsifvP15zcbnj3Q5vceMUq0zZwdmuMqUr2D3pcd9UqL/+0f8attz7v73lG/u2vwbCi9aLjo3PQ3riAz45zWpGZOAZCFPAJAZxIUoY1Go3xEdbW1zPjxWB0PqRkOYWYErUP+PyZEtPIoblnuvgm0dCxozRFIeBDaRSFAatENyQwz4b7zE7bmzTZZU4CBaOFeSU7v7DxO5vxpcJglJRvhZy5K6QmZw4YppzdD4HgJXbtdF1JUezLC82w36MqStEiyuXAFnGWgixcndta62x7bkqwIgK+u7WFG+9S6oSqJ9S1o/GBnd09Ob80npGDuvXs7u4SmhpiZH15IDFIO2UaGlxbM51MCRRgKqw1JKS/2taL9mrsBLM1Ac1OHZk6R99qQgxoJOZyMdF4ERovjKJnNb0sCVJHaDK7v3VB4hlk/0pKk6yi6Eu91U6IRNdQucj+ukZphY+RSR1wLjHT/sp/aCVshr4Rx+jSqgwSLjJjoM1sNgElhRFmigIXFCOX2Ko923tTRpN6XoqVQZLWBaZKnqlfaPqFYasOgMQCwuySkh+XnRAv5etyDH05hr4cQ/NJx9CfMPDkg2w6PggyGxdYPOSvD1HqW2sfZ3MmzlgtELwjuDaDDCJWrZUsoDoDN92Dpbz+KNUxahLGdOCTyhutbKA6191qI0iw6ZzrkMWvE5uebWQsfLbqAqv5vy0+0+KVZmhhtyGqGYiVOqQ+M5eEIdZhiCrbtmXRRGsFfNKGGdwR5+3ZfU1KiNuOtVhbCLtJZXZNEnDKaIMtCspej7Lso4CgzUXiY11Jnplt9EmcfhQEhPGktZZFI0Y8LSYJGyqGQMwAaojMFtjCMENp5rS9lMvVcpvP2jEDhHl8RC2TB8VMQ6Cbp52ivoCHmbIdO/BJkHQfIk5LFq+1msJI5mHGpJLbwqfEyEWmPjBqowS8WhOV2JsapagQyrRb7OfF18f1CR/3vr9pnFyql8srT4qRaZLsi/OZLpuYLaAqg2wdDV+TxeONyhoOLOir5fexiKMvXmnekPm9Mcl46BrZIO6JlVXsGxb0jKJvNdpqcEJ7j7kUd+JFP60LpCk6yvzFgGD3Z0jMWZnd/SnRZCsKgzYql+4E0WSLmTI8+4ROWLVbKwREltLPSPBBAFzXZgahRilhCiitUNZQ9vqEENnbuEBop5RVRasLahS1NjjXEve2GI12aKctCkW/NyTUI2LwxEaBCigViX6P2NQEN8GYUtZG34q1qfdSztplumOSenClaXxAtYndxmXa/DxCn62AiVkZMHnDkgSAAPpdlich86y0in5pMCpRGM20FlvX8dSRlBwsXE/LmNFdDXoiRDXroQ5UvmjULE6olFfbtDjbuiC6S07MB57uNkvVhXDdQS7NP6Nbt5mXFai/9sWX3nXi3IjtUUtKiodP7XHq/Bir4cEzE6yWuWm1whYGnQzeB1oXZuC+1gajBNwfFonlnqGNiW3vufGGa/nsV3w6Spd0rfHOd72fza0RX/f1D3L06GGWVtd4+jOeQXANDz30MFdfcx2FLVhZ28enfMq1rK7v49u+7d/kAEjmytbWNg88+CAf/cjHuP+BBzlz5nwecIk/fP1fcvPxUxw4sJ+NrV2edsVhnvPEQ9z+yEOMfchBviIpSSS1PkGEfcs90RwZO5qmYVo3nN9zFL0Sknz8yY0xH37wDO878TDnt/dY6vfY2trhimrINfv3M1Etg4HlmvWCYQkpRXzwkrGNirXVJVw9wbuWfk9Kx8L2lJMnT7O9s82NN95AChHtPSkneFyasrayQlmWmKpg4/SUZjrl5ltv5cF77ubEyRO86NOfRj2dcOKxCa6piSFhih79fo9+CXt7I5aHJf3S4L1npW952jUHePMHHmDLOUbTlp4R3atR7Ugo+pUwQs5tTzh9YcTV+3rcdOUhnv60Aad2TvLY+V1CiOxMAmw1nBw9wNGjhzhx5hwvfsGz8rqvOHPmNHfe9TFe+9o/oHUerS1XXXEUWxTYQgSZUwwoLZofrWt5/PHTvOOdt/PGN72Nn/zR72d3d49fS5E3v/mtNE3LF3/JF3P0yCGKwvL4iVOMRyN6lcGnXLofJUgPEbYnLauHEsslnDgZcEExrDSF1YzbwPHNCc+96QCj2vHQ6W1UUdDrl6yuDXjuc2/lcz/n8/4hpuXf6lJanMQmASotSTrXCYrnIKM72OUwHx9h6lL2nEm0bYu2NuO6wigyWueyDfK63ZX8xLnAODnm1WKFTcqHTCV7e68Q56RBoalyHOaTol5gfsco1QKNE5cqq9KsZK1Lanb7SVdW1gkPy1fN2VDdYVa0o3IpXgbg5L7V/KWl1KwsDNaINX0Xc6bgJR6JaWZsJN8hB/uqskRlCEA9GeNrKX+pksf5QIiJybTGJwFZ6qBpXKCeTAhtg06RWGlcEKkQ5xqca2kah7ZmZl4gVQKO1oWZSPyMtZA0Uy9nqJSCnHeSlPm4JLpQNmebTWaKJUAncb+LUfS4OivzrsQIpdCF1Mo5hZRNRWiaFrTGxMS0DnOnUDq30MyWUFAY6FlFlVU/fBS3Z5crDUJuZ62E/VAWhqKw+Ii4ajaJcd1Qt252NqEDH4Pow8i+I+MswYJLuTyDJJizQ9wlfF2OofP9XY6huRxD55H+d4ihP2HgadR6Jq1YLXYP2h3yZ0BJ/tpuY9ELz6oB3wqFvrfsZNCWpdgZOtHtEa0emdTK5IdOXf2xZAOsEaRVZ0qoijKpUYqimNeCp4i4hgRmtpCQ1ekV8xnWddqsUxTzJpxP9FmT5h93C4ZgRt3CIHWtHTjW65WzX6i9wmFIuoKinKl0pRBIwQOelHxGyeczvBj0qXoDhuvrFApM9PixsHBICltYbPn/svfe4ZZmZZn3b631hp3OPqFOpe7q3EB3A93QTU4KSBJGMGAOqOPomNMYRr9x1HHMiuPMiKAgSBAQFBBESU3sJnSApnPurq5wqk7c4U0rfH886937VKPfJcPMWN911Qunq+qcffZ+w1rredb93M99Z+SdnCTNEfRRXHp0bDr1VmxeXS20YmcFbEpUQOtcaJJAVTXYpsFZS6LEgjsxEM19ItMttgJqM2M5tb3gsy/ZH8S2bTlPFxTexkGnZfOTaulP1iYmLEqqbGkUzEujQ4TRMVAhgbuKDefjys1o4Sb2v0uyFJM1G9iYWqaNY9wE+rmilxicSUm0pqMcXV8QfEUR0bM2qO+K60gC2J6jiDu2z0jGzsMQqdP0eGBUYr3oflRKMYnCjqGdyLuPXYtPauQLiJVZGeMt2OpiT3t7n3a/lQpRZJFI4W6gqDzbBVjjybTGY1jsdcnSlIvyjMY7bPAUOCbOUtQuruYQVKAJEujTmHArzYz5GKRcF1FMJcJ+GrR2WCsMttxI4mQ6hs3tirKuGRclg25OniR0jcJ5cR3COkKqCSSExOAV+LqiqRssjjAZoYxCZxkq74tlslJS9TCGtN9jsLiMrRrMyZP42uNosDmkmSJLU1xdUxWWyjbkSYIG6qagk2WoNCFM1xlvn8TZQJKBxwA5Hk1VNRw//ABJloNS1D6hbgxNKYuvinPCaUXh4aHtCh3dOJPUtDsEXBDLZ4WejWdJUuXG5okhTxSN0zO9i8qK7W1mAgeX+nQqcWDZHk/ZHBXSQrx/kc1JhTOKOgSEK7EraHrQmLimC0giIhDz9VgSJC0sUC9rQe0cTQS5dYhumRq0AWOkEd4pRY0WGjphrsWH9KwbbSSmaMfchOE0PkLAVSOm24f5nY8d5/CDIy5Y7XH7yZLKwb69C2ztFOxsliytrNDrpSxrx4ktqTxPi4qnnT8gTxQfu3ubJ168xBNXO7zjEw/EREvHRVu0dyBw66238Pgrn8R/+8P/ykte/AK+6mtezub6GqlyXPOJf+CRj3wESW91npkC0XkDdMZrX/sG3va2t/Pxq/+ez3/+i3zn9/yg/FzJz2+++S7gTrzzPO5Jl/GKH34eb7/xNTRHtgjaMOx3cM7z0PFNFgddup2Uz963SVk2lFVDordlM6YMvikwiWFp/zl8+PaT/MPnH8CFwCP2D3nq+ct8eDTmwVHD39yxyUrmKU9u8o5P3UnjAijF56+7iSc9+jKe/8zHcsuJE5xENrUnp7UwAWzFzskddk7A9uaUn/6RH+Dff/938Cd//jo+/ZnP8YEPfIS/eP+7sM7zopd8E4++6ioee/lj+M2f/iH+8H++hlfdczff9ryruP3eI/zFrXfytMddhLUNH/nsrdx99wm0Cuzbt4ftacOR9aN4lQAJ9dST5j2WlzMuv3gvN91xlLXtKeccXOKc/Ut0slU+d/P9nLXU4coL9/CxuzfZKo8z6N3IZ+5e4/DGGO8afvInfpSf+okfA6V5w1++iSc8/Wv5wN++FtdYlE756Z/9JRSBuq5ApwwXF3n32/6EQ+deSHfxAAklwVUobQDFvffcw1Oe9hwm0ynD4ZB2E9k+/09+8lNcfvnjePtb38iFF17AU5/5fPb2HI85e8BNRyqSbp/e0hJbR49wwDh++jE9fvPaCSdLzx+/YMgrr9nh6runnH1oFWsdZVFz2b4eJ3dK/mFS0x8mTAvLxz55Hy976QbB1yjT+9eZm//C4/DJgknt2alkzBVWmCVKKxJlBJDxMQdWLWAsoEuqIVEaQoV2GhUcxoiej7YJU+8pGmGOSF4eMInkRT2NuMsp2SjXIVBpMJm0u3XzlGEvo58b9vUMuZbk5v5tS+UsReOigLlocc0cr7SKHQeIVk3clOuYMQWl2JlG6Q0nminCxAmSazYW7RqUNgQlmmaSqyt63Zw8TWRtIqCiZpVRIp8QnMNay3hrW5h0JqHT60krMYEiS0m1YqHfpXbiujcup9Re4kydSeFbJymbOxOSoqJTlLigsc5TTEtSI+c7He/gYgF1UtnIilAsdlNQgWNHj0hBtLFsT0uJjUoczIIXZpZJUrnvZYMODoMnT3XM5dsWJi8uZtbHgkGIbmWBopb7rxHWWkdDgrDYdKJZWOhQNFMmTcOJjW3SdIoyCcemnvVJTVFUqBBIjULniRQptAgJ91P5sxPZHJWDTaAAqggcdYzinMWcsxZz9i/kVFb017amnu3JlGkZnTKRPMzaBuUEbBlFQfuWTdH4wNa04eBShyzR1M5T1AJInM7HmRz6TA59Jof+ynPof3mrXaRbthfSXrY65b+tzpKatSTtAsjwwYnLQl2CTkVzSBvQDpyavXNidm/k1Uy3KYuMJpmwMgmFYDR/fauybl2IKOwuiqBSsy/iBAtfcq9aVEnt/s4cxZyBTgG8ACczMKplXmlZXNPExDulsCgwOWQ9VJqDFhTTN2L96uoK30h/vwpx0itFkmWk3S55v0/iHbqpY1VHnCWC1rGNQqqSoLHoKKwu/blScQFrXXRMkTYMtEGRRJQ+zDYfSmlhG8U9iLOt82Cs4sCM1SRucnGxap9BuwbPvtUCeFE80hM1nQJoAaJm1sARPRVXFGE97Wah+dDSgD3TxgklkDk9UIKaVCamDYxrT+nm1GSUULQ1njyUmGDxYS6dNm9xlPNo3U2DEuQ78KXxZRfwfVof25VEdaWC3At2IfUPO0KY42nxFojLAe09CLFVoH0XZhU+OUQs10X3lHZ2a60YdDT7laaXeJY6mn43o5NqtPH4IBarpfWMypqdwlHUkoRrozCJQjsvbhkRtZcqQpuoqfkpqQiEehn7raujDzCtLBNnGWawf9BhobvAke2GqnLURUPW75ItZPimEZ2ZusHkXRnDVjQtamfR25szK1iTBpRzeII4FRlNEjz1dIJznqzXI8lyTGIIMagmJiOEnGA8ynhsEGDT4dEhQXmFUQk+CXgDVotwsQ06BrhA3VbQgMZC3QSq2pEmSXzWQpFXStqqQMDjJDJlZf8gjqUqiii3KHt7P10rnOnnjkUqzgup8hh6uaGnNP1cUTQ2iuI2jKeWovJS8dPMqmuouUWrimOqLVy0o6j9uwS1WEU7ZXGR9uY2ILZrSFtVEhePSDOOb6YUMwtyHebx4/SHngKf+vT1/Ppv/jFPubDLseE+brh3m8efs4DRiuuOltS1jdVpT1M7iqbBZB1SbfG24YHNkkGmecyBLkVpueXBMQHFtddey6/+2q9RNXDH7XcRMxdCCJRlgW1qvKuZjraYTkYYFfgff/ZWnvG0J/PN3/gSYLfGTryTSjSKyrIkSxPSNKYbbTXU2/ZTQGk+8dl7cf/9Hzl8ZIOqsvT7XcaTAh9gaaFLv9shSRMmO2MAulnC0tISzjmSZIfJtGYhT3n25Xu59paC4xuWFz3zSjY3tzh8Yp0rLj7EuKo5vj2hH11lV/bvi+LelmlRcd+R4yIK6i11WbCwuICthQ/byTSD1f2YJGVtbZuPXP1RdrbW+cLtd3HixDp79i3zl3/11zgX6A2HbG1tccvNt/HK1/wl13/xNvJuh3+4+lM4C5eefzbT2jEpKrJOl5Cm4kTWW6CyI7SqWVwcMKo9H77lsLQ7eM9d9x1nzyBj70LOTh1YH9VAzf7lAVme8uDY43TKxAY+f98aJzZ3GPT6/MLP/DjPec6z6XR7oDRPfvKT+X9++Zc454JHsXPLbRA8jtgGl2he+ILn8jXPfRZnn3shC4srJJ2c4BSumVKevJNs4SCre5b5j7/4MzjbELznlX/0x1x//Y1orfnRH/lBDh7YDwQe9ahHsph7fvqrM7a3HZtjxW3Ha5qmoRiN0Fqx0Rjec69njwoMEs8bvlhxosm48EDCVlFT1RZbNxSjMVXRxHVfIpP3nne/5/0cfvAhfuu3f///9CT8io6JhdLNi3k2aj61mwitDEpLi5aLAIpWrUuVAADKgFEe29RobUiTFKva/ObUxFuHqKEzW1MjgKO0VPITQ5oaenlKPzfkRuG9Y9J4Gid6UbUVUFlyeyCCYW0slaVc1lMFohUVmf8B0Zpql+x2c6ZDdN7rJOxf7GNMQtAp65OKsrY0dUW/16XXycXNsq6p64pRUWMDoA11ZBcFr8k6Ltq092ilOST/DVhno1N2oJNntILiIMLlxmi8q0nThLzbFQCssTSNJTHCjLcqgDIihk4qm1FjyPMcpRSj0SgKJCvSLKeuG3zce4jTtkeRSDHeaLxVBK/QTs4zTXQEC2WT2Oq2OCdjwSjReWpsbJkkoOOm3lWONFHsG+RkQVzBFwY9VBSfT+uGzBg6UUDd+YDTgW5qyIymk0gRWGJm1OCCmTN2CIFOaljsJpy3d8jexS7dTsZaAdPGYetS2nAhFryl6ch4T1lCaAJea2HZ7GI0Oe+EpRMBtHY8nc7HmRz6TA59Jof+ynPof3mrXaTatjjLKWjA7BA6llbzk29DqgJC8DhvaZqKNDoiaGNQTqodRCc8MwOI5jdAK3GeaMEFr2RCBh1mD75t9fJeqj7ex38LvhFZWLMroD27LwETToGb43XFv89QvXZRUe2b73ogcSKn0ZUnBEENSVJUt4fOcgGDnMMphVMQTFQ8mlGTRVAuSVJhhnU6mKZBBz+rTCul8VqTGEOaGEyaEdCz9kZFEJFGWhBOKMDeeZSRUa+VOIiEEATIioJOidFoJa4LTbNbI0tAHhfEGcH6tpXx4TduPrZVfDYBEZlHx/ERX+7iRES1Wk+xqtWOJTVPInyQlj+FaBi0LZdtVdDouYDhpAlMG0/jQSeGtpoflMZgyUONCSKUuxuB3D3xVDzRsAtdCqeMH8G41T85H06vY9IEYZslRDj0X3bOszAYRK8rRAR/9w/ncyguyrNFS5JrzZz+Pugk9DopeeIYZJpenpEoR0BcP6YVTOrA+rimqANlI8+hpSo3LUPOt4CjBhUrxGiUiklvzL9bZ5s2qHofqJyjrh3nrmYcXOly8Vl7+OSdG6xtFIyLKZ3lIfliH9802PEYOylJZBsg7RHe0ViHGo1Q3S46yzHK4GkIwUvCqiXA19MJDkXe7WLyjrS1lgXaJJhUrJ5VAJ2IPhtevF4UCh3A6y5qJvCfRpahwymJepUPqKjBYB00jTBT06QdsyESLBWg8d7G3ns9e3LtvVFKt0hyDGBt0GTm+mj0PHFvCeIBTTfLSNOElUHCTlExLmuq2lPWjrr24pypW5OIqBmhdwfNdkip2TnNWovbF7Q967sCK8T1JRYhNO35xfoAsR24/SUFKrSuSez6Or3n8OLikFtuu5svfOEWXvnvnsRZiyt84rZNLtnfo5dqPnbXNq7ViQme2lqmRUN/aUCiFI2GtXFD1TE884IBXzxWcN9mjdKKG264gZtu+jxK5aKzIRmwrMlK+qpV8Ax6KdNxQlXXvP4t7+bExpgXPPeZhOAYj0cPO2NFnmUMF/oSi1omVLsxDg3dbp8sF6bu5287xqdvuBcU9LoZw0HO9qQGpdi/Z0CWZaA0zvloF5+wMBzibE1wUybThm5meNKFQ+59KGdcOp771Cv46Odu5fq7jvLixx/i2NaYO49tU3YSev2cg6v7KadTimnBeFrx4No6xza32bc4wAVHb9BlZ9wQfKDf0ays7iHv9lg7tsEnP3UtH//4JxisHqDXS1lcWeRt73w33sPiyjLb2zusn9zkrrvuoZNq+oM+H/7k5zi0fx9XPupR3H9yjdLKJhFkrKdZF5MUaA3LwwHjquFTdxxh0MuBwP1HNnjyJWezZ7HP5x/YZntaUVWWxxwa0gTFkUlAJyneOx48ucN4POGcpRW+/3tfwdLyShvQuOKKy7niiscy3tmiaG4n4FlYXCHr9rHlhBe+4Hn8yA99LyhoGtG7GQwWBIjcOkzSWWRlZQ8/+9M/RjEdc+zoUZ7yjOdz8uQGSZrxva/4Dq64/LEzkNGt38UPP3OBz95acf09jkRryqbBjix5ptl2CR87Bk9KIVPw9nsse4c5h/YYjt27SVlb8J7tnRHTOogr0q6Y+8EPX80HPvDh0x54Kn0sQhJdvtrc1YfZmqiQhVEbLfkePjozM6u+azy2KcnyHiZJCHqeE0qbixfwh7hBiKubCrHIp0XPqZOn5Imhmyd0jOSDdeOY1o6i8UxrKd62LnMwz29RRDvxNrK0P4Pg58/GGA0BGuUJzsd8UToUulnCgaU+WZYT0g5hY8poWjHyjm6e0+91cQj7oagqxkUtsgpJStU0NJXFWzCIxXjS6aLUXO/EB09TW2xs6+p0csnLlaKuK5IIiNtGk2Ypea8HaJqkISlqEh27K0JAG9mvZEZy5cQYkiTBe89kMmGgjeTqqQBT4nAWW9uMlKBbaRGHEh3qqLuVGDUjmUg+K7HZtmbXKjoMxqKqaZ+v9djKoZRhTzeja0S7J+928UHTBEVWBvLU0UkNndTgg7DsellCngrYqPHoEPAxH5b1Oszy9k6WsNjLObS6wEKekiaGydhSWoezNQTZjmtjUEr0q3Tw1LWw6/I8RPDPz7KGFkBLlbQZzvRjTuPjTA59Joc+k0PzFefQ/2LgKZ7Cqf/cfaWBU09CPfzlEXhwlp3tLRaWDN1uSpa19sAW68T9QqEifUuU31sx6iSCJUGp2CMrUdtb6Q1u7JzhZNsG2CAVl8QI2t/eSAGmIr3xS1AnmfEt4LGrgZHQKsadgqqo2XW3DxbaBIBYgdao6B4h98KLwGBUmw86AlAhkCg9cwTBeVzTUBZTUucwTY0wIRVNULHKFGIbosajsYCta6xrqMvpbEDpNEWn2XyUeIdrCoJrUEB/sECadUjTlFR7bD2lnGzT2LFQq+Mi5EKgahlHlSXdxTpq0dXwTyB6qr1fyPNr9ze6HS8wG+xS5VNYjbCedgn1Wd8mbAHnhQY+rV2cgCJk7oL0qddO3lzMSjTaJGSJIleW3E3Q2kV21xyzDUHYTbtRY0+kd88vIQJlYdd4OL2PbmoimCjufnF00s7NU5YMQXLlr7pFyT1pvM5UMRMdFRbbXFhUjiggbxRJomaMuFQrBplhoZNI/3nwlK6kajxFHTg2cpS1sCsXeglJIiKFoRGqcKLSmVtPajSdLBG6K9IOk6SaqhGEvg6QEkgTxf7lLtsTR1E5XBPoZIE9eeD8IVx2zh6e++Sn0s1v5+b7j/LeteNkqiZJHb2FnB07YbJT0TSOLGi6xtDgQSsGvT69Xpc8z0gTw7SqmFSlzMvG4XYmjJoSnWUMD55NpyfV3elIzAKMNig9p1d7n8kmpM1CFULr1aB0QJtYbUVRN1OqqmT75BZVp0uSJNKuqwPKaCkUeCLQq6IGnsZWwqy0zsYnBSjRzRAh6vj8o8tOXOIkcVGglKaqPSc3CxZSTTcz9LsR8I72wb08pddJ6JgMn2YcL2GtmoBvKGM7RQgBG4LQuBNNohO0ahmI8QNjUp5oSYqlQUFjsqhP4UGA4SBGAF5Otg22rh2TLYNTydhwiPmAigWElixwOh8333Qdf/bnr+M//+pv8Mt/eQP7l7o891ErfPD2LU6Oa9E2TFNQmu1Rwf6VHpedv8Kt929STCuaxvPtzzibhU7CWz55hJWe5pGrOVtVwva0ZloF3ve3r+Wue+7nB3/sF0myLmnWpb+0Sm/pLPaddT7XfOx9/Nkb/obf+ePXM908wrvf8WY+/qH3QbDUdR03fHEAuYrv/b7v5ud+6odZWuhRT6botIe3FaIyE/i1X/lZvuWbX4bSXf77//wzfvv3Xgne07jATuVBy5Z5e2oxpbhcTcZTFhYG5P0FppvHmRQ1xzamoDVHNqb86ls+y/6VIefsW+S3X/PX7BQV07Lhxgc3GU8LmrrhgU3LQZPxogv38KHr1lk7scEljzrE2rF1jh09wXRnB0LAe0tnuIROMsal5577jpN1My598uUcf+AhTjx4lAsuOpfJaML999zLwvISaZZiNCwsLpNnGY88NGTPwpBB3uFvP/JpJmXJQycf4ke/+UUsZJobPv0pHlyvOLZd8rl7HqKKLSv7F3PWtyoe3NnmooOH6GZ99g8z7jq6xS0PrHPx2Su4JlAWDcv9HK01K13LwX6Hg0sJV13U54/+/l6uu/8wVz7xGfzSf/w5fvjf/7tZAPMeXv4t383nrrseUPzub/wCL3rh81AqYWFhIO1PwfGOd72XX/mvf8C73vaXXPKI81k85/HopEebAP7u7/93/vTVr2NjayI8/Vk0iXCEUjS15oE7Sm4/Ajdvi+aOinHFWscl+w2v/JY9/NZ7Go5vW978/Yf4Hx9e4x3XnyDtdTk0zDh7oPng/TVJlvCUxxzki3ceZ31rip85qp3+QXjvMKdu4kbCekaVZ31qcUEYB8H7CPYqtE5QwUIQ9zFjxFRlUjma0kGxzp69ioXBkCzPcUHaeKzzWCegkI0tcU0Sq31aYYy012it6KeKzAS6yjIpHKX1nJw0tFuKQW7E4Vcr6orIcJecRzRt2qKsiiwgjVGKysVNrDb0uh3RZ6pqilqq+LWTNo1ulnLJuavs27uXlYPncfNDWxw+vsF1199IbR2jSUFd15RVRVlVJFmGqxw1FWXt8CgWeh0G/Zwsz/CupCwsRdlQlQXeOYrg0SYh73TYu2+FbidHAUeOHo35vaE7XMKYBGdSgvd4o8n7AxE6D9Dr9WZu2DqCUUYptrZ2qOuKqqpEHLxJqcqKpqpwtpFWlDSh25E1IQRPY1stuSAiyEb2O2kUYddaRdAwzArt7RbEW+lAaGNVCDAZlehaWGvKSD6kTIpWmhTFQk8EqR2KUWnZLmq2pjVpZEAtdNJZl0pZNzS1ZWotE1tTWXmuK4s9Dq70WV3qU9aOrcIzdQG8ZcEXpBG4srbBaUWDZhwM3eBIQ2DUKAqv8FpBECDfec+0qMDpCG7ysG6X0+84k0OfyaHP5NBfeQ79ZQJP/1/HXKAqsOtk4vcEjBDUtLYNnbohSRqSxGCduJwoLf3QPoRI6ZoHMh2DZju4Zq1eTqwGbQSehPEkaHoLgO1u/RO0L8xQXAGPwgxDa39HkEQ1C6gtLjmzwGvB6oflOnr2+2q27uz+UiFEO+pAsBa8Q7UWgQiiqLS00Rlj8M7SVCXT8YgsBLRzKC+DzQZInEM1NXUxFtAtKOqylgDgLHVVxGvSIqSmhS5I8HgcOBvRN0ViEvIsp9PpkmhHhacpJxII44ALkTsqNqKeyjpqZ5h16zH/OuVQ7R/zEdE+B+sj5RypJrSfoZWwnloqYYu++/YcfKBR7bjzs2qbjA2FnckQqCiiKGJ4BocODhXsfFzMUMP5H3I9M8RxjinOLu6fYcydpsfuU5+f85cgxA/7t1Sp/OwXdv0s9lSeKk4XaLG4FrNNlFT32nnpgyOEBhU0jQtMSse48kzrwMZIeoVTo+h3Db7yTJtWh01cdnS871rNxwjMWxLa2Ro8ZElKZiKNXUkSqaLWRaY93Tyjm3fI0l5s+fSERNNUlmZUkDWWjguoTpcsS0l0Im4/SuE0mCQGvSCaFcE5VAh476Tv27TUXCV6blYCVZokBBew1qG0QhtNkiTY6MBpnSVNEkzLGHAWbz1pJpVqrQ3eemxjqSsRU3RJgkqE1K116xnZrlEPG6WByGAUUdigolaBmb9m3iauIugsgS41hjzL6OY9WhHIxMR5q1pdNo3RkOWGTqbpZZo06gjIWqj+mTnVwr9SZYlduRCft1FthY5dLcLtKe4qfMQKmArRsWWWqO+es208aas5p/csvvXzn+X4Qw8Ciu3Cstx3rHYVGIM1KQtdg4uio01dU1YNG1tTlhZystSwvhk4tlUzzi1L/YTgA5Pas2+QgQ8UdcMnPnktR4+fBCB4i7MV1XTExz7+SZpyQnAViVG84ju+kXL7qFTHdco/fvBqNk9uo3SKMl2UTgh2ynBxmbMPHaIupsyNPOaJ9U03387ej3yCKx57KY96xPm84nu+i3e842+YFlOqomZl2GPYyzl/dci4cYwrC9bS6eZ0M0PiPQeWF7j00H6uu/soo6JCJR2mlaVqLGsb2zQ+ENACzMXN31l7hiz1M26/7yhVWdFNNePCEkxKb7hIU1u0FlbGeWfvA6W5/9g2+/Ys0ut12NnYpN/psHDR+dRVQ/COpcUFBotD0b7AobUwA7xKxF3WWx7/yHPZHk84emKDSVmzd3kvT3zmV3Po6DGOHz+Br8aEZBWShMMnNkFpzj97L0XZUJSWlnuidKsZKYyNxX6HXEs4P7E9YWHpAI995ot5Wf845929xj9+5FOU5QRX7YAy3HHXfXzimuu57fY7WN/YBAwryyucdfAgqJlzCIqEQ4cO8fznfhUL/RyFR6ddUIayqrn11tu48+77OLYmY4Yggtbvff/V3PjFO7FVAQTS8RqHtiy1TSGRjY72DbZx7F3p4pXhH27a5MDQcPZixskdhfPCiFFpQu1Fr/Gx561Qe7h/fYrJUvqDLqPtMZzmc7c96kbErBWio1O7yG5HzeaHicx8H0B7jUaTp0Zc4SKDnSDz09sGaxtMZN+kiSFNRH/Eq0CqZd1NUx3jFrM8aaaV5ANlDePKUjSiE5UmiixR9DJD1Ti8U7NNhaRKMcAHQM9jMcHPRIw1bR6bYIwic5bGacnLnJ89sSzR5GlCN09JI8vBeS9AtlWkODrKk6SavJuSpilZbijHkuOlqZGiohJdVyJLjCCsoBYc8N5T1410B2hNlqbiDOelCyAEEWBu28u0ES2zFiQR0lSb80hLj+TrBq3FDMD7IG12AYxJyBJDkrSC5xGwI7ZYachMwgy4mN1LsaUnzB2gIVDWVsx9gDxPGfRyloY9Oh0BF9BSeA6ia0Jrf04Qd7FUCXBSW8NkVxE+MO8GMcagE1AWlHYkKXSShL3DLqsLOcE5qsYzaTzGO0y8xzJ+Y7zV0jrYyRVZ0KRBkWUJVeHRtZe9HUGExhXihmgUxohV/Ol8nMmhz+TQux/xmRz6fy2H/pcDT7NNeFwk44n9Ey+bP56HAREBNVuYy7JCm4xur4vzCU1jcFbLjXI6Pqs58LQbyHEBmqjfVEXnnhaA8u0EDhFwogWeZAFvhdH9rpvXxk9Fe/PnmkHCsGoftAya2Wod5letaLWoWuaPUOekvTD+ig8Qg5z3Dt/IBAq7gCeU9Ii2lRJbNyKsWdciBKdAWxctFBUd1+DLCWEngN4RWmZto2uEp64rtBFUOO0O0Bi0SvC+IbhGqs8BtE5ITUInz+h2uxg8wVlKk8yApxb88Z4IIHqmytJNNKmRSdImUO3zhjB7di3AI8BcgJigiGVriNRzNevEaEGn3cCTV61TgIyDh1uWKq1wreVsIDLnIDOQpYY8SzGhRocGjUVpYTfJDGP+UMNsRJwCoqld32hngkdFh47T+2i1w9r7N++nf3jgbPuHJfi42GPrvYqJE4SgZ78WmPe6t2uDBE2ZE6lG9EECNMFT2YaiduQ+p7SBjYljs/BMKs/JHVjsQydXLA8T3MiyXbg4PaTKGOUOZWzQWrbKOMlNiEmnnFs3T8mThLK2sRoRSBKFMZ5EOXqdDmnapbIZVVXT2AqVpdhxTTn1DHJYyDNWFoZ0erE/3XvWlcIrUCa6CTlHaJqYcCtcY/EKbJqg0gy0oSkrTAiQJqRZh8pa6lqYH1me0slSbPB4Z6mbWpJwpWJ7ck1V1/RRUtVMpAWmroVpEryXjUevi0JhTFzaZxQ9aENRO9ZFN0BBTENm1Ypd43v2tzjHvPd0soRBt8fS4grGVCjlSbSnRXF9QNwolZLNQqYZpIrUxPVTgShM7gpep2AScy21tgoDUrFJlBJ3HK0kwWlX7rj2qqhVIf3nsv5n0URUISzXNi9vq/pyV/xMC/B0Pf7k9/8Ldx3eADQ6anasZIGFfoexguV+KoyCxlKEhu1xwdrJHZ565YVUNjCq4DP3bNNPA489NOCOYwXHx47Lzx4AsDa1/Off+L249CW4psQ1BfV0i9f++et43Ws1ioaf+akf549/59dx9VTs3JMuX/dN38va5idoyjFZfz9JtkAzPYLJBqi0g26stKoQZvEUNG988zv5u/d9kF/48W/j6V/1Ar7l27+bT37yU9x9973URcnB8/Zx8cFlnn/ZQe7eLHhouxRH1FiYwSc8+ty9fP1TH8V/fO0/UJQVZ+1b5vCxdba2J4g9rkKbhGEvxTvRWbn8glUI8Ncfv4WDqwssD3IOnxjT73dZPXuRrRObZFnC4tKAJz76PJzzbE0brrj0ApYWurzpbX/PZY+5hEsffQkf/tjnSDWcf94BTD6QNhxfY5yFADsFBDvFZVNe9LTH8oU77+fNf38PdzxwjOV9B3nBS1/O+MEb2Dp8B6vlFisH99HZs8S//Z230+mkXPnYi7n62psZTSv6w0XyLKGnE3ZcgtUZWQf2Dnv0E49qAlffvInbezGXvfQnufQlDffe/yA3feePkKdQjY+BMnz4A+/jx37m1yXzVLFRSaeg08ggkrmgTcozn/40nvm0J4OfEHyFDxkExc7OiHe97x+5+94HUCoh+AaQ/Oa3X/ln0oK08RAq1Bzqa37vKct41aHby8gzQ1nXNE3NBQf2Ma0bfuGt9/On33YeV5wz5J1fcIzKhIPLXTZDzs6kZG2j5D+8bD/Ht0p+/k0PcuicvfQXBkzHJd67GSPgdD5GkwqtNUobtksn7ozGRJ0MOVr2egiyoUowDLopIQR2JjUSBwMKh2tq6qok7fRIE0+epljrMNrhDaLrYxS9VM9YNMH7WewM3tG4QGUDm4WjdCJu2801vSxhITdoxNClBRfaHAAkJzZt7kuYy1s4j06EYa6SBG0UqTMkLmA8hHruaNcCOc5abNPQNA3WWlzjSZRnsWcwmTDAesMOWZbQ6aRMdgyFjW2XJiaWIUSZCz1ba1IjbB/vHOPxmIAnz1I63Q5NY7HWYaMLXFB2BsIkRmzMvffUZYlJUkxsrXPOYZsGnaSk0WjHWot3DU1klmRZTi83Mdf1aBSegMajYqeDrNmOqrFxbyL3WNxIA2meoBDgazStYp6rGPRylpf6HNi7yDBTJEhB21uRmVCNj+wEhYtW5AmBXqppXEJeWUBhIxlAwCfZuKdBkaSKJHGkWrHY73DOnh4HFzs0Zc2kVIxqSEODDTaCXHL/lfLRqUsz7GtM0BhgoZdhdcNaUUvE1po8haA1TmlUojEmkJrTW138TA59Joc+k0N/5Tn0vxh42o2znHIzd004mSzz/mq1+yW7Dh8Ck0lBbaHb7ZIYQ5YmeJfgtcIbJ05nBpzSRCaYaAo5T209Re3ERSKKns/QtjB/8gpotaJ2f3ar+zRjPDFbN0XbSCuSxERnPWiCi0FSqkM6MEMCW92rGXJs1Jy9RQRpnMcFR9AOZS0+SK+YjA95bas/pLTGpClJIm2IrqpE6LCqcKlUanSLexmZwL4qaVw1Y1UR+3YBVHAoJ+iNoxb3H23w3kbwy6FUJqCgs9iqolayKDVVPXNaUKgZEi8rrxIb0eDY0Q1ZK1zY3nslFNB24LcTYfdYaqtvAaitDPYmBmSFEhAKcdZLQwSfmOsiiM1nq/cloJMKaha8E6Ppd4TGuNDv0MkzjNaUOxM6pkJlYRdDjTko1n4PqTgZJRUHYcGFh/W+qgiCPWyQn4aHQgKLMQprW2x6DhH+U69XiAOJA4IXRF9FMLYVn88zHdl2YSaiCETwU+6NDR6LJyiYNIppBUVVymJtHHlmUNowKdr+eRhNGsrS42wQ5w0l490hwogOjw8G4xFHIKTaDlLBSzNNg6dpaja3G8rKgwdrA1MX8NazViS442PWmy9y7e33c2Jzi7PTDn0tTkDLqVSb8ySh1zSU3rNha5RTeK8o64rlbsqg12Fp/vR+CwABAABJREFU4SDb4wmbW9sRbPZo4wBN8JaNE+t0ex06nQ7Lezqcd84hDuzbx2DQ4djxNW66+XYOHdjHnpVlLjz/fD5/860cPb5GL+9yxWMfzQXnncMXbr2d9fUNTqyd4PLLLiGEwM133BEFkj2FrXEq0ODI0TGpDwQna6TDU9cOjeL8A6skWtqbb3tojeAUechwkfZuTAxsQTYJOs6HraLkwZ0JXzyxwxPPWUInSE9/B9I0kGWJJFtIO8a0tDy4WXBkZEmV59wOmCSgUuhlhk5iSHSCo6bd8kpBOOqZxLzWBhPnfEBZhXIqWhJLVXumrasDSarIjSLXSsCHEGLVbN6T71uw23mhF/+Ts+D0OT583T1UtUXYnSkOQ9FobNOA86QqsDEpGE0azjtnD1tbE45XW9x2/yYhBFxZsH+5R2oU1z8w5enndLjwkgHXntCQpDz6QJeb7q8pm0jrDbs3AYo9e1Z521+9josvvgh0iskX+MS1N/Crv/0n3PiZT1NPNwje8x9+/Dt52cu+nuAb3v/+9/HUZ3wNwXuuuuoqrvnkB/mhf/9jXHfddUDgl/7jz/P1X/9SDu7fw2CwQJ4l/NUbXkU53UH5guHqeWRakW7fx5VHbmF04jB337tK1u/TW1igaRzLKytccNFF9N76Car6BA+eGFGUll435/lPfxx33neUW+56kLsfOsGhfct839c9k47dYWNcsf+886mrgum4otoe8bhzLuLJj72Ah44vUzceawOHj22xstDlF1/+dP7mo5/njjtK3v2WVzM++iAn77+bx3ztlTy0vsMtD57kwn198tQwLSswmeQPkxGPvuRiLr7wPP7xYzfSTQy/9j3P5Z2f/Cwf+9R13PmZj/P8b3g5F1z+fJ6157Ecu+067r/1eqY7W6ytWU6e3OJbnngIi+I9N28yGRVY2zAMI7qdDgtLy5w31Nx7ouQDt20yDkskvb3otA8JnHN+j7e9/k9561vewrOe922gE06ub8XnKs85hAaC44EHDvPt3/X9uJCxtLzKm177+6wsL0QQpMdnPnMdP/5Tv4jSCUnWYe9Z57K+NUF0Emezl+n2cRk1SvGyQzmXrxiGCyk0OYXrMBpN0FmP1fMOcvN9a1y+X/OeH76Q4Ho8tJFw4VLgpqOOw1sVaa5YymBpX86rP/IQhQ3s27tAYz1nnX0eb3zDW/nDP/hD3va2t/7fm4z/i4dGJASSRFydnQmYIOY94mbnqJuAc5o8y3DO0TSW9bEVsEkJmNS2yXhXUxcTsk5P2OwmIUmMtG8pw1I3IUs0qQo4a/HOUtVizlK7wKYNND5QWAGcPJI32aAoHZyYCgNq2gBG2oxaRtAsFYzXliY6OqUpJrUTQFMrqtpSESimFVV08fM+YG2gqCz3Htnk2GaJum+dB9fHbI2mKG9Fq4VANuiSp1rYXMqjXENdOJq6Efe3oiBLEtJU0x90KZuaoqxoWRteKdE2tY6yqqjKgjzP2bu6l4P7D7BnaZFxUTIajzlxcpPBoEev12V1zx6OHjvOzmiEJmfv6gp7VpaZTiaMR2PWNzbYt2+VAKyvb1CVJba2GKWxzs1AIu9FB0kh2lJGBbRRdBLNhfsX2RoXbI5L1nYKGqWwqUhti7OXtO40zlM1AhaZxDCpPdul5cS0ITU5HSPFX4LD7Mq7ApqxDYwrz3bRYL3E8EEno7DCDBnVjsxBaqRrpLKeovHkqWGxn3PpOXs4tNyll2o2tkt2mkBhYdVNUKFhYkSPTEyOmGlobU0aDi1krPYTbEgxCggibeGRz+53Unq5Yaf0KK3wrfHEaXqcyaHP5NBncuivPIf+X9J4OhXbDV/yihZ42j2B2r+1QluNdXhqETJFaHO2tVr0UchLzds0QxDB8MZ6auuoG9F1si2AEz9D0p5dfee7zs0Hac+bg07yOyr6wbbtdS3DJ8Tf8TEp8EEGAREFDEo0flontPihc+SCdsB56Z3UDmXdTMV+3sY3/3tLGZSvVkAzvodT8/fXChUEZfUh4Bu3q/deEXZrFkW03FPjlYjFhgimBRcIRmhDzjqaphF2mBbnAQH1IgGvBRRD+6wDzkPlPK1koHvY83j4eNkNYO5GhVsMMKgQkd4wI4G1tEAAHQeXgE9z9hMqisspAaCMgixRdDJDJ0vEcliJ4GPTNDjcLCioiEar3efVglBKXqN33fqHHzPA7zQ/BMne1Toa4NQnsnu2tqMnMstmAKuaVdJaof3WnWH+HmHXk1fz7tQgiW3VQF156loC5ELOTOxetXagKKyLVNYwPx/n25EWZu22OsyBVnGRUbP5VMde6Lp2EsTiMHZeUTaatYln7CYc3TnC0c0JReEYdnuk3oozhgIbldOm1lM4x6SxEHXYnG1o6gqbSiuPsCfjKh+EPqwUUc+hwbkU58VZ0igR7ezlGakxsVKtyBPDQr+LMeJKCZpOljLs90nTRFh9wdPNpFe911ZuG0vlatqWZllX4kbBCwtQxYq0UjDIxUlrZpHdBtj46GQZaye9ivNA7vlOWXPfxjYHFzNWOildNIkPaC8uNa37CXF9apzQ83MdZpoFiY0APm0/+azWN1vDJWC2z3Q+DqRmx0w0d1bhiHO2ZZ+aeYxkVrGfjfR5ZfGU+X+aHlujknaunruSs9RLuX+zZiHXKKOYTiuaRqzLXRT9RRsm00reINL9W0C/cZ6y8UzqwEKm2dPvcpsZUdrIUg0wGPR54hOfgNIpK3tWecITnsBg0Md7z2c/ez0f/8S1fO6z1zHZ2iREvYPpdEJRjHnyEx/PBz/4Aa6/8RaCt1x40SO46srHsbAwmF1TUZZMJhOG3b2kRjQHx+MJC/0ej7700YwnCVubW9x0z1H01iamrLjo0Co6zdBpSvCB3kJGlsg48a1uCAFjDHVjcc6BgkFq6BiNDYHjW7LZC4iYsmscS/0O564MuGT/EtNxwaRoKAjkRqzEd0YFe5YWGSzt4aylPqNpl2ypS7+boJViezTl0EoPYwwntwNOJVIsA0zw5HiG/YyVruGCAwMGuWFja8S113+Bsy65HNNZYP++PYxXVhgs7uGxF5/FuLAkScZjzt+H9YHb1z3lUoa1FnRCkiZ0UsOR9TGHNwqOjyzWGba2dvjoJz5H8JbgHSFYQoD+wiKf/uyN1HUdx4SajY2bbrqZ0XjK5z53PZ6U4eIePnL1R1leWiB4hzIJ113/eT533Q1cccUV7Nt/gIsvuoCH7r2DeQyRwzXlLNc7Z5By3jDheGNIUsXBgbBuWoerSWWxLmV1occDa4pJ4ViIdu8uKJZzQ6YCzitS5WlUzHlqi1aKxz7qEKvLA/7/cLRrlrQ1xQTcSx4VYt7ovYxjk/iZGG3lRIQ504i7swalNRaP8w3BiWR5mhhckqCDI9dh5lQXvMd6aGJMbVygbDxTG2i8vL+L2hgmbpSVCzTeU9sgroq7LyQmdbvXTKO1aBUZTWkj69wHGitstLKRLgXXhkcUNsCJnYKkaAi6YHtSUVU1mYZaEn8R045fddPgUNQeKuuwNqDqBm8dKsj1W6dn63wIzO6nFI8dTR2NebwnTzMWhwsorWnqGq0CWSLxdqHf44TRBB8wRtPJcxYGfbR3uLoi1YpeJ0MpzSTLUN5jY/wJtcc1LuqY+miKIxmr91GzSyt6WUKZSksePHwWSbG9dd9u8xqAorZsjmuObEzBeXqpEUaEjoyW2HZng6JyULjApJH1vvECQiRG8mHnAw0+um7N3ct7WcJiN2XfQkfAzgBTC40LKO/Jg6VSXgrtEUzR4hKEUqIL1k01vTRh0mjEkF3NctAZuBKY7ctOc9LxmRz6TA59Jof+35BD/8sZT2H3JPtSQKl9jY/WjyYCYy0DVmm5QO9lwS0bS90ExuMpvV5Ot9uFIBUZ59vBIn3UPrKaysoJ8NS4eWIdgQal2s2/zIrdLJZAtLGMIm4uilrPW8HiwhmFF1u2UqsdVVk7u+kp4p5hUFEsLH5efNAoJX3jMbA552IAksxC6RKdJBB7TFWk6Sol/fCttpMxZvZvrQ1aB7mJ8TNkUGhA2gt9cHOkGmZuGlqbWKHyNK6etQzKwqnwmDi/A1VdS3WlrjBJIguCDVin8E6JY2ocAy1g5oDCiXNcHRe4XZgeLVMqzt3ZEu3je8A8CSFI292cG8XsWlND1D2QBEoFSdZ82PU58Ss1mixRLOSaYS+lk2d0Ol3qxlGXktg0eEInTtoIJLYTVbXuMkomXWJkzIpIfPspp4KaX5IxnIZHJNXJqPeiXRDTwziNT4WKW2DPBgHnMh1IU2F/STBUUTtv14oTiMBsiHNBXHx8/L71iu1JYH3H0U9hOdOsDlMqnzEuRcy3XcT8bI4CqAg+zxOxKkAaq3otUGx9m6BpnNeMxrWg8U6o7ipRgKFpoKw1XzwypbE7TEYFmVEMuxnnrvQZjSZslzVTHNp7lC2Z1IHaKiqbYNKMJICtSraaKdNxQifNmBYVVV1hsgScUIbbBTkxmiQz6NRQ1xO2tk6SKsdOp8v65jbBeaaTCZtG8cD99zDa3qKpSxQJGydP8GCi2d7ekvdPDJOtTQmyRpOqhEbDdOpQwQmbUbeBRypTou8mSZ5Wgb4W0L8Onrabve3f17O7HgOUVmgjbRJpknByPOX+E5usj8dcsDrkqy46AFZaAnodqX6LREZAmyDOVTV0DKhM080Tuj5QRu2BRGsxjUDNmM0qZlkqEaZhYsCYyELUifzdiNaBFAbUbO0xMWBqE/CNVHUSPEZLpW+W+MUhe9qjTkC7yBit+OYr97A+dbzu2hN8z9POZpAn/I8P3Uun36HTzThyfAvrwaQdbFOJdkOiWBuV9BLNJaspNx4p+OCdIw7t6XLucMhlZy/yqbs2mFgxW3ANXHzxRfzD+/+OJBEdAtH/8TR1ySu+7we54447d+UFchP/8L+9mre98x+46boPo5IOSXcFW2zEhb7dvsoc/f0/+G+85U1v5Oo3/hJ7zr4Y19nP9/7gT/GEJzyRv3rzX/CFD/w913zqWn7pj36Pi/Ytcuk5e/ndX/wWdtY3OfrgcRYHHYyr2PFTbFVI/ComdHtd0Jr3fuTTgCJLE55+8X5OjGve8dGbmIxGeG9FE8I68iTlCVddwlMfdS5POXcP191yL0XpqHXGVz9yD5s7E/6fP/8H/tuv/jgveNrj+Mhfv4MDB5c46+w9TB8YcdYS7LvUsLS6QGGFoTCdFEzrmqO1onPfYcL2Cf7NUx+H957tjW1e/tWP59YHjvPH7/g4xzdfxZWPOJtf/OWfZt9ZZ7G47yx+85x9JErR7/ZxJ+5jtDNhz+IelhY7BK35/H3bbG2us7G+wZ9/7A5Kl2LyRWy5zfWf+wwv+abvpxqfxNVTUJr/+uu/yN/89Zt4zOOfzrGjx+bPIf75q7/+W0hlWUCpjXKLl3/zt/MlwS3Ar/zST/HSr3sJAD8zXuNz136yDeTyAt/M5tVZg5yVfs5fHuvw3Ed4Xrx3yl+mhu2yZPvEMbTWbFY577s1wU+mdE3giguX6XdTBt2MS88a8ND6hDsOT/ixr1lkbafmP/3tGmmeMt1ZZ+vej1LtPMT/HyaxnmlsQi6pGY0VLROFsFmqytJYS+1a9kPAagGX0xBYyKV9buqNrO04fF2QZB06vS6JCphg6WjPSkeT6sCkcPggYN+09oxrx7j2NKHdrLSAgDzCohHXYN9uwGLFvpWbkDxp7m4XkPbAJNGxTdDiguiaOSdF4qK2s/U5iTlwExR3Hd+RzbjRdFORk1jspIwROYf1wtFpPHlisT5Q2sBOFSgaeb/aT1nIu7gskzjmRSZCKSkcN41smBXinhy8GPZMJwXeedIknTloqeDQeIwK0qJnLU1dkUZ9ml4nx9cZZZGSJppeZtBKM+h26CYK61KmRYlzDdOipqkcxkjrX2Oj/EVjGeRJ1JNSInGRpmRpglJK2lCrEEEgR2KkIN3vZjPzpJPbBaNpzZGTI1YXOgy7KWct9Ti0OmSx36Gf5tQ2UDaOsVVs1YETU8eoqNFK3qufSDfJuGzFioXPYLSmmxr2L+TsX+xy9kJGU1uK2rPRaFJb0fU1XWWpDGSplpmnFJgEHzwGOGcpZ7WXMUhT6hiDhQkSnfw0FLWjcSKyXzVz0Ot0Pc7k0Gdy6DM59FeeQ38ZwBMzlHR+qFP/GlFgULPN+8yRQUX70LihD0EcInZGE1CI6JhJhSYWHNbLAts4h4tudXXjhTIbEMbP7P1OgSrmaCnECS0Dt0XmZuJYLRKCgE7zICrfbymVmU4E5PCAi0iiUphOSlACRAUvfabBC1LpaasJonxvG1kFNAqVZWhj0EkqbxoCeCtCiEqBd7FX2wvYYTRp0pklLSr4WR+6iKVGMMmHGcgkyYFcewssKbk5cV2T6RCCImjReLA+gPcEJy1kzgnIY518OTe/rexCUGVhjWDXDNydPx9CrObtogWdGl7U7FxnYy3MX9lWGIyGzOiIGM/tHonjrP0adAydVBxZ8izBGC0OKdOC6bSk42WxEN0vHcenn42dGRsu3rsW/W1bPhWiP6W1dPaKPfE/N3NOn0Nmb3zmxHHwz9AjA2GGeOdGNLKSSO1zQe5DaIXp2jdj/uzaXvTEK5TXJHHOVA5Q0a0lBYxUL2trJSDOkD1Fksgih2qTXUWeSrbuEAZkcAGnZX0IKuA1c4qu9zEUSFCtG0fwsG+pz/7lIXsXh3z2ngeZYkiXF7l435BOotiajOnlQ/odxfZ0K4LGnm6WSHUjiF6E9+JKY5HK68bGtojkRzp7iNoObVKfdbugNNY6pq7kcLXGsbUN0jSRKpN2HF0/ybH1k9x+3/00zhG8p6oNt999D/fe/4DYMHthDBw+eYI8TRn2utHRU3QhsklBNimYlFNxE8oyfNS/axonjpkKivUxhQ9MfMAkCUoLIJxEpULvpDqmgDxPSI3Bew3ekxlDPuhwZGvCTlEzKWquOLSHs5d6DF3Um1Cw3OmSaYP3gZ3aMcZxeKdhMc9Y6hou3mtYXcjI02RX5cUTEIcQ5yTIq6DItOj9oaHBUbcV/CBJmSTOsaoUh6T0oyuM9mQmkCctizb24+t51fF0R4/f/ta/5L3vez+vf/2b+JsbTrB3Ieebr1jlrrWCnSZwzjl72BnXlKVlYdCRDZa1jKc63h84b9mwOki4eDWj8OB1zdkLhhM7Je9Zr8g6GUMUO+OKX/7ln+dZz3ymaB0o0Vx44K7P08lT+r0uf/Db/4mPfep6/vjVb6YcnYxudVK42drZ4ru/5xXce99hXDUmBMc111zLN33Ld3LzzTdz0YXn8xu/9kuYrEu3k7H3ghXe96FP8473XsMv/8ef49LLLgWleOvfv4ePf/wThOA5ujWidI7fffv1XHnukMedvUhdTKltYOozBkvLLK4UTEYjDh7Yx8LCArfccitJmtLpdLn61sOgYKlvKMeeTp7xqIvPZ2tnRDdL+Hff9Bxuu+NefuuvP8bjHnEhZ9WWwye3mEwcywtLvPLHvpF9bpu7r/80l11xEaPSc8+JmjA5wrG1bT53/zrf943P49BCh8yWXPeAtDV91SOX8XVFaRumlbTYLA0Mt9y7iXKBn3r5s7jrgaPctjbmj/70jTz5yiu44jGXctYjr6QpC6Y72+RnX8ry/obLzp7imxpva563mqJWnsEkPYt3f+FHKbcLFB6dZMIw2TmKdy5iQZ7gHN084zWv+mPe+/4P85rXvgnXTGTBVibmbh6ij02/P+CVf/BbfPZz1/Pq1/wF8wxT3AXxDnTK93zPd3H5FZfzkz/x02xvb8fRKnHbJIa3Hw48svZ899MNn7h7zNtunFJ5ifm2qknShOXFDk+/6jwevOUeRttjbl1vaIJmpZ9ybGPC1rjChcCffWINlObg/kW2dgrWT67ztre/k/O6m/zcSy/4V5iVX96RmHmO2U2kUr5tHdZHQW6vZ1IQvhHzExPp1iYW4HZKJzlL1K3MtGJcTMmVIstzunmKs4pxWUQjFc/OtKZsHLV17FSB2iscwjhoc6ukLeCC2J1bTmE5tXkYMGOr+RCiQ56mdpKvg6VsLKAxifyO1gJIeS857vIgI08MqdGMphV5lrKyuIBWgeAcxbRgmKT4EBgXFbX3BOtJUgGJeplGVQ2NdVjn2J5MKJuG8bTAekdj7ZyFEGOYNpo8zzEmQSnNaDzizrvv4djx4wSlqJuaaVHSWMvG9g4n1rfY2NqmqCp03XD/g4GtrW2CbaiqkqIsOXJsTYArbUiylNQbGufI85yulcKzWNhrrBX2oVYelMEGxdpOSdmIqDuxAE4QYCbE/ZSOzJC0a2isXJu1TroVHEyKEts0lLXF6YRVpzmU9ymcY2o941raJWsP41rylqn1LPRy8sQw6KQEZwjB00nE5WzQSVnKNIPcYIspO4WAQzsTyzAUdENFnXvQkBuHUQ68p2k8jVbULqEJOdNGo30rAyUtpr3M0DhZj5LI4kvxojfWOE7n40wOfSaHPpNDf+U59Jeh8RS+9D1nicjuf6gZ2KNVmLmGqfbbu17qg6coKvI8w1on7J5gUErLxPMhWsPKpLDOM8cE5qBAW2vdzciSF+3++y7giTnoFGEy4m1ESHkCKKRJFBnUhspKT3odKc2gMKlIvTsU3ko1qZ2mgnzuElv0TuAVa8EYqW6Z6E7gA8q7KOYFtFarygkopA1pkgraCjF4KenZ1Xp+T9qKVEvpIjCj6LT3vf0jIqOyDsZJEgLOudni2tJuharMvP+4RTnVrvsa760OLTDHnNHU3u9TFmd16r93V0vbMRda4bY54GUiG02FOWOq/X5i5KubaTqpppMZ0iQBLc4sRVkzLSrytAVH56fQosS7sMhTz3CXvpVqA4pirhHF6X/Mx3+YVWJmdM7Zf9SuV8dkQYt97CkxMoQZpts+txCie+jsM9phGN8LFT85ov8RrHMBbGQ1Mku45ucwO2PVWkEL7VXFamybqLeK8pITS4uoaq9LxYU1BBKjWex3OGtlQHof5Imm0+txYM8COngeWt9iMOzRyTM2JiM5Lwd5rvEmUmX9XEjPxyA9Hk1BG2lnbe8JRKtR0W6T18c24bLGOk9iNFmW0u/mTIuSummYFgX9Xk8CngtMJ1OctQyHi1FDTjMqCqxzLA0GpIlQpBMNKhhUMFRNTZIosjylDlachJzFJIpEKcqiZuICYx/QiYpac+0tl/sYPCglvelqF5KcaBFf3S4LilqKAysLXdI0YU8vI1OQxTU/eDm3Oq5PW4XDaOimmn4umw+UnJNwONvxKWuC8/LVzjUZMx4X2gRp7jo6m7uKGS29/bfRSDIzG13yOQ8b8qft8Q0vezEPPvgAAXhoS4Qzn3Ruyq3rE9YKx3Cpz3hq8d6K8LaKNOqot+c9LHY0y10p2S7khj39lFQrRpVjfSJjURgLgYsuvIBHPfJilFJMJ1OK6YTpaJvt9QrrLBecfx4bOxWPuvRSiq2jTEbbPHj4KPv3rTIYLvJ3f/feaJgqie5DDx3hne/8WwiB8849xDd8/UtIsh7Weu659ZN85sY7eO8/XM0P/dAPsLK0yJ133s3a1jo75QQITMqKynk+euN9ZP4g5ywalvpdahJOnBwzHPTZt7zAfaMRWZLSyXK0EsHcJE154MQJFgcdzj97lc2NbfI04cKz9nKyk5AmYhm+NS35/L1HedpjLqGbJUynCSFo+t0ez37CI7nv3vvZObHN6oFL2LE106bBT8eMpyO2JgXdwYClxR4bmaKXp/Sd5oLVIeub22zs1BSlRWWBDFlDulnCJefvY2dact+xdW78/C0cWF7kokP72b/nIOgMP6mhs0imPN3hlOnOmHo6phwdIRsMYXgOWiezAhZoCBbXTEElSCk7cPLkOvfe/wCPeOQjePTh4zzyUZdw7123UhYFs6QsiFpplmcsDAdcdtklHDl6fJYjtHHQ20bs4rOMyy9/LOeddy5/+qpXc88997C2dkLeK+YAa1axZBVnLRuKxnP3iUbEZNu1OUh704E9fY6nAryUjTB0tIKdQgxWeqni3g1xJcu7KVliqOuaaz/7Ba48t8+TLtn3rzQz/+WHVkRx/YAhstNjXJKC5TxPauNhyw5JtAiPV43kwZnyEKSBqaordCqaUJmRTVjtYFQJQDiqHLX10mLnJOZ6pUi0nr1vauYtuE2I7WmoXbl27AxA4VrmU1u80yqux37WoaC1MLy00aggG2ViwbDfSiAkhrJuyLOUhUFP5B5sA2VNJhbH7BS1DEsfSHJDYhI6Oo0yG5KnVnUjLLG2hTQCTrOELo5FY4zk7WjKomRza4vt7W3STjemoOKmp5Rie2cieUmQtsPRaExT12RGRTF7GI0n5GnKUtSnk26J2EYapDuj/WznveStWlrhAortopb7bd3svIOXZy6ghJ7Jfxit455C45AcXwWPteKUWNhAb1SCTllaEve5svGU1lM5ccFu4j6qdl50bFF0M4NJNAbFsJMw6GYs9nI6ykvLY2WZVAI8TauaLhVeVbiOxsdrbb+cC3gf2Vw6xQUZh635jo4aYM4rGWOhzdeYuQuezseZHPpMDn0mh/7Kc+gvg/G0u6c1nsgpn+NnJ5ZqMDq228XB+7A3Q/CVwKQoo+uaYmVliEk01ll8sJEtFBE5Fy8wtuy1dEfi+7Q2k+20n4ECzAEQZgtdmAMMMSi5+EAtguj1M83+YYd+rO5ujGp2pg3HN2QSORXIOwkqEYpuPbW4Rpz1QjvYkB55G9sLtBLEMTcmuvUFrJOKDdZKBdF7XFVLayCQdHvoJCXvdlDaCKBl7ey6VLwRIQJHAjz5GbDWAkCz8R7/oqKKmABZHh/EpcM6T6gDLkmivpWb9YG7iMrN7ivzGzhrM4zfE4xm3o6mmRl07vpt1f7/Ye0aIdKkW/CpBQeFaZRq4mCPP1ECOGWJCIkPu2JjnaQJOu1gvWJrZ4ftUUVR1iwPZ+YBUfcrtmD69jOZj/P50In3UxamNH75sOu+nuZH4wzBMEPlQwTS2nA2P+LzCwG8l/7vqP8gLgryPxPHVgsS195TRVA0N4kEo0RJVaWt4nrx0FBaQ3AEr7BNZBMGWT98CDQBSgtNDEzGSMBMtKLyUunDQ9O4uIDGOe1EI8MYSDO5PuehrkEZjdawNZ5y9+GjnFw/SeMtq8Mul52zgPI1G6OCYxtb9DKDMZ7RVHQWvHL0euI2EIIIlYIIxCYKvHesra0L+m8UqTHt5MPkCcoYvI7gpmuvKSXLNJ1IsQ8+0M2yqC+RAwkKg1aKXjcnMYpe3hML4uBpbI3SGufh4MoC/TxjOq4Y9SrGRcVC1+CCAxNYcxOCgkwZ+p2UTCt2dgqmAQpAG5lbKvbUEym3SgvDsKwtVQ21k+cggDvs6XeorePEpOBDtx7m84Me+omP5MAgYyU3PHRyh82dCc458lRRWcVmGZg2JYmpGWZdeiagMQwyETO0TjYZETmJdtaBwmq8V7KWWI+PSyZR8hDi+IzJm434ezbzkhVmpvWK1EDpAklwkcI+X2NO18MWG7hmilaKZ122j8IGXv2ZNZ54wZC9w4SP3HyM/kKf4WKH7Z3pvJ3bNKgQsHVDkvSZNPD3nzjMMy/ey5PPWeRvvrjBY87u8sLLF3jtJ46yOW4A+Kmf/lmuvPLxvP/v38+nr7mGe++5m2//zu/kT179F/zyf/oNdNrlJS96Hp/6wNvwruaGGz7PV33N1/PLP//jvOB5z+bxVz2FnZ2RBEOdAR58M7seZSRFWltb45kveAWbm9s453nJ132TxCxtePffvo2f/Ikf4auf/Tx8ANtY7r79Zu674xbe/L6ca973P7jtrgf4uV97Nd/+rEt59Oq5/NY9R7jtjrtRKhpmhHYd8Rw6cIAXP+c5jCfvJaXhOY/aTzFd4MTmDi/90d/lseft42seewG33vcAq8Mujz5vmcIsMhh0qJothquLqF6P9199Axedv49LztnLG2/0LHf28KMvuoSzVpeZFBXX3X6SSy/YzzOWBowLTT2ZUFNx5MiDuGCorOfKxzyCuir51Gdv5rmPfxRLz7ycv37vR1m77wE+OhnzlGdO6SyskPaWGU0KjPIsdHNISh7amvCt/+FtNLwLZToU4y0Rpi42weTxDrc03ACh4Y//5LX8yZ+9CYDv/q5v47Of+gDPevbXcsMNNxJc2U4m0CkXXnwh5557Fi968csoigpJMnz74JhurTM+eYzFsy4ENIuLS3zkIx/gT1/9Wn7yp38eFSVOG+v40Ss7PPpAn1ddm3D56h5+98WL/NBf34NTKf2VJaZb20xGU44/eJRPH6kYTwI/cFHFrYfH3H1kzGA44MAg4fH7Feedfy5Htirefe09XHTePrJU886P3I1+3hNYOvvi/6Pz73/HYb20aCitmDSewgXR8ow5sTCDAgotznARdFrqKHqpfO0ohY3itdPK4YJjVFpKJ2yIfXv3EoyiUSmjwuKsRwc9A5u8EgaEAfq5xOhBLowX6wKbUy9soSBxV0XQQ4AKYpuOJwQleVYishDWulmBODGGLMvo93rRadjibUODbL77maaba/JEU3Qz8jwjTROmZU1RWSaNp5dqtNKUjYPIFBomCVmekWY5dVXjnUN3M6qqoa4bxqPxrvaPgNIGk6QEND5oqsYL8yTRdBf61GWFrSqxQUeGeF01AgymSZS90BiTkmYJeWZYHnSFDeA9Jza2qZsG62rOXlpkeTigmyq2tnfY3Nrh5PaUSdUwLgSoDd6TGiMC3FqztjMVgC9Izuu8p/aWxW4mgulZyqRy1M5TRrYJaPI0ITPSQpwYTeMD25Mae2yLkzulWKjHHGRrUjGtGnEm1JrgPJOipqgtqdHsGeSs9DIG3ZRDyz0WezmLgw7boylVY9maOk7WmlEFo8kUo0tC2rCc5kxqMQAYlU7AYhtQKiFNDYvDPh1XY5qGUWlpIttN9nWOqnGcHIE2Urx3QZhhp/NxJoc+k0OfyaG/8hz6y3O1exiANAehWjS2/Zor87eFrTng0Aau+J4ErG0oqxJreyJkpYTlo7UgHULp0iLsBjPEsJ3Y4hK7q7Kx65x2I3HOt0KDYRe4oGZoPCFgTCDXioVMsX/YZdjvsjhYIDNTEl2wuTOhjD3rniAOFbGdMGhBmsUJTUhvqn0gWqOMjtpNwqRS7U1sYVHfsqbi6URgRAdBpnVErHeznIhMIh1p0oRYjYpvotXu3v35wti2P2olVTblFI13WNvgnMO7NBYjI1i069Gfgoq2FbH4pzDj1Pz3QJKqGbAUf2+GhLX/DrvedC4oRwSfZo9yN5Cm9ew68kS+OonQxuV+p1gPVWPZmZSUtY3OEWoGJImGQfsZ7Tg49UJD+CdED9X8JT4IlfF0P1oat4hsisiw/GD3q069jggDzvrLZy9W8ylXN/Ks80xx/tKQbmroJIra1lhnqawX/YTYmtg+dqXn1P0ZkEqA4PEOamsE7FQGkAp4bS2Nj1UhFSuqSiGCijLOXfCzc5XkQJiFOoKV1nu2y4pJU2OyBOcsx09usVOUFLVjaThAGUVpG2yoRPBeaYyWJE8bzaYtsDbE+yCVmySNrcIKnFKRaZGRpJHFqcyuBRqM0hitpZUpiP4DsU5htELrFK2E5Zi0jD6t4jUb6gAqKKaTAr00YNjJuWD/fsbTktF0yt71DuOyYGc6YTKpKUIAFciM0IQ3gpc1EUWXttVYEpJZn3pkjZ7CBFStFavCI+43K4MOjQvsVBUfv+Mwj9q/xIV7hzx6fw+TW3xQOC9AQzeJiVbw3LNRkKqGUZlwsnBMbMAHHVUTAmhmz1US9BhdlFTtsiSIoKoOKKdhdr5qtm659r3CvOITXzW/LjUfi6fr8bF/fA/33HYzIcAdR0asLGQ877IVHtqsGNWes85apqg8ZWnJUzVbl5TSpKmikyXUHrSD8/b02WkCt54o0UaxNrZ89oEJhxY7PP6CVZ702LPJugkh7fNLv/TL3H//gzjn+eZv+3ae/rQn8Sv/z8/imppHPfIR5HlO8IYLL7yA3/yNX+HosTVe/edv4Bd+7qeiJoJG6ZwvfPFm3vSmN/Nvv/fbefrTnozWGUQb4qqueeYzn84LX/A8vC35wk0385a3vROjHWmSArIGgIoFIsO0Vvz+n/416xvbrJ3c5MM33CObdyWm5VorDq0MuejAIufvG/LXn7yNzc1NvnjLTTzjkfvpJbB27ASjoqKoG178lMu4YN8S5+1b5OaHtuguLnHO+RewPanIEoNJuuSdgFeGs5c7uGnB4fuO8dhz95LrIA5PO2OmVUOWJdx3fIv713YwAYqqovIpdnubwaDHOXuX0d6hgbMPrnLfkRO4Bxx7l1dRKrC+M+GG625kcThkZWWFPQf20V9ZZeWCx/D617+eaz5zPYP9l/G0pzyeJ135aLwtue7Gm3n3+67m333PN1DVNW9423tpJlu4poQQ+JrnfjXPeMYz+OxnPsN4Z5tf+/Xf5Bu/4eu46vGP5TWveQ1oqSYTPCfWTlCVJZPJFOc8Wif82I/9MOPxhD9/7ev58DU3YZMh3/VdF6KNzKY8z0nTdBZnIKC05r5JTn+c84i04OQ23HXSo7MMZQPVeEy/36Ofp7jNTS4YeMaJ4YtHLNMysNzRLPUNTeO440RNf9VSNIG8k7E9KlleyPmOF17Os5/3fC6/8in/CrPyyzusJNK0DMRZPhp/7uPmsm0t0YpYwJWN6bQSnZVEa2ofZhXoVIPBEWyNdw0EYfeIdqi046WxcBloZkXKTqLJY85UO4UNorOJUpGxpGb5VvDRpTgQHbIgTZMYN9ScwRAE9DBa4rm3DufsrHuBABuTim7tyFNDYwPOVzQnNhhNKzEecj5KIcj7GiX6Lgph9Dd1jXdW8jZtRAfVBJQxs31AniVkWUav26G28k2TCICkjbTEJd2ckGdok840WfMsAwVplsWuAoXRhk6Wkmdi2Z5o0aLy1mKdaEgZrejmCefuX2Hv0oDp3iWOrm2xOZpwfGMHHRrqRmO9mYmJ13WI+6VAniYQVMzNpG0xNO0mVtqiWkZiP0tIEg1aUwcRg7d4xpXDhooj6yM6eUJiDNOyEU1dKywtpTRZmsQ2TomlSSIMtH6e0s0MmYmAkNOMg2LcOKZVQ11OyQaBxVwTMCQqMMgSMlPHexVm8982lto5lPXiru1dvF9SGO+kmn4nQWvNpPFoLWDH6XycyaHP5NBncuivPIf+sjSe5C8RDZj/5JS/z8Gn3d+NYEQLLkQQIsYrQnDYpsbbBpXMg6XWHqVspPj6OfNFtXnNHEBqAS6ZfLvavXadQ6tUPwca1AxYiCrTJHg62rCQKVYXOqwsDFheXMI6hbWeNNGUER32eHQUptaxj1BpSQq0UjPwDXaJh5tWMFwAGdWefAs6eT97eHKJsbrkfdShMgQtThvtJcxEHuMSh9az6zWREaUQwfYQB1X7O0ZrlNCz5POtxTbN7POUjp2eEShqm9/i/Jvf4HjtuAgKhl0w1wx4as+X9j8zMGl2MQhwiVICWM1+xuyz2wW21bgyihnwlJmYKGmFMgm29lS1ZVLUNNZGGqmau+IF5ud2yoCf/xHmpyA5jToVfPP/FDB1Gh4tQbKlXfoZXeuf/435b0ZGYRvoVKz4RIpsahRZYnjE/gUWckPHwIPr22wXls0GcgWpVpKYtKJ0ag5WBiVjtrVr9j7QeIML7UIo36utxwaNDy3VWM00MJSKNf5di1CI1UQRhpfrcUgrh60dB7oDrG04drJkbTQhKMO+1b2goXIWT41CAqZRhjRNyU3KeNTgvLh4taBllufYIA4xSoFJUzq9Lmm0LHG+XfBj+0QMmlqZ2Otu8ThJ6A2kJhUDgRCiBodonKXGkJmEGnHxKIoSnKeTJFx06ABlXTGZFqz2O6xv7/DQCc36aIxG2oUl5w2Mgo+CgYpUzcd1HdfnVvNOmgdol8u4GZIgblEkaBbylK2iomgcN9x3TOjYWcpl56wQkgIbpI9cKalyhyAisUe3KxIck8oSvGLcBBw68iXaVg5m1SwforNIDJpp4mc6gnGVmy8ncQFuWYxEMHu2/JwyzncFi9P0+MLnPs2R2Gp3/8kJ3Vzz5AuHvPna4xwfWS68YJkjx0fsjCu6/QzrwTmJJ0ZrOp2Exgl9+5yVHkcmngdGJd3MsFk41sYTvvq8IVddso9vfuFjMLnilvtO8vU/84dYb9h/8CDWNjzpCY/jiVc+hmq8SVCGaVGSp4YDBw7wsz/z4/zET/08//iPH+T973kzw+FQmLq6w7ve817e/Oa385KvfT7PePpT2BkVdLsdYlrE4x93OT/wA6/ANwV/+66/4y1vfQfjnU1s04kPTDaBw+FQnLZqz5+/6X3EyhOfv38dkyT0Ohm1DWit2b/c56oLVnnKxXv58A33UBYT7rvnTp73NY9n2Em55ov3M6otKkl5/lWXsDzo0usk3Lvd0F8YsrJ3P0avSYw3HVLlCCj2DzNObhYcXdvh8kvOxfua0c4W08mEonKYxPDAiR12piXLHdFzVEmKm45Z7KfsX+pQlg2EwKGz9/OZG27j5Po2j3vERYyLCTvTMbffegfLgy5n71+imz+awfIyi+dcwidueoB3f/h6LnzcC3nBC7+W7//Ol4B3vOUdf881Nz7AK77n29jaHvHW916DLUdQC5PpyU+6iu//3u8i1Z6Pf+Ja/uptf8Onr/kIm5uP4zWveQ39wZA0zQiuELv4kxtE6jZKwbd+68vZ3NziHe98FzffdRjTv51v/daGTFQuGU0KinLKzEkEUFpzpMxZmmY8Otni2g3NjVugshRlK8ppwcrikE6a4HZGnN01jJKEu9dqygaGuWbvIOHYZsN9m5YLp5baebIsYVLWLPZSXvTUi7nq6U/joqte+K8yL7+cw8aNapuLEmNT6y7YOilJIh83LlHM0nmorSeP1X0XZMOQGEWeaLSBRIkwrkLHDZ48m0xDL5O2uqkVVpIPgSwR3Slh24jDnYtJjtbMYoDE3zaXFxBIa4lFIZ63cy1zp23n0bJt9Xam59J+bU9qylQ2XFprnLfUoynTSkCxTpZJJ0QsQuoo0K0VeOewjcM7N7tRyhgp+Lr52Ot0OvS7HZYW+hS1VOWVSYS5paCsITEZiTHSgmYdTcvqMJosz2edE0Zrif1pSpZKm6c4vQXqpmY8LVEEEmPYt2cZFRaxtmHQyVlb30R7i3INRd1E7VYB4fSuXCVPNSEonAYXncSct6LHGhAZjCDxLU1SkkRYL9ZKG51HU1pP4xvWtsf084xOllBaTx3dwGUzrEiTJLLphGWUJYY8T+nkCXmqSUVvBKs00wCTumZSNTR1SapSBnkKXmOUoZcmpLMNfSxCh4BrGmrvUM7LHsNH86gIPnYSRT8X4Kl0VlrRTm/C05kc+kwOfSaH/t+QQ395jKf2/f+ZTbaa/VDNAqianYyKwVZuej83DDqapV5OlsiNVKEk+JSQ9mJ/NqSmiVetpBrQghgzvCbsxkXkSyu0aZ3f5i2CLRCjTBCXgNha1TKdUu1ZzGC5q9m/kHPW8iLLC4t0ewuc3C5IjIBnPojIuZuUMuiNpk9AKUPSSTFpitZSUZkoGVh2dnLtecbebS8BPIS2nc2LBlQEeax1hFDLcMgykiQhy7skWUKSpCSJwUcBc2dlEku1Sd6jrpsY9B06TkJttFTZfBCACRXRaEMTn5NtGmEUmZZdpWatfjIg5s9ht46X0PqI18NsEM+XXwmuba61G25qgcvdqLAivi5O5LYS2NKhWoCxRdGD1jidEEjAK3bGU0aR7RSCVM5OtW6du+YlOtoUq4dPqjkI2PY4t+BpHNn8i2fcv+Jhgyd4oXc2TsC33c9m9/FwBFsh1Pz28ErsjPGBx549YN9wwP6lAU1VUdYNm2WFDw6lhIWmozaXi+xEreRp1s6zXTisS7C2rfJqEqXIjZFkFqkqKB03nwhwmyKVB51Elp8T55pzVwYEAkVTs1WLQH6n28U1TmzBFVEwOaWceCbWUZUNaKGIt+2lBE+aiK13mihpUwigfWxBbTyNtQz7Ob08ZbHfw3mhFaeJuNR081xEIVEErUmUITUJq8M+3U5OnqdMSsdkWrK5M2JSiZ5NJ89IlADYjYvnrBV7Fhfppim9PBNAtao4ur7F+uYIV1suveBczjm0jz2rixx+4Agb61ucd3TIxQf2sDWecv/aCY5ub7FdTOlladSiCNQY6YTyIQrmy1OPy/CueSnRKDGGfieZtRYrH9jT6xIQ98yTWyM+vlOQJ5qtScV2M18HGuRZdlPFBUsZ/VzhlOKeLUdphR4u2h2QAk38Ra/E9ntSOzokONq1J9CKG7Y2szNHDhDqcDRHaAHiREm1TBIDT1D+nwtrp83xA7/wBzSv+jPe/ZEbeNpjDoKCV3/sMJceWua8A4aP3nZSxH6NZtIIDZ9g0crQ1A2jjQ3OuXAv3SxjXEBRloTG8rInXcAtD4349N2bfMuzDnB8p+ZrfuadONeAdxxc6rIxacA3+HqH4DKUyciH+/nCzXfwZ2/6M370+7+VR118AaD4tf/8y/zb7/senv+ib2I8HtOOnLJqQGm+79/9JHmek3SW+J3/+ss846lXEbzl1a9+DW95y1sATVGWQOAVP/CTKKWiY6vnwP79XH31R3jt697Ab//O7yMBVVam17/utVx83iE++Fdv4B1XX8ONd97LnSemXHJWhfLwn775GcL+Mgk0JWVRcs45Bzi0uky/k3LnA2uUWzssdFOee9kBdkYVH3rfR7n4UYdYWlqgrmv8tKEaT3ng1qMkwwVW9u2hu9gj7+xl77mXQBgxPnKCL956lAMrGWft63Hw3EOsnVhn7cQGZrCHcem549bb0N1lllb3cOWTLmf/vj1sb2wx2dlhT21o6i6TcpGT04aPPFDwG+95I4+5/HG849nfBjqlaSz33HQ1m8efDK4m+JKXvvDpPPtZT2Z5kPKJT36K0bHb48YoATy//wev5FWvejVlDVVdnRrjlOGVv/dfeNELn4cyKf/lv/wWf/KqV8uzC9IG8T///I088arH88XPf4okzfDOcucXrmXPngVQnhe89Pt48KGj0k6pFFonmLzL0y7scdFKxv/4YMHjz+ryjRdn/OqDFU0TMGmH6WTEeNJlrPZy7ZEKGzzfeUWXw9cWXHPU8azHr7K0UBLSnCfvVxzfsXxsXHDVY85leSHnd//io/zsOc/joqscX0ZK+69ypDOxbcXESSEwScA1PjoRq1nslRYvJZbg6Jlux6j2uKCk5SGINMS5e/rsXemzf++QqU/ZLgIPrCustdQ1TKqCELzES61RXp7ppPa0LUKVkxw0xJyozVW9D1gvQMlMJynSsKyPGkPO09QNJjGSoyYJqdEkeAbdDAUsdjLWdwomVY0LitoFaXdpKpxz4lbtRaxc7NE1qdEMeznDrmHYTagaz6SybE7qWNFXWGfp9XLyNCVZ1LFNMDDodeh3MpYWerPcrXGIsY8xdPJcWtYSw9b2iKKqGU+LyJ7SdPJc8tdZZVuQwFQrulnCsJez1O9QVhVHT2wwLUpObO6wVXoO7l9l78oShw4dYHt9g2OHD3PixAbTqmbUWO58aJ0T22O6TU6IwHnLBApBU0eAxvuGbp5ijDgZNk7y9tRo8iQhSw1KewHclKK2ovOzPqoYlw2Z0RijI/tV7pdWiixL6OcZvTzhwGKP/cOc1X5GLzMkGnzwbNWwXgQ2pp5jGyMmkym69jTeEMhwlaeqAuNaAFUP4D2JklmoypLMgCEwbjzOBpSXFkoboh5YUHH/MQdmTufjTA59Joc+k0PL+P1Kcugvj/E0e9c5wPSlKFRsY2qhvzaQxkNrRT+X5C81CQudFKPk4kvfxK4zG6u0hiRSZ7WC2ooYm/OC2M33/lF3XytaN71dOM/slE3L3vEK5XZdkBKU2CjIjKKTGDpZRppkaJ1QN56qsdRNg/MSiBIPxnoSHeLk1Rilo+uanFPwHr2bUhP/0DEYpEZuv38Y+2o3W8hZKyJwqm2nE8Cqk+f0ut0ozG6ZFgVlrIb0ul0JmlqzMxpT1zXWQrfbIcsyup2caVlS1w1lUZIkInNpTF/onEp68ltYZfcz3v0s23vbxuQv/empmmAzRDREcIogIngzbHI+rk5hUwns/v8B78S2Eg94QY8JUDeWsqwpq3rWrodqAaQWxJQSy2zc7PoMdco/WkCNh11T+8LT/2idOFqm2Cnz45QjfncG8Lbg7vzVGnH2gEAnEfFE5x0nRwW1dTSiqCeVFLVrrvp5m2OI4J/3skC6sIueqmUhDEHo71XjQEllQ2tmYvfOe7xVWC9OS9ZJIEuNoZfmrCyuoLShtIG1E1uMxg1pqmbX0iY/OslmAHVVVOhM+poXuwlZmggN3igq6yirhqJx2BhUh90uS4MuS/3uTA8tBEVihJ5vmNcR+nlOL885sLJAr9Mhz3O2xlN2DOBqUm3nFd9oldhYK8w+oxl2MrpZRq/Toc4aslRT1TVVVVM3lnseeBCVBLLUsLKyTJ5mZCalPxgwnkxZGuSYB4GTgWMbY7FkzVOpkMQNRJLE5TvIyjpbzmPVSwVZ61ItIL5Xcr0qOl2mOsFqhfeKe45tMCosJ3emszW9DV6yZjMbi6atrsyH3mycqDBvadYI2zTsmohi980M1J6N39mQjolLyyiYsQzmYyHw8Il9eh333vEF1teOoFDsGaQUlePEdsWF+x15AlV0CDOpwVtLlhs6eZ/trRHeWbJOzrCb0ksN956YkhlNP0u598SUjUlNauDT92xTlI6hskxCwBjDoT097NGRbCx0ClrEeZU2bG1t8rlrP8Vf9Q1nHdgLKIaLq0yLhoeOHmc6kSSQ4Lngwgv5ppe/nL97z7s5evQYOt3h/e//Rx647x7qpqEsCsbjUQSSJEHe2NiKVx94+lOfwGWXPooPffhqbr/9Ttp16sILz+c5z34W995zN/feeTtfuP0uTm5skOnAi59xOY9YTqmsZ3nYp3GBSWFpGqn+D7rd6DYE+1aX8JG1QdAMFgZc8Mgh/W6CClDUFl8WNHXFwt49dBaH9JYWISiJ07qmN+izsk9zxZWPIW220F4MLRobQCdsbI/opOA6kIYStTPm+NGTuLomTxQlULjAqHLccPdR9px9Hk99zlfz0c/fzda4gCAtc4NOxn03foazFiMbTKX0eh16g5TgGlCpMELaRCgoup2cvatLXHnVk7jn3vv55DWf4d1/949MpvKMrrvhJoaLy3zDN7yUZz/7mYzH2/z1O94lGk9K88UvfIHV5SFnHfwOALZ3tvnC7fcyHW+xuXGS+x88zHgyjdoj8tQMHu0hQ3HWQkrQCScbEUlRSqxYmih2nWQa5S11ZblnO8Mqw2I35fD6iM2po6g9Xzwypmgcexd7TKYVdd2wU1juv+8Obrn+ozz6quf+35qO/0tHu8L40OarssmXdrt2TZJNqqx/cc3FxBiiZ+yDPDVtTZeFrrRH2cYyKRuKCvBSkPOJoa61CEw7YTtYH0R2IG40UZHB8bDkpj23VnxY2ixatrlosxJZLmkLOmVJBHQ03dSwOuxhtJKWr9pSNRbiBjTMBJE1ea6pGxeB5pbZo1kZ9hjkmn6msb4BHbBEgCkKUwzyhGG/Qy8aFTXWk6ZJbItT5FGUuKwdJsvJ8g7nHNhHqgLaW4apYjwt2Uo1NghbspuLO2TY1Q4Z4mf1uxlLgx5VWaOCZ3nQQSmwdclDR4+L1q1RLC90WVpZwShNJ+8wnkxY39nhwbWtKCwvQJtRwuRqC7YuOmPLZ8pzVwZ0ELZJq2vaSQXKsDqQKGhM1FDy8lut4PQcBIkOecbQzVP63YzFfs5CJ6WbapT3VN4zrgJbU8dO4ZhOhdE1LSqGqZ65GFZ1g/N+3tnR7l3in855bBzJSrWxXlzVTADrNElsWUqUsPdscnpTns7k0Gdy6DM59FeeQ39ZwNOpb6lmN7b99xzNkz9a7Kn9rkKobgt5wrDboZeJo47zjsY56sLiXSCoBK0yMOLmZpTCGQU4seGMNMJ29s0Agxn9sAUy5EtFZX5lmKHPjWqFMuUhGCWMp06a0skSenmOMRkew7SQhXdSSGVG+UAaILOOTCs6CrrGkGpNFp3nvPfUzqK9F7RQtw8liBB2mpBnOUGJtWNb6fIhxBY8OTfXWFDR4SWKxRqt6XU7LC8NWRj0KctKeuEbAewWBwOGwwWSJMF7z0TJAxwOBiwsDFheWuTExibjyYSqqsiSJIpBJmRpijGGaVFIz3sIgoS3k4ddD3T2cHdrZs3y3FMHb0Rx4lpKUG2fsgzeWfBSzK599yLtdAtG7RrioYUcwXoRztROoTF4r7C1BMuirOPMm59OC1TNWFuoGfLbVvrm2lUPnwy7AsnDwKrT+WgdKnSsslo/v3//1PnLrZEHGwC0wsx+IPfGIyyxsmk4sT3mzrUdQLHc74iDSaoIdbt4KIKPqyI+jhlFUDoCgRKIlQ5oA0oJU6+uHUXVoFVConOsliS9sS6KZiga3+CcUNgnRcVCt8vKYMAVF19E3unwwOYWo+0pJ6odlE7nCL+Xyk2n041ipZbpZEpHG7LUsGfQoZPndLKctWnBTlFxdH1KbR2JNvQTw96FAfuXhgx74uJivaecNoiWgokaHaLdsLefs9TvcmjPUIDjLKerLB1l8U1OhsN7T5ZmeKSK2MTKQ2o0C52Ebi5B04WEbp6gCJzcHjMtSj73hZspyoJgHVc94XEsLi6zuLyH7Y2TNOWUUKzgvKWpLZ+74wEG3SHLwx5bhVSovKsxqYg61jbIpkK1cyC2AiPsyMxoFA6n5lUQrdokP8EHzW2H1xiXksDqJCVN9MymW6lAGu3FjQp0M2gCFNGtvR1q3ku7T+vAlKhACNLzHiPgzPXDe3XK77ZzdKY5SOveGT/DEHWIxHHodD7+4W9ex2033QlKsadj2HSO8aRiZ1KSpwm2aUjzhCQ11NWUXjZkz+oS68dPEggMVxbZO+yQqsCDGwWX7O+yfyHlw7ecJDXQzxSv++gRDgwSnnp2jxOVQRnDxQe6bExq1ioIqgMqnWVVGyfW+PTHPsinP/4ROcngOP/ix7O0coC6tqckAVddeQV/+j//gOfccStHjxzB12Ne//o3IFoDUQwXj/Ptitq69kh19Ftf/nV89TOfytOe+82MJgVKJ2jgSU+4kv/5x7/H817wUj7xyWvk9d5zYHWJX3zF13L8/vu565bb6AxTyrrmoY0RiRJNldVeR5ywfMNFF57P5k7BxvaUceXZf/Z+rrzi0Tx0061MxhNGRY2fjsE2HHzUBfT6A7qdLtP1YxTNhFAXLB+4hEN7D/Gycy/inhuv49iD93PXkU0qrwhJl8OHH6DbzfH79tBxBVXjuOnG29m/lImYcoBpHTiyU/OuT9/ON778sXzvD/57/uyN7yQEhfeWf/t93803/5sX8K7f+Bkec2gPKIMyUZ9JgUo66LRLkqTznC1oHnHx+TztyY/nF3/x53n7O/+OT13zaX73la/Cxw3Hq//8jVz98c/y4he/kJf9mxfxVU9/Ih/40Mcp63VQmhs++xlWF3sCFACjScnVn72Vaz7xMW75whdQ2gubREuVXQE6NJSFaNU89ewud5UZX9wxkCRob7E20DiFQ9PJDQNqxmXDR+7rUfiUs5c919+9RuUUtTf83YmCxV7Gxefs4Y4H1plUNQf2Dbjj1s/xobB22gNPfleBMdEaoz3W+pm20ymtRi3o4YguupKYhCDMo0EutvQKAZ5CcKxvTzi+01A5jSPD6JQ0FWffohEWjdLM9Ja8i0LjMQGYr/Xy+c5JPHORUaPiRthE98vUaLySja9BNJ+yLKXXSemkCcNuxvkH9tBJDZujKVvjgp1phVc6mgJFh740od/NmUyr6KYsrTZZmrB32KVjAqnyjGpQDQTtsVYKipn2rHQzDiz3WRz0KGvLtGywToAOAww7oj1mgLzXZWE45HGXXISqC3wxZrNn2J4UrG1LCyco+t2Mxsm1Ny345APLvYyFQZc9Swuc3BiJPtPSgNG0oKxLbr/zbupigiunLF5+GYPlVZZX9jEcDNjZ2kAfdnQSaQ1wzpPEArtF2PjWBQGdoq5tUBqvRCNWedCISHhqNL3UkOrWAVxEf73XFI2jciG22LWFa02aSEtcluiZe92ehS7DDHomEJqGSePZKB1rI8dO0TAaT9geTajqmpVOlyQxpIlmPBWAII2siFbL1Ud3OrurGyWJ7VyJVnRNgg2K2gswoQmkKpAlCq9Pb5GnMzn0mRz6TA79lefQ/2LgafcGexfewAxwapGph32unv1IRZBH0U01mQkY5ZhWDhtbzJx3WC8WpEl3GJ0kOnjXYJxFqwZjHXUTgZoINijdagXtEl1T0kOpI1Mofhcb+1WdC7O2PW3mqKHWGpShDgnrkwY1nXBye8wDJ7ZY3x6jXKCDUBN7WpFpRa7F4UwrT3ANTRAKdNmIHoGPKKHQiSvqSoJOYkwUSPSnVCRmd3oGccufARF4s7amqUuqMhN73aqmriqstWilsLbGNjUEh3cN3tlo/yojRXrW275eCc5pohl0O7TWCForGuuobYOrostJrC/pOBAh9ifvAnTaoeBDkPuv2z59+b5rtamCPKugWy0nNQeb1K7xRNt3rGcru1LtpkQSIKU0FkOiErTJhPZtLaOdMUXVYF3b9ilnKaKVbVXRM3dslM8MEW2fDek4rtUMc5+juyGCirObcBofszZC0af7Z9GyU4adEnpmq4no4iuscwL2Bc2DmxXdpKabahbyZEbzrZXc37j2xkDl4thReKcIWmq5WdzLqnj/rQ9s11B6MGnGpefvRStPY0tGxZjSOpTWDEJCN014zMHV6GaRMeynLPd7HFpd4dHnHsJ62BqN0EF0HCCLOGggeEen12HfgVW2tsZUZYGdiiOY01A1gXFRy1xQDU3j6WcJS/3ejBl4YCHloj09IGO7LNmpK/KooRD3zSSJZnGxz8pwgUG3S5onoD3Oiz1zL0tY7Kfk6SBS7MXFpnEW7yqsVZRo8p0CetBLDJ1Uk+UJ6VIfRWDLKI5Ox9x61wMcPbJGkioOnHU2B84+F7TGlhMYK06Oxtx79CQEg1IJmgTflCTBk3UMmYk2qwGUN7PqHjGxIYZzjQEfUD6QqHl11joViwCB1cUeSdJQ2ZraK9nAtEMvQO2hskSqvcKoQG4CTVDYdgmMYLMKkjh0cllTrANnxZUyqDkVfb5iRvp/cFgCTkew2oPXsXIMmIAYOPzvmWb/x44/ev2HGE9LvA/83Q3HyDPDRecus117XNkwGA7o9rsi0Fk1bG3tsH5ygySTyv1oa8zVt1fs6Sd8x5NXOVkoNqaBbs9yYJBw4UqOyrpsT2s+cO8WKx1FN1GMypL9PcPBvuNrX/xivuM7v4sf/7EfRRZFDSpFJR1hKtiSow/dy9rxB3G23lV9eBg8rxRKpwTv2Lu6wtvf+gYG/S5lWfKt3/H9HH7oKEopfv83fp48z/jRn/tNfvePXser/vxtTIsKk/boD1f4y1f/Jhtb27z0O/49P/YTP8bv/95vAfBffvu/8YWbbmHfVS/l6tv+kj9933WctbrCRQf38NRLDlFbS91YDh89Qb/bQRvD5z/xebrK008Ui4+4iHo65cFbbsMqSAd9lrzjyLamsIbLlhfRBGgm2Kqg0++zdOAAZANqr2mKEb1exurqEjZAUTUUlcWfe5AEx1BXpN0BeWZY1DssLj+S4Z79nL24wuP2nUNnz0G+9Sc3+PinPsfTn/Vibr31ds4991ze9Jb38f4PfIjpZIc//vWfY+XgOYAm+DrmDgmEhic8/jFc+6kPyb0OAW8rBsMhg8ECia948fO+mk9fczVKZ3z2c9fxwz/yk5i8x9ETG7zghS/BNjVFWbJ+cp3QOhEqxac/cwNPftpzIDgaazl2YgdjHAfP3svmxqY4m1lLkndRQG0tm6WlaGqedJbD72RsbnUkzsbyvFINjbWsjTybhaeoGvZNt7n5RMUt2w2DhR6mcajK8lPPOchO4Xjj59ZofOCCCy/ijX/xat7+V2/kTe96Pz/+K/9XpuL/8uF8oHGexorwurPRCRkVNTxDzFcVZVOjEqn6Z9Hty3pPEvO2cWlj0RLuP1mIQ1aAaeVR2tDNPSFPsSrF+j5FZLl772i1YbTR86p5m8fFHNn7QCOCTxij6eUp3SxhqZ/T72SilaRFDsJFhlInz+h1M4a9Dv1OzvKwx/ln7SMAN99zBGUSGuep/dx5edDN6HVzlgY9YVvUDeb/Ze+/w23LyjJv+DfSDCvscHKoHKxEkbOgCAgKChIVxMCL0m1WTN0o+Jrb1HZja7c5IgpGgoCiREkFSBWVc9XJYccVZhrh/WOMufYpu7/vw+Z77fK6zryuXadqn11rrzXnCM+4nzuIqCIwMjKjJlWH7VrWJzXTxtF2McYr04oDK0Mu27fMod1LaKXYmDV46/E6AiyDXNM0LUJpVlZWOLRvL7uWxwx8g1IOWWqkH5BrFVlDSZaT5xmzuqVuLZO6o+kiC8Vai+9aRNewa2QQQaNCzubUsD2ruPfEGg8+cISNtTV0XnLw4AEuvOAw4737kVnG5uYGy6OSpcJwesMhPBgEF+0f07rAVuM4uVVTd5aujYl2MkTPUpSO3rdSorVmWJjUaPW0nUjAQSCUii6NtfXKUttA1XkyJFrAMFOsDnN2jUt2j0tKYdG+49h6w5m54+jUsVl1TOYNp9Y2mVYNgggyDbRgZCS+1PgmsOUDDoUXUdJlfQLqiNK/4DxtCEzauK9P6o7WQe2gbeKB2fqYLO39/4FJ+S+4ztfQ52vo8zX0F15D/4uAp//Vq4Z/9u/nfp378z0Fz7ND7+scC8O7noIWQpyQ0nXJd8jQJzko5VEhoHxCdgkLEKJ/Cj1A1qe5LYCnHhnuUb3Qy8ASIpJ+t0dig6C2sDlvcL7l9NaU7XnNvLGJGRMfbq+D9yImSogAlrjodh5q57GhlwVG6Z2zHV0XzQ2tyXDO4bxbUN56X6PFfU/0m95AzoeAtZambaiqCgF0XZfkdB1SCJqmodIKpRRN+r51Nv5c01DXFV3XYW0CvZKxeU/F00phdC8D9JFxdg7qeC7AJNJzZQFAiQXdViTjukzpBf22swn4C7HDF7skYoHbiB7ZFOd0EYTojfbjo+6frZTnpCb1SYgyJqh0HW3XLfT+8TWTRrZnxfXDRuxMtf/veO3//Lc9MPUwJ0sA5777Hfg4ENl159xyYMcDyy9+rqf3RhCvS1TPQExUMcnIWEmdgL10T9Pr9BtlEhTQd8KkiH5sfYphH/spfAAbGBYle8YDdg1LmrZlbWtGqRWFUQzLguUiY5xnXLC6yrDIGRQ5ZWEYD3L2r4zYtzJg3qY0jhCSZp7FV0jMDWejF5ogUKZoZyEVTWeZN4KqsTgR02u8DwwyjdEKvGaU6Rhh6gNGCDIpkapf6AVIQZ4Zdo1KlkdDBmVJlutIH0504kxLciXAKIKOiUAD52idJbiW1sXirOssnY3RzGVWRNmulMwLQ2cNRZ7RNg1nNhruue8ILkhGSytoLdFFhnclw+GY1aUlLtxr2bs8YNcwRzgb1wDvsL6lsQ6JTcaNIqGrsbuuRJ9a2ndL+gfar139ZE4dFiXjOr1Y484ZhaFnHyazXRE7Uy6B0HEfid+PfhCJoqygC3E0RYPMnaZDCLEj2SeHJi/T9JdiZ3ynsZhenoeuvA+/69jJDeIeF1jNBcoIZj4W69bFNdy2HcHHRBcbAm3bsjQYxPSUrsUhaDx0HiaNY7sO7FsqKDXMG0uhPWUmuHRfzta0o3aB3VrgrKBqHDfd8zmuvOGTfPTjH+Uxj3p0fGNC8JhHXYcxGZ/6pxu5/PJLOHhgH+B44IEj3H3P/UDg9Jmz/P0/fICNjQ0AegZwZjSPftT1rK9vcOttt+GdZ/++fVz/yEfw5Cc/kSzLeNYzv5RbbrmVe+57kKc/7akcP7XOidMbbG1tc+TIUT796c/woz/wnTz2sY8BIXj6076YpeVdlCt72XPhZVx+/WPZszzmwgO7uejqC2m6lrquyM6cQfnoj6imbTTazaJfoLWW2fYEmedIIdDBkucGdGSXKRHAe4Q2CJ0hlKaazmITbbYVk7dCQCpFZiJnONOScVlw4Z4xZjQmzzOWhyXH1hvuXnuQwcqUx+y9lIsvvIT7jp7gyJFjfOafPst4aYwXmn/86Mf41D99jqZtufHuB7muWOGS1X07gyQN4fF4zGMf82gQgvl8zic+8Un2HhhxwQUXUm+dou2q+ByEYntrE/Bcf+0Xsf/AfpSd0llHUTfxgJU6LyormVUNn/nMPwEBoxQH9y7jg8QFQZaMoqUHk2RKzbzjvvWKgfbIXZ6igCv2qUXtJJVAaUmeSVaWBCJTeKnYkwUGOu4PLpkwl5miSQdolzaVshxw3XWP4M9kzgPHzv6/Pwm/wCsyjSIgIINYsMf65uiidmLnYBGIBxhJ6m4TwZgmudVKoO4CisiWd9ajFEhvCd6iZJTBWaXwymMTY0qkRmesiXZ254V8J2JO6GQivjLMGRUZu8cFgyJDq3gKt8k43GjFoMwZDQrGCXjatTRkz+qYpnXpfcfa38bT96K+Cz6yL6LnKBEEkvE9TauWtm1iymIdE756n6NBbti9PIpAV27i+0hm655o1jzIVGTaa8XSoGRlVLAyyNHBxnuWjLG1jObNWiqUlgyHRZTnSEHdWZwTOJm8ar3D25ayKCLzS2i8t/EQrhVN29BudBw/fhIpJUvjEeNCk+U5o6Ul9u5eZVp3TBpLpiSFkRxczWmsp6i66L0lBMG5xbjYqV37ACYRfbBkZMEoPJ3YAW+MEjgtaH1ACE/nzqm9EyvJpYRum/6/jdqzXjm2ase0apnVDbO6xbqQvJ/C4r0MjKTyAdEBsndz7cdOf0D1OOsj+6rzdC5Qd4HWQ+sCpRLoVIt5H42bH87X+Rr6fA19vob+wmvofwHw1IM8i9/+kD/637d4c+fcz8VGRlxAp7XF2mh06HwEcoTspXupo1DP0MZRDlfxwUCQyODRKhBCHNzey6Rf3pnYIt3sPmY2RioqvIfOxk3f2kSbDf2C53EiUlVbL5l3ko3Ks1ZNaDrHmfUtqqam6xxlpiOyFyLY5EQEmwQWgsC6QOtiYV+5CJB5EV31vXO0vkMEH827Q5xo1vrFoiHlDsgSiH5QQkaabSAmW/QyuKZuMMbgnadNk0kIgQ+O6XyGEIJ5VdM5h3OO7e1tuqahrWuqrqPtbGRhEcA7WqMIzqIFZFrHQe0drYzGZf27Cv29Tguo8IIgQ/SyFfEZO+/JEoA1Kgt6Kl/VdrTW4bqwMBKUIr5WXwwtZlMaSKKH8eNATICTSMbuOsoPs3wRl1nPKtqmpeu6xcvEGkosfp9Om7ZU0e9rB3pKG0R6C9HTYGc8ewJBhMXfL5DffwPIkw0eiUR6GbFcnz5Rf49CTMtAxCAkT0DY6IPV+1u1zuMDWGRiFUKuIdeSXCta11t+9kZ70VxPELuqLmnRfYhMQ2UCJhP4LqS5DxDwxOSIKw+t8qjLL+KBU+ucXGuYz2ZctneVvctDLr9gH7uXxywPS/aUY8o8o8hztDEI6RGyYXW5wE+a2FnyDrxN63scA8pIbNNy/MgxbBcTgw7t34XK4rs4vb7OpA5MarBtPABpDYd2LbFnPOTA0pilIqfrOhrfoqVk1yCL3YcgCUGSGcGozLlk3zKj5d1kRQnSYRuPrT3lwOG8xRBQWpAZw97VJXQmsd5xy92WWeOo2oBzlqataVrBrnFBnkUZhetqNIZglzm9uc3a1pS//+hnufLYKVw15fpHXUNZFtRiiUdedy0rK7tZO3METYfG0TXLNJ1n3liOb62zPa9oqoZcC4SCWWeI1HBPpmPXJD5jSQiOVBsgREz3IEmLfXD4EMNYoR8HIjIYISWdxoNEqrFRSiJdlBVAQKaZ21rwXiGDZmBsNPqUnjyDvAPRQp+OUhiJjsMba3fA4bgXxTXG+VgA9O/r4Q07Qd8rlULwmifs4dTM8YsfOMHBXQOUCGwnPyQpJfv270IUJqbAjQYMMs2oiMzcprX89U2btGkPfumTL+WOYxu8/7ZTHFgd8NTLx/zkiw7zo39zmmObHV986Zh33rbJp47X+ADvevc7+cSn/pH3vvM9qSnk+ekfex27du3hmV/z7/iBH3gd3/SqFyGQ/NwvvonX/8hPEoTgQx/+GF/+3BeA74CQ4rPSJRRveetf8iM/+uMQAi9/2Yv5k7f8fqpsA+9551N4zbd+J+/7+w/yV3/+h/y3X/st3vBjP803fvO30uu3uzaamxLg+77n2+PrBsdLX/4yXvqyl9DvAgiFr6e4eovu7F0cv+NzbJw6waFDByNjwMcULetcTJ6aV0jh0TpwcO9uTFZw5Nhp8qKgGJTolX14rdiatWycOYqtK5RrmE5mzOuWjdpTGkFRaOpqxqWXXMBzXvBcipUMPVwh3/soXvmqb+FP3/oXgOenf/qnuejqR/OqV383R48eIbiGqx/1bJzt+I3f/FWy0SGEyvnqF7+Kn/3pn+SHf/gHESpnMYpFSjEKHoTk+Mk1XvIN38WP/vB38brv+laKlYP83Z+9l3/3bd+FEIoQPPiG17/uNbzoa74a7y1S5Wxuz7nu+sdy8uRpEJJyvJvgLbP1oyAM42HBi55yIR+5+Rifvfc0+/esIEyBNyVaeNq6oZ1PefvNp3mPUVx+YInvfI7n667z/Np7PJUUUbaT5ezfO+SLH5Nzw4kRG53hkYccJ6VhQztuPzFhPMzYt3vAb3/sDAjB3j0jtibdohjfnlacOr35rzUR/7evunW4eB7Edo7OJ9aRVAQCrm2xNiwakT7EJLtJYxkYEQ22XTyozmtPaWRco6VK0rWUXOY9vmvxYUpQGVk2xidKRAiJ0ZQ8Q0VqyPXJc9b7hQ2BlopBHiVzl+1fZnVYsG95gMk0IunzQvL5GZUlo1HJ0qhkVOaUec5oNETlBWe25syTh4q1DutC8oiS6XuW2byisxGIWRkU5ErgrOPE5jbzuqGum9RgFCghWRqU7F4aceVFB1gZ5WilaGxLJiTD3OA8FJliqcjIjUCbjH2rI/aNoll5sG2q6URMW7MtrmtQmSHPNPt2LZEbxVRXTKsmes8EEHhc11HPZ+xdGVEWUXkQo8kl2/OG42e3OLM55abP3cz62VPY2QbXXXcVg7Lg0EUX82ipOHxoHxccOEFwFhE8BwZEU+lpjQ2KtUnNGUKsl31YSOxkOg8oqTBKMjQCgqeVgfk5P5+nA7VRkq3G4YNl0niq1jKtWta2Z1hrGajAINcoKbhv27FdOyatY30yY141zJsYFqCFpOk8TRdZjbsGgk4pCh8N56VMG3g6I3giAGKto20cTe2oas80MZ8AypFhYASzJvoQzWr3z6fMw+o6X0Ofr6HP19BfeA39L/B4Old61IMALA7kEFFu39eTPrJY+nQ7lwaqoE8V6xPuIrIr0uvGjgjYLqLsQhqEypBSYb1eLGlCRq0zIjGlUlEpEwqrE8oYwRNwLtB2gc5GmV1INMmQGEnOC6wUzFpB6x2TrqLrIkNnXrcxTllqlDFRx+h9GgwBR1oFRHwtK6J7f49wx8ETV50QPB2O4EGKZoFU7kjL+mWbiH6mTUZIRW/YV/uGtrPMZB2lZoj0WeLArJqYCETqPMRHJQjOM59XbE+n6b3FIsOnTo6SAZlc6nOjFxGLzjmkTKaFqSvVv8f+uUXwqR8sCaRJ3REjQUmFEhKloG4FPnhaa2PSgvCxAEq3gTT5FkOsX3Fhhx4uRDImFyCjSaEMDt92uK7BO7sYC5H91oOTvRFfBAWl6F86nCO33EHzlQwLWWLwOzGTiwnYj/t/A8fWXWXBZlVzajJjVAwAgXPJkI5YDBsZE/4OlibB2J7aRs6eCDsAcSYlPkS6qHMCn7qfyBivHOWzfeRs2jhFoNCS4ARWx03JOWhbT9NGs8miFHTe0niPbDzb04qz65tkUnL5/j086oJ9XLR7iaUyZzgYok00OBWhIxBpp8HKxZrSdS1dV9N0TTIsjd1C7yINNzoKxM2t7zydmdRonZ69KTDOkzvP3lFB5z2zrmGpLNg7HnLF/j1szyvWZg1KCTKdkUlF23UIEbtXK+Mx40FOlkmEa/FNlAh31tN5x3Q+ZzKbM53XjAYZuTGMRznOgbPgnSKTElMIrK3RAurWUrcxeTLLJMMyRylB1zmsGwKSyazi7OaMT9x4K0Vh2L9/L7sPHOK6qy7l0gv2M1nbhW1qbFvTzBqqumEyq9i7WbI9m3NiVDKZz5g1HbO6A+GQGoosZ5TnrJYlmQi01lL3YQSpCyJDktoKjcbHbtk5lxQ+Ae0xzltKgZaxEx4L/LCTnpGG1tR6HtjuEDiu3R033FIKRIjJnJmR5CZGhIe4HCOJTIms8UjpkmcdyawyLlRxSxf/FtSyQFwTVwYZl1+4zH+95hr+8O9v5vYH1wBYGpWMR1HeknmLcQ1PuWTAduv45INzjm5U+BB4wqWriHQA/eyRDbbnDXtXS77iuhUE8Pq/PsJmFSiE4B8fbDhbBYoiY/fKEnXTsbU5w3vBk578JP78bW/mUY96FFmW8ebf+WUeff01CGGAQD5cYmnfISZnj+NdlGy98fXfw7VXX0HwgV//3T/lEzfcxKu+4dXce999CZQSxJVV8sY3/gS33HIr4Hnykx7PM5/xNF77bd/Lzbfclva7XoLt8dUZXHUGVexdAGKu2Yz1gy6AwIc/8jH+66/8BsE2BG8JXcNrv/kVPOnLvoTZmXsJ3hFcx4kbb8QLhV7ejW2jZFArgfUW19SsrC4BnuBrTj9wgsEgZ9/+FfaMIIyGBLWXY/90E3fde4S/uelBQnAMi5wf/6mf5JJLL2G0fx9v+PEf5+57H0Tmy9xww6cTYKQRycPxf/zqL1BV0VB8de9Bbr75Nj7z8Q/imu001wLeVrhmA5UNwHf4Lha7QhqKpd3gLcHVtLMNXFstJkZMrI3G5I+87mre8B+/iyc/+ckIaZBCIaROoI6H1OH+8mc8idWVZWwz4cSZbbpqxub6cQ6NDMWlu/jc8Qm6DIyLnPUz61hrMSZDyijZXJGOv/rYGf7upg2+4RlXcdP967zvs0dom4Zb7mv5mb+CS0LLVXs9HsPprZojZxuecO1BNicNx89O+bon7GNSO9592yYIOHHiCF/7da/ipps+x78F6Hjf0DBtPZuNS1YGkQmitV40xEjN0yLT0U5AxIZe6wXT1mN9MtktDPgIjhI8w0wwzDQbUyDE+PC2a+k6R90KhDZkWuGM4dx71XvQOJ88nZI3klYxdXrXKGfvUsmVh3axPCxYXR5gtETKnmUV040iC8GQZyaypAxkWKpqxnwyYWt7Qt00yZA6GlybzBBNsN3CKsJJmDVdTPwSgs7GBmkIgfGwINOGLNPsWRmxZ3nEgX0rzCdTJpsVOoDRmtVBQd12ydQ4Y//uCBCNyoxCWEJXIbMsNoqto25qqqpiOp+SiTFZWTAaDQnOIoNjkEfv0yILlMknSRAZbM4FCqNSoxsypdg1HpAbFc3vtyfcdd+DmNywe3WFfXv2sG/fXlZXltm3ewXfdQTXUdg5TV2zPZ2hdM7mrGFtssR21VC1lq3a0qXkQa0iABcgvRdJ8Ipcx0q0ai22/1kpyZVkkCkmbfR92pw1+BCo6hajIzMMIZl2gaqz1FVN21k8gbwsUu0b2Kgsd63VVJ3jsr05aMXKUDMuBVUnmDcSY2JNUgwkVkqUUGQi0ITA0AZUF/dcIaPJfW2hsjE57RzK0MPyOl9Dn6+hz9fQX3gN/fkDT/3XuU3K9I8eHOiZIT7VgxF8iP+Pi9+KEZCh99OJOsZzf0lIYImzDiFBtw0mjyan0R3cg1AIfPrdiS1EBBfOldgJEdlD1vfmeymdo38agf7W4UMEI2pL1J+3LW3nEyU1kOuYRCelisCTkAl19pFK6UOCItN9OofxxeLzRpaVc5F8KZtoYuhhEcn4kJvbA08JQo8vkUA26wG7SBaJXkfx7yP1Od4XmTokUsgIenWCphUoFQtLIWXUdwZB3bZkxsT4S6UW4E+eRePStnOLZxmS+eNDmG7n3Nb4FYE2ISLtV0tJCCrRoWVEX0NPSY2Lstx5yYfUkQsgasGKil9RZheLM7wjuHbhadWz3/75ZX386rzYAeYS2rwAntIniWMpdiWcSKw8ER4yH/qvh/u1b1BireM08+SpJtMYSX5ZQlBoKLRgdaBxIdAGx7yJc0aEkBYwsZjHEJKhIcQ7IhPQmhajkDbNkExQM4HVAqP75xBoukDbRSAwywTBxn/vwwfwjl2DIavDkgt3j9m/VFIYg5Aah48gZldBMkwM3uMT4OiTd1znugj+0j/bGDkb50zc1KUUBBGYti2ZE2RaMBzmtLZDScvKaIALHtNoxkXOMDMMjGbDe+rWUeQyySR2aM9KCQZFxqDIU0Kni53VIOMzCI6maek6S/CRaVhkhiJTzCqHs0AQGBnXnybE9xwPCC6mTwYdac0ChkVG0zmciwzP1nYcP32WY8dPIoVkdc9+dq8usWdlxGwQaKo5bV3TzOZU8zmTyQSTKSbzgtJITq4r1icVp2czelluTNRRlEYRvEFJgW/Dwj/Ph4BMTQUtYne6Hx196IBIUuXeb21hnkvPRu1bCWkdJ8qXN2pHpjwHBoLcxCLOSLkwOO2TooKPG1NPQ9cqFs6p/FuMAfr3dE4D5eF7xfsDMLOwV2dceWA1JleFwIGVkgN7l1ldGTEsMoyXFN6zp4z6ex1cTPhEsFxqBJ7Oeu7bqumswxjJcqGY1I771juW8thRPz0PdEjKXJHnhrrpaOqOevMkF+2/mhd9zVdz5IH72Nza5uorLqKuKu68624IgfX1DXSWPYQafvFFF3Dt1VfivWdleZmqrnnnO9+1+JT5YETTBe66537+9u/exyc/cQMI+KrnfTnPeubT+eU3/Q9OnzoJREbPeDzi0P49FLkGl9hUBAiO4LsFi/ro8ZN88oZP8Zd/9XaCt4BAqJynPft5XHZ9TtV49uxaZvfKErOjJ/BSY1b38+CDxwnBc8H+PRx98F62tzbIyiW8s9iu4fgDRzl0cA8XXbIfY5aoWs8DJ7dpVYEarlCrM5w8eZqmXefyRzyGCy+8kBDgwVNzPnPzvRw5cmznCae5orXkK57zTLa3p5w6s8aFFxxikCmuuuoqvGvj+w/7cK7jjttvRedjlkYFe3cNWTtzCqULDi7tAqIE6vJLLmB1eYxzlvsfOEpV1VxxxWUcOXqC4WjEddddx3Q6586774UAu1aX43zv10wBj7z2SnbvXuXo0aN0QTPdFExONmghWB5k0RDaWbyNnpPeB7JigFEBoyA4x5EzHfZMx1OuLTm4nLO7lEzawHTecdu9cy497FkdC3RWYENMEx6VJppFW8f+pYzcWJwLSBnY3trir/76HexaHnLJBXv+356AX/C1Z5ShKkflBLPaRnNv55LcQ2GUQhHXxlEZ6y6f9jQXkjwn1SVGCbpU2wpC8jmRTJRI0ojI2mu9pxE1mZRoLTFapRo87p291UUvDQqAFPHnlgYZu8cl+5cH7F8dsTQsWFqKz1QSUMEnSwxJnueJha4QxMAegadrLU1TM6+bCJKRgC2tyDKDsxZ8NDs3WuOBunPoBQs+dfilZFjklHlGWWSsDEvGgxyjo5xnOq8ZaBP3UKMgeIyJrPuV8YBhYaIEL8SanhCNjKPvVvSCsdaRAVIp8iyjMZpMK3Kj4vcClArwKQ7e+uQnE9dlKSKIMy5zMqPY2J7Q2Y619U1OnjyDd3HNG5Ql49GQ8bDAtg2+a2G+RVtXlLmh9YqVqmFlVLAxq5nWHdnWnKp18bCfzjg+7OyjC9P3VNP1RwpBVH9kSiJJEmzrIpMpwOasQWmNENGs3lqL69pUW4DWGucceE/VOc7MOkIIDAeS4QDyUjLIIrBllNjZg0VAqeiHq72gtHHMKgXK934y4iHj7uF+na+hz9fQ52voL7yG/hcwnnpPJBIjJR7QM5XSClRilYh486JpZA9gJ3Sqp8KQvJd6RlJ6/YjsgktUYrCIMAMhyDLQpgB6PSN4b6O3RYjwkVI7nk4RaIkIdNM6WuupG4ezyVtogawnF3dickTXBAKRtqdSV2ZlVCzSIEjpckpKhIveSW3XgPBEh/movQ6+RwNjEkb/uRGR8eU6h2srdnTRfgdUEiyYTihJ6Add6OGQHUBlodVPd7LfZBAiUfd2QLh4++OgVDIsPJggDtLWuQg4ISizbMEIy5Sibjskikk1p+k6OtsmwEcsUJee3dUz4qzztAKctRFEVAJpIr3QB01jbUwztH7x//fadbl4Pglg6u8T0RNKCIlSGm2iy79yNaFrCN0c4V1iT/WhxDv3JwRSaodkOHXJFD5+6WQSr1V8r1rFe6lF1KGz+F4aN/+GNkyA511wkHurin17V/jMfSeZNB0dkqXCsFQqDiyXLGeSoZbk0jHpHBsNHPfRk8L3vK4Q/Rhc2hhIm41LKS0BkDIi7o5AF2LXQRAooqSbxkDVBOrOM+1iUWOUZN+oJBtmDDLNYy89xP7lIfuXR1x78SGKLAepqOpp9EXDI41EKUUpDcFJgpMRCI4rKFLlBDqatsZ1luA8ne1YHg9ZGQ/BCuZ1w9r2hLyMsoOqqVDkoHMO7NlDOLvNZLbJwdUhu4YDdo0GGDq8t9x67AgCFc0gZdwUrWsptMZkMeJ8PBozKAuUMoRQ42xNXTvQkiAltm0xQrF3ZZVDB1cZlBlZpjizMWdzOidXMVbaGIUMBYE4d6N/gqNrO3SmybKMldGI3GhWBoaloWarqlifbPOZz93FyRNnGRo4eOWVDFZXEeEA2chiOkvRzRjOp4y2N9i9OsFZi3MXcHSj5sjZbe770Kew2zXTacVk14hlI8mXcrJhiQuBJWvZnM2puo6u6yLFX8YOsEyFSd8pic9H7iQ4pYOPghQx3TNlz0G1BZjUselmgcZ59g4Nh5cKDi5lCBxnNhs6A50TdJbo1aMFuZFkyiN3EHEgBSykiGrxb2IWx/vhAvz2Z7foPrPNA6duQgrLBbuH/OBXXMNVl+1iuJTzht/4KCdmHVMbePctM5ZyxSP3Dzi4WjDpAjc8sMn2tMFazxOu3M2JTce9J2p+7YMn+JKrdvHH3/FIfvG9J7jnTMvl+0cMN6esbc+58/4zBAFlrrjtL/4j2ZOexZVf9Xr+3Xd+P+//wIf/GQLfsygghMjVDni+7bt/BCFlWkc68I4eVJNSc+3jn8PdJ1ue/IwXM1m7nzhA4j6wf98+PvCet/CLv/w/+Mn/9CakNnzlVz6P3//t/4bJshgOgoDQAhZd7mb79D2cuv9mvvKVP8SDx04TYiUa36Gd8SNv+Ene+OM/j2+3+ZEf+WF+9PU/zDUveyL9qPi5b/sRCJ5ff9Nr+U+v/S7e+ta/BCGQukSanG6+zite/jV8zeteicqX+ejHbuAFL30uv/Pbv8Xr3/ASftg5fvwnf4b/9qv/g+Bqgu8QuuQPfvfX+NCHP8JXPO9li30q+I7gGoKtESrn7e96H9/9/W/kfe/8Ax73mGv5zMf/LpZ+6QDwEz/18zz+qc8n+JZv/qav51d/5T/zV+/7S4o85zUXX4qQGRdfeiWf/MRHUcKyvbnOs7/8eTzzS5/GB/7mLXzli76RT3ziBh7zxGdFdhQBISSv+/dfz4uf94x4QJcGqQxf8aynsra+yQ+8/mdZzTrGJrBvWHJy3rLWWPbs38N83nDi2BkGwyFCStoQUMlX6NMnW15+/S6efNGQH/+zT/HIC8e88QVX8Eefm7PkO1622vCPZwOf2Vb8wLOW+aLNwN2V4H0fv5u9ywWPODzitz56Gi8kh/aPOXrsLLNZlF996yu+jK97/pP+dabhF3A96Yq9HNtuGa41zO5vcTZ2wJeGGUVmGBY5I+0pFYxzwaRxrM8dG5UjACYxa4KAznta5wnBMdAKJTxNF+h8TIa0QjDtotdoExqQKrLP8hytJI0UVE0L3uFciDWtEEgvGRaGcWG4bN8yh3ePuWDPEhcc2stwkDEeGIRvIuvfBVRix3XWx9eyXVypdPTyms4atqYV88YRhECn5OThcMBoOKSqKpqmxVqH1AoHbFYto0ERzcyXSpq6oWkaLtyzxLgsWBpkcamxHffcf5ymrgnOUQwEwWtEcFF+ZzLysmQ0zBjkmkxLplVH01nqrQlaK6SSkeUhYzLX/tUlVpbHaJPFdGQbWMo1SmmUUnhraduOyrZU83naK3OsjU3x5fEgNaxdlOpVDVvTOXff+wCbG5sMc8NFF1/EYGWF8epu2rqmqyv8YMCga1hqa8qlCU0TfeimVc2sbnng9DZr2xVbs5rtWYUSIfpdBRXPYlrRuYBXMMyhS4mE0cA61syZUSglMITIJnOek9sNRRYwJoBtEF0N7TyyP0NsXFvv8NZhQ+Ds3DHvoupkeehYGTv2jgu01FR1R3CeadVxbK3mQCbYZWBgBHMv0LMIqLY+1uZlFs3OWxfZMQ9zwtP5Gvp8DX2+hv7/Qw39eQNPMQJQoJJxn1YRzSwSIKNk3AitD7S2Z4QkNkn/IiEsPICiPCnhZiGiaJ4delhvuhgNU1tEEBgZEUmtdUppC5B06YJILQ5E6M0TUxKcCzRdio71CxEbvTxNCJkigCPQ4yLVCCUlZWYoM8XyMI8biXd0HSmmMnaVrAspoSRKtfTi9funnTohUizuRkhspM76nUfVY3O9lKzvHMVfll5xB2MUCW3uTcd2cBqxkIrFxUstfraXnUkZ6ciRDaUShnnuq4PRKsX9CoyQFCZ6UgmgUi3zJiKuEWANKYZxB3SCHZArosoSlEcKgZFQJHO7eDhx6Xn7qJ0+Z9D0/gM9gBkQi66aMQYtQQWHcG2iiu4464f0XzvgU7xaF5h1nrUaCiPIFJC6dpmK0a59vHBI4BKJRq2T2eS/Hbhp55pZS54ZLti1yi0PnGWlEOzfP2SlzMiVRKp4oJm1lhpHbT1d13e9Q3oWcWD13bQgIDgBOgLP/YjvafvOxc5q/wRyrbAhoDuH9xYtRdy0Mx0NDncvs2c8YGVUcPnBFcosozQG5zvqLnYKvLcIQKoQ54pSCJ/mgNph2SkJmXQYEXW1ymh0ZtI79PSJhj4ZNPeGt9Z5ioFheVAy0AZFoHOWQgVGuWDXwLA9TYxIK8gNGA1K+LhJKMkoK8gyTV5olPJI4TDGEFCokBFk/J3eB0xsbaCNSuA9mDynKAxlo9AqzoOYhJkMWoOlamIHufCBkYJMaYZlQQhxM927ohgNDONS084arOs4euQIZmmFVWHQ492IrsWrhiBBCUOmSlS2TrAdWM+lI8uuXctszLa55f5T3HtiHQcxEnd9m9GgjKaymSL4PBqrJhlAlMO6HWpsf9hfAOnpSYQeVE+jRCRAPf7UYvyGtMZnSoCQTFp4cNvSBU2ZwZX7DB6PkYGq9RgBWkis8AvTxeB7CTApkbI3/Ix9xof3le5ICJzYqChyw+F9A+q6JlOCY2cn3HF2xmbnuOPklHnn8ULy4scfICC5+0zL+myb2jpWlwZoArZzbMwtnZcsjUouWDIED7/z/iM0TWDfAPxswvakZn1m2b1nmXnV0NU1xnt0sEDHngMXs+fAUY7dfzsvfcnX8ITHP4pq80E+8vGbeN+HPgMhcOGhfTz1iY/kY5++g9NnN2maipe++MU84fGPph8f1jr+6M/+jgMH9vOaV34Xdr7GAw/cx6/9j9/lbW/7a44dPc53//tXoXQiersWKQJ5MeAP3vKXOOf45q9/MW9729v59Gc+g1AZzWSN6cYJzpzdwHZR7vdNr/waQPAHf/J22rZCtBEQsm1DXc34zT98FxddeIgXPv/LeOmLv4L777+f17/xZ/jMZ2+jC4pgO4RvENbHBC0UMhsilOHiSy7mx3/sP/DoR18fD9nS87yveBYrK0v8+u/8KY9+1PW87CUvJMtzrr76Gn7u53+GN//xn3LjjZ9DAP/woY/Thjcxn2xx8823M906y5t+9Xd46lOeyGu/5Rv4k7f9NTffcju2a/jQhz5O00Z54j33n+Av3/X3fOAjn6JpOu5/8BSv+NoXcd21V5PnGXhBORjxQz/0/Vxy4WHGSyOklDH9p64heJTWrOxe5YZb7qWygte97ru54VOf5e3vfDdZOcbkDdLO+JIrxxxcMnz2jGCMRyjP+tYEFyTlYICLNG60jo2/UgS++NCAjVnHu2/fZHvecN9ZzT/cPeXYmRnOwPaKZpxrdKaYzy1nN2tObtbs2r+H4DoeOD3liZcs0wbBHWc6jDFcfPF+vu3fv5anPvZKLrji4L/+lPwXXse3W9Zmllkb/UJHuWbPOKMsC4SUTOdxb3PO03TxT9E3JUOqaUVYMM+75ElWd55M6ygtywSti/YRUkVvVNc5qrrBOsd4mOoopciNxvZrdfALRv4gN4zLmHq2Mh6wtDRkOMgocxXlHDYu3kqb2OSFKKX1aWGVcZ/qPMxax7z1MTVJqWgonOpgm0CczkY2hfAy1ZRQZBnj4YDRIKfJDE2t2D0sGJcZoyJjUtU01jGvmuh1VWTkmUYbhdKK8WiAMQaT5eRZZDRoLdFdPKeEpsETTTq1lBTGoAcwzA25VgQfGaFdSmYLInrJOeuSH5ajbZtFVLlMfrJLw5KmaWnaKDvNtWKYG+q6JnQtm2vrrCyNMVKhs+TNpgwiG4LKUKZgKA1511JUFXlZMagbPJJBYRhNDJmKoUKu65h3jsxHOatJygcnBUpF4H/aOIKINVgv21yoPoREiKhCcF1c/6ztcKE3mfcEa1Oq9U7D3gWoW0+uHY2RWARGBPaNDXXryST4xtEhaBEMBxqpo1zZdz55FiVzfckigOnhXlefr6HP19Dna+gvvIb+F0jtUuKZEAxySaYlpZEMTEyDkALmqbvSOXEOzSt98LBj2NzL6XwIiVS489/RIyqkwgWC8njbYQGZFUilF9TPSIpyaVIKeh8qnya2ddDZCPA4lyR2YQd06t3mjVaRYSQlteujZiWDImOYa8aDnKpuaTq/eI+QgCcff48IoEissLADdPRu7wvwKC36vQF3SGBcBIESWysBYVKpiHKxkxjRc3cik0lG6mF6+eD7xW0nG7cHnoSQCxpdn3IiE+gW79s5oFGIHlm50eRGY6Qi15qYCRo7Yz7YxUbhvUeItLiGnXsc+9sR2fdKgo9pQVqKhZGeD4HGujiQPah+Q5QifWrBQo0pIrAY0+sihVoFi/QW4dpoepdAtMhu6umrPXAVr87D3Ho2WijruGEXWaSXZyouYqo33DxHARmfTzKAYwfYYjHOH97XWtMQioLlsiSXklEpuObQiKGMqYPr9ZxpY2k6B87FWFzLAigFFjeyn8OLQMAFWrhjtOhSugZpcQwi6tqt8hQGtAqUWrFvVHB4XLJrWHLJ/t1x41wesHu1iCi/h8Z2WBdZdgKZqOVRAy2EinNeRM83EfxCHqlCh0z2/9oY8jwjev17nLV4K3D+HEPLENmUuTGMipxSKYyUSAKFjlHCQyPZDNELQ6BSio5Ay7ioayUZFAV5pjCZQEmPkA6tIQhNQBEkuNZj22imKqQgK3XcHAloHQ1Oi0xFoDtEnzgpIfhAcI6q6eicR0jB0GsUijzPaduORneMC8moMIzyjNN+k+AtJ06eYmnvQXQ2ZPeuC4jy5SjVkrLAZCOUAmFbpHWsqMDeboTvZmTGgNJsTbZonOPs9owAjMqccaEZZJpcSRqpcHhc8LTePWTusbPEEOi7N2JB30XsJJOKsLPy9VuqFFG2K4SgsrDVOgZZlBFctFuzObPIkAxQdWTPxsSeNJ9DT10PCxl4P3I/30SO/1OXUlEmEnxgY9qwSwkuPjRiY8Mhg+e+k1t85viMu9cqhItSMq0VX3bNbiad4PbNTabNJm1nObRHUcqYqrpRWXwQDAc5X7S/ZHve8icfPcGTrtjF6kAz354ymVm2azh8eCUCFdM5bRvoOo8IHRdfegWXHl3n+AN38PSnP5VXveIlNGs307Yd7/vgp4DAoYP7eOHznsnadkCoY2xPNnj2s5/N177saxgvjWJTo5rz27/3x+xZuoDv/bZvwtspn/70P/GWP/0r/uEDH+Kmz32OV7/qhVgb9+nxqGRQxsPb+97/j7Rdyze/8kV88MMf5y1/8mdMqyqaLLt2wRISAl701c/BmIx3vPcfmU63aZsmsoSDo63n/MGfvJ0nP+HRvPD5z+R5z306n/hEwRvf+AYQmtVdewi2XuzpwRuGozFSZUymM4aDktd88ysYrRwAILiWL37KE3jUox7JFz/jhZw+s86zn/k0okxwmW95zav5+Mc/xc0338bS8pg77r6f+4+fZePkA9RVjW0b/vwv/4a19W1e+y3fwLv/9kP89Tv/lkx5qvkUqQ0hCI4cP8PfvPcD3HbH/WxsbvPxT97Ik57wGK75osvxPh4w8nLIK1/5CrxtmFVzhsMBK8tLhGBjjaANS6u7uPWeY9x3bJ0P/+3b2L9/Px/68EdpOmgaSyY7Hnkw59LdJTdu1AxyhZaKY2enqKxgMB4wmUafSW0kjY0JddfvybnhVMUtZyuc85yadHzk/hkbGzOykeK0XWKcK0a5oppbNiYN69OGyy9eZrI54fTZLa45sJfKCm49UaO0Yd/+fbz6m78BrTUP90MrwNGtlkntmNWW0iiWSs0VB8bozNC5wP31JDIKvEOlAxxJ8hiIYTQ9CBXS33sfqK1nGKJEM9OJPWH7ujLgnadxDZ21DPI81tFKIULv5SkWnpxWeorMMMgNy8Oc8bBgOCgYFJpME/fTEOsro01cQ71PUiJPn3TsElA2axzzzkGqV42SkZnjPW2fyOySYTGpphCQZRmDsmR5VNJqSaejt90wNwwzSVVFln7XdKwUA8ZlFm0ijEYZzXBYkhmDSoCc1hGQ0tqhXDRJDjaC81pKVGYQWsZ9TAu8iw3rrnM4F60tRIhgvbUO7zxd20aGipAUeYYximEZk7ittQxyQ5lrlgY5Z8524CyTzS2mm1sUxjBcWk6NTQ26QCiDCI7SGIJtaTNDlhvKokFKyI2kMJF1NZ0LJtZRJSCn1BqdFBfWS1RqCM+6CBr4XhIWBD2MgRCJferx1uHayMLrE7KCB+ttHyweFRLJV7dzEVRpG48VEchYHWgmwiFDgM5jpaBNTX2Z3ltM0osNXO8Fgp3zzUMZsw+/63wNfb6GPl9Df+E19OcNPO0eaopMM8oMhZE7fjgJyfU+omTW96juThkQwaaweHMLyVgI+DTJXNiZZD5J7oSIxnkKj/Ad9XyCyQqKoqQscjKnkULSCIlzUbbV2QBEUMraaIbddTtovUxIoJSCQZaRG82wzOmco7YW30XjzTwzrA4j40kLT2db5nXcZARRW9lYS9s5OufRAiRioXcPxAW2wxNsiCbYaaD0QJRSKg0WYqywUmityfM8+TIJdjDEOLFkz/gRYgE+QRwE0YAxotB9CqGWaiHFi4ynuHmYBGxFzWxKVLEO6cEnA3EjJUtljhwMcM4zLhpGRcasbigmis510cTOWroupmZEv6s4ySECP3VnyRBoHyhygxCCPKH0WXLlq1ob2XLOo4JEeR8/Z4qVU71XldRkWkfZnmvANTjXIlNSUr+NPZS/lQZhv7cRogTTBdYbyCzkNtD5aKi5exCBJyOTVMSDdXGR7sfxAu31CVR9eO+XAPzWzQ+SSyiVYLlQ7Bll7B1oHjw7Z33WcnK7IjORyTjK5QIx7xK4qkTCQeklhrFw8Yv7mWC/tOhF2WwsUG1I+mBnOTwuuP7QCo3IWSpzLt415sByyTDPyMpBSkiRNF2IfgBGkisdQUihcT4CpW3XorxHyiZ5lqU1Q4CzjmpumWw2nNyc01nHvl1jBmXG6c0ps7pjfXsdnX6XLnQs4EKvbQ9kMjAy8IjDu7hq3zIX7RpACJxcX0ORMS5iR6ZnwuVZHJ9SaYZjnTrQilLnZMaQl4q2i6ma0jVRo21geWkZqSWmMCkdR1LPKrrWYZ2g6uImGW3teg8bqH0gI2NF62gUbTu6RN3WOmc2mQGgpUZqRWs9ZyuPueMOtk6d5JrgGO27kGJ1L7X3eGtxnUUPlgmuI7Rzplvr2PmE/YXnK647zDOuuoAHz65z7MwGdx89ycn1Gac3Z6xtKpZHBXlmkEZjpEEKQdMJNqVLEtm0SXliCmYaR9ZHfzcr4j7gHQS/43mwIHwSC5rOpS4dYETgvo0KJRX7lwr2l4ZxBtJUcUzagAwCUqErkzTYhYD1LoYiLAyqH97XlVdfxPraFqdPrTMaljSd55M3HmN11wilJG/99HGkliwPMl77JZfRNJYzmzX/5T33ccHeEd/xpRfzZlVz+7EJdx3d4tBqyfLAsL0xo7MOQmD/FUNyofFKc3JtzuaW5EwH5CW7C8n9952MHf8A3/fm2/mqzYv59Rc5fui7v5FnfvFjeM4H38Ubf+yn+dVf/e98/3d8PXfff5q+JDl00eW88BWv5Tlf8020TU09OcEv/tqf8Ht/8i7e+9e/z7DUeNuA73DNFtXGfQghuObKi7j5xk/wfd//H/nbv30ff/WX7+Dmm2+lKEre8zd/wVVfdAW+m/Kff+p7ifuk4md+8kd4zatfwTOf8xImXctDzCSFZHX/JTzhCY/lc5/9Ur77e36QP//LtwNRPqfyZbbWTzHbXuv/Bx772Edz802fXHwWIAFZnuA7ynKAD/DKV34Tn/70PxGC47//2pt44Queh63WkHpApgxveO2L+PAn/4nrrn8SSJNex7G5tcWFFxziH973rsh+IeBdw5+89a/4gf/wU3z7N72EpzzliRAcw/GY6x95PW/+rV/gt/7orfz+H/85x++6hXvuvIXjRx/gz9/6B6ysrvAXb383e4eOk3f/E7fft8blV13F6p69POOZz+fM2iZZMeA33/QTXHXFxXjfofMxDxw9xVe99P9iNtlkPMgJaL72a7+O5zz3K3jdv38Nt99xO6t7VvnTW6YEt8XdZyqKImNQZjz2EZeytlXxwIkNgtAgBG3tuHj/MrmW/M5NZzm4q+QRF62yNMg4NbXcv96iM81pG3jzvVP+3bVDHrFHUNJxaDnn0n1jjtx7nEv3lHzJEy/kjz5yHC80Fxzax/YDp/jsZ2/iUY95MvFkFjhx4vi/wkz8379uPLoFqSm7K5fkOkpO17crJrXl5PqUTAtyo9izVCBaTx0cbhZlTq5v7gFCypQuJLBOUrWBydwhiKlIQnrmIYXBiBiOIr1lJbeRMag1XpRY72nalrqN1hV00XA3CIGNKT4o5dG0BAuz1iJ1htIalMa2Ha5zkWmfWPEdkrqNxsanN6ZMphW7BobpRFGraNpb1+kQHDyZklFuaGIzclo1MZ7ctox0wXCloFQ5uRIE27HdRM+qcjzgkoMDlodxL561njwvKAcFqysrZFoiCOTGoLRCKUluoiypFiGxrSIzKZpsS0ymkUBbN9jO0lnH2tYMl8A1Lfvzi0cKjzGOIlMUOqPIY6y7ywzeRU897wECRWqYb29uc/LoMerpNAb5DEZkxQC0IYYlKIyRCJNhsowsjz5QWaYYDTJ2rxQMSsPG1pzTa9uc3dhm3lmc71guDaVReCFpnae1AakD0jmksmgV4niRSTGgJAZLKSwGy5qP8iebPmtsvIqH1M6SWGMNpMA7x8bUs1ZbEJLBIMN2gSKdhwIKS1SS9KSCxkUDa+0DIo+eR7mJbC2t5P80Zx5O1/ka+nwNfb6G/sJr6M8beFoqNaXRDHOV9vgokfKJYxWSKVYIPTobetbX4ub0oNOCFMRO6lv/M720yRNd02PUZFyUnBJpUoOXkk5G47PgHZ2Izv4RifNJ4hWSyeLOJRKI0QNOZWYwRuHbADZ6+xgtGeSK0ogIpjlHZy02ZRVGlNGlz+8imCR2QKcYjRulWU6AiLl38fcTTcWQ8QP235dKonVkcxV5FtlIMgJPJMZSD75kKsrgpIyJdr2crbVd2hztQlankmfTwgMqAYYm6dWN1tEPiWggmz4gITqOo6VkkMeOcpFlGC0pc0PAUrUtjW0RTYOg775JvPTIZEwm0kTovKe1AiNdSqWTZFKCgc7HlJUudUJEGhcL/6rEQJMyatQzJWKEo+uiX4ezC+10Tz18yBX+F/+x6ChAR+w82ODxIUpHjYwSvB7hjVLAaKB37uvtjNuHP/I0bz1WBpwKFFqwXVseXJ+yUXXU1qMTsCnOOVyJc9DznlLbd888PSyaDCJdAuIECClS4p9YdHYgmoYOM81le0bIcokiy1gd5ozL2J00WRaLURkIrkNJg1EGY4jvKUhU2jR9kOecA+ViUQ7BQRAoadhuKjbnDVuTmq1ZxaxuF+/HhcBSrhiXGbvGA5rOMWs7jqxbOmfpbMueoUHLHIibsXUerWPqo5aazGTxvkkwKiCkRspI6TdGkmex22qkSutIwHYe37kFCFwMBnH+m2j+GkKgmrdMp3MmkynedemMG/3n4p0QOG9xQuBsh3PgZexwF0VGlivWugrbWdrWIYiU+i7ApOqACUfvvZs9rWPVWfIyxymVOnM63lKdIbMc6SzYIYUJZA4OrozIUrG4NJoyrRqmkymb8xZZtZR59CopTYaROgLxiW0SFmMiMT3PgYqtj40Lz7mNz3NbGGLR5bHp1QKQpbG2XVmCDUw0iCHoIQwUKBUSAVQs7l3UzKfCLv2Gh7u/xCu+7hV87KOf5L3veR8H9o5pWst9mzPKXDEqFMshwxHX9JO1YDrznN7q2DMq0Ag+cfc6p7daWhfIM03Vxs72oNA0raC1jiMzh5KKRx1epm0aGuuorKDQ0RdQqrgfaQJLRlE061T3/iODQ4/mskv2862v+UY+8IEP88ADD/APH7qB4XiF137rq4HAysoKf/hHbyGyhCy23uSmG2/knnuO8ju/8/vkmaJt5mxtbxM9lAxC5RRSM1wuKIuMuml4/4c/wXi8xKu/8eVcfvnlrKzughD46Mf/Ce8DL3zhV7O8ssKll17Gq7/5VdR1Rdc2vO1tf87+fXt55pd9CTd8+kZuvf0uIHD02HFG4zEvf+mLedzjHovJDF/7kudzxWUXQ4jzbWsy50Of+ByzrTUKI3nZS1+M1nIBPt151z386Vv/nFtvu42TJ08CUNV13LeyMUIafOf43J33cvvd98WfkZqDB/bz1V/9XECQ5znvee/fIpPsSQjBZ2+8BfBcc+1VHDx0kBtuuIkTx45w5uRR3vGOd3HbLbdRzeexHrOO+WzK6vKYPbt3MR4Ncc5x9uxZ3vE3f8fzVcYTdu9la+7Ys+8AT3vK49CmxAbFBYf3ocwQnQ/5pq9/GU09Rwp43wc/jsRRTTa44977OXFmnaAUl+3JGGnNtAsIrVHasLFdUzWWLDNxHnuPs55Z1eEzyYGlGJVzdtIybx1btafrLPuXC5yLh/sbjgXmTcZzL1+mcoK5Fameg4DiwPKQygam8wZkLJxPnTrNU5/6ZK679pr/E9PyX3TNW5eYBPEAPqktJzYqKhv9mnITO8+5jqz0QkiGQaJ1g7OxEdbbAET2U2wmZiruzZPKRpApdaSjz09Y1MUigHeOstQMRgMaJ2ltDI1pXSy+vY8s9bqzzOqOqulo2w7bRRPc3l9TSElnYwAPRCY8xLW0ajzbteXUVsVsXmO7LoJhIY2LpCyQCEojGZeGfctlZENZT9d2Ea7wHaWKHkvLhaJtLJZ4EM+NxhgT07lyE03TRcAYiRYieqygMFosahg8BOsJncO1LtW5gsxosiw215WJRttORNlh17nUWE3VuopnoFj3+VSPeAguyiK9R0pBlhnazmFtFwGokBrJAaqqQakpG2fXGC51lENLNhhF9pEQya9WIZVGaoMKgSzLITiUCtStiwmALlDVDVUtaKylslFlgAg0NjLh5q2n6jx1F9veQspUs6Sd11kCFo+ldT6a1Yvo2xsEOLvj79uz/pUkAqEOggjRR0qAbzzOBqwMbHWSMpORNUNfQ+7YnWiVfn/c1BH05sgP3+t8DX2+hj5fQ3/hNfTnz3gaGHKjGBjNtLa03lN30aSzXzxsz1gKOwtVSMhTJMCEBeiU/q/4wdPC03s/LQZ/Ak8GRjHMFEIrtJGYLLKcGgcBE4GfVtJ2EQxyKU7Qp/fSE8Ai0ymi6sMiY3lYMCwyOudobEy/ybSMvk6loTTxzk7blraLjKrM6OhF5T3W2UQxDAl0EinmNC6zrQyJ9tc/leRSr2LKnBKxq4QAJRVax0NDkUxSewpkBLUiO0kryTDP0r+riHY6T912Sa9q6WyXfJ4SyHUOJhLvQ4gyNaXIjVlQPRthkx9T1LfiI/C0NCwjlT3AoMiYVRVKwKSaM21q+q2ktT7KB33/e+KfjkjLrX0gE6CDQouYPqCSn5WSksZ65q1bjIEedOoBPa0URWYwwiODp21bSAk/vVuWWEwsHiq1WzyEc25EWuytJ3aHQlyBS6Oif5kSINwCUYZeJtm/1I5E0Z/z0g/XSwUJBKzwbDeWadtxYnvKIBVt41wvQGBCLNaUiFRcLyJIh+uB1zhHeyJBCMQixEfTSaTCB5GKLb/YqGa1ZZgZrt6/wmjPHpCK1nugBKkRSqFMlG56PEpJjM7RWe8HFhAuPqcgJV3w0Y+gi15vzkNIsczGZEzbKeuzhrMbU05vTZjVLePRIHWKJXvGOYdXh1x9eBcbM8up7Yoj63OatqNtaw4vZQzyDK00R9emBKBUGSsDQ6bihmpUNG3FdzGGXMb7aYyKGvPMIKSgbS1NExmYNB0mk2RKU4zHyVDfo42ibS2z+Zz1jS02t7dwnT2ncxZp8xKwXYsMjrbJsQacEkgCo2FJXgyZTjdi0VvXQFxHPDCpPXUzo77lJi6abRPqbS649jFIo/HB4XyS75oCM1hCakMdHKKpkDTsXSrZvVRw+eHdHFmvOL62zQ233suJsxtUTcPuoYalJbJRTASKm+YOInxug0KKneCANkUq9x2/eO1smv0aHoA29DuIYJwragubM8upzmIkhL2CcSHYawJGxrOCECziYbWM8aPeg6X3cXt4T+I3/Mj/zX/9L2/ib9/7Pi67YBfTecsDR9ZYHWkOrGRcsF+yNoXNBj550rK2UbO+Nuc7nnYRZ2cdv/3BBwneYZRg78qAta051VbHFRfsYt5atuYdN65bLl0peM5Ve/nIPac5ulljXSA4jxSBsizx3iG95/r9Ay4SZ9n+9J+wUoy56NDV/Np/+3n+3bd9P3fdfR9v/au/44d/8Hv5mZ/6MUKw/Nmf/xVf+3WvXqy9atHdDnzf9/9QZIKECHApZRB6gMzGALT1Fs51VFXNX7zjffzw938nP/6GH8AMd8f9NsCb/scf0TQtL3jB8xFSs7prL7/8Sz8LwHw+5x/e/yEe//jH8V9/+T/xrOe8kI9+7BMROBKKiy++iF/6xZ9laWkZITU/+WM/EP8uWBCKB4+d4o2/8BucuOuz7B5pXvCC5yNlhncWITUf+9gNfNu3fw+LjT4l0SIUerAfgsU2m7z13R/k/vsfACJb4qovupT//qu/hBCCe+65n8c8/kuYzWZxHdUFJOnS1Y+4mt279/EHb/5r7rz1Zu68/Va+93U3okyJ0HlcH1L4SV9XCWBeNWxtrPObv/fHHL7kUp74lKcw3n0Bz/qSx/Nzb/wO3v13H+POe05w8SUXEYJi965d/MLPvAEQbE9nvPDrv5P777qF9WN3EqTGe49t5zzyqgNctqfE5xkzJ5lZuPGes2SZYWVpwGRexXrMdpzenLFcKL78sgE3nqy549Q0HthFbPJdeuku5nXLkeNnefvtcz67nPPEC1dYqwVrVeyyWg9bVeCxl+zh7LThQ/dsIJWiHJR021O+9mtfxnd+x7f9a07H/62r7Vz0IpWCWWOpGsvadoVUEqMke4YancJ6Mi1RWqA1nNhUWBdofcAkgKfuejmMZGAUrfNs1BbZr2NC0NgQk/CSX0wg0HaOXZlh3+5lNufxPdggkK0FLM576tYiCGzMGpaHGVWd0bZZkq4ZjNEEBNNZg8ajAK2jXMcGwaRrODNpeODUJsHGREItQmwS2/g7VKrHe9Dpiv1LKAHTumNrOsfgkL5lqDyrZfR3OuvmSBcPh4MyJ8+iCXqZxXpY6giMCTxNVUNmUMJEYCOICKy1Dlt3dHWHFxK0TnK2nLLMUUk+WHcd3kXjYdfFgByZbCpi0lc6fPu4PsZUZYsj2ngUeRbvbd0ymdaxmZy8Vnu/LaVOslzXjJcaxkGgTIYyBisiOKSURigTI+t9EaVVeazh8zya/k/nNYg5a1tTJq1nbqMxdd3FFLqt2lF1jlnropm6lGil0/rmomogWHxwUXkQoqw7I3aNO+t2FCuiT9EWtC4efB2AVLgA0yqaqmcSThtYLQNagcEjQ5Tu9ft+rmUcqyEkz6eHP/B0voY+X0Ofr6G/8Br68waeqtbSOhcBji56JnXeLxzXYycksmkW4FKIbzSEOMl6t/VAQsl8/F4/UeNC3ht/Ack4bKUwHFguObhnFZNlaJ2x3gQ2a8vxrZotBbUWWO9QyuKsjGaFifFkrV98jkxH8GJ1PGBYRABnc17RWgsSlsoYwzgw0NmOrnNsVw02hAgGqURRdBaXfI6kjJGPSiUWUjJbjHKstDElcCkzikGWxShZpek5lVKqBZhUGLMAskTarIyKEZG51owHJZmJsjzrAk1nmdcN2zNF23U0VsXBKHeAp+AjTbunUuYmix21LItyPIhJH4lyHULsRs5mNXuWlyiMYTwqGQ1zqmZImWk2J1O2pjMUYKQipC6n6OmiqfgVMiqE6wCmc+Qhft+omCiilEErTesCSnVJvuiiH5WKgNwgzzBKUChomjayu5oaKXzsGIgd9pENcSz9rxHfeIWQKInsdGGsC7gg6JygUZArQZY+Q6FFjBBO3R4pROKipf//4X1mBWK3gQDeClQuyTRRNpt8wHqVtkgHwzgFJR63QLRDv0naHu3ugT5PnxQBkVYcadoxUlkmcLq2ntoFmiBYzeNm4tsWJUkgbcVs1tB2Ha4LCNEixAQbutgJlApsnBcmFYom0/g2atCdh7/91D1sVy3WB645PMaIjmEeN7boiRrpwNYHRsZwaDzkMQf2cHR9jnICvGPPeIlL9q1w8Z5ltquWs5M5EsFQx+LbGIFKfhoidVI8Cq0zTJ5hVE/J19i+22pB+JiUaMZL5EUseLWWcX5ahzQDcpWza3fAuppBYdicVFjbYH3HQJXx8NdZuqTRt66DUKCEYlAUFJkkzwIXX3SI6aRifW2bWdfRdB2zWcX2fEbdNlEie/8DrJ05jfOOlb37WT1wmApiGECbfPW0QucaO59g5xPmk+0ELguuOrTEZQf2cM0l+/jcPUc5enqdO+47wemtirVJw/7VgqptYzf8HFPcsOPcRkhMwyhVjkmZvm+BpsbETrNlxxMQWADHEhgXMWLYhcCRWdTyzxrBY/dKtIQiiwzUHkQWyVcvDvx/AxPY14QQo6y3Tm2wMsp48VMv5LYTU268d8IN0xnaxKjxZ1wx4IQT3NloPntim8v2l/zGa6/iv777CHccnzNvHStLBbuWCx48tUWWGYaDjItKi+5mfOSuOXeemZMZwWuftJf337XJTcdnWFJHzzs+8qAjDEZ86QnN3W/+7wz2HubR3/hD/Mh/+B5e+uIX8ZKXvzJ16XxsoEiDUBkIybXXXsXv/favIfFsTyb88m//GffeeRunj9zHb/yX13Ps5Fme/PSvRIhYogTf8eCRYwugSGUDzGA3QvQMbJdSmNJKFQJ9RyXYCldvEFzDe//2b3nK05/LXXfeQc9mgsCJEyd5xrO+mm/7d6/hta/9v+JrCAHp9zfzKUdu+wztbJPdo/2A4Dd+8/f5zd/8bZCK9bUdWV7c09PenlbHrpow3zxJ3Visi4yC3/6N/8pTnvwkhMwAwQUXXswH/+4v+ZVf+y1+7w/eEtdOEau9V3/Ld/OkJz2Bn/2Zn+azN32G2XzGn/zx71DkBdZZPvXBd/Ohj97A297xfoRQHDtxhl//rT8kF5bDB/fwvvf8KZdeejnD0vAnv/2zLI2GqKzk6V/82FizyJwf/MEf5v3v/0D6GBofBPfcew9dW+OdI1jHIy9Y4j8+/xH87gfu4y9uXadCUeQZmVHkRnDB3gHXXLKXD910nLaD5dWCvStjtBS8755TPP7CJZ75RXv46H2bHFodcM3hZf7shiNoLfjGL72Ce05sMZl3/NTH11gdZDzn8iH3zWBzWvPR24/xiMNLVK1lc3vGYDSMRbR3hG6ObzdR+Z5/hYn4v3/lmVnEk+s8JnoJC1muyLQmL6LvmvWBSRX33XbBXIoSiZBO6Tv1TqAJoJViuVTMm47G+ciiQixqnP6wUtWWQgsu2l1w2eEhG9OGu4+sgXdMpcQmq4W6C5zanDPMFCtlxoHlEcZIMmMiA8h5hHNIFYGgoDVdkFQO7jl9htNr2xw7ERmCzjpObU5Z266Y19HgXytJkWlWRwX7l0su3jOCEKiayLYYFtHP6fDKgEGm0QLGwxIh43uQCYDz1mIFSBMYD8rFYd12NiYA5gbnAgSLcH4hDRRCxfNEkZPnOSbPMVmOMlmctUqSFTl5UTAsc7QErQVZkdNaS0gsfucCs8Yip3PapiErSrKyJCsK9uwtKMoCKSWus+DjYa/tWqq64cTJ00y2J4yGa+yv5gxGI0bLK5jRCIQmCIPQaS2yluCjqfmwSHyFENiajBFSsl11bNYddRfPaE2SCbadi1WskGgR6yCJp20bgrMYGpCR0aBU9F1yxP1a9N/rG6zO45WM447ey0ss0qYlISaHicDJeUcmHU0n0bJk0npciLYoCEmm5IK913aRyeLcw3sfPl9Dn6+hz9fQX3gN/XkDT411KC+wUkRjwB5xW9AJF/9K/xbi5zqHwQTn/Ht4iMwufvUMkh0wwIUQWT6ZZt9SSZZnKJ1hak9u7AJ1FyJSEKWIqKWWLno8ObFA5QIktF9hlCIAnXNxEyEmLuRGYlSkzrZdR9M52pQ+1y8IIdGFY2EYknxPJOM9sQDWeslf8AFUZDBlWkd5n4761f7miRQlqZWMTCApUEIuGD+Z1oxyQ5FlLA/ymNaRNKd1Si6xnU6m2JHq2zOeeqTcJwM4IaOHwOK9KJ1+VibjbEHTdXgfaNoIvoXgyYyOFGKjcdYunvW8aVKXrKVqVXx2KQWRBSgkUixoQPqA8gEdAjIkf6sgUISUWBeQC6BPpnsVN6k+BcXaDumjl9Vi/oVzjM/+f0yDfsz5kKIqF2M20IWY1OB8YKoDuRaMXKDUCR8W//N4/7dw9QSDQO/3JVJCX/r+4rDGggbsF3Mx+pQt5nV/cwXp5x5KG37InCeOKSHAep/mXCyGklV+6tJ6rOvihtB5nJWE4PCho3Ft7DYqTXBxo0dLypChEAitU3HteHBtm9MbU2Z1y3LhktzTp003FoquZ66l96AQi3Xm4l1jLti1xP6VMTZAl+irSkYTUiN11JErgdaSPszHR4omUku0Ykd6kMaLlBIt47zI8+ixoLRJwyiCwsFHU+iiMCwvj9BaIqRmXkmqGoIyWGvxwsbUSxEZj52NneTgouGjtS2ZySnLwGjY4uex/PG5oukUIfm6tdYyn8/YOH0SpSSj8QhhBkih8CKkCE+PFFF3Lo1BmAzfOVzrEd5RKMGB1SHV4T2My5y28WzPKuZNw7TpmLeWzvfrfQqB6IdQCAuQ2oeH+vstUjMXY6iHsndmdj8NpYhRsV7FPdAD0y5wtoK1KjDtItDcv2YgjXWx8xoPd+xp6+Q91JOzEGBtY0pwOXq1oKodTetZzk2UDVvL1qxB4Tm0pDkzbSkKyebMLqQxdWORIpp6uiTV7jpHayVdgGnlGGWScR4PNC5AbhRFVtA2LXXt2G4sdYBiuWTzjmPYpqM6chOH9l7N8LGP4Muf9SVorXjf37+fpz71i9m//wBf/pxn8+lPfYZBWfKYRz8KKRzbk22++En3cNH+FdZPXcLjn/AElu66n3379nPDpz7DxsYGhIBQmnI45HGPvJpLL74AodL+GeIe/PjHPYqmaWhmU7JyiDIZBM/9Dx7j1ltvpa4bNjY22dj8HE947PVA4IZP38gjHnENhw4eBJkzGJTgOxCK4C2ua1FZwfLSkC99yuPwvmP/vr0opSAEnPXcfuft7Nmziy//8mclYEwgZMbBAwfoN4l77r2fz37mk1RVzYGDB7j+2i/iiU94AldeeWV6uhLnAmfW1phXc0Aglebgvl180aWH+PSNt3HT54bcfvcDXHbZpezZvcJjHnktWV5EBlp9Bi8zNitYWhozrxuuu+aL+MynPkk4bnnkI66hHI4REq75okvoR/3y8pieobW8tMTePbvT/uCxtuP2ZkbXdUgV0++sczQucGbuWKscl+4bsHt5zHCQU7enEcBs3pBpjcuirCekYnh3qREhULWWQysFw1wxqdrIfk6NS4TCEsdzrqOcyHsZWd2di5IyHY2KA4HhcMgTH/c4LrzoIjinEH+4XmWucc5GjxKRbJXTXtx3050XC7b+Ym8NO6bijmRITJRCQfSQUZrFfi6IVg+ql0GEnX3bOo/wllxYdo8NuRJsb5e0nSUAdZtjbTQQb61n3nlmjaNLzWLvA946vI+HYSmi/yhK03aB7cZyZnPG2taMaVXTtRLrHFuzhqaz0YRXpCAdGZleudYMs1j3liaCbGVmKLL4/d77x+jYcC3zLN6vEBumIhVkWkWPpCAVEBkTMQzHpxNT/P0IgSlydJ6jixyl9SJ5WqSGr5E5g+GQUeuxXYcI0a2I3udE9Pt+bP4aGQ8aQWpUloMQDMoCANt1tFWzSMRz3uK9w3YddQV4x2hQIPBRWlRkBCVAmKSgCPFPGcEoqTRGe8rcMSgyirxDKUXrWmZtVA70xvOksdXXPwIi+OMtCkeu4hE2pOeSLFyAxEwyasGE6UcXQiyYdULAgt2Tzh0CCE4w6wJrtedM5Zi0cV9e3DsfpU0C8Cn8qU8zf7he52vo8zX0+Rr6C6+hP2/gadbYBbNHJ0CkX8TO/efiH/3NSJOnX0/6idQv2DH7LG4gMaaPxV3yxAEhhaDIDPtXhxR5jsoMu23U147LnLvOTlibtZFilimCs/jW0XaWpnVMg6dzYF2UbPXyrqrtaJ2l6joyLRnm0ZgPPFXTsT2LHhetT8wbFe3yQoiSMkRAEieO1nESRdApIvdt57AuSsfMAjzKWR6W0TRNqzRwIIToPaXSz/Xm4YI4+aL8L2dY5KwuDch0NEts2o5KCzQObzNqJdApFkSI+L574Mn5yC+TQlAaQ2Y0wyKPv09KOqsjvVErtqYRMJtVDdN5RZ7F9zQalYvnUeYZg8zQtW00Y+wsVdPFZ5/i4AQsCiqEoEpgHM6jfZRViMA55uuRzqyNQpuo7S1zQ6GiDndrOmde1zhnGZrIQGJnyJwDXO4s2P/zbOh/V1h0IUgAlBcCZyOlvQdHfYieT6WO4zN2FlhICXdiKx/eV6596gbKJMU89870dyr+ab3HBZH0wmFxb91DNkyRNqRojKhCwKQb4VL/5tz0FELAOkvdNkzrOXXjMcYAWUyZ8B1d3eI7gXAZPoioE3eWxvq43mSBIPp5DLmSDLSBssD5lqqueGBtm3uOnuHUmTVyOWcwyNhqG4QQFNpQN9GoFQR159muOo5vzZm2jtEg40WPu5y9S0sM84wjG/OUCKUxSiJT9m+hDdpIhJF0nafrdfsAMpCbEqEkyHjDhJRk2iCTL91wAEEpvDD4rkKIgDZgmwlSSsrBkGKwG+t3sbw24fTpNc6c2aBD4kXU1kuZJ0mAYLuqsd5SKEnbdcg6Y7y0G60Nq8sDrK2QIaClQcqSpjU0XUcmA1LB8SMP0lUzMl+z6+JHoPMhjTJ4OoKPxtNIgcwUZjDCTSvqZpt6e5Msk6zuHfKoyw7B5YprLr6QO46e5O5jp/j07fdwZtoxaQNSKBSCZCVyzl4QN8zWBVoLrY3MVKH60Im4Pi781UTPOEybnu+Zi6B06CcljYcTVeCmsw6HoPZx7qp+3ouYZqKTKe7iFPcwve74x7dy+t7PEgjcduQMWmuGgxyPYs8w4xWP2s8txze55+yUv7trk+sPlDzlogF/fOM2txyf8Z7PniH4eKCsvGAyj3v48iinajrOrG3jfAQi5q3nldctUyr47x85waE9Qy45uEyxsosza9scP7mG6BrGK5orn7iXzZNnma9tc+K9b2Lfl7yG3Vc9gz/709/h537hV3jB13wdN934aZ7+9Kfxnqd9Mc981nOYzmbEaBzLqMz49q97NqZcIhusAnDokkfypc9+Ps981lfywQ9+GBCYfMDBw4f43V95A/sv/KIE8sj4heLnfvpHaasZZx68l9UDhxksr0II/MU7P8DP/udfZ3Ntk35f/MWf/3GEkDzj2S/mB7//e3jVK1+G0EOCrfDtDGkG2DqylEZ7LuLaq6/kb97+xyA1ICE4nvH0p7MyXOK7f+D7eNaXPY3f+91fj56DsJAL9DqKt/zZu/ipn/l5gnd84zd8Hb/7W/8tspkAQkz8OnHyFC966TdSVRUIRVaO+PIvfSI/90Ov4Llf/x+45dY7ePk3fS+//Ss/xlc/92nYekKwAmVyHvOUL+OxT3km3/49r0ujJfCOP/s9Xva138BNn/scIfjIBgsSQaxx4vlb9u153vCG15MSM8BvsLF2hOsf/zWcPrO+YGzcfWrGT7zjXtanDfuXB7z6SRdy+cUXsrSywo+8+YMcWZtw97F1Lj+8j9Eg5/hmzan1OXtKyauv38O77zjLP9x5lm9/9lXcemyTP/3EAzz7EYdRQvCx209zto5MiGccLvink3M+vr7N0ihDKcHKcsG1B0ZMO889E0/dtFxw+CDveuc70ObfRqrd3nFGZ2Pd5p3tgxajXMEFqsbTJbq2TGCcl7GWdgCpky1IQEGK2W1c9JfJRDzJGwVlJtluPXSp+QlADL3xbU2Yb3HBcDf7BjmZ3I0QgnxzjvWCrrdcCJZ5F1ivLLUT5C6gmyhBg0CmUsNVKnxWsD2bc3Rtyn3HzrI9mdHWNZsuJiSd2Z7TWh89hgQLA+TYXJQURjMuM5RU7FtZin6pgPDRi86FQJaZRU0olSSEmLQV8RWBkJq8LMnLkiyPUtVgO6wLdN7h24aAR2WapdEIk+XozKTDbASIpDHoTFOWQ/Yd1AyXVhiXOdVsm2Y+Y9bamJIdoi+p9z6CAF7SWkWJRGY5mQuMhkPKImeQG6ZbE9qmoa5qpHC0EuoQwadZ17KhAq6tMcJRlFn0QCoGCJ0TgkZ0XUJrgGDRGga5Y1hmlGWH1FE1MG+j15ORktxEX9QQohIgpvU5ZlVFKR2F8uwaqJg82IYkB0zSwQBGSYZZvL9tl3y5krLDRNwCJQS1i2MxN4qmTxA3mto5TlQBNqKcs/UxzdqGeKbUqJTeGEOaOuf/pznzcLrO19Dna+jzNfQXXkN/3sCTlCKxcFgwPcLiKy7Ci5tBwPeoeQ8AhJ3/J96kxDaRPRosFh+8/1mIXk3We6yPLJSIuEbzxeXSYFQEU1aKBus9dRsNyEYjFWmpzrI2aZk3nu06Fqqt96zP5tGIO3i0jpTfQa4geFprmVYN87bD+lREIhZdgf5LpXuSabkTY+o8XRc7RXUXN0xENFIb5hnLg5LlsiTTEcjq/YyciyCWEBHkWHSEUgRtmWnKPH5FPXGMw5XBg1d0RtFkGpmiMIHF/ervd28yLmRMC9QyGVkahZIx5lbKiFr3HXBrLbN5RWYU86qmKDPKMk/68uhFMK+rWJh6T9V1CCEi4Ob9zvNM4FNLpKN2ztM1Hcp6pI4LtAvERAGt46aZaQotGRhJV9dUdcvmtMZ7hxBhh9kUdphOLvT61x1s9yHspPD/uTwVRDN7I2MiQyBu1lMbOFNBlmSllSXRTcNinj3Mz6xABDBD8j9z6TlE1v4OANyTGL3YWcwWE93HsSPS30fmX4iJf0LgExIXu0C9JLFfE8QC4PM+YK1P4QEBLzxBZQilKYSiKBMVVKl4MCKCujvIehxr83pOZQO28QywbG5tcersaaxrkUaiy5L12jPzUb7pfdTaX7JvzHbTsVm3dM4iZWDfSsnhrAQhUyHZYW2Dczb6rylNngmM1GTKkOfxUNkFySCHkEFmMophRjEw5FkWY1+FWQDWzjYIJVBaI2ROEFHiKqSMXQTpCcSkILIydne8p8jnaAUEy2ReJ/PPGIlKiAzUECTeS6ouRssaJcE5lJaY8YDl0DBsc+g8y2NL3VnOrE1o25qqafFewuYEd9/9WFkwWtnNaM9BOhEpw94p0AOEyNB0lLokK4fY2QTbNpw+O+NkqICYpHl4acSKMaiu5a5T29THtjg7qelcwCiJERKh4obV+tjl37uUp8QMOLLZ0NhIOzdSEYLAOoHAo0IseBdWtiqtdUQvmEBAEciMQCs404ANHhtYrK0BErU74Bcz4OF9/dAv/gVHT64jhOC6S/cilWRzbtmed2w1He+9d5thrjl8cBePHGWc2qh4583rvPj6vQQheHC94YYHttioOpYGMebbaMnGtENpza7VjCt2ZXTWc2zTctOpOfuXc17/wqv5wO3r3Hpyzj45ZDqtqec1eMfGiS3u/cCdHL76Srbmlre+4/1cf+ovufjwJ1guOp510QrX/f7PcvDAbgiW4FoA7rn3QV7+9a/l27/16/myL3ky+XAVqfO+Jcc//uPH+IVf/M/ccuudIDMg8JKvejaPfuS1vOGX38YLvuor+LqXXQQEPvKRj/NL//lNICRXXH4pP/4jr+PXf/ct3Hrr7fz8j34L87UHmG2cJohoiAzpIC5BmBKpiygBxPPWv/gb3vq2v4o/KxJjx/eyBMM3vOS5XHnZhfzWn7+fe++4lfvvvI3tyYwPfOjjvPjl30pwNRAQQvO67/sOnv70p4LQUQroYprO+9//QV700m+k35+Qmu/7rm/l4IE9IAyICF61802ENowPX4fKhtiuYXL6Hn7mp3+Gv3jbZbzy5S/kk5/6J267/W5+5Vd+iZWlwQI0EzIaJP/wD72Ora0tMpPxlre9g/f+/Ud47jOeyFVXXMIjrr2K1//Yz3HfA8cQesAPfvf/xeOuu5S1T78L4Se09Tbf/OSL8VzKeGnM5vEHeeDslPfcvcXIxDXrDz5xhOVb1tizOuQHXvPFfPLm47zl3bdwZmMSU5iC5PC+MfuHGadrx77VEY8yOX9/2xma1nLJ7iEHVgrmnWfbSpSJ6UFHrebRl63wtKsDb73hFJ3SDAYl77nlNGWmuXLPkNuPVNx159285KUv47Xf8s08/3nPBf15l7T/R65q3uBC9Lx0XUASyISInpohIBQYYj2xWdnoqyGjybW1PtoR9KwVH1AhQIjJR8EJGiEwInpyGAU67cVFbmiSPG7aOqadY24dtp5QZjmXrORIuZuT2yO6e84wrTvq1mG7mtYFNmYtm5VFK01hdNqHY3Hn0p6+sVXx4Ml17nzwNBtbE6oqpsLVXZQOZlmONrEemDdtCpmJtXFuYiO2MAalFDYIrI1G18727fuoVFDJy0xKTZRsaTqbak0hUcaQlwVFURCco6tCtMUIgdYm8ERLBsNBYkxosE0EqYiAn9KarBiwLHPKQYf0LdvSEVzLtLGpTop1SGwwWwgm1vuyQ81rhFSUgwIt4tkhNwqJBqchJENlAtZanHPMGwuzCmW2KEcjBJCXQzAZUmaoLLKnpBAEEQhBIW3A6Gj63tpohdK0HSCQUi2SsiWQC2jrmCa4vj1l30iTS8msC0zaQN0G9i4XBCHpgmB91tAl6ZtJoRJBRF+2zEgKFWtlLWFYyAWBwHuPEwGtFC3xbLPRxCLSEet25+McGGoQqk8bPxeReXhe52vo8zX0+Rr6C6+hP3/gKSGzIhWGPaq7oA6yA8j0k2PxMwHSNpVAqp15yEPe7LlvO7GmfB9p73cMpEWcRIUQGCnZO8wQwNqsY1O21J1lYCRGeBQepQyT2hFkx7yL6N+87dIyAUMTC/BcS6y1idYdEx5CEBglduhqwdMb7amUDmF0YlGJiG631tF2Hut6rDrRiY1mkBkGWQTMlJQxtjREaVnPnlEL0CmCQCbJ7/ovk76n0p928TMSHxTe64UJtg/nYC7p4cmeoybiotabd0eqcSwmChMTaLyLsruqbqnqGueHCAFlmS82zKXhgM5a5nXBIMuwzjFv5OI+Lf5M3QEXIm3TW49KsruQjNZDYmlpExNGSi0YaticRxpk3dqIbMsdkLJv5vUgVO+4r9Li3n/WHgA79+r/qx/bMiRGUw9qEWnscxuYtBGA7Xz8DH1/45+/5sP12hnDPSusb9ekG/jPwLkeMD6XFizO/SF6ILlH3ne4j1GyGehpx+GcZ+RDwDkX5yZRfhkfjURpiZQOKQMi05GeKgxZFpdI5z1aKOqm5djZDVrnQVQcWC7Y3Nri7MZ2pATLSB32CHxayAmRMnxodYicVMy6OH6lECyVGeWgBCTzuqPtGpquTYCwXDScpAJt4jwKaX70AHReGIpck2cGkxsQBh8ylAK8w3WktBEJsqfQCxYukwikjmai6BwhBdL7BdtSaxm75AGEkov11idvNeejrwMqJms626F0hjKaYlAQjIbWoZ3DtB2TSU3XtjEUAPCzGm8bxsunIQQGy0sLqW8QKkkMNMpLlDaQ57QSwkxSbc2omwYfPMuDnFxp8mHJ4V1LTBvPsa2aedPhg09ef5G6L0X0MrBBUBjFwChKI9msPaKJsp4IFKSCLkR5ikzzmpBAYpFGZ+i/B1oEjBTM/A4g3ZuX9h5w/d70b4Gy+KFPxRQ2KSTDMgMp2KosuZF4H3hgq+XwSk5RKA4tZ2xMas5WltWBRkvJ1tyRG4VuPUarRcNkEbqhJUbEpJULlgxbbUDVgUOrJVLA9qyhnMaDSy+1nmw33Hv7Ka674EryUcZmo1g7eoTR5DRqOOfip3wlj3/GMxFFCSGyhS+66EJOn9ng7nvuY2t7AoDKCoSIPoGnTp/lczffytvf/i6EyigHQy656AKe+qTHcf11V/NH7/gwjz+9jveW++57kE/ecAN//fZ3IqTmSU98PMVozNm1de699z5sO2dlXHDpRQe499443iHwwANHEUoBkuMnTnPPPQ9w6SUXcuedd/P2d/0dIJEmwxQj2vkcCGRFzpWHV5hunuFv//6DHLv/Ls4eux+C5cjR4xw98R6Ca+iBp5e//EVpgCUWUXLWPXLkGEePnSKEKAkQKuPlL/oK9u9dZrHQAL5r2Nqecs+xDZoueli18w2OHT1CphWTWcXNt97F33/gw9x8y+3sWRlimy1UStETynDlFZcxGpYQLPc/cJSPfuLTjDPPZHMNGSzvee/fceTYaS657Comk218O2N+/BbsfIumnnPFvjGD4ZCD+3dzRM8p84xb5ppmOqNtGu46M0OenbFydovvWH4KF+4bc/m+Mae2Z0wby/q8I9cRDzo+aXFCsjQsOHZim1zBnlGOc57GOjwiJRgL1hvPlUXGBcvxYBGS9Gy7dQQh2Cti0TzZmvCOd7yD66+7issuvYhrr3/8v+aU/BdfUWoWPTK8C2hBNMSGCDz1YCSxOedCBJ5sShvrD0yCpBhICjKXjMctkOUp6Eb2CWSRlR9T8AKNdTTWR5Ndb9FoxiawbylHSMWxcZGkax2119ggmDeWWWMZFZFvJaVAhD4ZK3pQbUwr1jannF3fpmlauuQx1FgPCLI8i01WH6g7i0pJzmVmKEyU0/V7XfCCjrindT4kWd5OHe5DrJsfyjgBiPurTN6gjoBQMpkpx98dGTsKk5uYJC1lNHWGxSFWKoXShlwalNKUZUFTZJhkN9HX5yS4obOO1imkCxjradoOVTVUszomMev+WfQMryjV9SbaX3iiHKnpYqO3quaYLMPbNu61UiCUTrIijw8O4RwQm+LBQ2sd1kammlw0kaOvrEmshO0G2mT0TXp28y5Q20DnYZDpCMRJRecDVeeoWhdBERn9ivozSa4jESF6Q0Xfp9b6SE5IzyogscHTRIUivUdNBFvimF54pgqx2J8frtf5Gvp8DX2+hv7Ca+jPG3h66ATamWQ9iOR9pAu6xYRMCQb/7N2E0FO/Ak5EX59FmzP9pvi504cL0Veg7SzO+kQVEyB6qqPgwFLJyiBjWGTceWbKye0aHwKDgWHPMOPCA5LtecuDZyfce2ab7XnLtGrJjSI3itEgT+bRMKss86ZjVncEVDLPkukBRVqtIAIfmU6AldEEGb0yWmupWkvT+mS+LtFKUBjNMDesDnKWkqm587EIcN6jVLwPcZAmxFtJikQtHg0LBmVOkWcorSJqngaPVjEhIjdqoTt2SdLW2dht6uVvPiSTShs3JueikaRQ/SFEoSR0Nk+dpUDbdmzPZpw4fRaTkhEO7t/DeDwgM4q2aVKx4Jk3LTrJGKuui8wn5xfjxqWx4UOg8jZ9zkCeGbRRGJOTZxm5MRwYaYYKxsox3w6Rch0ChPh6nReLybMw7kNQmLgJahfjTzsfAaUe0e1HpSROOClIXgWCoAIqiMW4lmljbT2cqmNhaAPUyTMsatrDv2jS/Z+60pqT/iMsKq0IukVOX0iLiSQtNB5sFw0Hld55pXOBYxZbJclotDev8zEeNplOBnyKyHbMu5pCVSgc0wrIWqRUSK3xoSXgMDL+Qu8FVdXFTpCSDMcZZ2cNv/MPt3HvkVNMZzO+8pGHWRkWlEWO9wpCjGU+tGuJlWHBeLvljvYMVdPytKv28tkHNzi1VVG3HoFk7/Iyc+/ZrhruOL7OZFbRdh2rgwEqbeKTOpDpjkHRxcCCINF6wHiYoXKNo8FaUI0izzVCqpQAA8ERuwJBEdCEvECmTl81i10OpQvKlTEqL/CmRHiPCB1SGUbjZfZZkeZYx7S1rG3PYhGhNNDhnKK1HYPGMcwgU9t4P0CaMcPhEnhLM9/GzgNKKkaFZloJ5i7Q1hVGwlRJfLiPlbWz1M2U/YcvZzBeplEBLyzBW/I8+legFNIoRJYzqATt1jptPefU1japxmR1UHD1gRVWM8PR/TXbTcfGbMakqmg7S9112CAISKrKsXeQc9XBJfYuL3F6u+ZzR9eYW0vrIZDHfcP1DY7o/xLHYwC6RSESQjysEQKlkoTknLBZxzSizgvyoM5ZB3iIbPdheQWP1AplNLcc3cA7TzVvedJV+xiVGTefrLnzxDa3P9BBNWY8yvnKxx7g9284xVbl6LxkZajZNS6YNY6TZ2c457jw8H4m04pTZyasbwgec8Ey3/mMy/ijz65zx+k53/sHn02SksCRB44uvBYQgiMbNX/wkfv56tmcKy7Zy/d/5zM5eu8226dnZEtT9NJBRH4hvdm2NEN+8zd+LTGONNgZXT0jGywD0LU1P/nzv8qnP3UD8RCpuf76R/D+9/4ZWV4ymc55wXM/zjVXHKSabfNVL3gp99x7P+AJriH4DiEz/u8f/QG8a8nKEd/23Y/hVd/8ah77hGfwwANHgMC3fNvrAIF3nh/90TfyW7/5m9zw0fdimy1cfRaEwrUSO1+LLCSgqjv+0y+9CQFY251z3hAQLKGbRJQgGYKLJHsKvokyt/6ULCRCGYJNrQ0f2cFxn2zpfaIg8NfveA/veu8HI2AWERh+/j/9BC95yYvQOuPImTk337/G877qpdiuoZft9Wvyr/+Xn+SrvvKZjFd2cd3Vl/PlX/Z03vzmP2Y+nyEFdDbwZc/4Ev7mnX+BosHPTjNYGXPnkdPcc9cp7p6XXJZ7rl3u+Fgz5NCVh/nITzyZV/3AH/L3/3g7F+wZsbY15/jZKc//rjfzgsce5ideciVKlXzynjVe94ef4NiZCac3JCdPbbK0MmZlecRTL9uF9I6m7Xj3Z4/hAly4a8iewuGD5caTNXU1ZHmQs7Sywqxpmc9q/v0zL2Vr3vHmjz7IoMxZXh6yvr7Nz/3Cf+EX//Ov0DT1v+KE/Jdf21WH87H+LbUiN5JhoRFyh50tEqCiBFStY1I7qsZFVg+pIEmN4JAaakkZlXx2onQtyxTaOhSQKxN/xgdcG4FjZzuyIkMZSV3NGSnIBor88j3cfmKTo+szThFNeCe15ex2S5EXHNA5BoXEEZyjsoFJ03LX/ac4cnKd9bUNRPJAnTeWLC/Isozl0ZBZ3VI3LUopRmXOrnHJRftWOLCUU2RRPueFpHGOeedoWwvBo4nAiXU+fgYHwcY91dp4ENNKIkcleI+3lrZpYl9QKqRyKK8IQiYzLI02mkgC8fFADUiVDMdNBsogiCE3xmiKPGM4KKjqduHr03YaISJrCSIzrbOWqmrwLtb/g8JECaGIu5DqQRYpUVpjEAipqDtL1XnaSU2xtol1nmJQkgdQeQlCIZPUyKXwHx8kVWPZnjec2ZrTuChljFYYOUWRsX8pZ5RLlnPJmcxT14YLlwzb85p5azlVtRgpKHT0oR0PMpaXBoyWCtYnNXcd2YDgF+Myk5KhESznmqZzbDeO0EVQtOkcS4MMIyVr846qi+eNYqAwCowMbNUt1no6J2i9R/p4Dit8n0L+8L3O19Dna+jzNfQXXkN/3sCTT1MjhJ1pcu4asQCm+uZe2Dngh3/+M0kKtUDKFtPu3AP8DmMnSu1c0km6aPAVIgoriN2cgRLsVwInBEuDnAfOzmidYG3mWC41SmfsGo84O2mw1lPV3YJZE828Y2fSJRQ+IGLXQ8qFCSTpPfaFd5FFFNVoSZfAFGuThxEBnSaNlpGNVGrFMNMUWiGFpOmRSyKKK9Pnia8vMCn1o8gyBnme0mMMKhmVy9R5UgmkMgnB9T7SsSM6CdILrEtRnSEOMe89znq6zpFph0+/TyeQLdMqTkKtaDtL11m2pzM2NycoKVhZHkXJY54xGpa0Xcd4XjIuC1prGWTZAoR0fseIXiBABFTqkkglybOMLDPJNLJgnBvGuebi5ZxSBnIc2+P/h73/DtfsvOt74c9dVnvqrtNnpBlJlmRbsiT3CgbH2MZACMVUk0MaoSQGzAGSwEvNm+Qkb5ITXkgBQjE2YIPtgAu2Mbh3W5LV62g0bc+e3Z62yt3OH/d6nj2C8weOE6Jcl9Z1bc3W7s9ad/nd39+3FCigajyNi7RpJWLhPjfvm9OWOqlqTekEo8pTWc+kdouCT7Rdivk4juDVfjdNXtGJkG1nVRJwbfqEDU+cByzG8pP7mpv3wxOw4/jfcAX8LYhjC9rCLH48eLhStxha5FyLaEqXyAjKORu7tbWNBbEQ8flb56inls29hse2Sqrakmc63kvbEGTM7lCJQKARThKCx/sGnajW3F/EVInJlNo6ysYwqxp2Zoai6DBIi7ZbC+AptKSXKkZaoYTEeji7NcFYx3o/Z61I6eQp57ZHlDaactaNi34FaaQuR3aIIoi26z6NxvtSSjqiwZiWFp2mWBsIoUGVVQQJlMbKWPAbF80PJYAzBBfpq3U1RQqFEApXTuLnigBI8B4hdFukKoqiQCYpaZsmZEzscPoQu8hNFMiDkPhdT9EYjHWkSSAER13PqMoo21BS0ityfIDRbIpoUy8tgmnZcPbxi4SQsbRcMji42nbZF/8hOIdSkizPWV5fJs+hqXOsmWGsxxrHeG9CliSsDTsUnZzKWMZlzuXRlFFZcWE0pWxiV2ZrWrUGmYGDwz5rvYzrDw15fGfGXmUQIgL0QcQUjvk4FmE+QsUCB6Dt3oRA6y/XdsPaA70jxCQfGTs8SoR2D3jyXv/m3/xf7VyyvOP3f4fHz13gTO04szll2Gl4+nqHjdSxN5M8umdRY4/WNS+8usekDtx9saZyHusFWVFwdLmgm8JmGcnSWgn+1q2HyRPFH96xwcMXp+xOaurGxv1Jxvt7y4klXnTdGgevOUIv0yyHgGo8m2XKobEj1ZLhao+lG2/lwuVdPv0bv8RuLTl64gQvfvlL0K25Jqrg9rse4tLGBV7+8q/kQx/5GH/8rvfyhbvOsnF5JxrpBs/jZ87wT3/6F1BJQZKkXHVgwO2f/Szveff7uXjxItZEUOYHfuAf8uIXvRBwvO3tf8RDDz7EG3/47/ORj36KP373+9nZ2Y03Ugj+wd//XoSQ/NIv/2eMMWxc2uSf/sy/ZG1lmX/+iz/L//Wv/x2nTl3Dd3zHd/JLv/yfefT0aQiO133r67j1lpsws10+8Gcf408/9EkWGeEQ/w2xmfOmt/wBj5w+zxvf8PdYZKAKiHOnab82ELD8zlvexhduv4Of/5mfRKroofFv/t0vs7u7S1OXfMPXvQZjLO96z/t48+++lc9+9nMgJIePHOPHfvD17Fz+Gj7xiU/x1re+ncVpCHjzW9/Jpz57O2mec8MNT+OVL3sOb/3dt2BNgxCCN/zjH+JFL3wBaZbidh/F7j7GrBT0145yTb7GQe+YjPb4+Ocep6cVuh7z8fd/nqcPM9aef5Jrrxry/tvP8sn7LuJ84M4zu/zK+x/kpmOrSCn40dfewAfuvcyZrZKlYYcjfc1q7jmzUy9MxZ93zQqT2nFmu2almyMJ1I2lIx1rWeDRjSkmgNKKj9x3CecD3U4W15johYBzDuccT/ZLiNioku2Wa0JgZDzdJDK9Ui1wLnaW5/45UsQa0ikWNZ9oUac5WKUFZFqSa7mQSqkgouVD45kYhzEWay3Ce8qyYWd7xmhU4Ts5AYGtS3CwquC6tYzlXkq22TAuG8qqYa80ZKOKpb2aYS5JpCC4wMQEJpWlrg1awFI3w1lLY+O+lGi9SKELIUozunnK6rDDkdU+64OCfhGZRJ5orG7cPLxHLEDuuaxNishKalzd+qm6KP9LI0AcvMcZg2nvN+zXeVqrhUdR8J7QsvznbBEhozQpEP2evIsgliDEGjvRZKleMCWMTZCyZZG0srP43KLlhTMNRgYaFdkI8zGAiNy2mKwc3xciWm801jGZliilmI7HoHOSIJBJ1p5F4v7uvKesai7vzdieVNQOtE7RiWDQLRh2M4adlJPLmlxBKgJLyRBrHdY0XJ7U7FWGMzszprOaWdVwZntCv7YsW8fyIGell3ByvcPu1DBrHDtlBAKNEzGlzoNv/26I0iUfYvqd82FRQ1ofP5foeE5pPAR7heXK/KD45N6Cn6qhn6qhn6qh/wfU0H91QXwIizVhfzEXV3x+Dio9EZD6Sz9DiAVQPL/EX/ia9scRQYUQ9e3Ox1Q2H5H3+WaBiIwfLQQruUQqTa/IuDxumDWOvcqT6tgF6uUZnVQz0+qKdDsddePCgW8p0CFuQkpKlFTtjZ3/0aHV3goyrSIIpGWb/DYHWeIfplVLeVZRxpe14FOmIqJonL8C/IigjGyLU91+X55o8jRZgE5JoiNgM0fHW1le/D0xRjaaiEcwRkmBdJEeaWxLjfZRh229x7mYshEWiXYglVgAT4lWGGtxzjOdluyNJ2gtKcuaTpGTpQlFntEtcrqdnG6eURlDkSZUzmJ9ywUnLhyi7QSLtgjQWpFlGWmakmhNv8hZKTTLheboMCclIJ1ht5cjApHy3UiMc4jgAMeVhn1SQqYVWbvQCWFJmmha2Nj4/ILfh0PntPV5AbfoYFwxNucu/o59H6n5J6/ASf83ucRiAYn/FzfM+JFwxcsILeDG4gbtz+s50BbnhG6lj1oIKhfjn2Ocr8C49gcED95jLUwqz9bEUhtPotsf6m2UN0qJIkMKjUTFoiT4SP9G4C1MqxmT6RQX4vi11jE14EVCnhdxc22R8U4SN82sNdB3PkZEhyA4POxweNClV6RsjCbUdTTnsy76E8SkyjhG80RjgaqxTKomFgsqkCUGY+NakQWFdQHnDbqqUVqhtSWIeVpRBEuF8OBMC/7GIlCpJBYITRm7rzrBSx1rGNEmxUhI0hSZeDKiNX7TWKraULV0X+EtSlmkNjTTuGFKF0iSaFVpXENdBbwXZFlCN8ta9qXDuRjX7IjSislkm1RlBGtZOrjU1ksCj19E10shkUlCMlQUicM1CdYkVLWlqi3TSUWWQZooVpA476iqjEGquDxNmDQOT4Op43317eFipduhmyVctdqnNC52/7BI4sHFebEYp/MxvA8Zt0NOxBEdQyzmUvHWsLdFjoUE6efg85N7Ev/wD/9jCAZTT7n7kx9ksrfDha0pG3sVdWN5zokewcfD1+bUUtUNxjq+8enLVBY2Ro7H9xqaEFjJM46up6x1JBsP7bYHRMkLTi1zYa/mdz97AWMM3sf1tZdn5KnGOc+tJ9f49hef4uRzrkdISbUz5bNf3GbSBCa7MWiiOyjoXfMsbn//n/Onf/BOzo89Nz37Vq6/4RBLayskRR8hutz/wMPcd//9vPQlL+CLd97Bm970FjoHrqWa1UiV0i1SJqM9/v3//R+RSYe11RX+5U98L3d+4Q5+753vgxDQWlHkOV/7ta/hRS96PgTLxz72CT7ykY/zj77v27njjtv5nTe/tTU0j2PgG77+tQgZgSdCYDQa8cv/6Tf5P3/0h/g7f+d7+OVf+S+cOnWS17/+O/i9338bjz76MATHq1/1Cl73Ld/Ixpn72djc4k8//Kl91pOYFz+xA/ee9/4p99x3mu/5rm+irOr2KcaFNPiGufE43vPe9/0pDz70MHd87kMU3T6Tac1b3/lexGOPYcoRL3jes5mVFe/+kw/yrne9l3cFBwh+8ed/iu/6lv+D0XiKIFwBPMUV/f0f/Cjv56MA/MQbv5+XveA21laXIcSD9Ou/+9t41s03gTeY3bNUW6epXUJnuc/gYEqRTvn8HRUfumeDF950GBlqbv/UfVw77HDb0WMcPT7g8a0ZD21MGM8aTl8uefD8iL1nNjzr6mX+1vOP8fnH9nhoY8raMGM1V6xpz6c3I0C50tE872ifnZnhvs2KIFX0/fSeTHh62lNXFUFp8qLgjtM7JIliZWXIzqjEWI/Wmisyfp7018KyQsQm1tR4EqXaFCexqCHnbOvYGBdoJB7RJmu1nwjxqKAlFFrQzxQzF+0BsIHaeOrGUlae0LJWlBR465lOGibjGi0UaZHhTEwKHiaSfLnHisiYhJqtccXOpGLWGHamDRf3SqzPSBXgLNPaMakNdWNRUtAvUkbTKgJJgVbmEkGXuedNp0hZ7nc4tNxnqZvRSWLDM5qIR6N1aL1lW2AjJv055j6lZRNtMXAWDaS6rXu9X0iBhZStSXlY1JyilaHFVD7RWkC0YF4LcoUAxhiCcwRn470TsVmaJlES7L0nT+MRqrGxIa6IIGBMlw44a3BSYFsn7nlTeX52mjfgA7H5jIsStFlZo7VkNpmg8y5CapRKIqAh2gaoc1RVze6kZG9aYzwx7TrRLA16HBjkrPVTTi4LVHAE6wi9LN5La+lPI9hQSc0Fv8e0bLg0rphaTxU8w15KJ1UcXS7IVZR1z5roU2e8Y9y0ydVSLu5P2ja/nY8+erJVcBjvyZCtmbxA2vneTDTLnzeP/7eYw0/V0E/V0E/V0F9ODf0lOTGKKyZQnG7tST1E/fJcG/iXwKdWCz5P/5Jzto6I7Jvo+dMOWN/K93z0g6h9ZKvslQ1VU9O1Cbg4wAKCIKLmX6oIJK32UpY60Uzr7PaUx7amnN8etelyjsrUKOHoaCgSSZFEw8LYZXG4IEFo0lQu2E77puIeKaPRXpoo8jRuBJ64URrno55VSBJNnHhtt6qXJfQyTZHI6D0UInEtGgy2Mrf25kb5nCJLNP0io5PnDLpFywqaa+ADwYVWyzsHyaKuH93KA4VAyJhQYpxFirYIaaLPgHdRi54l0TcK72NXW4jFhurDPGrbUjYN27sjnLWsrgwJy8MoByxyus4zrA1LoynWe4bTksY5fIibTvCBMEdMZXxeaRbBpjzPGHQLBnnGqfU+B7sJq4WiEA5vHU0jOLbcZ7mTs9YrGFcNlTGMy4ppXTNrGsaVWRgWVrVFC0Gvk1GkCY0NJFowrmKR1NiAkHOTQ2jlx4sxO2dnXTnoQ4hU+PkmItu9xy9q/CfAp0/aK+DbyNo41uJiHudhq6xEEGmU3rf3R+wvUPPbEkLU6UtipyZqjmFUQWWhNDAqY9ezMZ7Vfsb6UodrnnaQE6s9Tq73aUiZBUXa06RZhlQaKTPSJI3styQh63bJuj3GexuMdsdcurjNuJpycWeMc7M4J4Vm2Fvi8NoKJ4+ukt31WFwAjeP4wRWOrA6YhDHZYxeRdU03y7jxyAGedngdENSmZlSNMT7KUoWMDEItgVDjXEItAjpNkUoRRIpq+5S1aVBJggiQN77dWAK1LNEuAdfBC4vzjto0FEWO1AmumhKsw1tPf+UwOs/QnS6+inKdJM1oqgZvDDpU4EpMM2VrtBNTJbOEQrZx0zplRwkqYwg+UCSCbipABrSep3cUJIlmUGiMqXHWUJY1iU7ohZREEenHZc1oFjd06QXnLl5kNhuxst6jt7xK0e0z2primpLQlMhEEkTLTDUmSqFFh6wQZAVomWFMQ21qptMxrmlIgkKt9Fntd1geDtidlezOKu4+u81oVvHwpT32yoqDS11uueogNx9dpbaOL5zZYGtmGdcxljeRgaTddOamngEZN1DVsh+uAIcjPtBuYD5S2G0bUtA43xZ4T+LLVwTX4MyM2x++xOmNMYfXe9RNZNq+884trAtkSvIdzz/Bhb0Z95zf4Zc/eoFOqjmx2sHZhhAEx5YSHrqwx6f2SkyIcehJXvAz/+3e6MtSR/GykJI0T/mxb7mVv/mCq9ndali/6giHrjvBh//4M6Ract0NB7ntudfR1IZLDz2EzpdI+13cbJfPP3yO//yhB7E+8K47z/Af3voB3vyvv50XPucm1Orz+dztd/KRz9zHG36w5u9+7/fwLd/yzfzKr/4Od9z1IJ/4NPybH3s9Csvf/tGfxjVjNjdmvOH/8++p64Yo37PcdstNfN/3fic/93O/wPLqGn/0jt/jZ974eqp/8Br6y0f4h9/3fXzTN34DL3/l3+Lxs+cBwX99yx/GNd/HAyoBgpnyH//Lb/Dmt72Li5d2+KM/fg8f+tBN7OxNubIVcf7iJi97xbeyefkyzJlLf+kKECxnzz7Gs5/7UqbT6f7HIVZrVx60FgVT9J3qdTv8yTt+k8cfP8cX776Xf/tv/wMPP3o6ekiFln8uNFLnTCvPy1/xdTx6+rErfn9bEe4XbPyH//jb/P7b38s73/E21tfXAcnKyhLBlpjtB7j3fR9mcukiN772tZy5/34uPvAw11+zwswqtuly/fNuZlBkLD+0w3K6y+54xE/81p18yytv4B98x8v4V297gHsfPsP99z/Mhx/d466NKXee3ubBSwaPZnfc8NntuEZ1ltcQKjC1ljd/+jw6STl65DCDrCbFcMvVQzYnltOPjbn2+DqVC+zVgcNLq3gEu0axspxEdt2gx6Bf0CnSL29+/TVcZWPjNhoC3TTaGiBgXDZMK6gahVKRxe4qy6T27FUeh4xhLlKQtZ6jjQNrHSIEepmmlyryVLO5WzOpLXuzOhqKt4eG9UHGSi/lqiNLrPYy1no5VdVQaUW3SOmv9kl0QqoT+sWQoczY8hM6xYQinTAuayZ1w6fufbxN5HPx8NeuqZJAKgOpkHHft61nSmPwITCtG6oWuDi8OuTE+pCr1gd0k+hTU1lP05hFTaWVQup4xohx5xHoCO0hMnpNSbRKyfKUNMtQKh6cnItGyEKAFdFSQQhBJ9d4ohG2qRt8m6yH0ASpQGga48DVOF/hrYmyvemEpqwwbe1MC0JlSYxUz4yOfjsCUhXrbiFAESPYCX5h25EiFsqIWro2/az1TpGCJAhM01BOYbQ7QuV9vEjJdQev4msx0ynjvRGXt7bZGk0Ylw1SKXq9LoNuwdNPHeLaQ32OrXZIyhFVVTOZNdRNjbMOZx3rS32WliDvZqx3Ejb7GVuTkt1pw+nze1SzmgP9jOsP9RmuddpUtMDmuGZ3GhP28kTRy5JWphePrY11OBcZX6mKDIlRZfBW0hjFrAmtmfO+z0xtPbULVPZ/2dT8K19P1dBP1dBP1dBfXg39JTCeWkAsXIFptaZnYvHJJ359/Ge/YJtjwXM9IES6l/UB4wONDRjXUguJC3EioiwN5CI1z8+R4pa2LKRqXe01WkaTwrVB7A4JKbDWMa6a1mBcgVYkiYqu7iGyqayLG2V0dBcoGQsAAczTLgLhCbK2ufTAeb/QTUIE1mgBJz2XzCWRgaNa9/32z4+IcPvvHHhSYm4WrhY+VKmO7KMYQRuBkCDCPpLbDo75vdWyNenWksRLjJPUddPSg92CZregxbYpdErIBbU70fFvSJTCO48BGmMpq5rptKTbKbCdAq0VSaLbqNv2TWuSRJM4h7YKh8e34shYLOjo5ZSm9Ds5h5f7rPZyTh4YsJRJ+qlEOos1Fi0V1nqSRKO1optramPpppJRqRhXGqgWppm19YjakicNeZKgpWApT5BEZtikcu3Y9JHdFiIt9koK7ZXDef94cAUg1b4XrviaJ/sV/gLVMCLg816xWNDH56/d03pnhfk8nrds4n0QrQTVE4vg2gZ2Z5HyaduiZJCnLHVSjq10ODgsuO7IkKVOxnInR6caqTU6zUnSBK0TkqxPbWFaO25/8Axpp0PR79PxI0LTEIInSVLSJEMJtdikMi0YFAlrg6JNaYy65bK2TCrDuKqRStAtMg62nnBFoqga13Yv28jbEIjm9ZJECZTQSBm9IaSIoG+RxQhaLSHRgbwoSNMMpdUVJqg2jg8R6bkhWIS3LWUOggKpE1SiSboDZJoidQK6iQu6qXFNiW0aTFUihaDX6TDsziJoLTVBqJgc2Rh6eU6eaoyJ9F9rHWkmFrrrOTA9T46JtG1PaH3fAnNZg6JuSqxz0TejUggluHBhg1XnWfI2doyTDBcEvpW7ChHTKUW7KQkhIUDW6SKNRjRgbY0Bgo0HFKE9S0KSKkE31Uwrx/Y4ZVNKjDfsTCsevrTL4WGXVEvWeymlCUzq1pQUYhpHfEWL7iltM0OG0DYNWCDLIsy3rShzsG2Tw/9vIJcN3sQ9T2X0OhlZqiOjwXi0gKetdRlVhsZ6Hrw0YVw1uAAnhikewcYodsUdcGm3RCAYdlM2dsvYhZOCunIMc8UzDvc5cmCVXq+gu5Ry6/VHWB702dvYYLJXcvH8iMEwp9Pv0zt8iq0Ll7E2cOCGWygvXSBUu6i8i5WaSRW9JWobQzv2zp5ncmiZTnKSa4sZ290xv/kbb+J5L3gBt972bM6cfpQ8Efyd7/lWbn3us9m8dLF9fAHvHLujcftQPUJqllfWuOXWW2h+9Xe4//4H+LXf/D2uPaA4vNYlBM+99z/ARz/yUaazMt7HELj7zjuvuLH7q/h4tMtsVuFsgzWOqpwQU/XiuP7gn3+Cx85ucnFjk7quSNKUb3vdt3Du/Hk++KcfpOgfAKCcbLbMXolTGSoX5FJTT/YW+wwEDh06wGtf9VU8dPocXij+6P0foy6nTMcjQLCzvcWZM49x8dIOs8ohk4ITRw+RZwn3P/AQzlSYasTm5ibj0aj9uftg07zQUEnOdcdWueX6Yxw9uMrSyjKEgBlfYLS7wcUH70Akgt6BVcrRDltbe1zYnHL9jcc4euwQL32RYLw9phIjhDWITJGlHZ5+oMMQj9kec8CNKQ4UPHP5Ot7/xcfZnRkeuDSlNJFNXTeWQ4OUlU7ChvEMNRwtJDujCDD0tWW3NBhj2asie2K1EEwqS2k9deNZW+lSe7g4bhBplD2trw8YT0p2Nyb/0+be/6hLCokPvmX1RG+URO0HozQuoAN4CVrvm+6Kdn2OATMAV8pOokzP+EBTNozKhrJxNNbTKyI418sTjq/1OLTc4doTq/TyhH6eMEziwQuhkCL6w+hOj2mQjCvDxYsX2Z3WTMoGWjaaVIqqsTTGU1dN6//mW1AsJp2NS0PZOKwL1MZEY3PiWp0kkn4npZdrOolECr+Q0TQu2nDMa2XV1tjRmDeglFrUvF7EBmwiBWmWkaRpy1aK+7nAL/Y7oURMw1IqmqIT/d3mPysIiQytZ1T0ZMBYizcGbw3WNFhjcda1zKv2ecr9MCAlVOv9KlvQV7bnHN+eIVq2gNIoZdE6oJXEeYlvWVmEFoBw83NJIBAlgAiBcxbjDJcu77KxucvpzRGjymNRdDsdDh9Y48BKn+tOHOTwMGO5q/EqoJMMmdRs7XiMi/tdtlCKJIilgq6CIk8o8hqUxnjHzszy+NaMpU6KkoJuptidyQU4OJc6VkR2SyIhCIlQvrUqaePXRVx3XVtzzBu5tQ2L+eBCaxr9JL6eqqGfqqGfqqG//Br6SzIXJ4gWfNr/mGgLmzmodCUydiVxhPb7Rcv0aW8tjdufcNUceHJRN6hF1EUnWiOVxvm5Jjr+XCFovSdU+5YgZTQkWxvmdPKElV5KVTVsjASTxoHWiABZ5tAiRgvOU+hq47FtuoVqZXK0g8tHV/OI4rZvUkpcCFgfWnpgRCxi4kVkISWtzK5IEjKtW+8lFpTZiAjPdZOR9aR1TLHLk/23tJWlSaX2i/ArbrBoaW6C6J+UtA7+eZ4uDNqrJoka8sYuNNkhBKx3WCfx3sXCgrg4+KBIE02aaJz30EgaY5kJGE9m9Hpdej1Lt5OTpglZlpK04FPSemeliSOxcQFx7cBQKj7TTlbQLTLWhh1OHVzi0FKX69b7ZDKgRcBZR1MbSl0hhMAYQzdPaZoGYy3jXLM7S9gtG5AyHnCqhlkdKZOEwGpPUGSalW4WgbRa4kOMpLSulc21rKf5prCIRGVf//8XcdUrkyme5OfVxbVInKTdJBELU3bCPChg/9V4BDbsp/vNoba5qT1t0eY8VC01eHPStMkxgqtWCg4MCm45vsq1h3ocW+1y6tASLggaF6gRSJWQZh2SRJAmKb3BgAt7FRvTMW/9yJ2oJKPX6/GsdcVaL+fwyoBO3qPXCLRKkSIWbHkSGHY1h5Y65FmC1pHGtjOpEFKyORojtWR1qcuJlT5LeYJ3lmnZUNumNXCMz1ni0YoW8E1wQeLCvuxWKk03T9EqLvhJnqK0RkmNVhEcdWYW6crSE5wFLBqPsLEoCYlAZR2STpeks9TSbwNKZYRgcOUMW8bkqGbWkKUpy4MBwdct2CCwXmGtozGOYadAKZiUhrppaBpDlqUxMUbG4AQtA96bWLxahzGOyjQYZ9A6xjwooagbS20akIEgMgyCR04/TmNKcDOGB44jdEbQnegVExwK03b7orlxCILgJVqkCKMRymFthpAS6yWJC0jnGchAP9N4l5OphI3RjG6e8eilTXbLhu3HLmGOLXOgX3B4ULA7c2xPDdYFFBEsmY9aTwyjCHHwohA40e4X+3TGxd7j2qowtEXvk/2yTQkyw5NzYHnARq/g3NaYprasFpqXn1rh9M6Ux3dLPvTAJVItWSo0r7ymy+bU8fa7d2MMsRA8enGPaw/3OLzc5eLWXpyzbVPl2EqXr7/5EC953s0cObLCypEUU8FsbLi4sUPYc6SXHc+4Ycjg0DEGp27mofs/iDWC53/1Kzn3wbcyPnMG3V9Gph1CiAusVAKlFeOzl9hd6aOHF3j+Wsnw4Ji/809/hh96ww/zjJtv4xMf/zjPfvat/KuffyPOWT796c9wJfxPcIviXacdVtYOcONNN9Mpcm7/4j288Sd/ge/+hpfxVS+6haueXvKed7+Pn/n5f4FOMrTWEDx3fv4zVzBb52uewJsSb8onfGz/EvzWW96OVBnGWIRU5EWXn/mZn+ZDH/owH/zgnzNcP0kAyukuSIVOM46cvI7pdMJktMvlckJoZUAIwcmrjvMvf+4neeu7/pzPfvEBfunX38bpB+7m/OmHkGmX4Bp8M0amA2TSRemUW259NmsrAx49/SjBTjDTy4t5HuuU9vDWMqOEgCTv8vLn3MB3v+o2OmkgmBneG+qLd7F99lHu+vinufGWZ7C0vMT2+TNcPLfJ2Uslsuhz/Y0HuPEZ1/Det7yTcjxmfW1Aky6Rpz3+5i2HqJuKh+94lIOj8zznxGGecfMzuevMZR44v8sj245uEZs/s8Zy3YElbj4+4I/u3uZAKnnGUHOpzLHAUJTcO6rZmkVZ/I2rmiM9xYdOT6hMLPDXiwGzxjObloiQ0+lkHDqyzLkvbHH/A+f+J828/3GX1gpjIyOnsdFqIWuZ8QGwXizkJINUkSrIlGDSNlHzVJMqCMEzrVvgSURwqmwcu7N42HA+1tAHlgpWehmHljtcd2SFYwf6PO2qdbI0WjbUpY+eUnOAQ2hUt89kt+Li7oT77n+Qygac0Kyur6CVptcpaGygtoFxHZiWFU1jULJteArYm8Y9yLho5CtllHrkaUKiNMNOFhUAWiBsPGTXLtbgQogrUu4kDkGCRAtBmuhFk1XphBCid1CWxpoziLa+bkG5Rcy9lBBa2V0bHmO9R3iJlGG/xglRwha8p6kqnGkI1uKaGmPMIvXa+fg9c+mcFALVpltHDyhay4729/s5e0AuvKJCiHIkPwcifASoPBHMcfMGsdQInURfq9pSlVMePXeJxze2ePjcLhMDQaYsLeVcc/VRrjq8ys1Xr5BLT4KlVpqsaMhNze54RqgtLkRZV6IlKlf0dSeakI9rhpOGvFvx6IVddsqGvcmI4ysFgyKhm+kYQd9eczCpbJPJiiTWRAqBVKBUKyNTcc3zV4BOQghK46hsBJxcO8afzNdTNfRTNfRTNfSXX0N/CVK7fS10LGdadL5FwTytqdwC2Y0v5Yll2/5lXJSnTRofwScfOx2JFHQ7mtVexqBIOLJUcHBYsNrLWRr0yIocmaYtZU+jdQoyglKj2tJYiwuWTpG02m/PyeWCQSpIZeDcRDFpHLM8Q8QKAOk9iRSIJEHMmS8iAjJRc74PPCGi+aBUkSgYgaf4WnyrxZVi7h8VPZq6qaaTJmQ6Qouh1SLKtmiI3yMiMCcESRuBmqearAWdlGztSRfPfu5KH1pNdfwbfdtZinK9aE4eiOkIZV0TfAs84dvOTSuls5EZpuZeTyJ6Rs2ZV85rtNZ4ZzEuMJ6WDMuKujZ0up3Y4RESFwTGBUpj46bS2KjXFypG12pNkef0e12Org1ZGxRcd3iZY6tdhkVKoWhtWANJJkhSR5IVJGmkG1ZVSVMrbGNJlCLPUgYt+DWpGnZnNRu7U8rGMCqbtmugWe0XZEqSdRKCc4xry8jFOMog9sfxfH7NO1rIllm4MF/bR4cjUNUutv6vPpP+V13ez1+iiFLVEMfclWc62vHvXGiZiFei2BH9nhubmhAB1zO7Jm6lQnDV+pCDg4Ibjgy58fAya72cg/0cnUpUIpmEFIEEGce3kK3OUWiE0GQqYJqS7b0dPnXXaarGkGiBuO04zzi+xnWH+lggEZIk7SDb1I7gbXRktGY/ahM4c2kP6+DmYwfpXXuEIlHkSUplwLgKFzxSSwrdwUtHCIJuplnqZXTyBB8U1ku8lwyX+yQ6dmkieCuRuiBLJUoTZa86QaoEU+rFhhaIXVqdaYRzeFMjikjR93hcPSJYhy0r6qqJm6xoQAmkEkzKitF4GlNyckWWF6wsdRjPpkxLy3jiWh29pMgdSIVoQJBgmoBpJgTbxEJCx4LFtcBr3TjKpmHY75ImklzDtF8wqSSjssQGQWXh4u6E8XTK44+d45nPkAzXDtA/dBhXlwRnEa7CiSKuRy4g/LyQrlBotOiigqJJDWlSYoMlBIcKBVVVx6QjrTgwzHnaoSGPHR2yNS45fXGb01szTm9NObnWpbKeXqZiGiiBykWaemu5imuhYhckJtB6CrZhBnMiiBRoHed18GAt4J+4Pz0Zr+e+6GuQSiOU5syZs2gVOHlijdTVyOD50PkZG3sV08rykmuXmXjN5Ubxjnt3WO2nfOvLruaj92xyaa9Ca8mZjT3OXHDUVcOtV63wFTce4lVf/zyGqURtb9MbSqaTHT78tgscXM0YdhPS4TIHThzlyLVXsfvoQ8x2HmL79CVWClDDnK2H7uGOL57h4ukNTm0/gq+2gbhmhCCwFgbX3sDg5FEmj32O3/34vbz7k49Ru8B//c3f4t3veS9nz53nOc++jRA83/cDb+TDH/lY9HdcPKF48szSjF/9v3+Bi5tbPP/Fr+Thhx/GO8dstMXTbzzBrbdcy7/+yZ/kzz59J3mnzx++7S0cWh9gy03+3g/8E+744n0gVPsz54v4fMG/4hJiURe4ag8nYjLO1dffwIlrr+ebvvW72b58GalyvuNrX4rzln//y5/GN47aVTxy37284sU388Lbns+/+Pe/xWhSI5McV+1yxxfv4Ste/W1MjcQETdJdZjqdEYLDN5MWtIsDNXiHbUpe8+pX8jWv/Eq+/+9/J4cOHWJ1dY33vvdd/P5b/4Cf+7lf5AkteSKbpJ5c5k3v+ih//pk7+Z3coWTOxUuGI4dzkizh1hc/n8nmLhvbZ+kPNC980dN4YZrjJnvsjktcyHnWrTcgpEL3D/GhD32a6XSHb/6ml/FHf3YPn3rgND/wjS/ji49s8HO/+1G+/aufw6xq+Pjtd3PPxSnbU4NSks+eGfHQZsmLTq1xfnvKb9+xyU3XrFM5+PijI65eyTk+SEEqLk8a7thsuPFgl+3ScX5iuXurRiUpJ04cYUlbrjlxiH/yhu9jPK6ZTGqe7JcLRPBBA0RPTutip3zeaDXW4nxgtzTUlpgM5mIQjXEx3c45z7RqFrXkw5s21jdacsPRFfI8YdDPueXUKgeHBQe6Gd1ej7yTkxc5SZKgk4Sil8Zoe+Mik01JvA+MyobzO1M+99A5ZmWDB2674RhHDixz44lDXNjL2ZtZOkXK1s6Y8azEGINs5WSZFaAabJi1HqSQKEWRKrqpoq+hEB7tTXtnWumciA3fVEu01iit0Uk8bEml0G36H96TJHGkaynRrRogJjO3b7TAkAio1o9VStk2wKNv1uL84g14gXeWNNXE9cC2PqKxcAo+euEYG88FPtB6Fl0BIkhF3u0s6nxb1wQC1hqMMfE566xtvnqyNLLItBJYG72kauK+JXRC2u2RdbukRY51DRuXL3Ph4gafffB8lGf6hKXlPmsrQ555/SlOHV1jqZOiZ9sEKTACxqWN5xcf6AwGqLwg75T0MkkiIBQJk1mFqGqWO4JBUXDV+pBhotkelWzujtkYGy7s1mgl2Kscs6aVEBJTu0OrmRPBM648HtA6wYuAI7LknPcxYbsNMNLQBgEJLDJKR5/kdfRTNfRTNfRTNTRfdg39JTGeQhBc4cu8/3ERKVmefWT3ifynK74WWh+nNryvlbZpKciTZEEtPDQsGHZTjq50Wenl9IuUoshI0wSp4oakdEKSpNigsN6zNanZm1RUxjDsZuQqkEtPrgW9VDPMEy5NG2QI6NbQS2pNMA3ChbiQ6rhAuhALNu/8glq7j1XHy4eo/fS+NewO82fSdkDkvmQuUXPacDSOnC9EV5TSbT29bxa+oPZJFl2eObcsMp78gvkUWhBpDva1cvFW9gciyDZlT7YdmnZAeWI87QJgaxPo2mI7bqyt35WUBB/5arZNlIkJGS7Go9poajaXvEXpYoiFllQoqegWOf1OwepSn+Pry6wNOxxZG7LcyygSiQxuAWrGBDxF0iZ4CCUIOETwLWUdhFLoxIKIZu+JihGg00qx296PxnnKxkb2nIr0T91q8OfMPN9SCmn/v4Wg9j8vntgb3x/R82f55Oc9+UC7UcJiNs7HYrhydBEZYV60Jp+R8inE/v2wdm44B908pUg1vTzl5PoShwYF1x3qc3ylR79I6WUJXkY6eRAaITVSapI0bTsaoQUtwVQ1pqqxdUNtPZOyRoQYGepDIE8VdYgy0Cc2x2JhGFw0wvdtDKgg0EkUNxxepcgEWkE5iQXgXBIb31cIFQ+3hU7p5BlFlmCDQNkIUCZatqksLaUa2a5BsbMnNUitETIheA/KxfjUIBHBIb1t5QoaneVR6+4c3lm8dXhnIptDxOIM2udFBIetMSiVIaXDOoN3huBj3LP1Hmz0l0t1gkRFL8rg2zcd9zCnFqmjUsViXSmFj0sfaSLpdzKEFDGamZgmVBkPLhCsZ2drG6E1Wa+D1lEq4cK8HXHFpAqxTSElbXx1Bq3URAdBCAq1ANChZwPGKvLEcjB0SJWkqSyNi/4g27N4EDMuPMGgdz5XhYgHCtEyFmMXZsEJfSK3Rex/TLb//2S3abvzznsiRVtJVJLR7WTYNq40IdDL4w0xHnqpQosEl2ZsTCcYBNMqduy9dxA8SngyLbnp6Ue56ciAG48O6ePxtWdr4jHaYI2nKRsIBSotKFSBVpowm5B2uhAESic0kx1me3s8cmHKrG7oDAY0O5v4aoZOUtyi4w+2LLGzGd57Ls8s58aGEGBzc5PLm5sUacLu9mX+5H3vBwJHjx4meMPGxgbj0RiC59SpkzzzGU/n2c+5jY994jPceefdtIsU3tY8fPosn7m9z6e/cDfnLmwggEG/j5SSixuXaYy54s6GK/69ckeOa+SVISrBG/I84znPvZXj1zyN9aPH+Y2PfYjR3hghBdvbl/Bz36j25yZpSlXX7O7s8tKXvBjrJUJnfPzD72d3Z5u77nkAnffQaYfekqOpZvGgG9ziNSVZwdLSkKdfe5zZdMw9d9+LN1MGw2UOZQVPf/qNvPAFz+OVr3wFn/zUZxm1srsTSwXDXMdiv+jRH/R5/JHTZCqhnMJesk6n36O3UiCCheBIix55v48uOozqCU3lMNUUITQyScgyTbdQuEaws1eiJRxYzlk7eoTViWdpcI7jw4xREsiSlJuuGTA1gbsePEtZO+rGszttsM7TzRNK4zE2UChw1lE2IHUb757raO4qoJ9rBLEZ1u8X+NmYybTknvsei4cA8yQ/tcLC4Fa1B/ZEClLVGopDy6RpeTptHeLZt0RojIvmsD4ywFTrpZJlmmGuWekkHFkf0utkDPo5Jw8OWe6m9LVC5ylKJyiloyQnzUCmCA9CRp+hADgbu/m1dYxnNZNZFf2I6opEOA4NU5CQJYa9sabMU7z3lAvbB4FuWfJa6RZ0EnRzTb9IGHZSeqkkV5EdhZIRnLABpaKdRbxPMr4pHYEjrdBz2drcHAixAJzmzKNouyHb+92+zX+WmO8DYu4jTsATnI+hZF6Abv2ZRPSq8W1DOIRoq2Gti3U/0Uh8XmtDfF5zVQIhYJt96d88edH7eEITbcDR/CzgXOtbG1o5nk5IshzZnvDqsmQynbEzmjFtHB5Jr5Nw9OAqh9ZXuPrwKsu92Ly1C1CkNWoPIIWi0+uSGkMlIcGh8ISgSZKEzAW63rVG7nCwn5ESCM6ysReYOUNdx9retf5ZghiChBStqXoESONKGtpGeLxX84bBfLkNYa76iOwOJVtmxZP4eqqGfqqGfqqGjteXU0N/ScCTJyy6BfMSzbdAhxMRnHNXpDTsf+f+ey5AZa+YfEGQaU0n0xxd7rLSyTiy3OHIcodhJ2V9uUuWJFFu174pnaB07NikWYYxgtms4v5z2zxy9hKX9yas9zOOLBUcWy44vDygmyqWihSabcysBiHJe13SNMFVGtc0uKZBSkljA7YJGOPaDpNbbC7zQsAGwMe0NNPK7HwIsdPSgjuJkmRJy3ZKNErKFuTwhECLL7b3JuwPgjloFdlHYmFwznyAtUBJ9Jbyi4kRfDtQ56boLbhC+/1KzUGkRaYGcOXPCgvWlGyT3JSUJDomDWit8S265jwYG83KJ9OKWVUzntbszmr2ZjXjylBZh/GREp2nGVmWcmBpwIFhl6vWl3jmqaMs9TssdQsksbsUglm8ThBIF9AyIYVW/xu7TNpYpNakztFxnm6RUjWGadnQTVPGVc3mOGV7MqM0lq1JSSfT5IlqPbAgkTFZ0MdHuThzxO0k7O8tCGhd++dfM9e5Lo4nT37cKero246NaMFH4eddnFhkxXSDQGkjC7FyAu/jeFEELNEYcm/m6CSKXq551okhp9YHXHdwiZPrK3QyRZ5C7aJ2f+oBkSBIKNIsJq+kKSrpxEQEaagqQ2MNW5cnVHslVA39pT4meOrplCRJWxP6LjOvyWYGESziilLFO4epa+q6wbRsxvVexnWHhrzmWdewXY4ZlTPOh0nsbiiFaRdZJQQrOr7vrKLIcpJUE+XXFcFXmEbircZI1dLIFXniFsBwTMzRCJUglCIJkHuBtxXeNJhygsp76KxDZ2UJU1WYqsTVs7hJ6pS0m7aVrKSaVdimJkkUzkYQYDqpmM0qxqM9aM37s0Qxq6KZ4UqvQzfNkLnk0u5eBBmkByUQWhOCRoqAVIFEK6QSJDqhqisSKcgyxcHVPv3aIVTO3nRMbQzCB5I0w8qUxx8/zWyyhZ9tcfTqY8gkpaoNIUSuYvRLs7GD5pu2M6FQuUK6BKmI0l7ncMaTprEIV2jKqsJYy0qh6SVdltMuwyJnYzTlrgtbbUQ3rPV0292O7JN5oSvbjTMe1ogFNyyaInOPwP0mAchkXwb85L5CWxQGsizBmJqz5yqq2rDaSfjbL1wl2FhgusYzHGgODnoc68P5y2Pe+fFH96NwjeHg+oCnHV3mX/3A30A2NeOtHd77jk9waSq4LJZ50Y0rHF5KufrogMMnTzBYP8DuRFJvnuP0I/fzjK97FcXyGiIZ8Lk3/ToP3HU/f3TfDt/8mhfw4ufexujRhzGjEZ3hgMnuHjF9K7B99x1s+m2Wb3kxMusjdUpon53WiuOrXe6747O85mu/kQ++/4+49rrr+K9v/kPe/gd/yO2f/wIEy7e97pv4hZ//GRCCO+4/DcFGLyYhCN7y7375dxBSkWYdbDNDYHj/+9/HI6cf47d/+80sDLoJ7fv/b+BT/Ny8ERMXec/a8oD/9G9/mjTJGI9nvO1Nb2a0NyK4ht/4nd+O3ypkbJrkHU7ecCN3PvAgH//4p7nrri9w/NhRfPC8+MVfwac+FRlhtp5i6ynVeCsWzsGBUNCyN/orh3juc27mV37x+/m+H/5p3vCGPwMc/99//gv8+I+/EYLna175N3jFK76aF7zoq/jc57+AQPB1zzjE808MWRoULJ18OsWhq3jv+z7MSgE3Hu1y6YwmLWYcmo3IspTuak53/QDOaJqppL+yzHR3m2rvIucvG5JEcixU3HZdl/FI8P4//hjXH+vwkpceoLt+gluzJa5ZH3Lp/vvZ3tllq5T8k+/6StaXO7z+n/xXLo1KxpXlvXdf4Najfb75lsP8zu2XECHwwmMFnzwzYWPm0GnGV5/q8fS1Dr/yiQv0ipSr17sspYq8SOiuZHz20iXueewS7/r2H1k8w2/9njf89UzF/85LKY0MHi89nURSaEk/VexVhtp6xrWNVg5SkSWCIAJ1CLjKRdCjaiiSaOSt8fSyhH6RcNXhJY4uFZxYLrj++DqdTkqWJ+SJRASoZg3ORl/Qbi8Gu2SdDmUNSInMdQRFrKGpS6yz+LZpV5sImDhjKTRcs95hqRvY2JOcPW9Z6qRkiWZa1TGB2kd/JELAmgQlPEWiOLQUZUOr3YxDXU0/V+Q66rGk9Vgv2uTjWAOL9iQTWU8RPJXBQhCLKHYhIjNKXgEAyRasms/kOfA0/6L4sfk+FUODYuhCW4OnEdzPEokT4CRYqxf+T2VjFgBhkcaaXqmofnBtozWmVF9h2OsDTWOIQFlMYZRKkKRRQiesoDIOLyQOSd4+n7zbRer4bHa2d9jaGbM9KlE6od9LOLDU5YW33cCB1QEHlgvK8S52VhGEbwGRgGsP1jLNWO/meGsYK0Ezm2KbBo8mSQU9lZBoy6ysmVYzrhqmHOgolrspWis2RyUbO5PY4A4eISHVgn6u0CKOSekDIonyMhNcZIb4gAuiDVoC22qyogF5ZItpEcFH/yTfhJ+qoZ+qoZ+qob/8GvpLkNoF5gZPC6nfAuqNv8/4eedmHxebg1D7DJ/YkSiSmNq23M1Z6mSs9jKOrfQYFCkr3YxOkZImiqLISdoujUqS2E24kk4bwBlDVVdsjyY8vrHNuc0dRv0UYZdYzkGu9Fumi8Q0ltm0ZDQrOYpjsNQnG3RoTEbdWJK6pjEGJSs8HmkEPsRubeyQRMaPa1+6cRGAsa25lm67KvPiVUu58GlKlFp0acIVaOGVeKIQ+wDRvIsjaBe19ob6FiAKc8aTf+KbEH7xbOabLEKg21jbOagVCNjQbo7tpmp9QPvQJj1HIzUp2y67UiBit6dsLJNZTTEuqY1nXFZc2t5jczRmt6ywBLI8J5OSXqdDJ9V0Us1aJlgrBAfSQC8RFC0CTlAwN31sAbQ4sh0IH/2tRNqyuBQ2sSjdGsN5R9NossaQpVEfvNxkDLsZl8cZk6pha1zSWMuosgSikb3z+wcO38K+81DU+eUX43b/38Vn2/95sjMl5pfzAtoFkxALpoiptd27MDcAlTTe4dtuVmOiSejEBpLExySrA12uXu1yZCnn+kNdljodljoFLgSmjWVqPGkW9dpJkqMTjUo03U5OIP5uZ0ucddR1STmOdNOO8syqhllTxg5sG/FpXOwQWWsom5qymsTo0nb8To3jgYt7jErDxt4UoQQnTxxgqSjwjef2hx5DJnHeOQ/g8SKgpY6MP+vJWq1zXddUpkIoRbfTbTuVgfG4BKFQUtPtJKQJOFmD0CAltTWoVKLT6DkXOagNtqwIIaCzHrroIdMMWzcIJEnWZVYZcBHslcK13VpNlnXRuoNSKVqPkGLE9sUdqsZS2cjY8AEaI7HOgAiMZzV5C3QbG82lLYIwmpElmmERk08CEusCearp5ZqySRbrBASyRHN4LaeTK2Z1xWQyW6xtIc0orWPz8mWU1uSdLmm/36aUQAhmwRVBZnFEidbQXwuESlFG4r3HqIBHYh1I2VAUMaFoMp1RNYbgak6sDljpdxj2Ci6NS3amFbuTGRDju1M1Z4gCiHYutxHN3mOhXf9YAOrOQ/ACFCgZFia+T+br7W/7LWa7j7J78R5+5Xc/yfmNEbNZzXIvJ0sV77p/l0LBqZWcu7caxO4uWo2YljWNdXSK2NS5+tCA17/6JkRjcJXhvR9+EGdjkXPzrU+jri2Pntnh1Lqm388ZTQdUjaOY7bKyssa77rzM7/7R7XQ/co68yOgVOc/qOA4fOMqPfN2rOXvvI3z4I7fz9d/9apLheapZBbQ1gvEceM6zOPKsq0Eonnt1n2pjhd/f2cOGQJJl/MSPfCdrKwPK2vGMG07SX1rjdX/z1bzsBbcy2huDEFx33fURmPGGl7z4+bzj7b/LT/3sv+bue+7Fu7rtSku8SPjmb/oGXveNf4Mbnvkc3vsnH+C3f/stPEFit1jI5f6bt+3HJTLJgWglQLBc3t7hB37s58l7K8ikx87OFi//yhfzj//RD/ETP/lTSCX55z/3zxBKI1VCf2nIr//ab/KOt78z7vhCIAP8q3/x83z0Yx/nn/7UL/DGH/7HXHvtNfyjH/4/ed23fiuvefWr+KF//OPcestN/OAP/F3SvMfy0oDVI1fxUz/9U/z9f/j9ANx4w/XMZjN+8B/9GFtblwm+4aGHHmDY7fDMa67j5HVD6Al+6aOP8LQNxYlDW/zBp+7j+dcf4bm3XMPV1z0DhGBy6XE6h5+OzjpsPvRJHn18m0vbM77qq2+hbgR7dY+jJ3NsXXLmkcc5eOwqhgdTnn+TZ7hUkHQzPviBj9NP4GhfsXb8GDcOlvnGoLnnrgdRacobv+0rqCZj9vZG/Oc/f4Czo4a3f/ESLi1QUnDPnmf94CoHhKCajDm9U3Fmt+baI0O8D4xLw9nNCYNuxY15hkpTOv0+Osv5pq95MS973jP/uqfkl3zZEJOMM6nQOkqUpi5gPCAFwzzFtfVYFRxOBrIElDQ463E2gIqBM0cO9jnaGg6fPL5KP08Y5JpukSAJ1JMKn+i2fstIsoykTRImBFxd48oGawO19UxHU7y35EVCNa1oZpP4l7S1qm/niSDgbUU1G/P4+QtUFlyQLA0GoFuApjHgHab1ZJJa4okhOXmqIzjlPI3zpEojWk/UCErEA36wLhp+yxrwKJGgJQsO4pzZJJVq986WL/AX2E1C0J4Z2G8OM2cxxVrTOxfracA73XrRtK7YqFbK10r1fKwdbYB8ngiqFc5ECWRVNdFQm4CxtjXTBmEcDhuj3FPdhgRZTOMoTfTMqm0E+xKpCUmG7vaojMeUM05f2GZja8x4WtKVjpVUcaTjSKYbODFm0hQtmy7WdFKAUIL19WE7+gLSexxQZFm00LCO8azCNQ0eS8g0SigypckSQVEbGjHmOiE5OOzSSTXjxjEzlp29KbX1XB43LBdJvFU+RBJCiOei+aF1buGhiP6ziIAjgJQEIcmyNJrqP7lxp6dq6Kdq6Kdq6P8BNfSXlGqHCFdQCuMf2MJPbTR9WDCeWgbiE3+ZjJOwm6mWPphyeLnHSjdjvZ9zZLlDJ0vot0ZjUil0mqJUlNfpJNIKhZyzqqKZprMG2xiqqmY0K9kdz0iwTJdyjHWtSXi8Kd57jDHMpjNC00H7gk6qkEK0mWuhTavzmBBa4zfH3Klf/gVgKRakkR47n8BXMr6iXv2KTYt4H8Xi5szT7OKPFIh9ltOCsXQFyCfmFLiw+HefKDf3fIqDJix+A7FzJOXiLXaU9kGTENgHr6743vkXzV9zIH5dYx1lY5iUFaV1jGYlO5MZk6qmshYhJbmOINCwW9BJJB0t6WtHVwYyHNIZhDMQUvbvWJv6RyDgFoWDlDIm9pFACG0E7jwhY85Im6cQQp5E+jUCskTTWM+oBFMbTKs1n9+5ObA3H9aifT5X9sDnPQER2oSOK27PE6GqJ+8VQrtpin0weDFW2xs3l5La1oBzHh0bpflRu93PFVcvd7hmvcuRpYJD/Zw8Tcl00n5vXAtSoVoftiT6KciY1jLvCjnTxJjf8YRmViO8R+cCYw3GmwV9lBaM9K2PmbUGZ82ioAsBZsZzeVJR20CiBKv9goPDLiv9LomSbOyO6HRSkiSJAGeI0tKEWBh74hjwwdNYE9MthUCpJLIePJSNQUgfUzicwklPXRukEiADxlsSJEEo0kRGCnBTY02Ugqo0b4veyDiRUiOEaunbAW9MlJEqiU4ylIzFKd7hTE1TJ1jrqWrDtK4JMnbSqlrgQox19yFQWxsDCSQ4BAbwlcE5F1OEAITCWL/wonNaR786Fwg+gtVFqrF5gsBRzuLaFQtuRdk4vLXk+YSeg+VOAbIF1oVfrGlzAatoCxIRYtdIBBCu1ZJbg9MKrxRatH4Qzi8KD61TutaTJJI0UWSJpKobrI2yBddu9Ml8sYzDvF0zW3q8imN7rtBYzNcneaF75fXqV76EC6d7PHT3FnmatJJsGQ13leT8yHC0rximgsuzGD8sQ5TnDHoZN15zgMO9nFOHhjznuoOUoxl7OzPuf2QX4xxKC5ZXlhHO4mclvTz6b1ReRcl0sGSF5tK04WMPbeLv3yDTkkEn4dhLrufU8TVuvvE45+95iI2LW+iiQCVJpOwvrkC2vERnfSG6j8YAALn8SURBVB1TZwx7HVa68bVIHw9wt9x4kuOHl7G1QVYT6r3LnDpYcM2Ra3BBcObiDOvh3nvuI4SGwaDP1732Nfzmm/6A3d1dep14kLUOHruwx9LSEtecvJpTp05y9NgxlldWGY9HcV7OV+94kmXuMLi42jHV6XQ4cfRq8Iamqfnwxz5L0l0h768yHPQ4cfwYT7vh6eSdLv1uwWtf+6ronSFir/ADf/I+vA88+NDDSCU4cvggL3nxC/HeIRAcPHiAq04cR0rFjTfcwKtf9Ury4mfpD4dcc80pALqdgqzT43nPey6NMTzyyGM0xnDXXffw7ve+n2q0xVpPoW3DynCZG04cIenAKNQ8PvHoS3tUxjKalmxNa87u1WTOxwNoEAido9IOPmimk5Kty9uU4zHO58i8T385p55A3XiCzEjygvXlgnTQgzRnMr2IF56OVSyvrzIY9Ljp1AHuOLfHdGp57nWHocoYjzJO3nuJnUlF1TRorbAeNmeGk4OEbirxZWBUB2oHx7vFIgK+to5ZbRlPq9Y7Mkqtnvn063nN13zVX89E/DIu5z0SEZU3InJiXBvaI4jeRhYVGSPGM/fxlCLK1QSCThojvY+t9ji+2uHQsODwUkGiFKqVmAUPznqUjECLSucSDaitQyEwXtCUJU1jmVWG6bQiQIwPNzXe1IvxH3/onIke5W7OWibTGbPG44Ng0C3IssjGaJoUIaK8DGLtH4gy4Np6RqWJh2eh6KvQKgDiFbvpgeBaSZs0kcwgBV6LxdfMGejzVOc5JDWX++1LgObN1/lp5coZPq+Z21py/n6Qi/pYStGqGOSiJr+y+ShauZgg1g+1MSQCnAhY6xY1lnEBoSEI2eqKJK6xbaJ3jCK3HkwAdIJIUoLUTMqaWVmxszemnM0IpqGjoVCeFIsvxxgMjbCkeY7U0axeSNGyqmJ9HYLH1Q0CFunYUil0E+XXcWwGkixBakUnUySZoawMiZJ0U824auhaz8x6msbgrGtVHz76UrXj2bVjcH7FlVW06WCxxkzU/rNJtEK1z/3JfD1VQz9VQz9VQ3/5NfSXwHhiASbNF4e5YWgIgcZFEzXraX2C2m8QkbqVKMlKN2WQJ5xc73Jw0GGll3NouU8n1RSZIs90y/ZJFlS7LMtROjKdpEraPyMOOmcMs7KinFRU0xnG2AUF1rrYvZAyGmzbEFE58HjvMMaAbUhsxRIVux7G1qOLgrTo0A8DeuWUqmnYm01prMF5v4hOlVISkPjg0NIjRCSiuZZxFDesaAzeyVJ020EJCMScObYAnSJQRLtpzuMk5Zx/eCWYNQed2ucdN9l9BljcYFp6q4+UOtmCWYlWJPN0PGkR/krQMG4eiY9aXMUiDyQCfCGmgDQuatxF3SBGE0prqZxnWtXsTGbsVTU+BHq9LoMip0gUfeXRwaK9I/eS0AQmI8vOJYGddZFumSSLZvHMtfkh4F2ka0sREDrqwIWSSK1InCMxMtLDnUMIhZRRdxyjMO1CT7xUZHSTlO1JyW5Zc2Fvhg2G+V2c38s5gNQ2+JCLjYNFEuG86Ljye+C/a+79r7lCfKbegaVNHYFF4Rbp4rFALBtL2RhCSFgqUq450OH69R4H+jnHV/poFYuwvSpQeciDoJdmaC1IpSXPeiRpSpJmzKqSclKyN7rM2uoyhw+us7V1mb3dERcubDIYDMmzDBMk1sdNNyzQWQHBEXDtgjgHYeOnnA9s7lZAAkryypuu5sCwy9MOr8YYb2M4t7VDqCWpg04So4IbZ8k7ebuxS2ZVSWMdU0uk1/pAWW5F5l6WMSk9qQ7kOiBFjnFwaaehkzckGpytyeoOobDIImDqkvHeNirropME7S1uuoUPjqBk7GTIBBFmmKpiNpkihCLNc9YO5pFmGwRaerRO0GkPpQrSBAIOqRWNh9I5nJEEb6maisYaplKx3OnEzmJwlNZTSkkwApk0CBVB+KZOqLXGyxguUDemLVpByEBwHkUgCMG0rjDGMauKRXdZJlNsCPQ7AtUdoLIc8h7C1WBrGtN2s0SKaiHc0HagpfAkGlKVUOSCWSLxbUG0NhjG4SodW7szpmVDJ4f1YU5lljna77AxmnF2Z8LlSRUPRQkkuk33EtGnYl50zfcjKcJCZhvly9EY0ZqAtU/uWbx77k7e/2cf5b+86Y954JFNpBAcPzhga9pQGji61OHizph7xyUi2LYQFAx6BV/9/Gv55X/yWh669zLnH9/it3/7z8jyPv1+j7/1iqcRnKcqLed3A51Ozq3PezoPPLbFzuUpo+kuRw4dp7u8DMk6QXQWYNK8432k7zheTNi6/XOk1ZjVYY7ZPo9oxhSdhOnYoKWg00moLlxiduk4S8/9Zu4t7+aDD48x1pGnkn4Glx48zezhhzj34H1cHv8+/UHBK//GcZJuwuVJzdf90B9zaWfCtKxASL7lW76J3/6tX+ebXvtVfMPXvJRv++6/DTjOnj3Hbc9/Ff/l136Lt7z5d7j9C5/mqqtP8Lrv/C7e8bbf5eL580Q5W3uDgyNGtEB7SgUcvt7jpmffyAc/8F4EgcfOnOG2572c2WyC8IYf/7Hv58zGiK987f/Bztl7eP5zbgI8Idi4vwsJwTOZjHjVq7+O7/6ub+dX//MvQRvTgkr5yZ/6RaSQOBIQkuAqIPDf/tt7ePe734d3DS97yfN49zvehJCKxx59jBe88BVUVUkIAWst3/C8k/yzb34uv/eBuwmy4CXPOcG7P3MXF7Z2eP1Lr+PO81O+eKHkH7zymdz1+Bav/5d/yHOOf4CbTh3mO17zEsaPfYbu8jLXfs3fo7j6Ho49eC/n7ruL9RNHeNbzn0W1t4MWklM334y0I6rJDnsTWB2usrRymG/5jhN87hN38p53/BlPP36IoyeOcOsrXsL12yN2Lu/w5x/8DCIrSIouP/bNL6OXNHTkmB/4jdt58MKYaWlYymGaSB68UPLsq5e4er3Dn9yzx2ohuGZZc+3BdfZqz52P77I3mtI00aND9Q6yeu2L/non5H/HVdeGhkAJ6I6mSBS9XEXvzBDXLNmuT5UPlI2jrAyZlnTzhANLOUeGsXZ+2pFlOhoSCeVeya6F0sDB1R5FpullKUWvR5bnpJ0em1u7jLZ3qYC00yHrdGF3F1POmI3HiDQny1MSXaDwSG8XYAtAcJZgG5xpEFJFuwsl2BuNGU1rBJ6rjx3i6JFlVpd6zKqG7b0pTZsGV1U1j2zOeOTSmF6mWe1F6d31R1Zio1CIReOzucKCzVcGk6W4PKNJdVsXK9JEoBR45fYbtG0nVXDl0Wj+fmgbyH+5XpNC4Fs57ZXfGcGF2OjUWpMmkQkhpG9tZKJ1Q5IQfWyMYzItUQQUbUq2EAShkKkkVSl5v0+aRtuK0faYWWmoaoMJgQpBiebQ8hpJr8/O1PDY4+fZ3d6m2t5Ah4Y14RgMl3DOcWFjRB48tt8lSzOkbBAk5EUHqeP5YVY2rYxpv6nbWLcwTh8UkloqGuGomxqda7Kig0wyvLGsZpLLWyNG0xovlknyDKEV93ZTtkcztvamzKom+rClitrGwCUtBMbHWHbvPJ1E0NESKyJomCpBKiFV0NWC2gUa9z9h0v2Pvp6qoZ+qoZ+qob+sGvqv7vF0RWNw/4Px4y6IFqFlH9ltWTudNNKCB1nCoUHOsJNyfKXDcregX2R0s2Shk4ybnEYqjdQKIdWCLgtRf2qdxRiLqesorPUualubGuftFaCMaA2/A967+L637fsRIJo1lnHZkI1LRrVnVjv6QJKldIqcREsyY3BCUDVNTMxr40DdAuKW0axR7iPHkbUkyZOUPE1Jk2TxWiKQ0apqrwAz5ol2CzbVvGOzAKOuoA8HEUGR+ZLSdmUidVcsOlPeR0M1hEDRfu/865ij0y18EkSbTDgHoiJ91IWAsbEjUzaWylis93grCI2hEYLGh+gDgKDXyUmkYJCn9DNFrgTaG7wVMW6TGJ1bWcd4Eg1mlZLR9DBLSZK07U6FxSY5B+QEAYQnCNlqglOktVghSeeO+tH1re1MxU5Vpi0Qk0+KPEUpxbhuGJUNk7LGOtc+130T8ScOfggiSinnxonzT7QY9BUMtifv5bxvFzuxAM2cj4uIAFwIzBpPZQLGxQ7XgUHG4eGAtW7OqbUOy7mmSDRZmi4kod1200m0IElDZGHIHCk1SmmGgw6PbuzywJkNPvXFh1lZ7nP04AoHcuglkrWlHrX3VE1FImNBpoRuD20Aoe1cxq5jpyjodR15kbUU7sCg0Nx4fIVbrz1Kr5PSzTKWez22R3u4WSx6CA5rAruNafXKgUwZlIr0VmPnHYCA94Lgo/bZGocUjiJP2k04kDYBIT1pIuJPCoE8z0jSJKa0mCoCtDJFtuub8hZrDd47Qtv0VApsVRG8Iy1SknSA0glVWTEXN4DA1jNMNQNhCcJjESwXGZ0gMKamIrRU2+iTYXygNK7tqDtSpUhb+W5tLc4GtBJMa0/VNDHe2Udzycp5XHAYa5BS4UMsII3zNNZSm2lbfEG3SEEKjhzoR7mC9yS6IEiNF4rdjTNIlZJ3BnSyFCEUQbRyaeWQwRC3IUneAWcUphY0rd4eLJ0MEqWRsoNqLFI6rlofstwrODjo8fDlXSZ1zaysMfPFS8yB87ZIDPNQi3hHE7WfErrIXv1LE//JdfXWb6B2X+CxxzapG4fWOs7XssF7zySJO0s310iVctOxAS+8ZoXOykHWhgW3f/IhLl3YZjKuWFk/wMHlDiv9HFPWnN2c8tD5ESevPoZ3gcfPjsmznGNXLbN84gT+8kUev+80vf4W5eXz0TzYupYBASOjmTDgxFU3cXQmGGxvkyxdg+qcI9FJNOkFGuPJjjwTvXyMix/+bc49cAcXt3bjlicTUBmq2ebc7pTf/8zjvOSaNYINvPuj5+jmARks3/n8g+iDLyQ/eh1hdo5po/iRH/kxskRz1VUnSBLFW373D/izP/sIjak4dGidU1cdREvPpQtn+cRHP8x4by/e1EVbft52uOJ9IREyR6hYsKZp7NxqJcEbgjfYBt7zpx9jb1Kxt3kWayoeeeRRfvSN/wyd91lbX+eHf+BvQ4hzOestc/vdD/GjP/6z/MDffR3eNgihcdZiMQhheNe738vZxx9nd2cbZxucEwRvuO++B/jRH//pyGDB8cbveBGbZ86zvbHFseuv4sDyCg+Pe5w4fpitccXvffQLJCJweKWH9paesAyU4f5zuzTG85xTa1zamfDoxS2m5x+ikMeRsuDBj/wxzgvyTkZ+/FqMK3ngU59kd+LJ8pxjx9a5fGaEqUrWTxzH1RVbj91PPshY6g952Stfjdw9i8By+t6HUOWUpmpYPXSIs1u77Gxc4lDXsNUYLo4rXvvca3hoY8TbPvYg2+OYnNUpUjYmDZMmrrFCSsYGHtvZJUkSnnF0yF3WkK6t8cNv+CFe+tIX8+S3JmZf/gU0XkQnAeOxbYjNzNQtEyrufVmqGfRy1vo5K92UE+s9hpkm1woFEdjwUBQ5qYfCBYo0+nJ6oWM6k5LIRLI5qXjk3DYPnttCak2WZZzoCJY7moNLHdAalShqYyP7X0c56rzUVVlC0u2QLy/RnQX6VWC5m7GZKKYy+rOtLnW49sQaAslkZri4NWFvMqOsG0aTGXXT4KwDKajRjKxgY9IwzDXLRRKZUSGme83rYRHp+DSNoTGWue9ZkaUkrZQvzBUFUsSgI+/3WU5SECLP7P9VsTCvt0WbeIdQBCHxIR4sfQit8XdoG9kJ0nmUp/VLDdAqCYSInlh4jwg+1v1SoLWIHqUqAoxNY7HO0VgX99YgmFoPKqW31MMFGE2mbF7eYW93j6ackQhL3RimxjD14/aQW1PkGqtSOi6yISQKkeQxbC14xuNdBIFEC/IsQUhNVhR42xC8JVhBmoo2cXpemGimsxpvDME5ep0MrRVGaZyQeAQ3HF1hvFSwMy44szmmMnZhem9DtPGQSkZA0TkCUNpIDBBCoEQ8ozTGUtYNjY8soSfz9VQN/VQN/VQN/eXX0F+Sufh+bRbfmacVzP/OeSoGRHAjVYJBkdDLNOu9nCNLBUtFyqFBTjfPKNJoSiiVbFnurdGg0gipQEQ3+CB8a7blqOuGuq5pqgg8yRAXLtMykjywL0drcYjWMNt79wRfpNp4prUlL2sq47GNIwkZhUwYFAlpmpIaS2N9TBEwJhq3usiaEpEfHRPblFqwgua03LQ1RddKMfeGmj/AuZZ5n9h/BeA0v0R8LRF4UgsGlBTgRdjfmMUctJNtxygynSLw5CNYw5WASQs6tR/zi78slm4OomEeMQ60dpHiXhlD41yUqXlPMBH0sSGyq6QSdJKMjpasdVJ6GhIRcMZSB0HjIbR/U21gPK1wLlIVZUtV1krBHDQS+3/1IqVEzrX5Ein0/n1rR2loNz6pxCKJL9V6QectWolKp0xIlCJ4T2UEVWPxwS9YfeIvTqCWdhiYd9X+cmfsyX750NI32xcXiF4Kqh0Lxs99BjwawVKRcGS1wzMOr7Deyzm+VEQDe8BLvYg77hYZUvqordaxGEtk2rLQFJ0iY2tSc8+ZHf7kcw8z6OYcPTDgRafWOHVwyMkDR7i4O6OxlqYJ4BPkE0DnOYU+grxFktApHEn7LIWAbqa4er3P8552CJkksUNAwt5sihCCTAsaEzDOMasdtBtwZRzaeaTwWGfaNWwun40dQh+ibKFX5JFdYByN8aiWUSdal/ksy6LRqZIYawjBI4SOY7HVRnsXMNYThINEIVHYugYlSIqcojsEJPV0FyVdq6dWONfgbR29BVr6b54kCARFYgg+zoeAxGBxzlFZ2643niLR7aYpmBlP4x1CKowLBBcogPkK1VhDYy2zuiLVKYgo/YhrSvQPcD5u6ZfHM9JUUtYWlRiUThBCRYYigumsIlEOrXJCmrbRv203CIEMluA1QQayFIyIm35Z1m3qSEORJmRaYX1OoAFh6SaK5W7Owb7DCc/l8Yxz3lNWDdaHhdQi7gXtM3RtKquI6SP4eUeb9m96che9neWr0fkq1qpWGhHis2z9VOpG0MsTVvoZQqU899oDfMeLjyGWjrO9O+Peux9iNh6BlKwfO8Hx1YyVrmJnZ8bFrSn3nd3l6qsP471ja2fM0ZPLrBxa58RN13P/BzfYOH0B1i5jJjuRym3dYi2ZOs1M9iiOXsva9gYd1aAHx1HFctzfW4jeB4HoH6WRXR7++H/jwqMPszuastTL6XS6DIcDlJuwO97jc4/v8cJTQ4IzfPrubZZTy0oBr7nlMAdufR5rt70ct3UHb3/3J/jFn/hlvvmb/ibHjh4i2Bnve9/7+a03/T4qLVhePsLVV59gMt7j8TOnuePznwMCWiv6vW7bEArs7Y2vkK4HEBqhC6TOcGi2trYhWHa2t1vTT4cNgY996guxrnAGvOHS5iZvevNbSXtrnLj6JN/9uq+jrCoQkPcGPHz6HHfc/qt81UtuwTQNc5YvIRB8zcc+/kk+/onPgm/akBJFliWMdy7z6//l19Bpxslja7zjX34Xj93V5fH7Up75FTdxcay58zHL8fUVZmGLj3zsbr76mVdxZLlPVU7JgmE58Ty+NaNfJFx/aMi5nRk7k5JL507TWz6AVDWP3fnnLB09xfDwCTqHjrFz7hHO3ncf23XB8toKp06tU88qmqphuLrC9tnHGF86Tznp0ls7zrNfdCuPf/aDTPe22XjsLGkzQyBZWjnG43tj9qop21sNFyeBB7YCr3/lMziy1ueDd56jqWus9eRZwtbUsrHXsDwoEFJQOji/M2NtUPC8tS6nL+6ydGCdH/qhHyTR4goQ8cl7zaPUBW1AjQtgYjCMc55pS/kQQtDtpHQ7GQeWOhxf6bLWzzh5oEfWrpHTmYn1nhAMsxwpYtGbthHrXkY5V3yD7WnN6UsjPnn3GUIIpFrx/KtXOHV4iauPLM87mFEeBrEGby8hQCUJOs9J+wMy4cg7Zr9x3AJPS72cY+t9UqUYTw2plGymiklZowSUtaY2LgbySMnUCi5PG0II9DPdJtrF2zIHiWTLQnLWLlKw472MgJRWEhE5J3E58gEpfASRJIQQGYe0zXDaw9R+1SbaORiij6uMpv6+ZbzHpnVkJyolSVONdAHZqiriPr9fizfWLzyjkkSSyPg8VVvn+jYUyFiHsR4ToodM5QVZklJ0e3jnqWYllzYuEYxBeEemHMZaxpXB19M2ar5h2O9AmjGsDCpNkIknSI0gsk6qsoFgsQoSPUBrRZLn2DqydkKIr0vikULgEFgkZm+GrRuUdWSpJk0TvNJUbWL1cK1P2csY9zKsD+zNGkZljXIRDa2NI1cyyqhCNHGu3RyMAxUikONdrL9tK9F7Ml9P1dBP1dBP1dB82TX0Xxl4ci0FWDGnqsY/JEZGRiRMINBKsFSkLHdSVrspR4cFvVyzVGT08oRUq9YAOkUoDTIOMt1qMrXWJGnGuKyZVTWbO+N2cioKrQjW4ExDcHGR1EpRe09jIzK5r0OfS87cAhCL90ssXo9tPakG3S6Hi4ROlrI2iHpWJQV7laG00NM99uouU+sZVZaqbqjqmrquCd7FaNlcotuoVS3jZFJJghOKmRNo16bizQGYds9TLd1OtQ8XP6dqzqNIYwdG6VaGJuY8K1BBoLzDB9+ake9Hswbis6kbR2Nj2kJpDLOqYVpb6nbTcz4CZ4GYTNiEQLAOaxzWeSrj2J3NKBvDqG5iQ0gr8ixHZyk6SchFIBGBXHqWdCATkKs2o6LV/NIm+ZWNaenMgklpKFJD42h9uxxpotDZ3LxN4J2NyRutZlarOCmVBKEUUhicEqSJwCWCNJXUOkrtrLHkafQY6eQp/cZQNZZeJ2FWGya14fJuwbhq2BzNGFXRhDca7s3v4hMnFgFkS1EVzJ8pPMkbNQBtJ3EfVAserBfsVTXGeaxXrA8Ljq7k3LBWcGjY4chKj36RIISkcoIiS0m1pJNJhNSgVJzLMhrSS5Uwjx4WOhCwTLbHjCcl47rBB83lvYq9acmhfsLysGCpXzCqQDWOolDUNWjpFlTUaCyqSNOc7mAJiWR75rGVxbs4z0tjGY/H7GxssmsFjQ1UtWc8ntAYS+2iqaVSEplAkaQUaRZft/MgQkwLEeAqB94hlOPYgSHGgjGBQSdFJQlCa3Z2xvi6ouindHs90iwDVBv7LEmdoKoq6ip6ySEz9PIAJS22NJR7W/jcEorAbGbI0oxup6DodKPunAqtJEpIgoBBklF0uwhVsLkzYlJeZnuvxnvP7nRKkiZkeSzcZ1VD6WpmlUcp3W58SUwvkgElfIxgdQKFQiWCPI3MVWNFjHJGkM2bCd5TCEjTFKs0TdhrzShgc2uH0WjEpa09bn7aMY6sDVmtZyS9A6jOClc940X4aoKdbYGIaTZK6Na8UOKDIhAlTt4aFIEizwgYZlPY2pxSV6C1ZmlYkCaCrJKMJhVCCrJMcuORIbO6x8m1Zc5s7XJ5MuORzb226BF0E00IAiuiFFwIj1J+wRBtXBvq8L/BHH79d38Hr/3aV/KKr/kGHnn0NHWtkErRKVJuPHaAb/3KE7zoGQfZ2U2RLvoY/Pmf3smwl/CS246wvXsYoRQnrhmye3HE3k6JQfGMG6/lmc9+Lo/dew+61+WZz30Ra8eWGc9K/v0v/BqH1IhDfckNr/2brE8/gnvfg7HICNHPoJt5Bl3I+gXnLs44/8AW1/wtjZMwmUZG1rCbcPXhIZ/6/d/kk97z/3/PZxmVDcu9gj/6/30bS6sHUfkyOw88yDNPLvNbP3aUz33xAo+PDDcd63Bgpc+wl1OmBV/85OfYe++fUY/GnNut+brbrufvvDDn+qddpn7kD/GjRyFYvG24794HePjBh/jgx++lmk0Xh8ybnnEjb/n1f0fRX2Lj8i4vf9W3Mp2MFsbiUmckRQS+vvCF23nGM28FwDlHWTbxgQSPN9PYmNIZ3hiefdutvPMdf4AQgouXLvP13/XDPP7wfYQQ2D5/OpamHl7/d38kMrR9Q0xz9SBUu9kYikJz1VLGbYe7fNvX3Ewq4POff4gXfu3LOXryGHuPncWKhOzoUT5+b01jxohqzEykDLsDvucrb+a2q7t41/D9//EzvOxp67zo2jW2k1XuP7vJu+94iB/8+ucxq2re8PZP8YvLJ3h26rn/rke4amZIXMnwpltZOnQIqV7IjdkMLT1uvMFVN16Ds4FLn/8E2cGjHLjhZs7d/UWKwQ6DzhaDYU5HDzi+OuP9dzVs7JRcX97Lq55/Pb1Dt/GNP/Jmbju+zHe95FounNuhm2e86Ue/gXpymdMXt/jRN91Bmgi6hebS5T2uPtDj5NFlTgwTJDDdG2Ftm6nsKtCd1oT1yX/NG4V2wcj3NG3UuVaCQZHSL1KuOrrKycNDnnZsBdlYvDHUowqVxTr60EqnTVQWqCQj0YJUR/VBEApUBjLWhKa2zMqG3UnFxa0xzjkSKRivZVhT0NGhBZ4gqP1UuZiCLPFCIoQmiBQbOkyamp1ScXFsmDaRFZQIj2hK7O4Ws1mFd45lG1hZ0TQh4VK/z6gKzJrAqDSMp7EOmFY1e7MUEwTr3YxMxfmZt9YQRURuCAGmxmGMo64NZfD41KKTyCQSSsV608Xmo5ICPPjoso0QikSl8b670MbcR9BJJXHsBCEIKsO3jVBrBd5bYuy7Js1zEAJjHdpEBpZ1Ip6DXKy5y9ou6sU8V+RZyqCT0yni+cYYS9W46LfWBGonMCT0+l2UCIRmhixnJHVFp9rFiRhJvzOzCCTdPGVnFtUdmZY8fHaTRy9scfcj57n55AGOry+RXmvIesvovMdw7QimnuHKSWwWADqNqeBBSYSKZyrvPDrtRM/AJKG2gcloys7FGb1CkKUJx46sUpY1Vdlw6fIIEQJpknDbqQMY5xiXJQ9sTLi4V/HghRFV7ahFlBulOoZKmQAyQCohSVQLwnrqxsXI+Sfx9VQN/VQN/VQN/eXX0F8S48mHea8htBK7eaSeoEgkRRrT21a7xQJ4WutmFGn0OcrTyP5JExWZQO0AUyoyhqIRWEzhmJSGy3sz7jtzGYipCOv9jG4i6SaStE2I88Ff4Sn1F161ACEjICMQJElyRToFZFrRyxMOr/QYdHN6RUYvzwhtIZDLAMJhFYgUciUpdE6Zp5SmYFrVGGOo65q6aSJ11tiY3iDiZjQzDlU1IKIBoZLRqDWEGCXq2+jVIGK3JbTG3Uqr1nAwoHxkHkl1hexsznQSEilUTOFQCtmyj1zLeKrMXNcrKBtD2cSIU0+cjKEdsiFAZV3cFKzHtL/T+EAdwMk5IBRBwk6WkGlJpgKp8KQyUMhALgOauPk77xasK9t2eZxzC1CtacEvrSW9bqTydrsGoTVSR9ZbIBpXOudiIST3Dd5jgomKna+2YA8h4FO3OBRFOUiMcc10RLRjgRfHXXCBItUoKcimilljmLSxwM7P0wr3yX5ezKmGEcxcmAz+VSfS/8IrtB084wPCerQSZFLSzTOUEPTzjBPrPQ4OCw71M7qJJm2ZdrJNQswTRdK+0XYGY5Ea55TSMQBAEqWxpu0a4A1JImIh3I6HxkVDzSAU/W5BpyMYdFPczLBnBa2FHwBaiUXK4yPntrn/3Babu2O0VqwtD1jtdwDJpb2KrZnBtbGTtbExelkI0kSTaEXWyVBCoto5IESMQy5SDUFgvWt9IwIhRImmTiVpkcU4bJVSdKK3SKJVjLZNUrxQSBlAxHHnjcNbh5cGbyXBtQkSWYpYXkcnAqkCKqkROgEVmXlSafLBMviA8B5cFZOOWv88QfRHyNLoMzdUnajn95HiqaQkSRKsjx0vFzwxQ6YNUBAaJT2J0GRp23GSNlrctCRyKQJKC+rKxjkqYG50q6VCKh+jj0Nkeu5NKi5u7iC8pZtKXNhBG0s6WI7zuRhEzXpwhFAzTxWLI8UCfl8CIQJpmhOCZLAUMLUlBE9dzXAuIOcxEJ64thgHzpMrONAvyBLFtHGMSsOsjnKG+ZoRWsaokqLtbkMuoPTwJK95ASg6Xda1Js9ThISmqnjO1cscXi5YH3TZGxvueGibZZ1T14bJrGZ9KaObJ+yNLVme0njPx79wBlHW0DiszNCFJOlAPZuRJxLMlNmWpZrNWE0rDh9c5dCBAb6a4ZsaBIvOrZCCWWXY2t7j9B1f5PHHznNpa4Qrx3hTtQmsgcZ4dkYV2pcs5ZrnX73O8NAB1g8ukzaOcntMLQNb22O8MzGi3FhE8Kgkp6od+JJebtkZlWzsWTIbSJXg6iXFxbObaOF5Zr/H845lTG89wB9/cYdnPfNpPO/ZTyfprHH/Aw/z3vc8BgS2d3Z557s+QFr0MNbz6q96EXfdcx/3PfBQPOh6jzMlUiqMMWzubbVPIR5kEVHS9G2v+0b6gyWETPnDt7+TNO+yvr6GEKB1wtd+zVcw2X0Gk93LvOV338p0ViN1zqQKhOAI3iwk4nO5WCxnEgbdjGsOD/jsQ5dIlWJ5OOQL95/nnosTnnd4wNQlXK4aLu9t08sUR5Y7WC+Q0nP1ao4Qka310qcfYaWj2ZpZ1o6kHFvK2Vzt8PD5PULw3Hb1Cg+d3aaqHdc881oOHFhmuFxQ723gvESnGdVsF4XDpQnd1KBlwCDJpEDrgKxHVNuKzcd6bF3eJU0U66eu47pwmZWtPdz5xzh9Zge/aXjOiSWuO9gll45HLmzR6XS46tgB8k7G1QeXeP2rbuTS5oTL2zM+P62ZVJbHNicEazk0SHnuVX0e2KqYTsb8yn/6Vb7y5V/NzTff8tc/Ib/Ey/mWOd1KL6WKzbI8SVFKMCxSDi8XrPYLDqwtsT7I6UpweLwAmWqKLHqHaimpTdtY1NFINiDj/qITSHMCBtMYTNNgqgrX2kVY5xGtvUKQGpV1omxNSpxQ6Mog9Jyd0srThMY6wXTWsLW5yeVLm8zKikQLBt2cpV5OqsDWJbujMcF5tBAonxKEpCsCWUfjCs2k32F7nJKmSez+K8nICFQdyJSPpr6tHEa29Xr0KdVIGetdJUJkEYlYy2ml0DoeaeZeTvvcpiu9T/cVB3P2imqDaBARYJKtya9G47WPLCJn8c7GOrtuWi+qaONh3DyUJzKb5uBimmakaUaSFUidEqSicjCz0ThfJgmdJLIkktDE+laARmB09Kcd1bFmXxzqQvSP8i3dwDq/qLW2t/foqsBsNMRZ0HmDM1GumGRZtBtpGuqqWtRTiZhrH4jruvOEUEd/2iLHLS+hg4lsk6YmmIZgzYKA4IIHF+WFqVIcGHTQSrM3NdTG0lhL1Z4nSuPxCJSIHlDCt69XxZrG+yd39+epGvqpGvqpGvrLr6H/ysBTBJhoi6OwkNeFNi2unyes9nOWOxlHl7sM88h6KhId2Uy6pRUqSdJ+TCmBTiIYo1otq1LR22l31nB2a8LnHrhAYw2CwNMODzm60uXEao+sU0TAJoT5n7TYRMSCjSIWA0ghyFIXf7eOaT2dTLHUTTl1aMiwW9Dt5BAkZd2wO7akwoOwSBHItcRqhdEZFZoSze6spmoaJrOS2SyaKFZ1RFAJgco5Qt3E1IcQSLUmS5PW2C3eVC1b5pZUSB9wwiOsQxhHaj259QjlUe0mPvcumkvw5jG0SkXTcB+iH9Pco6l2ZpE4WBlL4xyNowWeBL6NaHQhYBuLF3FyGR+12F4IvFCQaPIsJ9OKRAm6GjLhybAUwpEqyFUEe2IHz2LaIscH0XYDIggVKcYOHwSJjhGWvU4svAb9DlKn6ARQOjLrMDhn4vPWAYlECknU3MdFCgKomIyRpAEpbCuxdAgfaaDpgtYpWwmkIZWCunH0soQi1YzLGiGgrE3UrDv3BOApxvvCHOQU7Hc/nuxXaOesDQEfHHkQdHPJsNthkGdce6DPdYf6HF7u4BFUtaMsLT7EOVq02vREa1SSsJhoIfqPKSWiR1e7uZWjEdbUCOmQNBRp6xvh4zOzXkSAFMVwUKCThMGgi92dsmvmkoR4cxMtUSoWOp9/8Bx3PHKRc5s79DsdlleXOL66hBIJ57drNndHCAKdTCBUipSSTGuKVFPkKZ1eh6axVJUhEDfjPFVkOokgZ3BI5REiYIwg72iKXk6aZiihkaT0B4EQLNp7Ep2idYJPdOuZ0GDrBtMYvPU40eAU+LpGy4wkT+keOAQ+diimo1n0ftBpO4w1ur+CLSt8UyPKmuA8pnHUtSU4T6El3W6kaffpsjcaU1U1jfHx9SYZMogWhI4dW4/AhRQhdARilaKXazqFYlrZyCoMIrphCAmJpBlbqtrQzdSiO59KFeWmyhNQOBeYVoazFy9Tl1MOrwxI68skahudKFTeQfVWsZNLBGsJvgKZtl3o6L0hQmgTOOLYTJIcrXPyvMvu9jblbBbZKCIhoBZrvzGW6dTgvEMJz6FhwWq/g0NwenNMbWbUzrSa9Zj2o5WIxoitP0CqoGmIhdaT+RIAEiET0ixFK0FT1nz1Dcs889gymzPJF8+M+Oidl/jKazrMGs/OzPN1L70OKRRnzk+55qSmMTW//967ObGcsN5PcaKP1BOU3qTHlE4O1d5FZlsWbw1PP6w4duPVrBw5QrW1iRmPFpIWBEgl2Zk2nDt3Gf/Bj/DQ/Y8xrhrMeAtfTYnVmGBWWc5sjBgWkmceG3C0fx1Pe/HzWD12hLs/8Odcnu5wuVaIZtQyEhSurkmlxOmC7dEYYUoODWCnytl0fY52Nf10Sl9W3PXFxzl7fo9Tx1f52hsH3Ny5mg/ev8OrX/E8fvrH/x5B9Pi9P3gPH3j/BwDJuQsb/NOf/7cIqTmwvsp/+lc/we+/U3LfAw8C0VfJVSNEPlisQ4vkOxF55nme87M//eOcOHGcgOKL9zyAUgprYtBFv9/lp370H7ReK3u8971/wqzaRiYd0t4QXEOoLi+SZJVkUdNIqRj2Ck4eWeIX/9s9pDrlDa+5ld947xfYnDa8+ae+jV2bcHYsmGxtMDy0zKlDBzizXeGtYamruFwnND7ne7/qRj738CXuO7fH9dco8rUO+clV/ujuCyx1NX/3RVfx9i9c5HOnd/i1n3s9uQbhLRceOY3XPUTnIDuXx4gQGK6skudTlHTYtEtQAhlKdL3L7KJhtCvZuHyR5SOH6V57Cy84vsH48iX+7O1bfPbO85zbnvK6Fx2lSCSmmXHvYxt0e12ecd1hhlng4Gqfn/3ek3z4E2f45OfPc/+FHXZnNf8Pe/8dtdt513fCn6vtcrenP6cXHR1JluQiuRcZYzDVJjgkQGCA0BIzeVMnE5JMMkPyEgJrJhlSgCQkBAJDQgBjmnHB2Ma9yZYsW+1IOkc6/Zyn3m2Xq71/XPt+5Mys9cZZXmtQ1tL2etaRdI7Pfe+9r/K7vr9vubk/x3vPq88sc9/tS3zicsVnnt7hb/3o3+Onf7r87wJ4cj4ggkB2DTqp1EHKc78wHFvpc9uREcdW+piiRIaA6IJ0lBAU/YJRodFKYF2gdZFZE0D5ZAgbFb2yRBcFquzR7G7T1DWhnWPrGcF1TD2S51oQElSOLEcUpUEpiQ0CXbdIw7M+q0IQhaa1sLdfceXiRa5eus5sPqOXG4pRj82VAb1MYpuK7b0x+EBPS1STI5WizCSDXp+sMDTFKjfGDb3enKs7U5wP7DmwVSBXgoERWAJ5ECATuJxpSZal70ORmpGLZDalNdoYssx0FhuBGBOgIuj8O7tmZ4yyg6MWkpUvaeZK2bFPJEiFNJ1OQgDBE73rrEEqrLUpyChA65N6AhIzaAGElUVJXhbosgcmw0WorWdmk5G2yXP62tOTHqbjdD9ZTis0kkivl7NTT6mtZVgYok8KgkwEHBG7OI/5JLne2d2nEJb93WXyeY0xOWR9sqIk7/dp5/vYumU23afX75HnBm0kIqYkZxEh+BZnLZnOMIMeZTmg3tvCNRXNbIptHK71aSkUYKOjbppUJEvF0ZU+K8Me09qzM5kznjcHTfTa+QRgKEmuE7ivBPQzDVGinuPF9PM19PM19PM19FdeQ3/5wFOHZHmAThM8KDTLvZx+rtkcFqz1C0ZlxnI/J9ea3GhynUAmY9LmIKTqEE/R6cJTdyGZZydNsm8C01nN3rTi5rhifzrHOociYJTg8EqfIs/QKpl2iRCpQpLdqS/ZRJRUaG2QOsP7SOuSNjSEmNLdlEQLCG1LJcC2ltYGGuuYVw1th/QqKSlJrCShLEEEgghsjhSWHk0cMnOBxnkmVU1VNzStZT6v8M4xd4HZeI4SyWco06ozj5Pd81GYmEzrpBB4IXHC40SLpSKvHQMbKTLdpdLJ5C8VwZOMzn0UuCBog6D20LqEiDvf+T2RpIXpR1J73xmdJSPACEidnpfWinLYQ2uDyUzqbkSH8pZCpE3PRIcWoEUqClRn9OZcp8EXnSlZFMngPIICtJKEGBMi7hzWCvYngYsE9ifJbHx1uWFpWNMbLiOUJsuGGF2QltfQyTwTmyqx7xLza5EmqKVAGoUQGRCwAqz1QEKQikx1HbSICBEjJVqmon+5NPRzw7hqmNQt18cVtU0eVwuQKXTeXojOPkGQNMrP8WtaeYosbZRHlgs2hjm3bY44tDRgkBn6mSA3GmsTJXSpp1gdSFDpuSJTTGeUgiBjB+AqCAKpM5TJ0cakMT+dsr83RkTP0Y1BSqSM6qAzhkzRzkpLhsOMeRPwvqGee9q6PZBXRiGJynBtf8b9j1/m5nbFx89dY1o1vP72w7zg6AbH15Y4sbkCJLaf0oGqaZnXDbmJaJ0ibHVn8tc2rku9FNRtQ4wwrxQyzoGADZ61tXV6vT51G1BZ6oaGdo5QCm0c62vLIDVtG5A6eWkYBd76FCcsFDLL6SvNcKmXaNZTRxQtQkEm5miVoaVhNByAjCgd8fUW0Rmkt7RtnWTF1ZjxzoS93Sk3d8fp8KIURAlBIALIqLsui08siujJlUjeES241tIEn6TBpG55v0yGliFKlMrIEhydNn8CQtONh874tmqomyaZpqKQMmNStwgRGfYzmgA3p55HLlzn5JERR9b7VHvPYMol8sE6UpukrW8cKT0sdcQEDiF8Ar69xfsmRcYm3jn9niQzGdHnTOaWqm3RSlJmkdxoIgUhRLQKaFUghGJt0OPuo6uMm5Zz13bZGldc26tofQLhWw8mCLQQ9FRA9jXDnvr/N33+5K/gDrpcK72Cb3rFGf76d9zLO971EL/58cssra7xgqNLfM0LD1MUBVd35kxvTLhweUyhQUfL9auRYtDjx/6nP03ZK4gh8qE/+CSliayONGtH7+LijTE//45P8/3f+40c21zm8U8/yLmHLmCeuMZr/4fvpfz0mOA/nBa/GPHO8cz2nM3DG7z1LV/N1fl72Dn3DFGPkKpIRqF0DnlCcPjul3D7S8+i+iWPfO5xHn74k9x1x634qzvsPnODS7sVhzeXeP1Lz/L445e5cn2Pj3/qC7z2pbdx6tajXHrmOusjzZljhmGvxIuj1HHIPSuaosyZqTUuj3fZD3N+9+f+KsdOHcfuPMPDH32S24YDPvXBdyBUBtIgsz6xHXPz2hX+2o/+OFev30jPWkikzlFZH9/OiMEjVJeSQwAUm8dOc/rsHeTlCKFypFD8wr/5ZzzwwOd5xau/ujv4kthMJLPhW4uW4arikZs36OspLzgy5C9/52v5Z+99jKe2Kn76f/wmPv7Fi3zmsSt8+9e9hAvX9vkn77vA3/gfvpYzxzZZW9nkT0fNtRvbXLi8zdZOg68rbjs0ABH55KNXuOXYiK15xa++/1FefHyZUS/nA1drzq4ZvvHOTSSpNloZlPwfb7sD7yJPPHyNH37TWVCCH/3JX+NkX3LLSsEbv+VNTG7c4OlPvYt73/qdDJYHiPYmsytXqedzllZLoiyZtkPWXv517F69wbWnLnHmlsOgNJ/5/feiZU1mBK+4715uu2uHyf4e7f4uH3hsi9994AZ///teRdta/t3v309vUOCF4Pz1Pe5c7XG0l3FibYVIINOBJ67uc27b8rZffZSbs8iR48f5nbf/IqdvvZv/HnjHwXuMlhRKsT7MWRsWnD26xMnNIUu9nFGW0TOSTEmsc2RaUBaGUKZDqtAC4QLOBZwX5HmBMBIRHJk29HoDBsMB1nt2b9zEz8YoAsOVIdlgjClnnUdIYlwtItGt80wrUrKiULgoiJ1nKIASkXa6x9blyOdFzePPXGE8rzl7bJU7Tm9yfHOZzdUV8ujRwRJ9pKpb5rMGISRaKgZFTs+oxLCpdlmxLVo0ZLnDSQVZSVDp4Nq4AFJghSB4iXQeWTsGmSLXiiJLch2hJGiNUKnOV1mebB3Cs/eXDlfpAOuqBpOnOiUrsoOmYXAOYkB4h/AqHY67v0+qFI7Q1A11VTOpAvOZZTprqZpkDi61IZMGnUVMoAOuJJQ9nMmoREE9a2jbhvl0TCY8mYbDG0P6KlLg2a0ENgiqKtXLEuiXBUdXwXpPoeHm7oyduaPUApkbhM64tjdFh0CeKSofuDZuePLKFkudgmM4rFGMkD1NXuRoLVHSkxmBVhFjJEFKoouIYLsDrOj8cBR5UaB6BqcCtZFUvqJqPbkOCKWRxYBnLreIGNnoa5SW9DPFG+4+Tt00zJuGB57eZnvSsDWumXZhGERBYSSFkiyXinkbqJ7jybLP19DP19DP19BfeQ39ZQNPogNFlJAYJVNSXZmzMSoY5Ib1Qc6oyOjlml4HkJhOVqe6X0Vnsi1V9yNFAqM6quGCkh9jwPtk7mV9pLaBtnXMG5uM+yIYo8m0Saihh9zR0W6fTcGjk0Et9NR7kxRlKIBBkVFmSStvrSfGFiEcbedtZK0jdgZbC5YMsvueQCQxkIKQOCnpeUUTNKWWVLmhaR0To6lbS9MmJlSMsXOMj8iYkvWCkOgITiV5npIpetQJj8cRREvuIh5J4wyZScBVAloE3vlO4ueZtcmTadp6GpcWBuu7bk8aph3RKk0mLxRRdakhQqCMxhhDZkxnogYmQVZIPEZ4ChkxRFSMaCHQMnWikv1UxC/ozUJ2HTiIbiGFjEjoADa67kZa6Oa1hQi7+zO0TICg1jk6y7vNPy0KIrqOaphooJ0LFl/yylnIEVUXgRsjaOOJ3ncmkWlxUB1IFaVIY1pLYlQMcg0kwLGyHikdEdElm6RmQ/fI0qd19Ojn+lUYybBQrPY1h0cl64OCtX7JIDcURqfuhE++aNqkZytFopD7GPE+mVFKKTEJqkzFqbMIH1GB7iBqsW2KA5dKos3C6PBLMgE71l4yHbRUddokJRnOugMvggXC1zpP3VrmVU2/MPQLwwuOLXF6Y4XN0YDcZDjv8D6QZxIXJLKVyW9NpjVrETu+UL0nr7HQ0acjWqcWnozh4HOVkgc+bFKKDmRMnmUSOjB9kRapiDIQVOiYmxJMhlI6YZ7BETpae7A13nuisOmZhIhrHCqL4AWhmqcNLvh0QDYZJs+6cZZiTq31eB/xXmBtwHemi75L4hF4XFejOL+4B9+BpJLWWZCSKCTWpW6F846se19SCUQWcCrgfPJpSN4Z3fwWitY7fEj/vvCXG09nTOeGqjGURSS6mmjnyMwAIKVOiTrRE1WSF3UQMjGG7r4DkeSBILq5mGVZWgsjSNI+IIIgN4oYYvKq62SwhSbRrXPBrO5jhIQAO/MUkFA7n9Y4AdpARjepn8PXu979Hk6fPsVtZ89w62affmgZaYnRGSbPWR/l9DOJJFI5gdGCQ0OZxoSLEBx5XyKkom0d02ZG6wKHj6/Tk55hFnDWoZTmyKmTIBWzecPupKWnLWUhSb289Iy/9KBvtO7YsJHVUc7h1QFS5SBSgAOQDs4IfNvSzFNizf72HuOtHeoTa8xmFfvjGT4KhFRolST2eWbYWOnTy5O55+axwxTS0VOe4coyURXU9AhuRlW1RFEjywHlWkRLw2x3zJWmoR3foJCeTdMyWBkiVEbVWIqBYlkU3Hp8RFONGU/mvP6+V9IrC6RMps+7e2M++ZmHgUhZFLz+9a9n4/Amh49sMn3mCcbtPsPNVU6NWqbrkaOrinY8JriWYn2Vy5d2uH51mxeeXaOnJVUQHBqV3Hp4iTO3nObOk/vk5YRjG+tsrkxYHY3xIdkDbK4OgcTCvTmeE2ICjm5ujTFKcmwtw4T0XnOd0R8McTLjxMlD5LLB1XOsg0wla4FHb+6TycDqqGRWWWKIjAYGIyVRwqHDy4jZhN3dKa4NROeQocbWLd7DcDSg2hkSG4Fz89R9tQIKlWoKqVg6dJgQYfz0NuhAjGntXxqWDHLYIrI8atgc7SJDINOKUyeWCFHTtJ7VXOKsZa+K3H10iMk0Wa4Z157xvGHSBGrrqOqaK1evc2OnRqiH+eZvfvP/29Pyv+nKtKDMFKNSc2hUsDosWCozBrmhlymKpMdIByMhkKKraaXAx5QeHFufDHZ9MmOOAkR3IIoxsXKic8S2QYkU2GKKHGUMUj0rvYkkBlbbNUklXXJylmMtB6E8sbOG8LYl2AZszSDXGN2jHPQ4ubHEoeU+ZWaINhJsxCiFU4s9v2MNRUH0gYDHO4/wlgzHULnEItceWeZEodJ9ktYLmWVE73DeUftUxwYRkmIixqQIcIn1RWd1IeGgCQ0gvO+YAKm+9sLjpD9oUocQ02EwBrxziX2oXGewLiBIrHU0jaVuLI0N2CDwMrHyY2eXEWIkiNR8jQhs45AuoFtLU8+xbUs7nyJ0RBlBNZdkuSLTEhtSw7j1ybtJSUAoernB+/TveaaTRy4RbTQ6S+FN1qfnIUk2FuN5jZKJiTIgQHTgG0AdMCOESOuy6Orx0LEtofPxdS3RdZ5hMSKUIs8yipC8XmxVIXxiSuVaIkJAS/CdjHPQz+lnglFPcWLekpuUsuZd6M526QylBRiZ5kZ8jjOenq+hn6+hn6+hv/Ia+ssGnowS5FrTzzQr/YJRYdhcKtkclfTz5O2kREqN0B0rx3TSsgXtdCEIlCKBUVIptHm269BWFcG7RLULNpGB071ig6D1XZwfkjzP6RUJHZ7bQItKaRMH1OAEEDgfuLk/Y29Wc+7yTabzGiUEx9aX2BgNGBYF08oSQ9t5EqUJIxb3IdVBbKtSqhtYEecCuUzpGUoFWilxSJo8o6HERsHUBqZ1y6Rq2J1MaVpLVScpnguROniqQJIDKo9Rif2kvEe6iJaRrE0xjr3KUnamkoUxXQynSgu489StY1LVNNYxqxtq67De46J/9oggZdLHa41QGmHSgiK7KNgyzyiMIleK2FbgKqhbpGvRItLTkAmFFonmY1SSrpVF8mJyPk3SKNImGTuTyHoxIGPajpWIGClQOi1kIULTWpzzXLmxi3cW1zZoInmvR9Hrk/WHiUaIIC5WAvwBjTR28kbBs2CUlILMmAMfgLapsW1KRfQ+FVQHWlWRGFlGCIa5pmc0tpc8BPbmDduzhmmVDATbDswDMIjnPD14cR1dMmyOCo6vlBxf69PLDKXOqFvPvPVAir41EoyReCVoRSp4nU8SzmTwLhmUOZmJKOmZVdNUvMhEpRciEHxNURTkeUZe9DBZhtKKThObZMgygb472ztsTZrEJFseUVcRVzsWUe3ExNbLMsWJQ31uOb5JWeScXFtKrL8Q2Rm3ON/ifYvsIlqLLKPQGZlWZEYk4LpJJnzGSDItyZUgyGQYubwyQkrJfNZAFLRNS57rg1CFPCu61AZBPZ0ilEb3hkn6iUysBxRaGsrWJpmqznFtTXAu6d0BoiDYQOumOGfJVJ42vNajD60CGj+dIkzyOmOwxjDvUy4NmNVT9sd1ij11tpPWgnPpsDJv2q7whYBLZphojBWICFpCEA7rYCu0DMoBZS6oakvrLa1rOL6xlNI+ImhjcSrJZbUQZFoRouHZoiKB3q0FoxOLcDobs7WTQPSzpzZQwhGaPaQYIKRGKUNsGoJzOO1S5G4ksXm6BKZoXUfdj3ifdPjDfo88MwytYzybp0hqF+gbQUDig6CqHNY7EBadSQotObu2xOFej+OjHo/c2OP6pOb8zTalJUWB6Sl8iMjo/l+fk/8t15vf8m38tb/yw/yTn/r7/Kl7D3P9QsMfvueLbIxGnD6yxj0nCh65sMMXntqHcpnTy4FXnxA8uisZV4H9iePE2SW01vz673ySp6/v4ELkn/2jP0/uHPX2Hn/8R59m9cQJfvR/+Yt84YMf4tHHnuLRC9d57UtWOXumj926iJvuIWU6QECSupxaH3JilLP75DluXdacetFxTF4SSMDXQqospOD644/z+OQ6F66NiTFJzZ/8wjmeurbHE1d3OXnyJCoKrl2+RjOdsVwavu0bXs5ka4dmss/r/9Sb2Lp0g2tPXqV3+Da0jizZMe9+16PMpnNefOdJTtx+Bln2+Jl/9z7Wy8CpFcXLXnSM6uZ1Pv6J93DXK+9FasPjDz/J6TObrB9a4T/+kx/kJ3/+3fyLX/lj/v2//glObuSEyVPIpTN87P7HecPX/wDEyKFDG7z9P/8ipdzF7l3gwz/zi4yPrXP3N72O+qlPc1pK3vHv/md2H/okdrzN0Te9iV/5pT/i13/lj7j7yDJBGe48bdhcK1nbWKc+dA9veo1kurfD1WmOlQMGgxG//YmnecnpZf7Ot93DL773i+zNW04dWuPGfoNrPX52mdfee4wX3bnJH36uZnOl5CW3LuPNOieKjK/+mnv4o3f8EU8+/gy3rq8w6hsqH3nnpx/jxadX+c77zvATb/88o0Lxd7/1Dv74wWtUGP7xj303H3vPZ3jgow+zf2MLg+XwiTUufeERlo4c4sVvvIt8o08rp9x84uMUcp9MwZ43tC1ko1XW7nxJatKJcxg9w9maZ566zMbakOXlJbLRBt+8uswbTuf8weeeZuPoCv/ob34tF8+Nme9VDPwev/Lh83z0sZv8vW89zmhlFdFbZWfq2N6fMlCeTz15g/NPneet3/G2jlUWn90znqPXcj9jtW84spRzdmNImSeGeVNZovUE0x3cpGR1VKb9zUfQULWOG/sV+ED0Ee/o7CkkhYZWQa3BqHSoK2JFMUghMHm/1yVYdQfXjuU+ayz7kxk3rt0k+pgOGsvLVE5i2xSe430y9HbWksnIkeWMoxvHUCajNxqkLn8I7O9Psa3FtW13SEzGvgGJjyntjRgQWKZWEINHEljWDqRHCM/6ckGWG1ov2J7DzEn0cAlnPba1zOZzcBHpAkYmr87SRZogyVtHNm/IsqS26JV5d9CVaANSeAiJ+dTahrqyqRmukl9UaohGbN0ipEO1Hm0apEr3MJs3TGcV42mFdQ6nMqJKrH7v6dL6Ak30SZ4TAvv728hgMbTEepaUA4DMDU4rdqdTDq+MWF/qs1t1oJdz9Jd6ZFqB0EgR8D7tb0u9HkYqqrrGGEOvyJChoGod+7Wj1BqjYG9SoYzB9CSHSoNQAddMkxFxFMnnZeEHk7SJCAKdRQ1KROr5HGs9bZghM4POc1Y2N8iGcwbzOVcuXCM0Ne2sYbOXDrcxeMZVi0egM82g1Ix6JS8+o9naq9gcTPHWszdrGFcNtYi0meTYUkaZSXKe27X08zX08zX08zX0V15Df9nA06m1If3MMCozVvs5pdEMCs2wzMiNpjCmW+RTzN/CSG2hYY2SA3+ihKd1UqwAMSYvnrZtDxZAsfAzAhY8Fjpjq4V8UsiEttLR4mQHGCWX9ch43nBtZ0LTBqrWM523HFrqkWvFkeUB66Ne+v5KJn+mNvkyCRGRQmE6I23ZdV4OGrwdKyu41HlJoAcJGTY5Q5Xoba6U2IGk9RnztkfjA5UNtD6Z09Wto7EugRk2JWFEItangr6NkdoFhI/s2YCuaqSQZCYZsEshOs1oZygekn7UConXGrSm6EzctVLkWSpyjNadprvr8ngHISBchbDd83Rt0smHQIyeIMDFpAUPMqHgQqeJIUR6wUJElEySQYPqDM6T/DEZi0fqpsX5xJQKIXUC7JcAOY31jGcNUgiGvYyAQwqH0gJ0StFDKRCR4FNyHjGmLbMbB97b7nuniaciaBmJOn3P1gqET6hwYmelTk1mVJLqLcYtyUxvfVhwqG7ZmlTMGsfurGHepiLDx4gM8dkx+hy+vur2dYaFYamfY6ROjDCVjP2EFPggEDiUCEiZADwfIoic3EgGPdV1K0AIjSAQQosxMlE+cUjpkn9bVhJFYueVWU5uTGfyDxCJguQDZh0+iIPIUS1ztHJo3SaNePdeh4Xh5NqI177gOJU3uCjxMSZ5bGvZn9Xp7/KOlVFOaUAPPArZdT4VZS+jEJIQOo2yFixlA2IEZ6HfL4DUPfLeYZ2nLE0yVDQGk5ep+RkjKitTkpWS4Ju0BpiumxxTl0oKiVCSKnpcsDjfIEyiU/fW1wjO4m2DaGe0taNtHJP9GqmTIWUznxCAtaO99L0CnTlkigTwPoUG5LnGeocLHhvaBCprBV52xXRI8cXasDToobMEz+7PkiQ4+mkyVuykQVXr8B5ENFhrcSF1eKVMqUlaZCmYQEKmCpxz1I0j06n7IWVaX3a2JzzlAsNBj5XRgKJfY/KMYjBA9gpCyKmbcVf4pu+ntMYUPUQvzU9rW7SziQ3rNJkGI1MkcNMEqtpR2yr5xtmQ2IcIGgvTse28JdI6GWPkyLCkbwylNuzNa2pvuTy2qWP9JUacz9lL5ES1xG89uMP2xW2O9iRnexXaOj52znNxq2VSBb7+tpJJHfjDZ1rme9toIRiWBY89foWdWcPvfvoJ5o0lCvjh/+0/UihBT8Jf+jOvYKWX88gf/C5Zqdk8MmRpe53HLlVc2b7Km09sEd2U4A+gJGIEGzVBGYZrGTcvtVx6epvf+fF/yicffhohwOQlo17G8bU+ytdcu9Hyrgeuc9/dx7nz5DqrJ46Tre8zWNsm1hWhmnDpsuXs3bczWhpiVFqL59MZv/cb72c+nVJPp2xcuYIxCi3hhS95EUVZkIVdHnjwUbb2ZnzTa44w6pcUeca/+O3PcPrIiO940yuJoUddWUxvwJVduDYekz/8EV57dp17/vH3UX3hA1wqDUVfY91N1q3mt//zzzG7/CgmWkyc8MjHPsEjH/sAYbpL2Ik8+ZkHePLRZ+itbPCGe2/j9x/6CBfOXeNvv8rw8rvvZPX7co6uCT775Dbv+8AFRrvXOT5pOXpmlw9+8RnOP3OFF98yYzy3aCX5i299KU88c50f++UP8dUvOolWS5y7NuOOjRwjM9778DYzfZNrY8fhjQ2km/LQg9cwKu2RMc+YOcnS4cO4yYy8HDFcXeZv/fkNZJBMreJPvXCdGByPXZxz99lNopT85E/9NkeYc6Lv+chnH6WfCTb7ken8STbshDv31skHh5HFOiGehXlFqGrq3Rssrywz2jjC/e9+P8G2DApDHVNEO8UyMVMELNev7OOqCh/73HW8Zb9t+emf/xSvueMQSsA/f9fjvOJlt/KjX/sK3vGeL1BX24jg+NNf80Kevr7PT//Hj/Ijf/blDPs5f/tn3odfnJif49dr7zzCIFcslxrfJiaYlop+ZsiNQkuB86mWaxpHcB6vJXmvIM8LDh3uE3wy3q0nFUZ0zG2jcAh2K4sepMMvQtM2Dh8lipyoCoQpIMWxEGIKn2k8oDXGJCadEOmQklhqC5Y86CynvzTiyMnjKfglRtraJhPkCNNpWod98KyOeuhM4yNMK0sgoEyG0qmmXilB6xRNHlHETlEwHPWRMrFplIy0UdJfL/AenA3MqmSe7xA4FwgxsWemUTBvQeFRbUCrZE9hdKp7lUwHsmBSszb4VDMTBfh44AcaQwq/6Xg/SK2RSpP3SqwL2CixOqeNiiYkFUYIDhE91XxO27aJvdKxp5hNiSIQVbJjKPKcw6sjpEgyxt3xlLaxTGcNBJ8AMJ0a51Ektshs5hKbxSblhnWBQW4wWmOUZKmXMSwNG6sijQciRidV1nw+56kLllGvYHXUp+gO4soUlMMlstygYoNrSONRpMNVEJKYpbTN2NgDG5Pp7oQQLNJ71teWGPQLluYVs8mMSdVybVyTFzmZkuzOa3ZmyT92UjW0jcXVlrV+Ts9olgYFsyo14i/ut/hA55P13L2er6Gfr6Gfr6G/8hr6ywae1voF/dywVGYs9VLkaa4lRqnkbi+7wSkFiNixmBKwIEJEHpBeOl94kcCVINPDSSynzgtBLgz/DiAfWABVLOhknhB8QkRDOGC8LHy7fUi05HnTYpQ+GHBLvYJBYTi6MjoAzdJm41PAgOAA9FLdT5oHX9pNi4u5kb5bTI9bENEiohdhBTpt4EEkxpaNgtoLmiCwAeato2osjUsbmHMB631ngNjRd7v7ISbf+u6xIkL3jLvOVRTJdE5BR3NMMsGyyNMGpVWi73ZyyehdBzoleWMIHufTpnnAOovxIMlQCEHo5MWCSJQJMIzIA+lZCN1RRCSQUZG6K7GjmDqZ0jeUSLGLIcaOYpi6eotiyDpH1bRUTYPWKfUls3VasM0C8Rdfcv9p3ESelWqmtCDPwnpJLr6TShI8L9NCIkMq3IJMqQ+gUCEgxLPJJLmWKemJSK5tt8C0CKD1yST9uS7TATix2ic3KRXHuVRgaKnIdAJsfQe2LSJYF/NVdnMxyTvTuNJS05He0aoztyMk3ywBifTdsdwOns2zADIi+bkleS3d392lfwg63XLqOYgYUCJp55f7JaIW1C4wbizWW6xztK3FdVJKiUZrgTYaEVJ6g1I6JWEojXdJs26MJM8zQojYNiRz/pCSSnzwXQKGI4SkwY8B6Do7QhmEVITgwTuIFloIQRLCs+uWJHT3H0GBykzymCj6BNcipSS6OtF3pcBajwwCXUham7wQREzJHrZxB54biDR3JCniVspUQ0u5aHqI5BtAh9MuSmmZvPDSq0ibkY8+pUOKBJ6HEPFikaKTAHfnXWI7KomRmigijpA+G0n0KSVES4HWgtZGbOvYH1cQIpkUIFpiyFPn3ZTJFFaZlIqzEFbITu4BBO/S74mUTOJDGpsoSalScpcQDpRDtgJrLRqBCCKlkdjEavQ+QtfRHuYG0wVYBALTGprQdmPzuT+Hd3b2+OIjT/LMjQnN3HJi1KNqElt3Eg1zG2mCQIj0626t2J80LBWKExtLbE8brmxNOX9jP/FCBVz95GOUmWZlUPB3/tI3Y3zL/R99gLtefhf9YZ/R0pDdrYZ6r8U1c4K3HNCUARBMG8+0DUht2JpaHr+yyweffIor+w1CCFYGBUdWSu4+vsRo2EcJiRwto/MCqSRVFGRlzqG1EU9f2ENaSWZyev2SwagPIeCbnKau2bm+RV3PsW3yTMmUojSKU3fczWDUZ29rm+2tXW7c3OdFt22yNCopy5Kb45aV1Ug2GDLdttS1xUZBDBkCTag8myeWWD1xlObqFW7sWvabwKHlFUZrh3nT61/DlYcs1f5NYr3HfG+bvetb1NUcX+asTGp2dhtaHQiUjFvD9Zng4oWbuNaztjqiMTWhKOmtLnPl6ZtIrZChonGBcRu5sbVFnpesDnqMegYI3NidMCwLBr2Sm7PIcilRMtJbGVIHyY2dmttO5UzHDZeubDHqaZQ2eFPiMURTkJs5ZZHRH/RYXoNqHtnd9pxeH1A3LTcquG25j1Lw6EMPMzxRcvJwyVNP77CxXLIxHFE3M+aTMXvXtxGDAkyP4dohnN7HMiZsuWRr0y+Z7e7TVnPUSp95zAnSUCwl76DGR9pqTl1baqvolYaZbbl2bcrs+DJaCZ64OuMNRcYLTq7yK1Vgf2cO7YxBz7AyKhgWimMbQ9bXlrn7rju5dPkqOzs7f1LT8su+jq/1KYykbxR74wZJMlrWMtVmottjiRHbJfLGGNEhrd1SKXzHHzS5IRMBLRJTKQRBjCqFwsROYRIdsfNlQXSWEV9yHQSnKJm8OpVKZpe22+8WlyCZH+u0j4IguGTp4EkNz6Zpk6cone2FFGSZwdgInZ9rlpvkMSTAmKRSiDIjklghxphUSxtFITwaQU+HxCxSAoPGCYWXmsZ6nAs0XcOa2JmHBxA2ILQhF5IYUkociGR8DEQRiclpmYW0MUluElMp1d0CXEAqTzQG5xIzwTrXBQlZqqqGGCg1CN8gfUt0baqtQwDXHDTihUxnkCzP0tft/Gat9TRNqgUkIh30VVKNaGOQKh1MnLN4FwgBMq1RKu1Z+cLqwiT5lhKQqUgdBU2MzGYVMkQKpZCFSubV0iCVRucFKpAATumJXdM7IolSg0pp2koblNLY1pKUBpGiSAEXmRZE72l8TKwOnVLMnE1WH9YFmsbirYcYDnxUhzGyrSVVY6msTY3c53iy7PM19PM19PM19FdeQ3/ZwNPx5QG5URRdnGI6dIOwvjPrTkkRYgGUdBNEqYiUEu3CgQzOB38QL1nkWQcpBRJRKKVTGFN1xuPiYJJFSIwe66iqKnkPSEXjE6XPO3/gJxE69hBE1oYFRWbQOmO5X1CYxARaMISct9ANvmD0waKQadX5FAWio2P0dAWCTpuY7FLzFotCinpNMYOZFl16X0ryozP6QmVEoXCkzkIgyQiTH1SSyvkQcQha6/Exicd8N7SU7vyO6CZDx3rSSnX69q4LpgSDXokieUpV4z2qecV0PKXt0vdiZ0AeXcQ2La6jCCfv8i5dRyQqpXZpKfQiIDw0IhlTOp8WVxfSIqqkoGeyruuWJqL36XOMTO/fe3/QDWisTSl3XWSniB7bNownU4geoyA3BhkdXoTOFyy5jaR7SL5Pize+0D4LAdH7DuyUne5fUeZ5it5VKkn8vmS38yp2tOYEghkZUCYt2JnsMS89o8xwI6+T+fikTmChfe4fWvvlCCWTRHEhI80zk+imIenBtRZoaXC+K1BFir6trOXq3pRIoMgMtx4+TKYjSgWcT/NQK0MbU/xqNZ+ljU5r9mTGdDqnaeskvwwRUu4DiNhRQdOmK6JDYBF0RZZPQOK0ttzYq3js4h570wbrHUK4Lj5ZEmOD0RJtUufWGI3JdOoiCYE2GUVZYIwhOIfJc7KiTIdP53HBMa9tAmRF2mhiDOxs72N0RmayFAebaYpeTgxJNtzaFhHnEFrclgUMyJzeYJA8GqJNZvdZjun1GCyvYsoeLiiiawltwNap810MCpomPZMgQJiIDB5XTRlvT9jb2md3r6a2IWm8bURISa4MmUl67X4+SKVMhDYuilDBvGmZ155re4LSJDanIZLpiFGRLFeATEmTSpIZwVJfYcMA6xyMx13xEtFS0DhP1TY0bfIEiD4QtUzJI86itCIrNFLBvKlpr1estkPyrGG2b+mvDMl6JcVoDds6rG3BdgloweODJsa01pmsJCKw+tk1CxfoZYFB3+N9Rt227O1PmdcN3gdWVQ+CIATYm1ZUrWXWNIQgGCJYH0nWlzKmTcuVnYZpVVM17f9jzjy3LsGv/sdf49d/4zf49pffwp1nl3jV7av8yw9cYL92/J03b3LuGjy9VfNbn7rO2Y2cVx/r8cuXNcXKgDe8+gR//MUxF6sktY5fYlYXEFghUcNNnrx0g3/8nif4idvv4UUbh7jzTMbesqKtZ8y3HK6CvMxpquagqH7omatII3jj6+7lNx7a57c/9AxVVZMixTVvvnOTl5wc8oa7Bizf8TqKjRN8y8kzfOK3foMvfuJTfOT953jJmTVednad9z18gzNHlnjba2/lxjPnGV/LOfOiM9SzCe1sypvuO8v21pSr1/f5/M0WEyy5r3nkkx+ijYrHdwRn1nPuOL7OL7zzAq+8Y4XXv3CVv/tdr2Jvb8ofvet+NgaaEOHSTsu9993NqdtvY+XwCp/4yGf54O8+wPf90Jv51Ac/w9t+9F/wjp/769wzzLnw2Qf5vT/4CNeuXeF/OXKI229f5/gt387b/ub/yQv0Oq990euxzqO0ZnzpAt/2NXdw4wUlP/UPf47atrQh8Iln9vmmN9zLv/9fv523vO1/5+r2Lres1nzvN7yCK9st7/3gh7n79Ap3nFznL/3073Lv6RX+7V/+Gj5yXtJmA/7a976Cd/zBJ7m+u8//9Y++jXOPXuGpc9cZbJ7i2vQCD13e5Z4X3Mrh9SVuObXGBz97ietbU+7cGHJks2BjI/Lz//GjHNtY4r57TnGzGtIKUEVG0Dm5aHnZEc362oB5b8RDN/Z43aENXvmau/n85y8xnTW8/w8+h7IfYbiyzH1//keIvSu0Zcv4CxPmjaBu+9zz1fdRzaY8+eBDlP0coTRtNWaXEdOmYKkv2JsFHrpiGWrB4dUl/sbrXsCjT25z/eaUN79kA3HpGR5852W+9a4RMQwJzvOzv/k5jq3kvP1v3Mff/82H2DOH+PjHP87f+tG/zc/93L/6k56g/9VrNdPJewfJxqiX2OFKYL3H+0CvMBgVETJStQ4pJEpHYhaoZhXX9neYNg6tJbceXyNXAi0jwkeWhj1Mf4SIgbqq2N2b0c8jhYwIX4O3z7K8SeqEwhhKo+lrWCoTG77Vhuu1PVjbIdlB4Cz1ZMKNi1do23RAVZ33T0Awmc4RIu3BwTu0UowGZQKapSTPFOWgj8kzXGNTyrUxCKVoW0szrZjP05qRFyXet9SNo75ynUyR0u60JsvT/hqEwgfBrI5IrXEILm3PmFSBaRtZKpYh0zglmbQR62IyOu5qv8FgkJj9bU1j29Q7lBqpE3CWlQWurSE4sswyn03Y3RkzvXGTpm6Yzxsa5yhyw+Gj6wwKcEYxnwtc0FgPSrcoCZmRKAIhBC5d3yFGSfCRpm4TDSNYjm4uJS8bNEvDkjzPyIqCXr9kXlVcuXAZhaN1yRC4DYFZ3TAsDZHAbFozyCSFFihtGPRKBllGO6lRCOazChN1Ski0nt7SEJVn5KMVLBkhzHDNdueFmsA4lKFYGpD3i3TAn03xLh6Yg+d5zqBXpF8HcxSR1gdQkiOHRhAF0Ue2tvYYzxr2pg2HVg1aa/I85/Jexe6s4enre8wbS2Of23L352vo52vo52vor7yG/rKBp15mUgqcSolsCdvqkFmxYCAlw2sWTKXOTHTB0jnw+YmR5MgeiEEcdE/FQo8t02dIKQ/8mmDBkAmpK+ECQSZn+C40hkV8Kh3wUnQG6EdXB5R5Kn6MUokaHAJN6zvAY6G71YhcHWzKRidzs9h1iha+TwfS6JCAJ6013iczMrfQsUeRkjE6SpuUKdEPqRA6gVB6sWgQcUrSUwpnYCXr7pXkfeQ7k0ehU/dD5Sm5g+DBd2kdzh+wtdL7Se+ml6d/JkSi8PjokMESve38rOjMI0MXGxk6m7LFk1zAiOk9Ju8utQg0Sp8bbQdSLVBRSQiBIFNHKfp4MNiVAKkkRooOeApIETAyvZOUfJdonN45mrphIhNslBctPefJixylUzoiUgLqIOEuLXid1CAogvQH9ydFSJu8WUhBU6KE9SHJ+ZTrzDZ9Yk/5zlQzpM5N8Im5l2vJKDdoKfAB5tbRHhj5PXevnUmD0ZFcR/I8sdmcjdR1MrfTMnlzSRERMlAaTS9TVI3n8t6MT5y7go+RTGuOr445tJSxNsi448gqUkaaaGlDwDpHXXtkjHgdqXs1oeukpUGaOrZh0YF0qSBzruXpa1Oe3J5xfntK5Rx5mTHqGYaZwbeO81e3k4mhkqyMCrTOkUh6mUMphTEabSRZrun1exhlEERaW2PbxHKo6wap5ig1QYo0x5VU5EriUczr9F5DiEglCMHTNA3WQYyGolAp6QqVOnQBYpA4C9qk+eG9JXhwRLQxqQsiJbZO/mJZ3qOZTRnv7NBMx2RFwWB5CVFXKC0Zra9jZgWubRONOteMlgumc0X0jsoFqtahpGQQXDITjJ5p4xJTU0l6mUkMwhCwndljFjsftpA2OqdFSrfJ0tpeaJMKFZcSOERnOKolCFLjIMt0kgPIyLBfElygmnehAJJOspHW/9YmT7Q6RFwcU+QZK6NkrErwmLKH1DmZKXAziK4h+hqETozPoFLnv+tGJzZjABU7NqNERkmmBYOeA2IC6306DIGglxu0EuRGMKs7abP3DIwkkxl6RTHvpSCI5/L10//kx0GmIvGTf/AbPL1Xc2wv8LUv2aRxns88scPKsOCu4wNGPcctx0bcemaF7zl8jNl4xh9+9BxHbjnDC+/Iyf4oo+2iihedzF6RsX3uYQYx8j1vehFPnb/MztYur3rBGpfmFTu7c14sGoipoBVSHnRilcnZbyK/8ZHHeeraHkorXveCYyxlgtVc8qbX3c3xI6usHF/F9HvUk20ee885nnjyEtfmkGvBaGnE5vETvOX1DhUDT16ecujoEbxQ/OGHH+XkasFw2OOTj9xkdZhz4tQ61uziGo1sM7J+gbcB3+5S9kcsD3Nob2DkgKIwPPCFmwzXNnnFm1/HB37/XdhqxsvuuR1fT7nw8MNcfDxgguBlL72dRz/+cZaE5Kd+/G9S7ezz+U89SFkOuevMOrefXub8uScZLa9SDIZ82ze8lrXVZYQds3b8JCFItrduYucV0Qm+6iXrxHyJmC9x9IktTm0MOP/AQ/zp19zG9njGz/7e5zlx9DRlXnC4Lzl3eZcvXpvx/X/qNbR1zW/df43bj20Q/Jh/+faPsSkq1svIj//cH1CEQE8IhCnwbcuLz57izNEheSa5fnWXwwPFWt5nrYicu7zPJ8+Pee2rX8h4WvPeB69yfNSnNIIl3bK3ZblpHddrOLm6wq23HeUVD99gFBseeOgZPvTIDZrWsVYqbltVFLFi98EP0j98gnzlNs7c03Dt8k0eP/cko8PL6Dxn7eix1PmOkbKU5L0ck2XMrilWVld59aEh9WSfaj7nfZ+5yon1HmfPbHLbXbfwmc+d4/5HL3PqCBw/vMap05vcu+2Y1zW/8YkrvPz2E6wcOsrTD32Ur37FWU7+2F/+k52gX8Z1c9xSaEEvk+SZJghJ45MhsRSCrBA4m5jlVW3JtCIPitnOlO1pw2NXdhnXFiEFV3amrPQylnsZd55YQ8aAshUS0n6gFPO2xWEp53NsUxN929V13dU16SLgnKNpLZd393liq+HpnTneewqjyArDcs+Qy8hkMmPepJp5pZ8nOZqU9Mv8YI32LpBlGf3BgCxLe7C3LU3TMps3VPMq1apKkWWJfaN0kt3EGNgbT6nbJHvrFyax4GuHVi2DGCjLLJW/PhCaFhE0UgiWtKPoS1b6mkO9gNYeIQI+z7BBMm1BRo9SsLpSMt+vmc+m2Nk2WgmKXkGMoFTOcGmNvT1L01hksPQzgRpmFG3BeAa1D8zrBkvyygohpQPuTuZAOjP0cpPqHRFoWotAkJssHeZj8nFtvMdXsNQ4ykxSZNBUc1xbY5saGwLBOpTRZFGgdKTXKyiloE9MdYtzEDyZBC0kea5pfaCdN9iqxoZIE6FtE3GgyFp0f4dAoOyXCK3RZT8d/pv0uVJ240MK5tM50Xu8bVNjmohSyRRai8QKkELSLzJE3SYj/MqS6fReXBBkec5aUeBsOsPtT2t6eUrBq22bauz/gmb33Luer6Gfr6Gfr6G/8hr6ywaeCqM7+Zn8EvkZB3rVECOSQEJOD/azzkeoM77qtGkL0ZyIyWAwis7MG30g0xJfAl4trhgT7St0tNjQmUM/K4PraIWE5IWk0sK/Oizp5Sktw3XAVe08rXO0bWLpGJ2AJ90x6AQdyCRFp5tLwFPWPQcpF/eZWE5ukSLnbCf96sC0BGN10q1FMt7CAD19V0REk+i/SJkcxjrmWK180j6HgMk1KsvQRQnBJUlc4/E20LYxAUadcV0MHgQUupPBEZlHj4oOEVxKPgnpzy+eX4KcuthrBP/lld7dwrtLCA4MFJPiPl1Cik66l0zhD97PAvyRCaeXQhKIKcFIBBSRGJIET8kubc4H2sYyR6BF2lwVydCdaLrvkRKQiGmhJ/BscosKCNlRUb1Nb6MDQ6VM9FYpJMqF9I4kyI55Fbp7iPFZjG8hrcyUTKkuKlHaTS2pnuOdGoBJ1ZBrgU9J4qkY9IGq8Ym+rcSzc1MGFJJBJqmt49p+xaeeuoEPESUkG/0xtx4acHpjwJn1ZYSgM//v5oGlM0F1tJ2+eME6PWAwRkHwYG3EWcu8sVzdGfPFy2Oe3J4RYmDQy1jrFayUGRrY3p+T55KySNRvowxSqOSPoRRGJ9BaaUVeZJR5H0IkTBqaxlG3jvGkOpDNlnlBnmX0+wVKJVq+s3Qsw5SqFVxMKZshYowghoD3daKjkwGSGDQh2kS31RLnXQJ7Q0R3qYxKSpq6IdYtuTa0VcV0PGY+nTJAsqQyhKjShjcaIaShrRrcbIrSgrKnMDIxGoMPtDYgVaTtvM5EDNStJTcKJaEwedqwXEgpFiJ10hcMSds6YkwGpoukrMzoJB8Nnrpp0J3vmeoaClIqlFGdFDpSFAXBe6S3CJH83fJCJZp5CNSVx7r0XSvbUlpHkWVprMVINpxj+gU6K4ld8e6p0lqYNCB41xI6SfABEC5J3dRAN59T4s6BV56X+LS6YrREyaRtTxHASc5bKEGuNIVUNLmkdeb/MWeeS9df+f/8BYTKcEHx4T/8fa7sjtmeR1511wrg+Q/vvsjqsODoakFpYGN9SH91iftuGfH4uSv8pw98lrN3v4Djgx7GpGZJesapu5lnmv1Lz3BodcQb7znF7/zxY1y+7HnlbT1m85r9aYsyIGTE+0RrJ6aUKKE0lYt86pFL7E9rlns5r37RGQ5ngU0TeOmLTtNfXUMP1vDTLSY7N3nkE/dzbWyp0Kz0Ff1+Ymy8+q6T7OxOOX95i2O3DXAu8NDDF1l9+WmWl0acu7THXWfWuG1ljWPVjGoumc2gGAzwjYW4hdaSrMgYZJ5eLslyw5PPbHFmdISz97yMt//We2mryJnbT3HhyWvcuHKd+f42Z+6+g1tvv5X3/9qHOHL7nfylH/x2fudnf5YLVy+xvrHE7S+8ndHyEo8+9BhtE1hqA1/9qheBgLYaM1g7hPNw4+YewVpiUNx5aols+Th6dIzV0TbteIdzDz3GPbcc5umdHv/ytz7Da+/pc3Jzmb4RnLs65fwk8N1veQ1feOoav/+p89x1fImqcbz7E+f4jns3GPUVb3/X5zh7aMQdR5bp54b15SG3Hj/ExrKkbiwXLu6zvlzQG2To2HL/MxMeutrw5re9gS8+eZV3f/o8K7fnlEpRhBl7u45JHZhHBWVJb2XI3YdL9uctDzx6mYcuTogxcmYl4/ioT9tWXHv40xwyI9bWznLkthewNw9sPfAE0+mcwaDPYGWVZj7Bu9S1HvQNWa7ZcYrR2oDDp45y9VLG+Ys3+fyTFzh1aMiRQ8sMjxzjY1+8zGNbLSafs7yxTra0wi3rfS5cbfjY4zt8/zed5OzpFc5/4ZO86M7b+fqvffmf9BT9r177c4vLkrQieaBC7QXOR6RK4Tm1TzKLqvWEmGqu3XnN1d0pj1/aZm+ewKNruzM2l3scXu5z64l1dAiIpkarlCSptKauWnzraaoqxYp7d2ALELtDa4jPWlNUdcuFi9s8vTXn0l6NiIEyNyz3MtYGOb1MJcVBG5JReSrYEUpTFIa2aWlbl+Q6UtLr9yjLDGJkNvbMp8nUdzyedXuwoFdmlGXJcHkJAbgQmEzmyYZBCswgo7GRWdsl1mmF9y228Tgf8a1Pacla0jfQVxKUZjnvQKcQMUWOFwqTSaL1SBFZHRrkPOB8RVXvozNNX6YOv5aapX5BNVXYOhKdTbLGXBJ7hjZ4VOVoQ8RZT9Wm+tL5wKRq0wFSSfqDkkCy0HAu+dCqLC27SfIisBGsizRtwOgEQNZ1hSBimwahkl+qUImJoonkZY42yf9GhIhrW0LTpVd1fnht7bG1wzUN3iVz69omJYcvHPn+GKEESxtrINLZQoY+RPBtm+rsrpndVE0yjQ8+Ce2EJMtBxa5i7M5CmTZY6YjOYxuPJiWYu0BK4OvljMcNtm6Z1RVLy33yQrHWFouD13P6er6Gfr6Gfr6G/spr6C+f8ZSbgy7Jgt6X4l7Tf/EeokzsJBs8rQ80LiXWZFozKNOmZXRydV/EmEbRmUyHgHc2xaIGkdIxnEuGVun5JAAlJnmXDymekOg7c+6203MmyRXEA/30fN4SXBelShdt2UV6RkLaJLQiMwqTJYRedeCSkDIlX3T6e2NMx+oSiXK6AFXoviABZ20XZ5lS0ZRSZEUyxjZ5TuwM9LxvicF2SKtAysSMUmoxUCHrfKJQClOUKJOjTIZrmpSs0SW8Jbn3s6yf2DGpgreELpGkqdtkNunTJIokvyelElMp8ypBT520bwFIiY5J1jqHtjJJ0LrOVAJ8fFqouvhL1VFLjV6YzWukS5uriGljTV0QDwG8SMlwofv/aZGAp8TUCti2ZRwCdV3TNjX9qiYvMvoDj8ozlMnQWZnAT+W7ZxqJQSKVQshkiC51x2DqJJnBB4T2mBDJC49zGc45pvOaurW0VpJ73Wn/oepkeY11lFliQQ2KnLlzNP8dMJ6MtkQhaZzCTlxn0C9QpJjlIBzJUFRgOvDN4Zh4x8QFZk4RGk9wjr2dm1ibKOqvO3sMqRRtCJR5ij/v90rm8waIzJpEc2fRzBLdPPGBWe24sVdxcXvO9f2K+5++wdasoXGeV5xc5fhKn5NrQ249vM5gUDAa9RItv3Fs78zJTQIQg4hUTY2bBdbWljBpslM1qVNU1Q7rEljricyrmqpq6GcVZZkTQj8lj4RI06RDtVId69EohFDkZYEQgqoJBFcjhaAsNeUodfer+T6+rfHNFBcUTeupKofKc/rG0OsP2blwgelkjBQNSsLK6grz8RyiRBeawuUopQlVhQwBSWC2fZ3pfMZkPuMLF24Agl6WdWmSkVlVU2Q5vV7G3EXKTFNmCi2gdR5rawZFQZ4lY0SVhPfUbY3RGdpkidGqZac7t8SYjE6DTyp7IXoolaTTk1mFlMnLLgaHJNLv6ZReFkEKhfMtznmmVd0lkQpybXBBsjurqL0lq+aU0wnLaxNGy+uUK5tYo7ExEu2kK2xypDII4ZNsVmREJG3weGcJrkX4Fu8cVdXiQ1qD8iLSzGrmTYu1ruuup2IqI3la2CiS3NoFCqXpmec28CSzESn4YcZTV3YY+Qn3njJcvh5AKv7HP307Dz+xyxee2Oa+Fx/iQ488zd/7Dx/l9Sd7HFvr8+avuovzT13lyesT6qqmN+iR5Rlb13dpWsu81ojBBlfmgfd99Ivcud6jZyR/8KHHOTEseOnJVdZf+FJ6D+6mtTmmrl9wKW3q+ErG9776CFdPK1pKvud//QfE2R719YvE+UW2Lz/DhSc+w+T61eTFsrTBy25ZYnVUYozkE1+4xE/8zG/xjXetcsutR3nLW1/Fu37vk8z2JnzbKzaZec+1K2Pe8tJltnanfPQjWzRmmTKD9dJx6ljJ3PV4+MoGXzx3hVIHfuC738rKMGDUjO2rV2Cyzaf8Bd54doXe2lkGx1/ILdmAzUPXOP9wgPkO++enbB45SqEV1x74BLed2eRSIXjXxx4lWzvF3StLvObP/iCfeP8H+dA7P8yf+/4/w854zmc+9ySvf/U9SV7Ul4xWjzKrGn7il9/FUn6NjdGDnD57O+dvbPOB+8/x+G9+iqOrA/7Bt7+K37v/aX7v0SdwZLzuBRt8w8llfugf/AcOLff5+rtO8OsffZrVUclP//Dr+cX3PMgHz834zX/8AzxyfovHL2yxNCgoNPhmj49+MbA7mXP12lXyckC/zLnzSIkRlpOjyJWnr7Psa/7cvWusrg2YN47HzrdUtqXIFD/0TXfyi+9/lL/783/IT37HK3ly7PhPn3ya775njfVRgcv7/OfPXeX63pwXHSp4zbl3cO+Zj3HP9/wId7/+TZx9xRv4g1/6JexsyqlTR1jqBQyRq7uSU7ljecmg8x4itIS9Z9i/cpPl4PiBN55i6g2PPLnDhfd/gZecXuZNb3sV//btn+PtH36Un37vOV5zvOS2zR4/9m13849++7Oc36n49jfdy9LRU9y6evpPeor+V6/VfpLaoWDSSeZ6ec68TalH08Yh5cJbJZKVhlE/Z6edUwXJztyxM6lprefm3py96ZBZE5hGzWzmqGcVq6MhRWZYXl5iLBL7yTUO1zq89ammFenwsDtvuD6ueWanom0tO+M5H/viJfbnLY3zHBsVnNwccfbIEi9/wVGWlkaMltfZntTMZhW7V6/gZqmuGJQaG2FmPesd64NgcT7VxjEGtAzkKsXSzxvHvLW0TUNd1YkRFRMIN69rrE+gltEpuW+5n9O6SPSwszvHNelzVTGgHCyTFyVZsCkS3nm2xjWTWcXNnQl33nqSQa9PX2SM51OsbxErJYW29EY5l65LSmEYZQNyGcnyEg30i4xgDVeevsB8XlFXDbtVgzIZ5aDHaKlH8I6mnbO6NEKrvJPPWUT0EB3Be6y1LPVLcpNYYDJJAWjaBp1n6MxQSI3WmiA0u7MWET3DXk5WpDOAQ6GNSNYTucKHQFXVGJEOoMN+D9eBdVmWoesZ0jYQAq2PTGyk0Mm/aWgM27sT9iYV0/Gc4fIy/dGItUNrSK0SQ2t7r1MkgMlzpFJU02kyIO9AS+sFwkpaH2kcTLwhqIiUgX6W/Fi9D2RSoIJH1zU9PJmGYpjThuRZtdE3aS9+jnulPl9DP19DP19Df+U19JcNPPkFK6YjFi0YTSGQHOKVQKkEekwbz17VsDNtCB2tcKlXsD7M6eea1UGOkkmu5Tvk0PsU5alU0p/7TgJ34NmDOFDrLf58ax1NdOxVlq1pzf6sToiqUvRynah5PjKrkumh6BhbC0laAjdSZyJpWxV5nnWsLnmADi6+I4QDZD+ZNIpnJYQhHrBjFuwr51Lnx3uPVAndVEoe+FCndI3OBBtBlB3aFBOoF7uUwIU3VErWC0SfgCTbtLSNBWJnbJZAMpNnxKiT/wYiRUIe0HfSvQS/WOST5G1hnLZAF9UCVY8C1730hdRR+oV8skuU61hwC/BpASwRI7EzypOCVHBFOmAvdftkB0A60iFGxJQwp2SnoiM9T2vTs1wY6TnvkVKT06G12iSWnFbgkmdYiP5LKOXyWVac6Jh3Mt29FJGD5p0QFFkCkQQCJSNBglPpb3Leo2RK39NKIGTyLsvUc7xVAwQRyTTkRnZjLJmFms6XzBhJStpQiGAxCqx3iVYtJWWWUduaIMCLZFgaQjLN0xKQaRFKPl8hmWJ288f7LkGiY51JmQrMWZM6QVf3W7amDhcV68MepVG86PgSx9ZXOLaxyubaEsYIpAgElyKLmybROqPQ9PICIR1CWqSA4D1VVWFdSlRc0Lt9jBRaEvMMYlpIo4DGtsxqj/fJDwwRkZ5EodXJTDBJZhPYPneWgEBlWVojnDswenQ+0jQ1ICl7hmo6x7YWHxxCRooyo561SKkwSjBYGtEb9dGZIRQlApmosZ2UdjxNuuu68fSKlBqS6a6LFENnHigO1reIwHuB1IqIT+xM6IB4R9utOc47XIwo7xBkaK0xWQYhdLaWoZv7qVsTY5Imt85381syd+l5685MNrEbk1TEeZG6VKk5RwgCayOT6JjWDqUEvczS+h2axnOkLJFaUY5G1OOmA4gjyuhkmmub1OFL/MQUcMAi0UAhVI4Qrkvj9JhMUYpEEU6JHY5I+q79XknVJVMu1uPn/AwWqvvVYH1IqU4+srs/pXGQmT6D5WVuXVnj/PU9ZPC84tSQE4eGDMucxgk21ofMSR1H27qD9dH7SNVYJuMpwXvaqkKIPkppdGy5vDNle95w+zPPMN/d6bqQKSlKCMFaP+PwKOfwSp9Rf0A0JXl1iXoypt2/yWPnnsbOK5Rv0JlGGEO/n6NCSzVpOL/XYoziFS85xe7+DvWFLa6FcyyvjxguFTx2bZ9cWcqiYHTyKMGM8WKPrbnoIrwtz1zZxwXBUDWYYUm/MOSxpp221K7itW/6GkoV6A0cW/sNdn/M5PolQjVFC8Wx209z8+pVLj1+hbN3vYimcTx4/+cZZp7caF7xmtegleTqM8+wVztMlvOi19yHKpcYiJKzd8DNK1fYF57lgeKLz1xia2/K2WND1tcGrKwM+MzjN7l4Y4dJG3jDq+9gkGs+8Pmnubw1RgBvePFRTi3n9CW8/u6TSJW6jnlRkGUZbWPJs4yi8Ozc2CaLlsPLOee3ZoxKybGVHCMFS/2C7NhRMiwEz7mrE5ZHJS843ucDDzzFsaWMFx0b8cdfvETTWA4Vgse35rRBcOZQSRYCp0aGJ6/uEyO87gWH6OcwnlseubLNiSMr3HpsFbm3xfXtMZ9oLY/85rt5wZ238op77+DM7YfZu7HFzs1t1l94lsFoQK32aF3k5tYMIyr291quXG9Z7hlEkTNtIiE4TPQMhyWPX53w4MU9XnzXadSlPW6eu8ntp49Tqsg7P3eJF9x5khMePv3w08x/93185tFL/LX/6e/9Sc3OL+sKnVR/UGoCyZbAKOjniVWfZ4a8SEnEeW07Q1koyoyi6OLUF9K4mDwyffC4uqZzamE2r/Hep4CormkYDhQBqa5JTHewPjCtHdf36jT/5y1BSJYHJZmWHF0bcvLQMmeOrXL40DpFWaIzg5xUBOeYN44gEuMpz/PU0e/kOkLK1Kib1al+dh7rk4VEXphU3ypBdB4lBcF7GhuxIR40PWPoaj2RGE06K9LfKyRt5z1TZIYYEuMjElLwDpHoA1IoirJHU9UI7xHSgG9RRGw1S/I0o1leWSLPM8p+j1xLtDaJ3a4lpVEUKhK0IBpJ7nK0VhQSlkuNtamWrxqHVqnOTdHsHhUNSIXJ0jMPpFqoXdQLLkmraC1OGXyWJbNjner5LEu26JGA0ckkXUmY1ingIQpJ5TwiRFSMBx6vbeuSEbqPyMxgFJQq1f+N9WxPm9QIFgvTcge+ZTjsJRP0coDMG7xN+73WqSFuXGJDIJLthtIqpY8pjckEg6GhbRu8S+loWgm0hpXlAU3TUlcNdZMOsYNeydwmkoJ1XUNaPrd34edr6Odr6Odr6K+8hv6ygac2eGJMFjnRd+aEHStFCkEwgSymF7c3b7m0O+PCzTG19eRKsdIvOLU+YH1U0M80RidaWjKzTrQ3YkTJQAwceC8dICGisyDvaMHWeYIP1K3j6t6cG9OarfEcFwJ5phn2cnKTHPbH85rc6bSJ5FkHjki0iigZE9tJJ4pcWeQH5oPWJtaVbRP1MYFPFinUgan4grkVAgnM8c9S2WJwB7+vdScpkwLRaXVD7DSXISSbOJUWFd95TkkhUopAFwVLiIQutcM2DU1V01QNSiny0nRGlJq8LBOMFCKhaboiI3lPxRjSJt0BT7Gj9qXrWfAppSx0zC7rD8zaF99tgUCKGAkqgXBSpZTDJGcjAU8hskg5TBLNzsdLSWSAGJNBm5eiA+IcSsYOeEoTMMTEXGst1E2S+LXWobqEFiFAFf0EvnU084hDRv+sXC6RK7vhJA4o4nTAU5JDpkVn4X0lREcZVaBDWji8TwkWSqaJCAkky8Nze8ME8AS00QwHGt94pFBkeY5RAq2g15NoVaKkpm2ntI2jaRwiajKlGJQZvm0JQeJUjujM/11I70IqheuiiUW0KG0QEnxMMaXOu7S4i5Ti43xkUjsu7sy5uGeZNoE8yzm93uPYSsk9J0Yc2jzE5qHDZIMM2zZM9nfSomwDTduAEgitKcs+xjuMbVBS4L1jOpkxrdIY0Fky4JRE+kZhlCLLcnxwxBiorWV33OA8DIscj0PIwKCQCC3RKvmyKa0pcsls3hCFxJQl3gVsW+F8i3cB5wV1XVMUGcujPteu7OOCp2r2GPQHFOWQ6V5LlkfyQrOyuUbeK9BZBlETQkrnUcESfMPueJKo1EGwsTQkxIALLdiIdTBvF65saY7FAG0EoSRRKKRUBB+x0TEn4g7WVgeiSR2fOh1siyIyzMHIQCRtKkRJnpOkyb6laX2Kpw6CpmnQWrK8VKBU6gJ553FWYJ3EmAwZIi6kOOzWBtrK0XQFbL80TOctk8mY5bUBg9U1+itruHZGrGt861DGgJR4LN4LROj08jKCDISOzm+ytLEiLBFPXqRDnG09k2nFbF6jtEJrTa9fwLRG2qTnX0SYP7cvAUKDSKlIzgXmc8/2zoS9ueX6nuVrv+Zuzp49xL/6+fdwYsXwXa85huyvsj93PHlpn1feeZzeapJT1FWDqJMZpPWBeWXZ295Ocmff4oUkasNyafj0k1vcmMx51RceYv/q1RRm0XkgypBxdKnk1Gqf9eUh+fII3Supn/4Ek+0ZO9cmfPQTTzAsJK+8bQ2xOiJKw6BXMNnb4uremA8/usfrXnMnb379C/m3v/ReHrp4lZufvsTf+xvfRFlm/NN//X5uX+txelNQrJ9iY7DHcJDhzu8xmbXsTFuubm8hiawULWsbhxiNlgizG+zNLXUT+Nbv+YuEtmL73EM8/OFP43ausb70MFpn5EXBmXvu5Py1LT7x+cu87tu+g4tPXuBjH303L751nWOnb+FPvfVbePBD7+H8Yw8zvv+zvPRrv5nXfuO3sHPlIuVQcPzMGX7vF36BZm+be+48zof/6H6eubbF973lXo6cuYVy4xD/5+/+Mrt7Ywa54m3f+Xr2JxXf9lf/LUc3Vjl7fI3vfsMtbN+YsHVzwg9900s5f2PCxx6+xMbqEv1McenaPkvDHkIbPvvAoxw7tMrJ1RHve+gyy/0MKRVHl3M2l0t6o9PoySXG+7v86me2+bqXjnjxmTX++e+9j9fceYSvesk9vP3jH4a25q9/zS1cuLHDpX3LkZ5h2UjeePs6D57f4uyJNb7rvjM89vglLlwZ894Hb/Lj3/96XnJyhY+/7+M8tdfw2csTHv3Av+c73voGXn7XOi977VkuP1Xy3l//MHd/1Vexeuo4OnuMq1e2uHZ9n6PFhItbMz7zxJg/9813gNA88fiUQ4VjoCMnj2/wC3/4RT76yFV+9ye+g6Vzl7mxs89rXnyMc5d2+ae/9FH+8z/7YY4fXua+7/o/eN+nzwHiOQ882RAZasnSIEeIhUcMqVGqFCbPGQwL8jJjWlvauqWdN/R7Bf1+Q5aZjlkeno1ljxE3n2MyTaEE+9OKtmnJZSB4hxSiCxI46OEeXK2PTGrLlZ0588bSWkdeFBxZ7rExLDhzeIljh1c5fnSdtdUlIoK6cfi2oa1rZrVDao0RkaIsKYqcQc+RmVSztj4wntb44CmNoHUpuawsc0ymKZ2nrbrDL9C2DhsSA4OuIRqD71QCEp33QCicEFhh0UJQFHnyA7UWpZOnqSSlaefGsLo6oJ2PsdMpUknyIifLNM18hpSaLNMcOrSONoZ+r0duNEKkNOpcScgUo0Ki0WRSEDsP1SwGVKGpVWR7ahnPG6R0SJIcpW4dRQbKKAqdaifrA1XTpCRS59DR0gRoAywVOa4s0CJSZN15pdA0NnnJFJourDyyPU1jodfLmVeW6DwmRkqTUrjmc0/VeBoH5TAnB7SLTKc1ddOyPY00bfdd6znRNgg7Z7i0RDEYYvojdM/iqppmMkfneXonEehqJq3SvquUwmmDVIZsYJjNauq6YX9/TJZpylwxHA24uTNha6+irlqKLGN1pSTMW2gt1Tx0vq1fXhz7n9T1fA39fA39fA39ldfQXzbwNGuShpnYgQdEZEygSipUI4h0yt9vLDcmDU9vz9mf1kignymm85rjq33WegW9PEub02InFPIA2Gpc6uZ630HrCcVIhuDWM6scN/drrA9sTWou7kwZ1ykS8tCopJdrbllfYm1Ysj4sGfbyzmuoS7vzC5+gBJ744Amxi67sqFyxA4CcD7TW0rYe5z1t6zomjKQsE3NLKIm1nuBT7KDs6JcJwZQI2RlhI7GtSzpOpdAmTwsLSRKXdK/JUI2FHlR1JmQRnJslA25j8E2bzP58Mm9L5owKpTVKqrQ/xEBdN1TzOdV8xnhWMa8aGusP2FwueHTHAlNKIbpuk1Gpux5iPADBjFbkRidQqvNsihFEumFAdDRciDExjqBjiJHM5xaMo5CEpR0TShE6SmLwi1cQAY8LyTi9saGTXQqisLQuvau5teTzOUMbyYseeW+A1AbCAmhyLIz4FmNJiNRdJCbgKxA6z6uEaEcW74wuKjPdi4/JR0ssfLSALCQ/sSCe+8DTtd05hVGs9XNaLQ+ilIuuIyGjoKlrrIe6aVOMqvf4IHDW41x6llKB9tDawKR2VN4jnEeFxJxwHaUzFw1GKpYHPfpl8vZYsO6IKT6Zrsg6s2nIjObkxhJHN9ZZHQ3olzoZW7Y1189fo6lb5vOGaedxcfL4OslTTjCdjtGqS5jQBd4LKkvqkMTkoda6iI2RSiXPBesCIaoDaW1ZmqSlblv6fUNRFOR5gRQRbxuKsgXvmI6hP+iR5QW95RGurnC2gZnAk1IyiyIjzzKUkOT9HrSW6f6MIh9S9Ao2Tm7SNjW2rcn6yyAks4nDlDki64IV6tQVWV4esDeuaOYN/byksZFJFdgaz7Deo43GTevkzeBtR+WTVD4Qgj9IoZEydVxDZ/arAilpRKfue2q9NQRlaCXYNjKdTnEusDRI2nQpJSFmiJCig1UXQ2utS34EIWnknU/rZWOTrj/533VNg5CA7BAjk8qxN6kodiXT+vMcPrrJyVtOsTxcIdN9xuMxbbfWgSD41BVztkUg0KpM6Sx4lJyTGUEICicNzqXvgZBkmWE0LNifttTWMqlCx/JMa6eISeP/3L9SmmmRK/b2LO984Cqvvvc2XjjI2b1wnne++9NcmXm+7kzB9VnLv//oDb7mRTkrfcULjms+9JnzPHplgtCGTKVudTWb08sNK8OCjY0VRISlm5aXveI2jmwOmd64Qb+IbO3UnL3vWzm6+yGWP3KB6f6k82FRPPDMDqpX8hfuup13vPMzPPzIM3zPG+/g4fM3+cxj13jrm+9jOqv56ANPoKRgeVjy6nvW+fBjlqeutvzI9389T1/e5Zd+/ZOMcnjpmSUGvYzffsdHaVrHC0eRjRVJVjg+9P4PMJ1bZpXnzuPLbCwNGC2tYNo9RAw4scJwOGQwLNk4vcl0Z5f9Gzs8+Dv/gelkxtaNG9z7yntYO3qC0S0v4yO//Z+5/tSDvOnwCe44dYSNb34Zv/szv8jGyRO87W//ZfaffILJ/pj3/vqvcOjISe542Vch3HXs+Cqfevv/xeZmjhkdZmbv5OXf+B3cvHSBd/3Wr3DHqWVuP7PK3/qVz6HVAwxLzde/4BCIdcaN4Kd+8SMMC8m/+WvfQN4bsl85fvB/fye3H1nhtiMr/PID24x04HTPMSxKtqYN//LTV/mRb7mXExsj/u7P/xEvOTHhxSdXufd4H+vh6taEh6/M2FwuePO9it996ArXt8f8uZce5uGbY372yV3+4Q+9EV81fOhT5/mrb3kxk3nLx5/c4oW3nuUNK0t8wysO84Untnny4h7f+VUZ95/f4m/+wof5gded5rV3HeG+l9/Gux94irf/8Yyzq8u85O7jvGmt4G/8uz/m0vnLPPS+j3H2ta9iaf0k9913lvf8/h8w94of/N6vTWyVxhOLjBfde5xXvuUkD/zhR6lmFYOyhwoW7wQVmh/85nv5gbe8mH/1qx/k6OY63/V19/Gr7/4cRgR+9odez396+0d4/Op+YgGILrzlOX7Nm4blvk6pSCYdsl3HPElNR8v1rYYmRIaZ6hQ1kbpuaJo2mdQajYl0ZsPJYLuuW4RPHkKubgkNbLuavPNp0UWBzDOEMQel0IKir0Sgpz1HhjllvsRw9Q6OH9lgbXnAQDRdIzCydW2LtmmZzebMK4cMgWOHlgidq83O3pTCCHpGkhXJpHs2m2PrOjU7o0nnBhk7ECbJh6RKVhdFYaiigMZRNy29XkmvLDiysUTdNFRVg212yYyhX+aUoyF5kbO8vko9nWDrGm/nJLuJSE9KpFHoMme3itTOMZ97DvWHFP0hMstp6oZm3jBcHoGQNC7Vs8lnNnX3PSJFhtce21pKVTCrWy7vj9mdTnE+JGZiaPERmtaTaUGuJc7ZLrU5WTtICUWWahJiYNZ6yiJnqcxQnZqjbVoKZXAusLXvmMxqrHMoIQ6anlWTDnj9wtA3nVrCBay11FUyTV54AV3bnRJDMhKeV5bGeqaNpTCJpXN533Fj1lJc3efM2LKxucHh48fIl1bp9SJkU6rxHr5tyGSy2Vj4o2olyYzEaUWIKaENHdAGKDRaSyQijU8io0FG07aMG8uNi7tJgicjhVE0nT3Lc/l6voZ+voZ+vob+ymvoLxt4ih0AISQoOkpaB0gIkjv7wlfJhZTS0bpI1SamjXeBad0ybTJa5zE6yc+kXJhvywPlWojx4Ofg6kg21gXmrWd/bml9YHdmqWyKQRyVOWvDkuV+wcnNZUb9nFGZY7RM0gLrsR2AgYwHMi9YKOYSnTFG8CI5u7tuw1gwhUJH4yUmKZ0XAVyi1iZT6pBQ3ZgINUolFFt2TKCU/JbWjcV/Q0AINkkZOzApodqJdSVDt7E5dwDYpBjrlKinDn46xo84uCGstbRtShOxLqWELMg+sWMxpeeb3kWkGzti4Vn1bIPsAFuJdKBTPGBBpUkRECRtr4yBRWKfiOrgOXdqwW48RTq4Kv1Wl163eCMLWd2z46HrirlAjJ5p1dK4gGkcQRh6LoJU5EWBEBKpdVr4Y7rnZ286dPfOAeV88UPXL0OoDvvrgL3wf38+HWimVALSxHOdLZE8toIXqCjROhWLUkS0TsCj85HWpfcYQkAuJJ+RZ/2+OMBmD9594wJKJoPPKCJKCEQMxAaCV7R5hu+kqOlaCDsTNTzTsFxkDMuck+t9VoY5vTIjCJJ3W9swm85pW0fTeHzoxlhnBLqQUIYQ8DbSCJeA5JgozMSIdmlcSQmBcDBmQ0wpJKmQSu80yJiSX0wyX1xIMTMt8R4a78hkhlQRgj+QkUaf6MLOWco8Q0hobSrcM63QsodUetHHTV0IrdG9fgI9XZuYiT6AjdSzGfVsStNaQkyGqNYlSv+kstStJ5CKPN/RXWOIaA1KpQ0cYgJFF2vrwo+OxTSXGCmh8+dLnaCAjBCiPPDxs84hVUTEFI4QYqBpI+CQgfQ2fZLD1p05IUBjQ8dqTeB+iBEXXEpiCYLGJ6qvD47tvTGio2ObkwqTGYyR+DYQvO+638n033fsYCmeTemIeCTp8LkItEifl6jFovOgiyHSuO64JGICxMWz6anP7WsBoAuKQnNkc0C/VyCkYnfWsLM/Z29imc4l00Yws5L9SY1rAWqk6tMv8255DwSfzIuBrtPoGRYZZ46vUNWWa1sTqp0Zw37JoOwjmjGhnXe+jKkzGyPgPbZpuXZ1B2xDqeHRp/fYnbQMexnj2ZzJpGZWWarWUVvHeH9KaRQbywN0dMwnU67d2OaeU0OkiOxXlhvbU5SUnD57FItM9USAsjBkZUFjPa6pmbkG2VYYBatLJVt7E7ZnNZvHNxAy/dn96ze5vjXm8Wdu8pLXSMqyxDtJjBIfI1vXbtIvBUePH+KpLzzNoJSMeppdIj5Cr5d8XYp+n3ps2NneYufmHoeP3oMyimDnrGweIkTHYGWV5eU+SgtOnz7KZG8PO5syqVpG/ZJjKwWPXr3B2MLW1LKZBTIlWRsN8UiujhvG04asFMSe5vruhGnjOLZcMJ3VXBWRfq4Z144nbowZDIbkStLXAtPvU2aSc5e22Zlb5l6wO7fsTWtmU8uxpYxrbcPTN2cc3eyDUGysr7A6GjLqZ2zvpEJVScHV/QpP5JYjI6yQ7FWOth5TaFgeZLRCsjW3RBW5/fAI6S2fePAJwtI6q0slq0eOMyqvYfcmXL54k6aqKTJBVTXs3thnMr+CMIbBIGJ0oJ57QDIYJMZ401pWV4cs93NK4emZjGGpOHtik9/+3GWu3khSwLvvvoPTt9zyJzctv8zLeZ+S2HzAddIOqRVKpENs21isdcm/VIvOPkEipe/m7JfWGfHgQNK2XZ0I6fAjwFmXPD0g1bIda3+RNS2kREtBoSWjQnF4uWQ46LGyuczm5oilQQ8/87i2oaprmk7u0lYNIqb0JSkkLiZwxnmPtVB5IM86JUAyoY0hoqQgz1KdGrxDdMzysJAM+tgpKBK7vDCaXmEoMt39OYn0Ai0lUoROxrWwylBgFMGJtNc4j9RFqumbOnmLSokyGhBdfHlMbAZTkBW9pKiwLjHZY0AES1XXzOdVOvx1DIjaOmZ1y+60pnIpdcZIQd2BaRFBX2X0i+RNZX3EdfcZvcC59N2FEJ0hsaTQ6iBFuWodmU4yxEUyWHqljjYu9imFd45Z1VB0IEXdtrjWdr4wDmMSg6iu2wPGmwud4bMAYiAEiRUCb9OY3Nraw0eBE5plkZHnOXmvoJ1Lgk0KDWN0ql2604PrjJQXoU/EgOpqKNkBnM6ls5SLILWGEGgajzKqqxshSvnseeQ5ej1fQz9fQz9fQ3/lNfSXDTwZmRDE5Hovun9OqDcxFQkL6VggzSwhn2UxVTEBRqnotGRGokM65MuONSW6AjjEcGA4/uxG25kOtp6daYsLaUHfmzuQmmEv4+hyybH1ERvLfY5trpFnCq0lbZ3c+Keh7iZdQoWUSoh/euBp4FVVA52kL23UCXCCJKlaUEEF0FrbgWHPJqBJCXmmkCK54mstUxSkMR2amtDDlFBhOkBloWtN3k0hJO2wlJH5LHlTmVx1IB8EmzZ8ZXRiOhmDLnKkVAfPnOAJ3tLUc+azOZNphbWBSErri6KTrHVFCnQHkBjxIhIOBh0Hkyzp7bvnEdOGu/if8x7rPZlJetBMdwkAB4uj6BbVpBO2C90+SXOsVCo2lFTpnceI92li+ZC07AtwqLGRxjpmrTvQOk/mLaNhhbUtq5sbZHlGlpfEGHFCsEBiYwQX2wMJ3+Igl9hudDuCSpxmJbpfPFFEopDg0iYKabzmmUoJi/9FQfjcvCQKvMS1IEwkM1DmGusWWnGLtZYQPIVeQIKKzgOeEMOBD9aCEO0jzGqHsxGixBQKrcDHQDuzSATWCiazltalsZwUj8lzS4nA0EROrvVYGfY4vFrgoqOpJ0ybwLyaMZ9NDxq0QUhMliS+89kcFxQgWR7ktHXLpG6xoiIzkmEpqdsa5yAGQdnTqTvnYmJWtuBiIDOKPBeJ+SYCOodembqqKHOQ+NXr9WiblmpeE2OTpL4TQaENMgraxiUPg2rO0qggBMd4PEarHv2ix3D5CG10tM7T7G8zWNlgeXUTTI73Dts2uMk2oa6hqti6eZO98ZhrWztkWZIE7O5X7M5bru3PUNKT6US5tp6uSBX0lWZYGtpgsQ4qK7soWACBFim6s402rVcGirxIciubuhlKSozOGfU1MXrqZkbrLJ7IsBS0jU/GlyJJb42QtK7GBY8NUJqCzGTMmpDMXqPDZFma/9FhvSREiZcZlkgMjp1JxWRaceXiVaSrWV9fYf3QBr7q1khnCWgiBhchBgu+BhL7MgSSMD6k5SmEFM9c26SVt0GiMoPqPA7qpibGSK9Iso7n/rUA79OB5cShET/81rv4/JOWpy5P+OC5fZYGGac3enzu6X2y/oDDy0vc3NnliWnDwxf3+St//mu54zbFv3vnx6kbR/BQlAWt82ztzbh5c5fNMxt841ffwq+/53GevrSHaCre+Lq7eeFtR9i5//fYPXeB2WR2ANwTA4f7iqGr+MPf+AAvfuFh7vmqW/jJX3uMl9+2xptfexu/+of307ae9UHJM9f2kBIOZ56X3HqMlbuGPHL/Qzx9bZ9qNuH4kdM8fXPKb3/6AhtLA249sc5r3vhyPvqJJ7l8aYeXv/AWDh8dsLJZ8lvv+CyXru1y6eYu01ayNiz4M6/K+cRDz3Bpt+b45hGGo5xieRVx7QZX9yre+9geb9xrGO1PmF5/nGFZIo4d4ZGHvsjtd5/m9rtO8nV/5nW0s5rtxx7k2qWr6N6Q13391zDenTHZn/HMxSlPPXGRq1cv87Xf/V30yoxq/zqD5RMUvZN87Td/HftXLhLain/991/PFz7/GJ/77CP84h8/we2Hh3znq07wqjPLnLs65v/7a/fzphcf5yWn1/mHf/7reO8D5/ngQxe4ZUnRzzWtynnvg+c5vFTwk9/1Sn7ufY/w2NV93vrS4zxwacIHzu2S5TX3HhvwLXetcPc9t3Jxe8Y//U9/zMnDa6yuLPNrn7vGZiE4MTTY/R1ubM34wrWKDzx2g7PHlvmf/+wruHF9nxs39vi13/oCRzbXWFoa8XPveZw3vfwk/+avfw0//85H+NgXr/He+5/gn/7IV/OiWzb4T3/0FO/+3DPc2Jvyv735dh66tMc//71P8q1PPsm9L7mbt/7AD/AN9824cfkZ3vV7n+Ku29Y5fWzI04/u8M4HH+KXP36RP/qZH+L0WsH180/y0E2LDYKve6Hnt9//JPc/ss2P/Z3vYOviFb74qS/wTS87SznokfcK1peXWB9N2Nod8xf/wvfxV/7y2/4kJ+eXdTnraVtLVVlcdJjMMBzmyEynTvd4hgyRopN5aa0RSlPGVDMnsCAcAL/WeerGMZs1OC0RMdIv8k4uEhnPG0Rt0cMJs1mS4CFInqNIykyz3DMcWym5/cQKK8sDBqtDikIhpePabMpkPGU6naLcIipbkGeKiKBqmo5dLlBaMa8aduY1WeMoy5ylUcm89cmz1UFZlvT6Ba5tiFistzRNANd19l1Axcig0Cz3M4b9nFx1YOowIwqFbxvsfIIkIIJHeEueabQuaIKnmXnq2jEYaVzTMpvskBtDkRcU5YgYPLPJHJUH8v6I0dKI3miAD4HYNExuXE/+T+2U3fGU2byims/JcoMuMrb2ptzcn3N5d8baSonRaQ2cT2qaxrG+MmBtlLMxKtI+YwNGOfbniaHioyCT6ZAulCbXkr4RWCmprWd/3mBDSGy1zJBlGZkJuHpG1ThaHxgMStq2ZXdasTk0xOC5uTvFty3OevbrQC/PKDKNdy3eR6wPFGVBnikGuUxSTh/wOiPXybT8xtYuN3annLu0xbFxy5Ej69xz10lim1MLy3x/jjAZpj/A2QbXJmN4V1e01jFrHP1Co6VIVic+edza1jFrLDtzS1EWRB2Y+5o8T/Vi0wa8UmCe21K752vo52vo52vor7yG/m9KtZNSdN2FRVqZPEAIXQcUBZ86koKEYEqVkLLFBEtMKIf1GuMlMiSPnSgjWqnEqOqUW/93PXqM6XNcR3nrG82gV7DUL+iXGUdWBiwN0j8XeVqMm7qlmje01tHalBgiuvsQnYRPyoTaxRhoWpsmpw8HFJ/YGTQmn6IFU+hZdpYPAe879LBDPRcGalJEJB6iIlHSFCZLCXc6M3hniR2NbwG0yaSyQ0pBa7tBQKAocpQxSGk6dFEkt3qpQCmE0l/CoOq6EDENnBgTKo9Pz7GyKaHNeo8XiWEVFwbpPHuP6f46NljwyeMJIHYeA4vFTELozB6JKdnOkxB+25lHKgHI9BkhJJf+zrkLHQUhIVEHz6LpunTOR6xLpnY+cJB+sZDeQVq4x/OWybyidp7BsM/q6gpSJPDRxc4wLYaDsZSoVx5J6AZcMg+UKqKQ3dhL6S8SiQqKGMHqlCQYQ2c83wF0z/krxsSGU4m56ANUdaBqk+dXa33qDAJ5l77ofKJPL7T8sTND7Po2SAGFiZSZQoqMXk8n7wrvaBvwQWAXoOwBly0xAwWQKclKqbv0DM/WfovzU5x3jGedvBfJrGmAgFKCEET33SNLgx5loZlVLZN5zf60guDRWjDJFYm5LZiEipnVCTAXoITu/N5k8nnDk0lNpmDQVywNcspM0/jEerMhsj+e4VpP2wSyviEGQ1U5bGyRIjIc5vjgadvIrEoU3MGoh4g+dZak67o/hqZW2Lal2t8i6hxd9iiWVrBRYOMe05vXmM0rxrOGizfmmC5xM3aRtKNSo1QKEJhWDUabdDBBU7nAfL8mkBal2HU3F+ua14l+7QhM6oa6bsiztkuA/P+1d+bRllX1nf/s4Qx3ePdN9aqKoqoohgKEYp5kECXGRJw6hhjTxkQxwQxNEm2jnaSTlbXsCCGdxAQTAYcMEtNxjoqCA4JREJFgBBQZC6qKmt987z3j3rv/2PveKjrdHXvZRFzrfNd6q2pVvXffufecs/fvfH/f3/eraEXay+kFRJE/54Pcy4GVdNS1J8eVUKH7ZClthZMyBAuA0hKtYbKbUFaSvAjnHV+8qTCaOzJNdMhxbHRm4V+++xRzswNOlTGdNKbTTVmaH1KZgtqCkIknsqXEWh+wANqvCzis8B4USipkAlWtKKRf/2Rk0ZEjz8ODW2nB+QLx2Q+/T1VVTSlrysLSZoW5dMiJm9Zw9JGzTPfafPauR5lMNMdNCqbnNqCV46JtQ/RgkScPDiiLCue8L5+QgnXTHTauaXPiSUezOCz4nffeyfpYsuWIHj/6skv4yp0Pccv/+Ce27zvAjvksKIAtx26c5eUXPYe779/Bdw6WzE3VPHrHk/Qrw8Jqxko2wWIGe3JBmVuszXjt619KksR85VO3siWOUJMtPnnfATZPd3jeyVuZm5sm7bZ5tTBs2Xo8WWW56vpb6AjDZKrRHMGu7as89O2Cs07fwjELszz4wHZueWA3ca/LKT/+SiaOe4LFA/txg30sLheUVckje2HdpuO4+sU/ynD7Y9z9xJOsDOHEM89k88lns/Tlz/GhT3yJh96fc+01v8djB57gfX/7eX7uJecyPTXBnbd+neNPO40jjjmOJG2jY0scl5TLy+TzBft3bue/XfdJlIDLn380648/ibQ7RX/PgxzcM8/C/Apvfc1FPPTEPq752Df48fO2cdoxGzlqzSzK5AxW+vzhR+7i/NM28duvu4SHH1uhHcPaKU1hSvbOr3LNTfezeW6SS2YnuffJZU7YNMOLzzmG5ZWMxZUhX/z2Pr70+AqzvZQrX3IiU7OTqChm557NHHnMZubWr+XuW28niVu88RXbqLIBi6sFH/jctzltLmYqjTjp9IvoJDWdpOb3L7+Qh3YucMU7b2W23WLrhil+4vkv5cvf3M4n73iMiTTl1I0TTJ84y527KtZPr+F3f3YLf3vLN3ngtm9xIHsPF59/KuuOO4tLZxb59sO7uOWeXfzIaVv5+VPP5eVXTHPTzV+gIw0XbjuaY7dOszzMueofHuDc07fw+vO28ZY/+wRnHruOn3jBGXz5rkd5fM8S33hynp/76Rfx/Beewy//1+u54T1/w+c+fxuf+cxnf9A36P8Vy1nFRNuSGUErjnAWFhb7WOlTgm1RgVReBRXMZhF+dCovTajFGKvRlRBo5dOjYu09NmdmJ3xYjnAsLvVxSNK0TZK0iZM8NIt9bVgZS+VAxDGVVAzKmv6e/b6DDxxcGHjvDgPF0KuuIq2IpV9nl3JDnHjFfVH6NDlrDPlgSFUU5HlOXZR+jEzCMMu8V03waBWOsa+mM5ZIOKRSJK2ETjshbUX4Xq9BmoK8CoE8ODq9LlGcUllJmWXUdUmcpFRV7YN38gIhBJ2JCZQfMfCqBKm9XsSUUGXYXOJSidQxaatLNVHhnGRh/gDD1VWG2ZCDK0OMkBikH1Oyhql2SqQ0Sgm0cKyfmQiKFkFe1uxb6COkojaQ1xbpvPIrL33islaSJJYsD3KWlgc+QQ9BZaCfQaEtLSfpJF6DsJpVnhxzjn5eIZWilY7UYHhlDRInoZUmTHRSuq0YV3sVV1FVFMaG0Rm8j5QQDK33m81qR6wTKmfJB0Pyx58gz/psWdshiTRRr0s5zBhmGYOyptuOfchTUfs06kiTRImv/WpvoixCYFArjuk6QYm3JRFI5nodwNf6tajDtMyze9SuqaGbGrqpob//Gvp7Jp5i7TdBJUWQifp/N25kpu0OG1c69BTuJYVBlhYktXWQ6NXG+hA36W9or5ARQfnkDiOdRqqUw49H0ko07SRhzVSXiZb/sxXrcKK9MsWPmvkYSBPIpPGIXThWT54EAskeStkbJeB5BKpJjN7niJQa/Y8/OinkOBVvJLGTIT1t9GLei0l5Us6OptpGcjd3GGnlf84GmSbCew9JrUMkroQo8aTR2Czbf681tU+WqGtMYC3FSB7owhyx8XJJK/AU0GHsiQ1jZWOCx/kZ8TpIO0cLsL9wGUtJrXUYYTHGy2b9ebCemAqEmkPgnDh0VkOigFdqBV8lY30CivFjm5WxQfI3UqL568jif66sfRFlTE2cRBhjSJOENKQUSiEwjOSuhOvVX7DOjW7c0TXr36ML1+74K5CWo0RDL5MNJNoPA/GEv0SkluF6d5SmHm+axni/Bx+sqBCADv4OMjiZjgjXse7UhZ6O9B5gcaTAOUpjkdK7YWrlpd3SuUPbZiBzpRBEyqff5IVByhJrC4ypyLMSISOEisjLGkKyi7XSb8ZGjK/PYV4yKEqGZYWrfdpDZRRxrJFC+M2zAoQikQqhQSsRvN/8GK4cjfw6fz87AVr7VMeqrMmqahwgIGWEUhF1VZMXBcIZelMdoijyqRbO/y4dt8Dkfk1TXqXohEJWDlvXFINVZMshkwSpFTptY8vSK/yC15xAUtaO0tY4V/qZdx2B8OetKA2R0iGZUYQuuMEIT7RLJZCBaPU+E/41vVzWUBhLXnu1YpokY5Wp/2xcCHNwKOVNW2tbgxV+Xl2EkATniKQnvkdjDQCRkjirqJWmdsZfL6N0NrycHMAJgXFyvBYfXBrikMwvrBKvmyKNNVJJXF1jjEGLKByj9LP1zq9hfo113nzXSSCkz4Qrr9Ya5SyxdEgsZenJfRMUnj8MEEJw7DHHMBcPUb0jmJxLcWnOVnkEx2xcw2SvzZEHNOs7gqPmEibXH0FV9lna+yhP7p7niQNDZqZmfIR2t0sUR6yfaXP0+gk2HHsi1d5lltxBnrN+ii1Hr+Wks8/knx8dsPrgCotKoif6bFQrPLV3yY+HTbYZVJal1YKdi0N2LgxYGOToSLN7oc+je1bord+MdDAbObozMz4A5Iij6a7fTDTd5qF9fTasXc/xJ57E1BEzmIV5tNyLjBTWSpaqlOm5FrOzHbqza3nq4R1858GdXLB2iqjdYesJJ/LtQcrEmjnWHHsySWuCwYG9LOx4lDzLMHmO7qV016xh/ZGbeGL3QVYO9LnvOw9x7DkXMn3ksUyuWc+ue3fwha89yHd2LPLQ9nnuuP9JLj73JETUojQa3Z4i7s1y4KHHWRwWLBcVDz68nSrP2LdzO7fedgeTvTZv/PGTmVi7kfb0GoZ7HmGpX/LUgVXOSDVFVfHNx/Zx+vHHkEQxU21Nq7WWlbzmnju+ztYtM3RSRWlA1v4ebcUK4yz3bD/IbK/NZCehX1nWr53m3JM3c/e9D7OnKHl47wrrNk2yvreGc854Dq1eAlKxZs4iJqaoooTv7u6zdjJi/RE94lRxYLHmnx/eS6fqsmG6QxavoyorclNy4oYey8OC27+1i/O3HsHG9bO86Pnn8fGvPsY3HtrLKVvWctrWTZx2wlH806N9Nmya5qJT1vHJB1bIspzloWHnoiXX3uy5UG1MSzJz1AnMbtpEd+Nmvvqlf6ZflcSzW5ib1cT9AYvmSeY2HcW2M45m8cZ7WXUxtFIe37vAtx7fx9ce2sub1kxy3JYj2HbS8ex8ah/fefDhH/St+W/C4tXbQnnD2toYBsOCKuw5kTMI7TvqxoITI/V3aAByqOYUYbRBhFox0opWrImT0UOP9Q1YPCGllDxkeRBexwRD2Nr6ESFV1uTDPIzsOfpZ7R+UkQyKGgEkMT4IR4jxMSEYG+4K4ShL77ma15ZUjhKNvV8nwk9HBAZtHC5k6pokkuH9yPE8khCAqXEG8kHuH7wk6DgmSmKqylFWNXVVkcYxWvmgIGt9inScxLiq8or1MLkBjrrKqcsC4cB0Up/gqSPiVoeqLP2DXGgeOyHJaz8CU5UVwjnacajD8XtWmmi0EFS1f5+DKijlnR9xE2GCoqpqpNCAQitBVlRkWRH8VH3XffT84G1LLAbLsDKIQDZQGRIpSSM/slMbF0oOhRaKSMa0kpgk9umBfuzRUnjGw9fuoS4WoYbyD8K+FitrQ7m8wlKimT+wyOxMlzhEqZdVTVX5c2XDfiycxQhBjUA6EC7UeM5bXSgliCNFK/EJhEpAqqVXgBhwWlPX7mnPIM9WNDV0U0M3NfT3V0N/z8RTmshx3KUfwXJhXt34tLcwtSTkYZ45Y07Xf5mwiGaVISm96ZcKc6FKQFX7xVApHTaxp0/8OkKCmIa1EzHT3RZzUx0mu12SOEJHMbUxwYgwo65r6qoOBmgjczA/422NlzxaHMYZT4aEdcBaT1pppVBSosMiY12Y3XWeONHKq2LkiDiTkjTRpElMHGmiSPt4RaXC+uKJkpFZo3A+IUDhRho/nDMhchIEhihSIBQqpEY4qRBao6IYFSWIOB2TZsJUYGpsmZOtrpINh6z0BxRFibE+WjUvDf28op/77gmBZBGIoLYakV52fE6DsnN8Xr3FkQhdFsZEm1YKnMUYQeEchxOO1ljq4P/kL+7RTLvfnGTlAgHnz7ux/rc450cCi7IOMuWRl9aIjPJjJ1SGvKoY5BlFVdJtLzNYHbBu7SzdbotWkvj52ZHvQbhm7XiG3sdHelbbhB6BJ9tgtHjgby4pcUJigCqQZM/+RCxQGpJU0evGLCxXZHnJSjag9AIunFVoCVoKrDN0EsVEqkgSiCJvpu4/t9G5ct67bVgSq4RWIqmNJzWLwtFpR7QiydqJiKeWHAqDNeBqrzQzVnlZqYPFQY6gZLqOSGOfKqmihEFR0+8PqE0VVJQSiSHSmrUzXYqqZn4lZ2Fp4HsBwjGsLMJISmA2sUSRdw7zSkGfWGOcZZj7JB8TFHZzE13A8Ni+ZebW9Jjuddi4YQ1LSxkH5/v0h32ffNPtsrHdodVuMahLntq5xKDfR3da6EQzPd1GyQojBLkVKKeJVExrYhKU9iRlWVL0VymyAVNHdZC2plpdJepOEicxLbOVGfUkSayZne6y+8AKuw+ssGfZpwOt6Ur6eUlR1+S1o4NXSGK88WHtKlaLMnxmCi38Z+MEpE6ghQS8qjCvDVm/ppPEzEz44IV2okl7ksWVIYOsYiWrQkHlzSVbcUSvrcGZQJhLJlod0iiico6iLCnLCmtrv07oGMo8bG6K2hkqa8HWSOG7RKsFwbvDEmv//h548ElqU7FmtsfU9BQsr1CtDrFVjVQKpWNs7VNFpAAVaxSCyIIzFmckMvKFW6IFkUyonaNyllhK6siglWBYlRRV9X+8d549EERRwkc/+uFxsbox7LDPGz2UCMGpPztSk/qd59M3fYaf+o3rQUjm1qzlNa9+Ha+87OWc99yzw8v6vVoKxzbg0l85RLpLpfmF//JqLn+bXzMf+dYX+OZXPsxbr/kUD27fx+/f8LnQnIAde+dH/RwA7n/iAB+98xHuuecujjvuOHDw4pe8jEF/wJe//CW0gt27d7Nj/7V0tp7FBb/ye+AM3/zYJ/iVd/05Qn6Rs886k9u/dDNqpOg1Obf80Z9x9ac+hLzpHl71qsu48QN/zaXOIBAoHaEnNjF1bMFRL1o/Hgc8f2EHt935IFf+8Rf586t+jemlvfzyX7yQc143y/NPewHrT7mYrw+vIrvtW7zip37Br2/G8mt/+EEuvOB8vvj5m1Ba8+SOXbzijb9Pv7+Mswb5wbtCQVpirOPCC57Lc152JVKDMwUzJ57CI59/gBvvfIK/u+O7Y2PSv7nla6GYc9x4499w6VlncPXfn8t1H7qVGz78pUNNPBHWXSFwQvGPdz5Ir5PwH15wMieccSLrzjiJP/mDj7B3/xJSKa774Ec566wzfF1SL+DqARuqIb/79mt557tuRERpUOxWITHMN7fufni0N98z6iB6JTgSKyLufHgfnaNO4phL30z7fXeTlQ/zjUf28eo3vpnLfv1KfjLsC0I4PvbKtwECIRWved2VfPbmD1P29/JHf3Q1v/27v4qSvnmDEFx9/Y3AyGvMYMsB77/gx0h6M8TdKW697XXc8YVP8/4PXMeH7nyE+eUMoRT79x/glBOO4s7b/5G3/PY7uP49N/673IHfD6anUmZm2qyZ6VLkhmFRcXBxQGH8Q2QaKVTs0BFIBp