{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Функции и модули"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В этой лекции мы расскажем о том, что такое функции в языках программирования и для чего они нужны. Также мы рассмотрим понятия модуля и пакета, обсудим концепцию пространств имен и вкратце познакомим вас с парадигмой процедурного программирования."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Содержание лекции"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* [Функции](#Функции)\n",
" * [Создание и вызов](#Создание-и-вызов)\n",
" * [Аргументы и возвращаемое значение](#Аргументы-и-возвращаемое-значение)\n",
" * [Рекурсивные функции](#Рекурсивные-функции)\n",
" * [Лямбда-функции](#Лямбда-функции)\n",
"* [Модули](#Модули)\n",
" * [Импортирование модуля](#Импортирование-модуля)\n",
" * [Пакеты](#Пакеты)\n",
"* [Пространства имен](#Пространства-имен)\n",
"* [Процедурное программирование](#Процедурное-программирование)\n",
"* [Вопросы для самоконтроля](#Вопросы-для-самоконтроля)\n",
"* [Задание](#Задание)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Функции"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Функция**, также иногда называемая *подпрограммой* или *процедурой* - это фрагмент исходного кода (как правило, именованный), к которому можно обратиться из других частей программы. Можно говорить о том, что функция представляет собой маленькую законченную программу внутри основной программы (поэтому ее иногда и называют подпрограммой). Большинство функций имеют имя для того, чтобы к ним было удобно обращаться из остальных частей программы. По сути, понятие функции тесно связано с понятием переменной, только первая связывает некоторое имя с блоком исходного кода, а вторая - со значением в памяти (числовым, строковым и т.д.)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Создание и вызов"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Функции в языке программирования Python создаются с помощью инструкции `def`:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"def function_name(parameters_list):\n",
" code_block\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Имя функции *function_name* должно быть [допустимым идентификатором](04_Data_Types.ipynb#Допустимые-идентификаторы) в языке Python. Поскольку функция как правило выполняет некоторое действие, то в ее имени рекомендуется использовать глаголы. В качестве примера можно привести такие имена функций: `send_message`, `get_inverted_value`, `make_job` и т.д."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Функция может иметь **параметры**, описываемые в *parameters_list*, который представляет собой 0 или более переменных, разделенных запятыми. Эти переменные \"видны\" **только** внутри функции (в ее *code_block*) так, словно они были созданы в ней явно с помощью инструкций присваивания, и к ним нельзя обратится из других частей исходного кода."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Компонент *code_block* представляет собой последовательность произвольных инструкций языка программирования Python, в том числе других инструкций `def`. Обратите внимание, что все инструкции в *code_block* должны иметь отступ относительно инструкции `def`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В любом месте внутри *code_block* функции можно использовать специальную инструкцию `return` вместе со значением произвольного типа, с помощью которой функция может вернуть результат своей работы."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Функции используются следующим образом:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. В начале функция создается с помощью инструкции `def`. Не любую последовательность инструкций имеет смысл делать функцией - как правило она должна делать небольшую и четко определенную работу, необходимость в которой может возникать в разных частях исходного кода основной программы. Процесс создания функции, а также соответствующая инструкция `def` в исходном коде, часто называются **определением функции**.\n",
"2. После того, как функция определена, ее можно использовать в других частях программы для того, чтобы выполнить работу, реализованную в функции. Для этого в нужных местах исходного кода пишут имя функции и в скобках `()` указывают значения для ее параметров. Это называется **вызовом функции**. Переменные и литералы, указанные в скобках при вызове функции называются ее **аргументами**.\n",
"3. Когда интерпретатор встречает инструкцию вызова функции, он вначале инициализирует с помощью аргументов ее параметры, а затем выполняет *code_block* функции. Можно представлять себе, что при вызове функции интерпретатор как бы вставляет в исходный код инструкции из *code_block*, при этом заменив в них имена параметров на имена аргументов.\n",
"4. Если в *code_block* функции выполняется инструкция `return`, интерпретатор берет значение, указанное в ней, вставляет его в место вызова функции (говорят, что функция **возвращает** значение), а затем продолжает выполнять программу с этой точки. Можно представлять себе это так, словно значение из инструкции `return` заменило собой инструкцию вызова функции. В `return` можно и не указывать никакого значения - в этом случае возвращается специальное значение `None`.\n",
"5. Если инструкция `return` не встретилась, то интерпретатор обрабатывает *code_block* функции целиком, а затем выполняет действия, аналогичные тому, как если бы в конце *code_block* была инструкция `return` без значения."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В большинстве примеров в данной лекции мы используем функцию `print` для вывода результатов работы наших программ на экран. Эта функция определена в самом языке Python и в качестве аргументов принимает список литералов, переменных или выражений, чьи значения затем выводит на экран, отделяя их пробелом друг от друга. Количество аргументов в вызове функции `print`, а также их типы данных, может быть любым:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"test 10 10.3 True 30\n"
]
}
],
"source": [
"a = 10\n",
"b = True\n",
"\n",
"# выводим 5 аргументов: строку, целое число, число с плавающей точкой,\n",
"# булевое значение и значение арифметического выражения\n",
