{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.6"
},
"colab": {
"name": "2020-06-04-02-Boosting.ipynb",
"provenance": [],
"toc_visible": true
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "5mXDAjLZLEsR"
},
"source": [
"# Boosting\n",
"> A Summary of lecture \"Machine Learning with Tree-Based Models in Python\n",
"\", via datacamp\n",
"\n",
"- toc: true \n",
"- badges: true\n",
"- comments: true\n",
"- author: Chanseok Kang\n",
"- categories: [Python, Datacamp, Machine Learning]\n",
"- image: images/sgb_train.png"
]
},
{
"cell_type": "code",
"metadata": {
"id": "lxKzBC5iLEsa"
},
"source": [
"import pandas as pd\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"import seaborn as sns"
],
"execution_count": 59,
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"id": "1x-MW5ypLEsb"
},
"source": [
"## Adaboost\n",
"- Boosting: Ensemble method combining several weak learners to form a strong learner.\n",
" - Weak learner: Model doing slightly better than random guessing\n",
" - E.g., Dicision stump (CART whose maximum depth is 1)\n",
" - Train an ensemble of predictors sequentially.\n",
" - Each predictor tries to correct its predecessor\n",
" - Most popular boosting methods:\n",
" - AdaBoost\n",
" - Gradient Boosting\n",
"- AdaBoost\n",
" - Stands for **Ada**ptive **Boost**ing\n",
" - Each predictor pays more attention to the instances wrongly predicted by its predecessor.\n",
" - Achieved by changing the weights of training instances.\n",
" - Each predictor is assigned a coefficient $\\alpha$ that depends on the predictor's training error\n",
"- AdaBoost: Training\n",
"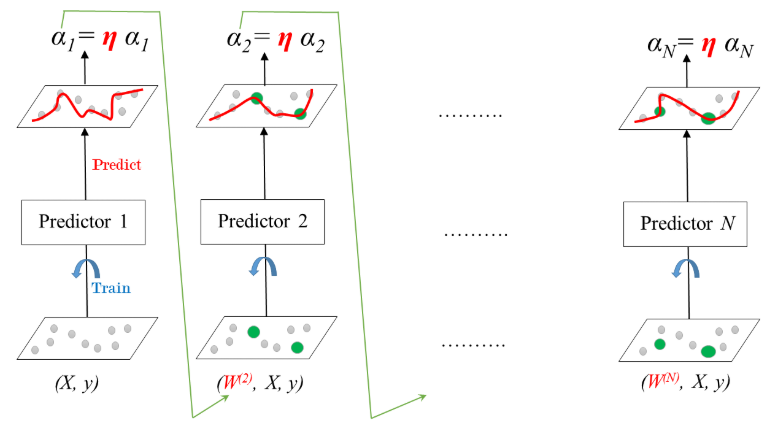\n",
" - Learning rate: $0 < \\eta < 1$"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "RKHgRHAnLEsc"
},
"source": [
"### Define the AdaBoost classifier\n",
"In the following exercises you'll revisit the [Indian Liver Patient](https://www.kaggle.com/uciml/indian-liver-patient-records) dataset which was introduced in a previous chapter. Your task is to predict whether a patient suffers from a liver disease using 10 features including Albumin, age and gender. However, this time, you'll be training an AdaBoost ensemble to perform the classification task. In addition, given that this dataset is imbalanced, you'll be using the ROC AUC score as a metric instead of accuracy.\n",
"\n",
"As a first step, you'll start by instantiating an AdaBoost classifier."
