# Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
[](https://openreview.net/pdf?id=anQDiQZhDP)
[](https://huggingface.co/amphion/Vevo)
[](https://versavoice.github.io/)
We present our reproduction of [Vevo](https://openreview.net/pdf?id=anQDiQZhDP), a versatile zero-shot voice imitation framework with controllable timbre and style. We invite you to explore the [audio samples](https://versavoice.github.io/) to experience Vevo's capabilities firsthand.
We have included the following pre-trained Vevo models at Amphion:
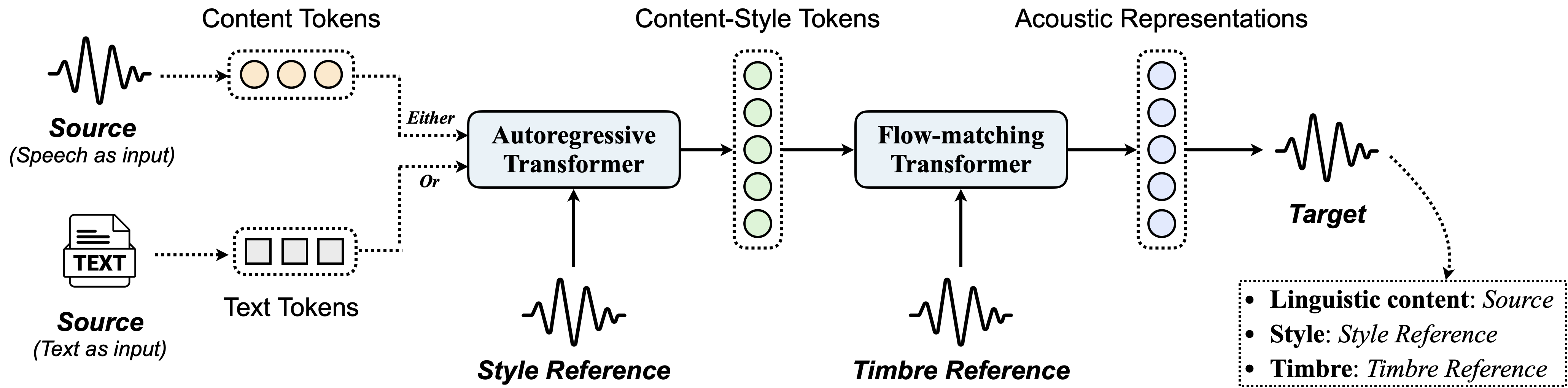
- **Vevo-Timbre**: It can conduct *style-preserved* voice conversion.
- **Vevo-Style**: It can conduct style conversion, such as *accent conversion* and *emotion conversion*.
- **Vevo-Voice**: It can conduct *style-converted* voice conversion.
- **Vevo-TTS**: It can conduct *style and timbre controllable* TTS.
Besides, we also release the **content tokenizer** and **content-style tokenizer** proposed by Vevo. Notably, all these pre-trained models are trained on [Emilia](https://huggingface.co/datasets/amphion/Emilia-Dataset), containing 101k hours of speech data among six languages (English, Chinese, German, French, Japanese, and Korean).
## Quickstart (Inference Only)
To run this model, you need to follow the steps below:
1. Clone the repository and install the environment.
2. Run the inference script.
### Clone and Environment Setup
#### 1. Clone the repository
```bash
git clone https://github.com/open-mmlab/Amphion.git
cd Amphion
```
#### 2. Install the environment
Before start installing, making sure you are under the `Amphion` directory. If not, use `cd` to enter.
Since we use `phonemizer` to convert text to phoneme, you need to install `espeak-ng` first. More details can be found [here](https://bootphon.github.io/phonemizer/install.html). Choose the correct installation command according to your operating system:
```bash
# For Debian-like distribution (e.g. Ubuntu, Mint, etc.)
sudo apt-get install espeak-ng
# For RedHat-like distribution (e.g. CentOS, Fedora, etc.)
sudo yum install espeak-ng
# For Windows
# Please visit https://github.com/espeak-ng/espeak-ng/releases to download .msi installer
```
Now, we are going to install the environment. It is recommended to use conda to configure:
```bash
conda create -n vevo python=3.10
conda activate vevo
pip install -r models/vc/vevo/requirements.txt
```
### Inference Script
```bash
# Vevo-Timbre
python -m models.vc.vevo.infer_vevotimbre
# Vevo-Style
python -m models.vc.vevo.infer_vevostyle
# Vevo-Voice
python -m models.vc.vevo.infer_vevovoice
# Vevo-TTS
python -m models.vc.vevo.infer_vevotts
```
Running this will automatically download the pretrained model from HuggingFace and start the inference process. The result audio is by default saved in `models/vc/vevo/wav/output*.wav`, you can change this in the scripts `models/vc/vevo/infer_vevo*.py`
## Training Recipe
For advanced users, we provide the following training recipe:
### Emilia data preparation
1. Please download the dataset following the official instructions provided by [Emilia](https://huggingface.co/datasets/amphion/Emilia-Dataset).
