{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"This is an [jupyter](http://jupyter.org) notebook.\n",
"Lectures about Python, useful both for beginners and experts, can be found at http://scipy-lectures.github.io.\n",
"\n",
"Open the notebook by (1) copying this file into a directory, (2) in that directory typing \n",
"jupyter-notebook\n",
"and (3) selecting the notebook."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Blind Source Separation\n",
"## Independent Component Analysis\n",
"\n",
"***\n",
"A notebook by ***Shashwat Shukla*** and ***Dhruv Ilesh Shah***\n",
"***\n",
"___Required Packages:___ Python(2.7+), NumPy, SciPy Toolkit, Matplotlib\n",
"***\n",
"In this tutorial we will learn how to solve the Cocktail Party Problem using Independent Component Analysis(ICA).\n",
"We will first take a look at Principle Component Analysis(PCA). The limitations of PCA will naturally lead to an understanding of what ICA does."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Overview\n",
"## The Cocktail Party Problem(CPP)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So what is the Cocktail Party Problem? \n",
"Imagine you are at a party where a lot of different conversations are happening in different parts of the room. As a listener in the room, you are receiving sound from all of these conversations at the same time. And yet, as humans, we possess the ability to identify different threads of conversation and to focus on any conversation of our choice. How do we do that? And how can we program a computer to do that?\n",
"So this is essentially the Cocktail Party Problem: Given **m** sources(conversations at the party for example), and some number of sound receivers, separate out the different signals. (We will talk about how many receivers we need later.)\n",
"\n",
"We need to make some mathematical assumptions and also phrase the problem more formally.\n",
"\n",
"### The data\n",
"\n",
"So first of all, our signals here are the sounds coming from different sources. \n",
"At every (uniformly spaced) discrete interval of time we record **m** samples, one at each of our **m** microphones.\n",
"\n",
"Note the implicit assumptions that we have made here:\n",
"\n",
"**1)** There are as many microphoneses as there are independent conversations(sources) going on in the room. This assumption allows us to come up with a method to retrieve all the m independent signals. We can say that our system is **critically determined**(and is not under- or over- determined). Henceforth, we shall only consider this case in the tutorial.\n",
"\n",
"**2)** Each microphone records a reasonably distinct combination of the independent signals. This simply amounts to not keeping two microphones too close to each other. Due to practical computational limits (see floating point math), it is always best to have easily distinguishable recordings. \n",
"\n",
"How are we recording this data? We simply record the amplitude of the sound at each instant. Recording the pressure amplitude is a convenient thing to do(and is what a microphone does. A transducer then converts the pressure amplitude to a voltage).\n",
"Note that we are recording the signals at discrete intervals of time (at a rate assumed to be greater than the Shannon Sampling rate)and will be working only in the time domain with these discrete signals.\n",
"\n",
"One very important thing: We assume that the sound that any receiver records is a **linear combination** of sounds from the different sources. This is a reasonable assumption to make as pressure adds linearly. Each receiver will receive a different linear combination: If the first receiver is closer to a particular speaker than the second receiver, then the linear weight of this speaker will be proportionately higher for the first receiver.\n",
"\n",
"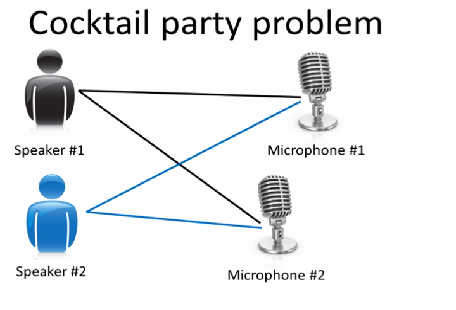\n",
"
\n",
"\n",
"We further assume that each source is **statistically independent** with respect to all the other sources. We will look at a mathematical interpretation of statistical independence of two signals later. Within the context of the Cocktail Party parable an intuitive understanding of this assumption follows naturally, as the conversations happening in different parts of the room are independent of each other. Hence, knowing the signal at a particular instant from one source does not allow us to predict the value of the signal from any other source at that instant. They are independent variables.\n",
"\n",
"This is the key assumption in Blind Source separation that allows to solve the problem.\n",
"\n",
"We are also making one vital assumption about the sources of the signals: that they are non-Gaussian. We will look at what that means and why it matters in the section on Statistical Independence.\n",
"\n",
"### The math\n",
"\n",
"We will index our microphones from **1** to **m**. \n",
"\n",
"The signal received by the microphone labelled **i** over the entire time of recording will be denoted by $X_{i}$. A particular sample of this recorded signal, recorded at the time index **j** will then be denoted by $X_{i}^{j}$. \n",
"\n",
"Hence, if the samples of the signals recorded over time be **N**, then $X_{i}$ can be seen to be a row vector in **N**-dimensional space. It's jth element is given by $X_{i}^{j}$.\n",
"\n",
"We had said that we have **m** microphones. Hence **i** in the above description ranges from **1** to **m**.\n",
"\n",
"If we stack up these row vectors, we will get an **m x N** matrix whose ith row corresponds to the samples recorded by a particular microphone. A 'vertical slice' of this matrix, i.e a column corresponds to all the samples recorded at a given instant of time, indexed by the indices of the corresponding microphone.\n",
"\n",
"Let us call this data matrix **X**.\n",
"\n",
"To reiterate, $X_{i}^{j}$ corresponds to the sound sample recorded by the **i**th mike at the time (indexed by) **j**. \n",
"\n",
"Let us now similarly define matrices corresponding to the sources that we wish to finally recover.\n",
"The indices for the independent sources also go from **1** to **m**.\n",
"\n",
"Let $S_{i}$ denote the signal generated by the **i**th independent source that we wish to recover (the **i**th conversation in the room). It is defined as a row vector.\n",
"\n",
"$S_{i}^{j}$ is then the **j**th time sample of this signal. \n",
"\n",
"Again, we vertically stack up these row vectors to get a **m x N** matrix denoted by **S**.\n",
"\n",
"Now that we have defined our data and the signals that we wish to retrieve, we will describe the (assumed) relationship between the two. Note that we had assumed that the independent sources add **linearly** to give the recorded signals. \n",
"\n",
"This means that each $X_{i}$ is some linear combination of the vectors $S_{1}$ through $S_{m}$.\n",
"\n",
"Putting it all together, we conclude that $X = AS$ ; for some **m x m** matrix **A**, called the mixing matrix.\n",
"\n",
"Our objective is to then find an \"un-mixing\" matrix **W** that satisfies $S = WX$.\n",
"\n",
"If we know this **W**, as we already have **X**, we can calculate **S** by a direct multiplication. \n",
"\n",
"\n",
"
\n",
"\n",
"### Outline of solution\n",
"\n",
"Our objective is to find the matrix **W**. As we have assumed that the number of microphones is equal to the number of independent conversations, it turns out that the matrix **A** is invertible and hence **W** is just the inverse of **A**. \n",
"\n",
"Hence, it suffices to find **A**. We will employ [Singular Value Decomposition(SVD)](https://www.wikiwand.com/en/Singular_value_decomposition) on the matrix **A**.\n",
"\n",
"\n",
"
Courtesy: Wikipedia
\n",
"Hence, $A = UDV^{*}$ for orthogonal matrices **U**, **V\\*** and diagonal matrix **D**. \n",
"\n",
"Note that **V\\*** is the conjugate transpose of **V**. Here the conjugate transpose is equivalent to the transpose because we are only dealing with real signals and their linear combinations.\n",
"\n",
"We will then determine each of **U**, **D**, **V\\*** by considering the covariance matrix of **x** and exploiting the independence of the source signals.\n",
"\n",
"The details follow.\n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"## Covariance\n",
"\n",
"An important term in the concept of statistics is *covariance*, which is a measure of how much two random variables change _together_. Covariance provides a measure of the strength of the correlation between two or more sets of random variates. The covariance for two random variates X and Y, each with sample size N, is defined by the expectation value:\n",
"$$ cov (X,Y)=\\langle(X-\\mu_x)(Y-\\mu_y)\\rangle\\\\=\\langle X \\rangle \\langle Y \\rangle-\\mu_x \\mu_y$$\n",
"where $\\mu_x = \\langle X \\rangle$ and $\\mu_y = \\langle Y \\rangle$ are the respective means. \n",
"For uncorrelated variates, $ \\langle X Y \\rangle = \\langle X\\rangle\\langle Y\\rangle $ and hence,\n",
"$$ cov(X,Y)=\\langle XY\\rangle-\\mu_x \\mu_y=\\langle X\\rangle\\langle Y\\rangle-\\mu_x \\mu_y=0 $$\n",
"However, if the variables are correlated in some way, then their covariance will be nonzero. In fact, if $cov(X,Y)>0$, then Y tends to increase as X increases, and if $cov(X,Y)<0$, then Y tends to decrease as X increases. Note that while statistically independent variables are always uncorrelated, the converse is not necessarily true.\n",
"\n",
"As you can see, covariance can be a good metric to analyse the dependence of two datasets. To read more about covariance, follow [this link.](http://mathworld.wolfram.com/Covariance.html)\n",
"\n",
"As a special case, substituting $ X = Y $ gives $$cov(X,X) = \\langle X^2 \\rangle - \\langle X \\rangle ^2 \\\\ =\\sigma^2_X$$\n",
"where $\\sigma_X$ denotes the _standard deviation_. Thus, $cov(X,Y)$ reduces to the statistical variance for this case.\n",
"\n",
"\n",
"Given a dataset vector $X$ _(nx1 vector)_, the covariance of $X$ is given by $$ C_x= (X-\\mu_x)(X-\\mu_x)^T $$\n",
"This matrix $C_x$ has very interesting properties, which we will be exploiting in the upcoming sections. This [document](http://www.robots.ox.ac.uk/~davidc/pubs/tt2015_dac1.pdf) would be an interesting read.\n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that we have the necessary tools required, let us dive into some algorithms that involve manipulating the information matrix and separating them into components. The first such algorithm is the PCA.\n",
"## Principle Component Analysis\n",
"\n",
"_Principal Component Analysis (PCA)_ is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. The number of principal components is less than or equal to the number of original variables. This transformation is defined in such a way that the first principal component has the **largest possible variance** (that is, accounts for as much of the variability in the data as possible), and each succeeding component in turn has the highest variance possible under the constraint that it is orthogonal to the preceding components.\n",
"\n",
"What does this mean? Let's visualise the problem at hand. \n",
"Let us say you are given a dataset of point in the two-dimensional plane like the plot given below. 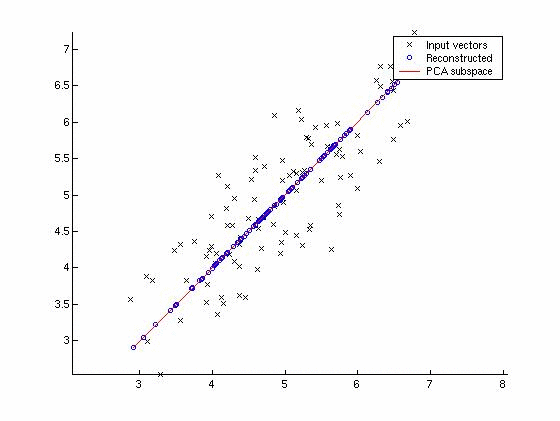\n",
"
Courtesy: Vision Dummy
\n",
"The given dataset is two-dimensional and has a set of points arranged in a roughly elliptical form. What the PCA algorithm does is that it identifies the first principle component of the data, that is, the direction along which the _variance_ of the data is maximum. This is the direction indicated by the red line. The second principle component is the one orthogonal to this, along the approximate minor axis of the dataset. Another such example of PCA on a 2D dataset is shown below. 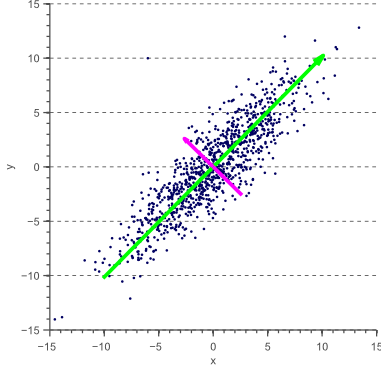\n",
"
Courtesy: [Center for Machine Perception, CTU, Prague](http://cmp.felk.cvut.cz/)
\n",
"Here, the green line shows the vector corresponding to the first principle component, and pink shows the second component. To visualise how PCA can be applied on higher dimensional datasets, check out [this page](http://setosa.io/ev/principal-component-analysis/).\n",
"\n",
"The PCA has various applications, some of which have been listed below.\n",
"* To identify the most important feature(s) of a multivariate function.\n",
"* Reduce dimensionality of data for saving memory, preserving maximum information.\n",
"* Speed up processes (regression, for example) by ignoring the features with low variance.\n",
"* As a pre-processing technique for further statistical methods, increasing efficiency.\n",
"\n",
"Before we go ahead with understanding PCA, it is important to consider the following ** assumptions and limitation ** of PCA:\n",
"1. PCA assumes the dataset to be a linear combination of the variables.\n",
"2. There is no guarantee that the directions of maximum variance will contain good features for discrimination.\n",
"3. PCA assumes that components with larger variance correspond to interesting dynamics and lower ones correspond to noise.\n",
"4. Output vectors of PCA are orthogonal, which means that the principal components are _orthogonal_ to each other.\n",
"5. PCA requires the data to be _mean normalized_ and _univariate_, as it is highly susceptible to unscaled variables.\n",
"6. Since it assumes data to be uncorrelated and accurate, it is _vulnerable to outliers_ and hence may produce incorrect results.\n",
"\n",
"Here, we see that PCA breaks down the dataset into uncorrelated (hence, orthogonal) components. \n",
" ### The Algorithm \n",
"\n",
"Principle component analysis relies on the property that the eigenvectors of the covariance matrix for a dataset $X$ represent a new set of orthogonal components that are the principle components of the dataset. Mathematically, given the covariance matrix $C_x$, the matrix $U = eig(C_x)$ which returns the eigenvectors is the desired matrix. \n",
"Another method to do this is *singular value decomposition* of the covariance matrix. In linear algebra, the singular value decomposition (SVD) is a factorization of a real or complex matrix. It is the generalization of the eigendecomposition of a positive semidefinite normal matrix (for example, a symmetric matrix with positive eigenvalues) to any $m \\times n$ matrix via an extension of polar decomposition. The theory behind SVD is exhaustive and beyond the scope of this tutorial; you can find some interesting stuff [here.](http://web.mit.edu/be.400/www/SVD/Singular_Value_Decomposition.htm) For our use, SVD is called in a programming language like Matlab or Python as $$ [U, S, V] = svd(C_x) $$\n",
"Such that $C_x$ satisfies $ C_x = USV^T $. Note that $U$ here refers to the same matrix of orthogonal eigenvectors.\n",
"\n",
"Thus, $U$ here is an $n\\times n$ matrix with its column vectors as the eigenvectors of $C_x$.\n",
"* If we aim to perform data compression, define a matrix $U_{reduced} = U[:,1:k]$ which stores the first $k$ principle components. Thus, the required dataset with reduced dimensionality $k$ can be given by $X_{new} = U_{reduced}^TX$.\n",
"* If we do not want to compress data but simply express it in terms of principle/orthogonal components, we have $X_{new} = U^TX$\n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"## PCA vs ICA\n",
"\n",
"Now that we have seen what PCA is, let us see how it can be applied in our case - if at all. \n",
"We have seen that the basis on which PCA separates out the components is *orthogonality* and *variance*. Drawing parallels to the Cocktail Party Problem, there seems to be an issue. Orthogonality sure is a measure of independence of two datasets (vectors), but it is not the only measure and as it turns out, it is not applicable in the case of CPP. Two different sound signals need not be orthogonal, even if they are independent and this can be seen by simply generating a counter example. _(Here, orthogonal refers to **zero** inner product.)_ The very fact that independent signals needn't be orthogonal eliminate the possibility of using PCA. Further, PCA identifies the separated components on the basis of _variance_, which according to Information Theory is a very shallow metric for decorrelating components. Statistical independence of the third or fourth order is generally preferred as a metric - what this means is that we must study deeper features and analyse correlations, but let's leave that for now. \n",
"Given below is the simplest way to illustrate how PCA fails due to the orthogonality condition on principle components. \n",
"
Courtesy: University of Colorado Lectures
\n",
"Despite the two branches being independent, PCA would not identify them so because it doesn't separate out _independent_ components, but _principle_ ones based on orthogonality and variance measures. ICA, as the name suggests, looks for _independent_ components and not any dependent variable - hence avoiding side-effects! How it does this is by using a metric for ***statistical independence***, described later, and then picking a model that minimizes this dependence. Before we can get to that, let's look at the pre-processing to be done on the data to ensure optimal results in ICA. \n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Preprocessing for ICA\n",
"\n",
"First, let us consider the basic statement of ICA. $$ x = As \\\\ s = Wx $$ Where $s$ refers to the source signals, $A$, the _mixing matrix_ and $x$, the signal we receive at microphones(say) and $W = A^{-1}$ \n",
"Given below are the pre-processing stages performed:\n",
"* **Centering**: The most basic and necessary preprocessing is to center ${\\bf x}$, i.e. subtract its mean vector ${\\bf m = E\\{x\\}}$ so as to make ${\\bf x}$ a zero-mean variable. This also implies that ${\\bf s}$ is a zero-mean variable, as can be seen by taking expectation on both sides, above. This preprocessing is made solely to simplify the ICA algorithms: It does not mean that the mean could not be estimated. After estimating the mixing matrix ${\\bf A}$ with centered data, we can complete the estimation by adding the mean vector of ${\\bf s}$ back to the centered estimates of ${\\bf s}$. The mean vector of ${\\bf s}$ is given by ${\\bf A}^{-1}\n",
"{\\bf m}$, where ${\\bf m}$ is the mean that was subtracted in the preprocessing.\n",
"\n",
"\n",
"* **Whitening**: Another useful preprocessing strategy in ICA is to first whiten the observed variables. This means that before the application of the ICA algorithm (and after centering), we transform the observed vector ${\\bf x}$linearly so that we obtain a new vector $\\tilde{{\\bf x}}$ which is white, i.e. its components are uncorrelated and their variances equal unity. In other words, the covariance matrix of $\\tilde{{\\bf x}}$ equals the identity matrix. A _whitening transformation_ is a linear transformation that transforms a vector of random variables with a known covariance matrix into a set of new variables whose __covariance is the identity matrix__ meaning that they are uncorrelated and all have _variance unity_. $$ C_{\\tilde{x}} = \\tilde{x}\\tilde{x}^T = I $$ The math behind whitening involves a greater understanding of eigenvectors and matrices, which we shall ignore for the purpose of this tutorial. Let us fast-forward to how whitening can be done on a given dataset. The whitening transformation is always possible. One popular method for whitening is to use the [eigen-value decomposition (EVD)](http://mathworld.wolfram.com/EigenDecomposition.html) of the covariance matrix $C_{\\tilde{x}} ={\\bf E}{\\bf D}{\\bf E}^T$, where ${\\bf E}$ is the orthogonal matrix of eigenvectors of $ C_{\\tilde{x}} $ and ${\\bf D}$ is the diagonal matrix of its eigenvalues, ${\\bf D}= \\mbox{diag}(d_1,...,d_n)$. Note that $E\\{{\\bf x}{\\bf x}^T\\}$can be estimated in a standard way from the available sample $x(1),...,x(T)$. Whitening can now be done by $$ \\tilde{x} = ED^{-1/2}E^Tx$$\n",
"where the matrix ${\\bf D}^{-1/2}$is computed by a simple component-wise operation as ${\\bf D}^{-1/2}=\\mbox{diag}(d_1^{-1/2},...,d_n^{-1/2})$. It is easy to check that now $C_{\\tilde{x}}={\\bf I}$.\n",
"\n",
"It is important to note that the whitening transformation changes the matrix $A$ corresponding to the $x$, and hence $$ \\tilde{x} = ED^{-1/2}E^TAs = \\tilde{A}s$$\n",
"The utility of whitening resides in the fact that the new mixing matrix $\\tilde{{\\bf A}}$ is orthogonal. How this affects the data is a little complicated to explain, but I will attempt to illlustrate it below. \n",
"Consider a two-dimensional dataset as given below, with _uncorrelated/independent_ variables, along the sides of the parallelogram. 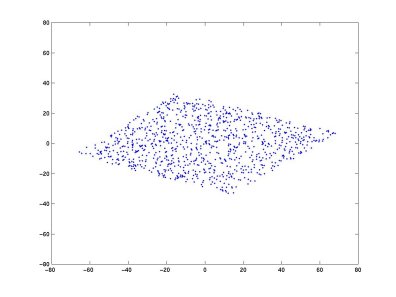\n",
"
[Swartz Center for Computational Neuroscience](http://sccn.ucsd.edu)
\n",
"Evidently, this data has the two independent vectors as the sides of the parallelogram, but when passed into the algorithm, since the vectors are not orthogonal, they might end up showing unnatural dependencies which may not really exist. Hence, we perform whitening of the data to give something that looks like this: 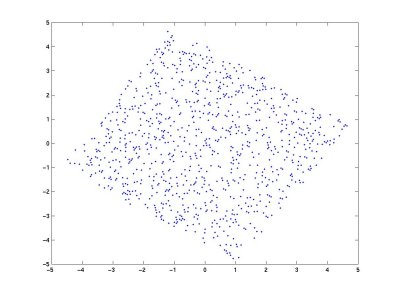\n",
"
Courtesy: [Swartz Center for Computational Neuroscience](http://sccn.ucsd.edu)
\n",
"Note that we haven't lost any __information__ in the above transformation, nor have we created or destroyed any existing correlations. But this new dataset ($\\tilde{x}$) is bound to perform better on ICA algorithms. In the rest of this tutorial, we assume that the data has been preprocessed by centering and whitening. For simplicity of notation, we denote the preprocessed data just by ${\\bf x}$, and the transformed mixing matrix by ${\\bf A}$, omitting the tildes.\n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Statistical Independence\n",
"\n",
"This section gives a brief description of statistical independence and it's interpretation in the context of this problem. \n",
"Recall how we looked at an intuitive explanation. We said that voices are independent because listening to one won't allow us to predict the other. \n",
"\n",
"To exploit this property mathematically, we construct the **probability density functions(pdf)** for each of the signals that our **m** microphones have recorded. \n",
"\n",
"Why would we ever think of doing that? Well, for a number of pragmatic reasons. Statistical methods that work with density functions are very well developed and extremely powerful. \n",
"\n",
"It also makes the math simpler. How you ask? \n",
"\n",
"Well, notice that if we are representing a signal by it's probability density function *alone*, we are saying that at any given time, the value of **the signal is simply a draw of a random variable with this particular pdf.** (What this means is that we are basically discarding/not keeping track of the local correlation of the signal's contiguous values.)\n",
"\n",
"In the context of the Cocktail Party Problem, we use pdfs to quantify statistical independence. There are many ways of quantifying the independence of two random variables if their pdfs are known. This is why we are working with probability density functions. \n",
"\n",
"Here comes an extremely important point: While solving the Cocktail party problem, we assume that all the source signals that we wish to recover are non-Gaussian.\n",
"\n",
"First of all, what do we mean by that? We mean that the pdf of each source signal is not a Gaussian function/distribution.\n",
"\n",
"This might seem like an arbitrary and questionable assumption at first. \n",
"\n",
"We invoke Information theory to justify our assumption. Simply put, there is a result in Information theory that says that the **Gaussian distribution has the greatest possible entropy (for a fixed variance of the distribution).** Entropy in our context is just disorder. The source signals do have order, as they contain lots of information. If they were purely Gaussian, then the signals would just sound like (Gaussian) noise. \n",
"\n",
"We are not going to prove this result here. The mathematics is very involved and doesn't really shed any light on the present problem. However, an intuitive understanding of why this result *should be right* can be acquired by considering the famous Galton box(bean machine).\n",
"\n",
"\n",
"\n",
"
\n",
"This is the epitome of a random process(that contains no information) and the fact that it has a Gaussian distribution is confirmation(if not justification) of the fact that the Guassian distribution has the greatest entropy. \n",
"\n",
"\n",
"Hence we assume that the original source signals have non-Gaussian distributions.\n",
"\n",
"This revelation about the nature of the pdfs of the source signals actually allows us to solve the entire problem! We reiterate that each of the recorded signals is a linear sum of the original source signals. We now invoke the **Central Limit Theorem**.\n",
"\n",
"The central limit theorem says that the pdf (of the average) of the sum of independent random variables, tends to a Gaussian distribution, as the number of random variables tend to infinity. Why is this important here? Well, we have assumed that the source signals are non-Gaussian independent variables and that the recorded signals are linear weighted sums of these non-Gaussian variables. By the Central Limit Theorem, the sum of non-Gaussian variables is more Gaussian than the individual variables. Hence, the recorded signals are more Gaussian than the source signals! \n",
"\n",
"We finally have a way to recover our original signals. Remember that we are trying to *linearly transform* the recorded signals back to the source signals. Thus, now we have to just find the linear transformation that minimises the \"Gaussian nature\" of the transformed signals. The signals that have the least \"Gaussian nature\" simply correspond to our source signals.\n",
"\n",
"Notice that I have put \"Guassian nature\" in quotes. This is because we have not yet quantified deviations from a Gaussian distribution. Indeed, this is precisely where FOBI and fastICA (and other ICA implementations) differ from one another. The steps that we have outlined in the previous sections apply to both. But the subsequent sections elucidate two different approaches to quantifying deviations from a Gaussian distribution and the details of the solutions to the Cocktail Party Problem formulated based on them.\n",
"***"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"## fastICA\n",
"\n",
"The first method that we will be discussing is known as the fastICA which uses two important algorithms used widely in numerical analysis - _gradient descent_ and _fixed-point iteration_. An understanding of both these is very important and hence we shall be discussing these before we encounter the actual algorithm. As a brief, we must estimate the matrix $W$ such that the source matrix $s = Wx$ has minimum _'statistical dependence'_. To quantify the stastical dependence/independence, we use the concept of a _cost function_. We must choose the matrix $W$ which minimises the cost function, and hence maximises statistical independence. Fasten your seat belts, as we dive into the world of _Machine Learning_ and tackle the topics one at a time, eventually solving the Cocktail Party Problem. \n",
"\n",
"### Gradient Descent\n",
"Let's assume we are given a function $f(x, y)$ , like the one given below, and an operation - say, to find the minima (or maxima) of the function over a domain.\n",
"\n",
"\n",
"
\n",
"\n",
"With a small amount of data, known function $f$ and just two variables $(x,y)$ itself, the problem can become difficult to solve algebraically. Simply computing minimas of a complex function comprising of exponential and trigonometric terms can become highly complex and computationally expensive; also, the solution is dependent on the type of function we wish to optimise, and here comes the need of a more generalised algorithm. \n",
"\n",
"\n",
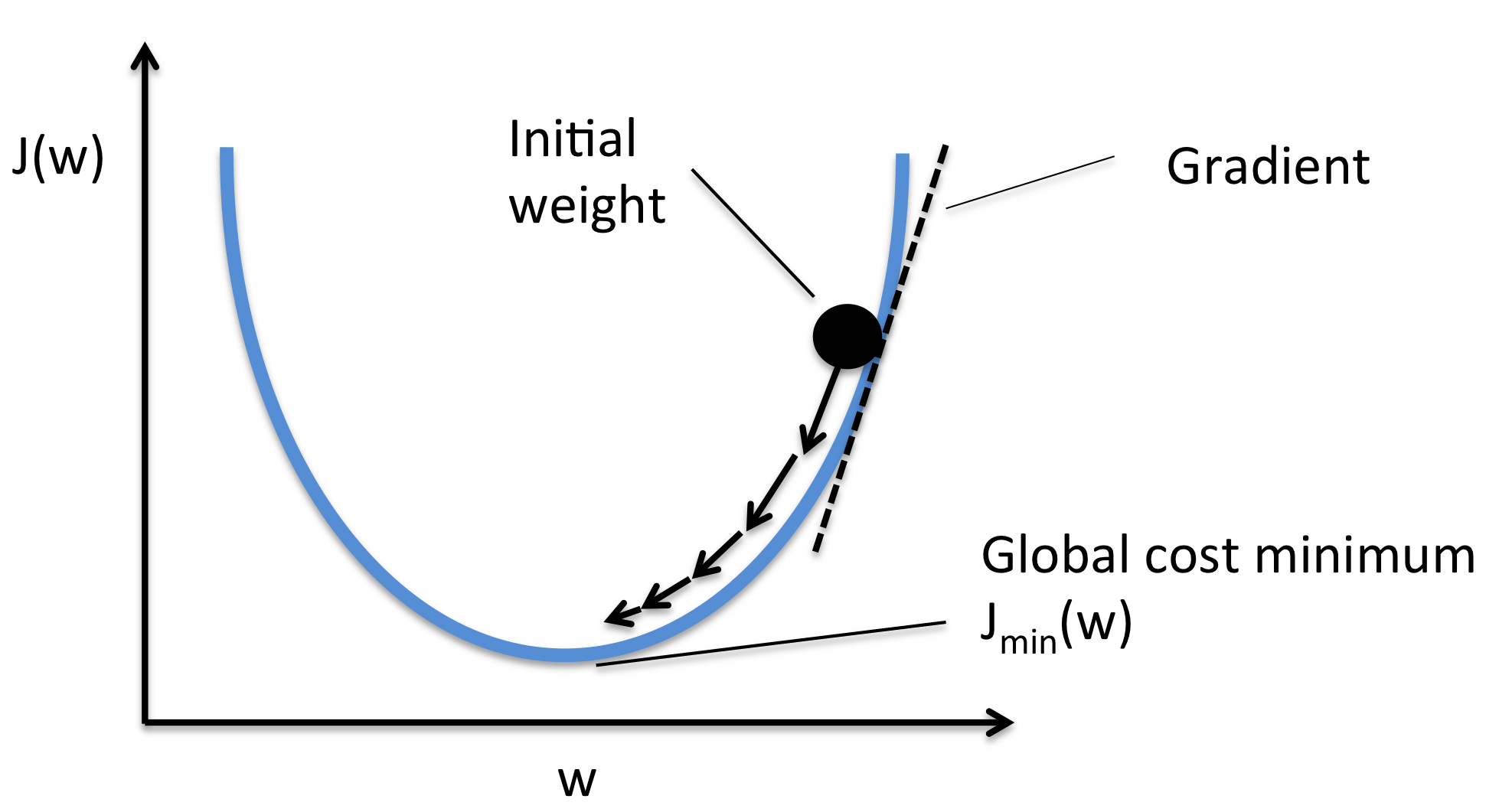
"Come in, _gradient descent_! Let us now try to intuitively form an algorithm to solve such optimisation problems without any dependence of the function $f$, albeit some necessary conditions. Given that the function is continuously differentiable, we can claim that a minima is the point where the function is decreasin, no matter which direction you come from (similarly, maxima is where function is increasing no matter which direction you come from). In the given illustration , given a point $p_i$ or $(x,y)$ in the two-dimensional plane, and its gradient $\\nabla f(p_i)$, if we could somehow follow the slope of the function, we could slide down all the way to a minima (or climb up to a maxima) and the value of function $f$ at that point would be the required optimised value.\n",
"\n",
"A simple way to look at this is to imagine a hill, or a complex terrain just like the illustration. Say, you are sitting at a point on the terrain and wish to reach the bottommost/topmost point in your _neighbourhood_. For the minima of potential energy, for example, you could simply let gravity do the talking and slide down, in whichever direction it takes you, until you reach _one of the_ minimas in your neighbourhood. What you just actuated, is known as gradient descent!\n",
"\n",
"\n",
"\n",
"
\n",
"In practice, it involves moving a small distance in the direction of gradient (inreasing or decreasing, based on the optimisation objective), until convergence. Note that we cannot be certain of landing at the actual minima, but we end up converging in the neighbourhood. The distance is controlled by a parameter $\\alpha$, known as the step-size. Optimising this $\\alpha$ is important because a large $\\alpha$ can cause overshooting and failure in convergence, and a small $\\alpha$ can slow down the process and make it computationally expensive. This can be tackled in two ways.\n",
"* Running the algorithm multiple times and choosing an $\\alpha$ that gives good results (a value of 0.3 to 2 should do fine). In fact, a good implementation of learning would be to provide the program with a range of $\\alpha$s, say [0.01:10] on a logarithmic scale and making the system _learn_ the best parameter. _(This would require some background in Supervised ML and hence we leave this for you to explore!)_\n",
"* Another smart way to do this efficiently would be to make $\\alpha$ dependent on the error of convergence (values of $f$ between two iteration), ideally the difference. This way, $\\alpha$ automatically decreases as we get closer to the optimisation point. This _adaptive_ model is generally a better way to implement gradient descent as it guarantees fast convergence in a simplistic way.\n",
"\n",
"An important feature of gradient descent is that we can extend the algorithm to any n-dimesional space. We use 2-D to visualise it because visualising higher dimesional spaces can be complicated, almost impossible. But on extending the feature vector $X(x_1, ..., x_n)$ and a scalar function $f(X^i)$, this algorithm works just as well. **It must be noted that of the various drawbacks gradient descent may have, the most important one is perhaps the fact that it converges to _an_ optima, that is, a _local optima_ and not necessarily the global optima.** This can become a major issue with complicated functions, which may have multiple possible local optima. It is also possible that the algorithm converges to different optimas on different runs, depending on the starting point.\n",
"\n",
"\n",
"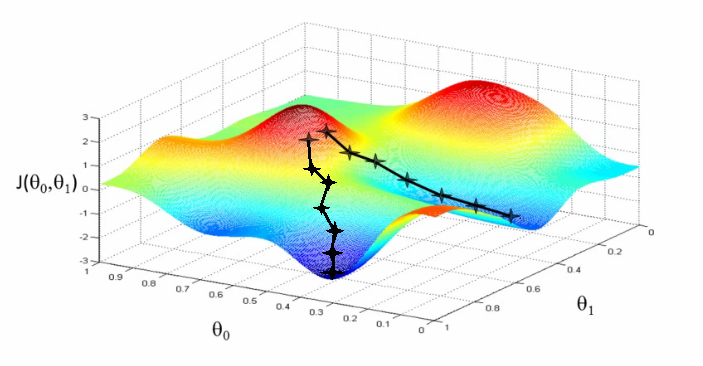\n",
"
Courtesy: www.holehouse.org
\n",
"\n",
"In advanced machine learning, we use more complex optimisation tools in scientific packages like SciPy, MATLAB etc. (_fminuc, fmincg etc._) We can ignore such complexities and assume that a run of gradient descent gives us the desired optima because of our choice of _cost function_ (Coming Soon!).\n",
"\n",
"_That is all you need to know about gradient descent for this tutorial! Feel free to explore this topic further if you are interested. Gradient Descent has a wide range of applications in numerical analysis, the most exciting of which is in Machine Learning and Artificial Neural Networks!._\n",
"\n",
"### Fixed-Point Iteration\n",
"\n",
"Next up, we talk about another famous numerical solving technique known as the fixed-point iteration method. Given an expression $f(x)=0$, where $x$ can be a scalar or a vector, it is not always possible to solve it by standard methods. Consider the following equation. $$ e^{x^2} - tan(x) + x = 0 $$\n",
"It is not possible to solve such an equation directly, and thus we must use a method that can allow us to find a numeric solution. In general, the given function $f(x)$ can be anything and it would be nice if the method is independent of $f$. Consider the example of gradient descent above. We talked about what we would have to do, but how really would you take _steps_ and _move_ along the gradient? This is where the need of a solving method comes in. For now, let us consider solving an equation rather than an optimisation problem. \n",
"\n",
"The FPI aims at solving the problem, as the name suggests, _iteratively_. The first step is to convert an equation of the form ${\\bf f(x)=0}$ to the form ${\\bf x = g(x)}$ so that we can update the parameter ${\\bf x}$ directly. Let's tackle this with the help of an example. Let's say we want to find the roots of an equation $ x^4 - x - 10 = 0 $. We must first convert this into the form $x = g(x)$ to apply FPI. Some possible cases are $g_1(x)=x^4-10, g_2(x)=(x+10)^{1/4}, $$g_3(x)=(x+10)^{1/2}/x $ etc. It is intuitively evident that since we want convergence and run an iteration, the function $g_i(x)$ better be a converging function, and hence$g_1(x)$ is not a good function to use.\n",
"\n",
"The algorithm next involves iterating upto convergence, the following expression: $$ x_{n+1}=g(x_n) $$ given the function $g(x)$. We run this iteration untill the sequence converges, i.e., $x_{n+1} - x_n < \\epsilon$, where $\\epsilon$ or tolerance is a small number.\n",
"\n",
"An important parameter that we must consider is the extent of convergence, or tolerance $\\epsilon$. It defines how close two consecutive values of $f$ must be, before we assume that convergence has occured. Choosing a value between $10^{-4}$ to $10^{-2}$ should work fine. Very small $\\epsilon$ may take too long to converge, or not converge at all, and a large $\\epsilon$ may give unsatisfactory results.\n",
"\n",
"Let us look at a simple example with the function defined above, and $g(x) = (x+10)^{1/4}$. We make an initial guess of $x_0 = 1.0$\n",
"$$ x_1 = (x_0+10)^{1/4} = 1.82116 \\\\ x_2 = (x_2+10)^{1/4} = 1.85424 \\\\ x_2 = (x_1+10)^{1/4} = 1.85558 \\\\\n",
"x_3 = (x_2+10)^{1/4} = {\\bf 1.85558} $$\n",
"\n",
"Similarly, starting with $x_0 = 4.0$, we get:\n",
"$$ x_1 = (x_0+10)^{1/4} = 1.93434 \\\\ x_2 = (x_2+10)^{1/4} = 1.85866 \\\\ x_2 = (x_1+10)^{1/4} = 1.8557 \\\\\n",
"x_3 = (x_2+10)^{1/4} = 1.85559 \\\\ x_4 = (x_3+10)^{1/4} = {\\bf 1.85558} $$ defined as the normalized form of the fourth central moment of a distribution2\n",
"\n",
"This way, we can solve an equation, indirectly, without worrying about the nature of the roots and the function itself. This is method in some very famous numerical methods like the [Newton-Raphson's Method](http://www.sosmath.com/calculus/diff/der07/der07.html). Note that this method again finds _one of the roots_ and can find different roots depending on seeding point.\n",
"\n",
"\n",
"\n",
"### The Cost Function\n",
"\n",
"We've talked all about optimising the function and solving for its optimal value and roots etc. _But hey!_ In the problem that we were discussing where is this ___function___? In this section we'll see how we can choose a function, whose optimisation gives us the desired result - separated sources.\n",
"\n",
"In any optimisation problem of this sort, we talk about a term called the __cost__, which (in the case of a minimisation) is analogous to the price you are paying by deviating from ideal results. A similar analogy can be thought of for maximisation. Hence, we must quantify the property _statistical dependence_ and minimise it for the sources to be best separated. _Note that the ideal case of perfect separation can generally not be attained due to various limitations_. So, how do we quantify this dependence, or _Gaussianity_, as discussed in the last topic?\n",
"* __Kurtosis__ is defined as the normalized form of the fourth central moment of a distribution. $$ kurt(x)=E(x^4) - 3(E(x^2))^2 $$ If we assume $x$ to have zero mean $\\mu_x=E\\{x\\}=0$ and unit variance $\\sigma^2_x=E\\{x^2\\}-\\mu_x^2=1$, then $E\\{x^2\\}=1$ and $kurt(x)=E\\{x^4\\}-3$. Kurtosis measures the degree of peakedness (spikiness) of a distribution and it is zero only for Gaussian distribution. Any other distribution's kurtosis is either positive if it is supergaussian (spikier than Gaussian) or negative if it is subgaussian (flatter than Gaussian). Therefore the absolute value of the kurtosis or kurtosis squared can be used to measure the non-Gaussianity of a distribution. However, kurtosis is very sensitive to outliers, and it is not a robust measurement of non-Gaussianity. \n",
"
\n",
"Hence, maximising this _kurtosis_ function can be our optimisation objective!\n",
"\n",
"* __Differential Entropy _(Negentropy)___: Entropy is a very complex concept, which we wish to skip here, but as a fact, an important result in Information Theory states that the Gaussian Distribution the maximum entropy among all distributions over the entire real axis $(-\\infty,\\infty)$. Thus, it can be used as a measure of _Gaussianity_. For more information on this, you can refer to [this site](http://fourier.eng.hmc.edu/e161/lectures/ica/node4.html).\n",
"\n",
"### fastICA Algorithm\n",
"\n",
"Pheww! That was long! Now let's finally take a look at the fastICA algorithm in a brief manner.\n",
"\n",
"1. Obtain the data matrix $x$.\n",
"\n",
"2. Subtract off the mean to center $x$.\n",
"\n",
"3. Whiten the matrix $x$ to obtain the matrix $x^T$.\n",
"1. Choose a random guess for the initial value of the de-mixing matrix ${\\bf w}$.\n",
"2. Iterate the following: $$ w \\gets E(xg(w^Tx)) - E(g'(w^Tx))w $$ You will realise that this step is in fact the implementation of gradient descent using fixed-point iteration, as discussed above! The function $g$ is a function used to capture higher order features of the matrix $w^Tx$ and is similar to capturing the negentropy.\n",
"3. Normalize ${\\bf w}$ $$ w \\gets w/{\\|w\\|} $$\n",
"4. If not converged, go back to 2.\n",
"\n",
"Convergence can be judged by the fact that an ideal $w$ would be orthogonal, and hence $w_i^Tw_{i+1}$ would $\\approx 1$. We thus use this condition to examine convergence.\n",
"\n",
"The gradient descent step uses a function $g$ which can be a function like $cosh(x)$ or $tanh(x)$ which capture higher order correlations and hence we finally aim to maximise the function $\\Sigma E(g(y_i))$ where $y_i = {\\bf w_i^Tx}$ is a component of ${\\bf y = Wx}$."
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Sampling rate= 8000\n",
"Data type is uint8\n",
"Number of samples: 50000\n"
]
},
{
"data": {
"text/plain": [
""
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXd4lFXe/j9nSjqENAgEgnQEBBEbooKuBVyxgOvSLOtK\nFEF9Lfsq6k9hd11dCyiWAK6iguDrKoi6LsWCgBWVIiwlSCiB9N6TmTm/P77nySQhIItIAM99XbmS\nzDzlnGeS+z7fepTWGgsLCwsLi/8WruYegIWFhYXF8QkrIBYWFhYWhwUrIBYWFhYWhwUrIBYWFhYW\nhwUrIBYWFhYWhwUrIBYWFhYWhwUrIBYWgFJqslJq9pE+9hCuFVBKdT7EYx9RSs09Eve1sDgS8DT3\nACwsjjSUUjcCdwNdgGLgXWCy1rr4QOdorR871Ov/N8ceyuV+ieOVUnOAPVrrh//7IVlYHBqsBWJx\nQkEpdQ/wGHAP0BI4G+gILFdKNblgUkq5j94I9799M97bwuJnwQqIxQkDpVQLYAowSWu9XGvt11rv\nBq4FTgLGmeMeUUr9Uyk1VylVBNzQ2D2klLpeKbVTKZWrlHpIKZWulLqw3vlzzc8djRvqeqXULqVU\njlLqgXrXOUMp9YVSqlAptVcp9dyBhKyJ+ZyklFqhlCpWSi0F4hu9/5ZSKtNce4VS6mTz+nhgLPC/\nSqkSpdRi8/p9Sqnt5rWNSqmrDutBW1gYWAGxOJFwDhAKLKr/ota6HPgQuLjey1cAb2mtWwHznUMB\nlFK9gBeA0UBbIBpo1+hejV1Jg4BuwEXAw0qpHuZ1P/A/QCwwELgQuO0Q5zMfWIMIx1+BGxq9/yHi\npmsNfO/MQ2v9EvAG8ITWuqXW+kpz/HZgkNa6JTAVmKeUanOIY7Gw2A9WQCxOJMQDeVrrQBPvZdJw\nBf+l1vp9AK11VaNjRwLvaa2/1Fr7gJ+KI2hgita6Rmu9AVgP9DPX/l5r/Y0W7AZmA4N/aiJKqQ7A\n6cDDWutarfUq4P0GN9X6Va11hda6Fvgz0M9YYU0PUut3tNbZ5ud/AmnAmT81FguLA8EKiMWJhDwg\nXinV1N91W/O+gz0HuU67+u9rrSuB/J+4d3a9nyuAKAClVDel1PvG1VQEPEojV9RBxlBo7u1gl/OD\nUsqllHrcuKSKgHREyA54beNmW2tcXoVA70Mci4VFk7ACYnEi4UugGhhR/0WlVBQwDPio3ssHy2bK\nBNrXOz8ciDvMMaUCm4Euxl32IIcWOM8EYsy9HSTX+3ksMBy40Fz3JHNd59oN5qeUSkasn9u01jFa\n6xhg0yGOxcKiSVgBsThhoLUuQVw5zymlLlVKeZRSJwH/B+wG5h3ipd4GhiulzlZKeZHA/MFwMBJu\nAZRorSuUUj2BCYcyAOPu+haYqpTyKqXORQTDQRQiloVKqUgk86y+aGQD9etLIoEAkGeslz8AfQ5l\nLBYWB4IVEIsTClrrJ4EHgKeQGpAvEdfPRSZWcCjX+A9wOyI8+4ASIAch7CZPOcjv9wJjlVIlwCzg\nzZ84tz7GIGnI+cD/A16r997riCjuBTYCXzQ692Wgt1KqQCm1UGu9GZgGfAVkIe6r1Qe5t4XFT0I1\n94ZSSqmhwDOImL2stf57E8cMAaYDXiBXa33BUR2kxa8aZoVfBHTVWu/6qeMtLH4taFYBMcHObcBv\nkJXeGmCU1npLvWOikdXVJVrrvUqpeK11XpMXtLA4QlBKXQ58jCxsngbO0FoPaN5RWVgcW2huF9aZ\nQJrWepdxL7wJXNnomDHAO1rrvQBWPCyOEq5EFjUZSK3FqOYdjoXFsYfmFpAkGqZTZpjX6qM7EKuU\n+lQptUYpdd1RG53FrxZa6/FOtpLW+mKtdVpzj8nC4ljD8dBM0QOchlTwRgJfKqW+1Fpvb95hWVhY\nWPy60dwCspeGue3tzWv1kYFUF1cBVUqplUiV734CopRq3owACwsLi+MQWuvDqgdqbhfWGqCraUgX\ngviZ32t0zGLgXKWUWykVAZyFFGY1Ca31Cfn1yCOPNPsY7Pzs/Oz8Tryvn4NmtUC01n6l1CRgGcE0\n3s1KqVvkbT1ba73FdCLdgDSmm60lT9/CwsLCohnR3C4stNZLgB6NXpvV6PenkMIwCwsLC4tjBM3t\nwrI4RAwZMqS5h/CLws7v+Iad368TzV6JfiShlNIn0nwsLCwsfmkopdDHaRDdwsLCwuI4hRUQCwsL\nC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vD\nghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQ\nCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQCwsLC4vDghUQC4tfCbTW3H//E2it\nm3soFicIrIBYWPxK8M47S3nxxUwWLlzW3EOxOEFgBcTC4gTHrFnz6N37ch54YBWlpdOYPHklvXtf\nzqxZ85p7aBbHOTzNPQALC4tfFikpY4mNjeOee1YCiqqqAH/72yRGjry0uYdmcZzDWiAWFic4lFIo\npSgqqqJXr7spKqqse83C4ufAWiAWFr8CpKXtYc6coYwYcQkLFy4jLW1Pcw/J4gSAOpEyMpRS+kSa\nj4WFhcUvDaUUWuvDMkeb3YWllBqqlNqilNqmlLrvIMedoZSqVUqNOJrjs7CwsLBoGs0qIEopF/A8\ncCnQGxitlOp5gOMeB5Ye3RFaWFhYWBwIzW2BnAmkaa13aa1rgTeBK5s47nbgbSDnaA7OwsLCwuLA\naG4BSQLqR/MyzGt1UEq1A67SWqcCNm3EwuIYgq1u/3WjuQXkUPAMUD82YkXE4leLY42wD1bdfqyN\n1eLIo7nTePcCyfV+b29eq4/TgTeVJK3HA8OUUrVa6/eauuCUKVPqfh4yZAhDhgw5kuO1sGhWOIR9\nxhnLmrUQcNasuTz44AvExl5oqtsf4uGHn+OOO0Zxyy3jjqmxWjTEihUrWLFixRG5VrOm8Sql3MBW\n4DdAJvANMFprvfkAx88B3tdaLzzA+zaN1+KExKxZ85gx401qa/uRlvZXunV7CK93fQPCPpr45z//\nzfXXzyEysh35+c/QocNkpk0bzMiRlzJ79hsHGOvvSU/P5LHH/mSLGI8hHLdpvFprPzAJWAZsAt7U\nWm9WSt2ilEpp6pSjOkALi2aG4wYaP34MU6ZMpKoqgNOOZOrUSaSkjD2q43H6aj344Cqqqv5AQUE1\nISHXkJNTUlfdnpIyttFY/XTr1p6YmDjbzPEEQ7PHQLTWS7TWPbTW3bTWj5vXZmmtZzdx7E0Hsj4s\nLI51HE5MwHEDLVq0vFnbkTQWsqysIiCD0NBc5s37I/PmDa+rbm/cOiUrq4jFi7O58843bTPHEwzN\nHQOxsPjVoH5MYMSIS7j//idQCh577H/3E4KGMYanGT9+OC5XAZ07x/D99x+waNHyn2xHorVm8uQn\nj4jLyBn7559fw5dfbsHvPx/4D1VVcYwadQ89erRj06bldcenpe1h9OhwVq1aT1xcHFlZl5GXtwYY\nTl5eCLNn22aOJwKa3QKxsDjR0VQ79eTkC5g27V/MmJHBwoXL9rNOYmPjKS9PpqCgAlhGUVEyAwee\nwo4d3Vm0aDkjR17K/fff3OA+ja9xJPb/aDz2zMweeL1eIBuYhlK5tGoVSUZGnwb3mTx5PDNnPsrU\nqZPwepOA8fj9Ltq3j6S2toNt5niCwPbCsrD4haG15u23l3DPPSvZs+cxXK4/AN8TCFwG/I2QkBuJ\niNhERcVZnHxyOjU1Cp/vVNLSfMBHQC/gddzuFPz+TBISwkhIqNovgP7220u46aaljB4dzurVG45I\nwL3x2Dt0mEy/fvl88IEbt3szfn8p0Ad4tcn7OGMKDy+itDSS11+/HKUUaWl79hNAi+bBcRtEt7A4\nEfBTsQ1npZ2dXczJJ99FaGgEERHtzLtv4PNtIizsXGpqLmfDho5kZ+eRl7cZ6EJUVGvi4uIARSDg\nAiYRGtqVKVMmkp6+F631flbCp59CSUmZucahB9ydeQQCgbr5GHJh796l9Oz5PxQVVbJnTy4XXVRO\n167hhIdHAKGAIj09m0GDTmlwH6cLcFbWK8ydO5zt2zOatJ4sjk9YAbE45nGsFqQ543r77SU/6Sp6\n991PcLnymTLlYqKjv6WyshKXqwj4FxBKTs5qYDVav0ggcBpFRbtJTPwAn68lFRV+kpJS0FrRvv2r\nFBdX8fXX63jxxSwWLlzWRNaT5tprL6W2Nvm/Crg7Lq///d+/N5jPjBmvEwicyW9/24Y5c4YxatRv\nWbbsNf7ylzuIiOgIROLxjMXrDeOSSwY3uM/kyeMZOfJSlFJWOE5AWAGxOOZxrO7lfeutk3nyybe4\n886lB8wucqyDNWtCqKp6k5SUV8nK6ktcXAVvvnkFV10Vzdlnd8Dl6ojHkw8oamo0d989kr1732XE\niGSuvjqM2247nXvvPYnTT48mOnodr72WUXfPPn2Gs3z5ygYZWllZ+bz66jA2bnyaOXOGHTTg7oxx\n4sR/UVo6jRkzdlJamsbYsQ+j1Ml8+WU4kMqMGTsZM+ZP/PDDujpBKi0toX37TMLC4pk4sT3bt2cc\n9vM8VhcKFgeGjYFYHLM41ornGo+rpqYv27efi8fzPj5fKjExdzB79mV1K24IxhBuuOEFKitBminM\nwe3+I0p9g9/fnlGjetOuXTyzZ2cTHV1BTo6H+fOv3C9LySHYAQNO4d57V9XFJKZNG0xa2m66dUtm\nzZr1nHFGP7Zvzzjk1X4wzvEZe/Y8jlK3oPVVREY+y+DB7VmyxEsgkIrbPYE77+yAx+Pi8cfv4/HH\n/0H37skNNqn6ORaGEy+ZM2eozdA6irAxEIsTEvu7ZpqneO5A46qu1oALvx+SklLw+RRvvPHufsfP\nn78Yvx9crp1ACKDw+wP4fMlo/SErVvh57bX36dx5G7t2zWT+/CubtBjeeWcpqalZfPPN+v3qQSZP\nlrrb1NQslFL/FZEHYzQlxMZeh9aKyMgnKC/vRHZ2LoEAhISMwe/XpKXtJDU1m4ULlx0x95RjAaWk\nLN7PkrNWybENKyAWxyyOtb28HTJzxlZUVEVCQiqhoQU888wIUlIS+fDDoKtNa83VV0/g3/92c/vt\ngxg27GzkX+4uHCGBp8jJqSIQqGXjxmQWLly2Hxk3DpK/+up3REd/z+239+eVV4YyefJT+6UJN1Wo\ndzAyfuKJf1BT8x2lpRuBtVRWhgMvsnZtBbGx3zNyZCtiY9fy8cf7jngxYErKWIYOPYeiIo2zUHCS\nBA4lvmTRfLACYnFMw8niORRf/i+N+rEYZ1zZ2e9y/fWdmTjxL7z3Xhk1Ne8yefJK2rU7j9jY/ixe\n7KO6OpnXX9/Lv/61Gqmf0MB6oBT4BL//S6qr++H3p3LHHUv2I+bGllhERDemT59c58bLzOzN0KGD\nGlhq9bO0Go//nXeW1gmJI04ZGRHAQHy+ZCAUrdsBiqSkAcyaNZV5855n5swpxMb2AZ6kstLP1KmT\nGD9+zM+yEGbNmkefPsOZP38LWofh9Y5j7958Hn74SZ588p8HjS9ZND9sJbrFMY3Jk8fX/fzf+sWP\nRCW21pphw25g9+58fL5T6zrPOrEYpRQzZ/6Niy6SWglQ5OWVEhGhCA3tA1QBWeTn76ZLl/ZkZhZR\nUZEJVAADgWnAZZSX1wKKnJxq3O6S/Qh53rx3yc5206vXXezZo1m+fCWPPPI8tbX9KCubzvz5N5CT\nE05i4k0UFbXk66/XMXt2DmecsYy8vNy6WFJp6TQmTbqe7OwwCgoeYMCAXibltx0wHa3H43LtIBDI\noH37FIqKIgB44IGnGDDgFPLy0nG5isnLK0CpC1i4cNnP6ribkjKW2Ng4xo//BzCWyMhZuFzbyc09\njUDgcnJz3697prZ6/diDtUAsTgg05Z45nOytpqq5v/gilmHDzm0yFuOIFEBRUSVhYddQXl5Lz54d\nyM3diNRI7CQQiGfv3lx8vkjatUsGOpk7ulDKi7i0RuP3+7j22mENkgTeeWcpH3ywFZ9vLVOmXMKc\nOcPo1KlTA6uksrKcu+46iYcfHgKsapCl9eyzCxg0qI+pCxlObq4XmM0HH1QyY8b/0aNHO/x+F+JS\nczNwYB9OPz2MCRNOZ86cYSxa9DHPPLObMWPuoqZmC4FAFh5PGb///d11mVuOhTBz5tz9akkOBscl\nGQgk06vXUny+9nTunEhNjeJQ4ks2RtK8sAJicUKgvlg01TrkUGMCznVuvfXBeteYzoIF2ezdu5zE\nxCsaxGLefnsJ06Z9xKJFHzN4cAVVVXH4fOuprgalooEfgURcrnSqq73cfvsgOnf2ATsQ6+QupCn1\n58jWOHk8++w8Zs2ay9Ch19G27dmMGfMwgUB7AoH+jBr1PLff/ldiYsIbxIcCgQ4MHHga8fEJ1NZ2\nQWsvTifcP//5di6+eDDl5TW43bsIBDyAIje3mpKSEoqLywkL89Kr112Eh3tRCrZu7cSuXek8/PBz\nrFkTQnX1c/h8iQQCsUAbtA5w551jCQmJoL5LKy4uvslakoOhvpvyllva8t13mZSW+mnZ8tkDxpea\n+twtjj5sGq/FcY2mUn09nnWce+4pLFmiGqS61k+vhYZpo/XdPHKdB6ms/ILy8lgKCxcSHX07N9/c\njieeuI9Fi5Yzb95itm3bTUFBLFlZEcCnwCDgZeBWYDngBc4F/gHcDHxNVFQrwsICuFyanJy2wDvA\n2UAhMBL4G3ATsbGbKS9P4NxzW/Dpp/8hEDgNeBmlbiIpKZ2HHvojBQVVdWm0t976IIsWraRVq8Gk\npZ2LUu+hdSYuV2sWLLiKe+99lKeeepCvvlrL9OkZQDhQwd13dyQ+Po7u3TuSm5vDo4/+g8rKBPLz\n/0nXrg+Sl7eMoqIAUABEAOcBM4E/Al+gVChKnYPLtYnERBc1NaeQkzMDr/dWamv3HrDtSlOf45Qp\nz5OfH6C2tgMwHq93Pm73GrzeCBIThzZI5T711JNYt25n3ecVE3MbbdvuafYU7+MRNo3X4leL8ePH\n0K1bEpWVfhz3krPiLiqq4uST7yIr6zsgmK7alIXiuHkaV3PX1HQgNvYSysu3cPbZ/XG5XIwceSlD\nhw6kuLiM7GwFpKLU2Uhg/A3ARURENxIT4wA34hpyAdG0bHkOqakPM27ccKANISFjgURgCLIljgKi\nKSpKpLraz4oV3xMIVAHpAGjtpaKiAq0bVnnPnPkoL7zwIHl5pcAetP4eGE8gkMW4cfeyZ88pfPPN\nepYs+ZywsAIiI/cC2XzzzUaKi4sYMeISUlLGMmBAT8LDuwKwfftqbrjhKkJDzwbaAm3MPBQSPtXE\nx59HIJBFbGw/SkpKqK2Fxm1XDiX1OiVlLM8++zBRUV2BncA6WrSI4bXXnuYf//hLo71FkmjXLomH\nHrqFtLRVABQVaYYOHcSOHXutO+sowgqIxXGNhQuXsWxZCHl56Q1Sfbdvz2DOnKFMnXoJHk8PFi36\nuO6chllNkJW1lqlTJ9WJTv1q7ltvTaSysjt+fxSLFn1Ub1+MsZx6aje0DgMUWnuQHZkfA3xUVOyh\npCQSEZDfAblAL/Lzd6KUYuPGdC66qJgWLbYRGhoLzAJaA/2ArWjtAs7D7x9MSIgCegCjAM3JJ3ep\nW2XXd8PNn7+Y2lpFRMRCoD/wJLCd2tqBQCpPP53G5s3p1NZ+Q3l5DHAm69bl8OSTP3LLLQ8wcuRt\nLFniITNzJaGhlwC9eP31xUyc2B6lqoASJIPsWkQkk8nNXQG0pqLiR26++Xf4fG6SklLw+3Vd25VD\nSb1WSuFyuSguTkd2sf6a0tK9uN1uXC5X3eeSl1fGhx8W8Pzz60hJmYw0mrwYrUN5+eXVPPXUDm69\n9cHD/4Oy+K9gXVgWxyUau67atr2LmJjtnHvuKXTq1IWYmLCDVrE77qvo6H1kZMRy770diY2Na+AS\nmj9/GTU1vampeRV4EI9nGVFRPoqKqmnfvg1FRXGUlXXA682ltjYcj+czfL7fMGBAFunpWRQUgKzR\nqhEB6Ed4+BZatNjGn/98Kx9+uJrly71ERBSTnz+XsLAUqqrW4fVqamurkar1CERYXgauA34gPt5N\nly4n8cUXb7Nw4TJuumkpKSmteeaZXURHryUk5Gyysp4xx3+HuJ1mA1JsqJQfrTcBlUBv4A3c7hvw\n+zcCfsS66IFYUzcCXwPJxMeXkpzcmrVrA2idBZQDZwJzgJtR6ksGDerFsGGXUFhYQFxcHN26Je9X\nod5UdtzYsZNYsOBjtB4AzAUeBD4kNLSKoUMvYOfO3WRlFZGXF4Pfn2TG1MuMUdxpItYb6dbtQbze\nDdaddYj4OS4sm8ZrcVzCSf90Umc9nnCmTp1U59LRWjd4v6rKT69eSWzfvof77/87W7b8SHT0NsLD\nzwEe5dVXJ9G69ep6qbmP4vf7efnlbMRlo/H5kigq2g50prRUU15eDgwjEHgKlyuDQKAbkMqGDbei\n9XZEPM4G0oAyIIvKynx8vlwmTnyMQGAQWj9HZeV4oC9VVYlAMoHAHiIiFFVVHQkErgUWmTFEAI9T\nWvp/fP31Blq06ENkZC9KS6uYMaMCvz+VsrLfUFPzGXA+cDJutzIZVr8D4hD31j4zNi8SC1H4/dlA\nDSIIXYDd5p4QGtqd6upF5OefTkFBGlonACMQ0gZQKOVl0KB+fPbZG7hc+zs26otG/Y21Ro68FK01\nSUntufPOsTzzzE7EcioiIqIbF10Uw5gxlzNu3AeceqqX2tqOFBRMB04FoqjvToMkHPfj3/5mU36P\nBqwLy+K4xE9VqTd+33F9PPvsJ8yYkcG4cSOYNu0+qqqk+jk8vGWDwjiA6OhoJA13FBLkdiFk9R7F\nxV4gmVatXsfv70x8fAu07gAofD7wehVe76nI6j8fSEBqPhKorfXh97eqy5SCWsQacAGd8Pv74/f7\nCQRCiIp6zrw+HCeWUl0dAjxKRcXp5ObuAHqbmMMyamp6muN743LtoHfv7nTqtBVoAZxk5lELnGGO\na4EE/3chLrjvga2IsPwe8FJdnQ4sR+uzCAtzA92BdbhcZUAIHs8otIazz+7XQDzqu9feeWcpzzyz\niuTkC/bLjrvllvt59tndbN++C8hDMtcyqajYxnvvaa6/fha1tVewZk0iBQUfIvuPnIQI6iggQFSU\nl7Cw7rRu/Ydm71jwa4J1YVkct3jssZcO2szvscdeYufOdN57byXZ2T4Tp+iNBL0H4/UWotQQunQJ\nYc+eAHPmDENrzbhxL5CQUEplZTz5+R2BzxCCdyMkezvwJ6ASlyvKWAn/h1gbBUAMERFfUFGRAHyC\ny3UGgUAf4DVECBKRmEgisA9xUW0DihAyfxG4BHF9ZSJupd8A2wEf4roZgWRwfYHbXYvfH27GGImI\nwifABUA2LpcmEGiPCFk1cA6SGXYBkIMUNV4AvAJcae75F+BxMz5n3lVAR2Ae0o7lY6CW+PheBAJ7\nUMpFbu5XdcT9z3/+m9GjnyYxsYaIiPNIS/szERFDqK7ujt//MjExdxARsZbCwjAqKloj7rbTELeU\nc/0AInT9ENfWGOAHpI5mEjAf+B6vV7FgwZNHrLHjrwk2C8viuMfhFIT9VDO/+++/mZiYaJ55ZjIx\nMWchfnVZqWvdG58vikmTkti48WlGj45gwoS/8MADq6iuXozP14Hi4lbAxcAAIiND8Hr7I/t3LABC\nUcpPIHAmIh5hiHhsATZQUXESoHC5fksgkARkIW6XNgj51yCpvxuQ9ibjgA6ICCjEHZOBWDxDkBhG\nR0R4PjVzgU6dEvB4LiIhIcQc1wroCTwB9KJTp3YEAucBlbjdTkaYB1gGnIxYIwnmPBdQjASx/2Le\n9xIf38I8URey6leImFQDNfh8mhtvHEFNzcAGdTh33LEAv78PZWVtSU9fBjxERUVvXK4SevW6i4oK\nP0VFxVRUdEYyrxSw19wrHLEyBgGx9e4bbn7vgtv9GuHhUdxzzxj+/Oc76v4WRoy4hKKiApuNdRRg\nBcTimMCRKAhrek/wLL75ZgPFxZuA/wd8A7wJpBIInM306Qto1+5s+vc/mRdeeNBkZrnIz9+Iz/c9\nIg4zqajoS23tBmR17AUi0fpChNh7I0RcgVgLvYEPgO4EAjuBdUgcJBxxEa1GhOgsoCUiGikIsUea\n1x1X0TjzukLcaQlANBLPWEl6eoDq6l3k5vZB6jMc4VkKbCQ9XZn798Hvb22u8R3wFpCKx3MOImaf\nA30RkUpFxCMDaE1hYYUZQ7UZ192IIA7B5QqluHgPCxZkU1o6ncmTVzJ16kz27csgLy8MmE5xcSE+\nXxludyaQSlRUPIWFawgEllNe7ox7sHl2PYBLETF2I+JaigjIGISyNJGRXxMIZDFhQhLx8QkNFg+2\nuPDowQqIRbPiUKvGD4TGfnapIn/AXHMlpaXTmD17B35/Fi1b1tCpUwvTVh2gikCgE+3aJdbVKWRl\nfUdExO+orU3A4wEhbmXSajsgxOsBhhEk9jCEuN9H3FHO6y7E4ohCWpWEIdXmTmA+BPHhdwGuQIRk\nNULkn9XdW1xX1yCB4nzEBfVvoDNC+BPr3TMCKV7sgqzeCwlmYSUiIlCFU8/h87kQom4JxBDsEuxG\nXERdCAT8QCGhoWWIGP0LEbFZaH0WSlWQm+tsn+vn2Wcf5A9/+B0+n0IC4h1p3boF4iVRBAIezjij\nN6+//jQeTzgiysuRuMwsRCQ/Q2Ihl5vf15rnto527aCmJgmtu7JmzcY68Qj+La00f0uf2QaMvzBs\nFpZFs6JxNpVkS7Vn/Pgxh3S+E5x9440PCQ8fRGnpNN56awI+XwZVVa0BRVmZH+hJScluSkoqED/7\nhcgKfwLff/8GrVqdQc+e7VGqK1VVmUAmPp8PIdQRSErtVoRY3YhF0R0h/jaIa+lagoTvZD0pxGIZ\ngFgWLyCEeCUiNgVIzGEtIjSDgauQFNmtwOtIRtVWxCIIR9xMLvMVAjxk5vR7RCQ+R2IXIAJTRFCw\nLgNWIf9St6NhAAAgAElEQVT6V5qxdEWsEMxYR5ixPQskER3dj6KiG6mu/osZ68WIBaLQOoTevTuy\nfXtn/P4x5OXFMn/+YsLDI/F6C/D7XSiVT05OBRCK1zuCmpq2LFtWRLduG01cajZivUUSdFP1QARj\nPPCVeaZeXK4i9u3zIaL4KKtWXY/H05vf//4C5s17jtjYOCZMWAooCgoqmDnTZmP9krAWiEWzoqls\nqaVLC1m0aPkBz9FaM3To9fTq9dsGMYv0dFnZFxXtpKysAp/Pg6zcvcjqvgaQVFuprP4SSZHNprS0\nnDVrIqipeYFAIA5xSUUgZB4DrCBI2hqxHDYjvvvvEashDyG9zgjhr0XSdyORYHBHJBj9BZImuwEJ\nnmeaY840Y1tl3itEOvbOQqyfInOPUCTIHDDXqkLiImGIQNQgAtQG2GPmP8oc/62ZTwwiSHuRgH2C\nmcs3JCZm43JtICKiDPiKoqLNwKNmPIPMeNogMZ2dbNy4lVatStF6HiEhubz77icsWvQR4eGxBAIv\n4veHmWdWRm1tPJWV/6aqqozU1CX4/UuRQL4Tn7nG/DwBybbqa+bQCriTQCAesfYke06pMO68cyxz\n585g9uw3uPvuxygoqAbuoqCgirvueozZs9844N+Sxc+DFRCLZkda2h5Gjw5H661ER5dQVXXRQV1Z\nb7+9hE8/jSIy0ktVlR9wUVKSYVwm1yKWQQyyCr8JIWkPIhpS9yCk2gUh1ZOA81CqBcEVsEZI/VKE\nXE8imMEUirhxQs2IzkRWxHmIJfASEoguRCyXXEQQ3jTn9TPX6ov8C5YiLiQnrTcbyTLqTZBYnb5a\nFyPiNI2gRRFvjgtBMrM6EXRXlZvrzUeIOgdxg/3NHNcaWeVrJAYxiKyslrRsWcu0aSncddcYlOps\nrj8GESnHPZdEZGQWffueQmlpBOCitLQl8AzR0X2pqPCb57PZnJ8MXI0I1nYqKnbVe9atzNiKzHgz\nzDkdkDYuucAwoqI64naHmmc7Cq2lgt3lcpGSMpbzzjuT2NgyYBqxseWcf/6Zzb6D5YkMKyAWzY7J\nk8czc+ajTJ06Ca83CRi/3/a1YnVcR+/el3PnnUupqXmBb7+NJiNjOYmJw6moyEGEIhuJT1QiVsR9\niFC8i5Dq90i6bQhC/DWIJbLD+OhH1Tu3FzAU6VG1D0l1nUVw9b4NIXYnk6kbwVhEOZIV5TXvFSO1\nFpOQOMIZiOvG6ZeVb76PMN/TzfEOcXsRV85gxOV0KmJ5xCEB71Bzj72IVZJjjvOYebvMOGIRAbva\njDsMSS3+ARHHJFwuzeDBpzF+/FgSEhLo318jojzHjOca88lVUF5eRnr6TsrLtwGjCQQU8BjZ2V/g\ncoXgcp2OuO78wBIkxpOKuPTiCKYQn2GO2WvG+S/zHMtwueKBU4BBVFaW0b59Effc05G33rqB884r\n44cfdgCYDKyLqKmJp1eve6ipiWPEiItsPcgvCCsgFs2OhntqNF0Y+M47S/n005akp+8iM7McJytJ\n6yKystYiK2mnZ9QjiOsnDVmF+3GqqoWweiLZWHEESTrTfF0GrDHnpyLkm4ZYIwkEU1gvRlxSBYir\najoiAhsRsvMgwtUbEaSAuf9XBOMNimAMwmvum4+4sNwIwWcidRdZ9Z+Y+doH/MeM8zQzt2xzXn9z\n/w7m3meZMZUhgrnB3CsLsWhOQ8TrRwKBDBYv9pOcPJCnn36ZdetamjHGIfUlmYhrLwKIpLS02Nxj\nnLleFnAhtbUfEwicilhv0Yh1kUHQyotE6ltSCYqfD3EXtjD3CCcQKKRHj62Eh5/GwIHR3HrrGJ56\najK/+90wPvvsDU49tWtd5t2xtIPlrwFWQCyaHU721KJFH/Gb31Tyww9PMWfOMLZt290g1lFT8zwh\nISebs25C3BoXIC6c7ohY7EN85zMRS8OFEN5YhJR7IC6Vs4EZyApcm+NikP5RHQmKBYiIxJnr/w4h\nYIfkI5Hgd38kvnE6YsWUIET6I0Lo3ZGVv5PhlIUEvasQsuxm7pONxBfKzHUd66GtmecH5vUWiBA5\nmVrS/VYsk1BENLPM81hlxncSwY66XRHSL0bEJRVZ9X9u5voSe/eeTH5+GYFAmrlWgrnuKTguLBGp\nS82zuxsRo0QkQ2sg0rNqIWLNdSSYedY4kw3ExZVEaGioOW6oeaZQVNSXysoZZGd3Yu7cd+tcm41T\nduvXBl199cW8++6HBAKOeFscaTS7gCilhiqltiiltiml7mvi/TFKqfXma7VS6pTmGKfFkUfjFN4V\nK/y89963TJjwAGvWrKdr1/b77QZYU1OFrNS/Q4j0JcQdkoGQcbG5uhM38CJkvgEp8tuBkOnV5rsb\nIb8KhLSuINgA8Urz2sUIsX+CBJovQETJjZB6DUK+IUic4m1kxT0NWWn7ELJ2ejiBEHIrxIIoNePN\nQ4SkHyI4zsp+FELcOYjgVSOipM3v1yNEfDtiDQUQgZmGkH044p5aba4RjqQBg4iwk7pbZubSnWDd\nSa15zqeZZ3wBIjbzEGGqQMT6ZPOsqxCraxgS2K80z/kaRES+RqywTUjas9OmxY24FOOprvaYsZ5r\n5nU++fmy5W9eXilTp05Ca/2T6d9/+tPf+frrNtx33xNY/DJoVgFRSrmA55ElTG9gtFKqZ6PDdgDn\na637AX9FGMPiOELjAr9gS/QxTJky0exhocjMLCEQGMD8+V/x97+/ydixT1Bamkhqahp79rxLmzbD\nqa1tB5QRHh4gGHR2I2Tj+NpDCJJ/J4LtOEoQsXEynTYiBBqOuLU+MtcrQGICxQipL0dI+0zEEkhF\niHQ3wZ0FO5vZjjPHOMFvhQhIO/NzPCISNUhMoCNiEW1D4iaJ5nzH8vgKEYU9CKEXmmNdCLl/jbh+\n1iLxkQJEPCCYutsesR46IGIZYebU1xznRuot3GackYh15Dfz1kgCQH3LzIVYKv3N75lmTueY55OJ\niOVFiFivQtyGEYjolSDi9qmZWznBivhw+vfvzvz59xEVtRvIbbC1rVKKW24Z12BL3/oxs7FjJxEa\n2pfnntsJvMizz6YTGtqXsWMnYXFk0dwWyJlAmtZ6l9a6FvkrvbL+AVrrr7TWzrLyK8RutjiO0NjN\nEHRZLUcpKWaLjb0O8ckHKC+PBkZSW9sdWEtl5XZcrvNxu4sICdkE9KCyshJZnQ5GUlM3I8TVh2Dv\nqjTEZTUUWSnXJ9ZshFBLECJ2IbUhvyWYqeTERgqQmMhshOSGE2y5cSnyJzkBEaIRCGl7kYywUILW\nkOOy8iJk3BIRqhiEeGvMuLIINmA8HyHVNDOHGoT4WxEsUMxHVvcvmeMLEGthOCKeO3Eqz0VQc5A+\nV6mIuGxGxHQlInbDzNhWIULWwsz3RzP+sWYOboKZaR4kEL4ZcY9JQ0exThYA7xEM6CvgHGJjs3C5\nTiYocB+ZZ+rnwgsH4vV6UaoHCQmBuq1t58y5jLS0PQdtpjl37gwmTvy9aTApm1tNmjSauXNnYHFk\n0dwCkoQsPxxkcHCBuJmg7W1xjKOxi2rChJcIDe3LxIn/qqsUvummB6mt/TfFxZsRcpuN1lGIG8iD\nrPCTCQRmsm9feyoqyhFffjhiAXxCMDVXIYTWDVndJyGupXMQt8zJiFVxFcFMp7Y4vnc5vyPBthou\nRAA6EiwKdCN/pjlIvKMrEsB/CGn+1wZZwW9Ddih0YhmfIaTvrNQzEPEqQ9xDrZGVebBrrwSdWyCr\nfMePn4S4wpLMWG6vN3anEj0cIftI4E5EDJydBAOI6HSuN9/LkNTaEESclprj4xHrwWnUGI2ITC1i\nueUh8aC+yNruB3PPCxBR1PWe2UmIlbHZjCeV4uKWBAKbcSrMJUPsG6Afb775YV1APDv7XebNu4nt\n2zMa9Dw7UMDc5XKhlAu/H0JCxuD3a1wu1WSbeYufh+OmEl0pdQHwB8RXcUBMmTKl7uchQ4YwZMiQ\nX3RcFgdGSspYYmJiuflmSckMDe3KpEmn8dprOTiVwi+//FcCgQB/+MMcKisdIQhHSPE5JKjt1B54\nEathBiIKiQg5tTLvXWN+djq4liB/LjMQF9VLSAHeZwhhtUaEJRshyCxEOF5BVuHO6ty51kiEGDsi\nldHF5pwChPx8iEvpMiRG4GzodCGSPrwX8fvXT6E9Hem++6C5d62Zq99cz40Y5Rpx9zhBZ7eZv1OE\n6MRv2iFFfw+b628w1wlHYiktEVFMR6yVMsSqeA0pEsw09wIR4ywkRtMVsageM88j0XytRoTBiRt1\nNs/5D0jDxi8QQW9rxlGJBN4VrVrF0aNHf9avL6K8PAKJB50GzCYi4kHmzVtctz9L42pyrTXFxYWM\nGHFzk+9v3LiDe+/twt///r/cd98Tdam+zrmNN7T6NWHFihWsWLHiiFyrWdu5K9lIeorWeqj5/X5A\na63/3ui4vkiF1FCt9Y8HuZ5t536MwPknranxMX36Htq395Ob6yUycg2FhQPQOgylKklK2sywYecw\nd+4OqqpikFVtK/M9DCGcRMRN08p8L0FW5m0QgstASPRmhOBikFX+qQiZXYeQ092Iq2aLub4PWT3v\nQ1wsvzX3moNkaZUgZB2HCMR2RMCSEWI8E2mLfjOSvZSIrNIT6r2+AVmdX40Ilh8RO23G0g0h7/EE\nXW75Zg7fmad5FiIy5yBxgxxzj3VITGcTQuDliID0MGMNmGe0xczlTMTKex9xL/3HnNcZeBUhby9B\nUTrLvH4z4iYcilhVuxEr7UokhNkOEeEN5vVXkSy5LebZ7USssAGIldIdKCUkJIbbb0/mhRfWUV0d\ng9bpiKUyiw4dJjNt2uC6jKrGcHaUnDNn6H/dquTnnHsi4nhu574G6KqU6qiUcvL73qt/gFIqGRGP\n6w4mHhZHHwdrwX7LLQ/w5JM/8tJLnwBXEhYWT0LCRsLDw/erFN66dTdJSfkIAa1FyLmIYPX0CoRM\nP0FILxFZ5VciRNkfEYPrEDKLA/5M0IUShVgT7yPkvB0RkC6Ij74MiRcUEuwR1Q+xgnxmRgsRgs0y\nx/gIuo0wvxcgriOFuMlCEDfQmQgpbzDf1yHWSCdzjBP8zyGY0vslQvouhIifQMTpOzP+lYigpiKi\nlm2e2R7E2tmMiMAsxApzmec3H3HlzUasslwzpsFIDMOx9GIRKwXEKqpBXFtuxGo6CbGyMpAq/N7m\nfp56c/cgrrwwxCL50txvDXASISG5zJz5T045xcdbb13F3XcPweNxHXRTqJ/TfPPnNu602B/NKiBa\naz+SvL4MWUa9qbXerJS6RSmVYg77f8hf84tKqbVKqW+aabgWjdBU22znn3TFCkUgMJOqqs7A8+Tn\nb2H69MlMn34/NTVxxMXdQE1NLDk5+1i1aiu7drVF3CHdEGIdSDAQCyIG0QT3s4hASPIMxMroighJ\nLSIiTyJEeBVBcr8BJ1AfjHHchqzYHctnFUJ6q8w9eiOEu9z87kWIvo0Zx93mmhcQdP2sNO87xO4x\nv5ciotfWjHEfsqLvh5D+ScBT5hotzHlRyIr9K0Tgqsw1+iAreofwXWYMIYiAXoQIozLjSkZcV04/\nryfrnbvLvD/LPH+XGZtTiR9inusAxJrIQ4S0yJw3jmA7ks8QS2urGWtP87kkm88q0jxzF1VVuxg7\n9hK+/vptrrlmKPHx8SxYcCU33tiTV14ZSlranv0WKSkpYw+YffVT+DnnWjSN5rZA0Fov0Vr30Fp3\n01o/bl6bpbWebX4er7WO01qfprXur7U+s3lHbHGwlVzwn1RW/36/i/btI6mt7YBSiu3bM7j55tbk\n52fg8XzB55/vROtqfD6HBEORVW4BYpCGIaQWhqyCPQihvY8Qcf2W6jGIH96prfjOvL4GiVd8jhiz\nlyCEt5agldIJsR7OI7ji3oWIS2fEzbTK3OMmc/31SFyiFbKi70Owt9ZMc7/TzLW2Iy6mPISYz0cE\noRtC3L0QsemDCJRD/kkE6yycrW+7IORdba7zA0LS5xNMY34OIfJTzTxBxCjKXP9HxBpIouFGUT8i\ncRInHTcJEfZ2iAUTilhV0whW6fdFRDTWfI1AhOJU81l8i7MHiwjyeyj1PR5PZy6+eEidlTF58ngA\nUlOzUEpx//0377dI+amtjA+Gn3OuRdNodgGxOL6gtSY9fS+PPHJbkys5558xK+s7EhJuwOWC6dNv\nZM6cYUye/ARPPfUPXnllPdCXsrJEKiudjYO8yAp6JyIe6xCS/gYh4FqEIBVC5HsQ8nIaKIKIhNOx\ntpygC8kJ7jr7cPxo3otB3FW7CMYTZiPkGYcEnvcgq+0SJHj+b4RQa8w4/0qwHiUCWWm7ELdVG3O9\nUwi2ge+CiNY4xLKonyBQjbibPiVYGe8U+WlEZHojK/sspCrdSzCzahziqnPOqTXPsIOZc755BpEI\nmechWW4KEdv+iFBdZX73m2dcgrjcLkUSFZwxOwWSv0NE7D/mnOdxqtHFkiwn2MLEDZSjVC0TJ57K\n9u0ZwP6Lkttu+4DQ0L5MmPASpaWJ3H9/cG+Pn9OuxLY6ObI4brKwLI4NOLv8paQE6lZye/YEGqzk\nFi36CI+nB9dd144XX1zHokWfUF5eyo4dXfH7VyOr4OnU1t6IEKMHIZmuCKndgqxY1yCEug5xySQj\nxJ6JrJLjkfgACFm6EUsiAYk3dEJW4teba1UjBNgaCWD3JNghdzjBmo1whAgrEbKchgSS1yAxBKdl\nO+a97kiQPMHcoyVCxjkEK7qdwrtchMhHIWLZF8l+qkKslVQklvMtwZiCkz1Vi7jx/Ii4tEZqJ8LN\nPe42Y3Kb+TgpyphnuwkR4UzEa9za3H+5ec7LEVeaU5TYA7GQWiCWWSqSxfYdwYC+QoSjtflKQKwt\np5AyzHx1xuW6ikCgDXARgcAuZs9+myefvAuon7H3PAChoZFMmjSKV1/9D5BFQUEu558v+8TUT8f9\nb4PgkyeP/9VnYR1JWAvE4pDQeIX46qsZREev5Y47+tet5JxjPv64hsrKGTz33E6qqnaxYMESFi8u\nw++fiRDROmQXulCiojwIebqR1frJSErrSmQVOxNx63yJBLJ3mxG1R1bWTvsPJ8idTnCF7JCYy7y2\nAyHRjQhBzkZW8FcgPv8QxJoJMz9X0TCtNhpxgbmRFXkOQsarEYvga/PdCV7HIfGNvQjJO23bvzXP\nwNl5sDOSIlw/RbcrQtArEAspBxHFr809exO0lgLmetMQgVqBkPoX5jk5zzXKzH0v8D9mfFcg4rwV\nEVxnT3Zng6sfzfONN68XEtwZ8WPz2lbzOVxmxrbXPK/h5rMKQalMAoENBCvSZ+F2n8mMGW8ya9Y8\nlFJ8/fV6Sks7EhV1OTk5m3j11fcoLAwHplFQ4GXx4jVMmPAgPxd2y9sjBysgFoeExgHIiIiWTJ9+\nPykp4+qKu5xjQkNlZzmfD6QzbheCBFRFMCMqQFlZNUJcDtlrxN/ewbzuvHYt4jIKQVa5HsS6SDDn\nvoEQ81kE3UY/IC6UUCQu0RMh3DIzq/qFgW0R0gxHakCc6vQQpIJ8lznvByS2EU6wHXkFMBmxPgKI\nKwvE/dMRKfaLJdihN4C4y15CrI9NiJsoBCFdrzl/G9IS3qlQH2zm0p5g7CbUjKUvYl2cbO7v9NRy\nCiADiDXyiJmrkybstFfvj4hDDCIO8YgQDkGEr8o8u12Im9CL1Lc46c6nmGecaMb2FcF4SEe03kvb\ntjHmebdBNv7yU1JSwsqVX9K79+W89loG8CLl5e1Qajfh4YqICBFVlysUrf/Kxx9DfPwZzJw5l/o4\nWEagA5uFdeRhBcTikHAoAcj6x0RFyWY/oaFTkP9pP8EurE6PKaddSBnypzjKvOYx310EdxR8A2lq\nWIMQlhcYbY5xI/t9eGhodZQg5PcRQoitENIOI5humoeITiFCxl5kJT/AzCoPyd7qTnCPj44EM61C\nkBX8Q4h1lWDufSkSsyhF3EWO+20vEph2rI0Q895qRCTcyMr+R0RsZiOupBpEbAYgJL4WIWcXImCr\nEKskDxHNdPNcy+s9V4A/IQJ9uZmHExdyYjynIJlXTnB8JCIMSxFL0Nn4ygmQf0Ww9f2bBAP2TyBC\nNhQRonBatIjj8ssHopQbcbcp+vfvydy5zzFoUB+Ki6sBhdaRVFV1oaLCh8/nJilpvPkbclFUtIeK\nirOJj0+gPg7FqrBZWEceVkAsmkRTK7qDBSCd47dt201KShtqamIZMCALny8BIcOvEDL7D0JabRG3\n0yCE9D5B3DNOLMSNuHf+Y747270ONscsRuIfxYjLZh1Cfk667i7EIqhCsq6c4O8QxNX1MeIOi0Bc\nSF3MOFYixO/sBbIF2cd8LxIneAkRgtMQ0j/DnD/A/L4HsVDiCdZofERwi9pEgg0cHQFwMqKcZoYt\nETJ3rDYvIm7jzPEBRDTamfEqxNpINedkmHk5+6jPM2PajAjat8D/IfUc1BvHJvO1F7FmUhEr72vE\nQpmFiEi4uUY4EvdwkgicWE+Y+cy2IgIUAhSybVsWS5asQut9eDxZQCGffprOKadcYcbhQcS8Ekih\ntrYtCQk/cNllsbhc/0GpO8jPD6OycgYpKYvp3ftyxo6dRO/el5OSsvgnrQqbhXXkYQXkV4hDMfeb\nWtHV32uhfk8ikOrep57aQWrqG8ydu4+amhdYuzYBv78MWXGXI8TgEJ7TmwmEOJKRVXshUqNwCkJI\nwxDSdWIf+QiJXYqQYRFCUIMRcm+FkHUoQqLnIkT4D2SVHkCI8ByEhLcjYlKIuMymI8KjEPJ3WnZM\nRAjeqS9xmiGWIX7/TQT3yuhJMC3WQQFC2Klm7p8iBHwVIqZeRAwHmnF5zDjGEswmu8q87kVcVM8h\nllF3gplX9fcFqUaspCcRQXCytbzmnq+Z5zkeibF4zNgnErSQEs01nLiSJtiuLhmJ+YQgmVgg1kZn\nxEXZ1Vx/A3ASUVFJnHXWqXg85bRsmQD8Ebe7JVOnTqJTp84MHRow494GZBAa2pnp0ydz0klduPPO\nYYSFXUxUlHRuLirSDBs2iLlzZ3DppQMpLJS9UbKyipgyZeIBrQqbhXVk0aytTI40bCuTQ8PBWjnM\nmjWPGTPepLa2H2lpf6Vbt4fwetdzxx2juOWWcftdyzm+sLArmZnTadXqNsrKvsXnuxNZeQcItsNY\ni7hZopDVaSRiKXgQMv7UHPcFQnLOroLOvhfbzXFDkX5PFyDk3Qch1D7A00iwW+IwQmLPILUbn5tz\nrkZINQshu85IgH0nEgh2UoGdwsLzzNjdyEo8G3EpOZtXjUUsok8Qq+A+pKFCJkL8KxBxuQgRuRSC\nRYcvmTmXmXHvNXPubJ5dT8QCcLLCahBxao24nXoj1tViM55E80ydeMYuxDqah2yNux4h/Fbm2byE\nuN+WIYJzlnnOPcz12pjP5UIzxhZmXrXmeUUiVoZT5R9B0B32J0Tkksx4onC71+P3X4JSJXi9uSjV\nhhtuaMnq1T+Qnt6aysqXEUFbg1JtGT++P6tX/0BmZgcKC180730LdKBlyzCqqrbickVQVdUflyuX\nQCCOiy6qZPny17E4NBzPrUwsjiIOJYh4qH7ioBUToLi4hKwsyd4pKqrG50siOvpDhKiKkOrqdYg7\nKZRgW3En3fMagtXeTnA4FiG7TEQcPkRItW29Y5IRwnJW6+8hVkNHZBXuRgi3K2L5DDL3XYC4mgII\nwTu7/fmROo8Cgi1UAghhnUYwK6wGCWRXIm4hJxB9OkKe7yPWUR4iBmeZe/yIBORBAthugp2B2yPi\nsQVxp2Wa+W1BSLwHIl5exJoLN9dUiJtqD2IFLScoyo7V5gT1nRb02jwnx0W21zy/SEQEM5CYx1bE\nOvMQzDDLNp+bk2BwEWI1hJmxlSEuwEjgAfM5zkaspPW4XAroQmxsGfPm/ZG5cy9ny5adXHrpQCor\nxRUmxzxG69YJLFy4krZtW1FUJJ95ixYhxMT0BtpRXb2XyMhwqqp8wBUEAtHAFr74YpcNjh8lWAH5\nFeFQxWH+/MUUFlYe1E/8zjtLeeGFfSxZ8jmnntodWcCkAB46dMijtHQtXu8GhEiXIGRXTTDI7UFI\nx4X4/50g7AaE3IRoZPXvBNSdIHcREhgOIdgPay+yqt5orvt3ZJX8hfn9QoSUsxBi1wRjJk5HXT8i\nAhvMdUFiJm0REqxGYg3xiBvsbPNaJsGAeAcz3jLEOlCI5ZOPCOGNZqyV5rnsQcTq32Ye5yN1Kf0I\nutzKzHMEscCcXRRTzHN0qvL7mHs61eLnIcJTghB9L0TEOyHushJE0LyIOHvNeTeZeWtkz/JaJAZV\nYJ69G7EqzjRjfQEJuHcgKOaLEVF0XGEFwEnU1tYQEfEPqqtjcblcLF/+GStXtuCVV5zMtt8TCGhg\nNTU15YSFedm0SaF1GF7vOMrKaikuTjO1IO3p1CnRfGYuc6/JxMYOtMHxowQrIL8iHEoQ8Z13lvLv\nf7u59dbEJv3EjhUzefJKysoqWbwY/vWvlQhJ1gIj2LcvgkDAQ21tHkJ0fRFy9iB/cr8j+KfXnmDX\nW42s7nMQwvQgxB2LkEQ2wVV6OSIOyrwXYn73mHvtRHzpCnGFdUFINs3cw6mdcNpyOOmu3yEWTAkS\nIJ+NuKWGm/cjCcYDQOIV6eZ9DyICGxExm0mwmK6/+d3ZVtZZvRcgiQIdaNiaJRRxF1UigleBiFB7\n83oIYilsIBgsd4L+ChGTWYjgrDfPJBURlS3ma725926kE3EyQQtqvblXJiImsxEB8pnPuRwRO4+Z\n6zQzRmffEqfnVv3miptp1SoMt/scBg7M47bb/sz771cBsygu9iNuwnJgBy7X55SXJ3LttZdSWVkB\nDCMyspywsK+JiGhLIPAiPl8Y33+/GxiE2/0W8C1hYVMoLq6ywfGjBCsgvzIcKIhY371VXf08ixeX\n0qfPcPLycrn//psbbEM7aFBvduz4gGAgvCNCkgFgKH5/R2S17UEExNkAyYWQRAskNdRF0N1yBcHG\nCADejYMAACAASURBVL2Rbrr1A+2RCEFVIWT0A8EtVGea16oRsv8BWTn7zH03EdxZcBLBwHg0IjIg\npOhH3E2DCe7x7dSKVCIkH4YInbNlLog4bUZiBskE92J/0pxTSzDInW3GmExQnDBjryCYuqzM71mI\nAG431wwx89iGWDA5Zh6tEYFohQjROnPdOPNex3pzqUViQQ8hIpGIxBaScDKmxBroSDB5QCGxqwTE\nJegx800yz2SZeWZOL7CrgWpCQ78kNDQJl+sTYDBFRT5KS6exbl0M+fmF5OTU7/mlgHZERYXx5pv3\n88YbV5CVlU8gkEyvXkvx+ZKZMGE0MTG9kP1EYvF4pJljVFQEw4cP4OGHb7LB8aMI28rkVwanYR00\nbAORkjKW2Ng47rlHsqSqqgL87W+T6o5xsrIKCx9gwYKPCAQGIHtUpCCkWIGsmscjJDgeKVpzyMeN\nrIa1+fl1xAW0HrEWkpGYgxsRiw0IMTktOVwIkX6HEFUa4pbKQWpE1iFi1Qpx21yNCEk6suoeiuxy\n+CdzvYeQQLzHXKeLGd9eRKRuQdwwVyMkXIsEix9ERNCDrN4vQVbYIC6nGsQ1VoLEPHYjgujs0+5k\nlLVFSPcUJO7gM/f5wlyjBiFsJ4vsZiQVGkSUWphxnIKIY5iZYwszfmcrX6c3V4gZZxuCsZyHEBda\nezPPEPOZfIVYZl4kftUNSfVta+6fjohMGGL57CO4Edd1SLypGperLdXVkUgcxRH6G4C+5OaG0adP\nMps2eZHgfgtcrhrati0mN9eLy+Vi5MhLSUvbw4gRyYwYcQkLFy5j4cLlFBX56dXrbrZvr8bnc9O+\n/S0UF0dwww0j7f4eRxnWArEADuzemj37jXqB96eZN+87ysqKCAay44COxie9CcnYyUJ2xCs1x9xl\n7lKN+N4/RUj9E2TFejqSDXSmOX4l0jJEIyv/FQRbncQiAd4LERdNFGKtlCAk3AshqifNa30RAl6F\niE8Zspq/BxGMvggRrjb3m4gIYYaZR4r5uRJpEtgf+bcpJZiWuwohcz9CvLsQQd2LxBYuR4h6C5KZ\n5kFE1+lQe555LqPN9SPMmB6nYTPFKsRiOdUcE4MIpyYYPC9ALIdU89msMuNfiVgVVyMiMxzp7dXK\nfA4/mnnPREQpDWk54jOf11Yz58vM/SsRcYup9zk7rrdqoBWBQCdEjJyMMqfPWATg48cf96D153i9\nEcDVhITEEB1dzo039qqzIBqnjvfp04PRo8PReishIWlAF8LC4omOXsu8eYuxOLo4qIAopXoqpX6j\nlIpq9PrQX3ZY/5+9Mw+vqjr3/2efMQMEkkAYkzBPIoooijhrFa2zVi1oq7Vgq2jV2/6q3nurVm8H\nsaJSZdBWbwWtvXXA2tZZUVARUFGQUVAgkEDITOZz9u+P77tYQQGp1bZS1vPwhHPOPnuvtfbZ3+87\nv/vGP2PszLzlHO/l5cqorq/vi8DblfhoBGpIp51JpBcy5xyIJNYSZB8vRVJ8FiKKaciG3myfTULA\n6rr/jUAO26T9G4Gk13IESC6CKBuZcAYjybxthFbb/IUteLNZe5tLgc3R5WHkoQzpNCKprsj8VoKI\nahmSpo+0c7nii2UItJ3TeKCd2+VTTMAXNcyzeQ6214GtJYmiw0qRZnQoIhCQ9L8E+SKSiCiyEBkO\nQgSab/viOjW6BMRsRFz97PV7+IivYrw5q23lX5dngq27vX0/gTTLJHLEX2jn6Gjr/Ib97WVryMb7\nQeLo95IBFJCRkaahoQennnooXbt2AsaQTPahubmee+65hcrKcg477CzSaedT0bj++vFMm/Y/3Hzz\nRHJzDwEmUVZWzR13XMfjj9/Dno49yYXaNz577JJAgiC4CunwVwJLgiA4o83HP/uyJ7Zv/OPHzhIF\ngyDg+edfobLyZYLgUSTZBgTBm8iU8SK+/8VrSAKOI42hHoHV6Ugb6IPs++3xZq1sZA75EEnhWxE4\nTUNmpfUIxJYjSbojMplsxQNST+QTCPF9RGIIjF1P8XXI1DPQ/h2NTGcuAiuNgPkoRFKuDIrrHHgA\nCkXNRWVTXAn6M9BjVGnz74j3V9xmn02wv90Q8HdC5i/XhPMjFCZciQA5Yt+vR2a4Zfb5NxABrUMa\nT3dUFHEuvtHUfrYXLkqtyO5RxOb3of07BGkZSUSuubgoKK3tXaR9tNpcXHSbW28amfQybJ6bbQ6v\n2DycE/0CJCS8ijS+U4Bm85M9w9y5NZSUVJKdfT4NDa2sXt2Rs8++nMmTFzF/fmdGjTrnUyDfVlvu\n0WMCtbUp3npr8d/kNN9XUPGLGbvTQMYDI8IwPBOJPv8dBMEP7LN94Q1fsZFOpznssLM/JdHtyait\nbSEa7U8YOn9GK2HYSjLZFfUgd+aLjQjM6xCQtEN29xYkwa5CZqRMBNRvIPApRoTR3q7oNJIyBLgN\n+P7lGShS5wU7XoAkcPoAgaVLOMxGORxLEHhW27lTiEz6IO2o1t47xOaRa5/Pwxf/m4wvM1KIQPp5\n+/sRIocD8X0/XrV1r7B1ltn5e6AyHwlkOlqFyG6azWc+8P8QQG9mxwz212wtJ+Db616DfDsp2/tp\nNsdapG2sAa6zPanCE+J0m3OZzXENIpOO+ETOwxFBJZBG8pzN13VtrLY9z0JlaTqi30E18jVtQuXv\nXfRdSGbmfUARLS3Kmq+urgVeZNu2d2luViTZn/60gJaWTcCZvPVWF6LRwYwbdwXXXXcb6XSa6667\njYcemk1OziK2bdsAnMEDDyz8zNyPMAwZM+ZbDBny9X9KQcW9UevZHYFEwjCsAwjD8CNEIicHQXAH\n+wjkKzd+9KNfMn9+F37849v26Hg9bBfRrdsRPP74VlKp8fgWsRGGDi0mCFLIfJKBgCwJrGbEiGF0\n6JC0M/0ageZ9+MzyTKS1tMdHcE1C0nWIgP8ZJBk32nmcOSmOr0obA36DAL2tlXUEIo7hyK/QHZFP\nDzu2AddW1UX++BayjgwzEBF0aHNcFJVQ6YcAvgsyRVUik1UlivI6wI7d39bjfBwDbf4dEDn1xScF\nBm3+5tg+5dnc2kZwFaFHca2d60i7Rju8uS6BDAddEFH3svd7sWOZkpw25+iLtI5SlHA5BJHM7xEZ\njbP3Q3xuTHvkqB+ByDSbSKSd7c0AZFaLAP1IJDoyYMB6iotriEQqbD+uJQx7Eot1QP6UbiinxPm+\nngOm0qHDMcyZs5Q773yNH/3ol0ye/BEXXXQ6558/hupqaWxZWf0/M/fjscee5fXX8zj55CP+KQUV\n90atZ3cEUhYEwYHuhZHJqUj/3v/Lnti+8cWMceMmkkwOY8qUj4B7ueuutSSTwxg3buJuv/fYY88y\nb14+Y8eeQvv2uch8VEdeXjbXXtuXzMwsGhtdSYuNSJLfBnRk0aJlVFcfgkCtDEnHAZJQ+yIpOhMB\nWQyZp9YgU0w2AqBhSLMAgVkJcvwWIGf6IQiE1yNzTikC0FFICi9G0vx6fDhsCQKuItRJ0DVeykJ+\nhkxkbosg8nFRXiCFHGS+Al9eZQMC0DHo0bjO3ova/PohUOwL3I2k8u7ID7QW7x+4Bh9iu9nmnYcq\nELtsfWz+NyEycq10RyLtIoKioALkyymwa7a3z0rxPp4jkTboujC6SsHV9jrX9maDrRNEMM5/VYju\nm0Be/psFpNOtdt0SW9+ZQB0tLQ2Ul1eyfHkf0ukJSAt6FXiN5ubhyKG/zvb9AOAWu28BVVUN1NZG\naGpKc9ddq2huvofzzpvF3Xc/ThgeTiLxR0pKnuf55+fs1Iw1ffpDdOp0GDfc8Cq1tZN55JEySkqe\np2vX03dbUPGL0hj25jLyuyOQb6Ff3PYRhmFrGIbfQmLNvvEVGA89dDdXXHE+6bSk6HQ6wsSJ3+Sh\nh+7e4Tj3sEyf/tD2H3td3WQefng5FRX1wLNEItnU17ewZs3HnH76CXTtGrc4/J5I0m+HpNXDkcbR\nHpmznAO1HgFUGkUDbUPmk0wEKB3t+Dy8yShtxxXZuZ0ZLQuF0OYhTaU30g4SKKz3fWT6mYKS6hbb\ndXogwOuHzGzv4zv0bbLj3rI5z7C1zbNrrrTzlyNyq0VmK2deehuf81GPiNNFH7XifQNZiABB2kgd\nIuAqREID7LsVyDy1HvgDvr2uy/nohUC+GhHvC4iwe9t5XTMs10/+YyTpO79V2yZWnVCOR1Gb72xG\nZrUkIs5CfG5MBrrfrmpAaHPOxAsN/YGPycycRxA0U1ubjUK/ZyPyasVH4A0DNhMEmQbm8qEkEucQ\niSRpaQmBWlIpzTcIsmltbQIgmUxw9dXn0KtXH3Y28vI6sW1bkf2OA+rrU1xzzTmUlDy525yRL0pj\n2JvLyO+SQMIw3BCGYekuPpv35U1p3/giRyQSIQgipFKQSIwllQqJRIId2oKCf1jy8zvv8GNvaNjG\n4YfX8oc/XMqjj57JwQfH+ctfNvHgg3+gtDSX1tbVCJgeRtJqiDQSZ5LJQJLmKnt/LDJHTUHg5cC2\n1L57HD4zPYYI4mMkoW6198fi/SndkEKcQNJ6HNnje6Of90w7bjTSOlyRxQQy4ZyAiGCAHd8JAV8j\nPprL1abqh4B5gn2/BwJBZ15y1XtbbO2OTJx5rxlJ2e0RARxu196CCDgHX1DRgeg2O28EH8nlku4y\nbF6FbdafgZpbuTWeh88TcdrGYch38Ufbr3MRWdXZPF1wQld85nwjIrAAkX/a1peNHOWu4+JGm+t+\nOL9WQ0OKdLqZlpaByNSVRhpPHTsmKWYRhlXEYpm0b38XUMawYSlGjNhCa2t7cnNdufhrSacD4vFu\ndO/+KrW1KSKRYIccJ/CS/3/+51waGy+hoqKJROJcGhvTjBp10PZck7ZVpdt+74vSGPbmMvL78kD+\nDcaSJWv44Q+LaWiYyQ9/2Iv331+z/bNPPiw33PAa1177czZvrmXIkGtJpwu55pqLqajYyo03/pp3\n362iuTnFhx/2QQUOXVG+CL47YB8E8h8hcihEINUNmYKiCDQLcDkDksD7IBKqR2aMj+z1IQjMTkJE\n0w2BeQkC7pNRpNK1yHHcat9xWkQ2AlMXGXSWrd6ZdVzUl3PQv483KyXwWeYu+mgxIrqleDNY1I7p\ni8Cx1Y7dgBzeLyHNo4td2/lUnFY2DJncVtkcogjwXZOsa/EhsU6DSyPAfwn5Yqbh+5w32/s5yO+R\ng9c2Mux+5CNt5AOkkYT2OomCE+L4UvH727lfRmTzNtIyluHL0ve1/2+z7zyHL2t/KL7e2SKCoJF4\n3PmxLrBr5hOPx4hE5tCly3BgJAsXdmHBgtUcc0x7xow5gHi8nMzMBUAZsdhmsrI6A2fu1Im+o+S/\nYXsBx5kzT9ttpvoXqTG07ZOzN5aR30cg/wbj2WfvY9Kk64hEIkyadB3PPDNj+2c7e1iOOupQZs48\n9VP5IKNHD6WhoQu+vEXbAodn2P9bUNRRMQLmDCQxD0eRQINRlM8QREAdbSZO4p6ICKcRaR6H40t+\n/Bn5SrbiixmWIpPIschEVIeA7SmUxJaNyKQK2dUXIYJ4Dw+uLp/DJcFFEPA7v057RAJLEamtxocZ\nz0EkcBYi0I2I1DraPLrbNYfY+bfZtVzORGBrXWzrce1sR9u6eyAt4C3724q0Mlf/6mJ869/Artli\n13Xk8ztEFnHkxkzY/WhGeSRufd3wxRgfwOfVFKK8mGLbz1EoeGIU8vnEkQ+oj10HFMTwe3SP++JN\nX3GgkDDMpU+fQoJgKW3Dew88sB8XXXQqa9Y8Z/dyGnAcL774Pn/607MccUSShoY411xzMGed9TWa\nmkJgzE6d6E7CLy1dxODBH9DcnE8kEuHcc8fw4x9fut2/8Ulfxyc1hsrKembNepLPM5xmP3Bg8S57\n6XyVxz4C2UvHJx+KXTkEd6Zen332CZx77phP5YN87WtHk0hkoYipAEmOKeRM/RAvufdCYJuFTDIZ\nKDO9AyKEKAJil8kex0vxDyDgc4UVXWSRs9O7WlSBXaMWgeVUpBU043NCUgiAp9i1KxBIHotAewDy\ntYAk8hjylzTZcefgI4lCpDU5UA4QcLuIsjHIX9KMr4cVQ+afBmRGKrY5rcDXswJvbppu8z0KaSIB\ncpa7PuVH4hP72iOtzOWYuJySuH32DXtvHTLjbbT5v4dI978ReXRD2t5Vtm43ry5IM2lGQQ+u1EoO\n8gFdb9f9mc31fHzl4JNwRRF9gmg7ZE5LIwJOsHbtNmIxV2V4OkGQ5J13uvLuu6tIJPoQiWyxPWgh\nnc6hpSVg/vx6YBjTpy/i1VcXsHnzkl2ahcIw5MYb7yIWG8hPf3oSv/3tGKZM+V/CMNzBv7EzX0fb\npNrLLuvKX/8a/Zt8IXuz47zt2F0iYW0QBDU7+VcbBEHNP3KS+8bfPtxD8dhjz3Lddbfxxz8+s0uH\n4Gd1aXM5JCtXrqO4eCkCow3IWV2DpHtXyLALAqCPkcmjHtm96/BmlEMRKI5BgPIBkmxXIJ9EGR7M\nQZFRUZTp7vqQn4ak5lZ2rLdViByzuXhT0CykjWTYOWcgk8wLNve3ERGtQgA/CJlyKpBzvMm+fxy+\nW+EFNrda9BidbmtpQqaoWlTQcQLSuLbY+TvbWouRiWkkAtdSW1N3fOXbIXauzfi+4wehToL7I7/Q\nfrZfHyA/lEsovAefcX+6Hf8kIqQViNw34Ds0jrD15iBSPAVpKQ32OhuRRSYKKjjE5l+GiPhiRFZp\nFGZdgLTNN22PeyKtbD7SVCI0N5fR0oLdq/WEYTatrfeycGEOsdhq5HM5w+5xSFNTM/X1eUA36utz\n2bChlJ49t7b53a7bLiRNnz6ToqJjWb68kIaGu7nhhle55JLrmTcvh6KiY7YD+9ixDzN27E+orT1o\nB5C//vrxlJdvYejQ03jqqTqamn79N5HA3uw4bzt250RvH4Zhzk7+tQ/DMOcfOcl9Y8/HJyWfSy/9\nDb/85SouvfRXu5SErrvuuyxYsBhgp+q1yyGZPfsZxo49jz59XDXb5xHIpfDNo/6KAHEUspd3R9J7\nR2TK2YYAazCSqlcjKfcABG5/QZpGPwSopUjDKUGSdCsCpSxkf3emr3PxPo0u+Gz4ADmLB7SZS4CA\nPBcRW4OdfwsioHKbz/6IyJoRKY221y5o4GNk7lmKpO13bT/iCNinIrB3pqko0k7a5mIkEJH2svm7\nObfYfjgTmiPChXY+l1cTsz2psDn1QADtMvT74EvjB4iAXL5N21yYDKSlFSKSuA8JB+3s3nVB+R/l\ndo6j8OZBV4XA1QybbuucZve51vbiTURUT9pxR9u+/MKu48xcKsKYmVlKMun8T71sjlvtHm/loIMG\nsmLFawAsWLCYvn17cu+9m/je967nhhum0NpaSBjmA7NYteoZ6ur2p7V1Kq2tw1m79jlgFu3b55KT\nMwC48FMg/3lIwGn6wF7rOG879tiEFQRBQRAERe7flzmpfePzD1+7ahlwGvX1ucAM6uv7AKdRXr5s\n+0Pgfuy70k4+mUOyYEE+P/nJZNas6Yds8rcj0OiLwLkKge4wZN7phZfqXca5q2EV4jvq5QNP2DmX\nIsKII4e7y29wdZ0y7XV3RAIR5Idw5cezkfN2OQKxsxBgliIQdaVOXL7Cr+w8rh/3ETbfHJRDMcDm\nWopqP/VGwBxBJFqMfBMH4suhuFpTpyHwn4HAPkRmvtvxJU4SyEex2dYO0hgyUUXgQxGQr7c9+qRJ\nb5idqxGZpd62eWxFZsUP7FwfolyXJkROQ1Cr3wgyKy5A5OF6iCxDfpkaRGKrUKOpLLsXF9r+tq0H\n1h8RWB4+KTLEJ3Je0GZfetq+DEOaThPeDNdIS0s++fntaGo6liBosPU04vu3dGLJkrXcf//DDB/+\ndSZN+pCrrnqE2to7mD27hIqKblRU1Nl+PGVzzQMCNm9Wy93BgxdRX9/Ktm0tDBnyH58C+c8TPdXW\nHPbv0H/9MwkkCILTgyBYhbKC5iDj9V+/5HntG59zuB94S0sR3btnWZgtpNMRevbMpqWlcPsxl112\nww4P3nXXzaFTp0OYNu0hwjCkR4+eHHnkUFpampH0uxgBoYvbL0HmqrV29TfQQ+q6/JUjyfVeRDIR\nBM4X2DEuoqgEuNk+H4wk4SIUXTXIjslAEm2mvT4IgYmTrF2ElWtw5EqOjLH3jrb5vIAA8U0EpC48\nthWBoSvHkouXzGP23hn2f1czKt7mutlICypCYN3LruM0HqeV5KGoK1ea/TW8VN4PEZ9rnLUBr2FU\nA5fgQ4NdIUvsWt3tGkV2Tw7FBzpUIG2m1NY/CGkELky30t5z2k8ET4yu4GKISGOrzelcvFZ1GtLA\nCtpc37XvrbBjYii8utjm7a4VALVEImlk3mqHwr6XsW5dHCghDHshzdQFaQRkZEQIwzS33HI/773X\ng3R6GmVlZcABbNkSBS6jubkc6EUk0kIyWQ40EouNIxJJcNVVIzj99K6ceWaSc84p2iXI7ykJ7Mzn\nMXPmbMrLt+x1jvO2Y080kFuQzrwyDMPeyLD75u6/sucjCIIxQRAsD4JgZRAEP97FMXcHQbAqCIJ3\n22bH7xs7H6tWrefBB0/mggsORBL0ccTjAZMnX8KDD57CzJmPs99+p/Lyy5BO92Hz5iRwGiUlb1BV\n1YH8/E489tizTJtWRmZmNgKKexFQOTNDEg86BYgg/huBUWckJeYh0J6H7wL4DgKQd+yzGCKlq5FU\n/D1kSnoBSbPTkZlkOSIxV5fpQgQmtQhgaxCIxe08zpbvMssX2byOwzeliqHWtxX44opr7Zz1eD9H\nFnI+19ixGXb+l+zzI5FpaTPeT/GGrS+K9+FcgkC7zv5W2f1xJFiM+ogX2NqfsfMPtbnH7NquxMsy\nBOihfdYJPZpHogAAVy+rI/KJ9GdHn5GL+DoEuNTO7ebqci7c3DKRlpXA5+RU2H1cbedejogORIbv\nIv+PixjDXiftPC5wYRhBUI9I+21b+zGIlH3EXzRaTCKRTefOF9PcDC0tfairyzYzVUAYFpGZmUs6\nXQrcShD0AaaTmZlPU1MFsIRUag0/+EExpaUV3HtvKeeccyIzZ07aDvJto7Ng5wVGdzb+XXwenxx7\nQiAtYRhuBSJBEETCMHwZGYT/7hEEQQQVSzoJiWffDIJg0CeOORnoG4Zhf6TTT/sirr03j7y8TK68\n8lbuvHMZArRRtLS8xiWX/Ijy8i08/vg0brrpCkpL1wCbSKffJBpdT0NDDqnUUL75zXu2OxZffHEl\nicRcpHGsQj+ZMxD4DELAUmjXcY2FXAa0k/BfxZuxvoVIphkBoUtuG4mifZ5Epq0L8BJqDEm2s/ER\nWtfie6pj5yxBgHwfAuiXbc6v4su5z0Ba0Va8eSfH3u+NgK4GZakvRIDWjEjpRPu71q7bDmlMNchU\n5RIgEzbHCHLGL0FAPhOvhX2MQPYyfB4FyLzVisxwG5Hp6lQErlfb+p9A4FqCSPMDW8/Fdt1FSHuY\nijSRLYh8A9uXpJ0zis+PUakamZKc099pWTn4HJnQ9vFAfOvhEYjoO9l+H2T76cyBLvs+Zq9D+26e\nXasbqdQh+BygDugx74IKS64jFjuLVKqVrl3fJ5H4kHS6HBhIdXU5IrKzSCRifP/7JxGLRQiCKsJQ\n5rVt21oJgl7Aq4ThACZPfojnn1+7g09wzJiLPhWd9beMvTlZcHdjTwikyvqBvArMCoLgLvRL+iLG\nSGBVGIYfh2HYggLHz/jEMWcgIzFhGM4HOgRB0IV9Y5djwoRx3Hnn9eTmuj7f9YThAMaPv4C1a0u4\n8MKJjB37I+rq2qMw1oNIpZqQY3MyYdiNVKoZeJOWlnqSSdcVrxMC1iX4Zkk98cliMQRASWTfz7DX\nW+34OtRvexACtl54jcZJ4FsQyD2N76ft7Oy56Ge4Ep+j0ROBUl8krTqnsJOue+B7ZYCP1oqjiK8j\n8H6FqJ1vhL0+HJFIT/vuWgTWC5HpKYoAP47APo4yyiO2xg5I48m172fb+pyPpRTf0c8lKFYjSb4r\n0ugK8cmX3fBZ6O1tfofaeYfbnufaPpa12YdC9Gi5nJxNdu3F+Da5D+JDqvNQxFsO0mg6ogCClK3D\nVSceicjA3cP++N4mDjiLbG2ZQEdisTyCIGrz2WjX2oTudXeg1RIM3fcjwGpaW+uAA1i3rpqSkkIU\nGLEYke0LRKMFHHhgKUuWrOGRR67i6qvH2p4pGVSVpCNAN9q370VFRQecpjBmzGhefrmSoqJjdxl2\nuyd1sf4dfB6fHHtCIGcgZLkG6dQfIqPnFzF6IBHLjQ323u6OKdnJMftGmxEEKlVSU9OETBINwAQe\neOA9Jk1aQ1ZWe4qKOuHLcHQjEilAD7DqZUWjnRk0KE4s1ttyPwISid706dMDH557Pz47+5v4khRv\nIKn9LARebhyGpPTlCMA2IfA6G4HbcjuuDJloXka3/ixbw0K71qHITJOHCMqZZCYjQDsXby/va3Nd\nY+c8DRHgAYgUXVWe0/DO4MUIrF0Zcmey24LA9CRUtHAkXhkPEKk8hEhmFSLIo/DVcqfhuw0OR07z\np2w/G21/Cmw97VA/kQCRaBzff/w8+1uKzElbkER/MCKTQ23urndHGbrXZ9qxJTjTkfb/dRT88KYd\n1xmZvFbZ6wRKJDzBXq+2NcfxEXgXIC3QaTXn2OebkHkwA8iktbWCMOyB8lR6IKFCod/JZJpodBit\nra54pKLlMjNd4MLPgN4EwQabTx87z1FkZLzFokVdGD/+XBYufI/S0koyMioYPBji8bVEo2lisXFA\nI6lUSCKRRdeu36GkZCsPP7yM5uanaG0tZO1aEe8nTVB7opk4cxcoKuzHP750l8fuLeMzCSQMw21h\nGKaskOL/hmF4t5m0/iXHTTfdtP3fK6+88s+ezj9trFq1npEjq4jHe5BIvAvcSnV1Dun0NObMiVBZ\nWY9/8BtIp2uIxzMZPPgaYrGAgoImTjutK5dfPpy6uhaGDLmGVCrKxx9HEVC0QyDchADZmXtyNbc0\nVAAAIABJREFUEXC77GQXiXMgSujrgUhkIwL2OXa+M+2cS+18PZG56xC8U7eDnesNBHhz8b6Bl/Fx\nHh8iCb23HVOPAGwjMoO50iYuc/sFRDDrUf7DUHzvDJff4fJE2iMieN+u1WzzSSOyuB1ZY8faNS9E\nZi5X5HE5MoVNtes4E9smm1cVsv+7Ei8vIbnKlX13TvaTEZiDNIUoyg7vgbSADXgia4eEg18jv0y9\nzfEoW5dr+9sX+YFcnSvnM1mOyOlcBPbyq+leJJFWepFdb6PNuRr5aLoi81ah3R+33wkkGHTFVVNu\naioilRpDGK5HWuZKIEVDw1pb31iULzIQEdxUm9tb1Nfnk0pN5dJLH2fSpD+wevVqZs78DkuX3sE3\nvnEgo0Z1ICOjMz17bmLbtmouv7w7JSX3c/XVvWlo2AZEaGkJicczyM//FlVV9Tu0dJ4wYfYeJwSK\nbDZy9tnf/5fs/fHKK6/sgJN/z9iTKKyzzYFd/SUkEpbgK8SBj3/85DGFn3HM9tF2Y4455pgvaJpf\nrTF9+kweeuhJPvighpaWe2hpGUYsVmcPZkBjY0hhYXdOPRXatetCLLYA6M6YMSlOO60rV11VTFlZ\nB6ZMeYfS0gq+/e0cPv74ZVKp90mlPkLSf0cEDAWIEHIRiRyBl9qvRSDuoqichqJsYmkMHVGE0GJk\nOoog8NyA/ASuftLbSOKOI+n9Xvtbj4A3hkDuQiSBn4h+Kp3wJrZCpO3kIeA7FwHuIKSBdEHmos6I\nsDYi57lMHwJU51R2ZdiTiByPsrmuQlrNw/a9byCQTiAFPhPvK+mMyCXL7tyf7fV9+IisoxFpud7j\nUTtmsq2nyM7ZDeVTRJH5rzsi+MD2eovNx2lMrbZXPdrsjyul/5G9P8PmHyCSuBH5gKba56+h+38s\n0pYyCQJX76s7KnNS1ObcvRA5Hm97MMY+PwMYSDSagcxwBXbsy+j3cgwi6022dufHOg0HBWEo7bm+\nPko6fQuVlUP4yU+mMGPGLGbNmsQppxzLgw+ezB13XEwyWUhpaQWRSIRRo4aTThcxZMi11NbWcMIJ\nzTQ15XHZZd22l/AZM+ZwqqoUTbc75/iOkViTmT07RVHRsf9y2efHHHPMP45A0C/j9DAMO3wJiYQL\ngH5BEBQHQeDE4ac+ccxTSBQlCILDgKowDMu+oOvvlWPChHGcfPJoqqqKgOfJy8vmqqvOIyOjHwUF\nl1BV1cBPfvJ9otGARGI+ra1DgD/z3HMt3Hbbo0yePJvW1qdobOzDww8/zv33P8m2bXkI7I9CD3AG\neoA34du0RhBQZSOTymIknbvmUmchsOuPzCY3I2l2KpJW1yOJNMv+ORNbHJlEeiDJ2JFRCgHQm3be\nFXZ9RzrvIxJyVV/nIC2mPyKG1Sh0NIVPahuNgBpEZDFb41a8w/t0RAg97fv57BgCC74b4mLk5H3T\n5udCX5XvoPW40ieujPss9GgMR2TSH5HPQkQUDsDnICm9AEn1lTbX5UiLW4XvupiHSHk1PpfjdHxP\nFles8RBbm9v7EBHYfojwcvCCgPNbTEWEW04YunDlTDyhuWq/CdtH5/fZH5HV60AXUqkE3ly31eaX\nb3twqJ3D+XaiyKyZiwSad8jKOo5USsELTU3hDkCfm5vBZZf9Fzfc8BqNjb/nrbcS7Lffqcyc+RQP\nPDCGK68cTkFBNa+/XkFd3WRmz67l7rv/l+7dR/Hww8sJwwzi8QvZsKGcW2/dsRWCG+PHjyUeT203\ng4VhPq2tRdx11yP/ciTyRY09IZCyMAyXfRkXD8MwharnPYdsF78Pw3BZEASXBUEwwY75C7A2CILV\nSOS9/MuYy94wXBfBoUNP45FHNhOG95JI/JHKyrm89tp8xoxpZdOm3/DAAyczc+ZsVqxYz7ZtroR5\nYIXpIoThEEQOzwKFJBI9kCYxEa9dgAC2GQFpDfIJxNGDXY5uawsCo2VIauxmr/fHS/IuTPQIBEQJ\nBFoOrAO8zds5bU+3v6uQBOvm6KT7EJl9XDMk14fEdT/sh4gibnP9IQL4Q5ApZq2toz3SkFxl3Y3I\nRDbHzuucs07biNh3JtraRyJJfT9EGKWIVLMRwbXa9Qrs3FHUJjjNjr3jY0jSX4VkuhQeQCsQoB+B\nAglG2D4cji+Bn2v7+rGd+1V7vwQfZuvksh523Nn4/vAVbf65nvN5eO0lYcdFbe9fs/eqUYmTjXZv\nm2yeI20NpTbHTeg3Mt72N4XMis7UmG3r7YXu/Uc2t07ANLKzDyUWqyEM59G5873bo6AArrvuNvLz\n86mvP5SKinXAbWza9A433XQFTzxxD+eccxKXXXYhd9xxHZmZfYFJNDS0MnLkEO6887/NxHUyXbr0\n5OtfD1i+vPd2X0hb5/rjjz/H8uU5RCKJ7f6WlpaQn/70yr02nHdPCGRhEASPBkHwTTNnnR0Ewdlf\n1ATCMHwmDMOBYRj2D8PwF/be9DAMZ7Q5ZmIYhv3CMDwgDMO3v6hr723DdREcM2Y09fXqAlhQkMeI\nEYX07duXF1/M5Iknnuecc07ipJNGUVa2haamLghoXXLfCCSdu4zqA2lsrERAezs+cQz0oA9AwN4b\n2e+fRQA1FIFyK3r4eyNJdQXSTpbho6GcU/h1BKqumdI7CIRftGPPRoDxEiKiN5BGsRGB1sEIcC6y\n8zYjYE0i8B5t53WRXUXIfFVg8+yPTEN98JFDh+Lbxf4JX4urOwLECXadhUhDe97m+ktkYnLxHy66\nqR++MOPz+CS/OgTALyGJ2mkAp6MM/UOQ5jcUNZdahSfHFlv7vcgM9g7S5O5FWsMBdq/SqGdIHSKJ\n79nasTWutHvT1+b0PvIhOQ0yD+V2NCINKbS9GGufB7af020+W5FPyVUdmIuv29Ub/daabZ9n2/7f\ngsjMlfoP0W8zw849F3ifIKhApjD9zlOpgP3370cyeRSjR3fjt78dw6pV6/ne965n0qQ/8IMfPEdD\nwxQqKuLATOrqenD77b4qtQu5LStbA6xh06ZVPPNMFb/61f2kUoV07XoPGze+wKJFWTvUxfre967n\nzjvXba+v1dR0PJmZH5NKZdOhw4fU1tbstMjj3tIbfU8IJAcZmk9EyHEaCiLfN/5FRlvbq7oILqO2\ntpmuXb9DaelqFi7szCuvlG93AnbvfiQ333wPYTgCOWNfQcCQixzEwxAorUImj04IdBvt2BoENkcg\nsGhCuQd9EDA5CfRlBHy34EM9QeDoWuq+gi/e12L/XG2sDigD+Thknpli1z7S5nkQkkRbENn9FQHU\nevuba+eK4pMSk8i88yaSYANkY3eVcp3E34RAcCoi03nIHDUXSc9pPBhmtllzxOZzJNJihtj8XZXc\np2yfNiLfyf6ImGrte4fbNUciQnWJguA1tVttvuC7LLqM9xa8D8KZ+RoRcefZuY+0ud9q+/EjRID1\ndj2X9T8SaRq1yPfwNBIYXLRcPvoduLwTV3LGRa01I6HjIHSfXWOqSqR5uEz6vnizmDOZDUEEvNhe\nn2Jr6QRcShgejMgR4CIaG+GNN5bR1LSGJ59cyXe/+5/cddf9vPRShHT6p5SW1uGrKRwPnM1bb3Uh\nL+8Qpk+fybhxE7nggv+gtTUTmEoqlUNT0xoWLGggkXiDG288l6uvPme7YFZeXktNTQ0vvRShqWlK\nm/pairK79treVFTM5uGHL/9UOO/e1Bt9T6KwLtnJv+/8Iya3b+zZ+GQWbEPDNo47ro68vDI6dy4k\nDKdTXi6fRXn5Mu6663pGjhxGczPABCKRUeiBV/x9ECTo1i0PSexXILAagwijCzIj/Bgf71+DJOu/\nICkyRFJuMb52VRz5QKIIyLLxJdXbIWDridcUXC8M52cpRqDtKvqCJNUsm2MjkurfQQTyLgKwzsh/\nsh+S+CsRgDgNoQofNhyzOQaIvJx5rZtdLx+B4TQkoa9CgH0CIps0MjPFbA6uiVIxIoNSvLnLaTZR\nZOo7DJFWW5OQq/NVgHf6uwRFpxW4Ph4ZCPAjeNPdeLw/w/mLnNlwgN2zdSgc22mNffEdEbNsn/rb\nOkFkmoVA/TDbP9d6uCs7Nr9qwXcmdAUlHcHd0WaPS5GWUW9zP9iu77okRtvMsQoJDVMRec+39c0h\nnW5Cv7f9gH5EoxmUlLyH/BFrkICRgchOiZbp9EHcfffvOfLIkVx11ViCwHWsBGk8fyGROIz/+q8p\n1NRUk07HGDLkWlpbA84772R75ibR3BwSi/Vh8OBFpNOFO+14uDeWeN+TKKy7d/LvliAIPpnwt2/8\nk8Yns2DT6UIuu+wibrppIrGYitqlUr4W1vz5i3nuuWqamwN69pxAMukcuxESibGEIeTktCczM4Nk\ncjLevl+BbNoJZOoJEMAnEbC7LOsGRDhd7LzXI4l7OTKLpJHUXYRAfiMCSVdl10mxrhJuAZKgP0RA\nHyKFeAACsqfxkU7DkMR/kO1OH7vmaJuH07J+j2zsLQjMshBYv4tAtQCB0Shk0huOJHYH8K54YzXw\nfwh0j0DE57LTgzb/MpBWdbpdcynSgBYBj+JJKUQk5mpujbP9eQUBZRkCdRcFpmoCIs7hCFRb8SHO\nZyLTWtTW5TL86/Hl20sQmTTZ/mQgc6GrDhyzezwGX325D6o0XGjr3Q+B+yZErC4vxQU8ZCDTYgFe\nW0rZGrrbfZyPfhOVSEt0JroVqPpuEu9jcef8OYrQOxZvQrub6uo4lZVVNDSUkJFxKyLBjfjgh81A\nQHNzwE03Xc7atZsIgoB0GiKRs/H+mwh1daXU1x/KvHmL+e1vT7JEwVMoLa2gvHwtkchaqqs3MHHi\ncJYuvWOXSYR7Y7mTPTFhZSBde5X9G4buwKVBENz5Jc5t3/gbxs6yYGfNmk1VVQMFBZeQkRHj5JP7\n0LHjuzz44CIaG48nM3MVZWVvEIup/0YisZDevSs54YR60ukoo0ZV0NT0MbJ3r8P3IF+GpOe5CHTW\nIwA/H4GNa6+6Bm/yWYYk+FH4aq/vI8ApQD9FV9E2goC2FT3oWxHYJO3vIgQ0U5E2tAaBSBQB21FI\nUj4AAXo7BNIu69qBT4CXynsiYBpqx/VGhLcFX0DQAaorHR8ggtsfaUtOY3H+F9coy313CyKOOnyj\nrWq86czluFTb3xYknR+GLzcyAZ9L0YqvMba/7Xl3e68Jr0mMtHWvtH1aYfvW1fYfO74cSfdn2N9S\nFIq7CvlhRtie74ec8K12L3+N75OyzO4HNpcEsni7tf2n3ccz8AEIITIR7od8OP2R+W8YIpYXgWre\nfttl6LdHWmWI8puPRaQ7CpXCuRLIIBbTvkaj7vdYBGwmCJYgYekcGhtDHnroSaZOLeXRR58hL+9t\nOnbsavdfZf3r6trT0DCF5ct7cs01v2DGjFmUl2/hhRdeJze3G+n0vRQUFPK73/2JGTNm7bJm1t5Y\n7mRPCGQYcGwYhlPCMJyC9PVB6I6d+GVObt/Y8/HJom/9+xfy179uZMKELlx88SB+97tT6dOnD3fc\ncR1ZWf2BCXTocDBXXvnN7b2pm5sPJicng7PPPoGKigrefHMLejhd7aojkRmgFyIUFzEVR5pBPgKb\nEuTjKEWmmmnIF7INgVAXO97JJmci8FmMHtxSJEm/jMxdT9i1mxGYZrBjE6kWu86tdo2N7AjoMWQy\n62r/dzEgjkScaa29zb0AgaLL++iKzwwvt7W/h4+UqsZJtDpXyt5zGtYcvCnsWLtGM9KUEghQz0OP\nVS+7RsKO6Y9v39uI/EmD8WG0g/EFB50fwZnS3kbEeQ++xHq+7bFz5ieQX6HJ7mM35NDuavcgtP/3\ntTU509ZFSBvJRSa4YkQmrtdIJ6RRVCAyclntG5CwUYZ8Rnm2vgMRYV+JTI0H29qHIB/VCHxttZOR\n0PI63k/1GtIeE3YvoKYmBtzCtm1pm3cOiURXwrAvkchLRKPbgOX86U/vUFvblebm/cnMzKCubhHw\nHrm5vTn++P2sUvCOYblhGPLrX/8XsZh+Q7FYBvfc89+MHz92tw7yva3cyZ4QSC76VbqRDeRZCG7T\nlzKrfeNzDRfG6+yszc2zefjhMm6//f94/vk5XHfd+B0koC1bljJt2iwqKt7HNUBasCCfiRN/xtat\nm6mvd1L+EcgstQIvvbdDgOFKjRcjwMxAYLMED1LOpl+MkteieOn0A6Sl3ItAwoV9HoMAtoN93yUE\nvopMJSBzTDnK4fjYjitHEvA2BMyn2xwuQWC2FP2kXYLjW8jE45zAUTu3A+OOyNxTbev5AJ/pvR6B\nWkc8qC1DEnMfO0errcGBr8uKr0Gms0IEfO3wgQRJO97V0HL5JX2RNrQUaRzO7HSjrfFoRBojUe7E\nAYiUb0BAnInqa1Uhc+Ay+36pnS8Tgf5yZBYcjUjLNaxK4bWvPyON6lVEUvfamqtsLi/YvA/El8Yv\ntL3JREJEDN/P3RVbLEO/jQrbTxft5fwomxEhJmz9ztxZhn5/xeTmxujWbbmd5z079kygidbWHOBq\n0unjaWx0xT8DYAMNDeUMHz6Q5uYDgSYaGloZNmwoQbCOaHQsbcNyL7vsQoIgoLx8G0EwlvLyOoIg\n4PHHn9utg3xPq/t+VcaeJhK+GwTBA0EQPIiMrZMCeZte+DInt2/8baNtGG95eS0QsGVLE+n0Lbz0\nUmDE8ovtdtxvf3s/Wlsj6MF2hRchnc5FINbW1pxEBOBKnDfjs8U3IzB5w871AZKkXcirS7xL4ntn\n5yLJtge+HlUEaQ8RBLQzbF4H4tvOtiCgedde5yKw7IDMGS6CqD2SSt+zuf0MAf9+CJyeRiaPNNIQ\nGmy9g/D9u11L3HxENE7i/TMC6QDfM93Z/0HE97Qd39uuPxKRcRJvcnre9vRse38G3rHfHin4ATL3\nJFDYbTvkK/kAEco7SEOcgyT2c/CaVzvbrw127QEo4qrG9qjY1jwC1feqsO8NRFrFGnSfXU8PF/48\nz96rtPvktB9XVn4J8r/0Rxn5OTaPEuSn2YCEkXrbC6cBdkcEtsK+PwX9jgah4o5xu8Zae78VH5zh\n6m6tprKynObmOkSMr+DL5MwhnV6BfhdTCcMMRKwFwEjq6lbw9NN1tjeDaG39kLvv/i3Qj1gsRc+e\npdvDcmfMmMXll99CEJQQhjOJx8s4//z/4PLL76e29g7Gj3/yK+8g35OxJ1FYv0GxhU8iW8IRYRje\nbzWyfvRlT/DfbXyeGPGdhfFWVzfRseO4HTJzTzrpcD76KLH9ex075nLFFRcgcGrCx9u78EhXFM9J\nzu+ih/Rt/MM7Ch/r/ySSBLPwvT6WI9v7MiQhOjPRKQg8ViKAOAb9HPsjU1TbaJiOSGLub8eejw+B\ndU7q4XZul3zXA4HSIASINUjynW5/65GEfZCtswUBWD3SJtojST8fAfqRtjdtKw+3Q475CgS2PWyu\nG5Dvw2VRH2HnuhJpBEcjQH8E+XNm4cNaP8T39lhg+7jcvvcftu77EJE9b8e53vEBkunieCe4K6Xu\nHP8tiDhm2d67Uux/RNJ4FwSgjyACdeBfhEjGmfhcEy7XE8YVxGxBhDe0zTzLbK8/su87osq3NXyE\nBIevozwV19nxNLvWDIJgE7CEnj0dAdfYPi3GkVwQJBg4sBBoYevWgxkxopDCwuHI+Z8kCPKIRAah\nkOXTbI4z7L4/CiSJRFxkYS3pdDOdO3+dVGoqeXndyMmp4+KLh2wvcXLRRV+noUH+uw4d+vKDH4wl\nmewHBFRVhZx88uivtIN8T8YuCcT15QiCwMUJrrd/Xe29feNLGJ8nRnzChHHceOPllJa+A4RUVKzk\n6quLmT59HMlkJe3a3UFJyVZ++9u5tLQM4corH6ao6FjuumsuCxYsJRJpIhJ5F0nx8/BgeCa+rwbI\nJNIRAcsBCKji6KHvisjGAWE35EdwkUVZyCwTRUAzE4Gjc8w6s5ezjYOIIonMNoeihLXNSLLPQuCb\nROBVYf/PQpFLLUir6IYidYrZ0SdShMxpSZtPhq2lAHjAjnNA5cCwm63FVZotQcmSHWwN+TZXkJTs\nHPYOuBfgS785cowigHM9QpzDez0C78eRVlKJQHgLnjSLUTRbT1vTCza/YiTFv4CIOAsJB1F7HQUe\nQyanthFv4xBJu/Pfamt3fq6DEGGsRWbGQ2xPXCmZs9DvZoXN3503jmTPo+w+ORI7AgkBLqN+vM01\niu9gqXsWhpCV1cSGDVuRPBugyMAW++7vCcMBrFjxEfKr3MeiRfWsX1+Ofh/tCMNm0mmXxJiFD4Rw\nwRCdSafXAucTBE1Eo11oadHnsVgmN988kWnTfkZubgZDh562Q4mTkpIK/vKXl9i4sZJ4/ELCMMms\nWcsYOvS0vVoL2Z0Gcq39/dVO/t3+Jc/r3278PTHiQRAwf/5iamuLycsbQ3PzcCKRCB9+WMLMmd9h\n0qRxdOz4HjU16uNQWhpn06Zqmpq+wcKFVXTvXsdBB3UkmXwHAUEeeoDHICk1goBtOr7O0RwEailk\nHtqItJOQHRPfXA+J9Qhw30EElULRSM6RDTJ1HYDAZqVd5zQEpHEE+JIwfTjvPAQgr9s5T7ZjPsQX\nOzzcrpmFzFyZ9voofE5FDiKn0+2zDXbeSnx/71ZkOslHJqQifIirS56L4arI6tzX2NqakCZTa585\nc9DNSDvbaPN7HpFlo51zFgLdzrb/HZEW4sqeRBApdLb71Q4RkSt42cH2pB2+/4frlngQvqaZ87O0\nDc1+DWk/2fhil1NtP7sgsr8X7z8ZY+c72l5/0+5Ppc1nql2/3vZgsp0nQILH+fjfzOs2d5f/EqWh\noZFo9FCkNRTgtAaRGfa9GPKNBEQiVcBWEokapPH2IgiSJJPL7HoxfBMuF2Y+ALiYgoIG0ukNVFY2\nMGTINZSVye8WBAHjx4+lf/8e1NfX4UqcXHNNb4qKenH11b3o0qUncAoNDdu+8mG6nzV2SSBhGLpa\nVMfu5N9x/7gp/nuMzxsj7ohn+vQPgXupre0NrGfqVN+T+bLLLuLii0/HA12MzMxuwEU0NRVx3nlj\n6NGjgDAsIBarx7eDPR+BZNumQSECaBd2uxAPWmkElP3wLUsT9p2j0INejUjiVSS9utIjCdRLYyEy\nZ221az6IzDQJfK8xl7HsEto2IGm2M9IeXkAAUYyAujcinTLkuC7B+zzeQ0CSgyKaXOZ0HgK6Q5DU\nf6btxSv2vajNsaPtxag2d6Udvg+Ha90bRcC6AZkAQ/v/i7afASKN/RFRHI40sumIsIYicslAxFZu\nazrL/t/BvvORvT8VaQtlqMz7Frtf2fgEv+dQdFQBIr1H7ThX0uRNvBPdNYtyARHr8P3t62wtw9A9\nvc/2pQZvAnPan9PIeuGj6EAaQAekpR1j19qCQoCzgA8JwwipVJQdtYYk8mOMQb+X/khrG0w6vT/w\nOM3Nxaib40rCsA+p1BASiVpEGg/YPqftHk4H5rJly/uk07245ppe3HTTiUQiFTz55IuArARPPx3Q\n1BRnyJBnqa5uZNSog3j22fsZNWo41dVNDBnyLOl04Vc+TPezxu5MWIcEQdC1zetvBUEw2xIJ8/4x\n0/v3GZ83RtwRT16eHu50OgJMJDd32HYCCoKATZu2kpERZ8iQa4hGoa6ulnj8IsIwyW9+M5fZs0N6\n964nHk/jJfn2SNNwfbRH44vzDUBAMQKRRxcEdBegB3OuHbsCPZiuV3gMmZ4iiEycA73c/jopd6Sd\nw/kg5iEwXoF3lNch6ba7ve5ox0QRcBUhYMlCIO2CALoh4Cm3ORyBgHc+AuqpODu4QD8blXR5G2lS\nbyICysfnYThSdH6ADJtbEQK0kbYvHZHJqQsC4XI82KeQFudAuhMyFxawY1n7Znt/CQL6eXbu39s6\nO+NBdotdo6PtUW/b+3W2f90RYFfa2h9HpLnMjhll363G+8lcXstARMYf2f60Z8fAi1q8CS2CTEkJ\nRMyBvQ5p3z6TeHyjraMvAvFuNvc78IEHHfGNskJEbi5SsMDuX4HNua0WDNnZGXTpchxwCtHoKpqb\ni+wenE0kMpRTTx1NIuG04Y2k08WE4Z+ZMmU548bdSGPjqTz33FqSyWF897tPkEpNJSsrD1jJN7+Z\nuT0cd28L0/2ssTsT1nT0SyUIgqNQbebfoV/SjN18b9/4nOPz/Pg88TTRo8cEUqmQnj0fpLq6cQcC\n2n//QTz00KksWXIH55/fjiOOKCI7ux5YbKat6WzePBCf2PUsIoBjycjIJhKZj6TWtxHIOY2kFdnS\nn0EP9CxEFL9AmkjbkidJfL+OA+0c2xBQPcqnczcKUCTO4QhY2qGH3p2vCIGai/PvjoityuYSxVfI\nbUFmpxxEMrkInA5FoOlqS1XZubIRGF9oc8lH0m0+CifdiojTJe1NRcCVRAC+P+rn7dZThqR0J/1P\nRxL7YtuzGALafnigHYqk8rZ+CufvybTPEogA48g3EcMDfRwBeTe8GS5q8zsCX2F4HD4E210nRKQ3\nw77vmnU5Mi1A5OWc6b1QpJTTPMG3M25GfjSXWd7BXm8A3qK2toGWFtcr3Tn8M+xaf0UEONK+t9Cu\nvQkRndNIXH6LS6bsAkSIRs8F4nTp0pGmpnXAfTQ1FSOHfSmwnnT6dZ5++jVaWyP06DGeaDRBdnYS\niBCJJIlGk8A4WlpStGuXQX29rllbCzU1NQwfPmR7OO7eFqb7WSPYVbRPEASLwzA8wP5/D7AlDMOb\n7PW7YRge+A+b5R6OIAjCvaHC5d86fv7z+xgwoIgVKz6msrKC/Px8+vcvYtWq9bv8Af/xj89wySXP\n0KHDJkpKXHOo7zFo0EesWFFHGNYhkD+eSORO0umBCOguRgDcHYGlq+Y7DDl0tyB797koIW0Z3pRS\njRzuyxCYj0DhsYcigHKmkq3IhLTSzp+DpO1SBDBHIECsbfP9WuTIX4tMJ7VIS+iHpPNWfKVhV1hh\nFCI+19jpZXtvo51rCwKoXCTdJpC55H8RsSzE99D4ne1NA77x0TuITEsQCLt9G4Ic+98kvumUAAAg\nAElEQVTFa16dkQSeiTSR3vh8FyfpuzDXw5ApLbA1PYQCDBYgAs2xf3MQwB+L13ZyEWll2307yK7T\nYGvejAD6FaSZTAe+jbSrBCK/vrbvg20Pqu3YkSjEuQZf3fdoZCpLoN9BH0S8K+36oOiuJUjjcv1g\nam2+KVv3CnQv37Y5l9ueuP3tgjTDAbbmBYwY0Zn58x/jrLO+z9NPryAI8kinO9t9fRz9bkYApQwc\n2Mitt15FGMK4cb8lnd5K1679KCkJgXJ69kxSVdWFY45p4M9/jhKGmQRBPddeW8ykSdd9pc1UQRAQ\nhuHnWkBsN59FgyCIhWHYiqrPTdjD7+0b/+Bx/fXjd/lZGIZcf/0kfv7zH+3wI1+1aj0PPngyzz77\nMvfdtxVJrJ3YsKGFaLSSDh2SbN0aAy4knb4fAUKA7yuRRMDjaj5lIwCoxEfwdELgMhdJoceg6B9X\nXHEh3mT0bQRKqxGJ1OBBwpX8zkRS8/tIGnUA/xIqkLAEH5JbizQaOVJ1zTdsDr9GUvfjdr4QOc7z\nELn1ReaYJTaHRnxos5N4Y8ik4sqjnIaA7gIUYTbH5liMAPMlfNSa66nRHoFYqX3u8kmORQAew5ve\nnkcg2sf267t405WT2F2+Th2+mnA2ItWVyNR0gF0jje8uONbO/R4ip7Ns7aCIs1ybyygEBXfgEk81\nj9cREb9hxwR2rq8h35FrF+wIogbvV3OZ5Jei38livMaXb/fkHVvTRgT4CZtvoZ3/D4jgMhFRVgI5\nLFq0mKysoeTkDCYMW4lEchEhnohI+ThkDnuVFSv+wnnnXUmnTgfS0vJ/BMFFlJTMtet/m7KyuWRn\nv84772SSTHajd+/urF1bSWlp+680efy9Y3cmrEeAOUEQzEbiyWsAQRD0Q6iwb3wFxq7Cgq+/fjzl\n5Vt48snX6NChBiV81VBXt4XW1jhbtxYjE8NwJM1mIad6HXrwn0S27DIkXU9HgOiyjbegh9k1cXJR\nXAORNpCBynI4s4mrH9UFSZrX4DPGx9gcjkZENhSRRB6+Qq8rrbIK758oRFpFf0QmA/DmIGdOcfWc\njkHgdp0d8ys7/9G2roPQzz6JT1h0Zcnn23y22Z7FEOk02379xdYfRQS1CZHgMkRMdTaHEIHuuXZ8\ns52/DgFme3asqJu0vToVX4rlMkRcq2wOERRd5CKhZiMNrm3RyvZ2rk729z17r5fdg5fs/Y9QZFXz\nJ+5bDGl1hyEtaL3tZ28E7M7hv8XWs4Udu00GiOSH2vpdD/kBSBC4GUVRuWtNQb8DVyU6iX6DLg9n\nC7CBgQMHEo0eT0NDDPgv0ukE0qLbho+/hsg5kx/84OLteRx5eZ3Iznbtgr9LRkY2M2b8lCuuuHB7\nr/WZM7/D0KED+Xceu4vC+h+UufQgSh4M23znyi9/avvG5x2fLGmys7DgMAxZs6aEX//6P4nFuuFj\n7p1Evhk9sP+DHv6TkTS7AD2kgf3NRg/saehh+yuSqkGSZgECK+e3yLJz9kN+kgBlfW9CoNUXPdgu\nT6TVXg9FEuoWJJ13RuR2MCKydQjojkHE8V8I5I5BkmtvpEQ34gv5NSCg6ots/Z2R3+JtJKk327xc\n6OghCHCGI80oisD4cLzvwyXyudItrgVrzM43GhHVkYiQHkSAW23ndaDmEi/72L1wjmtXGdmNxUi7\nmGP3Y4zdExDgv2fX7YjXIl0eTAQJBa6nuuvzstrec428Mm1NgxDwDsDnYYRI20mhSDtXB8uVSHkP\nn3RagLSXAnweyyokVKxB9386Iq06RNodUPb8fNvnaqQxOcf8efgS91eh+6xCluvXd6ehYQrbtuUA\n1xOGa5Gg1IxPON0MdCcIuhCNRqmqaiQ//0SqqxvYtm0t+m1cQF1dmmuv/QV5eVn/Vj6Ozxq7zUQP\nw/DNMAyfCMNwW5v3Vu7rCvivMdLpNIcddjbpdHqH99uWNHFhwaWlVdx00xXbw4Ife+xZpk4t5a23\nFlNX10K7dheQkZFpxeEOQ1JtNwQgvVC8fyYCokZEGC481hUNBC9VRhBQ9MOHWI7H5xqsRiCzBF9j\n63h2JJpx+HDPEEm/g+xcH+DNHUfb9V3TqHxEUvPx7WjB169agsimIz53wOUf5NixEZv7FW0+d1Lx\nTEQC+UhCrrJ9eN/WvArv1I4gc89CfJhoMzL7NCFCrMHnPCgKSHt6ED4q62wExK+iul7v2Ovh+Da6\nxSh9ywUsXGXn34bPK3GlZBbaPLPwzZpcEmJfdK83IhJxQoUr5XIyIofliMyjKLLsdUTa6+z7v7L9\naWxzDwLbqwKkyfXDR8y5mlm5+AAG8L1MXCDFUqSxLLF9e8f28jrgQ+LxHrRrl6a5WZFoMjG5cO/V\ndg9dWZ0QWEVRUQ1Llqzlssu6UFeXJB6fTyzm+rn0Bd6gW7dcJkwYt8fVIvamzoO7GntSC2vf+Bcd\nP/rRL5k/vws//vFtwM5LmpSUVNCx4zhqa1O89dZiZsyYtYNm8uCDi8jOfouGhg5Eo/Nobc1DkSzz\n0MP1MwTwXfB9FPohyXoOAqC5SCJPIyk9jqTQQvTwP4Ue9nn2vZ8gYK9G4Nlk5+6MAMgVQHzSznWN\n/f0tAp8DEChttGtOR1pCAyoX7kisCwoZdkX3nkYk0wH5TFqR38JFa8VtPj9F5NKKkt0i+OS6y2ye\nc+36mYj4YrY3cxFg90eEU4bvC++aQH1s5+xt+/QTBKhr2lznY0SANQis37U5FQN3IpORa/d7hK25\n0u7DRpvDRcgclGnHf4i0tTmImEtszc/Y69A+L7W/MQTmjUjz6GN7NQEJF53R/T8U+U2w+bq9e86u\nDyL+wI7LQAUe5yLSDRAx1CPf0Da8phVHv49qm1c1vipzPXKcd0Aaag7Ql5aWDYwffx6Zme3p2HGc\nAXjK5nsoIsBqpG29iZL+9uPll9/kd79bRFPTbDp02J90WoJDLFZBMjmI//f/vgfAWWd9n3vv3fiZ\n1SL2ps6Duxr7COQrOMaNm0gyOYwpUz4C7uWuuxSf/uqrb+yQjFhVVUnHjm+Tn18EnMkDDyzk7rt/\nz+jR+9kxs6iu/phkcjSp1DRaWw9EEussBMwvIJDpgUwujyAzwgwEkFnA94EjiEYDcnPfJh4/xPot\nOKnxAwQCDfjWqs5UMwLf02Ih8lecaed9Ew9mXZH0mIGAdQEC2WF4W7xr9boFmaDWIknVNax6BYHV\nawjMpiEiKsdnxL+IJNX/wUdC1dv7K20OzsfhwDMbaVZVdmwlAuuVCNTOxXfziyCAdFrROPvOo7aG\nfnbsmfiyKL2Ay5EprhmRVG8EvjFkErsPOcTL7PpLkTlpEL5vvetTvt7mMQ4R/Hyk6SyxPeyMzEyu\n+nE2AncXurvF1hTgOx++h+vwJ99NC3Koz7L3jrK1LLb7stz20VXQjdvflUgrmmfXc5pils3nDiQU\nZBAEcxFBNyCN5118Q6+jmDz5dxQULCQWW0sksglFyLmEzQl2zWJkDktSUfEmRx451HwgEVpaQiKR\nJD16TCAzM8nEicOZNesJioqO5amnUtTWTt5ltYi9sfPgrsY+Avknjb9HvX3oobu54orzLWlQyYMT\nJ36Thx6askMyYjzeh4svPtta144hK6s/N988ka997RiqqhoZPHgRsVhv+1ytbOPxvkSjfwEGkEh0\nR5L6hyhJrRifpBZD4HEhsJVUKk1l5SBaWu4hDAcjIHsNmW8OQ1JpBiIDl2zm6jIdhwjBJf5l4jPa\nXYRUAoFlBwS+rgFU2wZPEQQ0MZt3LgK3iM27AJ+sBz7XoBaBVDdU7rwGOdBdeG8UgX5PBLhxBH69\nba4nIQBvtbXMQET7NsqnybLrvYGk5KmI/P6AN30Nwhf2+7Ud3xc54F9D5qFmRE6O/Frx5rUMRJQf\n2j6dhUingR2r5Rbavl6IhIAk0syG2rXBl5ZxGkcakf50W8sKBOzb8CXZna8njgijM94kF7V93d/W\nvx/SerD7k4OIZaAdezvedHkiIt2P7Pg0cAJheCBBsM32YCBeAwyAziSTA4nHc8jOhnTahQYvwpez\nids65hCLbSUW68MBBwy1LPJrqa2t4eqri1m/fjoPPHAKq1evY8WKDbS2FhKGqly9dm0Zo0fv/6lq\nEXtj58FdjX0E8k8af496G4lECIIIqRQkEmNJpUIikYBIJMLKles4/vgG3n//9u1tNz+Z3b569QYe\neGAMS5fewRVXDKeuroUePcbT2BgybFgrAuxnaW52kvp+SPKvQMDuihxm4M0MXRAYTyIS2QocYX83\nIc2iGgFwf/SzOxOBQSGSoPvi6zBlIbBcighjGr4XiCv3nrD5uJ4Wm5C5rRyR1P1Ist4PXyTSXWMg\n8qdsRUC8FQFgB2S374AA0FUXPgoB26t2rbORplKGJN9CRAqjkT1+FiKyHvbaOZBdsyXno9iGwLcQ\nD34xpBH1wgP/PKRF0Oa9OD4z2/Ugd+a5pUgjOMvWl0QgvLXNNVzl5a5IM5hjexi170WQNtDL5l6H\n1/SaEdnfZvf8YHxF3ggisdxPvHe7fT+NNJBmpM0k7Lg/2L08AJUd2YgP8V2PSN1VTj4RyCYzE9u7\nGrtfTsNrJJWCzZu38PHH+9t5b7P9r0OazAYgmx49irZrGEuXfrQ9kffhh68gP7/Tdmf544/fw803\nT6SlRUEDsdg44vEMTjzx6E+F8e6NnQd3NfYRyD94fFHq7ZIla/jhD4tpaJjJD3/Yi/ffX0MYhrz1\n1tu8+GIGTzzxPOeccxJDhw74VHZ722zZ1avXEYvNo7JyGVDN++9XUVAQp7g4nyBw0i1EIi0INN9B\nIOUc6O8g00NPJNE9SjqdD5xNOn08sdhqBCbOlr0BgVV7fJhvgEw5qxFofR0BxfF40MtEknNHJLFu\nRU5iFzm0GUnFy/AO4wARWw8E6h8gUBptc22HpP4B9r1lduyFSOr/EBHBdASYCQRspyDgHI7Az4F6\nph33f0jajSLJPhOBpVvrmbYfOQgc17R5H7vOK0i6PgFpJ+/j8ydOt3P2Rya+tj3Ij0Qg+RQiEdfo\nypWBKUfSfju7H65OlSsE+YJ9/iYijjn4CsCn29+D8NVyQUEFm5AmtgJfwv8lfI7LVmSmdGSdjQj6\nMPQ7ONzu7wzkp9jW5h42I/PkIJvXjcAa6usbkaa7yc5Raut6h9bWJioqOiHho9DO19n+XQB0/f/s\nnXd8VFX6/993WgoppBASSUINHRQQMVZQLCiogEh1dV2KAqKIv5Wo6+ru2la/sOIqEFZlpei6COpa\nUBR7xcIiwkJQSgIESCE9k8zM+f3xnJOb0KUq3M/rlVeSmTvnnnvunedznk7Pnmls2SIaRkJCIkuX\nZu83wsoQQFlZKamp2wkPT2TChFQ2bMhjXzhVSpo4BHKccaTqrTF9LV2azWOPTcXlcvHYY1MZOPCC\nfdpn4+MjDhh2mJQUQ0VFgMrKzsBNBINt8fv95OYmoRS43UMBt470MvWTdiMC7VzkC2tyB7ohAs+2\niYtfZQd2dnYVIvhWITtNU58qHhGoIWRHfTby5U9GzD15iC/gDIQgGiFO9S6IUO2K3fypBWLWMiXX\nwxBBmIYI51H1/raQr4Ep0LgJIYELsTsUGnv/UERwDkIE73KEoEKI8PchAnKtnsNuJGKqE3Yxxxx9\nzT8hArwau2T9NoQI8rBNd82xtRuP/vxZej0jsasg12L7VmL0+Xcg9v6m2EEQvRDNoxA7RycG2RAM\nxg4IMEmhsXouBYhmk6/HcSFCPQzZDCQhAQYmwikRuw1uHz2fTD1PUwTRmLc66DFMTsgPem71zU1T\n9LXHIUEHbZBno6Oe/1n6+guRZ2wjdrfBHcjzUYOQWwyRkV/x7beBuo2W+V4cyLSck5PLwoUT2LLl\nBebOFdLZXxhvVtYYBg26lKysxxg06NKTNtzXIZDjjCNVb/dl+po9ez5PPPHCfu2z+/pSzJ49n5SU\ns5k7dznifJwJvEEw+BGVlfGEQpcTG1tMbOwGUlLqm2FSEaGXj5BEAPEdtEJ8Cb0RAWx2rSay6Rx9\njpaIJpCJEIgxnexAdq8mmc0IExN6GoYIVvNeISIUv8UmgSF6Pl9hm2U8+u9ViADyYZt8PIjgd2FH\nD7VFWqaayCY3IsRMD41V2GVTYvWcViPmtFhE6F6A7KTTkaiwzfp4P6I5SGlxIRoQgnkZIcMi7NpW\nLWjo40jS83sDIfIcRBvojmhO72In+W1DSNH0LinEJo4aRDi31r+LEcFqqv+mICRfpMc2BSF7I5uI\nd/Q926nv2y69hiOwu0maApwp+r4mIKHgF+rX87HJYRV2Z8PByCbBpc+RrI8Nx04SXKjneT5CFAXI\nvS7Q8zRNrnIRcmqNaGJuhJTfJRhMIxh8bS8LwIFMyweqc7Wv75gTheXgmOBw1Ns9TV/1W2aOHTty\nL/usUh4uvfQCLMva60FWSrFx41b+9rc/4PVGYZt8qoD2VFdLqKbH46Oq6hxiYkzSlgv5Atdgl/II\nIaaesxBh8BB2xvZ1+rUzEAFxK+JINu1deyBf6kQkQ7qpHj8M255tel6kIL4UD7Kz74DkqpgS48ux\n+3dEIsIc7MS9cH1sJWKPX4c4pqsRgehBdqnZeh4v6s9vQ2zm25Ddc3uEENZiJ9gF9Dn/gxCpmZNX\nj9Fcz7kJIuifQ4gsRa9fGGJiM7WzZus12oJoRCZIoAAh3+16vGZ6HYMImX+u169Wj1+t5/itPsdO\nZLfuRzQqk+Ue0p8pRHxQfkRzO1evR7KeTxE2oX2v51SFaJ1fIaas/+lztdXjF+j1MGti6Xtj6ljl\n6fm79fxN4IN5Bn7C3hyE6bU2hSEVdih0CFtbdGNZiWRkNEMKipvQ42S95nH4/cnAY+zaVcIDD0xE\nKXVEpuX63zEnCsvBMcXhVOzc0/RVv2XmnvZZj6cxLtdPPPbYM/t8kMeNu5unn85nxYpVBINJiKC7\nCvmi3YwIkw4UFrqpqprBrl0dcbkCyOMSxC4qaL6wKUhUzQ6EXAKIMKhChFIGIvDeQ4SayYg2jZDa\nAI9hlyspRYTkGfr3fOze5jux6z7Nwe7rbWpdNdbHVCJCb44e1zS/ikR2rhciAtKLmG2qsUOC3Yiw\nzECEztV6/Av0PC5EiCQPOxfkDWSnbnqimGq4EQjxNdZ3ch3iH/gc2ZWbub+sP29qixnbf6Reg5b6\ntV2Ir+HaevMN6TU05rRk7GzvCuyijAlIGZDuyO68O3aNL5e+pgpE85mAfX+LsP096Xpd22D30BiI\nbAY66c/7EfI7U1+3qVhsHPdNEaJ9Uc+1qV7/c7G7URpSnoU8J/+uN08XdhDELsQsJ9frcl2NZYWh\n1N0UFbUjMrJIH29Cjy/Tx68AllNRkY9lWYwbN+qI+vHU/441DJV3orAc/AJgWRbLln3E1q1F+2yZ\nmZOTy403diY6uozGjcuorR1CcXFbSkvLKShYC1gUFKyltLScDz6wdBJhHmFhP3HRRZWI4DIlx9O4\n8spzSUiQzODSUmMWyUO0iyQkwS5Jz24Dshu2kFDQPOz+DYv1uG0QoZCsjzPNodyI0JiHCPo5iIDa\npMcBMUFsR0hhNyJQ1iO78XX6GB8ixN5EzGWG8Ix5y0T9fIoIypn6mB+Rna3xHwzUv5sgZo9V+lxR\niPA9HTtaKRYRfJ0Q85FPj7kSsel/ruechuzcz0F22JV6vFv1Zz7W5zFdBofo17sghN4e0Vpq9TWe\nh+SOmCRLn74HOxDNaJ0+j2kw1QvxVxifj8kcN5nepqbWO4ig9yBa2hZEKzOBBI0Qcv4a0S5MpvbH\niPakELIxRDNL/96EkGgMElwQ0K/lIE5xpa/1SYR0SrCz4S2ESIzG1AjRftL1vWwGzABa4/V+Trdu\nIeLjpSZZZGQMbdq04o470rnqqnjc7vWIyatSf/5NamsbMWTIZEaNuvWI+vHsSRYmVN6JwjpGsCwr\nzrKsdyzLWmdZ1tuWZcXu45hUy7KWW5b1g2VZ31uWNelEzPWXgpYtW+63ZWZW1hhmzXqQBx6YiNfb\nDJCw3Ouuu4za2nQ6dryD2to0rrvuMoqKTEMfL88882eaNk3B5fIjO8F3ARfr1v2I3w8dO07G6w1D\nbs9vsHM3RBC5XFG43d1wufIRjWMz4jT9M/JFH4AIujmIY7wcER6liPDIR3ajjyAktQCxxZ+JCBTT\nLc/Ul2qECOc22LH/afrzxm9iNKVwZKdqcjwG6jkYM4xHf2YGthkoSs+xBjF7GKdwo3qfmYiQTAgR\n5i2RJMufEAFlEicDiLAq19c4HTu81YfkvDRDBOg5SGXbHxAz0FbEV/IhIijD9TXnIUmA0Qjh/B92\nWROPno+pejsKIfT6JsgB2ERyjf4dg2iQmYimtpOGfdlN4cMwJJ/jdESbMI5wkxBYrdfiPBoWWxyu\n5/QFQuJ+/XpI3+d79NxNpFwmkqDqQTQH41eIREjFlN5vVO++eAkE2nDhhZnU1CTSseMaiosrqKws\noVev03njDReWlUB8fBW2H82FZUUwefIo5s2bcYT9eIQsiosrWbDglbqxvv/+cS6+uJr167fs9dmT\nodTJidRApgLvKqXaIQbsrH0cEwDuUEp1Qp6qCZZltT+Oc/xFIStr7AFbZu7LQZ+fX8jcuf1Yvfr/\nGDGiEXPmLKKoyA9MprCwkmHD7uA//1lLKOTHsrYBC/F6N7BhQxvOPruI1aunMX58Km53Y1JT/4td\nUn0YEEKpcHr3jqRRI9Oxro9+fxWyQ92NTTjGbu1Gvvh+RNDUF3D/QXbHYNenisTu0/4/RFB9o48z\nNaAsRJu4GltA5GDCOmVXazLKzS7f0uP2RQS8pY+/ETHjjNHXW63nc7U+ZjqiocTr68vXv42vxgQK\nhCFmmT9hC22PPn9L7L7obbDt9J0R4Z+sz78au8f4DsR0eClijkpGqtd21+t0ib4u4wu6Fpsk/4po\nJilIiPAWZMPwNXb9r436tXz9d3eEDHyIc9uFEJYbMT+5sUloE0JWOxGNxIVEq3mxS6eU6bXertfP\nEOl0PcZM7G6OeXoeq/VaWnrsfISITH6LF1McU6mbmTlzA7Gx3zFpUjdatlxPTk5rRo6cSTA4k+jo\nJkRG5iKaYQ1wHUpJXpXL5TrsZlD1iWfcuGTeestNu3bNdf7IO7z3XgRt26bv9bmTwcl+IgnkaqQz\nD/r3NXseoJTKV0qt1H+XYwfqn7I42C5pz/e7dGlf96WYNetB+vfvQ3x8OfB/hIevoVev0zE7QaVq\ngatQKgPIZvPmVDp3HsCGDRu54ooUevSIJSLC9L9eSFRUMdHRVURFRdC+fRpiBlqBXap8Frad/0pE\naFUj5ohOSFSPKbL3AEIOOdjlT0ZgO9F3I4LPizhmExATUi0iXO7FbkZl2t5uw+7pUYZdR6kCIZIf\n9Gda6M+49XgPIcJ6MKIJ+PS8tiLJhJuRqsPbsSvMJuhxNyKmoCBiljHFEE3lWDdCnF/pMYuw29v2\n12u1RX+uh573uXrebbDLhfyACGbT7vYcRGP4IyLMV+i1WIOUKy/GLrvfCztaKgn5SvXW9y9fX4fJ\nlfkaIQST3OhCBLgbIeYdek3aIJpSF329pUj023KE2D9BfE2mc+NGPeYqfb7/IRpuEMEahCATkXtv\ntLkwRHRkI5uQVUC+3vzkUV3tIyrKYvz4R/jhh2Qgm0AgGRhAcfFGSkvLaNTIxZQp5/HSS7/lvPNK\n+f77nzgSmNYInTsP4LXXyvH7/8748a8TFtaV8eP/sZcj/WRysntO4LmTlFI7QIjCsqykAx1sWVYL\nxKv65bGf2i8X9ZtHDR582c9637IsBg3qy+uvv01q6nDy8rrg92+jvDwd2d1FEB8forhYfAfV1YqH\nHpIIld/97h2effYyAgHFG2+IthAXl8G0aaNRSjFixGt4vT8SGxtLUVEAl8tLIGASBD9AzA5tEKFu\neplnYyftpSKC90YkauhLxDRVjuQXfK6PCyK72HXY4aJfYZf4uB4hsGT9fn9E2H6BkFYytlM6Qc9h\nLKIQT0MEXieENP6KXZH3X4hQNs7/87G7AlqIkOuICOSPEGFralndr8/bBpuovkbKnnRA/BetEWH8\nFaIFmSzuXD1mR2wtxvQyj8U24YRj93Zfj2gjm7B9QTuxgxd8esxERABvQsjlab1+P2Bn0iciwr6l\nHqOFPt6PEMFwxL8SU2/sNnpel+h7GqXnayKxTOVfk+MzCFiC3Oc5iJlrE6JJubA1jYv0mpumZem4\nXDmEQsko1RS3exnBYDLbtoUTCpnClcbnUwOkkZ5usWlTOzIzuzN48GUMGdKPo4GxY0cSH5/AlCkf\nARZhYY2YOHEYL70kQRHV1SEeemhi3Xey/rF7vvdrwjElEMuyliHbq7qXkCfn3n0cvl9DoGVZUcAi\n4DatiewX999/f93fvXv3pnfv3oc+4ZMQe3YknD9/CbGx6/D7E4Dv+eabFojgvQeX621KSkrxeALE\nxf2WnTsjmTz5YSIizqOsrIYhQ+5ABJ30SMjNjWLo0Am0bj2UQOBpUlImo9QXhIVVUFW1ETFzGeEW\niwiHG5Ed/KZ6752L7fAO0z/dEWHbDjHlPIOYq7ogu9ibEFIJR3bUfmwTUVfstrMvIZrHufrndT1u\nNWIKGoxdQDAdu41qCCGAWuwQ5W6IKWkFQkJtEaHfDhGYlyOFGPvoc/REhPJoPVeT/Hc+QginIVpN\nG30PzA68CPk6rNPXcROiSaUgu29TyHE8Ev58FUIInyImwJGIT+b32GXPW+q5Z+pzK8R0dD2iSUQg\nwj4XEdDLEQJ4UI/3MXY9sQSExLYigQYLsE1JW/V7TRFyvkl/Ng8hy2EIoYT0/fwEIdyW+r51Q3qk\njMYm09OQjUcBdkOya4BE3SSqLfAdwaAU0iwtjcRuWnYj8jxtA3JYvToMeIMxYwbwhz/M4LbbhjNu\nnAkmOHzsaT7OzQ1hWbF1tbXk/4bm5obHHj8n+wcffMAHH3xwVMY6piYspdQlStSNXpMAACAASURB\nVKmu9X666N+vATssy2oKYEmw9s59jWFJPY1FwDyl1KsHO+f9999f93OqkwfsbWddsmQW06bdRVhY\nBnA3lmXH1EdGtkGp05g06Ty2b3+Gfv2CnH9+Tx1h8iRRUc0RAdcPIYRvCYWiKSyUdjHl5esZMOBC\npL1yG+xEO5NAZwjChIpehQh8U7ZiAHZ2tCm7YSKBOmFnPssXzeMxUV+79etXITtgP/JoN9KfORfZ\naUciArBGv9cc2V0316u1DiEuDyJ0MxEB/ByiFbkQodgFcZgHEO2kLQ2LRLZEyMjM1VQcLkF8LbMQ\nk9NuxOdhyDMBuxyKH9t3FNJz6qTn/ZEey/gJ1iBOZXM+r17DkYiJLgG7RtgZiP+ofoRacyQM+e+I\ngI5CyErVGw99XTdhl0BpgZjlTETcKoR8arA1syKEUBtjZ9p/hZBHUI9Vo9eiXb15mT40f9TX/6C+\nd5sQMl6kz6uQEPCeQEt8vijsUit5+t7tBOJJTGxCVFQH4B12707niivOO6qhtXuaj1ev3rhfc/OJ\nLHXSu3fvBnLySGCdqAgAy7IeBYqUUo9alnUXEKeUmrqP454HCpRSdxzCmOrXHNFwNDF79nxmzHiR\n2trTycn5CxkZ9+L1/pdJk4aRkJDITTe9TWzsNvLyYhF7dQxiOhhHRsbHVFV9zK5dXZk4sRnZ2TtJ\nS7PIyfme2trW2D6IHxBBFYUIjhLCwxV+f2eUGoVEN/2EmC66IsKxAtmRtkGETkfsku3r9P8ml+Fj\nhBT+i+x+RyD1k4KIoHkfu2zJ64hASdHnidRzHIRp1yuCsgpxpvfBFqBrEUFbgJjSliPRWs9g9x73\nI36C5xCT18eIyagMIYgAsusu0Wv5A0I0BYjwfF+v1TmIJjYGO1+ldb3jCvXcv0PyTiqx/TmvI73D\nP9bzb6TXc6Vek3jE7BOtxzHhqu9j98yYi/SfN+XbOyMCvZle8zmIVrIKIWfTydBknZtkPNNoqjN2\n35XuSHJmACGbAoSw5iDalTEtbsKOGHsP8Y38D7hL398SfU5T3uV0RFN8GfEbKX2un5Dnokyv+W5E\ns9yAy+UiFDJRZfFADrGxpZSVWXg83aipySYlZTJxcRuYNGnYUdFCfq2wLAslu76fjRPpRH8UuMSy\nrHXIE/QIgGVZKZZlva7/PhfZRl1kWdZ3lmV9a1nW5Sdsxr8iHKjmVk5OLsOHh+P35xEWth64gdjY\n3ciX8yk2bnyHYLA7fv+TzJ2bR2zsd9x66xk0blzBueeW8LvftUR2wSbTeb3+3ZLq6kYotQYxTbyB\nEAXITtTsmE0svw8RfF9gdwbcgQiRPEQYPoxtB/8LtnN7ux63KXY/Dku/XoKQUT4STrwFIY4eyO41\nVR9n2uW20PPdjl2mvn7VW2ODd2NZV2N36NuOkJM539uI4P8aMddsQcjvXewy8/UjwDbrY97X6/Ed\ntnYXQgg2HjtMdygiWD363D8igj0Bu//KV/XGCSBkc45eB+NDMU7uDCS0uSkijI3GYRz9pyNEs1qv\nWa2e20wk/Nar1302skEwQQXoMf6k/zZE3QXTf0PGeRox5+Xp9+9EyLsa8YF9rz+zHnkOIvRnt+s1\nXa+v7zfYkWO7gPOIjW2HZX1MUlIuL710De3bR+DxhHH77YNp2lTK/VRWBk/aBL/jhRNGIEqpIqVU\nX6VUO6XUpUqp3fr17Uqp/vrvT5VSbqXUGUqpbkqp7kqppQce+dSGiS2HhnbW+slMkjPyEE89dS9J\nSZlAPzye0wgP70T79q1xu1tQXLwGgMjIGKZPn0pCQhOqq3sxefKN2lZrOgOa+lM7EKF5LyLIdmCb\nI2IQQdcYsbGbjoWPIztfF7KTbI6YIkYiO9USxAkuGegeT0Bf5WPILjiIkNEwRHMJAmFER58O3Eqj\nRn5EEGYgu/G3kJ1xcxpmWqcgJFKFCKT6gj6EmJ1igI+Jjt5I165bSUyM09fg0mO2RXb+jZHd8T/0\nOBfp6+2KXVbeaG8+JET3Av1eTz23DfqzbRE/RUdEOBbrdWmBkH2pfj1fn3MOInC7I/6MQj2307AL\nQ45ECBL9/+UIOUQhAtrUzopFhHYUksj4lL6/hoR8mA6ANtFO1OcL12P+TV/HlQhZFiPaTZye5zL9\nfqpe42rE32TmYCoJmGq6kUCIPn164HYbP5W5thQ9565AK8rK4hg9eiD5+V8wZMgVrF37JgUFn5GZ\n2Y3iYul7Hgy6TtoEv+MFJxP9JIPxebz88ts8+eR8nn32sr3srMaxDtQRTFlZDRMndmPNmulcckkc\n1dWtSE0dzs6dq5k8+RHuueeTuhpc8+e/iQhG00TIjZ0YZkxJHsTUE0RMFsXYtu8wZLf7f9i9QXwI\nYVyBkMlnwNn4fJWY8t6BQBmQi8fTBFiP212/ftJMRAArKis3EhPzHBUVmxG/wWxEQP0X2dVGIKYc\nN2IiK8NOfOuBkM7biCA35ds7A+FUVipWraqmsDCAZfkQ8xl67qaeVB5CrkmIv6Mn4kMpR4Thx4iw\nbI/swFcgJDcTya8wfcxNAp9br1m+Xts3EGdzISJAS/QaD0AIJlsf70c0BD8SUZaPBBbs0PfLq+fv\n1vdjLaIprkDIcaC+Bg9C0iZZcZC+n131+GP0fbwbMacl6c/uRjSKUoQMc/W6tNDX+gKira3Sx3RA\ntJ0vsP1UFnYuzqdAC779di3R0ZF6zboivpsVyHOTAyzCsqQWXFbWYw0S9XJychk3rik1NR25+eaU\nA/oeToZEv2MNh0BOEuwZWz5p0lI++eR/LFv24V6JUYZkXnlleb0GOlezYcNGOncewOefe4GZRES0\nokmTMlJSYrUp7FaKiz+kuroXIpSTES0CRKCtR4RaAiJEZyNC6kqME92yXEikjtEMPkR2uS2R3fv9\niIA9E5hDTU0rZJct2kyXLgksWPAbvF4vLpcLESymz4YkJ0ZF5VJU9AlJSVF6bhaQjMvVXI+Th1hN\nN+v5vo8I1eZ6zp0RQqtENKQxiJAdRiBwOlCGUlUo9YG+lhYY04mcqxLJJanvhC5GCCZHv2ZqVY3C\n7jViggzCEUHtwd6NP4pdfNGM6caObmqBCF2j9RktyhQnbI8QTZa+PyHs4pRfItrXT4jJ0TjVGyEk\n+h6ibWxGhPsGfc/m6Hu2BiGCcH2ONGQjkY/dzXE24g+p0XM2AZkRSKTUaYg5rwLRTMz13YFNIlnA\namJjI/W9NyV1TKXjQlyuWMLCWjFpUnOWLFneIIBk9uz5zJ//Kq+9Vk5Z2XRefbWMefNe2W/+xcmQ\n6Hes4RDISQLj8ygoKAMsdu3yEwr9meXLrf0mMK1Y4eO++54kO3uBzpqdxf33TyAyUmL6q6sV06dP\n5fTTO7B1axFudxEiSIzpZ5M+ew9kpx2NOENzkS/1VYjQuwQxWTxMXFxX+ve/ELu8exJ2z2s3Xm8t\nHk88Hk/9uk0TgRZ06ZLOtm1l3HzzU9TWLkVSg4xDXQRN//4XUlS0CrfbTc+eZ2B346vWLYDT9JyW\nI4ItDrsQoeldnovPZ3IgTBa2KbAYgfgTMhEhV4uYizIRgdpLH3ef/uy1uN3hSMBhJvCEPmaSHms4\nNlkM0ec3JqYCRGjvQIgqXI95jT6+DCFao9VEIkLZNKyKRcgpHSGJIn3uz/Ua9EE0rFREu8hEtJc4\nRJspQDYILfX4pu9HHHZUnenbEYXddXGTnltz/RnzvJgosU6IKc10VRyLbARa63Odid16eBN2Ofdn\niYjoxuOP30vjxpH1xnUj2sdmPJ5aLrjAy7x5r/PVV17KypKZOvVDOnXqj1Kqnl8Q8vO/4/77J+zl\nAzmZEv2ONRwCOUlg7LgVFQGaNRtDMChVXv1+VecoPFgzq/31KmnVqhV9+pRjWTnYAuFaROhEY9eW\nciOO3mTsTnb5+HyPAi4iIp6gvLyW4uJyIiJ8dOx4B5YlX+aYmPfx+ZoxZEhvbrvtYtzucGJipL9E\naupzRET46NKlIzfc0J/du9OBd3C5KhCBtQOvV/pTlJRUMmfOQjp16s/y5SbMMxZxLBcgGsd6hDDW\n6GvI0/+H4/VeCnSkpmaL/txObB/PN9gOYZd+PYTs1E2SnBsh2UjEXFaBZX2Mz2ciw6br9forsptv\npOexE9lFf6bX7Swkua4DQsivYWfdx+n17a0/9zQinHchpqMAYtJxIYJ+HbLz74ndT70AMTdlIPkk\npgqyEfRF+nwmzNeDaCg1iN/Eg5CMybHIwG6QlYFdcsaEaF+HrXX0Q0hvhV4/U+/KmNtqEGLZhBDJ\nj5iGY273Zzz44NPs2mXmaoioHK/3Im699Vz69OnN3/9+L8XFW4B8iotzeeCBiYwbN6ru+U5NHUZZ\nWXO++uq/e/lATqWe5kcKh0BOIrzyynJcrkKGDm1JWFgxTZrMbOA8P5RmVvuKT8/KGsu4caMIBk9D\ndoVpyJc7AxFaJonMhzxSponPb4EANTXbad9+Az17JrBgwVVERUVz/fXRKLWeRo2kI15SUguSktZQ\nWVlJQkIiCxZcxV139ebOO1swYUJfrr8+hmXLvuCFF3ai1NPAfKqrK4AEYmNraN26hL59o4mMjKwT\nAOHhpwM9saxdiEAKQ4RvOSLETkOEUwImizsQaIpoRr0QYknEFpyX6eu/E683F5/PR0yMQoSfHyHP\ncKTgYBoA4eHluN1e/P4KRPDuQATnZr3inyJk8Qp2m9kKbFI2RGX8IDsRwd8T0XgSEdNQI30f/o4I\nfj/id5iGmK9C2B36fAiZXYAQ66cIsTTVY23V522DaHZh2DnH7ZDIs+3653/6Wi/Q/3dB/E0d9Rx8\niKnMmMISEBItxDYnbkXIq1z/ztX3y2TuVyEkEw3E4/cHad++BVFRWxCT2QdAIrW1T/Paa+XMmPEM\nY8feR1FRBDCNoqJwJk9+hOzsBTqR9jsiIloDT/HUU8vo2PHKBtrFqdTT/EhxIkuZODhKqJ/zUV39\nIv/85xASE3dxzz2jadIkaZ8JTIMGXcrixe/s5UScOnV0XRvO+qUVFiz4DyIseiP9Oc5BzB1nIyG9\nvRDTyTRkdxsOjMPtXsltt51Hr16nM3r0MizLYunSbJRSLFq0lClTPqK8/GH8/iymT8+qq9u1J5RS\n9O27lN/8Zglg4XJFEAp1BOZRUTGG889vwuzZD5mYdhYufJXa2jCaNfuKrVsTELPN2Yhw24L4FFoj\nPo7miC9iEUoZs0gjfexOhBClC6Nlgc/XgS5dahg8eBKtWzfjuuueRLSIND32An39xdTWNiEmxovf\nHwf8Pz2H/yJ+lpbYHRXrC/YURGhfixBeC8SH0hS7+nBkvc9UIYL0Ej0Pk+1evw6XISCTtd4MIQ8T\nMWe0g8uRyryd9P39DSKga5CETFM88X2E8KYiJftHIQEAZYjJaRdCRnOxy9OkIyQyEvHLJCHkfDZ2\n18r1+vOdkKCLCxHz2WvAaYSFncaf/yxdNkeNmkmzZhEUFHTA50uirEy0hRkz/sjixctYtixEYaFF\nfHwjLrjgzDot3Dx38A7V1W254or0vbSLg31PHAgcDeQkwJ4qd2RkBtOnZzFu3Ki9qooerOKoOA63\nMWjQLXXRJ2eddSWvvrocpc5Edqq9ECG4ANmRpiK7+csR4VeD7IyHEQzWMmvWi9x776cN7MnZ2Qt+\n1i7PvOf1RnLaaaMJhX4EavB4RuH1hnPppRfWkcegQbfw5psuzj67GBFIOxCz0rfIbnemnudXyE7X\n9j+4XOFIlJGJSipDQm6laKJSSfj96/n6az+PPvoU11+fhez839LjlyEC/DPgPILB7QQCFVjWduyO\nhxnILvtMPS8fIlTDkF34TkRor0F26P0Rklujj/0e28Fs0Ac78TAJu5NgN30uv57jeuzIsiRkh+9B\nTF9u7JbExsfhwe68uBrT6160JoU4tt2IBmdMgdP0uVfqZ2QT4oeqH/LrRnq3nIVoQEV6TgohXxNy\nPQvxzawBPqOwsJBlyz5iw4Y8Fi6cQG7ui0yc2J2aGuqeI5fLxeDBl1JTY9Ghw2RKS9cwcGDfumfo\n3Xc/ZOvWZfh8L6PU0yxcuKOur47B4VbmPdXgEMhJgKOhcjd0HE7nlVcCxMScwaxZ8/jss1dp1SoZ\nW6i4kd35f7Dt5dWICcc4b0+jWbN0+vd30aZNy/0mNP6ccg5yfD+GDWsFtCEiYjPh4YlMmJDKhg15\nzJ49n/T0C3n1VYuamqvYvDmVsrIKIiMVYlZqjmVJmY3w8Cgsqw0itHYQEVEGFBEKmTwN8/s2RMgb\n/4PJRXmd0tIu+P21iHBfqI9xY2tqFnAmZWUhJM3JOJHDEQ1gFGJWKkC0ik8RM00/fUwIOwrMq4/Z\niJCIcaybcvlePV4z6pd7kWiwcEQwX4II+hTsUvUme309ojX8FTuSy7QUbobkbzTH1lZMCZqmCKkU\n6nMYM5nxj/0DMWf9W78+GCHJLthNuEYhz1M2QnRV+jMmjFlyhNzuEH37xtGyZcsGAt6YPOs/R+bZ\neuCBS/F42rFkyXt1z1Hz5q2chMKjBIdAThIcaW2dsWNHcu65ndm40QiIasrLM/nLX+Ywfvy9/PST\nEVSmvesmREB8gNjj1yDE8THgx+WyKCzczI03DuYPf7h5vwmN9Xd5d931O6ZO/SuhUGif8ffx8RHc\nd9+T/POfW4HZpKZejGV9woYNG4mLC2fGjBcJBLprH8nHbNy4jJ492+FytaZJk1l4veWEh4eTmjqW\n2loLpcDtfgdowjnnJBIfX4toBdn6dzUiGJP0tZo2snHAu9oxngyAy/UGYtIpRRL5TK/y1diOfB8S\nceTW4wzBTrpbi+zQH9SvBfXYJqHRjWgX7fV4+Xp+W7Ad+AMRwW5yazxIro1pcZuBkI7J/3Dpz65G\nyLIS0Z5MqfuFiFaxGTFFrdZjXq9/hxACMya3kL7GAfr9XfqaZiKE8SliNjP5MS8gmuyXCDHlIn4b\nn14PD2I2K0OaP8Uxbtz1TJ1qV5wGMbuuWPFfgDptwTwr99zzCVVVM1ixwlcXSXX33dJXZ/duKXQY\nCrkdH8dhwiGQkwRHqnIrpXj//S8JBHIR23UEMJNt29KZM+c1fVQLoAzL+gAowuX6HDFBzEYE7qdA\nELe7K6HQ0/h8jRk//k/Mn7/kkMjNxN3//veP7jP+3pjqTJhxUVEltbVtGDlyYN17tbUAFh5PIR5P\nK5KSkpk7tx87drzCkCFnMHBgOFu2zKZTp3zOPz+SmpqXuPPOVng8jbjxRlPcEUQwt0GK9pkmSWGI\nkE4AplJd/RFCJt8QCpkIrUjscuMJ2M2uTPMlP7Jj34wI6sZIzbBEJEfkFcTJrhDy+hghlIGI4Dd5\nNqcjpN0S8ad8imhKGYig/x8irDchIcuViE9ks359BeLH+J9+fTdiunoV8f9kIOKhGaIx9EY0gWuw\ntaXe+v8WiLaSrMcsQ8yAJhDArMtjiGZRhe1zMfklGxCSmYVoRWcifque+no2EwjsYsKEPzNr1rwG\nG4x95WscLJLqRBYzPJlwwoopHgs4xRQPjD1Lu9fHlCkPM23aRmADHo+LUKglodAcLOu3KLUJ8Xs8\ngst1E3361PDllwmMHZvMrFmbqaychV0csBdudy7B4EzS0qYybVrv/TrGDUwQwK5d4ezaVY3X24za\n2lkkJU0iGFzBgw9OYNy46wFYtGgpo0a9jlL51NYmotQ1tGnzEcXFyxg06GKef76MJk1qKSmJYNy4\nFBISErnrrt/t97rrY8SIKbzySg2QQ1VVC0QL+AxoRKNG4VRUtEVMMll4vWtQqoxAYDhxce9TXPwj\nbnccwWCaHq0U2ZlvR4RjZ6Q0+2gk8kshJq92wLNIxNo3iPAuRrSYCxHHdCt93u6IwG2j/78RcUbf\ngRBdS6R8yA0IIVQixLUZ2cmbIo6fIH6qOMT8mKDP2wbRdpYgGkGEfj0fcWL3QbSeSmST8Tx2YcZ0\n7NDb05F8lx4IAezC1pK2IKS6HaP9uFzVhEIt9LimV4kpZLlDz7UUCBAf72Hw4N68+KKf4cMj+OST\nVfssGDpu3CgWLVrKTTe9TVqaRW5uiOee6/er7LlxrPFrLabo4DhjXzu1kSMn4vF0Ytq0NYgmcTaB\nwE5Coc00bjwSl8sk9JUAFxIK/Zc1axIpL/8bc+a8S2VlEJdrCLLDLMWyFhAMhkhNHcvu3dWHZBow\nu8WwMGneFAgAWASDbioqmpOQ0KTu2JycXObP78+8eTcRH18B5FFcvIXKyrOpqAiyYMFVbNkym+ee\nu4KEhESmTh2913VLiYpHueuuRxuYySory0lI+J7Y2PaI2UV6dVjWGYwb1w+fzwcMx7KKqK11EQqV\n4/PNpri4AgjT/ShWIc7jWGR3X4aYv7yIj8hoOAV6TU2ZEEny83hMs6oypMFSjD6mN0LiNdgZ7iYK\nazF2Bvy1iGayDiGU3jTs3JiIXa+qDHHsd0cE9UqEsExS6A+IFhBAkiU7IGYqU3be5IzEIqTn078D\niK/Dh2hQtYi2tQUhgs8JD29G377VeL0VhEJn62trScMQZpNE2hwxnSawe3clc+dup6xsGu+/D6Wl\n5RQUrAX2Tgx0tIxjD4dATgHsP7N2Hqmpqdx663Asy9SCUrjd4Xg80WRnjyIzswzLKqNZsyJ8viTa\nt0+kslIcpZbVmP79LU47rRVwBRERMQwb1o8pU1owfnzPQ/7SGpIpKfETFzcLpSxcrmsoKqqmuvq3\n3H33x3X266ysMVx77eW4XC7Ky3fj882iqCiizs59331P0q/fbxg06FLi4sL3ed3jxt3NjBl5PPHE\ntw2izUyvFBFImZhwUqVmM23aagKB94mNXUNSUhXQBq83kVCoGjHJjESEbgdEc1gD3I4IWFOz63/6\n9eGI0PZh+wUaIe1XTfMkUw03BxHCaQiptUf8BpmIoE1GNIAcRFvyIu2BIxFS2IGQhSGwEn2faxAS\nMLXCmmH3dTfEVI0I/F2IE3wmdtl7nx5P6TF3IOa1RkiSowQl2O2D07GrM1cTCLzJl1+uISwsU4/7\njZ6/qZN2FRKu/Vc9n1eANng8EcTExGEqJVx33WXU1qbvMzHQiaQ69nAI5BTA/uzB8fGJzJy5gw0b\ntqCUC9k17iIYTCYQWMQ993zC+vWbGTOmL7m5L7Jw4Wi6d+9CKOShY8c7UCqNdu1aUlJSQ8eOb+Px\ntGTw4Et4/PGsui/voX5p589/jdjYb5H+Yc2JiCjH7nPd0H6tlOLJJ59n3rzxzJv3J+LjG9Vd1+WX\nn8unnyawePE7e113QcFatm3bwdy526iqmoHfn8Irr6wgPr4bs2fPryOysLB2uN3SAtXs9qOjY3nh\nhcfJzn5Ylzl5jKSkrlx+eSaycx4HxOHzRRIXl4OYrLKRKKXf62PiEB/At4gAfggRrB0IDzftZiOQ\nSKk0pF5XnJ6DyU9xIVpGc8T5fBoi/APYLW6LEIIwnRbDkVydKoQUyxGTWQtsbaaLPrcPMYl5ERIK\nQ4IDmmCH4MYhocVRej5B/f4ifX3GqW4hhNe43v8+IIWJE3/HP/7xF8LCTD6LqexbgpjcaunRYwd9\n+7ZiwADw+ZJJTS0kGIygsjJYF5Dx8cdf0bjxSp0Y+DRz5+Y6ZUeOIxwCOQWwZ5jvzp2lTJ78cF2F\n3ffe20pExBeMHt2G/v1deDyiYVRXh3jqqT8wa9ZDdbu4zp3b7dF17aejYiZYsuQppk2bSqNGbYEs\nwsOTCQtLJyHhI3bvrmxgCnv55bf57rumuFwuXC4XNTUWyck3sXVrIQsXrqW8fDpZWR/RufMAli37\nqO66a2vTuOmmgTp6ykJ2+X8hPPxCZsx4sa7YXiCwnGCwJ7L7LgKGUVkZxO324HK56kWUVdeVZUlI\n+A0eTy1nnbWb1FSwrBwsayuyM5+KCEWjRZg+7hMQ4d+e6mqFlPsIR7SSldjC20Q3mciq7oi2Y6K7\n2iOayD3IV/rv2OHGJqTWhF4vRqK+XkJ8VsWICa0cu2TLNsRH4UX8Hq56x3kRJ/fzem4ma307opEA\nbGDMmE665L0XISdDfBZwKf/6VwFTpjzC7t3VJCRcr69vtZ5HCvAm27a1IC8vH5fLYuHC8WzZ8gJD\nh/Zk4MDwuudt0KArmDbtLr1+FhERMU5I7nGEQyCnCOrbg+fPH8AFF5xVtzNPTOzK888/Snb2I9xw\nwyAiItruM59EKUVJSTGDBl1aRyhLl845KmaCPUmurKyUvn1r8PvjGTdOym7vbYr7kBtumEqrVmvJ\ny5vD7be3pKpKai8ZraVly5Z11z137hXk5xcRCpnEQakXVltr8cADEwHFN9+sxe83NaMigI/p3LmQ\nzp13kJOzZa8S+VFR0Ywffxp+fzx9+sSyfv1mqqs7o9S7hIV1An7C5RIHsK1FJCJC3Is4nVsihBKB\n5KWE9LFLkbBWU8KkJ3btK+OE34GQUkuk4dZn2B36PIgZzfQHN2ZKU3TRg+SVrEG0IhCHv2nO1A7R\nojxIuPYXevxteu5mrmcCfREC+Jzo6Hg2b86jffsUJAz4S0RjCkfMcZ9QWRkkJaUJKSlriYtLQ8ix\nDVFRXiIji6ifn7Fkyay6Z2z+/L+SliY+MXnexuyVAwXsVcbdwbGBQyCnCOrbg6+99nIGDrx4n7kZ\nB3I8Huvy1ubckyZ1IymplM8/91JebpfdblhNVcJ4a2qa8P33zVmyZBmZmd0IhdIbXFNW1tgGBNe5\nczsGDgznjju6ER5eTEzME5SV1bBs2Uc88cSLBAJpyK7eQnb17bjssotYufIV2rRJ47vvmtStVUHB\nTr7+ehWvvVZGefl0fvopjcrKMvLydgGPUVvrAx7B6z0fIQQfUq6jCojGsozZ5gXsjO85iJ8hHiGI\ndxFtoyWSuAludxnih4hGBD3IV7kEMX8FsJMNf9DjNcZoU4J0xKyVhN1D3ULKikQjDUKNeSkd0Tb6\nYtfIigCmYNf0mon4ZYJER1t89lkiaWmtSEmJ0NcsPh+Xqz0dOmQQCrn5QyoEwAAAHv1JREFU/e/H\n0K9fJps27USqGJyBx5NBVdU2kpOvIhRyAw3JYF/P4J7P7JIl7zll2I8TnDDeUxQPPzyHtm3TG9T6\n2Z/2cKD+6seil3T9Olm5uQ+TlpbFtGkXMnjwZbz88tuMGvU6gUAewWAistt+Ebf7BiIjf2D48EuZ\nNeuhg17T3te/hdatU7nllgUUFkYhJpkU4BoaNVpEbe1XxMa2Zdeuf9OmzT0UFy9j4MA+zJ+/Ca83\nkbKyp4mKGorfL+1uA4FElNqB1AP7K8FgMRIl1Qep/+RBnMtGeLdCQmz/pd/3I7t2aaIlyXmvI6TS\nDSkRcjGioXyBaAKmg98Y/VolQggLkGimjxHyCiAksEwfG49d3n4eEh68Wc8rDPFvbEVKj9yAhCEH\nERNfIz2fbCRJ8hMiI1OorLwRr/dJgsG2hELzkF7uK+naNYmVK9+quz+tWzfjhhveoLa2mECgCZGR\nW7nllu789a93sWTJMhYvfpf//CfA8OHhfPLJ9wd8Bo/3c3qy4EjCeJ1iiqcosrLsbN6DxcaPHTuS\n+PgEXYBOzEMPPTTxmMXU72nOys0NNdCQ5s/vz9Kl7/HMM28gO3MLpSKJjW1Et24d67SNA2Ff179o\n0VLKykqJjNxAZWUpUVHhlJfnER+fSG1tBC5XK8Bi27YcKivP4MUXf6K6+ndUVz8BnE55eVOkfHtb\nlJqJCNspBIORREVZwIWUl89EfBWvI1pJIiLA2yK78MV6Vl2RZLyXEKL5N0IofiQqagC2T2UEEsll\nyoiYUN0fsUNiY7Cd/U8j5DgAccL3we43YsJna7Db7L6i52ic/CEkx+MDhJBcuN1DCQbj6NGjLRs2\nuIFRxMS8TWlpOKGQRXR0BBdeeCY1NarB/Xn44TmMH9+M2bM9NG6cz86dNWRmdmfOnIXMmPEiNTVd\nKStL5L33dlNdXUplpfS72dczeLyfUweOCcvBIeBElLfenynNhPFedtlFeL3NECF6B6EQDB3a75B2\nmvtrVZqTk8utt2ZSWxsNtKOqKo6OHdewY0cJ+fmnkZ//Pj7fmVRWRgHZVFbGIH6HUsQBno70hDe5\nMy7EdPMF5eVNKS+v0a/nazJqh13vqRCJggvpz+Uj/oMCRNPwIgRiftdgC3yTfGf6w1dj15Dy6ddM\n+XS3PsdORLPJR+pflev3BmC3JzZmsUhEQzKlXBIQjcUNNCYycg0ZGWX07VtJIGBpM+IUKipqcbvD\niYrqQ1lZgB07drF0aXaDNc/KGkNCQiJz5/Zjy5YXWLhwPDk5uXURdKanx+7deQwd2o9AwLXfZ9Ap\nw3784WggDg4Jx7u89cE0pA0b8ujVK4mvvy4mISFIfn4R+fnRhyQsjB29Z8936saePXs+jzzyN0pL\nFZLI14Ng8BnWrNmN+BCuRqkvqKn5FNmtW4RCHlyuEkKhZsTHf0hRUWvi42dRVJRCXNwoiou3ITv8\nFxAySEfqSDVCaj1V67+N5vA/ZNd/PlJxdwaS8T0Lycr+DCGOAj2WFzFRdUIE/gp9/CbE1JWLmLFO\nR7LPE5FaWx0QAgjX85CGTOJP6Yo4tL9GkhF/QMjjGqQ21neIbwWMyayycjT5+au4/fbhFBVV15kG\ne/W6lm+/fQ+/vzcQZMWKGtLTe3PvvWMaEP2+7vXs2fP5y1/+QVFRBtLTYyz/+Mdihg+/hFmzHtzv\nM+iUYT++cHwgDn7ROFD5lZ/jx4ED28jHjh3JSy+9yejRf6e8vAViGhpLt275rFyZglKzsayb6dZt\nO99+m4Lsyis599wSzj67K6tX/0SXLq1ZtepHunZtzeLF7/DTT20QUjgNEcYBZId/AdIqNhchj3OR\nYoWmLEhPRDP4L2J2Wo74F75FCMGLRHEVI+SwHCGeGMRnkYYQxnlIciAIUfiBCNLSoqioqKWoqBQh\nRwvRYAYhJrTBiNnqO6Q17xKkdMo4xD/TCjGrta57/Y47WvD441Pr7pEhgLy8dKSEy83AVmJiLFJT\n1UH9EkopRo68k3feCVJY+DcSEm7nsss8zJ//mKNRHGU4PhAHJy32pS0Y/Bw/DhzYRm5ZFm63G78/\ngIS4XgfEs2bNjyh1GjACpWL4/vsNeDxeMjLS2LixmBYt0nn88ay6cxiSKinpAPwdl+t3hEI/IRnZ\nHRHt4XIsaxFKtUCE9yr9aR+iWaxChH06Yua6HCGGbogjPAWJqOqEEN0oRGOpQsjlU2zN5R4kHNiF\nkM4Otm3bQTDoRjSI8xDNIhm7t0cAU5/LsrL09WciWsrpetzJei7n4HZ3IT+/qK4fS79+N7B5c4GO\naDO+EwVMxON5i4wMP2PGjAD2v0GwLItBgy7h9dff1n4wGDToEoc8fmFwfCAOfpHYf/mVw88wPpiN\nPCcnl44do5gypTkvvfRbzjuvBK83QrdOnU9U1BYSEhJ44YXR/PDDNObPv4nOnds1OMeeFYOV8pGa\n2hSX6zRcrnJEmHZAqW8Rs9MghBg6AVuIjPyRqKgyhHDSkBDY7UgY7RxEW/FQ3/RlWcaxXaM/1xkh\nEiO40xBCbA6cQ1LSNSQkGG1lN+IY3wgkExHhx85O9+LxhBMZuQ1oTPfurYiMNBnzQaKikpg8+UqG\nDo2mSxdZh5dffpvPPovniivOp7ZWclUsazDgIj5+FqWlft5+u5glS5bVHb+/kFunltUvH44Jy8Ev\nEgcK5T2SXejPNXsdSkXX+rtogIEDb2H58nAiIkooK2vE88/3Z8mS9/j002/Iza0mFOqCtHaNQZpH\n/YWwsN/i93+LZbnIyIhj/fp8hCwGIyGycYhWMBYhHYmkcrt3oFQS4eEFVFaOQcqx/w+J6irV59iJ\n6Vfu9X5BeHhfLriggjfeWIVoKjuASlyuRqSkFLJrV2dqaoqAxrhcn9O0aR+2b59OcvIN7NgRjlKl\nQCxu9y7+9a9xDB582V7mwZSUyWzfvpzY2HgqK6Np3z5Ifn4Jbndr8vPPJylpFbt3f1gXGu2E3J44\nONV4HZx02FtbqGTBgleOeNw9C+z9/vc3cfbZgwiFQnXH1I/S2tcueM8orvq76Jdffpu33trGuHHJ\n5Oc/y7x5A1iw4DVef/1NNm/OJxTqhJiA2iImpZ2Ahd9vAY+i1IX8+GMxokl8i4TxjkXMW1cBCq/3\ncXw+6NFjJxdf3ITbb29JMFgL5JGQUE67duHASsLCfkKc4FGEhSXRo0cBF12UyfDhEbz11qeIpjIL\n8Z9UEAqtY+tWE521EJdrO6FQiJKSH5FaYj+i1IdYVjVwDcFgAUOHTmHkyImMGTOCjIxmVFeLVlRZ\nGWTKlOEUFS3nhRcmMnz4QJ566l4dOTeGsLBGTJw4TFdg3rtfh4NfBxwCcfCLRX3hPXZsMm++efSz\ni//f/3uUL79MIjNz8D4JYV9dEwcNuoWnntrGzTff3cDMNmLEQkaMuI+amiG8+mopTZpkUlCwk8WL\nnyI7+69ERTVHzE8LECG9GzFFDUZ8D9LNMRisICoqDvFFuJAIrq3AJrp334llNeLWWzOJiopg6dJs\nMjO74fO1oWPHtdTUJNKjRxcWLfoz8+Y9QEREd5KSvHi9rUhLS+aaay7g449XkZTUA7tAogtx7J8N\nRFFTkwC4iI1Np3//TAKBNDp2vIPw8B5ceeUFuFwpQD/c7k7cdttInn/+CQYPHs/SpbspKKio6/KX\nmdld9ye/jKysPUuOVNdVYHZCbn+9cAjEwS8WWVljKCjYRefOA3jttXJqal75Wb6Q/eV7gPRBCQvr\nyt/+9j/gar76qilud1tiY3vs1+9Sv+d6efnlLF9uUVJSSkGBJLdFR8cRE9MWGEVRUWVdL5O9HfSv\nIBFM4YgJKx4p974aMSf1wedz4/HUIr6M95FIrnBWrvRTUxMkO/tdPvwwiptvvnsvLalLl3YMHnwZ\nGzbkMW9ef/Lzn2XcuGTeestNYmITHnhgovZP+LELJH6LkFszIJyEhOsJBFzExMSwcOHVupbYlZSU\nVBAMgs83gmBQsWrVGlq06MOrr1r4/enExpag1DqGD4/cy2ex5zxXr97o+Dh+7VBKnZAfxKj7DhLf\n+DYQe4BjXcgT/tpBxlQOTi6EQiH10ktvqrS0qQqUSkubqv7977dUKBQ66Gf//e+3VHT07WrRoqV7\nvRcMBlXnzpco6K7gbgUh1bjxONWs2QUqLm7gXueaNWue6tjxSpWcfJuCkIK7lcdzprr44hEqOvo2\n1bHjZBURMUF5PIOVzzdYWdY4BW+pjIwslZDQS1199Rh1+unXqClTHlLDht2hIiM7KRinXK5rFQxR\nMEZBWwUjFISUyzVKQUcFZykIKuit4BoFZyi4ULlcoxWEVErKbapjxyvVrFnzVCgUUnfd9WiDtTHz\nzsiQa8zIuFulpl6o3O6zVUzMlcrlGqNcrkzl8WQqOFevx1sqOXmSSk29QF1zzS0N1u3SS0erO+98\nWAWDQdW37yjVqFG3vdZk7Ni7Dun+7Hmf95y7g+MDLTcPS46fSA1kKvCuUqodEsiedYBjb0NKhjo4\nxXA42cUHi+CaPXs+XbpcRW5uY0QTED9EVVWQoUMvp7Y2fa9z7b/negrPPdeP779/nBYtfuS661o2\n6JZYVFRJcbGLkSMHsnLlEjIy0li1ah2hkLSADYV+RDSR2Xg8vRAH+ALi4hKIikoHMnG5hgIWkZHF\nSOhtCaGQNH7audPPli1bCIVCh9wb/Pzze/Dii39k9+7/MGxYDMOHn8v9999A//4diY1tAVxOVVWI\n6dOzWLz4qQZr+/bbc3jssam4XC7eeed5nnvuwb3W5JJLev9sU9SxLtTp4NjgRBLI1UiGEfr3Nfs6\nyLKsVKRu9D+O07wc/MKQk5PLs89eRv/+TXn22csPaurYXwMt46C1368CumFZHqKihhEIuMjPL2Tu\n3H57Oc2zsh4DoLy8ltTUsUREhDFxYje6dm1fV+Rxw4YgAwderAlvO17vWxQWVhEKpTFp0gt06tQf\npRSXX34Ofn868DCQrptoWQQCPkzV3cLCcioqdpGaup1QaB1QQiDQAphFWFg6ErY7jGAwQGVlax56\n6Jl9Eua+CHjw4Eu59trLsSyLBQseZ/78x7jnnnHccMOgumrGoZD7oERt3t9zTTZsyDvke3sswrUd\nHD+cyETCJCXlSlFK5VuWlbSf46YD/w8JFXFwCiIrawyLFi1l5sx8zjrrjIP2HDlQMcb67/t8bYiJ\n+YKysnCee+63dcUaTZhu/SKLTz+9nQEDdrFgwVUNQoBN29yionhqazty660Lqaj4ATiT6OjvKCqq\nBQrZubMD1dV5/OlPs1GqFUrF43aPIBgMoZQb2T8lIsmA/8HjuQq3u5by8nVIPa3rCIWknHtNzXYs\nayuW5ScUakMo1IZAoJaNG6VveXV1iAcfnMA336xqEEl2sPIe69dv4eKLq3j55adZsmTZIfkkcnJy\n91qTn9MTximA+OvGMSUQy7KWIT09615CvIj37uPwvTydlmVdCexQSq20LKu3/ryDUwj18wtkh3ov\n99335EHzBQ4mNPf1/p6Cb89zr1hxLytXPklBwa56JcTnUVpaTkHBaUAP8vOn43Z3JhicRSh0CxJZ\ndR6h0Hpuuuk6evU6g7FjnwFGkpLyPs2b5wLlrFkTSXHxZuQr6SIsLI3GjUsJBNKRLHEXgYAiMrIf\nlZXxREXtJCrqIvLz/wbcy86d7+NyRdKhwzfk5Sm+/HIl2dk76dnznUPO2G/bNp1HHlnLkiXLDlmA\n/9xqAHviYGTv4JeNE5ZIaFnWWqC3UmqHZVnJwPtKqQ57HPMQUqchgKTLRgOLlVK/2c+Y6o9//GPd\n/71796Z3797H6AocHA+oY5RQeLTOrZTizjsfZvr0LbqE+0Cio0+jrOwc4P+Q0h/PAaNxuT4nM7MD\nK1Y0pU2bMHJzQ1x8sZ8RI65m1KiZREVVU1TUioSESsrKopg4MY1//vMHCgubIKXTQzRunMnu3U8T\nFTWEyspYQqFn8XhuRqmd3H57TzIyUvnLX56huroTBQV/r0vQS0uL4623nt/nmp3oPho/N7nTwZHh\ngw8+4IMPPqj7/4EHHvhV1sJ6Delc8yhSRe7VPQ9QSt0N3A1gWdaFwJT9kYfB/ffff7Tn6eAE4kTu\nUA/l3JZlsX17IeHhXlq2vIOcHA9VVYoOHb5m3brmun2uhWV5Oeec00lNTeGLL77g/vv/wJdfruTJ\nJ78gMvI9Fi6cwPr1mykqKiI+PoG2bdNZvPhdioqKcLvzdY92RUmJ5IaEQi5crjBSUsZSWhrBuHFn\nkZCQyNixo4iPT2xgEhow4Fyys3ewePHe9cTgxJuRjlSLcfDzsOfG+oEHHjjssU6kE/1R4BLLstYh\nDQ8eAbAsK8WyrNdP4Lwc/MJwImsiHcq5u3Rpz7x5/Vm9ehpDhrTkuuui+OGH6VxxRRLgxucbgVKb\nWLt2Ix98UEAweBbDhz/FjBmLqam5lhUrfNx335PEx0fy2GNT65IXAXy+aCZNuoiEhCogFqU8WNZw\namqquP325uTmzua5564gISGRqVNHNyC95OSb2Lq1kIUL11JePn2fDur6AQJOHw0HPxuHG//7S/zB\nyQNx8AtCw5yJESosrIvyeMboPI/RyrJOV/C8Ski4rUFuy565G8nJ1yu4TFlWZwVXKQiq5OTrVZMm\n56pZs+btdd6HHspWixYtVcFgUN1xx0MqNnbQfnNoTK7MiBFT1KJFS1UoFFKLFi1VDz8857itk4MT\nC36leSAOHPwioNT+M9aPZIylS7Nxu11YlsU778xnwoRhBIOSvxEKWSgVD3xDUVE1v/1tFtnZohns\nGYZcVVXBHXdcwIsvPkJCQkvAhdfbjKefvneftaOMBuNyucjM7FYXmltfs9gzfHbFijDuu+9JsrMX\nMHjwZY4PwsEhwSEQB6c8jkYS277GqP9afV9Jhw6Tcbst3O4KYDphYbuoqoojIaEJsLfvJRRK45xz\neuByuampsQ5oZtqTyPZngjtYrowDB4cCp5y7g1MWRyP6aF9jlJW9h2V5iYq6oMG4GRnNuP76Qeza\ntZN77plBUVETpLNhAjCQpKQ3SEzcyKRJwygqqtorMkkptddrd931uwYNmUz5+eeeu/ygDulDKVXv\n4OTHkZRzP+F+i6P5g+MDcfAzcCR1tg40xksvvan+9a839jtuKBRSw4dPUfHxIxW8oSxroII5Ki3t\nrp99fuPDGDt26l41r0yNrP3B+Eocv8epDY7AB+K0tHVwyuJohAjvawyXy4VS6oCZ8IMG9eX1198m\nNfWf5OU1JTX1K3bvjjzk8++Z5Lh8+T1UVZVSWSmVgQ8lFNcJn3VwpHB8IA5OaZjyHd9///hhhwjv\ny89wsPBf8/748Rdz553NGT++5886/54+DL9fMXRoPwIB13ENxVXa5xIKhY44EMHBrw+OD8TBKY2f\n4zM4EiilGvgqjgb29GEMGOBl0KC+xzWj28xh7NgksrN3HvN1dHD04bS0deDgZ+J4V4E92uXKlVI8\n+eTzPPvsZXs1khIT2aXs3l10zDQCs34TJrxBWdk0ZszYRFlZDrfcMseppnsq4XCdJ7/EHxwnuoND\nxNFwoB8K9tXQ6WDO7UPBgZplHcr7Rwp7/e5SoJTbfbOCt1Rq6s8PBHBwYoGTSOjAwc/D4TSqOhwc\n7XyLQ2mWdTw0K3v9/DRrNpZgUJGaOpeSkmqnDMopBCcKy8FJDXUA38Oh9sk4knMc7WKQByt8eDwL\nI5r1W7duM8XFRSQkJJCRke70Nj+F4BCIg5MaxvfQs+felWiPVhjrgc4BR4+o4NCbZR2P6sX118/B\nqQknCsvBSYnj0ePiRPXROFj/DKe/hoOfgyOJwnIIxMFJCaWOfSOq43EOBw6ONZwwXgcO9sDxcJIf\nL0e8Awe/VDg+EAcnLY6m7+FEnsOBg18qHBOWAwcOHJzCcExYDhw4cODguMMhEAcOHDhwcFhwCMSB\nAwcOHBwWHAJx4MCBAweHBYdAHDhw4MDBYcEhEAcOHDhwcFhwCMSBAwcOHBwWHAJx4MCBAweHBYdA\nHDhw4MDBYcEhEAcOHDhwcFhwCMSBAwcOHBwWThiBWJYVZ1nWO5ZlrbMs623LsmL3c1ysZVn/tixr\nrWVZP1iW1et4z9WBAwcOHOyNE6mBTAXeVUq1A5YDWfs57gn4/+3da4xcZR3H8e8PkIitXVMJtBSK\nENLgC2ltoJJQoWhMCkohmBiDASWammjQmKg1aoKvvLwgAkpMilCplxAFlYqaANKmwbTQht6UIq2Y\n2tZQrEgRTE2LP1+cZ+0wzO7Mzs7umdn+Pslkz5x59sz/v2d2nnN5LvzG9tuB+cDOSYqvr6xbt67u\nECZU8htsye/4VGcFcjVwT1m+B7imuYCkGcC7ba8CsH3U9kuTF2L/mOof4OQ32JLf8anOCuQ02wcA\nbD8HnNaizDnAQUmrJD0paaWkUyY1yoiIaGlCKxBJD0va3vDYUX4ua1G81UQeJwELgTtsLwT+TXXp\nKyIialbbhFKSdgJLbB+QNAtYW+5zNJY5Hdhg+9zyfDGwwvZVI2wzs0lFRIxRtxNK1Tml7RrgY8C3\ngI8CDzQXKJXLXknzbD8DvBd4aqQNdvtHiIiIsavzDGQm8FPgLGAP8CHbL0qaDdxp+wOl3Hzg+8Ab\ngGeBG20fqiXoiIj4vyk1J3pEREyege2JPtU7InaaXyl7QmmltmYyYxyPTvKTdKakR8t+2yHpM3XE\nOhaSlkp6WtIzklaMUOZ2SbskbZW0YLJj7Fa73CRdJ2lbeTwm6R11xNmtTvZdKXeRpCOSrp3M+Mar\nw8/mEklbJP1B0tq2G7U9kA+qeydfLMsrgG+OUO4HVJe9oLrnM6Pu2HuZX3n9c8CPgDV1x93L/IBZ\nwIKyPB34E3B+3bGPktMJwG7gbKpLrlub4wWuAH5dlt8FbKw77h7mdjEwVJaXDkpunebXUO53wIPA\ntXXH3eP9NwT8EZhTnp/abrsDewbC1O+I2DY/qI7SgSup7hMNkrb52X7O9tay/DLVKARzJi3CsVsE\n7LK9x/YR4F6qPBtdDawGsP04MFRaG/a7trnZ3uhj9yc30t/7qlkn+w7gJuA+4PnJDK4HOsnvOuB+\n2/sBbB9st9FBrkCmekfETvID+DbwBVr3o+lnneYHgKS3AQuAxyc8su7NAfY2PN/H679Em8vsb1Gm\nH3WSW6NPAL+d0Ih6q21+ks4ArrH9PWDQWnx2sv/mATMlrZW0SdL17TZaZzPetiQ9DDQenYnqi/Kr\nLYqP1hHx07Y3S7qVqiPizb2OtRvjzU/S+4EDtrdKWkKffah7sP+GtzOd6qjvs+VMJPqYpMuBG4HF\ndcfSY7dSXW4d1lf/bz0w/H35HmAasEHSBtu7R/uFvmX7fSO9JumApNN9rCNiq1PKfcBe25vL8/t4\n7QegVj3I7xJgmaQrgVOAN0tabfuGCQp5THqQH5JOotpvP7T9ur5CfWY/MLfh+ZllXXOZs9qU6Ued\n5IakC4CVwFLb/5yk2Hqhk/wuBO6VJOBU4ApJR2wPQuOVTvLbBxy0fRg4LGk91QC2I1Ygg3wJa7gj\nIozSERHYK2leWTVqR8Q+00l+X7Y911VP/Q8Dj/ZL5dGBtvkVdwNP2b5tMoIap03AeZLOlnQy1T5p\n/nJZA9wAIOli4MXhS3l9rm1ukuYC9wPX2/5zDTGOR9v8bJ9bHudQHdR8akAqD+jss/kAsFjSiZLe\nRNXIY/TRz+tuHTCOVgUzgUeoWuY8BLylrJ8NPNhQbn75420Ffk5pJdLvj07zayh/GYPVCqttflRn\nWK+WfbcFeJLqyLb2+EfJa2nJaRfwpbLuk8DyhjLfpTqq2wYsrDvmXuUG3An8o+ynLcATdcfc633X\nUPZuBqgVVqf5AZ+naom1Hbip3TbTkTAiIroyyJewIiKiRqlAIiKiK6lAIiKiK6lAIiKiK6lAIiKi\nK6lAIiKiK6lAIkYg6StlWOttZSy1i8r6lZLOn4D3+9cI6+8qPfe39/o9I8Yj/UAiWii9xG8BLrN9\ntMygebKrgR8n6j1fsj2jxfrFwMvAatsXTNT7R4xVzkAiWptNNS7QUQDbLwxXHmW00oVl+eNlUqyN\n5czk9rJ+laTbJP1e0u7hyYckTZP0iKTN5cxmWbtAbD8GDNK4UnGcSAUS0dpDwNwyg9sdki5tLiBp\nNtXIwouohl1pvqw1y/YlwFVUE2gBHKYaEvxCqlFPb5moBCImWiqQiBZsv0I1tPVy4O9Uo7A2D1S5\nCFhn+5DtV4GfNb3+y7KtnRyb70TANyRtoxoL7AxJo86FEtGv+no494g6ubpBuB5YL2kH1Si6q5uK\njTYnxH9alPsI1VDg77T9X0l/Ad7Yo5AjJlXOQCJakDRP0nkNqxYAe5qKbQIulTRU5i354GibLD+H\ngOdL5XE51RzVzWVG+v2pNoFRDLicgUS0Nh34jqQh4CjV8OvLy2sGsP03SV8HngBeAJ4GDjWWaTD8\n/MfAr8olrM28dr6Flk0iJf0EWAK8VdJfgZttr+o+tYjeSDPeiHGQNM32K5JOBH4B3OX+nzkxoidy\nCStifL4maQuwA3g2lUccT3IGEhERXckZSEREdCUVSEREdCUVSEREdCUVSEREdCUVSEREdCUVSERE\ndOV/QyjF03dlXsoAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYIAAAEZCAYAAACaWyIJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXl4VNX5xz9nMskkIYGQhDXssi+yKbJD6wa4g1oRl9pK\noFZcawVp6/KzpRULggsEW7ECaquiYKmigmwuqGyKIIR9TULIvswkM3N+f7zn5iZsorYmkPN9njyZ\nuXOXc+8k3++7nfcorTUWFhYWFrUXnuoegIWFhYVF9cIKgYWFhUUthxUCCwsLi1oOKwQWFhYWtRxW\nCCwsLCxqOawQWFhYWNRyWCGwOOOhlAorpdqc5LMblVLv/thjOhGUUnOVUo+d5r4tzX3Z/1GL/zns\nH5lFjYJSaqJS6j/HbEtXSi05Ztt2pdT133Y+rfXLWuthlY47qWjUQJzWJB+l1BCl1P7/9WAszl5Y\nIbCoaVgF9FNKKQClVGPAC/Q8Zts5wMrvcf6zcQal4uy8L4sfCVYILGoaPgeigB7m/SDgQ2DbMdt2\naq0zKx13sfEScpRSzzgblVK3KqVWm9crEdL8UilVoJS6zmy/XCm1QSmVq5Rao5TqVun43Uqp+5VS\nm8znryiloip9fqpjeyql1iml8pVSrwLRJ7tppZRHKfWkUuqIUmoHcNkxn/9cKbXFjHuHUirVbI8F\n/gM0VUoVms8bK6XOV0p9bMZ1UCn1tFLKe1rfgEWtgxUCixoFrXU5sBYYbDYNRryENSfYVhmXAb2B\n7sD1SqlLKp/WnHuIed9Na11Xa/2aUqon8HdgLJAIpAGLlVKRlY6/DrgEaG3O/3MQoj/Zseb4N4F/\nmM9eA0ad4tZTgRHm/OcB1x7zeSYwQmtdF7gNmK6U6qG1LgGGA4e01vHmvjKAEHCPuXY/4KfAHae4\nvkUthhUCi5qIlbikPwhYTVUhGMTxYaEpWutCrfV+xIPowcmhKr0eC8zWWn+hBfOAANC30j4ztNaZ\nWus84O1K5z7VsX0Br9Z6ptY6pLV+A/F2TobrgKe01ofMdaZU/lBr/Y7Weo95vRp4zzyHE0JrvV5r\n/ZkZ1z5gDjDkZPtb1G5YIbCoiVgFDFRK1QeStdY7gY+B/mZbV473CCqHiUqAuNO8VkvgfhNSylFK\n5QLNgKance5THdsUOHjMtfaeYhxNgcoJ3yr7KqWGK6U+UUodNdcZDiSf7GRKqXZKqbeVUoeVUnnA\nH0+1v0XthhUCi5qIT4AExOL+CEBrXQgcMtsOaq1PRarfBfuBP2qtE81Pfa11nNb6nz/w2MNAyjH7\ntzjFuQ4DzSu9b+m8MDmJ14EngAZa6/rAO7iezYkSxbOArcA5WusEYDJVPSELiwpYIbCocdBa+4Ev\ngPuQsJCDj8y2Y72B74IMoHL56PPAeKVUHwClVB2l1AilVJ3TONepjv0ECCqlJiilvEqpkUCfU5zr\nX8BdSqkU4/U8WOmzKPOTrbUOK6WGIzkLB5lAklKqbqVt8UCB1rpEKdUR+NVp3I9FLYUVAouaipVA\nAyQ34GC12XZsfuC7lE4+ArxkQjnXaq3XIV7GM0qpHGA7cOvpnPtUx5qk90gksXsUyQG8cYpxPQ8s\nBTYhIlixr9a6CLgLeM1c5wZgUaXPtwGvALvMfTUGfgOMUUoVIEnsV7/luVjUYqjqXphGKVUP+BsS\n9w0Dv9Bar63WQVlYWFjUItSEuuIZwH+01teZOufY6h6QhYWFRW1CtXoEJqa5QWt9TrUNwsLCwqKW\no7pzBK2BbNOMa71Sao5SKqaax2RhYWFRq1DdQuAFegHPaq17ITXaE6t3SBYWFha1C9WdIzgA7Nda\nf2Hev07VsjkAlFK2oZaFhYXF94DW+lvnj1SrR2Cahu1XSrU3my4Etpxk37P25+GHH672Mdj7s/dm\n7+/s+zldVLdHAFIfvcA06dqF1F1bWFhYWPxIqHYh0FpvAs6v7nFYWFhY1FZUd7LYAhg6dGh1D+F/\nirP5/s7mewN7f7UF1T6z+HSglNJnwjgtLCwsahKUUuianiy2sLCwsKh+WCGwsLCwqOWwQmBhYWFR\ny2GFwMLCwqKWwwqBhYWFRS2HFQILCwuLWg4rBBYWFha1HFYILCwsLGo5rBBYWFhY1HJYIbCwsLCo\n5bBCYGFhYVHLYYXAwsLCopbDCoGFhYVFLYcVAgsLC4taDisEFhYWFrUcVggsLCwsajmsEFhYWFjU\nclghsLCwsKjlsEJgYWFhUcthhcDCwsKilsMKgYWFhUUthxUCizMGWmsmTnwCrXV1D8XC4qyCFQKL\nMwZvvLGU5547zMKF71X3UCwszipYIbCo8UhLm0+XLpfz0EOrKSycxqRJq+jS5XLS0uZX99AsLM4K\neKt7ABYW34bU1DEkJiZx//2rAIXfH+ZPf7qTUaMure6hWVicFbAegUWNh1IKpRR5eX46d76PvLzS\nim0WFhY/HDVCCJRSHqXUeqXU4uoei0XNRHr6fubOHcbmzX9l7tzhpKfvr+4hWVicNVA1oQJDKXUv\n0Buoq7W+8gSf65owTgsLC4szCUoptNbf6jpXu0eglGoGjAD+Vt1jsbCwsKiNqHYhAKYDDwDW5Lew\nsLCoBlSrECilLgMytdYbAWV+LCwsLCx+RFR3+egA4Eql1AggBohXSr2ktb7l2B0feeSRitdDhw5l\n6NChP9YYLb4ntNZMmjSVKVMesBU+FhY/AlasWMGKFSu+83E1IlkMoJQaAtxvk8VnFk5F9q+//i6/\n+MVS5s4dViNq/q0wWdQ2nDHJYoszGydq+3D8TOCVJCf3JS1tXjWO1LaosLA4GWqMEGitV57IG7Co\nWXAav6WlzTtp24fU1DE88siv8fvDgCInp4S8vKYkJiZXy5htiwoLi1OjxgiBxZkBx6pOTEymXbsU\n/P4QTtuHRx+9k9TUMRWzfrOyComKupajR/2EQqncfffSaiHgY4XJGevYsTd+526mtgOqxdkIKwQW\np4Vjreq77nqFRYsyycjIP2Hbh/T0/dxySzzJyZnAYeAAmZnFFBQUoLX+UQn1RC0qAEaNuoNnnz10\nylDRseO04SWLsxFWCCxOC45VnZ29FbiC7OxoYARJScVovY3Ro2OrtH2YOPF29u07SGlpAGgCfE04\n7KGkJIBS/z1CPV1BcVpUfPXVk7Rps53bbpvMokWKoqJhVXIYJyb+Q/TsOdyGlyzOXjjWWU3+kWFa\nVDdee+0dHRd3t05JuV4rNU6D1s2bT9SvvfaODofDx+0bH3+3rl//PA1XawhruFqfc85FulOnEbpd\nu4c0hHW7dg/pzp0v07Nnz/veY4qPv0e//vq7Wmutw+GwfvDBvxw3HgepqQ9qj6e3TkgYb8b0kPZ4\nemuvd5D+17/+o6++epyOi7tbp6ZO0p07X1YxTvilTkw8X9evP+GU921hUZNguPNbOdZ6BBanjfT0\n/bz44nCmT/850dGRNGx423EhoaohpOnk5nYC9tG48ZXExKRwwQXdefTRO4+L16emjgFO38I/WQJ4\n3LiHjvM0tNYMG3YLnTtfxvLlHsLhxygo0Mj8xcOEw80JBvtzww0TeestKCoaxocfwqFDmezY8bnZ\nL5lQKJn8/ACNG/+CzMw8gJOWoZ7ufVhY1ARYIbA4bUyaNJZRoy5lx44DzJt3ORkZLxzXCTQ1dQwD\nBnRl9+5MhEDrUa9eIxISQtx8c126detYEa/v2PEeDh5cWkGWEyc+weuvv3taIaNjE8DZ2VspKChi\nxQp1XOjmjTeW8vHHiQwfPpBAQAMewmFITLyZ6OgYfL6DwGqk7+EsYDW7d79P797t8Pna4fWOAfwE\nAgEaNtzIU0+NxOPJ4a23lp10fE7o6403ltYoQbACZXEi1JgJZaeCnVB2ZuG1197h1luXUF6eSzDY\ngKSko8yePYZRoy5FKcWUKc/Tvn0LPv54HdOm7WPgwAI6d27B3/72AY0aDeTw4em0a/c7IiM3cddd\nNzBu3E0nvI4zYa15c8W+fSFSUxvz2msF7N8/hebNJzFsGKxZ8yXBYA/S0x+nSZN7ycxcQ2xsJMFg\nC+bNu41PP93AzJmf0LBhDAcPxgN/w+sdj9ebyzXXNKNJkySefnoFDRvW5+DBzUB/6tXLJz//nycc\nY1rafGbOfJXy8u5Vrnn77ReTljblx/sSToKaNsnP4n8LO6HM4nvjh1qNO3Yc4I47UoiObkCzZhkU\nFhZUCR9t3ryJG298gKef3gvMYs0aD3PmvE04fCFHjgQQC7+wSsjoRKi8RsGLL44gI+MoeXmlJCXd\nQl5eCZdcMqRKGKqkJMQ994zijjuuYt6829ix4wBJScm88sqvmT7953i9kdStO4aYGB933tmTc8/t\nxOHDRykv95CZ+TVK9QHmkJ8fC1zBgQObjhujm1QvBBRHjgQIh/+P5ctVtSaX7VwKi1PBCoHFcfih\nFT2TJo0lKSmZF18czr59r/Dyy3dUhI+01jRr1ow77vgZ4bAHCR/5gA5AAsGgJiVlLMGg+tZVyJxQ\nlVKKUaMupWvXDqSmNiIQSGTcuCbs2HGgStloOByBUjBrViZKKSZOvL1KuOvVV68mL28+L7wwnEWL\n3uell95kxYoQ8B+CweZGGBUQhcezB7//EHB8nmDBgkUEgx5SUsYSCkkoKhDQ3yps/0ucbC5FdY3H\nombBCkEtR2Xr/1ircezYt7631XgsSU+ceDsgIjNrViY7duwlFAoDVyO9D1NRaiXwER06FNGo0Vds\n3773lOOtjLS0+cyfv4jFi4soKprOokWFzJv3FvPnL2bu3GFMmNCTevU28OKL605oEVcer9aaXbva\nkZmZZTwUDxCJCNa9gKJnz7b4fP15+OEZVcbyxhtLeeedQ4wb15jp00fi8+XSoMGsirkLkyZNrZb4\nvF3u0+JUsEJQy1E5qbl790EefviOCqsxL08zfPiA/4rVeKzILFt2kMTEDdx+ewciImTCmcfTGriR\njz7aw44d7Vm+fM1Jx3ust3Iii/eRR35Nhw4tGTnyEsaNu4lp0yYSG9uOk1nEzhjvvnspodAsAoHu\nBIOfAecBAWA7kAccZt26LPz+5mzZkkKLFj9hzJg7K+6vrGwRixYVcuedj3PLLW3IzHyTuXOH8+ab\nH/zXJ6N9lzCeXe7T4mSwQlBLcfxM4XeZOvU1/vCHJzl4MIfIyJvQ2seCBVvp2vWK7+UVVCYph6hL\nS0PAVJKSujF79qMcOZJHbGwbUlLWEgrtAhYQCHQBZrFyZQw+37mMGXMnaWnz6dRpBDfd9DsKC5+s\nYtFr01UUqGLxrl27kVmzMli48L1jLOJ7yczMY/78t44bb35+AVlZkqcoLtZABNADKCMiohD4O1FR\nJci/TgbgJxhswfr1uxgwoGsVIXr22d8ze/afmDNnAX/4w9N8/rmvwhvp3Pkyhg275Qd7B98ljHcy\nL83CwgpBLcXJkppHjnQkIWETdeqUACMoLS0+rVjyiSzTyiTlEHF29m5gJwcP/ptPPlnPO+8crgij\nREXVIzq6DkK+inDYw513jmbevJmkpo6hbdsUAoHzgKlVLHrnOm+99QEXXljKhAk9ThgGcsJEDz98\nMcHgRt5+e1sVAh037iauv/5SQqEQcC2SD0gCnge6EwqFUKojZWX7gfbAHsBHVtZXDB58LhdfPJjM\nzHyio68lL68EkFDQ2LE3HuetDB8+kI8/TjxuvsPpWvcnT/7Os+WhFt8ZVgjOcpyKXE6U1CwvV7Rp\n05hgsDmdOy8lHG5+WrHkyiEmZ/JWZZJq2nQQt932APXqNQI+Ruv+TJ/+TkUY5de/fpxOnQr41a+u\nBBQRET8jFNJ4PIqbb76L6OjuvPMOSJ1/Ovv3L2LixP+ja9creOihVRQWTmP58hCLF3/Bhg1bThgG\nGjasHxMmPM7o0c8QDvckHG7G6NG/p0mTvgwbdjNpafOYOfNl4AhwDvCRuTuFhIbK6devC+3btwJ2\nAo2BXShVj4svHspbb31IMLgRvz+JoUP9LFz4AdOmfVAhhHl5fho3vpKDB9/nlVcyKSycftx8h8rW\n/am+u5MlfxMTk20vJIvvDCsEZzlOFjo4UVIzPn4GhYUh1q07zPjxTU4rlnysZTphwsu8/34MTZsm\nVISBSktDzJjxEN27n0Nm5hJkYbrWSKVQdw4cWMHNN1/Ozp0dWb78c37zm1aUlb3Cb37Tiq++2sW8\neTO5446fEQrJaqYREVFcdtkAAgH4/e/Hs2ePTF7LyvKbUk0P9903hayswmMSo+DxRKB1I+BZIJJQ\nqIwuXdqwYkUekyc/RyjUB1iI/GuEgDBwn/ndgPXrv2b79n1AW+A5oA2hUAbXXz+Wl19eQjjcDZjN\n22+X88orb1Ne3oYJE17mjjv+j9GjYzh48C3uvnskR49uBsDvDzNwYFdmznz1OOt+/PhJJyX1Y5O/\nWVkF3HvvFCZPXmPLQy2+M6wQnKVwCDo1dVEVYjhRUvOXv/wd8CV+fzJwNVo3Z8aMhTRt2o/s7COn\njCWfqBldODybr79uwIED7wKvcOTILmbOfJ5PPkkHhiJW/R7gE6CE0tL2TJv2OkVF0ygu7szcuW8w\nZ84Cpk6dyLvvzsHj8bBjx17Ag9d7A6GQJiMjiwMHuvHznz9IeXkkMJZwGMDD0aNFDB58AfPnX15F\nzLSG0tIStI40o99NOOxnxYr1BAIh8vIaA/UQD+BrYAiSG9gPZNGxYwxXX30FXm88sNucI4KOHVux\nYMFzxMW1RP6lFgCbUKovMIvMTIXPF0mvXp3weDwopSgra0dKyg1kZKzjoouGHDNLupCCggKWL/ec\nktS3b9/HhReW8tVXTzJ//hUMHtyn4hylpSHat2/G2LE3fv8/IotaAysEZyGk/PEgl17aj7w8CSuk\np6/m978fT0pKMx5++FdkZOThhBT+/vfHefHFJ4mPrw9sBHYTF9eWmTMf/tbcgGOZlpe3ICWlDqGQ\nzA3IysonNrYB0BePJ5OPPtqKx5MMRCFEq4EYYmLOIS5uA1KZ8x4HDqyiuPgCkpKSmTjxCWbNeonk\n5PNZtmwb0BKtNwErWLeuLjCLQOACYCWQDWzA53uCYFBxzTUX8sUXm5g48QlGjryEiRNvZ9y4m+jY\nsbUZ+Q1AB6KiPIRCQ4BBaO1BKoO6Aw2BOURHtyIhYTcXXRRDy5bNGDXqYoLBAJIjuATwcPhwBL/9\n7V8pKTmKeBFTgGZo7QUUWkfTo0d7pkyZRZcul/GPfxwAniM3t5xgsBVTp86pYt0Hg4rrrhtGZuZG\ngJPW/Ldv34Jly2J48833ufbaYVxzzYUV58jO3s3SpZG8+eb73/0PyKLWwQrBWYhx4x7iySd38cIL\nH6F1NHAR0JmxYycxe3Ym8+YtorAwTLNmqeTlleLxeIiIiKCw8BDwKXAe+fl7KqxXByeLWR/bjC4u\n7ga09lJSEg08RyBwDvXr18PjKUUE4HpEDHIoLd1LUVF3YDbwEn5/KX7/DiZMeJmpU3eycOF7FBdf\nQCCQiyRsOwB1gRhzDi/QDDgI9ODXv76IuXNH8OabHzBz5gFmzlzPwoXvEQ6H6ddvFNu2pQNrkXkB\nsygr62uOfR+tdxAZeQTwER0tglanTjklJX2JiYlj27bN3HbbZKALEtpqAWwkPz+dxo3r061bCr16\nZQKD8Hq3Ah4iI8cA0Sxdeoi9e/14PCHC4cPAFZSUJKJ1Gnl5nSpCR+LBjODzzzdTWNiSZs1GHzcH\n4WSJ4vnz32T06GhgO/XrN6G0dKYNEVmcFmyvobMIbp+bc0lP/yPQFbFQ+wN/B24C1pm9p5Oc/G/8\n/jW0adOcbdt2EAhEA30RkvsSpdbTqVMTNm9ehlKqSp+akSMvOW4heKeHUFZWJg888FeKi1OA/wCp\nREaupry8DhAPFNOrVxM2btxOONweSAD+AYwDWgE7EEGKJzKyO+Xls4GfIwSuzPhaIl5AIrAMCePk\nEBNTSiCwD62T0Hol8DsiIz8Acigvr4vPdy6BwPXAW8AcIBUYic/3BqHQGiCeYLAFUIgsqNMHqRq6\nFfgapXLRuguSI9iDiEhPOnbcxq5dOWjdj/Ly2Xg8lyGhp6bAb4EZwATgMURI9pn7SEOp27j99kak\npU1hzpwFzJz5KpmZLTl69BnatZtMaenHNGlSj2++acMLL1zKZ59tZPv23axfX5/9+/9M8+aTmDZt\nSEXvoNdff5f7719V0XPJ+cxOHqt9sL2GaiHcShKnFUIKYoF7zfs4JOk5BFAUFW2ipKQvkyf/iksv\nHYzPlwxkIvXxRYwYMZC9e7sxfvxDx1mgLVr8hKeeWl0lkenUqY8ffzM9enRCyPo+AMrLw9Srdx7Q\nDujB+vVbCIcHIYQbBfwMiAa2Al8CdYBSyss/NWdvghCn34yvJRBP69bbOffcrvh8+4DGeDyK4cP7\no3VX4H3gG8rL/ZSX9wceJxCIQv7sPcAVgCIxcTbhcATBIASDvcx1lLlWmXkdDVxswj0NgGmICPmB\ngezc2YJgsJRgECQc1Jzk5HhEMJ4BmpvzBImK+pjY2Lrmvq9Gax9169YDYNcumdQnnyuys4vQOkx6\nejmFhX/lrrve5cknX+Xtt7eSnV183CxhO4PY4vvACsFZhMok0LDhbURHt6NOnUhEDByi7YBYsX/A\n7+9EOJzIjTc+zuLFqwgEsoBkhOSSWbJkNcXFR1m2TCZaOXMOdu3KICcnRCDwFpMmraJTpxG0aTOI\nsGRrAcjJKSAi4giRkXuRcsxm5Od/DJQDaYiXcggIAqvM6+FAFkLEsYg13ga4GCgFdiFx+UgklxHL\n4cN5fPnlVgKBMuBZiouTWLLkC8Sz+S3wDVBi7t0RgD+a7Y3xeJZTULCd8vIPzbVmAUVmPI2REJQI\nBmxDRDQfh9SV8gJjKC//knC4K1qHgWvROmwmpmWa86wC/gD0JiWlEYFABkotB3KBq3jxxXW0aPET\nZsxYw2efbaqSL4iOjiAvrwXwPocP56N1N8LhMZSV7SYn57PjVof7ITOIbZvq2gkrBGcZHBLIyHiB\n+fOvpKxMIRZ2PDACIeICJDwxB9hPKBQArjT71MEhOSHcBA4cSKdp0yTKyxWdO9+Lx5NHSUkX4AP8\n/jBt2zZj9+6uPPjgE4CUpu7a1Zp77unN/Pm/JDJyD0LiYYSQpXGbWPbFZuRdEAEKAJsQi38O0Akh\n4HeAnwDXICGvDcASyssjaNIkyez3PtIPyIuUgPajUaN4GjduaK45GViOCFMrYA7h8GCCwbAZT7LZ\nrxSJ/49BBOErYAXiHYxCPIEewGG0LjNj740IWabZf7V5hnHAYERQ2gKz2L27CUrlER0dB3RGKp3i\nyM+PIBBYxIsvrqNevfV07+6nvHw5O3dKPiMi4l/muzyIhNvKeOqpSdSvX48HH/xlBYlPnHj7955B\nbNdkrp2wQnAWQVok5DJy5CUVJPDoo3dx//1XEx8fR1LSfIRgAwjJK8TyrotYuQ2QUMcNSAxbARcQ\nCJTw+edJKPUekE6dOg2BWSg1n/3732TJkj3Ac0ybtgKlOvGLX7xOIPAMixcXcf/9T6BUCpGRScif\nm0bCRR6EcDXugjDRSOgowlxbIZZ7fbzevjiLxogIlAMXEQoFyMlpbz57FckXhM09zSIzsxsZGTnA\nu+Y69RDCd5LNHvP+z+b6fRAxiUByFqXmXOcD/zbXX2ee23YzjkRESFIR678RsBkRgQgkN9PJHKOA\nLLQO4/d3RuYivAp8RWGhtK6IjW3H8OH9WLToI/z+toinoozHVWTGNwy/P8j8+Yt47jlpo1GZxL+r\nZW/bVNduWCE4i3Aia85pCT137nDuvXcAjRtvJCamCCHLUQghFgB7gQMIMecjM2v9CEk1AZ6nUaOr\nyc8vwO8PAQqv10evXu3RuhVCcK247LKBJCSIZZ2RkcegQb1ZsOBOunVLQcI13yCJ4MO0b9/cjDIL\nCb80RMJGfRDLdwhC0g0JBh1hOIyQb1/EY+hHILAJScR+DvRDSNch+mTE+q8PDEJCUjnm/p3qpULE\nyt4GnIuEcRwvqQ0ijI4nk2m2aYT0IxBRpdL5PIhX4pTL3oB4BxHASKAtoZAy5arOfZUB9YiIuIpD\nhz7g9dc/pKSkFyIuCskl5KDUEKKi9iIzmwtYsqSMwsJpXHfdS/zsZ5MpLOx10hzOqTB27I20a5dS\n8d3aNtW1C1YIzgK41twqY82tPGGL5ZycXDIyelBa2h74AiHAjQgBv4NYyytx++v0x62MUQQCmqZN\nk4iMjCUx8WbKy1XFRC+PZwDhsLSEyMsLkJKSSmFhiA0bNjB69P2sX18PIfloJJTyJdu3HwYeR4i1\nCPlzVAhhliG5gQzzOgoRiwhcgnVItxUywSseIXMPYn3fgJB+LlJiehMicjFI+KkuEk7qgyR02yLi\nOAQRxk1IaCjHnPNm88Q3IkLxEZKQL0OIORMJPTkhpL3AGqQqKgvYggjcJ+Y+PEgb7kikuqs5oRCE\nQt3Jzc032w8gHlA6Pl99tE6jrKwn4m00NJPjFFp7CYebAzexe3cmwWALAoFFFZb97Nmn7kG0cOF7\nLF2ad8IEtMXZDysEZwGcaqGcnBJAkZNTUsWaGzPmTrzeLkybtgWp1+9kjtyHiEEKQqrFyEQpn3nv\nWNXbgf4cOHCUzz9Pp7Dw3+TkfAPkm0Xgl+HxdOOKK+DTT79C6xXExCQBV5OVVZ/4+DoIoV6BEPIc\n4KeIZf9HlMpGvA5F3bo34vFEIBb8eQhhxiElpQopGW1KVUs71/xuY85/BInXxyMkWh8h1fvMcXkI\n8X6EiN0cRPw+QspdZyHiEIOEeFYi5O+8bmw+/wARhCaICNRDRMRvxtsX8QwOIQJR14xlACIWK8x1\nrzbfxyokPPc8EsZaBywGugENzHrLzveSbO7PA4xFBHYXMJhgEAoK9gOeinbc77yzmunT9/DGG0ur\n/O1UDgn5/RdSr14+Wm87LgFtcXbDCsFZgDlzFnDffVPIyQkA95KT4+fee6UmHWDevJlMmHAjSjnh\nDY2UM96ChIAOICGR9sCvENK8FrfXzkVAJFp/gFjaQxHCPQchugsIBmexdm0UPp8Pvz+OzMx8YBhK\nNaekJB/jFih/AAAgAElEQVSx2v248f8wEkv3oPVuIiI24/V+g1LbCYe3mjHehZDnEoRs9yPEuw4J\nEb2MWNqZiPUN4sG0RLwPjcT46wNHkWT0dkSEHjH7ObmSlmY8peZ9pBlrd3Ov3RGvJd7sOwt4Bddi\nd4TjeaAjbmjoAkQIepoxD0D6HA1ARCnXXG8wIg5B3NwN5jvIRIQhFhGX9eb7u9CccxsiYl2Rf+kd\nlJSUkJR0CVlZmxk//lEWLy6nrOxZ7rrrXZKT+5KWNg84tnldKpGRKTz22ARmz/6jbVNdi2CF4CxA\nauoYBg3qQ2JiETCNxMRiBg/uU+EReDwePB6PiUk74ZIIPJ7VCJHtQsIXMeZ9htknA7FY0xDCSUTI\n/3nEq/gA8Si+Bp7g6NFicnMVweAhCguDwM0cPfqlqVxahpAcSOVPlDlnR1q1qsdjj93Jyy9PpGnT\nJDyeWOAyRHC2mGNiEc/lbcQib4D8+TZGRKUD4jmUAR8jhL4FIe1zzfE9kPDPHKSCaBdiSd+LeEES\nApPxeRDhOmDudQ6SMC5FiBdEAHxmnG3N9S83n8cC6YhoBZFQnMYl/gZm/28QQZuFeCdf4YbAynDL\nWDsi4aeulZ5jKhLWywMGmu+hEyJ8CRw9Wk4gsIGcnEKcHMfhw4UcPdqIdevkuZ5s3gFgy0hrEawQ\nnAVQSjFy5EWUlSXTufP9lJUlMXLkRVXiu5s372LgwEL+9a9bGTCggOTkLCCXunUjENKphwjBu4gl\nuwcRgzyEfH6CxL3jESI7ioSSnDDOJ0AegUABEttfixBpGK395rhoJAySA3xots1h//7mLFjwNjNm\n/I2tW5sTDh9CSPoaxBLughBipNlWYl73RchVIWWvbYBeZlwHcCt9tiAkryvt3w2x2jMRTyHT3Mtn\niChuN8+jeaVjohHiT0Is/PrmWZUhopmJhKXORwjZSVSHkKR7M9zJc37zuR83YRyPeECLzPgdD+4z\nJIfhN889wox9IOIdyEI+8qwOmO/soNne0xznrLHgBX7FihWqYnGc7dv3Vcw7eOGFYTz99D94/fV3\nbRlpLUK1CoFSqplSarlS6mul1FdKqbuqczxnMk41iUhrTc+e7Vi1agHXXTecNWte4eKL++Hznc95\n57VAyCaExNUTUWo1vXt3R8IuUQjBzEasVw1cZfZvj0uqhYRCWwkGO+CS0ldIHuBSpF6+mdm/kzm+\nEzCVUCiLLVt28OmnsYi3kUjVeH1vRAi+RqzsegjB9kAECCQJnGHOG4eIQoCqVTnx5ucGhNAdj+J6\nJCwUMtf+BBGW1ma/HHNMhLnOHvM6HrHwoxExSTD3OwDxHD5GBC0KeNqMfxniLXyIeETNEFH7GULS\nCeb5NjbPOgEJO/UxY2toth8BHkKEw0mcR5jvIs/sO9Ns/ynikeSY7/QAfr+uWBynffsWfP75JgDe\nf38Fq1dv5+67l560jNROOjv7UK29hpRSjYHGWuuNSqk4xI++Smv9zTH72V5D34JwOEz//tfy8cev\n4/FU1ffKPYKys48wc+arZGe3JitrJl7vOILBT5Gyy1igmNjYVZSUgIRVhiDkOxcYhhBJEVLv39G8\n/gR3XkA58EvgX+b11chM3p+YY3sDLwG3I15DM3OObCROPgdJfi437+ci9fz7kfYTjRAL1wkT/RQR\ngAuAF82xHyPE38LsF40kZusjHoND0vGI1R+NkHs8Yu3HmLEmIKSajHghQTOOaKQUdQ4SxklGeiXd\nYu5jCXAbIhJHzXHO3I1eiAgMMp/lmeukI4QeZ94fRDybxohgxCATAv+IVC9tMGOKQHI4h5A8Sp4Z\nezskRNUOEdebUWodWjfH5wsQCGQRE9OP0tL2xMYuo6TkKAkJYZKShrNzpzPmF6hf/y7S0oazbt2X\nTJny2+N6Tjn9jSxqJs6IXkNa6wyt9Ubzugj5T0+pzjGdqXjggb+wdm2jitm9cOJJQjNmvMKAAV3x\n+WQGsdaOFXmEpk2LUGoLpaUKsah7IsQVidTUt0dIOIiQkxPqaYuEQ2SSl/TjvwAhNalkEkIK45aI\nNkAs7giEAJ3JZT/DzQd4kZh7GCHKS81Y6yMhm/fN72jcpC+4yei25rjPEGvfaTOdg1j6P0HEbifi\nZTQ153cqqPaYZ1CKkHYsQsjnIOTv3EsUYsVHmfOONL9/ZcaQgczVqIeEbgYg5Fwf8TAOI4TvR0j8\ncnOv0YggROL2jXI6riaYa9RFBK+JeR47zDNJM893vfk+otA6CNRBqRAwkNLSncAGSkraANfh8w1h\n9+4l5r5ySUq6mWBQsXbtRp57LoPx4yfbSWdnKWpMjkAp1Qrx9ddW70jOLIwZcyc+37k8/fQe4Dlm\nzNhdseD7iZYzfOyxCVx88ZCKWv9QSFO37mGioyOZMWMU//znZPr374FYlrnAE+a1Bt5D4tJOrPwN\n4GGEpOYgSVPHMnXWCChCkqAxSFjDqUgqxU1+OtU7qxBiG4GIzUqkZPMbJBQ0AJmM1gy3audrcw0v\nYp0fQEi/H0KGnRBrPAYhz3MRwQoiXss6hKDjESGYjohUELf5XBtEGLbhClcAt3x1HTKPYS1C/M0R\nj2NxpW+qhRnDr3GbAEaZ+30YEco4xANriQiZ1zzLzuZ1rrlmrtlWZs69wjyPQea5OpVZ2pzrC9xJ\nb0fw+9uY76s5EroaCLxPZuZ7hMNdzblakpPzBcXF7zF79k4KC6fx4YdQUFBkFiGyk87OJnirewAA\nJiz0OnC38QyOwyOPPFLxeujQoQwdOvRHGVtNx7x5M2nUaAozZx7AWfD97rtHM3Xqg8dVhOzfH0Yp\nVZFP2LZtL7m5OSQl9aZduxakp+9n4sTbjYUXQGrnuyPhkn8j3kEa0vhtF0JGTqLWsVTvRIhkMGKJ\nf4YIQRPcPj8+pFVDKyQ53QIhpf0IiS1FLPOPEHFpjRDtTcBruETqzOBthXgmLyKkHIfrIXgRa30p\nIljTkdDVfjOOKCTpXNlbcTqM3o2Enz5DPJy9Zv8yxIqva8bVCcmHDEA8olcRQdhgnmNH87MLaYSX\ngohhijnHb83zSURyMb8w99EU8RIuMs/UmQTX13wPNyMT1Foh3gCICHqRxH59xPtZiIhkHWASkox2\nkt8dzHN1WnO4c0iio7swfnxPXnrpCMXFMj/l1lsvZc6cTDp3vpcdO/wAdtJZDcKKFStYsWLFdz6u\n2tcjUNK+8d/AO1rrGSfZx+YIToH775/CtGn7iIrKp6ysLr/5TSumTp0IuGsEjBx5CQsXvldB9qdC\n9+5XsnlzE8LhbxAL+hAQQqn6aD0XCX1sRUijFRK3P4pY5hnIRDCJS4tFn4hU1AxESCYPEZmfIvmF\nRghRrkasfSeMk42IgawFIMRVhFj7WQhZt0Q8leFmTJuBRxECP2zOrZDJc81x1yAoQYh6ECIizjoB\nTpjmY6RC6XEk9r8eNzTT1ryOMPeVi+Q+5iEkvgnxMnIRC30g8DckL7IJEQfHWgcRmAASbvrEnCPT\n3MPPzX3F4/Y16oR4Un81Y55n7mk9EmpqiMxoHop4Ms3Mczhivp/u5ndD8xyjEfH8EnHKC4C6eDxH\nSEg4SG5ub7SORqlS4uI+Z/ToS7nookHccsuLjBrVgnnznjhubQqLmoEzIkdg8AKw5WQiYFEVJ6rY\n2Lx5F7/5TUtKS+dXLPjuwGkvISWml5CXl3PSag8np1Ba2o1weDZC8iuBMny+o3g8PoQ06yMk3Aix\nMjMQITiCG4JwqliKEOJsbY51uqG2QsgthBuS6YqEXzaZc/ornSuEWLcpCIE6ovOaGc9O83lzJFTi\nlFGmm9fZ5lxXICS8FSG9Vkj4qwCZF+E150oy559q7iOAEGqSOb6P+X0r8m/kWNJe8zMaN29SuXXG\nKMSzamDOd8i8ro+IiVOd5LTMLjD7+xFxOGzu821zr04YKMl8F/UQcfOYa/dE8gZ+JOQWi1j/65FQ\nXBYyj8GpuPrKfD9b6N8/logIL4mJhTjzUzp1asWaNV8yefIa/P5X+eyzKFq0GMJTT+07rtTUVhed\nOaju8tEBSK/fnyqlNiil1iulhlXnmGo6TtRYbunS55k6dSIej6diwffTPbYyjs0pxMfXwefrREpK\nLMEgtGu3m4iICCRskYUba29iXjdD4uAxuD10OiPEdAgJmTyHEKRzntJKI5DFZcQyBiHboeZYPxKe\nWYKIwG6EtJxy1DTcCVrrEQE4aMb2b4QgVyBEuh0h8SLEK2hnxlHPjHc0EibJxhWYJghZd0QIeZEZ\n09OIyMUjHoQ2z+Q9ZP7CT8157jX3NNeMrzUS7olEhNKLhM6+QDyjXYgw5iI5ihbIv2u+Od/Pzbii\nEHHJMc+trrluD9yKofMR4YvBLVd1Oqw6s5GbIxVJ7RFxXMWnn3o4cqSEgoJckpJupawskQceGFvp\nb2QBu3e/RyjUi0Dg6eOSx7al9ZmD6q4a+khrHaG17qG17qm17qW1frc6x1RT8UPaBJ/uscfmFAIB\nmDChJ7///eXExxeSnp5NKNQU+BNCfO0QgtpqzpCFWLAfIeGOrQjp3IQQKYiFDULSUUhyNNv87mCO\nK0QId5Y5/z6zr8ccn4HbeK4lbsimEGm7kISQ+lAzHoWEqzqYY/YghLoPqQCajcTdSxFrONacq675\nrA7i7ZQggtPVjHm3GV8mEmZpiISUipEQVUuEiOsiwuTMGsbc5xBEvEbitJqW906yu9yMaT9uQvxS\nJEm/xtzDh+bcGYjABcwxCbgT0ryI1/W2+T6cstM25l6vRYTvL+bzbGAqwaAXKEOpTI4e3U+fPkdJ\nT9/Pyy8vIje3lE6d1uH1tiI3V9pyOMljrfVxf2/O5DXrHdRM1ITQkMVp4EQVQKdbsXGqY49139PT\n9/PCC5dy+eWNWLDgSpKSkklNvYm0tD+RkNAJIfA/Ilb4bIQ0ChEyLEGs+KbAdUg8uwVCyHsRUt6N\nWO3OovHfmM+cSqB+CHFuR0jMh5B+XyT8tNNcswwhTY1Y9T2QUNXTCNk7S3I2QmLimxGybIAku71U\nFZEo87qhOUd73LBLJCIGSbh9gGJww0c9EPFzVlOLN+dzktrRuJO9kpHw1hFzn+ci1U9bzNhALHin\n8ZwzQS7BvN5N1XbYXiQZn494ItmIcDgCeL05Z7rZvhrxuspwJ/ttRUKAYfN8fYhHIs35ysqSge58\n8UU5f/rTc7z9Nowf35ivv57GRRfVx++HlJSxZGTIetjjxt103N+bM3nNegc1E1YIzhD8kLVoT3Xs\nse77pEljAZg1KwOlFBMn3o5SCo/HQ1FRGRKq8OFW5UQihBGBWN1pCNG8h5DSRoS0ggiBPodY1AfM\n+04Iae1DiG4dEmLpjMS3NyBk+6E53yxzXL4Zi1M3X4AQm0Pq0pJZrtsC8QJ6IES3HfEOjp013AVJ\n1vZESNOZP+HMD3A6nnrM6wKE3OeY43chFUbnIB6Jk1PRiFh+ipDujeabaYTkRiLNOOuZsTr5hjgk\nWa2QkFGxOeZaM75tiGjMMvfrQ8JnzvyMLPPsnIlldc321ohg+ZDS1YGIMGQinscgROTzzLUTgd7k\n56dTVNSZUGgWL710EK+3K8uXfw1cQzDoJxhsxRNPPF/l761x4ys5ePB9Xnklk8LC6XbuQQ2FFYIz\nCD9kLdpjj50/fxFdulzOpEmrKCxszMSJK2nSpC9Nmw46YQhp/vzFKPUNQijSmVOpq/B4wOdrgdut\n00mKFuK2bfir+e2UmR5ACKczQqIXIqRzDmLFv4nE0f2IVayQEsqGSJlkEeJlRJjxgFj30QhxO3/W\n9yHklo5Y3nMQonRm/LZAvJJPkfxBFuKRzELi9p8horEVEQyn9cSXuBPgDuMuqjPb3NNX5v6zKv04\njd+ikWqq+rgeQ4QZb8CMx4fb+M6DVEwNQQg83YypkKqT2pw1maMRr6EXUjbaFhHQZuYnaI6PML+7\nmnEPxl3bwfGSzkW8lFhEVJsjYqXIzpZZz1rXB57h6NEYtE4jL68DXbpczvz5bzJ37jAOHnyLe+4Z\nRUmJXfCmJsMKwRmESZPGMnLkJUyaNJWRIy/5Tm2CK1cPjRp1KW+88Qzt2qWQk7MPyCA3dz8zZz7M\nU09NMqtUQUbGBh555NeAJj19H9HR/RGL34fHs5bbb+/IPfe0przcuYpCSDGEEMg4xIp9CJewrkbI\nJtvs51S8xCAku9ycqxTJK3yDiMBVZr+7zbavEIvZ6QzaDAnPbDbnyEA8Ey8S8nD68TRABKAUmcPQ\n1Bw7FDec4syN+DMS6io1174AEY1cc+3m5volle4viAhYOULqSQgxO6uZeZCwWdjsf4N5HcAN+1yF\nhJeWIa24GyBk3RwRlcbmvCDE3w8Rzq64YvcFMqM4Ajfc5fRH6ol4B04oyvHsGppxOxPXnFwCuCGm\nELJaWhTh8EWUljYjIqK0YgU5v1/z6KN38uabsxk16lI8Hg/9+vUkHPbaBW9qMKwQnGH4b1RiaK3p\n1WsEixd/QU5OJDCNnJxo7rvvLyxbtspYe8MpLGzBZ59tQmvIzy+goACENBoTDmuWLVvN9Ol/Jxwu\nQGLq1yCW7ke4RHc+bqJzNRKmcBZ02YPEt3cj5BSNWLBHzXlyEcu28lrF9RGr+yqEGJ0WFjFI6CcF\nqdRxFmqJNJ9V7vrpQUIhKWasrZGYvDOTuLI1fhAh9yFmn+7mfY55miMQ0UjHbTPRCbd0sw4ihg2Q\n0NPXSPgrE0n4LkCse2ei2nmVrl0HEah8XM8hFllNLsFcZxlul9jKZape4K1K5xqKiEMHcx+HETE+\nhFvt5JT6bkW8obXmXEcR4d1pxn6Q2NgcYBfR0Zvp2TOOmJhIYmOvJy+v5Dii/7aGiLbEtPphheAM\nwfepGjrRP1la2nxatBjCpk2t0HqUmRugiI310qRJAgsWLMHv/xCHgKdN+5pHH02jY8cUwmGA+1DK\nwxVX9OWXv7yVu+76OW7Pm2EIefkQkvknbgI4jMSap5vfyhzTBSHKaxDre6c5Tzck3ONY6ZmI5f4H\nc8wLZl8/UprptGsuRLwBpxooGhGddxFr+kNEeHoj3U2dVb4cqzjdjD0Tic+3NON1yNiLCMvF5vdS\nhITbIsJ2BBGg8xDrfDvigXyJ21n1YnOtAUio66h5Pk5Y6klzL05CPgERuXQz7p+aa88x1x2EWOp7\nkXkNR83z24gkgfORnMJR8xvzHQXN99URqXaKMNduZu671PxeiAi6k+voSXFxGbAXv78L69fnc9FF\nZXg8TUlNbczTT/+jyt/csd5oZU/2dA0bKxj/W1ghOEPwfaqGjv0nS0ubz8yZr5Cb2x4hnG8Ih0Mk\nJIzB44nit78dT2rqDWjdDiHnqSQkJDJz5mTTiC6LlJRCfL5c6tatx0MPjTNrFjdAiG0UEjpx1jhw\nkp6RSDijA0KyOYhl64Qy6gEPIsQ4CLHCNyPWswcprwQJCe1DEtHOOgCrEfI6jBBVb6SfT+WKH2c1\ntK4IyXkq/TTETQI7MfC+uGGrXYilHMJNHDdBQmSFiJg4M5bPR0TBhxBrR8TrONeMoxMSUjoHEb1D\nZuw55hpOAv4c8yx85pnuQki5FSIMIXP+fkho63kkfJZjnn99s22IOYeT9L3YPLdrcHE+bl+jeERw\nihDPp4O5znxzvB8xEAYhItwAGEg4XMzbb5dQVDSd559fz8qVcYwf/xCnwnc1bOychP8trBCcIfgu\nVUPH/pONHfsWXbpcDmiGDRtAcbET992C17uHOXNuYvToOtxxx+O8+uoRpF3BPmAnubl7ue++P7Nt\nWxmQSkxMMl7vdjZv3kqTJn1ZsuRjJISzESH58xARiUXI4zqE4DLM+1cRa7ZyN81oxPK8CbdfUSfc\nypfXkZBSGyRu39tsDyGkNBC3UZwHiYcrRECcUE0TpD9/E9weRVcgYvINIhRbzPuFCOk5sf4EJLeR\niBDtEXP+VrjtpRVCsrG4ay2DeDTTEFINI2R9GBG5FESYnOUxo83z0uZe9+KuP5CCkPp7iKBpqpao\nNkDIO9qMcYHZ5iT3WyBi1cmc9wMz/k8Rb+kCxOMoN/cxzYw9Fkn270OEJMN8Ty0Rj+4QEhbMAq6g\noKAekMbbb5eekthP17D5IfNnLE4fVgjOIJxu1VBq6hgefvgOMjLEEszNLaNJkwRmzHiVl1/+BohB\nqeHAeXTs6OXZZ+cxa9bjPPvsZHJz04HH8XjqA7PxeutRUFBCOBwGhpGbW0ow2J4+fboQERGNx3MB\nYr12R0jjGsRKzUHI5iASe49DSMfpPVS5m6YHIc6rEFL7i9mWbPa7EiG0/yAVRusRErwA8WxaIyGQ\nCNzmaWsQYj+EtHVugFjQ+xASXYWETALmWk6s38knDEUE4HcIKQ8z2/sjYZcbcOcU+HDnOXgRa9xp\nQdEJCf+km3NGIuExZ4nNHbjzJVYgIvEpsr5B60o/h8w9vmre90XCV6vNc3BmaDczz3cx7hrRsYgQ\nKFxRaYcIgM+M9QtEGJx1qt9DcjH1zDNqY551G7N9jxnTbvO7Fe6KdYqMjFIKCgrQWp8wrHOsYZOb\nW8KCBW9xLH7I/BmL04cVgjMIp4q1VoZSijlzXqawMITHMwqIZPXqb8jPLyA7ezuwEY+nBTCLvXub\ns3r1dn71q8nGuxDSDofFyg0GYxg8uCfFxU2IirqWnBw/fv9tfPhhBLm5mYTDGxECmINUskxGCNXx\nCKKRpOlFiBUZj7sUZCZiSa7EbTf9HlJeuhw3Jp2Bm3xORkIuCjfeXYyQbB1EKHbhtmhORharUYhA\nxSChD2dWckOz7UEz/oWIYLyEiNnTyL/JlWY8KxHiW4AIkhOm6YG7PvECcy/nIeT5EkLUg8y9d0fI\ndQ5uy+lyhKzrIKGdWERYnPWju+M24svAbVI3ABGXdbjLWGaYcxxChKYUIXynhbUXsfavxFkuVEJE\nR81+m3DzO93NOQ/hdnxtau47Fvl7KUNELNI81+vQOkRCQh127z7Ea6+9w7RpH/DGG0upjMqGzbhx\njXnnnYjjQj8/ZP6MxenDCsFZBseV/uQTWdErHE4AWlJW1oj8/CKUSiIuroxQSIi1tDSCcPj/ePPN\nQm644X6iorYgxB0GRqG1jw8/3IHWy7j55tYkJhYD+9m/fxmhkBeJjztLQjrvr0OI7RwkPv4MklTN\nQEi2P65HcACJZXcxdzAU6aPj1Mg73oQXqfrJNz9hxDLtihDddnPuUbhzD0oRsnIWg09FiDgKIf0S\nxILeiYiJIzbSWsGdnLYGEZ1liLA1Rqz83uaY3ghpnot4HM/hLpiDOTYFCalEI2TfCrfaKQ4RMA9i\nafvM2BogIZpkJPSGuXYvxNtpiVj2g3DXS9hizrsaIWanCukjc85tiJeWYMbhJMrLkMSz01rcCds5\n4aGWyPfqMWONx2385ywiFIF4X3WBvWzdmsETT6Rz442TKS/vzIQJL1cJ60yaNJbs7CN07XoFixcX\nEQg8c8LQzw+ZP2NxerBCcJbBcaUTE/sh4YONyD/svwmFehIffwS/vylRUVHUrXsjoZAGPERHx3H3\n3WOoW7cP0Aafbw9CFiMoL4fy8iFkZuZTVpZMs2YfEAj0JCbGh1LOIu9XI2TgEEs5QjwOkZUg5JGG\nu5ZxDm7L6i4IMX2CNInLQSzkNHPOVQjJfoSEWS5AEqeNEKLtiBDw00j5YwAJkVxl7uNDpFGcz4wj\n2fy8hxCbkzC9DnceQQixwBsgonWhecobEYs5DXdt5gXms3Nw5xJ4EWHrjHg2V5rrOAIxAPEqOuB6\nVHHmd6x5RiAi5zP3Wo4ISjOEpA/jtu/ujBD4xWY/n3lG/RCi/xIR+UJEgA/jzv1wZiU7nVadkFyk\nuZdPzXPbiLS9diYMTkOI31nPYa455w5CoQjzuzcwnawsD/v3HyYcDleEik4n9HO6nrDF94cVgrMM\njtucnx8gPn4z0ByP5wiwgEBgEz5ff4LBS0hMLCI+/iAREVtp0GAWeXl+lFIcOVJEVNR7BAJxSDjg\nt5SVtQFms2RJgMLCd8jLKwKeIy+vHK0H4/Esx+Mpw+v9CCGR1xBxcOLjDvk2R5rGeRHya4XbGE3j\nxrdzkBJJZ3KXs+h9a2AKVfsANUes5BBC6s0R4k9AiM1pEZ2CWPSfIyGpTYil3wex5vsjZLcBd5GX\nPgjh7TPHO+0zVKWfeIQIXzX7jUc8gx1IGKktIlDliLX/KSKK1yDxd2cOQeWWEl5zzkxESJylKX9n\n7mWwuVYjpFdQV0QcdyIicA1C/p8AExAx+6l5FhebZ++s6bDcXBekKd1mM77l5vxO76FyREzzkLBT\nd1wPyhG3O82+68y1Qub7SAYU4TAUFSnmzl3Is88eYuHC92zop4bACsFZCMeVnjTpKq64oiGRkZE0\nbboSaE5ZGUAqkZEpDB58Hq+8MonMzDeZO3c4mzfvZv78y5k37xfExBQCnYmNdUhWoVQsXbu2oqgo\nAyG77sBswuHzCYd3EQzGI7Hx7QhZz0II8nOE8AoRYtlhfpxlH29A4tPZSIjjfIR0nUliGWbfrUg8\n/gKEcByLdS9iqb5qrtkMIa4BSEO39QgJlyOE3spc16nscUI0TvfNBNyJbC0Qou2MCERrROwikNm2\nzoxoZ/H55QjxtUcIPBYRqG7mWm3NPb2IVDB5ERJ18hhOm4gEhOyjzT5xyCzjD8318s19rTHj7GWe\nyQDEQ9iMEPRKXE/sJ8iciwDiufTGDUflmTF6zLX6Il5KH+T7L0Ga9TlzRraZ+70Xt1fSn83rLojg\nBMx5A0hYz4vWfj7/vDFFRcO4445/m3YUi23op5pxyqUqlVJOIfTayktIKqWG2XbRNRdO4ziAKVMU\nt97agnA4zJgx08jPD1QsWzlq1HBGjboUgFGjLq14/frr7+L1dqNzZ8033xQArfF6rycYTCQjw2kN\n4aw74FiEbZCQzo0IQVVeqMVZkSsWKfX8DCHDIcjKXQUIAcWa/ZySSMeiPGD234NUDvlwq5TWIMRU\nbAEZ3nMAACAASURBVO5YIRZra2AGbk+fJNycQRnuzNyjSF4hESGyvkh4aAZuSGUY0nH1JiQM5BDs\nYKTa6K/mev9BlsH8Cres9GMkNPeCOf5rRLScf716Zp8GCGFPQUh6M24F0zmIpzIUsfKd1hXNcEtZ\nfeb9TYiotMBdIc3p8dTAfE/7cFtbJ5pnd465xzGIRR+B2/K7zHxvs5EJa9nm/tYhs4+dai+fGd9Q\n4Bm83lsJBjcSEXGYcDgZ2IrW/RHhmkx29kquumo4aWl/rvAAnL9Bix8XJ/UIlFJ3IUHVCcBmpdRV\nlT7+0/96YBbH4/vMrkxMjOEPf3iayZPXUF5+HcnJxWi9jdGjY4+zvMLhMH37XsPMmS9yww1R7Nq1\nDK9XauhbtTqHOnXWkp1dTnS0M0ErBsfSc/MDdRGCjEQIFZRqQKtWjRFL06lBj0KSt+cioYoGiMXe\nxhx7De48gkaINVuOEGd3xNIsMvuvQ8jOi9seohixkmOQ/MGF5vN9SGy8LWLxZiEejBMSicRtvhaL\n26vI8RrCiG3kWOrvmn2d+3cmsDVDRM3p+OlUUJUhCd5Y3FnBLc2YnFLUbHO/ftzZ2G3NPk3NufJw\nk71X4baVcCaLbTT35lRK/cycdyuSl3FCNj5znkzcsF0982x3ImLiTMxznsEgc2xvRCTbmPs9YK4t\nbT+CwRgaNozG5+vPZZc1x+NJxONxnmUm4fA51K2b8J3CQPI3OtKUM1v8t3Cq0NBYoLfW+mpE4n+v\nlLrbfGYDeNWA7zO7suqcAgkJPfbYBGbP/mOVpJvWmr59R7F2bQM+/TTEoUM5+P1t8PlaA8PYs+cI\nkZHtgfUEgy0QQhuOEN1qhKSd2vp0JIRRBhxB60z27HFKSkfjWv2Xm6vvQCzMEGIxv48QVgZCOmWI\nRV2IENtsxIJ1yiMnI2LxFWIBL8NNNNdFQlNvm+s2QDyBSNyQTQi3kkkjdk4GQrw9zVhuMGN1QjZ1\ncKue1ppzOA3knE6svXDzGVeaZ9MG6T6qcZfodBrSfWTuKRG3pNNJREcgMfieiHA4IakMRMQ+xW3P\nvQrxLhpV+p7ikWRxormfw4g3EY2QejZSdrsT8dDqmOfsrNnwCSLwh5BwW3Pc9tebzPFB8/ydCq9o\nsrIaU1LyJcuXH8TnyyYcVohwRQLjmD59C3FxPUlLm8fp4IEH/sLatY148MEnTmt/i9PDqYTA44SD\ntNZ7EDEYrpSahhWCHxUnm105e/a8b/UQlFKsXbuJwsIQcXE/ITe3pMICc44dM+ZOIiI68fnnjYCR\nlJdHsWTJOqADhYVh4EqCQSgoKAciTKfJlsTEPI+QhDMhzFn79pDZVh9pKd0TIRmnVDIXIb2dSIil\nJUKU/RCSTsJd1Uwj1nAhQmpO2EjjEuhnCKm1x2354CRznUR1M4SsGyFhnA24OYXzkSUwD+Eun7kN\nEYfZ5j42muvcUuk+foF4Nn0Qi3oEEuapj7S5yDHj+xQhytVmDDebe3TuRSECE4GbPHc8iGbIzGqF\nWOx+xNJ31ihuZJ7Tzbg9j5yVzRQiiH83526PCG5PxJJviISItuLOCeiE4LC5njPruyXi+fza3LsT\nFnTyPI6gtsFdunOE+Z5aEAhk0aVLe+69txWJiXGIx3aAOnXiCYXak5TkdEI9McaMuROf71yefnoP\n8BwzZuzG5zuXMWPuPOVxFqeHUwlBplKqh/PGiMLliPnQ7aRH1SL8WI2wTlZil5SUfEoPwRGQf/xj\nHdCS4uKOREV9wvz/Z++9w6wqz/X/z9qzZ++ZoQzM0IYy9DYgigUVEEGioglRsYsmJ0VIxMSg8UTM\nSY7pOZLYiFLMNyYRME0iJlHUWAFjw0JvgpQBBmaG6TN7dlm/P+7n5R0UDSrmFyPvde1rt7XW29a6\nn/488xfzpz8t4fbb3+K4487ltde2kp8/FoHic4jDi6OHeg/QiZycdWQyO5FxsJpIpIKePWvo338H\nsVh7BEARBFCO43Z2glpkD3gJ6eQjiNMHX1RmHT7v0PHIDXEFAtMLkI7aRclehI/idb7uJ+NtDU5F\n80X7vwCpcDoh4tMHSQpwcNzAWQhEnUrG+dIrFkP9z8UTmm/ZeObZmH+Gdw2dgaSPiYjAVSGVSU9k\nR3CuodOtnzK8Z08WjqMWh++kpGwk3Rxn67IcX8x+i507D5+naCey12xFRuy1+JiHpfZfPwTcNWiv\ny20PUrZWT+PVXq6wUGcE/pcgCcjFJ4yzY463Odxn860inc7ihhu+xJYtO2hocEWK/kpdXYampi9w\n881LD8QPHOq5uv/+u5g27VIyGbknZzIRrr32cu6//y6Otg/f3osQfA7dGQdaGIapMAw/h2TET3w7\n0omw3o2wvN3Fbu/e1Uyf/lO+/e1lJiE8S4cOp7xDvJ4yZTKjRg2hunobUEcY3kMq1ZlHHlnGl7/8\nZ5qb72blyi6UlVXQ2LgNn+WzPwKSvyOu+3WamiqQPv8JoC+ZzNVs2NCXiooqkskGxOGdj0BnBwIP\nZ+R1RVtSCPB72/cRCMRG4Qu8ODA7BYHnK4jLd1lM1yPu/0m84fY4FD/Q0cZYgVRGFyPig123Edkj\n/og41mx8ios2iDg5r51aW4PpiDCUIlA+Ca+bT+KroqXtszuvmYO9ekYjgH3S1qcZqXSOR1JEd5v3\niQjgK21uaXxqil34jKTDbD1X2phcTMVEW5+f2XpV2nqMQ5KK0/WXIYJWYp+7oJiApF272fbTqca2\n2HshIh5rkG3lWSTh9UXxIE3AN2y9FiID/xagHddccwuPPrqLk06K8sc/ns/06SPIza0Adh4UP3Co\n5yoSiRAEEdJpiMUU/xKJqHLe0fbh27uuYhiGO8Mw3PMu/y3/6Ib0798+qkRY70VYWkZXzp8/jdNO\nO+GAhFBZ2UB9fc93iNdBEHDmmWOJRnsTjVYAAclkSFYW1NT4hG+VlbUkEl2ReiYKTCUIuhMEmxEQ\nNyPAuhcB1ovAHwnDu6mtzSMImsnNXYbcOPsjAOuEiEM7vLF1AALJlkXVeyIw6Y1Ay/3nagj35uCk\nbDchbn4cUk/0xvmpeyBuj7yXfou4VRCxGIhA2VXn2oXAqgyfbK7ZXvkIzG5DYAsiFLMR0diODKo5\niFjE8GkXmhGwusL2Ab7O8eeRsbkOuVkuQhKKywXUZPNrsOs5e8Eo6yvT4no/QmC/AmUIzbI1b6nX\nP93m8jgiQG8iO03U1sCpnd5CRKQL4vMSeNXZiTa/UxAhmYn2uZftb36LfeuHCFIhXkLsDjxKZeUw\nmpszvPZaFf/7v3dTV1dLVlZ3SkrWUlXVyBNPPMfQoRPf9blavXoL3/xmTxob5/PNb/Zi1aotHG1H\nph0lpx+gHelEWIdDWFpGV1500QQmTTqTvXtrD8r/01K8dm3z5p1cc81wIpEI3bpNIZXqwfjxJyMg\nuB4Iyc5uywknlHPCCQHSP+8kL68NYZhEHOilCPwCpI92KR8eJ5kcSCaTpLExbcfMQaC7FUkErsbx\nRXivmBCpewLEFZcj4tIXgeUlCNRCfMoEl+vnmwho7rV+ShF3ehme2+2MfB1qkLolY+c64tffxtoV\nPQJdkE1iI+LcA0SUOiPBuARvBHX2iSI7fxkikqXWTwqBXx+bfxRlQa1DgLjDzm+FAL8WSTlO+ihF\nkpDLFurUS7sQkchGajDw0ksrZEzPtmuvsWuNt3UcjIijsxM4F9BWtj4pRFBd0jhXltJ5O8UQwD9t\n309CBGWEXbfK5nUxIoKu3OZFNiZXRlMG78bGzowadQy9e/c+KH6gd+/e7/lcPfbYvcyceRORSISZ\nM29iyZJ5HG1Hph0lBB+gHeloyA9CWDZt2nEg+Ev5f3a+a3j+nj2VRCIV3HHHJB544Hx27NhHdvY+\nZMQsI5lsYMWKLaxY0QWIkZ39DPX1KYqK8ohG1yP9by56sLMQIL2KT0w2As+lukjiBD4vz/kI9F5H\nnG7Grve0/T8CuXg24D1cnkIcfBfEeb6FOHPnJulcGtsi8HGlHfOQRnMYvm6AMzrvQQQjhTd0XmQr\n9SdkHJ6HT/Ps/OVfaNGfy7dTg1RFbRBHXoQ4+HwkBexBIN4egWYpMp42IT1/NT7+wOXtuc3G5NJD\nuD4TiIhkIelpGCKcP0CEdoRd41lbpwpE0GbbWr9q/Y1AhHoBIrBt7fsJyDb0lvV5ua1JBJkFs5Gr\nby5SF7rI7f02rhgiXH0QMY0iY/xmROScRxXArcRieZx11unMmDHlbakjrv6nz9Wh1KdHi9Z8+HaU\nEHzA9vZEWBs3bv9QN+PChYvZv7/xsAnLjBlXc9FFE4hEIjQ3dzggXrc8z0kaL78co6npd9x881K+\n+91Z9OrVlRNPVOqFeHwdAsYzECgUkU6vY/z4etq1a09WVi+kc3YA/SoC2+54DjwbcfOPINfCVxCQ\nNiMQn4AH75EogKsn4khBnKjLpuly1ZSgkox9kNrjFBQ/0AeB2/mI0CTtuN32PRdF4LbG6+9jKNIV\nBFA1CHifsHEsxWc2nW/jd8Xfc/ApIDbYuVtsDP0RyL1laxTFg2Iz4qp/bGvVDUkpcXwyvaF2nSzr\n+3xEUJxX0oV2zVZIIkkh0Ha2hAqbx112fgZJI23w3LyL7fgiBxe6H4VPfJeFCHEbm8cD+BoTga3t\nU0hNNR5JkoMRUXge7fUmRFyqkQqtDyJ61YgYLkTEcDc9e65l82YXc3Bw+2cJ5lqqTx0B+NOflhwt\nWvMh23sFlNUGQVBziFdtEAQ1/8pB/ju2tyfC6t+/xwe+GR988DEefTSLr3ylyzsegLdzOy2/h2HI\nrFm/5Ve/OptVq37G+PFN3HXXrw8ceyhJY/TooWzatJ033kgBx5JI9Ea3gYKAIpEGYrG+1NQ0sGVL\nX846qz3RaC/gbiCLIAjxOWhCpMZxwVwzEUg6rt25Il6KOMVtCFT+G6mgXIKz9fbajdQWa+3YryHV\n0XDE2WfsvDeQ6qkAcaafxefeH4nUOvsRoF5t83sVqS/OtGt2ss+7kNTRBYHtz5Fe3ZWmzEagPAKB\noeOAC2yMLrBrKgLJWsStJ/AEK8vG4Ljibniu/SUbu6uPsBQB9xoE7msRQSvFExoXJezsKgvwgW+n\n2TwiSNoJEFF6GJ+WI4KAOoavunaNza0QqbIG2xxLEGf/d/ttLgL1v9hcE4gxGGZjGWHXqMVHk2+3\ncXShb98uTJ58Cfv3l3PKKRe8IzDMPVcAL7/8Bt/61peAQ6tP27c/nltv3czXv/7A0aI1H7K9l7G4\nTRiGbQ/xahOGYdt3O++T1j6M4bjluYnEL1i8uJahQydSXr7vQLDX2w3ILb8/+OBjvPZaZ4IgYNGi\nx3nssWxeeilzgFuaMWMmwEGi9pNPPsfatZtpaGiP13MnEaidB2wnGt3Myy+3I5H4BX/9awOp1DMI\naOqRF7HjaF9AQNwdAeI/EFhUIW6zHA/uAxHgrEPc/fMI6MbjddAlSPLoj4DqFbu2kyYiwHesj16I\n2+6JgLQXAsctwK0IxDZaf08iTncU8i4aijj7UYhY7LZj/444beeBczwiHq4ojeOer7VxDUZg9xIC\n8tnIAOzKUr6OAH0TUmstRKC4HXHJsxGH7+IjXE6jFOLalyJw3WrvHRFRuszmHEFSx8M2vhhyk22F\nDzp7yva3BhGVnYiYPoCI4EY8kQxRXQEH/DVI0uuE7hNnY4nb+rasnbDZ9rAfUo2VWf/78JHd5WzZ\n0p9f/OI+br/9FV58sdO7Boa5+/zBBx/jpptu5eqrr2jB1Cxg69bHyc0dQxjOoaxsB/AZysvXHS1a\n8wHbYauGgiDoFARBsXt9lIP6OLUPYzh+r3PfTmC++tV7iceHMW3a36itPZ7LL/8OkyeLE7r44vu5\n+OIZNDaOoKmpL5dccjMFBcO5446lPPTQU/zqV2fzmc905le/msAXvvB5evQoxBc9qUAAkk08vo7c\n3DKamlrhsmyGYRZ6oAeg22Us4jgXIxB7AQGnktR5t9AyBBxbkEF1DgLZ1ogTPh6B2/NIr+48Zi6w\n8XRGxuDVCKQ+gw+q2obAaBICsv149VIV3uunAYFdGyRVOO+ibJuTK43ZgAC+b4tj0vjcRPdbf066\n+D/7fScCwnE2ThcI1sPGmEGG3Z/jE7p1srV1sQh7bJ0GICLVFm9wPtbWpCPKgxRB0kQ+kopcgFw+\nMih3tD4HIu+qbdbPSuu3vfVdiryNavH1FP5oYxiICEd/xCg8aPsUtffL8Cq4KJKqnM2kyuazHxGJ\nLBvbEtuHVoThXMrK+pNMbgNG87OfrSEaHcKQIWcQhiFz5txPhw4nMWPGc9TW3sbXvraQmTPf5Ktf\n/Z8D9oPBg1cQjfamvj4JPE4YDqSgIEky2eNo5tIP2P4pIQiC4LNBEGxCbImzRj36EY/rY9PezXAM\nHFbU77sZx95OJOLxflx77WXE462AK2nbdgBt2rRHYJ1DTk5vlDDsdTKZbmQyRSQSi3n55RjTp/+Y\nO+/cwYIFD9GhQx5lZTX4urQdEPDsIpEYR0FBK1KpAgSqkxEoZ5A+PQvpp7sj4ClFhsVhvJNj7Iv3\naClr8XsxAuAs6zeNgDuNJIpGxAln8LEDTi+/HgFafwRCaUR8cvDqhzpEaErxKSl62dhcFsy4XccZ\nfp3LpzvGeSD1Q5HRzpgaIAmjHHHaVQis5yLAG4IAbxPiyC9ChM95zExEAOqyeH4WX9TFuV+2R8Sg\nEKnfsPG7/Ed/Q8TP6eCdAf0eRNDGIFvGZbY2OxC4l9v/EUSURiPAdlXUihFx2WP9PGJz2mb97LM5\nNdocsLGPtf6dxOLuqTo8YRqPJCQ3xxwb0y4gxoQJI9m27RgWLXqcgoJCqqryKS39BzCRvXvjZDJ9\neOqpkGnTfsDll+fw9a8fTySymtpauTHDbKqruxCNPs/8+Ys42t5/OxyJ4AdIlt8YhmFvtKsvHKkB\nBEEwIQiC9UEQbAyC4FtH6rr/ynYoA9fhBpu9m3Hs7USiurrJvicoKbmB6upGKisbyM6+EogbwZiA\nHuhG6uriwOls3ryIdPp4EolZLF6c5gc/+CVhmCErq2Uu+f6IYy5lx44YAtxnEUAuB7KIRtN4jtdl\nFC1GHKOzCbgaxAFSicQReGzBB4vFkAoqFwFTDOnGXSK4RxBn6gy9rVCO/iIERi66N0AcuUtLUWbX\naY2I1XEIzOvw7qBr7f/ldm6dja8dXgp4AwGx++7UQQMR8A/C1wfuhQDbrUk9IkAuencvUm/dZPPb\nZuPcigC3BgXFubKeF9qY2tpeHm/7U4aAfqWtQVeUtfVY6/NRRBxOQm61/RERGWW/RRCh64pSRDgX\n0a54tVsWki6G4yOJY4gwnYFA/Unbh2q09xEkocVtnOCzzwS2l0ORV5VTDbpMpaW2DhUsW7aL+voT\nufzy73DFFXeTTg+lsbEtWVk7yGT+Aexmz54t3H33d5gz58dMnXolEydOIBp1tpKAeDyPefO+z6JF\nczja3n87HEKQDMOwAogEQRAJw/BpxEZ86BYEQQTVMTwbsVOXW+rrj1VraTguL9/H/fc/dNg2g3er\nvtTSEOyIxOrVW/jVr85m4sTOXHxxb0aOrCUWK0fuiBuJx7viEoFlMlvIzw+IRAabBBAQhoXU1bUi\nmexLOp1FQcFVCCyvQQ//tQh4xwLdCYJVCCQvJJNJI07OebLEEAfvvEo2IHfQFYh7HmfX7oGAfb39\n/wbi1MvwKSwCfGxCBF9T+EJ8ygjnpeQ8laL4tMsuh34a3UausExbBLJbWoz5WWRQLrLvf0WAOABx\nqBkEtq/b2J130lREqP6BJBmXUqMGET+XtTPE2xNqkFqqGqnguiGwdaqasxHX3mzrthGB7VZ8RPKJ\nNq6LrN8YXpUGIkb32FydgbsDvjSmkzbiiPj+2sZ9Pl5Fdr6Nez+SZpzReYVdfy66D5zL8Rpbh822\nf2tsbFkokA+8d1QbRGxdXMVq24MIMJvs7HyLfH+BdLqZMHSJ+BpJpxOIqN5OXV0bLr/8mwwdqipx\n3bp1JJUqJgiqCIIrCMOoRR8fVQt9kHY4hKAqCILW6OleEATBnfjk7x+2jQA2hWG4LVT00u8Qy/Cx\nbUcq2MwZggFmzJjJpElnsWTJvQDcc88eLrzwTE4+eRj19XmIM4Tm5pY1AEIuueRUrrvuJCKROJGI\n8vNUV5cjjrGCuroVwF6C4EdItXIjAqo5QFtyc5uIRCqA+WQyrZBRsQMCBBeg5VI3tEJZQHMQlz4P\nn5l0NAJfB+TH2rm7Eef/GZSbxxWpaY3AsgmB0//Zf+ADlXIQ8JyHtJVNSB/viuGsRgD6XQT0exHA\njrWxtULceI319yjiXvcjYKtG9ouMjXOnzbs9Ara1SMrYjcBwr81pkI3LRe/uxauHQgSkQ5Eb61ab\nUw8kOZxg69MbXyzeff8t4tadN9J0W/e3bN0j1p+Lk4jgPYKcR5UrDLTE3sttbNuQkXifvdrZHjbh\n4xkiyEDc1vo53Y5L2rV7IvtOrxbrNhkvcfw/BBud6dOnG7FYHyCgbdv25OQMYdCgbCKRjgdyCUFX\nIpFOiGAHQIqCgjw2bx5McfFYfvObncAEOnWqJy9vNUOH7jxa0OZDtMMhBOehO246/g6aeIT674aU\nmK7ttN8+tu3DBpu93Uj89a8vYebMPzBmzIUH/X7ppbdy2233o+WaB/QiDDPAFwmCCBMnnkrv3v0o\nLCxk+PA9BEEHxG2mEKD/iebmHkAlYdiErxgGENCmTVu6dGmHvPs6IDsACKB+RxBkEY22x3sQnYDU\nFc6Q6HTBLmo3gjj2kxHH19m+90USzc+R940z8rqUDbvt/WV8ta/16Dbsh+f4nSrJgedFdu3/QVxu\nNQeno4jZ55/iddeOiw0QBzse3fpF+DTWlYiLd4VgFtk4Mna9jYiQ3I+4+rT1nYtub6e+GYaIgqsb\n7AhFR0RkWlZgc4XqnSH+eaQ2qsfbYbJsTTrYWpXbnq7Eu4s22z51wueOPNP2xNkqeiK1jbMJ5eBd\nYPcjYtINGbYH4l2Ai5E6yxHLOpvzy+ieORZJB5Vs355FVlYOhYWfo7a2mWnTjmPixC507txENBph\n8ODpZGfnkMnUIGIkiSuR6EVz8y9IpYZTXf0SkEcqFZLJnM5///dXjtYy/hDtnxKCMAzrwzBMW8K5\n34RheJepiv6l7ZZbbjnweuaZZ/7V3b+v9s+CYlq2t8cJOImivLwWCNi3L0Em8wN27x5IdXXNgd/z\n84fSurULygqIxQKys7cxaFBb4vFKNm8u5aabvsyAAcW8+mpncnJeRIbEC9ED/DgChptQSUoHkvI/\nb2rKUFRURCw2nng8g0ClNQKBCwjDJKnUHgQCQ5D6oDsCzmxklMWu51JGpOw/EJjnIk68GF9o5mk8\nh++41kEILPcicO6EQH2mjcn5+jtPogABZXdk4uqECEaEg43BnWxcLsI4sN/GIEnBRSmvsfOWIiC+\nBwHoBg6uFdAXccFDbGxj8CUzH7H5uqjmFL7+sFJ9e6LXDx+N/QIiEC5AzBniH7LxZSNC0wdJITUI\nsNOI2O1HXPpOfI2Bfgicn8dHh/e3sa6zda+39XNFiJbbnjgJKrBxueC1LJu7S59xCiLs9bZ/zqB+\nGqnUdsLwJSorcygqWsXu3ZXMmvUaZWXtuO66YiZO7MLZZ2eArkSjL9O6dSdOOKGcpiblnEomAXKJ\nxe6gsjKXxsY7mTJlFiUln/7ExxA888wzB2Hl4bbD8RqaFATBpiAIqj+CgLJShAKudbff3tFaTm7s\n2LFHqPuPpt1005d5+eU3AA7S+x+qyai8i0mTvkoYhgekh1QqQuvWl5FOS/3S3AyXXnoOqVSEkpLr\naWxMk0ikiESqCYIryGR6cN11Z7B27e1MmzacjRsrKS4ex7RpfyOdnk1DQyF6MDeiB38WAoRvAVk0\nNLyF416j0V2kUs/w4ouVNDffTSLRAwGHy0iZgwhDG3z6BseJt0eqnraIIy4FvoAA3aVoHo+46jbI\nXz0HAUYrpHIYiE+pcAoCryF2/Bik6nkVcbSvIqLQHa+/34MMzBFU+tFF5iYRd+3SUaRRzEEFUiXt\nRcRoHjJA/w2BnlND9cUZJ8UZ5yKJAJTtM4IIw3Jbn9nIVvI6IjRdbY0m2nt3fAWwlYgQOLfZCdbn\nZ6zfEBGLLESM8pAO33HNAUoDUWl9fsfWrBXS2w/mYImpgIPzMznDvrO3dLffE7b+x9t/Ha1vVwlu\nP14FloOISARJh93wxNR5TCmzbFNTkjA8jW3bBrBw4V9oakqSSj3Mbbc9xK23/p4nnkgCfyOVGkws\n9hKRCMRi/SgpuZ6amgTDhxfy299+j4KCVsDjVFUVc+65o7n66is+0ekmxo4d+9EQAvSkfDYMw/yP\nIKDsZaBfEAQ9gyBwCuKHj9C1/39pYRhywQVf5Z57dr2nx9DBKqDbWbw4TXHxOObOnc+mTTuYMqUz\nyWSGaLSCjh1nU1XVyJ49lWY0/jkXXBCnXbsGfv/7z/KHP3yOSy5pw+bN2xk6dCIPP1xHOr2cVKoH\nlZXiosKwu/Vcis8y6fLoL0MA3Ab4Hel0CXl5OaRSiiXIyspFgH8iAqg64FMIkGIIfC7HE4J7cJGk\nAqkFyA2zKzI1dUEgWYIkkifxeW3m2TU24A3ITs3kDKBxpOLobHPqgIy+JyB99z4ETHvwxdNBxOBR\nFPn7KWQXqUZEYASKjehv6/MWIkgJxFG7WAMnUTid/EZ77UBEqTXeduK8cbDxfxoB/kZ87qF9iABk\n21phfVxo12xr11tp77sQGMfs2qcirn2P7aWz8SxDUheoaE21nXOx9VWE7AIuAtnZA0biYyFcxlOn\nSnOZRjvbawO+/OYepGJyksQIRKS6IQLs9sCtSQ+0l4HNcRUwhjAcAkRIJBxz0YH6+ghbt+7l8stz\nWb3653z968WsXNmVX/5yIfv3LyMWe5AwvIeFC8vo2fMM7rhj6dF0E++zHQ4hKAvDcN1H0XkYc34V\nDAAAIABJREFUhmkkUz+O5O/ffVR9/Sva3LnzKS4ex8MPp6mtvf1d6wQAXH31FWRnZ9iyRV4zYVhI\nKlXMLbfMYtas3/Lww3UkEp+isDCXDh2SXH55HsccM/CAh9EFF5xJU5OSvb3yykrmz7+VRYvubmGo\njpBMhmRn55KffxYyRp6GOEEHagsQwJyI9NYFwETCcAf19Q0IGM4nnc5GILAeceGlCKRKkVSx3T4/\nj4B3DQKGSrumMzj2QCDWCQ8AXe13GbjVtiMvHqeqcv7+MSSRRBBnvw+BuwOrCgRkNYgoXIPAzAWZ\nuaC3Y5CqIhcZYJP4Au9RPICuR4D3hs03aevVCnm+7EVA9xQ+QvhavLrEjbs14oyn4APLXIZUZxdw\nev69iDA2I47+r7Ye5Tbn7ohXqkR692W2LjW2Fs7ltcz2ppvNcS+SVF5BkkRo6/EkMlzvQwRik819\nte1ny2ywZTYOJ1X2t2Nd8Nk627PHbc372Mu5swaIyDrieLF9bmfHVNlan4B3Ra4jkehMJpOkrq76\nAKOTSPyCFSvaEos1kJen+6usrIZUqphEYvHRdBPvsx0OIXglCILfB0FwuamJJgVBMOlIDSAMwyVh\nGA4Mw7B/GIY/PVLX/Ve3uXPnc+edD5BK9SAM5Vv+5pt7qK6OH6gT0NIesGjR42zc2IdIpJpodDLQ\nRDIZctddt3DHHTMsrXMV0WjXg2oMv92Y7CIvp069+R0pJWpra+jUaQWxWD2tWp2MOEUXVfwW8q6J\n4nW+MYLgLXzO+wZEJNbjyx9GEOc3GoHSTMThl9uxzyKCsxmBskvffDHerdJlo3RVxgYjYrAPqTVK\nrI9GZDOIIylkO3Lj3IkIzakISEoRKHZE0kgXBG6P2Pdhdg1nmN2HjLbDEQE8FanNPmvzOAOfS+k0\nBLoDEDg9YefH8KkXsDEVIw+nLDvO1QkGn/bbuVQ6Y7BL0XySnVeNr+dwl/XrpKJ+yNNoIyIscxGh\ndfaThI3rKnzN5CgC+Aji5s+2tbwQEeJutpd/tr6PsXmnkZrtHLzR9wxEoJy0k0HS0hJ85tnNtpd9\nEMFptnGORhJELZIKXXnMC2wcG+3YY9F92g6p1J4FziWTOZHXXnuLUaOGHvDIi0RqyWTG0tS0j5KS\n6cTjuSSTksY+bGr4T1o7HELgqmSchcj5RHzV8aPN2pQpk/ne9661G1Hqg0wmm1TqpgN1AqZOvZk7\n7lhKcfE4br55KY2Ns2jVqiPp9AbatXuN2tpqFi5czIIFiykv30okspXduzcCHPA6uvrqK+jfvxtv\nvfUEcAr79uWQyczhL39pYObMPzBz5lzuu28Cq1b9jGOPzWLXrmO56qrPkEq5hzeNdPRbEffXGT3o\nlwEZunTJQ9xlW6Rzd6kHLkUP8VCkk1+LHvRTCYJsxAluQxzxi4gIzEYP9DOI0wsRuPwD3VJ/t3Fk\nIY77BQRMsxGw1tjY8hDHfCLSPb+FVFmz7fgtHMwNd7V5OU+iXOtjKD7oqweeAAb2+3Yb71wEegn7\nPAbZC4Yi/f0uBHTfQoDuiNebiHCkrb9ldt16W68diCM/FhG4lYgAZfAZReN472wnoQxBaqqdtm6n\n2V48joC7i803GxG7NxCIPooIShMiZoNtzcagojYViDDsQo91ZxvHCdZPdzve5S7agwhNBAF4Nj6h\nnvO4AhmHH0GEqwZvg7iJWKwfQ4b0tv8KkKqxP1BCmzZxpCF2x8eJRE4Frqa5OeR737uWsrL97N27\nmljsRCorc2luvpv27YuATYwaVUVtbc0RSQ3/SWuH4zX0hUO8vvivGNy/c3u7t4+76Wpra+jefRc5\nOQW0bi31SXn5Ompq6njmmYBEYjGpVA+2blXahTCMcv31F1JR8TRf+9qpLF68jYcfXk5ubgGZzD2k\n0/l8+cvfOSDiLlr0OI8+mkUyKUNcOi2w27tX3kX795dw7bX/S0HBSbz8cjXJ5FvccccDJBIB4hSd\nKmI8Aj3H9bUBVrF7dz3ikG9BD2oKAcGViON1tW33Iw6yjFjsDaQ2GIxUCl3wXGMvBIyjEYB/BwHz\nGgRyBchwfaytrON+nW6+HhGOC+yc9TZ+d1xPvNHa5QOKI84+gwiSc3HdYn0fjySLBPKOzra5uWhZ\np8dOIe+gyha/tcZH6y7Gl5mcjQzbO+y/0+29vc09D3HELo30KTb3JgTATg//Y1yeJ28c/gI+DcdA\nfIzGDKT6OhYRhtMQYR1h1yzFG/X7IMDH1iVm5/za1jDRYk2jNt5NiJC4eI9mW7+ViKNfaeeNsrmO\nQAxBGp/+OgfvbX47yaTz+im3vZVkmJUVpVu3IsIwIBa7ApeWIx6P0737FFKpCC+++DpLluzm2mtH\ncv/93zdDcUA0mkP//t0ZO3YMCxdec1jeekfbwe1wvIbuOsTrB0EQfKwDvz5sO1QKiU2bdrBw4TS2\nb/8d06b1oLk5m5KStSSTPbjkkrNpapLY6nT3JSXTyWSyqK2tpXv305k1az1h+DdgOPv3u/KMrcnN\nHcwtt8wiP/8ELrlkPs3NdyPQrUUgOZJMZgMQUFq6kmg0B3malAC5ZDLNiCtPIQ50LQKugUil8AMg\nQm5uPdnZceQm+XsEEP3QAzsWcfydUT6ZzohA5JFIuFq+s63fSrwREsS1ugIrM2xcXREgDUIqhTzk\n3ZKLABAELMUItG7G2xbc2lyEuPgqW4vzEJFYbv29bn1vsTG5AKgI4q4dMD6LiNsO6+sCG9sApDrq\niMB2O+KU19taliJi5QDURRMPwXPWVfgI3G4cHLPwI6SeWoUIQ6TFdTbY73ttrL3wrreOKDmHu6VI\nUrnX1swlsmtrYzzNxt0TceDO5pO2/vfhVT4uCC2DL5/ZycbwJj7YrB9iBDbZNZYhY/m38e7DNbZm\nzbYnrQnDnWzcuA2p616zaz4DbGDbtr2MH19LXt56YrFXgBRt21aRSq0lN/cf/PrXK2huXszDD9dx\nww0/pa4uRWHh5ygvr+Wxx/YzaFCvQ0bpH23/vB2OaigH3WWb7DUMsUBfCoLgjo9wbP+W7b3STrdM\nF1FY2OEAd/LrX5/Lnj0V7N/fSGHhWdTUVDNtWjdWr76NX/1qAuvXb+OkkwbTunU7fGCRc6IKaW7O\ncPLJxzF37veIx11eGlfPt4sdO4CcnB+RTofs2rWH6uoY4rSdD/449KD+GA9GTrTXA9vYmE8yWY7A\naxUCwk8jgNxnK9AycOtTSEvo/MgdN9kH76q6F5+bZ7/1PRrpqR3x+B1SM61AgLMGcYyVCIxORKD6\nKgIvF/gUQyDr7BYRBHwJBHz98FlP6xFwYec9isDVpbg4BV9Qvg4BmwPmZlujzXiArbVxbse7hLoc\nTG4t8u3YY+yzW6eWNQpy7ZyErdV3EdFpRoS2E/AYPvYgiq8aFrE1a1lWMhup57oiQtMNGZd7IHtJ\nd0Q4XL2GKIpJiFg/a5F01xsBtVMDHYsn5rfjvYBOQffZCHRvfBPtewe8zSIbEaMQSYXONjPa9mks\n6TQ0NWUBIfX1fWhuPh7oR319BXfd9W3mzfsReXn9cdH6Y8aczOjR+6msXEM8Xk5T06cOPIsTJlz1\niXUf/aDtcAjBMGBcGIazwjCchZ7+QejuOOujHNy/YzvcFBJvzyE0dOhApk7tTHNzCdddN4rCwg4H\n9JcvvZRiyZIotbUup4zzzFhIVtYOKitf55FHIixY8DBNTQEiEJUINCsRoM0hK2sgsdhuMpkcBLhf\nQw/5qQh8xiGDJfjMmB0RUB+HwG+oHdcOPbhTEPffEQ++Lt/QWQg0XF3azyIwqkLAnUDg2QfdLuMR\nwP0CgYbTB3dG6ov19v8w4CuI+LyCN4YOsTGVIOArt/dOqHCOIyjj8N46jmh2RwCaj4yVHREg1tr6\nzLV353baFxHCS2ycRYjojsPX5R2GwHqpzdVVZXMBYs22jnfYGmxDXjogdYtLneEI635b/3vwuYyW\nI52/K5e5FoHsOluf2229s/GS1LfwsR0ZDiZODiATNj8XBZ5v+3M6IvzViIDeY/Nbi8+AGiAC3QXv\nERa3+fTGR133srGl7D2JD+5bYPtwnK39KYRhJU8+uYJkspX9Noi6ut1ceunXmDXrl5aCejqlpU/w\n3HMvs21bT8LwB9TVFQBXU15ey4QJo1i+vPCo++j7bIdDCNqjJ8q1VkCBuX4mDn3Kf277ICkk5s6d\nz/z5i3n44VqLGajhrrt+Q37+EK644rs0NfWlufluUqk47dptY/z4ArKy8oDPkclsIh4/kWSyF3/9\n66vAKwTBWlwKAPWrwvL19RHq6lqjh9GBZwypSFwSs5Pw2TffRJzuOKQecQbD/gj0H0cP6ir77qQD\nV/DlJ3b9qI2nM7428KM2hpZgsgwRjDY2xlykQnBZQzMI0M6xa7+ATyO938abRATgTQReMUQYvo0A\ns6WK5FUEbPvwBV5GICK1FkkJDnDd/rlEbEm8x4yrNTAAqcVq8BXBltrYtyDutoetzVak8kjYuTvx\nqphz7fd9iJC2RwTgW3ii0BrFZpyE99UfY2Paj+wcHRFBz0UEd5ftdRGSyP4P2SHOsDWebvNraQPY\nZmvWEamznNptNx4eliNgH4a3XUSRodllFA3xIUC9kDHcBeiVIcLZZGN0kkwxnpCE+ASF7Vv81pOR\nI09kwoSzue++CXzve2cRi51Cz55FFmsQIZ2Gdu0mU13dxMKF66iru/19u49+0useH25A2etBENwX\nBMGvkbw4MwiCVsjt4xPXDjeFhLu5XHWlykqVg6ysbODOO29m3rxbadt2AI5Li8f3Mnfu95g69Sqy\ns9ugimCjyWS2442QOXb82cD/EIat0QN2KQKEdugBfJ6srFIEIMX4mgBZ6EGrslH2QtzXYATwGxCQ\nu/z1DYhrzkfSQScEAuV4gtMWAVchAqnRCIxaRh2XITVFoV1zNwKnRuvP1bZNIkAYjEBmJwL0IQg8\n4/jiNluR2mW2rU8zXgqIIsmlBNlR9iIwOg8B+0BEkL5i13QmL8fz9ESSi0vp8D92TeepU4gIX8TW\n/1M21sVIYC60axUj4tPLjo/ZOroKYmX4mgguedylaJ/X2dgTSPU1CviDjfsuu75To7n7aBAiwsfi\nwfxeu/7LiKgPs73oamtYjHcZboVUSn3RvTLWrrkH70C43669xca/ARGiDCKSm2yMICLk3FjBxyO4\npHtZKC1IzPbQuS079+KAU089jg4d8pg69X+5+ebnaGrqwebNUUpLK2nd+nbi8UrmzbuS667rRWWl\nvOwaG9MMGNCdq6922VDfux1u2vj/1HY4XkP/D7lePIScjUeHYfhLy0F040c9wH/H9m6po9/e3M31\n1a9+m+uv/wmVlQlgOhUVTVx//U956qml1NcniUSqgHNoaurDvff+ji9+8b9Jpd5EXNhcksleSLea\nBZQQhnmIy34OqCEScVW+zgVSRCKtgVak04PIyorjCoB4l79jEKe+Fa+aWIu4Z1ewxnmuRBG3mkTc\nZwyJ+iCONhc99OcikIwjzvIYfEF5pxN/CxGbGnTrrUIc6yK8vn43UvHMtv9CBHhz8FG0FciLqTPe\n3pHHwXmDoogjd4VvhiCu9yZ84rdjkU77daSWcsXgQwSuzixWibydVrQY27FIihqEgN4Zyo9FkknS\nxvd3BISv491bW1b5GmLzPh8R8WdtDV3Ucf8W+3Aluife7tk0yNanpbeWU2W5Wgu51ueJ+PoPk+37\nm3b9Sfi032WICDl33sFIynA1IYrQvjtX156Ioehl115t69gyMZ2rg7wJ3a8jbI+62/x723+ryc0t\npXXrV+jbt45Vq7bwyCPLqK8vZs+eLcAeamt3MX16L6qrH2X+/C/y5pulBEFAc/Nwune/nPLyrTz2\nWDZ//rNLSX7o9mFKzf4ntXclBK4uQBAEx6Nd32GvLvbb0fYube7c++nQ4RRuvlnl9p56KqC6uoHc\n3AoEsmX06tWdnj37cMwxCbp2XUdR0SBgNq+/3ob8/AJisTb4aNedCKCOQSA7BKlxXiErqz9B0JWs\nrAgwj6ysHnzjG6cTBMcBK+nf34HlbgQaq+yzyhQGQakd6zxdOti1tyPQPQWpI7ahh/RlfGWxApRj\n5y3kRhmzvhYgji8PPeD5SC3UCq+zrkdg+SYSOl0KiZ/i1SP9OTiVcRSBW1+7bhU+9XIuIhhP2xzX\n2xyeQMSvG8ogWtzi+q6O8X4khSxC3HItIpqt8OkfxtAyO6vmX8TBbpcuW+cwfCGacQhIhyGp5Bkb\n9+v43DuulvJ+6yuOCJULYgvtdxfh6xwJXIbWXCTRODWdAhR9qovLbNwuzYWTuq60c9raerpCRF9H\nBO1yPKGN2Hl7EJFYZ33vxFdgcxJFa/vuUn9k7JiNtuZx/P12ku1ZOVLTtQbak5PTkfvu+zE33vg5\n1qzZyMMPb6WpaS91dW2A22ho6M3vf/8Y99678EANEKWmHklZ2Zskk3EaG+/6p8B+pNLGf9zbe0kE\nzqr480O8fvYRj+tj3QoKOlBfX3xAFZRIhIwYMYimpvZkZ18FFLN5cxYLFjzMl750Ibfd9i2iURnt\ncnPbcumlE0inOyFO9Dy8D7cDsAh64HqRTq8nnd5FGJYB55FOL+O22xYQhio/uH79NgSCi9AD34x3\n6+wJbKZNG/BZMZ0nUU/7zaVGcDVvx+FTC5QhED/VPrs6vH/Bc3yOQ3U5jdxvrjxkCbIFONWQM6A6\nVY3jUJ36AGT0LUUA8w8EHuciDjW0MQ5Guu84PjrXAdZu+88Fj3W0tV6ApJUxCOgyds1dSP1xC17C\nCW1N3CPkspfWI8khHxGKlkQsird5ZNsau//2IfVP3P4vRwQ4z/ZtJZI01tvcFyKwz0GSWD4C0nVI\nlfaEra+rKvYq2s/v4lV6Loaio/WV3WL9ViAvIhepHEOE4wRbl0rbtzH4gjkX2Xo4yeTvtnarbD49\nbD7d8SrDKCJkD+PTlm+hpmYXjz/+LDfffCfJZHdkWznB1jqgsLA1Y8acyJQpkw+AeV5eW1TGdSDt\n2ini+p8B+4dNG/+f0t6VEIRhOMXexx3idca/bogfn+bEzG9/exlNTV+gsjJBLHYRe/fW0LlzEd/4\nRi86d+4OnENl5UZuuWUaU6ZcCUBZWTUlJdOpqmrkuedeJAzX0LlzI/I26YvUFqDgoixgD/H4ejMq\n30oQdAGuIh5vh1z1ZiJgiNsLJNDloBiBjsCjhOEIamvrEAhcaO+Ogx+H55pXIYC63c5tRhyvy7Lp\njlmCpBcXZPUAArFSPBA3IMAdiVQag5FksAZxwHsQ91huYy1DQOZcWH+NQMUlSasAvo9PHTEbgdNr\nCHinItD8LCKqLme+A9GhCJBcuoy5+JTQgR3bA+UUcvagV5H6Ix9vU3mmxVrnIEkpQITSqa+akYE5\nDwHqqcgzqsTGfQyyMwy07z1tvSrwEb69bS27IaI8HoHpTHwN5xH4KPLOyGZRiSSTrfZahSSANJL8\nXsQX9zkBSTD77NjnbZzYeFwMyGybg1OtLUd7nYOC8aI2Z1esqBhf43gUPgFeM061ecwxvVi48Lss\nX/4ajY2nUF9fATQTiSgIsVu3KTQ3w6RJZx4AbQ/mN1Bfn6ShIX3YwP5+0sb/p7b3Ug2dFAhd3PfP\nBUGw2ALKCv41w/t4tYPFzJ0UFNQxf/6XmD9/IsccM5BTTx1OdXWCbt3uo7l5GC+++DpBEPDQQ08R\niVTwve+dzX33ncOAAX0Jw57s27caAca96AF6HhnfdhOL1ZJODyadLqag4E7S6RXAEBIJ93Buwues\nd3ltXEEVl5tfbn/ylFiGQK0NAtCT0YMbRwbdCrz4n2XHjuZgzg5EfGrx3iCOE44jFYXsIQIAZ59w\nee0/hYB6C5IgFiFAW4eI0EOIwKxGINYHV03Nxx04qamD/b8fmbZeQ8C8BhGhZgTmLfPxh3iDJQjM\nGvHZUssR8euEL+QyAQF3N5vTdATmNTbn5fio6RQC0VEIXFfis3OCJJJViAjMQQRoOZIyRiJ33VK7\nzuUt9sTFJDippApx9CfZHq5EarI8+15ofWaQeq/A+mnFwRJMD+BLiFCC7qk3EMBP5mDX0ZvQ3v8f\n4t6dl9NgW0N3n8RsDsvQ/fgakvA6IK+pDA0NDdxww62sW9eDxsZZ1NV1Jhp9miCoZuLEkGnTTnoH\nYLcE80mTirnggpzDBvbDtfn9J7foe/w3Fz2ZBEEwBilvv4Zk6nl4/cLRZu1gzmQdO3YUEolEuPDC\nswE4//yp5OdvIJU6DridX/zii8yaNYz8/AE0Nf2Ra665mOrqjbRrdzrJ5F+QCqIUCMjJ6U1TUyuk\nSz6G5uaAePxNUqlLCYLXad/+Fdq378SWLQ6s00glUoTUJ8MRmF2JwK4dUg10QpzdSHyWS5f/3gFC\nPuLyXSbQdgg0XkGc5CQkJWTbuS/YsVcikE4h4AsROPVFYB5DBupaxKnOQdHFK/B58l0CtD62yjsR\n8PTDg1bc5rnTzrsMgXc2AryXEWF7HqmR+iKJ4yo81+5iIfrZ+W0QoXvF+lmAQPBY9Gh829bxzwjQ\n3PmTkTrG6daH2Lp/DkklHe38zyEuur+NJYo8gorxvv1OBdjd+j7L/nOSz3wEoFvwHknLbc172rtb\nH6dycq6pLoakwq452fpye1yLJJ0/Ar8CvooPRHMeRpuRLaUzIgAD7HznTFBq4yu0sU3C14UYgWDk\n84iQNhEEOZSUBGzZUkt+/pADyRsjkQhf+MIEzjprLJs37zwkUM+YcfWBzwsWzDzw2T17R9t7t/ey\nEWSFYVhpny8F5oVh+GAYht9BT8vRdoj2XmLmhAmjCcMM5eXyLU+nc2jdOodkUiqIWKwvw4b1obFR\nxrVWrXLIysohN/cikzLWIUB/E/gMiURP4CHq6l5hzpz/pbDQeYg4w2E+Ap3eHGzMq0Vi/358ZtEq\nfDCVy13v/M4b0K3iAryeQADSwWaWhwx+jUgvHCKQcG6ZHfC64M32AoFRCnHPjvA48MpBtoksvFRz\nGeIws/H1fh0XfDYCuqV4dU0Sga+TkobaueXILfKPdv2Jdv3Q1tYZTZcgFVEU6bBdsNTb/d7/gueg\nj0cc+FCkrnJSTwQfEe0ITx/rrwipncATJmcTaYOPg1hs81+Ez9WUi4+KdmNqxqtfLrPPuXg9PrYn\ne2ztH0fSUYWt637bIxcD4SSk/ogQrgMeRDCwAd0T1TbOH1o/hYhAufnsRQQ9jr83nTeTqqhFIt3I\nZODXv/6hJW9ULqJoNM5ZZ43loosmHEQEPum+/0eyvSchCILASQzj8XcqvLck8Ylu7yVmTp16pRmC\nAa4nnQ4ZOfI4UqmelJRcT0XFW7z2WoTa2hTdu0+hqWkfkUgFxx+fRgDXGwEaSE2ykyCoIJEYzvz5\nD/Hqq0mKipxB0aX8nYRAIwt5neQiDrMKAcUgfIlIl0vGJYXbaL9XIYnhz/Yex3vpbLF+Po+ki+F2\nTKn1+V0ETsPwoDwPAegKBPxZeBtFiEDqfAREy/GpiyP4HEkpJFWsQG6NWxGwOt12HbpN2+O9r8ps\nDC4LZ2d0WzvVU3vE5S9DoOeSxW1BYH0S3kvJqWXWIwL4GtJxD8dLT84m4iqSNdv1HIFdaXvgmIV1\nSE1zgY3F1VxoQlx4y4I3eUhITyKJrx6llnB2jbWIiFUhCa3G9rTUftuHiGF7pN7qbZ+/gQC+EJ/S\n4rPW91cQU5C0PZiLCJ+T2l5HUtk+O2+uvVfaXrVG91DUxnsJIvh9gZdIpzeybt0urrxyOhUVr5GV\ntR1YSF5eJddc88N3pI54u+//UcLwwdt7EYIHgGeDIFiM7vSlAEEQuGxTR9v7bEEQsGfPfuLxSgYP\nDonH97Njxz6uuCKXysqXSCbjpNMTgE3s3LmMTKYbyeRnefHFHQjkjkPc2yDEse0lJ0dGxr/9LUk6\nHZBMdiUScamwm9FD2BEZMn2sgcDSpR3uhYDmGAQSA+2cHQjwx+D1744HcAbDEgQEv8WnOp6HDNbL\nEWF5GqllHKfvOMwyxGm3Rv7zNQiQWiOQdCquVgh82uC56xMQYJ+Kbs919l83BICbbJ5j8WDWG192\nMkDceT4C8zq8W20evg7zUMQ5r0dc8DJb+/YIWLshTv04e99lY40ij6pKfNK1FALKnyNbQCv0KI22\nuY213ybY+ecge0IrG1PCxu/KRL6BCGqhrfNvbC9DpHLbgC+oM9L2pJ+trYsTOBFvXC9HKrDZ6H5r\njQC7jfX1QwTaP8QT13iLzzEknTxkaz3R+pmMry2N7ekLdt651kdvZPc4lSBoR/v2ebRtq2ywYdiJ\nq6769IHUEe/m+/+Vr8z4RAeFfZj2Xl5DPwJuQC4ao0NPZiPIVnC0fYA2dOgA5s//ImvW3Mb8+V/k\nsss+zZw5P+bOO28mL681SqOcRatWxRQUdACuJD9/EBKf/443bh4PJGhu3gkEhGEcuJbGxihhOA4B\n+lv4+rRdEbg8hvTQIV7vXooeypX47KJtEdCfjDj1QsTV77LfQcTCeRE5IlGGvFc64PX4fW0cTrc8\n3X4fBExDnDY2nr/jVUgu8jhh18hDXKRL7hZBINUJge0qJCE4N9LuCCh3I0KxFM+tX4JXe0QRYeyF\n98SpxqtwQiQVtLdzT0QSwVg8Bx5FnLsjLpsQMfmS/T/M9qAIGVvb2twGIYJzgo0zYec9i4jPbERs\nQaD7HLJ5PI8I7Gy77k5bs5W2nnNsD5oRUbgIX/+gDtkbTm6xJ70QYLukhnEkcUQRwWvbYl+cw8AU\nfEqQMfgEiI7QN9t6PGt7m4080Y7H15iYi+6t0OY0m1RqCEEQUFcno3hNzcGpI+688wFGjhzKnj1V\nQEB5eS01NTU89VTkHUFhmUyGU06ZRCbj7tmj7VDtPSOLwzB8IQzDP4dhWN/it41hGL760Q/tP7Md\nSnU0b94CS6sbIrVDX+rrt1Jd3URh4dnU1TXjQcgZUdsAzaTTCeDThOEW4Abq69sShnNoIl1DAAAg\nAElEQVTIzT2V7OwIUst0x/t+O9E910Y0Dj3Ug/D1cRegh/9T6EF9AAGIUwsMRg99Sy+iLuhhL0eg\nuRUBW3dEKMbasc8j3XsZ4gbT9lsrZGTdbZ/n2LVc0JSrm9AKuTnWINNVgAC43ub1X/g8QBFEAJzh\nuLdd71Wb0wt23Uktjg0Q0U0j8MxGQNwZn1L5eVsHF0k7GBGgBnxUcXsE6vcgMPyCXWspIlyP2N60\njBK+Fi+1uEhpx2l3sXUcbWsQQwTAEatO9hqFT9vdhMB+LmIAyhBT4FQ/zyHAd4R5MWquctpKe08g\nZmE7khZvQVLSMqTyeRgRtWx7nWTrt9mOwcb+oo15to1hGVBHJPI0ubnbcLEsmcxOGhuTFBbWAwto\n27aGsrI3gAU0NWX4/ve/Rtu2bamtzVitgoBLLjnnQJ3jlrEDN974f7z4Yme+9a1bOdrevR1OrqGj\n7X20w9FTvv2YKVMmU1TUHgFMX2A20ejJZGe/QF1dnBEjshk9uh0+WtRF0nZDHO8aBFAdcEbXZDKL\naNTpmfcgwrEXqRBGoIduOT4Sdhde/fNnfK57x+26ILJqpC45wf47H4HuDsTBViLwiyOpJIM40Hl4\nDrSLvST9aM7Olz+GgO5xfLZR7JgleL/0mM3rTaSWyUWAfBXiujM2p1I7ZhRSlSSRHv8cOy4f715Z\ngIgANq8o4mY7Io43auvYZMdj80zbWP7Lxtls6/40Ioqv2/p0x3vwuLxRMQS8ESRdYWs/yPq7FC+x\n9MZnSU1Yny4BXJnN7UFkryhHdSacB1INUumMtc+LbY22216U4YsAuYjwpxCBS6D7xamRjrO1bMKX\nIl1n+7YcGM6nPx0QBNnk5joCPBefX8k5LbQFvkEmM57GRiW7y86eDBRTVNSO+vo2QIRotIh4fBCD\nB69g797VTJ/+U37zm1eB88jJ6UB+/ussXfrKQUFhd955Lzk5xzJr1lvAPdx551bi8WFMnnwt77d9\nEmwPRwnBEW6Hk7xKx+xi0qSvEoYhQRBw441fIR4fSDQqMM5kouTnDyORuJgXXtjESy/FkErBGRhb\npigYjR7iU4BsIpHzSad30Ni4G4FeP7z3yTPITbHIRtMVAVAXBLpLEYhU4ZN/RRGX1wXvbz/IjnFp\nHQZYH0OQa+UaBLYt01bsRkBZjy/uvg8BbT0CG5eZ8kF8sFJ7xGkfj7j4tggYa21cc63/jXb8auTf\n8DpS0fS3cZxuc3GGd5f/xqmXbrF5dUN6+jokMZ2HB+KXEIAPRDrtwK4xDnHGW5Fnzel4H/rhKBLY\n1R5w0ckZm1cCgW4DkjAqENC65G1r8bYZp7bB/t+IwDeCpL3x+PQOzljtIojd415ka90REaItNpZ+\nNoZcm38vW/OuNl8H4iG+xGk7dN+1trGcDkzisccShGErGhvdfC9D95VTy2UjoutUnacCO8jKeosb\nbuhLUVEXamuTdOs2hdraZq69dripU6dx2mknWG2CCSQSIbffPoMLLjj7QInW8eObOOecs5g27VIy\nGUlcmUyEa6+9nPvvv4v32z4JCemOEoIj1A4nedXBx9zO4sVpiovHMXfufDZv3sm0acPJzc2hW7cp\nRCIxc6G7iuzsVqRSa9ADdR4CpCjiMFsG//QlEtlFq1Yuz8449JDloIe9NRAlOzsPAUATXtUUIKAf\ng8A5iTi4tegBX4KAI4Ee4CcRUK6047IQp+gygbZMi+F0+n3t3Ho7fw0Ck7kI8Nrg/d9bxjFciCSG\nh+z44XhvpJbHDURgc7yd08/GmGpxTBpfIL0vXt2zEgHqVMQdD0NgNweB1avI5nKe/TfbxvICPjPs\nWgT8A5Bhdgc+IV0fJDFFkUrmLaQ6aURqoriN/68IXPMQAG+w/TgFET4XlDfKzjkBqYFybN6/tH2s\nQKm8d9kcXf2D/Xh1m4tWdsXi1yCCkG/zzCApdQyKI2jpQZSHCGa1jbkUSVRKhphKvYYYl9OQSmg7\nXl3kyle2w8eCZFNQUEQ63Y7f//4x3nijHKgmlWqkU6c1bN68nSAIuOiiCUyadOY7UkLMmDGFCy88\nm0WLHufJJ3MZOLAXQaAU1bHYFaTTIZGIYhIOt32SEtIdJQRHqB1O8qopUyYzatTQFvWKC0mlirnz\nzgcoKMilsLAD9913Djt2zOW663paIe4bSKc7kpXVi2hUft6RyMu0b1+LHqLpCBA2AL8lk9lHbW0e\nQdAHcYUBekidnjmHZHIXQbAFnxPmVARoxyLOeTgCnbUIgFwW0Tz0QD+OQK0agXYxMvo6nbbLrJnG\nu4Q24ROb/QwBo8tlFCAQKUZShDPATrJrPoRUNGsQOOchKSaCwOw86/OrCLR2IkB0JTOzUOos507q\nYgEiiFD0QkR1OQLvbJt/y+Iuzt5S3+L87BbHOJ9/Z49xmULd/LJQ9O2pSH11op0/Ep+vaaf1W2rH\nlNn8TkDEMg8RrH0IvE+yPQIRDcexOy+qp/CxFGtsfOfburRFhMcZd8uRNOGipXfZmrsaEzvtt71I\niumGr0B2CgUFMUSsn0Aqq/4I6DvZe5Wt33/bPO6xvYjibDT/9V9nUFISUl1dS1NTb+AB9u7dSVVV\nLWeffQquHSpW5+2gffXVDzF37h8588waGhvn881v9mLlyjffl4rnk5SQ7ighOELtcJJXBUHAmWee\nTnZ2DtGoMkQmkyHf//7XmDJl8ruWurzwwp6cfHKM3NwcuncPyMo6mYKCtujhvA2BUwF6SLOBH5pI\nnEA65mxklKsiHm8G+qO6Qi66OBvPPTvO2fmsz8XXtT0Hcexn2LlFCECyEZi55HABevCftjHkI87z\nxhbX7YkAzmXHrLfPf0GSy4s2vycRmMVtXA7YIkgNsx6BYakdH0VG12rrqwhxwTsQkLXBV1PL2HGb\n7RqDEPdfhM9FdAECO+eK60pOXmTnF9q6rbPPWTZ2l3o7F+/u+TN7f8juCJduYT0iwF1tfh0RUWzG\nG2EdgU0hIuruq2IkYTjO+jxE2Aqs/x7WT67N60c23mMR4dyNJJwifKrvb9ialdheVNg+dESEqqut\n2WBb05eorHS5kR5AhGIgIj5/b7EXKWSnqED36mbg70SjKxk/vpEnn3yJLVsGcNppw0mlNgCPEYYD\naWjIoUOHTrg2Y8bVTJp0FjNmzGTSpLO46aYvvwO0q6pCvvKVi3nssflEIhFmzryJq6++8H2peD5J\nCemOEoIj2A4nedXmzTu55ppu5OR0pHv3PdTW1hzy5mpJFBYsmMm5547jvvvOYfv2uSxceB6xWJSc\nnF5IT90BcV5D8JxuEqkzWiMQzyOT2UUiEUEGw2zEcX4bAcNGfK4c5ymyFs/txhGQdUS5j4rQA+9U\nDI0IkNYjY6WTIIrsvO6IGMQRGAT4vEEv2WuNjaUcX4BnPLIl9MKDeAaB5EhEUFwRnCV23VvxRe9b\nA1+0sWyz6+zCR9U66WMkPsmbi2nYicC/BhGAauSiuhO5ha7HRzAPwkfaDrBrVth8NyPbTDW+LkHL\nQi5OwnB5g65ARXEG2nzj+BoL7hiXhno3IiLO/vOarWXa1i1ARDaNIoCH2ucsfLoO533lpBwXG9AZ\nEVBXJ+JppJJ6w9Z3tq1bA55YtbN9cu6+BfabW79jbKxyNY1EOhIEZ7Jhw3YaGkqorb2dJUtWI4Kj\nmIZMZihXXPFdiopOZsKEzxGG4Tv09kEQ8MQTz1FaWkl29pWEYZwFC9YxdOhEJk++liFDPsOUKYvf\nt4rnk5KQLvg4WMKDIAg/DuMEeRjMmDGTn/zkxnflHH7yk3sZMKCYSZPOYtGix9m0acch86e827X+\n9KclXHbZL8jJ2UF9/UkIVPJQHvk/IhWHU1v0x3P7yxCwFKOHewjiqp2Y34Ae7OXIEDkKAWGh9VyG\nwPseJBXsQobqe5FP+UsIRF5AnOl6BOQ1CFiewqd8LrF3V3wGRMyeRdz4cQh8FiP/9lfwdojjEAFZ\nj0DGgbGLSv48cD8C2qEIgJqt7w3W13581PGbSKXkct+8hHTbG2ztfok8gl5AYHwmqkP8eXyytk42\n9w7AfS3WI0DqtVeQOqYNkgKq8emuh9n+1SNC0QEB5S+tr2025hje738lInCvIwmpg62p83IKEeg+\nj2cMihGh/9Hb1r+X9eGM/6vss8sNNQFVRBto6zoZMRmfQoSixv6rsP0ox6fpfgvdJyl0bw20dX0B\nr5a6ni5dVlBW9pQVXSpBhO+hA3uSl7eDqVM/xT337KJjx1Xk5o5m06Yf0r///5Cd/QZf//plVFTU\n89BDS9i9ewA7d55Bfv48fvlLSQ833vhTbr99O2E4hx49ZnDbbacfYLT+k1sQBIRh+E8neVQiOMLt\nUB4Gb3c/e78Vzty1WupB0+m/kEp1Qx4wNfiyjllAnCBIIsBchB7MlxD47UcP5+lI7dMJgcpqdDts\nsWtk0MO+DhGAZYhoZJChrwoBG+hhLkSccAIBW4ONaR1KjvYSAo5Gu76Lbl2NgNH55Z9o5462sU1E\nAOOyZTYg4N+JT+fQFl8LoY+NLRcB3eNIsmmLVB/F9ntnu97X8Nk7R9p4huNVYq8hztS5ifa3ObiU\n3c7O0hMBXsv1cJ5ZI/HFgVYhwns6BxOyTXgX0ATe3uJsKRlkeB6FCMjP7DpOyuqPCPLJeA8sl4Au\nbef3tjUIrc8qm+98G/txHCwpjUWc+S7bWxcV7qrU/RWBegFShbk4iVW2p5sQoUggQldl13c2CudC\neyW1tQlisUG0a9cRXzvCqRpjNDTs43e/20siMYtU6ji2bn0cF1fg9PYDBvRk1aoYFRUNlJQ8RibT\ngyeeeJZjjvksCxeuJwxzyM6+ktLSCp544rn/eCLwftpRQnCE2nt5GLxf97N3u1YYhtxyyzT27asG\nZpJIFCFgy0eAtASIEAR5RCIuI6a72RsRpzUBH3nb0pMmGz2scxCIRvHc+nbEGbuKVIsR59gJ7xrY\nhACpHdIzt8JXIhuCAP58+y9t1zvN/muPgPQJBDJ9kbE1y84fiL9VGxHA9EFg3c9+22ZjrUMEy2US\nbYPXqTu12bG2Vj2QPrwZcdID8MnenO99T6T3zuDjKXYhIvmczXOgfc61dbzU1iMLcdsdkWTSZHs1\nBIF2WwTmu6yvHbaPLnvn5Bb9tkdcNPg044ttvs34wLSoXfNFRMicNJaFQNvFepTia0e7bLNl9l8W\nqmTmvLnmI2Lq8ibl4GtKn4bumwlo/5OIgPyQIBgA3EZ2dmsbYwGyaXWwcecBXejWbSrJZMC11w6n\nf/8sG8utOKLxmc8EjB49jOrqJiCgvj5JNNqHwYNXUFXVyBNPPMvQoRO5+ealNDWNJz+/mjDcwOWX\n59GrVx9uuWUajY31wDl07tyd6dN707t3b442344SgiPUDuVhMHr0UO6663fv2/3s3bwVpk69kiAI\nqK/fg9QsLyOw60sQrCUSWUlu7lKys6Ok01cTBDlEo5Pw1bx6oDTWvRCnfDpe3dCEzxmTh8DBgesw\n5CPfF4GMq6+bQaqJfASEKxHXOQ/vGlhv13gNSRWzEde6B4FptV3zHlQPeCUyJLpqV8021v421h4c\n7KGUi1Qdx9v3WruWq41bjaQSZ/+IWx8L7RqFNh5XttEZZS+y/5375VpEUGbaOXn4lNEFCNxrUQxE\nO6RHd9k8/2DzHo2I4LMIULvaWg1GINwG+JuNdYX1+Zz101KV4uwJ/RGBcGVNW9oRnLdULzu3m/UR\ns/M64g3wG/GpRQYjQuRSSeQit9MOyEawCUmU2zi4ZsVxiMh8ysbxB8LwFWAGqVRPvEQV2PXjRKON\nBEEld/x/7Z13eFRl2sZ/75mSnpACBAgJQQIaQBQEBVSwISCixIbC2gkiLqi4q6ifuk3XsiioCLjq\nKgFRFGRXRcCCbVfFgguuSkCE0EkgIT2Zmff743lPTgIBopQAOfd15Uoyc8p7zpx5yv20J7KYPfsi\nPvpoGcuWNceyVgHvolQQ2Mnixf/lP//5hrIyDdxGcXGAyMi1jBvXnRdeGFQj7OX7ko3P14Y//vG3\nTJv2FyZOHIVSilAolczMRRQVVdC7d3fuustpW+2iERWBUuoRpdT3SqnlSqnXlVKx+9/ryEV9GQbn\nndf/V6Wf7S1bYeTI33L55bdTXR2F06KgDPg7fn8SYWEDuOmmqwgLiwHySEgo4dJL23HBBWlY1gnU\ntYoDOIVp9pAVcATgzQgNoRABYn+BS3GEgZ398QEiYK7AsUztGEVfRJin1jqO3VK6G07mkJ2mWYVY\nsQk47Zf7AAtxOpU+jDOIBZyeQ4nmWuyaCLs/Uqw51vmIBRyHZCcVIl5SKSKsP0YU7MXmej4z6+tm\n1hHAoUB8iHcUBTyNCFCPOeb75hpDZh+72dp6RHBn4rSKtoW6RpS6QpTpXxCOvw0Sl3kXJxPoMnPN\nhYhlHUQUbTOkMjiE49lsM8dMNfeoDaKcfjbni8NJ9bU/Y2W2G47zvKTWuo51Zns7dlFlztke8Sg/\nwo5d9OmTySmnaCIi7MwvUcbR0SGGDDmFV1+dyN13P8x99z1JYaF0prWsTkhWVwD4K35/PL16nUh4\n+HfA30hMLGfgwH6MHj2SSy45v0bY7y27p6kEfA8EjekRLAY6a61PQiTLxEZcS4Oxr3LzVavWc845\n5axY8VjNAzd79gJ27iz/xeln9T28M2dOYfz4ESgVgXx0fmArlnUylZUJlJc/yfPPf0txcRvi4mZR\nUlLIJ598zapVLQiFshFhfxHyxY9FgpjbkWBpFZK1Y7ek2IAjzEOI0E3FGXeZjFiRKTizh3uYNdnn\nao1YxsmI4LEQQWohaZpexDr343DuFyKUxsdmHS1wZg/EIdZ0AWLFDjDbTMDJ/7ePVYAonnWIIpmH\neBwbEIG8AhGcMxCaqxJRrHb3z0iEFnrarDPWrGODuUf2kD7bSg+Z86cgAnc94o3YaZ3nIcoiz6yr\n0Oxvt7Lwm9/Z5v781XxOrREefw7ikdkFfmVmzbsQZbARoYN8iGLzIQr6ZCSwr3B6ICWbv99DBHqc\n2T7brMNvPq+fEDrpD4giPB2hguzCwkxzbLstuZ39ZM+vziAQKOezz+Zz8cUDTO+gSXg8mxk69Bzm\nzZsGwObN3Rg4sC8VFUJXBoMW8fEetG5LWNi9lJSkUVVVQUVFV1JSrqKqKpGsrHPrfI/2JezdCWT7\nR6MpAq31u1pruyXgZ8g36IjHvvj+jh1Tee+9CObPX8Ill5xPRkZbFi70cNNNyb/YGqnv4bUsC8uy\nEB10OfJl3MH48ZcSFrYRuJCiohhgBoFAB5o3L6ZVqzjTpXEDPt8WRPDbLZBnIK68x5y1FBForRCB\nY3sOFiLIvkMEwjZE0GlEGJyM0FT3IEJgFZKtsgPhzz9FhNiHiOBebo75H/O7nTn3J0h2zQ+IJ1Fm\njtcJ4Z1bI1ZnH4TeyEYEst0WoQARfjYl08yc1x6wonG6aKbiNG2zaZaFiPDugaNYLkSopZ6IwCw2\n+w83/3vN3/bQoBhzD+1JXD2RQHkaQg+dhgjZIsRz+AER4sfhzGpeY+7HRnMu+zx/N9u1N/t3Q7wG\nhQjo45CAcrX5rPogFnpbnJTSUvP+2QhORtJVtyBfQ7u6eAOiuEbhBHunIZRRPk7FdFvEA9iGM+h+\nLfHxm2jZchNffdWSefMWU1ZWTHFxDAkJVxMMtmbFiu9reP2SkseZPft7Nm7cQXT0cMLDvYSFbSQ6\n+ksqK2Wy3tdfJwJ5VFZWExe3nJyceYBjmN11142usD8AHCkxguuRb+ERi30Fg3d/b8yYZwkLO5Gx\nY9+isvIpFiwopkuXC8nP337AD+jKlT9x+ulFvPrqdQwZkgKUM336K1RWpuLkhytKS2X2a2xsNMXF\nIdq0WUYg0BxnpGQqDhXQCSfQl4RkFm1ErEGbmx+NCIZHcKzhOCTmYNMiRYgAtlsiHI+TaRJnjn0/\nzjCcaoQG2YYIygBOlW9zRCD1QDh/hXgJ9mCVEE4fpG44TeNammspQQK02WZbu6PmXYhwXodTlewz\n61ti1mZXHH+HCO2TzZpOwakyfhaxxm0apBkiKFvgpLIOQDyprjjZRzHm3iQjLUBOQRTSBYiA3Ykz\nHKiVuZe28rrc3OevEQWyGengagv6RCTAeyYObCqut/n7R3OPp5vzL0OEvN3ddjtOLyFwKqTtquXj\nkCC2/b8fp2fRF4gSO46KigpiYs4lGHyG3/52IQsWvEtV1bsUFoYBF/Pdd5pVq35mw4algKK8vJTb\nbmtHUdFs+vbdyZYtlXi9HbCr48Vm7EpYWAaPP35XjTfRFPoAHQ5497/Jr4dSagnOEwWOWXaP1vpf\nZpt7gGqt9ex9HeuBBx6o+bt///7079//YC93n8jOHkFCQiITJnyEzfc/+OAtNTNRa78XFtaBW27p\nzty5u+rd9kCwaNGzTJ+ewwMPPE11dTfgWyoruyFCzKYzrgP87NhRyHvvfQVczJYtb5mZBZEkJZWT\nn28Lx1Y4g25saqQ9klVzMvAccCPCtfsRFi8Bp+jL/kjb4BSE9UW8jZGI0OqNCMN0pDr5MZwJZ/a4\nzO04c2zvMddjVwQvwslk6owIsAU4HPU4xBNYjngoc805a7dGWGvWugEnILzSHHMdIuDnIDUAVyNC\nzR5s8wwynWujuc715l73QxSBpOw6fDqIhf4McC/igYUjcYlkxOq36wiWmHv0P8SD6mf+L0Vos/sQ\nmqgDYrV3M59ROaJ0bE+oA85ciO04dM2l5vMqBNpgWd8TCtkZY0mIUnjYXFcvc08ykELFN3Cqou1j\nxSO0Xh+c9tWFiNcQRALIF1FeXsrq1W8AJ7Bly89IfOa/puJ9IFrPZ+DAFD74IILMzNtZvz6Fd9/9\nmC5dPjHP9Qh27fq7Oe5wIJY2bX6iqKgVSilmzJjFlClzqK7uZgyze7nvvicZN244o0ePpKli6dKl\nLF269Bfvd0gVgdb6vH29r5S6FjFpzt7XdlBXETQGdg/g5uWF6vD9e74XR2FhZb3bHiiys0cQH5/A\njTc+hSN8fMiXtBSZFiZzeCMjEykr+xfBYBhiof6F/PxzEOvaFl7/xUkhTEW44ba13g8hXsMGRGja\n/XRAhH4XREmACGk7QBmOMwTdg8QSLkeEjz2E5TokUFuKw7fbrSHKzHmfRrJphuBw2V8ilrTHrHkz\nYhFn1Fqzz+xnN29rhSircER4hSMW+elIoRQ4Vq7PHM/m+DXSuuJhs53dkvkGhNIKIUKzubk/9n42\nX74BUQKDERopBVGU7yMKIMzcy2cQOuYTRBF5EOW3DFFy68x2S805vjT3064/GI6TRfSx2aYd8jy8\nSihkK60ROF6XBsYj3VcLEaU/1axrq7lvdl8pO+C/CVHGVyPelDb3ZCqi/L5HMtH+bK67DzbdaFmX\nEwolsHPnLs47z+L116fy+98/zFNPBRg7NsUYUBahUAVRUT9SWtqWHj22cemlg8nISCU3N48777xh\nn4ZZU8XuRvIf/vCHBu3XmFlDA5HmM0O11pWNtY5fgn0FpHZ/b+XKnw5ZpoJSis8//5bi4jRSUq7E\nslJp3tymXqIQa04CgmVlmxFL/ASc2oEUxILsjFAfnZG+M0GcQi87M2Q4IhRvMMfvijMx6yNECdgt\nKnojFn1zRChsNOfrjFiwJyHC6kNEKdiTtLw4wnA4TqfPk83xkhHvZTNiifdG0isrEME5G0fh7ECs\nTzvd8VtECUSY9yeZ33Y6o017xZnXrjbraYF4Jj8gQlQh3Tzb42Qv2Xn77c25VuJ0bq09Z+Ans9Yq\nxNNqZ/a3ZwlY5ty1O8FWIbTYHxClYMcYAuY+tEHiMD3MsbeZ+xZlPhf7Gu25EDciAt0y96M5IqwD\niKIahDMLej0i5BPNtcYiCsv23pqZz+RK83kkIs+Uvf5tiHJOM/ex0KypBPiQ2bOv4Y472lFSUsHC\nhV7S0s7in/8sobLyKV5+eSsbNy4hLGwisIGYmAxgGD//7GHmzAU19OreMuuAY352wKFAo7WYUErl\nIt+WAvPSZ1rrm/ey7VHTYuJQY/r0HKZMmcPWrWkUFDxFRsY9lJf/m4KCnZSXhyF0S4ikpAoiIiLJ\nyyvG4XGTEcsuCrGMixAl0RXxCN5ChPdJOG0q0hDeN4hY0IMRK+8M5It9ByLYP0Ny+V9ChM4liJBf\nhQjKFsDzCNWyFadH/ziEHmmGWLqrEIGzGbHUX0SU0H8QgXUbYr1/brZ/EbGgs3AmqbVGbIw3zPGO\nQ6isZPM7HhHcXREBts3ci53m2lchwvxUc40f4bTtzkSU1KmI0ok3a1GIYluFBF9nI0J1J07riwRk\n6E9foADLqiIUsjOSUs09sts+vIuwqrvMdXdDKKJR5t6+bNYcidBnJyBK72JiY7/kjDPieeutb835\nz0WEe1tz3E6IJ5Bac7+UKkDrFuac281xWyBWfDvzWgtzrVGIt5aGGA4R5hrPwDE2PjP3Ziui/Aeb\ntXxJamoi0dGJbN7clp07p5KcfBv5+Z8SCIzD73+RW245m0ceuZPf//4RnntuE0VFT9a0hcjKGsDd\ndz/GQw/9jr/+9e81rVpef30RTz2Vw9ixI7jhhsW88MLAJu8dwFHQYkJrnaG1TtNadzc/9SoBF3Vh\nF5tFRsYiLrHm8cfv4owzenLHHVkEg+9y7rltKS+vIjy8N0JXxCEW/mZE+OXjZLWAfFFfQoSFPcTl\nJJyc9eaIEExFhM9ic5xmCL0B8ijlIUFPD9KLpwVON1DbWjwOEXx2fKEYEdD9kKHuiYjg6YqTChqO\nKLi2SGpnuDlnBEJx2O0IWiNCdCNSDTsNqRa22yl8gPD1/0H48EHmer4296ej2cfu5/+t+f8Uc49a\nIWmottW9E6Fo7LYadqXz04glvgWnk6vPXNdliDJphlLRiMDtatayEVhNVNSnOPRUB+zuseJBeJA4\nhj1K8ltzT6cjyuAlSks38sknn5p7a9NNrRGFrYFyYmICiKchVctaB5BSnmeR5wO8s+0AACAASURB\nVGUVTv+j9gjd9AniqWxFnoUVOIHmZJwGeNsQr6yt+VwTkaQCmZVcWdmBn37KY+dOidtUV4PX2542\nbd6kqioDy7LweDz07n0yoZC3jsU/b97imuBw7cy6JUuW8vHHPzB+/KJjfnbAocCRkjXkooGwXeKd\nO8tJTBzAzp1lKKVYtOjvPProXViWxaJFL9KhQzJr1thB0gokIJyH0AK9EaEBYun/gHz5y3Cqi6OQ\nL/1niJXaBRFUn+FMlUrHydjRiCAtRgRuISLE2yB5/grh9nciQnMHItjsvPUqnLGMRYgFuRHxXD4z\nx/cigtSHCMSNZp3bkGymCkQRROJw9BaiiNLMPTgOpyDMztk/HieAbccIYsz12f+HmX2V2b6TuXen\n47SEsGMJDwHleDx+nKBwPkLFxCM0SznBYDecTKBsRFiHKC8P4PUqc/xRiDX+PqKc1iEW/kaEb09D\nhLAYfXFxfmbPvo/ExLakpydTN4jtJSOjA2FhLejYMcrUo4TMvfkTWtufvQfxlH5AlFR3nNTQXjRr\nFkOzZpsJC8sw9+h4ZM5AGyQLqwKhwMIRRdoJoQcrgCfZutVPRQVAKT7fSAoK/ofHs4rIyOOAqfzj\nH3l07jyEnJz5NfTqlVdGMmbMn/bI2rM7i77/vkUo9Ee2b5dU4fz84mN2dsChgKsIjjA0ZD5qbm4e\no0e3pKoqk5tuarVH/GHevMX8+GMMXm8EHk8RIqDbYFk+nMZfpXTq1AHLqkS+qFU4PWluxylYW4Io\niPWIoLoER8hi9luPCAvbAvcg1uG/zL5hOINlYhCrMwpRSl8g3sl3iNX/b8TCzkaE9RlmzcVmeztl\n0+bo7aygExCO3u6b5MeZGfC4ec2ugygx/9scvS38LJw0U3sW72U4/Zj8iKDDrLESsYpb1jqfD/GG\ndpl6j9NxhshsRQR6B5yCsR04U9ikxXTz5j3ROoAo31mIoI9GPLDjkUKwZKBtrbkT0pa6tLQFHo+H\nNWsW07lzR3NNdiVyFOvWVVJZeS1ffZVMREQ1Xm86lmWPkPQQFnYpSnkZMqQlnTpJgz+l/mLWtgOf\nz8egQecwffofjCKw231sQFJkf0QMjtY41cpec80V5t7ZbbS7o/WPnHNOEkOHnl1TUBYREcsf/nAL\n8+dPq7H4p037C08/fc8eVfozZ07hgQfGmsH1MpGsTZtRlJaKt+s2lmsYXEVwhGF/edHTp+cwc+Yb\nPP/8JxQXT2LBgmJmznxjj3qGiopziIwsIBj8ERGubxAK2SmHk4DmrF69jlDITlNMRwTkZoQD34xY\nuj0QSsPuM9Qd+SJnIV5EOiKIavfUt63p1QgNEkIognIcq9uH8OZtEQGxHREmg5HH8iScyt8MRCGc\nhtBUQZzq6LfM++/idCINIspitVl7sbkH8YhV3Q+hdBLNWoJI3ONTRIANQxTV14ig/sxcQ8is6WtE\nwXU29yABy/rCnGeFuc5TECVpK5oknIll4NBZ35h7HTTnCmfr1mUEg3ZWUgRC4ZWZbVaaz3C1uZYC\n7CBxZOQPBALpNdby559/R9eueXTqVEJkpDSNq6rahaTJTsOy2hEbm4fP5yc2djIezzZycm5k7txL\n6du3F9dccymvvXYzt946EMgnNvY7wsOjueSSAaaw0Ut09JOARWzsB4inl4zET/qbZyLLfNarcCqR\nQ0ABSpXh9bbnppuurnf85O5DneoLDluWVfN68+bPEBa2gyuuSMeydvDGG+/homFwFcERgobOR83O\nHsGgQX0pLEwFltTpX2THD8rLg0AhoVBzTj+9M3PmPERqakvEqhT3XynQGnw+O2A8DIjE6/0Rp49M\nM5zZw3ZLBHsOrgcR2kHkC28hNAcIHVKMWMrPIMpkI87Q9WE4fWvGIsKxCBEiHRHBmIB4LhciCmgG\nIlD/Z9b1JxzlYzday0SEXDfzenOkc0kXnN41pyEeSU+k7sDOuW9hzlmOxCFORIRwO4Qn72u2X4co\nw3zzfyXQhVAogGUVmbWlAs8SCh2P04OpAtD4/TaN9DtzH88393gNkh5rF3bZMRQPQm21Mtukmvte\njDN2syOxsZsoL48EZtQ8E1u3fsK3377Jn/40jsTEvoiiS0MpUU5hYe0ZOLAfOTlDKCx8m1deyWb1\n6g01lbkJCRHcd9+TvPTS10A2LVqcRFzcN+TkLCA3N4/s7JZUVXlp3Xo5JSXfGs/Cbrj3AU7Ppo8R\nhfmMuY5lwGK0XkMg8F9mzfpnTdadPXw+N3c9u2NvWXv263/846UkJW3hxRe/pqJiDl984XfjBA3E\nIa0jcNFw7K9gDZyMoZ07O6D1VPz+bDZu/IYlS+DSSwcCYjnl56/FsoqoqtrBrbdej9aa7dtPNsVE\nFcBVaB1NfHwUgUAS1dU+RPg9TiCQi9N2uhpx8yuQL3QRTmfKdkjQMgIRSO8iAvtHxNIOM/s8iiPM\nnjD7BRGLvCOSc94DEYrhSNCzF8JPn4AUsNk00HbEqraQbKFYnKI4cKzvAsSDyDfvl5jX7MwnhSif\ntuaaWiAKIB+hyYaa19YjysgudBuBkx/fCxF425Ci+DhCIYV4U73NerYiHkac2c8iK2swq1evYcWK\n46mqqkDrLYhSzESotFZIuqmdftra3Od083nYfYh6Itz+amAZFRVhhIf3ol27W1m9+n9AvxqL2p7c\n5fFcRTDoQ+u1eDzDKCxsQVbWoJpnbPcsm9rPZEHBQCorP+TxxydSULCdKVNeobq6G1VVC4iMvJtm\nzd5j585Ec19eNtcxEAmu184mijLrnwVE4PFsYd68p+3sFoYNG8P774czcmQqu2PiRKdjaO212q9r\nrUlMTDLrdWsLfglcj+AIQUPmo2Znj+D++2+moGAlAC1bJnLbbZfQrl17QBTF2LF/Ij6+FaHQVPz+\nOK644nZuvvnvlJc/ic8XBvybuLgNeDyryMzsSCBQBfiwrCsRQe5BhJBGqI9q5EvdFxGkiebveIRz\nj0Rol1RE2HbDmdplN7TLRzyJNCTjyKZj1iIUyjBEwH+ICOIZ5nj/RqxvcALLGxCaIWCO+wNSeRxA\nrPWTEU9gBkJRrUEURLE5jh0D8SA0TkeEkik05/wUEe6fm20COAH0aHOsRERBRSIUSAWiUPIRofed\nWXd3xDLegigLD3PmvM2XX26isjLXpGtOQpTOSrOGNYhisL2yL8w1bzHX/zmiHJ7B4eXTqKqKJyLi\nC04/PRyPpyP33fdETZwpPT2dW29tR6tWadiZSOPH92LOnGH7rG/Z2zOZnT2yTlfdykpo0yYRyVJ8\nzzwHfsRDDEeoK4XEV/KQorwwYAaVlT2xrBNIS+tFbOxJLFgQoLj48V+V9dOUZgwfbLiK4AjC/trl\n2oVkVVUZpKRcSWGh9Fa3LaLs7BE8+eQ9lJSsAiAuLoHx40cQFibtjcPDj2PChCvZsWMpr7wykdTU\n1gQCUaSkbMfvj0es1kxEmGvEMk3B4eRzESt8OpL9E0CEoZ0WOhyxiHMQIRaNBEqjEet4IWKdL0UE\ngd247GNzvEqc6uIIxGJvjzPq8EJEENu59/MQ69tuoxyOtG8GJw6RhmSw9DPH+B91BesniABvj7T2\n7oHw8SciAj/GHO8yhNtORpRXMU6RVytz/u6I5R5ntklALPc8pK6gpXn/3+aYdstne4KYF6lB6IuT\n4pqKZfnNeReh1HGEh0cj9F6VWcMYIiN9BAIhli61qKi4gB9+SCc1tT/Tp+cwcWI2JSVFbNr0Ln5/\nFDCdl1/eyv33P0V8vJ2KWz/qeybrF7hhDBmiSEjwIs/MUvMZtTL34mPk2fAjz0DtgrwwCgsDlJT0\nRpSqYu3arfTt2/UXZ/24Lad/HVxFcARhX+1y7RjCiy9uAKYSEdG+ThdG2LPiuLCwAqUURUXS6iIU\n8tC7d3csy+KSS86nS5eOXHttFwKBtVRWvofQI50RQR+JWNsrEIH1IyJ0YhGr3u5vH4NkvID0+MlE\n+hOlUzcw7EOonlPN33aGkl2JmobMN/YhCgXz/geIMMlD4gJdEc7epoG8SFpjC7Pd38xrWTgN1+wh\nLc0RusKPWODaHCsORwH5EC9oBU5wczUioArNz0jqjm7sgAjyn809SMaJafwAhKPUmzitpt9FPCq7\nf08s0BKlWprXvkCUygwgnogIic94PJehNVRXW6SkZBMe7sfnK6V582lYVnt69uzI2rVLgE/QeirB\n4MlMmTKH6dNzSEtLp3v3FFq2lAB5WVmw3vRKO2stFArts6vn7gK3ffuWLF++ip07I5EAfltE4f0I\nTMfj6YXHE6Rly82IElXmM/IAQXbtykSUajhwEoFAHkuXfl5v9ty+MuvcltO/Dq4iOEqwt0Iyuwvj\n3hTFwoVL9xqEmzhxFNOm/YXJk+8nIqId8uUtRXh9PxJYbYEIvVMQQfc5Th1BJyRg+pV5vat5vT0i\nAEHoAA8OJ38qTsWthQRSIxHv4xMkqDwbEcT/QwT3NkRob0cUgx0cvgwRKMsQq3oRYul/g3g3PyIC\n2g5in47QSvbgdbteIMKs4SrqppJ6Eet1K2LNzzXXbFcfK7P+zeZYmcAfcZTKZiQmYqH114iV/AMS\nwLbn/IYBn6LULrS2+f80JD4B4CEpKZ4JE9KpqnqVM86IpEuXLaxfP51hwyK4/PJubNkyj3PPraR5\n85Z4vel4vQWAoqqKOvN8V64MIz+/tMYoqI82sbPWfv/7h/eZvba7wJ03bxrJyQlmqpgyz4BNpSks\nK4w5cx7jrLOkXXZi4lc42WUR2EpVqRBeb3OgmtzcDtx55yN7nNvtOHrw4SqCowT74z/3pihWrnzH\nfFEX8957EWRkSBDOtqqmT89hwoRHKCvbggj69Qh3/y0iRBMReudHhLqpwKkS9iLC+SxEgNk0kf1e\nFiKYNyNWswexplsh1v9niKAcZK4yA1E8lvndHxHA9mzmDjjN7RbjxCCSzDb2DN0Ks204MmnNHhSz\nw1yXPZy+FyKQf0YUToQ53iDEe1mKKDoP4iUoRIlFI4rpC/P3WHNPbO/DQmgsae3h8cQACYSFJSPF\nZWmIcpVztmlzHB5Pa/z+fyO00E7geCIiBhEREU7fvj147LGJWJbFRx/NYvnyN1BKMWvWY+TkPFrz\n2VqWh7FjTyYiIpyUlGyKi6tYvPhDmjfvxcSJH+0xz7c2bTJ9+kySkk5j7Ni3KC6exOOPr6G4OJcx\nY55tEFevlOL3vx9FWFgklnUpTp1JNB7PFVRXw403TuSrryKAt/D5Tke8sncQKslDWNglaL2BQGAr\nYoRM57HHvsPr7cyIEbc0OLPOxS+HqwiOIuyL/9ybopgxY1a9X57Ro+9m6tTNfPPN/ygoKMSp1i1G\naJiTcBq+XYgI8444bSnsYqyTEGv8n8jjZBecRSJpjslIcDMXiRuchDPX+DTgTSSjqC/SoXILws+3\nQBTQK4jA3YhQV2fizEMoxGl0F4nDP59qzlcIPGWuKx4RsD7qFsR1ROIHD+FQVZ3MfeiH12tPctuF\n04BvF6IQEsw5n8WZp/AIEnMAsf6XEwxuAyqorCzASaPdCQzH4/GQnh4kFFpDVVU/JHDeHthgsmBW\nUla2CxDlfeedD3PXXQ+jtd5DMC5b5uell97kyisjWb9+OrNnX0RpaYCyslPZuTOP3ef51qZNEhKS\nKC1NJRiUeyBdSm8hLKxDgyt0V6/ewM03tyEiog0JCevMvRpEq1bp3H77cQwefE5NgLm8PMjxxzfH\n729BTEwhSi3nlFN8eL0xeDx27yKFUuGMHz+Cl16azE8/beT++2/+xaNfXewfbvroUYS9pc/ZsBVF\nVtYA5s1bXNOu12lZDfn53xMVVcLSpYri4km88MK1BIMhxKo+E7GOhyHN0WzLvhSx1iWFMSrqC047\nLZMPP9xJMLgGrVNx+hfFIJk3dmqnnTefgAR9bQFsB4TtZm3PIAphIyLMQ7XOX4gI3NaIJX830h2z\nDU5aYhjivSSZa4hCOnfORiinSLO97Tn0xhmx+RLSdfRTs7YnEU9kE4FAK5zU0a9xxkp2QZTXLMTT\niEGUWKK5T98hFNAcs54rEe68EkglImItY8Z05+OPP2fVqnxiY/tRWGjPL/gGGIDfX8Ljjw/hkkvO\nR2tNVtYYFi7ciWW1oGfPxfWmHE+d+n9kZQ1g0KCrycvbSXV1N8rLH6GiIhu//xS2bWuFUv1rPEk7\nJbm6uhsVFddRUbEAofNaYVmT2bSpLUuWfFSTnrwvTJw4ioceepYXX+xOKDSQa655m5iYORQVxdGn\nz1lorXnzzUWmNbuH7t278Oc/n0d+/jb+/Ofn+PHHRAKBpxDKLB+4BK0TsSyL+fOX8MwzW8jODu21\nFbyLXw/XIziGUF+gbPcAcnV1Wy6//Pyacv7Y2Hi83kiESlmA8LmP4rRbCCFC9j9ILOAtLKsXn3/+\nA/AVWpcj1vZbCH2zChHk+Th9ejRiRVcgVJDdbtoy+9qcehDJPrJ75tutLjDHtgevgDNpLd8cy4Mo\nn8cRZSBjPJ2iq1KExmltriUN8V7sc1vmdwWioNIRQS/KKjq6mTnOSUhmkh8R2JlmLfebe5iCZa0B\n2pKQ8Ax+v11nMRrw4PcfR2ZmAK83hT59evD552/w1FP3Egza55eGbl7vkhoef8aMWSQknMQbbyyj\nsrIV5eVTuOqq2bRpcybvvvvhHl7gvHmL+fTTRDMHWBRqQkIUOTl/IidnLKtWra8JttqUYkVFENhA\ndPROwsNLgDSioyO57bZ00tPT9//wGdjP4OrVG5g5cwhbtjxf473u7tF27Xo8l1xyPtnZI5k06U4i\nIoTW9HqrGTJE8corN9ChwxqeeebVGq/nH//4iri4r/ntb092s4IOIlyP4BhG7ZbVEkC+B/g3H3+8\njsLCdDIzb2ft2gDBYDgpKfls29aS88+Hysr25Odv5uuvqxFuvRina6jC74/kmWf+wqeffsnkye/j\nCNMwROjFIVZwLg7n3Q0J6q5FaJ9YJBhsZ+rYk7R+Rh7LrYgQtgexl+DMR4hDFMsOHI9iNs4M4oBZ\n02uI4mmGWOwbkUrej83/3c312QVkFhLw3oIovY2IcL+CkhI7Q6oUsfS1Oe+zwDVIO+5IIIrTTkvm\ns8/WkJISQ0xMIZ9/HiAu7mqKiqrp1auQjz6axeuvL+LJJ2eSlTUApRSlpUEs62JCoSSgiECgB9XV\n7/GnP62huhrCwvqbtf8LUPh8kUyefLcRrmlkZQ3gppvuYcyYP9GsWT8zB/gatm2LIDn5enbsCGPW\nrAXMn/8Mr7++iOuv/x89ey6uMRzy80tR6gOqqhKwLMjM3E5eXlt69+7+qwqy9ue9ZmUNYOLER9Fa\n1zP0qSPXXiuFbpddNojXXnunxuuJjMxg0iQnk8nFwYHrERzD2FsAediwwTWW2bBh4Qwf3pP1619m\n9uyxeDywYcMWNm9OR/LqWyFCeCXgJzHxagoLK7j99r/y6qsFyFB7CxHkChGkPqKiIlAqhPD7CYiw\n3YFY7j8jgeRMxKL/BBHK/8UZngIi0AsRhdAMscArzHbVSCxhHo6SKABuRYLE9nZvIQrKnqH8PE6P\noamIwjnN/LYnscWbcweRwHGYuY6rkcKxckTpJFG7s6dlFQDbWbEihlBoCeXlmeTmrqd//1gqKxO4\n9dbTueCCs2sE2NdfN6+h8F55ZRj9+0cg2VdSq1FZ2ZOCghL69u1MIGCfRwOXEQp5sCyLu+/O3mtj\nNnsO8OTJl6J1Pv/85+ekpp5VJ17UuvUZXHfd70wQOQe/fzt+/0+MG3doLe7dM3/2Fv9yi8QOD1yP\n4BiF1pqJEx+lR4+ue3CqEydm12yXk/MoEyc+CojllpU1gNdee4dRo95GLLAdWJaPkpI2wMXEx39E\nRMSntGqVxKpVQYRXX4sI8nYIJ24RHa0pLfUhSiAPoXkG4IxGHGi2zUDy9F9CsnheRAbR2MNi7G6h\n4YhnYQ+PGQG8jgjiLUhQuoM57ixEmG9HvImfkXjAEiTDaSsQxOPxEwzGmWN2Nsd626yxLU6Vc5I5\nTipwHEoVo3Usomz6mH0D+P1nUlFxGWVl/wQeZcOG7Xg8xaxd25aSkodYsOAeNm6cyZQp/yA6ul/N\nrN3i4vdQyofW3ZGq2zfMWsIJBFJ5++1/U1jYmdjYyVRVxTB2bHc2b95Rb8FhbaG5Zk0Vzz03jylT\nfqC6+lXgbjZtehs7VlNREWLy5LvRWnPHHR8DFvHxh9birh2T2H3W8N5aXdQX+3JxcOF6BMcobIvr\njTfe32elZW3LzFYeAKGQl+TkoZSXb8Lr7YAI34H8/PM2Bg3qw+9+dyOhkJcTTsjAsjoiVMzJQG8s\nq4yqqvYIjbMBEcR9kICwRpRHZ8TSjkSsb/sYdoD4FsS7iEC8jh1mm+Oom6Z5GpIS2g0R2jlIymcI\nCQ53QFJK45CMnkyEBvoIpVKQ+oUliFD3YFnNkUBzEeKBxCLB83SEEvoQrXcidNl3iFfyEeAjEFgH\nKILBbSj1E4HADiorO7J1qwxg2bKlkEAgk5SUJNMYUITxlCn388QTEykvD+EUv10MhKiqCtGv32nM\nmXMxhYVvk5NzA0lJzZk169F6i6VqW9Y5OWMZNOhMwsPtFhnlREa2JiwsiszM2ygsLMeyLCzLOmwW\ntxOTaHjmj1skdujhegTHGHa3uJYtu5fly58kP387o0eP3Ot2Eyfey623PsSmTSUMH76dF14YyLBh\n5/G73z3MtGlfA5V4vSPw+eIZMKBfHSutW7eBrFjxrTnyc0REjKK42K5D6Exk5E7KyuzUTLtnTxEi\nwIOIoL4ECVYPRaz7PyLCuROSKfQbpJbhbLPvn3ECzfb8YZs+KUHaRMQi2UF/QeoXXkU8k1JgKIFA\nhdkvGan2rSQUCiE1BMchgt5uyPchQkdtQjyIDUi30L8QEzMarb+kpKQYiRX0QOtnCASuR+tVVFdH\nAd0oLm4FnMmyZT8DP5CcfD2FhbEA3HPPY4RCJ9K8+TPs2OEhGNTAKoqKFFlZv9mrtbw7anPzBQX5\nfPzxMkpKOiMjPsspKVnPuecmsXjxSzXWtdb6sFnce8YD3MyfIwGuIjjG0JAupvVtt3btVqKiIgmF\nuvH++1trlEfv3ifz1FP/ISVlM4WFLbnpplasXr2hjsBJTm5LWloqH37op7hYKlq93vY0a1ZOSUkE\nZ5/diTfftOMISYjFbQ92aY1Y/RvMTyRi0Xczv2OwaRJRCschCmMrogh6IlZ9FeKBRCMKIMWcx04v\njUOonZGIULf79NgTus5BqKYeiAIYjHgyIURJJeAEtk/AsjyEQlsARXFxJaJM/gVci5OB5Af+Dwla\nJyLB8Z+B6URFjSIhYTNDh7ZkypQXWb06nK5df2T79mKCwRgkhvIdSn3CtdfeUUeR257bQw/9bp8C\nNDt7BB9+uJwFC9ZRVvYqiYm/4YQTTuLss8+ssa53x+Ho1OlSPUceXGroGENDg2u1t0tOvp5gUFFc\n7AeeID8/nF27SgBNbm4es2ePZf36l/nHPwaTmJi0h2u+aNGzbN2aT3FxkOjoswgGLcaOPYlt2xaQ\nk3M9P/64ngkT0rjhhvYI3RIAmhERYVMWGhGiKUhQOAEJmiYjiuEKc6YSZMJXa/N6MhIA3o5kAnVB\nqpWTkRYTVdiFW/K3TSXZlNSXSKHcZ0iM4kSc0Yp3IsHnrxDFkI9kERUhQejvccY3+pE4yMuI4lhP\nfPxItFYkJEwDvERErDLvgQRyvfz002qee+6f/Oc/McBbrFzZmi1b8nFGVFYSClVx5ZWD61AnDW2x\noJQiK+tcPJ4UMjMnUFWVxK23Xl1HiUPDpuIdTLhUz5EHVxEcg2hoB0Z7u40b/84FFyhCIWmjEAxa\nXHGF5Hfv70s7fXoOqan9WLasEghRUtKJUOgTPv74y5p9Vq16h4yMtixa9AXC+38EZFBevh1JMf0Q\nsdgvRrKTNuAMQx+IWPYbEWG8ElEGwulLfyEZBi/0Ti8kaD0AoZK2IMJ7GSK8uyHKqAqHTkrFmXOM\nWVMKzjziXkh2UqY5bziW1c6sty2itHyIMlsHdCA+fhN33NGOU05pzh13tOOMM06mR4/2yFfudkIh\n6NPnFGJjI2pqCLT24vdbSDzidkDj8SQzYMBZKKV+VYuFhjwLbu8eF+pwWQEHAqWUPhrWeTTjqqsm\n8MYbVaSne1m7tpphwyKYNevRfe5jxxk2bFDs2qWR4Ow0YDQ+3zckJnp44IFbGD16JFprRoy4gzff\nLKe4eCpK3YDWa5AAcDukEO0fKDUKrVcjVnY6Hk8uwWAHhCpZiCiBNsB6EhPDKCgIIML4IqTraTnS\nYmIGcB1CL/kQwd8NyUq6DrH0WwPbsaxTCYW+Me+vRVo8fIMoiCqkYOxZc9xuAFgWhELPAjcigWyZ\nnGZZmYRCz5GUdAstWqxj3LjhNZTOiBG/Y9689aSnt2bt2k1kZaWya1chb77pQeoiYmnVaiXbtyfT\nsmU8BQVF9OzpZ/Dg/tx1141orWty6vPyHqJt24lMmtTvV2f41I4T5eb+mYyMe/H5vq2zZhdHN8zA\nn/0+HK5H4AKArl2PZ+bMIaxcOYmZMy+ka9dO9W5Xm0YYNeoqMjLa4PW2Rxqv2Xx8JLGxnZgy5X5G\njbqKu+6SDpJZWedRVhZCqb5ovRzJRJqOCNGvkKBxHkL1tACewe9PQ6ibOxFqKA1pRtedgoIyRPDb\nFFIZolTsOgGNeAphtdZmfydaYPdKCoWmIlb4h0jdwlQk2+i/SFuJ9UiWU3ckXhAkFPoKCUSvwePZ\nDLQnISEWrSXzyR7AXpvS6dKlIzk51/Pdd5PIybmerl07kZeXj8/3E8cf3wKf7ye0tpgzZxR5eTPI\nybmhRgnAwc+p/zUZPC6OTbjBYhfA/itBbdg0Qs+ekm66aFEhgUACCQnT2LGjFSIoEyktrcayLObN\nW1yzfW5uHnPmXEwweCE33vgUJSVCzSjlxetNorr6XbTuB1goFYbWiupqbK230gAAFWNJREFURXy8\nj7KytlRWtkfonc3AKiIj0ygra4ZQRPMResmLBKGvQILGGqF00hHaxs5KaoXUIkhPJb8/iqqqaETY\nL0EC2BaiRLYQFtaLykq7F5DMKs7ISCA39ziCwW+48MK2xMREM39+FTEx11FYGMusWW/U9AnaPbhr\n32OtNR07ptYJnNpVt7W3D4VC9OlzKUOHnn9QA62zZi2gsDDczeBp4nCpIRcNQl0a4Xh8vidR6gSq\nqvqSnPwJweAaYmP9nHpqD4YNO5dHH32Wn3/eQlxcf3Jz/0x8/M20apXHuHHDSUxMYvjwGQSDLYBC\n/P54YmKKKSjIweMZQzCYCqxDqSJ8vmYEAl8RCjVDFMCpCE0zCviU8PAwKirSiY8PsnNnMU5dQltg\nJUpplGpNKJREdPQu+vWL5a231iCCvhpoT0REPuXlzZB4wr+A65HU1u1I9tBFSOrpP8x5tyFezBkI\nHXUT8DFhYUGuvjqL+PhmBAIhnnrqM2bPvhmtNddfv4gXXhi4V8VQG6+99k7N9rZSqKoK8Pjjedxx\nRxqPPnrXQflMX3vtHUaMmMq4cX145JE7axSLG7w9duBSQy4OKurSCCOJje1ITEw8dmvjqVP/j9zc\n95k16zEuvXQgn332Gk89dW8N7bBzpyYqyseHH/6b4cMnEAzmAxehVAVVVe+zY8da2rTJJhhci1Kz\ngU1oPYuqqnWEQsVIwLc9znjHJDye44iJieS88yIZODADrzeasLAA4eEdmDDhOLp1a0Xfvh2Iikoj\nJUVRVZVIXt42UlKquO22PihVSVLSN1x0URoSTK7CqUXYhaSsaiQjye6HFGne8+J0U7WIjk7jpZce\nB0I89thcXn55K1VVl3Lllf/HiBEv1wnu3nTTRJ5+ehNZWWPqZOrUFwyOijqRhx9exeTJy4CpTJ68\nlrCwExkx4pY9PqOGZv/UPk9V1QIWLCimS5cLyc/f7iqBJgpXEbhoEOry0xMoLa2mrCy4V65aKcWS\nJR+xceMOfL6RgIdlyxQffbSS/v274fF0BgZhWa04/fQevPLKvdx88ylMmNCP4cMHkJhoZ9i0QhrX\ndUEsb7tzaQXNmsXz9NP/R/fuJ9KlSyfmzLmF8vJ3yMkZSlJSc5Yvn8/gwf154YVBNf35w8IUGzZk\n8vLLP6L1jRQVaebOXY4Ep9sjU8rseQX9Ecv/TaTXUHvEQ/AhqaCpyPQzTVlZARMmPMIHH3gIhf7I\n9u2VwEh8vjSjMBX5+cXs2rWL99+3KCk5nwULVM1cYdhd2c5i7drFxMWdDTxLKJQIXEh19U/ccstw\nZs6cssdn1NDsHzc24GJ3uIrARYOgtebJJ3N4/vnzWbnyb2RlpTJsWPg+0xLT09M566wSQqEfkJYM\ngwiFuvPNN6sJBkP4/VcRDGpOO+1ELrtsEHffnc1jj00kK+s8qqoUCQm/AXyEhdlzAP4KrMKy4oiN\nXU1x8S4+/3w5U6duoVOntHrTXO+660aWLfuWGTNyuO++J8nLawdMZ9u2MOAVfL5IfD4LyUT6DOnw\n+SkSdJ6BBKeDCCW1Do/nRfz+44BMkpK+5dVXr2PChDS6dGlDeXkxlZXSJiIYhDZtRhMKqRqFGQgo\nOnVqy88/1z9XuLayPeGEr/B606mutgPcHiyrAmhPbu46LMv56v7StFK3kZuL3dHoikApNUEpFVJK\nJex/axeNhddfX8Q33zSvERizZj3KrFmP7rMoaOLEbEaPHonP197MPBhFVRWkpLRmwoR2lJfncMcd\n7Vix4qc6++Xk/JO4uK+RquKLCQY9REV9ztChHTnjjNZ07bqVRx65ghYtinjxxQ37FH62lfzll9+x\nfv16Y6krQiELj6ec8nKLiorjiIrahhSb5SDB5VSked33eL2nINlNfoLB5ViWVB4Hg9154IGnycho\ny7nn9qKgII2tW3fRvPkzhIXt4IknssjKSiM9fTUrVjzGCy8MpkWLVnudKwxO3v93301i7NiTKSmp\nxu+XTKXmzVsBw3jvvY11rvXXWPi5uXk8//z5DBnSkuefH+hW9zZ1aK0b7Qep2nkHSd5O2Md22kXj\nYNq0mToz8wKdkXG3hpDOyLhbZ2ZeoKdNm9mg/R98cIaeMOFBHRMzXqekjNJ+/xj92mvv7HOfUCik\nX331bd227V0atG7b9i49d+5CHQqFGrzN7utOTh6pYaiGGzVco+FGnZDQS4eFXaMhpC3rBg0XaDhZ\nQ4aG0RrGa7jIbK91fPwtesiQUTo2dqwGrZUarY8//mzt83XRPl+2hunasi7WXm9n3abNqfrBB2fo\nV199W/t85+m5cxfu9X7MnbtQ33nnw3Wuz972tdfe0cFgUN9++4M6Li5rr/dj7tyFOibmVp2ZeZuO\niRm/33tce5+GbOvi6ISRnfuVxY3tETwO/K6R1+BiHzhQPnnixFEkJibV4en3Z302hLrY1zZaa9au\nlfm2+fnfAxeSnx+BtLzOx7K+wutdxQkndMDv32aO50M6np5Ep07t8Xo3I49nFeDH47mCoqJKVq/+\niZKSany+kWgdRmFhG2JiIqmuXge8g9YtGDiwD/n5pzB1ag7jxr1MdXUmv/3tbDp3HkJCQsQe92P+\n/Pfq5fbtqm7Lsujd+2RCodS93o+GVpPDL6eSXBz7aLQ6AqXUUCBPa73C5SaPXByMbpENrVGoDVuw\nDRt2HpdccjOrVq3f6za759QLHSTzbaurU4mL+5qiIrtdxTxatLgNr3c5W7ZsoLg4k8jIwZSVpWJZ\nkwmFOrJli0Uw2BKZMwzwM3FxLbjuunRWrAgxeHA7Xn21iA0bzqK8fAZnnNGNN9/MBdLQ+hM+/fRM\nKiufZPPmawgGVwK3kZ//MV6v9G+y70fdDrCP1OnNv3tl7/4atf2Se9zQxoQumhAa4jb82h+kMue/\ntX5WmN9DkchcjNluLZC4j+McKs/JRQNgUxShUEi/9to7+qGHnj1s524ofREKhfT554+sQwclJt6s\nU1L66VGjfq99vku0ZY3SoHVU1E06JeUMnZAwRkNIR0eP0pCpfb7TNLyjw8LO1KeffqW+7ba/6LCw\ny3Vs7Fna7x9acw8uumi0jokZr084YbyG/hoyDLUU0kpdo+EkDTN1TMwYDReb10frCRMe/EX01qHE\nr6GSXBx9oIHU0CH1CLTW59X3ulKqC5KW8a0S0zIF+Eop1Utrva2+fR544IGav/v370///v0P9nJd\n7AW/xqI/UOxrklV9fXBef30Rn36aSHZ2JnPn7kKmq8UyadJdrFq1nnHjmjFjxlbi4rLZts3L5ZcP\n4oUXpA6gvNwDjKC6ej1+/7MEAsczfvwwcnPzmDXr+jpW+OuvL2Lhwk2MG9eHUCjE9993pFWrarZt\n82G3qfb5OtChw5fk5obw+bxkZNzO2rVeNm/esU9663BW9rqtoI9NLF26lKVLl/7i/Y6IymKl1Fqg\nu5bRT/W9r4+Edbo4fND1NFj729/O5Kuv/stDD/2+Rlju3jgtOVkGtrdoUU1paSwvvCBD0B966Nk6\nrRzmzXuX+fPLqagoQMZOxpCYuJWrrz6BqVO/5dJLU8nJcZruOec5kdzcIuADJMvoOdMo798o5Ufr\nXlx4oWLBgmmMHCmVwzNnPrLXqt3d1+VW9ro4mGhoZXGjZg3ZP8hkETdryEUd7E5fSLZNXZpod3ol\nLi5LT5jwoA4Gg3ulsaZNm6mbN++jk5N/oyGoYahWqquGAea1PbOjgsGgvuiibJ2YOF5DUIeFnaOV\nGq1Baxile/QYqqurq/Uddzykzz9/1GG7Ry5c7AscJVlDAGit22utdzT2OlwcWbDpi3HjTiYubnm9\nNQO70yuhUFt69+6OZVl7rW/Izh7B00/fi8/XBrBITEznlVf+ym239aO8vJT6sqPGjLmbBQv+Q0FB\nBTCBysogWoPHcwVgcdZZvfF4PHg8FgsXTq9zPq0PbPDLge7vwsX+cEQoAhcu6oOdPpmdPZJJk+4k\nIiKW+oT03lIn9yZAd1ceVVVgWR769Om+R4rmjBmz6Nx5CPPnlwDnIY3pJgG78Pk+YsqUwTVFcXtr\n8XCgg1/cwTEuDjVcReDiiMf+6gr2NkVtdwFaWzHUpzzqe82uowgPj0YUQTIwGqV6Mm7cbxgz5mo6\ndEghL2/THnn5I0bcckD5+m6+v4vDBXcegYujAr8ky2VvGUenn96Fl1+upGfPxfvNhKr9miihSmJi\nJlNcHE6bNn4KCmDLlhiUUnvNy8/KGsDrry/61fn6br6/i8MFVxG4OCpwIAVT+fnFREVJ18+GpKLu\nDlsJ/fjjCezcuYPExEQyMlJrlNHe0kAtyzqg9NC6TehuY/Xq74B+bnM4FwcdriJwcdig9b4Hshws\n7CmYFZdfPqimvuCXWta1ldDesDeP5UDz9e39Q6EQ11wTYP7897j00oG/6BguXOwPriJwcchhK4Ae\nPbrWjK081PTG7gJ43rx3KSwMHJLCLa01RUU7ycq6sSZOYeNAi/ESEiK4774nqa7uRnn5FJYtu5fO\nnYe4A+ZdHFw0JMe0sX9w6wiOamRn36ktq4du1Wr8r+pg+ksRCoX26OZZu03G3LkLdb9+Vx60Vg6H\nsotnY7ahcHH0g6OpjsDFsQk76+X9961aU7uEsz+UE7HqS7esnVkE8PXXLQ84HfNwZPW4Q2RcHA64\nisDFIYOdellZqXGmdmUTCKhDIsz2J5gPtuA+XCMff0mLaRcufg3cGIGLQ4ba1mzz5s9QXBzOE09c\nh1LqkAiz/aVbHux0zF/SNE4fQKC8oXGGAzmHi6YN1yNwcUhhW7Nbt75BTs71rF69Ya+tHw4U+6NR\nDgXN0lBr/XBUB7sVyC5+LY6I7qP7g9t91EVDsb9unoe72+fu3VEzMu7F5/v2oGb9HI5zuDg60dDu\no64icOHiEELX00570qR+dQLXR8M5XBydaKgicKkhFy4OIQ5H1o+bWeTiQOEGi124OMQ4HNPA3Ilj\nLg4ELjXkwoULF8coXGrIhQsXLlw0CK4icOHChYsmDlcRuHDhwkUTh6sIXLhw4aKJw1UELly4cNHE\n4SoCFy5cuGjicBWBCxcuXDRxuIrAhQsXLpo4XEXgwoULF00criJw4cKFiyYOVxG4cOHCRROHqwhc\nuHDhoomjURWBUuq3SqnvlVIrlFJ/bcy1uHDhwkVTRaMpAqVUf+BCoKvWuivwWGOtpbGxdOnSxl7C\nIcWxfH3H8rWBe31NBY3pEYwB/qq1DgBorfMbcS2NimP9YTyWr+9YvjZwr6+poDEVQUfgTKXUZ0qp\nD5RSpzTiWly4cOGiyeKQTihTSi0BWtZ+CdDAvebc8Vrr05RSPYFXgfaHcj0uXLhw4WJPNNqEMqXU\n28DDWusPzf+rgVO11gX1bOuOJ3PhwoWLX4GGTChrzJnFbwBnAx8qpToCvvqUADTsQly4cOHCxa9D\nYyqCF4DnlVIrgErg6kZciwsXLlw0WRwVw+tduHDhwsWhw1FVWXysF6AppSYopUJKqYTGXsvBhFLq\nEfO5LVdKva6Uim3sNR0MKKUGKqV+UEqtUkrd2djrOZhQSqUopd5XSn1nvm/jGntNBxtKKUsp9bVS\n6p+NvZaDDaVUnFJqrvnefaeUOnVf2x81iuBYL0BTSqUA5wHrGnsthwCLgc5a65OAXGBiI6/ngKGU\nsoCngPOBzsCVSqnjG3dVBxUB4HatdWegNzD2GLs+gPHA/xp7EYcIk4G3tdYnAN2A7/e18VGjCDj2\nC9AeB37X2Is4FNBav6u1Dpl/PwNSGnM9Bwm9gFyt9TqtdTUwB7iokdd00KC13qK1Xm7+LkEESZvG\nXdXBgzG8BgN/b+y1HGwYj/sMrfULAFrrgNZ61772OZoUwTFbgKaUGgrkaa1XNPZaDgOuBxY29iIO\nAtoAebX+38AxJChrQynVDjgJ+LxxV3JQYRtex2KQNB3IV0q9YKivGUqpiH3t0JhZQ3vgWC5A28+1\n3Y3QQrXfO6qwj+u7R2v9L7PNPUC11np2IyzRxa+AUioaeA0YbzyDox5KqQuArVrr5YZyPuq+b/uB\nF+gOjNVaf6mUegK4C7h/XzscMdBan7e395RSNwHzzHbLTFA1cW+1B0ca9nZtSqkuQDvgW6WUQmiT\nr5RSvbTW2w7jEg8I+/rsAJRS1yKu+NmHZUGHHhuB1Fr/p5jXjhkopbyIEpiptV7Q2Os5iOgLDFVK\nDQYigBil1Eta62MlhX0DwjB8af5/DdhnMsPRRA3ZBWjsrwDtaILWeqXWOllr3V5rnY58iCcfTUpg\nf1BKDUTc8KFa68rGXs9BwjKgg1IqTSnlB4YDx1r2yfPA/7TWkxt7IQcTWuu7tdapWuv2yOf2/jGk\nBNBabwXyjJwEOIf9BMWPKI9gP2gqBWiaY89VfRLwA0vE6eEzrfXNjbukA4PWOqiUugXJiLKA57TW\n+8zMOJqglOoLjABWKKW+QZ7Lu7XW7zTuylw0EOOAWUopH/ATcN2+NnYLyly4cOGiieNoooZcuHDh\nwsUhgKsIXLhw4aKJw1UELly4cNHE4SoCFy5cuGjicBWBCxcuXDRxuIrAhQsXLpo4XEXgoslBKXWP\nUmqlUupb04ulp3l9xqHosKmUKt7L688ppbYqpf57sM/pwsUvgVtH4KJJQSl1GvA3oJ/WOmBmP/i1\n1lsO4Tl3aa33mMGglDodKAFe0lqfeKjO78LF/uB6BC6aGloB+bXame+wlYDpatvd/H2DUupH0+12\nhlJqinn9BaXUZKXUp0qp1UqpLPN6lFLqXaXUl8bTGLq/hWitPwF2HqoLdeGioXAVgYumhsVAqpks\n9rRS6szdN1BKtUK6wvZCGpTtThcla637IoOSHjavVQAXa61PQXpi/e1QXYALFwcbriJw0aSgtS5F\nWvRmA9uBOUqp3ftW9QKWaq2LtNZBYO5u779hjvU90MK8poCHlFLfAu8CrZVSLXDh4ijA0dR0zoWL\ngwItgbGPgI9ME8OrgZd222xfjf9qd1C1txsBJCGdY0NKqbVA+EFasgsXhxSuR+CiSUEp1VEp1aHW\nSyex55zoZcg0vDjTk/+SfR3S/I4DthklcBaQVs82e9v/WOs26+Iog+sRuGhqiAaeVErFIQPaVyM0\nEZixhVrrTUqpB4EvgB3AD0BR7W1qwf5/FvAvQw19Sd1h4fWm5imlZgP9gUSl1HrgfnvOrAsXhxNu\n+qgLF/VAKRWltS5VSnmA+ci8gWNpSpcLFzVwqSEXLurHA2YgywrgJ1cJuDiW4XoELly4cNHE4XoE\nLly4cNHE4SoCFy5cuGjicBWBCxcuXDRxuIrAhQsXLpo4XEXgwoULF00criJw4cKFiyaO/wdX4ieg\nHdPIswAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"%matplotlib inline\n",
"\"\"\"\n",
"Cocktail Party Problem solved via Independent Component Analysis.\n",
"The fastICA algorithm is implemented here,\n",
"using negentropy as a measure of non-gaussianity.\n",
"\"\"\"\n",
"# Import packages.\n",
"import matplotlib.pyplot as plt\n",
"from scipy import signal\n",
"import numpy as np\n",
"from scipy.io import wavfile\n",
"from scipy import linalg as LA\n",
"from numpy.random import randn as RNDN\n",
"\n",
"def g(x):\n",
" out = np.tanh(x)\n",
" return out\n",
"\n",
"\n",
"def dg(x):\n",
" out = 1 - g(x) * g(x)\n",
" return out\n",
"\n",
"# Dimension\n",
"dim = 2\n",
"\n",
"# Input the data from the first receiver.\n",
"samplingRate, signal1 = wavfile.read('fastICA/mic1.wav')\n",
"print \"Sampling rate= \", samplingRate\n",
"print \"Data type is \", signal1.dtype\n",
"\n",
"# Convert the signal so that amplitude lies between 0 and 1.\n",
"# uint8 takes values from 0 through 255; sound signals are oscillatory\n",
"signal1 = signal1 / 255.0 - 0.5\n",
"\n",
"# Output information about the sound samples.\n",
"a = signal1.shape\n",
"n = a[0]\n",
"print \"Number of samples: \", n\n",
"n = n * 1.0\n",
"\n",
"# Input data from the first receiver and standardise it's amplitude.\n",
"samplingRate, signal2 = wavfile.read('fastICA/mic2.wav')\n",
"signal2 = signal2 / 255.0 - 0.5\n",
"\n",
"# x is our initial data matrix.\n",
"x = [signal1, signal2]\n",
"\n",
"# Plot the signals from both sources to show correlations in the data.\n",
"plt.figure()\n",
"plt.plot(x[0], x[1], '*b')\n",
"plt.ylabel('Signal 2')\n",
"plt.xlabel('Signal 1')\n",
"plt.title(\"Original data\")\n",
"\n",
"# Calculate the covariance matrix of the initial data.\n",
"cov = np.cov(x)\n",
"# Calculate eigenvalues and eigenvectors of the covariance matrix.\n",
"d, E = LA.eigh(cov)\n",
"# Generate a diagonal matrix with the eigenvalues as diagonal elements.\n",
"D = np.diag(d)\n",
"\n",
"Di = LA.sqrtm(LA.inv(D))\n",
"# Perform whitening. xn is the whitened matrix.\n",
"xn = np.dot(Di, np.dot(np.transpose(E), x))\n",
"\n",
"# Plot whitened data to show new structure of the data.\n",
"plt.figure()\n",
"plt.plot(xn[0], xn[1], '*b')\n",
"plt.ylabel('Signal 2')\n",
"plt.xlabel('Signal 1')\n",
"plt.title(\"Whitened data\")\n"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
""
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZUAAAEZCAYAAABfKbiYAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJztnXf47ETVx79f4NJ771xABEQEFZQiRUSQZgVfigiioggo\ngiI2qgIKCkixICpFLKB0QdAXEKSpSBNBwRfp5dLhUu897x+ZXPLLpkwmk0ySPZ/n2Wd3J1NOdidz\nppw5QxGBoiiKovhgptACKIqiKMNBlYqiKIriDVUqiqIoijdUqSiKoijeUKWiKIqieEOViqIoiuIN\nVSoKAIDkLiSvckj3O5I7NyFTqpyfkjy06XKU4aF1u11UqRRAcnuS15F8juTDJK8luUdoubIgeTnJ\n3WpmU3nTkohsKSKn1yy3FiQXJ3keyQdITie5bEh5+oDWbYsE3ajbW5K8iuSTJB8k+SOSc4WUqQxV\nKjmQ3A/AMQC+BWAxEVkcwKcBrEdyUsuyzNxmeT1kOoCLAXwQDo3HuKF1u1fMC+AwAEsAWBXA0gCO\nCipRGSKir9QL0R/5HID3l8SbFcDRAP4L4CEAJwGYzVzbCMB9APYF8AiABwDsWjHt/ubaqQDmB3AB\ngEcBPG4+L2nifwPAqwCmAngGwPdM+CoALjXx/wlgu0T5CwI4H8DTAK4DcCiAP+Xc52wATgcwBcCT\nAK4HsIi5djmA3cznmQB8B8BjAO4GsCeiBn+mRNxDAVxt5LwEwIKJcn5t7vdJAFcAeEPi2k8BHFry\nf8xsyls2dB3q6kvrdj/rdiLuBwDcHLoeFb10pJLNuogejPNL4n0LwOsAvMm8LwXgwMT1xQHMA2BJ\nAJ8AcCLJ+SqknR/AsgB2R1SpfwJgGRM2FcCJACAiXwNwFYC9RGReEfksyTkRPXRnAFgYwPYATiK5\nisn/JJPHYgA+DqBoemEXRI3RUoge2E8DeCEj3u4ANjf39BYA78foyGEHk98iiB7oLySu/Q7AigAW\nBXAjgJ8XyKS4oXV7In2r2xsB+Idj2nYIrdW6+AKwE4AHU2F/RtTLmArgHSbsOQDLJ+KsC+A/5vNG\nAJ6H6cmYsEcAvM0y7YsAJhXIuCaAxxPfZ/SqzPcPA7gyleYHAL6O6CF+GcBKiWvfRH5v7mOIemCr\nZ1xL9ub+COCTiWvvAjANE3tzX0lc3wPA73LKnB9RT3Ae811HKlq3x7Zum3jvRjQyWzF0PSp6zQIl\ni8cBLExyJhGZDgAisj4AkLwXwEwkFwEwJ4C/kYzTzQSAyXzi9IapAOa2TPuYiLwSfyE5B4BjEfWW\n5jdx5yZJMTUuxXIA1iH5RJwFokb3NEQ9qVkA3J+I/18AG+T8Hqchmsv9pemN/hzRAzQtFW9JRFMb\nMfdhlIcTn6cCmNvc30wADgewLaLep5jXwgCezZFLqY7W7Yn0om6TXMfI9iERudsmTSh0+iubawG8\nBOB9Gdfih2MKooqzmogsaF7zi8h8GWnS2KRNP0z7AVgJwNoiMj+ADVPypOPfB+CKRP4LSDR9sBei\neeFXEE03xORaTInINBE5TERWA7AegK0BfDQj6kOIHtDSPDPYCcA2ADYx9zcZ0b2xKJFSGa3bSUF6\nULdJvhnAuYjWra6oUG4QVKlkICJPI1p0O4nkh0jOzYg1EfXCYHpQJwM41vTOQHIpkptZ5O+Sdh5E\nc73PkFwQwMGp648AWCHx/UIAryf5EZKzkJxEci2SK5se5m8BHExyDpJvQDQXnAnJjUm+0fS4nkP0\n0KZ7ckC0GPk5kkuSnB/RYqwtcyNq7J40JpNHoIIlF8nZAMxuvs5uvisptG5PpOt1m+QbEVk27i0i\nv6tQZjBUqeQgIkchsm7ZH9Gw9mEA3zffrzHRvgTgLgDXkXwK0eLh64uyTXw+oGLaYxE99FNM+ekK\ndhyA7Ug+TvJYEXkOwGaIFjEfNK8jES0gAsDeiB7mhxAtkv6koOzFAZyNyJrmH4jmj8/IuKeTzX3c\nAuBvAC4C8GpimqToQToNwL2ILIluw2u/sS0vILK6EQB3IOotKxlo3Z5A1+v2voimyU4h+ax53Voh\nfeswe8pSUepD8j0Avi8iy4eWRVF8onU7Hx2pKN4gOTvJLUjOTHIpAAchmopQlF6jddseHako3jBW\nPFcCWBnRdNSFAPYx0xWK0lu0btujSkVRFEXxhk5/KYqiKN5QpaIoiqJ4Q5WKoigAAOP+ft7Qcij9\nRpWKoigx6yBygaIozqhSURQlSeNucUhuRvIhi3jLkVyp4PrsbOFkRqUaqlR6Asm5Q8vgA5KzMuFp\nUOkcH2+hjA0Q7WQv4zoA/yq4/i5Eu9V7BckVSH4otBxNMWilQnJ1kj8NLYcnnk37syL5aZLnhBLI\nkZcAfC60EEounyW5QGghDLOXR8mG5Fkkz/MpjEeOQOQaZpAMWqkgOndh13QgyW1IrjAavRzjTC4U\n6f9rZ0SHBfWNN6UDAv+uykR61ftn9pHE2wJ4b4U8liD5EX9SjS9DVyp5nI/oaNBKkFwd0WFGoVim\nPIodJK8w7iZC8LGULKvC8XcleQDJ//EilRKzZGgBDLYdjfU8lLUPomOFlZoMVqmQXBKRJ9M8XO69\n9WkBkrMmvq7oMeuNAKzlMb9CjIv1PHf0dX7XIxCdY6744y2hBQjAnHUzILkSybG3nhukUjFnQzwA\n4G0F0ayHxgmKzrpuipdI7pUONPfYJw+p9wO4J+fah1uUQ7GApPN6hgVLl0dpHpLrJr5u7iHLfwG4\n3kM+vWaQSgWAzQl1LuQe9tMwx5v3pNXU3wEs4ZIZyU1qS1Sd+ZBv8bOoS4ZDsYgrg6TT/2zSLk3y\new5Jv+lapgWVRkIkP+FbAFN3qp7ZY8NiFnFKO4MkFyJZdAZNZxmqUsnE2LVnetAkubs5/a3L+DLF\nrbye1BQk3w1gK8fks/iUpcM8aBuR5JMkv5oI2h/A3iQPrFjmRlUikxRGx942wcmpso4h+daaedLk\nFT9TC9fMb2Lm5Ew5BgQAsLZFFmcAuNOjSK3R9UbUGyTnQ+SyOo8fAlgkI12XjqV9AwCQ3LZmPmt6\nkKU2JFdEdJqeq2uQuIMwa2GsAZOawgGixe3kwnX82x5SMeuRRpvkfUZp5bUbPqaQMiH59YQC2AeR\nWXrcqch9RkmWrZXErutnM/FH2gBHTgHwnxrp3+NJjtYZG6UChykWkosCeLEBWVyZ2RggnJUXgeTJ\ngaa3KkFyX0RHzuZd/6BF7zo+ynVZb4L1iIIpnC0L0sxVo8ilESmtXWvkAYyOEmw4FMBHE9/fg9dG\n7peRXCdl1BJTtnaaVjq1OyjmvtZBg/WS5OEkd2gq/zqMhVIxw9B0jy4zaup71+bsF0BkgFDEJ5Ay\n2QUAkht2bNRVNgV3IDJ61yS/SzK29hr3w4BcpkOfIzky719xYf4Uh3KTxB28qiPuorWIawEcXiEv\nH2bIeXwIQB3lbcOXARzQcBlOjIVSAbAXgFNDC+GB/V0SmQbjSmQomy5hTtcr4/MA9jOfpxdFHBIk\nv+CYdIZxCcl4nWQt8z05eg/hOmdk3xXJi0jmjS4OKslvv4ywyTlxP5gT7qMjeRYc9pSR3JLk4x7K\nD8q4KJVjHdNtCETrKiRX8yiPVzLmjdMNRCx74cJ2B6ypbraMF/eqx2mkcpSHPK4w75PM+yMknUYd\nZmE+7RnhiKrZpPKcBdHU3UEktyhJm7n2YeS60UKm7XNkKSu3EiSXJDkXyZUtoq8PYMEK2Y94pugC\n46JUbEk3xrHfsDkA3JaZIPKkGrpxe77k+gbmfS+SRQ33s4HXY1aydddiFlRfl3PtBpK9cjXiiOvo\nIukvrs7eK9tOQJp4hJmW/2vm/S1wtwgEgEpWaMajQzxK3q5GuVnMA+BbAO7wnG9nGWulQvI7nHgo\n0VsT13JHJkaRxCaIi5gwm6mbxkgtwDIRPgteG4qvjIm9m7ky7tNm7alJ4sZkgqI2JprJxuIcALck\nrifNNNdG5Bdt6DwNjHhdmEGHTeTzOmHJTsKeWRFMfS7Lx4bkqPyixOd1auSZxTKIFMsIJC/NcpWU\nmKYspaKxQyt0tdLVxdZkdl8AxyS+X5D4nByZpP+4ewBckgorm+9tmqdywq9HdJ9ZHIbREVholydn\nmM1+k1Lh3wKQnNZIT9Xd0KhU3WZkAZvkBQCmtVF4jYYtnc5m31FV0+g8km3f8jnhuViYKsdsXXDt\n3Yg8TcTEHdMrLPPuJENVKlV8ZK1J8rslcZ7ICEvb8Xtfj6j4sM6SuI8dEyOnot3LTVuouPIgzDoQ\nyVhZfzQVZ41WJeoAJD9g1gzOJ5m0/Mnq1W/allzImYYsIB5h7JEKt3EMmjQ22bFiubFL/C9XTZfK\nYw6UTzm7UGU9JUZHKi2xd4W4b0FkUeRK6PWUJMn7sLGRt3EpEZrYf1vpPiN25xyQpvited8GExeg\n9yY5ORW30ETY87RJbjtCcp7EVHEaF991SZc1Lo4vt8VoB6UqVV3k2y6oV/JiYFClMmBWpn8PpXX2\nlViv8aSH8iRPrFGub3I38mUwYTNYxm7zIVO1rrRlOXQegMdSYX03Ba+y6ZBo1oOFKpWmIVnkmdg2\nD5c/alMAV9UtO0WdYfqnK8RN3+9napQbkvQi6zUkNwwiSfdp5NknuTXJpEVZ1n4Nb+cC9YCm21hV\nKi1QpWc7gjEPtvqjSO6JaOd3jO+HpaoTwCRV1pWWJnlGMqDAGV5lEusiTbMzyZtSYVeSdJmr7htB\nGpeMDtivUX/HvXXxjulW8SpFMSPHVqQhGRulTHbIv3PntwxRqfjwXGs7V3soUr6FSG7jofxkRXOl\nyojtEAA7pcJ8NsQH10lM8p0Vomct4HeuN9cB0gfYua4NphvooKb1Pqhg2eWL9Wuk/bc3KTwxRKXy\n1fIopdg6lctSYOd7KB9wPGMkwbwkr7aMm2V182jN8n3yv6EFGCBHesrH24jWgaY6C64ucVy5vOXy\nGmWISsUHtj2HTJftqTllVxbykEedHhBIdq4X5IiOVJojsw3xOX0agMmhBYjp4ubGMlSpZPPtmul9\nzCm7nNbnm6r7D0boyHrGYynniUqCmg1XXlordzsJGY5zKHsFhzQ2dKkhL52K75rnhE4Jo0zAxWa9\ni6waWgDD0Pew1GFtuDekvhrgz3rKxwdl5tlt7k2zGfF1SQmqUmmKwI4Zu8RKoQUwdGmTateos7hO\nRJsxh0TZPhSn/WMFm0Dr0tSIzYlxOeM7BH9Ex3oQLpC8R0Qmh5ZDKSXTaWFLLFFwrRMdV5Kfgr/G\n13WtcjEAUyqmsWlDOuVuqRN/uNJp6trBd0Wxpv1MDY2vBCqXKP6Pu9KL/jIcD7kLjM3z06lZEVUq\nDUKylvXVQOiKUtkntAANE8raqiv/by7maIC+Tn/a/L6LNy5FBVSpNIvtPpFOQ/KWGlZcnW90lFr0\n4f9dBsNWKqW79ttElUrDGFfl7wgtR01WR8XT9JSxIa8N6Zqy6YJSaeo36ZQXA1Uq7bBeaAE88Adz\nhG9Vuta4DJU6jeZyWekDuCtpki4oFRd69/yoUmmHPpxbYoOL65YubH4cB+o0mnnTJ2vnhCchumM2\nXkQXlIqLDL1ro3sncE8ZOYd6jBi61dWQseklE8VH5naFLigVF3SkomTy9tAC+ILkzBXdevTuoegp\noX7nvvy/3ts6kidVTOLiKqgvv+8MBqVUSGY6eOwAk0ML4JFXUe3wsN49FMoMbEcqfaDK+UK2VB2F\nuzia7cvvO4NBKRV0eJqJ5H6hZfDIvhXiLtuYFEqSUNM7eY1eX6ebKtGCM0dVKkouR5N8imSnXCo4\n4sMtv+KXJhqfD9dI26V6vnyDeb+7QlwXRatKJTBOjt5aZD4AW/bxjIQ0JG8jWcm9udI7bK2/sqh7\nfIRPmjQk2LnBvAFVKsEp8y7aBX4N4ILQQnhgNQBPhhZCmUHd6aasxsumQftFTvgEB5eMCOX0sva5\nQAWs1WDegJ1i7xRDUyp92Q+yVdcO1lF6T5VpGFtslMrSOeFpz8XvB/BMPXGc2arBvAUASB7WUP5b\nNpRvYwytYdsltAAVmEayU+4VXCCZ20Mm+c42ZRlzurb7PT0qWTKIFO2xu0Ucl6my3rXRvRN4YNyV\nDjC+wnplOUPyxIyw9wL43wDiKNVZG9nTZ3Xah/T6ZuZiOclf1SijC6xi3uduKP+R/6Drxj6qVMKy\nJMkFSc5C8laSk0IL5MhnSM6eCjsviCSKT+osEi+T6hzlGdHUsTBrDJJVz4FpaqS4OMmXSJ6aCPt7\nQ2V5QU9+DM/jic8vB5OiPi+QfBlRI9H04qWSQQPrdD43DK4CACRHzv4g2cV2KN1JyoXkZg3KEY/w\ndsJr0/ud9rXWxT9T6S+zAjg3tBBjzGk10mbN9/ucZtnUvGf1skMdMFbEmwDcbhn393ULI1lmgt3F\n3ygTnf4Kz/V4zTR325CCeGAtRG7UVymLqDTCTjXSZk5DkdyzRp5ZZJ1S2MV2aM0mMi04PuKLTZQX\nAh2phOVUEdk1GdDXfZEiMkHwvt7HGLNpTvgJJJdCNX9vVZnaYN6uNKXoXI6PABAZ8aSfsy7SxR7C\n2JBWKIYrADzbriS1yZom2bB1KZSmaFKhdJU3ZgWSzNvs2Qp9sAwdmlK5PLQAFfhgVqCIvFNEuupt\nOYvtRWSkpykiV/WhV6UoOWwRm/eb1yeNe6XtQwvWdSjSecVnDcm9AXwvtBw2lDW4feiRAP26j74q\nuS79hko36VLdHtpI5YTQAljSh5PyFEVRKjOohXoRkY4vEC8uIo+EFsIDNwL4CnroQVVRHHkWkZfx\n6aEF6TpDG6l0mW0GolAA4FAR+b2IXBJaEEVpiMNFhInXvBKtFXwytGBdR5VKS4jIhaFl8MTdUJ9e\nyvDJW8c6p1UpJvIAerAJUpVKOwxmoVVEXicifTN5Vtw5FtE0+SYNltHFjX+vZAWKyONZ4R4o7XSK\nyNIi0vnpN1Uq7fDr0AIoY8HXa6TNdPEiIp8XkWki4stcf8TRqIgc7Slvn/ygoXzzRhrvbai81lGl\n0g73hhZAGQvOqpH2j96kiHgxJ/x0z+U0RZ78WexrGzFvpCElezu6ZDJchioVpWl+HlqAMaJKQ5jG\ntyXoE6nvccNr66QxNLaN+BMARs4T8sg5AL7RYP7eUaXSDuO8sP3j0AKMEXXm++sopCymAfhE4vvx\nAL4iIv/0XI4NaQVnw6uW8bYRkSaPrLhbRNLTmns0WF5tVKm0w19DC+CJQxzS2D6cSk1E5LkayWu7\nb0/xKRE5Jf4iIq+KyBGey7Dl+1UTlPyWyfWWKkY4Ll7Is0ZMP3TIpzVUqTTPrCIyJbQQHvghgEMd\n0k3zLYiSydk10h6H7N78kRZpf5cTbjsiWdgyXh18G8okFclNgPWax7UOZd06UnjHfWupUmkYEck0\nTbTgYa+CuHOmeb/X0ZzxOp/CKLlcVCPtX3Iaqpst0n4K0f6JNFbGKQ2a6E4oprGMRV6oEN2lLbjB\nIU1QVKl0l0+UR2mFWJHc6ZK4670qBUD+aPJXFmkF0UgnZuFE+FD5PoDDqlpkichjDmXd4ZAmKIPy\n/aU0Qtw4XB1UCqWMOo14pkVWhQ7BNZ7k6AUicisypqUaKqt3v6eOVJqjyrC4yxxl3vtyP9eHFiAQ\nzo2PiNxSs9xk2U855uOyXmfLENY0e8MQlcrPWiyrqLJm7lCuQNsjgx2yAk2vDOjPgvuuOeFNuhnp\nAqE2x00oV0SmGweMlZSciBzkV6wJeT/UVN7KKENUKh9vsayfAfhRKuxu815roV1Enq6TviILicgv\nU2EfTn13NTgA2vPt9LKI5M1B90UpKs0Q0qvFkmi2k2hjUNEag1MqnhyuWTlMFJEvYtRc8Xnz3gVv\noo/aRBKRLHPS5Dz7PA1v8PLF5qnvf0P0QAP9mb5zJdTcu0AVdhELi8hDIrJBg2V06hj1wSkVT2Se\nH5/DjIfZWINsDmAldOO3faNLIjN98Y/YuqXmpjrAbUezCxNGdyKylpn6WFlE/tKSDKFIT38d02LZ\nfy+49nUAp+Zcuzv1vY5DzE7Sksl0m/91KV1o+DqHiPzBIlrmgyIiD4vIXUg1cIGYGloAQ93F88ss\n42Va5IjIv2qW30duK7j2ACo4QSxhemIUe0/6ooh8Q0R2zUm7YzpuxbKzprTmzYl7DJr10eUDp9Gm\niHTKYa0qFXfK/shjAKzYhiB5iMjz5bFambqo66rlJptIIjLOLmHS074/K4h7IoDfeCo32RB+vmLa\nLMW3YIX0I52VvLN+RORYEdmrQt4h6JRycEWVSkSyMVrWMk2hHywReUVE/uMuUm1s9yAt06gUEXWO\nUT4egI1l0DiORpJM6OWWrC3+CeXWYgdYlpucGq001SMiIyNpEXmyJFnyWY07RHG5J6Xi3l9FngZY\nqmL8kxuRomVUqUTElk8Xish9FvGniEgbPfyqbsLnjD/YyteSuaWL5Vj8gH3OuMIoM8B4h0MZfcGm\nTqbXJ4oo2qW9FoDPwnKePjUatvV0PHJQVwWSJySmFWPawmotAPNZ5JnutNj4PMvjRQCPAbhERB6s\nmPZI5E/f5bFhxfiNo0oFuElEdjaL09s4pI8r9i98CmWoNAdc4IeoCdmssZyGSzIVwEsmbdwDLzPR\nbssYIATLAdi4JE6WUslaG3ydWTzO+z2fEJHjG7b2qzPNE9eH3+O1fWL7AbhMRNL1/GUReaY0QxFf\nGy8XArAogOUBvL9qYnPCZqWjukXkqqrlNI0qFWD3mun/a94vqStIBhdXiDtP4nO6h9QHc+CYi0Vk\nLhj/SonwlwLJExyJuBLACYng72JipyNrkTdrd/v9Js8mfk+bEZUNRU4UbwLwH0QHV+0PYBMROVVE\nNktHLJlKe6t593ZssIg8ISLPisjzdX7fPp3ymMXYK5UCU9P1LbOIG/D05kEfWFuDJMx+NwKwVeLS\neai2KOtrAdeVXQBARG4XkQMT4RsDWDWIRN1hxohPRPYD8M2S+CekA1KN3Qcw6nreyQTWjPS9eNYW\nkbcXXD5NRFYUkatFZKqIVN2j8Zwp40bzfc+MOP+umGddPt1yeY0y9kolDxG5Bvn+iEYONOrK5kAR\n+ZOI3JT4/n4AV+REzzI2CH3ca2YvTUTuzdgtn+yJJ9dcKk0h9Iiqver0fzmhsRSRc5P7KIxiKJ0u\nSlC2qN4EWW72XVk9x6DB94FlZQxq6nZclIrrnpE888SP1JClLm+umiAxT5telO+rCW48dz5DAfXR\nm2tVROSegssjDXyGq/XdPIqzrohUMf9N4vJfzW+UXh13QUDUEZkOACKSuZdHRHwqLhtCd+S8Mi5K\n5QJMNH2M8eHSpVWSoxAHzkx9D+neIc/c0mY+OW6UYjc0LifqDYEZddpyj8415VHsEJGmD1+bsLu+\noi+8nxdcezuihfQucELsvSK0ID4ZC6UiIjsDWLeh7NtcVKtr6RG7OI8fumC9ewdzywnJzXtep6DX\nC50WHAXkb/RLkexM+fq/P1oz/aUo753X6fAdl3dBRB7M2YG+Xo3yXCkyrT6nNSk8MxZKxZD1QBX5\nLAJea5zu8SuKM3l7T4p6Zkni3yCeQsjar9C2onGZT45lvNSnID1hZhHZP/H9fgDpneIzRhEiMo+x\nJvqqRxnOqJNYRC4SkdVKov3WvP8a+ccZ5OHSqYg3Yl7pkLYJtgUwd2ghXBjnkx/Xgb3L6FMRWR9t\nhNEe1gsI69BtiQpWN1cB2AfAmkCmd+IXEP6QK1vnld8C8EMAewNIr3H9BNXcffSG9MKyiKQ9ImwL\n4K8Z6Q73UHZrI0ARuYMkAOyRUU+bpE3T9dyNx+Z/rrq/qxOMk1JJu7GwaTxjL70HAwBJQWpYbv58\nX875XKiys3+qiBxH8qdZF0VkzqzwhokbqudEZJ7CmK8hInIAyYXMl/+kLn7Op4B9QkRCm4R7o4YS\nq6P8ysy0fXJXi2W1xjhNf7nQ5bl5l13yXbaQqrLGYusORFFsESAyyW+twHobUDv7DIyjUqlyZkMI\nO/wiktN1Ved+7wFQZQ9CW8SK23babU20d5Kk0k9cGtxbAbzHtyBNISJzdHXn/VCVSlaDm16ktuEU\nhDU/TPvympL4XGmPiYgs35BrDlv+7CMTEbm5onmpMmaIyM0AVqmYRkSkrU2P97RUThCGqlTeCWD1\nVFhl9xPGwds9XiRyQEQeAbBAIuhX5v0gAOe3L5E7IpL0IvzHYIIoY4GI3BlahgL+L7QATTLIhXoR\nEZKxZcUmJuxRACS5IOq5emjVIkNEnjJWMD8SkX+bsEMBwIR35XTHKrzPvL8bkfyLArgxP7qiDIrr\nEXV8B8kglYrhFQBIO5wz5omudvYrIcy6xDcB/DgdWGNO9Y+IzKPbZgcAs4hxhS92xzYX8QQcXIwr\nitIcHLLLJJILJR3mKYqihIbkEQAO6OpCe12GPFKBKhRFUTrIhQDeFlqIphj0SEVRFEVpl6FafymK\noigBUKWiKIqieEOViqIoiuINVSqKoiiKN1SpKIqiKN5QpaIoiqJ4Q5WKoiiK4g1VKoqiKIo3VKko\niqIo3lCl0jIkv0zyR77jWuQ1neQKFdPsSPISH+WXlLMRyfuaLkdpFq3bmeWMXd1WNy01ILkrovPp\nVwTwNIBzAXy5i4dIkZwGYKX0ee5dgORGAE4XkWVzrh+KyBvxqgAOi13/K82hddsPRXWb5CIAjkPk\nMXxOALcB2E9EbmhXSr/oSMURkvsBOALAfgDmBbAOgOUAXEYy01EnyZnbk3C0+IBl1+XfiI4QvjC0\nIOOA1u3WmBvADQDeDGBBAKcBuIjknEGlqouI6KviC8A8AJ4F8KFU+FwAHgWwq/l+EICzAJwO4CkA\nu5mw0xNpPoroeNHHAHwN0alwmyTSn24+Lwdguon/X1POVxL5rA3gGgBPIjqE7HhEZ5fE16cDWCHn\nfnYFcDeis2LuBrCDCd8FwFWJeJsBuMOUcSKAKwDslowL4ChE55zcDeA9qTJuN2XcBWD3xLWNANxr\n8bufDuDA0P//kF9at8PU7UT8pwG8OXQ9qPPSkYob6wGYDcA5yUCJDp/6HaITDWPeC+DXIjI/gDPj\nqABA8g1hmARVAAAcyElEQVSIKvAOAJYAMB+AJVNlpecn10d0WNimAA4kubIJnwZgH0Q9nnURnXj5\nmbIbMb2i4wBsLiLzmnu7KV0+yYURNSJfArAQgDtNOUneBuCf5vpRAE5JXHsEwJamjI8BOIbkmmXy\nKa2jdTtQ3TZpJiFSTL1FlYobCwOYIiLTM649ZK7HXCsiFwCAiLyYivshAOeLyLUi8iqAA0vKFQAH\ni8jLInILgJsBrGHyvlFEbpCIewH8CPanO04DsDrJ2UXkERH5Z0acLQDcJiLnich0EfkeoocpyX9F\n5CcSdblOBbA4yUWNfBeLyD3m81UALgWwgaV8Snto3Q5Qt0nOi2j662ARebZK2q6hSsWNKQAWJpn1\n+y1hrscUWX4smbwuIi8AKDtYLFnZpyKalwXJlUheQPIhkk8hOoJ44awMkojIVAD/A2APAA+ZPFbO\niDpBVsP9qe8Pp+6FCfm2IHktycdJPonoQS6VT2kdrdsRrdVtkrMDOB/ANSLybdt0XUWVihvXAngJ\nwAeTgSTnRlShkmevF5nXPQRg6UT6ORANr134PqLh+YpmOuKrsFzAFJHLRGQzAIsjGvpnmXo+BGCZ\nVNjSGfFGIDkrgLMBfBvAIiKyAICLbeVTWkXrdkQrddukPxfRusunbdJ0HVUqDojIMwAOBXA8yc1J\nzkJyMoBfAbgXwBmWWZ0NYBuS65CcBODgkvhFFXUeAM+IyFSSqyDqnZVCclGS7zXzz68AeA7Rwmea\niwC80cSdmeReABazKQPArOY1RUSmk9wC0cKoFeb3nR1RfZ1EcracnrRSE63b7dVtY0n3G0Sjsl0t\ny+s8+mA6IiJHAfgKgKMRWWxci8hyZVMRecUyj9sB7I3ogX0QkfXIo4h6iplJCr5/AcBOJJ8B8EMA\nvyxJGzMTov0IDyCa2tgQGQ+tiDwOYDtEi5RTAKwC4K8Fss4oU0SeA/BZAGeRfALA9gDOK0iX5mRE\nD972iH7zqQA+UiG9UgGt263V7fUAbIlICT1N8lmSz5Bc3zJ9J9HNjx2C5FyIzDNfJyL/DS1PESSJ\naN55RxG5MrQ8SrfRuj0+6EglMCS3JjmHeei+A+CWrj50JDcjOR/J2RDNawPAdSFlUrqL1u3xRJVK\neN6HaHrgfkQuMbYPK04h6yLa+PUogK0AvE9EiqYIlPFG6/YYotNfiqIoijd0pKIoiqJ4Q5WKoihK\ni5Ccp+8WXkWoUlEURWmX/QFcHVqIplCloiiK0i6ZxwcMBVUqiqIoijdUqSiKoijeUKWiKIqieEOV\niqIog4LkAiT/ElqOAkbOqx8SqlQURRkarwewVpUEJGcn+d2G5EmzcUvlBEGViqIoCrAygM+3VFb6\nWOXKkFyCZCcP9Bq0UiH59tAy+IDkm42ju15DcimS6cOQFMU3zr6nSM7nU5CSsmatkfxBAF/0JYtP\nBqtUSC6ADC+jJGcl+RbHPO8geUJt4apzI4A9M+RZxyUzknuRDOH07SYAd2TIsxrJeapmRnKuQPfR\nWUieTnLT0HL4gORT5uz2Nvlxi2XVHrF0kcEqFZh7ixsd0wBdhuiQnr855rkygI38iFeZ75BcCgBI\n/oLkcgCuJelyzvtb/YpmzcIA5iR5EgCQ/AzJjwC4DdEBSVWZ3adwfYTkaSR/lgj6CICPZsSb2UNZ\nM5lOWVvHQM+H6ACsqtTpaCxQI21VVsm7QHJDkru1KIs3BqlUSL4D0QluSZYFsCl61BAxIvmAxI3F\n9ojuBejJOe+p+4hP3zsRwPHm85ztSjQYdgawS0YYAIDkhSQvAPCqB2UwDdFpiAfUyYTkwiQ3L4nz\nPvNxDZIb1ynPkkXM+7taKMuG4wCcEloIFwapVABclREWP1CLZFzLhOQqJE/3I5IT6fWH5HC5UgNB\n8uqac7hNY1UXSR4zZGd8ZZAUklUa9a0AbO1ZjMNrpv86gEtK4sRTu9sCuLxi/j+sLBFwmUOaumxY\ncG3N1qTwzFCVShH7VYj7PoQ9Cz39/7wx8XnkrO0S1kc0ndBVtrCMtw+A3ZsUpAccAQAkF62YbvGi\ni/H0qg0kK5nsOjBBcZJ8iOTHLdO+Oe8CyX1JHlxHMI+sS/JmksuHFsQn46hUAMw4h9o6Lsnc36ro\nWoPExgZVyi69jxbny2PiabEq05Jl98EA9xGCGeskJCdZxF+55Pr9JG0Xj68h+TnLuD5YHH4W0Q8B\ncBCQ/5uRnMNDOTZsDOBNqLinpuuMk1JJNzI/MIvdRcQN3vcBxGdrJ0cLMKa+0+qL58zDFazAVkdC\n1oyGdxqAHXwJVpE5SdoaQRCRrG8CMnvs5wO41qNsnaCkRzt/RvzXpYL+YFGMren6JADHWsZN46zw\nPXfgXs7pfHzMYxk2vL7l8hplnJRKmt0RWR0VESuV9wBYOidOF9xY2zag6V5o1j6est6sb5JWSVeQ\nXMwiTdwQrGDef5m6vjGy763vpDe7lTXOO6W+T7AAI/lxR+vBEUiu39Lo8A0kP0tyDjMgdVpfI7li\nweW291J9o+XyGmUslArJ1ZB6oAxlFkexUikb0bTFxiTrKLG4NzuXec/6/1uZNkrch8s+hFjGfcx7\nbyz6XCG5IaJF6yqMjPxIJuv8jwE8loriao57NV6bki2jsAyS2xdcPhCRZdRZAN4A4Oo8BcHsDcNz\nm/e7zPv0YlHtIflDkod6yKcLHVVnxkKpIBqR3NxQ3m1vvnulRtp4rng7824zKmiKOvcRE1uzrZsK\nH9SGSJKnArgyFTYrJlpQLZSR9J0ZYR+wKM9VSdu2J2Udl18UXIs7eFsB+Iz5vJuxils1FXduWEBy\nZOrQkd0BfJ3kJLOfp5K1pVnTnA3A8xXSeBlp+mRclEoeZfefOcdvsRbTKRILkt9KXfp027JYYKMQ\n1jDvkxuUo0uMbGZEtF9k9cT3tS3zOoPkqgWN0fwAXsjp5ZdhO8rdrjxKLm9LfF7QvMf1+DupuF8g\n+SWLPJ9MfV8jM5Y9/0L0/7xUMd1+AF7Ea50lG9pygmnNuCuVXEi+G/n2/X/OiN/JPSBmET/Pomez\njLDJzUnjDsllScY7kFcz77MmrienDCq7fBkaJTvol8drU6Bp/m7eP2hZTnI0YDUygDFtzrKyqrgu\nM9m8x8olbZZ+AIAjTb5LkrRdELc1by+Tqyqrl0cZYefyKO0y9kqF5I7m/V0pE8NLC5Ile3Ermff/\n8S1bFWhcdZheaHIkdS2ieWhbQlfSRwCA5Lwk10uEXwHgnwXpBjXl5YEtC64dbZH+TMtyksqpqnFE\nlvKvYl5rva8G0ebGOyvED0HRWlJvGHulAuDnJPdEZG5ZOt+cQTyNULd3k8XkCnF3IXkegNuRmn9H\ngY+hLkLyPgAHY+KIsPdemlumaLF3VQDnNlDmyE57ktuSzPPfdVYq7swAbqhQXpX26w0V4obCaYG+\na7MkqlQivmnes6aDskjOR8c95Cb2d6RNZct4r3lPr/msl44Y08bGTYfNZEvDTHElpkPKNuUtUVWu\nMcebG5CM/TBJzkRkrZVF+gTEqqa1VUYqfcDV8rLI3UvrqFKJiN2XfNzW8oXtuOR2ts6ivSv5NjZ6\nuaxxxAr+S5bz7Pc5lDFkTmupHAFQ5C6maKf/5NT3Wo4qgRHHpcEhWWXq2RWr9a+2UKUyyguW8Tpn\ndZHiGUt79zbOj6jjTvwIACf5EmTApJ9l20VzpVkOIbkDyXsaLKOqH8BGUaXiTqFzO5LrkizzxNo0\nXtYhSD5RYk1URt3DiKxMn0kWOkxUGmHBdABbPD2xJ5wJxw3UNfYMBUOVSgYkbddWgMQ8KMk9SE4m\nuQaAbQAUnhnRAoe5JDI7gyeRjC2IFkA12/k0TidtOjDBZJTkcSTnIbl1TaWo5DNhAdxMCz9Vda2O\n5K+8SjUx7z57Ac7a1NppVKlk83ubSMbqIrngeRIiU+SbENbJZMznbSKl9hoA0c7gLQBclAir0yi3\n5TH4HanvnwVwKoALELn+VzLw0BueNeNz1bWND9eUoQivU4Ek50+Zu9umGwfP2cNTKiQnt1jcZRi1\n+Y/3rdRSKrRzZe6LZ0m+KRWWHmXVqSvvLY/ihW+STPfsYjPxsXigHXl/ViDtzkwhJjq6XCURPlQO\nBfBnhxHQIM+kTzM4pQLgmhbLKjLlq/vbVpmC80HaN9pngAk7s+usz2xQI21VfpMTPvSF6zqNeJ5B\nxyYWaT+AiS5i4lNX27COtMW3got/r/9UTNcpy7SmGKJS6cp+hX3Ko/SCr5n3HYNKYU/emSwXtipF\n+3ysxug2zz2IzZpg2r1+TJfWMXy3c8l11LQTyyJclEqW37dOM0Sl0hXq+p/qSq8m3tjWq135Y8iG\ncN8MuH+Op16bkUoeX6yR1jeVp19LNuwm1+eqjMhcTsoc6cxV2IMWBFUq3eXLoQUwfMS8uzi7UzPf\n/lD1rJYyNkhuRCS5gHFPP2EqiuQVnsvN4hCHNEXWjslnIXaOaaO4bDwmp8mauvujQz6toUqlYUiO\n2PFbkrZkCs1kx8ODilx4KH6ps3bg21oxbS34hHnfOBVue4R029haxJ1rzKjPa0iOSSQXSYXZHnMQ\nBFUqzfM47Y7I7TpLIcNhoNIpViiPkkuRqxUX8tY23+i5nKaoMq11UXkUZ14P4NE+mSOrUmmHqg4V\nu8pnyqOMUMWVuVKP82ukPbLoosdpzE96yqdpquxramNWwduxx02jSqUdfM9XhyLvYKci6pzyp1Rj\nzvIo1SB5PcmzAfzWU5Yja3Mkr/aUt09WzgqsO2IgmamsSJaOdki6PH+t4+S/X6nM0qEFCEjlncdK\np3gbJh7h2wRd9HaQpzxWywm3JU+BFh2qFvMcerCplCJdsVz1Q9dcX8eISKXKoPfhn6qyd4Uu/YZj\nxFUA3oVo6no6gJlF5OkO/BdvB3B9OrBLdVuVSkv0uTFO0uf76NKDV4Uu/YZKN+lS3dY1lZYgeUpo\nGXxA8vauHV+qKEp30JFKi4gISe4E4A8i8khR3C7fB6LjYc8AMKeI/KkoYpfuo0u9uSp06TdUukmX\n6rYqlUCUVQK9D/906cGrQpd+wzHiYURnxUxCtJHzFRGZ0oH/4osAjkoHdqluD2r6i2Sb3nAVRfFD\nF52V7igiT4rIoyLykIhMMeGu/tV8cULg8ksZlFIBsGJoAWzpQI/HC0O5DyWXAwFsDWDhBss4p8G8\nXVkjK1BEHqyZ7/Y10v5NRF6sWX7jDE2p/DS0AFXI8jZqnO71qqEmOeLmv4/3MQAKd8WXkOdB93AR\nuUhEHq+Rdx/xvpHUkLeJdIuyhCLSC+8UQ1MqfeOZgVhSHUOyjt8pxQ91vNc+lRUoIr4dTe6ZEfay\n5zJ8YHWkuMHaFb2IvJITfkmF8jqN7qgPz0skLwHw39CC1ORuki8AOC20IGPMHTXSZimPqTXyS3Mq\ngF1E5CSSJyYviMj0DvpLtFZ0IvJcg/L/AcCmeM3Lc+dRpdINngZwU2ghPDAHhnEffeUBx3QPItt1\n+//VkAUA3g3gMvP52Zp5tU2hyX+LSIZl1/zIGVl2AVUq4ZlHRJ6Lv5D8fkhharCjiPwi/tLj++gt\nEm2Eckl6P4BXs7KsIc6/ReQPCXmey4mXdxxxUETk0YpJHkX58QF/cRFlJCByF+OQVTvomkpYZksq\nFEMfe/oHJhWKwemkSCUIRLajQp+GFpmjKBE502MZIYinHO+ziHunQ/69M3YZmlL5Z2gBKrCHiIzM\n24rIm7u0kckGETksI+y2vt3HGJP3P9VZpE9PH10F4LYa+XWV+Ld7V0P5d9GIoZChKZW9Qgtgi4j8\nILQMPlDFMQgE2T1im4OhvpcT/syEAkRuFpFQo9fjmy5ARJ5uKOtjG8q3MYamVB4LLYAlvdmkWcKn\nQgugNMp3LOL8KCf8dp+C1KSuwUERIy5TCnDpgL3gkCYoQ1MqWYuNXeIpAHOIyH9CC+KBDUQkr0FR\nhsHDFnHyGspv+RSkJnWOWS7j3ApxXZRK79ZUhmb91XVb7sWy1lF6yLoicl1oIZTGqdOg9a4xdKEF\nTwO9m14elFIRkUe6amo3oLWHlUXkXxXiT0GzfqOU+uTVzTqKYSj13SdeTIq7ztCmv5SGqahQAOD5\nRgRR0vw9tAAdpwmPFZtUjH9ZeZQRVKkomZwVWoCA9O6h6Cn31kib9x89kxNuk3bwiMjloWXoIqpU\n2iFvN/E48MvQAiilZPr4EpEbLdN3/oyPjjAWC/WqVNphZHNgT9ndIc3d3qVQfFPHZT4BZHreVcaT\nQS3Ud5RJItJ1U2cb9hWRkx3S9a6n1VPqLIy/UDO9osxARyoNMxCFAgBnhxZA6RXamRilqd+kU8Yw\nOlJpkKGYEQ/lPpRGyHPx0iVsNnH2mU55BNeRitI0XWlwvhBagIa5IrQAXUVEOtWTb4CbQwuQRJVK\nQwyld+/hPrqiVC4ILUDDXBxagBzuCi2A4XJ0rPH1SKe8P6tSUZrG55G0dRiEki8g1P0Rfk5JrONm\nvxQR+ZiIrOkpuz84pnMZMXWlU2aNKpVsjggtAIYznXFVaAGUUl5CvcYr6yjiqsznIQ9flO2tclLg\nInKPQzIbX4FNeAtwRpVKNi4+epJ80IMMLntCfHNo3QxE5EEfgtTkDAD3hBaiYeoohesbKLdSw+u4\n7tHU/pgXS663OSq8xSJOU2e5OKFKJZt76iQWkXM8yBB82khEDgotgyf2EZGXQgvRVUSkiSmWpr33\nAnZH+LpgczhZK9j8NyLSGXmBYSqVuvsp1ob9gl6Wq/331Cw/pu489VQA81jGvSgj7Os1y/fJ0jXT\nP+VFCsWahhTVSDEN5XtJQ/mOBUNUKj+uk1hE/gr7yrotUlNEIvL7OuUn8qm7afJaEbH1ObYHRpWI\nz3WlWnO+IvJAhejpw6G2E5FGF4F7yvqp765TOiHPB2pKqZR1TH1Pf61bI20dFzuNMDil4qtRtyzr\nckw8Va7uWkyaM2qktV4gF5H7ROQbqTBvDbGITPaVVwlHisgBqbDftlR2aKo2sF6OqRWRf6eCurCG\nVgvPo6yfWMRJ/4ZV6NwU9eCUig8cK9UvAWzqWZQ6vZDf1Ei7bI20IUlbIa3QtfnmMWAdAKuGFqKE\nO1osq1R5J06PdDlmvHMmx0NVKqe3UEa8qSseCj8uIjbnT1Th9hppnd3ti0hTC6AuxNOZpcohfcSx\niPxfIxJ1k04cr2BGvclG+yYAj6ai1Tn7RZmIKpWW+EeFuI/jtUr/9pw4Qcx7awzDr7a0ifexaa0J\nktMBe5v3Tu0aDkQ8JTl3+kLFdSegvZ3uO2B05Nv3duc7FePbKnyXjoEqlZa4rjzKDPYVkcXM52QP\n6pDE51+n0mwDYKdU2FEVymyCSxIuVZIL41sif+HxSAC7pcLaGOUVIiKvR9TDhYjEewbeCeCYRLS0\nhd4hGD6zA9jE7OlI7g5/a0bcwr0WIvKsR7lyR5Ei8mqGOXedhe6kQYmrmXjZPpQyLq0Y33Zd709V\nBekiQ1UqVogIReS0nGsHJ75OS127UERuMF+nmrCQu1oPE5Etsi6IyMV4bYdw2rT2/0Tkp6mwoCc1\nJhQjU+FPiMi+BekOTnx9FsCf/UsXFtNAX24+3wzgQHMpa7qyzf/RddTzt9T3nyc+Z/oySxmUHO5Q\n5iqIOlp52EyzvuLJt98aADZKfHdRkjpSCUTazDSP9B90KgAY09yvZCYQuR3AMu6ieSE9Z52+j3g6\n8BAAOxbkswzCOiZ8qELcXQHsnHNtOfjbL9RljgEAEXksfUFEPgZggTaEcJimjRvkX6XCk52eKRb5\nVN4gLCJ3ishDAJLrn006mvwFgH/myHKLiCRHJy+Z8CoKS5VKINI9Iltm7EERkdx9GyJyv2P+vig8\nTyGxcPqKiPyiIN79LW1ay8PWauhFEbkJwIVZF0XkyQp7dIaMjeFIiH0mcaOZrmvJ0X6bz9SXEp/T\nI/e6PAzg24imLr0T+HnNZFyUiittuJqoQuZw33JPyRQAN5TGCoiI2PgwOgnACU3L0hMKe7QF5tTb\nJz7vnROnjN8DmM0xbZ5S+aN5vxTA1xzzBoA7E59L65TZ2xab/t5Uo9ysvO8WkemWboKqrvVUNc5o\nhXFRKhcD+G5JnP0ATJhGEJGnO3YuyrMAPlcSZztkuFgRkUVExPfmzDpsXXJ9ZwAj60QisqeIfLEZ\nkTqNqyHIrYnPsaPT54AZa4o/csx3KxFJj3K+apk2U6mIyI3m469yFOL+ic8jU36IpnnXF5FVEmH7\n5ciQ3hwcy3J+OmKLHI1so4s8utbpBTAmSsVMhXwJBf6sROS7Pdgo97yIfA+jFlszEJGzHV1st4qI\nXARgg4Lrt4qI+mAyiMj+5bEyiRvqpKPTrLWrSr1kTx4XRnraRtHZ7ELP4ksick0qLM/78TE54T7u\na3EA/6qaSEReSCjW3jIWSgWY4UvrmwA+G1qWGtwNAMZiK23SXIU6myq9ISJXI3LgWddybuhnkOfh\n0gDOldVwVZybX92h3CTxSOWKiunOSnxOpr0cwKymo5Imb12psalgEXkE7Xg67tQ5KjFjo1SA6MER\nkeNDy1GDGQ++iJxZI5+zyqO0g0QOPNO9S1tip5tjuSgvIlOR7cE5y6hkqUQaV/5q8sjbiGrbkD5l\n8qmy+XbB1Ag82aC+KCJ5Z6uU7SlJr6H4UgZHI3805IOFMHFtrDMMVanchWg4X7To5rLRaBs3cWrx\nNIDX5Vxz3fz1jfIo3vkpgLy1kMy9QmWohdfoTnozfZQ0f3/YhFd19PizjLLWLlljtHXmWnnzoYg8\nmfi6OoCD8ZoCyG28pdzbd+xF4xkTv4pZey4ickrRvioP+T9Rs4PQGINUKiLygIjMgezzTmKKruXh\n27dXKSIyv4jcbb6mLVmcTKUtHjTviMhuInJ0zuVOnVzXNWoai1ztTZACjDL7e0PZfyBV1m0SeRWI\np/+cd8gnjA18ehgow2Y01NtnYpbQAjTMNQA2yQjfHG6eSq9DtOkuFOmH9qNw9yi8M+x7lr5J7wX4\nK9x/13fArYMwFojIhSRndkhaZi1Zhz8BeJNtZBE5twEZnsfEevhkXsQKPAC7/TVnA/hwSZwtUX/t\nKghDVyqZf7CIVPXdE6d7GWaXfSAm9HDMCObunLiFiEids1rqMuH8CDMf7vS7isjg3LH4xsWqUURu\nLY/ljI8GvBbmN0laUV4B4G01s10VfqzHYKzYXNcagzJ0pXIyRp1B9pWFLDdQdZ0F0O5Ug1Id170r\ntthO500DYDPK8mEFVXtnuvh10tlbBrmmEmN2sgbvFflARAYxxSMiT3na46A0hIh8KrQMBqtGWkR8\nnM9yBIB3echn7Bn6SEVRlGr0yf16UUdrS9iNcgDMcBH0v7UlsuMwRHtrBokqFUVRkjS5llKVRwHM\nmXdRRK4luUjOtZDetgsx+3wGe+icKhVFUZJ0yT/c+gAmFUUQERsX+UqLqFJRFCXJX1so4xabSKow\n+gk76I5fUZQAkBQAkyXsKaZKz9GRiqIoMQuISPrIaUWphI5UFEVRFG8Mep+KoiiK0i6qVBRFURRv\nqFJRFEVRvKFKRVEURfGGKhVFURTFG6pUFEVRFG+oUlEURVG8oUpFURRF8YYqFUVRFMUbqlQURVEU\nb6hSURRFUbyhSkVRFEXxhioVRVEUxRuqVBRFURRvqFJRFEVRvKFKRVEURfGGKhVFURTFG6pUFEVR\nFG+oUlEURVG8oUpFURRF8YYqFUVRFMUbqlQURVEUb6hSURRFUbyhSkVRFEXxhioVRVEUxRuqVBRF\nURRvqFJRFEVRvKFKRVEURfGGKhVFURTFG6pUFEVRFG+oUlEURVG8oUpFURRF8YYqFUVRFMUbqlQU\nRVEUb6hSURRFUbyhSkVRFEXxhioVRVEUxRv/D1l9FqIv/qfbAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Now that we have the appropriate signal,\n",
"# we proceed to implement fastICA on the source signal 'x'\n",
"\n",
"# Creating random weight vector\n",
"w1 = RNDN(dim, 1)\n",
"w1 = w1 / LA.norm(w1)\n",
"\n",
"w0 = RNDN(dim, 1)\n",
"w0 = w0 / LA.norm(w0)\n",
"\n",
"\n",
"# Running the fixed-point algorithm, with gradient descent\n",
"epsilon = 0.01 # Determines the extent of convergence\n",
"alpha = 1 # Step-size for gradient-descent\n",
"\n",
"while (abs(abs(np.dot(np.transpose(w0), w1)) - 1) > epsilon):\n",
" w0 = w1\n",
" w1 = np.dot(xn, np.transpose(g(np.dot(np.transpose(w1), xn)))) / \\\n",
" n - alpha * \\\n",
" np.transpose(np.mean(np.dot(dg(np.transpose(w1)), xn), axis=1)) * w1\n",
" w1 = w1 / LA.norm(w1)\n",
"\n",
"w2 = RNDN(dim, 1)\n",
"w2 = w2 / LA.norm(w2)\n",
"\n",
"w0 = RNDN(dim, 1)\n",
"w0 = w0 / LA.norm(w0)\n",
"\n",
"while (abs(abs(np.dot(np.transpose(w0), w2)) - 1) > 0.01):\n",
" w0 = w2\n",
" w2 = np.dot(xn, np.transpose(g(np.dot(np.transpose(w2), xn)))) / \\\n",
" n - alpha * \\\n",
" np.transpose(np.mean(np.dot(dg(np.transpose(w2)), xn), axis=1)) * w2\n",
" w2 = w2 - np.dot(np.transpose(w2), w1) * w1\n",
" w2 = w2 / LA.norm(w2)\n",
"\n",
"# Forming the source signal matrix\n",
"w = np.transpose([np.transpose(w1), np.transpose(w2)])\n",
"s = np.dot(w, x)\n",
"\n",
"# Plot the separated sources.\n",
"time = np.arange(0, n, 1)\n",
"time = time / samplingRate\n",
"time = time * 1000 # convert to milliseconds\n",
"\n",
"plt.figure()\n",
"plt.subplot(2, 2, 1).set_axis_off()\n",
"plt.plot(time, s[0][0], color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Generated signal 1\")\n",
"\n",
"plt.subplot(2, 2, 2).set_axis_off()\n",
"plt.plot(time, s[1][0], color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Generated signal 2\")\n",
"\n",
"# Plot the actual sources for comparison.\n",
"samplingRate, orig1 = wavfile.read('fastICA/source1.wav')\n",
"orig1 = orig1 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"plt.subplot(2,2, 3).set_axis_off()\n",
"plt.plot(time, orig1, color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Original signal 1\")\n",
"\n",
"samplingRate, orig2 = wavfile.read('fastICA/source2.wav')\n",
"orig2 = orig2 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"plt.subplot(2, 2, 4).set_axis_off()\n",
"plt.plot(time, orig2, color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Original signal 2\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"But a good way to represent the audio files is through a spectrogram (short time fourier transform), google this if you dont know what this means. So we plot the spectrograms of our separation."
