{
"cells": [
{
"cell_type": "markdown",
"id": "26a10eea",
"metadata": {},
"source": [
"# 🗣️ Comparing Speech-to-Text Methods with the OpenAI API\n",
"\n",
"## Overview\n",
"\n",
"This notebook provides a clear, hands-on guide for beginners to quickly get started with Speech-to-Text (STT) using the OpenAI API. You'll explore multiple practical methods, their use cases, and considerations.\n",
"\n",
"By the end you will be able to select and use the appropriate transcription method for your use use cases.\n",
"\n",
"*Note:*\n",
"- *This notebook uses WAV audio files for simplicity. It does **not** demonstrate real-time microphone streaming (such as from a web app or direct mic input).*\n",
"- *This notebook uses WebSockets to connect to the Realtime API. Alternatively, you can use WebRTC, see the [OpenAI docs](https://platform.openai.com/docs/guides/realtime#connect-with-webrtc) for details.*"
]
},
{
"cell_type": "markdown",
"id": "5120a023",
"metadata": {},
"source": [
"### 📊 Quick-look\n",
"| Mode | Latency to **first token** | Best for (real examples) | Advantages | Key limitations |\n",
"|--------------------------------|---------------------------|--------------------------------------------------------------|-----------------------------------------------------------|-----------------------------------------------------------|\n",
"| File upload + `stream=False` (blocking) | seconds | Voicemail, meeting recordings | Simple to set up | • No partial results, users see nothing until file finishes • Max 25 MB per request (you must chunk long audio) |\n",
"| File upload + `stream=True` | subseconds | Voice memos in mobile apps | Simple to set up & provides a “live” feel via token streaming | • Still requires a completed file • You implement progress bars / chunked uploads |\n",
"| Realtime WebSocket | subseconds | Live captions in webinars | True real-time; accepts a continuous audio stream | • Audio must be pcm16, g711_ulaw, or g711_alaw • Session ≤ 30 min, reconnect & stitch • You handle speaker-turn formatting to build the full transcript |\n",
"| Agents SDK VoicePipeline | subseconds | Internal help-desk assistant | Real-time streaming and easy to build agentic workflows | • Python-only beta • API surface may change |"
]
},
{
"cell_type": "markdown",
"id": "25308313",
"metadata": {},
"source": [
"## Installation (one‑time)\n",
"\n",
"To set up your environment, uncomment and run the following cell in a new Python environment:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "bc940358",
"metadata": {},
"outputs": [],
"source": [
"!pip install --upgrade -q openai openai-agents websockets sounddevice pyaudio nest_asyncio resampy httpx websocket-client"
]
},
{
"cell_type": "markdown",
"id": "efbbb76a",
"metadata": {},
"source": [
"This installs the necessary packages required to follow along with the notebook."
]
},
{
"cell_type": "markdown",
"id": "6d6ba036",
"metadata": {},
"source": [
"## Authentication\n",
"Before proceeding, ensure you have set your OpenAI API key as an environment variable named OPENAI_API_KEY. You can typically set this in your terminal or notebook environment: `export OPENAI_API_KEY=\"your-api-key-here\"`\n",
"\n",
"Verify that your API key is set correctly by running the next cell."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "e4078915",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"✅ OpenAI client ready\n"
]
}
],
"source": [
"# ─── Standard Library ──────────────────────────────────────────────────────────\n",
"import asyncio\n",
"import struct\n",
