{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Boosting with tuning"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "43d5dd4e-3630-4a49-b160-fdc784d60ec2",
"_uuid": "cef3de7d-9bc2-4da3-a6af-cad2bd153807",
"papermill": {
"duration": 0.074091,
"end_time": "2021-01-06T05:21:31.460195",
"exception": false,
"start_time": "2021-01-06T05:21:31.386104",
"status": "completed"
},
"tags": []
},
"source": [
"## Introduction\n",
"In this assginment, we will take you through the step by step approach in solving a House Pricing regression problem. This notebook aims to:\n",
"1. Provide insights on Housing Data\n",
"2. Understand importance of Preprocessing\n",
"3. Introduction to feature engineering\n",
"4. Use of ensembling algorithm \n",
"\n",
"We hope that after reading this notebook, beginners will be more comfortable in tackling any learning problems and able to use the taught techniques to solve any problems from start to end. For non-beginners, hopefully you are able to get something out of it from this assignment and gain new insights and knowledge along the way."
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "cafb9d66-00ae-4e35-a616-ffe5aa173f66",
"_uuid": "3d727265-896e-4cfc-af04-fefcc4c44f10",
"papermill": {
"duration": 0.063268,
"end_time": "2021-01-06T05:21:33.665869",
"exception": false,
"start_time": "2021-01-06T05:21:33.602601",
"status": "completed"
},
"tags": []
},
"source": [
"## Understanding data"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Task 1: Imports and load data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "fe81c591-4742-4704-828a-6af36118e906",
"_kg_hide-input": true,
"_uuid": "3d5850e4-c681-4157-a4bb-001d446a98a9",
"papermill": {
"duration": 1.725872,
"end_time": "2021-01-06T05:21:33.536473",
"exception": false,
"start_time": "2021-01-06T05:21:31.810601",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"import numpy as np # linear algebra\n",
"import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n",
"import seaborn as sns\n",
"import matplotlib.pyplot as plt\n",
"sns.set_style(\"darkgrid\")\n",
"from statsmodels.stats.outliers_influence import variance_inflation_factor\n",
"from sklearn.impute import SimpleImputer\n",
"import warnings\n",
"\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "1fccf717-7dd7-4e2f-8045-a3dd89908e7c",
"_kg_hide-input": true,
"_uuid": "cc1ae4d3-fe55-4e91-8714-836dd971542d",
"papermill": {
"duration": 0.205352,
"end_time": "2021-01-06T05:21:33.935262",
"exception": false,
"start_time": "2021-01-06T05:21:33.729910",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"train = pd.read_csv('../../../assets/data/house_price_train.csv', index_col=0)\n",
"test = pd.read_csv('../../../assets/data/house_price_test.csv', index_col=0)\n",
"\n",
"\n",
"print(\"train: \", train.shape)\n",
"print(\"test: \", test.shape)\n",
"train.head()"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "da490359-1dc7-4203-9614-31f9439aa566",
"_uuid": "8eae8563-12a3-45f7-b963-1968786d9e9c",
"papermill": {
"duration": 0.066398,
"end_time": "2021-01-06T05:21:34.066356",
"exception": false,
"start_time": "2021-01-06T05:21:33.999958",
"status": "completed"
},
"tags": []
},
"source": [
"Just taking a quick glance at the top rows of the dataframe, we can see that there are some columns that are filled with **NAN (Not a Number)**. We will investigate this later on."
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Task 2: Concatenate the train and test together"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "1a51615a-f2d5-4116-a247-030827eb8d0d",
"_uuid": "e07ab78a-380e-416c-8138-e7cbfd093c15",
"papermill": {
"duration": 0.062772,
"end_time": "2021-01-06T05:21:34.192669",
"exception": false,
"start_time": "2021-01-06T05:21:34.129897",
"status": "completed"
},
"tags": []
},
"source": [
"What we did here is first to concatenate the train and test together for extracting insights into the Housing Price data as a whole. It will also be more convenient for our preprocessing steps later on as we will only have 1 data reference"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "d70cd957-0db3-4a10-9168-d3c6e04807e6",
"_uuid": "a7895aa2-24c4-4e88-b854-ee1ebdda60e3",
"papermill": {
"duration": 0.098199,
"end_time": "2021-01-06T05:21:34.355737",
"exception": false,
"start_time": "2021-01-06T05:21:34.257538",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X = pd.concat([train.drop(\"SalePrice\", axis=1),test], axis=0)\n",
"y = train[['SalePrice']]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "39f98f11-a9f2-49c2-9436-d1270a27083d",
"_uuid": "2b91e151-631e-46cb-98d3-e6729ae00b34",
"papermill": {
"duration": 0.123665,
"end_time": "2021-01-06T05:21:34.543693",
"exception": false,
"start_time": "2021-01-06T05:21:34.420028",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X.info()"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"### Task 3: Isolate numerical and categorical columns"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "a7c68d51-b0a7-4bb3-b51b-8f4b1f655e3c",
"_uuid": "34763e92-a3bc-4d35-b1da-6bf78659e540",
"papermill": {
"duration": 0.063308,
"end_time": "2021-01-06T05:21:34.671577",
"exception": false,
"start_time": "2021-01-06T05:21:34.608269",
"status": "completed"
},
"tags": []
},
"source": [
"Lets isolate both the numerical and categorical columns since we will be applying different visualization techniques on them"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "4c37b84b-ff9c-437e-b689-c00bdc77c686",
"_uuid": "d1964d03-3ef0-440d-a705-e75cec4e8038",
"papermill": {
"duration": 0.085004,
"end_time": "2021-01-06T05:21:34.822018",
"exception": false,
"start_time": "2021-01-06T05:21:34.737014",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"numeric_ = X.select_dtypes(exclude=['object']).drop(['MSSubClass'], axis=1).copy()\n",
"numeric_.columns"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "f518fe88-f0e6-475b-b029-55bc0b1bdf77",
"_kg_hide-input": true,
"_uuid": "95781db4-5984-46fd-9501-99abb56a6b98",
"papermill": {
"duration": 0.077367,
"end_time": "2021-01-06T05:21:34.965626",
"exception": false,
"start_time": "2021-01-06T05:21:34.888259",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"disc_num_var = ['OverallQual','OverallCond','BsmtFullBath','BsmtHalfBath','FullBath','HalfBath',\n",
" 'BedroomAbvGr', 'KitchenAbvGr', 'TotRmsAbvGrd', 'Fireplaces', 'GarageCars', 'MoSold', 'YrSold']\n",
"\n",
"cont_num_var = []\n",
"for i in numeric_.columns:\n",
" if i not in disc_num_var:\n",
" cont_num_var.append(i)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "24e98ee8-8afc-4e43-8cdb-93471a0b739d",
"_uuid": "391f3bd0-7b7f-4d28-a208-516d28e2b883",
"papermill": {
"duration": 0.08181,
"end_time": "2021-01-06T05:21:35.111572",
"exception": false,
"start_time": "2021-01-06T05:21:35.029762",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"cat_train = X.select_dtypes(include=['object']).copy()\n",
"cat_train['MSSubClass'] = X['MSSubClass'] #MSSubClass is nominal\n",
"cat_train.columns"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "00b3ae3c-e84e-4356-965e-4b7df918171b",
"_uuid": "80b41c8a-fed8-4d41-a83c-186cb89f94ff",
"papermill": {
"duration": 0.064139,
"end_time": "2021-01-06T05:21:35.240161",
"exception": false,
"start_time": "2021-01-06T05:21:35.176022",
"status": "completed"
},
"tags": []
},
"source": [
"### Univariate Analysis"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"#### Task 1: Numeric features"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "bb869173-7f26-4e0d-a43b-00dce37e77fb",
"_uuid": "119eaddd-c51f-4213-8b7f-7f41dc92fad5",
"papermill": {
"duration": 0.065394,
"end_time": "2021-01-06T05:21:35.370043",
"exception": false,
"start_time": "2021-01-06T05:21:35.304649",
"status": "completed"
},
"tags": []
},
"source": [
"For numerical features, we are always concerned about the **distribution** of these features, including the **statistical characteristics** of these columns e.g mean, median, mode. Hence we will usually use **Distribution plot** to visualize their data distribution. **Boxplots** are also commonly used to unearth the statistical characteristics of each feature. More often than not, we use it to look for any outliers that we might need to filter out later on during the preprocessing step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "a0fcbd43-0e07-4c12-87ef-6b5b74549bab",
"_kg_hide-input": true,
"_uuid": "bc931168-7977-4c72-b227-b960568a99d3",
"papermill": {
"duration": 9.539932,
"end_time": "2021-01-06T05:21:44.977914",
"exception": false,
"start_time": "2021-01-06T05:21:35.437982",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(18,16))\n",
"for index,col in enumerate(cont_num_var):\n",
" plt.subplot(6,4,index+1)\n",
" sns.distplot(numeric_.loc[:,col].dropna(), kde=False)\n",
"fig.tight_layout(pad=1.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "800d1a77-93c8-49a5-947e-846eade5aad7",
"_uuid": "e1b7a8e9-c059-4e7e-9cde-e95fd8e60e2a",
"papermill": {
"duration": 0.068751,
"end_time": "2021-01-06T05:21:45.117928",
"exception": false,
"start_time": "2021-01-06T05:21:45.049177",
"status": "completed"
},
"tags": []
},
"source": [
"Some of the Variables with mostly 1 value as seen from the plots above:\n",
"1. BsmtFinSF2\n",
"2. LowQualFinSF\n",
"3. EnclosedPorch\n",
"4. 3SsnPorch\n",
"5. ScreenPorch\n",
"6. PoolArea\n",
"7. MiscVal \n",
"\n",
"All these features are highly skewed, with mostly 0s. Having alot of 0s in the distribution doesnt really add information for predicting Housing Price. Hence, we will remove them during our preprocessing step"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "1924c1bb-08ba-46d9-bf2d-1013c0b795bc",
"_kg_hide-input": true,
"_uuid": "c2ddf027-d95c-47e7-96dd-1c1622d6e2dd",
"papermill": {
"duration": 3.396018,
"end_time": "2021-01-06T05:21:48.582272",
"exception": false,
"start_time": "2021-01-06T05:21:45.186254",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(14,15))\n",
"for index,col in enumerate(cont_num_var):\n",
" plt.subplot(6,4,index+1)\n",
" sns.boxplot(y=col, data=numeric_.dropna())\n",
"fig.tight_layout(pad=1.0)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "d2bb7db6-55df-4aeb-92fb-632a872661aa",
"_kg_hide-input": true,
"_uuid": "f708d1e5-ed8d-49cf-bdac-4916ff54f95d",
"papermill": {
"duration": 2.996989,
"end_time": "2021-01-06T05:21:51.651286",
"exception": false,
"start_time": "2021-01-06T05:21:48.654297",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(20,15))\n",
"for index,col in enumerate(disc_num_var):\n",
" plt.subplot(5,3,index+1)\n",
" sns.countplot(x=col, data=numeric_.dropna())\n",
"fig.tight_layout(pad=1.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "4910c82a-cf41-4f03-98a4-9699cd075542",
"_uuid": "8c861b90-d97a-4373-b736-5b4abbbfd84c",
"papermill": {
"duration": 0.073548,
"end_time": "2021-01-06T05:21:51.799437",
"exception": false,
"start_time": "2021-01-06T05:21:51.725889",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 2: Categorical features"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the case of categorical features, we will often use countplots to visualize the count of each distinct value within each features. We can see that some categorical features like **Utilities, Condition2** consist of mainly just one value, which does not add any useful information. Thus, we will also remove them later on."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "a36ccbe6-f20d-4d94-840d-464bc734f272",
"_kg_hide-input": true,
"_uuid": "3502025c-95f1-4f4b-9998-81962c985aa2",
"papermill": {