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsvX+cXUV9//8c3K0usqssmJVuIItuhLRNlIhBGylR6UPy\n9RtRbAWl9UfFKlW0oqW1aIEi1fJBQLFSFCvqBxWroKRtrMQSi6nyw8Qm1o1mlU2TNQbDRnfRVffC\nfP6Yed95z+w599692bt7N8zr8Ti7c8+ZmTNnfr5/zXuMtZaMjIyMjIyZ4rD5LkBGRkZGxsJEXkAy\nMjIyMppCXkAyMjIyMppCXkAyMjIyMppCXkAyMjIyMppCXkAyMjIyMppCXkAyMuYRxpinGWO2GmN+\nZox583yXJyNjJsgLSEYpjDHPNcZsNsb81Biz3xhzlzHmmS1+5/3GmOe38h1thouA/7DWPsFa+6Gi\nCMaY/98Yc7cx5iFjzE+MMZ8yxvQ3+gJjzJ3GmD+ZrQI3kp8x5gZjzA5jzMPGmFfN1rsz2gt5Acko\nhDGmG1gPfAA4EugHLgN+Nc/lekw759cElgD/U/bQGPMHwM3A1cBRwG8Dvwa+box5wpyUsDl8Gzgf\n+NZ8FySjhbDW5itf0y7gmcBYjeevBr4OXAf8FPgu8Hz1vAe4EfgRsBu4HDDq+et9mnHgO8AzgE8C\nDwM/9/ffgZtgHwH+BNgFbPLpX+zTjQH/AZyo8l4JbAF+BnwO+Czwt/7Zab48FwF7gU8AT8Qtlg8A\nD/pwv8rvTl/+zcAE8CWgF/i//h13A8fVqKu0rCf4+18FKsCk/97BgrQjwNuTewbYDlzqf18CfEo9\nlzo7DHiPf8cv/Ds+6OM8AlwA/MB/95Uq/Yzzq/HtdwGvmu/+nK/WXPNegHy15wV0Az8BbgLOAJ6Y\nPH81MAW8BXgM8HK/kDzRP78N+DDwOOBo4JvA6/2zP/ST+Er/+ynAsT58P/A89R6ZvG4CuoDHAkuB\nh4Dn+3f/BbAT6AA6/aT7Zv/spTiuSS8gU8Df+biP9YvBS3348cAtwG2qDHcC3wcGfL38D7ADeJ6f\nVD8BfKykHp9WVlaV95+UpD0Bt6AuKXh2KbDZhy8BPpnU2cPAYWXv8HX6VeAJwGLgexKnmfxq9KO8\ngBzCVxZhZRTCWjsBPBc30XwEeMAY8yVjzJNUtH3W2g9aax+21n4ONwm9yBizCFgLvM1a+0tr7X7g\nWuAcn+51OIp3i3/XD621u1W+Ji0OcIm1dtJa+yvgbOBfrLX/Ya19GLgKt1D9LvBs4DHW2g/5ct0G\n3JPk97DPb8pa+ytr7Zi19jYf/jnwXuD3kjQft9aO+HrZAPzAWnuntfYR4J+Bk0qq8uUFZe3yZa2H\no/3/vQXP9qrnzeJ91tqfWWv34NrnFQeZX8ajDB3zXYCM9oW19ns40RHGmKfhZPHXAuf6KKNJkl3A\nb+Io1k5grzEG3IJggP/18Y7FiU5mgj0q/Jv+XVJOa4zZg9PTPFJQrt3J759Ya6fkhzGmC/ddL8SJ\nswxwhDHGWGvF2+g+lX6y4PcRJeUuKutuX9Z62O//H6PzUPf2c3DQdSptl5HRMDIHktEQrLXfx4mR\nfkfdTifB4wg6j18CR1lre621R1prn2itXeHj7QaeWvaqBu7/CLdIaRyLWzj24kQy6bNa73g7Tiz2\nLGvtEwncR8oJNYOysu4piBvBL+B7cCK/KoxblV8GbPS3fg4crqIck2ZV8gpdL9J2B5NfxqMMeQHJ\nKIQx5gRjzIViLmqMORYn4viGirbIGHOBMabDGPOHwInAv1lrfwx8BbjGGNNtHJ5ijJGJ+UbgHcaY\nlT7vp/r8wVH2T0mLk/z+HE5U9jz/7nfgFqz/8uWrGGPeZIx5jDHmTGBVnc/txiuyjTG9OP3CbKGs\nrN+ok07wF8C7jDHnGGMea4x5MvAxX+ZrfZxvA79njDnWW2b9VZJHUZ0C/IUx5om+7t+KMzY4mPyq\nMMZ0GmMeh2u73/Bln40FOaONkBeQjDJMAKcAdxtjJnCT8zacZZTgbhzlvh9npfQya+0B/+xVwG/g\nLK3GcHqCJwNYaz8PXAF82hgzjlO49/p07wXebYwZM8Zc6O9FFK/nhv4I+BBO0f8iYJ21tuJFU2cB\n5wEHgFfirKpqmR9fi6O49/vv/LfkedMUd62yNpK31y39MXChL993cMr+1VLX1tqNOMX/NuBe3Pdq\nfAD4Q2PMg8aYa9X9L+HMbLf4NP90kPlpfAVnqfUc4AYfPrXWt2YsPJgg4m3RC4w5AzdAD8NZqvx9\n8vw0XEf+ob91q7X2PS0tVMZBwxjzauB11tpU2dx2MMZ8E7jeWvuJ+S5Lu8AY8wjObPiHdSNnZJSg\npUp0Y8xhOMrrBTj56r3GmC9Za3ckUf/TWvviVpYl49EDLyr7Ho5i/yNgOfDleS1URsYhiFZbYa0C\ndlprdwEYYz4LnImzodfIstGM2cQJON3D4TjO9mXW2n21kzzqkBXhGQeNVutA+olNKMXUMsVzjDHf\nNsb8qzHmt1pcpoxZgLX2E+0qvrLWftRa+2RrbY+19hnW2sx9JLDWPiaLrzIOFu2wD+RbODcQvzDG\nrAW+iNu9m5GRkZHRxmj1AjKKsy8XLCbZ5GWtfUiFNxhjPmyM6bXWjul4xpjMcmdkZGQ0AWttS9QE\nrV5A7gUGjTFLcBu8ziFxl2CM6RP5tDFmFc4ybGxaTkBt83xnBfoN+088x/ypv9dJWK8GgWEfXoSz\nLIUjfv4GHnqj9wjxqetxfuUEsn3gHpzZPTg/cg7X2h/w52fd4H7cptP24vzMSRkmw3v/4HwX/Pw4\ncI2/3wW80Yev8eXD5+fCL7M9fMGM+PtfxdklCCpMx2nVb3QunGTP2RSwzIe3E7qAzuM0gvePKfWs\no+Rdc40u9+8DF8Fbz8P5ZdyMq2t5LvU/GeJzbrj/iqXwGamTzcA6H95E6fdecZH7f/EQcKu/2UNo\n30lCP+nF+VCUfMQArAtnYQzOubH+Jkm7DM5b44I3Xq2+axLXHvhy6eE7iLOU/hRuvyc4S+zlPpx6\nc9HvlX2OqWqyndCBvfFdAJjzPksY15OA7E/dRrAGv4Vn2PcB8O0/ezZcf72/XyGMi1W4MQBunMn4\nneJp1vWH75sVOEfI4OpTj03pV5Ph/pHnu2gAlStUnAsJ7d2vyt8LH7jABd96HXFf0u2rx91yFefl\nPvx3Kv46nGW84FJahZYuINbah/0hOV8hmPEOGWPe4B7bjwB/YIw5HzcyJnF+jprAagCeYwYIE/9m\ngseJMcLndlZTPXTa0XDflf7XRYCExUEqPp00bG81/OefvKHEmcQYoePoKl4Nn79FxVmkwpMqnl4/\nXaf+gukjqI8eS+hQvSp+l8pnu7q/nTA5TeEmG7kvdaE76NdUuIv2WDQ0/CT61ivh+MXw1FNg49dw\nCyW47+pS8X35X9EHd/S58GduJPSTDtyWFgijX9Bdvf+xv3YeXF538Tnq+WQSX+qqh3giv8SHr8D1\nS3ATt3go6SC01xDcKG0kznol3KXCGhM4L+9X4vZzpt+iJ8hu9WyKsHDoBbNdiIUAc97HfWgNzkZC\nsMX/7yLUTyff7nm2C05cAVzs719JDFmQdxEWny6+/0q/KH0POEEvFLoOdf0sdf8ObFDl6Vfxxdcn\nxF5wxuGtN/rwBYTFSr4HpvfJcXX/H9W7JN908WkdWv4Wr8A8Ibl3gwr/A/APrS5HRkZGRsbsouUb\nCWcLTgdyaf2I3ZfAhFAAmykWJWnqarmKczaBQiljHzsIlMqACstRETBdBCRUfj/O0zg4NlNEKJrC\nEK8aUmahQsYBTz2zRYU115FCOJzFBKpIvgFi8Us7iqrKIJzYGG6z+zNwIgGh4LuJfQ8KNb+SIHrq\np0o1VttB0kqddKk426hyOB3nQkX6iabsNeXXRRAV7sPVNTjuSItBNKScw8SiMPmuCWKRY0r//RC3\n2Vv62zChf2quWLc1xKIYHW4n9BM4zC5gyIf3EdebYCdBhNhHENN9mlBvkxT3837cCQbgREES/wHc\n2IaYwwfXt8CNMwkPEdejbnfdT+S7RghtN05A2VhcSZhPUql/rwq/ZcHqQOYQp7t/E+KVAVzjyMBd\nThAdyHlD4DrC63x4H3Ejv9SHb0OLMkKDjhIWig7iwaf0HtWJYh/ukDZwDSxyym4Qrx32CmKZd6+K\nL3LTflUG3UFTEYQsMuPEE48ecGWdU947ruLUWqzmCh2EwbUSN0i3E0+KywiL8riKv5nQH5ap+Ctx\nnjbw92QimiRMVFCtk4qWVUPc7n0qPOIfnw+Tm/z9bhX/5QRRTId676DKZzOF4rjovfKtx/l021Uc\nEdEEvd90SFuPMr0/pe+cL3SrsK6TTsIiv4t4l4Bux9U+rPVjWlegp8JJ3EIDrp/sVM8G/P+vEbeL\n9JNXwjJfnqEtId+jL4b9WjzVqf73q/A2H06JVvmtCZydBP3P3SrOIGFhaS2yL6yMjIyMjKawwEVY\nmvITCkIrrlJlYaXgvrbOQuXTR6DeNMupKYNBAlWnlfQ96r7OXw7MS8vTS6CwtOhFUx6rKLekKYpf\nC0ViipTKSRV37QJdzpUEr+gTVLlQ1hMbTGgxoFhbbUQbUwSqVLedpjDFR6Pkv0g90+IpEZXsIhYZ\n6XedoeIIJ6y/SyuDNQeooftSqjQt6mPa8qesn7SbEj0tj1Dbe4jLpjkrzTkLFzdFmBN03XYQixF1\newlXoMXaOq0WCXZRbMii81xCbKyguUfdl1KxpsQvkgKUSQS02BPg0paJsDIHkpGRkZHRFA4hHYhQ\ngQ8QK4aFChkjrOKaetlHscK8l2AW10UxBzJG4FK0bHspQd+iOZMuYkpU8honUE5aZ6LfpRWimipN\nuRpBmdlmbxJPl0UrF9tVmao5BG362klsKCBIy69l3poLlTpJ60bvuxDdWgfTDz0UaM6tQ/3Xprii\ntO8jlu2X1XWZ4ryoHdN8hLrVpqPaHLisreeb+0jRQ8ytCQbVbz32dV2NEhsTCHcxRXl9iiTgJuJx\np/fV6HlG0E2sLxVoTkbrSPX7NVcDxf1hivK20/PM3CBzIBkZGRkZTWGBcyCawtNUqabYROZ9IzGF\nLWFtGqmhZcaawtBp9c7jSQIXtDmJQ53wMvVb73CdUnlq6qRCoIqmiKkugZalakqozBIHYrlsagWS\n5j9f0PWmdUK6bNoTgKb+9eYv3Y66bjsL8pI4us8IFhHrFtK+kpYvtY6TvLrVuyYobqey8teyjpN+\nkPbxKXW/KG076EA0xom5Nam3o4h30GvKXtpF6ygg1P82dU9zLF0q/wlCXfUTrK26KOYAJ4n7h3A7\nlxG3geYS9FjVesiiealCsT5Eo4w7nn0s8AWkaIeuHlgdBHGBFh11Ujwp6g7xNQL7P075ANWdZcD/\nH6VYkanjp4rqItY1HdxF4TJFeC2ULQhlivN2mkhSFl5/ixZDdTIdnYRv1HWlF4cB4jrVfaJIPNVD\nLCosWjT0fV1OjXTiKUK6b6FIJJuibIhXGnw+n0hFdkX1M0VMxAk6KRZLdhAWgT6KDVz0t6ftWTTn\n6DTpPFGmXJf4ZWLItByC1Ny4XvzWIouwMjIyMjKawgI34y2CpuxTM0ANERc8kDwTKqQjiVO0wUpD\nUxgVYkVaEcUs8QRLVFib8hahLA/9rOx+Spm3m5K8WaSmkboeisxpGzVhLlKIShoo93Cg45S1RWpu\nKSijJGu1exk0dd4OXMVModtOUCZxSNuCJI3kN6XiC1Iz/yJlvM5Hb8wsi6OhjWyKTHVroVHJgu6r\nujzvyma8GRkZGRnthUNkAUnlpKJIr6hwD0EBVcFRASklIHJToUaO8pfGoiS+fq9AuBGhjlLFvlyy\nMalD3dMUaS35tFxlcSTfIuWpXPpZB8EEsZZqrCjPuYQup/wW+fUEoR16/CV6JDFySN3MLCJuC9ms\nRpJWK3DFQ3FFPUvL063iSJrUvHJl8lvHL0LZs17K20XqpDe5r8vczpD613Wu7+tvKOJSirxJ9xLM\n2fsJroGkDhvRBcq2gDRvPSekek15L9QfR7U4mrJxqvt2j7pah0NkAcnIyMjImGsscCssQVcSLjLZ\n00jl5dp8UjskEwd7qemuQG82hGLLq1R+KWZ9owSKSTt403F7KPYmLPmm8TW0HFd/ly5PasXUiD5k\nvuXoupxanp26j9DfJVRqyt1pSjOl0NO0RVZdkk8ZtPy+TG9WpDNJ21o/L6t/be7dSPnK9ITtZr6t\nTacHfXhYPe8lPlNF1/mkijOm7utNx0U6qDLXIqmeU0PyTMeorsPFPryDuM6L9HK16rxHxSkz6S3q\nz7OPQ2gBKfMhIxWpPZTq3cz6IJYU0jHTEwa1+WeRkj5tfK3wmyq4P0GYqJYT9jfoHer6+8pMDvUE\nkNZHkcmhrgd9vx0PkRLofRTaTbpm3wcJppqpKXSZAlt2GGujih7CpDVE/eGiRYraZFh7he4kJhb0\npKi/q+hd6R6VIn9Zun5GCQRLjypPuti2q98zjV5iD7Op+DUNpybvZYp2ESPeTaiHTsKcIOJviF2s\np3tS9Pygy6wNYuRdmwjtNUD4rrI5JL1fNF/pxTPt861DFmFlZGRkZDSFQ2QB0cpIrWzrwa3WQtGJ\nUk02jnXgqLRT/FXBHQd6IoES7SCcJSDvEmp3ZXJf0KHyKTKbFergdIIHWV/m7rWqnFrpu1zlIaKb\ndBNSSp2KkhgcpSvUbtF36fuaekkVrUXK4LlEhbjeRKHYT2wwIQrLCq4NOnF1IUrTHpwHgGU+zWZ/\nrWK611XhVEQpeZqK06/e1a3e1a3idODO/ng5EddzshwINOJvaKVvn79S5bE2ytB9SdJ2Ulz+viS+\nVhhrQ4R2gnBTfbj6lPaC0J81FzlAMBroIvQN3c9XE7fpan+Jol7EyXq8SBxdt6J418r6dFycEv88\nustdkWJbczVpPro/lBlkSFiLrCZV+QdpJQ6RBSQjIyMjY65xiOhAtA5By6H7iSkxiaMpBaE+JVzk\n3kJT4RsJcuVtKi/NJdxDoHBSKnHAh7cTTlJTfreOACa0Cwbti0mjSH+iFcypvkXfl7T6pDUtQ9Wb\nzlJdSC3XC3OFTf6/PqVxjQoPER97K9CbOocJJ1Fupyr/7u5TKgF9muEAQXk7AHzZhycJylG94VSf\njjcGyzzVObQovGsAuE+3o7yrS31LSlkWbazTbjt0/9ebInX/T3UeZS4z5lsPViF81z7i8gyosLRL\nB/GJhNL2W1Ra7ZYo1S0Ita51IFrnsIig09CeuCvqvamPO3XC6U/l/jixXztt1KK5E+3DTSvvtQGE\n3E+5xxHmApkDycjIyMhoCofIArKZQOmLRYroQLYQKJCl/tLyTqHghTo7y19K9ti1lCDbXqXeVVHh\ndTjKV6x/VvorlVmPUqUuz+9yl7aqOBf1LggbHmttGtL39Ldo6kZkyTrt7xPrSSS+Nn1O5bq6bPMF\nVYdV6M2b4l1XdAJ6M5qWHxds9jwZYpmztKOWo4+qNGNJngKx8vKUqu4aor/6KTjOaY2/L+9cpfIR\nE2C5inRfk8RtLX0m7R8iyyepC8m7bPPdfAoq9FjWHKF8464kjug8xwjtq/UAy4m/VyAWU7t8Gq1n\nG/CXtmxcSTwWtF7Ft9E6iDa3XuCvqE92Ay/1l97IXFQHRRuH5Vt6ieels9TVOhwiIqxVhEm4zHx1\ngiCymSJ0xNScU+Io07/3AG+XSVYfSAPBPFiLF7SopId4wlLvulcCoSMv+z9bGbpKN4ukXUpgn1NT\nRJ2/sLeLVBztklpn3QuT2nRRUGT2WvZ7riEKTIGUfyfFHo1TgwDN/he40b4TgihyC7EIS4sytals\nkddXbfo9STgMSU30G9MDhCS8hmDKPVESZ5zQFloxu49YZDqp7muRpYjGkj5ZetjYfEMU2xC7b9cY\noXjh03U1Fsd5m/9/jRYHjRPEkh3qvVpkKostxB6i5ZlkF/rfkqtduXddo8eQGDhIXO3RQKDnKNnR\nLuEiEZY2PW4tDhEOJCMjIyNjrjHf5OQsYYjYi67gQeKNZrJyVwgretkRr2rVf6++v4xAyaWb8MTE\nUPvZ0jtipwjiojGl5wqU8dAHTwK+pb5FKOZqZGIFv95cpqmiCYKH3x3EVLvH5E5Vnl0UUz8p9Tk3\nG5TKoXd1i7ksxO0rYgyIDwYbJRZnSDv2EtprC0HMo5Wvt6rwNuA8H76SWGwpnIPmVIdUGc4APufD\nI7DWm39vENNscMeoFu22FxN0iLmpVIkuWIU71wZcfcjhal9W+Qwwfbc1xIr2+VSo6/M0ZIwvInB3\nSwhKdDGzBVd/J/qw9jYxGcf5lLxHiyEHmD7ewPUdLTrVim2p/5VUuc3Nki/AFLs+KeW5I3mXGPFo\n0WGFMDZT82v59mXEB1wJyjYbzj4yB5KRkZGR0RQWOAeiXU4IBaA35mhFojZx1VTsSgKFMUHQaSju\nYv9OlXY9sdJZ8CCxfF3i9BFvFFOyyp8yHY+DQFXvUOXsIP5e+c6pJI6Us5+YiiyiII8i5qIkrZaf\n6vfKpryy/OYCFWKKU5/tUGYaqbu5fNuoiq+PEd5GzJloTka7ybhJhfWmLi13F460AuxRcQRD8OOV\n6r5WgmudW5kpt0CUvuD6ZxE6odt7Gp64TZVjJIkn8vjUu/R8uDvR+r0KYWzqTY+a0tYb6lJDiyIX\nP12wX5tOy7u2E+qhQhhrYjwBbowOqvi6XX1d/RIibqfqwmuA0MdGiE2SBd2qrNqUW5sMi4dxfFmE\nk9H+vlqLBb6ASOWNEsQ1elLR7H8H8ZGz0gibKT6qVLHtRy+F/aK46yM0qD6Te5IwSeiyaZGPtriq\nqDlYLSpfh+BCvuwQGt1BinxZQTx49CKgxRFavKYVb3pQ6j0hEm++oUUZ2teQFvtoIwlpX71zWTuY\n1Hb2WvT0AEEMsoLQBhPEIlOpEy1KhTA5d6v3nk5QqI/Abl12IRy02E2LW1NPA/JdUygTL+JJRfro\nJExIu+oy64VrkmLRx3xZ3ek9D1rUrEVG2lCgl/C93UlaCT9IcZ/X59AvIbSRPINYAT9BPMYk7dco\nRYcO6LJJProPaKQidmkjPbeMEn/XSHk5ZhFZhJWRkZGR0RTagZycBXQRK62Ldp1qxVKqRNcimgJu\nZD+EFb3Mt4ymYCoEdlKLILRHVF0GRUn8FJxnUIjFUNqULz2yUvtJ0v5yOlT8YaZjlJiqLfI4nKId\nTDoFmvvqpPiYYq0gHyWm8KTe1e5wJmDZ2S44dCVwuL8/lLxPlOhXq3xWEijQtP47wu1qc3fCf//K\nBfuhmDOEYo/Dug90EqhY3S92UOyNQLfvRPKuIozXed5KaJGgVvDrehDo70jHSBEqanO+bq+jCEc5\nQKjD1Nxf14vm+vxYs+NxnOoQ1JIL2b+R5qNF02n7CEfYr8q0LcljhLlA5kAyMjIyMprCIcKBpJtr\n9P1K8htiGSTEimGttBPcTVjpt+O8sUJM3Y0kZdI6B22KqMv34PQyD+nyPECQx6ccRNl3aYWuppCK\n5Ojpbu40vzQ+tIcvLK3XEqRUmpT7cHVPU/a6LZYS6qcThjRnuFPF0ZzqRh/WlG5KDRfop5LNZZzx\nWFU2abvO5F1Fh43V4hok3khyX7hibVhQ5C26HaHPV4Hicqb3tB+8EkyI7khz4w8S6xxlnKTjV0NY\nmRF1T5/TgjIZXqTyL/IwUQTdHySOPuMoTZfNeDMyMjIy2hiHCAcCxVRG2Sa4lJLTv4tW7hEVniKs\n/JXkvobIrTUlk5axwCXD8D6VlzZPTpuqSBehzVeniDmrIi5IW42V5dkOHEcKLb/XKKLeUsu4oj6w\nU/2uEFs0SfxfFKRJy6PTpe8Q3BT/3D7iA7qtddpaQ1RvmhPo+KkH20aG+3ybaaeQcjRiCZbqaop0\ng5r7qhD0jfr+aPK+ojlBW/FBcX2lFlm3+v96HkjnAF02jXrtoTcX6/HeWhxCC0gR0h20RbbsjTRU\nmUghTVfLjBamT3C/YDp03tqsr5EBrb+3TPRUSwxS5O57ph15PlE0oZaJtjTSfqFNOCX+riSOTDB6\nQW5EHJHek0WnzBy7Vn3P1G+V/oayeEVlboc2r3V4mkDXYQflfb5sTpD72oxax9F1k07QRfWWLjxF\ncdI5qqyuixaWWuN9bkSRWYSVkZGRkdEUWr6AGGPOMMbsMMZ83xjzlzXiPcsYM2WMmUX/w+mqrDdQ\nzQQjTN/dnK7w4vFTb9Aq2hmtIS6g9S5WvZN4itivVj0UcQuVJKy/Xx9nWqucCwWpzyDZmT/Tdpd8\nOihPK3HSg53qvWuxCotfo3H1WxtC1MNCb6+ZoJHv1PVfobh+0j6fmNpW72lIW+sd4dJOtdpqknCE\nMjhDmGFiv3QFPuqq+WsUfUut+a3s+2cXLV1AjDGHAR8CXgj8NvAKY8yJJfHeB/x7K8uTkZGRkTF7\naDUHsgrYaa3dZa2dAj4LnFkQ7wLg8zROajcJOdxlplxIPWpU4ugVXyibWu+S+EXmh/qsgdlQZGvK\nrKgMUMxZLVTId6mDwUqRtlHRoUppvUhdFcnXa71Ly8XL2mK2Nu41ong+lDiYSWZ+4JnUeTcx11qE\n1MihHrdZIR6/Ev8oFadM2b0w2qXVC0g/ytsPziQm4tmMMb8JvMRaez1gWlyejIyMjIxZQjtYYV0L\naN1IjUXkThUeAI5v8pUzoUbrxRek7j8aSVNmRVNmytcKzOW75hJllm+NoMhFxWyhFjc5223RDsN7\nrlGvvYu4cEk303qfjfiz6eVYtg58i7lyZdLqHjYKHKd+L2b69ueTgc8aYwxwNLDWGDNlrb19enbP\na/C19UzeaqXTStiZdJDUnLPIBj2F3NdpJwmehVvhQjvdTVt0gNBCRbMT8Ez3SkAwedYLwkz2WQj0\nTvnZXqxS8/NDBemY0t9YZMqdxmm2TtIx0uz0OZt7q/S3SL7HExPXNTwEz9LbW4V7gUFjzBJgL3AO\n8AodwVr7FAkbYz4OrC9ePDIyMjIy2gktXUCstQ8bY94MfAWnb/mYtXbIGPMG99h+JE0yuyUoo1TK\nDshJqZPwNcwHAAAgAElEQVRGKBuB9p6poSnORikeUbKl3nJnA41srFuoKBIhai/GZUh9fxX5Q0sx\nURCnEXFZurlMi8tmm1tIv7sdvQo0izLTc33EsUY9iYA+pK2s/vUZI43kCcXzTLpr/GBQtClyptKT\n5tFyIam19svACcm9G0ri/kmry5ORkZGRMTs4RLVsmjJI70FtM79GqIpG3w/x+SQpylxg6HNLWo1D\nlSoVLqIRk9hUZ9Xse5tBLbPeg8XcUaJzi3RDrKCWCW5RWl03iefcafmS5F3mKiVFWXla0S71pCSz\nj+zKJCMjIyOjKRyiHIjehFd0v0wmXss5WVEcjbKzwxsxGU7TadcWs0WplOVzqFhhpV1ZZOGNeCVN\nudMiy6oitxGCg6lDzfkIZ9wqCnI2uOt2QFn5+yg/46YsbZErkjTvonbpZOYmw9p9Sisw95uAD5EF\nJG2oeoey6HCjezc0u9rI4qDdYs/ERXMFNxAg+Mo6WHRRn91eqJNKvbZIxR31vjEVOdYTP0LhMch1\nTbfTfBr1f1UPjRBBtY4sbjeUjdMicU268JeNLw1JU6tO6k2Tjb5LfvepewdLuM292Eoji7AyMjIy\nMprCIcKB1BIvFCnPZ/rZHQRPnA8UvA/iDXp6U48WTTRK9Uk+s2XuV0tRXo9abWeUKb8rlJtbNpu/\nTq8pYIjbvdl67CWIXxrlBov6eSObZxfSsJ+J2E0fCjVTdFO+ibioDOmxwGX1XDZXzLSflM0Dep6Z\n+zGcOZCMjIyMjKZwiC4gQgmmcmXxkKs9tJZ5Yk3zawTaE2hFXTP1cttL4HhmQtVqj8H6GyqUeymt\nd6ZBO6OezkqoM6nPRmTcOk5fEk+3RY+/Ug+89bw2l93XPkZnSklKPy7qy0VYKO1dS3dV9L0ThHZp\ntE6K5oqyd5XVWzOmujP1sl02Xx0M13vwOEQXkIyMjIyMVmMhCUMLUM+6Rssp9UrdqCWVhtaflFlc\nFFlE1JJNlllQ9KjnM7WuKNNpzK+sdPZQSy9R1h+0pdNM6rOWQz7ZADhTL8xlz/XZMY22Tz3dTtm3\nLhST7U7KTaTrOT0ta+syqn+C8vEo+c9UMlFWhn3EOtWZoJZlXaPlmj0s8AVEJtopyn1bFaFbPUt3\noNZjK1NluUDv30jLUG9iSDvag6qcM5nwmuk4zXofni9oBWS696as/Iv8/wmKzZlr9ROpn9S8t2zP\nRiNtLdBpDyf055mabheJNqBcuduIWXeK+fDqO0V98VBqmt8IsVC2E70MEr+R/WMp9J40iTPGzA69\nqlWu+R2zWYSVkZGRkdEUFjgHIihjyVMqRD53MfALHy6jctLzPYTlTL2p1lK+6XdKuBGKUNjamYqv\nGqFIyjayLZSu0Emx19GysG7HMs+8tcy+i541UlfNiB+1mLGoPCma5Qrk6NeZpJ0vSrfsG4vETRUC\nF9cI96jv6XGcbgxthFsoE3+VcXpiNDHM7HB3eSNhRkZGRsYCwgJfQIoOrNfhXorNVIdwXMhiYjPM\nSkn8ik8zRDAR1HJ4TcUXmdmVYZI4vUBcmCxJ7tczES0zXYRyM15Bb41n7QSto9LtVcFRneIDS+ph\nEmeO24c7BlnQlYR1u+u0+r1yP61nHS4zIRdMUtyODxL3w3rmmR0NxCnT58m3zQ/VOjNIv9V11a0u\nfb+LMHbOJcwPur261H2ddgJY4S/JS/qV1FUqTRD0UGyWq+eWVFKx3F+oOGXju+y9GvNjmr3AF5CM\njIyMjPnCQhF8l6DsBC5tYVWm39jYQJ4aQr2n1hoSL7UI0s/ryTZTGa3kmXoWrZdPrXfVozZnw2nj\nXKBWHZRZVsm3b1L3NLWY6tAqJc9SirUofj2LHV0ene4o6nuS1WhEXl4rzvw64WsMFYr1FWU6nEnC\nd/1dSZ61xulQEg/KLdZ0uJGxk24p2FIQp6y9yt5b1MfnFocIByIsbtHOVH1f2OFxYNBftcRBGsKi\npmKxeiILLWYpYk2LRCKCAYpFamVIy1wmZinCQIPvmG/ouuggFh0U1VUXzvBB297D9Em/3q7lRkRG\nGrXquqicMz3Yq9EdyWVi1YUiwtJiSQ3xKpFCvuu05H6RWDA1VtAeIHR+Re2VitSKxloaR79fdsw3\nQ8MX5Z9FWBkZGRkZCwgLXIRVD2Wf1wmMlDxrZDdq0e7RWrt7G9m0VcSaNnJoTS00sllOMBPxyXyi\nl9g8U6NIlDBFaNOyXb+1xH5C/er21SaijYgdivKFWOQ4U9PaIm6z6NlC2BxaC2UHPpWNbbm/WYVT\nrqMZs+eiMujn9eo8vTdecr8RFKXJIqyMjIyMjAWEBc6BCHWyEri7JE6RzFO7w0ip1lqmjxDLLQ+W\nsikqm6auHiTIZBtR1DVTBm0E0M4oK2fRZjAdZxC3WUvyaMTQQSvCi/pDLW5zJvUvcnco54jLUGY4\nUgtF3FQ7Q8xuYfrGTL2pU7uVGfDhEepzAkV6Tslztrk43Y+0TqVsc2uK2dhsOPvIHEhGRkZGRlNY\n4ByIrOojFK/MXcTUllAwPZRvqis7y1zuD5e8q4wy0BRSo9SDPgtkJua16ffO5F0TtDcXInWoXcnU\n0gMIVhJ0H2UO81Kng/KumVpGpe5vGtGPCCU6huOWIHBMtdBLuU6njFqtx621G2RjINR2Wqm/a5kK\nF9VjWbtoTqDRcVrPjRElz/uJTx1tBM062mwtFvgCIiir1DK36qtxSrZ6aXSjy2QyUy+ajcYvmsBq\neQgtQh8zX0AkfjtPJBq1DAvKBrH0jzJxQZqfiHpmOlj1glPmCbcMHczMkKFWe2nxTlEfTsPtirI9\nG1D+jQP+f9n4LsuvzCdeo/u4ZoJJpvvUq4f2PAQsi7AyMjIyMppCKQdijLmwgfQ/t9beMIvlmSHK\nDpsRpGIoCQ8zc7NV8Z65a4bpmqHs5btmWsaZUjULCY2YQhd15y3qfhlHl1KZ9Ux0y9DIzuBa76ol\nBj3Y8szkWbugETP2HmJOcYP/P1PusUz824g5di0Utd0U9cXatbjH9kEtDuQvgCOIPZel19tbXcCM\njIyMjPZELR3Ip6y1f1srsTHm8bNcnhmiEXm/Vj7Jiv6LkrgaKQUwU85jJkjfNdJAmiIlaKMU0fz7\n0Jk5ymTeGkUc6WiN+GVopZlrqhsRrmim54c0U8aFwHVoNFIfqW6gEb1hEVcw06NlG0URpzFG/bZI\n+0mryndwKOVArLUX1UvcSJyMjIyMjEMTdZXoxpiHjTHvM8YYda/IlWSboshP/44m8qnnjPBg0Mz5\nyEXf1QyF2crvagXqyaSLNhq20zcWtZk4NyzDTJw4PtqQ6joeoF2p9ZmhGZ3HTByvzg4ascL6Hx/v\nK8YY2TRgasRvMzQ7+NJJvZWDeD4VZIfS5DTBdNGOPtSnHdAu5Xg0o97harOJ2SL0mn1Xa9HIAlLx\noqobgbuMMc8EbGuLlZGRkZHR7miErzcA1tpbjDH/A3waOK6lpZpVNLsiz6dyuZVU6qFMAbfC3LUV\naLaczfg6y5iOhWI40v5oZAE5TwLW2u8YY04FzmxdkTIyMjIyFgJqbSQ8S4WXJI8favQFxpgzgGtx\n4rKPWWv/Pnn+YuBy4BEcu/A2a22ZH4ImsBAottk6E+DRjoVSJ82Wc6F831ziUOUmFsacUIsDWZeE\n16vfFri1XubGmMOADwEvAH4E3GuM+ZK1VptBbbTW3u7jLwc+R+wRLSMjIyOjDVG6gFhrXythY8xW\n/XsGWAXstNbu8vl8Fif+qi4g1lq9q+8IHCeSkZGRcQjg0OYaG3Wm2KzVVT+wW/3eQ3AqVYUx5iXG\nmCEcl/MnTb4rIyMjI2MO0RbeeK21X7TWLgNeArxnvsuTkZGRkVEftZTo6wmcx1OMMbfr59baFzeQ\n/yixye9iariYtdZ+3RjzFGNMr7W2wJ3mnSo8ABzfQBEyMjIyHk24n5kfkdwcainRr1Lh9zeZ/73A\noLfi2gucA7xCRzDGPNVa+wMfXgn8RvHiAfC8JouRkZGR8WjB8cTE9dda9qZaSvSDfqu19mFjzJuB\nrxDMeIeMMW9wj+1HgJcZY14F/Bpnk/fyg31vRkZGRkbrYawt1o8bYz5irf3TmokbiDNbMMZYuHQu\nXpWRkZFxCOFSrLUt8V9YS4T1EmPML2s8N2SZUkZGxoJAs+5jMmqh1gLyFw2kv2u2CrJwkTtmRkb7\nI4/PVqCWDuQTc1mQjIyMjIyFhbbYBzK7aObgoC7m4zCWjNlEM+3e7EFT7XI41aMVM63/gxnfua1r\n4RBcQDIyMjIy5gKNHGm7fC4KMnuoMHNqo+go1IxDGx00fzJdO8vTM8U8HZPMx2l9rcf8S0wa6W0f\nNsY8FrgJuNla+7PWFqlZyKd0Ur4YlCm8u/3/ZhaRdp1MZIIEN3DatZzNoKgd5/IQqXY82OnRsHAc\nzEFczaLV7azL1ui7JM0k823EU5cDsdaeCpwLHAt8yxjzaWPM77e8ZBkZGRkZbY2GdCDW2p3Au4C/\nBE4DPmiM2aEPnZp/VPw1BSzxV1mcFBP+6m3iva1WzjWbfw9BNNdu1PLBoqwdZ4J2ptib6YfNiuMW\nCoTrqxAkBo2kkXTtaiTTTJtJW5/I7IyF5tGIDmSFMeYaYAh4PrDOe859PnBNi8uXkZGRkdGmaIQM\nuw64Efhra21VSWCt/ZEx5l0tK9mMIdTFFDCm7tXTa6RUifyulU7HkXiNyMV1efR7J2qkWe3/byQc\npTJJ+MYyrCI4UWtUB9LIt7cTTiTUwxj1v7EDx5kBjBOov5nKnmdK8el2r9VPioZjl7o/UaMMYuty\nDzOTq3ersrUzpzoIDPtwF6GstfqqjJcHVPxe6o+dLoLCvUJj7a7jNKKP1WUUB+UiNYDaY1Y4sMMb\nLFvr0MgC8iJg0lr7MFSPqX2ctfYX1tpPtbR0GRkZGRlti0Z0IBuJyeXD/b02w0X+glgfolG0cewi\nFRaKYbJGfIDT/QWxbLXexrR+HPXQ7cOie6mRZtlqd9GryjZOXZnuulMIpoudSdnKytlLkL+3q8wY\nqmVbfjbuXBi5GmiL7gvcxXkqfgehXVJIPi+luE4W1Shnv7+WqXy6qNtPzAU4DnIVQYcllG2RzLsD\nute6C1QcSVPrfV0EmXo764W0urWX4rZIv3WNvzpwnPxq3Ngpiy/Qh6YuorG67PFXB3CKvyaJ+1VR\n2gGCzlb3vx7KcZa/9hHarpv5GLONLCCPs9Y+JD98+PDWFak5PNfewXPtHcDLoesid7GC8onBYYnd\ngeski4BXq/g1BtPgSnfRgRMdLMd1MJkwyhrxXEIjL1b3dfz4vUu+u4Ml390BrFOXLI7ldu1P+PyP\ngZX+gngQlE0YL/dXL/FiUg9zPfH4sl0FXLHWXYxQv/67WDK+gyXjO4A+3GQiE4os5iU4fQVuIVhG\nXC81TMafc5676CfUfy1xpcPOR44Fs9ZdVfFXLWOICvYag73GEESeAulvJWkHz69bnumYB+Li/E7c\n+DkXzjubMBnrsd1JtMCeOuAuBuDY1e4C4jopWpCFYOsFlqp39dUooIy1QXWR5F/wrj9eDZztr9cQ\n2rqGmG1dn7u6zlNlm1Bpp50a3jI0soD83B/0BIAx5pksHCF5RkZGRkaL0Ajp+OfAPxtjfoRz4f5k\n3HLZVvj67/utKd3AxHp/d0sSS1b/oMjc9ZQTwZzobtubaYRCZFgo/7XABvVAn9ZbpNzaiVPopWWb\nIDYCCDiFu105OQ3YpJ7UVpq95Teu4/KTrnA/tm5PnmoFoYawzR3UOHm4AEL5zRWWuX8vASa3qTKM\n+LBWZGr0s+s439ZsJt5oWaaM9O2yEYISN6UOS9J+Y2P9ONF9JbawV/pAI7RaLze/7mUueN6+5Fkd\nhf2DEKj4B0rippiHHd3PBq7f7MI3bifUix6vSbnExOeFa2H3jepBHYOGkwZgq4ioP0foJ7pu07Sr\n/P8tPk36rmKDnrd/8j28v+IL+pkrKO4n8btecPu/AvDV218EZ04k8dJythZ1FxBr7b3GmBOBE/yt\n71lrDzWfABkZGRkZM0SjzhSfhVMorARe4Y+gbSv82R1X82d3XA0nQ9BjlCksw2r+Oz+8F56Bu1hF\nrFgtwUmd7mIRQe4u+ZZRmAB9cNIl7qrqJgQiv4w3Fj2WX/NYfs0P7e8SK+pq40f8Jk/bso2nbREK\nXW+qqrP56Mhm5OLNerZtBl4h+ibg+BXuYhV15c0s44gd+zlix35cG4tOo0L5RjzfH16rwpGMOaUU\n5eqB7tPdVTUf7lFp0g1xQZ+2yezBKe1filOu1qvbXobNFxg2X8BxYTp+HT9v72ggTsH7mtvseBD4\nJbzbfpd32+8m765hsrzJXUvsLoKOopO6eqEfA8cudRcDxDoo3a90e/s46y4gNrLRz6frjs7mFh75\nkOGRDxmcflP3k+Lv+iiv56O8nqe9eBux3q+BsT3LqDvijTGfAp4KfBt42N+2wCdbWK6MjIyMjDZH\nIyTjycBv2bLD09sEHzbn+dAV0HWxC07ek8SavlHuO8c9C3aLrHqRetZLsNBJVvStYwX39eajMmyH\nrTt9+ChivUeRPB62+w1iTznrRwS9yah6V7HO5t95IW/zjgLezkkEuX0t6sTHOXAHRXXVNjjV/z8G\nuF++azVBB7KrJOEKHnqfhP+dYLG0k3Ldl+cUP15m9VbDCmviZh/uIlDNWn+SvtNZ+bz+WKtk9n2E\n7ynbGNvHpXzXh7cQZOC19Hm+v118BUW6wdpoVFcyi9gEl7/ht/yPQcJOAj2FJeXf4/7t+s0TcW0M\n8VhLv9fntXcEx3mk+UM8ZnVar59ZP0zQh6Di6PkhtOOq27c7LTPgWCbpH7pscTmf8r//C8DLjruF\n71fnqLSccyMNaOQt38Epzve2uCwHCVfxi+3Z7DEycFdSbVggHny+I+zeBh/z7ObrriOIJ8qUyB3A\nHS540tmwVe+ILWOn5f5m3P4DcJPdNhVnsiB+hW8bN2jW2lvZYIQt3qji6J21oaPtMVO8nVeq+EVm\nl+mEdKv/X8tcsQjpt7cYd/kJ8hl9hEE5QvGAU98YSSZXEuqt1kQrz0QEAW5ykUm0bKD3ESaSxQRi\nJPX+o5SmHd444B3Atb6f3D9GIBxkX4GE5V2roNuLPSaXQcUbTziLkpLv6lVx9LfMZHFodMGZBXxm\nI0vsMwHY9aQ+2H+Jf3ClKkNSlk85AxTOOwVulLZ+NUHJnS7Gkn4LYQGZIOz16SQszukO9SEfPl2F\nVxPGuN7vpQiRM2UrAewyYwTR9oOEtki87i5xi+EXGCQQTbKvbG7RyKg/GviuMeYe4Fdy01r74paV\nKiMjIyOj7dHIAnJpqwtx8OhGzGnfwhC/sG6f46VmnEBppYpCoQI2wm+vcMFd58OSW/z9riSupnIc\nxcDWIQJHcTOBGtCUfaLYPdKX5196YbVQG1cSFGepTyd3NP2Gv78AhLC8+G0+DZT7R9qiynMJgSq6\nlXLxlGaxNSfWbmIsz2H+y4VI/bD5Ilit/WIJVNknb4brzvU/tsDxPnz/KKF+UtGEl4NEfreOIhZJ\nSV1p88lhFWcHnO65x42vAz7m78umTtw75bWXAz/14cFeGNacZ5Hfqn1KXHY6VTNnAMSEW/dnPRZ0\nuJtyEc18Qfr2Nnb9h6uHo/aN8uBjpK9qQ4S0n3opwqnA8ae48MUbCJS6rn+ddp8aUusA2RYwSqif\n1M+VDz9nBRzt55P1YyrOUEH5ADay6z99+3adCJObVHwtMtVtIebk2wjK+mHmo+0aMeP9mjFmCbDU\nWrvRGHM48JjWFy0jIyMjo53RiBXW64E/xZFTT8WRW/8IvKC1RZsJggnmRR/8IFQVpVPA36l4mvLu\nDGk/4IOf+TpucyDA9RSv4oqS61gGFdGxaJn6GEFuqmXKXYGyfBeBUBxK5dDy3m6qsvP9wBd1OcRV\nwo6knNp8U7iaTQTquIdYZ6IhZegi6IDagQpNsdT9WwPc7znAD0GQW28mUG+6Psdhv9w/NzBonEGQ\nVXcRy5JFgX0PsZ+tM3x4I7F/JUFCbX7L/+9eDBOymTFtu+vcv/0XUOWyhs+CU72y/67N0/MFHJch\nbTdMaOt1xJyVhuY2pa9OUL7JtAhz0TfCO7pOPgDAg4/ZRqDCpyjfrOfrYRi4XDb8bid4Lt5O8TeM\nQWWniiPjZRWuH0DsRVeV8xtjcKxwntcRziXS7pF0/9oJn/VcxBpgg3jQfjlBJ5niF/5/H4H71XrO\nKYp1nrOPRvaBvAnlhcwfLlXLg1xGRkZGxqMAjehAfmWt/bUxBgBjTAduH0gbYZIq5fRW4N3+9uWb\ncVQYOJ2AfO4DRNyIN6ri/DVwvZgHrgHvRsTFLbBOqewkWNr8I/E5JJqaV/Jm6ymbylIYElPNAZW2\nj0DZKE7pCyjB4QjlXIR81ygc6S1VDowBt6vnIjeWDXTyLsEuasuWJW2t362Et0o6eR18/EEXvreX\nYHFXIXAjk0Rmrcf6790NWOEcRMYNwTstuDoWanKZynMfQbeQ9gvdHqeEewd8GU7qg627VFzJ/wEC\nJzME7/D6mav2wF1HqfhF+qt9xO0lVnTanFmfNVEhUMGdFFvvzKGFVUOYYPIJR7rgBWurzJo7qkjq\npJfAmUC1bS6fhJO8ZGHr6VT1ZpHOp9Z5MjLG9baAfcRtIeE9sNvrzU66BLaKDu3L0bdE4eslvA3+\nwY/ZN20m1ovqd8k3XgyIzvZcFf865mqjZyMLyNeMMX8NdPmz0P+MeMS1AZSd/TtxXloB1q2B9Tf5\nH6lZrnKxvN8PrOu3wDGendx7i4o7kaSTyfseQlVcQFBsa6Qmrovdv7suA97m791IPGkV4P6NhAly\nHWEy6CR0Fq3w7oADwrYPE+Rl25K0WrQh5ewhTGZ9xJNVO0wq/nuvAv7Yi7MWA1/0Lr+HribeC6FY\ne3HIs3sDvNNPKu89jVDvekKVHcTg6s+LlY49F3ZfPb08UdvpetoOn/UGE+cMEYsXNCEg9wfhKj9D\nPu8CuFNmmF7CgnUiYSKpUBXrHbkWDojoY0iVQ09yWsmqD9bqppigmE+oifN7PnjCHnitH0cfPwu4\nyT/YRWxS7XF6F2z0cY55DewV45XNhLauUDwd7iO4kk/3lRUo0RmgOif8cgXB6/Y+4v0nGmIAMe7k\nPYATfYn5thzlIBCx1QYCsXC3ep6KYVuHRkRYfwX8BEdyvQH4N4KbsoyMjIyMRykascJ6BPiov9oU\nXVQpuffeSHW1fuwFBOpBs7pjBGpggsA5nKbyXOPTgFvxd6n4osA+iti/kWCKmCqVZ8tVnOXwAZ/2\nrSsJ1KRmjUnCPv2RK+GAqKE+TeCu+gmUdyeBOhnFu13FuTQTTkaLs/Sxn+nOeKF4dlHuVXYu4ctw\nP3C/p/beuS5YNA51ESg/bT55ImwUqm47vHeNC56/GK6XetD+sCqEOhyh2qa7hwjirO3ESnRFAQ/6\nthveCOcI1TtIUNj3EJTcE8TUvy/znRvgVO+b7K5thB3Y2jx8nGqfPHAzkcgUrbAvUqxqkanmgjSX\nMp/iLGW4INwjO+CFvn3398J6Tf0XKLa/ClUO/Mn4s3yAu9YTxvJIiE83VY4uEi32Eo+v1BMFcFIP\nbPXxfxsYEmX8IGEOSUyAO7y4snIlob/1hTKzJQlLPksJ/QdiEXqRYcfsoxErrPsp0HlYa5/SkhJl\nZGRkZCwINOoLS/A44A+Zc1ecZZDij8Gx/mja3ZuoUgm/gqAw024vtF+aiwiKqEknrAOcHLNLxddV\nJRTAMIE6H6HQfUYU3k50ZoWY9EZKMn1SoNZFDIXwAUkj+Yup4BiBMh4m6Ge00dxmAtfRSbH5sHaT\nsYTAHbWLYtVTn+uA9Z7COwM4TXQ+FYL8WPs3OwqWe+pz+ygs83V+/S3E9aAh9byZ0BaDxJSfVnCq\n+hnepO5LGTYTqGStpNeGF/cQ+uc43HWTij+pwtrFhnz7pMpTn7iouPQIqRy/yC1IO7T5AGGc7uCp\nZx8DwA/OeYjARWjjmG6q0gG7nioH/sxT4MZNPk4/cZ1I2gmCXmVS5a/1GBBz4z68dZxqOz4McJuP\ns5xQ1/1EJ2FWlN4yUoSLqfg2gi8vOWIXYjdNiwh9ppuZuyNqDnV1INbaB9U1aq29FnjRHJQtIyMj\nI6ON0YgISx9ccRiOI5lDz3m1ICvxGtjtV9+ONVBxq/uq2/+Te4y4rkitqkRgvgfwpxnS64ypAK7p\nJ6zo2oWBfq+WtY8Ty4+LsJzIOuhSud9HkG0vIlAhIwTZ5xSBu9iJ02WAo7SFctUbnSA2W9ZWGdqc\ns4CKiqw4dtAeeg+B0vOsH4e3XejCp+0kOKJbRuA8Jwhc4hRs92aVN6+Dc6VPnEJox43EblyEW9un\n7t9GoEQHCByadmwJgQrsIlCLHcT6E1230n9OJ3AXWwheg48i6OXOIDgF1DJ1zWmkXIRQ0sPqveMq\n3EnsrLEdIN++CXdmOMBKfnC411EcC+zWHLKMhdMIHPhqGPTm/DeOE+u19FSmx69IGZYT2k6bQmur\ntgphzH6Oah0+DsI8s4FYEqDba5MPr4Aun+fkeYBY+vUQ9KdbKG6bCUJ7ax1va9HIQvB+Fa7gav3l\nLSnNjCHF74eTfYXddxOiALvH/F7YBrJe2+v3EibgPYQOsgqu8Y1zzFrYKw2oTWX1JDGp0p5IYDmH\nCJOK3lcwSOQi/ggfnNBKdwgiji7CgnMKsfJblHy7CIrSpQR78w7ChKdZ+3WEHa6aPR8mdEBt+pqI\nZeYdg1QXSdMD10idTMHJvk7u20iYCCcIhhQ3U22LcxcTvquf2GeU1P9y4v05qDgysd1NqKt0Mpa6\n7abqU+sVr/FHl8p9KYM20d1CmPw6iMWVQpx8mrBgDhGLrSTPQcIeBm1soYmhdDIqMSOfN0gfXgFd\n/ht/2Quf9bfPHCceaz5+xwqoCFF2irKQ7oFhGVOjhHo7hVC323FGNODG3Kt9eIhQh3oR1kc/rAP8\nbhdK+9QAACAASURBVHLZX1YtmzaS0EYqQiTeCpOSzwBRO3b48lTuIe638i1TuAPIpJw7mAs0YoX1\nvLkoSEZGRkbGwkIjIqwLaz231l5d67kx5gzgWpz462PW2r9Pnr8S+Ev/cwI431q7nYYgK3GfcoSq\n/MOsBdZv8ve1iaKm5KCaeLAPhr2yau8QQYyjOYEBAsWwnqDAXqHi7CCmgH14cAUMKw7hbB+8UYud\nJonFCLKbeT2BBV5CMAXtIFAbh6s4k8Qmjd3qvzbPFAo0Fb8UGRxAW3EjA8DLPCdw1Y1wn6b4ddvJ\nJqtxqtzaWmCDtFfqsUArp/W3D/j/2wn1v5bALWgfRP0ERbvi4r4NgertJN7AGDzPBs5hC/FudQkP\nELigcUJb9xH64ThO7AWxMYcWpWpRjA5rzFeb6zG7ynlTBmAZ3Oi5r2N7nFeBKvw3VsYJXPrNsF1E\nQCvgeH///gqB6xsj1OcSgtIaQvueRpW7mLa5T9JuDHnu30Rcd9pcWjiQXoIochGhP2gvwPdARfqS\n9qmllfqTBC463bzcOjRqhfUsgi+MdTgZws7SFB7GmMNwbu5eAPwIuNcY8yVrreavfgj8nrX2Z36x\n+Sjw7MY/ISMjIyNjPtDIArIYWGmtnQAwxlwK/Ku19o8aSLsK2Gmt3eXTfhY4EyWgs9Z+U8X/JkHo\n2QB88Tu6YLesZ8PwD95FxZu0WesWlU67b9hOlZJYBgyLMkxT7/o409UEHYJWig1AdLykpvKXVosW\n0owGD61cROwGRajnbgLn0E/gfG7zaSQsOhBNden1fS1BUbeZmOIUSlSbKmuloJapt4PtRBfV8t8/\nAlcJldYLJ3tF+H2LCUYJmqLuoyov3/A5Ql2tIZz7AYEqrRDafZBgktkNR77GBQ9sJlCN3QSq9AE4\n1rOYuzeG++8DzixyPaN1TX0EY4glxFyiPqVOK4+1DkT6yShBb6apZc3ga85E9+davqHmEr4fdhDM\nXf97JTxdBB/LKFT8mx6wQSl+2I9/B4BHnnw13L+M6egk6D2uV3m9mmC4oP3p6Y16/UTnuugp7Giv\nRN+v5x9dr4sJnOoyFdZKcG26O0Fo6wmC1c91zIe5fSOuTPqAX6vfv6ZxI+N+YgZzD7UXiPMIBu0Z\nGRkZGW2MRkjKTwL3GGOE/HoJwUZy1mCMeR7wWuC5jafyq2xliiCb7HLuCgC3eUgouUkiD61iGnCn\nMtX8UAXWyyq+h9jDqVDkU0TcyameArjrFnV/kMBkaVm4piC7YKtQrrcScSZVrFDxRwnWREOE4wm7\nCCaHyyh013LkMuVYsYe42eW7upN3iz5hO7EMXmMezHvXnQLrpa03EPRdZ8EGoUr7CWVeDP/qOdIX\nXUbkJPJ0r/fYeBnBomkJVY7ipAtg62X+/tcIppQrlcNCvaFPU4cPwG6hOlOPt1o/oy1qxlRY2nE1\n8ebQbpXWuzhBygjQAR2+n1SuVt+rdV/9qMNQFHqIz/xuB/g6qWyq3jms7+c8Urhpt5dq/T8TuE/u\nd/LI5sf7cA+xLpSQttqdOwnjokuFlxLqRVtwjasyaKu5TmdmDLBfbz6tEHRumgsdJeisriZ2MyRS\nhrMJ7d1LPLes8WG9WbW1aMQK6wpjzAbcwZAAr7XWbm0w/1HgOPV7MQVfZoxZAXwEOMNae6A8uztV\neAA43oe1Hfwk/32Wc5rzdN5LzLorc78BqvGlGi4/7q94d7WhIN6ZHTpjEGtMwjck7g7CRKL9Du1T\nYe1hc5Cqnd+x58Hu61X+glWEzns30a7ld17sgu+9QpVzGxzt7+8fotqRD2jb8RFiEZl09tXE7r91\nM2nlul40NNveavj3rt9D+JaViDJ7z78dzeKe/e72xJUqTiVx/SkLxdfYe8cTATim96dwQBZkpcze\nuk+l66Yq+hk8C4alHjYS+sMUsRv/ARXHm1heC4EJHyIWkY348Aqq4rKTl3rFO14xrPuk3mWu966g\n4oiwYIzQ7j0qH912fRQvLFBOLLSSiNDm8yPV8CM/eDxhMdfvnaD6vZ2SBpduk8QZJCYGpQ+PQ0W3\nt6TdQCCm+gkCEu0fr4OgRN+syryRJ3zzqQD87LGj6l2dVPcdmRVghcgNBhtH/PxVPPT4G/yvLqpz\n13Jgu/ZvJqLatSEOXyc+Xrl1aFSofTgwbq39uDHmScaY46219zeQ7l5g0B+Juxc4B3iFjmCMOQ53\n2sUfW2t/UDu7bFGckZGRURvH41gwwZfLIh40GjHjvQRniXUC8HHc8vl/CUtuKay1Dxtj3gx8hWDG\nO2SMeYN7bD+CO/6pF/iwcadWTVlrV5XnqiEr/Xo0G/su3uPD6aYo+dzT4D65F0wv3/3dqwgUhvY7\nBIGSSzyvVoSjWEmokuviOFXKb6sq03D1vZwNXFV0BoVQFAKhNs5N+oRiyfcLS6sV/3cTzIEnVXm0\nWGUkeZdQMFrsJt8jKNtx30poBfDdCDX5Vj4AE1cUxB8MFDwQOMAlPBtvv3FAp9ObOnX7K8p+HwTl\ntPZQDPFuZu2fyse/bwXTldjg2kLaY2fI82G8iBZC++Ofj6jfShlfzbKTYMKs201veNT3uynnJOZD\npDVJbPzix86ZuEOlAK7TKtOpEGdE0vt013mjki+thTM3FbyrkyAO2kf43mHo8Fx9RfcH3e7aF9kU\nYews4meDIk8fI1b2+/5g+1U+w3C6e9dDj0eVoZNqo25fT6Hftu6VMLFT3Z+bDaGNcCAvBU7Ct6S1\n9kfGmO7aSQKstV9GOWL2925Q4dcDr280v4yMjIyM9kAjC8ivrbXWGGMBjDGPr5dg7iDr2LgKj7K+\n5zwf3kSgJm8jovaqRGAnVYrhtyE2XxV0EKpqhNisVVb9pSqsN7LpTUPaVHQqvOMqVDlHCbqUkaQc\nQiHthK3C7WidTC9hg5s+X0JvBnyQuNmVR+PonlZStgOkPKsJVGkFKfer+Be+wP/x928jouqEm7+v\nA8193c57AXg6nyF2HSLchvQF/X7gPcBbhSPVW5o6k/ipQQQwsZ7QFpqqV+bJ3BaeHQGhs2pd3wTx\nRkWhejtU82rFrW5TrUuRZ+DqcqY6jVZyJl2Ecd1DtT733wxHn6viSBnUJrt+YK92MePrcGgp8UmO\nAr1pV7sL6fJedSGY78P0MVKUZw/slnG1hKAz0SbzI0RuTapM5k5iJX2RHy3lrXui+sffnxsOpBEz\n3s8ZY24AnmiMeT3uEz/a2mJlZGRkZLQ7GnHnfhXweZyi+wTgb6y119VONVeo+EvcCviVeWIEJkZ4\nmR3FUS1CCU6G6xjcVaXGKsBmPmJv4CP2BqZ7MhUZtaZKwVEVu+DdK3FUyDDTqTKtj5DNgeIlth/n\n5E9vGhQMEMvG/fkOLz0fR4VrNxfgqI5l/ppS37sL3rHWXVXzXm1BVUGZpSXlX0M5dD4ammObZRzZ\no94b6mvNw5tw3zBAoA49h/Ih3AVoSn8rz2ArzyC48NDULHB8r/oW1TZfBEfZD+G8rcq7Jom/fRGB\nctzjry3Axf7SWEloL/Wuu8DJyzfjfJh2qOtsf4nLD09xH9jkLlB1ottpBcUQvVwR11l2v5WYhI6l\n7ooo6jHsDoPdYYitjSZw+oEHfHtLfVZwlP4ID77LJO+QtgNO7XJXlUNw+sgn/PLHPOGXP/bxdT+R\nODq+Ho+rcQ48bmf6vHGKv4YJ80PF7Qu8AGJ9V4XqPINWD6s6eY78HmMudZM1R7kx5jHARu9Q8Y5a\ncecHUvxRYoWwU2j9DdfyBV5ZkG4c9hbtV9zG63/yKQD+lKcSs/PCNqpdxRqPg+lKb0krAy/dR+F3\nqXIb8QCReJuIv0tDewTWJpn3qLCgA67SO56L8txWcA/ijpyioB6mvXuWEZkkBzzhE78i7BhOsFYC\narIAXvOWW3zo5sI8uX9IxVd1duce4oOmNLRSXLe3Vnxep+LKe7UnAt0XbiZMShuIfR+J6bc21IAg\n4ltKvPdAMEQMLdrSu5w1ytq6xahoQwSq4cs+/Zcu+Jl0zPl4z06NYNw3PndqC5jbKcRdUm+x+Odn\n/aIIH2E6YSlIxzY4sZnUozaR1wYWU3E+n5fABMULwT0UfZezB5n7NqrJgVhrHwYeMcY8YY7Kk5GR\nkZGxQNCInOEhYLsx5g7g53LTWvuWlpWqYciuzZR6dqv+0/+/7xF2bGtqYYBYESsYwzxdjn+/Inmm\nFXIaPs7FZZR6B+UspWzoF3Y4LU8JRXHbzcRKeo20fJLnpoL8Ncqol3miPEuxpfj267SfogRVcU6C\n67QJdhH3qPPU9baesLksPXdBqFdtjg2hXfop3iWs/Wjpd40SH0rUCHenlcpF8Yv6SPredkAX07kl\ngCku/a33+fBlyTMRGd6a3HdjcOgvTiL4hU3flXKTHvuL2kWjTGG9h/JNuGMqrLB3kw9MUtyf9xTc\nwx/bO/doZAG5lemtkZGRkZHxKEfpAmKMOc5a+7/W2ln3ezV7kNW4SGkNbNhDsbsNUTAXYG8ZtzDg\n/9f1Yk8s29aml7q6KwTF2hhho+Ioxc2i7/Wq310U+1lKUXQWQSPcRRm1Ol8oa5+UC613xgWETXZr\n1L30XBRtsq31IQM+3E2s49LxNcWp056i0uodoWn/gHhj2gBBR6FNTYvSybsEuk+W9ZF6z+YaXZRy\n1CM6TtGG3xI9z1V7iDcAStpuivUYEB+HLS5j9GZDLUFQ74r60XLCGBwj9tytoTnh1Cw8zVNjhGJu\nubWopQP5ogSMMV+Yg7JkZGRkZCwg1FpAtL3bU1pdkObgTfYi00aoUnyXLSaYyi4hmOCNqfvadLYT\nlvmLPpyce5BgnteL4xqWEE4iFOxU+b86KY/gFGJqVNABl53nrmoe4oxvpb8q6hoLcbovVO/qwpn5\nrSLI6AWSpzioE0pWl3M+TDVnigcoNnkeA17jr36CCWcHwQx2UZLG958jlxHaWlN4+wj9JNVNSR2u\nIDa1LjLn1OhQeWoqWc6tlzYSVFR8cVEhZZTwmuQd8u1dxKbEugzyvUXla5EJ9ozRgRtv2oOux+SY\nu1iNo+7FuaLUYT/F/fkBn2Y1cb2IE01pHw3ZCrCIuD/ouhLzed1PVJ4nn0XVDL8qBZB5Ro9tabtF\n0H2Ru6p1If2qqE3lfZ248Z/Oia1BrdxtSbiNIJN46o/Ihy8BTvc7VjfeSjClW0cw+YzNAxnyYrHn\nnAff0B5yl/nwCMVK0C6CaGIjYRLoJ4ggUvGXTAS9yn2WnnjGKVbCjVD1KnsCyq/XIuIBo8U4whqf\nGNJWj9IE15G1qa+gQuzDZ74VrauIfUkJJrH/7Gge84ffJ7R1BU690AXvujJJ4+rnP8Z+l+cb2cWu\nRAjPuxDuTNP4dM/xbf2N1HhC6nacsKhoEUcfQdz2YkLDrySINdL+JX1ijHAO8nXqXWkZNEEgWERU\nJ4WiIS3ebAdoP2zpVOXFSp84H14tC/EoYZxq03vdnzfBt3x/eOYQYXz1EXvULUDX+TApIlS9+PdQ\nLA6epDpHvRQ1TnsIi3cqspZ2OQ/e4INX6TF4PqG9tUn+OGF/zyDBnL+1qLWAPN0YM47jRLp8GP/b\nWmvTnTEZGRkZGY8ilC4g1trHzGVBmoNQYBNM85ILwK389x3vBODph30PrKcaTu2EuyaSuAJnDveT\n/7qIJ/X6OAeugA5PBVb2UUxt7IIPvMYFL18J+4s8w6YKXaFm+uGPffAarZzrUN84RKBEd4Hxu+PW\nAffpzV+Sv95IpZv5xTh/WAJJ208x1SJiBCl/+gzmlivppfAIUyrKVnAYJ0YEuFUVr5fpRxXD0/g+\nQSv7RqoZ3Qkxl6vO/ajq8rdAdbPqRuIjgiVSiaL0+LPhfhFFbCOIosZV2mW40xQAHoDn+Pb6BlSp\n4MFLYFg+fjuhvXRfPQv4Rx8WMQy4PqPNVIuUu/PFdfYQzKRTkaXjTOyXDIbv+3vj0D3gghOfIHxD\nbABhH/KcKv+m7q8m3pjZXY0fFPDAm76s4kj+IlKWckqek1TP/bgYguHFCGGsvZTgh02ZeB/T533k\nJfe5kbjtBD1wtD+kar8+jKq1aMQXVkZGRkZGxjS0i7asSWjZsFAAmjIYZcVzPHXyR8CnPGXwRuAu\nRf0X6DSO/s5DYZ/igQo8yYf3ThA2dm0kosIjQk1knH0q/zcC1/iw9s5JUMl0XQyTQpGMQJfnNCbv\nUd/b7V2nAJeIPyaATxOdGRKdPOzrp7sLJkTO36fKr4+uLTJjFcw3ZbqMcHyxRgdmyqvqjgZ+6m9X\nJuDNPvwN3U+CPmfxk/a7AwvAHdkicvduYEIo4EVEZp73iQx8HZzsqcz7tHnvOIFSFAU5RJzkZ4Bn\nL/X39xGoxgHio4zFjHQVvFW+RXGyw5cRlMgQu7kR30l9xNin4mhIm/YSuKAJ5qfddf/sITZUcN8/\ndCsEnUUfvNAHP68NRYaJyl/tPsPEynfh3LQOQaVbDFUOreMiqNzkH0wSjqj9GPHpkMLtb4DLvD72\nkqvDtxy9AvbLeB+jWrd7AXz+g+f5Noa4n2jOahz2S0ErwBnMBTIHkpGRkZHRFBY4B6KpBC3vV5uw\nXuODb7ya6ue+S+ehrSCCU7qtv7NMrfrdsFdbUG1SYeU2Qgj7/ZcRZOfbVdmuUemS88cnRIY9QrCE\nGYPJK4rTTMomuGGC/F6bj2rLHGU6/FhgQluZaFuIok16881xpNBcny5bD3zeU4cX9MB1I+HRVRRA\n6Sj2b4ZPeAucF22kWocT+hQ5bRI6SdUZ3vEXwn3SN3qBX6g4upzaxYnP59njBAp4nLCpUG8U1Xqz\nU+Acyed0QhsvInAUiQz+mDUuuPdugunnGLEZepEuS2/i62B+2l5R5JGUIIzTZbcDLx7w97dA9VBs\nbXkoaRz+6d1eZ/U3ywnWVCOEeta6QCXRuIoQrmwkcIldBG6/g+hslmq5J+CS60JY+th+beWnpSfr\nqXKNw9oEPfUIrnWqI/7/MuZqQ+gCX0D0bm/tBZVqePQNXg71xt4Q55c6D63sDHlewcXEppdLVRyZ\npB9QcSbgs/J8OUEhejfB7FT2oKRQh0t1XQiTspjoAaR9JUE0OI71rsF330zoRJqFV0rZ/dcTOuCr\nCYrVcLRvjArx4NWT6HxgH8WDYxxRRtrX/RHmuvv9/X4vloJ4UtcT4k7ss54LgMESzK2niE1xC4iU\na4EzpW9sJ0y62hhCQ+czTJhs9GQ3Snw07qQKS1/aRzBZTf2ACQHS7UUh4PrFRLhfMrkGtIPJ9oPJ\nb912rn7MZyw8z9++c3WQIG7V/VPvVu/gdYff7IKDwLA3Ujm5B+67tRonOuRJ6uGuDQRT2WWExf8f\nidtLoNu6Asv9no7tYwSZdTfxnCD57AnvPfICOCALyKcJi54+TK4T57kZnOFNuk+tNcgirIyMjIyM\nprDAOZAiKi3G4l6vWToVuOsm9aTMH5Srki+Yc/0hLcA3boSj17jw/i5inzmKSjsgyrC1BH//pxO4\ngjJfO+r42clNBAX8EEEhtytJI3kug93yrtMIlGVXkkZzDrLh8WaV/zD1D6JJ/Q7NF8qU/b78b4JQ\nztHgU8EmivAqHmD/k47w4U0qTl+Nd/l2H4ZA+Y0QlNWpj7IipGebdKn/RZzqJgI3qMUdqcJbK8JF\n1KnNkKE+d9EO7azLqI+Jhmr5PnMry+zxAAyZx8Fty1SckrabdEYJy3Y+jSHjuZz/OZ2Y2y9qu2E4\n3hu13H8LgQNMp9FKQbgTtuuNyUVjTc9jFapiqwNXEnMU0se0cYAucw+OU2k9MgeSkZGRkdEUFjgH\nIijyWgnQ4U+wgw/954d5s/FHmPzSPwPKqeqbee9/Od8D7zTnqDMBOog3GWl42eS718HlQiXcTEwR\nFm14TL9F+/bXpovae6+ibKrciD4rY5R4w92UCuvNhgKtKJ0vpWkj6KScsnecw8+/ehg8TijvLrDy\n7WWeTCf5OK/1YTlqGFxb1aHEP4OKs5bQFilXnCqowXEFsuHxE4Q2Sl2QaK5Jvn0lwSVKStHq9hWF\n8BSBIq+oOB0U1+fcHYtaji5iYwKNsInvu3tfBoDh/QSuAMrdtTjO/Lvrz8HwcZ/9JhWnrM0nWfXD\n/wTgHnMUYZxWiCUFRXq2Mwjz1Bb1rIfYXYuWFLzGh/UcAkHKoMepnhOWU/sk0dlD5kAyMjIyMprC\nAudARB6cnCtcRQXZZPSmiz/Gm3m6u31gF8Wnv+kVfR9/9bFrAXgnTyNQcim1pqkNR7X9zt/ey3cu\nH/H3NdXbWfA+SXuaDw8TdCCpXkKbgko+66huOKJHxQmmjtM5CnmvLk+F9uU6NGpxBO7ZEU96WN1b\nT2g7/b0xx3WR+aC6LeaWm4ndkaQyeeC+zcB5/t6NBKq3Qswx6nTSb08kWFVp6lM7ttSWfruI+4nm\nQrW7melWhd7kSN3XXHERtI5lvvrFaI13K8r7L+XeSkodIU5LB/+67gUEfUKtcSqY5J6//T0fvonY\n8lPPC0V9TJ9lrtsntbjTz0S3mZ4fUsTN6nRFnqdbA2NtmzraTWCMsXBpyVNtdpdOMG6gv93+gvcb\nv2O4TPmaNswu77VzyUdVGj1Jl2DwEhgWM719lB9/qssvHXmcYDI8RRj0epHUnUjbsuu9Cnr3c1on\n2r+T7oD1RFjtJtoqEz8Ocoz9XQD2mh8QFMlQPKmDTKS/8eCr+fVRI/7eZuIFuQgd8AfejPrzkwTR\nwU7iSaVoMl5C8CKwnbDQabFVWufiMXYnoc+UeRHQ711LELloLwi12lT3n/laTEr8nimssc4oZJN5\nHPGCXMujAvDNS+DZMk7HicdO0fd24J1aAVcT+lIQi5VDH1T2OsKen3QfWpoGn07mkHFC3yhT9qd8\nwbuw1pqCiAeNLMLKyMjIyGgKC1yEpX3OlFFGjnJ5/1+/i8DergYuK4mv0j1bqmcZYWPgFZRTJ2La\nuV7FuZAgYiqj9vRmvS6caAPicy+0WajOQ1OfA/y/9s4/6K7irOOfLwRqEEsTFXBeShJJR35MKY0U\nmFKHaJFG7YDjaKQyCjodKdNStI5SiqP9y1j/wGJbUSxiW7WB6WiJY38ExDCjljRtEpLqCxJLoElD\nUkRI0Hc6ecP6x9mTs/fknPve9773vPfH+X5mzty9e3fP2X3OOXf32X322c6V0HUaSH6tdHFiqlnV\nmaAOU/uo2pOkrmd8mCePZTI8gw10TnDWaY+ZFnr38tu45fgCsSnqTa9zZhPHpw8k5Uj9R9UND55C\n8UymGmPZTDw9z74k794YLq90r7rWv9I5FNaLRlHf618cumliBVuU34A1FCbqdyUpasp+xRYyL8WQ\nvUO514e6Id9Zinf5YlgStcfZ1Ptt3QLM1A/bOUk4HWpK73t6T6coVkjuo/o9LXuMKG+K1QzWQIwx\nxvTFmGsg6cRRVVWSnt+GXfDGOH68u1u+ZB7gQOwdXroWduY/pyaQVQuGIHPBsDYLLlsK/zPXmCV0\nmlXmY6t7SmnSye+qvT6WUPRiZug0b67yaTWbpElNHkdhEVmZql5d2Q1NzhHO+PPvxvAjFL12qO8p\nZnW+5Q/up9hYJDWnTcewS/xV+iXXXg5SyLau9572SldTmGEvp7gHdT3awxRzIPuTa6U+rFLNJz1P\ntx72KFF2rVPnly3OcT10JfxGjHom+bk233aWvpwZ1sycR+LNNs1T1h6j9v7umwpvJB3n7SbD3ABi\nC9V7sFSdD7JnY28MH6Z6vrd83cUxwx7zBmQ+KvZjXLArs86Z1vOl3+qGlTI7+7XbjrBFL8f4JaXr\nVr18h+COlVlwwwNU++kq+7bKw+voXAcyk6RfXorLr5v/Ke4uxecPUXqtsiVR1RBNN1mO0p9NnfXd\nDLx3bxa8+mp45G+S3+Z40e98BH4oDmsc2JL8UDc5DYTcams9VRtWdU72p43eYYqhidQaKp00Ta10\nXqSYrD2T6o7Gaoo/pPS6MxTPSflPser5HAXqJqbL9y6r4/prP8WD16VDfFXGMSlHmNm3LAu+8EcU\n8jxMfWMbw58EyB0hptsFQ/3Ef24kcZjOCfLUo0CVpVbqsaDTr1e1EUxWt8XAQ1jGGGP6Yow1kPkW\n/UWmfy3fNWhLj/mz3vkW3UKhFSxl7mGBGdiQm3O+SKcb7SNJ3py055BulpRudpWmL/cu0t5P3rM5\nSqeqWzexV6XedxtqG7bmcRbV/qDK5Yra2JaVVGt6ZfL8++C4glpeqV+VPj1neVI/zVPX+09dwefx\nS+k0qqgaOivH5T3R3cl1y3XNz18ewp1ryHJY5ttpD3vuHvWDa26keE/TyeYuvCkPnElnbz41WKl6\nxtL1JiuT9N28F6RDi/mK+eqh1BP+TzrW7RxJwnXP3uIMYVkDMcYY0xdj3IDMUqwAXU7Ww/s+slY4\nP0rcfzg7mCbrAVxA/URzynaySdGDFAu58vT5dcs9tOl4zIJuyo7jvZklZL2WWU7sqR5Njp+jc3Xq\nmnhAbR25Kh6zZD2wdDy9XMe0zGcl5zxC56LEUSAvz+EknPfSqnrHUf5PBYp7lOfppn0egg1kByR5\nIXtWqlYp5/doikwbfJbCFDs/x0xypM9oXpe9Mf9UTHNmPKrm2/Ky5OdbnoSnknLmearqm193lurn\nMGVYWme+z0/qEwtOLGcs/457yOYQ15E9zz3IYfaT2cENZAt430DnPcrf7bIMtlK8a2sp5D9L9r6t\nplO2KVMxz1qydy3PuyZJU553yeWwMok/FL+ncWmeundjcIxxA2KMMWaYjLkrk/laBOVzERdQWET0\nYrK6nGLMcpqexlaP995XJOnrXCTU5S2Pf8+VNzUBrvO0W5UnZ9jzG93o1/primLXv17y5tohZPMQ\nVZY8dfKconOcu2qvjzqvsuW5tZxu7irS3nXZwo+afOXrjvI9Ty3WeinnUuA9MfyxHvPkrKeYP+nV\njD032d5Pb/8JOUvo3NU0p5f9dsremXu5jx9uzJVJ4w2IpHVkG3+eBNwXQvhI6fcfAe4n098+mJek\nngAAClFJREFUFEK468SzzOULq1dSc7m5VhiXqfM1NBfzfQlS+rHXn2OVvFkk+tl8q+qPv5d7V77W\nODQOTdDN0KHp646yrJtrQBq1wpJ0EvBx4O3At4Ftkh4KIaReBf8buBX42SbLYowxZrA0PQdyGfB0\nCOHZEMJRYCNwXZoghPBCCOHrLEoTnk8qzVf7gGJCer7kE2v9VK+cp5fzVKUZ5d7RpNKPGWXZLTj0\ndu+qzHXbeM9nS8diXredNN2ATAHfSr7vY7G8fBljjGmUMVtI+M9JeCWwakjlMGYu2tsrNcPmGQrf\nWc3SdAOyHzg3+X4Onc6C5smPL7A4xhgz6ayis3P9WF3CBdP0ENY2YLWkFZJOBa4HNnVJ34ilgDHG\nmMHTqAYSQjgm6X3AZgoz3mlJN2c/h3slnQV8jcyG8VVJtwEXhhBeabJsxhhjFsaYLyQ0xhjTnebW\ngdiViTHGmL5wA2KMMaYv3IAYY4zpCzcgxhhj+sINiDGmB+baR8W0ET8Rxpge8Mp6cyLWQIwxxvSF\nNZBGGNa+BMaY0WXy9mmxBmKMMaYvrIEMlMnrYRgzPoz69sxVu4uW48cLayDGGGP6whrIQBnfnoQx\n4884vX/jVNZ6WqSBuK0cL3y/jBl1WtSAGGOMGSRj1s1bTbGh4cw886Yq41LgaEW8GR1OAZbH8KFh\nFsQsClPx8zBwZJgF6YLN88tYAzHGGNMXY6aB7BnQeearvZjFZ4bRuE+pafZkmF7OnyU0X9/9cycZ\nOmUZ2GzfGogxxpi+GDMNxAye9BE4JQkfTcLt7WF11r2tcmhrvediPnJZDC1u8XEDsiAmYUjDf5Cd\nNPGiL+Sck/nH0z4m8x56CMsYY0xfTKgGMo6TW+NY5nGn6vFvQv4LOaefBzO6WAMxxhjTFxOqgeS9\ntqU0awo6yN6he5qLj2VuJok6k/PmsAZijDGmLya8AZkh00KWMrHKljHGdLB00a7Ugn/VdAirSsXz\nMIaZLzatbSejbrY/W/psngnXQIwxxjRFCzSQlPkummuDllL3CIxDnZvWBOrOPw6yMYPH972MNRBj\njDF90TINZL60QUsZ13JDf2Wvu19V49sLkc2gtCPPt5jRxRqIMcaYvrAGsmDcOxwv6u7XoO/joM7n\n58uMLtZAjDHG9IUbEGOMMX3ReAMiaZ2kJyX9p6Tba9L8iaSnJe2UdEnTZTLGGLNwGm1AJJ0EfBx4\nB3AR8C5J55fS/BRwXgjhDcDNwJ81WabJ4JlhF2CEsCwKLIsCy2IxaFoDuQx4OoTwbAjhKLARuK6U\n5jrg0wAhhK3AGZLOarhcY87eYRdghNg77AKMEHuHXYARYu+wC9AKmm5ApoBvJd/3xbhuafZXpDHG\nGDNieBLdGGNMXzS9DmQ/cG7y/ZwYV07z+jnSRD48uJKNPY8NuwAjhGVRYFkUWBZN03QDsg1YLWkF\ncAC4HnhXKc0m4L3AA5KuAF4KIRwsnyiEoIbLaowxZh402oCEEI5Jeh+wmWy47L4QwrSkm7Ofw70h\nhC9I+mlJe4D/BX61yTIZY4wZDAohDLsMxhhjxpCxmETvZTHiuCHpPkkHJe1K4pZJ2izpKUlflnRG\n8tsdcbHltKRrkvg1knZF2Xw0iT9V0saY5yuS0rmokULSOZIelfTvknZLen+Mb508JL1G0lZJO6Is\nfj/Gt04WOZJOkrRd0qb4vZWykLRX0hPx2fhqjBuuLEIII32QNXJ7gBXAKcBO4Pxhl2sA9XobcAmw\nK4n7CPA7MXw78IcxfCGwg2zIcWWUR649bgXeEsNfAN4Rw7cAfxrDvwhsHHadu8jibOCSGD4deAo4\nv8XyOC1+ngw8TraeqpWyiGX8TeCvgU3xeytlAXwTWFaKG6oshi6UHoR2BfDF5PsHgduHXa4B1W0F\nnQ3Ik8BZMXw28GRVnYEvApfHNP+RxF8P3BPDXwIuj+GTge8Mu77zkMvngavbLg/gNOBrwFvaKgsy\nq8yHgbUUDUhbZfEM8P2luKHKYhyGsHpZjDgpnBmiBVoI4XngzBhft9hyikweOalsjucJIRwDXpK0\nvLmiDwZJK8k0s8fJXozWySMO2ewAngceDiFso6WyAP4Y+G0gnaxtqywC8LCkbZLeHeOGKgvvBzLa\nDNLCYeTNoCWdDnwOuC2E8Iqkcv1bIY8QwqvAmyW9Fvh7SRdxYt0nXhaSfgY4GELYKWltl6QTL4vI\nlSGEA5J+ENgs6SmG/FyMgwbSy2LESeGgoh8wSWcDh2J83WLLboswj/8m6WTgtSGEF5sr+sKQtISs\n8fhMCOGhGN1aeQCEEA4DW4B1tFMWVwLXSvom8FngJyR9Bni+hbIghHAgfn6HbJj3Mob8XIxDA3J8\nMaKkU8nG7DYNuUyDQnS28puAm2L4RuChJP76aCWxClgNfDWqrC9LukySgF8p5bkxhn8BeLSxWgyG\nvyQbm707iWudPCT9QG5JI2kp8JPANC2URQjhQyGEc0MIP0z23j8aQvhl4B9omSwknRY1dCR9L3AN\nsJthPxfDnhjqcfJoHZllztPAB4ddngHV6W+BbwPfBZ4jW0C5DHgk1nUz8Lok/R1klhTTwDVJ/I/G\nB+lp4O4k/jXAgzH+cWDlsOvcRRZXAsfILOx2ANvjPV/eNnkAb4z13wnsAu6M8a2TRUkuV1FMordO\nFsCq5P3Ynf8PDlsWXkhojDGmL8ZhCMsYY8wI4gbEGGNMX7gBMcYY0xduQIwxxvSFGxBjjDF94QbE\nGGNMX7gBMcYY0xduQMzEIml53Dthu6QDkvbF8A5J/9LA9W6UdEjSvQM85/q4P8OkeF8wE4SdKZqJ\nJWR+fN4MIOn3gFdCCHc1fNmNIYT3D+pkIYQHJR0EfmtQ5zRmUFgDMW2hw7OopCPx8ypJWyR9XtIe\nSRsk/ZKyXQGfiH6Ech9Vn4vxWyW9dc4LShfGtNsl7ZR0Xoy/IYm/J/okynfe/HrUkB4evAiMGSzW\nQExbSX34XEy2A+JLZLu+/UUI4XJlW+veCnwAuBu4K4Twb5JeD3yZbNe3brwH+GgI4bPR2/DJks4n\n2+3trSGEY5I+Adwg6UvAvcDbQgjPSXrdAOtqTCO4ATEGtoUQDgFI+i8yp3SQOZxbG8NXAxfk2gJw\nuqTTQgj/1+W8XwHujA3O34UQ9kh6O7AG2BbP9T3AQbKdNx8LITwHEEJ4aXDVM6YZ3IAYk3lEznk1\n+f4qxTsisu0+j/Z60qh5PA68E/hHSTfH83wqhHBnmlbSOxntzYyMOQHPgZi2Mt8/683AbcczS2+a\n8wLSqhDCMyGEj5HttXAx8E/Az8dd5ZC0TNK5ZO6zf0zSijx+nuUzZtFxA2LaSt0+BnXxtwGXxon1\nbwA393CN9ZK+oWx/84uAT4cQpoHfJduS9AmyhunsEMILwK+TbWG7A9g4n8oYMwy8H4gxA0LSjcCl\nIYRbB3zetcAHQgjXDvK8xiwUayDGDI4ZYN2gFxICnwBGcp9u026sgRhjjOkLayDGGGP6wg2IMcaY\nvnADYowxpi/cgBhjjOkLNyDGGGP64v8BMnt8eYtxp3AAAAAASUVORK5CYII=\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzt3Xm4HFWd//H3FxLwIglwQQIGSAJBQAdGgwYUGNkcwyiL\ngghuoKLIKCogy090EsdlxEcRBGVEGERckEG2jIIsAgMokBFQ1ICgJEKICRAlAa6YG76/P+rUrXMr\nvVT37erl9uf1PP10dXV11anq6j77OebuiIiINGqdTgdARER6kyIQERFpiiIQERFpiiIQERFpiiIQ\nERFpiiIQERFpiiIQkQ4ys5eZ2b1m9rSZfaTT4RFphCIQqcrM9jSzO8zsr2b2pJndZma7lnzMR8xs\n3zKP0WVOAX7m7hu5+7mVNjCzN5vZXWb2jJk9YWaXmNnUogcws5vN7H2tCnC9/ZnZ9mZ2lZktD/fN\ntWb2slYdX7qHIhCpyMwmAfOBs4FNgKnAZ4DnOxyudbt5f02YBvy22ptmdhjwPeBMYFPgFcDfgdvN\nbKO2hLBxGwNXAy8DpgALwmsZb9xdDz3WegC7AitqvH8UcDtwDvBX4HfAvtH7k4ELgMeBR4HPAha9\n/4HwmZXAb4BXAt8B1gDPhvWfIPmDfQF4H7AYuCV8/qDwuRXAz4Ado33PAu4BngYuAy4F/j289/oQ\nnlOApcDFJH9484HlwFNheWq0v5tD+O8AVpH8GQ4C3w3HuAvYpsa1yod1h7D+JmAYGArnO7PCZxcB\nJ+XWGXA/MC+8ngtcEr2fXrN1gM+FYzwXjvG1sM0LwPHAH8J5fyn6fMP7q3MvbRI+v0mn72s9Wvvo\neAD06M4HMAl4Avg2MAfYOPf+UcBq4KPAusDhJBHJxuH9K4FvAC8CNgPuBD4Q3ntb+BOfFV5vC2wd\nlh8B9omOk/55fRsYANYHtgeeAfYNxz4ZeAiYAEwMf7ofCe+9hSTXFEcgq4EvhG3XD5HBW8Lyi4Ef\nAldGYbgZ+D0wPVyX3wIPAPuEP9WLgQurXMeXVQtrtO/3VfnsDiQR6rQK780D7gjLc4Hv5K7ZGmCd\nascI1/QmYCNgK+DBdJtm9lfnXjoEWNLpe1qP1j9UhCUVufsqYE+SP5rzgeVmdrWZvSTabJm7f83d\n17j7ZSR/Qm8ys82BA4AT3P1v7v4kcBZwRPjc+0lSvPeEY/3R3R+N9mv54ABz3X3I3Z8H3g78j7v/\nzN3XAF8miaheB+wOrOvu54ZwXQncndvfmrC/1e7+vLuvcPcrw/KzwH8A/5T7zEXuvihcl2uBP7j7\nze7+AvDfwKuqXMrDK4R1IIS1ns3C89IK7y2N3m/WF939aXd/jOT7OXKM+1uLmW0FnAuc0Op9S+dN\n6HQApHu5+4MkRUeEStDvkfzRvDNssiT3kcXAS0lSrBOBpWYGSYRgwJ/CdluTFJ004rFo+aXhWGk4\n3cweI6mneaFCuB7NvX7C3VenL8xsgOS83khSnGXAhmZm7p6ONros+vxQhdcbVgl3pbA+GsJaz5Ph\nect4H9G6Jxmb+Jqm313LhMTGT4FzQwJDxhnlQKQQd/89STHSP0Sr83+C25DVefwN2NTdB919E3ff\n2N13Cds9CmxX7VAF1j9OEknFtiaJOJaSFMnk36t1jJNIisVe4+4bk+U+8jmhZlQL62MVth0lROCP\nkRT5jbAkVj4UuDGsehbYINpky/yuqhwivi7pdzeW/cVh3Jgk8rjK3b9Yb3vpTYpApCIz28HMTkyb\ni5rZ1iRFHL+INtvczI43swlm9jZgR+An7v5n4Hrgq2Y2yRLbmln6x3wB8AkzmxX2vV3YPyQp+23z\nwcm9voykqGyfcOxPkERYPw/hGzazD5vZumZ2MDC7zulOIlRkm9kgSf1Cq1QL6y/qfC51MvApMzvC\nzNY3sy2AC0OYzwrb3Af8k5ltHVpmnZbbR6VrCnCymW0crv3HSBobjGV/wEgLvuuB29399ILnKT1I\nEYhUswrYDbjLzFaR/Dn/mqRlVOoukpT7kyStlA5197+E994DrEfS0moFST3BFgDufjnweeD7ZraS\npMJ9MHzuP4BPm9kKMzsxrBuV4g25oXeRlK0/AbwJONDdh0PR1FuBY4C/AO8gaVVVq/nxWSQp7ifD\nef4k937Tk+bUCmuRfYein3cDJ4bw/Yaksn+P9Fq7+40kFf+/JmkyOz+3m7OBt5nZU2Z2VrT+auCX\nJC3W5gP/Ncb9pd5C0orvvWa2KjxWhvoQGUcsK+It6QBmc0h+oOuQtFQ5I/f+60lu5D+GVVe4++dK\nDZSMmZkdBbzf3fOVzV3HzO4EznP3izsdlm5hZi+QNBv+Y92NRaootRLdzNYhSXntR1K+usDMrnb3\nB3Kb/q+7H1RmWKR/hKKyB0lS7O8Cdgau62igRMahslthzQYecvfFAGZ2KXAwSRv6WCsqK0VSO5DU\nPWxAkrM91N2X1f5I39Fc1jJmZdeBTGV0E8q0qWXea83sPjP7sZm9vOQwSQu4+8XdWnzl7t9y9y3c\nfbK7v9LdlfvIcfd1VXwlY9UN/UB+STIMxHNmdgBwFUnvXRER6WJlRyBLSNqXp7Yi18nL3Z+Jlq81\ns2+Y2aC7r4i3MzNluUVEmuDupVQTlB2BLABmmtk0kg5eR5AbLsHMpqTl02Y2m6Rl2Iq19gS0tnl+\nL7uZZBgm0bWItfJaTCAZM7FX6b7IzCttz6VGIO6+JkyScz1ZM96FZnZs8rafDxxmZseRDHA3RDLO\nkYiIdLnS60BCBeYOuXXfjJa/Dny97HCIiEhrqSd6T5re6QB0kemdDkAXmd7pAHSR6Z0OQF9QBNKT\nZnQ6AF1E1yLTymsx0MJ9dYLui3ZQBCIiIk1RBCIyrrSqWrOXW2BJuygCERGRpigCERlXWpVzGGrR\nfmQ8UwQiIiJNUQQiMq50w/B20i8UgYiMK62s/J6AIiSpRRGIiIg0RRGIyLjSqg6AynlIfYpARESk\nKUpmiIwrrWp+OzFaVqdCqUw5EBERaYoiEJFxpVWFCqtRKyypR3eHiFQwEfVGl3qUAxERkaYoAhGR\nCgZIKs9VgS7VKQIREZGmKAIRkQpWdjoA0gMUgYiISFMUgYiMK62qs1Ddh9SnCESkr6klvzRPEYiI\niDRFEYhIX1NRlTRPEYiIiDRFEYiIiDRFEUjPUyWoiHSGIhAREWmKIpCep0pQEekMRSAiItIURSAi\nItIURSAiItIURSAiUoFa90l9ikBExpVW/vFrTnSpTRGIiIg0pfQIxMzmmNkDZvZ7Mzu1xnavMbPV\nZvbWssM0viiFKLGJLdqPmodLfaVGIGa2DnAu8EbgFcCRZrZjle2+CPy0zPCIiEjrlJ0DmQ085O6L\n3X01cClwcIXtjgcuB5aXHJ5xSClFiQ21cF8TaV2ORsajsiOQqcCj0evHwroRZvZS4BB3Pw+wksMj\nIiIt0g0F6GcBcd1IjUjk5mh5OjCjlACJ9K4JtC5XurpF+5H2egRY1JYjlR2BLAG2iV5vFdbFXg1c\namYGbAYcYGar3f2atXe3T0nBFBkvWlmkqeLR3jSD0YnrW0s7UtkRyAJgpplNA5YCRwBHxhu4+7bp\nspldBMyvHHmIiEg3KTUCcfc1ZvYR4HqS+pYL3X2hmR2bvO3n5z9SZnhExr8BWluRLlKduffGf7aZ\nOczrdDBEupwiEMmbh7uX0kBJPdFFxpVuaBcj/UIRiIiINEURiIiINEURiMi4UkbT24ES9injgSIQ\nERFpiiIQkXFFLbCkfRSBiIhIUxSBiBQyQP/O0KdcjVSmCERERJrSj8kpkSYoFS6SpxyIiIg0RRGI\niIg0RRGISF/q1wYB0kqKQEREpCmKQET6Wj83T5axUgQiIiJNUbJDpKb0JzKcW9fr84UPV1kWKU4R\niEgh8U9lPP3hjqdzkXZTEZaIiDRFOZCeNx6KU7qZrq1INcqBiIhIUxSB9DylkEWkMxSBiIhIUxSB\niIwL6gwo7ac7TmRcUFGmtJ9yICIi0pSqORAzO7HA559192+2MDwiItIjauVATgY2BCbVeJxUdgBF\nRKQ71aoDucTd/73Wh83sxS0OjzRMHQlFpDOq5kDc/ZR6Hy6yjYiIjE91K9HNbI2ZfdHMLFp3T7nB\nEhGRblekFdZvw3bXm9lgWGc1tpe2UvGViHRGkQhkOBRVXQDcZma7Al5usEREpNsV6UhoAO7+QzP7\nLfB9YJtSQyUi0nXUYCWvSARyTLrg7r8xs72Ag8sLkoiI9IJaHQnfGi1Py739TNEDmNkc4CyS4rIL\n3f2M3PsHAZ8FXgBWAye4+x1F9y8i0h7KfeTVyoEcmFueH7124Ip6OzezdYBzgf2Ax4EFZna1uz8Q\nbXaju18Ttt8ZuAzYqVjwRUSkU6pGIO7+3nTZzO6NXzdgNvCQuy8O+7mUpPhrJAJx9+ei7TckyYmI\niEiXKzqYYrOtrqYCj0avHwvrRjGzQ8xsIUku531NHktERNqoK0bjdfer3H0n4BDgc50Oj4iI1Fer\nEn0+Wc5jWzO7Jn7f3Q8qsP8ljG7yu1VYV5G7325m25rZoLuvWHuLm6Pl6cCMAkEQEeknjwCL2nKk\nWpXoX46Wv9Lk/hcAM0MrrqXAEcCR8QZmtp27/yEszwLWqxx5AOzTZDBERPrFDEYnrm8t7Ui1KtHH\nfFR3X2NmHwGuJ2vGu9DMjk3e9vOBQ83sPcDfgSHg8LEeV0REymfulevHzex8d/9gzQ8X2KZVzMxh\nXjsOJSIyjszD3UsZv7BWEdYhZva3Gu8bKlMSEelbtSKQkwt8/rZWBWR8Sy+zerKKyPhRqw7k4nYG\nREREekuRwRRlzCaGZ+VARGT86IqOhCIi0nuKTGm7czsCMv4MhAckrZOHOhgWEZHWK5ID+YaZ3W1m\n/2pmG5UeonFDkYaIjG91IxB33wt4J7A18Esz+76ZvaH0kImISFcrVAfi7g8BnwJOBV4PfM3MHogn\nnRIRkf5SpA5kFzP7KrAQ2Bc4MIycuy/w1ZLDJyIiXapIM95zgAuAT7r7SKG+uz9uZp8qLWRSR/zV\nqXmwiLRfkQjkTcCQu6+BkWlqX+Tuz7n7JaWGTkREulaROpAbydqjAmwQ1slaBsOjHYajh4hI+xXJ\ngbzI3Z9JX7j7M2a2QYlh6mErOx2APqGxxUS6QZEcyLNhoicAzGxX1MFBRKTvFcmBfBz4bzN7nGQI\n9y2At5caqp6lFHF79PN1TotIq0zaKdJGdSMQd19gZjsCO4RVD7r76nKDJSIi3a7oaLyvAaaH7WeZ\nGe7+ndJC1fMmUG4qeYD+LkXs5zqQTuQ8pgJLOnBc6XZ1IxAzuwTYDrgPWBNWO6AIRESkjxXJgbwa\neLlXmzy9J5WdQ5hY8v5XAzPD8hBZqrRTuZJ254j6MefRScs6HQDpUkVaYf2GpOJ8HCn7D6isKqJ4\niPjV4TG9pGM1op+L0/rBMEmiS/PPtV6ta9r917xI6DYDfmdmdwPPpyvd/aDSQiUiIl2vSAQyr+xA\njD9l5XDinM2S6LlTRTr9XJndaWUXw+ZpWuZy1Lqe3X+tizTjvdXMpgHbu/uNoRf6uuUHTUREulmR\n4dw/AFwOfDOsmgpcVWagxoe4/LJVZZmTwyMemqz7Uymt1/1lw+VJ68Ha/b3H9W8iiSKV6B8G9iAM\n9BQml9q8zECJiEj3KxKBPO/uf09fmNkEkn4gUlVaPj2cWx6rFeGxfQv2lRpLal6jAbffEJ1p9dap\n40o3K/LPcauZfRIYCHOh/yswv9xgjSet/INNv67ngClheWV0jGZ+4IoApIj03mp35b00bhKwqi1H\nKpIDOQ14ArgfOBb4Ccn86CIi0seKtMJ6AfhWeEghZaXQ0v0+DOwUlncmma4eYHFJx+02SgF3bjy0\nskdZkLFr331RZCysR6hQ5+Hu25YSIhER6QlFx8JKvQh4G+2bt1VGmRSeV5GUKBI9S3/pVIW2KtK7\nX/tyiHXrQNz9qeixxN3PAt7UhrCJiEgXK1KENSt6uQ5JjqRfe3E1qVVDfqjsWTpFw9bI2opEBF+J\nloeBRcDhpYRm3Jocnsc6GZAmgpS0N3i7i5I0FpasrUgrrH3aERAREektRYqwTqz1vrufWefzc4Cz\nSIq/LnT3M3LvvwM4NbxcBRzn7uOgZnhqeF5G66YhTVOBU8gm+VGKsL90qkOfKs9lbUVbYb0GuCa8\nPhC4G3io3gfNbB3gXGA/4HFggZld7e4PRJv9Efgnd386RDbfAnYvfgoiItIJRSKQrYBZ7r4KwMzm\nAT9293cV+Oxs4CF3Xxw+eylwMDASgbj7ndH2d5Il3XvckvqbNCxNBS4ha0k9QOentBWRflRkKJMp\nwN+j138nG4ipnqnAo9Hrx6gdQRwDXFtw3yIi0kFFciDfAe42syvD60OAi1sdEDPbB3gvsGer9z1+\nxC1wWlWvIr1JdV/SeUVaYX3ezK4F9gqr3uvu9xbc/xJgm+j1VlQo2zGzXYDzgTnu/pfqu7s5Wp4O\nzCgYjPFCzXglLbpUAkKqeYSkt0X5inYI3ABY6e4XmdlLzGyGuz9S4HMLgJlhStylwBHAkfEGZrYN\n8CPg3e7+h9q7U4tiEZHaZjA6cX1raUcq0ox3LklLrB2Ai0jakn6XZJbCmtx9jZl9BLierBnvQjM7\nNnnbzwc+TZKs+oaZGbDa3Wc3e0Ljm4otJB2F+Y6OhkK6TWfmaSmSA3kL8CrgHgB3f9zMJtX+SMbd\nryOJfOJ134yWPwB8oOj+RESkOxSJQP7u7m5mDmBmLy45TF2u0Zh+IFpuVTNbzQrXv5TzkEo6839Q\npBnvZWb2TWBjM/sAcCOaXEpEpO8VaYX15TAX+kqSoqh/c/cbSg9Z1xqm8ZFJW93BLw7DxBL2LyJS\nX80IxMzWBW4MAyr2caSR10h2saw/9+Hcs4hIe9UswnL3NcALZrZRm8IjIiI9okgl+jPA/WZ2A/Bs\nutLdP1paqESkAjWekO5SJAK5IjxERERGVI1AzGwbd/+Tu7d83CsRacbewF1heVUHwyGSqFUHclW6\nYGY/akNYRESkh9QqwrJoeduyAyIi1aSdUQsPANFnGm1WP161/zrUikC8yrJ0hfTPZCJJFx3QD6ib\nxUPxNyr9zJU1t5JeNZZ7I9ZdY2H9o5mtJMmJDIRlwmt398mlh05ERLpW1QjE3ddtZ0CkUWlqZRjl\nPHqBRgsoT5qC78WGBZvTy/dGkbGwRERE1tKDEcgEis+DNd7E557mPHo39SLSGkP03u9gIDx26XRA\nxqQHIxAREekGPZiUr1bema6fUOE9kV6mZqq19eJ1SXNMN3Y0FGPVgxFIpchhkOwLGc+RRy/+UGS0\nCcDkaHlFWK713R4Qnu8BlpQULpHGqQhLRESa0mM5kPxopGmx1YoK245nm0fLcY6r1yoS+0n6U4u7\nTy0v+Nlrw/NAza36l4r4OjVSs3IgIiLSlB7LgcR6OOhjtpwsFzKIysV7STO55TRlOZ7r98aiF3Me\n4yPXpByIiIg0pceS8RPJYuwB+jtFlpaf99hX2LeqpTTHR0q0s1o1GGG7TGL0992K736YbIDV9v0v\n9lgOZHW0PL1TgeigSeExQNYrXX88vSf97iaRJIomdjY4PW91ePRKI4NVwKzwaOV33/57qcciEBER\n6RY9Vv4xTFJpDPBwJwPSIWluYybZ+fdjDqTXi32mJE97HQO3pT2R7+hYaHrfcO65km67Z8r4vtvf\nnUE5EBERaUqP5UAADg/P/9nRUHRGqCR871vhoivCumVkqap+61DZS9Kf2kzY+u3J4hDAY3U+N0CW\n646/a2mMrlsZeiwCGWB0T95+E76ui74Em5ySLO8J3B7e/stnOhGoDujFP4O0cvMBeDR8T49Oon7L\noSHUz0e6lYqwRESkKebunQ5DIWbm8I1oTTyOkJqziki3S5sZr6a9/1fzcHcrY8/KgYiISFN6rA5k\nCrAwep0Gfw9gt7B8XvT+eOupPic8X9fRUIh0l/R/YICsTqkbSyTSjtBxM/zeHlFDORAREWlKj+VA\n8mWHs5In2xv882Fd/P54qxtJc1k3Mr7OS2Qs4o6EaZPnVWS5kXjG0k6Ol5WG8wGy0bR7u+l96TkQ\nM5tjZg+Y2e/N7NQK7+9gZj83s7+Z2Ym19xY3ZxwgGQ9reog8hln7T3XKWILehc4Mj8PJxlMit9wJ\nE6gchrLGJkrHBOslg+HxfmB2eAySnUv8iK/nVJI/m/TRqXMfoPvHmhoiaVyznGxsrLRYK320ylh/\nb2k4ezshWOq/jpmtA5wL7Ac8Diwws6vd/YFos6eA44FDygyLiIi0VtnJ1tnAQ+6+GMDMLgUOJsnD\nAeDuTwJPmtmb6+8urmw6AfhSWK4Wiy+j+8bAGYu0M9o9wAFheefo/S+0NzgjZpE1bmhHhWBclNeo\nTt0PobiVK4GVFcIQF7dOIPuuu6H3+QR6Z6j0VKUSiVbvf2pYHqI7iqJeH55vbdsRyy7Cmgo8Gr1+\njOyqi4hID+uxSvSbyVJm84D16mzfmUlWypN+XQ+TZeLm0/n6gLsZXT6ehrOsVGs6kmkzjSQa2T7O\nCYz1XOrllvITDHU611FN3FS236V1sp3+/aXuDs/PAPe15YhlRyBLgG2i11sxpoF99iH7o5pKfw7p\nLiJSyw7AS6LXzRT1FlN2BLIAmGlm04ClwBHAkTW2r9/dfkIYRHD4S7W3G9GJlNwg2YyJz5GVjy6v\nuHVx6X7y59SpFGFcnxCHIZ52uIywtfN8O53a7oam6PHxy7oeY6mb6nQpQ5Hj7k+Wcy77Grav3qzU\nCMTd15jZR4DrSepbLnT3hWZ2bPK2n29mU4D/I7kLXjCzjwEvd/dn1t7j5jD8vbBc9Eto5x9A3Kz2\nnhL2nw5l//3c+k79waS5wYlUrkTs1eKOMira43GQYvWOMRx9No5M2n1dB6LnbqgwjqXXZHOyP/Nu\nu+9uJLuvppL1Vxkg+68Y6/3W/gi09DoQd7+OJE8Vr/tmtLwM2LrscIiISGv1WCX6/sBlVd6rl2ps\nVVFAfMni/Q2QNTArq24mTWF0Q7EGZKmoWSTNU/N67PYaMZZrW+k+nADsFL1O75MBYFFYvp/RqeZo\nP4eFYtubgL+k77d77pe05/R02tlMtJg0V7ec0an8tLn0ZLJc01hyJoNUzn0V/T2m28TVwCsKfrY7\naSwsERFpSm8lEbfcHpZWi63TmQpXU7kscJjsdOOxcRotN0yHpICoP2RQdquwtBJuCln4J1E5ZdMO\n4XhfPBpOSzsSxtdkrI0GqklT8M2cb9kdCSvtdxB+emCyOAfwNMW8Avh1hbANRPvZDX4UFrcgq4oY\nalUutEg91SSYcXSy+MgtLThmJWM5l7SpdbyPJWS/07J+F+n3FedwiloWnifW3KrbKQciIiJN6bEZ\nCX9EUlacilOTH0oWd5oCC88M66vlLgbIyk1r1ZmkgzHmUzCdGg4jTVGtyIWhU+GJM7B7hOdbyZpV\n5pv3VtJES62BucnzUKP1ABPIkvC1cp5xTqDSdtVS/9XWT8rtJ93/ROqf+85k9SRDjE6xFrlu8T1T\nL5x5IZxvOZ1PXvFvAHzBtqScnGXcGa/RUoGZ4XlRtK6M30L+uoX7kJXAV5vYFxS7B8aqvBkJe6sI\na63JpELF5NlvzeZa+i5wSxjU97YvUf3LKXKDVethWu/PY3Mq/8jylXBj+ePP91xuRquKQYYZ3Ww5\n/QMoMnprExHI0BWNbT9imGJ/TqGIzI6GkfTVFWQJiXwEHu+/0vp8RDRcYZtq8kWy8XhZRcTNhuOI\nvcixQ2T1AHzBNg7ruq0Jb5zQi/s/tGNah28nT185Gk4qsn3cFHqownLvURGWiIg0pcdyILFB2Oyt\nyeLHLmB0pVSI0Q+cC/PTKW4bbS43TPVK8Uo9X7PJbA7xTdiapB/kIqazKmx/i00gqwhvRhkplbR5\nZjwBT1Fxyq9Syr7I/ppJ0S4Kz2WkLCfAzKOTxTcA56UjHuTPpdJxTwAuDsvxedWqKK2WC603nljR\n8z4mPF/G6N/ISG18jc+G9xaeSfmd1Jr/Hgee3hWAoY1Wk/1m86Mbp5o5j2p/k4uTp5MKjIpx4Vx2\nfV/y2//lF/aA09PPTCUZtBzGPlX1tPC8inblFJUDERGRpvRgDiQEecvjYGk6je1EKpZ9zj+HZK4q\nSOYOGVh7m5rHSZsGx7H5HmQp4Cg1s9lcTnricwB85a3Hw5XpkCvbRdtPZrQ4hdRApWbLFK0TqGLr\nkLp9NE6BNVr2XK2+qJY01VzkmsX1ToNkncti8X4msudDNwBwuy1m7aFHalkJO4X7bWG+gr9aB8O4\nCWq8TXqvVqozy++nlvSe25nsXAYZ3TCkXl1cvH4q5TSLbTZ3PczQRpsA8Cv/ON/nHQCc8b65cFH4\nf9jyFFia5r7+M/f50LyaG2uEIf6dxjm3Bkadfv8V/PL9ocTkQfjSJx8D4OSHT8V2CRVtQ2PNgRwU\nnq8lmxsEkpHLy6EciIiINKXHmvGeAYRhHUYN5VCjWeWnT08WP3sBWQe0exjdvLFaq6pKc0HMjapA\nojAcORd+kKbwLiZL6cYtkWodK1UrZZkeeGK0/0abddbSaAp3drScNq9uNAwHksxp0ohGW6+l9Tx7\nkA3DMUBWJxCn/qF68+34+JWOvSPw9rAc35+TgL3D8iKynMAURmYqfMvkrCXhdcCVaV3ZjcBRYfl+\nsnvgjiphyHtLeI6Gmjl+Llt9LakreGzbmfBImlteVGWfcUuhmZTbYbbReq0JZL/laCiTLU/PJsn+\nG3BnWM7nDEeahNdqsZk6kKwOcwXF6pHigTBT+aFVxtIxNpYcY2/flVss7qB6amnNeHswAkm/iKJF\nL8mfx7/6EN94aWjeu/QzZFnXa6n+px7fmKlB2PL4aD+paVQeb2cio7O61Y5VqSlipe1g7T88ovWN\nyDchrDTq6+oC+40jySGyP7lq5xubReMjFzcagUQjEFx8XLJ4OTD/obD+SkYXVdXbb75fR/44lfZR\nb8jxncki4QFGn2OlP6iizT/jP7nwRzXpGFj1+ej9Wv2lUvEYU/kRGFqhmeK59HNxQi/uHV5pLKy8\n9M97BfWeCBuhAAATMklEQVSu56ZrjuGpddP/hHPIKq1rXY/4NxUXvTZ7vrWk+9yJ0f3lyusHoiIs\nERFpSo/lQJzmRyGdw8DTLwPg5o0Ged6T4pfX279U2X6Akd7to3qZVivaqjVSZyO9n2ulllrd4zxf\nXBDP9hinXKsVWdRLRRUpjmimKW5aJNVo5Xs+1V4pRzeTLEUZjzMWp8ZXk1VOx8UO0xhp2jlKkdRm\nvtlpulytyKhaLigvrUy9lewc8pXo1aTFX/OBkHPj2irhGau4Z3a9USLyKs210mgqv9Z9mOznWr+R\n9Xl+ZO2+llbIX0f13EuaY4kbb7R7xAjlQEREpMv0WDPe83KvG5kD5FaGNloEwO78BCzNRVTr2DcE\nM0Iq85H8e5WGh5hE5ZxDPGxEPoWapk7i1EutZqOVmhWPwYzT4ZE0RxfnoPaAO6cni1sOw7Qzwvoy\nUk7TaSxFOwHeG1LDFxWp+IzFZeQwOsWf3g+7kH1HJzLPTwNgfZ7nWJJ50Da5fgj7eMi5F2quW+l1\nLfG2+abfqaLnHQ//k36maGVtMlTQqX4lZ1ja4KDsEZ+HGJ1qL3LdKtXVrGL099tIU+XKDrCjyHJ9\n72RvvxuAWyaeAsP1Skaq1VtC60sW2kc5EBERaUqP1YF8jrU7YqXqNT/MN6NLU/q1WqCkZe1xriGu\n05hM1opjkJHWRK8+LkvQ/pmkdSfAtXcxeriCSdFn03AO1QhTaPLZqvnWD5uLPxGKRs+Gz7wyWZwN\nvMo3AuDnvI5DLR1pN3+N862v8oqU0zfTbDPdvsj+DyRpCgvJd55+Mfn9pKneN8CWYfmrQNpY6UNk\nX93882CfkAu6OUp57jUXbktzyfHQMDuS5bJqnWtclh/XV1SqVykqbfZ+ZnTsqWS5zfz1j7/HncPz\nZOCusNyOVHIjozkDh4WmuJevIGuaPZ/Rv/1q9ZDN1qfF916t+zAc99JT4OSw6tELGP39pmEey/dc\nS3l1ID0egcT9IuI/4Eqj6Oab1haYRGfkTyX+Yk8BrgFgw2f345kLNgNgz4/ewO0HvSHZZP63yW7I\nAbIKtClUKgLY6PljeXr99Lyuq7hNYsdoOd1/tQrdIvaHSSFy+C5wcNz3ID33gRr7TYez/mEUnrLH\n4Gk0wjmK7FzuIDuXCWRhngMzdwHguw8dxrsmX56sXvV5sgQCZJHPCrLvNA7LUSRFcpBE8uF6Hnc8\nnHdttI+4eWn6Jz0Fvh4W/waclCQSNvfNWG4vhDfuJ0v4xEVTta5H2tR0Mdmf1gnw43Au0+HdL/8W\nAMuYwvWWRnSraO+Q46k40VdklIK4+PEomBmawx/CyGC5fAVYPywfkStq2ivcw7fVGu+rFY1FBsn+\nl7Yii7gGyBKEY20enYYznpAMyuwHoiIsERFpSg/nQCYx0vlu/3ey3g+TVN3RgxexCX8F4AybRpbq\nepjRTVOLpBgqpTJ3hElJb+PXrryZn5+5bxK+k+KwxSmWIs0Sj8LvnJHs57UOXq1CLm7qOylaTrPA\njY44PMjInCoApB3r4lRfrdRVmrKPx0daQdal+lbqp1wbHQtrEqM7ZBURUpkG7B5WzYG9/y0pk9qO\nP7ADDwJwip0I3BI2WszoTpH17p8BRnIsd74Tdg8pyy1nwdK0COieKuGfmX2W3eCwsHgT8Je0WGwo\n+mzRXEGlSch2YiSndOCsbPUDwMI0p3R3lf2V0QEu3u8w9TtdxuLfaX5Uhv3D8l3R+vw+01z9MPWb\nqw9S/V4t0qCHCtu0ckTp9P7cidHFy29QDkRERLpLj+VAzmAkNX/T6UzbNykzXPy1HeGLYcOli+Cn\n0wHwfzfsjvT8rmV0ZVW9CuDZZOXM+VTLYLScppZW5LZrZKiROFV9OtU7S1ZKmVXrgFZElIsbNZRD\n3Ny1Vkq3Xuevarm4fBgaGRE4vvZF61uqddKMU41xZWp8XnGz0Hop43xlbaVOfLWuZZqCjitWa13b\nsdQ3peHZPBemernBPYCnwnIrhzRJv9e4bqrIcC2bk12H/D1WaXRjcvtspAPvblRuTFCtc3E+DOX6\noyfNzLcdfJzzV7xnZP0H7RLlQEREpLv0WEfCAXbypKXTwoNg8X4/DOsnMSqF8cZk2fgW/u4k4rXT\nHF6RtnZYTFb2v5LKZZ8To23y5cFxqrpSM+GiKg0M+flKGwbxsdIUTZyyaTSVM0yW0s2nnNKcyWqq\n1+HUO3aRa9Jo654JZN/LPRTLvaRhW0nlFGE8oGB8bScz+hzi3E+leoz8wIS3RsvVOohWCk9clzVQ\n5bPVziUvzvnEy3Ez9hXRtpXqIgZGttnPn+eml4cRh9fqRNkKyxndnLmearM95nPjlfYVf7dFcnOz\nyOpMLqZyjjGvyDBGrTHj40sB+MlfjANOy9Z/sMRj9lQR1ua+mOX242htvrI3L4pUHjyR/3lZUql2\nxHOXstcG/wvAtQajR65M7QFfD5VwH84PHZ+Kb964J3q1rPTeZH0SgM1C5e6TRacMHaiwLu7b0Oif\n8VyyCCvfPPrAaP1ldcIzgeqj07Y66z7I5n4wAMtfuk1uRORqKvWvyI9jNhQtp/fVzjDpgGRxGNgs\nrN4fuCgtyriR7Bw3J7sO8SjGcRFH+h4V1k2usAzZfZUfGblIBBL3HapUpBMXIcZFRkOwT7g/7wQ+\nEVZ/9ttR2Cr9blppLEVYcbEwVP+NFBmSPeG3z+PsPZK/45vYn/mz3pa8sSFR/598EWCrhmovIo3c\nHmZ045hDVYQlIiLdpaeKsJbb1Yyu6I1VSoVFzS13+B5vZp+w/gdcO5JqqdTpEGA1m34oSTU89eE4\nJX0AWTPPXcgqFHeCGUlnND5OdmWfJOtb9lng4SgHkg4xxYnw/jPXDnPegaFX8fxbyIrd4qKJCTTU\nm/Ur8N0T7wVgEqv4P14NwN9ZxU/DeR3K5Xx6nS8n2/vnc2FLK4nvJ0tpxRWrcQq7Wiq56LwWqSGW\nf22bZPG7wH51Nt9yLixNO0jeQeWxpaZk6x/cn42m/xmArdd7lN8texaAFx58cZLShKSv58W7JctH\nLWLknH91XNaCeek5ZCnjnchyHZsyuqNcfN3ijrFpcdl0svstnivmYern7iaQ5STvYXROKR1dd2UW\nTpsO/u2wfjEbXZdch33Wu4WrLM1+DdF4r+0iKk28FI8fVWMMq+PDpHHfJusw+CQkDWcgaSK9VVg+\nh9H32wnh+T+pV4xle86LXm2Y5cqeB25Lc3r5aWnDeR04F/4nrPIhsv+NTWFS2GbVWIsE49/ewqpb\ntZJyICIi0pSeqgNJOhKmipSt58vgGxmaYTC3fVqG+UkYCCnr3eEffrYAgN9c8xpIK64WXsDo1Ew8\nhWlcFhrqWC7eI0vdHrqIpIKukjA/wya7wMZh1YtIZiKFZAiMqp0QK9mR0eMjpY0M8vUZh4fnhxk9\nDtc7wvP2ZOf4BTgmlJ1fcA71m/E2alI4HhQbE2w2vDvUY7ySLMH/LIQMF5v+wxLOWydJkX+VE/iF\n7Rk2+gKV608GyFLhp5CkaoFJp8AOYfVrgXNCx8x9ts+Kp28h6685TNK5EZLvc92wvDMQgrDpvCU8\nNTME+pEhIJ2q9H7ql6tPIMklw+hr9X54bUiRn0Y23euGZKnkX3yGJOUOo5t4F5mhshlxSUA8xlR6\nrGq/17iRwRSy72gWTAj1AGsAfyysn8+oHNRrw736iyHgS1WOUSkXNMjouqy0ziE/unc84nY81Ei8\nPg1zq4YyyX8/mg9ERES6TI/lQOaNcS/NzlBWpLNbvglkpWaDRTrTxcOCVDoGVE8FNlqfEHd8yw9I\nmQ9fur7aaMipYUYPcdLqljpxi6YiqeFGW4INkl2Toi1n4pxqKh7Us8ggfXllpPLj+7NSJ9D4Hsin\n/svuEBcPFxK3qipy3ErXMT6XfMvJSh0JGx0wsuh91Ug181ivbftzID1ViT52jXxBE6PtizSxzd+U\njRwr3n+19uT5YzTzfl7cj6XWZ6udf7VzTIutyhiZd7jGcatt34gVVG4uXeQY+WPV+z7K751c/Xj1\n+hHlv/Oyw5ruP19BX+S4lbapdl7V+jI104eqke3KaNJe7VjtoyIsERFpSukRiJnNMbMHzOz3ZnZq\nlW2+ZmYPmdl9ZvbKssNUTJFesNWMJSXQiVRp/tGqffaqeNTbRuQz9L1+HaR1xud9UGoEYmbrAOcC\nbwReARxpZjvmtjkA2M7dtweOJWmQLTWtNUl7H9O1yOhaZHQt2qHsHMhs4CF3X+zuq4FLgYNz2xwM\nfAfA3e8CNjKzKXRcN6cYFnU6AF1kUacDEOn0PbOow8fvJos6HYC+UHYEMhV4NHr9GKPnCK20zZIK\n24iISJfpo0r0MhqcTaiyLOXphutc9r2Uvm7XuQ5Qu+VZN1xz6UZl3xlLgG2i11uxduP6JcDWdbYJ\n5rUuZD3v1vqb9A1di4yuRUbXomxlRyALgJlmNg1YChwBHJnb5hrgw8APzWx34K/uvlZniLI6woiI\nSHNKjUDcfY2ZfQS4nqS47EJ3X2hmxyZv+/nu/hMz+xcze5hkhKL3lhkmERFpjZ4ZykRERLpLT1Si\nF+mM2GvM7EIzW2Zmv47WbWJm15vZg2b2UzPbKHrv/4XOlgvN7J+j9bPM7Nfh2pwVrV/PzC4Nn/mF\nmcV1UV3FzLYys5+Z2W/N7H4z+2hY33fXw8zWN7O7zOzecC3mhvV9dy1SZraOmd1jZteE1315Lcxs\nkZn9Ktwbd4d1nb0W7t7VD5JI7mFgGskAVfcBO3Y6XC04rz1JBhj/dbTuDOCUsHwq8MWw/HLgXpIi\nx+nheqS5x7uA14TlnwBvDMvHAd8Iy28HLu30Ode4FlsArwzLGwIPkgyA3q/XY4PwvC7JYOuz+/Va\nhDCeQDJ92DXhdV9eC+CPwCa5dR29Fh2/KAUu2u7AtdHr04BTOx2uFp3bNEZHIA8AU8LyFsADlc6Z\nZKq13cI2v4vWHwGcF5avA3YLy+sCT3T6fBu4LleRTJbS19cD2AD4P+A1/XotSFpl3gDsTRaB9Ou1\neATYNLeuo9eiF4qwinRGHC8299ACzd3/TDL3KFTvbDmV5Hqk4msz8hl3XwP81cwG6XJmNp0kZ3Yn\nyQ+j765HKLK5F/gzcIO7L6BPrwXwVeBkIK6s7ddr4cANZrbAzI4J6zp6LdRDqLu1soVD1zeDNrMN\ngcuBj7n7M2aWP/++uB7u/gLwKjObDFxpZq9g7XMf99fCzN4ELHP3+8xs7xqbjvtrEezh7kvN7CXA\n9Wb2IB2+L3ohB1KkM+J4sczCOGBmtgXZ5AjVOlvW6oQ58p6ZrQtMdvcyJuhoCTObQBJ5XOLuV4fV\nfXs9ANx9JckkuHPoz2uxB3CQmf0R+AGwr5ldAvy5D68F7r40PD9BUsw7mw7fF70QgYx0RjSz9UjK\n7K7pcJhaxRgdy18DHB2WjwKujtYfEVpJzCCZrPrukGV92sxmm5kB78l95qiw/DbgZ6WdRWv8F0nZ\n7NnRur67Hma2WdqSxswGgDcAC+nDa+Hun3T3bdx9W5Lf/c/c/d0kE5sfHTbri2thZhuEHDpm9mLg\nn0mm++zsfdHpiqGClUdzSFrmPASc1unwtOicvg88DjwP/ImkA+UmwI3hXK8HNo62/38kLSkWAv8c\nrd813EgPAWdH69cHLgvr7wSmd/qca1yLPYA1JC3s7gXuCd/5YL9dD2DncP73Ab8GTg/r++5a5K7L\n68kq0fvuWgAzot/H/en/YKevhToSiohIU3qhCEtERLqQIhAREWmKIhAREWmKIhAREWmKIhAREWmK\nIhAREWmKIhAREWmKIhAZt8xsMMydcI+ZLTWzx8LyvWZ2ewnHO8rMlpvZ+S3c5+FhfobxMvqCjCMa\nTFHGLU/G8XkVgJn9G/CMu59Z8mEvdfePtmpn7n6ZmS0DTmrVPkVaRTkQ6RejRhY1s1Xh+fVmdouZ\nXWVmD5vZf5jZOyyZFfBXYRyhdIyqy8P6u8zsdXUPaPbysO09ZnafmW0X1r8zWn9eGJMonXnzlyGH\ndEPrL4FIaykHIv0qHsNnF5IZEP9KMuvbt9x9N0um1j0eOBE4GzjT3X9uZlsDPyWZ9a2WDwFnufsP\nwmjD65rZjiSzvb3O3deY2deBd5rZdcD5wJ7u/icz27iF5ypSCkUgIrDA3ZcDmNkfSAalg2TAub3D\n8v7ATmluAdjQzDZw9+dq7PcXwOkhwrnC3R82s/2AWcCCsK8XActIZt681d3/BODuf23d6YmUQxGI\nSDIicuqF6PULZL8RI5nuc3XRnYacx53Am4Efm9mxYT8Xu/vp8bZm9ma6ezIjkbWoDkT6VaN/1tcD\nHxv5sNk/1j2A2Qx3f8TdzyGZa2EX4CbgsDCrHGa2iZltQzJ89l5mNi1d32D4RNpOEYj0q2rzGFRb\n/zHg1aFi/TfAsQWOcbiZ/caS+c1fAXzH3RcCnyKZkvRXJBHTFu7+JPBBkils7wUubeRkRDpB84GI\ntIiZHQW82t2Pb/F+9wZOdPeDWrlfkbFSDkSkdYaAOa3uSAh8HejKebqlvykHIiIiTVEOREREmqII\nREREmqIIREREmqIIREREmqIIREREmvL/AdrGU3GGMvG4AAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.figure()\n",
