{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Peter Norvig
June 2021
\n",
"\n",
"# Split the States\n",
"\n",
"The [538 Riddler for 11 June 2021](https://fivethirtyeight.com/features/can-you-split-the-states/) poses this problem (paraphrased):\n",
"\n",
"*Given a map of the lower 48 states of the USA, remove a subset of the states so that the map is cut into two disjoint contiguous regions that are near-halves by area. Since Michigan’s upper and lower peninsulas are non-contiguous, you can treat them as two separate \"states,\" for a total of 49. \"Disjoint\" means the two regions are distinct and not adjacent (due to the cut).*\n",
"\n",
"Since \"near-halves\" is vague, answer the two questions:\n",
"1) What states should you remove to maximize the area of the smaller of the two regions? \n",
"2) What states should you remove to minimize the difference of the areas of the two regions? \n",
"\n",
"# Vocabulary terms \n",
"\n",
"Let's start by clarifying some concepts:\n",
"- **State**: denoted by the standard 2-letter abbreviations like `'CA'` (plus `'UP'` and `'LP'` for the Michigan peninsulas). \n",
"- **States**: a set of states; implemented as a (hashable) `frozenset`. I can use `states('OR CA')`.\n",
"- **Region**: a set of states that are **contiguous**—they are all connected by a single tree of **neighbor** relations.\n",
"- **Neighbor**: a relation saying two states share a border. Implemented as [adjacency sets](https://en.wikipedia.org/wiki/Adjacency_list) in the dict `neighbors`.\n",
"- **Cut**: a set of states that, when removed from the map, cuts the map into disjoint regions. \n",
"- **Split**: a tuple `(A, B, C)`, where `A` and `B` are the two regions made by the cut `C`, with `A` larger than `B` in area.\n",
"- **Border**: the states on the edge of the map (neighbors of Canada, Mexico, Atlantic, or Pacific).\n",
"- **Area**: Each state has an area, given (in square miles) by the `areas` dict. A region has a total area, given by the function `area`.\n",
"\n",
"For example, one cut is {NM, OK, MO, IL}, which partitions the states into groups *A* and *B* like this (ignore AK and HI):\n",
"\n",
"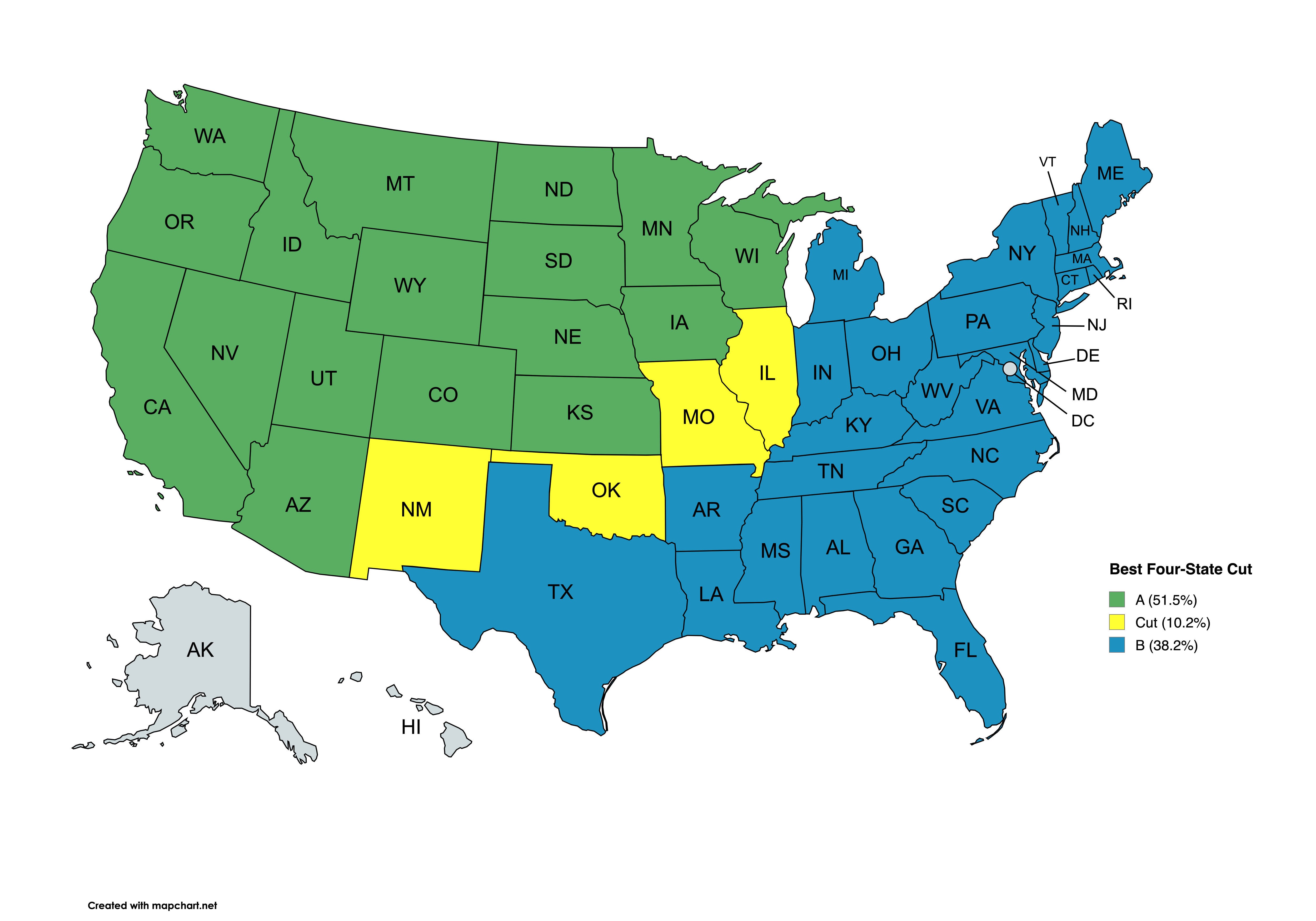\n",
"\n",
"Credit goes to [mapchart.net](https://mapchart.net), which is the only map-coloring site I've found that allows you to split Michigan. \n",
"\n",
"Here is the code to implement the vocabulary concepts (with the help of two sites that had data on state's [neighbors](https://theincidentaleconomist.com/wordpress/list-of-neighboring-states-with-stata-code/) and [area](https://www.census.gov/geographies/reference-files/2010/geo/state-area.html)):"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"from typing import *\n",
"\n",
"State = str # Two-letter abbrerviation\n",
"States = frozenset # A set of states\n",
"Region = States # A contiguous set of states (must be hashable)\n",
"Split = Tuple[Region, Region, Region] # (A, B, C) = (large region, small region, cut)\n",
"\n",
"def states(string: str) -> States: \"Set of states\"; return States(string.split())\n",
"def statedict(**dic) -> dict: \"{State:States}\"; return {s: states(dic[s]) for s in dic}\n",
"def area(states: States) -> int: \"Total area\"; return sum(areas[s] for s in states)\n",
"\n",
"neighbors = statedict(\n",
" AK='', AL='FL GA MS TN', AR='LA MO MS OK TN TX', AZ='CA CO NM NV UT', CA='AZ NV OR', \n",
" CO='AZ KS NE NM OK UT WY', CT='MA NY RI', DC='MD VA', DE='MD NJ PA', FL='AL GA', \n",
" GA='AL FL NC SC TN', HI='', IA='IL MN MO NE SD WI', ID='MT NV OR UT WA WY', IL='IA IN KY MO WI', \n",
