{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# pandas 기초 (2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* 싸이그래머 : 생물심리Py\n",
"* 발표자 : 김무성 "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 차례"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* 추천 사이트\n",
"* pandas로 데이터 다루기"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 추천 사이트"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* 통계 기초 ppt : Basic statistics: a survival guide - https://education.med.imperial.ac.uk/ext/intercalate11-12/statistics.ppt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# pandas로 데이터 다루기"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* 기본 연산, 함수, 정렬, 중복색인\n",
"* 기본 자료 특성 탐색 \n",
"* 누락값 처리\n",
"* 계층적 색인\n",
"* 로우 색인과 컬럼 색인 교환\n",
"* Panel 데이터\n",
"* 데이터 입출력\n",
"* 데이터 다듬기\n",
"* 데이터 그룹 연산"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 기본 연산, 함수, 정렬, 중복 색인"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* 산술연산\n",
"* 함수 적용과 매핑\n",
"* 데이터 정렬, 순위\n",
"* 중복 색인"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 산술연산"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* pandas에서 중요한 기능은 색인이 다른 객체 간의 산술연산이다. \n",
"* 객체를 더할 때 짝이 맞지 않는 색인이 있다면 결과에 두 색인이 통합된다"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"collapsed": false
},
"outputs": [],
"source": [
"from pandas import Series, DataFrame\n",
"import pandas as pd\n",
"import numpy as np"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"a 7.3\n",
"c -2.5\n",
"d 3.4\n",
"e 1.5\n",
"dtype: float64"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"s1 = Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])\n",
"s1"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"a -2.1\n",
"c 3.6\n",
"e -1.5\n",
"f 4.0\n",
"g 3.1\n",
"dtype: float64"
]
},
"execution_count": 5,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"s2 = Series([-2.1, 3.6, -1.5, 4, 3.1], index=['a', 'c', 'e', 'f', 'g'])\n",
"s2"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
"a 5.2\n",
"c 1.1\n",
"d NaN\n",
"e 0.0\n",
"f NaN\n",
"g NaN\n",
"dtype: float64"
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# 더하기. 겹치는 색인이 없다면 데이터는 NA 값이 됨. \n",
"s1 + s2"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" c | \n",
" d | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ohio | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | Texas | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | Colorado | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | Texas | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
" | Oregon | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" c | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Colorado | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | Ohio | \n",
" 3 | \n",
" NaN | \n",
" 6 | \n",
" NaN | \n",
"
\n",
" \n",
" | Oregon | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | Texas | \n",
" 9 | \n",
" NaN | \n",
" 12 | \n",
" NaN | \n",
"
\n",
" \n",
" | Utah | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | Texas | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
" | Oregon | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 3 | \n",
" 3 | \n",
" 3 | \n",
"
\n",
" \n",
" | Texas | \n",
" 6 | \n",
" 6 | \n",
" 6 | \n",
"
\n",
" \n",
" | Oregon | \n",
" 9 | \n",
" 9 | \n",
" 9 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
" f | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 0 | \n",
" NaN | \n",
" 3 | \n",
" NaN | \n",
"
\n",
" \n",
" | Ohio | \n",
" 3 | \n",
" NaN | \n",
" 6 | \n",
" NaN | \n",
"
\n",
" \n",
" | Texas | \n",
" 6 | \n",
" NaN | \n",
" 9 | \n",
" NaN | \n",
"
\n",
" \n",
" | Oregon | \n",
" 9 | \n",
" NaN | \n",
" 12 | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 1.230536 | \n",
" 0.954398 | \n",
" 0.779991 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 0.786592 | \n",
" -0.289047 | \n",
" 0.694158 | \n",
"
\n",
" \n",
" | Texas | \n",
" 0.374949 | \n",
" 0.655600 | \n",
" 0.573002 | \n",
"
\n",
" \n",
" | Oregon | \n",
" -1.460670 | \n",
" -1.101064 | \n",
" -0.326258 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 1.230536 | \n",
" 0.954398 | \n",
" 0.779991 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 0.786592 | \n",
" 0.289047 | \n",
" 0.694158 | \n",
"
\n",
" \n",
" | Texas | \n",
" 0.374949 | \n",
" 0.655600 | \n",
" 0.573002 | \n",
"
\n",
" \n",
" | Oregon | \n",
" 1.460670 | \n",
" 1.101064 | \n",
" 0.326258 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | min | \n",