"duration": 9.919139,
"end_time": "2021-01-06T05:22:01.793336",
"exception": false,
"start_time": "2021-01-06T05:21:51.874197",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(18,20))\n",
"for index in range(len(cat_train.columns)):\n",
" plt.subplot(9,5,index+1)\n",
" sns.countplot(x=cat_train.iloc[:,index], data=cat_train.dropna())\n",
" plt.xticks(rotation=90)\n",
"fig.tight_layout(pad=1.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.080466,
"end_time": "2021-01-06T05:22:01.954987",
"exception": false,
"start_time": "2021-01-06T05:22:01.874521",
"status": "completed"
},
"tags": []
},
"source": [
"Univariate Analysis helps us to understand all the features better, on an individual scale. To further deepen our insights and uncover potential pattern in the data, we will also need to find out more about the relationship between all these features with one another, which brings us to our next step in our analysis - Bivariate Analysis"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "b4ec3cce-db88-4b45-b90b-739e2d080fec",
"_uuid": "7a797c96-14fe-4129-b439-608c64f3d50d",
"papermill": {
"duration": 0.078971,
"end_time": "2021-01-06T05:22:02.117746",
"exception": false,
"start_time": "2021-01-06T05:22:02.038775",
"status": "completed"
},
"tags": []
},
"source": [
"### Bi-Variate Analysis"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "e1314939-998c-45fa-a3cc-2c6e431b21fa",
"_uuid": "0486dd69-b4be-4b08-8f2a-69e31b161abd",
"papermill": {
"duration": 0.079561,
"end_time": "2021-01-06T05:22:02.276756",
"exception": false,
"start_time": "2021-01-06T05:22:02.197195",
"status": "completed"
},
"tags": []
},
"source": [
"Bi-variate analysis looks at 2 different features to identify any possible relationship or distinctive patterns between the 2 features. One of the commonly used technique is through the **Correlation Matrix**. Correlation matrix is an effective tool to uncover linear relationship (Correlation) between any 2 continuous features. Correlation not only allow us to determine which features are important to Saleprice, but also as a mean to investigate any **multicollinearity** between our independent predictors. \n",
"Multicollinearity happens when 2 or more independent variables are highly correlated with one another. In such situation, it causes precision loss in our regression coefficients, affecting our ability to identify the most important features that are most useful to our model"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "27bfaa45-9a48-4458-a540-537807882a46",
"_uuid": "88f8472d-6403-4e84-9037-64d0f40fb287",
"papermill": {
"duration": 0.079913,
"end_time": "2021-01-06T05:22:02.437895",
"exception": false,
"start_time": "2021-01-06T05:22:02.357982",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 1: Correlation matrix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "47bc053b-3520-4732-aeb1-ed58f387a0bd",
"_kg_hide-input": true,
"_uuid": "65983c88-9910-4aa1-941b-3f16b9fb5e65",
"papermill": {
"duration": 1.22348,
"end_time": "2021-01-06T05:22:03.746788",
"exception": false,
"start_time": "2021-01-06T05:22:02.523308",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"plt.figure(figsize=(14,12))\n",
"correlation = numeric_.corr()\n",
"sns.heatmap(correlation, mask = correlation <0.8, linewidth=0.5, cmap='Blues')"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "78e0269b-2273-43e8-b104-fc6825988d07",
"_uuid": "46b1a9ef-9b17-4cdd-a820-a2b8bd348dee",
"papermill": {
"duration": 0.083266,
"end_time": "2021-01-06T05:22:03.916891",
"exception": false,
"start_time": "2021-01-06T05:22:03.833625",
"status": "completed"
},
"tags": []
},
"source": [
" **Highly Correlated variables**:\n",
"* GarageYrBlt and YearBuilt\n",
"* TotRmsAbvGrd and GrLivArea\n",
"* 1stFlrSF and TotalBsmtSF\n",
"* GarageArea and GarageCars\n",
"\n",
"From the correlation matrix we have identified the above variables which are highly correlated with each other. This finding will guide us in our preprocessing steps later on as we aim to remove highly correlated features to avoid performance loss in our model"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"#### Task 2: Identifying relationship between Numerical Predictor and Target (*SalePrice*)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "fd1f3471-d789-4cdf-91c5-a00c26a20614",
"_uuid": "147d8fc4-6506-4cb6-937a-81b50ac8674f",
"papermill": {
"duration": 0.092267,
"end_time": "2021-01-06T05:22:04.100892",
"exception": false,
"start_time": "2021-01-06T05:22:04.008625",
"status": "completed"
},
"tags": []
},
"source": [
"Below, we sorted the strength of linear relationship between Saleprice and other features. OverallQual and GrLivArea has the strongest linear relationship with SalePrice. Hence, these 2 features will be important factor in predicting Housing Price"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "3a15b11a-c9e1-455c-8dad-1aa8dc5387ad",
"_kg_hide-input": true,
"_uuid": "4a93a2ba-cff5-4e25-8847-337537e5d247",
"papermill": {
"duration": 0.110694,
"end_time": "2021-01-06T05:22:04.295116",
"exception": false,
"start_time": "2021-01-06T05:22:04.184422",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"numeric_train = train.select_dtypes(exclude=['object'])\n",
"correlation = numeric_train.corr()\n",
"correlation[['SalePrice']].sort_values(['SalePrice'], ascending=False)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "357f965e-9975-4378-93b6-3b1c2271e692",
"_uuid": "2a9f64cd-e751-444a-a826-eeb1975b2bcd",
"papermill": {
"duration": 0.084304,
"end_time": "2021-01-06T05:22:04.465333",
"exception": false,
"start_time": "2021-01-06T05:22:04.381029",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 3: Scatterplot"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Using scatterplot can also help us to identify potential linear relationship between Numerical features. Although scatterplot does not provide quantitative evidence on the strength of linear relationship between our features, it is useful in helping us to visualize any sort of relationship that correlation matrix could not calculate. E.g Quadratic, Exponential relationships. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "8da9a412-f65d-4c03-8fa0-582c3942026a",
"_kg_hide-input": true,
"_uuid": "aa188e82-a5bf-4cd1-836b-7b50c8040607",
"papermill": {
"duration": 13.323926,
"end_time": "2021-01-06T05:22:17.873028",
"exception": false,
"start_time": "2021-01-06T05:22:04.549102",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig = plt.figure(figsize=(20,20))\n",
"for index in range(len(numeric_train.columns)):\n",
" plt.subplot(10,5,index+1)\n",
" sns.scatterplot(x=numeric_train.iloc[:,index], y='SalePrice', data=numeric_train.dropna())\n",
"fig.tight_layout(pad=1.0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "35b98252-3904-4cbc-8586-d28b16b5e972",
"_uuid": "9f0321fe-5f08-4ac1-a8e4-7e124cdef629",
"papermill": {
"duration": 0.095526,
"end_time": "2021-01-06T05:22:18.066209",
"exception": false,
"start_time": "2021-01-06T05:22:17.970683",
"status": "completed"
},
"tags": []
},
"source": [
"## Data Processing"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that we have more or less finished analysing our data and gaining insights through the various analysis and visualization, we will have to leverage on these insights to guide our preprocessing decision, so as to provide a clean and error-free data for our model to train on later on. "
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.093759,
"end_time": "2021-01-06T05:22:18.255572",
"exception": false,
"start_time": "2021-01-06T05:22:18.161813",
"status": "completed"
},
"tags": []
},
"source": [
"We do not perform visualization and analysis just to create pretty graphs or for the sake of doing it, IT IS VITAL TO OUR PREPROCESSING!"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "974f4b02-a405-4aa8-9137-7c6d9e69507f",
"_uuid": "2d427ae8-3927-4184-909d-929d106fbc48",
"papermill": {
"duration": 0.094821,
"end_time": "2021-01-06T05:22:18.444310",
"exception": false,
"start_time": "2021-01-06T05:22:18.349489",
"status": "completed"
},
"tags": []
},
"source": [
"This section outlines the steps for Data Processing:\n",
"1. Removing Redundant Features\n",
"2. Dealing with Outliers\n",
"3. Filling in missing values"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "9ee2062c-f14f-4691-a935-23039323bf10",
"_uuid": "4669fa6f-aeb7-46b7-8d47-e62e8fbb9536",
"papermill": {
"duration": 0.092996,
"end_time": "2021-01-06T05:22:18.630356",
"exception": false,
"start_time": "2021-01-06T05:22:18.537360",
"status": "completed"
},
"tags": []
},
"source": [
"### Removing redundant features"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "d01cd1a1-246b-47c1-b546-0c23514a1a49",
"_uuid": "07f3cf69-9d89-4e0c-8259-0f46c4fc28d2",
"papermill": {
"duration": 0.096547,
"end_time": "2021-01-06T05:22:18.823242",
"exception": false,
"start_time": "2021-01-06T05:22:18.726695",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 1:Features with multicollinearity"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "f56b3de0-28cb-418d-92ac-3324552e6344",
"_uuid": "c6b6cd30-d33b-4fc7-904b-e24094747e74",
"papermill": {
"duration": 0.096701,
"end_time": "2021-01-06T05:22:19.016013",
"exception": false,
"start_time": "2021-01-06T05:22:18.919312",
"status": "completed"
},
"tags": []
},
"source": [
"From the above correlation matrix, we have pinpointed certain features that are highly correlated\n",
"* GarageYrBlt and YearBuilt\n",
"* TotRmsAbvGrd and GrLivArea\n",
"* 1stFlrSF and TotalBsmtSF\n",
"* GarageArea and GarageCars"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.092763,
"end_time": "2021-01-06T05:22:19.205547",
"exception": false,
"start_time": "2021-01-06T05:22:19.112784",
"status": "completed"
},
"tags": []
},
"source": [
"We will remove the highly correlated features to avoid the problem of multicollinearity explained earlier"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "9b23f9ad-3fa9-4d65-a8dd-2574a2f588e1",
"_uuid": "ff1a2462-4003-4f6c-9b37-0a7ea0ac7f3d",
"papermill": {
"duration": 0.107353,
"end_time": "2021-01-06T05:22:19.408582",
"exception": false,
"start_time": "2021-01-06T05:22:19.301229",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X.drop(['GarageYrBlt','TotRmsAbvGrd','1stFlrSF','GarageCars'], axis=1, inplace=True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "288a510e-aa44-44ba-b939-0ecce104bbd3",
"_uuid": "13e08b5b-19d2-4bf8-8939-138c28dacce7",
"papermill": {
"duration": 0.093631,
"end_time": "2021-01-06T05:22:19.596194",
"exception": false,
"start_time": "2021-01-06T05:22:19.502563",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 2: Features with a lot of missing values"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Apart from these highly correlated features, we will also remove features that is not very useful in prediction due to many missing values. PoolQC, MiscFeature, Alley has too many missing values to provide any useful information"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "2a8adc27-b8f1-4f5c-b40a-1a1a03c33ebf",
"_kg_hide-input": true,
"_uuid": "bee523e9-b1c0-4a7e-ac20-4faa9b68cd2a",
"papermill": {
"duration": 0.629653,
"end_time": "2021-01-06T05:22:20.322716",
"exception": false,
"start_time": "2021-01-06T05:22:19.693063",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"plt.figure(figsize=(25,8))\n",
"plt.title('Number of missing rows')\n",
"missing_count = pd.DataFrame(X.isnull().sum(), columns=['sum']).sort_values(by=['sum'],ascending=False).head(20).reset_index()\n",