"import base64 # encode raw PCM bytes → base64 before sending JSON\n",
"import json # compose/parse WebSocket messages\n",
"import os\n",
"import time\n",
"from typing import List\n",
"from pathlib import Path\n",
"\n",
"# ─── Third-Party ───────────────────────────────────────────────────────────────\n",
"import nest_asyncio\n",
"import numpy as np\n",
"from openai import OpenAI\n",
"import resampy # high-quality sample-rate conversion\n",
"import soundfile as sf # reads many audio formats into float32 arrays\n",
"import websockets # asyncio-based WebSocket client\n",
"from agents import Agent\n",
"from agents.voice import (\n",
" SingleAgentVoiceWorkflow,\n",
" StreamedAudioInput,\n",
" VoicePipeline,\n",
" VoicePipelineConfig,\n",
")\n",
"from IPython.display import Audio, display\n",
"# ───────────────────────────────────────────────────────────────────────────────\n",
"nest_asyncio.apply()\n",
"\n",
"# ✏️ Put your key in an env-var or just replace the call below.\n",
"OPENAI_API_KEY = os.getenv(\"OPENAI_API_KEY\")\n",
"\n",
"client = OpenAI(api_key=OPENAI_API_KEY)\n",
"print(\"✅ OpenAI client ready\")"
]
},
{
"cell_type": "markdown",
"id": "c2a95c79",
"metadata": {},
"source": [
"---\n",
"## 1 · Speech-to-Text with Audio File\n",
"*model = gpt-4o-transcribe*\n",
"\n",
"### When to use\n",
"* You have a completed audio file (up to 25 MB).The following input file types are supported: mp3, mp4, mpeg, mpga, m4a, wav, and webm.\n",
"* Suitable for batch processing tasks like podcasts, call-center recordings, or voice memos.\n",
"* Real-time feedback or partial results are not required."
]
},
{
"cell_type": "markdown",
"id": "0d2c053d",
"metadata": {},
"source": [
"### How it works\n",
"\n",
"\n",
"\n",
"\n",
"#### Benefits\n",
"\n",
"- **Ease of use:** Single HTTP request – perfect for automation or backend scripts. \n",
"- **Accuracy:** Processes the entire audio in one go, improving context and transcription quality. \n",
"- **File support:** Handles WAV, MP3, MP4, M4A, FLAC, Ogg, and more. \n",
"\n",
"#### Limitations\n",
"\n",
"- **No partial results:** You must wait until processing finishes before seeing any transcript. \n",
"- **Latency scales with duration:** Longer recordings mean longer wait times. \n",
"- **File-size cap:** Up to 25 MB (≈ 30 min at 16-kHz mono WAV). \n",
"- **Offline use only:** Not intended for real-time scenarios such as live captioning or conversational AI. "
]
},
{
"cell_type": "markdown",
"id": "4eeb51a7",
"metadata": {},
"source": [
"Let's first preview the audio file. I've downloaded the audio file from [here](https://pixabay.com/sound-effects/search/male-speech/)."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "ab545e4c",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"AUDIO_PATH = Path('./data/sample_audio_files/lotsoftimes-78085.mp3') # change me\n",
"MODEL_NAME = \"gpt-4o-transcribe\"\n",
"\n",
"if AUDIO_PATH.exists():\n",
" display(Audio(str(AUDIO_PATH)))\n",
"else:\n",
" print('⚠️ Provide a valid audio file')"
]
},
{
"cell_type": "markdown",
"id": "218b7649",
"metadata": {},
"source": [
"Now, we can call the STT endpoint to transcribe the audio."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "7ae4af8d",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"--- TRANSCRIPT ---\n",
"\n",
"And lots of times you need to give people more than one link at a time. A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo gallery, an album to purchase, like these next few links.\n",
"\n"
]
}
],
"source": [
"if AUDIO_PATH.exists():\n",
