\n", "PC: `conda install -c https://conda.binstar.org/topper psycopg2-windows`\n", "\n", "If you have issues, try directly installing with pip:\n", "\n", "MAC: `anaconda/bin/pip install psycopg2`
\n", "PC: `anaconda\\pip.exe install psycopg2`\n", "\n", "If you're still having issues (mac folks), please consult [here](http://mithun.co/hacks/library-not-loaded-libcrypto-1-0-0-dylib-issue-in-mac/) for additional help, but only IF you are running into dylib errors.\n", "\n", "Parameters for connecting to the database will be given via Slack.\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Class Notes" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### What are databases?\n", "\n", "Databases are a structured data source optimized for efficient retrieval and storage.\n", "\n", "* **structured**: we have to pre-define organization strategy\n", "* **retrieval**: the ability to read data out\n", "* **storage**: the ability to write data and save it" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### What is a relational database?\n", "\n", "Relational databases are traditionally organized in the following manner:\n", "\n", "* A database has tables which represent individual entities or objects.\n", "* Tables have predefined schema – rules that tell it what the data will look like.\n", "\n", "Each table should have a primary key column: a unique identifier for that row. Additionally, each table _can_ have a foreign key column: an id that links this to another table.\n", "\n", "
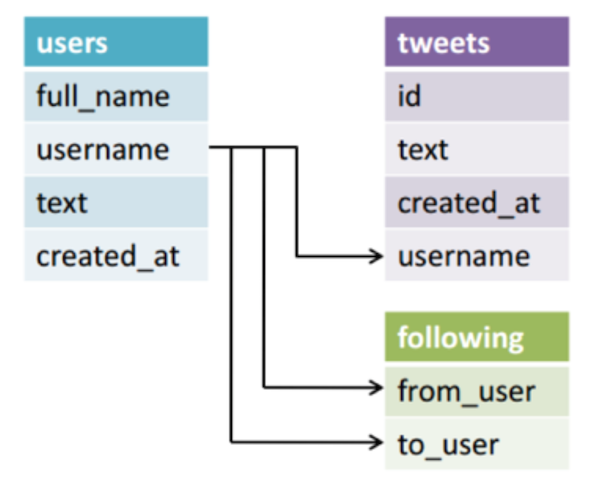 \n",
"\n",
"In a **normalized** schema, tables are designed to be thin in order to minimize:\n",
"\n",
"1. The amount of repeated information\n",
"2. The amount of bytes stored\n",
"\n",
"
\n",
"\n",
"In a **normalized** schema, tables are designed to be thin in order to minimize:\n",
"\n",
"1. The amount of repeated information\n",
"2. The amount of bytes stored\n",
"\n",
"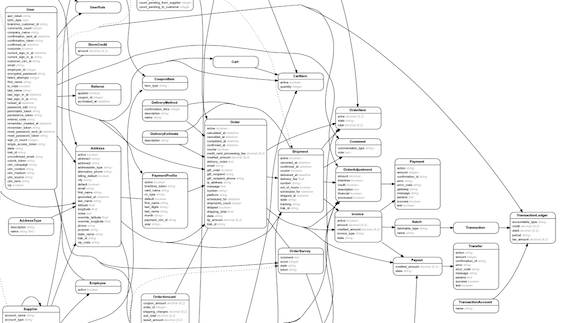 \n",
"_Case in point; here is a relational diagram of a typical ecommerce platform_\n",
"\n",
"What if we had designed the database to look this way with one table?\n",
"\n",
"
\n",
"_Case in point; here is a relational diagram of a typical ecommerce platform_\n",
"\n",
"What if we had designed the database to look this way with one table?\n",
"\n",
" \n",
"\n",
"1. Repeated information is increased; the user information is repeated in each row.\n",
"2. There is increased text storage (text bytes are larger than integer bytes)\n",
"3. There is no need to join!\n",
"\n",
"The tradeoff between normalized and denormalized data is **speed vs storage**. Storage (for the most part) is the same everywhere.. so let's focus on the speed side. Speed breaks down into _read speed_ and _write speed_.\n",
"\n",
"Of the two data views:\n",
"\n",
"1. Which would we believe to be slower to read but faster to write?\n",
"2. Which would we believe to be slower to write but faster to read?\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SQL syntax\n",
"\n",
"SQL (structured query language) is a query language for loading, retrieving, and updating data in relational databases. Most commonly used SQL databases include:\n",
"\n",
"1. Oracle and MySQL\n",
"2. SQL Server\n",
"3. PostgreSQL\n",
"\n",
"The SQL-like structure is also heavily borrowed in large scale data languages and platforms:\n",
"\n",
"1. Apache Hive\n",
"2. Apache Drill (based on Google's Dremel)\n",
"3. Spark SQL\n",
"\n",
"So it is important to learn the basics that fit across all platforms!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Good syntax\n",
"\n",
"While companies and data teams end up developing their own sense of SQL style, those new to SQL should adopt at least the following style:\n",
"\n",