"print('test', a, 10.3, b, a * 2 + 10) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Познакомившись с функцией `print`, попробуем создать и вызвать нашу собственную функцию."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"hello, Alice\n",
"hello, Bob\n"
]
}
],
"source": [
"# определение функции\n",
"\n",
"def print_hello(name): # name - это параметр функции, который \"виден\" только в ее code_block\n",
" print('hello,', name) # это code_block функции, только в нем мы можем обращаться к параметру name\n",
"\n",
"# основная программа\n",
"\n",
"name1 = 'Alice'\n",
"name2 = 'Bob'\n",
"\n",
"print_hello(name1) # вызов функции print_hello, name1 - это аргумент, который присваивается параметру name\n",
"print_hello(name2) # вызов функции print_hello с другим аргументом (name2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Определение функции должно находится в исходном коде до ее вызовов. Это ограничение связано с тем, что интерпретатор выполняет исходный код последовательно сверху вниз, поэтому в момент вызова функции должен знать, какой блок кода связан с ней. В следующем пример интерпретатор генерирует исключение `NameError`, так как в момент вызова функции он еще не обрабатывал ее определение:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"ename": "NameError",
"evalue": "name 'print_hello_world' is not defined",
"output_type": "error",
"traceback": [
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[1;31mNameError\u001b[0m Traceback (most recent call last)",
"\u001b[1;32m\u001b[0m in \u001b[0;36m\u001b[1;34m()\u001b[0m\n\u001b[0;32m 1\u001b[0m \u001b[1;31m# основная программа\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0;32m 2\u001b[0m \u001b[1;33m\u001b[0m\u001b[0m\n\u001b[1;32m----> 3\u001b[1;33m \u001b[0mprint_hello_world\u001b[0m\u001b[1;33m(\u001b[0m\u001b[1;33m)\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m\u001b[0;32m 4\u001b[0m \u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0;32m 5\u001b[0m \u001b[1;31m# определение функции print_hello_world\u001b[0m\u001b[1;33m\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n",
"\u001b[1;31mNameError\u001b[0m: name 'print_hello_world' is not defined"
]
}
],
"source": [
"# основная программа\n",
"\n",
"print_hello_world()\n",
"\n",
"# определение функции print_hello_world\n",
"# обратите внимание, что функция может не иметь параметров, однако скобки ()\n",
"# все равно должны присутствовать как в ее определении, так и в ее вызове\n",
"\n",
"def print_hello_world(): \n",
" print('hello, world')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Напомним, что все переменные в Python являются [ссылками](./04_Data_Types.ipynb#Ссылки). Это означает, что при инициализации параметров функции с помощью аргументов, первые начинают указывать на ту же область памяти, что и вторые. Если аргумент имеет неизменяемый тип данных, то модификация соответствующего параметра в *code_block* функции никак не повлияет на значение аргумента, в другом случае изменение параматра внутри функции приведет к изменению значения аргумента (подробнее об этом [здесь](./04_Data_Types.ipynb#Изменяемость-типов-данных)). Поскольку пока из всех типов данных, что мы встречали, изменяемым был только тип `Context`, используем его, чтобы продемонстрировать разницу между изменяемыми и неизменяемыми аргументами:"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"before function: var = 1\n",
"in function: var = 2\n",
"after function: var = 1\n",
"before function: ctx.prec = 28\n",
"in function: ctx.prec = 29\n",
"after function: ctx.prec = 29\n"
]
}
],
"source": [
"import decimal\n",
"\n",
"def add_one_to_variable(var):\n",
" var += 1\n",
" print('in function: var =', var)\n",
"\n",
"def add_one_to_prec(ctx):\n",
" ctx.prec += 1\n",
" print('in function: ctx.prec =', ctx.prec)\n",
"\n",
"var = 1\n",
"ctx = decimal.getcontext()\n",
"\n",
"print('before function: var =', var)\n",
"add_one_to_variable(var)\n",
"print('after function: var =', var)\n",
"\n",
"print('before function: ctx.prec =', ctx.prec)\n",
"add_one_to_prec(ctx)\n",
"print('after function: ctx.prec =', ctx.prec)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как видите, модификация неизменяемого типа внутри функции видна только в ее *code_block*, в то время как модификация изменямого остается в силе и после возврата из функции."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Аргументы и возвращаемое значение"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В примерах, которые были только что рассмотрены, выигрыш от использования функций небольшой - можно было бы просто вместо них везде писать их *code_block*. Рассмотрим более полезную функцию, вычисляющую площадь треугольника по длинам его сторон ([формула Герона](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D0%BC%D1%83%D0%BB%D0%B0_%D0%93%D0%B5%D1%80%D0%BE%D0%BD%D0%B0)):"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"a = 3 , b = 4 , c = 5\n",
"area = 6.0\n"
]
}
],
"source": [
"def calc_triangle_area(a, b, c):\n",
" print('a =', a, ', b =', b, ', c =', c)\n",
" p = (a + b + c) / 2\n",
" return (p * (p - a) * (p - b) * (p - c)) ** 0.5\n",
"\n",
"area = calc_triangle_area(3, 4, 5)\n",
"print('area =', area)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В этой функции мы видим инструкцию `return`, возвращающую значение выражения для площади треугольника, которое затем присваивается переменной `area`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Аргументы, с которыми вызывается функция `calc_triangle_area` в примере выше называются **позиционными** - они присиваиваются параметрам в том порядке, в котором указаны в инструкции вызова функции, то есть параметр `a` становится равен трем, `b` четырем, а `c` - пяти."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"При вызове функции также можно использовать **именованные аргументы**, которые явно указывают, какому параметру какое значение нужно присвоить. Именованные аргументы могут идти в любом порядке, и даже использоваться вместе с позиционными, правда обязательно **после** них. Какую бы комбинацию именованных и позиционных аргументов вы ни использовали, важно, чтобы в итоге все параметры были проинициализированы, или будет сгенерировано исключение."