" -1.460670 | \n",
" -1.101064 | \n",
" -0.326258 | \n",
"
\n",
" \n",
" | max | \n",
" 1.230536 | \n",
" 0.954398 | \n",
" 0.779991 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" b | \n",
" d | \n",
" e | \n",
"
\n",
" \n",
" \n",
" \n",
" | Utah | \n",
" 1.23 | \n",
" 0.95 | \n",
" 0.78 | \n",
"
\n",
" \n",
" | Ohio | \n",
" 0.79 | \n",
" -0.29 | \n",
" 0.69 | \n",
"
\n",
" \n",
" | Texas | \n",
" 0.37 | \n",
" 0.66 | \n",
" 0.57 | \n",
"
\n",
" \n",
" | Oregon | \n",
" -1.46 | \n",
" -1.10 | \n",
" -0.33 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" d | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | three | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | one | \n",
" 4 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" d | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | one | \n",
" 4 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
"
\n",
" \n",
" | three | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
"
\n",
" \n",
" \n",
" \n",
" | three | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 0 | \n",
"
\n",
" \n",
" | one | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 4 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" d | \n",
" c | \n",
" b | \n",
" a | \n",
"
\n",
" \n",
" \n",
" \n",
" | three | \n",
" 0 | \n",
" 3 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
" | one | \n",
" 4 | \n",
" 7 | \n",
" 6 | \n",
" 5 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" 4 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 7 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0 | \n",
" -3 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2 | \n",
" 0 | \n",
" -3 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | 0 | \n",
" 0 | \n",
" 4 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 7 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" 4 | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 7 | \n",
" -2 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0 | \n",
" -3 | \n",
" 0 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2 | \n",
" 0 | \n",
" -3 | \n",
" 0 | \n",
"
\n",
" \n",
" | 0 | \n",
" 0 | \n",
" 4 | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 7 | \n",
" -2 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" one | \n",
" two | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1.40 | \n",
" NaN | \n",
"
\n",
" \n",
" | b | \n",
" 7.10 | \n",
" -4.5 | \n",
"
\n",
" \n",
" | c | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | d | \n",
" 0.75 | \n",
" -1.3 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" one | \n",
" two | \n",
"
\n",
" \n",
" \n",
" \n",
" | count | \n",
" 3.000000 | \n",
" 2.000000 | \n",
"
\n",
" \n",
" | mean | \n",
" 3.083333 | \n",
" -2.900000 | \n",
"
\n",
" \n",
" | std | \n",
" 3.493685 | \n",
" 2.262742 | \n",
"
\n",
" \n",
" | min | \n",
" 0.750000 | \n",
" -4.500000 | \n",
"
\n",
" \n",
" | 25% | \n",
" 1.075000 | \n",
" -3.700000 | \n",
"
\n",
" \n",
" | 50% | \n",
" 1.400000 | \n",
" -2.900000 | \n",
"
\n",
" \n",
" | 75% | \n",
" 4.250000 | \n",
" -2.100000 | \n",
"
\n",
" \n",
" | max | \n",
" 7.100000 | \n",
" -1.300000 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" | Date | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2000-01-03 | \n",
" 3.77 | \n",
" 94.16 | \n",
" 41.47 | \n",
"
\n",
" \n",
" | 2000-01-04 | \n",
" 3.45 | \n",
" 90.97 | \n",
" 40.07 | \n",
"
\n",
" \n",
" | 2000-01-05 | \n",
" 3.50 | \n",
" 94.16 | \n",
" 40.49 | \n",
"
\n",
" \n",
" | 2000-01-06 | \n",
" 3.20 | \n",
" 92.54 | \n",
" 39.14 | \n",
"
\n",
" \n",
" | 2000-01-07 | \n",
" 3.35 | \n",
" 92.13 | \n",
" 39.65 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" | Date | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2000-01-03 | \n",
" 133949200 | \n",
" 10347700 | \n",
" 53228400 | \n",
"
\n",
" \n",
" | 2000-01-04 | \n",
" 128094400 | \n",
" 8227800 | \n",
" 54119000 | \n",
"
\n",
" \n",
" | 2000-01-05 | \n",
" 194580400 | \n",
" 12733200 | \n",
" 64059600 | \n",
"
\n",
" \n",
" | 2000-01-06 | \n",
" 191993200 | \n",
" 7971900 | \n",
" 54976600 | \n",
"
\n",
" \n",
" | 2000-01-07 | \n",
" 115183600 | \n",
" 11856700 | \n",
" 62013600 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" | Date | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2009-12-24 | \n",
" 0.034521 | \n",
" 0.004432 | \n",
" 0.002600 | \n",
"
\n",
" \n",
" | 2009-12-28 | \n",
" 0.012070 | \n",