2. Due to Emilia's substantial storage requirements, data loading logic may vary slightly depending on storage configuration. We provide a reference implementation for local disk loading [in this file](../../base/emilia_dataset.py). After downloading the Emilia dataset, please adapt the data loading logic accordingly. In most cases, only modifying the paths specified in [Lines 36-37](../../base/emilia_dataset.py#L36) should be sufficient:
```python
MNT_PATH = "[Please fill out your emilia data root path]"
CACHE_PATH = "[Please fill out your emilia cache path]"
```
### Launch Training
Train the Vevo tokenizers, the auto-regressive model, and the flow-matching model, respectively:
> **Note**: You need to run the following commands under the `Amphion` root path:
> ```
> git clone https://github.com/open-mmlab/Amphion.git
> cd Amphion
> ```
#### Tokenizers
Run the following script:
```bash
# Content Tokenizer (Vocab = 32)
sh egs/codec/vevo/fvq32.sh
# Content-Style Tokenizer (Vocab = 8192)
sh egs/codec/vevo/fvq8192.sh
```
If you want to try different vocabulary sizes, just specify it in the `egs/codec/vevo/fvq*.json`:
```json
{
...
"model": {
"repcodec": {
"codebook_size": 8192, // Specify the vocabulary size here.
...
},
...
},
...
}
```
#### Auto-regressive Transformer
Specify the content tokenizer and content-style tokenizer paths in the `egs/vc/AutoregressiveTransformer/ar_conversion.json`:
```json
{
...
"model": {
"input_repcodec": {
"codebook_size": 32,
"hidden_size": 1024, // Representations Dim
"codebook_dim": 8,
"vocos_dim": 384,
"vocos_intermediate_dim": 2048,
"vocos_num_layers": 12,
"pretrained_path": "[Please fill out your pretrained model path]/model.safetensors" // The pre-trained content tokenizer
},
"output_repcodec": {
"codebook_size": 8192, // VQ Codebook Size
"hidden_size": 1024, // Representations Dim
"codebook_dim": 8,
"vocos_dim": 384,
"vocos_intermediate_dim": 2048,
"vocos_num_layers": 12,
"pretrained_path": "[Please fill out your pretrained model path]/model.safetensors" // The pre-trained content-style tokenizer
}
},
...
}
```
Run the following script:
```bash
sh egs/vc/AutoregressiveTransformer/ar_conversion.sh
```
Similarly, you can run the following script for Vevo-TTS training:
```bash
sh egs/vc/AutoregressiveTransformer/ar_synthesis.sh
```
#### Flow-matching Transformer
Specify the pre-trained content-style tokenizer path in the `egs/vc/FlowMatchingTransformer/fm_contentstyle.json`:
```json
{
...
"model": {
"repcodec": {
"codebook_size": 8192, // VQ Codebook Size
"hidden_size": 1024, // Representations Dim
"codebook_dim": 8,
"vocos_dim": 384,
"vocos_intermediate_dim": 2048,
"vocos_num_layers": 12,
"pretrained_path": "[Please fill out your pretrained model path]/model.safetensors" // The pre-trained content-style tokenizer
}
},
...
}
```
Run the following script:
```bash
sh egs/vc/FlowMatchingTransformer/fm_contentstyle.sh
```
#### Vocoder
We provide a unified vocos-based vocoder training recipe for both speech and singing voice. See our [Vevo1.5](../../svc/vevosing/README.md#vocoder) framework for the details.
## Citations
If you find this work useful for your research, please cite our paper:
```bibtex
@inproceedings{vevo,
author = {Xueyao Zhang and Xiaohui Zhang and Kainan Peng and Zhenyu Tang and Vimal Manohar and Yingru Liu and Jeff Hwang and Dangna Li and Yuhao Wang and Julian Chan and Yuan Huang and Zhizheng Wu and Mingbo Ma},
title = {Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement},
booktitle = {{ICLR}},
publisher = {OpenReview.net},
year = {2025}
}
```
If you use the Vevo pre-trained models or training recipe of Amphion, please also cite:
```bibtex
@article{amphion2,
title = {Overview of the Amphion Toolkit (v0.2)},
author = {Jiaqi Li and Xueyao Zhang and Yuancheng Wang and Haorui He and Chaoren Wang and Li Wang and Huan Liao and Junyi Ao and Zeyu Xie and Yiqiao Huang and Junan Zhang and Zhizheng Wu},
year = {2025},
journal = {arXiv preprint arXiv:2501.15442},
}
@inproceedings{amphion,
author={Xueyao Zhang and Liumeng Xue and Yicheng Gu and Yuancheng Wang and Jiaqi Li and Haorui He and Chaoren Wang and Ting Song and Xi Chen and Zihao Fang and Haopeng Chen and Junan Zhang and Tze Ying Tang and Lexiao Zou and Mingxuan Wang and Jun Han and Kai Chen and Haizhou Li and Zhizheng Wu},
title={Amphion: An Open-Source Audio, Music and Speech Generation Toolkit},
booktitle={{IEEE} Spoken Language Technology Workshop, {SLT} 2024},
year={2024}
}
```