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"a = 5 , b = 10 , c = 7\n",
"area1 = 16.24807680927192\n",
"a = 5 , b = 10 , c = 7\n",
"area2 = 16.24807680927192\n",
"a = 5 , b = 10 , c = 7\n",
"area3 = 16.24807680927192\n"
]
}
],
"source": [
"# во всех примерах ниже параметры функции calc_triangle_area: a = 5, b = 10, c = 7\n",
"\n",
"# позиционные аргументы\n",
"print('area1 =', calc_triangle_area(5, 10, 7))\n",
"\n",
"# именованные аргументы\n",
"print('area2 =', calc_triangle_area(c=7, a=5, b=10))\n",
"\n",
"# позиционны и именованные аргументы\n",
"print('area3 =', calc_triangle_area(5, c=7, b=10))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Приведем также примеры некорректных вызовов функции `calc_triangle_area`:"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"ename": "SyntaxError",
"evalue": "positional argument follows keyword argument (, line 1)",
"output_type": "error",
"traceback": [
"\u001b[1;36m File \u001b[1;32m\"\"\u001b[1;36m, line \u001b[1;32m1\u001b[0m\n\u001b[1;33m calc_triangle_area(a=1, 2, 3) # позиционный аргумент идет после именованного\u001b[0m\n\u001b[1;37m ^\u001b[0m\n\u001b[1;31mSyntaxError\u001b[0m\u001b[1;31m:\u001b[0m positional argument follows keyword argument\n"
]
}
],
"source": [
"calc_triangle_area(a=1, 2, 3) # позиционный аргумент идет после именованного\n",
"calc_triangle_area(1, b=2) # слишком мало аргументов\n",
"calc_triangle_area(a=1, b=2, c=3, d=4) # неизвестный параметр d"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В нашей текущей реализации функции `calc_triangle_area` не учтен тот факт, что не всякие три числа могут быть использованы в качестве длин сторон треугольника, поэтому давайте добавим в нее соответствующую проверку. Если параметры корректны, то мы будем высчитывать и возвращать площадь треугольника, а в случае ошибки - возвращать специальное значение `None`, которое позволит обнаружить ее в том месте, где вызывается наша функция. Этот прием (использование `None` в качестве результата в случае ошибки) очень распространен и встречается во многих функциях в Python."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"area = 51.521233486786784\n"
]
}
],
"source": [
"def calc_triangle_area(a, b, c):\n",
" # из школьного курса геометрии известно, что сумма любых двух\n",
" # сторон треугольника должна быть строго больше третьей стороны\n",
" if a + b <= c or a + c <= b or b + c <= a:\n",
" return None # в принципе, можно было написать просто \"return\", но так понятнее\n",
" \n",
" p = (a + b + c) / 2\n",
" return (p * (p - a) * (p - b) * (p - c)) ** 0.5\n",
"\n",
"# длины сторон треугольника\n",
"\n",
"a = 10\n",
"b = 11\n",
"c = 12\n",
"\n",
"# вычисляем площадь (здесь a, b, c - позиционные аргументы, с помощью которых будут\n",
"# проинициализированны параметры функции)\n",
"area = calc_triangle_area(a, b, c) \n",
"\n",
"# проверяем, что не произошло ошибки\n",
"\n",
"if area is not None:\n",
" print('area =', area)\n",
"else:\n",
" print('bad triangle sides!')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Обратите внимание, что для проверки того, равна ли переменная `area` специальному значению `None`, следует использовать операцию `is` или `is not`, а не `==`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Убедимся, что наша программа работает правильно и при некорректных значениях длин сторон треугольника:"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"bad triangle sides!\n"
]
}
],
"source": [
"a = 1\n",
"b = 1\n",
"c = 5\n",
"\n",
"area = calc_triangle_area(a, b, c) \n",
"\n",
"if area is not None:\n",
" print('area =', area)\n",
"else:\n",
" print('bad triangle sides!')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Заметим, что внутри функции может находиться определение другой функции. Такие функции иногда называют **локальными**, потому что их можно вызвать только в *code_block* функции, в которой они определены. В противовес этому, обычные функции, которые мы рассматривали выше, называют **глобальными**, потому что они могут использоваться в любой части исходного кода программы. Перепишем наш пример с использованием локальной функции:"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"8.78564169540279"
]
},
"execution_count": 10,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"def calc_triangle_area(a, b, c): # глобальная функция \n",
" def get_half_perimeter(): # локальная функция\n",
" return (a + b + c) / 2 # внутри локальной функции видны параметры глобальной!\n",
" \n",
" if a + b <= c or a + c <= b or b + c <= a:\n",
" return None\n",
" \n",
" p = get_half_perimeter() # вызываем локальную функцию\n",
" return (p * (p - a) * (p - b) * (p - c)) ** 0.5\n",
"\n",
"calc_triangle_area(3, 7, 9)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"При попытке вызвать локальную функцию вне глобальной, в которой она определена, мы получим уже хорошо знакомую нам ошибку `NameError`:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"ename": "NameError",
"evalue": "name 'get_half_perimeter' is not defined",
"output_type": "error",
"traceback": [
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[1;31mNameError\u001b[0m Traceback (most recent call last)",
"\u001b[1;32m\u001b[0m in \u001b[0;36m\u001b[1;34m()\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[0mget_half_perimeter\u001b[0m\u001b[1;33m(\u001b[0m\u001b[1;33m)\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[1;31mNameError\u001b[0m: name 'get_half_perimeter' is not defined"
]
}
],
"source": [
"get_half_perimeter()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"При определении функции с помощью инструкции `def` для некоторых параметров можно указать *значение по умолчанию*. Такие параметры становятся *необязательными*, то есть при вызове функции можно не указывать аргументы для них, при этом параметры инициализируются своими значениями по умолчанию. Рассмотрим функцию, которая укорачивает произвольный текст до определенного количества символов, добавляя в конец индикатор того, что текст бы сокращен. В примере мы воспользуемся встроенной в Python функцией `len`, которая принимает в качестве параметра строку и возвращает количество символов в ней."