"1. Keywords are upper case and begin new lines\n",
"2. fields in their own lines\n",
"3. continuations are indented\n",
"\n",
"This will be explained as we go through examples below. To help make some connections, there will be some python code blocks using pandas syntax to do similar statements to the SQL queries. They'll be labeled ***pandas*** and ***end_pandas*** to clarify where those are."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### SELECT\n",
"Basic usecase for pulling data from the database.\n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" col2\n",
"FROM table\n",
"WHERE [some condition];\n",
"```\n",
"\n",
"Example\n",
"```SQL\n",
"SELECT\n",
" poll_title,\n",
" poll_date\n",
"FROM polls\n",
"WHERE romney_pct > obama_pct;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls[polls.romney_pct > polls.obama_pct][['poll_title', 'poll_date']]\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Notes:\n",
"\n",
"1. The WHERE is optional, though ultimately filtering data is usually the point of querying from a database.\n",
"2. You may SELECT as many columns as you'd like, and alias each."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Aggregations and GROUP BY\n",
"In this SELECT style, columns are either group by keys, or aggregations. \n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" AVG(col2)\n",
"FROM table\n",
"GROUP BY col1;\n",
"```\n",
"\n",
"Example\n",
"```SQL\n",
"SELECT\n",
" poll_date,\n",
" AVG(obama_pct)\n",
"FROM polls\n",
"GROUP BY poll_date;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls.groupby('poll_date').obama_pct.mean()\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Notes:\n",
"\n",
"1. You may groupby and aggregate as many columns as you'd like.\n",
"2. Fields that do NOT use aggregations must be in the group by. Some SQL databases will throw errors; others will give you the wrong data.\n",
"3. Standard aggregations include `STDDEV, MIN, MAX, COUNT, SUM`; mostly aggregations that can be quickly solved. For example, `MEDIAN` is less often a function, as the solution is more complicated in SQL.\n",
"\n",
"Questions:\n",
"\n",
"1. Imagine a field of poll_state. How would we find the max obama_pct and romney_pct for each state?\n",
"2. How would we return a count of polls by state and date?\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### JOINs \n",
"JOIN is widely used in normalized data in order for us to denormalize the information. Analysts who work in strong relational databases often have half a dozen joins in their queries.\n",
"\n",
"```SQL\n",
"SELECT ...\n",
"FROM orders\n",
"INNER JOIN order_amounts a on a.order_id = orders.id\n",
"INNER JOIN order_items i on i.order_id = orders.id\n",
"INNER JOIN variants v on v.id = i.variant_id\n",
"INNER JOIN products p on p.id = v.product_id\n",
"INNER JOIN suppliers s on s.id = v.supplier_id\n",
"INNER JOIN addresses ad on ad.addressable_type = 'Supplier' and ad.addressable_id = s.id\n",
"...;\n",
"```\n",
"\n",
"Basic Example:\n",
"\n",
"```SQL\n",
"SELECT\n",
" t1.c1,\n",
" t1.c2,\n",
" t2.c2\n",
"FROM t1 \n",
"INNER JOIN t2 ON t1.c1 = t2.c2;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"t1.join(t2, on='c2')\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"There are several join types used, despite the above only using one: `INNER JOIN`.\n",
"\n",
"
\n",
"\n",
"1. Repeated information is increased; the user information is repeated in each row.\n",
"2. There is increased text storage (text bytes are larger than integer bytes)\n",
"3. There is no need to join!\n",
"\n",
"The tradeoff between normalized and denormalized data is **speed vs storage**. Storage (for the most part) is the same everywhere.. so let's focus on the speed side. Speed breaks down into _read speed_ and _write speed_.\n",