" with AUDIO_PATH.open('rb') as f:\n",
" transcript = client.audio.transcriptions.create(\n",
" file=f,\n",
" model=MODEL_NAME,\n",
" response_format='text',\n",
" )\n",
" print('\\n--- TRANSCRIPT ---\\n')\n",
" print(transcript)"
]
},
{
"cell_type": "markdown",
"id": "765ec73a",
"metadata": {},
"source": [
"## 2 · Speech-to-Text with Audio File: Streaming\n",
"*model = gpt-4o-transcribe*\n",
"### When to use\n",
"- You already have a fully recorded audio file. \n",
"- You need immediate transcription results (partial or final) as they arrive. \n",
"- Scenarios where partial feedback improves UX, e.g., uploading a long voice memo.\n",
"\n",
"\n",
"\n",
"#### Benefits\n",
"- **Real-time feel:** Users see transcription updates almost immediately. \n",
"- **Progress visibility:** Intermediate transcripts show ongoing progress. \n",
"- **Improved UX:** Instant feedback keeps users engaged.\n",
"\n",
"#### Limitations\n",
"- **Requires full audio file upfront:** Not suitable for live audio feeds. \n",
"- **Implementation overhead:** You must handle streaming logic and progress updates yourself. "
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "d027fdb9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"And lots of times you need to give people more than one link at a time. A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo gallery, an album to purchase, like these next few links.\n",
"\n",
"And lots of times you need to give people more than one link at a time. A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo gallery, an album to purchase, like these next few links.\n"
]
}
],
"source": [
"if AUDIO_PATH.exists():\n",
" with AUDIO_PATH.open('rb') as f:\n",
" stream = client.audio.transcriptions.create(\n",
" file=f,\n",
" model=MODEL_NAME,\n",
" response_format='text',\n",
" stream=True\n",
")\n",
"\n",
"for event in stream:\n",
" # If this is an incremental update, you can get the delta using `event.delta`\n",
" if getattr(event, \"delta\", None): \n",
" print(event.delta, end=\"\", flush=True)\n",
" time.sleep(0.05) # simulate real-time pacing\n",
" \n",
" # When transcription is complete, you can get the final transcript using `event.text`\n",
" elif getattr(event, \"text\", None):\n",
" print()\n",
" print(\"\\n\" + event.text)"
]
},
{
"cell_type": "markdown",
"id": "f42c4da4",
"metadata": {},
"source": [
"---\n",
"## 3 · Realtime Transcription API\n",
"*model = gpt-4o-transcribe*\n",
"### When to use\n",
"* Live captioning for real-time scenarios (e.g., meetings, demos).\n",
"* Need built-in voice-activity detection, noise suppression, or token-level log probabilities.\n",
"* Comfortable handling WebSockets and real-time event streams.\n"
]
},
{
"cell_type": "markdown",
"id": "88ef332f",
"metadata": {},
"source": [
"### How it works\n",
"\n",
"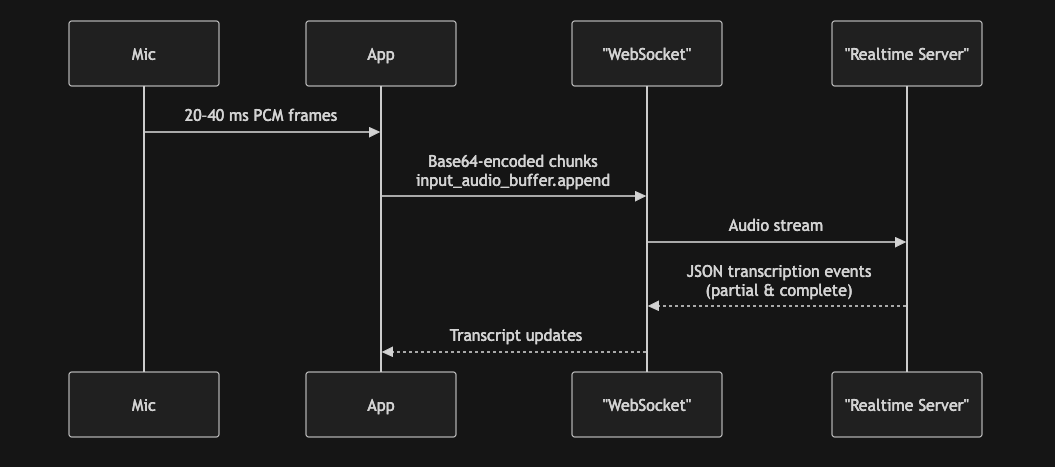\n",
"\n",
"#### Benefits\n",
"- **Ultra-low latency:** Typically 300–800 ms, enabling near-instant transcription. \n",
"- **Dynamic updates:** Supports partial and final transcripts, enhancing the user experience. \n",
"- **Advanced features:** Built-in turn detection, noise reduction, and optional detailed log-probabilities. \n",
"\n",
"#### Limitations\n",
"- **Complex integration:** Requires managing WebSockets, Base64 encoding, and robust error handling. \n",
"- **Session constraints:** Limited to 30-minute sessions. \n",
"- **Restricted formats:** Accepts only raw PCM (no MP3 or Opus); For pcm16, input audio must be 16-bit PCM at a 24kHz sample rate, single channel (mono), and little-endian byte order."