" IN='IL KY LP MI OH', KS='CO MO NE OK', KY='IL IN MO OH TN VA WV', LA='AR MS TX', \n",
" MA='CT NH NY RI VT', MD='DC DE PA VA WV', ME='NH', MI='IN OH WI', MN='IA ND SD WI', \n",
" MO='AR IA IL KS KY NE OK TN', MS='AL AR LA TN', MT='ID ND SD WY', NC='GA SC TN VA', \n",
" ND='MN MT SD', NE='CO IA KS MO SD WY', NH='MA ME VT', NJ='DE NY PA', NM='AZ CO OK TX UT', \n",
" NV='AZ CA ID OR UT', NY='CT MA NJ PA VT', OH='IN KY LP MI PA WV', OK='AR CO KS MO NM TX', \n",
" OR='CA ID NV WA', PA='DE MD NJ NY OH WV', RI='CT MA', SC='GA NC', SD='IA MN MT ND NE WY', \n",
" TN='AL AR GA KY MO MS NC VA', TX='AR LA NM OK', UT='AZ CO ID NM NV WY', VA='DC KY MD NC TN WV', \n",
" VT='MA NH NY', WA='ID OR', WI='IA IL MI MN UP', WV='KY MD OH PA VA', WY='CO ID MT NE SD UT', \n",
" UP='WI', LP='IN OH')\n",
"\n",
"\n",
"areas = dict(\n",
" AK=665384, AL=52420, AZ=113990, AR=53179, CA=163695, CO=104094, CT=5543, DE=2489, DC=68, \n",
" FL=65758, GA=59425, HI=10932, ID=83569, IL=57914, IN=36420, IA=56273, KS=82278, KY=40408, \n",
" LA=52378, ME=35380, MD=12406, MA=10554, MI=96714, MN=86936, MS=48432, MO=69707, MT=147040, \n",
" NE=77348, NV=110572, NH=9349, NJ=8723, NM=121590, NY=54555, NC=53819, ND=70698, OH=44826, \n",
" OK=69899, OR=98379, PA=46054, RI=1545, SC=32020, SD=77116, TN=42144, TX=268596, UT=84897, \n",
" VT=9616, VA=42775, WA=71298, WV=24230, WI=65496, WY=97813, UP=16377, LP=80337) \n",
"\n",
"# Borders:\n",
"north = states('WA ID MT ND MN WI MI UP IL IN LP OH PA NY VT NH ME') \n",
"south = states('CA AZ NM TX LA MS AL FL') \n",
"west = states('WA OR CA')\n",
"east = states('ME NH MA RI CT NY NJ DE MD VA NC SC GA FL')\n",
"border = north | south | west | east\n",
"\n",
"# \"Countries\":\n",
"usa = States(areas) # 50 states plus UP, LP, DC\n",
"usa50 = usa - states('DC UP LP') # 50 actual US states\n",
"usa48 = usa50 - states('AK HI') # 48 contiguous states\n",
"usa49 = usa - states('DC AK HI MI') # 49 \"states\": MI split into UP, LP\n",
"western = states('WA OR CA ID NV UT AZ MT WY CO NM') # The 11 states west of the Rockies"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Strategy for answering the two questions\n",
"\n",
"My overall strategy:\n",
"- Generate a large number of **cuts**. \n",
"- For each cut *C*, determine the **split** into regions *A* and *B*. \n",
"- From the valid splits, find the ones that:\n",
" 1) **Maximize the area** of *B*\n",
" 2) **Minimize the difference** in area of *A* and *B*.\n",
"\n",
"# Making cuts\n",
"\n",
"Is it feasible to consider all possible cuts? A cut is a subset of the 49 states, so there are 249 or 500 trillion possible cuts, so **no**, we can't look at them all. I have four ideas to reduce the number of cuts considered:\n",
"- **Limit the total area in a cut.** A large area in the cut means there won't be much area left to make *B* big for question 1. By default, I'll limit the area of the cut to be 1/5 the area of the country.\n",
"- **Limit the number of states in a cut.** Similarly, if there are too many states in a cut, there won't be many left for *A* or *B*. By default, the limit is 8.\n",
"- **Make cuts contiguous.** Noncontiguous cuts can't be optimal for question 1, so for now I won't consider them (although they can provide a good answer for question 2).\n",
"- **Make cuts go border-to-border.** A cut can produce exactly two regions only if (a) the cut runs from one place on the border to another place on the border or (b) the cut forms a \"donut\" that surrounds some interior region. The US map isn't big enough to support a decent-sized donut (only KS and NE are not neighbors of a border state). Also, the US map seems to be too wide to have a good East-West cut, so I'll start with cuts that go from the northern border to the southern border.\n",