"\n",
"Of the two data views:\n",
"\n",
"1. Which would we believe to be slower to read but faster to write?\n",
"2. Which would we believe to be slower to write but faster to read?\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SQL syntax\n",
"\n",
"SQL (structured query language) is a query language for loading, retrieving, and updating data in relational databases. Most commonly used SQL databases include:\n",
"\n",
"1. Oracle and MySQL\n",
"2. SQL Server\n",
"3. PostgreSQL\n",
"\n",
"The SQL-like structure is also heavily borrowed in large scale data languages and platforms:\n",
"\n",
"1. Apache Hive\n",
"2. Apache Drill (based on Google's Dremel)\n",
"3. Spark SQL\n",
"\n",
"So it is important to learn the basics that fit across all platforms!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Good syntax\n",
"\n",
"While companies and data teams end up developing their own sense of SQL style, those new to SQL should adopt at least the following style:\n",
"\n",
"1. Keywords are upper case and begin new lines\n",
"2. fields in their own lines\n",
"3. continuations are indented\n",
"\n",
"This will be explained as we go through examples below. To help make some connections, there will be some python code blocks using pandas syntax to do similar statements to the SQL queries. They'll be labeled ***pandas*** and ***end_pandas*** to clarify where those are."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### SELECT\n",
"Basic usecase for pulling data from the database.\n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" col2\n",
"FROM table\n",
"WHERE [some condition];\n",
"```\n",
"\n",
"Example\n",
"```SQL\n",
"SELECT\n",
" poll_title,\n",
" poll_date\n",
"FROM polls\n",
"WHERE romney_pct > obama_pct;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls[polls.romney_pct > polls.obama_pct][['poll_title', 'poll_date']]\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Notes:\n",
"\n",
"1. The WHERE is optional, though ultimately filtering data is usually the point of querying from a database.\n",
"2. You may SELECT as many columns as you'd like, and alias each."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Aggregations and GROUP BY\n",
"In this SELECT style, columns are either group by keys, or aggregations. \n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" AVG(col2)\n",
"FROM table\n",
"GROUP BY col1;\n",
"```\n",
"\n",
"Example\n",
"```SQL\n",
"SELECT\n",
" poll_date,\n",
" AVG(obama_pct)\n",
"FROM polls\n",
"GROUP BY poll_date;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls.groupby('poll_date').obama_pct.mean()\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Notes:\n",
"\n",
"1. You may groupby and aggregate as many columns as you'd like.\n",
"2. Fields that do NOT use aggregations must be in the group by. Some SQL databases will throw errors; others will give you the wrong data.\n",
"3. Standard aggregations include `STDDEV, MIN, MAX, COUNT, SUM`; mostly aggregations that can be quickly solved. For example, `MEDIAN` is less often a function, as the solution is more complicated in SQL.\n",
"\n",
"Questions:\n",
"\n",
"1. Imagine a field of poll_state. How would we find the max obama_pct and romney_pct for each state?\n",
"2. How would we return a count of polls by state and date?\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### JOINs \n",
"JOIN is widely used in normalized data in order for us to denormalize the information. Analysts who work in strong relational databases often have half a dozen joins in their queries.\n",
"\n",
"```SQL\n",
"SELECT ...\n",
"FROM orders\n",
"INNER JOIN order_amounts a on a.order_id = orders.id\n",
"INNER JOIN order_items i on i.order_id = orders.id\n",
"INNER JOIN variants v on v.id = i.variant_id\n",
