{
"cells": [
{
"cell_type": "markdown",
"id": "2a89ade7",
"metadata": {},
"source": [
"# GPT Image Generation Models Prompting Guide"
]
},
{
"cell_type": "markdown",
"id": "093e2be4",
"metadata": {},
"source": [
"## 1. Introduction"
]
},
{
"cell_type": "markdown",
"id": "f8e7cdd4",
"metadata": {},
"source": [
"OpenAI's gpt-image generation models are designed for production-quality visuals and highly controllable creative workflows. They are well-suited for both professional design tasks and iterative content creation, and support both high-quality rendering and lower-latency use cases depending on the workflow.\n",
"\n",
"Key Capabilities include: \n",
"\n",
"- **High-fidelity photorealism** with natural lighting, accurate materials, and rich color rendering\n",
"- **Flexible quality–latency tradeoffs**, allowing faster generation at lower settings while still exceeding the visual quality of prior-generation image models\n",
"- **Robust facial and identity preservation** for edits, character consistency, and multi-step workflows\n",
"- **Reliable text rendering** with crisp lettering, consistent layout, and strong contrast inside images\n",
"- **Complex structured visuals**, including infographics, diagrams, and multi-panel compositions\n",
"- **Precise style control and style transfer** with minimal prompting, supporting everything from branded design systems to fine-art styles\n",
"- **Strong real-world knowledge and reasoning**, enabling accurate depictions of objects, environments, and scenarios\n",
"\n",
"This guide highlights prompting patterns, best practices, and example prompts drawn from real production use cases for `gpt-image-2`. It is our most capable image model, with stronger image quality, improved editing performance, and broader support for production workflows. The `low` quality setting is especially strong for latency-sensitive use cases, while `medium` and `high` remain good fits when maximum fidelity matters. \n"
]
},
{
"cell_type": "markdown",
"id": "d312c387",
"metadata": {},
"source": [
"## 1.1 OpenAI Image Model Parameters \n",
"\n",
"This section is a reference for the image models covered in this guide, focused on:\n",
"\n",
"- model name\n",
"- supported `outputQuality` values\n",
"- supported `input_fidelity` values\n",
"- supported `size` / resolution behavior\n",
"- recommended use cases by workflow\n",
"\n",
"## Model summary\n",
"As of April 21, 2026, OpenAI has the following image models available.\n",
"\n",
"| Model | `outputQuality` | `input_fidelity` | Resolutions | Recommended use |\n",
"| --- | --- | --- | --- | --- |\n",
"| `gpt-image-2` | `low`, `medium`, `high` | Disabled. `input_fidelity` does not work for this model because output is already high fidelity by default | Any resolution that satisfies the constraints below | Recommended default for new builds. Use for highest-quality generation and editing, text-heavy images, photorealism, compositing, identity-sensitive edits, and workflows where fewer retries matter more than the lowest possible cost. |\n",
"| `gpt-image-1.5` | `low`, `medium`, `high` | `low`, `high` | `1024x1024`, `1024x1536`, `1536x1024`, `auto` | Keep for existing validated workflows during migration. For new work, prefer `gpt-image-2`, especially when quality, editing reliability, or flexible sizing matter. |\n",
"| `gpt-image-1` | `low`, `medium`, `high` | `low`, `high` | `1024x1024`, `1024x1536`, `1536x1024`, `auto` | Legacy compatibility only. If you are starting a new workflow or refreshing prompts, move to `gpt-image-2`; keep `gpt-image-1` only when you need short-term stability while validating the upgrade. |\n",
"| `gpt-image-1-mini` | `low`, `medium`, `high` | `low`, `high` | `1024x1024`, `1024x1536`, `1536x1024`, `auto` | Use when cost and throughput are the main constraint: large batch variant generation, rapid ideation, previews, lightweight personalization, and draft assets that do not require the strongest generation or editing performance. |\n",
"\n",
"### `gpt-image-2` size options\n",
"\n",
"`gpt-image-2` supports any resolution passed in the `size` parameter as long as all of these constraints are met:\n",
"\n",
"- Maximum edge length must be less than `3840px`\n",
"- Both edges must be a multiple of `16`\n",
"- Ratio between the long edge and short edge must not be greater than `3:1`\n",
"- Total pixels must not exceed `8,294,400`\n",
"- Total pixels must not be less than `655,360`\n",
"\n",
"If the output image exceeds `2560x1440` pixels (`3,686,400` total pixels), commonly referred to as 2K, treat it as experimental because results can be more variable above this size.\n",
"\n",
"### Popular `gpt-image-2` sizes\n",
"\n",
"These are useful reference points that fit the constraints above:\n",
"\n",
"| Label | Resolution | Notes |\n",
"| --- | --- | --- |\n",
"| HD portrait | `1024x1536` | Standard portrait option |\n",
"| HD landscape | `1536x1024` | Standard landscape option |\n",
"| Square | `1024x1024` | Good general-purpose default |\n",
"| 2K / QHD | `2560x1440` | Popular widescreen format and recommended upper reliability boundary for `gpt-image-2` |\n",
"| 4K / UHD | `3840x2160` | Experimental upper-end target. If the max-edge rule is enforced literally as `< 3840`, round down to the nearest valid size such as `3824x2144` |\n",
"\n",
"### When to use which model\n",
"\n",
"- Choose `gpt-image-2` as the default for most production workflows. It is the strongest overall model and the right upgrade target for teams currently using `gpt-image-1.5` or `gpt-image-1` for high-quality outputs.\n",
"- Choose `gpt-image-2` with quality: low when speed and unit economics dominate the decision. This setting has good quality for a lot of use cases and it a strong fit for high-volume generation and experimentation. You can also try `gpt-image-1-mini` for these use cases, but we have seen quality: low works just as well.\n",
"- Keep `gpt-image-1.5` or `gpt-image-1` only for backward compatibility while you validate prompt migrations, regression-test outputs, or maintain older workflows that are not yet ready to move.\n",
"\n",
"### Recommended upgrade path from `gpt-image-1.5` and `gpt-image-1`\n",
"\n",
"For workflows currently using `gpt-image-1.5` or `gpt-image-1`, the recommendation is:\n",
"\n",
"- Upgrade to `gpt-image-2` for customer-facing assets, photorealistic generation, editing-heavy flows, brand-sensitive creative, text-in-image work, and any workflow where better first-pass quality reduces manual review or reruns.\n",
"- Consider `gpt-image-1-mini` instead of legacy models only when the main goal is lowering cost for large batches of exploratory or lower-stakes images.\n",
"- During migration, keep prompts largely the same at first, then retune only after you have compared output quality, latency, and retry rates on your real workload."