" 0.013323 | \n",
" 0.005187 | \n",
"
\n",
" \n",
" | 2009-12-29 | \n",
" -0.011575 | \n",
" -0.003517 | \n",
" 0.007372 | \n",
"
\n",
" \n",
" | 2009-12-30 | \n",
" 0.012065 | \n",
" 0.005463 | \n",
" -0.013904 | \n",
"
\n",
" \n",
" | 2009-12-31 | \n",
" -0.004208 | \n",
" -0.012621 | \n",
" -0.015584 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" \n",
" \n",
" | AAPL | \n",
" 1.000000 | \n",
" 0.409605 | \n",
" 0.423189 | \n",
"
\n",
" \n",
" | IBM | \n",
" 0.409605 | \n",
" 1.000000 | \n",
" 0.496085 | \n",
"
\n",
" \n",
" | MSFT | \n",
" 0.423189 | \n",
" 0.496085 | \n",
" 1.000000 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" \n",
" \n",
" | AAPL | \n",
" 0.001032 | \n",
" 0.000252 | \n",
" 0.000309 | \n",
"
\n",
" \n",
" | IBM | \n",
" 0.000252 | \n",
" 0.000367 | \n",
" 0.000216 | \n",
"
\n",
" \n",
" | MSFT | \n",
" 0.000309 | \n",
" 0.000216 | \n",
" 0.000517 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" AAPL | \n",
" IBM | \n",
" MSFT | \n",
"
\n",
" \n",
" | Date | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2000-01-03 | \n",
" 133949200 | \n",
" 10347700 | \n",
" 53228400 | \n",
"
\n",
" \n",
" | 2000-01-04 | \n",
" 128094400 | \n",
" 8227800 | \n",
" 54119000 | \n",
"
\n",
" \n",
" | 2000-01-05 | \n",
" 194580400 | \n",
" 12733200 | \n",
" 64059600 | \n",
"
\n",
" \n",
" | 2000-01-06 | \n",
" 191993200 | \n",
" 7971900 | \n",
" 54976600 | \n",
"
\n",
" \n",
" | 2000-01-07 | \n",
" 115183600 | \n",
" 11856700 | \n",
" 62013600 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 6.5 | \n",
" 3 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 2 | \n",
" NaN | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 3 | \n",
" NaN | \n",
" 9.0 | \n",
" 2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 6.5 | \n",
" 3 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 6.5 | \n",
" 3 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 3 | \n",
" NaN | \n",
" 9.0 | \n",
" 2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 6.5 | \n",
" 3 | \n",
"
\n",
" \n",
" | 3 | \n",
" NaN | \n",
" 9.0 | \n",
" 2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" -0.864298 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 1 | \n",
" -0.056151 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.226936 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.825479 | \n",
" NaN | \n",
" 0.528780 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.040804 | \n",
" NaN | \n",
" -0.996493 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1.586317 | \n",
" -0.004980 | \n",
" -0.039019 | \n",
"
\n",
" \n",
" | 6 | \n",
" -0.311639 | \n",
" -2.297522 | \n",
" -0.975941 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" -0.864298 | \n",
" 0.000000 | \n",
" 0.000000 | \n",
"
\n",
" \n",
" | 1 | \n",
" -0.056151 | \n",
" 0.000000 | \n",
" 0.000000 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.226936 | \n",
" 0.000000 | \n",
" 0.000000 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.825479 | \n",
" 0.000000 | \n",
" 0.528780 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.040804 | \n",
" 0.000000 | \n",
" -0.996493 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1.586317 | \n",
" -0.004980 | \n",
" -0.039019 | \n",
"
\n",
" \n",
" | 6 | \n",
" -0.311639 | \n",
" -2.297522 | \n",
" -0.975941 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" -0.864298 | \n",
" 0.500000 | \n",
" NaN | \n",
"
\n",
" \n",
" | 1 | \n",
" -0.056151 | \n",
" 0.500000 | \n",
" NaN | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.226936 | \n",
" 0.500000 | \n",
" NaN | \n",
"
\n",
" \n",
" | 3 | \n",
" 1.825479 | \n",
" 0.500000 | \n",
" 0.528780 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.040804 | \n",
" 0.500000 | \n",
" -0.996493 | \n",
"
\n",
" \n",
" | 5 | \n",
" 1.586317 | \n",
" -0.004980 | \n",
" -0.039019 | \n",
"
\n",
" \n",
" | 6 | \n",
" -0.311639 | \n",
" -2.297522 | \n",
" -0.975941 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.070430 | \n",
" 0.929998 | \n",
" 1.464021 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0.834314 | \n",
" 0.040356 | \n",
" -0.028218 | \n",
"
\n",
" \n",
" | 2 | \n",
" -1.251520 | \n",
" NaN | \n",
" 0.568477 | \n",
"
\n",
" \n",
" | 3 | \n",
" -0.546254 | \n",
" NaN | \n",
" -0.464190 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.729633 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 5 | \n",