"INNER JOIN products p on p.id = v.product_id\n",
"INNER JOIN suppliers s on s.id = v.supplier_id\n",
"INNER JOIN addresses ad on ad.addressable_type = 'Supplier' and ad.addressable_id = s.id\n",
"...;\n",
"```\n",
"\n",
"Basic Example:\n",
"\n",
"```SQL\n",
"SELECT\n",
" t1.c1,\n",
" t1.c2,\n",
" t2.c2\n",
"FROM t1 \n",
"INNER JOIN t2 ON t1.c1 = t2.c2;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"t1.join(t2, on='c2')\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"There are several join types used, despite the above only using one: `INNER JOIN`.\n",
"\n",
"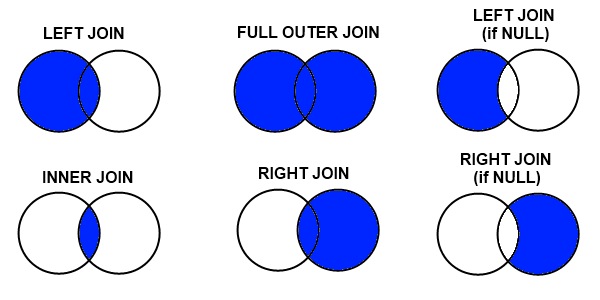 \n",
"\n",
"Note that using JOIN introduces potential change in our data context: One to Many and Many to Many relationships.\n",
"\n",
"
\n",
"\n",
"Note that using JOIN introduces potential change in our data context: One to Many and Many to Many relationships.\n",
"\n",
"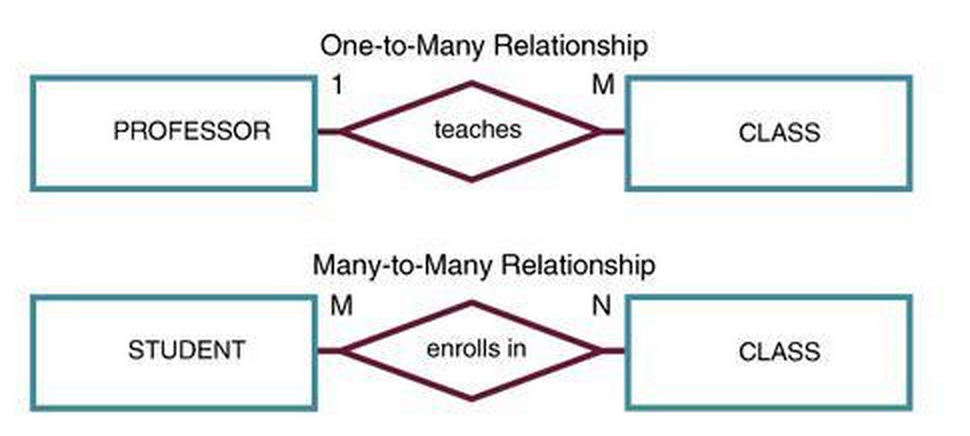 \n",
"\n",
"\n",
"\n",
"#####Troubleshooting JOINs\n",
"\n",
"Make sure that your results are as expected, so consider what the observation is (the row), and rule check other columns:\n",
"\n",
"* is your expected unique column unique?\n",
"* Is there duplicate data elsewhere? \n",
"\n",
"A common check to see if your data is not unique is throwing a HAVING clause in your JOIN."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### HAVING\n",
"Whereas WHERE is used for precomputation, HAVING is a postcomputation clause, filtering the data after the database engine has done the query's work.\n",
"\n",
"```SQL\n",
"SELECT\n",
" t1.c1,\n",
" t1.c2,\n",
" AVG(t2.c2)\n",
"FROM t1 \n",
"INNER JOIN t2 ON t1.c1 = t2.c2\n",
"GROUP BY t1.c1, t1.c2\n",
"HAVING AVG(t2.c2) > 10;\n",
"```\n",
"\n",
"```SQL\n",
"SELECT\n",
" poll_date,\n",
" AVG(obama_pct)\n",
"FROM polls\n",
"GROUP BY poll_date\n",
"HAVING AVG(obama_pct) > 50;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls_group = polls.groupby('poll_date').obama_pct.filter(lambda x: x.mean() > 50)\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Note in this context HAVING allows us to filter on the computed column `AVG(t2.c2)` after the GROUP BY has run."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Extensibility (Postgres coolness!)\n",
"\n",
"All SQL databases are finetuned to audiences with slightly different functionality. Since we are connecting to a postgres database, we can learn and adopt additional functionality not common in others, like MySQL.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Partitioning, Window Functions\n",
"Window functions allow you to _subgroup_ aggregations. Two common needs for this are:\n",
"\n",
"1. Providing a comparitive summary of averages or other statistical functions against different group bys;\n",
"2. `rank()`ing data observations\n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" col2,\n",
" rank() over (PARTITION BY col ORDER BY col)\n",
"FROM table;\n",
"```\n",
"\n",
"The following:\n",
"\n",
"```SQL\n",
"SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date)\n",
"FROM table;\n",
"```\n",
"\n",
"Would create a table that looks like this:\n",
"\n",
"```\n",
"user_id, order_total, rank()\n",
"1 , 100 , 1\n",
"2 , 80 , 1\n",
"1 , 25 , 2\n",
"5 , 70 , 1\n",
"1 , 120 , 3\n",
"```\n",
"\n",
"Notes:\n",
"\n",
"1. rank() is a specific postgres function for ranking and ordering, though any aggregation will do here.\n",
"2. We can use as many window functions as we'd like.\n",
"3. Window functions allow us to aggregate in different ways! What would this following SQL query generate?\n",
"\n",
"```SQL\n",
"SELECT\n",
" yearid,\n",
" teamid,\n",
" AVG(salary) over (PARTITION BY yearid, teamid),\n",
" AVG(salary) over (PARTITION BY yearid)\n",
"FROM salaries\n",
"```\n",
"\n",
"Questions\n",