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
"def get_short_string(text, length=15, indicator='...'):\n",
" if len(text) <= length:\n",
" return text\n",
" \n",
" indicator_len = len(indicator)\n",
" result = text[:length-indicator_len] + indicator\n",
" return result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"У функции `get_short_string` есть два необязательных параметра `length` и `indicator`, для которых задано значение по умолчанию (указывается с помощью знака `=` в определении функции `def`), а значит при ее вызове их можно не указывать:"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"To be or not to b***\n",
"To be o...\n",
"To be or not***\n",
"To be or not...\n"
]
}
],
"source": [
"text = 'To be or not to be, that is the question'\n",
"\n",
"print(get_short_string(text, 20, '***')) # явно задаем значения для всех параметров\n",
"print(get_short_string(text, length=10)) # indicator будет иметь значение по умолчанию\n",
"print(get_short_string(text, indicator='***')) # length будет иметь значение по умолчанию\n",
"print(get_short_string(text)) # length и indicator будут иметь значение по умолчанию"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Значения по умолчанию следует использовать для тех параметров функции, которые принимают как правило одно и то же значение. В этом случае функцией становится удобнее пользоваться: при ее вызове нужно передать лишь несколько аргументов, а остальные параметры будут автоматически проинициализированы значениями по умолчанию. При этом, в тех редких случаях, когда значение по умолчанию некоторого параметра нас не устраивает, мы можем явно указать нужный аргумент."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Если вы хотите сделать несколько параметров своей функции необязательными (т.е. имеющими значение по умолчанию), все их нужно указывать **после** обязательных параметров в инструкции `def`, например, такое определение является некорректным:"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"ename": "SyntaxError",
"evalue": "non-default argument follows default argument (, line 1)",
"output_type": "error",
"traceback": [
"\u001b[1;36m File \u001b[1;32m\"\"\u001b[1;36m, line \u001b[1;32m1\u001b[0m\n\u001b[1;33m def my_function(param1, param2=0, param3):\u001b[0m\n\u001b[1;37m ^\u001b[0m\n\u001b[1;31mSyntaxError\u001b[0m\u001b[1;31m:\u001b[0m non-default argument follows default argument\n"
]
}
],
"source": [
"def my_function(param1, param2=0, param3):\n",
" print('my function')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Функции можно присваивать переменным, а затем вызывать их через эти переменные:"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"---hello---\n"
]
}
],
"source": [
"def decorate_text(text):\n",
" return '---' + text + '---'\n",
"\n",
"a = decorate_text\n",
"decorated_text = a('hello')\n",
"print(decorated_text)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Этот прием позволяет создавать интересные конструкции, например, использовать функцию в качестве параметра другой функции. Рассмотрим такой пример:"
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"---hello, Alice---\n",
"***hello, Bob***\n"
]
}
],
"source": [
"def decorate_text1(text):\n",
" return '---' + text + '---'\n",
"\n",
"def decorate_text2(text):\n",
" return '***' + text + '***'\n",
"\n",
"def decorate_text3(text):\n",
" return '+++' + text + '+++'\n",
"\n",
"def print_hello(name, decorator=decorate_text1):\n",
" hello_text = 'hello, ' + name\n",
" hello_text = decorator(hello_text)\n",
" print(hello_text)\n",
"\n",
"print_hello('Alice')\n",
"print_hello('Bob', decorate_text2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Рекурсивные функции"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В языке Python можно создавать функции, которые вызывают сами себя. Такие функции называются **рекурсивными**, и они ничем не отличаются от обычных, кроме того, что в их *code_block* содержится инструкция вызова их самих. Рекурсивные функции являются элегантным способом реализации многих алгоритмов."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Рассмотрим простой пример функции, которая возводит число в некоторую целую неотрицательную степень:"
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"25"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"def calc_power(num, exponent):\n",
" result = 1\n",
" while exponent > 0:\n",
" result *= num\n",
" exponent -= 1\n",
" return result\n",
"\n",
"calc_power(5, 2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"А теперь давайте перепишем эту функцию, используя рекурсию. Мы знаем, что $x^n$ можно представить в виде $x*(x^{n-1})$, то есть вычисление степени $n$ можно свести к вычислению степени $n-1$. После этого эти же рассуждения можно применить и к выражению $x^{n-1}$ и так далее. Такую последовательность вычислений можно реализовать в виде рекурсивной функции (обратите внимание, что $x^0$ это 1):"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"25"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"def calc_power(num, exponent):\n",
" if exponent == 0:\n",
" return 1\n",
" return num * calc_power(num, exponent - 1)\n",
"\n",
"calc_power(5, 2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Давайте рассмотрим, как выполнялась наша программа:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. `calc_power(5, 2)` - при этом вызове параметр `exponent` не равен 0, поэтому первое условие `if` не выполняется, и мы переходим к строке `return num * calc_power(num, exponent - 1)`. Чтобы вычислить результат умножения, интерпретатор должен знать значение обоих операндов, поэтому перед выполнением операции `*` он обрабатывает вызов функции `calc_power` с аргументами 5 и 1.\n",
"2. `calc_power(5, 1)` - все то же самое, в итоге происходит вызов `calc_power(5, 0)`.\n",
"3. `calc_power(5, 0)` - выполняется условие `if`, поэтому функция сразу возвращает 1. До этого момента мы как бы \"погружались\" внутрь нашей рекурсии, а теперь начнем подниматься на повехность.\n",
"4. `calc_power(5, 1)` - теперь интерпретатор знает значения обоих операндов, и возвращает из функции результат выражения `5 * 1`, то есть число 5.\n",
"5. `calc_power(5, 2)` - аналогично предыдущему пункту, интерпретатор возвращает в основную программу результат выражения `5 * 5`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Лямбда-функции"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Лямбда-функция** представляет собой анонимную функцию, создаваемую следующей инструкцией:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"lambda parameters_list: expression\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как и для обычных функций, *parameters_list* представляет собой 0 или более переменных, разделенных запятыми. Для них можно указывать значение по умолчанию по тем же правилам, что и для обычных функций."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*Expression* представляет собой некоторое выражение языка программирования Python, например, арифметическое, логическое или условное."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Приведем простой пример лямбда-функции, которая возвращает модуль числа:"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"5\n",
"5\n"
]
}
],
"source": [
"abs_value = lambda x: x if x >= 0 else -x # используем условное выражение в качестве лямбда-функции\n",
"print(abs_value(5))\n",