]
},
{
"cell_type": "markdown",
"id": "90b8bc80",
"metadata": {},
"source": [
"## 2. Prompting Fundamentals\n",
"\n",
"The following prompting fundamentals are applicable to GPT image generation models. They are based on patterns that showed up repeatedly in alpha testing across generation, edits, infographics, ads, human images, UI mockups, and compositing workflows.\n",
"\n",
"* **Structure + goal:** Write prompts in a consistent order (background/scene → subject → key details → constraints) and include the intended use (ad, UI mock, infographic) to set the “mode” and level of polish. For complex requests, use short labeled segments or line breaks instead of one long paragraph.\n",
"\n",
"* **Prompt format:** Use the format that is easiest to maintain. Minimal prompts, descriptive paragraphs, JSON-like structures, instruction-style prompts, and tag-based prompts can all work well as long as the intent and constraints are clear. For production systems, prioritize a skimmable template over clever prompt syntax.\n",
"\n",
"* **Specificity + quality cues:** Be concrete about materials, shapes, textures, and the visual medium (photo, watercolor, 3D render), and add targeted “quality levers” only when needed (e.g., *film grain*, *textured brushstrokes*, *macro detail*). For photorealism, include the word “photorealistic” directly in the prompt to strongly engage the model’s photorealistic mode. Similar phrases like “real photograph,” “taken on a real camera,” “professional photography,” or “iPhone photo” can also help, but detailed camera specs may be interpreted loosely, so use them mainly for high-level look and composition rather than exact physical simulation.\n",
"\n",
"* **Latency vs fidelity:** For latency-sensitive or high-volume use cases, start with `quality=\"low\"` and evaluate whether it meets your visual requirements. In many cases, it provides sufficient fidelity with significantly faster generation. For small or dense text, detailed infographics, close-up portraits, identity-sensitive edits, and high-resolution outputs, compare `medium` or `high` before shipping.\n",
"\n",
"* **Composition:** Specify framing and viewpoint (close-up, wide, top-down), perspective/angle (eye-level, low-angle), and lighting/mood (soft diffuse, golden hour, high-contrast) to control the shot. If layout matters, call out placement (e.g., “logo top-right,” “subject centered with negative space on left”). For wide, cinematic, low-light, rain, or neon scenes, add extra detail about scale, atmosphere, and color so the model does not trade mood for surface realism.\n",
"\n",
"* **People, pose, and action:** For people in scenes, describe scale, body framing, gaze, and object interactions. Examples: “full body visible, feet included,” “child-sized relative to the table,” “looking down at the open book, not at the camera,” or “hands naturally gripping the handlebars.” These details help with body proportion, action geometry, and gaze alignment.\n",
"\n",
"* **Constraints (what to change vs preserve):** State exclusions and invariants explicitly (e.g., “no watermark,” “no extra text,” “no logos/trademarks,” “preserve identity/geometry/layout/brand elements”). For edits, use “change only X” + “keep everything else the same,” and repeat the preserve list on each iteration to reduce drift. If the edit should be surgical, also say not to alter saturation, contrast, layout, arrows, labels, camera angle, or surrounding objects.\n",
"\n",
"* **Text in images:** Put literal text in **quotes** or **ALL CAPS** and specify typography details (font style, size, color, placement) as constraints. For tricky words (brand names, uncommon spellings), spell them out letter-by-letter to improve character accuracy. Use `medium` or `high` quality for small text, dense information panels, and multi-font layouts.\n",
"\n",
"* **Multi-image inputs:** Reference each input by **index and description** (“Image 1: product photo… Image 2: style reference…”) and describe how they interact (“apply Image 2’s style to Image 1”). When compositing, be explicit about which elements move where (“put the bird from Image 1 on the elephant in Image 2”).\n",
"\n",
"* **Iterate instead of overloading:** Long prompts can work well, but debugging is easier when you start with a clean base prompt and refine with small, single-change follow-ups (“make lighting warmer,” “remove the extra tree,” “restore the original background”). Use references like “same style as before” or “the subject” to leverage context, but re-specify critical details if they start to drift."
]
},
{
"cell_type": "markdown",
"id": "45bdaee0",
"metadata": {},
"source": [
"## 3. Setup\n",
"\n",
"Run this once. It:\n",
"- creates the API client\n",
"- creates `output_images/` in the images folder. \n",
"- adds a small helper to save base64 images\n",
"\n",
"Put any reference images used for edits into `input_images/` (or update the paths in the examples)."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "faa04870",
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import base64\n",
"from openai import OpenAI\n",
"\n",
"client = OpenAI()\n",
"\n",
"os.makedirs(\"../../images/input_images\", exist_ok=True)\n",
"os.makedirs(\"../../images/output_images\", exist_ok=True)\n",
"\n",
"def save_image(result, filename: str) -> None:\n",
" \"\"\"\n",
" Saves the first returned image to the given filename inside the output_images folder.\n",
" \"\"\"\n",
" image_base64 = result.data[0].b64_json\n",
" out_path = os.path.join(\"../../images/output_images\", filename)\n",
" with open(out_path, \"wb\") as f:\n",
" f.write(base64.b64decode(image_base64))\n",
"\n",
"from IPython.display import HTML, Image, display\n",
"\n",
"def display_image_grid(items, width=240):\n",
" cards = []\n",
" for item in items:\n",
" title = item.get(\"title\", \"\")\n",
" label = f'
{title}
' if title else \"\"\n",
" cards.append(\n",
" '
'\n",
" + label\n",
" + f''\n",
" + '
'\n",
" )\n",
" display(HTML('
' + ''.join(cards) + '
'))\n"
]
},
{
"cell_type": "markdown",
"id": "9dc7f497",
"metadata": {},
"source": [
"The examples below uses our most capable image model `gpt-image-2`"
]
},
{