"\n",
"The function `make_cuts` starts by building a set of partial cuts where each cut initially contains a single `start` state. Then in each iteration of the `while` loop, it yields any cut that has reached an `end` state, and creates a new set of cuts formed by adding a neighboring state to a current cut in all possible ways, as long as the area does not exceed `maxarea` and the size does not exceed `maxsize`. "
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"def make_cuts(country, maxsize=8, maxarea=area(usa48)//5, start=north, end=south) -> Iterator[Region]:\n",
" \"\"\"All contiguous regions up to `maxsize` and `maxarea` that contain a `start` and `end` state.\"\"\"\n",
" cuts = {Region({s}) for s in start & country} \n",
" while cuts:\n",
" yield from filter(end.intersection, cuts) # A cut is good if it contains an `end` state.\n",
" cuts = {cut | {s1}\n",
" for cut in cuts if len(cut) < maxsize \n",
" for s in cut \n",
" for s1 in (neighbors[s] & country) - cut\n",
" if area(cut) + areas[s1] <= maxarea} "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For example, the north-south cuts of size up to 3 states:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{frozenset({'AZ', 'ID', 'UT'}),\n",
" frozenset({'AZ', 'ID', 'NV'}),\n",
" frozenset({'CA', 'ID', 'NV'}),\n",
" frozenset({'CA', 'OR', 'WA'}),\n",
" frozenset({'ID', 'NM', 'UT'}),\n",
" frozenset({'CA', 'ID', 'OR'})}"
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"set(make_cuts(usa49, 3))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"How many cuts are there in `usa49` (using the default parameter values)?"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"41700"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(list(make_cuts(usa49)))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's a more manageable number than 500 trillion.\n",
"\n",
"# Making splits\n",
"\n",
"Given some candidate cuts, the function `make_splits` creates **splits**: tuples `(A, B, C)`, where `A` and `B` are the two regions defined by the cut `C`, with `A` larger than `B`. A split requires that the cut divides the country into exactly two regions, but not all cuts do that. For example, the cut {WA, OR, CA} leaves only one region (consisting of all the other states). The cut {ID, OR, NV, AZ} leaves three regions: {WA}, {CA}, and {everything else}. To verify whether the cut makes two regions, `make_splits` first finds a maximal-size contiguous region `A` from the non-cut states, then finds a region `B` from the remaining states, then checks that `A` and `B` are non-empty and make up all the non-cut states.\n",
"\n",
"We find the extent of a region with the `contiguous` function, which implements a [flood fill algorithm](https://en.wikipedia.org/wiki/Flood_fill): it maintains a mutable `region` and a `frontier` of the states that neighbor the region but are not in the region. We iterate adding the frontier into the region and computing a new frontier until there is no new frontier. "
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"def make_splits(country, cuts: Iterable[Region]) -> Iterator[Split]:\n",
" \"\"\"For each cut C, find regions A and B and yield the Split (A, B, C) if valid.\"\"\"\n",
" for C in cuts:\n",
" AB = country - C\n",
" A = contiguous(AB) \n",