"print(abs_value(-5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Рассмотрим последний пример из предыдущего раздела. Хорошая функция должна представлять собой законченную небольшую программу, которая может многократно использоваться в других участках кода (подробнее об этом читайте ниже в разделе [Процедурное программирование](#Процедурное-программирование)). Сказать это о функциях `decorate_text` мы не можем - они используются лишь как параметры для функции `print_hello`, и вряд ли понадобятся где-либо еще. Поэтому этот пример лучше переписать с использованием лямбда-функций:"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"---hello, Alice---\n"
]
}
],
"source": [
"# обратите внимание на то, как мы используем лямбда-функцию в качестве значения по умолчанию\n",
"def print_hello(name, decorator=lambda text: '---' + text + '---'):\n",
" hello_text = 'hello, ' + name\n",
" hello_text = decorator(hello_text)\n",
" print(hello_text)\n",
"\n",
"print_hello('Alice')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Если нам потребуется любой другой способ декорирования текста, мы можем указать его прямо при вызове функции `print_hello`:"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"***hello, Bob***\n",
"===hello, Cooper===\n"
]
}
],
"source": [
"print_hello('Bob', lambda text: '***' + text + '***')\n",
"print_hello('Cooper', lambda text: '===' + text + '===')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Модули"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
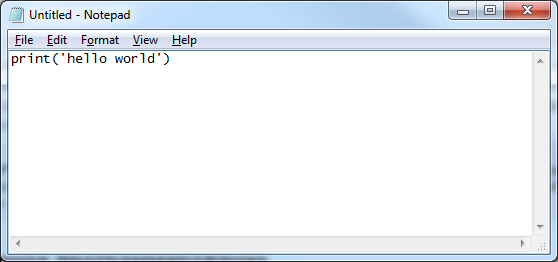
"Перед тем, как мы начнем изучать модули, давайте посмотрим, как еще можно создать программу на языке Python, не используя среду разработки Jupyter Notebook. На самом деле, все что нам нужно - это любой текстовый редактор и интерпретатор Python. При установке [дистрибутива Anaconda](02_Installing_Python.ipynb#Описание-дистрибутива) интерпретатор уже был установлен, а в качестве текстового редактора можно использовать стандартный блокнот в ОС Windows. Запустим его и напишем в нем простейшую программу:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Теперь сохраним этот файл и запомним путь к нему. По общепринятому соглашению, файл с исходным кодом на языке Python должен иметь расширение *.py*, поэтому в качестве имени используем, например, *hello.py*."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
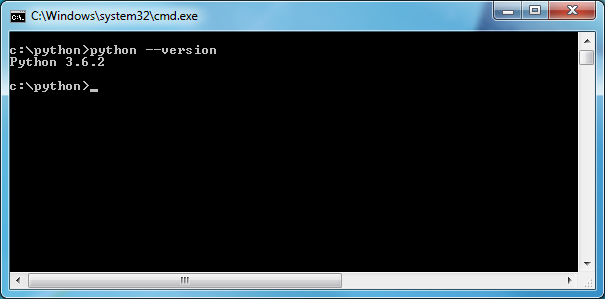
"Для того, чтобы выполнить эту программу, нужно запустить интерпретатор Python и передать ему в командной строке наш файл *hello.py*. Для начала однако давайте убедимся, что интерпретатор Python присутствует в нашей системе. Для этого запустим командную строку Windows и выполним команду *\"python --version\"*. Вы должны увидеть примерно следующее:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Если вместо этого было выведено сообщение о том, что \"python\" является неизвестной командой, то возможно одно из двух: либо интерпретатор отсутствует в системе, либо путь к нему не прописан в специальной переменной среды *Path*. Если вы правильно установили дистрибутив Anaconda, никаких ошибок быть не должно."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
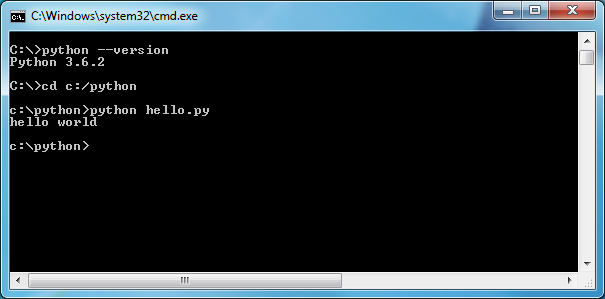
"Последним шагом является вызов интерпретатора и передача ему в командной строке нашего файла с программой. Для удобства, мы перейдем в папку, куда был сохранен файл *hello.py* (в нашем случае - *c:/python*), чтобы в дальнейшем не нужно было писать полный путь до него:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В принципе, можно сказать, что мы уже создали наш первый **модуль**, потому что любой файл с расширением *.py*, содержащий исходный код на языке Python, может им считаться. Однако, чтобы быть полезным, модуль обычно содержит определенный набор пременных, функций и различных сложных типов данных (о которых пойдет речь в лекции, посвященной классам), предназначенных для решения определенного класса задач. Такие модули затем можно использовать в своих программах и получать доступ к функциональности, реализованной в них. При этом говорят, что модуль **экспортирует** функциональность (константы, функции и т.д.), а программа, которая использует модуль, **импортирует** ее."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Существует огромное количество модулей для языка Python. Некоторые из них являются частью так называемой **стандартной библиотеки** Python, реализованной создателями языка и состоящей из множества модулей, предоставляющих средства для работы с операционной системой и файлами, сетевыми протоколами, криптографическими алгоритмами и многое другое. Другие реализуются сторонними разработчиками для узкого класса задач. Обилие существующих модулей является сильной стороной языка Python: необходимость реализовывать какой-нибудь сложный алгоритм возникает очень редко, потому что практически всегда удается найти модуль, в котором эта функциональность уже присутствует, и просто использовать его."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Давайте создадим собственный модуль, на этот раз более полезный, чем предыдущий *hello.py*. Мы поместим в него функции для вычисления площади некоторых геометрических фигур, а также константу $\\pi$."
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {},
"outputs": [],
"source": [
"PI = 3.141592\n",
"\n",
"def calc_triangle_area(a, b, c):\n",
" p = (a + b + c) / 2\n",
" return (p * (p - a) * (p - b) * (p - c)) ** 0.5\n",
"\n",
"def calc_rectangle_area(a, b):\n",
" return a * b\n",
"\n",
"def calc_circle_area(r):\n",
" return PI * (r ** 2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Чтобы вынести этот код в отдельный модуль, создадим в блокноте файл *area.py* и скопируем код туда."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Импортирование модуля"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Для того, чтобы получить доступ к функциям из модуля `area` его нужно **импортировать** в нашу программу с помощью инструкции `import` (мы уже встречались с ней раньше, когда импортировали модуль decimal из стандратной библиотеки Python). Заметим, что все инструкции `import` рекомендуется размещать в самом начале программы."
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {},
"outputs": [
{
"ename": "ModuleNotFoundError",
"evalue": "No module named 'area'",
"output_type": "error",
"traceback": [
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
"\u001b[1;31mModuleNotFoundError\u001b[0m Traceback (most recent call last)",
"\u001b[1;32m\u001b[0m in \u001b[0;36m\u001b[1;34m()\u001b[0m\n\u001b[1;32m----> 1\u001b[1;33m \u001b[1;32mimport\u001b[0m \u001b[0marea\u001b[0m\u001b[1;33m\u001b[0m\u001b[0m\n\u001b[0m",
"\u001b[1;31mModuleNotFoundError\u001b[0m: No module named 'area'"
]
}
],
"source": [
"import area"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как видите, интерпретатор не смог выполнить инструкцию `import` и сгенерировал исключение. Это произошло потому, что интерпретатору не удалось найти файл *area.py*, ведь ему неизвестно, куда именно мы сохранили его. Полный список правил, в соответствии с которыми интерпретатор ищет файл модуля, достаточно обширен, и мы не будем подробно на нем останавливаться; скажем лишь, что интерпретатор обязательно проверяет папку, где лежит файл программы (в нашем случае - ноутбук-файл *.ipynb*), которая импортирует модуль. Давайте скопируем в эту папку файл *area.py* и попробуем выполнить инструкцию заново."