"cell_type": "markdown",
"id": "42230fcd",
"metadata": {},
"source": [
"## 4. Use Cases — Generate (text → image)\n",
"\n",
"## 4.1 Infographics\n",
"Use infographics to explain structured information for a specific audience: students, executives, customers, or the general public. Examples include explainers, posters, labeled diagrams, timelines, and “visual wiki” assets. For dense layouts or heavy in-image text, it's recommedned to set output generation quality to \"high\"."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b8630e9f",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a detailed Infographic of the functioning and flow of an automatic coffee machine like a Jura. \n",
"From bean basket, to grinding, to scale, water tank, boiler, etc. \n",
"I'd like to understand technically and visually the flow.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"infographic_coffee_machine_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "914f04df",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
"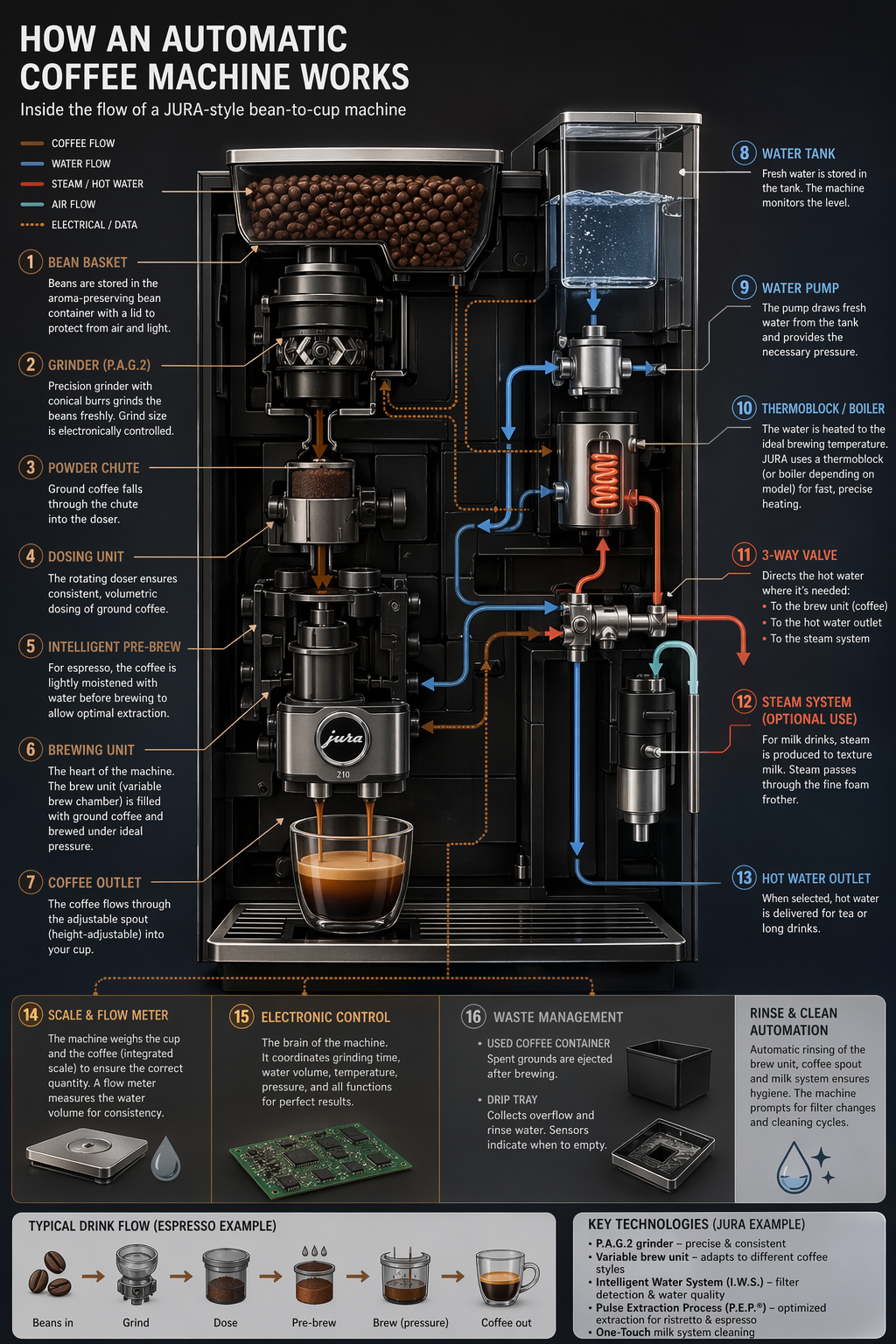"
]
},
{
"cell_type": "markdown",
"id": "f1deec1e",
"metadata": {},
"source": [
"## 4.2 Translation in Images\n",
"\n",
"Used for localizing existing designs (ads, UI screenshots, packaging, infographics) into another language without rebuilding the layout from scratch. The key is to preserve everything except the text—keep typography style, placement, spacing, and hierarchy consistent—while translating verbatim and accurately, with no extra words, no reflow unless necessary, and no unintended edits to logos, icons, or imagery."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2c91fb16",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Translate the text in the infographic to Spanish. Do not change any other aspect of the image.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/output_images/infographic_coffee_machine_gpt-image-2.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"\n",
"save_image(result, \"infographic_coffee_machine_sp_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "e147f345",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
"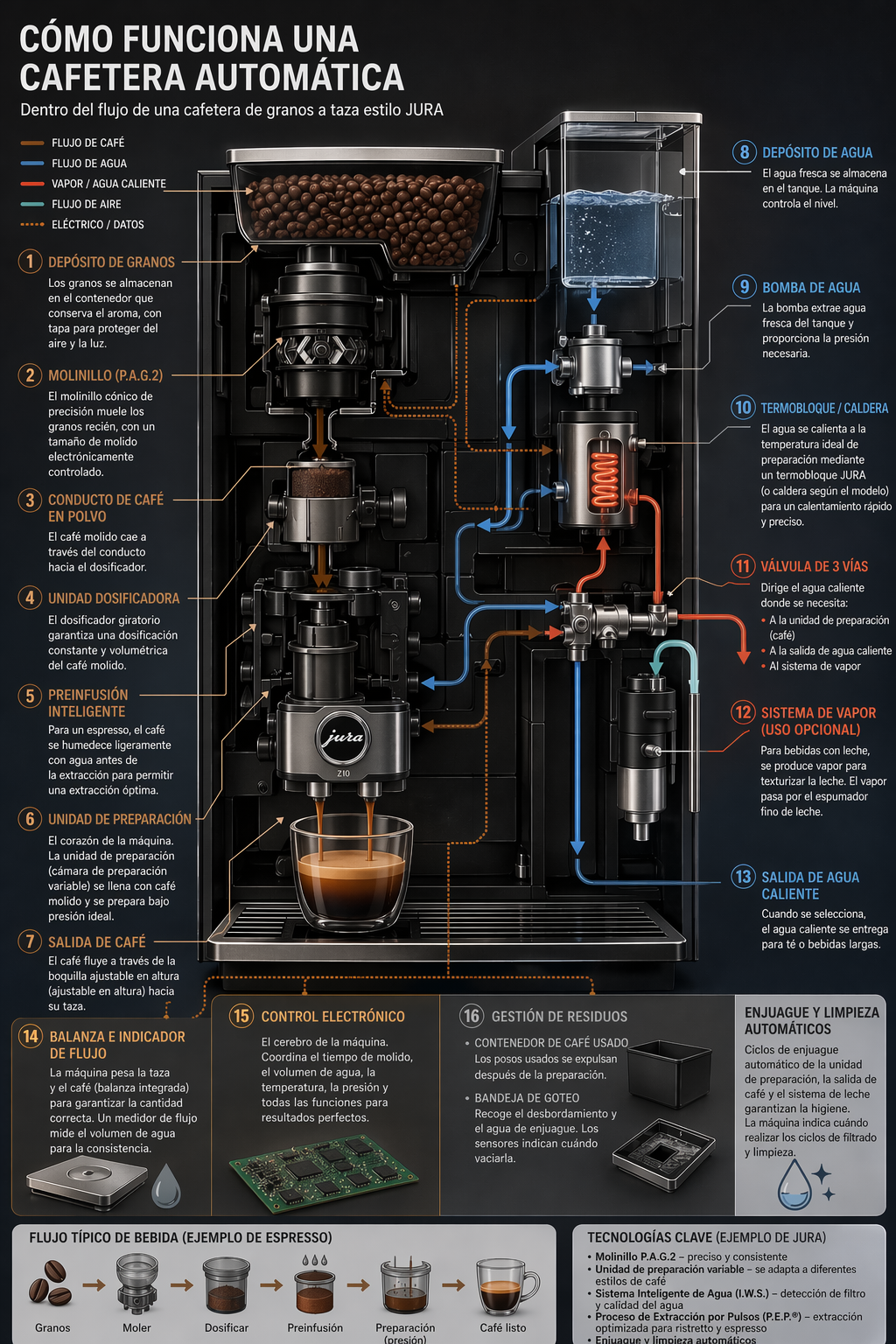"
]
},
{
"cell_type": "markdown",
"id": "efd3f6de",
"metadata": {},
"source": [
"## 4.3 Photorealistic Images that Feel “natural”\n",
"\n",
"To get believable photorealism, prompt the model as if a real photo is being captured in the moment. Use photography language (lens, lighting, framing) and explicitly ask for real texture (pores, wrinkles, fabric wear, imperfections). Avoid words that imply studio polish or staging. When detail matters, set quality=\"high\"."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "69415e83",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a photorealistic candid photograph of an elderly sailor standing on a small fishing boat. \n",
"He has weathered skin with visible wrinkles, pores, and sun texture, and a few faded traditional sailor tattoos on his arms. \n",
"He is calmly adjusting a net while his dog sits nearby on the deck. Shot like a 35mm film photograph, medium close-up at eye level, using a 50mm lens. \n",
"Soft coastal daylight, shallow depth of field, subtle film grain, natural color balance. \n",
"The image should feel honest and unposed, with real skin texture, worn materials, and everyday detail. No glamorization, no heavy retouching. \n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"photorealism-gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "32c1ea65",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "73d36fa2",
"metadata": {},
"source": [
"## 4.4 World knowledge\n",
"\n",
"GPT image generation models can pair strong reasoning with world knowledge. For example, when asked to generate a scene set in Bethel, New York in August 1969, they can infer Woodstock and produce an accurate, context-appropriate image without being explicitly told about the event. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6846fe27",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a realistic outdoor crowd scene in Bethel, New York on August 16, 1969.\n",
"Photorealistic, period-accurate clothing, staging, and environment.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"world_knowledge-gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "1a0cc9a3",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "4854e981",
"metadata": {},
"source": [
"## 4.5 Logo Generation\n",
"\n",
"Strong logo generation comes from clear brand constraints and simplicity. Describe the brand’s personality and use case, then ask for a clean, original mark with strong shape, balanced negative space, and scalability across sizes.\n",
"\n",
"You can specify parameter \"n\" to denote the number of variations you would like to generate. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "93f6ba30",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create an original, non-infringing logo for a company called Field & Flour, a local bakery. \n",
"The logo should feel warm, simple, and timeless. Use clean, vector-like shapes, a strong silhouette, and balanced negative space. \n",
"Favor simplicity over detail so it reads clearly at small and large sizes. Flat design, minimal strokes, no gradients unless essential. \n",
"Plain background. Deliver a single centered logo with generous padding. No watermark.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
" n=4 # Generate 4 versions of the logo\n",
")\n",
"\n",
"# Save all 4 images to separate files\n",
"for i, item in enumerate(result.data, start=1):\n",
" image_base64 = item.b64_json\n",
" image_bytes = base64.b64decode(image_base64)\n",
" with open(f\"../../images/output_images/logo_generation_{i}_gpt-image-2.png\", \"wb\") as f:\n",
" f.write(image_bytes)"
]
},
{
"cell_type": "markdown",
"id": "11aec7b6",
"metadata": {},
"source": [
"Output Images: \n",
"\n",
"| Option 1 | Option 2 | Option 3 | Option 4 |\n",
"|:--------:|:--------:|:--------:|:--------:|\n",
"|  |  |  | |"
]
},
{
"cell_type": "markdown",
"id": "ad-gen-section",
"metadata": {},
"source": [
"## 4.6 Ads Generation\n",
"\n",