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "c6fa0ea1",
"metadata": {},
"outputs": [],
"source": [
"TARGET_SR = 24_000\n",
"PCM_SCALE = 32_767\n",
"CHUNK_SAMPLES = 3_072 # ≈128 ms at 24 kHz\n",
"RT_URL = \"wss://api.openai.com/v1/realtime?intent=transcription\"\n",
"\n",
"EV_DELTA = \"conversation.item.input_audio_transcription.delta\"\n",
"EV_DONE = \"conversation.item.input_audio_transcription.completed\"\n",
"# ── helpers ────────────────────────────────────────────────────────────────\n",
"def float_to_16bit_pcm(float32_array):\n",
" clipped = [max(-1.0, min(1.0, x)) for x in float32_array]\n",
" pcm16 = b''.join(struct.pack(' np.ndarray:\n",
" \"\"\"Return mono PCM-16 as a NumPy array.\"\"\"\n",
" data, file_sr = sf.read(path, dtype=\"float32\")\n",
" if data.ndim > 1:\n",
" data = data.mean(axis=1)\n",
" if file_sr != sr:\n",
" data = resampy.resample(data, file_sr, sr)\n",
" return data\n",
"\n",
"async def _send_audio(ws, pcm: np.ndarray, chunk: int, sr: int) -> None:\n",
" \"\"\"Producer: stream base-64 chunks at real-time pace, then signal EOF.\"\"\"\n",
" dur = 0.025 # Add pacing to ensure real-time transcription\n",
" t_next = time.monotonic()\n",
"\n",
" for i in range(0, len(pcm), chunk):\n",
" float_chunk = pcm[i:i + chunk]\n",
" payload = {\n",
" \"type\": \"input_audio_buffer.append\",\n",
" \"audio\": base64_encode_audio(float_chunk),\n",
" }\n",
" await ws.send(json.dumps(payload))\n",
" t_next += dur\n",
" await asyncio.sleep(max(0, t_next - time.monotonic()))\n",
"\n",
" await ws.send(json.dumps({\"type\": \"input_audio_buffer.end\"}))\n",
"\n",
"async def _recv_transcripts(ws, collected: List[str]) -> None:\n",
" \"\"\"\n",
" Consumer: build `current` from streaming deltas, promote it to `collected`\n",
" whenever a …completed event arrives, and flush the remainder on socket\n",
" close so no words are lost.\n",
" \"\"\"\n",
" current: List[str] = []\n",
"\n",
" try:\n",
" async for msg in ws:\n",
" ev = json.loads(msg)\n",
"\n",
" typ = ev.get(\"type\")\n",
" if typ == EV_DELTA:\n",
" delta = ev.get(\"delta\")\n",
" if delta:\n",
" current.append(delta)\n",
" print(delta, end=\"\", flush=True)\n",
" elif typ == EV_DONE:\n",
" # sentence finished → move to permanent list\n",
" collected.append(\"\".join(current))\n",
" current.clear()\n",
" except websockets.ConnectionClosedOK:\n",
" pass\n",
"\n",
" # socket closed → flush any remaining partial sentence\n",
" if current:\n",
" collected.append(\"\".join(current))\n",
"\n",
"def _session(model: str, vad: float = 0.5) -> dict:\n",
" return {\n",
" \"type\": \"transcription_session.update\",\n",
" \"session\": {\n",
" \"input_audio_format\": \"pcm16\",\n",
" \"turn_detection\": {\"type\": \"server_vad\", \"threshold\": vad},\n",
" \"input_audio_transcription\": {\"model\": model},\n",
" },\n",
" }\n",
"\n",
"async def transcribe_audio_async(\n",
" wav_path,\n",
" api_key,\n",
" *,\n",
" model: str = MODEL_NAME,\n",
" chunk: int = CHUNK_SAMPLES,\n",
") -> str:\n",
" pcm = load_and_resample(wav_path)\n",
" headers = {\"Authorization\": f\"Bearer {api_key}\", \"OpenAI-Beta\": \"realtime=v1\"}\n",
"\n",
" async with websockets.connect(RT_URL, additional_headers=headers, max_size=None) as ws:\n",
" await ws.send(json.dumps(_session(model)))\n",
"\n",
" transcripts: List[str] = []\n",
" await asyncio.gather(\n",
" _send_audio(ws, pcm, chunk, TARGET_SR),\n",
" _recv_transcripts(ws, transcripts),\n",
" ) # returns when server closes\n",
"\n",
" return \" \".join(transcripts)"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "d90de5b9",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"And lots of times you need to give people more than one link at a time.A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo galleryLike these next few linksAn album to purchase."
