\n", "\n", "Aug 30th 2014\n", "\n", "
 \n",
"\n",
"Patrick Peglar - UK Met Office, Exeter\n",
"\n",
"### Biggus: https://github.com/SciTools/biggus\n",
"\n",
"\n",
"
\n",
"\n",
"Patrick Peglar - UK Met Office, Exeter\n",
"\n",
"### Biggus: https://github.com/SciTools/biggus\n",
"\n",
"\n",
"\n", "
\n", "
\n", "\n", "( this talk: https://github.com/pp-mo/biggus_talk )\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "Overview\n", "-------\n", "\n", "Biggus is a lightweight pure-Python package which implements lazy operations on numpy array-like objects. This provides dramatically improved efficiency in analysing large datasets, for minimal additional effort in the client code." ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ "Biggus makes data analysis on large datasets easier\n", "- avoids scalability problems\n", "- makes code clearer and simpler\n", "- uses less space and time\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ "The key technique is \"lazy evaluation\"\n", " \n", " Aka \"**don't do it until you have to**\"\n", " \n", " This goes by several near-interchangeable names:\n", " * **VIRTUAL** arrays \n", " * **\"LAZY\"** - or -\n", " * **\"DEFERRED\"**- evaluation" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "Biggus provides 'virtual' arrays.\n", "---\n", "A virtual array does not need the actual *values* of its data content ...\n", " * ... but it knows all about it:\n", " * size and shape\n", " * datatype\n", " * how to load (any given part of) it" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ "Virtual arrays can be processed in the usual ways\n", " * these manipulations don't process actual data\n", " * actual results are got from the result arrays, but *only on request*" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ "The 'deferred' operation is the source of ***all the benefits*** ...\n", " * copes with arbitrary data sizes\n", " * optimises data access\n", " * separates data access from analysis concerns" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "subslide" } }, "source": [ "The key features Biggus provides\n", "---\n", "* virtual arrays of arbitrary size\n", "* combine and extract\n", "* statistics\n", "* arithmetic\n", "* efficient evaluation\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "subslide" } }, "source": [ "What's to come:\n", "---\n", " * dead-simple example\n", " * what it's good for\n", " * summary of current features\n", " * how it works (in outline)\n", " * current work and future directions\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "The longest journey ...\n", "------" ] }, { "cell_type": "code", "collapsed": false, "input": [ "import biggus\n", "print biggus.__version__\n" ], "language": "python", "metadata": { "slideshow": { "slide_type": "fragment" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "A simple 'mean' calculation ...\n", "---\n", "\n", "(and so later.. the biggus equivalent)" ] }, { "cell_type": "code", "collapsed": false, "input": [ "import numpy as np\n", "array_1 = np.array([[1., 5., 2.], [7., 6., 5.]])\n", "print 'simple array :\\n', array_1\n", "mean_a1 = array_1.mean(axis=1)\n", "print\n", "print 'mean over axis 1 :\\n', mean_a1\n" ], "language": "python", "metadata": { "slideshow": { "slide_type": "fragment" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "subslide" } }, "source": [ "Simple mean calculation : The Biggus equivalent\n", "----\n" ] }, { "cell_type": "code", "collapsed": false, "input": [ "from biggus import NumpyArrayAdapter as npwrap\n", "lazy_1 = npwrap(array_1)\n", "print 'a lazy array : ', lazy_1\n" ], "language": "python", "metadata": { "slideshow": { "slide_type": "fragment" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "subslide" } }, "source": [ "### ... lazy mean and result" ] }, { "cell_type": "code", "collapsed": false, "input": [ "lazy_mean = biggus.mean(lazy_1, axis=1)\n", "print 'lazy mean :', lazy_mean\n", "print\n", "print 'lazy mean *result* :\\n', lazy_mean.ndarray()\n", "print\n", "print 'same as original ...:\\n', mean_a1\n" ], "language": "python", "metadata": { "slideshow": { "slide_type": "fragment" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ "### Repeat that ...