{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "Wmf07eJE8p9r"
},
"source": [
"# Assignment 4: Chatbot\n",
"\n",
" \n",
"\n",
"Welcome to the last assignment of Course 4. Before you get started, we want to congratulate you on getting here. It is your 16th programming assignment in this Specialization and we are very proud of you! In this assignment, you are going to use the [Reformer](https://arxiv.org/abs/2001.04451), also known as the efficient Transformer, to generate a dialogue between two bots. You will feed conversations to your model and it will learn how to understand the context of each one. Not only will it learn how to answer questions but it will also know how to ask questions if it needs more info. For example, after a customer asks for a train ticket, the chatbot can ask what time the said customer wants to leave. You can use this concept to automate call centers, hotel receptions, personal trainers, or any type of customer service. By completing this assignment, you will:\n",
"\n",
"* Understand how the Reformer works\n",
"* Explore the [MultiWoz](https://arxiv.org/abs/1810.00278) dataset\n",
"* Process the data to feed it into the model\n",
"* Train your model\n",
"* Generate a dialogue by feeding a question to the model\n",
"\n",
"\n",
"## Outline\n",
"- [Part 1: Exploring the MultiWoz dataset](#1)\n",
"\t- [Exercise 01](#ex01)\n",
"- [Part 2: Processing the data for Reformer inputs](#2)\n",
" - [2.1 Tokenizing, batching with bucketing](#2.1)\n",
"- [Part 3: Reversible layers](#3)\n",
"\t- [Exercise 02](#ex02)\n",
"\t- [Exercise 03](#ex03)\n",
" - [3.1 Reversible layers and randomness](#3.1)\n",
"- [Part 4: ReformerLM Training](#4)\n",
"\t- [Exercise 04](#ex04)\n",
"\t- [Exercise 05](#ex05)\n",
"- [Part 5: Decode from a pretrained model](#5)\n",
"\t- [Exercise 06](#ex06)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# Part 1: Exploring the MultiWoz dataset\n",
"\n",
"You will start by exploring the MultiWoz dataset. The dataset you are about to use has more than 10,000 human annotated dialogues and spans multiple domains and topics. Some dialogues include multiple domains and others include single domains. In this section, you will load and explore this dataset, as well as develop a function to extract the dialogues."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's first import the modules we will be using:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 451
},
"colab_type": "code",
"id": "aV4zpTnSVFIp",
"outputId": "e3a85dd1-e375-4636-ea62-b9b403f0952a"
},
"outputs": [],
"source": [
"import json\n",
"import random\n",
"import numpy as np\n",
"from termcolor import colored\n",
"\n",
"import trax \n",
"from trax import layers as tl\n",
"from trax.supervised import training\n",
"!pip list | grep trax"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's also declare some constants we will be using in the exercises."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# filename of the MultiWOZ dialogue dataset\n",
"DATA_FILE = 'data.json'\n",
"\n",
"# data directory\n",
"DATA_DIR = './data'\n",
"\n",
"# dictionary where we will load the dialogue dataset\n",
"DIALOGUE_DB = {}\n",
"\n",
"# vocabulary filename\n",
"VOCAB_FILE = 'en_32k.subword'\n",
"\n",
"# vocabulary file directory\n",
"VOCAB_DIR = 'data/vocabs'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's now load the MultiWOZ 2.1 dataset. We have already provided it for you in your workspace. It is in JSON format so we should load it as such:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 167
},
"colab_type": "code",
"id": "K58I5vFB7GlP",
"outputId": "3d086ea4-7898-4870-b52f-f362cb02e118"
},
"outputs": [],
"source": [
"# help function to load a JSON file\n",
"def load_json(directory, file):\n",
" with open(f'{directory}/{file}') as file: \n",
" db = json.load(file)\n",
" return db\n",
"\n",
"# load the dialogue data set into our dictionary\n",
"DIALOGUE_DB = load_json(DATA_DIR, DATA_FILE)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's see how many dialogues we have in the dictionary. 1 key-value pair is one dialogue so we can just get the dictionary's length."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 215
},
"colab_type": "code",
"id": "VGBnUfEk8p9x",
"outputId": "4b364506-1088-4f00-be0c-4fefa892dc4e"
},
"outputs": [],
"source": [
"print(f'The number of dialogues is: {len(DIALOGUE_DB)}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The dialogues are composed of multiple files and the filenames are used as keys in our dictionary. Those with multi-domain dialogues have \"MUL\" in their filenames while single domain dialogues have either \"SNG\" or \"WOZ\"."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# print 7 keys from the dataset to see the filenames\n",
"print(list(DIALOGUE_DB.keys())[0:7]) "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "pE6wiMUS8p91"
},
"source": [
"As you can see from the cells above, there are 10,438 conversations, each in its own file. You will train your model on all those conversations. Each file is also loaded into a dictionary and each has two keys which are the following:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "5KYeQLnG8p96",
"outputId": "b22f570d-a7b0-4b92-ba68-0b7236e61051"
},
"outputs": [],
"source": [
"# get keys of the fifth file in the list above\n",
"print(DIALOGUE_DB['SNG0073.json'].keys())"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "F-gj5aqF8p9_"
},
"source": [
"The `goal` also points to a dictionary and it contains several keys pertaining to the objectives of the conversation. For example below, we can see that the conversation will be about booking a taxi."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 122
},
"colab_type": "code",
"id": "PPPWwQ2s8p9_",
"outputId": "7e8efa2d-821a-44c8-902d-2c722baf5b4c"
},
"outputs": [],
"source": [
"DIALOGUE_DB['SNG0073.json']['goal']"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "B4N8RtWu8p-C"
},
"source": [
"The `log` on the other hand contains the dialog. It is a list of dictionaries and each element of this list contains several descriptions as well. Let's look at an example:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get first element of the log list\n",
"DIALOGUE_DB['SNG0073.json']['log'][0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For this assignment, we are only interested in the conversation which is in the `text` field.\n",
"The conversation goes back and forth between two persons. Let's call them 'Person 1' and 'Person 2'. This implies that\n",
"data['SNG0073.json']['log'][0]['text'] is 'Person 1' and\n",
"data['SNG0073.json']['log'][1]['text'] is 'Person 2' and so on. The even offsets are 'Person 1' and the odd offsets are 'Person 2'."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(' Person 1: ', DIALOGUE_DB['SNG0073.json']['log'][0]['text'])\n",
"print(' Person 2: ',DIALOGUE_DB['SNG0073.json']['log'][1]['text'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 01\n",
"\n",
"You will now implement the `get_conversation()` function that will extract the conversations from the dataset's file.\n",
"\n",
"**Instructions:** Implement a function to extract conversations from the input file. \n",
"As described above, the conversation is in the `text` field in each of the elements in the `log` list of the file. If the log list has `x` number of elements, then the function will get the `text` entries of each of those elements. Your function should return the conversation, prepending each field with either ' Person 1: ' if 'x' is even or ' Person 2: ' if 'x' is odd. You can use the Python modulus operator '%' to help select the even/odd entries. Important note: Do not print a newline character (i.e. `\\n`) when generating the string. For example, in the code cell above, your function should output something like:\n",
"\n",
"```\n",
" Person 1: I would like a taxi from Saint John's college to Pizza Hut Fen Ditton. Person 2: What time do you want to leave and what time do you want to arrive by?\n",
"```\n",
"\n",
"and **not**:\n",
"\n",
"```\n",
" Person 1: I would like a taxi from Saint John's college to Pizza Hut Fen Ditton.\n",
" Person 2: What time do you want to leave and what time do you want to arrive by?\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C1\n",
"# GRADED FUNCTION: get_conversation\n",
"def get_conversation(file, data_db):\n",
" '''\n",
" Args:\n",
" file (string): filename of the dialogue file saved as json\n",
" data_db (dict): dialogue database\n",
" \n",
" Returns:\n",
" string: A string containing the 'text' fields of data[file]['log'][x]\n",
" '''\n",
" \n",
" # initialize empty string\n",
" result = ''\n",
" \n",
" # get length of file's log list\n",
" len_msg_log = len(data_db[file]['log'])\n",
" \n",
" # set the delimiter strings\n",
" delimiter_1 = ' Person 1: '\n",
" delimiter_2 = ' Person 2: '\n",
" \n",
" # loop over the file's log list\n",
" for i in range(len_msg_log):\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # get i'th element of file log list\n",
" cur_log = None\n",
" \n",
" # check if i is even\n",
" if None: \n",
" # append the 1st delimiter string\n",
" result += None\n",
" else: \n",
" # append the 2nd delimiter string\n",
" result += None\n",
" \n",
" # append the message text from the log\n",
" result += None\n",
" \n",
" ### END CODE HERE ###\n",
"\n",
" return result\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"import w4_unittest\n",
"w4_unittest.test_get_conversation(get_conversation)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "Ugvx0noP8p-G"
},
"outputs": [],
"source": [
"file = 'SNG01856.json'\n",
"conversation = get_conversation(file, DIALOGUE_DB)\n",
"\n",
"# print raw output\n",
"print(conversation)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected Result:**\n",
"```\n",
"Person 1: am looking for a place to to stay that has cheap price range it should be in a type of hotel Person 2: Okay, do you have a specific area you want to stay in? Person 1: no, i just need to make sure it's cheap. oh, and i need parking Person 2: I found 1 cheap hotel for you that includes parking. Do you like me to book it? Person 1: Yes, please. 6 people 3 nights starting on tuesday. Person 2: I am sorry but I wasn't able to book that for you for Tuesday. Is there another day you would like to stay or perhaps a shorter stay? Person 1: how about only 2 nights. Person 2: Booking was successful.\n",
"Reference number is : 7GAWK763. Anything else I can do for you? Person 1: No, that will be all. Good bye. Person 2: Thank you for using our services.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can have a utility pretty print function just so we can visually follow the conversation more easily."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def print_conversation(conversation):\n",
" \n",
" delimiter_1 = 'Person 1: '\n",
" delimiter_2 = 'Person 2: '\n",
" \n",
" split_list_d1 = conversation.split(delimiter_1)\n",
" \n",
" for sublist in split_list_d1[1:]:\n",
" split_list_d2 = sublist.split(delimiter_2)\n",
" print(colored(f'Person 1: {split_list_d2[0]}', 'red'))\n",
" \n",
" if len(split_list_d2) > 1:\n",
" print(colored(f'Person 2: {split_list_d2[1]}', 'green'))\n",
"\n",
" \n",
"print_conversation(conversation)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "qzg21Kgc8p-K"
},
"source": [
"For this assignment, we will just use the outputs of the calls to `get_conversation` to train the model. But just to expound, there are also other information in the MultiWoz dataset that can be useful in other contexts. Each element of the log list has more information about it. For example, above, if you were to look at the other fields for the following, \"am looking for a place to stay that has cheap price range it should be in a type of hotel\", you will get the following. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 102