"Ad generation works best when the prompt is written like a creative brief rather than a purely technical image spec. Describe the brand, audience, culture, concept, composition, and exact copy, then let the model make taste-driven creative decisions inside those boundaries. This is useful for early campaign exploration because the model can interpret audience cues, infer art direction, and propose visual details that make the ad feel considered rather than merely rendered.\n",
"\n",
"For stronger results, include the brand positioning, desired vibe, target audience, scene, and tagline in the same prompt. If the text must appear in the image, quote it exactly and ask for clean, legible typography."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ad-gen-code",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Give me a cool in culture ad / fashion shot for a brand called Thread. \n",
"It's a hip young street brand. The ad shows a group of friends hanging out together with the tagline \"Yours to Create.\"\n",
"Make it feel like a polished campaign image for a youth streetwear audience: stylish, contemporary, energetic, and tasteful.\n",
"Use clean composition, strong color direction, natural poses, and premium fashion photography cues.\n",
"Render the tagline exactly once, clearly and legibly, integrated into the ad layout.\n",
"No extra text, no watermarks, no unrelated logos.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"thread_ad_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "ad-gen-output-label",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "1869e001",
"metadata": {},
"source": [
"## 4.7 Story-to-Comic Strip\n",
"\n",
"For story-to-comic generation, define the narrative as a sequence of clear visual beats, one per panel. Keep descriptions concrete and action-focused so the model can translate the story into readable, well-paced panels."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6bee45d0",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a short vertical comic-style reel with 4 equal-sized panels.\n",
"Panel 1: The owner leaves through the front door. The pet is framed in the window behind them, small against the glass, eyes wide, paws pressed high, the house suddenly quiet.\n",
"Panel 2: The door clicks shut. Silence breaks. The pet slowly turns toward the empty house, posture shifting, eyes sharp with possibility.\n",
"Panel 3: The house transformed. The pet sprawls across the couch like it owns the place, crumbs nearby, sunlight cutting across the room like a spotlight.\n",
"Panel 4: The door opens. The pet is seated perfectly by the entrance, alert and composed, as if nothing happened.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"comic_reel-gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "4d46a8e2",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "82834c1d",
"metadata": {},
"source": [
"## 4.8 UI Mockups\n",
"\n",
"UI mockups work best when you describe the product as if it already exists. Focus on layout, hierarchy, spacing, and real interface elements, and avoid concept art language so the result looks like a usable, shipped interface rather than a design sketch."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a5a99ddc",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a realistic mobile app UI mockup for a local farmers market. \n",
"Show today’s market with a simple header, a short list of vendors with small photos and categories, a small “Today’s specials” section, and basic information for location and hours. \n",
"Design it to be practical, and easy to use. White background, subtle natural accent colors, clear typography, and minimal decoration. \n",
"It should look like a real, well-designed, beautiful app for a small local market. \n",
"Place the UI mockup in an iPhone frame.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"ui_farmers_market_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "8e57b1a4",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "f8f7a6e3",
"metadata": {},
"source": [
"## 4.9 Scientific / Educational Visuals\n",
"\n",
"Scientific and educational visuals are strong fits for biology, chemistry, classroom explainers, flat scientific icon systems, diagrams, and learning assets. Prompt them like an instructional design brief: define the audience, lesson objective, visual format, required labels, and scientific constraints. For best results, ask for a clean, flat visual system with consistent icon style, clear arrows, readable labels, and enough white space for students to scan the concept quickly.\n",
"\n",
"When accuracy matters, list the required components explicitly and say what should not be included. Use `quality=\"high\"` for dense labels, diagrams, or assets that will be used in slides or course materials."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a6df0795",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a simple biology diagram titled \"Cellular Respiration at a Glance\" for high school students.\n",
"\n",
"Show how glucose turns into energy inside a cell. Include glycolysis, the Krebs cycle, and the electron transport chain.\n",
"Use arrows to connect the steps, and label the main molecules: glucose, pyruvate, ATP, NADH, FADH2, CO2, O2, and H2O.\n",
"Make it look like a clean classroom handout or slide, with a white background, simple icons, clear labels, and easy-to-read text.\n",
"\n",
"Avoid tiny text, extra decoration, or anything that makes the diagram hard to understand.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1536x1024\",\n",
" quality=\"high\",\n",
")\n",
"\n",
"save_image(result, \"scientific_educational_cellular_respiration_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "fbff5efb",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "db7a2d63",
"metadata": {},
"source": [
"## 4.10 Slides, Diagrams, Charts, and Productivity Images\n",
"\n",
"Productivity visuals work best when the prompt is written like an artifact spec rather than an illustration request. Name the exact deliverable (slide, workflow diagram, chart, page image), define the canvas and hierarchy, provide the real text or data, and describe the visual language. These prompts should include practical constraints: readable typography, polished spacing, no decorative clutter, and no generic stock-photo treatment.\n",