4sUgLQofscWmTj+kqENR7abc30RJvS+NRfVxtaoRZNZY2oC0yZe8VQ8L501lDmJYsLq0zGgjxSrPRzH3CDIIoUZe3IK8vySgZApCXrptu0koheJ8E6iylyVlf6JJGi00oYLA8pCkdla7asm6ST6mD56R/eWq2Yqqop8pqlfkZeVORFyZrJNknsyIzDKEVpIZnuUJUFw/6AXbvnQUe0ez3WCYlSEVnmRxerIkdFEUmiabd71HmFlAodRQwHFodEtXzdjBMszeesrCxSFgVpN6WlI5KWpTM1hU5iyuESExMpVTEknS7Zv7jCwYUVFoc5WgraLU1hLGVpWC4qRDtBJRGdNKGfVWSVYyUrEc4RSXCmwhhDVlRokaCFZrkoGeYlw7xiOa+JI007iekkmlhrIi1ZGmTkZcXysEYJhxaQ2IpWrJhKFQeXK7KiJqtgst2iFUd0kyTYbViy2lLW/k+pvcJVS8Egr3zKIN6rVCrJcmFCH1ggTcXK/CJ33HU/W4/ewJoZb2NSrSxTZAOWqxKFQznDcpYxqCz7clg3EdONJe1YUBQhXUwJT4RKB6kfq0qEICvAWI2a6HBgNcMMyx/Mjfk9oqmhmxq6qaG//xr6eyaeZGCPnPMGaiaoglxov4gwsyoCu44YbYlPhwubZuDng/qIMfOIsUhjgrz3sId5ceg4YiVoRZJWJImVRDiDqb15V1kHJ/iixARizATFjrX4mXDhiLQM/24piopRmKJUnoCpxwl1Eu2U17cEpZM3Qw8jdeE9qEihlSee4kh5A76QaufESE0UPJpCXKKzhS8AjR0XEYTY2FFRplQwgUxiRFA62SDlRHjPKSf8ouBKP2JX5zn5YMigP2B5deilx8G0vKhCUXIYNTmi9w43WreBSBmp2cCNz+Yh8sn/72j8zhgxHpUEr44TeBP62lYY6x8AnPApfSaMqznnu2TgDqXIWefjNzlMdeQOHdPomN1hX7VzCOMYZlUwYxQo5Q3a1cyk776IYOBuQ5doxMyHa2Fkluv+l0tv1FkcdeOkUign0OOx32e5RBiYaPtNMStq8rKmso4oihHSjFV+QoRrW3rTvdJIn+gQNP7+EhldCSIoCL3ZX2Wc70yGEUZbO1Yrx679i9y3a4mH9vcRWtBNYiYSzdFru0y1E3YvZAjl46RjYbE2IooUeWVYzUoW+wWzvchvpMIbU2rpmf6y8gaBnTQKHRavhNNaMdlJgYK8tBRFwWQnop0KbyRY+w4EjmDGWTDZaZNEMdPT0wghyIqafj/HGEOSKCwt4jii244ZDJYpqhyhFe3eFDLpsGf/Ap00odtuoVsxpjTkq6s+DlULpJaoKAYEtY5BxVhZUlUlyAzhoL+6hDGGusjoTvbotFNM7ufzha2x+DSLyjlMeLDrtnwCo792FXEUeZlu5LsiCoFxltoahlXlGwLCkcTad8lx9KzvXsVKUNc1GYaFVe+HF0eKuSDp98LLIAVWABEKQRq6bgLrvdqERErt73EcCItQ4THbt+sZj7fiH4Qc0pP/FlqJQigYliUPPbGPPQdXOfnYDcQ6YmZmktWVEicEVjq/IVuHC/Jx54y//ixYJ/x65/ntkMAUlJjOUFlDGbrFSj3bR+3GKzBaR5TDPgv7d/L3n7iZvLK89TffhJCK/uoq77jqGoZZjtYxb3vrm4jTKSbnTuC1//GlbDvpeE48/gSO23oMOtK4Oue227/CTZ/9PL/1tjezdu0ahKi5/v3/wMOPPIFD8NOXvYwLnnsW2IpHntzHx2/9NqsDX6yMSPe1a2Z4zStfxBe/cg8PfPdxQPAjl1zMy17yIt7z3r9i27ZtXH7567FEWPz+KJRkanqWa65+O6dsO8mvLzLh9DPP5k//5Gre9ZfvYcfOXfzBVVfxk6+8jNPPOBOk4sde/BLS7hRXX30N1oHUsQ+0AK8YSFo4HR2WuCpJJtZy8qmKK6/oceSGOao1Xf70ne/k7LPP8WrikZLbWeraQQiZGKXLSO0NdWemJ7n6qrdTVSVFkXPNH7+LhfmD4z1TSIVMWr7bqSJacyfwistezdqjTuIdV/0hS4tLgMAJHZ7DfSfaq6Ill774R3neBedx9X+/luXllUOn3/n7yIXu9N0P7GTf6u3cdPt9LK0MfPCIk2NFNa7GOQkiQbUmePlPvJrZ9cfzx+/8C5YWF4KJ8uEvP9pJ/b3Z7nT4nd96C71eD4TEmZzNmzYjVMzlP/sqTjj6SN553QcRwj+04gxf/eqdfOzjn+Stv/lmNhx5JCB5/c//DC+4+HxMOeB5z7soJPwe8stQOhofw3tueB/33/8tTLaIjBL/mcuE4zYfwU/+/C9zyo8scu+/PMAN7/1rPnLz3Tx5oOAdF/wMOuqA/J7L2R8YOmnEREvTa0vmC+8PkqYJcVAdVFVNSylasVezyLEJNcTSN8PGY3ZKksSaNPW2DbWD5awkyw1KSdqtmGFtWS0LBvOr7Nh9kP0H/f6Sxpp2EtHrpCgpWVwe0Im8KmUlq1DS78cdIVnNSpYHZYhPj+h0Up+0LAVpov2D1bAkUpJOGtPtJORhPMgIjZHSx5VXFb0JRSp94psSXkkhlhylMSwMSnozU6Rpi3Y79cnBtaEYZj6duagRUYqMIqTWrCwskkcZlVW+SS0U+w8uoOIYnSZ0Wy3qqma4vEKilB+1UZo4SUEqon4LkRcYm+GcoCpLqqUF5vveK0ZaQ7s3iRITpEVBpCTKGpypqSpDaXyDMlKSdhwhHD612vmpholum07HV/MSR5FnZEVJVlZeKVP5ZrBAkMYRaRKFMSZBWVeIwiGUJNIQa81EuxemHwQT3TatSCAVpEnEaERCax+KozDU1nkLEKmII3AKMuN/96A0lMabwhMMl6314UtSQCQFSaRRUtAfDHli134WVwaoYzagpWaiN0GW11RVRVZWXlWjQcaCYWWwpkanAqe8xchKUVEaR+n82KESgjh48LrasDgoqJwkSls/yNvz30RTQzc1dFNDf/819Pe8UwtxaPRqlEDhiaFRSppEuEAOiEPkE6Gjdzie9lAvBaMhOu/a78AKb9g8Jj9Gr+AJFx02rlh55t6rbII8tPIjV2VVjU0YRzSFtYATSEmQG/r3kpWBccQRaxHIFIeVLhBHI/JBwNilXo67yTIQQFpLTzppT0IJpQ6NZY1MvAMJZfHdCIlPBpJjmm7Upz40EiiVREcagtLGEyOBuhPeNwqlsKbCITBlSZHn5FnOMCu8P5L1HklV7X2d3OjUjD7g8ToYyCfrggLsEOnkOJSqYMc/EsgiAcL6z2X0PUJ4ryeEw9USY00gHgFhDktGCgU1nmkeeThJeSiBZcz6uP8dweNvBOv8eSsq7+eEdbRbCVLC5EQ7EGGHqapCeiChEzcaKRwdoh+nPESejsZGR+dfSZDKIZ0b+5g9m9FOvLqwrAxF5RdfpSOfUmEsFTUOP0roN01BZS3WCJyxT/vsRejEE77fz7KHkU5nUeFcZkXNw7uXeHTfMjsXB6AE7VbETDfhiOkOnUix0C9ppY5EO3Lh45UNgqK2DIua1bxk7VQcxn011LUnwq2XtFd1zWSa4IRXJQ4jSxJHTLRT+sOKsqpZzWq6LeuTdSIo8QS6J0wtw6Kkso5UKXqtDkWZU1aGfFjhhPPdKumNOdtpRJYPEWVBq90mbfeQieCpnTsQ05N0Ox1UnEKdUeZDhIgwzpOyfiPTCKVAaZzSmNqgRIFzjmxpyY8ExzHddodYT8BAUGY55XDIIC8ZVoZBaTAOkJI0ln4cwPmH5Uh781KlfRy3sFAYgzM+tcdZnzCSKEUY1g/3gcMZn3hiK0dlK1pRQqI1nU6EcRKLIJICY2tKU4LQaKloaQWmAmdReMJdytHDe0gJCvdfSJ/wf5eMfStABbmu9N5DSlDVNbv2LpImAzavm2FudoJuN2GYhaQPLELpcVPEmsrf+/gkMuP8dcT4vlajCQ9fSDgTkn7EWNr8wwFBVWQs7d3Jxz/yUZazirf8599ABh+V977v/SwsrpKmHa74xdej4zaTM5u57LJXcdEFZ3Bo0Xc4U3Lvvfdw3XU38EtXXM7auRmcKfnUp2/h1tu/hnNw8nOO44LnnoGzJTv2zPPle7aT5dXTjmdmqsdlL72Ex554akw8nXXmafziG17LGee8kJ279nD55W/wDykyguBW0OlO8MYrLg/riwWh2Lp1K8cds4mPf+LTfO2ur/OBD3yAU049ndPPPBuU5uxzz+Pkbafw7ndfH95HKMLCsQgV+3sMGFUPMu1x1NETHHX0lvAzk1x55X867HtGX2F3E94PxhNDo8/LMtHt8Eu/9IuAj0p+93v/joXFRcZ7hZAIFYfmW0QyuZELL17PqaefwbXX/gVLi8vhcLW/JoPSFlcDkvPPO4crfuG1XPvu9x1GPIXXDmtwWRke3L6PB7fvG7+/w9+r/6sJl71CRlNc+LxL2Hbq2dzwvr9meWmRf10EHHY2hfcFesMbLmf9+nW+YVT1xyTei194MZvXz3Dtez/CSJqPM9x333385buv5/LLX8eGIzcCcOmPXfKvXh9nwms9fY/99Gdu5jM3fQaEOnQ9AFf+6hv5tTf9Oi8Qis/e/AVuuOGv+Ke7v8vCUPMO1UGoJNRaz26kiSeVWolE4kdykth7dprga6mloBVGbnwN6C0GtHDhOvHkk5Qi1JwaFWlqB1Ve0R+UJHFEq5NSVDVZXrJ73zz75pc9QWktsfZqpXYae3KhX7AU+3S41dKSxI4kgjj2e/DyIGd2agKdxLQ6LaQtEUIQR5KyMgyykl7Lj3Z1Wgmd0lIjcSr2Xk91hSkqJjo+sSuSwnfpha/Ha2Pp5xW1iBBJi7TdQprKkzyFT+0rS4OIEmSkkUoxWO2TyxwRtUNjXLK0tIpstdFWknanyAvD/PKA2V4HGXkSRsUxUkXoOEFIFXKrwNQVVZ6z/8Aqpq6ZbQmSVpd2GtOtc6o8pxj06Q8TBhSsVhVa+hq3FUW+oVlbKmGJEk2SxKRx5NvI1rGqGNs3mDDyVhv//BRrRbcV+xXG+LpGALquaCeKJNK02wmlEdRWMjM9iXI1lDlRVIfbyB1autwohTvU4RpSAUXhQ4B8mtcIIvhu+WZsJIUn5rQGHHlRsu/gEv1hwYZ1s8z0UlqthLwcUFvISkMrjUFLlFPkxRCDoRcH/1kkgzLDOIEVgjKQHk4oRsLH1ayEOEHF8b/3Lfn/hKaGbmropob+/mto4Z6ez9qgQYMGDRo0aNCgQYMGDRo0aNCgwf8XPPtbRA0aNGjQoEGDBg0aNGjQoEGDBg1+KNEQTw0aNGjQoEGDBg0aNGjQoEGDBg2eETTEU4MGDRo0aNCgQYMGDRo0aNCgQYNnBA3x1KBBgwYNGjRo0KBBgwYNGjRo0OAZQUM8NWjQoEGDBg0aNGjQoEGDBg0aNHhG0BBPDRo0aNCgQYMGDRo0aNCgQYMGDZ4RNMRTgwYNGjRo0KBBgwYNGjRo0KBBg2cEDfHUoEGDBg0aNGjQoEGDBg0aNGjQ4BlBQzw1aNCgQYMGDRo0aNCgQYMGDRo0eEbwPwETLR5ZIOZ3NgAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAABJ4AAADyCAYAAAAMag/YAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjcuMCwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy88F64QAAAACXBIWXMAAA9hAAAPYQGoP6dpAAEAAElEQVR4nOydd5xcVfn/37dP25nt2fTeExJJIBhKIJTQQSkC0hVpKqDSLEjxK6JIEUSKBUH8SVMM0qv0DiEEQkvvyfapt53fH+fO7MzuJmwgQMD7eb02mblz7r3nnnuec57zOU9RhBCCECFChAgRIkSIECFChAgRIkSIECG2MNTPuwIhQoQIESJEiBAhQoQIESJEiBAhvpwIiacQIUKECBEiRIgQIUKECBEiRIgQnwpC4ilEiBAhQoQIESJEiBAhQoQIESLEp4KQeAoRIkSIECFChAgRIkSIECFChAjxqSAknkKECBEiRIgQIUKECBEiRIgQIUJ8KgiJpxAhQoQIESJEiBAhQoQIESJEiBCfCkLiKUSIECFChAgRIkSIECFChAgRIsSngpB4ChEiRIgQIUKECBEiRIgQIUKECPGpICSeQoQIESJEiBAhQoQIESJEiBAhQnwq2OqIJ0VRuPDCC/tUdtiwYRx//PGbfY8lS5agKAo333zzZp/7WWNrrevxxx/PsGHDPrLcrrvuyq677vqp1ydEiBAhQmwduPDCC1EU5fOuxmeGzdFbQoQIUYmPq8t/mrj55ptRFIUlS5Zsstz/2lgXIsTWir6uS0N8vtjixFNxsH7llVe2yPWee+45LrzwQtra2rbI9UKECPHFw5YeVz4pstksF154IU8++WSfyr/99ttceOGFH6nEbgn88pe/5J577vnU7xPifwNF2Sv+RSIRBgwYwJw5c/jd735HZ2fnFrnPqlWruPDCC3njjTe2yPW64+9//ztXXXXVp3LtvuDTfr5yXHfddVvdZlWIzx/dZVnXdQYOHMjxxx/PypUrP+/qhQgR4lNAucxv6q+v+uxnhXD9/+WE/nlXoDtyuRy63lWt5557josuuojjjz+e6urqirLvvvsuqrrVGW2FKMPDDz/8eVchRIgtjmw2y0UXXQTQJ4u+t99+m4suuohdd931U9+R+eUvf8mhhx7KwQcf/KneJ8T/Fi6++GKGDx+O4zisWbOGJ598kjPPPJMrrriCuXPnss0225TK/vSnP+W8887brOuvWrWKiy66iGHDhjF16tQtXHtJPL311luceeaZW/zafcGn/XzluO6666ivr9/qrEhCbB0oynI+n+eFF17g5ptv5plnnuGtt94iEol83tX7QuHjjHUhQnyWuPXWWyu+33LLLTzyyCM9jo8fP/6zrNZHYlPr/95w00034fv+p1+xEJ8IWx3xtDmTnmVZn2JNekcmkyEej3/m991S+Kzrb5rmZ3avECFCfDrwfR/btsNFyf8w9tlnH6ZPn176fv755/P444+z//77c+CBB/LOO+8QjUYB0HW9YgPp88QXfc7eWiCEIJ/Pl95xiC8uymX529/+NvX19Vx22WXMnTuXww8//HOu3SeD67r4vv+Z6Z5b01gXIkRvOProoyu+v/DCCzzyyCM9jn8cbE3zgmEYn3cVQvQBn4m50PHHH08ikWDlypUcfPDBJBIJGhoa+NGPfoTneRVly2MlXHjhhZx99tkADB8+vGQOWHRX6e4X3tLSwo9+9CMmT55MIpEgmUyyzz77MG/evI9V76JZ8n//+19OO+00GhsbGTRoUOn3Bx54gJ133pl4PE5VVRX77bcfCxYs+NjP3tbWxvHHH08qlaK6uprjjjtuoyaGCxcu5NBDD6W2tpZIJML06dOZO3fuFq8/wD333MOkSZOIRCJMmjSJf/3rX31uw+4xnp588kkUReGOO+7goosuYuDAgVRVVXHooYfS3t5OoVDgzDPPpLGxkUQiwQknnEChUKi45l/+8hdmz55NY2MjlmUxYcIE/vCHP/S4t+/7XHjhhQwYMIBYLMZuu+3G22+/3Ws8gba2Ns4880wGDx6MZVmMGjWKyy67LGTPt2L0VbaKcdIuv/xyrrzySoYOHUo0GmXWrFm89dZbFdfcWEyyct/xJUuW0NDQAMBFF11UGpc2FuPl5ptv5rDDDgNgt91269Ws+aNk8fHHH0dVVS644IKKa//9739HUZRS/1cUhUwmw1//+tfSfYp9fWP+773FqFAUhe9+97vcdtttTJw4EcuyePDBBwFYuXIlJ554Iv369cOyLCZOnMif//znXp89xJcbs2fP5mc/+xlLly7lb3/7W+l4b33qkUceYaeddqK6uppEIsHYsWP58Y9/DMh5YbvttgPghBNOKPXdcnexO++8k2nTphGNRqmvr+foo4/u4R5UHBM+/PBD9t13X6qqqvjmN7/Jrrvuyn333cfSpUtL1y6XhUKhwM9//nNGjRqFZVkMHjyYc845p8fcUygUOOuss2hoaKCqqooDDzyQFStWfGQ79eX5XnzxRfbee29SqRSxWIxZs2bx7LPPln4vEnvHHntsxbWfeeYZNE3j3HPPBaRetGDBAv773/+W7lMc0zYWj6a3eDbDhg1j//3356GHHmL69OlEo1FuuOEGIJwvv2zYeeedAfjwww8rjm+Onvnss8/ygx/8gIaGBuLxOF/72tdYv359RVkhBL/4xS8YNGhQSSfrTeeEvvWx8rn9qquuYuTIkViWxdtvv93n+gMsWLCA2bNnE41GGTRoEL/4xS/63Jc3NX/eeeedTJgwgWg0yle/+lXmz58PwA033MCoUaOIRCLsuuuuPVzwn376aQ477DCGDBlSGo/OOusscrlcj/sX71Gun/c21/u+z1VXXcXEiROJRCL069ePk08+mdbW1j49Z4gvN/q6rtrUvLB06VIOPPBA4vE4jY2NnHXWWTz00EO9uvF91Hz3Uev/3tC935ePD7///e8ZMWIEsViMvfbai+XLlyOE4JJLLmHQoEFEo1EOOuggWlpaKq7573//m/32248BAwZgWRYjR47kkksu6bF+B0r3iEajbL/99jz99NO9rin6qm98WfGZ0fSe5zFnzhxmzJjB5ZdfzqOPPspvf/tbRo4cyamnntrrOV//+td57733+H//7/9x5ZVXUl9fD1Ba9HXHokWLuOeeezjssMMYPnw4a9eu5YYbbmDWrFm8/fbbDBgw4GPV/bTTTqOhoYELLriATCYDSNPF4447jjlz5nDZZZeRzWb5wx/+wE477cTrr79e0fn78uxCCA466CCeeeYZTjnlFMaPH8+//vUvjjvuuB71WbBgATvuuCMDBw7kvPPOIx6Pc8cdd3DwwQdz991387WvfW2L1f/hhx/mkEMOYcKECVx66aU0NzdzwgknVBBYHweXXnop0WiU8847jw8++IBrrrkGwzBQVZXW1lYuvPDCkgn48OHDKxbcf/jDH5g4cSIHHngguq5z7733ctppp+H7Pqeffnqp3Pnnn8+vf/1rDjjgAObMmcO8efOYM2cO+Xy+oi7ZbJZZs2axcuVKTj75ZIYMGcJzzz3H+eefz+rVqz/XuCAhNo3NGVduueUWOjs7Of3008nn81x99dXMnj2b+fPn069fvz7fs6GhgT/84Q+ceuqpfO1rX+PrX/86QIWrUTl22WUXvv/97/O73/2OH//4xyVz5uL/fZHF2bNnc9ppp3HppZdy8MEHs+2227J69Wq+973vsccee3DKKaeUrvXtb3+b7bffnu985zsAjBw5cvMaNcDjjz/OHXfcwXe/+13q6+sZNmwYa9euZYcddigp1g0NDTzwwAN861vfoqOj43NzYwrx+eGYY47hxz/+MQ8//DAnnXRSr2UWLFjA/vvvzzbbbMPFF1+MZVl88MEHJUVz/PjxXHzxxVxwwQV85zvfKS2EZ86cCcjF7QknnMB2223HpZdeytq1a7n66qt59tlnef311yvM8F3XZc6cOey0005cfvnlxGIxmpqaaG9vZ8WKFVx55ZUAJBIJQC7IDjzwQJ555hm+853vMH78eObPn8+VV17Je++9VxEv7dvf/jZ/+9vfOOqoo5g5cyaPP/44++2330e20Uc93+OPP84+++zDtGnT+PnPf46qqqWFwNNPP83222/P+PHjueSSSzj77LM59NBDOfDAA8lkMhx//PGMGzeOiy++GICrrrqK733veyQSCX7yk58AbNb4Vo53332XI488kpNPPpmTTjqJsWPHhvPllxDFxVxNTU3p2Obqmd/73veoqanh5z//OUuWLOGqq67iu9/9LrfffnupzAUXXMAvfvEL9t13X/bdd19ee+019tprL2zbrrjW5vaxv/zlL+Tzeb7zne9gWRa1tbV9rv+aNWvYbbfdcF23VO7GG2/8xBYcTz/9NHPnzi3ppJdeein7778/55xzDtdddx2nnXYara2t/PrXv+bEE0/k8ccfL5175513ks1mOfXUU6mrq+Oll17immuuYcWKFdx5552lcvfddx/f+MY3mDx5Mpdeeimtra1861vfYuDAgT3qc/LJJ5fG0e9///ssXryYa6+9ltdff51nn302tBb5H0df11XQ+7yQyWSYPXs2q1ev5owzzqCpqYm///3vPPHEEz3u1Zf5bnPX/5vCbbfdhm3bfO9736OlpYVf//rXHH744cyePZsnn3ySc889t7QO/dGPflSxkXrzzTeTSCT4wQ9+QCKR4PHHH+eCCy6go6OD3/zmNxXt993vfpedd96Zs846iyVLlnDwwQdTU1NTsV7eHH3jSwuxhfGXv/xFAOLll18uHTvuuOMEIC6++OKKsl/5ylfEtGnTKo4B4uc//3np+29+8xsBiMWLF/e419ChQ8Vxxx1X+p7P54XneRVlFi9eLCzLqrj34sWLBSD+8pe/9OlZdtppJ+G6bul4Z2enqK6uFieddFJF+TVr1ohUKlVxvK/Pfs899whA/PrXvy4dc11X7Lzzzj3quvvuu4vJkyeLfD5fOub7vpg5c6YYPXr0Fq3/1KlTRf/+/UVbW1vp2MMPPywAMXTo0I22XRGzZs0Ss2bNKn1/4oknBCAmTZokbNsuHT/yyCOFoihin332qTj/q1/9ao/7ZLPZHveZM2eOGDFiRMWz6LouDj744IpyF154oQAq+s0ll1wi4vG4eO+99yrKnnfeeULTNLFs2bKPfM4Qny4+ybhSlPdoNCpWrFhROv7iiy8KQJx11lmlY937a/m9yvvh+vXre4xVm8Kdd94pAPHEE09UHN8cWcxkMmLUqFFi4sSJIp/Pi/32208kk0mxdOnSinPj8XhF/97YMxTx85//XHSfCgChqqpYsGBBxfFvfetbon///mLDhg0Vx4844giRSqV6lc0QX2z0JnvdkUqlxFe+8pXS9+596sorrxSAWL9+/Uav8fLLL/c6L9u2LRobG8WkSZNELpcrHf/Pf/4jAHHBBReUjhXHhPPOO6/H9ffbb79e+/+tt94qVFUVTz/9dMXx66+/XgDi2WefFUII8cYbbwhAnHbaaRXljjrqqD6NBRt7Pt/3xejRo8WcOXOE7/ul49lsVgwfPlzsueeepWOe54mddtpJ9OvXT2zYsEGcfvrpQtf1Hu9m4sSJvY5jvcm6EF3vuFzPGjp0qADEgw8+WFE2nC+/uCi+50cffVSsX79eLF++XNx1112ioaFBWJYlli9fXiq7uXrmHnvsUdF/zzrrLKFpWkl3XLdunTBNU+y3334V5X784x9/bJ2sOLcnk0mxbt26irJ9rf+ZZ54pAPHiiy+Wjq1bt06kUqmNrj3KsbH507KsinNvuOEGAYimpibR0dFROn7++ef3uE9v8+ill14qFEWpmO8nT54sBg0aJDo7O0vHnnzyyR76+dNPPy0Acdttt1Vc88EHH+z1eIgvN04//fQefbYv6yohNj4v/Pa3vxWAuOeee0rHcrmcGDduXIXuuznz3abW/72hu45bHB8aGhoq1rBFmZsyZYpwHKd0/MgjjxSmaVaMGb21y8knnyxisVipXKFQEHV1dWK77baruN7NN98sgIq5uK/6xpcZn2lk7uKufBE777wzixYt2mLXtyyrFGzc8zyam5tLJv2vvfbax77uSSedhKZppe+PPPIIbW1tHHnkkWzYsKH0p2kaM2bM6JXh/ahnv//++9F1vcJKQ9M0vve971Wc19LSwuOPP87hhx9OZ2dn6d7Nzc3MmTOH999/v4f7wcet/+rVq3njjTc47rjjSKVSpfP33HNPJkyYsDlN2APHHntsxQ7LjBkzEEJw4oknVpSbMWMGy5cvx3Xd0rHynaj29nY2bNjArFmzWLRoEe3t7QA89thjuK7LaaedVnG97u0Jcndp5513pqampqI99thjDzzP46mnnvpEzxri00Vfx5WDDz64Yidw++23Z8aMGdx///2feh03hs0ZS2KxGDfffDPvvPMOu+yyC/fddx9XXnklQ4YM+VTqNmvWrAo5F0Jw9913c8ABByCEqKjvnDlzaG9v/0TjbIgvLhKJxCaz2xUtkv79739vtjvWK6+8wrp16zjttNMqYoztt99+jBs3jvvuu6/HORuzou4Nd955J+PHj2fcuHEVfXr27NkAJRksjhPf//73K87/pFZ+b7zxBu+//z5HHXUUzc3NpftnMhl23313nnrqqVKbqarKzTffTDqdZp999uG6667j/PPPr4i9tSUxfPhw5syZU3EsnC+/+Nhjjz1oaGhg8ODBHHroocTjcebOnVvamf84euZ3vvOdCpeznXfeGc/zWLp0KQCPPvpoyeqgvFxv8rO5feyQQw6psITYnPrff//97LDDDmy//fal8xsaGvjmN7/5MVtXYvfdd6/wfJgxY0aprlVVVT2Ol+ss5TpuJpNhw4YNzJw5EyEEr7/+OiCTFcyfP59jjz22ZL0Jct6ePHlyRV3uvPNOUqkUe+65Z0V7Tps2jUQi0euaJcT/Fvqyriqit3nhwQcfZODAgRx44IGlY5FIpIcV9ObMd1sKhx12WMUatihzRx99dEV8thkzZmDbdsXYVt4uxbFk5513JpvNsnDhQkDqKM3NzZx00kkV1/vmN79ZYUUKfdc3vsz4zFztIpFIDxO5mpqaLepf7Ps+V199Nddddx2LFy+u8MGsq6v72NcdPnx4xff3338foNRRuiOZTFZ878uzL126lP79+1dMIABjx46t+P7BBx8ghOBnP/sZP/vZz3q9/7p16yoW2B+3/kWFYfTo0T3KfFIyr/tiuTgoDB48uMdx3/dpb28vvcNnn32Wn//85zz//PNks9mK8u3t7aRSqVLdR40aVfF7bW1tj4Hg/fff580339yoCee6des28+lCfFbYnHGlt348ZswY7rjjjk+tfh+FzR1LdtxxR0499VR+//vfM2fOnB5E7ZZE93Fj/fr1tLW1ceONN3LjjTf2ek4oK/+bSKfTNDY2bvT3b3zjG/zxj3/k29/+Nueddx677747X//61zn00EM/MjNtcSzvPhcCjBs3jmeeeabimK7rm+UK/v777/POO+985Pi/dOlSVFXt4braW702B8UxoDe3+iLa29tL89bIkSNL8S8mTZq0UT1gS6D7GADhfPllwO9//3vGjBlDe3s7f/7zn3nqqacqkvV8HD2zu05X7K/FuXhj+mRDQ8Mn1sm699PNqf/SpUtLC9FyfFK53hwdF6jQWZYtW8YFF1zA3Llze+gyRRJgYzpu8Vi5fv7+++/T3t6+0TE6lNkQfVlXFdHbvLB06VJGjhzZI95Z9/65ufPdlsAnkcUFCxbw05/+lMcff5yOjo4e9YSNy6Ku6z1irfVV3/gy4zMjnsotbj4t/PKXv+RnP/sZJ554Ipdccgm1tbWoqsqZZ575iRjU7r7exWvdeuutNDU19SjfPcPFlnz24r1/9KMf9WCci+je+T9p/T8NbKxNNnZcCAHI4Je7774748aN44orrmDw4MGYpsn999/PlVde+bHes+/77Lnnnpxzzjm9/j5mzJjNvmaIzwZbelxRFKXU18rRWyDBLYHNlcVCoVAK0vjhhx+SzWaJxWJ9uldvQYVh48+2sXHj6KOP3qjSsLE4VyG+vFixYgXt7e29LoCKiEajPPXUUzzxxBPcd999PPjgg9x+++3Mnj2bhx9+eIvKcbnlc1/g+z6TJ0/miiuu6PX37srplkZRrn7zm98wderUXst035B6+OGHAWn10Nzc3OvY0Rs+6RhQrG84X36xsf3225es5A4++GB22mknjjrqKN59910SicTH0jM/SnfbHGxuH9vYXLU59d/S+Lg6rud57LnnnrS0tHDuuecybtw44vE4K1eu5Pjjj//YOm5jYyO33XZbr79/nLg5Ib482Nx11SeJf/Zx5rtPio8ri21tbcyaNYtkMsnFF1/MyJEjiUQivPbaa5x77rkfWxY/T31ja8BWnwN0Y4pSb7jrrrvYbbfd+NOf/lRxvK2trRSYbEuguOPZ2NjIHnvssUWuOXToUB577DHS6XSF0L377rsV5UaMGAHItJEf9959rf/QoUOBLoa6HN3r9Vnh3nvvpVAoMHfu3AoWu7t5YrHuH3zwQQU739zc3GMHaeTIkaTT6S32LkNsneitH7/33nsVOxI1NTW9uukVdzSK2JxxaVPlN3cs+fnPf84777zD5Zdfzrnnnst5553H7373uz7dq6amptcsmd2fbWMoZvLyPC+UlRAl3HrrrQAbXeAVoaoqu+++O7vvvjtXXHEFv/zlL/nJT37CE088wR577LHRflscy999990eloHvvvtu6fePwqZkcN68eey+++6blOuhQ4fi+z4ffvhhhTVEX+fCjxoDkslkn+Tq+uuv55FHHuH//u//uPTSSzn55JP597//3ad7FXeR29raKgKy93UMKNY3nC+/PNA0jUsvvZTddtuNa6+9lvPOO2+L6JndUa5PFq8P0pJ2S+tkm1P/oUOHblU67vz583nvvff461//WpHB8pFHHqkoV67jdkf3YyNHjuTRRx9lxx133CrS3ofYutDXddWmMHToUN5++22EEBXzT299Efo2322unr2l8eSTT9Lc3Mw///lPdtlll9LxxYsXV5Qrl8XddtutdNx1XZYsWVKxIdtXfePLjM80xtPHQTweB+h1wdQdmqb12F258847e/iif1LMmTOHZDLJL3/5SxzH6fF79xSyfcG+++6L67oV6Ss9z+Oaa66pKNfY2Miuu+7KDTfcwOrVqz/Wvfta//79+zN16lT++te/Vvj4PvLII6V0tZ81igx1+Xtub2/nL3/5S0W53XffHV3Xe6QDvfbaa3tc8/DDD+f555/noYce6vFbW1tbRXypEF9c3HPPPRVjwUsvvcSLL77IPvvsUzo2cuRIFi5cWCFH8+bNq0jzCpSsjPoyLsHGx7HNGUtefPFFLr/8cs4880x++MMfcvbZZ3Pttdfy3//+t8e9eqvXyJEjaW9v58033ywdW716Nf/617/69AyapnHIIYdw991389Zbb22yriH+N/D4449zySWXMHz48E3GROmeohgo7XYWUwhvTEamT59OY2Mj119/fUW64QceeIB33nmnT1nlitfvHqsC5Pi/cuVKbrrpph6/5XK5UibY4jjRnejtaxa3jT3ftGnTGDlyJJdffjnpdLrHeeVytXjxYs4++2wOOeQQfvzjH3P55Zczd+5cbrnllh732tgYAFTEyMlkMvz1r3/t0zNAOF9+GbHrrruy/fbbc9VVV5HP57eIntkde+yxB4ZhcM0111Tob73JzyftY5tT/3333ZcXXniBl156qeL3jVkHfdroTccVQnD11VdXlBswYACTJk3illtuqRg3/vvf/zJ//vyKsocffjie53HJJZf0uJ/run3WY0J8OdHXddWmMGfOHFauXMncuXNLx/L5fI95dXPmu81Z/38a6K1dbNvmuuuuqyg3ffp06urquOmmmyrGpttuu60Hqd5XfePLjK3e4mnatGkA/OQnP+GII47AMAwOOOCAUocsx/7778/FF1/MCSecwMyZM5k/fz633XZbxe7KlkAymeQPf/gDxxxzDNtuuy1HHHEEDQ0NLFu2jPvuu48dd9yxV4JjUzjggAPYcccdOe+881iyZAkTJkzgn//8Z6+K8u9//3t22mknJk+ezEknncSIESNYu3Ytzz//PCtWrGDevHlbrP6XXnop++23HzvttBMnnngiLS0tXHPNNUycOLHXQePTxl577YVpmhxwwAGcfPLJpNNpbrrpJhobGysUjH79+nHGGWfw29/+lgMPPJC9996befPm8cADD1BfX1/BNJ999tnMnTuX/fffn+OPP55p06aRyWSYP38+d911F0uWLNmiFnMhPh+MGjWKnXbaiVNPPZVCocBVV11FXV1dhTn/iSeeyBVXXMGcOXP41re+xbp167j++uuZOHFihX93NBplwoQJ3H777YwZM4ba2lomTZrEpEmTer331KlT0TSNyy67jPb2dizLYvbs2TQ2NvZJFvP5PMcddxyjR4/m//7v/wC46KKLuPfeeznhhBOYP39+aUycNm0ajz76KFdccQUDBgxg+PDhzJgxgyOOOIJzzz2Xr33ta3z/+98nm83yhz/8gTFjxvQ5XtuvfvUrnnjiCWbMmMFJJ53EhAkTaGlp4bXXXuPRRx/tlWAI8eXAAw88wMKFC3Fdl7Vr1/L444/zyCOPMHToUObOnVsR+Ls7Lr74Yp566in2228/hg4dyrp167juuusYNGgQO+20EyBJkerqaq6//nqqqqqIx+PMmDGD4cOHc9lll3HCCScwa9YsjjzySNauXcvVV1/NsGHDOOuss/pU/2nTpnH77bfzgx/8gO22245EIsEBBxzAMcccwx133MEpp5zCE088wY477ojneSxcuJA77riDhx56iOnTpzN16lSOPPJIrrvuOtrb25k5cyaPPfZYrxYHvWFTz/fHP/6RffbZh4kTJ3LCCScwcOBAVq5cyRNPPEEymeTee+8tJd+IRqOlDZWTTz6Zu+++mzPOOIM99tiDAQMGlJ71D3/4A7/4xS8YNWoUjY2NzJ49m7322oshQ4bwrW99i7PPPhtN0/jzn/9cGnP6gnC+/HLi7LPP5rDDDuPmm2/mlFNO+cR6Znc0NDTwox/9iEsvvZT999+ffffdl9dff72kk3WvyyftY32t/znnnMOtt97K3nvvzRlnnEE8HufGG29k6NChFZs0nxXGjRvHyJEj+dGPfsTKlStJJpPcfffdvcat/OUvf8lBBx3EjjvuyAknnEBrayvXXnstkyZNqtDPZ82axcknn8yll17KG2+8wV577YVhGLz//vvceeedXH311Rx66KGf5WOG2IrQ13XVpnDyySdz7bXXcuSRR3LGGWfQv39/brvttpJeUFxzqarap/kONm/9/2lg5syZ1NTUcNxxx/H9738fRVG49dZbexi4mKbJhRdeyPe+9z1mz57N4YcfzpIlS7j55pt7xL3qq77xpcaWTpO3sbTn8Xi8R9mNpSHtnpb4kksuEQMHDhSqqlakVhw6dGhFCtZ8Pi9++MMfiv79+4toNCp23HFH8fzzz/dIkV5Msdg9rXFfnqUcTzzxhJgzZ45IpVIiEomIkSNHiuOPP1688sorH+vZm5ubxTHHHCOSyaRIpVLimGOOEa+//nqvdf3www/FscceK5qamoRhGGLgwIFi//33F3fdddcWrb8QQtx9991i/PjxwrIsMWHCBPHPf/5zo6nZu6N72z/xxBMCEHfeeWdFuY3VtdhO5Wm4586dK7bZZhsRiUTEsGHDxGWXXSb+/Oc/90i76bqu+NnPfiaamppENBoVs2fPFu+8846oq6sTp5xySsV9Ojs7xfnnny9GjRolTNMU9fX1YubMmeLyyy8Xtm1/5HOG+HTxScaVorz/5je/Eb/97W/F4MGDhWVZYueddxbz5s3rcf7f/vY3MWLECGGappg6dap46KGHeu3vzz33nJg2bZowTbNP6dRvuukmMWLECKFpWkV6WSE+WhaLqanLUz4LIcQrr7widF0Xp556aunYwoULxS677CKi0WiPNNUPP/ywmDRpkjBNU4wdO1b87W9/2+g4fPrpp/f6HGvXrhWnn366GDx4sDAMQzQ1NYndd99d3HjjjZt8/hBfTBRlr/hnmqZoamoSe+65p7j66qsrUoMX0b1PPfbYY+Kggw4SAwYMEKZpigEDBogjjzyyR7r0f//732LChAlC1/Ue897tt98uvvKVrwjLskRtba345je/KVasWFFx/sbGBCGESKfT4qijjhLV1dU90o3bti0uu+wyMXHiRGFZlqipqRHTpk0TF110kWhvby+Vy+Vy4vvf/76oq6sT8XhcHHDAAWL58uV9kv+Per7XX39dfP3rXxd1dXXCsiwxdOhQcfjhh4vHHntMCCHE1VdfLQBx9913V1xz2bJlIplMin333bd0bM2aNWK//fYTVVVVPdI5v/rqq2LGjBnCNE0xZMgQccUVV5Tecfn8OXToULHffvv1+hzhfPnFxKZ0Qs/zxMiRI8XIkSOF67pCiE+mZxZ1vfJ5zvM8cdFFF5V09F133VW89dZbPXR5IfrWx8rn9t7Ql/oLIcSbb74pZs2aJSKRiBg4cKC45JJLxJ/+9Kc+pXLv6/y5sbr2phO//fbbYo899hCJRELU19eLk046ScybN6/XtcA//vEPMW7cOGFZlpg0aZKYO3euOOSQQ8S4ceN61PXGG28U06ZNE9FoVFRVVYnJkyeLc845R6xatWqTzxjiy4XTTz+9R5/t67pqU/PCokWLxH777Sei0ahoaGgQP/zhD8Xdd98tAPHCCy9UlP2o+a6Ija3/e0N3PX1zZE6I3seyZ599Vuywww4iGo2KAQMGiHPOOUc89NBDPcY2IYT43e9+J4YOHSosyxLbb7+9ePbZZ8W0adPE3nvvXVGur/rGlxWKEB8j8l+IEF9QtLW1UVNTwy9+8Qt+8pOffN7VCfEZYMmSJQwfPpzf/OY3/OhHP/q8qxMiRIgQIUKECPGpYOrUqTQ0NPSICxUixGeNq666irPOOosVK1ZUZMH8X4Dv+zQ0NPD1r3+9V9e6/1Vs9TGeQoT4uMjlcj2OFeMJ7Lrrrp9tZUKECBEiRIgQIUKE2AJwHKdHvKsnn3ySefPmhTpuiM8c3ddc+XyeG264gdGjR3/pSad8Pt/DBe+WW26hpaUllMVu2OpjPIUI8XFx++23c/PNN7PvvvuSSCR45pln+H//7/+x1157seOOO37e1QsRIkSIECFChAgRYrOxcuVK9thjD44++mgGDBjAwoULuf7662lqauKUU075vKsX4n8MX//61xkyZAhTp06lvb2dv/3tbyxcuPBzC9T/WeKFF17grLPO4rDDDqOuro7XXnuNP/3pT0yaNInDDjvs867eVoWQeArxpcU222yDruv8+te/pqOjoxRw/Be/+MXnXbUQIUKECBEiRIgQIT4WampqmDZtGn/84x9Zv3498Xic/fbbj1/96lfU1dV93tUL8T+GOXPm8Mc//pHbbrsNz/OYMGEC//jHP/jGN77xeVftU8ewYcMYPHgwv/vd72hpaaG2tpZjjz2WX/3qV5im+XlXb6tCGOMpRIgQIUKECBEiRIgQIUKECBEixKeCMMZTiBAhQoQIESJEiBAhQoQIESJEiE8FIfEUIkSIECFChAgRIkSIECFChAgR4lNBSDyFCBEiRIgQIUKECBEiRIgQIUKE+FTQ5+DiCz9ciu/7CCFKKQMVRSn9+b5fKiuECI53ffc8HyU40PVbZZnS9VQVz3VL91JVtcc9VFUtnVeEoigV55QfL/7fvZ7lv3c/r/zaxesW6wgKSnDc9z0ExWuBLwQEf8L3EL5HoZDD8zw8z0FBAALf91FVDUVVUVWtWFsUpdhGKoqqoSgqmmagqMG9FUCAQEFTVRRFRVVUFDWol6IghHxOP/hfFGusKKiKWvYuu56zItyXAEHQlrJCFWU2FRqsvK3K31Wpgbq91+I76GrbyvfW233Lyxbfe/d3yUbqWP4ei/1BFK9Z9jtQ0ecr+hrBeyh73qmTxm+0TbYGLHhv0Ra4Svc2LX9fW+DyWzG65F5B4MuWUESpSSr7B6X+5wfyLn/vku/gAhD0u2JbytPK21mhR7sX79njffSO7vLa/bvSh5fXfaztjk3J78fCZoUfLI4P9Lltuo/vANtMGLs5NfxMIdtTxbKivPrqiySTtTz19Mu0t60mmYxz1FFHVbT5E088wb/nzuX8886jvr6BfN7hgQf+Q6GQ56ijjuKJJ57gww8/5Nhjj+X555/n3nvvZfiwsRQKBVasXMSpp55KPB7niiuuYNdd92Xq1OkMHJikULBp78hw/33/Zu3aNaxbt45//vOfrF61hupUIzt8dToDBvbjvv/8h2nTp7PHHntwzDHHsH79eu6//37WrFlDQ0MDZ555JoqikMlkuOWWW5gyZQozZ86seObddtuNxYsXc8YZZ3D77bfz7rvvct555xGJREplMpkM69ev56677kLXdc444wyam5sxDINzzz0Xy7J6bc8lS5bwu9/9jm9+85uMGTOGW2+9lfXr15PL5Tj33HOpqanpcc7RRx/Nfffdx3dOPoVUKkV1KskxxxxDVVUVIDOpqqpaymLT0dHBrbfeiuu65PN5LrvsMsaOHcexxxzH8uVLyeVl+umGhgbi8TgA9913H0899RTHHnsss2fP5ogjjqiow+GHH85dd91V+m6aJsceeyz9+vWjtraWK6+8khUrVgAwfdoOJJMpnvzvI+y7777MnDmTX/3qV3R0dPR4thNOOIFddtmFo48+mvvvv58HHniAW265hSOP+ia/+901fHWHGbz55jwATjzxRMaNG8eqVas46KCDmDFjBrfccguvvfEez734Nh8sfJZZu8zkgQceYPGiFgoFl7HjGvnBD87i1ltv5Z133uHdd9/lzjvv5O9//zvNzc0A3HvvvQwbNoxtt92WsROmMGTEaFYsXYYZiZKsrmHWDlOpSsQAQcHOUVtby7dOPIkzzzyTa6+9dpN6ydaAjg6HTCZLe0cnnR1ZdF2jujpBJuPgOD6u7eF5BRAuVakEruviODa1tTW4HrS35YknLBSgvT1DJBrBMAyE8DAMjYhpoOsaAvA9QcHOI3wfTdMxDA1FEaxatQxFVdB1HV8o+J6H4+RJJqsxTQswcF0P3/PQNUXOcQgy2Ty6bpBIJOns9PB9QSSiE4sKLBN0U+qoqqqiqiqu65PL21hWBAWVQg50A1QVfM8hm8mTyeSIJ6Qs+56L5/r4AkBD1aR+G09E8Twfx/FYs2YDCmBFDKqrY4BPW1srmq6haRqGbuD7Urf2fYjFIlTXJHEcj0LeZcP6TlQNPM9h5coVVFUlSaVSxBNRfM/DLhRIpVIYhoGmqaiqXI9EIiYoIHzBmjWtCCHQNA3TMFA1FVUVtHe0ksvnsG2PZFWSeKKK5g0dFAo2+bxNU1MdkYiOrkHBzeO4DulsjppkDdXJFL4LtuOSzTvE4yaarqEqKoWCg+/7RCI6vu9JnVUg1weKiu0owVTp4TkuruPS3JwmFjeJRDVaWtejqgqmYVJb2w9dMxCAYepoqgooCF/gez7ZnINpakTjBrmsQyHv0tGRp7a2CkPX6exwQHFB8YIe7QMumiLbQdd18nkH1/NQVY9MNkcuZ5NO50kkItTWVuE4gAK6plJVZSGEx4qVq9BUFVVTmDFjymcpkpuFUIf+ZAh16FCHhs0gnooLcOhJCHQnGrpQSYJ0L6N0u0bpt15ecOULK7tDQDp81AtTuh0vnrPJziS6ndxtgBAlUsJHCoUkekTxz/fxfTeY2Av4nofve3KiQkFTNTRdRwnIo7JKSDETPsITKKqGpqoIXylVSZRYDw1VFSia/Cwfr9iWQgp4kQQrcVZ+oEzIewVcUCWK+kZRtoPe6MuK4ft+BVnUg5Dqdqz4uYKE6gZR6vHdCCchKoivcsKp6310kY5CyNbZFHHVQ0Etq6OoOFzZv8ufVwjR1Qc2+lRfNnQfzL+k2IhQFAlh2Qx+BYFbPC0oKVtHUVCKvwf9W5QmwYB4rxC00khFd1momBjKDnWR3kr3osHH3vt8+Xi+KUK5t8mv9/G+92tu9uTZx8mya1zqfrzv0ii6N+ZWDl03iUYkyfHhoqVcdfVfWfzhiwwb1sQ3vvENNE1DCFBVhZk77si206aTSMSxCy4tLWmuv/5GOjpaOeKII/jXv/7FPff8m0MPO4xdd92VmTN3ZPddv8boMSP4882/K93zN7+5PNh8AOFDR2eOZcvWcMkv/o9p207lrrvu4q233qJ5QxtDBo/nhBNOYrvtp/DPf/6T+++7n0cffYy9996H+fPnc/7553P//Q+wy6xdUADfF7S0tPGzn/2MU089tQfxpOs6q1ev5rzzzivu5XDBBRcA8rPv+3zj8MO57e+38cYb83jm6ac599xzufHGmzj66KPRtI3PN8OGDeM3v/kNqqqyfPlyfvKTn/CDH/yAX/3qV7iuh+f5Pc7XdZ1sNstVV16BEBCPxznggANIJCRJ8Pvf/x5d1znkkENQVZWWlhZ++tOfks1mS9eY/+YCLvz5L7j/gX8zbfq2ABx55FHcccft6LpUyZLJJBdeeCEDBgzoIWu6rmMYRul7Mpnkoosu4sEHHyylUJdkBOy5534MGzqcF196hoceeoiHHnqo9Ht3/PWvt/Dccy9wxBFHsO+++7LDDjvwn//ch6Ko5G0PLbiv7wtuvfVWxo0bx8svv4xpmrS0tHDJJZdQ128bZs46lvVr3i89y/ARtaV3p6kapmni+4Idd9yJHXbYgaf++zStre1oWtf8qqoaX521B3P2P4QnH3mcN155hqcevoenH/k3Qvi4rouu60yaNImjjjy6YkNxa0ZHZ4FCwcF1fVxPAJJQcRwHzxVouo5lRdA0iEYtfF/HdXU0XcfzXFzPRcFEUZVALVIwDJ14PIaKHM/yBRtFAcPUyLZlcByHeDyKophomko0GkE3dEzLwjASuI5DOt2GoWuoKqiagScUFFSS1VEc2yafz6EAmqpiGDqRiIKqKtTWREG4CCEJMiEkFWGZBp4n8DwPhI+maySq9EA3FgjVwLJcfF/HtDQMXccwE3S0Z3EdD1XTgrkVMpk8+bxDLldg/bp2TFOjpjaBFTFRVejoVMhmM/i+T01NLVL/FdTWplA1Fdsu4NiCQt4lm3FQVB9fODiu/GxaCrl8DkM3SKZSmEZEboqqSolIk9O9wPN9fOHhuQLX9dE0DVRQFUgmq4jHY7R35EBRyeXygI+igqYpeJ5NLmuTz+fRDKlgFwo2ruviux6+r8jr+z6uJ4kdXxHkcgVc10VgyDWE8LFMK9DDBY4bzMfClRvdwseyVCxLwzQNIpEEEBCNvoKHwBeCSETBsiQhmc+55F3ZF1FAt1Ucx8F1HXzfRggPX6jkCzaCAqgOsahBPp+nszNNv36NaLqK5/lE4zoIhY6ODI5dwC7Y+ELW2/M8PD9YqwWrT1XTiMerUVXZp778CHXoUIf+39ah+0w8Qe8L+fJFeLGTaJpWKlNOOPRk+3qykL1ZtPRmxVROBPRm/dT9/uXnfNTzdT2PVLbVkkeiZGZ94VG0dCoRFsFOhOs6+J6L73t4vovwu4gpJWgbtWilpKpomrR46hLI8vpTkhshfBDydwFyh0IIfFwUVcXXNFRNR1U1aUVV5KV8v4w/k4IccFNBnbpEM6DPKgg3VVEDZSGwnhK9t2sPlP9eVoeyxu5xnrRAEnKXqTeSp9t9i+RXb/Uo5wyLfaR4vu97QM/rlhQMKvth8V7l9Sx9VlVKWvX/BMoH8y/bpNnteYq7MwqB5Pj4vofjutj5NJ7r4No5+fqRCpSqdFkwKqoa7JoaqIqKqmll/QsUJSBIu02MFUNUiQztvX+VH/+oHZnux7uPxxuT6Y3t0nQfSz9qfA3xyXHkkYdz/vk/ZtDAwQwY4PP3v11BoZDDMHRA5cWX32PZivUctN8OPPbw8/zjb//hnJ+cQUtLK7fefDs//MG5jB03DE3TOO3UsznkkG+TiEsiS0Fh/Da7MnhwIwDpjE1rc46Xn1/GlG0HMnBQimf+u4L+A2OMHTOEEUPH0Vg/uDTYjhg5jH/ccQNvL1jOg/e/yqOPPs5Tj77CI/c9TzSSYPfdd+eVV17B8yw+/HA1o0b25957F/HW/FXccN3VjBs/Hi/YpFEVFd0wuemmm8hmswgBr722jvXrsuyyyyDSnWnWr2vloQfmMWnySAoFm12m783U0TvxzW99jRefX8qlF97BD398CJqq4Tk+kZgWLNilErt0yXJ+f+2fOfKbX2f0qOFceN4lbPfV6eTzNj/87qWMmzCS7571TRzbDqyY4eKLL+acc84B4K15q/hg4TqqErW8/sqb3HXbPVx4wSXU1KZ48ZkXGT5qBA31/XjqqadLMpRudTAtnarqCFG9lvUrMzQMiBMx44wZPZHbbvsr+ZxKNu1TV9vAmlUdvLtgLdtuP5h4lYnjOPzq0l/x05/+FOiaA2tr6zjooIPZfvsZKApkMy4rlncyeZthVNfE2X6H52ltayeTztCvsQbTNNENg3Xr0qiqQn1dnN9d9SDr12dQFI2rrrqKO26/g3/84/8xbNhwknGLO26/nWVLW3n66VXM3LE/w4fXoGk6ra05Mhl4+OFHmD8vw7NPdfD3W+9i2LBqAFqa8zSvL/DS063st/d3OOaYE3j8npWMHFdg2o4Dmbnd99hxhs+hR2zD5Mmj6Uzn2XW377P9lFlMGzuMGROPZ+2qA1my6AcMH1XLq6+8wg/O+jFXXPlLBg8ZwMyZM0sWXls70mkHRQHLMiVJ7AtcxyOfL+C5HtGIhYtA+OC5Jq7nYdsOmpYlX8iTza6nuro/0WiM6MBqdF1HUVTSmRyapmDoGrZjA+D5Kh0dGWzHkTq5UNB1Fdf1cD2fgu2jaxqe65LP2yiKhyF8VCxs28VxPKyMnPc0TaO2LiFnQS9DMhlHVSUZhnBBeKiqwPF8HNdH00BVNCKWSXtHHrCprUmgKpLM8VxwHId8Loemg6aCrkdwHJ983gHh4Hk+AoFp6uTzBXK5ApGIgRXRsCxoa2vB8xza21tpbWmjULCx8za6rqLpKvF4DMVTcBwHhIbr+viei6FrGJpJ/6ZGotEImqrS0txGJBLBMi0c3GC+VtBNDRRBLl8ozdOGrqPi40mFWRJAwfjg+1DIuyiqh6YpqJqLgWwj17XxPJ/21gz9muqJJ6KkUtUYmgq4aJpKRFXQDZN0Jo/vgapqdKazuK6DwEBRfRRFoKmAYgAG0aiG7/nksx6aLklbMj6u60FBIZfzECjoqkIsBpqqUPSvkHqtCqqHorm4fgHhaJCHTDpHPl+goz1LMhXDMBUMyyGby1PIF3AKOh0dnTS3tJFIVGGaPo6tEI1poPgUnAK6oRCPm+TyDnbBIZvNE4tGUDUFRQlIBx9sR6AqoKr/C3p0qEOHOnTPz8Vy/ws69GYRTyUEbdjjJUHJVal07CMYu42t1z+q8Xuzein/rURSlFmjbIph7G65I59HBFaARcJDTjAi2PXwPTe4h7RuEr6P59p4nhuY+nqlK6mKKomfwDy26FLYdd9S7cvqKEr0r1L6pzhsFZ/NR/gBCyxAqAJ0SRgFrAtq6USldNmK/7tuXXpeiqaLpeYSG323XfXu/X1X8KHl55RZq5W/h+7vZmPYWD/rfh35W/l1N953Nob/hcGg7+iaTLra9QusMIiypyiysqL4WZK8ihD4noPnuRQcG6eQk9+dAlJwVBRF7lCqaPhCoPgKwlfRdBCqFpSjtDGjKgq+Ii0fSxWBsnatmBK78fQ9Sfsej9XLZNe1s9RTdja1m1PRWMH9+7obszmTaUWdP7pwz2r16R7yhC+atdNee+1NU1MTH374Po2N/aiqqiKZHMzCd1eQy7mAQjRqkUjEaGm2URSLQYP7Yxga0ajF4CH9GT16FP3792fBgtXE4ynGjKnnvXdXk6iKkUrF2XbbidTVVJFLu/ieQNVUElURTFNuZsTiBtGoSSwWYebMHejfvwnHFcyYsQPZbIbhI4awfn0WxxGMGTOWTJtPIaNg6Dp2waWQByui4XuCD97fgBA+TU1JpkyZSjJVQy7nlCx4hRAkEtXEE9XU1aZwnQY2rM8xceIAMpksLc3tZNMR+jVV4zo+20yZjO8LJk6ayOpVDpq2AQDXccnnXHTTor09zdIlaxk9ZiCaplFfV4dlWZimwTZTp9LYrx++79PUv4Ha2pTsK4pCIWezcsV6mprqqamu59VXXyeVSrLt9CYsy8A0TVI1NYwePZpkKsGH732I74PwFUaPHoMaWKi8//YqYgmLgYNrWLM8LS0IRIzJkycTjcWZMGEihbxCZ4fNG/M+RHgKsXgERVXwPR+7UKDguaDrjBwyQi56PY+1azsxTJ2hw0agazq27VNXl6e6WseyVIYNG0l9Ok0+l6epqRbPU8nmBTU1HgoCTRFst91XaGvLoaoqdXV1jBw1ivHjx2MYcVav7GTQoKEkkwNwnEYmTayjpsZi9YpOVF3Bsgz6N43Bc9roaFnDxIkjiMcNViwpoJsC09RIVRsMGVLPoKFRVn/wIZGYdM2avt1kIhGdbSaPpa29gw0bOpg1awfGjBpCMh5lQ3OGqqo6pk5tYMCgJL7ns99++zJt+jQMQ2XhwoWSXPgCQNcVfCEt/RBCWsOoGqap42kquhFYHakKni8QqOi6gS98HKdALteJ69YhRARdV0sWIgXbRgFsVRJLmib1TMuy0HQ9IFUMNE0hGo3iej6uG2y4aXLciFiBBb6m43kyxILcbPQBH1XREcLDdRxMK4pAULA9TC3YUNUVfDx8X1oAFeexXM5BCEhWRTFNXW4UCx8FDVXVcRwXTdMCKzYV0zDwPA/XlRZe0nDOQ1E8wMF1XbI5D8eVm6JyYaqiKgqe56MHbneeJzeDs9ksumbiOALfd0qbvqovXcwcx8X1PDxfWmcJ4SMCgkxR5XO4jic3RFGCWVn01MmVon6vlZ7fc6XVkOMWSOgJdE0nGvUxDQtDN0H1EJ6L7dpouoYvFFwfstkCvg+Wacl5SgHf99BVRVphKnJDW+BLMk+Tm6u6poImsKIWWrARremGfIWKRj7nBBZlgOLjuiquJ90iHdfF89wgpIfAMDWEMOT4o4Dn+3IzWlPRNR1Nk9Z5iUQCTdPlJrpVDPkhLTPRFIQByaRA16UFlkBuZKuKJtscSYgGGspnJImfN0IdOtSh/3d1aEVsamVfhrffX1x203IrEdkLyl2viiQNgdJWEXeneOOgY8gGLR7rIgTKP/cWW6q3/8tfftFCpYKEosvVq4crnqJU3KsUp4ng5RWtZYTcNfF8N7Bs8vEDc2LhCzzfKZnDlltkSSukSkseVVUDhleR9wu6iapqJWsrJSCARFk9i8/ne9LyqhSLSdVQVA1Dl8qGtH5SS7Ghis8l/C7XR+H7kgCSRwLmOSDigjoU29IPnlHev2j6SMUzFcv2iJVVJLK6tXexbPe26d5fuj4XLdEq+1zXZ/nGlG7vuMIyr6zflPeNjQ8yvbuSdu9nUyaOY2vG2+8v3iSR1x3didjy4z3xxZk0uyaNMlK3YnrqInwFAt918V0Hu5DFdWzyhRxCeKXxQdc0VE1D080gVpsCoiiboGp64C5rSrkIJk4FuTjQdaPUd5WA/e2a14K+WaagVMqFUlb1Yj8mGH67Twxlpbqd0/26RWxsd6ZcTst/29RuTl8m14ryfSjTtdtR/Np3RaI0T5VhmwlbrwyvW9vCDTdezyWXXMirr77OhAkTUFX4+UW30Nqa5srfnoKmqti2z3PPNDNgYJQx4xLkci6qqmBZkvBZsbKNq658nEMOmcrkbQbwi0vuYvSYYey44xRGjkzg2T7rV+WoabSwoppcFKhyTPV8uSBVVeho78AXKqoaIRbX0DQCt3JKpJWmK2iaQntbB6+/9ja3/XUuPzz326SqG/jbrS+zz77j2WbKAAA62nO0t2apa4ijGxqaqvDfZ97A83x2mzWdznYbp+BT308uen1fLjJt2yfdaVOVNGVdyzZuPFfQ0Zaloz1LbWOSV15ayJ+u/w8/+fkxjBozENf2MSM6igrtbVk0XUU3VGJRCwU5LysKrFyxgb/f9gi7zZpOLG5w5FHHc8KJR3LKKccTiVoUCi7tHTlqa+JomoJdcEl3FHAcj0SViWFIRfpvtz1EQ0M1M786nvXrChimzsiRjWSzeVzXJ5lMoKiQzeQ54YRL2W77cZx99pHSKqBQoL21mb//59+sXr+BH554Jpam4ToeDz21gJqaKGPHNhKPJohETKprIjSvb5WLWKFiaCqGrpGqrWLlqgxvLWhlhxn98B2bt15bzORpw2nsn6K7mL6/cAMvPreMOfuPpaYuhq4p5HMe7a05/vvwIqZM78/YSQ3YeYGqgW5Ikm3V8gKP39fKbvvUMGiYhe9BMaKA54nAtQZcVy7iVU3htlseo7U1zWnfOwBNU8nlHK677mkmTGhizpzx2Hm5MLYiOkLA/PnzmT59Oq4riafNmd8+D6xbnyaTydPRkcH1XCKWQW1tFbmctPBRiotwRaG9PYdp6sSiJrlcO80tG/jgg/cYO3Yc1dV1WFYiiOckWLFyA7bt47mCqkSUaNQilYrheT6qqhCLmui6nGNc1yGTztPZmUfTdUxTIxHX0TS5+PN9STy5nkcu24lj2ziOQyJu4vsu+XyWeFUDimrS0elRUx0hHjcwDHAdB9ux5VjgK7iuwuLFLXg+DBvaQFVVFMvQyXR62HYB28mT7mxDNzQSVXEiVgRQyOcdWlpayOWyxOIWrufi2DbNza04jovnecTiFpGIRV1tkva2DvI5G9OME09EiCWkJVM2m6WlpYV4LIEQKunOAslkFaap097WhqZJsi2XzxOLR6mrq0XXDXRdx4rIeFkA6UwmILdUOjtyUr9HIRKJoOkauqYgUPA9IclbDRRV0Nq6mnw+Rz6fY9zYCUQjCVyHwFJNwfVy5HNZ7HyBSNTE9QU522PDhgygUlNdjaJKazJNdYlEDSzLwPfA8yRpVJWIoaDgFDwMU5Uy5Qs8X8HzFDKZHJ4r8DxBR0cahHQvjEQUdB0URaDrhrSu6swTjUWpTiXRdekl4HkC2/ZwXR/bdkp6j6mbgWWKEozzKlZEJ1+Q5KDvF1CE1Gl0Q5d0nQ8bmtsAiMVlbK+iru550gJq0qThn7lc9hWhDi0R6tD0OKf7dYsIdeie+ETEU/fKVFjqBA/TFTS7O/vXkzUs/lbulldODvieB738vil3qHKrJyG63AErzi0RIwo+Ze5XcssyIBhkkHDfk7sCnif9qUtETvACymNhSfInsGwq7pQUmWFFkTsVpforxR8CVzM1II20kgLcRSmXW3OJknVVsYiq6RhmBF2XuxLFGFJ+UMcSnSYqYxQpZf7V5W3gBa52JYIGge/1wpQWySp6c62U9ywSab298+7EY3fyp/y9Anie143s7EZo9UIU9Vau1E96QV9imxXrPnn8mF6vsbUgnDQpDU3lfRlEEPIskCnfC0hWH9sp4HkOvluMYSHHmKLiWFSqim6uFTcq/R/IN2opUL+iyB1EuQBTg+CvBqpuBu3uBwRxacAojVuU6h78IxTKJ4uuSdPvdYwtvtKN9YWSOBf/34yJc1OT5saObawufZ40K75uvB/2vhv1xSGeCgWba665hvPP/zGXX3Ef06ZNZvvp9SxatJpCwWFAU39efmUey5avYr9992DdmjUs+uBDdtxlBp3pDC+99AazZ29PTW01S5e20NhYRSJhsXjxWiKRCIlEHCF8NFXFMjVefOltXM9j99lTufnmubz66jtc+qszaN3QyaL3V5H3l1Pf0MCUyduzaHGaDevXsej9x9h+h53pP2A4/7zvFQY0VjNmWCON/ZPkcjlWr17PsGGD0TSDZcvaaewXJxEzWLd0LUK3wXBYvcEmGrEY2FiD4ylouk4qVYXwwXV8mlvSGLqOrqg8+/ST1NSm+Mr2XyEatWhe38G/7nyOXfeYwqDB9dz5j6cZN34wEyYO5tJf/J36hhR7zpnGiJEDiMVMXNfld9dcwzvvLOSqK6/inQVvMX/emxxx9JHkcgXef+8DJk2egOdqvPbCUlL1cayoQnPzMgYO7E9jYwN/+tM/GTy4P/vsPYtVS9pxPY+qGkuSWLpKdU1MLuQdjw3NbTgFH6cA/QYkQfVobllDXW0DrgO3/eNhZn51MttNn8D8+R+SSiUYNrSJq6/6K4ahc9J3DmXpytXk8jZjho/AC8albN4PLNt0dN1gzdo2HnzkdXbbeQL9mpK8/f4HNNbWUpuqYfnqHBHLoCYVZe3alWiqQlNjI0899QbpdI6jjtmTufc+z3PPvcV5534TQzdJd+YxDANdV4lEZcxJ3xe0tWZZ35IjnXPYdkoTLz7/Lv+86wV+eO5B1NfV0LrB4dmXXyRfyHLIQbtzxx338fwLr3PZZWezbnWON15dyZ77jCWX7+Tpp19gxIhR+L7Kv+99nh2/OoHJk0bgegrpTJbOjjTbTBnB6tXt3HHny3zjG9tTyK9j2rRpkrxSdDwv93mL6SaxaNFa8gU7cBuzME2daMSiYLv4AixDDxb7HqtWtxOxDKriUVAdPM/BtrPE40kMw0LXDfIFm0LBob09Rzptk+60iUYM4vEI9fWpEqEXi5mYpoqhKyiqT6Hgks87KICmK0Qi0qJRCAXblsSgQKBrfik4tm5oIHx8z5bklK+Sz2tUVZlYlobjFFAUH1URJKqiAYmlkMlIi6dIxMIyDVRVJd0mLbgcN8+G9WtQFIEVMaitk26giqKwfMUK2traiERMXM/Gtm3Wrl2PrpkkqlLU19dgWQa67tPZ0YljOySTDWiBJZjvu3R0dLBmzWr6Nw3ANCwc16e+oZZYLEohXyCbzpNJ51jXvIF4VZwB/ZswDBPD0InFItJqUXSFyyhCUSWhrus6nueRTncgUBC+Qi6n4TgyRlxVlYrvO9hOHlO3ghh9cayIjNOVzaXJZfIUcgVcr4AvwAU8T0PTdOKxKJ7voqpQWx0jEjExTR3HgVzeo7PTpqoqgqYoeJ6HaUonlva0jesp+B7Ytiv7gQrtra0I4WGaCuAihIfruaRSKWLxBOm07JdVVXFMQw10EYVCQT6P57nYtovneiSTUXRdR9c1MhkbFEkIFwpOoJvbMnaXXozrJt3/mlvbEb5MipDJ5PA8n4hlkMna5PMOe+wx9TOXy74i1KEJdeiu00Md+mPq0H13tRNdDCZ0CVTvjaBUPHH3IkWuZ3PRxa921WdjL768fqJYvvs1yr+Lbg0uBEWzW98rxmvy8Fw3IJ88RJGRrciU5wdCUbR0kiRSUdhkmYCkqmjSIkvrgy+tl1RhoAmTontelxwGVmKKZGq7ZMkrEUSapuErgekvcqdR3lfpemDoIuEovsvixaR/vSTWApKlG4td3lRd9VJLbS8CcrFEOvX6pirRm9XRR5XrDUowOJXe+0bI0mLZjU0QH4WPIKC3MvQMqF98KxsbbHqzPvvCofvAWkFGBxkpg2P4fkAwS5l37HyJaPYDolPTpCm/Gmzfa5qOqmkoMsJ/t3Gxazel1N+Cf8sJbQhim6k6qGrZ+FjWwcqeo6LbKd1I/OItg396e7flRPKmmq07qdudhO0+B/RG0lbedwv0o+6XUHo51uf7dp8Ntl68887brF27FpCLjmzOJZdzqKtP4nvSCjWbzdPRkUY3PHzfIZ3OljJCdXZmcT0PIVxsex2+p6OqUQYNqgvGQJWly9qIRAyGDqnF9dwgQ5FPe3uaDRvaEL6P63jkcgVs1SabzbJhfTuZjEc2a9Pa2orj2CiqQjpTIJezcRyXttYOYvEIkyaPoa21FbuQY/jwWhzPJZOzcW0XXRfopoLruti2SqGQp66+AV+oLFq8nqZ+SeIxS1pxKAJVhUw6QyRmogaxHlzPp6MtSzZTIJdz6OzM4fk+VsSgrS1NU/9aJm8zgpUrV9LaKmhqaqStrZU1q1fT0d5JS0sLG9avlW4+rkM2m8OxbcDE0DXZjxSVkSOGEY1FJfnS1kFtbQpNU3AdD9txcRwV3bBQNYVsPo8iVBShEI9ZZIVDPutI9zsFHMcOrAkEHe1pCkFwaMt0MXQXFGhvT2MaBsI3GNBvgFSqhYPn2fi+S//+tWSyBZqb20klkxTyDh0dWXL5Ao5j4wsXz3dwPRvH8UkkVOrqIixb6mDoGjV1cRzXpbMji+cJ0ukcG5o7yGU9zJRCVSpCLutJQsIHRQ5TqIaL67vk8y6u65PNFmje0IFje6iaTzzlYzt5Ojqz2AWf5uY0K1duQPg+juPT2Vkgb3vkCw6ZdJZkMoqimjS3dNLZmcexXeoaqnDdAmuzBRRFvuOW1gyu45VkY+DAQTQ09Pt8BHMzkM7kcIPMY3o8hqbpgR6oSvesIGak4oui3Xagg4GmmaSqowihBn+Qzztksjls25cWZYq0/nYdj0LeQ1VB01UcR8oMqOi6HOdkOIZg/C6zBpDoIltEoKvaTrBJiIrjOvieiqbq+L7AdjwynXl0Q8EyJVmhIGN2mqYaTK0+juuhKqKUea7oDucLD5GXWeUUBUzLRODJQN6BZwH4gXWNimGYaJqBquqoiouuG4B0jXNdeZ4eJAYo3+AVQSRTVVWIxSJyLMsWpGsi4Pkemu/h+zLzsx0QLtLtTG5CGoE1ph4EY3dcj2wug4IKioamV+E4ckGsaVYQ81YE9/GwrCie8FCFgut5OK4cM7K5LAIFNA1Vs1CEj+u5wTtSA+JXR9dkgH9VKeq2Pj5KkDVbWl4VbOny6PvFDW5ZXtMluajrKl6XwQm+L/BcWWf5bqTuL61bFVRNvlOQhBtIy1A9INflZrSP44DjyBi3quKjq4FuohT1bGnd4gfBoD1XklGupuHYHnbBY+tGqENDqEPLuoQ6dNfJG7vwRs74OBZP5RX5KNOvYkXKG1PVtCDjm9/jYbpbPJUHDveCTA9Fi6GNoTfGsOgWVfqtaHmjFC1/5EArg48GbmxBkHDXkcqd73uBpZNfuh7drGjUovWOqgbmpaKi7qoi/cplL/cDssjHx8H187gihy1yqKqOrsaJmDUYWoSIkSi56/m+VwrAXZq4fR/PdUuBvHXDCMyILenOp0pTxmIn8bu1r6y/DHKOkBOw78nn9YqEFlLpVpRi9j4BQk5aIsj4oWtdJo/FPlg0jVQI2qe7tRECrfhsgVVbsR+AVFi63PECKyRflIS6O0vcxYgrFaRgb31iYwNC8bPvdycMu37v3v+35lTs0CXDPci97qRr+W8BPpoQ3Hon1XJiVMqr7L++8PF9R2aC8X081+sil30nSF3sBm6lAk2XMiUzQnURqaquldxaSxktkfKkBcH+5SRZ2ReLine51aFpRdE0A003gzgdxZ2brjeklDJSlnPRXb9XmAeLIBNlsCsFAqnDl03qXS3V9XEjOy0VclYxdig9/v/ouWHT2OhuzSa62saUv17NpXscE1u1xZPMKCYD/b766usMHjKCFStbmb/gPVQFDv3aLoBcjD773BIGDkwxbmwj6bRcgEajKr4P8+a9yc47z+SKK67kuONP5LXXPqCpXw1DhjZw4y0P0lCX5BsH74wQAsf1aWsvEI8ZWKaG58n4M6oik2y8+85K7rr9Bb553CwGD66htXk9qZoaorE42YwbuPf43PSH2+nXVM/XD9uLf93+NxzH4bCjT2Tx8vW0dWaZOn5w0N+ltUUun6atfS0N9YNYvLid751xGz88aw5z9poEEGyGgG3n8T0P1/OIxWKoqobreaxfnSGXdRk2qiaYB6TrkNyvUTnjzB8g8Pnd1Zfjei6dHWkemvsc1fUR+g2sYsL4yRiGKVPSFzpZuWId9/zrKXbddUcaG+v4x9/+wYyZ05i5ywxZzvdwXZtYPIbwBR2dnUSjMg38S6++wcAB/ejX0MDcfz5FXUM107Ybx5oVGQxDZ+zEBlYs7SSXdRkzoRFdV+ns7GTKNlPZc689ufHGG/A8n0yHy7L3s1Q3CXTLoWX1SvAVdE1n+PixvPjyu9x626PMmb0LI4Y3MXlqE6+9Oo+2tla2+coYOtoyZNJ5xk+YgKZpOK7H4oXtqKpg0PAIhmGhKDq2LTAMuVm1ZFGO9o4sbZ2dTJ7Uj2SVRSwmM+Jt2NDOTTfdw267TWe77Sawdk0HkYhBMhXBcV02bEjz+mvLmT59GHW1CdattHFcmTVr6Ih4KW7V8jUZdF1lYL8o77y1hFzWZtzEYXiuIJ93efXVhTT2q2bU2IEk4hFURcF1fXRdZcGCBUyfPo1f//rXnH766b1m69ua8J/7XkHXwDBUhg4biGka+D4YugaKiuv4GIaKpilksw6KIjO0rV3XCookS+yCnEfiMYNVa5ppbe3AdXVqUjHq6qrk3OUpeI6BbkiLpmjERNMlWWsY4NgehYIr4+5YKvG4EcRK0tA0g1wuRyFfoL29lVzeI1fwEYqFrgoswwXFwzR06uv7YTtgFzxWrtxAVZVJTY1FIhHHdX3SmTz5XB7fF+h6BMM0pDVR1CSXy5DNpqX8ui52wca0LCzLpCqVpLVVutpZphkE6paktOcpuK5KLlfAMHSa+tVCkOlw9Zr12IUCrucwYvgwVFUJLLE08nmbVavWkaquIpGIUVtbg11wKBSkNZe0yHFl4HddxzIsWjZkyOddUtWxkj5sWjq6oUmXN1+QzWVZtnwplmUSjUYZMmQUnZ026c48IPDcAgU7TWdnJ6ZpMmjw4MC7QJDN58ikc2TTWVo3rEc3DaLxBHlHQVHkPfo1pEjEI1TFDXTDQNcMbFcSPIWCXYqJle7MYRgyKFVnVsa+0jWVmlQU13HJ5golXToSMUvEoq6rdHTkSWdkxsVEIkptbRWapmIYGol4lIItrZgc10VXNTRNxbS6ZK2tLSOzM7qSYPM8D1P3MQwdQ5cZFItrFtuWOpXnKeRyWTxPrmcKtsBxYJddRn8ustkXhDp0qEOHOvSmjvVNh+6zxVNv7k7l5EDp9y4TlwpUNGA3S5Pu1y9/mPJjXZY0XW5UmyrbnYAqf8klwkmI0k6GED7Co+RSV8xQ5zpOSRh84ZXFOfJLrG+RGFE1aYZeJIhK1y3GSVKkCbAQLq6Xw/VyeL6NRwbbT2N7aXJuGkXR0JQoUbORiJEkFRtIxKhC1yyKWeZKBj1lg4EUC3lP3wfFc0D4CLWrDoIyYiWIM1VZ37I/lBKz6wuBUMp2JEqMd0ACla4bbHHIhqboYiiEkBn4gqMlclnpitFEt/dW/t6L1wtYrGAR0UVSdZl+dvWx3tCdTOq+g9E3AaPHeVs7NlrX7mx3yYLui/NsvaG89kX5RUiXXT8gVl3PDj67+F4wDhR3YAM5K7q8GobRtTssuiwWhe/jI4LdGgUFDV01g2HQL+2HFcdFAQhPZohUZSTZEqnt2FlcRcPQI2AVY7WpCKUoZ+WyFbgOi/JrV04qonS0OEaUTaJiI9scpYEFuq4a7L+Xja3didiNKVnFMh8Xm+qHmzIL3ti5X9R+7bougAziqkA0YtC/KcWGDQ2ljY2169ppbc8yenQ9qWQUgCeeehPLMJkycSSpGpPBgwdyxRVXsPPOO2HoGv2bGqiqiqCisNOMiaxZ1cG11zzJgAEpGhqrmDZ9GKtXttPZmWfc+CYc26WQd0gkI/QfUMu+B0yjti4RbNzIxXOmM8+ixS3U1cfp1xhn5123IxaLoqgK22y7XbAjDm3rPVavdhjUmKWqyiIaMfjg3UXohkZDUx2qotFQn+C7p+7OqJH9yOc9DAPWrbRZu6JA7QCftWtW8/pL89jv4N2pra+mdX07lhXBEx6X/t/lfHXm9uy081e57LLLMPQo48dOYbfdZlNTk0L4Ck898RjLli5hypTdqUpGiFeZqIrBa6++wT9u/38cdfhRpKprmDJ1DP3611CdirPTrtth6jEWvPYhT7/0HMOHD2bOnrvy1puLUBQYOWqQ3M1VYeigwSQSMXRNZ7sZkzBMHV3XGTi4BlVTcRyPmtoommFz5x0vsc02gxkzth8XXXwRgwcNxvcFK5dtwHOhaUgSKwaup7Fhg0e/ftXU1id5/c0FuL7L1w7amZHDB+ELn0effJV+9VWMGlWLaUSorbVIJHyee2EJjQ1VjB3bSKxKyrJpWqxc3UE642BZVaxd20Jbawfjxw1l/YY1PPP0y4wdfSBLW9Zy8813cdxxX2f48CHsttt0UtU1rF2XpSoZAQSZdJ5VqzP4vmDypIGsWdXOimUtVCWjpFJxohGLl19eRkNjghEj6vA9j3Quw4fptVSlotTWp+R4h4/AJWN34hHHMnX+c+9zVCWizN59Gvfc8yTPP/cSnudz9913895773Hdddd9TtLZNyRTsSD7nEKhIBfomq5h6CqaKlBNORcUbGlxrmmqDMyeimE7HoWCzFCnBdb01akYlqmSybhEIjrgk8lmgoxyCkIReEIh7/jguCgITCOI3eMLNASep1IoEMRVEwg08vkC2WwG2y5gmhaxRBUoOqoi0FUXgYcWEBCaL9ANhbr6BKYhUDWBokrrGsvUaN7QieO4VCWrcTwHJa/h+w4dHW10tLVgRUw0VUHVFRw3L/Vh4dLR0UYhn0Mk4hi6Voq3pAcLV9uWLjwdHZ0lawpNU6lKxmWWT0UEC19JSmuaQVUySaFQoGAX0HWZLa+QL1BVlcDzXHL5LI4TwTRNtLhCLK4TjRnEYlFc1w0CkbtBzCMPRdHwfZWa6jqisQiWZeIJgaqDFdMxdRXf13BdnUjUAkXB8Rx0VBRVuhsZholpCfr17ycnXE0lplgoioaiyE1sz/OwCyCEgq8r5Ape8I5yJGIxFFVBN1R84YAviEcNbNvGzntkdQ/b9shkC2iqiqZ3LeKlBaGG74Ou6STqYliWJAdNU1p2eb4nA6Q7Lq7roloWuqriOG7Qj3w6O2X2RM/1SsHz7XyOaDSCsCx8oZSCwHtekJFb+DLOl23jC9B1meRha0aoQ4c6dKhDf/J+vVnEU/n/3S1NSov5isapZHh7I5a6CANRIjiK5buXLVoo9cYc93bt7i9K1kFeSFECE+ZSwGw/sMKSLnS+5+I5MkOd57oU/Vi7SCoCIQxoFgWZ+jGwdlIUSkHGi+cEsobn5/H8AnmnA9vtwPVzeKKTgt9Bwe0g63QCKgoR4m6WqFGLrkVRFQM1eGXS+ih4mJIwdT17V9BraQapBoOBFIiumFGqCLJJqKoM7ie84NyiuCgls1s/YKG72jYwT/TL35mPEEUhUlEUKXBd5FggqKKnoJW/s15JnbLBoXj/8j7YG4GklH0uu1AFL9WdfNqUgH+q5o+fMXqzDCxH9wGpq8gX5VmDPlqS2yDzpC/9zT1XpjiWE5ZTkmspT35JsGXQQ2nmDmXWfgTdOpAXXwEFqSwWTYhLbVhsvGDCksFJu6zzQAbxdF1HTk9CZo9RFFWa6hfnN9G99Ssn0dLtioQvXcSwrHtx7KKXiwWEbvdJV+mtbPGxKvvNpkyKNxcVMrUZXa7YIt1lsrfdmd73hLZONDY2ks1mKRQKgWudj6r41NYkgx1kQXtHjuaWToZuU49lSTeYDz5cRcSMMmLgYHRTEI8nOeWUU+QOteNRV5dC+B7tHVlGDBlAZ4vHM0+/zLjxjYwc2cC0bYfR0pJl7dpORo5qwHVcclmbRFWEVCrGpG2GyCxcnosvBK7rIYTCunWdmJZKU784o8cMQwDZnMugISMAQTaXI5t2yXYIMhkbBYFTcFi7ZgPJVIIhwwbjuh7xmMmBB04lnXbIZh0SVTodbQ6rluYxqhTWrG7ljVfeYfuZX8GyTDrbMvQbFMHwBQ8/+Ci1dTXsMHN7Hn30USJWFcKPccBBezFwYBOg8sH77/HuwgUcePBxgLSiQmisWLGSe+/9D3vsujc1NQ30H1BPMhklkYwy+SvjWLmomaXvr+Opp54nm80xZ4/ZrF61AU1TGT9uBLl8Htf1aGpswHU97ILLmLFDcFyXTCZDbUMCz/NYs3oN9Q31xIXB668tJZWKMWJEA8ccfTQF26GluY0N69oxTJ2BQ+sQwsPNKBRsDdeXLvXLVqyitraOKVPGkYibrF3fwsL3ljNk0DSZedApYFgm0ajKkiVLQMD4cf3QdOm+pOsG6zak2dCco7FflGXLWlm5Yh2TJg+lUEizdPFihO/S2tLGf+59jDlzdmHMmJEMGz6QbFbQ0WlTnTLwXJ983qalJU80ajBmTC1LFm+gpSXNmIn1WJEY0bjKsmWtAAweUo3rOOSzOXK5ZkaOGE4yWYUTuEv5vguqD4pA+AoL3lpMbV2S3WZvy6uvvMcLL7xNfUM9r776Ks8888xWTzxVVUVRFNBUGbPNcTwiERPfkPFANU3BcT0cxwVFphI3DY143ELJFUhn8sR0meVJUQTxuEUkqqNpeYquZLZto+sahhnB8+UiyfGkZQLCB6FT1GU9X4CnQkEE1pQ+KBq2bVMo2PjCJ2rqJKpiEOhzqiIXeIqiBIlrfBQVkskIKC6KIoNhK4qCaWm4rozPJISN46hBQgKZbS6dyaCo0n3N0DQ5djhgOzaZTBrHKRCJmCXXWlWThI2mgaJIa4dsNodtFwKCKUosFiEai+A6tnQ/c70g3qlKIp6guSVPoZAnl8uViKdIJILrOuTz+UBf8IhFLayIjKVlWSaFggzbYTuOtLTwPXRNBthOVCWJxyPohoHny2yFhgERSwNFZoezIiau52HbDr7qowoFTdPRDR0zAlWxGJ7vU3AddD2GEsTIUoPndFwBqoZAJZ+3yeVtcrk8uqZjGDp64Oor8IiYBnbBxikUyKoejiOwCy5GQOw4qktx/nM9OXcoqkKyKipdoFQFQ9dQ1MBF0nGxbQfHcQI9SMf13CDuk0++kKeQl4SeaVnSssmRlmS6piLQ8HwNVZX3lBv3Ho7rSMLKB1030Q11o7KzNSLUoUMdOtShN79ufXa1e+eDJaUb92ZRJM0li5Y+xUB8RUKgZ6WLZSusa3y/om2KvqDl5FaxbLn1ku/7JZayt4Gg6DdfblWFAn6RaAnYW+G5gVtdYB7oFcmoruuX+4JKKx0ZQN00zWAHSCtdz/Pl4F5sL184eH6O9vxyck4rrZkVuH4OHxtVc2QqWuFiuzIYoyJUDD2OpaeoiY+hPjGKuNWIqUYDwfUCEg0URRJHRTKsSCpruk4pRpSilgRSCbIRCroCwDtuDtvNYLu5IHuRiarGEGhlBJt0xyux1iDJtoDN7WpfJdjxLUYqkG5yWpCftru1Uvk7K7dg6s3csPuxovVZBRkqxEZFYmPWTd0JrIr+Una8PJNdeV229uDiC95bVPH9owaznoz7Fq/SpwjZt0vpoD0Z2NBzXRw3F+zOSMWp+3wgguAHiqIQicfQgiD9rut0vX8h08PK3ZhArnwdHx8fF1tpQ1UNTK2KRLRBuqCqYLs53MBdV1WUkmInTYZdfNcrVl+aJes6lhWXY1iQVUdRpSwXFQK8rnGzaywVpcldCBEkCAgiXPhdsTsI4jYU/xSl9+D/QZXkk3br971Zl3bvWxXWpn1FHybN3nZr+jZplij0imNbs6tdc3Mz119/PRdddBEPPvACtqPzl7/cyTnnHM3YscNZsTxNXX2ESETjuedXMmhgFePG1bNqRRrDUKlvjPK3vz9JJpvn5JP25oUXlrB0aQtf/9oUHvvva/zjrifZcdrOjBrZxIwdBshsdK0uj963huk71DJkRJz5r7fQr3+UoSOqAFiyaB0PP/Am+x88jfqGGMuWLqdfv0YSiSo2rM8QixlE4zoP3v84zW0unU6KicOT6OR4672X2WHGToweOZZo3OLhB9/kgfve4PyfHkBtbRWuK1j47goUYNtpI3h34TpaWnJM/cpANFWVcW8MpBtJJseD9z+KosCh3ziI9s4s2WyOXCZDoipBVVWCQiGDrmtYVpRrrv0HiqLwox8cRy6XxXFcopEYt99xF//+971ceeVvSSYTpNMdxKIWq1at5ea/3MURRx3MlKkTyWUzCF9BeCoeBVxPYDs+NdVVmKaBYWjc9pfHWLZkHT84/zBee3k+8159h2+eeBC+Z7NqxQqGjxrFe++/x/fPOI0LLriY3XbdnVzO4fln3mP+G8s44aTdeOGFF/j9tTfxq19fyNChQ2lpzbFo+fvYTo6Z07fnztvu5pEHH+OSyy5g6eo2HnzsDUYMSTF4YAMzv/oVVMWTmz8eFFxwPahOxvCFT6HgMO/1xUQjJjt8dQyPPr2ElrY8++0xGkWRmrVh6ORyBTo7c/TrlwIEnZ0Z4vEY69Z1cP5P/srhh+/MHrtP5fkXFtKvsZrx4wbKOFGZHMtWrqUmmSQejQRB1ouxb1Q2NKdZsaqVdJtDdXWUKVP7s3DBSgoFhynbjqB5fTudQTbCtlaHdWtyjB6bQtc1clmfp59dRC6XZ87ew/npT37Mn/70x61+A2jV6nay2TydHRnWrm1DVTVqahKYuiZjF5karufjC0FtTRxdlwv3dCZLJpunuaWdRCIq440h3W91TStlHrMLLp7vYxoaVVWWdM8V0Jl2ABnnJ2ZpdHS209raiqYbqIqKqur4voeu6aRqakqDaMQqejQoAdENug75Qh6AaDROZ2cW23ZJJJPSAkpTScRMGcNMQCadxnYKFOwsjqPiegqO66MHll/gkc10sqF5DbFYDIRCR0dWuuSYJoMHDUAPEvWAQmdnmrVr1wVBhTVi0RgdHe14nsOw4QNRFIEnPNZtWIeq6MSsKhrq+2MaEXxflVZVnlOx3nBsH2lh5+G6BXRdo6YmhaEbaJqOacZobUnT1prGMDU838NxbCKRiHS7i2iYpiyrqgbpTIZsNouuKUQiFol4HIEMuZG3c5Js8Xw8oRC1okTNCJalyThptkM+L3UQXVNwbBmQORqNoKk6KCrtnXm5DlIEQqhoqoJlgmlKgs73Fdava6O1tQPT1KlKJKitrcE0LUme2XZpzbBhQ2ewWSAYMKAeVdUQAqqSkeAd+rS2tJPJ5Gnr6KCpXx21tSm5GR2E2Ohs76SlpZX33lvMsOGDqalOUZ2MUyjY2I6LYUTwhYLvKRimXCPl87ngGVQikRgCFVCZPLn/Zy2WfUaoQ4c6dKhDd7/g5uvQm2Xx1NuCv7dKyXX/pt2Qui/syxnF3q7Z6zWC3t7dNE7u/JQ1i+hyjetyBRNByk9PpnoMLJ1KE1LJ+qmLWe1Zb2nVUx5/iJKFk/wrdkchHFw/Q95tIW2vJmu3kbZbKflZCw1F0UGJoPgeyFiKOI6BUKHD6cTPryGiZ9GVSDBJ+lJBRCk9s4yjpAXKhIqhy+CGqqZjBKkqNU1HV3SKA4skrDwKdhuZfCs5uw3XF2hqBENLAZZUPDwfaf4r015qxbhRmt4lSGVucCVz0+K/QgZTVYqkUDdrtd761qbef29CK4nlLhfAIjYmtBszI+zNzLHYf8pjhZWTVFs7Ntc1sKcFWfH4lq7Z5qPiMZSuzQxE8bOcSIpx2nyngOs4QZBDpytOmOg6sbzP6JrcIZUx2XxcId1upU+7j0pAwKLh+gWEkNd0fGm52FZYhqIYmFo1sWwTESNFKt5PyiUKjuciVAVFKJUPQhm573sonoLr2jK+m6oiinHYlK4U96LifE3uAGkKwrMBr5R1UwRjZdHcWJS2bYrToUCUTZpF19diY5d2gMpuWi7DSpnQb8xsuK+KWkWpirnzo/vvR5HNpRFJdH3+IqC2tpZ4PI4QsHZDKzU1Dey48xTq61OoKqRznVT7OqZpMWBAFdXVgetTLo/payhEGT26P+l0gWXLWzFMjQEDUrS35aivSbHrzlNQPB9fyIXXggXv0dFRYPS4QbR2ttC2YA31DU1kcu288toShgwcjKqoTJg0CBDkcjbV1Sl0w8AHElUWa9esZNW85TT2qydZo9HcoZFKRTANgwn6RKpTVfi+TTYH/ZpSzNxxDAW7k45OG001qa2N0d7eyZ13zGXw4JHU1NTz+hsfMHBAHQMG1DD33/eRrKpi6lemMGLkEPIFmwULFlLXUI+uqbz00jOMHTueiZMm8c7b86ipqWHCpKlMnTqWbDbPO+8sol8/mR1r3ry3SSSq2Guv3YknohTyOdasXMGIUSOprqnmK1/Zhg8+WMSatauZNWtHFi9ewuJFy5i9+85kMm289dbbDB4yiKpEgmRVgqHD6qmprcJzPeobahk/aSSrV63HNHVS1TW0tRZQiHLgAQfTv2kAjuPRnslS25Bg8pTB5Ao2dfV17L3P7jgerGtuxbVd6mpSOG6MV9/8kERNLbvtsTNrmtejKAozpo/BcRwMKwZAR3s7vufS0NgPDx/Hc3nnnfdJphL079+Pmpo4vueybNkS6mt0Uskka1etoa4+RTQW4b7/vEBTUy1TvjKSd95ZhWnqjB3bn9a2HPmCx+zdtmHwwHqEL+jfVENVlYxrlcnkcVyXuhpJOmmaRktbmmjERNc03nt/BZqm09hQhV1opyPdwQvPraKmpoFUdZxFi9YSjRhUpWK0tORAqDQ0xli48AOEgFi8miFDUlhWA6lUNXP23ptksurzFM8+wfdlUG/TlOnrETI+krQukdqiYQQWJ4aOohSDcstNzHg8gmnIsoWCQ9F6RFVk8GvP89B16QIngqFaV1ViUTPQd+W8qGlGsNiXG7uqouF5BVxPZrGLWNLtSdcV7IK0BMpl85iWTnV1DNO0ALkA8zwHz3UCbTLQ/VHwBXLx5rt4rk0hn8H1NDxfIZd3MAwD4Uv3QNcTMi6LFugcioduWJimrLcQ0jJP+OB5rnSpS8TRDZnF0XYz5PMF0plmhCLv2dK6CiFULCOO6+cxDAuBIhfPniPdxoLkP54rQ1MI4VMo5NE0lVyhmogVxTAMTDNGe2uGjvYciSrpyheN6UQjhrRYCtxnVU2SeG6bTUeHlL1kVRURK4Lne6XnAHB9n450DuGBjoqqGjiuFyQXKFqTSd3V9xVcV+Cr0rrMMqXFUdHdTeryGoqqBXGtPEzTJJGI43syVIjjOKDITWbPF+i6tAiJRC2EL+dvmRVPwfPAcTwUisGbpVtgdUoS60IIHMdFVVXp+mgaRCJRkslqDMMCRcXzwRcKAunmpGsqqqnLDXMhrdw8T66hdF0NdCv3sxXIzUSoQ4c6dKhDd13w4+rQm+1qVx7TqSJYd7cyJX/QoF5yIO0WD4rKeDs9pLI3S5ayewlEEDCs7IWUmJ6u6wkCV7EgAJokqny8QIhc1ykRRr7XZaUk/VSDupaIpa5nLxJOmqqWYk5JcqLrr2jd4wsbx+skY6+ho7CKjN1Bxk6jYqEqJoqIoGkmmmqgujIjhfBkEEhbqBTopF1xSu52knASUManqEEQNlOPoKkGmqpjWVHpQ26YRKw4pmFiWVGUIFOG8JUg+FuBXL6ZzsxqOrLrcX0PXYtjmXUoIo7wg8wo6KiKhhVJyJS+hgVmYPVUJOGoJIK6bI+KI1Rlty53dev+jru7cm7KtLW7kHcX1E2Rpj36Vi/9vfjei+++vF5fBOLp45htdicHtzZ0kc9lx4KZUGZqsfFdB6eQx3NlNkofl+KORjl8z5NKuaqiGwaGLpMD+J6L53tIN1IZUBFMFDQ0RcFxszh+Gs/LkHPXkHZWsbJjAUJoGFotEX0gCauJoWI6yWgthm7h+S5KMC5qmjR/l20dWNXhowgfRcjkBsXAi/J3qdjruh7s4pQTsDqKqqMqapARyA92rYJxK5gouz4TNJ7Xk8gVVIwvRbJYFFc0orvcFMVv40knNvXblsLGLBorJ8svJorWtWs3tNA0cCDfPHpvYhGTQsEmY7dju1EUJca4MbWgyE2FtS1txCImgwYkmbHdGDrTBZ5/eRlDBtUwdEgtzWs7GTqoienTRvOf/7yMEHk6O22e/O+r2E6B886Zwn8e/JCF7y3n9O8M5835S3j6mZfZfecYTU21zNx5NOvWtpFJF+jXVIsv5H2jMYPly5fw5OOP8d0zzsSKVLFmbSfxuCBiaYyfOJrOjrTMyuU7DB/VyJSpQ1j47utkcwrVqVoGDmyiUEhz0w238oMfncr4CcOYe/8zTJ82moaGBDf/+VaGDh3MsBGDmTh5LB0dnfznP4+yyy5fpaa2inv+eTsHfe0Qpkzdhscfu59hw0Yybvw27LrLNDZsaOPJJ15m6ldGkUrFeO65V9lu+204+Gv74nk+H77/Hq+/+jIDBw+ioaGBPfeazR9uuIEPP/yAWbvszNtvL+SBBx5i+xnbsn7dOl556Vna2sZTX9/AkIEDmDx1CLF4Fdl0nkFDmhg6YgBPPfEaNTVJJkweweIP2jD0as4444d4LuRyDkuWb2DwgFqmTh3KkuXrGDJsCNO3m8xLr73P8pXrqKkyGDJkIK4H19x0H7N3nsyBB+3O3ff+h4EDBnDgvjN4Zd4KGWw4k6N53QZ8z2HAoMF4wiWXs3nu+TcYPWoII0cMpqlfDe3tLXzw/rtM3uYrxONVPPvUK6jqcHS9ntv+9igzd5zIDl8dy8svLyYWsxg7tj/r12fI5T2OP253cnmHQsFl9Kj+yExgDs0tneiGxoCmWoQQFGyH1eta6d9YQyIW4eVX3mXE8CZmfnUCrZ1Zli5ZzavPPM3Rxx5KQ78UTzzxNpMmDqaxXzXvvPshjY1JRo5M8c9/vYrt+EzcZhIzthtHfX2SznSeffbZlwMP2P/zFs+PhGPL5ClWxMDQtSCboUdVlSaJC0XBsnRMS8M0deli5bgUbBdQSCUTEGQ7k64t4HsC01JK1ieWZkqywvMQvo6qQzxqkssJmf3Ol/F04nFNum8Fuq3jSkv9QsEhFo1imQaKInC9AtlsnubmNhJx6V4bjURBQQYO91w836a4t+d7MsaPAvieS76QJ5/Pks124AtJPKUzNoZuYpsWqiLjixpGBE0LXP50sCwDy7JwnAKuTO6I58sNY9M0qKuvxjRNPN8lb+t4vk9z62pQpM3E+pYVuK6PikU6v0ES4kJg2zaO6+K5nowtpcmMk74PvguZTA5N02jrrCERT2BZFqYRI92ZJ5u28akjlaqiOl5LLGrKTHO6EST/UYO4bQXa2lrJ5XJ4nk9NdQ0FJ8hWGdEQKHieoLWtE8VV0IUmN39dj0wuTzwekfO9UFEUHVVB6t+qzBYZjVrk8x7ZnI2ChoKGTDUv6+D7PpFoFNOy6GxvQ24M5HA9UAIPB2mdpZJIRNE0uY6xIjJgOo7Att0gYLTse5ZpUltVFWzCyt9NUyadMA2LeEzQ0NCEZRmASsH2cD3whSr1FUMnFrXIZrNS79ENCgVpLaNpCsJzAfuzF8rNQKhDhzp0qEN/ch26z652C95bVCKPSkGqfVHiEMqZ3SLxVDSnI3Cz6o14KicoShZJitIVPLysfJHooXQvAUIp46nKeMuiJUrQK0SQ4lFGwJeWTa5jy2B4QSpGSd51XaPLtc8vPUNXVP1iOtViWkilZG3j+VLIHNcO4hR45JwW8k4HHfn1pPNt2I5NPu/gB+mJS5ZUCPK5XOCb7uM6voyx5MlJV5oT+l3knEKwM6IEk58qTRKROzmGZkoLJy0IYmhaRCMxYtEYpmERteIYuo6qCgpOM9lCKzm7HV/x0TULy4yDiOI6gnRnHs8VIDSiVjWmGcc0YsTj1UE2Erk7pKlaYF3VzRKJrqx2qqoGE3UlMSREEJep2J7dCMdSXyq/rqJ0vSMovceKPtOtXxAw1+WTQm9WVuXnFgfVjf0+ddJ4tmYUzYT7NmhVEoSVz7yFK/YxUKxOyQebQDaFwHUKQXIAG+HKzBqe68rdCiGCSa9rppU7MF5AnGpEo9GAQAXPdeSOrS/jvCnoaFi4fjt5t5U1nW+Td1twvE5cvwOhOAjFI13IoiigqRquY2Nq1fRL7sDoAbtRnxhOrtCO6+VxPVtOfop0S3CKu9K+VIpl3Di5k1kMvCgCEl0hcGXVNFTFCBTOPI6Xw/ML6Ho9CsEOprARSNP+omwQuNMQfCzKWo/JsyizdLnIosid+2LZIhG7KdPhcmxqUoVPtluz8UkzuMImLjFl4tbraieEoLW1lbVr16JqSWKxKI2NVVz3+/tpb8vyg7MP4p35y1izuoU9957GoiVrmffmImbvOoVY1MKxHaqSMdo7OrnzX4+xzeTRDBvSn860jWmqRKM6rS0ZhFAxzQjr17dhGBrTtx1JZ6fMbvbK/FUM6Jdg1LAadNVk4bvvcsddd3Li8cdRlUhyx9//xV777MbYCWN4+ZWl1FQb9GuI4LhgmiZVVQmEcOlob+eFF15m8uSJ9GtqYuE7y4nEolSlEhiaj2XpJOJRFEXDcRzWrV2PFZExR5Ysy2JZFvGYhUqOaNQklarmuj9chu3YnHzSD3j44UdZumwZhx/2dZLJaqLRGJ0drViRCDU1tZx//k9xHY+f/PTH/PXm23j//Q85/8c/QHgFctl2Fq1cT011NWNHjCSXc2SMlLyBouUR2KTbs8QSEaIxi5VL20HxMGOCwYMHYlk6jpOjrbUTz/UZMXIU7y5czofvr+CrO01i0aJlPPTQsxx99EFEYwavvP4S207dltqael6f/z6DBzYysH8dq9esQlV0IpEEBVcu3lta1pBK1mJF4uhqBFNX0DWBh8K6DRmWLm9l0vhB2Hae1+e9yeTxY6irqyFb8Phw8TpWrWlj5xmjKBQE6zfkqa4W6JqLEFn69RtMutPmF5dcw/4HzGb27JmsWd1GPB6hrj7Jq68swDB1pkwZy++vvZc1a1r5yU+O4MNFG1i9uo2ddhqN67l0dGapTiX44MPl/PHP93D8sQcwYfxwQGHN+lbaOtIM6lfPQw89zl9u/jtXXvF/DBjQj872VpYtXY3n+3xl2yl88MF61q7tYObMkaxcuZ63317C9Omj0VSd9evydOYcli5bwm9+dRa+kBkL33nnnc9bTDeJefNW4TgFCnaOtWtbME2DpqZ6kskYlmlgGGqgl0A8HpVBpW2Xjs4cvi8kUaKKwBJGIZtzsG0XVVdloGpNx3OCRDC+G7iKaRiGLskWX2CaOrmsTTpTIJ2WGQWrqiLk8nagHwvqapJUJWJohoLruEEGtbzMcpawsKwYoGLbDq6bx/fdIGi1ikAlm0mDAoausnrVCvL5HCiCdDqD7bhYkSp8X5I9lmXi+y6OnSNieUQiBvUN/YjHajCMKNlclkIhR8HOkc9nKBRypLMd2G4exy3QmWmlM9NOvpAhl88Ec4SP4+VK2dek9ZiK50mLBlBlqA3fxvdsPFdIt1lHx3XkBCEtgor6joZjCzxXYFkxEvEEtTU1NDbUE4vFSSaqiUarsMwoiUSStrZ22trbcRyBZUaJR5Kk01ksy2DI0CYc1yNXsFm6eDUaGqamkayJUyh4dKRtqhsiUi/3dXIZD99XqK6Lkg+CcScSUTzXI18okEgkMA0d0zRKHgdaQObJbJvSHcp1BZqmI5BZIdXSukUSDCKwqAO5yHZsB8d2SKcz1NZWE41aaDrYQZBxRZEB3w1do60tS6EgMyUahtTH29rTuJ5cLzU2pEgm49SkEoHrlnxLrusjfFBVwcqVy1i/fh377rv3Zy6XfUWoQ4c6dKhDf3Idus8WT6UKlFt4dHtupWgS1HUkEDClQtC6L/B7IwaE/FJ6wcXOLo3sKCOIuhqhPNViMYi1PNcLXOfcrvhLrtMV26nivMoWLRrQlHgeRS11CBl/KohrVYz273vYbgHXsyk4WTzfxfVtsoVWCk6GTCFHviAnAdchIJ6EJKiKJJWdkX60jiTKJPEkd7OE8HE9jxKVU7Q00lQMJPHkCV22SRC8UAtIHr1gYBgmOTtKzpaWUFErjmkYMnuFkPGdHM9DhmLy8HwHFakMCfLYrh1kpfAoODl0LULezmFZUSKxONFITFpXRWKS9CqlwuxqX1EySup9YC4elf8HQt1L2slS2SK5Wep1lF5YpRljJelUJKZ6kE7lL7xbZ9gK5ovPCL0Ncn2juTd7Z6fEoX5063Y3Wy5aL5ZbNLp2Ad+XkyZe0V22uEvRdW7X+CDlX9O6SOTSjoYfJAjAR0ULuoVL1l1NZ3416zLv4no5fGEjFBtdk7E6FFWao3ueNI0XSoFOeyXtueUYeoSolgQsSRCrRdK7GPuu2NJBIEcBqgBFlRYvCnJHSU6uSmkXxRc+6dxqck4rtpsmFrFR1SgKUVxPxuRQ1KJyqsh6KgpqsV277c50f0lFolaSw12BF8utFct3Yza1O7i5faQvk+VHXeHLgJqaGmpqalixsl3GU1FV6uuTKKgsX9KG6woSiSitrVk8xyeVimMYsk/6nkp7R5rOdJb+TXK33vc9OjPtWI6JEDLrWDbrsHpVM/UN1cSiJuvXt1CViNNQn6Iq3oxl6OArCMXHNA0a+zXiCY2CI4hXVZHO5Fm7tplo1CAWjRKJxKFQoL09zbsLlzJu3BB03SAeT2BaJiBYv24N9Y0N1NSmyOalVUgqqVEouIDKkKGDWLVqER2trTT1G8qG5lYWLVnJjjtMQfg+a9auI5msQdPAiihkcxnaOzppaGiks7OD1auXM2zYcAqFAu+8vYBUMkk0GiWVStB/QD8ymTSZzBosM4JhmqxrfY91zTprV61m4oTJJOJJdNUgVVOFpguWOSuoqamhujZFR6uLZqikaqPMnz8fXVeZNn0qkbyL68isZR3taVYuX4tpTSVVXUW/pjpMS0M3VJJVydJmXU11gqVLl/LW/DeZMmWcTO2uKbi5PAiXVDLFinXrcb31zJgyFSXI5JN3PVAhHjdxPRuBS21NCtdXyOSkS0wsalKTiuHjU3AcOjM5kkkd3VKJxWro6MjR1pZh5MghOI7Dhx8sZtToEdi2x6pVzdTUJtB1nfaOHMmUjBPl+UKShIkI7e15NF2666Q787i2oH//eqIR6crT0ZnBc2Xg4+pUnJqaaqqrGygUZLyb+vp6NjR3kMsVKNgOhqGSiFtkslkEPqlUAtsWWKZCbV0VSkeOmpoE48aN4Y033mDx4sWft3h+JOTGutTlVE0GE5f/q6iBm5njSpeTSMSU5IgXaERC4Lg+hi7P0zQNRdhBNjcFXVOJRAwcxce2HbIFW5JVmoaPH8x5ctNP0zV0TcO2CziOQNUkuSEECE+67Lmug0DqR5qmEYlYaJq0KHBcX+pmpcWRIJ/LIucJlXXr16HrGtUp2bc1TQvIiiDeaLDTryoyy5ncyDUwTL20eWk7eQqOTWtbC7mcJJXyhQy2kydfSNOZbadgZ8nk2yk4WVzPxvWk+5ymKmiWQNcEmqng+rZ0H7PB0KPomo6qK0EsmiCAPRqqAqoi8D2fgmuDKwPbK6h4Hngu5O0s+UInuXwHtttJPB4nV11DxIpjGBGibVVkcwXy+QKqaiKEh67KIOuq4pNJZ7Adj3zBppCziVoRdEtHVXSEL3ALAt8BT0irIl9IiyDLMkrJf3xP6jK6JoOy68Hmsut6Qew7BdfzcR1XPpOqYZpyPVBMRCHdnyhZsQghiEbNwOUz6Ktl65/ysBJF/Ul6AEjLEQKXJ0l4CfSS+2gXMeELH63kLSCJVB+5RtM0HcuyPjNZ/PQR6tChDl35kkIdWmLzXO2EDKxV4frWoy5KaWCSg1XwYpRiFrkuv0hBFyFQtIIpujN1XSC4qqIgPIGv+F1+maJINpUJQ/HfErEhgqj7Lr5b9EsNBkHfD+I3Vb7UYh0rCbHic6uliVQylFIgHdfG810ct0Cm0EHeyZDJt+N4eRwvTzbfieM6OLaN40hG1nMdglBlKIonJ0ffJud24joOBafQNdAjZCoUwFe8khKhazqKpsngbbpbcrfzfWlJJdUDBXwV21NQPZ2ca5IuyECIhi5NhTVVlZOxqgTxBYrXAd0Q6PhYEZ9cIY3tFSi4GfAN8HVsW8WMRIlXJalJ1RCLJqhONpCIpjCNICBiWUeR8ilNvosEXrkQqeVCF+hcqqJsVChlS/D/2XvveLuu8sz/u9bup91+r5oly5ItuVeMwTa2iWkGg4FQApkAgYQhmRBIG0ImQ8iEhJ6EFEoCCcRAyoRACAZsMGAM7r3Kli1ZXbefuuta6/fH2ufceyXZGGZ+iZ3R+nyudXzKPvusvcq7n/d5nncADD3eJD0UxV353LLXliH5/bEHSxUYV7CgjiABfKq2nyRLc8gR+L99A28wA432YGE87Osf73qCMdb/oShND4u8QBXpwLNt5WdWXltjygoYwgZOYRjYTcmYge9boQtAg9C4sgLkKFpMx7cw032EHYsP4IkGrqwQeQ0iJ8RzQxydURSaPFfU68NICe1sJzvmXBbivZyx7gpcpwpelcx0Bpuz53l2nZWKPLNrijEK6WocdHnT4OI4DnmeDua5ISMvuuyfvZ1mby/ddI7RoVPx5BgOk6RpghSSyK/iuAGO6xHWaqW3iCwTCiXUu3yuSVFukHYtX97/cAgIvBzcXfba41KDn2AoPdEofKL2xJmaZfmKp3EzBnqJwfNs8uf1r7+IAwfafPzPv8dlLzmF85+zmZtu2Mmq1Q1e+LyzmJlvYdKMsaEat975IEma84JLLyCOe7Q7bXbt2UW9Mszk2GrWbpkk7s1y2+0P8Yorns3ISMjNN9/NiScex9q1U5z/jGPZt3eWe+95hHXrJ1izZg2/+iv/je07Fmh1cy674jK2P/wYt932AC958QW0mj12755j0+ZV3H/fDv7X7/01f/TBX+a0047nggvOR0hNt9vh4YfuolI9g/HRE/jhzdM06gHjoxGdtg32wtBj9+6HOXDgMV784tN4+NH7+O4PvscZp26i2Wzz3e/fyOWXv5bRkQoHph8CmRNWIxabLe6791buuusmXv3qn2PP7r1cddXX+K9v+xU2bNiIMYZXv/rldDoLfPEfPsiZZ1zCGWdcxNz3/5Dvf+cuvnLl/Vx//ffZtHnjsv43bNqyEaUsA+Kk044tE1SGn37l7+I6Dt/57neorh0afGZxvsljj+4hTRM2b17H1q3HsTC/AMBFF15ItxuT5zlbj9/Ae7/493zyU5/ltluuZXTUStUefvQ+HMfljFPP4svf/Szbd+3i+PWbGKpFeK7HnQ88wOToCOeedRx33/8wruty0QXP5NY7HmbP/j0846wTOOXEYwDDdTfeQZ6D64QIIgKvxvjYaq67/k4WWx1+9R0/z7eu/g5f/tJXefs738bBgy1uvW07z3/emTiuy6M7prno4tOJKj7aGNavH2X9hjFuu2034+M1Nm8a44bvP4Tvu/zWr/0cAJ1OzK13bOP449ay8Rjr03HWmWczNnYcC61Z1GP7OWXLRjZuPo5enHH/tt1s2riKLVtW8Z3rbmPd2kme97yz+Ye//z7VWshlLz6HjXKUs89cy8te8s+8/e1v58///M///SbhT9jCioORDplyqDdsBTFl1ACESpKUbrdHludEYYDWhiK3njhKG5KkQES2JLnRUBQ5RZ5YGwVHEgYenmtQOqfVbhMGpRSs8HE9F891cVxBENhKa+meLmmW0u5ArTaE63pgrPl04oCUtkCN63plKXS7Vdjqb4IwdMmylCzrsTA/h2U8CR584AFqtRonnHA89UadShExMztHJaoQhoYkBc+1Vg1JEuN6PrVqnVrVsxX/spyF5kHanSZ79++k2+vQizsU2rIhjCxothfIigQlejgeOK4gDCqEYUAUekSRZ/2UpKDVisnTgiQv8IMQP/QIAx+lbLU1ex/gIKVHmtoKbp12ivVpNfiegy5A5dBa6JIkbRYWZlhsH6BaDZiYbCCFC8ahyDwwDgKXRmOUocYormsQ0voy7du7j14vJUlyms2EdetWMzw2hOeF5FmCKXLIPVQB7XaXxnCFSs2j0QgJApckKej2bBXDwHcGN/uO45JlikIppDB0Oz26nR5RJSCKAmq1Cp7rkZdxSVEo8kLRXLTm4gAjo7UBOCB9FwQkgW9ZUkojDWCsl02eW0BCChgaitDK0O0lLCx2UEozOmo91wyaNMvI8pwkzaiEEQBFoVClLLNQmkZjhFrtqe3TdjSGPhpDH42hf4KDHtKetNTunge3D8CiQ+VLSye0DAod3KwvgVTLb/aXjL7tewalE41BqWJwnAEsUAJJtszi0vGUsjK5/mcHIE2JwlrDxQKjlTU203qA7i4HmJYmU//8DEtX1diBKsuSjCX/J1eW6pukXTpxizSL6fSadOImSdqjE7fJ84y8yOh1Y9K0IImtvE4Yu6mHVQc/BL9idfKFTonTHkXJeBqAL/ZyAct8hTAD3aoFw6xeVQo5MH3rAzFCCBzp4Dqe1dLLEEf6eG5EGIR4XhlYlN/kuTZI8f0A3wvACIo8p91tk2YJSWblB3lmaC3GOJ5LFEWMjIxSq9YYG1nFcH2KSjjMUG2i1J4LpLCovD2fJfbYcpphH0QagJLSZmoOlcX1X388sGl5OxJAtHySH2kaLF8AftRx4akvtbv/4R+VEf4RS5VZPic4MiuMH43Er3hdHPaAQ1dT0QdPMRaoLTNqViabWUpwVpZ0Led3H3zug9srF1MLPCulyyo8Dp7n4zjLqjP2q2RoWw0IAaET0SsOMJfczSPNG2ln8yRpRpELtJI4JiSKQipRYNeHQpEkOa7nldnDDIzGd2qcvOYKJmtbGa1uJMlbKG0NT02/H7RdB/sVNqW0/g2e7w9K06rCAtDCOCTpNN14mof2XE9SxOSmoFEbxvcaBO4Y09NNkiSjSHPqlQlCv47rVhkZnWB4aIxKtV5mJ/vrjUarfJDRltIZUIVXzNXH+eu/vvx9hw+EJxwmh4yIHz9TuHIcPjE9uN+eylK7F7zgBYDN2F1+2a9x0smbufDi9Xzi419mZqbJa17zQoRjq7wM1ysEgUsQOOSFwnEkYeDzwEN7SdOCTRunaLWaxHFMvV4lTgyddkFGD991qEdVOm2NEJJVqwI6zYIsMxy7aZTp6Ta79y6y5YRxDh5o8d3vbueS525hbKzGwkKPPfv20ul0OefUU/FDieODKjTtdo/9e2cYHfWo1yNWrTmGZjOm100oihaNRoOh4SFa7QwpBWHgoVTBgQP7+Zd//gfOe9a5TE5N8tnPXcmJJ53CGWecw3e+cxPj46NccP45fPMb36DTmWPr1jrjEycyNLyOVROr6MVtut0WIyNTZFlKsznPunXriaJo0Lf79u3lpS99Hm/6+V/kTW/6RV50+flse2A70/u7nHvuuQwPDwPwshe/hLPPOouzz3smV175ea688vNljGOPc/PNNyMQnPOMcxBCsGrVKj75yU/SbsUszDXZcNxq0AlZbw4vmgThonOF47kgIU3b3HH3vWzbvoPXvOKn2fbATr7yL9/mdf/lhaxZO0kQRezae4CDB+a49/pHOOn0tWzaOsXdd84R1ARj631WDa2hOZfxg+9u56xnHkt92Od719/OWadvYesJ6/nKv32X8bERTj35BBYWm0gpGR4eositqfHE+Ajzc/MsLCyy70CXoUaVNWvG2LOvie+7bFg/xvxchzwvmJioMTPfptVKWL9ugpnpeXY8uofjjz+WRqNKfShk3/6DxHFCVKkxPtqgEgXceNODZDlIfE7YMka73ePmWx8GIalWQ555zmaGGlWi0Geh2bY3NYHPwkIH33eZmBjiPe/5n8zMzPDnf/7nbN++nV27dg3myFO1Pbx9L3Gc0Ol06XRjfN9jZHSEWrWC5zkIDHGckOcFIyMN8iwnjjNanRghJFEY4nlyEFenaUKR2xu/arVCrVZFSoc0zVhstijyzO5dYYgpvXbAoApNlmvm5xcoSilNtVq1htSVgDBw8VwrpTKUEpY8HzCh4th68VRrLlnaJc+TMmaWGCNotTsEQcDI6Ciea1kw7XaHXq9dVoMbQhkXpSWd3iJFkVCoHnneQ6mMTMWkWYc06zE/P1vuhZpqze6thcnJVBtEjl9R1shag1KytHOQ+J7AcQWuLymUHjCWfC/EdawHqhnsLEv3LkWh0Mp6lVkpmCkL9tg/rSTCSAQSz5O4nqRSkXieXQRazYQ4zkiznGpUpRLVaVRHCLwGwrgUmSDPBUY7ROEow0PDDA0NMzU1Rp5pOq2UoaEhpCPIVAZOjnQFjVqdLNGkqUEIe8OfpRlhFOK5Hp4fIIStahcGDmmSkmU5fuDabd1ofN8vJUcuvZ49x243tgCjIyxjLitIkqysXAetdm/ATgtDjzy30r1aPSDwXYLAw3VdilzRase02glKGxr1COvpY1Ba4bkuge/j+x5FXtBudzFGDCpgSlvwmmedd9K//8R8ku1oDN3//qMx9NEY+sjt/77UbvnjI7BNBs8fiuSVc3HFXFnRiWIZEGxWHMcsG/wl7FIOrD5goAbvX8GmKg3M+hK7/kRZ/r4VnWr6QMTSE8uBsf6UVapA6RylcnppiyTt0e41aXUWiZMezfYCvaRt9eglgFQU1tQzSxVJXGB9qQS+LzGOg5ag3YyiBJ7SLC012Vb/vKKfloNrMPB3ElLi6L70Ty6tbyX6JLA3LK7j4escKQqk8HClPb++AXn/IlvNuI+18XIGxomu66GNJlfaVkkxiqxIkFpgyAkjiXAKwsTDc62MIvRrNrslPYwjlsbMIe0wDeuRHh3Cejq0PR4j6kg0xsc7xpGkn8uP93ivP/3bIQzGQ7rHHPq0WbmUDfp18PLKfjls/RAsq0ix/FjL1xZRBod2QPcLAPRNL5Wym6YqsqVCAIec46FnsJyR6ThuWQWoz7rrjw8xYGsu0S4Vhe7QyfbQK1pkKsV1I+sfZ3RZZjYlyTSuK1FaoyhQuUFKg+sqsrxFkrfYv3g/rogIvRHbB32ZwyDDJMpzWd7XZdVNDIi+F4jd5vOiR5q1iNMOudEYISmUNUk1wsOIHoXqsdCaQ+uCNOjiUsOWj84ZEdoyHx0HV3rl9/bX2bLPWApCDp07R5yTyxIQK9fwle0Jk3ODBN4hGb1D2hNtlk+mPR3m8NVXXw3YMXvpxW/FKEOnk7Kw2KHT7TEyGtLtZaSZotEI6cUJBw4uMjE+jEAQ91LCIETKgmYzth6DGiYnxpmebjEz3UI5OZXIZ93aMR5+eIEkyUhSQZpq8szQbHVR2lCrVfF9ayLb62bMzkwj6OH7QyhlSNOcJMmtd4ILaaKIwoCTT9lEc/EgSiuK3BorKyU4Zv0x9HpdZqYPMjE5RbPZ5s4HH+CE4zcipaG5OE+RAwQ0m4topalW6vR6CXGcoDX2Zr7TBTPE6lWrWb36OCtX1w6FqvLw9kfBFPi+g9Z2/2o2m8zPz/PII4/wwAOPce8927j7rrtZnFYE7ggnnrieJEmYnp7GGEO73abT7nDP3fdwww0/5NvfvgaAKIoYHh6i1+2S5TnXXGOfX7NmDXfccQdhGNqgXKwBYf1XXM+yIuIkxQs9pCNJEk0QeDSGKgiBBRAWW0hcPMfHGIOrJZ52yNPCmkxrTWc2p1CCRiFIujm9dkZzsUcU+Aw3qrbiVyem3YqJgoBaJaJSCej2AvJcsbjYZdXkEL7vsnv3AYaH6xy7cQO7dt+L6zlMTQ5zz317CQKPU09ey0Pb9tBux0xM1igKTZrlDDVCZg5q9u+f4/QztlCpBSRpTpbnFErZalhAlhUkaY7AwY9sBV6tDXGSlZlzgdK2+pEQgqFGvWSnG0ZGGgN5w+LiIvv2HeDBbbtZu2YdW7c+dUHjfkvi2FZTcwSuK0uPHLdkDmgciWXSKVOaiuckaYrSGrf8zEA6ImXJQLBxoVLW/1MIK8GNwoCkvPF3XQeloFCaOE4GTJO+N0qhclzXxfc8oijAc+RAztf3FrV+ToVl4yeWDYSQFHmM1jlikFyU1Ot1XNdDCGuabQzI0rBXCpCOIc8zkkzRTRZIsx5x0iRJOhQqI1c98jy2Hk6dFqCREiKE1cxohRcYpCMIQocsNxQF1sKi9KnSGlwt0P3zkgLhSZB5eW9QDHxfhJD93Q4B6H7hoFxbKaAubSscF1d6pTeLYyV9EhxXI127R+NkFKZLnMUYEZPrLkr1CL0OGI88BYyPFAGeH9BNBFoUVKoCVRjiJKdej3C9gCjwSVWBQVnFRAFKMQC5+mb+ShlMCYT1pUYWDLBJZKVUaR5vcIRlsUlH4UiN6zm4rhxUFOwb2mtl77WMNhRaI1AIYceZZYnYPXNFcSXVV7D0k8gOyH78JtDKMvjyvCDLi5I1qkpZovzJSsY/pdrRGPpoDH00hv5R7ceS2h2OupXdcMjz2hg71A1Y6i3lIrVsMixH9kpWz9Jg7hvj2cEoYGDcNTiKYAlgKk2fgXIAW4Td9LWlg0p2j4fYlWBZeZGN6WtWS7aN61q9a57Q7EzTTZp0ek1m5g/Q6bZZbC6wsNAm7qU0F7sW6ELj+RIhDUIarJkhqMLguBLHk4QNg1tNEV5BnHUpipw8Lygya+6ndTlhB7+1P+nLhcRoNMYyxhyJo03JeHLK91lDbKVtHxW5LvXvLlJ4GCMpMgeBj8TDd0OEEUhspYtaPWJ0rMHE+BhhGBIEAQ23jlI1AjcldlN8NyVLyiBRGpAFyvToJLPkRUqrW0cpQ706RjUaJnQie80Fy5Bgab2q6C+m5RSRK2mJh47BvvSt/2P7LDrHcVZ8pv/Yjjs7eJYfZzn7bvl7lw3Wwbn12XpHQqX/n2jl4imEeFLL0VJXmsF/B5vvstfMoaDz4JWl8W/9DQqKLLYbZV6UJYrLDXXZ92pz+LH6FQmNsRuE54UEQViCh30gtVz8hQ3epHAw2mZxM71ATx1gMX+UOEnICkHgSELfRwTQ6faIs4R2LyeKIoQUaCPRWiG1nXcYn6wouGPX15jr7GGxt5ut45fhSB+JQZFi0Ajs2oExOPYHYbQmSXIcx8MLsAb+wgHhEBc9WtkimbFeFiAxOgIMjpuzft0Y7ZbHQvNRukaR5vNEjLD7wQdpNmPWbt7IUGOY0eExJkbWUQnrNCqjli1a+koIITBCLptLh1CCzdI1PtKc+IlmySAhcbT1m5SSF7x4MxNTY9x46yO85RdehkDz1atv5tyzTmDLpnUkvZy77nqYH9x0B7/wplfguS47HtnP5hPWoo3gmm/fx5rVDSYnrLRhZno/9911Jy97+Yuo1qp0ugmbNo9w8OAcH/mTz/PKK57LGadv4ctfv5HNG9dw9mmb6PQy1q4b5p2/9lP817e9i3anw5Wf+xi33dnmgW27ecbpJzE7M8/s7DRr127AcSSLzRbHHLMKRzrs3buI4wq8wMEYuOfOO/jh9dfxlv/637j22mt53etex9XXXM0F5z+b33rXu/j2tddx3zXX8MEP/DE33HAHn/nMP/LLv/yzPLpjD3/wgb/g7b/0BjYdtx60wQ9s4Cek4NY7p/nmtQ/zmb98A83FAwgh+O53v8umTZv48r9+mc/+7We55eZbUErxqU99is999rO85ed+ljPOOovzL34ua9eutYwRDFJIdu3axRlnnEG73QZsQLd16/G88pWX88lP/i27d+8dXKt9+/Zx4YUXAlCv17n77rtZt24dXmD7XesCN9RIxyaGGo0J/u0rH+PjH/9L7rjjDp717NM571mns+3uh9j96F62nnYCH//zL/DgA4/yT1/6GGEYECc5t952B6ecsY6XHH82f/mRr+K6kp//xYsJIh/XdfjFN17BfQ/s4oabtvFTzz2POM7YsXOaTcetotdNuenWR2jUK/R6Me//o7/miiueywte+Gye+9zTwVgT4IX5OSqVACEEX/3X77NnzzQXXPAbbNwQcswahee5+JFPY2KIStVHCpif73DsMesAuOHWhxiuhwwPRVz63DMw2pAkOd+85laqtZC3vOn5JHHK/GKLb113M88862ROPGEjc/NdKpFPYyjioYfm8XyH4zYO8cd//Cc8/PBefvbnPsiv/9oreO1rL8YRDk/ltn37YwyPDDExMWrNu12XMAisMXNpxdBsdUiSlKIoyLKMXpwwNTVeenFKFptttNLU6zWSNCdNMipVj0Jbs2lP2X1POh5BCEIYAt8ly20sODe3gBACz3MxRmArHDtl8Rkf1/VwXQsmKKUGQMTCfBOjbVyrTUZRZLSme3iuZWBlmTX9jyILmkjpgDakWUZRFHS7BVIGeKFDJ5lnbnGOmYVpDi7sJSsyCp3jByWzQefkvYw8zel1Y4RTIP0CJ09wPQfHc/AjhZCGvCgs+z43JKk1QdZKEUYWeFLGmqtbyYu0bCMjENJ6ntqkaxXX8QncCJT1eLJSNI3SmiJXg1jVc+2mpLXG94PSdgMKHaO0wg0MupOT5jFx3iL0fQrdQeTzGO2ilEOlUsX3A1S7iWj7CHwOzkT0OjmL8z2e+cwLmJicYnxygiKRqMKgcnufIxwLjzmOJKqELC7EIHLqDYnG/rnKJ8sVeabKMvIOvt8HByRxXKCKfsU5yIoCoQxDtYr1jfJcayGS58RJQhh4CClotdv4vjVr73Q7GGM9XQWWTZalClMaiueZspYdQpClOVJqjIsFBo0hCHzarR5ZluN5DlqLMnb5T96OxtBHY+j/x2PoJw08Lb/RXhqIK/WIh4IDKz+j+x8ZHG/FsZYzkEoQyoJBeoAWLpfELQFJZsBkwiyBCNqU7KY+qESf5QQrTsSejZ3BhoHJnj1GQa4Uaa9Hp9ekl7RZaB0kTjv0Ugs4xUlCp92j3UrJ0oKiUHi+g+t5VOs+jitsZQysJl8pcFxwPPCjAi0LNAV5mttMQGZKk0eBNqUutESOl66FBZ/siCr7RwtKP3WMXI6LlhkyJQaTyXNdoiBACEnhC9LYBhZJK0Hi4goX33XJXI+4k5HWU1xXEFVccCRCg68F0vXwQ0ngTwwykl7oWWDNkdbk1LRZ7BwsN20X3wtKynJpEj/IjKwcFywbP/IQAOqJmEpHAqhWsqDsWDz09RUMvkM/10eq+2PyiN95xFN6SrUjMbaezPv7n7Efs75my3Iyh39wxULXZyHa+a+XvemI83nw/mXngbEgclmNUpXSAKPVADA2y97b/5/l65Qus7Zg8Hwf13FxXHfwuq0G6WDKktSDg2iDxAFcmtk+FuKdzHZ2khc1dOHTi8FxVSl98O3NrrA/VwoH3/XLn25Agyc9HE+R5Smd5CB75u9kItpCxR/FdavlhiNt4qzcKAVuiT8btGrbCiFGIwKB4xgb2OUJSdYjU0mJnzvkysPJIJEOMgoRrqAxXKOTpPSyFBkGdPIF5ruLiP05zVaVxWaDNFtguD4BbKISDOO6EaqIMYAWfb7pIZf8/xR8fYKPPxFF+LCM4ONkap4O8/PJtEsuuYTXvObVrJpaRRD5nLBpihtuuJ1ur8fJWzbheT4z8x2GahGbN62jMRQRRSGOlKzfMMk99+2gF2ccv3mSoUZEFHo8tnuesFLnvGefzfTBRcJWwshogzQpCIOAV778ufiu5OGHH+Xs0zahNTz40D42bJig00m5/Y49vOhFL0DrnO9cdx9TU2OsP2YSpTMaQ1VGxo7DkT5KG8gEnXaXXi/h9lsf5pTTNtEYGuG2W3+A4wou/qlL2fXYHsZGx/nYxz7GyOgUBw7Og25x/OZNrFq1iq9+5XPUh1bxohddwraH5zHG53WveSlrVk/ie9aQ9MorP89NN92E1pp9Bzrs2tOk014opfnwoQ99iDPPPJNX/vQr+dpXvzZ43u77huNP3sqGTcdSqfjs2LGd3Xv28NV//RoA7XabXq+3FPcAu3fv5V//9RssLCweds36x+52u7z73e/m0ksv5ed+7ud4ePsD5HnGyMgwX/rnv+PA/oO8852/SpLEdLs93v07v0OtWgNgYXYBISQj48OctPUsznvWmdx40zaOO241a1aP8YrXnk3g++zf2eZZF55ETspDB7ezangc3wnYuyshjHxOOvEYbrzhHoaH66zfsJrp6S5KaU7csgbXAYzkZ153GRs3rqEoCm6/7V5Gx0bYvOlYzjxjM3mueXTHHBdceAZKFTiO5I47HuChh3fxguedT71a5azTNnP7nTupRAEnn3QMD28/QBxnnLBpNa4rcB1BlufkuSKOU8JqlSAKyHPN9GyTbi/hvHNOJfQjDuxvMjRc4cCBWW68eS8nnXQCnXaXv7vyVi6+6DSmVo3yW7/5ah566FZ++Zf+iU984hP//07A/8M2MjKKdB1anRhjcnzf3vjYQjJ2nwrDwJapDwJ836dSiahWbJUoow21asXeuIe+9d0RAt9zSdOcVjNheKhmwYHAxXVdtFZ0ur0ypoKR4ZplXDmOvRnMNJ1uRpoqjLEVLo2RuNICT0IIXE8SBK71fkp6dLttlCqQjkPSs+wnLwgsQzJOGB0bwZHWGqPTaZEkCb00Q+mEvEiYax6gFS/S7C3Sy6zHUFEoJBrfdYhcH993KIxPYlLyPEUVCYoc4RiEqwlrGuna0L1QhqIwdNo5RhnQBi/wLRApbGEioQT9SnraCBxHIaXGcTRKWV+a3Eh8WfpiOQFSavJCkecdbDSu8f0QjFmy8BAGzwsojEQbQaxiCnJwNElHkcUJ3XaGSiWqEBSFoDFUJaqEDDcaONLHwSdeCEljRTfO2bnrIbpxC9eXYCxrQ5PjugF+ECCRtsx7bogqAVJafy/XKw3ry2stBAOfsKwEgrzSFsNxBDKHdrewYJ3ROEZQFFZqNzExgu971GuRvT55QZyk+L6L71m/qryUzEVRaCWKuqDT6aK0xvfd8j7FwXM9tLIeZWHoDQC8aiUsqxrqslz9f/QMfeJ2NIY+GkMfjaH/z9uPBTzZf5dOoI+wLr/hN2aphH3/bzkt71D07TB2iVn+75J0jvIYywGn/mt9sMkc8hjMABJeAgdWIsOWfLNEhdNKWXd/o8hVQlYktLvzLLSm6fSaLLZnSPMeSR7T7rRJ05w4zknSwpZhFQLP9wgjl1ojxHWtztwYUdJ/Da4H0tVI35DkGl1YQ8Ci0LasqynPx/YupqQvL5EwzaAbRflTjLEadzlgepavGgtSaW0ZVH2fJ1uhxClp3TF5kZOkOa4IwAkwCnShUblCFRlKSxA+9AEwmSNd8CX4XsV+vymzMcJep0IriiKl05sn8CoEfhVjRoDSr0n01cCHj7Pl/y/L6gPLx8yPlsmtlNatZDRpjFk5Pg9thzGlDhmeh7en+I55WFu+8S1rR6BornhRLL1JPN4xDv2mfvlc05fJlp8elE0pr8lgbutl/W9PRCu7URZFYWnCpX/bEX8WLM3/8rHW1gtOCPA8fxmtuw/t2tKmRlqqfp/eKugDv4JudoBWeoBWMguqitYuaQpObpCOIQjt5iqEwWgBUuIIt2Tu2bXFc10QGs/1SPMW8yplvreTXCdU/Ak8t2IlsdKhD8Db/rOdoVWBEVZe40pbBcd1BErl5MrKde15SwrlkQuBk3o4boIyOX7ko5MuaZHj6R5x0aWXtpDNgiQLSLIFogoYkxD4NTy3gueGICTmR13qQxmAy+foE332cabOj0Pd/Uk2y6eDvO7QtmnzJi5/6UvJMgUkrF01wr/u2svCYotLn3s+7W7KQrPH6FCFsdEh6o2qNQzGEEY+e/fP0uulnH7qZqSwMoeFxS4jwxXWrB7n3rsfIUlzxsaGyVOFKz3OPedk7r/vIaanZ7nkuSewZ+8CD20/wMRElcXFmEd2zHLh+SfhunD1tfdw/jO3sHnjFPv3TRNVAoaG6sRJThJndHspnU6PZrPNgf3THLd5FUUesXv3DtavP46Nm47nvnseZGR4hDe+8U3s2TfHYrONJ1qMj69lZGScq/7t0zz7/Odzztmn8tWv30ut6nD6KRvI0oSZGWtG/vWvf51/+qd/WrFGjI+Pk+cezWaTr3zlK0xPT/O7v/u7rF+/nqmpKQA6nQ5aa9ZvPJZVa1cTBB5zczNs2/YgX/7yl1lcXCTLMsbHx+l2u3S7XcAwOzvH7OzcEa+ZEJJqtUqlEvGFL3yBLMt4wQtewGOPPUqWZ3Q7U3zve99j587H+MW3vmXAdPn8lZ8/4vE++clPcdoZx/MvX74B19VMTdXYvHWIuG1ozadsOXk93bzFTQ/eSsXziWSVXbubbN0yyaqpIa773q0UuWLTpnUsNru4juDYY4coshxjJM985mlW5qAKdu3ahwFOOGEja9ZM0G6n7N67yPEnrKdW8xFCsG//DPff/ygXPOschoYqTI6P8IMfbqdWDTj7zI1MTzdpt2NOPWWdDR9MX16T0ekmVKoVotAnjnNa7YSiKDjx2GNYmO/RbieMjddotbts27aLk07cSBz3uO2Oh9m6dT2baxEXXngCV3/zc/zN33zmKQ88NYYaA/lcoRKU0kRBhCoM2gDCerFJRxD49l8pBa5nTb8LowjDECGwyb3AszGnK4mTnE4nplIJkI7EF9bzU2tNHKe4novjSCoVH6esbGcLvCh6sSLLbHWzMACjJcoRqELhem4pIQEhNErlZFmCUoooqlqT6ELh+RFFnlnDXpVjSgZLp9umF/fIipQ47ZBkXfbP7iEuOsSqR15YzyCVaXwp8IzAdx2E51GgcR2XPLdl0otuhpEFWuRkaBxP4EqJNlYC1otzUDZetmweY0OMMvZQyiZ/dRlzOI6VjCllb5jRAj9wcaSLIwOsZUduYwisibPjuNiEb98/tl8QxxZQylSGFgXCNRglSAsbQ6e9ojRLBi1TChMRVTSe46OES9INyFPIFEzP7UVTMDE5bqv8OS4eLq7n4XkCo0ocQthqd1JKK5criwP1ZXBgd8Oi0MRJjtYWDPRcy0bRRqILXRp9azLHGqsnpYeX6zqEgU8771o1RtGXTUpQgqLQaJXhOBYIUyXrbgA8lKfhug6ZsgyssF+4zhg838Mtwf7ByT5t2tEY+mgMfTSG/knakzYXv3fbI4d92ZHAqP7zyw3I+7phKQ9noPQBhf7CTQn+qCIrXeqX+zLplWBTH+ktFzkr8SvHV/91+430EeG+znLFCQ8AK0WSJcRZl1ZnjoOzu+nGbXpJE6RGOBBEHlpoNIpu3LPeCe0eSdeWrnUdj6gSEIQuXihLGrMh6aXkaUHaSwkrEjcAv6roxm2SNKbTjlGZsT4WpjR0LP8QS8ZkfbcpXS4aemACZwYmp6K/GBhbkjXPrcwOI6hWIkaHh5gYG7VUa2Bmbp52u0tzMaZRbdCoNhgfGcP3PHyvBNB8iR9KsiIjyzJmZ9vEvYIsU1SiCpWoQqNRp14fwvMCPDciTlOyrKAbxwzXVjPSWM1xa08j9CN8xy/7ZiU7rs9uMuW17DOfVo63QybncpByWVsOTopSlncou+lI7+9L9ZY/d6i8btloH3z3mac+dU0RAe576FHgJ8/WHOEdj/fJZQt+afBXjlfRvx42ehmspaqk71ovtnKe66XsjdL5iozLoWdzKOuyfx6W5mqfC8MI3w9wHQ9VGg6WH0KYkr2GdZFz3LJyUKFQRZesWOTumb9irnuQmXYTx4xhtE+elyAmgjAS9L3k8twaJHuuQxTajKRSBs9xcByJ50GSxmRZgs8YUng4MuDEdT/FWP1YJhtbSLMeadbh4OI2CpVitGI0WovWhjSPrbbe8an4I8x2d7DQ28OD+79jf5eAeq1O5NWoeKPsnZmml8UkOsF1Qox2WJyJaS8mxJ2cqYlxao2QxmhEvV7DGEGnlXH8hmcwNbaRNVMnUBQphcrwpWUs9gOP5dLXQ/3PnowcVTxO7PVktqYjz+effNN8KhcIEEIQBAGVSpXR0VP4qZ+6mD/92O+SZ9a8Mwh8duycZ34u5uyz13LNt27j7//xe/zR+36eZrPF3115Fa9/3YvYeOxa4l7Bzbfczp49+3n96y9n28P7uOWWBzn3vI1MjI+wenIVc7M9Op2EmcUFhmohtWrAqlVjLCx22btvns9/8Uscs24Vb3rDy/mrz3yJJMl4x6+8jke2H2Rhoct5521m/545HtsxzTnnncDePdN8/d9+yMmnrGdq9Ribjt/AVV+/mh2P7uQtb3k9t956B9dffwP/9a1vIk5zbr/jPjZuOJ56LSQM29xz7ywLCwUveck5ZfUcF2Pgy1/+Mm9721tX9FW32yXLssH/R1HED3/4Q26++Wbe+lb73mc961lcf/319Hq9wXs/9KEP85d/8ZfcfsdtbNiwAVmyPopCEccxb33rW7npppv44Q9/yMc+9jE+9KEPHflaWbMBpJQ06iP82q+9gze88ed41rOexezsLLVajd/9n7+F6zh85q8+x+/87v/kpy69lHq9zv/4H/+D97///cuuuxzcIAjhUK1EuJ5LlhX80tt/hle++vm86fW/y/Of9yI+8uEPM91us7jQZPeDj7D5hE3Uh4bYN9uk1+6QpylnnnEC9923i69/43Ze8coLiCoeO3bv4vSTNlMJQq7+xm2cetpGtpx4DHGclje1Ll+/ahth6HLxc4/jqm/dxEKrw8+87BKbNMsVlSjkjru3861rb+d1r3kuUgruvGsbG49di+s63H733Zy89QQ2b9yAH7js27PI9m3TbDllnEIZHtvZYuvWSYTUXPXNGzn7zC1s3rSWu+/dSaNeYdXEMP/4j9+h0ajw0pedz5f/9Q5uufVOPv+599DptEnT9CkPJu/YuQ+tDXmhmZ5pUhQacBkdrhCGHmFofbwQEPheGXsYZuc7FIWVj4yNVsuqdP29zY6RLLO+apVKQFEo2t0evueilWFhvovnOzgSOp156+cUeLiOT1FWy1tcaJLnGY5jqFY8PFfSajWp1Wo06kPMzs4ShgETk2N0OzH5QMplb6Y73QzfdwhDF9c1pFmPZmeOuYUZ8iJFeg4L7Vk6vRaLnTmEC9KVLMx0yJKCrFswXK1QCUNG6g3Gx0epVALmWtM0e7MsdmeZa86T65SCjLBicD2B50mMa2012nMKaRxc4TE0GhEELmHk4XsSEOSpJsusb5MQgiiyfa6Vh8BF4jMxOk4UVInCUdLUkKQZB6b3DO5bRofHEEiM0mhTICUEgUcv7ZLkMc34AFJaNpVOArLUkPQ0MwebZFmBEYp168YYGqpQCQJbSaxQdLsGYzwQIY3GCFFQo1EdRxIQhXVOPflMKlEd34tYmF8ErOeqK32MgTQvCHwXKaDIu8uqGEYoZchyRaMe4Zam8VmqSLOc6dlFVAkqrJ4cKRlPia2qaAxxnHHgwDxpljM2PmTv1YQAYQg8t6yc6JDlBYvNlr3pd11GhocGzCtbNU2T5Yp6LSJOUvbtnaVSCQmjgNGxBk7pV3vMMeP/oXP0idrRGPpoDH00hn7i4z+ZGPrHZjwd+tyRZEaPJ8k79HMrjrtc9lRmKeyKtYTYLvWFRWLLW/5lLKol5NWIZdfBMJChAUufo4/kFhQl2tnsztPpNZlbnKbdm6dQKV4ocb1SQuY7aDTKKApTYLAaczBl9QsXL5BIT2LtBqzfVJZnZKnVSwvXxUiBP4A/Lei2bImyf0Yso4mVfyXKt8R7Wvpdpo+eaz3oDq01uqRwW4mbi+/6RGFUmn0aAt8n9TNqdajXIoZqFep1H0daU8ZeL4bYIDoaIxWFKmh3O7SbKb1ujud0CcOQWr1NY6hNFEY0GsNI6SKQOEKQFzGd7gJx0sGRDoEXLGNxHd6WT7YjgT0rn1o+SY7w+JCJezhwugSCPuHkPuJr/RuCx/3YU6b9uFTOn5z6uWyywSDTgLG0135GZrlzvi5BZVMyDg/dNAdAc3/eHvJtLH/WrKQbW1N8B9f1SvbcYFGxG3k5r4z90WWFSGs4qrUkR5GrLplSKOPgCFudRghwXbHsu0V5rmCM9XTLjcERxWBDUdhspCogywx5LtAiRogEIbrMtXegdI4wnmVWZm32LNyDMTmOkASyiiMCMBKtFLlOaBeztHvzdJNWySQEygAkVyk9FlnszhBnCbiaMLRUecdU0XlB2otJi5gKHkEUgJQYZTfBVmcaKR1GhlbhOPZGZTnZ+3FHwPL1ftkVWjGmzCFj5Mdsj5eh+c/c0tR6v/zMz1zAmWedwd69HXbv3Y6Ummc/82xcRyNkyo4dc1QqVZ57yRlkmcZxPM4992TGxoZwXQdkzurVE1QrIY7jEgYew8NVRkeG6XZy/u2Wmzjl5OOo1yvg1KlWQnxP8vAjjxAEEVOTQzzrvNMZHWkQhR6nnryZVith27Z5lDbUhypobWUgU6uGEUJQb1Q57czjCUOHZrPJNd/4Or7rs3Xr8Xzv299HOJKzzjqTG2+4hSDwWDVRY6jhYUzO/fc9SiUaZ3xiFbVanVtuuZnvf//7SCm58847WVhYOKyv6vU6b3zjG/F9H8/zWL9+PVprfv3Xfx1jDMceeyxCCKrVKlpr/vZv/5bbb7+dLEv5m7/5G0ZGRgB47Wtfy5o1awjDkCuuuILjjjuOL37xi9x5552Pe52WxxdplnDzLTcjHUG322Xz5s286EUv4swzzkZKyatfk3HiSScxNDQEHL7u9se567hUq1V6vR6dbgeAG394O3HcY+/evdx004187M/+hBe/7BUMVesUq6do9RZoZ4sMDa2mFrqoPGffwQWMEJx66kai0MN1JCNDDXzPQ0hJFIW4rkueK2648WEmJ4c46cR1bDh2GEdK8kyTxTl5nIOAB+9/jJ07D/Ciy85jeKjKpo2radQrLLbaPLJjH8dtXMvoaJ11a9aQ54Zde6aZmhzC8yRr1g1z6+0P4vs+m4/bSBxnKK3Ycvx6et2C++/Zz/BQjXo9wvd9TjxxA2DYf2COdWuHaS5Osbi4uFQJ+SneZmcOEoQRUaVGEHg4jkFruyf1K0T1mzGGLCtI0wIBuI4E7HstYGXIsrxkJXlWekUfiLLyO4FNfgZBAEJj0LiuZ6V8vo/junhGEPgBjjBkeYZWOWHolXubIQxDPN+jWo3wPBcpwfM9pHTwPDPwTzKihzEFuUrp9NpkeUwvbVOYnIKcouiSqA6ZiW21OdfFdT2qAUQS8B2qQYjveXheRBjUiaKQEVGAp9BORidtI3SBg8T1jAUrjINRpgwnCoQE6ZSxfT/mELKMC2ysobUu/WMcLHMpt1CxEIBCSF1ajBr6zCatLfCX58oyi0xpY6E1sclpdzvEWY8kT/ADjedZRpF0HILQJar5OBkUWuMGGte33m4YF6FdfEdjjANSIJ0cLXokxRxCRxgK2q0FHGEVC67rogpNmmSIwCoXut0UjLHm/DaDbceNL3CExBdLN7nGmJJ9ZRDCJQxcfF8Shj5xbOVYC4s9pHSIogrVqpXE1aqVQayb5SlKKbrdXlk1EXzfFinqs+viOCFLM4LAJ00L4l6G7zkYbeOQIHBxHQuaOo4ckBOequ1oDH00hj4aQ/+ft/9LwNPKSmFHki/1KXkDEAn7ow9lRpnBv8tBmdLHaIBCHQrALD+ppYmz7ETLiXooI8YyhgqVkxYxcd5ltrWfZnuembn9GHI8TzLSGMIPrO5bGYMyGqULClOgMYQqR0pTTkZrHC4cAxKUVihdkKQpaZIS91KLBEsHjVf+Fok5dOoPTnUZ4DQgZvb/30DJIFzSgvUlifZxv9KJUgbHtVI7z/OJgogg9NFogsAnyHw812OoUWWoXqFWDzAaikLRnLMGgErn+BUBUtPtdVlo9mguJOhc4nkOUcWjMRxRq1dZNTXFcGOMwA9xHEGexbQL6MZNa0YYNXCkZRZpow6T3C0fS8tZUHYsLQOKDvnMj0J4l3TWfQ38UqAnHWfZYroETh0q7Ttssoojnf3/460EjVdsZGWZ1n4BAMrMrn3ZLNs07Xzvj2W9jEIsDtk0+/txv5k+A1AvsdSkdAiCsKzgI0vPlWXXWfTXJ1E+dnCkreSotMGgyVSPXAuMsdWpMBqEsX4T5T6ltC4zSsvkstqQqBxHSvzApSgp8Hmmy+owDo5bIIQBoZhubqeXNMkzRVbExHmbx+ZuxZEQuAFD/joiZ5RANjCkFDonzudZ6Byknc5aqnM/62Q0mUpIi5hm5yBpkRFUPLygRq0aMVYfIuvFtBYUSdalIMIPA8BBGkEUuLS606R5j9UTm2lUxwjDOqpIjnC5jzx/7YMfNVaWXVCWbtqfTHui+f54Lx2214ofvW48lZqUkl/6pdcxObmRu++b5dvX3YDjZJx7zpm4nsJ1U7ZtO8Cxx45z4QUn8sgjswRBhZddfhFpZqsJGRSbNq23tHWgWg055pgJJsfGuPe+XXzhi9/jXf99gmPWj9IY8vFchyzLueue+zh+03Ecd+Y6Lr/sOYPzueDZZzIz0+Wqqx/hpJPGWH9MnTxTVKo+UcUCOCMjdc6/8FQefWQP2x/ezheuvJJf+K//ldPPOIP//qvv4tIXXsrLfvpl/OY738XateP8/Ft+mjDymZ1tcudtD/G8F67jpFM2UBQ51157Lf/rf/0BYAYeSp7nrRiHk5OTvO9976NWqw2eGxoa4uSTT6bPIMqyDNd1WVhY4N3vfncpnYP3ve99gB3DZ599NuPjNgv/0z/90zzjGc/gvPPOo9vt4vs+eZ4fcfy4rltmaXO+/vWr+Ld/+yoAl19+Oe973/sGn3nGM56N53lPcMUNjpSEUcCqqQmmZ2fpdLrkec71193G9dfdBsBNN93ALbfcxLnnPpM1p52Ot2aSu7ffTjdpc+G6jURBA4BvffdORkcaPPeS0+n1YrQxrJ2asv5Y2jA2PkwYBaRpzte/cRunn7aRk086hpNPniLPNa12hkoVIjcIBDff/ADXfOtWLnnumUxNjPCMs7bi+y6dTsxjuw6itGF4qM7W4zezc+cBdjy6D9+XNOpVNhw3yqc+eydjow2ed+k5PPjgPtK04NxztvL97z3Mtgd28tqfPRfXsQyNZ553EnPzTW69bRvnnL2VoUb+tEj69NvevXsYn5ikUq0RhYH1dVLCxqGFXhEPF0VBmuR02jFhJbDgjrbl50EjhCLuJaRpRhRVMMICLUrbIjJRGFDkBoWhWpGkeUpRaMtaCDyi0EeUe53nudSqgTWTjmM8z/p01qoVm5V3HKSolxx8hedKXMeCBkHoIR2BRtPttel0O8wtHqRQKVrkaBRaKHp5i1R3KYjxfBffDQncEFGJcPAJvSruoPKdIAyHqEQhQeQgfI12MhZ6M0hVoKStyCYQiMJFKzBK2XCsDzyVoJGVcfVjuP5zGus7rDDGmq4LjJX0CFu9zTK57PuLIkcpDUiKTCFcB+m42HLxGXma0Gw16SU9FDEGg5CCIgeBb4G7uoebGeIsxQkUwisQGFzpg+OjXetzpAEpCozQZCaHIsXogrn5g7iOR+CHBL5HrDKSJMGRLoWCbjfFdUR5w26T4gaIsLGt69oqiFrbu428sAoLKVyqFZ9K1S0BopgsS5mfXyAIAoaGGgwP1zEGqtUI6dh+bLcV3W5Mp93FlAbuYRCWwLWDlII4jmk124yMDNHrZSwuWimo6wqqNetlJqW0UlDXWQG8/j/fjsbQR2Po/6Qx9JMGnvrtSDQwex9/ODNl6eYdLFwibOKhZOUcyfxZCGGNihCALN8nLaCklmRyopxzBitl08ZK9JZPwkNOhr5m1U5QRaFTCp3ZDbFISPMeGW1kkFEf9XFkgONIXM8FY0GY/u/sTypHOrainCsR5WShXC80BmVsKdJcF2SqIM0zZFehcakV7gAdHqCsolxcEJi+CV3pD7XE4ipRaMpu6i9AK36vrUrQp1ZqZXACuzkEvocfBHiuR5InCClwPYeoGjA0VKFRjwhDhzTJSXoxi4st8lxZU8HIZjKCyCGMXOLEIVbK0rVTy4pK85Q0j5mJpgn8kEZtxGavAsViay+uA/VKA98fwhGOzUAZa3J36PiClUyk5bK3QVW7/oK7DDQ6MlOqvzj3F1fsYsWRJv3ysSmRkhXf0R9HQiwBpkfbymbjPIHsTwhsENxnHyq0NVsYrFyDT9JfOm3dxv57jtDL/Wvef2xA5Tb7LaUkiKLSk6EMuIQqvR1N6bmmyrFiMzqiLFFdKIVQ2mZTjQDt4jCEFAaIyVWMLjIKFaON1cvnqYfRjg3CXBfXlXieIM80uRbkqbFZEinIU4XSNuMaBJUB+6/Z6dLs9DjY3F9upBqJNVxUQnKw9zCeaeCpUdKsS6Z69NQsew4+SideZGysTrXqE0U+kJPnmiQtWOzMkxU96lIQdxuETo2JqQrHb1nNqtUNtm3fg5AFSS8lCC0Lxqk4zC/O0c16zDb3Uo0aVKL6ILN6qEz2SCzFnzzj9+/UnuKn93ityDX1us95z1jN1i0/w8xsm4//9fc58/S1HL9pDcdtDOnFKQ/vOMDQUEQY+ChluPGWbczMdagEI5y4ZYI1q6vs3n+QaiXizNM3YxAcv3ktH/zAzzM2Wmdursk//+v3uPiCMzl2/Wr27JRMjAjyvOC33/W/WLN2NW9/+y/yla9eTa+X8upXvog/+7NPcdvtd/H5v/sz/vmf/zef/vSnufLzn2ffngP82R//Be/4zV/i2RecyWln/DHb7n+Ma791C+/5w/dw3/07+JM/+SL/7R3/jUoY0prPEGOC0dFx3vK2N/GHf/g+rrrqKgBe9apXceeddwBw1VVX8eu//ut85jOf4Zxzzhn0keu6VCqVFf121VVX8Zu/+ZsrnvvgBz/IaaeddsR+Nsbwhje8gSiKBs9NTk5y7bXXEoYhvV6Pl7zkJezfv3/F9w41avze7/0+lz7veRhj+NjHPjbwH/rqV7/KmWeeaRNVWPDmIx/9CC960YuOeA4CuOKFZ3D22c/g1W/4DZRS7Nixk5e97ArSdGUAq7XmZ3/29YyMD7Nm82re8bZ3cuEznkuzFXPXzgeYPniQSy66gDTW7HxkGiVzfN9jfHiUO26/kzyLeeZ5z+bgTIsHH9rLO95+ObVaiDGGbQ/uw3Udjts0BZ5LhvV4edWrLuGyFz+LbicljHympob5w/dfSaUS8lu/9nq2bdvD175+M9KHjetW8YxzTsQPXLY/uos77n6QX3jz5VSiCtu3z7Bm9QiOI9j20C42HT/G6WceQ70e8p1v384//P21/Oo7f4ZVq0e54PzTkEjiXv4Es+Sp18bHV1GvNQi8kGDYPmeMIElyjDakSYEfODiuQOkCz5cMj1QplCZJMuYXW4yNDuF7HoXKEdKhUomoVEK7r2HXBoEkjDyUZ9k9Sml015ZLD/yQLMuZnW3jug61WoXhoTqVSkQSx8zOzpBlKVpr6rWIbq9Lp91mYnKMwA8weICD47hUqiFJ3iVNusw3p+n2OnTjDkrESB8CJyRZbJPlypp+50AmSHo5leEhxoYmGF+7isCvEAV14jgbGI0PDdWIIo+saGKkQAs4uLAfUWhymSMdiTQCCEFnGF0AMf3YzFbgEoOb8CUGh72/sFuTZZEJIawiQEqEcMqEpJXZ5kVOUXo5WQaZjf2llChdkGYJ7W6bxWaLXhIjnQRVCLKeoD2f40ifMFDkRVZ6qaYszrfIk4R6qKmFE9QqQ9TDMebn2uzefcDKBEOPsOrQ7S6SF3PMTc8yMjzJ6MgEx286hShqMDo6hCMDtBZldT5pK2QKl4WFNnNzTfLCoV6rMjRUZ/++WYqiwPdd6vUGjaGAas3D9x08X5bV+xxq1RphGFgpn+fjKlH60/bBIUOea9rthJnpFo4MkFLQS2JWrZqgVrOKika9ShQFDDVqZJlmeDgnDB163S579+6hXq8RRRHDI6PWR0weBZ6Wt6Mx9NEY+j9jDP2kgaf+zfxhMiXAPM5N/opzW/ZyH6g6lEnSZ/EIKRF9udiyzyy75acvyeuDSUtIzEpwYpDlKD+ptCqr1cVkRUyuUuLc0oGVyXF9iRYuofCXDYwS4Fp2jku/o+wLYbMjmGXfZpadfPlnsCwkXegSrBZL3kxiaQGxKHIf0S5pTSU7x/7yZYg30Bd5DsCpQeeZwWOnpD/2F3hRMrLAsoiCwCfwPDzXQQobxKap3SyVtppd6QiENEgBricIQwehZVmlwsErg6a8yOnFXbLcemfYaoGadm8G3/epVhpIKfFdf7CoDfryR7SVFEQ7/pYDb0cCr/rjYul5BhmBI6dMzYp/bVcvjbXlINfTKuV6WCs3rCf9/I/ZBOXcEPSd9QRihfR1RVZn2fcbbObliTy57OuDJ5bWp9KXxAaSNmvSn7COlNaIX4JS/cm5dIw+s9AYg9CqzC5hTVXzmCRtkicxqshReUb/9lFl5ZqGLd+qjCA3AlXYmwutLPiuZbkRl2C8rUhpCxAUhcKgyVWCI+289KQ/OLWk6FKgyFRGJ2mT5glx3iLJEvK8oNXqIESE6xqEY6n+jvRsBRsNwjhkaUEcp/R6baTjUm9UqdasCXVRKGRWWGp0kbPYmkcrw76DjzJcm2B8eA2O4/Unz5PaMJ/MnH6y0O2T06w/+c8+nZhO/aa14drvfJt2p8355z+LZtveCI2NVskzxexsly3H123Z6o4gDD2KXPHoIweQQjDcqBD6AVppOp2MwPfJkpwDnVnCatXuL8KyABCSifFhVGFoNROOWTeF53kcPLjA5NQEk5PjCAGNRp0wDKlXPdasmWBubh2u6zA2NsbmzccTBD7VWoX1x67Hc0EVKUEQ4gceYeAyOl5nYmKYqalRXM9BSJtYuPGmm+n2OlQqNe666y62bdtW9oFmy5YtAMzMzHDFFVdw5plnDp57vNZqtQbH6Ldmq0mlUuHyyy/nzjvv5MEHH1zx+q5du1b8f5IkbN68mWq1SqfTwXWXwqjnPOc5TE5MUKtWOOcZ53DsxmO55557yPIMz/U455wzWVxc5MEHH1wx9r797WtJ0xSARx/dQa1a54ILz+fgwYPceeednHHmuZx73rM57rhNANTrDV72spdyxx138PDDD684vz179oADzznuQibGJqlXG8Rxi2qlQr1W48CBWVzHp1oLeGjHLGHos3ZqkiRJiOOO9cQpK6L5vj/4fUHgkWaKRx9dYHioQb0WkWUF9UaVeiPi61d9j7Vrpzjt9JNYvWqMMPQJg4BaLUIZjesJiiJjfn6OSmUIjGMN8GtVAj/EmIzde/ajioLhkQYzM4vs2TPHOedspjFUYcOGKcLIpygUs/OLTI4P4zgWCIClDPxTuTlOiONYU3aDQStDUSzJBJOkQErLMBBCIB27NxSprXrnSMsGklLgUr5HlvItUbJatJ07Ugh6pTRXCDEwB5Zy6XUpLKAQJxkCQZ4rXNdBKVm+Vw5iYCkdu39pm+zNi4z5ZoduvEicdmi1WyRpQpImaFIrnRI29lO5RmmDLgS6EBSpASVxREC92iAKq4RBFYjJsgIhCzwvxHU9tEkJ/CpRUCfwQnIsc6KfNESUshVhysw7aKVtsrYM2ey+3Aec+lXfymrRQtoEsrB+L0I4YKQFrZRGq36Ssv++flKy76ejyIrcmm/nBa5RFJlEaIcs0fiuBq/0wClZK3mmSYXC1YpAagrXMq7yvKDXTRBCElUCXKdCntrKekKlxHGHtudzcGYvjXrMUENTDUeR0icIAlu5TBnr3+V6pQm0TfgLaa+bvZYCz5f4viRNS6P0wu7nrusShiHa+EC/MJFNYidJZmWYjrQMFM8jCsNBnGXlVaCUptPu4TjSSu9cD4EGI3EcYxP6rlU8GAyuK+0xn5aMp6Mx9NEY+mgM/eO0H4vxdJgvk/2fcl4sye5WvvfxKWSHggKWPWXLIB6qgFzBNClLJBqWaLT9Y/bPYQA8SbGMFGQoVEquEtrJLEnWJisS0jxGui6u51KtRQSFg5tAmiYYbQexQGLoF8I0S9RFQMgBFQnTB4D6G13JzHFciXQl0ikrcGgzqIbhSMuoEX3EaPkiIHT5rX2qpIC+lhfbB4M539+IESDL/XgAioHnWl2q73k4jv09WZZhjMaRkkoYEAQenudgsHr/drdHrq3+Oqo6eL4AaXF035fU6j71mjUx9P0ApM0wJVlKmqXESY+416ZabVGt1hAO5KqHUil5HlMJG9RrI/huiCPdwfkvhwufaNz0EaTHm5jLpZ/Lx6QxNmDr046PJA8d6KKPMKb7Z7e05D5dwafHO+/He/7JLzIDUq8UYCQCB7lMc97HVVfsz5LStNOa/a/07Dr8+82y+W+MZfYJKfE8W45a94NQo0uWosSVLlpaSYLTr74iLAhrx5EzABONKmyBAwriZIF29yDzzYOoJLPgce7gyCpCWGmqpegrCqMogEQYHMcty8laWYWUWIp5+ZuLrB8cSIQIGKSutV2/pO/YsaggdWIyuiD2Mxc3SZOCLHGQBASe5MDBXWRFFUWVsBIQ+DUqlWFqUYQrDS4RSazQeROV9xgfXc1QY5zx8UnyHCvFygxZnjLXPMj8wkHyPKfTiqmGQ0yOrmO4OlZWR4kHAbwdMkfePJ/EQPnRb1kxNw8B9g95/KM+bx/319WnX1Oq4Nd+7Z1cfvnlfOUrX+HBhx+zbKOXn8X1P3iIm256hE3HTeL7PvVKnVqlwq5d01z1tdu4/KXP4JhjxiiU5sCBDvv2djjl1Cnuuethfnj9XZx57ukUWrFr3x7OOeNUpiZHec0rnsvD26Z5bMcCl734DHbvmeb2O7fzS7/0Zmq1CG0Ml1z8LFShiXspr3rly3jVK68gDENe/JIX86LLLkNKyeTkFH/w/vey69F72LPzERbamtGRYdat3UCnfYAtW1dxxpkncfW13yL0fU447jg+8IEPcONNNx2hF5bG1gUXXMAFF1zwE/enQDAxMcEXvvAF3vve9/Le9773x/v8sjH//ve/n/POO2/w2vT0NH/yp3/C3XfeTa1a4z2/81vcdMttvOf3/2jFMT760Y/w0Y9+BIB6bYg1a47hM5/5G77+9av4hV/4BV7wsp8v2Vx2sVy1ahV///d/z2//9m/zgQ98YMWxgiDilBNP40/e9zHAzo3R4QbjIw2ydBN//vF/YOuWY3np5c/hX666lSj0ufjCk3FdCyoYDSPDNXw/4LEdC4yNVdh43Cjr10+wc+ciX/qXB3j5y7dy7LFDHJxpWXBE5/zFX36KSy65gDPOPJm3vvVy2u2EnTum2XTcGur1CKUUN95yG7fctp3N689g/YYJrnjJJdx33158X3HCCat4/we+wvT0PB/8wDv5y69exdXX3MGVV/46zzj3RM55xokIAY88up+vfu0GXvWKC6lUfaTwgAILPj21mxABQtiqvmmckaZlJbpqBSEc2q0MKcFxBZ7ropQhV4ZuV2GMoFGvE/g+nufiuNaIXClDu9MjinyCIEKKkp1gDHNzC8SlUbSNY+0toe85uE6I4zhobZieXhjsX7Wa9Z9SShEEPkIKPM8jCi17sMgLhMyJ0x47dm+j3Z0hybq4bmRvDg0YejhSUvgBeWqL22RZQZGCyhyyuKBIJSiPMKgShVUCP6IXFxTKQK7LfrLKg8CrUa9kRGGNzPRIEiuJs7F4jhEKhEa6Bl1o8lzgl96m/fyi7X+QjmUzCdkv2uMiPR9H+vhOiBQ+xti+L5T1NBXCVrPzXB8py71c52ijSg/XwlbdUwWOY1CFAGVvpIV0CFwXgUIbG9sWKcSFwMTg6AyhO/jSpdNdpNVu0mzNU62GRME6VArgE1SrVlZXZGx7+C4a9RGmJtdxzJqTqVZGiKIanWZsqw0GPvVanTCKCAKPwHcRaKpVa0QehAHVsvphr9cjy61v0MhIA8cJ8Dy39IBSxLFlfRRFQbvdZWSkWhZ8cBkZqVMJo0H+tlIN8X2PQin27p1hfHyYkeG67TPXwTcOxuT4gc/4+ChKW4ao6zgDeefTrx2NoY/G0Edj6B+nPWngabnPzkrJ0VLTfdOzPhXoCJ+DlTf5sqTllW8avE8IiRQlXtv/bB9BEsbSB7WdXEditQyeM5blVOicNO/SSWaJszbzrQO0O4skSQzGpVav02gME7kBQkqk4yIdBz0gMtnjrgCchEQKuQzcWWLe9DEkgUA6Dp7voQpNHnqYQiNwbGbKdXBdmw1UhUFI3afx2AOYUm4n7MJjN1G1DHjqM7EsQt0vW2mMwAiD1AbpCBwj8H23DFgkhS7QhaYb9yjyAow1L+1ndHpxav96Ca4rrcwulBgKVFGgTYHv2zKpgefjeb71c3JdlNZ0E49Ou02aaIo8JU4KlO7geJo0bxLnbbrpItVwiEZtnJH6KqrREI3q2BLLTB8B6AS0VoONbsBaOkI70ljtS+0YXKUloPLQMWQf66XzOaQWZh+wevqBTj9pJuYnyCiLEoyVlKBpCQIuO4cl5p6VXPbloYevMcsBQFt+WmDAaLTOsZR5SRRVbFbSaBwchHCQrmtBWgNGWC8vgb2JN5glrzQDwsj+0IBC0YsXaXZmmJ3bw3x7jlYrQ2iNNBJXRGjpIYRTZkbsetD3qdNaInERjoPv+0jpI6WL6/qWtm9XCBsAOw4CD7BZ6xIvRmtb6cOgKQDPdwhCj9EJTZ4p4q59Y5YmHJxVzM0t0mw32XDsJJWoweTEGPsOrCaLm8xPp0xNVfHDGp4bIEyAyg1ZmpCkmiyTVMM6Dh5Vr05loob1uFDMLOzi/kdv5IIzXkoUVhGmTpr3ULpA6X8vc9+fYAyuaGWQhJUzP/3mrg3UP/7xj3PSSaex67FFtmxaj+dbZsLpp61n8+ZJdj42y1CjwthYne07H8NoeMUrz2Nicoj5xTaf+dxVXHzhmWw9YQPXfOd2RoaqXH7FRdQbdQyazZummJ3psHfvDI3aWtasHWZ8oobSNpOY6y5Ka+64Yxuf/usv80u//GpOOGEDGFspdWFhkTe/+Td43vMu4ZWvvILf/7334Ac+551/HmumpoiqY8w3F6lUhhgeGSEIDa4XIITg3LOfwQ0//CFvfssvsO2hbUfoAcEXv/hFbr55CZASQvDhD3+YU089FYAizzhw8AC//Mu/QhzHhGHIX/3VXz2p/hVCMjl2PBc+5zx+4a2v453vfCf333//Ed8bRRFXXnklnU6LPI/ZsuWEwWt/9Ed/xDe/+U0eeughXvnKV3LZZZfx0T/5KMcdt4mrr74agFZrkfvvu4t//Kd/4d577XfEScxicwGtNS94wQv4xje+wQkn9I8r+IM/+AMeeeQRPvnJT/LmN7+Z8847j7e85S3Mzc0hpeQjH/kQYRhx2WUv5nd+5908+9nn4zp2nPuBx2te/XxUrtn+0EFe9uKzcVzB7Mw8W7ZsYW6+yW++6y94wfOfyXMuPJPjTxjnrjsf5m8/8yXe+raXMzlV44UvPI7x8cgyK1yfxbkuaRrzvve9m7GxEbTR3Hr7I7iOw4lb1pJlBbNzTTrdmIcemOGh+xd58QtWs+2hHfzN3/0TP//GlzM+0WBuvsPll19ib3AcyRUvP48LLzyZajXkG1//Dp/7u3/mAx94N2NjQzz3otMYqtdoLc6gTcbTAXQCWFzs0OsltJpdxsbq1uKg4ttknwGEZnGxQ7NlqFZDup2ExcWY0bFhgsAnDCQzM3ZsTK0awRgLMHmetVFwXWv/YAGpgnq9QhBaM3FrAgxhGNBpd2k2W7iOg+t5hGEEJSOh3W4Sxz3yPKdSqZClKWmaMjoyYl/vLbDvwG4WmnPs2b8DrXOEFKyaOBbH9XGFQ6s7j5AFyjh0koJCaYSrqAUVBA61QDE8NEIYRrhuYJOOwoJtVmoXUyiF0gbpeLjax3NCIr9KLw1RhUAZDWh0kYPU4Gj8SJB2DVlSEOTW4FsKMYgXpZA4DiWbzMH1AlwvxHWquDLAdyq4sgLGJ8sNeWHjjCAI8b2AwC89joxG6dyyx0qwRDoGx7Xm3igolI2pPc8lCF2SdowqNEZLstijwKfQEg+DJxSECa5nGB2vMjZWp1YLGRuLaLYUaZqDSBEywhEuRaaZX5hhsT3N/OIsQ/VJ1q3eQjUapVKplF5NGXEnpcgKFouEJGmXhSRCPG+CdruHkALHkThOyWpzBGmS02r1mJtvY7QdL3luQT7Lns1YXOyxc+dO6rUGExOryHNs5byiwBibTK9WQxzpoBSl/61lXU0fmENrRRiFyPKeQynN7Ow07fYiU1PP+Y+cok+yHY2hj8bQR2PonzSG/rE9nh6vDVghg9NYOTEfD6w61JfncY4+QNjscfRg4j0xzcu+nquUrIjpJgu04zl6SZPF1kGazUXiOMGVFaTjEEVVIhMg+4NYSjvRdMleWvZVAmE1pdKCTwOPpv730t/s+tpXF89VeL5XlmAtKdFClGUVRcl6OvT3LF1cU070PsXX2BmOoU8d7oPMpX69rIpnmV8209M35i6KnEIp0jS1ZpSi/5vt61lWkGe2zKvnurie3ZwKrcsJoku6rCQIHHzPJQhsEKO0BQaT2CGToHVOXhQYkdFLFi0VS9ogIM26KJ3jSg+BoBYN40hBX1b4eOMFys2s7O++vfehzKXlEtGVUrsnM1lWXoslLHP58+KQf58Orb8jPNk++PF/mznsa8RSBx76xhLYNZS+DEdYK1ayzvoU+pJKXK4HUoIjbeUNIQRoXZaCLRA6p9AFymiM4yCFgyPk0gZurMm9MVgvivK7hFJkWUyadkmSLmmSkCcaV0gQLka6mJKluTRP+1JZgRAuUnpliWEfx7GbpizHu0BCudk6jovAxU4OOeh3pTWU5WZt4GFfcT0fIZRdRxyD42kcx6EbZ+TtnPHJhNERTRj5hH4dh4LmQpeRITBVF9epIvAwSuAIB2Gs7MOa9gs81y8NmyVpFpMVXeYW99LqzVGLhgjcYLC+DdYcnuzcWtb64+TxxtJhGbtDB9DjfW7l60cOwp5O8xaCqMLQ8CgnbDmdY47ZRJ5pJobqOK5gz54ZxscaNFYN84Mf2hv/NauHyfKCMPBZv2GCxcWEubkevV6ClFaGl2U2Az05NU6r3cFzXVZNjjE32yVLc4yBbq9DpxMzMjqMUooiT0vJSEGz2Sl9ZBT79s0xPt7AcQQLC4u2IiqGZrNFGAVkWUocZ/huQK1Wp1KpEoYRng+iLDbRXFxgx45Huf4HPyBNsyP2w+7du9i3by9ZmjE0PMTGjRvJ85xer8dDDz3E6tVTKKWYn5+j17PA0/LkwvK2c+dO7rjjDoCBV5MjXaKwwvj4OCeddJKtCla2sbEx7r33XjZs2MDk5CQjIyNlP/ZwXZdut8vDDz/Mddddx3XXXQfA1NQUF154Ib/2zneyYf1GLr7oIlzXpdlqMjE+xHe/d/3g+EoVxHGPe++9h61bt3LppZcC0Ol02L59O9dddx07d+5Ea83mzZuZmJhYcX71eh0pJXNzc6RpRl9aY9dIybEbVjM/12XP7gWO2TCOUgV7dh3g2I1TjI15tFpd8rzA9SRh6CEltFo9tNFEkcsx6xpkWUKSJIRBhbhk3Zx15mnkStFqJaRJTu4oFptWimiMzY4Hfki9ZsdHnue02h2C0MVozfbte9i4cTVDjSp5rpkYH2FsbBjXcUjSjIWFRZrNDtVanXXrJqyULww5/fTTnzZV7aSw8q00yUrQQqCUraymtcFxIMsVqvTU7MUprXaXyckRAt/B9yVFUZBlOVmW22RjCdhIIVGFQXqWoZCmGY7jEEiB73vkWWblt6U8TClVJs+gKJwySVuglE0uKlVYmVzJ+smLlCyPaXfnmV+cYbE5Txx3ERJ8z8P3AoT0MUbYdUOm4EBaFGht8HwH1w/wpIejfYLAtzeKpdwNY6VajtNnFFmZm+eVnkplRTdHuBglrGrAaFDKxr7S4HjWCkJrrOG4BsrY3SxTIFjgycMp/3wvKoGnECE8jLGV4lQZjziOla35vlfK5WwcMqjeJYVlqRmB60Ghsb6q0sbNfesKC8A46MJFa2uKniaaNCgQJkEphe87jI4NUa9HDA35GDRxkpLmBiEsQKAKRaETCmKEkGRZQuBXkOPWE0c6dj2weIQhz3K63S5RFA0KGaSZnTNB4FllSDk2i/Kv101LRckScGeMNZbWOidJYqIownEEcZxTlAyzfqznulYKqrVBFX0mjCHLczAGKUMbd2ldmtr36HQ6/+5z8idrR2PoozH00Rj6Jx3bTxp4Wm7wfGiVseWMERvkyMOeXw4srQQPtB1c/Q8v+0EWLFBovfTXd/Pvo7kr5H3Lj2UMyhQok7PY208vXWChs59ub4Fe3ObA9F4W5jvEvYx6ZQLXDajXG4ClhXquR6E8UKBZXnXN1vUwlBNUugOmkDGmlObZSWg0iDK7YjcsQEMuCwuuaNdOBmF11YWrcF1QhbbosZGD78SUmtk+Q6dEbwd0POHY0qyiP7FMueksXRfLFFPkKqPT02R5TrPVxnM9Qt/Bc2zwYoyh243p9VLyTFGthASBi3B0CVjl5QJlsyVh4OJ5DkHg4HmWum2US1sY0MpWDiqvUZJqtOmRqy6FTon8OknWRKuCNO1Rr4wS+BU8LyjPe5mJ+CFt6bkl0MludHoA0g2Q82XjpH+8xwMtl14vP19ez+UMqeXSTyHkEfeDp3Z7sicsDnn85NDy5fulRFpu3vJFbMAeK7M0ugyIB3291A7dMPsbLdgyyMZoPCewpXz9AN/1kcJFCI+DCzvoxAt0erPEaUyWZ7SyhOHqOGP1SVaNrMaRzqDEslIFeZqUa42lMvd6beK4g0pzKDQOAl/WEcIGcBYa1kinv6Ebilzj+dYrwXWt0aDnB/iui5TOAJhGCySeDbjdfmUricQbZFLTxN58Cwmua6uBJHFBVtgbdTeUhJEkUILR8QbNRzT792bU603q1TY4OUP1ERamMx576CC1sELgBaxefSzSkSgtGKtN4NEjS5sUOrOBaCgRHview1RtI1mWsNjdww/u/N+MNFYxNbqRVePHErghruOi+9VQnjLtMMH2ssdPT7bTxuNP4pwLLuWrV93LqSf3+C+vfw7GGPbsnuUjH/wHXvWaizjnnBO5945pUA5bTljFhrXrSi8cuPqaR+n2Mn7vd95E0tOkPc2LX3AevThjeqbF1755A1OTw7z88mdTr9VQhS0r/g//+E1uvPEePvan78LkBZ25NkWhOOvsrfztZ9+LlIIdj+7nd//Hp3nzW17CJc89g//9v/9ucN7v/+AHrQ+g5/L1f/0aeV5w+SteSv8a9BMeaZry9l99G/fecx9xfHjlF9sMjcYwY6Pj7HzsEZ7//Ofz+c9/HsdxuPnmm7nooov5q7/6FD/7sz/Ld7/7vcGn7A3t4e0973kPv/d7vwcw2Dv2Td/HlV+8ny/+419x7bXf5rzznjWIXx577DHOOussfuM3foN3vOMdvPSlL2XXrl0IIfj+979PURRccsklg2p7g++XklNPPJFVE+PMH5xmdHKSoaFhLrjwUiYmPrP064ym3W7y4he/mDe96U186lOfAuC2227j0ksvRWvNpk2bjvhbtNb83M+9gUsuuYQf/vAHg1jMysotO0Yp8IKQ4fEJDsxkTO9f5JbrdvCyVzU4fusEn/z4f7dhBHa/fsa5J/Hs808BA0ob/MDluutvp9Xu8tpXX4of1skyywQ5uLfN/ffv49nP3sTefTN86MP/xFve/CJOOflYJvUw69dOkcQ5N/3gIdasW8OffvS3yHLFHXds4/0f/By/+ztv4vTTTmDvniaddkGRGU49c4KXvez5vOQlP8UPbrybTryLM07