\n", "But this time change the source data, between *forming* the mean and *evaluating* it." ] }, { "cell_type": "code", "collapsed": false, "input": [ "lazy_mean2 = biggus.mean(lazy_1, axis=1)\n", "print lazy_mean2\n", "array_1[0,:] = -1\n", "print lazy_mean2.ndarray()\n" ], "language": "python", "metadata": { "slideshow": { "slide_type": "fragment" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "So... what is the point ?\n", "----" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ " * **SPACE** (memory usage)\n", " " ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ " * **TIME** (optimised operation, especially data i/o)\n", " " ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "fragment" } }, "source": [ " * **CODE** (convenience ; clarity ; separation of concerns)\n", " " ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "SPACE (resource efficiency)\n", "----\n", " * data grows\n", " * eventually you can't fit all the data\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "subslide" } }, "source": [ "The space problem - a historical example\n", "---\n", "
 \n",
"\n",
"### Which means...\n",
" * A single forecast datafield now occupies over 200Mb\n",
" * there are dozens of stored parameter fields, and dozens of timesteps per run\n",
" * we do a new run every 6 hours\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"TIME\n",
"----\n",
" * avoid re-reading anything\n",
" * pass sections of data to all consumer processes \"in parallel\"\n",
" * eventually / potentially this leads to distributed processing\n",
" * (i.e. processes not co-hosted)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"CODE\n",
"----\n",
"The easy way to define a data analysis process\n",
" * grab all the data\n",
" * write analysis code\n",
" * don't worry about resources / efficiency"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"Code using biggus **looks very similar**, but\n",
" * deferred execution means it scales with data size\n",
" * no need to confuse the code with data access concerns"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Aside : the use of biggus in Iris\n",
"---\n",
"
\n",
"\n",
"### Which means...\n",
" * A single forecast datafield now occupies over 200Mb\n",
" * there are dozens of stored parameter fields, and dozens of timesteps per run\n",
" * we do a new run every 6 hours\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"TIME\n",
"----\n",
" * avoid re-reading anything\n",
" * pass sections of data to all consumer processes \"in parallel\"\n",
" * eventually / potentially this leads to distributed processing\n",
" * (i.e. processes not co-hosted)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"CODE\n",
"----\n",
"The easy way to define a data analysis process\n",
" * grab all the data\n",
" * write analysis code\n",
" * don't worry about resources / efficiency"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"Code using biggus **looks very similar**, but\n",
" * deferred execution means it scales with data size\n",
" * no need to confuse the code with data access concerns"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Aside : the use of biggus in Iris\n",
"---\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features Summary:\n",
"----\n",
" 1. arrays and indexing\n",
" 1. combining arrays : stack + tile \n",
" 1. statistics\n",
" 1. arithmetic\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The uniformity here is key:\n",
" * all operations produce an 'Array' object\n",
" * all operations can be combined freely\n",
" * so... the lazy representations allow efficient evaluation"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