"\n",
"For slides, charts, and diagram-heavy assets, include the numbers and labels directly in the prompt. Use a landscape size for deck-style outputs and `quality=\"high\"` when the image contains small text, legends, axes, or footnotes."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "9ce5f2e2",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create one pitch-deck slide titled **\"Market Opportunity\"** that feels like a real Series A fundraising slide from a YC-backed startup.\n",
"\n",
"Use a clean white background, modern sans-serif typography like Inter, and a crisp, minimal layout. The slide should include:\n",
"\n",
"* A TAM/SAM/SOM concentric-circle diagram in muted blues and grays\n",
"* Specific, believable market sizing numbers:\n",
"\n",
" * **TAM:** $42B\n",
" * **SAM:** $8.7B\n",
" * **SOM:** $340M\n",
"* A clean bar chart below showing market growth from **2021 to 2026**, with a subtle upward trend\n",
"* Small footnotes: **\"AGI Research, 2024\"** and **\"Internal analysis\"**\n",
"* A company logo placeholder in the bottom-right corner\n",
"\n",
"The design should look like it belongs in a deck that actually raised money: highly readable text, clear data hierarchy, polished spacing, and professional startup-style visual language.\n",
"\n",
"Avoid clip art, stock photography, gradients, shadows, decorative elements, or anything that feels generic or overdesigned.\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1536x864\",\n",
" quality=\"high\",\n",
")\n",
"\n",
"save_image(result, \"market_opportunity_slide_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "a90bf13a",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
"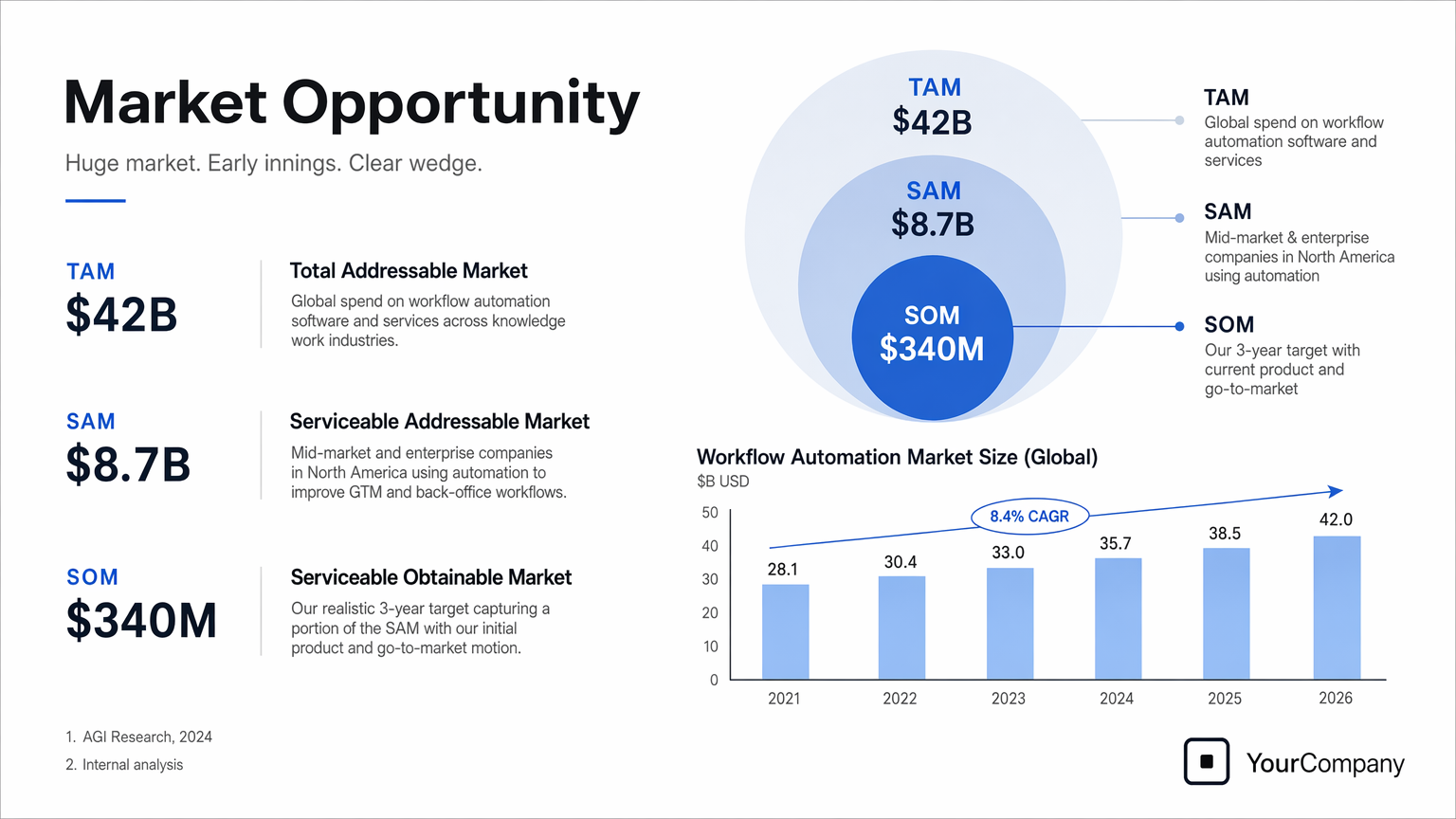"
]
},
{
"cell_type": "markdown",
"id": "ebb745b8",
"metadata": {},
"source": [
"## 5. Use cases — Edit (text + image → image)"
]
},
{
"cell_type": "markdown",
"id": "e072cea4",
"metadata": {},
"source": [
"## 5.1 Style Transfer"
]
},
{
"cell_type": "markdown",
"id": "2b96f5ed",
"metadata": {},
"source": [
"Style transfer is useful when you want to keep the *visual language* of a reference image (palette, texture, brushwork, film grain, etc.) while changing the subject or scene. For best results, describe what must stay consistent (style cues) and what must change (new content), and add hard constraints like background, framing, and “no extra elements” to prevent drift."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1c29d3d5",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Use the same style from the input image and generate a man riding a motorcycle on a white background.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/pixels.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"motorcycle_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "d9214e26",
"metadata": {},
"source": [
"Input Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "78527598",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "b38508a4",
"metadata": {},
"source": [
"## 5.2 Virtual Clothing Try-On\n"
]
},
{
"cell_type": "markdown",
"id": "5206991c",
"metadata": {},
"source": [
"Virtual try-on is ideal for ecommerce previews where identity preservation is critical. The key is to explicitly lock the person (face, body shape, pose, hair, expression) and allow changes *only* to garments, then require realistic fit (draping, folds, occlusion) plus consistent lighting/shadows so the outfit looks naturally worn—not pasted on."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "de640179",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Edit the image to dress the woman using the provided clothing images. Do not change her face, facial features, skin tone, body shape, pose, or identity in any way. Preserve her exact likeness, expression, hairstyle, and proportions. Replace only the clothing, fitting the garments naturally to her existing pose and body geometry with realistic fabric behavior. Match lighting, shadows, and color temperature to the original photo so the outfit integrates photorealistically, without looking pasted on. Do not change the background, camera angle, framing, or image quality, and do not add accessories, text, logos, or watermarks.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/woman_in_museum.png\", \"rb\"),\n",
" open(\"../../images/input_images/tank_top.png\", \"rb\"),\n",
" open(\"../../images/input_images/jacket.png\", \"rb\"),\n",
" open(\"../../images/input_images/tank_top.png\", \"rb\"),\n",
" open(\"../../images/input_images/boots.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"outfit_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "4c1a4ec3",
"metadata": {},
"source": [
"Input Images:\n",
"\n",
"| Full Body | Item 1 |\n",
"|:------------:|:--------------:|\n",
"|  |  |\n",
"| Item 2 | Item 3 |\n",
"|  |  |"
]
},
{
"cell_type": "markdown",
"id": "6501d32e",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "cc86dd0b",
"metadata": {},
"source": [
"## 5.3 Drawing → Image (Rendering)\n"
]
},
{
"cell_type": "markdown",
"id": "52102170",
"metadata": {},
"source": [
"Sketch-to-render workflows are great for turning rough drawings into photorealistic concepts while keeping the original intent. Treat the prompt like a spec: preserve layout and perspective, then *add realism* by specifying plausible materials, lighting, and environment. Include “do not add new elements/text” to avoid creative reinterpretations."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3141fac9",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Turn this drawing into a photorealistic image.\n",
"Preserve the exact layout, proportions, and perspective.\n",
"Choose realistic materials and lighting consistent with the sketch intent.\n",
"Do not add new elements or text.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/drawings.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"realistic_valley_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "e86fe9ca",
"metadata": {},
"source": [
"Input Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "0bad2770",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "d7b4f901",
