## Features
- **Two-Step Chain-of-Thought Ingest** — LLM analyzes first, then generates wiki pages with source traceability and incremental cache
- **Multimodal Image Ingestion** — extract embedded images from PDFs, generate factual captions with a vision LLM, surface them in image-aware search results with lightbox preview and jump-to-source
- **4-Signal Knowledge Graph** — relevance model with direct links, source overlap, Adamic-Adar, and type affinity
- **Louvain Community Detection** — automatic knowledge cluster discovery with cohesion scoring
- **Graph Insights** — surprising connections and knowledge gaps with one-click Deep Research
- **Vector Semantic Search** — optional embedding-based retrieval via LanceDB, supports any OpenAI-compatible endpoint
- **Persistent Ingest Queue** — serial processing with crash recovery, cancel, retry, and progress visualization
- **Folder Import** — recursive folder import preserving directory structure, folder context as LLM classification hint
- **Deep Research** — LLM-optimized search topics, multi-query web search, auto-ingest results into wiki
- **Async Review System** — LLM flags items for human judgment, predefined actions, pre-generated search queries
- **Chrome Web Clipper** — one-click web page capture with auto-ingest into knowledge base
## What is this?
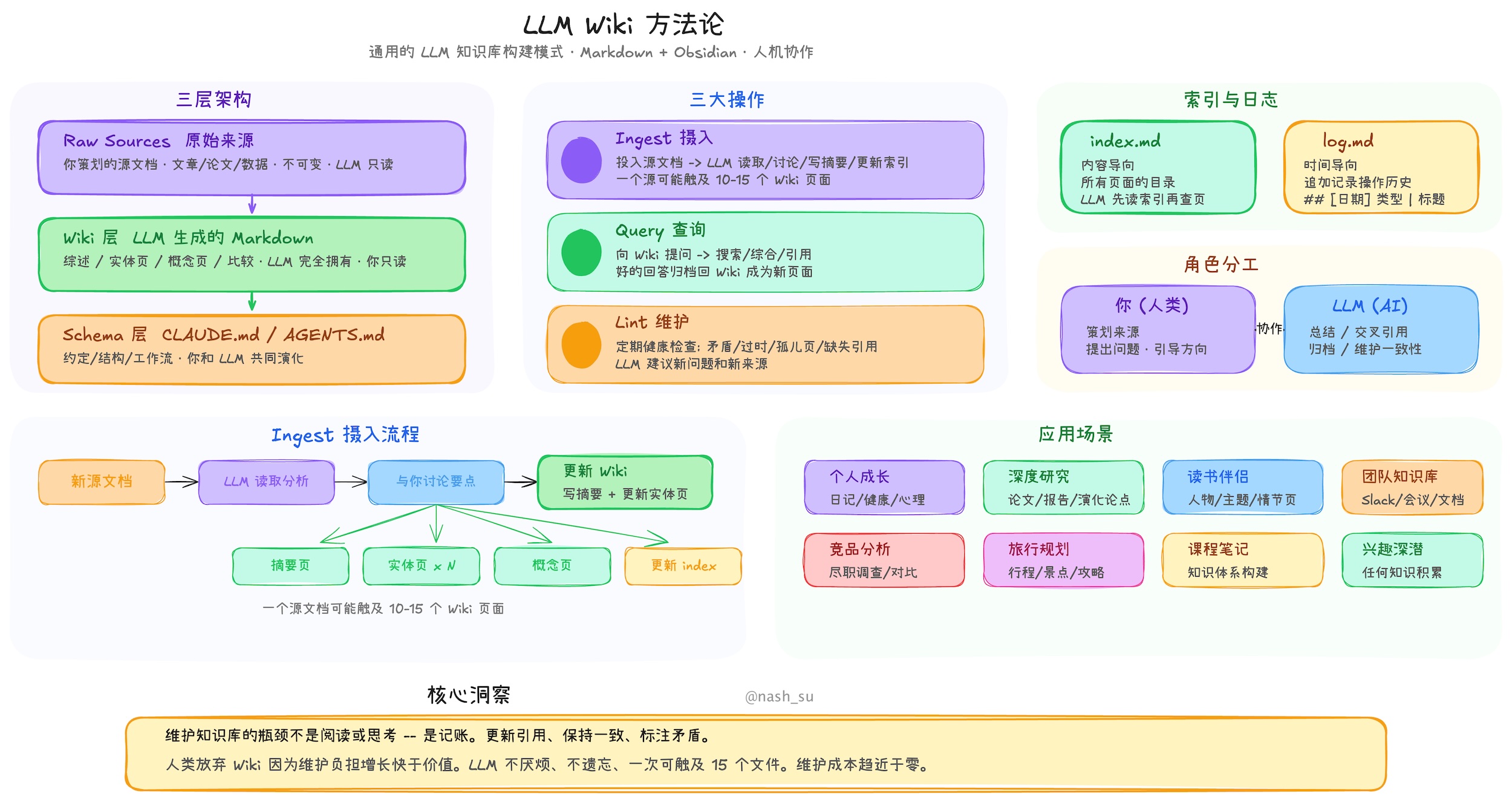
LLM Wiki is a cross-platform desktop application that turns your documents into an organized, interlinked knowledge base — automatically. Instead of traditional RAG (retrieve-and-answer from scratch every time), the LLM **incrementally builds and maintains a persistent wiki** from your sources. Knowledge is compiled once and kept current, not re-derived on every query.
This project is based on [Karpathy's LLM Wiki pattern](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f) — a methodology for building personal knowledge bases using LLMs. We implemented the core ideas as a full desktop application with significant enhancements.
## Credits
The foundational methodology comes from **Andrej Karpathy**'s [llm-wiki.md](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f), which describes the pattern of using LLMs to incrementally build and maintain a personal wiki. The original document is an abstract design pattern; this project is a concrete implementation with substantial extensions.