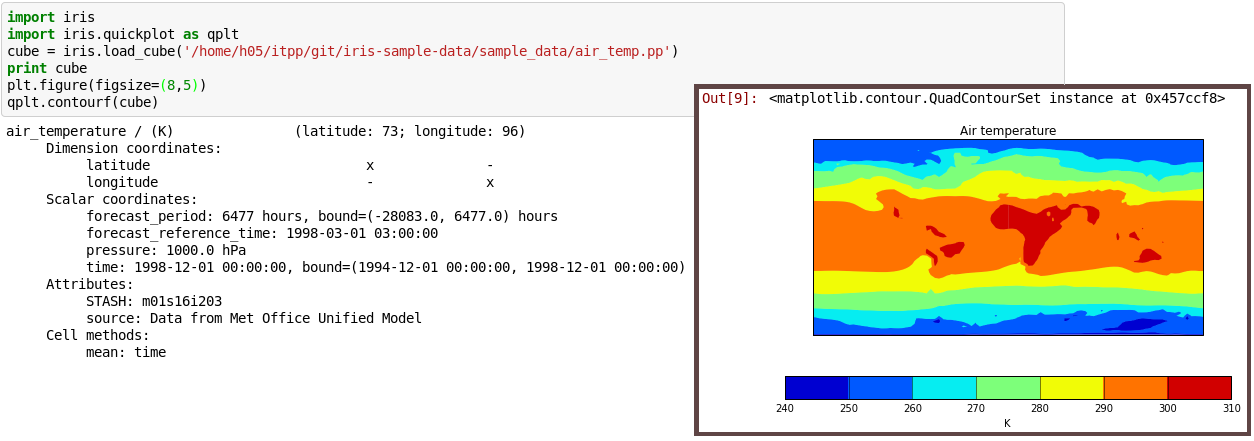
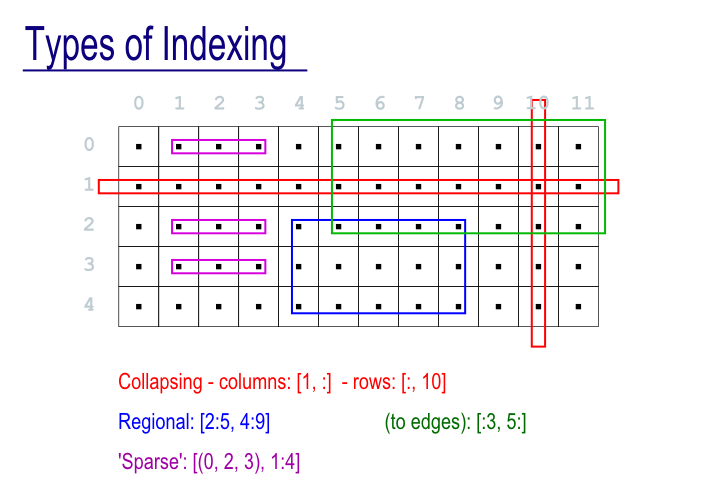
"Features #1 : **Arrays and Indexing**\n",
"----\n",
"Anything that 'looks like' an array can be cast as a biggus.Array\n",
"\n",
"All types of Biggus array support the major indexing operations...\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features Summary:\n",
"----\n",
" 1. arrays and indexing\n",
" 1. combining arrays : stack + tile \n",
" 1. statistics\n",
" 1. arithmetic\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The uniformity here is key:\n",
" * all operations produce an 'Array' object\n",
" * all operations can be combined freely\n",
" * so... the lazy representations allow efficient evaluation"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #1 : **Arrays and Indexing**\n",
"----\n",
"Anything that 'looks like' an array can be cast as a biggus.Array\n",
"\n",
"All types of Biggus array support the major indexing operations...\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"So, **what is \"an array\" ?**\n",
"---\n",
"\n",
"It just needs to support the minimum numpy-array-like properties : \n",
" * **shape**\n",
" * **dtype**\n",
" * **\\_\\_getitem\\_\\_** (i.e. indexing)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"### Here's a tiny example that emulates an array full of a constant value ..."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### ... a tiny example that \"looks like\" an array full of a constant\n",
"(and indicates clearly when it is actually accessed )"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"class constant_array(object):\n",
" def __init__(self, shape, value=0.0):\n",
" self.shape = shape\n",
" self.dtype = np.array(value).dtype\n",
" self._value = value\n",
" def __getitem__(self, indices):\n",
" print ' !!! accessing :', indices\n",
" return self._value * np.ones(self.shape)[indices]\n",
"\n",
"lazy_const_234 = npwrap(constant_array((2, 3, 4), value=3.5))\n",
"print 'lazy_234:', lazy_const_234\n",
"const_section = lazy_const_234[0, 1]\n",
"print 'section:', const_section\n",
"print '\\nresult:\\n', const_section.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### In fact, this functionality is already provided in biggus\n",
"(without the evaluation debug).\n",
"\n",
"It is called a ConstantArray..\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"lazy_const_2x3 = biggus.ConstantArray((2, 3, 4), 3.77)\n",
"print lazy_const_2x3\n",
"const_section = lazy_const_2x3[0, 1]\n",
"print const_section\n",
"print const_section.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #2 : **Combining Arrays**\n",
"----\n",
"Arrays can be combined into larger arrays\n",
"\n",
"Two methods:\n",
"1. **\"stack\"** combines Arrays along a new dimension\n",
"2. **\"mosaic\"** joins arrays edge-to-edge\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
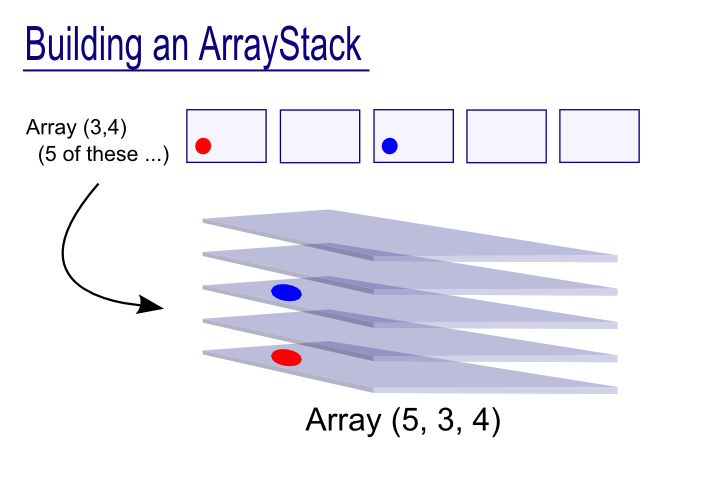
"ArrayStack\n",
"----\n",
"Analogous to numpy \"stack\" operations ('hstack', 'vstack' etc.).\n",
"\n",
"Given multiple same-shaped Arrays, it creates a *new* dimension to index over them.\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"So, **what is \"an array\" ?**\n",
"---\n",
"\n",
"It just needs to support the minimum numpy-array-like properties : \n",
" * **shape**\n",
" * **dtype**\n",
" * **\\_\\_getitem\\_\\_** (i.e. indexing)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"### Here's a tiny example that emulates an array full of a constant value ..."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### ... a tiny example that \"looks like\" an array full of a constant\n",
"(and indicates clearly when it is actually accessed )"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"class constant_array(object):\n",
" def __init__(self, shape, value=0.0):\n",
" self.shape = shape\n",
" self.dtype = np.array(value).dtype\n",
" self._value = value\n",
" def __getitem__(self, indices):\n",