" B = contiguous(AB - A)\n",
" if A and B and (A | B | C == country):\n",
" B, A = sorted([A, B], key=area) # Ensure A larger than B in area\n",
" yield (A, B, C)\n",
" \n",
"def contiguous(states: States) -> Region:\n",
" \"\"\"Starting at one of the states, expand out to all contiguous states; return them.\"\"\"\n",
" region = set() \n",
" frontier = {min(states)} if states else None\n",
" while frontier:\n",
" region |= frontier\n",
" frontier = {s1 for s in frontier for s1 in neighbors[s]\n",
" if s1 in states and s1 not in region}\n",
" return Region(region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For example, here are the size-3 cuts of the western states, and the splits (*A*, *B*, *C*) from those cuts:"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[frozenset({'AZ', 'ID', 'UT'}),\n",
" frozenset({'AZ', 'ID', 'NV'}),\n",
" frozenset({'CA', 'ID', 'NV'}),\n",
" frozenset({'CA', 'OR', 'WA'}),\n",
" frozenset({'CA', 'ID', 'OR'}),\n",
" frozenset({'ID', 'NM', 'UT'})]"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"list(make_cuts(western, 3))"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[(frozenset({'CO', 'MT', 'NM', 'WY'}),\n",
" frozenset({'CA', 'NV', 'OR', 'WA'}),\n",
" frozenset({'AZ', 'ID', 'UT'})),\n",
" (frozenset({'CO', 'MT', 'NM', 'UT', 'WY'}),\n",
" frozenset({'CA', 'OR', 'WA'}),\n",
" frozenset({'AZ', 'ID', 'NV'})),\n",
" (frozenset({'AZ', 'CO', 'MT', 'NM', 'UT', 'WY'}),\n",
" frozenset({'OR', 'WA'}),\n",
" frozenset({'CA', 'ID', 'NV'})),\n",
" (frozenset({'AZ', 'CO', 'MT', 'NM', 'NV', 'UT', 'WY'}),\n",
" frozenset({'WA'}),\n",
" frozenset({'CA', 'ID', 'OR'}))]"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"list(make_splits(western, make_cuts(western, 3)))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# The answers\n",
"\n",
"The function `answers` puts it all together: makes cuts; makes splits from those cuts; finds the splits that answer the two questions; and prints the results. For *A*, *B*, and *C*, it prints the total area, the percentage of the country's area, the number of states in the region, and the set of states in the region. Then it prints the delta between *A* and *B*'s area."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"def answers(country, maxsize=8, maxarea=area(usa49)//5, start=north, end=south) -> Optional[tuple]:\n",
" \"\"\"Find the splits that answer the 2 questions.\n",
" Print information in pretty format if 'print' is in `do`.\n",
" Return the tuple (cuts, splits, answer1, answer2) if 'return' is in `do`.\"\"\"\n",
" cuts = list(make_cuts(country, maxsize, maxarea, start, end))\n",
" splits = list(make_splits(country, cuts))\n",
" answer1 = max(splits, key=lambda s: area(s[1]))\n",
" answer2 = min(splits, key=lambda s: area(s[0]) - area(s[1]))\n",
" print(f'{len(country)} states ⇒ {len(cuts):,d} cuts',\n",
" f'(cut size ≤ {maxsize}, cut area ≤ {maxarea:,d}) ⇒ {len(splits):,d} splits.')\n",
" show('1. Split that maximizes area(B)', country, answer1)\n",
" show('2. Split that minimizes ∆ = area(A) - area(B)', country, answer2)\n",
" \n",
"def show(title, country, split) -> None:\n",
" \"\"\"Print a title, and a summary of the split in four rows. The columns shown are:\n",
" 'region name|area|percent of country area|number of states in region|states in region'.\n",
" The ∆ row of the table is not a region; it is the difference in area between A and B.\"\"\"\n",
" A, B, C = split\n",
" def print_row(name, region, sqmi): \n",
" statelist = f'{len(region):2d}|{\" \".join(sorted(region))}' if region else ''\n",