"missing_count.columns = ['features','sum']\n",
"sns.barplot(x='features',y='sum', data = missing_count)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "846025ee-7aa2-4c86-b1e8-24b995fad758",
"_uuid": "d25843cc-b92a-4efa-a477-626fe0153b1e",
"papermill": {
"duration": 0.108385,
"end_time": "2021-01-06T05:22:20.527295",
"exception": false,
"start_time": "2021-01-06T05:22:20.418910",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X.drop(['PoolQC','MiscFeature','Alley'], axis=1, inplace=True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "7d4c08ec-0fdb-4fa9-9514-9660c5df5fb2",
"_uuid": "5542af1e-01ee-47a7-9d5b-ef520256646e",
"papermill": {
"duration": 0.094122,
"end_time": "2021-01-06T05:22:20.715860",
"exception": false,
"start_time": "2021-01-06T05:22:20.621738",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 3: Useless features in predicting SalePrice"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will also remove features that does not have any linear relationship with target *SalePrice*. We can see from the plot below that the MoSold and YrSold does not have any impact on the price of the house sold."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "b25d035e-3732-4bcf-8723-41fd4268d2f9",
"_kg_hide-input": true,
"_uuid": "f10529ae-b975-416c-83e6-5ccf8c79896e",
"papermill": {
"duration": 1.445555,
"end_time": "2021-01-06T05:22:22.257798",
"exception": false,
"start_time": "2021-01-06T05:22:20.812243",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"fig,axes = plt.subplots(1,2, figsize=(15,5))\n",
"sns.regplot(x=numeric_train['MoSold'], y='SalePrice', data=numeric_train, ax = axes[0], line_kws={'color':'black'})\n",
"sns.regplot(x=numeric_train['YrSold'], y='SalePrice', data=numeric_train, ax = axes[1],line_kws={'color':'black'})\n",
"fig.tight_layout(pad=2.0)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "aff82a3c-2822-4271-ab31-dc3a0565c9b0",
"_uuid": "4aad385d-6b15-424c-a86d-656231969e21",
"papermill": {
"duration": 0.111975,
"end_time": "2021-01-06T05:22:22.470473",
"exception": false,
"start_time": "2021-01-06T05:22:22.358498",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"correlation[['SalePrice']].sort_values(['SalePrice'], ascending=False).tail(10)\n",
"\n",
"X.drop(['MoSold','YrSold'], axis=1, inplace=True)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "045a0c6d-1ffe-4a94-88ce-b2e128ca6fae",
"_uuid": "9006ed68-747d-4f5e-a88b-1704565891d7",
"papermill": {
"duration": 0.096788,
"end_time": "2021-01-06T05:22:22.664240",
"exception": false,
"start_time": "2021-01-06T05:22:22.567452",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 4: Removing features that have mostly just 1 value"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Earlier during our Univariate analysis, we found that some features mostly consist of just a single value or 0s, which is not useful to us. Therefore, we set a user defined threshold at 96%. If a column has more than 96% of the same value, we will render the features to be useless and remove it, since there isnt much information we can extract from"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "62569f20-b951-4dc8-aedc-2f756e9c7fe6",
"_uuid": "3ab556a5-88d1-4b9f-ad45-67c774f5863c",
"papermill": {
"duration": 0.188342,
"end_time": "2021-01-06T05:22:22.950107",
"exception": false,
"start_time": "2021-01-06T05:22:22.761765",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"cat_col = X.select_dtypes(include=['object']).columns\n",
"overfit_cat = []\n",
"for i in cat_col:\n",
" counts = X[i].value_counts()\n",
" zeros = counts.iloc[0]\n",
" if zeros / len(X) * 100 > 96:\n",
" overfit_cat.append(i)\n",
"\n",
"overfit_cat = list(overfit_cat)\n",
"X = X.drop(overfit_cat, axis=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "c5593fd6-d3d0-4780-8443-aa7d221d417c",
"_uuid": "b2269563-d96a-4f2a-8d73-9f640c040b81",
"papermill": {
"duration": 0.148596,
"end_time": "2021-01-06T05:22:23.197123",
"exception": false,
"start_time": "2021-01-06T05:22:23.048527",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"num_col = X.select_dtypes(exclude=['object']).drop(['MSSubClass'], axis=1).columns\n",
"overfit_num = []\n",
"for i in num_col:\n",
" counts = X[i].value_counts()\n",
" zeros = counts.iloc[0]\n",
" if zeros / len(X) * 100 > 96:\n",
" overfit_num.append(i)\n",
"\n",
"overfit_num = list(overfit_num)\n",
"X = X.drop(overfit_num, axis=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "0914e54b-6b97-44e8-9e03-2b79c8b8b4b5",
"_uuid": "b71f93c2-fa80-46a1-9c38-8e4b2acdd690",
"papermill": {
"duration": 0.113217,
"end_time": "2021-01-06T05:22:23.412416",
"exception": false,
"start_time": "2021-01-06T05:22:23.299199",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"print(\"Categorical Features with >96% of the same value: \",overfit_cat)\n",
"print(\"Numerical Features with >96% of the same value: \",overfit_num)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "1cb0d2d8-ed3a-4b98-9c00-a53fe8058487",
"_uuid": "191fff19-bbe4-4252-9c84-6fc61c783e65",
"papermill": {
"duration": 0.099749,
"end_time": "2021-01-06T05:22:23.609683",
"exception": false,
"start_time": "2021-01-06T05:22:23.509934",
"status": "completed"
},
"tags": []
},
"source": [
"### Dealing with outliers"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "ddf0ebed-9ded-47b9-8e1d-23494474200c",
"_uuid": "91aa5ebd-c093-488d-9bc4-533b1adedacf",
"papermill": {
"duration": 0.096765,
"end_time": "2021-01-06T05:22:23.803215",
"exception": false,
"start_time": "2021-01-06T05:22:23.706450",
"status": "completed"
},
"tags": []
},
"source": [
"Removing outliers will prevent our models performance from being affected by extreme values. \n",
"From our boxplot earlier, we have pinpointed the following features with extreme outliers:\n",
"* LotFrontage\n",
"* LotArea\n",
"* BsmtFinSF1\n",
"* TotalBsmtSF\n",
"* GrLivArea\n",
"\n",
"We will remove the outliers based on certain threshold value."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "81e847b0-9e13-4a2d-99ab-bde67f8dc1ac",
"_kg_hide-input": true,
"_uuid": "daeaacc0-332c-401c-ba23-1acfcf4088bf",
"papermill": {
"duration": 0.857197,
"end_time": "2021-01-06T05:22:24.757064",
"exception": false,
"start_time": "2021-01-06T05:22:23.899867",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"out_col = ['LotFrontage','LotArea','BsmtFinSF1','TotalBsmtSF','GrLivArea']\n",
"fig = plt.figure(figsize=(20,5))\n",
"for index,col in enumerate(out_col):\n",
" plt.subplot(1,5,index+1)\n",
" sns.boxplot(y=col, data=X)\n",
"fig.tight_layout(pad=1.5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "c16e2bcb-2105-48aa-8cf6-2e258c836a3e",
"_uuid": "409bd9bc-2107-4294-9d02-7f35516fa118",
"papermill": {
"duration": 0.126578,
"end_time": "2021-01-06T05:22:24.986820",
"exception": false,
"start_time": "2021-01-06T05:22:24.860242",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"train = train.drop(train[train['LotFrontage'] > 200].index)\n",
"train = train.drop(train[train['LotArea'] > 100000].index)\n",
"train = train.drop(train[train['BsmtFinSF1'] > 4000].index)\n",
"train = train.drop(train[train['TotalBsmtSF'] > 5000].index)\n",
"train = train.drop(train[train['GrLivArea'] > 4000].index)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "2bbd6dc9-113f-4788-86bc-bb9eff247e67",
"_uuid": "6a3fe401-41e7-4bf5-afdc-f779ac68be9f",
"papermill": {
"duration": 0.11337,
"end_time": "2021-01-06T05:22:25.202196",
"exception": false,
"start_time": "2021-01-06T05:22:25.088826",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X.shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "6de6641c-b762-4388-a28f-b2508e2c741f",
"_uuid": "0f404215-8755-4dab-ab89-c47b0323cec9",
"papermill": {
"duration": 0.099642,
"end_time": "2021-01-06T05:22:25.400554",
"exception": false,
"start_time": "2021-01-06T05:22:25.300912",
"status": "completed"
},
"tags": []
},
"source": [
"### Filling Missing Values"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Our machine learning model is unable to deal with missing values, thus we need to deal with them based on our understanding of the features. These missing values are denoted **NAN** as we have seen earlier during our data exploration."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "7ce5eb3b-235d-42bb-a919-a1148afeda6b",
"_uuid": "2c1479c7-bb71-46ba-94fa-9c9f0274d78d",
"papermill": {
"duration": 0.127339,
"end_time": "2021-01-06T05:22:25.627109",
"exception": false,
"start_time": "2021-01-06T05:22:25.499770",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"pd.DataFrame(X.isnull().sum(), columns=['sum']).sort_values(by=['sum'],ascending=False).head(15)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "540068a8-9811-4528-bc22-a16c72a0cb2f",
"_uuid": "fd6fdce5-ed1b-4579-ab70-ad9cfa2bec96",
"papermill": {
"duration": 0.102159,
"end_time": "2021-01-06T05:22:25.829522",
"exception": false,
"start_time": "2021-01-06T05:22:25.727363",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 1: Ordinal features "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will replace the ordinal missing values with NA, which will be mapped later on when we encode them into an ordered arrangement"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "b9453f9a-4ef4-4f9d-ab46-7ea5955b9c9d",
"_uuid": "8da77588-1265-45ab-b382-851c3b2f223d",
"papermill": {
"duration": 0.126161,
"end_time": "2021-01-06T05:22:26.057057",
"exception": false,
"start_time": "2021-01-06T05:22:25.930896",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"cat = ['GarageType','GarageFinish','BsmtFinType2','BsmtExposure','BsmtFinType1', \n",
" 'GarageCond','GarageQual','BsmtCond','BsmtQual','FireplaceQu','Fence',\"KitchenQual\",\n",
" \"HeatingQC\",'ExterQual','ExterCond']\n",
"\n",
"X[cat] = X[cat].fillna(\"NA\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.098549,
"end_time": "2021-01-06T05:22:26.259490",
"exception": false,
"start_time": "2021-01-06T05:22:26.160941",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 2: Categorical features\n",
"We will replace the missing value of our categorical features with the most frequent occurrence (mode) of the individual features."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.289433,
"end_time": "2021-01-06T05:22:26.647586",
"exception": false,
"start_time": "2021-01-06T05:22:26.358153",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"#categorical\n",
"cols = [\"MasVnrType\", \"MSZoning\", \"Exterior1st\", \"Exterior2nd\", \"SaleType\", \"Electrical\", \"Functional\"]\n",
"X[cols] = X.groupby(\"Neighborhood\")[cols].transform(lambda x: x.fillna(x.mode()[0]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "01dba69c-6948-467b-9325-30827d716cc6",
"_uuid": "5dce044c-ca0c-437b-9f21-12eca6b244f5",
"papermill": {
"duration": 0.125358,
"end_time": "2021-01-06T05:22:26.874873",
"exception": false,
"start_time": "2021-01-06T05:22:26.749515",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 3: Numerical features"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For **Numerical Features**, the common approach will be to replace the missing value with the mean of the feature distribution. \n",
"However, certain features like *LotFrontage* and *GarageArea* have wide variance in their distribution. Taking mean values across *Neighborhoods*, we will see that the mean varies alot from just taking the mean value of these individual column, since each neightborhood have different LotFrontage and GarageArea mean value. Hence, i decided to group these features by Neighborhoods to impute the respective mean values."