"1. Back to polls! We have a poll_id; how could rank the poll_ids of the top three obama_pct and romney_pct per state?\n",
"2. We have a table of year, team, games played, and games won. What's the SQL to rank the years for each team based on win percentage?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Subselects (all sql)\n",
"\n",
"There is a lot of additional, great functionality about postgres, like even writing linear regressions:\n",
"\n",
"```\n",
"SELECT\n",
" regr_intercept(yearid, LOG(salary)),\n",
" regr_slope(yearid, LOG(salary)),\n",
" regr_r2(yearid, LOG(salary))\n",
"FROM salaries\n",
"WHERE salary > 0;\n",
"```\n",
"\n",
"But often SQL has to be \"tricked\" into thinking the data is not aggregated, particularly with rank(). We'll subselects to explain this:\n",
"\n",
"```SQL\n",
"SELECT col1\n",
"FROM (SELECT\n",
" col1,\n",
" col2\n",
" FROM table) table2\n",
"```\n",
"\n",
"In this arbitrary example we can at least see that queries can be nested. We don't see much additional functionality here, but imagine in the orders case:\n",
"\n",
"\n",
"```SQL\n",
"SELECT *\n",
"FROM (SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date) as \"order_number\"\n",
" FROM table) orders\n",
"WHERE order_number = 2\n",
"```\n",
"\n",
"We now get access to the rank in the WHERE (window functions will not work in HAVING due to complexities). You can also join on subselects:\n",
"\n",
"```SQL\n",
"SELECT\n",
" users.platform,\n",
" orders.*\n",
"FROM users\n",
"INNER JOIN (SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date) as \"order_number\"\n",
" FROM table) orders on users.id = orders.user_id\n",
"WHERE order_number = 2\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Connecting via Python\n",
"We'll be using a pandas connector alongside SQLAlchemy to connect to this database. Please follow slack for instructions, however the syntax for connecting should be as follows:\n",
"\n",
"```python\n",
"from sqlalchemy import create_engine\n",
"import pandas as pd\n",
"cnx = create_engine('postgresql://username:password@ip_address:port/dbname')\n",
"```\n",
"\n",
"for queries we'll use the pandas syntax:\n",
"\n",
"```python\n",
"pd.read_sql_query(query, connection)\n",
"```\n",
"\n",
"The tables we'll need are below. If you need to look at columns, we can use this function:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def show_columns(table, con):\n",
" from pandas import read_sql_table\n",
" return read_sql_table(table, con).columns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Your turn:\n",
"Tables you'll need:\n",
"\n",
"```\n",
"allstarfull\n",
"fielding\n",
"salaries\n",
"schools\n",
"schoolsplayers\n",
"teams\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Do your best to answer the following questions! They are sorted from simplest to most difficult in terms of SQL execution. If you'd like to practice your pandas syntax, submit both your SQL and pandas code (assuming tables were dataframes).\n",
"\n",
"1. Show all playerids and salaries with a salary in the year 1985 above 500k.\n",
"2. Show the team for each year that had a rank of 1.\n",
"3. How many schools are in schoolstate of CT?\n",
"4. How many schools are there in each state?\n",
"5. What was the total spend on salaries by each team, each year?\n",
"6. Find all of the salaries of shortstops (fieldings, pos) for the year 2012.\n",
"7. What is the first and last year played for each player?\n",
"8. Who has played the most all star games? \n",
"9. Which school has generated the most distinct players?\n",
"10. Which school has generated the most expensive players? (expensive defined by their first year's salary).\n",
"11. Show the 5 most expensive salaries for each team in the year 2014.\n",