" print ' !!! accessing :', indices\n",
" return self._value * np.ones(self.shape)[indices]\n",
"\n",
"lazy_const_234 = npwrap(constant_array((2, 3, 4), value=3.5))\n",
"print 'lazy_234:', lazy_const_234\n",
"const_section = lazy_const_234[0, 1]\n",
"print 'section:', const_section\n",
"print '\\nresult:\\n', const_section.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### In fact, this functionality is already provided in biggus\n",
"(without the evaluation debug).\n",
"\n",
"It is called a ConstantArray..\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"lazy_const_2x3 = biggus.ConstantArray((2, 3, 4), 3.77)\n",
"print lazy_const_2x3\n",
"const_section = lazy_const_2x3[0, 1]\n",
"print const_section\n",
"print const_section.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #2 : **Combining Arrays**\n",
"----\n",
"Arrays can be combined into larger arrays\n",
"\n",
"Two methods:\n",
"1. **\"stack\"** combines Arrays along a new dimension\n",
"2. **\"mosaic\"** joins arrays edge-to-edge\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"ArrayStack\n",
"----\n",
"Analogous to numpy \"stack\" operations ('hstack', 'vstack' etc.).\n",
"\n",
"Given multiple same-shaped Arrays, it creates a *new* dimension to index over them.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### ArrayStack code example:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"arrays = [num * np.ones((3)) for num in range(1,5)]\n",
"print 'array#2:', arrays[2]\n",
"print\n",
"lazy_arrays = np.array([npwrap(array) for array in arrays])\n",
"stack = biggus.ArrayStack(lazy_arrays)\n",
"print stack\n",
"print stack.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"LinearMosaic\n",
"----\n",
"Analagous to numpy \"concatenate\" operations.\n",
" * joins \"edge to edge\"\n",
" * does *not* create a new dimension"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### LinearMosaic code example:\n",
" "
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Make one of the components arrays smaller than the others\n",
"lazy_arrays[2] = lazy_arrays[2][:1]\n",
"# Combine into one\n",
"mosaic = biggus.LinearMosaic(lazy_arrays, axis=0)\n",
"print mosaic\n",
"print mosaic.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"Note:\n",
"* this handles *irregular* sizes (along the joining axis)\n",
"* the join is **seamless**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
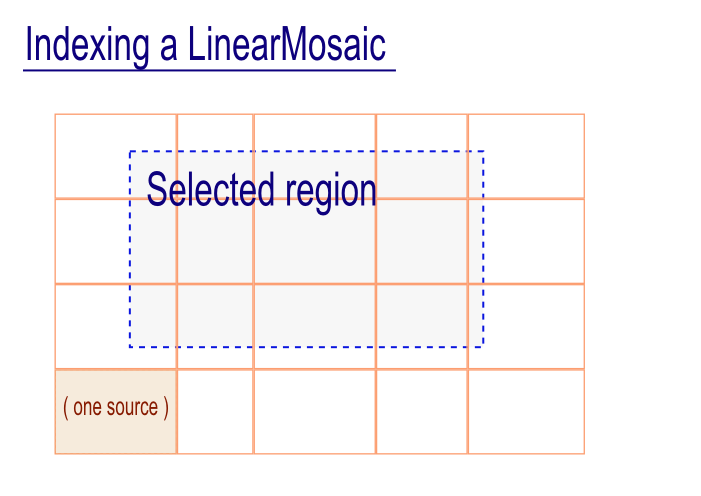
"Combined usage : code example\n",
"----\n",
"With a nested construction, we can make a complex patchwork + extract 2d regions seamlessly ...\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### ArrayStack code example:"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"arrays = [num * np.ones((3)) for num in range(1,5)]\n",
"print 'array#2:', arrays[2]\n",
"print\n",
"lazy_arrays = np.array([npwrap(array) for array in arrays])\n",
"stack = biggus.ArrayStack(lazy_arrays)\n",
"print stack\n",
"print stack.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"LinearMosaic\n",
"----\n",
"Analagous to numpy \"concatenate\" operations.\n",
" * joins \"edge to edge\"\n",
" * does *not* create a new dimension"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### LinearMosaic code example:\n",
" "
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Make one of the components arrays smaller than the others\n",
"lazy_arrays[2] = lazy_arrays[2][:1]\n",
"# Combine into one\n",
"mosaic = biggus.LinearMosaic(lazy_arrays, axis=0)\n",
"print mosaic\n",
"print mosaic.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"Note:\n",
"* this handles *irregular* sizes (along the joining axis)\n",
"* the join is **seamless**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Combined usage : code example\n",
"----\n",
"With a nested construction, we can make a complex patchwork + extract 2d regions seamlessly ...\n",
"\n",
" \n",
"\n",