" print(f'{name}|{sqmi:9,d}|{sqmi/area(country):7.3%}|{statelist}')\n",
" print(f'\\n{title}:')\n",
" print_row('A', A, area(A))\n",
" print_row('B', B, area(B))\n",
" print_row('C', C, area(C))\n",
" print_row('∆', '', area(A) - area(B))"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"49 states ⇒ 41,700 cuts (cut size ≤ 8, cut area ≤ 624,072) ⇒ 13,146 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,345,558|43.122%|29|AL AR CT DE FL GA IN KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TN TX VA VT WV\n",
"B|1,344,149|43.077%|15|AZ CA IA ID MN MT ND NV OR SD UP UT WA WI WY\n",
"C| 430,653|13.801%| 5|CO IL MO NE NM\n",
"∆| 1,409| 0.045%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,267,033|40.605%|14|AZ CA IA ID MN MT ND NV OR UP UT WA WI WY\n",
"B|1,266,994|40.604%|27|AL AR CT DE FL GA KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TX VA VT WV\n",
"C| 586,333|18.791%| 8|CO IL IN MO NE NM SD TN\n",
"∆| 39| 0.001%|\n"
]
}
],
"source": [
"answers(usa49)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Here are maps of those two cuts, representing the best answers to questions 1 and 2 with my default parameter values:\n",
"\n",
"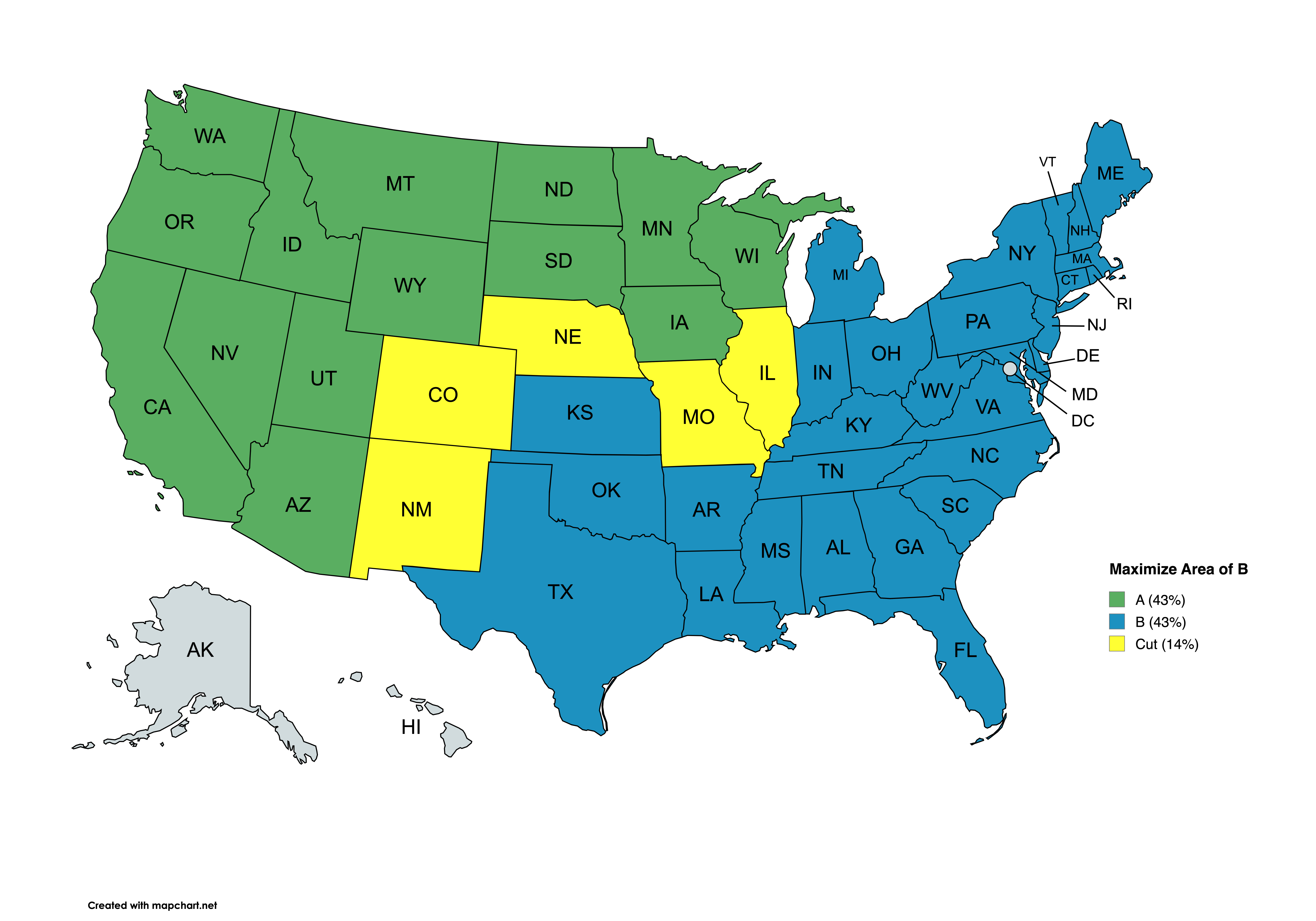\n",
"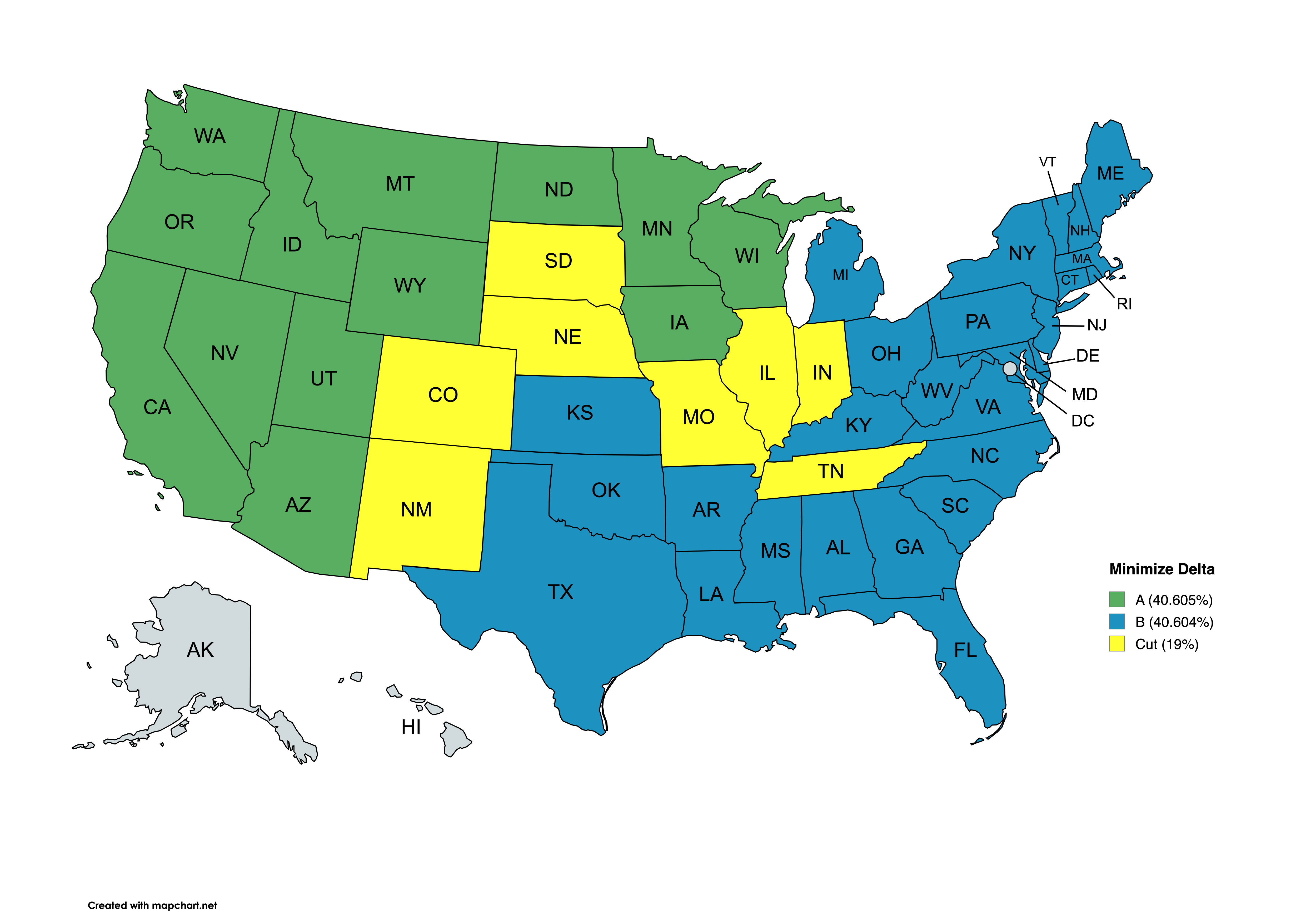\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Improving on question 1\n",
"\n",
"The {CO,IL,MO,NE,NM} cut gave us two regions with 43% of the area each. But we limited cuts to 8 states, so this may not be the best possible result. If we looked at all possible cuts, the run time would be too long. Fortunately, we can tighten the area constraint. We saw above that the cut {CO,IL,MO,NE,NM} produces a region *B* with area 1,344,149, so that means that any cut that is better for question 1 must create a split where the areas of both *A* and *B* are greater than 1,344,149, Therefore, we can reduce the `maxarea` for the cut from `area(usa49)/5` (which is 624,072) down to:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"432062"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"maxarea = area(usa49) - 2 * 1344149\n",
"maxarea"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"With the tight area constraint, we don't need the restictions on `maxsize`, `start`, and `end`. This will be the first computation that takes more than a few seconds."
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"49 states ⇒ 547,779 cuts (cut size ≤ 49, cut area ≤ 432,062) ⇒ 42,685 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,345,558|43.122%|29|AL AR CT DE FL GA IN KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TN TX VA VT WV\n",
"B|1,344,149|43.077%|15|AZ CA IA ID MN MT ND NV OR SD UP UT WA WI WY\n",
"C| 430,653|13.801%| 5|CO IL MO NE NM\n",
"∆| 1,409| 0.045%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,345,558|43.122%|29|AL AR CT DE FL GA IN KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TN TX VA VT WV\n",
"B|1,344,149|43.077%|15|AZ CA IA ID MN MT ND NV OR SD UP UT WA WI WY\n",
"C| 430,653|13.801%| 5|CO IL MO NE NM\n",
"∆| 1,409| 0.045%|\n",
"CPU times: user 36.3 s, sys: 437 ms, total: 36.8 s\n",
"Wall time: 37.3 s\n"
]
}
],
"source": [
"%time answers(usa49, maxsize=49, maxarea=maxarea, start=border, end=border)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This confirms that {CO,IL,MO,NE,NM} is indeed the optimal cut for question 1. \n",
"\n",
"# Improving on question 2\n",
"\n",