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.099498,
"end_time": "2021-01-06T05:22:27.080590",
"exception": false,
"start_time": "2021-01-06T05:22:26.981092",
"status": "completed"
},
"tags": []
},
"source": [
"**Note**: My initial approach was based on the means of both train and test set. This exposed us to the issue of data leakage, where information from the test set is used to compute mean values. The right way to do it will be to impute solely based on the mean of the train data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.111346,
"end_time": "2021-01-06T05:22:27.299970",
"exception": false,
"start_time": "2021-01-06T05:22:27.188624",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"print(\"Mean of LotFrontage: \", X['LotFrontage'].mean())\n",
"print(\"Mean of GarageArea: \", X['GarageArea'].mean())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_kg_hide-input": true,
"papermill": {
"duration": 1.092719,
"end_time": "2021-01-06T05:22:28.492254",
"exception": false,
"start_time": "2021-01-06T05:22:27.399535",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"neigh_lot = X.groupby('Neighborhood')['LotFrontage'].mean().reset_index(name='LotFrontage_mean')\n",
"neigh_garage = X.groupby('Neighborhood')['GarageArea'].mean().reset_index(name='GarageArea_mean')\n",
"\n",
"fig, axes = plt.subplots(1,2,figsize=(22,8))\n",
"axes[0].tick_params(axis='x', rotation=90)\n",
"sns.barplot(x='Neighborhood', y='LotFrontage_mean', data=neigh_lot, ax=axes[0])\n",
"axes[1].tick_params(axis='x', rotation=90)\n",
"sns.barplot(x='Neighborhood', y='GarageArea_mean', data=neigh_garage, ax=axes[1])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "eadd7271-a374-4441-bf60-621b54afff1f",
"_uuid": "c4bfeb02-485a-4d97-9eb1-9d1abf9f561b",
"papermill": {
"duration": 0.169463,
"end_time": "2021-01-06T05:22:28.765002",
"exception": false,
"start_time": "2021-01-06T05:22:28.595539",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"#for correlated relationship\n",
"X['LotFrontage'] = X.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.mean()))\n",
"X['GarageArea'] = X.groupby('Neighborhood')['GarageArea'].transform(lambda x: x.fillna(x.mean()))\n",
"X['MSZoning'] = X.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))\n",
"\n",
"#numerical\n",
"cont = [\"BsmtHalfBath\", \"BsmtFullBath\", \"BsmtFinSF1\", \"BsmtFinSF2\", \"BsmtUnfSF\", \"TotalBsmtSF\", \"MasVnrArea\"]\n",
"X[cont] = X[cont] = X[cont].fillna(X[cont].mean())"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "da693dc6-a77e-4510-a135-5a3aeebf3f42",
"_uuid": "5df006e3-9186-4788-82b8-2c200962bcfb",
"papermill": {
"duration": 0.102032,
"end_time": "2021-01-06T05:22:28.969592",
"exception": false,
"start_time": "2021-01-06T05:22:28.867560",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 4: Changing Data Type\n",
"Since **MSSubClass** is an integer column based on some mapped values in string notation, we change its data type to string value instead"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "08d77967-aa22-4d20-820a-16bf23f600b2",
"_uuid": "c2e81782-e4ea-4791-867b-7b2be5740b9f",
"papermill": {
"duration": 0.113965,
"end_time": "2021-01-06T05:22:29.186534",
"exception": false,
"start_time": "2021-01-06T05:22:29.072569",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X['MSSubClass'] = X['MSSubClass'].apply(str)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "17ed5770-f76b-4743-8dd2-80ab4b61c125",
"_uuid": "d148af81-3d63-4566-a375-0af322e9b067",
"papermill": {
"duration": 0.101968,
"end_time": "2021-01-06T05:22:29.390622",
"exception": false,
"start_time": "2021-01-06T05:22:29.288654",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 5: Mapping ordinal features"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"There are some columns which are ordinal by nature, which represents the quality or condition of certain housing features. In this case, we will map the respective strings to a value. The better the quality, the higher the value"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "bec8411b-b2ce-48e3-a264-cddebd423ff9",
"_uuid": "66bcc949-9bac-4a77-a58f-bef47eb89a07",
"papermill": {
"duration": 0.116753,
"end_time": "2021-01-06T05:22:29.611871",
"exception": false,
"start_time": "2021-01-06T05:22:29.495118",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"ordinal_map = {'Ex': 5,'Gd': 4, 'TA': 3, 'Fa': 2, 'Po': 1, 'NA':0}\n",
"fintype_map = {'GLQ': 6,'ALQ': 5,'BLQ': 4,'Rec': 3,'LwQ': 2,'Unf': 1, 'NA': 0}\n",
"expose_map = {'Gd': 4, 'Av': 3, 'Mn': 2, 'No': 1, 'NA': 0}\n",
"fence_map = {'GdPrv': 4,'MnPrv': 3,'GdWo': 2, 'MnWw': 1,'NA': 0}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "2602f721-a995-4cae-9309-dcd5c473ab1d",
"_uuid": "83c1b3f8-bb2f-4998-a732-cd7580d56ce6",
"papermill": {
"duration": 0.14804,
"end_time": "2021-01-06T05:22:29.863181",
"exception": false,
"start_time": "2021-01-06T05:22:29.715141",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"ord_col = ['ExterQual','ExterCond','BsmtQual', 'BsmtCond','HeatingQC','KitchenQual','GarageQual','GarageCond', 'FireplaceQu']\n",
"for col in ord_col:\n",
" X[col] = X[col].map(ordinal_map)\n",
" \n",
"fin_col = ['BsmtFinType1','BsmtFinType2']\n",
"for col in fin_col:\n",
" X[col] = X[col].map(fintype_map)\n",
"\n",
"X['BsmtExposure'] = X['BsmtExposure'].map(expose_map)\n",
"X['Fence'] = X['Fence'].map(fence_map)"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.105229,
"end_time": "2021-01-06T05:22:30.075594",
"exception": false,
"start_time": "2021-01-06T05:22:29.970365",
"status": "completed"
},
"tags": []
},
"source": [
"After removing the outliers, highly correlated features and imputing missing values, we can now proceed with adding additional information for our model to train on. This is done by the means of - Feature Engineering."