"The pink cells show separate data sources, joined together with nested 'LinearMosaic's.\n",
"\n",
"The extracted area is a new virtual array, seamlessly extracted across the original boundaries. "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #3 : **Statistics**\n",
"----\n",
"There are basic functions to perform statistics on an Array ('mean', 'std', 'count', 'var').\n",
"\n",
"We've already seen an example of this:\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"mean = biggus.mean(lazy_arrays[0], axis=0)\n",
"print mean\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The other operations simply follow the same pattern."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"#### Statistical functions must be individually implemented :--\n",
" * the algorithm is recast in a standard form (subclass '_Aggregation') ...\n",
" * data is processed in sections known as \"chunks\", with the simple pattern:\n",
" * initialise\n",
" * process chunks, as we are given them\n",
" * finalise"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"*Chunking* is managed by an \"evaluation engine\" (see on..)\n",
"\n",
"However, a statistical operation can specify constraints on its chunking process.\n",
" * for instance, a (future) median function would need *all* the data on the aggregation axis"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #4 : **Array Arithmetic**\n",
"----\n",
"Basic lazy arithmetic functions are provided ('add', 'sub').\n",
"\n",
"### Code example ...\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"values = npwrap(np.array([1.0, 2.0, 3.0]))\n",
"constants = biggus.ConstantArray((3,), 1000.0)\n",
"sum = biggus.add(values, constants)\n",
"print 'sum:', sum\n",
"print 'sum results:\\n', sum.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The implementation of these is much more straightforward than statistics :\n",
" * the function is an 'ElementWise' instance, wrapping the required (numpy) function\n",
" * it doesn't care how the source data is chunked, so chunks processing is generalised \n",
" * so, they are somewhat like numpy 'ufuncs'\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"**How it works**\n",
"----\n",
"in brief: **Parallel Evaluation**\n",
"\n",
"The point is to avoid the need to make multiple passes over large datasets, while keeping memory usage within sensible limits.\n",
"\n",
"The abstraction of operations provided by the lazy constructs means we can also take advantage of parallelism."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Evaluation example:\n",
"---\n",
"a possible processing scheme ...\n",
"\n",
"
\n",
"\n",
"The pink cells show separate data sources, joined together with nested 'LinearMosaic's.\n",
"\n",
"The extracted area is a new virtual array, seamlessly extracted across the original boundaries. "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #3 : **Statistics**\n",
"----\n",
"There are basic functions to perform statistics on an Array ('mean', 'std', 'count', 'var').\n",
"\n",
"We've already seen an example of this:\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"mean = biggus.mean(lazy_arrays[0], axis=0)\n",
"print mean\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The other operations simply follow the same pattern."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"#### Statistical functions must be individually implemented :--\n",
" * the algorithm is recast in a standard form (subclass '_Aggregation') ...\n",
" * data is processed in sections known as \"chunks\", with the simple pattern:\n",
" * initialise\n",
" * process chunks, as we are given them\n",
" * finalise"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"*Chunking* is managed by an \"evaluation engine\" (see on..)\n",
"\n",
"However, a statistical operation can specify constraints on its chunking process.\n",