},
"colab_type": "code",
"id": "Rs2R8q1d8p-K",
"outputId": "8a2f4e3f-4516-449f-9648-a5970707cfc9"
},
"outputs": [],
"source": [
"DIALOGUE_DB['SNG01856.json']['log'][0]"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "nf0AAmxy8p-N"
},
"source": [
"The dataset also comes with hotel, hospital, taxi, train, police, and restaurant databases. For example, in case you need to call a doctor, or a hotel, or a taxi, this will allow you to automate the entire conversation. Take a look at the files accompanying the data set."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "HQmYUcsi8p-O",
"outputId": "5730c55f-63da-42a8-935e-6eeb17f6f791"
},
"outputs": [],
"source": [
"# this is an example of the attractions file\n",
"attraction_file = open('data/attraction_db.json')\n",
"attractions = json.load(attraction_file)\n",
"print(attractions[0])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "I5kTg4uX8p-R",
"outputId": "3dacc4ff-4f05-4ae6-d099-33d1b3a6fa2a"
},
"outputs": [],
"source": [
"# this is an example of the hospital file\n",
"hospital_file = open('data/hospital_db.json')\n",
"hospitals = json.load(hospital_file)\n",
"print(hospitals[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "B5knaAEc8p-U",
"outputId": "ee0110c2-b2c2-4584-bd42-21f75109a579"
},
"outputs": [],
"source": [
"# this is an example of the hotel file\n",
"hotel_file = open('data/hotel_db.json')\n",
"hotels = json.load(hotel_file)\n",
"print(hotels[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "t-Rk01Mv8p-a",
"outputId": "8977e17e-2fc3-4073-abb8-fcf5cef3cfaf"
},
"outputs": [],
"source": [
"# this is an example of the police file\n",
"police_file = open('data/police_db.json')\n",
"police = json.load(police_file)\n",
"print(police[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "u-G9pD8g8p-d",
"outputId": "1dba6598-b9b6-4fc8-91d2-f844b98e45fa"
},
"outputs": [],
"source": [
"# this is an example of a restuarant file\n",
"restaurant_file = open('data/restaurant_db.json')\n",
"restaurants = json.load(restaurant_file)\n",
"print(restaurants[0]) # feel free to index into other indices"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "k9eAKw4R8p-g"
},
"source": [
"For more information about the multiwoz 2.1 data set, please run the cell below to read the `ReadMe.txt` file. Feel free to open any other file to explore it. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 181
},
"colab_type": "code",
"id": "2H8pB_yI8p-g",
"outputId": "aa039a49-3ed3-4f4d-fa4f-c2619de3dc99"
},
"outputs": [],
"source": [
"with open('data/README') as file:\n",
" print(file.read())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see, there are many other aspects of the MultiWoz dataset. Nonetheless, you'll see that even with just the conversations, your model will still be able to generate useful responses. This concludes our exploration of the dataset. In the next section, we will do some preprocessing before we feed it into our model for training."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "juJWkQI_8p-j"
},
"source": [
"\n",
"# Part 2: Processing the data for Reformer inputs\n",
"\n",
"You will now use the `get_conversation()` function to process the data. The Reformer expects inputs of this form: \n",
"\n",
"**Person 1: Why am I so happy? Person 2: Because you are learning NLP Person 1: ... Person 2: ...***\n",
"\n",
"And the conversation keeps going with some text. As you can see 'Person 1' and 'Person 2' act as delimiters so the model automatically recognizes the person and who is talking. It can then come up with the corresponding text responses for each person. Let's proceed to process the text in this fashion for the Reformer. First, let's grab all the conversation strings from all dialogue files and put them in a list."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 71
},
"colab_type": "code",
"id": "IrnQ9eNV8p-k",
"outputId": "2b159dae-78be-4a19-df41-b9e620216d43"
},
"outputs": [],
"source": [
"# the keys are the file names\n",
"all_files = DIALOGUE_DB.keys()\n",
"\n",
"# initialize empty list\n",
"untokenized_data = []\n",
"\n",
"# loop over all files\n",
"for file in all_files:\n",
" # this is the graded function you coded\n",
" # returns a string delimited by Person 1 and Person 2\n",
" result = get_conversation(file, DIALOGUE_DB)\n",
" \n",
" # append to the list\n",
" untokenized_data.append(result)\n",
"\n",
"# print the first element to check if it's the same as the one we got before\n",
"print(untokenized_data[0])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let us split the list to a train and eval dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "buE0b8bjx_p_",
"outputId": "cb73a95b-488b-4d1d-9c20-5e98ca71f9d5"
},
"outputs": [],
"source": [
"# shuffle the list we generated above\n",
"random.shuffle(untokenized_data)\n",
"\n",
"# define a cutoff (5% of the total length for this assignment)\n",
"# convert to int because we will use it as a list index\n",
"cut_off = int(len(untokenized_data) * .05)\n",
"\n",
"# slice the list. the last elements after the cut_off value will be the eval set. the rest is for training. \n",
"train_data, eval_data = untokenized_data[:-cut_off], untokenized_data[-cut_off:]\n",
"\n",
"print(f'number of conversations in the data set: {len(untokenized_data)}')\n",
"print(f'number of conversations in train set: {len(train_data)}')\n",
"print(f'number of conversations in eval set: {len(eval_data)}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## 2.1 Tokenizing, batching with bucketing\n",
"We can now proceed in generating tokenized batches of our data. Let's first define a utility generator function to yield elements from our data sets:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def stream(data):\n",
" # loop over the entire data\n",
" while True:\n",
" # get a random element\n",
" d = random.choice(data)\n",
" \n",
" # yield a tuple pair of identical values \n",
" # (i.e. our inputs to the model will also be our targets during training)\n",
" yield (d, d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's define our data pipeline for tokenizing and batching our data. As in the previous assignments, we will bucket by length and also have an upper bound on the token length."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "uZgK5FAAWwOu"
},
"outputs": [],
"source": [
"# trax allows us to use combinators to generate our data pipeline\n",
"data_pipeline = trax.data.Serial(\n",
" # randomize the stream\n",
" trax.data.Shuffle(),\n",
" \n",
" # tokenize the data\n",
" trax.data.Tokenize(vocab_dir=VOCAB_DIR,\n",
" vocab_file=VOCAB_FILE),\n",
" \n",
" # filter too long sequences\n",
" trax.data.FilterByLength(2048),\n",
" \n",
" # bucket by length\n",
" trax.data.BucketByLength(boundaries=[128, 256, 512, 1024],\n",
" batch_sizes=[16, 8, 4, 2, 1]),\n",
" \n",
" # add loss weights but do not add it to the padding tokens (i.e. 0)\n",
" trax.data.AddLossWeights(id_to_mask=0)\n",
")\n",
"\n",
"# apply the data pipeline to our train and eval sets\n",
"train_stream = data_pipeline(stream(train_data))\n",
"eval_stream = data_pipeline(stream(eval_data))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "HwFEbYuiYqbo"
},
"source": [
"Peek into the train stream."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 88
},
"colab_type": "code",
"id": "9iBQEvhLYRot",
"outputId": "78659fd2-4633-47bc-ebe8-3ae3a6e2eab3"
},
"outputs": [],
"source": [
"# the stream generators will yield (input, target, weights). let's just grab the input for inspection\n",
"inp, _, _ = next(train_stream)\n",
"\n",
"# print the shape. format is (batch size, token length)\n",
"print(\"input shape: \", inp.shape)\n",
"\n",
"# detokenize the first element\n",
"print(trax.data.detokenize(inp[0], vocab_dir=VOCAB_DIR, vocab_file=VOCAB_FILE))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "0J_0ZDc_18cL"
},
"source": [
"\n",
"# Part 3: Reversible layers\n",
"\n",
"When running large deep models, you will often run out of memory as each layer allocates memory to store activations for use in backpropagation. To save this resource, you need to be able to recompute these activations during the backward pass without storing them during the forward pass. Take a look first at the leftmost diagram below. \n",
"\n",
"
\n",
"\n",
"Welcome to the last assignment of Course 4. Before you get started, we want to congratulate you on getting here. It is your 16th programming assignment in this Specialization and we are very proud of you! In this assignment, you are going to use the [Reformer](https://arxiv.org/abs/2001.04451), also known as the efficient Transformer, to generate a dialogue between two bots. You will feed conversations to your model and it will learn how to understand the context of each one. Not only will it learn how to answer questions but it will also know how to ask questions if it needs more info. For example, after a customer asks for a train ticket, the chatbot can ask what time the said customer wants to leave. You can use this concept to automate call centers, hotel receptions, personal trainers, or any type of customer service. By completing this assignment, you will:\n",
"\n",
"* Understand how the Reformer works\n",
"* Explore the [MultiWoz](https://arxiv.org/abs/1810.00278) dataset\n",
"* Process the data to feed it into the model\n",
"* Train your model\n",
"* Generate a dialogue by feeding a question to the model\n",
"\n",
"\n",
"## Outline\n",
"- [Part 1: Exploring the MultiWoz dataset](#1)\n",
"\t- [Exercise 01](#ex01)\n",
"- [Part 2: Processing the data for Reformer inputs](#2)\n",
" - [2.1 Tokenizing, batching with bucketing](#2.1)\n",
"- [Part 3: Reversible layers](#3)\n",
"\t- [Exercise 02](#ex02)\n",
"\t- [Exercise 03](#ex03)\n",
" - [3.1 Reversible layers and randomness](#3.1)\n",
"- [Part 4: ReformerLM Training](#4)\n",
"\t- [Exercise 04](#ex04)\n",
"\t- [Exercise 05](#ex05)\n",
"- [Part 5: Decode from a pretrained model](#5)\n",
"\t- [Exercise 06](#ex06)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"# Part 1: Exploring the MultiWoz dataset\n",
"\n",
"You will start by exploring the MultiWoz dataset. The dataset you are about to use has more than 10,000 human annotated dialogues and spans multiple domains and topics. Some dialogues include multiple domains and others include single domains. In this section, you will load and explore this dataset, as well as develop a function to extract the dialogues."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's first import the modules we will be using:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 451
},
"colab_type": "code",
"id": "aV4zpTnSVFIp",
"outputId": "e3a85dd1-e375-4636-ea62-b9b403f0952a"
},
"outputs": [],
"source": [
"import json\n",
"import random\n",
"import numpy as np\n",
"from termcolor import colored\n",
"\n",
"import trax \n",
"from trax import layers as tl\n",
"from trax.supervised import training\n",
"!pip list | grep trax"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's also declare some constants we will be using in the exercises."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# filename of the MultiWOZ dialogue dataset\n",
"DATA_FILE = 'data.json'\n",
"\n",
"# data directory\n",
"DATA_DIR = './data'\n",
"\n",
"# dictionary where we will load the dialogue dataset\n",
"DIALOGUE_DB = {}\n",
"\n",
"# vocabulary filename\n",
"VOCAB_FILE = 'en_32k.subword'\n",
"\n",
"# vocabulary file directory\n",