"For question 1, good solutions necessarily have a small cut, but for question 2 we might need a big cut. I'll try going up to 10 states:"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"49 states ⇒ 1,180,878 cuts (cut size ≤ 10, cut area ≤ 1,000,000) ⇒ 266,863 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,345,558|43.122%|29|AL AR CT DE FL GA IN KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TN TX VA VT WV\n",
"B|1,344,149|43.077%|15|AZ CA IA ID MN MT ND NV OR SD UP UT WA WI WY\n",
"C| 430,653|13.801%| 5|CO IL MO NE NM\n",
"∆| 1,409| 0.045%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,161,198|37.214%|29|AL CT DE FL GA IA IL IN LP MA MD ME MN NC ND NH NJ NY OH PA RI SC SD TN UP VA VT WI WV\n",
"B|1,161,195|37.213%|10|AZ CA CO KS LA NM OR TX UT WA\n",
"C| 797,967|25.573%|10|AR ID KY MO MS MT NE NV OK WY\n",
"∆| 3| 0.000%|\n",
"CPU times: user 1min 3s, sys: 1.05 s, total: 1min 4s\n",
"Wall time: 1min 4s\n"
]
}
],
"source": [
"%time answers(usa49, maxsize=10, maxarea=1_000_000)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This gives us two regions that differ by only 3 square miles, which seems pretty good!\n",
"\n",
"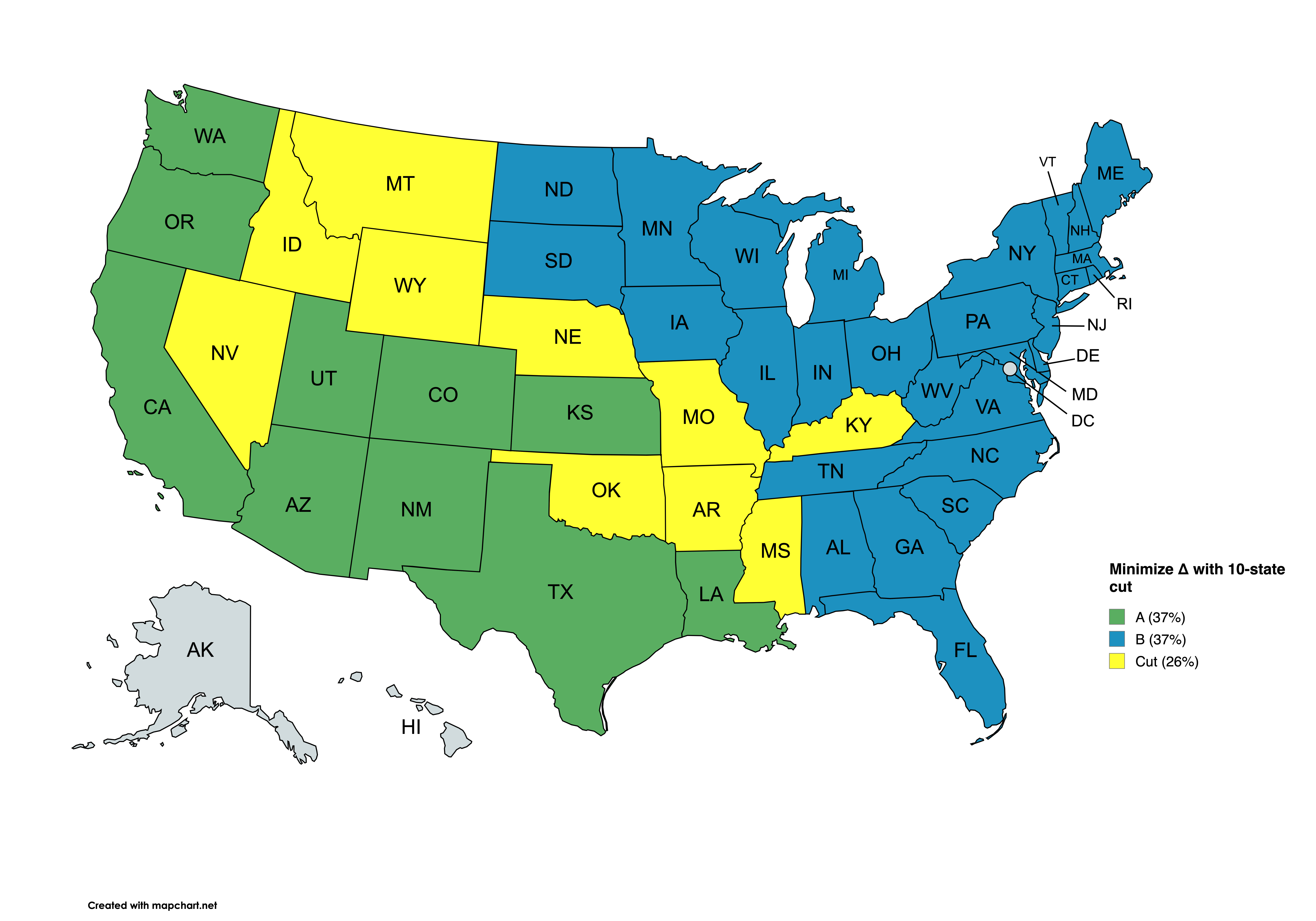\n",
"\n",
"Could we can find two regions with exactly equal areas? It would be inefficient to enumerate all cuts for much more than 10 states. Instead I'll create two lists of regions *As* and *Bs*. I can then determine if there are two regions of equal size in time proportional to the sum of their lengths (not the product) by creating a table of {area: region} entries for all the *As* and checking if any of the *Bs* have an area that is in the table. (We also need to check that the two regions are disjoint. They are likely to be so because I start one in the east and one in the west, but we still need to check.) Here are two lists of regions:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [],
"source": [
"make_regions = make_cuts # The function `make_cuts` can be used to make regions\n",
"\n",
"As = list(make_regions(usa49, 5, start=west, end=usa49))\n",
"Bs = list(make_regions(usa49, 7, start=east, end=usa49))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"How many regions are in each list?"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'There are 376 regions in As and 22971 regions in Bs and 8,637,096 pairs of regions'"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"a, b = len(As), len(Bs)\n",
"f'There are {a} regions in As and {b} regions in Bs and {a * b:,d} pairs of regions'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If the average region area is about a million square miles, there's a pretty good chance that one of the 8 million pairs will consist of an *A* and a *B* with exactly equal areas. It's like buying 8 million lottery tickets with random 6-digit numbers. Let's check:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [],
"source": [
"def find_equal(As: List[Region], Bs: List[Region]) -> Iterator[Tuple[Region, Region, int]]:\n",
" \"\"\"From As and Bs, find disjoint regions A and B that have the exact same area. Yield (A, B, area(B)).\"\"\"\n",
" area_table = {area(A): A for A in As}\n",
" for B in Bs:\n",
" if area(B) in area_table:\n",
" A = area_table[area(B)]\n",
" if A.isdisjoint(neighborhood(B)):\n",
" yield (A, B, area(B))\n",
"\n",
"def neighborhood(A: Region) -> Region:\n",
" \"\"\"The region consisting of A and all the neighbors of any state in A.\"\"\"\n",
" return A | {s1 for s in A for s1 in neighbors[s]}"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"[(frozenset({'CA', 'NV', 'UT'}),\n",
" frozenset({'GA', 'IA', 'KY', 'MO', 'MS', 'TN', 'VA'}),\n",
" 359164),\n",