"f, t, S = signal.spectrogram(s[0][0])\n",
"plt.pcolormesh(t, f, S)\n",
"plt.ylabel('Frequency [Hz]')\n",
"plt.xlabel('Time [sec]')\n",
"plt.title('Spectrogram of Output 1')\n",
"\n",
"plt.figure()\n",
"f, t, S = signal.spectrogram(s[1][0])\n",
"plt.pcolormesh(t, f, S)\n",
"plt.ylabel('Frequency [Hz]')\n",
"plt.xlabel('Time [sec]')\n",
"plt.title('Spectrogram of Output 2')\n",
"\n",
"# Storing numpy array as audio\n",
"wavfile.write('fastICA/out1.wav', samplingRate, np.transpose(s[0][0]))\n",
"wavfile.write('fastICA/out2.wav', samplingRate, np.transpose(s[1][0]))"
]
},
{
"cell_type": "code",
"execution_count": 20,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Mixed Signal 1\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 20,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from IPython.display import Audio\n",
"print('Mixed Signal 1')\n",
"Audio(\"fastICA/mic1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 21,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Mixed Signal 2\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 21,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Mixed Signal 2')\n",
"Audio(\"fastICA/mic2.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Original separated signal 1\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Original separated signal 1')\n",
"Audio(\"fastICA/source1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Original separated signal 2\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Original separated signal 2')\n",
"Audio(\"fastICA/source1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Separated signal 1 (output)\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 24,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Separated signal 1 (output)')\n",
"Audio(\"fastICA/out1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Separated signal 2 (output)\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 25,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Separated signal 2 (output)')\n",
"Audio(\"fastICA/out2.wav\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## FOBI\n",
"\n",
"FOBI stands for Fourth Order Blind Identification. \n",
"\n",
"As the name suggests, it is based on considering fourth order moments and using them as a metric for Gaussianity. \n",
"Covariance, variance and the covariance matrix are second order moments. \n",
"Fourth order moments are usually referred to by the term kurtosis. There are other ICA methods that explicitly work with kurtosis, but not so with FOBI. \n",
"\n",
"FOBI is a very elegant method that works without the need to search a solution space for the indepenedent components(as is the case with fastICA and other negentropy or maximum-likelihood based ICA approaches). Rather, it provides an explicit algebraic formula for the independent components. \n",
"\n",
"It has some striking and appealing similarities to PCA. FOBI is based on the following amazing fact:\n",
"\n",
"**The weights of the independent components are the eigenvectors of the matrix $cov(|X'|X')$. **\n",
"\n",
"The statement requires some explanation. \n",
"$X'$ is the matrix obtained after preprocessing $X$ (mean-centered and whitened).\n",
"\n",
"$|X'|$ needs to be explained. Remember that each column of $X'$ corresponds to the (whitened) set of amplitudes recorded at some instant of time by the **m** microphones. If we take this column to be a vector, then the norm (aka the modulus) of this vector is well defined. We find the norm of each column of **X'** and put these calculated norms in a row matrix. This is the matrix $|X'|$. \n",
"Hence, $|X'|$ is simply the norm of the matrix $X$ taken along the \"column-axis\".\n",
"\n",
"But here comes a caveat: The matrix $|X'|X'$ is not formed by the normal matrix multiplication between $|X'|$ and $X'$. We have written it this way only for notational convnenience. Instead, we are using the elements of $|X'|$ as weights for the columns of $X'$. That is, the matrix $|X'|X'$ is formed as follows:\n",
"\n",
"The **i**th column of $|X'|X'$ is formed by a scalar multiplication of the **i**th element of the **1 x m** row matrix $|X'|$ with the **i**th column of the **m x n** matrix $X'$ (each element within this column is thus multiplied by the same scalar value equal to the **i**th element of $|X'$). \n",
"\n",
"Hence, $|X'|X'$ is a weighted version of $X'$. It is easy to think of each column of $X'$ as a vector in an m-dimensional space. Then $|X'|$ contains the norms of the **m** columns of $X'$ i.e vectors. Multiplying each vector (column) by it's norm and storing these column vectors as columns in a new matrix yields $|X'|X'$.\n",
"\n",
"And what does the statement itself mean? Well, remember how we said that $X = AS$. After whitening, we can say that $X' = A'S'$.\n",
"Here, $S'$ corresponds to the source signals itself, but their amplitude has been normalised. (Recall how ICA can only recover the signals upto to a multiplicative factor.) \n",
"\n",
"The columns of $A'$ are the weights being referred to in the statement above. They are called weights because the each row of $S'$ is a source signal. Upon performing matrix multiplication between $A'$ and $S'$, we can see that $X' = \\sum_{1}^{m}A'_{i}S'_{i}$. Note that $A'_{i}$ are column vectors and $S'_{i}$ are row vectors. Hence, the columns of $A'$ act as weights for the source signals. \n",
"\n",
"Hence, FOBI allows us to directly compute the matrix $A'$ which as expected, turns out to be orthogonal. (The result says that the columns of $A'$ are orthogonal eigenvectors of the matrix $cov(|X'|X')$. Hence, $A'$ is an orthogonal matrix.) Finding the signals is now trivial. $S' = A'^{-1}X' = A'^{T}X'$. (The inverse of an orthogonal matrix is simply it's transpose.)\n",
"\n",
"Recall that in PCA, the principal components were eigenvectors of the matrix $cov(X)$ and they were all orthogonal. Here, the columns of $A'$, which are the weights for the source signals are the eigenvectors of the matrix $cov(|X'|X')$. And the weights are orthogonal to one another! \n",
"\n",
"The proof of this result and a good explanation of the FOBI algorithm can be found in the original paper by the inventor of the FOBI algorithm Jean Cardoso, [here](http://perso.telecom-paristech.fr/~Cardoso/Papers.PDF/icassp89.pdf). The notation used in the paper is rather different from the one that we have been using so far and can be rather confusing. The proof itself is however extremely elegant. \n",
"\n",
"Also, refer to the paper to better understand why it involves fourth order moments. Basically, if $X'$ were a simple vector, then $cov(|X'|X')$ is fourth order in $X'$. This extends to $X'$ being a matrix.\n",
"\n",
"So the FOBI algorithm in summary is: \n",
"\n",
"1) Obtain the data matrix *X*.\n",
"\n",
"2) Subtract off the mean to center *X*.\n",
"\n",
"3) Whiten the matrix *X* to obtain the matrix *X'*.\n",
"\n",
"4) Compute the matrix $cov(|X'|X')$. \n",
"\n",
"5) Find the eigenvectors of $cov(|X'|X')$.\n",
"\n",
"6) Store the eigenvectors as columns of a matrix $Y$. ($Y$ is just $A'$)\n",
"\n",
"7) Retrieve the original signals as $S' = Y^{T}X'$. \n",
"\n",
"\n",
"The code for the solvong the Cocktail Party Problem based on the FOBI algorithm is given below. In the code, we have used slightly different notation in some places. For instance, x for X and xn for X'. "
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Sampling rate = 8000\n",
"Data type is uint8\n",
"Number of samples: 50000\n"
]
},
{
"data": {
"text/plain": [
""
]
},
"execution_count": 26,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXl4FEX6xz81R05CyAEEEu5DCCAqiigquB6Aggq6cnst\nCQqIHCqgruLuCiouu+IBia7sLuCqIKiryKH+wJtFQRQUBDkMgUBCDnInM12/P97qTAjhikgE+vs8\n82TS011dVT3zfus9S2mtceDAgQMHDk4UrtrugAMHDhw4OD3hEIgDBw4cOKgRHAJx4MCBAwc1gkMg\nDhw4cOCgRnAIxIEDBw4c1AgOgThw4MCBgxrBIRAHDgCl1BSlVOrJPvc42rKUUi2P89zHlFLzTsZ9\nHTg4GfDUdgccODjZUErdAUwAWgF5wFvAFK113pGu0VpPP972T+Tc42nu1zhfKTUXSNNaP3riXXLg\n4PjgaCAOzigopSYC04GJQF2gG9AMWKmUqnbBpJRyn7oeHn77Wry3Awe/CA6BODhjoJSKAKYCY7TW\nK7XWfq31z8CtQHNgmDnvMaXUQqXUPKVULnB7VfOQUuo2pdROpVSmUuoRpdQOpdTvKl0/z7xvZsxQ\ntymldiml9iulHqrUzkVKqc+VUjlKqXSl1HNHIrJqxtNcKbVKKZWnlFoOxFb5/A2l1F7T9iqlVHtz\nPAkYCjyolDqolHrbHJ+klNpmjm1USt1Uo4l24MDAIRAHZxIuBYKBJZUPaq0LgaXANZUO3wC8obWu\nB7xqnwqglEoEXgAGA42ASKBxlXtVNSV1B9oAVwOPKqXOMcf9wDggGrgE+B0w6jjH8yqwFiGOvwC3\nV/l8KWKmawCss8ehtX4JWAA8rbWuq7W+0Zy/Deiuta4LPA7MV0o1PM6+OHBwGBwCcXAmIRbI0lpb\n1Xy2l0NX8F9orf8LoLUuqXLuzcA7WusvtNY+4Fh+BA1M1VqXaa2/BTYAnU3b67TW/9OCn4FUoMex\nBqKUagJcCDyqtS7XWn8C/PeQm2r9T611kda6HPgT0NloYdV3Uus3tdb7zPuFwFag67H64sDBkeAQ\niIMzCVlArFKquu91I/O5jbSjtNO48uda62LgwDHuva/S+yKgDoBSqo1S6r/G1JQLPEEVU9RR+pBj\n7m1jl/1GKeVSSj1pTFK5wA6EyI7YtjGzrTcmrxygw3H2xYGDauEQiIMzCV8ApcCAygeVUnWAPsAH\nlQ4fLZppL5BQ6fpQIKaGfZoN/AC0Muayhzk+x/leIMrc20bTSu+HAv2A35l2m5t27bYPGZ9Sqimi\n/YzSWkdpraOATcfZFwcOqoVDIA7OGGitDyKmnOeUUr2UUh6lVHPgdeBnYP5xNrUI6KeU6qaU8iKO\n+aPhaEI4AjiotS5SSrUD7jmeDhhz11fA40opr1LqMoQwbNRByDJHKRWORJ5VJo19QOX8knDAArKM\n9nIn0PF4+uLAwZHgEIiDMwpa6xnAQ8AzSA7IF4jp52rjKzieNr4H7kWIZw9wENiPCOxqLznK//cD\nQ5VSB4EU4LVjXFsZQ5Aw5APAH4F/Vfrs3wgppgMbgc+rXPsPoINSKlsptVhr/QMwE/gSyEDMV58e\n5d4OHBwTqrY3lFJK9Qb+jpDZP7TWT1VzTk/gb4AXyNRaX3lKO+ngrIZZ4ecCrbXWu451vgMHZwtq\nlUCMs/NH4CpkpbcWGKS13lzpnEhkdXWt1jpdKRWrtc6qtkEHDk4SlFJ9gQ+Rhc1fgYu01l1qt1cO\nHPy2UNsmrK7AVq31LmNeeA24sco5Q4A3tdbpAA55ODhFuBFZ1OxGci0G1W53HDj47aG2CSSeQ8Mp\nd5tjldEWiFZK/Z9Saq1Savgp652DsxZa6yQ7WklrfY3Wemtt98mBg98aTodiih7gAiSDNxz4Qin1\nhdZ6W+12y4EDBw7ObtQ2gaRzaGx7gjlWGbuR7OISoEQp9TGS5XsYgSilajciwIEDBw5OQ2ita5QP\nVNsmrLVAa1OQLgixM79T5Zy3gcuUUm6lVBhwMZKYVS201mfk67HHHqv1Pjjjc8bnjO/Me/0S1KoG\norX2K6XGACsIhPH+oJQaKR/rVK31ZlOJ9FukMF2qljh9Bw4cOHBQi6htExZa62XAOVWOpVT5/xkk\nMcyBAwcOHPxGUNsmLAfHiZ49e9Z2F35VOOM7veGM7+xErWein0wopfSZNB4HDhw4+LWhlEKfpk50\nBw4cOHBwmsIhEAcOHDhwUCM4BOLAgQMHDmoEh0AcOHDgwEGN4BCIAwcOHDioERwCceDAgQMHNYJD\nIA4cOHDgoEZwCMSBAwcOHNQIDoE4cODAgYMawSEQBw4cOHBQIzgE4sCBAwcOagSHQBw4cODAQY3g\nEIgDBw4cOKgRHAJx4MCBAwc1gkMgDhw4cOCgRnAIxIEDBw4c1AgOgThw4MCBgxrBIRAHDhw4cFAj\nOATiwIEDBw5qBIdAHJy10FozefLTaK1ruyu1BmcOHPwSOATi4KzFm28u58UX97J48Yra7spJxYmQ\nwpk6Bw5ODRwCcXDWISVlPh069OWhhz4hP38mU6Z8TIcOfUlJmf+r3fNUrvSPhxRqYw4cnHlwCMTB\nWYfk5KFMnTqakhILUJSUWDz++BiSk4ee1PtUJo1TsdI/EVI4VXPg4MyGQyAOzjoopVBKkZtbQmLi\nBHJziyuOnUy8+eZy/v73T2ja9MpTstI/EVI4VXPg4MyGp7Y74MBBbWDr1jTmzu3NgAHXsnjxCrZu\nTTtpbaekzGfWrNcoL+9Maenb+Hy3s2PHPmyhPm3aGG6+uddJu5+NqqSQlmYdlRR+zTlwcHZAnUnR\nF0opfSaNp6bQWjNlygymT3/AWVHWArTWLFq0jIkTPyYtbToxMcMoKoqiRQsPaWmauXP7HDeBnOiz\nnD79Jdq2bXoIKUyePOKXDsnBGQylFFrrGgmKWjdhKaV6K6U2K6V+VEpNOsp5FymlypVSA05l/05H\nOJE1tYuqmkB+/kFGj45n48aZzJ3b54RW+if6LKdMSeLmm3uhlOLmm3udNPJwwn0dVAutda29EALb\nBjQDvMA3QLsjnPch8C4w4Cjt6bMZc+bM04mJ1+s2bR7SYOk2bR7SiYnX6zlz5mnLsvSkSU9py7Jq\nu5tnNOx5fuKJFL1o0TJtWZZetGiZnj79pRNqx36WUVF3H/Ysf21U9115442l2uu9Ri9c+L7zXTrD\nYORmzWR4TS88GS+gG/B+pf8nA5OqOe8+4B7gFYdAjgzLsvQbbyzVTZpM1qB1kyaTK37wCxe+ryMi\nxulFi5bVdjfPaJysebYsS0+Y8IRWauRhz/LXRuUx2EQWFzdcw306Lm64Tki4XAcHj3a+S2cIfgmB\n1LYJKx6orM/vNscqoJRqDNyktZ4NOAb9o6C6yJqVK1fTsWM/J97/V8acOfOIjb2IKVM+/sXznJIy\nn44d+/Hqq5vROgSvdxjp6QdYufLjX82npbWmd+/hh4UBT536HHv27CMrKwT4GxkZFhkZRZSWXux8\nlxzUOoEcD/4OVPaNOCRyFNiRNRs3/pW5c/vQvHnLsyLeX59EG31N2oqJiaWo6GJyctKw53nq1NFs\n355+xHaOdB87HLe4uBDoTXDwAcaNa0GLFi1+tTG9+eZyPvssht69ux/yXZk1ayp33nkTfr8L+emF\noFQQMPSM/S45OH7UdhhvOtC00v8J5lhlXAi8pmTpFQv0UUqVa63fqa7BqVOnVrzv2bMnPXv2PJn9\n/c1jypSkivd2pM+iRcsOCe2U886sKC3b2XzRRSt+cYjsibRVOWS3uPg5SkqSCQq6kP37G7FmTV1S\nU/fTtWugHV0pqupI97E1SctqSkLCXHbvbo7LpZg8OelI3ajxmCr3v6Dgb7z66u3s3x9KXNxd5ObW\nxeVykZGRTUiIlxYtxrNli5vy8oYkJAwhNzfOyR05DbFq1SpWrVp1chqrqe3rZLwANwEnehDiRG9/\nlPPn4vhAjgm/368vvri/9vv9Wmutp01LPcShO2TI/ToiYpxeuPD9094ZerTAgVPRVlW/U0zMfTop\naZKOj79cx8TcfFg7Cxe+r4OD++qEhB5Hvc+NNyabc6ZosHRs7Cjdvv11ulev4RXPqzpndtVjxxpT\n1f5HRg7QEydO036/v8L5P21aqk5OnqLbt79Oe719NaTqNm2m6ISEHvqmm5JPeJ4d/LbA6epEl77T\nG9gCbAUmm2MjgeRqznWc6JVwpGiYCROmabhb33//9EOOz579bx0Tc6Fu1Wqyhid1w4bDtMuVrJOT\np5zKbp9U+P1+feONybpJk0kaLB0R0Ue/8cbSGpHi0YIQjgbb6ZyYOF5HRNynFy5caghgUkU7SUmT\ndfv21xlB7tdxccO0x/OHI96nal8iIkbpCROe0BER91U4r6tz2FeOljreMVXtf3XO8dp06jv4dfFL\nCKTWfSBa62Va63O01m201k+aYyla69Rqzr1La7341Pfyt4mqOQJDh44hOPhcnntuJ/Aizz67g+Dg\ncxk6dAwAMTEx5OZ2IS3tI2A7mZn5WNYc/u//OG2doYsXr2D58lyysgpJSBhEfn4z/ve/DTUyq9S0\nvEdVv9OSJR+xYkUQWVk7Ktq59toePP74GONfcFFervF6Q0lMHF/tfSr3JTKyF/n5XzJ3bhr5+X/j\nnnteIjj4XEaPfq/C2d248eU0atSNsWP/Q3l5Ivfe+yodOvQlNXVBtWMCKnwiVftfNU+lNpz6Dk4P\n1DqBODhxHKlo3uWXd2X06IH4/QqYgd+vGDNmMJdf3pUOHfoyYsRs/P7dlJV1BOZgWZFAP7KyNp9W\nzlCtNb1730Zi4vU89NAnlJREUlb2Kfv2hQAv8s9/ptGhQ1/mzJl3ws7ww4Xpz0dtQ2tNXl4OAwZc\nS2rqAh599DnWrg2iuHgWUVGNgB8ZPDiUbdt2n3By4fz57xAZuY7Y2AuAm8nNLQcU5eVxnHtuS4qL\n/Yiz20/fvt1xu4MroqWyskI4eLAAqJ4gKi8+jpV8eKhTvw8NGyYwfvwvc+o7ODPgEMhpiCMVzRs5\ncjhKubCs/cB2LGsfLpcCFHl5ByksjAdGI9E0CvASEaEpKMgHOG1Wk2++uZzPP4+mT5/LzBykUK9e\nB+rWjQIUoaF1efzxMcTExJ5wRn5VYdq6dRNeeGEPAwbcUy2JVBbEVZ+LxxPK44+PYc6caUyePKJC\nkH/33TNcd11joqNjjpoxvmTJC8ycOZnSUg38DHiJj0+mtFSzbt1+8vP9KDWYrKwCrr22JwMH9qqI\nlvL7XQwc2Ivk5GGHjCkrK5N58946obDuyk79xMTl5OWVcMklF/wip76DMwMOgZyGOJKpJTV1ASkp\nC4mKagjMJioqjtmz30ApGDiwN37/LiQi2gOMBzyUle0CWvPYY89W2DUnT34ay7J+c6UrDtW8/sZ/\n/rOP9PSVxMXdSGFhOUVFfhITJ7B//0bGj3+Shx/+tMY5GSkp80lMvJ7k5OcoKLiWt99WNG3as6KN\n6rTAjh37sXLlx0c0gdmCfPHiFXz4YSht2jQ56hzb12Zl7QB+RqmvKChYQ3HxB1jWQaAYrRdQUrKD\nO+98hE8+WUNIiJfExPGEhHjYuzf7kEWB1podO9J57LFRJxzWfSwzl4OzFDV1nvwWX5xFTvSqkVXT\np790VIfpkCH36+Dg3+uIiJ4a+mn4t1aqs4bhGiyt1AidkNBDJydP0hER4/TEidN+M5nrdrCA3++v\nEjE0piJiaMiQ+/WQIfdXZN0PHjzhqI7jY5XjsCxLX3XVEA0jKuaoUaP7DikNI32xHeWT9MKF7+tp\n0wIlTBYufF/36DG4UkTUv3VMzMW6dWs7iGFoRRCDZVn6wQef1JMmPXlIBFWDBpfqRo3u02Dphg3v\n1V7vOTo0dICGoRomaXhKR0eP1W+8sfSY5VNsB7s444/uND/SM/i1neZOmZRTD36BE72280Ac1BDV\n5XsARyzn3bFjW/r3v4r585ewdKkLv/9NLKs5EA0otPaRnp7Jyy/vxrLmMWvW3ZSXp3PPPWk8+uhz\njB07iJEjh53ycULlHIaVVcbn5pJLLsDlcrFgwYyK82+5pTcA7767/IhlzY+W6zFnzjweeWQWHs+l\nSB7rCKAfeXmKWbPGMGDAtUyZMoMuXTqRlVWIUkPIyooGIC8vlwEDkirutW5dQxYvlntER8dSWNiU\nnJyPgY7s23cQmMdHHz1E3brnUVwcSVBQ54o+JScPJTo6hokTPwYUPl820AmfD6AICV5sSH5+Fi6X\ni4ceSq4YQ3W5HtnZ0ZSXJ5Kauo569bIYO/YPxMY2OKY2YVkW7dpdzd69nU5Kns3RcDLzeRz8+nBM\nWGcYjmRqmDIlCa01//3veu69twn/+U8ydeqUAuXAICCMsLCmREXFAgrLcgFjCA5uzdSpo9mx48gZ\n1b8WqjMTjRr1ZwYPDj2mKeVI83Bom38lKWkWiYnXH2LesrPK8/P3mCM7CA/3U16egFKKxYtX8Pe/\n/8wf/vAIkZF5aD2fyMiD3HnnwzzzzHbuvnvKIf0eNepdgoPPZfDg+ykp+R7Lag/MARoA/di27R0K\nCjz4/RdQXDyLIUNepXHjyysiqPbv30hQ0IVkZ4dSXn4NLtd2XK7NhIZGAbMJDo5m1Kg/HSVoQHPw\nYEGFg72kJLrik2NV7E1JmU/9+t3YurUtBQV9frXyJSeym6LWTmXg3wxqqrr8Fl+cRSasE0H1BfF6\naJfrUu12X6AhSUdHX6vd7it1aOgYHR+fpGGkTkgYqCMi7qs1c9aRTHJ+v7/CzHGiJo9D23xfw0g9\nYcI0bVlWlaQ7v4YeGtprSNaRkdfpyMhztdfboSK5Ly5urHa5OmkYpT2eC3Vw8O0a/Dos7GodH3+Z\njoq6tyKHY9y4v+iwsGQNt2q4Q4PWcJeGDhru1PCehrs1aB0ePrIil2XatFS9cOH7+vXX39MxMfdp\n0DohYZKeMOGJiv9jYu7TCxe+r994Y2m1z6lqDodSI/XEidOOOWdDhozWQUGdtNt9pwZLw0MazteX\nXdb/mNdWNjsez/Op7lm/8cbSQ0x6NpzCoCcXnM55IA5OBQ5dgdohnlFRhfj9F9KlSyYPPHALAwd2\noX//EEaNupD772/OhRdGEhn5Df/8526zKlx9SvNFjhQssHjxiorIp2Ptl6ErrVa1ljIiK1euIj19\nJW73ImA2c+f+TMeO/QBdKYrqISAfpS4C5pCXF4vLFYLWMWRk5AKK3NxiLCuUiIgN+HxFlJYGASso\nKmpFbm4eRUUW8fFJ5Of7+eSTtRQVaWATEAzcBLjp0qUVwcFu4B3AAm6hvFzhcrlQSjFlShK33NIb\nl8tFWZkiMXECmZmb+Oc/3+LAgRLgWg4c+IHBg+9nzJil1a7elVLs3XvgqA726jBv3ixGjx6IZbnN\nkc/xeFowdmzSMa+1n8uDDz51XJFw1T3rNWu+4cUXMyquPREtxcEpQk2Z57f4wtFAqkXVFaisfNuY\nv5b2epN1UFAnnZh4ZbXZ0NHRYyuctb929nFVjaJysEBy8mTdoMGlFXtkBAXdpr3eizT8W7dp81BF\nqY8HHwysWiuvVt94Y6kOCrpHd+lyow4OTtRu991mPu7Q8fGX69mz/62Tkydpl6uL9nju0pBsnOhP\naRiug4L6Gk1hpIYbzWc3ajhHQysN7TT8wWgvnTW01cHB1xhN50INbTVcZf4frqG1eQ43mXv11HC5\ndrm66fr1ux+yj0tlB/nChe/rjh37mfuO1eHhvXX37oMqOfQPDxqoLujiaPNuQ6oaJGuX62oNI3WX\nLjcddW8TW4urX/9mDddrrzdZg6UbNBhzzLIwdh/nzPm3TkjooWNjR+lDy6/8W7/++ns6IqKPBqta\njdTBiYPTuZTJyXw5BHJkDB48QYeGjtFxcXcaIddFw30VArRjx17a47m6ogSG1iIMEhIu19DfmFdu\n0gkJV9SoztTxmpqOZp6oSoQxMffpmJihFcJkwoRpOjR0tA4JuVUnJ0+uZI76t/Z6L9Jut0RT1at3\ntzEdJWsQc12/fknasiz9xBMpesKEabpOnVuNuelGc15/E72Wao6103CdiYa6XsOlpq0bKkxjHk9b\nQ9Jaw8Xm+j+Y/5MM6Zyj4TZDOpeb53KNvvrqYdXu4+L3+3Xz5pfq4OAOhsje10qN0NHRF+vg4L66\nfftx1W78VHX+q/5/pHlv3/6aQyLHQkPvOioR2IsOKeOytIKk7Si14xHyR4smtMv02ObVRYuWOSat\nX4hfQiDOnuhnCaZPf4mlS5ezZs0WfL7maN0OKAD2APVxu7fi959PXFw25eU/8sQTowF48MFZFBR0\nwrL+gcv1B+rU+Y6nnx7LyJHDT+j+ixYt4667ljN3bu9qo2sqV4XduvUvtGnzCF7vBu69dyA7d+6l\nefNGPPfc62RnR5OREY3Xm4XPF4rb/SOxsZFkZOzE7T4Pv/9fwMN4PCsJDy/H5bqCnJyLcLlmoHU3\npEJOMvCpufNFQCjh4Xto1swiPNziq692oHUToBBog5RguxzIRgpCXwCsBTKBlsBeoC/QHvib+Tsf\nuNOcVwxcCdwCvG2uywZaAVlAFGLW0sBXQHfq1t1ISUkW9er1YP/+WRXzkZa2lfx8F9AV+CfwCLCU\nkJAi5s2TXJ7bb19K//4h9O9/VcWca625885lXH11CYsXz+bNN5dz113LGTw4hE8//e6webej7rSW\n/d3vuWcBBw7UJyYmizlzhlYkJh7tWUdG7mH37mgSEvzk5YWd0F7wdhtNmijS0iwGDw7l00+/Y9++\nZhw48Dxt2jxMZuZKfL4SGjW6odq+Ozg+nNZ7ojs4NZgyJYnVq99gzJhBQBzQFtiDUgq3+zP8/lDg\nb+zfH0x2dgnr1m0iOXkYI0b0R+sgJNQ3iKSkASQnH/+P83jt1kfKrrezyWNj6x9WTuPSSwu49dau\npKe/xYQJgwgODkMy7C08nmDuuuv3+Hwu2rf/Gq1j0NqNJFBuAzoRHt6MOnVKgBCKijJ47LF7iIuL\nByKAJohwFr8GdDLzFo0I/QLgEuB9oDmQAQwDGiGJmsq0EwP8DvgB2S9tL/AtQjyfADsQ0gDxi4QC\nn1NaWkLnzi0JCpIxpadn8f33Wygo6A4MJfDT/RyXqznDh9/EY489z8MPf0pxcVcWLlzN0KH/IT9/\nJrfeOo8hQ/5IQUEwb72l8Xo7VNTR+ugj+Pnn3WRlHaS6xMLU1AVMmPAU2dmhwEyys0MYP/5JUlMX\noLVm0qSnmDz5KSov3OwIuFGjruL++5sxatRFJ5x8eKR9bWTna0V2dhGpqX/i5ZefrPBJlZT4adMm\ngREjBjtRWqcITh7IWQRxzLrQ2oXHsxKfrxFhYV/g80Xh9zdHwncV0JGPPnLRsWM/wsODCAmJp0WL\n8ezYcXzO18qomstQUmIxbdqYw1aiVZ2oP/20lfHjvyA0tDv5+TN56KFHKC7+jJKSCBITl5OWZjF+\n/B0V7VxyyQXMnr0XpYagdTElJR1Yu3YTc+fejmVZDBr0JUrtIySkiKKiVrhcn1BYGALUB3qhdQkD\nB05ABPt5iIB+yPwtQ3YSGA+sQjSK/sAB87kfEWzJCOEEAQMQbaUe8BKSSzID2cHgKoQsdiHb33QB\nZpv2i/F4/EBLNmyIxeXaSfv249m82cLl6ohl5SBlTYIQYjqHZs220KJFa665pqeZ52HUrbsciOLA\nAYVlBWNZxebec4iIuIfs7C+BBeTkFFNaWh+/n2pzZpKTh7J69XpWrPBz4IAiOjqcK664kOTkobz5\n5nKeffZrfL5sNm/ezpIlcyoc/za0lsCFAQNGnND3pmqeU0rKfCZMmE52dgdgPNnZJUyY8CTnnJNA\nfn4E8fHJZGUFsXx5DpMmPU1q6n4nl+QUwNFAzjJs3Lid++9vQWnpa0yc2IzWrVvidocCXlyuweas\nOEpLNY8/Pob+/Xszb15fNm6cybx5/ejU6ZzjvpctPIDjqnBbuVZUnz7xXHbZBZU0Ej8RESHMmzeq\n2hyQrVvT6NjxZ+Lj9xAX1xSYw/r1YQwZ8gCjR/8Dy4rCsn6gqKghkIrWXREi+B9izpqNmIVcwNeI\n1lGKaAQhiEbhRwR3W6AHIpBvMMdXmfNbIxrODuBzwGeu3WWuvcDc6xMgByghoLEUAdegtRufL4Sy\nshcICqrHli3L0XqTKV+yE/gY2Ay0AGaza1cC8+a9xRNPPEdGRi6JiRPIyysmO7sIr3cYUAchs73Y\ndbKgGV7vErKzSygvP8/ks2xh8OCwQ+ZVKUX//leTn19GYuJ4ysqgTp0gGje+hCFDHqW0NBi/vx1v\nv72f6OiLDtMsjxUldzRoHYigS04eyuWXdyU6ugCYSWjoATIyMvnoow1AJBkZX1NcvJ2SEjfPPruD\n/Pyt3HPPS06U1q8Mh0DOMixf/hIzZkzG5XLxzDNTeOSRkfh84SQkZBIUFI3Xu5PY2K1kZHwNwJQp\nyUet1Ho02MLjrbc+Oq46SlVrRTVuXJ+MjK9p3348WVkF7NgRicslX9m1azcwadIfDrl2zZq3mDlz\nEoWFUrXW5Qqic+eWBAe3AgYimkQwYo4LRr7+iYj5aQYiyO8Fzsftbo7HE4mYpzzm+o1AY6CAiIhn\ncbn2IYI8CKiLaCEzgI6I+SoS0WhuRvZMCzfHFKK9NMXligS8hIb+3hzviVLx1KsnFQIOHizFsloh\nJNcKyAeuAHphE098fDx9+lzGpk3NgJ94/PFe3HprS7p3L6BhwwTgOoKCXISGhhMfn0xRkZ/77uvC\nvHl3ERS0EUjH42lE27ZNePHFP5Obm32I+eettz7C5TrA1KnXctVVJTRv3px+/Xrg8xUhfpvngPbk\n58PUqc+TkjK/wnQpe8THMXlyIAS8MjFUfm/DNo317383L7ywp4J8iooKKCuLISbmdsrKLHy+Bmh9\nGVAPv9+DEHpDfL4sIIGgoFanVZXp0xGOE/0sx/TpL9G2bVMGDLiWYcNki9sbb/xdhSO2comQ48Wh\nDvE/ExXVj7g4uO++wRWO2SlTnkZrePLJByu0kaqO9Dp1RlJQ8DWRkT5CQzuTkXE5bdrspLj4MzIz\nI5g/fzRDd13/AAAgAElEQVRr125AKZg27QE6dryWLVvSsaweiOZQBKzC5apHZGRdcnLCgYaIIC/E\n7f4Gv78z4tRuAOxDfBstaNFiGzt2tEV8F/sRsrkcqINS/0Pr/Yh2cQ1CDqsRDaQBQhIZQC7wMLAQ\n0TjCEKd9NuJL2YoQQgTnnx/B+vUeQkPzKS6uQ1BQI1q1CuaHH/JN/34PzCTgoL8N+J6QEEVJicbt\n7lARQOD1fkBMjIt+/a7ktddKaNJEsW3bNsaOvZSnn57E4sUr2Lo1jczMTGbOXItSDfB4snC73Ywe\nfR6pqfuZO7c3WVmZhzyPuDjZ7nbEiBiuvvpyhgz5Kz5fc+BlYAp16mznlVfuqCglcyTnu+3At537\nd921nFde6cVXX33L9OkPMHLkQ7z00g+Iz+kmWrf+mL1736Ww0KJTp8Z89902RCu8HMnovwbxL12M\nBBYkAWvxeCJ57bWHHTPWMfBLnOgOgTiowJEioU40qsWO3Jk48WPS0nqg1NtMmNCUGTMmo5Ri0aJl\n3Hbbe2i9n/nz7zpkv/BFi5YxcuT75OTMwuO5B5/vBho2XEZm5qdYVhguVxvq1y9n374OhIW9R1FR\nNF5vY8aObUpq6j4aN97Mli05wBfIyn8zskq+FOgGvIuYlzQBjeQqJHpqKLABKe9yIbAA8TNkIMIq\nBfFTfIyQQE9EoG8C1phzPkA0kihEAEYgwu5DIB5xzq9HyMZtPotEyGUi8AbiZPchBNgeMXVZQJ4Z\nw0vAH4BPCA31cuml5/PFF3UoKpoDTCEmJo3Zs4eybVsabds2Y8CAaytIY/LkEaSkzGfq1OfZv78c\ny+oFPGHGuQ+X62Is6xUaNBiL37+WAQN6sGjRVnJySpGotN7Uq/cx5eUZFBXlovU1pl91gQySkzuQ\nkjKdlJT5/OUvL5Oe3gatU1EqmcjIbwgJcRMRcRVbt/4Fl2s4bvcWysvHEhe3koyMEEJDP8PnC6O8\n/BrTrzuQIIN6wPm4XLuxrCyE0Dsg5sAkxEQYj/iqRgCRxMX5sKyv+NOf7nGiso4CJwrLwUnBkSKh\njscEUNkUoZRi5cpVpKW9i9f7Jlq/yJw5P9G48SVERnZh6ND/UFw8i5KSVgwe/EcaNepGSsq8Cn+J\nz+ciPj4Jv18DLnw+hQjlDsAu9u//GniboqIioCHl5S/y179+T37+Vnbs8CPCtyuibcQiZKERjSDG\nfN4NCMbjsQW8QoT404iwkmMeTwvE0b7NjLQIEWyXIILtJ4QQuiKCvTtCGjnAPQhB/YTLFYKYtnzY\nZjS42vQvCPFn9EbMUtcgP80LgbfMuAtxuWxH+ARzXjD16sXQsmUCWnuAm3G5cigsLMflcjF5chJr\n124ADq15lZQ0hK5dzyUqqp2ZF4WYx4ZWjNvvd1NY2IyIiEjKy5sSFVWGkOJX5OYm0LPnBWgdi2he\nXiSoIJvXXvuAlJT5xmfRhejocECc7336XMGzzz5a8f2yrHBE+XyWjAyAFCIjr8bnK0eIXyGahUZ8\nTs9hWXUQ899Bc7y/mavmQDDR0cNRygMU4vGE8sILfyQpaYgTlfUrwSEQBxWo6ZaucLizND+/HK/3\nHOrWFQFSWOhmyJAbeOmlPxERIRs/gaZu3bbMmvUYUVExzJz5AUuWfMjcuX2YObM/Lte3BAVN5MCB\nFVhWItAdy0o3YcU9gT8TEIBu4DLKypoBf0GptsD/IY7jOOB7hAQOICasFCAMn6++OTYI+Tk8AXRG\nQnX74/N5EEd3W0RTUYg5ajPiEE8Bzke0kAUIGfwJEcQTgd0olUlQkAfRir5FtI+eyOq5mbn/TiRy\nSwHbgaYEiMYHaCyrDVKBdwdiVgshMzOL/fvzuOCCA7hcsYwb15QWLQr48cefj+jAXrx4BStW5HHw\nYBlK5VSMPTp6FZZlodRNZGeXUFJyJykp2ykqWk5Ozk+IMI8HUnjvvSIzL/XM2A8AFxIW1p5nn/0P\nqakLGDDgGsrKFO3bj+fgwe8ZMOAaPvjgE9LTs41zP4SysnAzfzkAZGSsR+t6iClQinxKYEIR9iZo\n0M7M4RfIguBL3O61hITkcMcd7fF4tgNpZGXtOKz0jYOTC8eE5eAQVPaJVDZ7HAlVzV4NGowlN3c1\nkZFtycxsTWC1GEdcXA5u9w727vViWQ2A/bhc9QgL+4nw8HPZty+GsLB1NGsWQZ06wWzcGM+//tWH\nJ5+cw7p1cYiwvhGJejoXWZW+hfguGiACpRBJ2PsaEcStgTREYN8A/AUhBwtxRncFUk0/vYgmsBxZ\nja9DCKoLQg5/IJCz0RLxY7xijn+HCH0RaKLhfI2YwywzB25EO/EgocL/QEJ/d5o+5ZnPvAh5dEGI\nr8iMd67p1/eItrLNvA7i8bTE51tJvXqjyM39jHr1XNSvfx1bt/6FqKi+xMUplCoGwsyzagb8y9y3\nIXCAoCA3bdvG8/33RYSFxVFQcA1NmmyjU6csli7dgBDGRZXGvNbMeyZiwgoiOroRKSnDuPnmXjz5\n5Mu0bdsUy7IqfGodOrTmrbeW8eOPmry8n8y45iNmqC8QDW410B+llqF1ByS/ZgliSmyEaB3zkaCG\niYSHryY8/Afatm3I+vU7qVv3Cvbu/Rt1646ksPAzoqPbk5m50Ek0PAIcE5aDk4Zj7Y9twzZZJSUN\nOcTsVVxsMXr0QIKDWwMtqVNnN9HRccB1FBcX0qJFE1yuc+jbty6hoR2oXz+dggIPmZle4G8UFYWw\nZctOdu2Kp7h4FsOGvc433+xEch9uRb6yHmTF+jSSSe9DTBgXIwJpkfm8KSKMLwZeRIihxJz7O0Tw\nNUOEYjOELJoikVRhiOBvj2gV9uq3FDEtXWz+vwURwuchRLUKEapzTF8kR8TrbWzajDL38CBkaKMJ\nYtKKoG3bWNPPdYhgrosQj92HBGA6kiUfD3jw+WR/8tzczUAkBQWh/PRTBrCCnJxmtGoVz65dnejd\nu7t5VskEBzdASLQOcA3l5U3YsiULy7qEwsJo3O532b37AKtWbTH3LTNzkYQQ7sVAMV26NCcoqBFK\ntSEvL71Ca42ODuXRR58zyY2zeP/9Ap58MpV167LIy4NA5NoC4BvzHFIQUn8LrQ+aOduNkMcm87x3\nIxpeE2AYxcV+brzxClavXsTcuU/g8YQCisjIaO67b6j5LgYSDZOShuDg5MAhEAc1wqJFy5g58wMW\nL15RYfaKj08mP9/Ptm27yM0tISZmEeXlERQXW8TFvUB+/i6+/TYfny+NpUvLKS6eRWZmJyACy9qN\nCMimBAc3IjtbTBZae7CsMsTXsAkRHjnm734kSmorshpNRQR+XUTANQHGENgD/gdEEDcFLkME/jzE\nlHQ+Erm1CfgIyQ+5BBiJCKt+CBk0NOfFIlrHZoQUUoBzEBLC3M+DCF0/brdNQs0R7eFTxJz1f4gG\n1QEhnbZs3ZqBxxON290FCSuOBDwoNQgRuF4kKisb0WpCkZ/yINOH9vh8Fpb1BfAa8CLvvltKYeFP\nvPzyStLS1qFUO0pLI8ycNQK2oXU5fn85kEd0dAF33tmWqKhvKSrKRTSpBMRktR4xA6YC7fj66y3A\ndrR+kQYNOjNq1J8q/CCVFxc5OX7y8+vi9xea5/AwQkj/Nc/KzocJNq9wM74fCGT4x5vn4wKC8HiG\nERwczrXX9qgI8d63L4/ExPHk5paglCIvr5TExAlkZRWwfHkOS5asxMHJgUMgDo4bWmt69RpGbOxF\n3Hvvq5SXJzJmzKsMHjwOl+sTQkJko6KVK9MJCvqSgoJgLrrIw003BTN8+KVccEECxcUNgNHY9n2l\nvEhOQwuUuhlwU1y8F6291KkziPJyL7IK7YkIsQ6I8LZX6SD+CdsRbmsRLkTQjkMETz9Ey+hlzhuG\n5HTYfoYiRJNxAe8hwtJ24mYgZPGJOc8CliJkVUxA8OUhZrVwJNNcm/a7UlKSbs5dhwjLy02/vYg5\nzPblhKF1OT7ffvz+j4FpCAmtQevNiHmsJbAFr/dTAgT2CUIksxEzXj5CklkEclzGUFwcwvXXNyUk\n5Grc7lwzf9vNM2mG212f9u1DKC2NJivrILfffoOZpxAz7mnYWo/0Fxo3rk9Z2YXAKNzuEF544Y8V\ngRdPPDGLtLQsJI8m1PRVIeavd83f75AABxcwhIBTvAQh14PIYkEBX9GoUSiwHo9nO8HBMXTsmM62\nbZJbZOesPP54L+bO7cPGjTsYPDgUrbcQGXmQkpKrnTLwJxGOD8TBcWPRomUMGjQNv78Ql6tzRYFF\nrTfwu9+dw5o1fgoKGgPbiIuLIiPjn7Rp80eKiz8hI6MBWsfi9+8jODid0tLzEeFWH6XWoXUcssK/\nDLGB/4hEI+1HhLiFOK03mL8/IALZjg5qj6zIIxDT1EZEKF+N+CJyENIpR3wLmPPqm+tikFDcSxAb\n+/OI4DyA+Do2mvOaI6T0BiK07bySfabdl4HhSBZ6MKLZLEBCSz9FSMyLCM8R5p4RiLkrz/TxZzP+\n5ohw72Cu2YQQj6zoXa7VZlvidohzfR8Srvy5maOXkHyRTUAIXq+P8nI/YWGdKSr6BwG/w6XAJpTq\nwGWXFbJ69QIeeOBJnn9+N7Gx35CVdR5+/5f4fBeZec9GfBWh5hl8ipjB6qLUfmJj4fbbB/Ljjzt4\n5531QDHh4ZdRWNgfmIUQXH3zLF3mmXdF9kTZimglY03/88z3oC8wg9DQA1x7bVfatGlJTEwMWVlZ\nPP/8bm6/ve4Ri0ImJw+tFFY+nSZNpjBzZo+jFoQ8m+D4QBz8qkhJmU+jRt0YMuRR/P7uwJ9NzSyF\nZXnQ+mo+/HAjBQV1kGS3hmRkfAOMZdu2xezZU4DP1xa/fzZQTGnpucBniPBZhdZliBD+GSGLUMQ2\n/zXiMD6IEMCHBGL/6yLRUjmIoF6JOJT3IyYWD6K12L4IrxmNDyGOrYjzehWiFXyKkMFsxEG7E9Ey\nfkKEWGdkBRyPEJ9ts78NEXgl2IJd7t0Z0ZzqEIikagssQ6LC+iG5C6Hm/K/NfISavrY29wlF7P6b\nzHW7EaKdg2V1MePtgpCdz/SrlTnHDk3+PdCM8vICpHCkHyG1rwkEETRH60/53/++Ij7+Ct55p4DS\n0udJT29NaemH+HyRZm6am7bTzLPeZ/r4GJLBn0Bmpp9nnknhnXe+RrSlSygs3IsEAbQ2z+5r88xb\nIaSZjJB4OeJbSUIKWDYx8/ItwcEt6d//apYsSaF16wTmzXu7op8ffaTIyztIVlY+VUPQjxZdWF0m\nvIPjh0MgZyBOxo+iah2iZ599lLp125pPxTwUHT3cvL8SjyeKgNDSuFxRtGvnxuvtYMxUmxGh2QBZ\n1dsCOQSJWOqECJQPEEH+PSLc2iFC5WpzzfpK7aSa4zsQwZaLrOpbIpqJ7fuw56EIWZkvQTQB+5zm\nyCq8CQGhG1rp3g3N5yDC/t/mXLuAYhRCIsFIpFcw4jtpbO59ozlXEwgCCDf9zEVIwDJj2m7aLjTj\njzD3bYE470cjfgHbV9AUMce5EQd/K8TkZpdfCUG0hi0EEhZDgdfNfey2IgA3bdu2IDY2nG3b9pjj\njQgLSyBg0vOYcTQGBpv7NwIeBL43Yc/xZj606U+que93CIFuREiia6V+DyJQiBJE49iOEHk2sJ3S\n0kw+/ngtqakLDvOvlJZqBg7sg8/nqjYEvWp1X7uczi+p1eXAIZAzEifjR1G5DaVki1VJUMsFnsbr\nzeKOO9oTEpJD/fpzsCwPEILHcyvg5vrr23HffRfi9W7F7z8PWanuQLSMOGRF/RNieppNwA4egayy\nOyHmpK0IwaSYc5W51l7tW8jKvidCJvcjwioIEXbjCQgzH7LqBxG+dRDzVFsCjllb6MaZPpch2sUS\nc/6PiDDfbNoYZ97HEyClfWYMdiHFtohTXiPkp5G9QraazxKREirrzL0+RATzC4gmVoxoI2XAM6af\nsiWu4PdmHkA0sgjEQV8XuM70pymiibkRx30eQox2YiJAGJs2NWfTpjy0DjJO+3yKivaYOR1vzo81\nfWxo2i9BCNKHaEt7EXJsT8C3E4JoH40Qk9RP5rnkIFpTXUSDDENMmDko1QalvChVD5iNyxXNwYNS\nf8vWHtLTl9Ou3Thyc4vJyMg2fo/Da65VjS6Migo5rm0GHA3l6HAI5AzCydgz+khtzJ+/mBYt8nn9\n9RtYuPBBfv/7FmzatIPbbmtJ/fo+PJ4g4Cbq1IkmOnoDa9eu57nnXkepixEzUhGy0myJhNR2QoSe\n7O8gf6OR8NrRiODZgwhr2wxkO8hDEOF9C1IO3TZHzSYQXVWGCPGZiHDG9KENsnLeiWhC7Uz/2iCC\nNRgRil5E2LmQPT82I47pZub8Lub895EQ3rHIKn83IlCXmb5+iwhre4+RWHPdOIR03kUEbZjps+2k\ntwVvgZm3HDPWIqRScAlCSgqJjPoIIcxIJAigNUJIzyMa1g+mLx4CWtDniPbzo3lfB8uag2WBmBb3\nIea+MMRf8SOi3dyG+EA+QZImy4AClEpDtKiGpv3vzfU3IGRxj3l2X5h5n2XmaK8Zy0GEpOoArdE6\nBa0vQOsNwIKK/WiSkoYyefLTPPvsv7Csi4iI2MUrr/SmU6dzDgtBr0oAlmXRrdsARowYfFxVFxwN\n5ehwCOQMwi8pRXKsNoYO7c/u3eeglItbbunNggUzWLbsJebMmcbUqaNp2PA8oDd5eXDnnTeRnv4l\nU6eONmUlFGLyuBIxR9ilSSwCK9tQAn6Oh7DNFiIwQUwc9v4bdZAVbIi5xiYYOyN9MOIraWTeFyHO\n5wsQQgpBNKGm5h4KcXY3Mv16DDHZlCJazfkETC0uc74dQnsxoh0tRwS0hWhaGxC/TDFCPpgx5iIk\n1IZAJJNNjPVM+/VNPwYhRKERsjmIkFhPM5ddEBPbTkQgP23GZu87Eo7sgGg7raMQUrZwucpNP3IR\n57Vdp0shpsIWiHZ0F15vJFKGJRzRzJIQonWZ61vjdkfh9WL62tocz0e0Cb/5fzdCZoMIRM15zLjX\nmfs+S6CWmCIoKAyvtxXt239FSIjsR9Ojx6089dRWvvyyDLiJtWsbMmjQBObNe/UwTaEqATzwwFOs\nWdOQyZNnHLXqwslYjJ0NqHUCUUr1VkptVkr9qJSaVM3nQ5RSG8zrU6VUp9ro5+mAX1KK5Eht7N9/\nkPHjp/Pww58e8kPq3Xs4lmUxZcoMVqxYXVGeQutgFiz4gfj4S0lO/iP5+dsR230jxBYeg6zY9yOr\n5TREKBUgAsrOlwhDVvoKIZU1iKP7Z0SgdyDgYLeJ5RZz/juIOeX/EJ9JqLl3KRI9tRoR9J0R4dUe\nWcFbBAr3fYAI2OdM/3yIsHMjZqWd5r29C2IRgeKMV5hxeJHV+H5zj5mIlrUfMVuFECBGEEHbGhHy\nq5GijasQ4W8HAvgQU0+GaScfEfYKyafIREgxj4BvwQ57vtw8C41lJSCair2B1s9mnrojobX1zfwv\norw80xyz61PdZOa72MzhS/j9rSkrswtAdjN9a4wQgQvRTJaZcb5njvU38xVr/j+AkLxUUlZqMJbl\n5r77urBp098YPjyCDz74nE2b6gOpWFY4QvbdCQm5lB9+OMjddz8EHE4Ad9wxC6Xa8/e//wi8yLPP\n7mDQoIlERn7Od989c5jJ62Qsxs4G1CqBKKVciI7dC5EIg5VS7aqcth24QmvdGalD8dKp7eXphcOd\nhT+fsA23chvz5/fjiiu6HvJD6t27O599FsODDz7Fiy/upbCwnC5d9tOgQTx2xvmsWY/Ru3cPoqNj\nEDOH7bMoR1a79yCk4UIEoq1t9EQec7jpTT5Sg6opsrq9gAAZlCGr62BEA0hHTDG2kLeFZghi9mlG\nwB5/BVKB187wzkfIqD0SfdWcgFaDuccERKC3RMw4seazCYgA1shKPRUR+KFI6ZEwM267vbqIc/kH\nhAjWI5qUXZSwCaJVBZn5aWf6GmnuF4KQUQMCZPOj+WtHS0UiAv4H0+fN5pwUhETWmrnxmXmsQyB/\nJp+ApiXaYmio7Tj/ACF92wcUavq0h0BezjQkH0aZ55WHmK22I6RYgCwKNiMkbwdV1AdSUMpLaOga\nunQppG3bnURHRzNlytNERkYydOh15OZW9qvEAcMoKtJo/Wc++kjRoUNftNaVCADA4rrrLsXWfCzL\nRZ8+3cnN7caSJSsPq7pwMhZjZwNqWwPpCmzVWu/SWpcjabOV6zugtf5Sa51n/v0SkT4OjoCqzsLW\nrZsclw23sq148uQRFVVcb7mlN/37X0VubglxcXeRnn6Al19eSUHBNmbN2kl+/kzefDOLr776mX37\nviAxcTmW1QSlFCUlheTm5gAPIMLQdmh7gSmIGSYHEbgtEMFvJ4ytRdYUXZAig81NT9cDdyGEFGuu\nuxpZRduF9jogguk8RHB9g0QdvYgQhJeAKc2LEFc5QkoRyM/ChQj+QQR8EjmIaSsEMU9pxEGdjghT\nmzRsDSoIIbRm5v0tBGpdvY9kjddFtJQc024v05empi07ss0WmBaBiKhMRFBrZNU/jIBZLAR4CruS\nbyBL3k547GBea80cXopoeO3MPUJMf11AEZZ1vulzG0QD3E3ApNcLMXd1NnNxvnmmrc15dka+VWlc\nV2Fnm3s8dtkZMUVq3ZhLL+3Egw/eQ1paew4cOMDMmTuZMeNVXnllA1q7kFL94PEEUafOYHPMVbGT\n5siRwyoIICFhEAUFzdm37wCWBW73Lfj95Xz6aR4FBX8/onnqSJFbDgKobQKJR5YzNuxyn0fCCORb\n7OAYOFEbbmVbcVW7sf1DSk9/mXHjWiAmntH4fCLcysqC0fovxMaez759nzN4cAhLlnzA+++7GTfu\ncpo0sVfKscgaYDOBfcDPQQTPOkRY2pFTLg7d/nUjssINR4T8d8jqvQn2jngSqfQVEml1LqJ1SCXb\nwE6AtqO5KUIO4YjWACLYw5BIrHJklRxu/pYhG0NFIyYcZe7/rXllIyv0bYhwq4MQwyfm2jTzWT1k\nhf8D8lX+0Ywn3IylB4GQVx9i6nKbOfEgRPQJIrAbIgp5V4QkXyVQ5kSZ87Yg5HC36W9bxGltl065\nANEMVhIwM0YhBByCaESNKC39EtHa4s09r6w0R3btrw6m7+uRPBM3UkqmFaIN2fk3Uea5XgAU4fNd\nhsdTaPp8CxDKhx+uZ9CgZ8jP38pf/7qV8vIXgW7k5W0E9hMUZHHZZUXcemsLXnnldkJCDlK//uxD\nNIX585cQGbme0NBWwIt8+20kMTHree65G+jb10VxsZTLOZJ56njrwp3N8NR2B44XSqkrkdjHy452\n3tSpUyve9+zZk549e/6q/fqtIjl5KNHRMUyc+DH2j2TatDGH7c5WuZpufv4F3HrrQ3g8HSkr+ydT\npjzCo48+x9ixA1m79hv+979v6NbtPF56aT+RkU+Rl9cGl+v3WFYMoEzyYDFLl35JaGh3Sktn8N//\nPsKePbuQ1WYU4ly+mMBK2Y0I5XBEYH6GmLH6If4KhazyW5r3WYjJo555b0dx5SECeAsi5J5BtJmv\nEbJQCGHYeRUbkNX0HnPtlUh4cB+kGKNNVh+b/hUh5pImSC2rNxDBG2r61gYR2J3NPZMRh3AzxDdx\nJ0IcPRCH8meIwO5q7tsREdoNED9ROCJguyORWn5ECNcz4w8z5zxNIGx2B0LO55g520YgX8WODmtP\ngFTtYIZ2ph+7zLFzEXNYiBnrAkSz2IeQgf3c2pt5tHNJtLlfKOK8jwSeNP2JRJ5/Z4Rw5yGRVxcB\nL+Hz3Yb4SBKQdeIOtM4ELkKpHLRegCwOugJzKStL4ssvv6Rp02i2bdvN/Pl3HVJBGmDJkjksXPg+\nI0a8Byji4hozc+Zgbr65F/XrN2D16uW0ajWBtDTrrDJPrVq1ilWrVp2UtmqbQNKRX7eNBHPsECil\nzkWWRr211jlHa7AygZzNqGrDPdKP5FCiGYZlvUlwcDhlZQHS0VozbtwaysvXceutmcyd25stW9rx\n+edfsWxZGiI87ke4vSk+3w/s2JEBKLZt24PWFrIKz0AslOEEnKixyCOPQ2z1/RBB9y0iwG5ABG2U\neX2KCM9CAoUEByBCdzeBQoX9CERVlSMr9NaISUubNr5ChKntV0lCEuIaEUiQW23u0wNxtDdDtAG7\nqGExIlgLEW0hFfGPTEC+zhqJBMsx57yOCN48RNhfjJDTTwgJ7UJIzs5ITzb93IkI7xxzz6bmWDEi\nnPeY9kPMPfMQAsXMy1pE+A4wfcxGCLUu4o96lUCplBiEUDMJVBu2XZNe8wwbIT6jxubYIITcPGYM\ndRC/kF2CxSamAWY+nzTnu4GnUepnzj23FRs2NDTP8DW0DkeIJArJw0nA9s0opejW7VzmzZtVUUQR\nOGSBpJRizZoN5OdbJCQkk5sbVvEbsLXqqqRzNqDqwvrxxx+vcVu1bcJaC7RWSjVTStlxi+9UPkEp\n1RR4Exiutf6pFvp42qBqzPvx2HBl98CPTRTVcCCI/HyLoKBb2Ls3h6SkRxg27DVKSq7H7+/M66+v\nZMyYR/n4488455wW+P31EPNSLOJj2Mb+/d+h9R5gIFrvJBBF1Az5ytn28AaIU9aNCN9RiNCxq9Ta\ndv4vECHbioAD+HsCwnIzsvo/HzGNdEVMJe8jRJGAkMfnCKHYZT/CEYev7WMoRzSlNHM/u0qvD9EE\n7DpdZciq397bI8b0044gs0NU7byQOuZzu17XLkQbsfe6sBCt4ifE3DQb0XoUQoSWuV8mgS16bSFt\nJ1jmmr60M8dsS7DfzEeUGa9dxXgFokFtNMeUOXcPQl6tEbL62rSdiOTH7DZzv8KcdylisipETHuZ\nZu6aI0TjRgiuMYGSMbMRzSMI0ZJ+QutoNmzYAoTi9Q4lUIX3dwQFfUP37sH07dsQ8OJ2D0RrN926\nnXsIeVSGbcL917++Bm4kJCSWyMj1zJ//NvDrm6fOlgTEWiUQrbUfMZKuQJYpr2mtf1BKjVRKJZvT\n/sFeVXsAACAASURBVIj8ml5USq1XSv2vlrr7m0dV38Xx/khatGjBuHHNadgwAWhGWNhW5s//A//5\nz420adMMn28T8sN/EejCwYMFLF/+DS+88CMSsdQQEVwrAQ+WVYTfDyIkWyPk0gcRzBsQAVyG2M27\nmV5EIoKtGxKlU5+AQ9quLpuBCLW2pk07MqslItzDCfg57JBbeyOnVESQ5iOE8ntEgL+DkMZNiOBv\nRcAXYpt4ZN+JgA9iL0JQ+abfYwlELU0w74ciwjWEwLavG5Gv8gsEysH3JJDc9zsCG1b5ETNXDmJG\ni0NW4S0R4vhzpfmxcy/sHBdl2rOJz65h9TFS56s9EmDQ2czBBwTyOq5CNMJdiIZgm6U0og01qHTe\nvea6UjOnc5HvgR8hykWmjcYIqTRFtDW7fwdMv2wSrIOYsTah1E7gMuLjPyIo6GLq169Laanm/vtb\nUFb2H+6/vznffbedqqi6T01YWBugN6WlmpkzJ9O2bbNTItTPlgTE2tZA0Fov01qfo7Vuo7V+0hxL\n0VqnmvdJWusYrfUFWuvztdZda7fHvz380qSnKVOSueSS882+CX7c7k64XC5uuaUPDzwwAre7OXZ0\nlGVZeL0dgOmUle1DTEwJiJB6DVllehF7fGNEcDdG/AFbEHv4zQRW63mIYFmJCJGbEUFqV90NN+3V\nxy7UKCv1fYjwTjF/vyTg57AIlCopRFbaIAK8henj96bPpciqPgcR9OsQYW3XkrKF+0DTfhSyCu9h\njl9kxt0NcYjbpcezEQH/hDkn09yrcuZ9iZmnTxHN6iakfEs7059OCEldYeZhmLl3IrKhlNuMN5uA\nZuMikJhpJzXaJFPXzMf3iAnqEzPeBYgpLBchmSYIydVFiDSLgMkruNJzXY5oeW7TTh3Eqd4IWIxo\nbz+a8e1Bnr8b+c54zZhsoraTKS3Ky31ofTGQSkZGMFqv5r///ZmRI3/PjBmTcblczJgxmWXLUg9b\n6duCe8mSlYeF4a5Z8w2zZ2f8qkL9bEtArHUCcfDLUZOkp+Mxd2mtef75eXTt6iE0NIT4+CRcriAK\nCn4G3kHrJgQFlRBwiNthtL7/Z+/Mw6uqzjX+2ycncwgkIWGe51kmBZyotOCEA1JFpbbqBa1aFW2v\nYm8Hq9ZWe9GLlcnWoaC1LaioVXGoKA6tOIPKPAZIQkgImchwzr5/vN9iJRQUB7Qo63nyJDln77XX\nWnvv9/3mhUDdaQQxRBjpSOIchExV/RHYPIOA6Rm8iWMI8he4OH4n4TtpexQCZOfQDfHZ4SsRkEcR\nkLqw1QF2jVZ4x69zIrdHxOF8MsWIxJYgEK5APpoiBOwzEdC+ZNeebfNejcjtn7YeEbtGb0QErvaU\nS6672/5+t8HcB9vcmtnfBYgcltlYZ9jYF+OjzlwYcAUi2m12fidkBksBrkea2m5EeCEit+fxpe/j\nDe5bis2pABFDCSKVZOvzI2T2c9v2vmrfu3wbZ7pUKLCIpyNQRyTyMm3aODJtWGXA1cxShFQsFqG6\nug2x2JP7BGNHGJdeesO/Affll9/Eueem8KMfDaRp03e4//63PheoH4hZ6puWgHiYQA7h5h5o4FMn\nPX2cuWvcuNHs3FnC/PnP8M47LWjfvg1jxtSxadNsTj4ZYrGWCHBWW/2jKNIcNiHQ7Yr8A5uQHdyF\nzlaiR+43CChq8Zs45SFNxpk4oghE0xCwR5B0/i4C5Fl2jQEItI9B+SFpSNofZdeM2U93JCFHEIgn\nI6e5i/IqQ0SxA5l9BuKT4YYhc82xyDTlyKeTXTcNWWH7ICm+Od65PtXGW4nAvsDWZZv1cSc+hNfN\nPQkR2iwb7xU2nmqbg7tWa2QSK0NEmWJjOcO+Ow6R4d67OTrNaLjN9Xp7KmbbvQuRxuXIL7TrtUXR\nbR1szG5vk3aIlAIbTwRfhsWVURmDyLcCeIq8vBOprY3TtOnbpKV9aONbjwjoEjv3dGADqakKumgI\nxntL+vsq53733T9j1qxfc8klE5k27XozZ312UD8Qs9Q3LQHxMIEcwq3hA32gSU8HomJfeulUbr/9\nr1x11SLKy6fx4ovbeeyxOBkZ/fj7399E0vRsoDU1NUlIWqxCzuQ4eqz6Isl0PYpeSkRE8DwiDex3\nIpJmt6GoIhedFbH/N1u/ZyDA3ol3emu7WJnFVHZDGoMzqXWw62QgUKpB5pMQgbnbY/tkBFyp+D1B\nNiDwbWLXmIFIbaGN7bv2ewlyND9s5/VFZptiFAwwBIGmi9iKI0AvRhFYEXyhxMDmvsGOvwavsbyG\nNIq3kGY2E5FnPSK9MpvDOza/SmQSbG1r0AuFE0cRkHexubmdGR0pxvCVfFfZPWyG8kgSG6xfASK8\nljavYfjcmPdszRcjsmxl4z0CaYAPUlhYxhlnHEdJyVIuvXQC0up6IKLKBwpJSysCulFdXUivXlez\nZcu/CENV4p006Ty6dWtDdbVykT6unPvnBfWPe2f2pZV8kxIQDxPIV9w+S7TGvh7oefMWUly8fY/D\n/LrrLt5nvx+nYs+ePZfmzYfxj38ExOO/oqBgJTCWoqJkYDaRyHCCII60gABJ8R0RCHWwz92+4Xcg\ncKnB5zAswYd6bkKS+ksI/Abb/6utrw12fmt87kUp3iw12X7X453JrkxIxwbjq0WO53xkcmmBANft\nbd4aaSLNkfTuXokQSf7NEJBW2lgDRAIb8KafGN63kYwv4+4qEa+36w9EjvV0W4+3kPnpBCS5b7ex\ndUNmuEGIWE+2/qpt3C3s/102PrdvyApEiGtsbi/gzUKv23VdBr6ryPtdfEjyqbbWKiniib4MBRt8\naOcvQcS+0X66I5/IALvWQEQkFQ3W1WlW2cCjhGECf/3r09xzz0MUFJSSnFxCevpmIEJCwgMEwSaa\nNpUfJBrtSGHh68TjSdx111wAHnnkWZ59Noni4vXk5FzAzp1VH1vOvSGo33vvidx11wMH/M593Duz\nL63km5SAeJhAvqS2P6L4LNEaB2Jn3V+/HyeNZWc3p7KyPaWl1UCEMOxAVlaClYkIqKyMEI9HEMi4\nMhcBqv5agi+c5z53INUBSaTDEVG0QCC1zY7pjPcp7EC+gABJyi6sdyySeNsgbaQ5ksoTEYCPtxnW\n4IHRVe7djEqudUF5CAMRqEcRGQxDzmoXBnuifX6DjakAgXpLJCnPxocQj0QA6TQFN57++BpcR+BJ\n9B28qWsnvpqvS4JsisD4KFtXVxremQUj+CKJbm+OABHJGATSx6IkvY22ngl2/XLk3Ha7HS5ChLvZ\n/l+BnOG1eDNZit2vNfitdZsg0qtEJjCXlNjExjHbrnkC8qsk2v1xZWzWEwSvcsop32HSpPPIz9/C\n5ZcfQU2NkjDHjz+Sq68+ix07lgNQWxtQWpoHPMWrr5YQBL246KL5VFdPJyUlm5KSDxk2rJi+fbvv\nKcGzN3BPnTqJceNGM3Xq7YRhyNtvtzjgd25f78xzz71M375jvzHO8v21wwTyJbW9Af3zRGt8HAns\nr99Zs+buIbC9Vex58x6hT59T+elPX2H37gspKakhIeFWEhK2k5lZjADiTCTVtkRAtwlJtcsRkBQh\n6ds51KfYaJ2JJR8B10wEZBvwIaDOfJJgfdUg4HKA2R3liDTB77HhsqKTEChvQ47rEEneH+Cz0pOQ\nFP0OjR3VG5EWkIWq/XZFpqo2dtx2RFLHIk2ilfXRHxFNd+QD2WnjiTdYh2I79tdI6wjsel2sr+H4\nYpIBXlLfhKKiIshktwGRyAbkJ6pHIJ+O3wdlhR3zDkoAnIVMVlWIMHvb2DahzHWXx1KOHN9DkYnq\nOKTVbMOb5Prb/Grt/1a2llsQocSQc38s3kzXDR8htwI9J2uQkFEOjCcM2/Lyy0s5/vizefnldO64\n41Hq6+8GBjN//ov8/vf3U1vblUjkZCB5T62reLwNp5xyDNGotM6KCgjDm1i/vgMzZszlzjs37ZcY\nLrnkBm6/fS1XXvnnT/3O7f3OdOrU6RvlLN9fO0wgB7ntD9AbVwv99A/g/uys+9NOcnKa7yGwhtKY\nMnFnNTgnn+zsCv785+u56qohbNxYQRj+A4FXK7t6JQKWLLS7nMvT6Ii0ia0oEmgrApVjENjuQpJt\newRqP7B+XcJcMfJfVCM/QSUy48xAYas7kBlrLQL3DQhQXSHEQcj+/i38FrNPW5+5SBNyjupd6PEf\ngMqLt8OHFjvSSsbnnLgos1KkHXRF5q+/IOKrR2a7GCK6o+z43jbHLvh8CmfqOg5f0r3C1iUblUmJ\n2BhzkZbTBp/cV4wSLQutH7cvyFF4E1WanTMRvzlWFiLEQkRAucj85eqNvYuEBFdl2AUz1No6uHXr\nYWuaiTSLQfiaXnUogMGNA7s3/REp9UDPwA527aqgsLA7MI4wHGz37T1isRj19RpXPN4CCQYbcFpX\nJBJQX59AmzaTiMVCYAkbNjxHLDaImpq7/o0Y3Du4eHFAPD6L4uIUYCzFxR8d8Dv372apSd8oZ/n+\n2mECOchtf4DesFroZ3kA92dn/ff9PJYzZcpvGu3n0bv3KQwceAp33711j7T20EMLKS2tpnfvD9m5\ns5hrrvktc+Y8iQBvBJJqVyNzTiW+MN8sZNapQNLsWgRcp+GLGrp9Pdag/cRnIgn5EQSIi5CGUmd9\n9UUkUmmzfRZJ/LUItGYigIohIHR7pifjnesuG/psBD6VyFSTgECvFQJ9VzLdaU+n2TGXIcl8hc1t\nAj4fZbvNf4f12QGRyTXWbzEyO/W0sS6w4wJ8PkUiksyfR+C7Gfk6WqO8leftGs6k1dw+G4qIJhFf\n8t35V+6y4/pbf1H8FroV9rlzjPdHZfMdabptb7NQORdXjdclZDpfx1Z8yfoYiuA62sb9mN3XWUhT\nHYI0shjyP2HX3gnEqK4uY+3aZ/FaYQf7fneDjcgSUdTeEUA5kcj7PPPM63TuvIpp084kObmU3NwP\niEY7UVsL+xLG/Dso8o7FIrRtm05dXbvPBfrfJGf5/tphAjnI7ePMTQfrAWy8n8flHHvs4D37Imza\n9DwFBdt5//0OVFScyNSpL5GZOYgnnoBevTby859/GyijQ4eWxON9kUbhXmaQqSQZAWzDl7wOSdT9\nEMgsRPZw51zuhsDNAVaIwLY1AmUXxeU2cHJZ0G8hiXw2As/lyDfRF5mBjkUS7t9tfJMaXHOJ9eVM\nPNkIpHYg8xZ2jfORiWcFIrllCJTLbRyLEVi/icw3LqkxC4Gr22tjGjLtpCDySrZrbLR5r0NS/lJE\nijW2Ji0Q8E5ChOiKS7a3n58iB7YjidbWd6Ldn8vxZsB6BNhrbJ6FCKCd7+lou1cu6ssl9rn91ets\n7gXAxYgAIjTO22moRXVAWk47fNi1e1Zuwu+MOAiRgPM7Dae+PtU2tmoYvjwE6EU8HkVO/Yal9X9E\nEPTm+OMHsGZNN375y+nMnXshhYWPcfnlA6moqNunMNbwHczLu5CUlCh33HEh999/8ud6575JzvL9\ntcME8iW0/RHFF/0AOkf99df/155+x48/kXHjvsPOnbtp1ux4amrqqa3tTxjOAP7A6tWPUVHRm1hs\nJkuXNuG886YSi2Xy6qtvUVVVgJzNbqOjHUgb6Yhs+xHk0E5CgD4LgU++HZdt352DnLquxIhLHCtC\nYLsUaRaOkOJIOh6FT1JzYFePJPyZSKtYgLSPmPXXyb5PQKD2TxvvaKSZFFtfmxAArrHflyPzjcvY\ndlrTCATSryNzT0f85lCJiNSGImIZgU9SXI3Ph+iMTD9dEOl1s2NG2vyrbD0m2Bia2XxqbJ5uj3cX\naRZBhNgTaUPX22en2VyqkWmxg/UxFB8NVoDAuA/aza8AkVMRIpUBKNw3F+V8tLT1PwYRijPjTbBr\nJiI/SxoSACL2fxQRX4Fd6wxkYluCiGgmYTgQWEFCQoL1/7addwpBsNXu0XJkvgyBO4jHE1i2LEJl\n5YmsWNGJKVNuZfbseSxduox588buVxhz72BBwb3MnTuWNWvyv1LQ/7rUyjpMIF9CO1hEcaARXW5f\nhObNjwZuoqrKOW7T7ceZfuSkVH2roQhwUlB5iw/t2Hvw1WRfRNL6WgQkzyKbv8sIT0emizeR/b7Q\njv8+ksaz8dJnGR6MHFBuxO8o6IgqGWk4VyCn8XHIR5Jr15qD8kEG2v+78M77zkhTcfuR70YA7LLg\nOyOw3IrPpHbhyAnIv1KN91u4SLFy+ylFGkY3lIS4xPp02/U2QZpAEQLTe/Aa0VKb38l405wrVL3V\nrpuAEjYLkb+gG74M/iJEXh3xlYm34RP8AkR8ZbY2MxBRbrA5f4B8NWcg0nGE8g+kfb2PSH07SvCr\nQIEHa62PVXbeUgT6i/BlYD5EWtBsFPH2AQoUiJKQEKF58yqkfbl8osmEYVvgO0QiKl8fjf4TSKBv\n300UFr6FKiHMIBYbyC23/JF//ascYI9fb+937D9NW/i61Mo6TCD/we1AieKTIroefXQW06ZdR00N\nKDw3QnLyWQgIa/DFBF2xQCdZdkSS9wgEMs40FNp3rZB0WY3A3iW49URE4sJSRyDwGITs37+2859C\nJou+CKSKkEZQhKTjHkiDKESJgG5P7vbWtysV8ix+n4vReNt9uo11HSoi+C4CsFk2plSbbzne/JSG\nwN2F9TqJPwcRQAby9bhKuycjU5bTJGI2lnuQyeZRBNpN8TsK7rLr3N5gvSvsPtyLNCtXz2s0IsBW\nNs8Vdr1ZCLj/aeM8zj77yK6bhTSwOpvnaXZ9R5iLkEbUzObYy469C5HOo8jc5cKVB9o8oijMuTWK\n6HIbZK23Nc2wdfpOgzl1xJOyC+teCETp2rUdSUltgQuMLFLxe9uPJjGxNddccx41NW8zf/5VZGbm\nIOKUFlhYuIv6+vbU1Czkyiuf4bbb/srAgSf9x0r2X7daWYcJ5CC3z6OqHihRfFJEV0MbcEbGzcBr\nJCVlI7NUOpIa38dnNJ+NwDkBl8uRlJRIUpLb4nUHECUS2YYk0KZ23DvIaeuK7Q3AZRULEFIRsThQ\nuh2BuwOlxxAhfYSAyGUvr0PFGHch8JiJgHcoiipyxHU0AqoKZDJzYbLdgfsR8ThfQSIihfaIOCYg\nH0E1IppcG+MERAr1+OKHjkzaIMk5FQG2M+G4bWhdCZcfImkf5BDug0xp6239jkJazvtIO+uBL+6Y\nh9/HPMfG54gttHU62+btQmnn2DiW2zVfsnM7IqJ5CYH/LPssERFLR7u3vVBxyxg+sGEW8tf0Qqa3\nCNLO3Ba4Y5BGuQtfUn6Q9fcRIhLna1lOYmJIJLKWmpp6ioqWk5Q0lHg8EwkyTZHG8lNqagKWLHmD\nOXMe5Ec/upnXXovYfUoEziAej1BSoj3ct2+vIQzH8d57HWnffuR/JCh/3WplHSaQg9w+i6q6P6KA\nfRPFv0d0VfHgg4816tPZgMvKXuaaa86lri6CQDsdAe1IFBXVGZmZliDt5LtASEZGE+LxF5CdegvQ\nlXi8I95hm4iAcDuNfRmdkJR6to3EObSXIwDNsM+dn8NlKw/B+z2c+acH0k7cZlH3IJ/Ce/z7Fqqu\neKPbFrc10hoiwPfsmltsPN1RSPGbyGRWbWP8CAF6PiLWHbYmnWztXPJggMrVZyAT1UpEPEkIlB+2\nNX0ZnyPSBJmROiFTU1MEvv+LwNqZr5xTugaBucsad4mTnRCBdkB+koYE6bLQs22NKvBkVIa0ss22\n9vlIm+lj6/WQ/V9p4xtr15qJiHOxnZuPnp2Z1n8M+T1CRIi1+OTPXFvjdGKxNcTj36e8vBnR6GaG\nDu1AELSxdXUh10nACpYuXctVV93MKaeMIDm5ysazkezsdE49NQLEadbsfOrr6+x+ziQWG8j06Q//\nx5HI161W1scSSBAEPYMgGBUEQcZen594cId16LfPo6ruX0rxRNGr1xQKCt4C+LeIrsmTW/LUU/su\nrxCJRBg+fCCJiamkpp6NAMrtNucAOwkBdDWJicsYNaqKwYP7kZ6eTHJyc5QDcDsykWQjsHIJcnkI\nPMYisGxpfX2ITD8hMnn0w9vhA6S9uPBWV4JkAr7C7Gr7uxN+jw+X/dwB7VeehCK0XIRXHp7MUu3c\nQuScXWJ9DEMO3J/bmOYgrafOzj+pwZyOQ2SYgci20Ma1Da/huCKPy5Gt/9sIZJORBD8MRRe5fTsc\n6fW18btKtp3xO/Zdg0DeaUWLkc+hCBFLrY3lajv3NHw48/F2LxruxZFo13kSkbILbnB1v8DvTujW\nvB7vK0tCWkBzFI2X0OB6OTb2MYjc+9jaO2Loh3xt9cD/UV5eSX19d2prY0QiyfgijCl2TzoDJ1Nb\n24I//GEBu3dnIPNXa0pKlrNs2UoeeugyZs06jyBYRxDsAKC09EN++cvLP1VF6i+rfZ3Cf/dLIEEQ\nXInu1I+A5UEQnN7g618f7IEd6u3zqKqNpZQpFBbu3PP5qlWbGDWqmhtv/A7RaA8effQFQASxfXsR\nublHsnBhObW1j+2XtFav3kxe3ptUV7+PTC+TkT3dlQs5EoHkP6irG87KlfksX/4+ZWVHUVPjalE5\njWInkp4dUNciMngfSeLbkAnK2a3TELi75Lwofp/tdxHRVOCd9hsRUWUhqXk7emzjSAqvtDFsRGaX\nVij01+WQJOOl9SZ2nQpk7nIhohNpTDbNEXi3Q3b9qH3fGRHeIuvjA0SQAQLqMjwptLd1dBV/Q7z5\n7TUbz2l4U1AJvpLtmTburraWq5H244jz23ZsMxQUkGvzdvuWr0XaQ55d722kTUXwZr7V+Jwa5zPZ\ngrSHAUhLOcvm9Roi/bh95vZZ6YMP1R2P12ReRgQzCxGjq0Lwgd2rzjaWQdTWplBTs5ylS9cSiy2z\neX6A/Ek/R2S30+b6LVyCYhAE9OzZiksuOZ+zzhrD448vJhpNICWlM9nZZ7B7d2feeOO9T1WR+stq\n/2kO/c/TPk4DmQQMDsPwDKSj/iwIgqvsu0NT3/oS2+dVVZ2U8stfjiYSKeGxx0QUGzeu4/HH3+Sq\nq56luno6S5cm7SGJnJzmVFUdRWmpktb2R1pTp05i5cqX6NGjPQKqF9ALvgaBwxwEAGOB5eTnF7Bt\nW287JhWBmtsrIx2ZKBLs+I7IRJOCgGIEkihXI4nUJa+5ek5JiMBa2vGv2DkbUJSPq8bbFkndyxHI\nLUNhpYUI+KqRJnEcAsRiBDzPI42jAAFvc/v8JRtXEr6GVRSFHLtciteRxLzRzl+HfBOZDea9zcY+\n28bZHwH0ekSmVyNgdWXrXa7GK8jc8qz1X4hA0u1D8h4C6SPwkWS1iJSmW59LbU2dr+o5u2+1iKhb\nI9Pecvz2sUMROLt9PFw03s22/hsQgbjs9Pfwm0q9gsD9eUQ4new+voSIfZONpZbGARdtEMlFbO6u\nWm+2zb3h7pM97e+1Nu/X8D4l91wOIAw3c+qpI8nOTqNPn1NZujSJurpO1Na+Qnl5M2Am99+/eZ8C\n1NfNkf1Vto8jkEgYhhUAoTa2HgmcFATBNA4TCPDJKvDnUVWzs1P5+c/vsvpUD/Pss+tJTu7Po49W\nEI//iu3bawDYtOkNjj66D9OnP8xPf/oK1dV3UVKSQlLSEIqKlu+XtBISEkhKAknrJQgARyBQc/6E\nGmRyaYKA0+UQVFsvAbL5d0Egvh6BQhYyf6yzc1KRJOqq3dYhAshAxHILAhwXkbQOPW5uxzq350Ua\nXksYgMwi9QjIEhEwbkSg3hMBkNscqTOSiQrxZd67I8l8Gj4stQkCxGIE2rPwiXvH2N9D7HrtUf6I\nS6wL8WaydFuTMXYdtwfJGQhQe9g5p9uc81GAwSV2/E4kjXfGR6xl0Dhc2gFvBQL7jkiLa2rrU4Zy\nOrIQ4XTGO74jtt7n4iPNnKbnwL/IzsmzczKQFuBK3+fj9wZJxu/x4sxcbrfEBOvzMVvfTLvOaht7\nAT6vZTq+vE29zWOOzWms3d9smjSBGTP+tlcAyWyaNetDZmYWEJCamsmNN17BpEnncf31txGPxxtt\nd/t1cWR/le3jCKQwCIIj3D9GJqciEa7fwR7YodA+SQX+PKrq3iaw5OSuXHHFBFJStClSLAZZWWdQ\nU9OFzMxmjY7Nzk5n3rybmDfv8o8lraIi5yx2DuwAAcJf7O8MBExuU6Bp+LLjAd5BnYhAfxcK/8xC\noNAFn7G9HL38NyGwOQGRVQECy072d3+8+aMPMp3UISl0EALpXtbHGATiG21GGWiHv1xEeN3s+FIE\nVv3tfxdm7EB9IALETCT5JlkfUet3s313N9I2ZiECWIY2jIrgy8vvtPGXIGl+nh3fGZFVKTIvtUZB\nB8/gc0vcjoxP2TrnIpB267MVmaNcocMj8OHGiSj/pRZpGXMQsC9HhNacxhUFQJrkXPt9BX7P+SjK\nx4nYHEIUSdbXxrjT1nq63YtaO9YVksyx76vQ8/ORjeVcZGprjyzjbr/0HrbmNBif85tU4AmpFD2f\nzaipKeWBB27ZK4DkWior66iqijXS+h955FlmzNjGf//3b/e8rw8+uJCdO6u/Fo7sr7J9HIFcgJ6o\nPS0Mw/owDC9AdoJvbPsyVOC9TWBlZbvt/xoyMm4EXiclRVExDzyQzzXX/JaiouX07n0NtbXYnuYn\n7pO0Zs+eR+/ep1Bbm4nCOZ3zMkDgUI4AYCfJyelEoyDzEfi9L5wEGyCAOB4BnrP/NyyvkYC0h7UI\nhI5EQFiFN7e40iHukXTO3mQEYrko6upoRAYv4m38g/EgBiKUXfiigp2RP6YWv41sDgKnODKPbUIk\n8RNEWFvxRNcDaWMt8GaoqK1FawTAQ9HrcqTNtwe+7Isj5qlIq+mEysu7DPMWNvcuyCw1ApFKLwTS\nTWxOLez+OI0nhrSZakS2zi8SR0EOKfhcDbd5l7vP2LrdbvMfaT+ZyGyUhwi+DK8hYWOIoecjQNpe\nB0R6ffGBDf9ra5xr49iB7v+7tr4yZKSk7CAra5utUwQ9R29ZH04bGWKfuT3by6it7cO55/6YnMyu\nPwAAIABJREFU3NwjWLVqI/fddyLLlv2OTp3KOfPMZJYv/1/OPTeNH/7wJi6//O+Ul09j+vQNlJev\n5uKLb2Phwk0cdVQJy5b9jlGjdrN69SYOt0/f9ksgYRjmh2FYsJ/vXj14Q/rPb19WLPfeJrDly9dZ\nKO6rTJlyDlVVsg2npmZy7LGDmTfv8gMyl02efD4nnXQ0O3e2BxYTibyLgKAYgWqIA9Samr7k5WUh\nif0ERBou4WsrMjFk4zWGJghIf4ser7PsdxkC/1l2jbUIWFoiInkbaQxO8j/TRtuMxkAcRaDYCR/J\n5CRrZzbpgUDVVeF9Gpln4njSS0KSeQQR4JF2nbkIwOtR1Fh7fPHHUjt+rPXRDjmx+yFCqLFzOtrY\nc5FZ71Q7fpqNOYq0HjffUuvrfQSuKTZ2RxSJtt7/tLV2mfA1Nofhdm4lIoCd+IrF/4NIJgeR6A6k\nFQy0+/E3O2cO0lZc1vxM6zfP7tETiBi3I03O+YsSbJyOWDMQYZ9ma1xga9gJaZCF+PL3LzBgQG/6\n9etO+/bJpKWVIi1mNyKj52wdx9n9SUUaTH+gmLy8puzYMZzS0lLOOmsMjzzyLPn5PRg37jsEQcCs\nWbdw990/JTlZZsz6+hiwi8rKLsDf2bixLR06nMDTT2+hWzcXNn24fZp2OA/kM7QvK5Z7bxPYM8/c\n0ygUNx6P7rn+WWeNZvz4ExuZy/blo5k9ex59+47lz38uIgxnEASFxOO7EEg9QhD0AjaTmrqKzMw4\nsIWtW10pkFZIAnQVeRNRQJ4zfyUg8EhCQOCq9pagR80B4g4ktW5Hkm0qArpSRCavIGB9FUnotXbu\nGXb+b/B2+7Pt/BokOafaWF2SoQtddZsqRfC5G7VIsh+GANTlihyNbP0xPDlFkcmp0Ma5FG/vB5HG\nJqRhdETAuwNpFTuRxhTid0bsh0hykK3XKnzk1UbrtwSZfVy2fFcbRwYyny1GBDsTAWyIJHxH6E1s\nXQrs3tUgU6PTRtxOkll4oupiY5+ASD2GCKcYBRUcj0KbtyHSWoYP247b2ryMSMklqq6337Nsvi6i\nawz/+teHvPJKBjU1JVRVLUUaozONPmRjeBxvNixHmlMuW7eWA0czbdpKgqAXF154VyOLwJw5D+7R\n2tu0mUwYRsnOTiEel2a8fn3Rniz2z2JF+LrUs/o87TCBfMb2Vcdyf9z13YM9f/4zzJixjQULFnH9\n9bcRi8W4994F/OIXP9yjvYRhgCTa3nv+79GjA/ff/2sSEjoh6dVJ/8oZSUxMIyUlAV8jypVBT0TA\n0goB+ftIcp+Pd4CPx28klYuApRZpFdUIINwufYORKcrlgdQgcNqMwPpNu97piLgq8STVFF/b6juI\nrNrgk9yKEHgm4x3tUaQJuD00mtv3bo/2zTbnU6yv9vici0vtuxI77i1kernH1jaCwHW9Hb8CEeUM\n5MtIRAQxB4H4SkQG30fRU1k2zn7IPOTCi13eSALSMlxl5NvxpVoSbb7d7ZzQPv+uPTFViDCiyPH/\nAdICOuLNmU1sXFHk78m1+brEy1aI0CLIx5SEfBh9bdzr7Lqvoft9FCKJo4jHX6KwcDsip3F4zTJE\n5OvCr9OQZjYRv+/KROLxCKeccjTNmsmE1tAi4N6Tyy4bwrXXdqBFiygpKYnk5V1IYmIydXXSnj6L\nFeHrUs/q87Tg68SeQRCEX6f5fJoWhiFTp97Orbf+hEsuuYE//rGEvLxqCgoeoGXL71NUlErv3ptY\nvrwjY8fGePbZJOrr84nF8hDoxdFLmcuoUdWsXLmZ/Hy3sVBzvBR7JjJ7vIqiklYhKXg9PrcjA0nq\nP0dO9fEo8e5VBHxvIwAGEYFLZGuBopDmo5pQFyEpfhUCrF7I3zAISfEuuulMVMMpwfrYhcBtrZ0b\nIK3iKJQ8twqBk0subIsAtgmuTIuk+H8iMKtHEnUd3rEdIKncOfddn8OBPyCQ+whpOy+jyC6sX+dL\nyUEE818otHUU0q5+YOe0s3k0xRdydJn3A+yY423M2cgE5e5BK2RiXGbnn4Si3c63NXRJic5kVYvM\njDGkfeUjv8Z/IaI7HhHaIPQstEAmplSkwf3B+v7QxtwRPQM5SJAYbOf3wz87sxEZ/QO/33tffHhv\nCxRx5upquVyVEGlJ75GQ0I5YrDmDBxewalUn2rUL2Lw5zn33ncRZZ42hYZs//xnOP38GV145gttu\nu46f/OQ3TJ/+OpmZu6mp6cX995/8b+fsq82ePY/p0x+mrm4Aq1ffTLdu/0Ni4ntceeUELrlk4iee\n/5/WgiAglCT5qdvHJRKWB0Gwax8/5UEQ7Prswz3cPk/bW21uqG3ceecS2rf/FvPn7yQen0VhYSEw\ngIKCeuLxWSxf3gbYzBNPLKOm5iliMefUHI0Acj3wHC+99AY7d1YSBE2RFLkVgeEWBCy5SMJcgl74\nlQhk01COgNv/+48IrP6CwGIA3jxVjEBrFwKMGAKM25DE/D18BVxXRfYVBEAzEei/acdcj0jsFBvf\nSnxuQgICVRcplYvXqHojYC1rcM4aW4eXkElrOCKUQqRZuJyKOCKXoxE59rc1qMfnVnRAmogzl0Vw\nmdUKDACZ5bD+XEl3F87cDYH1cwg8XW6K2xgqAQHsy0j6r6RxmZRM6yvJ7rMzobW34zsgDWOH3bt0\nZApz5rzjkMYwzO5flo2lwn73tDE5rS9q19yBiKQbIos0W7te1o8r4OiKJoIIpr2N81m71hnomVhs\n92Wp9Z2Lnr0sUlO1hu+9t53MzLdo23Y7f/zjaKZM+TXxuPbAaRj0Ulu7kIULy+nbdyxr1mzgyiuH\nU1vbm0svbXXAVoSvWz2rz9M+zoneJAzDzH38NAnDMHN/5x1uB7fNn/8M06Y9z4IFiwC49NKp3H77\nX7nqqkXU1CykoiKP0tJqZI5yjlhnAkhAAFxD06ajkUQ+AGkESUQiaUBT6utHkZ4eJQwTEei2RhE6\nrRBwvIEkzG7I9t3L/s5Dj1QrJNmvR+YR50dwGyC5iJ18BC5PIwB1zvwVCLxKECB9y753e20EiATa\nIs2jPZ4g2tp1ahCYVuFzEaYgADoSScnJyETicjpa2E+NrXYblDfRF19XKgEB4DGImBLt2G0ocDEF\nOZcj1vcm+y7D5pJgn+cgckyx76uQ6WgFykdpWO4929Ypye7XbGTuAmlhadZvUwSurn6W23TKlYY/\nFpHmbhtfObqvUev3Zrw5Dxtb373u3wl23gkogGCo3bfj8dV+s2wsC/HFLC9v0E8MkUJT+52EntF1\niKwy8AU2+9n37fHReq8TBEcCT1NVlQn8niZNWnDOOSfx+us5/OlPj7F5c2+uu+42YN+Af8wxfVm9\neguPP15OefkdLFy4i7lzHzsgH8j+fKDA5/KJHIo+lQP2gQRBkBcEQXv3czAHdbj9e3NS1JVX/pm6\nut5cfPFtjRILCwurgQg7d1Yi4BiLXuw2yMxwDnpxnwBSKC9fav+Psyu8QDzu9vueSWFhPyTlDUHg\n/TKS+J1k2R0B4rVIQ7kU7y8AgeJSfIbxeLw07B67ZERw/4OAqBYBe1cE3CvxDu6jrM8ASaaqEiwn\nc4gk3PPseo7InFaTit8JMN3664qI8x8I9JYhYO8I/Njm3DAMOYKvqNvSxtcOaSQjkTT+V1sjt3th\nDJmAXB5LO6RxrbUxubIuLtHxFRQdFeLBNg0BuwsLdtFOOYikE2wu9bY+cRqXmqnBlxjpgdfeeiFN\nohsyKy5B9zgBv/dKGjIl5SM/TQtbuz6I/ObZ9zFbx90N1srlCrlk0Dvs81MRKXVBZq/BNr63rf8z\n8SHY4+2cVHwZ+jQgizCUFhmPRwmCdZSWfsiMGasoL7+DJ5+MA5uZNm0xycn9mTjxR/8G+N/5zkh+\n+cvLKSmpAgJKSqo+lRaxLx/k/PnPcMcdG/YId5+2HYo+lU8kkCAITguCYDVer9+ARMbD7UttIbt2\nVVBcnALcQWVlFzIyUqivVzRSGEbIzv4eepk3Iekv3f4/CcgkM3MpN9/8I/r2TTeyeA+/H/VRCLhc\nZFFzfETVmwgc6tELPwu9zCsQQA1EUUZbkdRfaJ8n2E8RMrm8bX2MQI9eDT6XYCYCFoV36pgkfLmN\nDCThvojI4HUEbA8h80ZX6/MkG0N7m3u5jWGA/XaE5gjhW0ijSEamrDjSJJyZygFxBdJc4niTTSEy\n1R3dYPy1eGdyJiLsAqTFbUOS9iybTxnyKbRoMJdSRAyuhpcLkXVBAA0LDiaghLxWSDs40n6fZGu1\nGF8RuaEGELV1zbCxFSByW2JziqNnZxMC8yjyn7h5O1PcA4g4nWaVZNcaiQgK6+skO3c5uv9LG/SV\niEjsd4i8FyJN6QUbXwe7fgkSEAYiosfuU4QpUyYyZcoFJCe73BQVqAzDDgwY0IUHHriTu+76E/fe\nO2YP4D/44KNcc82tlJTUAFMoKdnNlCm3MmfOgxxIaxghWVy8nblzH+OqqxZRW3s3V175zKeK6DqU\nS6sciAZyExIDV4Vh2Al5+v75RQ0gCIITgyBYEQTBqiAIrtvPMdODIFgdBMG7DbPjv0lt8uSJnH32\naGIxSaDxeAIjRhxBfX0CubkzSU4uYfhwt0HUdgQ+u/FVcgOqq7vTs2dH+vbtRxB0xO+G58wdPfE5\nBtrJTjH0oDpSqXgQKkTAMQpJjcUIBDchQG+JJN5sRE7DEXgUIhv+K0gSrkCmC/AS/zAEKr3ss9Nt\nPLcgTSULScQ5CFCc3T4FJQI2Q6AYtXm1szFWW/9u69gEu/Y6vL8gAa/VbMfndvRC8pPTok6z9WuB\n14ycKSkTv0XvZrt+B+SjcealJEQqE/Hazm34LO5NiOAL8AULW+CT7JYjsvqdzTvH1rA9cJ8dk4fP\ntr8fn8OyDZ9tPw0JC26DrCK7T/9E5FaHr3WmPTjU3rf7NxsBvzOFluNzPbD7czcinALrv61d4xzr\nMx+R1xv2udM437e1cyZEFx2XZWuTSmLiOgoLSxkxYhDxeNSEqDiRyB2EYRHvvdeK66+/nXfeabHH\nzLR06XssWDCTY489kuzsCmAa2dmVHHfckZ+ogezLB/nII4soKyuz8kIB27fXsGvXrgM2RR3KPpUD\nIZC6MAx3AJEgCCJhGL6I7BqfuwVBEEEZWGOQXnxuEAQ99zrmJKBLGIbdUIjOrC/i2odaC4KAbdt2\nkJKSSK9eU4hEYPPmIu677yR+9avxNG9ewAsvbEXAcAQCGOeIbAa8RF3dFs4992c88sgOwjALSbsh\nCueMolDZTcg2/S5QT03NBmSH/gM+eug0G1UKApCX8ftNZCDQuAqBxjb7fJb1U4ck9sHI/BEiu7xz\nHsfx+SMFSNNw28zm46XncrtGa7w0W4c0kacQGbpM9u7oEYsjEiiy8Xawcbm6Wdi579gatrE1cdFb\nRyKA+8DGvhwRZzLyr0Tt+wrrs96O22R9ujwVFzKbgEyIDpybIfDNsz5jyGSoqgBaj1wUqLAeaYAl\nNv/Q/nZVjNviHe+bEdGvRMRcZMeDz+FJsvtQauPtj4jV5e/cYuelooCKhjtUptg9G2RznoYILQFp\nEivtZwQyx5Uh4aISmb7SkKbWlsZVmtshs6