" -1.925968 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.070430 | \n",
" 0.929998 | \n",
" 1.464021 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0.834314 | \n",
" 0.040356 | \n",
" -0.028218 | \n",
"
\n",
" \n",
" | 2 | \n",
" -1.251520 | \n",
" 0.040356 | \n",
" 0.568477 | \n",
"
\n",
" \n",
" | 3 | \n",
" -0.546254 | \n",
" 0.040356 | \n",
" -0.464190 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.729633 | \n",
" 0.040356 | \n",
" -0.464190 | \n",
"
\n",
" \n",
" | 5 | \n",
" -1.925968 | \n",
" 0.040356 | \n",
" -0.464190 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.070430 | \n",
" 0.929998 | \n",
" 1.464021 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0.834314 | \n",
" 0.040356 | \n",
" -0.028218 | \n",
"
\n",
" \n",
" | 2 | \n",
" -1.251520 | \n",
" 0.485177 | \n",
" 0.568477 | \n",
"
\n",
" \n",
" | 3 | \n",
" -0.546254 | \n",
" 0.485177 | \n",
" -0.464190 | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.729633 | \n",
" 0.485177 | \n",
" 0.385023 | \n",
"
\n",
" \n",
" | 5 | \n",
" -1.925968 | \n",
" 0.485177 | \n",
" 0.385023 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0.299331 | \n",
" -2.320418 | \n",
" -1.333153 | \n",
"
\n",
" \n",
" | b | \n",
" 0.757166 | \n",
" -1.473082 | \n",
" -0.300510 | \n",
"
\n",
" \n",
" | c | \n",
" 0.986354 | \n",
" 1.393783 | \n",
" NaN | \n",
"
\n",
" \n",
" | d | \n",
" NaN | \n",
" -1.309509 | \n",
" -0.417365 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" Ohio | \n",
" Colorado | \n",
"
\n",
" \n",
" | \n",
" | \n",
" Green | \n",
" Red | \n",
" Green | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" Ohio | \n",
" Colorado | \n",
"
\n",
" \n",
" | \n",
" | \n",
" Green | \n",
" Red | \n",
" Green | \n",
"
\n",
" \n",
" | key1 | \n",
" key2 | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" state | \n",
" Ohio | \n",
" Colorado | \n",
"
\n",
" \n",
" | \n",
" color | \n",
" Green | \n",
" Red | \n",
" Green | \n",
"
\n",
" \n",
" | key1 | \n",
" key2 | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" color | \n",
" Green | \n",
" Red | \n",
"
\n",
" \n",
" | key1 | \n",
" key2 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 4 | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 6 | \n",
" 7 | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | color | \n",
" Green | \n",
" Red | \n",
"
\n",
" \n",
" | key2 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 1 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 4 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | state | \n",
" Ohio | \n",
" Colorado | \n",
"
\n",
" \n",
" | color | \n",
" Green | \n",
" Red | \n",
" Green | \n",
"
\n",
" \n",
" | key2 | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 1 | \n",
" 6 | \n",
" 8 | \n",
" 10 | \n",
"
\n",
" \n",
" | 2 | \n",
" 12 | \n",
" 14 | \n",
" 16 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" color | \n",
" Green | \n",
" Red | \n",
"
\n",
" \n",
" | key1 | \n",
" key2 | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 1 | \n",
" 2 | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 8 | \n",
" 4 | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 14 | \n",
" 7 | \n",
"
\n",
" \n",
" | 2 | \n",
" 20 | \n",
" 10 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" 7 | \n",
" one | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 6 | \n",
" one | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" 5 | \n",
" one | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" 4 | \n",
" two | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" 3 | \n",
" two | \n",
" 1 | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" 2 | \n",
" two | \n",
" 2 | \n",
"
\n",
" \n",
" | 6 | \n",
" 6 | \n",
" 1 | \n",
" two | \n",
" 3 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" | \n",
" a | \n",
" b | \n",
"
\n",
" \n",
" | c | \n",
" d | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | one | \n",
" 0 | \n",
" 0 | \n",
" 7 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 6 | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" 5 | \n",
"
\n",
" \n",
" | two | \n",
" 0 | \n",
" 3 | \n",
" 4 | \n",
"
\n",
" \n",
" | 1 | \n",
" 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 2 | \n",
" 5 | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" 6 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" c | \n",
" d | \n",
" a | \n",
" b | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" one | \n",
" 0 | \n",