"VOCAB_DIR = 'data/vocabs'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's now load the MultiWOZ 2.1 dataset. We have already provided it for you in your workspace. It is in JSON format so we should load it as such:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 167
},
"colab_type": "code",
"id": "K58I5vFB7GlP",
"outputId": "3d086ea4-7898-4870-b52f-f362cb02e118"
},
"outputs": [],
"source": [
"# help function to load a JSON file\n",
"def load_json(directory, file):\n",
" with open(f'{directory}/{file}') as file: \n",
" db = json.load(file)\n",
" return db\n",
"\n",
"# load the dialogue data set into our dictionary\n",
"DIALOGUE_DB = load_json(DATA_DIR, DATA_FILE)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's see how many dialogues we have in the dictionary. 1 key-value pair is one dialogue so we can just get the dictionary's length."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 215
},
"colab_type": "code",
"id": "VGBnUfEk8p9x",
"outputId": "4b364506-1088-4f00-be0c-4fefa892dc4e"
},
"outputs": [],
"source": [
"print(f'The number of dialogues is: {len(DIALOGUE_DB)}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The dialogues are composed of multiple files and the filenames are used as keys in our dictionary. Those with multi-domain dialogues have \"MUL\" in their filenames while single domain dialogues have either \"SNG\" or \"WOZ\"."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# print 7 keys from the dataset to see the filenames\n",
"print(list(DIALOGUE_DB.keys())[0:7]) "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "pE6wiMUS8p91"
},
"source": [
"As you can see from the cells above, there are 10,438 conversations, each in its own file. You will train your model on all those conversations. Each file is also loaded into a dictionary and each has two keys which are the following:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "5KYeQLnG8p96",
"outputId": "b22f570d-a7b0-4b92-ba68-0b7236e61051"
},
"outputs": [],
"source": [
"# get keys of the fifth file in the list above\n",
"print(DIALOGUE_DB['SNG0073.json'].keys())"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "F-gj5aqF8p9_"
},
"source": [
"The `goal` also points to a dictionary and it contains several keys pertaining to the objectives of the conversation. For example below, we can see that the conversation will be about booking a taxi."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 122
},
"colab_type": "code",
"id": "PPPWwQ2s8p9_",
"outputId": "7e8efa2d-821a-44c8-902d-2c722baf5b4c"
},
"outputs": [],
"source": [
"DIALOGUE_DB['SNG0073.json']['goal']"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "B4N8RtWu8p-C"
},
"source": [
"The `log` on the other hand contains the dialog. It is a list of dictionaries and each element of this list contains several descriptions as well. Let's look at an example:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get first element of the log list\n",
"DIALOGUE_DB['SNG0073.json']['log'][0]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For this assignment, we are only interested in the conversation which is in the `text` field.\n",
"The conversation goes back and forth between two persons. Let's call them 'Person 1' and 'Person 2'. This implies that\n",
"data['SNG0073.json']['log'][0]['text'] is 'Person 1' and\n",
"data['SNG0073.json']['log'][1]['text'] is 'Person 2' and so on. The even offsets are 'Person 1' and the odd offsets are 'Person 2'."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(' Person 1: ', DIALOGUE_DB['SNG0073.json']['log'][0]['text'])\n",
"print(' Person 2: ',DIALOGUE_DB['SNG0073.json']['log'][1]['text'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 01\n",
"\n",
"You will now implement the `get_conversation()` function that will extract the conversations from the dataset's file.\n",
"\n",
"**Instructions:** Implement a function to extract conversations from the input file. \n",
"As described above, the conversation is in the `text` field in each of the elements in the `log` list of the file. If the log list has `x` number of elements, then the function will get the `text` entries of each of those elements. Your function should return the conversation, prepending each field with either ' Person 1: ' if 'x' is even or ' Person 2: ' if 'x' is odd. You can use the Python modulus operator '%' to help select the even/odd entries. Important note: Do not print a newline character (i.e. `\\n`) when generating the string. For example, in the code cell above, your function should output something like:\n",
"\n",
"```\n",
" Person 1: I would like a taxi from Saint John's college to Pizza Hut Fen Ditton. Person 2: What time do you want to leave and what time do you want to arrive by?\n",
"```\n",
"\n",
"and **not**:\n",
"\n",
"```\n",
" Person 1: I would like a taxi from Saint John's college to Pizza Hut Fen Ditton.\n",
" Person 2: What time do you want to leave and what time do you want to arrive by?\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C1\n",
"# GRADED FUNCTION: get_conversation\n",
"def get_conversation(file, data_db):\n",
" '''\n",
" Args:\n",
" file (string): filename of the dialogue file saved as json\n",
" data_db (dict): dialogue database\n",
" \n",
" Returns:\n",
" string: A string containing the 'text' fields of data[file]['log'][x]\n",
" '''\n",
" \n",
" # initialize empty string\n",
" result = ''\n",
" \n",
" # get length of file's log list\n",
" len_msg_log = len(data_db[file]['log'])\n",
" \n",
" # set the delimiter strings\n",
" delimiter_1 = ' Person 1: '\n",
" delimiter_2 = ' Person 2: '\n",
" \n",
" # loop over the file's log list\n",
" for i in range(len_msg_log):\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # get i'th element of file log list\n",
" cur_log = None\n",
" \n",
" # check if i is even\n",
" if None: \n",
" # append the 1st delimiter string\n",
" result += None\n",
" else: \n",
" # append the 2nd delimiter string\n",
" result += None\n",
" \n",
" # append the message text from the log\n",
" result += None\n",
" \n",
" ### END CODE HERE ###\n",
"\n",
" return result\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"import w4_unittest\n",
"w4_unittest.test_get_conversation(get_conversation)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "Ugvx0noP8p-G"
},
"outputs": [],
"source": [
"file = 'SNG01856.json'\n",
"conversation = get_conversation(file, DIALOGUE_DB)\n",
"\n",
"# print raw output\n",
"print(conversation)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Expected Result:**\n",
"```\n",
"Person 1: am looking for a place to to stay that has cheap price range it should be in a type of hotel Person 2: Okay, do you have a specific area you want to stay in? Person 1: no, i just need to make sure it's cheap. oh, and i need parking Person 2: I found 1 cheap hotel for you that includes parking. Do you like me to book it? Person 1: Yes, please. 6 people 3 nights starting on tuesday. Person 2: I am sorry but I wasn't able to book that for you for Tuesday. Is there another day you would like to stay or perhaps a shorter stay? Person 1: how about only 2 nights. Person 2: Booking was successful.\n",
"Reference number is : 7GAWK763. Anything else I can do for you? Person 1: No, that will be all. Good bye. Person 2: Thank you for using our services.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can have a utility pretty print function just so we can visually follow the conversation more easily."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def print_conversation(conversation):\n",
" \n",
" delimiter_1 = 'Person 1: '\n",
" delimiter_2 = 'Person 2: '\n",
" \n",
" split_list_d1 = conversation.split(delimiter_1)\n",
" \n",
" for sublist in split_list_d1[1:]:\n",
" split_list_d2 = sublist.split(delimiter_2)\n",
" print(colored(f'Person 1: {split_list_d2[0]}', 'red'))\n",
" \n",
" if len(split_list_d2) > 1:\n",
" print(colored(f'Person 2: {split_list_d2[1]}', 'green'))\n",
"\n",
" \n",
"print_conversation(conversation)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "qzg21Kgc8p-K"
},
"source": [
"For this assignment, we will just use the outputs of the calls to `get_conversation` to train the model. But just to expound, there are also other information in the MultiWoz dataset that can be useful in other contexts. Each element of the log list has more information about it. For example, above, if you were to look at the other fields for the following, \"am looking for a place to stay that has cheap price range it should be in a type of hotel\", you will get the following. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 102
},
"colab_type": "code",
"id": "Rs2R8q1d8p-K",
"outputId": "8a2f4e3f-4516-449f-9648-a5970707cfc9"
},
"outputs": [],
"source": [
"DIALOGUE_DB['SNG01856.json']['log'][0]"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "nf0AAmxy8p-N"
},
"source": [
"The dataset also comes with hotel, hospital, taxi, train, police, and restaurant databases. For example, in case you need to call a doctor, or a hotel, or a taxi, this will allow you to automate the entire conversation. Take a look at the files accompanying the data set."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "HQmYUcsi8p-O",
"outputId": "5730c55f-63da-42a8-935e-6eeb17f6f791"
},
"outputs": [],
"source": [
"# this is an example of the attractions file\n",
"attraction_file = open('data/attraction_db.json')\n",
"attractions = json.load(attraction_file)\n",
"print(attractions[0])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "I5kTg4uX8p-R",
"outputId": "3dacc4ff-4f05-4ae6-d099-33d1b3a6fa2a"
},
"outputs": [],
"source": [
"# this is an example of the hospital file\n",
"hospital_file = open('data/hospital_db.json')\n",
"hospitals = json.load(hospital_file)\n",
"print(hospitals[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "B5knaAEc8p-U",
"outputId": "ee0110c2-b2c2-4584-bd42-21f75109a579"
},
"outputs": [],
"source": [
"# this is an example of the hotel file\n",
"hotel_file = open('data/hotel_db.json')\n",
"hotels = json.load(hotel_file)\n",
"print(hotels[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "t-Rk01Mv8p-a",
"outputId": "8977e17e-2fc3-4073-abb8-fcf5cef3cfaf"
},
"outputs": [],
"source": [
"# this is an example of the police file\n",
"police_file = open('data/police_db.json')\n",
"police = json.load(police_file)\n",
"print(police[0]) # feel free to index into other indices"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 54
},
"colab_type": "code",
"id": "u-G9pD8g8p-d",
"outputId": "1dba6598-b9b6-4fc8-91d2-f844b98e45fa"
},
"outputs": [],
"source": [
"# this is an example of a restuarant file\n",
"restaurant_file = open('data/restaurant_db.json')\n",
"restaurants = json.load(restaurant_file)\n",
"print(restaurants[0]) # feel free to index into other indices"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "k9eAKw4R8p-g"
},
"source": [
"For more information about the multiwoz 2.1 data set, please run the cell below to read the `ReadMe.txt` file. Feel free to open any other file to explore it. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 181
},
"colab_type": "code",
"id": "2H8pB_yI8p-g",
"outputId": "aa039a49-3ed3-4f4d-fa4f-c2619de3dc99"
},
"outputs": [],
"source": [
"with open('data/README') as file:\n",
" print(file.read())"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see, there are many other aspects of the MultiWoz dataset. Nonetheless, you'll see that even with just the conversations, your model will still be able to generate useful responses. This concludes our exploration of the dataset. In the next section, we will do some preprocessing before we feed it into our model for training."