"metadata": {},
"source": [
"## 5.4 Product Mockups (clean background + label integrity)\n"
]
},
{
"cell_type": "markdown",
"id": "d42c73d0",
"metadata": {},
"source": [
"Product extraction and mockup prep is commonly used for catalogs, marketplaces, and design systems. Success depends on edge quality (clean silhouette, no fringing/halos) and label integrity (text stays sharp and unchanged). For `gpt-image-2`, keep the output background opaque and use a downstream background-removal step if you need a final transparent asset. If you want realism without re-styling, ask for only light polishing and optionally a subtle contact shadow on a plain background."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6ee50b1c",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Extract the product from the input image and place it on a plain white opaque background.\n",
"Output: centered product, crisp silhouette, no halos/fringing.\n",
"Preserve product geometry and label legibility exactly.\n",
"Add only light polishing and a subtle realistic contact shadow.\n",
"Do not restyle the product; only remove background and lightly polish.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/shampoo.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
" background=\"opaque\",\n",
")\n",
"\n",
"save_image(result, \"extract_product_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "e4210a50",
"metadata": {},
"source": [
"Input Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "a6fdbc44",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "0e0643ef",
"metadata": {},
"source": [
"## 5.5 Marketing Creatives with Real Text In-Image\n"
]
},
{
"cell_type": "markdown",
"id": "d62b664d",
"metadata": {},
"source": [
"Marketing creatives with real in-image text are great for rapid ad concepting, but typography needs explicit constraints. Put the exact copy in quotes, demand verbatim rendering (no extra characters), and describe placement and font style. If text fidelity is imperfect, keep the prompt strict and iterate—small wording/layout tweaks usually improve legibility."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0a5cf36e",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Create a realistic billboard mockup of the shampoo on a highway scene during sunset.\n",
"Billboard text (EXACT, verbatim, no extra characters):\n",
"\"Fresh and clean\"\n",
"Typography: bold sans-serif, high contrast, centered, clean kerning.\n",
"Ensure text appears once and is perfectly legible.\n",
"No watermarks, no logos.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/shampoo.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"billboard_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "09c6d234",
"metadata": {},
"source": [
"Input Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "c6092840",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "cfac21a4",
"metadata": {},
"source": [
"## 5.6 Lighting and Weather Transformation\n"
]
},
{
"cell_type": "markdown",
"id": "d3a02279",
"metadata": {},
"source": [
"Used to re-stage a photo for different moods, seasons, or time-of-day variants (e.g., sunny → overcast, daytime → dusk, clear → snowy) while keeping the scene composition intact. The key is to change only environmental conditions—lighting direction/quality, shadows, atmosphere, precipitation, and ground wetness—while preserving identity, geometry, camera angle, and object placement so it still reads as the same original photo."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "acd39e37",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Make it look like a winter evening with snowfall.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" input_fidelity=\"high\", \n",
" image=[\n",
" open(\"../../images/output_images/billboard_gpt-image-2.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"billboard_winter_gpt-image-2.png\")\n"
]
},
{
"cell_type": "markdown",
"id": "743f5de8",
"metadata": {},
"source": [
"Output Image: \n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "30e42165",
"metadata": {},
"source": [
"## 5.7 Object Removal\n"
]
},
{
"cell_type": "markdown",
"id": "476b3307",
"metadata": {},
"source": [
"Person-in-scene compositing is useful for storyboards, campaigns, and “what if” scenarios where facial/identity preservation matters. Anchor realism by specifying a grounded photographic look (natural lighting, believable detail, no cinematic grading), and lock what must not change about the subject. When available, higher input fidelity helps maintain likeness during larger scene edits."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c2dd9dde",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Remove the flower from man's hand. Do not change anything else.\n",
"\"\"\"\n",
"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" input_fidelity=\"high\", \n",
" image=[\n",
" open(\"../../images/output_images/man_with_blue_hat.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"man_with_no_flower_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "c4abc891",
"metadata": {},
"source": [
"Input and output images:\n",
"\n",
"| Original Input | Output Image |\n",
"|:------------:|:--------------:|\n",
"|  |  |\n"
]
},
{
"cell_type": "markdown",
"id": "ff6cc213",
"metadata": {},
"source": [
"## 5.8 Insert the Person Into a Scene\n"
]
},
{
"cell_type": "markdown",
"id": "4a1a7f21",
"metadata": {},
"source": [
"Person-in-scene compositing is useful for storyboards, campaigns, and “what if” scenarios where facial/identity preservation matters. Anchor realism by specifying a grounded photographic look (natural lighting, believable detail, no cinematic grading), and lock what must not change about the subject. When available, higher input fidelity helps maintain likeness during larger scene edits."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "42f08fa3",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Generate a highly realistic action scene where this person is running away from a large, realistic brown bear attacking a campsite. The image should look like a real photograph someone could have taken, not an overly enhanced or cinematic movie-poster image.\n",
