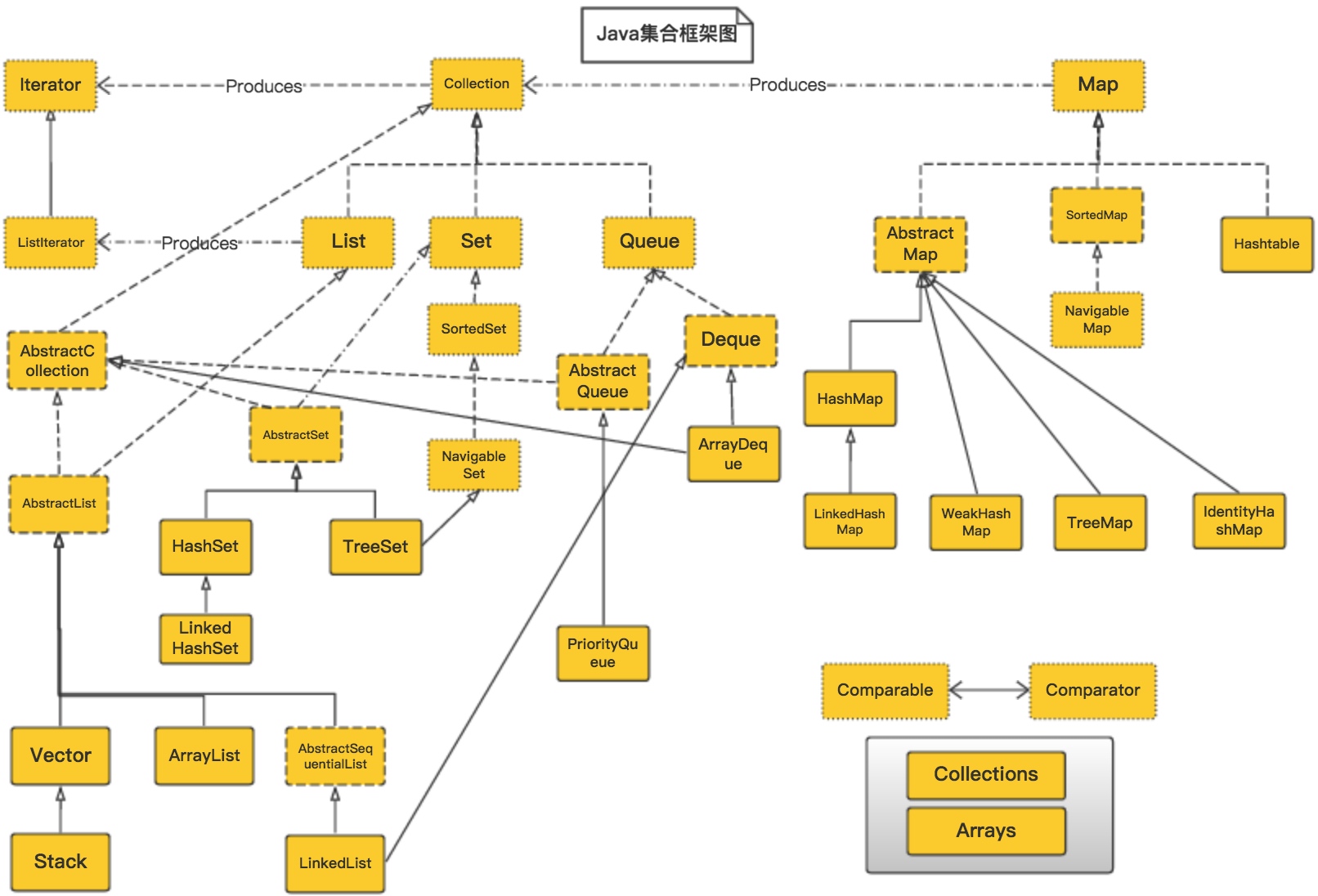
Collection包结构,Collection是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法。实现该接口的类主要有List和Set,其目的在于为各种具体的集合提供最大化的统一的操作方式。
Collection包结构
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
ArrayList和Vector是顺序存储(物理上连续的内存空间)的集合,使用的时候可以根据下标进行访问,索引数据的效率高。但是在删除或者插入时,需要移动容器中的元素,因此插入删除时,效率低。
另外,Vector的大多数方法前都有synchronized关键字,因此是线程安全的,ArrayList则不是。
容量扩充:当ArrayList或Vector中设定的容量不够容纳新的节点时,会自动调用grow()方法进行容量的扩充。ArrayList默认扩充原来大小的1.5倍。Vector默认扩充原来大小的2倍,指定capacityIncrement的话,每次扩充指定的大小。
//ArrayList
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//LinkedList
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
LinkedList采用双向链表实现,无法使用下标访问。每次由下标获取元素的时候,先判断其在前半段还是后半段,在前半段从头结点开始查找,在后半段从尾节点从后往前查找。因此,查找时,效率较ArrayList和Vector低。但是插入或者删除操作,只需要进行节点的删除或者连接操作,因此效率较前二者高。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}