"12. Partition the average salaries by team and year, against year. Find players that were paid more than 1 standard deviation above the average salary for that team and year. Show a count by playerid.\n",
"13. Calculate the win percentage. convert w and g into numerics (floats) to do so. (`w::numeric`, for example)\n",
"14. `rank()` the total spend by team each year against their actual rank that year. Is there a correlation of spend to performance?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"###Setting up Postgres\n",
"\n",
"This is an incredibly complicated subject matter! Macs should try using `homebrew` and PCs can use their native installer. Check out their [installation guide](https://wiki.postgresql.org/wiki/Detailed_installation_guides) for more details. If you start reading through and have no idea what they mean, DO NOT attempt to set up postgres on your machine."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Reading / Next Steps\n",
"\n",
"1. Read through Hadley Wickham's paper on [tidy data](http://vita.had.co.nz/papers/tidy-data.pdf). While code samples are written in R it is an incredibly familiar concept and important on how we think about querying.\n",
"2. Additional comparisons between pandas and sql syntax on the [pandas](http://pandas.pydata.org/pandas-docs/dev/comparison_with_sql.html) website.\n",
"3. Some recommended GUIs for interacting with postgres (and other databases):\n",
" 1. [Postico](https://eggerapps.at/postico/) is the new version of PG Commander built for Mac OS X.\n",
" 2. [RazorSQL](http://razorsql.com/) is cross platform and cross DB, but also expensive for the product (not free)\n",
"4. If you're looking for something in python between pandas and psycopg2 in terms of complexity, [dataset](http://dataset.readthedocs.org/en/latest/api.html) is a great python module to learn, particularly for moving data around.\n",
"5. Additional SQL Help:\n",
" 1. [SQL Bootcamp](https://github.com/brandonmburroughs/sql_bootcamp) from GA (MySQL)\n",
" 2. [SQLZOO](http://sqlzoo.net/wiki/SELECT) can switch between engines\n",
" 3. [w3schools](http://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all) has a practice database.\n",
" 4. [SQLSchool](http://sqlschool.modeanalytics.com/)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.9"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
\n",
"\n",
"\n",
"\n",
"#####Troubleshooting JOINs\n",
"\n",
"Make sure that your results are as expected, so consider what the observation is (the row), and rule check other columns:\n",
"\n",
"* is your expected unique column unique?\n",
"* Is there duplicate data elsewhere? \n",
"\n",
"A common check to see if your data is not unique is throwing a HAVING clause in your JOIN."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### HAVING\n",
"Whereas WHERE is used for precomputation, HAVING is a postcomputation clause, filtering the data after the database engine has done the query's work.\n",
"\n",
"```SQL\n",
"SELECT\n",
" t1.c1,\n",
" t1.c2,\n",
" AVG(t2.c2)\n",
"FROM t1 \n",
"INNER JOIN t2 ON t1.c1 = t2.c2\n",
"GROUP BY t1.c1, t1.c2\n",
"HAVING AVG(t2.c2) > 10;\n",
"```\n",
"\n",
"```SQL\n",
"SELECT\n",
" poll_date,\n",
" AVG(obama_pct)\n",
"FROM polls\n",
"GROUP BY poll_date\n",
"HAVING AVG(obama_pct) > 50;\n",
"```\n",
"\n",
"***pandas***\n",
"```python\n",
"polls_group = polls.groupby('poll_date').obama_pct.filter(lambda x: x.mean() > 50)\n",
"```\n",
"***end_pandas***\n",
"\n",
"\n",
"Note in this context HAVING allows us to filter on the computed column `AVG(t2.c2)` after the GROUP BY has run."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Extensibility (Postgres coolness!)\n",
"\n",