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {},
"outputs": [],
"source": [
"import area"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Теперь никакой ошибки нет, и мы можем обращаться к функциям и переменным из подключенного модуля. Обратите внимание, что для этого обязательно нужно указывать имя модуля:"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"78.5398\n",
"100\n",
"3.141592\n"
]
}
],
"source": [
"radius = 5\n",
"side = 10\n",
"\n",
"print(area.calc_circle_area(radius))\n",
"print(area.calc_rectangle_area(side, side))\n",
"print(area.PI)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Иногда бывает полезно указать другое имя, по которому вы будете обращаться к модулю из своей программы. Для этого в инструкции `import` можно использовать необязательное предложение `as`, после которого указывается альтернативное имя модуля:"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"6.49519052838329\n"
]
}
],
"source": [
"import area as calc_area\n",
"print(calc_area.calc_triangle_area(3, 5, 7))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Наконец, с помощью инструкции `from ... import` можно импортировать определенные индентификаторы из модуля, а не весь модуль. К импортированным таким образом переменным, функциям или сложным типам данных можно обращаться, не указывая имя модуля:"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3.141592\n",
"10.825317547305483\n"
]
}
],
"source": [
"from area import PI, calc_triangle_area\n",
"\n",
"print(PI)\n",
"print(calc_triangle_area(5, 5, 5))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Можно даже указать собственные имена, по которым вы хотите обращаться к импортированным идентификаторам:"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n"
]
}
],
"source": [
"from area import calc_rectangle_area as r_area\n",
"print(r_area(1, 2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Наконец, в инструкции `from ... import` можно указать, что нужно импортировать всё, что есть в модуле:"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"28.274328\n"
]
}
],
"source": [
"from area import * # из модуля area будут импортированы все переменные, функции и т.д.\n",
"print(calc_circle_area(3))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Несмотря на то, что использовать идентификаторы, импортированные с помощью инструкции `from ... import`, более удобно (поскольку не нужно писать постоянно имя модуля), применять ее стоит аккуратно, особенно вместе со специальным символом `*`. Причина этого станет понятна после того, как мы поговорим о пространстве имен далее в этой лекции."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Пакеты"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Пакет** в Python представляет собой именованный набор из нескольких модулей, которые связаны по смыслу друг с другом и предоставляют функциональность для конкретного класса задач. Например, можно представить себе некий пакет `Images`, содержащий модули `Jpeg`, `Gif` и `Png` для работы с разными форматами изображений."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"На уровне интерпретатора Python, пакет это просто каталог в файловой системе, отвечающий одному требованию: в нем обязан присутствовать файл ***\\_\\_init\\_\\_.py***. Этот файл может быть пустым, или содержать произвольный исходный код на языке Python, который выполняется интерпретатором, когда что-то из пакета импортируется в программу впервые. Код в файле *\\_\\_init\\_\\_.py* обычно используется для того, чтобы инициализировать некоторые общие для всех модулей пакета константы."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Чтобы интерпретатор при импортировании модулей из пакета мог найти пакет, соответствующий пакету каталог должен находиться в одном из предопределенных мест в файловой системе. Самый простой способ - поместить каталог пакета в папку, где находятся ваши ноутбук-файлы *.ipynb*."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Давайте создадим свой пакет `geometry`, в который мы поместим наш модуль `area`, реализованный ранее. После создания каталога *./geometry* и копирования в него файла *area.py*, не забудем добавить туда же пустой файл *\\_\\_init.py\\_\\_*. Если все сделано правильно, то мы сможем импортировать модули из пакета с помощью инструкции `import`, указывая перед именем модуля имя пакета, в котором он содержится:"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3.141592\n"
]
}
],
"source": [
"import geometry.area\n",
"print(geometry.area.PI)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В инструкции `import` с помощью предложения `as` можно задавать альтернативное имя как для простых модулей, так и для модулей, содержащихся в пакете:"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"113.097312\n"
]
}
],
"source": [
"import geometry.area as calc_area\n",
"print(calc_area.calc_circle_area(6))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Чтобы не писать каждый раз при обращении к модулю пакета имя пакета, можно воспользоваться инструкцией `from ... import`, которая работает точно так же, как и для простых модулей:"
]
},
{
"cell_type": "code",
"execution_count": 32,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"4.683748498798798\n"
]
}
],
"source": [
"# импортируем модуль area из пакета geometry и делаем его доступным в нашей программе напрямую\n",
"from geometry import area\n",
"print(area.calc_triangle_area(2, 5, 6))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Наконец, мы можем импортировать сразу конкретный идентификатор из определенного модуля в пакете таким образом:"
]
},
{
"cell_type": "code",
"execution_count": 33,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3.141592\n"
]
}
],
"source": [
"from geometry.area import PI\n",
"print(PI)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Пространства имен"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как вам уже известно, любые переменные и функции (а также классы и объекты, о которых мы поговорим в следующей лекции), обладают своим собственным именем или идентификатором. Для того, чтобы правильно обработать инструкцию, в которой происходит обращение к некоторому имени, интерпретатор должен однозначно определить, на какой объект оно указывает. Например, если вы пишете инструкцию `a + b`, интерпретатор должен определить, на какое значение в памяти указывают имена `a` и `b`, чтобы ее выполнить. Очевидно, что никакой неоднозначности при этом быть не должно - иначе программа будет работать непредсказуемым образом. Ситуация, когда одно имя ссылается на несколько объектов, в программировании называется **конфликтом имен**. Простейший способ устранить их - заставить программистов использовать уникальные имена для всего, что они создают. Две очевидные причины, из-за которых такой подход не работает в реальности, это:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. программисту нужно помнить все имена, которые он уже использовал\n",