" * for instance, a (future) median function would need *all* the data on the aggregation axis"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Features #4 : **Array Arithmetic**\n",
"----\n",
"Basic lazy arithmetic functions are provided ('add', 'sub').\n",
"\n",
"### Code example ...\n"
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"values = npwrap(np.array([1.0, 2.0, 3.0]))\n",
"constants = biggus.ConstantArray((3,), 1000.0)\n",
"sum = biggus.add(values, constants)\n",
"print 'sum:', sum\n",
"print 'sum results:\\n', sum.ndarray()\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
"The implementation of these is much more straightforward than statistics :\n",
" * the function is an 'ElementWise' instance, wrapping the required (numpy) function\n",
" * it doesn't care how the source data is chunked, so chunks processing is generalised \n",
" * so, they are somewhat like numpy 'ufuncs'\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"**How it works**\n",
"----\n",
"in brief: **Parallel Evaluation**\n",
"\n",
"The point is to avoid the need to make multiple passes over large datasets, while keeping memory usage within sensible limits.\n",
"\n",
"The abstraction of operations provided by the lazy constructs means we can also take advantage of parallelism."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Evaluation example:\n",
"---\n",
"a possible processing scheme ...\n",
"\n",
" \n",
"\n",
"\n",
" B_mean = biggus.mean(B, axis=0)\n",
" diff = biggus.sub(A, B_mean)\n",
" X = biggus.count(diff)\n",
" Y = biggus.mean(diff)\n",
" Z = biggus.std(diff) \n",
" x, y, z = \\\n",
" biggus.ndarrays((X, Y, Z))\n",
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"### Parallel Evaluation code example ..."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Make test data (ordinary numpy arrays)\n",
"src_a = np.arange(10.0) % 3\n",
"src_b = np.arange(40.0).reshape(10, 4) % 7\n",
"print src_a\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Process in biggus to make 3 lazy results. \n",
"A = npwrap(src_a)\n",
"B = npwrap(src_b)\n",
"B_mean = biggus.mean(B, axis=1)\n",
"diff = biggus.sub(A, B_mean)\n",
"X = biggus.count(diff, axis=0)\n",
"Y = biggus.mean(diff, axis=0)\n",
"Z = biggus.std(diff, axis=0)\n",
"print X\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Evaluate.\n",
"x, y, z = biggus.ndarrays((X, Y, Z))\n",
"print x, y, z\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
" * As evaluation outputs form a stream of \"chunks\", each consumer must process each chunk.\n",
" * To gain speed, the consumers of the data can also operate concurrently."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Content Review\n",
"---\n",
"Current status\n",
" * **existing features** are immediately useful (e.g. Iris)\n",
" * virtual arrays\n",
" * combine and extract\n",
" * arithmetic and statistics\n",
" * efficient evaluation\n",
" * *missing features* - still lots\n",
"\n",
"Future directions\n",
" * direct-to-file saving, with parallel evaluation\n",
" * more intelligent chunking strategies\n",
" * more statistics\n",
" * **whatever gets asked for ...**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Winding up:\n",
"---\n",
"\"**Forget all your memory worries; calculate faster and easier with ...**\" \n",
"https://github.com/SciTools/biggus\n",
" \n",
"## Biggus is:\n",
" * a fully open-source independent project\n",
" * licenced under LGPL\n",
" * developed by contributors around the world\n",
" * ready for real-world uses\n",
" * a key dependency of Iris (https://github.com/SciTools/iris)\n",
" \n",
" \n",
"## Just using it is a contribution\n",
"We look forward to your contribution !\n",
"\n",
"
\n",
"\n",
"\n",
" B_mean = biggus.mean(B, axis=0)\n",
" diff = biggus.sub(A, B_mean)\n",
" X = biggus.count(diff)\n",
" Y = biggus.mean(diff)\n",
" Z = biggus.std(diff) \n",
" x, y, z = \\\n",
" biggus.ndarrays((X, Y, Z))\n",
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"### Parallel Evaluation code example ..."