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "juJWkQI_8p-j"
},
"source": [
"\n",
"# Part 2: Processing the data for Reformer inputs\n",
"\n",
"You will now use the `get_conversation()` function to process the data. The Reformer expects inputs of this form: \n",
"\n",
"**Person 1: Why am I so happy? Person 2: Because you are learning NLP Person 1: ... Person 2: ...***\n",
"\n",
"And the conversation keeps going with some text. As you can see 'Person 1' and 'Person 2' act as delimiters so the model automatically recognizes the person and who is talking. It can then come up with the corresponding text responses for each person. Let's proceed to process the text in this fashion for the Reformer. First, let's grab all the conversation strings from all dialogue files and put them in a list."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 71
},
"colab_type": "code",
"id": "IrnQ9eNV8p-k",
"outputId": "2b159dae-78be-4a19-df41-b9e620216d43"
},
"outputs": [],
"source": [
"# the keys are the file names\n",
"all_files = DIALOGUE_DB.keys()\n",
"\n",
"# initialize empty list\n",
"untokenized_data = []\n",
"\n",
"# loop over all files\n",
"for file in all_files:\n",
" # this is the graded function you coded\n",
" # returns a string delimited by Person 1 and Person 2\n",
" result = get_conversation(file, DIALOGUE_DB)\n",
" \n",
" # append to the list\n",
" untokenized_data.append(result)\n",
"\n",
"# print the first element to check if it's the same as the one we got before\n",
"print(untokenized_data[0])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let us split the list to a train and eval dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 34
},
"colab_type": "code",
"id": "buE0b8bjx_p_",
"outputId": "cb73a95b-488b-4d1d-9c20-5e98ca71f9d5"
},
"outputs": [],
"source": [
"# shuffle the list we generated above\n",
"random.shuffle(untokenized_data)\n",
"\n",
"# define a cutoff (5% of the total length for this assignment)\n",
"# convert to int because we will use it as a list index\n",
"cut_off = int(len(untokenized_data) * .05)\n",
"\n",
"# slice the list. the last elements after the cut_off value will be the eval set. the rest is for training. \n",
"train_data, eval_data = untokenized_data[:-cut_off], untokenized_data[-cut_off:]\n",
"\n",
"print(f'number of conversations in the data set: {len(untokenized_data)}')\n",
"print(f'number of conversations in train set: {len(train_data)}')\n",
"print(f'number of conversations in eval set: {len(eval_data)}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"## 2.1 Tokenizing, batching with bucketing\n",
"We can now proceed in generating tokenized batches of our data. Let's first define a utility generator function to yield elements from our data sets:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def stream(data):\n",
" # loop over the entire data\n",
" while True:\n",
" # get a random element\n",
" d = random.choice(data)\n",
" \n",
" # yield a tuple pair of identical values \n",
" # (i.e. our inputs to the model will also be our targets during training)\n",
" yield (d, d)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's define our data pipeline for tokenizing and batching our data. As in the previous assignments, we will bucket by length and also have an upper bound on the token length."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "uZgK5FAAWwOu"
},
"outputs": [],
"source": [
"# trax allows us to use combinators to generate our data pipeline\n",
"data_pipeline = trax.data.Serial(\n",
" # randomize the stream\n",
" trax.data.Shuffle(),\n",
" \n",
" # tokenize the data\n",
" trax.data.Tokenize(vocab_dir=VOCAB_DIR,\n",
" vocab_file=VOCAB_FILE),\n",
" \n",
" # filter too long sequences\n",
" trax.data.FilterByLength(2048),\n",
" \n",
" # bucket by length\n",
" trax.data.BucketByLength(boundaries=[128, 256, 512, 1024],\n",
" batch_sizes=[16, 8, 4, 2, 1]),\n",
" \n",
" # add loss weights but do not add it to the padding tokens (i.e. 0)\n",
" trax.data.AddLossWeights(id_to_mask=0)\n",
")\n",
"\n",
"# apply the data pipeline to our train and eval sets\n",
"train_stream = data_pipeline(stream(train_data))\n",
"eval_stream = data_pipeline(stream(eval_data))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "HwFEbYuiYqbo"
},
"source": [
"Peek into the train stream."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 88
},
"colab_type": "code",
"id": "9iBQEvhLYRot",
"outputId": "78659fd2-4633-47bc-ebe8-3ae3a6e2eab3"
},
"outputs": [],
"source": [
"# the stream generators will yield (input, target, weights). let's just grab the input for inspection\n",
"inp, _, _ = next(train_stream)\n",
"\n",
"# print the shape. format is (batch size, token length)\n",
"print(\"input shape: \", inp.shape)\n",
"\n",
"# detokenize the first element\n",
"print(trax.data.detokenize(inp[0], vocab_dir=VOCAB_DIR, vocab_file=VOCAB_FILE))"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "0J_0ZDc_18cL"
},
"source": [
"\n",
"# Part 3: Reversible layers\n",
"\n",
"When running large deep models, you will often run out of memory as each layer allocates memory to store activations for use in backpropagation. To save this resource, you need to be able to recompute these activations during the backward pass without storing them during the forward pass. Take a look first at the leftmost diagram below. \n",
"\n",
" \n",
"\n",
"This is how the residual networks are implemented in the standard Transformer. It follows that, given `F()` is Attention and `G()` is Feed-forward(FF). \n",
": \n",
"\n",
"\\begin{align} \n",
"\\mathrm{y}_\\mathrm{a} &= \\mathrm{x} + \\mathrm{F}\\left(\\mathrm{x}\\right)\\tag{1} \\\\\n",
"\\mathrm{y}_{b}&=\\mathrm{y}_{a}+\\mathrm{G}\\left(\\mathrm{y}_{a}\\right)\\tag{2}\\\\\n",
"\\end{align}\n",
"\n",
"\n",
"As you can see, it requires that $\\mathrm{x}$ and $\\mathrm{y}_{a}$ be saved so it can be used during backpropagation. We want to avoid this to conserve memory and this is where reversible residual connections come in. They are shown in the middle and rightmost diagrams above. The key idea is that we will start with two copies of the input to the model and at each layer we will only update one of them. The activations that we *don’t* update are the ones that will be used to compute the residuals. \n",
"\n",
"Now in this reversible set up you get the following instead: \n",
"\n",
"\\begin{align} \n",
"\\mathrm{y}_{1}&=\\mathrm{x}_{1}+\\mathrm{F}\\left(\\mathrm{x}_{2}\\right)\\tag{3}\\\\\n",
"\\mathrm{y}_{2}&=\\mathrm{x}_{2}+\\mathrm{G}\\left(\\mathrm{y}_{1}\\right)\\tag{4}\\\\\n",
"\\end{align}\n",
"To recover $\\mathrm{(x_1,x_2)}$ from $\\mathrm{(y_1, y_2)}$ \n",
"\n",
"\\begin{align} \n",
"\\mathrm{x}_{2}&=\\mathrm{y}_{2}-\\mathrm{G}\\left(\\mathrm{y}_{1}\\right)\\tag{5}\\\\\n",
"\\mathrm{x}_{1}&=\\mathrm{y}_{1}-\\mathrm{F}\\left(\\mathrm{x}_{2}\\right)\\tag{6}\\\\\n",
"\\end{align}\n",
"\n",
"With this configuration, we’re now able to run the network fully in reverse. You'll notice that during the backward pass, $\\mathrm{x2}$ and $\\mathrm{x1}$ can be recomputed based solely on the values of $\\mathrm{y2}$ and $\\mathrm{y1}$. No need to save it during the forward pass.\n",
"\n",
"\n",
"### Exercise 02\n",
"**Instructions:** You will implement the `reversible_layer_forward` function using equations 3 and 4 above. This function takes in the input vector `x` and the functions `f` and `g` and returns the concatenation of $y_1 and y_2$. For this exercise, we will be splitting `x` before going through the reversible residual steps$\\mathrm{^1}$. We can then use those two vectors for the `reversible_layer_reverse` function. Utilize `np.concatenate()` to form the output being careful to match the axis of the `np.split()`.\n",
"\n",
"$\\mathrm{^1}$*Take note that this is just for demonstrating the concept in this exercise and there are other ways of processing the input. As you'll see in the Reformer architecture later, the initial input (i.e. `x`) can instead be duplicated instead of split.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "adX2eU762BkF"
},
"outputs": [],
"source": [
"# UNQ_C2\n",
"# GRADED FUNCTION: reversible_layer_forward\n",
"def reversible_layer_forward(x, f, g):\n",
" \"\"\"\n",
" Args: \n",
" x (np.array): an input vector or matrix\n",
" f (function): a function which operates on a vector/matrix\n",
" g (function): a function which operates on a vector/matrix\n",
" Returns: \n",
" y (np.array): an output vector or matrix whose form is determined by 'x', f and g\n",
" \"\"\"\n",
" # split the input vector into two (* along the last axis because it is the depth dimension)\n",
" x1, x2 = np.split(x, 2, axis=-1) \n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # get y1 using equation 3\n",
" y1 = None\n",
" \n",
" # get y2 using equation 4\n",
" y2 = None\n",
" \n",
" # concatenate y1 and y2 along the depth dimension. be sure output is of type np.ndarray\n",
" y = None\n",
" \n",
" ### END CODE HERE ### \n",
" return y"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_reversible_layer_forward(reversible_layer_forward)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "jYGdCdAsbY0S"
},
"source": [
"\n",
"### Exercise 03\n",
"\n",
"You will now implement the `reversible_layer_reverse` function which is possible because at every time step you have $x_1$ and $x_2$ and $y_2$ and $y_1$, along with the function `f`, and `g`. Where `f` is the attention and `g` is the feedforward. This allows you to compute equations 5 and 6.\n",
"\n",
"\n",
"**Instructions:** Implement the `reversible_layer_reverse`. Your function takes in the output vector from `reversible_layer_forward` and functions f and g. Using equations 5 and 6 above, it computes the inputs to the layer, $x_1$ and $x_2$. The output, x, is the concatenation of $x_1, x_2$. Utilize `np.concatenate()` to form the output being careful to match the axis of the `np.split()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "0xTCG9WlaiiO"
},
"outputs": [],
"source": [
"# UNQ_C3\n",
"# GRADED FUNCTION: reversible_layer_reverse\n",
"def reversible_layer_reverse(y, f, g):\n",
" \"\"\"\n",
" Args: \n",
" y (np.array): an input vector or matrix\n",
" f (function): a function which operates on a vector/matrix of the form of 'y'\n",
" g (function): a function which operates on a vector/matrix of the form of 'y'\n",
" Returns: \n",
" y (np.array): an output vector or matrix whose form is determined by 'y', f and g\n",
" \"\"\"\n",
" \n",
" # split the input vector into two (* along the last axis because it is the depth dimension)\n",
" y1, y2 = np.split(y, 2, axis=-1)\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # compute x2 using equation 5\n",
" x2 = None\n",
" \n",
" # compute x1 using equation 6\n",
" x1 = None\n",
" \n",
" # concatenate x1 and x2 along the depth dimension\n",
" x = None\n",
" \n",
" ### END CODE HERE ### \n",