]
},
{
"cell_type": "code",
"metadata": {
"id": "XeldclBSLP8P"
},
"source": [
""
],
"execution_count": 59,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "hbcrrikLLRLr",
"outputId": "833d4537-be40-41a0-9552-2a69ab552012",
"colab": {
"base_uri": "https://localhost:8080/"
}
},
"source": [
"from google.colab import drive\n",
"drive.mount('/content/drive')"
],
"execution_count": 60,
"outputs": [
{
"output_type": "stream",
"text": [
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
"name": "stdout"
}
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "jNjzJ0kBLEsc"
},
"source": [
"- Preprocess"
]
},
{
"cell_type": "code",
"metadata": {
"id": "5qkiIBDvLEsd",
"outputId": "9437c378-7bee-440d-bf36-d978c03a520c",
"colab": {
"base_uri": "https://localhost:8080/",
"height": 241
}
},
"source": [
"!pwd\n",
"indian = pd.read_csv('/content/drive/MyDrive/colab-notebooks/indian_liver_preprocessed.csv', index_col=0)\n",
"indian.head()"
],
"execution_count": 61,
"outputs": [
{
"output_type": "stream",
"text": [
"/content\n"
],
"name": "stdout"
},
{
"output_type": "execute_result",
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" Age_std | \n",
" Total_Bilirubin_std | \n",
" Direct_Bilirubin_std | \n",
" Alkaline_Phosphotase_std | \n",
" Alamine_Aminotransferase_std | \n",
" Aspartate_Aminotransferase_std | \n",
" Total_Protiens_std | \n",
" Albumin_std | \n",
" Albumin_and_Globulin_Ratio_std | \n",
" Is_male_std | \n",
" Liver_disease | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.247403 | \n",
" -0.420320 | \n",
" -0.495414 | \n",
" -0.428870 | \n",
" -0.355832 | \n",
" -0.319111 | \n",
" 0.293722 | \n",
" 0.203446 | \n",
" -0.147390 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1.062306 | \n",
" 1.218936 | \n",
" 1.423518 | \n",
" 1.675083 | \n",
" -0.093573 | \n",
" -0.035962 | \n",
" 0.939655 | \n",
" 0.077462 | \n",
" -0.648461 | \n",
" 1 | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1.062306 | \n",
" 0.640375 | \n",
" 0.926017 | \n",
" 0.816243 | \n",
" -0.115428 | \n",
" -0.146459 | \n",
" 0.478274 | \n",
" 0.203446 | \n",
" -0.178707 | \n",
" 1 | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 0.815511 | \n",
" -0.372106 | \n",
" -0.388807 | \n",
" -0.449416 | \n",
" -0.366760 | \n",
" -0.312205 | \n",
" 0.293722 | \n",
" 0.329431 | \n",
" 0.165780 | \n",
" 1 | \n",
" 1 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1.679294 | \n",
" 0.093956 | \n",
" 0.179766 | \n",
" -0.395996 | \n",
" -0.295731 | \n",
" -0.177537 | \n",
" 0.755102 | \n",
" -0.930414 | \n",
" -1.713237 | \n",
" 1 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" hr | \n",
" holiday | \n",
" workingday | \n",
" temp | \n",
" hum | \n",
" windspeed | \n",
" cnt | \n",
" instant | \n",
" mnth | \n",
" yr | \n",
" Clear to partly cloudy | \n",
" Light Precipitation | \n",
" Misty | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0.76 | \n",
" 0.66 | \n",
" 0.0000 | \n",
" 149 | \n",
" 13004 | \n",
" 7 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0.74 | \n",
" 0.70 | \n",
" 0.1343 | \n",
" 93 | \n",
" 13005 | \n",
" 7 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" 0 | \n",
" 0 | \n",
" 0.72 | \n",
" 0.74 | \n",
" 0.0896 | \n",
" 90 | \n",
" 13006 | \n",
" 7 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" 0 | \n",
" 0 | \n",
" 0.72 | \n",
" 0.84 | \n",
" 0.1343 | \n",
" 33 | \n",
" 13007 | \n",
" 7 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" 0 | \n",
" 0 | \n",
" 0.70 | \n",
" 0.79 | \n",
" 0.1940 | \n",
" 4 | \n",
" 13008 | \n",
" 7 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"