"She is centered in the image but looking away from the camera, wearing outdoorsy camping attire, with dirt on her face and tears in her clothing. She is clearly afraid but focused on escaping, running away from the bear as it destroys the campsite behind her.\n",
"The campsite is in Yosemite National Park, with believable natural details. The time of day is dusk, with natural lighting and realistic colors. Everything should feel grounded, authentic, and unstyled, as if captured in a real moment. Avoid cinematic lighting, dramatic color grading, or stylized composition.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" input_fidelity=\"high\", \n",
" image=[\n",
" open(\"../../images/input_images/woman_in_museum.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"scene_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "4edd57e5",
"metadata": {},
"source": [
"Output Image:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "embedded-4edd57e5",
"metadata": {},
"outputs": [],
"source": [
"from IPython.display import Image, display\n",
"display(Image(filename=\"../../images/output_images/scene_gpt-image-2.png\", width=500))"
]
},
{
"cell_type": "markdown",
"id": "41c192fc",
"metadata": {},
"source": [
"## 5.9 Multi-Image Referencing and Compositing\n"
]
},
{
"cell_type": "markdown",
"id": "838be37e",
"metadata": {},
"source": [
"Used to combine elements from multiple inputs into a single, believable image—great for “insert this object/person into that scene” workflows without re-generating everything. The key is to clearly specify what to transplant (the dog from image 2), where it should go (right next to the woman in image 1), and what must remain unchanged (scene, background, framing), while matching lighting, perspective, scale, and shadows so the composite looks naturally captured in the original photo."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7b304f05",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"Place the dog from the second image into the setting of image 1, right next to the woman, use the same style of lighting, composition and background. Do not change anything else.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" input_fidelity=\"high\", \n",
" image=[\n",
" open(\"../../images/output_images/test_woman.png\", \"rb\"),\n",
" open(\"../../images/output_images/test_woman_2.png\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"\n",
"save_image(result, \"test_woman_with_dog_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "9fec8b1e",
"metadata": {},
"source": [
"Input and output images:\n",
"\n",
"| Original Input | Remove Red Stripes | Change Hat Color |\n",
"|:--------------:|:------------------:|:----------------:|\n",
"|  |  |  |"
]
},
{
"cell_type": "markdown",
"id": "8487bec8",
"metadata": {},
"source": [
"## 6. Additional High-Value Use Cases\n",
"\n",
"## 6.1 Interior design “swap” (precision edits)\n",
"Used for visualizing furniture or decor changes in real spaces without re-rendering the entire scene. The goal is surgical realism: swap a single object while preserving camera angle, lighting, shadows, and surrounding context so the edit looks like a real photograph, not a redesign."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7afdccb9",
"metadata": {},
"outputs": [],
"source": [
"prompt = \"\"\"\n",
"In this room photo, replace ONLY white with chairs made of wood.\n",
"Preserve camera angle, room lighting, floor shadows, and surrounding objects.\n",
"Keep all other aspects of the image unchanged.\n",
"Photorealistic contact shadows and fabric texture.\n",
"\"\"\"\n",
"\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/input_images/kitchen.jpeg\", \"rb\"),\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1536x1024\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"kitchen-chairs_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "9a0433bd",
"metadata": {},
"source": [
"Input and output images:\n",
"\n",
"| Input Image | Output Image |\n",
"|------------|--------------|\n",
"|  |  |"
]
},
{
"cell_type": "markdown",
"id": "7be9b836",
"metadata": {},
"source": [
"## 6.2 3D pop-up holiday card (product-style mock)\n",
"Ideal for seasonal marketing concepts and print previews. Emphasizes tactile realism—paper layers, fibers, folds, and soft studio lighting—so the result reads as a photographed physical product rather than a flat illustration."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7d7b15ab",
"metadata": {},
"outputs": [],
"source": [
"scene_description = (\n",
" \"a cozy Christmas scene with an old teddy bear sitting inside a keepsake box, \"\n",
" \"slightly worn fur, soft stitching repairs, placed near a window with falling snow outside. \"\n",
" \"The scene suggests the child has grown up, but the memories remain.\"\n",
")\n",
"\n",
"short_copy = \"Merry Christmas — some memories never fade.\"\n",
"\n",
"prompt = f\"\"\"\n",
"Create a Christmas holiday card illustration.\n",
"\n",
"Scene:\n",
"{scene_description}\n",
"\n",
"Mood:\n",
"Warm, nostalgic, gentle, emotional.\n",
"\n",
"Style:\n",
"Premium holiday card photography, soft cinematic lighting,\n",
"realistic textures, shallow depth of field,\n",
"tasteful bokeh lights, high print-quality composition.\n",
"\n",
"Constraints:\n",
"- Original artwork only\n",
"- No trademarks\n",
"- No watermarks\n",
"- No logos\n",
"\n",
"Include ONLY this card text (verbatim):\n",
"\"{short_copy}\"\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"christmas_holiday_card_teddy_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "0d1f671d",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "24228899",
"metadata": {},
"source": [
"## 6.3 Collectible Action Figure / Plush Keychain (merch concept)\n",
"\n",
"Used for early merch ideation and pitch visuals. Focuses on premium product photography cues (materials, packaging, print clarity) while keeping designs original and non-infringing. Works well for testing multiple character or packaging variants quickly.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8850bfbc",
"metadata": {},
"outputs": [],
"source": [
"# ---- Inputs ----\n",