]
},
{
"data": {
"text/plain": [
"'And lots of times you need to give people more than one link at a time. A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo gallery Like these next few linksAn album to purchase. '"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"transcript = await transcribe_audio_async(AUDIO_PATH, OPENAI_API_KEY)\n",
"transcript"
]
},
{
"cell_type": "markdown",
"id": "c20826c4",
"metadata": {},
"source": [
"---\n",
"## 4 · Agents SDK Realtime Transcription\n",
"*models = gpt-4o-transcribe, gpt-4o-mini*\n",
"### When to use\n",
"* Leveraging the OpenAI Agents SDK for real-time transcription and synthesis with minimal setup.\n",
"* You want to integrate transcription directly into agent-driven workflows.\n",
"* Prefer high-level management of audio input/output, WebSockets, and buffering.\n"
]
},
{
"cell_type": "markdown",
"id": "90bc7055",
"metadata": {},
"source": [
"### How it works\n",
"\n",
"\n",
"\n",
"**Benefits**\n",
"\n",
"- **Minimal boilerplate:** `VoicePipeline` handles resampling, VAD, buffering, token auth, and reconnects. \n",
"- **Seamless agent integration**: Enables direct interaction with GPT agents using real-time audio transcription.\n",
"\n",
"**Limitations**\n",
"\n",
"- **Python-only beta:** not yet available in other languages; APIs may change. \n",
"- **Less control:** fine-tuning VAD thresholds or packet scheduling requires digging into SDK internals. "
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "754a846b",
"metadata": {},
"outputs": [],
"source": [
"# ── 1 · agent that replies in French ---------------------------------------\n",
"fr_agent = Agent(\n",
" name=\"Assistant-FR\",\n",
" instructions=\n",
" \"Translate the user's words into French.\",\n",
" model=\"gpt-4o-mini\",\n",
")\n",
"\n",
"# ── 2 · workflow that PRINTS what it yields --------------------------------\n",
"class PrintingWorkflow(SingleAgentVoiceWorkflow):\n",
" \"\"\"Subclass that prints every chunk it yields (the agent's reply).\"\"\"\n",
"\n",
" async def run(self, transcription: str):\n",
" # Optionally: also print the user transcription\n",
" print()\n",
" print(\"[User]:\", transcription)\n",
" print(\"[Assistant]: \", end=\"\", flush=True)\n",
" async for chunk in super().run(transcription):\n",
" print(chunk, end=\"\", flush=True) # <-- agent (French) text\n",
" yield chunk # still forward to TTS\n",
"\n",
"\n",
"pipeline = VoicePipeline(\n",
" workflow=PrintingWorkflow(fr_agent),\n",
" stt_model=MODEL_NAME,\n",
" config=VoicePipelineConfig(tracing_disabled=True),\n",
")\n",
"\n",
"# ── 3 · helper to stream ~40 ms chunks at 24 kHz ---------------------------\n",
"def load_and_resample(path: str, sr: int = 24_000) -> np.ndarray:\n",
" \"\"\"Return mono PCM-16 as a NumPy array.\"\"\"\n",
" data, file_sr = sf.read(path, dtype=\"float32\")\n",
" if data.ndim > 1:\n",
" data = data.mean(axis=1)\n",
" if file_sr != sr:\n",
" data = resampy.resample(data, file_sr, sr)\n",
" return data\n",
" \n",
"def audio_chunks(path: str, target_sr: int = 24_000, chunk_ms: int = 40):\n",
" # 1️⃣ reuse the helper\n",
" audio = load_and_resample(path, target_sr)\n",
"\n",
" # 2️⃣ float-32 → int16 NumPy array\n",
" pcm = (np.clip(audio, -1, 1) * 32_767).astype(np.int16)\n",