"All SQL databases are finetuned to audiences with slightly different functionality. Since we are connecting to a postgres database, we can learn and adopt additional functionality not common in others, like MySQL.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Partitioning, Window Functions\n",
"Window functions allow you to _subgroup_ aggregations. Two common needs for this are:\n",
"\n",
"1. Providing a comparitive summary of averages or other statistical functions against different group bys;\n",
"2. `rank()`ing data observations\n",
"\n",
"```SQL\n",
"SELECT\n",
" col1,\n",
" col2,\n",
" rank() over (PARTITION BY col ORDER BY col)\n",
"FROM table;\n",
"```\n",
"\n",
"The following:\n",
"\n",
"```SQL\n",
"SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date)\n",
"FROM table;\n",
"```\n",
"\n",
"Would create a table that looks like this:\n",
"\n",
"```\n",
"user_id, order_total, rank()\n",
"1 , 100 , 1\n",
"2 , 80 , 1\n",
"1 , 25 , 2\n",
"5 , 70 , 1\n",
"1 , 120 , 3\n",
"```\n",
"\n",
"Notes:\n",
"\n",
"1. rank() is a specific postgres function for ranking and ordering, though any aggregation will do here.\n",
"2. We can use as many window functions as we'd like.\n",
"3. Window functions allow us to aggregate in different ways! What would this following SQL query generate?\n",
"\n",
"```SQL\n",
"SELECT\n",
" yearid,\n",
" teamid,\n",
" AVG(salary) over (PARTITION BY yearid, teamid),\n",
" AVG(salary) over (PARTITION BY yearid)\n",
"FROM salaries\n",
"```\n",
"\n",
"Questions\n",
"1. Back to polls! We have a poll_id; how could rank the poll_ids of the top three obama_pct and romney_pct per state?\n",
"2. We have a table of year, team, games played, and games won. What's the SQL to rank the years for each team based on win percentage?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Subselects (all sql)\n",
"\n",
"There is a lot of additional, great functionality about postgres, like even writing linear regressions:\n",
"\n",
"```\n",
"SELECT\n",
" regr_intercept(yearid, LOG(salary)),\n",
" regr_slope(yearid, LOG(salary)),\n",
" regr_r2(yearid, LOG(salary))\n",
"FROM salaries\n",
"WHERE salary > 0;\n",
"```\n",
"\n",
"But often SQL has to be \"tricked\" into thinking the data is not aggregated, particularly with rank(). We'll subselects to explain this:\n",
"\n",
"```SQL\n",
"SELECT col1\n",
"FROM (SELECT\n",
" col1,\n",
" col2\n",
" FROM table) table2\n",
"```\n",
"\n",
"In this arbitrary example we can at least see that queries can be nested. We don't see much additional functionality here, but imagine in the orders case:\n",
"\n",
"\n",
"```SQL\n",
"SELECT *\n",
"FROM (SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date) as \"order_number\"\n",
" FROM table) orders\n",
"WHERE order_number = 2\n",
"```\n",
"\n",
"We now get access to the rank in the WHERE (window functions will not work in HAVING due to complexities). You can also join on subselects:\n",
"\n",
"```SQL\n",
"SELECT\n",
" users.platform,\n",
" orders.*\n",
"FROM users\n",
"INNER JOIN (SELECT\n",
" user_id,\n",
" order_total,\n",
" rank() over (PARTITION BY user_id ORDER BY order_date) as \"order_number\"\n",
" FROM table) orders on users.id = orders.user_id\n",
"WHERE order_number = 2\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Connecting via Python\n",
"We'll be using a pandas connector alongside SQLAlchemy to connect to this database. Please follow slack for instructions, however the syntax for connecting should be as follows:\n",
"\n",
"```python\n",
"from sqlalchemy import create_engine\n",
"import pandas as pd\n",
"cnx = create_engine('postgresql://username:password@ip_address:port/dbname')\n",
"```\n",
"\n",
"for queries we'll use the pandas syntax:\n",
"\n",
"```python\n",
"pd.read_sql_query(query, connection)\n",
"```\n",
"\n",
"The tables we'll need are below. If you need to look at columns, we can use this function:"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def show_columns(table, con):\n",