## What We Kept from the Original
The core architecture follows Karpathy's design faithfully:
- **Three-layer architecture**: Raw Sources (immutable) → Wiki (LLM-generated) → Schema (rules & config)
- **Three core operations**: Ingest, Query, Lint
- **index.md** as the content catalog and LLM navigation entry point
- **log.md** as the chronological operation record with parseable format
- **[[wikilink]]** syntax for cross-references
- **YAML frontmatter** on every wiki page
- **Obsidian compatibility** — the wiki directory works as an Obsidian vault
- **Human curates, LLM maintains** — the fundamental role division
## What We Changed & Added
### 1. From CLI to Desktop Application
The original is an abstract pattern document designed to be copy-pasted to an LLM agent. We built it into a **full cross-platform desktop application** with:
- **Three-column layout**: Knowledge Tree / File Tree (left) + Chat (center) + Preview (right)
- **Icon sidebar** for switching between Wiki, Sources, Search, Graph, Lint, Review, Deep Research, Settings
- **Custom resizable panels** — drag-to-resize left and right panels with min/max constraints
- **Activity panel** — real-time processing status showing file-by-file ingest progress
- **All state persisted** — conversations, settings, review items, project config survive restarts
- **Scenario templates** — Research, Reading, Personal Growth, Business, General — each pre-configures purpose.md and schema.md
### 2. Purpose.md — The Wiki's Soul
The original has Schema (how the wiki works) but no formal place for **why** the wiki exists. We added `purpose.md`:
- Defines goals, key questions, research scope, evolving thesis
- LLM reads it during every ingest and query for context
- LLM can suggest updates based on usage patterns
- Different from schema — schema is structural rules, purpose is directional intent
### 3. Two-Step Chain-of-Thought Ingest
The original describes a single-step ingest where the LLM reads and writes simultaneously. We split it into **two sequential LLM calls** for significantly better quality:
```
Step 1 (Analysis): LLM reads source → structured analysis