"\n",
" # 3️⃣ yield real-time sized hops\n",
" hop = int(target_sr * chunk_ms / 1_000)\n",
" for off in range(0, len(pcm), hop):\n",
" yield pcm[off : off + hop]\n",
"\n",
"# ── 4 · stream the file ----------------------------------------------------\n",
"async def stream_audio(path: str):\n",
" sai = StreamedAudioInput()\n",
" run_task = asyncio.create_task(pipeline.run(sai))\n",
"\n",
" for chunk in audio_chunks(path):\n",
" await sai.add_audio(chunk)\n",
" await asyncio.sleep(len(chunk) / 24_000) # real-time pacing\n",
"\n",
" # just stop pushing; session ends automatically\n",
" await run_task # wait for pipeline to finish"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "611c11e0",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"[User]: And lots of times you need to give people more than one link at a time.\n",
"[Assistant]: Et souvent, vous devez donner aux gens plusieurs liens à la fois.\n",
"[User]: A band could give their fans a couple new videos from a live concert, a behind-the-scenes photo gallery.\n",
"[Assistant]: Un groupe pourrait donner à ses fans quelques nouvelles vidéos d'un concert live, ainsi qu'une galerie de photos des coulisses.\n",
"[User]: An album to purchase.\n",
"[Assistant]: "
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Un album à acheter.\n",
"[User]: like these next few links.\n",
"[Assistant]: comme ces quelques liens suivants."
]
}
],
"source": [
"await stream_audio(AUDIO_PATH)"
]
},
{
"cell_type": "markdown",
"id": "e34ebc6d",
"metadata": {},
"source": [
"## Conclusion \n",
"\n",
"In this notebook you explored multiple ways to convert speech to text with the OpenAI API and the Agents SDK, ranging from simple file uploads to fully-interactive, real-time streaming. Each workflow shines in a different scenario, so pick the one that best matches your product’s needs.\n",
"\n",
"### Key takeaways\n",
"- **Match the method to the use-case:** \n",
" • Offline batch jobs → file-based transcription. \n",
" • Near-real-time updates → HTTP-streaming. \n",
" • Conversational, low-latency experiences → WebSocket or Agents SDK. \n",
"- **Weigh trade-offs:** latency, implementation effort, supported formats, and session limits all differ by approach. \n",
"- **Stay current:** the models and SDK continue to improve; new features ship regularly.\n",
"\n",
"### Next steps\n",
"1. Try out the notebook!\n",
"2. Integrate your chosen workflow into your application.\n",
"3. Send us feedback! Community insights help drive the next round of model upgrades. "
]
},
{
"cell_type": "markdown",
"id": "e0b68b9b",
"metadata": {},
"source": [
"## References\n",
"* Explore the [Transcriptions API docs](https://platform.openai.com/docs/api-reference/audio).\n",
"* Read the [Realtime guide](https://platform.openai.com/docs/guides/realtime?use-case=transcription).\n",
"* Explore the [Agents SDK reference](https://openai.github.io/openai-agents-python/).\n",
"* Explore the [Agents SDK Voice Pipeline reference](https://openai.github.io/openai-agents-python/voice/)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "openai",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.11.8"
}
},
"nbformat": 4,
"nbformat_minor": 5
}