Zguc7bD3xeG644YePM06eem39+nHL5CkUtVpg94rCxmFaaYZHGqQp5Lkq75s0hpxKVVKt2ipyjaGIOJa0221qtSqVSkS1YuUf87M9oopHkibMzs4zMlqnEgVUqxF7F5rMLy7SqFcRoqxQJiDNUg4e3IPWCsdxGRkZKVkoijAMSF0H4Rj2z+yg1Zln/8GdxF2NFILVU+twJfiezzGr19Pr5TRbHbqdjIIOcZGQFaaUtfngSqQHvo6QjkHrYqkIjtQlM8uUUi9FklovOCkcJALf9XClC0qSJjbB6XoG1wGJKGNxewOtVcl6QGLKm04pnRLgdnDdku3kRURRA1eEeCJEaInSkKTW6NwY+/t83yfwPfKsQEgbe7sywAgLqlVwKJSD6xi6mSHPFbXQep5mRU6SpWS5RhKR5wE6dxFK0+tkoGEubwMCKT2GGuOMjY8wOtKg3mgTJ13mmwfp9WLavRZJz8FxDVHkkyTzxMkiB2Z2c8Jxp7F6aj2NodPxA0GdKq4n8XyB62n7G4IIz/fpxok1bS4Evm8Bq2arB0DgBwgJeZozt5BSq0V4rqTVTomCgMDzGB+fIvADkjTnsd37EEjGxkdLZp2DrdZtE8SdXoLrCjzXelf11QwzMzNkeUa9br0F6/X6f9TU/Ana0Rj6aAx9NIb+SdqPZS4OHBE86oMDh7730Bv7I322P7EGr2EGGRldZl+0KgbPWcPA5abiy48ElOVTc5UQZ2262SKL3b0kWYtOb55Or0Wv16HbbRPHMWmiCNyULEvIswSV57ie1XIrXVBIQUG2DB1e+ipb7UyWlR9yrHG4At0Hh+yFccoNUfgCaQS5VNZoULiWkmgEjvRwXYX2ClShl+ipg77r9yksGWmWZShFabQoLCxmJXhLfbkEkSiUslU4kgzSLKfTjalVJIFnz1VrW60i6eXkmWVCWYmetFmyMlMmBxRd2wdS2qyONS801tRNWCKkUtoakjtgS9dm5KpLkjQxuijpzz65SgmCiJH6FPXaGIFnfQ+Wj6s+gHmY/vVHMJoOlWM+Huh06DFEibzrknG3HJVe2gQ0h8rw/vO0n3wRXAL+rEeZPdoSY9FmR8q5XmZKDvv2w7I05Z82KJUhHYnr+IS+rbwhhUM36dJN2sy1DvDQnptZ7Byg1ZsdBJGe36AWjdKIJujGJzBUHWNsaBWu8ABDN7VFB5Qq0LkhzVJQLp4T4bsZhacIfR8hPPKilN9alNeej+vhuQGu5+EHpZmsdBDCtWxArekbmBojEdJFaYnO7fyV0uB4Zf9gBuC1ZS72+8MB4VuPiSy38gHpMLVmnG5XkKaCJIZ2W7PY7tEYrbIqGWX9hlW0FjskcYLnOzSGq9RrEfWoTmPII4zGCNwppLReJJ10lqzostA+YDNLSPbNPsrBxd08cuAuJhtrGW+s5YT151IJa7iuS14cmaVy+ABZMZEe99of+nhlBuaInzzk70jvW8mofGLm7FOnHdjzGLdd/y3+4L3PJ/Cq/NH7/oFXvOJCJqeGeO3PXML6Y1dhBFx48XEcnJ7ns1d+jxe94Czm59pc9bXbOP3MLZy+dgrXdfj+9bfx4LbdvO1tl9NqdXlszwznnr2F4eEq2hhGRyplpltwycXPYOvWjWhjmFo1wbMvOIdarcKDD2zn81d+iZ9/y88wOTnBz7/5MrZsPYZms8V73/t7POc5z+HFL34x7/+j97Nu3Tre8gtv5uTTTsVoWzo+TmwVrY98+KNccMH5vPBFL+SX3vYrLC426XZjwDKSPvCBD6y4Rhc950Je/ZrX0G63mJub45d/+ZcB66mU5xmf+czfcP31lkV02WWX8dKXvvRx+/TxmFBnn302b3jDf2HTps0rDMQdx6EoCr7yla+wY8cOZmZmLHtkWZKjKOwePTo6yrt++7e46DkXo41hx65dPPrYYzy2ew+/+3vvQWvNRz/6UW699dbDvt8yC1ZKwPtg1vT0NL/yK7+C4zhkWcbi4uKy32OTdINquWUTQpClMb/33vey5YRTeMUrfoZqNaBWGSHytjA+WaO52OWLV36XZz5rK1tOXMN73vMHnHHGabz+9a/ljju243oOJ564nlNP2USWWamR77moQvHXn/4Gq6bGOO20zdx7717yLOeVr7yANWvGOHDgAH/wB3/AFVe8nIsuupiTTl3HzFybb1xzF2eefiyrVo3xpje+mCioMzsdMzZeZWhI0+2mfPoz/8zWLRt5znPOYXJsqqycJPiLv/gLFhcX+J3feTcP75jhsT0LvPCSkx73Oj8VWr1eodtt0+y1eeyxeVzPp14fsgk7R5BlCc3FFnGcsHrNKhqNqEzq2ex+kWuGGjWq1Yg8zwmDEN/zEcKaNrueM2Dh+L6H61gJX7sZk2UKtI3VsjQliXu4nosQUKlEpQm53Y+kA0Jo/NCll8a0e9Mk+QJFnlEJq9SCyEa20uBIgee4hF6EiHzAYWx0hEQblJORdWKKQhPHOY4jQCikFmSFR5J6dLttjDHUnGppRu0SBj5FUZAmBR2nQOuEoigoXW6QSLLYMhlMxeB4ljkljIvvCohE6WXqoJUAxwJOdh6XjIhyD1aqH6PmgMAUlsGXFwpjFFKA41hDbQsGqhJ0cnFcgREaP5BI30EbF1NAHkCRWhaUMqr0riqs/5WWGCUwGlzHmiHHvZRms0e1UmVsbIRadZRaZZQoaKBUgFFVAgf8aoGpKHQjsLG2VCgSsryg2UyZmz9InqUEvk81nCAKRnCdkMykpGmBdUNxCXyNUXZ98D0XzxW4jkBLYwsQSYex0QZxkpGkGfVaiOMIOp2iBK9CGiWryfc9KlFIniuSOCWvRmVM71DkGlVk+L6k18vJsoRWq4PnOoyMDOEHPm45vjvtmDiO/0Pn5/8/7WgMfTSGPhpDL28/MfA0OJNlIMDyAd5njPxI6lj/TX3DHlNOKq0te2gZNXiJ7WQGby8PMvhXl+9Nix7ddIFm7wCt7gHSvEucdIiTNnHSIymR27ywGaeiyCwVuSishMzzcB3XHrP/3ZoBk8YCZlYm50rHbvBak5eSuAHjSAiMtBVBpCtwhMDBVtywFEGbWnSkh+vkKFdii7z1Qa7y2/r/iD4IsjQgRAlALfXGssWlPBdLX7QyuSxPyQtFkuQkSUrkR/RLzGplA9c0VTbbLSSeawEmrTN0GQxbaaCwnlClhE+IJT5Yn8INpuy7sj/QGBRaZ2RFFzA4jq1sp01OsFjBGjl6ZYURi/cvb4c5/ZfA0KEyuyOBT08GdDpc9rn0uT7QN+jpp8f96v/V9niVAp9sW5LLWo823fcs+xFZGmP6RqF6sEZI1y19FLwBXbXVazLb3Muj++/lgV03Mt/eT6s3XwaLHqNDG+jELRb9RVzpMDmcUgmGCD3fZvWLnCxP7JqQKJTOQTl4MsRzEhwnwSsDWLsJApgy2PLwvJAwqOG45XlJ12b/tC2/LNDYRIwAI8vNU6AxJXjbn+flZlwyhm2gWa6rSCsJ0MKuXzm4nsPQyBCjEwW9niJNUrJc0O1ljDSqDI/VWL1mjJ2P7qW52GZ4fB+FGUbIIaoVFz8MqVaqNPy1uKKOIwKmWy6teJpOawbpeAjh0YsXSFWXpGgxX13LMRNbOW71WcjI/v4nvWn+RO2JN8xDN9cjv+fIx3s6tMX5GbrtRbaeMEWrKfjed+/hOc85nQ0bprjgOaex2OzSbvc48eQpZhfmufPOHbzweWewsNDmm9+8g4suPomtW8YAeGz3fu68axvtzk/R6ca0Oz3OOPVEAt+n28kIIx8wLCy0Of74DZx00ibmF9oEYUAYWoPjmZk5rrn6Oq54+QvZsGEtJ5+yjqGhKq1Wi69f9XXGxsZ5/vOfz/e++11OOvlkjIFao06WZRw4cAAhodlc4Gtf+xojI8O84IXP57LLXkKW5SwuNgHDvffey+c+9zkWFhYGNybrN6znoousF8g3v/lN/vRP/5S5uTkAJienePDBB7jvvnuZnZ1lcnKSl770pczMzAwAmtHRUXzfP6x/e72YOIkZHhrinHPO5s1v/nl8397kz83NMTw8jOM4rFq1igcffJDbbrvtsGP4vs/q1aswxrBu3Tre+Mafw5EeBw4cYP/BgywsLLD/4DRvf+c76Ha7fPKTn3zc693r9Th48ACjo2Mrnm+1Wnz6059+wrFijKHZXKQoFOPjtvqgUgXXXH01Ra54/etej+e7DNU9RkdCwtBhZnqBm2/cxvoNk2w6fpJrr/02risw5jXsPzCH53kct2kta9ZMIIQgTXNc15pl33brw5xxhuKCC09i/y1NwsDhWedvpFqJ2DG9n6997WucccYZ/NRzn0u17vHY3oRtD+1ny/FrGBqq8sxnnkJn0dDtZIyOB1QqHq6nuf22+wh8jwsvPNtCDqV1wE033ci+/ft412+/i+2P7uPG2x5+ygNPUeSTpIJCpczNzRJFFarVmgU0yr0njnt0uz0cR1DzA2rVEN9zAUGuNGEYgIA0zfBc3yY1B1YLS7GRZTkKjDb0ejlFbrDeJ4YsS+l021SiivUgCoKSuS2QwsFaOBgMBWnepd2bIy/aSOEQBRV8t1GamGtcKXEdt2RJgHRchoYaeHlCVy9Cp6BQOUWS4/mWme8RUKiUNE/o9rpI6RAFoU1mupIg8MiLwlZF7uYIkWBQCFP6uRhJkRkKBTIwYKSV5JgAz5XIUJZFe2wlLHuT2WdE9KvWlfuupkwY29LzuqzAp5TtASEFbhkDi7Kwjq345eB4Dq4pcD0bCxtcilTg+1D4AuFYw+U0z1BGYbA3yjakt9fIaE2SFHTaMYFfpVKpUYkaVMIhAr9OnjkoNyBwCpxA4XoGabyylL1GmR5xmhJ3W3S7bbI0oVqtMjEqcIYjKlQxxlaaE0LjSIUq7FiQ0nrA9kM615G4noPv+dRqlYHsMQp9HEeQZlZy6HkBQro4DjiOIIpCpMhRuRpUFJQIK79TBVK6JElKu9Om0+kSBD61WhXXdZDSJQh8Oh3I8/zff1L+B7SjMfTRGPr/5Rj6xzIXP1T2pAegBmX1uD4I5ZRG48ukYIMTXglg2RKt9pcYXWrPixxVZGhdYNBl5m8p+2dMnye10hRaCEOadUmyDtPNHbR6M7R603R78xQqI8sz0jQmzTK00TiOwPNs+bc8z+j2uqS9GAk4rlsaHmJ172A3PmUxGuv1ZnWdrlPq24WgyHMybSsDWAjIwjDCFTZX40iEZ19XuaHITLkhBrhOgfZylMpsZYJcl6ZoS31nMCX7yYAwJXWY0hJJl/TD5T5YBZalI613RBKXHhI5WabodTOGKiCMY/XmqkAVil4nRymD53plsGDopilZXqC0IXBs/7iOrWjnuu6gIoXWmjzLUYVlqvUnuxB2c3ZKU3atM/ICktSi+VmRUBhFN11kvrWPYyZPplYZplYZRghnMGZWXnOxYlweSdJ55P9fKUWEw+V8y8etPf7j0WR/jOoDT4vWn1//p62syIEegI+6ZDBaNmNfLrv8e5ctfIdspMboAQNSCEEUVfG8oMxiWl+CXBXc9vC3eGz6fu7fdSPVqIJ0JJFfoVarU602WD91Et1eRqvV5ab7fkA1bLBu8gFO23AWw9URoqBGVqQ2E5k00UqhlINjJpFGoM0B2p0EY3IMkiCM8DyfSlTF9yv4frQMNIWsUChlTQxtZtHBc2xm2AhppbzSBvzVyHqqGIpyPdRgCvIiRxlFtWZlBwIHmWtcIXBEhNGaooCwMsL6jS5T6yr0ugmuW6Xb1bhODK5h62nHIWXA7PQii3NdfN/D9xxyfYBKWGWoOs7xUxczFK7DFxEbJjcS510ePXgvB+Z3MdPajxd4pHFCHO8hHN5AozrM+Og6jMkpiqdC4Ph4GZr/PM0Yw1lnn8A//vPvEEX+oDT1VV+7jttuf4Df//23cdGFJ/Hs804gDH3mFxd5xoWrqDd8lDJg4I1veBGvetXFfOvbN3Dsseu4+PxTcBzJzkfnufobD/LSl59CoWJ++92f4C1vvpxLLz2HoUaNf/inr/K3n/1HPvNXH+KCC8/l2u/+I5VqhXvvvZfnP/8FfOQjH+b1r38dN950I0kvZubANP/8pX8mCAPA8KY3vXHARnr/+/+IV73qVdxyyy0EQUAYhQgE11zzLd72S/8NVRScesop3H333bz97W/nC1/4AgCf+MQn+OxnPwvAS17yEu677z5e8pKXkGUZ3/zmN5DSYe/evZx//gUIIYjjmOc973ls374dIQRXXnnliupz/fa3f/d5/uGfvsTf/tXHOeaYdYRlJa9bbrmFyy67jE9+8pO84hWv4LbbbuMP//AP+dCHPnTYMc4++2zuu+8+wO4b9Xqd97//A3zkIx9hcXGBV7/61fzlX/4l9XqdH/7wiWViX/rSl7j66qu55pprnuTIWNqjpJS84x3v5L777uP6668nCALq9TrXXfc9XNclqshBcstxXFRhGB0d4s8++cs23pOS73znGisBUPC8553N7j1NPvPZW/ipizYzOhrww5vvYdPG9axft4oPf/gX+f4P7+E33v1JfvvXX0cv7vBHH/4EL3neZWw+9ljuuP0OHNfn4MEmb3rz/+SSS87hHb/6OjqdhJ2P7efr19zAT7/8YqYmx7j623dx4pZ1HLthko9+9L+jlWBxPuYDf/x+pqYm+P3/+W4+8YlPUChFN8v5xtf+js/89ad537tf+yT76T+qWZAmCEIqlSpSOnR7Ma1WF2MM4+MjVKsVfN9nqFHHdb2B92aeW8Z6q2NvSsLAK+OiUjqSZDQXu1Rr1kut3e5gi4m5JKkGXBzhc3DftGX9x22qG2oI6ZBmNrB1XAsCLDTnWGjOsLhjB+32Ip12m43rjicMKvhOSKvdQ6kE3wsIqxWiwJqE+4FL1RGkaorFriJfmMfoRYospxcX1phbGryoijYpufKYmTtAHPcwWjMyPITnetSrEVmWkiYF+/bN4AeaIDDoXGBySZEKTG69sYRx7Xf7Hk5ehdBFhC7aKAQaVSgwLlK4uF5I36A5z0AXkOkCTAthDBiFLmy1JomPI0Mc6eO5HlLY140pQHhIV9qq01LhBgYhXQQChUTWwXOhOd8lzWKStIcfOLjCQRcSN3SReFQj3zJ9ejlRWGNyYhVbtpzE1NQ66rU6gV9B5T5GJww3fITIMCJjZuaAXce1Q6+XIYRkdGgtvbhFXiTs3v0IrVaTuaG9bFh3Eo50qVRCK6PyQvzAxfNtLJ3E3QGTZfXqcVzplPcPiqLI6XR61CoRURAwMRqQ55DnJWAlLfC0ZvUEWWpNya0vnDUpl9LeH4R+gMBKKwGKomD//hkmxoep1CPGR0csCPI43q5Pv3Y0hj4aQx+NoR+v/djm4kugBktsJVg2z0oukBCYQ2jeR0J2l8gjpd5blcCTypeBTWbwXmOWlIUDnpPWKFOQ5THN7iydeJ6Zxb1043k68Txx2kFrW2610BYMsdkQqwUvioIkSel2evR6PaSU+EGIdC0dV0pnYBam0SVgsQRiONL6I2EMjusiC4UWypobotHYvjDl71SFRuWaNLHmjZoC6Wm0AI1ECAcplQVrMKXfEyyvnSlKLzZRMo+WKq/ZjIwpJWBSGFsYD0NeFLbyRKZJegVFrtEZoCRogVb22hZ5HzgD15MoY8G/NC1L3dKXGdoqAo7jlIGqKOmb1tepUIUtr+mUVEdnAEUDZXU6csh7IBxbmtPxrEmmVvhelSQbR2tFtTKMI73DJJ2CklW2jOG1BCwdedbYsQhL+tV+xudwY/KVDKryPYOR1x+F/9mYT0+8YT6ZDE2fF2iMNSy1czm3YLJRpZfK8rlULnT0jQpN+ZTtW22KcuPVuK6l0Hueb7P4WmF0gYWCYaQ2Rpyupjm+gWq1YqUZxhCEEUEQUa9WcYQLGtqtBKVy5hYPsjN8mJH6GKtHj8EYiSs98jxBKY1WCo8qjmmjCwnGw5EBYVQlDEM8P8D1Ajt+pUdff27K3yGEsJWHXAdHyhKQVmhT2OCtNCFVJkNpy0xQ5drneeB4LgYP4VhfEDvPrGmrlNgKPY6L74Y2uDAKZdoUaYcsM3g+uNLDD12GRusY8f+x999hkl3ltT/+2eGkSt093ZNHoziSRjkjMpgkokgGhMBgsgPXBoNtEEEEC4OFARssbBMMRgQDFzBBCAshkYNAKCCEcpzcsdIJO/z+2KeqexRA/O69XyM/s5+nZ6qr65w6YYf3rHe9aymsbxMnGmMkzoAmoxWvJ1JNpNI4LEoqMtlg85otNJI2E80Z5vMdNJOURqw5eL8T2bR6K0oqSlP8ds4cv4F5eE+//3bjbKVKwj2Jbf42+/rdaoOewVSeTifjc5/7HP1+n+c///kcetj+ZI0ErRVXXnkN3/vej/n9338K7VaDhzzwWCYm2hR5xZ13zrFmTYeJiSZbtuxPu9UhH3rSzNPuJBx97AbiJEJbz+Meewr77bcGYyy//MU2Oq0pTn/KY2i3m9xyy6185Stf5RnPeBozMzO86EUvYr/9NrFnzyy/uOY2ZlZ12LhhFe12G6UVIHj840+j3Wnz6U99mgsuuIBdu3aRJCmnnnoqD33oQwEoipzdu3binOP6G67jwx/+MNddd934/IvaaQvgqquu4kMf+hA7duxgzZo1TE5OceGFF/L9732fsiz4wQ9+wHve8x5uv/12BoMBQgja7TaTk5N3u67eWnZuv5PzP3k+nVpvJMsa3HLLLczPz1OWJVJKJiYmeNSjHj3uU7/4xS+44IILOP/887nlllt4znP2BkBOPPFE/uAPns+HP/xhrr/+ej70oQ9x3NFbKYqC17zmNXjvWVhY4GMf+xjGLI+hzkSbgw45kM997rPMzc3/2j5x9NFHc9rjTsPjieOYc889l8svv5w8X9bKEkLQ6XTGv8/t2s5tt9/BRRdfypOf9BT233wI22+BqdWCtGn4/P/+CgcesJmHPvTBXH/tHN1ewTFHrWdqKqORaQ4+cAPTq1rEsaw1f1bzwJOPZmKiidaeAw/YxPR0mziVbNsxYGZa0WgkPOXJDyNLMy65+OccvvUAJjotTjrxcHbvHLI0v4sD9l/Nzl27uPGmGykLw36b1nPooQfwiIc9hE6nhZSCb3zjG9x4003kZcllP/kR+fB3X5h4fm5IUZo6oSiB4CKsVEispWlaJwndmIEQSiw9xlrKqsJaQAiMCqLRUNHINN6D0nJszx1cl2sdzkyhJCjpGfQlSZoSpSFmzfOcfj+n0wljdFj0WFjayZ757RR2CSkkE+0psrRJpGOCnndgBY0Ef6M4qZPTgIckbpBWLZKoSaITKl0hqDCVpSoqfGbw0oFw9Id9rA1amVEkSNMMJSOcM7X+1TxJDGkWBMVtBWXu0UqjtaTVjGg0kgB46ATvFM4LKuODuLgP9vBB26lm0HsRhJGFwhMEs4PAssHbIJ0gvK9Z/eGhQyuBrstxQGCcpayGlHYA0gQmFhIVxZAGfVrjKow3IEPcItHgNLFK0DImiSKKPIjET8+sYmb1DNPT02Rpg0gnhFLAcB7BNMDihaHf7+MsSBHTbq1CKkUSJwyLCcpyyEJ3J1IKrMvZM387zaxNuzlFI2ugVRJYSfWz3EjqZKViixCB/RHFQbcVPNb5Fc8bEhUFSQ2lwKkQdxtrwrZakiS6ZkdFxFpRVUE+pNnMsDaU5S11u+T5EB0pysIhRHL3QXO/bPti6H0x9L4Y+t7abwU8jZlObvkAxIqDWj7QMHFJsfIhnfH7o840YkiN61VHoFP940Jt25jpEwCC0f/hKwVgXHDcWOrPs2fhThZ6O9mzcFsoqyu6FFWBkBDFGu8Dd0mpsBA7MXJUyNGqR683QKmIZtOiaxEzJXUAksaueiOqXjhHoRS+FkmLtKYa1Yp7i7MC4R0ueGGOnYCq0jDol5RFAGdUbFCxR0USoUYU2Pq7JLWz3opLXNOq5Qrgqb5L9QUOA06Oqvm8p6wM3oVjyvsWb0HVivy4sMA5G0QRnQsZDR3JWtfJkBfBzU7Kmu4swrUZaTyFhcdiKktelFRVFWiRKuxLqpXsowDKYSustXgHRhuk0lhnyascbz150UcgiXRKEtcClSv75F1638p+ujxIlsHQewJAlynqnpVldXt/y95MqbuOi/uLRsxv31YuoPcEHO/NJhtvU9/fkdigdxXOVqFUc0TzHV230fq414JZL6T1a2uqEfpKHIXa70jHGFNiTIXzNgiQCsWGqf1ItEJqT9IMrMYkTsd0XVsNUUi0UCzO5+R5wUJ3Dzf6iqn+DI1sklRGSBVTljnWhP4Z+QaRb+CsQqkEHTWZ6KwhScPxBBp9GHojkcCRxpoUEhVHRDpCSUllyzqYMLUrjkJqSeXCYjmyL5YSGo0YFSVIlVA6GRyHXEFlKjyOWAd6rtYRkWpSGQuuIi/y2iGpT9ZISZMGUZTRmWoTJQ0QisoMMHaI8JpETTKVHYRWjfBgQx4kGqOIAyYPZbq9jqXBAjfuuoZhNU1p13LEwQ9lurMJIUSolXdmPK//urZXf7lPi+evH1/3vLCKe3jv/g04jVq/VzHsG7KG5uMf/zg7duzgzDPP5ITjD+PYY7agtOIHP/gpb3/b+zj1gadw+GGH8KiHnYwHut0h11+3jShStDsZJxy3laXFkvn5kihOmFqV8cAH789w6PA+4swzH4vWiiI3/Oyymzls6wae9KSHYq3hkkuu5i1nv53jjz+Ohz/8obz1rW9hfn6WHTt28vULf8ADTz2aLYduJi8KtFVkWcZLX/pSjj/+eL74hS/y5S9/hS996T8BeN3rXjcGniAwmJUSbN++jTe96U1AKGMry71p6FdccQVXXHEFADMzMxRFwac+9SnOP/984jjmW9/6FhdddNF9uq5Li/PccuN1vP1tbxu/Nz2zZtxnqqoaA14Pf/jDxuV+n/70p7n44ov5p3/6J6644gqe85znYIwZazI96lG/x4Me9EA+97nPcfnll/OLX/yCl73gWTzwgQ/kXe96F947brjxRj75yU+Ogac4jtm030Ye/LBT+ei/fZQd23f+2mM/5ZRTeOe73klVVVx88cU8/vGPJ4oitmzZMj7mUVMq6N3cedvNfOfSS/mrvzqLzZs3s3pmP355+ZCtxzdYk5b84z/+K4997CN52MMezM9/toNGI+Jpv7+VsjR4D8cefXAQhraO7mLFhrVreNJpM7SbKUp6Tj7+aDZsnEIIuOLK2znu2P047ND1/PEf/z6XXPxzPv3JS/iTV65hv82rOWD/NXzxf1/B0tIsL3jRA/nil6/jW5f+hIXZPo/6vVM46qiDePYznz6OeT7xiU9wwQUXUJbFvVyR3722Z3cfRAlS4uwocaeJ48BsajQapGkDjyCKIqx1Y70wU4XkHzWoZCrLcGgwxqFUExDEsUZpibLhISrcZ0WiFaUSQXtTaZpZQppF5PmAwWDI7J5ZGo2MONF0+0vMLtzJrtk7yBqSdjbBRHMVjSyUbOV5Wbu9hcqAKA7C26J2pvPekUQN0rhNFnVIk4zSlEiZYytLkZtgai5DMniw1KPIC4q8oJEFwClNG6FMxxQsLMyRJIJGpYlihymhHPjwvZlgcqJBoxkHAxyjMIYgoREQOryXQRKidpIOAXG47p7wAGt9HRu78CDqHTjjUAKkCGyLSAcQJk1CqWNlDf28S+UGOCwyqLkSRxlgcL6icgbnLSryRJFC14LNrSwl1gkCTb9XoJVm3bq1rFu3lpnpGbKsgVYRpgJjAsiwqjOJ0gKEo9frgxdoldBuTgQ3LwmVqciLAea2Ah0J8BW7Z2/BTK4JQvRZhhAxg36IHTwuOPLVtvQjACMYImmMiUiSCA8Ya1GMpDVUKPmry5eMDPuqqgohPFpLGo2EJAnAk7NBpsIaS6fTDkl6Kdm2bRvGVEGbTMTA/xTgaWXbF0Pvi6H3xdAr230GnvYWdPaM7A5HTJvlA6pR9CD4sxd1ciUjJSDsYsxqctZgyiBGZqvAlhmVQe3lUjbalwv1m8ZWLCztYWkwzx07f8V8dwe94Tzd/mywLyxzZBRqtJERWgYx7CTSuKgCaykLw2A4wFpPo9HAOkecxHRUJ6D+Og7iodKF+cDVukW1I50UocMrqbFuuTSwyEucMctWi4DAUZQlZVGxuNCnt1RSFhapoNkRNCckzakUoQ3IMqC51uPHGSxYBuD82E63cMt5sgABAABJREFUZlvXk5AN5W0CZCzwTuCcYNCvqEqockGVe6RXZLHElhJbCXDhfJSWNFoalEMnnmFZUFYV/X5FEmuSOJQX6igiqgUcBQJrHP3+kOEgZ6nbIy+GGFugdMie6FjX2SINPjgBgsB5R2VyjC1D2WNcEJsCZx2DsstCbxd50WeyvYbVU5tQOrCiRh1vhOKP9KzECveiu07qKxlRd80YhPf3Bp6C29LezKbw2zIIuhKIvX+2EXz3f3F/3uNtCOZsVeBMGca4NWMgeayFVm/j/ehYwo+tGZDBbUehVUqSNNEqaFBUVTmea0K+LlCR108dzHRrI+umDua2+SsYlLPkRY+qdCGQrxzeGaytiJTHKo2rNEXlmO8ucc3tV9FSKbEXDBbmEDUzThDT0DNsnJZUWiJVRJq0gyaGFaA8YPEYqioIkCqliGvBV6nAmJyyCk4iWgviRKK1xDpHr98P1GkCUJtmMXGsibMUhwxlqMM+pi5FVlqihSBS0FuapywsuD3EqULH4E2GKXsMizmU2EQaabRKELKP8zlCRjjZw4sea1cdyeaZY9iy4eEIJfDCBFAdgReWQdklTmPWZOtpt6cC8K0UzeZkEKMczocg9v9qP9rX7rkJpmZSOpMxxng+8IF/GjtS/cP7/53vfPcnfORf38FznnM6j3jEQzjooP0QKBbmcuJMkaQRD3/EkVx/025+dcmv2H/jNJ1Wwsx0TJYprvnFHfzbRy7mpS9/LDpyvPYv383LX/ZMHvawk4k7MDe/xM++fxP/+pH3sn7DGn78k++xceNGbrrxNs56/d/ywj98Ng972Km85tWb+MQnPs5xx70c7z2nnXYa73vf+9A64rjjjufyyy/nrLPO4vOf//xeZ+e957GPfcwYTFrZduzYwROf+ET6/f49XpmrrrqK448/nh07drB27Vq++tWv8vGPfZz3/cP7fuNVHQXyd23z87Pj16973et4xzveEe6CWHZRfcQjHsFPf3YZZz73eePP/vVf/zVf+cpXAPizP/sznv/85yOl5PTTT+cd73gHkxNtsiyr9yX3ipVarRZf/epX+clPfszfnPM3LC12f+PxQ4iVzjjjDH784x8D8Hd/93ccc8wxPO5xT6bfW6SsAvvpWc96FmeffTbnvPN9/OQnPwHgL/7i1RxxxEc4/9+/QLsTo6OYz3/uYzSbDYSAJz/1sDq55Pn4xy5gx455XvbS38eLUH40varNd3/wc/7jC//FC57xVDZtXMPWww/lmqt2MxwannDaMczNz3HV1b9i3cwGjjjiIN76N/szOdXm5pu28+6/+y+e8tSHsN9+W7j+qllOPvZ4HvqgE7DW8eMfX82f/dk7ef3rXsr6Daux1vGP//iP/PznP+fpT3/aXiyx3+VWGUsUySDQnKYkScLExCStVojl4jjBWBcs6J1DCIhiBT5IW8SxqrVRoMiDHIJzIakYx5JOIyOOIhomOFRpDWWVc9utNwdwQghKM8QJjZCBVdWZaJOmMSIqme/Oc8Mtv6S7tIQ1nrUbDqKZNUiTtGa7S+KkwcxMhhCSJI7J0hQdR0QqDkwo60jjFt47zEROYYbESYzUjrIMxzvoF/i4gDghr0rywSL9xQFSGSYnJuh0Jti1a575+UWWevMklcDaiHY7w1bgSk3WVDSaEdPTU6RZTBQpFBWDYUl/WDIYBOApjjRJEiQp+r0cfIKWiplVEyFu9p5BAcY6IMIaR2UM/V4ffAE+iC9naYNG1qDZ6GB9xbBYojtYoDRDjCugiMBaIuWpbEVpSuIGZCoiiSNS1UCLjJgWzbSFEgmLCzmtdpMkbXLIIQeydt16skYDgaIsLYsL3QDMaEVnogMixK2rZ9YHC3ipSKK0dvRSlFWJjjWNTgvHEOeDlurs/J30+gs1uDdFlkzT7Q6prKXRCHGGUoI9exZotlKmptp02q3AwJOavKionAsMqJEQOeGa2RoYlVIQJ6FUM8sS0jRlz54FFpdmSXRGWRVY41lc6JGkETPTkxgTmKtRpMGPGGn3x7Yvht4XQ++Loe9r+61L7YCQcRm/XMG0Gb0aP7Tfc73uSge7EegUaHFmbAl5T0HgMssqoKHGVAyLAQvdPSz0djPf3UVvuEBe9CjKIVVVYmyFVhLrgruFF6EOO7iyKbQGIcL3lmVBfzAgimMGgwFZI0XKBBmFjImTilH15cpyKyEIYoMCoiiq9Y4U3oUslSkcOFmzwDxlVVCWFXlekg9LitwEq+k4Im0ExFkoiZBgzIi9FITMR+DIyOVOSoGQsi4HDICYWHF8UgbQyVkR2Gn17rz1eC9xRuJM/XcRBrbwkjhVBI5XYC8VpaEsHZGGIEoYgKMgPiiwzmEqw3BYMBiGxaSyNYquBVLJmk6ualRdo8VyDa/1tl5UK4wJwbGSQdzWe898L2R7m9kEjayN0DHj0riVjKNfgxIvf+aeENsApiL8Xd5b2XFX9mEYaT6NSvDuv+2ux77ipFeW0q5gM959Fysuag0+O2dDLbpZXvzGjMGV37GCJjzaNlBhXb3wBMq2UgHk9Pga/PXLzL9ao8sHTi6RjmmnU7TjabxzLJUFtqpCuamBohqQFz16wxJbKbxPQoZYg5MFA1ORW4/zFYpAQJYiJlECGQn6qoeTHkuBsxEgkSLoIjgf6OajhRLh8SLor7l6TMmaBahUeHC1xo4ztFIq4liPGZdl5fAiZJjxJUq4ACgbS1kalmaH9Hp98ryi6CsmV6VMTIYHDyEbaOVpJQ0aUYqSIdvtjKcwOakCpVOm2/vTbqwjUimGfAz619NN0MSrM6FZ3AAZ5gCJBB/cQ+6ahPiN7R4e8u8ZwL3re/eUmbnr9n7F30eg8fKc/X8/UPz/rnkPV/5sO4oZDjtiDTt2zFOWFZs3b2bNmlUcdOB+SBXKxduTU+hIY0pLP8+J0gbWenbvXqAo60RColnqFuzY0eXwrWtI04hN+02TxBFSOTZv3kir3UIpyX6bpklUTBrFzKxey4ZNm9iyZQvf+973ueXm2znwwP2YmpogSRIazZSiGI5L5I499lgAvvvd77J7924A5ufn73Z+QoSykna7w3e+8x2stTziEY8AoNFoIKXksMMO44gjgpD0HXfcMQZP8jznuuuu48QTT+Twww/n+uuvZ+euZaaQVDKcl5TMzc1x6aWXrriuoc8/+clP5qKLLhoLmbuatQQB+NqxYwcARxxxBFu3bsU5R6vV4pfX/JJTTjmF1atXA7Bt2zbuuOMOHv3oR7N69Wq01jzutNM4+qijOPTQQ/c655/85CdcdtllY4aUlJKDDz6Y66+/nvm5hfvQK5YTgwcddBDOOY4//nhOPPFE1qxZw3W/upZubwlrS7z3/PCHP+SLX/wia9et44EPehDHnXg8P/rRj/jFL67moov/k+OPP55DDtnCpk374awn7zv27FkkihSN5ipmZiYQIjCiwwNQcJrrdJocsP964iTCOEe3NyROFUpLPDZs3whObfMLi+zYuYsTTtxKo5GwceMMq1d3WDXVIO9aFhbmKPcMOfa4w9m4YQ2bNq7le9//EZs3r+fkk05gft5S5BmPeNTjuPaaq7nj9lvvw3X6721ZQxMngjQJc3+kQ5Yd4WvGCeBFUFVwfrzseh8kGqqyGpeaBEdBgZGewSDH2pDUi7SuQawIhEFUnqoqoGb6CxGYKlIKWq0W1lX0hGGxP09/sIS1ljROkUmTRtIm1jFKRuAcUikiXZfVjWPfsPYLKZDU8aCP0CohSyZoZZMhjjQ9hCypjMNWngqL9EHLtTIFw6JHt7+IikBFioWlOeYWFsjLAVJqTOxxLkYgiHWKqsvbrHFUhQULMvX1+dWJVxnKc6QMtRllacApnNIIIUNMLILRj6j7sbUOa0KcLIWoXb/CeqxVNC5Lk8JjjaUcGvr9HDOs8EYiRQ7KIZQlyUJpUBIJMlkDT6IJXmGMw7ngKBjFKRNTHbIsRQBlVWEqR1mW6EgTxzVzyAUtpiTOAgukjnuscwinxgC281DZCuOGdfmOxXmYX9xFZQxapXhRV0T4AAY66amq4KrtXai0EEi01vjc4Hyodhj1R2MslbFUpUFgsc7TaKR4D5VxKKmCZlBp0DKUZSZpCnX5URRFpLU7olIB8Putyox+p9q+GHpfDL0vhr6v7T4DT87aGuBYadFbA0EryudGB343mtioPKzG80Yd34xL68qA6N6VQrhic+tcWBxE7bxWDplf2sMdu25gvruDuaU7MS7HukDRtc7gGQFZFmstI5khJaJQu+wFSpeYymCMZXFpCYAsS8ka6biThOAAinLIyPFjBJ9B7VqHJIkT8ihG63AuRVEyWCoDw0gwrkE1VcVwMGTQryhyhxSKJA2ocaQSlLY4qbEGBIGmOBKSrMlk4QbqoEGllQ6Lh3MYFVBsLwKd1TkZyuuUDYYeGpywgQlVSUwpsFVd4xpLpBJklSIvK/p5Rbc7pCgsZWHJkkAP1nXApLXGe1+XDuYsLfYZDIf0hgMcJUhHHEdEcdhGyQglIpRISFSGlBotFU5UOG/I3bCmLuZIqYOAnrPsmLuZvOyRJg2k3I+GDG4Yo8k19MO9+9xd9aDG/7vl35e3qQdSPcju2qfDe+Ha+xq5Gn3mf5aw+HJbPi3/awE9WMbrvA+luNaaQGc1Fc5UWFeNg6a9rysrZj4PjMQPwz2Noog4iYmTDCEE1oGpqjHAKkcTtZBY77HWUZh+7cYYM93Yn4gWvcESrioxlcWjWFhaZOfc7SzOOyLVYKI5QyPNaDRjWhOapcUueZmTaEXsFTEKTQOlBa14AitvIPdDclOAScFrtAcIzjFaBxcYVbva4MB6ias1FZJYobVASk+3W2AtOAdJmhDFEa1WE/B4Z1laKpHaopRFC0OUBPeM+T2LdOcX+cXVt1DaPmVZsXsbHHhgiwMO7LDpoAPRegLhBWvba0h1EsqFp6ZoJDl37r6eVjNlsj3D/quPp5msonKDMGfWi4rQNRPDh5r5YMoQg3cYE+ZXUZcx3HvfGOXj2Ov/X9fuvZZ8OZvnVwRye398xVjf6/XKv99fx2xIEpz3nh/yqMc43vyux/CP//hxdu2a4ytf+Ree86wn8pxnPRHv4cZbd3Lt9duYmmjinGOht8jUqpR8WPHlr1zGSSdsYethG1mzuskl376Fr37tOl71ygdx4IHreNVfPJlh32KM5+1v/XPSVBHFggc+YGugwTvPi/7o5aRJsGN/29vPYXFhke997xKCzfG969696U1v4pJLLtn7rMYZ13COKz87HA75/ve/X7NPw06f8Yxn8Pa3vx2Az3zmM5xxxhl77e9P//RP+b3f+z2OPPJIer1l7Z8kjlg1PYGOFL/61a945jOfOf5O7x1vfvObOf/88znqqKO47bbbfu2dePaznsUb6xLAf//3f+dZz3o23/ve98ai5UII1q5dyyc/+UkajSBS/s8fPO8e9/X3f//3fOYzn9nrvfvOohUrgADBu971Lqy1DAZ9sjTjpptvZph3sbZCSoW1hosuuohvfetb/OhHP+KEE04AwjX9whe+wJlnnsE557yTP3/VayiHnip3DHuGC796JZOrUp7zvIfwlNMfxojlMGLdOAfHHn0YJxx3OLNzA+YXulz/y1s57phDaLUyfvmrW9m0YTWb91uP93Dpd37MP/7DZ/jwR9/EwQdv5I/+9CnjMzpgyxT/8q8XcemlP+H9//hGTjjhCI455lAe+rAnsmnTBv7jPz7KJz5+CbfdPss57zmPd5/zZj7ziY/ex+v139fWrm8S1/bxgmmsc5RliD2t81RFPe8igvNYHWtaY8mHOYuLPeJIo9OIJNakqcBax6237yCOI5rNdJwQlEqueGigTrYGICaOAzNl7bq15MWAfrHAjj230+93aWeTNCZbJHFGM2uP45soDg+vzUYzuOx5Tz4c4HyI45ORK51UWGuJdYNWJsirPkrHGAboqEdelOQ98FWJkTLosfiS0g5Z7M3hpUFq2LFnO7t2zuLdEKVSUuexLkUrRac9idFdnLV0FwdIodBKsmp10GsSwqEjiVaKNNVIJaiMYzgswAVxYmtASocXJsw4XgSx8SIwOqTUZHFCFEVkSYs0zUiSNJQAC0cSC4SBomvZfmuX4cBhylCm1+hoWhMRm7c0SWJJhKKpp4hEi4gpZnd3GQwKrHVMr51mzdo1TE9P1swySz4cUFWWoixZPTFNu90ijiOKwuNsuNahCZaWujjnibSpx7cgzw2Dqk9uF3DGEqkUISJ27LmFdr5IlqXEySqUTHE2sParKvTB4OgXnP6MdeBl7XYd5jTvPJW3DIYFZWkoi6DJG8eamZlJBoOKosjJssCAQ4T5KY5jorhFUQyIIonSmjRpIaUljiSDapGyvGcm6/217Yuh98XQ+2Lou7ffqtRu9OVypGw9trlfBom898vglFgGmfBhOfUEdD6o8ltMVeBsrelkg4vd3U5wDEI5XA00zC/Ns9ib5c5dNzK7dCeDYgEnC5yrsN4gVX1pBXhvavFCEZwpZFRnMBQSRSOLKaShLC1FMaDXF8zNRQG9d5Yo0UgVBqFSEc55grtFXQpYiz0G5FgSRTFxkqB1hPclZWnoLhTgPVoLkFXQMcqLkP1xPpTqqZrSG7XRscOrCm8VpgruBULWwNPountJlqREkSaOAgPIOktZDrG2wnuHVDXwZCSmWVFGnkRDtyowpQMbwESlQjAkIwsyiLD3Bzl7ZrvMzw8xxqOlxrUkoBFCYR0UpWE4DOV13e6AxcVFyqqksgU6CuLkSRKjowitouAQIlMS1aAZTxKrhCRK8RgshqHpktsBpS0oqyWcK/C+pCcE1gftLOcsk521TLXXMsr03lNbSUMdaTvttRDs/em7vDsClvzyd/jQn0b7xC8Pvv9Z2NPyA97y7/fU7j75jOrRTVViy3wFm7EuaYS9sjrL21mcD9kRKRRRHJPESdDAqNl8EO5jpBReyjpbs1zTLgClAsjqvMPZPGiQoel1h3hJrZtgacRtZib3Y81kRHdpwLY7t6F1cKiZUJN4CUZ4KmHQ3qG9Y0ol2EpCATpqk2mNS4dYGY7b1g6SHhnOxViqypJkDYRUOB8ESgXB8bPIawq0DhbTznniJGQCdRTTH/QwpiJrpDQzTZpoinwQMkGRZHFhjtm5Wfp5jzSTpDKmHJQMB5ZhbphqN2gkbSLRBBSlMUhpaWSCOI7J4gPppJuYSDeRyMlQApEvoVVSZ5pW6qKFUg/hPFozzjb4EYXSiZD5/jU9ZeX/v67dv8tW/183j5COJz3nUE455UAEgj//s5dQFBVSSm64cTd79vQ46cT92bhuik47Q3iJlpKD9l9HlsakScwznn4qnXYQDf32xdeQJCkveN7xVM5yx/Y5SjNkw5oZPIKrr7yTgw6eIU4ML3rRi3n84x/PC1/4Qt70hr/mgAP2521vfQN/+4631+VOtcCwGNm7Lx/5t7/9bR7zmLuX0E1PT/ORj3xkzGACuPTSS3n729/OFVdcgXOOxz72sYxEwT/96U9z2GGH3ePVOfzww/mHf/gHjjzySKy9e/b8wQ95KG960xs57NDDx85zK4MrCGXhTzz9Qfz0J01+/MNf3vutWHFyj3nMY7jwwgv54Ac/yGc+8xne85738PrXv57FxUXSNF25Ed/4xjfu5oZ3+umn84QnPIGXvvSllGVJv9/njDPOYHZ2lru2N77xjRx88MG87GUvq/WuQsLpq1/7Go973ON4//vfz5YtW2g0mvzN35zDNddcwxe+8AWiKKLX6/OiF/0hc3Nzd9vv2WefzVOe8hRe9rKXoVRg03jriWNJayLmKU8/gZtv3ckbz/53nvvsR7Bm9QQf//g3ePCDj+aEE7agtcQYx3BYceW1txBpyYnHH0o+sMznAw45aCO337bAr67dzQMecBAPfdjxHHDgBjZsmMFZTzG0fPhjX2bbtnme9OjHc9LxJ3PiiUfwhS98k8MOO4AHPfhY3v/+d5IkCVIKXvqyx9DtFTSiBH0/ccPavWt7SFYBrdYEzsNwWDI52SGJo7Hj5DhTu+Jf58BWQbsEBP1+QZJGaCWJI0WWRjQbCVpLpAQhPNu372Qw6NNsNrHWUJYVjUYKCCpT8qvrfkG3P8+2XbfQXVxECkV7cpKpqRlazRaCkWyBQEVRHdsrQCFkEBsuiyCRURR5nYyMa7aCJtYNptobiaMm/eGQod2OqxYDu8JA5YNWmFTQmIhxqqJwfbqFxogcIsOwX6BLj84JZZ9K0Ghm9E1OVRpmd3eDnIWUSB2jdKgYSNMouOy1IowBX1UY53CmxFiYX1gCSrwoSOKUqvLkg4r+Ug8pBNOrJlk1MUWz0aLV6NSPao68XEIKRxRphBFUQ8vi3BBT2WDeU0CctIhkxERzAi01lJKp1v4o32DY0+zZtZulpUX223+GzkTGqlVNpHSUVUGRg6kUSkZMTnZoNFJ0pBgOh7Xek0drjTGGoihrgXdJmjYxlSVykv3WHs5ifxVLgz3snL0FLChvsbqCgef27dezfu1BtFsztBqra5kOmJwMoKQQIR4RAuJI0WokQYvVBjaTMT5o3xiHdwH8DGCJq53WQCpBoxHKANutJhDiw6WlAlMJkjimqhzWeKwOZXv3l5LZ39z2xdD7Yuh9MfS9tfsOPN0rGrfcme+J6TRKuOwFJTm7TCG01RiEWhYTW8F2qpFd70NHsy5YfC715scldsOyS+WGIIJYoRA+ZHuQICQjQXHnXHAFAJwydWmZJI4VzrsxIFZVBYNBn36/h9aKZtEmThOEDmLaVprlTjPqODWlETkS7oxCTT0hm1DkFd55dARSWZy3wcKUQFWOkzDhx3FEpBO09nipiFWJcBLhLQhVX19J4MFKtMqIVEQcJfViYUO2rAae1Ah4UpJmwxBrT6E85cAhffh+rVXQsko0QnmsHzn9VXS7Of1eiXeCLA0D33uwHryxVMbR7w0ZDHJ6vQF5UWBdBdKhtEJFqhZy16E8T8RomRCrBo2oRaxT0ijDY4MDgFKoSiGFpHQFeIt1BaUZIBAs9nez2J9B64hWttLp7l7Ap7v3ZEaTfY0l3QVIYtyfw1t+/Pm9OvI4o3//ZU8IsUL83698H+7bOY0oxMvXbzSugzOlqcU6a/OAEctstM3o2rrwN8+IFhyEP7WOapaZqCnDteaWUDUI6Oo5w40X1eX5w+HrsSCExBmPVx5q+nikE5qpoJE2EE6xU87iva+daoJ4qkcE+jkOaz25L5FO4gswOXgtx4CxlCAcBLtJOWZveMJ8IJTCG4+UIVvjSlvPN54kDsG9dTZkeGoNhShSSOGII4kSAuE8UmiQ4VyNKTG2RGqDUinOK0xZYW347iSKSOOEiIyqqjDeobzByxDoN7OMdjJBK5lGIMP8KAxSRgi/LDR6174xog6z1xhxCL+su7ay/f+/UP7msTUChld+0z1Tg3/9d96fWItCwKFbZzjg4CDavHXrIePM1UiAOM8rhJCkOq1LeFytRRcC20FvSLuVEumYqrRMz8QceNAUV1x1C847JicTirIKbqc+aCY451laWqQocoQQmKrAVCXOwzHHHDs+vltuvZW52T1AWEeOP/54rrnmGnbt2sU3v/nNu52PlJJOp8PCwjw/+9nPOPLII8efPfTQQ5FScvHFF3PAAQewdetWHv7wh48ZRHdtwW3uUdx6661cc801tSvucluzeg0PefBD93rvgAMOYHp6GoANG9aHUp44Qkf3HB7FccyRRx7J+vXrV7wXMTk5yXA4JIoiwHPkkUdSluUYPBu1H/zgB3e7Di95yUs46aST6tL10Dd3br+dNGtw4okn8stf/pLBYAAE97rjjjvuLhlSz7Ztd7Jjx3Z+9KMf4b3n0EMPZTgcYq3lkY98JHEc0+v1OPnkk9mzZw9SSm699dbxODj44INrUKeWBZCgtEBK0Fqwcb9V9AYDet0hxob5a3FxGMqXgOGgHGfiB4OSNAnCxMUgxAlFYShLQ5FX3HbbDqamWpx44uFs376AIKfTajIcFPR7Q6rKsW5yitbkKi77yS8xJth/z0xvIIpUvXb3KYo5bvtFj/m5uwN0v4ttOBzibLAtlzLGe8GgX9BpN6EWE1cylC0Gnc6RfU9gjWgddJqc8+RFidYSrSSNRkqahutdVQVChHs2GPQZDgc0ms2wBhhDFGmMtVRlyezCDvrDRfr9BYJYdUwcp2RpgyxtBke1em5ROlqOi2pWllIRUoX43dogGeG9G1c3SKFIoxbOQaqnEG4BV/bD8iElwkucF2itQ5mZ9lgMhRnipUXGYHuWwlQMcolxFkRYI31Vlx9agyBCaEFVBu1X5UFFkihWpFlEWQisEcRRhBUK4VVwccbgfEmapEEo24N3BqEUSayIo4hYRfWDe+jzQUPVIZdp8UjhUFGYm4thcM1OopgsaiBRVF4QyRbYlGJQ0OuGRK3WEEWCKBKB0WKhKhzeRsRxGH+e4BRtnB1jkiNWjDFmRXytagYLTLSmawqNYPfstnC3pEbIIHbeHy5QlEukJsX7VTCSwJACZw3DoUEIhfO+ZpCF2KsoAgvWGhe0hmoWlKzdF4uyrE2hBFUVxKyVkkSRxJgAphR5jlISUwWQQUpVH/sy2Hp/afti6H0x9L4YOrTfJoa+z8CTUmqvLwl1wa6+iKGjj0SWRyr0y6gsY0TV+1rTqSqxtsJWdXmds/VJrjiZFZ1/VII3zPss9ha5edu1LA32sJjvwPhuXdZVISMQWiMjibMSayXWgvcG7yvMiAkkFZEEqWOyTAc7RQmDQUVZDVlYtMSxpiwLkjShI6ZIVbCSDEF4YGt57xHe1zTU0Gm00iRxTJIkKB2Dl+TD4EagNOjYgwgDUWtFnGhWr2mzalWbVataNNIGUnmsryjlSGS8ClpNDhwSKTRCaPAp+Ajh41CPLh0y1lhX4QmT/ihDlWUCYxxFGSxji0GFLR3tyYTOZEqrnVA5x7Dw9IcFCwsDdu3skQ9sLfAWBzq4dQzycP9MVTE3O0c+LIImhjQo5UnTsOAHAfIANikZk6gGWdSmnUwx2VhNpBMiFY1mUlp+gtIOKeyQxXyW0uUUrsC4Ht6UuNywfT4mr3pkSYtmNkkat+6104dAaHmC9h6W62gFeMdI2mm0gCyL6C/3xeWu7PcCqBiVOdyPHlxXthEL8f+0eRdA4arKgzlAzbobLZTjb9grU7Ps2BEWREWaNIPtsAwWvq62bUbJceC9vKswP1gbwOgwT5ixG2aYd2zIzMYpS8MBhRnSaXZII0UkY6YnVtNKJkmjDoUssN6xbdtOlIxDxjaWVMZQ+ZLdrkAYjywdvdt6IDyNA2I66zLSVkTLVUFbAuiXFqRCRTFJlgSWog+ArPMVRdVDihilE9IsDot05UF5lHI0Y1g9MYWSMLtnlqX5RXq9IY1Vk8EBRkOUxbQnY9YBw6WYXj+iyiu0SGg2GmgR4S0UpsQR2KSFMeRlF+cM7UYDwzyWNpVrIWSEEBFCAiK4KUkhQQviWI0DxHGyAbnME/QW/GgOVPcwTkb9bUWfuad+dLdtfl3fvLcc0O92tuf/tAkBWw9dx0H7zwAQxSI8IDjHQQetZvN+09x6+yz9Rci7kuNPXcVgmHPllTdzwvEHMze7xEte9G5e9RfP5GlPezCPOu2YoOOTV3z8o19i3boZ/vzPzmTnrnnA88AHHVy7llK7w4X58ZOf/Hj9ACQoiwA+NDLNO875Gz7ykY8ghOA1r/kLLr30Eo4//gRuvPHGezyf3bt386hHPQqALMu44oorxv3gvPPOI8syHvKQh/CGN7yBF77whb+Wkh6a521vezv//u8fv08Z9Le85S2ceeaZ9bUVDAYDvvT5b3PLLbfe4+fXr1/PJZdcQqvVGr/3ta9dwIte9CIuueSSutQu9PRt27bx8Ic/fAwawX3LRmZZwj+c+wYOP/I4Nux/DA9+8IO57LLL7vXzQgTXXOccL3zhC/m93/s9vvGNb3DOOX/DiIUOy6LlEEppHvSgB3H55ZcD8B//8R97sc4A4njvdW3Llo387d+8mCgKGemXv+J0Op0UIeDqq3YxM9PgoENWsXFqHcNiyC+vvYmDD9yPBM0Xv/oDTjnhUB5w6gH89V//Ew94wJGceebj+MhHL2Zqsskf//HjeM1rnj2eNq795U5uuXKJP/zDpxInGmssZ7/hfNaum+Jd7/lD/uIvXs3XvnYBvyk4/l1qzgbh6qo0wWXYwnCYMxwWeC8oS0+7nZI2FAIXHhqlwDtDmgpWrwnslsoEhr5vSuIkYXpmEiEc3htuvPE6vPc0m016vS5VVRFFCXleUpYFSin6wy5L3Tm27bkOcLQaTRLZIY6aJEmGUhqkQkLtWgjeyQAWSYExwcAmOL0lKCnJ8yHGVgF0EoFxZYwljhsIYqYaB7CjWqTs9sg6FVmWkKUN8kGExeJEjpNDHJZ+2UVlnoyYxS7085LBsGB6zRRSSipKimKIMSVxlDA5OUPWyPC+T1Xk5EVJezImjjSd5gQii6gyRyxSTCXxTpFErdr9rqKdtTARaCqcGdTC6xWD/hKDpSG2mkUoUJGnMxl0sqy1eG2IW451ByYoL7EVbLs1Z2qiyczkJJ14EluF61UOIvKB5eabdrJr5x6KsosUa/FuQFl1KQooC8Wwr2hkHZCOvNBUJrBOkrhBkqREcUyRB53YsiyZmFgVdGwKi7PhwXrVZIdGI6bdarF9162hvKnVQscVzlWUxZCF7nZKM6AqNY1siiRuMbtngaLMKfKcdqeDc9DrDVi1agqlInbt7KFqgMq4nDiOSdMMHYeH+J07d9LptNFKs2vXAniJEJosjej1eszOzbEwv0SapLRbbZI4DfpDicCYDOvK3zCCfvfavhh6Xwy9L4b+7dp9Bp5WauKMmE2jB+7Rj5RuHIiuvDxBzykIpXlrA4XwLkyn5bKoWvAsfCk1UgAe8nLIQm+OXXPb6RfzlLaHp0IqV5fQSfAC7wXOOpwUSCWQJghpjwAo5y2lyfFKoKVDyAQVQSIUlQn19mU1YH5xjrIqUTrGOkHHeqJUo2WEi+LA1qqd0QJS6VFS4QkZiIA6g1Q+DBZrccaDFAgZhB6Du0nM9Oomk5MN2hMZUaTxOJxxCKfxxuEqhzEBrLI+6G0p5cllEPWuKlAyUGO1IgQNgqCppDVKabKGxpggWNhf6jOMJK7yNDsJWStGR4p86Mjzku5SYDoVA4OzQSsK6amspagq+gNBVRVURcFwMMCYCoQhTkKpQprVuk5KI4VGiggtYlLdJItaNOJ2DTrFaBUtgzciIXYJmWugZETpCgqXU7oiiMr5nH4xC8KyfW6SmYlNTLYEWdKqg++VnKa9++2Y5bQXgPrr+vsyEjzqhiKk8vba1o3Ybr/j7d6OceU5hXbfJh1PfZ1sWPisLTE1Ndg5U2dgguZB+J6w1cg8wLmQGVVa1RapIUMTMnxVTQMOwa5U6m4A33IZZC3+X2faXJ0NdCZka7K4xcEbjuHGbb9gz+J28qoMyQYvyQch0Jla1Wap9JTWUBQCLXVw2sCHQFoKjHegPWSeXYMFbGVYtdgkWZsQq5TFJYOWoFVwVox0RJYmgZIvJY0kPBx6JykAKSOkSoiTCKVDlgZX53lMwfY7d9PtDbjj5j2oWBE1ItprpxDSU5VV0GUjot2eQNgYrGTzgR3Wb2wztapNURisKRFe1Kmk0Ke1ivFSUTlHt9xJ6YZMZwkxU8RyKmigSV/X/i8DsOOfgLKHm1A/0Hrn8MEiCKnCfH2Pgv9jIPe+LIZ7bXK31/e45X3a/71vd/9pgquvuobzzvsof/wnL2Z6ejUf/pev8NjTTuGEEw5j7doOdhW4SlBVBi01R2zdry59kPzV657D4Yfvz+LikM989jtsOWQDJ524heee+RhazQaNpmbdug4QdHw+8Yl/54orruCtb30r3/nOd/jiF7/E2We/mTvvvJMPfOA8XvnKP2fr1q3hIblOSgFccMHX2bFjJ7t37+LEE0/kFa94Beeeey5FUfC6170uxAs+PMB+7Wtf4+tf/zree04++WT+9V//la1bt6KU4l/+5V946EMfuhfoVFUlb37z2fz4xz9B64g/+eOX86AHPShkZ50dg05PfOITeepTnwoEVs+oHXzwwfzLv/wL11xzDS9/+cvH7xtj2LNnNiSnophXv/pVHHTQgQB86EMfYseOHbVI83K/PvXUUznvvPP43Oc+z/e+9z1e+9rX8q//+q9885vfJM9znHMkScJb3/IWplatAuAd73gHN99883gfa9as4QMf+ACf/exn+e53v8OmA49mZu0BRJHmrLPO4rvf/S7vfve7+eAHP8jWrVt53/veN74eYyq/s5xzzjn84he/4KUvfSkAa9eu5eyzz0ZrzXA45E1vehPHHHMMz33uc/e6V+edd964VPHUUx/AcDjknX/7bmbndlOWOW94wxvYuHE/pBRcefUe+v2Sww+bQqtQUnDQwVNorShyw4ZNLZxvoCPHtltz8qHlgadsZdj1XPXzXTzr9x/N+g3TeA9PePzxJEkEwA++/yt6vZyHPexo1q7tkCSCD553PocdejAPecipvPDFjyHLYoqh44/+6E84/fTTAfjUpz7FxRdf/H84pv7ftzjOkCpojTSyjOCMHJyTQQbtz2GOMQW9fpcszWi2WpSlp6rqBKeURFrXLKeEOA5MJGsdZVmxtNQDfO1qp+t+nJAkIITG2Iph3mWpv5tIKxqNDhvW7ocmQ4qYOG6Eh1Pvau2wwCj3LszMUsp62ndUxoYSNxWhdNCNKYpiLFzsHFRVWI8bScpUawZTGoycJY1jGs2EWHUCcE5JxRyly+kNh+hYksmIiVUt8n5BmVdUyiKFwyqD9UHvJlIpM6um6UxMsGt2B8OiYlCVJK0YYz2+imhmDUQkiEWEMRrvgjvVMIdh4cjiBlYJFJaiWKAyQ7rdBbrzc+QDx6DnaLQS2p2EtDGDMJ7KFJS2wEtDmilcCc54okSGygbpKYsCU0IxrLh5180sLVbcdMN2BsMuUWQoyz794SJJVxFFHueC5bsxPQbDnLLq0WpOkKZNkqQZGFdlRVkG2YksawaRcmspckOaBFdDrRWRC5UQE+1VVKakLB3OCyrr6HYXsbZiMOzjrULKijjyWFdRVRV5XpAkZWDWDYcURYtIhyRulAQm2dJSIB4kSdCDNdYwHOY0GkFLyFhDmqSB9VgUDAZDBv0Bq1ZNkKUN4jihLGvWVqSoqpI8H/43js7f3PbF0Pti6H0x9K/f7r60387V7i6DbiX4VL8THtXr7NuY9eSX3etCvWq1YmCtEBJfcWPuiWw2LIb0hkss9mYpbB/jC5AWqVyg/8m6BM1LbE05pHZzcy50HGvCgDW2qplAoGUQYtRCoKNAY7aupN/vUVWWSKcB1VcRnbiDFBKtYyqZh8CNIHoeEGeJ9LIWeKzpg9IhZaAzWuuQNtD+dCRJG5pGM6YzkdFqp2SNuC6P8wQVdQkuOM/ZEoz1GAtCOayySGlQxtXWkw4lBUms0ZEEFbINWsVEcUQUx1hr0VqQNUMdvreQNWOSNEJIGbQWiophvyQfVkEHqmYjIQKVsTKGvPCURU5V5JRVgfc2ZIliRRSH8kWlawtMoVAi1KzHOiOpf7SMxiV4Wun6s57IRzifAprKFxSuYGCWqFxBYXJK04fcM7e0LewrapDEWaBS1gP3nrvv3iymu/av5U436od328PdhsMIoFqmqd7/271fp2U65mjBDJNoTQ2uKmxVLVODqW+FD1L8KxdNV7uXjFxToigOJQZCYWwQUcSF8bTS1GBlOe/ynCyQQuDvsqA675BCEquYNZP7sWtuG4u9eYwbEtTdFFVRoRNFs5FQCI0rPcbIEEwjMHWZLoTh6CX4CPquoKpKslwF3Qgh6A89SgbnxzQVRDo4eeAcUkAU+1C6hMDr2uFRSqSHWGqajZi8V2FMRVHm7N69mz2z89x44xyTM21m1k8gVLh+VVHgrUeKiGajTd6zKO1ZNZMyOZXRbmehlNdVY5t2UbvYCBFo7cYZBtUShevRiTeiZYz0q+q5WNRsSTG+7uMf6ksi9p6nR3P4uKf82vF2bxm85T/c21bLuxPjT92VjXuPW47f/90Hie9L27V7Dxde+C2e85yn08g6/OAHV3Pc8YcEXQGg2dI0spi5uSFKKdavX4U1HpmmPOrRJ+IdLC4OuPzym4ijiBOOP4RTTz26FuwUdHv9GpTIuPrqq/nmN7/JWWe9gRtvvIkLL7yQ1772NezcuZMLL7yAJzzxiUxPT6EUe7F7rrzySq688krWrFnDCSecwItf/GIuvPBCFhYWeMITHl8LgjriWHPjjTfy9a9/HYADDzyQF7/4xeP9vOhFL2JhYYFt27aN3yuKgm9+85vcdNNNSKk46eSTOO64Y9m2bdtex3DIIYfwxCc+kdWrV1OWJdu3b2d6epo1a9bw4he/mOc///mcf/75488LIVi9ejVTU6tI04xnPvMZHH/88QB861vf4s4772T79u2sXbt2zHo65JBDOPjgg3nqU5/Grbfegveen//853z3u99lzZo1QWciS3numc9lamqK+fkFzjvvPOI4Znp6mjzPGQ6HvPCFL2THjh3ccMMNGJ+w2C1Y7G7nlFNOGQNpl19+OXmec+6551KWJd1ud3zszjk+8IEPcOWVV/LhD38YgC1btvCGN7yBwTDocHzi3z/Box/zaB75yEeGcpi6fetbF7Nt252ce+65aK1ZmJ/n0ku/zfXX/4qdu7bxzGf+PlnWoNNZxe7dAxYXC44+cjpYWC9VrF69im53yB13zrF+wzRShDKy+T098qHhgEOnuGHPArt3DXjkYw7HY9mzZ44jjtgEwNzcAjfdtJ1er+TBDzoKpRxSlvzssquJZMKpD/CcdNKhNePGc+KJJ3PCCcfTbE1y2U8vv18AT1JGKK9Au7okU+LrUjMhg3ZqVRmqyjA7O0+nY4njBGuCHsu4VKZ2rYt0zT4xNWBQlOR5UYu+2xVlkwqpNFI5hnmXQd5jkC+RZTGd1gSrV61H+HA8eAUilOcqpep1VdSJWxg9qHpPXV4XyqWU0lSupDIV1tTZ+5pVDoJYa9rNCSpj6ZUlUQRaKXSShQddYnB9nKndkJUkUopmOwVCKZFVgaHuVBDvFQi0jGi1WkxOdNgzO4c1MMwrKlMFZtnQIRIRShLTBGtivNMIGWFNRFlqvJHgaojNC6yx9IY99uzO6S5W9JYqJle1cL5NWbXxePrDAZWp8LhgGuRCHKgiUTtxOaqipCrDQ+6e3UMW5gvm5+fRkSFNZQ3I9IkzTaMRo0RISBszxBvBYCiIdEqk01DKY0NpUYjjI+I4IR+GZHlVWhqpqGPp2qVaKFqNCfrDPsO8T+k8hTEMhjnBsr4gVjGNrEmWZozWVO89xppQYeGCuL0UDq0lUaJIYl1rw0qiSFHZWhDfufF9l0Kg65KnYV5SlhXGOlrtFlnNqvPe1M+GgYE5EsS+v7d9MfS+GHpfDH3v7bcCngTLmbW9D3b0eoT81ifmAxIfRA0LbFXincWPkNwasd0LBRztCEAEG8jS5AyrIbfvvoF+voCRfbQKgIi0EuMVnuBUEfQsQkcVXgZBMiFwTiFcuFgj4TZMEfSaIhAqQipF2pRILbB4Br0ew3xAvxd0DLpLfQ7SB5I2UrKsgTUlZVUEt726NFMJAUrivSLSkijy6LgiaQQTSNO3OBfArs5EzPSaBp2JBlOrmyRxgtIaax3G2nriD2i3t0HE3JlAX7aFwXkYDIowWXgP3qKkIMuSkA3LYnSckEhNHKfEcRQEV72j02nQyGKkVEyuatFsp1jrGfRLFuYHdJdy8kGtSxWD0h6EwdiCorBYKzBljqlyEBU68kSxpNHU6Cj8jFz4pFBoGROrjEbUIo0aRDrQMIMjX8jQKCmRAjwaPMS6Qa0uQuFzCjNgMd/DwPSp7IDd3Vux3jAoukGUPWmRxI3xYBNSBhS57k9uxWsYLQ4rtJrq34MW2Ii+P0KsxXjbALiKep+j936bkXR/acuTEiteeR9eO2vxzlIVg0ANropAPx+V2u61Ubj2xpRhshWQJFkt8h8AUWvrslrCPCC1Gteq+zoYsja4L452PWZcal3ThGs9OABRa0J4j7QVG6Y20UobXL/rirAoexsYkaK2R65F9oWSOCzOlwyL+sFMCJQMwbcxkpkta/CmoiEdqrKY7oB+2aeoLJXxRAK0hEg4VOyIY8FUJ8IWBVVp2L1QUpZgKkEjyZicaLFu/TTXXn0L/d4AqUA1FjEMWcj7TKo2nWYHSkeeD5ndM4cQnqyRkjUnuO7yO9l+a5fJyQwtO7RbMYKyBoorIp0hkFjrx44mOk4wFGBKuvFtCCSpWA0iQgmNVJpRvx+B9N45rBgFtdROLCHh4F2gZwsVsjlCiDFNfGV3uMcl7a4L52/sk8sB3N579Hf57F2/fdxzfsP3/G43IeDhD38Ql//8W6RphhSSz3zurcRxRK9X8J6/+zrHHX8Aj3/ScUxOhbm9u1QyN1uyMD/kml/expFHbWD/A6b5+3e/CGOgqgQ7dwxIU8XqNRkveclLmJ2b4+JvXszZZ5/N619/FpWJec4Zf8DznncmzWaLTZv24+qrf8GZZ57Ji1/0hwixN/AEkKYpF1xwwVgQ/KMf/Sg/+9nPOOaYY7HW1ucjyPP815bRnXXWWXzyk5/ca7/f+MY3+OlPf8pLXvJSXvGKPxkzkVYew0jw+4c//CE/+tGPePnLX84FF1zAAx7wgNHV3Ot7sizjoosuYvPmzQA0m829/n7nnXdy4okn8frXv46//Mu/XHFPBJ/85Pnj1+eeey7nnHMOALfd9iu2b7+F6elVfOELX+KP/uiP6Pf7POABD+CrX/0qr3zlK3nf+97H97//fV71qlfx/Oc/n0c96lHs3LkTAK2jMfD0nve8h6c//ekkScLf/u3f8t73vnd8DN5Dv7/s4rfy2P7+3X/Pe9/7XrrdHp/97Gf58pe/vJfj38yqKdatXY0Qgh3bt7Fr5w4+8tF/5tOf/jRnnXUWz3zmM3n0ox/Df/zHZ3nkI/YLbJNI8pa3/BOf/Y8v882LP8eFF36Hv3nb+/nSl/+ZwQDe9IZP8RevfTqbD5vgjW9+H099yqN59Gkn8cPLbuDHP/4hl1zyX/zNW86m1+vzz//yEf78z17C8ccdRRRr3vvez/D1Cy/lw//6LmZWryLSmn/+wA+YmEx57h+cwItf8kquvOp6/uRV7+ba63bea7/5XWrdbhFKX6yj3QqaSFVpSVdFpFlMu5MwN7fA4uKAubkFlFSsmpoiiiKSRKKjGOcdZRGEwvNiiCdnx447EEKho4QkbRBpjY4ShsN5KlOhdES326PbXeKWbVdTmSHeVxy8/1amV61hcmLtWPeoKPLaPcsF23GlEZGmMrXAuXEoLUMZYA1AeS/IGg38wJMXOQtLS+A9kdJoVSdatWLd2hlmZqbZMddksb+TPbt30UwTlAoGPkVeMigLhsWQKNYorWh1UlQsiRoRJvGhOEUIoizFlx5HBAgcwbBnMMzpD3KW+oJ+r+LOG3vMrE+JE4WwAlskYCJUnLC4MM/SwgLYXTgLxlgWFvdQFDl5McTYkfaNwvrgvNztdxkOC3buWsCJHGsMec+wMF9SFpa0HeFESWn6LHU9rlJUpSCKmkxNtZjorMMzxPuCnbv2kLuKvumxeb+YZqLI0jaze/pYI9CqRZa2aLcmEcgA3hhDs9lCCIW1kA9L8IJmo0Gapmit6PUGDPOCojSsnTqAXrLE/OIebr79Oko7IMoycjOg8hVyaR5jb6PX63PYlmNod5pUUx26Sz0irZk54ADyPICHmzdPMooJkjhF65BkzhoRnXaTZrNFs5kQRYqpqQ67d8+xfcduysKRpimbNu5Pq5mBF+TDimYzQUjHYneOJI1JszX/ncPz/0HbF0Pvi6H3xdB3bb8V8LT80L43Mub9CoS3fpAfldYFgbSg5WRNWWdQV7CclncU9utXDAQR7ko/77LUn2NQLGHsECUswofys6JwVM7iceiEZVTXBsQx4KWyRkY1Ukb1fTF1hqJmDXnwyiO1QHlBbFWdRXCYMqfbX0QpxfzcFJN+gijSKBWhvV92zxEeIT3SiVDmVpfZSeXqHw8yuD3oSNJoRzTbMY1WHKiCSoMIznTW1WLn3jGagsbXxIeMR2UsGDtGqQVB1LD+BYenVRrStJ6EZLC5VlKRZQk2joKbXRqjdVTToi1lMbLi9Cjt0ZEIwBMj0buA0jpfgbDoyAcxtzjQOQPraFT3PDr2gIArtYy8h/9rG+hRPxACWYM9Y89EAdJL9Pj4I0pbBj2qcon5vmJ2cRud5gyTUtX0zmWUedy/Rqw6lvtr+JwPYGXd/5bZSyuzAsv3IIBT/zPBpr2pxKPJZcW4r1dM71yweLUVpiwCi9GFLOQokzPeywpwWY7YhSoAjqEsZlRqWx9D/a+QIlzkelEbA3/hQJePa8V3jcTvlz8SsknGWrKkiY5iNtoB3cEsveEcHovzAmt0fWou6MX5ulTABsdJrQVl5cbzXZLGeCNwVRG+rwZoS+tqYX9B6QzOFHhRopRjcVEgHDjr6eZVmLtKT1emLHa77Jlb4M5te6hKQxYnrNaaLGmQRkPi2pK1GOaUZYn3nmariZBQGcNg3tCfM2zYINGRw3mDd8H62HuBtMvguPfhOllrQXqEFDiqEFhTIdF1VuauC1LIyIdF9C5rwV7jZ4U9bFgc9srk3FO7t2Vv/J6/e1YGVior3LUvjMbuqJ/cda/3b/DJOc8dt+/m61//AU94woOZnOrw4x9ex5YtG5lZPcEDH3wIGzetQkrHJz/5ZToTbR7z6EcQRY5GU3DIltXMzDQRwnPppdeyYf0qtmzZiK5dW3fvGfDYxz6BqgpC4t/+9ne4/vrrec4ZL+DaX97Iz356JWc89yns3r2DL37xi1x33a9YWlq8x2M1xvKpT31qLOB9xhlncOCBB/Lyl7+cCy/8OrfccgsveMELSZJgXT41NcW1117Ll770Jc444wy01nziE5/gxz/+Mc45XvKSlwRr7ihi48aNXHPNL/He0e/32bBhA8973vMQQtDtdvnQhz5EURTMzs7yT//0TzSbTV7xilewbt268fE9+clPYtOmjePf4zhm06ZNdDqd8Xt33nkn559/PgcffHANNglOOumku53rSpAqyzKyLANg06YDaLVbFKVh/YZNPPeMP6DVzkiSmA9+8IMceOCBHHPMMSgVHHlmZmZ4wQtewHe/+10uuOACpFRs3ryZV7zi5ZxwwgljplWe5ywuLl93IQR/8Ad/MD6/L3zhi8zO7uHcc8/lkksuYWlpCYCyLGtHPNh///15znOeQ7vVYO3atSil+Mlll/HNb17E5OQqrrrqatK0Qb/f5+qrr+Jd7/pbnvGMZ3DooVvAw6kPOIEkiWk0Uo7YejAveOHTmZjo0Mjg9Keewv77T9Nupxx71HG0GpP0uwUb1k9x0glHMDWhWbt2iomJJo95zMNZt24NRVHx/e9fxerVq3naUx/H1KpJFmaH3HbLHWw5dJpV0+EaP/7xp7Fx42a+ccH53HrLtfdx5Pz3ttWrpzA1Q30k5D4qjTHGIqVA64g0bTAzs5pWq1WDO7XlvQl6LGVVIaXHe0NVeRYW5kmSlEYDyqIIDzfW0elM4PFkWcZid4Fh2WWQL9HIMqYmVtNqTpFETZwNcZirH0xr4kr9gOAJ9uYKZ5cz9/iRdlhgI41AGg8UZRFYMgjiSAfXNa9QUQBGGlmT/jDFGo2xJWDwQtLv5/TLnKIuYxMIhAsOyk5AFMWI2g4+ULk8UkNv0MMJy7AcUFQllbUsLeX4sqDq9hi4oDWjpQaTInyEkDHdhSW6813KQWDRVYWlN+hhTIl1pi7fUbRaCUkSk6ZxWPuEQ0hLI0mwlaZYcpiioMwtjU6Ex2BdSZ6DJENHbTZvPgAtW0iRML+wm15/nl2zCwwHFrmYU60ROB2hRRaecbSi1Zik2WiTpY2wjkuFUqE8Ey9xFuIoRghZJ5Yt1loGwwLnXEj66hifBtbSZHsVhUkRUUUpBI6SXtEFInCSufldaJngXUS320epmDi25HkwY0KEkkvnwrONMQVFWZKkSc2Ik7WDuEN4R1GUDAc5QkZ4JKCojEdJiGKFjkL81+/1UEqGUqn7edsXQ++LoffF0L++/XaldnA3l5i7txGTKTCdjCmxpsKYAmsM3rvlYejvMsDGnV2gpArgiTf0hovMLu0kr5bwvkIKA9ZiS0veq8iNwQtHVHp0FJzqlAwslXBZgt4ReKS09U2XY2RZmAqnPVoQnACEIEHXncpSlgX9/iLOOib2TKKUIms00HEMQGVLnDWAr0vuPFJQi30HFX6pHKLWYFJRcLFrtiMaK4AnvMI7ia1tSd2YEbbsRjDKCDtjQo0qwWFP1GwhK+tRIUIwUBQllQksKymCFL9SmjRN8QRx8ySN0ZHG2RDYlKWpdYtcEEOPPEp5PBZrK4QYca4rhDToODioRFENPEmJY4TkEphp9bFLqcZ1r1KEiSBQ6er5saboilHZXL29RhO5GC2CJtTQDFnM5ynKHqUp2TU/gXcuWF/qlJGTw949c8X0v9fgG4FPIyB1NKBWuBIwYvstLyS/EVj+HWv3XYdqdL7Lc9D4VL0HF5iMpiqxVRFq0r27uwhi/Xnn3HjhjOIgNh/KDAKdf8x6WMEug9BfxYpS3tH/ozHgaz2Z0VK6/O0r7rRzwUXIlTTSDk0dI1TEjvmbKKpecLl0AmuCu05wV+zjXRiLzkkUgTLrS1sPLU8caZyE0lY1K9ERxR5ZBGqusYKqLMiHPSrbxzuD9watE6RUWG8pyyAQK20S3HmKiry0SKGYyNqsmezQTBSNeJFYBUZgOcwxNgSBrVYbLzy7Z2cZLhmKRUu7o4kiH7QCjAeicF29RfqQcapnqVpbIVxni8VSYSkRPoE6OzZaV7ynphgHl9BxYFKDssvzedBs0NG9uHPcLdlwTz3vbhvdfdu7/m3lxuP4674vivc3jSfv4cYb7+R97/0MRx11MFpHXPC1n6KfHLFu3Soe/8RjgAAwfPTf/oODDtzMk5/0KOIUZKQ44KBNaC3p9XL+88s/5WEP3coxx+6HKqHXN+zclfOsZz+XZkMjhOSrX/0qX/3q13jOGWdw+eVX8e5zP8TDH/4Arrr6cs466/VEUUSapvd6vO9///tDsqSqOP7443nEIx/JOeecw2DQozIlZ7/lbDrtZaDnoosu4nWvex0PeMApZFnG61//epQK4MvZZ59Nu90ef1YpSZIkQCh5e8c73oEQgjvvvJPPfvazzM/PU1UV733veznjjDP46Ec/utexPe1pT+MpT3kKAFprtNYURRGEmHV44L/xput589lv5EMf+hDPetazgNC7jA0BrBgF+VAHjkHvEiGIo5h2e4okabHY63PIIYfxV3/5BtZvWMWPfvwDHv7wh/Oxj32M3//93x+7tyVJwqtf/WpWr17Nt771LQAOO+xQ3vGOd+x17KPrbq0dP3y89KUv5aSTTiKOY2644QY+//nP88Y3vnGv7UYAF8Dhhx/Om9/8ZuI4RghBURR8+9vf4QMfOA+AJE5pNNpIKbj99tt429veymGHHcrmzZtJkoTHnfYIHve4h1OWJccdv5WTTj6afr9ACsHLXvbYEIfkjkc+9JFYWzC3Z8DBW9aw5aC1PPLhp4zXmc2bn46pLLt2znHRRZdx2uNP5YEPPArnPNvu2MGPv3sDZ7zoQUyuajAc5jz/+WdyzTXXcNJJJ+5VMvi73Navm6GsnSeVkggZ4kRrLUVRESdBoyXLJGmSoetyEhwhLqwMxgTWi5QB6HHO0Ost4Zyt9XSGeO8wlWViYpIo0oQZsWJYLlKUA6ZXrWLj+v1pNSfROsNUwb3QOahM2O/y+l8DT1JhBVhHYFZQmw5RM/N97TLl/RjYtMaRJTFRJAFJpkBHCVkayse8S4ILsgBlYTDI6RcFhaqwpgrssEKg44goTYh1CrZ2VRYiuEtFsNTr0h/26Rd9SltirWNpfkiZGwaLJQtDgmZUGqNFhhQR3mn6CwP68wO6cyVF4SiGgd3gvUdoT9aIyLKYZDomSxOyRnCPlsoTxdBuZZjSs7TbYqs+VRlKcRAW63OGpSHRMa0k5YADDqLZmEbLhFtuTdi1S7Jzz50MB0OsLymHCh8nSJpIYdEqYqK9ilZzgkbWYpjnaBWeKYRQgX1mXS3QLYkiHeL9KmgtaR0kLGKdhsS7UAynlxiWfUozoO8chevSHczhncIZwc7d20iiFrFustQdEOmMLK0YDg1SqRp0qo2lpKWo+nS7i0xOTQOBMVdVwbVcEmQ7irIky2JA4JykqizUOrBKBW2yXq9PFGuiSP23jc370vbF0Pti6H0x9D23/ycaT+PaUJYV/IOt60hwq+7AzmGqIghpW0NlirG2U6DvrkRca2FmakaMrnV+aieyyhTsXtzOXHcH3eEetLYUw5xer8edd+5h0M/p9Yd4GZBIncgg7KclSRqyLFpLlK5L8KAWQBcobXEuAEZVZcJiqiCOwyDVkSJrxugogGVVPmCxV3DTzYK8KHAO1myYQWhNHCcsLfWxpiIf9gkTrGM46FMWAXBzPixISapodRLaEwmT0xnNdkKSxUgV4a0CZN2pQ6DhqcGqWtjPOwgC6uCtC0yjSBGnCXESI0VAS62zFMWQpW6XKNIkUUwjzRC1PlWzKQKgIxVxlCCEoixLTBWQbYRDak+cQpzWjCdvcQasFyjp0ZFDRUFsMAjX1doAiFrUziE9wWHPG4RweEYIsUeqMBClCCJssmZB4QNoJrytx10AobRUKJER64S2MzTjSbpll6EZsGvpZozLQcDaVQcS69qZZcWgWFkqd/eBsqzrFFwHRhPFimzCiv2Mfr8/O9rd1+ZHULFbNgYoijwwGEfjeu8NwAcm4MgoIIriIIAYRQEUxdZ/E3e7flrF4cEorgFEKWDM+1umrIr6e0dgoLIWKyu8D4YF1plQqinAI9k2dyuDskflQkZmsrOGsuoGHQMriUUMyuAbYUGrqpDFVS7DuwYCDcIRtBEsUsHk2iZL3R6zewqGwxKVenTqGeTBxTKSDkUEKsIJNZ7jtASb2hB8mLqe34mxhkNlely/rQde0GqmZGmL6YkJ4maFcRXDoqCRNikrh3I9Dj5qknWbY9bvn6Eiwfx8iRAWqarw4KEVmgRFilYKL0VtbRycImPRIMpKfGywrkI4WWuJhHtjrcETWItxFPTuIhVRmFpLgDAHQ6CCj26prN1Q7a/L1NyXBes+by9W9MW7biPu5fX9rwkBJxx/JP/24b/j8CPX0GzHvPavnkG7kxHFgoWFHvPzObNzAz543jtptTKcg6U9kqqCyQmPUtBqpbz1Lb9PlsVUVcXpp5/OAQccyHve+w+85i/+kvmFRd7/gffzl3/1Ol71qlfRaU/wnOc8hUc+8oH8yZ+8nNtuvYWN69Zz7t+/mxNOPBEYzZHBoUdKFZJIwDe+8V+8+tWv4a/++ixOOeVkPnjeBzjrrDfy6lf/Ba1m617OU44TEG9961t59rOfvZebHMBpp53GlVdeCYTyu9F8snbtWn7wgx/w/ve/nw+edx6f/MS/c/TRx9ztO17/+tfzpS99iUgr/uRP/pQ/fNGLePzjH8/kfgOe9Ieb+dWVS+SDgv/1zmP55dzHeet5n6HX7zE9HQxBbrhhNzPTExy19UDWTZ7Mwnyfr1z0OXZt69HKZjjv3P/ggx/8Zz72sX/jP7/8FdatXQc+CMKO2l/+5V/ytre9DYBXv/rVPO95z+MJT3gCxxxz7PjcRuyple1P//RPeeYzn8l/fetivvud7/Kl//2/ec5zzuARj3g4H//4x++1/zzjGc/g7W9/OwA///nPOfbYY3n/+9/Pli2H8KQnPXkvLa2yKnB9x+c//zkOP/zw8b34l3/5V770pf8kjiMWl7qc/pQzecxjHsHrXv8q3vKm/6TTafCa157GNdfuZDisOOrIDURRipCexe4SN944y1VXbmfrkVOsXTvBIQftx9ve/g/ceedO/vYdf8mO7SXf+uatlG4X69ZMceZLHkKaxVx6yY941avfwPvffw5TU817PL/f1ZYXZR1/1g/ggJKCfj84JE9ONihyQ1EYRvbySguiWFNVjkGvZDAYkuc5s3N7SFNNmioOPvhQjCkpioJ169bWiVXP3Nwi1hr6wwVuvu0Gds/eyarJ1ayd3sia6U14pynyitxVaB3m6v6gXGZ9C0EcQSJAyXBMWtXAkxd4FxK9CBjkBUWRU5YFcazwXmKqgmFhqIxE6gjjCoSEooIs1WzetD/G9/CUeAoO2ryFyhkGbpE9cztZ6i6we24PsXeoWCNNAD9wCrRAKo/ODDt27WQ4KFFtj4igoVO23zJLZSu8NHQXIIoU8RpF3K5QsWewVBC3g77coJtDbjCVQSWABCs8VeXQ0jPZaTE50WSi00QKQyOLiDe2me6sIu87FnYGlz6Hp93OiFJR61A5rBgwrJa47vprkb6Jt8GZMI4yDtx8GDt23sn8zlnKzU1KnVAmgkGvIk4UWdak2WzSbDVROqKs9b8CwCXJ0oQkjgJraDBgOCywxhHHMUooBIqycCgd0elM0ezELHbnue7GX+LKGHyTibaiKoYs5NupbilZNbmWdas3s2nTAcRRitYxjVaFUgIdeaoylIcZk7O4uMD27dtI04xms8X0dIOFhUWK3NButdmwfi1r1sywuDhEKU0cBzChtGBLE8gIONatW8fI+Ol/YtsXQ++LoffF0Mvtt9R4Enjha4X3vf/mfUBknbV1pqJ2rLMmgFBuZM9Yd/1l2lOodZSiFkYLg6gyBXk1pJ8vYuwQT0lVFgwGA5aWevR6Q/JhQZFXAchQAlsDFjZyjLSohKiV7muGjfMKIR0j/aFAU/RAKAE0xo3BL6UkRJo0rSfa0lKUffqDJbrdRSaKNpFQSK0w1lIUBa6yULvqDXpD8mFZT9QBpEiSiGYrodVKSdKktr3UjGk/4eqM2TeM/69tMY2jKiy2cnjna+c6QaQVcaRrMFDgq8CUKoqCvCjIi4Dy6hr1FWgE1JoYI5q1W3YYrEsCVRQE10d22uE6hUkslBaCkCtKIz0rJjJwwuO8xXmL9RbrTaAwBgQNQc2GqhlOQgRgU4xpiqPSu1EPXBZN9AgcASgKtcEDlvq76TRnwn1XrTHL9W6gE/7ug3UUazESyYeVQnyj7fd+7/79AHvPbW9G10j80K9gMIYF0y7rsrGcHQ39ta5VFgShfa3QSo//7kYWOYCs6af1XsZst1F/ENT03/Hf7nKco2P0K1hrI2py2CNCSPJqwNJwln7RD6xEKYjiMLFHSpL6BOU9kiauGlC5EqUC209pj6gAExZjcEgJUapZnC/p9nsUiyWTa1M6rRRTDqgwtZ1qONVQBx/KhHGAt4BFKotUdTDgwnwkK0OvCpmkickOnYkJWq0284PtIByxjkniCLzBGWi2EuI4mAYgBEVh0ZFEi5oyTFFTqIPDpUDhrcO4UbYpBEXeGpyvcEIGi14EXoqQsRIBRJAyWL1WtgQCWOzqez5iCAbXFQuo8Z26p1r15WzLr1kU7+39e/zDvY3H/xnjdMuWLZx44ol0Oh2arZQth26g2x3QG5SsW9dhz+4eO7YvMT2dkaSaVjOhkWZIBLNzS0RJGIuzs90aVPds37GNNWtWsX7dNFu3Hs6GjRtJYsWmTRtot9tEWlKpCK/CBe902mRZyjHHHM1+mzbQabc59rjjOOSQQ+qj9AwGQy74+tfYcsgWjjnmWCAIjXvvuOXWm1FK8rnPfY6TTz6ZdevW8eUvf3kv1soPf/hDAC699FLWrVvHM57xDKRUXHbZZVx22WVs3bqVI488EoBWqzX+7rm5OT7/+c/vNbdPTk7y9Gc8g2OOOZb1GzYAcMkll+C955GPfCSlXySXu4gmJLfP/4wf/nwdeXozc/mQn/+sT78bsrNrJjp057sMB/MM8hI9KJFxhVAS6wTdpQLMLhYWenSHi6A9IjJcf/OVLPRvR2Vdfnj5JbSbE5QDw8kP2EpudiOlYufOnWM9p/n5eZRSHHnkkRx11JErruty6/V6/Nd//RdVFdgZRx91NEkUo4Xg4osv3gs4uqc2MTEx3u+tt97KDTfcwH/9139xxx13cPTRR3PEEUdQVRUXXnhh7cpn2W+//cbbHH300fzqV7/ii1/8Ascffzwb1m/giCMOZ/XqtSwtVOy33yranQwhIU0jpBAkqeRX113Ltjvv5KSTT6TVSlm9uk273SDSUSjB27AWrTW7di9RFMGopJG0yNIUZwXWeJrNJscecwSddot7nx1+N1ueV0RReHgcdVElg/6Rcw5jQxleWRkaaRyMAoSo7bnDvGpMgbElcayw1pAPDZ12g9wM6fW6TE5O4ZwPIIStMLZgkC9SVUPAMdleRbPRIdYpxgRBbCt8zZoL+iXGepwPchHeB7Fq9Cj2AyFCenQcOo9t3V0tfC1xTmFjhTW2Xm8VgTVvWeot4YlAxDgRHrikkqyaXAVSMTAtnHFgoZv00FqjkJR5HpKyVOgkyGg46pKuYUGnk5FkwYJ9Ll3A54bSBKcugSdIrgRh5rIwJAqiDFTsiTOJEDFxU2K9Y6mbI3x4bswySaTBuYphr0BFjrSlibTG6KBzk2QRKE+r1UDGBi8MQnucKynKLouLd+BMivQx69evp9VogphAyT1UJUHrp8zp9RZYWlqi0axLGUV4vipNQVU5qsrhfTh3rYNrmHPBuj0880iU1EGE2YVyIFnr/MRRA2Mr2q0Orm+QRoT5S1ZUFAyKLmneJC+GIIK7ltLgjA0C8NZQloYiD27iSkW0O536OUYihCfPc4qiopE1iaKIOInoD3KUDI7bgyoAm1q6utzX046TIG1iyv/Px+T/m7Yvht4XQ++Loe+t/ZaudgEGWMnHCotPGFQjwKkqhlhn6zpzw8j6cWXZEisGwUiQLNzMwILq5z16wwUWe7uwro9Whl53ibm5RXbvnmdxsU9VWYwJIuNCCpRxWCvRUaiJ9z4AIzoO9DipFL6Wq5ZKB6qyAGeq2vrVgjcoFTISSmpkPLKPLSgLQ97v0R/MMTunmZqZoCEapHFCVVUMBgN6iz2c8Tjj6PV7LHUHDPsGa4JQetpMmZ5u0ZpIaTQytE4RIsaj6gE+Emb3wZKxvlbWBkHJYmjpL4X6c09gJGlVA0+1M0oAZMK1GeZD+oOIKFJMTrQRSUISx8gaPFRSI4UGAbamenrcGHSKZGCRSSFwFoSoXe7kyEkwdIwR9dD5ZfAJPKLOfBtfYVxBZXOMjUNmwztE7eIRSvDC94Tj97WLSwAN96aPCpQQKBET6waVN2zv3k5lc3Yt3UqnOY3AkyZ3yaKvzAqsAKPGb+wFcC1PxKM+endUWey1y/95LQSWvmYsmjKnLPOg2WYrGFF0xyCyG1OCg75AQPfTNEXWoHJlSnwN8kKg33vhUUKNAyyAYDM9YqY5KluN74Pwo74w0ptw9TGZscCic8vGBQBSagozYGmwh22zN+KdQBKxaeP+NBoNskZEbDTONShFRNG/k4HJSRNJnECSePLC47yhLHMiTXB4SSV5lbPQXSLfXbBmXcamdRNUdjf9bo7NK8LCMRIPDGCp82BcyPBJHXQ9ojgN18RD4mNK28dbwYEHbmDjpnWsmp7hqht/QZZE7LduLc1GjMBjchvsohsZWUswHFTkw4qG1HgZroFjgMBgvSKRk2gV144jFZWrgiOk9zhTgtDgPXkuSJMmkZboSBOpGK1jpJKUpmBY9GmmUyipUUJSVQWuLgselVvXXiD30LXuMvbuigGv+Pu9vR4HaOPtxV13c98yQSuP43e8PeEJT+A973nP+PKtWqP5yYXbGQwqTj/9SH5x9Xauv243f/CHpzAx2WTdWs8Pv30HeTkknqg4euv+aKX5yWW3UQwDWPKfX/0Sj370yZz53NN4z3veO/6ul730D/He0W6lXH3lNdx223ae/JRH10xSyXvf+557mf8ECwsLvOTFL+MVr3jFGHhyzlFVBYvzBT/76RzPfvaz+dCHPsRppz2OF77whXtpFY3a2Wefzcknn8wPfvADXvKSl/BXfxXEvF//+tePGTsr2/XXX8+zn/3svSQB3vCGN/CJT3xi/Lv3nje+8Y147/nOd77DQcdMcyqb2HQE7Np+Ce//xNc57mmC2dsll/7ndh70mM1MrkrpzhkQmkYzpTnRpNFokmYtTjj2UKTT+KHl9oUlBnmP9esOYP2xG2hkbS645FPEkws88VlH8t6PvZXZO7vM39bnw+efFYAIHVEZv9cxZ1nGeeedd6/9YMeOHZx55pnkec7ExATXXHMNj33Uo/jjV7yCU089ld82SPTec+6553LooYdyxRVXkCQJCwsLHHHEEezYsWP8mVF77Wtfy7XXXstxxx3HOee8g1e96lX803l/x9yegjtuH/LSlz+CNFN4DwcdMI1zniSRfP7z/5vPff4LfPfbF3HE1k0cfthGlBIM+yXbblvkBc97Jv3hkA/+81c56aQjOPrIg9mwcT92bx9wwzUL7L9lgiOP3MrH//0f8R6uuurqX5fI/Z1rve6QVjuj2czQUQhJggyBCIBTaRjmJUVRMTWVEWmJUuPVDikc1g4QomTN6g57ZucZ9IfkRZPFxSV27NxBkqQ4J5mfH+J8gfMFpZ0HWZI1Itat3shEaxql4rDmOo/yjrIsMKaiLAuKwgURXWMwJgEEpCN78JCUxAVdqlD04PE2zPnOWeJIoVVMrKHfHyIQxHED60qqasiOXdtqQCslzmKiRNJoStauWU+WBuBDe0UiY/LBoE6GCrrdBVAgIkg7CuEFpjukKCrK3JLqBhMTMc1JSW9xnvlZx54dBVECUSKIMxEqAkrLYKlATQrStkRnjjiOyOKM5kTEcGgY/Cq4WWklaXckUpUMB5bdu/s02hFrsybe1U/E2tOciGkQMT0zwdD0yasBKrOYvGBY5tx2206qXJPFHdaun6bVWUOUp2iZYCuPZ8AwN/SHs+zY2WVycg1SCpwzFFXOwtIctgpGSWncREaCKFIUZUFZVVSVCcl7pYhkTFE73RlfIeMYIWOiOKEl2mxcvxG1R9AfxhSuTyUqSlExrLr0himLS/N02l2kFCSpohwE8DlLUrrdIYN+SbOd0G5PsGbN9JhBU1UVCwtLDPOCiYmJ2uVao6RFKUEUeQaDPsY44ighz3MEniQV9Po98nxw74Pnftn2xdD7Yuh9MfRd230GnlZq29RP7bWOUzVmOQUhcYOpCkbCWq5+eHd2GXgSCKSStVBeGExSjOholqLKWervpp/PgxhQVj36eZdB3sc4Q5REZK0UVRqKvKxpvx5TC5dZU8MeLny/jgAhaw0igRISZRVWKaQN+RNnPd4YTOWC05q2oR5cKdIkRuuQuenpAqFyBsUeFpYmcGIVcbYaZwTl0LN7xxLDfklZVBhTUlahTjRJErIspTPRYnpmFc1WQjNLUTpGSB1qrH1wsqvKElNWVGVFmZeUhWHQLegvVgyHlt5SSZR4ogS08OAc1bDEVbXWk/Z1zX2wN82Lgv6gT7fXxXtHpHVt8yhriCWAcQiLigRJGpNkMUKBMpI4Cpa8Xjmo9aqkFiH4EBJBjBIaJaNxuZ3D12gtQWrOlshqQBENiFSMdVUgfgpRg1/LmZ0Rcqu1Hj/YOGfGqHwovRAgwkCOZcbGqYMZVn365RILvR0hIxg1SeImSuoxa8yv6M93HVAjp7q7930YQ2krwKiVjKj/aeV2zi0HkSYfYq2hqkqcrUKmZdRqAM95W3/e18y+hEhH4+ti9yqzrd1wWME+G4HQIiyi1huGRX98/1eW99r6/nsEI2fMYD3rx1lhfKi7Nt4AgijKWD25mSRpYL1lsTtLt7dIkQ9IkgidROTFEt45mukkayY1nWYBwlPZKoidVnsQwjPRCRl8pSVUsGn9WtZPT1Pu50mziO5sRKexhkguopglHxqsFSgUI7cg732dofFEUVz3veBU6cf2xQYvJbNLuylvGnDLthu55tqbWTszw9rJ9dgSimHFtp27mep0aDYSnDFIQllBkqgwRj2UhUNrS5I5hA7Z5VimyNjT8jHtuIUWMWVhkTqcd+pihoM5FkzO9oU7SKM2SdygMH16xSLzg90csv5E1kxu4rCNR1PIHGNLimow6kR4a8bBjlvBeP117Z7G5l3/vtx+O+rvr9vv7/oQvvjii/nRj37Eox/9GB76wDM59tgjeOozT+Hkk/fDWo+zcNAhM6yaaeCd4Ec/upHvff9aTn/SA5iYXIUXBnxEMYSZqdVMHBCTZpLDjng+P73sCv70T9/IWWf9L2668Tre8tazOeecv2Fycg0ve+nbOeO5T+C44w7l2c9+Jo997GP4wxe+EO9b4zK4le3cc8/li1/8Iv1+j0996pP86EeBvbR79+57PK/p6Rm+/OUv87GPfZwPf/hDd/v7tddey6Mf/WiuvXZZQPr888/npz/9KR/5yEe49tprefvb38573vMetm7dykUXXbTX9t/5znd4whOewIc//BEGwyHf/u73eOX/+nPSVPH973+RothJK4353v/exsxmzdr9E+y2VUzplAc9JsWWPRZ3C1at7tBoBReh3nxJOfTMVyX54MqQcMsL4qiDkikzUxtpNWK0zhlWu1i3dgOrZ45g+/wSZusiWWPIp//jSyQy4w1vP42vffUqluYl737XP3D44VvHx37BBRfw7ne/mw984ANjV8CV7aUvfSnPf/7zx8LtUkrOO+88tA6h3dlnn83pp5/OS17yEsqypNls8m//9m8cddRR93gvbr/9dh73uMfxx3/8xzz2sY8dv2+t5WUvexmPfOQjeec73wnA5s2bufDCC9lv00H0Fi1XX92nMyHZsCnlk5/9LJ1Oi2ec/iS+8+0rWFoa8OTTT+WFL3g+jz/tsdx00y7WrDFs2DDNX73u3UxOdPjzV76Yfj7A2IrnP+9RdDpNvPf85Wv/jmOO3soTHv8o/uG9H2b12in+16uex5ve+HYuvvhbWGt45StfydOe9rR7PKffpdZspXgvWFgYEsdR0OaJBcYETbBGI0GpwKCPIoVzhiqviKKKsizJiy47d95JZSoOOuhAGo3AYmk2M5yfwAvL6tUzCKmYnCq5/c4bWOou0M3nAkiQrmdqai2RThkWJVqFWDBScdBilSLIIMiwllcl5LUhDF6jFChZr/mImhZez6s+WPkoER4MtZZEOgmC4CjiKKM0grIKuixz87MsLvaI4oTORIt1G1czObmbOF5kYWGBpaUuGM3BG49kz+wsu2d30WMWpywignbeppFkrJveREqTYX+IkAIzsPSMCVbphOOVIZNIMTBYK7GVx5nandlbdCrQSBppRJIorHVoHRhfKnYsLnWZn4eq9CwsFqxa3aQzmVCklrKyVJUjTTRRLJnoJFRzJUVfIpRDSUEyqdiwRYNNaMRTrNnUpjORsXv7Au2JmLXrO6xe20arhLIURNFqJiZmaHc67J7bSX/Y5bY7bidLJmlmU0y0JxgWku5AgJdIoUmSBoIgOh78joLwejNJiBOF0kHaIolj1qxeQ3ewyCDvMTu7By8qEIoka+KlpzecpT/YTRxBpDt02h2c85RlhdaSrBGxe/ce4ljSbEasXj2DUoqq8qxZswZnIdIZIDGlYX5+niROoNNhamoiiDZ7QdZIkUIwMZmRNmKq6n8K42lfDL0vht4XQ99bu+/AU/1vmL9HiKypwSaLraoxYrp3veqIFhjKp2BUmiXHJW1jTzPvsc5QVkPKakBlBlhXYGwRLCQhaC9lCd6DjoIoYQB5XL2Q1HRkVWeTFFSVDJS+OFCWJQGgGf8Q3DxGAolOhEXURrp2YlMoJXFa1eAWOF+SF32SMq3dO0I9dVU6Bv2C4aDA+yB6DrIWJkxptRs0Gw2yNCFSQdtJCIXxhO+2DlOZQHcuAx24zCuG/ZJBPzCerLFEsajdLcBbS2krKGs7y1iG7xWA8rULSskwz4l1hGtYtFoW+Q4znwNRa0bVWQpfl9MF61wCQ0laUBKlXQ0eSqSMkTK4/I30kQRuTO0EAqjmK4yvwgRLQHUDjVwu45lieXIcO8j5oFlFzQYTUiGQSBFATCU1zShBSo2vv6syOUXZC6i0kOE4xmS7ex44gaYcjj5MbCt7/91H1EoQ6n7d/MqX4UY452oHw9qRsn69EhikDjaXHTcCeKeURGsdhOYRNetxb8Dubtes/lXIZWbb+J6J8cGFiVeMLAUF+HrprZlxoywOovZKrN8TUpIlQZB4VXst1ljyIq9LA+rSXFxg+wlVu3ekeOHIyyHOO7QWdWYJ8LXrooE0SkDFaOsohobu0hCZgheaOI6xtkRYjzEu5BP86BDDtQjjq6Y8j0WCLTokTVjsdun1B4Bgbk+PVtyhLDxVEb6v3y2Zngy6drYKbjbBeSdc2LHriaMe08E0QStFJFKkiIh8A+kibF2+G4a7pTucZSmf5/bZX5FFkyRRm6Ls0q+6LJXzNJJpPJ61k+vHDitKRSuyKBbqTNyojHY8sEYU4ZX97x4WtXvN1oxf3j1Lc0/7+k2Zm9915sTDHvZwLr/851x6yaUcdfiTxhoxcaSxdRlcq5WEEnEPphYxbrYjGs2IQb+sNSEkrWbK4tIOZuf7HHbYEdxy883kwxxrLEVZsri0UJcra7q9AWmWMjHZ5vvf/x6tVoNjjz2aU055AEVRcsMNNwDQaDQ44ogjKIqC4TBn7ZoNzM8vcskll9zrOd1yy81ce+21PPBBD+SGG27g5z+/nKuvvpqiKMafcc7R6/XYtGkTmzZtAmD79u1ccskl/PSnP+cXv7iab33rWywuLtLpdHjEIx7B/4+9946y7CqvfX8r7HRSxe7qqFbOEopEBWSRRY7CNjYYg8AYbGN8uY7gAA5g+2IMBkyyAZtocrJIQhISKKuFYrc6h+pKJ++81vtj7XOqFcDiPd9nMYbWGNVddeLea6/w7fnNb84dO3awsrLC7OwE113ns7S0yKDfZRgn9Ps91q+bIwxgZeUeeu0ecbdAlgG1sMbUTANTTiCUh6x7tA8k2FIQ1QJMKUkLQRTUKdEYJHHac9nsIifLLUpmRH5Af1CgtSWMAleObyyTMz7SqzExEXJwe5/c5jSnZ5meC/AjzboNG2i3Oxw6dD1SKq699od873vfo9frjftj+/btbN26FWMsRx99NOeddx4Ai4uL7Ny5k5NPPplarQbAKaecQqvV4txzzyVNU5rNJk984hPHQNX9WxzHfP/73+dRj3oUa9asGZc/CiGI45iDBw9y/fXXAYIwDLngggu4d/sebrzxJkpzJJNTEfW6Jstz0jRHCCjKkuEw4d4dB1g3N8uWLZu55ZZ7xwyvOE4IgnCcWCpNQZL0aDY8lPJJ4pQ8zxHKVsLaOdZCnKQM49jNAd9/gPbXw7IJJ6ZcFCWer8eMo7JwN5yep6qkYFXwX7ER8sLFwEWRj7a3cV8UVcwN7kbR6W06PZ406zNMOqRpzOTENFMTa4iCOsY6YVxRsbY9rceSB3LEwlLVXlXFxiMnX4EdxwmOceGE9ZXSaKkplEaYwrHZtcD3HUMSq6CQYCVBECFllyxPyfIM7UuKomQ4HJDlCf1+lzwrEFbTrE0y6KZI06a0hqIy89FZgG9C6mtaMFES+pLllR6DTkFe5iS9gjK3eL6q4mTIhtUtuqnEjq2lyEFpjcIZKRQV+9ALndyG8qHXS0jjkmRYEieGIPRI4pIiX+0XpQSedtfNGGfzbq0TMpVSUW9GaFFjoj5FEHkIWSJUTqPlI9Qkk1NTKBmQpYpmo06jOYn2NYOVLkudQyysHKAZ5VWpXV7p10Lg1fB1hBdFLvoRApRASYm0VIL1Lr7Bumvl+UEVr2uwEqV8lPYobYbFEmcD4qRHLaphTIEQLpaL4xitPXxfY0xJkqSU5ZDJyRbGeCRJgVY+aFkBYCWFzcaVC1juqwWLXa0yqCQ0fi7bIzH0IzH0IzH0Q46hhX2IPKof37NjfHgj3aaiSMmz1AFPRTZGTQ+fhas0PoOqUDtPe0jlQJ/Dv96YkiQb0O4eoDPcyzDt0IkXGcZ9Z886EjS0TqQxjjO63QGddp8kzoiHqWMuGVsBKBLPl7SmfMKapjGhUT6AcW4LSUaeFSRDZ/1qCidSNhpojUZEEAQ0m3V830dKSRIXZHlOkRc0GhO0WjOsm9tCmhb0ewPuvvNeDh44RK/bQwiD52v80GN27STNZp3pmUkmJybwPc+V+1XlcVmREw9j4uGAztIKWZqRJRmD/pB4kLO8EBP3DUVuCUJNc1LSmJBYUZJllnhoyHMBQuEHHn7NZV/CurMs1Z5kemqSqdYE69auZaLRdIwiKTAUlBTE+YBOt0en02XvvkOVs0+GUi5jNBIEF8ptsiPWmqd8tNLVQukmRmlLFyDYEmMLlHD1yTO19bTCaabrc8w01hN4NSKv7mqdx2CUK7lDWIoyJyvTSqDcPad1gJIarQK3YaqAKJzCCqfz1U+WAIunQmYmjyD0WyDkamaOw4Gtau23Zvz3SMdptBGsrtyHT3I7Ht8jgfFzz3ygcO3Dqd25fdeDPzFex8pK48uQJ5nTksiTwxiM1VmP1jzjtM/K0iCqUlY/9F0NM9LZkBpLacrVPQ2AStNLqftA5KtlB87JR6jKeWO0uFYaEuMNB8b046zISJMhSTykzLIqc+OyRO6cBMo6Kmya9znY3sO+lZ30h23q9Rrr1q0jKQYYSrRYBVHzsiTNUpIsZZB2iOMh3U6XIjVInPhnkabkacpKp8v+3Ssc2N3GlgFzmwNOPLdBKbuOKr8co5WHkrpiipQIDNpXjp1YQhq7DVooCAKNMZJdOzPSPuQx+Ci2HLGBc84+hdaEptMecPUV9/Do87ewblONHfu2QdWPoR/i+z5hGGGMW299X1OPIkI/YKoxiS99POETr0yDiVCyzmRj0okn2pyb9lzFvva9HOjvIfKmCdUkZZ7j+yFhVCcvc0IvYt3kJk476gmsmz6SmeZakqxPlg9d4KQ0Qnk4mT/nxWzNfdmHHPb7g212q4Ha4Y/f74H7D+ufcdMEePRZj/ovX/M/1YaDhH98z7v5oz/6Q2644UZOPvlkpBRcfeVekqTgoouPpL2cMOjnTM6E+L5j+fb6OUuLK2y7exunnXYik1Mt8jzjd9/0Rr72ta9y4423MDMzhZQQx869pjADmvUJtPRIsgwpFIcOHeKMR51Kp9MhDENuuukmbr/9dl70ohdjreXss8/immuuAaDb7fHud32U737vm3zvim/8xHMSQrBp0ya2bt1Ks9lkOBzyqEc9invvvXf8mnPPPZerr7567MQD8Pa3v50/+ZO3MDN1BHmR0u0d5IorruD8888H4Nd+7df4/Oc/y6+8/BIe8+iLOPvsC4gHS3ieT60+wZ+/7U9J4g6//srn8E///G9svfN2XvXmC2g0pvD9BmGwyP4Dy9y09QANMcnEZMiJZ9b4wRXzLB4yvOB5TwGbk+VD9i0uYfHwdIvbb7uZfr/jEjO2RbMxzQsueSo/3nYzt227mQ3HS/yyjtefYdPxE8zPL/Ph917OMSdGtCbqLNx5DDvu2c6e3TupRU3yIifLYq699lrOOeccAC699FI++9nPYozh7W9/O//7f78ZEHz4wx/mta99LT/4wQ84uxJ6H7XVMj47Tg6N2re//W2e/OQnP+C6jMxjhBB4ns811/yAQ4cOcckllyAQnHjSidxwww38wR/8Af/6r//KLbfcxtzcWoSA4cDpckR1RTws2bNngT9/+0d56aW/wNOf9mjHs7bV/lBa+r2MPbt7HHXMJEvLB3j5K17Py3/lZTz7WZcwMRUyf7DLzh1LnP6ojUQ1v7pBgx//+DbOOeccyrJ0mfzy4S1OfNNNewCX4dq8aRolBUmS02476Qg/8HA5NkG94bL5Qhh6gw5pkjMcFPiBxpqSdmeZ+YMH6fX7HHPMcQwGfVZWVjjmmKNBFLR7h9h6xw10em1Cv8ajTn0MR20+Dk/XSBInUm5L953NZt2x7fOMlZUOowoHKTRKa7TyCMPAuTQLg7FlxXoCT3sopVFCkCQDhnGPPB8glcDzFWFQx1rBoD+g02kTx0Oskhw8tJ9983tYWDxAs9Vgy5FH4QfuTjGOU7QM0CqgEU2ztLTEoYV55rN76KdtOsMldDzBTGOGx597LjLskuUdrvvhj9m7s8OBvV3CpqU+pZje4NNbzshTiykEzamAoKbBLykLg8kNyjSwhaBIIUkHGFuAb1BSghUknZJBO2fYKwgij7kNLY47aY5jj92IELBn70GMSRDC0GzVWOlndIcZazdGTj6iEOhimkY4zZGbTsAUI1ezLo1mnVazyREbTkOKGqb00Tp08bW23H7v9RxY2MO+A/vxRAMtGkjp3DKjMGTD2iNpRJNM1GfwvQhP+0RRVFUkgBCujCovMqIoBCFI85y9+/bT7rbpD5fxfIPUBYeWDhInA5Kkz6Y1RzEzOceWjSchRURZwqH5JdasnWZqqkm7vcTi0gLzBw9w4kknI4XP8nJMszlRsXUkeTHAmIRWqwFCYUrJwqEVLIIoCukPhpRlSa3mEQ9jsjThWc/5hf/ZSfpT2iMx9CMx9CMx9E9vDyWGfsiMJ1MhruYwLaeyEkkb0Qnvo+HESKTMUfbGzKGKZXQfpLV6V1GkFMWQohyOLWPT1CH8prSVNWRVTlbZh2rPIYF+kDr2U5JT5G5DoQps4r7TcNIeBIiKnmecq1oFojjZfoGyo6BMjumPFuMySNojqvl4eUlRlGjtgYU8ywj8ENEQzK2bpTQpXujsGP3AI4wCJmea1Gs1avVapTXl0P+RWPao3ExY4UrsUudQMlokPF9jI4PxodZQRA2JHwoKY5DGIJTBZG5hSVPjnAVQaH/kkidJU58088nyFGsbDte2FkuJtQVQIiUoT+EHvruSQjjgSQp0VV4nBAjlKJ1CSLcQKFUBWe5qClO4cWMLCjPydLCjbsYKwShbZq1b4ARV/XE1KPIypygzijKvUOaRyPkIla8E2ExJaXKUDgh0gJSzGONE/LIscRk2f9V++/7aTaOMy4O3EVA1AqjuC1KNPu/ntVXbUQUOu4yq02lLHXuxLMblssB48zRlOe4QrbWb21ojcI6GpS3HS8EDMzSiWtirLEVVruOyhq5m3W2s1aYpcHO5Eq90qP8oS1RtpkXhgGljx5kaIQV5WVAUBVmaoKVAC0ktqBEFdSKvwUB0naBqWhLWaiAsSRZjTYEwjv1hLXhSM9GYQivPlQIvrzDsZQxWFvF9ENLQH67QbicM4oJAC7RqMBmtw+gWWTHEpIsVWKqdHWzpkhlTExP4vo/v+3Q6K2R5Ql4mhH6ItZJhq08WCLJEsLC7TXep5NDeAbNr1zG7TnPi6TPgZxxqp8zPZzQbPq2mj5YhnvIJPJ8oqiOEJM9K4mHGoBezstQmy0qKwtL0jmGqNse6iQadeJ4kH7LUP8R8+wDDJGMimiPwmgS6DsailI+nA7TMsNYwv7IbC+xb2s7pRz+Omt/A9yIK41g2QlbMQCvGTMj7Z2kOH2OjcXP43z9p9D7g0f+CZvzz2l772tdw+x23A67kY++eNjfctINjjl7PkUdNUJYl+w8sszDf47Frj6a9lDF/IOGo4xrMzrbw1LF0+wdo9/ZTjzbzgudfyoUXXkir1eBb37qcz3/+8/zRH/8JB/bv5x/f+w+86Y3/i5NPPgWtPD7+8Y/xn9/8BsPhEM/3aTRbSCk588wz+cAH3s873/nOcdJJSkWeZ/zn5V/k3nu3PeA8fu/3fo8gCHjb297mGC4jK2jhWDR/9Vd/RbfbBeBv/uZv2LFjB5dddhlCCKampvjzP//zCoSy9AaL2Irt8dd//df8y7/8CwCxt5unvexUNh97FHdsu5Nrr7uR5z73Yg4dWuaKK2+iFF2m1mh27ryXdXMbQAfs3HWA3vJe+iuWxz2pSZoJWtE0GzYH+L5i/15DLx0Qm4R7t8+T5ovE+QJza45iaanDPXdvZcsR6zh+y2Y2r9+MVAEIye5925hoKh57xgl85YvX0u8dxJa7aF4TEdQF5168kVYk8dDUC8MJJ52KMI/i3z72Lc4982x+6Zd+kY997GO8733vA+BHP/rRGEj63Oc+xz333IMQcNdddz8AeHnf+97PDTfcgLWGF77wBTztaU8H4Pvf//7Y9e7BhMjvPx+LouDP//zPieN4/N179+7jsssu4/rrr6fb7fK7v/s7/MLFT+V5z38pWgj27N7Pl7/yHZ7/vF9g/YY1/Porn8F1113Ff37z0/zZn72F+fkVbrzxDk477TQEHp1OjyJvMDs7w++96fUcf9yxaE/wH5/7HnNzMxx//JF88YtXMDHZ4GlPexz/+tHPcvVVP6iy26tZ/odza9QdI1F70jm/GYO1BWkWkyQpg3g1Li6Ni6m0VsTDjCRJ6HaH1GohxpQsLizhByHrGk2CICIIQiYnpwgjn06vx96DOxjEPSdwaz0o3d7se7qKjQ2D/oAsyxkMhmhPIaWk1WqOhcbl2ITHMex1pX860qLJiryawwVSK3fj7AfOrVgJgsAjTWPyLCWOh2glqNfrWCmo12vUo4hlZRHSIGVe6cYoamGzKtGTLHcOorRiw4Z1qH7CUs9nmAzIbcZKf5kbbtqKkDF5EbNnxwrLC0OG/ZQwqlHTE2ycXsuy6DrWnDA0JwJ0oFha6VMkFpMIthxxHJ5WIAoWV/aRlyk6UAR+gECydLCPMD2yZOAYEt2c7lKGPMYjjCRTs5r5Aym9Xsz8wgBd1/gNj6lWnSK2dFcykkSgQohblk5vgSTtI0RMr9egHQ5ZPKCwRlOWkpnZKeqNkMk1NUrRQ4cZYU1QZjl5PkRZDydlAvv276MWdIinEtatXU8QKjzfsUCklM4hSyqUDhFKY0pLUQgCv06rKWk2mvg+SFWC0fSHHbp6GelZSjLSbEjgOVbU3LoZarUaSmomJyfxfY9Ws0EY1CiNpFaTBKGPpxVCFnSWlul2l0FsQgofazSe7ypWilxgSoFjXGmiMML3gv/pKfozt0di6Edi6Edi6J+tPWTgqSycM5kpy4qKNmI5ORFxY+/PdHL/OJaKowArpSqwYrUzVieSpTQZZZlhbe4EqUvnVpHnTvBMyYpGjKiowRKhJFmeI5VwtPCqw8rCjLWf0thNWj90ZWQV4jJm8EglKiZVlVEdBTHCHZe1DvxRSqKVj1bWAULWnUtR5ERhAxVppqcniNMeqJwkFfi+Rxj51OshURTiB04xv2JYOi6NrQTMK0ClyMtxuZ2tnvN8D4ED02oNRRA5NwGTC6SqPkRYHBjqzl+pkrKsCtylEzPLi5Q8z5yTwmiQUmIr5zkrrKNNa4UunTaS0lXQodVhLisV/VIItNSH6XXhQCLXcwgjXPYIRjztVUpndb6ruK0Yo/DgghmHtpfueqEOc9CrOs+uuuZpQCsPrX3KMic2XcoyIxcS36uPAav7o8OHA1mjx1Yn8H0SCtV4+NlR4IdjGx21GYF3RU6RZY7SX9FNR44b9n59MwKUnb2yRmm3aY7ECI0xFagqxtpZ434eU2TlA8bSSKSyWjbH/1pGw8e93looq2vhsjiuTNUYW9GD3TtNZXCQZwlWCVAapRpo6aGEdutMUZClOVGzhdCQFmn1WSVFkSMrJwrth5SmxA8Dsiyn2x6w/94+zQkPPxAMsy5xbCmNJaxJarWAuj+J9UJSFTD0E5R0mm5IiUJiUDSjNURhSFQLUcInS2OSbEDoR1irmJ0MyQtBlsHCzj5ZAoNeThAGhHWfdZvrtId9eksxy0sZnvJoNTSeDvG0RitN6PtYK0gGhXMETROydMggSUiygvXTdaTwmGnMsJLM00s6HOjsZZgOsRaawZTLpioXiEuhkdJD4BxIe/EKeXEPveESm9cegzfp0/AmKNJ8fI0YUeztKCnxwHnzkyjBP2mO/X+ee+Mk0MP/pvVb374cgA0bNiKsotNJuOeeg5zxqCPYsLHphInjlG5vQJJldHs5C4cSNm7xqNU0a9bMcM+OXfT7AwbdBmc86mympmu0O8vcdtttXH755bzxjb/L4uIi3/vO93nFr77KrX8I7rzjDr7//SvI85xms8Xk5BTD4ZBjjz2WV7ziFfzbv/0b7XYbC7Tbbfbs2cOtW2+4T4nYqJ177rlMTk7y0Y9+FGMM69evH7OZlFK88IUvHL/2Yx/7GDt27OCb3/wmIJibW8urX/3qMTCVZQOiKGLN2g384JorMaYAZXnqS0/l1HOPoqEnuPPue7nhRzdywcWnsHP/Xr5z5Xc484yNTAYtllYWabYaCM/n4IEfsnKwoLdoWVq0KBUReA1m5iKU0uy/15UNRXVnd96LV+gn+zlq4yksFR3m9+3mtJOPYMPcLFvWbUFqRVqk3HTb3WzY0GR2ei0Htw9YavfAN8QdWH9Ekxc/5WSy5QQzFKw9dobJ5hoC3eA/v/EjTjvtJC699CW85MWXcv0NN7C0tHifvrzhhhu44YYbAFfquHHjRtrtNouLi8zOznLLLbfwta99jQMH9rNhwwbOOuscZmdnuOuuu/jwhz/8U8ebEIK5ublK4Njwla98pWKEu9btdvjkJz9NvV5jdnaW73//Cmr1KU4/4zyO3LSOdrvPD6+9jQsvPJujjtnI+eedxve++yW+993vkaW/z+Jim623bWPduqOo1+pYW7C4tMjEZMgznv4kkjSj0x5w15278D3NxETEPdv2MDXVJC8Kbr3lTq6/7lastUxOTtFotH7mOfX/d/N9je8rglCjlSS3JWVZkKYxwzimrJyRBBYpa/iej/V80jQjSVLSNEYpMKVzLJ6qTdFsNgEx3kOStEeaxyytLFCUGVJKfBU65yvjnKi0kvieYijcTWeeZQjho7QkDINKXNjpaY5iecekkGjPQwrHoittdcNqnNixsQapFBq/ShJq0nSFNBmSpjG+F+F7PqUoXRmbkuOKidLELgGrPHwvQmmJMQWDZJlmbZJGo0nKDFmREugaKX16cZ/+4k6syTFlTrvdJ+7nmNKg0ERejcnGLNZI8jJDqpxa3UdIwfJiiiwklB7TjfUEkQSdkNs2WaEIo4BGvYkSHhQe6dAy6OZkSUyRGbLEfYevJWEkSbOMdntAtw/TG+uEM5rI90kSg01zsr5B5AXddszSyhLDtI2SOX0vxdcpZZpgjCtRS7J1TE7XkVGL3AwRqiQIfQo0pZUI4RgeWVaQ9JcZejFaKiYnW9RMCHLkZCcoTeV6hrvHMdY4DaZKnkJrge8LpLTEwxgpnbaYUM49MM1id7OvPSaaTXfTLxRB6CpBavWIeJhjDARh4O7NlJOrSLOEwWBAmmSOPYbA8zSlgSQ25JkBnGaPM3x6+O/Dh7dHYuhHYuhHYujRfw997j5k4CmNB47ZVBZYW9Wbjil4DkIxTtXrsMSTW2ScntOqgDiVfs6q7o7F1YZmICyKgDKTJMOCdqdNmiYOVDJiDHCEtRDPc2Vs01MtGo0aQeDT6wwY9GPaS33KvKTIS5Khu2iuBlviRwIZULF7LF4g0Fo71zYctXYEySAcoFUUBVqVBIGzwhVCgdVOuLoSg/M8n/Ub1uNFkqleg/mF/WOFeqEtSEfBLEo3sY1xLnJug3C1vFLI8aJkrSUIfEQoiSJZLUSWILRI7fSWMmOwwmKFQWlZbSIK5ZdIXVbOc7JiWWXOlWDQYaLRHAsNCmswFKS5m0xpmmJL53inIo0fOBFMpdVhIMwYineTqGKySTGq29aAoBQCg7OMVFKhPA/paaRy48Kh+2ZM7RcIDI7KXVZAmJSq+myJlj5qlIUbjSVTYkyBoQRpUdJz3yUUeZlhTU5RpOOa9jHYaVdLEEbldXD/ibhadjd67YOhwT+POk8jBmOepZRFTh4PKSv9BMNhFq+s9smo1lwAvhegtetraw3FYXbosFqucXiJDKNNUqzOMVG9dvSYrTbDMh9l7w/TIgPn9lhdD5eZLclSt9lbCpQUThi1KEmTAUWeQhlT4mGsZbnTY3FlgYXlvRxc2onv1SgzwcTEJFFYQ034LK0cIk6HKOsC79JCmaZIKZmdmWWPWiZLYw4e6FLagFpT0e9btPZYvynkiRefwOREk0Ytot83yMzgm2nifkaaFgzjBOXX8IKQZc8gxQBr2rSaEb6eIGi20FUgMrf+SEpbkKQpy4cO0awHzG6ss3b9BFLn3Lsv47at+9i9a4UikSgbMNkMqW9oobVz8dm1c55ut8+effNkJsXYEqEsyndg/GJ8F718J7uWf0gv6SKkptWYZXZ6LVHQQMkIg3OttNbNbUcvFygZMDuxkX6yyDDrsNQ5yNrJTbQaMyRZTF7m5EWM8iIQTnjWVpm+wxmvDzY+f9pjP2nO/b/aSH8OsOPbb3dsJ2sttggRQvDay55EVPMQgOdpzjxrCyeetI4vfeNqjjlyI+dddBzf+s63wGqO3Hg8m7ecxEp7iXe88x950Quey4knHseznv08nvWsS7jxxhtptzNOPfUcbrrpZqKw7rZzCW9961t41ateyaMf/Wg2rN/ImWedzb9/6t951KMexaUvvnR8jALBW97yFv7lX/6FXq//oOfx8pe/nLPPPptbb711rPP40/R5Tj/9dC6//HKklBw4cICLLrqIpaWl8fNPf/rT+dCHPsQnP/9O9i/eSbg+Zn5byM7rBAfrNxFOFJz3jFO4/u7ryIqS8591Gj+4/Cbqu0Je8WsnsO3Q7ezft58yTnjKk57C+RdexPs/8GEGdoFww36a4llsnt3ARSc3WV46kyS1zEyfzp6DP2Lf/E2ceOT5HL3xEBs3eGR2ibvu3cMH3v050jyn2Qp59WsvwZYlO/csctwTfc5trOPELXN86B/uoOE1eMIx53PNwbsYDBSXXfbX/O07/54PffifePc//2/WrtnMbbffwAc/+CGuv/5Gnvf8Z4972tcBpSkqa2p4wQtewLve9S6e/exnMzk5yZe+9CX+7u/+lle/+lU8/vGP54Mf/Ajf+c5VfOELn3lI463VanHFFVcwMdGg3Vnkec99MXfccdf4+VqtweMedzEvf/kv8sxnPgVjDf/6rx/jaU8+l29963ucfe5JfPRf/4xdO5a55ca9HHPMHL/9ht/hjb/zW0RRnbm18Jhzn8ia6VkmpyLWnrmeX/7ll7F79x6+8+1vcfk3b+Tmm+7hN9/wAjrtjGuu3slvvu4lWEq23b2X173hVTz9mRfxzGdezO///pt59atf/ZDO63+yFUWJ58lKXwiSJGdhYZm9u/czGDo2U7/fpygKTjn5OArhWAidTg9rS5qNiCJ3SdiTTjyRNMtI0oTde/YxPT3J3NxaltoHWFo6xGAwZKo1Rz1qsnZyM83GBGVpSNPYrZGypNmKnHtdXpLErmogDAOCMMTzfLTyKEqXCM3yFBCo0uKHodNLVZJut00SD1haWcbTGj8IqEURcZrSm28Txx1MmSOEpTQSkZf000UWlvZycH4Pe3cdIGwojOxz0gln0WjWkDJkuXeAYbyCCpcZ5j2GS0to1aQVTHHk2uO5bfHH9JaXmd+5H1MYBNBoaeotzZp1ATNTIVOTHp4QbFw3hRUFSTqk200YDnKKQchktIbJ2Tk8WmSDIf2kT7+bgjQ0o4jNc0cyOTHFxrU9ttV3E+g97D9wkKmpiNl1dWr1CErL/K6M3fcMmZ8fYENJOOMxUYb0ljNIwVeSdrrMcnuR7Tu3YXUCooBCYXKJLSQCj1rUZGJymtqkIbMBvVwyjFOslaydOYaJDbM0apN0+intlTaH5ucZDNvkKnNu1XsF7e4yWzZvodVqUavVKUxZORTiNHBxAEQUBg6EMgVU3llrZzYRhhFKWbrDBeJkyLI4iLWCmoWwVkdLzznVKedilyYl+/cvoJRmzdpZDJn7HgPr129mw4aNlIVFKw/PCyhKy2CQs7I85OD8IYoiYW0/IgpqeDr8H5ydP3t7JIZ+JIZ+JIb+KQfwE9rPUGqXVxpOBbaq7x6JjI8m1Vhp/jDhcKWcDeIDjqpCXq2F0uRORDzPHbOqFGR5SpLGxMmQNE0pigJTiOqzNWVp8QMnwCW1xNOKVquGFM5iNE8KkjgjTayjluaGPDaUmcBqhfKFIzZJyKlqXqUDW0bIWVk6FldRuPcXqsTzCgfmYJA4S8fS5NXi7VXudTWyIsMYSZ4XGFOQ+AlYgZYeAlUBTGbEiKyAD/d9o4VGa1U5n+gq8+SySlobrCgYVQyP0E+tFVpJ6g0N2oIyKM+iPIn2FBZDluf0+n26tT7WOOcRIwyWyqGwYrAJW1EtK6EzpR3whHXicaJibbm+klgk1lYuCyNCk1RIY5DCaUmpqpZ49Wf0utF3ifGCaa1FSCfZbrHVe2VlO+nExVddHawDnowT2RyJjkulUdVYLcrELdhiREPFscRGc+YwYAlWJ+Rqid1PR4t/LlhP43Mx2NJtmEWekudpZaPqGIzGmlXgFcYZmMPLE7XW7ppIKr0HJ5g4ztCMMjH33zTHnzrK/xxGBbVuqx4T0Eavs/a+r2MV7bdVltXYHGsddbm0bjNN04QiSyiLHAwUZUpphqTpAdrt/fR6beYPLOPpASb2mJmZwIopmtPTBH5EnmfkcR/QDqQNPGfjakqEyFA6pd6y5EXBoG+oNTymZurMrGnRnKijPE2cpFXJaOFYmIVzHwNIkyHDOCGvqNlpMmSyVScMfZqTdaZnWkRBSC2qkRcJtixYt3GSRq3OxKxzsEmTlKXFPoNORjowKGndHI9TltoDyiIn7vdor/RIs4Q476EDiacl0pM0/Ab1oMFkfU1VNw9K1R3zUShKU5CXKZYq0yIEYBC4bI3WLoOKyKtyWw9jS/rDDovtgwySHkIoPOWt7hWHWfSOr/JPmEc/jfL7X829hzwnrfi5mL/vec97OPfcc7n44ov58W0L+L7imGOmKQrn5OoHkquvuoG77ryXU888hYMHDvCBa67lzLNOYqI1Sb0WcvPNW+n2O1z8CxdgioJ77ryHF73wBZx19pk06g0+85lPMj09xXOf8/Txji0F6Cii2WwihGBpeYk77vgxu3bfy/Zt29mxfQc7d+5kcnISgIsuuohGo4kxJddeey1XXHEFACeeeOLYeWzjxo1MTEwghKDf7/N3f/d3nH322TzhCU/ggx/8ICsrKwDs3r2bPM9573vfixCCbrfL0tISaZqiteblv/pyzjnnHJYXlzh2yzmE4RTfv+FrbJibZOPcFL2lafzmAL/ZY8+BZXSg2XTkDEceuwGLZV++gKwJWlNNDnZTpPKI6rB/zyK0+qw5I+Saq27ntmgXJ59fZ/6ulLgt2XxMyr3bb2fHvTvYsfFbDIY99h/cRpJ2SZKMUqQuIYSlsDG7dy+yY+c8fqQZtg037D1E0BTUpgV7dh5EmAxblvzTe9/PD675IYNhTL+3j3okyT24Z5vCWPj93/99jLGsrLT5l49+lAvPv4DHPPYxAJxzzjm0Wi3iOGb//v385V/+JQBLS0uUZcnk1BRr1q7lve99DwBvfvOb+ehHP8r8/PyDjjchBM1mk+npaaJayGWXvYZrrrmWT33qU4Bznd24eR1r1szQarWw1vDoc8/lta99DV/5yhe5444f88IXvZi1cy1nAFNmhLUQpQVf+fJ3aTYnOf74I+gN2+QrPayc4OKLn8yg32M4yNmwfg1SKNI059ChIdu3dbl72+2snWvyuMedwT23L3LX1nmsdc6FRZ7zB3/4h//t8+6/s/mVS5IxhqwsKXInwN5oRCjt1qEoDDDGq0rDHBsi8D3K0mlYSVlpbErJcDCg2+sRRQGeVpQmp91ZptPtkmcWJQICr0GjMUEY1vH9EKkUpiwA62JeIVDSAyylcfqn1kDhlYShqIAKF+8VZYlN0oops1qC584pJ82cyL41hjgZsrS4QGkypBDUahGLy8vEyZBcrNAbLmNJyPKUog8Lh2Dd3BJSKiYnfDyt8byANDWYIseWCVEwgZQhVk6glMYYyPMCSouSgnrDZ2omZHI6oBb4BDWnR+NHgTMVKjVJ39LvFJSZwG+GNBpNOp0Ow7jNSm+eJI9RHgQ6wxSSwAtZu6ZGt53Q6QxJij6TUzUmZyKkFCRxweJ8RmepoN8tCZUgHRYMOhnzvS4UgjIxxHlGRkmhDUq7eH16ZgYtPBQaTwc06pNMTa0jbEqMKFhpd0kTg5YB4bqIwPdQniDNBlhR0GhEhJ4rn0vzlG6vS2FKmq0GaZ4QDmoUhUQIjRTeWA5DSBDWiXBQVYCAE1nXWuN5PnlRYMoUk1vq4SSBHzEcDClyi59ZaqEiz0qytCQMwrFDeRWiYQx4voeS0FlZwfdLanWFUhrfU9TqHmvXtsgLH2yMMTnGPMwTuI/E0I/E0I/E0A/ywp8thv6ZNJ5GdEJjy/FBjWpXV09ulZKrlKqELF1p2urQX72xd0LUBWk+dM54eYktrRMjS4ck6ZC0cq0rc1uBNgVFURLkPgBRPcDzNGHDRytFEHjEA+eKUxQFRebcLbLEYDIJvkbZVSoh5Iykt2S1eGKFA9lKQ24MeV6iZIHnZ0hbIqXC4oQWCysrNz+D5/kEQY0gzSlzSRqXZHmK7yVgQSvt3OykRFqJGGkmyVVmzUhkTnseQeCjtMbzNJYCaw0CVzNcOIqWY4tZi6clQaBptDyMdGwhq6iYUAorLFmeUeY92n4PjKBRDzG6xOJEwB390yKsQOIovVJ5SC2RWmJNDtY5n7jyREfftVY6e10cE0kKnD6ANBjrgi0HHlX7HIdX3MkxG87a0SJYMZ3cYEFXwJPEUUlX2VGjiTWyIi2x0lQglcJKXdE9E6TQWKkPW8TFfcbuaFKv0n0ffBO8f93s/+162P+uZuzqsZoipyxysjQmz9MxcIe1HF477MDkSkjUWLT2UUrh+T4j152xrkh1QYV0fe8eEpUzx2oWhvFsY4z4Wzt6zIydJhEjRuRIw2OVobZ6fHactbMVKFqWhjxPSdMhRe4EVIVRpNmQNO+z3NnNcr/NoN9m4cAKUmqKGGZnmwhpmZpdTxjUKMqMuN/GuVsIAk9TWEmWFCASlBfTmoZeuyDLBGs3Ndi0pcnmo6aJahFFBsM4pTQZuckpyrxihYKSguFwQG8Y0x0kpGnGoN+lVa/TaNRYV8zSmmihdUDgB1hTooVkw+YZoihiYraGtZJ4ULB4qMewV1Cm4NfdHO8OhqhFxXDQY3n+EIPBACENjSmoRXX8yFG7p8NppoM5phobEEJQUlIiSE1CO10kL3NsZvE9l9125gEeSgRI5eP50vV3kaG0wtMBxha0+wtOZw+IggaRXyMrTWUHO6KeH5aOuA8lePzbfebWT6tXfyjz78FfI+7z3Q/n9od/+Ie87nWv4/GPfzw7dy3SaoUcf8IMcez0WIJQ8r3vXMs3vn4lX/7aU9h60y38w7s+zJe+/BG2bNlMMsy5/gs3MkyGvPn3fpsrv3sld96+jdf9xmvxfE1/MOCb3/gaRx11JM973jPIM1cqMFoPkyTBWsvy8hK9Xnd8XF/9ylcBmJubA+CSSy7hqU99KmVZ8Hd/93dj4OnUU0/lbW972wPOq9vt8md/9me8+tWv5vTTT+Md73gHO3bsGD8vhLjP+6SUhIFjZbzhDW+gUW9wz113c8SW0xFmltuv+TzH/2LIyaetYdctJ+NPLOBN7uWenftphDXm1rc47qTN9NIh+/JDNBoeU+Uk+3cl5MaQZm0OHDhEQxnqU9N87SM3kWUpu5oB+6+VxAd9jj/nANtu28v2rXuZmt5HGpd0lmLy1FBrao45YwI/CKk3ItJywL279vGja7dx3kUbOTQ/5PrvH2DLGQ3q05a7795B5EtMmfDO//O35HlJGPoc2HsX2ITpWcHWO/ezZmYTb33rW7BWcu/2e/nMpz/Fk578JH7rt35r3DdxPMQYw7333ssf3g+EmVs3x5HHHMm7//EfecHzn8873/lOLr/8cg4dOvSAuaG1JooiB3xon2bD5w1v+C1OOeVUvvSlLzngz1Os37iGsBZUrPCcs846i3POOYfzznsCM7NzPOs5z2d6tg7WsrTSoSg1SVrwhc9/m8c94UwueOIZ/OD6XU68eVjwghe+mEbNZ+/uFbZsWc/xJxzBvn0HObC/y+5dA759xVc5/VGbueSS87nn9tu46Ye7sNbyla98ha985Ss/B8CTRgqc03CWkmYpQlgmJhtEWUC303f6OAKKvHBxtFSEQUCeQzxM8T23B1tr6A/6tNsrbNq0iSD0KMuMlc4y3W6HIrVIG+CpGrVaizCq4wchSlZJTuPEy6WUaN9pBuVZwaAfU+QlUuUI4RgDUlashbIkMzlKeRir8b0qvvQEiJI8L0gKQ1EUDAZ9FpcW0No5UwVRg0OLCywuH0SHPYoyxVb24WVesnAoY3FxHqUlk5OTBL6PtXU6K4KiKMGk+J5CSI32nd4UuJhgJFfRmghZM1dnbn0dSufKnGRd6uUESmjIFGnfMuiWFMYJIEdRyIEDe2l3llhcOYjSJX6g8aSbz1Jopqdm6MwO6HR6xMUKE5MhU7N1UJCmBYsHU7orBcNeideQpIOC/kpCOuggjZOPMF6BURZRMygZEAYhGzbN0YgiIj+gFtRpNGaYmtzI0uAQnV6bzmKPIlGEnsLXvrt2ZPSHy1gjaDQjwslpkiTjwIGD9AY9siKlsRLQG0R4OkTKBr4XEgZ1Gg2JxumaWlExJlzpAFY4LV6tPcemLCxpmhCbAWumNlCWTfr9Ab5n8bRFibBy3S6c7pNSuPjfwScOZNFIBd3egCgs8Xwfz/fxA2g2PSYmpimKlAMH9joG2MMcd3okhn4khn4khr5/+9lj6IcMPBVl5r5CWDCrLJsRy8laW7GcVFXS5NDaVaTXlXzdxzkMS1nEFEVClidIsyqqJoRD36OwiRQZWVGQq8LZGRrIi5LSJKRZRi0JCUOf1kSdMPAJfY8yLwgCD6UEvd5g7AyAkUjrEcqQHI0gw5qMIi8cwl8BK9ZYiqzElBYMCJNjS4X2CrR2DhDYDIFGiYI4DrEYtOdhS4WwAcOuoNstGA6H2MKSNVPAOHql0ni+j/YUQiq3+BiXLQIX+PmeR+AHTtdKjRhGpgKHhMtUacfwCgKIQk0YaqKGokBikAjtVdfDY9DPSZOUpD+kGPgMpzMmJ+voqEBoi68VhBIPj7Q3JC8MRWEwpRmLio/AOikPqxk3lWNc9TfWYqUrwUMoV7dfgZGjASor61QpVcUyqxZz7Lh8T4+AJ0Adhv6PkXqH2DnhROUjhVqdGMLZtboaaIs1GabMKKTCOwy4WtWX4j7EPGtHbKfDGFhC3Gfi/tfCbQ+vVhTF2N61SFwWoyzSsYC+5X6bUeVSOQpOw9BHaze3nRuRA6Ndzbis5nc1x6UYrwGHM9yssQ/oU6gyNKM90hpWIxA7/n/EqjSmAriFrKxcy0qTosSWhixLyPOUPBtS5DnDZMDeg7vpJ/tIyxX8aEiJRxB6HHvsWnr9AcvtvXz3uwtMTc5y0UWGzUduYtPaI4iTAdaUSCAIFaqEvFAIOcSKAVaA9p3uxYlnTjM51SJsREjqCFmCyilyS1EaEIZ6IwAj6fYSJAm2MOggozVb47jj1lPmBVmWsmfvHoJQYY1lzfQairxEyIIjtmzE05rQjygKSZpCkRv8wNJoQdQAKxJ6vRWEjcmzmKLoMzkrCEOfickaQgdI6aNpMOltZjbczJrmBmphg3qtxdAMaCdLJAtbybOYNE/pJwm+F+B7Pp5nsLIAkRIFsxgDZmDIyz7DtMMd+68hSWJMUfKY457BxtljmZvcRFb0Kr2DVfted71X58/hcae1cP+Z9eBT7fANd3WDvf9m+6DtsEzgz0P7+Mc/zre+9W0++cnPctxxm8lzQ1RTWAvDgeHVr/lFXvSSp/PpT32V9evX8vnPf5gbb7iJW268lQ3rNvG85z6Lssz45Mf/BVBMTjeRSvKxj3+Cd73rXbz//e/j6KOPZdAveO1vvJrrr/8RzeYMw2GX4bBHr9fj137t13jzm9/8gGMLggApJX/0R3/EZz7zGay1tNvt//KcRtfpgx/8IJ/73OfYs2fvfZ4/7bTT+MxnPjNOGFhr2L9vLwf27abfX6LfW0Ipw/49t+F7IR/4p4/yqS9+gI/88/e59Pl1brrtLq75wi1MnJixf3fBj75zC7XNNdZt2MBTj3k23/jqN9i1czvPeNFJ3H7jrXzmk9/g0S/dwIHtXT70+ls56gKPmoDv/l2Hxz9vPevPa3DbrbtZf7THiccezVc/s4PhsEBqweRxbs7edvUiz3j+ozn1jCPwTJ3jT5hmav1mzjvtPK77wQ6+9+XdkDcRNmdo97B7e0mo5rj22h9SFDkrK0v87ptey8ymHTzh6ds5/eSnUSaH+PO/+l+ccdoT2Lj+SK659lo++tGPcvrpp9+nL/ft23e/HhZoHXL9j67j3u338JUvf5nrrruOM888k1ZzkuOOO5G7777jPu/43d/9XS677DJmZ2fv8/jjH/94br31Vl7zmtdwy623EniKq6+8kiu+8z0+/ZlP8fznP5+3vvUtfPazn2PH3kP8/Uf+gy2TR7BxdpYLLz6aG354F9vv3sdb/+w3SRLLj364gw1zm0nTkt27OsQbC9rLbf7orX/PC57/DC48/3F0+wVHHTvNGWdt4ddefTz33H0Xl7369fz6K3+dE884n49/QXAYWflh3TrtHnlRkKYp7ZUFknhIv99j0+aNNBohRZ5VGiswNd0aJ0J7Sx2EEMzMzjnWCpBlKZs2bmTDhvUorcnymGHcc/tfpb9aloIiF8RJRhDkeFq7ZKKUBF5VamUNxuRoT1RSBDWyrKAoDb1+34n2Bj5B4GOtpSxK8jyhKKE07kaq3qixbt1aOp0u7ZU2u3dtpzQWXwdIrUmznB/feSvLg130s0VIEpdEtJKpOUU8NAz6KffcvYOlxTYSyYa5o5hpbuDArjYKi9YCpSEvY7rDZYxOkFGJF0lqQUCzFnDEEbPMrWuxZk2DXt+Z85TGMn+wjzCSejjB2rVraE3k/PiuHdy7805279qBETFhXXH0SVMYA2mSszC/wl333EV/0OaEE06mMDnNyTpryjXU6h5B4Fwn4zQmzROkbwnqEqUg6WUspSXEqduvI5/WWg8/FMjIusoLYckyg9doMtWaZXZqBiEURT7E9wJqtSYTUzP0Om0MfZZ6O1nsW3JTcmhpmVrYYnZyPcIPCLXP3IY5kmRAlifcveN26tEU9WiKDeuORQYK33dJ2JwSYawTgNfgK0cOcDGVoFmfIPBD8tzSHSyx1NlDkvcYpj6T9RCtcpR048paB9KVZcWYUpAX7ubYiqISm/fYvGkjWkv8QFGr+cRxytIhx9QLg4Bjjznup+/TD5P2SAz9SAz9SAz9YB/4s83dhww8Wbu6s49ZTmYVdXU6TqqaKPKw960euKiQXHHYc0WZUVbMImsrnSMpCfzIZQCiCZRM0HlGLNKqJtVZkRpjsUVBkqRYY5x1a+SjtSKKAvKsIM9z8iKnLAps6dB9KQRaeY4lU1qE1U4gvRSUynWkLS1F4Z63JeRZiVIFRVHZXlJlWgRgM7IiQWSKoHJR09LD16ETJjQjSmpOlqVViaF1pWsjKmZFbSzKYtxPzunACfU58bjqtaUrbYMR0GfR2qKUWHWVk1VZolZI4Sh+RWHI0pJ4mDPQMbUwJM9zdOjo1p7nVSPVoj1JaSwmLyomUcVmGpXISSeCOGKHWcQIhD1s8XVI1eHjwRVYVqwlJALHZLLWgnCA2mi8jMTWBYcjteMpVwVQGiE1SvkOYBOHj0GnCYZ1xXXuemdYFTAut7vPJByV7TnW3uGL+v3H8/hgDgOjHu6tyDOXpclHwodOvB3M/TI0tnKpdH8rVTluKD1ejOxhAKGsxiujDXPcJ/cF6cSI7oZwYKAdJXhGC9wDFz/Gx3VfVqW1DqAeseOEEAjrQElTlpiiwJQlaZoxjIcsDeaJi0MUpo1HiiACUSOoQ4EkygWdZEint8Rdd95NEEVo7dNoTNDrLdPtt5E4jY7ewLnmZKmhLGByKqI5UaPZquH7Idb6481AwNgSVwiBKQ1lbmgvxMRpjjDgey4TFHgBVkuENCgt6PV7LC55DOMB1kIYBBgca1Jrv2I9ukmnNHgBhDWBlCVFlpIlFkROWBOENYkfuGymqTIUWnkEOiLyG9U1rtiYdghUgpnClSQbU1CUbi5q5WOFwdgMY3NAoXWANAllWTBIumR5irASTwdIoV2JRjVuxiuZtffZNA/DfcfX/L5ZHHvf535Ksw/yvp/yan7WjfN/qq1du5azzjqT2ZkJyrJgx86DbDliDWWZ8+3Lr+Skk49l3fo1bNiwlnqtRpbkTE9PobVHs9Wg3W6T5wnTM2upRTWiWo0D+w8Q+D5nnXkmGzduZDgc8s1vXM7NN9/Etm3bqNUOkaZDlBI8+9nP5sILL+SYY465z3FdccUV45ItYwwnn3wy3/jGN5w244O0lZUVvvWtb2GtJUkSnvnMZ7J161Zuv/12nvrUp95H8+mYY47h2GOPHSeyFhaX2WAtjXrA3gP7KfMSgUKJAUEQ0ChnWDO7nmF6MsOszczMDOee/gTUumUO7jvAofxO1gTT+FKzb+9evLpgdvMEWZmystLl4L4Vjth4JhHL7DnmIPmgxBrLxKzGrwksJYfu7dE6LqK1JcQYw5q5Oqeds5bbtx2ku5yCFczOataslfz41r14zYTJqSaB7+EHiqApmFszxeSkTy/r4TcloUy5+eabsAbSJOaUk89mWO7n5h/t4azNLYKwThLfhVbOYcf3QzZvPoJTTz2da394I7Oz05x80rGsrKyQpum4/5rNBs94+rO4dest7Nq1g1tuuYWtt93Gvffey6+/8tXESfwA4GlmZoaNGzfyta99jTiOkVLypCc9icnJSY455hie+tSnctRRR3LqKadw4w03cvNNt3DPPfewuLgAwKZNmxBeje37VphrtGg2ArrtIZ6nmZppkWduHkeR09Y0pUF5JUI4h6eN6zfRbDSQ2jI5Vaff7bNr+zxnPfoE4uEG1s5sZHbNJI1GyIte9CLSNOd+hn4Py2YqIe/hcMig36cocrTnBIWzPGOY9Am8AO35WFtUjDOPKIpwAKLv2BHWorTG1wFCCOJk4Ep9ipwoCjGmhZIezcYEYVhzmpdKVsyl1b1WCMdsNwJntoPAD1zcVJpRFcAoPnMxmdSCrHAM/6IonYuaDmi1JrDWGREdUodWpRsKKIqcNEsobIYROXkeO1a9VUR1l0BMU8FgMEQgmT+4QKM2g5I+9XDCaY8mCQcOLJDmQ7rDFQa9mDJzwMfkVI2pyTqtiQZBEGLxCQOfNK90d0wBBrIiIc0Ewzhn2I8xxRCsJGqCCn0K45yy8rJwrnntNlIJWhNTLjFtCxqNGlHNJwgjKAssBqEsYVNgA4Vfc/c4ZWYJfFeFUKsH+J5GSlu5glsKSobDlKJpwXp4OmLkjOaCIwcOWWEo8ozFpQWsMhhhyGyCMopB2kFJHyV8gsgjKyyUroLB3QeF1GsRYeCjlMBWBkWjuEsKXPq1IhAYl21FSU09msQYwzBpk6Qp2A6hnsA3FqsNnlbkRUmWZwjpwFAHdjrQ0sUMmqKURLUAIYyTwRAGpSCK/PGY9P2RoP3DG0F+JIZ+JIZ+JIZ+0Ffzs8TQPwPwZMf/27LKkpQOhBFSOMc3rQ7TdLpvk5XA9UiJ31qDMIYsj52gWmWKJ4TE0z6t2hS60lvqJX0nUqb75EVOVuTkWUZZVO5vw4IsdWwibJ2oFlCv+w5lVu6Cp0lGHKdOEFFIAu1DJYCnhKM8GmMxI8aOrdg+hds4U+kEsmv1yAlDIp2YdcXSidMepSnRyicIWgS+z0RriizJSYYpRZ6Qpjlx4oQdfWvwfW88JsqiJM9ysjQDIVCVLa2u+kxKW40q4dhMpQLhxM21Bs8HoRx4U5SAFAipKoCtEorLStI4Z9jPCERMLQzIs4zIeCihiPwQLS1SGoJwSGEKTJpTFhIhLdaMROIlUnruOls3AU1JNQmqcVIB7qug0WiRdGr+SmiEqLJvQldCfG4xvU9QVP2MyuBKU1GDhUIKD6UClPLx/XrliOI7BpWoxNilRgmBLFRFhTVoXXOlgocBRoeju4cLjt+HofcgE1Ec9v6He8viQeW6kWJtUZF1D0cLGS9sRVFU404RBKErexRiXL8uwDHNRiLv4w2Rsb6btVS0UJymAKt9udqvh60r1pXujliSozbKHI3/rn6c86Vz1HHlly5z5DJSBWVm6A+GrPTbHOrvwuhlrOyTdxM8r0bgp3iRT90X6KiOsR16nQ5XXHk1WkUI47Pp1HV0+ovsPbCDFdkiSwu63R6L80N6HUuWwoknT7N5yzTNeoQloshClFdW64PTArAlYCXJMGXYy9h+xxJh3dKYENQDj0ArTCYJaj5Kw0TRYLmzQrffZcsR65ianKLZaDIcOh06X0cU1lJY48oxfIFXQn1CkiWGLE5JRUHUgNasRijhNDHwKEyOwLpSXi8iCuuUuEA7MwnDtMsw7ZIWSQVea2yROv2CoiTQLQQWITLSoosSIUHQIi8zyrKkn7UJ/BqNcIqZiQ2EfoNhMsQw2jgfpD3I4z+x/nwU3P0XG+fP1n4+wKdnPOMZ/P3f/z0A2+89wNe/+SNe8LwnEA/bvOn3fo/f/d3f5MUvfj7Pfs6TuP6Ht/Ktb3yfl1/2YqamJylywwc//CH6/T6v/43fJAg9iiLla1/+CqeefBK//LJfotMd8uUvf4lX/NovM+rofn8FgJmZdXzoQx9kamr6Acf1F3/xF3z7298G4J//+Z95wxvewCmnnEKn03nQ89i2bRsvfelLMcawYcMGbr/9dt7znvfytrf9Be9617seAGyNWpYV3H7Hdqan6sytW8+3r7ySNM2ZbEwyMZUi4oxtu2/jtFMu5AnnX8zlV72Hx57xFC449zlsveuHXHfr99m/ewfHrNuMQfLVb3+esy44geM3nMhdV21l8VAfaXxOWnsGJx65wNqjFvnIH+8gHuQ88Zcn8SLDwr4hO65cYc26GHVUhPTgjHPW80d/ewGvfPYX2bd3yMzaiM1HwuzaAW//k6s563GbedyFRxIPhxidMbnF55TTjiaoK67fdjNnnNDAK7q8/BW/gici1szM8vkvfJLvfO8K/tf//kNe9qRNzG5cz/q1Cxy5+Xjm1qzn+1dfwXnnPZEXv/gX+cVffj3nnXcOf/j7v8FjHvOYsdMdwLp16/jIRz/IW9/6Vv7mb/6G17zmNYBzELzsNa9iZWWFj3/8Xx/Q1/1+n8suu4yDBw+ilOK6667jjDPOAOBNb3rT+HU/uPoHfP0bXwPuO1c3zk3z8hdcDLgSsR/fvJO5DdMcc8Imvv6l69h4xDRnnH0k99y9RJolNGdytG9oNiZ5xS+9jKk1HkEoOP64tXzr69v493/5Csee8Fts3ryFX7r01WxYN0lzMuATn/gEg0FJkj78kScpLEWREQ96DIdDfF+zds0spSkZ9gYsLMyzds0aanWfJB0QyRphFDA7O0NZWJIkZ9AdYo1lZnaCIPAQElbai6RpTFFmzExPMTM9DfhoMYGnQmpRSBj4+L6mKNKxRojWlfmPVhRFgVXgVfo7UiiKwumv5IVzjBZS4nmK0ji9pzzPiaIWYRA5kMuvEfoRSwsLdLtd+v0+VkjysqhALIEC+nGMLYBSMrXGQ/mKLFOsLKQkgxIldhGGdcAwM72eQ/OLLC532bnvduJ0QFrGLC13KPKCehSwYdMM6+YmmVkziUARx5LJiWkY9lnp9BFejjUlw7RkYT6nvZyyvNB17m3CIMIQYh+7VLpzM4ZSZxxaXqTT61EUhnozolaPmJhqUq9HNBp1kn4XIS06gNZaTYQHQD4Ak0im1oQ06jUmGk2K0pCVOcN+SmFcDNUuekzXU/IJEMLD+Yxlle5thrHO6TtJYnbs3ImOBDqSRBMRibEsdAssmprfpBFNwrAEWVCvh8zMTDE3s441M9MIISmtJc9TLBYlpGM8CTuWCTGlk6iwuPi9WZ9ESk2SJSytHKBddtG2Ri1qEIV1tFYkaUa/P6DZaiHQ5IUlqe7NnMMhWAzTEy3K0pJnzrlPa5iZnWAwTF3yH0meZ6TpgycqHi7tkRj6kRj6kRj6J7WHHkM/dI2nwxy9TKXspZRyZWBSoj1dPX845sZ9qIJQgQlSUJSG0jjrSVO4bARYJBJf+TSCFlpoVx+Jm5PGGvKywC8LUu2c7lJhyTNX/9kb9EEaijKn3ojQWtBshpSmQTxMENIgtXDOZ1oS6gDtKVqFwfNyPD9DKDN2KXClfQYrnPB2lkEcJwgZorRCam/c3XmZYQCVdB3go0M2bZ6j3vSZnKkxSBcRskDpclxyqJRHWRjiMqXXiYmHMUmSEgTOktT3fYfy4oQTpRwh1cYxjITE81LKEpQyYIRjbRUa7SkcgK4ocgdqJXFKlpaUhUUp8DxnqSuR2FzQHxZkRUmaF5WbHHhKIIxBlAYMKO256y6c2Kk1FleL6AChEehu7kMFdMwuVz4X4qkITzsHC6UChPCQohLWkxrLSGTPobXGWiomr6vv1wFKefh+A0+HaB04tFiqygFPjBl5btxUAvZlgbXgB3WQPuJ+w3+cDbD3p7CKB7zm/s/9l4Dww6Bl8aDql7LaMN2yI0abpbHjTVFpWbmQeIyE741ZrRUe6QGMdNxGGbOxGKJSbs0wUFqDHG+KFahnq6wOjDM87oMPz3iNmHLVGKuakmq8cfraAYx5UZBmQ/r9ZRaW9hHHQ4b9ISvdFYZ5jyDQGFWjtDBIMsrCUBQZfumhlUfkB2za5BPPJhyM2iz17+LunQO2nPI8yDVxx3LDDXeRZzlKO8dFP4g49YwZjj1uC2vWzAAW5YdI7bPSbhP3B/RW2uRJTpokLCwusbA3o98uKXJBo+kxt9FjOBiwsjhg0FskagT4kSaaCGhETbQn2XbvTjZtyFDrJIHnIaSkLHOEKlBewdp1axgkGVZCGIRoaSj9AnRCKQ1p5qyTrQHKjNIaECXd9CDdbIpWPsFMtBkpJHkZo6Um0AG+9inK0un8WEVepJgyIfFiQhHi+y1Kk2KEQeChKttuX9Q4Yvo0Ns+dzOzU0QgEaZb8TLjOT8ywjMbfQ/+o/+qbqv8f/qDT4W3+wAqB9njJiy7gq1/6Gp1Om499/ENs2rSRorRc9huv5awzzuIlL3smP7zue9TrNU499TSeeclTKAo4tLDIHT++h0PzCzzxFx7D1NQkaZLxG6+9jEajzne/+x3e9KY30el0eP/734+Ukn6/zy/+4i/xnOc8Zwxe/Czte9/7HhdddBEAvV5vHFMsLi5yySWXcNFFF/H1r3+djRs3jt/z27/926Rpyrv/4T3s3XuI5eUOszMTtLuL7NpzN8cetZ5+r8v8wQXOPPMC+kmXT335L/jK5VehZZ1jT9nErrV7uOGeb/Ke97yfIzYdxV//3sf44z/5E/Yu3cOxz6jxg6/eiOo1+bt3vpX5p2xl+94f8g9/8e/0en1K2WfjaYKy8Ljmsz0m1uTUJjye8NJ1KF1wxzdzNp7QYtf+FV7/S18l9foccbaHH1o+99nbMYlkZSFmebHPwfk2s5NzDAeQLnscfbSPEIovfloTyJSZ9ZrL3vo4OkspRaKYXT9Hrd7CWku/uIZ7dkre+55PcvyxJ3LCicfx2Ec/jsEgYefOg/zWa1/Dxk2zVQnFfVuSJFx3481c8qxn8vgnPJZXveq1PO6xj+WNb/wdjj/+eIqi4Lvf/S4Ae/bs4ZWvfCXve9/7+OIXv8jy8jLgtH1e9apXcdFFF/E3f/M39/n83/iN3+DZz3Zue9dffz1PefJTeN/738fRRx8NOG2yPXv28n/+/t1cf/3N3H33dp721CeT5QVbb72XequFQnDo4ABb7Gai1eDIY45g165t3HPPPI9+7OM5+9GnsumIdezYvkC9MeD4kzbz3e/+kO3bD7L9zgF7D/yQhZU7uPrqK37mcfn/ZxsMBiTxkCzL8H3Hfuj2evi+kwpYs2aWWi1yLsk6QlifbAhe6PZVT3u0Wg235+WVJqcwaA11FVGvR3jBHFhJWSpWlnrkeUqcWIQsSXPH9NdKoUduyhXrwvPCcczmVkPnBO2Y7l5VNlRSWIPWLjbQvqJei/A8j16/y/LyCotL8xQ2pqBPL50nyXK08tm4cRMHFnPyjiUeLiClQWvLwsESJQWNlketHmKMwhYl8wsHybKc47ZMURQpaZKyb88CSTrAiAIdKCZbTTZtnGHtXItWq4aSNXwdoXVIWVgGg4yFxQ5C9DF5Qdw17N+T0GlnFGVGY0LSbGmsLBn2YpbnEwwCocGrQy5ykixl9559bNqwlmYtINQKWRoG7QH1umB6bcBRpzaZX8zp9Q1xzxCGCh1pwpqmtIal5QFF6mzicyPwI49aLeSILTNMTAoIumS2RxjUmZ2YI1vejcicNtAoPHKi7RasRHoRoRfQ8FoUeUYnWWZxaREtDb6nWTe7nrnpdcxMrsX3fRe7lTlOFsuxjkxpKK0hS9PqHktU7to4MoGGeq3GRn0Uwki6vQ679u5m47pNzrlMSaIwQCnJMEsQpSTwQ/r9HkVRMtFqjsdYmrvyvCCMKCvN3GGcYa0b10lSuNI9o/6npuZDao/E0I/E0I/E0A/4wOr//0uMp9FNOVQAkhpNGqfXsyp8xvg19/8Zf15l42iNqRbT1e9y1MOqjEq4ulcpFVprR/eVEnD1qcaUDp0tDUWRk2UZSgn8wENK4QCm0MNaQ5p6KC0QyglIS6WRVhJFNYQqENrH4EQyner+aomYY3gVFHlOUXiUpUV5TsHeUC04tqQoU4oyQSlFsxUhZIn2QXYTyjLBCufGo7WH1qoqHbT0e0PSJHMZpDCoaJnK6V3h6M5KuIvsWELVOUgHAomKfWSNhFHJ4piC6cTY86ykLFx5oOcrPF850XEjyDPDoJeRFjlZ4V6Hte4z7OhnxHZy5XHCWEYa7a58rhoe93GLGy2ILoCR0kNJD618VPW7Uh6mApsQjk3nxtpocR8xkCRSeWgdorVP4NXxvNB9ViXYLpTE2rJC8MVh16+s3AdLisKNkdEmi3jwCXN/kOn+E7la8lfRtod5c042o4yMa2N68DhL4s5LKzc+ZSVw+GDnfrjjhrWj0tP7scTE4d172KaLc++wq714v1aNqjEdfDWTNKpxL4vc1aYXOf3+Mt3+Iu3uPMvdQ8RxzHAwoNPvUtgE1RAgFMZ4YLWzFjYFxmQEno8fedQbEX6gSZOcggGd/jxpHKPQNGqTDAY7ybKUMBTUmiHNiRobNs3SbDXx/ZAit2gZoH0fKQRlURIPhhSZY1xmaUkSF6SJq1OvNTRRTTEYlmR5yWDgdOb81EP5kqghEcKw0mkz2WqSpFM0wggrXCmAtDlSGpoTdWqNGllRVFpnJcaToEqkttXMC1DCuWjYykElMzHDvEMvW2LabsBa5cQvpcJTPoEKKcsYa4uq/w1FmZEXiQum8DA2RuAs3QUuoNHSpxZMMBGtxffqlGWOJT5sivyUufITMjQ/aRP979FXqzI1D/8pzPz8PNdddx0zUxvQWmNtQZ5nWGtZt24tgR+QpClJkoCw1BpOVDNNMnrtIXPrNyCEYse9+0iS1JlmKA8h3V500003cNJJJ3HhhRfyuMc9jna7zYUXXoiUkoMHD/LDH/6Q2dlZzjnnHE499VTC8IH21zt27ODmm2+mKArWr1/P5s2bAVheXh4LjR/esizj6quv5oILLuD8888fv3bbtm0cOnQApRTDYZ9+v89gMGA6qJGnKb1eh5mpECUbzpTESEwhmJhcy7a7djHsp5xx7ikM+n3u2vZjSmNQwkOYgOnmOgZ5B1O26bV7lEslvaWC0lq0D3du3UW3nRLVNKc8YQtCwN1X72JuXcTMRJ1oTrC0p8/K/oxTTz2d5YUOd9x8D2uPjYiamiAM2H1bl6V9A/LU0F6K2b+ry+knBNTrAWvWatpLXcpSYoXA8yKCMECVms1HzNCI1jC/uBcrhzzqrCOZmIrIUlcC5wc+pSlYWN5PmkjKXHPySccRhJrlpS4nnHAig/6AO++6E6gy22XJMUcfycknnUAQBGPxcCmdkPOFF14IOBfBRz/60Wzfvp2rr776PtfphhtuYGZmZvx3kiTcdtttbNq0afz+paUl4jjGGEOn0+Guu+7i4MF50iSlVgtd0rHIyExM4YIFVlaWsRbqtYiiMMRpilCufMVYS5ZlaE8zs2aK5aWYPC8YDlLiYcbyUoerrvwRe+d/wFL79v+v0+v/erOmHAM4VEzwkdD4aC918bREIDEGCmswaYasWOye76QhisKxFVxJXlXOo93Yw0qKXKBVTFm6GLIsS/LMmfmUSmM9z1m5q5H26khDzZVMjRJwFidPISoxb2csUyVBTUmWO8epTqfN4vIC8wv76cUrDLM2adkhzlI8L8KSV/Eu5LlBagNCUGQW39PUG4ogqIPVJANFlqZ0ul2KMkUoWwmzO00TY0uCIKTZili3fopGM6g0qARSOhZCmg0pckOSZGBSyrxgOCjdulcUBKGi0ZS0phW9XkGRGwa90jEbfIEKFYV05WlJHJPnGViDtAJbWuemVxd4vqA167EyUMiBBOM0WgPfwyIwpaXMCpR01RKeDFCBxfM1OoDCpgyTNv1hC6k0DeU0lkI/xNfOiU5phVKO3WJEARiUBE8pkrQkzw1xnBKFyiWU/RDfC/C0VwETzsGwyl0jcGVt1pQO1HB0mnGVwejWRwiNkh6N+hRlYWkvtykKd4+U5xlSafzAJy7cHlSWq0ybMQPHWNI0c6L5nqqMCErKogBktW6745L3keV4+LVHYuhHYuhHYugH/RR+lhj6ZxAXL92H21WU1vf9ChwaCV+vTpAHA51WJ5SjG2dZAqUd4xSu/tgde1pmxHnMIOm72vAyQ1WbMngEnk9RFgSeT18K0iwmjvvEaUxhMqywBJUgYlQLUFqCKNFS4XsKpQXa95BK4YU10sKQ5iVJHpOmQ7CGWMQ4xzbjgDIsWZpWm4BHEIUoJVGyYoRZS1YkxGkXawtmZzbRmPCZLloEhwripE8c9wi8Gp7nE9ZqDAcpw2HCwkLbiZkXhlajCZ7TKBp1qqf0WHcIWyCFQguLlj5KGDAKW3puoyBCC4WWgM4wcUaaFWRpgTWCwPdoTURMTNSoRSHxMGEQp+zfs0KSZ+RlQVRz11VYibLOgc+5c1SaTBUt1G1ocrz8KVEtxMaMOEsuQzMSAZchWtfwvBq+X8fXIZ72KQ8Dmcw4OMtdlsC66yalxvdDBzjpkCh0OgbOktJzmSEpyIsEQY4RbsxagauLL51Dg5A+vt8k8J1bi+C+rDxbldUdTk0dl9odNrFGxMLD8NiHdRtlSkYVwqPgsSwd+GvLEu15aM+jVquPdcesNeNs2GqN+Gpg4Vyv1Gof4RZYYMy6g1VL2VE7/LNUxVQT4+2zcttRnrMoZeQElJEkfbIsYRC3GcQdBnGXe/f9mJXuIu3eIlJK8iJzts1ZgdKCSc+nLCXGSpSOyJKMNIkpiiH1eoS/dopmc5pG3aMWzrC0PE+addl97920mtM87tzz2L1rJ8NhD60V6zauZXJqii1HHuXKV+NsXBoshaJZaxJ3BvS7A+J4iLXQbE1QrkuZmCyZ2+QTRKB9iBoeRgoKLMNeQj5IMPMDpkqfoC5JTEa7V6PTb3HE3AbKoiAZDrA6RWnDzNw03WGC8j3yNMbzPHxf4ofTju1XGgIdoLUi8D3SIiEvUwbpCocGexmWXeZaG1FyAi1rREEEAqaDWdL8IIlN8LGuRr1IGcZLKCmp16aw1ok3piatSl0ltTBCCTBF4spb75OBe+BEuX/Z6gNpwf83J9do83noNOH/yfbJT36Sz3/+C1x/3XUYo/nIhz/Fqy77RZrNiHf8zd9y5lnncPIpJ/P+f3o/O+7dzrcvv5ynPv0ZZEPJ1uv3EIUpYU3T6+Y8/rxzabUivv7V73L0MVs45bRjGTFqwfKud70LeGAZ8Sc+8Qn+4z/+g5tuuonjjz/+Acf4l3/5l4C7jq973et4+9vfDsBnP/tZLr300od0nt/+9rd56Utfype++AnOOeds9uy8i9xIghosLiySJzGNQBMnfebWbuaCC5/HJz/2T5Rlybvf/hne8+E/5qbbruSpT3ksP7r2Br70n9/jr/7i77l568386mtfwofe/QmELnnFm57D7FEt5LGSF77oV1CexI8UvU5arTmGJ53wywQNwW23/i0vftnZHH/sev75Az9k721t5nfkfPYD72UlvZMvXfnXJP2IQDfYOLeZ62dvZts9u7n2G/u4+5Yl9m0f8PIXXsqax0P9mIh/+tOrGGaSR79sPU967Mm0aPCyZ/0rv/e7f8CvXnYZf/C2X+L4E9fwua+/mXWt5xDoNTzvOb9PHBt27tnFb7/lV3nyE36Rp5x/KTOzTfbtP8TNN9/N//k//8gtN1/Pk5/yZACiMOSx555NGIZ0Oh1MafjC5z/Pl7/8Ja699lrOPPPMcb8fccQRXHHFFbz5zW/mb//2bx9wXUbitEJIdu7cyQUXXMDb3/52fvu3fxuA5z//+Tz3uc9FSsk3v/lNLrnkEj7175/j6U+7hGxgeey5j+aMM0/lHz78Yc445WSe9dQn89Y/fzfTUxP8zhtewe49C/QGMTt272du/UaOO+EEDhyYZ/euebbfvZ9nP+8C+p2cL/77jTzuopNZt2GSv37H61wp2M9B8wONTl3iNC9ylJKEnk+7vUKW5S5T7oXomk+W5ghZImRGZ7mD7/tMz0zje07DUuWSwTAhSYYIaRBKo70AayWmhLK0RFGIH3h42hvHVsM4RkqBpzWe52J4KTVZXjoWTGldSUhZkGexc6QLI+rNVsV2F3R7beJkQKe7hDGurGh+4QB79u9g9757sKIHKkfojMzmDFNNvGNAJ+4ySPskZYbIIUVQizz8SBPWAtatmSPwapRZwJ7dh+h1+sRpl3rT48hojsXOEax0l+gMF5meaTE7O8nxJ20iSRKyNKfXyYh8SejXSOIhZV6SJznDXkKZF5hCENU0Yc1neo3P5BpoThvuuW2ALSxlavAj6SC4wiADxzxR2iUYy6wkHzoQxxjBsJZS6pT6rEDuFhSJhMzDCwKC0GfYS5HC4imPLUccRa1eR0WCpcE+kqzPQnuBhXIRaRT9Tsbc7BBPeMw011IPW2Slq1AQgBKW3BtSeinG5JSlY/FXGCFKKYrCkKYFeWpJk4LETyGUSCXRagRm2irxX0lPqArYkgrf0+NYOE0LSiOwSOZmN9GqT5EkQyyWdmeFNEtptSaYnpqlWW+QFyXDpKBerwOQJk6eJC9KiqLE04rA1+S507/RyiONHRCple/YQf5DviX9H2mPxNCPxNCPxNAP+PbDvuO/udQOHBotlNuwpFSrmk3Vl6mRa91hNaeu3bdUqSxL8jyjyLIxi8pNPllJBjk02QrHShJSOc0em1cosST0QvAE9aCOpzRJOkBgKCuxtySNGVlYBmHgHPJqIUoIfE+jPCfeLZXGKkFJQWFAlcoBGdJ3on2yYuJUnWus05XKkpQ8i8AX6DEg5jJaDviwFCZFaZ9IBzSaTbd5CUMU1B1jJwzI8hLp5SAsWVaQxQXLi32imk+t4a+WwymJqMrOsiwfAz9lISgLSZk7phPK1a5Gvkb5UEiDtZIiB2vcwheGPq1mjUY9QkpFkhb0ujGdTp+0yChMiTUB2vPwtUeFJjnhwDzD4r6nukirY0My4pxipKpopVReDyPGk2MneTrED2oOeFI+hR1ZeY6sPUvKUo8XdiVd5sXzQwKvhlYBvhdV7C85RpNNaZx4Y0VRhqrG2q+RZj0Km5JkbQfm6RpCBA4eO2zBv7+u04PpN7mX3heceti3EW5WZT1WLVRdRjOoRXjaQ2ntwLTq1EaBiOW+zn6HO1eOsisj5Hm0aQpB5TZoxnTuUYZn1fHyMFbZOAtUAdBZTFEUJFmfNIvpDzp0uovEcZ92d5F+3CXJh/STFcf8EJAbQ5wWLK0MCUNBFClqLYkZQmZWgwUpwfM1UgtKkyKkwfM0gT9BGDaxBgbDIfX6JLWowdmPPpOllUPML+zH6pKsTBgOBpjC9ZW1BjIorUvfCenWS6d9p5menqLRSCmLgloknDOmzEnylOGwJO7B2jUt/BCMHqC8DJRkerJOYWMOLu7jiLUbCXyfRj2ia3r00yELSz2SYYa0ismZKUdvlxKpHWhuMEgr0Urhhz6iVOjSwwqLMRmDrMfS8CBCKurRlNN6MDAVTbASLxNngiQfkpsMg9PlS/MheZ6Q2xyLRWKRooGUGoVmpbebvOzQaswQeS08FZGX6f02RPvADZOfnoGx40F8v8cfysZq/6tN8eE9lz/84Q8Dbt416i2k1Fz60mdz4003kecZl176Ypbby2zbdjtXff87HHXUUZx11jnc9KNbCcM6J51xND+6/hqyIuXC8y9iMFih3d7PmWefwp237+GrX/433vjGN3PMMUdAxWAdtc9//kvccMNNvOMd73TJFqVYt27dgx7n4dfi61//OocOHQJgdnaWD33oQ7zjHe/gzjvvHL9mcnKSt73tbTzmMY8ZP1aLpjliwzksLin27O0jyoLMAFKxZctmDi0o5ueHHH/8aXTaC3zhP97LCSedivYDvvuDT3PbrXdx712LfPeaT7N++lR+6dJX8+mvf4wsP8SzX3QUn/nSB/DUBK+69Lf4z+9/k9u2/pgsLRCpoEhLTnnMNI26phkqbrz9CmbWtnjjZc/ghmt3853P38O9u5e54AlP4vGvv4h3vvNvObBwL7vntzO5JuK4Y47mOU86j5nJjRx7xE5u/9HHWXdExDEnzVBvRNx+p+Hz/7bMwr6CcNoDadmzrc2EKXnmc0/i7u3X8Htv3sZyOc/iNYvc9MN9RN73kCJECHjBiy5hw5EzXPjM4xm0t/Mf33wfV90ywea5Yzn55HNZ2BfTXvI545zn8YynnsNZZ56A53l85jOf5fLL/5O3vOWPueaaa/jYxz72IPPGjtf1Ubvwwgt52ctexp/+6Z9Wj7jn1q9fz/ve9z4Wlxb567/5K37zda+nXq8jpWQw7DGM++7G1pcsrczzx3/0Fl74whfwC79wEc9+8pPpDVK+8e0f8eSLz6MsSr7wpe9x7LFH4PseW2+/l6ICQm6/cyuN+gSPP+90rr7qZjztc/6Tj6fTjdmx/aDTQPk5aZ12h/5gSJKkY6ZRmmaEYY0okoR+xMTkFI1Ggx5dijJ38hKBK9fp9ftMTbbwtQZrcTblRaUDM9JPdd8lJGhfoYwcO2lBBVCUhROxHcTkfkkUCbK0IMsLhsMEISxSWMJAkxcFSbfNcnsFKRV+4NHrr9AbtNmx+w76/QFJnBCnQ4ZZm8Qsk+WDyikrRyrHxhJhB2OHWFJnHCNsxcYZ/QiUVHjKww8iGo0QKS2GmMlWnVZzilycxP6FvWzbNXRi3QpnsS4KjCyIs5hu30MYSRQF1KMa9aCGJgY0YeBhhY9UHq2pALwhpRw4wWFf0pr0ac1qdCAQvqXIHct/Zm2AERnzi8tIO0W9Uac5UWNpZZG47NAth2RDt8/62kfiQ+HhCfADRb3ps27DFPVmA+tDttiGQYZIStKkpEwFRSEQQjvXa1HiS8FkbYa2GNDNchbnD6AnMryJgjwfMCwlZazQTCFFQOhHeFrha4+8SOkMFinKlOmpdYRBRBhElNX9lqvocLGJ1trF0MK5eY8qOLIsdwZDRroEtNLMzswRD/sM4gG1eg1rjdNmigssgloYVpUPI0KBoMwNQjpHuCJPkcJp6iAsSjpH7DxPkZKqquNh3B6JoR+JoR+JoX9Ke2gx9EMGnkaAj2M76VXtJlaBB1kJjY8WnpFl4+gTYBV4MtXGx2GURcQqVrtaXufsJ7X1KMq8KiFzAuRaarTSzolDa/IiIc2G5EVGURSVoHlBYCNXXxwELvugK4cPVX0HEqVcDbwQEkklgC2dCHZJCVTsmSpTkGc5RVYgpUBrd+6jhcgdJ5RljvY8PN8jCiOsLcnLhCBwi5Pne3h+6vSYtHMOydKCXiemyAssJY1miKec68GohjjLC9dXEsrCUuZQ5MIBf2h8LyTwNMqD0g6d5nrprqFSzmUjinzC0EcgyLOCOMmI44SsLDCUpJ4CJJ70oMqQmCKnUBaBQiFASIR1+gDj9bJitGEs1krGvCAhEUJVpXW+02XyQrxKrwkjx6iusWVFOZXj4aO1K8vzvRDPi6oMiT8enxZXD+/YUlWGoRp3bryESOUE4bOyjy5DSpMjlT+GxUbj0w1FtwmMRM3vP91GrxtRY38e2ggsc2CguY+bhVQSP/Crua0oi9V5O9rEqj/vQxF2n2urx0c3LJaR1pu1o310BOYxLiVww8MiqvcfvnQaa0izhDSNSdIBvXiFOO3T7S+zsjzPYNhlpb3EIO2TFgnKc0GrVIo8LpwI6yBDeooAgfItIjUIaUFYpJJ4vkZID60lxhRVIC/w/IAobIJVxHGKKQ1aa4486ki8ULKwMk9e5CRpQhwPHQsQibQCCtznj3TNhEBXem2NRo2orjC2gNKABGMLcpOTF5Yy10xORkQNS2wHFMaCtDSaIVmWsbiyyHK7zdTEBFMTdZaHOWkeEw+HlFmJMMplVCt3R2sdJd8Kgy2rMg7l4wkHxhpjiLOCrIjpZR0a5TRKaooiQQBNv4EvNdIa0jzGlI6VWJYpRZmSFxllpc1mybHaVuuzYpAukxRL9ONFlPAJvYkH2TQPG5urA/QhU38fKpV4PHB