- Key entities, concepts, arguments
- Connections to existing wiki content
- Contradictions & tensions with existing knowledge
- Recommendations for wiki structure
Step 2 (Generation): LLM takes analysis → generates wiki files
- Source summary with frontmatter (type, title, sources[])
- Entity pages, concept pages with cross-references
- Updated index.md, log.md, overview.md
- Review items for human judgment
- Search queries for Deep Research
```
Additional ingest enhancements beyond the original:
- **SHA256 incremental cache** — source file content is hashed before ingest; unchanged files are skipped automatically, saving LLM tokens and time
- **Persistent ingest queue** — serial processing prevents concurrent LLM calls; queue persisted to disk, survives app restart; failed tasks auto-retry up to 3 times
- **Folder import** — recursive folder import preserving directory structure; folder path passed to LLM as classification context (e.g., "papers > energy" helps categorize content)
- **Queue visualization** — Activity Panel shows progress bar, pending/processing/failed tasks with cancel and retry buttons
- **Auto-embedding** — when vector search is enabled, new pages are automatically embedded after ingest
- **Source traceability** — every generated wiki page includes a `sources: []` field in YAML frontmatter, linking back to the raw source files that contributed to it
- **overview.md auto-update** — global summary page regenerated on every ingest to reflect the latest state of the wiki
- **Guaranteed source summary** — fallback ensures a source summary page is always created, even if the LLM omits it
- **Language-aware generation** — LLM responds in the user's configured language (English or Chinese)
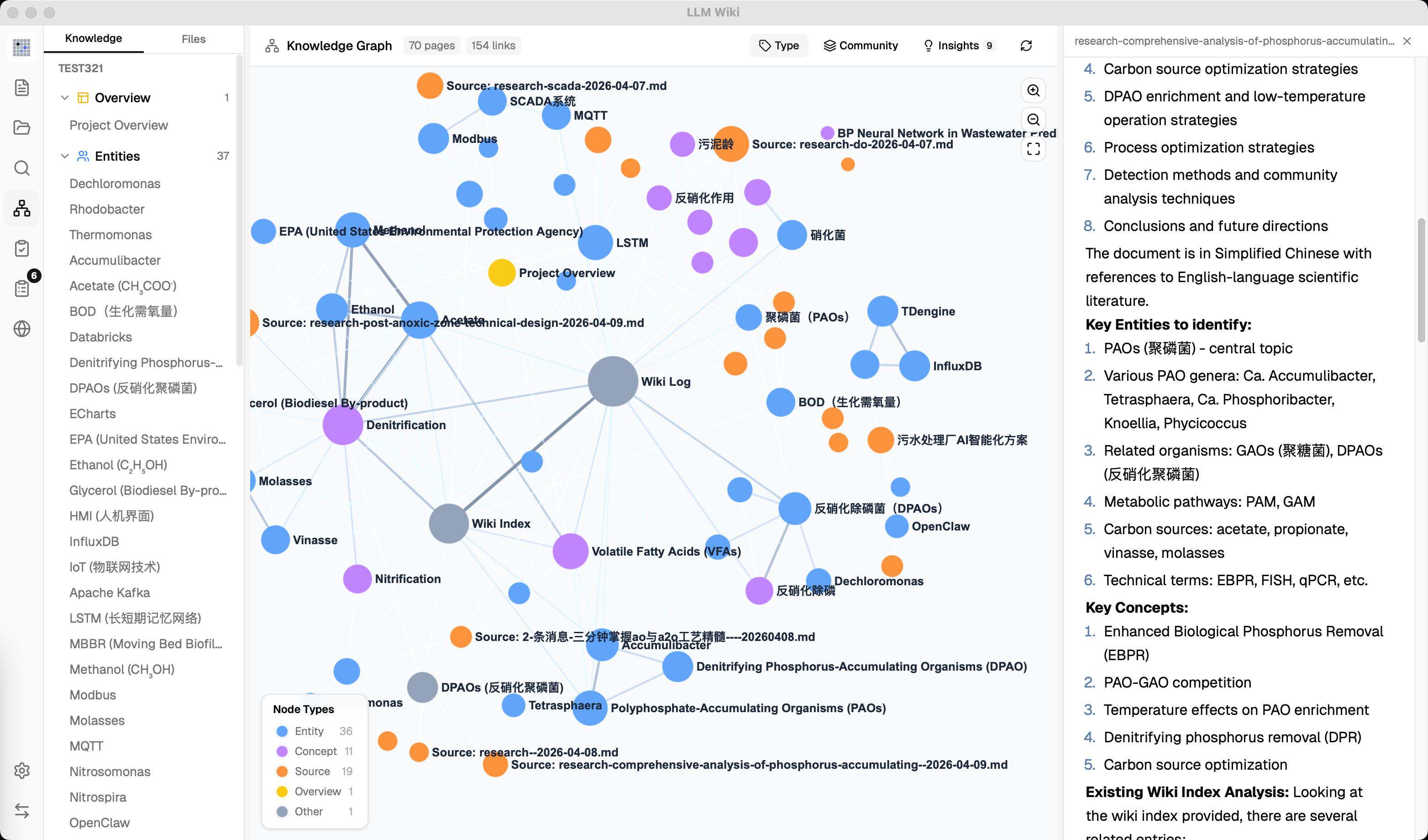
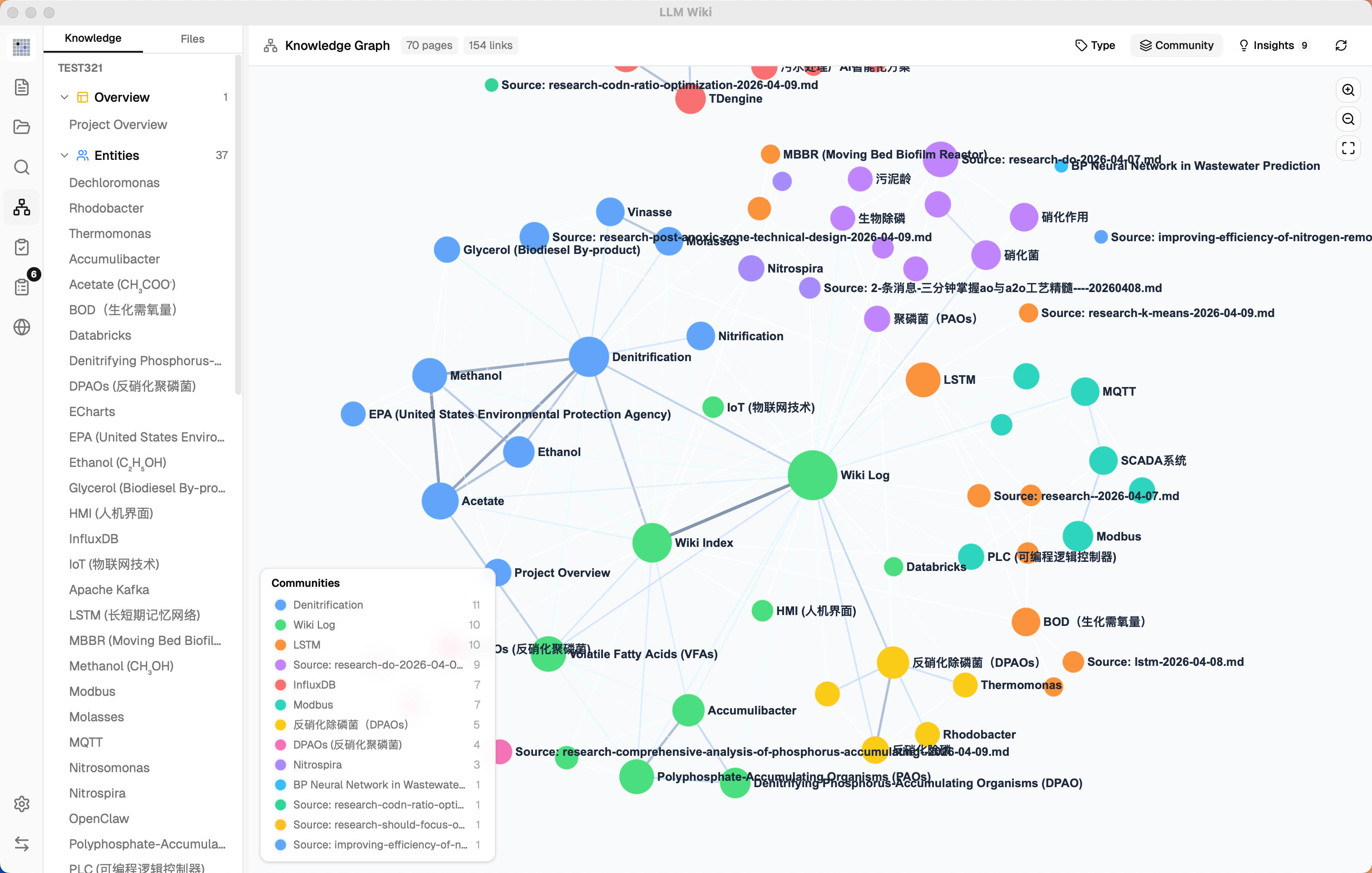
### 4. Knowledge Graph with Relevance Model
The original mentions `[[wikilinks]]` for cross-references but has no graph analysis. We built a **full knowledge graph visualization and relevance engine**:
**4-Signal Relevance Model:**
| Signal | Weight | Description |