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "e570e4b3-2521-4a6c-b894-db21d65ff302",
"_uuid": "03942f49-d3fa-4a3a-8fd9-d4da1b5fff40",
"papermill": {
"duration": 0.105726,
"end_time": "2021-01-06T05:22:30.282564",
"exception": false,
"start_time": "2021-01-06T05:22:30.176838",
"status": "completed"
},
"tags": []
},
"source": [
"## Feature engineering"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Feature Engineering is a technique by which we create new features that could potentially aid in predicting our target variable, which in this case, is *SalePrice*. In this notebook, we will create additional features based on our **Domain Knowledge** of the housing features"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "e2a49c5f-8a48-4222-a988-28ea7da26aec",
"_uuid": "e3e53d60-daef-44e5-b098-80ea0324dca6",
"papermill": {
"duration": 0.101996,
"end_time": "2021-01-06T05:22:30.489410",
"exception": false,
"start_time": "2021-01-06T05:22:30.387414",
"status": "completed"
},
"tags": []
},
"source": [
"Based on the current feature we have, the first additional featuire we can add would be **TotalLot**, which sums up both the *LotFrontage* and *LotArea* to identify the total area of land available as lot. We can also calculate the total number of surface area of the house, **TotalSF** by adding the area from basement and 2nd floor. **TotalBath** can also be used to tell us in total how many bathrooms are there in the house. We can also add all the different types of porches around the house and generalise into a total porch area, **TotalPorch**. \n",
"* TotalLot = LotFrontage + LotArea\n",
"* TotalSF = TotalBsmtSF + 2ndFlrSF\n",
"* TotalBath = FullBath + HalfBath\n",
"* TotalPorch = OpenPorchSF + EnclosedPorch + ScreenPorch \n",
"* TotalBsmtFin = BsmtFinSF1 + BsmtFinSF2"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "8d14e8aa-8cc0-4054-af93-83bb5ab93f57",
"_uuid": "537a5bdb-ceed-47fa-8489-d0f74b00b523",
"papermill": {
"duration": 0.12165,
"end_time": "2021-01-06T05:22:30.713965",
"exception": false,
"start_time": "2021-01-06T05:22:30.592315",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X['TotalLot'] = X['LotFrontage'] + X['LotArea']\n",
"X['TotalBsmtFin'] = X['BsmtFinSF1'] + X['BsmtFinSF2']\n",
"X['TotalSF'] = X['TotalBsmtSF'] + X['2ndFlrSF']\n",
"X['TotalBath'] = X['FullBath'] + X['HalfBath']\n",
"X['TotalPorch'] = X['OpenPorchSF'] + X['EnclosedPorch'] + X['ScreenPorch']"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "9b21223f-3fde-4f47-ae1d-bd3221cd5f11",
"_uuid": "5ddbc3b3-dbd8-4b10-b1db-ef4670694ea6",
"papermill": {
"duration": 0.102175,
"end_time": "2021-01-06T05:22:30.919040",
"exception": false,
"start_time": "2021-01-06T05:22:30.816865",
"status": "completed"
},
"tags": []
},
"source": [
"### Task 1: Binay columns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We also include simple feature engineering by creating binary columns for some features that can indicate the **presence(1) / absence(0)** of some features of the house"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "c8c270c9-dabe-49eb-88ce-74754ea93987",
"_uuid": "c216ca40-f71b-49be-b952-b72dbb872d3e",
"papermill": {
"duration": 0.135681,
"end_time": "2021-01-06T05:22:31.159309",
"exception": false,
"start_time": "2021-01-06T05:22:31.023628",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"colum = ['MasVnrArea','TotalBsmtFin','TotalBsmtSF','2ndFlrSF','WoodDeckSF','TotalPorch']\n",
"\n",
"for col in colum:\n",
" col_name = col+'_bin'\n",
" X[col_name] = X[col].apply(lambda x: 1 if x > 0 else 0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "7037b73f-0475-428a-9f4f-4630e9bcaee0",
"_uuid": "07123d34-0bd3-48c8-af96-aea9cf43b0b2",
"papermill": {
"duration": 0.103509,
"end_time": "2021-01-06T05:22:31.367042",
"exception": false,
"start_time": "2021-01-06T05:22:31.263533",
"status": "completed"
},
"tags": []
},
"source": [
"### Task 2: Converting categorical to numerical"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lastly, because machine learning only learns from data that is numerical in nature, we will convert the remaining categorical columns into one-hot features using the *get_dummies()* method into numerical columns that is suitable for feeding into our machine learning algorithm."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "6d172695-3a75-409c-8efa-03e4705622b8",
"_uuid": "b4e57c5e-104c-428f-91bf-4ecb1d98fafd",
"papermill": {
"duration": 0.153736,
"end_time": "2021-01-06T05:22:31.625146",
"exception": false,
"start_time": "2021-01-06T05:22:31.471410",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"X = pd.get_dummies(X)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "6c57b5c3-9b5e-4c66-80b3-a2a7f6587e95",
"_uuid": "d2182dc3-4fae-4be8-ad12-b87ef3e61928",
"papermill": {
"duration": 0.103776,
"end_time": "2021-01-06T05:22:31.831430",
"exception": false,
"start_time": "2021-01-06T05:22:31.727654",
"status": "completed"
},
"tags": []
},
"source": [
"### Task 3: SalePrice distribution"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "dcaa70f4-d821-4f2d-952c-208db91c917b",
"_kg_hide-input": true,
"_uuid": "c27b93e1-3d23-4282-a63b-ab2330a2db0b",
"papermill": {
"duration": 0.544934,
"end_time": "2021-01-06T05:22:32.480161",
"exception": false,
"start_time": "2021-01-06T05:22:31.935227",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"plt.figure(figsize=(10,6))\n",
"plt.title(\"Before transformation of SalePrice\")\n",
"dist = sns.distplot(train['SalePrice'],norm_hist=False)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "5d86db94-3f69-49f4-ab3c-c5fa497271e8",
"_uuid": "15ea2521-214a-4dd9-bf4e-8578bdf4d9f4",
"papermill": {
"duration": 0.112326,
"end_time": "2021-01-06T05:22:32.714906",
"exception": false,
"start_time": "2021-01-06T05:22:32.602580",
"status": "completed"
},
"tags": []
},
"source": [
"Distribution is skewed to the right, where the tail on the curve’s right-hand side is longer than the tail on the left-hand side, and the mean is greater than the mode. This situation is also called positive skewness. \n",
"Having a skewed target will affect the overall performance of our machine learning model, thus, one way to alleviate will be to using **log transformation** on skewed target, in our case, the *SalePrice* to reduce the skewness of the distribution."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "613cc684-ce62-4826-82e5-fc37b3512abe",
"_kg_hide-input": true,
"_uuid": "572351b8-9fec-4a1e-92e9-69bf86ea323e",
"papermill": {
"duration": 0.517077,
"end_time": "2021-01-06T05:22:33.336269",
"exception": false,
"start_time": "2021-01-06T05:22:32.819192",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"plt.figure(figsize=(10,6))\n",
"plt.title(\"After transformation of SalePrice\")\n",
"dist = sns.distplot(np.log(train['SalePrice']),norm_hist=False)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "3fc1f1ff-79f5-4b0f-82c9-e4f141ec09aa",
"_uuid": "44d93b9d-67a8-4f95-b409-9bc59ad91582",
"papermill": {
"duration": 0.116216,
"end_time": "2021-01-06T05:22:33.568561",
"exception": false,
"start_time": "2021-01-06T05:22:33.452345",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"y[\"SalePrice\"] = np.log(y['SalePrice'])"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.129572,
"end_time": "2021-01-06T05:22:33.803741",
"exception": false,
"start_time": "2021-01-06T05:22:33.674169",
"status": "completed"
},
"tags": []
},
"source": [
"Now that we are satisfied with our final data, we will proceed to the part where we will solve this regression problem - Modeling"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "db866092-d9e4-42e4-b67c-764f8c5b8ea9",
"_uuid": "2ade0b13-1635-4fda-96b0-6eaca5901712",
"papermill": {
"duration": 0.103977,
"end_time": "2021-01-06T05:22:34.013253",
"exception": false,
"start_time": "2021-01-06T05:22:33.909276",
"status": "completed"
},
"tags": []
},
"source": [
"## Modeling"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This section will consist of scaling the data for better optimization in our training, and also introducing the varieties of ensembling methods that are used in this notebook for predicting the Housing price. We also try out hyperparameter tuning briefly, as i will be dedicating a new notebook that will explain more in details on the process of Hyperparameter Tuning as well as the mathematical aspect of the ensemble algorithms."
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "2c372d63-14ef-4f8f-8dd0-045393d3eddd",
"_uuid": "51362b98-70dc-4278-932e-50fb831b5f16",
"papermill": {
"duration": 0.103531,
"end_time": "2021-01-06T05:22:34.220830",
"exception": false,
"start_time": "2021-01-06T05:22:34.117299",
"status": "completed"
},
"tags": []
},
"source": [
"### Split into train-validation set"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "9d0cdb5f-bf80-4c4d-b606-526a84742d96",
"_uuid": "04d8c6bc-8dfa-47d9-ab44-3401a7d7dc67",
"papermill": {
"duration": 0.124725,
"end_time": "2021-01-06T05:22:34.452412",
"exception": false,
"start_time": "2021-01-06T05:22:34.327687",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"x = X.loc[train.index]\n",
"y = y.loc[train.index]\n",
"test = X.loc[test.index]"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "89e0d991-277c-4af8-b1b7-091df43c8f49",
"_uuid": "27d6aa28-9262-4afb-a826-33c8a741f8d7",
"papermill": {
"duration": 0.108953,
"end_time": "2021-01-06T05:22:34.666281",
"exception": false,
"start_time": "2021-01-06T05:22:34.557328",
"status": "completed"
},
"tags": []
},
"source": [
"### Scaling of Data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**RobustScaler** is a transformation technique that removes the median and scales the data according to the quantile range (defaults to IQR: Interquartile Range). The IQR is the range between the 1st quartile (25th quantile) and the 3rd quartile (75th quantile). It is also robust to outliers, which makes it ideal for data where there are too many outliers that will drastically reduce the number of training data."