" return x\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_reversible_layer_reverse(reversible_layer_reverse)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "o66C0Nfoafjf"
},
"outputs": [],
"source": [
"# UNIT TEST COMMENT: assert at the end can be used in grading as well\n",
"f = lambda x: x + 2\n",
"g = lambda x: x * 3\n",
"input_vector = np.random.uniform(size=(32,))\n",
"\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert np.allclose(reversed_vector, input_vector)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "XSRjn82B3Sh8"
},
"source": [
"\n",
"## 3.1 Reversible layers and randomness\n",
"\n",
"This is why we were learning about fastmath's random functions and keys in Course 3 Week 1. Utilizing the same key, `trax.fastmath.random.uniform()` will return the same values. This is required for the backward pass to return the correct layer inputs when random noise is introduced in the layer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "IjElqUtc2BYG"
},
"outputs": [],
"source": [
"# Layers like dropout have noise, so let's simulate it here:\n",
"f = lambda x: x + np.random.uniform(size=x.shape)\n",
"\n",
"# See that the above doesn't work any more:\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert not np.allclose(reversed_vector, input_vector) # Fails!!\n",
"\n",
"# It failed because the noise when reversing used a different random seed.\n",
"\n",
"random_seed = 27686\n",
"rng = trax.fastmath.random.get_prng(random_seed)\n",
"f = lambda x: x + trax.fastmath.random.uniform(key=rng, shape=x.shape)\n",
"\n",
"# See that it works now as the same rng is used on forward and reverse.\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert np.allclose(reversed_vector, input_vector, atol=1e-07) "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "IsfaBEyd4Ks4"
},
"source": [
"\n",
"# Part 4: ReformerLM Training\n",
"\n",
"You will now proceed to training your model. Since you have already know the two main components that differentiates it from the standard Transformer, LSH in Course 1 and reversible layers above, you can just use the pre-built model already implemented in Trax. It will have this architecture:\n",
"\n",
"
\n",
"\n",
"This is how the residual networks are implemented in the standard Transformer. It follows that, given `F()` is Attention and `G()` is Feed-forward(FF). \n",
": \n",
"\n",
"\\begin{align} \n",
"\\mathrm{y}_\\mathrm{a} &= \\mathrm{x} + \\mathrm{F}\\left(\\mathrm{x}\\right)\\tag{1} \\\\\n",
"\\mathrm{y}_{b}&=\\mathrm{y}_{a}+\\mathrm{G}\\left(\\mathrm{y}_{a}\\right)\\tag{2}\\\\\n",
"\\end{align}\n",
"\n",
"\n",
"As you can see, it requires that $\\mathrm{x}$ and $\\mathrm{y}_{a}$ be saved so it can be used during backpropagation. We want to avoid this to conserve memory and this is where reversible residual connections come in. They are shown in the middle and rightmost diagrams above. The key idea is that we will start with two copies of the input to the model and at each layer we will only update one of them. The activations that we *don’t* update are the ones that will be used to compute the residuals. \n",
"\n",
"Now in this reversible set up you get the following instead: \n",
"\n",
"\\begin{align} \n",
"\\mathrm{y}_{1}&=\\mathrm{x}_{1}+\\mathrm{F}\\left(\\mathrm{x}_{2}\\right)\\tag{3}\\\\\n",
"\\mathrm{y}_{2}&=\\mathrm{x}_{2}+\\mathrm{G}\\left(\\mathrm{y}_{1}\\right)\\tag{4}\\\\\n",
"\\end{align}\n",
"To recover $\\mathrm{(x_1,x_2)}$ from $\\mathrm{(y_1, y_2)}$ \n",
"\n",
"\\begin{align} \n",
"\\mathrm{x}_{2}&=\\mathrm{y}_{2}-\\mathrm{G}\\left(\\mathrm{y}_{1}\\right)\\tag{5}\\\\\n",
"\\mathrm{x}_{1}&=\\mathrm{y}_{1}-\\mathrm{F}\\left(\\mathrm{x}_{2}\\right)\\tag{6}\\\\\n",
"\\end{align}\n",
"\n",
"With this configuration, we’re now able to run the network fully in reverse. You'll notice that during the backward pass, $\\mathrm{x2}$ and $\\mathrm{x1}$ can be recomputed based solely on the values of $\\mathrm{y2}$ and $\\mathrm{y1}$. No need to save it during the forward pass.\n",
"\n",
"\n",
"### Exercise 02\n",
"**Instructions:** You will implement the `reversible_layer_forward` function using equations 3 and 4 above. This function takes in the input vector `x` and the functions `f` and `g` and returns the concatenation of $y_1 and y_2$. For this exercise, we will be splitting `x` before going through the reversible residual steps$\\mathrm{^1}$. We can then use those two vectors for the `reversible_layer_reverse` function. Utilize `np.concatenate()` to form the output being careful to match the axis of the `np.split()`.\n",
"\n",
"$\\mathrm{^1}$*Take note that this is just for demonstrating the concept in this exercise and there are other ways of processing the input. As you'll see in the Reformer architecture later, the initial input (i.e. `x`) can instead be duplicated instead of split.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "adX2eU762BkF"
},
"outputs": [],
"source": [
"# UNQ_C2\n",
"# GRADED FUNCTION: reversible_layer_forward\n",
"def reversible_layer_forward(x, f, g):\n",
" \"\"\"\n",
" Args: \n",
" x (np.array): an input vector or matrix\n",
" f (function): a function which operates on a vector/matrix\n",
" g (function): a function which operates on a vector/matrix\n",
" Returns: \n",
" y (np.array): an output vector or matrix whose form is determined by 'x', f and g\n",
" \"\"\"\n",
" # split the input vector into two (* along the last axis because it is the depth dimension)\n",
" x1, x2 = np.split(x, 2, axis=-1) \n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # get y1 using equation 3\n",
" y1 = None\n",
" \n",
" # get y2 using equation 4\n",
" y2 = None\n",
" \n",
" # concatenate y1 and y2 along the depth dimension. be sure output is of type np.ndarray\n",
" y = None\n",
" \n",
" ### END CODE HERE ### \n",
" return y"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_reversible_layer_forward(reversible_layer_forward)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "jYGdCdAsbY0S"
},
"source": [
"\n",
"### Exercise 03\n",
"\n",
"You will now implement the `reversible_layer_reverse` function which is possible because at every time step you have $x_1$ and $x_2$ and $y_2$ and $y_1$, along with the function `f`, and `g`. Where `f` is the attention and `g` is the feedforward. This allows you to compute equations 5 and 6.\n",
"\n",
"\n",
"**Instructions:** Implement the `reversible_layer_reverse`. Your function takes in the output vector from `reversible_layer_forward` and functions f and g. Using equations 5 and 6 above, it computes the inputs to the layer, $x_1$ and $x_2$. The output, x, is the concatenation of $x_1, x_2$. Utilize `np.concatenate()` to form the output being careful to match the axis of the `np.split()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "0xTCG9WlaiiO"
},
"outputs": [],
"source": [
"# UNQ_C3\n",
"# GRADED FUNCTION: reversible_layer_reverse\n",
"def reversible_layer_reverse(y, f, g):\n",
" \"\"\"\n",
" Args: \n",
" y (np.array): an input vector or matrix\n",
" f (function): a function which operates on a vector/matrix of the form of 'y'\n",
" g (function): a function which operates on a vector/matrix of the form of 'y'\n",
" Returns: \n",
" y (np.array): an output vector or matrix whose form is determined by 'y', f and g\n",
" \"\"\"\n",
" \n",
" # split the input vector into two (* along the last axis because it is the depth dimension)\n",
" y1, y2 = np.split(y, 2, axis=-1)\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # compute x2 using equation 5\n",
" x2 = None\n",
" \n",
" # compute x1 using equation 6\n",
" x1 = None\n",
" \n",
" # concatenate x1 and x2 along the depth dimension\n",
" x = None\n",
" \n",
" ### END CODE HERE ### \n",
" return x\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_reversible_layer_reverse(reversible_layer_reverse)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "o66C0Nfoafjf"
},
"outputs": [],
"source": [
"# UNIT TEST COMMENT: assert at the end can be used in grading as well\n",
"f = lambda x: x + 2\n",
"g = lambda x: x * 3\n",
"input_vector = np.random.uniform(size=(32,))\n",
"\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert np.allclose(reversed_vector, input_vector)"
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "XSRjn82B3Sh8"
},
"source": [
"\n",
"## 3.1 Reversible layers and randomness\n",
"\n",
"This is why we were learning about fastmath's random functions and keys in Course 3 Week 1. Utilizing the same key, `trax.fastmath.random.uniform()` will return the same values. This is required for the backward pass to return the correct layer inputs when random noise is introduced in the layer."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "IjElqUtc2BYG"
},
"outputs": [],
"source": [
"# Layers like dropout have noise, so let's simulate it here:\n",
"f = lambda x: x + np.random.uniform(size=x.shape)\n",
"\n",
"# See that the above doesn't work any more:\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert not np.allclose(reversed_vector, input_vector) # Fails!!\n",
"\n",
"# It failed because the noise when reversing used a different random seed.\n",
"\n",
"random_seed = 27686\n",
"rng = trax.fastmath.random.get_prng(random_seed)\n",
"f = lambda x: x + trax.fastmath.random.uniform(key=rng, shape=x.shape)\n",
"\n",
"# See that it works now as the same rng is used on forward and reverse.\n",
"output_vector = reversible_layer_forward(input_vector, f, g)\n",
"reversed_vector = reversible_layer_reverse(output_vector, f, g)\n",
"\n",
"assert np.allclose(reversed_vector, input_vector, atol=1e-07) "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "IsfaBEyd4Ks4"
},
"source": [
"\n",
"# Part 4: ReformerLM Training\n",
"\n",
"You will now proceed to training your model. Since you have already know the two main components that differentiates it from the standard Transformer, LSH in Course 1 and reversible layers above, you can just use the pre-built model already implemented in Trax. It will have this architecture:\n",
"\n",
" \n",
"\n",
"Similar to the Transformer you learned earlier, you want to apply an attention and feed forward layer to your inputs. For the Reformer, we improve the memory efficiency by using **reversible decoder blocks** and you can picture its implementation in Trax like below:\n",
"\n",
"
\n",
"\n",
"Similar to the Transformer you learned earlier, you want to apply an attention and feed forward layer to your inputs. For the Reformer, we improve the memory efficiency by using **reversible decoder blocks** and you can picture its implementation in Trax like below:\n",
"\n",
" \n",
"\n",
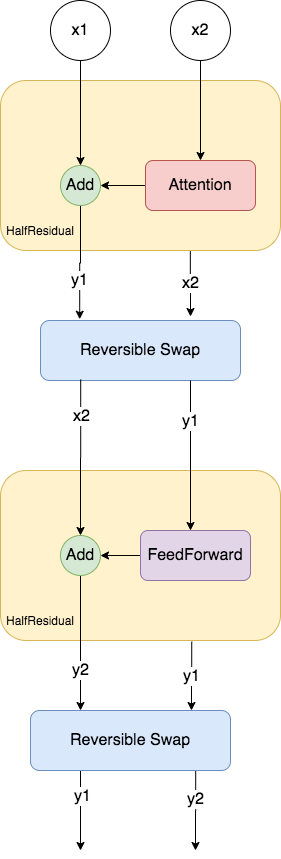