" 0 | \n",
" 7 | \n",
"
\n",
" \n",
" | 1 | \n",
" one | \n",
" 1 | \n",
" 1 | \n",
" 6 | \n",
"
\n",
" \n",
" | 2 | \n",
" one | \n",
" 2 | \n",
" 2 | \n",
" 5 | \n",
"
\n",
" \n",
" | 3 | \n",
" two | \n",
" 0 | \n",
" 3 | \n",
" 4 | \n",
"
\n",
" \n",
" | 4 | \n",
" two | \n",
" 1 | \n",
" 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" two | \n",
" 2 | \n",
" 5 | \n",
" 2 | \n",
"
\n",
" \n",
" | 6 | \n",
" two | \n",
" 3 | \n",
" 6 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 1 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
" 12 | \n",
" foo | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 1 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
" 12 | \n",
" foo | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 2 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
" | 3 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
" 12 | \n",
" foo | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" d | \n",
" e | \n",
" f | \n",
" message2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" | 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
" | 9 | \n",
" 10 | \n",
" 11 | \n",
" 12 | \n",
" foo | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 1 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" one | \n",
" two | \n",
" three | \n",
" four | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0.467976 | \n",
" -0.038649 | \n",
" -0.295344 | \n",
" -1.824726 | \n",
" B | \n",
"
\n",
" \n",
" | 1 | \n",
" -0.358893 | \n",
" 1.404453 | \n",
" 0.704965 | \n",
" -0.200638 | \n",
" M | \n",
"
\n",
" \n",
" | 2 | \n",
" -0.501840 | \n",
" 0.659254 | \n",
" -0.421691 | \n",
" -0.057688 | \n",
" N | \n",
"
\n",
" \n",
" | 3 | \n",
" 0.204886 | \n",
" 1.074134 | \n",
" 1.388361 | \n",
" -0.982404 | \n",
" N | \n",
"
\n",
" \n",
" | 4 | \n",
" 0.354628 | \n",
" -0.133116 | \n",
" 0.283763 | \n",
" -0.837063 | \n",
" Y | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
" d | \n",
" message | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
" 4 | \n",
" hello | \n",
"
\n",
" \n",
" | 1 | \n",
" 5 | \n",
" 6 | \n",
" 7 | \n",
" 8 | \n",
" world | \n",
"
\n",
" \n",
" | 2 | \n",
" 9 | \n",
" 10 | \n",
" 11 | \n",
" 12 | \n",
" foo | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" age | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Scott | \n",
" 25 | \n",
"
\n",
" \n",
" | 1 | \n",
" Katie | \n",
" 33 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" StoreNM | \n",
" Delivery | \n",
" OpenTime | \n",
" PointX | \n",
" PointY | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 가산디지털점 | \n",
" N | \n",
" 9:00 | \n",
" 37.479965 | \n",
" 126.882637 | \n",
"
\n",
" \n",
" | 1 | \n",
" 가산현대아울렛점 | \n",
" N | \n",
" 11:00 | \n",
" 37.477620 | \n",
" 126.889053 | \n",
"
\n",
" \n",
" | 2 | \n",
" 가양이마트점 | \n",
" N | \n",
" 10:00 | \n",
" 37.558193 | \n",
" 126.861816 | \n",
"
\n",
" \n",
" | 3 | \n",
" 강남NC점 | \n",
" N | \n",
" | \n",
" 37.509400 | \n",
" 127.007309 | \n",
"
\n",
" \n",
" | 4 | \n",
" 강남교보점 | \n",
" N | \n",
" | \n",
" 37.504570 | \n",
" 127.023590 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" a | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" c | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
"
\n",
" \n",
" | 6 | \n",
" 6 | \n",
" b | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data2 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" d | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 6 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 6 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" lkey | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" a | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" c | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
"
\n",
" \n",
" | 6 | \n",
" 6 | \n",
" b | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data2 | \n",
" rkey | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" d | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" lkey | \n",
" data2 | \n",
" rkey | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 6 | \n",
" b | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" a | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" c | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
"
\n",
" \n",
" | 6 | \n",
" 6 | \n",
" b | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data2 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" d | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 6 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 6 | \n",