/yvM/D1P45S9/+fj3QwcWKI3hqKOO4MofXEW/3+eZlzyNrbfdzO7dy9x0w01MT81wxJYt3HTdj2k2E047+3gOHtpPvz/EDyXLK0N6vQ6PetTx3HzjDm68/k7+6Fm/zJFHbRh/T57nHDp0iFtv3cptt93O//7fvzt2nJufn6fX62GtJU3S+x8uAFu3bmXr1q0AvPCFL+Cv//qv+NjHPsb27dtZu3Yt4MSvX/ayl1Wfa6vSrIKjjzyVLPfodDOmGm48O/daTRAEhGED32uQxHu4d/tWTjjxsXihzz23/ogD+w5y6ECfW+/4EevOP4FTTz2NL1/1CWqNAWefOckXPnkjNX89z3v273HV1dfSORRjSndTJgUcd8o0ky2PUFh27dtBqaZ5zrFP4rtfupcf37jAoByycd1mzr/gfN72V3/G4uIharWAbmfIZH0tE80Zjj86oBa0mJypsenoFic8ahblCZYO5tx0xRBrLf6k03nce2+bTlFw9PHT/PCabdxy85Wc8thZhm3D/rsPkGe3IKQiDJqccsYGajPHsfmoNWzf2mHPwUPsX1ZYIzn1uHPoLiXYMuT0R53P+Rc8jjNOPxKlFNu23cNVV13F6173OvI85zvf+Q6+75OmKYuLi4fd6Lg4bN26OZTSPPaxj+VXf/VX+fSnP83s7CxCuJK6JEm4+OKL+dSnP8n1N1w/djC0WPbt20O7vcKmTZuI4wHbtt/Nv3/qY5z+qFN4ylOewlGbj+Cu7XvYumcvz3/GefR7A2686UrWr1+DUpJeb8DKSgdfSdrtZSZaLTZsnOW7372ORr3GYx9/Cku3dkninI0bN7pY8uegpZmTUyiLshL2duLBYRjheT5RWCeKamjfw+JimdIUeH6AtYK8KFwcrhTWOBfAVUVNUZXeuObK7xQoqhspPdYXdULOCVmeYwxIoUnTgizPGQyHqEqmwve1c9sbDul0OyAEQeAzSNp0+8vs2reN9kqbYTwEaZFejvBz4jQmzwrSpCAINH5gCCIFMkeIstKnWS3bG7PGq18kEAQSYxWlTfACyeRUk01spFQpexd8bO6YVlmWUJiMoizIq0qKVMXUawFaaTylEYGH0pLWRIjyIpTnEzV84qJgkA5BgOdLfKWZnvXRAeSiJOlbsJLGpEfaL+h0+0QqQaqAiSkXH/SzmH6aYwvwpEZq5SJkowk9TRBKanWPetOj1vCxHkSDgLz0KcuMFENRWEbO4J6nENaghaARtvBEA/IenZUhNV0ga67kKy9TjBkSqXoF1vmElT5sXmQM4g55ntBotJxMCRGjG1VbCSqPmG9YxvcXI3FqBxw6G3vnxiZpNCZIk5g8yxgZARWlk/JQShMGPqNqgTIvKMvquxCUpqQsMpQCLRVmJKUiHBMHnBj5w7k9EkM/EkM/EkP/hGd/hhj6IQNPrqxOVZpO7iTLshzrCElZTSRkBV2ObvvF+KhsBSgURUZZFNiyWK0lB6e/IJxmVA3GoESzNklWJHSHK+R5SlHkRH5EoEMaQYuZ+lryMmWyMUV3uMIw6dOPO+5YjEQROOcAbREyd0CRN6KXyipTZMeMGYdeu1pOqQqEcJRRi3WWhmlOmYPXHRLmPkKAF8qq4wvK0nVQmiR4KkT6iihsYoHcpASBj9YaT/s0mg201qydG0IhSAY5i4td/ECRpCGeFgTa6TullbVlr9cHYbDCMhw4F5DBIKfZiPC9gJmpCcKaAFXQXy6xuUUaQRT4eJ5Hre7cTZQUDglPM5IkxQqL8tymICsRQlezXUBuSLIcFXgo36M2MYOUThzVLZgwFhjHLaASibEWaaUD8ZRP4DeIgha1aJIwaKCVc8ez0jG6hKCqPzZYL6yGjnRZBKndmBCey+zhdLdK4/SbqKbvKIAeTQaBxFMhvq7h+TWGyRKq8PCLBkoGlS7UKgDqMoNu3BpwTLPxI4fjytVvFTj1cG+rcZ2pShMsQgpqUQ3P81BajWnzWFHRdDVKufcd7va3astcZbeEhGoxXt00V4Hmw7M0ozXB3q+UsTIapTtcptNf4tbtV9JPuwzTAVlRVnakGcN+jyLLMZklz3KMsYReSBgGBJHPnr130+8kJL0cYRQUBd1ZKMQQ6WWEdUmgawRBDSskaZLS7/RJkgIYEie9qoTTxxNTZNmQfr+LUi1WFiTXfmcPs2s8pqZr+EoReBFaeQgFkxMz1Got2iudsRjg5NQUvlcJfAqJFQpMidJUApSSWl0Q6Yg160N0UJB2ClrRJJ5fI4waLC4usn/fCoMDN3DSiUdywRNPJ+sOwKasm57AdAYM4oIi1Xgtn6DuM+wsVzcfksIqDJJhiluTREgUgBU5QlqGIiUhc/a6WJT0qIV1QiQii1nuHCD0mgReHWMS8ixlMOzSnJhASEuW9ZCycAxVgRPftCV5mTora8SDZFkOe+DwBMT/m7H9X220PyeldA+1eVHJLT/ayv95x8f5gz95PWvXTfPWP/kLHvOEczj3MY/jMec+ncnJBllueO6LL2Hvvp18+jMf4alPfQZSRfzDB/6Fp118AWee8WgO7O9z3gVn8QtPPosnPekiTjzxRD7xiU8AcMcdd3DRRRfx9re9nX/7t49Qq9UASNOUSy65hHvuuQeA4XD4Xx5zWZbEyRBjSk499VS+851vj51+RmBWkqQ87WlPY+3aOd7wpjewYd16Wq0Wa9bMsrR0iIWFed73z+/mMY9+PI997BN45a+/kJNOPJU/+eMPcOlLX8rBpXt4wx+cR9TMSbOUO64bYuMvsv/QzfzZb/89V119Db//v36HP3/bH3L0URvYs+dq1MYlZs7RdL4IjQnNmg0Rz33yE2h3hlz5g7s4+8xjWFkc8uQL3sVb//SVvPJVL+UNf/QX/Oun3seH/vl9zB0d8gsvOIfnvfjx/P5l/871P7iLd7z7D3jShS9gdnYT5zzxeKIwoBi02L+yh5X4EDoQlAUUccnirV1uuGmR3nxBc63k+MdN8pw3bWH7tTEX/sLZvPS9z+PWm66iWVvH0y5+Ex/53Nv4yL9/kM7ONVz6kpfwh696Bjfcto0rrvgWL/qVZ/CxD/47T376aZxxzlH8rze/jl27t/GDH/yAN77xjfzKr/wKF110ERdffDFbt26lXq9z5ZVXjsXBR+03f+OVfPvyL7B+43GEYQ2lFJ/73OfGe+PrX/96vvY152T3lre8hX/5yL9WY8M5Z738V1/J7OwafvzjH/OKV7yCb37zm+R5jpCCLM9493s+wUknHcOvvvAp/OimO4migDf85ku4/FvXsXPHQV7ygqdy1VU/5FvfuZVf/ZUXMr9/gW99/Qqe//yLWFho8953/RsveMlTecWrnskv/srF/02z6v9+W7N2lm63C5QYW+B5Ho1GiyCMKiBKkGQx/UGXHTt2EEV1WhNTRFHTaf0oSaNeR0rI0iHGOraFkj5SeC4pqKS7Iau2V3dzbDBljjCudCxUEWFYo9/vkSYpK8v7KErHmpIqILclpJY4HhDHfXq9DnfedQe9fpdh3Ed6BVYVlKqLERmy7kqp3DKvSFNLv5fTWR4SBT6tiZBNW0KnLTrQtA/F6MgQ1GCwkmNzCLWmGy4y1B3iniRsSJpTkjhfYJA0GQyn8Whi4oilPTn9Xo9aXdJopu5crUKXs0w0ppibWcPuvbtZWllkkAzwfOmYGFHNabQgWF7pIrwEqQ21ukLVfZq1JjPrI5CWpU4P3y9Agj8pGMQ57cGQQXsbnX4TGczQmrKEWY3hTsNsM6SMSpYXEoQVaKE5+tg5jMwZ5v3/h733DpPsqO+9P1V1YsfJO5uDcgDlgIRAAokgC4NkEwzmYkww2TiRDA4Yg7m2ARvwNSYaY2PA5CyDJCSEJVBGOa42z07sfFJVvX/U6Z5ZIe6LzfW94nlUsJqZnp7u0+dU+J1vfQO799+P7weEYRXfV0xXp1H1hJWwT6+TM7muSnPCJ4gK8kEOOC+6UC1h80WW5nrkViCkx9RYjSisEPgVFvcv44mEymSNRq1JEPjML+xCCA9fhayb3kFRWNKsKL1ijEsXVCV4YewIDKVknSnPQ0k7Sj0bsgqFUE6x4IeuBkSjbUalEuL7IbVKTJrnJIOExflFojgmCAN6Peer6nkeK0uLKKUYazYxRQhWEfgxlUpMtfaTnoGPpPZoDf1oDf1oDf3zt58ZeHIm1kNJ05oDLIGnIRi2etO/9jmipBO6gVfkWWlqVjAyLBdixCwZGrMJITDW4imfUMcIJFmRkucpnvQIVEDgR3jSG1FHwyBmkHaJgtgxrizUw3EnVVNghEu3E0IxBJMEFiUEvlKkQiGsGh2rLqmnWAvaYgwoafCUdru8wqJ8iZDOuBzcOTBGk6UJeZAR5gZfhYRBQawrrnizTgOd9FMGg4wi004LzHCnAWcEbldZZVoX5U5VihUuSS5Lc/LCGQX6niIIPcLAw5qMvMhI+wUYQegHeHVnVBhFgStOcNpVrR07zWmQJUIZhHDMrkFusMPIWT8nIMQXbmfECeGHqFM5gY52VIZ5D25C9VRI5Fephg3ioE7gxavXwNpVc0MpsMJgrBx2L0A4H4LSRN1YjbAGK9z3pjR6g9HWQNnt1nyPcPI8r0LXHqQwCXnRJfInRsc7RHONtavDaw211vVjOzrmtfrqXwTWk6PlmlKGOIx5DVHK6ap1UZSnQKBKCaMskURHZjv0mqzdOQN3DlbHf8l8W8N0dMdgSzBQlOd2eM6NAytFuZuXJ7T7i/SyLolOkDYAC0oofC9AWEmuc6TUTt6aFlRqMZVaTBAFqH6GtYZsYMg8gcxj/MAVbStpy9GjKciSgjTJ6Xdy+jWNwBDXlEuQKXLwA7p9JzGYXr+FWlynWZsgG3TptjMGSY8iL/CVA5GVctT1Xq9HmqZIKYmiGM9zqUC+UggpyU2ORaG1Y28IY9FAf5DiWYMXlKaiUpHlCWmSk3YNS2mbdrtDkadU/AhfKbxmjc6yJi969DodZGAJYjXaDFAqwHk7COfZYIe74gpfhQih3XjQbudYrSlu6lGDscoEalm5ucnmKK+cS8mxVmONLSN5C5Qs0DYh8GvEYZ1aNEXgRRQ6XQ0N+N81e8iXNY+vfUSMnvQTS+1/ceX9+Zbs/zvtne98J6effjrnn38+nldh0+atXPLsp7OwuJ9W5yDnPemJzMyuw/cq9LotCq2wtsbXvvZ10jRj/eyRZLnAw3DqCcczMdagKHIazRBPSawt6PV6DAaD0XtqbWi32664LkGna665hksvvZQHH3yQTqcDwPOf/3y2bdv2vz1+KQX/891/ya5du5iamqZebyClpNPp8Nd//dekqWNNPfnJ57Fp81Y2bdpCv9dDr7Sp1ycwtsALDZs2z7J//4N89cv7Oetx52IMvP+D78dbt4+JsQGXfeMOxmctj3vqFLdd1+He2+fprKScc+oPUX7O0857Hjf96E5uuuEmBukC9999gO7egqimeOzJ2zjl9O3ccPMuatUmjzvjHO64+1ba7WUueNYs9zxwN3fft5uFPX3SbobNDV7FY/++eb786evxJjTVUHLbLfuohNeybnYnjWqVyalJpmemwDgpuDVw+JkxfijZf2dKre4xNR2zdfN6ooYlXSyQccGuffv50mev5pQTj6dRa/DDa75BvTrFUUeewTX7rqen97LYvo/rfvwdvDDnRb/+Iq750TU8uHsP5z3hyVx00UUsLM6jlOKqK6/i8isuZ25ujuuvv54PfOADvPjFL2bTpk289rWvBZyp+4c//GGu/o8fojyPP3jDW0cG8kHgj9a5wWBQAiiuDfvG9dffwDe/9Q3OP/8CpmemufeBu1hYnEdKj2f98q9xxOFH4/seZ511Es1GnV4vYdOGaVaWV/jCv32Tmdn1jI3VueKK6wkCn+OOO5KvfuVbTE5McNgR27jrjoMUec7pZz6WiYkmy0tLfPwTH+P888/n1FNP/T8wyv57W5qm5LmLzFalrijLMqrVGkHg1og8c7HyUVQlDCv4fgg4xlIlDkqJjSZNE/K8oCgsUlqUsiUD273XsIYdMsllqWkbSnZcuSRGITW29Mnyfb/cWC6Ym9tLp9ui010hjEKk1yCuKQbFCoV1z5cl4z3wgzI0JqQbQCIgz7oIUxBGBUIofAWBb9GFReZgtJO4WWnp9lJ8v0cQuPCZNBXkuYSqj9YpVmR4YUhQFVTGfDpdQ5IUzM+3CUIHhkxUAqSSFFrTbnfIc81Yc8yF+vggpE8QhSAEnaSPyS0mt6P1TlvjanxPUa/HJGlKrgtaiymtpYxOK6ce9UGFBDFMNCcpck237tFL2gzsACvBFoZCa9IiwwssUewx6KVk0qDqFVePK0Gv3wUsQSwwok1ahHT7FTw7hsAnSTXCOoVHvTaGNClJW5MPLIECGUFUkQgLmoRufwWVKtIsI/R9lB8h8LFWoAtTbqC6ml0XBlNKKsHZmniltYkSzsw8wCkflOeCeLIcGvU6ga/wPd9Fv3da9HoZcVTF3+BjhWPNhJEDp4y2TlmiFIHnUa3U8DxFJa7SaTmjcql8BkleBg48ctujNfSjNfSjNfRPe9uf/Q9/ZuBJDZ35YRRT/1DTcGOcOfQhyQQlCrtKKTQUeepYT9pR54cSu1Km7jBb6TuzNCSBDdFGo6TTLmdFgtVmZMQYehECQRCExFGVJOsR+hWK0rG/Fo2NdoEy28OQI8hHg14gUFIQKA9PeGQUWC0otEUb45g1xhmMGy3wlMZ4kmTgPKockg/WKpTv5GVD4CkLUoqgwItDQgyFraJ1RpEXDHoZ/e6AQT8lGaQURVHuTmmsdTsRbuJyr+loxRlplmHRDnjKNEXhrkwQKKLQw/clg7QgTVPSfoFAEIUBqqJGg1qVCSUO5HLgk5NKglAChKHINXliKfIMhMYLClAWqVTJShpypVdhpyFld7jLBu4zBF5Exa9TC8epBPUSMZajDivX6pbLxDwhhubkTuMs1vhomRJjslZjyuu4Vqo5pLeuBZQ8FRJ6VSyGwiSkRYeqLZDWrJlILGvoTWWfXQWX7Oh914JOP+so+n/bXBHqdj2U8vA9n6g0wbPWUJQ0fpceKBHSwcAjz4hDTkppwG6HJP/y4YdIFYdAHQzPl/McGy6pQ+pySS3Dlkb9pihI0i5J3iW1GRUVuJ044SECF3NsC4spNFYbsqxASElcjanUIpJ+Ssf2yBJD7vn4RQ0R+EjhMRgsubFmUrpLfbJUk/UN/UaB5xlqYyFZnpWpLQGdPuRZwcbNh9GsN5ldt579+3aS9nPSdEAuCjxV0Gg2R4tNt9slSRK8cpfVU4pBv1em1AiMSSmMRWtLFIRIU5AYS7eX4GuIxgKU55h9g6RLOsjJ+paW6NLt9kaLJl5MUK2zMNahN+gzv79NUFFU6gFSCpT08FSAAYwAqy3WiLLgdOkZnrJonZBrF8zgeTFSKIy11CtNUj1N6LkkEGNzvCBAKBhKQRDWpdTogkLmFHpArTLFWG0LjXimnLeTQ5iIa9tD19GH/nxo33oI3bcEve3a3aCfuv49zC9+UQYv8Na3vpVXv/rVnH322ShZYeu2HezYsZVPfOJjdDptXvWq17K80mN5pUO7+yCVqkdRjPGFL3yeyYlZXvGqN9Htt/D9hCecdRpFkZMkA8YnJsjSgtZynzAICYJVCbMsAScn1XDtmmuu4d3vfrdLzivb85//fM4777zRz0JIoiikKIqRBOsLX/gCL3zhCwGYmJik3+8jlWRubo63v/3tJElCs9HgS1/+PJu37EDYiNsXb6Po9hkfTyhsThDD0UcfztVXfp8ffP8a/uRP/yc33nQjb3nbG7jwtWOM+4Jvf/B2LnrxBk44epqbf9DiwftW2HXfCj+84FtsXX8iz3nmi3nLn76Ce3beSn02ojOXkvU1zamIk07bwYUXncGfv/MzHH1ElWdceA7f+u73SfI5XvqKo/hf776Zqy+fAwvVqqRWV8ig4P579/Kdz93HY54xTnPS597vL5JkP2BmfZPHHn8862ZmWLdxFpnPARblCQ4/u4rJLd+9ssWJT6ix7agxHrP9aHbvnWP37jmICu5/cBc//MY8j3//JcRK8bVvfZCTz/1lZjYcyXU3Xsby4F7u3lXjqh99mbNPfhKvedGb+K3XvJpKpcpTz38Sv/rs5wACpTy+9e1v8Zd/+ZcAXHfdddx444085SlP4ZRTTuYd73gHAHfffTcf//jHufLKH3Dzzbfxmy95FZ7nA2B0jlQKz/MZeopEUXRI37j++uv5n+/+S7773e8yNtHgW5d9naXlRer1Js965q9x+GHH4Ace5zz+JNqtPouLXbZtn6XbWuHT//wV3vK217Bx8zr+6j3f4ZnPeAInnnA4f/f+D3HeeedwwVOfxIf+5rs0mzG/9htnk2UFt/74x/zRH/0RQRBw3HHHjQCwR2obDPpkWTaSzwkgS1OEdGwQXbiE5jzTVKsNgiDCUyFWAwiiMCqZ+ZokcXI2J2dyILExxikSrNtA02VQC0IgPHcTvDaxTkiB9BSe77uUNiRhEIAQZLlgfuEgyyuLdLrLbN60BS+oYVWNxXZKP8uxqcSY0pbBD4iDBpHfoB1q+p6mKOaxuiBLnYzFUwLfs5gCdAE6By+UWG3p9pyyII59JmcESc9iCoHvhRRFhiFBhR5hTdCciVg8KMnSnIX5LvWxKrW6TxAHIJ2kcaXVRUrBxMQkad4HoZHSEEQRUgnsMhQ5pbeSq2eyvCDLLJEnqNdjhDIw0BzcP6A1n9NZKaiuT/HCgrimGG9OYnJoNQyZSehlifNIKuVmgySj4kkqoaI1nyGsoBbgNoGFoN/LQVmCSJCbZQapoNUNGKtMgvVJBinWQugHTIxN00uXybpd0r4ljJzHTlTxwAgK26fVyxFIdF4QenV8L0aKAGsVRbk575ZQMbI6UdL553iewvfCkmAg8KVFCuN8oHwPBMgEPNmkWomdTDAd0Ot32bd3jlqtwcTEJEFUQymPSqVCXji5nlKO+RN4AarewPMU1VqVdmuZPM/xfElvkEKS/b8cnv+/7dEa+tEa+tEa+iHtv1BD/8zA06qJsh0NJinViCpvoXTUV2s0quVBjWiFpkRi09Lpf8giETjzcIM1TrGuhAIhnJcTrtDxpD/SvGtdlACVctIwhJsEggraFDQrU+RF7qIVVVAOeEti+hQmJaeLtgOszZDSECufwPewnkPsOzohTZ33kTFFmVhgSfsO0RUYkoEhjFy0Y1FYotin2ghKsEOztLxImliSnmF8agaNJs8tnW6PQb/P0kKL7kqffi+lvdIj6WckgwzPE85RP/AdfVN5FIVLI+n2emRphvQknqeIIo84kqiGz9R0jWrFDfilpTbtTsdFrFZDKtWQqOqVum5FVPHxAg9tTClVcxRMKTSylErm2jIYaAbdDCGhWpPU6gGBCPEJEEYOxW1uF6383BaDsQXG5kghiIIG45UZJqrrmapvoBY1Cf1otAiuhoEOwcs1fRqnjXbG9ZTXokyWKEEuu4bpNEyeczpauwoSGYsvIwgg9GpoU5DkKxS672SVwunfh0iXKV9nbbzpsNhemyzxi8B0GrYsH7hdpyAgjmtI4eKatXH0awBPyZEXhDWGwhSrfm7lZx2lc+CSPIqiKKN+V032h7Gyh05UFiHUqCge6t6NKSWuOHA3DGIm6+s4av1J7Fy4m50Ld+NFitALCL2IAo3VOf1e272nJ1EEmBwG7T4nPuYIDh5Y4ub0HjqtNmFFsGF2muXuEkkvJ+37qHqACmKEGqA8CCNDp7OCIWdsqkoQ1ghCV4gWeY80z9i3/24azSYveOHF3HH/jay0D9Lt70fijO7HxydYnG9xx493s2vnPmamx3jMCUeSpIY8y1GeolKpEATOT8MLJKEUdHstitRQDDQyrOBZHw/n329EwdLeFr12gc5gbLPPxEzMeKPOg7s7LLW77FnYT7WmqDcjGsseIs3pL/aYmB1HSg+MJLe5W+AwpSwBx1iUEouiyAeO0mtdnK0ABlmXWjxJHDVpxNPsa+3kQGsPC70FEJpIlN535SXOc+tAYeEKWikkvqzixtOQRfOfHy/DtFP3w+oO4EOftfrlF2dM/mfbP/3TP/Gd73yHL37xy3Q6Xd773r/lla98GeNjDX7n9a/nkkt+lbMffw5bt8xw3z0P8q1vXMFb3vzHRJUq1kKWeMjC+bcYHWKsACsIQp/JmTG+9vWvHQI8HXPMMdx0001MTU2NHnvxi1/M0572NH7pl36JBx54AICXvexlxHEMQKVSZ9OmTXz2s//KP//zp0ZgR7fbG73GbbfdxgknnIAQTu7d7XZ56Utfym+/9re54/b7WJi/jfWb1rNj63byPOHOe67m8MOOYNPsUWzd5FENGmxYt563v/P3OeLIY7ns8it509tex66Dt3H+y6e47op5vvv5/TzvVduZP2DY/UDB5z/3XU56TJdff86xDPoD2gsZeWKZ3Fhj48kTvP7VF/OjH93Bu9/5Gf7od/+U5eUFPvHxT7J3bjeddpu/essN7N09wPclWlvOeFKTxz2pzsffN8fKUoH0DXd8Z5nquGLb40L2/bjNYFHyrj8+i0u/fTMf+9wVvO1tz+KCSw6jfspBvv7h3XQWC0572iQz65sY6/Gxj3wPgUYpS1AJOPGko7notU9gvn8FRbaB333DB/ny5R/m2lu/zJYNR/IfV93GV/7tezzu4qOYy+/ite96CS/4jd9k0Ovzkt95DmeefAlH7TiRJz7+MWj9k0Xj8Obm4Vqn0+Hcc88dbVR94Qtf4Nhjjx3+Jdu37+BLX/wiGzdtHP3NRRddyBFHbOUNf/D7PLBzJ/1Bn3arjdaWN775Fbz97X/C7Ppf5SlPfQpPe9rT+cM/fCs33boL4VX4h4++iyuvvo077p7jzW98EfP7utx+437e9zfvJo5i+p2UJDlApdpESMGHPv4NrrzyP9DG8K53vYu/+7u/47777vsvjKr/e63RqBNHMbVqjTiO0VrT7nQZDFLyvMD3FZ4XElcCWq0BSZKiTQfP96jXK0SRdOyELGUwcKnLvheWUj1Zeo46kECZEniyZZhPkTM08JbS+bV6pd9pEATUa3V34xlX8X0PbXLmlyexXotu2qXVnccPAsLIefN40kNoRdLLyNKCnrCsn5libGwWf9MYleAA3XZCknXxQx+dB4SBxKsYxqcq5CbHoBGBYwiZXNPtJRRaUx8LqdaqhF6AUILF5Xm6/YTm+CxSwemnncK6+izL8yvs2bOfWE1QC8doNiZpLXZ5YG6Ouf0tpqabzExN0R8sU5gELXqEMUhP4Ps+vpRYFdGTLfq9nKVOB60FtWbIbFgFKzCF4OCDfXptQ5HC+hNnmZ2ZoRmvY9/OhF53wL79S3SyPoM0Ix0YIt9z17lSB6tpLwwYq8wihY9OFAsHW8igoDEZYCgodM7OB+apR9AbnyDYLsmzhDvvvI84jpicmuCMsTPZs28Xcwv7iL0KngmwWYApUqzNsGoFjMAaiU586pVJwiCkVqsQeCFCijK0pyBNBxSF860NfKckkEJhC1x9ZQ2IAikMQrk6WhvIMoMs5Xb9Xg9tIPBDer0eINFFgbAGqTzCMMLzDbooODg/TyWO8L2mY8hZSZ5ZwkqMUD5pWriEc/FT73gfEe3RGvrRGvrRGvrnbz8z8FTiYQ4oEKJk4qjRgHqYkoa1A2YIThijS+2igXLgDMEn57ZuwAiMMgi7amAuhMCTHla42E+jfFzQp0AOiYtW4CNGTClfFRRKO9CiBCOElhQ2QBlBYRSGBCEyrJJ4KAJl8ZUDskooA6ST4zkDt9L3SIMYCLQGaxwIp3PrKHSOeUw26GPyAJMHRHEDg2aQZbSXe/R6XVaW2vTaCUk/o99NKXJHuVOeM4/0fVV+FkGeadIkJ0kzt6uFRElFGAX4nk/oB9RqIb6vSNOUQZIwSBJ0iaZKxeh1Pc9zr60EWmuKIi/ZYTlWasfRFmr02aV0XliRH1ENGtSCOhWvipZQYMl1XgJPppx8DRaNLE0wK0GdejRGIx4nDir4no+EVeDpkOLXjjr+WvN6Mex8GIb0OGuH/YpDFyzB6HqvBaecuXlA6NfJih65HqBNirEZ1kYjdtWw6z4cpfFnNW17JDalnHbf9wJH/wW0KUafyY3lNWDyKh54aBuOWelih9cmaqxN61hdOA+lDLt26Hl019Itwu5YPSZr6+gkLdqDJXKbok1OlrmUjjzPEMKMomKxrt8vL2TUatNUKgFTM3WKYoAfKjxPEoYhFVNlemoWPxIEkaRllx2DE4GxOUWRMujnVGohfuA5cNpIJIJWex45ppia3sDM7CReVJAdWCL2m0RhFS/w0VbTT3q0lgeEXki3lVKU3nbupsBRzt2iGeAFHsJ6WKPRBQjrowgJvRDpJ+RW0+1oitzgB4KpqQbNRhVP+rRWBszPt9m3f57JqQpR7HbglFBILZDCQwiFEasgqaN6l7ueUDL9HH1aCA+ES/UU4B6ToPCYrE2TmxQQ1Gsb3UtIg6UY6c8LnYMVRHFI6FeJ/Fo5p9s1Gyz/+/Hz0KjgUZd7mD99aDqHtcPnPPx7PCxIbO1Dl6pHdJudneXUU0+lUomxwNFHH8XU5Az1eo0jjjgChMe+AwtEoQVhmJqeoD9QDJKELFuk1UrwA591G6oEXgVjLV/80hfYsWMHJ554Ips3bz7k/YIgYPv27Yc81mw2iaII3/dHj+3fv5/x8XEuuOAC4rjK9PQMSinWr1/PaaedBsDu3bs5eHAOgGq1ymmnnTa6Jmee+ThOPeUU6o0q0zPTaGNIM8eKVlIyMTFFvT6GlB5X/+BqWu299M0cmZqnNdjD/Q/cRSJ6aGVY2pe7hKrpAJ0rNq3fyJZ1U3zu09+g1WqD7HPW409hen2DB+ZvYXyyysRUk0ajSlz3UbHhnnvvwVOCrVu2Et9yMwPbpV6VrNtQYXxaMjU1yezmnMRkZIlBCmiOe1SaCi8WdBc1U9MVxqoxP/j+nRRpyGOPPYU77tpLVl3Erwp6S5q0I5heP01nOSHpdalPCLZtPJYN67Zxx9w1mDBlz4F9LMwtMjXW44gt+5hozLB1w1Hct/tB4opHoxEzKPoEqs7k2BjzywcY9PtEFUW9FhHHAfOLKxxxxNFcfPHFfPOb3yRJEqy1XHrppbTbbc4991yuvvpq7rzzTi655BJuuOFG7r//Pk466ST27t3LDTfcwNe+9jUWFhZ44hOfWPYNnx2H7eDOO+/kO9/5Dhtn1zE+McbRRx/D/MICu3btBtzNVKNR54wzT+bAgX382+f/jbvvvpvTTjsdT3k06jFFUdAfaMaadTwlufXWO6lFY9SbVVrLXfKqpVbzWbdpGs/zuOO2vVQrFTZunEIgWFxcZHFx8b9lzP2fbHnuNkPzvCAMDEXhfDuDMEQIv5TsuBtP38vRJkfnBSqQUJrQau2ACsdYcmE/nu+jlEApUW4Mg7tJdRI7KYfsibVzoMBTXknhBq2Gke8CzxMoJOMTTfrJGP2kSTbIGfRzul1DUnTJioFj1ieaPNdgDZ1Ol6VwGV/FVKIaG9dv5uDiPvxAEKg6lcgHaajWYnLtYTAUZBhboI0zOs9zwaCfU40EfuhhhKGfdWl3BxgTMTbeZMOGTYgtklpUodvuM1afYKw2TqM6Rmchod9LSNOMNHEAXZFnWAqU75J2jLbo3OCXBuoYRZHlpH1DlkARSXTuY7REa8gz48yiraIaNYj8OsKGHDy4j+WlNgfmFrEqwVBgtUFFgij2qFRDdFGQpxm+FyKEcsFEeYYgJ7YehTHkhUFrAMc+C4IQJSW1aoW4EpQAYQxiE7V6nfHZGGRBblPa/YMYWxBWy1RDFNjApUB7Eb7yHchhcQoB40AkM6rNhsoC6zzDyvswIcu6ToIuNEVhKXJd3pd4YCWe9JG+x9jYGFFUwQLtdgvHsgzxPYmngtEmuj8EuaQC6QAcIRXWCoQSI9DlkdoeraEfraEfraF/4g3/0zX0zww8uRt+Ue6UlDsmSiGVM0Q75MMOKYHlzT+UenNdlGl2modGQw5fww0tXb6dRbKKFCvllRfAKxdSd5asLkogyyHpSoAXBM6jyRtSEx2S6KkAYzWZjsh1D20HGNF1F0UKMh8S5XZCpASp3N9Lz72dV1iyxFJklrzr/J6SniHPIK4UWCCIJFJBZyVloGAQQhjWMdbQS7ocnFui2+2wsrTCoJeTpZo8LZMRyoHlB8oZgCs3KSdJRq+X0uslaGMIhMT3fcbHG1TjiHrNmdsVhWFhqU2336efJAhfY6Vx4Jl0evo48gkiD4UgSzLSLCXNB2T5AIXTffvSBynxA4mMQgIVMlEbZ6q2jnqtQRyNMzAJA5OQFekoSc4VRw548r2Q0IsZr84wUZtlqrGeSlAtDcWHck1HSx2CSKvme6Xu/hA8aQ2zCVZZVrjBP3peOdELVtlJQ/M+TwXUo2m6qSAtuhRmgDIhStRG7yJY7c9rB5qjOR66OIiH9P1HcgvDCM/zCfywTP9zE96IGlwmOUqpGKLMLrFQrP4bflRBubi6QsEx6dbEcAsHBK+emyEjrfypfNpwUXWphJTFj8Eqyez4Fqy0SE9w/9ytJGmfLOvT77fRWhMEIaEf4qmQJNd02m363TaTUzFhINi+Y5pB0nUGmkJTrcVE9Qr1yS2keZdB2mKv3ktRgLIeghytBSuLPSqVClEUux1ZPAQ+C8t7kZ5gk7edyalxVKhp9fYzPbaBWmUMVAq+QauU1lIfnUDs76MxHbgiNApddLFUtNo9qjVJ1Y8gD0cmj9gAT1ZohOPoaAlTZKwsGSigUhVs27qedTNTCOGzb98yD+7ez4P75+i26tQbFdZNT5apKh7SKiygS7DWzS9eeWNiKQqJNq5QjfwApWKkDN0/IfCtQZsUMNTjBkptZbK2nvGJo2kNltm3cj97l26hKFKEsKR5gpaW6fEZmpUpGpVpCpPDTxkfh0pYH36xdA+IhyyQh641D3nop7afOk5/2gbQI7BdeOGFvOc973EbCgj+6I/ezMpSH6Mtv/f7v881P7yVH1xzE2ONjO3bD+OcJ57Jxz5yGb3uMpNjAw50Ia5WWL/BZ8PsJgqT87KXvYwXv/jFnHjiiT/XsR122GH8y7/8yyE3D7/8y788Mq7+3Oc+xw9+8AMAduzYcchzjbY8uPt+7tt5F6ecfBbdXsKdd99Hq7VEtVrlxOPPIow8FpcP8vZ3vI2JDYbtR1fZ/BjJ8oF7+PM/fzPBsR0qFcsPvrTEWc+YYuvRde6/SfP0Jx/PU857Ml/49OVOHi9a/M4fvJT9yw/yvi/8Hl53grqcYGmxTWM64ugz1/H+D/0N55z5eN72lt/j6it/hOj3OPuJkyy2JUbGnHfe4/jxfTdzw203YIB6w2P9Jp8jzqnQ72n+/R9XuPhFW9m4tc4bfu8f+YPf+z3e8Psv4wWveCamvsRhZ1boLGcoU2Pd+u3cevUNzO9d4LmvPIKLn/I/OOf05/LGT1/Efbft5hOfupdABKyfmkYlhvMveCGnPfap/MUnXseOI9bRPOFwrt7/Hxy39QQuOvuX+PtPfobC5Jz/xDM5+ahjmKjPctf9u3jq03+J5z73Eo477jj279+PMYa3vOUtnH/++Zx77rm85z3v4bbbbuPmm2/mbW97Gx/96Ef5X//rf/GVr3yFV7ziFbz5zW/mKU95Sgk8DW9uFP/8z//MBz/wAX75KRfwS898Ji/4jRfj+6usOd/z2bJ5Cx/4wPv4sz97F3/8J38CgNWQp4ajDl/P3r0LfPvb13HBBaegTcrLXv4mXvXKX+fCp53H3733H9m8bRunPu50TjzjRA7sW+bLX7yOC3/5ZI49eoIPfUCMjLQf6a3d6pDnOWnqbBryLGdlZYV6vU4QBERRTJGDFJa4UmBETlZAGEnC0JnoZomTsCAknu/h+z5BMASeOISVLXBrs+/7bhNPiNIqw014QRCO/DXzIh8xXaxwMq71szN4fkEQWe664wFWVtrM7V8iKxKXLKXc7rxFY8g5cHA/rZUOWzYcTqVS47HHnciPbxdonVML1zHWqKACy9j4/tIjxrKw1CIvBujCIqwhzS0rSwPGm2P4gaKQBb12l4X5PsUgphY12bbuKCaqdRamD9Jr9Zgcn6VZn2CmOcui3yZLizKIp8PcgTl8L8P3DdVxi8kzNJD0MqLxmFo9wmpFngiSrkE3fEwaodMKWZGQ5RJtAJzsphZNEntj2CLkgZ172LdvjgP7l5mYCqlUHBssDAW1hsfYREw6yMmTjMD3MQgGeY/cpqBzBgmlvE/jBxHVWoXxiQb1ZhVF5CRxpg82RynFunXr8LyYerPG0vIiO3fvZNfSHLlN8SNVGhNLpPAJvJg4rI7kc4Uu0IWhKJy1hl3dsi/vqzTaOO9YhMUP/LKGtiRZSppqsrRwCYl+gJIBvq+IKwGHHXb4KDFx377dZFnG1q07CMMqYRCSNhuEoU9cDbFGABIhPOKKR2gsXqngUN4jO9bu0Rr60Rr60Rr64X7Bf6qG/pmBJyGcXlXIUrs68nESzp9HqVXZ05BlIoaaVIsxBWnWJ0275Hl/JGUCz3GW5CrzZSTVA4wd0tCGo6zkvRjne1TC+OU5G8F1TrJlSmCqjLxcNZEWeCJEeRJLjCYCcozNCYKMMLSEoaFSEaAUVgR4yk0IYZCTDixJH5IemEKQpYb2csqg5xaQqKrwPEGvmxEFHlkcMDmZYqxl0MtZWejT6fTodlKKzDqDRekTVwPiSkAYKeI4oN6oEEY+Ugj6fU2a5WR54RIpPIkfKBqNKrVqTKNaodsfkGQD2v0WuUgh0BiZk5mMNFdUhNulrtZioshH59YdR69Dr99D28wltGmQGjwVEDcCqmOTVII60831TE7MUIlryNCDZIms6KPznvNzEhCHFTzlE/gRtXCMSlBndmwbY7UZatEYnvJKwzZW4VWxClZaa1xfK7lslEbmWuuH9OuHA4YeZgdghBQPvcgktcokVhiyou+AJx0Q+dYBl2t2BdfuQgxfzwFmq78fAV8/60D6f9jiuII1ztfLmAKE8ycbBgdIoUafTUiJN/TUKseXuzbDXR5dSm0P3aFaOxFK5RZS936OmzrUGA/H+Cr9WK0BEV26jw4NzfoMnufTrEySZQPSrM9Saw/9tEO710PKCIskTZdITJ9Ed5k7uEi1FlOphszMNlxwQCBRQYwWivZSh6LQCOtTjZokekA2SPECgVSCbqvFUuxTFJr6uPO+SNO+SyvJNf1uj9CrUw0NQRjhhRIvgiCos3nLJsaaDToHNEsHu9xy84NsObzB9HSdqcM3ooTFFDkrrQ6DrEc39Vha7tFayVlaSjn++CPYsGGCDZsa3LnnICvzHRpRiAmcT4KwFqNzsiyhP0gorGZqtkZUxkVrLXFzWcLcvmWCapXK2CS2lEB7yhUhQliECBG6pNBrg7YgPJ9KddwtvHnX7ULrnG5/CSF8qnGVwzYcTzftUK80WO4+QJr3SfKEPOsTelXGq4exrnks68aOIMsHjIz/f4b2nwFx/48Cvr8AA/h73/seGzc6WZOUiut+dAPvftd7+L3ffx3jY01e/Zp3csmvXMJTz388vm8ZDGDX7g5PfdpJLK0sccddd3HmceNMjjfYMLuFarWCUgm//uu/xs6d94+YLOecc87I8+eee+7ht37rt9BaMzk5ySc/+clRAt1Dn1ur1X5iPviXf/kXPvShDwGwsLDwsJ8rz3PuuvNWgqDC9q3HccOPrqFWb3DiY49BSsGevffzpre/kMWDAwZJylHneKzMD7jl+oOEkc/EdMQ5l0xz7VUGO0g4+9mK3bd12HlLlxe/9rHcc+8P+fc/uIbn/OZR5Dn8y+f/lde95E8RvRmu+sdlpO0xPrGXx5yecuOP5rnx6hXe/uY30+m2+NM/fzt7FnZiPMPuA5Jms4qUHh/7+8uYParPcSfUuP27XXYcNs0zn3MM1974IN2FDsc8rkp9m8SOGfzA45vf+ga7993NhZdMsXdXhWu+0OHiS46i38v48seu5pJnncW2HVNces1V/Pv3v8Tugz9m5c6Ao2eO4Vd/Z4JPf/JaGvUZLrzolSzO3cSBvdfy9DN/i29//Rt84+rLeNxv1Gj1dvKRz3yIY448G2Ms11x3E5vGzqQZbqVeD+j323TaCYUuuOiii/iDP/gDAMbGxkbXotfr8e1Lv81Tn/ZULr74YiYnJ39qf3zwwQe54IILXPpapcJvv+ENHH74ESil+NCHPkiv18fzAoSQZFnOv//7lTzwwC5qtQbv/9uP8ZjHHkeB5lUvfSXNZpM3vvHNKKFIU8Efvvn1HHbYJqTyePqznoZS5fzWLVg3Xed5L3gcUnkcnHeG9K973ev4lV/5lZ95LP2/arrQKKmoVqvEkWNZGwPLK23SvGBywtLvJ+RZztj4GGFUJa5IhNAoiUtC6nVJkgFFUeD5ISCdIbQSZay5Q+GcV2hZtxjrUpzLWPJyQcetyY5pL+VQ1+BYVcZCHDaYnQ4Zb8wy3dxGq91m/uA888tzdPptDi4foNNrMUhzkl5GQkZbtIlqIeOpQkUAAQAASURBVJNqinpzE3HFwxpJtVqnXm0ifYG0EXEsqMQeg3ZBqjWDdgs/tFjP0B+kHDiwTK+fMLEuIIhhajYk9gzSzxgMuhSiIKj5HH7ceurRGFFQoVaRbNg4RmG2kuTL9HsDbr/9QSqhoNGIOLKyniiuYSVk+RwLKy2We8vML7XpdzVFIZgYW8fMumk2b1zPPbtuJ+unRH4NFVgwCms8B/qFguoE1BJBvOI5yVSuqTQkViUMdIv5ZY9A+dSaPkXiWENIZwBvJLTbQ08jjyCICMOYMAyJwhhfVRkfV2gdo3VKkvRLxlJGsz5GGFSIgjppkrKwsp+5uQfwfUEYhGyc2kCzPkO1Mk6RuyTxQdrDWI2UkkolckCPBIHbMBaYMrVclmbgPtZCURiUBN8rqNU84jgiDAOknXB/Jyz1eg0hFEEQMTE+QVEUVCsRySCh3eoSl98vLCwyPj5OGMZEUQDGUBQJBw7sxPc9fN8Dtv3fH5g/Y3u0hn60hn60hv5pL/azP/VnB56kLA2g12hV11AIRzfoFqywayRSokSGNXmekOUDCp0CEoQEa5BWOClbmY4xutcfAUruhUc3/AB2OAjNKoAxNN4agkwMc9WGD68ifs79PwDhIQFjMwQSTyl8TxGGkjj0QPgOr1XOY8jJ/pwWWVgoMpwBd2FLk7CcojB4viAZFAhTEHgFRmsHClpBnmrSvibpOzNHKVwCRLUaUWtEeL4ginyiOHAT8drPYkv6tBR4ShEGAb7n6NJZlpOkKWmeYkWB8MoYXTS6TE7wPc8ZjXsSnWuSLCMr8jIhwKx5H4NUEIQejahGLRpjrDFBvTJGFMYUQjuKqC7QRYKLaFX4UhH5MdVojEY8RSVsUo8niYManheUmyslC00bR0U1q2istaCUP9pBwJbHVHo/rWX6jSZgVlHbkXnasN8OdXeI0YaDr0ICLyb0q1hboE0GmFUK5dp+vwZk+mntF+CeFXDgsRXGmeNRDl/pzOuH43o4ANfq0c2oehWryPaaDz0E6A5B3x/mrLhfO9aYmyHs6Hqu9dFyC7HFSEUQxG7XVngUOiPPEyI/oDNYwdi9ZNqQFxrf9/A8gZCGbq+LUIJKtUqlGqGkQPkS5XkIFIXJy7AAUfp7KVcIagCLLQqSfoLneVSbqpz03VjK85yk36famCL0K1QqDfzAQ0hLmuTo3IUVBKFCKOgPErKkgi4Moe9hrSHLc5IkdUaFUtIfOI8MYwz1eoV6PcbqnKSTkXRyxptVCuPGgTOHLRMwtLsYUcXDVxKpLMkgRYgcITNy0aMiLVFzHIE/ovaOLrOU5Y6OorAFVkgXlRzEzlcOg7IarTOStIunPEK/QhzWsViqQdXJmMu+hXAhBEqE+KpK6NVIs165iz4cqWv6zs/BMvp5FsxflPH60BYEwSgUYmW5RWulTZZlDMH7LMtod9qstFbYsX0rrdYCOx/Yw6mnHE4QjTG3NEk1VkShpFKpsnv3bg4c2M8pp5zC3NxBrrrqKsCNxWuvvZZjjjmGbrfLVVddhdaaiYkJrrnmGur1OlmWkSQJUjp/mGOOOQalFD/84bVY65Kxjj3mOHbu3Dl63bWt1+tx7bXX0mjWCAKPIs/LudgFgnQ6Le699y6kkuzedx937byJ1lKGMZaTjl9HoQ0Liz0CEdFoxmw5bIxrLt1P2rbUJzyMGdBrG3rdhOV2j/lWB2u3owtDr991qURSIpSgszggTzN279vP0kqforBs2rSBu+/pcOONtzAxO4EfKBaXE6ZnqlSrESudPTS6mmIgieuSIHKsiCioUK9bgkpKr5vR7Tgvy5XuAfbO51x8+GmEesDtYi+NCYNVBYN2gudLqo2IRrPCgbl9tFsLTFW2M1UPCHxFrRFRHwupNWHvrhb9XpfDjj0W8svY9cA8p/eqSFmQ2Z5L/RUhjdoMK+0lDszvpNKoY0xBfzDgqKOOZvOWLSMvr36/z7XXXsvS0hKDwYBrrrmGCy/8JR73uMcBMDMzwxlnnAHA0UcfXV5BwWAw4Pvf/z4AjUaDdrfLzl0PsnPXLixQqVSR0ueIIw5HCMGevfvYtn07RVFQqVRHfdlJPiyTkw3uvvNBBv2U448/iqWlRX784zvYvuMwkkHBSqtP4CvyvM++A7tZN7OFWq3K6aefwaZNmw7xJnskN1frlDH12iKlR1EY0jQnK2VYRRnVLqXE83yUECgpy0CAPoNkgNFijQelm4OllE5CJZy1gCj9Tw2UlgmKoJTIWuPMkJ0FhnFG40MJkChXaREQBh6BHyOsR7XaIApjgorHcjuml3dI8j5pJgn8CG0KDJpUD8h0AqLAkd8kynPBNEq42ltJgV+yFzCCPHPyLpAEvmaQJAgJtXGF8qBSUShRoBnQ6baQkcD3Q8Ynx1BWIUxBr98hL9Iy88aSpjkrSz2Kqo+nFKZQmFxhBWSpAZ1BnlMUGovF9xVh5BOGvvM8yhW28JgYGyMNnJTH9wOk9HFJg06q12hUUJ5GeY4tlGUZtgue51GJqjRiFy2vFKATrC3TyZSzBlHSQ1ofYX2wAcI51ID18H1nTzHsLxbrWDdGEAUxSgToXLKyNKBe8/GlolZrUK3UiMLYJSUWOWmaIiSuVlIevucS0Bx7dmhHIct+4moloHS3KOtEzyVfy/IexCkNLEopRGm9EoUVjG8JgpA0cWb5ge+7RMcsP6ROdPI60DpFSpem/Uhuj9bQj9bQj9bQP38N/TMDT8NkE4RgGDY/7OSGoSr90KNaNUnTFEVGf7DEYOBotUoGSOFj0Cj8ctGTDP2chtIrRu/lcKohm0rropTPGYYY2Ah4wqXRlQe8Sklk+BoCa0yJNvtYfAwZ2nqEYZ+qzRgvahR2jEEakeZ5CWBZPJURhgZdteiGJE8Ng65heTEhSzSDJMXruMlZYPEosLFGKusGrYih8MgHgt6KoVLzCash6zaM0RyvUm9W0Frje4pKGBJFzlDdCwTKF0jfydJ8zyPwfQIvwGhYWekzN79CP+mTFgmoAqWcrtVRMDVR6FOphNRrVWwBic3pDhKSokBj3E5UaSQ4RPKjyGNifIJGPMNUYwOV2CVWtJNFdDEgS1ukyRJSCQIRU/EDGvEYs83DaFbXEYcNqnHJdBLSxUmXhU5hnLa/sAMc9VYSBHVCWcWXgVv4rXDg02h3roSZ1rCNHh4cEiVAJ0eF1JCxJKVH6Neox9Msd/chSDA2Q63ZrRgBl6PXPJTpNJrk13b4R3grimy081KumIAEWcodKVmKWDzPY5jMIsvPadbSNYUrXC2QpZnzDvO90Zww1JkPr5Mxtkw5HCL3DmgeJhkOm/OPEyAUKItH5CJryxREpTy2bziW7qDFTfd+nz0LDzBIO2yYnGVRGbRts9yZw9iCsfo6orhKGEj8KAQEptBonZZ+BYasyNEiR0WaTlsjhKTZ8Oh3e26BrlqiSkBcjej3Wwz6XZbmD1CtTlGNmmzZfARaD0gHA+65fT/tlTbdVpulpWUMBZPrYqqVmEpYoVat0O23WWl36PcGGBRC+nTafUwhqDcC1q9vUKkobrr5x+zet0SawcmnbqefpfTSAcoPMFaQ5Tngo2SIpyxBBNicvTv3YUwKIqMymWE9QTWdJVAVlwppU5fUOWQBKieZ1rnBkxFR2MQP3RgvhDP1d4WlS0TxvKDcveqSZ0tY20cpQ101SaR7fj9rkWZ919/MsKB1fUfY/+JKWQ6xXxRZ639HO+uss/jt3/5t/uqv/prvf+8a6rUaX/rKZxgM3Hn+3Of/mfe9/2O86Q//gg/+7V9w+63X8/WvfpHNm17H7OwGnnjWyXz3O5ey6/6Mo494LO95z1/zxS9+kVtvvZX5+SU++9l/A+DKK6/k7LPP5lvf+tYhjJelpSWe+tSnjn621rJr1y7OPvtsLr30UprNJo9//DlorZldN8vl372SXnfwE58D4I477uDxj388pz/+MZx82gm84y3v59bb7+KH132f3/yN53HF5d/lmc++mOZYjeZ0hWPPnubEc8aoVUJuvmqF+QNLtJIO7QdXmJ6J2b51E0nyYxYO9Ji/P2LjYTXyTZr3/smNnHfRZp796h2841XXcNjhM/zGK88AfwUx0eFpb1rHNf+0yN5bEr76hZ1sO2IjT3juYdx0563cfsvd7Nq1xBt+7w0oX/LWd/wpp595Mkcdu4UV2+X+2w5wxecWWL89YGFlkf/5zst55e+fw8T0DHfennLZ5/dz3209hA8bjpSceVGNE7Y8mx2NNlPRD/nkZd9kYbHLWU88mu9ceTPf+9HNvPVdj+czH76Fr37iVv79+y/h9jvv5QPv/RwnPm4TW7YU3Lrzz0myUwirj+Hw7VsYb9bJs4LbL+tx2jnbuOQ3nsBfvO2fmG5u52//4hN88gvv5ppbv8jvvPi9dDttBJK/+tv38eUvfomzzjqL1cp1da1791+8m4nxCR5/9tkAPOtZz+KZz3zmIddPlDKS4cBst9tcdNEzyt8Jms1phIA07fPZz/4rT3/60/kfL3wBL/z157O4uMjxj3kMFz/rV/jrv/4bPvGJj5HnOUsLK/zrZ75Cq9XhPe/9Q/7mfX/P5//t61z9gy/R7SbccvMDPP3pJ/KDH9zEL//yM/nKV77MhRc+nauuupLXv/71nHXWWWtCcB6ZTXmCJOnT63Vpt1ziWCUeR3ruuJM0QUhBGIa022mZ4GuYGK8ihGYw6LO8skR/0MdTMUFYAQRKgqdKw2IrEShEWesY47xVlXRsBLdOA7b0pyl9Pv0gdEwXzx+xKfI8w1qBMYJqdZw4qtOojzM22WRxeZ5Ov8Wgl5Arw4b1M+Q2JTMDVGDQpCR5l6hmEdKQs0Ka+3g6xJd1KNPutHUBN3lq0JkljKA5DoXN6KeGfjukPuZTqXkY2nRTwb33C448/ARqlTGiyYi5A3tYXp5j785llhf7LC/0mNvXodvt020neJ4gyzVZpllZTslzTWs+JawWRDVD6CmCqsJvBIRxQlEssmdXh95Kl8CEHH/y4XQ6fXq9AZNTU0Rhlbzvk3UifFvjqKOmyW2XLB9wYK7FynJCmlrCsE+zNs7sVMQxR69HKUU6Z+hmjrE1NVUj8iJ8QjpzHlmvSt6vkwych+3CYo/ZdRPEFR8pfQaDvpNZIkiShPn5BXbev4s9+3axc88BjjiyytRYzPrZaSbHx2jUqqRpQaoH9NIucRThC4WnJEYbCqPJssSxdaTEEwprPYxSGOtMq/OswBi3ueF5CmM0g6RgpbWMUoIwVO6GXoICYt8ZMldjJ6vzAo96o4KUYLSmGsf4QYDvuQ2KwLeMjTWcf5J8ZEvtHq2hH62hH62hf/72n5DaDWVwq4+tlSINB9ghj5UDTOucQdIiydqkeQeMwZi8HLQ+ygRoG+KrcuHDd2ABawADy6EDcUiPYXWACtY8bn+SISPl6g9CCoYSLwebKSDEVzXiECYaBZ7nk2QprU6Pbt/R/IusACHxPUElCtCFJQqdx1NPZKSthKwwCDS+EhSpRmcFusjxPEUYBgShjx/6hLFPfTyiMRYztb5OtRYTVyKKwuBLRRy43aaiyFGlBtrzFQJFFIVU4pg816RZQavVo91J0NYQR1WsSjHkGGvxFEhpUMrRqYUw5LpA2xwvhFozxIsMhRUY43aehbBI5f75fkAYRsRRFaV8LJok65KkHdK0g7AFEoUnLYGShJ5P7FeJ/RqxV8UTHhjrjkfnLkVPZ/TzNrkekOo2ygvwVECV0kBOeg7dtZT64uEEbA5JexiZ2z9EFnfI0BzST83Q64mS3RYjrKOmFzpBqAA5oqvaQ/rf8P3W9v3hrsbo50d4M2WcrlROp+zGWEkFplxH13ymYXsoyDdM5BiO9+FiOXwu1qUCDhfV4d+pMo1jeB5FiSQ700DJ0JvC/RKUEOhyg2ioc5ZaEvixM8jERdtKITlmwwm0xjaybnwDS62DNCrjbJ8+hla+QEGfJEvxZIFAsKGxkeWVHoutFkvLXaxNqVUUvW5Gnmq6Kz2qNc8Ve6JHc8LQmIAglPT7XW6//U58f4aoWmGht8LK8jzt9gq77ptj0E1J+hmtxQQLeJ6TPyhPgfVZWepzcGGJLE+JqBMFNbZtq1CJIsbHmlg0B+eXuf+Bg1iZE1YUKhRIDMoYGuMRUeyR5wWFTsjyHkm3Q9130mEjcjqdnKRfcNR0jYqqERGhrR7Jll1ypMYKTaEHGJuxefxYNo4dxkRtFmsNhc5QQ88BBFHUwFMKT/pYAbnO6af9EqTO6WVzZFkXJXzayQEy00KIHE95aKMptMbVRmtYig8ZMqv+bg8ZU2uYqv/ldigmfejXX5BmreXb3/42rVaLl7/0FQgJn/jHj6CzDClC6tWj2L7lCI566eHsO3CAmdn1vPB/vIiFRcGevQ+yvDzPYTu2MTU9DpQJomtA9GE7/PDDeebFv8zWrVuZnJzkIx/9CJ/4+Cf43ve+97Dz3HAe2LZtGx/96Eex1hJFEbMbZvjVX72E7Tu28ta3vpWtW7fyqle9ine/+93ceeedWGt53KnnccH5F3D55ZehvApHHHYsb3/Hn1KJI97/N3/HPXNXsdzdz0qrxX0/XiLwYn7zBa/iW//+bfZ8+d8Y2+jhV3zmH7Bs3t7Aq+S0VnJqMwpVl0zN+izMd7j2yj28+nfPo5+mXHXdHXz/ig8wNT3L8y5+I2dXdvLg3bv48Me+xJNOO4VfOe8ZvP/dH+O+e3bSXtTMLTxIveGxccLHin3Mt3pc/73dHH/MLOefcwwf+/AP6HY1Y7WAay97kPGZgKnDQlRFoiJ3jo7ecjrnPeZ83v3nn2Lu4EGWWwdpbhKMq4hbrt3JM59zHlu2z/Chd3+XI7Y9hrf90TP4m7/8PLUpy0XPOQHrJSwtdPnrd9zFb73kqWzesoFXv/q1bNu2lb/+6/fy3ve/i1uuv5/mxoizzj0eZWv84xc/yMpym2a8nrm5Lsb0MeSMV5pUgnC0zg3ba17zGk455RQATj311EOu8UPXhNe97nVcfPHFozorTTM+86+f54Gd97Nz5710uy2EAK0L3vOe9/DZz34WgOc///mccsopWGMw2lKkhu994w7iqs8Z5+7gkl95KlmWI6XkV371Qk455TEY7THWqHLGGYcT+D7HHfsYPvrRj3DssY9h5wO7ecef/yk7duzgYx/72M8/yP6bmzXOJyiOY5SMUCokCGtok6FNwcpKm8mJceq1OoWWZRhPged7JEnC3MG9tDvLpFmGJwuiqELgB1QqHtpYKCzauFpdKoEnvHL99lxNN6yBy3XYWWgopBwmNbk5ocgzCl2QZ6l7Hc/ZHhhdkGc5Eo/QqzBenWbQLKh6TY48/FiyImGQdeklbcYaTXZs3cHcYkSStsnSDpkfIX3YvnkHS0sLzC8e4MDuNisrPZKuQWDJBxYpUvxQ4wcaqXvoInYSxZok6yc8uLiPSrCeSq1Kopd58MFdHJw7yL4HVui2U3qdjJWVPnleYA00GxUazQpCwtJyi3Y7od/LCKuSaiUg3BgTeBHVuEYUh+RFzsGDi6R5gvAEvf4KfgTTjYCNW8eQhCR9Tb+f0+4kIAuE785Zkmj6PU06sDSrDSaa69i0cTu9XhdLQVg1jDViCiHo9TIyqwgJ2bz+SNZNbmHzxsOJwgZaW8LQsQaVDBhrTNGolfdYVpIMUpaXl1haWmZ5qUVnqcfS/AqRH7MwN081GGOsPkm9GhIGkij0yHODMZbllS5D1YgULtlOCuVkeeSAY4EZY9xNcpZhrEGVZuxKSvI8x1hK6xW3SZzbDF8FZbKiJC8MySCnqA37lyAvNFneZXFxQKUSgQBH8BOgHtmL8qM19KM19KM1ND93Df2fMBdnOKpWQZ3hwYjhYHEPjE5L+bM2OWnWIy/6FDpxg8FoRz8kxFMFoyhKfOcBhBoSCd1nHtEULavjbi3IZNccx1Aw5n69Vgtr7ZBCzOh5Qigc8GSRMsD3IuKo5naeshSjPfJMkGGxOkF5TnoXRQHGgCctUZyTZW4S0bnBGpC+RGeaIi8o8gI/MISRwg88gtAjiD2q9ZBa09Howzhwk3rmkvVC33lLmVIXLJRjUnlKEYUBUeiQ034/YaXVI801yhNEQYiRoJGkeTZCSofMJ2eIl2NsgRcIqrUQP5LkBeR5Qp6DsTlSgZTW6YzLNAcrHNssLQZkhZNNSgGelPjlsfnSI1TOkNxTgbuO5fsWRYbWGZlO6SfLZLrHoFhydGI/xvdigiJCq6ikcK6hj2NGN0trB9xameeh3XV1VFi7ClwNYUolfIZeZdqkeNIZK64uEMNOvwp4UlLaR2iUeGQvlIc2d7xSihETzIGuQ5B2lck4fPpD23DRXLu4SrVml2q4wNpVVporbkuGpCkpwqNzeyhoNwKVcZRYzRDU1k4agHWRxCVj0VMBUVBhtrmJeqVBJa5RDetUgyYzjY2oQcCgaNPT+7AiR0nBRDxO2rEs5B0GSYqQOTXpUWhLmhp63RStLXluwQwAgedL/FgwSAbs3b3C1s0tqoWltdJj//4FlpcWWJhfIu0Z0oEhzyyeL/HKQs1JZhXdbsLKSrcc087sfmKywvhYjfXrJml1MpZX2iy3etTGJBXfJWoIafF8qNZD/FCRJBl5kZAXAwrdJ9YglIfwLMYKisyjGoxTD8apqTodkjIZZChPNmiRoW0G1jBT38xkbZZqWCc3TlMuhSqTWwRBEI0kAda6XXhjIfIrhHlMN21jbAZW08+WyIoO2ib4yi0xudajMSuEHc3rD73+D/fzz7Jgrv2b1SH504z/f5HG7GpTXsjeffu54ooreO1rfhutC+6843YwBUpWqFcaPOkpJ3LUsRu4/MofsH3rJk45+QSuvOoeFhaX2bfnAGee8Vg2bpxmz549BIHPunXr2L9/PysrK6P3mV2/jouecREWS6/X47xzn8i/X3rpwx5THMdMTU0RRRGTk5O88IUvPOT3J518Escedyz/9E//xPbt23nSk57EP/zDP+D7PtPTMxxz1GM55sgT+eKXPseWLUeyffsmvvf973DM0cfwkt98OfKu3Ty4N2V5vsPC/h7SarZvOZKtG+5ldmIjHbmAH0QwGGdiukYuB7TbZYx8UVCfVHQ7CffeYXjuM7ey58A8137tVu6//j6O3H48b/qdt7K9eTP3z9b55Me+w6bx7Zyw41Tm9v8VB+eWMUawd99uxvoetVChZEKeCfbev8JpJ23m2Mesp71gGQwMU+t92gfdeGnscDdR0hNYDdONzeyYOYWrrn4vD+7ex2CQc+EvH0ZkJSsrbXZsn+XY47fzgb/8DCcdPcEZZ5zEP3zkkxzx2HGe+Mwz2bVvD+1Oys03LCJfWqPeaHLVVd/nuOOP5sKnP4UPf/gjFEnB0kKPw7cdRppobrnlaiar66g2xhkMcqTSCAW+lDTrdTZt2sTc3BxSSqanp7nwwgt52tOeNrp2xmgOHJgjjmPGx8cBSNOU+fl5zjzzTM4777zRc7vdHj+4+jrSNEXrdPS4tZarr76aJEkAwYknnjgCtzBgcsuD9y0yNhETxSHbt21Ga1fvHHnEDjZv2ghGYm1GEBRgDROTU5x//lOp15vsfOABLrvsco477nie/OQn/3wD7P9C09rpAzzPx/cDPOXjBwptPLLcMBgMMGYM5blgGa0FhS7XQp3T6iwzSPsURYERirzIXBISLlXYyaYcC8MZHK+94fjJuPqhn48QBmsF2oLFkGUFWZaRZ6mTwQgPhHEJbXlRAmg+9UqTqWZBGmVs2bCVrEjpD7qsdBZpNpusn9mEpU+n67G4uA+rC/A1U2OTdFsdeu2c9vKAfi/DlgnRuYbOkiaIwQ8tQicEvqISh1Rjj7SfMX8gYd10m0Gq6WXL7Nk9z4F9c+zf1SIdaLJkWCs6A/xKJaRSCbEY2p0+S8s9sjQHG+L7HmOTY1SiCo1qg25/QJqltNsryMDgSUU/6TBWiRmbCBmfDMgTRa+TkSQZ/X6C9CVepLG4NdbZJklqcZPxxhTrptexZ/9uCjug0iyII4UWAb2lDGEUvggZb65nYnyWseYUUkXkQhOGkZO8WUEUVkeBTv1Br0yaKxw4YSwmtyTdlG67x8pyi+mJPkWeUYliPC8kCDw6HZf21x0MEOUmbOAprBIjUMh5qjoZppPplcCTMUhPYq2z93ByUIHxlWOCGItBI31XL0npNjfy3JmZO9aUxGhNnme0WitYW0MqhTGOVSfkI31tfrSGfrSGfrSG/nlr6J8ZeNJajyh9zvy57ODlwiaEcBTD4a5J6fOkdU6a9mh35ygK50ehTc6gaJPpBCEqeDp0FDVbw9M+uY7KGEOJEquo8jC5bJWJMmQ7Wcd2spQI8VpkeRVtHqHH5fdDUrby5OjkZoUm0zlJMQBp8ALFWLOOlIpKFKOWwaCxopTOaTCeccZ4nmPpGA2msGTG0O/l+H6fVquDkIK4GlFtBuREyDhmYl3sENi6AgqyokBYhZTOwA9jMUYwSN1i7yufyYkxGrUalUrM/v3LtLsDVto96vUKlThkrF4lyX2yPCUVGpMXDLRmebmH0TiNvXQDsT7u01QVsIJer0On06LTa5Mkuux8llwnJHmXTrLoKNE6pZMsUpgUpXxqwRihHxBHVapBg9ivEvrRyAOqMAXGFBiTkxU9sqJPkrdoDfaTFD0GukUYVAmLipO7laBlLVJIL0KpAHSOfghqO+qLQq6y3ViVeK6ClCXAOAQnyyErhYfvVUpArI+vGkgbjBhUxjh2mBA/ueNbKv4O6W+P/LZq2r5Wj/5Qs3RjVosOrXWp3xcjTw4nddWri2f5N9pafN+NW1vuwBxCKwbswwB1w+tl1yy0q3NdeYzS0bmtNgyyLtoUbJo4nOnaRrcLJSWNaIJGPMGWqWOxpkDnKRuCrRSmoNWboZBzWNmjrqp02x08Zak0QEhLVCuY3W5J+paDuyzLSwnz+wWVSsbCwQGNfV027aiyON/jrnuWOO7YNhbJ4t4+O++dY2FxjkatxqCT0VrSPOaUjQSBQNuc9RsnaDbqGGNYWu5xcKFLtR7hB2DI2L79CMaaNcZqEbfeeQMHl1aY3lYlKdp0bcrc/Aq1esTY2AQz6xok7YIHHtjL0so8/bRNVDf0el281GNm/RhbZqeJaXL09hMZH5thcmKW2xd/zPJgkaVkniiIENLSS5aoRxNMVNZx1MaTqEfjWJPgKQlSIYQ38gBRSozkzN3BPEoqNk4fR60yxUpvjvsO3EA3nSctOrR6u1js3MdifYYtk48hLzy0KShKfwpnpba6bIqHWdzWjqlD2Ytrvn+k16j/h9uWHafzgl97Jr/3+pfyjS9eTaNZ5U//9J3lb90ObKfbY9++A3ziY5/i6U97EiedcCxnn3UY1u4AcSaB73PbbbfyxCc+kXe84x28/vWv54lPfCLz8/Oj95mcmOLxjzuHSy65hMsvvxxwgMPDtfPPP59//udPEceVn3rcQRDwjW98g69+9ascd9xxDAYDjj32eD7/+a+y0j7Ig/vu4eyzz2XdzDSTM2M8/6Vn8qNrf8ypZ5xEoxpTqUVMb5rGiwWaFZ524VP4zRe/nC994Zs85fzzqdvDeP6v/CE33HUPlTjh+c96Ip/86Pe4/vq7OfpJHr0FmN+j+dAHr2R2m8+Tn76RCsusH58kDEJu2Xsbdx+8nrf/5a+yYWaa/Qfu4MMfeRs/vOFaPvHpT/CRv/82Nodt2ytcFJ/JEZu3smHHXVx3723c8tFbWWz3yAaWbr/ga1/+O/yq5ZVv/1Xm96TYxDFqD86tcP+u3TzjVQ2uu6rDtz+5yI0/2s+6jRWe8/IjuHfxOuZvuZtPfP4FfPXzd/Oa17+Fl73ldJaXEv7lozdysNVm04YmH/nMr7NpwsPzc3503X9w403f4Wvf/Dv+7TOfpVprIpXlly5+Otpb5C1/dQmXf+MeHtw/4EXbpxkkGe1el30HDnDek57MC379hTzpSecxNjbGV77yFeI4PuS6dTpdzj33XC688ELe9773AXD11Vdz8cUX8+lPf5oLL7xw9Nw8z/jOd7/OMy56Bt/69lcPeZ3nPve5fPOb3+Sh1a/VQK54wcvPRvmCotC84x0fZ27/Ih//xz/iU//0Va647If8r3/4E774b1/mj//4z7nssq8xd2CZl770zXzoH97JOU84jRtvvJE/+qO3ceyxx9LpdP43I+j/fWu1Ovi+chuPoY/WmoXFfYyNj+P7CqMNB+cO0lppsWnTepIkpdvtIiabJOmANO8hlSaQikCFhEGI7wcOGEJgratFh2lZLkHaoo0d7RsPvTGcf1SAtXoNoxwn7ytTio0pJT4aLI4B1e+3SfMcYw0bNmxk6+ZN5cZjxVVZ1uIFRxCGoQsi0JpuOEksxvE85+mTpgv0uvO0VhbQomQejdcgd/YVraUe6UAjZEFnUZP2DEnXYJIGvY7hwN6MjRt7pKnh4NIiD9w9x969c7QXE3zPJwp8tm6bwljDYJBQr1cIfJ9BL2dpqcP8YovMFqRZSDbwOfrobc4vCY+FxQdpt1OSLAOTIzKDzjXN6fVMzjRQwTKtdsaeuYOsdBZod1cYaONurD3BzIyHNxPjyxqHbT2GjRs3c9gROzjQvYtefx5NQmBCpAqYrq1nsraF8comIm8cqwOSJGNyskZFBgQ+dForrPRzlBgjrsYoX5FlOY3GGCeccCJBELBr14Ncc22EEGAyyYE98wRiJ0VSsH3bYdQbTcYb4/iqT5rlxFGIRUMJPpkywKfXTSjygrwoStaS6xeF0c7gurDO1F4Kev0B1WqE71egrNuF1FQagihy6gzfVygl0SVTKAicmgUhRuCqUh6+7zxi1UOMth957dEa+tEa+tEa+udt/ynG09B/adjvV1HbQ/Wla2/2rdUl2yVHSZemkeUJmU5Jiz5CWQpb4FkNuUVJH89kqNKwzJmWuR0cYYcggywHmmNAjTgpayiI7hBWB99Qlzuil4vhOR/yYizGajKd0M+7tAdLWOGAMg+fIBQOABFjFFo7MAVDZgqSoqAoCgrt4mFlSRcVUmIwpEVBv98nigPn3xQqotgnMx4qAKGMYyAVmiLXCO2jrMSEFl0Y0kyTJDkWge8HVCsxSknyoqA3SMjzHN9XVOKAKC6NI7XAaIEixFqFKQqygSXzDUWmiSKFLD2cfC8CJFbn5NmALPOxJsD3fPc+esAga7HSVxhr0KYg1874MQhC/FASeCGhX8WXMZ4Iyl2TfHglStPYzMktix79fIWk6JHbBCsM2mTkhSQrBg6BVqmLBLVDo3qx2v+QiHLQiWFfG17XNYOq5CmV/bA0KbdDDyvpzC2VT46LvDSmwApdFnGrr7LWV8qBoKMB8VPQ4EdmE6V8FVsytqCMwD30OaPnjoDm0WA5JFljeD3KP3C/X/O6rGEpjlIljRmNt+H5PGTRHH4dFsHldbVDYBk7KoorQY3Ij0dzjaPBWox1EgVdBg9YY4m8GkYarKiBzBEqw/P7VGOB8iKatSa5TskijdCGdEyQD6C1nNHvFxTGIqRg0M9QKIQsCCKYXT/F3XcGdBYMeTfF933Wb6qwZfs6EJZ2p0u1WiGOQ3wfwtgxHS1OThJ6PpWoStIvuG33LpbbHVKdoKIctEEbi7UF1UrI9NQEcRTQXc6YX+w6bzZhEMqdd20MXgBj8RhT8RbGmtPUKk0CP8LkA9JkmV5vP3GwkVrYZLJ2HM3KOsYr66iETZTy0aZwRqcoPC/EWufLMBxNAkYJlp7n06zOEAd14qBJqrv00mXu2HM5g2SJfQu3MVvfjhA+gTfsB4zIgnbUrR5CA14lGQ5/y3Cj3v7kAP+Jtjok16wFw9dd+/ghrMmHf61HUltZ2sN/XH0FH/QTzjjlXJJ0wN/+7d/x7GdfQq1W5R8/+SnOPONxbN9xGL9yyUX0ewM++IGP87znPYt2p8Ol/34FFz79fKampnnta1/HaaedxszMNK94xSu4/PLLueKKK/gfL3wRT3jCE1BKcckll7Bu3bqRfO7h2n333cf73vc3CCFYv349L37xi/nGN77BjTfe+BPPve222+h2uzznub/GCSeexEp7ESU9GrVx8qKgO1jBzPc5+bgnM1k9ipnKnbT6y/SyLkuDA3RbA5L+gHBDwb723fzgPy6ltk7TmBakWZflhT4ryxl+6BOPS6IxOHhvQWMsYMvRAa3BCrVug7CYYXprB+Utcdnl/0ZjfJbTj7yI9tLdzK3sY+fuvbQWCu59YCfLBy1J4m60vEix0u6yb98icw8mrNsmGZ8O8eSAuKlYv6nGHfd8jyTPOXh3yrlnn8Vkc4pPf+ZrNMammJrYxl0/zKHX4BnPPIxMzGHIeOCeFsLvEYRLrNyfMNE8il97ztnccNU3sX7B1KaI7UfPIArLlz77Y3792U9m3XiNm2+6AykaHHP04/jBDy9j6+bDOOWUs/i1X30huw/exWXfuYUimWCquZmkr8lzjS0MnX5BFGlM6saK53nU63XA+Xh99CMfIctzBoMBBw4c4Ac/+A/e+c538ZKX/CZFUdDpdCiK4pBrG0URr33taznuuOMOST0EJ6/bsmULH/7IR7j00kvpdDq8/OUvx2rJe97/F7ziNS9l3ewMSMs5TziJTqsHAk448Siq1Qppqjn88CP5rZe/hMmJCTwv4td//VfZtGk9nlLU63WMsXS7vf8zA+2/sVWqMVIySqtyRsBQiV1M+2B8DK2dJ4xjI63W3FJalGdRykcKjzhoEARuo8yZ+o4ECeV4NaN5TYqyPqLEnWxpDD0a1o61ISXOmiEO8AOXlGe0Jk1TrC2wFsKwQq57GF0ghaRSiYkCn37PMRukcgl2QggG/QGKgChoMN4QWDKszVBKMzk+xsYNswz0gCQfkJsUfIHyNIOBIvAVSgp0YckSzeLBPlIIilSSJsIBb16MNB46B50ZPE9Sq4eMNWts3T5DoQtWlttUq1V8P3CG7FpgjPNSUXgIHWByRT/T9Ht9Vlo9kiQljDwGSYG1AlWVRKFPHAV0OkssLnWYO7jXKTg8S1wVKA98X9BoetTjMerRNBs3bGSs2cRaZ22R5gntxTZjjWlqlQqzE1sZq22iEa/Do4LvKYpiQJ738DwP3xMOSBSgPFVeXwdIhGFIXInZunUrtVoNPwgcEwPHys+ygr1799NsTCKFT63SwBQaqzUCg6cUw1u3JMnI8oLeYODAymEKYikVkspt7UopUWWn6nXbjhzg+U52Zp0HUafXo9dP3T1RbvB9Qa/bRUiB8kTJ6tNrUh0Nnq8cE6oY3jM8MtujNfSjNfSjNfSax/+LNfTP7vFU/uehg+oQPevwptza0c6Ho5MVGFugZICwgn7JmklN4tIRhEbbAotGCQ9PByjprwJPJcLsvnePKelkUhIHQK2m6K2enSFdcWRWXi7G7gSuATREecwl8DTIOqwMFtE2QUqohTXisEocR0RhSJYVpHlOL+mjcwcO5UVBoTUIi/TKwkIIjLTkuqDX7xNXIwpd4PseYewTGoXyAWmc/CxNSQcZyob4wkdrS5YZ0lSTpAUCiedL4jjCGEOapy7dxEAUelQqIWHouQlDW0wh8ESIQWGsIk8leQY6s6hYIj0BShIEIRKFzlLSICQLA0DjK5d+kZs+5BZtsxF4U5gcoSD0QudZpSICr4qnImcabzSFHhYrzki80Cn9rEVSdOnnK6TaeU4gLdpkCKDQA4oipfDy1d4vVhPphBBliTRsbsANF9zRY+XXQ3cAhh5k7tpQ7vgZW5BmPbTJUaJAqdVhYe3q61DuTNg14+AXCnhaM1ZGC9YhbK7V3Zvhgrl2snF6dDM6n8NFc7iwCgHa2jL9UozOlykXvGGyxzCJcuQvA1AC1u55OOq4Hb6fYUh2s4CxBSCIgsooEaI/WHYFk9bOwHE49xiNQBD6MRBgRE7KboSXE0YpzVqA5wU0q5PkZkAeFwRBDrlHPrDc2VkmSTS9XkHS1whhCaSHkJogEoyNT6MI6S1b+jJj0/YKm3eMs3n7OrK8gDlFpVYhjhxAG1V94lpAp5OipCQOQ0I/ZG55iZtuuY/EDsAv8IMMEpcawnDRnBwnDH20Niyu9MitAeUKXq3d+VSeodkYY3ZiC83GFGFJ783TDml/kV5/HzNjU9TCmO2TJzFWW0+9Ok0U1sC62GUpHa3bRQQrrDg0ytXJk51EIw4mUMJn0+SxGAGdwQJzy3eSZV0OLN1JuvFcQr9KoBztXhsoNKPiSA638tYuWg8dUtb+tPXxYcffWnbiIUf9MC+yOo5/yhs8gtrywgN89zsPcOX3vs2NNz6LPbv7vPc9f8tpp53KunXTvPe9f8Mf/9EYp5xyCi94/q/wyX/8LO99zz/wtKc/ib179/Gxj/0zJzz2OE477STe8IY3EIbOi+PNb34T1WqV66+/nle+4lUcfYxLLnve857HkUceycc//nG01g9zRIK77rqbv/iLv0BIwYknnMBznvMcvvKVr/CpT32KweDhjcWf+7znc8KJJ/Lj225gy/ptjDXGmVveTavbpdO1PPaIJ3H8YRlnn7KfG++9gfv23s13r3mQ5EBBvwWTJ0XMde/jsisGjG0y1GY0S8t76Cxn9NuQ5AVhEyqTkv0/zhg7PWTLUSG33dCl3wux7QrTWwMG/SW+/q1/5jee/zaOO/IM/v2G97Fz/33ceesD3HF9i/ZKQrujMUYQVBS1RsDi8hJJUrD/gYTZdXU2NOpUwi7jkxUee+IMP7rx68wf7LPyYMa5rz+Tk085lm9c9l2mZmZYN304t34vY/2mGhe/4HTu2XUtu3bPcdVlB5EeYAU/WNjPG9/wFP7HC17EE574cca3Wp78a0dxwuGHs/vuFd713mv4pfMk/jF1rrryK5zzhDM48YQz+NSnX8JJJ5zOGWc8nhc894Vce+PVvObP/pULHncx6zcfTq+bo01GkWUkmaHbzVhe6OB7Ab7v0+/3AdizZw9/9o53UOQ5QkoGgwHXXfcjbrrpJn7pl1YZTmmajv4mCALiOOaNb3wjRbnJtrY973nP4+STT+bjH/843/zmN7n22mu57bZb+dzn/o3f/d3f5ZLnPYPpdVMUacZTnnIG1kKSJJxy6nGcetpjuP/+gxx15DGcfdYZWAqqtQav++2X4vtOmmatpSjZA4/0Vq1VsEaXMhcHPCmliOOYKIoo8oLBIKHQ2t34K/dPlCHQnuf8Lz0VUavU8f0AEG7+x0mArHFVrksJG9bFq5tv7v+lZMcemqQlBHiexPcVWOcJ1e/1SftuI9BTiiiuMhhkaPcqRKFj2nc7LVcPCJ8oDCnygk63hbA+oe8TNmLyooPWfUIEM9MF2gq6WZ9Wb4WV7hIEBulZoopHrRIS+Ip+JydNC5Z6A7JUI/ERJibwQuIgxhcBwiisEQSBR3MsZt36Jtt2zJBmGX4oqEZ1FB5ZYsB6YCWe5+HJAI+QLBUMBilzc8usdDsUJiWOfZJ+Tp6VaXdhQBSGtFqLLCwsMndwD9qk+KGg1lRIafF9Qb3pMzM2xtTYRjbMrMfzfPI8ReuMNE1ZXOkRqxmaYY3ZiW00quuohJNY7cBFrQekmcLaAM+P8QNV+tysBZ7cTWsURWzetJmZ6Rk2bNiAtZY0zdi9aw8HDhxgbvEgG9a1iKMqeeb8uYoiwxQFgR+iPDUCNBzYnDiAqZR2SU/ie4pAOI/cIAgQ1klGl6RESIlSPp7nY40hy1M6nR5ZVtDt9Gg261QrMSutDmEYUK3GDAY9hJA0GnV04TxfPc8jLdLSOP2R2x6toR+toR+toR/+uf+ZGvpnBp6kUg5Es6uGziPWkXv7Eci2ihcItMkwpnBgkfCxWNIiRQNCKYSnwBq0TUh0tgoyoUqAwBuxXEb/ExJPuEhTX4ajOEcp/dHEIIXTRa9F+oaTwggddChZecCl/AqFFAFShuRFhtGaJE+dYZ7yiOMKceh2TipBSNcbYDUsR13SNMWLQCqBUoIgdANaCk2SJ/STAckgxZM+kR+TBqGLV0WT5wm9Xp9eOyGUFo+MvGbo9VIGgwxhoRIH+IFkkA3o9vt0ej2Er6kGEc16ncBXGKvp9fqAwPcVtbACJSW0VvGp1QLGaxFxJLHCYtIcPTAUxkIuqQY1wkY4QtqFkBgD1iakOmEobVO+KgeXS2IYUmSTtI8poMgNnlc+LgzaFmhbMMg75CYh1X0Km4Iw5Tly1zr0akRBgzho4PshSkqXfKfzElxavVbGGMxaBlL5W230aFI+RHZZPtMMEw2FQOLkkY7xlGFEjhDBaOFYawo4GrxrYhyHcca/CE2qtQDt6nkbLl5ud3Vo1r66yGntFkpjLL7vPNi01hgswlo85fzRrHEeEKa8CXC0YlcID0Fgh/K6nRxtChDO4HCYD2jKhB2tC2RJDR4ekzNGdRHDLlJ1wHD8Gu3kAS71Q5bzsHA+F1gQGQYPS4DHLJtnYtZPrefoHSew/+Ayt965i5VOH6EMs+snaMxUUFKRJQH79y1z4MAK/bYh9AT1SLJysEUlqjB2xCRx3aM+6bN+ywRHHL+Ow4+bQQpJUASs2zDFZL1OqCTWOHNAVzR6bJhdx1GHbefOe+7ngQcPcvNt+3n82ccxPhFhvQ777Bz9pAeqj7EDirzPwkKbzPaZ3REwsXUbhc5IBy3a3bYDbG0bQ4GUEdPjmxlkXfavPMiBhftpDw5SD2KsaVEUi6xrrKdRXU8cTVAUfSeHLXI6aUKSd1jq3UujtoFqZYoNU8eRZT3yrDeiixujSa0rIlPdx1MhnvI4ecdFZPkAbTTWCrJiWMw6NqiSHoUGbcoCSazOzP9d7RcAV/pPtWRQcPrpZ/LDH32fyckplFRc8x/fp1qrUxQFd952G2ecfiJf/+anmJmZZnZ2hi9+4R+ZmBjnzjvv5FnPeiZ/8id/wgte8AKMtbzoRS/iWc96Futn1+MHjjX7spe9jO9+97s/BXQCsJx//pP5+7//e8By1113c+KJJ/K7v/u7vOQlL+GCCy54WOnTdy/7Ou3uPE9+4gV0Osu0OgeYGpspb7AFd957F0p6NGuT7Jg9isFSynVf3sWf/ck7ePzjH89Lf/t5nP6MC/kfv/YSPvQvr2d5aQ9/9be/xxt/+w/pdjWv/Z2XsbzYpt9PAcMdP+xwzw1dNh5Z5f6lJe6++Tre+Mdnkqea33/rpUSVL3HMA7fy2S9/mn33tji4c4AucObXhaXIC7ZsGucVL386X/36Ldx44/VkaYFXsTQ2CJ79nLPZsXUDjz/ncH7vdz/NvqU5nvX6Jh/99Ef50D9EvPFPT+DMx24hCHzCiYJ7997HB//+AFtPqNLraxb35fgRbN6ykS9/5+N85jNf5snnP4l3vf+57O/M850bruebn7qNozY/hhtvuB5p6izOabYd8Vhq9UmEVfzBq/8ntUYVYwwvfPHzue76H7G4vMCWZ09x2uN3MN6ocesdO3lg13086+lPR5uEpdYB/vWz/8LNN93M8ccf7wCcoqDX6/GmN72J5z73uVxwwQUsLS4RBuEh69xrX/ta3vCGNwDw1re+lZe85CUA/Ou//itve9vbDrneH/nIR9iwYcMhjzkpmFtnbr9nmetv/nf+5i//jL99/7vZsnUrr3zVm3n5y17Auec+jle/5tU85Snn8TuvfyWvetWbmJmZ5s/+7M28/OWv5oorrkDrhKWlxYdsPj0ym5ICjUBYSkmcS5mz1t3Ujo+PMzbm6gzndSrBSqzNMSbH2AzPr+ApQZolFEVBliaOveP5KM9z5ckaptRw1R8yH4TAeXUCRaHJc0OW5o4FpCS+F5FlCWmasLC44Oo96RMEAbooWFpawQK+CglDRZ5ldHVKEPoI4T5jv7fi6gZj8H0HUIDA86tYQuLqLNXGNOPT6yisx4G5g5hsFwsr+0iSDCFgeqbKWLPCytKAfXvaLBzs01lJS9a/oN1pOVCp5jM+XmUwaCA8zdbDJth+2IzzztKKWiVm+5btBH6FbjtnfqHHoF8wPhGxeVON9eur7HrwAVZaCYvLXabW+TSrEXFVIqyl18vIE+i1cpYPujo+Sw2VaoVNURXpGyoTKX6cI6Qh6/sYWcPzJ2g0Ivr9Hgf27WV+T4t22xDYWepspeltIlJT+LJO4EVMzY5hdEaStllY3O88trShOdakUq2BF5MVmfNyW5on8AOq1SqeF+B7komxCaR0N9XSxozV19HvD9i6dQthFNDrt7j//gdJBikWy9h4kygKQUoK7fx/xieaKOnMnIeG8tbo8iZZEPieYzcB4xMTjtU2KKjEri/7vk+apVhrSNOUQT8AI0nTfFQ3OJaVIctzirwALJEncT6/j+wx/GgN/WgN/WgN/fO3/2SqHQ97kz1EUofsoeFTrDVonbvBUcK+jgk1fG5pvFUOYFuiwcIKjIOmkORQpnSUww2BwJceyvhYFePJECl8FAGiZEhZWwJPtpwIhpdFMBqgbgwPUWF39XwZEXl1GuE0mRc7A27pgC6sR1bkLs7QCHxPUYlCxhsNWuN9hBCkWY6VBqEsQWhHJ8cKx+jCGqI4wAsEWlWQfoZAkwwykkFBMigIYlEeO5jR4q2IQoUXCJIsYZAmpFlGFIREkU8U+c6ss9Tye77C85who5AKKSS1akA19oiCACWgMIY8zdCFBiMQBEQqRvkSr2T9WGvJdVbqjwt3bcvdD4aMN+k8lozNSYsuhc7Ii3Qk1XM0XVNKExMKk6OtwdhSLmedP4mSAZ4qDcb92IGHAmxJCx3J6YaUUWtG1/QQpqEZkQ/XdNLVfjzaZSiNy12fdsbrdhRVWnZkO0Qoh2ivA7OkXaNFHy0Gj+w21KOXP5UM3iEj0I4mw/LJCCvXsBxdIuLaGwZTnivDKg0YVhH0VVBuaMIoMLpA2LIYLuNnjTFYU5RJRwV5kbpFU3iIciE3Vo/mhyHrThtHGR/uAI0YjuU6OewjQy86UW4bayPIjCE3OWEY0qjVWDc5hbF9CpOVc5Sbq2Qp7cUKdAG5hUQYWittamNVhIBKI6A5HVGf9IhqCuVL+p0OOreYXOCPT6CkYqXbottLyVLNxtlZxpsNfE+xa888rXafyfEajboDtlu9Lj4xgbQsLaXUqz2qUZtG3UMITVSDyco0hS5YPKjpJ32yInMJkGhyM6A9WKSftWkPFlxQQhARVnzioOaidVHuPBntdh51jiky+nmHbrrIQvsBZzqqBEWROIq3kKPkjNUkFVPu6Ljz3qisoyjTK8XIs2G4QoASFpQrZHNt1mxWDEHiQ/vtQxe8h6UMr33+Q7Ze7Oirfdj16793uf7vaUJAq7XCD390LWeffTaVSoVbb/8x27cdwcz0emr1OkEYEkVV0iyl30vYv3eJaqVGlmXs3LmTm2+5ha3btrFv7z6OPPIITjzxRMCxXq688kpuuukm9u/fD8Dpp5/O4YcfDsAdd9zBzTffzIUXXsiTn/xktm7dymWXXcaPfvQjdu7cyU033UQURVx88cUURYHWmq9//et0u10AqpUG9WoDOQLvLYUWdLs9+v0eURyji5z5+T1YmRFHdZ7y5CeycXYjkV/l8ac9gaN2HE29WmemsYPANDCFIB0cYHmxxcL8CmFdMj1ZIRQR7eU+rZU+7YUcYwqSQcq+XV10bui0UwIVUg1r7HtghaX5PkmiMQWsWz/Gscdv4eab7kP5gtZSxtJCj5WVLtVJSbdT8MAdGeeddDyelPzg+/eR2QzpCxZ2OxZtGFs2bVxPb7Cfm+64lH5/gNYFRvXZ96Ah9CTnPqXJ0sEKE2Nb2Lb1MJrTHroyRyufp5e0oW84+fjHsXn6CPbuXmRmKiSKYjZtmCEd9Ln/ngfYsnUb2jppzbHHHstg0Oeyyy7jxzfeTqM2xnOfeQbrZsbRZgPzCysYk5GkOVs2zFCt1Nm5cycA9Xqd5zznOZx11lkcfvjhPPvZz6bd7hD4PuPj4xw4cACAo48+mnqjzje/8U2uuOIKxsbGuOiii5idneXss88GYP/+/Vx++eX0+30ajQbPe97zuPbaa9m7dy+f//znue666wCoVTzGm5Occeap6ELSXhlw4onHMTk5jhBw6qknsH79LEvLPbbv2M701ARSCo488nD27d3Lty/92i8M89glVdlyLbOrqWFpjpKF8xstaxzJcD0W5FlKlmeYoSmtMVDW1QLIC2fFYGA1jEaW65fA1dnD9VGKETBljPNvdUCT29wbDCR5npHnGf1+D88LCAOwntvY1Fq7hGWl8JWHNRmFKVCeV5ouC6zJEUISx7G7wTYaa106n5Q+/aRPt9+lM2gTRj6NRoOZiVm6vRZFakBqilySJIZBUrg0tnLjT2pDlmcsrSygQkOlomg2q6Spk6pUaoqoBt1Oh6RfkAyykbwJLEEQUKvWWTczSbUiscbS7Q7IspzAd5K6wHfXIYw8V6No6LQz5g508CKDH/is3zCN0QHaZCTmIKYwzjtLeRg0ue7T7c8zGAxI8xYYCL2YRm2WOGwgRUCa5NQqgiD0yxt/A1bQ7/dod1ssthaYyWdoZuNEYeRqfG0pigwhLFnulaCCC0hy4T2WMAxoNhtUqxU8Hyw5aZailEB5kjwvaLfbdHsSP3Cp1UEYEoaBq7mwWJw/mBFDpo/EmCEzRxJFFaf2yCy50iglkMqtTVJSAiyOQODuBYbHKl2/FYIojhBAUTgPQQdyPHLbozX0ozX0ozX0z19D/xeBpyG1apVNMpxIQKDUkFIIee6kU4I1cjfrQCchVAmKOFhIMzQ0NFjcolpASRm0YN0gERh8KfCET2EqRF4NJUOggvPnkVjjOrqbMl20p5PpeasUyCHZSejyswhiv0GgYipBg1wPHFNHZxiboU1Gd7AI1qIE1KI6oV+hWa2BsTRqEYUtyMwATY4XFxjtYoOtybGiQEhLo1aF/4+9/w637SrL/vHPGGPWVXc/+/ST3khCAgFCIAkQunQxSHgFAbGgr4AoCAKiiAi8IioqSFNsgEqRFiAQEiAhjYQkJ72cXnZfdZZRfn+MudY+J+D3i/L9vYbryuDanJO9115nrjnHGM8z7ud+7ls6wkwzzDvk5ZBeJ6fXKRj0DK2adxFxCEwVMGtpSK0WIJVjubPCYOgThal2m3qakCYx2cAzowJV6T0lXg9KSk/XbtYj35KXBpRGY8qSQcdQFiU4SbM+SaM2QaPWopbUgcqR0AwqDaYhDg+gGefFJR1eEM+L6WUUJsM53xY5CjZRHPnFIwXGOYzzvcMjABIUSsYEqkYStkjCJnFUHyPt1o2AJ3vE9Hbr1qZCjPuiqwnpN2U5AhzXg8N6VWLUshmMNxo/247Qrnjg4quArzFgNhYX/OGF+mAcjhF9V1ZLeASorVdExmxFJEK6Crhdf4+RSKIQYvwcta2cHowZg5Ejm1jvOqGQSCzeXlvgbWH9GrSUpqQsMqwuMTqnLLPqdQoVRqggwlSMN1EFQltZmwrr3SUqWh5Alfg6cNavv4oppwKvDZbrktXBKquDA8xMtmm2Es445ViSXSVrvTX6ZcEwKxEY8txgtEMYiTGCXDuKwnHw0GGiup+fk7M1NmZtGpMCFTmGw5LlpQOYwoIJUJuOQciIw8v7WFjq0usXPOXxp5GmAdqW7Lx9L/VazBmnb2N2poGxltVdJSpoEJOw8757KIsldCE4/eQNSGlJ6pYdO7bhNLhyyMLKKtoMCVWMdQX9Yon7F26mKId0hyukaZ2kltBo1GgkLRrxVHXoyZAEFCbD6AJTZqwO7mctP8ih3l2I0Dsj9QaHiYM6oYrJisERQPBo3zcY00cIRaM2C/hELC86OGfgCKBWCUcgBQ6J0N5JR1s3gnuPHlW4Gf9bHB1ER60jR//OuPJxxOuOfp/Rdf8ULNsfOYJQccutN/PLv/yrfOqT/8KWrZt50++9iV955W/y7J95vhezPbjC3XftZ+OmGrvuP8Bn/vVKfuXVLwT8Z7/yyivYvXsXX//a5fzKr7xqDDxdd911vOQlLznq33v5y1/Oq171KgDe+973snPnTt773vdy4oknAvCud72Lyy67DICPfOQjfPnLX+bWW2+l1WqRZRlnnHEGd999N0IITjrxDE468Qz6w07lYBbRG5Tsvn8ve+6/nxde/GxW1w5y802XEzU3MjHR5k//9M3sunvA/Xft4jd/9TcJo5heb4VNjYezdSJgw8aNXPv9D3HbHbfi0Gw+rc38jiatwUbuvesAd96xl4O7MnAgQ8GVV+6q9gg4ZvPxPOyYs1jepclKS1hXDJZKTjl1C2982/P4gz/4BxYPrnHNlbs4sKuLzi1zx0cc3F9y6K4ev/PKC7n6qhv53Td8gIddOEMrSfn2pw9y1oVTnPrwGWZaO9h557V8/6aPs3xojfqEYOOOiGu/vsqO7Sl/9OET+PaXNtJfPo4oarPttBZnPKXGN75/JQxCGlnMm9/4FvJ+zB+/42941S+/mLPPfhiN5iauu/p6rtl5B7/4a9tZXepw04238rtv+F1u+P71fPOb3+Rf/u6zXP+dW3nZxb/GmQ87iVNOPJZ/+ORXCYVgfrrNYKMmz8344LRx40Y+9rGPEscJAH/xF39xVKJ52223AfC6172OE088ka999Wv88z//M1/92lc5//zHc9FFF3HRRRcBcOmll3L55ZcjhGDz5s18/OMf53Wvex3vf//7efWrX41zjiAI2LG1xelnnM7Tn3IOV115O4uHBrzzj95AWZaUWvPOP3oLhw53uO++BV71ql+kXotxzvFrv/arPP5x5/H1y778Q5pTD9ZhjcVY/6WNpig1w0FGtzNEl4I4jbHWu9Q1GzX/emMYZD2GWQ9jS/9ZpQajEaHASUFZFhjrkJWBzigvUsp3CKiRXozzQsQqUASBN+zR2jAY9FhbWyPPh+SFb19EQKgi4lgjcCjpQWJwBIEiDALCQPkYaUqSpOkFdIWjyAeEYUi9PsHS0mHKIkObknY6QxBF7Lr/fhZW97O0dpA0mmBycoJGMsXq8hIuF+S6pNeBfi9jZaVPf1CABKUETljyMmP3gV0U9Dnt1GOYm58kThQHl3eTNiGsFey5v8Owayn60O/1sNoxHBbEccTU1DTHHXsCeb5Ct7tAt5sjlWBmukmjHoJyDPI+aS0kThSryyVLi316a5atx9eZnGqz47gN6GGNTqfH7feskfdznDRMTkdYhvTzQ+w/nGOMJTcZUaRIoibHbDsRKWNwkk6nw9TkNPVaTK/bZaTL1e11ObSwj1vv/j5buluZnd1AGNSJVUIgQp8fCUdRVBIkQuGcJMsyjLEEQcLEVMO3sBWrFKU/FLcnaqRFzNpaj0OHDpNlOfVGnY2bNjIx0aLdbmGtoSgLsrzAWYt3/FYIJ9GlL4orJWjUmwz6BVk/Y+g0QYjXjsURKEGjXiMKY4IgJJWKKAqRlYSKEx5kmpqcREjYt3dPxagK/yeX5//reCiHfiiHfiiH/slz6B9fXFysW0aOelrXQaijtXSM0Yz0lMpyiKnQbFcBCB79pPo9g/M+kd5K0ymEXEd9PeLu+xitMRjjgaDSagIZ4QLPUlIirB6kZxVpo8cP1l+hACdRqmJHiXgdfa+qQghJKCLCICKhUVVYPBLsNYoypEsY5Ktk+RpFuUQUBNTiGrMzbdrtBu1Wm5XeMr2sRzdfptAFpdZEAuJUECeCyekGQoLr5AwGXQbdkuXDfYrCYo0gDGLCMERJQRTjaV65Q5clJjPkvZIASTOtkUYRURAggSgMfEUjcihlMDZjmDkPskhFGFqUirBOYrSgzGHQNzgjUSIkaU1Tj2ZppVPUYo9EOyzaFV6zyeYgSsBgXI42BcaWFCYbs5wKXYmCW4tSnhZJxVwCiVR+wx4htEJ42qCSCUqkCEKsE5UTRPXsxqCm9BskI7HNdeBnfbGtz8sjhfvG7CgEQnoHDlcBa8b6z2Fd6YG1Efr/Q2ug2pSrrtqfBmr/kWN9k3OAv3dKqfHGMQJfRxT9kai6MaOkvlpJQoyRcomoXG8MRuvxhiWEqFw7JFIG4+qu1j5oWuG134zRHpwuc6wpsTr3dF/rAWihA6SMkDLwCbOq9g4nMKZKhMdr3H8ZbbCuElAUvqdcioBQhYCjmx9mz9od7Fq+iWBRMNWY4ti5Y3nYSceDDVhZ7XBg5SALy0vsWzjAMNPI1DKzIUVWG21uS9Y6fVaW16AMiUWTbneByZmMMC5ZXV6mHDqwCboE7Qz33rOPRq3G5EQNLXPu2reX/YcPsXFzytzMNMcdt5l9B/bTHw6xaNK4Ti1IOeOE05iaSJht15hpT5GbAu0keafAlCXogo3TdaZbIfWkSWE77F+5CYTydt1hQr1RQyp/4KjF0zTiWUIZYnTGQOdok1HoAcNijcXhbgrbp9mcZVgss7haMJlsZaZ9DLXGJKXJfTXLVcxHP3sY0bOLsv9D88tWlGEP/AbV+oNIeT2JQDlKXe339gFVlSODn3tA4PwJgKOx0cBPIeMpG2rOevgj+dKXvsDJJ59EHMd8/CMf5/DBHt+7+ka27NjBWvcwC8u7OfHkCznr7Gm2bdvK3IYZdu8uOfXkR7C40KHfu4MPfODPOP300ynLkpe97GV8//s38sPpyf/zeN/73sf3vvc9XvWqV/Hbv/3bPP/5z6derx/1mgsvvJA//MM/pNWeJooDmjXf0lPmJbWk5GGnHcfDzzyFK6+4imazzkUXXczXv/lVFrOcyfMu5IbVz7B7992cfe6vc+ftt3DLD67jcec/m0F/iTtuu5InXPAynvKUmGc8/R4+9o//xDVfvp6tp/XoGk17ssab3noud922xMf+5jqu+eZef1ESnNNAweR0xOJCTp45fuHXHsv2rZu5/84hm+bbnHz8sbzmVW/nXe9+Nwe+/nX23Trghc8/nWc/8zTe/JZ3sv/gIhPzknPP3gxCsLS3R69rOHB/wZapWW5cu4s7b16hOR0ytzlh+/GTnHZek6yr+aO37OXlL3kFZz7rPK687D+48drb2PV9zYH79vKUJz2T33n9G9n5g0MoGfKW3381hw7dzbXXfZWHP/wCjj/5eGY3zDHsDwmU5PgTdiBlwBmnP5wrrrgC52B5aZkXv/hF/OzzLuFnnvFcnvHkcxlmA7rdDrt272FmepYrrriCN7/5zVxzzTU86UkXrTvDAs95znN4/etf/58++1e/+tVccsklTExMHvX9Rz/60VxxxRWceuqp4+/9xm/8Bi94wQsA+Pd//wx/+Zd/Sac35NrrbuafPvFpXvSi57Pj+Bne+56/4+yzTmfr1nne/adv5dGPPpufv/j5gODqq67lD9/xR7zjHW+jXk//kwrsg3PU662qnUUz7BcIETA/t70CDqrDJsZX3HWBCgT1RsTymgeerCsZZDlKCOqRFw1X0gNBQipAVi5KeGaTNn53c74VR1C181hTfVWHH+Go1VNU4N2NizL3rVcTE1hbkOeaPO8iVUgUJWRZj6EzrK4WpElKGIUMBv0x4ylNG1grWFpa48CBgxRFRhQHqCghKGP27D/A0uohVroLCLvqxTWcYsdxLY4/aYpGbTOHlhZYWl2mM7wNpUtCKwlqCowXEl9YWKTUOY1GQD70+kkIh7aaLM9YWupSDEG4iHt37yFQIfmgZDAo0Npyyy13URZ9irLPhg2zNJoxk1Mpy2srDLOCYqiY2zBJWouIoyHt+jQTrWm2HxejAotF01tdRNsB8xsSCu2BBKFCup2M1YXDHBDLpLWQ1kTI1u0NdBmyuLyLVmueVnOazVvmCUPJ0vICO2+9lTAIaE+06Gdr5LZHblY4tOgYDHskbGRuejPTE7PMzmxFKhhp1VrrMNpQlENKrUliENpgnWSY9ZBKEkUh7fYMRWFxCC/VoST1Rn1cHC619Sw4rRAu9nOmisnWAXjtVSECkjjCaYlJJI4M4Sy6NAyHOVme0+0WRNGQKAwqkeUYKQX9/pC8yFhaWgAMcRQxHGZEUUAQPLgZTw/l0A/l0A/l0Eevh/9ODv3jA09HMUpGYEBFvWIkULhO36MCnowpqla7kSCa9S1OjDvP1+legvGHGAmv+fcHD8qNVP0dxjikcx4EdBLw1oW4ESXRVNejK+Fyh7UgbY4QAUokKBl5EEp5Sqi/piM0osYaVsIDTzIiDQfVQs8pdZeCEikz4rBGFCkmWg2EssRxgBwYhsWQLM8QVlWBwhKEIzaO10LKh5psaPBgt0CpymY0kAQhGOs3mDK3lIVGF6aybpUESqJEpXsVeO0Ap8FYjTEWazz1VwUBxgYYpyo6psNohylBiZBAJSRhkyRqEocNwiCtnoUjIK0o1iVCGhCmYoCVaFMQ6gHa5hRqgJQ9tC3RpvQAZfU4pIBKSZ6RPLi1Hh6SIkAQIJC+GmhKSlMSWK8r4WmlHmkfVfOoqJ+jeXMU9DQCnsYU1weOatN3fn5q69tBvRC6Hs9HN341R/1NyB+2rvzpSH59UByt3TEQNwa33QNeS7WJ+bXkLV6dt3Ot9oCxBtYRwPP4+TgPLBtdVkHQoCvxSAFY66twuqrOOGtwRvtKjLVYU+JMCSJHqbiiageUZV4J6NsxgH2k4Hylu8iR1NPRD0b7ihIBSvrqsrE+WXXCEKiAZq1GrttYbWnWI6zxFam45QgCgRKQD0rysiDPcpIkYaLdZrlYReAoi4JuJ8OWklpcw5jKqrg/ZG4updmO6Wd9ltZWObS0zObpWaamGoRhQJblFHlBrZbSaCTEUUSzGdBuhEw0I5IwxlhwZUB/bYA1hlDUmG3Vq9aKkLzIyIu8MgAQKGW9jbWSCCkw1pCXGSu9w0jhdRyE8MYKme6Q6QGGAhUoL0hM7p9YtR+sA7uj/2d9XeL3HsG6WOa4AijWf8vPAd+zrkS1ppQvuuFGzSbrz+9IpuPoZ0eG6x+e5z969h85RqD2TxR5/weGc4577t5FqzXJYx7zaO64/U6yrODYHaeS9e6ms3YInGdF1WsxnU6HifYEO47ZzM6dt3HzzbfiHPS6Pfp9O2Ynj957amqSxz72XG69dSdra6uAd6+76qqrALj//l0/dE3rhSj/d60111xzDeCFqLMsY3p6hnPPfSx79++nKHJ8fAYQ1NIEh6A0fn/Qxusb1tIGYFlcWEApSbPdoNtZoCyGhEFcHbolaa1OUpsiTmOm5g6yY8vxLB3KOLx0C1nXgQmJk5Ao9gebXqeo5pDg0OJ+9i/s5rTTjuP2nXvYs2eJ406dIA0V993rq671JGXj5nkvrkvAaSeczvYtW2i1Qm6++TaMdRx7wgxREGCxzG1KGQw0/a7mlpv2srzUp9ZIOPus4whrJbpYI04kulR0BqACSZxoOv29rC6tsnbIsm3uVKbqm+muGrR2pI2Ibds2s7J8PwurC9x86w3U6k3q7bo/cOuCLOswGHSJ44SHnfYwwjDmwP5D9NZyirzEOceg1wPpaE802b/vfhr1Go97/HlMT0+TZdn4OY/GzMzMuH1u586d4++nacq5557LYx/7WB71qEf9yLk6SqqHwyE33XQT27dvH7/XoUOHuO666+h2BVoPyPOSTmeVKFLrhUzr29OWlhbZufMWTjj+RIQUVYuCqMS3E7Suio4P8qFHBwNnyTPvRpy2Gr5VrspHpHTeTa4S9QUodU6pC6/5oY2Xc4hhlHOPKnnOOS/PQFUgq/BDZ3UVGC1GeyZZUZZe5FxJojAmjiKkgCSO8dX3Eqm87o6xjlL7Q3Cpc/JsiDUaXeZMtCeo1WqogEobSPkYk2lWVrr0egOsK4mTEGs1WoMx4JwHN6z2wJeUmnozJElSmmmb0hmcFExMtRFK4KRBRL5qGUYW40rKsqAovBB7ImNyE2CNo9ct6PdyrPGi4JkeEpjCnwGk1xRdWFhGlxnOFczOThKGAWGkGLWKxVFIvVaj1kgYZo5Wq87UVJPpiTqlzVjrrjIY9iiKgkaagmrgEGS5YVhCzgh48HE3rQcUmWN1eY3S1CltTK77lL0Cpx3dbgelJNqWdPMVhsMuQmocPicCX2z1rY8pQlZO3EWBMYayLEH4OA9U+jAW5yrVXBUShL5AH4QRcZzinCRJa4RhhApG8hpUh2KvLaS1wWj/XrJypgusXG8NxFZdBL5QPWLqyEqCw2FRgT/rlWVZtX5BUeSURY6SIwdHhVIPbsbTQzn0Qzn0Qzn0+vjv5tA/NvBknR0zSMYtR5X2kr9hjJkuzlZMJlch8GVWIXZ+0oZBhLYxFjNWe3f4Gzf+gLZiG1mzvjCt9VpENkBUQUu4GoomStQIZMOzmADBEGNz3zylh2jr0cjSlFgHwsXEQYtINagn0wQqRqpo3B/vpERJDxBJoQicxDrvyhfKlEjVWOnvpdA9lrvLBKpHqGLqSZvZySlmxRSz2SRr/Q6r3Q6rnR4CQV4UaKPBwmAwpNsZ0l3LyYe+9z4MvdtGFIUkicI4H0B6/R6dlYJsaHCuJFDeXlEJT2uNogAklNq7+vR6fd+zHqXESUpSA+002ii0KSkKKEuDNYJGrUWjNsnMxCYatRZpcrQdclj1LRtpqnviE0pfuTMY6+9vaXt0sgVyPWCQr40nY6gUSgVeoF5Jb1tpJFpXqb8LEE5ijWOQ9RixngIVEKjIM6Kq5zpaKX52lNUCcw9YnEfoL42x3XXRPxBV5aBgmPfIyj7aFGibo2xBEFSJXAWAjpbUuvPEOg12HCR+SsY6Qu3vl3U+yfJBzOuqCSE9aGltBbJ6sU/fv17Z6+DbBtb3m1Efud8DxPgka8nyzCfNRlMWA6zRuLH2mwGsBx7Hz8ZgbYl2OVrnGJMhAg8QBzal21vG6JJIxYQqJVCeFigIUCI8ShPO4Vs0jdVoXeKAiWQj8WyTzROnYGy3EhfMuHHP9xHOcezcCZy07VgefkKNVEm+f/u93HznLqKJjFoD6i3Yc5shKxPKLGPbjjm2B7Pcf6jAmJyFA6vs3TOg1WixddM0pXbkWYHTmmO3zzO3ocEV113L/kMdOp2SCx69nVhFrK6sYnJIgpRjjt1Is5kSR76q2G6GtJohYSBZWytZO6wZdPcTBSmb5k/m2E0n0G5MMsiX6RerDIoOhV6jNBlFOSA3eVWxjFjq7OFguZs7d91CLUmppSnNdgOkwOLIrfZVMD0gDlKScILZiWOIgoS87DF+6KN9+Yhkd5xAYapDY6WtIUBJNQ684yKCAyUgEBBKgXGC0giK0h92rKt0/Mfr/oi5/P/NihjP35+WYYzlfe/7EBdd9AT+6I9/ize/+W3ce/de/vTd/8TEzDRnPWKOHTumcG4zWXYi//bv/067PcnTnvoMXve613HZZV87KkH+xZe9kte89jd517v+mH/8x3/Ex3bL05/+dL7+dd8+9573vIf3vve9gH/GcRwfdU2vec1ruOyyy3DO8a53vYs/+ZM/OernzjnOOceR5wbncqzt0xuALkARsmnjNr591RV884pv8Ou//Jvs2nU/f/mXf8YvvfLV1Bshn/rkn/G0p7+ECy54Np/91z/m5FPP5xde/ut89Ysfpdme5qKnvZSrr/kP7tlzK9++7TJ+9UW/z+t+8y08/MwzGQx7BFHB+971PYq8JIglzXaEs7B6OOMLl3+We9du5O1v/S0+/nef5eP/8O/MbC/Zt/t+PvOlO0h1jaCss2fPd9i/fw9Spnz603/H5d/6DB/8239iaWHIGadv45KffTyXfud6BkWPM8+aZNe9Aw7uH/Dc57yPp168g2e++BR+7rHv41tXfId3vOct5N/qMrupwfNeeSZ7D1/K4lev4NjTd1Bc3mP1oOXr3/skV377Kp7/ghfymX/7N0464WQO7FpgdnIHeQav+vUX8dRnPYmn/czT2LLlOew7cC+XX/45zjnnPNKkRWelYNOmY0mSJn/wex9g23FTxHXLX/7BRzj9jFO55BdewDe+dT1pr4cpPcjzo8bnPvc5Pv/5z//Q90faXv9Z/Pve977HM57xDD73uc9x3HHH8YQnPIF3vetd/OZv/iYAz3/+83nOc57LRz54K2Es+L23/Tb/8PefoNvt8Na3vpGiMOSF5sMffA8f+tBHedrTnsO3r/w6559/Lt/85pdxDm7beSf12gasOURR/rCQ/YNtHD68hHMGazVFrmk2JXEcI6RnOPV7a7TaLdIkJRt6nZZSa4bDAXnu2SxWu3F91VpDqR1B6dvzHBqjvS6IimICpRA4jCs9q9uUFMWAvCjJ8pJSW8IwImgGtFsNlGyQRIrBoEteDLC2j3YaY0qGxZDBMGN1tcva2hpalyghmJuZY3Jigrm5GdJajAxjVtcGLC91uOfufdTrTZrNOpNTkyBKjB4yM7mBJGrRSjei8wxHjhV9RLJG6QoOLxymVm+zffMESVOwd/8u9uzbTb9XoEKoNSS6p6glEc36JFPTDcIY9uwr6PV67FrosrKYk9RSJmZjkqYhDhSpaKMHMf2u4c7bv49AE0WwutLEuhIrCpzQ1OqKDc02U1Ntwiii3x/QaAomJ7yI91qny/7uGgcPrCKA43dsZW7DVpKkwYEDS+iGwuiAMBI42ceyBGRonUG4TN8U5L0FeretQBGBjpiZmiXPc3bvWWCxcy+aHrVawNzsBFOTGzjmuM1MNGZppi2AMQDQ769R5AVlWdJstQijiLIw6LKkMJo49gfyMIzIc0NZWJwNadRmSGNLs5XSrFzDBAJnfU5mjaYoSvr9PloX1b4foVSNQMHaap8iL8mzkvZEHakk2lqCUCJUzMREY9ze1W63yLKcTmeNyckmZRmzsmzHuWirNUkYhgTBj8+F+J8aD+XQD+XQD+XQR62I8fz9ccePvcrdqHecqiWumpJi1KY2GkIglfK6TKO+Vev8RK5oiEpGKEKUCyldPmavrFdNjxA6q/4l35da9TMriZLRWAg8UA2UTBB4VzuB74EUKkTJFCFChB6gHehyiUJn5OUioVglVDUKPSQOG8RBg6CiJAZhhBMO6RSoMQ6MkiFJ0ECicM4wKNawTpAXA/JygLGCeq1OHMW0mm2CICQOEkIRE4QhofIuIMZYep0Bw0FBWWhPMw0VcRJSr6cklYOd6XmL0+WlLt01TVEYak2JEQKLp02qQKICQWk1xhqK3FIWAlMqiBUqVERxSFD152pdYrQH96Iwpllv025O06i1iOO0ovatP285AnKUQFXCeEpJb47gHM4lPrFxTYSMyXQfR0xW9jGmoDCOAIvCLw6JB/RUsF4RUhKEMJS6xzAXOKeJgoAoSImDlEBVz1auo8RKBuN5MhI9GwFQ662fHNGWdwTw5CzaluRln7zso12JtjmhyytmlThqVR6l5SQE6wCU46cFd1oXLKyqLyNBdTnqTR99YFtRiUVVIRkxxKr3qcRRfdtrJX5Ysc+s9kmqKTMPGtt1gwFrDUYXOOvFRmWlRClFSGn6njVnOj5BtiWFyavfLaAEhMD1JZnOsU6jyGmEbRLVIJDNcYVOEFROlwmhSlEyxAn/vK0zKEIaQYt60Abh54KxJYGr0Rke5q79t7HaW2KiPskJxx1Pe2KWk449nnsP3smg7NDtdGhMBEw2Qmp1wYaNE4RJyP0HbmPp0IClQysUmSVohzQbLcBbtG7ekZKXQw4eLOkczGnHdeaOmcYWmlIIpJHMb5zCiZJBtkCR+9bTTDvmpmsYV2dmYoqyEHTWNE4rkqDOVGMHsZpF0SANEkI1SyMuMXaAdTnaDciKHtrkHhRWHe+OkzjCUBIFDovGOYVFIkRQmQc4oqBJEk0QhXXf94+tksmKmm19QLROjZ/nKChWs2X8x7h65zTrIv9qvH6pYkAY+PVtjKAwnjZ8VCVxXKZ5QNh8APPxiHLMUZcyWrA/XTwn+MQnPsFXvvIVPvnJT/KqX34RW7cew1e+9F0uvvjnieOIkx82RRDBYNjlt3/7d3j0Yx7N8577XM4773EEQVhJOBx9L9vtNu9+93t45CMfCayzRZWSvOENb+SCCy7kbW97Gy996Ut54hOfOP5dpRQbN24cv8+Pet8/+ZM/4bLLLuMzn/kM73znO3nYGaeztLZANjRYGxHXayws3sG+ffv41rc/Ry1tcOqJp3H1964kiVN+/udfQmdtP901y3mPex6Li4c5fHg/J536ZJKkzT133cm1N1zLjmNO5tGPTbn2xpu5476bIHZ8/OMfIaLJi191ElvnH8nGmUfyN//6x+y59wDlPktycuSt4gclh3atYrL7+PTGz3DTzts8vV86soFm//19Hn7ORnou53ff+FcsrR5kdqPg9a9/MwcP7mFpaYXf+q2LaU8GFGLArruWUWHA8599LkV2J3Gc84pLfpvpTYdotPfzsX9+L4PhKk97xmYWVzpYIVjYu8Jd168xXNM8ZrifU86Y5mGnP5M/+IO3MjuzhT96xzvYsmUL991/L+/+43fxile+kvnNs2w+tsWe/Xfyuc/16d6/gZnpFhc96fkgLGGUsHnTLDtvv5n+oM8jzjifxZX7uOu+ffzsxc9g4fAyH/jA3/KoRz+KeiPhmhu/yy+87CU89rxzedOb3vRDmkkPZPi+733v49Of/jQAl1xyCU972tN+aL6eccYZ/P3f/z3f/OY3+dCHPkRZen2isiwIw2j0znztG3/NzMwUF7/4rfzMzzyVsiwJAsUnP/nvfPe71/Dmt7yR8x53Hn/zN3/O5i2buG3nvXzwg//KL73qBThXMhwuos3wv72u/m8OYwqSJKZW8y13Sik63cNI6avcvX6PNE1xSYq1osp5ZXXIAGtk5bwssVZTFiXWOLLMVa00XhtUCklZZgRBUB2KDc4VXoDYFUgBUSX+jBAMh0O0HiClBXKcLAmTgkIPMfmQoR6wNlijKHNskBPUMyg1unB0hg7tegRRSZLFRFHE6sqALLMEUQBCUJaWlZUejWZEEIakcUSoIlr1CZzRGJuRlx0yUvr9PnsOHqKWZkRRjEih2WywadMGyn6McTklHQZ5SRyGtFtNpiabhLHgwMGQshD01ixlCYnzLKx6KySJQiIT0ssVFktUhyBwxIljWPQJM0W9bBLXAqSyFEXB8soaIFle7BGrOo04Y/+eLqudHgf3DkHXSdM6s5OnMtXcSBjGLGGJ44igljA9Nw0ix9hVsnyZYdZFypTu0IvF9/sLxLJBHNSwpMgA0lpMXTfItUObEmEjFBFpdcBNazFZllEUOcN8gMMRRAFBFOIAbYwHmoIAHJUAuCXPMko7QJeQDQTOxCjhZTachjIrxnmeEoIoUkjpgBhciJCCWpoSRSFKKVaHw0qqIgcRVW0NDqEcgYQoUpSFZ6oIBGVZ0u/3CKMAKQT1Ro04jpBSsrIyIAzWne8erOOhHPqhHPqhHJqfOIf+LwFPAE6IsaOXp1M+gMD1gAvziN4RQBWgRIBEIVBQAb5OVBzY6kM6OwKdRgCAQIFfDDIgwIt0haqOqlztRp53HjkOUYQgHFYKrBJIM8DiKG3OsFylYIgSCQKJNjk21ERBnUDFYycAJEe0BYISilAlCBS1eBKHIC8zsjzzQtw6I7IRAQFxmJKaFGElurQIJYmCAGcsuizJswJdaIxxhGFAkobU6jFpGhPHIVIJysK7cnS7Gf2B78lPVYiTEif8e0opQPoeb220r14a7+onlUIFgXcTUZ4SaIzGVElNGESkSZ162iCOE8IgREo5dsdDrAONynlBQC9WqUZPB+tCFAZLipMSWabkxqItWCt9YMI7KUjhabVKeLFxXCWQJhwIg7E5pZaAJctTnPXCls55lztZJWLjtSEkI5fC0fWOLFmPFkGTlYPi+tw1VlOaDG1yLyLvSr+gOXpBHQk6jSiwY6rjTwnoBEc6ZHg3GyEE0nonnBGQNqJNjqo6YgQkVxR+WwkOGmPQWo8DMPh7ocvCU/nzPrZy2fCabyPjgJH2mn9GQnrBxNwMPOhYLmKtb48tTFE5Thqc1Z4pZx1a4KuT5TIBGoVFighjbNUjD4IQKRJwzu8PSlX0UlEJ8CcEKkFKL6LrnKFoDgHJ7oM7ceYQw2zA/PxmtmycY3pikrzosNgLKPuaIHXEqQRpqNUjolpCnmt6qxkrhwfe0lgqkriGL3I52lOK/mBAPrBkHcP0fI2ZyWbVOqEIgpi4piiNY3l1DWELcBE5gloNmrnEGtClI8s0aeDF+Fu1WQLVABJCFREKUe20OY4SJzKyokuphwzLFUKlyHWPrMz8WhwvRYET0oPtDlzVgqtkMl4QfvqPKjL4FgDn7ylivY2WI8Jm9ZvVnyNTAA8EK1GF2JFxgPB7hKriSuAk2hkPmvDD6+2BBhc/KhQ+UAyR9eX7UzUuueQSFhcX+dSnPsUxx26i3W7z/evv4klPfgxzc5MsLByiXWsTRYLrrruejRs3IqViojUJQlJJORw1kiThZ3/2BQRBwO7du5mfnycMQ4QQPOlJT2J+fp6PfexjPOlJT+LFL37xUb+7f/9+VlZWcM6RZdn4+1NTUxxz7DE89WlPodvtcOONN/KCF7yAyZkp9h7Yj8m8c1OmSq811Fvhpptu4NRTTufY7cdxx103Mze3kVNOPZ1rvvs1jC4559yLuG3nVawsH+S4E57L0uEl9uzeyVp3wDDLKIouiysdVlaHzG1scuftd5L1c171+pM4edupbJ05j0t/sI08z1ndNyRIJSqSTGwMydcKFvd12L3/IIXJmZis0VkpWFnM6K6U1CdrOOm48qvf48yHH8vM7Cyf/dyXUELQaqWcetoORDDk7t2H0IXXldiycQd3tA5h7ZCnPu1cjL2L1a7mw9d8genJmPMes5X5bIZuT7Nn7xprK4LOquXAwcOcc/ZGTjhmOx/70Ic599wn8ovn/QK9QZd777+Hm2+9kb0H9lKbCJmaS+j319i1K2Pv1GEmWlPs2HEyhxf3IYQgraf0szVWO8vENejvW+bQod08+1lP5Oqrb+D7N9zI05/2ZOrNlGtvvJ3jjzmeifbkUfpOAI1Gg6mpKQ4cOODbeYBvfetb3s560yYuvPDC8Wt7vR7Ly8vjuXXJJZfwqU99ii984QsAOGcpy5KDBw/hnENrzc7br2THjmNIk4gNcxvQlXjunj17ufHGmxgOc2ZnZ5k49xzq9RrLy/dyxbdu4AUvuIiJyZCi7NFuN2k2m/9fLbX/v42yzEnTmCRJkNJR6oJub4VarVa1UVTDCXRZdQMccRBxToyzUWc1ZVFQFCWyMAQqIggrZ2chPatc+mKd18vUgBnvv/6QH6GtIc+H9AddECVJYoljUIFDkuOKIaXtkxWrHggJDEGsQVm0MxRGQGbI8jrWFRRlyOLSGtYGRKqJsZZCF3R7XaK4jQoCQhUQBV5sWuBbCYe5QhSCfCgYDvdiii5BmFFTjjAIaDXbqGSSvBzQzcAEPaIwopZ4Ix0VOIwFXYLvRpIIqQhUQBwHhKHCDA156ciKAhU7ogSSOgjpEEoSBClRCJaC/qDPYOjz8143Z9goyYaGhYU+q2s9lhcHKJWQRpO0m1upJ1MIoVDsR8mYKKox0dqAUgbLBINBnUG8hhMOu7SI6w3J8gIRFARhiHF9hIyIk5BaWUeWjkGW4UyA1RIlfR4fhiF5nvl2nyJHSenzfKkqXR6LCHyeLJzEliVWW/KyZJgXGCNwOiUQoc/jLZR5iTXWdzMoVXUbyEpLJhw7IaZJ4g/PVf7snPGavNL64Czc+jFOUHU3VLnCOBf03R1BoKp2PNClZ3f41s4H73goh34oh34oh/7Jc+gfG3jyLgriKLvLEXrnrP/g3tLRizg7p7G2QIqAQIUYI8BqnPB0PukUwvh+11HLnZAjAeiKWeV5LSinkHiRL0noNYlEihQhgYoQFbXQC+1V7VCMnAMkQYVGKhVWOkMOIzJKM8A5KAc9YtUgVk1q4SxJ1KLhZqirwIMdcl0MHUEFvIQkwSSKxLfehQmF6ZPZHpkZkPWHdLoh0imkU0xPTBKGiiiOcFJ469VKkiBQgmYrYWamxcxMm40bp1BSonXB4kKPQwe7LC/kiBBUJAjqDpUKRCRRQYDFMcwHdHs9isxQ5oI4qBOkIc3JiDgNidMAgXcoKI0FFxIoRbPWolFrU09bKBV5YEnKI5JPUbGM/GYrK9aQ/3m1MIyoGGgBcdykbjVJPM1yeJD+cIXl3l7yfIAxOYkKScKYWlzzFRkpcMIvPicsTlo0Jc4MWR0UBDIiVAlRUEfJkEAmRGGCkiFhkFb6XAHqiNVknH/MKji6X3zddcJVzh0ZhR5SmhyLQZscbXIQ/mDknGdK+c2Ao6rA6zpSI1D1wT+y4QCpvENGoELvNKgC/OeQBEHISMDQB7fq+Y6CqXOURY41GqsLL2xoNaXOcMbgtKUoMv8sMUdtcLZykJLIymVSkJs+Wg8pXIe14WEKPUCT4UyJswbhAoKoRhg3KV2OxPcyh1KQF30Wl9Zoq+3E8Uaa6WZK3acoO3SHe8nKDt1sEaMjAtlkpnEq7doMadSo2g4KDAXSDcag/lSyiXY0y0xzE/ccvoZDK/fwz1/+RzbPHMv2+RN56hOeRFFkHFo8zJe/dQVrizm79iwSN+oktZBbfnAnlDGN+iz98mClxxAyM5eijWHPwTVuvKHDwX0FGzfXyPWAXj+nmWyl3kyYnpth9/5dLCwucvste5ianqXVnmDbcVto1kHIkiz3mnG6yDlm+9lsnNnGlrlt5HqAtgO/7yEroDVBiBpSTFOrq+pgo+kU++nnh9mz+gPAazG0ojoykBAI8tJSakueGWypGLqSvYt3Md3exERzFhesawgcGZB85WbdeVIgxuzAahoBgiBYXzPWletgiKOqzPjkLpCeAZqXUBpHVppxvHvgivvPWl4fyNQYMSB/WtbsjxplWfJzP/dinvbUp/Lhj/wt1ghuueVWnvq0J/Dud7+bV7ziFXzpy18gUAqtS37/bX/Ghg1z/O/X/PJ/WqL6+Mc/zu///u9z6aVf5uSTT6FeryOE5JRTTuGmm276oda6PM/5mZ/5Ge666y5AkGXrjJM/+IM/4HnPfy5/8Vfv4VGPPJfrr7+eWq3GoYUldu0+TE1ZskGXH9z5Ay447yIefc5j2bbxOLReodO5m7lNDXbvuZN//p1/ZthfodWss9o9xKZtmznm5GMZDG7nP77wFT71yUv5zOe+gJQrfOlL7+SZT3w2Rfnz3Hn77TztES3iWsFXbv8rPvlP72P/rf+HL3zpy+zt3cjffuV3+MbfHiIIFc9/03Zu/lIXuzTJH/zWBzjUuZY7dn+TP/ztL3L4QJcwkMxubrBpW8IZZx3PI7f9Oio7lq996flMtmHDTMQv/9J7mZxLOOn0CV7yqpPZtHEDkZIIMaTf380Xv/AWzn7EMzn2uBexf88XWT3omAunePkr3oi1gn/6xEd52dtewKatm/nK5R/gwJ7bufWGz/PcX9hEJ7+N3/mLF3Ljl5d42AmP4Mrvfpdf/dVf43d/71Ke9Px5HnbGGRyz41Se+dinMewabr/lLo49cQcrK0t8/KMf5wlPuohHnjXPN75xFRs2tHj4mecTBBHbtm/hmc95CsvdDoPCcsymR/GmN/4ml3/rUoqiOOpZv/CFL+R97/tTHv/487n55pvH3z/22GO56qqraDTWW/P/5V/+hde+9rUAXHTRRXzmM5856r2CICTLci644AIWFhYAgYxnOeX0DQgBb/jtP2b37v18/osf5XWv+3Ve85pfJY4TPvShD/HmN7+Zb3/7Sk459Tje83/ewGkPO44DB/cghOBNb3oTv/Irv/LfWE3/d8eBg3so9SxJ4mPgoN/n4MGDHH/CCR6w3XEMw6xgOMhYWlwjCCVJorBOg7DIAMpiWLW+pGRZh+FgiFIxcVJHyjpKhRjjyLOSosirg60lijz4kiQRI5TLOEdeFKx21lha3YW1AyamBTMzNZpRjIwkovBW34UpcBiSWBGlEcZ4E5vQtYhVnXo6hRACYx1rayXWGtI0BLmCkJq1zKLZTruYRghFoCxhYKu/R0g5SaBSQpocd6zlwME9rKweYN/CKrVGk1Zrgk0bjkEXmpWVaWr6AHEiCaKc1ZWcLMvZff8SSEdrpk6pBe3WBFONjbiiYHWtz12338HKYk4+LEkmS+KpgPZUynHzO5hsb2DD7FYOLSywuLTIXfcsUJoScDRqEwwKSb8Iufe+PaytrrK8uMDDTjudDdObmN9wDHmeMRwOsNaR5z62NxozTExMMDu9mTLdSKkHTDS2UAsP0O13GBZ9lDRIqVlZ2kcYNGnWN9BqbyXPSw4vNBisFdisx9rqkHpqaNYlYRQRO4u2GlMWPrBZ67VpERRZgTO+fTaQEQKJEgFJJKrDfAMpFEYbFhcPkWUDSl0wMdmiXk9pNOtEcUikJPVaA1u5jWudkw8y8jyjn3WJopiJVoMw8sVg4SLfRloYFha69DoDiqKkVvMtTzMzkyRJTJZnLC97h/A0rbNx0wzGmMrF+8E7HsqhH8qhH8qhf/Ic+r8MPI2R1gdcoHezO/JGGnBeIEsiMUdcpKhQPeEEzlgcFotBqtHt8MARwguYBYRIERKJBCl8D6oUkRcpl54t42mN/k9PPwPwgFNp+hSmS246GDfEUlTAifDkGFG5tDlBaWKUlmhdx9o6zgVHlYml9BpFvu1SAApFTBq0CVVEJLytYqkLuoMepgCrBROtBo16SpomyDAgiQ31ekKtHuMwpGlEs1FnamKCZj2hKEu6vSHd7pBer8AYSGrSf6URYRShVORdSbBYU9Af9ihyQ1mE1GsRYRxSq9cIQo9+Gq2BSoxMBgQiRsg6cZgQBBFKqTHwdCTauk7pq+6ZWAdcBICsJqyAQMUEQUwYRgghiIOEYbaGLTVlmVGYEkWADcApPwcQXiTROcZzwYoSWxqkUB5olJ3q2UfEYY1AJaTxBFFYIwoTwiAag45SKD+LjighjqiGXthTo21BaYa+GlBVEq1zFfpsWWfPAc5Wvb3jGTyuavjXPLiD5frwFqna+YqyQ/nAWQm4GsH4Ho0EUMfCw9X3ymLohQ51ObZjLXUOY203X6U9cnvwv+/BW4vFugzjSoZ6hdJmFHaAcRakFyssK1pxFCRIpZBKIp23jbUYyiLDlSXteCu1aANhMAFOVrRgQSNWSLHCUBs6w70Ys0SpS/JyG/V4hkjVCCNfHQ6Ckfoqvm/eWUKazDaOJZQpZXErWpQc6OyhvhgQq4g0rHHaccczLHLqzRSnDf2Ophw6QgVBLJjf2GDDfIuJiQmUEvT6Bbvu6bC2mlMaQ9DSkEiMFDTqbZQMWO0soXND4BJmmtuoNyNqzYg4jZBKY03JcNhDlwVRmNBqTNKot6uKdgACRq4XojIc8HukqNotBBDSTDcQR00GRrM2OEw/WwGXExpFZJU3K1ACFXsLXyUNq70DhCogkIp61AQcxmlKkVUCo1WN5ihLV1f9xVVfR7Zl+9aRUTusn55HxhTHSFdASkEo8G6X1vn998jf44gqEkczFH/UcO5HhUz3QzHtwTbe/va3c/XVV6OU4iUvuYS5uVne+9738Lzn/iyzszO87nWvI46aXHH5tZx73tlIKSlzzUVPfhxxVKPX0Wh99F5Vlpqbf3Ar99+3i06nwwc/+LfMzc2RxCkTU202bdrI85/3Ar74xS9y/fXXj39Pa82ePXvYunUrF198MeAZUB/+8Ie59NJLWV1b5dxHP54TTziZOI74y7/8S8Io4cyzziHr7ce6IdPtjayuLrHL5SS1Hrnukes19uw/QDfvsPUER7frK653774FlWaUZpJvfONugqTFL778FXz1q5cyN9fklFMuYucdByhKwVlnncShA7tYXFrmKY96GSx+g3tvuZwP/s3f4OqrQI2ffcFLKDLDD756KQfuGpKKkG7/Pm679S6uvOpONmyZQYYRe3ctkndKBqsBVkm+fsW36B66lua8YHarZONWgUxnOfaY47ngiY/j+hsv48Zrb2fj5jVuvGEP2cCy49lP4ZYfrPIfn/84jTDkpONP4/zzn09RSBYWDnFg330cOHCIenOW00+6iGM2n0mvt8jBtRvZe2CBw/sP8axnnstka5ZP/tsHOePMU9i+YxN37fsqywdymlEPYyGKI9qTLe6+7y60LjnnUeeQlyUHDx/k5FOOwxSG3qpm5x13sLpU4LJ5pidmCQLJwQNr9Ps9hsMfblkLw5B6vXEUE0oIyerqGu973/uOao+59tpr6ff7ANxyyy28/e1v54477hj//NJLL+XgwYMcPnyYwWDg398E7Nl1kE//652c/YhHc97jLUEg+frXL+OWW27hl37plzjzzIfz2te+lqmp6UpIecjtd97Jnj33YZ3XHHugi+KDcfj7KBgM+kxNTyGloJ21KUtLv5dRS71QtGNEzh4dYg3GlpQ6R2uNEdYfVp2rnKoUUox4+RacwZqCIu+hTYl3tUuRMkHKFOtAm5JOt0NeFhTlgDRJQSqkzD0zhoIoiCmNd9pSQYB1numBAWsEwkpClRIHTaKgiVQS5xz1Wo/BsE+3twCqiww0kZMsdyRF2WeiuQmnHFZDGFDprgqyYYEuLNOTs6jA0J5M2HfAs466q1266WHSuM7GDRuYnpHEsWN2tkW360XGrbWVGLBkcmKK2ek5tszvYK23QC83rCwO6fdyjDEkToENwSY0m9MktZRCDBjaFUrRpdYKMU4iJUxOJQSNjL45ROE6CJVRS5W3uRdiLL6tlGB6appub8hgmNPrdQlUQCOpUxYF1jkiNcVEUxFFfbrDJYqy4/XJhEabHv0BtFobiaKQqYlZlu0azkmWFpcJVYIzgiiKAEEapWTWVbpMoAIPPJWFBzR0aShcVh2rpNdoChRRZBFYpDKk9QAVJmgdIAModMZat0AN/LwaMWCdA61L8iKvBM09hUIKidamYvb4Yq9nMzrSWoNGM0CqgMGwz9LSChMTEAQBG+c3E8dJJZkhxmyeB/d4KId+KId+KIf+SXPo/zrwZCVuRKusoIlqTXk7SGuwxlRgkBkDFutK7OvsGYHAmYrxhMGOHjiq+vDSO7yJmICIUNUqJf1w/X3EyL3MW8WOHpQQwgMYTleg0xq5WUXbAY5iHKidGF2P9r2cdoC2IdpmWFtibVRtBBXjR0qEt2Pzk8NJBCFJ0MSKGBsE9PM1nLUMhkOGg5I8868XUjDRbvq2OhfRbKR0+4mvIiUhjXpKu9mkVkuwPUNeZPT7OYNBgXMQxYq0HpCmMVEYE6gI4yzaaLQZMMz7FLlFFzH1ZoswDqjVU4SwOOudKcA7pkRBdV9lrXovT7v14JP0AfyI5+9ZTt7pYgw+QcUA838RgoqiG6LCFkoFREHMytoB8myAMwJtDEZYbAgurMBHZ/0G7alzYwphafLxc5YjFJqQOGgQBbUKKPL3Vkrlhc+pWupgPA+qGcxID0rbEq1zCp1VNFT/Ylcx9kaa/x7Ff4DTRPXGowX5QG2TB/MYAcfeolWgqtZHIZRnG5p19N1UVqzW+PU8MhQo8j5Gl5iyGNM7tSmqrUCMgV93xOxxVowZZJaCwg4pTI9BsYi2BYUtECpCqAipFEXRxzqLUqHvj5eehjpiVZZ5H6klk8kOatEcYdDCWockQqqYSM2AaNAt+mTmdgb5Cv3hMqUe0ky6tONN1Fyz6r2X4/tS6hxjHcLETNV20EinGZarrA1WWewdQB2UTKaTzNc3cPKxx6BtSS8fgnP0+zmuFCBBRbBxU5vN85NMTU3gyOh2B9x/d5duT4CShK0SGQdYGVCvtdA2Z3HlIOVAomzM7MR2osmMuOWI4hCJdyAZmj7GOJIopVFrU0ubOOE1d4TwLbKjeS9HXxLfSoDDWUktnqUmBZkLGRa3sVwOKG1OFEhqJqQexwRSEkZUlTpNp3+QSIWEMqA5PeVZkc5XbYQYaflVoMaoyuf/o/rvEQX/hwsWruLljzTaqujvQWhnUZUNMAiK0lEaTxevZlz18upzH7E2R+/P6JXjAL5eS/jPLGcfjOPtb3874IGAV77y5ezZu5eXvvQXOPusR3LBBRfyhje8gS9+4XK+853rOf3Mk0lif0h54hPPI8ssq4slxqx/xiiKiKOInbfczoH9BzHG8JGPfMTHXRly0inH88hzHsHznvt8vvCFL/ChD33oh67p/PPP521veysg+P73v88nP/lJvvzlL3P99ddz66230m63GQ6HfPjDH2bHjmM5/3FPYNAd4FzO3Mx2lhb3cPDQ7WzaFKPCHuRddh3YSZTACadNsrAS0l3N2XfnfUzPhJR6lc/+x1d50Qtfxv968Ut5+cv/F6ed+jCe9ex3cuVV7yHPBzz1SeezZ+9tHF5c4gXPex377uny7au+w9986APMbW1y1oVbedbFP0t3ueRzv/YFiqJkZnbI4spt3Hj9LXzlczu54BlnkjQj9h9Ywgwkw1XBGoarvnop++7tseWMlKnjFLPHw+bWMZxxyrk846kv4hMf/yJ33H0bm0+8h4XdlnZtI9u2PJmvXvoRPvqxj/LUp5zCaSecwvkXPJtbd97M3r27WF7ez3333U+cznHuo84nDAXG5Xz7mo+Td+5mP5YXPP+JdDprvPfP/pzf/a33cfyxp/OG3/sui/tzZLnIcKhp1BKmpttcv/Na0jThmU9+Bt+7/noWlhd40gUXsPe+w+y9/xAH996HHrYRwy206xOIoCDL9xJGijRNjwKfarUaUkr6/f44OQaQQrG0tMI73vGO/3S+3nPPPbz97W8njn1rWZZlXHrppVx66aVHva7MVtm3+yD/8R9389rXPJ4zz5xFa8Nll32Df/3Xf+P5z/85Hv7wszn33MeQZTmHDi2RDfocXNjNfbvuwTlHnuf0+/2j2FcPxtFuTyAEZHlGmsQkcUxZasrS0OkOiOM+KvC9SuPiqTUeRDAlhcnQRqGE9ZbcAi8YrMIqBlDlwRZnNbrMKMsc5zRhKAltgJDSyz3ogtXuAmXF5G40GqjQod0Kw6zLIMupp1XRTQiCMKgc6Qxe01ggjWeeR0HN5+eh17NpNnponbGyuogNVpGh9hIRnZJh1iMOJzDKEUoHsQB8K3A2zNBGM9GeotFSZGWdvOywvNhhrdOn0zlEPDPP7MxmwkQSJ46JqTrW9ukP1h3TpJRMTU4zP7eRLZu2k99b4PIOneXcA3HSIUSEsBGYhFqtjYoU/bJDt1gip0+9HSEUBKFkZkOCc0MGuo+RBUEsaDZDotDnD1p7J+8wUExPz+BYodCGwXBAFMYMBkPKLENISGtNWo0aaa1ARhFrXcjLDO9M2acoejQaLeKozeTENNnAMsxKFhcWEQTo0jI9PePXVZygixKLz2GCQIGQ6NIDGtrk5MUQFYTEUUIU1wgChQo8QIC01BshsVFY4yiN157qDYfgQClJFCUElU6R12gr0UZX2mOAkJRliZSSWImqIO/BxFazSb1WR4qSLCtYXl4jCFMmJtps3LgRXVq0sQwHWQXSPLidKR/KoR/KoR/KoX/yHPq/oPFksM6hK9BlNI5mlXjE1lTAk7ctDfEdqCXr4uEV44mqGdgZrC0qLSGJBJQMKzAhJhARgYgJZeJb34TCiRECuI4NjoSwhfA9z9ZqtM0ZlosMymX6+WEKM8Q5R6xaKFVDiYRYJb4nsppkgYyRskCbAUJQATIBUnp021XAmBd78wi40RLnAqxIiaRDhSEbpi2dpE+312elu0ym/eTcsnmeOI7YumUDSRLQ6XXp9noYXdDpdJhstQiVotVoMDFVR7sSF+RMTMU0mjGzE1NIESKcB88s3sUkjGOkcrg4pjkZ0WxF1OsxZVGQ5yVFWRIKCEXoW9hkTCgShJNg1yfvqLI5mtBjdhjrgOZ69fMI4EWAcwbrJKGISKM6UijmJ44hEiGJChnmSygl0CLDlSMHQbBOexBIgKiE+ioIFqrWuGqqEAV1wiDFoMl0j7hoUIvbXvMrSMZ04xHraYTkGuvdZLKyTz9fo5+vUhpvUewtg32VSAg3tnHmAQvwaHH99UX50wA+tScm0bogL3LKIkPrgjLzSYmQR2w+wPoi9xa4xhhfzbBe2NBYU2khirGWmsOtW/hag5Bed83hKEyX0vbpF0uUJqc0GU4aLBbtIKlEULXr4px3zlBhChKMyyhNNt5f2sEm4qBOI9yIFIKiXPW6cRUobTAY+mjWSJIEVJ2izFkp7qCT38OK2MLcxEnMq1NIE4sQEocgCBKEMOR6QDYsKUvB1tZZbN84QKR97rjnDm66fS+f2vkNzjnzYWzfMs8jzziRbj5kYXWNidkaWhucyHn6hc9henqSJE35ymXXcPute9hzO8xsC5mYD6i3AqKgRiQbLHQWyfUqy/37OXBfiTB1Nk+fxJYNs7RnUwa9IVlegs6Zbse0Gw2SzVO0GhPEUYJfs0EVlNbn4QjAlZUhgKd9G0o9JAxjTtv2CLZMb2epc4ArfvDPLKwuUeQDTp5/GI20jqpBKUssJVES0tf3k60cYKV3P0nYph7PMjnhBVW1znzFyOGFE6v/CfCEwIpN6Kqgth4LRkvMr7XRHm7daB55Zw6q/TkOJWGgKEsfOEtTVW1E5dxxxBgleutz+cHNaPpxh3Nw553LnHTSGVx37bUkScShw/fz1a9/hTPOeBRnnPkc3v72v+a8xz6c5zznibzkf/0a8/Obeetb3koQrt+lt771rbz4xS9mebXDHffcdsT7+0T4Lb/3ezzxiU/6Ic2fI4e1lrIsCIKI0047jR/84Ae84Q1v4Morrxy/Jo5jPvWpT3PgwAG+c9U3aDUccZwS1epcf+uN7N5/Iy975WMIRYOanAbRxBqBLaYZruwlsi2efv7/4vgT56jVA+6/Z5YrL7+Rv/voBbzoN7aiszt41a++kN949RtppHU+9Bd/xkVPex6PPfdJvOwVL+TJT34GX/iXK/j4f7yWm66/i2/92x3c/b1f44zTz+K7V17NLXd/mqW120lqdYpC0OsUqFZG2LVELuUVL34j4HjJy17E2vIQjCMsY/b+QHPwNsHf/fVrWOjv4j2feRkXvKjFmYtn881v3s5zX3kSW7ZP8e5/+SWGA8OFTz4BZ2BxYY2777qXPbtvod2O+fO/+lf+5sN/xSf+6S+YqL+ZxYP3srSwm/Of9Cw2TK0yO38rX7ryW0ixxqte8Tgu/fpH+ULR5s/e8wn++oN/zb/966f5pV8cUIvrCEKefMFTWVle5DP/+knOfPg57Ni0g0//0+c5ZusOdmzbgjikaTbabNywkc/+22dIawkv+Lln8bGPfow77riNZ/7M0ymKglarxde//nWuvvpqzjjjDA4cODB+psaWP/Z8/ZM/+WO2bt3CxRe/+IdEy0fjuOMn+d3feyyRsNx68z6+e/VNPPvZF/PLv/LLfO2yGzjxhK2c+5iH8Xcfu4xGM+G5z3s8xmp27tzJn7zjD3nnO9/JX/zFX7Br164f+7r+J8app56JELYS8S4ZZhnGFuSFwBhNt7vXW88Ly+LCErVaRKuVok2JNiV5kWGtz38LU5IkE8T1+libc8Q+88LDIQhFWRaU5RAZSLTT9PJV8iJnkA1YWttXMcZSNjQnSNKY/lCzuLxKf9Ahq+WoSovHoTG2pBiWSJsSiJhaNInVln5vhQM2J4oTojih3tBEqaI5XWdhMWOY5fRWDWKiAyrjtjs1MxNb2DC9jSCIyPIhy8urNJpNrLMc2r9IvRkRJTOcccq5dPuLdHqHcaxSDA+z8/Yl2m3J5GST6cmHMTvTIK1Nsm3vLjqrQ7Kh5fTTzmTDhmk2bm6wa2+BE0Nk4EjSgChVbN4+QbNVo95IObx0kOGwYGllhYWlwwgsG2Ym2LJphlY7pZ9nGAaoICedViiTEJkW8xummJpqkyQJcdwEZzm0736iIGB6YpqJqXnqtTqtehNdNsizgpWVNZoTTRrNFtu3b2dh8SCHDu/jmr1LWNchSTK0XkJJQxymzM3NkOeOffv2cejwIcIwZuu2rbRaLSYnJpmZnCJOUqI4RFsvWjw502SYBQwzRffgCiGWWMVIBcaVdNdWQTiUUjRbkwgRgBN0Oh0vp+K8ibgUAukC7zyNIAoi4gAPRAYBSvmOFpzEWi9s7nWQHI2Goyy7rCz3qyicsG3riT6/JyYbOvLcu39FcUIQKN9x8CAeD+XQD+XQD+XQP/n4sYEnIRVUqO1IDG3s8AUVqlexQ6wZC0ePUFwY4WT+vz2AFKBEgKv6WXEjxooc/0wSIglY77tcZzmN3uuHdHaOoKZ58EEhpRf5QiiEk4SyTSjqBCIhUikCkMIBIy0rh3U5xkqMTSphbo8aqurdlQkqZ5LAUyet8ECUlDihCGVEGmlszTN5gkBW/bwlQSX+l8YxzlokEEchzlrKosABaewrmEI6UAW1mu/3D4SAyjXQgHcERJHGNVwsCIKUZrtGrR57kAcLtmohqyarFB76c9bTI7UuK3BHQdXmOJ5q4/7SdcbTOgPoSAbUaA74yoVAEMiARjqB1gOcK3BkWAq0KzEjob4KiffjCGVC/4MjHyoIsBiMLcjKXgUo+T78UMWEJkWJYH2zYH2ujIClrOySlz1KPaw+s/Ob/gg5Hl/POhVxhCKP1vdP41DKL3f/GZyfs6VnfwGMKWwPGEbrqnKjGXluj1Fud+QfFVBXtaD6lnSNtkMK2/OOKq7EuHKs62adb67UtkRUB17fy74+l5zTFOUArCQkIVUtYtlAKoUQFS2ZCrCUil62j06+n16xB4cmkAkqbKAcKCQRAiG8k44xGkXgK8VS4ZCVrWk1F0yIKFOkErTSNhNNzcRUn8W1JYQyzM20aEzUaTVrnHTCdhaXlun2eqysrJEmCVMTbeIo9q6SdUibgkYrYKo1hSJF2ATjfPIglAJlkFIQt6DWSKilKZ3lDqYoEFoTyAARJMiwPnab9MCAfQArD0bY7ShACfDih9gqKBmSqM5kc56p+ibQlpVh3/8c500RjBeplML4ZyRyijIjEEt01BJRklKLWygZ+bWEWd8vYGwS4TOyah2NLmx8nVWcsG5ULGVEAx4FVO8J49uqlQAXCITxP9O2esVRa/WIybn+L/3Q3P5pAIwfOISANA1J05ggCDyDNvEHlJWVLquru9i2bROlMVx7460ce9wxTE7NcGDhMEVRkCQpJ514IieecCKzc3N85nOf584719uhtmzZwgUXXMCBAwe5+uqruPAJj0frdd2fU089lbPOOgtwnH32IxhFiiiK2LZtGxdddBGzs7NVO4ifnzMzG1lbXWFp4T5mpk5CBSG333UNM9PTTE0/irvvPkirPkE9naQ1UUPrkpXlNUwWIYkYDpc5eEiTpCHzc5NkeR2ZwJ57VwgCRWuj4robrqJd28DxJ57G/gOH2Lt/gTNOPwtj4JrvXc9pxz8GVc5y6N7r2LDFUJtY4dtXXomLD5LWBVOt49iybQvHnTLF3rtXaNfmeeELzqM1CYuLC5SFRig8M6gVkNZqNJo17rjzfvYt38Odt+9mKpglUhHnPuo4ZqYnAAnBEpNTLdLGJOXA0WhEWGvZMLcZ50r27bqbdmuCY489kVotodWewJqMQ/vXCGoBJx53KoXtsbR0PzfffB0y0Ey2Anbdv5P5DbM84cKL+OY3vs78hs1s3bKdjRs3EAYJ09MbcMKbqcxvnCOzPe47cDvN5ixJTVG6BTZunsEB99x3B/MbNjE16XV6zjrrbM4555GccMIJ3HDDDezevfu/PV/vuOMOlpaXj1prsnKkBccznvEMzjvvfDbN17nsq5dz6NAiW7YeQ6Bq9LsBszOThEHE8sKAjRunaLVrJEnCddfeyvXX3o5zjpWVFVZWVv7b1/h/a6RJUnUDWCDAWFfpwhRoY1FSoLWXT0gS38ZiTFk5RBuM0YDyB9EyJxCVDqaMfDtNJWIscEgVoALvdGac9h0ApsBmGVmZMyyGlPj2L6ygl62iiSjKHk4UyMAfsrT2cbrfH2JKi9OSWlInCRu0ajNk2QCjS5QKCIOQKAoZZB1KUzAcFihRJ43qpFGEkEOcNkRhRBQpwgiCUBA5RZom49Q9iiKskZS5I4gkcZDSbrbpDfpoWSJVQb/vWUaHDi5Qb06ghGJueg7KZUzepShKylJjjSAII+IkJq3HhLGgVg+ZnWkThJ4hb2zmWfB5hi4NYaRotOq0mxM0aikrK/shcMjAtxgGRIRRk1p9kiRpUGpDmqYESpKkDWRo0BaSNCYMA4S0BGGAMQaEQUqHkpI0qtNqTKELw8zUNvqDw+TFIcoy9EZGUpAXJUXh54NxBuOGHF7aTW9Ypz9cIopOoCVbJOkkqjqdyKpFzjpLvd5CSUUURR7YMJqi8ACwUqATi5KWkeB8GAS4KK4MhsS6BIfwItnraaLDOU2pvcnUiG02YvE4a8nznCJ31NI6UkVIFREGkkAFWOsIlIIAAiXpDTOG2YPbnfKhHPqhHPqhHPro8d/JoX9s4EmpwGthV610o0A4WmcjAW7f1+pQSKiQc3+Wr0SdnUcRpQjGrBsxupm4CmEMxyynQESVnlMwuuPjGz9mW7kReDHC5tZZOAJJoFJiKocQB0IEpHKSQNY9k0ol1W8arBtgXYF1Q6wboI1BG6+BNHIn8FQuSVC1ZYXGUBY5ONA5WAm2YkrVopQ4CkjiCLAI6SjLHCEglBFxGBOqkGYtrRg5huGwTxjF1Gt1tm6Zoz2Rkja9jSbOIoxFa58QOCe82F0Y0ax7Xad6o0GjUSOKIuToc9myqrQplGLcjma0pshzhAjQ2rcgOhcyamOsRLCqeT5iQq1PtnUG25Hoq0XrslL7V7Qb00hhCQOFps+wXGVQruKMB8Jk5cIihELJkc1y9Ug8BcpTWcVI6FxinGWYdyh0TlD2KE0xZjwFMvLaYEE0vi4pRVU1LBgUa2RFn6zoVQv9iDbNI6LAkevpyAV5JNp8ZCveg30IoQhCRRCGBCqgLHKGpjt2z6BC9zly03FUblij3vPqaYv1wOLcEcmG85sbIsRSYlzOQB+idEOMKz1TcdQSLuxI0Yu8GIDTaJ3hjEM4L6jqmZY5g2yV0CXUVJt6fZpI1dDkFexZAdUyQqqQxd7trGT3sDi8hVhsIRKT1KNt1KKYSEkcfSIpKE2HsmzhcJ5+XtGGwzBEBA5XaoqhgaFEyoT56a206hNMzU7wnau+z/6FvfQHfR5/3tns2LaJJzz+HG6+bSe33n473//BLeRZzvHbdjA/u4G1zUMmtt9He04yORmxfXY7uggoMomhixIBaTJBozUkUDHtTYJWO6GepORZhs4zhMuJgxjpaqiy7o0ZnEUp5XU3jtAae6BI4Ei3zeupObTRdPtLJEmLVmOWY+ZOJ5UhNltGBCVaFDid+KTX5IhAIAOFVII8W0WXBl04GvVpaG1nqrGJwvZ98D+iKDAClMUDg6QYeVG6SueNqtV19N11yvqIienZl55JG4USq0AZAYXvWzcWkA9YuEeOH46qP7Vj86YmaeL4wc13cfbZpzA7O88Tzr+Av/vHy7jm+rt51x/+BjfctJNPfPIL/Pb/fjnWwnev20m332dqcpKfff7Pceyxx9HtdHjHH7z9qEP7Ix7xCP7+7/+epz71qew/sJfPfe5fGGb98c+f/vSn8+53v9uLp1JxS4+4pa94xSuOulbnIM8svW6H5YU7aD/qMZTGcellH+W1r34bjzz7PH7l9S9g46YJTjpxG/Nbm6wur3LfHbtpyuOxIuGe+7/NXbsCwijh9JPP4pSHbyeZMvzSxV9j24kpv/LWk/jDX303regkvv3tb/PG3/ktvvvd7/DlSy/jbz7417z+9b/FV798KcfNrxLHUxx/xgH23LefV/ziy/m5Fx/H+Rc+jK1z5/LIR+1jqbyZj7z7Gp719EfzgT//K6677UPcf+Bq0oaASCFDSXtTwomnzLH9mGn+/h8+zeLKMkvDHov3LHPyifO8/29fwHe+d4Bdu5bYuj1iomzSKqcpSsWmzZNEYcjxD38sB/fey4ff/xYe/aSf54lPOpvNc9Ns2jxDnp/IZz/9NY47YTtPfdYFPPzUs/j2d6/gub/3AX73LY/hzDMb/MM//inPetYv8pIX/yLnnnsemzbv4DnP+3kedfZZzM3O8OhHn899++6ku7bGBRc9lq9d/h987/rvcMlzX4Ojz/6lW3nCUx7HwsIyn/zXT3DBeU/BFH7dvehFF/P617++en4/Xmz7UcKkAH/91x98wOskYZj46j+Gd77znZx++ulYC5/81D+ya/cevnX5V7j8G3fw3W/v5OIXn8Owr7n/3hWe/JSziZOQorD83Ue/wDcu+5Y/zP+UjDD0oBFOeqBFBKwlA1bXcqzV1GphxQIxzG2YRuucLOuhtUZrgzGGoHIryrIewiqctURxghOqKviCd3STqCDE4kArSltgTEZRrFHoglznWKkxwncpHFzZTRgKwsADO2ldoARkWclgULC0sIZ0AfW4TWtqmnZzmpkpr9M2HPaJ45QkTYnTmLXhPjq9Lvv3dZia2EK7McHM1AYOL+6mP1hjbm4DE60m9bogTQRJnJIkdRYXlzBGM9GeoNvt0e8McSInrUkatUkG3RVCBc2W49CBPt1ORlHczo4dxzAxOcW2TTtwhWDYHbB4+DCBksxMT5MkDZrtCdpTTWqpotmI2L55ll5/SKc7REQDhCiRGMJQUaunzG6aZmpqlkjFdJd2E9csSUOSDYQ/uNanaTTnSWqTDAZDWs0WcVxjcnKOwhhKY5CBP9gbkxMGKUEoCSODlAYpLUqEtOpTRKrGScefzd5993L3PTlF1ES6lEBKVlaWKQrN/MYNFHrAsOiy//DtCCFJk5RaLcKxmXZrwhv2VAfjIAgRUjE3s3GElFDkOWWhKQtvsS4lhEFGGFZSG0IiwqgChiwjI6FRvhsEysdm63M2bTRGG+r1tv+sVW5nrfUte70B2VDTaHizCqsVcT0hDCXWGmq1BKUU2hi6vSELh5f+h1bmjzceyqEfyqEfyqH5iXPoHxt4iqLEg01hRJ5JjC4oi6wSg3O+B/WI6/Komzzqpnm6GmgcgYrAOZKwjZUlxpa4cRqrCILEO6UFqdf3EWIMBK+zTsQRfcYcAX5UN5iAMJA0ma8QYq+VJBBeWNt5JpUUo9vgsC7GuAxtJMbmOJdR6GVPwcMipEJI5fvqA/9gTaAJVIAzBikEWju0deRO46RFSMlEOo0KJEEEcRIBjsFwSJHnWGtpNlKiMPQMJVOiM0NWaJKKghpFjrXOIsNBn16/Q6l9v6qQIWEYIVXdB+9aQqPZIIpCpBSUWYbVDmECQlJCIQlkyKjN0WjtK1bGEIYRtbq33IzC+Ih7OdJBqp6PEONnBettd9aBrEAYW9FFhfDVzSRughAUZkg/ryOHikGx5gUzbeEF8Kp7JVBIN4Z2PYo3ArcYbezCt+aZAmt9n6x3IAyIlBcsDGQ0rtTAOuNpWPTGVNWKw1jN0RHbrppnYhQwqulRkbBGwOZoizqS8vjgHuvPMax0vYIwZtiPKIohw36H0f0IwvCo2CmoclonqgBZfY2xfapgqXC2pNQrZKyiXUZJVtnqwiDrY8mwDMl0QWk0RVni9BBnNc4I4rhOFCb0sjW07VPqDsPhGo1wjrjZBuefvZDroKXnLPt2zDSawIodqKDORLidRE3SjDZWzAxLaZcoTZdC72WQxyRMEoezBKHECUFNhVjn96hOuYguDEWuWd23how10/UmFz7mnKpdYY1Ob5VduwXdlT5bZ7Zx0lNP5P4992DNkO9dezWbNx3DzNQG6i3F4uIBinxA3u3T6w3p9YcEQUIYhbTSDcyf0SCtp0xNTaOcZtBbxjEkiDRBVU30Vrs5y0uHKIqcer1R9XAH48RmvedbHvHfAJUWmpBY48iyPlIN2TZ/KvU0JYgM+3t3YooDpFGzWm8KpWpg/TOM1BSRAhLYt7KTzvAwpT2DVjJJFMQU5cDHikqzbTRGFaNR5WZUCHhgS+toX5dSHgXqjoBeY+yIe0gQOJRQGCvRRlDo0otsIo9gO/40rM3/2rDG0mo1OOech6EzwepiweTMHOc/9ix2bJ5l377rUPYAjzjBMdmMuOHGm/nj3/8tXv9br+Hssx7O/PxGPvLhD/PFL32RTqdz1HtfeeWVPO5xj2Pnzp0URcHFP/dSdu/eO/75P//zP/Pd7373qN95//vfzyMf+cgffbHOcvDATowpOfuRL+S23deyNlhk68kncfXOy7lj/7U8+nEbEQRkRY8br78TaUNma1t55tNfiJKKz3zmI5x//tPZtv04vn7VR7n0O3dxzx37+bM//TD7D9zPB9/2AX7z1a9hy8bNfPk//pJnP/vJ/MyznsPvvem3OOW00/nnf/okv/07b2Db9g286Oefxhe/9FmGecJff+ISPv/p6/mrP/82a90Xc/ppF/HK576bg7f8BgcOfZ8nPPFC3vXut3DGKVvYcNzlHLh3lTSKeMtv/CzfuGwn//GRW3nZKx/FbbcE/P1HdnHOs+Y568xT2Db7ZD5y7V9x7Q238prfP5XvfOUg112+h0/8/T8wzBzf+NZlPKf9DKZmN/Bzv/DbkNYwrsett97G/IZjmZzcyPR8n6jeZW21h7OKE445jUu/+HU++KF3840v38afvvdDfOlLX+Ov/+al/J8//VMOLt7Hd274d753879w8vFn8KbXvJPp9jTDLGVx+SA7tp7KdPsYQqU5dHiVO+9aJWIXcZzylAteQJEP2bv3Xpxz/NVf/RWf/eznEAIOHjz4/zofW60W//iP/8jU1NRRBywpFb/zO7/Dd77zHQD+1//6RX7mmc9i8+YNfOaz/8773/9+P0Wqr997y5vo9wesLHeJ44QtWzcxOdlgMNzHweXbKMppDi+s8pWvXM/FL34aT3rKw3jxJZf9py18D7aR5971zBqHoI41knraZGbSkGUDsmyZWFlEKMBmFPmAfr9DkRXo0oKWtCZbxGECFUNKKINQFqEcQvkKubUlhenTzzuVw9py5RztCGLvIueEQtDFWe9QlZd9jLOUusS3bEAcNShLh9USU0jiuM7s1BbazVmiMGFpaYkgCGg0pgBJNizodHro3CFsSKgaNBsTTE7MsH3rdpIgptPpECcJxjo6vQ5CQJI0mZqeRQVeqFoqQVqLGAwzVtcWKfWAojtAOEcgAoSE+bkdWCMoTZ89ew6yd99htEnp9FYwgUbFkqwo2b17AanqzM9u5cLzFXm2jNZ9OssD+uWATA+xvZJAhGzcMMmO4zaR1lPm5mY9S0kXtNtQakHeVSTBJqJgAkeDpeU+RREwN9Mk7xdQQF5oClNSWE1gFaEKkC6kGAxwWJqtNnHiRZ8Hw17FKoKtG48hCWuEqs7C4mF63Zzl5QOoAMJEULhVtBsCQ+o1WbHacnbtuYOVlSUGg4xN85upN5oYx5ggIGVVYC4LSu1Zm1PTUyjpcydnvMxEUfiWTGNLrNVEUUwgQ4IwIQi81IhUPm8w1kHpwTOULzYL55lMQRBUgsYwNzdDoGI/h4yXJhlmJWUJQehANJAyYNAvKPIcKR/sBdyHcuiHcuiHcuifdPzYwJNUXpRQWEUQaoTAg07a4Zx5AOtDjD/kOltmBFh4PEEKhZIhoYyxBBXTZQRmSI+8SoUSlVXlA6qqIwDkSLriqB9zBFJ5VpQiUDUCPH15RCmUKNwYxTrCrcVV648SzxTydEJtBgipCGzNa0FJhZIKW7nASSnHVFNRTQqjXRXsIUhiIhUQRwEqEJ767IaUusQYjdYBSvo+U2O8yJg1JWHk2ynqtTpF4UXput1+dV0eqa04ktU1BQSqqjwIVwmWKYQNkYx0rNSYmucq8AknyHLfq6xUMBYj8xP3iLs+YvwcAUSNaG9i9Lp1ZLB6ngKlIqKwRi2ZBBzGFr4qYjIgZ+Sc5/8xW73zER2no0Um3JiODT7gWRza5GNQylmLkgotinFvLjAW6Sx1hqmsTj3LbsSOExX4JCrFdLGOHleZsWMEiB3x+X+KxhgyFAKUJBAhUZyCEB5INr7/3Ius++FGyC6jx7COoo/XvPMry7oSbTNy3aEQPQyld68ZVX0YibeDKXVFbx9gdNcHTRuOK3bagTF9tO6hbEBIQqRq408hkL7CVLXg+kqyJQ0nkSomjto0gg3EskGqWjjw1Q3nKzHa9ijNGkoHGDtJQOJZeoGv2GjtgWAjfDJfaou0vlo5UZ/C1i2doSBQAUVZsry6RhgpJtpNZqamyfMhq90VWsN5gjDk2O3bkGSsrBg6nTVvPpBlhKFFyDpKNGk1m9SaNZI0Ie+tkec5ygVI6YiCI+61tWTZAKkChsM+adogDKLqufywy+II0h8xF9fZib4VIY5qNGpTTLe3sZjtYViUZGXPswdlRFgFOGcBpXxQU5Ks7AGCld5+QikRVIGWqoX1iM1DjIoER+wPvjXbVSzC/5w1ceTngGqPrrYe4TuDEQiME2AEZrw/jMK0GFOQj76mn571e95557F//3727t2LkDAY9Lnv/nuZm9pCHKXs3btMo1bn2GO2sHvvnWSDjEbNIiX0+z3uues2jtmxfQwQHTp8iOuuuw6ATZs2sX37dm688UaWl5e56qqrxv/uDTfcdNR17N+/n/379x/1ve9+97vkeQE4jj/+eDZs2DD+mV93vrJY2pLecI1+1iWMY1b7h8i0Zn5OIJxEF5LFw2tMNec49uRTscZX8LZtO4FApfR7GQ5Dv2dYOmw4+aQTSKOQuNzM7MxmmhNNbr7uBh677TSmZrYhhKDVarBl6wZ/2DWGleUVdAaSiHo9YnZmO73VJnfceSO16FhiTiWoOYLU0u3m3HfvArVmxCPOehR7mvfiyiHdpYLBIEeT0+v3SeKA007ezkknz7Jx8xwrqxlRbGk3YXGfBjvJzMw0Bw71wEmSJKLfGaKsotGaYi3vk+cZQajIs5zOcofZDdM0GjX6vR5C+NaZM087i41zp7K86Dh8qMvqWocs79OeiunkEuf65OUay2t7uOmW7zMzMUMtrdPtdYjCmJmpBv3hMtoYmvVJiqJEIImiAAgJq/bIXbt2sXfvXs4++2w2btzI/Pw8N91009ix7oEjCALOOecc5ubmABgOB6ytrXHffbs4KkZW693rY67vU6srK9xyy05OOPFkNs7P850rv0MUz7FhwyQ33XQjpclpthNW1wZ01jKkFGR5h2G2gnOOHTuOYX5+439lOf2PjOFwgDE+8Q+CqIqhwuuMOEs+lEjlW6COFCa2FrAC4RRJGJMmNYS1CBEghI8PQlgQFiG8xo6QvrqtlEMFIKRCSkEUxxhnCbSmp/xh1TrrAShtfCuPNjgrMFHoDYWMJI0a1JImtbRJEHhXtTzPGXUwOCcwxqFLgxKhjymNNmmSEkcRgZSkSR2rJVY5nM0prdetCoIIhKZWS6sCsxdwts4S9AO0kRUjQWCtw5SGMEggCJAaiqJAF5q8yDxwJi1h4u9lUZTESUgS19i0cZ5uBwYDwYHDCxQUGFlSaFBRQFqLmJ5pk9Zr1NMUYQUaL8xujcIaSVqrezH1ICTPCpQckuc5eZgjrBgb5Xjmv8MZn7eiPWM/SEYHfSh16Y93QhCFMfV6i+mpDXQ6A4rCUhR9YiWQArKiBKdBaNI4xFqLsZZsOECJLmudVZrNpme6hbGfcML/rpVi3DEghfCsHel1m0qfmPm4KKo4LPHtc4rxochhPWjq/HORyucR3tRn/WA+KhM7awnDgDiK6fVWcS5A4BgMCpSCOFHeFU1R3S+D48EPID+UQz+UQz+UQ/9kOfSPDTwFQTBGaZVSGFMSBCFFMcTogqLI/WJzrgJQBKoKdNZ5dzpryzHBRAqFUAJn8JJCrJ/nKzhgDASM7o484mF7oMeDLSNQYEQJZQxg+L+HKhojhaOWPje2ufSb9+iOShkhCVAq9DahdkhedMnKVUqdecV/6kgZehtQZQlUgFKq+hIoqzA2xGjQ1veC1sMAqerUZBMVabTLGMQ99LAgK4eYTka9VqdBnTAKscahdYErvNp+GtXQ9TZSCNY6a1gpURaiJCYMYlQU4oR3BnHWjumbxgjQMUrXCKQlFJaw6ueuZhrGeBBr0O9UgJdGIgmjmDiK1yeBYJ395PCBB0/5EyNI342Ru7EouXMWKQIiVWOqsZl61KYeT5KGB8nKPsOyi3G5Zz+ZzG+swniwk+r5OzGOjcjRBrAOKnm6vUEgK7BoxI4abQ5uTKscgXJCeHvRUaudF2UTBEqCkjgnyUuL8WYVjFptRx8TRk5/Py2tdtWfUGlF+I0srbdI0gZRFDMcrFHkffLhcD2ROFJc/sg3gqOBW2vpF0vkusuwXBprTigRoSmxThOFCmFTsCl5WaLzITZbI9MrGFeCiChMFzUMUMIgnUE52Dz5CJq1zdSSaXCmauf1em1jZly1pc40Tx07UZiKEVeWOQiJEpJQbEDKACUVvcEurOsRqJQg3kKggooG72nDKqiYjYEmdgmdXp/79+7mpG2PYmJiks1bN0HkGJQD9izuYt/Cbmp3pzz7qU9jkHe5a9dtfPe6q6nX2lx43oW4UhMpuOrqG5GhJEpDhrrAGUfDTYKVWA2DfMggG1IMS1I9RxRb4rCas9IzCfKhp7ofPBwwv2EHQSOq5vSIceDviRAjh6T1teDBYOVptTgKMySKmmyZPYuyyFjs7mb38q2osCQISiKX4LXyBGU5QMmYyNUQzpEVPe47dA1FscZkfZ75iROq9VqiK5apfzS2KhaMes+rwDnSWZNyHDj9PnMkwDuaxPis+Khg5w9ZURV3jJEMNWhTsTCr3/vpgZh+9Ljiiit4//vfzxve8AbCKOCmH9zIK1/5q3z84x/mxBNO5a///LM881nncfrpJ3LZlxcQwSrNqZJh4XU4Ro5TP2q86EUv4h3veAdnnXUWd9xxx498zf/TeO1rXzcuSnzoQx86qt1OCMnU7InsX/w2V1zzYY4/6Wxa9c3cv/s25jcb4rrhjrs6bJjZytz0PP3VglO2b+cXXvrr/M4b/jdlUfIXf/5x/ux97+U73/kWP3fxRbjTm0xPztDP7mPTfIPf/d9v4Ko7b+Wq63cS2EXuvvdWjsXx9j98D7fcdjVf/ca/8LGPfZjvXf8d/uj/vJFLLj4dp1Pe945Ledtb/g9nnf1IXvkbF3L51z7Mnl0f4NjHhzzlCT/Da3/xj3jpJS8nDmP+4/OfZ9/yv3H7nVfy88/5EGc/o80FL53i/7z1Cs4/73Q+/He/zL33OA4vrvGpL/8jj39GxAVPfxi/95ob+OVX/AZ/9Lsv5cInXcjjH38+73//X/KDy+/kvpX7yaL99ApBXGvyvGc/i5u/dyvXXn0NT3/RM8jKIfv37yVOLYGIGCxN86Y3vIn9h/dx1lln88pXXcIf/fEb+LtP/xmhCDl122lsPbbGvgNLvPSVl/C+9/w5jzvvQu6+cYFGOiRJDLfdcz/btmzl2c99Gnfedi8Li/vYte96Lnjcs2lOnDZmMDebTT772c8yPz+PMYZzzjmHm2666T+bAkeNw4cO8I1vXM6rf/11FMW6bssn/uHj/MM//F2VSziCwKeg3/ve93jmM5/J5z//eY455lh+/pKL+ZM/+WN+/udfxBmnP4Gfu/iF/OmfvocvfOF6avWYV7ziqTznOc/my1/+Ms5ZXv3q/82v/Mqv/Zfn7f/tsbC4ULnYabx7s6LXy6nVGqRJjQ45ShZIqRnmFm183qtEgBIhkYypRXVa9Ra1tIEd2bgbENIbo8hAIJRDqogoamJMSrtdHwMPcRJT6pIszymHBQOgb3KEET72DEp63ZwiM8RhQa3WoFlrsmPzcSRxnXrawhqDthpjNP3BEEFBoGKkFCRxHRmENOuGmal5hJAoIVhaWiAQMa1mg+5wQGkl2kCn16U0Gidhfu5YoqhGqQuKwpAXJXFcI7BgnCDLFsmzgl5njVZzijRNmZg+hqIsyIuCQwuHfRwJBK3phCSMCZwCKwhExOzMBtIEVlYVN9x8N2GrJJ1wZANHJGOiesDMbLNyc0zIhyWl8zl4FEhCFNMTLcKggZIx/UHfO7o5hZwVuIYliD1oE8iAwWCIKQ2m1DTSJkGksEYgrMKfxhXWWIyxWOOQImBmegOdTt/H+GKAFUPyMmNlsEizVqNRq9Fot8mGJWudISqKAUl/0GHfwd2sdpeZ37CNNKn5/N0ZlPTaTWVZekkPrSlKXR3AfZ1VhRFxHI6BJ/BrVBtLnvs4fiRYnMT1qkitGAyGHggbaxkZiqIkCgtwigMH9hJFCc1mm6WlBZQKmJqeRqkaaRpSryesrWnKsvs/sSx/7PFQDv1QDg0P5dA/6RDuxzwxX3fDtePL9wdviy5LikrZv8iH6LIci6cFUUgUReR537eOlYVnmhjttSGsrwoYrdcXZwWEjOhg/nvr4IF37BgBRCMBaTkGjUavXV8+4MEBdcQnGaGEdowmeuDJP0gpZPVMRKXxNCTLlyq3CEiTOeKoTRy1CZSvoGbZgF5vjSIfMhh0KXVOqQs6g0Vvf2tL2rU5ammdVnOCuKWxKqdXLtPtrjHMB5iyIAgCoiCk1ZhASQ+6jCwPVSApTUFRZhxeOkBRlpTGECVNpAoJVEwchoSh718PY9+vXfQUuh9hBgGB0oSRIamXBDLCmQg9bOGcAicJwoAoSoiihFZriiROSdN61SvuN05bIcGqYnoJMQKfWH8GUhEEIcp7UK4DM44K6CvROqOXrVLoIcOiQ1Z2Kco+neFhbCWcN7YBFf4Zu8pOVIwQ+qpiM6IEuv8fe+8dbllRp/t/qmrFHU/uHOkmB8kZRUAdARMmBIxjuCqGMY3OXK/jmMZRR2fGeM0oKipBBUQMICA5N5mGpuPpPvnsuFLV749aa+/ToPfnXO99Lj5Pl8+RPvvssPaq9K33+37fNweoerLoC2wnF5YL2kxN3sfY8Sow1EtjVIIhlo8cZINCI0gynYNOFgkuAGhLkc3HUz7YnnPy8X/OVPp/1m6745Z80ZIWdMWClL0FSFuL5TSJabXmSeIucdzFZH0zAZEvbBZQtEFLksXEaZNuPE8znSA1EWkW4So/33gUtsA2Q3dTsliQxpI4aZBmXZKsSZQ1SXWXWM+hhIsSLqE7hKsCXBUyUl+H71XwvBJgx4ByPDsORdH/tisc5fdsULO8xj3La5/t+CkEFRNmmw+SZhFpZhgdegahP0wQVOl0m3S7bWanx+l228RRhyiJmOtMsnNuI0sG9mGgPMKSxctRAw1SZ56HH3+IZrNBp91i0fAIA7VBxoaXsG18J2maUi6XCUOPTCfcdtcNxFmKEYKB4WUIXEgVi0eHKFU8KsOC1lxG1IR46zB+2CWodKkOJui4Qjw3ZsX5pcTzPQYHxqhUBhgZWZKvfyYXMs21GZTbYxVazFTgeX4+j1UfVDWCZnuCZmeKbdOPEmdNkqxNK5pEOQ7S8ayAqZGAQgjPgr1GEDhWcHbF6L6EXhXfLeVzsJ+1KYjlmS5YsvTW3mLdtRuffVnxu20FWJ4/ls9Bo3WeVBC9dSDVkGqbtUnTYs7qfH/Jv+uTtlEhBKecdMz/4Vn3f66dc845PPjgg9x7773cfvsdDA0Nccstt3HMMUcT+CG/v+Zmli1fw9DQGPOzc2S6SWrmaTerXH/DNfyPfzqfn112KUcffTQ333gnX/zyv3PjjTfw6U9/miOOOIJDDjmEK664gt/+9rd8/vOf/5PXcfrpp3P22WcDcOutt/bKpYp29NFHc8QRR/DpT3+aX//61/zkpz/hJS89Az+AZmMH9aFBWu0Wv7/+GrxKghZd7rh5E+VSwPBgnWce93wkDtNT89RqVeI45dFHtnDgAQezaNEito/fRxiWCMMq99+3gWq5zj5r92N8eheduIPO2nTTWVzP4TknvQ4hDVHS5jvf/iEDgzWOOvYwrr3mYiYnH0en24g6a/D9FbzorFOII8HcbJefXP2v1AdrPOPQo1gUHkS3mXHH3bdw2t8cTG3A47Wv+RDrjiiz/zEDbLyzxaKRUQ49eD31gQqlYIDByj788heXsuWJjRx/7EF41HFMjdrw/uwYn+C+Dffz+nPeyNjYGHOdKUqVKp1uzGWX/IRnHHgYB+x3EPc/cSvDQ2Pss/ZgJifm6Ha7dDst0gy6UczGjY+wY+oRJmYep2V2sH71ao5/xjFcctm1KFnmlFPOZPuurUgpOeO5ryRLYnt4kIJup01zbhYyhXIcKjWfZqvFxo2Pcd6rX8tZZ53Fi1/8Ys488wz+8Icb+cY3vsGVV17J7Oxsr5+XLl3KJz7xCZz8QHvttdcSx1aEvtVsML5zF7feenvPjObJ7dTTTuXV572aG264gSAIOPLIIznsGccShmVuvPkalixZw8DgKA89eAeeV6VSW0y5LBgarLL3+lX8+te/5eabbuKfPvo/OPjgZ7B+/d786EcX/qXT7P9qu/ee+0lTq9FZqwygDbRaUc4ggm63QcG03zFuS8LSrEmru4t2Z47pmXEG6gOUwhL1+kBPeiLLS+Msw2VBHJzHtqB7cZqUgiiO6LTbbNuxg063RafbxAms9kemBXEX0gSSOCIMAqrlCqtWrMfzfCQqT9qCEA5RlJImBoGD7/sEgU8QWsZFliV0OxFZlmEybbWElCJNtT1QO5JUN8l0QpZFrFy+L7XqMPX6KNu2jTM5Oc3OXeMoZUuzpqYep9WaYnZ2GyYt4/tVlixdy8