DTok5Az0GESESbXKWmduS5515j3rxHGDWqmtatdxIE\nH5KRUUJq6m5qazfxf/+3nvLylvzwh0/Qvv23uPPOJTz66HOMG/dtamub07v3tdTW5jBu3Lc/MZdr\nbzPTggWLeP31HAYO7EUsBnANsVjIOeecdMARWYfyHiEHQiA7bT+Ql4EHgyD4P3yt7M/bjgRWh2G4\nMQzDOlTk5/S9jjkd+BNAGIb/ApoGQdDiC7r+IdX69evJ3LmncuONo0lMLKVv326cddYYLrlkIied\nNIza2s0ItMcj0CtGUvRG0tM7AUvIzOxOkyZZwBiSkmpITy9FVW0/QC9vRwR0yXiNw8Xlu8KFIiRf\nQ6sAkc5oO/4jJLU/hcDMhb02RxLyRHyc/zHI/NPF+nSS9jS7Vhz5J1rbGBOQw9nt1eEcxW7L1nS8\n3TzRjitFDtkhNofOCJBdNFbMxpaCl+bTUCmNJBqbfnKRaagtkoxHI1Cbhi/3MgJfmNCZvOqRNnMS\nIq538bkeBQh8t9p4nVaQiDQ4rK8h6NVrbf32Q69QUzzxFiHSe8T+/7at19OIXEfjc1wiiMyw9cfW\n9wikNXTBm8KaI99NNtIWWtixpyHNYwRy+vdAWk6+fZ+FtM/rbJ4/wxdNbGn9F+KDAmqQZuJyfVba\neScDbQgCbb4VBCKvpk2zufvun5Gbm83jj4esWFFEGL5MWlpPamtbA5dTX18EFFBcvJGSkhg1Ndrq\n4LLLbuLcc1MPKJdrbzPTZZc9SXJyfy677A+Ul9/B4sUFhOGrtGixmuTkUgoKSj4VAXzVeWWftR0I\ngZyOdP8pqJLaWvSEfBFNcaW+5eMTBPZ3zJZ9HPONaHtX6H3jDZVynzjxRzz99L+Ixwej8M2XkXSc\njOzU3ams3Env3j/eU2yuZ88Pqa0tJx7PIzf3YRIS+iGQyEdg1BKBUCe7+vkI+BahR2AkAusp+C1R\nj8JvxuTMOpV4s5graX4W3iHqQLwIgU/DUFisP2ern4bs56ORdHyNXesl/JawJfh6T/V4Sb01IioX\nWuoAaywiiVMQiKfiS5aMRoTaMOS0FjnZXT2wt5EP4lwEuK40SQHSROoRgLqNme5DINnWzneJgPVI\nwi7CawUxW59kG+tKBMhu75BONidXBHEzIpV+du3O9r0r5LgYBT30RGHSy5FmtBkH0CK7AhoTfk9E\njp1t7C5AwTntM/HaSBTd8ySbt9sXfRo+EdAJHnG7f9/C++CW4Svzxu3cvsAkUlLSSU7uSZs2ycRi\n0LbtZIqKyrn66l+zYMH7xOMzqa/vB4xi1658IpEC4L9tHtMIw+ZUVVUBN7BhwyJ+//ufMmvWLfss\ndrq3qerfi5umc8UVE0hO7goEJCR04Nprz2Xr1oXMm3cRffv24NO0Q3WPkOgnHRCGYUNt44GDOJYv\npP3yl7/c8/fIkSMZOXLkVzaWL7pNnnw+2dk5XHvtyzhb6a9/fQXjxo1m4sSfMH/+TurqnEaQQhCU\nEYl0JRabCVzArl3v0K9fM7p1S2blytVAW1JTX2fbtjfo0GEkW7YEJCbupq6uCx4Q6pFPIx2foTwE\n2akvRNLudgQiE5F5RSVQZJXsiIChGbKrpyJz0RBEdE4KzkESeC/0WLq91b+P8jxcufMRCBT/C5UH\nT0bgMwv5RzYh0PizXdflrMTxW7gOsvEuQaaaM5GJbi0+auklu9ZRNle3N3g1AlMnHbdBZhjnq9mG\ngHaQ9THYxvs9fHJgsa1vGvJVbEBaxJ8QifRDhFiDCKVjgz7etHtxEzL7OEe02842CYU2n0DjKLJk\npK1swIc8r8VrE5MQmbS3dR9r98RpfV3xDvQJNu5d+E2uXAXfHJufMw9ORHkdSbYW30OlSU5D2lZ3\nW9+J6DlrikjmbhvTK0hLm8Du3RmMGpXEqFHHUlJSQnZ2Dt26teOHP1xKaWlvFGLeHCikqmo9QVBl\nc3ECSRS4mSB4iLq6kFtu+T/efns5v/71j7nhht9x660/AWDq1NsZPLgfM2ZsY+jQZ/cAe0Mz0+bN\ncYKgKWVlNfZ/AsOHDyISiRxQMuJX2RYvXszixYu/kL4+kUCCIBiHKuO5Iv0BEH5BuSBb8Js/g56c\nLfs4pt0nHLOnNSSQ//TWMHv8QNTdfT/EAffc8xBLliylrq43XiOIEQQQhs780ob6+oAVK97krbdW\nEY8PBSZQUrKQpKS+xOMxcnKyycoaxZo1JXbF8ej2rEYv/UAEbA3zDCqRhFhix+cgkilAuRwzUanw\nV/HbpbZG2eZRBLjnoDDP3iif4BEE0KUIPI5C4BujMSjmIB/POgRSQxGof8+utw5pL7uQBvAnZDIr\nQkUThyFiGmPjaY/fCCoZXypkKJLgJ6IoofeRH2eFzX0X0pRG2jjr7dgnaFwGJkRElIXIMhuR4DB8\nUmBPpCmsRyTXjcbFIpMROTnfxHfxFXhdiO/37BlIaHBP0u3/LXbc+YgEXHHEKba+a+0nbvfqRBtX\nGT4xsqX1fxYiz7eRZtgan73vxuyi3lwBznx85YMPEGE4P4qbK3gNqCNQTRAUEoZxWrQYzdSpkwGZ\nlX7xi98TjQ4H7kSVC5YBiaSnR4A+VFYOR8/SaUhTjBCGqcDNvP/+X3j//b+wcOEitmzpz9Chz7Jo\n0WKr4rCc8vIHmDr1f/j5z+/iyisnUFJSzX33nci4caN55JFnueeeBdx331l7/j9UzE57C9Y33njj\nZ+7rE0uZBEGwBhgbhuFHn/kq++87Ab3xoxCSvAGc2/BaQRCcDFwehuEpQRAMA+4Mw3DYfvo7pEqZ\nzJ//DBddtIj77jtxn1LLvgjm1lvvoXv39o0e2uuuu5jzz/8JTzyxmYoKuZEyMyuoqckhDHOJx8uo\nr88lLe19otEd7NpVgS9vcRMKm4TMzGQqKjKIx9shZ6xzClejaK0mSKvIQS9lNnKStkXg60I1ExCY\ndEAmtUmIhLoi4Pw78ru48Ns/Iom3JdIEfoCP0uqIzD7fRw71byFiyUEAno+Atr8ddyEind2ICJLs\n+1oE9nNtPP/C74m+wub1gc3rWERATa3fexEhfIjMZs/iAfMFm0sR8jVsQ8RZZuuWh68n9RoC0j4I\niIci7ecRFJ58tM3hAuu/JfIdLERSfRbSarrZtZqg1ycXX4KlrY15CSK2akQ6nRGhTbS+M+x+1Vh/\nj9lYtuCd5Ufb/fgvW4/ONuc11ucipHU1t7XrZH1HEZlusZ88/L2P2/Ev47dOdr6fYru3PZGPqhW+\nMkBnoAstW5aQnV3ClVdOYPLk85k//xkuuOAxdu92ZVHWA1GSktZRV5dMGHa38T8IvEs0mkp9/UCk\nLU0DakhM7E5d3WwSEr5PJPIRdXVXEo0uob5+K1lZScyZM3mPFvJ1bAellEmDVngwyAMgDMMYEk+f\nRU/gw2EYfhQEwSVBEEy2Y54C1huRzQYuOxhj+TLbgcZ97yuxaF+20jlzHmTJkjeorMwGriEIWpOZ\nGaN//zhHHllKNJoFrKC6ejcJCSkI+Nsj0HkWmUw6UlFRQjyehwLjugB1BMFWJDE2RS92FSKedARm\nXREYdERAXIcAZLv9fRoCqgzkZG2FyGKL9ZOEJNkoehwvRNJtHxufM6U5Cfo5fMJftZ3XcI+MAAGr\nK+h4HAK9Exr0VWfHO3NYG0QEBaju0lt2/M4GfUbtuIk2zpYIrN13ffGgl4GAzEUfNUWmM7cO/7A+\n3sKXeTkeSfIP4qPHOiOCLEAkVWDfjbD7l2m/K5D20NXmvAJJ9F0QYXWze+zWMcvOaYffG/5sm1MF\nfjdKF17tfB4us7zKPh+EyGs80k6X4TWhd5B2VGvrfxe+1PwyW7MiRB6bEPHkA9tJTnbk/S5uO2DF\nzdxBcXGKCUDhHo08MTGVIDh9z/qmpzehZcs2RCJdiUSygRNJTk7hmGP6MmBAK6CIILgVPUNj9lTn\nbdYsm8zMHsBEYrEIbdumU1fX7pCJiPoq2oEQyJtBEPwlCIJzgyAY536+qAGEYfhMGIY9wjDsFobh\nb+yz2WEYzmlwzBVhGHYNw3BAGIZvf1HX/qraJ8V9f9rEosmTz99nTPuFF57OW28tp2nTMuAp8vK6\nUF1dhV5K99L+BZhJQkIS8Xg9CQmb8A7sIQTBSBITE5D9uhgBxn0I4LLwTmAX31+HtJZk+6wMSd4u\nITCKJPIOwAIEivkIcF9EJpBtKGPZWS4vwleQdclqjyKp9VjrK9HOScBnWLfH11560r6bgEA8F28+\ncT6S1ojYXDXgrvi93hPxme+J+O19v4deo/V2vXYIfHchJ7KLVttmfT2DpHN3H5xDubmt329tDFXW\n79/xNcJaIWJ9DJ+H0cauN8TmtNL+748PYgiRZO8irkoQkXRG/gcXmrve5jQKEVAPRKhFiFCPsL7K\n7Rq7Eem9gjTNgXjT2UBkVsqhsQluDCLbFniid36sUqCGmpo0m0dn4EqgLXrtHyQWi3DOOWOYPHki\nYRhyww2/IzHxdcIwF7f9bmXlClq0aMLVVw8lPT2Ntm0nE4aJHHVUf959dwdjx+bx8MP/TWJiCcnJ\nT+xxyFdV1VNZWUde3kWkpES5444Luf/+kw8Z09RX0Q6EQDLR0zwavUlj0Zt6uH3G9klx3582sSgI\ngn3GtDdv3pza2qP3lKxOSmrLkCH9SEhoiTPtJCRIws7IyKBLl1wSErpaMlYUWEo8/hp1dQORQ7Ql\nIoN/4naGk4nhDGSieh8fttoXAV1H+6wdMhu4cuOv2d+uhEgVksJbItCZZGNYgwhhJQJMVzbDmXDm\n2O9/Ian3FQSys/HO4B3oMX4XAZdLZCtGoJqGwLcdytiGxhnXLmx5DcoWd4CSb/25JLyNNqctCJSd\nVpSDJ9qH7FrdaByh5syEKfiSJduR2ew1JKkXWD+D7dxHEfg6J/mxtmatkU/JJReuQ6amSrtvifiw\nYqeV1CAC6YjIbgjSzvKQsHEMMve9ZsduQkTSFr/nistdOcKudyTebOUCNx+zuW1B9/4F+/xMRHon\n2DWvx9fDaksQdKBnzzdJSYny9NMvAaoDt3p1CWVlVfg8pFmkpQ1h48Zi1qzZwL33nkjv3tXk5i7n\n/vvfIhZbwooVzbniilu48MJu/OIXP+DHP+7AZZcN5cwzUzjrrPYUFNzL3LljWbMm/3NHRB2K9a0+\nTTuQKKwLv4yBfNOai/velwNuf87yhmr03v6Rhv1deukNXHbZr4hEhhCLdaKk5EkSEwezdWsiZWUx\ncnN7UVDwBE2bnkpZWZSWLS+irCyNDRtCpkxpT37+dv7ylxdJS0ulstLVVnJA40pguNLnPRCgj0RS\ndw0C3LoG56Qj8E5DdupVCCQeQXLJZuQPuAcfDTQckdAqBFBDUTb1RORnOREf8toaSbKm5RdqAAAg\nAElEQVTL8ZqBc7TX4c08zW18zyGQdhqSk6OSgVuRM38cAutBiDDHIPB04aV1dk1XGr3axrndflzx\nw3PsuBCR2OP4nQrbI8ttT6QNNrdxFtp4Ygi4uyPiycdXIz4PEXYzRAjvIud3Fo3zVpKQNnAS0n5W\n2/hb2Jim2HkZ9nlXGpsEXSHGiTb/Dog8XCzLR9bXeLunOcg05za6Go2PtnN7s5+FosHqGqzXz5G2\ncwvS6q61654O5BIEH7Bs2d+4/vrbufPOjbRrdzwVFRpbLJZr/W3F1cfKzExiwYIZPProc7z+eg6T\nJvXmb3/bxY4dEshmzPjZx/o1vqhIKmeGdtFcX7d2ILWwpu/j56ZARsfD7TO2T4r73ldiUUNpZu/C\nbQ37GziwN4mJCRQVbUag05wmTSJceOHxnHLKcSQmtsEl233721VkZRXStOkuYrHzeeyxXTzyyFNE\nIi1o1qwe2bATEdDUI5BogqTPjghEjkOagMtE3trgnJj1UYmA+Ta8VhKxv9MRqILPfo4igMxF4OYi\njKJ2zvF4J7jLOdmFJPs0RADOdLTavluJJNWteMfxCLtOESIWJ0WvQeB4rY3hLiQhN2kwnleQCakL\nAtXh1qfL6H4JAelqfN5EM3wp9lT7/DUUvvykzS0Br8VtR8CbhDSkhtJ+N2SGczsKvoiv53UGjetN\nTUAa0nE2/gob4/v4sjHtkf/EXWM83jd1tvVXia+o3N/msMnW5XREknn4sjHtbI3ygBsR2Z9on9ch\nwvk2PkrNmbpORM/YKmA18XgaiYl9+NOflhKLPc6OHVBWthlprGfhTIzR6Bns3h1nzZpm5OUNNzPw\nHfz5z4Vs2fIcLVue9qVkeh/K9a0+TTsQE1YK0klX209/JH5cHATBnQdxbN/oti+CWbBg0Z49Pz6u\ncFsQQGnpLuJxl03di5074zz55Es0aZK4R7OJx9txySUTufHGK4xUJrFu3XJqa48nFjuWLVsGomoz\nBciUUowA6kIEQq2QyScJn1lei9/OdRoyUwRIg5iJ3/u7AL8Nq9vKdgySttMRcLpNrlzW+BT0OK5D\nEusrdr0M63sgIrQ0FCjwCr6gpCuGWIckZjfmKrtmE7zjuTN6xKvxJjcXknozMpG5EOYPbTw98E76\nGCLSNsg00xJfhqUYAa4271J0Uy4+PNll0+fg/R8uM/0Du8Nn2PUvtc+Kre/jbJ4vWT8uL+MFRIhN\nkGmvu93H9xBhzbI1W41A+2R8nstLSLpvgvwddXZffmfn/BaRWBSRbAdEQM535PxnnYCrkcZ2ta3V\nDvu+CyKeYnxAxRi7Dxkor2cYEGf79jeBI9i9uwL5amaiiLN8YCn19Y4AT6akpC+rVz8K/IiqqhhT\nppzFli2PfSmZ3odyfatP0w6EQPoD3wrD8K4wDO9C4kJP9GaMPpiDO9zUGkozNTXfZevWUrZtq2R/\nhdsmT57IwIE98TkIIdFoe6ZP/wUdOnRupNmsWZNPEAQUFS0nKWkI8fhuvD3/dMLwW0gSjyGTU19k\nhokgoLvDrupKb2ch8M5CUmsuAiwHrsko8icZPVov4sM62yJA6GB9Dba+InhCykfAXW/93EzjvJSu\nCPgTrN9XkWTt/C3pKDQ2EV9kYbKNBRvPU0gb6IEAOZHGlXFTETD3RIBbiojLOeldbati9Irk2vHJ\nSPs5Gr1GWH+1CJQn4MlnJyI5V7k20f7fjMx8bj/5JLSLoYsC62zHpyEpvgkyDQ3EmyKjCPT74Z34\nMSQQtMPvAVOHNEZXJw1E/K4kfTF+X5FiW+9X7PpZ9vl2W8dN1s8QG1e+3Ysm1mcJMsMNRCbDm/H5\nNTciAjrOxr3Lxuci5Apt3qNt7VrhfWgtyMurIB73iX7jxo2mtHQH1133W6677rcHxT9xKNe3+jTt\nQAgkC4kBrqUD2RaCW7PvUw63L7I1lma+R1paa/Ry7LtwWxAEtG/fhqSkZILgPIKghFgsQiQS4YYb\nJjfSbK677mLuuutPzJ17GXPn/oqMjC5Iwn4TV+o9OXk4kchOFGLqtIMQSbZRBCZV+F3xPkJahivo\neDG+XtVGFDq8C5l0RiIHuIvWeRABvcvgbugInoDAoR75MJx5xWVHhwhEnR+hIeB3tOv3Qj6bj+z7\nQnytLldapQ8yZ7kNpF5HIF+IJO4IAu4C+3yNXbcI+SoKbT1GILNWCTJdZSNtxJVJcSSWYGt6AT4C\ny1UGHo6c450RQLdC+Rx5yKcRRYQeQ8T7tF33NUQqWUjrqEUaxPH4fdIvsvmeZv24ZD+3z3sP5Mx2\n2+c2wVc3noXA/Gq7H0mIjLvZ/F62PlriI9o62nl/QVpNpa3JNLsvNajYxZG2np2QabTh9sTZiHwL\nkAblSsyUkZj4Cl7gUDmbwYObsm3bvY20jgULFjF9+tvceedGpk9/+6Dtv3Go1rf6NO1ACOQ24N0g\nCO4LguB+pIPeHgRBOqpbcbgd5NZYmrmW6urdJCYW06tXuN/Cbf369WT8+DT++tcL+Otfz2TChM77\nfIAXLFi0p9T1Qw89Tl1dhKysj2hob4/FEojH2yCgSkFAVoJAazsCshCBh5OWdyLwaoYAOh+/414d\nMkkcg492cvZvl5joNJZEpMG4cNXncZsKiYx+gojoIQS+BUiCdXb5c5DUvxmZm2YiaXknMuPkIlPR\nNnxW/UxUBfYtBLwdrO8Pbf4VNpZMJME3xftxxiJp/QT8HiEvW19uDgBTEcmuRRrSY4hYC/Bhsn3w\nm0Ytwte8cualjxDJb7T74TZxSrY1rqSxQ/0sFC672tbgJpvXLgTO2219V9p6nYo0gLcQuXVCznS3\na2Hc7nktMicV4s1gR9i4FiOynIPMcWOt7z7A/za4z5sQER2JgimOQM/CcEQgx1q/bYA5RKMpiJTc\n3jDF1NVVIwJ0GuxiCgtLueGG3zFu3GiyslJo1WoYEyZcx+7didTW3s3u3V347nd/TKtWR33h/olD\ntb7Vp2kHEoX1xyAInkJ3FuCGMAy32t8/OWgjO9watYZRVhMn/jcA8+bdtt8SClOnTmr0//jxJzb6\nf/bseUyf/jB1dQMoL5/Gj340hYKC1+jZszk7dtSQlpZAVVUbEhLOob6+Ce3a7WDLlr7E4ycBP8VH\nFlUgSfUYZNJphTSKpkgaDBAotcTXOuqDJNHT7POz8cl2TyKJ1+1Ol4dyR19G0rVLBExHJo1/Iunc\nJffttu+PQqCbhwgpHynSjmi7IgBuhoDrKuCGBsekIYl6BMpen4yAqt7674PMY92Rb2YmAtoYkrRd\nWfIYfq/wDTbOJSijvgJpBQ6Qq/D+ljgihXykhW1r0M+fkB9qC9LgXB7KEdZvFiIuN1dXV2wxkvQj\nSBNZZdfbbcd3RkD+AgLqSTbWpgiY37NjAnxpkPOQaXMeuv9uc6q7UUWBN22ejsSqkM+jGmlSEaRF\nuHNd5WeXSOnyYSaisOUiYCyxWE9gDpHIxcTjyxBhr7T5TSUn52q+//3v8/TTLzNjxlaGDn2WyZPP\nJysrm4suuovKSrfmxYRhN847b8jXzj/xZbT9ljIJgqBnGIYrgiAYtK/v/xMT+g6VUiYKwb2NMITf\n/Oa/vxK7qIvkuuSSpyktnU4kcinx+Om0bPkM0eh7FBfH2b37p7Rt+yLnnNOURx99nnXrXFnynshE\n0gOByGYkGQ9GUmwZkmob1pRyOQbXorpT9yJH6RYEJu0QkCYjc1VH66cJAqu1SGL/ENn04/ZZM0QS\ny21ceUjj2IEvv1KIALG7fZeJgG0IknZHIYm8rR3jdg5cgiTg+5EpZwkCsFr8HunHIqK71uaw0dal\ns/WTjvwqiUjTSEKE8AAi4scQ+WYgjWExPlR2CCKvnyK/zC7r9wfI99QTAfckVAXoJ6gsTCEy8/RD\noLsWEUUTW7fBNqdzbT2dyexYROwXI2IObP4FKFhiITL/pSJSybR1fRMB91xUY+sDG8vzSJg4ztY3\nGxGmG0dPfDFO7Pse6Flqhp6xbkiYcKHNLfDa7WykGbmSLanomaklGu1LZua7lJb2Jwzn0K3b/1Be\n/gI7dpRTV9fOrr3dznmJlJQcOnduzpVXTjjgfTz2bp+2tt1/SjtYpUyusd//u4+f332Wix1uarLB\n5h9U++snNWcWq6qKE42eSTwOEFBYuIzKygri8X7k5DxIWVk1w4YNpLCwEB8t4xLWUlDkTR8kZb6O\nAHYjAqxsBE5rkWTcBB+iezoC3BgCuwq0PWsJIiUXetsCAdEOBEJpCMQ2Wd8fIc1mILKuLkEksQuB\nUIDMQSF+q9e1Nmb3+LtNoNz2q5ko+shpD+chKb0ZfsvfRDv3HaSBjEAaUh6+nH0mMjGNwmddX4E3\nKxUhgilABFuAAO1pGhckjNvf3RHAPo7fMthlsXdAJWiiNoZ0pDX1QNpWEtLKWuKdz2l2T9vg80Kc\nppCBTFbP2VrLHyZDRC3Splrb/OtpvNNiT6RduATHFYjg37X/C2ztZuGTOvOQlrHN1uVf9vlqu0Ye\nus/LEHmAyCqVSGQlQ4Ykk5q6hkgki4SEfkSjr1Fbm0kY5gAB69cXcuqpIxk3brQlz56IiGoNcCSJ\niYM/d5TUobin+edt+yWQMAxdLapv7ePnhC9viF+fNnv2PFq3Ppbzz/8z1dXT2b27C+ee+zNatRq2\nT/vrwc5iXb16M/PmncoVVwxGEt5vCMPutGjRnCuuaEtNTTbDhhVz8cU/o6pqON6O/TCN9/IIERn8\nAgFCU/RyFiKJ0G021BztpbEcmU+WIil7FgL0KQiA/o6k9GpkFipG5pMcu9a38VKoywu5C5lw3G57\nWQiMNuGB94/W/zAbV4iIrQcy4aQis1cCAtoE/CZKH9o1ByDNyW1JU43IwW3Q5EhnEwLBobZuPW3e\nP0PkM67B+WsQYLdAIP+89R9FzuCVSGtYa3//wNZ0J/Lx7Lb70ApvDnOlS1YjM5grwd8KgfBw638o\n8i1sxZuTAnxmeA4i6qV4goihXJcXbPyd0bNwjvX5gc3n3Qb3LIK0iVeQr8iVX3dbC3dBmtQuO/c4\nu4f1+JLvHRGRbEbPTwawg3g8hTffXE51dRLxeE9isZnU1Q2ksnIb8AHR6PkkJqYwZsxIxo8fQ0JC\nJ+S4bw8EZGervP5njZL6puR87Kvtl0CCIBgaBEHLBv9fEATBQkskzN7feYfb/tvkyedz551TbUdA\nAW9mZnemT//FPiWfzyPRHAj5TJ06ifHjT+SJJ54H1tmLNZOVK5tz112PUlFRx4svrqKyMm+PJKeX\nvRYPsBOQdhBBimkS3lHsJGgXPurqKG1HAHkrnoScb6MDcib3tv8zkZnL7TToSmz0teunIEALbBzH\n4UuMuCz0RLz24TZGKkXaipyy6m8DIq/l1tcgZOZ5E4G8c7LPsvPi+HIelfh9Mlba9d2ujm4NXPLe\nKkRC7+B9H26vlVnA3xBIPoeIy+2tMdTW4l5kvslEBLEYAe2l9lkB0tLi+L1aGtajKrVrVSGN70i8\nWa8AaQzr8dsN56J7fqbdAxcYkYl8DychQl6NiGa3rW1LZEZrZn2tQObIznYPH7ZrVlq/g2xsWciB\nP8jG+xbSTjch4eRJm+9r+Mz6nsiMJi0qGk0mCHJo0yaNlJTmXH55W9asyWfevEcJgldI/n/2zju+\nqiLt499zbslN7xAghIQmVQUsIMXugmKhrKLg7tpAQVHQXUV9d92irhXFlabv6mpARRFxbYgVUEEU\nkCJIlySQQHpPbpn3j2eGCYrIi+vaMp8Pn4R7z5kzM/fm93v6EyUNxny+LBoa9nHxxdFHHCX1S8n5\nONg4lAnLxP7hOM4gJNj8KeSbMvsQ9zWPbxiO4+C6LrW1YRznEly3jJqaIK7rHiD5fFeJRinF8OHX\n8Oijuw9JPuY50oznbhxHHJg+X4CEhM7ANJTyEAhIrSTXHYntEtcBAcBi5A/ZNJ1ajYBVPOL8NiYr\n0zM8Afnj9yBfKfNelJ77E0yBR9EUTO+I9ogd3jhZvQiotMTWbkpHNJ0BWAnVg5DIU/oZqYiEn4wN\n8TXkZkw5Js/DjzUDxSEmmzX69IwJayACoDsQMNuhz6Gzvt5FrMGu/n8bhBCyEICs1tcaM5Uhm2S9\n9vZYJ7Qf0SCaFoE0pOTH5lYYR345omkYX5TJLPfpZ3yOaIkzEPCN6Dm66HMvQUi4Qa+xEiEID+K8\nNybCsfr5HRFNtIXebyvEV2OuM6VajOlNKu3KdUv1GoYg2uZSpEBjH8CvQ3TbY/umdEdMi0frNbp6\nrjIc52KCQbjhhsGMGdObf/5zMCtXruXmm69gwYKZTJgwioYG+R5lZLTiySfvYubMu444SuqXkvNx\nsHEoAvEopUxnoYuA2Uqp+Uqp/8H2A20e/8+xZUsew4ZFMW/eb3juuQsYMSLra5LPd5FoZs3KJSvr\nZBYudKiuHvyN5KOUYvv2Av70p/HExiYCLuEwtGkzFo8nipqaIMnJwwmHj6G2tojMzD24bi3iGzDO\ndGP6MrkB+4BjiYqqRMC8BWLqWoW4zooQ23NnBJRqEcAy/cRNN0KT3GZ6shsJ+j5sBJCLVAWO6Lma\ntsJN0881EvYGRHJfjYBmAmJ6icHmDJis6EbE9l+KbURkeorUIsA/GAHhRIRYTOKdH1uUcZP+fTOi\npexFJO1SJBhgDmLG+pVev8n7GIEtcngatinWMP1M0z7WkEGUfi0DAdY9+j7Tv34tBxKTKSVfpq8x\nvdkcRHM4Q6/Vjzj/1yJaxCy9fkNqJut8CULYLraY5u16Xab8TLR+lvFvGKEhgHyXrtZ79CFk0xFb\nTsWHxwPB4HEIsXyGFTCKsJpbRM+9mkBgA0pt5uOP1zN16pcsX76GVata0LLl8XTtejYzZ5r8mVHk\n55ewePGSQ4L94Wjzv4Scj4ONQxKI4zgmzPd05JtnxreG/zaPg48pU65izpz7GTlyMCNHDiY3976v\nST5HKtGY0NxQqDdKTQeWsmPHm/Tv353t2wsO+AOYP38RM2YU8vHHn1FeXk96+gyiokp56KHhtGjx\nGQ0N66iuzgBmolQ78vNXEAptR0ghGZsVXouA73bkD38mDQ29kD/m+xCg6o2QTQsEoCqxRfsaESlS\nIY7XLoiNfhACPKYh01I91yr9/016ripsNV0v1idgEtsiiLR8lH6uo+eq0mv/HGlWtUfPuQ/RghyE\n6NYheS7FCHnMQCTmJfraTdhKs0P1dZsQQJyNkImR9JVeWzECfP/AlkGvQ8KCO+i5Pdj+KasQcC7C\n9hkxJiNjJntNX5OCmLtyELI3pqjl2FLr1Xq9Sfrn6fq99giBmf7yIcRRbcrrRyG5I8bPovSZxujz\nNKHKxkChkBDtQJNnmQKKRngwUXRefdabgHHYxFMIh7OAx3Bd00jLmD0r8flyOOmkE4mLi0dMcSHq\n63ui1Ht88ME+GhuXMXXqF1RVTWXfvu5s27aL2tq9iHAwl4SESp5++nVmzXqabxqHY0r+JeR8HGwc\nikCeAd53HGch8u1eCuA4Tkfk29s8vsdxJBKN0VyCQTBRPo7Tjvj4RGbMKOTFF9/8mnnsySc/JTFx\nFX/5y0hycy9n69Z8tm9fwg03jCYSMRKkDzgGj8cAdTqOczGO4wPO4JxzzsDvb4NEX4GASgsEKPoi\noNsH+QpNQOzqIxCA3qmv74LY/I1Zph1Sk8lkmp8D3IU4ynvre9/Sa+uGANA7iOlsI0IcKQiw7cH6\nEPwIoGVgtaEhCHDHISDaiJh+ZiLO6gBi2jLmM2Pi8iBEuBmJQFuNzao2Ur+JpjL5F2dgs77b6j1X\nIYDfWc+TqN9z9DlU6ft26X19qX83bWDNM8zejK/K+CAC+nN4F9tgK1qfVU993m8jQsAyhNSOQwhh\nDkKcX+o9rNX7uErP62LL2J+k1/ulPj/T3jYD+d6EkPyTsdjkwUIkafO3ek0uQiy7EYGhPUYjTU7u\njs/XFtPKNzo6huuvP55gsI7a2m14vSXAX1FKIsKUageMQimTrNiKUKg9tkOlS319Akp1JjXVFPO0\n4z9hSv45l3KHQ0dh3YkEtz8JDGiSYOEixufm8T2OI5FoHMdh8eIllJTU4vFcBMQQCu3joYfmUVXV\nmylTlvDww8/Qv3+P/eaxmJhOTJ06hXHjxux/jvhkXMLhMLbMxdWEw20QCfpVlNqMUvHATF5/3aGx\nMR8BgO4IWJgkMSOtpiEAGUQk6qUIwMcgtaGMU3UN8scdQKKmOiEgvQiJ8spDNIJCBHQ6I9K31D2S\neUOI/yURAS9TGTYW2wujJSLx+pHihNXY8iDRCGjNQbSHkxBTk4lSCiPgZrKmT9TXr0O0iHHYkiAR\nxEz0ATbL/SR9f39ETluDEOkXeu/ZiJQ9VN+fiZDZcVhTXSyi+aXqcwxgI55MXbI2+pxa6ftPQYA5\nTp9JECFR46xOwpqOTMBDPUJqphjmu3ovJrnRhOr6EH9HK30+iQhRrUAI3fR6+VB/Xk0DIQr0mSXr\ndbyNEGoi8p3IBEZRUlLNiSe24PnnhzFv3uXk5GwlNTWVCy44m1NP7UokYio8e3CcYXrud7Fmymq9\nrzREI72IhgZFfX17br116dfI4bs6x38JYb2HLGWilFqulFqglKpp8trmH2MSYfOQkZOTw+TJObRq\nlQOcTSCQRHJyD2AM9fUR/vKX6zjzzJO/1Ty2fv12evUyhfNMvSjTafA0bJFBh0ikEZHqXkM0hGUI\nYLRFCGIUYvuvQoCnLaI9GEe1ySEwUT+mp0QA0Q6KsRVkN+o15ennzESAvAobtdUJqVmVjdjtHcSU\nEo2Qm6P34yLS9TrEpKQQjSBT7/NFvVYf1nT0ORL1pLDkGMDmvezGlm5R2FLtxqFvrs9E8h78CODH\n6Pd7ICalPYhmsxQbZebT609G/CQ9EV9EN73ePQhgr9fnFIMApVmnF8lDaa/Xuxcxoz2KgGqF/qxN\neXSjgWbrOe5DCMKvn5Ouz9vMbaLpwgi5XY98D75EiCwWIW4hdK83Rt/fHulbbkqhmAZX9frafKRU\nzT7Wrt1MSUkxjuOwa1cXVqz4lJSUaL744ksikShEeypCqU3A+7ols7l/J6L15ANnExeXQlxcAdCe\n+voId9wxgR07rKn3QFPyJIqKyve/fqjxSwrrPZxaWM3jJzSmTBlLv369qKhooFu3RUBbamqCdOt2\n436y2Lo1/5DmsdGjr+W991awfn0rpI5RBqKI7kX+4PtjW7ya3I1MhBSiELCPQwhnCGIqWY8AZw0C\nEimIQ7SlvtbkECxHSOhv+voHkdyLLxHzS1e9pqa9MVxsImBXbEVfU6TxYz3X2XqHMfpZOYj55EwE\nPPchDtohCNDs1Gv16D101s/qiDW3TNZriEPAPwpJ9MtAQHMQYrYzkWe/1vf5EM0HbF96QyJj9f0G\nlLMQAoxgm3ZlYslwL9YPlIYQ11EIqVbpa4xW8nf9zFisGe1e/fxovdZY/dlkImRWq89mOybTW0B4\nBeK/qUdIYwQ2HHs1khBpCilu0fdJC+NAYCQm98I6w9voa7frPYQRYcWE+XaloSGa6667h/HjX6G6\nuo6FCx3+9rfHcF0jFCzU+/OQlBTDFVeci8/XCnBJTMwhJycV121LZuZ86usVoVAC3bptpLy8jhUr\n1jB9euEBGoMxJd9xx1m4bikvvfQ23zZ+SWG9zQTyExqHa1Nt6j8xbTqbksWhzGNKKTIz2zJ+/IWE\nww7iV/iCvn0zSUgIIwA3BgGsvYimsAcB52cR4FmHgF0WEillqt5uQ0BqAKKtmP7hJvt7lZ53J1Jy\nfSki8U5HiGEPIpG+i2gDpmmVCUutxUrBIARhCjdWIj1EAgghrUE0CVP1txUCVCaqKk3PZ8qyb9PP\nN+DZB9EQIgj41en30XtYqu81/SqCCFEkIGSXp/+ZHvBr9RpMlJnpepiMhM72RhzMJtzXp89uFPJn\nnK7Xn6XXsFZfvxUhwzMR7akQcdKDLZ+/RZ9HImK1XoYQ3kkIAZbrZ87AhhBH9DrPR5Ixl+hzWI5t\nfmVMhx5E8zGVB76kRYsSLrwwjtat/Xi9JpLKRb47xqyVg2iY2cjn/x6xsW0ZNKgnJSXLgAhKTScS\n6U0k4uA4ITyeUYjprBM9ehzFWWedTCAQr/vfeOjXrw/z5k1k165ZXHhhHCNGZDFxYi8SE9fwr3/l\nf01jSEmJ5o9/fITbbltGff2zfPyx/1u1iV9SWG8zgfyExuHaVJsSxJw595Obe99h+1JMdNaWLbuI\nRFZhqs0OGHAsjz9+F45TiGgI3ZE6S9nYHuA+RMJOQTSG3dgmT8bG3g6bFFiJgEQuVpNIwjYSSsWa\nX/wICOUgIBSD+BEeRMipLyJ1RyEhr7sRkjFJeKYdbykiFQ/SezNmpRzEB+LBakO9EPLbiZDlNmyD\npNl67q1Yn0QRQlB1COB10XMXIWa10/QZZeg5fo34NVx9/VC9viKEdHIQE1gbxIQWRrSFHL32jYhm\ntAYxGTXtfhitz8SLkMo4vYaQfu1obCdDV+8lWl/bDSEXhQgLbfRzDBnco99fgPVn9NfvV+n5PtfP\nuVC/fj/WJHYLe/bA6tUbOfvskwiHu+mAjABCoo2ID8vb5JkZJCW1oKJiO6tWbSMSydLfD4fCwnJa\ntUrktNNSCIe34DgrgSFs29aCCRP+xsUXR+8XoHr27PK1v42xY8fw4IM3Ex0t5rimGsORahO/lLDe\nZgL5CYyv2lSvuuql/7hNdebMp0lLO54pU5ZQVfUgr75ag0jgnYiJcZg+/TkmTvwLShkiAAs+2Uj2\ntIRWCrh1QKTVQgQAvNgGRHWISaUBAT+TDAgC/CsQv8ZtWEnXRZy0Jvu8nV7HMH3/ZwjgrUaAxWgH\nZp2xSL/tjkjYbRHWzm/MSgpxGNchkvBOxEFehUj4JoLK5KmYroQJet99EKd0CqJdbEIkdBDTTwnW\nzr8XKaRYjmhk5YjzOBlLZBG91hYICXZBSsHs1Ws03Qfr9BouxpZAqUI0pSyEbO6DMMcAACAASURB\nVC/Se4xBiGSbPn/Tj+QyfY47EE3CRcjsEmyDrJFNziybAwMUTNRXO/0ZpOnnn6E/C1P6X/xQwaDD\nxo1beOmlGpSqR6lj9BkejxDY7/VzhgF+cnLgD384l2ef/ROZmS2Q70s9EmXlZ9Cgvpx22skMHXqc\n/hzaUVsbZvr0/2HmzDsPKUAdSmM4Um3ilxLW20wgP6LxTSaqr0pB5eWKIUP6/0dtqqmpadTWnsju\n3VuR6KNNCLDNpLY2mtraOgoLk4BrsGaUUQignIAAyodIFFMIAdBoREMwZUVSEUKJQ0BwF6JZLEfM\nDsOxWdMmK7oQkbQ/RTQTUyq+I0I+hfq1Sv2vG7bCLshX/Fws2fkQMmmPgNpqxHT2NgJKR2N7ZHRC\nNI10bHXcVL2vc/X9DYi2ZUqsLEXMR2fo+7cgpqsAQhI+hJg2IQQQjZBDMaIxrUek9wZE06jFakkh\nvYd+WMf0aVjiuEqfp0K0pwn6PI2JsIPey1Ys+ZjeKPlY81+inj8f8Y0UIMRqikT+DZtc6dWfm4v4\npnIQUoogAP+a/qxK9fqrEJPk0ThOgH373kIIdxAiPGzU53gc1lR5AYWFMTzwwGyKi/fh85myJybk\nGWbO/JA///kfLFmyB6UexXX/TmXlhyxe/P5hmY4OpTH8UrSJIxnNBPIjGt9kojLhuQUFpfh8Y1Aq\nijlzNtKjx7nfWQsx2s1tty2jru4R6uoScd17EAAFaz5qj4DBAgR01mG7772KgFIKV1xxJllZydiS\n3Qb4UhGi6IGAdQAbOaQQh/JriFbhR8BnMSLJdkAk/X56HT0Rk0gLBPCNX8PFJpmZNrJvI2C9F8kj\nUXqODxGn+HLENh/AFj5sjZQoKcU6uIOIgz1arzUOCWc9BiFPk2tQhEj9pyLgago7btPP7aXfv1Tf\n59XP6IF1xBtNZzkCkArbK7yDPqdkfR4zsL6ogXr/Ji/kAQTQH8PWmspBSMW0BQYhgrcQYjUNour0\nObyBLcliSKUzok00IgC/Qe9vh36u0V7NdXsRIWM9tgz8VJQ6FiHHEsRUZgorSs4GdMBxooFiYmKS\nKS1N5Zpr7mTVqgRsAU6JjGtoKGTgwB6YWmpKdWHo0D5kZ7fncMahNIZfijZxJKOZQH4E43DC/nJy\ncrjhhmxatswEzqauruY/EtnxVe0mJSWW668fhUiFYKOsjARv7OI9sU2cjF2/jiefXMDu3TEI8HsQ\nSd2PAJeLgE40Ij3X62d0Rzr0VSIA2xchpG0IuOQjEupT2MTCkQiob9E/12Dj/EdgI5A6IYBcoNds\nyoN3xPoAsrCtes9FNKaBiESci5WItyJax2Bs//Xp2CS+q/R8FQjAefVeVyGgvkY//xWE1DYjRPys\nfkZbhAiSEDMM+pxMe+A8vc7++qf5XMoRwi5AiNGPAGm13utqBMTv1vel6bWZvJj1+vezm3w+KYiE\nX6Q/g+MRIgHRXDIQwjtK7629vjZPr/kEhODqsFn5J2OLXorZKy7O0fs+DyF8H6LZ1gM+lKrCde+h\ntDQapV4jOroLlmS8SJ+WLni9OQBUVX2E696DUo/yyScx5OYu/FmGz/5YRjOB/AjG4TjqvhqeG4m0\n/Y9EdnzVxtvYCEVFZQwY0JFAoIw2bapxnK1YX4QHWyDxAv16BQKExxAOdycUakBMMCv0UzYhDu++\nCPAWIxJqNALM9QjwB/U9ryJAlIztLjgT0So2IdLyRgQUS7GaRxkCbqmIdqAQMpiOkMcn+tp6RFqO\nQQhjFwJq2QiJuQhJZnNg8cYo/ZrRBhx9f4Xe0wgErBUC4nuwobkOB0aJebE1qZrW/vqbXt9GfYYn\n6D006HvSEcIYgg0FNoUUfQhhttX77w7cgYD8ekSDGIJoAY368xiMLdz4DDbzPYRoEhF9/z8QAqlF\nSPRtRJMw/o06fVY79DmlIaOBA3uF1CGEPQLwUF1dj0Rw1SKEZ7QuEQw8HkVu7p2YgolSHcGHCRn2\neu8DtnPGGUl4PLGcc04flJKqBrW14Z9t+OyPZTQTyI9gHK6j7vuyxX513p49u3D22aeQm3s5eXmz\n6d/fhLjuQaTM1/TPnYi9vgbbs6EbtmQ5iM+kGpGOj0E0kQQEVFrq95IR0IpGwCoBMQHFInZ8A8BG\n6j4LAbgsrLmlSL/fE7HJd8PWxDKg3U4/FwQM38GaZBIR8tmHgOZIhAhM7obJe/kMyVPYi5hutiLS\n94uIiasR21FvF6IZnItI7H49z+Qm8x2LAO65WFIxWeIpwEN6LpOs+CBCkLkIKZTrNachZp/d+vdC\nhMyWIYR8nJ5vkj6rfkg02iaErD9BQq5Ndvkxem1NqwR79GcGktW+Q39enfQcpvaqMUG+ghCeB1uR\n+Bj9/M1APlFRXWnbtgXyvXhH73Uz4tOpIxJJ5bbbHkSpAHFxo2hoqAW20r59GVFRHxCJSO/4N99c\nxXvvrWDJElBqOn7/C1RVfXTYPpDmcWSjmUB+JONwyOH7ssUebN4pU66iuHgv6en9KCpqh4CriUBK\nRKTOeASgcrAgrxBgVwig3aivPR7RIjZiQXYHAoaDkTyFYgQ8jsY6r/+AAPFQvdq2ep4B2JIkQQSQ\nTUlx0/rWaEsXYCONWuh5duuf3REgNWapkF5jpl7fcoTQsrGdC49FEtZO1M8sbLL3oD6nPYhUvROR\nwk1RwzLEzGTCc4fo+03BxelYwmuNzWkJYetjhbDVjD2I1lSj7z8WMZWVcmCyZQyi3RxD0yoCsv5+\nCMGdp8+nHeI36ar3vgQbprsP+bz36J/TERNVMdasV49oKKan+x79rxCbAJkE7KShoZHCwjL9OZkm\nWa30Z9IOpcrZsaMOuIDq6mhMufydO/00NISIRHKAaYTDvYmLi6GxsQBwaNkylUmTRhy2D6R5HNn4\nwQjEcZxkx3HedBznC8dxFjmOk3iQazIdx3nHcZwNjuOscxxn4g+x1v/GmDLlKoYPP4spU+5j+PCz\njogcDpVoeCSF3VJS0qipyaK01JhekvF4dgHX4PUW4Lomn8OAtymLDhJyegk2D8E0pDKFEQcgYLsW\nIaELEDA1wySrxSBAtBUxy0SQkhoukhdyIgLu9Yj/ZCU2N8OH2PErsZFGYT3fIAQcjYlKYfMrjD/A\naAcehEiOx5ZzMRqRKQkyQp9BNALmaxGbfwfEEd0KIYxjES2pUf9/LKIZxOk91SJgG4UA+Sg9rx8B\nz0v1e631XgN6Xw3Y7o7d9PUmb2Uo1neUoPcYQAjD0a8Z8nxL/7wP210xiGgaX+jPsY3+5+rrovT5\nTdCf3T2I6W0XEg1XiPWZvaefbRIHdwEOHTps0Xs35W0chNTSEIHClNBvjWT6Z9O791EY81g47HDS\nSUfj9XYkNfU3lJfX0a9fb6ZMuYrm8f2NH1IDuQV4Syl1FKK7TjnINSFgslKqOyImTXAcp8t/cY3/\n1fFdi68d6v7DnVspxeDBv6Fbt3N09m17SkpqkDyCToTDWXg8UwiFehOJBPD5xmBrVG3HmnhM/aYG\n5GtmsqZ9CHiv1k+MRgDW1LXK1vedj+0aYMDKNLPahki89yNmnD2ItF2AAPYsBLDA9uxojUR1eZGv\nleld4WBrdRmHenvE5m+6972PANkIROsCa5LxYsnwPayfoy0ijbdEgHo3og1swvb7iELMcesRTWi+\nfv5mfc1nCLjv0+fWESHD5di6XW0RoDVVAoypqbOe/3P9/kpEW3D1vt7Tr+9AnPypCEGcpefajpSA\n6a3n/BjRGjzI570Gm1y5FdFQ/q7X80eEuPsjn2knpGTMcGzV5SAwENdNJhxOYdu2jsTEtEcqEASQ\nz79En7/J1RFtzO8fQyQCtbX1+P0eHOcS/H6XvLwixo3LoKEhhXHjWjWH2/4Xxg9JIOcD/9K//wtb\nGGj/UEoVKqXW6N+rEZRq89XrfurjuxZfO9T9h3rvYFrJ/PmL+PDDFIYMGaCd+u2Ji8snJSUDkfZ2\nkJ5+KjAbx6kkGFyFgMJSPJ6jEHDx6H+36VlDCIAac8hNSJSTSTDsgDW1hBB5YhO25/ZYrCM2FgGl\neD3ndsQkk4OVgJv6S0yRxXf0a5/oa/Ow2sNKJH+jWN+/CwHTd7BVZV1sW9xC/b7xF0zD9iNpQDSK\ndEQzKEYANgcB41L9vkJIsw9CTKYzojmvbP2cdxGH8tF633X6mXkIgc5osj6Tk2Nqd4F1WPfVZ/ou\nQpxpWG1lN0JKJyLkm40QhCkpkomQyl4E1AuxvgwpRmjDn5cgRBPb5LMwDcfGIJrgIP3aOiKROm2G\nmk1tbTLwNxznM+RPfTWihb1Pamo+sbHLSUqqpbb2abKz17N1awEpKdUolUsgUMz69dt46qlPqa6e\nysKFVTz11AIGD/7Nz7qc+g89fkgCaaGUKgIhCqxx+qDDcZxsRP9fcajrforjuxZfO9T9h3qvqVZy\nINFM5ZlniigoWExGxisEg/FUVDTQuvU+oD01NdL5T6mOgIvrRvT/YxBpvCUCSj0RoPQioarG72Dy\nLY5DAGWzvuY3CHhlIRJ0KmIXdxGg9XBgBdxL9TVnIZL0Pdiufn5se1cHAdb3kK/ZKATkemDrPfn0\nWo9FTFBnYHtl7NJruBAhwbUIOaxH5JnFWAezFwHZLgixmE57GxGQbolk1PfTc36KEIuJLDKmpmpE\ncj8aAegAki/SHpHGT0YAfQ426ikHMeO9r68/Qz/XlEU5Aev76KnXXaHP+mIsSXuwJWeu1Z9HOtZU\neRRCNN2xTboMUbRHSu9HsJWGTVZ7L73/x/Qc9djEUYlMy8zMxHESiYuLw+vtjQQADEApxQMP3ERZ\n2QoWLFhMSclxTJw4Gp9PtNPExA5cf/0lREV1xHzPhwwZwIcfpvysy6n/0MP77Zcc+XAcZzE2bAOs\nsfn2g1z+jWKC4zhxwAvA9VoT+cZxxx137P/9lFNO4ZRTTjn8Bf9A46tRWHl5kf9XiO633f/V9xYv\nfp8//ekfBIPHaK3kdny+z+jfvztvvCFkUFsbZtKkEdx778107nwm27ZtJBI5DehAVdUORGGUTnJK\nucTGXkhNTQriHA4joLEBkYRbIyafNojkbr52exBp269fN5FHhcjXwWR3X46AtrGbj0JMG8a5OwMh\nn5UI+KchCu7H+vpjkTImV+prQKTqrXoPaxDpezcS5XQlQhphBETLEG3oJAQEv9Tr64dEQ12OmJva\n6nk7YzO7jfTtIqAeh9U0Agg4341Eon2OzcJXCLia5li79Vn9E4mk2oAAvvFB1COk0x4xo61GAhOy\n9LXtEU0m1ORcL0PCr+uxWsV5iL/mMuRP7ib9/2JEi/FhTX8mSMF0D2ypz+pkhKAvQMjs33ovw/Q8\njr7nTr13FzgPx2nJ1Km/Axxuvvletm9n/3PC4RT+9Kd/8Oc/zyYubpAWciZRVLSMjIwNlJe3x3ES\nKSurw+vtRl5egGeekeumTLmdP/7xESZOHMW4cWP4pY/33nuP99577z8y1/dKIEqpM7/pPcdxihzH\naamUKnIcJwMRpw52nRf5Jj+tlFp4sGuajqYE8lMaJgpr+PCzePHFN//f9ttD3f/V9zZv3sUZZwzi\nxhuXYKS1u+66FqUUzz77piYaD1VVlfTseR6OcyIwgOLifyPg/G9EcpUoHp9vK4mJIWpqPkZArQEB\nx1MRQtiK1H0yoapeBPiPRgDHmFuqsXkRTZ3VEcTEE0TMMBcDj2PDbE2UUQKS9/Ay4sM4FrHv78Zm\np2cDf9H3ZSPk0RuRqK/UawwiIP0iYqLx6X1n6PtOwNaTMutz9P+NI/sq/fxYPX8dQhIhBFgzEDPe\nJsTMVqjnOVGvuQDb56MWmzfjIFK/V5+tCf3dhzjATbOqTCTcOqTP2hDjBwhxGxAfiWgi+xCCycOW\nkVH69+36+nVYoh2GaH8RhPj26j2YnijHIY7v9xHtZyui6f0bEQDiEZ+JyeyfhVJ7GTPmDzz00O+p\nqKjC7/cSiYwmFEomGGzgscfuQCnFTTct5atCzoIFi3nssfmceiq88srJ9Omzh61bRfs03+8RI35F\n8/i6YP3nP//5iOdyfij7oOM49wClSql7HMe5GUhWSt1ykOueAoqVUpMPY07VbO88vPHCC29w+eWL\naNvWIS8vwhNPDGHz5l107px1ANF07JjJjTcuIS/vZBxnIV7veoLBYkQSn4P4ORZgE8miEIk1hEi9\nwxHyKERAeLleQV/ElDEaAVETIdQJkfDbItJqmn7vC2wy4j5sldzjEEDNQAB8p56nSK/Dq+es0tes\nQMxmvRDt4bcIKTyJ+Fq2NFlDIgL67yDAmI1I1nsRgO+NgLHZVzeEMJ5EzEf5CNn8C5HoP8UmI9Yj\nwLkCAdiVep40BIDX6vni9N6TEALch2hNe/X5GLPSl0huxgVIYctl+oy66nv/hWhKS5H6Wbux9cee\nQQSCLISE+mO7He5DtJm4Jp/Z5Yh259Nn3Vlfv0df3wOb4xOv199Z7zEa0UQ3YSOt/Pr6x0lKugbX\nXUNpqUOfPi354otskpIK2bu3jrlzx6OU+tr3dsSIXzF69LW88MISlOpHMDgTj2cs4fAHJCQkotSJ\n+69rHl8fjuOglDqiZJkf0gdyD3Cm4zhfILF+fwdwHKeV4ziv6N/7IwhzmuM4qx3HWeU4zuAfbMU/\no7F58y5OP72Odevu/8Y+IVOmXLXf/BUXNxWldhMKVWFNNCAmo3isRB9BgKle/34PYv9uQIDY9AlJ\nw0rBJYi5CASY2yI+kmgEYJMQE8gJSJOiTQhQ90HAzTSLakRIo4WevwAB2s0IQG3EFN+zVWUrsIl8\nIMTyFhZgTS/1SgSwZyJgWolI+F8gknl/hMACiHSeg5Co0+RfPeJ76KPn/l8E0F9EgH62fu5KhOQK\n9L+j9P6Mc3mvvt+UbvEimoEp5viB3ssA4Gpse13z5258NqX68/EixPsu4vtYo88sTz+3n36O0YAi\nSESYX6/lc33mDXod5+jXNiBmRh+i4R2jz+Az/XxTMNI0+HIoL6+jtLQUuIbVq5Opr3+LQYNSmTt3\nPFu25H1jvtTTT09jwoSLdKa6QyTiMnToAEpLlzUXQPwexw9GIEqpUqXUGUqpo5RSZymlyvXre5RS\nQ/XvHyilPEqpY5VSvZRSvZVSb/xQa/4pjW/L++jcOYu3345mwYLFDB9+FuXlpSiliEQi9O07XPeX\ntuav++4bTVTUdpTqgwB5N8REtRMx1XRDHJ5BhBB6IBFP7YArkK9ad6y5ZxXilI7COmjbIdKpAdwA\nAjAfYQH2ZATMCvXvNdhQ4BwEcMMImR2NEE0MAoRZ+l8KtgxII7ZG1W4E2M5ApO9qxMdgciE6YEkP\nLOl1RQCyB+Ko36vnaaH3ZxIZc/RcryPgHUQk8Ay9J+NX6ICQVDYSWeYi2pHpN98FaUPbWV97LQcW\nc+yCJfN8vY8gQi4gmoTpzrgHAfkGhChf1ft39D2mwq/pdHi+/lyu0c/36rW2R4jfr9faQ59hJ8Sc\nZnKA/oaY7oyJsgDRzhxEG4pCvgOX4jgBJk4czVNPTWPlys+4+eYr9gs5wP7XAFzXxXFcwmHw+y9B\nKYcuXdrj8XiaCyB+j6M5E/0nPA5FEgfL+5Acj0u/FtablXUyDz20ixdffJPf//4eVqxoyc033wug\nM9L3MW3ac0QicYhp5UtE4i5HwGMWIuH3xoLNDETiXI74HNohINGIbSTViEi91YhmUIYAIIjE7EOA\nKhvRNOZgk8xyELu+i4DggwipgEQpxSMawV5sZrUHm6H+OTb660oE5LbruWYhpLNPz1GFDTk2yZID\nEUAfgE1GDCAmnVT9ey0Czjv12rKwzZ9W6fl+pfdZquf2IBqWqb01FQHukdi+HOWIH8iUGfm7fu8C\nbBa8ceC/rT8Pnz6jBP37WH3mJlqqEwe2yPVh636ZCDXTn930GQ/o847RZ1elnz8CIYhKvW8/tmbX\nWizB/x0hi/v0dWFsQ6wLCYcVruuwYMHir32XD/b9Xr9+Ozfd1I66ulxuuimbdeu289VxJAm1zeOb\nxw/mA/k+xi/NB2L8GE88MXi/VDZrVi7Tpj1LMHgMW7b8jU6dJMJq4sRRpKamcdllbzB2bEuef76S\nvLzueL0Pk57enz17piJx+puAG/D5luE4H9GxYxrr1r3F/PmLuOiivyBBcKaO0vmIj+BMBJy6IVJ3\nBWKeGYqYlPYhgFOJgNrpCDCOQbSUeGxDplORGkpfIGaSYYgGUoYAi9LPWIY4jDsgppYYRBvZhGgB\nV+k5ihGNYx9WXkpDnLvD9HtPAr9DAPJ0xNl7D6LB5CIO9bexLW976Xuu0OvvixBAEkIYgxBt6TQE\nzBP0XL9G/EGL9HPP0Hv8FwK+Ef16MUJoPRATnolK8yOg/yckKdD0a29AQL6b3vd9iGQfQLS09fr9\ndISsjW8jHSHsKmy/ELPeDfq5DyN+rhr92byv9xWN+L2WIWRxG1JLa7d+fwkiVBj/zLFIpNyDen+J\nSKWCJ7AZ/Ca6LUCbNgnEx7vk5VXQuvWQ/d/l6uolKBUkPv70r32/DyfC6mB/M7/08VP1gTSPIxyH\nSg48WN7HgAE9mDbtWW69dSnV1VOZO3cjBQWltGz5Nl5vDo2NAA7x8Yk4TjtgDJGIy1ln9WXXrp68\n+OKbzJ27EK/XlGh3kbDcQoQQnkOkay+Sk1GAAGZLBEhNPkZQX2ds6dKdTgDtZERiH4uQjovY+d/S\nv0djixM+hpDYGsSZW4iAqXGuD8NWvDUmtUTEVBSDAPNbeq5dCAGsRaTwGCRSKAdrFopGJOZsJOzU\nFBc0mfabEceySVEKITkbXRGyK9PrfB7RzAbqdX6IENEx+lyORkxLKYjW9ABCComIH8QQ7BB9jZHe\nTYOszkjkU5Z+bgc9n6P3WaTvNd0SP0d8PybZco0+k/UIYZyJONhD+oxm6zP4AJsUmazXdQlCDO31\n2rP0+l5DCDdKr60NQmzx+jPojhSlOEa/9gBwPK1bp7B+/Vs88cSdB3yXH374Vh5++I/U15sIq8Or\nuPtdk3Wbx8FHM4H8BMehkgMPVtn3zDNPOeD6uroaJk3KZvfu/2XChF5UVwfp1m0yDQ0KpQpw3ZGE\nw0GWLauguvohrrtuLi+9FGHQoEQcpx5xGi9C/ug/QiT6ExGQuAubAW5ANg4BqCgEfEsREwyIucQ4\nzdORqCojieZjm1Z9hoC7MWGBANUeBLi2I0Ryor5uOUJkpyBAHtT3HI2A+LOIWawDQjwJCMkN0evN\nw/amKNHrLkdKbRhTVrGefw9SNNIk3K1FSHW6nt+HSOvGqR6N5EDEIATxNtY0tENfa5psKUQbMS1s\nS/Szo/Rr/0RA3ZyrMYNV6rX8s8neGxANpRVCzoa4WiJmtihEeytDCGIGtgS7Ic1uiNb0HDZKrQYh\nxZP0HnbqdcboPdTqMzgfGzXWACTgujsQEtwEHEtKykP4/R4++QQWLFj8te+y67q4rktxcQ2OcwnF\nxdWHlTP1XZN1m8fBRzOB/ATHt5V//2qkytat+QdcH4m0pV+/3jiOw8qVG8jNPZf16x+gVatNeDxp\nPPvsFQwd6lJV9SVwLsXFAWAmb7+9A6UasQ2GZmM1gZ3Y/uAmb8BBAC2AkAQIyG1CwH8pAnImIgtE\nCo1HJOgihEBSEfA1TmjTx3sDAmZLEMdxZwSMAsC9iJ+mEPmaGylcIb6UzxDJeTYiXRfpOd/Qz6hD\nzFPbEUL7HAFCL0I8VYjJaiZCWgohkt9gHe3GKZ6p92PyLnYiUnemfn6Gfk4GAtpH6T2Z1rZDEcDf\nqPezSZ9zNOKj2aR/Lka0oHf19e2wmeaNCJGeqveQp6+dhzjOT9DrimCj6owWl4KQwSg9z26EdN5C\ntJVNCLHM0Gf6ATZnp0qv+139zC+QSKxMUlI+o1WrBjIzw8TFSd/38vKWhEIfoVQLrrvudX7zm5sZ\nNSqw/7ucm7uQ8eP/SmJiBUrlkphYyTXX/PVbNYkj7W3ePA49mgnkJzoOVf79YOXZD3b9Cy+8wUcf\n7WXx4vfo0eNc/P6TCIdf4bbbPmDNms14vem0aRNLKAS2tWs0AtZgQzrbIVKr6XQXg0imHyNgFAsU\nkJR0KgKMnRAzURd9XQPieAWR/q/Ur5sy8n58vtbAIDyevaSkxAEj8HpbER+fhDVxRSGRPH5shvQE\nhAza6vVFIXmpxuTm6OvjsY7mAgSAP0XMOPv0/O0Q8DsGiXwyiY4+BPR7AeOwTnVDdMfoM/gIMbWZ\nRlFNCzjSZL5oRLrvhJh8ohEQPh4hxV7Y3JkA4nMwBRTj9TWvIgRbgGiMg7B1sz7G1u6yZUTkc8tA\ntMBibBkSBzG3mez/ZCSR81Q9X0aT6zyIdtkbIcmeeDyd9TU5wK1Ad1JS1jJo0HHs2vU+ffocRVJS\nChJ+60GpHGAme/fmUV9/IsD+7/KLLz7Ko4/evr+Eic/XhunTbz8sTaK5t/l/fjQ70X+BwzjaS0tT\nKCxMoWXLErzeL6mtPZaysmm0bTuFAQMaiYvzM2/ea1RUeBBp2zSBGok4gysQSfhjBNx2IGBcjJhK\nFiBSdgVQR2xsG2pq+iN27mOQCr+PIJJ9RzyeZYTDOfpZcUj2cgmQg+OU07VrH3bsaESpfbRv34bN\nmz8lFOqMSLmVCFEUImBeju3E1xORfI2WcZrexw59fYZecwtEus7Qr/8b8cl8pv9vfDY9sPZ/c//n\n+nl7sKVIdiCgfp4+oyJE0+iJaEFXIaQSQMxTp3Kgc7per7VCvwbiY/hIv+dBtIpcxKFfpM8yC3HM\nX6nXNx7pX9IBIZW1CJmG9JpL9fntRKLKHkMSLFfr12MQM5mpe9VZr+tBhJhaINpdMaItrkVMhZv1\n51pCOGw6R7YE4pk8OYf777+F+fMX8ZvfvIpSe0lNTaCgwINofiCO98fo1Ok2fL61+x3l4gh/A7+/\nlMbGZJ544uxmh/h3GM1O9OZxyCGhi/dw88336PBFRWVltTZNTaWkJJq6+Kh4UAAAIABJREFUunpq\nayP71fsRI85i1qy7GDLkDGJjTce4CYhf4m8IUM7F1mj6CI9nN667Bak+E42tRvsM0dG11NRsIibm\nZTyebBzHp9+PYtKks5g3bzjdu3fF661FwGsjfn8xHs9JtGlTQsuWivXrH2DYsAAjRmSxfv0DXHjh\nCbRrtxWfrx6YiMcTJi0tmUsu6cDxxycCS3DdHETyboMAuyngV6bXthHbV30TQjQf6z0Nxzrzo/Q1\nCiG1L/S9RQi4Vul5tmJ9QBFs9ruDhCTnYKX+MALG5diaWw9iTYEmpDcbAeN0xH/RQ+/DlIwxGsR1\neu5obGKkixC2Kb1eiW1NW4T4XxoRYkvEmhPNnMbnVAX8j37Ngw2cqESIciNCHJ/qeZYDe2jXbiPp\n6fuIi6sEOuG664HPefnlN+nR41xuvXUpdXXTCAaj2Lt3DSI8pOD1hhDToUNpae0B/ootW/IYO7Zl\nc9n2H8FoJpBfwJg/fxHTpuUzbdoqXnzxTcaOHcOFF55FOCxmh3DYpWvXTgweHGLt2vs4/fR6tmzZ\npc0GZ9LYGEbMNPciYObHmi1MxI2L46Rx6qknIgA3HQFHMU3U1e3D7+/Kv/51GUOGpKOUi9jsW+Lx\nuIwcOYT27VsSCPQiI2M6rltPaurphMMziIkZRDDYyOzZucyZcz+5uffhOA4DBx5NSUkJoVArYBGR\nSDcCAR+DBvVixYqXmDz5UpQyxQsDiLTtQwiiHCGIeERL+jfQibi4OAQsv9T/8pFIpuOxZdJNSZUC\nBPA+RkxSRYgzeRci1Z+CSPUmH+VWBKi9WFPbOMSH0qjPylTFjUIi00J4PG8i5FWEaBQNiDYRi+1N\nD1L4EGyhyyXYcNx4xF+TgfgiBiKmrh56b930ew2IZmgCItrr13ogZswYxJzVEtfdiPX1HEVUlBcx\nXd0A9KNPny7ccstYUlISUao3MJNI5EQgxO7djVRUVFJcLMEWSUkpREW1B+4mKqodCQk+/exJlJbW\nM2nS3cyePYdZs3LJzV3Iyy9X7y/b/vTTLzVHU/1Ao5lAfsZj1qxcWrceyOjRz1BXN436+vZceOEk\nWrXqy9KlHxMI+OjWbRKBgBfHUbzzTjQ333wvb78dTceObRk8eAy//e0tREWZgneliOO0CvnqnI9I\n6oVAB0KhKSxfXoFS7yOAk4IAcE/geBobH2XChNd49dVlBAJrgGdITMxj+vR59Op1Dq+95nL11RkU\nFLzEDTcMp7S0BiOBlpe3JiUl7YD9paamUV+fhde7EniA5ORq4uPjUCpCjx7n8vjjq1GqqdP9GkSC\nr9XrHoNI48ZhHKShwYvkPpgKt2nYbOwAtmDiDIQ0diDA/gU2sKCLvn4gonHs1veN0/PuwZqX8rE+\no5UIaa3BlP9w3e4oZRL0MhANxWh3XkQzMSXboxET0WBEWzFBB8l6nyCEEoeYwVy9pvf0PEG9VtMf\n/t+kpnYlJiZer/lT/VwxLcXEHIXrLgcGkpJSSzgc0tfMA2awYUMKjzwyj5QUPw0N6DNOAzpRV1dJ\nly6ZhEIusbEXUVpaQ3V1IzCahgaXqqpahHQfJCWlhkGDTvjW9gTN478/mgnkZzqUUmzbls8JJ3Ql\nLi4J+ePNIxIZxOjRFzBs2Nk8/fRQrruuN6mp61i1ajdVVVuYNm0nVVUPcsUV/8uiRdHU1/tQqg0w\nGMc5DtE2YhDQSkNyLlogAPowDQ2FxMYOQBINa4AvcZxYjGmkuLiG007rRVraqYAH1+1AIOBh7dp2\nNDaex8KFVfTseR6ffbaBhgaF45xISUkd4fBYrr9+Ed27D2X06Gvp3n0o48a9TCj0b4LBY/F6e1NR\nsYvNm9uSlpbOHXdMwHEiiPawBQGjfESD6o+QxnDEQR5AkgUDhMMNiA/Ap68rQ3wYfkQiPhVxShsT\nTwvEb2A66RkneBuEoEwXxT4IWGciJHav/vkG4CcxMYE2baLxeFoTCPgQ8HeIRMJ4vT48ngRsuRPT\nlz4O0aqS9M9heg2jEPLz6WcYzeIsRNMoIyMjjJCCOZNj9R574zh7gACtWxfT2AiZmRnAHny+Chwn\nBlOSXjSGWLp0+ZTa2iChUDp9+rSlbdsW+8/nz3++luuuuxKfL4DHc4leVwVKdaKhAcaObUkwWIPH\n8yFCsk8DuwgGHaANPt+llJVFExfn2x811RxN9eMZzQTyMx3z5y/ikUdW8/rrXsrLVyMAEQBm8Mwz\nReTmvkxx8T7GjRvD/ff/gWCwCriGUGgXcC6VlQnAbCKRLtTUhHDd87XZCUTCNqU9BmN6V7dunYDX\nm0MwaCJy4oAISqUhADaaSMTH6tVb2LdvAxkZ51FR8SGRyHEoNR1YyrZti9i9O48VK4qAHShlnLH5\n7NvXQGVlJQMGnECrVkmUlZlmUaUo5aBUO8LhGUycuIjJk++hvr6RmJh7EXBNR2pQFSAO6hKE1FIQ\nqVmiryKROsTsdAxCgskIYbzPgWag47AVcT9DMuulr4WN7BqGaCcpiPY2GdsHvgzxb1QD59PQ4HLy\nyX159tmrGDbsRPx+DwkJo4ESgsGB2mfkQQIYHH1/DULkvRDfy4uIJpKAdebvRUxqbyHkPwM4kZKS\nciCI17sIcImNNeVPtutqA4OoqopQXf0aW7dWAAGCQQ9KpQDR+HxjKCmpJhKpIT//XRITpXVvfn48\nBQVlZGRcjs8Xg+M4bNtWwPjxbVAqHtc1pUzG8uGHHqZNW0Bj44X4/a2RPJK3gDb4/enAUFq2zGTS\npByys7P3lyBpjqb68YxmAvmZjVmzcmnVqi+XXPJH6us70Nj4KEpl4fUGiYmRtrG1teEDEg9zcxcS\nDB4PTEapLJKTDTk4QC1xcflMnHgCjrMar7ccj2c7Xq+R+M5HJOxbiY3tiOt+rjPbTf/zTojN/QMg\nDb9/O5mZrcnNnaBNVSNobBTJ2ustwXECVFfXUF1divgGZiPS/DRCoR106ZLFP/4xjw0bHGxuQjXh\ncB2mW+G+fQ0UFhbR0PA59fUdkeTA3YjZZieiBQQRIHsdMbf1QvwQQf1+CpJTYvZpOiSa//8Vm5Vf\nj0QdvYU1KbkIcDciZBTW75fr8zoJAfdMYCaO045hw07nk0/WUltbS0zMh9TVbQZyUGoWoVA04ns4\nD6+3EDHBNerznYEQWj1iNvsYySB38PkU1uEuzvH4+BiCwWTOOSeTjh0rgRXU1OxBor0KEO1nGlVV\nUSjlEomUIdrYXxFSGkIo5CUxcQ9wBtXV/SgqWgsUUlm5h0mTsikoePyAKs+pqWk899wwnnnmJlJT\nxbSZnJyKzxcLzKOuLhOYgc/3ArCaYDBIt25vUlFRT79+venUKWt/7auDhak3jx9mNBPIz2yMHTua\nhx/+IwkJnTEmj7i4BKA1kUg7nUjowXEcxoy5jqioo3nttQgCQn2B90lI2IvfL9Ku66YTCiWwd285\nzz9/J42Nq7jhhtNRKkCbNuVERfmJiytHNIRNhEIuiYkVSIRWJQKirYBepKR8CUTzxz9ew8iRg3Fd\nl379ehEOe8jMHEsg4Cc720c4fBpiojEmmyhat+5KVFQCLVq04o47JlBXV4sQQyLJyQrHSSAScYDJ\nhEKKiRPHcMMNl2nJfSzi9zgbIQgTUWZIMgkB8mL9uw8xe21DNIcuiP+kASFMF9E42iAlPFxgMx7P\naQipdUd8RiF9zVTEN9GA+D06I0EGfZBopQCJiZVcccXtPPTQLsaMOZ9Zs+4iIeEo/ak6+Hw5pKYe\nC1yK62YgWpUfIbE5iFZjmlkdh+Mci9dbRSgkZVOSknohGuFFVFU1AgN4443dbNqUhZjmIvpn03Mx\nbYM763W4iLnrcVw3iqqqfGygQQfgQerqMnnuuUU89tjcA8B9ypSr9n/mjY1pdOv2ObW1IcJhyTVS\nSvxQGRmpDBjQmYsv7sv69Q9w8cUxXHPNX5tLkPxIRzOB/MyG4zi4rktNTRAxc4yiqipMKHQ0SUmV\nKPUFF18cw5YteTz99DRyclKJRIIIYLTCcY4iL6+CVq3W8vzzV/LccxcwYkQWPXsetV/qE2lyInl5\nz3Lttb0JBgUQ6uq8KNWZSESaQLluAOhAXFwDgUA5s2Zdzdy5E77WLXHOnPO4/faB+P3L2bbtKJQa\njphhioEReDxeHn74MubMuYKePY/CcRwikSxatHiW6Ggfs2ffSP/+nfB699G6dRVQxMqVG3FdD+Hw\np0iuRA7i20hGQPd+5Ov/a4RcXIREEhFzUAICxpIEKVFauxENYzkCsssQSb8TsI5w+F1c19XzL0Q0\nFuOg9yBaSE9sW1uTpV5FYeEnQCsaGh7h1luXMm7crZSUrEK0h0kEgy4lJTVkZFxBOOyhR49GfYIe\nJN8mgCXcNJRqTShUgVIDgdMoL98IxBATk4zfvw5YilKtEQ2vLdYx/yTgEgiMxPZMMX3eb9VncBke\nz6dEIgk4TjIwQYduO6SmJjFo0HHf6NRuan4aNizAyJHtmDr1d0RHR9OixWWUl9dzww2/Y86c+3Ec\nh5kz7+TRR29rdpr/SMf32tK2efwwY8uWPIYPz2LYsNP48MPVzJr1NrW1F+Pz+fnLXy7ZTwQAZ599\nBl988SViCspAKZdJky7lvvtu1mAII0ce2MNrypSr9v+emprGb39bybJl60hJ6ciePb8iGHwJxzkf\nx8ng3HNbcNJJZ9OpUxZbtuR9zdwwZcpVOrHxOfz+kxBp/XYcZwennRbHuHFX8tJL77B1a/7+e+++\n+7Gvte9NTU0kI2MDgUBnYAQrVz7CqlXPc/rpXejZsxsPP5yH5EqFkdyHOMSvYRzWO3AchVJhRBLP\nwGaZ5yBkbGpGTUCqyII40KcjmsFaIpEwkEVU1FYaGgqRUisXIP6WFkiDp5cRTSYd0VY+xettjdfb\nHgOSHTtmsWHDLhoa9hKJzAcGEB1dzTnnDCY3dydlZTV4PEkotYNIxIMAfHek/5pkmTtOLErtRvws\nHYiN/ZC6us74fO1o08ahoMD0ZqlDKgNvxnU3EolE0aJFHHv3egiF1hCJSOSY45yAx7OGxsZ3aGzs\nQ58+haxb5yM2diZlZa3IzBxLRUUMw4ef+Y1O7abfnTlz7t//eT799NCDtmP+qtM8Ly/S7DT/EY1m\nAvkZjqZ/pODw+OP76Nbt84P+8W3YsJM+ffbx6acZGjy8uK6znzwO51lKKV544Q3dYz2fuLhygsEo\nrr02m7S09G+1UY8dO5qUlFSuuWYRxhfi9Xbl6qsvZeTIwfz610O+cX8mA9mu4X1gMPX1L3HjjQO4\n775buOmmv6OUi99/CY2NJ+LxfEw47EXCbrcQHV1IY2M6Xm9XYmI2U1bmw5ZXSUZ8AwsQIgiTmDif\nioru2N4WQjQ+XyKOcwxRUW9QUdEZ0WxGIGGtS5GcmXxEowExkSmgCx7PMsrLfaSmnkVZWVcefHA8\nH320iqlT85DorR4Eg0t48cV1NDRcS0HBQmJjVxAMZuLzlVBTE41oTt2RrHgXpaKQMOMSYAP19aej\n1GpOOKET1103mksueRnXHUFjYzpwFjExNZx5ZmtGj76A//3fBXTuXMtbb5XjugEikf7APwiHxyAE\nPJkNG94lGPyQjh07cPLJ2aSkpNK5c9b/26l9sM+z6TBay8EIpnn8sKPZhPUzH98WsbJo0WOkpqZz\n003ZBIOvc9NNAw/aiOdQw5DS3r1V+P2LqKlJpqHhcl5+ufqwkrzM/dXVQTIzxxIdHcW11/Zi69b8\nQ9731TkWL15Cfr6pSOslN3cj6ekn8PrrS/c3Gjr66B2Ew/W4bjdgFlFR7YiP99K7dwIjRsTQu3dL\nxDm9DjFBLcXW1koHwlRU7MRWIY5BEu88NDTsITb2E6KiemLzQR5BSoKEsb3PW+O6nyMRWicBM1Dq\nOJKSyqiujuLqqyW7eu7cV1BqGT5fBBhGKOSnrKwNov3MoLExGY9nBzU1pUh47sVIwMI+JKzaQXxb\nCUiIcn+UOoHlyzdz6aW/JzZ2OUlJ0cBaHOde6urCvPpqCW+9tZS8vN3s3JmFZLHn6DkcAoFYvN4A\nkq/hQ6m7KSs7itdeW0ZKSvT34tRudpr/eEezBvIzH98m3YGQiBn33XfLET1ny5Y8cnOHEolEGD/+\nGUpK8qmvj3DXXdce9LlKKaZMuY+77/49juOwZcsuhgwJM3/+TBYsWHxQc9ehxqxZubz00hISEjKp\nqHgG+B1FRavw+QYyc+b5+81w2dntyc8vpaJCepI0Nnrx+z1cfvkIrr76Un71qysZOjSTVauS2L37\nA8SB3ZFQ6NcolQx0ITa2npqa63Ccf6DUEFJSXuN3v8tgz54kQLFsmcnO9iJkdCKtWq2nsbGGkpKn\nSU39DV26nMAnn4QIh0sJhRxCIRe/vzOlpU+ycOH/UFf3Bvv2JdGjRyLr1+8E/oFEc81GkhBPIxgM\nEB3djrq6HggZjUUy3SuQEN+2eh0piFluDLCBhITOTJ9+CQCXXWbqkn1AYmIa5eW/4t13d1BXV01N\nzSZgENLduATHuZhgMIFwuBUpKcMoK5O+LQ0NirvvPvjn3Dx+3qNZA2ke/5FxsCibQyV5fbUlaadO\ntkf7kUiZY8eO5tFHb8frbYVEgG0AjicYnM6tty6le/ehzJz5NF27ZvPb316gQXEy4OWii4bs72a3\naNHj/Pa3wykt/RLH6QGkE4ksRqmtiEP7bGpqUnHdP6CUIjNzPsGgw0kn9Wbu3PsZPvxMyssbCARO\nAVbi8Uh4allZZ8rKNpGRcT6Njam0a9eaa6/tRXR0gDZtxuK6foJBBbhs3bqbUKgt4fAr5Oe3QyLB\nJILN1tCKA16jsjINcer7Ec2rDDG7RbBJhTXIn/oFQAk1NUHefnspN954L3V17YHpKNWHysptQDT1\n9REuvPBXBINZpKfPwHX34LqbSE7ejsezBxiC358DLCcu7s/NyXy/4NFMIM3jPzq+zWT21c5w11zz\nGFFRRzNhwqvfKUyzqRksNvbfBALtiY+PoWnkTmpqGtOnF7Jy5edERZXStasiKqqMwsLS/eA3a1Yu\nl19+G8FgFErNBAYSDschjugk4CqioqK56KKzuPHGQYwff/wB+zT7v/32izn33OOIipLCieGwy6RJ\nIygoeIl//nMwBQW7SU1N5YknhrBr10x69SqiqqqSNm2uQikfZWVSxkWipzxI+Gw0kj1vilW6QBSO\nsw/Js9mLx2PCj00TK0Omm2jRYjfz5g1jxIgssrPbM3BgH1JSJHcmPj4aSTR8leLiagoLS7jkkmjS\n08O0bNmXSORd6uv9hMPpwFXU1YWZPPkiKiqWHVYyX3Mv8p/pUEr9bP7JdprHj3lEIhE1b95rqm3b\nWxQolZl5s5o8+U7Vtu3NCiIqPn6ImjfvNRWJRFQkElE333yPikQihzX3XXfNVpMn36l8vjPV0KFX\nqqio8apbt0kqKmqoysw8WXXqdKuCiEpNHa8yM09WM2c+pV544Q11992PHbC+5557VaWmXq9AKbhF\nxcVdqLze05XrXq0cZ5TyeMap559//ZBrmTnzaZWZOVA5ztUKblCOM05lZg5SM2Y8pS64YJyKi7te\nvfDCG0oppZ5//nXl8ZyjUlKOVx07TlFwl4KzleueomCcgqsUDFHwuvL5TlXQQ///IgW/VjBORUcf\nrY4//nz13HOvKsfpq6C/glv0Hi5XcL668ca7Dljj88+/ruLjb1AZGZcpuFIlJp6tIKwyMi5V6en9\n1YwZTzX5rF5XME75fCNVt243qPh4u/7DGeZZ/597msd/Z2jcPCLMbdZAmsf3PlQT6fOrYZkVFfX6\n/w1kZo6iqqodH3/8GY7jfM3M9dURiUTo23c4kUhkf5XWuXM3EQx24733dpCevp7rrutFbu4EBg7s\nsz+XICYmgalTb2Hs2DFfM5eZPJra2jCOI32+a2uD9OvXkueeO59Jk3riOMW89NLbh9zz2LGjGTjw\nBFJSqjEFAVu3TuPOOx9j4UKH6urBjB//ClFRRzN+/OOEw//G7z+JnTsXI2Xod+tEwhm6jXARMTF/\nJRjsjOPEEBOzF8lJSQBmkJR0KjU1IebOXUj//jn4fK0wLW69Xh/nntuS9et3HPCZPPJILv/8568o\nKHicyZPbIyavA5s03XnnI+Tnv4nfPx+YQVxcGrCFiy+OPqxoqOZe5D/v0UwgzeN7H18lgqZmrv9r\n786jo6ryBI5/f2GNLGFxgWYTB9CJCMqItoKAYytbizsInLbbGUirIMhis7RHZI4T2vEoLdAacdoN\nohygwa0VwdE03eOGIgiKCkrbiIBDYiAsYan6zR/vVVEpKrW8qkqlwu9zTh0qlVuv7n0v3F/d++7y\n9NODePbZpeTlfUJu7j8Bj/PEE9uCFWu0Sufeex/igw/OYtq0/yJ8j5PKSmdOhYgzj8W5NxHfAnxb\nt+7ghhsacc8955OT8xmXX55L69Z5zJq1gFdfPcjx48v48MOGwTyFBsgAEeHGG3/m3g+awoED5Xz/\nfSk//tgtuO5XWdn7XHFFdxo16gIIx45B/frncN5559KwYVd3SRihUaNSmjZVcnMvxKnEe9KyZVP3\nk5yJikePwuzZ41m5soghQ67kllvOZtmyG1i27FcMH96Myy/vzapVCwEneNx4452sX396MGBedtlF\n+P0dq5yfFStW88UXnRk69F846yxnGRe/31kgsaioMK77VLZ6bt1mAcSkTXXfPgPDPQMV+JEj/Rk+\nfCCVlc5M6latTmf8+FuDFWt4pTN69HgaNerB/Pl/Bx7nsce2M2HCwzRpQpU9TkaMGEhBgXNzPJEF\n+Fq1ymXDhi948cUv8fsvYdu2enz11T/o0+f8YEW4e3c5DzwwjoKC0dW2lEI/c/HicXTq1IaDB50K\n35nrcg49e3Zn374j5OdPpqLiKOPHX8Tnn89l3DhniZf8/MnUr9+FgoJbOO205u57G1NRUUFeXhcg\nl3r1RlFaepA1a9YiIsyYMZbi4oe5+eZB3HzzIIqLHw5W9k8+uZiOHfsHW0GBa7J48cpgXkeOzOWu\nu/6DmTP/ypEjC/j449PYufMt2rQZFlwGJ94b5idanIdp3fo2yssP2Q33OsQCiEmbaN8+Q4PLgQNz\neeGFLezcWUabNv9GebnTrRWoWMNbDIsWzWPcuBH4/U6w8PtzGD9+JBdd1KvKHie7dp24OZ7YXIKq\nrZm9exuzf/8BAMrLK2nXroCKCh9PPbU4uKteIEDm5w9l0KDb3GHKzmcuXFjMrFkL+PrrhgQqfL/f\nT9++Dfnss78HK+7i4mGsW7cZcGb4FxcPY/PmR3j22SHs3l0abEEdPy6MGXMzzmiswbRt25EpU86h\nc+fOUa9HYCvj48d7BVtB27evpm/f7qxcWRQ8P0VFhSxYcF/wuh065AsOAPCy+q3tIFh3WQAxaRNt\n74bw4FJWVso995xYxXXz5u3VthhycnIQycHng4YNR+HzKTk5Qo8e5zFw4DE2bXqERYuu5YILzq0+\ncxEEuqLGjh190o6NI0YMZM+e/eTlrSc393Tgej7+uLLKrnqVlX4GD+7Lu++2qtIaCZT18OGDBCr8\nSZM6c9VV/Vi1amGV1tj69WdEXHG2e/dzQ87HEHbvLnO7nN4Mrlg7ffrYiOUJdK0F8nHsGIS2gq6+\nekCVFkH4dfP763HZZb3IyclJeIi17SBYt1kAMWlVXddRaCXVrl0BR492CC6hctNNA6tUrJEqrc2b\nvwnOLp869Ww2bfom6bkkga6olSvXsGtX6UmtmZdeepxHH53OkSMKDKJJk26MGDGY48dzaNNmGDt3\nruHFF/dQUTG3yn2bQFmrq/DjudF8ckDpFrNLLrxrLZEZ/6nac8PugdRxXodvJfvAme20GmfNhTeB\nvChpc4D1wCsxjpnceDZTo6677k5t376fduniDBNt3fomzc8fqkVFixI6TlHRIs3PHxocptu168yE\njhPp/WeccbkWFMxQv99fZahvYDhqfv4kbdZsoo4aNVWXL1+lPp9PJ08u1Ly88QqqHTpM12XL3ggO\nQS4sXKjLl69Sv9+vy5a9of37j1Sfz6fTpj2kPp+vytDm8PeqakJDmqOdj9B8hA9hTpfwc2ZDeWsX\nkhjGm8kA8hDwG/f5NOB3UdJOAhZbAKlbAnNCAnMuWreeeFLFmchxolXAqXp/tAp46dLXtWHDO2PO\nk3Aq1Inau/f1wfkgsSrZ8HkU0QKK1/Ph8/n00ktvUJ/PF/OcJSITQcvEL5kAksm1sK4D+rvPnwNK\ngJMWYhKR9jg7Af0nztoTpo5YuLCYBx9cSFnZ+cAkysoqmTRpDqWle4NLi8Qj2SW/E3l/tLXFXnrp\nbXJySpk9+3Z3fa+TZ+HPm7eEvXs7U1Exj3XrxgIbuPPO7xDZxciR/SgqKqyy4mzgPceO9XS7t+7j\n/vvn06fPBSxZUknv3qtPyofX8xE6LNrrmmiRxLMem8lOmbwHcqaq7gFQ1d04myVEMhe4F2fda1OH\nRJps16/fJZ76x5Pts0/k/Rp2czpwD2PduoZUVi5h5sy/cv/982nZsvFJ5e3TpztlZYcJbPwEHSkt\n3U7bts1p0SIPoMr9m/B7CHv3bmH//gOUlEjUOTKJlCfSsOhGjXowevT4hM6hOQV5bbrE8wDW4Gya\nEHhscv8dBpSFpS2N8P6hwAL3+QDg1Rifl7JmnakZqeofT3TZk2RE6k6Kt8to6dLXNTd3nNarN1Jh\noopcrzk5F2qDBndo48bDI5Y/9Bw1bTpBJ08u9NxdF4nP59NJkx7UevXuUFCtV+8OnTy5MOVdWaZ2\norZ2Yanq1dX9TkT2iMhZqrpHRNoAP0RI1gcYJiJDcFaPayYiz6vqbdUd94EHHgg+HzBgAAMGDPCa\nfVMDUrVZUGDEUaQunVSprjtpwoRbad369Li6jLZt+4677mrH/Pl+GjVax6FD5ahegd9/HceO/YXh\nwydxxhnNmD377mA3Xvg5WrFiDeXlvpTt0Bc+LPro0eYJbSpmsktGSe6WAAAKCElEQVRJSQklJSWp\nOZjXyJPsA+cm+jSN4ya6m6Y/dhPdhEl2BFYiorU0ErlRXFi4UAsKpmt+/hBt0eLXCn6FmQoXKIzV\nyZMLo7Yo0nFT+pprxujUqXPU5/Pp1KlzdODAsUkf02QHsnQUVivgLZxhvKuBFu7rbYHXIqS3AGJO\nEq1ST0e3Viq73E6MQFukcJHCLxX82rbtxLQFQWPCJRNAMtZGVdUyVf2Zqp6rqteoarn7+i5V/XmE\n9H9R1WE1n1NTm0Wb7R5rNV8vYt2cVo1v34vQSX3Nmv2ZBg06B/cvOXTIZ5PtTFawTk6T9cIr9cWL\nX07bEuKx1tRKJGht3bqD4uJh7Nv3AhMmXMzRoxJcOsQWHDTZQGJ9U8omIqJ1qTzGG1Vl+fJVTJmy\nlh075tChwwwefbR/lTWnUi30BvvWrQ/Stet9NGiwkQkTbo1rTsucOU/RrVvHKoMJEl2KxRgvRARV\n9fQfI5MTCY1Ji2QnFnpRUDCali1bMWbMAgAqK/0UFo6Pe0SYTbYz2ci6sEydlKrFAOMlInzwwUYq\nKjrRvv3ImJtWGVMXWBeWMUkKdF/t2dOJ0tIFdO36Ww4ffpeLLz6XlSufrLF8qCozZjzMnDn3WuAy\ncUumC8taIMYkKbDcSGDHwMpKZe7c6axYURRME+/orGSkY9SZMdFYADEmSdGGEgeks3KPZz8RY9LB\nAogxKVDdPZeaqNxt0yaTKTYKy5gUqG4UVUHBaFq1as2UKWsJVO6JjM6KRyZGnRkD1gIxJq3i6d5K\nhZoedWYM2CgsY9LOJgma2iyZUVgWQIwx5hRmw3iNMcbUOAsgxhhjPLEAYowxxhMLIMYYYzyxAGKM\nMcYTCyDGGGM8sQBijDHGEwsgxhhjPLEAYowxxhMLIMYYYzyxAGKMMcYTCyDGGGM8sQBijDHGEwsg\nxhhjPLEAYowxxhMLIMYYYzzJWAARkZYislpEvhSRN0Ukr5p0eSKyTES2iMhnInJpTefVGGPMyTLZ\nApkOvKWq5wJvAzOqSfcY8Lqq/jPQE9hSQ/mrVUpKSjKdhbSy8mU3K9+pKZMB5DrgOff5c8D14QlE\npDlwhao+A6Cqx1V1f81lsfao63/AVr7sZuU7NWUygJypqnsAVHU3cGaENJ2BvSLyjIisF5GFIpJb\no7k0xhgTUVoDiIisEZFPQx6b3H+HRUiuEV6rD/QC/qCqvYBDOF1fxhhjMkxUI9XbNfDBIluAAaq6\nR0TaAO+49zlC05wFvKeq57g/9wWmqeq11RwzM4Uxxpgspqri5X31U52RBLwC/Ap4CPgl8HJ4Aje4\n7BCRbqr6FXAV8Hl1B/R6EowxxiQuky2QVsBSoAPwLTBcVctFpC3wlKr+3E3XE/hvoAHwDXC7qu7L\nSKaNMcYEZSyAGGOMyW5ZOxO9rk9EjLd8btocd5TaKzWZx2TEUz4RaS8ib7vXbZOITMhEXhMhIoNE\n5AsR+UpEplWTZp6IbBWRDSJyYU3n0atYZRORUSKy0X38TUQuyEQ+vYrn2rnpeovIMRG5sSbzl6w4\n/zYHiMgnIrJZRN6JeVBVzcoHzr2T37jPpwG/qybdszjdXuDc82me6bynsnzu7ycBi4FXMp3vVJYP\naANc6D5vCnwJnJfpvEcpUw6wDeiE0+W6ITy/wGDgz+7zS4H3M53vFJbtp0Ce+3xQtpQt3vKFpPsf\n4DXgxkznO8XXLw/4DGjn/nx6rONmbQuEuj8RMWb5wPmWDgzBuU+UTWKWT1V3q+oG9/kBnFUI2tVY\nDhN3CbBVVb9V1WPAEpxyhroOeB5AVT8A8tzRhrVdzLKp6vt64v7k+9TuaxUunmsHcDewHPihJjOX\nAvGUbxTwJ1XdCaCqe2MdNJsDSF2fiBhP+QDmAvcSeR5NbRZv+QAQkbOBC4EP0p4z79oBO0J+/o6T\nK9HwNDsjpKmN4ilbqDHAG2nNUWrFLJ+I/AS4XlWfALJtxGc8168b0EpE3hGRdSLyi1gHzeQw3phE\nZA0Q+u1McCrK+yIkjzYRcZyqfiQiv8eZiDgr1Xn1ItnyichQYI+qbhCRAdSyP+oUXL/AcZrifOub\n6LZETC0mIlcCtwN9M52XFPs9TndrQK36/5YCgfryX4EmwHsi8p6qbov2hlpLVa+u7nciskdEztIT\nExEjNSm/A3ao6kfuz8up+geQUSkoXx9gmIgMAXKBZiLyvKrelqYsJyQF5UNE6uNct0WqetJcoVpm\nJ9Ax5Of27mvhaTrESFMbxVM2RKQHsBAYpKo/1lDeUiGe8l0MLBERAU4HBovIMVXNhsEr8ZTvO2Cv\nqlYClSKyFmcB22oDSDZ3YQUmIkKUiYjADhHp5r4UdSJiLRNP+Waqakd1ZurfCrxdW4JHHGKWz/U0\n8LmqPlYTmUrSOqCLiHQSkYY41yS8cnkFuA1ARH4KlAe68mq5mGUTkY7An4BfqOrXGchjMmKWT1XP\ncR+dcb7U3JUlwQPi+9t8GegrIvVE5DScQR7RVz/P9OiAJEYVtALewhmZsxpo4b7eFngtJF1P9+Rt\nAFbgjhKp7Y94yxeSvj/ZNQorZvlwWlg+99p9AqzH+Wab8fxHKdcgt0xbgenua78GCkLSLMD5VrcR\n6JXpPKeqbMBTQKl7nT4BPsx0nlN97ULSPk0WjcKKt3zAVJyRWJ8Cd8c6pk0kNMYY40k2d2EZY4zJ\nIAsgxhhjPLEAYowxxhMLIMYYYzyxAGKMMcYTCyDGGGM8sQBiTDVE5LfustYb3bXUeruvLxSR89Lw\neRXVvP5Hd+b+p6n+TGOSYfNAjInAnSX+CNBfVY+7O2g2VGfhx3R95n5VbR7h9b7AAeB5Ve2Rrs83\nJlHWAjEmsrY46wIdB1DVskDwcFcr7eU+/3d3U6z33ZbJPPf1Z0TkMRH5XxHZFth8SESaiMhbIvKR\n27IZFisjqvo3IJvWlTKnCAsgxkS2Gujo7uD2BxHpF55ARNrirCx8Cc6yK+HdWm1UtQ9wLc4GWgCV\nOEuCX4yz6ukj6SqAMelmAcSYCFT1IM7S1gXA/+Gswhq+UOUlQImq7lNVH7As7Pcvucfawon9TgSY\nIyIbcdYC+4mIRN0LxZjaqlYv525MJqlzg3AtsFZENuGsovt8WLJoe0IciZBuNM5S4Bepql9EtgON\nU5RlY2qUtUCMiUBEuolIl5CXLgS+DUu2DugnInnuviU3RTuk+28e8IMbPK7E2aM6PE11769rGxiZ\nLGctEGMiawrMF5E84DjO8usF7u8UQFW/F5FC4EOgDPgC2BeaJkTg52LgVbcL6yOq7rcQcUikiLwA\nDABai8g/gFmq+oz3ohmTGjaM15gkiEgTVT0oIvWAlcAftfbvnGhMSlgXljHJeUBEPgE2Ad9Y8DCn\nEmuBGGOM8cRaIMYYYzyxAGKMMcYTCyDGGGM8sQBijDHGEwsgxhhjPLEAYowxxpP/BwO91YQRVMCK\nAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAYIAAAEZCAYAAACaWyIJAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsnXd4VFX6xz/nTiaV9ACBJIQWkRAUsSAKqKs0RUXAVYpl\nXQgIiAK6ErvuLq6yC/xAMaC7uFIsFMVVaRaKqIigCCgQipAQWnpvM+f3x3smhRoUCeV+n2ceZu7c\ne9qQ71vPe5TWGhs2bNiwceHCqusB2LBhw4aNuoUtCGzYsGHjAoctCGzYsGHjAoctCGzYsGHjAoct\nCGzYsGHjAoctCGzYsGHjAoctCGyc81BKuZVSzY/z3QCl1JIzPaZjQSk1Uyn1Qi3vjTXzsv9Gbfzu\nsP+T2TiroJQap5T65IhrKUqpj4+4tl0p9ceTtae1nqu17lHtueMKjbMQtdrko5S6TimV+nsPxsb5\nC1sQ2DjbsAroqJRSAEqpSMALuOyIay2Alb+i/fNxB6Xi/JyXjTMEWxDYONuwDvAG2pnPnYEvgG1H\nXNuptT5Y7bmuxkrIUkq94rmolLpPKbXavF+JkOaPSqk8pdSd5novpdT3SqlspdSXSqm21Z7frZQa\nq5TaaL5/WynlXe37Ez17mVJqvVIqVyn1DuB7vEkrpSyl1D+VUoeVUjuAW474/n6l1E9m3DuUUonm\nuj/wCdBYKZVvvo9USl2plPrKjGufUmqqUsqrVr+AjQsOtiCwcVZBa10OrAW6mEtdECvhy2Ncq45b\ngMuBS4E/KqW6VW/WtH2d+dxWax2ktZ6nlLoM+DcwBAgDpgMfKqWc1Z6/E+gGNDPt3w9C9Md71jz/\nPvBf8908oO8Jpp4I3GzavwLod8T3B4GbtdZBwJ+ASUqpdlrrIqAnkK61DjTzOgC4gEdM3x2BPwDD\nT9C/jQsYtiCwcTZiJVWk3xlYTU1B0Jmj3UIvaq3ztdapiAXRjuNDVXs/BEjWWn+nBbOAUuDqavf8\nn9b6oNY6B/hftbZP9OzVgJfWeorW2qW1XoBYO8fDncBkrXW66efF6l9qrRdrrX8x71cDy8w6HBNa\n6w1a62/NuPYCM4Drjne/jQsbtiCwcTZiFdBJKRUKRGitdwJfAdeYawkcbRFUdxMVAfVq2VcsMNa4\nlLKUUtlANNC4Fm2f6NnGwL4j+tpzgnE0BqoHfGvcq5TqqZT6WimVafrpCUQcrzGlVJxS6n9Kqf1K\nqRzg7ye638aFDVsQ2Dgb8TUQgmjcawC01vlAurm2T2t9IlI9FaQCf9dah5lXqNa6ntb63d/47H4g\n6oj7m5ygrf1ATLXPsZ43JiYxH3gZqK+1DgUWU2XZHCtQ/BrwM9BCax0CPElNS8iGjUrYgsDGWQet\ndQnwHTAGcQt5sMZcO9IaOBUcAKqnj74ODFNKXQWglApQSt2slAqoRVsnevZroEIp9ZBSyksp1Qe4\n6gRtvQeMUkpFGavn8WrfeZtXhtbarZTqicQsPDgIhCulgqpdCwTytNZFSqmLgQdrMR8bFyhsQWDj\nbMVKoD4SG/Bgtbl2ZHzgVFInnwPeMq6cflrr9YiV8YpSKgvYDtxXm7ZP9KwJevdBAruZSAxgwQnG\n9TqwFNiICMHKe7XWBcAoYJ7p525gUbXvtwFvA7vMvCKBR4GBSqk8JIj9zknWxcYFDGUfTGPDhg0b\nFzZsi8CGDRs2LnDYgsCGDRs2LnDYgsCGDRs2LnDYgsCGDRs2LnCcE7VHlFJ2RNuGDRs2fgW01ifd\nP3LOWARa6/P29eyzz9b5GOz52XOz53f+vWqLc0YQ2LBhw4aN3we2ILBhw4aNCxy2IDgLcP3119f1\nEH5XnM/zO5/nBvb8LhScEzuLlVL6XBinDRs2bJxNUEqhz6dgsQ0bNmzY+H1gCwIbNmzYuMBhCwIb\nNmzYuMBhCwIbNmzYuMBhCwIbNmzYuMBhCwIbNmzYuMBhCwIbNmzYuMBhCwIbNs5SaK0ZN+7lU6oZ\nY8PGr4EtCGycE7gQSXHBgqVMm7afhQuX1fVQbJznsAWBjXMCtSXFMyUwfs9+pk+fTZs2vXjiidXk\n508kKWkVbdr0Yvr02ae9Lxs2wBYENs5ynCopnikt+vfsJzFxIM89N4KSEjegKClx8/zzI0lMHHja\n+7JhA2xBYOMsR21J8Uxp0Uf3s5KIiKuZPn3WaetDKYVSipycEuLjx5CTU1x5zYaN3wNnxQllSikL\n+A5I01rfVtfjsXH24EhSTE11H5MUExMHEhYWztixq/AIjPHjR9K3b/fTOp4j+8nKKqKwMJbw8Pqn\ntZ+UlFRmzuxBnz7dWLhwGSkpqae1fRs2quNssQgeBn6q60HYODvhIcXNm//FzJk9j0mKZ0qL9rR5\n6FA+3t79yMoqoaTkTzzxxOrTaoEkJQ2hb9/uKKXo27c748YNPi3tni+4EJMHfk/UuSBQSkUDNwNv\n1PVYbJydqC0p1kZgHAunSiopKanMnt2LWbMeICysEEiz/fhnGHZG1elFnQsCYBLwGGCL9gsQp1Oz\n+7Va9KmSSlLSEPr164FlWZSVRRAf/5Ptxz9DsDOqfh/UqSBQSt0CHNRa/wAo8zomnnvuucrXihUr\nztQQbfwOqE7+danZ/VZSOZYFYrssTj+qr6mdUXVirFixogZX1hpHnnp/Jl/AeGAvsAvYDxQAbx3j\nPm3j/MG8eYu1j88IHR3dRbdsmaThH7plyyQdH3+LTk6epd1ut3788Ze02+3+Xcfhdrv1e+99omNi\nxmnQOjBwuH7vvU9+U7/z5i3WgYGP6Pnzl5zGkV7YOHJNPZ/j40frwMCH7bU+AQx3npSL69Qi0Fo/\nobVuorVuDtwNfK61vrcux2Tj90N1Dby0dCoVFZexa9dHQCrZ2amVmt2ZshKqB5ijohLJz3fx7bcb\nf5V750jrYty4lUREXEly8ulLK73QcDyLbfbs939VLMjGCVAbaXEmXsB1wIfH+e60SkkbdYOaGvgs\nbVmXa7hfg1srNViHhFyhIyM76Li4JzS4dVzcEzo+/hbdvfug3806uP32B3VUVGcdEtJTwyc6PLxv\npWXy6+emdXj4QO3nN1LPm7e41s+fCSvoXMKRaxoTM07Pm7fYXqNTAOeCRVAdWuuV2t5DcF6jugZ+\n8cXf4XY7CAz0AxRhYQHcfHMX/u//nqnh/+3R41rWrAk/pnWgT4M//v33X+Wuu3qQmxsLWPj7xx3l\ncz5RP57vPPM7dGgz3t5XkJXlR3HxlFqnlZ4uK+h0rMnZAntj3ZnDWSMIbFwY8ARYX3ihO05nE4qL\nNfHxYygrgz59umFZFjk5JURGPsC+fZnMnfszBQWTjhnI/a3kOX36bBISbuXttw+h9TS8veezb99y\nli9fWYNsqvdzJNFW/07SSkcwa9YLhIUFUJtg5unOgjkf0io9a+x2u5k6dTb/+U/3o9xAbrebq6/u\ng9vtruPRnh+wBYGNM4qwMD+eeWYqTz75JeXlXfH2PojW2+jf35+UlNRKQbFv3xs88kgziosLOZJQ\nT0aeR5L1sbRkrTW7d+/j2WeHU1TkAhQNG4YzenRfmjZtDhybpJs0uYHJk1czbNgTR303e/YiMjMz\nTFqpqpUWe7qyYM6ntEqPMPvLX17i++/rV65f9ZTgxx57ibVrG/L44y/XePZ8sojOKGrjP6rrF3aM\n4LzBkX5fpYbqsWPHH9Pve7zskJP5jo+XZVI9u8RzbezY8cfNQDmyHy+vP+vIyHs0uHTLlkk6Kqqz\nDg19qHIM7733iX788X/o8eOn6/nzl2i3263nz1+iX3zx9ROuyenIgnG73frddz/WgYE9Nbh1TMzj\n+vbbh2qXy3XKbdUVkpNn6fj4W3SDBiM1uLWX1xANl2tf36t069Y36+TkWXrAgBHa27utdjoTNbi1\n05movb3b6gEDRmit7aytI8G5FiOwcWFAKcXy5avYty8Lp3MQWvswZ87PJCTcepT2erw8/aSkCQBH\n+Y5nzJhDmza9SEpaRX5+JA8+OAMfn0sYMeLjSi25cePONGp0daXm/OabacAqHnqo3VEZKDV91KNx\nOn0oL9eARWmp5q67elJRYVWOYe3aH5g27QAXXRR7Shvbfu2O6CPXde3ajeTnxxId3Z+MjAKWLs3m\n/feXn3JbdQWPdeTjI241lysDuIqSksb07NmJxMSBzJo1hREj7sLttgCF220xcmR/One+6ryxiOoE\ntZEWdf3CtgjOK4wfP12PGTNeR0c/rmGJDg7uU+tsEI/GN2DAo0dp3R4NPjx8oIZHdFjYQD1mzN91\nTMzj1fYJfKzffffjatk9D2tf3z8eN7tn/PgZlf2MHTtee3vfVqm5e8aQnPyWjo6+TkdEDK+R7XSq\nmUe/Fh5NOjx8uNGS79UORzsNiTou7gnduvXNunv3e86JbBvZY9JLW1aChoEa3BqStGW115GRHXRy\n8iw9Zsx4DUO1ZV2jIVE/+uiLdobRcYBtEdg4W5GUlEjHjpeRm1tKfPxS3O6Yk2aDHOkDX7fOm2ee\nmcqMGXMqte4ZM+YwZsxLZGX5ARPJzvbjzTc/4NChgsp9AhMmvM6cOYtqXTSuetmK8PAI5s4dXqm5\nt23bir59u5OYOIiJEx/Hzy+II/38uhYZR8f6rrbQ1WId/v7Sf1BQKCEhbYBkSkrc9OzZia++Cjsn\nAsjbt++lZ88o2rVrDjiQYgNFuN1ROBxOtNZs3ryLW291ExBwJbfeCps27bIzjH4jbEFgo05wqu6Q\n2gRVExMH0rnz5ZUZO2FhAfj5+VC//ib8/CKA3qxbV8KHH35F5845zJr1AKGhBcBsiotdJw3Sjhs3\nmHXrNgLUcPmciISOl8WjtaZPnwd59dX030TQ0v4Bvv12Y2X/RUUVFBaWExl5O/v2Lefttw+Sn3/s\nzKu6gkcIut3uSmGotebbbzeweLEXW7bsBPyA0UAxsJvWrZugFKSl7Wfr1vrk509i69YIUlPTmT59\n9mlxsV2wqI3ZUNcvbNeQDV0zqFqv3ijdu/fQo0z/IwOv8+Yt1kOGPK4t608atIbHNQzSXl5X6JCQ\nS7WXV2dtWcO0r+8fjxtg9Gz2evfdj7W394N63rxPjtr8Vd2FNH/+Et2794M6Pv4WHReXZNxFVSU0\nkpNn6ejozlqpYRo+0aGhN1cGQ2sLjzvIs/kuPHy4jo6+Ticnv6UHDBirBw58VLtcLj1mzHgdHDzy\nrHOXHBmsT0wcp6Ojr9NKDTbuoHs0tNXwlras3tqyOugBA8baLqBTBLZryMa5Al1LF0l1jS8xsSH/\n+18KCxYsPe49M2f2ZMeONLp2vQ5vbz+UuhbRLsHbuymFhSWEh7fD7Z5GaGgjhg9/genTZ5vxvMTj\nj7+E1pqhQ59gwoSdDBnyJmVlsQwevIgJE95j2LAnKsc+btzgGgHihQtf5bnnRpCVVYTnAJvnnx8J\naKZMeYeKivZoPQ14m+zsxkRFhR7TGjne2hxpIfn7BzFp0jgSEwcxZ84/mT17ApZl0bHjZbjdXpWW\nCkBS0oTf5I76LfC4+IYPf4P8/BSmTPmF/PyJvPFGKvv2HUbrCsQdFAa0wOFYiNPZmDFjetO27cW2\nC+h3gi0IbBwXtSXo34oFC5by6qv7aNXqxhNuEEpKGkJGxmESEm5l7tytuFxteeihuTXcHccqRb1j\nRxo33VSO1m2B9UCWyf5JoKIiG1B4efnx6qtPV9Y6mjIljX/96xOCgtrxwQf5uN3J5OWVALvIzd2E\n2+3PwoXbadLkOiZP3lvDvaO1pmfP+xg9ejxZWaXAaDIzi/nTnx7H7dY899wI8vJ2ArcCTmAGmzeH\nU7/+VUfVJjqea6m2hHikYHz//c/qdMNZVWZQS2BEZfZPaGgE/v5NgACk7FgZ9eqVMHfuEHr2dBEe\nHl7pirNdQKcftiC4gHEyov+9d6lWDwAXFPQgJeUi6tfveBIftiYvr4CMDF9gEhkZvuTlFXDkcRae\nuSUnz2L27EV8/bUTeI2goHi8vPZgWbspL+9OVpYv3t5XcOjQZpYvX0lUVBcGDnyb4uIpuFztKCjw\n4vDhLxDSbgAkA62BPDIytuBytae0dGoN//v8+Uv44ot6NG0aTVhYATCRevVSKSm5hvr1G6CUoqIi\nhoCACmA3AHl56RQVXU1ERP3KtYmPv4XExKnk5//rmP792hCiRzDOmDGHZ56Zyrp13nWeXjl37iJy\nckqIjn4TlwuioxMpKqqgpKSEsLDtQAhhYemUlXmzdu0PfPzxLlq2jDlqTvbpbacPqq5MxFOBUkqf\nC+M81zB//hIeeGApM2f2qDzb16PN7t2bSUVFO1JS/kZc3FM4nRsZNepuhg4ddNr611rTpUtfvvzy\nF6An8Dccjj/jcHxHv35dmDPnlWM+8+ijLzJp0l60TkapYYwZE8uECeNqaMOeuf3nP93RWvPgg0vJ\nzJxMePgj3HdfA957L4+0tH8QHv4Ir70mpJKSkkqLFlE88MCHFBYmAw8CtwHzgLXA1cC/gcHAt1hW\nc0JDm5KZOZmYmCR69IDVqzeSmlpBYeESQkJGkJOzAofDict1GfAmcXFPceDAEhwOF1o3Jjc3BvgS\n6Ai8Xm2t72L79lQmTUpF697ExKxg4sTrKgmwNmublDSBF198DICkpJdp374tjz66mtTUF4mJSTql\n9k4X5s9fwqBB/+Ohh2IICwsjKyuLsLBwNm/ehlKKNm3iyMjIYObMd/H3DyE3N4KCghgiI7MIC8s6\n7f8Hz3copdBan/QHti2CCxAnKkewYMFSvvoqjJ49O51y2QOPFl49E+REUErx0EODcTqbAYeQDUIO\nRo7sz6xZU477zP79mfj6OomPH42vrxf792dVktmRcxsx4mMGDHiMzMxtwGiyskp4881FHD68pbLG\nkWVZ9OvXg6SkIViWhdvtBfQGXMAifHwctGoVjaQz9jYj8cbt3kNmZiGtW4+u9L8fPHiYwsLmwHJy\nclyEhtbjuusSAC+zli6aN2+Av38Qubn1gWQsqwPwDTCbkhI3nTolMGXKu8yde3QNJKBGls3x1rm6\nNXeszKIz7Vuv+l1WUVr6CosW5TF79oe0bBlNUtKQyrhGUlIioMjObsShQ5mUlIRzIsvPxumBV10P\nwMaZR2LiQMLCwhk7dhUeor/hhgSmTHmH8vJLyc+fxNtvj+bgwS+JjNxCTk7zWpGGh3wqKl5ixoxD\nXHnlskpL43jYuXMf3bqF8fHHO3E47sTlCsWyFJZ1fB2lbduL6du3CX36dKss9na8ufn4BNChQ1t+\n+skiO7shWs+iceMWPPvscBPUXcb27XsZN+5lXnzxMVJSUmnceAs7dx4GcoGLKC3NYMeONCxrF253\nfUR/8gFygIOkpHzB1Ve34/3391NYGAhMAxKBNRQUVLB+fQ4QBPQjNTWE9PQALr3Um/R0X0T4KSCA\nxo0/JCcniq5de3DTTddx//2LAEVgYAD339+X8PCIyjW+8kopgOd571nn6dNnV/sd29O//9Mo1Zqy\nsjd5882RBAdvYdSoPxMR0eCM+tY9v8uwYUuACWRmFjJ9+sgalmhCwo3s2JGB1h2BTygvvxUoQ3YZ\nW9x1l+zZsPE7oDapRXX9wk4fPS2oXvPek77XuvUj2unsqt9775MaaXnBwSP12LHjtcvlOmm9nCNr\nxEgdmFt0/fq1q+1/ySW3VaZlPvroi7p79yHHHHNtcWQK6dix47Wv7x813K4hUV9+ee9j3p+YKCme\nvr7dNVyu4T5zVsL92umM19BMwwMmvfFPGlppGK4t60/a6UzQDRpcrmGohiUabtMwRENLDTdoGKfh\nMg3dNczQ0FPDnzVcqWGwhj/qkJA/6ujo6/Sll/bQUVGdNSRqeEQrNVQHB7fTAQHtKtNRnc57tdN5\npYa3Kncyd+s2UP/lL/+otnParcPDB+rw8IdPegLb730egidlFu7QMExDbx0d3aXy/8a8eYt1vXqj\ndEJCd3NGhdbQW8MQbVm3a6dzqB4w4NHfZWznM7DTR20ciSNLJs+c2YPnn++Gl1crPvjg8xpZKG63\ng44d22NZ1kkDckfWiJFMkJH4+LSsVQnmoqI2lJXFkpS0mk8++ZI77uhyzDFDzQD38d5v376XG28s\nZtOmf9K/vx8TJ/6bkpJtQDyQzPr1ASjViqZNa9an+eIL+OWXNOMSuwM5RRW0duLtrYAYqna7WsDF\nQC/c7r04nQ4KC9sBrwFvAalAZ+S8pQzzOQhoAgwxs9sEXAqkADeRkxPIgQMZxMc3p2nTaOAw0J2w\nsEISEuKpqIjjwIEcQOHrG0BQ0EXAoMpzG1auLGPq1LRqLqCxFBaWU1TkOukJbLVJDKi+xqcOTV5e