" 3 | \n",
" c | \n",
" NaN | \n",
"
\n",
" \n",
" | 7 | \n",
" NaN | \n",
" d | \n",
" 2 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" a | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" c | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" a | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" b | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data2 | \n",
" key | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" a | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
"
\n",
" \n",
" | 2 | \n",
" 2 | \n",
" a | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" b | \n",
"
\n",
" \n",
" | 4 | \n",
" 4 | \n",
" d | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 2 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 1 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 4 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 5 | \n",
" 2 | \n",
" a | \n",
" 2 | \n",
"
\n",
" \n",
" | 6 | \n",
" 3 | \n",
" c | \n",
" NaN | \n",
"
\n",
" \n",
" | 7 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 8 | \n",
" 4 | \n",
" a | \n",
" 2 | \n",
"
\n",
" \n",
" | 9 | \n",
" 5 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 10 | \n",
" 5 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" key | \n",
" data2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 5 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 0 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 4 | \n",
" 1 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" 5 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 6 | \n",
" 2 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 7 | \n",
" 4 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 8 | \n",
" 2 | \n",
" a | \n",
" 2 | \n",
"
\n",
" \n",
" | 9 | \n",
" 4 | \n",
" a | \n",
" 2 | \n",
"
\n",
" \n",
" | 10 | \n",
" NaN | \n",
" d | \n",
" 4 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" key | \n",
" value | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" b | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" a | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" a | \n",
" 3 | \n",
"
\n",
" \n",
" | 4 | \n",
" b | \n",
" 4 | \n",
"
\n",
" \n",
" | 5 | \n",
" c | \n",
" 5 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" group_val | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 3.5 | \n",
"
\n",
" \n",
" | b | \n",
" 7.0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" key | \n",
" value | \n",
" group_val | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" 0 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 2 | \n",
" a | \n",
" 2 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 3 | \n",
" a | \n",
" 3 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 1 | \n",
" b | \n",
" 1 | \n",
" 7.0 | \n",
"
\n",
" \n",
" | 4 | \n",
" b | \n",
" 4 | \n",
" 7.0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" key | \n",
" value | \n",
" group_val | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" a | \n",
" 0 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 2 | \n",
" a | \n",
" 2 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 3 | \n",
" a | \n",
" 3 | \n",
" 3.5 | \n",
"
\n",
" \n",
" | 1 | \n",
" b | \n",
" 1 | \n",
" 7.0 | \n",
"
\n",
" \n",
" | 4 | \n",
" b | \n",
" 4 | \n",
" 7.0 | \n",
"
\n",
" \n",
" | 5 | \n",
" c | \n",
" 5 | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | c | \n",
" NaN | \n",
" 2 | \n",
" NaN | \n",
"
\n",
" \n",
" | d | \n",
" NaN | \n",
" 3 | \n",
" NaN | \n",
"
\n",
" \n",
" | e | \n",
" NaN | \n",
" 4 | \n",
" NaN | \n",
"
\n",
" \n",
" | f | \n",
" NaN | \n",
" NaN | \n",
" 5 | \n",
"
\n",
" \n",
" | g | \n",
" NaN | \n",
" NaN | \n",
" 6 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0 | \n",
" 0 | \n",
"
\n",
" \n",
" | c | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | b | \n",
" 1 | \n",
" 5 | \n",
"
\n",
" \n",
" | e | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" one | \n",
" two | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | b | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" | c | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" three | \n",
" four | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 5 | \n",
" 6 | \n",
"
\n",
" \n",
" | c | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" four | \n",
" one | \n",
" three | \n",