"You can see that it takes the initial inputs `x1` and `x2` and does the first equation of the reversible networks you learned in Part 3. As you've also learned, the reversible residual has two equations for the forward-pass so doing just one of them will just constitute half of the reversible decoder block. Before doing the second equation (i.e. second half of the reversible residual), it first needs to swap the elements to take into account the stack semantics in Trax. It simply puts `x2` on top of the stack so it can be fed to the add block of the half-residual layer. It then swaps the two outputs again so it can be fed to the next layer of the network. All of these arrives at the two equations in Part 3 and it can be used to recompute the activations during the backward pass.\n",
"\n",
"These are already implemented for you in Trax and in the following exercise, you'll get to practice how to call them to build your network."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 04\n",
"**Instructions:** Implement a wrapper function that returns a Reformer Language Model. You can use Trax's [ReformerLM](https://trax-ml.readthedocs.io/en/latest/trax.models.html#trax.models.reformer.reformer.ReformerLM) to do this quickly. It will have the same architecture as shown above."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "RidbAcoR6duP"
},
"outputs": [],
"source": [
"# UNQ_C4\n",
"# GRADED FUNCTION\n",
"def ReformerLM(vocab_size=33000, n_layers=2, mode='train', attention_type=tl.SelfAttention):\n",
" \"\"\"\n",
" Args: \n",
" vocab_size (int): size of the vocabulary\n",
" n_layers (int): number of decoder layers\n",
" mode (string): setting of the model which can be 'train', 'eval', or 'predict' \n",
" attention_type(class): attention class to use \n",
" Returns: \n",
" model (ReformerLM): a reformer language model implemented in Trax\n",
" \"\"\" \n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" # initialize an instance of Trax's ReformerLM class\n",
" model = trax.models.reformer.ReformerLM( \n",
" # set vocab size\n",
" None,\n",
" # set number of layers\n",
" None,\n",
" # set mode\n",
" None,\n",
" # set attention type\n",
" None\n",
" )\n",
" \n",
" ### END CODE HERE ###\n",
" return model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# display the model\n",
"temp_model = ReformerLM('train')\n",
"print(str(temp_model))\n",
"\n",
"# free memory\n",
"del temp_model "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_ReformerLM(ReformerLM)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 05\n",
"You will now write a function that takes in your model and trains it. \n",
"\n",
"**Instructions:** Implement the `training_loop` below to train the neural network above. Here is a list of things you should do:\n",
"\n",
"- Create `TrainTask` and `EvalTask`\n",
"- Create the training loop `trax.supervised.training.Loop`\n",
"- Pass in the following depending to train_task :\n",
" - `labeled_data=train_gen`\n",
" - `loss_layer=tl.CrossEntropyLoss()`\n",
" - `optimizer=trax.optimizers.Adam(0.01)`\n",
" - `lr_schedule=lr_schedule`\n",
" - `n_steps_per_checkpoint=10` \n",
"\n",
"You will be using your CrossEntropyLoss loss function with Adam optimizer. Please read the [trax](https://trax-ml.readthedocs.io/en/latest/trax.optimizers.html?highlight=adam#trax.optimizers.adam.Adam) documentation to get a full understanding. \n",
"\n",
"- Pass in the following to eval_task:\n",
" - `labeled_data=eval_gen`\n",
" - `metrics=[tl.CrossEntropyLoss(), tl.Accuracy()]`\n",
"\n",
"\n",
"\n",
"This function should return a `training.Loop` object. To read more about this check the [docs](https://trax-ml.readthedocs.io/en/latest/trax.supervised.html?highlight=loop#trax.supervised.training.Loop)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "tQehGhoD4Psl"
},
"outputs": [],
"source": [
"# UNQ_C5\n",
"# GRADED FUNCTION: train_model\n",
"def training_loop(ReformerLM, train_gen, eval_gen, output_dir = \"./model/\"):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you are building\n",
" train_gen (generator): train data generator.\n",
" eval_gen (generator): Validation generator. \n",
" output_dir (string): Path to save the model output. Defaults to './model/'.\n",
"\n",
" Returns:\n",
" trax.supervised.training.Loop: Training loop for the model.\n",
" \"\"\"\n",
"\n",
" # use the warmup_and_rsqrt_decay learning rate schedule\n",
" lr_schedule = trax.lr.warmup_and_rsqrt_decay(\n",
" n_warmup_steps=1000, max_value=0.01)\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # define the train task\n",
" train_task = training.TrainTask( \n",
" # labeled data\n",
" None,\n",
" # loss layer\n",
" None,\n",
" # optimizer\n",
" None,\n",
" # lr_schedule\n",
" None,\n",
" # n_steps\n",
" None\n",
" )\n",
"\n",
" # define the eval task\n",
" eval_task = training.EvalTask( \n",
" # labeled data\n",
" None,\n",
" # metrics\n",
" None\n",
" )\n",
"\n",
" ### END CODE HERE ###\n",
" loop = training.Loop(ReformerLM(mode='train'),\n",
" train_task,\n",
" eval_tasks=[eval_task],\n",
" output_dir=output_dir)\n",
" return loop"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNIT TEST COMMENT: Use the train task and eval task for grading train_model\n",
"test_loop = training_loop(ReformerLM, train_stream, eval_stream)\n",
"train_task = test_loop._task\n",
"eval_task = test_loop._eval_task\n",
"\n",
"print(train_task)\n",
"print(eval_task)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_tasks(train_task, eval_task)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 187
},
"colab_type": "code",
"id": "p9jERXY46I6J",
"outputId": "b6e00b37-6f13-486d-ba49-2d4542b0d398"
},
"outputs": [],
"source": [
"# we will now test your function\n",
"!rm -f model/model.pkl.gz\n",
"loop = training_loop(ReformerLM, train_stream, eval_stream)\n",
"loop.run(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Approximate Expected output:** \n",
"\n",
"```\n",
"\n",
"Step 1: Ran 1 train steps in 55.73 secs\n",
"Step 1: train CrossEntropyLoss | 10.41907787\n",
"Step 1: eval CrossEntropyLoss | 10.41005802\n",
"Step 1: eval Accuracy | 0.00000000\n",
"\n",
"Step 10: Ran 9 train steps in 108.21 secs\n",
"Step 10: train CrossEntropyLoss | 10.15449715\n",
"Step 10: eval CrossEntropyLoss | 9.63478279\n",
"Step 10: eval Accuracy | 0.16350447\n",
"``` "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "hAGlkMZW6rKn"
},
"source": [
"\n",
"# Part 5: Decode from a pretrained model\n",
"\n",
"We will now proceed on decoding using the model architecture you just implemented. As in the previous weeks, we will be giving you a pretrained model so you can observe meaningful output during inference. You will be using the [autoregressive_sample_stream()](https://trax-ml.readthedocs.io/en/latest/trax.supervised.html#trax.supervised.decoding.autoregressive_sample_stream) decoding method from Trax to do fast inference. Let's define a few parameters to initialize our model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# define the `predict_mem_len` and `predict_drop_len` of tl.SelfAttention\n",
"def attention(*args, **kwargs):\n",
" # number of input positions to remember in a cache when doing fast inference. \n",
" kwargs['predict_mem_len'] = 120\n",
" # number of input elements to drop once the fast inference input cache fills up.\n",
" kwargs['predict_drop_len'] = 120\n",
" # return the attention layer with the parameters defined above\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"# define the model using the ReformerLM function you implemented earlier.\n",
"model = ReformerLM(\n",
" vocab_size=33000,\n",
" n_layers=6,\n",
" mode='predict',\n",
" attention_type=attention,\n",
")\n",
"\n",
"# define an input signature so we can initialize our model. shape will be (1, 1) and the data type is int32.\n",
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now initialize our model from a file containing the pretrained weights. We will save this starting state so we can reset the model state when we generate a new conversation. This will become clearer in the `generate_dialogue()` function later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# initialize from file\n",
"model.init_from_file('chatbot_model1.pkl.gz',\n",
" weights_only=True, input_signature=shape11)\n",
"\n",
"# save the starting state\n",
"STARTING_STATE = model.state"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's define a few utility functions as well to help us tokenize and detokenize. We can use the [tokenize()](https://trax-ml.readthedocs.io/en/latest/trax.data.html#trax.data.tf_inputs.tokenize) and [detokenize()](https://trax-ml.readthedocs.io/en/latest/trax.data.html#trax.data.tf_inputs.detokenize) from `trax.data.tf_inputs` to do this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def tokenize(sentence, vocab_file, vocab_dir):\n",
" return list(trax.data.tokenize(iter([sentence]), vocab_file=vocab_file, vocab_dir=vocab_dir))[0]\n",
"\n",
"def detokenize(tokens, vocab_file, vocab_dir):\n",
" return trax.data.detokenize(tokens, vocab_file=vocab_file, vocab_dir=vocab_dir)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are now ready to define our decoding function. This will return a generator that yields that next symbol output by the model. It will be able to predict the next words by just feeding it a starting sentence."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 06\n",
"**Instructions:** Implement the function below to return a generator that predicts the next word of the conversation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C6\n",
"# GRADED FUNCTION\n",
"def ReformerLM_output_gen(ReformerLM, start_sentence, vocab_file, vocab_dir, temperature):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you just trained\n",
" start_sentence (string): starting sentence of the conversation\n",
" vocab_file (string): vocabulary filename\n",
" vocab_dir (string): directory of the vocabulary file\n",
" temperature (float): parameter for sampling ranging from 0.0 to 1.0.\n",
" 0.0: same as argmax, always pick the most probable token\n",
" 1.0: sampling from the distribution (can sometimes say random things)\n",
"\n",
" Returns:\n",
" generator: yields the next symbol generated by the model\n",
" \"\"\"\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # Create input tokens using the the tokenize function\n",
" input_tokens = None\n",
" \n",
" # Add batch dimension to array. Convert from (n,) to (x, n) where \n",
" # x is the batch size. Default is 1. (hint: you can use np.expand_dims() with axis=0)\n",
" input_tokens_with_batch = None\n",
" \n",
" # call the autoregressive_sample_stream function from trax\n",
" output_gen = trax.supervised.decoding.autoregressive_sample_stream( \n",
" # model\n",
" None,\n",
" # inputs will be the tokens with batch dimension\n",
" None,\n",
" # temperature\n",
" None\n",
" )\n",
" \n",
" ### END CODE HERE ###\n",
" \n",
" return output_gen"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"import pickle\n",
"\n",
"WEIGHTS_FROM_FILE = ()\n",
"\n",
"with open('weights', 'rb') as file:\n",
" WEIGHTS_FROM_FILE = pickle.load(file)\n",
"\n",
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)\n",
"\n",
"def attention(*args, **kwargs):\n",