" from pandas import read_sql_table\n",
" return read_sql_table(table, con).columns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Your turn:\n",
"Tables you'll need:\n",
"\n",
"```\n",
"allstarfull\n",
"fielding\n",
"salaries\n",
"schools\n",
"schoolsplayers\n",
"teams\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Do your best to answer the following questions! They are sorted from simplest to most difficult in terms of SQL execution. If you'd like to practice your pandas syntax, submit both your SQL and pandas code (assuming tables were dataframes).\n",
"\n",
"1. Show all playerids and salaries with a salary in the year 1985 above 500k.\n",
"2. Show the team for each year that had a rank of 1.\n",
"3. How many schools are in schoolstate of CT?\n",
"4. How many schools are there in each state?\n",
"5. What was the total spend on salaries by each team, each year?\n",
"6. Find all of the salaries of shortstops (fieldings, pos) for the year 2012.\n",
"7. What is the first and last year played for each player?\n",
"8. Who has played the most all star games? \n",
"9. Which school has generated the most distinct players?\n",
"10. Which school has generated the most expensive players? (expensive defined by their first year's salary).\n",
"11. Show the 5 most expensive salaries for each team in the year 2014.\n",
"12. Partition the average salaries by team and year, against year. Find players that were paid more than 1 standard deviation above the average salary for that team and year. Show a count by playerid.\n",
"13. Calculate the win percentage. convert w and g into numerics (floats) to do so. (`w::numeric`, for example)\n",
"14. `rank()` the total spend by team each year against their actual rank that year. Is there a correlation of spend to performance?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"###Setting up Postgres\n",
"\n",
"This is an incredibly complicated subject matter! Macs should try using `homebrew` and PCs can use their native installer. Check out their [installation guide](https://wiki.postgresql.org/wiki/Detailed_installation_guides) for more details. If you start reading through and have no idea what they mean, DO NOT attempt to set up postgres on your machine."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Reading / Next Steps\n",
"\n",
"1. Read through Hadley Wickham's paper on [tidy data](http://vita.had.co.nz/papers/tidy-data.pdf). While code samples are written in R it is an incredibly familiar concept and important on how we think about querying.\n",
"2. Additional comparisons between pandas and sql syntax on the [pandas](http://pandas.pydata.org/pandas-docs/dev/comparison_with_sql.html) website.\n",
"3. Some recommended GUIs for interacting with postgres (and other databases):\n",
" 1. [Postico](https://eggerapps.at/postico/) is the new version of PG Commander built for Mac OS X.\n",
" 2. [RazorSQL](http://razorsql.com/) is cross platform and cross DB, but also expensive for the product (not free)\n",
"4. If you're looking for something in python between pandas and psycopg2 in terms of complexity, [dataset](http://dataset.readthedocs.org/en/latest/api.html) is a great python module to learn, particularly for moving data around.\n",
"5. Additional SQL Help:\n",
" 1. [SQL Bootcamp](https://github.com/brandonmburroughs/sql_bootcamp) from GA (MySQL)\n",
" 2. [SQLZOO](http://sqlzoo.net/wiki/SELECT) can switch between engines\n",
" 3. [w3schools](http://www.w3schools.com/sql/trysql.asp?filename=trysql_select_all) has a practice database.\n",
" 4. [SQLSchool](http://sqlschool.modeanalytics.com/)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.9"
}
},
"nbformat": 4,
"nbformat_minor": 0
}