# DOI-Extractor-OEG
[](https://opensource.org/licenses/MIT)
## Description
DOI-Extractor-OEG is a tool for extracting all paper's name and DOI from OEG publications.
They are extracted from two main resources:
1) https://portalcientifico.upm.es/es/ipublic/entity/16247 , corresponding to all papers from OEG.
2) ExistingPapers/ Papers.csv with already extracted data from some OEG papers.
The resulting information is placed in Outputs folder, which include:
- A dois.txt containing, for each paper, the URL to the pdf if it was founded or if not the doi
- A results.csv, containing the title and the doi of every paper found, in addition to OpenAlex primary location attribute
- A results.json, containing the same information as results.csv but in a json format
## Project Structure
```
DOI-Extractor-OEG
├───doiExtractor
| ├───ExistingPapers
| | ├───name_doi_papers.csv
| | └───Papers.csv
| ├───Outputs
| | ├───dois.csv
| | |───results.csv
| | └───results.json
| ├───__init__.py
| ├───doiExtractor.py
| ├───main.py
| └───openAlex.py
├───.gitignore
├───LICENSE.txt
├───README.MD
└───setup.py
```
```doiExtractor.py``` - Contains the functions to extract the name and doi from portalcientifico.upm.es and to merge that information with the existing papers.
```openAlex.py``` - Contains the functions to extract the primary location from openAlex and if the DOI was not found with doiExtractor.py, it tries to extract it using Open Alex.
## Installation
1. Clone the repository:
```
git clone https://github.com/ptorija/DOI-Extractor-OEG.git
```
2. Change to the DOI-Extractor-OEG directory:
```
cd DOI-Extractor-OEG
```
3. Create a virtual environment:
```
python -m venv .env
```
4. Activate the virtual environment:
(Linux)
```
source .env/bin/activate
```
(Windows)
```
.env\Scripts\activate
```
5. Install the package dependencies:
```
pip install -e .
```
## Usage
Download the package from Pypi or install the tool from Github:
```
pip install DataExtractorOEG
```
The tool can be used from the command line with the following argument:
- ```--start``` - To start the doi extraction
The script will execute and extract DOIs from the specified webpage and then merge them with the ones from ExistingPapers.
### Options:
- ```--url ``` - Specify the webpage of the group you want to extract the information. Default: Ontology Engieneering Group
- ```--output ``` - Specify the path for the output files. Default: Outputs
### Example
1. Install the tool from Pypi ( https://pypi.org/project/DataExtractorOEG/ )
```
pip install DataExtractorOEG
```
2. Start the execution
```
DataExtractorOEG --start
```
When the execution ends, the following files will be saved in doiExtractor/Outputs folder:
- dois.txt
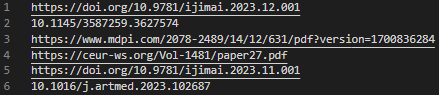
- results.csv

- results.json
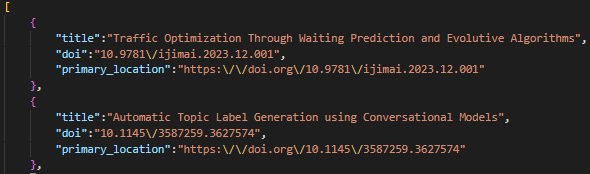
#### If you want to use RSEF with the output provided by this tool, follow the following steps
1. Clone RSEF repository:
```
git clone https://github.com/SoftwareUnderstanding/RSEF.git
```
2. Install the required dependencies by running:
```
pip install -e .
```
4. Use RSEF with the extracted results.json from DOI-Extractor-OEG, this will create a downloaded_metadata.json and a processed_metadata.json:
```
rsef process -j
```
If you didn't execute DOI-Extractor-OEG previously, you can also execute ```DataExtractorOEG --start``` and then the previous command
5. To check the implementations of the papers use:
```
rsef asses -i
-U flag to check Unidirectionality
-B flag to check Bidirectionality
```