|--------|--------|-------------|
| Direct link | ×3.0 | Pages linked via `[[wikilinks]]` |
| Source overlap | ×4.0 | Pages sharing the same raw source (via frontmatter `sources[]`) |
| Adamic-Adar | ×1.5 | Pages sharing common neighbors (weighted by neighbor degree) |
| Type affinity | ×1.0 | Bonus for same page type (entity↔entity, concept↔concept) |
**Graph Visualization (sigma.js + graphology + ForceAtlas2):**
- Node colors by page type or community, sizes scaled by link count (√ scaling)
- Edge thickness and color by relevance weight (green=strong, gray=weak)
- Hover interaction: neighbors stay visible, non-neighbors dim, edges highlight with relevance score label
- Zoom controls (ZoomIn, ZoomOut, Fit-to-screen)
- Position caching prevents layout jumps when data updates
- Legend switches between type counts and community info based on coloring mode
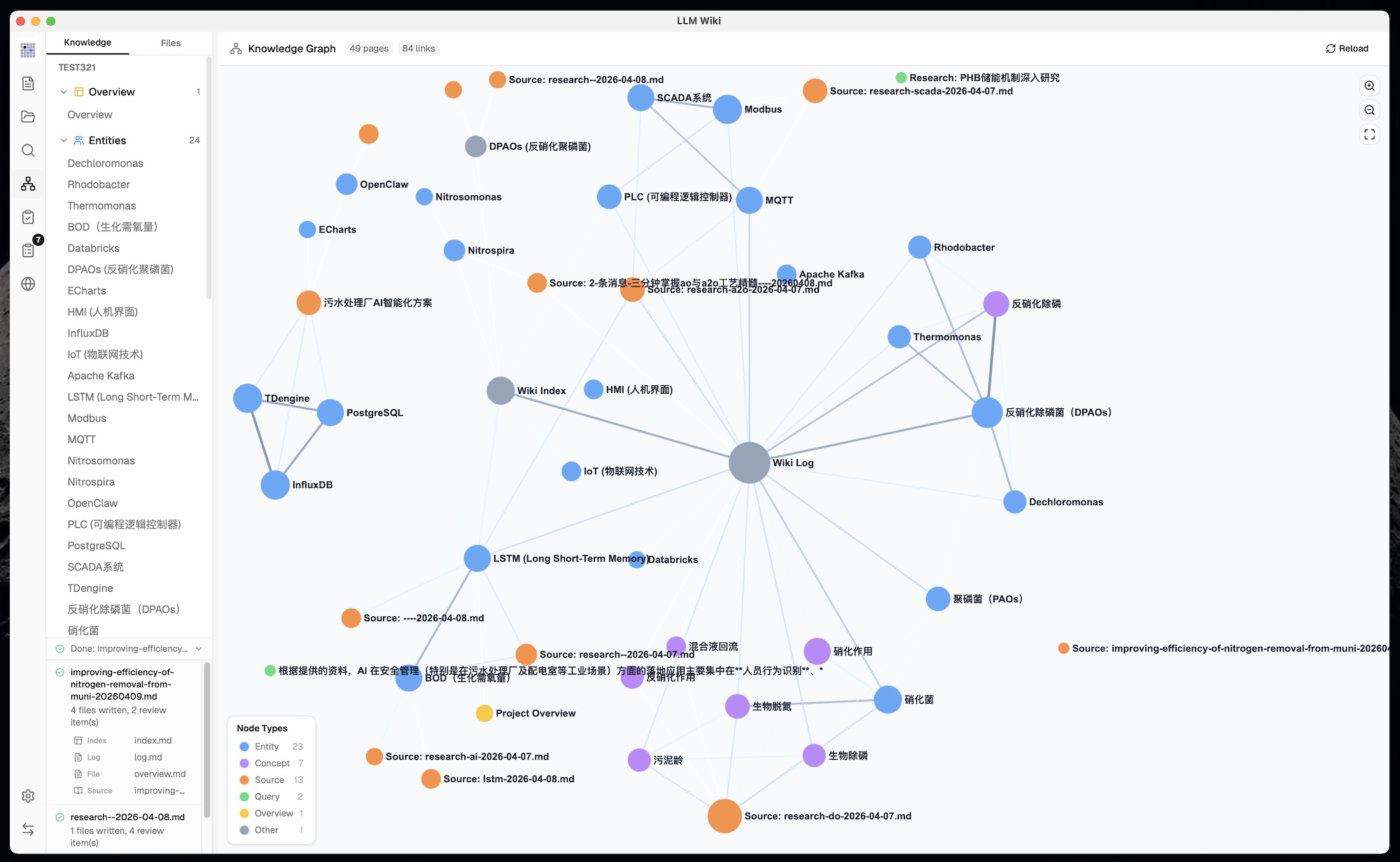
### 5. Louvain Community Detection
Not in the original. Automatic discovery of knowledge clusters using the **Louvain algorithm** (graphology-communities-louvain):
- **Auto-clustering** — discovers which pages naturally group together based on link topology, independent of predefined page types
- **Type / Community toggle** — switch between coloring nodes by page type (entity, concept, source...) or by discovered knowledge cluster
- **Cohesion scoring** — each community scored by intra-edge density (actual edges / possible edges); low-cohesion clusters (< 0.15) flagged with warning
- **12-color palette** — distinct visual separation between clusters
- **Community legend** — shows top node label, member count, and cohesion per cluster
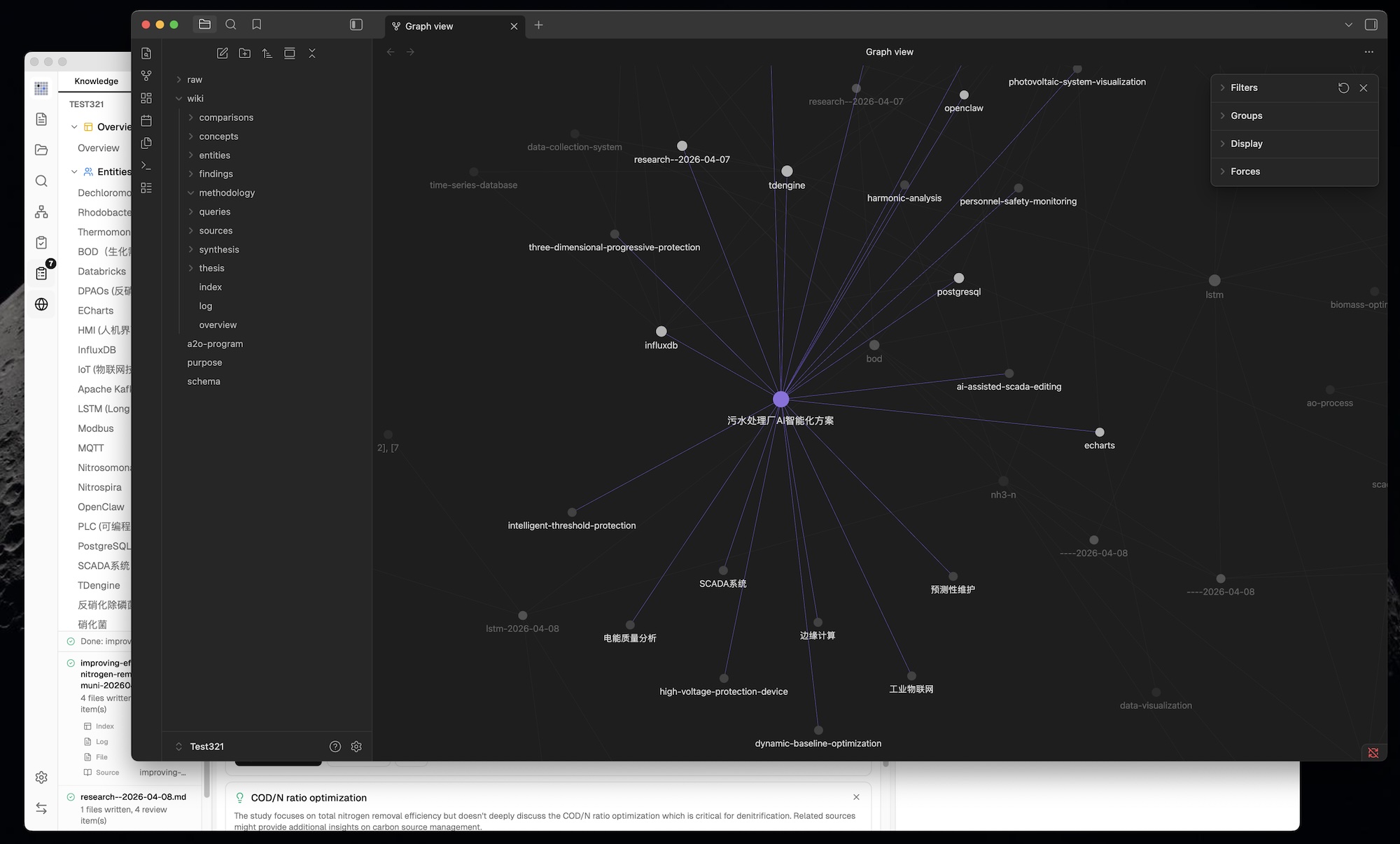
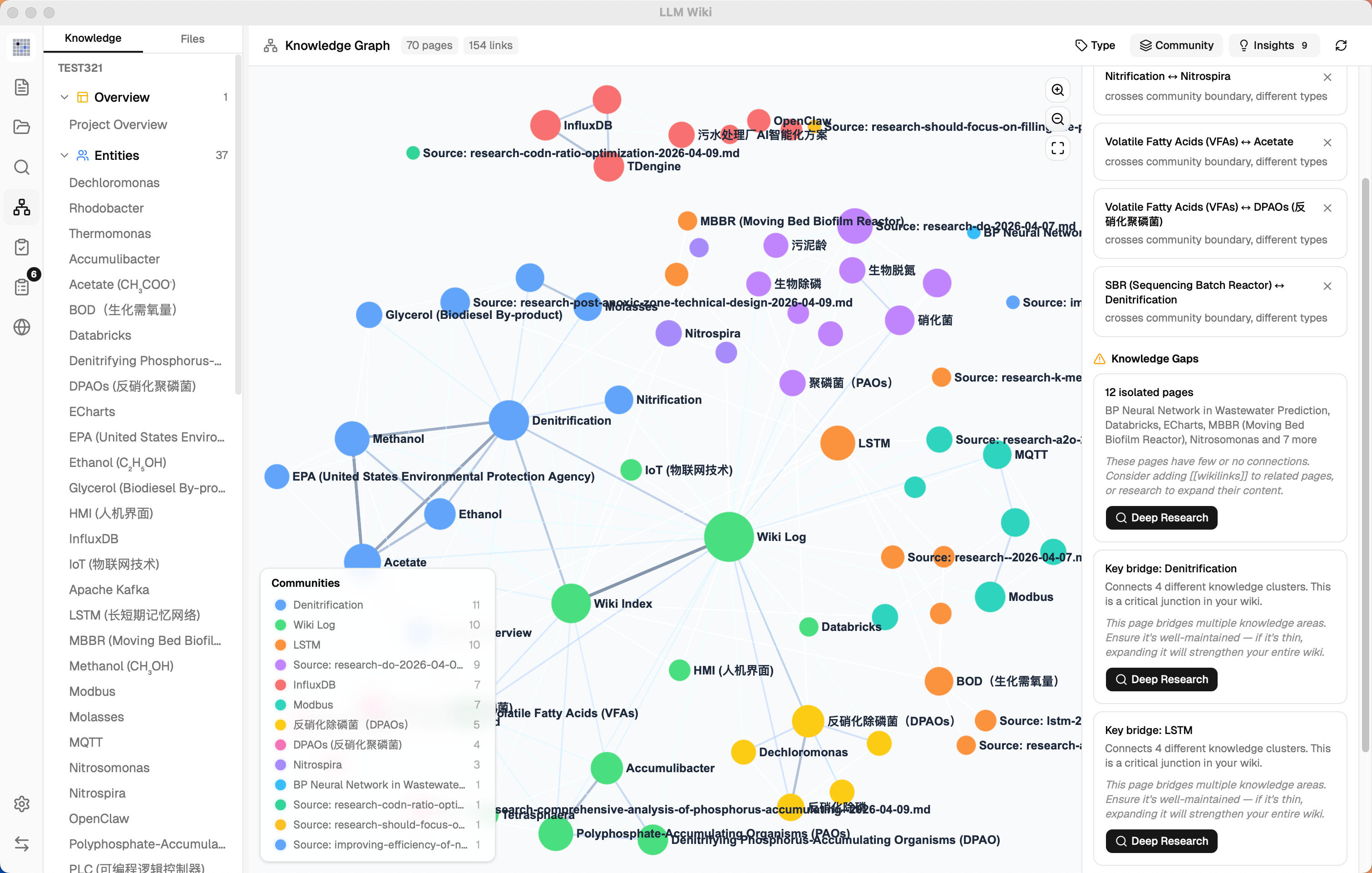
### 6. Graph Insights — Surprising Connections & Knowledge Gaps
Not in the original. The system **automatically analyzes graph structure** to surface actionable insights:
**Surprising Connections:**
- Detects unexpected relationships: cross-community edges, cross-type links, peripheral↔hub couplings
- Composite surprise score ranks the most noteworthy connections