"2. поскольку реальные программы редко пишутся одним разработчиком, всем им каким-то образом нужно договориться, кто какие имена использует"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Проблема, связанная с возможным конфликтом имен, в различных языках программирования (в том числе, Python) решается с помощью **пространств имен**, которые представляют собой некое отображение имен на объекты, на которые они указывают. В двух различных пространствах имен могут находиться одинаковые идентификаторы, указывающие на разные объекты, а интерпретатор или компилятор используют дополнительную информацию о структуре программы для того, чтобы определить, имя из какого пространства использовать в том или ином выражении."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В Python существует такие разновидности пространств имен:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. Встроенное (built-in) пространство имен - создается, когда мы запускаем интерпретатор Python, содержит имена встроенных в Python функций (`print`, `type` и т.д.) и типов (`int`, `bool` и т.д.).\n",
"2. Пространство имен модуля/программы, или глобальное пространство имен - создается, когда импортируется модуль или выполняется программа, содержит в себе имена, определенные в модуле или программе (функции, переменные и классы).\n",
"3. Пространство имен функции, или локальное пространство имен - создается, когда функция вызывается и удаляется после возврата из нее, содержит в себе имена, определенные в конкретной функции."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Во время выполнения программы несколько пространств имен существуют одновременно, образуя следующую иерархию:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Рассмотрим пример и рисунок, поясняющий в каком пространстве имен содержится то или иное имя:"
]
},
{
"cell_type": "code",
"execution_count": 34,
"metadata": {},
"outputs": [],
"source": [
"import decimal as precise_number\n",
"from area import PI\n",
"\n",
"var = 10 # определено вне любой функции, такие переменные называются глобальными\n",
"\n",
"def global_function():\n",
" var = 20\n",
" def local_function():\n",
" var = 30"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Из рисунка хорошо видно отличие между инструкциями `import` и `from ... import`:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* При выполнении инструкции `import` интерпретатор создает пространство имен модуля `decimal`, на которое ссылается добавленное в пространство имен нашей программы имя `precise_number`. Как видите, в пространстве имен программы нет идентификаторов из модуля `decimal`, однако мы можем обращаться к ним через имя `precise_number` (например, `precise_number.getcontext()`).\n",
"* При выполнении инструкции `from ... import` интерепретатор не создал никакого пространства имен для модуля `area`, однако добавил к пространству имен нашей программы идентификатор `PI` из него. Поэтому к переменной `PI` из модуля `area` мы обращаемся напрямую, словно она определена в нашей программе, но не имеем никакой возможности обратиться к другим идентификаторам модуля `area`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Продолжим анализ рисунка. Обратим внимание, что каждое имя `var` в программе находится в своем пространстве имен, и при этом указывает на разные значения в памяти. Когда в программе происходит обращение к идентификатору `var`, интерпретатор определяет, в какой части программы оно находится, и использует соответствующее пространство имен в первую очередь. Если в нем идентификатор не найден, то он пытается найти его в объемлющем пространстве имен и так далее, вплоть до встроенного пространства имен. Если и там идентификатор не будет найден, интерпретатор сгенерирует исключение `NameError`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Давайте проверим, как это работает на практике:"
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"30\n",
"20\n",
"10\n"
]
}
],
"source": [
"var = 10\n",
"\n",
"def global_function():\n",
" var = 20\n",
" \n",
" def local_function():\n",
" var = 30\n",
" print(var)\n",
" var = 300\n",
" \n",
" local_function()\n",
" print(var)\n",
" var = 200\n",
"\n",
"global_function()\n",
"print(var)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как видите, внутри функции `local_function` переменная `var` указывает на область памяти со значением 30, причем если его изменить, то это никак не повлияет на переменные `var` из пространства имен программы или функции `global_function`. Если бы переменная `var` не была определена в `local_function`, то интерпретатор пытался бы найти это имя в пространстве имен `global_function`, а затем - в пространстве имен программы."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Существует две инструкции, с помощью которых можно изменить порядок, в котором интерпретатор просматривает пространства имен в поисках идентификатора:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* `global` - говорит интерпретатору, что имя нужно искать в глобальном пространстве имен\n",
"* `nonlocal` - имеет смысл только для вложенных функций, говорит интерпретатору, что имя нужно искать во внешней функции"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Рассмотрим пример, в котором мы пытаемся изменить значение глобальной переменной из функции:"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n"
]
}
],
"source": [
"var = 1\n",
"\n",
"def change_var():\n",
" var = 2\n",
"\n",
"change_var()\n",
"print(var)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Как видите, наш способ не сработал - значение `var` не изменилось. Причина этого в том, что инструкция присваивания внутри функции `change_var` выделяет область памяти для нового значения, однако заставляет ссылаться на него имя `var` из локального пространства имен, а такое же имя из глобального пространства имен продолжает ссылаться на старое значение. Чтобы исправить это, нам нужно указать интерпретатору, что он должен использовать имя `var` из глобального пространства имен:"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n"
]
}
],
"source": [
"var = 1\n",
"\n",
"def change_var():\n",
" global var # использовать var из глобальной области видимости\n",
" var = 2\n",
"\n",
"change_var()\n",
"print(var)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Для похожей цели используется и инструкция `nonlocal`, только по отношению к вложенным друг в друга функциям:"
]
},
{
"cell_type": "code",
"execution_count": 38,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"2\n"
]
}
],
"source": [
"def external_function():\n",
" var = 1\n",
" \n",
" def internal_function():\n",
" nonlocal var # даем указание интерпретатору искать имя `var` во внешней функции\n",
" var = 2\n",
" \n",
" internal_function()\n",
" print(var)\n",
"\n",
"external_function()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В заключение упомянем встроенную функцию `dir`, которая возвращает список идентификаторов, присутствующих в указанном пространстве имен. Если вызывать ее без аргументов, то будут возвращены идентификаторы из текущего (самого внутреннего с точки зрения иерархии) пространства имен. Рассмотрим пример:"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['In', 'Out', '_', '__', '___', '__builtin__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', '_dh', '_i', '_i1', '_ih', '_ii', '_iii', '_oh', 'exit', 'get_ipython', 'my_function', 'quit'] \n",
"\n",
"['var1', 'var2']\n"
]
}
],
"source": [