]
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Make test data (ordinary numpy arrays)\n",
"src_a = np.arange(10.0) % 3\n",
"src_b = np.arange(40.0).reshape(10, 4) % 7\n",
"print src_a\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Process in biggus to make 3 lazy results. \n",
"A = npwrap(src_a)\n",
"B = npwrap(src_b)\n",
"B_mean = biggus.mean(B, axis=1)\n",
"diff = biggus.sub(A, B_mean)\n",
"X = biggus.count(diff, axis=0)\n",
"Y = biggus.mean(diff, axis=0)\n",
"Z = biggus.std(diff, axis=0)\n",
"print X\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "code",
"collapsed": false,
"input": [
"# Evaluate.\n",
"x, y, z = biggus.ndarrays((X, Y, Z))\n",
"print x, y, z\n"
],
"language": "python",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"outputs": []
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "fragment"
}
},
"source": [
" * As evaluation outputs form a stream of \"chunks\", each consumer must process each chunk.\n",
" * To gain speed, the consumers of the data can also operate concurrently."
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Content Review\n",
"---\n",
"Current status\n",
" * **existing features** are immediately useful (e.g. Iris)\n",
" * virtual arrays\n",
" * combine and extract\n",
" * arithmetic and statistics\n",
" * efficient evaluation\n",
" * *missing features* - still lots\n",
"\n",
"Future directions\n",
" * direct-to-file saving, with parallel evaluation\n",
" * more intelligent chunking strategies\n",
" * more statistics\n",
" * **whatever gets asked for ...**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"Winding up:\n",
"---\n",
"\"**Forget all your memory worries; calculate faster and easier with ...**\" \n",
"https://github.com/SciTools/biggus\n",
" \n",
"## Biggus is:\n",
" * a fully open-source independent project\n",
" * licenced under LGPL\n",
" * developed by contributors around the world\n",
" * ready for real-world uses\n",
" * a key dependency of Iris (https://github.com/SciTools/iris)\n",
" \n",
" \n",
"## Just using it is a contribution\n",
"We look forward to your contribution !\n",
"\n",
"\n", "
\n", "
\n", "\n", "( this talk : https://github.com/pp-mo/biggus_talk )\n" ] }, { "cell_type": "markdown", "metadata": { "slideshow": { "slide_type": "slide" } }, "source": [ "END\n", "====" ] }, { "cell_type": "code", "collapsed": false, "input": [ "def ta(id, dims):\n", " return npwrap(id * np.ones(dims))\n", "\n", "row1 = biggus.LinearMosaic(np.array([ta(1, (3, 5)), ta(2, (3, 2)), ta(3, (3, 2))]), axis=1)\n", "row2 = biggus.LinearMosaic(np.array([ta(5, (5, 2)), ta(6, (5, 2)), ta(7, (5, 5))]), axis=1)\n", "tiles2d = biggus.LinearMosaic(np.array([row1, row2]), axis=0)\n", "\n", "part2d = tiles2d[1:6, 1:7]\n", "whole, part = tiles2d.ndarray(), part2d.ndarray()\n", "\n", "print 'whole:', whole\n", "print 'part:', part\n", "plt.figure(figsize=(12,4))\n", "plt.subplot(1, 2, 1); plt.pcolormesh(whole, edgecolor='black');\n", "plt.plot([1, 7, 7, 1, 1], [1, 1, 6, 6, 1], color='red', linewidth=5)\n", "plt.subplot(1, 2, 2); plt.pcolormesh(part, edgecolor='black')" ], "language": "python", "metadata": { "slideshow": { "slide_type": "skip" } }, "outputs": [] }, { "cell_type": "markdown", "metadata": {}, "source": [] } ], "metadata": {} } ] }