" kwargs['predict_mem_len'] = 120\n",
" kwargs['predict_drop_len'] = 120\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"test_model = ReformerLM(vocab_size=5, n_layers=1, mode='predict', attention_type=attention)\n",
"\n",
"test_output_gen = ReformerLM_output_gen(test_model, \"test\", vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, temperature=0)\n",
"\n",
"test_model.init_weights_and_state(shape11)\n",
"\n",
"test_model.weights = WEIGHTS_FROM_FILE\n",
"\n",
"output = []\n",
"\n",
"for i in range(6):\n",
" output.append(next(test_output_gen)[0])\n",
"\n",
"print(output)\n",
"\n",
"# free memory\n",
"del test_model \n",
"del WEIGHTS_FROM_FILE\n",
"del test_output_gen\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"***Expected value:***\n",
"\n",
"[1, 0, 4, 3, 0, 4]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great! Now you will be able to see the model in action. The utility function below will call the generator you just implemented and will just format the output to be easier to read. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)\n",
"\n",
"def attention(*args, **kwargs):\n",
" kwargs['predict_mem_len'] = 120 # max length for predictions\n",
" kwargs['predict_drop_len'] = 120 # never drop old stuff\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"model = ReformerLM(\n",
" vocab_size=33000,\n",
" n_layers=6,\n",
" mode='predict',\n",
" attention_type=attention,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model.init_from_file('chatbot_model1.pkl.gz',\n",
" weights_only=True, input_signature=shape11)\n",
"\n",
"STARTING_STATE = model.state"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def generate_dialogue(ReformerLM, model_state, start_sentence, vocab_file, vocab_dir, max_len, temperature):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you just trained\n",
" model_state (np.array): initial state of the model before decoding\n",
" start_sentence (string): starting sentence of the conversation\n",
" vocab_file (string): vocabulary filename\n",
" vocab_dir (string): directory of the vocabulary file\n",
" max_len (int): maximum number of tokens to generate \n",
" temperature (float): parameter for sampling ranging from 0.0 to 1.0.\n",
" 0.0: same as argmax, always pick the most probable token\n",
" 1.0: sampling from the distribution (can sometimes say random things)\n",
"\n",
" Returns:\n",
" generator: yields the next symbol generated by the model\n",
" \"\"\" \n",
" \n",
" # define the delimiters we used during training\n",
" delimiter_1 = 'Person 1: ' \n",
" delimiter_2 = 'Person 2: '\n",
" \n",
" # initialize detokenized output\n",
" sentence = ''\n",
" \n",
" # token counter\n",
" counter = 0\n",
" \n",
" # output tokens. we insert a ': ' for formatting\n",
" result = [tokenize(': ', vocab_file=vocab_file, vocab_dir=vocab_dir)]\n",
" \n",
" # reset the model state when starting a new dialogue\n",
" ReformerLM.state = model_state\n",
" \n",
" # calls the output generator implemented earlier\n",
" output = ReformerLM_output_gen(ReformerLM, start_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, temperature=temperature)\n",
" \n",
" # print the starting sentence\n",
" print(start_sentence.split(delimiter_2)[0].strip())\n",
" \n",
" # loop below yields the next tokens until max_len is reached. the if-elif is just for prettifying the output.\n",
" for o in output:\n",
" \n",
" result.append(o)\n",
" \n",
" sentence = detokenize(np.concatenate(result, axis=0), vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR)\n",
" \n",
" if sentence.endswith(delimiter_1):\n",
" sentence = sentence.split(delimiter_1)[0]\n",
" print(f'{delimiter_2}{sentence}')\n",
" sentence = ''\n",
" result.clear()\n",
" \n",
" elif sentence.endswith(delimiter_2):\n",
" sentence = sentence.split(delimiter_2)[0]\n",
" print(f'{delimiter_1}{sentence}')\n",
" sentence = ''\n",
" result.clear()\n",
"\n",
" counter += 1\n",
" \n",
" if counter > max_len:\n",
" break \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now feed in different starting sentences and see how the model generates the dialogue. You can even input your own starting sentence. Just remember to ask a question that covers the topics in the Multiwoz dataset so you can generate a meaningful conversation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Are there theatres in town? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Is there a hospital nearby? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Can you book a taxi? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Congratulations! You just wrapped up the final assignment of this course and the entire specialization!**"
]
}
],
"metadata": {
"coursera": {
"schema_names": [
"NLPC4-4"
]
},
"jupytext": {
"encoding": "# -*- coding: utf-8 -*-",
"formats": "ipynb,py:percent",
"text_representation": {
"extension": ".py",
"format_name": "percent",
"format_version": "1.3",
"jupytext_version": "1.5.2"
}
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
\n",
"\n",
"You can see that it takes the initial inputs `x1` and `x2` and does the first equation of the reversible networks you learned in Part 3. As you've also learned, the reversible residual has two equations for the forward-pass so doing just one of them will just constitute half of the reversible decoder block. Before doing the second equation (i.e. second half of the reversible residual), it first needs to swap the elements to take into account the stack semantics in Trax. It simply puts `x2` on top of the stack so it can be fed to the add block of the half-residual layer. It then swaps the two outputs again so it can be fed to the next layer of the network. All of these arrives at the two equations in Part 3 and it can be used to recompute the activations during the backward pass.\n",
"\n",
"These are already implemented for you in Trax and in the following exercise, you'll get to practice how to call them to build your network."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 04\n",
"**Instructions:** Implement a wrapper function that returns a Reformer Language Model. You can use Trax's [ReformerLM](https://trax-ml.readthedocs.io/en/latest/trax.models.html#trax.models.reformer.reformer.ReformerLM) to do this quickly. It will have the same architecture as shown above."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "RidbAcoR6duP"
},
"outputs": [],
"source": [
"# UNQ_C4\n",
"# GRADED FUNCTION\n",
"def ReformerLM(vocab_size=33000, n_layers=2, mode='train', attention_type=tl.SelfAttention):\n",
" \"\"\"\n",
" Args: \n",
" vocab_size (int): size of the vocabulary\n",
" n_layers (int): number of decoder layers\n",
" mode (string): setting of the model which can be 'train', 'eval', or 'predict' \n",
" attention_type(class): attention class to use \n",
" Returns: \n",
" model (ReformerLM): a reformer language model implemented in Trax\n",
" \"\"\" \n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" # initialize an instance of Trax's ReformerLM class\n",
" model = trax.models.reformer.ReformerLM( \n",
" # set vocab size\n",
" None,\n",
" # set number of layers\n",
" None,\n",
" # set mode\n",
" None,\n",
" # set attention type\n",
" None\n",
" )\n",
" \n",
" ### END CODE HERE ###\n",
" return model"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# display the model\n",
"temp_model = ReformerLM('train')\n",
"print(str(temp_model))\n",
"\n",
"# free memory\n",
"del temp_model "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_ReformerLM(ReformerLM)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 05\n",
"You will now write a function that takes in your model and trains it. \n",
"\n",
"**Instructions:** Implement the `training_loop` below to train the neural network above. Here is a list of things you should do:\n",
"\n",
"- Create `TrainTask` and `EvalTask`\n",
"- Create the training loop `trax.supervised.training.Loop`\n",
"- Pass in the following depending to train_task :\n",
" - `labeled_data=train_gen`\n",
" - `loss_layer=tl.CrossEntropyLoss()`\n",
" - `optimizer=trax.optimizers.Adam(0.01)`\n",
" - `lr_schedule=lr_schedule`\n",
" - `n_steps_per_checkpoint=10` \n",
"\n",
"You will be using your CrossEntropyLoss loss function with Adam optimizer. Please read the [trax](https://trax-ml.readthedocs.io/en/latest/trax.optimizers.html?highlight=adam#trax.optimizers.adam.Adam) documentation to get a full understanding. \n",
"\n",
"- Pass in the following to eval_task:\n",
" - `labeled_data=eval_gen`\n",
" - `metrics=[tl.CrossEntropyLoss(), tl.Accuracy()]`\n",
"\n",
"\n",
"\n",
"This function should return a `training.Loop` object. To read more about this check the [docs](https://trax-ml.readthedocs.io/en/latest/trax.supervised.html?highlight=loop#trax.supervised.training.Loop)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {},
"colab_type": "code",
"id": "tQehGhoD4Psl"
},
"outputs": [],
"source": [
"# UNQ_C5\n",
"# GRADED FUNCTION: train_model\n",
"def training_loop(ReformerLM, train_gen, eval_gen, output_dir = \"./model/\"):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you are building\n",
" train_gen (generator): train data generator.\n",
" eval_gen (generator): Validation generator. \n",
" output_dir (string): Path to save the model output. Defaults to './model/'.\n",
"\n",
" Returns:\n",
" trax.supervised.training.Loop: Training loop for the model.\n",
" \"\"\"\n",
"\n",
" # use the warmup_and_rsqrt_decay learning rate schedule\n",
" lr_schedule = trax.lr.warmup_and_rsqrt_decay(\n",
" n_warmup_steps=1000, max_value=0.01)\n",
"\n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # define the train task\n",
" train_task = training.TrainTask( \n",
" # labeled data\n",
" None,\n",
" # loss layer\n",
" None,\n",
" # optimizer\n",
" None,\n",
" # lr_schedule\n",
" None,\n",
" # n_steps\n",
" None\n",
" )\n",
"\n",
" # define the eval task\n",
" eval_task = training.EvalTask( \n",
" # labeled data\n",
" None,\n",
" # metrics\n",
" None\n",
" )\n",
"\n",
" ### END CODE HERE ###\n",
" loop = training.Loop(ReformerLM(mode='train'),\n",
" train_task,\n",
" eval_tasks=[eval_task],\n",
" output_dir=output_dir)\n",
" return loop"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNIT TEST COMMENT: Use the train task and eval task for grading train_model\n",
"test_loop = training_loop(ReformerLM, train_stream, eval_stream)\n",
"train_task = test_loop._task\n",
"eval_task = test_loop._eval_task\n",
"\n",
"print(train_task)\n",
"print(eval_task)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"w4_unittest.test_tasks(train_task, eval_task)\n",
"# END UNIT TEST"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"base_uri": "https://localhost:8080/",
"height": 187
},
"colab_type": "code",
"id": "p9jERXY46I6J",
"outputId": "b6e00b37-6f13-486d-ba49-2d4542b0d398"
},
"outputs": [],
"source": [
"# we will now test your function\n",
"!rm -f model/model.pkl.gz\n",