" two | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" NaN | \n",
" 0 | \n",
" NaN | \n",
" 1 | \n",
"
\n",
" \n",
" | b | \n",
" NaN | \n",
" 2 | \n",
" NaN | \n",
" 3 | \n",
"
\n",
" \n",
" | c | \n",
" NaN | \n",
" 4 | \n",
" NaN | \n",
" 5 | \n",
"
\n",
" \n",
" | a | \n",
" 6 | \n",
" NaN | \n",
" 5 | \n",
" NaN | \n",
"
\n",
" \n",
" | c | \n",
" 8 | \n",
" NaN | \n",
" 7 | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" one | \n",
" two | \n",
" three | \n",
" four | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0 | \n",
" 1 | \n",
" 5 | \n",
" 6 | \n",
"
\n",
" \n",
" | b | \n",
" 2 | \n",
" 3 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | c | \n",
" 4 | \n",
" 5 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" level1 | \n",
" level2 | \n",
"
\n",
" \n",
" | \n",
" one | \n",
" two | \n",
" three | \n",
" four | \n",
"
\n",
" \n",
" \n",
" \n",
" | a | \n",
" 0 | \n",
" 1 | \n",
" 5 | \n",
" 6 | \n",
"
\n",
" \n",
" | b | \n",
" 2 | \n",
" 3 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | c | \n",
" 4 | \n",
" 5 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" NaN | \n",
" 2 | \n",
"
\n",
" \n",
" | 1 | \n",
" NaN | \n",
" 2 | \n",
" 6 | \n",
"
\n",
" \n",
" | 2 | \n",
" 5 | \n",
" NaN | \n",
" 10 | \n",
"
\n",
" \n",
" | 3 | \n",
" NaN | \n",
" 6 | \n",
" 14 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 5 | \n",
" NaN | \n",
"
\n",
" \n",
" | 1 | \n",
" 4 | \n",
" 3 | \n",
"
\n",
" \n",
" | 2 | \n",
" NaN | \n",
" 4 | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" 6 | \n",
"
\n",
" \n",
" | 4 | \n",
" 7 | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" NaN | \n",
" 2 | \n",
"
\n",
" \n",
" | 1 | \n",
" 4 | \n",
" 2 | \n",
" 6 | \n",
"
\n",
" \n",
" | 2 | \n",
" 5 | \n",
" 4 | \n",
" 10 | \n",
"
\n",
" \n",
" | 3 | \n",
" 3 | \n",
" 6 | \n",
" 14 | \n",
"
\n",
" \n",
" | 4 | \n",
" 7 | \n",
" 8 | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | number | \n",
" one | \n",
" two | \n",
" three | \n",
"
\n",
" \n",
" | state | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ohio | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | Colorado | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | number | \n",
" one | \n",
" two | \n",
" three | \n",
"
\n",
" \n",
" | state | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | Ohio | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
"
\n",
" \n",
" | Colorado | \n",
" 3 | \n",
" 4 | \n",
" 5 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" date | \n",
" item | \n",
" value | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0.091794 | \n",
" a | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0.524387 | \n",
" a | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.412385 | \n",
" c | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" 0.247175 | \n",
" b | \n",
" 3 | \n",
"
\n",
" \n",
" | 4 | \n",
" 0.731769 | \n",
" a | \n",
" 4 | \n",
"
\n",
" \n",
" | 5 | \n",
" 0.286297 | \n",
" b | \n",
" 5 | \n",
"
\n",
" \n",
" | 6 | \n",
" 0.881872 | \n",
" c | \n",
" 6 | \n",
"
\n",
" \n",
" | 7 | \n",
" 0.404667 | \n",
" a | \n",
" 7 | \n",
"
\n",
" \n",
" | 8 | \n",
" 0.383669 | \n",
" a | \n",
" 8 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | item | \n",
" a | \n",
" b | \n",
" c | \n",
"
\n",
" \n",
" | date | \n",
" | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0.091794 | \n",
" 0 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 0.247175 | \n",
" NaN | \n",
" 3 | \n",
" NaN | \n",
"
\n",
" \n",
" | 0.286297 | \n",
" NaN | \n",
" 5 | \n",
" NaN | \n",
"
\n",
" \n",
" | 0.383669 | \n",
" 8 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
" | 0.404667 | \n",
" 7 | \n",
" NaN | \n",
" NaN | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" k1 | \n",
" k2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" one | \n",
" 1 | \n",
"
\n",
" \n",
" | 1 | \n",
" one | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" one | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" two | \n",
" 3 | \n",
"
\n",
" \n",
" | 4 | \n",
" two | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" two | \n",
" 4 | \n",
"
\n",
" \n",
" | 6 | \n",
" two | \n",
" 4 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" k1 | \n",
" k2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" one | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" one | \n",
" 2 | \n",
"
\n",
" \n",
" | 3 | \n",
" two | \n",