"def my_function():\n",
" var1 = 0\n",
" var2 = 'False'\n",
" print(dir()) # выведет имена из пространства имен функции my_function\n",
"\n",
"print(dir(), '\\n') # выведет имена из пространства имен программы\n",
"my_function()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Имя `__builtins__` из глобального пространства имен указывает на встроенное пространство имен, поэтому следующий код позволяет нам увидеть все встроенные переменные, функции и типы данных Python:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__IPYTHON__', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'display', 'divmod', 'enumerate', 'eval', 'exec', 'filter', 'float', 'format', 'frozenset', 'get_ipython', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']\n"
]
}
],
"source": [
"print(dir(__builtins__))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Аналогичным образом можно посмотреть идентификаторы, определенные в некотором модуле:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"['PI', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'calc_circle_area', 'calc_rectangle_area', 'calc_triangle_area']\n"
]
}
],
"source": [
"import area\n",
"print(dir(area))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Процедурное программирование"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Разработка любой более-менее сложной программы начинается с этапов анализа и проектирования. Первый нужен для того, чтобы понять, какая функциональность потребуется от программы, а второй - как разбить ее на множество более мелких задач, из которых в свою очередь выделить еще более мелкие и так далее. При таком подходе итоговая программа представляет собой некий конструктор, собранный из значительно более простых деталей."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Такая декомпозиция очень важна для процесса создания программы, а также дальнейшего ее сопровождения. Объясним это на примере сборки автомобиля:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. Разбивая программу на мелкие составные части мы ее упрощаем, так как разобраться в нескольких небольших программах проще, чем в одной большой. Принцип действия автомобиля тоже проще понимать, если познакомиться по отдельности с его узлами.\n",
"2. Если части, на которые разбита программа, слабо связаны друг с другом, они могут реализовываться параллельно разными программистами. Аналогично при сборке автомобилей - кузовные детали могут делаться на одном заводе, двигатели на другом, а коробки передач на третьем.\n",
"3. Упрощается поддержка уже созданной программы: если потребуется внести какие-то изменения, то их можно будет сделать в небольшой части кода, без необходимости модификации программы в целом. Когда для модели автомобиля осуществляется рестайлинг, затрагивающий только форму фар, нужно перенастроить только соответствующее производство, не внося изменения в конвейер по сборке двигателей или КПП.\n",
"4. Мелкие составные части программы можно использовать повторно в других программах. Еще один огромный плюс от этого заключается в том, что повторно использованные части не нужно тестировать - они уже подтвердили свою надежность в предыдущих программах. С автомобилями та же ситуация - многие технически сложные узлы (двигатели, КПП, навесное оборудование) переходят из одной модели в другую на протяжении многих лет."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В процедурном программировании в качестве элементов, на которые разбивается программа, используются пакеты, модули и функции, которые обрабатывают некоторые данные. Поскольку функции представляют собой некоторые действия, декомпозиция сложной задачи осуществляется по тем операциям, которые в ней присутствуют."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В качестве примера рассмотрим интернет-браузер. Очевидно, что две основные его подсистемы - это работа с сетью и отображение веб-страниц. Поэтому мы можем создать два пакета `network` и `display`, в которые будем помещать наши модули. В пакет `network` у нас попадут модули, реализующие различные сетевые протоколы, например HTTP, SSL и другие. Эти модули, вероятно, будут содержать функции `connect`, `send`, `receive`, `disconnect` и другие. В пакет `display` мы добавим модули для поддержки HTML, CSS, Flash и т.д. В них попадут такие функции, как `show_page`, `run_flash_player` и другие."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"В заключение скажем, что этап проектирования является самой важной и сложной частью в процессе создания крупных программ, требующей немало опыта и творческих усилий. Если на этом этапе разработчик не учтет что-то важное, в итоговой программе может наблюдаться целый ворох проблем: низкая производительность, большое количество ошибок, трудность модификации и т.д."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Вопросы для самоконтроля"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. Что такое функция? Чем она похожа на переменную?\n",
"2. Что такое определение функции? Что такое вызов функции?\n",
"3. Что такое параметр и аргумент функции? Какими двумя способами можно передать аргументы в вызов функции?\n",
"4. В чем особенности локальных функций? Рекурсивных функций? Лямбда-функций? Какой еще тип функций бывает?\n",
"5. Что такое модуль? Что он содержит? Как подключить модуль к своей программе?\n",
"6. Что такое пакет? Как он создается? Приведите пример пакета и модулей, которые он мог бы содержать.\n",
"7. Что такое пространства имен? Для чего они нужны? Какую иерархию образуют пространства имен в языке Python?\n",
"8. По какому алгоритму интерпретатор Python ищет имя, к которому происходит обращение внутри функции?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Задание"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1. Реализуйте функцию `get_word_count`, которая возвращает количество слов в строке (подсказка - для простоты считайте, что слова разделяются одним или более символом пробела).\n",
"2. Реализуйте два варианта (обычный и рекурсивный) функции, вычисляющей [факториал](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D0%B8%D0%B0%D0%BB) числа.\n",
"3. Добавьте в пакет `geometry`, рассмотренный в лекции, модуль `perimeter`, содержащий 3 функции: для вычисления периметра треугольника и прямоугольника, а также длины окружности. Обратите внимание, что в лекции модуль `area` содержал константу `PI`, которая потребуется вам и в модуле `perimeter`. Ни в коем случае не создавайте ее там повторно, вместо этого подумайте, как сделать так, чтобы определить `PI` в одном месте в пакете `geometry` и использовать из всех модулей, входящих в него. Возможно несколько решений.\n",
"4. Представьте, что вы создаете программу наподобие Microsoft Paint. Подумайте, на какие пакеты или модули вы бы ее разбили? Приведите несколько примеров функций из этих модулей."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"- - -\n",
"[Предыдущая: Инструкция ветвления и циклы](06_Branch_Instruction_And_Loops.ipynb) |\n",
"[Содержание](00_Overview.ipynb#Содержание) |\n",
"[Следующая: Классы и исключения](08_Classes_And_Exceptions.ipynb)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.4"
}
},
"nbformat": 4,
"nbformat_minor": 2
}