" (frozenset({'ID', 'NV', 'WA'}),\n",
" frozenset({'KY', 'MS', 'NY', 'PA', 'TN', 'VT', 'WV'}),\n",
" 265439),\n",
" (frozenset({'ID', 'OR', 'UT', 'WY'}),\n",
" frozenset({'GA', 'IA', 'IL', 'IN', 'MO', 'TN', 'VA'}),\n",
" 364658),\n",
" (frozenset({'AZ', 'CA', 'OR'}),\n",
" frozenset({'IL', 'IN', 'KS', 'MO', 'OH', 'TN', 'VA'}),\n",
" 376064),\n",
" (frozenset({'ID', 'UT', 'WA', 'WY'}),\n",
" frozenset({'AL', 'IL', 'IN', 'KY', 'TN', 'VA', 'WI'}),\n",
" 337577),\n",
" (frozenset({'AZ', 'CA', 'OR'}),\n",
" frozenset({'IA', 'IL', 'KY', 'NE', 'SD', 'VA', 'WV'}),\n",
" 376064)]"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"list(find_equal(As, Bs))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are 6 solutions right away (and probably many more solutions with larger regions). I'll show the map for one of them (the smallest one, with area 265,439 square miles for both regions). Note that the cut (in yellow) is not contiguous, but that's in accord with the rules: all that matters is that *A* and *B* are contiguous and disjoint.\n",
"\n",
"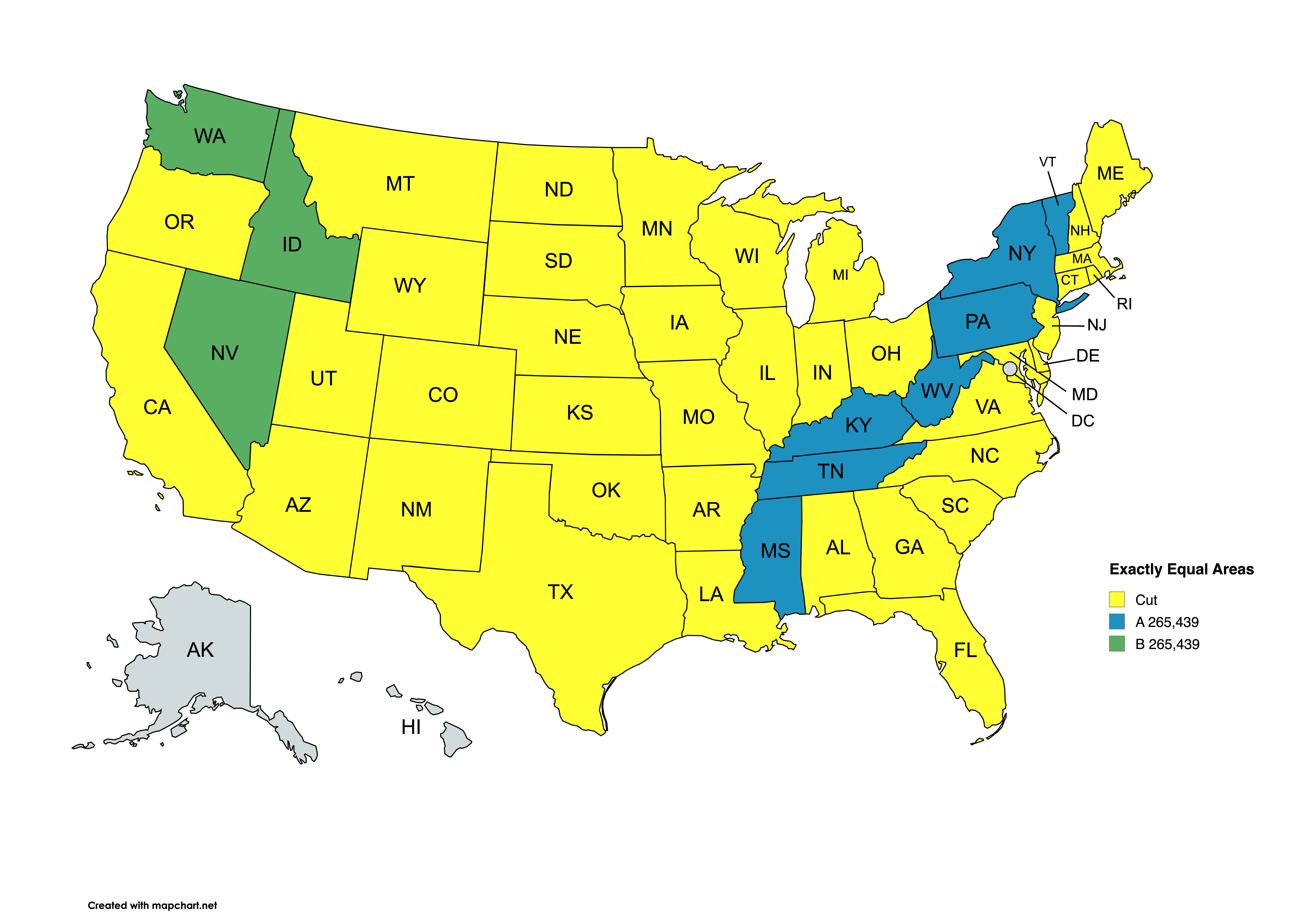"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# Enfranchising DC\n",
"\n",
"Would anything change if we made DC a state (besides, obviously, the voting rights of the citizens)?"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"50 states ⇒ 43,600 cuts (cut size ≤ 8, cut area ≤ 624,072) ⇒ 13,134 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,345,626|43.123%|30|AL AR CT DC DE FL GA IN KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TN TX VA VT WV\n",
"B|1,344,149|43.076%|15|AZ CA IA ID MN MT ND NV OR SD UP UT WA WI WY\n",
"C| 430,653|13.801%| 5|CO IL MO NE NM\n",
"∆| 1,477| 0.047%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,267,062|40.605%|28|AL AR CT DC DE FL GA KS KY LA LP MA MD ME MS NC NH NJ NY OH OK PA RI SC TX VA VT WV\n",
"B|1,267,033|40.604%|14|AZ CA IA ID MN MT ND NV OR UP UT WA WI WY\n",
"C| 586,333|18.790%| 8|CO IL IN MO NE NM SD TN\n",
"∆| 29| 0.001%|\n"
]
}
],
"source": [
"answers(usa49 | {'DC'})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We've seen these cuts before, but for question 2, adding DC's 68 square miles to the eastern region means that it is now only 29 square miles larger than the western region (previously it was 39 square miles smaller)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Reuniting Michigan\n",
"\n",
"What if Michigan counts as one state, rather than two separate penninsulas? "
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"48 states ⇒ 41,735 cuts (cut size ≤ 8, cut area ≤ 624,072) ⇒ 18,642 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,348,646|43.221%|30|AL CT DE FL GA IA IL IN KY MA MD ME MI MN MT NC ND NH NJ NY OH PA RI SC SD TN VA VT WI WV\n",
"B|1,341,666|42.997%|12|AZ CA CO KS LA NM NV OK OR TX UT WA\n",
"C| 430,048|13.782%| 6|AR ID MO MS NE WY\n",
"∆| 6,980| 0.224%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,267,816|40.630%|13|AZ CA ID KS MN MT ND NE NV OR SD UT WA\n",
"B|1,267,672|40.626%|28|AL AR CT DE FL GA IL IN KY LA MA MD ME MI MS NC NH NJ NY OH PA RI SC TN TX VA VT WV\n",
"C| 584,872|18.744%| 7|CO IA MO NM OK WI WY\n",
"∆| 144| 0.005%|\n"
]
}
],
"source": [
"answers(usa48)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The results are not as good (I think because splitting MI allows IL and IN to be north border states rather than interior states).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Cuts with smallest number of states?\n",
"\n",