"loop = training_loop(ReformerLM, train_stream, eval_stream)\n",
"loop.run(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Approximate Expected output:** \n",
"\n",
"```\n",
"\n",
"Step 1: Ran 1 train steps in 55.73 secs\n",
"Step 1: train CrossEntropyLoss | 10.41907787\n",
"Step 1: eval CrossEntropyLoss | 10.41005802\n",
"Step 1: eval Accuracy | 0.00000000\n",
"\n",
"Step 10: Ran 9 train steps in 108.21 secs\n",
"Step 10: train CrossEntropyLoss | 10.15449715\n",
"Step 10: eval CrossEntropyLoss | 9.63478279\n",
"Step 10: eval Accuracy | 0.16350447\n",
"``` "
]
},
{
"cell_type": "markdown",
"metadata": {
"colab_type": "text",
"id": "hAGlkMZW6rKn"
},
"source": [
"\n",
"# Part 5: Decode from a pretrained model\n",
"\n",
"We will now proceed on decoding using the model architecture you just implemented. As in the previous weeks, we will be giving you a pretrained model so you can observe meaningful output during inference. You will be using the [autoregressive_sample_stream()](https://trax-ml.readthedocs.io/en/latest/trax.supervised.html#trax.supervised.decoding.autoregressive_sample_stream) decoding method from Trax to do fast inference. Let's define a few parameters to initialize our model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# define the `predict_mem_len` and `predict_drop_len` of tl.SelfAttention\n",
"def attention(*args, **kwargs):\n",
" # number of input positions to remember in a cache when doing fast inference. \n",
" kwargs['predict_mem_len'] = 120\n",
" # number of input elements to drop once the fast inference input cache fills up.\n",
" kwargs['predict_drop_len'] = 120\n",
" # return the attention layer with the parameters defined above\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"# define the model using the ReformerLM function you implemented earlier.\n",
"model = ReformerLM(\n",
" vocab_size=33000,\n",
" n_layers=6,\n",
" mode='predict',\n",
" attention_type=attention,\n",
")\n",
"\n",
"# define an input signature so we can initialize our model. shape will be (1, 1) and the data type is int32.\n",
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now initialize our model from a file containing the pretrained weights. We will save this starting state so we can reset the model state when we generate a new conversation. This will become clearer in the `generate_dialogue()` function later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# initialize from file\n",
"model.init_from_file('chatbot_model1.pkl.gz',\n",
" weights_only=True, input_signature=shape11)\n",
"\n",
"# save the starting state\n",
"STARTING_STATE = model.state"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's define a few utility functions as well to help us tokenize and detokenize. We can use the [tokenize()](https://trax-ml.readthedocs.io/en/latest/trax.data.html#trax.data.tf_inputs.tokenize) and [detokenize()](https://trax-ml.readthedocs.io/en/latest/trax.data.html#trax.data.tf_inputs.detokenize) from `trax.data.tf_inputs` to do this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def tokenize(sentence, vocab_file, vocab_dir):\n",
" return list(trax.data.tokenize(iter([sentence]), vocab_file=vocab_file, vocab_dir=vocab_dir))[0]\n",
"\n",
"def detokenize(tokens, vocab_file, vocab_dir):\n",
" return trax.data.detokenize(tokens, vocab_file=vocab_file, vocab_dir=vocab_dir)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We are now ready to define our decoding function. This will return a generator that yields that next symbol output by the model. It will be able to predict the next words by just feeding it a starting sentence."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"### Exercise 06\n",
"**Instructions:** Implement the function below to return a generator that predicts the next word of the conversation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# UNQ_C6\n",
"# GRADED FUNCTION\n",
"def ReformerLM_output_gen(ReformerLM, start_sentence, vocab_file, vocab_dir, temperature):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you just trained\n",
" start_sentence (string): starting sentence of the conversation\n",
" vocab_file (string): vocabulary filename\n",
" vocab_dir (string): directory of the vocabulary file\n",
" temperature (float): parameter for sampling ranging from 0.0 to 1.0.\n",
" 0.0: same as argmax, always pick the most probable token\n",
" 1.0: sampling from the distribution (can sometimes say random things)\n",
"\n",
" Returns:\n",
" generator: yields the next symbol generated by the model\n",
" \"\"\"\n",
" \n",
" ### START CODE HERE (REPLACE INSTANCES OF 'None' WITH YOUR CODE) ###\n",
" \n",
" # Create input tokens using the the tokenize function\n",
" input_tokens = None\n",
" \n",
" # Add batch dimension to array. Convert from (n,) to (x, n) where \n",
" # x is the batch size. Default is 1. (hint: you can use np.expand_dims() with axis=0)\n",
" input_tokens_with_batch = None\n",
" \n",
" # call the autoregressive_sample_stream function from trax\n",
" output_gen = trax.supervised.decoding.autoregressive_sample_stream( \n",
" # model\n",
" None,\n",
" # inputs will be the tokens with batch dimension\n",
" None,\n",
" # temperature\n",
" None\n",
" )\n",
" \n",
" ### END CODE HERE ###\n",
" \n",
" return output_gen"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# BEGIN UNIT TEST\n",
"import pickle\n",
"\n",
"WEIGHTS_FROM_FILE = ()\n",
"\n",
"with open('weights', 'rb') as file:\n",
" WEIGHTS_FROM_FILE = pickle.load(file)\n",
"\n",
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)\n",
"\n",
"def attention(*args, **kwargs):\n",
" kwargs['predict_mem_len'] = 120\n",
" kwargs['predict_drop_len'] = 120\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"test_model = ReformerLM(vocab_size=5, n_layers=1, mode='predict', attention_type=attention)\n",
"\n",
"test_output_gen = ReformerLM_output_gen(test_model, \"test\", vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, temperature=0)\n",
"\n",
"test_model.init_weights_and_state(shape11)\n",
"\n",
"test_model.weights = WEIGHTS_FROM_FILE\n",
"\n",
"output = []\n",
"\n",
"for i in range(6):\n",
" output.append(next(test_output_gen)[0])\n",
"\n",
"print(output)\n",
"\n",
"# free memory\n",
"del test_model \n",
"del WEIGHTS_FROM_FILE\n",
"del test_output_gen\n",
"# END UNIT TEST"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"***Expected value:***\n",
"\n",
"[1, 0, 4, 3, 0, 4]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great! Now you will be able to see the model in action. The utility function below will call the generator you just implemented and will just format the output to be easier to read. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"shape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)\n",
"\n",
"def attention(*args, **kwargs):\n",
" kwargs['predict_mem_len'] = 120 # max length for predictions\n",
" kwargs['predict_drop_len'] = 120 # never drop old stuff\n",
" return tl.SelfAttention(*args, **kwargs)\n",
"\n",
"model = ReformerLM(\n",
" vocab_size=33000,\n",
" n_layers=6,\n",
" mode='predict',\n",
" attention_type=attention,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model.init_from_file('chatbot_model1.pkl.gz',\n",
" weights_only=True, input_signature=shape11)\n",
"\n",
"STARTING_STATE = model.state"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def generate_dialogue(ReformerLM, model_state, start_sentence, vocab_file, vocab_dir, max_len, temperature):\n",
" \"\"\"\n",
" Args:\n",
" ReformerLM: the Reformer language model you just trained\n",
" model_state (np.array): initial state of the model before decoding\n",
" start_sentence (string): starting sentence of the conversation\n",
" vocab_file (string): vocabulary filename\n",
" vocab_dir (string): directory of the vocabulary file\n",
" max_len (int): maximum number of tokens to generate \n",
" temperature (float): parameter for sampling ranging from 0.0 to 1.0.\n",
" 0.0: same as argmax, always pick the most probable token\n",
" 1.0: sampling from the distribution (can sometimes say random things)\n",
"\n",
" Returns:\n",
" generator: yields the next symbol generated by the model\n",
" \"\"\" \n",
" \n",
" # define the delimiters we used during training\n",
" delimiter_1 = 'Person 1: ' \n",
" delimiter_2 = 'Person 2: '\n",
" \n",
" # initialize detokenized output\n",
" sentence = ''\n",
" \n",
" # token counter\n",
" counter = 0\n",
" \n",
" # output tokens. we insert a ': ' for formatting\n",
" result = [tokenize(': ', vocab_file=vocab_file, vocab_dir=vocab_dir)]\n",
" \n",
" # reset the model state when starting a new dialogue\n",
" ReformerLM.state = model_state\n",
" \n",
" # calls the output generator implemented earlier\n",
" output = ReformerLM_output_gen(ReformerLM, start_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, temperature=temperature)\n",
" \n",
" # print the starting sentence\n",
" print(start_sentence.split(delimiter_2)[0].strip())\n",
" \n",
" # loop below yields the next tokens until max_len is reached. the if-elif is just for prettifying the output.\n",
" for o in output:\n",
" \n",
" result.append(o)\n",
" \n",
" sentence = detokenize(np.concatenate(result, axis=0), vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR)\n",
" \n",
" if sentence.endswith(delimiter_1):\n",
" sentence = sentence.split(delimiter_1)[0]\n",
" print(f'{delimiter_2}{sentence}')\n",
" sentence = ''\n",
" result.clear()\n",
" \n",
" elif sentence.endswith(delimiter_2):\n",
" sentence = sentence.split(delimiter_2)[0]\n",
" print(f'{delimiter_1}{sentence}')\n",
" sentence = ''\n",
" result.clear()\n",
"\n",
" counter += 1\n",
" \n",
" if counter > max_len:\n",
" break \n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now feed in different starting sentences and see how the model generates the dialogue. You can even input your own starting sentence. Just remember to ask a question that covers the topics in the Multiwoz dataset so you can generate a meaningful conversation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Are there theatres in town? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Is there a hospital nearby? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sample_sentence = ' Person 1: Can you book a taxi? Person 2: '\n",
"generate_dialogue(ReformerLM=model, model_state=STARTING_STATE, start_sentence=sample_sentence, vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR, max_len=120, temperature=0.2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Congratulations! You just wrapped up the final assignment of this course and the entire specialization!**"
]
}
],
"metadata": {
"coursera": {
"schema_names": [
"NLPC4-4"
]
},
"jupytext": {
"encoding": "# -*- coding: utf-8 -*-",
"formats": "ipynb,py:percent",
"text_representation": {
"extension": ".py",
"format_name": "percent",
"format_version": "1.3",
"jupytext_version": "1.5.2"
}
},
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 4
}