"character_description = (\n",
" \"a vintage-style toy propeller airplane with rounded wings, \"\n",
" \"a front-mounted spinning propeller, slightly worn paint edges, \"\n",
" \"classic childhood proportions, designed as a nostalgic holiday collectible\"\n",
")\n",
"\n",
"short_copy = \"Christmas Memories Edition\"\n",
"\n",
"# ---- Prompt ----\n",
"prompt = f\"\"\"\n",
"Create a collectible action figure of {character_description}, in blister packaging.\n",
"\n",
"Concept:\n",
"A nostalgic holiday collectible inspired by the simple toy airplanes\n",
"children used to play with during winter holidays.\n",
"Evokes warmth, imagination, and childhood wonder.\n",
"\n",
"Style:\n",
"Premium toy photography, realistic plastic and painted metal textures,\n",
"studio lighting, shallow depth of field,\n",
"sharp label printing, high-end retail presentation.\n",
"\n",
"Constraints:\n",
"- Original design only\n",
"- No trademarks\n",
"- No watermarks\n",
"- No logos\n",
"\n",
"Include ONLY this packaging text (verbatim):\n",
"\"{short_copy}\"\n",
"\"\"\"\n",
"\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"christmas_collectible_toy_airplane_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "86dfdc26",
"metadata": {},
"source": [
"Output Image: \n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "1327a5cb",
"metadata": {},
"source": [
"## 6.4 Children’s Book Art with Character Consistency (multi-image workflow)\n",
"Designed for multi-page illustration pipelines where character drift is unacceptable. A reusable “character anchor” ensures visual continuity across scenes, poses, and pages while allowing environmental and narrative variation.\n"
]
},
{
"cell_type": "markdown",
"id": "f33aec9c",
"metadata": {},
"source": [
"1️⃣ Character Anchor — establish the reusable main character\n",
"\n",
"Goal: Lock the character’s appearance, proportions, outfit, and tone."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b3fe3d4b",
"metadata": {},
"outputs": [],
"source": [
"# ---- Inputs ----\n",
"prompt = \"\"\"\n",
"Create a children’s book illustration introducing a main character.\n",
"\n",
"Character:\n",
"A young, storybook-style hero inspired by a little forest outlaw,\n",
"wearing a simple green hooded tunic, soft brown boots, and a small belt pouch.\n",
"The character has a kind expression, gentle eyes, and a brave but warm demeanor.\n",
"Carries a small wooden bow used only for helping, never harming.\n",
"\n",
"Theme:\n",
"The character protects and rescues small forest animals like squirrels, birds, and rabbits.\n",
"\n",
"Style:\n",
"Children’s book illustration, hand-painted watercolor look,\n",
"soft outlines, warm earthy colors, whimsical and friendly.\n",
"Proportions suitable for picture books (slightly oversized head, expressive face).\n",
"\n",
"Constraints:\n",
"- Original character (no copyrighted characters)\n",
"- No text\n",
"- No watermarks\n",
"- Plain forest background to clearly showcase the character\n",
"\"\"\"\n",
"\n",
"# ---- Image generation ----\n",
"result = client.images.generate(\n",
" model=\"gpt-image-2\",\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"childrens_book_illustration_1_gpt-image-2.png\")"
]
},
{
"cell_type": "markdown",
"id": "54dcc746",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "608a2f84",
"metadata": {},
"source": [
"2️⃣ Story continuation — reuse character, advance the narrative\n",
"\n",
"Goal: Same character, new scene + action.\n",
"Character appearance must remain unchanged."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3fe5ac63",
"metadata": {},
"outputs": [],
"source": [
"# ---- Inputs ----\n",
"prompt = \"\"\"\n",
"Continue the children’s book story using the same character.\n",
"\n",
"Scene:\n",
"The same young forest hero is gently helping a frightened squirrel\n",
"out of a fallen tree after a winter storm.\n",
"The character kneels beside the squirrel, offering reassurance.\n",
"\n",
"Character Consistency:\n",
"- Same green hooded tunic\n",
"- Same facial features, proportions, and color palette\n",
"- Same gentle, heroic personality\n",
"\n",
"Style:\n",
"Children’s book watercolor illustration,\n",
"soft lighting, snowy forest environment,\n",
"warm and comforting mood.\n",
"\n",
"Constraints:\n",
"- Do not redesign the character\n",
"- No text\n",
"- No watermarks\n",
"\"\"\"\n",
"# ---- Image generation ----\n",
"result = client.images.edit(\n",
" model=\"gpt-image-2\",\n",
" image=[\n",
" open(\"../../images/output_images/childrens_book_illustration_1_gpt-image-2.png\", \"rb\"), # use image from step 1\n",
" ],\n",
" prompt=prompt,\n",
" size=\"1024x1536\",\n",
" quality=\"medium\",\n",
")\n",
"\n",
"save_image(result, \"childrens_book_illustration_2_gpt-image-2.png\")\n"
]
},
{
"cell_type": "markdown",
"id": "4b58553f",
"metadata": {},
"source": [
"Output Image:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"id": "db028cc7",
"metadata": {},
"source": [
"## Conclusion \n",
"\n",
"In this notebook, we demonstrate how to use gpt-image generation models to build high-quality, controllable image generation and editing workflows that hold up in real production settings. The cookbook emphasizes prompt structure, explicit constraints, and small iterative changes as the primary tools for controlling realism, layout, text accuracy, and identity preservation. We cover both generation and editing patterns, ranging from infographics, photorealism, UI mockups, and logos to translation, style transfer, virtual try-on, compositing, and lighting changes. Throughout the examples, the cookbook reinforces the importance of clearly separating what should change from what must remain invariant, and of restating those invariants on every iteration to prevent drift. We also highlight how quality and input-fidelity settings enable deliberate tradeoffs between latency and visual precision depending on the use case. Together, these examples form a practical, repeatable playbook for applying gpt-image generation models in production image workflows."
]
}
],
"metadata": {
"kernelspec": {
"display_name": "venv",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.13.0"
}
},
"nbformat": 4,
"nbformat_minor": 5
}