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.109523,
"end_time": "2021-01-06T05:22:34.883581",
"exception": false,
"start_time": "2021-01-06T05:22:34.774058",
"status": "completed"
},
"tags": []
},
"source": [
"Previously i fitted the RobustScaler on both Train and Test set, and that is a mistake on my side. By fitting the scaler on both train and testset, we exposed ourselves to the problem of **Data Leakage**. Data Leakage is a problem when information from outside the training dataset is used to create the model. If we fit the scaler on both training and test data, our training data characteristics will contain the distribution of our testset. As such, we are unknowningly passing in information about our test data into the final training data for training, which will not give us the opportunity to truly test our model on data it has never seen before. \n",
"**Lesson Learnt**: Fit the scaler just on training data, and then transforming it on both training and test data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "84e723d3-4a21-4503-9154-e886673d20f8",
"_uuid": "0f61a14b-5a02-4c3c-a62f-5a7d0c047473",
"papermill": {
"duration": 0.541296,
"end_time": "2021-01-06T05:22:35.533787",
"exception": false,
"start_time": "2021-01-06T05:22:34.992491",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"from sklearn.preprocessing import RobustScaler\n",
"\n",
"cols = x.select_dtypes(np.number).columns\n",
"transformer = RobustScaler().fit(x[cols])\n",
"x[cols] = transformer.transform(x[cols])\n",
"test[cols] = transformer.transform(test[cols])"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "b330c7e6-0e08-4a3a-90d0-83b39911389a",
"_uuid": "b0f5d3fd-d192-409e-9081-93f5f9a125f6",
"papermill": {
"duration": 0.106999,
"end_time": "2021-01-06T05:22:35.746331",
"exception": false,
"start_time": "2021-01-06T05:22:35.639332",
"status": "completed"
},
"tags": []
},
"source": [
"### Ensemble Algorithms"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "f09691c4-0d52-450b-ac3a-6f650bd17be2",
"_uuid": "2915d7de-de67-469f-b202-ddaf4e3c8210",
"papermill": {
"duration": 0.138187,
"end_time": "2021-01-06T05:22:35.995695",
"exception": false,
"start_time": "2021-01-06T05:22:35.857508",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"from sklearn.model_selection import train_test_split\n",
"\n",
"X_train, X_val, y_train, y_val = train_test_split(x, y, test_size=0.2, random_state=2020)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "ff381ae0-4f74-4831-9783-891e2559d070",
"_uuid": "da14af19-9f27-4a88-8476-fb9a79f698b4",
"papermill": {
"duration": 0.11005,
"end_time": "2021-01-06T05:22:36.220564",
"exception": false,
"start_time": "2021-01-06T05:22:36.110514",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 1: Ensembling models"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Ensembling methods are meta-algorithms which involves combining several machine learning models into one predictive model, aim at decreasing variance(reduce overfitting) and improving bias(improve accuracy). \n",
"The 3 main ensembling methods are **Bagging, Boosting and Stacking**. \n",
"In this notebook, we will focus mainly on **Boosting**, which is what we will be using for our prediction. "
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "519bfa53-8061-4c24-b29c-27be733d7ec4",
"_uuid": "ddd64897-b267-42d1-81e4-72c7b2675055",
"papermill": {
"duration": 0.109436,
"end_time": "2021-01-06T05:22:36.439312",
"exception": false,
"start_time": "2021-01-06T05:22:36.329876",
"status": "completed"
},
"tags": []
},
"source": [
"**Boosting** works on a class of weak learners, improving them into strong learners. It is being improved sequentially where the misclassified instances will be given more weights so that during the subsequent training, the learner will place more emphasis in correcting the previously misclassfied instance, less so on the already correctly identified instances.\n",
"Over time, the eventual learner will possess the ability to predict accurately as a result of learning from past mistakes\n",
"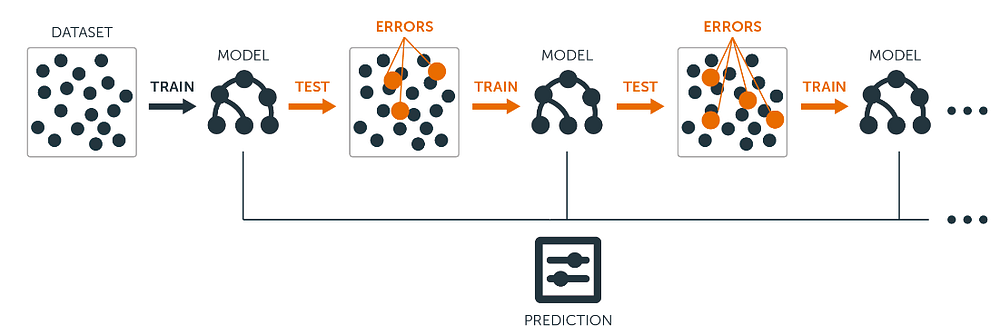"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "6b4546b3-0941-48fb-ac60-fe914a4a7253",
"_kg_hide-input": true,
"_kg_hide-output": true,
"_uuid": "bfec12a5-5fa0-4800-a82b-9808827f0476",
"papermill": {
"duration": 1.471138,
"end_time": "2021-01-06T05:22:38.019772",
"exception": false,
"start_time": "2021-01-06T05:22:36.548634",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"from sklearn.metrics import mean_squared_error, mean_absolute_error\n",
"from xgboost import XGBRegressor\n",
"from sklearn import ensemble\n",
"from lightgbm import LGBMRegressor\n",
"from sklearn.model_selection import cross_val_score\n",
"from catboost import CatBoostRegressor"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "91c2f46c-cff8-4b2c-b5ee-f00c2a1f7d94",
"_uuid": "2a593901-67b3-4f87-a586-c85932b75a78",
"papermill": {
"duration": 0.10493,
"end_time": "2021-01-06T05:22:38.231962",
"exception": false,
"start_time": "2021-01-06T05:22:38.127032",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 2: XGBoost "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Extreme Gradient Boost (XGB) is a boosting algorithm that uses the gradient boosting framework; where gradient descent algorithm is employed to minimize the errors in the sequential model. It improves on the gradient boosting framework with faster execution speed and improved performance. \n",
"
\n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.116259,
"end_time": "2021-01-06T05:22:38.456579",
"exception": false,
"start_time": "2021-01-06T05:22:38.340320",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"xgb = XGBRegressor(booster='gbtree', objective='reg:squarederror', tree_method='gpu_hist')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.10517,
"end_time": "2021-01-06T05:22:38.669791",
"exception": false,
"start_time": "2021-01-06T05:22:38.564621",
"status": "completed"
},
"tags": []
},
"source": [
"XGBoost hyperParameter tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 1594.877769,
"end_time": "2021-01-06T05:49:13.669029",
"exception": false,
"start_time": "2021-01-06T05:22:38.791260",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"from sklearn.model_selection import RandomizedSearchCV\n",
"\n",
"param_lst = {\n",
" 'learning_rate' : [0.01, 0.1, 0.15, 0.3, 0.5],\n",
" 'n_estimators' : [100, 500, 1000, 2000, 3000],\n",
" 'max_depth' : [3, 6, 9],\n",
" 'min_child_weight' : [1, 5, 10, 20],\n",
" 'reg_alpha' : [0.001, 0.01, 0.1],\n",
" 'reg_lambda' : [0.001, 0.01, 0.1]\n",
"}\n",
"\n",
"xgb_reg = RandomizedSearchCV(estimator = xgb, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
" \n",
"xgb_search = xgb_reg.fit(X_train, y_train)\n",
"\n",
"# XGB with tune hyperparameters\n",
"best_param = xgb_search.best_params_\n",
"xgb = XGBRegressor(tree_method='gpu_hist', **best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "2bf3cd60-9980-45ea-aea8-3a693daaee53",
"_uuid": "ef971018-b0b2-4c92-b797-7a4e80bc4b71",
"papermill": {
"duration": 0.117778,
"end_time": "2021-01-06T05:49:13.949827",
"exception": false,
"start_time": "2021-01-06T05:49:13.832049",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 3: LightGBM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"LightBGM is another gradient boosting framework developed by Microsoft that is based on decision tree algorithm, designed to be efficient and distributed. Some of the advantages of implementing LightBGM compared to other boosting frameworks include:\n",
"1. Faster training speed and higher efficiency (use histogram based algorithm i.e it buckets continuous feature values into discrete bins which fasten the training procedure)\n",
"2. Lower memory usage (Replaces continuous values to discrete bins which result in lower memory usage)\n",
"3. Better accuracy\n",
"4. Support of parallel and GPU learning\n",
"5. Capable of handling large-scale data (capable of performing equally good with large datasets with a significant reduction in training time as compared to XGBOOST)\n",
"\n",
"LightGBM splits the tree leaf wise with the best fit whereas other boosting algorithms split the tree depth wise or level wise rather than leaf-wise. This leaf-wise algorithm reduces more loss than the level-wise algorithm, hence resulting in much better accuracy which can rarely be achieved by any of the existing boosting algorithms. \n",
"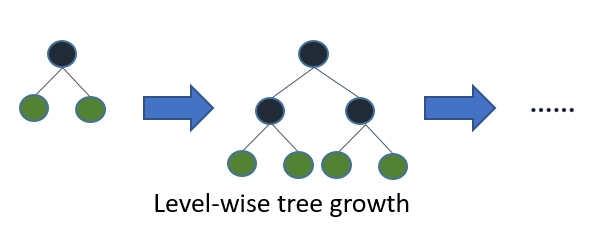 \n",
"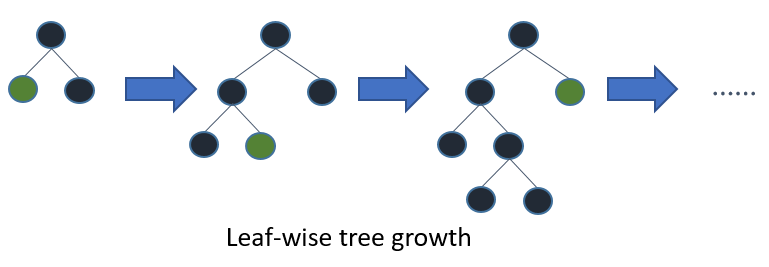"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.116269,
"end_time": "2021-01-06T05:49:14.172785",
"exception": false,
"start_time": "2021-01-06T05:49:14.056516",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"lgbm = LGBMRegressor(boosting_type='gbdt',objective='regression', max_depth=-1,\n",
" lambda_l1=0.0001, lambda_l2=0, learning_rate=0.1,\n",
" n_estimators=100, max_bin=200, min_child_samples=20, \n",
" bagging_fraction=0.75, bagging_freq=5,\n",
" bagging_seed=7, feature_fraction=0.8,\n",
" feature_fraction_seed=7, verbose=-1, device='gpu')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.103934,
"end_time": "2021-01-06T05:49:14.380135",
"exception": false,
"start_time": "2021-01-06T05:49:14.276201",
"status": "completed"
},
"tags": []
},
"source": [
"LightBGM Hyperparameter tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 342.419179,
"end_time": "2021-01-06T05:54:56.903829",
"exception": false,
"start_time": "2021-01-06T05:49:14.484650",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"param_lst = {\n",
" 'max_depth' : [2, 5, 8, 10],\n",
" 'learning_rate' : [0.001, 0.01, 0.1, 0.2],\n",
" 'n_estimators' : [100, 300, 500, 1000, 1500],\n",
" 'lambda_l1' : [0.0001, 0.001, 0.01],\n",
" 'lambda_l2' : [0, 0.0001, 0.001, 0.01],\n",
" 'feature_fraction' : [0.4, 0.6, 0.8],\n",
" 'min_child_samples' : [5, 10, 20, 25]\n",
"}\n",
"\n",
"lightgbm = RandomizedSearchCV(estimator = lgbm, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
" \n",
"lightgbm_search = lightgbm.fit(X_train, y_train)\n",
"\n",
"# LightBGM with tuned hyperparameters\n",
"best_param = lightgbm_search.best_params_\n",
"lgbm = LGBMRegressor(**best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "2826ec94-eff3-42b0-99b4-05f8dfd620b8",
"_uuid": "49f459aa-514b-4f17-8b32-3fba422d4d78",
"papermill": {
"duration": 0.114416,
"end_time": "2021-01-06T05:54:57.157528",
"exception": false,
"start_time": "2021-01-06T05:54:57.043112",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 4: Catboost"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Catboost is another alternative gradient boosting framework developed by Yandex. The word \"Catboost\" is derived from two words; \"Category\" and \"Boosting\". This means that Catboost itself can deal with categorical features which usually has to be converted to numerical encodings in order to feed into traditional gradient boost frameworks and machine learning models. \n",