"If we are restricted to four-state cuts, the {IL, MO, NM, OK} cut is best:"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"49 states ⇒ 1,237 cuts (cut size ≤ 4, cut area ≤ 624,072) ⇒ 384 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|1,607,869|51.528%|18|AZ CA CO IA ID KS MN MT ND NE NV OR SD UP UT WA WI WY\n",
"B|1,193,381|38.245%|27|AL AR CT DE FL GA IN KY LA LP MA MD ME MS NC NH NJ NY OH PA RI SC TN TX VA VT WV\n",
"C| 319,110|10.227%| 4|IL MO NM OK\n",
"∆| 414,488|13.283%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|1,607,869|51.528%|18|AZ CA CO IA ID KS MN MT ND NE NV OR SD UP UT WA WI WY\n",
"B|1,193,381|38.245%|27|AL AR CT DE FL GA IN KY LA LP MA MD ME MS NC NH NJ NY OH PA RI SC TN TX VA VT WV\n",
"C| 319,110|10.227%| 4|IL MO NM OK\n",
"∆| 414,488|13.283%|\n"
]
}
],
"source": [
"answers(usa49, 4, start=border, end=border)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"With a three-state cut there are no good answers; region *B* is at best only 14% of the area."
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"49 states ⇒ 367 cuts (cut size ≤ 3, cut area ≤ 624,072) ⇒ 89 splits.\n",
"\n",
"1. Split that maximizes area(B):\n",
"A|2,393,960|76.721%|42|AL AR CO CT DE FL GA IA IL IN KS KY LA LP MA MD ME MN MO MS MT NC ND NE NH NJ NM NY OH OK PA RI SC SD TN TX UP VA VT WI WV WY\n",
"B| 443,944|14.227%| 4|CA NV OR WA\n",
"C| 282,456| 9.052%| 3|AZ ID UT\n",
"∆|1,950,016|62.493%|\n",
"\n",
"2. Split that minimizes ∆ = area(A) - area(B):\n",
"A|2,393,960|76.721%|42|AL AR CO CT DE FL GA IA IL IN KS KY LA LP MA MD ME MN MO MS MT NC ND NE NH NJ NM NY OH OK PA RI SC SD TN TX UP VA VT WI WV WY\n",
"B| 443,944|14.227%| 4|CA NV OR WA\n",
"C| 282,456| 9.052%| 3|AZ ID UT\n",
"∆|1,950,016|62.493%|\n"
]
}
],
"source": [
"answers(usa49, 3, start=border, end=border)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Unit tests\n",
"\n",
"Here are some unit tests; they also serve as examples of input/output of the various functions:"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'ok'"
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"def test():\n",
" assert states('AZ CA OR') == frozenset({'AZ', 'CA', 'OR'})\n",
"\n",
" assert len(usa49) == 49 and len(usa50) == 50 and len(western) == 11\n",
" \n",
" assert set(areas) == set(neighbors)\n",
" assert areas['MI'] == areas['UP'] + areas['LP'] \n",
" assert area(states('AZ CA OR')) == area(states('IA IL KY NE SD VA WV')) == 376_064\n",
"\n",
" assert all((x in neighbors[y]) == (y in neighbors[x]) \n",
" for x in neighbors for y in neighbors)\n",
"\n",
" assert neighborhood(states('CO UT')) == states('NV UT KS AZ NM ID NE OK WY CO')\n",
" \n",
" assert set(make_cuts(western, 3)) == {\n",
" states('AZ ID NV'),\n",
" states('CA ID OR'),\n",
" states('CA OR WA'),\n",
" states('CA ID NV'),\n",
" states('ID NM UT'),\n",
" states('AZ ID UT')}\n",
"\n",
" assert set(make_splits(western, make_cuts(western, 3))) == {\n",
" (states('CO MT NM WY'), states('CA NV OR WA'), states('AZ ID UT')),\n",
" (states('CO MT NM UT WY'), states('CA OR WA'), states('AZ ID NV')),\n",
" (states('AZ CO MT NM UT WY'), states('OR WA'), states('CA ID NV')),\n",
" (states('AZ CO MT NM NV UT WY'), states('WA'), states('CA ID OR'))}\n",
"\n",
" assert contiguous(western - states('AZ ID NV')) == states('CA OR WA')\n",
" \n",
" for country in (usa48, usa49, border, western):\n",
" assert contiguous(country) == country\n",
"\n",
" assert contiguous(usa50) != usa50\n",
" \n",
" return 'ok'\n",
" \n",
"test()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.15"
}
},
"nbformat": 4,
"nbformat_minor": 4
}