jIGEEQsGtqF1t3bmTHxCaWrlpMtTTMYGk5Scdq0HpBRpw2aEfz3PfwPXiVjKBmcN3AMleUz8hIlXIYUqsO0pqRtBsZO7dvI/ChFDoMVkdwZAUpB2i27P6SJYZlS5YzODjEoiWLcDwbu+7atYtOu0u33WHRqH08o0tYquC5Pr5TJo6s2HemE5I4odPtECeWCTbfmGbn1GZa3VlwOgSeg+c4mEQQx9DtGuq1EXw/JCyXcD0Xz/cZG1lCtVKnUqoShiHGZKRZTBR1LZMsNTmrQiCx8aDO479Cv1cqlcffudN1fi6zZzfTY6MabfADKx6NNDSa80SxLQ2t14YpBRV2jI+jHBffD+lGETrTaCMZGKhbQ4VqiVarQafT5vjjj/p/NT3/f9ueGHpPDL0nhv7LY+g/m/HUf2MLzhgjcFyBNgVzxH6pTAh0llLUReZ3aiEz7CkXWjBZxIL/9cut6N+QHir75N/Fk9/0Sb8vZKmwoA9zoKsYSDlrx4pcKyQhQkjSrINOGmQmJk1bONJFqwChghwVVqjdyu1UT29IagUkpGlCEqfEUYJMLNChlML1XDLj0s1iMp0SJRlpliCEtBtMLn5ttEYKhev6lMtV3DgmTlMcv2QBGKny+6jJshQnAyMEUjtI7aCN12N8CdmfTAvvodFWFBwgjjqW/eO4PZ2kXn3pwoGX0/v6bFGDyN1qFvZf8SKVo+CO8hHSIUkjXCdAdV2UcGh35yzZNgeYChpyb8rlE8wIUGiM9ebrjwGx4DmmP/C0XjD4ZF9c3U48OyAsZVz1r1nkFXe5VqClUVubWZ2/diEL6uneijsgsGy0YuMs4GTluEjp4DiBBWOFtCJ6upsvOP1n05s/hlTHREmTdjxJN5vNy0it06LdWDOkkyBI0YkmixRZZK1bPRFYJxxVItUdummGFC5KeFS8MTyniudWCL3hfPPN+0mKvBTUzrUCRC4WZWtmkNfSC2Hnh8l6QbiSPo5TJfCG6USTtLrb6HanUcKjFNZxpGO1GVRuJS2wLEflohyHJInpdmOSjosog3BhcLCOEBmZ7rJ9YisaWL54LUP1Gu1Om9m5CXx/BYFfZ3RsjHa3Q5SkDAyOkqXQahZinf0st4NHmpUt250UIZI8OVUA6oYkimg256xNbm0on7O9lOWTFr9+f2ud5a4e+VaTa5zVK4sJvDpGeDQ7u2h1p2i0d/bEFaWUGA1pluDYGg4Eina3SRRHVMJxTNmuV05uFiBy8NkUi1CxWeZJpd0SgIbdnDxsoAN21vUNDoA88M33CiHsOgw4SiAkKGOdOzNtdQiNMMUynzMdF6Qwn+btwgvtodp1XYwxDA+NcPLJJ6OES5IkrFu/FK192p2UpSsrGFMnSVZw5y2PkUaCVStX4vseUTdi29YdtJptXNflqKOOYuXKlRagOOMMPM/j0ksvBejde9Of9Bx33HG86lWvAiAMg6cATzfffDNbtmzhYx/7GNu2bePGP9zI0cfvzYoVS1m2ZA3IlKTbRaYaEwsy40JSpTnTIW1PsP/eBzI9Nc1NN/6B009/EUmqueTiX3DoM45kzdp1TM9toV4bZLA2xK+3/Z5qtcvSZYvxHPDdCkFlKXc/8Dtmt48zud9WVq5cx7Klq9mw4T7Wr1/P+tUHcnXnt7QaHouXKm6452467c184APvo1arkWUxV/7mK8zPTPPg4zdyzBmn05rN+Pq3vsT6fVazavVylqwcpFJyMR2fvQ+ukXQEd214jMOOXESp4hLIASa2uex4QnDIW1bw2IM72PTwFs5+9ivodO/gtltu5sUvfBFjy4cZri6iVq0xOzvDhnvvZf26fRhZMsTO27bgui6lUoksbhB1NFHWZdeOGYyRvPCFL+bHl36bm267hvUHj1Ip1xACpicT6nWfA/c7kIce28Dk9ASYCEe5SOEQlhUTUZupqSkGakMETkg5HGZiYoqZ2WkADj30UF72spcCgvHxcf7whz88pcyuVqvxyle+Es/zmJ6e5gMf+AC7du0CLCjlui4rViyzh+/Ok92qBKtWreLU55zKJz/1ScZGx3jnO9+JI+pIoTjxxJOYnunSbmecdtpzeXTjdm69fSPPfOY6avWARqPFcccdz+DgEB/9549w5523c+edtz/tgadSqUKaapI4w3E8ayXv5XGMgEq1jDGQphmOamFMAsK1gE1kAZtmo0kSx9Y5SkqQlvVkKxJAyaIESvWiaSUKt2Crv9ntdmm1WnSabbpRRBQn9jDpKXwnxAt9jKdomllc6SJwcB1rhGOrBayTmeO4ZJnA6Iw0NXlJrcD1QjCaBIUgw2hDmmUIaVkbJlN4rk/gh0RpRrub0GjM0WzO4DkeQ4OLrX6O4+XrtnXscVQFKdtgJJ1ukywzxN0OjlKUSyVqUQV3wiWNMtqdORzlUvHbpKmH1hDFCYlJiFNtDXjKhiAUlCohWWrotlNa7RZGp/ieT6ft022ByUJcJQhDieOAEhYxsNIOGZ1uh0ZrDsd3GGUUqSSua2UvlLKHPamkLTvSPfqCdZXWtvQy0zb2T5KYcqlMqRQShj6dqIFB45eqoC0I0O5GaJ3vr0bZ/TjNegF3szmXxxASz3XROfCUJF0bC2vZ06mxVSN2f46iiDS15xXXtbGO49rEs8zPCkbYPTfqdknTlCxNbYmulOjMakmlSYzACpY7jku5XEEqB9fzCYISUZwwN9/uxZ9SCSqVCqVS+P9oZv55bU8MvSeGZkF/74mh//di6P8S8NTXytE57dKglBWdcz2fNE3RWUIcdSnqzClQVF0gc/liu/Am5oNdm/wr9JgqAtMDRizYVTBsCrS+sIyEPDqWC6+1ABd6fZQPD5NT0PoDqQBhCl0jqw1UQkk/F06XJGmTJJ2jqKVXykXg4jouruuTaY1UDiQpxoAjHTKpkFrQThrEOiLSbWquj+MDngajcISP52hAY4Sm0Z7HUx6hVybwLD0vs0X+YAS1yiBxmpAkCamxE1oL0Doh0YZWO8bEJTyhEF0XEoXQdoFDGjuYpAQkWkqMtswkpWSeJcvodptWtFtnaK1xXQ/X83sZEHtf8+XJiN6/kRKDQmhLtSwGZ96xoBwkEum4uJ6P1hlhUsV1AjrdEnEckZoOmYktuk+GNimpjsmMtsFLruVle72oT86DrHyhLzIzBfhkAVKL4Bsj0CavfTcWFhYCHOXhuoHdiLUd5wJdFPuhHDBGkGlI8iDrr+C8unszBSRIb7wXzfa1/Xe1NkSpXCdNY1rNObI0yUUnc5Q9s6tdpjOiTotOOkc7niXWeeYu6ZDIBCmUtXpNG2RZB1ogTIAUIcgUJR08L8RXQwSOoOwM4jghjgrw3JpdBJVEC0vZdnBz9w27IPd1wGz/qnzhh7yqV8t8DBSZXwv4Oo7EcSSDlf3xvZ0YEdPsPEqSTlItj+I6LlJU8NyQOIlt4JtlKC3xZUgmE9p6jh1TGwlVhIpi2k1NLRxmrDbGdHsnzVaLX//hcg7d+yhGaqMM18ts2TlJsxOx15qDmJ2dYmZ2ChNbzYXBsRrzs5N0EoPv1RGtIdxOSIsYLRK0TPMspAW6s8ymOFxXkaURzeY023dArTpMtTKE61v7ZCtSmCHz9dOWl0JWMBaFgtweNgU8r0ToDbCmOsLM3DZmGzuYnNtk7y8yfz/QyNweVuc2Epo4Tdm49W7Kfp2yX6NaHumVXCvp4jkB1XDYGkagyIgoWIuQg8X0M4L2sf7wXZAioL+wFxufnZtCaIQBJa3+hCopslSQJIYo3T14/GttUkq2bt3J5T/7PSsX78/IyCh7H7yGZjum0Wrxm2tvZ9WKpey/zz4cccxKjjp+Fe/74HkEgdVgeN3fnsMdd9/Idddfw/HHH8873vEOPvGJjwOCU045hQ0bNvzJz3Zdd8Fv/+u7+IY3vIGzX3U2X7vo4/zhrofImjET47uYnWnw+ONTHPSMpey97wr+9eOf48EH7+H2O27gwosuZu2aFZz/9tfz819ch1IlLv7plfzd372Hj3/8U1x3/XVcecVlfOXLn+Zj//yvzMxt54pfXYDoLGX5snX87VvPYtf4o+x4/FHuvvcnuP4ZLF2+mm9987v87GeXctjhh/LTn/wIL3g+r3/Tq3jpGUexbs1i3vOul7Jo6Rhji0f59RX3s+qAGkedvpo3vuV1LBvaj9/86nr+7r3v4uv/8+t88J9fSGO+xcxcm5NOPoG77niIb33tEo45Zpitmx/mb9/+TT78kfP52799Ad/+3ld49omn8Jo3nMvZ57yGI484iiuu/BlveP0bCYIS37ngezz2+IO0Oy2++70LeeLhTdx23W284LTzyEzC5q0b2b5tJ6VSmSOPOopbb7qGudlpBgbL/M2zz+LQfU5k/4PX8uOfXsQLz3wfl17yE5rNFocediTf+MY3ePmLjuAf/ul9vPjMl3HKyc/hwp/8ByuWrufEk06n0Zhn4yMP8tUv/wuvf/M7OPHEk3eXLABe/vKXc8YZp3PiiSdx7733/v+OTcdx+OlPf8pBBx0IwMte9nKuvPLK3Z7j+QF33ns3H//cx9k1sYuHH3qYAw88kB//+MesX78fr3zVG3nXO9/Mi190JpdcfCOz81N04zlGho6k3Y659LKref7zjiUI/nT56NOxzc226bQT2s2EwUGrhYI0dOMOBk0QGCrlMlUvRKklNJuzzDchnZ5DCgedQavVJYpipOPa8lllBX0LR+m8cMCuq4U7ijGkSUKWJnTabbrdiE6ny9xcq6+lpBS+6zM6uJhadRTPKzMzM0W306bTbTM7N0/g+1TKIb5vNZ6SRDMwMIjr+OzcOUWr2WJi1xTl8joE0Gp2yTJwHZ/BoSHa7TlbITDXReBTLofUqz5SSJpzk0xObKHdnkeIgDCss2L5SrqdDlNTuxifnGLJ0hEcJWg2Z1CiDcDszBaSpIHrBURxxtYtO9i5fQ6vntJutRnftpNlo/tQ8qso5TI3OUO7O8fiRcOUqz7lSoByXeabLTpzEzTmmnSaLbrNlOZUiI4CFo2N4nqZLWeUFeJY0m416XQEQjoMDg4wM2uBW+UIhoYGqdfrDI8MMWwkJoUkSpBSUB8YxOoladrtedLU5Hs5CGFwVEaY6x8N1gcoh1XSJKFU9dmydTPbtm2h1RinVAoZHhliYtckmdaEYYlFixfhSp+JXRPMz83j+wHDQyNkOiGKW2Q6sWBceYByqYbnOCjHI0kyojhmamqCqNshirvU6wP4QUilWrNC47ljWZalCJMQxxFRt0sUdSlVqshM0k1btNpN0iRFGBclZ4njhInJaUqlMgMDCil90kQzMz1rv6eC+XmF6zoWpHu6tz0x9J4Yek8MTf/d/+vtzxcXl09Wdi9qHiUiZ5k4joMuSrJ0gsniPoraY6EUF92/URb0zSmI2MlcgIw9jZ8cfS2eXyDGfREwuxRIY9/TBiMWj1t41/UCNozYHXvK37pPHrNzTKJkgKsq9nuZBGNSkrRBklSQMkCKIM9mFHaS9h1kznwSQtLszIMQtGMXrzZC6Hl4UpGmllrbbrV6NGXXsaBalHZB2Fpxx3HzOyaItdWVAolOUlJtf7RJcvDFijFKHJzEwWSqN7B6AtrSahgtLO3toeDCltSlmRVrlMqxtD5sUKmUA0+qXuwBe/m9tVmxLLdmLG6u7QuLmJreB0sp8ZwA42vqlTFSHaNNTJo7z0Wpdd3DaIxJewAkxgql2w1b5tfQ1+7SWS7Cl1+TlNISzvN+NUbm48AghXX7K9Dl3VuBmOaQpxC4SqClIEl1b1w/3VuxmSwsbX2q64GdHzp3JFTKJQgrvRJZnaULQD0L3A2KRZRLFerpKEmWWAH3JMrnriHVCXHSJku7ENgsjsBFG1uWIXIzAavZVkMK6y7hSHcBTVTaPtMyl1bUGJP0WHhCCvv6fFHvL7hmwfcTvYC8cF4EB1eVqYSrmdePkeo2s43HKIeLcFQZPwiI4g5SKBIdoZRLvTLExPwEcbKTXWYbew+vYjis0e3GTE5NMjszw9JlS6iFAWW/ws6Zbcw2p1k0tJRaqUbgx8w1ZkAqBgbGmJ6fJ0pTsigDUozxaE+HeLGHyMUZpcp185QkUwUFzzL3lFS97x/HEa12A62hUq3b+eqoPkivTW+f6QG0pm9HLoQgzSKkTtDCateVghrLRw9GmxRNwlRzE3Haopt0CL3BvKQWUp2QJSlJnICBNEtJdNxPWBhb7uEqj4HyKCW/Tr06Zq+h7xHZu47i12LvKEp7ESJ38Vi4/tvkhtVcK9bufBORdn57rk0L6VyzzejCS8auq39NSFQSaySabidhcDRgYFjyyCMbmJ2HbixYv9caymWPucYUteowjz/+OJdddjHnnXcue+21F67r8IIXvIBly5YBcPTRR5FltrxZKUWpZOn44+PjfPWrX+WMM87g8MMP/19e09KlS3njG9/Iz3/+cx5++GE++clPceqpp3DyySezcvRAhsIV+FKwbXATc3NzDI3OU6u5pFGJDQ9sYHZ2ikq1zvDIUgSGq355HUuWLCMsVbnuxqs49LADWbt2Nddc+3McF1760rO55+7b8UOHk5/5Im67+X7mWru4+eZrWbJkPSedNMiGh69h2+WXc/XVG3jd617Pvvuu56Vnnc4D992JcmKe97wD2T4+y2OPTVOqjbHXusPYb9/9+ab3O5J2RmN7xLqDXCrhLFf+5gIqQ10OeMYKrrn6AQ44YC0H73cgP/vRDUw1x1l1iMsD9+4kVMOc/84302hEXHfdnZx04gnMzrS46KIrednLXo5Uiot+/GOedfKpGK358pe+wJFHH8PKlWuYn2uR6YwgtOYqrWaTXTt3snTFEjrdmIsv/gWjQyGjY4vZvnUr4zt2MDU1jevuxzMOPpy3vvld3HbXzUgpeM/fvZNHHnmIzVue4PnPOZMd23fwxS/9B6OLB9i+cyc/uOxrHLL+RAK/xnP+5oWkCTz26BMLYjzbHMehUq3ytre9jRtuuIELLrigt3donfHLX/6Sm266ibe+9a3ceuutXHXVVYRhSKlU7r1+YQvDkHe9692sWruKxcsWcfmPL2dqYop2u02WZgwO1nnD689h7/XrSOKEAw9cyR13zHPH7RuJowTf8xkeHMFz/9he/fRuWZqzW7KUOOkgsnzdNHaNV46LVAYhM6QyIApxcYOUDuVSHddVeJ7H4OAwIjf90ZAngwsNEJtY68GHxmqGpmlCO2gQxzHdbpew3LWC4mmK7+cM/NQhijK0tuYsfhDiuC6lUgUpJVGUksQax3EplWs4jgSpKVdCXNehXCnlr5VUKmXiOMUYTRIluG6IUh5x1ECT0eo0qTkhnlticHAps/OTNCemmZi4k2VL1zJQH2ZoaIA0bRNF83Ra82Rph0olYHJXiyRO6YiISs2nXB4gDBXhrhkwDiYF6Wq8ckLKFN2si0sJ6aR4nqTbSQnDEoqAxkxEo9ml1W4jVRdXuXgoymEVGZTJMvClQ+B7RJEmSwXgUipbfaU0TfA8HyEkExMTOQBhGBtbbEW6871bSsviT7I8Phb2lJLpjLm5eQQax8ljF62JkgidZggEoV9heHARQjt2HJmYTrdJpWbXaq0Ns7PTNFsO1WqNLNN02h0enXnUxnIOKEeAhMmZScqlOqFfYXRgKVJIXDdgYGA4HycxnhdYYoFQ1ihJWx1VkzP9w7CM5wWUswyQdKOI6flp4igGA6Hn4LgOQeizZMkiKyXieQjhEMcSjCaOEiInxnUDjI4R8um9Ce+JoffE0Hti6L88hv4vAU+FsNzCSVegajp32LClwJIshUSnC56fd1YPPrEMHMs8FL3axJ77nSnuWcEhKx4TvR9TMFmKm2bvHBLZxzXYHRQoSq4KQGK3+2Se9Iux1yulh6MqCGHr0Y3JSNIWcTKP42g8ZWl5hdBe4RhngSdLUW1H86TaliAOJiV8Y0vxkiSh0+4wP99ioOZSCX18zyHVCd2ojTEC1/HwXB+k5fckOsk/R5GkKZjMuilgRcGlUPZfxkFpx9KhFnw/KexGKMzu/DyZ1y6LfCHNsjQfrAqdZXl/hBa1VWrBnVoodGaFuvuLUs5LEgUC2wchRa+GQ+A6fo/NlumEzCRESZsoboIRxEkXYVIKO1NLWy1q0GX+uL3vWme5c07W78cCBZYSofPlXAgspm+vTykXJRdm8xcOBwPC1sFKIZGOk7OirJOL2X3wPC1boZ228GBRbJr9ZieF0ZaSaQPPUq4BkOWbZlHrbQE+1/Py99AkWWKFRzOr95aZlDjtkiSWwi103wEzzSJ0lpImCWDng+P6iN5l2MCsAKALpps2ILTB6LRHmXWFysczZHkmaaHw+8IaZrt22OBfIFAypOyvoh2NEyfzzMxvxFEBTlDC90Nct4WUksxkOMohCIZ4bOdDzDSmiaOEtfsvoVyq0WjOMjE5yUMPPczS0dXUhyqU64q77rsdnUpq4RKqlSpCZTy87REqlSEq1SGmZyeIohbtuEO1VgYT0J0JEHgoHKQyOSCskMpgpMzdHUU+F3O9MyFI0gTTbpIkCUopgrCE61gXkwKDL1ZMm7XJf/L5KIUgS2Mycg0IIQiDKstHDyRJu0Rxi7nWDoyeJ07m8J0qUrggDFmWEKcRcZKgjSHJUqLUludoNFHSIctikqTNitF9GaktZ3hgOZlObZ/1Sn/7y1J/ZuWPFza2aT6OtOm9xo7HfvbR5CUNEutyKZSDRJFqiBNDWsyFXsLv6T+HXdelUrEW51JolHQZGvWp1A333PcgUzM+malw6inPpNOdZ2JqJyMjI2zd9gT/9m+f57jjjmX5iuUkccJJJ53EM5/5TMrlEt1ul/n5ORzH6xlluK7Ljh07+NjHPsbQ0BD77rsv5XL5T17bokWLePe7383jjz/OHXfcwac//WnSNOGoo45m2fD+mKGM+kDA8PBiGs1Z5ppNpifmaM63uHvD3VRKAfX6IHuv34snHt/C5Vf8jne86x3UB6tc8vOLeMHfnM3qlev49Gffy4nHP5fTn38W//yRv2f5ilWcdtobeXTjNnbs2MLNN1/LM086nf33P4bf334Vt934Wx7eMMkrXvEK1q1bzdlnv5Cf/vAitJnnha88hM/8y1XcestWzn3tWex/wLEce+SJlEr/TBZ3aOxIOejoQdIk5seXfo0DDtqXxcv34Wv/8UtWLF3NXqv24h9+9h2CsRZHvbDMg9dMsnJ0jI9++G/59L/8Bw/c+gBf+so7+dH3f8Vll13HD370I+6+5x4+85nP8tlP/zudTpu3nf869lq3PwcfNMa2bdvJ0pRKrUyaxrTbLWZnZth//4PZvn2Cyy//Fa98xZmsGVnM+I7t7NixjdmZGZI0Zb99D2TFkrW8/6OvozZQ4fP/8iXOf+c7efChh/n5pb/kP7/071z4w+/zDx/6KJvHH+R3N13C8Cv2Yu+1+3PqaWdw1533sHnTFkqlMsYYms0mQO/AeO6557Jo0SIuuOACSqUSlUoFYzTXXPM7fvCDH3LbbbcyMjLCVVddRbvd7r0+TXd3qgrDkDe+8W8ZGRmxuh2lsl2rghCpFIODA7zlza9lZnqOxnyTgw5exWMbN7L5sXEajTZDgwHLFi/BGE273X4KUPZ0blZyyaDJSFLLcoriGOn4eMLFcQRCGoTIrCQCugdiSOVQqdQpV8qEQchAfQQhbQLSlkHYeFgWujxC5PG4PQynaUyWJrRLDeIksuBTHJMkVgIiy6yQR5ZKupEtzVLKwXc9HGUd6dI0pdVogckwvkMpLKGxeq2lckC5HIIRRHEDJRzKlSrdTkwSJ7TbLUrlMk7g0OkkGGPodJuUSz6OEzBQX8zkzDRTM7Ns3byJNFGYFYIVKxcTRWVaTZe5uV1ARLUcMJ4aWu0UrRNWOiWqtRGk8CmFO5C4CK1wHUG5Dmk6g07baFPH9TRSuXTaXbJYQObSmGnRaMe0212kivFcQVk61Go1Aq9KY24epTyCwGO23UZnds8tlcsYbZiba1IKrSX79NRUHmsohoZGcR0LHiiVM/UNuaB4lleFaDKdMjs7h+c61Otl7JmqKH2z5wbX8RmsjxB4FdrtNnPNSeaaE4wtGrWMsWaL6elJtDZ5yXBGkqQ88cQTOK5DpVLGL7lok9DozFAJ61RKA/iqQqVUI/RLDAwMW9c6neaO2CYXr7d6NwudswK/ZMWvpaLZbtONI6Znp5BG4iiXUlDBdR3CMGBktJpfT4wQCj9SOEqSxCldFROGGanJdjvAPx3bnhh6Twy9J4b+y2PoPxt40lr3gIs+YFAwXfoXDhbA0KJA1nKBaXIhM1P0X96Jun9kl6IPhBTX33+sACvoTSStDTpfDIvrKjZdi3f08j09Noy1a+iDEdpoyBE/YawEo9EGLQz0BNcEEg+kInBTkmyeJG3QjiZxkg7a02B8Cmc3IWznOsYlUx5Ku8RJZCl1UuRWpWBMQhS1aHXm84EmUCIk8AIyY3We2t0OSZxg0JTDEM9x8JVDnGVkWYrrOGidoVDEUddOCqVwRIogQ2pNQaUs2E4ir201xgqpW2CqD/rZn0LI3ZCmCUYXzhsZruuhfd0TVbMi4CALe0IK8EfnG6aX27g6+VtahLhvv2ophLae1aFgLSVOROJ1KQeDhH6dKGnRiWeIsy5ZzvICSxPXRemx6ZeCWm2sPlJvtAXbjEmQKBxh63sd6eG7FXxVxlW2xjzTGTpbaKkpEPkAtAwpjVEC3wgSoS1l86+kLZyrBZhcbCgmr/XWPRTc0mtFsdSKBWuLsCWvnhvm81lSlmoBwKhzALIArMHkGTO7UJtc0DKl2KxlIdpoCvE8+zzRm6/GmhPklr4ms8+VxcVZ2Nm+H4VFb/6/LLPjIzN5Ka0EUoRwUE7AYHlfuskkO2fuZHrOo9tpUKustlk/x260jnAoeyXSVBMnCUIqyuUy1XLI/XNb6CazOIHA8yu4ThWpBfusO4hGZ54N225i7+XrGK4Ns3JoKTOteXZsf5Sli1cyOzfL409spGGaJC5UAtAxkBpMliIyLHVd2fltXRlFfz0UFvD3HCcPbjNmZibw2yFxuUqlMpDXreeZk/weZVli9QOkh6McHOWBSfIsiMGRVk/IiAzfq1Hx6jjqWcy1x5ma38R8vIskm6UTZzYYFwI/8FDSQQmFcnxb6+94JKZLuzvDXHsrrXiOUjKAFJKMYsNbsIf06Oum51KJUHYO5xm6YhwWgHcxnsWT1v0sMzlN2ljXUSlwpCBSgjSDNLO5IvFXMIXPOedcPvQP/8jcdIzjwBvf+kJ+cNHPabVavPENLyfLoBPF3HjbDQzVB1m+ZClZZjjxhBO55967ufvu2/m3z/8rX/3yN9BaMzo6ytVXX8VFF/2YT3zikwAsW7aUY084lje/8S29z/3IRz7Cd7/7XX7zm99Qq9WAIuHQv2n33XcfBx10ENPT0/kjhq9//etcdtllfOSj/8rIcJ3Z+S2MDC1j8ch6XM/lic2PMTM7Tb22mEVjQ4yODXLfhsfYZ90KXvC1c/j973/DxK5Z/u78j3LpxZdx6SVX8u53fpKHN97FNy74FGef+xo23PcAL3zR83nf+97DCccey2OPPchNN/yKJMr47+/5El/84pd5eMN/kmZttu2a5Fd/+BWyJKkHq4kmjkeZu6hUdrB4cICBSgU38HE8wfCiQQ4++lDGRgfZ9Mg4X7n4Ap51zAs46VmH0W1P8vCDG3j7+bfx3W//gBtv/gP//Z8+wPPOOIywYvj7f/wAxx1+GM895UDue/QPPPs5x/OiF7yez/zbh1mzeh3f/tbX+Kd//BTGOHzj6z/jztuv4Wtf+gTHnnQQSxcdyNDAeu68/fcMj45y2nNO52cX/xCQ/NvnP8H45p3MTsTse8BBrFi2N42ZNjdedzvzM13mpyLe9ZYPk8hJvvqjf2S/owwr9lnGS1/1Ql5wxou48PsX8u0ffgnXFzzvtNM57PD9mJua5YMf+CfOfc2bOO+1Z3Pmi/+GL33pSxxwwAEAnH7GGZz/zvN52397G/flJZif//wXOP305xMEJf7+7z/I299+PkHg5WYzKS95yUvwPA+MdXJb2GZnZznxxBN7c3x8fJzjjj6Br/zHt1ix1yK0hpmZDldf/wvue+RW3nzueznxWYdzzLGH8OH/8RUWLR7hw//9TbzpTX/L1Vf/6inA1tO5hWUXIxLizNCOmni+y+iiASvRICBJYzztIIRDGIYkcUS3W6bdqeA4PmFYp16v43s+vhcACoPMdZZMD3gCCzZhMhAGJcF3Q8BQrQyx8BCVJAntTofG/DxJkuS6Uz6u51Iuh7iOY6sZMru+ZoMFQGBBiMB1kUrS6eTyD3FKvTaM9fTJcH17qIsTn6mpGeIkZnh4EM9zcBxFEncxEYBgeGA5wlR44rEZmq0mc/PTjMZVoqxNbLrESYLreITeEFkyTRKD63qUS3UG6sMkqSAIywRhyMjICPVBn4HhgMcfGSfqdAldj2XLF1Euh4yPbyeOY8a3z1ArLUGJMlEHZue3kwhDkHVw5RymZBgZqVCtK8pVRSkcI44EnaZBmwgpJUODNebnOsRRC9+rkKXQmJtj6+aHKVfK1Gp1Qq8OGNrNBsp1cvZYl263Q7cbMTY2guu4BF5gQR0pCXxot7qkScrcTIskzkjijFp5jHK5wqLFwwi/S5K06Zp5VHuWpJvw+GaN71XxvRJji0bQJiPTCY12w2psiRQ/cCiVPcqVANcRGGJmZyaJoi5R1MH3A1zPIwjKFhDN9aBsbJzR6nQQghxQsLFEN2rjSmssVClX8HPxZRB0ohbTc5MM1AYJyg777r+W7dsmaDTaKKXyMswmcNj/i6n5X2p7Yug9MfSeGPp/P4b+8zWezFM5HX/yMwqqb07rsiijgwU36DFbELvNwNw5rfi4nL5VlPhhFjzX/i6NRku9O/CUo7e7CWtBLswle+9jQQmrmWT3UP2kQNqWYPU+URSCWyHGpBiZkmRdMh0RJw0k1tK2pytEzowRCiWtyJ5BIx2B48hcdT61Qn5ZahlTUvWd+4zosWlA5+VnLgaJoxwrcC1sTaktE7NlfdpYgfBEdS2QIwKUsCJ0BdXQjqkC/e4zyvpoqchZUQueg6WEFuLjUiq0clCymLwLX79wvGh6ZZYsECLLx0JOiMqzBsVksMCORdztPQSD54Q4yiVOWyQ6Jko6NjtTLMTGum2IXL9LAFpiwaZiJBSpgFw8T0mFo1wCt4LrBDjSLVBK+naa+YaSfy/77v2MgPorOLACvX5amLEpQOM+4t2fN7v/3n+9BZZztqIQPRC5h62b4uX9+Y6x/za9Tjc9gFdJi/YX81vnc8gxxQZr7Dw1xeKa0XN16Dlt5IL2Jnc37S2idnPNkgStI4zJUMUGLaUNDoTBmBRHVfBNRuANkmYdWt2deJ6lnhttemw3R/p4ysd3fRzHxVF23s3Pz6O1phSW8HwXKbH1/Y2UTjdDSUmUdugkTUp+lVKakqQpUdQFYLA+xFx3ljiOaKpdhGR4ThnPL6G8LJ+7+ZoqBUb2M1h94Din8+cGEJlO6XTbKGV16Hzfs2uZKBxVNFmeES9mbDEXF1JwZc6wFEJQDgaRUuFIF9Vy6aYtunGbTKVkWUaapSDy9QmrP4KwVH1HeQzXlzNUXUq9PJYvO3atsR/35MlUjBeN1nnCQdqgztCfo72YiWIYmf7L83GstUZijRWklDgqDyDF7lT5p2s777zzWLJkCddfdx2HHnIUQmoe2/QYQ0M1KpUS9z+4kaVLFlOpVHAdHykdm1wQkqmpCW644XruvOs2Hn30ETZv3owxhrm5OX7wgx8yNTXNs571LABa7Ra33Hwro0Nj1Go1zjnnHIwx1OuWdn7//fdz++23Y4zh9ttv611fHCds2bIFsKyWF7zgBXieh1IO1VqJoORRFkO0Ww06nQ6DAyMo5VMq1Vi8eBFSpkxN7WJkZATXUcxMzTA8NEaaJTy28VGq1Qpr16xl86ZtpLFk2dK1dKIOjivZZ999iOIWzfY8S5asZnZqmunJCe67935GR8Z46Utfxm9+/VtKVY8D9jmM22auIUlbVCqWhq+Uz4EHHMr4zknu/+GPmJ9vsra0jH33Opabb/gDmzZtZd/DfSbmn+C+hwJWr14FpkIpbHL7HbczPbud409cRxzF7No1RaozwlpAdXCQezddR9apkZZ9Vi5fSqUcsGXzRvbedx1xLHjg/gdpNmdwPMPAwBImJifY9Pg49YEBhHB57JEtDA2NIZVkbnaGIPStg9euGVyhKJVdxhYNUynHDNRTli9fSZRVGd2+DiHnaAZzDIy0aMUzbB7fSKXqMjqymP33OZS5uSla7Sb77ncQQgna3SYrVqzgGc94Bps2beKyyy7j9ttv55KfXsxDDz7IxIQFkTZsuJfR0RHOOOMMBgYGCMOQi378I2691Y6H8fHx3rg47rjjqFTKXH31r3vzcNu2bbuN7bAUsmbtSq6/6Rqa7SYnnnAaS8aWkqT7QWap/cJx2f+AvRgZGcD3HQ4+2IKcV1xx+dN+7hZNmxSEtprgyi5OSZoSOg5SSdKsYBMIKxVgrGBtEJRxc6ZD4JdxHRtP5+nEnnivMKYXM4ueQY/BEtQLJrrZLQGppIfAlm+lSQpCEAQBnufheVYcW0mF0arXf1onvb24B3RRMAqg0GIQAluKh8Rx07yUyiAVuJ5D4Pt0jSFJrDYsRuC5PsNDVtek2+0yOztHHCdW5Drft13l4ygfz9WUK1a7KYkzxndOMj/fxGhBtTRM4LmkkSaOU5IkxnO7GJEiFdRqZeIY0lj2Euu+6+IqF61T2t02YdjC9x380hDSyUh1jMmZI46jKHKTSghcV1GQ7NMkpitS4sTFTxyyLKXdaQK57mkeS9n43jIuPNfu0Z7nIYrKCcDz7IHWgNWbNYJarYZQIcKrEGUzdGNJnJSIa2WU06XdipCZg8gklbCC0KDTDEeAlB5BWGWgPkC1XLMHcZOSZqllwiVd4jhCOQqZSQwZQqje+UEbG/9GcSc/Q4FfLiGV7WspRD4GjHUo60QMjwgrmJ+7dSupkK4FNh3HIQxdIMBxFiZ7n35tTwy9J4beE0P/5TH0nw08Fe9nD+DFrDB/FH0SOepagCnacXDEAraNcBaAHr2vvJuOVB8QXgBkmEKzJ79pxoBjejdpAQhtxbiN4cn3oZiEdsBY29BUR/lzjQ0KegyhfGGhsB5VeE6lh5KmWUSWRWRZihIanTl5eZoV5hLCDixXeXiOj0LieBLXdZFK5It8TJqmeF4Zz3NxXAdjjHU+iYytrUaTuDGp9nBR+CpEGKtVlGYahcRVHq7KHTuSiIgmRqZWG0qFNrh2BcqxmlxCyNypoKBfFaLtC0DDwvGgEBs1lv2kta05t3ogDjaQsKCZKDbWogdNXpeaW47KPPthwUcs6tzLBRiMpAfwWCDNzUXyQiuQmAzQTRvEWYdWd5Yki6zwuI5tQGQysgVAlCxoogsmkv3+NgPhSAffCakEwwSePbAhFmbzCzZfDmaKYqMpNhtlXU4WIM1P12b7ys7PNE17bLBiPBf3vad/xoJ5n/+fDXDzDVXbjarYLE2e9dptTcizLL0FMV+gBcaKMIoFZZtCYLKslzkSwulh06YAkKGnA1AI32tjyHSag74L65yt9oXOMmLRIdKW3q4kKGUDx9SqJ2JMjOtUUNJlsLqe6blHaHcnUGqIqJuiU50H1g5KBJSDCpmJ8AMf5UjiJGJiaoYshYHaEKXQRTqabtxg6xOTxGnC6JJhoqzDXCdleHgRUrgEqsSj4xtxvYAVy9fQ2ngf7W6DCfMwg8FyKv4oA7U6UmZIaVmQVhjRQfcyTqqXwRBC4CgH5diS0SzLaHeaZJnG9wKEqPcDW/LSDzKMzHXRTIZQCmHytSdfZ5Xj5huVphzWKYcDjNRWEs4N0IpmaXQn6cazRGmL+dZO+14IcssEMiRR0sVzAtYt3ZslQ3tTDoZsn0qJwoUnBUn9/aHQd7NzG2PzcXkEvKC/ixW7DxYv3EmNMaS5poHdNO1PYe+d6ad30Pud73yHL3zhC7z5zW/krrvuQsiMn/zoZ5x79isolUp89t+/xnNOPYXDDjmYseGlOI4iSq3Jw9333M3rX//63TJbQggajQZvf/v5vOc97+E73/kOAJdeeikveclL+MP1f+DQQw/l5ptv3q20+oorruD973//btempAIhesKpAwMDfPnLX2ZgYABjDHfddy9KShYND/G73/6SufkGK1bvR5YYAr/CsuUjPPLoBh588G5e+uLXM7Frkt9c9SvOfPGLyHTCl778r7zspeexfv3+fPITn+K444/nuae+ikt+9l3CMOSd73onN9x4FTPzE7zgb15Hks6z8bEuX/nyf/Dil7ycL3zh3znkkEM49thj+c53vs2dt1zDfHMHI0siHFfjOmVOfe5ZfPazn+Gf/umfAHj2s57DCQe/nH94+xfZMXMnb/34Cm7//e+5/d47eM/b38IB+1ZIYsMrX/ohDjl6lA9+6lT+8d0/Y9fOOY44fjFO1SdSAY9s3sjG+a2Uktt45avfxsaNj/HDC7/JBz70aWZnOrzpdW/nuWceyqFH7M/qlUdxyaUX8tvfXs7nPvcNtj0xwRWXXs2r3/QKDJrLf3YFJ5/yLEZGR7niF9ezYvkgK1eOcNiRB6CUgzH20BF1BzjxwNewbfIOpsPNnPb8IR569FG+f/FNPPdZJ7DvXkfyjP1P5corLyTwQ970lndz13238ODDGxgZHuMVr3gFz33uc7n22mu59ZZbuPWWW3br7y984QtcddVVPO95z8PzPFqtFu977/t7rnYL2xvf+AZWr17NNddcSxzHf3RsSwf8iuTf/+PzPL5pEzff+FxOOPKZaH0i05PzTE02mZpt8KY3nUUp9MkyzTvf+W5OOfU0rrrqql5C7One0jRCmxSpDJ5yMUCj0bLiza7MXZDt+hbFsXUqQ1CtDvT61nNdEJAk9rBFHs/ZtVL29EIwdq8XGKQsDqOaLM3ZSkhczzLNfd+hnNn563k+5XIJz/NI025vT3VUiI2DNFka26SfseVTaWr1RZV0kK6bayAJXM9BKlAqI44z/MCzMbYCz3MplSsoKWk1GzTmW2Taw5Eee61dRzfq0mp12L59J64LYVBGOdYEx3U9fD/AGMXIyGKkdGk029y7YQMzM1NkKQxWlyOUZnZ6km47JtFtQiVIsjap9hkZHaTbMXTbmrnpLlkWE/iSctnqODWacwShRxBKwoqPpkk7akLcRWof1ykjtczvs6FcDnBdmJ/rkOmYJM3QukxmrIZWo9FACodatY7ODYuy1Nh75ktrUuS5+L6PMbYcymiDH/g93dXE02SpxvNquL7ADwVTc9tpd0MEGa7r0Gw12RJNkRERZyCcAKFTBCmhcgnDMqMjSxioDhP4IUoa0iQijXNB6yQmzWzppTbKAk/KakRJZbVhTJrR6TRJ4oQsTVlU9nBdSRB6VpRY2aqBycmdtFoRUjj4gU85qOJKH+tJLRkcrAMG35OktQCtn97sxT0x9J4Yek8M/ZfH0H828KRkgQiSM0j6dZ+9C8sBnT4eJZDKgk5SaqQsAKf8S+cbY4H4/jF3kt5Eyf9UILnF5HgqMmevSy24kP4c7tsIGgy6EPhD5nW3iRVkFH2MsP9qW6YncHBkiHAkiRORZh2StE2azqMzSZzYSWoQOfjm4hBQLdcxMsULFIFvndO6kd2cMm3wPBfXlTiOptvt0mx1mZ5u4ngKz3OsjS1WZM53QpuNyp307ODPcJXC6IxYZCS6iaaLqxTSTXE9gwo8lAfSKTJlOaorFZgcjZWiBzRZkFDm+kzSLlY5KJNkEZlOkZmDweQCol4vCCpQUIS9NiEEu2uf7T6Y7T9N/3GBteHEwQGECDFGE+oqcTJAkkWE7kAPeErz60kz6xxh8qBIG0s11QsnhBA5E82h5FUJvCqVYBjPCVG5XpeUEi0WsLVMTj80xaItclAt2y3b8XRuSqneHFFaYTBI+nNZP5llmM8hk2dlLBgobGYVhV6Q+RFYt0RdQOpFdgUDZP17tnBWyQItN73NFfpgs03s2Gvo0Zml3H1KkrPzlGPZj7rQCFB5aafAOOB5IcpxiaM2cdxApzGpTi2wKgRKCYyJAEE1WEWWJTjOOI3OY6RRSJqUEMLBoEjSjFp5kLDsMTxSo1yqkGbQjmIc4eG5Dr6fEsURO3aM88SmSTzXZ/999iLSUxgdM5tMUQvr1OtjNDvzNLotxnduJnRdlCjRjmaJZZOuK4ncMr7r4DqSzNgyUqUUQjsU9HdrjWsDEOsmKVGOQjkK13NIk4Qozpid05RKZTzPI/CtmxBCWj20DBAmB4cXlleLXhmsHT+ZtX7WKbVwjKo/wlh5NZ10jm7aZL68gzjrkmQxUdJFZwadJdTLo9TKY+y1+FB8J7SlBrmBglQO1jrY6oUUWgN2PDr5OCr2GpF3/sLIbsHakbcie9UrtV2wH1hasN3SFZmlgfcK1Z/+zRjD8MAQxx15IgMDA5TLIeee/TLCIKDRnCXudsgcO6bbnRpHHXUs1113HU9epqanpzn77LMXvjNCWF3Bz37uMzzzmc/cDXT6U+3fPv9vHHHEEQB88pOf5Je//CXPfe5zee1rX8ub3/wWssij0Z5natcO9lq/H3Gc8cADW1m3ZjmjIwM8sekxRoeXsOa5e/O5f/s3lixewlkvfyl33vEAaZrytre+jzvveIA77/g5b3jDG2i0O9x06+3ss/5wjNFMTrRJ4wwlE3ZN3I/O2iweW8JHP/YpHnvsYb7x9S/w9a//T+6//wFOOukkznvFcyiVFP/5n1/npWe9gn/8x8PoNFqsXlPmpa88gG6rygEHrmK+OY87YJjfrvnep6c499y3sN9+B/Hzn/+YWt1neGSAb37jm9x9z12cf85XGVwjOOCYxey9fi9+fsnPaTckbz7/VVTUMCIqc9HFVzJQH+blL/tv/OqXVzA5OcHhh6/imCNPZPnKFXz1a59i330O5gPv/yg/v/SrjI2t5hWvfjHf/+4FuJ7HS856KTt2PMiWzRtYt3Ytvq+Yn+tw1c//k7V778OzTnseP/zBNxBITj3lBQTeAINVj/VrT2TMv5fHw8c48fDTmW90ufyXv+HA/Y8BHXP1FT9h7wMPZqA6wvvf/WGef+ZpHHr4QX92BvN/1T72sU+w77778Otf/5pvfet7XHbZ5WRpF63tOtLptMgiaE5kfPJjn6YTdZh6IuG7P/oyf7j9Wr71za/TmJzjD7+6hX3WLGHDPffyoQ99mE988qOUy+FTxvTTuZVKZfw0I/ADPN/quiSpxnFUT0NF64w0Bdfz8bMs1wISZJkmiq3+h8Dg+V7Pvt0UuqZ5s/pOdl+Twq6XcRQRJxHtpEuSZKRZhlKWGSml1Sd1fY9SKcD3PRxHkOWSDmmaEpmEwmClkFlwHY8s1UBm9WUc+15pmuI4VrcLodFZShgKXNcjzRJa7emcWePghy5ChKS6Qhw5aC2p1V3mGw067Q6tRhelNI7S+I6HkoJud57Fi8dwnJDlK9aBSGm1GszObscAg/Uag/XFNFsNdu3cxNR0A6kShkeG0cYjTR26XetCXa56pLFBRpqs46DRZCJF+CnCiUnpsHX7DvxA4PsQShcprYaUwMqIYASe5yCEptuZIwgd/CDAD0KMEczNN4m6tizPcUCKAIGTH1pNHjdnyMxKbsSxBRV0Jgh8J++LFD/w81hG5W5pLQJVxw1LBKpK2Z+kU25RDhs02x06nS6Nxjye51IpVxgdWUQ5rFKvjqGkLYVtt5q9PXR4ZMSy1qRCqvwcUDjNCRvvSiUJQp9Fi5aQpAlpHFsAwghKYUiWprjKpVyqUvJrGCMJ3Spzs7NMTE2waNGYNQbIXIKShyHjiR07LbPuae5qtyeG3hND74mh//IY+s8GnkRPHHr3SzMFnLrwMfpZVSlV8a/c8a0QNzO91xWo2sIAYiFtsU9DJBc76wtJI/O36b22YLgscLszUNTPFoieMSBFhtbKCqQJS+fO6+5y9lOftSMKbSgMQlh6si2702SiS0ZCpkFr2e/DnCWlpEPghwiV4ZecHKQxJElKmlmaoyOVDRKkIUmT3HUkpqxCJApX5eir1iRZauuohcJ1XLQxpCrNxcENIrd1xGSkIkIrH6MShGOtd0VvbOTC3MJSoYtB1lu0KFA4+1OUm9ku1xZH0pBltia5AKykBKTs4etFf5h8ISUXNe+BhrsNn/4gWAjoWNBH9l5nJxJ42gJNSRqR6WR34InUovh5rbPFuwSYooTPIfRrBG4F3ynlJX30gishBaZISCy4vIKhZ/LxiRBPmq5Pz9bbg8jvrQRDTpVFIOiXidrnFK+il9Wxv9iH7QZm8jJWi7JbSvCTQNuF4yl/r4VZooWb6cJ1IN97dweXn/yd8ifLXBhR95D6wuI012gTAjezgqZJ0raAZJphKxZk/lkJQjg4KsR362id0Ik22XuEAKygfJpmhEGV0PEYHKggJURx1zqNOSCFg+cJulHGfLNtraodh1q5TKPbpptoJmdm0RWFKLvUqwMgBe2onWcsrJisJkGLmNTE+EL2GA3kgb+Rkp5+mygowmLhFEIgc+MGyxZN04QktVpzrmNLoMUCp5bCEEDk87ZwwzTG5AxIka+RNnPjKC8HpLXVtXN8lBDEWUScRXSipj24ZBmVcJRaaYSSX7fZOvSCcZXT+DW5llpvNGBEfy3pPVpc2sJBzQLKerF0Lxi3ve+04CX2LXQ+Vp7e7frrr+exxx4DoNHoMDQoWLVyOc3GPFHUZvWq5XQ6HbrdLgiD4yh836PVbBKEIUceeaQNthaMj5mZGU444QTWrFnzlM/bb7/9OOiggwB49NFHmZqa4pBDDrYOo3/kuQceeCB333231edLEm699Vb23ntvDjroYIJgCCUV83MtarVBXNdFoJHSIISm2ejge2XKoWXOOq6D57t5ECgZGRkjDDcBMDs3R5SkaK1x3ZAo7tBozTI4MIrOIh5+6H7qAzXq9VFmZmbpdLo2oeKAMV3i7hRpHKPdAGFUrpGRkGVNMNa+ukg4CAFh3aE+XGPRwAGsXL6MRYtL3L9hE+Wqw6IlAxx9uGZ4rEa9tBdusB2tNHPtCGRCGHrUy2WyrqTVifH8CkFQwvEEURThOA6HHHoIQrhMTc7juA5COmhtjUmyLKbVmiLLUjzhW4DCgNEa33cIAhchHKRSpEnC/OwcGKvHMDM9SafTJc0yorZhuLYId02AMAE6izFk+J4DmUEqSXN+nvlGh5tuvJH6YIlURxx22GFs3b6dXZOTTO3alYvYPrW5rsvRRx/N/fffz8aNG3f7m+/7DA4Occwxx/Dww48zPTVHmuY6jWlCHHdZumwp199wPYcfdyCDQ4Ps2tRFOQpH2XIrrTPCwOsnf7Rd7/+aQCcAJa0jcE9TJTelsa1IpuYCr3ncWTgq2fUYsjTF6kxaCQepFNqI3pgF+jHbgj0X7BqolCLLNCITpEmGkOAogRs4uMrBUYrCmcseoOx+1G63LDvK83KtE+uWrBwX6y+Y2BjNFAlLlTMuDEiJ66bW/TlTdDoW1IrjGNexdu9BEGK0lZiQ0n6OzrLc7TAmIcHLyxPTNCEMS4RhjaHBAdqdOTodjSHGUR5B4ON7Ie1ulzTT6MyWioV+Dc8JEMKuRY6jcBwX1y+jhUeahQjhgJBIB7TUpDqh1W4hlXWddhwfoV1Mzk5DFGU5IITBdSWe5+J7PhiRuxgmvTg4SbooKRBkeWml3e+CIEAIs0DYW2BLFjVaG+KobQ/3ro19kySi1WrieyFCKDynTODFCOEiZIijWjiyRZZA6PpUSjVq5UECv4KSAUbbMSNz5oaUAs/x8kO46iWahchZThbZyAEQhyCUuKlD4jhobBmT41r3bSXtmPWDEMfxcaWHajm2NExnZJlGGk3htqYzjaNUPwZ/mrY9MfSeGHpPDP2Xx9B/vqvdAiRaGL0bulpcXNF0LnJoACGVtdlD59actoRLZ7ovvpa/l5QFMFRoxi+kL/bBOXKMuUB79cI7YC8Gnev82M2zYFSp/J37A0EbA0KSpZY1k8YdC1ZkffFEgbB2glgbUcsU8gi8AVsfLwxpNoshITPGajEZleMrCiVcapVBlGcoVawVbpxGdLoRSZKhNXYDVJYZ1olspiLqxtQqVXw3oByUiVMrMjjbaRJ6VoS85JdwHVv73uk0SXKxdC0s6yoTHTLhkikX4XjYdaRwL7AbvNY5my1n+hRldqIQau91fI6Mi/7Cl5kUEtET9AaLJCsUQvVXP200psjuLOjzAtySu9XY5n28YP5b20bLXJJCIpRPRfnFX0nTGJ1n5zKT5FPSMqB0Xr9euPnZHrWLauBV8FRA4NfspphpjCzujUNRC10o/xfMvCIINAsA1Kd76x0YBfmGLzC5KLzJMyJZli1ghxXf9Uki6wXA2Qt0rW5Elul8vbJ4uHVsWQD89lpeBimdpwTGiAWieL01Ruf10bt/n96aJOzcViwUdLSbpdZ2jEmlCPwSjnRI4w5p0rGHn5yWbF0NJTLXWAvcMTxngNTMMW9miaIZYAU6g6gbMVRfilc2DI5qummT2cYsnWaKE0pk2adaCWl2OkzNdli0dICx4QGWLA5xZwaYnBbcdOv9VCq7GBkc4JQTT2Q0auM7Dnc9fBvznQYoic4MpKC7CuG4uNJD5KYDuK6dT/n9t5nJXEvP2MwkKRSGC45y7c1FkiZFYKvxPB/PA+k4FmfX2tKt7bv2NmljwFMeUro5vbvYsDWZ0WRZDEIQOBXq4SjWbtUQZx2KjG45GMDJDzKpTnNjB+yXsGIHT+ljQ6ELtwCABhCqtyH0NBGgFwBkWZqXW2sLcuSAeppa56YeqlC894Ls0NO1PfOZz8IYCyg9cN9WwmCEgw9Zy/cuvIBmo8kb//ZNtDyHlqtITJuhgUHGhsf4w403235296FaCXGcfoAwODjI5ZdfvuBTRM7CiHfb0z/72c9y6SWXcP1119DttP7o9T300EM861nP2g2Y+v73v89Pf3ox111/A4sWDzI/t4vt26ZAGJYuKxOls2zf2aDZ8hjf/hjd1l383bvfQ6czz623XscRR55AEIRsfPwhjjz6EJ5x6IGc9dKX8YIXnMlrzjuPex54hLnGLhrtJzjlhBczMznLB97zNt713g+y19qDOPLII3jrf3sb73nPe3jOGcezz16jfPcb7+dzn7+ALHV4+1vewYc/9nk2PPAJbrrxBzyxaSdXXb6VRnOWgfo6aqU6i/cqM7zqYD7+jm/SFpezactP+f2v70UbqNRc4ur9nHTkWVxxxZW85kOnc/dDt3L3Q9v4+ze+geOecRAPPngTt9ywhQfvneM/v3gR27c9yM9+/mWOP/5sVizfm3Xr9uOTH/soDz/8EP/zW9/m4osu5fP/+u98+t/+hfvuvZXPfPxDvPeDn6I+MMwdt9/IuvX7smLFfmzdvInh0RUsWbqU9fudz47tO7jnrrt4wYvOpjHX5MpLfklpKAOZcu3vbuDkU57Nac8/lUsu+zmji4Y5+eSj2PTAbQRBidOefxZf/+rnufba33LLXb/nxtuvYXBwkPvuu4+HnniCCy6+mEu/8x2m/0gpHUC1WuWyyy7jS1/6Em9/+9t3+9snP/lJzjzzTABe//rzeP3rz8PKCSQkSUQQlLjqql9x+unP5rLLLuP0009n2T4lPvDf304cv4Xbb95AqRLwkvNOpVYvc+ghh/GTC39KedDloUfv/1Pnqadps0nXNEtodRp4nsfg4HAu2Ey/VMEYotjGNEoqC0YYTZplJGmcL1Vhby0zmV1vdW7oUggaR8UBR6c5iGAtwtPUilTPzrVyvVCD57r4vosUWDtvDL4fojNJpDN27tyF53osWjSG67ko4dBsdihXKrieQ7PZotVq0251CEs+CEmaZijHQUiJ55eJolYuLVHCZAmtZgN0gut6VCsDYFKiKKXb7eB5CqkCGo2MZmOeTnOO0eE6UkoSrSlVQyqVCrVaiDYNPE9TKbtWNy4M8HwXL3DwKi6l5giB77F0ZG9KFRetE+6+/T6kAj/wOOjggwnKVVw3ZNfsDCLVSD8iEyndNEK1Z6lVR6mEZcreAEksacd2v5FC4rqKTtsK6y9aPILnBXieT7drDXCEEIRBGSEg6rZwXXtQ63YMWc46GR4aRClBmkZg7CHZc31Ak6Yx01NThJ0OYamEF/jMz88xMbGTenUQzw8IwxBFSOD4lAOfqh8TVWIGg1l836daq1CqVDEGmo0IsJUsgwPDuEoiJbQa88TdDnESW30+x7WlUHn8pU3hBAYoRZaX2URJhNIWbMuEldzodiOCoEy5EuL7JZQv8MtOT7fVVS6lcoAQsChbhOd5uO6fcJV+mrQ9MfSeGHpPDP2Xx9D/BcaTvXkIkNpaEfa+mDE9OjDkFLZc6Gx3TZ+8flD3RbjsaxYiaLqHDPY+eAENTCy8Ub1re9INlSDM7haXhR5PMZmK67aXWWC8Bq0SMIYUW79bgApS2g1dSd3PCOCiZIDr1HCdCK0NUrYx0mC0gzFujoo7lLwKTqDxQ4MxCUnSJepGZIkBbQXIi1JEY0C5imotYHCwRKUcEHg+nW6XVitmZraF7wWUgpAli0ZQyqVaqtLttjE6o9WZt6irIV8EjaUAaokwqlc+BxKUBJ0Le/fqDIuFUfYXsH5n2/u3ILNm55rObV/Fbg4MQhqr+pSjSNr07Vj77yXQot/VBRhV0FpFDttLI3LwOAelRE8QCqEEWmgcmZFpz44jYdBOLoyX234iBCqfcCIHl5R0eyiv6Q25vKxUypxTuLBOsF87q4pJ9zQ/tNqWz6HiYsWCRcoUC2yx6FgBOUHfLnb3ksiFzW6iBRux9+iCLEABHttsgAX+niLQiL2G3qKdBzkFcFzc5mI1WHgtfRve/neTQqJcO+eL9UmWx4jGAAEAAElEQVQqief5CDKMTnulu2muDybzeVOINTpiFE9leH6HVLesdhs1SiEoL6bTmWKu1WJmroHIfMphheHBOt2uIksdKqWQ1csHGR6so7XL7GyXHTvmePThHdQHqzRbCQ89/ggD5QpLhlfQWNJg18w4D48/iF9yCAIH3wtxZIAxLlJkIAXCUWSJ3XSkEnm9ubIOlaLf29aNEhzXsWKGyuutk1mW9eyaAx+U4yJct28zK2VvwxKiuM+61w/9v0mEsplZYzRJ2u2VXThOKe8vG2Rluf1k8bssxmE+zrTWvfHWH0cLLH13yxqafo8vWLMMII1lqPZdLfPAQspisFMsLrK3AT+9J7Exmuc973m8+tWv5qijDifqZPzkR79l3dr9MWT8xxe/zwnHH8Zee63krt89zMhwnTWrGlRro5TLJcqlAIO1Sv5zShoW7rHkgWelVscPwqc89xOf+ASe5/1RNpQ2mq3bp4lTW7YhkjgvcVmKySKyJKHbjli0eBFjo3tx/c23UKuWOeigI7j4kkswxvCyl72MzVseZdeunbz1Le9gn33WUa3VWLt6FfPNGpPTIT/+6Y/JEs3b3vEB5mbH+f01G/nMZ/6F8fFxPvKRD/Gu899PszXNt358PTff8QSLx5Yxtnw/XvzSQzjo8ZRLfv1L7nv0AcpVh49+9HO02x3Oe/V5HHvyc1mzZi2BKPOjHzzMtTfciMZw7LNXcsyzVnDtrx+g3NnO0evvZeu906j5Cq8+9xSu++X9/PJHt3HciYs5+KATedbxB3Dpxd8DrVm79DhIYcM9d/H5z3+FY44+gsOOPILPffZTLFu6ivNeew6PPPgwRnu85OWvZ765i5m57bQa82AMYVhi5aq1bHzsYa79/e+I5z1WrF7KQYfvz0033AEGnv03z0L59oCyzz4NkrTDbbffyEEHHkizPc/NN/+BA9bvg+d6PPTQ/Rx5zAmMjC3lJ5f+ile84pW8+MUvZmBggB3XXcc1v/gFzbm53fp1+/btvPrVr0ZKSaVS4TOf+QynnXYqF1zwXaRU3HPPPfzLv/wLn/3sZ7nuuuv45Cc/iVKKZrPJe9/7Xo4++ijOOeccPvjBDxFFEd//3vc47LDDGB8f5+Mf/xRnnfVijj/hOBp6ilIwxuBwnRvvup6kk1FRY+y93xp0tvsofbq3bjfOWV4ZSWoBhTSZJgh9wDA/36RUCvMSDgfh2ANuFFnbc9d10DqwyUVt6EYRxsRI6dHf+wq3qzTXXLMW7iJnpDuOtEY4hrw8xqCUwZjYaosmwrKEtKHTTrGnM8mSxUtwXIdKOcRxrJFPpVbC912UI6nKEhYkSdi5cyee7zMyMkwQ+AghaHW6pDpBkxH4ZTrtFp1WTBp38TxNWFJs3TpOHCdUymXiNCJJI9KshVIpQUkyMztLuVRmeHiMRmuObtREqC6dTpu5uXmmpyPCwMNRgvnZJpnJGBoaZHRkhHIYsGz5GBOTm5mYGGfL5h0oF8KSS3XIZbA+wvDAChYtWoI75/L4+CSOMLhKUK+XCHzQWYu5OQMmRIoaYRCCMCRRm1K5hJIeygmIopg4igGD63n4fkinY+3Z67UhoqhLGicYA6WwhB+USLMEIR08L0B6heSDlcBwXMXQyFgvMYwRBEGJ0ZHFZIkhjVPm4zm0sAz/NG0ihGUQjYyM2WSwo0iTDAO4nrLaLFKghLanImN1t5SSudYsYAxJHPdjOexjxhjLvJMiP7c4KOHhyBA/lDjSIfRKOK4i0ymbnngcx1F4vg8iF5f3FZmIbYmpAtd3Cf2n7i1Pr7Ynht4TQ++Jof/SGPrPL6gVvTuVf5bos2N6Fyx6A7P/N7lgARUL0Nz+2/Uv2PzJj3zy4/3Dv3jS5/dV6gtl+p5GkeizehYKZ0ulcnFsl75FpOgxoiyKrfN6d1ubWWhDCeGiZIhS1r3HAlQZQlqmTNEpNuPs4ShJplOSNCZJUuwYtAu17Tz72Y6jKJcDKmWfMPRRUpLGhnY7YXq6yfRMg5m5BlFs38NzPAI3wHf9XI8r18MqXAsMObpqUdbevVrAbOp3r8i/W1F21+8BY7ADsffM/iKstS1py3TWu1c6R/975XaF61+x2PWWQNNbKA1FqWQfpOqX3RXXWmho9Z0TlbQAniNdlPJwlY+nQnwnxHdKeE4p/73U+3Gkl9u90vs+/cFXMLwW/hTDVfTG01+DvlPR8p6lv7nk/+kBcTIHjkV/bi6YW0UrUPze+4rCMfFPz8f+Dl0sXn0AuAhmigxN74f+Zlow1npjYUGf9IwHFq5R0pYBKKdw1Mw30ryGu5jrRf/pHEBP05hUJ1Y/TZeQBFYHw4kQTgwKlGMQMqXdmafVbtlyHiShH1Crlml3M5IEwsBn6ZJhxkYG6bQzpqda7No5R6PZodns0Gy22bZjG9OzszjSY6y+mNHaGA4OWRoTJx1E4RyJ01urpFqw3hbrWMEazOc4xjI0da7D1//uuYaZtsFjEsckcUyWJpZZaAoAtj/HivXb9nW+fuaBrZQq1xpRls2aW3hLCa7j4TkernRtH+cHod6GV6w7C5IHT95XWPD3/9W4Lv4hZDEvC1MEsBlC0x+T/ZnObg6fT/O2ZMlijj76aJYtG8PzHbZu2cXY6GKWLl3Oo488wdxcEwzMzbaYn23SaDSRysPzAlzP5pm6UcSmTZvYtGkTW7ZsQWvrJvP444/z+OOP02w2WbNmjT1U5W10dITly1ewa9ck8/ONp1zX7373O6666qo/ftEGulFCkmpc18FxJI6USBWgVIhSPlpnVCoVli5bysTUFPONFoODw2zduo1Nm56gXCrTaMwxMzPJSSc+k+XL19BspgwNDjI8OEy1NMSmxzexY3wHxxx3AjqL2b71MU585vGUKyH33b+Bvdbsw+DQcjZungVZwfHqTM12GR4JWbWqwpYdTzDTmEY5cOYZZ7Jk8RJ+9KMfsXJ4Xw5aexTTkxPcftMT/OGazdQHA5avqrFm/SDzOxVbHp1hwwN3oaKQsXAZ+69azZZNO7j+xrtpNw3VyhgrVuzN1q1PMD/bYGRoNe12h+3bt3HHHXcyNDTIfvvuzcMPPYByYJ/91jG+YytZmrLfAYeSZl3arTk812V2do6JyUlqtTqdTofNm57g8Y1bmJtpUq3UmJqYodXqsGb9WkZGxhgcGGb93nvjBz4zM5MM1YfwHI+Z6RnCcIggGGC+Mceq1Xtx4MGHIqVk5cqVHHnkkbiuy/zMDI898ABxFO3WrfPz81x00UX88Ic/5OKLL6bb7bJu3Xpe8cpXctJJJ7HvvvsC8Pvf/54rrriil5CKoohLLrmEO+64Eyklv/zlL7n77rs5+phjGBwcoNvtcvvtd7Jjx06SJGViZiftqIUf+EzPTjIxvYtWp2nFff+aUCfsIUbrXBQY62rW7nRJ4pQ0zYijJNdfspqiMi+ls88mdz52kMpBG3LmUtwT9e+fmCyDQmcZOrPxa5pmpKkmTbQF7EwhECxzAErnzmaWdRR1M6KuBaMEkmq1RrVSycEDMGiE0AhpD8ye5+B6Do4riaKoB1i4jmuZLKK/3xskWSZJU0hiTRxlRN2EVqtFq9Uiiq3chBWjt58hJLTaHaIkIwhKZDqi051lenYb07OTzM7PEUUGYxyUCmg0WsRRSqVUZcWyVSxftpJSWKLdbjE5OcHc3DzNZpN2t8nU9DiN1ixSGUphhcCvkEUKk9m9VErQmS0LjaKILM0Q+X6q8kOe67q90jJQZBlkmrxkTmLPiwLXLWG1WKyvj+c5hKFHlqboTOdlRh6u6+VAhN27HMdHShdbtiBxlEcYVnqO4VmW5eNLk8QJOrO6pOVymSAMc3FjG+cU/e660vahsOwa17WfHQShlUaRMh87KWmS2J+0/6NzWz8hFFK6ONIn8Er4fqlHHsh0xvz8HJ1uBykFqU7JTIpQoLGu1NKR9pD9NGc8wZ4Yek8MvSeG/ktj6P8C4ymHjMzuaO3C0ix6qGw+CaQtr+ttigU7BSxzxfRvCoWoWv5ZxcS1b2d2+0yDJer8qWZMcb2FAx99IEEVrKf+ZHVwkCLXj9I+CeTOAqbnlKYL4ccc0U2FdXWzHe6iKOMIg+O0MCZDyASTpXn2wMXzNUYlJGmbdrdJu90miRIUCtf1CIISSnnoTOK5PqVAUC4FDNZqCCSNRpepySa7JmfZvmOKIPApVwLC0GWgWmGoVqca1PGUR5YmTDUn6CRt0qyL1va7CIqae5kz0SzjyWR5Xa8Q5MWs+QJp3e5krx/o9bHEZq+tyKTTxw0N6EwT6zifcArXkLsE2Nr5Bay+3qQvwCSrmZQv7sUCKfOBr4uSPPqzJEdidW/RzOteda/LsTpbCwE0kQcThVCgyCeUFUMvAjj72bZW3ZpH5E58xYQr7svCL/Q0bqIH1trfjTE9UBL68674d5bThnuvF7217k9+376ooug7T9oHbOBclNv21hOrf1Bcj51z/Ss2BjJjkCoreq1HBRZ5UC7ImX3F+kMu5Jfbn4LAaEGKQWtrIFDMd6X83kYdJxFaZ8RpipOPp7nZBlEsieNBnHASQ4bRhnYak8Qtdk5uRvk1O6ecFpWqz+jIIp7YsYUsTRmsVjj6kGehU8mFF13GzTffxfiunRx86AilcgXfD3nw/vvZWtrEjiWbOHz/4xisjRF6Ze554jbGt2+nXtrAEncdVX8NQeCjE5c4NgjhIJF2bkmbjZGO19ts0iSyIzendGMKerbdOJXjkKUpWZrSbM7iej5BluAFISgHWyYskKhexlQWNeoI8PsJg6K2XeuMNIvpQdhS5iKKGVonCLH7GEGIXEpP9DKGxU/BpC3GglJFhm8BbX3BhkhPL8GOdSVlj91aDHrx5Dn75Pd7mrcLLvgeF198Cb/+zbXst+++vO2dL2V6ep4s0/zrp9/PzvFZNm+a4rmnnkqp7BGWXG644Rbm61VWrRjGdRQP3P8IJ554IiBYvGgxN99yE9/97nf50Ic+BMDf/M3fcO+99xIEQe9z//Ef/5HXv/71HH/88UxOTv6XrllKwf77rGDJkkVMTHjEsaHTjtiyfTOLR8aoVWoMjO7CmJjpXZrnnXwK3e4cG+69mTe+4U0ox+WRR++jXlnG8H7rWLJsiN/89l5+/et7eP/7X4SSMLFzJy864xWUSwGdxnbWrd2fgdoYP/jhtznqyBN51dkXc/zxx7Nu7Wo+8J53sff+B3P/gw9x/AnHoZRg2bIhLvrp+bR3znDTbx9CKIl07DgdHqsy39nG+/77edx7+3akEPy3dx3JH67ZzN+dcyUvO/t4dmyf5tyXvZ0ffe9iFi0OuPjyv2fs0C4jx65k73VHcelPr+a633+BK355GcrJeOjRe7ju6lsYqI9wzbVXc+N1V3DHLVfzH//5Ne679zZ+dcUPaUYzdLNlVCZDFi9eRqVcY3B4Of/tLe/g3g338fNLfshhhx7NEYedQFhx2bFlnGuvuJHnnXEylWqV9nzG5Zf8iIld2zjr3PPZe/2BHLD/QVx7+e0MLxrkpWeew47H53FcweGHH40Qkl27JgD43Oc+xwUXXMBtt932X+rrgsl81llncffdd/ce3z3DvzuTDuC6667j4IMP4qKLfsxzTnsOv7zyCqIoY8umSb735Ut49rOfycF7H87pz34xMjdA0Rq279zKX8Xmm7faQIU0TUmSFLAuQHGUoHINz2qljh94uI6y4IY0udaXwWgLFElhHc+yzMpaGHIASak83tbWNU0YMvJ1OQefjE5JcztsIQS+H1KIkBdgVRxrUhsyElR8qz2qBIm2bki+cmm3mnQ6bSYmJlmyZAkDA3VcVwIpjmNYvXoNYVBicGiIUrkEOagxOa2JujFbN2/B8zzCoEw5cNEmIeo2WLRomChKmZiYJAxDwqCCH/js2jXO+NQcnYbBL7k4foWRsYA4S2hFu5iY7TA7GzM0PMLqVXuxauVaNm7cSLlSZvnK5awaWwcm45FH7uXu27aw6YnNCKUZHAkZXVymORtBMouId5AlirQLw85ihr0AD8n9925iaLDCyFCdtatW4sgyOvOYn20ghCD0K8RdTas5x7btk5RKZcqVMqXAJ8sypqcnWTS2hMAPMAbCsEoYlnFce+jXukvUtWwl1w0ol30Qglaryfj4OM1Gi6QDtXqNWr1KpVYiTWOazYgwCPEqVUoVH4Q1TGq3I9IcdNS5bp2tIHBtzGUKAx4B5Hu9yl0OlYtSLu12hziOaLdb9lCd2XOc53m582E1D4EN7ShDSZeSX8P3XLTWjI/vZHBwiEq1xuDgoAVLM8HO7ZMoR7F4kaBcDfG9gDB39ZPq6T2X98TQe2LoPTH0Xx5D/9nAk85tHxfGDwvRLSlEbx49GZgCQ2HlWnyB/LzfB3Bzwecen/BJTRTvX4BXCz77KbRFsdsL6YEIRemYEGBywTxjN/8+m8X+V9re7T1mqYs5Myf/PEs9tIMxSw1ZKjDawSpSZwhlkV0jTO661iHWTSuilsQYo1HKspuUshS5OElxXZdSEDA8UEei6HRidu6cYXp6jsZ8C6UMyjFIqWk05jFZgklTqmEZIST10hBplqKkQ5R2SZKIyGmSmUEMCiE9hMwV8HvopewBRQU6W+hxiRzAM9rsdo/FwltMjqQXlE4KXSeDSEQPjVcuPTBJCGlxZdFH7otu3Y3lZAp8KBd5yz/cYpk6F+fvvRBpVB9wLP5r+n/vTU65+4TKMepiUO328mJcFCBVsYMUgfZfReq12DBFfz7rQrtqAcgLOTXYPpC7bBTgXHEfoagd3u01PepmodeWC90vaE8p4ZH5MpR/lnL6G7wFfnVvXGQLNmJh8jFZZCzy15ge41FRUEQdxwY9AnrrkBTSWqbmm6YFmK24aaZTsjQmitskcYrOJCYNcHwHv6KY7UzTiRrEscZ3E5CCStnFc7GCiu05quVBVq3am5m5NrNzs2yf2IbwMmrDJYyrelpi5VIZrTO27NhOvbaR4YFhli9ZzUTDWqpOTO+gHAwyUBsjy0IEHq7rkDmeFQjFfmeK+VpkcZTKxVot3N8D2ymyYf37gLRW2t1OGw25XbVECqv/IbJCb8BupsXmp/XCZITtB0d4Pd29QqzRUQJtdzOUUv0pYwrEOh9UC0aJHVN9PaJiIzUFBbi/4fTH94J1pCiXLd5N5+t87xPy19nj2V9HS9OUdruDowRbt45z5RXXctpzjmd4eIC77n6AocEhBgbL3HLbPaxcsZj99t+LlStXIKXDzvEGP/v5j7n11ptotVqAoN3pYAwcddRRvO997+OLX/wiGzZs4FOf+hSvec1r2GuvvQDyLHhAp9MhSWzJyNve9jZGRkb+6HV2ul2uuurXbNu2lanJXXzpi//JoYcdxsknn0y7PQdCs2TxUiQprW6DpFuGssQNuszOS5R0WLxoFc1mg04UMTUzw5KxFYTlgOtvuBEhFKc8+yCSWBDHkoHBIca3P86uXTFTEwMsW76CJctW8Z0Lv0OaRnSTnbzu9a9menKGb333e4wsWoLvh7z//e/nsssuY/PmR7nwwusYHFjNe95zDN/4xjeQUvKRj/wTV//qVzSjSUrDLi952UsoOUPcceM1TE4m1BcFaH8ed6DN2DrFz676MXutXs2zTnwD1959OY9t3chPLvoNSxav441vfAO7tjUIKy5LF63lpBMdpian+cxnPsthh+zL2nUH8cjDDxB1IxYvWUG5fgBCKNKsgzRjNGcjHr73dxx/7JEcc8xRBGGFRx+7iye2PMRJx76EMCyx136rueD736VWq3HO2a9hnwOewbIVawkDn8c2PsiOHU+wYu3+zM7N8Yuf/ZwjDj+WVLhcffUGDj10dW9+xHFMu91+amyVt1e96lUMDw/zpS996UnllXYN73YtMwRg77334uBDDgDgyiuv4IYb/sDLX3YWJ55wfO9Va9eu5ZxXncu6vdYxPTPD//zaNznxxBPZb7/9Offcl7NmzSqUA1/72lcZHBjg3PPO5Qc/+BGPPPwoH/7wh7n88iu4+eab/8LZ9X+/zc3O94CnWr2cMxD661mSZgRC5MwP68prD/y587XOeolQrUVvPdeZJsXqeto1WfeZ5nkAJYXVozHa2Iy+kMiei69lPFmXogR7rhEEQYDKDWlM0s0rCKw2kJL2YNpjO2iDUg5hUMZ1KwgcOh2NlBnKEfiej+u4OMrF9wNKYYlqpUzgSZI4IktjJLYMbGCgThQnVhw/jXGdgMVjy0nqGtdx2Lp9J/ONcQwdSjWBFIbQd0hLHuVymXK5bFn3qUaiaMzP0Ok0eezxjczNNtCZoVrxQQsaszE6dWhmHcaTcUr+EI7jsHzxCpygjaYDfoJWhswIpqdbeI7Acx1q1QEcZfuv1e4QJwnlSplKuUS5HBIEHkZrgsBHKU2aduh0kp6ekWUG5UdPkxBFCXNz2+lGCUEQEAY+gR+QpQZHWNBHSdWrlHAdl1KphOe7hIFLFLXRxhAEQT5mjNWO6SVb80NsavVohRFI38dxPFzHydkdoHWu7yKsE2EvFtNW78Um0z1syWeKkgKjBFqrPHaThGEJz/dRStFqt/FcH6fsUKlUcByF67o05hoYownDEGOaGA0rVi39fzI3/6y2J4beE0PviaH7n/C/GUP/F4Gn/sU/mVK128X0H1yAzBWlVIUoG096/QJAoYAuejd+wYRegFj14QKzG1a1ezeIXnanRxErKIpao3UBavUBk2LC2kUgz0gInVPost5iYoWnDRhtKcwp6EzlKKQBkYA0GJmR6DZJ1qGbtIiylCRNgAzluLiuneDaGOI0wXU8SmGZgfoQjfkOUbfDzp0zzMzM02y38EKB64JUhlarSZZEpHGEGpKEQUglqFsBSiGImh3SNCJKmqQmwuD2FpTCzrNP5cxpf3npmqXqqV5faJP27nt/cbQ3W+RC7wUjqUfz1IY0Z1xZRDVnOCGx8l8FoykHp1gIAD6J1ibIwTDbV1bEHozQOUDWH339xSHPRjxZeE3uPmZ3Hz+FPerC8flUrau/vlaQbvv9A/zRhcTSTi34ultdcPG18zLfJ7fiOUb0LADI/Q9ZCBj31jmK8Zej/sVn5+uG0BpygLcAPwuBy/719qmyNqtn563BAsbFQl1kqgrbapkHzmDr5pVxEFpAJkiTOKf6t8lSgdYSk5VwpKJac9k+M02jNU+aKRydIRVUKj6uK8myhCztUgpLrFm1P7umnmDrts1Mze3Cqyi8Wo1MCSu7pjXlsEyj1WB8coKg/AiRjth77T4sGVpGEkc8OnUvjYEZummDUubiYuvNHccyJK0CouxtwsWPkgrN7uKGeTcAliUo8nsHhixLiZIYIy1o7LkuWlj736xwlKQA8BeCtbr3XkUQlM8gLGOyqHc3vfvenz4L2az9AKzYbxbuFX+SAbvbv4trKgLEwgjA7PbcHmBMP4j6a2lC2PKM8R27+M63L+PIow5i0aIh7r77IY479lAWLR5kwwMPIJVhv/3WsnTpErqdlInJFt/59gX84cZrARYElXD44Yezfv16LrzwQh566CE+9rGPcdJJJ/aApyiKaLVaFCUl9Xqdt7/97axbt+6PXuPMzCxbt00QxzE7x7fz1a9+hef9zfM55dTnkqYxAEsXr2Byaitz802SqATCwQ0idu7UVEsVli1ezLYddzI1PU2jnbB0icTzFbfefjuHH3ooJ5x0FFu2NYhjGB4e5t57r2VmapKSt4Qly1czMDjAlse3EaW7aKcbOf+Nn+d3v72et335K/l3PoKLL76YRx55kEcevZ+fXXYnr3/tMbziZedx2nNO4+ijj+bzX/g8L37xi3ls6/2c+KI1nP7801lUW88ZZ1yMNxAztrJM18zgVFNWHVjhsisv4sD1R/L2t/6cTY8/webprfzi8mt597uP4tWvOYfrrr6TweE6BxyyjmVL1nDb7bfy3vd+gC/+55dYs9dB/OJnFzG2aIxlK9ewePE6GvPT7Nj+KCZzmJ+Z4fYbb+D5L3spe+2zH625mEcfu4cbb72c9SuPZ+myZaw7YDWXnH8JtVqV173+dey7/zNIE41yBJsee4Tb77iB937gZKZu38mvr/4Vhx99OGkm+f11DzE6VkZJKxzv+z6lUol2u03UtRbZCxf8M888k3Xr1vHVr361x4RoNpvUalWEFJRKJSqVCgDr1q9ln33WIQRce+3v+f73v8/3L/g2q1atptFooI1hr73W8cEP/gOOK3n00Uf55je/yeIlY5xwwjG86CVn4DgOSgkuvPBCli9fzrnnncvlv7iSrVu387trrmB+vsH99z/wf3yu/Z9u8/MNkhx4qtRKqGKfBQr3XYTMD3mgU02aGrufGUOWC9dqndkSLmH31EzbuFTbsAdDYfDTX+9snFUAUZbNLUVh+KMQOgWhESJFKhtr+X4feEp1ht1eLavDAidWeBoDOrO6LkHgUS7ViSLNzGwbKR1836FU9nCVBZ7CoES5VKJaqeA6EEnodBxSnSCloFavMjk5Q7cT0e10KJVLDIwMg5HMN+bZvmM7ExM7kSpm5Zo6SihKgUMWlgiCEM/z6B04jGF6ZoK5uSm2bH2CTqeDkg7lshU/n5+O8X1JGnVpN3YxMhgwUBtgydgSutkOOmmMCjTCMaRGMDPdJPQV1WqFypIBPN+h022h2x0ynVGplKmUQ8qlgCCw2lvaQJZEJElMu9NEqjqup6xIu7L7aZpK5huzbN+xk0zDQL1GpbIkZ54KUteCd45yMJmNnZSjCMIQ33fxPEW30yRLMoIwtJoxAtptW96Jtk7O9kBjx4oWAikDHBXgOC5JGqOzlCRLenuw63koR/VKN5WTa8+4nhWtT238I3M3wzzSplyuEAQBjuPQ6XTAYNeFsgWePNdlcnKCKOoyUK8Tx7bM9Ond9sTQe2Loot/2xND/uzH0nw08Fa2oGzTGkKbpU+oIMYU7nQUs0txmsl9/bvrsqAWIYYH4FShgAVRh+miyyJHBHiYn8prVfFPWevdZXNSwWvG7vEN7tbJFjaJAi7Q/1ih0hWQPCLOC3xYlTlJLUbUZpQytU9IkptOxLKY4FiAVQoLrAyrFyIhmZ4o47dKNu1ZtX2e4HrhK4DkShBXBRkuGh8aolMooFTLXmGRyZpaZ+VlbvuZBUHFtPb2jMElKu5PQblvNg0q5ypLRJdQqQ5RLVZLckrHdnaMVzaAcKIlSHnhYEUGhXbRQPZCOIhDJ9a+KSWanlun1SZGF68F2T0L9TZ55M1i2WKH/JB2F43h28BkLGopcMLxgXRU1xL3kwILFthj4CwVytc5ysMj0SjttnxVCm3rBorlgA+jNyTwYE3ZSF2OtEPLLL4Jiki/MWlhM66lg6tOx/bHNcmE9eNEWMs4sup6zFvNAVwrZy6gW7/GUz8pBYkep3i0ssuNPXujsfd79OovrcBynj9RLC/jav9n3t+g9/TkuVY7O5yYFT0oC2AVZIqWHFAptdC56bxfSuNum3Zwl6rZxHOtamaUC16njuQLH0+ya2kmzNc/SsX3ygN8wOrKCcmUA5fmcetIrUVLRbE5ywx1XM92YYekB65HKJ9OG8e1bmZ7vkrbbJK02jg+lgSqP73iCXTMTpJ2IfdbtxzFLVmE2KLIk4dHN97LvygOp+i6e71KuDoNRpLrTG346TXvZLd8LMEYjdYYsMty55Wmx1vaYgNj1QBpBGkeYNKORZgRBiOu6uI5HmiZ51gaMkWidUrBAAdLMUqiR1pFHKUWWFNojCzMyMi99hcxkxbRC9GzsTcH47QVT9ppzy+I/kl0s1v/+uDK9El475vRTxn2hnfKnWB1P52aM4aijD+YXV3yZoaEaUkpe+IJTaXUiduyc4/y3nofWhrn5Jjfdch2DA4M888RnUip7vfewttbWvepb3/oWH/vYxxgfH9/t71pnSKn4yEc+wgUXXMD8/DxvetOb+Id/+AcWL178J6+vG3W5+qpfMDW1e1meMYYwqNi9X8cEnoOolAmCEtVaFUmV9asV49t38JOLrmWf/dexYsUqWm1JknRoNDuc/bJX0mwk3HHbYzyx7RGGh+scfOC+DA6vxw9HOHDdKL+4/Hts3zHFd77/I2Ynt7Ll8ft45StfwTOecQT3bbiPJMq49957ecYzDuGFL96PL37lTZx03Pl8+9vf49mnPpsLvnsBd999DwcffDD//oV/J0lj3vCm1zD70FcZHRllanoHi4dKeJUqV/1oK+vWD/PcM/Zj0413s3PHZq74+b9z7FHP4+STX8JhJ7yfB+//Fee+4Wre9NqTyORqNmxosmPHo5RKJW677TZ0O2P7Y1uZa06yfr99WbP2AD7/L19n9ZpVPP+M07jv/qtxXIc3vue9PPLI77niF9dw7VVzPOu0o/jge77G97/+DfbZ/wDOfOnL+eEPfpjHZbB160PMTs3iiWUctN8JHHPss/GcMocfcQT7H3gAd1/bxvEM73/fGfzd353PVVddSRRFfOhDH+Kcc87hrLPOYvPmzTz5hHT++efjOE6uwQNzc3OcdNJJvPa1r+VjH/tnLrnkEpLEln+87W1v5YrLr+YfPvQR/v7v/57zzz+fkZFhvv/9C/nIRz5CM4nZ58AD8Dy7T6xdu4brrvsdAo9HH97O377prTzveafwvve9nYsvvhjHsZbcn//CZ8iyDMdx+NCHPsg73nH+Xzir/u+3SiXsxbaVcqkHJllBV0XNqSCEptNpEydxfsgQuI4DxpDEaa69o8iSFFi4Ruaxqyx0ZmxZVZH0kzbbRpZmpJkhzazpijYSB3CkRChQjj1sCmFjKCUtuyUIA6xbXoIrFWEYUipVyLQmSTMcx8dRLo7j0my3rEZUlFhXNMeQZbZMyPdcfE+i04jGfMpAfQAhXFyvzOObHyCKOwyP1nE8a7DTbrWZnpph184JSuUKQkjq9UG2bnVod1pE8QTLly9noD5MtTRMlmZs3ryZxUuWYEzG+M7tzLa3k2QdRhYPMjq2iDTWPLH1QVqdJt24y+giCTImS5tMzEGUthgcqDE8tphBf4RGu0u7kTI+NcPSkcV41Qqjw4uplIfxA496fQjfr9BoNBgf34XMk6f1ep2CdRKRIZXED3xcz8d1PJuAxUUaRRI1MWmG6ypcz0E5Eq0TNF2kk7BoZDGu8lHCZXpmmk63TbPTJAhdsswnjRUzUzPEUZeBIUmpUiUoWcH3JEqJuilx18ZOoVNBuXmJkQkxqYfWDlI6SJXhOBnaS3NgM99fjc71xHR+/rGHYoRLmsWkaW5kZMBxHBYvXozne0gpWbxozMpuuD7jO3YhlUSIQarVGrVajUq5RDeKe+vJ07ntiaH3xNDF/d0TQ//vxdD/JY2nhQjpbofvJz2v+Fvvyy083Nsn5ThuH0HsA8Gif4hfAD4tANzsK0XBvOl9cu997H8tIGZL64pyMQuqkH8TI/5YB+RASI5E9eiKefZESFvraolOtn43TRK7gWuNMQJhHApGjxExmpQoaZOkMVmWWrcS7OLsOi6e6+YZPQepXAI/BCFptls02k1acQc8gSM8pFHg2O+SZhqdZpZ+naXMt5tkGMrlCpWStb2shjXacZNu2iZJIuKkS5x2cYSPwIqZ4fx/7L13mGVHde79q9rxhM7T05PzKOcMSiCQBMjIgAWYDAYMmGCBLBHse51I5ppswBgTbMAYEUQWQkISEgKUszQaaRQm98x0PGmHCt8ftfc5p0fyd/G17/X4eaaep2e6T9ipVlWtete73hW4SEjJCBIUk03BDCvBla4lPxlo+v+xnOLZuoXKKvCs6X3XOsBLFsCPYwAKh7ZbUVxToTvVZ2NlH/e3haBYjwrpBqHtTSyiBDttN47raOal+YnCHm1pDoDLaS4Hbfec/z+LxgHZSjsuQbinuO7y+fX/Xf6/gApcRmb2D9sIN8L6Ufiyld/vmwsRUnSrE3VjAP/GHFNqe/QA7NJmeyzF0i6EtN0D9l9zyXC0lOkIbgxppVyJ7zTBFCViAz9wQLeFKAqRfk6immDAEz5RFBeaGTAwOMDwwAhD9SFq1Zgk6TA1s4tma440S4mDGM+PkQbCsErWzEnSjFylbgMeBGiryXJNqwO58pGyysTYMuY707TyBs1kBiljQn+cSAik8PFlIdxagLiUYGsB9ru50jEF6RPDF8IsqNzpHmOPsahVTpbJYhMi8ADhyYL5abuswS4tWUg3fqULCJSA9cKfYi4o5+BSawDh+qHfUJ/SPhcyEfv71m28iveLc/cw4T62437N2cN/n6a14Sc/uZpTTpnlzDOfzgMPPEiaZBx2+GHs2TfLvn2zrFo+zvT0DFu37mBsbIyx0RGEEJx77rlUKjE/+tGPKINHmzdvZsuWLezYsYNDDj2UicWLWbt2Dffd9wC7du3G90M8z+OMM87ge9/7Hlu3buX666/nwgsvZHBw8Kkv0tqi2kvPGZZCOB0PKVFKkaRNwiAi9ENUs0MYCKIoojk/S5blDA0NEVdqeJ5HY24fA/Vh6rUBqlGdRmOadtpg8eIxRkcGieOYMIQ0MXTalkVjY1ghuOmmXzIy6DM8XOfII49l0fgYT+y4H6FCms1JlkxI1q4+jKWLj+b662/EGMvpp5/OHXfeyY6d21i7YQWbH95Mo9FCpYKR4QmWLl2JENCay5je2WbZ8hECP2TTPftYv36MkcFB5uee4PbbY4JolBOOOZ9d227mjj33YBKfhJRGaysjI6PEcZWdO3cyWhslrlQYH1tK2m6z9YnNDA2MUavWyFWT4dHFzM7OccX3v8+qFTUWj6/h8KPaeH7G9u0PsWb9OlqdDv/6jW9wzjPPxRcev77pRgZqVYbHRvFtlfpghSj2ueuWBxhbPMz6w1YRVGfxQ4/BgSonHH8cFJH1OI65/vrrefzxx5nbr5od8CSdL2MMO3fuZGZmBhBMTEywc+dOrrnmGrZt286ePXv46le/xooVE0xMLGJiYjGrV6/mWc96FlG9xlFHHoUxcN1119JsNbjgec8nSzXGwNOedhIbNqxBCNizc54oChkbXcTd99zFjh07CsaQG8Gvfe1r/+MD7P9iy/MMr0gzynO3yfak55hMuKp1WjtGlFcASL7nYa0qgmeOiSCFhaKQkJQuNc8VyHFivy41w+v6P9bY7nRsLfjCgnCi4lBKZRT+kgFbbrKkcGx22asGLehtgo2xBeBg8L2o2EAaJ8CtLVHk43turndsFrep1YXwsFLQCUMHXuV5d95WKkESueCo76OUds9Auwp8nudRrcVIT1GpCMKgju9XkSLAGEueK8IgQFtQuaLT7qBMSqUS48sYYQztliZVTmojzTM8v9Cyylq0OwEzM7OMLlpGNRxibHAJMp9jPm1jybFkWDK0SjAa/CAkDEKiKHZsE8/H9wKkcH2Qq7zQynHaXJ703T5AOJBPW4vVmjD0GR0ZpFaN8X2vEFufR+uMSlRHViR+GCCkJUk77JvaS6USYwcHqVZHqFZr+H5AGMYIIVF5TrMxj1YGo8D3XApernLSzFUps1pSiSUy9Iq+d5qvpggGe56zAR+QkefYdcalMGqrCkkNumttzw8TtFsOQA3DEN93RS7CKOx+xi8rf+NjdNIFqw/odtCHPuhDH/ShF7R/rw/9WwNPnvS6jJISoFkALtEbbO5/UYAXC8Gq8nPlTfaufCGo2t8ck8khdX0f7x63+1p/Bxa0QdFHSbMF44kSXLEOrJRCYAoUy5gSvCgp0AUCjMCguwCcQ4O1M6w8xRTAU7dqHOB7wuXdW02SNlFa40Sf3LWGYUAUhERBRBzGhFGFMKpSieukWYfpuX1MNaZpZC2Ceoy0IcYatErJtSHXGpMojFUYk5M1FJ08cWUfxQT1ap2RgXG8jo/tQJol+H6LdtogkBWEdBXwPD8ELyyQW9MDX4pn5myuBOF66F+3UmD5QPv6w9Kb8ETxeWNNUeWup8Fkpe/MoJzsygm1BBClh+fhrk2UC1s/Ou/GfImJISyy5GbZHpjYr/mkC1TZ9ZeLCJriM6IUaxNOYK33vZ6dOz2E4qjaPGkQH6jNiZKWqYd07bBf1L/8/6koxN0Fp4jc7D/TPGmR6x/zxb/OZspZbT8Qz/TG+MIIkrvYUouiv//7mWeuApAPwivGt4WCVqy1wRUzcOmjthB2FTYrQFFFlqVkWUKStLFGO0feD5FCkAuo1iO0bNNo7yL0PGRUJ45r5DpDSMGysVUMDw8zNDSIEAnN9h627XyYLEnBSIzxkDZASEm1MkxbtkizDC1yAk+AX1TYlCFaj9Bq+1QqgjVL17JrOkBNK2Y7u9FIAm8c39dFZDukxGClJ7G6cAIKtF5SPJJiPpa+S7fFKLTJsSWN29KNioOLrOmkQ+5lbi6NJL4fYLQqusRR/cuqHC4StBCULatTFoOpeE33QOCCfWhFj/260KZ6uoD0OWLWij477a1J5WRTBipE107A0cdLJLlPq03sZ0sHeNNa8f73/y0XXPBczjrr6Vz9s+uYnZvj2OOOZmrvPh7e/ATHHrWRHTt2c/dd9/L7L3sBQ0ODZKnikne9i3PPfXa3ylie51x33XVsfughpJQ8+7xzOeP003npi1/Cc57zHH7+82uJowqf+OTHeetb38rPfvYzrrzySq699lpOOeWUJwFPvTlAEAQxnud3U+uk9FwKjAClM5J0nolFK6lWBphtPkgYQq0e88CDO/Gk5Kijj8CLYhqNebZvfZDVq85i8aKVzM4kpKpDyjxPO+5kKnGMRRP5HebzJtu3DnD88SdjZIeLXvQGXvS7z+B1r3kB77j4T3hw85384z9/mAF/nFrs89IXn8CJx56HJ5fztredwbve9S4+9rGPcfzxx7NyzQRvedtr+ciH/oHHH91KfWCAU046myOOOJq/+/RnmdnVpLEv4TVvOY1tj89wxeX38+73ncPaVcMk8zv4169ez+x8ld/cfCMP3BXySzaj5hYzN2fZMfUgp5/5ZjpJxuc+/1le/KKXcujGw9i45hi27XiAhzbdzvHH/B7VAcvUzKOsW3csN99yO69//Qv4+j//Cy960fM55TTBz372T/zkJz/hjy/+LD/4wY+55B1v5QffvpJKJeYrX/wCb/qjt3PksUeglSFLU+ZnG1zx9Ss55qTDWH/oSoZXdpDCQ6Wat771bcgCiLjssnfzP//n/1ww5/82rd/Pu+eee3jd617Xfe8Nb3gDz3jmSZx51smsW3cY55xzDs961rPQygEjOrV84hOf4PEnHufcZz2HKA5ZunyUD//N/wAsWml+9N1fMDI6xIZDV/OpT36SK6/8yYJrO9CBp1a7SbVaoVIJaTYbThOpUiNPCuHmOKSVpWRZysBgjTAMCPyg2NhZpMi63kwQeHie6IpCe34BPBUpPp7n5BusKSpNFVWGpec2UNJzFatcADUnz50gtVIF61v6LoXKA4QhL6b9QBbfUYZOkpBlCmMhrtScRpQyJJ02nh8wMODSqgCSJMNad11plqBV5sq+4QK7aZoXekIanacu7YWAKI4o01M86SGFQErLokV1tHYV2Gq1UXy/7tJmCqa70qqoQm1IE40yhiiUID2MhrnZFOvnyMjSaqfEkUetHtDRLWzbsHPXTlavWko1HGLl+AY8vQ2d7cSKDso0yPJZOokHok4QjBH4AXHkqlfHUYU4riOET64SOu02o2PjeDKg0zFOcFhIBB5aK1SusFZTq4aMjQ8SBDWU0sxMzzDb2INSKWgfRgW+HyB9QStpsnXbE24z7wlWrliB7wVuwy98cpWRdDrs3rUTKZ2Q/NhoFWNgfqrF/Pw8RhsWLXL6Q37gY4xAaUuurdsbSUEQeoShqwIWFgwQaywq0xiTFcFvustvGUTXyjA5uYfZ2RnWrFlLter2Ns2hlgMq/QClHWhljCRNskJ78MBtB33ogz70QR/6P+5DC/tbehT33ne3O7CUTxpk+yOr/TeSpQlKKyemXQh0SyG6wtO2ZL9I0RWvdgwj273B/sFcIm9l/iqIbopdKR7eS/9zek7d51QARkJQvG6xxpDnCSpLybOEtNPEaOVSwkoExFp0gegqnaPyjDzPSJMWSmVOGNG46JzWOEPyBFFdk+pZOmqKnZOPYi0EYRU/jLrAWC2uEUdVFi9aRhzXCKMKSdphZm6K7ZNPMN1skRsQQRWlXenG5vwcWScha3dQSQchLDIweJ4TgKvHdZYvWsHo0BhLFy8mUS06WYP5ZBbPl8RxxEh9KZVgmFq4goARJBVcTq9xCzflQyuMuTBAWeTACuhWVujmEnf7pw8Q7ENOEQ6sc6KWjgruSQ+/KLfrqgqUE4fn0v3KPi3Lk/b9LKCa9v1TTMcLclvL8dFvr04s0fW16kZaSpqp7QGRhW15fbTCrnBn3zWcetoZv81Q+i9rDzxwX7eccxcr3G9RLNv+gG7/ImatXUD3LZ9Fmc7YzwLr2VFpGz0W2lP1o4CiEkt/MYJeE6KoJrnfd7v25AVIv4h66qLcbxG5yLMOKktozu1x5YGVwmoH2mqV0um03Gt9AnqFH40xUBtXtNM97JnZBKqC50fURobw8ZB4CK+ONi2MbTE4UKXZarNjz172zM6SKIuWQ8RxHd8LyNoZs9N7mZ3ZixflBJGkUvXxrCQiYsybYMmiQxgeWsTIMo2libIN9jT2IL2ISjjKeOVIYn8R1WAxyiRYNJ6UzlnAkisXmbRGEwUhQrrc/SAIkFJgVOZKsxrdja7pPsfFBVzKSioeUVQljGLiOHL6EcUmQAiBJwvGZqGfV4IPpij9qo2mpCQvXHJ6EQfbJ6C54DO277OIJ9lYl2IuwNGBKdYSd2xP9hZzrXV3nijFGymLIgjBySc+7Uk2d6C00iZ9P+BrX/sGxx9/HBs2rGX37j3kWc7wyCKyLEWp3Im9YgvB34gg8KhWA4yW3H333Zxx5mlccsklnHPOOVzyrnexc9cuWq0WV/3sZxx11FGMjY6yadMm5ufnEULyzW9+k+uvv567774LrTVRFHH33XdzyCGHdK9v06ZNvP71r+c973kPz3nOc7j33nv50pe+zGc/+xkAhodHWLduPX/4xrdx+BFHsXz5Up7Y9hDN5jSnnHQGd911B7fc+hte/OJXknYSHrz/flpJyuDgAGed+XRuv+0eJieneNZ5z+KB+x/nnrsf4Q1v/B0eeeQB/vGLf8/xR51BrRoyN30X8+0UbTw2bjiV+dY+ZuZ20pqZYmLpCo4+4enc/dg3efjhh/jx1zbx4Q9/mnPOeSY/vPJ/csvNO7jnrmmedsYEXpTTVvNc8S/3MTKwnA+8/y/5zne+z0OP3M8pz4yIK86Z/96/PMyyFTWeed5KHntQMTuVMT05xytf83ZWrTmMD33oAzz3uc/huc87l91TV/Lwlse5+eZHeOPLP8iKZevA67DpoU3s3LWDx7c+ymmnnsrJJ55EJRrjgXvv4+qrfsKzzn0RA0MDNFq7CMMMlbd54N4HWbf+ECaWLucfP/85lq9czRnPOJep3Y8QRTFrNhxDKCo05uf59re+zFnPPI9Tn3YWu3bsodVMaTYT1h+2lAc33c9ll17Gh//mQzzjGc8A4LLLLuPzn/883/jGN7jxxhv5m7/5m9/KRicWT7Bm7RoADjvsMN785jcD8Nhjj/HqV7+aajViYKDG0qWreOlLX8rFF1/Ma17zGsYXLeZjH/0YD21+iDRNOeqoo7j8W9dyy8338xd//gauu+56vvCFr/C+976blSvXUIkH2b13C5s2P8yl7/sMU3sepDW//bcGyP6r2k033UK1UqFWr5FnOdLzqFZqJGmKMYYoCsjzHGsNA4MDRaU6j5mZaZJOh0azTZ4XKU3CEgYevi8JowDPd8x5cP6PkNJVqjIGpfIi6OeEyr1Ca8nzA4zR5HlC0umglCbLJYEfEgQhIyNVgsDH8z2SJCVNUtrNVnfj4wUBuXLlw+v1mDDwCQNXMUori1KQZhkWQ+BL/ACMyXj08YcwKsHqnCxNyfKcdiejVq0TBJLAU0xNz9NqpwgvZmhoiOGhIZrzDaan97Jt+6MsGq9TrVYYGByn2dQkHU2nnRTML8nU9F6k8IjjCtt2bCVJOjgh6xpGG2674xasn+FFmlrFJ4596tXQJb95EcO1UQ479FAmFk9QqS4iMw3SfI7Hn9iBxKMa1di4dh312jBBOIYsUiCNFVTjOnFUwaiMJG3T6swxMDiKVoJ9k03q9RqVSszYeIUsa5NmHdJEIYRBeoZWIyfLLO2Wplp3zy3v5FSqdSqVOkNjY2RZRqPZZHh4mGqlwtDQIGknQecarSTWgDaG2XmX2hbGAaMj42hjmJmeYd/efSRJRjUeZGholHptEItPkmW02gnNdsdlVRjHXAsCj3otolqNqEQBPhJtcnKVkGRNDAYpXGECayGKKszPz9HpdJhYsgxjBFlmCUOPLEuZnZlGK1cuftny5TRbc3Q6Lc559oHrRx/0oQ/60Ad96P+4D/1bM55K1FQsQF+La90P5XI3VQA8/UCBKEA726f/U3xQ7PeMSvCtHNT7gw7lU+oHo8rc9i4Y0tVp6r++EpYo/hKi+xnRnUj6PlrGlxaAFS61zWhdIMwghddFTD3PAU9Caqw2XZ0gR5suFnzPJ/AC4rBKJao6Kmrg43mSNOvQSVu0Oy2UVhjhE/ghvrQgPIQMsDZ1kQljkNISAEa4igVZ7mi0WWYQhIS+myQT1cEKjdKKTCd4MiG2yh0XgSh1nigV7233/rqW298PXfS9NObesxN9X7EF6NR72x3XoMHa/UAir3sOjADpJqyuSH35/QVK/j07cV1WorZiv7cLZNZNzfTE4xfah+3CvPSq9PXZWWmP5f8HurNbNlsCit3B9mR0uvtKH4j8VCj2k+jCff+X33PHEz12WxfI7AGB+4PWom8SXShUX373yVEk93cvyuA6rrzHkipa9LMoX3GLgau8oYp0WWePTl/MTf5aW3whXEUbGuS6Q5Yo6tU6YVR1lSukS4Hd22xjTAtLC2NyGu02s80m+D6+lK7yZZ5jckOn3UYrhe/5BKGH57tJPAoCPDx03qTTnCewMfXxYcLIUPGhlqU4WUeFpoWmUpTGlb3IRHHfrpqGexYliLuwMkd/r/eiFgvo3dY9La11NzVEeiBNgOfbovqJKCJh/XO1A4qlJzG6OOt+gYkFgb2y73sd2j1Wf7niMlrXr43QH7HrMiNl2cPuWCUrU8jC+BAuOt8f1XmK8XCgteXLl3PooYdyyiknMD4+wSNbtjEyOERtaBCs7ZY5HxsbdYwmpVAasgxaLctAfYBavc6ZZ57J05/+dI499lh27trFzMwMYRiyZGKCsdFRwAEHZfvSl77IHXfcwZNCtEW79957ufnmm7n55pvZs2cPQRBwwgkncPXVV3c/Mzs7wx133EaSpgRBUKwt7nhpmmGsKXSD0q52TxCYYjPtCkhI6WGNwZchlXCAqX3TTE/PkqWWOIqIAsns/CTCG6ZaHWLZklGSrTPMzM2ze9ujVKo1RgaH0H6CDlKGR4fZvv0JHtx0HyeeeDK33bKLO++6kze+6VKm53dz1bV3oXSC9DXtdhtkhyBMUMonzx0POtcJuQ5QuSHVGbnNwNNkeUrSadJp76HTnqbTaRFVPIaGB5hYsoLtOx7Dkz4nn3ICd955G5O7d1AfGMAayfxMG0Yy8FoMDAwzuXsX1uYcftRa7rvvN+zevR3Pk3TaOdP7Wi71qBIzOlSlORM6p1gnNDsdGnNzeL5PkrSYm93LspWL2bVjL9u3byfwV5ImKbfcenORJtdrnudxwgknoLXmzDPP5I477vjfMhIm90yyZ+8ejj/+eMbHxzn11FMBWLJkCWeddRZ5nqOU4rbbbmPlypWccMIJ/OY3v+GQQw5BSAeIeL5BSIHvSYLA+QPS8wijkLFFY67iWccyWJtgeKBNyVr+79DCMERKrwCEg6K8dSkWbnAVj4r52FKkxPT8ZFmkYNj+qUr0Zq8y2wDozm29CDVQ+FqelF1Ra4HEepLA7/l/QeAXP4FjSEFX1DzPM4R0PkDgSaQBjAso+75PEDoJhyx1DIhy4+UHHp5nEcIBQ2gPIxTlRlqb3B1b+FRCl44YhhZ8jyAU+IEBkYHIsDZloL6EWn0AP4jAttDaaV5pnZHnmizvAAKlFWknI8/dXCKKik6e5zIdhC38dysxGoJAurTf2JJnTZqNCG1qBLFPHA3he/swSpOlCVnaIfECchVSrQ0S+mGhc+U2kGV1MBDoPEcpUbCDSv/Z+ZbGQqPVQkpLFEmcfo7TMXX9ZLEY0tSBQcL3CMKI4aFh4ihCCGi1mlhtimxZ2Q2W1utDbmz5pUaNq1ZYrw8QBBkeEdZIsrTQccotWoHOcVpgSqOUwfdkt5qeRCL8gtGhtOtTIfE8aHc6qFw5f8OCVzwLpQxZpogrbgy4/vIRwlXnC/0YHRzY4/igD33Qhz7oQ//Hfeh/J/DkSri6m3TDoTSunup+/3coxLacw+g6oK/Ma4HiYt299nT2e+ldPfZSD3zoXU+BFHoFQihFj4XjlbdWontFsl6J8nUBBHeNnpQY6Sq6lSr25T1Zq7tCqypPyTPHeNJaYa3F93zKKgBCW/xQIn0LXg4qw9iMyI+Rnk8c1wlCtzhFQZVqpUYcxQSeByYnyzJmZvcwNzdDp9NG4WO9UvxNFvmoMZAUVSmsq5znS4RXphb6KOWRZR5J4hPGHrU4QpOR6Q6patHJmhgrCf15hFcjkAGBrDohdulAHUepdelxXcpf/+Qmy4mo1AOQXUQeazDaIe6ipAgW33S2arFGYYTognnS8wiDEM8arPVdBRWKnNMihRH6BNBEbzIUyGKuLEmPzt0xumDZSc8N3BIM2w8BLu3E2URxzBJ0Kj4mi4XUVYToLTAl9fhAb2WEpQugFQhvd/IpU2OLdas7dRbPoxy3QgiCIHBOh9bd5+Z5XpcN6R51b1IrHeD+ybrMMy8XQyGEK8pZoP9FEZ7uMbtU0OL3hdcnwYI2Fgpx+b4ltCiR6s5ntLNrrEHnGXmekqYdwFGNA79wtoVAa4kVAqSlkT9CksyTJx7eUJUwrhF5HpWwgjaWR/dsYmggZmSwytRswt7ZOR6d3M6qNWsYiGvEaUCnpUlaLXZue8RVBQojojDAClfFw4QaiyHXbRr7tmLmU4ZXrEPIBtK3LB9bTa4VnTxFhE209MhZROQP4skQRFpsEAy+XwoNhkV57jJ6YjAFGGxFWWmDYnyzwC6E7D5BR6NOU7I8JQhD4kqlEI6UWFxIy/MkCA8/EPiBq5zZG2MFM7JI53Un0l3KuZQBpWn2j0eN6tpAyRTt2QNuo1WOa9ErHVs6aF2jF65KSTfCRyH4qRTiSQD0gdkuuugiPv7xjwNw3/2P8I9f+DZnnXYm69au5LBjl3DVT67mtltu50MffT8Pb3mcG3/5a85/zpmoVPLAPbs459wTOOKIQ7j22msBmJyc/K3O2z/2nqpdcsklXHPNNb/VsZavGGfJ0mG2b3+E5UuXE0Ubuf3OW1m/bgPnPOPZ/OhHP6ZarXPq084giiOazRmuu+7HnHDiGZz9jLOZ2jvPutWrWb54NTf96ioq1Tpv/6O/xJNbmJx8hMeu387LXvZ7HHHEiXzvXz9Ks5MQBYa51DA5NcnWh3/JQ1sewQsFn/rkG/jAB77Fp//u89xz990sHt9JGNzIM876A2688Uau/t4/snx9janmNl7+ilfz0U+8nT9449k87/w/odNO8QPBs148zr5dHT74Z7/mFX90CCccPcCQHOTL//S37N6l+co/vp0f/uTXvPa1X+bLX/gQZx13Os8+aR0f/Ni7uOPuCsce+/fM792D6LR5x8WXceX3r+QTH/wop55b57DDT+Udl76dT334f7Hp3hmsOZLrf/FrWh3FX/31p/n8Zz/Ldy7/CJdfcQVbHr6Xz37iL3j7Oz9Ip9PiU//rvZxw0qms33AYf/K+v+T+u3/DL6//Ps887/fJ9TxK7CTLDifPnqqSVG88PP/5z+e5z30uJ598Mnfffff/tn89z+OLX/wixx57bPe11atXd+1jamqKI444kiuuuIIrrrgCwDHnBHzy059l+46dXP6v/8RFLz6Hi158DkLAhRc+h995/vk8tmmW6T0tlq4a4Dv/cic3/fIWtj96/ZOEdQ/UVq3WUbmhMZ8xOjKEwNJpdxxoYC1B6JHlhVCzhVLv0hiFLkRppef8YV24M2WZe2MsZsEU7gK8mLIacK94S+mrWeOAn8DzkZWKYzko261cFkVxV1JC5TlaqSL9Kugy043J0ErhySpREFGr1ElSQ646ZColigOiMGCgXiVNW3Q6KcIojMrJM00YuqptSZayfftWpIT1a5cxNDzI6KKQuVaDTjrDzPattBszqDxjcNBj8fhKfL/K9h27mJufJc0y6rUhpqanmJ7ZQ20wotVMmNw9R6eVE0VV1q5ZThT5KJ0xMlolU2BtxkA9cv6GtoRVn2o1YHTUp9OZodNukeuEReMTjI6NUa+uwKoUTEaaaKxpgTTUB0aI4xqNVgejO2SZolqpOCYUHp1OC4HP8NAwURwShn7h3/go5fPAgw9TrVZYvmwJq1asxvN8ms0GjeYe0qxDVKnQaqW05xo88thjLB6fYMP6Q2jlTZTKaLUbjI6MUqnUqMZVhHAaU8PRYLHpzUlabuNbrQwwODgCCFpzmta8oTVrUco4PzysMDzgo4wmU4pOJ0EpTaORFtozFhvjdGPTDnElcpkeUtBqtuh0EuoDGmvdXszzfPzAEobCVUELLdVajSioEEUV6vUBrPHBxv9VQ/O3agd9aHe+gz70QR8a/s996N9eXJw+xKu4sdJQbT9daf/viR4rppdX6jR5+j5EyaApv2OKY/anS/W2+iWqWwi1LTiXoxj3WCqO+WSwiAL1s9ii7mxvYtj/fwdwFPRHnWOMKoCnAnAypqCfFelXBVjlAdIzCE+RqQ5K5VgNlXgIPwiIKjUCPyzyOQNypdG2Q246BThqmGvO0U4TNAJtHHqaJhkCz2kTKQtWIqUraSo98HzwfYkvPQIRYI0mS1Ja8wlGh8S1gDgYwPedFoApBlAnbyBtzeXGigBsgDQFql2Ie5fIvAOzy8EkwDgxcEvJkSr7sIeGI0QhbGn3f8DdY5VMMqmc6JqvA3zfQEDPudEShIt6d49mizMLoJRaE0CRg20MBZJdAk2i+3sB/juHTZcC5AVoKcqyoSXLiW7EUeBExoX0yjcwVmDlgQ88dfOQCxTeTUz9QnmiCyxqrSkjrE9FGe7+LcWCCUcWqbjaPvVGYCHgR5+99NlW8ZyNXfjaggqaxdd6DMgeFNidFKXslo7VWqOyDJWlzj6Mq+iTZQlGqwLAdsCz9PyukLyUPsIX4Gnas3NkeUIYVonCKnFUZagaM9uYZqYxy76ZHVQry6nG48zqFu1Oh7mZeWZrexkesSxZcQTNRodm1GRyt0CgMNYSBDHSd7TbTDVBSAaGFmGmDXneQs00yKzFigpJup1KpcbE6DJmGtMk6Sy52cJIdSO+NwrIMj6FsboMg6CN6YqeCmGKsel0HJClo+GenSkA5nJcgu3NzxJ0QS9WeUYcV/G9gCB0GxSLdSVfdZELX+K2srd+uCicC0KUTpdbE3p21HPQeqnT/c5Tf0RJlLp93ahfCZz3RYm6tu0KQLhjA1YgfX+B/RzI7corr2Tfvn184P0fYtnSCV79mt9l8dg4vhfw2MOTnHDiSRx3wtHU61XWrllFFEZMLJ4gSzUbD/W56+6tXPWzm7nmmn/BWkMURXzyk58sqOOSpUuXcOutt/Dxj32C977vvQwMDPCnf/qn3HLLLU95Pbfeeisf+9jHuPfeexe8PjMzw5/8yZ9w++23d1875ZRT+OOL38EJxx9HrVplcHCcvXunyNUujjnqOJTK2PzwAxx33DForZie3s7o2DLCsM7RR54BaoCtj+7h3oduZe2qdWxYdyhH641oJRBS8aMfXoXSbd7whj9lz+ROrrrycqb2pRxyxHEcdvQJbFx3H8ruZNbcw+Zb9zAwsJRlL38Wz3/ZLOseuJc3vfkP2bjhUP7u05/me9/9Mvfc+yCLFi/mpFMWkecZO7c8wg++fwO33nofccVjzaFLWL52hCBZwXGHLOfFzz2UO+//Bb+5bhfTu7dy8oknsGhsEX/78R/gxz7HnHQ0tz/wIB1d57QTT+Q1r/5jnnjicf7sLy7jrDPOZM3GQ3jTm/+I0045lT946xsYWexzxx338omPv5JXvPRlDA9U2L39fp5+6vmEcY1rr76cjRtX8b7/8Wds3XITURjzytf9MVN7N2EMvPxVFzNQH0Vrw7988XOs27iRE049h82bt2N0zqLB1YRBzLHHHsM3vvENfvnLG7n88ssBuPvuu5807/e3Sy65hJNOOukpbcJay9///eeZm5unpP6vWLGCD3/4w3z961/nyit/yrnnP4fNDz3EHbffysVv+muefvqpWAuvefUraMy3mNqRcPPtt/DAQ48Q2kGOPX4tZzzzMB586F5qtQor1p/EWecdQX0s419/fOCP27J5nuei1wInBmwdCwRcqks514F7jirXpIlB6xREkd4mnQCtROB7ogCiuo6K2/wWTQqBLeQmyoBdGUQt104pJYHvFzIaFotL+TImp9GYKQAtS66KAjrGkCSpC8Z5HhLwPY92q4NWliRRIAJarQ7z8x2GpYcgZ2ZmH3v3TjI/P0fSzp1ERd6h3UqLzS4MD40ClkYrZb6ZIICwUiEIJF4YM9ts0EoTWrOKdidjaKjKsuWD5HqGTtJg585pvEAzMhbQTmZpdZrMzc8yOryUgdoglYpPJ50jzRosWxVjrKsc12zkSAFh7FGpeXi+YGq6jS8gCAImJsZQyjA5uZe4ElAfGmRkOMTYBipv02x1GOq0CKMBBgeGyHOnmbV95z6UylE6Y/GiRVTiGtXKCK1mk07SotlW+EGElBHLl64kCD2q1Qp53iHPLXnWLvrbPc9WO6XTcdeqVMb8/JRjZVingVZqYRmr0Dp3FZy9KkoZkiRjcucUSmnCKGB8ySiVakylHmBsDiKn3VJIT+D7Hl4QIESAkII0i9HKkGeWwPOwCubmZlEqIc8TpD+AZzzILNZ4+F5MvTbUBVFVbslSTbuV0W7m+L5koD6CwInnZ1kKmK4e2IHaDvrQB33ogz70f9yH/ndUtSt+6W7A+8y9yyLpobO970nXScX/tovCuQdXbua7zJniZCWc1E9H7J0bxwYrwYHe2bogVgk6ldXZhLUgip8+JBnb+7EFSlk2FzFygozaqF56ne0hh+X9dnXiPOtS7IRGq7SoACEIw0pBHY4J/QCQKC3ItcbqnFw5gTJjDe1OmyTPCjqgo/YZVeTZ6mKBKQzK8wOk50onOsfFwxNeFyRLWim+7xGEAUG14iiyniVTOQiBNinaJmibYK3CWK8LKJYG6cZd4SwVkcViLFLSuu1T2VsZGek+0D6Ar89wHBXcYoShz3R6oKIQGK2wUuKJvmPg+rOrdy7cJNzLiTYLz1GUrVsIPD15AIpyci6BrOJsvb8XAlKyqEhzoLdy8XHP291Ld+wt/CDG2u7CsX8qYfcYgqdEuaWUGFlSMMuJrPeMi5MsPOV+1+gAyx4zsjyFlL1FQYg+sLk7WXavsigaUEQEtIvaapWDMY5tZxTaKFzJaK+bX92zf4pJ24JnSbM2ucrxvCq+7xP6IZEfkmYJ861ZctUGLIEXUoqb5klKqzFPFFYIfEcJDiKJHwps4chjDVK4/PpUabSw6EAiZTGHNFvkQYD2ITUzeL5HNaoz35wlNxlpPoXSy7H+wILxU4oSCiu6kTHPF935rwv1CwHCUI6NPj9mwTjtt3mtjItyCwmBdWKibk1FYAsavcAWud9SyoXztOtBV9ShDGj09WVPR7DfZnprTNe5EqJrj5ZyvVkwjffKAYu+NBRK26F735b9xsEB1tatW9dNU2q3O4yMjDIyXGVsvEaeWe68bRdHHLOaFasWsWvnJEEYsmHDOmbnZtHKsnjJKE9se5SHH9nK5Zd/E2MMixYt4o//+I9ZvXo1o6OjWGuYnp7m5ltuZn5+Hs/zuPXWW9mzZ0/3OoaGhli6dClBELB9+3a++c1vPulaO50O3/3ud5mbm0MIwYoVKzjppJN46Uteytat29i7dy++H5EkThdiYGCQubkpms0Gy5evIknazM7uwRhDHIWMj69i7+QsM9OzzDemUWYZcVWybNkEM9MNdmzfxe7d+/ADyfj4Wh5/7FF279pBGA9TH1jEyNBi1i5fye7pabbseQzTERBUmJvzOeTwQ4iHct73jS9w5NGH8/zfeT5ve+uL2bp9J8tWjDI6WiXt+IwMD7J9xyTTM9OMLa6xZMUgS1eNYPatY8WStZx0yjFseXQruzo527Zt47xnjbF69RK+efkv2XDYCpatWMaWrTsIwsWsXrGbI484ESmrfPSjn+K8857L8lVrufPOuzn55BM47MhDyFOPVuN+br31Vl7x8ldSGxxCEDEwsIgwrvLY47ex8ZBjWb3mUDbfezXV+mImVqxg+2NPIEXAilXHkiSK1sw02x5/jFVr1zM8soSHNj9I6HssGh5mcnIS6UtOPvlkfvKTn3DTTTexY8cOrLUMDw//m7Z45plncuGFFwIwPT1No9FgxYoVeJ6HUoqPfORvC/DK+QsbNmzgDW94A9dffz3f/8H3eeOb3sLInj0IIXnGmedx/InHAHD44YeSdhStfYadO/ax6cEnqDDGokWDNOY7tDouap2litXrx2kmyxACxsbGGBoa+k8cbf93WslOskZ39Zcc48zNxkrpLntaK0WeOxZKrlSRhiW61YwQju0vPUk38Nadr3uB3GL2LjZF5bpAd/0sr6t0CDzPlc82WtFpZ85/Fl6xjjgQKlM5FqdnGocBnueRZznGCJSCIHRV7LJUo3NNjiHPm8zMzDI3O0voeehckWcJuU4QwsP3Y/xqhDGGJG2Qph2s0Yz6HoEPfuShZUJuEzJlaScdKtUag0MRYSgQQtFozjE8UmFgIGauuadgWDXwRpcShBIpDVp3UKZFpSax+BgDjUaKRRRBXCfU2+7kBFJh0Xi+RydJSTodwnAY34+oDVRIsxZGKHRLk2YpaZpSrw+hlUJrxdz8LMY6FoOQngs+xx6ttkbpjFYzIa444e/hoWGkZ/B9QZq1nYC3yoq1SZIkLttCa+VSNoUlS9sFQ6KX0mctZHlKlhVMNN9V4i4BwzxTqFyTpYoosvihIIhAafDyQmzZF4V4vYcfeISBh1KWjlBuC6UNWZqhTYbSWbHeF5qC0scLQ6rVGqIjgQyMwChLninSRBPHIUNDdSg0fvNiP+IHBzjwdNCHPuhDH/She6//H/rQvzXwVKJf7mQly4cumgcLDb9sXiEKba1FWVuwZESvQ7soWnmnokAx+sEAumCBRHSrdpTn6n5S0j1WD0AoUUM3Q+gCkBCUD9qBPWW6l7MR9/hsoeWkVIbWeTcPX+Loo11RbQS6AJ6M0GjZwZCQZu2inHRAHA+4XNYoxJMeShs6SYtEJWijCH1QeU6WZ+ydnUVhEb6HHwWAj9aQdlLyNKfVnHUIszWujK5vkb4tSl9akAqlWmTK0DL1gl5dwYtqeEFI4AdEgXMchPQQXoqRDRRVfCetWJR6dWhnqcUlbTmwin4qgb3C6I0BK3QX9ywdnrIfS0S113rsuRKVKtMXtXZlWn3Pxzchxi+YTyUwJlyHC2OwwmkW7D9v9iZgN4GUOntlylwZ/XNCeBS59L4TES+vs3s82RvAgq74fcn+6oc/D9RWXq9D7XuLl2MVuv4zWgO2SHMErBPLK6Mlpc1r7cT0hHRRDq01SrnIbT+NeH9k3fPK51Y8f4f2dvsqCILuImwpqck9OrJLm3TaFKXYuwOfZVeQvr8rpHAps3mWkCUdsk6bNGmR5xlK5wicBkEQON01cFVdtHHlTn1hsaQY2rTaDYzVVEKfaiSphAJDSlPP0WKelSuXMDwwiNU+lVAyEEuGq9CcmiVtZqjMx69orKeoD0o6TUvSyti7a5IwiqjX69SGa1iRsnN6E4vsUnzfI5uepJUJ0mbOVLqFZRMJ40MrGKwOU4kUs/MzpPkerFbEwWKktAhhMDrFFEURhHD3Jos+FUAQRl2nyRTOQ5fmjehS6ilAWyvpzrtl/2Rp4iK6KqdSGyAQERKJMikqT/G8gt3ZVxyg22/FjC6l1+3zcoz5vt8FpIUQjqrd10oRXWA/m8QNUdFj2JbNzV6eizP0g9xlMOMAR4/7WUVxHPOzn/2cV77idfzrN7/KhvWH8C//+i1eHb+AWt3nwt95Jb930e9w2Xvezp+/71OML17MH/3xH/GCF5zMhg0Rf/u/3GZ13759nH766Vx88cV88IMfRAjJM5/5TG655VcMDo7geR63334rF1/8Tr785a8A8LrXvY4PfOADxHHMXXfd9b+97iiK+NGPf8ShhxyKlB5vectb2LVrN5/8xKcZHV6KNxZy7bVXs/GQQzj+uFP51c0340mPJePLGRkcRkqfyd2zbN3+KI3mHC978e/Tamq2PTHHqrUT3H//vbz/A+/jb//2MyhtOfPM07n0kj/jhS+6mOUrx/jXr3+Rv/3QBTzj5KU8un2K7127iX/86uvwA48LnnsOn/zEZ3j+ue/g/j/7DcccvRhj4KbfPMLipYY3vPl4Pv3Rm8iSgDe/4SWkwRQm6DA25nHXnTu4/Vfb+Ms/ey07dm/jw5++jA++9wvUanW+/cN/4Pvf+jmz3/4l//KVz/DoE49z/0MPctOtv+Kn3/8Nl7ztA/z8mp+zctlaXvd7l0LHZ3bvFDf+4gYefeRWfvr9LzPzxBrWHX4Ed915F+effz71ep0f/vCHvOa1r+Gee+7lV7+8iZ/+9Gv8y9c+ydve8Gmuv/EG/tcrn823r/g2vhD8j0svZTadZXTxIj71yc/z6ObN3HD11Rxy6PGIADLd4mWvfCWbNj2EEPBP//RPXHLJJZx66qmkafpb2+VHPvIRvva1r3HnnXcyPj4OUMwnvYj9li1bOP7447uCtJ/7u09hjFt7JtZ5LFrl1tff3HQbjfkWF77wfF6z4rm89BXnUql47Ng6xW2/fpTzn3M2SgnuumUXhx09TqXigkTvfe97ectb3vJbX/N/VZuZ2VswQFQRyLM0mx1q9RCjDdu2bqc+UCeOIqampwmCmLhSwxLgeS5VSSuLNs5HEr5XMO9l4WcbtC6Dq07ouZzTyyCbW/PcJtEaTZplzM3PIKWrmDZQH6TdbtFqtdi5ayfVao3BwWEGaoNYa0izlE6SApZqrYrnx4RhQJJ0MNaBT75fReITelWSjsJ2MtqdOfLM4Hsh1YqkZQwd03ZgTFRjYGCEpNMiSTrMNzvMz8+S5RlhKImFR+hZrJdTGfAYiOvs3PUYM9NTrF23FsEA1YolDDRDg+NMLBrjgQeeYHYmpZO22LVnG63OPGGkCSOLF4RsfnieXKcYoxCBxZMeWgMiJY586gMeqDbKKB599H6iyCcKfaamZkmzKkoPs3r1EoaHKgzXQxqNNrsnHycIZAHspKgsJQhC6tVB5mcadJotOslerBFIXwCGdnOeTnOe0UUxuc5pN+fodBwYF8cDTisrVzQbCZ4nqVYiJiYWEwQ+vi+KKnIBcVzDl5C0W0xP7WNufpZOp83qtesYHhplZHScVWuXOvAnzTHG0Gy2CaMAJFTqEFSc/pg1OcZkWCQGH+F5eFaAcawna6BWr2NliCUEq9HGIoXP6OgioihmfPEo7XabJEkQBN1qidYo8lzTaqROu8t3gGtccXZ0ILeDPvRBH/qgD/0f96F/e42n4mK6f5cPk94GXfQhZgu/WF5biaz1DtZP8SuBit4Nl5+R7PfM+g/aB22ULJUSzOo7fT/NZf+HY0twxfQQ4gKI0lqhVb4gN7e85h6tTYIsgQ6LRmNMjjYFhVoGBIErsxp4AUrn5Cqj2WmgrMJiCfwIZSxJqmh1OhgsXhhQC2pFvn1UIKQ5xuTOqRO2rxKcRQjtwDW0A8CscpTdJCXvKFQaAW5i8aQDTDw/Ku4/Q9kWQnhI6+HJWhfNdP5jOXF6vedQ0sJFj7W2ALm3hQhmmWIJOL2mXm93+6YAn6ylyKG1iDzvRgh9ExQUVL8YgI65JShtyiCN7DHkbO94pR2U11hqH5iufpWjRTpkvmc31jo2lVPr7xl0H87ds7wDH3daQOMHur/bvmclu2LqT42K97/W38pFdX80vWxPhfr3ffspr9cx2hza7hXpj102migLGLjr9TxXbaI81P4ToLUGo3JUnqKKSpvKKDzPwytEi/ujBtKTSMDzNKlp0mlPkaRNfD+kEtcQ0iM3mlY6R2Zb+IFm2dgqIlFHaM38/DTtThvPr9BopKR5TqUxx1AU4XkwvbeBUSCtZGx0MVEUE8UxUVVgyDE2gsQnUyntdAa8EIQgyxVzs7M8se1hli5ZTRRVGR1dgukEWKWwWkNRmlUI4UrhGoOUBmFdVcwS8O/ShaFb9EEbU9i7LPKhbfd5Couj7gtwenOFTViLyjPSpI3WmjCK3ZwkXDqvsQZhVZFe3Eu37tnJU4tvuv4u1ovC2eungJff7/98mWaLLUUbS1sqA5QLAeSunRn7JJs50Nr73/9+nv70p3PBBRcAsGHDOt797ktYu3YNg4N1LrjwmaxavYwwinnzW17DoYdtxBjLs849h3Y75YZf/IanPe2YbjCobEmSkHererrUksHBESfEKyS1Wp2LLnoxGzZsRGvN0552GlEUceONN5CmCR/4wAe44cYbyPOcc555zoIUrLPOOosLLriAFctXEIYhAK961atoNJqsXLmS6Zk55huzHHLIYSAEDzz0EEsmloCRJKng0ce3OoZFVmHxxGIWjQ9yxXd/xrp1a1i/fh1X//RHNJtzvO51b+bOO24hyxTveMc7WVSP2HTr9Vz/8908fNdtDOZtpp7Yy9zeBkJbvvPN21i1ejWXXvJeHnzgIR58aBPnnv86Bqp1Htx5Nf5IwlQz5aofb+YZ569G5ZIbf3U7J52+jEVjdW667hGSJGF8KOb73/kxUzMzPPrIJP/w+S8wOjKCFg1WrR1j2cpBntjxKHfefT+33Ho3JmyxYtUYhx56BN/45tdZvGgRh25chhfD9FyLr19+GyPVOoOVZaT+w0w1mjz6kMcrXvEKjMm44brv8/RTT+Pow4/l5z++giisce75L+XuB24grOa8/R3voDHzMGEQ8KKXvYRN9z9ClqY8fO/NIGKWrVjFfHuOgaE6S5Yu5S1veQs333wzX/rSl/A8jxUrVvBXf/VXKKUIgpAnHtuLyiRLl48tsMWvfvWr3HzzzQBcd911TE9P84EPfIBarYYxht27d7Nx40Ze+9rX8tWvfpVNmzaRJEn3+0opTj7pVH7nggtZvnwJu3bs4qqfXsuhh25gzbqV3Hnb3Sxdvoz64AA//MF1jIyMsOGwldx6yz1EUczateu55vqbuPOuO9DacNVVVzE1NcUHP/jB//yB95/YdLeynNO+dJu/cl12qXUl4ynLcrCO1R4EdFN2XOEci9Gi8N3K6ljgNn0GrQ0qV+TKBfK8IqAmpWOwlHOxsrpvzXaB5LSoSub7AcNDw3h+gMCJdAshqNcHqNZqgBOsdkL2mnqtipA+UrqKT2HoMzJcJ9ctciUJ/IhabYAoCFDZNEhLEMbE1RqBFwLWsSkwDA+PEgQRWZ4SRqBUm2SuTdK2VMI6ExPLmJlJMTpj1+RudC4QMmJi8RLCIKDZ6JB23DZpYDDG6JR2Z549e/ZQqwcIYWk2M4QHfhBQjetEYYVqXCcMJUIokqSFzQ3C5FQrGXmuMNo9M2Uy/BCW5hNU4phFYxNIMUunkzI1vc8F2K3Tf3WMqhaVMAQ8jAalDXlu6CTFxl0IkrZLycvSFCfAHhCEIc1mhyRJqVQrxHFIFAUoleJJ8KMqAlBZyr7GHFFYwZMeQhoqlcilrlkntN5pzxFGEUEYElVCsixHa0WrlTkQK/AIw6C7ZiaJq7SoTYq1TvtWBIbI95HSozZUx9gUpTy3flgLQuIHThZj7759ThfMaKKwQhR7jI8PMuM3wAqEtIXPIVBK0Wy2EEKwcvXo/7Px+O9tB33ogz70QR/6P+5D/7sYT71UowI6sE+lqr7/nff9V9yEEI7t1AOg+qCjLtLWG9D7D9guAlyCTuVFdAEnsfC4XVbUUz8VWwJPxvQAKOvo0KagRGNdOlV/qcPeJOQ0pZzYmAalMTZzaWnWQ0qfwI8I/MDlM+cpWZ7RTpoOAfUkiBilTVFWNsEKS2gNtbp1FUj8kCxNyT2wOPqvw3TcIu9JicUh7QaDEa5qnFIJeZahktwBTwKEJwgiVzUm9ENybRyzy7QQIkASEXo1B+4AJc7pUiGdkbvHXQyuLvDU1+FFf9OdPB1IWf7eN4cuMJUeul+cQ2uMpwu6suf+t27hk5QbKIEwAiMNnnVVcEoqZHmsLiBZ2EHZ365Epe0K4fVohoWYOsJRYWWPith/xeWYeKpBf6C1Hkq+sLnUxAJMFSVOWERUBF3B/pK+2b8g9kdjytx0cJRroM82Fk5Kvce18Ln1T4L9qbt+ELA/+t5b0GV3XJruNXUtCHCUY61ydJaisgxtnU25qj2FHVnhqKJSFIs0SC9DdZo023vJ8oQgiKhW6sWimTOXTpPbNkEEKydWk7UUjdkWc/MzdJIOvl9x5WWtJU3aYHyk9ZiZahEFIbVqjbGxCcIodiWuI4lGg6igmSdLc1rNaaJ0AE9UnBM732Cb3cLw0AhxXGFkaDFNm5J1NFYrsK4IQTkDOgDVuAVUZZTjUFMIZVpX1adr89Y5rgi/2NgUQ8qWwG1vrJfj2eicLAGtdDHf+eB5LgokAFNEWIRzThxLsK+/S8cNUcwvPTC7t3D3HLhy0XR2Vq4HRXxhQVCkmG+6C2XfKkrv2Kb34gHbPvOZz2CM4YILLqDZbLJ06RIu+ZOLyTKno/HcC85yqdZS8vo3voo8V6RpxjOedTaPPPI43/3OTzniiHV4nmRgYJBms4FSOfV6nSiKuucRQhIEIe12uxuBPf300zn99NPJsoxKpYIxhhtuuJ5Fi8Z561vfShiFZHnOey57N0IIdu/ezcDAAM985jO59NJLF9zHy1/+cqyFLNXsm91Hsz3FsUefyeNbt/LIli2cdfoZaCXZsWOWnbt2kOeagYHVHHboBGFo+Nxnv4p3vuTY4w/l5l/9gmUrVvH7r/wD/vLPLibPFX/1oc9w0w8v575br+Pa22+irhRjAqa2z9JqpgxGPj++4m5OPCXk59f+EX/wB3/ITTf9inf98T1s3nUDtzz8A4KRnH3bO9x04xP87avORSnNP3/hxxx94jD1eIi7b97D8lUVVq2pcs3PrqXTcVoTX/3a1xhfNMJ55z6NNesWE9d8Nm1+gPvu38QDDz7KxqNilq1ZxfHHPY1/+MzXGRgM+MsPvhrPeMxNK37wk+9w1snP5eknnI0/eAuNpMPDDwT87vOfz/z8Xr719b/jec//Q8bGlvN3f3Mp5/7O73HaM57NJz7+bjZuPJqXvPz13HTt35MHIc98zmsZqa5gctsOHr7/NtYccjxLVx/O5i2PEFY84ngpr3/96znkkEP49re/je/7jI6O8s6LL0Z6HloZrvzRbzAaagNBXyQXvvOd73R/j6KIMAz59Kc/vWD+Pv7443nve9/Lb37zGzZv3kytVluwTj7taU/nne/8E4JIcMdtd/Pdy3/MX37wMtasXcmPrvgplVqF2kCVn//8Zp5++nE869yT+fGPrmJ4ZJAzn3ECt37+Hn5+7U1Ya7j66qu5+uqrD3jgqav3UZafRhCEHtKThRZm32e1QQlFnmdEUejmYGOQnsBDoKQofBzTXe+shTTNUbkiSVK0dj5MGEIYekU1u7AImvZmvO5GFOsqLwkHQA8Pj3TT64zW+H5ArV4r1mOBVrnTeDGaWq2GFB4ID6UMQeARRxUazQwhNMZEeFKifI+p9k7AEkYx1eoAIDBFeppEMDw0TCWukakUpffQ7LRpdKbJOpaBuMLYoiXkepJmM2HP1B6q0QhRUGN8fIhOp8H83BxZ5kqjDwzGNGYT0lQzNSXIVRXPl6SpIox9pB9SrY5Srw4xNDAGuIDt7FyOylKE1dQqCq0FeW5JsgyNJog9OolioO4zODiGmyobTO7Zhy8KQW0/IMsVrUYLf1AQBG5VznNFkma0Oh1Czyf0PZKOy35QSuGHVXw/LFgvrmLY4MAQ9boDn2ZnpjAF281aQ56nzExPUq3UCcOISnWQSiUmrrjFV+UJ7bZgaHgRvu+0m+bmFFme02knxJUYISIq1UIk3BNFlUFNbnIsLojsBUXVP9+nXo/R2iPNnB0b48oxeb6r1Di1bwZZABC+5xHFMYNDVZTOUUoXwtfOtpTWpFlOXqw3B2o76EMf9KEP+tD/cR/636HxJAoTLLgq1lXR8P1SiNlV1HCIb18Jx77BI6XAJaq50qW9zf3CexEFfaz/9ZKW3X9rJei0ICex7ANbPHghKFPFym+VwIJjvCiH4OaZG1R5jtYuEuBS7JS7Hll2oqQnJtf7cSCUwRbllZO0hdIZvl8hDALiyEUfpIBUdejkDRLVIgxjPOk5QetycGcpSiuypEMU1jAVS1yTWJEiZI4XGHSuMdqglUTggBjhuWswQqOEQlpBbhJU2iKXMUkkkZmCvENUyYmjkEo0ANZVQshU06GZVhD6VXwbuAiWcOVeSwZXCR0J64xNip7A+wLjR1AWeXCdY1zFhaIEYw9vdH1k+iZjgXOyLI6VpFSOlBI/CFx5Vq/IJy7E7Fz6pcTKkr20HxAkHdLsqOaiy3hyVV0EQnhdGqwt0WxZItJluqaLBpSgmS3Arf2jIP/dWgnOdZkQAqztaXtJz+uO5V5lhB5yrpSLevi+K6OstXL6DH2LnntGFq17Y777vgRJKYBqut8xRYmehRGmsgR0r89cumdRHlRrJ8pY9J8typ+aLCNNmrQ785iiNLsvfNenFrR29Hvf9wkqEVgH5OZmH0lzirn2durVxYwMLWVi0aG07SyNZJon9t3LQG2U0foyNiw/hUcff5An5p9gPmthPMvI6DADA0MIIYhqAUknpTnbwbchi8dXsGzVasZXLCYKYyI/Zm62ibaCwbF1zE1vozO/l11Tj7HEW83iaJBhfxmtfIon9jyK8DRLJ9Zy4nGrGRgO0XXLzOQ+jB5E6zpGOTHaMAihoH9brxB7FLIXpaAQQ+xOnhqjncaIswfZm+f7bEYIgzUFVdwPUFqj0g5aa6I4JoxigtBVAnFG1Vu0RN9xSsahpZzAy7TZJztm3cBD9+2edomzJa83TwOlrlvxbte5sgTdqpsGTV/JggO2PfDAA9RqNfI858ILL2T16jV8+ctf4tuXX0mj0eINf/hStmzezuTuGQ49Yg1bt21n08Obef7zns3KFcs577znsGhsEdXaUm699U7+x/94H1df/VOuv/56VqxY8aTzveENb+CGG24AijFYzHdvfvObufTSS/nud7/P448/zgc+8CG+8IUvcPrpp3dtZPHixdx882+o1epPeS9CQBh5HLbhcJZPrGLTgw8yvngR5597Dj+/5ioGB0Y47rjTyPMEsBx77Hr27NnD1FSLD3/kvczNKh64Zx9vf9efct3113LKqafy6U9+go3r13LrjT/hwft/xeTOzTxtaBmNRpupuQbXPP4Eh6wY5T0veBrfvuMRagN7uOXRNxFO3M/640eRnuTq793D//rov7Bog+SsZ6/meRccy9f/8Ta2bZ1hxVEVHprZTHvnPv78oxfw6NYdPLp1O+/4izNptjKe2DrF3n0NpPWhOs/Ssafj20E++7lP8NrXvZGPf+IfeM5zns3Wzfex7aE2/+M9f8rIWJVHN/+SYzacyNrDj+CrX7wQk/qYzOe4097H7Mwetj+2hfe99210moYTNj6HKBhldPEAL3jVC0BVuPfWuznp+OfQau3i8q/9Oedd8HoeengbRx55JJ/8+Kd4xgvP5LY7M6Zau5l5cDfLlx3OVVf/lBe88HP8+Mc/5rTTTuOBBx5gdHSUZqPBdT+6hsOPO5INhx/Cec89hW/867/w4t9/Lnv37n3Kvnz3u9/Ni1/8Yp75zGeyb9++rr30zxfr16/nqquuIgzD7liuVmtUaj6/uP5+PC/ma9/6LDqTZB144Yt/ByF9QPKhD19MEPoobXj9m16ClAKtDO979xt5/nNP5dnPvrILkB7oTUqoVOrUa4OYwlceGhrs+szDIyNd7acVK1eQJBmdToonfcCQ6pw4KDeJElkEcdMsxViBMYI01ejcoDUEQYTv+1QqlUIPSiCEKrRHDQJLGAREYYg2uis5EQahE5j2/O7a78SSwZMQRyGeFyCE03ZSuUbl0E4TOmkbhKJWrTE+vpi4OkiWxUxPG/bumWN2dprJyWniSoVavU6Wia7QbhQN4vs+cVglEB2yzLJz7zzzzVnmmjP43jDkAY15w8TS5QxnHR7WD1OpQi0OGKuP8vDmSR597CGiOCNAImSENCFGC1dAR2qsVCxdMYAXBoRRxJJFKxmoDTM0OIIQkGc5cTTG7MwkadJCyAhPeIBPVBF4gSBXsGnzo+zcOcvsSsHE4qWMjQ0yuXu+3I4yMDCIbjZpd2ZZtXIpg4ODDNaHmJ3ZztRUg63btrN4fBGLx8fwAo9ASCKk28QJQ5LMMz7uUp7jSOIVJIrxxRNuUy81GEMlDlgysbIAFd1+IM9zlFJoYcmsk5VA+I5lFtfRJsOSkqk5SBMMEWEsiWVMEMYMDQ5irQOFnOaXdUL41vnmU/umXfA6DLDF2u57Psa6VMNOO2VwqE69XiMMg2LTbJGeIJA+1WqEyp2khpQWZQzamqccNwd6O+hDH/ShD/rQv70P/e9iPJUnFwX6VUZNnE/qBluJsPXSnaBMhxIF6CPL0oFAKdDmvlxoKxU7+zKNyxbizaVwVff45dH7kcMuIFT+1xu4UFT5sIVGT7HIGq1dtEX1qtcZXYqWLaRJ9msadbk0BfBmcUwnpVOUTh09TpTaQQ6xNmi0zTBCEYSSKAwIgtBhk9bl4grc4Fe5odNqYw0IKVF5gjEp1mr3YyxWu7xRYSWeEA5lle4haq3RIkfZDJ0n5EkIRqFNG2VSjIkYqGVO10hKfN8WxpNjTFosnsXgEiXgZLqGq7GFXlKvb+mbKEstphI97bHJLP2mXOxo3G9d619oe9YUZzcSVFmZxeCZgjYuvaJ6S39Fut5BvELXCfrKDxcLqvu+3wUViweOFAW1tnfzUCLVos/uFqTiHbitfxHrb+V9LIR0RbcPFrAM+44limfgeaWoZXl8WSyexUTdxZ5FN+JSipm6Nbocr09BPy7edf1k8bzetZVi+kJIjO5dvlegnUIIlAVrNHnWQeWpo/KXYHUhXi+KKhzWaLJOTmduDp3laJXRSbbSUNNYbahUh4jjCgjITYtUz9FozzIxuoGxodV00oRWp0GzM+eu3BMI3+JbB1p6VhIFVaSNGB1NiKsSS0qjMUMSxERBFURI6IfEUZWWF2Ktx2zSYiBwJZ0Hw1Esijm7m73T+xAiZnp6FwODI3h+AF4TrQTGZeL2bLfoVum5aInFVTzpUn1NCdT3FidtirFR2oftzZ1uDpau762bA8pmdI7KnT2J4pye9PvGTzlH9+zKFOuBWDDwLRZZLjA4OrFzgsQCocXywOX9ykL3pIzk9C2qfRG/0u5lkRL8lAUSDqDmB0Ns2rSZ++67gyOPPJKNGzeicsPy5UtotTpM7Wvi+T4jY4PMTncAnyWLJ3hw02aqlRorV06wb+8U/qxkxcpl1Os1PM9j6VK3Idq/7du3j/m5eY4/7iQe2bKZXbt3AnDTTTexePFidu3axezsLLOzs/z85z9n586d3fFbzgXHHHMMJ510IiB4/PHHue6666jXRhFCMN+YYu26jYyPTzA8MoQUkrnZeUaGx4iiAZrzOYMDdTpJh1/eeAcTE8PUB6rs3t3A9wIGBkN+eeMv2b1rN8865xwG6nX27dvHT356NXXdZnRwMczvoxrFiPEKJ1tFGEnufmIvxx29gkVrhskby1i+JKUaupT12gAsWgJkltaMYufWJkOVYfQin6aeZm5PStaYZVV9jn27EtrTkiMPOZsdO3fxwL2/YNHSEawW7Nk6x/GHjjJUX8rMTJOtW7fwyOY7WDY6TBiFHHrIKjY//BDRVgmiwQPpQzz2yDwqmGOwNkY9HmLX1BOMLxpm4/rVGK0JAo9jTj6arU/sYtfu3aw9ZCObH3iYJx7dxKlnnE2eDzEzFTG5e5K00+K8886jUvGYm5tkaGDI6SYaw+Tex9i581F27txJlmVEUcSyZcu49tpr2fTgJu697W7i4Sqr1q/he9//Ltdffx07d+78N+1yaGiINWvW8IpXvIJbbrmF3/zmN/zu7/4uJ5xwPPfdew+nnnIKq1at4uc/vxYpBVEU8aIXvYg4jrHWMjJSJ4p8xsfH2DfZQClNrV7l3rufYNu2vTz7vOOYmp7hvvse4rjjDmd6apqrr76WZ597DqOjbkNy2mmnccQRR/xnD7n/9KZyhYlc5TmdKvAEInTzp7VgjdO7USrH81x6XBRFhR6H7Yb0wFWSs9DddAik8+M8txn0fK+74Y/jsNhAuAAgxna1TUsftwzmBb5j0Zc/IN1aJso5XRSbZB8pgmKDJciyxDETjCGMA6c/KiXgIYQlSZzQd5q0iOIqxkKj2aZqqoSBT6065IKMecbkzu2YvEWWtdizZw+tvEGickZGnX/WnG8RVyM8GTEyOsxgvU4cxpg8J8nbNNrz+KHGK3y1KPTBOtZNEDtN1DTDrS/WrYhKpTRbc668ObKoTtdGCEOaKWqVgqnhCXKd0Wm3abX2MTfbQWcxWI+hwWFCPyyekSQMQ2rVKiMjw3ieY3W1Gh2E8Yj8KvV6HaU107OzhItGAIvSOUma4nmCoaEKFpcOmWegC3+01UnxPElU7CHA2VCuLFiFta5qoFI5cRwhKxLfD7FWoJSl3cnIMoVSpljXrRO8VzlKeSjld7MAfFmy8XRRVdulcqZJig0CPF+itEJKQRCGQICUPiOjw9RqVSpxjOdLjLYknbwAZxxYEoQexogiDdf5eAdyO+hDH/ShD/rQ/3Ef+rfXeLLltdseiCRLIIYuk6T/nkvWUWnAQgpEAaKUD798NACirJDWNzgd/bc3cN25u+/2gU6FuGIx4B1a1wOqoFxEnVAaRWURoxU6z9Aq67KejC5LkRZaQ1IU4ISkrPJmTXGdomRVaQw5ue6QqQ5Z3sEWE6kfSGQBTGmbokixUlGpRlTDCoEXgaKg8in3WaPJkpzm3DxZmmJQWFThPJbaRzhGmQFhPXzpIX0LnsLkOVpolMhRpkOeh4i2QGc5WdbGyxJyFTNUb1GJ666cbigchckolO4UdKZS98iJl1vtwDFjrEtvK22hMMIuyFhoMEFZWaEErEwXZ+pPpyxZRMYW1VmEXVAWGGGxVhSVBSmee47n+4WDVqTfebqXmytKWyhsrwS3jMEUIqdKKfxAOieq6GNtSh0F1+/lxblFAJwIn7O3A32h7G/ls91/YeoxFIuUSuuqpGB7aPr+C245FqWU+H7QpeO7xyYIghBrs94zK7rD8yRFldkF12GLdE5R1g7FIvtYj1rnWOsVUaLCKfYknvQRSIxSCBwY7vnlIi6LKhyKJGmQZR20zvGCyI1pr2DqSYkXR6RzTdJGk6kntpLON0jbLeZndhIulsRLQwYWDxJVYnKbkOoZ2tk0c41ZRuorWL7oKPbN7Gbv7C5mGntdhEuAkUVlCiMxqUe9tghZD/GDFCs1nXQvszv2IL2YMBxgxbKNRHGFKAjx8LDasq/VZCCYY6wyz9KBI5AC9ubb2LVnL+12zorFm1i9biMDQ8MQzKGVwqicSAy78KhRuEkCPM9FVYzppQ47m3deRzcVtgCui7+6iw7WVdWk2KgI6coRaG27czBWoTKDzjOEkPhBiAwLCrmQeIgFQLPLX++bO4rzuFW+XGsAJAgPIQotAuvSP5wt2SKf3s09vhd078MxG50d92zOzesYW6xHBnuAD+VHtkxx+Te/x+c++2HuuONODj3kMNJUc8ZZJ5MkGffdtY3V68ZZuWoxt/76MUYXDbJh/Uo+/4V/ZGLxIl772lfws5/cS9JJWb1mGb4vu9T+p9KcABgbW8QbXvcmvvLVL3aBp5/97GdcffXVQLE+W8tHP/rR4hv9zjdcdtllnHjiCQghuP322/nDP3wTK1cchZSSx5+4m9f/4Zs4/7nP44LzzmXnzl1s3ryFww8/mjwR7NrWYOX6AdLdbT73d9/iLW97MatWr+DHP7ye409Yx4knreF1r/0wxxx7LJ/6zGe4+7bfcPPNv+ZzX/xn3vi7L+C0Q45k00M/pTq2iCVLlnD6+sX8estWPnH9bXz386/j6KOPZGfjOI5a/zBmQ4oUglXrY55+7hi/vmaGrZvmaU9v4awTjsbbYLhzy93ce9sU05PTqF2bMdoQBCFHr3kxav4OHn/wGs66aBlaKe68ehMvfO4oK1etJckUv/rlNUxP3sMJG5azYv1qjjj1GC5798dot5q87IVncMdN17BjZ5Nb77uBU086laOPPIZvfPtfuOii3+Ozn/0sSyaWElcqnH/RGXzwTz/Hloe28qkv/QU3/uLX3PDrn/J7r3glQ4NjZMnpfPdbf0dcjfnC57/A7bdcyyOb7mTd+o14fg2lJddc/xW279z8pL7+3Oc+xxVXXIEQgvVHbuTEU0/mne98J5OTk/+mTZZrR6VS4aMf/Sif+9znuPXWW/mLv/gLBgcH+O63L+f3f/+lpFnOCcefQJqljI6Ocu655xLHMSA47LDlzrc0FucgOr/qhuvv5uc/u4MzzjqCLY8+wfd/8DPWrl3B/fc/wNvf/k6+/Z1vsHz5EgBe9rKX8/a3v+3fP6j+H7c0zQgjhVaGLFP4HkShRWtTaJllJFlCrlLiyMkz1OtVwsADYQnCgCxLscbiB15v3S1S3ITwiWMH9IhCZ8nzPILAVRt0FZqhDAhmaVYE8Sy1Wo0wCqlUKkUQtgjueT6e7zs/vZiXfc/H9wKkDMgzB2Z1Oh0X+ZaCeq1OFFUQeFD4rbOz+2g0ZugkLYZHR5mZnmVqagajBCMjI4yNLmVudh+txjyb77sLmzdQeZsdU9MQCGTVY8kSCVYxPTVDtTpIZSBi2fJlDAzW8WXArsfnaKbzzLfmWVT18Yp1Q0QhgR8yNDJAXAXhG6anodPRZJkhz92memZ2L5V4gGplgKWLl2NMG8/T7N69m8GBYUZHh7FWMDs3y57ZfczNz2GRTO6cx2jBsqUrqEU1fE8WLKWQOAqp16tYldBpNZlvd/D8iKH6CMK3TO7dzY6duxgcHMBoQ6vVZmZ2lkolYmR0LXnWIjU50ko8EQI+Oyb3Ecc+Q8M1xkaGEXhkmSLLcpQyKJWTZx20yhgeGSaMKsSVAYx1It9pq4NSeVFYx0dYUVTRy5GZE0UOwrDHbjDWpX5mmjxT5Jkm7WRgLUEkUSojCEMqlRhrXUrXyMhgof3j/IL5+Tbz8/NUqwGuILgmjEKM0czOtpwv6cl/a+gcEO2gD33Qhz7oQ//Hfeh/B/C0H9Jre5RB0d2g2y5IJITA8wshagPgFZ91HWAMriIZfQhdT4erVymsPC8Lhd36leMd8ipcjmVxLAccFN/s4mHlmWzBdnEspzxNyLMEVfwYo1Fad9Fjrw8VLvFj6wFWFAgiaNvBmA5pPkOaNchUQuAHeJ770bjyqYlqoESCF8KigVFCWUMYj7nZWdLM0ZStlSAcxTnPNULm7rqsQSlFp5UhhY/vhQwMjBDFFeKKy1sXEmxRQtIohRWKTGW01Ty2Y7GeQWUZSdYmzxJ8KRkbWUy9NkS9PgY2AhtiM421Ocb4iMJMRIF8l7pX3VzR0j5sr8KbkBJrHPhXMtb6NyQA9Cnzd7vKlIO073h9YKPRqoQpEcKJWiqZd0Ej2aWrOuDIFuiwp71u7xul0UY7kbhi0vDK7/SBmAjRTRUVxUB3gBndQdbTfTrAd63QTRUEN37KyGUxT2Jc3iTlEHePQC7YlO5P2dS6HyR21YzK5qpcuKiNA0zdxOp57qessmOMKRxU58C6w/ddG/1jv4z4eMiiyoTFOk1EW1CCi1VZCOlsNUvpNGbdwio8fM/vTcZhiE5zsqlJph98hPbeaeZ27SJpt8nSlFbShq0eDPrUd86xdP0aJk5eyXziMRCMcNKh57Nk7AiEGODm+y7niUe3snPbbgYHR4jqPn7dZ8+uPeiOpi7r1NaOUqnHzM9W8bBID9IsZ741xfTsY8xNzVONB4jDOsLMYHSD0YkRlFXs6uxkqV4DaUY+Z5hvaJK0wYMP3ku7M8/Y+CLGxochBGE1Vg+jldN587y+0tvWIqwtdNLKSEifodiiYoffJ+QvinRYQPq96hpGa0e7Fq4CpUtPLRwwa0nSBr6OMCYmCutYKxCyEGcsbKjUNPCkX6TuFvZEOYX3AGq3EOo+O3GsVXCBCxeNsmRpWjiBplgUC4FI2xNLLCtoiuLY9rddNf+L2lFHTnDjkgG0NvzNX/yAM8+e5PV/9Ay+993rmJtrccEFZ3PPfXewY/c2zjvnOdz86zv41Cd+zhvf8kriuMrVV97KxkM3MDLmNFXe9a5LufDCF/J7v/d7vPCFL+SP//iPn3TOwaEBzr/gHH5+w0+7r73iFa/gHe94B+CEpd/97nf3fWPhM+yP0J5zzjn86le/4uKLL6HT6fCrX93EP3zhC3zor/+K4doEtWqFwYEx4jDCGoWIUn51406Mtrz7PX/I4iVD5ErzgheeRqeZ8dC9k3zq7/6eu++5g9+54Lm84vf/kKOPPpMbrruG+3/wXbbc8UtmhieQoc9Q0sCrDbFsdJRnHbaID3zipxx69B4+8/ev55DkCPZO7eZdf/H7TO/ZRXM2YN3xNVARohVy/7b7yXLFrm1tothj5fqQ408fZd+ehN07W7zkJRdx6mkn8YXPfYr3vO99TO6Z5IzTT+BrX/8CKoe//8L7+OlPbuQX193OV//xg9z/4ANccun/YngoY82KQXQnZcvjD/HwE3tQOieWOWNhzuEr1vD4/ffz1j94Ga96/ZsIggqf+sjHOeOZp/C7F53DTT+7liMPPYETTj6NV73q1axbfQQvfN4rOfbI56B1k59e8U8MLVrCoom1NFo5883tJGnKhRe+mST5NldccdOCvvrQhz7EZZddhhCCK664gnPPPZfp6el/0x7XrFnD17/+dX7wgx9w2mmnAbBnz57u+8uWLePlr3w1IyOjPProo90AY9l27NzHw1t2cPSRa0hbKfff+TBHn3AoA0ODbLlnmvPOPZXzLziJai1m3dpVvPDC8xio1znl1FO4/hc/Y+PG9Wzbtg2ArQ/PcNt12zj5nFX/5vUeCG10ZDlRHOL7IVI6sKnd6XRBHpVbWs0WSdohjVNq1Sqe9FHC4nkSP/TIMrd+a+VKmWutCi2UwGmJBqLwaTynv1KwZBwDfeFarjUY4/ykNM26aVVh4JhSQjrAKmklYF1VstAPyJVF6azQeFJkmUJ4oHOFyjPm5lpUYqefOTMzSbs1j8qzompZheb8HGHgs3zpUgJr0c05Hrl3F3smt9OYmWZ266NolZCrnLn5NikW5XlUK4tYPDHIqtVLmNw9iTfls2bDSmStAkKzc/phptu76NBkvhUyPBwzsaTG1J4MlSvmmwrhVwisR3OuSDm0ht27tpJlmnY7w1qPMIgYG32Mej0kinwmlgwTRpJW0mBmqsN8Y57p6TmEr5ymUs1n247HmJqaZNXKxYyNDjM0PMhco0W7kzPfaDNcG8IvNrHSOl91sF7F95YwNjKE71m0NcShz8jgML7v0ZprIn3nq+XGkuQpeZ7QbnWwNqJSjbEW8jxjctckU9OzdJIEIQWLFo0xNjbK8OgYQRCStDvOp7cSrR09QRAQBb7zD6TEKOEqaqMKRQzHwGq3W+RZTp5ZoqhCpRZSqQ46kMSz+Mr5ChZJFLkgrlGqywrJMk2zkTA/28aTFYRnHbga52itmZ2bJShs7kBuB33ogz70QR/6P+5D/7tHeRd4KgZaV0upuLknx0zLm+7jKZWMGFHSqPooxN3Dl4yV4qb6jyx65ypR35L2t9C36U0A7nnbLrOmpJaaAnzSKseo3BmBLauOiO7E0dMskNiC5SMpgadiUrAZuepgrDMK3wsXAE+5yUhUG4szsFplAM9EGOVokEorR1ktoiVBQJFnL9zUoA1GWawWyMAnDCKiSpU4rlCpVBHFJGOEQcsQ7eUY1XK52TYlUKETyhYCoyxZqmg254mjCp70qdZG8KXLX9UG0AaMxlqv+xC7YIvt7xH3hrUGYVzZRqsNWNkdGD0Gat+3ymdasOXsguO5Rc+NomLSXtC31vVFfzVCKQvdAjAlDbQAffvZclq5PjbW4ImiKuB+onvlNRhju7bdA6x7qYJlbvd/hyYo6Pz7XW/ZPyWTcf+x2v+5/f8uPyMK5LD3PEoA2OlOCCGKaFExX4j+xbn/mL3XyyhS7xzlgln8lIO5N2n0Fn8B0i8ES/MUlSXYYqEQBXMRKRxtvJWQ7N5HvmcGPTOHaCaINEXkOVKBahlUntEaECSjznnTWhHImCXjh1KrjGEszM7to9lqkCU53lDoNCE07hy5IiMhSxOCLAUVIq3FAyqh7xx3DEl7Hp1lJLJJraIJA8nI2AS6ldBuJyR5E6sVVVFzOf0GkkQzOzMHwlIfCJHWOABapZiCWeoJseAxUcxfZUSDst/Ek593+btLqV3Y3+X3estCD4i11mK1QiPIkXgyw8MWWnTu68IKF20tx5pwjlN3LehWDSmOaizdNO3SZsr5ogSqrSgKOxgKojHutwIAL5m1pi83/r/BEB6oh6xfv4azz34Go2NDCGGZnZ0FII5DavWILDPMTickqdPEq9UqeIFwgsSex9DwAHEc8uCmTYyPT3DkkUdxzz33smzZcn7965s57rhjabWa3HfffaxatYq1a9eyaHyMo48+klNPPYXbbrudJUuWdCvXdTodzjr7bO65+27m5+epVGK3gX0KzZ2RkRFOPvkkosgjz+Gkk07iF7/4Bfv2TiFEr+KW0k7bL4zd31Za4thpzgic/orqlpnO8D2o1qrovI3O2oyO1hiuVpirVJhupnSaKXsSj43rjyGyFmUs9bEVVIfGmU0eY+9kmx07dvHIlvuJvZChoVEawiBDJ/q7Y/cU1gpWrV5Gq9PAGMXcXBM/DFm6YoRHH95DkjaYm5mjWrHUqtBotJmf3QlaUY0DKpWAIJJs2z3JfCtjfGw5YTCJNZat2/eyb3aGNE84ZP1hxEGF6X0zDAwuIksbPHT/A1TjmMGhEaIoYq45hRauElWz3Wa6PUccx1QqsasoRVE+WzlgwwqB58X4fkaEZfHilazfcDgnnnQSDz74IPPz8wAceeSRbNiwAYDLL7+cO++8c0H/nXTSSdTrPc2u1atXc/LJJ3PXXXcRxzE333wzeZ53N49hGLFkyVIAqtUqZ599Ng8++CCtdptmK8HiBKqbzQ4qyQkCjyxLSTodp0UUgAwgTXIqccyqVcvZuWMv1WrMiScez7333sftt9+GMZYtWx7hhht/wcnnvOo/c8j9X2g+1ggn+l34UUopsjxzehlGOm2ePCeM/O685DaNZVU8090E6AIocix0WWwoClHfUibAgiqChSWzyphyzfec/AROo1XoAtAqdF88bBFgdewHlwoIWqdYBFoLrHGrehD6KOUKHaRphpSSiopIOh06nQ55nrssh2KxiMKAOKqSN+fodBrMTe1hfs8krfk58labNE/JlMIqDQgwhizJsCYjrmpS1UDqAGkDVGpRScbefXtpJw2kbwhiiRe6YKwyOanS5EZTNT6egDByfq6xOG1Va/ACTZJmmDyj0ZZE8TBxpUqtNggakiQrmAk+UVQlzRsY7fROtcrJVYoyHQxVEBoKGxdC4vsRgechRYbFBbalgMD3HBMpyxBIojAmjnwEFqNT/MB3LBeBKxSkc+JKSBwHhIEEHBvDC2SRHicdo8I6MMmTbqOscjcnWzwEfpFqI/D9gv0iwBqcbZaftQalc1fYKM8BDynB92UBkNhenwqBNk6rFeOqKkrPQ0qLVo4xIYtiStIDY71u5kgURl3plgO5HfShD/rQdJ/WQR/6/9SH/q2Bp3Lh6z4scJW+9oOa9kd1Syp+OaB66WlO6NAUE1UpHt49fhfocX87ppShK1pdXIwUJZWzEJcu8Iky9U8Uk2FP2K3QdCrzmfPMiYtnKXmWok1OyWrpNxqLcA+7yL116L4AoRHCkNkUbVsk+TzGKjwZUImHieM6YVShY+foqCbNdIYwjImjCiMDE6jUknRSkixxFTysIggDPD8gjnEVJgpWTq41Rll8GTiByoFB6sPDxJWYSqWGyxMFbQROlFvR1ntRqkmedQi1TyBCIhuTKx9tU2bmpgBDlnWo1Uao1WKiMEAJD5NbdJZhrctBLVCnLugkhENWhXUGKYr+oWQtmYWsNejRQK11A8ylwRV00NJ+iom9ay/W4tB5CsDRduFIdz2OAmuEAKGcoFuRHlmCW9pTlEtCP3XVL3QNnH9mwTrRzXJYGm26tlDODK4IgLsnB1j9N9i1Fq2k/ZabAxdxcU5GGERY20tt7U2cxX33MRyBrmaIq5Lijp9lilL4sJeOWDit2P0eVfEMS3jeim5/9QBu0T0GxRh01SYkWptiYbXF9ZXOuHW54XikSYukPU/ebuOFMdIPQEiEHyD9gGzvPjrbdzN3z0PIVkJFGaJanSQMybWijqXVSWl2UrIdgmRRRquzj1anTb2+mOMPfyGz7Sn2TW8nT3J8BPVKheGRYYQwJPMNqn5EHoHutJie2U0z6RCko04DIvAYXF1lIG0RV2M6jTZ5Ns98llGtLKFaW8SyNevYsfURdm3dwmRjB7FXZe3AeuayvWgpiKOlzM42abf3UK35DFSHqESDaLUXqOD5daQvivm6mNek46BqbZyQZDGzSiEXzL1Slr8vLPULveCAKOn0smc7ZRVQtHHlvXOFsBY/jJC+oOCT45VMWCuc7h4KNPiyiNSZXiVRkIX2ngI0QnpIz9leN+qjypFbOHSAsQVLUhTrRvF2uSbY/tcP4CaE4KKLLuKiiy4CYM+efdzym9s56+zjGVs0itKKkaE1jA7WuOuOrWzYeAjPe/45fPO732BocJjnnnsBRlu2bt3GRz7yUV71yldw5BGHIwT84Ac/5qZf3s611/6Ee++7hxe96EVcddVVnHvuuQC89a1v4cILL+CUU56+4JpOP/10rrrqpzzvuc/j17/+NavXrGLXzl3MzMz9Vvd06aWXcskllvk5xfz8nPtpzON5PmOjgyw/c5zpfbP88AfXct5znsbg0FJ+8N1fcuSx6zj2hHVc/NY3ctjhx/Ctb32Xn373izxw2/e56r7HOfOoEzjn7Odw5Vc+ygPT8Hg+zEXvfRGP3vYrfvGlr3LDDd9j7aHD/Ou17+Kaqx7j8Ufm2Dg+zqFHrmXdISu5/Iu3UBlUrDrR59c3thkbXcQ7PvhiHnrkPjY/9Bh/9/7f8LwLT+N3LzqNZStW8+sb7uEVv/8GLvvI8aRpzJ+/9Rpe8OxVbFw7zr9++Xv4NcPTz1jBH739LVxw/gv41lcv5+JLXs/td97Bo9u2ADA+NsElb34PN/3yOn5+400cfvyzCdMZGlMPse3heznimGN488Vv5aUvfQl33XUXd999D3/1V3/J3//933PvvfezZPES8kTx0x9+AQuceNrvsHXrA8xOT7LhkNOYWLKUMIQg8DnrrLNYs3Ytr3j5y3nwgQcAV6nuhS984VP2k+d5/MM//APHHXfck957y1vewktf+lKOOOKIPsbTwjVx9erVXHXVVbzzne/kK1/5J7Y8tod161Zy0vGHcPc9W6hUIp7x3NO4944Hmdy1l5Oefiw//OH13HbbA7zspReyeGKEpcsm+Jv3f4nRsSHe8vaX8Kd/+qf85CdXYq3he1d+le9d+VUu+fMDG3hqzHUII0meF5WJir3B/HyTPFdUoogsT1FKEUUhQeAAgrgSoXXOfGOu0GVyccE8z1Aqp0zv0DqnZDVZiwNxjSFJUxdwMz02BAjCwOlsuWBrCSRAlity5fyEIAipVirkmSXPFc1WSidpYbRBehHVao0oihiqDqBVztycS/cSCHS95tIHk4Rms+0yCaylWq1Rr1apVWJ27dtGZ2aSmW2PkkzPoToJpq1oJTkdrajVIuqBRAQegeggvRlEtB3jTyHEAIEfMjfVZGZ2mk33bkHZNvVBj2VrBhFWMDufMj3fJMsUYUVSNYLAq7Ns9TBplpHlGbVahDaGJM3ZNzXvMg3o4MV1/NBjqD7BzNQsM9OzDA2NUq8Ps3jxUu6//x7anZyskjO2ZJzhkSFq1Rjf88AIBuuLqNcEw0OawdoYgS+RXk6SzJNlCa1GQpa2SZIOaSulXhtk0fgIY+PjKJWwc9vDVKJBwihGW4tSUyRZwpq1y4lCjzAAa9r4gWTl6mUMDY3TaWVM75mm4oeYTKGyNlL6WOEjhEHKgCB06ZOOGVeu6y6jQuUashwVBM5fNoo8zdFGU63FhJEkCGFutuk8cSkxVoC2dDo5WlmkEOSJA8c9z8MajzD0GBmtMTDosjOkqNNqddDaZ9Wq1XSSNlma/JeNzd+2HfShD/rQB31o/kM+9G8NPHmFKn/vggrjRnZR0h6o0D8yemKE1ngO8OmyT4oqYhbKlDUHTnT3+MWGH0oBPNd9RYcKief53U7tO2UBXrjKHrYAJ/olra3WRRW71KXZKZfrbrsfKe+tBMEKfSdDgQDnmFyhTYZWLTrZFKmeR6WJE14MI+K46hTpPUOWtkh1k0wlDNTHqETD+F6VRDdIsg6drE2mcwwW6UuEEXiewJfO8fC8ABH6+FIjSYkqHn5gyXUHUo22hsCv4MkAz48cOi4V0gvIgEylBEZSBeKgSkSV3EpaWYvZ+TnSLKde24O1Hp4M8P2KS63TFpMbMB5WO/DJExJ81+nC9vV3ieoWkRNRWoroobpdY7UWU4J7pa4Toqv71d9EFzLqfRd69lai9t1yxLbQn5KmQOZFwYQSBTJrirQ8nyAMe8KdCyaE8tp7yHX/m+X1lsDqgZ6mA0UkqwTRoHvt3TKq1nSrK3annv5n0n0GbjyV6Y3uc/0LbRllcQh/uShKKbugX7+wogMhRQ/862v9I1sKx8aT0qfsofJ7ZRTY3Y8oUm9Ba6fdZowTGpWeRPg+FlBpRmfXHtTMHLHnIeMQlEKnBi8MUdbHph0yIBCCiY0rGFk5jAkyhoaWMDSwgkptmH0zT9Ca34VMc3wtCWRIJ5tx1a2SEJlX8Y1ERBk2z9C2TWiHEMJHElKPBqjWBhgYGqcz3yBPc5IsJQpr+GGFNBUIGRHX6kw29jJRnWDF8GqWJEtJRI4MFfVwMaHvMblzkmwoY3gwR8+3icIxagMhRnloXJppGAZFXxiXcqq1EzgsFp/S2envi5LtWQZRLEVeeTE/uxzz/ihcyXYsQWhFmjbQOkUICKManheCV475guqNswWzgCVp++Z6EEagjQsClPMC3XFa0sltaapuOViwRLhfPM8B04Um5MIxfgC2l73s1Tzveefzqle9AnCO/x23PszGQw6lVquz+cHHGB2tc+ZZG1A6xw9h9549VFlDhRrNZspjj2yj1WryR295E6tXreo6wued9yze8Po/ZMnSCe69z53v/e9/P9dccw0f+tCHCMOYpUtX8JWvfIV169Z1r0lKSeAH/Pmf/zm33HILH/zgB2i12guuO89zLrnkEnbv3g3A/fffj1KKl770pfzBH7yOI486indf9qc8+9nP4vd+7yK2PbEbpS2+H1IbSAiqgvOfdzpjiwYxaJ7zO6cQxgFJ0mHV6nVU4jr333Y/czv2IZqK5UPj7Nq2jUmlyCfW87QTlnLBimX8zcf/ivnGbs47dYLt9z5MmB3K7zztT7n5x3/D/M4bOf4lQ0xu3cuPvrWDYLSFMh6bb4WjNwxjrebD//ObTCxNGRqUXHzxS3js8d38/ad+wPEnnkLemeOUkyZ48MZp4sDytleu556H5rnxdstll7yJK3/+K370s1+6dTvKmZ3fxY7JfUzuc2yjN77uDzl042F8+V//gbPPOpP3v+SD/NX7/4Zjjj6Cd176Ib7yT//IL+94gA9/5Gm8+qK38bwzp5H4RaoFYGH35FY2bbqD9YedgBCSnZOPEFWGqNTGmZ2f4Zqrr+SXN91AGMacffbZvOpVr+LjH/sYN910E3/9138NwK5du/iTP/kTbr/99ifZ3781Pv75n/+Zn/3sav72b/+WX/ziF3zpS1/iTy69lGec/Qze9773Lfjsq1/9Gs4482yOOmId27ft5RdX385ppx/B0GCNvbtnWbJsotAXgZNOOpLVq5cxPTtNs9WiUqly3nOfRr1eJenkXHrpZbzmNa/hv1PgpzbgdyPSw8ODIARpqqhVh1BKU6kEVKox2uRo5ebXMAxIkpQ0TWg0mlSrVXzPc+ySotqc84UcTcHkTgfTWtktpNLPQLSFb2yNRRvnC4VhQBhGRQVjx8LSRoMqfDWtkcKJZvu+k3kw0hJHMZU4IAwl4EThPW8CY504rTESz4tABDSabfwi/W94eJSk1WTH1HZm9+4lnW8QakAEhD74NR/ph3R0Dr4lqgVUBmNWrFrM8MQwtXiQiXEfzxtgaKiOUi2EyBAidQyBzJJ3LL70CIipx1U6IqWTJExNtmnPWcaGwiJ4HDGxej0A7aSDsttJ0g5u7+KhtSSOhhAiIctgbnaaOAqoVSoMV6sYYxisVbFG0261mBEd0lZOM06JQ89VBROWdNC4EulCIT23UZWeZG5uhsnJ3cTBEIE/ALYCePhBxNjicUBirEUrSxhUqNcEWnVQ0gkOe15Emmn27NlFlkkwHosWL8b3Db5vSDoN/CAijKrElRpC+hhjyFWKEILIK9hGUuILr8ukK9NvjAYhIjzPAJI06ZB0mrRbbefzex5hVAckeeYCvIHvUa1VukwLGUoHnCWKZmEHcRyRJq7ynhARrWabVrvx/2gk/p+1gz70QR/6oA9N95f/Ux/6twae+plMZevfmHevve/E5cX3ACWJsNYJdYkyx7EQQhTlRr7/nOUtChClOFdvw+9QXNlH/ep7WO5ie+gh9D3HkvlUptllGKMKRlWPKVXem2M7ueOVFfBMrsjTFJUn5Ok8nXyW3LZQIsOLI7zAK/L4JQjjKtkZhcUS+lVC3zGUsjyjk7RJ06IiSHHfJQgthDM/Dw98DyldzqUfSKQ0KJVirEZpgwkFvg+xFxdQjZsMtTVkRpHpjNCLEBYCQqzVaG1p6w65UszNzxKFNeKoWhgUIDQWgbU+1rhqKWV/uyqLthhshQ0I0QOCSnim6P8ehdQWA8lN4mXqIpTpbD3mWx9o32d19B1H7Pey7Z7HGlelDyGKHNretbtB4gZimdPaD6h2Uwm7dkAXlOxeW3m7Jc3uAG/991S2coIr3y+jpd3JqK+VqHjv76LPrF2wYJXVGXp4ZA/p7+Uj9xZt90f538LzuusreY6iYP+58xrz1A+9LANqrXVjVefFvdFlwiml0FmGmm9gOwmh5yF9lyetMllU0DB0cFENT8LIkmEGxgbwQkE9GKNeG0MISZLM0WrsRShdFA4S5KqFZ2L8PEZoH2F9pC8dhznXCM8JP0rh49sALwioDgQE1iMPUoI0c2WgvRCjHPAcxRGN2b0MmSECL2AkGqMtOlipCPyAwAuZmmsTEhDYADXTIo8tmBpaeK4YgVJUB+qEYYj0JKZIVS1t4CmfZ2/AdOdGVxkJyqlR7P+N/hcKRqSLClpUluBJVzlIiqA4hqFIXqaM1vd9vagiW6whWLD96c89O3NjfIFBdedRh5L3DMtRxUEY86RjHYjtO9/5DsuXL+VVr3oFU1NzTE83UMoyOzNHGPo0mx1Gx0ZYtHiQdrtDmid00g5DtcWEgc/sTIO5uQZCwMnHHYcnZZehsn79Op53wfkLznfjjTcyNTXFH/zBH7B06VJqtRrHHHMMWmu2bNnCqlWruhoyZ511FrVajfe85z19+oswMzPDww8/zD333MPmzZu74FN5P4cffhgWy49+9D3WrVvF0GCNbUKglSZXKWEFKtWIVWuWFnoChrXrlzIzM8+ePVOMjS8j8iK2P/EYNofIr6BIaTfbqCwjGlnCilUrWL9uCZd9/p+IwpSzj19M2mzTmM4YSZeT/n/s/XeYZUd1741/qmqnkzr35JE0o5wllEaZJCFAZLCNsS/JBkwyBux7icaEa7DBNoYXm2gbTDBJJtmIoIAA5ZzTjDQzmp6ezn3SDhXeP2rv0z0S18bm93uveJ6pefrpnnP22XufXVWrVn3Xd33XUkjecRx25MHs2b6DO2/dyWGn1SnSkIWHDec8oY4pcn74o/vIjwixB41wzLkb2LVzmj0PTbF5wxJJlNFqBphOC5EIDtrguOXuZbopHHv0Fn585U3s3rnI4UeOEQQ5Dzx4L0mtycjoBP1sis2bDuLQLYcyvzBLrVVj6xGH0u0vEccBxx5zDNt3PMLsQhfnYOO6gxhO1oATjI+Nc8ghB7Nr1y6ESFlcnuHQQ45HKsXC7lmi+ghhWMc4zfS+Ge6++14A1q9fz+zsLOeffz6q1Fqcmprijjvu4Bvf+AZ57lOlDjroIILAsxaiKNpvfBRFwc6dO7nyyiv5/vf/nb/6q4/Qbrf57Gc/y49++COyNOM3fuM32LBhPWEYsXPnTg4++GCOO/4EnLU8vH0v03vnwfmocJ4VREmIVL56z9joCLWkzl133+9TJPqOY48/iEAJ9u2b57TTTiMMA+YXlmk169Rq8f9f5t3/L5tSfl0y1hKGXhDcaEjiBBs5kkSBiLBWs7jQBvxalOYZRaHLzaoX9V1JNy2tXblx9RtIg5eA8LIR1toy8u4dS2d9FSTrtF+DAklUzuVBhgC+8i/O+2pR6EWjg7Kgi7eb4FM7LUI4giCgVldeCNh60fRCGwqt0cYQhqFfq8KIpTxnbm6OtN3BpRnKSSKpUIFAqQgZSGKd0zUpURiQ1ELGRloMtYapRSOMjjRQqk4YBSAN1mUoaZFYrHEUmUUEEBAQhSFaG9q5pVcUFH1JXWmk9MyfWA37gK+oU68tIYRA2wyXC6/B4xRVRkE/7SJcRC2UNGu+QlccBRRF5gPYGrKephfmgAApcNKRp5owDHDOEicBUSSpJQF5ntPtdomGhnHOa+/kmUGFkNSbZGmKzjVF7oXe62ETKfqD3Y4TAVobFpfbWBMQBjHrJtehpAYKtGkjrC9tL5VfC401mDKfKrClwLEoRaUNg72Qz14QCBFQrfRaa4zJ0Eb78elA1BQgKQqNkgolJWEUYsvxF4QSWfjq3n4cO4IgxJTA+aN9w8drO+BDH/ChD/jQKwPrv+tD/9LAU4V+VzfnnH9NlkrpQRA8hvWx+stLKXx5PuewuRkAGCrwjCVjRNl5rjxeDj7vJ1tV3rVMdZNq8JC8cSwncQl6eFTRw38DerHwaVZGG4o8JUu7ZGmXoshKtlNZSa0674B6JUqGkyFbbpN3uqTtDv2lJYq0T9bvUNDFBQY5KohHBdKGiFE7cDKc9Qa5EY/Rqq0jjpp0el32zU4zOz/N/MKiH8BCIMJyYcg10iiUiAjrNZIoBiVQQQXc5KSdHG2h0I4oahFFNVqt3NPsnCPr9/yC6DR9HKENKUxOEjTAOlyu6OQdDF2UeNjTsU3B+MSkd0iFxIkCRAyiDoR+cVwFIlWAYpUL65zPBw2k9Ah7aVhF1Tc4JFWluwrTq/p9pXpgRd0bfExQCh6uAEFiBdlagaEqRtRg3IrSYSt1CwL/WyqFLKvhDSrVsQKwDvTLxKoLlujzylArQUr1a4A8rUKsfWnVKk3VDeapzyHHlxVlxZGt2kpOeuWIOIoiHxgdbwfKHHGqrvDzejX12J9jFZjt2O+9lUjBij3wLDVZ6lP4180qu7Rf8QFnKfIeRdrHZHlJLS4NfxRAp4uZnSfspkjrCBp1ZLuLMA6rIrJCk2tL4EBKhwxhbNMww5vGGBkbpRZtIVDDTO97mJ0P38aunbcinKTIC9qdDkEzRBKDrqPNItpmWLyDGgcRtSQhDmvEUZ18pkvYCogmIpZnp3zkr6sZndxIo1VHqZBaVMPVGixFDzNvZ9ixuIONw1spyLmveyc93adAYpcEy0vai6vOzpPlD9PPb8FZP8ZjqVh30CZG10yy+bhDUVJ4BmMZgRPCzxnv6CiUUkghy8xuXxFDhSFgkaUgrp/PrCrP6hAV7FyW4/YbGT8G+ukSed4jCCJaQxNIIpwKy/VE+sVTDLrYzzlrSxvtbapcHakpx5JSq5YzUQ32coGv4o+D2ES1CROssG0f303rPtZ4MdYPf+SLTE6M8rZ3v4pP/t0/sbzc4a1/8jr2TXW4/+5pDLNMTE5wyObNrBkv2DO1j5/8/BqedP7pTIyNMr1nltHxIaT6j7/43Xffzcknn8zHPvYxLr74Ys4++2wWFxeJ45jrrruOww8//D/8/Oc+9zm++tWv8tOf/pRbbrmF3/md39nv/Q9+8EMopciyDPBO7Zatm1la7PLI1BzNegulBA/vmmK41SJJEhaWe9x564PcduPdHLTpFPJsmgcf+AGnnPVb5IsdLvnAmzjl9Gdw8EFHI5YfprN3jhvu2E7WTen2LDfd2eO173gCmbaceOKJ5HnO+g3redLxf8HdV/4dU4/cRHNE01nW7Nze509eeQpHTE7w5CDm//npbr56zS5++IN/5OKnHsFH3/dcNhx6Jj+47Ebe/78v5Uc//hFGay666Gm86jdO5JxTtzCz6z46i/PEccTLX3oi998/xYtf9iq+fcm3KQrDb7zkxfz5h/+cjes2csnnvstnvvRJLrzgQs449Xm4BcHf/uEfc/jQIRx67DEEkeQjn3wXt95yGz8/72r+8I1v4qUveylnnrmNCy+8kI/97ce49mdXIRAce/zZbH/wAZZ685x2xml84APv5/3vfy/gWUonnXQyV131k0Ff/NEf/RFSSvI8B2BoaIjLLruMdevWAoI43h/Y2b59O2eccQbdbpfh4eHH9P3PfvYzTjjhBL7+9a+zdetWtm3bxvvf/35e+9rXsWv3PIdsWccb3vx8/vWbP6XVqvOsZ5/NF//pUhYWOrzujc/jjtt2sePBaZ753FPoLhfsfWSZKIzYtfsRvvyV7/KSlzybZqPBB/73Z3nRiy7gSU889T8ci4+HNj+/RLVuRqFPYwuCkOHhGipQBKHwVckKQ95TYKHd6SOw1JI6a9aMk+cZeZ6x1F8CB2EQEsXRYK1O0xwhHFhV6oUGhGHJjMChjfY2z1ji2IsXKynLTY0iiWNqSYx1loX5OYoixxpH0PQpUkEQYo0jTTP2Tc8TRQFRHDAxMUqeGfqpJlABzhUURY8HH7yfTmeZVrPJ+Pg49XqNpaUlpqam2fnwboatJtKCUESgLGEAE4060mkKnXPH1CMY6+hmmjAcpVU/iHVjxzI6rCmMpp8us9yeptPbS3NIInuSNDN0lzNMBM2GIijXOZsKMmswsqCbpAhCpHDs2r5Eo9Wk1WrRCCZxMmJmYQqpNVr02TO1hyJPaTRD5ma7WN0HnbNpw2ZUoJhvLzE1tYtOp02rFhIHdZSMeWhXmzTLyXTG4Vu3ksQxWmsarQbDw0Ns23YqtXqddevXsXbNRpJ4CItlx/YpwkixcfMovV6bftqh0+6wZt16JiY8m8mUleuy3JCmmjTNyfMeYRQTNxX1eo0oUiwt+5SuVHeg70q2S4h1fv3rp4YoigjDyP+WiiAMsMYDlLpwuEKssOtwKClJal7Y3DpBEidoDUvtjgcDZCX74bDGEdf8/QRBQLvdQ2tLt5t59l4gEcISJ2tZw9r/q/PzP20HfOgDPvQBH/pX9qH/C+Li+98grAzSqvIYrJ5Uq0Hhkp2kFI6ShoZH1QdgAEEJElSoqizRWTGgAIpKX6kSNisBhSo9a5BvWOZ5iRKo8u+V+bXW4oxG55nXdtI5VT4tFSJYAU5ClKl1ObrbR/dSejNzZMsdsnabfrtNkWVkaY9CZLjAQSrROZjMUYzlhEIhlSCUCWHQQAV1askIzimWO7MsLM2zuLjgK9UFEhUGHt00Dp1ryDVKWuKg7kESESJtCGJF6stYn/rXL9rkaYbVlqCMYAjbRwhHGEcI7TDSkduUyMTgLEJLTAGFNXQ6XRbjRUIVEoSSOI6J49hjqNIhZISz3hmyVg/6eJBfPOjrUiy8ZJzZqgPK3w43GE4DpL9C3oXw0CxuFbpapdCtHn/+mGqi+whDFZ1ZfVw5WSkXBOuQrjLwIWo/qutqiLj8LpKBsUWu0rfyyGb1jfebH4/XppRcNT8f3WfVcyxTSvebx/45VlU8VtB4/7dPw/VnqiIoFVXYG79SVG9gNzzDbL8UxUGnDe6I1S8IoXw+sgzAeV24Kq++WmxXuk/grMFkKbrfQ2epnwtlaMFqr2Gg+hlRbjBpQZFrZF6grCMMAnzljpC27nkNM6cJaxFRHBOomCiKKfKChx++lbm5KdK0hxAxQRgR10KSMIEc+v0OKgpRqo5TjkBGSBn6iFYJvutM4KTBBn1CYQhkTr87A0FAqjWqMYQlQskmUZCgrWZffw/rhtajRIDrK+b6i1hnaOhRess9snaXdruN1gZTWGpR3W9QooSlvbPofkZztElrdJh6q4kufElVLCXgW/6UZYH9S1V1DvA6ASs50VJCtYwN8sGxlPm0VS+W3SlwTmOMI0s7BLZOEIEKg1LU0u7Xr9XE96zU/R2q1VPW24CVd6s1wv/4ik7+U+X/8UKMVcnhX4f205/9lHe9+92ceOI5bFi3gZnpLieffCJ5kbF7z152bp9jca7LSadsxhjHjh07GRsbZmgo4bhjj+Can92OEpInP/U0pAgIVZ23v+1dnHSSZzJ99KMf5ec///nges450jQtmRP+7zRNKYqCj3zkI5x77rm85CUv+T/er9aaNE2JougxjJnq/SoN6PLLL+dtb3s7UbCBLVsP4UlP3sbMzAICx8SaUYy29Ls9Mm0Znxzl1NOPY+eOW2k2Io485lnsuG8Hup/yzNf+EeyZo1jcyZrNQ6Ayuv02p69rsZCnFMISKEl9OOYpTzuEWgwjoy1+ftuX6HIXR53cIlvSHLp5jBdevIGZ3TmyXeOkF7yRF6z5HofceRvfvHKaG27dSbvTY92mDo3WJH/23veR7b2TPF3m9a98OltGClyvz9LMPs46/TQOOeI8Ngz1edjeQZHfwV13Xc9QM+KCbRt5cPscRZ7z+a9+nmZriNf83mu55mc3kqoWQ5u3sGZ4Eq0cb3/72zjqqCM54/QzufuOKRbbO5lbfJg/eM0fcNCmLezavpfZ2WmCMKLTTrn0Bz9kdnYfp59xGnG88vzPOOMM3vWud7F+/Xrm5uYASvFg357+9Kdz4YUXMjk5SZLUfmHfTkxM8M53vnMwNj760Y9y4403IqXk9a9/PevXe2HxI444gtHRUd75zneybds2rznU79HtOhYWJEccsRldGH52xe1sPmgth2xZz713P0Stpjj2+M2kPce+fUvseGg3Bx06zNjYCNtOfwIjw0PUagnPetZ5zO7r8s//dDm/+7In/xdm0//3zQe6QElBnhc458tzZ1mO0hIpQ5QUyDig3owodOE1nPCFZnyajC8vrgvtNXqUKjcNEiECtPbhbVHS5r0Oj9f7EEgi6cfBgN1f/c+tpNtUKXphEBEogS/jHOCMxFgwxldc7nZSXCP28hJBgNEgReknOIkUika9jtY53V6PIAgpck0tqbN2ci0xYKYfQXe7ZL0enkNTiZXXCMKYJEnoOkO3b1loWxoZCBXijNeuenjXdqand7OwOIuSAVHkQGqkBG01y52OF92VkqGRBs74tSGMvC6JkIJ2dwGEIY4DAhQBCpN5UWXjLPv2PkS9HpPUAhrNBGdAI5FhDScE3V5Oked+r5BbisxgdJe5hUW09vuRrNdFOYOz0F7w1bR3PrSDRqPO6Og4tXodKSSFTklqoWdHWYEUIUpFCCXp9nq42TmGW8NIGSBEA10sIoVi7eQECFVWh3OA39RGUYQxsmSMmlIc3SBE6P0qJLrIB+l11WYZWwV3BUoCzmGKDOtynNVYRNk/NV99TeKfDY4sy2m3exR5gTF24NIbg686LRxFblDlPi/NsrJ6+ON7LT7gQx/woQ/40L+6D/1fqmpXTRSBN9YVGLQyQcR+xz3q06VR8UbNA64WXyVBMhCLroCn8oFJ4UUYPVVYDX6gJKDYVQ+uYkdVzJcKfEKW1cnKcoZGo4sMo3OMzlfBgmJwXVHm7DprMWlOsdwlX+6Q7p0la3dI223SbpeiyMmyjAKDDcClfmG2FnQ/R4YRMlIEKiEM6zQakyTRMFme0em1abeXWV5eIksLojjyeaLWlpEGjcssVjp0lKPC2IM6NigRRk+XlngByaLoAxm2MN4RkJIk8ir1URyD0FjnyGxO3RYe+DMKtEAbR6+X0o7ahCqgVgsxjTpKNQlLdhmywFmFcwptDLIEnUTZH4O+dz43mBIU9GvJgNo0mDjVZFhtPAdQVSUUVXWtsytjbxVoVbWKOrp6LRggvgOmUvU5P6FUEHrWU5WCt9+E3B+EFIgSsXb4iiRisCBQAVOP87ayuFRJkIN3BsBdNZ+tW0l/lSW7dSV3uTJGvkmpVpV1daWD6wai8QNmGqupmGIgirqS07z/M6wYi34+KoTwDDxf9tUOxkR1dNUcHt03eY7OUkyeoYQYlD21hYa8IEhz0BaXabJOHyktTkhiFREGXkND9mQJpFrCJCRIYl+pUkq6WY8HHriNtDdLURQ4FxAEEUktJglqZLmg32/TqtcI4sDT/l2CdGEV3wAh0Fpi+gZDTqggVIYsW0QvRWTaMbzmIKRVSGrEYQOTpcyl0xQ2IyBG5hGLWY9U99kQjLA0n7I03aNf5GAN0hqiliKKBDKA3sISebfPyOQYYRjRGBrCoamohBW0Wvbi4P+yrBTpu6rSHpDlGKDMunXlQrlCoZflAWJVv/ry4Zos65WLsi/YgLAYVsDs1QENr22waqyIcr4O/K5y/Vg1HoRYoa1X7ET/OTEwEEKW+oWPYuw+3trw8DB33HEHt956K1dd9RwO2ryZmb1djjnmaISy3HXvgzyyZy/LCynnDZ/A4uICjzwyTasV06jVOeLQrXz7q1fQ7nR55nPOQ+cQqoTXv+4PMTZnfn6BL37xi9x7772/8PpSSoaGhgbg06c+9Wmmpqa4+OKLAeh0Oo/5TBzHDA0NlY/6sWkUtVptAEjdfPPNXHPNdYyPnsyznn0RL/yNC9n+4E6ssWzduonFhWX6vT6dVDM2OsQhB69l1/araDTWc/wp5/GzH34YU2he8PY/4Y5//kdm9jxAY/I0Cl3Q7HQ5frLJ7g7syHzUfmg44fynbGG4KQgCxy33fpuuW+Lgo+ps/3mbQzYM89u/eQyXfOImeksxF7z6BVxQ38eWDW2+f/0S9z44y+1372HLIXM8+9nP4Y9f/Wqu/Ke3UaQzvPK3n8z2m29gaXofaafHaSedw8bDzuXy73wfZWZoNBvcddeNbF7f4slnHkqgJQ/uWORr3/oKr3rlq3jBc5/PNVdcSmEk8eR6jj36GB7c+SDv/8D7+H8+8QmeeN5T+fllO7jrgeuZmrmd9/zphyl6lh337aTbXSau1en1Mq766U/Zvv0+3v6OtzEyMjJ41ieeeCInnnginU6HbrcL+MpzYeij9BdddBFveMMb/sPxOD4+zlvf+lbSNGXv3r2cccYZzMzMEAQBr3jFKzjhhBP2O/6tb30rujAlMyOj3UnpdjJOPuUoFuba/PC713PRs85gbLLFtT+7lUOP2MyGTZMszhsWFjrsnZ6h0IaR4SFOP+1E6o0EqeCsM4/j8/9wGT+49KbHPfAUBCFBIAgDiTY5CEHsnN+0CUGcSIIwJJCSeiOk29OkmU93C43XjpFVIR232tb5jIIgDMgyU1bBkgO7PgjOlVHtqiiPtd53rDagOFdWvjNY6wjCyAc7RUSeCa+ZikVrh9aWLC2I4xCcD+SZAJTSHjwS/l7rjQZ5kbK0tFCCHJaR1giTYxOM1WPmuou084ye0WjnkAiMBRXGSKWI4xrdIiMvDJ0M+tpXbs6Kgnanze5HHmJhYS+93hJKRoSRQAQC6QRFrul2C6LIg2Mjow0vaWFBhRCUZenTrEMQSPKsjsDXfXPaYHKL0znp8hLB2gmGh0ap1yPy3JGnAoNnp2RZWSkQS1Hk5FlKP7UstxdBKJIoweocW0iEk6R5Ttbv88jOnWw59FDWrltPLamhtSPLMqKkThQEOOMZSoGKEDKg0+3R7mYIEmqxL1JkzRKBVEyMjxEnnlUkpSs3pr6ku1ISY3x6lHO+CqJS1VrqdYNsAc4aVJkKKZB+zcSTLqzw382YDGsLkIowiknihCBQWCmo12P6/Zyi0HS7ffJMY4whCFW5yZZEUYQVnklVpX4WucaFAUHw+PajD/jQB3zoAz70r+5D//JV7SrVqvJinkZWbbjFKiSXATBUPtvBl6gmSBQnpQEzK+9JWYIVVb54peZfVf9YnYIlqUS6nADhlRQBVz5sNXiwPnvPPxxnLTpLydMeedqlyFJMUTAAxYQo9X78iW1eYNOcbN88+ewCeqmDnV2ANCPIMsLCIAwIESAM6NxRGIcJLIU05L0MmYCshdRrYzQbE4yPbiUrCrKsIM/66CLHGUuoAkIVEqkQZ3yKXeAUBoOzBWnaxjpBENR83mugCANF3AyoCU2tmdPv9dCF8YCV0RgnkapJUkuI45is38VlBZ1en6gICVAMh0Nok3uGlAwxWtLvWebnlslSD861GpZQFSgkzhicDQFFqaC0Qv+UwqfvMQBGvQEtx6M/btXrlJpOshpb5WuuSpFbMZrVgPZV86ox56gmj7VVvmo592EAjpa40wBQDMKIKEqIomTAeFo9OT0NsZpgK2Pcg14e1qyqKrqSGfXr0Lym1v6ALgODgl/kqme1KvJURb2iKB44uz4P3T+vIPC5z9ZWUXOHlMaHt8o2sBeDXHiBEAbw2hMVxXMg8A9I4fW3lJLY0u5Uj1tIgZLBfkBheSXAYnRO3u+Q556toaIQESj/9nIXtdxHdv2YlkLhgKzQGCkQcY1aw5cNl7sfoh5GhKN1GmubJMMhUmm2P3gfu3ZO8ZMrvsuJJxzKxNgatj98L7UkYeO6TZieop+3Wc73UpctGvUmk2s3kXYKdGqRWTjQQhBhCM7g+gLXqhHWLWs3bSCbaeNmd5DrHrXWMLVmi/Vrj2R+cS87d97FXVM3MV5bw1FrjkLNDbF3cZ57792L6RWQGSYmJ0mCgEQpmkmdOExoNYbIeilGG+YenCIQIUoFNMeHvQ20IGU4iKRXi1XlTA3SX50t+24l5VnnuRehlaXDJaW3B8KD/+VUBec8DV34/k77XYoso+5GPBgcRtgyyuMpy2VatnrUuvIoANpag5JBuVZ5dq11trz/inUrB1GmAdvS+AX3cY47ceedd/KZz3yG97znPTzrWc/moosu4jOf/izXXn0T/TRj21mnsHn9BjqdHjP7lhkabrJt28kYDXMzHe65/V5e+ornEtcCbr9lO5sOWsPE5DBSCj71qX/mLz70Eb7whc9w9z138fu//6ryqmJgCycmJrjmmmv4xCc+wfvf/37A8cMf/pBjjz0WgDzPH6PR8Xu/90re9r/+F5guC7N7HvOd3ve+9/Fbv/VbAHz84x/ngx/8IAuLt9HtHU4UCTZsnGBpqcN119/C+nVriOOE2266l5FWxPqJJk97/kuYnnqIL/3DX2Hby4hezlf+15+wcWKcicOOZ2FpK80Nh3HkoSn/dNUVTPUCsngcK0J63ZTbbnuIh3fkCNHiHe97M1/74ne44pJv8vrnjrBnboqnP+drfOidTyRQivPPPpM3vuY8zjv3OVx/w2f4q7/+Wz7193/PB9/9Ku578BFOOP543vj8IQ4/ZAPTUxnU1jN66Gae8JSX0XnkDu7+8cf44Ce+y0FbN/N3H3sHV15xNb2szh+89c+59aG3s3zPZWw7aAP5jru57pJ/5o3PeR5X3X4b7/voe/jud77Hb13wYp7xG8/kHe98Gx//2Mf51jf/jbUb4d6713HLNVcThD6o95QLn0VraJg4SWg2Ex566CFOPvlk3vGOd/Da17528OyttbzoRS/ihhtuAOCjH/0oz3jGM3AOhoeHBscVhSHLcur15FHsZt8+9KEP8clPfnLAnPqP2nU/v4N77tjBuRc+gaAWEtYE3W7KyEiTl776Ih7Z0eaR7V3Of8qpXHnlz/nev3+fV7ziJZy2bSsnn3Iw8/MddGFZs3aY22+c4tZb7uBd7/99lpe7ZGkBvP8/vYf/my1JJEmcUK/XMc4LiKdZRpF59n/TJDhXYJQgjiO0jsiUZmbfHFmt8KlgjQZJrY6QcsA+DMNgEOBz+HQKbTTWGaQURCL07KUg8Oudc1jnCEO/vgZBQJ57oedeL/X2XypaLa87ZI2g3++T9gs6nYwi9+v8pk0baA3VqDcioigcxI6LXKMLn+IVKEcSK4aGGkRBSBQ40uUZpM4RWcpQlBDECS4MmF5eILWCeVkjWjNO3GrQn5+jkcSMDTU5+sSjCeuOB/Zcy1137WBhYZH20gz1WkCzVUMXNbrdPkXaR0be5896hvHRFq2hGuNraszPLdJeTlmcLRgdbTA6NsLIyBi6MCwvz6LtAo6UDRsk07s69HoFjVAhdZu8KzGFod/LWFjqkuWG4aExjjnyOHbtrjEzM8UDD9xHmmrywhIndUaGRlm3ZiP1QIGDLNcYGyNwzO6bZ82atWAKmo0aWaEpdI9Ob95Lk9BCKoGUPjVuenqaubkFpocXWTO5joM3baFZW+M3/KQgDJjCM9YABL46ooqII4VzcrCmFzrD2BxrUrzWboDRDmsKijwrfTRJKEOKPMXogjTtlIFXS5SU+wAnybJiwJhrNmvgoNtOqSV+ryJLQX2HRapoP3ZdGAasXTsJTjzGm3u8tQM+9AEf+oAP/av70P8lxlOpTkUJd/kJWN756uv9nwSmqteV8pUivOEpmSzVeVep+YsBWKVWRWxK2lqFxgFOrNyDWLEBiEFZSwaVPYoi82l2eVYKJ3qgTJQpf1SGw1psWqbYLXewnT6unyK1JSiZXk6qVdQ4j65YHKEMiYIQqco0RKmIoyZx1CKOmqTZvGdb5RkYixgAMmWaoBGgJdIGWHwkytpS1NxqX1lAKiQhURARBjGhTAhUiC60T7cz/mGEYeLBqiBGhQajHQUpuckRMiJRMbWgBhKMkigRIvCCl3lm6fdSQtXDKv+90ICLEaJW3nM1kL0O16NHnv+vrbhNAwNcDggfTUHgSqRqANqXBvKxI6ka3Ks0mBCrWG4lyIgnTFUMuIqSKZUHnpQKyoV9FcvJrUzAVRy4/a9dHbcyqAdH/tq0/W7ZrZrD5RMvo47+NUpjt2qODpo//rGU4vJdV6XI7v/ZFWbwCpV4cGurnmeVViulWlXt0JULv2dg2CpfedUiXl1bF9lAwF6qCKTyiH2ae0pwYXwFkjCEJIbML/IliRnnPGVcthLq64apjwwRJAl5rtnx0HZ273wEbA7WYh1oW+BIUCKknwdYE5EEMSLvYXuWog0mBaeVj/gEoS9p7ATWCSwKTJfQSiaBIA5RQtEQGZHtE+iAvDaCCROSWpP5bAkpQw6LAlpBg7bIWVzsUEPRCCNqQUgSRSRRTBQnhGFMEEVI4fUbCl1gc03W7tEcGyrnzQpYWzlYlaVdAWcZgLnV3BHV39U8FpU9rc4hy2iKP8GKDfCfs9agi9SzMIVDBWXEtXSCKpr5Ck1d7L/oDO6ritiU9+JWrjGwUX50VQbCj1Me/23Dhg0MDQ0hpeTss8/hlFNOIYwUST0A6YVrh4YbJLWIonBMTU1z3XW7OffcMwhjSdyw1Js16vWEkbGcqb2z7N6zlxNPOJwtWw7hqRc8mRtvupF77rln1VX9k/vpT386iMyFYcgrX/nK/e7t3//935mdnX3MPTebLdZv2MD0Iw/8QsbT7bffzvr163nBC17AOeecw8te9jK+8Y1vsH37/fzjP/wDp55yFiPDQxhTYJ0lK1JGWnWGmyG1JGRu3xx537Bhw1byPbdR5B0CaUCBlaDTGWamemT5AlYUyFAAISDo9zX33jnPUUeexcFbDiWzDyNrSwytidgxpREi4rRjh5ic2AJGcPjo7QzFhizt8PMf/pD23C6OOrjO3XffR5rBOWechKpp2nlC3N5LkXtf5eF7b0YVfVRtDWedfQZBEjE1vYBKOjg1y/333cixxx1JFMbcc/U1jC3sYaTl0GqSNWOTPO/5z+Oa665hamovZ512Nk846VTWrlnL1O7tKFWw+aA1CNkhadQZHVvD5VdcwdDwCM985jO44IILiOOYKy7/yUo6O3Dvvffyk5/8hLvvvnsAGI2NjQ3S41Y3KQVBoPaz0+CBxge372DHjof2E4231nLJJZdw/fXXD14bGRnhec99Ho1GzNhEi0bTAwR53xFFAXPzM3z7u1dywtFnMjmxjoXZDq3WEIceeghSCTrtPnMzbVrDdfq9Lj+76h6atTW0RiKmpqb2q9r2eG69Xhul8P4TEAQSFSQUgdeFsdYDQsI6wtIGKqloNhtEcej9WOPBpDAMyfJsZV6V9tGzT3wE3JTMp0AFVJW3jDUDf0zIMt1KKKwtMKbUUxUKFYQ+fc6U6T+Viy68bS296zJ1UGKNpSi81pAAtPFARae9SJb1GB4aIhAgnSNrL+CyDNKUKC8Q1muCxlGIcAIVh3R1TqcHmSloBg1ajRat+gguyOn1l5ifW2JxaYFA5WVsWdFPNXmuMcYicsBAoiQ2Lyj6gt6yBWOJAkWjFiKcpN/JiKMcU2jyLMWYDCkL4lhQDwVEgLUoKYjCkMIJnO3TbnfALRFHCUkSE6gQh6LbL3BOosKENRPraDaGaNQbJKEXzUcVkOeAI6k1sNbR7XQZnSgQQhInMTOz8wggiWOEgbzImdo7TZ7n1Bt1xsZHGR5ukSQRSnnwwVmHNRqHLaVkPMvIIfG6rJVPV+2z/GvGaISwCOE3vH4j7Mr3/W/nDNaVaVnlnkYFMSDJM0OU2CqaXPpirjxeedFyKdG2oChykiRGKklSC32GB66spAfO/DqsxBzwoQ/40Ad86F/Bh/6lgacB1W+wI/c37Sqk4FFOyaPBp/0nT5luV4JBQqjBwy2h4vJDHpZQcqWzKtV2WR0jyslZTuwB/di5UluIMpfVUOQZedonT3sUWR9rtDcQZWUzIaUvfWotzhhMN0Uvd9Hzy9h2F/opoXUoITEqQALGWo8mOxDOIqQgSRKSWo0wVqjQL+BJMkySDBNFDayZpsj6FP0+TmuExS/izvhFoFCgFcKGSAp86pnGFgVWBgjlmVmKkDiooRKFSCRZrYEuNGm3j9Ye9Q6jGmGYeCci9FpQWlpSnSERjMQjNCkIXUiqNFFQ5s+agCKz9OijkOiwIA5AWo2kRhiFQOAXtcFAsAOLKAaj0K0YvP2GiRgARRWhqZp+++elrjLCA8THluBgNShLzbCSDWdLFBbnyw07KKNGldCmzyOWqkrZLA2tXRHvG9yjP3Hp2FTAU7W8uJWox69BWx2BAcq+cmWq5Kqqg2J1LzEwnrBC36xAvxUA0B+tVlUI9GNwfx2ulUvbcqGrtNoqY6uogupeGLVkpPmavt5vK+8JKQebqZUcen9f1hiKrE/FnpRBUtpfg+xnqLRA5gYhA1wsiEOJXNI4bVDOO3C5NXSylEZziKEtk7TWTGADaM/McfvttzK9dw+tuheIzAuNwVfdwgp63QBTJAwnLWR/kSJfopP3cKKOVA3UUIQKY1QUI2yBJUSLCJstEhaOyUKzptGg2VIIl2FFhimg74YQUcLs2Foe2fMQRgjCyDAU1umIgsX5ZZLhYVpDNWoqIAljknrTg61BCFFIrV5DIsiWO4jCkS11cUbjZOj7y3q6NPgNRcX8E3K10yQG/QhyEF31Pm1Z0UQGyDAs+7eaz24w7nAOJQRVSfg866JsTkDizyGDckNUARYr6daD18TqxbzctA2qTaxOAffXNEYP0kyqaI0x+tdiCnsNDodSine9890DptHEuhZ5HgOWej2m2ayhlOTyy37Cx/7285zwL0cxuWaYNQf5ikrOSLYeup5vXHIZt9/xIEcfdQgXXPAUzjvvHE4++aTHpNo55/jCF77AF77wBaSUvPWtb+XTn/401dy31nHRRRexZ49nNIlVfQIMxDN9xFbux4r6/Oc/z2WXXcbTn/50nv70p/OkJz2Jn/3sZ9x888287nWv4zvf/je2bjmEJIlZai/R6fU4dNNaGs2Qek1w3ZXXMTI2xllnPZOlHfezVMywbmICJUNSk2Gze3jowYfYfv92gqBPvRGRZgFCSDrtghuu2cfrXvUcnvP8J/O1q36HYHSaQ08d5vIfLrLthFHe8sqTGBo/gaJr+B/n3c+GMZjb+wB/+MY/48RDG5xzwjBf+ep3OOfs8/jAO97MD398FbPLe6gt3Y8uDibPBdvv/RyHHftkDjvuSbzpD8/nuptv4Qtf+QZbj1rAhYt879uf4PkvejPPuPi5nHvOeUSNPuOjGTsemOLUCy/gDX/8Wp745CdiC/jb//1xfufFv0MQC/71y1/i4EM3c+iRG9k3lzM+Ps7BBx3N/3jF7zEy4oGn17zmNVz8zIt56e++kuHh0cGzv/LKK3nNa17zC8fZ6v7xa6b0ZZsf9X673eayy69k565dj/n8n/3Ze6vRgxCSY445hosvfhYbNk/QGooYGW7S72o6C5pmo8attz7Aq1/9ar71rW9xzAlbueGn97D1yM2cse1ksiJl16593HL9QzznhduYnV3i8//4L7zxj36fw4+eKAOZZtU69Phti0uzqACGh1s4awjDiGarhdYWoy15nnvGurPEoV/LgiBk7boJhPC+bJbl+Mp2ZTTdGh94K+1aHEV4VrbCWINAEAaVHXbkRTHYdHqQQWINFIWlKPwKGwRek02pAOsMDouUDhVAEEqs9VkOhc6x1guRF4Wm38tYXurSaMYUOqXTnWdubgrnLEcecRwUGSbrs/eRaYpOH9vNGFIhtvAFhxqNGolUuKEaC2mHdqegX3QZVsMM1xu0ohFyUkSxxPJ8j3a7zZoNgNAU2rC42PUFhKxBp4oQaCUK0+3R6ffpd6DeiEmimGR0mG6nYH5mGV0EPnxpMzA5gTIoIWlFirihmF80BEFIo97AyYJ512FpsYMgptVoEkYezDFG0O1parUGreYIW7ceRqi8GHur6RkgQT/HtTs4Zxkdn8QB8wsLjK9dS5w0aTRbLC7egzGW1vAw1mm63Q733XcfGzZsZOOmTRx++KE0ak1qcZ2sv4TRGqNztPGatTL0GRQqiHBIrBO4QbU6yvVYAZ7N4NAIHGHoECJECXCUFceRWFt45kS5T5JKEkc1rA3o93LCOCrHE+Vm1WJdhnMKnz4VUmQ5WZbSaNQIo4gkTjCllliWZuS5xRSP7zl8wIfmgA99wIf+lX3oXxp4WhnwVeqSBxuER3wGDxZWKeNXm/YSUa0etnMVeifRuo8QAVL5STJgOQ0QuYp+uT/ia12FvrkB0LB/virlJBNYqzFao4uUIuuRZ70yxc6jilIFA8aTsw5baIp2F73kASeZFyjnEEpBoLDGC2ZrQAsDzpILv/DIWkBrrElz3TCtsRbRUIOw0aTZGCMKa+gio9uZo9ueJe93MXmB1baMOpSSXUWI0w5nqlHoYRolvHq+KmnQioDAKpRVSKcQylFYKITACb/YSBEiRFgKFMYEQYoKJZnOkA4MhnpYJxE1QpGCUgi8CLfJDf0sQxSWTKXEqkC6HpKEpOaQKkaosKxM6CmEYRSupGXaVXpbvgtX0QxLfaiqn1ah8avzlT2ltWI/uRWgsfy7zJD0fe88VVX4AclqdpWQvoJdEHjKeVVhcTWFsGrW+Qp8QpQosfROnGUFDR7MhpLW+li66uO4OYcTlWZWaV9KY7dCubT7UUVXt+p5VQtUECiM8Ww8gVpB6vE0T2NWMx1kuYCWEbWyVWWfq41KRQ31F2SFslqV7SzvuXq9WqAHNsEYdJb7RTiIEFEIRY7ICqJ2hsx8pCaKIm9blcVqH5FzKHppn36RYcYCwoOHaR29nmZzkrm5OR64+yEefmiWotCcceqROKvoLPeJSVhaSpmb20Oro1gbSQ5qCYRVGK1JFxdI9QIFAd2FJezkJpjcSL1W8xqCOmWdNQwLyaZakzCuIVWAdbrMiQ9JgoKJIKJZ28TlvTZ5XnDzrp9z8ORxHNqc4NC7D0F3+yzOtRlrjCCDAJUkxNUmQgpQCqUiRtY2saLAFppep+ejQypEVgUOwFfZlAol1X4j3PeBX7w8xO/1SlQ5vwLly1RXG5uBI+YcxpkSOPZ0bikqx8titMaaLkYbpAoJo7jUrFAoFM76YgqiKg0uxGCs7b/uVWPusavhIHJDKaTrjF/LHufg07Zt25iensYYw9/81cc559xzePkrf4c9O/eRZRmHHnIUP/rBFdx7zwP8/qv/B09+yrkcfviRWC2Z3tPFpKNEo35DeMVl93LUEYew7Yzj6HVSnHUE4X8sEDk+Ps7Xvva1VZXsBFdccQV/8id/wn333Tc47h3veAfPec5zALj00kvZtu1MdJFxyimncu211/Ka17yGG2+8EYB3vvOdvOAFL6DVaiGEr5z2pS//M0VeEIYxhx92OLoouPWamzniuMNZd9Bm7r39AXARoUgYmxim0EvccP0lHHnyuQjdY2Hnv7P4wBL5IqzZEtMWbXa7NuvXb+WMo07ilKe8iM2bD2LvzE5e9JJzGBsV7Lh7Bx/+X3dy3EnHcsG2C9l3x7/w4J4OH/m7e7BiOxMteOLRhi9/+i72LGv++h1P4NqbZrnylkX+5E/eShI3ufzK63FimaRu2DunmVuexYoxTj/tpQzVNYt7b+AP3/YVjjr2BP70nX/Ku97zJuIo4oPvfT9F/iC7HrqZJz11M5ta62jVJ/jSpd/n25++k49+7yv8z//1P1k/Oc6+XTdzx7euQ4Q1nnrRxUxP38d999zMSadcyE9+8nN+7xVv4b577+P0M04f9MfadWv5u09+nC9/+UucccYZAL+QnQaOnTsf5sUv/m3yPKfVavG1r32N8fHxwRHXXnstr3/9G6gCSv1+zr7pqV94rqp9+MN/yYUXXkgYhuzdO8WunbtYs2Ed4xN1whMmsNZx8kmnc+2117LlkK0oJTnsmPXENcVyZ5mluR4TE8Nc/LzTWV5YoFlv8I53v5nRsVFwjp/97Gf8xV/8BV/96lf/w/H7eGhbDtlCkiTESUCeW1TgUNLhpMMKQ5r2mZ9fIk1TDj/caxzVmyG1pIYxhm6vx/xCBwRMTgyXulyKXq+PtZYgCCgKzzqQyksGSCGoCvkgfLqOMQ5dGIq8D5RMK1tV46p0SASF9gK24EhqEXES0mrV6HS6FHlBnudESUCcBIRBgGvVysp3Auu6WGdQKsAZS9ZNIU+xaQ+RW2Rucbmmb4133KI6EyPDOCVYNoZ7HtnJrvl54lizZnyCOAxoL2Us9Trs2DnL8myOJWbt+CY67T6dXpeZvVMgDFJBaAImhkK2ro+RqSNNDY/M9Jidz3AqotkKCQPFWDNkfLRBURiW2wYZjpJEIZPjI8zohymyBUZahomRBmvHG7jZHnEYEChJqyUIo4zdex7C4hgeGeOgg7dgjEXJgHqtjlIKnWuaw00v9VDLSHWKM4YNGzfS6SwxNT2PFtvZtPEgjjhiI0cdehLOOUbHh1jszJKmGUtLS0yuWUMchaxbP0GgvCh4P+2hbZ/CpoRx4lOupA8Ia10gVQgqIFAh1miMNaXUid/kSxV7ILOK9ztDUWiqFJp+4ZibXyTPC2qNGrVGnVrUYGjYp2Ea7ajVExyCPNM4a+j3ezy4/V7WTK5jfGyCOBmlXqvRaCaeuWccnU5aah8ZlpYWGOy6fx3aAR/6gA99wIf+b/vQ/7VUu8ET2//yrN7gV4ATFQBQfWDFqIhyxMuKNYXFlTe+crw/rxMeQF95vUR/y6sPcgwrlkt1D6zkC9tSPNHowldv0EWJ4opygq9C/IzB5QU2y7Bp7pX7V7O1hGdb2ZJu7PCUSinKqoehIq5HJM2EuF4jTupESROlYpyDNOuR9tukaQejfS72gKrmnGfd2DIiUaY2VgyvSt9KDoyKxGlwGjB+0GEtGI3VBmMFMjAo60oQqqyKohRWZGgKcpsTBzGhVETCoZ3xi5MQ4AzOaDIrMNJhhEAYjSAj7yuEipHKo8CVga3Va6ggIAiCEt1dGTPC+UmIq1ILxWD8/GfjbWVKrLCg3MrAWBmPlT4YpaBbCYpW9ydLyrlA+GddAV2P0nlaaRZR5sUPUOb9r1iOw//kOzxu2goA/Ggz84u//y9uK+DgyiK6eo5UEVWgFEtcLai4f78JhHe8y9TIFR23EmN3rtTr8q/432LFoohVkabyeFelLEjp9QWkQGiDyHJUrpEWRKAIZOgBUAVBFGGx5MaS65ysyKCmCIYS4pEmwkmyfsbC7CxGp4QBjIwM0VnOyFINVmKyjLxXMCwjxoOQySQCm6C1plPkRKYgNQV5dwGb1MniGnG8AfwSRENASylaUR2CEKe8hoJSIYEKqSvJqJBsEAETjRbzdNjXmWX9ZJfhWoONG9Yw+8g+2rOLYPFsSseA0WlF5SQJojCmsBZtjV+kgoBAMgD9V/TRXIXuUlGyBz0nVvpFlvn2SoV+sS4B6Wr++QBNad+sxYtcqpV55ZFdfx2jsQ6MrCqAOKTyRSgq9qFwzp9jMJr8OFppJf3/MQbGDYDiXyfAuAJrpPSlqYUQ7J2a8WM4UbTbfShLWxfaEkUB4xMtsp6vtpLENfbNzJAXGUGg0Lmg14FktJrDkjPO2MaGDRsAuOWWWyiKgtNOOw0hBKOjo5x66qk0m02cc1x77bVcddVVg/uqWr/fJ01Ttm3bxo9+9KPB+4cfcRSnnHIKrVZrv2Pb7fagDDA4Op0Ow0PDnHTSE7j55pt5eMdObrjuZpbTJTYdtIlmvUmgFHleDJwyYwwqbhBEIXFzDKdmSHWHqbmUPorGxBrWbziY8fF1KFGwb89uev02Z511DrOzc+zaMU227OjMFczv7XPYIQfTnm+zZ1+HLYcdRtCAO3fex/xSjskV2JiJyUM44ugYJRJM7sgzw8jEGEYH7FneTWFypOwRBZrO8iydpUdwThMqRxJYxoZH0Rruf2A342M5YZiwecPBDKkhAtnk0OMPZ3p6mqmH7iMsUmKn6XQWgHr5/dtevydqcNutd3LDDTdx4003kOUp8/PzXHbZZfv1S6EL6vU61157LXmeP2Z83X77HbTbbW644QaKoqDZbHLFFVcwOjq63xi88cYbOP74E1izZg219XWytM/8/C/Sd/IaIocffgRHHXkUczNzWGupN+osLiwTJwHDww06yz2UUhx91NGk/ZxOu+P1eqwmz3RZjlpgnPH2HIlUEUJIkiTiCU94AmvWrPlvzKj/75uUXiOlYgH6ojAFea7R2pQAgLdovvoYg8iysdZXWDJusGkIlK9QZUyHyseu0m/89eR+P36HaHHWoLVD4NPunK3OycraW25GrfWC45XGjAgESc2LpEeRJE5CglARBIqoXCPyIsMYi9EOJUMcBl3kSOM361IE3q+3Fik8+zwMAmqxwjiLS/uk3Q7d5WXkkBe8D6OIXOd0Om1m9s2gi4IwUTTqI2Q9wOUUmUYIQxAKAqWohYLhekgSB6Shpd12zPQ1/TTH2R6tZkytkRAF3icMw4Q4jKglMa3mGMuLc+RhShhrWrWARixJwoBGrcbI8DBDrRpRCPPzc4RRi3q9zto1a1hebtPv9+n3uyRxjShKSja+T1F11jOJhHHozJD3cnqdlCzzFQuDIPCghPO6QLVajXq9TqCCMlPEayoVRd+zlZQP+gZhiFQBDjClQDzWlqCSX5sp7aW1FUgiB/ZfiopU4CvcGWtLgLKgKDRJCWAGZRqmtT74Wun9hqHCOQ+kRHFEGAVeey7wrwVhFeD34Ohguyg8M+TxXtXOtwM+9AEf+oAP/av40P+FVLv9wRd+wa2suqf98IDBQ6N8PniKr1NusKhaowdOBVQV8xzKVRNtZUKvTocaADar6Ih+UJS5w85hdYEpMvKsR5H3MUVGSbnxk0muLLQmzdC9Pma5A70+IssJyvsXSmGF9J1WflGHZQBzSAgTRTKU0Bht0BwaIm4OE9eHwYZkWUanvcjiwl7ay7NeSKwywPhBIBw+z9myAohIn6vrdYmCld8iwObOI08OjMwwJqVIO/TTAm0csZWA8sykUkBcBRGFbJNZy3KxxJicIFQJNSHpmQ657uN0b0DrMsYirAadoXNb6kfNe30AGRAEHlGNooihsVGSeo3G8BBxLUIFajAmHCDdysBY6Uc3GFMDeKkcQ+V8QcmyOoCzAzBp1ZkG58MJhNrf8fKC4iFhGBNHsTfIzlPUywGKAs9oE5RF9cobxpYsqhLYrK69P6b2i0Dhx13zBQBKZ1SowbJTMciEWDGY1c/qBXS/hbH8v0+18U5pEIR4PQD/bKuKh47qmivGdr+F2TEQea+qVwohMNqnvDonkayMI08FXakb4R51f1prbMl+DIIA67x7LXp95GLHU4SFQNYSgihGIZAWkloDIyDtL9PL+/TTPkErojbSpDU6QtrrsDS/j6k92xkaSmm2aowMN3CFI08LTAGiq0mWM44+pMFYI2SkGYJqYY1gqKbp9zv00x5u7wyd6Yz24hzx0DhRGJFgaIWSVhATDyUYU+CMF9mXYYgMQggjmg62asdx4xvYEcxzy4O3s6E3RVyTnHbm0dx6tePumUXQFgrjnYS6X6A0FuMs1lhCIbAIjBNgBMJKlPQOpVArIqTOOS9COQD3Vxyu6plLKQlU6O1U6B3gSuxSUrIbhcQ5i80thfWlnoVUK1NHVAtoGWmxGp07H9FRAUmyEpmpho9AgPG/lVK4slztYGg5BlFFWQYZwBvwip4s5Uop41+HppTkDW96NUPNUS77wc94ytPOZmR0mNtu2cEJJ5/EU5/2RBbmUx7a+TD3PXgnmydPYnx8lDUbGnz+i9+jn/Z58xteyZf/+UZuvvFm/uwDF5PUQpyDz33uH6gc04suehpzc7P84Ac/2E+UEvzm6WUve9l+TKeqfeQjH+HLX/4yd95553/6XT784Q/zpS99iZtvupHR0THyIuf3XvkqTjnlFL7yla/w5je/mSuvvBKAZn2cLQcfxpVX/Tu9To+9u6foZ4YkHmHjmi1M7dmHLQrWjJ3D4tormMv28oNrFzjosK2ccvYZbNl4JI9MPcQXP/Nh1q8/nC2HHc1rXvmnvPwVL+fb3/k6L3ze0dx5504+/ZPb+eRH3s7evbu55NuX8Lb3vJ+lTsZTn/oUXvGcEzh6yxo+8Y/TvOLVv8+fvOcl/MFLfpeJ8VGe/oynsvmYQ1juzXL/7rsZbmrqYp7lPZfwwPZFHt7V402veyX9rMf3v/MPPPsZJ7LjoSle8JvP5zOf+iwXPPn5HLZB0OvN40TKpz/5Ee668Xq+/unPcuknP0ZjdJyDTj2FJz/jAsYnJ7nkKx/n5NOezPEnPoUnnHYyU1MrzKNbbrmFpz71qfs96w9+8IN861vf4thjj93v2Kq95z3v2e//nU6HF73oRb+w3973vvfy7Gc/G4C3vOUt/PVf//VjjlEyIImGUDKg1+3z08uv4fiTj+HoY4/hx5dew4ZNkxx7/OHcdsttGF2wbu0wc7OLSKk48ZTjyJYNWWrYsHmC7TumuPXqB7jwwtNYmG/zr1+/ioufeyaHbFn3n46xx1Obm12g0ajDECAc2lnSdJlut48AJiYnEVLRyjTWSAwCJwXtoosuNP1+RhiEhGHoQQjhcBjyPCeJFWEQI0WAcwbjvO6bKpneQnhNn7Rv0IUhzwxKraRTejkCMSgZr7XBFhprPOgVBAqpBCoQ1JsRSiZEYVSu86KM0EuUEizsmqez3CNLHVFYB1uQZ21qUR0VNAiSBrqb4qz1fnIQEAcCl3fp9bv0ZxfJl7uYfkoWB8ggoTY8TGZ7zC9N8eCOWxHS0GoOM9Qcp9sukLKHsxaBQ0mYGI+YHIkZb8asaa7DaEUUdcm3P0J7dolH5vaxbs0wtcgDIUEQM9SqMzI0QrOesGasQXd5HmEME42c8aGIVmgYaiRsWDOJDOrU617T6v7tD7Nly9GMjY0zPjbMfffdx4PbZ3jwgXtZv24zRx16LDo3dHo9dj0yRUBIEoTM7Zwmy1NcrpGjEpsb+v0ucwv70Nqi3QijEy3iZD1HHXU0QRDQ7fXY/chOwlAghKaW1AiThCRueNaM8zpgotT+MtYird9gJnEdh0WpkCzrlVW5U4TwG9woruH1YDRp2sU5S5H76uNB4PWnklqDWr2FEBJrNXmREduYMAxJmjHOCWpJzPHHHk8UR0RhRFAGp4UUaO2zDGr10PvVVjEqRzxwFqj/YPb8328HfOgDPvQBH/pX96H/C4wnMfhZjchWI/bRjqm/YTd4XYgqd7TCGPzESJIaeZ6R5xkDwe6KVeYqoMGLWO2P1vq/K4pwdb0KHRxMeGt87nORYfLM6yQZM0AsK3DHlSUFXJpBP0X0MmSuoTBgLM7YUgi81JdSldoUFNaXj5XSoWJFEIcESUQUx4RhhJIBnW6bdnuZudkp2u0F0rSHdSBlQBBYKNO5pJPk2oAAGSiisIaUjkApAryo2QrtTuCMwFaUt9CWESSDMym60NiurzyHECRxBE4SyBilIpzT9HSXetDwpXhlhNOgC0vP9cAKpAkQqcUVgqJvKXKNNRZnlxHSA2BRmBAGAWEUo/sZSbOO1Ro3OkRcSwiioJxmFb1zf5Bp9d+rc2D35zJVY2rVZ0qU0eJWGWQPRnpwUyKULNPsVAk4W6zVVOKKFTvKOsC4Afrs2Xo+GuScwdlVhn7V4lFVt/t1iNNIoVahZAMZRCqWorW2ZNOJ/fJ3V0ehVvLU5aDsq4+GesTdv+2QwpXFAzxoWLEQffnX6poDmHEQoRGlXfD36ed1RVkWUN4fUC7WVZptlRfvSjadkAIRSFwpkSaNRWqH0g4llE/rDXwJWwkESKIoRjuDSNtorcmzDBtqAqFI4jr9fo/lziKLy3OMDMeMjbWoxQmLsotzhsBCKwwZbknWjDRpJN6RkkEThyIILTKMUFGN0SzHdgry5UU6M3upt4ZJWg2UMQhh0arp2YmhISgdNoTESolyUA8cm5o1nBpjujiCdpGyZ2EPJxx9EIcctw6UoffwMspJmvUWigAVJES1kGJ+mU5/GeYWCZoJQSv286H8ccLPpzAMqJJKtc4HEbfV82AA7Cov9ihl4KOusiqf7A+1wq8RkoBIhiB99Q4hyioxgMlznPWpHVJ5p84JP2bQBVjr8+zDACHDlfFTDuSVfHM7GKuezm4H81SschYrTuzqKqyP5/a1r32N733ve3z+81/ggx/4PKeeejLPee45zO/rMr+vxxFHbuSee+7m6p9N84RTTmXNmgkmxs/koQfmmJtNESxz3lmnktRipJSce/5hHH/CBuIk4KYbb+Wqq67mpS97MaOjIzgH7373u8nzbNX8d6Rpv9zIKv72b/+WH//4x3z4wx9+lHMtWVpa5qUvfSnbt28fvH711Vfzwhe+kDvvvJNDDz2UP//z/40QklqtxtDwCN/69rf56le/yjvf+U6OOuqox3z/NGuz65EHeN3r3sSFT30KFzzlyeRZH2N6LHV2MD23mzhucPLpF3H3nVcxM9/nic+9mHozoVZT7Fu6j7ENE/zem97BBz7wIW5/8CHOOut0zt12BKPDT+fB7Xdy5rYL+N2XnMX3f/wt1kyu5w2v+wseuOln9Nop7/i9P0Wwm8wa3vfnb+CRPffz0b9+J694w6vp9ed5YNetbJ++naGhUZ759Ddyxy03MDe9i0Iuc+hRh3LIEaP80xe/y2GHHc5znvlC/uXrX2DP3h0882lbKfr3cM9dBWHrHoaTJqEbI22HTK45kote9Ls8cMsV1JpDnLbtHO664wYynXHek1/ADy+7kg/8xcdZWFj4pcZQo9Hg05/+NN/5znf45Cc/+Z8e+zd/8zdcf/31fOpTn/o/HvfSl76UE044gTe96U0sLS0NXj/hxON597vew9o1Lfbt3c7pZz+BB+/bzc3X38dpZx1Pv59y9U9vZnxyjFototEIGZsYw1rLvpk91GstRsdaFLmh2axz2BEHceMNdxCFIU+/+AyEidi7q8P6g1q88pWv5Pzzz/+lnsH/3aawVqC1o1ZLAIExlnpNVC4dzhqMLcizAqkMUgl6/Q4Iz37pdy1FYRgZAb8ZUAy1hnBODFiA1gl0YXDWC2UrpQGJs4I09YwbHyz0DHCpPGu/stdGG7Qzpdi4D+BKJZCoVRtggbEW52Sp6WnJMk2/m9Fe6tLvZqAhiRKkCEhiAU5hDETNFpFSyGaDhhHEgSSJFUVqcFJTCxUTtYCiCLFRQD2JqNVi6mMx63SNI44aRsiCuBZQMIUWczi1RKMBsQxoRAEHbxxiuBahTYQO1xA2GmwZMth6xNj0LDfft8hSu2CpM0MnDRkfm2T9hoOYHG1SDyHM97F5Mmb9yCRKd6jVEkIVcvDG9awzEZtTxezsNDNzcwi7TK/bIQokE2N1JkcD7IYh5mZT+u15dj/yMBOTa6nFMZvWrWN5cRlbVosMw5h6rUUcJfR7fXY8tJ09+x4BJzBkjIy3GBoa4YQTTmR2bobFhQXuvPMuhodbrFs/yVBrjDhOUNJrwWA96CSDACEDvKZugHMCi690FscNpAqIdOFTkcq0O+e8iLoMQpyro5T16jMqxBjt04DCiDAIydIyYwNFluqyAJtEF5UWoRdgzl0xWENkSTqw1pBmXrjaOUeeFVgjsdHjO4J7wIc+4EMf8KF/dR/6v6HxRHlBVm5arCC3jz2WwYQpeWBU4FVF2dS6AGc966mcQFWanqd9uhI0WHFuK/raasHnwb2Un8X61CujC8960h50ssauhnirj4G1iKJA5AWyKKAwOG1BGw88Wev5WOW9SyQWi9Rlqp0UnnIcK4JohSbnrKPX69BpL7G0NEeW9dG68ILkpcZUID1a6mxZ/lBKhChpqspXhVA2RFJS7yq1eleKoWuoFO+lAIEBW2DyPiaIMCoEJRHWoYSPghnr6ZC5yQhlhCL0FfWMICu0B540uK7D5JB1tAezrMUZVyLsASbS6CDEhAUKgdXa02zjyIvbBcrjPI9iyj2KGLd6ZO0HND1qOK1i2q1CPlcg35ItVekbyJU0OufpidYYkKU58CqKvqpCOY5X7mHl/H6cVUj1qnupQKdH3+TjsA0qYFCBa+U3ktUCtv/8fXS0ZvCof8F3HbANV1WuqliIPoe8iuyYQcRoNVw30HUbGDDHSg48g3TblS3w6ms4lCorclTnErIUjy9No3VIY1HWleOhdJ5NKZwoBVGUUDg7EFQtTAEIlAwJg5gsz0jTPmnaZc3aFkMtT313ZYqqcoKmCphIFM1aRBxFCBEgwwSBwipf4lhISbPRpNtfQhV9iu4yRRThWi18aqfFiQCkd3SCYAX0d2WaaCih5WDYJYyOTpIvTtPNuwQ1w/j6Blqv456HFymKAp3mSCcJZEgQ1kiLWYpum6AIqQcS2axVnbDSt4LSzvhnakyVBlLaYbECIssSvJclwKtUsOo8YjA3q4qkSkoCB1aWoqYDEF1jnCw7VwzuxznvHGldlI/BoUKFQA4W9XLE7G8vXMVALl8UK2vPYE0Sq+fF45v29IIXvIDdu3fj3OfZsWOKQw45lHXr1zA/s5MiL2gNNcjSlJmZGQqdMdIYpt4YYWr3Ilk/Y3HWcMxJh5M0Yh544AEmJyfZtHkDnXaPfftm2bXrEfIs98EcA2eeeXYZBBJ0Oh3SLCVJIhYXl1haWmbLli0ce+yxHH74EThnSdOUXbt2sW7tWhrNFt/97nf3E6p+5JFH+OY3vwnAwQcfzPOf/wKk9GkfDz30EFdffTXf/va3edWrXsXY2Bj3338/4+PjbN68mV27dqFNzlJ7gX/7t39jbHSEE084jlo9KStpLSCUBWXp5D36hUOLhIOPOAylLM70WdJtaq066zYejFMh7eVFdt9/F2uHYuzhB3Ht9Tdw6hNGOemEY/nXb36SsbFNbDvzQv79qx8k7aRceP7vctu9V9DJZjn2+CPYN3c/u3Y/wKFHb2VmJuDO+xcpljXSxkwOHUwSb8eJGRaX5zlk63om1x7Frs9+jeHmKHHYYnlRk/YsWw8bZXF+F9tNm6C+gE6hnybM7JnHYqiPTSJrAVE9YnJiDfc9cAdzi/MUNuKOu+7le//23V9q5M7OzvLQQw9x+OGHl/12ODt37iTLssccOzQ0xLr16znuuON+ITuq3+vS7bZpNFqccMIJHHzwwXzyk5/kwQcfZGZmhjAIWLtmkqc8+Tz27tlOlvUYm4zp91Kmp+ZIsy7dbsriYpv1G9dSb9So131FXa017d4CSD/P87wgikLWrh1l146HqSUxQ8N1ukuO9nKfzv17OfjggznxxBP/23Pr/6tmrfBBLCvwLBNR6o9U5alZAX9KzRbnfIU4JVV5nE+1qCQkrPX+li68Ng/IQXpcpe1krRchdtZvcqUQpRaTP6dPlfIG05gqoOt8pbGKro43o9UGxLtNXutGOh8c1tpQaFMGJ13JoApRShHHkqxv0MagophISaIkIlruEilBnIRIYSiMJo5CGlFAMwrIgoAoCAjDkDiR1BuKkVG/aVKhwrg+xvWxZMQh1JSgEUvqtZAoDHGEZC5CqIRmQ7Fu/QQqkjw0K5mdW2JxqcNwO6XR0J5tICySAlEsMVyPELKJ7lmCMCEKE5ojoxhqDBURnaUugegRhjHWaArdJ1Axw60E9AjtxWl0nrK4MMfo6Bj1ep1kZBjd65PqgkJrkqROvd4gCiOKPGffzDS9fhulArTRJfAQMjY6RrfbYYF55ucXkFIwOTlRPt/QjyvfSwOdXSc92CdEmWJjwSkQMiAMPEvGWkOeZxidD/ZRsgzMgi/ME0Yhykkvo6ECX6VOa3y83pHnhQcghPTjDgiDUtuoykgp//mUT/85rY0XsS4MSlYpgY/fdsCHPuBDH/Chf3Uf+pcGngb5hayIeEsq2pV/qNXTXm08KgrhaqGzlQoktnzIHj3Nsz5CBojY0+L8uf1xftKVDxMYpNjtN9FX0RtxWKsp8pQi7VGkPXTaxxSeerdyT2WinLaQF8h+huhnyLTAZP6nSDNwFuEcsZAEUqGkV+K3uUNlnqosQknSSqgN1UiGEkQgyIuUvJuxe9dOlhbnmJvbQxT6amvaOr8AhB7FNIVFG0theigglIqklni6tJC4QoEJUPiF3FcrULgykmV1ANIQhDFJnCEx6G6XoGsQeQ+hRwiCgDiQiLhFLvt08gWW8yW0zlGJRKGoqyE6/YIsK8j7mmI5w6SWolelBZblMqUjUA4ISl0qSbbU8dpY2gN1Oh0iWKcIohAVSC9sV/aXK43yIICAwDrLSn6sB9Ocq4xnpbjPSp8Lsd9gd1Ceo1w0g2Awia3V6NyDiEopjyoTUpFOPcJcGoCyMoQbMO0Gw7ukv3qjv8L+e/wDT8BgfuzH+nNqv++wOkozEEZ8lD2p6MFVv5Rnh9I+aF3l8Ps55p1kM9iIWmu9KKEQJQArBmCqP/dKtMdfzw4gP6+LtsKyXA14V8CwCpTXhJDSVwGwBmENwhkIJdJCUDhUWvjUhXpAOLyWSOe005QZsYfcpATDE4StYaL6MAt7H6afdihcn/GJLUxMrsGg6OU5naxH6BytSDEeSBIFSRwS1YZxLvRGP8+IwhqmHuO0Jc+hKDTtrIPLWnRtQGEcRlqUMcgoRgQKITWIsiqYCoikIlIRZmYGYSxrRlq0yXBFyu4997J2/cFsOuooph6cojfdZ2rnI4yv30xNxUhbI0379HpLjKg1RFaRGL/ZUyXgXUUviqIYgLbiUWO8At+rl6xznrWpfDDBGO3HmPWbgyAMVzldkjhJ/Dgp1wJrLSIwfl0zmqpMhACCMKQqHmCKApMXBLFGBTFBlMCgZOzKOlCuVPjKkyv36azFyrIUr1RenNEU+wHOj/cWBIqPfeItbN50CPfcs5OtR64jjiN27VrkpCecytnnnMm+vbMsLiywd2aKE04+gvZcwe0/24vOA+7dfS9nn302f/VXf83vvOR3ueRrV3L4kZv40F/8Kb2upr2UIwnIdIFSgrHxmEt/+H3uvOsO/vjN/5Mvf/krvP3tb0cIwcUXX8ytt94CwE033cS5557Lu979Lp72tKdx8skns7y8/J9+n+npac466ywWFhbQWvPMZz5zMN6+853v8KY3vYknPvGJpT2wLLVn+ftPf4IvfuXzXHftNQzXD2PH3XNceOEapvbez1tf+yJOecLZHL3tAoLCMTTUYnhiAxvPfQ7XX3M1b3ndK3nbH7+XyBn+8X+/ifHJdeQo7rh9GqO/yJ5HLuOoQzZz4nFHsPaQUeLGJHFTcOYLT2X4lg7bH7iNv/rrN/Okpz6Xv/ybf+BrX/4EOjVsHjmGTUcdTbrc5Ut/8UHWb8iYlF2+eulN/MZLT+GMp5zFK552BNt33sf73/Fyfvvlf4AV2/jaJV/m5huvJpCClz7/SVxz/e1cc9N2Tjnsapa6XR6ceoSNYwGHb93K8dvv4/xzL2Ku3eOJT30inU7nl4ZL/+Zv/oaPfezjCAH/43/8D26++WbOOeccbrnllscc+7znv5ALLryI5z7vecz9AiHyG669kqE6PO3i30RKyfDwMJdffjmf/OQnedOb3sSmTeuIhOPH37iE05/8JEbHa3zlc59l23nnc8q2i3jWM5/PhU+7gLe944+59aa7aC+GHHnUVu67czt5rjnl7BNYmG+zd888OM3QSJP1a0e56BnncO/dO/nIn3+Jl/3+MzF0OeuUM/ngBz/IH/zBHzzu1+FeTxNHfoPmrPRMdWfp9bo4HGGoiCIvXN1ZykpNTMnocMsT/51hzZo6QkjyPGV2doZut8PGjesBsM6Q9bqDDWsQVsxsX2wGAVEYDNLrwsgDT0GVFmIdRhflRpJqJ+yBhDAiKAsAVeu7FdW67H0ooz1zYs3aUXpdydJcFxUGKOXZEFOLe2gvLDHSalCv1WmFLYo09UHMpElca2LiBs3lJeLFOcJ+Hx3WkYEvZKONJssLur0CrQVhEtIYGUWnPbJOh0AbYmmJheORR5YZG2lx8IYWe2b3IuQ8IyNN1q5bw9qDDiEYtdx9933c/8CDbFw3Tq2mWJrfS3vfEs1Ic9g6QSteRxy1CMQ4SWOUWnOE1tAEvW5Kd2mWudlZur0+mzevJwghihRhVGPDxhE2bdrK7Ox1tJd6tOdnsGvXktQi1k+sRfSWWRIFhSuQtZDa6DBJo8bC8jw7d+1i3YZ1jI6Oc/BBWyhyyfTUIkudKbrdDkEgGB4eodEYJlB1lKzhjKDTXgQoBemb+P2iK1PlBCAptEYY77MGSiFVRL0eEAR9tM7B+ep1WZozO7/oRcaNr74YhhHNepMoVAhhsAb6vYJOJyOuheXaH9Bo1InjiFo9KceGFzOGanMtCcOQWs2xtLRMnhe4sqTXr0PuwAEf+oAPfcCH/tV86F8aeNqv9F651TfWokr0+tF5q6sfbnm7q378/z0Y7tHTIIjI0hRnCnSR+QkxiKxUk7YColYhiuWjFdUL+A60xlDkGUXWR2d9dJZhdYFwtjytRyJxDqs1FAUuzZFZgcs1QntWj7MOUTq8OIcIPCIZlBRDIQTOWlSgkElIbbhO3KoR1iO0NXS7KcvLKbMze+l2lkj7HUIV4/B58/4ZSaQLy7xRg3QS6RzCFFB4dXxUAMaDf1X6WGXEASwSKwzSWUIUDamoSYVQhlAYApuT6B5KREgVE6qAvotIVUBucpy21IoGcVCnFtRIZAtte+Rph7RXYAtf6S4MPOgVKUUoFYFSxGFMGAREgRf8FBaKfk663EMiqbca/r6rFEEh9u9Jsar3VnevECvIazleHk2TGgic2Urku0Jk2X/Cr/qYT7cDoz2g5Z9lUJ5NeKZcCXg9JrVPsMKwEw6cXDVRH99tsCjicCXQ5wHACqkWg+/26AW0PHoAJFOeSYjqd1Utxy90q8Xz/PvOS6qVAsJAWV2jNNJVOdqyHytUHirq50p/ru4UISWUC/Lgnm2Zmx4mBEEExuCsLlF/P8cEikBKQhUSVHppKsDqgrTXJy8MBoFqxsgkQqmISA0Th0MktRqtVoNaLSbPC2/4rQXnz+sLFoSlnlrgo9vWgfLiohYvSlivNxkqDKnyxwqVkOqYVGt0e45geBwR1D2rTpQOW5ygqsiWGsJmGcsLi7hCI52l088ZsTki0mw6bj0z0Sx7b5ums7CAtIJ6E2IrEGFEHHiGpggUVjoMvtpNEPgqmRXnD1mxBn1/SrmSZupTlUWZZ16p3flZ6VZHalj526eu+r9luXAJCVb41FgZKkr1Q69PgHfAlPILr4CyQIQfSSqIyhxzsYph4/YHhcuIb1W9VMoqBRnviONTdh/vrXIoL/nG1Tzh5B5nnn0k1117E0VRsO3MbXTbHeZnUsYnhgkjhewKlFS0hhWHnzhJvRWyTq7jT//0Tznh+JPodwuGRkapNzwtvd/JAUetIanVAqb37eEvP/x33H3PXaRpin6j5pxzzubP/uzPADjiiCOI4xiArVu38sEPfpCpqSk+/elP87a3vW0/X+D222/ni1/8Iq961as4++yz97MjWZZx7rnn8rSnPQ2A2267jS996UsD7cBHN2M0nU6Hv/zLDxNHDZZm+1zwtKczPj7Ei377teTdfVizwOZDzmepPcOO+x/k4fsXyIuC573wd7n7zp8xP7WL2ZklWrLG8NAwr3neM+iYNt32Ejtnd6CdI5Yp6fIeCmP5+N98gGOPPpKDtxzPRc115F3Dj//1B8T5etZNjnHwEYdwy09+wtK+R6glc5BKBIbjN42hZx7mtqsu5YRznsvEw/dSv/Yylqe3Y4OEIw89mqJ/D7Ozc1zyg5vo93ImhxvEsWIibFGLtxDHhsl1mzn46OP47g9+xHU33kyn0+GCCy7giU96EjjH9ddfzze/+U1e//rXk6Ypn/nMZ/eLnl9wwQWcffbZXHbFlczOzfPe976XF73oRZx66ql85jOf2e/53nTTjSwsLLC4uIjWPqL6xje+kU6nw2c/+1mu+tl19DPLBc940cAHieOY4eEhNm5Yy0te/Lscc9RRHHX8iezafT+Fzjll21nsm97HA/c9wMtf8bu0apP89N/vRNU6JBNDRHHE+s1r6XVSHrhtJ62xJmNjPoL90I4pfvhv1/GUi05jcnKEpz1zG/MzGVla8O53vZtt27Y97kEngNZQw6e6qgrYkUgRUq/XcXjQRuFZKc2mD+hhAGvo9jrsm5lm3dqNJHGdPPeVmhqNlgeynCNQEW3T9pXohNcbUVIRBNHAT/EaOyBKPSe5Ko1HCldquvg6NRjrfQXn0IXGWYm1niklSieu0BqjLbmuCuRYVCBIkgg3MoQ2GUYXtJcX6XeWyTpt+nlKEAX+RyiQEZYEJxxGFBRCkSHJEFgZgowQMqDb6dFpa7odydDQGPVGjTiJUKFASB/M1UZgNLSimGa9ydDQOKbIcM4SuBRTpKQI2ss9rO5RDzXOpGAUkhpRmBCEhsJZ8sIiRI5zkf871QRh6jeUQlBr1CgEFMICGVJZnNCEyRC1pMnE2vUEwSJLbgmTdSk6Aa6VMBRKZD1hX6dHP+/SzbusP3gDteEacSuh0AVFUTAzu4+h5jiBCsnSHKMNSig2bdxIqzXMyNAoTkNuC9I09cyVQBLX6qjSV9c68wBHuUEVZXDVUPZxWZkKVwpKW69fY8t0mzAKS5aT14+x1mK1IUszL4pvcpZn5gnDiLGxcYw2mGBVZonzvoBnXAm/z7F+QxtHIThHt92nT4ouzGPmzOOpHfChD/jQB3zoX92H/i8BT9UGnlWD01UduArR8yyWlYfkH9SKAPijW5VyB55GqHVOaGOElCixovjumxj8PYCbHuVwVOl1Os9L4MkvNlYX3iAAVUK7c+C0gVxDViCyAlGyYqT1hlg6N0ClhaCkDyscdjCJZaiQcUgyVCdqJAS1CK0N3W6H+bkl5uZmyLMuxvSxLvTMHFsCHUhwgV8FrEAhUM4iTYHIFdigTAkLvC1RK1XtqhK53jcIwGkCJDGeJhkFkgCHQhOaDKlAEhDIEKUs7SAk1X200fRNnyiokQQxiWzQdxaddckyjSsMkfAsqygMScKIUCkCqUhWAU9llUdsVpB3+kghybopUgWoMPToc9WDqzh9g9TKVePD+7PVd1s9Bsp+LgFJz3Jyg3zxSix+Ncuugoa8s2Q9Vd1pkBYhrS8l7kpBelxZyW7lWquXgCoCWI0992sSqRnMW1ZxKeV+k3QArHkBdj+XBo+h7Lj9U2p/saGp8tvLE1d440C41IN/3lhKEQ76ylozgKf91PIOkXG2FNhbKUk6YMtJiS0dQVHmzftFM/ZRApNTaAYRXWU0SF9xKaxorXija6yl3+1SaIuRirCZIBMvjBnIBlHYpFav02jWB4tm5dA5Z3GVKJ8IQCiEUCCsf8xS+JRd5/UP4rhGrWEJiLz4fxCTFwmpTik688h6C5XUcKUWmZKSIIxROLAaIVsYF9BZmiNRFhkYellBqjO0yNl49HpMathzxxTdxQWUhtiExFYQBjFhKFChgED6iijOossoi3Bl9ELiK1+UA6Cy8XLVguTvLSjp+Z616MTqsVUVixDl6PNRHE8LL9ORYWDPXKBAu3JOm4GdXYm6OHRZGciPreqZi5UKsJTlw8tr+NVxBbBfCVqUKQm/BqBT1ay1XP7j25CixXOev4177r6PpaVlLnza+czsnWbf9DzrN056x9WWKccxjGyQhLFgTWMNb33rW+ksZbSXU8Ymx0nqdfK8IOv5ORnGjnozodtd5NOf/jSdToexsTGMMZx22umcdtrpgE+V6HS61GoJa9eu5a1vfSt/+Id/yKWXXsqPfvSj/SrY/eu//itf/OIXufjiizn33HNZXl6mVqsN3j/ppJN49atfDTguueRf+dKXvkSn01nFpvY2p9Vqkec5aZry6VWASdIY4/TTzuDZz30+t1z9DWantzOxZh0Li/vY/dDDzE3dy9bDjuSCpz+Dj3zwNTxwx63ovsa0+9STBr950fncLSMdzwABAABJREFUcP/9XH3HXezZu5Plub0s77yds04/nVQ7LvnXb/Gq176FQ7Ycy6kHn8hP/u2HXP3DKzn7zGezbnwT6zdt5Pt7/oG5R+5j46TFFkMEhBx30DhFe4r7b/o5F73izYyMjBEsPMD26Z3YqMWRhx3HvqlFFuZ6XHntfRy6cYJDN04SxwH1uM5B6xosdBcZHl3DxsOP5LJ3/ilf/8Y3ADj//PP5kz/+YwC+8IUvcPnll/Pyl7+chYUFPvu5f/CFSsqxfcYZZ/CKV7ySxXaH6669hm/96yVce+21LCws8JnPfIZ6vU4Y+gpi9917D7ffduvg2Uop+a3f+i0WFhb4+te/zoPbd6HC+n76mu12mzBQbN16CM977vPYuvVQVBJw36U3sby8wNMvfhmXfufb3HrjDbz13e/m/jv2ccV3buXU8yeIgmGCMGB4bAipFLfefj+H1SLWbBwjCCSz193DZZdex2lnHsOmg9Zw/pNP5sf/dg+9juPNb3nLqk3a47t5Nkjo2UvCMyKkDMp54DxzvvRNIxWgc0eRWSw90jRl794pWs0hBJI0dURRSK1WIwwTBBAGll7a82uo9XINUgYegApkmepRDHynauOzOtqtAnwlJ1+DxYsMl8CTNRIXKs+aUrKULrDkeUE3zQc+Vj2CKI5QqkWv50hNQbe9RNbtoHsdsh6EUUAYhzTjBk4GGOej/LmFzFlyHDkSISNQIciAbien29GkvYC1a8dpNmtEsUYFDpTFIPDqGIJaHNOoNWjUR8iX5zC6ILQZRdZD55rlxXlM3iZWGqcznI0JpCCJ60ShpbAZeWGAHEEI0uDIUaqPNSCkot6sYwNF7jR5oQGLoUBGiqTRZGLtOiQBuu9lL/Iu6G5CTUpkHDG9vEReZPSLPo3hJkPBEEOjw+zc9TBpmjE7u49Q1ajXGhhd7g+UYt3atdRrTepJE11oiiL3adJOI7WiUWiU8vqyAr9WGmNweN0YCV4sGqgq2DlnMWV/evDD+21h6Df1UioflDUWLQryrE9RaIzRLCzME0UJreYwutA+zc5avx9Y5ZNjwVJdxxAECmdD2rZHnhUU+eMbeDrgQx/woQ/40L+6D/1LA09VdbISP/WoWQkyISrBspUJ6CjZQqte8wrono1UNU8180atVm+SZ3363XZplGLiWgOp1KA05AoyLAfXGdAHnaNMfkdnKTrtUnTbpN1ldJ5R5JnvACkQyquwO2NxWY7sZYhuiki9thPWp16ZwCFsgNEanCOo8lrB035NQWpyRKtGNNGktWmS+vgIYa3B0sI809NzPPzQLuZmp1HK0ayHfhFwDm0M1ggwDl0UuMKhcseolChhUDoj7HpBMicihEhAJbha5JHQIEQEpVgZgtAECKOItaApFIkKaDakB7IAqSRIhxOGvgrpyBDbaDJtDb0sY7lok0Q1mqJBM4xJZYbUEp17gfUwjnz1kTCiFtcIg4AgCEiimEAFRCr0KGulL5AactujO7s0qNKXtOqgFFUq3aAJKENrA5DJuRVm1OqKcuVqWUbXVgDNikEnq8lR5icL51BlSqV3jPxZrTWePioNGkrUWPkcaWEGC+8K2FpGbSjF/qT0kUul9hMP/HVoj6Z9VgtcNY+rOfVoU7J6wRSisgGCSpCuou6upNO6QSSlKulsjPFiiuX1VoBnb4idtb4vhAIN2uoyAlOK65XstIrG6u1hyfwzXisO8DoSUQLWkuc5VgUgBDLrk4sCoQqEiAlCBTXB1L7tzC/MMD39MH0VwvgawvFJCC1Z/xGWuh0K22FkeJjR4XGSuMYjs3NgIQ4iFgNFVzsW0py8n6GcxOQSbbzNSRJFXhSkWcHe2UWWejnLmSFcN0rSGmKoprDRQXT6Tab3zTC5uIAscsTwOCjv8InAoLE4nbOkG/RJSGoNbHYneTGDqDkW5pfAKU4+5akM1w4iazd4+KZ72Dc3w0GdZSbDEerhMHnUw6oeKoyoBWO+ogbCb/Sdr1JUwbarU5ofPdYFVTTJ22mjjY+6VOKGzpHnOaqc937MGKwDJcpoq/WbLiVjAkJycoTxOf/OGT8SnUGX1HRftQWwhiLreZ28qIZTYTl+nbfZAiIVDCJKQTk+rckHm2ap5GC8P96bEL4s9Yc+/DKOPe44rIWXv/LF5FnB7NQSk2smmFg7zjXXXcuGDes54vDDkULygx9cyite+Qq+9MUvcd5552MKh5QBjVaD007bwtTeGa69/k5OOfko2u0u11x3F6effjxHHnk0N914G29/+//ksst//Oi74YYbbuJDf/4R/ux97+KEE44D4L3vfS+/93u/x1Oe8hQ6nc7g6H6/D8DLXvayAUvqIx/5COeeey4An/rUp/jKV76y37EvfelLS2fa99W6deu44oor+NznPseHPvSh/e7m+S96EuOjwzz/GU/kN3/rtznp5PO59Nv/SBxEbBgaY3TvvfRuvIIvXfo9NkrNpg3Hoo6K2X7/FHc8PEvxjSsRoeC0ZIRt5z6RWx7ezVd/fiNPPG8dx2/ZxAlHHs0nv/lN3vbev0DKkKed+SyefvaLOOc5p3D5T37Iy5/0G/zd332CNO3x4pe8mLe85LWcf9IJqOx7yOEjsbVD+dh7Xs+RJ5zK81/119zy3j9CFAVPfuZzGR5ucsx9d3Pc/YeQZ5YiM+yemmZoZJx1myb41lWXcuRcmzdItbLheVR74QtfyAUXXMD4+Dg//elPB3awah/5yEf4+7//ezqdDnmeP+bzf/PXH+HpT78IqSLe//7383d/93eD96y1fOzjH+f0007jrrvuGtgBYzXGSNrtDueffz7nnHUen/3Uv7Bm7Tg7Hr6bz37+L/ndF7+Wo1rbeOsfvoVnP+9ZvOntb+efP/95pHBsPK7Jcac+kZGRcfJU80+f/ifm5+b4wz/+I6anl7jjtoc49riDOOvcEzjxCUcwMtokywy7Hp7h1LMOpl6P/k+P43HZut0cXWi0TsnyjDiOmRgfH+h9RlFUrnECL9qc40RBrdGk1oio1xOSuAUoiqIgSWKSWoQk9EFR5Wg1mxRFTj/Ncc5QFJYiN8RJSBgqhBQDjaii0AghCQIGFZS01hUkQRQH5HlOlmv6/RQpPZNJ4Fn+AkGW5fTSnNn5JZSAMJDIVkwUSuKkiS5ydFAgnSMUBis1gS1QRAgEBo3RXWzeZX5hlqX2Eo/s2U6ed0nqIfXxcZrNIYIgpr2cUWSKoeZ6Dtt6JEnDsXvuBpxKCWsOkTTJcku7L4hUAiZgaUETWIdymrzbY3phnuW0YO+uOfIsR1oDrkUcxUyMTzA6PIQShn5nH/2s5wPG2iFkgVQ9xiYcca1JrTXOmrURSa/PvoV5+vkiedHBdhdIEkgiOOGkI5ieGkOFktldO8iWlqlHOSENpEo4eNNmqNcQ9YQdO3cwOjLKujXrGBsZZ3FpkT1Te1gzOUEU1zho82Y67SV6vS4m1xQyJReCItelTq6vRuZMwdLyAnVtSJIGRWEotCbPM68TFiiiKPbyHTiKvI8uUnSR4Wy51gJR5FO4nLNEUVkoSQnSvIfpafICsjSj3+sz1GwiCFnc10FZkFjUWAvjLKZwZN2MKI5I6gEygKyfsXvXNM1mnSiJWLd+gn7PV1r8dWkHfOgDPvQBH/q/50P/F6raPZalMvhd0Sl/AeL16ElWPuX9WtURURTjrCGVAp2nGK19WlsYQxD48pUlOlixY1YzYZwtkXtjKLJ++ZP6nMayakMFG4synCOcRWiDKDQyKxDaDkASqRQSBzZA4hk1FehknaWwGu0MWkHUiAiGasRDDWQU45B0Oynt5S5LSx2fjxsq4jgCSsNgHLrwtFWVQ2gEkYOWgkB4khODSITDCFeKicVYKTFBQBiFla1B4ggENBC0pKImAhoSX3GvAm1kgAgkkRIECHouphdFHqnNNblNyUyPIKgTh4paHNORga8E5/BV/fBRFxUEqCBEqgCpAggUCuUjaSUgJJCYTKOzHJ3m2CQuUeAVtf4KgKpoiKtfc6wabqxC8MuxtaLytXKSigYopfLaAYMFojrpo0ZqhQqXOmbCyfKYVRUeKlZTOXYGi46oPm95vLdKm80//tLwrYq+VK+tphPv9/9V9OHVwOEKu3HluP0EFQc3QNk3Vf+KMm21EtKrnqnwSP/qRyp8fxhrUKttdnXvSnpBU2cH0TspfHUWFUbIMMKGAS6QXoBPgpaCTChy7XBdzcLSLEvdRbJYYuoNRKtBXK+hQolD40gJAkur2SAMa0BAP+2Dc0RhQJTUsBl0tWCh3aeXGmRocDJEScjTgjTP6WUFC8sdUhHh4iaN4TGSepNICVTUREhHpzaJ6ndJsyUaNiKMopLyXmAF5M6xrHP6LqHVmKDvRtBFD5v3wVgk3rlMmnUaYy1UK8GqHB1DXxeYviUrOiSxolaLIPPVbcLYp2YIKVbGfzUGRBm9c6vTqiVI6Vm9JVuwioQMGLIr3bS6QxFV1RZbUf2rBThACl8AoJqTUFK8y0WzEtAUPnqAA89oxYPBA3C6TB1QQrJSIMSV5zL+vuT+juKvQxseadBpL/Nv3/sx5z/xDJqNJrfccR+HHrWBteuHmZycZKg1hAC+/o2v8dCOh7j4mRczMTnJ0nKbyy7/OcccfRQbN2xgx4N7sc4wMT5Cnnvq/oYNkyzM9ch6jg0b1tNoNHjMwg20l5e5887b+epX/4Vrr7168PrS0hK7d+8eAEgAW7Zs4YUvfCHf+973BoLV3//+99m1a9eAwdTtdvc7//z8/ODv8847j+OOO47LLruMe+65Z/D61q1becpTnsJdd9/B4vw8Dzz0MFddfR0LnT6nHncEMu3gOl5XpoYg0IZItVChRA5Lsq4giTvsXphnqFFnJG4yObaBQ3LJiVv2cccDD9PupZx6zCEcNDrK8tpJoI/u7ubmu64inJyhvbCP8885G9nZS5BlPPns85loOvLOQ9g8w+b70IHikC3HMjoyzOwjtzA6OkShHXfefjNTex6mvTyP8wVuUQp2Ts9w7NqNnHrWmXz90n+jX4qAP/WpTyUMI374wytIksbgOdRqtQGD7BfZ38MOO4xjjz2WJEm49957+elPf8oll1xCr9cD4MabbqI11OKFL/xNnvzkJ9Ptdvna175Gv9/HOcedd9zBmslJ1q/3ekLdTpcrL/8JC4sLLC0tcc4553D6qaezdu0afnLV5Sws7ePE488gbxsWuguc+IQTqdVC5uamOGTrFoJQ0GhGPHD/3YyOTnDk0cexZesWRsdGWZybR0nJ8EgD5yDLMtrLi3Q6KUoFNJsxaZajrWEyaT3muz5eW70WEYSCIPT2MgzDVYwjhzbaO/hO0ukssbzcZnl5mU2bN6BUwFBrGKUSrBUUBQgpyspUXszbWeM3L1Ih8Pof1oIuJMYawiikVgtLvZhy0yArdoUZCD5LpbyMRrkGeLvrmRt5kaNyQWAVYRBgyvVeCoFSgkAJcBZTWLLSJgcqpJbUKeoxooiIja+ehjBo7ce1tppOb5F2b4lMZ8S1GmEYM7l5MxOTkzSbPk2xntcYzltIJHk/Z9+eDmkHhK1Rqxm0TcnTgtmFjLzokGYL1Owy2JRe3qWtLam21GNQIqJQgtbQGK3WCLWkUeq3en1Qo0Ebr3kUhBGRUECAMZZ+v8Pi0iK9rCAIIoKghrEFWbqEswFhWKPZjOgNRTSHQxZnBRSWzBT08y5CaGrNIQLnw5lzs7NYbahFNWpxghoZAyz1WkKgIJCOOA6BBA9GFOQ5nrUgHGEUIINkwKRzzqF1CT67ir3mkCXLwfuDK4xILxtSvWLL84pB9StrLf0iLYtPWPp9X2gojEKsLVk4JkcGEATeSUvTlLSXgVPIUuNVCg9+JbWYMA4Jw4Aojsqx+/gGng740Ad86AM+tH/9V/Ghf/lUu1XfunqIsmI8Dei45cOSK0r+VYqez2mUJePJPgqk8g84+n/Z++twW6/y3B//DHlt2vJtSXbcE0JIQoIFSUiDhOAuBy+cCrRIW6TllNJCW6C4FC0UCFAoTikEDZBgUeKyk2xdOvWVIb8/xjvnWpvQU87hd31PuK499rWutdfUV4Y8437u576TjFCj3GfU7+H8xoEskZGGWidoDDmMxZ/Hav+2KrBVSTHsUw4HQVTclLVdqK/1keofZ0MpQmkQRQV5hTQO4UAJhY987QphkQSmlgyK01hngyMcBhuBms6I51ok0x1UlOCsoLs6YHW5x+pylzQN1OJGI8MYh7MeZzxVYTClIy4rMiFpSclCBJEQKGSdzbAUVUnpSyqhqUwwn5NK49JGDawoIjwJnraQTEtNQ0Cix0Bb+C1loPR5KWkATqYMTYYTsK/qM7JDBkbRiRKyVNFpNegux5SuXuCcR3jqzEkUBLojHTqxUigVB9F5grud9x5XGOyooooLTCMJ2gKRYuNGZr+ytskAHeOEYr++Mg6GmDCdJrN3GHRSImpUX6lAXxTeQS1IX9P1Jp8WVmSLr+tUvQiUUQhuAOOvV6omFm4EnwiCntz9cadamN3DuEQTJg6FiPUMzl1F+9db+Htd7HB8LcOcMBYzdBvq2PcHEkXtMqiEZqxpEUXRJOMjRXBi8V5gN95bxoKLDqHFBKweiyRqrcME6R3OmQlgqOIY7z06KTBxsGbGhkxBpSSWiqocMeyN2Le0m341opxu4qankZ0OjXaTOKnBXVkSp4KZmQ5aNbDG0R/20FKSxDGNpsQLQS8X7FzZQySGSJ2jG1No6WmUywyLglFZsXe1Qk9vIZmepzO/hThJiKREN9vYNGWtOIzhndcQ91dYGEqSVpO01SDTmkpJulKwWIwYes3s1CZW7AJDP8Tki0g/SxonSCGJ4ojGbJN08zRmUOAbCav7cvygohqtMaMgihVikKPqrKbWOmTfXNCbgzDeJ0xBO96YBFahkAovBBaH9D7Q+8X66B7fq7H+mhw7wHiPtWaS2ZNQ040VWmksYKRFEurVx8KazgbzgPXgywcQ3+dEQuJFhKi1AMbrjRAONZ4zGNPUbdisWTHJJN2d20ZhUTxce+3N/NVfvpX3f+BvOfqoo/nB935Je6bBoYcvcNLxJ4LwFGXO6173Oo455hj+7d/+De/hhhtu4R/+6T386R+/gIMP2sIl3/0lx514MPe9//HceecaURRxyinH8YNvX0dZrHDQ9tmQZFB3DRf6gx433nwtb3jD3/y3x3/aaafxvve9j4c85CET4OmjH/0owH4irBud8DbOU8985jM455xzucc97kGv15s8f+97n8m73/1uzjnnHL7//e8D8JkvfIEf/PhSnvK1i+ndciW7brue2c0Ho+fnOeSQLeQrYY6SjYJmusBib8hnvv1ltjpBQ03TmT6EE7MO05nlvf/xI9JGg2O3P5X7H3c8Z20/DC928q3Lb+QzX/k2v/zlIdzv7HP4q9e8iiu/8E7KPOcvXvz7LF3zddZ2/oKRdQwGq1TmFh763L9jNLyFay75MNsPPpLVvuPLn/8UeXeRMh9RlB0aaYTWcMOduzjl/g/kUU98HG/8pzfXGXHLc5/7XM4772HceOPz6HTmfu21FkJMMufjdsEFF/AHf/AHzM7O8qEPfYhLLrmEv/u7v5vMse997/u5+OLvcMEFj+bRj340D3rQg/j6178+AQ8vv/xyNm3aNCl9XFpe5oP//BEuv/LnrKwuc9WVVzE/v0BZGD70wfczP7/AO971br7x6S+ztnIHz37+/+CKn/2IX/zkBzzysc8AKegNunz4Pe9ifm6e4086kYec9xCG/RFXXHo5hx17GAcfupWqcuzbu8i111yLZ4ZNm+e491lHc+XVt1MUhoX5zn/b9+4ubWq6gZS+nrvSMIeiEDKsm0VZhKlRSXbv2cXefXvZu2cPnekWU51pWq0OQuiQiPQhI11WFUoFFkRVVSRJXRaFp6oKqspR5FCUcT2/y0lfwtc5QDl2yAtgRaqCyO14UzN20vLOUZYhex5FGpGN12BPEmkiLUiiEDNXlaHKC9I0Jo5S2p0ObtRF+4LYWJQFjKUqRzhvsb6gO1ymN+pTOkN7dp7mzDxHHn8Cmw86iJnpaaan2yhl0NpgS0OvP+C267voRCFUi3Yrpl92GQy67LizT5ZUtFsF0+kAXMlqv4+VGhUptm1uMcgjhnnCwqaD6LSnaTRaeB/iBxVFFJWgrByDvKQhQKcJQiUYYxj193HnHTspnWLTtkPI0lACudgbAk2ybJpmQ9PuKKZmFct7NWZkKTF0+yOMVcy2pmimEbGL2b1nF/lwhEZx5BFHkszOsmnrQoijncP7iiRWxFEDa0usKShcEVgWShHFKUJlIOpYTwSDJYhAbHRAq/2avSNk2et5VoaYzDkb+pYLIIdSCd4FHalef5VIJkih6fUGJGlCu91iOMqDppMoiBNBnGjwAZxeXVml3ZlGGYWxllho4iRidq4zMUmK4xgpLFH8a8CWu1E7EEMfiKEPxNC/fQz9GwNPEzRLrP89bh6PNZaxhadw68+NawSdW2e0BIV1vyHI9DXIIInilKnpebyzFPmIQXeJqhwRxxlJo4OOYpSO64EYLoKzBu9s0HTKh5iyYNRfpcoD68nXX66iKAiwiSDAJqsAOOlRCXmFKA3S1QwhpZFaBeqpcBgBztbCZvWiXboKqxy+rYkXWqQLHeJ2E+s9+TBndXmZwWANY0Y0shbNRkKzkdLr5eDAG6CwyMLQRjIba+YTyVymiZRGiZSiMFTGURQVo6qiMJb+aC0wrkwVrkeSEcUJkfCkUtCKNI0oJZOWSIU7NL4XogaelFQkhOuQ+yaRCs4CzpV0y1VaaZukpVmgzbA/YNAdkXcH2Lr+e0L71Bqp9XqJmgr1n1pEoS7fB0tdXzmqYUE1yBGAihRKr0+q6/1sXDu6kdm0bvE40QqjtvSshfScG2ciBF4opIpIkywMBsDZQEUO77frwNUYUXYOhwFXZ3qICVqKnpAgqqmJfh10lfXAD+Dn7wDyBAF8FOvAsKjZa78KVP/abMvkcV/TQtf/Hi+41lbUcehEQM/7jUh4PUEpFejDBFeKKIonFOLx9Yy0ngCDpgaOwVOZEinkxKYZCBM3Fc6GRdA7WyP5YSxHOg1Wq9ZgWxlUBm8DFXVYjFjurdBtaKpkluamTai0jU5jmo2crBGRNVtMz2XouEUkHcN+yerKGnfevodDDtpCp9UizwpUOkUkpsmH8xhn0N7ifUlR5uxasRA1IU7pHLFAY2aBxsw8WbMRRF6FIMKilKQ5t42ey+n3OhT9NdK1Pll3SCsSlGnKctzAkAAa5UakcRvvNrGW34Y1kqqy7N79S/IcpuYjDjvmGKrcoGTJWmuZ4b4u3R8u0dYZjVSSaI+QlqIsMVUVgIBo3dJ10j3Een26AKTUtX5bzHie8QTRS5wL9t/jzM2EeRheFQIziVLhMVeVofzVb/zOWmQRgUOidNAgGQO9bhxo4XAmx3sbXEsaTYQI4LPbsPjbGgw3zqxnoWr78f+qz99d2plnnsnevXvBwy1X9zjiqCP57OfezaGHHkSSJDz3xecxNR0YMFLBxz/+r7z9HW/njW98I8ccfRz50FJay+z8PB963z8wNzeH1oqHPuxU2p0MKQWzsw1uvWU3n/nkN3ngg0/loIPnKXPLy1/+cn7/919Iq/X/f3bJwsICn/nMZ2g2mxRFwZOe9CTuuOMOAN797neRJCnPfvaz+eu/fj1vfes/TVhRSZJw0UUXIVXG377p/bzq1X/F7Ew4vte97n9x+S9+wdxBC2ze8iA2H3US33/Hx9HGsXnzApVYRrebzB17NtGe28n0bh54+GkY2wfVpyr3ohVsmd/Mo07Zxu1LK7z63R/h1MO3csTmWU466nAefMYsZxx/IlffeC03/+IHvP4Vl3PWcU1m2y1Wbvgus4ccwaYjjuTOX3yRbUecSGPTidzwi4/SmtvKsWc9jyt+/lPa8xl/fOH/4J3/9Hdcc+XlPOExj+WYE4/lkKO28/uv6fO9732Ps846i+uuuw6lFGeddRbeezZv3sz73vdmDj5426+9pqeffjo//vGP93ts69atTE9PI6Xgwgsv5NRTTwXg0ksv5cUvfjEg2LHjds4++0GImn2ztLS032f86Ec/4swzzwSgLEvuuONOXvjCF/KkJz2R6akZBoMBK6ur/OXrXs+wu8Z/fPYith99DKdsOpVms4UQkkF/xFe+/BW6a4ss7dvBIx/1RAwlH/zkmzj3/o9n26YjOOGeJ3P5L67iW/95CY963Pm02tMcctixHHzwAt21If/+2R9w4j2O4NBDFvgNY927Rdu3bx9jLZNN85twEoaDITOzDaI4pihGLC8vsdbt8strriHNMrZs2QpIllbW2Lv3FrZu2UqaZJS5JU40SRw2OiHO9uQji0DQbLQxJmjwCOlwVlJ5gbVjvRiBrZOJ1gQ2k1KCNM0Yuy1VpQ0uwRKiKDgoQxCwRkBZFkFMXAmmWhlRIL6TD3rYsqAYDYARSoKONDPzm3CdJtXabVTdIWUxohwaKm+pREUuwKUpU1mL6fnNtKbnyNIIU+asLS/RTDO8NRR5yU033cry8iLd5S5SR2gdMdXukM0kLLSnqQpLpzPDtoMOYXH3zQx7q4yqgizLSKMU6xeYW9jC9s4C3gickfRXR8zOTxGnbWTUYmXZY3sClQ+RYoh0glG/pCwrur0BEksaa5LIoWRMpBp01zKGQ8uevV2yVKOkZNP8DKOtm8kHBaqSLA2WWe2OuPXay+nMzDI9N8vxx5/AzNQUc9MdrB1Q5iWyLkkO+1VDFCl0pPAinjAOkihGqQitkwAwybHjFQEcqBzaKuJ6jVZKkqYRlSnCRrTePwUJlAQhba1x6sBJvJMsra5iTUWn3SSSQTtqYSFBCI+QnumZTr0PNPRGq+RmgIoVaSNmIVoITE4J3pnwHQTgazQygMQ6+RtvWv+ftwMx9IEY+kAM/VvF0P9HwNPG3xueYcxA2UgjHD8XKgXXEdtfZbCE5wPSG8AMRRQlxEmKs5YyH1GVeci4SImzwXFiIpDmg/2rswZT5FRFjilzTFnUj9saj5ATSlu4eg5hHLKyiNIgKouwHoVECh80fAR4KVBW45QNt9kGYTzjLNZbrPLIRKMbCbqRoLSiKkuKvCAfDbCmQEpLkiiSRKOjuvTLhxsvrUc5aChoaUErlmRxcIyTUiKJ0JOFAISvKIyhqgpMPsAUeZgwdBQo+gK0lGil6nrPQMOF8SQmJ9llgaBhPW0dUThHI44py4rKGipKtJZkzZhWO8NbT9kfBVqpCyy3mhE4ubZCivEDtYK/RIwzal7gjcOWBhsbnAn3EOlgnIlZJyLV95aa+TSmBjPpa5OuV/ehunMihERpjVZBf2pcGhmsi0EE6XDEGOxk/H2esU2Ad0FEU8C60N2v9PjJ+2omFXfzTeuvtslY3QAkb5zUNrIONj4Pd1lff037NbXvNXA9rlEXtRPDGE0n8pNPrjHB8J0y3E/r/QQU9N7hBChVv2ccBDhf17bbkCW0FiFUAJmlCFThLMM1M8xwAKMc4TUVjlILRLOFbmRkM7OoKENHikhZXF6RL3WxJkOpmNbUAnvvWGQwGJGPSvChvj7ShkilJLoFcYz2hgSDLrqUeYQdenSjiU4aNKYXyDrTpO0pIh3EZkP1qUciiKIU1ZzG4ChdhSwqtLFUpaGUjkIArq7DrgZoqYmjJkKkGOMZDXP6vVW8jUkaMTNzM0E7phxQWIPDM5rKEChs30HlAgNUOLyvafMEJqtw68KGG9MNoV+s/4QsHnVGJLxmnDUb38+Nmnxi0k9+FbhdpyZPRA/HQDPjFcdtPArGE5JzVR0AV+hITspOgsjqeiZyzMwdr093d9AJ4Gc/+xkAkY6QOtgdI4OTaFGM+OW1vwA8cRJz1ln3IU1TZqZn2H7QkWya2xpKawQkccJhhxzK2lqfPbsXmZ2boihKdty2h7n5aZJEkzUS4lSjorDBXFjYzNzcfKBg/5p26qn3RGvNZZf9hOOPP55t2wIgcuutt3LTTTcBsHfvXr75zW+ysrKy33sDw+oUlpeXueaaa7DWsmnTJk4++WTufe8zSZKEc845l6uvvoobbriBBzzgAdx++x3ceecdrK2t0e3t4Yc//AEXXvAgTjrxWAAe8ID70263SRspsU5QUYPpQw9DGUd70zxLewaUxjPq5mStabRWTN14E93cMLIVQnkUAu0Fhy1sJmt0WG4rsqbDOsNqb0g7jdk2N81yd4aVXo/FtX3IZBM+brC0tA/VniZrZlg0OuvQmNmE23stxlQY55jZtI1Ga5pDDjuSymv2LPW4ffdujj31Hhx06OHs+OEP2bFjBz//+c8n8+lPf/ozwLNt2zZ27tzB9HSLubmZu9yPdrvNve51LwBGo5yf/PSnGGNrgCKUro3vw1iH6x73OJlNmzYhAr+bqg6e15ug1+tN+mGj0eDMM8/kXve6F/c4+RSgLsNSiiOPPILVxWUWd9zJwKwgc0O0KkiyhC3bDqY/dERSM9WeZmpqisrlZGmDpb2LKJOyZdtBNFoZSZpQlRatImZmp+muDen3hiRJhCkrilEOMw2uv/56br/9ds4999zfdDj9P2muriQStW22IDg0ipDRoqwqVtfWWFpawjlPlmbMzc2HeDgvsM5OGBFChjkgOMyFOcxUDmuCq1wcJ2it0bpCysBYUjIkG4Wsj2FDjC5EWE/HshiTmB5QUtZsf2qWRZjrPRN7HJQUKEmIOccJOSzWGvDBXTNKUlDg8xSjCyyO3JSUzpJj8VFMFKU00haN1hRJmlEWI5z35HlO3AjuWVIout011tZWA5hhQ1I5lglRmqCEx2aCqakZZmbm6K6uUBSeKBqRJQ3SNCNK5mg0Z2m358gHozr56Cfxq44SoqRJVBmi2IR4wxe14PtYMykOjtZ4tBR4JYi0ZDQasri4yMJ8CyU1zeYUzdY0SuT4wtOatlgV0V9cxpqcvN8l0YI0ksSaoLtkSoSzwVFOBTt1pYOOlxchppZKhSSu0sGC3Y2TtTWLVEjAIUVgtYyZa9T3eJxA9c5hjKWqCPsF4YmTNAg4xxnDwQDvHJGKiHQAOtNIUpmCshzV99rjfK0lJBx5MSDSKUka40zoKWVZklTxhngg7CfKsqpZHL87WqkHYugDMfSBGPr/Lob+P9J42kgjXH9s/YJAGCBj5lN4PoAP9Xy4Thck1AsGW83wiKhrk0WU0GzNoFTEaNSjLAa4ocUUI3SUEsUpSdqcMJdMWeBMFQTFywJbFZT5AGdDtkYqxbhXCiEQ3iNM0HSSoxI5KgPbyQbxcKUkkVQgPNYbjK0CyCQ81jlKZymqgtxVWClQrZik0yBpZUgVNgH93ir9/hLODcgyR6cT02rExDUYIgigU+ogQjAXa+bSiJksppkkgXElIyIN1joinQdbXJlTln0wI6yxVP0ueILWUuRQEiIlwt8apHJ1JwwIe1hUVS3YLmhJmPNB1X650WbJ91izQ0auT0NDM02Z39QhjjSjtQGSACB5EwTHx65JQorgjFDPw04QWFtSBWdCGeioVV4ilEQnURgEStYBT7g3staIWu9cAbz1Y0oqY/wWhBsr8TNR2hdSkaUNkjgl0nFYEF0I0qjBOzmmnwqH8BugJ+/Bhz4TqIQGpZPJ5+6/WtSTuHe1qP3df+MKgPeTstixKOG4bfz//mNc7Pf/8KednPP4+SCAyEQYdfw5wfI1zAWx0kEwT8ogrD+27zU2lCAoiXNhXFtCOWkUJ0DQfKtcFRZ0YZGuQk4mQ4d1Fa7O3JmqxBZ5OA4hUAJUkuLwlJtnKPflVKMB2iUUscZ25slmZ4iaDaamZmpmpEcKz2DHKv0bbscetJV0psP01iO55abdrHX7eCOQIkKrFB2VZHFEO81IWgeRRJJmBHZlN6O8xMwpGq02SZqSJRGqDihFHW8JCVUt7pmg6LTnKZst8ukE1Rsg+0NGBeTWMTIEC1NfMervJW100Ok0vXiWfGTYt3cPUSOi0WjTbMWkehPVSLK6uEKz3cJsGtIoBfpOw9piTnslRzUSogWHtxr8mILt8DJQsxW1llu9qXC+BuMJ1GEdReuLnB9vXDaUt9Z9xUk3EeBUCkxlsLZizKIc6+9JAZGIaw0TP3FRCguOmiyA4XvG64/D24piOES1InSiaTTaeA/W2HruECita/eocLDjuvffiSbg0OPajKpV3vYPn+WlL30CzvV42MPPxxjDpk2buOaaa3jc4x7Hox/9WC67+Hpu6u/mqHtso5HFeOvZe3ufK666hj379vGEp/4eN119J9/7zpU889m/xxFHbuHoY7dx8y172btvlaOP2sIdO5dYXulx6ilHI7W6yyH93d/9LVPT09z3PvfjT/7kT3juc58LwBvf+Eb+/M//HIDvfve7PPShD/0vT+sTn/gEr3rVqwB4whOewKc+9anJc//xH1/nOc95Dt/4xjf4whe+wNvf/nZe/epX88xnPnPymle+7PlAAJ5e9rKX7ffZjZmM8/7sOZO/v//+Los33sryt77OKU94HFOHn4L9+fcZ2oSeVyStKXw+pFzrctSWk7j3oUfysic9iW9/8v1ce+n3+fnlV3Do1k0cdvAW7nnG8eRFxepqn4UjTmFUVFx95SXsXvkZjUgiZBNZZKQmZu6Q+zPId3PtlV/mwY96KbObDgNg70qfn//yJn7+y78mmk456V4n85SnPIU777wTAK0iPD6ICAM7d+7kEY94BH/7t3/LK1/5yv9td9m1axdPfOLT+fM/ezl/9EcvBuCrX/0qL3jBC/Z73V/+5V/ymMc8ZvL36uoqJ5xwArt37wY2lj0G9GT79u189StfRakIZ0DFgkazQZplCGB6doFTTv89/v2Hf8ue1eu59/EP5cTj7sep97of11/xS6Zmp9lyyDauu/xSoiTh6Y9/CZ/50Cf4xfLlPPslL+TM+5/K6fe5JztvXaXRUhx88Axv/8fPMTXT4n887zx+8O0ruHPHHjZvvTfveMc7eMc73nG3B5AbSQsdS+JUkjXiwJyvLM4bytKzvLzE7TtuZ9++fRxxxJFs23Yw27dvxwtJnud4L2g3G2gd4WMRBMO1xlhHWRjW1oakadAzyRoNirKBEJ7KVMSRDv3IWxASrYOjHl5syFaH0g1n1+dGpSRSxROZCe/dJFfonAtlN4TYybs62e4dUni0CiK03glk1ESoBCEUOpmCqMDILqvVkFHlGBhJY2aOZrPJzMwCiOCQtWvnDowFj+KYE04AJ5Fes7a2TK+7RBILIp0RRy3SqEUjjchSTas5RavZYmZmjv5KQSzapCKl02mQNjKy6YNptJqkjQYCVdvFVxhfBt1Xl5A25tBRE2E1wgzBjWo3N4GzkixNkXGCwKKlA+3JEsHS8m527Lid+fl5ZmdmmJneRHfKM9IDTFXSWdiMsZaFnTtZW15h1B/g+mv4RCGaMYN8RGUduVNMT8/TarWZm5vB2hHGjHDe1GBUPCmDjuOEwWBIVRpGeUGz1aLRaKAjTVmUGFNgbYlzYpKQDqLUMUNbMByV9Ac5SkuSRLPtoENI0oxIx0Q6osxzNI60EQDhpJmwurpCr7eCHQVQ1JiSVruFloqV3h5mpzaRZRk6SRkMhqyt9sK6rzVCarSSGBzD/qhOVv/3kMz/83Yghj4QQx+IoX+rGPr/CHja2PanfDEZIOs1iHJDTSITdGwdWVv/nPFj4/279xAnGUJKWp1ZBt0V8tGA0bCHlEOk1CRJowa1BNaUOGuxZVEvmmZizzjukWNdJ1wQE1dFhcwDCiqNQ9bZA61knd0JlGJcoBkKa0BaLA7jDKWpMM6A1KhEEyXBdtI6Rz4aMhh0KYohUlqaDU0zS0iSuM4Yh5PUXpBIRaYFU2lMO01opuFzgn1phJRh8UUovAgCcEVZ4cpQz1/lQ6yKsGkDpyRe1CWMSBwSlEaKGniSY0S+BuHqDtCINFYIZrOMyjsqKSm9RVGSqoLmbILUgv5aBzOogk1jaXDa4LWFdIy81qLvAtZVvAKLzQcYN7hxqBI5VCAlMgpaUUISBqp3ExR3gg37MdsJYD3L4JxjghtJGVT5dRxApzip65c91GKdgVso6+OqI6QxYFr330lgha9tSQOIp6We1NIH/YSxw91YP+vuHfACE9DYO4caA2n7D8dJ2yiSuPFnndkYwMrxPVpfZDdmTMfipaoWoVcT54yxUL+XNTBtDE4I0KpG0XUYwwRwOrhDhJJdKAm16hVS1cKozmFNAInHk7W1JUqEeugoirE2TJbpdBvv+hjfp9f3uCQjnp4lm5khimPiKMbW4z+RDcq1AfmioW92U44KZCOht1aQjyxpmgVwUsVkyRRZ3CZJmjTTFI1BVH1EnJDoBps6bXSdOY60mlwPUbvLeOFRcizS6UmiJto3sECudzOQA+YbLaRO6OiYPWXNwJQCW5UI4YlUh6pcoix6jLo53oC1JbFLkKLN9OxmymKFSikWjjmEotnF7OmzunORjnSkM01opnipcCZ4aova4jVk1iwh8S1BqkkA44VH2Jo2LKJJNtXYqk6o+Uk/CaKltftLPT9oQtZ1P/YiwdXDIxA+BFbjbN04SxcW2DCWvfDrw9A7TDGiwJOkDYKn7didNvTPiYVvDZbL3yAPeXdpznm2H7KZF/3+oznkkE3cdmvQPHr+85/PIx7+SHbdvMRg2jA13eaok7aitCRWkk9/9HsMhwVPedaDuFfjOPLycJIk4phjD2FuvsP0TBNjHWvdIdPTTVaXu7znHZ/m1NOO58hjtte07/V25pln8tnPfpZTTrknURTxmc98ZlLCBdQbopSyLBhPNK973es46aTggPfOd76TSy65hGc84xkTZhSsB+Kvfe1rufrqqwG4z33uwznnnMPzn/98rrrqqrtck98EdPje977HW9/6VpZu3UHZH+Kqiteed3/O2XoqD3728yjKisFoxMff/g42zc1x9tm/RxR1iDszjNYMJ97vfA457hSu+tbXmNm0hbltByGShLjZoDk9TdaepiwMc1tPo5FqVleX+IvXvgJx8Y1Mz3+Ht7zlzRw1cxpl1edv/u4t3HpbKCm87LLLNhyloNFo8P73v3+irySF5MqrruK1r33Nf3OGnsGwi0DSaISyQ+ds0Jiq8l97rU4++WT+6q/+alJC9+uaEIKHP+KhLGzaRKPR4ec/vZJ2qw1CIJWgP+zzxy/6I8466z485znP4RWveCWahKdf+HyOaD+Ew6buyz1POoH/+Nq3ufLyj/Cyl7+EKy6/hte/4c084eGPJS/WeO97X8Lvnf8wTr/fmXjj+fKXLuaKK67jBS98Knv27uKb372Wsx9yEkkSc80VN3LIoZvYt7iXJz3pSRMW1t2+ySDXUJaWXbvuZGl5keuuvY6DDt7G9NQUmzZtYmF+E1naYtPcNtrNaaTQOO/RUtPO2tjK4UxJkqXko4KhywNDMYmYnm6CCOLOzjniJAMhyIsCcBhXIL3A+7AximONc54ir8hr8EBJidYqOPZKMWGNr7M75IT5GNbo9XI8vMeZwJ4JGkF64oJkTEgaSgQ6nYKoh5ESozVoTRq1aM3OkGYpcSNCRzGI8PyevYvsW9zL7NwsSRrRjGHzXActS7q9HgsL22g1ZkOJi1IIGbNp4WC0gKrfY749zVTSJu/MEGWSKNW05zZRVjl5vkZnZqaOWUp63UWGhSXJU9qtGRpJG9MUlMMVTAFxLEnjhLjZ5Lbdq5jBEESDNEtwTrK2MqTIhwgq8uE+8tRSZh4dlSSZJ9IxnelZ4iRhy8ICu3bsYN+unfT33onrr5KvLZN0Oui0wVR7mkYjJY5VXYIVQN+qKPBRHPSXvMRZH0SaCfuY0WCI8z3KomRmdqZefw2D/kq430nYjyit8N4Fwea8wHlDpGLiJKHVbpNlzVDChWQ0HNJbW6aXr9CtKjpiBustzWYHa6k3t4Zmo4HWCoNh2BtRDZeYm9uMihTNVgOloppFIRkOhpRl2K+pukrj7twOxNAHYugDMfS4j/7fx9C/MfAUSpHG57O+EE2ApZp9NBadCujZOmAQxud44Rqr+fu7MKjGTakgiJc12qEOvCxCGZ2pEB68tYHB4wXeBkqgMVVwJ6sRQl9ffMT42wM6LKwLDKfKhh8XaPXjyXAdxQ4oo6zZNNQ0N+sD3d7VwtNKa1QUtI68c5RVQVGMsLYMWZ9YE8cRkQ56Q2OAQwGJFGRC0Yg0aaSJI41UEUIGxpOQAlG7iViX4L0njmIiU6C9wZgSX4unOxfh65rhUA0nQCiQAXUeT2Zj3S0I1OhEgUHQjGMya0lcqAG2WCxVyAh5QXs6Y2A9dlTTMI0NzKdacFzU13qszj++fmIMRxM6vqsspqjQqSGMPRWYR6IeEBvotuF6jXvgOuqLrwXt6z4lRaAbR+MMUO0qIPz65B/0Cer3eDG5BrBOUZ30deeCO4i1IFUN3Ml1NHm/Abax/vru2zYuer/axnprv1pS+6sA8/p45y6P7f8+GM9GSslJZmL/zxCTy+hqZxbh64lUCJwIxgGOcRluKBF1LiwyzltEPdeE7EHtvOM9eIcg2M2Kuu8JAShJ1Eip8gzVzKisQWQZ2dQUWatNVJeiIAKIK71CeAVGYpYGFFIxnFnD5BZvQ7YQBM57lI5QOq7BzxhpHVQWoWKUjmimbYS34F1dqjAu/R1fTBcYhXicdGgZIwHpIsrKMSpGFK0OqdY044jIjSiMwymNNRopJZFsUNqVUO47KMJ10w4pu0RCkSZbED5DSRDzgPFYYcl3DYjXEuxajmq0f23m0ft6FP4qKOw8SFdnAV0IqOp7X/cGfvXjJpmc+rOkUIyT7KLuQJM1R4QlbR1lHnet8bgNny/qhTRMEw5rKygJwZUcmxkEuNh7MRHQnKwPvwvZ1rp575HK02oGVkGSJBx99NE88IEP4uEPezhX/+RGilGJbTnirC67VpJ9e9bo90ckmaasFI5g3T413aTZThkNC6xxGOtrq3rPzjv3cuppxzE91QoMZTHOyMK2bdt4zGMewx133MHq6honnHACRVFw/fXXA7C4uDTRixlPE4cddhgnnngiADMzM+R5zhe/+MX9zq/X63H99dfz9a9/fQLKXHDBBZx77rm8+c1vZs+ePZPXtttttm3bRqPR+N9er1tvvZVLL72Uz33uc/s9d82tN3LUnTsgyZjduo2DGw1KnUBrioVjTuC2HXsYlIbNHkzUwGQdnEoZ+ghRKkwBW6fn2H7cqSAEvbUe/s4+c9sPJl0YMNTT3HHHHZQ330FjZo6Fgw/Ge88dd+7mJz/5Cbfffvtdjldrzfnnn0+322X37t0ceuihbN22lY997F/2e521dnKtp2rgYmVlGSnVBHiKoojDD9vO1FQH5xy33noreT7iqKMO5/bb76TVanHiiSfS7/cnnzU/P3+XLP2p97onmzdvYa07Ih9a0jhl9x37mJ2fxjrLddddx/ZDDsVWnhtvvIlMNwHD1tmj0ElEI5lidanPzTfdQtZokhcFN15/EzwsxpQDbrrhRvSFgplNHbyHpaVVbr99JzqWVLZicXGFB9xvDq0Ut9x4O0JZVtb2cuUVV6GU4phjjvkv7//dpUkV4hznPN3uGnv37uGmm29ASI+3lm1bD6LTniJLWrSbU8RRgnNQFkH4O9IxxozwPugxVaWjMpaMhChSKJlQGQN4iqIk6H/EpGlKVQYRWusqpBdQj/3QfM1YsVgRstraK2Ss63lcTOZlIUTteAfe1HqfQiCFr9kgHms9wURaTdQtqrKaSF1oneFlhAF8HKFUStKcptFpkyQRunY6Q2oSC0hJXpQMel2ET2g0FI0kYpjErHUFSZzQaGT0e6YuO0tot2fwVU5/uEa7OQtNRWlaeFUhtCdrJLhRRWk9SRqSn9aGOMhUBmkNPg3XT4uE0iuMFTivieKMLJ3B7VylKqvgeqc13kuqcgxMGIqiS5ErilwjZInSFklEI8toNNvMdKbxeY4vRvSXlsidAW9RaUqUNsjSlCTWAcgxJd7XekxuY6wjcICtTL0BD/OdqUy4H9ZMyjOrqqx1gXytCxPYNMba4DinajdvFQBJVzNtwpYlaA2VtsKYIUmR4WyIq3W996nMuGpBBoDUFxjp8LN+klAO4VkACYyxGGPG0Au/FsG5G7UDMTQHYugDMfRvHUP/5sCT95MFaF302e8/AOT4+YDUjktcBQGMcDWqtg7qjC/RWG9nHZiSOkKJmOnZLUCgC1ZVga2qIJg4DCVmogY9GNMf68sipFpn9sgA+AjvoCgRRYnsj5DDAllWSF8PbFHXMwoxcUKThCBQWYW0wZLWWkNVVVhl0VKg05Q4zYiiIPiXF0MGwy7WlaSpptXMSNMUKRWVcZiakaWBhla0EbQSTSPWJHGE1ClCKJBR7Sgi0SpQHSOlAm3WQWVDKaB3QTPJOE3lwIoxdQx8TZNEAqJWeJ8wz0IAkaiA+na8ZwgUSrEy6GKlp/AjOq0pkkaMZ5YlKRmsjKhWyqCjJDXeOFAB/Bn7dHoXxOxwHj0OPoQAC660mFGJSYL4uBACrwPAh6g5SX5dG2yM/I8pgeNu47yvrUUVSZKRpg2aWYtIRRMaYmDdgZBRCLostXh4XV9eD7ywOKxrGqz3cVtrPlVsBKjGA3q9z/5uNCmDu8mkNNatg79FUaBUAF/j2slivAjtv9iGaz4GBMdN1JkRqEtra4ZdpIOAoZCSIs8n90VrPXHimZTn+rp0UwiED+KJ1qyL2MVxKBWwNox9rULWoyrH9c3BTREf7Fm1VuA9ZVFgfBgLcZLiG00oOwyzCJW2aM8skMVpnWEo0TrGCRiO9hB1NFNqluKKnRR7F9m9Yy9ZluLiGfqDAb3RAK8rIho01Bw6CosmxmPLBIPCS43UAknIOsU6zBV2bEdKCNJDjbiEJAsOI2WO33kzozuuZ3XPrew73rNpYSsHb9rC7I7roTdg1bfIZ7eh0jZZNEM56pEXPVbuXGRqfppmYyuOJSqfQ5HSbG5G6TmG+RI6TUk2TbG0ciWsrKEu38lss4WeGteGhwyZNQ4d1W6RQk+y4XgXpNHMekBkbBH0Q6Ssg4MwRibJAMJ4Ds45ddZPBF2ZSVlrzXIMRgYSJQRCR4DC+0AFdy5Qw4VQ9bRW6/7VwIi1BpOXrC3vJU5SkrSxXhY7XuwJm8Fxn/xdaUIIvve97/LEJz6Jf//3z3Puuefws5/+DB2F4PTks45BEILR//jy92h3mtzvQafz4pc9Auc9prT860c+z2WX/oK3v+/1jCrLnbuX+dG3f8rWLfNc+NgHctutO3HO8Jr/9UK0Dk6fy8sDsiyi1Uomx+K94wUveAEXX3zxXY7TWrtu6V235z3veZNrXVXVXd4jpeIb3/hPTjnlFMqy3O+5zZs3ccklP+CNb3wjf/VXrwPg/PPP56Mf/ShxHP+X12s0GvKwhz2Mm2+++S7P/cVf/AWveU1gEr361a/mVa96Ff/w4Q9MNtTP+ZOXIITgW9/8Fn/ynJfwqU9+8i6OQ097+tP4wH0+AMDV113JuY88l498+CM84YlP4Mc//hGve93reMc73rHf/fvYxz72X5Qfrs+pn/vc53jxi1/Md7/7Xc4443Quv/zy/V75ute9jlNOOQWAZz/72bzzne/k+9+7hCSOecxjtwOhJO7SSy9Fa02v1+Occ87hnHPuzyU//CrnnvM4fvzjH08+Y9z++n+9jmc885n7xXcXXvA49u1b5IILLuBfP/YJTj35DP7sBW/iyc+7gIc/7sF861vfIu95lu4wfPj9HydKBWkzuLb1ukP+88s/4vyHPZIX//Hv4wrJ+ef/Hg+/4Dy8q/AeHvq4B/KVL72Pf//sD3nas17F0575KJ78tEdSDB3HHHkkJ5xwNDdefSdRrLnXmSfx+Mc/jltvuY3//Pq3aE+3SNLov7z/d5fWakcB2LCG/qDH2toqvW6XNE7ptKbJ4hbTrbmwNtYb/+5qn523L6EjxabNU2gtUVqSZYFBb40jjnVgtEvJoD+k3x+yb+8ynU6TtJGwZcs2VlcX6fV65HkP7wMrBaiTp5I4Dgz7siyx1uC9Q2s53gHjXGClRGkc2BHWhphBCnQS4Z3FVo6qCgAWOLSSIELMPMzXaDRa6DhGyhQjNcPK05ieJ2lPMbX5IOI4aKxKLFKleBS6FLTaU8zN5VTDLoPCY9YcZXdA2c9ZXuzSSHdizQDhBO3GJmamp5ianqIaaUa9iLktc8RpBsqzvLKLYd6jP1gkbbSYnj0IgacscvLBkFS3QEpikVCt5ZSmS1kskg9XGI66FMMGM3NTbNq2hbnOPrrdNYbLO8HMoHRMq9EhMR7rBGsru7HVGmWxRByDQINvUZUlVnum5hbYerCg2exw+41XUhU5zg7RSpDEUdg7NFKEFPS7y3gfyojiNEWgqEpDHIe5uSjyMJ8KaLXbOBvEx7tra2G9NRYlolB6FaVY56iKnOEgxxgXwLtmYMhZ67nml78k0hFzc/PcuWMXVV5x8JbtKNVBioxiFPra6kqPLZu3Yo1jz+4V2o0mSgh6w1WmpjtMTU8hJAwHOfv2rTI11Q7lYN5RlmFtCPujcVR+924HYugDMfSBGPq3i6F/81K7DaSQ8eAJ9aj7o7vrLx6/rkZsawAAWEdUJ+8LOj8eED7IVk2YJToma3bwwLC/RiFH4dOtnVg/Clcj5TVoFS6AqrMzslbmd2AssigReRl+GxuwmLEQtlpnAo3/UWd3ROAjhhvpHNZbvBKISKOzFBUnCB1RGUNVlcE1QIVBnjWy2skPrCtrS0OLwhMJQSwFkRoLgiuU1iACcOYESOGwhOe9jkiihCS2JMZRSBUwaQ/OS6z3mLqzOWnAaVAq1Nuyjr4HkfEg+KisR2FRBG2rWGkiHSOFI/wr0VrQmk2phk2klKz2K5x3mKrCVRavXRBL12MtJB/AMB+OHaXqUr8w2fnK4UqDFQKh6iyNChO4k3W/8Ovd6VdrXEHUAp0apSPSWtdJKQ2TLEDILoYROz5nAkjpQIoxi2r8FglyXPJZs/VqaqShpCpzlHYoHW2Y6Gog9u6/XgaHRikDqMmGS7Mh27IRVIZwfusLp6szmHX5pB9TNlmnM0zGYKBlhhpkNVkQN2rBTb5jDFbiw1geA5BC4OsfqIUwVaAce8DaKjh4wASADDpoY5BfUBkbrKeNR+jgelH1+5SjEUVpaU5vQWdN0iyrra1BySSw9nzFiC7DYR+xNMAtjRDeonJHcyZGSEhtgskNfVmRuBHaJiijabebaKnQaQMhY7zSqCTDlgZv3eSYtdzgBuEd6DiMuSqnWrwN291LvHQT0+UyceQRvWX81AzELRYWNpFGi6hdOylGMRYH6TQ6apFE0/QX90GpSHyLqQWFV55ysANJRJJOo5UmdinEnuygeeTQUORD/CiHJMKlcQh0vUBYcFIhFOh6jI2TBXI8nwjB/sO2zsgg1um760ke8IGaGxiaps7AiElJ9DrDcPym2iBgQ2LU1wyc9T4VvsTXRgpCBkdLU9X6flKPO/3+4wJCvf/vSPN4jj32WP76r1/H0UcfhRCCJE2wxjEcFFxz5S1kaczUVIMjjt5OHGvWVrtc+ourMMby0Afel7Pudy8OPfwgoiiiKAyJh9NPP55IRNx2xW7SuYRkqkUUafq9kiI3NJoxQghGI0ua1toKQlBVFUVRAPD4xz+ee9/73gBcfPHFfPWrXwXgxBNP5MlPfhIf/OCHuOWWW4Cg5XTGGWdMzquqKt7ylrdw0EEH8bSnPQ2A22+/nXe84x1cdNFF3HnnnbzsZS+biGRD2AgkScJ73/tejLG8+MUv4tOf/jQ/+clPGCe2qqpi9+7dExDsRS96EULAu971bowxk8erqiIvRrzlzW/l8MMP58lPfjIveMELuO2223jln72Syy67jOJXwDBgP3DtsMMO46//+q+5xyn3CPclSXjEIx7BzMwM73znOzn11FN54hOfSBRFHHvssbzpTW/i4x//+ARU+vbFP8DZf6TXX+Tyy39Bnuf80z/9E/e73/144QtfyMc+9jGuuOIKIOhmja/7L3/5Sz728X/hi1/4ImVZ8sMfXcYznvEMTj75ZJLaHStNU17xildw+OHbabc2oZTGOTf5DCkVU1MzXPzt77Oy0uOlL30pl156Kf/+7/+OUppjjz2WN7zhDZxyz1NYWJjlSc95JMff40iKIucf3/wPHHv0iZx/7gVc9qMf02glnPWge/O5z32BPbv3cfZ9HsJUe4bVPTlvf8+bOfVep/Dox1zIP73jbXTaHZ71jOdwx21rLC8t4qzjK1/9Kj//xS/4oz94CVdecy3f/PY3efyFT2Ru0xxSSJ7+9GfQXVtjdn6aOI3v9mU6ACsri5Pk5fT0NEqFzeOxxx7L/NwmkiSZOGQZWwFhIxqnOpyf8MHVUXjSLMbawFhZW+sRRRFJEko0tJakaUyaJWRpQhzHNBqBsbiycgdlUVEWVS0+HqG1Ik1jjJFBYmDs1FvHchBkHgIryFDkBa52s9MyGMuY0q6nk4XHE8TFjclrQf0S4wqEgaIckZcVqJi01SFrdWg0mqRZFK6JVPR6I0bDnGI0opEmHLxlC8O9OyiHQ8pqhOkPITdoBOWoR18alNBkScqo0WTQXcSWOabK6Q9XSShJmxlpI0PFklFZEckYYRVVUeKsJBIZUZKF2HVQUA3WsMUA7Cq+6COKEaUV2FaJ8J7ZqRaRMCzt6+GLLtbGLMxO0R96BiNYWRkwGOQMeiPmZpsoqSnyiuFAkaYDTAVlNaI0DhknSG/xlSFJNHEUXLXz0SBUWlhTO1Y54rSBEBopNfkox4v1tTKAHZYo0igVURUFtmYW4RVlVbLaXcRRsxWcDBUDUiMJwuE6VljjA3tMxDQaTWxs6cx08FgclqLMiSNJqynIsgbOOaZnDY0kC6VEyqAjgXEjjC0ASxRJoihsuq0zNRAniCPFWm+VwaDPSdx9mYsHYugDMfSBGPq3j6H/rzSeNqK3kwEBv35AbACDxsymMQoMrL9fiKBX6MHXwNEYJEnTYMObNFr1BGxrPfYgZhhq79YHGYh6INYK8dYhrIOq1nTKK2RhkNYhfC1oPr7Ifh23GANPE+FqIXF+LArm8EoG4ClNUHGMUIEOWxmDMVVwFkkisixFa01lgiOedQ5nA4VRC4jqwaPqQR+uiWIMgPkaOHEquAtEUUQcRcSRRQuJEZJAipRYQqbFWlvTLMeIYQhaqBF1MS4rVCqoQXmQSJRQRNLXtGGD8xbrKyKlaU5lmFGGQNDd1cVZF9hnlUFFYzabqvtk7b5iPcYJRFTXJyvAAsbhShuubyRrQUqPV/WMV4NpY6bgeHKeTMaAqOueIx2TJhlaR5PvZ3zvxgylMIuG++gkUgYdrLGTHbBBg6zuiDUsFQIxT1UV4f7D5HX/O+rt3a05H7TM6tRH/eivLpLhsf/qbMagpajLFmt+2PoLxljzBBz89YKRfsN3Sq3wtha8q+nCMJ6QJb52yRmj+koFXYKqDrCc9/W9Hzs2rh9RVVqM9eAgEhIlIB/0KUY5ZeVot6aJsmBlHTxsQUmNc8FQoGBIVXQxq2sk3WAvqytIYofQ0LARRV5R+QJHiaoiZKko5g5BxHEAcFUoGVBK46XH1dpiY1aewAf6vHd4HYGtsHkfu+8m7NKtxKMllHM0E4UYruGLEVZGzMwtkIqKauc1dMs2uVRU6TRKZcTxFMvdO6AQJLZLlmYoXZL3+kgxhakEcSNklKST6Pk2bnVAkffxoxyfxPhU41y4D9aAUA7hALGemRF1gBQCDlH3Bj8ZRuF2+pqFKurxvHG8iDBXeAdK1mW6AlWXDEgVyly995PS2ZCYCPdYbui/40QMNQ04XGOFtxZLifeg43otGo8DqO/7/g40d8c2PT1NURT1BsJz+OGH88d/9BKUlhOdFrynyEuuv/Z2pjsNDj54jmNOOhyPZ3l5jZ/94hqKsuKcB5zFKfc6kVNPPylcu9rd9R73OIrBSsENl97OsVsOpTPdxHvPcFAx7Jd0poPjS5Eb4nhs4ytotzt0Oh263S4PeMADeNaznkW73cIYMwGejj76aF7ykj/mhz/84cRR7dxzz+VJT3oSnU4HgNFoxAc/+EGOPfbYiUD4z372Mz7+8Y/zrW99iyuvvJI//MM/mMQ8nU6HZrMJwJe//BXKsuTFL34R3/nOd/j4xz9Or9e7y9wshOApT3kyURTxiU98kn6/P2FeeUJm973vfS9nn302T37yk3nqU5/Kj3/8Yx7+8IfjvWd6evou92Zc5tfv92k2mzzvec+bHBfA/e53P0455RROO+00du3azXnnnQdAq9Xiec97Hj/84Q+58sor6XQ6XHfdTdxxxzJ7993EaDTAe89Fn/oUe/fu5YUvfCFf/MIX+ey//RudTpuiKJBK4azllltv4bOf/Sw//9kvWFvr8h9f/wb3uc99OPHEExiOhiRxACCe9rSn4Zyj37c0m+39zkdKRas5zWWX/Ywrrrian/zkh2zevJnvfOc7KKU47LDDJvfFWsfZv3cGWSNllA/5+Mc/ziMfeQGPecyF/PxnP6fdaXH6/U7j+9/7AXfccSdPf8pTsblm384VPvmpf6WohlxwwSP4wr9/iS2bt/CMpz6b7pplZdninOeHP/whn/nsZ3jhC36f6264nk986pM8/GHnE6WBBf97552PqQxFlVPU+lUzMzP/5wPr/8PW7a0EPVJn2bZtG7Mz0ywsLLBtyzayrImr8UvvA9AglazFgWtdJekZDUc476hmKxxBA7TfH5ImcYj0pEBrRaOZktXaorpOzjnnMVVF6SqKwtBqt0mzAI4qEcZzWRYYs8ElqV7ilQraKcYYiqLAO0+jEQx1pBBs5DWO9Z7AYGyBsSUeQ2XLUBXQ61JUFULHpI0OWaNNmqU0Gik6CkLDvf5uisJQFTlpnJA2G+y48waKXo9q0MWVDlV5MhVhy5wRJVLGZEnGMM3oru4FZzHViH5/hdKVqEQSJTFREuPJwStcBdXIIVBEOkZpgaEkL7rk/VVM3iURA6hyZFXgjMKWJd5YptstIlExXPWUZgi+YnrTHEIEMHvfviUEjn48JFbBJKDfHyAwxFEf4aN6LbNYKfFKgAvAYbjelmI0wtblN97VgtSTRKomzwsQsta9Hce7LoiExxFlPgzMhcoCgqq07FtcwtadrZE0SJMGKolQBH2eJAtxjRQKLROaWQOPp9Vu4BwY67BGkMQKKRRRHJzqpqYhVhrweFFi3Qhj8jp2HpfyhT2IRyB0iBuiWFMUI1ZWl/+/GIb/1+1ADH0ghj4QQ//2MfRvDDxJFahbrqbYTjq/X68d3fj3GFxSUk0GEPUJbRRZA2qEL7BXpAhgyHigGWOCs0KcsHnr4ayt7gOxl2I0wFmDUKo+aR9uaH0jRC24JryHskSUVSit641CeZ2xqPp1GxFBSXA9CxhEoBlHsUQ7izKhzt54h8FCmqBaGen0FCrNECrGjEahvh3IspRGs0GzGYTQnTNUlcFWgeYmncOPkXOhajCoVulnbMe4n7JRDRyFGvYoEWifQpTgdYKMMlCOwo6ozAjjDL7SeCnwSk1E06WsXe/qel+FR3mHEiCcxBsffnuB9ZZRMQTpydpNprY0SVoJq/u6FKslZb+gGA6RUpFmTZQPIu5OCipfYE3FqMqxtTOGTmOEDswyMwysM+cdOo3xsQ7WtJ5Qt1sDkqGTb8hmCoEXoeY5S1shU5ZkE4V9D5NS1jDR1iBp/TvMqgIpazTZuYlN8Xq/hjGqO3ZpKfMRUlVYY4LgvAyZot+V5n0ovZG4eozBZOYQIL2cjFXnAigLrDPFqGm3QuJrGnewda6F+2uwj/oz1K9ZMKMoYizOaE3QJIiUxnlTi1OGxxnPKYK6Jt3VU4if1LlLqUPJq6twkcXZoG0htaSyniIvMFUtEK9iBBZnSnoru7FCIxpTpO1pdBQjfBWYeTVAGQQbNZ10E73CUw5zqniNpIro0KTck6O05/B2gzuWC1ZwrOguRjqcHHHVTSNanQ7zB03TX+7hHOhmm23HHEtnYQFnSrwxeGPCNdIKSUTpHKa/gr3um6SDnURuSDQ3X99AR39lGbt6J4vXXsb0kSfSPKjJEabL2r69dIc3c7MVRI0p9PQW2ltuIV/tc9sNv6S7tIU4S4g6ml9e832GQ+pgQxNpTdJqkkhJJgWNvbtpVzmd9qH4KMZJiakMrgxszUgqtI5QUTxhpgYNNT9xzxBe1NmosMR4qFfQcCpjwdoxyByyPTKMfWepJgzH8eIHzpkwJ0tAKqSzYGXog94T9NsCUh3098bzgQ+16NYj7ThbWRuJCx8m/N+Bds011/D+97+f17/+9UgpWFkecuXld3DKqYdQlYb3vvkbnH/hPTntPkfwmCeeXWdVJcPuCKkkW7cu8AfPfyq9tRGX/McvOebkg9h26CzFsOS6a27ix9+7jGcd/BSm5qY4/uwjkVKQ9ytkJJiZy+hMp/ziqkWm2hGb51JGgwIdKdIs4gMf+Gcuu+wyHv7wh/Oa17yGD3zgA3z1a1+qRcVD01rTaLT46Ef/ZVJC97rX/S/e85738p3vfJtWq7XhbNfvycknn8zVV1/NS17yEr773e+ysrrMaDQkTVO+/vWvc9xxxwHw4Q9/CAgB+xve8Aae+9zn8sAHPjAwRH6lCSG5171O4+qrr+YP//AP+exnPwsEsU6l7hoW3ete95qInP+6lmUZ3nue8pSn8NOf/hSAd73rXTz60Y+evCaOY5737Ofx05/+hBNOOGG/96+urnLIIYdw8cUX02g06yy55ROf+AR/+qd/yhMedQH3v9/9xwfPYYcdyje/+U0++vFP8vF//RQ3X381d95xJ4v7Fvnc5z5Hu93hYx/7OFu3beaWW6/nVa/6I5785OfwkAc/grPPPpu9e/cileKjH/0Ixx93/GSs3HzzLZx//sMYjYZ0Oh289zzxiU/k/PPPZ2Z6Fmd9DSrALTfv4NGPegYv/ZMX8cxnPonvffd7RFGCswJnp9i3u+QbX7iEFz73hahI8m+f/E9OP+skjrvH4Vzyw+8jvGTQHfGpT30qCNJmES955Z8GF9845s///C/4ny/+I676wSL3OPK+/OfXvsaTn/xkDt1+KB/96L/wkj/+Sy6++LuUZi/eh7Vo166d/+U9uju0ubm5uuTfsnXrVpIkRSAxlaWqLN21PpFWKC3RkcI6S16OyO0QLTSIhEYzBULWvChKTGlQQoIBMzQ02ylZK2F+fmYcGmMtpGmTNG1w9DHHsbq6wurKCqNRD+cqhGiHDYZjwroK5iouSCroIEFR5AVra2vB+VlrokiFBKQNouReSbwTxJHEuuCupXUDpVN07FhZWqTf69JbWSKJEhqdWdqdWZJGhlYaY4KuSO6Ca5zWCXGsGPaXWOqtsOv2W2GUk1jLwvQsWzodDtm2lX29FVaHA/YurTBYG7B35x2MFm+n1choNTLu2Hk7MkpZOOgwth1yOO3ODEnSYG3fKt2lZdK4RbPVYrozQ2V6DKolVld2Yob78NWASEtiIIliMuGIyy7d3TuY3ryNRrNNM8tY3nsHo1EfWfSI8TTTBmnUoj8YsLrcgyqwM4cjQ5HvAq/Zt2tPqKQQYEyfSDnSyDE1t4rQMc2pWYaDHnmZI5Wm2Qj30FQGKUM8rVRIAPd6q7TbHeIkRkiHtQWD4YDRaIh3AiEUFkNpCwbDfmDIxTHtdpupqRnarQ5Z1sJhMLZkOBygZcx0OzCawJHbEcvLK/R6A7YsbKUZt/C+we133IpSgoXN8+xb3IOpDJvm51heXmPQ79JoLDIqKrrdAWU1Ag+D0ZAszWhkDWZmD2Z6ZmqjvOvdsh2IoQ/E0Adi6N8+hv6NgaexTlPghgk2Uv7A77dph3VUV9b1ruHkfY0IrINPYswtEoKx+9xGyuj4dVIK0qxJVRVUVYmpyoBwGsv6sJzQY8BbsC6wnfIAPIm8RFamdrFjUkMpx8cxvtnjv8fsmdrdLIgmBqDESRCxRmUxUTND65hgTSsnnSCOY+IomkwUY7G+CRYeeHaTQ3YuTGrOhpsfmIPrFMLAMLJUxlG5wGyiBqvQunY98DjSmtZswsSkAkDn6w68rp8kanCtFvQWEcESV+OsnPTxcSmC9QadahIiGjMZvvLYMggWRlWFMwbhauFZqcPkCkF8LlCHwjX39TGbmpqt1oFIJSVy7FagQrmhH4NP4z4jw/NJkhEnCVEU15ezvq7jybpm2eHFfpO3FLXQuPBjo7uAKHs36d4b2Xv1RwQbSixWVgEp9mos8f870tbH68TVYOOzY4CYcK5hyhq72oh6LZT1XFAzwnytxFWzFNenH7Hf569rYv3K0dQLqGD/exSeWp9jhAzV/9a7AChD2OQ4j/OBLjwW5RsLbxq7XkqJCHRRXxV4HDKKUY1WvTDX9FIVwE4hFb4scbZCOIv1llwbjO3RqhKaPiZONFoItNAMXQNhHbtGyxRUdMWQZLCGdmBmUihGVMOCxVvvRHlB2R/Q2bIQ5rlIY8ugy4BU2MEarreIHi4SK4iiDKk1tScGaZbhfUW5fAfV5kMQaYKe3kIzz4EuadmnNBmVSmm2ZxFWYvqGQb9gMHT4oWJ1tSAvAls0MCdj0spRxhEujVjt9UArWsMRshO0Bayx45uCNcG2Velo/3u8IQPDJHczyQcy+VUHJmLDewTjTI7DWQJzdcxQrF0mpaiZkeN+IkK2xlsR7um4Xj7khibH5ep5Rzioa2wn3zs2QtjoLnN3bVu2bKFdM4MEgtXeIj++6mIOO/qRzE7Nc+I9D2F2voVEkGYxxSin1+0RRQlVVXDbjj0ksomzkoWtU+zbs8Li4gpHH3cw85tnOfako9GRxuGQKogXe+fpdXNa7YQo0sxMJzQzRRSvC5ZDYJocd9xxvOAFL+Db3/42t956Kx/9yL9gjOEFL3jB5DXvf//7N5yR58orr+SWW27hAx/4AFmWUZYl3W53I4ubKIrYvHkzWZYxHA75+Mf+FU/QijryyCOZmpoC4Ac/+AHWWh796EczNTXF4YcfznOf+1zyPMcYw0UXXcSWLVt4yEMewo9//OMJkHT77bfTarV4whOewGmnnUYUBVbQUUcdNTmG5eVlvvilL+Gdo91u84QnPGG/cr8bbriBT37yk1xzzTXs3r0bgDxfd5GD0A9vvPFGbrr55slrtmzZwqMe9SggbPi/9rWv7aeT8POf/xyA0864N5u3beOjH/0Xbrv1Vvr9AV/60pe4+qqrGPS6ISaxljzPmZ2dZWZmhqnpNkmSYIzjmmtuZHHfCt579u3bx/T0NGeffTZXXXklRZ7zsIc9HAgb42f/j2dRViVKKT7/+c9zwnEnceYZ98Fbx87dq1z6ox2cdb/DaLWanP+wczjiiEMxpuIb3/gWh24/lDNOvzennHYc3ZU+w67lqstvQMWCQ4/YBjju3LGLnTv3MTXVYeuWTczNzbNz5518+tOfRgiYmZ7hMY95HLfdcjO33nIrW+dOZmHTDAtzHc4551xmZ2bxznP66aeQJhHD0T50JFH67p8EaremQqmdsXinqIoQ0I+lBUIYLEK5WaQwNsx5Y90Yb6HRaKJU2JQ64zBlRRJHaBkRq2iyEYqiqAZyPFUV5m8pBa1m0P/xzjIajajKnKIYkiZtpNIh4WhtraFpa81TEUx1bPg7jsK6MBaGDuUdMHZOlqoux0ASxSro+VQjrHUURY53FqUkcRqTNmq2hIfRYIgxDmcCuz9WGuks1bBHb3kv1WiELA3eC5SHGEmiY0YyppIlDRlhjaUwI1bX1pAepppNEiUwzrCyvIzxmiRbwRuFzR2+8Ey1m0gdkZcl/UGPfDQibjQZDZcpK4iQNOJgACSUCVotLpj6KBGRNlo0W22EcAyrAoki0VG43xb6vSErqyM8QVDbW4kUmtFwEEqhvCevBkTKU8Ww1l0jThrMzpvgMqg0lTW1gHSQ/vDeU5bFpDQzaN0YnAt6sM4Gi/WyLLHGYx0gQ79oNJpIIUjimM7UFFmWIbUiL/Kw7VEiaNvWrlvDQXAMR0mKvMTUSXglg8vZuGpEjwWwvUfHMWnaBA9RnFCa0MGroq4gKA1lsUqeD5maalMWFWNL97tvOxBDH4ihD8TQv20M/ZsDT/XCSL0ITUAAMQZN7DpgUwNFQfwsXNjgeBcocWOKXI311J+1DjptDLxEfXGFEGRpizFdcNhbw5Yltqwmi52nxlA8gZJqHFQmMJ2KCjUqQ6md26DwL+U66OTCEUpq5zelJ2yykDVyVFWF8Q4nBTqLUc2MtN0KpXZSQ/DHQ4qgO5EkCVEUURass8X8ejdyBAc66zzWOkwV6uKpv1PWLnW+FqSsjGFUVuSVo7DgtUYojdIaHcVIJXDCYIoRpaswZUXtlxnK50TdUTz1JD8GoASeOIAv1mFNoOMp4Skri9SGylbEzYw01nQ2t3CVo8oNVbekKosw+F0A7wLTLehsGVsFkEmYYKXrA8rrBeA8lsDvkyZcm7FLoIoihKr7Rc2CG5fXaR3RaLRJk4w4SgIoVIO7ckPfHGORY4riuiZT+PEyXBDpg6PJeqY99LtQEOnHcDPWebwJd3lMTdy42Nydm9gwke3nvsH4eq2DbeMSTSlrQHh9vZ0kZcZ0T+/DhCbkBscNv+HFv3ocAUcNs4EPWmBSjSetu07CYgMQ7VwNGiNIkizQhJ2lqq1QhagFjW24V/UJ4iXYssBXQ1ASnWVE7emA1vuQYSBSgQ2nY1zRw5Q5vhxRVjl9WbBWLVPmKTOktBszqCQOIKeHhtXsW91N7gwDP2A2jzFK44YlEY582GPHpT+n6HaZO2w7xzz4gSStJlGa4PI8zDNSYNb24FfuJC1WSKdniNIMZ/04t0Cz3aHMRwwXbyFfOhw/s4loZjvNaoBWnvbuPqtVk5Fo0JneRqQSfFWyuKNiOCzpG6hsFRxsPCRxTBVVmNJSZinWNolcFysE82t9slY7CE9KGeZFwJgSIQXW1oKXbHAmrdcHUQeinvWO433tkOLEJLO5Lu4fuktIYDiE1nWWUAYBQ+drZ1EmoPK4rNp4A04iRJgDxuN7XPcf5jSQ3hNW5Hr4M2Yzrvfzu3sTG/6zb20n/3nZpzj3nNM54rDtPOYp997v/HtrXfbcsYejTjiG3rDL5T//OVPJwcxMzXLyWUfytc//mGuv3sHRxx/MUccdzpHHHobFYqoKUxridoa1ntWlLpGeJkkiDt/eXg+JlKyDqOAws337dt71rnfxwhe+kA9+8IP8+Z+/ile+8pW85z3vAeAzn/kMT3ziEyfnMs66Arz0pS+d/H8cA2xkVkM4r7W1NV796tfwF3/xF7ztbW/b7/l//Md/pCgKLrzwQoQQzMzM8Na3vhWA4XDIN7/5Tc4443Te8Y6386AHPZhLLrlk8t7t27fzlre8hXY7uNH8zd/8zX6ffdNNN/HiF78Yay2Hbt/OhRdeuJ5FBi655BJe9KIX/W/vnTGGr33j6xMXOyklxx133OT63HzzzdzznvdkMBhsCEDD6+7zwAeGMsInPpnV1RXyIuclL3kJUtabPvYX9hQSVEwd8MItNy+yujqcXPezz34Ab3/H2zjnIQ9henqGhz3s4TjnmJub481veTMAq6trnHnvszj3Qedz0lGno1LL9dfu5U1//S3+7q2P5AEPPoJ/ePNfAbC8vMJrX/NXXHDBIznzzDN56CPPZM8dq3z3q9fwxS9+Ea8KPvKJt3HTdTu44mfX8e1vX8app57EBY86GGs8V155FX/wB/8TgBNOOIFHXXAh3/rmf/CNr3+VD37403SmOpjK8aq/eDUQyj+e97yn4axlaXGJqZkOzfZ/7Wp4d2lT07NYG4Sey8Jjq4LRsGJqJkVpgdIKHSmiSJOkMcYaRBWAHoHEGcHUTIs4XhcNrvKSTqdFpGIiFRFFOuiFyuBy5LGUlcW5ACY3W+3AWIoUN974S0ajIZUxzMxsJUmaKJ3WRkAQnJDCfGKrwKiIoiAfIYDhYEgcxxMBXOlEDZzF1MVUYaOHxfaXQgxdlgF0ijVplgTARkqKKmdtZZViVGAKwfT0TDDbsRVFb5W1vTuxRY6wgNBI49EGUidpE+FFjEkyuqMh/bxkdXVAGmdEOmaqETGsDDv37mHHnfuonCKJWsy25plvL9BsT+GFZa2/xuLSXpwtmZqdY3F1kZ4ZIInJsgaNZkYcDxBa44WlLAq0D0nxVnsaLQW9PXuQOiWNU+Zn53FWsLzUY3FlBWMMUkIjjkkiqMrRJP7vDQco6cljWFpcJtIpW7cVxDpGSkXZX6ulPoLrt/ee0XBIuzMVzB+cwdmSqigRaYQ1hrKqyPOSoqjIi4qZ2XmSJGV2ehZjSqIoYm5+Du9DuXa33yVJY1qtlDRLET7Mw2urffK8wOEpqwo8WGMDOKU0SRKE7rXWZGmGtZY4Tmh3Zmg02jSabayTxFGOKWtgw8LK6jJCeJrNJq7mCtyd24EY+kAMfSCG/u1j6N8YeFoXz/S/8kw98MR6vWV4xQbaoGdy8OEd44sqJ2Nr/KljZtD4kTF6Pkby4iij3ZLMLxxETy9i+gPKbg9fVaFsbFzzaRzKOGRlkaMSaRyqMmHA1aCTrMu5hKtBJweqRp2F1PhaeDOvSvLRiNFwSF4WVMLhkgjdbhC1M6JWAsJhXUllcsCidKA2J0mKkhHWBIE/Z8cTicQJSeUFhfMUlUGJEhwI5eqJSqBkuBbWGoajklFR0RsV5FZQeIWIUlSSkSQpUZSglMQpSWFzqBxxOSShxFsX6rW1xkcajcPXdbyBGCbwIsKLFIQCXwSwjRJhHZWpGOUj4iwjjiRTW9s4G0S6VwdrlNWIYa9LmjYQKehUo1WE145SDTHGBqeEEUQ2ZDwimSIQOBzGliAFNg+Wu6IWbpeRJkrjAO7JQFHNshZpktFstNZLOTci/c4FF0XqmlgRwKX1Plg/JnytKybxUoKQk4Ed2E+16JoXE9RfQBh4bh0cdEywxLt1c94FwLcGWjeKH4oaHB5nVtdLYcdZmfAZpqa1hjJNjVKiXrgCYLpRJ+vXLsR2nN2pM0JjJuB4bqhZFhsXXO9C7bIQAl3rmYyPLQTQwfEyMD4FWkcYU+FEmKClCJR9M1jBjnqIuIHOpkjas8i6L+hGiisKbLfP6LY7GS7tphqsgS+JXc6UVextpSw7j1pb5IhuRLPKUCJlKk5oNWKah5zGlTtu5arbd2C0J2okxC5i6tDDmVrYwnClYNBdY/flV7J62+3MHXk4c0ccztxRR+CFpigMbrCMyldJtCBSEVolVC4E/HhP2mwSRYpIWtzqDowvsPOno+aOIG1u5qBoH6nLWCXGkKFaDZKDplhZvgFb9skHJa1WgziJQlZcKbRUJFGE84JqVLIqBSLP6Y56RMUsaZKgkKg6o22MxfkS54IYpUYHkLzW+hibBTjnkWI9mzdeqMIYWh8wSoW5eKP7i3TB8lmIsSnFGO4AqJmwSoMStfWzqzO8Hm9NDVqE92wsnbLOhkCJjRCzmqxNvyvNVo6TjroH73nDP7N1YRs33XA7f/wHf8sznv5YHnre/Zmej5menaXZbqPjiPn5eR78kHMYdgtAYErDfR90Eve89zHcdO0KswsNtmxrEemISGmSOGbHjXswlWX70VswuWNl94Arr7uBdqvB3Ow0s/Mtdtx6C9/40ld47NOexPbDDgWCM9zjHvc4Hv/4x/+Xx3/CCSfwkY98BCklS8tLvOh/Po/FvStUleeTn/hXdu7cOREoH7fbbrvtt75uX/va17n3vc/khhtu2O/xXbt2cfbZZ/PiF794wtDa2LwPJhMbJ/r3vve9EwbX8vJ/r00ydmYd998PfehDnHXWWZPnDz74YL73ve/xtre9jQ996EOTx51zPOtZz+K0007j6//xNV72spdx7bXXctFFF01Ew4si5wtf+AJvetM/ALDzzl188H0f4bOf+jzbt2/nW9/6JoceehitVouvfOUrTE1NEemIf/7nD07czV7xilfs50zYaDT45/f/M4cffjidhZjVpZJjjj6Ij1z0NP7xLa/jbe/azUc++K8kqaaRNfi3z32GmZlppIYPve/DJEnKIx73KE65/6agMVMIDtm+ja0HLXDqvU+k0UxJW4JnPPNpZFnKpZdeiveQJik60jzl6c/ikY96DO2pDl/44hd433vfy3vf/x5279rDy172Z7zh9a9nYWGOZz3nabz85S/nKU99yn97D/5ft9vuuCVY11vLptmtSIIeTpLGpJmm0QiOccE1zlCVJWVR0EoyvBM441he7KKUpNUOekjNNqRZTBRFaBWc/Zx3jEa1M5IguN6JoOuhpCTLMrSWbNq0mZXlJXbuvINlu5s4zmh35oP+pZDgY5xxOGXxzqG1IsvS4LbsQ7wwLgeqqhI8aB1jS413jso4yB2OALRNTc2TJQnlcJEkSUnTuGZmGYrBkLLboxoO8SNLPuxjhKDct5O4N2JOpbjZCFNYimFFr5czGhga/RItPdMypjWziX1Rj72yz9A48lJQVoJOu4EuKnbmayzuXmKtPyJLWthNhxJ5xSBfxWHoDZcZDNaItGRqep64MQX9ksprZNwiazXJYgc6wUcJS2vLGC9RScz0zDTNxjRyZQAqQsUp0wtzNJrtcE9udQwGw9oJUAfpCa3QKmwQk0jjvMX7inxU0Ov16K6u0JmdI81aSKWx3jMajYjjrA55HaNRL+h6KUlZjnDeYG0MQoPTWBtjDJjKY8uQSZdSEulptEoZDVPixKO1qzW7BNY6yrIijhI60x2K3DLojRis5VhvQNZlWz4kxJuNKeI4ZroTgK3BsM91119Hnud47zghORFrDZGWpFGDOE5otjP27GtQVnlYoyd7v7tvOxBDH4ihD8TQv30M/RsDT76uD91I5dtv0ImaGjSmQG18TX2x1o9STH7E+OA3XJiN4Nb4r4mImpBoHZM12tiqYtjsYHsDjLW4ogzi0giE9WAcwjhEaYK4uBsLedXA1/iQ68EmWM+2SqUIty044pRVSVmVGGdxkajL7BJUGqMiGTI6zmFMiccGJ5J4HAjIICjuAkwoqEE3oXBeYLygNA4lLFAFlk/NAFMi0B+NKcmLirwwFJWhIsIpjY6S+ieuqbEBtLE6pbIFhRlBZcF5pK5q/S/BWLxcisC4ck5gPXjGzKIUXIVzIZNiraOsgmi61hFJIyLrpFRDSzfp4Y2jLHKqIg/OCFGMJIgfChWE7ywO4wzSyhDEu9AnhAdnPF6EMsMJihpJdJYgtKyZRTKIiUcxURSvC9DDOio86X41OuwV7DdIxAaMSkw6mPACFHgn6wHk1/vx/l1y3LMnIFbQ4vrdaJ4ACW8Een/VHGDy/zHZa8N4Hg9v7/3k+o8ZdM65GnxenxOCVkm93fLUaZr1yc+zXuI4YVPWWaD9dOBCB6jpnhIvAzOPCYisEL6mCrOe8xnbmWJLnClwpkQlTVScIXVEoEgSXDJWurjVLm7XXvzaCowGSBm0HVpeM5V2sFXJsF/RHfTwlaGVSITQKCGZSdtMJ23acYO14YjWcEgxGiGlIk5TmlNtTFngjGG4d28olSgN6cwMqtnCqQxchXDVRI8tlMDWWTCCZp6MIkhTKpcjzQjhHSLKEEKQxss0rKD0YOMOJiophayzqqFMIoo0SZwQRQqJCBzNelHDBeZfaSz94YB2PiJK09qG1dflpn6SWRn/SCE39BU/zhWE19ZR0n409Ak9eP+2H1W8ZnqOBdvCvXT1elH3ByGDYWd9/MLbcD3EOFBjPyZIWIfcOlDtRQ1Ui1+XWLxbNu89l1xyCWVZctrp9+Kaq27hphtuZ2amQ9ZIkEpQVaGUJW1k9NZ6GBPWpzgNAsS97oAki5meadJbDQ6xeV6RZsHuPS+KMC5w7Nm1h2bWQqngmhXckkIQG0URzXablX2rpHGDTdsWOOSQQ2g2Gjz0oQ8liiK++c1vct/73pfNmzdz3nnncdlll9FoNDj11FORUrKyusJDHvIQlpfWMBWcdtrpdDrXs7CwwGWXXTYRIgdBmmbc97734eijj77LdTnjjDPo9/vs2HEb8/MLE3Hvm2++mauvvpo8z1lZWWFlZYUzzjgDIQSXXnopJ510Etu2bQOg0cj4VZo5hDLB8847D+89mzdvRinFvn17ufrqqyjLiq1bt9aC4etz5ZYtWyb/v/HGG7nqqivJRyO2bdvGySefzBlnnLHfeVhrWVxcZDgcTh7btm0bJ5xwPJdeehlXX301u3bt4thjj+Wggw7i1FNPJY5DmXlVlSwuLvLQhz6UTqeD1pqTT74Hv/jFzzHGcPLJ9yBNgzbQSSedNPn8Y45Zd5CamppiYWFh8nez2eLEE09ibm4GJFz200tJ05gHn3smmzctUOYFQgh23Hori4t7OPGke5JmCXhI04xGo0Grk9JbS6lKgxBw645b2btvF/e97/3Ys2cPl/7kh8RRxCGHHMI9TzmVa66+htFghDOeleVV9uzdw+bNB5OlKfML82itiJOI+YV5kjQmTiK2bttKs7Uu5H53bpUta42nwJ4X3lGUFd61Q2wbi1DGZEKp1FiDUkldSw5AUVQh6WdDGWoca6IkCkk4GWIpV29GlR4ndx1unKXWBIFzY4mjhDTJapaKoSpHlPkAIQOTnliH2Gi8ONQjI2xwAogVWj3nIsELqspQlpa8rDBO1kCFIk0bxBoGNrjwSaWwtsJUFbYsEKZCVhUuzzF5jvUOPxgSW0c7SnARFMrgjMSWDm8MeZ4TJyHWzrIGufOMrKcchbK9tf6ILE3ACzKtaCqBkR7lC0zRpdfbx9JSeyIqnkSSJNZEwtJIYlqNBokVRJFECof3FpzB2QpnPNaH6gipI3QcfiN1EOpvtTHWMjc7zfLy8jgdT6RrpoOoxeClQiUp1tsQc3swlSUvctrOoaUkTTLyqqidswukDO5opswDM6KW9MCLICQuZEiqeoH3AmeDlqlSkizNcK6BIGbQD0lmkQmarSbeu1AKVK/ZOgpjrqosZWlCjCUdSRKH8lbv0ToODpneUxQlg8GQtW4XU1WTDTGE/hJFCq2Dhm2apDXQFRh5vwvtQAx9IIY+EEP/djH0bww82bqU7lfL4Pb//3r5EQQ2DMbWxzdmjYwHxuSdjBHhMUo8FtmaMKWcCwiuZ8Ksardng9q9ADsYMCwKytUVhAgDWbvAZBo7qI0vsNCBFaVkEOESHpQXKAKoFakIoTRCRRg8xjpGoyGD4YDBaEjpHS6Oke2UeKpJ3EpRscD5EmNKijKINUopyNLgtOa9qHWSQoAvlQr61lpgDBQeBoWlMp64MEjNBPwSrsBbg6lyhoWhMI5RKfFxAlFK3GgTNVpBgD2KUEojhMCaHOs9vhyQmoLSFzgnieIYm9bglwcvBdYLKu8w3uOERiiJVh08DmP7wfbUOPK8YDTKEVLRaTVhQRHplJXb1yjXSob9HlmvibcepSKk1kQ6RscplfdYZzHeIpxBGUPsAuAj0fhao6KqyqDhZStcJMimWugsCXaxOibLxuV1cRhUk/633qPGiK8bg5V1n60LPZF1rbOnph56wAehcF8L8zkXgLCNE/d+rUZ3nVufFH4X2hg5Hx/tr4LHk/MVYTwIBMaEc91v8vEOj0ZIXesJhCyus8HCU+l1g4CJrtk4+zOeWPH4YHzKeCIOdp/rY5+aHeldEGBUSoGW+NqSGkDI2lXF5LjKgKuClahXtSmCoRosYUY9nKmIZ7ahszZKCIg1vjK4bg977c3YfUuofYvE1qK8B62JnaRtNY2pw1mWPXYUu9hx6y5aXnO43o4vImQWMZumHDI/i9OCz1/yE6xa5JDdu5k6aAatFUk7Yy7ZislzFm+4hdVrb2L3T6+GJGLqiCOZOuZ4hA/sS6misGAi8Oh6/nII75Bao1pTREWBkAXKDBFxjBARsRuQeY+VEY1tWxkNc1b2CcphRTUsyZKMLAlOR1KKYBttLdgQBMUqChuHomLvvsW6fEAhF+YxxoK1aB1Nyl+DwxrEUtdimoBwYYETEl9vVgJ1WE/6nJhk7+xECwGYUIzHr6sqMxFfHJcdh4VFBG24UBcdxnStVycEE7D8LsmRuteJCelZBMFF6mP+HWjGGF70P3+fRz7yAj7/uX/nPW/9LEv71vjwZ/6GKAraH6vLqyRpQtbMuPnGW1ld6bG2OuSMs06h1Wpwy3W30G63abWaHHX8HINeweLeHnMLTfJixK5duzjs8MPIBzkXffRzPPC8+3PSPY/nrM0n1cM3XNdjjj+WY044lq9c9B/ccu3tXPj0RyCEYHZujs9+9rO88Y1v5IILLuCKK67gAQ94AF/72td4yEMeQr/fn5zPzPQM73nnByZxAsDWrVs4++yzefCDH8x3vvMdAJTSbNmyjX/7t3+buOBtbH//93/P7t27ueiiT/DQh/4exx8fBLw/8YlP8NrXvna/vvDmN78ZIQQPeMADeMUrXsHTn/50gHodMqiaOTIGoU444YSJO9+4pWnK1NQUS0vLnHvuuXzkIx9hfTuy/3rw0Y9+lNe//vUAPPOZz+TDH/7wXY5/586dPOpRj2I0Gk0eO++8h/Lud7+b+9//Afz0pz/l/PPP56KLLroLmyyKYh7xiEfyiEc8cvLYV7/6FR7/+Mdz5ZVX3uW7fl17zWtec5fHypGrN4SOv3jtH7Fp02YedO7XeOWfvAZroNlWfOm9n+VLn/887/vAJ1jYvIkkS3jCk56IMZbu2pCffP9qhoMhT/39w/jnD7yXj33sY1xz9TV88Ytf4KUvfSk/ueynnHTSyRjjedub384dO+7gk5++iPe+55/5zL99mh9+78ecf/75XHDhw0HA9kMP4fOfvwilwwbty1/+8m90fneHliYaj8I5T54PMaWj382ZnWvXDsihdNLLIFmAGCe2HEpr0jgOSdZa47PVbpFmEVEigwZoZSnLasIcEWg8UBXFJHmsRMJoOKDf6yKFpt2aQh+s2Lt3J/loxKC3lyRtkMQZWqZoLYl0ALTwlrLICXO6JIp1LXIcRHadkRgP3e4ao3zEYDQkToOey9RUg0gq8BFVvoRSMVJGDGrZDDMakDiDdhXlqEs5yLFFhfKOJFKo5hROS0ZFhWBEr9sPAFeV04k1WmnazWmIEqIkpdy7myovuPG2O1FC0EpTtnSmaQnBaDRiUAzol8vs3rnCKN/F1Mw0W7ZtZdv8DFksiYtVNrdi2moGZSqassCXKxRFHyc0TlokHWIdoZMUXYvCx3GMrXVF2502OlJgS8pixNpqk8Wl1VqSYjyNCqSSNLI0zD/OggjSG8PhEFMFt9JW1gQhcG5Ir7dGHMc0sgZFMQDvkVqTNdoorRkNc8ZuzNT7KesqqmqEjhrMz2ymLFOK3LFz9x1MTcdMz2Qcf+ix5PmI5eVlVH0+Qlh07EkziVJNjA1gw8zcFNY68lFOFCnA0+/3uPnmm1haWaLX7RJFEWmWBVADUJEiSiXWluzes0SzmZEmGWtr3QCk/Q6swQdi6AMx9IEY+reLoX9j4GmjHsPGthEsmjBIauQ6UAADXWts4xgmwbr5GoxEbPgMsDUlzhNQWj+25mA8WMOFiZOUqbnNVIeO6DdbLBUlYjDC5SWmsmgnaiZTQHOlEmhZK78jEN4jPegazJI1o0YohVcaWwwpyhHDQY9hPiSvCmykEY0E1W4StxtEWRD0Nq6gqgqMzZHKE8eaOEoDCOSCBa13gQmlpMYriYtCFstaz8iXGAOVBIVHSo90DqoKZw1VZSkMlF7hoxSZtlHNDnGjRVyDTlrpWpRb45MmDsdolAUacxmsKhPjMbVavnMeKQWVkBgvqLzFCYWXkjhuIowFP6iF5wxVWZHnIdPSbDjiZorWDWa3zdFTfbpFl6IcIkQQE4yyDKF1sHlFYKSAyuClxAhH5R3KeZSvRdWdx5QVxlYYZ0mnWqSdNs2pGdqdadKsQbPZJorCoB1vgELmoK5vFvtnF4Io+0bgSOy3NQiDnLojhmyRAIStFxjvJt+xUeDc133R1Sy6/ZCvu3EbA7m/ToRw46JYlRVSBYvP9bE/tmMdMwbHmRUmWRNYB6QnAGAdAAURxVC+uL8jwwbkfsKQXH/OOxsmxjqbJ0UoowwCl2FijOMUH2l8EoMtwBgqM6Aa5lhTUuZ90DGiMUOctZBK4V2FMwLf6+F37EKs9dHGo6ZmUEWJqwxW1mi+8szm0PQZnelt3KC7rI1y9iwvMiWnyZSgu3eZdqw4dmqWU446gv5gwM+vuRabD5meapPOThHFET5L8Nu20IwbFKsDln/8C4a7lxjlJXPOEaUZlOOFItCg8Rbhgz5EAPU9cZYh4ggxWkXqOYRUJMpR9LrsGw5opAeHa2cLDj9yO72FOQZDy6g/pLfSrcuSw49VijhWJEnQbIikxhKT5wX5YMDUzFwItnXI0o5djVwNKFtn0XX2ztaB09jwcawrEGlVL0wqLFQbqLlj1qCbLHKhL0mp8d7inME5y9iVU9b6caHfhN9SeISKQvBqPVABQTRzPSgMfZX6HMICWz93NwePH/3oR3PzzTejteYtb3kLp59+OkLC8/7g0ezZvci/fvLz3Pvep3DMMUfQ7LT40SU/4Vvf+C5Pf9YTOeTQg4Nr1soa/W6XI47ZHtYMrfDOkWaahbgTBD+VYsvcNiIVo9sRD3/secRpxr59XaY7TW66bi+/vGoXD3zo8aSJZtSvOOnUkyhLw7U/X2Sqk9FsJrTnNY959GM58cQT2bp1637ncuONN/LYxz6WP/zDP+Scc865y3z0gx/8gL//+7/nqquumjz2nOf+D8444wye//wXcOGjL+SpTwmlVd///vf5h38IJWaHHnoof/RHf8gnP/kpbrnlH3nzm98c1t5flzyo28bv/tSnLuITn/jEXY5n3F70omdzzLFH8drX/C1XXHEla2tdnHNcfPHF+znYAfzpn/4pD3jAA+7yGb/utS972cvuco3CsclJMmnc3vSmN/HVr32Vl7zkf/LN/7yYyy77GW9/+9uZnZ29y/tf+cpX0u12ieOYT37yIv7zP7/Jq1/9ZywsLJBlDV7+8pdz00031a99BWedeVbQw1BBX0IIz7Dfp7+6wt+/8U0kWUZ3tUuSZsRSU4wsD3/ko7n3Wfdh80ELfP/73+cTH/8Er33dX3LwIQejdMZ9HnyvoIchBM95znN56EPPI4lanPvgh3HRp7Zz6GGHYo2jv1by4AeczaDfRUj4H89+Jvc/+yz+5OV/xDnnnMOzn/McXvnKP2d+fp4/+7NX8DevfwM//dlP8d7y/Oc/n0c84hH/5T2+u7RiWBLphFin7Ny1hDEOrVS9NoYYOrDdHeUolD1IGcTCx9nqZivB+yBA7j0hvvFjDdFgBFNVhrIoSLN04kg9znKP52NrLcWoQCrJVGcO4WE46LK0dxdmZMDkuHYDKyzCa5wxeA9VqA1ACoExup6Pg9tyURiGg4rVtVXyoqQ0JVIHhospCwrTxZkhnghnBaWrcNUoJKirkthZvAAdaeIswUcRWsiJy5+PBFllUbpBaS12NKIYlTglEFoRJyktLZFastxbZm00YqW3xuJyk6KR0Y4TsliTRQ3aVrDUG+H7OUV/kVxV5M0I3w5VCq5cpR3FtLQOmiplDuWIshhhncR4Q9TpEKUp7dl5tCiwZY8s8RSVxzjD8tI+yrKgKEbEStBIIzrNZnC3Ng7rQiWBcw6tY7RSxDrCYcDBoN9n0O+jozjE1FKRxSnD4SLWhGR3mqa1KLXAeYW3kv4gp9sbMByO0DqpmQ+WdnsLcZKSFznehyT35s0thAgi9avLy0HjryjZunlLYKVJFdaJ1NOZyoI7l7MYUzEY9FlZXaHVblOVJbfv3EO310UryfHHn4CpTCg/k5qiNIxGJVFU1qZJdhKAB8bOWHPm7t0OxNAHYugDMfRvF0P/n4mLs/+mfkwlXKcZ1l1/rHBfv34yPjcCVGwcNOttwnAaA001NwX8/qckQl1imjVpzc4Bnv7e3aF2sggOa9aB8BIla7QTtQ5yUQNehBsUysJqcTep8AIqU1GVBXkxojQVpbM4rVBJhGokRGmMSjRIX39fhfMmUGe1CtRT6yb2uaE+uKY1KonSAuEDzdLYMbAG2kukF0jnA23aOErjqbzCCoWIMlSSEaVNojiU2YW64iDwJZRERBG4FKMSnBhhvUBXNlChpSGOQp1xHGusBOMl1rtAwhMCpWOcT1Eyw9seE1e9KtCinXMkkUZFKa25DlXuGCwNJroEpixQUYySCq1ifBwWGSeCxoiTAksQQaPWC/B1MOS9RyhB3GyQNptkzSZpFvSy4jheB5kI4M96n2BD5w/9ZVLrPKEqwkQxfmN3moBHAfTzXiK8RDgxZimu95vAQazBJ79O2rubt8m1GYNt7L/p2tjGwoleeNbX0vHEIyfuCBvLDDfSjcfidJPf9T2Wv2bYiwkbcrzQTnDm9QOtP8u78XyyLsoItZMiGq8EUZxhoxwtBZUp8FWOMxUybiHiJrIO4seijH6Uw8oaqqxCHBQnSCtwKKSsQW/niUtHJmOajYTb44ReUdIbDWiaNsKDzSsyrWnphEPn57jdWW7cvZtdt+3EzE1zyFQHHWmEhrTRQHc8iVPs3b2LkVTI6WnaWwWpCpmNMBdplNChLNWt02Q9IpSzagVmCG4aZBCl9T6nzCvcYITwBoqcZqsR9ASiCltWuMrirQfhapcLOWEDaiGQSJxQwUWzqpDOhTlFKqhdmIQUeBPse0NgFAwJcB6kH1e41uPDTf6YJCHqxMNEYNOtz/bS+0nQYMw46AquGyLYJ03G4XgmD7hw6JdSaqQPx2Stqbt8EJgMffRXxsZ4brgbty984QvMzMxw/PHHc/7557N5yxZuuOFGjjxmK1sOmuHyj13x/2PvvcN1q8pz799os7xt1V3ZnbapAoIgIPaICogaDViiplhi1JiTaI6eJCbReGJLbDk5MecYFWJNFBW7KIiCBalKb7u31d82yxjj+2PM+a61LYk5Xl9Crouhi73KfNuYozzjfu7nvtm5azdJati8cSOD/pBdu/aSJAmtdotedzDSamy3W8zNL9IfDFmzapJ+f8DiUo+JiUm01LSaLbwLmfjN2zYzN9el2x0we3CGXbsWmZvpk2UlEkk2KJleM40tHXf/eBafW7LugHRskqOOPIpjjj28LG7z5s3s27ePu+66m4WFhcP+5r1nx4M7uOGGG/jsZz8LBGbRli1bOO8x53L66afznne/l0ed+Si899x3331873vfG1175plnsnXrNnq9Hvfddz/WWqampjj22GO57777KIoC7z0PPvjAaL3as2cP9957L9u2bePOO+/kc5/73M+9B6eeup3+YIHPf/7zdLu9kQD6rl272LVr12HXXnLJr/3M59i5c+dIYLxul1566c8EnhYWFrjrrrsOc8jbu3cvrVaTfr/PrbfexpVXfoGXvexlrF69+qcev337dtrtoDHzwAMP8J1vX8ctt9zM2rXraDZbfPnLX+aBBx5g06ZNdJe61TwEL8KcnDk0Q5ENcUXOli1b0CbCWsfe/btwzrN29Uaa7Q5oQZxG9PpdHnjgfvI8Z9AfsGvPLjZt2kAURdx5552sX7+eE44/kaxv2bJ5C0cetZUdux7gkJ2lk67mmGOOoSyGWAfbtx/Hxk0beOe73sWBgwdx1vPggzvI86AltGvXbm695Tbuu/9uTjzxRI488kiOO+64n3vvHgqtLCxKgNCaQT8Ph4l2o4qlPaUN621ZlOGAb+sSGkb7njH14aMK+r0fJe5qZoRzljzPg1g5BAkKF/bWwGALcbH3OQKFMSmt1jhKSBZnD1EWOaUbUOYDcBYnTRWXU1VZ1Bo2oXRLKoUsA+MqG5ZkWSVNYW2lHRLKtIp8gCuHKKHCAclayixDWou2FkVl/GM0GgHGo9Eoo0bAk9QO6w1RvEBWFpCLSqcksERiZUBaGpFhkA3xZcZSt4uzFt2CdqSIjCYWCVlpycqc/jDD5X2GvUWyfhNtFcp2MVEbZWIkKsTIpagOcR7nCpQURFqTJDHW9sFmGC0onad0jl53kaLIybIB3lcSHEaH7dBbCuuw1lVAYFUGpMJ+711wxuwP+kRJTKPRDPbqSiEIh1WKnLTRREhFWXq8FzgPeV7S7fZYWFykmTaJY0OSJDRbTZTSLC72QFiUVIyPNysAwpJlGbYssGVJEicorcjzotKQMaSNhLIIbtnWlWRFRn/QpdlqUNqCxaUFpBTEcZPVq9fQXewyHAzAQWkDG6/fH4R9vE4eCz8yD1oOGh6a7eEY+uEY+uEY+pePoX9h4Kmu0R1NjBXAkfPusAlTn8QDAlzXEEpqlzNW0BRXPu8yulvr5yx3driv1cJU0QxFdbPHJteQNjsoYzh095109+ymGAwobUmeOzAR2hkkAq9rEKrK0hCQPykDUCSMpvQwLDIWuwt0u/Msdhfo5UMyPL6VotoNzFiTdCwlbkRIBTYPwBOUaC1RKkJJE4CrQU6WhSBDCYlRCmkEMjZoY9BO4m2BxwWrSxGE4oQrGZZQlpLSx6EG1cRErUmiZpuo2SFutFAmWOjW7n5KCLwJoqN5c4wCTw74YkhW2CA8LiAtLVorMqXJhKdwgtJZLA6tY4LDQYEf9kJ9a9GnzAtylZPnQ9K0TaORsnrLOpQyDLs5wwM9snLIoLdUbSZg4hbKKKJGgzzrBxE85yikx/oSaUM041xJ6XNUMyZuJazafATt8QnGJqdpNsKGqWS4VyHiCuPDVw4sK5WWarTfjcbKyknhVgBIof7VS0ZZiJUosIBAR/VFeN4KeR5tOnJZVP+h3lSFgHuClpYQAllZggtqkLiq69eh/LEsi5Bdqamaog56qRa5wwOF2mLcO4e39aYZdBG8c1hfPVclaDuiJlcL5iiQHj1jmKPYauN1wTbV+2Dv6Z3HeYstizCHpUK3VhHJhMhCVjqkiEgbqyGKEcrgijJ8bmNw80vI+R6qlwU9Nq8oBwWKIMSvUxUsg5HY3gAtgn3zUavXc0DNsP/gvmBfH6cYkwION3Q8ctUaxoCZmVnuOzDDbG/A+jVrSCbHUJFBlo603aTVbqOGGd25PjNfvY7G2RuRqyNWj3cg7oBJkc7hCwveYkvwQuKlRsUtTKRRok9e9rFC0Fi1kVY5T6dc4tCgF9gKh/YgXYkxhnVrp5ienCDPSuYPztFb7DLoD1A6CGJWVTVVIlJReE/hLNKWqLSBSBsMB31CFXVJHf5YOwRvK2apClRnCSssNLGiRAiPVH4E2EplRmOPKgD33lbbRB0Q1ToVHiGC8QNKjA5Bgc5OoKuLAHBLLVHV9mbrcUgov5UEkjDOUpl9IKQPLm0P8fa85z2ft7/t7URJxNe+dhUv/s3f5vIP/yPnPeZcXvrS5/Gev30f73rfO/jERy7nyec/lic8+TEszQ25/ZYH+ebXf8AzfvWxHLFxNYtzOX/73k/ynetu5LLL/ydf+cq1/N8PfpKX/sarOHb7Jk58xCpm9ncpC09nqoGWMTbv8+IXvYZnPftp/N7vv5SF+SF5WZI0DNookqbh1LPXc/VXvs2Oe3dy4boLaXYSohGjA5CCD3zgA8uaH6oydKjWlCzLeOHzf53b77h99JlPPPEkrrnmaqIoIs9z3vGud7Nl80aGwyEXXHDBiLFTNyEEf/7nf473HmMMr3jFK3jBC17AqaeeOhIof/GLXwKEcffGN76RD3zgA9x4443/Zv+/+c3vDCzhovw3r/2p7Ma/2n72geszn/kMn//85ymKYvS7t7/97Tz72c9Ga80Xr7wK7wRPecpTfiar65/+6XIuvvhipFRsP+YYznn0mbzoRS8ZlfMVRcHjHvc4vvjFL4YDbaUz5B30ewP+/j3/yAmP2M4zfu1pXPCUpzG9ahWXfexyXv47L+Oeu+/h+u9ex3ve/Dd85LLL+OENP+SiZ1zE0y98Or4QXHXVN7jkeZfwsU/8E1u3buHMMx/FX/zFm/ndV76KpBks4Muy5LnPfS5rV6/nE5f/MyedfgrOeQ7tzrFNR9xo85UvfB2Q2FLx0Y9ehgDKzPOud/w1P/rxrZzzmEfzV3/1V7zjHe8gy7J/R5//x7ciz1HCYJUlijTaKFat6ZA0FB7LzMw883ML9HsDxsfHluNpH6oOTGQCwKKC7k4daxd5AAPKIjwveLJMUtO64ySi38spcovWEEctGqtaGL2ALS1lBs3GahrJJFjJgT0PsLRwiIUD+0FpkEE2QcgQE0kVmDBlKVEVq6OQgixz5LkFCULJyqzHUdoBhw7MIKVFy6Cl5mxwpdbOo5xFFRmxABkZlGqHygnnoZRIrZBGg9HoogSZ0WkuIj0oZ0kihdYeJQOwp5Rhup0gfEY2FBycPcghqel22hwxNcZku8Fku0MSp0x12hyYnSErCub378QNZ2k3DBumY1q+RNFEx21MswkNgyfDWrDERIlCGw9ugHc53luiSFF6T2k9MzMHyYZDBoMuw/6AsrBYW/VhdXisQZ9+NsRVh2EhQjlmd2GRg3ofg34P7xzNVpuk0aDdbIdY3XmUDKLGg0EPrRsoGQCyYliS9TJiZVi1apqjjjqaNWvWMBwOmZ2bRSpFZFK2bt0cGFMeDh7YS14OyfOMublZvIdev8/adetoNpp4zyiWtq7AlkUASis2XBwlbN68mbHOGLFJWZpdYmF2gVazzaA/oNvtsnffPlrNFtuO3BYSAdYz1mlTlEUoRXoIt4dj6Idj6Idj6F8+hv6Fgae6jcqaRuyl0JxzFU2wqh2sgKERMscKG/vAExyBVzWTZIS+VmBCff1ynetyZ9f1q3UNq9YRrfFV2I0ZJmkwV5S4hR5uqU9my1ADKxyykOBDXW1d+ocQeCnxSlISrBIHwz69/hK9fo+8LCgFOK2QjRjdTIiaMXEaYaLAjvLYkNEQvqJOC5yFPCvo94fkeYkUjAAipAITo32M8grhgqCXxCF9Ca4EK/E6wQuHEAoZN1CVrlOUtoiTRmA76UDlFLJmc/mqRtgg4wbO5jgXGFu+8izN8xItRdAzEhJfgycVEh42RoWSCaoSGvduEDIdRU6R59iywGNpjjXIeh06q5bIF4a4YckwG2DyNOg8VQucVBqdxIFWWBaE3FxYTEubBzS2qWlOtWhOjjM2OUHaaBNHcRjmy2mBynpU4J2AEQZbob7V+HDUY0eMFuN6Y5BKVgh//fdqHFTjUQpZKQgGcU8natHxeiKEh9bsqp8R8z/k2oguiRiNlfpAGJD65brgOmtSlxWGxaau7Q3NO4/DV2N6+bFh/Ijg0OJcZc0c1gNXiez7MmT3qF63pvsGcXmqeSkPA/jwoWS1tDmu3oi9X14LhK+Ycx4vFSpuohvjoILemRjxVkWoiHcWuj3EYIixwc0SDUKJCoiWmFaMdB5pHT4OnEmjNOOtDmWWs3TwIMaBtB4Z1WNRoPKCtTLm9FXruKWf40vHvp37WZtbWo0GpgxlLNJbYhPhlcXbgsG9B5hfNMxvb9CSQ6IKPBXeIaVGyLAxCaVHG5TRCqTFUlIQg26gY2gkKa4oGKqIg3sP4Kyj0R4yNjGJMQmNRoItgtOmThpEUUScJGhBKDl2oZ9K78iGS8SxQUem2lDDjZEqyGw65xBVqBPuXwjOZFWTLkeZvXBACuNQHj5uKuBX+nC9WJHlGYlsVrTx2lkm7BtBw09JGdiT1XwPm20IfsK4q13Jlsd3DS877/EP8aD3ne98J6eeehpxEpIK27Zu5fd+9/e48eZb2bV3L8999jN50uOewLFHHYN3kj279rB/3x6OPHI7q9ZMcsIJ21HE9JcsSgue8KRHccLJW2k0Ex5x6nH8lvo1HnHKBlrNBnMHMuLUkBVLfPLj3+JRZ53Axo2recXvvJhjt29Da0mzHQXNQgSf/cwXKIqCX3v+xWzZtpHx8THSVlQJx3q89RUjdzmwBvjRbT/i0KFDnHPuOVx99dV89rOf5b4H7qPX742u2bVrJ294wxsQQtBqtfi1Sy7lxhtv4P3vew/79u0bsbhe+cpXcs455yCE4FOf+hR33303r3vd67jmmmv43Oc+t0KkHF7+8pcjhOC9730vZVmyf/9+/vt//+9MTU3x1re+lbe97W1s27aNSy+9lPe973088MADAFxyySWcdtppgOdLX/oyX/3qV3/u/frIRz7Cvffey+te97p/895+5COX8cMf/pC/+Iu/QAjBcDjk7W9/JwsL8+R5znlPOA5bOr59zZ1cfvnlfP/73wdgcnKKv3zrWyiKjOuvv55PfOIThz3vBz/4j1x77bUIIdm+fTsXPeNCPv3ZT5PnOUIIXv27r+Tss88JIuUeirxk3wOHuPnmH3LPfXdx9mPPYN36IxgslLzkN34ziHh7eP6lz2dubh6lFE97+tPYsmUL7XaL737vu1zxmSt49atezfYTjuEv3vJnHHPMMYx1OvzFX7yZc889F2sdP/jWXiZXpWza1uHVr341iWky6FpUbDg0e4C3vO3tPPNZF3HGmafz9rf/FY94xKlc8PSLePd73s3E+DgvftFvcuWnr+H6679bsU/siH32UG5xkiAE5OWAiakWHkdv0OPQ7CHiOEYSgAhr7eiw4KwLxieEGHh+fgmPp91qkOclpXUkcYIxmsiEMgljJM1WWFfL0rFnz36yQbCwn141SRIblNQkSRqY7NZRFoHVHicdJletJ202mJ85QN4bUJQlcdIIGj2RJopTEBrvNWXpsAKMiZHKkDYNjUGKqbQypSzxLqcss/C6WmOtQ3gRypDIUc4hra30VwXSrzjoCIHQMSJOkFGElgVRDs0oxUclNhqglURKj6j0SRCQGkM7SZhst8m1o0QiTdC8Kl0oc9NK0Upjho2Y3tBTuoIyH5Bri/UR1pXYMscaizZBR8rEMdoLUA10GiENlNk8aIHSMVEqKSkoXUkUOYqq+qIoAvBXlgLnwr2t36vznizPEUIGwfgKVHClZWlhgSwLh9LxyUk6Y+PoOEG6YHzU7y5hHQwHBZHKkNKS9QcYrZmYGGfLts2Mj0+QJA2yYU6e5URaI1UwI1pcWqgOoL5KPHus96ECwjqybMig38e5oHcbhNElS70ltNFs2rSZ8bFJrC1JkhjvPEtLXVTb0G530EozPjZBo9mi2WqxY+cOjDFhvSmCHplWmrIof0FA/z+vPRxDPxxDPxxD//Ix9C/uajc6WS+DTSuBp5WUvfpUPiprq4CluvYQQSWcuIKuVVO+RnRA91PPN0KTK1qhp6YNBlAjbY3h1jhUktKbPUQuJGVZUHQHeOsQBFAI7xBaIFWY3q7Cn5wQWO/Iy4LhsM9g0GMw7JPbEqsF3ihUI0I1IkwaYRKDqkT1fAWWCSlQXlX0tADwDAdDyrIMAmNGhrpQqRDaoIhRGKQPg056h3QZWFU5uyUIBUIaVNJARwlR2iRKGpg4GS1YUlRASj2YhcQrhYwSKEN2qcwH4MNELUpLUUhsaXEy1N9W2AsCX90biZQxUsZ4P6R0IQgqy5KyyCjLHOdKklaH5niD1lSbuV0zlHlBlmUkRYYuDd7ZapILlDJ4K7DYkT21857C5iCC1WVjos3Yqkla7THiOA2ZtjDIRov8CNSs6nVlJZ5nXQAYgRGldLmOepmFF2jqcsR+C596VMAHlRAbTuIrdwRraxLj8rAUNQj6EKcIA6Ngth4v9Zyrwba6rQR0RcUsq5aa0WI42qiqvq+/QhlEBfh5f9i6UL9CsDXlp5hiy2yy6j7UOCgeKSSu2jSH+TCAvHIlsE2gp1OLygtUlKLTDl4YbFGP/XDTnPNYLHowQA3zYEZgAhtSajBao7QmajQQhUVkJcIEbTglJe1mm3yYkUiN9iJsmlQUVjwqz5hSEenkKvYePMR8r8+hfTO0hSbpOLQx1OzNSBukLjFCM7d3gd5QsbBOYcwAJUKYolRFwRcEur2ugebwPcIiKen7CK9SVCxJ0wSb5/SihKWFLll/SK9XEsVNzFiMMRFRXGALF9aVOCZK0gB+SxXWaMJGlWdddJGibULQQauythV4G2jClRDxaGOqbV5DAFQ7rzhslfVjJIKLqDZNESjKo7ziTyC69d4QxkZd7uGoRQ4ZrWEVgCwVSnmgHCUzPMv7Wb0+uCoAfCi31772taPvB/2M1dNrefELX8xb//pt/PjOO7nkV5/NKSefwgnHnYi1nkMHZ7jv7nvYeuRRjE20OHb7kXgLvcWc8VURjzrzRJSWDIc5Rx65iWOP3YY2gkG3ZP/OIWvHU3zXct23b+TIo9ZxwombufgZ5xPFukr+lCgliWPDD75/I92lHs+59BlMTE3QbLWIEg0+ZMts7pY1FlU1qx3cfvsd3H33XZz16LO49dZbueyyy8jzYgTyCyHYv38/f/M3fwPAunXreN7zLuWHP7yB9773vQAYo2k0Gjz96U/n7LPPBoLu0zXXXMNrX/tabrnlFi6//PKRoLkQggsvvAghBe973/vw3rO0tMT73vc+Xve61/Gbv/mbvP/972fbtm286EUv4uMf//gIeHrqU5/KJZdcwvz8PHv37vtXgacvfvGL/OhHP+LFL37xYYLhP6t94Qtf4M477+SWW24hTVOWlrp8/OOfZOdOyPMBJ528icEw59vX3MmVV145EtR+61vfyu/8zstZWFhASvlTwNNK4e0/+ZM/4clPftLIuU5KyQte8AIe8YhHANDtdukt9Tm4e5Ybrr+BH9x4HS/8rReiiNm76yAXPeNitFEsLXY5//ynIoRgcWGRM888k/POO4+yyPnxj3/MZZddxq+/6IWccMIJvObVr2IwCIfLV7/61eBh2C+569YDbDpynA2bO/zqs36VfOhYPDAgHZMsLi7w6c9/jFNO385pZ5zEJ//5E5S24MKLLuCzn72CDRs28Bu/8Zvc8P1bue5bP2R8fLxizf2rXfyQaCYylKUly/uMjU9QFiWz83PMzXviOGK8M75i71V45wl4WtiHnfMsLvVGluy93oA8L2i3xmk1G8QmRlQHiDgWZHlBkQ04cGAWW4AUms5YB6M1IDGRwVoHpaU/zLClw0RNxqYUzXaLpdkZbNZj2OviihITGUQzQusA9HgnsC4HHFIOR+LaSRqhyxAbl0VOURY4WyBljNYmCPj7wCBRLuiZKucqIKpa16mlHwAdIaMUGSUon2F0TqJjSpOTaYNWNRAQWCiKADzZJCG3LXpGUHiIVNggrHWUpSUxQVOpmcY4LINigHdlAIaECE7VrkRZizIGoQ1aB9FiGSWoJMJLKPIljG4H4EnEFG6Ithlx4smLAipmU1EW2FIBGnwljVGNjaIIrtx5UQQgDXDW0e12EYMu1mZ4XyJwjE+uCk7ReUFeBGBrmHmMGiCloRjmxFFEq93kiA0bieMELU0ogcwLlNLISmtmaWlxJFhvjMG6UHnhfXDBK4qC4XBA6Urm5+Zod1qkaUq3t8T4+ARr16yl2WhjnSOOY3bu3EG/36eZtGk1W7RbLUwUkwLtTofZ2dlwdvNUOle2KjX0D3nG08Mx9MMx9MMx9C8fQ/+7GU81MrdSRA0OR3rDm12uYw2g0cqJKUaTzI2sBT3eBmQ3uNitUPEXQXRuJKZWfVDhRYXaVoCUVDQ7U6TNMXSUsLh3F/O7HiS7fweuNyAbZrhBDy0lkY4w1SZidIz0BuFLsjxnMBywuDDHQneB/nDAwDtsHEMzJhpvkI43aIynxGkAnqzzWBdALK0UDoG3nmxYMOgP6PX64cZKPaJZSqFROkLLBCUjEqXREoxwKDvElwVllmGNw3qJMElwzjARSdpERxE6ilDKBDaRrDde8KKi0CExOsbFjYpZlOPzDJsNyL1HWReseWWYwAIRkFjvwAdEVOqEUjfBl1i7hC1zCpGRDfr0e4sopZmYbJKOxazaPM3C/lkWhGNx9wKypyhsiUoiVBwhncZLHyxjbUlZ5EGk0OYknZi03WTD0dtod6ZoNseJoxQl9MjyM+zEwerVCokQZUB3Rwt7AI9qSuGKVbeaIOGHWvHf1ZmKirk0mqB+edIF9EnhR+Cnq7Ie9Z5z+IbwUG6lLZAotDQoEUodgvg/rGQySikpClvNYYVSUYWKVwBr5V4gpEAJWc3VUMse3DPCPUV4kD44SwIgKivR6nvvRxtlvcAFF56wJsgKzPNAaXOsLcnLnCzrY8sS70u0DoFsEqfh2mrtQIDSGm0M3ha4YsX9dbULhMUMCqLcEaHwMsxNlUiUkygv0VaikGhtkD6tnFkFnbWrKCJI97SDhkaWY9oCLYMtrDDQ0p5VKTz+SM+e2RluuPPHLBYC0xqy+sh1yxuO1Oh2m3h8gol+n4EbsP+Wg6hjhrhVKY32GF6mOGEwOkUKC74ESrxQOCK0K5AOhmVCEU3gxw1TncAWtHnB1Jp1DPoDjIlZ6nZZ6vUxIkIJSdJsopQijmMazTZJqwN4in6PKGmgo4hhP0OZpeAG2hinFmisEwxSqiqjxijDqyrgN2SZageMel6GbNXy4KhzhtUtCs8KKtTDh3FXv94yqDyaiLC8lwiogWUpV26OnrLksDEHAbwWNVn3v0Bz1vHB//VVJqZa/NoLH8trX/Zq8qyg28v5zCe/yW0338sf//lLOP6E4zj2uKO55dbbaaQNjjvuWL73zf1kmeW8rUew+/4F9uyY41vXXsspjzyGxz/5dLyTJA3FpmOaCAGrV0/zute/jFVrWnQXe/zdO/+OU886lcef/1j+5i//kTXrpnnRy57Jf//j3xutIR/4+3/ke9fdwAf+73tpj7VQRrD7/gVw0EgjxtemSCno7h/y5c9/hW9dfzW/+6rf5aUvfSnPec5zeOffvIsbbriBb33zGibHpxAIDs0dBGD//v085jHnHQbknHvu2fzxH/8Rf/ZnbyVNm1x55ZX85V++hSzLaTabvOIVr+BXf/VXOe+889i5cyfee/7qHe8aZatXtve///188IMfZGZmhs997nNcffXVhzGlAHbv3s1jH/tYDh488G/eq127dnHaaafR6/X+zWtXtlaryde//lVuv+OHXH3tZ/nwBz/Lrp37f+a13W6Xxz3ucdx///3/6nO+853v5PLLL+czn/nMCHyanJhAKY0tPK9+9Wu44847+OLnv8grj/sdhoPfoNPu8NGPfow3vvGP+dKXvwAO/uYv380r/+B3aI21OP/8p/NHf/SHvOjFL+Tqa7/EKacdx00334gUsLiwQKs5xjVfuY3FhT4XPvsssqFn0M859XEDJibamETynrd/iGywyAnHr+FRY0/k6KOP4uabbybSMUoarv7mt0iThMgYrvjMFQDkWc4fvOE3+b3XvYiiHI5ioId663UHLCwuMjs3x5YtjjRNmJwap9ftkuc5jTQh0gZbWqQwDPOCbOBot4JRTZHn9HsZRVGQpgm97oDBMEeJBlpFJLEHEbR65ucX0UZRlAXZcEijGUT/p1aF9R7vmZuZoygLvLfBgTgOzPLxiSniZC1pq8GBnTvYv+MBBguL2Cyjt2hhIidOU9TYRNBycgXWz2GiDGOGOLeE0ZpGs8niQmDap2mM0bqyHfcoBJGQ+CJDFAXCQVn4UD7mBPVyTqSRUQPVDGNVYLBxXrH9dTDT0RKvDFIbhHN4W5LoBNNKaY2vYW1nilLAYHGWfHEGOxywuLiIS2NEGtNoN9CpIW7FWO8Dc6E9jbWOgYXuwhLJMCeODb7wAWATGmliHJAPhui0FRLgjXEKv0hWLDE5NUbSaKPjlEG/R150l53EhKqEp2UQKy9LpMzIMkVidKWBJOh2++RlxlJ3nmy4RL97iEN7d6JMA520cXGDrHDMzC7RSJaIo5h2p8m69etZtWo1xbCktzDHYDhkcmIS50NCnLJECkFRlqNyuUajQZZn9Ht9Wq1W+JyJCVUKQ8vC4gJChth5aWmJOEopCkd3MSQLSutZXOwy6PeZ7Kwm7rSIIs199z04ShCkjUawpNeGOInxzpGmKXHUqCoYHrrt4Rj64Rj64Rj6l4+hf3Hgqfqsox/94UjaStR19H2F8or6YL/i6UZMqAokWclIqZG/laVRQgi8ChkU4ZcnXGDAVMJqNdqnNI3OON4GYGIxtxTz8xSHZnC5xXpP4Up86Sm9pXQWUWqQimGWMRwO6A+6DPOMzBWU0iMihUwNphkRNUJGR5mwcLgaVazANYHE+SCkl+cFRVFi9LJzXlhwAviklUarCG0MRgqM9OhS4JQCgl6TQCFMEii+xmDiGFWBZsEZoUImV9ygengFtNLgTIyLktDPrsSVJQ6JdQTHARe0pQJ0Q1i4hESiUDLCqRhRRuGxlQBmlg0xwz553scjiRqadCwmG8R0DwmsL8nzIdmgh3Ilyhq88lhcoDC7EhREqaEzPU5zrEOzNU4cN1DSLPOP6jFQ4ZDhnlsqVTU88vDxWI23uhb9p7ey2pWuGjM/MbYPH/TheimCxbFzdfleRTP0jtqy86HeamowBOfIetyMKJgjFHwZGK4zOwKBF260oQV2nwrjrwbyqpp3Rq9hR5mbaoqP/gbL+m4rmYy14ORyWWMYj7Xrg3WWeq0M7OOwAJZlQb3w+tFzyiCSbyxSDkItsnOE8kkLrkRZUMiQCUEivECLULqqpEJjUAS3BxkrhFJBryzvobWhbBisBG8dBolWIcsjJCjv0Q7WjU2hnGBHo4OylrzfQ2YWHZvwOmkToxVxktBYv4aMAjMcA5MxKEpkv492EuUNzkqUBK0ExnmwFsoezhlK6XA6RfgIIwxCKqIkoTM1RXN8HC8UtrDV+6uzMWHHCBoBjjLL0eMhoI9UcAlSOmiqeQSuLDFKVWPeB5C3CoCUrAKpWigUMaKmy9E4qTNay3P5J/DhMEx8vV9Uc7S6QhCyjFIsj88KEg7P56oy7ep56rSfGF1f7xvL46saML/M1PoPbUIIjt6+nkYzpnSW3Xt3MxxkrFo/ydat6zFKYW2BtWFvmZ6eYmFhkW9882pcdw1J1GL3g7N4BNNrWxx/0lbWHTENAm684V4azZjjTtjITd+/g+GgYPuJxyCcZbCUsf2k7bTHEg4ceJDtJ25hcnoSIQU3fP/75EXOr5z/FI4/cTtxEhMlhhtvvpEf3PADnnje0+l0OkRasbB/kXxY0p0dcuojTqM5kfKhD32IM844g1NOPZU9u3fTabV5xSteQbvZ5sCBA3zoIx8azfVDhw4d1h/tdoejj97OcJjx4IM7+V//6+849dRT2LJlMwC3334711577WHgz7333P0zV+xerze6bjgcHibqDfC1r32N++67jz179pDnOcYYLrnkEnbv3s1VV131U8/nvafbHRJFKVNTbebmDo7WPYC1a9dy0UUXcM+992FLy4c+9KHltRjYu+9B7rjzLg4dWmAwyAE4Yu164jjh/h0BaKr7ZGlp6eePGQQnnnASZ515FhuO2EBnbAzvHPv37MI7aHcmOeP0M9i8eRNKSW780a3cfscdvODXX8DWbVt51rMvJjIpwgke9ehH0W63iaKYp5//dLZs2oa3gjWrN+Ayyf7751m3ZYrFxSV++IMfEqVjjMmYyy/7FKec8giOOnobU2o1jWYHqSTbTziashiwaeM4UkgW5me5/94fsH79sUxNbmD+wJDb9tzBA7vu4tnPfhaDQclXvvg1Hn32qaxdt4ooHhvFfg/1lsRNijQk/MrSYq0nNjFlFIxnAvugSmxVZalxLMK6rwRRFNFqtSiKHIGg2WzQaDbotJskSYxSElclx/r9IY1mjMDTaiakjYRGGgWZAxucHvuDPkUZGBYklXt1tSRKpWm2x5mYznGlZ07uJe93GXYX8INhEMQ1ColHS1BCYMuMIs9YWpipnJZLfNlH+BytBGBxDiSBOSG8BWcRziO8xBa++v5wfU4vQgIwVApoVBSBViAlTspwMFMaKua796ClIYpiWs0Ocu0RlHjmpGch6zPIM8rS4TwgJVFsULFBJgbrCC5ySYsiyynzIB0RyphKRGkxXiEjj/GysiKPAhPBeUwlEC61QZkILyTWC+KkQZblZMPisLVHVuyLes4HM6ISUMGcyIMXirTZxEQJHsnc3AImcTR8jPCGolpSojgIgKetBtoYnPMMB1nF1Akarh4fEu6RDjIdUoVSN2tRStFoNGg0GngcRV6S5znj4+PEUYz3a0mSBGMi1qxeR6vZRglNNszD8xpFI21UidwQZzkn6A+WiGyENjKMXSHIi5w8G+K8Jy5i8Arcz3ZPf6i0h2Poh2Poh2PoXz6G/neX2q3MEh6eLVyefCBH76U+1UspRhStEe+pvt4vfxDn7Mg6EpadAQLqJ+vuWQE8jbq57iYQgrTRwZiY5tgkCOjt30deZvjFAS4Pm37pLJQg5JCaZjbMMrLhkG5viUExJHOWMlLoRCNbEXE7IWnHpK2greQFQdmeMF2lkHiCNehwmJFlOUVeEJtkJIwthQCp0GiMidAqwsQxkRJESqBKgS00iFB76tBBVDyK0Fpj4gitdLCzpGZ7VQvJiIUTFhstNU5HeCxlnIAI9Z2OgJNa5xHW46VHqFCDLEWo76ZC35VKcC5HigTPEGdLiiIjGw5QSjMYLKF1gmlENKdSijxjYZ/GDgpc7uh3l9Blji4NTgkcDovDa08UG5pTLabWr6EzPkmrNYWSGoFcnlTVZ0FUS2I1juSIoCRYWZpRa1XVelej2SM8YkQTrGquK/BJrhjX9bMGLLEGNJeR31HWwvuKNVXrmj20m6rEYxFiRNXXWqK1HgUCzgax9SRJg05YtXlAEJCrqZ71PZEiLJK1c2Ogv8pqEw7zWKlQclNvjrC82flqzkrU8tpRN29H9zFoeJRYW1brgKoWOo/3liwfLm+8I70yiYpivPeUOsK7LGyYhM1GFCHDIZEoY6AKeI0IYK1UhohKZF86SAPgG0Ux0dIcSmmypqGwASyPqqyOSiIoJcp6dOE5YqxJU8XsmdwbNDMGXfQgJ1IGExma7SY6TTCdJs2t67Ba0Jyd5eDSPXSHB6FYQJcKbSNQYLQkjRSpFWALyPsUMiVXAtdooaQhUhLnwSQpk2sTOtPTWC9YnJkjjgNF2BYWb2vsVGKtZdDtMbkuuIXG7RY6dagIpInxlSZcqlUIpp3HeTEKchR6eSOr7ndpS2oquRJ6NJfCHPYjp8/DdpJqw6xLqaWsAr4qgyNq1mi1SYtqk8SHwC2MK0ZTstq5wtorl/eNUfLOrdhAH8ItZMTD537ck06mdJYsy/nBTTewtNjlzDNP4+xzTwJxArPzs/T7kOiUrVs2cePNt/Dhj3yMi3/l+Yx1Wtzxo30cf/I6Nh+1ii3HTIxo+F//yk2sXjvOcSds5Jtf/R7dxT5nPPp4Zvf26C8OeerF57P/4H3s2PkjnvqMJ5CkLfDwsX/6KEuLizzpKU/mqRc8KQQ5Ar729a/yZ3/2Z9x04+OZXLMWW5bsvuMQCwe79DPLxRc9C5/kPOKUR/Dyl7+Ck046mR987wZOP/2RvP/978day/e+9z0+fNmHf4qdBCEmSNMmq1cfgTERDzzwAK961av4wz/8Ay688OlMTk5y5ZVX8qY3vQml1Ehf6sH77/2p5/pF2j/+4z8e9nOcJLzpTW/i6quv/pnAk5SKTnuS8fFQfri0NE+eLwtgH3nkNt7xjrfxqX/+DN/5zvW84Q1voNfvUeTFTz1X3Y49ejvTk1Ps3re7yrBTudrKw0CtlU1IyQVPv5Dfe/XvkTZjXGkp85J7f/xjvIdtx57Er7/whUSxYdjL+NznP8dlH72ci5/1DM4++9GcddaZzOwPblQveumLyIc51jre+pb/icdTZI7jt5/Kj75/F9d88fs867fOZ3Zmjk984p94+St+lyTp8LJXvJI3/ulreORZ20mG2xDC46zl/AueUCdwmTs0y57d9/O5Kz7AU5/2EqanNnDjdXfw1W9+ns999Z84+5yzWZjNeN/fXMbU5BSTkxMkjXRFHPjQbp3WOFpHGBOR5UNs6YlMik8qJpALa5h1JUpHARyQMbYMJjiNVsL0lKAoCgaDAZ3JNo1GQqPZAFfpihYl1ln6/QFRrIiMYmK8TZzEGKODyxhhfe71u5RFESJoKUIJnl8WvU0abSbXGNLmBEoolmYOUva7MBziyiFWFqg4sPFjKelnQ5Z6S8we2k0cxWhZ4GwGFdiBt7jSEQmB9CWiLBC2Ap6cxhYObMjEh9grHH6dkCGDLxVSa2Qcg5I4JbBChhhDmVES0DuP0TFx2qE1tZbWhs0UOGQ5IF+co+j3KMoBnpCojtMUFCTCUzoR9v7GGIXrURYD+sPFIN6uJZoyxOSFI0YhhEaalKDHZUEKpFIhOWwipIkxcYNGq8NwmNETXaqTGqKKn4SUQQ9LiGCyY4tKU8XhUSijmZheSyNSaAkzszPEDYE3YxgKvAiW8Z3xNu1Oh0YzON0NBxm9pR4m0iSNmNLWbtYx7XaLKDJAuN+lsxRFTqOZMjbWYefOHZXkSJ80TZiYmGR6ek1gpVnPmjVrwyHWSRb6i0gJcZIy3hkniZJQnWCLqoxzCesTokQzGPaRIoB9/UHQjjLGIIkQ/y9FOP+B7eEY+uEY+uEY+pePoX/hWR6ozMtCVssgk6gA2OXBqqQeAQTUrBNBEK6qIwzPSAzS1aATAS0OnV7r8cjRh1ymdlXvSUi0kstBxwpgQkjC4h9FdNZtxDTbyHaL/q5dFAsLuENz+CyH0mKzoursIMqXFzn9YZ9cOFwsMRMx0VRKPNGgPdWkNd4gbSdYH+qS87KkrLNILog5FnlJvz8gz0M5maqEzPC1MLtEK4MxIQiJk5RIgpYOSciIeC+ITYRDIXRU1cyG4LkONEe3WVCBfJ66flhAQJx1BNLjaeAVQMh6OOcoHajS4SlRwqK8QgtH4Uukk3ihq7r8Blo3Ke0Q7z3ZMEeIPh4w0QxxkpImTaK2IB1GJBMJAzukHJT0Bj2UzVGFxhmBijW6ETG5dorWeIdVa4+g3Z6sSutMtbAH8NJVTCwrwuImRwt/NcS9x2FHWl81QFVPAv8TULAnuDCGkSirLzEa4/XiXoNLNXOKWq2/Yjs5xygwCG/joR/0hsWm+qwVbRI81roq6xaNsoWI5Tkfsi6h36pnGo1hqDM/wcXDWVsx0iRaxaGUcoUjk1RyVJ9ez38hBJYCWy+LVSDmnRjdB2sD045qo61fTyqFFHLZktg5pKwBUxEyEz6GtEUuBKUIGdlaNL76OBUu6ZFItDGoKEJpg4rSKigG0WqglSYWIUDOrKM30aAoIryPiZxHAUJphFAoDToSRI2UTjPl2O3HcO9tOUsHZzALQ1LdIGmltI/chJxsI9eOo9aMYxLDBiXROzcyf+gAM/ffgs26+P4cU5OrEEKSF9Cd65JHinxinF6ynsJMIFRCLAUmEvRzS81h3HTkNjqTE9x/130UWUFWlIy1O0TGoJWmnw2wpcMXnnxpHoOlvWYVKvaoWNLoNBFZH1dkuDxDmhitg8h1mKfLNep1ECaEoCw8EhfEEGXYNL13K7QJZKV96BE1krycmqji82rPqA4hAoHSajRvV0qvBTA46FUIuVL/oArOpAy6KSsOqmIFWP9QbqeffjoXXfAcXvLiV/CBy/6K9evW8orfeg2XXvJMrHWYWHHzHd9hz/4HeNJjnkWeD5hZeJClHZpGNM5b3vzHtNLxiim7miQ1zMzM8MxnPpOLL76Y33/t7/Pi335y0Dvw8PzfvJDuQo+br76d9UeuYd2Rq7GlZ2piIxMTa4iiBtkgZ2Gux+vf+Ab6/SWu/uZX2LjmWFZNrWd8XXrY+7/1lpv50If+D8+88OlsOXkbYxNHkDQTUJ6rvv5Nstk23/3cEllvGTx52ctexjXXXPMzARVjNL/76pfT6/Y544wzRu523ju2bt3KunXrefKTnsp9991DkiT8y7/8C+vXr8d7z0te8hJuuummX+p+rD1iI2vWb+CZz3oWc7OzAGgd3KHqtc3akpnZvTz3kot53qWXcvHFz2D//uWSuRtvvIlzzjmP+flF+v0e3W733xTJfs6lz+H888/nDX/2RtauW0ur1eZLX/oSn/jEJ/izP/uzn/kY5yzv/9v38sUvXcmnP/1pHrj7Lj77yY/z6y99GWuP2IjREX/11r9kxwMP8lf/8z387itfw4te8mIS3eJLV3yJf/rIh/mTN7+FVjPh65+9EsVmWp1pHvXEI3n3u9/D5z//BT75yY9x5AmbWb1hmhtv/R7GaN74x3+KFC2shc9+4cOsXbsKZz1KST75iY/zzr9+Bx/96EeZnujwo5u+wzEnnMGRRx/HK1/1Lg7uXeCm797Eky46nVPO3cJzX3wRk+PrmByD9/3dG9i8ZRONZliDxOEb/0O4SZqNFq1Wg0F/iJQKV0qK3KGkJElS4jjCOcviUo/hoM+wbxG2SZIEln2Ze4rC0e8NMZFGa0WeL6GURCtFt9vDWcvatdOkicF7y9zMEmWRIZWgKH0FfhmSxODjcCguy4I8z7GlxQvH4tICw0FOI2nSTFus3ngkzc4UOmkxnN+Pywe4LMdlQxBDyqUuA1uQ5UP8sEdR5izNCRrNJAhmJwnZIAuMK+9xZYErc2R1WPWOKnMa9n0nfLCiR2Ed4X0l4KTAKkmJp/QeKxUog9ARrjocKRMTxy3SzjjNiVW0xiaxeAbTa8n6PbTSDJcWabWbNMbaNMaaCC3xUuBEYG+YtIWTDVB9+r0cbEFpy3BYFA5MScMJtDZo08L7krK06HKIkoIkTbDWY7QhaaRMTK3ClpalhdkqWb183pEsHz4FjjzPQumNMqxdfwSd8XG2HbWF+blDzM8eQqiUKGrRaXYQaUKUJkxMTrJ23TpMFPPgjh2AQClJc6yBMSFhPTc/jy1tFR8pyiLs2UVZUNiCbrfLpJ2g027TarZJowbTE2tJooR8mLO4OE82cGG8ami1m0xOjjE2FfRmpHKUtqDIM0SUkyAxOmHb1vWVGHObVmOM4XBIt7vE5OQURmuEMEixLLD9UG0Px9APx9APx9C/fAz974CXVwI+4rDJtww6yRFdeASAsPLNVJNN/kRp1Mo3+68c4Fce7it2GTVdbQSAeQKrZ0UnKBNhmi1SO43LMvIoIrMW1+3hhkOKfqh9ta4k8wUFJaXyYCQyNuhOStJJScYapO2UOI1QSlG4AmvtCHSq0WnvXBAvLIog3FgjhaICySp6XkAPgxWtqihsUiwvSEIppA8TUCpV2dZW4N8I9Ftmeq3o5dF4qxF1KYKKP1bjtcZX9qkOV1GeA/tHCY8KswBPcFKQQuGlQcoYbISnwNqc0oYMSZ4HUUnnI5QRmFhh0oihznHSktnKMtd7jIkxjYjGeJuxqSmanVBeF5kUpaJRxipQSwOA5gnllXiQXo0+5WgQ1B/U+5HzZD04a3LhyjEiavBTrFz8q7rXnzlxKvBKhGJGKWX12h7LT+uEPFTbcgnsspB8+DEwt7RUeBX6eSSI6PxPTUlBcKOpn2RUXz6iA/vq1sjKWaFc7iMfHl9vfCuZjfV7FE6AFCMnjxokrV07qgur16yzA/WHcfUeSF2GK0VweDRRjCAI5HsbWH9hKobMjlCVJJ+UFY5bOWEog4gMqtlCe5C5xQoolYBmii8MzprQHUqGjGwUjQT/RZJiipSpbD2H9h3AFRahJDqOSFpN9Nop5HQHsXYCOdZARQaTGJpZQSE0s7Nz0D+EH85TOI90oISh0DFEMT5aTW6mKHWbSIT5HhyDQhbVeUej2cA6x+SqaZbmlyiyIpRjS4kykkgoijwYK/R780jpGbOTGBVhoog4bY202XyZI5RBSRVESPHBYfKwcVLnSJbXpbCRBcnYZUeN5X3FV+OyfmCYcrX75Ir9ZMXYPWy6ekZrBrjq38qNcsScFOGeIxHCsWI4/Wtbz0Oi3XLLLaxetYHNm45G6+AYJIRgaSGnLCxTE6CVITIJWmqsDEGlMZo4TpieGkNrQ6/X43vXX8/xxx1Hq91mzZo1tNsdAFavGePQwVm+cdV3eMQpx7N2/Sp6B/ooo3C+5Me33cX06ik2bDpilHiSQrBx40ayfMDi0iy97gKUns7qrWzdupUnP/nJRCZhIAaMj0/QareRBnbsu5NWc4JG2ub444/nwIMlO3pLnPfYxzC9eowvf/nLCCHYsGEDSkn27t3H4uIiANu2beO444/j7Eefw4033sQtt9xyWF/dfffdNJtNbr75Jnq9LnESMTk1iTGaBx/cEQRc/x9bkiScc845rDniCMYmprjs//7DqMztp9ZKIYiTmKXFBXbt2sG55547Ejm//vrrWVhY4NZbbzvs+p+3n0xMTnDG6aeTFzl33HkHAO12m9WrVnPcccdx1lln8Su/8itcf/31o3465RGnsGbNGgAGvS5GSIaLfbDQGZ/gx3fcxfzSgJNOPJlOe4zxiUmkknS7XQ7OHGTD2s0kSTjUzswdpMgbJGkDoxJ0pNj5wAwCw5o1q0eMvM54m0ajyXDY59577mP9um2MdSbYftzR3HvvPfzo9h9x5qPOpNFssnbtWrK+Zxg7kqTBgb0HmD20gDYZ+KClc8fdtzI2PsEjHvEI0iRBSjjq6E3ESYNev8t3v3n9qM/OP//8/+f7+h/RQkI0MCfqMidjJFGkCOYrAlDY6sBYlgXDbEgkY6xTFWgQnsP5EucCgyHPHMZofKwZDoZ4RyhZqZK9cRyDtCAcRiiMURhj6A9qN0CPUgatJd6YAAz0lpifX2J6chVxFLSMpIlIm+PgSsphj3KwgCvyIGvhh9giwxYDfFmOYkylIkyUkCQNXBn2XspQYoe1yHrPEtXaXC/G9WF2VHbig+amA+sdpa/Ex5UKHSIDg0AIidQKFSeoOEVFCUpHCAlJo0Wj2abMMrCWOG1i4vAljAIlw6FXaUzSpLTB1SlKWohyiCgzbJZRWk+el9jSIQ1IGVWC3B5flcYoHfS1hA9xfZI0SNI0gAvCgwtsGWp2f8VewFsKB1oK0tjQarfodNpIJbHOkRcWkzRIGk2SZhPTbJA0UsbHO7SaTaQyQb9WaaSSFHmBsCBdOGcE0kQohdJKYa0gVAJJjM7xHrJhjpYmuACWgrK0FGXJYNCnLAS2hN4gQxuFp402AQwZZgOUEsRJRBSB1hIhPVoLtAoW7FpqcIJer0+cRKAFZeFQyj3k9+CHY+iHY+iHY+hfPob+dwBPy6wjpdTy+/W1q1zFHhFixFJyvhIL9+C9RWk5QoDrCfCzgqwRfbBC1OrJvpLxVItH14KSo+4X4XF2RCu0IARRnKKnIpJmi6zfZX6syeDgfuzcPMWBjEIWlFjyxIdN32lUI0Y1E9K1E7TWTNKYaDM+3UFFEqEERW5DyVk2pCwHAamuGE9lUZLlWWA7SRlEFaWqkEmJoBYW1CNQSQYYg1F5l1SBWic1SulK3b5mTLFi8ITFKhCBwv9GelneVwNEIYTBqwinDKVUKOcpnatcRTzae4xwGBy4Ai+DXoCSEQBSNZA2wdkC5wqKwoLMybIAPCWJIYoUthGRtlO6s4HxlOcZBo9RgvbUBOPTU6xet45VqzcQx02MSat7vbJck9F9rseKkuFzKPkT17DCarJyZRCEzJmQIWhx1eaPCHaeoacC+FfXVPtKWG1UY+0r/S58SE7VIFVtKSpAWDuiRP5XaCtLZuvIznsXROGUCMGKrJB35yisQynDSgS9tvx1gMOPrD39aF0Ij5fVuItMFKjjNtQOh3krR+uEtSEbExiO1X1zHl+5KLiKsu2cDQtundWpap6DK0UIEJ0MmaUaAKbajLWJUEpj4mDjPHSOMstwUuClDKBuZMIYcR5Kiy8d3ilEJ8WMjaOnplCDIao3wzAS5K2IJJ3GFZ68BN8X1ebawKyehtggIokVBll41rWnWCpKzMQ4Yn6eaHqc5hGr4bgNyMkx9MR4qJWXoA20V69CJE3m8gZF9wBl9wCDg3dRSgGmjVq9GdsYZ9hcXfWDQ/kuTmgcBq110BEpCuLIoCfGaDYb7Nm1n/m5BQ7tn8EJj9Ax7Zai3xvS785z8NAM/f4EY2NTtCbX0WyN02pNMPSe3Flc1gcdgltbDKv1CvSo7tyP/g1TqQ6ubJUJ9ITYpAaZw7jyVOeNwwIiUz1XcBcK3hvhucI6V+0H1TW+CrKCXp0LpbWuDtqqbI8Q1Rj3YQT7Ufz3kG9f+/oXuPqar3LDD3/IcduPw1nHp/7pmyzM93jTW1/CMVsewbYjTkCgiXSDybH1rF+b0O8P2b3jAOs3rubBB+/jggueznve815e/rKX88lPfrKaM2GW/+D7N/MbL/59Pvrx/8VjzjuT4886muGwz8H9B3jPe97L4x//OC593iVEqSKKNOOT4VBkTIdzznk8133rKu677yY2b9/Ac371OTznV5/LwqEhE53VvOENb6LoOx7ccTd/+w9/wbHbHs2RW07mKU97Emu3GtZuneSyp32QT3zykzz1qU/lG9/4BsceeywfvfwyPvbxT/D9H/wAgEsuuYQ3v/nNAJQ/oyrtXe9612E/W2u5/vrvcNddd/G37/+7X+oerFmzhn/+50+RJDGLiwt87p8/OQKefpKtpLVh06YtXHnlF/nUpz7Fj3/8YzZs2ID3nrPPPpvvfve7h13/r+0jJ598Mp///Oe49NLn8ZrXvAYIrnavf/3rAXjKU57Ck5/8ZM4880xuuOEGAN74xjfyrGc9GzzsuON29t13P4N9C2xcu4VX/eH/4IlPfBytVoePfeRT/PbLfhepwpHmI5d9mMsu/wg/+MEPOO9Jj+Xsx57Dxz/xURqNJs+46FmYWDE/1+Pyv7uWxz7+abz6NS9n9tAM87OLYCPOfOTZfOe6a3nxC1/Ee/7mvTz+8U9AePjQhz/CJz/1Ka695houuOACLrzwAu744SF684rTz30K/+fdf88dP7qJ1sRuzr/wtzj6xHM4/0lP4OkXXsSfvOnPsTZIBQSHWcF99z3ABRdcWOmTPPT3YR2XOAdF6bG2QGtBqx0RN+o4mlC2UcXVZVnQH/RIOm2E1JS2IG6IAHaYHEdOUSgWFjPi2NCwEYsLXYSHNIlJIk0Ua6ZXT2P9EE9BFCUoFSGlYe++nQwGfZyzbNq0hVarTZo2uP2OH/Pgzgd58MEdHH3UUbTaCVlvAFaQNMeImy3yYsDMoQcpFhaxgz4mG1AOB+T9RbyXiEhhoiaN1hRpo0mj2Q7i0c7jioKKNo6RahS3KqNwIsQUSI/QEmlipDIhZtCKwoaSpsIWlN6johhhDF4qhoUljQLQpRttVNpCxCkoU7F/Juj0ppEE/Zi02SRptYgabaTRSKPQSYLSGhOnSNPAxH2yQYHNerisT7fIKK0j7w9pZznohCiJw0LkLc4WCBmAH1v2AYEtDY1Gg1a7HZhQRY53EEUGa6EoHVmZhwS2L1Fe0zCK9sQY41NjtFoNZg7tZ252lu5Sl/bkNGNTq2ivnmZ8fIwkTmg2UiITIaRkanIynC2E5NChQyilSIuUTqsdBNqFot1qY7ShzMvKpEjRSBcobcHc7CKd1hjCe3r9AYNsgPMl/X4PYxroOOLg7DxJQ+PFFEIqirzgwIEDjI11GJ/sEJmgt1XagmywRCFzbOEY9ARLC1327N6LENBoNinyEHsq9dBmPMHDMfTDMfTDMfQvG0P/4hpPIyCIETpPBXAI4RDWhTpCoUagRxCXq13uqg51gT67Ujg84CwhjeOq57TW4kalTjWlZfmGrKTe1zdlBLi4Za2okVB5BShESQOtI7Q25NOrKfpLLB7YSdZfIh/0KF02ul4nCSqJSafGgztDmqCjsPkPsoxur0dRDMmKbhBIBIQ3lGUQ5AtaDh4TaYwxKKFxZY1iq4paWus+MUKI64EUkEoFYlmA7qeoqCthy/oWBVpP6DFfly4qpNT4WoRRK4Jdani8xKOxGBSRdBhpKSkpXY6UaQC/dBNRpECGs31s6ZHCkg2GSA/aS6RNsLlHygjdSIlRREbQGm/THmuxds1a2q0OY51JmkkLpWOk0hUyv2K8rZh4AUxy+ApSDTTTqpySkCkcPXw06ZazEzVqzwicZHTxaBNZ7lAQYXQ77zi8xMNXmYgKoCIw2X4egPpQayMBQrEsWAdBe0EIiaucD6QMAn9eMtq0Vo5HIeVypoNQn+6co8yLYFHqWaGZFaQUhdRI6UauB75+P/hguuBl2KwI/S4q4Np7W7mGVEAsVQZE1C6X1Z2r3kugIdtQdUrIHiNCXTUV27IxPoWMIoTW+KUMWw6xwyG0Dd6o8LldsKqVjQZ0Gsh2k8h7yjJnoVhkMXYUOmKdnCayFm0d5UCiWy3EWAPXSRFxhIgjMDHKSZKGp0NGsXaawdwe1KpJzNpV2E4DGSlkGayQpTQo1SCKLUnqSGJHYiZhrM3ScD/KGGRnEjm1CRk3g0YGNtRpVwAs3uIrdqCQiiIb4p1DI1i9epJOp0lkNGEjgbQZo3QAmBeZx7uMvQ/cR2OyQaPTJEoSvG2BtZSL+xFSoaMUoaNwQCoKqBictftoGF9VGUdRgnTVPQArSnAebQS1Y4ezVenBCFivsjT1XhFI2BXQu3zvra0cVmwZQGpXPyYU31sXArWwD9X7Ue1+uZxPEr/orvmf1K644gogrOebNm5i7679XPO173HWOdsZn2yx/9ADNNMJhDdc+YXPsmnTZk484STu+PGDaKNZf8Q0Wms2bdzCpz/9aU484USyYcnVX76HDZvHOe7kNaAEpz3yJP7xw3/DiScdS3exx3VX3cCxJ21j9RGr+L3/9iqmpqYQSvDRy65ncqrFU556Ip/99BVkWc5zLn0Ox2w/iY2btmEiw7ev+x5Xf+s6fvNFL2Tfrr186p//hRe/6IVs3LKR337J6xhrT2NMg+u+8wOEMBjT4NTTjuLcc8/liiuu4MQTTyTWCWed/DhOPO5UhrYPwNFHHz3ql8c85jFcccUVvOENb+BHP/rRT/Xbc5/7XF74whdy/PHHceUXvvBL34cDBw5wySWXVrocJYcOHeLxj388r3nNa3j961+PUoq//Mu/HMU9zWaLD37w//LpT3969BxCCN7+9rdz7bXX8oY3vIE/+IM/4KijjuLVr341v/Zrv8bTnvY0XvnKV3Laaafxqle9CoDp6WmUMrz+9X/Er//6iwA47rjj6Pf7vPKVrww25d5zzz33LL9ZAUtLS3zuX77MMUdvZv1x2/lv/+31nPnoR/Oq33sNb3nLm1HakLQj3vPuv2b37l38z7e9jec9/1LOPfds0rTJVV//Bh+9/HJ+62W/xdTkGm79wT18/kufZLE7z8t++/dZs34ChOfQgT3YUiNpct9dd0GueO/7/o6TTz4ZoSXz8wd59sUX89jHPI6xsTG+f/1NfOlzV/GEXzmJtWtXM3dQcOa5Z/CIRx5HezJm2PPcfdudvPVt72D9+g0MhwWve90fsGrVNG984xtwDjZu2MBlH/oQOjIYY37pe/v/d+v2FomjlCRuooRGKUFpM7K8hxCCZiMdlbzEUcLUlGFsbAwpNNaWLPUPUXhDUWTs2bObtevWEU0aVq8ZoygK8mzI+EQLKSQahVQC60ryLEcZgTYxjUan2u/hiCM2kOVD8nwI3pMNBsFVSgWR6PGxcYw2DAYDlpbmMVoz1mojpCBOY1Y3tpL1umT9HnN7dpDbklIOyft9vOwHJ7cyR1tDYYeUrqT0niIvUFmOzTMUIjhNSwOhkgTnPSoyEEWYNIhq6yiARwJHPhxQWovDh/1wRYIRqVFRjEpSdJKi4gSpNEJLdJyQNFrYLKPo9YjiBjpqoKMUaQLDx8RJMPFJElInAU3SWMQqiVWKQX+RMh8GN78KLJKygRQqlKjYotrDFQJPkQ/J84wiHyLwNFttRiIZXrO4FMTOB/mQOFFMjrUYnxwjTZt0xsYYFH26h3rMzy8AEtVoo+KEKElpNVq40jKwfYbZEC80ShsWFhaJKl3YTmcMpQLDbdAfVBpilfNfFGMLgdYpQhkOHZonywfk5YDxY8eJ0wSpFQtLsxRFEQTnWy2ajRZpI0ZKmJubwxhNr7vEjh072XjEBjrtNj4JTKmyLKvktaQswrkubRqOOfYopldNkyQh8VzLhzyU28Mx9MMx9MMx9C8fQ/+7XO3qMqTlg3wYmPUEGB3Aa/bJ6Cy+kqGyzMY5vImKMVWBUFQDX4a/hf8f7mYX3otDVMu4F7WA+TLotfJ1QmdV7CGtiRopZd7BGYvpL5L1l7B+SChGBRPFqCgiajVRSYzSASDJC8twmDMYDCjKAUUxQKvgXKBEAMXKqvROqVADrmSlJeRgWdxLjdDDADqxzFUTy+WLNbi0klL3k00Q2Dk//fuqZ2s3vUo/yQuJE6LyVwivq7xHS4cRDi2rBcsXeBJAIEUEQgMmDDgH1roQRKAYioxIVK4ByhA1Urw2qIZhfHKCsYlxJianSeOUJEowygSBdCkRdY3qT3xEX6NJK8eZc5UeU42uHU7xG2k9UT+W6rOzIunwk1eswL2q+xAWnxW96mv9rGUQVgrJCv3/h3Q7PFNTz9F6gYNaoN05ESjn1QSsHQ7EiKK5LGQnqGt+HbgAEq5cGUawniAserKCrD3ACmFEISvHj3qdqRh7rgIaV4CGUtTrxIoPt2J9qcs0l0sqCTRWFz6F0hEmTgMjstmEzOPEAOktDgmxAanwUkO7iUgTRKTweU5eDln0GVkk8ER0tAFbIktLqcG1YkQzwic6bJppiozTYMEbSRK7mjRV9OMCJtsw0QwbpvQIW4Y1AY+QwRFHRzmREQiVImWLLG2GElwTIZMWwqQwXKwmwPL4DDNbje5XzSiUQgRba6MZTHRC3b/zRNX6JqTElY6in9NdmGXYXaIYDCv6c4SKYgrAuxJbDsKmiagjqJ8z8Kp76hz1JHS2Wt/18vyswdzl21lvkMu08+oOj8aYF1UywwWXFb+CSl4nIA6fmX6UEVo5F/4rMJ4uvPDC0feD3pDuUp+52QXOefwqVq+b4P777kS4CKMTFhbnWVycoLvUY36uS7vdoNlOmZuZxVnL059+AcN+wdLCgIW5AdOrm3gP87MLxHHMk558HgAzB+bY+cAeNh15BEmacNTR28IBX8DsTG+UoV6Yn2c4HOKdZ3xiirHxSaRU9Hp99u0/ADjyImPfvv0UZU6URKxfdwRpMobzkm63B0REsWDm4H6arQZPeuKTyPqOYdey6YgtTKxvE7UU99/3INaW3H777QB0Oh0uvPBCPvjBD7KwsEC73QaCGPu9997L5OQkRx55JBs2bGTN6jV0Oh16vd6/qaW0sqVpypYtWwAoioIvf/nL1BqU09OTbNxwBEceeSRJktBut7nwwgsPC8KuuurrOOe46667kFKyfv16zj333NFYXbNmDZs3b0IIwfbt23nqU59Kmqa0222OOuooABqNBkIITj/9dIqi4N5776UoCm677Ta+8IUvUOQF69atY9XkGlpph4OH9rJwaJZ9O3cxc3CW+bWTNCca7J87xL6D+9i/ZzdnnHEGUimKLGP//n3s3r2LfDhganKCSGvKvGBuZpadO3ayevUaxjvT3P/jH7Fjx07yosfmbdNkWcb+vfNYW1axjWdpYYlWp8WZjz2rMiMpwvtbu551azaytDjHwf0H2LfnAI4uuY3Ys8eyau00cbyeYQHD3l7y4TxHHX0MrXYH7z27du3EuhIpFTt37mJxYYHNm7eweetm1q5b+/80r/4jWziEerwFvBz9rj5g2krfxQNGa6LIIIQIFvf9km5vHqnaWFdpcFSH1kYjZmmxoD8YMN7pBLfkar+1zjHIBsSEJJ8QmrBzO5qtFlERkeWGYpiPBIgjY2i1moyPj5MkKXUFg8eB9kGzRkiSZjvsU0nK0tIi2ll0WSKGGc55smxIng3RRmOioP0qZHB5806A9RTegfRoJRDo6qzrkVohjEGZGKmrskHvsGVBmQ9HfSVqgdx6vgkR9khtRmVztTaPVAGY0bX+jA5nAVkJIYe/R8GRThm0sRhj0SYKIsS2QClNKeSor7wrD5vrriyRunYp9HhbBMH3MkcAjWYLo0Ip0nBYQK9PYYPDc5JGjE+0WbV6kjhtEEVNFhZ79IcZeWlpNBqkjRZp3CBO0gBuVC6G2TCj0cyJfNDDcspVwsLLEh3O+SoxnpHnSQA3CoVzBQhPUVjK0uIqzSKlFVFs8It+9PugRZagtKA/6LG4tEiz0WCY5ZWZUklRlERakWfZSDcslFJa8jJDSMX4RIdWq0Ucx0gpMTqUnz6U28Mx9MMx9MMx9C8fQ/+7XO3qetKA3srDSr+890Gg23rQy28ooLQSpfVoALtqY12uWV2ebFJIUDp0lDxcTHxUOuZcJawdAKZ6SjlXAU4+1K3biu00Ylv5ZQ0lrQxR3ICGJ252yPMuWbFE6RdAWoQO78f7gAbmec5wmDEcZAyGPQbDLt3eQZzPQBS0m22kCshwaQvyIgBYWkekSRQGgA0LkhYGJZezNGIE1FU0Su+rQVh9jbqgXrrC30WFbFLNCeFXAHM1ylk9sgafnAz1t04EV7vCBTcBpCeixFf18blwDGyBsx7vDUH5SQIxiJgAPoWNaNDPKTOwQ0HLNJBe02y20UkDLyTtiSkmJlcz1pkkAoSz4AqEswivRoCQFwJZr4ywnCUQaoTQO2fDBHPVPa3YcyP9rHpK1d0mVlBK6/Hn7ChrUQ+vGtCqwaYRU66mHo7+DV9KBQaaljJsyD/HTeih1EZWrVVbaRZQp1GECHLrtnSjslihAr3TjcZmCJ6XkfnA/BI6lCvWiRIpFeBH2RYQCBUWPOc9lNVretBKgVIhEzdiokm8rx0ul79qqrGAKuhUeATe+or6KUaieI5KRDGKKbMh1paUeYbREcnEKnomhdYsZekQhxYQA4GdWoVeNY7otNHtKVTfIhYzFg7tY84OeDDNyRpNIiloGEM2yHFFybBlSTpNVKeBixQijlDtDlGjVeltaOIoJ2kISvoMOjH9ZkxbBh0IvK7GsEKYCGUdunQ00hivYpCG1tQ6KAaIskfkCkSYtQF0RwTmqQAhwaj6/niSZgNX6c6VRYF3jnVrV1Mj3nlWoqOEuDnGcH6Gub17uOPa7zDz4A6kFazethUEqDjGtMeRPljQKppoFaOSRsj24UZ7xGizE8sl0WEgQekKnLTBZUzIyu2lOkgJiawORyG4r0ptK3eYleW4y8kQh7Oh3CYUC9Xrp1yxfPoqS8nyQaQ2vKhB5f8CzXvPbTfeRZJGvOz3nofH0V0csPfukpnWAzTGJJde8jzuu2snX/vCt9h+wtFMTbYBwde+9s/0e11e8Ou/x1237WXfrnkuuvREokjjnOOTH/s8E5NjXHzxr+DKYA2ctBQqEuRZzjXfvIqNG7ew/biT+M2XPhbvYdgvuPSFL0AAed8hFEgVev1JT3wsj3/cuWR9ywnHn8jf/e93018csvP+e/nCl97Hlk1PYN26k3nsYx9DHGsQln9491uIkjYnP+oJ3P7tBRppg199+ZkIKdizZx9PevxFzM7vJy9Dedtzn/tcPvKRj/D8FzyPX7vkuTzz4mchhGDnzp2ccsop/P3f/z0f+9jHuPHGG1m//gjOP/9pXHXV1zh06NAv3OennHIKV111FVJKHnjgAU499VT6/T7GaF79u7/Fvfc9wCMf+UiKouCcc875mQFYv9/nqU99Ki984Qv5h3/4h8P+9kd/9EdIKSlWiMh677niiiu48vNX4vE87nGP48tf/jIAO3bs4KyzzmJQOZQVRcGLfv3F/O37/hc7b5vnB9+9jje95eVc+cEP88B3f8jr/vodfOIT/8QHP/i3fOKTH+OOm2/hbX/8Rl77x2+i05ngzpt+zB/+t9fRbKfsuPN2PvHJT/Ota6/nTX/6xzzqtEdyweeuJE4MBw8coJ/v5U///I2sWbcOLHz501/lB9fdwP94xx/RarfwDloTKUopklSx455dDAdD1m/exDe/+i1++P0bSVtdTj3jUbz3/7yZ3Q/s5P4Hbuar17yNX3/hmxgXm3nHW97Nhc96GqeddRr/4w/+B486+0ye96Ln84lPfJywLsDrX/+nfPnLX2U4PMi7/vqd/M7v/M4vPon+k9r0xFq6S0MO7JvHOUezldAZCzog3nuyQR4SlUqjjBrFLN3uIgsLs9x//z1s334C4+MTnHzi6bTaDZI0wrmShYUFHrh/B9u2baLdbJG0WpS2oCxyZmZmaDSapGkDKdNKtoBKSkGSxCm6OvxalzM1PcX41CSrVq3HqOC+HJkYCCDRzOx+rHVMjK+l1erQ6kzS7EzRXZplce4g/p4f0+8tsbQwh5SCRquFW7UKE6WkzQ7ZwON8j2EpsL0lZJnTdwVpnKJUAH1UHKHSFJPEKCEQ3tJfmKO/OEd/YYEiG1KWZdCT0UELR9Ugi6g0VJVCSFXFyOFkJOXhfxNSBcCpAqlkzbypT1Jy+UTlvUfLyk1Penw5wJVJoHd4i7cF1pVoE6HjlFgLXF7isi4uG2KUYuOmrcRxjHWO+++7v0oAW9atn2TNmmm2bN1EZ3wCITTD3NEbOrRTHHnEVqYn1zA+NglFgS0dWW/I+Kop8qLgwOwu4qRLs9lkYmIKExmkkjz44AMopWg2m7RbAbQs50scAgsIDf1hj7xwjHUmSVJNo6UwWgexZCtxOWT9gtnZQ7QaLeTEOGWZMz83y85duznmmGNopE22bNxGGqdIDEpF9HsLzM/NUBTzxGmTRnOcQzOHMDoiTtYxGPQobUEjTUiSJkkS/6fOz3+rPRxDPxxDPxxD//Ix9L/bu3IlulX/PEJFV3JHqgtWAlOj9+585Sv5E8+74mAvpAyC0vXvwwOp0bZ6Ii1PqPC6tYDaShG10XsGVlI56xI9rROCGGBE6RK8KEGWWJdTlBnd3iyLi/P0e1263XnyYhCAJTK0EaSpQVc6TaFG2wKOOI6IIlM5FfgwqW2oh/W1oKCnmujLn8NXn7F2+8OJkaxQ/TlgGYgTh/2Ww/rEO4cXPuDiFcDnV/SRdZbSSrSARBCEAJXHCksswUiLE8GeN8eCClTDUsc4ShyW0nm00AgSjG4iiZFeUOZDnBPENEhUgzhuorzFlxk+L/C2wEsRSv9G7/3wsbXyXgkqMApAeFTQ+gcfsmOjCYCvMbqR8n8Yg9ULrMgn1KiXqIejDxbPztoVY2gl+MSKcRfYditLSR/KrV4UnFsGY5dB2RqEC6Ww4Kryxap/Rui5wzkCsl8/bzUvpRRUd2eUIQUOW+RGNp1QaZ6JILRZNVWDzni8K6rH+NHmGbIwlTUtEumpGHBhEVRKjZYDIcCLyvVDKZSJEELi8nxUmhnHCW5sHLfJ4oRCFgWqAOcLSjGkkBnOBr22WV3S1RJvGiQ+lNYqJYi8wuqSouiTa0EZSXQrQUYRRAKZxiFrayLErATpMLHBCUW/8ESDApNIotSgo/AVG00+cFU5QTXDpUC1pyi7hyjm9pBkPZQ2yCgGa8GBUjFehPvhKlDeV/dAKhWMA2StZ1aXk/oRsCvwNNotfD7Fug1r8cOMpX2HyJf6mIYmSgx2kIDNsTZHFlnwhoyaCBvGhq8WtrDOeKQKdeajjc45ahOBorRIXyCkq8oogv6fk9XIkwq9MvvG8hpRTUVWrp3LugtBrFGK5YwPvgqykCNAuh4rvpoDD/V2zTXX8OlPfwZJwvHHH8cJpxzDLTfdQ6874KgTNiKVRWpPNrSMT4xx8mnHMX/oIDMup9lKOeGE0ynLkvnZRSamG7THEgQwWMoZLhacfPIxNNspQgis98SNhNPPPgXtY/Y/sMAxxxzP+MQ4UsFttz1IksQcffR6lhYGlEWBJKPZaaN0wuzeWaI0Im4mmEhx8OA8d/x4Byc/YitTq9fwmPOeTbu9iWZzGmM0t916F7fe/GNOOu1cnJfs3z3HsacegbU5H/k//8AZjz6bNWvW88Y//kOyvB/YuB76/R6vfe1rWbVqDZs3byGKIj760Y9y1VVXkWU55513Huc/9amMj49z6623ctNNN9Lr9f5d/S6lJIoCJX5lSVdZlnzxS1cxN78wEiy/7777eO1rfx8hBJOTU7z+9a8bXa91zA9/eBO///u/z2te85pRjFJbaQNceeWV7Nq1i4WFBZxz5C487+23385rX/taAIwx/Omf/imuBFd6TCIZDoa85c1/zqXPfglHn7SB85/8WHpzBxnkh5BCcsojHkUrmeCmb9+OUpJnXHIJ13/7VlqdNo88fTvfvOqbzM/P8/SnP4Wzznki45Nb+cH3r2dQDFm/ZQv/9x8+hADOOfdshouOfcMZ1m6a4qTTTmT1+lUYY7j9Rz/iu9ddx+Of8BRarXHm5xdIGk1AcMtN32ZqTZOnXPREtCkY67RZOLSfZjNh0+ajeeLjn0/ZT1nIBlzwzKdyxBEbyIdw4TOfwdp168gGJe9+718zMTnBb//Wb/P85z+Xc885E8eAc8455/9xRv3HtmyQ40qL1oI4SUgSQ1nklUaLZTAYEkcJ2sRIoYkqjSYTKcY6bbZtO5JWcwxJRJFJbALWhDiw3WmxZcsGxsfHEF4wP7tAFBuElEyvmsLoCKUMS4vDKvTxeNej3rvb7SbaBI2WpV6f4WDIcDik1BrrHL1+nyhSjDdbjI+NY50jiuKqnCq4HUdRyvjUKvDHMej3WVpcRMggEp+XgLRBksMoXGQoijis5YMe3YUew6IkUppG2iAqNRQSO1wKFUTO0e936XcXyXo9bFHgvUV6hZEQK4kGhLf4sghf1obPWTlw2SKnqMreyrJAlQW2LLBljhcOJRxl7nFWYW1BkeeUxZBs2CXvL1EMlnBlhvAlkQJph2AH4HLwJTiL90XlXNVHuCGSAiU9vixCzFwYSikonaN0BSoSNNoRjXYLkzRxIqJ0Gu8ESwsFMzNLZMOcdWu2IEX4vfXQGw6Yn19AN2LiJGHz5s000hYC2LN3L2maEMcR7VYLpTRxHNHv9wNTDFCVyPeBgwcCkUJKpleNB6F7grC9d1DmwbSi3ezQbrcYHx9Ha0WkNa1mi+nJaXCerBiG+90uAEOWJ0SxYmxinKKIqvKnmLHOOMZEpGmD+fl5SlvS6XTIi4JGo0l7rPWfOEP/9fZwDP1wDP1wDP3Lx9D/LnHxMHmWJ9fKA37o7vrK6gPXk6VGTVd8yLpjYQWQsuLVQklY6J3RtUJUQus1QrcSqKgBKUddU7uMFlbPKVdO/hG6EdhHQqFVQmFjPCVe5OT0KDwMhyWLC0ssLs4yN7+f0g5xLidtaFIZo1WCrrIkRVEE4El4othgVKiXd6XHlx5nwQsJPiCUI5DM1aRKPyoRdE7gcCAlPw/WGAF6y5Akox6qQDzngwp+vfliw7/OBiTUCo9zoPFoCUZ6vPREzmGkIPclpQBlS4R2aCnJRUTuqppm60BEKJFidAslIkpnkWUOpcc4gxYRRsVIUWK9xQoRBMusRFToOyvG0Agaqm8TKyiDNetJCryzAfnXnrqMcAROVePocNZc9eSjCSJqqGo0doM2WK3vVC073q8Yuyv73Y/G1H+FVpfCwuHA3k9dU2VvvPVV1iVkQAJe7EcLx3LtcGgjYwFYtlqVdS15sI2tM4lCiOBS4+Xoxiwz+DxWlKP77yrh9/pv9XipgdfaOaZeTWuAcPQRK2tWKSRZZQWLExgT4VqSXAv8IMf3Bwhncb7EklGQUbgSW2YsGE+uFDIxGOsqxw4PhOzp0GWUSlJoMI0IYQwYgUyisLEZg1PghSOKIryQZKUgy8tQFlBlz5QUKOFwrsSWBX5UJuqRzUnIehRZn3K4hIwSVHM8MC+9Q0gDlCM71NEwrdftyrI4OG/aitHol//uHXGaIsfHWHPEWvbfN0t/boF8sYuJ2+hmgjJxAMUrO2wqV068ROID63U0PoKUYT02oMrUVfPSOofzZdg0ZRTWfIIbixASVenb1Tf1MO230b/Velfff6p9QQpGYgOuDh4Uo/LlimXrcYfP6Ydwu/3227n88ss45piTSZsp3nl2PrifXm/AaWccGw4mVjA/t0DSSDhy1TjX7XwAV+T0u2vZuuU4EIKD++cYG2/TbKaUztJbGLKwr8fRR27CxIai0uLQsWbjtiPYf98ii7NDtj9qW3BXspadOw/SbjfYujWwOIosI0n6mDzGe0V3rkuUR5RY0kaD7tKAW2+6j6OPPYLp1as59bQnsdTtkuc5Ugp2PriXb19zA0/6lVeTZQXf/86tbDlrmm53jg9+8CrWr9/EhiO28KIXPw9dl2V4+PgnPsGf/smbeNnLfpctW0JZ2le+/BU+9OEPAXD88SfwzGc+izzP2bNnD3fddScAWms6nQ4Q1pf5+fmf2+9FUTIzM4OU4rDrrHV8+zvfO+zaAwcO8JGPfAQhBBs2bOQlL3lxxUwSRFHCXXffw80338j555//M931vvOd73DdddcxNjbG5OTk6Pf9fp+PfOQjAGzdupVvXPVNjIixhacUAz79L//CWz7wDzzj4otZfUSHRz/qVG699Xs4LDMzs2zetI2N67fx0Q98nKOO38KTLn4Kb/uz/02z1eCi5zyRH7//x9xz571c/KzncOxxpzA9tYXLPvw2xleFcrpvfP2bTE5O8oIXvZC7brqPuf4SazZMse3YLWzbvgnvHDsfeIBrvnEV5577BJRSLHZ7pKZBaXJ27riL0x51Lsce/wjm5+cZdpdYnJtjbGqaqek1TK96Cjvvnaffyzjp1ONxuaTIHI945OlExlDkjs997nNs3LSBl770t3nseefizjmbien2v3se/We1bFjgnScyilYrRqkqZrSOsrQBGCjBGI/WEVKCicOe0Gw2SNMmuAhrJbZwlCXY0mN9SSNNA9hgIga9ITNLPdqySRRHjI2PBQ0iBwsLg2rNdzg3QMrA4J6YnKCRNpBK0h/mOOdCCRhh/8jyDKUSTGRotVpY6xEiIsss1hYIgj17I24RRSnDwZC0tcRguFgJG5fYSq9TVHpJudZILSltQd+V5HlBLBVSC8iDVgwDDRa8dfQWF+j3uuSDfth78EivMRKMEijnkNbiixxXFnhXhmSit3jrKPMhRVX+VxY52mhsmWOLDI/FC4vPinC4UprSWso8Ixv2yAZdin4X7QokDqVAuAzKAd5mYItRqYorcqzKwOdIYdEScGXYisqcQkhK77HeoiNFKhKSRhMVJVivsFZjSxj0HUvzfbIsQzqBcAJngynQIM9Y6C4xMegTJzFrV69BCEWWZfS6S6EEkEblBBmYDkvDLtZalFaVPqlgYWEJpYMTXZIoamHsmpVT5B6jDVEU0Z5oEcdRYJYpRRonjHfG8NZSZDnDwYA0BW2D3bw2ESZukWdJOFA7aDUl2hiiKKbX79Hv90djrCwdsO4/a3r+Qu3hGPrhGPrhGPqXi6GF/wWvvOmWG8MNVap6b5UGUSU8JkdOXyG7IERVimSCmv9KUbZlcK3uiPr76uC/Em6tO8b7qpaysmOtr/euugHhIWUZLGaLIhs9Lrx2JXQmwuSXKtDQPOBKO/pMNbPFOYt1OWWZsdibYd+BHczM72fn7rsoiy7WDRgfT2g0YjqdNkbH4KE/yOj1e2TDjKLIg62lF5RDiXAa4WIiPYaSEZFOMCbCaE0jNkFbSXgoM0oLmZVYGSOUIY7jUWmjGtW0rwBV6sWk+rdmTVnrAtDjLMNsEZv3KAYL6N4iuixolCWtyNCINBMTbUwSoSNDIQReSLxQ5E5SWs+gyBm4gqG3HCoz+qVlaB2JbtOI2nSSKZqNSbCC4eIic7v2BeeP8VWs2rKJqSPWk7RivM0psx7Su4AgRymoOIBGK4bjSufDeuzIFQuu1mExB4iTNFCmpRo9hxSiohXWZZnVwKuZUFJUlpQVam1tcMypxs7yJK37s55cdVld7eAYfjrr3Cf/QpPuP6t9/4bvLfdjvUBXLhrLVM76C2qgWQmNEDI4Vyq5vOGxPGcgbFy4sIA5AVXd5AgIlFUpaABCl0FnDyN9s3ouIsDhsGUQ8CyKsgIDl8fC4aWSVLfWB5taagR+GcqUVQ100e8FO+fSYnQUnFfqrGee4+e6qEaBSjy61WA4EAz7BHaeDEKortaPK8vqsSVFnqGUwxhYvWEVUaODaUwTt8YAyHpLHNi9m+78fAgePHgqm2El0AaiSGGUJzGWYSHIrGC+H6yOBJ64NUbv4A4O3v09hPekY6tZd8oTyPtL2DyvgH4HWPKyBrDBe3tYP4U5FXQqXBXkCKGQypAkCVpCRMnt3/kec/sPMb1mE5tO3s7aY7bS7/YpK9ts4cqgm5d0gq01IRMkqn4fachVd6QeZ7Kal0KbkVlAo9EMVGClyIossEt00H8IdHDC+PIeVzmWltZSCyBiS1boHC5/XuxoL5EyWg7arAPnsK6gdlI9+7yHrh27974S+e2y964BjVbCkSetYn5uiZlDB/j2tVdy5qMfx9at2/naZ69mevUEm7cdwYHd8zTbDbYev4m7bnmAsig5/pFHMuyVFJklbUX86JYb+MH3ruUxj7oIbxW7d+/m1PNOZFgOeO/7/pZnXHghjzrjdLRRHDy4xN6982zZOs2+3Utc/ZV7Of+i7azfOIYQnm9fdQ+7H5zj4uedxs233ch137+eS5/9fDqdoNNz4ME5cLBu22r+8PW/z9XXfJNrr/0WRkf0un3uvC2wcI45/nj2PHiAMi8Zm2yiI421lttuvJWNmzey9ZgjsZnjC1d+lT/4b3/MBy9/L4868zSSJObFL34JH66ApzRNaTSaSCnJsiGLi4sAnH766VxxxWdQSrN7924e85jHjA5BP9mMMYyPjwOBnTQ7O/tz79OZZ57JFVdcgRCC3bt386xnPZuDBw/S63WXM5bej57vZwFerVaLq79xDevWr0Pp5T2mbrawHNw1z6q1UzRaMb/z0pexddtRXPzM57B/582Uw0WUKzjujMfSLTwXXHQxf/gHf8hv/9Zv87lP/h8mxjdy7HGPoT2lMbEmjhIW5xeZ2b/EVz51N0LcQ9TYzzm/8hyWZrvsvGsHj3zCaUysmqDdbnPDtdfSnV/k9Ec/iUOLtzLfvZdWtIZGaxWtzhHsvH2RKDZsOX6a227/LoNhl0ee+hiMiVlcXOIx5z2Gp/7K0/jTN7yJa77xecBx9NFHsWbTVnbvO8CznnURr3/9f+eii57Nc3/1lTzl/PP4w9e9lLn5WZRUjI2P8Tsv/SP27tnPJz/zD1Us8PMPgg+V9t1v/5Bms0F7rE2RF9jSUhY5Jq4O/F4w7AednDiKiBNNnGoWF2cQUtNsTFBkCryi0YxRWgCWffv2kaQx7XaTNAmgz8H9MyRpgjYKqT3GREilyLLlPoqiarf3jmariTFB8ygbZuRFzjALa6OznkF/AMJitGVhcQbvBZ32OpQOMf7MoQPkwy551kerNt4pbK5QcYFQJU7kDIc98mJINhywtNhlabFLYiJ8McT2FljcswuyjLYxpHFCZGKMaeIqPdGlxSWcDYCSFxZpFI12m1azSWQMPsuCDbpQjE2vpzG1ivaGzahWg6LImN33ILP79tBbmGPQXaLZbNJst2h0mkgtQUFZu4ZVJSxlUbLnwQcoBn1sNmS83UBLhxY5yucoHRG1VmPRODQyagVLLaVBVYlwa9mzawdZXiCTFk5FlB7mu3MjO/VGcwytYrROWD21ASNjyoHnlhuvY/bQftatmebI445nw5YjmanYkHhQApI4YWJyFWmlAzczc7BiYMDe3fsoiwLrHBs2bSBtNIjTBmVRVhIngiRNiOMY7xx5npMNh0yuGkcIwWCQkyTBMS9JY4o8p8hzut0uS90uC/MLKO2Jk5jx8XGU8jifMzO3m2Zjkjhqs7iQYUxEkiQsLi6gVGBCdXtdrCtJ0pTFhR793oCnX/jQjaMfjqEfjqEfjqF/+Rj6F2c8/cR+PgKLcOAlXgZa1nJtYHWdq8GQaoL8BMtp9IOnUpP/iRcZASsBaAkA3DI/BV/7Q6xE8uqvFWCDF5Vs0spFgRXMrMB9EUIEWq93SAxaChpRh4n2GrQwUFoG2QJZvkgUW4xW4DRlGWpji6KkLCxl6Shzhy893oLPJNJ7tFB4O8TLElcU2MKAUuRlhBOeUniELSgd5KXEqhKhDMLbqvZf4atshZShJLHuP1GDmiv4OwiqgebwZQ5FhswzIldi8MRaEUcaExukCVlkpWVwkENAZamo8FgvyYlQ3hOpGIwgcoJEt4h1gzhqYXQCEnzSIElThHXYLKccDCkGQ5JWjJASpQ2+zJcZTKoCK4VcBnxGXytuWTXpVgbwVKivHA2ZlfWrHHZvazZejeq7CsZ1K/WcfmLMr0S8wzhbHpOhj/gv0Vb2CaycH/XP9edbARIj6g4MfcsKEc+qjTIm4UVY8U/4vnpR55etQSXLVFUx+g8jkVAhqoW90mNQCqRcnt/1oPipbI4XFbofLqzfhl/xQsrosFFYF8a3rOjFwgTdg2aJSjQ68iBUKFUVtetKBTZKHwiZUuFE2FCl9wjpcMIzHOSgcnRqceUAW1q68zNBw0UpTGSoS1/rbi4dUHhKG4KFAISClq1qGoT7o5MmzVVb6O2/j2KwxHBxJog4ahNAeS9AKKQIFGMpOWxd9ZXzCV4EwUNBWGPqN1JtqDppMrZ2OnymYY9i0KPoD4LQKw7ryrDaC4HA4qskxHIyYXkceFaOtRXMxlESotZ0q+aoqA0RxPIaAaH8uh41QoJw4T7WG+cKw4GVrMb6v/V3o5etEhH14euh3tI0JU1TVDFk584H+du//SRPecr5TE5NsHXrMXTnh9z943tZv2ktY+NtkkbK9FpFnhfcedv9mEjTbKdkvRIBaCM5tKeHy1PWTG+lNd5CCEUhpoljg4zgkaedyvT0ZJXVksSxZmKiifKaViPl6ONW0eoklKVlz45ZGo2IzUetQhvNxNgEW47Ygi09u3ce4O677uHIzVsZHx/De8/pp59Op9PCl4KDMwfYu2c37U4H6+DmG25jenoVUao5cGAP3kbgJavXrubgwf3ce99dnHHG2WzasoFff8klTI9PUw4tJPDEJz4R8Hz0ox/lhBNO4MwzzwTgrrvu4qtf/SoAMzMzfOpTn6oAqZxnPutibr7pZm677aed8Yqi4ODBgz/1e2MMl156Ke12G+89//zP/4wxhtWrVwNhzXj2s59FlmVkWcZHP/pRut0u8LMBp+UmyHoCLVKmptt86lOfQmvDRRc+g6997Wvs33eAx5x1Hv3eIjOHupz56LNoNcZYPLTA3t17SBLFKac9knvuvo/9h+a4+BkXs23LUQx6BWMTa+mMTxInii9+6UqarZQLnn4Re3bv4MC+WbYcOwluC9pMsmrNaroLPfbs28Vp7nS6831uveFmmqlh3aYN4dCYjDFhNpGacQ4e6HLzjd9l26btNMc0w+EC4+MTJMOUB+99gPnZgtnZHuf/ylM5/fTTiRoRR2zeQpF3yYt5smGPJDI84+KLWTO1gYWDQ8447Qy2bNpKllm+/KWv0O60ueCCp3P6Gadw7z3387//999x3nnncdJJJ/0yU+s/pA2GA7TRpGUwqBH4ILytNVLJwHyPKrtrW+KdBC8wJhkZ44goGNMYI4PQdlkEBoqoSiAIe5qJqzXd/3/svXe4LUd15v2rqk47nXzOPTcH5SxQJAghEAJEMjkZjLEJDmCDMx7bGGywAQOGAY/j2DiRgwEhgkBkRSShHK9uTifv1Kmqvj+qeu99hb+xPMwM8vPcenR10t67u6trrVr9rne9y2maBkGIUAqbFl7eASD0eiYCXWonRl0YirJ0QtJKYK0TR9ZaDLqj1Wot9xBrDdK4hFy/l4HBM7VcN2YZKQrTR6CpNeu+PXmNrlIUpSbLM/8wHhOoMYJ2i0IKekVBkaUEeUGoSrf/aUu33wVrUEIQRBIlFaEKXELS+tKYUpMbA2sL9KWlH0fIbkJZZKwe2s/q0hHSTpsyT1HSEEiNFDko0MKQFQUWkMqLuwMBGTKwIELnf4VGWoHJMkyZkfVWsKLmdGRE4jRIlUCEzndkaY9Mg5YhKkyQKiIUgvFAuQ56YUS9Pk5ZGtK0oN9L0YFlrN5iZnocJTKCEMBgrKbVbLlnjKwgDBVKBaRpQRBqpBTkeemS7AjCoIbRUBR9dOE6HJbaDgTEx8cmiMOIQIXI0KKUQCmL1gVlqel0ukRRPHjWMNbt/drmBKGkOdZE64wwDBxwqVws2aiPEQY1hAgRonBxXBAQRYm750KSpil5kfk4zwFgj+RxLIZ2/zsWQx+LoX+cGPphA0+C4UJ2i9WXHA2rJxGowUbn33EU+2QwbFVteDRiO7y+hyDA/tdSekBEDv8uEQNmjDbl6BxVB/O/8/WIDLvEVaOir4mR41pjPUMqoh6OE45HTNanmahPsNZbpN1bIC1WsBQYU2DKklJrsqwkyzV5rin6Gp1rTGFQpXT5EO+8rXDtNLUKsUqRZRGl8DqGRqMN5BqMjBFBhC0Lwtip5kex604ilUJaLxQmoYIqKxqlddiKX7AaihSRp4R5n5rVxFJQDwNq9Yg4dkwnGQbIICCoQEBrsNJlgFQYIFBYFBERMRFShESi5gIbFREEsduohaAca6Gw9FdSim6PrN2hNd1CKglB5LuSuBaOlZj7oLvDj6wJBoZUCcRXntAxu3yXF2kJg4DRRWD954oKJLJ+jrzjrAzaiYs75yv8OqzWr/XHF+DWfrV5CHn0cnsED2dx9qjNsnJUUG2iI6/2DgUhPBBpj7Kt0XrjAeVX4PWyhoChFNIDe5UzdBuxHgX5Kr+i1MBXSGMc604qgsDVM0sph+vGf54b5TBjU22axvqTsR4Ad0dTYejKQ6WmkpFTIkCUoAOBbdQIEkMYWgrtMh9gCGQ1Hz5zACihnM69lugRyL3TTjEiImkVlFlJnmWsLhymsAoRhIRxSNUIwVrXrMJqyEoLlGTCEhnXJSQKYrQI0DgNuaDWYnzzqfQXdlOkHdqH95DMbCKojWF1D4vbJYUEib+nVg78bCXI7w0DpCKuu65m1mjKLMUagQhiZjbNU2+EHLpzJ2W/Q9ZuE0/PuEYAWiOEz8RhsNIlHcy/s2kO/JLFBwruftgq2PFr0dGDBWEUDUQQtSndGjM+y+gq4r0tKl/e4FrhOnusgr/RlY+7/1UE5xMdQoCs9A7+C2g8VWNyPuZ7N97Lm3/tzXzhxBM47rhLOf/8i7nmmzdyxwO38JLXPI8wCtGlYWxKsmfnQa796g+57DmPZW7dNIv7O4zN1IjrIfuuP0wYTHLq8Y9lZsMUKpJMbxonDAMass6LXvh80n5KlmaouqLVTGi2EtYOlzTrCY+7ZBuBUqwu97jtxt2cee42Nu+YAWDj/EYm6pPkheTO2+7nH/7u4/z+29/I1LrNlIXhZS99GUJYeqsZ9955D9df/z1e9fOv5cC+I3zps1/hFa95EUkj5ltXX0fINM3GNJc977F88bOf4bOf/DgnnnQqp5x6PGc++hQO7Vxk5XCbWjPmp1/+cp74xIv5/Oc/z+WXX85b3/pWdKn56Ec/yje+8Q0A9uzew5vf/GsYY5ifX8enPv0J/uEf/vHfBZ7+/0Ycx7z97W9j8+YtWGv54Q9/iFKKoigQQjA2NsY73/lOANrtNl/96lfp9XoYYxyI4Jdc1aErCFxIJoVk510HadYmGJ+u8d73vpdGvcHlT30GH/n7f+LW227j+dc8l3tvv4377rqLV/3cz7Lr3j18+8pvc3BxH5u2bebkcy7iX3/tzdx/zz389Uc/QZ5CezljfGorE1MTNCci/vwD72NyaopnPetZ3HjjtRzYu49Xv/aXMMVWTC5ojdcpbcqhpX0sHl6j1+3wxU9/hle87lXsOOUUOstdxsbWE9c3o1TID274Gn/74X/gPR9+B1PrE44ceZAN67eSpZrPf+xT3HNXm9UVwdve+1aaYwkWwxnnnEt79SD33/Vt2iuLNJqzvOOP/4Tddy9xeHebV77kpbSmavR6BX/yp+9i27YtPPOZz+ClL30et/7wNi55ykW8+93v5swzH/nAU7fbc3o7SY1ut08UKhrNJmEQIaXEaJA1SRQGrC2v+jg0oF4bdwk7GRLE4SAJm/ULsl5KLYoJg3CgxyGkJK5F6BywkjiqEUQBSEFZpmhtMBqiMEQoQRBIiqL0mXCBtU7kVgQSoy26NOSZJk4CkqSFCkKKoqDXzwCBLi3dbkotCWnUx7DGlxYBveU+QsJ0PI1suBgkiAIMltK4h0NJSCjr9NMeNgzoLy3Qz3JEqQlwLCZpod/vIYUgCkMiWSdQIWEQgnXPAaXRFGVKnmWs5Sky7RIUOUEco8uM3uG9pJ01iixDCYuyJcrkGN3BCENhSjr91MWSSjHWqpFEIYnIkXGIEgnNZgNhS0wBWYYTG86WIByDwGBtDRvg5B+MpN/vs7KySGYkKoxRSQsZhMggYCyKaDXHaDbHqNfGabfbHDp0mMWFRZIoZ/3cFBs2zDDWlHS6bYS0FGXB1PQG8n7OWrlGo97AAt1+TlzTSCXo9fpIAqQIaNRdmWVR5OR5QakNWeFEieM4Zm4mdnutFdQbCZaQUitWV1fpdfssL63Qao5Tq9U9Y6ZEmwJrC5JaSHO8SXttDSkFSgoCpRAiYGJsHUYHaC2RKkMFiiAISWoND4wErLXbAyZoo9Gi1az/JM3zPxzHYuhjMfSxGNqdy48TQz/sUrsf3naLn4QhRW8o5gwCOewGYUcNzs1c1SXCPfe7hYx1gFR1AhV1cKj8zxCtA0rtETshBovTGlshJF7kywthZ+mITs/I5FXnL8XgzMXg/1CxX4weIslCgCkKjC4ps5RS55Q6o91fIs27dPrLdLM1srzHameZfq9LlqbknT6q1KjC0LCWWErqKiAOApRw6K7FCY1rq4YsI98etSw1hQEjJAQxMkxcO8akQRAnBHFCmNQGLWGFqlg9DkUGgTElJu9i8y6yc5hApyQmox4GRGFAnCSEoUIG0mXDhMQKSYlEoyhlQCFiShGSEg06A0gR+4Ur/bx6FpYKkEKiJOTtNfJul4Xd+0lqDWrNJvMnHUcQR6gwoMxTrNUILFJFrqNIGGONp5JqzcD3egprhfb7xUhVbqiCcHBvwyjy3SKGlFYp1SATIMWwO6PxAf+gNa7VXpDSHWfYctsO6mSdyVTXLQfr5LwLL344pvQTGzfedBNuNofgmmPOeRrwiD1XbdItIH1QXHXCATc3Srra4bIo3GY5kg2yZrihVQ66QuGruRc4O1RSujrlAQ24cq4Vzd94kcWK7TYUjK9EectyqEVR1ci7klwzkhURg/JKXeSUmRO5l8JpU1jtzqHICoIgQyqNkgFpX5P1tc/oCB9EAH4OtNEYXZLn/UFGIC9ywsDQSCxxkmCsZKVrUFGCUKHTh/BOutSepmoMQrhjaECYPtIWJIGl0AG5cRunDCKCKGFp9130lg+ytvduZk46n+bcFuLGhKtdz/pUaaCBzfh5d9lG12UT6Tr5JI0GxljKIscWKQIvVFj2MXlG/+AyqlYnaDQZ377NiR73eyhbOPsVoFUNKxQM6tOd/3Ge3bhsoPBZ6kX4WssAAHzrSURBVNhlUI1xft0YR9mWynVLjaKaX5sK65rPOp/m2w17JBgEFHkXqzW21AP9BEvhxTJ9Oa61gCYIa+7+UWUZ/T30Gf4LH/fE//OG939ojCZFrvr8LWibs2FHjbFwnl67y1Xf+mcefe7jOPHkM2g2m+zafR93330bJx5/Oo3mGLV6k4UDy2At207YRBgHWCu476ZlWlMRMxtrWKHptzMW93aY3doiikO6yxqlBEEoaE4nHD7UZf/eNiedMst3v/dNfv033sxf/eVfcc4559Fe6VFvOsHg2268h6mZCWbXz/DDH+5FSsvsbEIsLUkcMbVhjmuuvoX9uw/xtOc+gaLI6HQ7xJFr316UOXse2MXikRUevG+Zk87cwPRckztv2s36zbNsPW49GzZt5vprr+ED73sv/+0P/pDp6Um+9Ll/4cLHXcrmbSey9+AeZmZmGB8b5+de8Vo2bFjPS1/+IvLVnLzXp7N0gPf/3V/znR9cz+bNG1laWv5fltGNjjCKmZqc5vrrr2HTpk0A3H///dx000380R/9EQ8NrZIk4U//9E/57ne/y+///u/znv/2t5x55pnMnhDyW7/1m9x+++188uOfRJoInUtOOG07d9x+B1d8/koue8YlTE81IW9T2BAVJezYsYPP/9vn+M63v83b3/Euir5m5127WL9tmsOHDvDpf/4kT7r8KSSNGr/zlrfwype/mmdd/hw+9IG3ceLJp/PM576MI8sHWDp8mHtvuoMzLzyHKEn4+N9+nIsuvYRHnX8OX7/yY0xOz3PCKWeztLgbFQTMzG1k//1LmBLOvuhkvvWNL3H7rTfyip/5JRYPZtz9wwOc84QTsVrz4O17OPHR24hqhu9f9TnWbT6F2Q3HMb9hik984hO8+z3v4V/++Z9IlOLLn/4kT3jaZUTJOH/337/MEy87nxNO2cQvvO51XHrZk3nDm9/AAw/cTxiEbN60lbe/9R3s27uXN/za69m8eRPT09M/wiR4pI3vXn0jURwQ10Kvi2RR0hKFdaQIKAtNksQEgSLtZajAsdGNcaBkrVHzgsKu9G1p4Qjddoex1rhjxIchSTMizfssLC1QT1wnu3Xzc5SloSg1nXafLNXkqaHeiIhiRaMesLbapygcQ0CoHCsK+llKGMREYY20mxEGAc1Wg5W1RdrtVXbt3sWWLVuYnJym1+kN9gIVxIN9Ou13AEu93qTq2GSFQeuSosjZuWsnWueowJKma/R6bQ7ue5B+u0OeZpALkjAmCWJEkUNZYvKCKHCNe+Kk5h+4NHneJ80ysjyjtBYRRoi44UAPATUK4kASKkEUKMcSk5K0yCh0SVpkaBwzp95sMNkMqccBURBSGvevKArH+hcWafsYk5MVfXJCjIwJx+aJag2CuObOw2hKo10MryKCuE6jOU4UJygVMdYcp9lokWUpCwsL7Nm9h0BKwkAy1lAI4+RD2mlBL9PkGs4442wkUKQpjeYEQipyrWmNNQkDRafdpb2c0V3L0HmPILSEiUApJw6NEDTHm0RxhBKgpCKQitZUgiGj1F3SviHPLL2uZXJ8xpVtJoYs65EXKVIEpGlJp5PywM77iKOQ47fvQKCRwhKGEiEjSiO4/c47ieM642OTLC/3CcOQmdkJCt0DXJlnt5OS9nMue9ojN44+FkMfi6GPxdA/fgz9sBlPo0HU0BgqE6kgWjtCUxm8egjw2qGYlSeU+M/D4ZwVu8lnbY6iklRAmzjqTcDQOAVVOZ712USDEOZHAkA3idWp2gETZliK5YyzOgUhJDJwwmvSWAIVYE2MsIJI1VCEBCIhVT0wAZGokQUpfduBvECogliXxAJiJaiFikA67hA4gb/COKTTIhBWoKWgxJKXGm3x7RBLbBlQ6gJbJOgiwegCGYaoKEKqwIsiKqT0TDSdI8sUUfaJRUkUCBLhGU6BQsUhVkq0EL5GXWFQFARYGWJVTKkSNAGICKUipAgIZEjFbBsAQLLS+3KOMKrVkAJqrZqjheoCnedOFDZytG+MQNjS3eDR9WOH2YXhMrBHrbnhGhrtmujWkQtufrTjn/8Uf98dE8pY150OXWUyzMh7RpBnb6jDdSiGP/+XGPYh34uj6aN2sCf4n4fZFLfBycpPOZtzKPKwo59gyHCsOn2M2tfInFbJn+oAg83Ob3JY8xDUf9g9sLJ3KeUg21RlaI6630J4ENxlKAanDCAcUF6KgkpCvmptqwKBJfcbu/HAZjAAda3/bDE6Wf41ToTPZUut1RRZihICIwOEjHydtV/XUnjw1jpKr8ADmQKJxIoEawOQORInmGj0cBbj8RmM1nTUfeSdZfphRFRren8VYjyAWgVD1gcj7j76NrF+03Q/G1ciEQZgNMaUBFIRhDFhvYFFoPPMsScZtS3rr9v4jN2/bxMDiL9KdfnfuexdRe3GZ6+coKK7rWLw6mrRDAKxqptLNXfWcNTCGh6IoxitgyBPjL7gET2uvPJKtm3bxkknnUStHlOrtzj11O0c2LlIWnQZn5hgcmqS1liTfbt30m2v0mg0WFleRJclzWaNIJSuU5HWiNIlDlpTMWEiyDIn8o0RhLEi6xWUuUHgSrClEqwudcmzgjgOkBJq9YRNGzcRxQ5simNHfy9LQxgGCCkotXElGc2YzVvnWdhzkLSfk2YZQaio1RPSXkZci5iammHn/Q9Qb9TYvG0zex7YgzEwOT1Js9WiVq/RHGsghKXT6bC2uowxJbNzc2AFZa6JAiema4zmyOHDJFHMWLPF3Nws27Zt44wzzyRdTin7KWlnAxfvvJdkcgxtNPfddx+rq6tc9PiLiOMYUxpUqFhZWeGaa68BIA5jzjz+bCbmJphaP82111zH8onLnHHGGRx33HGkacrGjRuPijt279zLngMH2bHteDorPc4/83E86lGP4uSTjycYX+MxF1zAzPQUse0iASMCdj1wOyvLh5mcmmTHjq2MNRP27ryHMi8oCsvioQ61ZIyt27dz+MABkqjBuo1zrK4eYXV1hYmpKTZu2kpUi1g5vJ+s10ZKQZE6tksQSPd9KWmOtxhrjRHXa8ysm6FWq2G0YW1llemZeeY3zPOtb19Bo9ngjEefx7e/dj2LC0s8+omnUG80GBubRPjGHnlRIIR7GFheXKQonLbj2PgkSRyibEm/u0oYSjas38CRAwdo1evMrt9MUqshA8Xk9BitsRr1ZsLmbRuYmBpDFwXKxihcV8HJyQk6nR6Lh/scOfRDtM14+tOf/pMwzYc9siyl1IKsELSaTo+nKAqEdZ3PHJNduIeHIMACRa69tqoYJF2NxUk5GKevGoQhgWfBV2UvURQTxRFRHKCURPsHxzAIKJUFUXrGgHCi3wawbv9DSp/1d23hM52TZV4I31pfuuNL/3zMJWUVO1f7smvxXuWZXfkXIByorAJFHNdp1MfQukAFkNScyHZe5qxGS/S7PcpMI2Xg9qpSOYkKCRmS0sfpRrg5ya2llBIbViWEAUhc0hjIJSjr9tfCSgrr9tS8DDBICAJUEKGCABnXIAywgcIGIUUOaWnJspJQgA0USoZYAYUsKazC+OePirlhhERFEVEYU1oX32sjkDJAyoAi90x9BLoskUJSrzW80LOhKHLiOCQggNQ9fA7iXyF8tyuBtoZ+v0sYSUwU+n0fpBKoOCJOFLVGQJZ5Vku1R1tDURTIKEGOdOtECLela9BF9Qzl42bpCAN5WpD2cnrdzDHxAhffSCrh+tI9+ApFELiEtNGgS4MUDiApSw3ogYaRksPY4JE5jsXQx2LoYzE0/Hgx9MNmPN140w1HiakNwZqK+TEUuwKPikq3MKsxqqZelUs5Voo76VKXIBytcFQY/OgaWo6aEGtGgQnjKYQO/XOo8BCsGLSh9Khl5Uyl8DWwUg7oh1h7lAMQ1lHaTJZhtcFqg/Dd87QuSbMehc7o5av0iw5p0WdlbZm00yXtdgjTHhEldaFpRoJIQhJIh5QjvTK+vz7jzr8sC7I0pSg1aaHJCid2lmmJVSE2iBBJExHFyKSBjBNkEBLECUoIFIao7BDrHrHu0wxKx3KKY9ctwLfuzI2ltIJMxBhVwwYJpUxQYUIYNVAqdMCMGSlZo2KiCddiUzrgyXjhdwkoYbG6oH3kIGUvReclE+s3ErVaxOPjbhM1Bkzu14EEFQ/mwbHO7ACYBetrnJ2zctmCSrF/yMILgtCvPekR3+E6dHil9YzRoVieY8n10aVjtlXgUsWYs5aBsL5b+nKwwwgPQJ173uMfjin9xMYNN97g7EuObpDDOXJOaqQrhr8PYRyjVEAYRoMA2HpWnrHWl486KyzKEiEc3boSmzvahTpgzxjjO5gw9CkecC6KnLIsnYBoxYwc8T0D2xVgtPY/MwANhz7CA5nWurU2yBq53wlryLs954+kIFKuhMEaSd5fwJROi0WIBCsSsCXad7IQSlG1FS3KAmM0USiciGdZgFAImyF0myipIVREKRqeSuvOQalgIOJojKHU+VFzZW2AFU5fQknXFjorIpeRsBaZjFH02yw/cAOrB3aiy4LN5z+TIGkiw4i8t4pEoFTgwlU/D3KwaYaOKahcW1/rbUzisk9Fv0ugnO9Ll9fQWYbVJdOnnIwVUGauC4i0DqrWso4VIcgQQRX4jAatwusNBAOdNql884mRFeKYicq3gE4AM7Kh+fVTlmhdorVrFywQCOseMIzVWFzmS8qh8Ge1SVpctk16GrKw1pfqGi587CU/ppX93xtCCH7lV36F973vfYB7IMh6JTv33o42Baedcg6msHTbbT7x0b/glDMezWMvvowrPv0pdFGwYf16jj/1dGqNFguHVqnXayS1mNpYzJEDq+zftcT69TPUmxGNyZAHbztIkWm2nrKOMAkw1vCD797Nuo1TbDthPVlPI6QgqklMackzzeKhDkEEQShoNBP6vZxOO0VFkjgOabUaHNx5iCzLicdDJibHCcOQB+/YT3O8Tmu8zqc/+VHWbZjn6c95JnfdfB+9bp/6ZI2QmDiI2XTCHF+54gt88XOf41nPegZbduzguJNOYdft+8nTnPGZOmMzLZZWl3ji4y/i1a/+eX7913+TpFEDXGvptN0HAbVW3ckceN/zh2/7Q/7sz97DbbfdxsZ1G8jaKbWJOt+/7hqe8IQnYK1lfmo9//h7/8qJjzueyZPHOPOMs3nCE57A3/3t3zLsnDuMd4QUfOjP/pZ//JuP89HP/h2yiLjv5gM86sk70HS5+Tvf5PTzL0SFgnf/2gtRapIgmua+Aw9y0aVP5/VvegvLC3vRRYkUdT70wQ9yz13385LnvplTz9nC5uMn+Ne/+Z9s3radiy59Mr/9q6+jVqvze3/0PsocDu/by7t/73Vc9uyX8ZgnPpNPfuRTHH/acVz6nCfyptf8Ac2xBu94/++w/8Hd5P2MraccT3spY+VIh+98/bNsO+E4znviRTzmwguZm5vji1dcwYtf+CLuvfdevn/N94nCyMVa2vLtr1/HJ//1i/zO238ZazK+9OnP8LTnPof1mzax676d7Ll7D4sHFzjtwo3MrNvI1OxWPvY3f0FrfJxnv/wVdFZXMKWmNTlFWbiObVFNknb7rC23+Zu/+BQzc1O85g0vRheWu+7cybOe+joW23fRy/f9O0nGR9b4x7//KAiX3T7zjNMJlKLTbiOF0/mZmZsaZNP7vZwsLcjSgvGJFlEckcQxFkFZaJaP9LC6BGGYnG0O9VNC4XV4NMrHPkkSU5QGXVrKwtLr9uh2O0SxB5BkSJE5e262Yqfho0tnv50+7XaPXqfD2FiDrds2OXZRUbCyvEwUOZBnZWWJKE5Ikhqryx2klNTrCSvLy5RFiVIxtXqMVIIjh/fTbLUYG5+gKLWPGQJUYNEmZ6W9wMEjB1hdXabfb1NkOUVeYAtNWRQUaZ8yLxFIakkdJQRYQ9brECnP5q+Y70rS62UURUmaZSgcI8RagbEhhoAwSkhqCa3xJiqOBtUa9VgRBRKrNe21VdrtNqbIiUNFo5YgpMZgyMsSDb7kpkUQ1lBhgpA16o0xxifnWFxZIk1Tur0eM9MzRFHEkSOLzM+vY25mlm6njRCSQEUsHlogz/oUZZtmqwVCsHfPPqJanVqjxY7tJwKWPOtTqzfo9nrc98B9TE1NUKvViIMQXQisEUyMTRHFAVESsHD4MHleYA2o0MfGwjI5Nc34xDgqtK6znyhYOtKh005ZOLzG9uM2+zXontOKPGfnvXvo9zRpCus2TlBrxDRbNUIF2ILu2hHCqI5UCUvLKVYrrAlZXe2iAsnEdIO9+3eS5T1mZ2dpNlokcZ1HnXv6T9ZI/xfjWAx9LIY+FkP/+DH0wwaebrrlRioqYXUwZ3ij5WvSo6rKZWw8MlmBAhWg81D2lPAI7GhZ3AD8qcAihoBUVcM48uLBjTFVO1NTlUgN8FmgqoH02j7ewEaph0aXlVUNW1l69FFY60ruytILkFlP9LLosnBifLqHtjnGlvT7TlA0zTLKrI/VOVZnSJsjKZEmR5gSYQ3SVJ9nQWuoaJO6RGtDmuXkeenqs0tDaaC0UKoIG8TYqIast1BhRJDUCAUEwlIXOZHQREJTjxyFOIgiV0rnMw7agBUBQX0aFdWQYYK10msKBANgx9X7Hs34EUgHPCm3QLXRvti2ROJSJkVnjbKfYfKCuDVO2GgST4xjvQEIUwyEEK2KsEgXFBiD9cLoYlBbWqHk0iPo0tMNB7A+Srr1FwSBF7qsEH6Lq1EVgw4QFYBmrKEsMmd0ZUGFLWtb+jU0Wi5qB6WMjuXlDn3eeRc9HFP6iY3rb7iWQWeNwVwCVPMjUVW5prFULLYgCvymGbvOOL7ksCwLV4rod+ChY3LDOWnXIWMAIushmq79awZlrX4Tt76Nb6kdddMYQyAkgXKZ3SorVOjSAZ3G+pyHu7/aa3WNUpUr34DvhOF/RdrtUul61ZIaQkhMYcm7h9F527dorSGUYxdWZbhCeedrq13Y6RsUZU5ZZO5arEaanCAUIBQlket243XMqmCl2vCdz/L0baEG2SpjNEEgCAIQ1lCUln5uQLgMpbAlK/vuI1tbQAlLY2YT9amN2DDGUrWSdn5N+CyFK4122V2pQqrOBBZca2ijsWVOGCqwlv7KKqbfxRYZzS1bEEGMxWWwMNrXxYdYFEhFNcnGVBm/UYq39K2eLUEUo4IYGUTgBf6NMR5QVgSqKqFlmM3D6cLpsqAs8iob4fcB70erjp9CDo6JGMnW+EBMCIERw8YCF174pP+zRvd/cFTA03ve8x7e9vY/Zmpymp9/1WsobY/l5QW+/qWvsmPHCaxfv5GoIem1+3RWe6zbuA5hFelqwdyWOWqNBG2tY7wqidbQXc5pL2bMbK4TJYogkvQ7OWmvz5GFQ4yNTVCrN7HWsHQoZWF/n+NOnyWuBSB9Jx0gqgWDOY4TVzqU55pOr02gAhq1pgt0tSZNS5YWVsn6OZu2zZKXGf2sjy4Klhc67Lr3IGeeeyLNVo3OSpsoSigKzZVf+SobN6/juOO30KyNUavVaY2N8bUrP4qxhqc/++V019bottvct2cnW7ZuY+OGTfzKr/4Kp5xyCm9+85v4zD/8A9ZanvvKn+E7V1/FoYMHeNbzX8SuXbvYuXMnF5x3IfVaDSklN171NZZXVtATLYy2xGHMOaecw2233catt9/KxEyD7Tt2cO75j+Hv/urDqFDxml/8Rd773vdx991388EPfpAbvv09bvzetbzqDb/AjdffwIff/wH++M/exezMBD/47lc4+azHMj41xwN33MgXvvBlvvuda/n1//YbPPDgLv7ti1fyjj9+G+tnN7LzrkPYMGVlbZF/+vtP8cxnX85lT30yK6tHqNUbTE5Nc/edt6LLnOnpSQ7tP0i/26der3Pzzbdw3/0P8NKX/yz79j3Itd//Jo99wtNoNccp0i5bt2+jl/b53T/4XV70wpfyjKc/i/0P7qPWSJiYmeBzn7yaRrPGs19wMdff8D263TYXX/wUPvov/8p3vv0t3vmud5N2Mx68fy87th5HluXce8999NNl0myNleUHOPnU89i06Xh+eO23md+0hRPPOpu11SXuuutu/vFfPs4b3/hLTE1N8hu/+Vv8zM+8ioufcDG/+qY3c8F5F/LTL3sFBw4e5NbbbuF/fuSv+f3f+wNqtQaPe8yT6KeraJs+4oGnr33puwSBIIwccGGNpt9vMz4xRRwnBJEkL3LPfglxuqnKdXeLQuqNGkJKdAlrSylSWqSCWjMcJM1daDISlwuBkJAXwwfVw4cPcuDgXuIkYnxsnE0bt1RPTQhhKQunWVqUljTNSfs5gpJaEjIx0aIoNXlesLK0SrNVJ4pD8iL1x5Ok/YwiL8jSjJXlNkYbGs06Urm4qjQZ9UaNeqPO3r37kELSqDcIQy/kKyz9LCUrcrQpaa+usba6StbvEShBEgfkac9JJWCRXpMlT1NMWWJK7eUVfNLRa7IU2oFrCAlWAQphnfZQGIUktQQZ+M7d0qIkSOFKjvI8I8/cnCsp3QOlcG3ggyhhZa1NP80wVjA+NkWrNUkcOz0sGYR0eh0slnotIgrd3tnt5Q4oiiKWlhao1xtMT83R7/TJs5Ref5UiL5x+bJ6zurZGv59yyslnYK0h7XWYXrcOISTtbsc9SwhBs9kkSwuKTDM2NuHKkqQhy/ouVhZiKEJtXReuKI4JE4PWBUWRgqmTZ5a1lZT5DdPU6wla5wSh+6wDe/dibYBUNaJ6QD/rsf/APtbNTFOLQ8qsR63eJAhrHD7cR0oXj+/fvxcVSObmZzCUSCloNBr0ek5H8MmXPeEnZp//0TgWQx+LoY/F0D9+DP3wu9oxnHD3sP7vvMB6Nok8GlCqDPTol9oKwPOffbTB+Y87GjeqXltpSHnW1QCwsnbk5T9qxO577cAdC9ZW5XTDLKWjswxBjAHq61ktSP/PVK8FhWMBuc3IAAHWGmLVII9L8qIkK1JK79CtzrCmwJZ9MLlDpU2JMF7wrSypaHfSWDAapQrCqERqA6VBaYPUBiEDrIowYeRK7sKIIAgJJK6do1KEyn0vogiCABOElNqV7xUmQxuNtQqlaoiggQprDmoZ0P3cPFg5nJZqEVbGN9jgwWlVVe0gpSCMY6QF7YW4BcZd31Fro7pr1dz7+yXsUWttYPQVGDg4x2rReMTeCKp2ncP3u3spYOCo8MZiRoTFR1bo8H3CrwKfJRikO/yfH9nhrhseZvM/PTSD4r4a45a3Ex1kaGcV4DfyvXNGQ2DYWjtoLVvZpByhhFZD4GxICX+PTDX/IGW1gfpjiSGTbegIhQMijaQS2Kts2G3SDiMdANT+Pglrh7TS6lyUxGq/Zqo153FW53+qNqQK0AjjzrtqOWqsHfg5fDbCZT+qzTmkotW6Rgyjxx+uz6HI48j690GHsWLwL5TGUeiFQOvSdd5pTlKfnHe19Efux6QddNpGBRFUG5V1G1kFF4/6x6pu38soYowE4co+KgHksFZDmwxrM0zedx4vdE0OrNRgc6zxfuIoOxreRzwb1oIT8sdgjWvTKqVy82ncg4+Uzrdq47JLroOLn4/BvPlyhkE2yDLqLI6y18G5jCQ+bFV0a4Z7zSN8LC0tcfvtt/Pgg7swpUuaUEp0YVleWmRteo7JiSkm5zaSdkt6nS6lLYmCkEZzgiLTQErcSAbl5MtLa1AE1GoJQeiSRaaEpBGB1OT7HFsgMZZGq8by4YLuWjHwr0YbrLZIyUDAtCxL7rnnHsYnJpiZnmVpucAoS6MORZlhjCGKYox/sC10SWk0Vhjm1q2nSA+zunwvQRBQr9co+ilhGKCNZuHIEieceBynnHY6y0dWfZAPhoxC56ysLaP7ORjYsHEjExMTSCXYs2cPU1NTlHlJe3UFYw15lrG0cITDBw9gjWV6epYwSFBKsbK2ypGFQywcOoRSklNPOp5GvUkYhuS6w1q6xMriCpc99YnUmzX2732Q/fv2EkURK4uL7Nu7lwd37WL/3n2MjdU5+9Gn0E/XWOsukpoV7t95L2k6T3O8xcrKCnmpOP6MC5m/9UEadzzAxk0nsGf/Ag8+uJMHHtiFKQJ0adm8bRPTc5No0acoM4rcMDYxThi5NsfbdxxPlvXorC5w+NBe0jTnqc94MXff9wDLqwvMrp9jYWE/hw4cYOu2dcRRje9+41Y2bduCiiJ27nyQTrdNGCvWej2MFIwbyzlnX4AxBbt27mL7th3ESYAuU5aWjrBv3z6sNQSRolZXlKVGEDAzu4G77tjP4uJB8mKVvOxiVIYpBYuLy9x1152ccdZZjB1aYPeu3eRFibGwc+dO2u01LIbdu/ZwwvEnoYKADZtm2bk74cEHd9Jpd2k1xjjuxHn27ClYWkp/wtb5H4/xsXHCSBFFAUXWQxuDkMKDwII8T8myjLIsCZQmDGOiIPAxNYO4SEoIowAhnd25pizgEqZ+7/a+HwtlUVIUjvGkAoEx2pW7lWCsJgiqxkCgy9LHdm7fDcMIkESBJQyq7kUAAikClAwcy1x5vZiyJIpCp0OlU8D5FBWoQZKvemBxrI8SK4QDpKVAooiTBItCqdgxSGyIJCSLe8RRwFirQZZ2PUjiSgCNMWTdPmnaJ+tnhGE4KMtx24t1Yr5S+YcpLxdhBcqXK4ZJ7JnyeJBsuK8YITFCEkeB7xYlUSokCCPqjSYFEVb1SNMURDD4bKMN2hYe3AqYmmyhiwKtXQUCForCuG7aCJSSJPUaUgnysofWFoWk2UpodzpkaZ8s7WONJUszdFGiwpA4StBFjgTiKMJox0IU0ifcy3ywr5bGDBLJCkU/y8jLgqZy2mN5XhKpYQWBK7nUZP0c6oogEgTKxfxhFEIAtl/Sabdp1RIwCdJaLzbs5kEISRBIhDQgLWBI4oQgCAiDCGxKWZT/r03yPzWOxdDHYuhjMfSPH0M/bMbTD26uSu2ckJo/5oDuNbrIgzDybJPQG5H1JWl6wGRyRxeDtppSCC8qPjymC2r1APWtjgkMjNNaj856lpP1TCHrJ9uxroYib0ZrR107ilo4WtJXle6NbDhmWBpotXYUtbJw4AqOYYMFazS66GB05lTiCbFWgPUdCbBofxONNZRl7sS/rcbojLLMKcucouh7lfmR4N4IJx5nwVZWLVyZG1KBlB55lZ5+KH33jwAlcWLmMgChECi0EegiJ2svkbcX0UVGkDSJmpNEjXGCMB7Mr78b1R3AbY4BQrjSSqkChpGRp2OaAowD0IQu0VmOyQus1gS1GtHYGCJ0Gga2LHFScCBkCCJwAmvVGhhR7Xc+sOrkVwGblVMb2RKkO8eq/DMMQyoTqRaStRWq77I81rhzt8YM14Cornp00xgCbxVib7E85jGXPBxT+omN6264FiHEwHagCmLdetK62igh8K1vVRAShI5OGkUxYnBfhlkXIaAsS4qiJPQ6Aa5rkxoAv1rrQSMAp2MRAMZnP/SApll9rajA1fmGnsoqEGjr6MmugtkNU3qGo69DH4jHm6HvcJka74fwa9toyiKnSHtEkaNDq6BG3j5Ema0hVIQM64ig5piIfglp60Di0g59WrVmqvkwZYHJUgKZu+BPuawPMsDYgoqi7d82mM+jyoutz2r566yFxvsiRZqBNu6ag8R1iukeeoBs9TB5Z5na1AbC5iTR+CyoEKzBFH2q7JxSzncI79OrsgRT5lhdYvM+UZK4uvsgpljeR7l6kCzvI+pThJObCeOG0+3IexRlgTaacrDvu/Osgo6q04pFoAtHMVZhSBjXUWGM1a4VtJTuIcBYKAs9kjzwjFY/91hX7nz0nJmBzx4Gdv4BTKjB51Rn6IIjM/Al559/8X/OqP4fjspWk6TG1V/9Fqeediq1ZsRXr/gqvV6fZ/zU5awcWWLh4BG+cuWXOePRZ/H4J13Er//2a1m/fhO/9ea388NrbqWz1mNuy0YmplooJbnii99m+/bNnHX2qVhbYDWYVBHWQSiXYY0bbm/Zf+8StbGYsZm6D0irGMDdq6VDHcYmayyvLfKoR5/Na37+Nbz1rW/jmq/dzNhkk7MecxKf+efPkGc5z/vpn0LKgF4347Mf/QYnnbqNs887kd33HiGuhazfMsnCwTbWwuyGFkWmfelVgNGGMi85cOhBavU669dvwRrDnt27+KsPfZDnvuDFzM6v54ILz+OXf/mX+b3f/336nT5ZL6O33Kc5VccYzeKBI5Smg4pgxyln8zd/+c/84//8BJ/43N/yjW9exatf/Wqu+trXaMQBv/RzL+byZzyDHcdt46bbv8mTnvwSLnnSi7j/jl3cccf3ufrb/8ov/8o7adbG+NYV/8YFT34KjYlp/vQP3smlT7+UJz7lEv7lHz7Mpi3bueQpz+bSp1xKHMd85ctf4YPv+TPuu/te3vau95DUYsqi4K/f9RGOO2UbT3/xpTz9qZdRrzX45Cc/zV033Umv0+XcS84n7Wk6q32uvf7zbNy0lXPPv5gffO9qgjDgrPMfz//8m//O3l27ef3r/hvNiQQVCe6+fh+tiYT5HRPceeM1HD68l/sP3MVTn/Yytm09hX4nI4wDOr0255zzaJ75zGfywQ98kMO7V7n1plv40Ifey/Nf8jJOOf1Epmf7TExtpjW2HqUUn/7kZ3jfu97He//8fWzbug2TCQ4d2UOe9RlvTfCVr3+U2+66hj9+x0f47Oc+z9v/6O184fNf5KSTTh4EyABZmjsdylDR7+WY0qILy2233kStnnD6o05nZZ9BlzC7XfGmN7+JD3/4w494xtMD9+whCCRhpFhbXUJr7TRRlNMka68tu/1RKvI0J4kT6vUmYxNTrqTDl8qA6ySXpQW6NNRqMSpwbIu0l1GVvoSxi3t63RRPiqBWT8jyHr20SxgGRGFEs94a2SvtgCWR5aUv7ZBESmK0pshyNM7HFnlJGDgNqdLkdDsdOp02YxMTYFzXvbJ0D69xEvnka8bCwkHiOKRWS1xcgURYd/4qUCT1hD379rKyskKc1KjX69TrDYIgIImdZpsucrQuyXRKlqVkecqhgwdZWVmh3V5j4/p1BNJ16Ot01sjyjG7qmDdCKqKgRlGWDpQrS+I4ptlqEoURURTRaDarqJMoilk4tMjikWWmJqcJg5hQJTQaTeIkZGw8ptvrkKY9lhf2015eprO6SmkUYa1OY2KczduOY2xsjOmpCY4cWmB1pc3+fUeo11vUG2OMTURO30tAFMdkaZ99e3cxPT1HrdZEScXunfdxYP8eNm7cDijKwjAxO4UFVle7NBs16vWE+fWzZFlGlheEQY2yyMn7PcI4oJf22XfwIBa3R8Zx7MoYreWMM09FSkFZlOgiIE81qytdJqeahKGis7ZKo5UQ1yLaK0secBBENYW2hl4/o8wdg6JWb9AaH6dWr9NuZwRBSBTHLC8vYq0ljmLSXul0nqQdrN8LHnvOT8Y4H8Y4FkMfi6GPxdDw48bQ/wlxcXw5U9Ua0U/ASIvBUSZKNQYopgApR1A2MZhWd5GD3x/NUhqIP1vgIdpPA5R5gNZVCKtglB5WLUzjWTYVdUd4x+tYukOUcfQznZiY9mvaMvAqwiGbCIGDh3GLcqAp5W5+1bVOjmhHIUBaX65lHWqpy5ggKB0VMW74BeHFHxFopD/mUakvxzZCDJFmIbxAX5Wxctkx5bNiWIG1ErR/RWPC1WdmPYwusEWKSRV4FhNSDmZWWDsAXCqE131VQ/oyTpzMCicuKao59w7TWCcmaHXuTkpIkE6AUozcV1eT6lZW9Xa/ooYIfAVIWuvp1I6BNcSHqns6woobgvcOODIVQ8oznhyu5r+3g3WOGPxviJsy8ln/hVqxm0GALzw6DuAyp7bqiqGCIbjn6axVhnKYuRnNNLjSxqobBgxBy4FNSzyiz8h9rkBMedRGKaTLFFZ16UL6bKwxg+6XYuQYdnCbhMsA4DJFVaZTa+2BQonr0mF8dilAGU3pM64gUZFEBgqlnaCpVAEiCF1WYLAJO0esLFTtXP2SBOuo+AiJFnK4NKyjPlN1HZEeVK2ySWIE9jbWC7EKJJVWnSXLXRckJauAx2emygwhJHFrxnX8qLXQZQq9ZWyREjQmkWFCENcZ1PBXWTDpSq6qeQ+TGlY7XyQsAx09GdeRzSlkr+1owqYclDTLygaldLbq7X1UhFF4Pb/qoQgEyguSAj4hUGVpfCmrwJ+b9EkG1+1T68zrwxknBCuHr3EnVAHDLiFQleqqIMB5futt32KNRloG5/FIHe9///sB14Fo4+b1ZGmXvbvvY/OWTWR5wdev/A7bdmxmen6G6ZkGzWZMEIQ89zkvJVI1Vg71mNuwjtkNhvpYk+UjKZ21lFNPO56Z2QmiRIIIHfAUCG65YSdlWXLBE4/HGihKw/hsAxkqjIEwcmvVaFCBW49B6ALlVmuMt73tbZxx+hlIKdi0fZ44CTHacvqjz0CXGl0I9uzbz9LiGiectI1166cRUtAv2uRGER2WqFDQ7fX40pdu4PTTT2ZmaoqvXflNtm7bwgknHs/s3DpWF7vccPUtbD1xA1EU88QnXcb8hg3Uag1+5vmv45zTL6QsSj71sU8xMzvDRRddxEc+8k8YY3j5y17MjTfcyZEjB4nCWU454Xhe/wuvoNGo86izH8W73vUubC+l28155atfxsmnnsfM7AY27DiB+XUb6XWPkJeH2LBlHc99wWtQQtJeW6I5VefQgZ0kq4s8+4XPYdOmTWS9jNtvuwejY9CKX/6lN5D1U3547a0EqsPGrSFxLeTu2+/g3jvv4oJLHs3M7BTpWo/Xve4XOHjwEH/6jndzyRMvZmJmnLe85S08+UlP4aLHX8zpZ5xLFNZYWVhl/ebtCAmry4s86tEXcMopZ9EYj/nG1Vfxg5tu4Kdf/Gp6/WW+cdX32Hvv/dQbdR5/0TMoUs09d9zD6oJl83FzTM01eMvv/De2b99OUZRc8aXP0213ecWrX8XJp5/K1MwESvS55rs/4IEHdvPiF7+cjbM7ePbTfpqZmTm0Kdi3fzfGFoRxxNS6Wc4863FMTs6z5+4jbF63g9/6zd9GZznXfvc7fOPqq3nBi17C9h3HoYuST3/xi9x222288Q1vIgoSsrRkbt1G+l3NtVfvY/v2GSamaigleMELXsCJJ574E7TOhzcOHTlEq9VgcmKcUrsW4Vk/o9FoOMZ84NhFIAjD2CUTRejjGjF4sAGnfyV90lEq6UXJBSqU/kG0QGhwflZRpg64LZRFqZhWM0B5IXIhPCvIWoqyHOiKBEEV7zkGEEhk4DRJwXgdYON9vUCFAVGckPYKB1bFEXHirt1aSLspadonSerU6wmNRp0oiimKnG57FUSIME6zJIkTms0WSb1GWWpW11aRQlJLEoTW6NKBJSJ05yOsYmpmnqQ2xvh4jw3r57FWk/d6CBsSBRlhXBDHNYIwIpQR3W6PbrdHEAYkiQOeOp02RgsCFbPa7lAUBeNjIXFUY3pS0hprURaaXreNoaS0MbXGGEGoqMs6am4DWgt6/YKyX2BLg0xzDhw8SLffJwpjICSOG8S1NoUuaHdWmZ3f4oTEA0kUxxS1hLLMqNXqKKVIu33qzTpz8+vJyxwVRMT1hH6/gwWUAqksCCcYvrK2xlp7jWZznCgIiZIaKlQkKCbH5zybBZK6GiRhO90OZVGQphnTk+uIEkWt7qoopBAYI1hdXcOuFBR5l0A5plXayxFSksQJOggoipLDi0sUxtIoSg4dXiBJarRaLRaXFhFCMt4aJwgiLIb9B/eTJDFRHP6o0TwCx7EY+lgMfSyG/t+PoR828FQ9YLubLEfAJb+ErBiU2D3knYObO2AUjVL1/EobBQYqLSdRgStWOkV9b5CVcY0aZ4XpVOCAEJWxSvd5g+MZD0xU6IT1FDlHx7PWlYi5tSw8CjsEpIQQrpRMVGCP/xjphPwGBu2QNrdQkAhb1bKaCttA4EXasWgZesaWBqsd1GRd/boVYIQXMJNqAPKB62ji7oEdLuAKoGO4QKUvvbMWtLGOZYtA1ppYqylVQNFZBo/SUmuACP01uGONAoOCIVVUeoDKAX0uA+KEydy68LxTnNfLEBiszhE29hNRLcPKmF1/v1G21eh6Gg7r//P0x2rOR1am9Sh41fZRDD5jdO2MgJkDUNTN6aCT3VGJ1Ap1rrIF4ujTeqSOaq4Gi9Y/OFrnoKV0rLpqDqpM56hG1gB0G7Hzyi7kQ5zOj2yaMKTg2qGem8viOsqxMdoDzW7Oq3NwDnBA6GR0ZVi/Y1VXNJRmq7pTHq0V53cnB1hKhfEih863efv0mWWD9MBqgJAlBu0BeG9/gBVmJCPkNj4pJUZVwK2fO38exkLojdFUXTKEGGyYo2P0TjmNCosRgNJQaQlogSlzF7jUxiAIUUmd7tJudJFi+x2EUFCzBLUGrvWH3/jlUJSyApIdi1Kildtg3C5oEWGCrE+gjHBIA44d6BJGPuMhJcoIrHAb2ihNe/jV7WlOiDPwPrKyURzAbcxgfVZrsNJxM8YJzFqvFRR7+rFSwq9x4RmQbns0VQcR77escP7JCOs3dwNmZMN9hI43vvGNg++zNGP5yCKH9u3nxDNOpygtV13xfaZnp9i4ZY65+SmCULKysspFj3sKeb9kcU+bmc2TxA33YHdob5eVxZRTHrWeejMmjJzeEwKCQLB39yJpWvC4y06mu5qR90sm1jUw2lIUbl/JsozlxVWmpiechkXkEgD1Wp3Xv+71LqGkLXMbphBCUOSa407c4R9CC44cXObw4SXOPf8sklpI2k8pbUpZSNZWQ6bnWpQ645Yf3snGTeuZGG9x2823kcQxJ596EvV6i6UDHXbetZvJuRbj001OP/NMxibGEFbytIsvZ8uODehS882vf4dTTj+Zpz37aXzv+9/HGMNrf/HVLK8ts+vBB9m+YT9bN2/k3AvOwmDZumULr3/da7jha98iz/pcdvll1OubiJNJTj79XJYX93Pk0F40babnpplffyEHd++k32szNjPO2soC3fYaZz32KYQyIOtlHD64yPy6Nrq0XHbZZawsLvPD799GoyEZmxqn3++w8/77uPmGGznvTY+hUa/T7/Z4+tMu54c/vI03v/HXefS5j2Z8dpKPfuyjzM3N8rjHXcj2HSfT76WsLraZWjcPaFaWjrB9xwnEUY0oibjjztv5/L/9G697/etY63e5/babaB9us3XHcZxxxmO4+fofcGDvPtqLNcKaIGnCz7zyZ8iynMOHF7j5lh8wOTXFz//yz5NmXbQpCeUM9979IN/4+lU87SnPYnZqA098/NNI4gbd3goHD+5janqCpB6j0WzddjKz01vZees+1m9fx+MveQz33HY799x5N5//3Oe48MLHsWHDRoos44brrueKK6/k51/9CxTKsLy4wtz8Osq8z923PcDEtKQ20aJmmlx88RN44hOf+BOyzIc/1tZWCALJWKuJ9jpJvW6PMAiJoggpg8GDqFRVm/ZhZ7hqi7Dg92r/cCi9/ofEd5TCg0/OFwaBIrcGU1qMhigMiWsJVWIP/9HGWvI8oxI1jsKEo+IvcXQ0ZqyvOBACFQrHaoks3XZKGAjCekigXJI2zwrKoiTPCsYmGtQbjsUURSH9nqVjC0pjEcY9vAdBQJIkJIkrMev2ek78tiyIpaQsXffEiARduu58rdYkUdSg3siZnJ6jzHPaZoValCGJkWiazSZRlBAIhSQC47Sz4iSi1kjodVMXG4iAPHNarbVEE4YRtfGEuJbQ7XZJix4lBVrEjBUOnAnDkCiaot3uE7b7UHQwQlKUlqXlZfKiZHJsmlDFhKETNO92+6RZnyiKSGoJURwQRzFlEmGMu0ajS9pF6v4eRRw+skAgIa7HdDurWGsJoxghHDGg0CW9fo/VtTWnP1NrEMc1EJIgVIy3QsqywApDrSGotvpOu02/n9Lr9ZmamiNQkjD0lSP+Wabf7ZOmbRAZcZygAoUuNCoISKKEMIoxCNY6XcI4BilZWVmiXm8glaDd6RDIgFrizskKw9raCqVuUNPJ/20T/PHGsRi6+sOxGPpYDP2/HUM/7FK7W269eQD6uAt1pzToTielR82CAb0wDENflufeVwFOD6UBVqcgPTospRzSChkaXxA6cEYPaIWOrVJ1sKs2bPdZ0msuqQFgpY2m9KV7Ix0EnWOvRLmGCBaVQJsTHB9OkzWO2lgWGa6No2NVWWMo+quuzMxaRy2kaktbOZAhIKIH5+0XpbNkJ25tNcKUeGoSVkaO6udpb0O8ujop9147+H4IyAnpDCKQ7trcXAgHEAmXHbO6pOyvofM+psw8Qh0hohoyqlF1j6vut0NePRKrvIC3Ut64jdesKl1bWCkc4GY0ZWcRazTGalR9yhliWAPj2V26pFLMH4ggugatHuSTA7rhsO0jhEndldXJ4GjXI53+lkX4uvzK+bt2r1qXDuwbiNF7hpUv1xwy9ipA0zvRwTwM9c7Ou/CRK4oIcN31jiZclWNaWzHBqtU03OTCpE4UJcRJDSXFwPbDMB5sjlo7YcQgqEpv7WCDlT4wHG4weOQ9cDZVddWg2mwr8E8P5rTI88ESr7JAWmtGx6B8V3hfBE6oz1qfMDAg7MDpWuPQeWO0b5UqnU8pc3TRByGIaxPo3gIm72KsQoZNZNTA6My9rxJXtNbXkJcDunNlE1EYor0gadlbwpoSqRRa1ZyQvwdJbRXA+Kyy8UGLBLe+/XVUW6f1a1cbTYjTtrDCZZUcI1IM5lXFISZPMb010pWDWKMJwwZRawqVNJGtaeerpUTBwK5dpxGD1IX3lwaU8HYekPc77nxV4Npw6xKTrmGExAqJkLH7TCmG/tZFYYMHF2lLhACpap6q7EBrZ2c+yPVpriqTJKUiz1PKMiPP+q67UZ67bJ+UKAlh4LtwqMBnhMDqws+fHJSJa8zg78IYfyzBBY+75Me2s/9bY3SrTjuu60gQWa762pX0ej0ue+qz2PPgLpYXlzjrnLP42Ec/zQc/+Jd86jP/wpYtm0k7qQueEGhrCSNX3nPN925m4+Z1nHjSNm69fjdxLeS4k9ZRFKXvtmr4zpfvZM/9C/zMm59EnIR+X4EvfvGL/OzP/iyf/MQnXdc3LP3VnDLXtGbr9Na6dFa6TK+fot8vOHhglfn1E0SRIsv6lDlgJI3xmBuu+SHXfecmXvjTz2BqZoK4FrN2pIvRhngiZOnIGmk/Z8PmaYR1Ass3fu9axibHOO3s0wjjgCOH9/OZT/w9l1z6LNav38Rfvuu3OP/ip/O4Jz2Xv3rHl9m4bZpn/fR5LB1ZptdZZXn5ftZtPB4lI674+L9y2qPO4bRHn8OVn/wXtM0Yn61z2hlPwhRw8/eu5q67bqLQGW/83Xfy5c9/lau+dBW//64/5MEH7+Hj//p3vPSFP8/GjVuJ6gFhVGP/wUM8/ZnP4Bde90v8wut+ke9f9SVm5uc584ILedazn0kYBnziY5+g2+6xd89u3vKW3+RFL3kJlz3t6Tz1qU/liZdcwnve9R4+9O6/QwWSn37t8/ngu/6OB+/fw9ve+xt89d8+xfevvoq3/tmHmZ6dJQgDdt63Bykl247byPe+8X1Wlld5yrOeQq/To9fp0ppwGlZCupJFo6HI4YpPf5blpUVe/cuv413v/hM++rF/5Wtf+RbfvPob/PEfv5WP/NM/cdppp9FoNnjVz76Ke+6+l4//82cJQom1Jd21ZQeABAFf/Ny19Nsl061ZHvvkUyno8Ctvej0//3Ov5+lPfSb/+D/+mpPPPJUnP+upPHj3IYwxtCZibr/5GrI05byLng6iBKFptSb4p3/6CO945x/xmU99nhNOcB29fvbnXsmBg/v42teuIoq8SOyPJD4fWePO2+5xcyRgbW0Na4zrpjwobUsJogChBCury4y3JpmdWg/W6+nEIUIqtDasLLep1+vUkoRGK3ZxjnUaTW5PNIMOeWhJnmu0ttSaCSpwDCf34ONK67TR9Hpd7r3vbnr9HsZYTjnxNOdfEQShoMgLup0OY+PjCKnodjKKwjGPJqfHMKWhKEp0qVHKMZ6E9HGtsXS7PcqiYGzClflKz8Ioi5w07bCwsEBZapKkzqHDR+h0uzRbLV9qV8MUhlAF1OLYASfWIKWlNKUvHYrpdvv0en3GJxq022vs37eHmfEWAs3yyhEmJieo1WsgLXE05gTAUaRZl9X2AkEQo6QikIo0Lyi0oSwtY80mzWaDLO+R5Tn9fsrC0goAkxPjRIEiUAG1uge2wohD+49Qlq6T12p3mbIsEQi2bdnOxNgExjqQSBvL/Pw6J0wtNc1mCyyk/a4rJ8xSdj/4IK2xKZrNCTrdLkoEhEFCUXbROqfMe+RlhpCCufnNlCWUJYRRRKfTZmFxkSgIqdeazM9u5OD+g/R6XVSkmZqZYHyiQZp1KUtDWYIUIWk/49CBI2zbuo1ms0WWpvS6q6Rph6LsUJQZWZFSi8fJC83C8grbd+yg2WyRZhmtVmsAHFYlpWlaEKiQsdY4AldSdWThCFFYIwpjzn3saT85A/0PxrEY+lgMfSyG/vFj6P9UqV3FKBru7XZwg2AE8ZNuQ6ke8ofD/TyK3j70+6NGZQRHvdZNrgNwjSs5rdg0AyR6+LkVtjsk91WfV2GjwqGHDCmEeKN1N3sATx99XhWCbb0Am3WG76hmDmhyLVmV+9mMnp/1hjFkKQ0RdB/RW4fqygpjsR5ZlP/O+YzOUTXjg4Xq32+MK5AcAF3Dj5BSYkWAip1uh5bKt+E0UGZYIRAqdEJoHpGlAp68cOQoKOUmVLi2eyPidFJKTOg6GwhT+HPz4JJn0enBdQ2/itHP9Z9V3UFR3Wv/+orp5V4mq1cMAMZq/o1xmToXpBkw2h/HH7tyVNVnCzEA9/AraZgxeGQzJR463AboqQ3DBTOgDzvRzIq6awdrsNosh2DpsNa9AjlHh2PDGbS2A8S98h/OjkdfO7zf1edIJQf2WjEiR32EGQCDD/EdFXcW43W7fDkAfs1X9usu2wGWYYz1gLHR5eD8hZAI5fyay3L4dTZYB8aLMDomofSsT2O9z6k2CwSYEiHNSFlq9Vl4B8sQ4K7AXZ/BqDYQ9+eKNm1wHEuNtRWrswJKvY9RISJpEY2V2LKA0gUIpt9GWONow3ENlTT8/aqo4CCkE4+tVnullyZdWxukCtB5PtgUhVAgFBZ//WYYhFVrBD8vVbaosiu39ty5DzpcUtGo/ZwOGKHWB39Vh5bhHmJ8yTNo97AmxcAHIEbAG2/iQoBQamjW/wWGMYaPffxfGZ8Y5znPfRaz0/Ms2gWu/c51TEyOMbtulrIwbNu2lWc/+3IajTq6KMiyPrW6a7tuyyrwE8yvnyUMQhYOr9Iar5HUnVCw1O6BOEsN6zZNUm86HZkH7l/k7juP8IRLdrB502Ze8pKXsG5+XeVGUF6gHFyQHCUx1kIQKMbGXeMKXboynTiJkELRWSkYa41z2lknkNRqLBxe5b57d3PySdupNxJWlpbJU43Vln63R5K4zPrYWItms0Fci7j7jp2srixx8qlnk3bb7HngbnaccBZxMMahPYc447zthEnJfffewrrZbYxPTNDvjXP/3Q/Q62Ucf+ppZLnmpmtvYn7zNoqspN/NCYMG/XyFXQ/ewuz8OsYn51g+ssjszAwXPO4xHD54P9aknHfBRSiaHNq3xAP7b+X00y+kFk/wgue/gDPOPB2h4HvXX8cJJ53EmRdcwFOecimHDx/mr//2rznzhPNoNcZ58lOewoknnczY2DjPfMYzOenkkzHG0OkdIakljI9PcObZpzI/P8vs7Cwnn3YmWT/lc//2OY477gQuOP98Go0aAMtHVpmcniSpJex54EEmpiaZmJrie9++nnUbZjnj7JP5+Mc+RhCEPO2yy5ka3wTZGJ0lOOWks3juczOyNsxNb+S5z3semzZtYnFpib//yEfYuGETxx93Ao1WQhiGFEXB1V+5ifWbpjjz0ds55YwdrC316S3lFEUHFZdceullTEy2WFjax6mPPp1uv8/HPvoJzj/3cYSBYvd9u0jiMcbHZkhqIddefwM7H7iPl7zkZZxw4vE8/wXPZ3pmggMH9/DFK77Ajh3b2LxlE//jf/zFIEZ4wxve8JMyy4c1kjjyLaxL7+MkoPzzhHsgUkoSxCGNZpNarU4QhIx2GCpy48TbhUAFkiCq/LZzfd1ODliiRBFVcbgUhHFACESxwlrtOhD7fdyHVUgpqTfqSOU6RYWh18lEEgTOV8dx7GJkYylL1/VXyUpywznSIPTdpjD0+6l/4A7RunS+3seDUgqyXo7WBiki4riGCpzOTRTGxEFJKEOEdZpWRluqFvF5liIEJElAnmdoYwij0Imx12tEcURSxM4/xBHCahr1hFq9Rq3mys6iqE4UxuhSExFQK2vEUc3tN0VBHAeExqKNIqk5n7Oysog2hiAIGRsbB0DJ0JX+6ZIgVKhAoWzo7mXodKyiWkCapk6DqtPBaEsUh2R5RmlKZvUUQRARBq60EgFh6MpojLU0xyZIanVUGNBP+4QqIghdqZrWJb1elyBy2rpuniQYiUQRBBH1eg0l3Vpba6+Q5j20KajFdSfELpxmVJ6XZHlJLQ4RVhGFzp+4dZujAklSqxEZRZY7vRspYgJlaDYcYJZnGZ21NlHomHyNWp1ur8fKyhJJUicKYgLpABSBJQ7HPMD5n+p39RMbx2LoYzH0sRj6fz+GfthWbsy/96lDAaogqIxEDgzvqMny46GL/N9b9MOb4BZJNYkVCDGsRXST45BZM+h2N3KwwUQNDF0Ir8w/CmzgQBRr3eK0TtvJWscKGrzGnZwvK3NGXWWqKvDBAU9Ou0mqwKGXSEebo1rSFQzm9JvwKLf1hiOkU993M+5+Z31NrcPF5IjNjV6zL4erDuS/mIH2lPVGWIFSo4CORMU1x1oKIsqs7RZomTomkoo8C8oFIhUyXKHTQgzZahXeZTDg0d5KB0rGNSgVlPIoxzFgFslha0yLAwSHDCvnUAdrhuGaE75Dk7VeGFwMs2nVWhgylHz2QWuXNTPGz8mQsl4Z2aimlROMf0gZoKgQ9P8KT62DyThqE6rmU1szABIDL2RqjMH6+6qUGtwbJ3woqLId1edaWzmvakOTgKZqTFDZtlKVY6xe685Fe4YFuO4e1co2XsywopSOltr+KD3ZHVZ4LbNBdxA5XKfCCteCWbsWJGJUELAsBhRlpEQoL5Km/RqlaoRgBloYxkCpLYEAJRgReLROKF9o0BkyML7ZjbsOt6CHQccAHB2seVAwtF/folcJiTACbIk0KSWu1MDdT88kLQuEDFBJiyBpYsqcor1EmfexeR/bXcI0p7CNKaJay+m6OYfhO1JKlFADn+nWOkjlxRSDEPIMcP4LGWBFgLbWdSizhjDwDERjRzpnaKwEwWjAZV1mTIKVQ39bbZoIgSlLsJU/ka5hglJDjRHjtS+xCKtB+fLah+wt4F2PDwcqSvF/FeRJa837PvBnbN++g2c+83J2bDuBkIQPf+CveNFPP5/Tzz6dxf0LPOqss7j4kosw2pD2+vTabRpjDaIkgFSTec2XE0/azuKRVQ7sXeSEkzYR1yKEhDzV5GlJkVlOPnMz9THXsv3WWw7y0X+6ibMetYEzzzyTP//zD7gTs053JowDP78QxiFSKayBMFTMrRuj380oCw3GlX1IJVm+v8/8/HpOfdQO0k7B3bfv4uP/8GXe/HuvpDmVcP9t9zPZmqOeNDi0bz8z83PMzTdYv3GeKAkxxnDD929FG8Mrfv45XPfNK9i/6wHOv+AZtFdTdt+zhwuedDYHDz/INd/7Bo97zCTjY9NMTm7kyi/8M7se3MU7PvBurvnG9/nu16/m9b/5i2RtyT03HMTqmF5vjZ0Pfp/nv/wtnHLGRTx41+1s37Gdcx57AV+/8m+YWbeVF7z4Vdzxvd3cc/ftfPJL/0CsZjj3vIt5xzveQRAoer0eH/+3z/C4x13E817yct70q2/iu9/7Lpdeeim/9Qtv56lPega/9IZfcaXy2vKW3/4dLIIiKxHBGqjMtRt/2uNd1lkbHn3+Yznx1DN46tOeyrmPOpcdm7ezfut6ykKz5759bD5uEyqUfOsrV3H8KScxnyRc8fnvc/Y5J3P6mSfy/j9/PxMTk7zgBc9n4/ypJKbP/gdSnvj4p/G8Fz6L+25Y4eTjzuSJl11IGIR8/evf4Dd//bf56Mf+hWc843J0qSmLkk4n52tfvpsLHncij73kbC556gUsHFjimm/cTK+3wERS51ff/Bvcf9+t7NpzJxdd9gw+++l/4/3v+XP+6ePnYKziW1+9mksvfwZbj99GXFN88Yv/xsc//jGe/ezn8NjHPJYLzr+AOAm58stX8hu/+et85jOfZfOmzZx77jkUZQHwiAeeoiggzzRFrqmSqMY4UFZIC8J4vaE6SVwnDp0Gkgqcj9IW0m5OURpf1hUQxgqphCNtW0t7NQUBLZHgpC9dXBMFygk4h4o8KyiybBBPBypEWEkURsxMz1CWJRZLUksGsXcQSFTg7NUYKArtxMUjJ57sYgODsZo4cs1pjDWstdtorWm1mmR57hv8WALcsdNuhgV/3Q0sTlS5UWsgtCSOHHCdp4VvG2/pY+n3uygpCKIW/X6fsiwZV01qcUyjWSdOAkIFwpQoNJgCFbZojo2R1BrESeIfBAVZphEyQAbjxGGCtYa0u0bg65qsrBHHNcIwot3uIqWi2RpjdmYSgLSfkvWXKcuMohTIXPlYyJAkCZNTU0zaMTqdLr1en7W1NdcBbqxFt98lLzI2bdpAnEREcUIlQB1GMVI7jZypmblBKebK6gpJUiOpJZS6IM9T1tbWmJ6dJYpqaG0pc4suLUEIURgzOTnpAbuCIwuHyLMcKSWNVsOX6SnyTNPrpXS7feLpMUKV0Gq4OK4oC/IiJQwVUVJDiDphWkOKGFMGhKGg3mwhBaS9lIUjhwnDkCROGBsbZ3l5lX379rNpwxaiqhrEGKxVREELY1zXxUf2OBZDH4uhj8XQ8OPF0A+71O6GH9w4fNMQtPRlZpLQU0tVEHj03D+8D4CDIQooPe1wVDNodPLcMYasI39U/2/079bT9vS/++D/I/o9I7/TWg8pjYMJGwqQVei1McZvdsPXDG5ykXu6YeHKD7GgU0xFAQ7qTjgb5W+29Y7WpaYqQT8Ylhw6G3KIsS4yrHbAj0GAjEF6Gpw3firARjCkXpqRrmwMgeDqHjigZci0sji6ohDKf4ZxyLVx5X46d+r5UipUlCBVhAgTUE53Kohi5EA8z7eilRJb5F48zWcBlHQ1pUa7OfIAFkJhy4JKad+parkSOwdiDRecsZYK6ReiAtkEMoip0PWqBlv6TnduGoSndru/67KkLDKyrI/RpaOMetaWq9f1x/WglhTCo8AV8OUDEm/QABde+MSHY0o/sXHtdde4axlsMm69jbZvVcrRxVvjM8P1ZZ2tBEEwAO2stQSBQkoxyHpWIKIxhqLIPYgniePE27LLmh0ldghUfVWNMeR5PliD1X0APK0e3IY/LFEd9R/VetcVu9BnXio7Hog74rc+Aboo3DVKSZGm2NKVXsqyg7AZWkUQNEDVsRVNWBvfddKV2wKDYKECLq12GeWyKF2Gtkgp2weRyRgiqiNrLW+YxpWHVpslQx+llLMp7Y9ZAdwum6acvpv1FF38RhzUqDZj4TMVQgDW+QxbacLpgqLtyl6ttQRxQtKYoDG5jlprErDk3SVERastC4ZZEw/eAqbsYn33Sm1DDNI1KbBOwFJJ6QIQ65TyMBpb9JBB7Ci7Uc2XngiErIRFXXvxai1Z3ANMmaf+fI170BwBk6WUhMqVoNgKXK82aYEP+gLA+07lSqMtXuPP7w8XXHDxj2dk/xfH6B52//33c3jfEjtvO8Qpj1rP1EwTFTX59Ceu5Pbb7uFd7/tdjuzfw9233sIZj76AsclJmhMtitS4NtsCojhEScny4YIwhqTh5n11ocd9tx7ipEetZ2yqhrG4UgFjOfzgCqUAG0rIBUJZRFwyNTFGHIfIQGBKHyxWmp8+kGuv9tm3e5Gx8ZBaI2ZqdpKDBxbpdFK2bJnnnrv3cOcdu3j6M88nCCQrS23IA6QS1MYVURShAoUxJUf2r3B4/wrHnbSRhSNHuOWGmznzvLOpN5usLHbYv/d6smyJS5/+SqyRFHlBY6yJNgVp2mVx/yJSKjZu38zK8gqry8vcdcP3WL/tOKY3bOF1r/8Fzj7rbH73d36P97/7nRRZyste8nI+9ql/Yt+Bvbzrff+dK7/4Db585dX8/h++kdtu/yEf/tCHOH7jRrZt2cFTnvECNm3bTC/r85rX/BzPeeYLeO5zXsjC6h72PPgAt//gBzz58ksZn5qilxpmJudYWV7lFT/7Ml77mtfykhe/lDf84qs5+1Hn8Iu/9GYWFg9zx+138IH3fZjf+O1fY/PWTbz4xS/hta99La985St54IEHWD6yyuG9i/zLp/6a+Q3r+JM/eS/33bGHbrvPcSdv4gtf/Bzf/963+ZU3/zbr1q2j1Wqye89OTCGYjNfz7ve8i3379/Chv/nv/MNH/o4rr/wi/+PDf8u3vnM1f/bn7+Kj//pRNm7ayK4Hd7Fxw2baa23e+tu/xwte+kIuffpT2Ltrmdtuu45rrrmSV/70L7Ju3XpkGHDbjfeSZzkXPfVcvvKFz3LzDdfzs699I0JJ2r0OvUMBYaiYnA8pejFrq22uuekLbN2xg/UbthCYea76xhf46Cf/mr/+y79nbt0s+w7uJihmue/enTz/FU/we9DRSc5H4tj9wG6KIifPU9rtLtZCoCLiOMBazfLKMt1eitaWM888gyROCFWEUF4yQAh6nYyiKMmLjFo9JoojrHasI6kkndW+2z8CSa+TYY2l3oyptZx4s0Vz6NAB9u7dQxiGTExMsn37dvcQBlSlKIB/QHQPhS7JDEoJ8rygyDW9buqTcoZ2p00UhSS1mDiKBjF8u9umLF0MUTHgx8fHPGhZUOQuJgjjgHZnCeNZQ+3lVbJeShTXKEpFUbg9IYoV9VZIr7sGGOr1kF63T1mUJFGdOImJkpi0v+auQwgUkrLIWFzYhwoiwihmam4j3U6XbqdLa7yBNpp+v0+zNkYQBCgl0MaSFwUP7t5PszVGqzlGZ2WZIAioNRqstNvkeU5RFEyNt4iigNW1Fb8/SvKsQAUBURwzNTGDLjWHDh4ZMBHSNENIjVSGybEWU9MzrN+0mUa95QB7H8OUZcnaapsodh3DDxw8QBgGNBp1hLAUec7ayir1RgspFMsLaxjjhK+X2ouEYUCtnrjOaXlOt9thfn6eJElY66w54ALB/Lr1WO3isHrSBCspCk17rUueFygJcU0ShLC4skASJbSaY/TafYIwYHJmyjWiKAqOHDlEkkTUajETU7OsdTosLi0yOTlFWZYsLS7Tao0TxwlJ3OLAgX0sLi3yMz/3gp+Uef6H41gMfSyGPhZD//gx9H+C1zjc0N25uJOhKruqDGwEGavQMKh+PQSOhh8nRr4OgZJqER0dSNiHvMd9X2WOHnrYClUe1EeOvmtkwt0iGzqD6iOGLCYxevnumFisUk4YzWoPVDC4ke5OicHP1rgb46auAs+GoNAofc2vTqwXRXd/8o5geAFHzYuxDwXu/OdYwIuv+b84tpetrtuM/N6hwwI57GpnFdKYwWJ1elcONR9wskzgeEAD6qcvfJPSIbIVQi4EIpBgPGOquj4zOgcVkDZCoxSMrJJqnYijVsFgPR51j4aU0wowrJDdqiND9drqyIP7bgUIb3jWzbyAH1lHFVDIQ37/iBzWX5f7oZp013FBVHbk7Nn6tSaFAKGGa9qPoYMf/uxYiO6zh0DqQx8ERgBli3d4o/ep+lkNbZPReR+hEVflrgwzMgM79HdzyJAcOX+/Vqq/VTmEak0atLunA+MctT4P+PqA1n0/vP2DeanOVgpAYaV0WhqmQJocb2gj9+Poua3YmcO/+WOPHMNUJyaUB5JH/KMYfma1iYDTCfGTB7UxjM5dJ01dOI2I3hpRUnPCtkHk7RCKomTQZAE1OI6SEisUxtP6sW7NWF86W3WKHF6Op5OP2tTA3hmc7yDb5wFgyVAjwdGFLQjHXK2yehW4Xr3HUYqrefBA8eCo1RWIH3Udj/AhhGD7tuOoh+Ms7O2wvLBCWRScfNoOpqdmmZlZIIwiwjgmriUEYUiWGhbvX2N6ukYcK4QS9LuaMnftd7NM0+2XzM7VXClF3bd01hapJLp05T0qlDTHYpqTNY7s71HqEuvLQoABNbwoSm664S7m18+wbccGt/qkIAyVF/J0jGElFYGSRLGkVo9otWpIAXEcMbtuin33LWAtzGyYYWlxhTTNmF8/RxhFxLUIpEAFAfVGg/baGkVZEkUJk9PrSNOQW266ifUbNrFh4yaEEHTafXbv2k8ziUmzHld9/eucftrprFs/z11W0Gg2WLdhnk2bNzE3P0tjLGZmbgajLRu2Hs/M9AyLCwe4685baa+tMTk+RWt8hsmpOdav38DGrZuY3zhPs1anvbrCanuV9evXMzbWQikYq7eYGJtgcnqaOHbMhAP7DzM1OUNzvM7GDZuoJQ2KvGTd/DwTE1MA3HffA+zdt58NGzeAkWS9ks2bNxOFMavLHVe2GMdMTI2zbt08E+NT9LslnbVF+r0utcYJTE5OMrduHZs2z5P3C279wa2s2zBHXE+QpWDDllnChqHeCpgYH2N6ctYzO1ps2bKFIAjo93rs2r2L6alpwiBgZnaOtKfZt2uRDZtmWFqeZWpy1unKdNs8sPM+JC2CKOSbV3+LtbUe6zdsRgUhy6tL3L/zflRniunZKU5cv4Hrvn0Lh/YfZGxsjFA2MXmNsCYZG2uxYX4ji4dWGW9Ocvppp7P7zh7aVZVx6qmnsm3btv/3xvifHKtra0jp/KbW/mFIW6LIJRSd/kuBNqVnFzmmuBrE15IwCkCAsQ5sM6XrZOSkDiBKgkG3Ifxea6yh38tJsxIhLWlaDjpJg3XvrbrWyeG+a7RBVL7WmsFDd6AMhIIkidHaoMsRX2uh38+dxlMUDkuJDEgVDBKARri9oWJzlaXG6EqDpvQP6/7BKwhRMsJgiGJJHIcI0fBld6VP6jp9m7IsILUO0BKSIAx8rG0psgxrhWMOGVe6Z7Qd6NUYYymLSmvGEIQRQoT+wbbS5XHdvbR2cb/F0u/3yWp1pAxRMnH7vhS+5b0blbaNEK5cUcrqnguC0FIWDhBaOLIAs9Ix3TzDxe2rXkzZGOq1OhYockMUByAUpTFOL0aALgVYp/FiKxaDEWBcQjapJchAon0nu0AFRGHkAA5twSqKwrFoIs9aFUIPYyLwSWIHRrrOZ4Zev08S11BBSBLXCJVCoDx46bV5PcvFWDfHFk2vv0qnt0qnu/x/3QZ/rHEshh7Ow7EY+lgMzf9eDP2wGU/X33j9AKgZ6BIBQRQTqIAwrqFU4GoGAzVs/ccQ4KkmzYFB/gT8Aqg2huqflBWFbASUcbMyMKaj2UzVsh6iFNYY13Fj5BIHbKWR2lY7AkS4dpDOPB4qwla9tir9c/XqJbrM3YkOStP8+4Ia+JpNtzCrG+4WnxRQejqhNU6Ee+gESnRRYPIursudhSBBqBBkSKWeb2GkFnSwIzhEXFRlYMOF6H0ajlNkwDoxbwd0eQV+f3Mrip3VXv2+SLHa14cqNRAgD5ImMogJotjXNXt20UD8e3CzqVp+an8u1jr2kSkzt8ipALejywaP7qPo/q+kXzg4iqIULlCzeHF5FQyc6QB8FK5DSKWzYEzpxOIHaH41P24MqKWCwf1xsKPnyVVrUcBjLrzkR9bLI2lce+33BxsFjNiVtykVBAMbjpM6QRAQhCFh4Lpg/fubIIBvqarUIKtQ6mJg50EQMCy9tUcdW0pJFEWUpcuqaG0G8z1gHBo9Ar46Bw4QRdHAdosi95cy3BitP77wx6kEGY0HiithPFeK6rQNjG8zKrMVpM4gqGHDBjZoUD3lWLyfsMbZuql8RzmcEes2DGO1C/zyPvnyHlASEUREk1upmI+VyxoF2is6s59elyEa2XhM1QgBi7IGbAYYkHWsHIK2lU8csP9EtdFKovo4lch+urwPUxSgNa2Z9cSNMWrjc+4TjKbXaSMoQRhcxsNli5R12bVcG4rSZX4keNDddV9z52BdlsMa50NUCDJAhfGghbAZBf+rPUMKAt/9I+11vTBi4a/MvTaO44FtS6kGzQeM962jGinWKd25EotBUDHcbC+44KL/wIp+cmPU9norBUIJaq2Aj3zoX1k4sMrTnvYiZjYltKZDolpAUTpmRb3W5P67FvjkP9zMS19zDjtOnAEBd9zY5uDelMc8eYr77lnilhsP88znH8/4ZIwQsHKkjy4M9UZMmuZorZle3wQEVluEcrorWV+T1F3mtsg1QShZWlrl5c/7HX7qBZfw+je80GuOOGBq6UAPgLltLYq0QJeGsOaELIUUpH1Xipenlgfu2oWQgrMvPJGvfP477Lp/H89/6eW0Jhsk9YiFQ8sopWi26nzo/f8DrTVv+q03YK3h8MGDvO7lL+enXvRifuY1r0Uoyfe+dR0ffv/f8Qfv/E2WVxe47NKn8OEPf4jn/tRPsfve+5lZv465TRt8gGvddY7E24d33c3uB+7mz977Hp76tJfyjGe9grG5aFAyEcYhK0sLXPuNr7FweA0VRDz/Z16OUq4D4BUf/TfmN2/k8ZddjAW+/71refYzX8iHP/x+nv2cZwKWXrtP2suY3TCNwAk6X/yki2mNtfja177K/bfspddOOe0xx7Fn5yF23bePr3/ni5xx5uk87wXPo8hKVpd73Hv7AdqdG1Bhj/Me+wLixGm5BKHim1/5Jn//4Y/wpKc9heNPPo4LnnAOxrsvFUraS306KylZP6A1FTKzMSFPS7761a/wrOc8k89+9rM865nPJuuVfPuq27nrtt28+o2XEccRZWGIEsn3vv1tXv+qV/Pf/+Yv2bB5C0+95Bn8xm+9mVf97CuJawl/8Rcf5lff/Cb+4Nf+hAsfcz6XPvsi3vKbb+bggf381f/8Rz7x99/imm/ewds/+Grq9RpFqrniY1fTHG/wlOc/hsMP5Nxy0608+xWP5b3vey+//Mu//COJoUfa+LfPfIGpqUnmZmc5fNCVOxWlZt38HEktwWj38F6aku3bthF6aQOn9aMQQqG1a4fd6/UH+0IYBARhQBQpH4pailyTpTnGWFQkWVzs0e7k1OsBQmYImRKGAc1mk3Xr1nEUwxwfuZkqYWcpCu330mqPhbK0pP2cPCvop91BrH/k8BJxHDEzO0Gpc1854Mptg0BSq9fQhWMzCAlpVrDW7lKWfawpsLqDKUqssdSSKcKoQRA1KHQfFUAYC+LQMXiOHD5Ep92hyHPq9bpjUmlDHMUoFRKqGGRK2l9l7647aI3PUG+MMzWzgbwoyfMcqXK0sRSlRRQxZaFpd5eZmVtPUm/Q7naIk5gwCrj3rjuRUjrR82aDfppy3333MV6fplFrMTMzTa0ZkzRCtDaUZUGeZVhtybOMxYUF1m/cRLM5hi4NURIQBpIHd95Pp9uj2+tz0kmnMDY2TrPVRAn3MOqYLK5iQAUh3W7K0lKbyekWWd7nwV0PMDUxTRI20F0nYiyEom+c6H8QBFgMKhDUmoHrFNjtsX//PtbNzTM3N8fmTVsoMkN7LePIoUXCSLJh0xTddkaWFmTdlLgGQWRZ662hpCAMA4wWpGnO4tIKWzZtpVFvknX7TusqUMSNmENHDrFrzy42bdpMFIVYa6k36hhteHDXgywvL9Npd/j133zzT8w+/6NxLIY+FkMfi6F//Bj6PwE8XTfYVEaHqz8PieP6gNWiAoWSCqUqvR732moNVMZkbaVt5FE9hqeifBvC4d+GdMZqOCPwCvkjqK4QfsK8tpGbGDsAIUbH0eV4huEJj5bnjUzYENfym6keiApiSmzZB+syIjaogXBK+WXhqHNOqM2BN0NGljvPSpzbWu1b4ZbYou9oeDpDBAkiiEDFg7muABrjKcwDwMQvOBAjzse1VxTCo/BYhCmcU8JiRTBA6ysIevCZxjkK69Mn1l+DwCKCCBVEBHGNuNZEBSFBFIMtB84LN6OD+XTn7MHBMnfBhjE4YTUwVjjxywFGPhIQ+d87fTnXnQefkRID8T056BQxuNfurlHkuQOfqk56Iw58UHpZ+ZbqrO0QGHSvU1QZyMp4H/OYJ/7I+nokjWuv/f5RwCzg7o9wlN0wjAjD0G2cYUSglG+PHDHIgYxkR6puGK601s2drkQFpRwYzqiLkf731lpKX+4a+u4VlT0rFVB16ajqvB1gfXRHDlfv7uxncNwRMNlF4O4atUfuKwDSNZUdsiGFkL5bZkmW9aC/BEWKipvIuIWIWuiiN3I8XanwwaB23G3uFuvpqlVWT4Apob+MLlyrZtXa4DY3b4sDNh5DwLdCXa3xgLoVSOWzEcIOQHU76IDpO0vIACEC3zbXZcLliN/2q50gigdZ76oMwmqNtAVSKZJa0zMfA4Ko5jKWRqOLzHUMDQKwBm2gKM2Adiul69hpPE0a432jcXRyoWJkEA4yvpXdShEM1mYlLCmqc7dOTNZ4sLj0fl9rTRRFA0r0cFn7/QCIosT5YwtQ+jn32nQ4ynO1t51/weP/03b1/2pU11SWJb/0C29g/Yb1vPWtv8++3fvprqXobo0szeh01vjSNz7LOec9iqc+/TKiJKDfKzi0v82GLePUGxHGQGe1IEsNkzMh/X5Ju50zt65OdyXngdtW2HryGM2JiDBSlIXriKVUgAoE2ha84Q2/zObNW/id334LP7j6MGWuOffJ80glKIqSm2+8k3Xrptm8dR6ArK9pL+Y0J1yQvOf+RTZsm6DeirjuO/dSdnJEaTj/aaeSNGKMsXRWHfglbUI/X0PbnLl1M6wu91lZ7LFpxxRKOh2kXQ/uBeC4k7awtrBCZ7XNkZVDbNy8idn59bzhjW9gft16nv/cF7Jxw0ayLOPG629g3eQ8U+MTzO+Y4dOf+wxf/NIVfPhDH+auO+/lgx/4S/7wD38XMPzhH/4hP/+zr+TE47bz3rf9AU9+xnN54tOfxTvf+Ra2bj6e5z/7FbzzfX+CEJY3v/GXKMuSLOtzYM/dLC3ldDrw2IvP5Qe33MRH/vkf+dN3vouZ6Tm++61rOfvRZ6CU5Ld/5y381E89m8suu5T3/ukHOOmUE3nRy57PdddfS2ctIzZzbNo6QVZ0+JP3/CmXX345lz75UhYWD1OvNZiamiWuuYRLv5tT6hW6nRVu/s4POfms09l24glc/83bkIGlNRUzPTvD0pEVrr7yOzztuU8haYb8ypt+hWc//Xk89cnPYGy6wVXf+Cp/83d/yZ++492MjY9xy60/4Etf+hJFUfK+P/tzOmspiwurfPXK6zjplK1c8pRHc82376ffWyNutFk6mFEWhqkNCSsLHfprBSdsP4Fc9GiXS0SdjdTrMbNbAtb6y6yttbn7ln1sO34b41NjvO+Df8wll1zCa37+tezfucDNt9zEX/79B/md3/w9krjGYy8+jxNPPJFt27bxxS9+4Sdlng9rfP4zX6JZbzA+NobWBVmWsbraJU4SklrM3LpJiixDm5K5uXnCMCb0EhbCJ+SMcQ9ReV76PdgQx05Q2pSGIKoa/VTZaEtZaJaWe3S7udcRgjCCOAmI45BGvU5VGlc9oIHbuhx4osnSAveALAYspaIwFLnTeup0u07/Jw5YW+kSKEWjUXPNopwL9zEUgwoArKXX65LlBWmaEQQKawv63cO+ZClkYnI9UVwjjBKyoueShmVOFCVYY+l02nTabfIsRQlBPyvopzm9fkoS15gcn6bTPkKRd8nSVSwKFYTMzW8my0rSLKfZCuj1eywsLGIyQSAVzbEWM+vWEyc1Dhw+SK1Wo5bUWFlZQpcFxpRMz0xhESyvrBDIBElAUZaEsSKMFbU4Qmv3UD8+PkGeZezetYt6o0Uc12g0GmR5Sl5kjLVaZFlOe61DHCWApdAZ69dtoNloOdCxLCjKnIXFBSwSpSJmZ6cpdcnBQ/tpJC2EVRzZt0oUxwRhRL9ccXFW4JIRMhDUW5F/xoJet0etVqcWJ2AFQZAQRXUOHzoClDTHApqNcQIZ0u+kOJaSobB98rRPv99lcmoWrS3Ly22mxmeJoxrSxx9g6eVtVturLK0us252IxZot1eZnBonCp3AetYvyPOSZz/vqf/vDfNhjmMx9LEYGo7F0D9uDP3wS+1sBRt4ymdFjBHSncCo6BhisBDdoqxYNxXaWKG2FaRQPfy731WUviG6e7SodDWc/YnBpiZE9fk+WzNyzArsGL5XHvWzvxr3zurLv5M9G4I7Q2OjEr5GjF4kDF951Ptx/ewccON/FsIMp8P693pgAxxAg9FYrRFqOFdUjKLRw1bvZbgYjgINHVSNsNaLxI3O/3C+hucsQYEUagDOWV14Gl7VUrPAlBJrErBe0E5Id28rBzqCuFcAGGL4FSkHTKLRqRi+bcQJW4MR+BpdBk6hQufdrfDg2WDenVaBrQTtjGW4qqtzEYMJEAMMsnJODI6BqETXqlvxo2vlkTZENSfGHn2+1jJKVx2u8VE0u/qMox3TAFQcAVIrR1eJGD4U8LUjr7dVBmWwAVR3fBRIrhzeECCsjjm8tuGmPmC34ZagMc4JM1gbwpvM0aWpUkms785pfMtYNXIOYvC+ETMdzBoDwHbUdqpgGykRUc2VBpR+AxEug10xF/HTZAcfbo/6vFFKa1XyYK119fgycGKAHuytLmpo92L4WYNshm+7jSBIGoP7rjPXraMSihQyIAhjjvZk1tm+t1e8tpszRhC+7r3S6QfQ1tF6kcr/GxW0rIIB3xXEsx/FUetshPZdZblGHP6oLQ9pxsMM2OgaqkoEKld7dCT5yB+HFw65UjNg49YN5GnJ3nsXyVJD1s85cvgI3W5vwEA1NiPVB3lg5yH3AVYyv36e6blJENAaixibiMCC1pZ+t0QqSZQ4ofBAKJQB7Z49scbwzW9+k82bN/NTP/UcbrhuH3mqqc1v8mxcqDVhtbPA2h2LnHDCCYDCaMu+g7vJspysn2CB0mhuvP5mWmGD+alZBIJut8OevXucWLmMmR3fyszcNElTogvN4UOHufXm++iWG5icGGdmco6t27Z6EzSUeYGwgnMvuBAVKrI8Z/++fURhSJgIEJYwCFm/YQOhDtHa0hwbY9fu3XzpS1/i5ltu5oe33MGXv/wVnvOcy6klETvvf4BCQ9Icp59qDh45xN3338nV3/w6x28/yAnbzuZrX/s69UbMa3/u1axbP4dSE+y8+0buv3cPD+xc4Pgzt3Pv/fdxxRVX8KIXvITTTjmNdXMz1GoJq2urXHXVVWzavJ5tOzZz9dXfZGllkdMfdYprX29z7rzxEKVsU9pV9u3bR6lzJqaaHFo4wJGFI+zbe4gzzj6ZZqvuyyUbJCtN0t617N27l06ecd01NzK/eYazNpzEcnuJnbt38a2rv8O6bTPUxiK+9KUvsW5qA9s272BqfZMbb7qOK664gpe88OWcd945XH755fzVX/01t956K7fffhtbt21h63FzrK064WQpBf1eTlJrcdEl5/BX7/9n9u3Zz/PPfirt5T6dzgppL2fzCZvYcdoF3HvDKlnaJ89WOPGkk0nTjGuvvpPp2RYnnLqFQ4cPsrK6jFSCdrrC3oN7+f73bqafd5nfOM3pp5/Gnj17uOOO238yxvifGHGUIIWiyEpU4FpTSxlSFBqpCpdcDQOUcSVSWrs9wBUAOA9nNBgjcMKy/u9S+mSlRRmQgSthU2oYeyWxEwAPw5AwkoSxIElCwkAN/Ki1ljTLB7qmtVo82Kd1WSV4j05qgvV9Ylyb+SBQ1Gox7oHPd7wSLu6Sg/f5+FmKQaleWepBdzWp3AOUFfjOSwFRHFAYJ55clgYoXPzgr8mZvibQBhkoCqMJrWdmGouxkqTWotvrU2Q53W6XosR9lkiw1mlX6VxjA6elJP15a88mAUGj3iTPU9K0616jJM1mE2EDjBEUOqfUBptp4tA9WApwJYNSUhpDnhcI4ZhfWZbR6/eZmZ5FysCVNecleZHT6a4xMTZJFPoucF4rNs1SgiAiSepUlQFJnBCFMdYIDBorNEJp1126WjvWgHFlgoFn09VqNSIPfHQ7XZJEEMV1olihjaYocoQwyACs0P5B23gQwyXflWdUgBOdV0JTr8cURUFRFPT7fcdsVTECx+opi5IiKwlkQLPRoh5LjHlk78PHYuhjMfSxGPrHj6EfNuPp2uu+PwBalK87l1I5QXEVEMUJQeDquaUaltqNGsOonVY3sjI0V1PNcFIGGj9HG8/wvcPJqVDjUWBi9LijBj0cRxvc4PWVUHkFZngQoqLkDZwHzhC1doikLnMXlZddRHUeQQMrFBZJ1QLWdV1ziIbTS6oYNWZgKJVjt9agsz66SNH9NYecqpCgPgFyNFjAI67DeZEDUTuOmpPBNVdiYKYYCJsNdZdcZs3dCzECJKpR2AhrXdlgWWS40j1LFNdRYUxUa6HCkKr956C+nYrtVs2iReBqv60xlGZYGujd2tBorK2K1QfzplTo6v+DaAgEDu4ADgWWwndW8hTW3GUUK9E86+c88EJ0o8w6O1hHZjAPVRkoQngKrFsn55//yC3TAbjuuu8PUHTpnbUYAY2lr/MPwoikXvfCfI556HDBoZihC0S9cPxDmIgI4ejh3p5VEAwyEmmaDjbJYRmj9FmYYWeOh5bpFoWnhlo7uD+VoKzbmIdi+dLXjA/LLA1Zlg92/yrrKoRFl5XvEKgwxBpNv9cmW96HSTvUxucRcRMRNdB5hmP6GcdyHJSuOiC0AtCtP7b1/5wZGsoyx/TXoMydIGCUIMPYXY9f2i6pZKGqBbeula5XsXfBu3IZrsrcTbWZWQu6i7GuoYGVLuulpDhKA65iVlY4OUBUqxPGdZJ6kzCsY01J1l2i6LfRRYbOC8LIt2+Om2jtAtIgcIzOyl/61UGZp+jS+wUPzuelqw6vfJfAdXMKAreH5KULhsMoZNRVF3nqRWhTD1JbiqIY3uuRMSr6qXW1ztz6k8ozOf1FB2E8eH1l2/8VGE/g1r4Q4mgWsGWwHisGbHV9n//853nB851oq1SSRtLgPe99D6/62Vf9/xzrf42lZ1nGWWed9f+1d+4xdhX3Hf/MmfO4e+/ee3cN3hiHRxpoKNjeUBvq4sqlEWAkDAJEiyCorUypDdQUkGNAcluwEAuJDS04LBQqFClEiiggCnZUVdT9wyDRqAVVOCoRRYqcyAZ7n3fv+54z0z9mzmMxoqTIjSvNR1rZe/eec+bMmcfvfOc3vx8ffPABvm/SYqOt3ZgZIKa8Q0NDvPPOO5x99tloDVdcsYFms8mBAweQUnL48GFWrRrn9ttu46GHHkJ4gpdeeombb74ZreGiiy7kwIEDubGsFI8++ih/9cCDCAE33HADL7zwwqLydZst4sGA4ZF6diPNuQYvvvT33LH1z9i/fz9CCL7xe9/g+eef56ZvfhMhYOfOnezcudMGgTXzu5SSNRf8Ji/87XMs+7WzmG7MM75qFe1OB7NCnWR1ncQJo/Uqv/P1VWz7ywf43UsvQyvFAw8+yMTERG7o2vOmc/gPXvgBq9esZnx8nF6vZ85VOK8QgtO/fB7XX3s/P/rH75LoGX7843+lUqnQbDYZHx/n8OHDSCl56623WL169aL6UEqxY8cOHn/scSDApGI2nsNmi4OyNoNpW8XU3enqtJQ+GzZczr59+7j22mt57bXX8H2fXbt2cdddd5l4QFZMSMdUIeC6a69j7969CE+wa9du7rxzq+3/IjPxsvk6NbDjxKQCFyJr60opfnvtxcweU1xy0Z9wz19cxfjqs4jjmLvvvpvJyUk+pzn7K+On731It9OltdBCxRrP8wnCIQaqjx8KvrRsBJPGGqRXod+HXlczdlqVIDQr261GQhxrpIRePyZRCbV6aGyiRBEEJnudH0rzmTZeTGalX9DrDWywXU1UCgl8I+poreh0ehz62WG6XbPt5mu/cZbxilDQafYyO94PTWblJElDJkCn3SOKfKJSQDJQ9HsxnWaPoUqIRrOw0KQ0FNm4T4F91ppmo0Gz1WJ2ZpZqzQToDkPN1LGPabfbjI4uZWTJKdRGRjly+GN63R6D/oDBoEucDOj2epw2tpTq8DDxoE8CxFozNzdPFEaMjIzQapjMetKDI7/4GfNz0/T6CeXKKJXhUzj9K8vp9TpMTx8lGfTxpWSkOoIQJj5Ro92iVqtTq9URCvqDHp1Ok2q9SpwkfHR02s5jkjAMSGLjjVYpD1lPAujHMQuNJv/14YecNracWrVOpVKh1W7R6bVZeqrZlpMkMYHvm4DiC/PUqiNEYYhKWpSGyoRRiVa7jR+ElMsVZo7NksTKBLSu1ZBSMj0zjR+YbW4LjSYCiS8j+kkXIRRB5NHtdTNRaLS+hOpwlfmZDmFYojJco1QRoI33iko0/V6fI4ePmERSfsDU9FEq5SGWjNapjYyy0Gzy0/c/YHR4jGq1zle++mWOHv2I2dlpayMGCB0xXK8Cim6vgaclYRCZ7KTBEL6MOPPc0V9Bz/x8OBva2dDOhv7iNvQvEVzcXksrlOfh6VwISg0pT0o8ZKYqptuY8h9sY/XSYpK6gqUdt4jRfFKV0e4JLRhipnHmwlQqZOXH58KM+T0Nfp3eTy4qpN8XnszEhvTgVNPKRRfThu2VTdk9jzRbgRFTCt4zCNOwhDLpKW1QPl2ohVStNC1Z2avYAGOeXQHy0u9oK7yYAcCqYJ94VgVlVZureHZbWFq3AEqI9G0hL0LhPnPRqeDdY8+PkAgpCTybtU8laIzSmgxMAxfSN8os+UCIHRTy9QGj9CrhGV8wZQYgPGGyKijz/eJggrAraVYsym41fY6kCr3xckKkQcVtzRfFyfR3rUAtVudTo0qnEn1B1DIioRWkWNx5T0ZSsU+QPofCC6LIW2Im4qb9ErKX3MQGpcu8ybzUq7GwMpAq5Aq00AilSFt0urXW9O1UYI0L/TIfUyB/FvkKTfEFfLEwnf5b3DppUrXalZiCsGu8bfMVj7S/aIQpNxoltFllWSR4m/pIbJvIeqonzLtcGhAQnX3XtC8bh8wP0CiSZABJgJYadGz7hszFYyFs3Zgyf2IXsFmRTrd+Ss82fIVKrAGjEzwR5PWaNVo7NmO3yQob4NQv2ZTaArR54Q3LNfxwiGTQp9uYIQ3c6ocKKQDpWa/H2Kxg2xcb6aXJHkz2DiElUgZmfd4KxkkSm3rzc4PLGBfFucKIwImXB7w1wUnN6riUdkXfziNK5f23GI8trStsitysSqytY1biT/7+W8T3fQaDPguNKb7//R/S7nTZvn07nufRbLV4+OGHabXMivx9992H1ppBPOD222/n/PPPJ5A+a9f+Vna+/fv3s3fvXu6//37GxsYQAiYnJ3n//fcBuPHGG1m3bt1x5dBaZwbtGWecwT333MOLL77I22+/DcBll13GVVddxdNPP82KFSvYtGkTcRxnYgJAvV7nkUcmWLVqVWaUX3DBBezevZs9e/YUjGODEILLN1xOVCrxyCOPfGosxiCKkEGwSD0bqpS5eN06du/ebbJ4CcHux3az5sI1x4lsxWumts3YmadTqpRZ4ku+/Z3v2K10PSYmJpidnc2M9GWnLefWrX/OOV8715TX89i4cSO1Wo2JiQnm5ubseVPLMN8iAHDllVeyfv16JiYmmJ+fz857bOoX/PO/fI/DRz5E0+W+++7H9yX9fp/p6eksxseniS+e53H11VezZMkp/PVjzzAze4z+oLPoO3n2XmP0R1HEjh07qNVq2ednnnkmAH/8R3/Ir5/9Vf7myT1Z+Tzp8eabb/Lyyy+zfft2li9fjhBw65/eyqWXXQrA+vXrj+9rBbvj2Wef5eDBg8eV/5JLLuG6667jW9u/xbv//hP2/cPLfHvXv7Hq6+dy7733Ws8+edxxJxsz89MEMmC4VqHbGiC0TyBLxInx/jh2dJqRUSNIeF5Eoow3uXWqN3UlBVKDHwoS7UFit74obV66ZL71IX3hNfOyJk5ijnz0c5Qy3uIjtaUEgaLXUURDXj6vFzpEcf5P5/4k1tlLca/TZ9CLiQcxvufhDXmIwEMrGARxbhdni43CitRmXB8ql1Fa02l3iaKIMPSJQkkYlBn45qVrYWGBZrvNkcNHjcAyXEOpgERp4n4HlZgEPt3+gG6/Ty82L3lKw9TULIFvgnQ3Gwt40qdcHqbTmsKXgnI5orkwj0ZTKVeZm5tjkBjvgjDwCDxJzVNID3rdLmjodjs0FhaQUYgQksCPrJDs2Rg92gb1tnaBNtuUoyiiXhuhVh1luDKMiRGbEA8SG+PHQ2tJvT6ClJJT46UmZb1WdLsm1msy6FOt1hB46FjY+HkKEQi6nS7C8xgaKtHutmm2F0BJyqWIanWEYzMfmzTtA2PHJUnC1NRUajhTH12CUsKIDJ5v4nEN1WnML9DrpZ5mMUmM8axKYNCHXjsm7mkjKCJBCbNFSJiYcSrG7jKImZr6iCD0qY9UCLwItODQzw8xVCoThqWTWnhyNrS5V2dDOxs6a0v/Cxv6cwtPwlZ01qnsQJWSBsjOVJ60ggo/6UPLDsvafEFMKio8aUXagTtReUDwxbGh0u9+UjZJi6g/0fDN58ZeyuNAifQPwkOTZLdSdF9M506RSp0i79haFNwZRbr9y4pPqahkDYTULTMVn45TfGyqxbQ8QuZu1ea6iweL/BqY82cVJwqnztXU/Jois2jSeEZ5PaQDq8iPtadV2gYw94z3GyqxgeFSw6SP9H20J4zYll7fsxVvU9XZdU+EkKYTe0aQ0jbmlREmVZpkzrZBK+x50v4UBMX01rN7LrbZ9CcffIuuolpptJdOCCw6gxloveyZZY8pa9fHxw87GTHP/TMGiMVdOBtksv6pjGtvfq7FE1w6+KhUyDMj5KL+ZzJupJOCCXyYr7AXClJ4CGl/Bxv0V6d9uvj/9FCd9QdtxykppVkl0lhhWWR915SrcFn7jxaF86Z9HZH3XTtpylSUFTZzBIASth0Wep8w7rFCSmKb8tbTkOgET2ikZ7I9pucyXooeUkKCsoGO82trpU1cfTPY2HuSmOQGKi9vej+FMcfUG/ieyfAj/dD0ZQCVIDyJH5UhEiRxzKDTJhl0UMkAYb1pkDZ2nbLBIfHMRG5T2yIESgtjOIvAuOorkyEz0akXqS1L2nFJFxPycd4TXh7sUCXESWzmgszAyJ+b0gqhbeBDOy6bF/x0tYbs3OlUk265NVmdTl6yId2SxH0WGrO88srLzM412LZtG57n0W63ee6555iZmSEMQzZv3pwdc80117Bhw4bjzv3uu+8yOTnJli1bGBszK++vvvoqb7zxBgArV678VOGpyNKlS7njjjs4ePBgJjytWbOGzZs3Mz4+zqFDh9i0adNxx1UqlUVlBDjnnHO48847eeWVV2i324vuGyG48MKLWLFiJZOTk59aFhn4fFKGkIHPeeefx3nnn5d9tnXr1s+8p+Kx1VOWIISgGobcdtttADSbTfbs2cPs7Gz23SWnnsrVv/8Hi45fu3YtK1as4Mknn8yEJ2EnqqJ7O8DFF1/Mli1beOKJJ5ifn88+bzZnePc//in7/Zlnnv5cZU9Zt24dK1eu4vm/e4n5xjwMPvv7URRxyy23sGzZsuP+dsXll3PG8tPY892nFn3+3nvv8dRTT7Fp0yaWL18OCDZu3Pg/li0d115//XX27dv3qd+5/vrruemmG6nXf8Tuxx/mPz+E936ykm3btpGv8J/cNBYa1Gs1apUqcV+AkvhegFDGW26u12K4WiUIIzwRMOjbVNUFU9ITAiQ21pIJ8SCEiYupVZ6xSmT2nZkjEm08NaZmjoEWBH5Eya+TBALpaWTgk3o0Fb3nzQu1yUCZpHN2bGxQP5D0uwndVh+0QpXSeKweyvfsmGu23BVtUTMtmyQ0YRTabJQmPo758Qn80LzIeR6dbod2p8v09DSVyjD1+ihS+Xhxgoq1uW8l6A9iOt0u7W6HpaeO0e/HzM83GB2tG+Gp1SKUHqVSCZ0kSE8QlXxa7Sa+H1IeGkbrBokyGeJM/BwfT0YkcZ4Vr9vt0my3qfRr+L7A98PMHjLe/enOBXOzSkEYSIIwolKuUilXKZXKNJtzNi5OgpQ25ouQ1Go1k/lOSnrdLv1+F03LJGMYxNRHyyQxdNt9K2KY593r9xAIqvVhFloNmq0m5aiKHwRUq1WmZj+2sVqNPaOVptGYJ4pKlEpDLBs7g143Yb7dslumQ6KwglZtBgNje8VxYj1FzEtxPIB+LyEeKCsAm0X4ODYBqKUvSQZpBsGYudasien2pTolv8SgH3P06MeUyxVKQ6X/i274hXA2tLOhnQ39xWzoz73VzuFwOBwOh8PhcDgcDofD4fhlOPmXiBwOh8PhcDgcDofD4XA4HP8vccKTw+FwOBwOh8PhcDgcDofjhOCEJ4fD4XA4HA6Hw+FwOBwOxwnBCU8Oh8PhcDgcDofD4XA4HI4TghOeHA6Hw+FwOBwOh8PhcDgcJwQnPDkcDofD4XA4HA6Hw+FwOE4ITnhyOBwOh8PhcDgcDofD4XCcEJzw5HA4HA6Hw+FwOBwOh8PhOCE44cnhcDgcDofD4XA4HA6Hw3FC+G/tZrlyk3Vc7wAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"for texture in textures:\n",
" distorted = model(texture)\n",
" display({\n",
" 'Initial rendered image': render_texture(texture, spp=512),\n",
" 'Input texture': texture,\n",
" 'Distorted texture': distorted,\n",
" 'Rendered image': render_texture(distorted, spp=512),\n",
" 'Target image': texture\n",
" })"
]
},
{
"cell_type": "markdown",
"id": "5846b509",
"metadata": {},
"source": [
"## See also\n",
"\n",
"- [dr.wrap](https://drjit.readthedocs.io/en/latest/reference.html#drjit.wrap)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.12"
},
"vscode": {
"interpreter": {
"hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}