- Dismissable — mark connections as reviewed so they don't reappear
**Knowledge Gaps:**
- **Isolated pages** (degree ≤ 1) — pages with few or no connections to the rest of the wiki
- **Sparse communities** (cohesion < 0.15, ≥ 3 pages) — knowledge areas with weak internal cross-references
- **Bridge nodes** (connecting 3+ clusters) — critical junction pages that hold multiple knowledge areas together
**Interactive:**
- Click any insight card to **highlight** corresponding nodes and edges in the graph; click again to deselect
- Knowledge gaps and bridge nodes have a **Deep Research button** — triggers LLM-optimized research with domain-aware topics (reads overview.md + purpose.md for context)
- Research topic shown in **editable confirmation dialog** before starting — user can refine topic and search queries
### 7. Optimized Query Retrieval Pipeline
The original describes a simple query where the LLM reads relevant pages. We built a **multi-phase retrieval pipeline** with optional vector search and budget control:
```
Phase 1: Tokenized Search
- English: word splitting + stop word removal
- Chinese: CJK bigram tokenization (每个 → [每个, 个…])
- Title match bonus (+10 score)
- Searches both wiki/ and raw/sources/
Phase 1.5: Vector Semantic Search (optional)
- Embedding via any OpenAI-compatible /v1/embeddings endpoint
- Stored in LanceDB (Rust backend) for fast ANN retrieval
- Cosine similarity finds semantically related pages even without keyword overlap
- Results merged into search: boosts existing matches + adds new discoveries
Phase 2: Graph Expansion
- Top search results used as seed nodes
- 4-signal relevance model finds related pages
- 2-hop traversal with decay for deeper connections
Phase 3: Budget Control
- Configurable context window: 4K → 1M tokens
- Proportional allocation: 60% wiki pages, 20% chat history, 5% index, 15% system
- Pages prioritized by combined search + graph relevance score
Phase 4: Context Assembly
- Numbered pages with full content (not just summaries)
- System prompt includes: purpose.md, language rules, citation format, index.md
- LLM instructed to cite pages by number: [1], [2], etc.