"The 2 critical features in Catboost algorithm is the use of **ordered boosting** and **innovative algorithm for processing categorical features**, which fight the prediction shift caused by a special kind of target leakage present in all existing implementations of gradient boosting algorithms. \n",
"Find out more [here](https://towardsdatascience.com/https-medium-com-talperetz24-mastering-the-new-generation-of-gradient-boosting-db04062a7ea2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "26ec1da8-ed5b-413a-b9e3-63e0b9b03860",
"_uuid": "08f7ea74-8d10-4acf-8ed7-7b547b15c683",
"papermill": {
"duration": 0.115328,
"end_time": "2021-01-06T05:54:57.375960",
"exception": false,
"start_time": "2021-01-06T05:54:57.260632",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"cb = CatBoostRegressor(loss_function='RMSE', logging_level='Silent', task_type='GPU')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.103176,
"end_time": "2021-01-06T05:54:57.583389",
"exception": false,
"start_time": "2021-01-06T05:54:57.480213",
"status": "completed"
},
"tags": []
},
"source": [
"CatBoost Hyperparameter Tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_kg_hide-output": true,
"papermill": {
"duration": 3306.310633,
"end_time": "2021-01-06T06:50:03.997272",
"exception": false,
"start_time": "2021-01-06T05:54:57.686639",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"param_lst = {\n",
" 'n_estimators' : [100, 300, 500, 1000, 1300, 1600],\n",
" 'learning_rate' : [0.0001, 0.001, 0.01, 0.1],\n",
" 'l2_leaf_reg' : [0.001, 0.01, 0.1],\n",
" 'random_strength' : [0.25, 0.5 ,1],\n",
" 'max_depth' : [3, 6, 9],\n",
" 'min_child_samples' : [2, 5, 10, 15, 20],\n",
" \n",
"}\n",
"\n",
"catboost = RandomizedSearchCV(estimator = cb, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
"\n",
"catboost_search = catboost.fit(X_train, y_train)\n",
"\n",
"# CatBoost with tuned hyperparams\n",
"best_param = catboost_search.best_params_\n",
"cb = CatBoostRegressor(logging_level='Silent', task_type='GPU', **best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.104875,
"end_time": "2021-01-06T06:50:04.216278",
"exception": false,
"start_time": "2021-01-06T06:50:04.111403",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 5: Training and evaluation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "4b2509e7-b611-4c07-ae4f-9ab0a313eb44",
"_kg_hide-input": true,
"_kg_hide-output": false,
"_uuid": "2577b8a5-09f4-4169-8753-dbb0056c119b",
"papermill": {
"duration": 44.134322,
"end_time": "2021-01-06T06:50:48.455796",
"exception": false,
"start_time": "2021-01-06T06:50:04.321474",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"def mean_cross_val(model, X, y):\n",
" score = cross_val_score(model, X, y, cv=5)\n",
" mean = score.mean()\n",
" return mean\n",
"\n",
"cb.fit(X_train, y_train) \n",
"preds = cb.predict(X_val) \n",
"preds_test_cb = cb.predict(test)\n",
"mae_cb = mean_absolute_error(y_val, preds)\n",
"rmse_cb = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_cb = cb.score(X_val, y_val)\n",
"cv_cb = mean_cross_val(cb, x, y)\n",
"\n",
"\n",
"xgb.fit(X_train, y_train) \n",
"preds = xgb.predict(X_val) \n",
"preds_test_xgb = xgb.predict(test)\n",
"mae_xgb = mean_absolute_error(y_val, preds)\n",
"rmse_xgb = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_xgb = xgb.score(X_val, y_val)\n",
"cv_xgb = mean_cross_val(xgb, x, y)\n",
"\n",
"\n",
"lgbm.fit(X_train, y_train) \n",
"preds = lgbm.predict(X_val) \n",
"preds_test_lgbm = lgbm.predict(test)\n",
"mae_lgbm = mean_absolute_error(y_val, preds)\n",
"rmse_lgbm = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_lgbm = lgbm.score(X_val, y_val)\n",
"cv_lgbm = mean_cross_val(lgbm, x, y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "6189c280-23e0-49c4-b730-3f7fd8146f44",
"_uuid": "c81ba937-f73a-4e9d-a76e-8ebb4bf3222e",
"papermill": {
"duration": 0.141615,
"end_time": "2021-01-06T06:50:48.735324",
"exception": false,
"start_time": "2021-01-06T06:50:48.593709",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"model_performances = pd.DataFrame({\n",
" \"Model\" : [\"XGBoost\", \"LGBM\", \"CatBoost\"],\n",
" \"CV(5)\" : [str(cv_xgb)[0:5], str(cv_lgbm)[0:5], str(cv_cb)[0:5]],\n",
" \"MAE\" : [str(mae_xgb)[0:5], str(mae_lgbm)[0:5], str(mae_cb)[0:5]],\n",
" \"RMSE\" : [str(rmse_xgb)[0:5], str(rmse_lgbm)[0:5], str(rmse_cb)[0:5]],\n",
" \"Score\" : [str(score_xgb)[0:5], str(score_lgbm)[0:5], str(score_cb)[0:5]]\n",
"})\n",
"\n",
"print(\"Sorted by Score:\")\n",
"print(model_performances.sort_values(by=\"Score\", ascending=False))"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "4f134617-1ac2-4315-b75a-b4ab2cbfd7d0",
"_uuid": "63548a4d-36ae-4676-a64b-63df014ad9b1",
"papermill": {
"duration": 0.120533,
"end_time": "2021-01-06T06:50:48.999452",
"exception": false,
"start_time": "2021-01-06T06:50:48.878919",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 6 Blending"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Blending** is a technique that give different weightage to different algorithms that will affect their influence of the predictions. Such techniques can help to improve performance since it uses a variety of models as predictors. Special thanks to [@itslek](https://www.kaggle.com/itslek) for the implementation of blending. I have randomly chosen the weights for each models in this case, however, you can improve on this by futher tuning the weightage to be given to each model to achieve a better accuracy!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "1ee137f6-4041-444d-8f1a-58637ae05b01",
"_uuid": "bfcd09ec-0c89-415e-aefc-8275fc3cd0cf",
"papermill": {
"duration": 0.115206,
"end_time": "2021-01-06T06:50:49.220874",
"exception": false,
"start_time": "2021-01-06T06:50:49.105668",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"def blend_models_predict(X, b, c, d):\n",
" return ((b* xgb.predict(X)) + (c * lgbm.predict(X)) + (d * cb.predict(X)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "f0bdb9b3-d1ee-4e50-9061-f2432f99e1d0",
"_uuid": "fbb31b13-03f9-424e-9187-e65fafd9df5d",
"papermill": {
"duration": 0.26284,
"end_time": "2021-01-06T06:50:49.592256",
"exception": false,
"start_time": "2021-01-06T06:50:49.329416",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"subm = np.exp(blend_models_predict(test, 0.4, 0.3, 0.3))\n",
"submission = pd.DataFrame({'Id': test.index,\n",
" 'SalePrice': subm})"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "d1ddeb0a-24ea-4778-916d-f9b66b692531",
"_uuid": "c762c6f0-b936-42f0-91ae-11025e796e44",
"papermill": {
"duration": 0.112592,
"end_time": "2021-01-06T06:50:49.843290",
"exception": false,
"start_time": "2021-01-06T06:50:49.730698",
"status": "completed"
},
"tags": []
},
"source": [
"Hope you guys have learnt how the whole process of solving a regression problems looks like, understood the importance of data preprocessing and gain insights into the varieties of ensembling algorithms that you can use in future regression problems."
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "d7c6a920-7a22-4352-b6c4-ad1c6403087d",
"_uuid": "508f0d95-437f-4178-98dc-e2e0fea3754a",
"papermill": {
"duration": 0.105686,
"end_time": "2021-01-06T06:50:50.268088",
"exception": false,
"start_time": "2021-01-06T06:50:50.162402",
"status": "completed"
},
"tags": []
},
"source": [
"## Acknowledgments\n",
"\n",
"Thanks to [aqx](https://www.kaggle.com/angqx95) for creating the open-source course [Data Science Workflow TOP 2% (with Tuning)](https://www.kaggle.com/code/angqx95/data-science-workflow-top-2-with-tuning). It inspires the majority of the content in this chapter."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.13"
},
"papermill": {
"duration": 5364.921472,
"end_time": "2021-01-06T06:50:51.183567",
"environment_variables": {},
"exception": null,
"input_path": "__notebook__.ipynb",
"output_path": "__notebook__.ipynb",
"parameters": {},
"start_time": "2021-01-06T05:21:26.262095",
"version": "1.2.1"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.116259,
"end_time": "2021-01-06T05:22:38.456579",
"exception": false,
"start_time": "2021-01-06T05:22:38.340320",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"xgb = XGBRegressor(booster='gbtree', objective='reg:squarederror', tree_method='gpu_hist')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.10517,
"end_time": "2021-01-06T05:22:38.669791",
"exception": false,
"start_time": "2021-01-06T05:22:38.564621",
"status": "completed"
},
"tags": []
},
"source": [
"XGBoost hyperParameter tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 1594.877769,
"end_time": "2021-01-06T05:49:13.669029",
"exception": false,
"start_time": "2021-01-06T05:22:38.791260",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"from sklearn.model_selection import RandomizedSearchCV\n",
"\n",
"param_lst = {\n",
" 'learning_rate' : [0.01, 0.1, 0.15, 0.3, 0.5],\n",
" 'n_estimators' : [100, 500, 1000, 2000, 3000],\n",
" 'max_depth' : [3, 6, 9],\n",
" 'min_child_weight' : [1, 5, 10, 20],\n",
" 'reg_alpha' : [0.001, 0.01, 0.1],\n",
" 'reg_lambda' : [0.001, 0.01, 0.1]\n",
"}\n",
"\n",
"xgb_reg = RandomizedSearchCV(estimator = xgb, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
" \n",
"xgb_search = xgb_reg.fit(X_train, y_train)\n",
"\n",
"# XGB with tune hyperparameters\n",
"best_param = xgb_search.best_params_\n",
"xgb = XGBRegressor(tree_method='gpu_hist', **best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "2bf3cd60-9980-45ea-aea8-3a693daaee53",
"_uuid": "ef971018-b0b2-4c92-b797-7a4e80bc4b71",
"papermill": {
"duration": 0.117778,
"end_time": "2021-01-06T05:49:13.949827",
"exception": false,
"start_time": "2021-01-06T05:49:13.832049",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 3: LightGBM"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"LightBGM is another gradient boosting framework developed by Microsoft that is based on decision tree algorithm, designed to be efficient and distributed. Some of the advantages of implementing LightBGM compared to other boosting frameworks include:\n",
"1. Faster training speed and higher efficiency (use histogram based algorithm i.e it buckets continuous feature values into discrete bins which fasten the training procedure)\n",
"2. Lower memory usage (Replaces continuous values to discrete bins which result in lower memory usage)\n",
"3. Better accuracy\n",
"4. Support of parallel and GPU learning\n",
"5. Capable of handling large-scale data (capable of performing equally good with large datasets with a significant reduction in training time as compared to XGBOOST)\n",
"\n",