" 3 | \n",
"
\n",
" \n",
" | 5 | \n",
" two | \n",
" 4 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" food | \n",
" ounces | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" bacon | \n",
" 4.0 | \n",
"
\n",
" \n",
" | 1 | \n",
" pulled pork | \n",
" 3.0 | \n",
"
\n",
" \n",
" | 2 | \n",
" bacon | \n",
" 12.0 | \n",
"
\n",
" \n",
" | 3 | \n",
" Pastrami | \n",
" 6.0 | \n",
"
\n",
" \n",
" | 4 | \n",
" corned beef | \n",
" 7.5 | \n",
"
\n",
" \n",
" | 5 | \n",
" Bacon | \n",
" 8.0 | \n",
"
\n",
" \n",
" | 6 | \n",
" pastrami | \n",
" 3.0 | \n",
"
\n",
" \n",
" | 7 | \n",
" honey ham | \n",
" 5.0 | \n",
"
\n",
" \n",
" | 8 | \n",
" nova lox | \n",
" 6.0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" food | \n",
" ounces | \n",
" animal | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" bacon | \n",
" 4.0 | \n",
" pig | \n",
"
\n",
" \n",
" | 1 | \n",
" pulled pork | \n",
" 3.0 | \n",
" pig | \n",
"
\n",
" \n",
" | 2 | \n",
" bacon | \n",
" 12.0 | \n",
" pig | \n",
"
\n",
" \n",
" | 3 | \n",
" Pastrami | \n",
" 6.0 | \n",
" cow | \n",
"
\n",
" \n",
" | 4 | \n",
" corned beef | \n",
" 7.5 | \n",
" cow | \n",
"
\n",
" \n",
" | 5 | \n",
" Bacon | \n",
" 8.0 | \n",
" pig | \n",
"
\n",
" \n",
" | 6 | \n",
" pastrami | \n",
" 3.0 | \n",
" cow | \n",
"
\n",
" \n",
" | 7 | \n",
" honey ham | \n",
" 5.0 | \n",
" pig | \n",
"
\n",
" \n",
" | 8 | \n",
" nova lox | \n",
" 6.0 | \n",
" salmon | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | count | \n",
" 1000.000000 | \n",
" 1000.000000 | \n",
" 1000.000000 | \n",
" 1000.000000 | \n",
"
\n",
" \n",
" | mean | \n",
" -0.067684 | \n",
" 0.067924 | \n",
" 0.025598 | \n",
" -0.002298 | \n",
"
\n",
" \n",
" | std | \n",
" 0.998035 | \n",
" 0.992106 | \n",
" 1.006835 | \n",
" 0.996794 | \n",
"
\n",
" \n",
" | min | \n",
" -3.428254 | \n",
" -3.548824 | \n",
" -3.184377 | \n",
" -3.745356 | \n",
"
\n",
" \n",
" | 25% | \n",
" -0.774890 | \n",
" -0.591841 | \n",
" -0.641675 | \n",
" -0.644144 | \n",
"
\n",
" \n",
" | 50% | \n",
" -0.116401 | \n",
" 0.101143 | \n",
" 0.002073 | \n",
" -0.013611 | \n",
"
\n",
" \n",
" | 75% | \n",
" 0.616366 | \n",
" 0.780282 | \n",
" 0.680391 | \n",
" 0.654328 | \n",
"
\n",
" \n",
" | max | \n",
" 3.366626 | \n",
" 2.653656 | \n",
" 3.260383 | \n",
" 3.927528 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"
\n",
" \n",
" \n",
" | \n",
" 0 | \n",
" 1 | \n",
" 2 | \n",
" 3 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 5 | \n",
" -0.539741 | \n",
" 0.476985 | \n",
" 3.248944 | \n",
" -1.021228 | \n",
"
\n",
" \n",
" | 97 | \n",
" -0.774363 | \n",
" 0.552936 | \n",
" 0.106061 | \n",
" 3.927528 | \n",
"
\n",
" \n",
" | 102 | \n",
" -0.655054 | \n",
" -0.565230 | \n",
" 3.176873 | \n",
" 0.959533 | \n",
"
\n",
" \n",
" | 305 | \n",
" -2.315555 | \n",
" 0.457246 | \n",
" -0.025907 | \n",
" -3.399312 | \n",
"
\n",
" \n",
" | 324 | \n",
" 0.050188 | \n",
" 1.951312 | \n",
" 3.260383 | \n",
" 0.963301 | \n",
"
\n",
" \n",
" | 400 | \n",
" 0.146326 | \n",
" 0.508391 | \n",
" -0.196713 | \n",
" -3.745356 | \n",
"
\n",
" \n",
" | 499 | \n",
" -0.293333 | \n",
" -0.242459 | \n",
" -3.056990 | \n",
" 1.918403 | \n",
"
\n",
" \n",
" | 523 | \n",
" -3.428254 | \n",
" -0.296336 | \n",
" -0.439938 | \n",
" -0.867165 | \n",
"
\n",
" \n",
" | 586 | \n",
" 0.275144 | \n",
" 1.179227 | \n",
" -3.184377 | \n",
" 1.369891 | \n",
"
\n",
" \n",
" | 808 | \n",
" -0.362528 | \n",
" -3.548824 | \n",
" 1.553205 | \n",
" -2.186301 | \n",
"
\n",
" \n",
" | 900 | \n",
" 3.366626 | \n",
" -2.372214 | \n",
" 0.851010 | \n",
" 1.332846 | \n",
"
\n",
" \n",
"
\n",
"
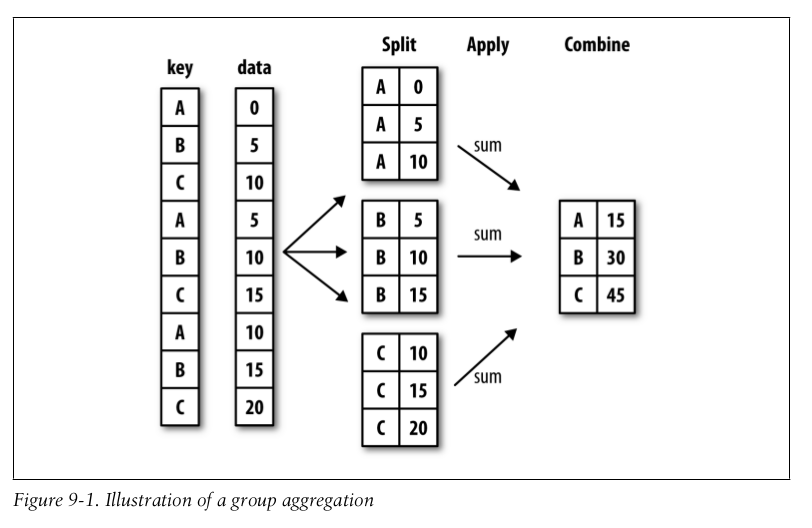 "
]
},
{
"cell_type": "code",
"execution_count": 365,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/html": [
"
"
]
},
{
"cell_type": "code",
"execution_count": 365,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"
\n",
" \n",
" \n",
" | \n",
" data1 | \n",
" data2 | \n",
" key1 | \n",
" key2 | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1.150765 | \n",
" 1.199915 | \n",
" a | \n",
" one | \n",
"
\n",
" \n",
" | 1 | \n",
" -0.997174 | \n",
" -0.451814 | \n",
" a | \n",
" two | \n",
"
\n",
" \n",
" | 2 | \n",
" 0.046486 | \n",
" -0.155385 | \n",
" b | \n",
" one | \n",
"
\n",
" \n",
" | 3 | \n",
" -0.610441 | \n",
" -0.153514 | \n",
" b | \n",
" two | \n",
"
\n",
" \n",
" | 4 | \n",
" -0.394982 | \n",
" 0.011194 | \n",
" a | \n",
" one | \n",
"
\n",
" \n",
"
\n",
"