```
**Vector Search** is fully optional — disabled by default, enabled in Settings with independent endpoint, API key, and model configuration. When disabled, the pipeline falls back to tokenized search + graph expansion. Benchmark: overall recall improved from 58.2% to 71.4% with vector search enabled.
### 8. Multi-Conversation Chat with Persistence
The original has a single query interface. We built **full multi-conversation support**:
- **Independent chat sessions** — create, rename, delete conversations
- **Conversation sidebar** — quick switching between topics
- **Per-conversation persistence** — each conversation saved to `.llm-wiki/chats/{id}.json`
- **Configurable history depth** — limit how many messages are sent as context (default: 10)
- **Cited references panel** — collapsible section on each response showing which wiki pages were used, grouped by type with icons
- **Reference persistence** — cited pages stored directly in message data, stable across restarts
- **Regenerate** — re-generate the last response with one click (removes last assistant + user message pair, re-sends)
- **Save to Wiki** — archive valuable answers to `wiki/queries/`, then auto-ingest to extract entities/concepts into the knowledge network
### 9. Thinking / Reasoning Display
Not in the original. For LLMs that emit `` blocks (DeepSeek, QwQ, etc.):
- **Streaming thinking** — rolling 5-line display with opacity fade during generation
- **Collapsed by default** — thinking blocks hidden after completion, click to expand
- **Visual separation** — thinking content shown in distinct style, separate from the main response
### 10. KaTeX Math Rendering
Not in the original. Full LaTeX math support across all views:
- **KaTeX rendering** — inline `$...$` and block `$$...$$` formulas rendered via remark-math + rehype-katex
- **Milkdown math plugin** — preview editor renders math natively via @milkdown/plugin-math
- **Auto-detection** — bare `\begin{aligned}` and other LaTeX environments automatically wrapped with `$$` delimiters
- **Unicode fallback** — 100+ symbol mappings (α, ∑, →, ≤, etc.) for simple inline notation outside math blocks
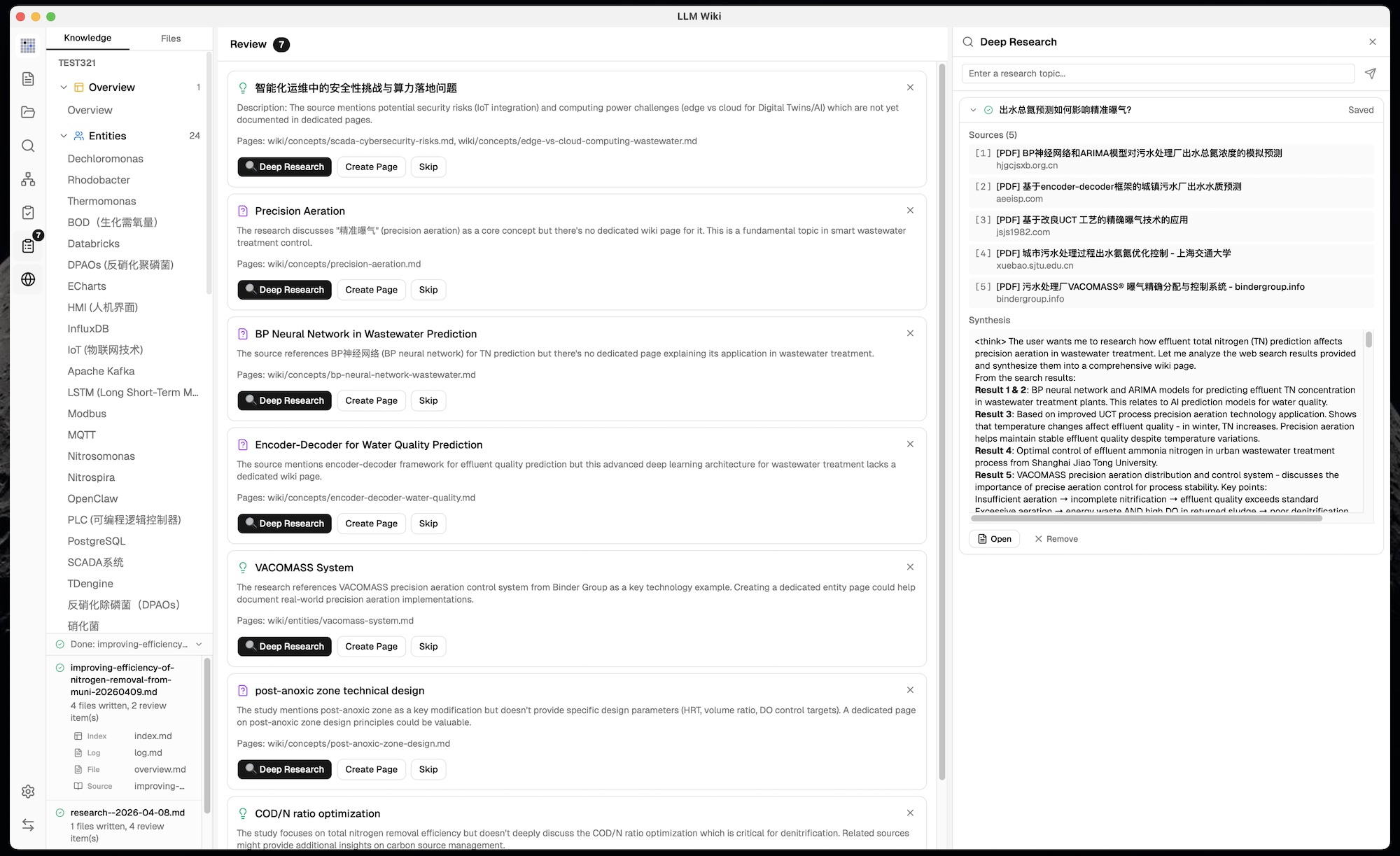
### 11. Review System (Async Human-in-the-Loop)
The original suggests staying involved during ingest. We added an **asynchronous review queue**:
- LLM flags items needing human judgment during ingest
- **Predefined action types**: Create Page, Deep Research, Skip — constrained to prevent LLM hallucination of arbitrary actions
- **Search queries generated at ingest time** — LLM pre-generates optimized web search queries for each review item
- User handles reviews at their convenience — doesn't block ingest
### 12. Deep Research
Not in the original. When the LLM identifies knowledge gaps:
- **Web search** (Tavily API) finds relevant sources with full content extraction (no truncation)
- **Multiple search queries** per topic — LLM-generated at ingest time, optimized for search engines
- **LLM-optimized research topics** — when triggered from Graph Insights, LLM reads overview.md + purpose.md to generate domain-specific topics and queries (not generic keywords)
- **User confirmation dialog** — editable topic and search queries shown for review before research starts
- **LLM synthesizes** findings into a wiki research page with cross-references to existing wiki