"LightGBM splits the tree leaf wise with the best fit whereas other boosting algorithms split the tree depth wise or level wise rather than leaf-wise. This leaf-wise algorithm reduces more loss than the level-wise algorithm, hence resulting in much better accuracy which can rarely be achieved by any of the existing boosting algorithms. \n",
" \n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 0.116269,
"end_time": "2021-01-06T05:49:14.172785",
"exception": false,
"start_time": "2021-01-06T05:49:14.056516",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"lgbm = LGBMRegressor(boosting_type='gbdt',objective='regression', max_depth=-1,\n",
" lambda_l1=0.0001, lambda_l2=0, learning_rate=0.1,\n",
" n_estimators=100, max_bin=200, min_child_samples=20, \n",
" bagging_fraction=0.75, bagging_freq=5,\n",
" bagging_seed=7, feature_fraction=0.8,\n",
" feature_fraction_seed=7, verbose=-1, device='gpu')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.103934,
"end_time": "2021-01-06T05:49:14.380135",
"exception": false,
"start_time": "2021-01-06T05:49:14.276201",
"status": "completed"
},
"tags": []
},
"source": [
"LightBGM Hyperparameter tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"papermill": {
"duration": 342.419179,
"end_time": "2021-01-06T05:54:56.903829",
"exception": false,
"start_time": "2021-01-06T05:49:14.484650",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"param_lst = {\n",
" 'max_depth' : [2, 5, 8, 10],\n",
" 'learning_rate' : [0.001, 0.01, 0.1, 0.2],\n",
" 'n_estimators' : [100, 300, 500, 1000, 1500],\n",
" 'lambda_l1' : [0.0001, 0.001, 0.01],\n",
" 'lambda_l2' : [0, 0.0001, 0.001, 0.01],\n",
" 'feature_fraction' : [0.4, 0.6, 0.8],\n",
" 'min_child_samples' : [5, 10, 20, 25]\n",
"}\n",
"\n",
"lightgbm = RandomizedSearchCV(estimator = lgbm, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
" \n",
"lightgbm_search = lightgbm.fit(X_train, y_train)\n",
"\n",
"# LightBGM with tuned hyperparameters\n",
"best_param = lightgbm_search.best_params_\n",
"lgbm = LGBMRegressor(**best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "2826ec94-eff3-42b0-99b4-05f8dfd620b8",
"_uuid": "49f459aa-514b-4f17-8b32-3fba422d4d78",
"papermill": {
"duration": 0.114416,
"end_time": "2021-01-06T05:54:57.157528",
"exception": false,
"start_time": "2021-01-06T05:54:57.043112",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 4: Catboost"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Catboost is another alternative gradient boosting framework developed by Yandex. The word \"Catboost\" is derived from two words; \"Category\" and \"Boosting\". This means that Catboost itself can deal with categorical features which usually has to be converted to numerical encodings in order to feed into traditional gradient boost frameworks and machine learning models. \n",
"The 2 critical features in Catboost algorithm is the use of **ordered boosting** and **innovative algorithm for processing categorical features**, which fight the prediction shift caused by a special kind of target leakage present in all existing implementations of gradient boosting algorithms. \n",
"Find out more [here](https://towardsdatascience.com/https-medium-com-talperetz24-mastering-the-new-generation-of-gradient-boosting-db04062a7ea2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "26ec1da8-ed5b-413a-b9e3-63e0b9b03860",
"_uuid": "08f7ea74-8d10-4acf-8ed7-7b547b15c683",
"papermill": {
"duration": 0.115328,
"end_time": "2021-01-06T05:54:57.375960",
"exception": false,
"start_time": "2021-01-06T05:54:57.260632",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"cb = CatBoostRegressor(loss_function='RMSE', logging_level='Silent', task_type='GPU')"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.103176,
"end_time": "2021-01-06T05:54:57.583389",
"exception": false,
"start_time": "2021-01-06T05:54:57.480213",
"status": "completed"
},
"tags": []
},
"source": [
"CatBoost Hyperparameter Tuning"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_kg_hide-output": true,
"papermill": {
"duration": 3306.310633,
"end_time": "2021-01-06T06:50:03.997272",
"exception": false,
"start_time": "2021-01-06T05:54:57.686639",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"param_lst = {\n",
" 'n_estimators' : [100, 300, 500, 1000, 1300, 1600],\n",
" 'learning_rate' : [0.0001, 0.001, 0.01, 0.1],\n",
" 'l2_leaf_reg' : [0.001, 0.01, 0.1],\n",
" 'random_strength' : [0.25, 0.5 ,1],\n",
" 'max_depth' : [3, 6, 9],\n",
" 'min_child_samples' : [2, 5, 10, 15, 20],\n",
" \n",
"}\n",
"\n",
"catboost = RandomizedSearchCV(estimator = cb, param_distributions = param_lst,\n",
" n_iter = 100, scoring = 'neg_root_mean_squared_error',\n",
" cv = 5)\n",
"\n",
"catboost_search = catboost.fit(X_train, y_train)\n",
"\n",
"# CatBoost with tuned hyperparams\n",
"best_param = catboost_search.best_params_\n",
"cb = CatBoostRegressor(logging_level='Silent', task_type='GPU', **best_param)"
]
},
{
"cell_type": "markdown",
"metadata": {
"papermill": {
"duration": 0.104875,
"end_time": "2021-01-06T06:50:04.216278",
"exception": false,
"start_time": "2021-01-06T06:50:04.111403",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 5: Training and evaluation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "4b2509e7-b611-4c07-ae4f-9ab0a313eb44",
"_kg_hide-input": true,
"_kg_hide-output": false,
"_uuid": "2577b8a5-09f4-4169-8753-dbb0056c119b",
"papermill": {
"duration": 44.134322,
"end_time": "2021-01-06T06:50:48.455796",
"exception": false,
"start_time": "2021-01-06T06:50:04.321474",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"def mean_cross_val(model, X, y):\n",
" score = cross_val_score(model, X, y, cv=5)\n",
" mean = score.mean()\n",
" return mean\n",
"\n",
"cb.fit(X_train, y_train) \n",
"preds = cb.predict(X_val) \n",
"preds_test_cb = cb.predict(test)\n",
"mae_cb = mean_absolute_error(y_val, preds)\n",
"rmse_cb = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_cb = cb.score(X_val, y_val)\n",
"cv_cb = mean_cross_val(cb, x, y)\n",
"\n",
"\n",
"xgb.fit(X_train, y_train) \n",
"preds = xgb.predict(X_val) \n",
"preds_test_xgb = xgb.predict(test)\n",
"mae_xgb = mean_absolute_error(y_val, preds)\n",
"rmse_xgb = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_xgb = xgb.score(X_val, y_val)\n",
"cv_xgb = mean_cross_val(xgb, x, y)\n",
"\n",
"\n",
"lgbm.fit(X_train, y_train) \n",
"preds = lgbm.predict(X_val) \n",
"preds_test_lgbm = lgbm.predict(test)\n",
"mae_lgbm = mean_absolute_error(y_val, preds)\n",
"rmse_lgbm = np.sqrt(mean_squared_error(y_val, preds))\n",
"score_lgbm = lgbm.score(X_val, y_val)\n",
"cv_lgbm = mean_cross_val(lgbm, x, y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "6189c280-23e0-49c4-b730-3f7fd8146f44",
"_uuid": "c81ba937-f73a-4e9d-a76e-8ebb4bf3222e",
"papermill": {
"duration": 0.141615,
"end_time": "2021-01-06T06:50:48.735324",
"exception": false,
"start_time": "2021-01-06T06:50:48.593709",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"model_performances = pd.DataFrame({\n",
" \"Model\" : [\"XGBoost\", \"LGBM\", \"CatBoost\"],\n",
" \"CV(5)\" : [str(cv_xgb)[0:5], str(cv_lgbm)[0:5], str(cv_cb)[0:5]],\n",
" \"MAE\" : [str(mae_xgb)[0:5], str(mae_lgbm)[0:5], str(mae_cb)[0:5]],\n",
" \"RMSE\" : [str(rmse_xgb)[0:5], str(rmse_lgbm)[0:5], str(rmse_cb)[0:5]],\n",
" \"Score\" : [str(score_xgb)[0:5], str(score_lgbm)[0:5], str(score_cb)[0:5]]\n",
"})\n",
"\n",
"print(\"Sorted by Score:\")\n",
"print(model_performances.sort_values(by=\"Score\", ascending=False))"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "4f134617-1ac2-4315-b75a-b4ab2cbfd7d0",
"_uuid": "63548a4d-36ae-4676-a64b-63df014ad9b1",
"papermill": {
"duration": 0.120533,
"end_time": "2021-01-06T06:50:48.999452",
"exception": false,
"start_time": "2021-01-06T06:50:48.878919",
"status": "completed"
},
"tags": []
},
"source": [
"#### Task 6 Blending"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Blending** is a technique that give different weightage to different algorithms that will affect their influence of the predictions. Such techniques can help to improve performance since it uses a variety of models as predictors. Special thanks to [@itslek](https://www.kaggle.com/itslek) for the implementation of blending. I have randomly chosen the weights for each models in this case, however, you can improve on this by futher tuning the weightage to be given to each model to achieve a better accuracy!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "1ee137f6-4041-444d-8f1a-58637ae05b01",
"_uuid": "bfcd09ec-0c89-415e-aefc-8275fc3cd0cf",
"papermill": {
"duration": 0.115206,
"end_time": "2021-01-06T06:50:49.220874",
"exception": false,
"start_time": "2021-01-06T06:50:49.105668",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"def blend_models_predict(X, b, c, d):\n",
" return ((b* xgb.predict(X)) + (c * lgbm.predict(X)) + (d * cb.predict(X)))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"_cell_guid": "f0bdb9b3-d1ee-4e50-9061-f2432f99e1d0",
"_uuid": "fbb31b13-03f9-424e-9187-e65fafd9df5d",
"papermill": {
"duration": 0.26284,
"end_time": "2021-01-06T06:50:49.592256",
"exception": false,
"start_time": "2021-01-06T06:50:49.329416",
"status": "completed"
},
"tags": []
},
"outputs": [],
"source": [
"subm = np.exp(blend_models_predict(test, 0.4, 0.3, 0.3))\n",
"submission = pd.DataFrame({'Id': test.index,\n",
" 'SalePrice': subm})"
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "d1ddeb0a-24ea-4778-916d-f9b66b692531",
"_uuid": "c762c6f0-b936-42f0-91ae-11025e796e44",
"papermill": {
"duration": 0.112592,
"end_time": "2021-01-06T06:50:49.843290",
"exception": false,
"start_time": "2021-01-06T06:50:49.730698",
"status": "completed"
},
"tags": []
},
"source": [
"Hope you guys have learnt how the whole process of solving a regression problems looks like, understood the importance of data preprocessing and gain insights into the varieties of ensembling algorithms that you can use in future regression problems."
]
},
{
"cell_type": "markdown",
"metadata": {
"_cell_guid": "d7c6a920-7a22-4352-b6c4-ad1c6403087d",
"_uuid": "508f0d95-437f-4178-98dc-e2e0fea3754a",
"papermill": {
"duration": 0.105686,
"end_time": "2021-01-06T06:50:50.268088",
"exception": false,
"start_time": "2021-01-06T06:50:50.162402",
"status": "completed"
},
"tags": []
},
"source": [
"## Acknowledgments\n",
"\n",
"Thanks to [aqx](https://www.kaggle.com/angqx95) for creating the open-source course [Data Science Workflow TOP 2% (with Tuning)](https://www.kaggle.com/code/angqx95/data-science-workflow-top-2-with-tuning). It inspires the majority of the content in this chapter."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.13"
},
"papermill": {
"duration": 5364.921472,
"end_time": "2021-01-06T06:50:51.183567",
"environment_variables": {},
"exception": null,
"input_path": "__notebook__.ipynb",
"output_path": "__notebook__.ipynb",
"parameters": {},
"start_time": "2021-01-06T05:21:26.262095",
"version": "1.2.1"
}
},
"nbformat": 4,
"nbformat_minor": 4
}