- **Thinking display** — `` blocks shown as collapsible sections during synthesis, auto-scroll to latest content
- **Auto-ingest** — research results automatically processed to extract entities/concepts into the wiki
- **Task queue** with 3 concurrent tasks
- **Research Panel** — dedicated sidebar panel with dynamic height, real-time streaming progress
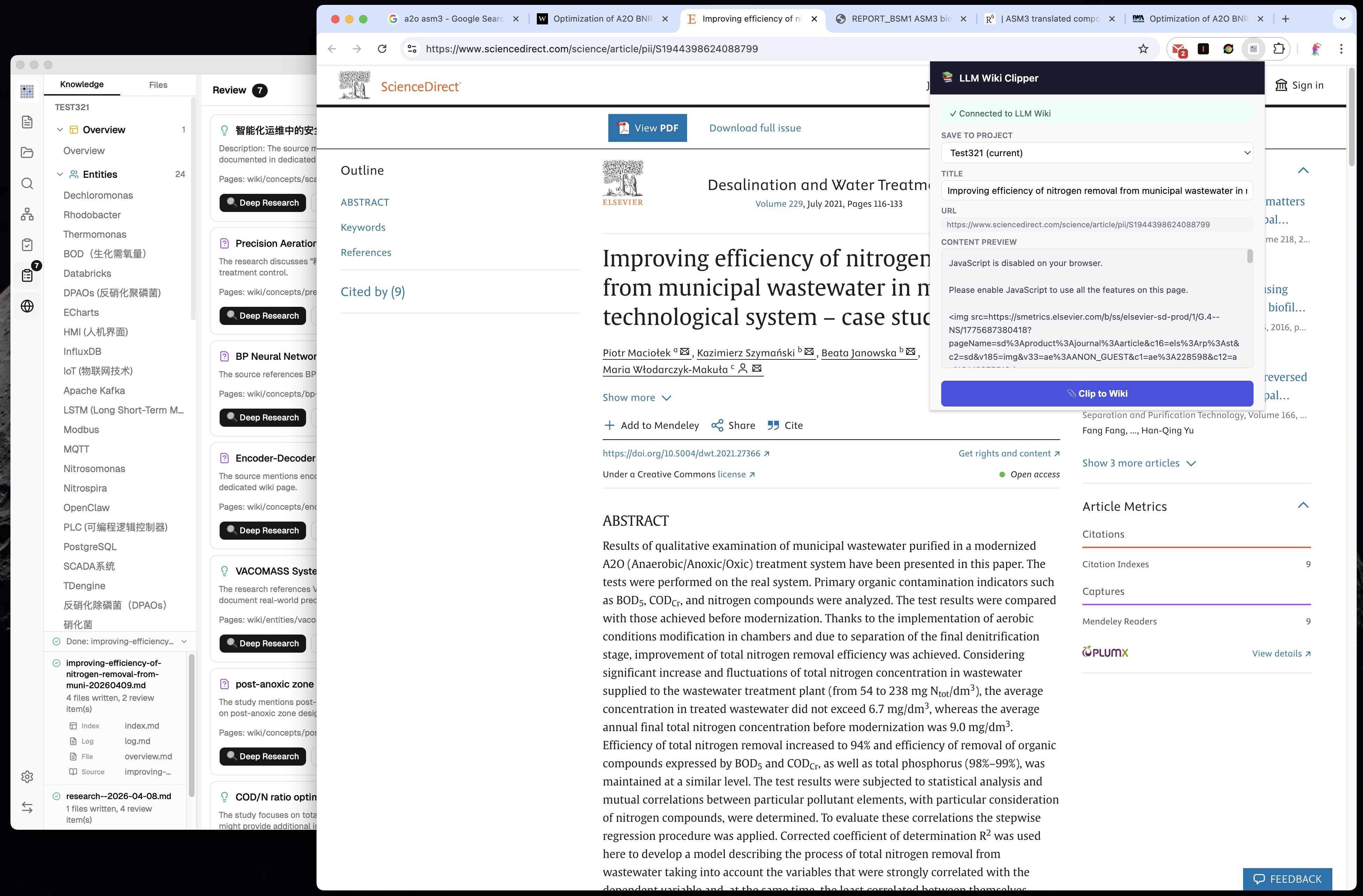
### 13. Browser Extension (Web Clipper)
The original mentions Obsidian Web Clipper. We built a **dedicated Chrome Extension** (Manifest V3):
- **Mozilla Readability.js** for accurate article extraction (strips ads, nav, sidebars)
- **Turndown.js** for HTML → Markdown conversion with table support
- **Project picker** — choose which wiki to clip into (supports multi-project)
- **Local HTTP API** (port 19827, tiny_http) — Extension ↔ App communication
- **Auto-ingest** — clipped content automatically triggers the two-step ingest pipeline
- **Clip watcher** — polls every 3 seconds for new clips, processes automatically
- **Offline preview** — shows extracted content even when app is not running
### 14. Multi-format Document Support
The original focuses on text/markdown. We support structured extraction preserving document semantics:
| Format | Method |
|--------|--------|
| PDF | pdf-extract (Rust) with file caching |
| DOCX | docx-rs — headings, bold/italic, lists, tables → structured Markdown |
| PPTX | ZIP + XML — slide-by-slide extraction with heading/list structure |
| XLSX/XLS/ODS | calamine — proper cell types, multi-sheet support, Markdown tables |
| Images | Native preview (png, jpg, gif, webp, svg, etc.) |
| Video/Audio | Built-in player |
| Web clips | Readability.js + Turndown.js → clean Markdown |
### 15. File Deletion with Cascade Cleanup
The original has no deletion mechanism. We added **intelligent cascade deletion**:
- Deleting a source file removes its wiki summary page
- **3-method matching** finds related wiki pages: frontmatter `sources[]` field, source summary page name, frontmatter section references
- **Shared entity preservation** — entity/concept pages linked to multiple sources only have the deleted source removed from their `sources[]` array, not deleted entirely
- **Index cleanup** — removed pages are purged from index.md
- **Wikilink cleanup** — dead `[[wikilinks]]` to deleted pages are removed from remaining wiki pages
### 16. Configurable Context Window
Not in the original. Users can configure how much context the LLM receives:
- **Slider from 4K to 1M tokens** — adapts to different LLM capabilities
- **Proportional budget allocation** — larger windows get proportionally more wiki content
- **60/20/5/15 split** — wiki pages / chat history / index / system prompt
### 17. Cross-Platform Compatibility
The original is platform-agnostic (abstract pattern). We handle concrete cross-platform concerns:
- **Path normalization** — unified `normalizePath()` used across 22+ files, backslash → forward slash
- **Unicode-safe string handling** — char-based slicing instead of byte-based (prevents crashes on CJK filenames)
- **macOS close-to-hide** — close button hides window (app stays running in background), click dock icon to restore, Cmd+Q to quit
- **Windows/Linux close confirmation** — confirmation dialog before quitting to prevent accidental data loss
- **Tauri v2** — native desktop on macOS, Windows, Linux
- **GitHub Actions CI/CD** — automated builds for macOS (ARM + Intel), Windows (.msi), Linux (.deb / .AppImage)
### 18. Other Additions
- **i18n** — English + Chinese interface (react-i18next)
- **Settings persistence** — LLM provider, API key, model, context size, language saved via Tauri Store
- **Obsidian config** — auto-generated `.obsidian/` directory with recommended settings
- **Markdown rendering** — GFM tables with borders, proper code blocks, wikilink processing in chat and preview
- **Multi-provider LLM support** — OpenAI, Anthropic, Google, Ollama, Custom — each with provider-specific streaming and headers
- **15-minute timeout** — long ingest operations won't fail prematurely
- **dataVersion signaling** — graph and UI automatically refresh when wiki content changes
## Tech Stack
| Layer | Technology |
|-------|-----------|
| Desktop | Tauri v2 (Rust backend) |
| Frontend | React 19 + TypeScript + Vite |
| UI | shadcn/ui + Tailwind CSS v4 |
| Editor | Milkdown (ProseMirror-based WYSIWYG) |
| Graph | sigma.js + graphology + ForceAtlas2 |
| Search | Tokenized search + graph relevance + optional vector (LanceDB) |
| Vector DB | LanceDB (Rust, embedded, optional) |
| PDF | pdf-extract |
| Office | docx-rs + calamine |
| i18n | react-i18next |
| State | Zustand |
| LLM | Streaming fetch (OpenAI, Anthropic, Google, Ollama, Custom) |
| Web Search | Tavily API |
## Installation
### Pre-built Binaries
Download from [Releases](https://github.com/nashsu/llm_wiki/releases):
- **macOS**: `.dmg` (Apple Silicon + Intel)
- **Windows**: `.msi`
- **Linux**: `.deb` / `.AppImage`
### Build from Source
```bash
# Prerequisites: Node.js 20+, Rust 1.70+
git clone https://github.com/nashsu/llm_wiki.git
cd llm_wiki
npm install
npm run tauri dev # Development
npm run tauri build # Production build
```
### Chrome Extension
1. Open `chrome://extensions`
2. Enable "Developer mode"
3. Click "Load unpacked"
4. Select the `extension/` directory
## Quick Start
1. Launch the app → Create a new project (choose a template)
2. Go to **Settings** → Configure your LLM provider (API key + model)
3. Go to **Sources** → Import documents (PDF, DOCX, MD, etc.)
4. Watch the **Activity Panel** — LLM automatically builds wiki pages
5. Use **Chat** to query your knowledge base
6. Browse the **Knowledge Graph** to see connections
7. Check **Review** for items needing your attention
8. Run **Lint** periodically to maintain wiki health
## Project Structure
```
my-wiki/
├── purpose.md # Goals, key questions, research scope
├── schema.md # Wiki structure rules, page types
├── raw/
│ ├── sources/ # Uploaded documents (immutable)
│ └── assets/ # Local images
├── wiki/
│ ├── index.md # Content catalog
│ ├── log.md # Operation history
│ ├── overview.md # Global summary (auto-updated)
│ ├── entities/ # People, organizations, products
│ ├── concepts/ # Theories, methods, techniques
│ ├── sources/ # Source summaries
│ ├── queries/ # Saved chat answers + research
│ ├── synthesis/ # Cross-source analysis
│ └── comparisons/ # Side-by-side comparisons
├── .obsidian/ # Obsidian vault config (auto-generated)
└── .llm-wiki/ # App config, chat history, review items
```
## Star History
## License
This project is licensed under the **GNU General Public License v3.0** — see [LICENSE](LICENSE) for details.