\nMZYVAkzDskLJyyti1aqvK+tDFRQ0Zts2p1nj24FSoBkQitu9ii1btv6Kfm3UBrYguABwrJjAlCn/\n5qGH/saTT66muHgK69Y5GTHir/Tv73vKaXlVqYylREUl4nJpoqPfJDe3pFYlmLOz9wIHahxXebw4\nxrBhSUybtp8FC5bW2JlbncguuqgJn33mx/vvLyc5eTxvvz0ZX9/miH9ZAb5AI+6447Yaufi7dx/C\n6WyMZAXNA+KAKwAXhYVxwEXADiSA7ACGAi8DmRQV5VFYiGnfCTQCBgERQIjp8yDgjwiIPea+6UBL\nYBGQRkiIDz/8sJudO+sDHbCs98jM3ML69T9RWnqA/Hw3MJr8fBeZmT8SFNSV1NQMJk9+h9LSlhQX\nT2HSpJ9wOL5k1KjLaNu2Aqfzq8qd1TNnfkd8/C306HEvWutTKl/9W7LIEhMHMXjwHWjtDSi09mbI\nkD689dYU4uKiKv8PlJfn0rTpDhwOh1mf+mjtxcMP38OGDYtOuV8btYMdI7gAMGTIABYvXs2GDVJ3\nv6TEzZQpz6K1ZvjwZXg2PCUnP10jLe9U4LEwtm3bQ3Z2FuHh4cTFNTmhMJkxYw5/+9sbZGXFARPJ\nykpk9Oh/kJmZcZSvPyMjn4CAPD7/3CI/fyJ3390Ll6sxsJf+/Z/C5WqF2z2LAQPuR+ufKS9/iKSk\nVTzzzFQ6dUqgrEwjmT93AcFAd1599RemTp2LUl2Ijx/Nrl3e5OfvQgLXbZDAsAWsRIj/J6AT8BkS\nSP4MEQ4rEOFRD4ejPy5XAPKn1Q/ZGBUCvA7cjwSFAeojFsVywMLhqMDliiEzM5vYWCdbt34NXENo\naBkdO17BypWHKSlphmQYfYO//12Ehobwyy9L+MtfXmLKlO8AEWihoeG89toL9OvXg8TEQcyfv8Ss\nYw/8/VfSs2cQr79+kIULlx0zXjR+/Mgav3/NuMNEkpKe4plnpp5SBk/1IH+zZqPZvVuC/MOHP8mi\nRWuQjKyJQCJ79nyD03kAl+t6vLyWUVERctK4kY3fBlsQnMfQJoXw8svbsnRpDkp5Ex8/mh07Svj0\n01V88skasrLa4MmmGT36RTIzM35Vel5S0pDjfqfNTt2VK9fSpUsHXnrpcZRSJCYOZOXK71m2zEVm\nptQG6tLlChITBx61YSo1VdGoUTg7dmwFbkXrxsAM4AnKy7chwVtFYGAocBGZmYMoKXmC8eNHsn37\nXgIDP6Wg4AouuWQf33+/BQCXyyIyMhx//238+OOn9O79IB99dB0Oxze4XBuBWCTwey+wAXEN9UM0\n1S8Q18Vy4D7gB+BSXC4nsA4RNuOA8YgVoBDXUAZQDyG+ScCfgB+xrDzq1XOQm+vN+vU7EKuhB1lZ\nC/j007Vo3QR//68pKmpHQEAv3O7mZGZaLFr0GUpZuFxXAdtRagBFRWFYllVpiXnWMTLyNvbtS+ft\ntzuZ2kNPVQrKnJxSs87uo6y42giL2qB6kH/YsCd5//1VBAd3AbqiVB6S5RiAn18DWrYMpGvXWF5+\neRqPP/4ymzbtOqW+bJwabBF7HmPYsCQmTHiPUaOWUFJiERSUQ27uBsrKfmT+/OXUq+dPaGg+MJGw\nsEK6dLmKIUMG/Go/8PF8yAsWLGXSpPWsXduAyZM/r3QtKKXo06erOc1rNPn5pdxxx02VJFSzpEQk\nGzbkUlzcmKiogModqXAA0a4DcToHkZVVSG6uCI+DB3NYtmwFEye+Tv363XC5XmP79oaAN7Aat/sA\n+/c72bHDh4YNrzWbzpKpV+9q0/Z+868XUARkIxr5a4jLKAuYY+5pDnwObAFuQKyId4FMJC5wF/Ln\n1tj07zLPhQCRlJf7kJu7CSgArjF9rEbr7ygpcVFevpPi4jhgOoWF9Sku/oySkt307/80kyf/BCQT\nGRlDVFQ6CQlpNSwxzzqmpb1P+/bRlSeyedKCmzRpVhlTOZZL8Fi7mOHUS1VU3wiWnPx3Xn31SUpL\nNdAdrZ0o1R/LKsHtjuCZZx7kn/9MwrIsJkwYx5IlM2rdj41Thy0IzkN4/L6ff27hdr/AoUOpQCQH\nD+ZQWBgJ3ExW1hVs3VpKXp4EFcvKwunT5yYWLlzGq6+m06fPgyf8Iz8W6R/pQ54+fTbBwZdy551J\nlJfHAcmUlzegX7+HCQ5uYypGSmD32We7YllZfPDBZ5Xt5+Zmc/jwIRISbuXDDwtwue7Csn5E63Qs\nC4KCBuDn528CuT1p2DCaa68t5I9/bMZzz3XDsrL4+ee9FBV1ID19B6AoLFRAX0Tj3mJ81p+QmRlB\nZmYBoMjN1UB/wAfL6g04UMoT6M1ECDzAfH4PIfYOiBUQQBXJeyHa/yFgNz4+PyO1jhoDmxHhUAGE\nExDQBstqiVgd/sAERMg1BW5Bawda+5h2fRBX1QiCguJQymnmVsGkSeNYu/b9GsF9DwG///5yNm/2\noayMGnsJWrWKrYypHC8x4HSXqvAI+wMH1hMRMQ2HYytjxlzCu+/2pm/fE7sUbZx+2DuLz0NorZk/\nfwmJia+Tk7MHuIwqH/VaIBpxaQwDVuN0ltGwYShlZd4EB19PSkonlPqQgICvmDDhUYYNu6dG2x53\n05//vIyZM3uQkXGYKVPeoazsEnbsCKZly1y8vX/koYfuIjQ0jMGD/0tBQQvgRWAIAQGp/Oc/o7jz\nzp4MHfoE//53Fg0aFHPgwH8rd9Zee21b3nmnhP/8pxuzZ3/A+vUhpKXlAtCpUz4PP3wPfft257HH\n/sHUqd+1WsrPAAAgAElEQVTQsmULUlPd9O/vz5df/sjhw74cPlyC0xlFeXkyMASlvkRrJ+Lnn4YE\nc7cipY7n4XRGERiYT1ZWABAI7GD06CuYO/dDDh1yo3U9JCaQiWjyGxBivwgpQfER4qdvhOxBqAek\nAaOA94FVwOXm+wIktuAEmqBUFjff3JaPPz5kVjoS2I+PTzGlpX/Ex+c9SktbIEKiEPiCgIAQCgtz\nEQvEDyjCslbTqlVjNm9exhNPTEBraNasEU89NY2wsD+QktKUyMgvCQnJoKAgg7Iyp/nNj95B7hH2\nSsGLL/4FpRTTp8/m//7vbQ4cgOzs/xEX9/Sv3nU+YMBYPvigjLfeuqVyZ7ddLuL0orY7i+0YwXkI\njylfXOyFEIRky8iuWW8kJc+TAlmf8nJFerqD6Ogidu/2pGlOo6Agkb///d+V/vykpAlkZWXy739/\nRsOG6ZV+ZiHuNixcuBeoT3Z2BsnJ4kNesGAppaVuxK1yNxBEWZmbzz5bzfPPT6O8/BLc7mQyMoYC\nt5KWlk14uJMVKxT5+RMZNWo0+/evQfzxNwK92blzCc8++wqZmRmVh8VUbS7by003dWbMmJXAdbjd\nHwKK8PB6XHppez7/fAOeTUpCqmVI/SAXFRU/UVYWjZD8dqAt//d/a3C7i/H1LcOySikq+sKsW3tE\n+89GahCtQIRAOrDTrHkRIlAWIMJiOyI8upo+/4Sf3w9cc00on38ezccfLze/13WIoPoTpaXfERn5\nIQcOlADf06hRAvv37wRaUl6+2/R50PTRkYiIENLSEvjLX15i2rR03O5DtG1bSna2wuXKB5bgcMRx\n882tmTHjAImJkcybl8exfP9SfG8DSjWo3LSWmDiQ7dv3MmlSKrD8V8ULqgefi4v/yRNPVAkgG3UD\n2yI4DzF9+myeeeY1HI4r2b+/O5KamA40pEoAZAGhwDaEEJsj2ute4BLgTWAc/v7biY0tJTzcj6++\nCqd+/WIOHrwLpRai9b8JDR3FnXf688kn37BvXxxaz0CpRKKiUnjqqcEsXryGDz9cgdaRQEu8vTdT\nVpZFr17X4XAovvsuhH37woAlREXVJzu7IfHxqezcGUN29lQsazBu9/dIFs9/gaewrCUMHtyV5OQX\nj5ma6qkzFBycTlpaGNHRLg4fduJ0fkVBQQ7QnSrN+lPTdgkSHP4J6AXsQgLDkxGN/h9IZtBSxF3T\nAAglOPhbcnODgBbAncDjSCD4U0RTX4XsX2iGVD4NM6//AA9iWWuAS3C7ZyFB6W8Qi2UmMI7g4F1U\nVGylsNAFRJnf50ogAXEvrUMsD/n78PYOp6zMCYSb9Rpq+vUB8oFrgVU0atSN/fsnERl5H4cO+dGg\nQTmFhUHMnNmTjIzDPPfcK2Rmuikvvwn4O97e9+Pruxl/fydKXc3+/ZPw9k6kouJ7Bg/uyvTpL578\nP6aBx2IdO3ZVndY9uhBg1xq6QKG1HF04deqTOBy+wBzCwvIZPboDfn7ZyMamdcBGJLh5ANGApyKE\nVQKko9TdQAlFRQc4eDCTgwcvwu1O5uBBgMfROo3w8HuoqFB07Xr9USeDdelyBVpr1q//Ga2vNn01\noKzM48qAZcucpKcvRzToEO6++zIefLAxP/zgoKQEoqKGoLUnDVPyzy3rMN7eLTh4MPuoeXtiFh5/\n9vDhNzJ2bBOaN8/n3nsDKS4uRfL6DyJEvx+n0xsRgFciWUitgbeRP42piL9/NJLr/5oZ+36EhL8m\nL68QL68cYB/wGCJs9yEB3+sQqyEASY2MQwSwF7IXYRtudyhut2eTWg4ilLwQ66mE3NwdFBZ2QFxK\nSxAhlGV+t3zEhVSIWBx/pawsFiF7p2lTA38zY3Ei2U3R7N+/DHiI4uJCRo9uyr59b5hA8V527drH\n5MlPmw1rYk0GBobyxht/ZfLkp8nKKgQUDRuGc/nlMcTGNjulzWb2mQJnH2xBcJ6heoGxjIzdWFYg\nRUUVWJaFl1cMDRo0xOGIRYjBUzMnEM/ZsEJW29G6Hpa1DQgnL8+XlJQvTQ/ZSKXM63E6wwgO/oE5\ncz7kjjtuIi/vJ1q3Hk1ZGdSr520OYIlBgqgPIX7yKCCNjz4qpbh4KlonIC6TQ/zrX7OYPPknKiq6\nExycS27ueuAnlPoACY7eg9YWDsc2Pvqo5hGP1QPVniMlx40bQocO7Vi1KovXX38Xl8sbCfAORcj5\nJ8rLO1HlXvEQZzfEhZNjXhHmO4UIpGYIWedTr54Tl6sCEbBNzL+5iItnEBKPCaDKEuuAWGf5iHAp\nNH23R4TIzYgg2Qx8jFgeM8zzHYFfEPL/l+knB3GbrQfeMONeY37XvqZPz595DPAsEIvTGcXFF3vh\nckWzc+eeyr0jLVpEM2nSZ3z77UYKC8uxrByTklqBZTn49tsfKS31Ijo6kYyMAjZt8qZVq9hT3mxm\nnylwdsF2DZ0nqO53TUm5GMuajFJtcLn+S6NGo8nLW8VllzUlK6uM9PQYcnKuQcikEdAKIacgoD5K\npRIamkJJSQOKikYCDwNdEIKRcslwP0p9z5AhN5Oc/CIDBz56ROBvLy1aRDNs2Gyysg4AoVhWFm53\nS8Q1cgBxPw1D3B0HAReBgdeQnz+N8PBHyMn5gYcf7sY332ziq69+BppgWXvw929KQcEHxMU9SXr6\nYurV86asLKIyeFlcvIb9+0to1MgXl6sd+/dPRKlb0NpC3F5tgIkoFY/Ws5Bc/k3I7t944GtEey5A\n3DR/RNxr+xGyTgOcOBzbcLk0IgAiEMumPZJi2gnR3EvMGhchAuEbhJjbISWtByGkXw8RDP9Fgvrf\nA38F/omkog5DrDgvc9/dZkxrkVTW7aavLEQItDbjDTXziEOyl/KBFsTGbmH37tU89tg/eOWVNO67\nL5jVqzeyZ08+RUXtCQjYRFnZPlq3bs6TT47k4Yefp6LCC60bkZk5GKdzLi7XRtzuxjidmZWF7X6v\nkuU2fh1s19AFhppHFw4iNLQ1ISFheE7fevPN8axcOZ9rr00wJ215tFWNnAXghxBZc7T2Iysri6Ki\nFOARxG0yHSGcH5DcedA6iG+++Z6EhFv57jtfioun8MQTq3nmmamEhvqhlCI3dx9KxeHjY3HZZR7L\n40Oq3B8+yCarMsAiP78CuJ3MzCJcro5MnfoBX3+dC1yPUhq3uxi3uxGe3dAVFRdxxRWXkJPTBFjO\n7t0Hqahogsv1IOnp2ezfXwhYJk3UgRDl/4BotPa4ZALNy41o1p7Mn64I0c5GtPTtCJHvQypigtTE\nyUEESQLiPopENpylIC6oVYggiEV894VUuW78zNyzEUHUDbE6SoC/IILpRjMmF+Jy+g54BwkoX4II\ncRALoT4irB9ABM82JLNpO2JNSMXU9PQCfH0vZdasdEpLX+GDD/LZtu0XiorkwJ/i4ljKy538/HOs\nsQ46cu+9vfD3jwN6EBQURmhoW+BjAgPjsCyppFq9ZPlvq01k40zCFgTnEebMWUROTnGNYmPVfbCW\nZdG163X4+ATg5TUIIZxYRAv1RmIFPwMWjRo1wM+vifneszPWiQRF/wd406BBOT/95I2/v1dlMTQP\nEWitGTHirzRo0A6tp+HllcPGjbuIiPgOpToREbEJId9IRJu2EM36Z0JDD+DvvwPIxeUqQ/LuJ6GU\nBVxHUdEmLOtqMjN/prT0IEuWuJDzf+dSUbGGw4d3AvficHi09EcQ8t6G07kKsUZSAG8cjgGIgAgB\nniUkJBan00I06VcR4t2IuHyuQfL+OwD7UCoQcbGVISTtZdapiZlPNHC9mWMokGS+8zW/mCdL5mJz\nv6cw3peIgLwSESyeQHMoYj21MM8pM/aR5nmnGc90YJa51wtxHTVF3EYJwFbKy3Pp3DmB4mIpS5GV\nVYSvbyMzvjm43T8AN1JePo1//esn8vO/4403vmLfvuVERt5GUVEFBQVlhIf3IC/vECUliujoxBr+\n/vnzlzBx4qdHnStt4+yDLQjOEyxYsJTFi9MZOjSSzZv/RZ8+TbjjDl82bfonN95YQkqKVNLcsSOV\nhIR9+PhE4OW1CyGHAuBbRDPfB+zH7da4XCGIewGkGqeFuDECgQIOHapHRUUO3333C/n5LkJCBnLw\nYA5z5nxAYuJAXnnlKby8/IBlFBY68PV1kpFxCVpPJzOzJeJq+hTJvw8EyoEArr32UizrElq39sGy\n6qN1GnCrOQtgBv7+DdD6Ery9c4DLcbk8/vtcoBMul0VIyCAqKvIRl8haIAgvr1BGjrwHh6McaIZl\nbcGygs2cyoAJ5ORkUV6eR5XGHoG4YkqQgHcnsxY+aF0IDAeuQgjXQuoTbTP3KSTgHGXW+RrTrhew\nzFw7iMQF2iHaenvTZ3C1MbiQWMESRCjnIsLsNtPnOITow6lZWC/OrGmeuQZioUTgcLTAz68e+flu\n6tW7G629KCrab8a2EBEIAAqlfIEngVgeeaQP9957Lb17+xATc4js7CwcDifQG1/fcIKDv+evf32F\nNm16MWrU25SXxx91rrSNsw+2IDjHUb16ZFnZIhYtyich4Va6dLmUOXMmsHDhMj77zI+4OPnDjotr\nwo8/NubBBxvxwgvDGTu2D40bH0a0xgjEP+0mIyMPpb5HXCRbgR4IoTZF3B7BiNDIRTTe3uTlWZSV\nreDDDzfx/vvL+fTTlaSlLUd2yWZRUFCGEJRCa39Eu3YgpJgA7MLhUHz77UZmzuzBli0Tufrq+kiQ\nsxTxm/eiqCgMradTVtYWy1oO/Ij4/cPxZP7k5KxH6zIzxobAJVRUBDNp0n9xuUqBkbjdFuXln5s5\nHUAqi2YjpaHr4cncEbL2Av6AaNtLEHdMBXCT6bMdspdgK+Kfn2HW81bTdhCi0fdB3De+CEk3QspS\n+5h51kesgtaIlXab6dsH+XP1QjKIfJByFqnm2heIwMgy4/ZGBEA9057DtHkxEITW2Xz00S6gCQUF\nwbhcnyHkH2vGlYO4s+5Ga0V09JsUF1ewevU6Jk/ey+rV3wHX4Ha/QFlZDPAj6enZTJw4joYNg8jN\nrTpX+vBhX1JT97NgwWLbTXSWwt5Qdo7jeAXBMjMP06ZNr8qKkcOHj2LAgMcIDr6I0tJ5LFr0FE7n\nl7Rr1xTL8kG0WsnTh724XEW4XNcjAc0rkXz6jubzEIR4ShCtsw3QA7d7LuCD292LO++chWVtwMcH\nSkraI5ryy4jGOgaw8PZWlJVlIJuhZgD34XKtJSPjepRSzJgxh23b9uDlVUhFRRHiZtmKaNgKKKdj\nxzakpaWzZ09jqrRhf4RgLcTaaYkUePsz4i7piLh9WiNWUCFCeiGIz73I9FGO+P5DzGq7Tfu/IHGV\nHxBh4MkIamn681goXubzRYgAmA+8YsZZjri8FLL/IA8RGO8iewi6mc+5CInHAwORmMIPCFH7m347\nmXXZi1gtjRBXUgt8fIooLf3RtHGjebYYt7vEtD2vWhu5SCD8F6Acy8rA7Q7Gzy+PrCxNeXkZ69b9\nAbiVigovdu1aBrjRWo4ZLSo6yLBhz1BQcBXduvnz8cdSD8rlclNUFMuqVeUsXHjyU+tsnHnYFsE5\nhiMDcMfLyU5MHFSj1r6PTwAjR96Nj09LqvvyZ82aQufOl+Pj40NVfZtWeHs3QinJ3ZcSFR4/uMdd\n0gohpd2Itn43QiRXAj+g9UZcLjclJS0Bf5SaQlWq5B7zrzdiWWgkAL0J0TKTzZkJ79CqVQPERdIR\n0cbjkWBpR8CXNWs2sndvDOK390Y08EKESFsipO4w7f+AaNNT8ZRwEC18C6J5O818YhCtf7/5nIYQ\nbzqi+ddHCD3M9NkL0fAPmGsg7iNM/wdNGxZVNYqCkQ1kOYglkkJNIRJr1hvTZgbicsowr0hECEUg\nQi7K3O8pa/EHYAelpV6I1RKPWD5RZq3KEEESiygBP5s2v0Q2F96L290JcFBcXExRUSdEwEgxvAMH\nVqN1OUp9bObyGuBHdnYpZWVXs2JFFlq7sKzbAQcuVyKlpS3p3/9pGjW62nYTnWWwBcE5hmPlax8r\nJ/toAVFisnhKawiM11+fy+rV6ygtPYz4j7NQagtlZfmIrLkVIWovhPTuQrJQshBCK0Py3TcjxDID\nCWY6EaLKBPzQeh8SBxiKkNXPlJd7qnpaSADaQ5CKHTvScTgqyM0toqKiGM+GMtGkixGS3oX46n9C\nNODeiPb+DbDaXMtGNPmFCMF72vEEWdsjZLjS3NcGcYFdhKRa+iDEGGv6/btZdYUIwC8QAbEaIeUe\niEDYigSqI8z9njpEqcjJYyWIUPA3c2qNELUPct6xw6xTC0TA5puxvY8I5r1mfT3z0Yjbx4UQf6hZ\nb0+dqXpI9pNlPl9rxl+IWEcJZmxOROD8jJB7tGnnR7MOlyJC0ougIC9uuOESqoLk9fD2bggMwuGA\nMWOaM2fOEOrVy0GEkyYo6CKmTHn2N1W59cDOSjp9sAXBOYITnSRVvbxv9eqRRwqIzZt3M3NmD378\ncQKRkT+ybdseqo4QDANeQ6kQAgMDiIoKICxsHZZVjpBkAKK5BiMaeRtEGEQjBNccj/9fSCkecRsV\nI0HhQIToewCN8PdvjdY5CGFtRXbz5iKCoS9aO9myJZfNm2MRwnIgLiWPjzwY0WCvpEqA9ECsFM9G\nrSvMc18hAmu/+dzPjHOCafuwGWd7pAZQc2QvwR6EmNsAi00/zyJ/NrebzzGIW2Wg+Zxo+nIimvdH\nZp3KkB3dCQiJhyEusTQz5/2IEOuNWAarzXMXIcKknhkLZlyFZi2cyM7ndMSquBSxnLIQoeDZKOeH\nBJzjqCp/3dD8ftUF4x+QWIunzLcPImwuQVxGvmbOl9G2bSvy8wtQysLpFLdVaakf3t5XUlJSxjXX\ntMfLywuXqwFKfY5lZZtNahYLFy77TdVL4bedmGajJupUECilopVSnyultiilNimlRtXleM4WHEvT\nqblPoGa+9vGeHzducA0BsWTJDPr06UbHjv1ISbmIrKxMdu9O589/7l15hCD4cNVVrSgoKCMr63Lc\n7iLEDbMeIas1CNEmI1qsp1Tygwhp3I4Q6xaEqIIRss9AiOQu4EeKirYipaAXI+R0G0LKuxErYiVu\nt0Lr6QjxrMGzA1lcPD6Itr8J0V69EULcaz7HIhrt5YhgKgEGI2SZj2Qr+SAEWmD69qMq46YdMIWq\nvRae65i5bTNzvwLR6Bchf079TN9+ZqxLzTodMvdOR7T0wwjh7kAETSOE9HuYcbmQVNBk832Fmdvd\niFvOacaVh5SvyDXr7ZkDZlwxSAzCk4HkKf6nEfK3EGEK4mIqM9edyM5kByJAPGmsWeZ3TGbnzgbs\n2ZPBH/5QSMOGMcDN+PkpZs/+K7NnjyAlJZWUlFTuuMOH9967l3ff7c0ll5QyfPgLtToa83g4leM1\nbdQOdR0srgDGaK1/UErVA9YrpZZprS/oU6o9mo6n4iMcHQuofpKU2+3mmmv68dVX87Es65jPAwwc\nOJJ33/0cl6sL0JtJk5Jxu+sTEbEBX99raNZsNCkpqXz77SH8/TuRmzsZIdfPEGFwDaJJZlNFjAMR\nl0KaeWVQRczlVLlYFEL4W8zz/lTtT/BC/iskINr4LwihxVLlL/dBNqLdiJDbHjOWMISsChCy6kVV\ndo3n3ICByKauD037nh29mxCSbYCQehlVx0v+gqRltqSKPAOpsoJamNc+Mz8XUtrbk+HjQrKcypAg\n/EAkXdRzkI3bjOkP5pmDpu2+iOCsb14ed1im+bch4sppi7h3DiFnJyQgFoeFWE6e5zYi2vxGM49y\nquod1UOCyzdSJSA/RoRACOKG6kJViYxM4AaczsOUlytyc0v473+fxu12c889HxEfv4TU1GZYlnXM\ngLDWmnXrNnL55W159NHV/NrTzk7XiWk2qlCnFoHW+oDW+gfzvgBhkKi6HFNd4mSazvHqszz22Eus\nXduQ7t3vO+7z06fPYunS7wgM7IIQyDO43fWAGWh9NeHhmxg1qj1z5z7ELbd0obzcE7TMR8izCCGP\nbgjReXLYPS6EpQhhNzTX8hEtfC8SP7gaiR80Q7RRj5bd27zfg+xl+BnRgiMQYpOApfR/mRnLJ4gL\nZC9VaaP1EbKOQgSOEwmCYsbTlCoBMcHMoRTRqL0Q8l2BxBc+M+OvjxDkBsQVU4ho98VUZQ8FmfdZ\nCLF60kJ9ESHgcZcFmM+vmjEpRLMvNf2nmrmnIAJEm+/uMmvTwnxOQwRyA8S6CEUspE8R4ekpqHeI\nqsBzphnHDdXmlY9YJdeb3yUWEU4RZg1bIyVIgs26XWqem0F5eQRwBUVFvzB69Iv8858zsKxMnn++\ne+X/S49V6na7K63bBQuW8tprUgfrtxScs4vWnX7UtUVQCaVUU8QeX1u3I6k7nEzTqX4ucJ8+3UhI\nuJFnn52C1h2BZFauHIbW3+N0ctTz8+cvobCwCfLHPghJGxSSKiuD1157nH79elT+MS1c+D+CggZQ\nVBRETEweu3dfjZDM3xGyOGBG8j2SBqnN+yDzaoi4XZ4E5iIuHxCycpu+dyEVRVfidrsRsvQQpwMh\n6WKE1A4AcSbltC9Cip2pKg6Xi5DlSkTYfINYMd9T5c7KMmNQSCDXYdq+EiHiLCTgWoJo2LEI2a9D\nNP+eSCXPGxCXzuWIFTIIIWRPae/OiOtIyluIhu5ACPYgQtreCOl3RjKQhiBxgVizVvURd5M3Ithi\nEYvkJ8SN1BqxQLT53AERkJvNM8WIxXUQsZa6mLHej1hCbjOPH8yaOJHfdpXptwCxOtIQYbQaEXAe\na+avOJ3TycvLwNf3WkpK/l7jXAGPVVpR8RKvvPIVc+Z8gp/fteTnT+TNN+8kOPgwDz00mPr1G/yq\ngnMepajqHAq7aN1vwVkRLDZuofnAw8YyuCBxKprOggVL2bu3LV27dqg8v9fttujevSMVFaW0bj2a\nnJxili9fRULCrTz55JeUlPyJkhKwrDvw8nLicHjh49OP/HwXEybMICnJU8Z5Lz17unjppR5ERv5M\nWpoPVdrnYYRcC6k6y+AworHnIwTSHiGo65DD23cgweOuVP2XcyDEn4rbrRH3hOe7/ggxWQiBRSKk\ntZWysvWIBXDQjKkhQky7qRICvyD++NcQi0EjAqM1QmbJiMDxZAm9StWu3O1UlZz+ArESvBF3kCfw\n2sTM2+OP92zaCkYEyXTTBki2TRriltGIZeIpS+2xGjzk2hLJyLkCsXbKzTOBSMqrl3lFI3WG3kFI\n3bMfoSniBgpDMoeuRcg8nKrU3y2mz5uQFNf2Zg32mPXOML9Nc8Rai0CC2nmIFTXa/DaP4naXMXhw\nX3PusKK42IXTWcGUKW8zYsTH5OdPZMqUXygtdZOXZ7F7t6yfv38ckyYlMXTooOMejXksVI+dHS9B\nwsavQ50LAqWUFyIEZmmtFx3vvueee67ytWLFijM2vjONk5Xnre4+KiiYzJo1ebhcFTgc/XC5NDt3\npuLldTEvvCBmerNmzaoFmdMIDy/mnXeGctll4O//HdHRQljr1mXw8ss7GTbsSeLimvDZZ35ERDSg\nVasoyss9B9pE4ud3MVWHr9+AaObxiGDwxA3SEC22i7n3eoRYmyMaZxlCZhsQrb2V+d4bIds15hVl\nrrsRjdSJGI2enbx/QITQ3xF3SRAwACFED/F5spiuN881Nn16LAIPmXvSXWORrKjZiKYdjGjRe8z9\n11CldTsQbdnXzL+YqpLeUhdJ2g1CrBYnQqYtgKcRK8Zp2vAzbVpUldvobO73xFLiEJeQx2pymj63\nIgRuIYIhgKqSIFsR15AXEjRuZ95/j+wZeM1cS0MO1VGI8PgZETSXmDXLR3aA/xPYz8UXN2Hu3JEs\nXryS7Oxi4uPHkJGxm23bWuLv78THR+IKoqQ8hJdXI5xOP+LjR1cqOEAlsdcmFdTOEjo5VqxYUYMr\na4s6L0OtlHoLyNBajznBPXYZaoMjT3fy8bmVbt0a0bNnJ55+ehrFxQkUFb1eoxxweHgEDzywlJgY\nRWqqm5kze9KnTzeGDk3i9ddXIn/sB4APkBzwrbhcj+B0fkp5+TqE0DMQ8v4IEQAHkODrzVSVQPZH\nCLcPshPZU3+nDXLC1/2I56/A3NuZqrOUv0e0+2VIds8a09+nSErm7Yg2eg2e09OEkNORE8cOIULk\nf0j8wkNegWasDUxfQxGXjD+i5bZBSLjAtLEDIW4vJNC9ybT3tpljB4SIN5p57kQIfQui0bdA3Eye\n/Qv+iIVShgi8eMQlVooIlzIkDuLZyBWEWECfmnsuRgRbhvnOY7F4fP0bTP+9EIvoACIIuiBWw31I\n7MUXcYF9i1g0DkTbf8Pck41YTD+ZufhRVXL8z+b3iDV9XUanTrk8/PB9DBr0Pzp3zmXDhhRKS4Mp\nLFwC3IFSDQkOLiQnJ5Do6BwOHSpi1KhreOmlv9C373Cuuupy4uJieOCBpcyc2QOtdeX7I4O+NUus\nH322so3j45woQ62UuhZJp/iDUup7pdQGpVSPuhzT2Y4j3Ufe3i24776+DBt2D6+99izh4ZJpcuBA\nDs89N4LExIHHtDIGDXqImTM/QogwGSGVW3E4DuPnJ1aCy7UZydDpjRDAEoQcZiCk3YuqXazRCFE5\ngJeoqg/k2Xh1F1XZQb4I6XjKQHvu8WQJ+Zn7mgP3mGt/o6r+zl0IKXtcJT+YtjxarydbZifivtqJ\nEHwHc08e4krSCNF/hhDoLYhbphTx93+BxAqWIQIuHNHsPXsUPCeZgVgvFUgcYacZeylyzGVUtbmn\nIpaG23wOQKykAKqsh5sRS+QGs+47Edfbcqo2rwUgm/1CzLj+YdrsQVWhOlXtvS+yN6IjIuAOm+9u\nRayOjojl4AlMO6v9Pp404CWIYFrBmjVf88QTqyktfYXNmyPIysqjsLApnsypoKB9eHnt4qabChkx\n4kbmzh1BeHg4ffoMZ/HifUybNqcyqWHAgLncddeT5Oe3P2Yq6KmkTtv4dajrrKE1WmuH1rqd1voy\nrWKKXjsAACAASURBVHV7rfWSuhzTuYCT7SSOikokP9/Ft99uRCl1TH/qrFlT6NAhwbTocWUU4nLF\nUFBQDqzH7Y5BSKsH0IT27S/C19fjSvkF0WyvRVIe21JVnbQC2cR1wLxPR4hkBUJa1cso344QTSuE\nqG5DyPIGhMR3INpoM4Sot1C109Vtru9HCGiXeSYNESaXmvduhDAvNW01RIixA0K0HjIdYuYQg5Bn\nHELCLRAffaDpA9NvO2R/RQ5C/J46Su0QTboVEgj2nCXghQTOfzHtelxH3kiGU6SZu+ccAs8u7UOI\nRdDUfO5l2nqFqnOMW1N1HsIViHvrGjPPUvO60XzviwjDz8zc+5h5eM42XmLG5TK/j9O8bqv2m/qS\nkpIGzOHAgdVUlb+eDeyhvLyITp0uZenS/zJu3BAyMg7zyiuzWbRoG6WlH1BREVMZM/DxCcDtbgIM\nOibJ21lCvz/qPEZg49RxvEDZ7NkfEhy8AT+/CKA3M2d+d9yNNpZl0aHDpYAXltUXgF694oiN3YWf\nXz4wCcuSk7hk16gvGzZsoaRkO0JSWUg6p9SeERdFY4TwHYiv3hPwfQchkEhEQIBo9F8jbhopMy1a\n6XaEpFoiVkaJ+dcXcRH5I1k8UcAIhJRCEE08wvTtjRDzdIRgtRnH9P9n77zDrCrPtf9be0+fYSgz\ndBh6H0HAhr0iElEELCjmGBOxQmI5iZjEL8Z2okYRDgqaqCciMYmCxCR2RcCIQayg0hEYYIZhep/Z\ne31/3M/LO6OARMSI8l7XXLP32mu9ba11P/15EFg68H8b73KZgM83dAUicM6TyCWbG4pUTGWIcy5F\nEoiLRF6N190HNo91+PQc7ZGEsNb6PwZJL4NsH6tszAqacvS/tnWV2HqXIBVbext7AN4N1YGj4+Kd\nbaEOqZNcPqluyPifjohqC0RoAiQBtUaEuw0ijO6+5gCHEIaZdk+etd+dR1Ea6elJ1NTEeeGFRObN\ne4lZs2Zz//1/pKIiHUkUL1NQUEoYRklKkrMCJJGYeDF5eTt46aWFnwP5PdnODqaa2Pd2kBDs5/Z1\nPqTz5s3g3ntvNC+OEaSl9dqjCL18+TpuuKEr9fV/4YYbulNfD/fc8zMSEnLp1+86wrCeSGQHzZo5\nFYIDl2PxqZADBKRdEFC1R14rryBwaIf8+zsjQD4LgfiPUWxBLeLQL0NA3hUBldOzV1k/UeunC97o\negfirrsiz5/u+GpfDkjb2BxcaoVk5NLqcugssfksRNJMHiJM+XjJIQmpxz5C6pM2Nl4rxAG/bnM6\nHHk8uXQYgZ3zE3xNgmV2fQJyO+1MU8JRjUA5xcZMRu6cA1DJzM62z0MRYduCpKYu6HUeg4+MdtHH\nBfhguLW2BudCutWOleFTVPy3zed4JJWssHvyoe3NSESoX7fPLhX22cAaqqoqCIIuVFdPY8qU17n+\n+nvYsiWP8vJ2yG7xJ+LxDZx0UgWPP36pFSHKoW3bTlx7bTe6devGZ9uevIQOGpH3vR0kBPu5fV0P\nqVzq7gZoIkIDTJly9y4J0QsvPMzdd99IJBLhrrt+xqGH9mTVqo2MH59CefkywnAY8fhEioo+QQVY\n0hEgOQByXHQUn8v/DQQoHVDB+n8i98q3ERHZgQzDi5BtYgjec2aF9XskUsVkIUDaiMBsDgKiaiQV\nhAj4XXAa9j0JXwqziqapFaKI+96IgNAFm4WIeNQB9yNCcAgC7YXI5vARPo+Q4/xdtO9tCGxL7NqN\nCGTLkDG72j73QsQmgqQJR5zOwevlY7Y/5cjrp9bmvALZQyqQZPAEMjIfYeM6z6pPEYHLtD3OQqql\n1vY9DRGLUjvnWLtnLezeHmX36R3b08DuXbLtx2X42IR77JzRthc9CIJgZ5lUlRPtw7HHHrbTzRkS\nGTXqKE4++UQikQjR6ED6949RWlrDsGFDuPFGHy+zp3Yw1cRX1w4Sgv3Uvu6H1BGcZ555tYkIPW/e\ny00I0e4kFHf9p5+uZ/HiD6mo6I/AZyFQS6dOTkXgQLcBnz65AKkZXJbOzohoXI44Ysd9ViP1Tw7i\nMAO7di0C0Vr778ZIsO8tkEohQMDeDO9l1B2B3xhbiTNQb0WEY4t9fgupnSqQsbenHb8Wgd7xSCKp\ntD6GIHVTO7wR+ghbh+P4IwgYu+GjrN+0eVyKpJUjEJft0kG/hwDZEcaViLN2NQ/SbW8TbB/74DOM\nOsJzGiIQ9yNAfxeBd0+be2/ryxl72yCDvouITkMA7gjtBJtLLrK1ZCNidCQykqci19KjEbHpjY9s\nHmJ7diMi/rOIx4ewY8fLRCLHUFRUQ23tJbz44nIgoF27S0lNTaRZs+ZMmXLZF7pL76kdNCJ/de0g\nIdhP7d99SL+sCumzBGfp0iRuvnk6EyZM4uabp7N0aXITQnTFFVOaEIbPXj9vXjkrV66jtNQFOuUD\nPdm8uQxf/P0CgiCHxMR8BMSXIwLwvp0fRWAzDoF2GT5C9lUEyFuQUbMXUqdswieVS0UAnYS41iEI\nVE9H9ol8pKpqiQzIBYhbfhUBaW98YZpcfFqLCnz+n1mIuDyPOOht1l8LBN6NbR9xBKQuRsBx/AWI\nE09CnlJOlbUVxQkcbXtwiK3jGKQ+qrQ+tbcC8yXW15H4iGQnXUQQxx1FKq2HbR9cRbIElOJjLSIy\nI/D2lkGI65+FVxltQm6jhyJCPtj26EHkCfWijTUTqbQWo7xDUdTS8IFw5YjAtcfnUooDzZk8+QyS\nkrYD91NfP5BRowLy8n7HH/5wJnl5eXsMDNub9+GgEfmrawcJwX5q/+5D+mVVSLsjOI8/Pq3J8cLC\ncsrKynj11UgTwhCGYZPzUlIyGDHiaMJwPVJXJCCgz0SGz+UkJr5LJPKGFbn5GwLMd1EeIuehcgYC\n3jUIOAqQO2ZbvJvpr90qEOAMtO+bkXvjP5H0MNPmUYjA9DgEYDG7thPibl2K6isR93w24vZL8OqN\ntki99RJSWdUjQLwaEbNr8EbXfOs7iqqrpSJueSUiGCsR974ar4uvRyA5AE9MPrFrJ1hf4xFxuwZx\n1qX4qmozbR5VdmwkIpr5SB3mKqKlokC6w5BBfbiN6wLFXDrterwhtwERq7V27thG5zR2FY0joui+\nt7B9dDmTchHhHGTndUbSQMzWnAz8ghkzVlFbu9zu4RjefjuN3NxR3HbbNJYta8PTT7+wW7Df2/fh\n8xLFxoOG4y/RDhKC/dj2xtNh1qzH90mFtDuCE4lEmhxvaAg477wzmqQD6N27ExMnXkQYhuTl/Yt+\n/X5CSUkNa9duBnrTsqULstqMXvo+QC6TJv0Xl156FpWVWYgDfB5xlTMRqBYBtyAQzUUqiVMROHdE\nAN0ZgaszMibZH3iJwhmPnVqkPQLTDgjQnRE7ZudhfWxGRAgEjBUIWGM2vweRJ9MyBGRvAtfbGI8i\nCWGsXe9SK3RDoNwMSTHZiCj1RMSnDwLsahvP6cPz8bWIz7Nj82zdM+x7X+BWvFqrKwLtNEToOqA6\nCF1sbJeobxGyWxxle38s4tDzrJ/WiEAmIfuI8146FhHwhXa9i5K+wK473Obi7ourivY6IuLbEHFt\ngQj2NrxkMhARyGepr//QxpoFLGLr1oV8+ukGPvigCxUVI5g8+XnuvvvPXHHFTbi2tyrV3aVa79mz\n85diqL7rnkcHCcF+bHvj6ZCV1Xqf9Zy7IzhNj49k27ainYShsHD9Tve+6dNnE4/3pGPH7TRv/h5r\n1rQBZpKcPIAg2Eg0+hgQIz19E8nJxSxevIw///l5wjABgVpLvB47FQFEEfLCKUAqkgcQCL+P1A/O\n338h4jaXIP15AgKvWfj0x6Pw/vbnIg44jjjbDCQ5bEecZyJSEbl6AI6TPQJJBKX2va391dj3M/BB\naL2sv0JEBIYgLvt29MqsQuqVnogwPIeIgrMhxG2urtLYJwhwNyIVV8TWvdnGc0brEK8CcgFm4+wu\n34M492UI4FfannXGSzAuBXYakuZqbP2bUVlMl2rC5UxyRCrF9mqLzXWJ7UEJAv96m0OGzbvGrs1H\nEs29ds8qEYHJQOqxHLy95y0gRix2OGH4ACIMi4jHT+HVVyE7+yhmzXp8r1Wqn5UY9tUm9133PDpI\nCL7m9tkH9qabFnHddXdSUFD+pfScYRhSWlrMmDHDP0dwPkuIcnN7M358Mvn5/6Rly/ZUV09j3Lg/\nsHjxSuBYFixIZ8uWbTQ0yCumujrGddeNY9y4w4lENlBbO4hJk4YwevQIzjjjFKLRt1CEbhICxHEI\naK63Y7nIVdOBQSYCiffwCdVcTeKjEIi1QuCInfMyUr0sRMFUzZEOO0QGTOdB097GdC6eW/GA5wrK\nuLEuQGCWiAKxeqHEarV4ryhnyO1s34/EF9yJ2Zy2IvA8zvqO4tVbW+y6rUgKyrT5PY9sBi2RlLLO\nxrgN+fOvtmPDECi/g4iQS6w3GEkrHfFFehpXXUvGu6iutLVvR95cc+36AkRc19t4xXjjfSGScGYi\nySRic21rx4+2e9jV9s/FWIR2H3ogb7H2iGC6Yj096Nq1JbW1YhgiEUe4T6K4uJrKyi5kZbX+QpXq\n7gAfwi/FUO0NAfkuSAsHCcHX3HbF8Rx//JHMnn3ml/KccJzMnvStjcXoU089gcrKHOrqAAKaNWtO\nEHQBJtDQUE9KSmegGQkJF1FaupwZMx5j7tzFxOO9aGh4gPvv/4jbb59Os2YJxOOpCDAbELDWI5D5\nFd4F8XYEgGfZeS2RMbPUrt2GAOFBBKIFCJxPRgCZa/2eiAiEqzYWQ5xuNt6o3M1+24KkkVNsvA42\nl40IHB0xqrW+t6JXoRQB6RN2rlNPuchrV0weJCWMQFKBS9j2oZ2XgtRi1yFAzLM5ugysgY17El7a\nCBAHDtLbu3rBLRDBKLM9dXaHFYgIdkCg3BJJQo7oFth805FKyRHFZES0r0RG9XTb9wE2jkt+5ySM\nmI3THRGHHvgCRLX4ynBOYttmv22za5fs3PcNG1wxovMt7fhGotH/oaiohpqaH3DTTYsYMOBMZs+e\n10TCXbXK6/13LzFM+FKG472RQL4L0sJBQvA1t11xPGPGnLqzFsDeptT9LCczadIc7r5b2UM/255+\n+gWmTt1ITs6JO9NRFxXVkpQ0jqqqGGEIkcg4IJH6eoF6s2YhSUn9GDp0CMnJ2QhgANZQW3s0Tz75\nEunpg1A6hDT7bT2wiqSk/ngvlQK8JLAIgWUOAtijEYCAwPcTPNh1QFzsCkQERiOudDHe02YmsgHU\nWH//i0CuAalqHkIgt8bmVoKv7VuBwMrl7T8Fr8qYiySTHKTuuAiB3OFIBeJSXDsjeQubdx3ixOM2\nzr1I3ZRga5iJwPF1fKrrfgiM8/DSzWcNwsfZb1vwKp2uSEU0EBHMZTaHpcjmsAkRj3RE/JzuP4KI\n4l9s/Fzb47cQcaq0PRhl53ZH6SMW230qRQTkWLw95l588Zvetu/r7F50RCpB1+8Im//rZGdHmDPn\np7RqVQls3gnC8+bNbCLJ9url9f57khi+jCvqnvr7LsUpHCQE/4G2L77TrjlOprDwY2AUhYUpxOMz\nee01GlUl8w9ybe10GhoGs379i8CztGpVwezZP2TAgK307VtDWlonhg4toL4+D1hKcXESdXUzWLIk\nkYqKPKSiOIT6+oE0NIwmPf04KioWAr9AL/yDiLttoK7OqQvKEGfvahYnIjXMGgQY05Fe/T1kvO2M\nN7I6X/dMmqZMHoYP6Kqz3XBJ3AJ8WgrH1RYhIO2H18V/ighA1P73QOCVgUDaJds7AxGQj5DffwcE\nbG5851VUgkD+MHya7Q5IInD1AOIovUN3++6iskPEsScgzx/HNZ+Fl0RS7LxuSM0SRdx4JeK25+Mz\niroI5Vtt7JWIoCzG22icmgk7P47UeREUN1GFiOSbdu05SGLog6SyvrbegbaXZ9ma6lH66jy8228i\nYgpa217NsOs70bz5qVx//V2UlBTSv/8KioureOKJZwBJsaeffjFZWYcxZcrCJkD8WYnBvT9ftkbB\n7t7H71KcQsJ/egLfxda40tiXrbPquJb6+hw6dtzKli0C0JqasElVs8YVz+rrISGhO716JbN5cxIv\nv/w6eXkFtGp1MhUV/Vi27HXENV6EUlK7fPLVNuoQBMa/YNu2hejFd9GwIBAAX6j9UAQYFyPA6oCq\naJ2GN9K2RuC6Ch8s5ZK/uZQWLfGqjUSkg/4jHuTftDmciYCsBeKeB9p6ZiBbxXoEoMkI6PvauHGb\ndz4C4WQbfyLibCvstxfx9ZPPQ0RqPSJqLi9Qc7xqZB4ihHHkOnso4pxdwJirg/yRzfNhRAyWIO+f\nKAoac2koPrGx1ts9cRJXL0TAjkCEIgsRpLdsP2rxBvj/suN9ENff3vq6DYF9TqN9qkaShSPCrs7z\nJ43uRUtEiC4G4gRBCCQShoMRcf2hjbMOMQBHW1//xdq188nKSgTq+H//7zTuuedhnnuuA3PnvkgY\nhixcWEc8fgRVVYsAmlTccyqfr6JO8e7exz3VCf+2tYMSwQHcVq/exGOPncF9911CSkoibdr8oIlo\n+9kHuby8jmuuGcyKFffy6KNnUF7eQGVlDlu2FKOXvCsCZhclO8o8g3IRaDkuOx8B3in4zJTDkSEy\nFYGcixFwKg4QRxhB6opkvNE2gjj2BARsY+z/rYi7XoNPZxFBwVuJiENuh4yYi5CxdZuNtx4BaWNj\nptO5JyPicx9S5XxofQzG1xlOQaDqkt45+8OHSBe/0j67VA2uQE2WjeFqKFcjwpCLT+9QhsD4HRTP\nkImIjZMA6hHBudz6+aeNvRVx9OOQasmlxHb1kHcgYr0C+BNS6fSwY85wvxwR6ZnWxz+Ruqo5ItTT\nbP61tp4cPBFOQCqzbFubK3J/ISJuxxKGEIa9aRoNHUUE73i8F1ci0Jr6+g7EYlmMH38jS5dmUVv7\nv5x77h8499zrqKlpoK5uBjU1vYlEDqGgYPnXDsRfhfR+ILSDhOAAbk4UXrNmM48/fibbtj3yuYe1\n8YM8Z87ZZGVl89BDT/DLX07j+ec/pqbmEqqqICHBpWiIIf/+D4BPiUS2If/5AnwqA5AaZRYCrIX2\n+wOIC3eRtQkI1CMIBFwitRjyBkq3PuPIeNkeAfv/4FNDtEXg8zEC31cRsC62/+sRqB2OQLYGuNnG\nc1z1OchzpgJffN6poJwKy+m9E62f0QgcX0YunwnW16l2TXukpoohItENqUlWIXD+FKm8SmyPGlcV\n6wrcYMcOQfaMEJ8oLgcRnxH2PRURhJjtew7isIfb97/ZfZlr+7IDeTk9ZHv7to2xHS+NOOO0KxN6\nKz5RXwIiTscgwpGApCMXU/BPZJNYhGwE7yJ10IO27yWI2J5t/a9Fz8XDdj8HIYJWQFmZJIp4vMvO\n8cV8ODdkSY1t2gwmO7uM2bPn8tm2P716vislMQ8Sgn1s3wTXsj09rFOmXMaYMcOZMuVuzjnnNEpK\nirjssgs544xjKCnJAaaTlLScSZMOA4qIRBYQBKUkJWUBpxGPd0CqmmIgSjQ6iG7dnO+70+XHECi+\nhB4px+G+iABiGVIxLEXc5KcISBcgtYZLv1yODMQ1CCx6I/XKcXiu1EWwHo8IlDOsRhAXuwPZG2bZ\n3NYgQvJPBOQ9kbqmAOUDSkAceD5SiWUioB2Bd4cMEDFwZTIPt/OdFPEhIgAbERfeB89RB4jwxBBB\nchlGZ9gdao8kk2ybRxIibi7NRgK+UE7E9uvHNq8HbfwYItwhMoSDJCPwuYvA1y5OQgQ6GalqPm20\nhy6avBQBeW/r07nCuiR1IK+n26w/F62dgIhQoe3RJ3gJyXlLgYijSxnuYiiSGu1Rgh2X1FhfD1On\nTmHu3Jl8tu3Kq+eb8F4eSO0gIdjH9k13LQvDkDFjrmTGjC389Ke/YerURXTpcjJ//GOBBfa0pba2\nimeffYmnnvo59fXvc+21Y4nHW+OLzV+MK+cYix3Lpk3pSLUyDF8AxUXrfmAjZyPuOY5UESBwWYzA\nryXypHkY6cCn4f3ScxHwdED65aUIXKsRIB6LAGM+Atsz8QbVSgRYQxEg5eDz6uQh6WUmAqc3UY6e\nzgjwRti8ViNVTyIigF3x1cRcmoVyPDFMRHr+gYhQ9LPfi/HRvKMRiC5CYNgMESgnmSRYvyDQdN44\nlQgwHWjPRNz/eygF9joE7oPt+Mn4spjjrf/WSGpYaWt5D5UDLUD2iD7I5Tff+iuwNT0J/B1JO7mI\nqHZF9/ooJC1ciySHc5DdZhmyh2Qh6S5qn12VukREBJ7CJww809bwCt7bqRooIAhqycxcQ3l52efU\nQnvy6tnde3mQQOy6HSQEX7IdCK5ls2bNJifnBJ555lMqKt5j2rQN1NbOp7Awk61bi/H6+9tYu7YT\nkybdxsMPzwECGhqSCIKfIw7dAVln4E+EYSFt235A27ZHWx/OW8X52m9BADwLqT42I3Byhud6lNba\nGZk/RaqQN+06x8GuQ9JCF6TWSEX67uOAKdbP2QjoFuOLvhfauA8hAjEKgXKmrcEBrzOiHocv17kK\nge4liJstQZJFM5v/cJtbLuLqo8i7qC/emyhERKw1IjjdEZFJsXG34qWEOD49dgQRFJe7Z6ytOcfm\n6fqP2p48hghYvd2nTETsHGFOtj1dj0A7EwH7AKS6W4EvLpSK1G/9EYE91a75L9unKAJ8J+XkI2LX\nOLbhfaCE3r2zyMhYBqwhMbHArn+PxMRWJCQsxktx9YhoZNiaT7H9zkNS1zM0a9aaTp3gkkv6f04/\nvyuvnmOOOYT77//jbt/LL8u4fdsJyEFC8CXbN921zBX8bmgYgl7+ztTXC4zT0zNJSkonEjkPgdZ8\nWrbM4swzj2Hq1Dk88MDfgBzCsDMCiCgCss506pROYuJQtm9PIj//FbyXzWg8R9+BpkFJ11g/J9q5\nLrdOBKkX+iN1kKs7nGjH+yCpxKUzwK6fgAD2SOsjsdEx5xLqQBN84JXLoOoioLMQt+tqFiTY938A\nv0cExeVQ6oE8c3IQZzzSxngNeVi1xatcChHhaoOIRISmhWpiCESzEHdeg0A5ilRe25Hk0gKptLZa\nnwGSzhzB6Ih3qXUG/qsb7X0SAurhCHSd9JFq8+iDd2PthVdNOdtJaPfXeVYtszmej+wn3Wx/HWFQ\npbhVqwIqKgAOpb4+1cYrYvLkHDp27IhA/1z7n4ykyMD2+Xhbq9RV0Wgyt9xyDTNn3rFL/fwTT8yn\npKR6ZwzA8OEncMst13zuvYTwYAqKPbSDhOBLtm96ClxHqOrrASJEIhVAktUzLuP00xtITASpCzZR\nWrqJ4cNPoLq6hJoaV0bSgZmiQQHKy1cSiWwlHr+Y1NTWSN3zFgK10UgdsBEB3Gj7fKP9/jBS62xG\nHPprCKAfRBzuoQhkF1g/DyIu9VO8kfMdpGrqik+bvAxx/32QameCnXsRPpPmAgR+6209L9rcVyEg\nvhZxu3mojkE6Avf2KNjtYySNPIyIwhwkJSTaHrlKYQ3IoD0QEZ45CCTXIL19aGvrgIyo/ZEdpBci\nDq585HFIijoaqYfqbA4X2nVt8UbfJNvf7sBvbU7DbK/SkGQ2FAHu0ahtxaeAuMDOc26qJyBC5BL0\nHWJj1SDj+Sp84r9UpNrB5j0dEahKpNIbgIzYh/Pb3/6BzZvz6Nt3Lc2br0MqOJfzqXFxob5ABqmp\n59HQENnte/X00y/w3HNbuPzydju9etas2bzL93LixAn7LQXFt6EdJAT70P6TrmVfJKq6F6ek5EM6\ndryMhIQYPXqs4uqrD2POnKtZunQ59fXLiUa7AX8jFkvl3HMn8emnCYgLb4WCxeKIq80kNzePjIxm\nVFWVAQ9TXb0VcYhODTICbzg8CnHmLqdP4zTHV9v5xyAAChA3OcA+n4CAE+uvzuZQi4iA42Jdf6UI\nBMciwPsLAv5lCIRHImnEFaV5B5/qIYqPAt5q8/q7zbnA5v8sPugrQGDfDEkOhyFgzrE9W4P32MlA\ngLwdgd0KG8Nd6yK2XTyFqwGcZdcn2dxcjqQa5G2Ug+wQLnWHU3O5cqGv4D1/yvDEogSptLYiAO+B\ndPLJtkchImLb8MF3gc2zs90r5y683vr52Pp4D28zCRBR7tDoezbQg1isnuLiMmpqDrGxOtv1cZrW\njG5OdfUHtGmz7HPvVWNwrqubz/z55eTmjqKwcDs33vgjVq3ayCmnVPPhh/fsfC+/LOP2TZf8v6p2\nkBDsQ/tPupbtjag6b97LJCX1Z+rUsUyaNIxNmzLp3bsLY8eeTl7eYn7844vwoFqB1DEtEbeejFIf\nd0Rqkg0sXx4nL68SrzKJIuCNIJDriThq5zPfGoGFK97iAsV+hUDf+eFfgAD6XXwxl8PsnMUIUDbj\ndfndEHd7mM0hBXn1/B7PwToC0s7GjdrxSrtuFtJDh/Y3DnHkpyGQXGR78S8E6HW2J652cyI+6K01\n4oQ74e0ZoxD4P2Tr2IqkmAQb7x68WusYRDTbItB3+Y2cWq07Ps9RrfXvQPgIRIiykerqMOt/Oz4L\n6jh8Ko9CJKU1LgiUAvzB9upUm1cnBPyNYz1uR0Su3OY73/qpsfE6IKOxYw5y0D0+wc6pAE6hvj5G\nba2IaiRShp47l1L7PRxx6tu3CytXvv659+qz4OxSql922YUA9O6dwyuvpDJ37ossXfo+P/vZDwFY\nvfrzBOKL2jdd8v+q2h4JQRAEfYMgOCUIgozPHB+xf6d1sO2u7Y2o6s55++0UqquncdFFf2TatHnU\n1Y3bef7DD88hCCLEYuuRq2Y2Ai0QgLyBuMkF6CXui3TpCQggVyGQeR2BlPN174jnch34BPjslguR\nfvlBJAW8jFRLC+389/GRrMfiJYmr8Rx5Ct54udb66Wz9unGPsnOi+DoAK+03149LwHY1ArLeSJXz\nLwRONyPO+w18ZGwp8rSptX4TbJ+us33agAC/Em9YDRGgd7F9LEZqkW2Is861Pl0BmWJ8NtHHWBtc\n4QAAIABJREFU8EZ1Rxw64EH4CZvXOtv/bnj1zzZEMP6MCHSy3ad0m9sWvB1iqd1PV7mtAV9O02WL\njSDiMBARirvxbp8uy+mHtpZNiFCVIcLxko3fg6KiXHSPBxCPt8K75CYiddSfgQi9enUlGnVr9+2z\n4OxSql955S+avBufrXfQq5cIxLx5L30lKSi+TW23hCAIgsnoaZsELA+C4OxGP9+xvyd2sO267Y2o\n+tlzmjVrSWZmb2DCzvPDMGTmzL+Qmek4vU8RF9sGeIggONR6i9ixaUjcd9k9yxDwZCAw/RNeBeQK\nxSciAGmBCM07SB1RjYLWutpvJyGA64KArACBnsue2R1FE0eQ+idA3OtU66PE5p+IrwHwho35EuLm\nXXBXW0Q8xuIjj3+GL9WYacdcfd53bdzOiNt2+YXWIHB9GQHzCNuXKCIkjiM/x+Z7JwJNB/zH4yOc\nnTF6AwLQjxCwv4fAfKXNrwQRIOd1k2HzTUPgvcP2wRHsrnji0gYRjpV274ptLs5AfBK+VkOV/Rax\nNTj7zO2oHWpzWWd/RyK12DhEaAYiwjfE9qPE+ki29RQj6c55iD1haz4SL0kuYMmSd9ldW716E+PH\npwCrdqZUf+01KC0tZ906Scnbt9cSj9/KvHnlJCcP5Kqrfvel9Px7K/kfyJ5Fe5IILgOGhmE4GilY\nfxkEwY/tt2+XXHQAtd2JqgA33ngX8XicKVPuBth5TlVVA5WV9fTvf/3O8y+/fAKPPXY7zZsPQo9B\nV3xa5oAwTEUifaYb2f4nIYLQEfEIOQgIxyNA+hhx95V2bXdEPBba9+UIoNci9U4BAu3O1v9mfN6g\nCAKNFxFAvm7XLsAXYs/Ap6xYgUDsDQS0gxC4fIw3gva2v4+t3x34KNarEEg7FU0BAv02KH7hWSSF\nPGfr34EA9O+IEG6x/Wtuc89DBGI5AkCXIbTYzu1j6wIB7fFICipFhO5k+5xjY7RDqqsP8SqbYrxt\noA1yaXUCvEvxfTLi2IfZPh+BJ1pltk8z7fqBiGC5EpghXrraZPdsto3xILq/Lq3H7TbfpYiIukSE\nTk3XGtli2iAppAwxEXNtnookTkxMIzn5EB54wKUp+XybMuUyZs68g1/96moSElJxebYGD+5DLDaU\nVq1GE4uFQISUlAyuueYCK626//T8B7Jn0Z4IQSQMwwqAMAw3IGJwRhAE93KQEPxHW2Nd5yOPjGD6\n9Md56qnneeCBrfz0p7/hgQe28swzr+4UZ885J4WxY3Oa1HV1xKKgYDlSa3yIwM7lANpOU1dCV8Yw\nhYyMDYiTuwtfNWsrAo509MK3wuvBW+FLJjZDgDYLga4zgoJUNC5ddQxx1skIjE9CXG9X5G+ehi8n\n2R5fF+EjfDH2Brz/vKtB4NJXu6LuPWz8V62vc+y3KUh98QkCrBb42r5P2F71wOvz47ZnKTbWnTbv\ny/GpIVwSvmxEOD7Eu8imIC+qJQjYe+OL1iy3OfVotG/vIeLgPG5KkTSA7Xkdsom4ugYLUBnOfsjz\nqRdSwyXj7zO2j3n4wK538NXWTrd1D8LblqKI+89BxCwbEdyP8UZqZwtxxuSGRp9TEUEtRUT8Aurr\nA2prL2XixOn07/+93XLujZmidu3OIi/vJV5/HeBBkpK6AUvIyLiFkpIagiCgtLR2v+j5vw2eRXsi\nBPmB1w9gROFMdKcP2d8TO9h23xrrOl988XUWLUrnRz+6m/Ly1UybtoHy8nt5+eUabr55Og899ASz\nZ99Np06tAWVX7NGjE/fe+zI33PBrsxG0Qi93NT7zZQuU+TIZAeKnNG9eSnJymXFaa9FLfhwCyN52\nfXPEnabiUynXIDfJfyBO2vntt0bgkYDAajoClKHITdIVoOmCwCsTRaQeiwjBenz1rlbWr1OhbLPr\nuyIjpasS5lJVuFKQ4xGQOtBcZH8pNk5PO68BcdbvIxDvisC9ccRsJ0SUuiDOeRO+6MutNI1tyEB6\n8QftmjeQ7SULqZ2GI4nkQ/TK1eEBO9nW3B24yf7H8dHEbhxnC0lExLcP3n6TYv20sPk4e4eTjrbb\nvFJQVbXGacCX2TVjEYT8j+13Bt5RIAs9U1vsXjXHGa6DYCMtW6aSlDSQrKx8oJ60tGJgCQkJ7xAE\n7wKvUlKSw8iRx+6Rc3f6+7y8Z/jJT8YSiYhAqbre+ZSWLubRR89g+fL1+03P/23wLNoTIfg+PmEJ\nAGEYNoRh+H0kwx5sX3NrynkMYfz4X/LYY1uIx2dSWdkDKKOhQYm7kpPTdz6MTmS94oqfM2DAmUye\n/Efq6/tTVJRqlaL6IU6zGwKnVuilfRGB2KFAhNLSjzjssJ506JCNgHELMuy5fP79EHhFUQyBS/lc\naSuIWL/pSMJwRU4S8EXQ19r5E6zf7ngjcEsEthPwYJiLJAns2A4EYPfaXFbb/H+HB9LR9rkjMnjG\naRox2wkRoHdtT8ptHhEkbbi8QhVIAmmGuPlSG/sBfF7+KALfiH0+y+Z5Bh6w3Z4cYftwAor87WO/\n1eBTY7vAtJa2d8+gmI8BCKhT7HstPtV1Aj7rZ5Edw86pQ0RovV1XaecfamssRMTZXR/a72ttX7rY\nsajtlVtT3H7bYeeVk5q6mLS0T4hEelNcnMGkSZ257bbT6NQpkUgkCziWhoZswrCaaLSIMHyAOXPy\nyc0dtdvSkU5/H4lEGDZsMPF4Av37X0c8HmXYsCFEIhHGjj2d559/aL95+H0bPIt2SwjCMNwchuG2\n3fz2xv6b0nen/bvGpaacxwQyM3uTmdkSCIjHo7RqlUwYJtCp00RKSmp46aWF5OaO2imyzpu3klWr\nNlBQEAHuo7KyM/F4A9LLj0Jc48MIPJehXDMP4oOJKlmxYiNr1xbhi6i4aF7HZbdG4Owcy5YjwAls\nDKdKeh8B5Uikd3eGy2Z4Y7Nz06zHu5hGUPRuAj7L5+/snPYInF0WzZj9NcOnwFiAJIezEehWIyBr\nbGhejohhGhKCE5He2yVlG2bXbUVE412kukrBF6ABcdcn21xvwxd7L8An6DsHcdKlyPCcY/fDBXMN\nQWBabdfH7X8J8uqJIe47Fa+qieGJ4kAE5jFkQ3kNST/v4SWDljZeF0R40uyczvgyoC4tt5PgeqH7\n/byN09n2wxG7ROAqgmAgSUnJtGqVSHV1MlVVg4jF5BF2//1P87Of3U1+/lYqKtoh+4aqqMVislVV\nVcXo1Uuuoe59cWrQz+ri/5PePQe6Z1FwIFi4gyAID4R5/rvtqaee59JLX+DRR0fsdYENd03nzgHr\n1uURBG1o1qyC8vJ0unZdx8iRx5GVlU3v3jmsXr2RHj06cf31C9m06U46dbqRQYN28Pe/R5H4fjnJ\nyQuprT0Geaw4HfSpSD99HPB/qLhIT8T1JyPg/h3yJ1iMuMr+yGj8Pt5fPwOBlitYcxJSe5QhoHD5\ngCYicNyEQOdkZB8oxwc1Od27M05uR8TpOOQJk4uMyRmIa1+PgO0VPNGqRITgRMQZt0RSj6s3MBx5\nJ7VFoPxzVNQeBP6PoiC7520f8m0dQ5Dd4GJb/zCbYyYSnh+y+Q7Gq4YK8EbUM20fo4gYn4Oijd3e\nLLF7sgY58h2F1EVVNofudn9csNprCFDn2FpdHMQG62eJjbOm0RzvQ3mFdtjeOBuRk4RqENi/Zn2M\nQVHd2xHhykEE4AnroyuSvBYhInokSisxDzEblwEFdOhQRN++nXj11WTkKnuF7V07kpIKCcNsotFi\nRoxoSevWLfj974tp06aabdv+j549f05x8UvcdttkrrjiYg62z7cgCAjD8AtFk4MBZf+Bti/GpdWr\nN/HII6czalRbzjmnM+eck8K2bY9w1VUdWbs2kWHDhuwUl2+88bImImtpaQ0lJeVEo9C370+IRtfS\ntm07xB06o+G56OV3XPL5CEg+xqd6dhKA+38SPoI1QGCxEb3Q5YhzPBwRmfaIO823/kbbNWsRoLp6\nxx0QQWjAZ7AcZOM49cVhCFR6IyLS3n5/2/p5H1/dbBMCXxDheB9JPs0QSKYhr6A0pDJyapBD8BJG\nY9XRLxHYxW19zgXyUJt/BpJ8HrB5tkHAXWL9bba/cmSQPt7mssz6dtJCIiLQz9l8+yM10N8QVx7a\nelyJy3dsP1wa8P5IIsizMR5ENpgNdi874YviJCFPsL6IQNTZOVfZvJcgIjcLX386xfa0E3pGXAxC\ne9vPRHwaCaceOxvnsTR+/Ejatu1ANOokDhW9j0RWkpi4klatKqmpyeKZZ/7FI49IDVpYqESCW7a8\nSVXVUWRntz6gXTe/Ce0gIfgPtH0xLrmyeg88sI2xY0/j+OMHkZs7ir/+tYK6umeaEJV4PM51193B\n739/Gmee2ZZHHhlBRUUtiYnFjBzZhjDswbZthTRv3gYBgcshsxKpRnagF9MVphmI11WPsxm1QdJB\nV7wRsQ0yYoLAuwVNg8Gqkf77RQRCL+OjcGtpGuA2DAFcJiJYqxAw/hrZKMB7rrgAtlzE4fbFB069\nj1Q+OcBPEafsAuFaIVVNPj5H0AW2fmc/SMQbR0sRsDqXx6itPQevhnIxFf0Q+PZCxKjG9jcLcfGV\njfa5FIFvIpJcViFCMRJJE6HN1RGlEKni+iKvp/cRMf2HzWsKkt764jOdOsDPtn39yO6NS2Z3FyJs\nNbbu7iheYwg+xYQjiF2Q9NAcn6Zjs83LeT+9Z+fUIGlrCyIUSlI4ffoc5s//B7HYCwTBSlzpy3g8\nTmVlQH7+GqQy6kcYyhDc0FALbKCqqgfV1dOYOHE+OTknMXXqIsaMuXInMThIHPa+7SmgrDwIgrJd\n/JUHQVD2dU7y29a+rHFpV5LEtGlPcswxA3ZJVP77v3/Dpk0DePzxZ7j//k1ce+2dbNkSpaamkvvv\nX0M8PpNo9HBKSz/F56pfgEB/EPLv7gn8BIHVOgRuCxEXuxiv/09GnjG9EJBORuB+L+JIk5AR9F0k\nHfwDcfyuwL0z1nbFe/Q4u8NtiLMtQyCShrxy+gDfs/Om2NiJja51CdEG2nWJto65+Opq9YiwpNnY\nDyNu/kNEqD5CILoNqY7et37/antRY7+tRkDu7BnJyPPJrUvpFTyQt8Ln429n+9TOrq+wOfTCp+ZI\nsd/7IWC9Fr2+hYgT305TaS2CCNMEvJ0lBXkHhbaXTuorRERqFQLyl3FRwD7G40F8zqOLbBznclyA\nJIDr7H8f9NyMtDm3s/vd0+aaAIwgObkL6elJVFWdQCTSjoSEVjbulUiq6W9/g4HNxONRkpJcau4k\nUlKkNiwurqaioi21tfOZPz9GTs5JzJo1m6eeep57732Zp59+gYNtz21PxuJmYRhm7uKvWRiGmbu7\n7tvc9pXDaHz9lzEueUlCqoqamhi33HINp512YhOicv/9vyMlZRBTp74ObOLZZ+PU1k6nsLAb27cr\nuCkWE4deW5tkvbuykctomoYhgrjHW/A+6zXItfIYBLKj8Pn0UxEgZSMwm4I40QLEtbpkZk8gUM1F\nnL8rYbge79o4Gp9euQABUXfEbX6MwCkLqSlaI2JWY/N2NYQXIW+YDKQaqcCDZRKSgL6HQKpx4Zls\nO97X9qc5AvrmtgYX4BZF4Flv/xfgM28+jQjWUJv7dJtvaOubjggQeNtBGuKimyMJJkRg+J7N8WE7\nZ6ntX+N0Hj1s/89HqrkAgbYrjvOSzW2xfT/e5tNg/Wy14+2QTv9IJFk4SSKG0oE8jiSituiZaW3r\nXGrHz7T/1yFJ7ieI2H9g90SBa7W1iyguVj2EeDyX+vptiPgGSPpqSSTyHtFoJtHoDuBV6uoy0XPR\nkpqaZejZS6SkRI4EYZhFWVlrJk36DT/60d3U1/dn0qQ5B5xf/9fd9lo1FARBmyAIctzf/pzUN7Xt\na+TgU089z333beDpp1/4UgnrnNRQWFhJEFxIYWEFQRCwZs3mJkRl5MjhXH31+YjDvRoHfOnpLUhO\nHkjLli1xrojxeEhaWkdkG2iFdNwp9vu56KXcjtwdQaAyDIHwBhQhugpxxb9BQNQTcZl/RXriZgjA\no4hj3Gi/dcMbg2OIA660vvKRmmQbUuW8hzjNUxAAOfVIFHGszyNuOYo42lTEkRbavLMRUPex38bb\n9etRXMDl+AyYDvj+164DcdBrEZHIQ3p/5/LZwcY/3K77xD7X2HljaFoPOLS1noTUZAlIegjs+x+R\nnQJExBwBdgQsFQH/QATaLtOoy9LqvHo+Rt5bK+2YC/RKRoT8YfSMrLZjdYgodEL3d4XtXwQRlz52\n/mA7LwlfmD7ZPndEksgQm7+THF0yQGyvGtD9dwF5dfgoZhfP8RbxeDEnntiJ2tr3+d73jrcxVRtD\n+z/f7muMaFSxJw0N0KxZqrlU30dhYQplZRXW/8G2q/aFhCAIgrOCIFiN3pjX0dv/3H6e1zeq7Wvk\noLv+xz9+gbq6GUye/PyX4lBmzZrNVVfdSvPmpYThbJo3L+PKK2+lVavUnURlzJjhlJaWEIYQj68i\nEpkKBGRlfZ/y8jomTRrCiBGDSEwsJDV1KZHICqqqtiKwuBBv0OuCXrRXkWeOcy+8AK/u6Ia40+5I\n5dIJgS/opcuwc7oiUDwbAaqL5t1gY41CL/iP8JW+nP7/KKQ3rrRj2/Ag5FIwO7tFOR4YE1E20qMQ\nMHVGRLEBgWUSMqweatc7420tAm5X2ex9fCqLY9FrMAhJMQPtmmo7dz1SH0URgRyGvLM+wdcCcLaD\nd20tzRE4ZyDQjaI02k533xypSTLx3D7I8DwGcfTJSEWTj/ImpeHtK/faWlsi1d4JSIXnUnREEbA/\nb3vV2AnAFe/pgqSFM/BFfybbuG4Petn630GE9QGbRyd8EB8I+BsHutXiVWl98W6wO4AuBEE32rTp\nQCQSoaDAxTKMxROec63fIiKR5nTqtI2GhlqOPvpQ4nGtIxaLcP75pzNx4gQOtl23vZEIbkVPyKow\nDLshlmzJVzWBIAhGBEHwSRAEq4Ig+NlX1e9X2fY1cjAMQ0pLy9i+Xfr07dtrKS0tY+7cFwjDcK9V\nThMnXsSMGb8gMbEjECExsSMPPPALLrvswp3XO6lFKaj7ct55ufTsuZIhQ5KYM+dssrKyOeSQPkye\nPJSEhKGMHNmfIHBVpCagF835kH+Az61/GOJO/4gem/PwGS/zEVCkAdcjjr+79ely5ixGxCYHr4cv\nQ6qAIgSKLs9QAwJAUE3h9fa5DQK2HKS7fhepYmJIZ55o88jCR/5+D19I/h4EatPt3A4objKKgLAd\n8o750NZfi+fyk2x/uuPTK6Qi4tDZ9qKfrcmlxcjAq9f6IQL4CQL1AiQR7EBxE3Fkuxhq++R88gcg\nYtIVSUWliMi0QJxxL3zm1cMQ4DuJBnw9iO/beS64LUAGf6cavMfWE7f5/wTdxyxEmPojia/U5uik\nuzpbzyxbX6WN8SKSCpZb/26sOHI/da6z7+DzWTlPsnF2XglhOIS3304mJ+ckli5dTyTyuj2v5yCC\nssLmmUpSUgHNmpVzySW5bNxYQCQC/fpdS0pKAlu3Fh1QAV5fd9sbQlAfhuEOIBIEQSQMw9fw1cj3\nqQVBEEHy9+noiR8fBEHfPV/19bd9jRy8/PIJnH/+CGIxgOuIxUIGD+7Lm29mMXfui3utctrdPObO\nfZGpUxeRk3MSV131N8rL25GX14u6uo384x+rWLeunK5ds1m69H1atkxm9uz5/PWvFZSX38c//lFN\nENQhbvt0xMGHKGK4E557a43Pi78EcaR9EfDdjrjdT/A6527256SLo+24A8d0fFqEMxEo/x3vjuni\nBXbgi7CA5yQjyMfeeTzda2uIIQnGZb58FAGbK8r+PJJEXsEHfxUhUHrVxnHnpiLwdfWCJ+DdWZ1k\n9AaSGuoQR++MwU66cJXPnPtqlu2ZU6+5FB0uN0+AT43hchs5byvwrq31SDp4BwXV9UEEu4XtjQuE\nS7MxJ9o630N5kLbZ5zft+nX2e3f8s5CI1H6HIntQCZJOZqLEc+8j4D8E2R962FgfomBERxxeR2q1\nFbaOh2yf8pDasRQ9Z1V2zg9p3rzEfqtk/fp8GhpycMReCRFHIBVkgIjhIaSkpPHrX09i5szbyc3t\nRWJiMb/+9ek8/vgoDjmkDwfb7tveEIISq0ewEHgiCIL78TkD9rUdAawOw/DTMAzr0dNz9hdc8x9p\n+xI5GAQB27YVk5xcRNu2qwnDf7JgQT7l5UMZP/6XXHTRH/da5dR4HuPHp3Hllbdy002LqK2dT0ND\nZ3bs+BTYRkPDduAaKis7Eo//mkceeZW7717LsmUfNZFuWrbMIhp1apXOSLXjVEUbEYCdj8/70xyB\nUDt8aupfIGC5Eb34mejFf9v+/oRA4UgEXGehR6898ibZjLjcFYjIZCGXwf626kMRQIFPftfKrstC\nRORcW8OpNubNiDB9iA/+GmZ9VeFzHnXHl5hMwXvIpCP1TDIiAJttbiuRJNLF9qrOxk20vWmPVEfY\n2K7ymUu5UI6IlyOwCUjHnmT77AzYhXZeDKlCYogofmBjun1OwXP9ztaywubxpq0xDYFoPhLuXXrp\nuJ3fDZ+Ce73tx5OIaLp9n4AkMafTd+mlj7Nrn0TG4ky840Bga4ngbQad7HgP5Ko61PZJKcqDoA9w\nBgkJHUhJGUC/fkkkJiZTXx8C3yc11ZX4HIXiVVLQczKNHTtCvv/9n9GhwzCWLk2ipuZJbrppETff\nPJ2WLR0hPdh21faGEJyNFIPXoifD3YWvonXE5+EFvW0dd3Puf7TtazWy3NzezJ59KVu2zOe668YT\njcq1LzOzN82aKU3E3qicGs9j5szbmTHj5wbqT5Cf/w7xuHPZzCIS+Smx2DLg18RiA4nHZ7JgQcB1\n191JQUH5zhTVkUhPOnZ0roETkSePi+Tti4DHebCMQuBfh88p46pZ/RYBWzV60R2BcaCXhIAihsAx\nhg9S627nuNrFASIuEcQZjkSPyrs2l4sRyG1AksRyG/NBBGwVSH/dFnHbuYgYdUXqE+e7vxAJuFtp\n6rZahrSgFbYnCfhi651s/Y8iqeEkm2cZXoqJIIAagwC9EHHX5yJVkFOBONfS3gioF9nvRyLQLkRA\nucrmXo2PVsbGCm0el9pYzfE2jCgCzFfs+4M21hpbyz14VRd4g7WzuySiZ8HVgYghYpxu+/gR8gAL\nbX8utPuShCCj1Ob7tq2vsWHc5Z4KgMUkJpYTjabQv/+1lJfX0aLFBj788LdcdVUnysvL6N//Oior\ndwC9aNkyIAg6IELj6m5kMnr0qdx//80HdAK4/0T7QkIQhmFlGIYxSzj3f2EYTjNV0dfafvWrX+38\nW7Bgwdc9/D63XSfHup7KynqqqmK7VTntzn6ghFt3E4/Hyct7gfbtnyUMe+30rYYGIpFa9FI6F1BY\nvXoxkQjMnn3mzhTV48Z1YeRIl8FyLFIZOHCegXedXINA9QoEDi6nzJUIGDYijx1nVxiGV+OcZ5+r\n8LWAmyFQidg1HRGwFFjf3ZHQGCIwboeAfSjyrU9EgDwYccAOxKN23nS8Z5IDu1oUl9DedtIVQzkC\nEa0VeG+cmUgt1RcRikPxBs7XEDin23mHIkI1xMauQ0BZhc9mGkXeUumI4BVYP644jYvorsJLMvOQ\nnaLc9nAQ4vRnI8nsWLxH1O+QmsfZCBKRSu90RNQdQQ4RwXApoqNI5+5qTXS1zxfYWjci4lSIpKLG\nUmELZNtwfV+Mr2q22n5/CC8lfYCkrwKkUowAPUlKOoaGhmQGD97GBx/cQ+fOH7NtWxY33ng3WVnZ\nXHJJf8rK3rX7MZOKipYEQSGSSpSbqqoqxtixw4lEIgd0Arh9aQsWLGiClXvbEr7ohCAIxiArkVPG\nBkD4FcUSuPBM1zrZsc+1f2dR3/Tm1DtjxgxnwoSfAjB79l3Mnfvi51ROzn5w2GEv8PbbH3DHHTdw\n0033MHToITzwwFbS0v5MPB5QXZ0FnEVNzXwkxLWnoaEZycnV1NZmoxd6ONCfc8/twrhxSgr3xBP3\nAHDHHbPo2PENduxoQ03NZGQsdN5BrmjKP9GLuxlxd6WIE92M93ApwqsFsN+XIPBegABmMFIpPIsA\nbiMCtzgCrcV2/H2bw0l4XftWxGmPQxy4M0C6x3EcvvbBxTZ+jc3PuchGkPSwAw9gMQSIdYhDX2X9\nOeJyCIpWPsPW2AWBrvNySUa66gmI+85CuviT0aszyPapwq65EQGlq94FTdVFnfHeNkkInCfg03D/\nwebwHALbTohAp9m+fA+fzsPlNXJSSBYC9WNQhHYU3ctqxAgsQLaPa2281fikfukolmAgSnNxMQLi\n9xDROdv6b2fXuQL2LiDOGYtn4aW+ZuTknExR0WssXVpEUlIu8fgJwGjuv38u9fWPkZERkJFx2M7+\nYjGXXK+WIMgnDOeSmnoeV155K0cfPYBHHx3DmDHDd/lO7ak5BuvOO//7gCQeJ554IieeeOLO77fc\ncsteXfeFSeeCIFgDjArD8OM9nvglWhAEUaR0PQW94f8Cxn92rG9r0rk9tVmzZjNt2pPU1w9i9erb\naNfuvygoSKV37zWsWtWTxMSPqa3NRNznWJSOOAGpOgYiL5EZ6GV0Irhy86SnX0aXLtuYPPkCLr9c\nLnV/+ctzXHDB3cTjNYgj7UTTRGbvIM61PXrxWyDAPgGBWTME3DvwBeAdN3ys/T/O5pODktlNRKqT\nSfg6w79HSe7+iQf4HBScNRqpgrKRb8Ebds6RKBDOAU4FAsk++CynzpW1AgFlKpJwTrbPlQh4VyJg\nPM5+74GAsSMC+B8i28MAROCOQqqrNvY/2cYqsHFDpJb6P5TUbant2Wrr+1V8QrkeCFBdIZtcfCI+\nB+aHIw77Yltz3O77sUgCecY+L7Z+2iEi/Boigutsjp2R9PZ926NSxCg8DPzA1vIsCgh8w/ZyGd41\n1wUCXookld9aH2W2F1gfx+KzkxYjSacSST/u3G5EImvJyKigrMzdvwUo59JzQMjIkUPMW/PLAAAg\nAElEQVR5660aduxoTUJCAZFIJkGwg+zsgLy8ZsDvyMr6CTNnjtipOt1V+yKg/zKJIL/J7atMOpe/\nP4gAQBiGMZQk5kUkkz+5v8Y60JpzWS0s/BgYRX5+PvF4HmvX9iQen0ldXXf0wuThom9btiwjIcEF\nTI1AYJVEUlIfJIYrqKlVq+ydelMX4zB58h+JxweSmtqWIIjhg5OS8QXs19jnTPuLIG+RVQigD0dc\n8SKkItlsq1mCVC8f4AHgMiQJ3ICAPp2mHHGDrSMDgcX5iOi1QtzpPFt/f6T3Pg1fIyEbAWcRPvdP\nLr5eb0/02EVsTi4grqON6VJAu2ybdUivfjICwW34WgMLESe8CHHZ/0KEYrXt/222h08gEBxsfYd2\n7RH2Pce+u8yslYj4rrQ9bWl/TtpKRHaTPsgj6yUE3MMQmA+1cYsR534IIjon29jd8JLMBTYvaJr+\neyw+S+vDiKgcio/eHm3n3okIr3MtnWJrx9aUbnOttHUGtq5Ku1f3Eo+3oaLC5STqb+vZYecn8txz\nG9mxYxnwEgkJLTjiiBIGDYoRBFsJgkTgWoqKarj22jt56KEn2F3bnYfet6HK2L60vSEEbwdB8Kcg\nCMYHQTDG/X1VEwjD8PkwDPuEYdgrDMP/+ar6PdCb02vW1+fQsWM6YdgVuJp4XEAQhimkpYGCbn4D\n5HPppQM46qgkotFEguBCgqCYIMgmGu1Eq1ZTgWRSUsZ9Rm8aUlZWYRkd76O2NpswrEOAraCgIUMG\nkJCQgl52pyoZjICwKyIKXZAncAc7/iACDpdrf5ldcy5SIX2EpI0QSR8DEXhegAgOSD1UgMCgBAFZ\nTySNpFs/aXi9d3sEWi0QwC20cQL73B9JDyCDenNEIGpsrjMQMXD2hC3oFTkFX5/XJeRbgfeGiSAu\nv9DOWYQAc7mNG0XuuJ0b9e1ca507LdbPsXg31CIErA9Z/9uRBDDarn0bX/azo+2BSy3hjNrZNv8S\nRIzetN8SETcP4vidt9jH9n21zeEDRPhG2RgP4dN6fIKI6Hbbj8D2ezF6dlyAWjIyrLvU2Sfa+M4j\nKSAa3Ug83kA02gXvhfQ2YjA6EoZdSEvLBt6jRYtyVq7cxA9+MJrjjjuCVq0qgHtp1aqS448/YpeG\n4S8C+m9DlbF9aXtDCDLR3RuOnoZRyEn5YNvPbfXqTTz22Bncd98lpKYmkZk5g1gMMjMvJDU1gZ49\nMxk1Cm6/fTzXX38Ec+e+wsiRJ3H++Rn8+c/f589/PocOHRpISHiTqqpy4GxqapqTmLiE2bPnc+ON\nd3HZZRdx3nnDicWU/yceX4Ze+NHohf+Yd97ZSkNDKXrpXXnJeejR6IiPpnXcfBUCsVX4nEODETi4\n9MU1CJSdV8oixHV/gi8PeQrieMsRKB+BgMgFqxXjq3AV4ZPApSDC0s3Ouw7PARchtVMJkjA+QuqX\nONJvO0+ZYxERapwGoQFJVfVIndMVAWAcgddRSFKYZHPoYv07t01nk7jU/tfatWfauJ1sfcfj00Y4\nwhsiItcNH1C3za53leTS7XfnYrvO9nImIhh34uMMypFxeY2taaKtM2ZjZiDC6zKyVjW6x45YDkOR\nzMfZXqbS1LaBzemfiKAssfnNtP1YD2wmK+tiIpEejBp1NBkZjjAmkZycCnRAOS6jRCLNgAQSEjpw\nzDG5TJx4EWPGnEpdXTb9+19PXV0WY8acukuVzxcB/behyti+tL3xGvrBLv4u/aLrvuvtq0iB6zyN\n1qzZzOOPn8mNN57FDTd04cYbT+Lxx0cxfvxZ/PWvs5gyZSJHHTWYwsJD6N27C7Nn383bb3/A2LGn\ns2nT6xxxRF9qalRuErKpqUniX/9aztSpi5g37yW2bt1BJAJ9+75tHFkOUi0lIDG/DVIpDEJg9C8E\ncE7XPs9m7PL0JCMwa4nUEi3xnHA+ApLtSEddjjjILghEhyIOdyjiUCPIPlCLTwpXi88m+hpSMYxG\nwFdvx+/DR74Gdk4qAtB6ZC+5CnkERWw9yxGhWII45CoE3jX4NAgFNtdifAGWLDxYpyKiFUXG5Jjt\nTbHNfxUC4Hw7vtD2x+Vicv1MQuCdZmNvt/OGWj/9bCyX0sG5hS5GxtztiJA4IlaPJKBiBOCVyI2z\nOVI9uepjrZGKzxHWfkhCcbEOY+1/f8SxP4mA3XlhfYA8zEcjoK9Cz4RTR4HzOUlOjpKQEOP009sy\nZ87ZrF27iXg8Sps2PyA1NZE+fVoydGgSiYnpDB26jepquTxv376OZ59lpyH4s/E9u3r39gboD/Qq\nY/vS9sZraNouDpcCb4dhOP+rn9K3ozld5OGHv7jPRidXg2BXrbFRWSLvL/jJT25n+/aBFBdP4emn\nF1BTk4uA4ofAO1RVtSMxMUpt7TNcdtlZNDRsIwi6ceutP+LOOx/knXeS8WUlr0Pqj4dQxa6XETed\nhkDmHAR47yLC8AkCtVnAJUhFkoFAdBziSNfZ/w7IjtAWGUrPRkQlwNsHmiNgwf5fi0AlGxEKbLwz\nECi9R1NbQwKKHnYBXyAwfRAFwr1jc1uM7Bb5iNOebfPKQISvH/Kq6YLP2bMZga3Ll9MMgbSLkShD\nRM/lNeqCuOP+CGR74OsUDEFqnTEIjO+0vtbbuM2t39/YNTF8zIbzXEpBhK8z8ghyMQljkJonwY7P\nREZiZ2z+xPYl1ebxMMpa+iFKzvdn9Cx8gJeqSvDVyxyhaYHsNj3IyHiLioqjCYKtJCS0ob6+BKnV\n2iPpI4ns7HSys6Pk5irqd82aRCZPbsddd93HFVf8nHnzimjR4gTq6m5jw4ZraNZsA0VFbxGPJxGL\nDWXSpOdo1WotkydfsDO+B9hZyvKz715jb71deRM1fs++DYbif6ftjWooBb3Nq+1vIJJhfxgEwdT9\nOLcDsn3dRqemIu8TrF//IrHYEGprp/PMM5vZsaMNlZUNuOCvIOgE/IOysjbAIRQX1xGN9qSh4Wwu\nvPCXvPOOc+d0xclH4IN+QgSOjgPuis8E+WskObjsk043nILA8izE0VYj8BmIooq7IxBxaSIi+Kpl\nrsxlDuLceyEwKsLn7D/e5nsBAnvHBY7GR8+ej7hcx/02Lq7SGQHYPUjKKLN1NUMc7N8REViCgL+D\nXf+R7YVLD5GBpI0ipKZ5BnHeLu9SB2Rob2/9uyyf0xHw32D9rLE1OFXcp8gY/IzNfQu+TkIJPjeT\nqyTXB4H/Bvv9XbwR+wg8cEcQMW+LJA/nqbTB9s+VBZ2Ar1TWDk+4WuMzmbraCFtwnmkVFUcAeYRh\nF+rri62/LEQQZwL55OVt4/33C7njjv9lypSF1NXNZ/78cnJzRzFkSL9GwZIBaWmZjBs3gtraWurr\nWwCbKSjYRFlZ2U7O3797C+3de50BA85kxIiLmxS63x8F7A/0tjeEYCBwUhiG08MwnI6Uo30RKzh8\nf07uQGxft9Gpscjbr98yEhK6UVqq4O+CggQU7OWDv5KS5E8ehtuRbvc6ysoygSeNa1OUazTaFgHg\ncAR8rmJXBQL0Onz06CYUd9ANcZQBXk2UhsD2f23GA5AKIxGBb4gvaO+iYFdanyMRMVqFgMQlX/sA\nn/dmFgL4D5B7p5NS0ux7JTKQvoeI2+X2mwuO32BzWIuIQIWtYyA+jiKKuHMHsl0Qp74aqT4ybW+c\nfh08IeyLCN7r1l8P+94HAbhTTbRGRLIzAuA2iEPvY2O4eIKBds6J+Eymi/HSSB7eHtPV9ikFSQPP\n238Xk1Fm96jKjkdtvBF2fC0iHuDVXg+h58apBTcjAu6iiR3TkIQ8s9rb3C7BB/+NRFLXCcA5VFQM\nY9265TR9XyY0UeUUFCznqaeep7Q0RM/lNOLxNIqLy3DaHffuFRVpv4qKqhgx4hjeeCPrS6eO/660\nvSEELdFb6Fo60MpcP2v3y6wO4PZ1GZ12VeRmxYp7ufrqwdTUNBCNfopexs1IpbAWqKK2No+mkbOL\nzUD8AXr5M4DTicVc/vbb8B4yi9FLfjJ6DDYh/3GX5sABn+PkdyCwXoh01osR0F+OAGqt/S9EgF+L\nwC2OOOjLkDTgAqMCvDTRHM/ZJyGu+TQEyiPwEc0nIu46GV8ruBiB3isInLojVVGlff8UH+A2Fl9M\n50H0OmxHnHEEAVpPFF17GP6VuMD+f2Ln9bE5Ndh3lyfoLNu7LXbO3xDHvxnZZCbiU3g7Q3MvpLZx\nOnxXfKba1uIMrlH7/jySnEJEEO/F2wBaIKN9BBG4B5CkshgBfXsbfyge5N25Lez3CxFxbWXnjLOx\n7sN7dT1rcz3G1jbE9nYjqj5WQ1LSYRQULN/5vjTW2c+efTUjRpxMQoLLoCpCO3hwv53ppR966Amu\nu+5OioqU7G/HjmqmTn2Sioqh3zl30H+37Q0huAt4LwiCR4MgeAzJmncHQZCOFMYH22fa12F0evrp\nF5gxYwtjxlxJSUkRY8YMJwgCsrKy+eEPDyUz0+WK+RiBfi3izNoTiaQ1SkXhjJanI05zIKo3fCi6\n1S4X0ImIw8xAXGcX9NKfhkAiA6k1XkTqhnR82cM0BOiuMMltCAhn2vEEu8b5uTvQPwuBpZNKzrIx\nL8WXpDwOqRvqkXTQArmEvoU4+y2IGP3MznfG6ysQ8UhA3O0LeJDOt8+bkCH2XzZfR3R+afPujwhW\nAQKn5fhI3jmIYMQQocvHG80vsDE/RhJJsa3TJUZzBuZE28Nt1v8nNqd1KKleN9vbEuvfZfJ0mUld\npTnnJRRHz8A4BO6u5vF0pDpbjlxMo0iyesv2shwB+UZ8DYgfoOfBuZFuQwzHQkRQXVnTV22cSvTc\n/IkgOBxffOZtIJeMjJ7Mnn0rjz9+FdOn/9/nVDnjxo1g7NjhxONRc4seT1JSEjk5nXYyWRMnXtTE\nnTQjo4Tk5NbAhO+cO+i/2/bGa+j3eCXlPODYMAx/ZzmI/nt/T/BAbPtTF9nYBlFRcTrz5wfcddcT\nXHHFTTvHnjXrDlq1csbFfAQ07XHRpvF4K2pqQuS2uAaBwcP4TJyt7dpuiHM8FHF3nyJAnIYenZUI\nwB+0a3rgc+47nXIMcaqZCDxcdK/zIkpDemiXUng94nhXW//bEOfugCYfb6R9BUkgY2lqIA4azedq\n+z7H+nPc92wE6gm2rhmICObggasdCmw6yubpbBd32nU/wtdsPgafW2mLjdcaEcRkBMC11rfL3ZRm\nc2xjY4GAth//n70zD5OqutP/51ZVV1f1QtMLDU03a8sOKiCILII7Go0KRBHMogZ0QDNuE8FkJiYZ\nY4wJDGjYnJ+aAG6J62jcN8AFEUQB2UGBhu6mu6H3raru74/3HE7jits40T7P0091Vd177rmnqt73\nu39d9NM/zPs20/gRpDn8GgFtFIFpHBF3jfnbgYihCmUhW1LYgSsxYTUdK+V3QoBvo3wC5v8gIrw6\n87mUmc/A7rP9rtlOZdmIWAMGpPcjslK/At+30VElQGcyMzfS1AT33qvYkzVr2n+sKWfr1t1ccEF3\nHnzwPB588MdMmJB2WHlpNWZy4aTxeDt8P5u+fa/7zoWDft7xiURg+wJ4njcIochu89fBvNY6voEx\ndepkRozox9atjwPL8f15wEncfffz5OUNY+HCJXiex9ChAwkE9iEAuAyBSSG2QmZa2h6uvvoEwuG+\nCPQsiF5pjuuPQHkgrjGNj6RdD4G1LZfcMtkoYK7RhMDuKFxp4j0ISLpyeGKUrV/U16zzH2a+ADIf\n2eiUVPP+rbhSEynI3JRk1hFAoFhh1nk3MqOkmPUX42z+FTiiqkZf81xcyOk61IhnoTl/GwLdA4hU\n/4QAbjkuw/kEBMS3IQnfOmObEdFsQaBptQhLJNuQs3mAmWcIksh3ohIQa5C03da839vs5W5kytmK\nC6l9G5HFo7jmMG+Y9SQhDSfXzBFEPoMQIvDvISKzDv4yXJexPWa/8hBhJKNIss7m9WpcaOpEBPqZ\nZq/bId+NzfQ+DwiTklJOKFRG9+6bePTR1/nXf33mE4MsZs6cwtKltzFhwlgmTBjL0qW3fUTIaqmN\nn39+hPHjO38nw0E/7/i08NFrkYHyTx/zno90+Nbxvzw8zyMtLQMBbDE2Rj49vRdz505mwoSx+L5P\nUdFerr76PObP30tT01+IxzvhiqRFqa3dxwMP7Kep6c9Isj0G/cD/aOZegwDASu7JCDxsu8oM9OO3\nWoSV8koRaNYhsvCQ5L4KV2piCJJsdyKgeQuBR0sHagRX6Ox8FBq6C4FcGgJgK6NsQWDcZNZinblr\ncTkDIKCqN+tagGzr1i9h+xtU4KKYalvcf6qZ41REcK/gJGlw5qwcRHQlyAzVB4Wp/gkBuW1WH0OE\ncDyyy//E7MM+M08aMu8sQ5L6CrNua6e3JBM0a2yHtK27kQZjP48oAuorkJbyqjm3n1nnIzizUQ7S\nHh4z+1eDS7RLRaasGnPv6TifS4lZ1yj0fahEn3db5BAuNZ/dGcBsOnXaSCIxgqKik0kkNpCcnEQs\ndjwwiv37/wfwKCurZtGiKz93GGfLEFBbUBG+e+Ggn3d8okbg+/5U83jSx/y1ksA3MKxZaOHCFcgR\nm4RKNgSpqFjD888vw/M8HnroGd5+O5ennlrBFVd0xPP2k5S0AmjkuutG8+CD/8rw4b0pLj6IKyh7\nCgKnIgQWQQSqHioq5iHp8xUcqDcgp6p1kNpIHNtkLoiSp9oi0PYREE5FoJWKpOsqBBjHI+AahkC8\nJ5Ki70PS+emIgJqQtdL2A34fAXzQvP6UmaPSHH8eMk8MQcDWydyPjfQJYSNRBMDWZGQjaa4192PN\nJFZiT0LgWYvLcG5AwGyJbZfZt0Jz7gGk5XiIsGwoLubcsNlvm/xWghy9IxCRJ5n3rU9hKyLH43H+\ngPbmuBG43gh/wvWYsOUopuKyhPuhz38iIpVOuASzKebc/0QSfz0i8DxUJHA/IptGJJzsRRrlCea4\ntWZ/TyMQaKZz505UVTXRt+8zhELHcsEFZ3DgQD0QIBaD/PypxGLeN2bK8X2fG264lRkzbv1SCaH/\nTOPTTENDPM/r0OL5jzzPe8zzvLme52X97yzv2zW+bLaxDY8LhyMIUF7FZdXm85e/PEFe3jCTwzCb\nTZvyWbDgfny/kGCwkOuvP5GcnHZMmDCW4uISfN8meQWRtFaAwCsbSdweriPWuziA6YGcx9aW3AZJ\n5dUIFN40c7yP/AtHIx/EUBRLPxqBTrmZwxZeews5mzHXzEO+iSQE2LZjlg139Mw6R5h7sA5dz5wb\nQsT2K0RO1sT1MALXo8xfCFfDPxmFNw5BmoG1h5cg4rKmsRDK/m2DHOavItIpxmkyT+EayK8292Cv\n02T+b0RRN5Z8XjTznGX2KIQ0lwAyP21DoHyW2Sfri3kHB/7v42o7vYfIsgaRUi2uIJ+NbKoy688y\n721EYD4Cfc++j9N+DqCy4CFSU/fgMrA3mXNfN9fqh5zQlmhHAhESiaNYu3Y9/+//nc7ZZ7fnootS\nWLTob5SXv4v8NMXAJi66KPUbM+U89NAzzJ27hrlz93xnwk4/zVm8EH1b8TzvROD3qAh6Ja49Uuv4\nHONIexN/0rASUizWmczM9kha6wIESE/vweLFt3L22aPZubMEWIrvv0l9/dHE4/NpaChk1qy/8etf\n/5FAoCvbt5chMLgU/fhuQGB0BQKxCnPVITgH7hU4x+FYXMXKSUiyLEWAeZxZVw0uFt+aTcIIeF4z\n/1sJfCkKU81AQHMRzrwRRIDXDmXJdkAmlGPMnJZkGszrVjJvi7SKdriQwypEYjOQ83g7inraYs4L\nIs2jDhHWYFzJ6npzv+MQwVyPCG+ROe4NBLYhXPe1HKQNWEdxEiIOW09/gzlmhZm7PS7m/wDSpE5B\npFGFJP9kJIn3QMS9A2kdL5n9bzTn3W7e98xeHDBzJeOKxa1BBJ6NkuesE7cPrgfyFnNv15m9XAQM\norZ2O9L4YogQC1A00+Ehntq/+829LaSubhhXXPFr5sxZwemnj+aYY3qZz2kakUgZo0cfz4IFN38t\nCV+fJowtXLiEvLxhTJr0HzQ0FFJfP5dJk+6lY8dR3/qw008jgqDv+xYNLgQW+b7/kO/7/47EqNZx\nhOOrzDbeunU3kyZFiccP4uK+76e6eiXPP7+c008fQ1JShGDwH+jHZW3cPolEJyKRNNLThyApvTuy\nG1cik8o2JP2WEwpZs8BcBHJrzQoC5v8VSIo/DoVYliBg+g8EMOXm74BZw2REDAUIXFKQm6kGgeLf\nEGj1MNexzl5b6LYrApwzzPkR85oFHFukrQKRyTsIaD8w138baSe2WuddCMyH4MJY1yPT1/XIH7IQ\nkcU6XFLXWkQUxUhOsrkMUXOd9uacNohY6s3eWDv8KcicdzyS3D1kauuOI4sNKOz2aLO2QiSxl+Iq\noEaRNJ6EFQY0/xicJuGZPUg1e2zbdQ7EZR9jzuuHIqS64ZzllkBsRngDLspI5rSjjjoKCQZN5v7/\nZI6xGocNDbafs4fvZ3PwYAcaG0uZOPEG3ngjCZhPMPggDQ117N+/9zNNQl9Uu/40YWzq1MnMmfMf\ntGnTE/u9Sk/PZM6cG7/1YaefSgSe51ln8ilIZ7XjM2sUtQ43vsps45kzp7Bgwe/43vdGk5IiaTsS\nSWLkyJ507dqdbdv2MG1aPtFoLllZlegjttU5w/h+d2pqtiEJcjkyHSRQ5m93bJhoLJaJpMLnzPsZ\nyBGZiosisYBgs3E/QPZ0a8awzuJluJj5s5Ak34zIJBWB7w7zfsys9W1cYtpWRFC9EJh3QpK/tZmf\nbx4rEUGsQyadCgT8hWad1TinbgZO+vZwGdPJuNwGe39xc+16RIrdcE3grQ8hYNbRC5FckZl/Ja5V\n5gm4+PmNZr5dZq+eQGRcioi0G4dXPY2Y818w6wwjBb0T0hTSkAZzp1nbW8hnk4RI7coW95Rqzovh\nqsDa0s9r0IiiaKIGXLJfxNzLNeZ+NrFt20Gz7iAi3xSkQbyEi3bqYa7pmz2qJ5HYB/yKjIz+BINy\ngHue/BBr1mR8pqDUMo/mSMjgSIQxz/MIBALU1jYTCBzE8yaZnt6Bb33Y6acRwX3AK57nPYa+scsB\nPM87Cv3iWscRjq8621jx0qcRDEZIS5tIQ0OAYcOOYebMKcyY8VNWrVrHXXedQf/+7cjP38Tw4T6p\nqSqNUF9fi343Nut3PK4RSIxoNE4wGELgKW1DoDISmYzKcc1wJpgVlSIptot53g4RSnvz3EaYdECO\nxzgC4jEIIE5EwDIMmWr2IfCxZaXLcQ1djsM1vgkhYLTJc+nmen3MYxsEeLchqdUC8jhca81kZANP\nRuRkezz7Zm9AAFiPIobORzkIr7S49ypEWosRAdnuq68gKfx1XBlsD2kT1kQ0GEdOtk9AJs5/cBEC\n/UYEshGkEbyNK/FcbfbeEoetueQjEvWBe8x9nWv2M2g+p+G4onUJc25vc41ZiIAz0XfkDLP2WeYz\n6m4+l264MtXTzZ5nmD0eZPY/ASwjGGwgOXkNkENq6m3U1cUIBqPk508hHlfuQkpKxicKSh+XR9O5\n85jP1K6PVBjbunU348Z15oEHzuXBB3/E+edHvxNhp58WNXQzMgreg5LI/BbnXPX1L+3bNT5PtvGR\nqL1LljxOUtKr1NS0Bbpwxx3/Q+/eZ9K+/RDefjuXN95Yy6uv1lNa2p9Nm7ZTW1sGNNPU1ImsrDAj\nR/bC89Yh6XM+qjD5LvX1bQ1RWOnRVsm0dXRCCLCKkUloLfpKpCEw6IkDPGsHT8YVoBuNzBydkA27\n0MzVFhFMO1xtoRwEljacExwAvYIAsI2ZewjyU+xB9uwC5Dc4gMDPRvzsQnkVW5A5oxQRyDnm3k5C\njs8iFFb7BiKBQThp3vYgSDV/Q3HO1beQTyWOM3NZzcGWcS5Dms06pLUkmzW+j2srGjfvt0GSda5Z\ncxhHWBuRIzyInMC2CmqS2ZsOZs+rkVJvtbL1yAxYY/YrBZHxOqTRPGk+l2OQ1rAfkclpZs7x5nEn\nrulOFjIv3Wr23jq/A0hjUiZ6PL6TxsZuwBPU13elsXEdublvM3v2OJKTD9Cu3fxDghLwkd+BzaPZ\nufNZYAW+P494fCBz597/qWRwpMLYkeQqfBvHp2YW+77/hu/7j/i+X9vitS2+76/5tPNax0fH58k2\n/iyn8sKFS9i6dRfh8AgETiU0NJSzffsu9u/vR3X1bGbN2kA8vpvm5uFUVPRCP+YI2dm1jB07mquu\n+inJyYV4XjWusmgacCmJRFec9BhEhevKcMB0Di7r9jgESsUIjP8FAYAF3zwkoecg0Es1x1vbeghJ\nkTHz2B0HPgEkvVtfx6lI2t5jjumEwC+I5JUOuK90R0Q0bRFgbUBg2gmYgwAvYl5biZzHvZAjdBgC\nzP9EgNgNSf02S9YmUFki+TNKBFuEAN5K71ZrOQ8R2HMIjNsiW/2xZm1PoaisnuZ6tg5TF6SBZOIK\n/r2KiMtHwGt9Iz4yw9jm8imIMPqZ/f8fc3+nIbKztv44KuHdFZFm2OzfNkQu2817UeB3SPOpRT6M\nkeaeKsx888y+r6B79xDhcD0iyCIzd5ZpK7kXawq65pofsmPHMrZt28OSJZdSUvLIIUHpw78D22/4\n1FNHEwp1w/MUwdXUxBGZWr/L/QY+axxJraHW8b80jtSpPGXKJHr0yKe62vaOXQ+0JxbrjoDXmhl6\nofINEeBWkpLKOHBgI2lpIbZvL2L69IFEIlFsLoIiR6YiAO+OgK4I13s4ihKfHkMOzt+hH7+tD/QC\n8j3sQdKrLWTXjDSBAPIFJBDgTDGv3YTMETchAA4jgrEdzbaaubshgjnBrPc4BEbLcM7OUeZ6NuIo\nhKTVtmYv9iDfwrPmWsuRtBzBOZ6DCEitj2IdjtxsobyA2a8SXBVPS6h9UQmIlxBw217F7ZDT3Drw\nMWtNxvUJ6IjTqHwUndUROagtccVxPRUWI5A9GsVwLEeE0WA+rzcQMeQic09vnDWgGl8AACAASURB\nVA8igIjnr2bPI+beTzbH2fySq3FJfDZC6WTkjxhu7iFs9nQ3kELfvj1pahrN4MEB0tKykBaWiu/H\ngEICgfHE4z6BgOzyLQWlsrL9LF786Ed+B1dcMZN58/bx2GMvceqpbfH9ENnZP6K6uumITK2tZag/\nebQSwdc4Pm9kw5HaMR9++FmeeeYgjY0eaWkT0Y+5F/o4G3ClG+pwYZhBfN/n5JP70LVrd2bOnEJ2\ndg7nnx/hb3+7jGuv7U4g0ISk/S7I5FOK1PxnMEVnEVG0QaBgfQs55v2ByFyUjyT2MCpgV4E0hoO4\n6BpJhXIYt0Gg1gOZbmxXKxvK2ANXbnk5As0oIqM9CPwXIhPNNvNeAvkwksy1d+D6GHQ289XjADjX\nvHa2WXc3BPQhRIrjzJzdzHw9kESfhwNQWyTvcrPWXYhMbUP5vohEPUS+IA0lBUcOVtPoaa5t17PG\nXMtmQduqnkEksf8OaR0Z5vjOiPwqzfV/gIhiLiLCXeba55lrLjP3t8W8bltvrjVr34gILxV936w/\nIsWs80kUcBABavjHP3xgAatXZ1BTsxI5mPPM2s8nkWhDIPAKS5Y8zofHh38HZWXVVFVV8eKLAaqr\nB/G3v73CU0/tBM4lM7OA3NwNLFnS2iPry4xWIvgax+fNG/gsO+aCBYvJyRnCzJnLaGjIIpF4jbo6\nGzWzAZkkXkeg9hqRyH5sgg7cSiAQ5vLLJx9Kw58x46d06pTL+PFnkJOTzeDBYYLBfARi7yAgAUmD\nK81cpyMzxUgEFkuBxxEgdMOaBqQBgPIT2iEHYwdcaGJ7BFKFiHhsNIv1Q4QRsAbN9awdez2S7AsQ\nAE7ncH9GZ9SCsgiBvy2H0BdJ89m4hDSb1+AhqfY5XKG7U5GjN4Ek7jvMvo5GYJeFHOIdcX0UfJwG\ntdcc4+Pq69gcihfN/m5GhDIQOX9PMMf3RBL5LqQNVZv1rjDzR81+XGD2KxlpDtZkZX/W65HWZH0b\naxAZ2sJzAeQAtiUqeuOioSzIp+O6nnVC5TIqzJ5MNGvJx5nEngZ6kEjYUiFBAoFm89mVIaJSmfCB\nA3tSVGTzJ9z48O8gFvO44IIzaWz0gYtp06Ynbdv2A8bS2Ogze/ZMHn74zx+Zp3Uc+Wglgq9hfJm8\nga1bd3HKKfWsW/fHj9gxs7NzqKs7ngMHdgPzyMwcQCSSCowlGIwTiewjO/s4YCHh8HFEIg0IlNKB\n50lJqWDatP9k4cIl+L7PuHH/wp//vJcrrriRefPu5a23cojH5yOQsNm/UfTDr0aAVY1re2gjVGLm\nGpZAjkFS5InoK/Y+DmyzkQS/DAHTTnN3w811hiPAfBERg7WPn4Ck8hwEWLZ0wq0IiM8zazmIJPJ2\n5pg6pCW1QTb8Pri+A9Xm2j9AIJptrp2HzFZBXHkMm0x2MQLElk1rChBxlJhzHzPz9Eck6uNCTG27\nzBScTyJk5m9ERHGWOb8U54Ttbv564Oz6NmroA7P++chXYU1cTS0+J9uNbSAy91QiArZE8EuzZ3/H\nlbGw/Qh2IvNWFa4R0NvoMz/LXC8VEbP1oyQjLSCJRMJHmlcbs45RQIDVq6uIRo9l8uQr+fA43J5/\nFsXFFYYYrqO2tpm6uvh3ssn81zVaieBrGF8mb6BHj8688EKURx557pAd0xLLL36xgvr626moiBAO\nD6Gycje+n0TfvtcSjR7PtGkTSUlRmYXU1DbEYjGSkjIQOASoqkrlvPNG4fs+nTuP5rHHPGpqGrjr\nrj0UFZXj++8iEO+CzCVHIYm0EgFaFpJW9wJJhELjkE3Y1rd5DIGBdQT75pzuCOCtz+B2BAbJ5pj3\nENgFzHVtTaE3ELnYEhTLUfmKUUgibYNMPa8hsH8JgeRUM3cISeyFiFDsmrrg6h6tNO+tRESVMHOc\naz6R9kjb2oUjHBvZc6E5PmbWHUYaSBrS0ipw5Tn2IOJLQgRhJeYLcOUxIgh8p2BLNCtBb6O59ypc\n9dZfmfPTzTlWig/iSkhfbV6zpSSstlOENKR5COiXoUqltvS17SFxFvrse5g9Cpg9fR9HonfgEsqC\niBBzkEnpT+aeM4CLSUpKJiWlCed/aWL69IkUFHT6iPn0w/b8/v17HiKGceM6c/75ka8sAq91tBLB\n1zK+SN7Ap2kRHyaWrKxUliz5LRdcMPTQD+Kee86iuLj8MHV6zJghNDd3AWoJhSaTnJyC5/ncfvsD\nxGKDTAnrOPH4OsLhKEosSuNwafdKRAjHmdfW0bZtmGuv7cbQoWFcxiy4r1PL1pbNCKgbkSTeH+dX\niOPs8YvMtc9BJpxO5lirffwIladWT1znJK5C5PUUIozdyCSyx6zfklJdizVZCTYZmTQKEeAfb9Zv\nk7r2m/X0wNUtsiGpGxF4W0eyZ/Yp3zx/x8wTQyD6EySN27IOAeR7qUJgW4EzWY03a6vEmYLiSDIf\naV4bgEhxkHnPx7YjdY7vmxHg3ovLy0hH5jRrErOlvVcgH8PRiMRCiCg6IA1rlDlfZUBCoSRcCO8H\nZu2vI1J4EgkM/c09h0lK+iHxeIDCwgJEBGqgs3Xr+8yfX/yZ5tOWxLB06W0sXXrbVxKB1zo0Wong\naxqfN1Tt07SIDxNLUxMEAoGP/CD69+/F3XeP5aqrBpKRsZaXXy5BZqNdxOObGDGikq5dCxkxoj8l\nJbaoXDa+35nGxlpSUt7CJWeNM49/QMC8H4FfiIMHozzwwNOsWlWC6g9Z0rgUSYZvAD9GAGGbo9Qi\n80BLv0Iu8Fuco9SaSGwiWjOulWUUmWmsEzkHV0PIRgilmjUPwHXgKkcA9yICMVvqOR/5LzYjm3ky\nIqPjzfuY9T1v1mVLOTyKTEhpyPeSjST0c3CmpGoEin3MfuxD0UMLEJF1Nes9w9zbe7jIpf2IPN5F\ngPkmzolciLSxhJlzKALr7ogU63Emtd7m0YbUppv76YYa61jndgI59E81c65GmtUapG3txfUhyMfm\nYsRijea61mFuk9JKcXWjBiFTUieam1cRDD7Pxo17SEnxsJnaTzxR+6XLrnzc+CrLunwXRmupiK9p\ntKyLfiS10D8M9rt3Jw7TIiyxjBt3Og8//OzHEou9pu/7ZGfnMGXKP4AppKQ8ypQp48nJacfMmVO4\n7rrf4fvW2dce2MeIEUdz5pljuPPOB4jF1pOZmc2uXa9TVVWHQgXTEfAdA2yjqCiGQCEXgWgprg9A\nAbJhP2BWNhIBlAVs2yDFhjCGkRTa3vy/CQGkrZlTgABlornWOchsYovWJSEzTQfzehFOAu6HJOKf\nIgm2CRFIAPg35BxdgMwx5yACqUOA/gYinPcQQbyFNJShqDZSZzNXsTlmF9J8oub+b0YF+dbioqSC\nCFhPQMT4JpKc55s1rMeZTmoQEWab+y5AUWAPI6J+pMWc3ZDGdDGuEU8UV9YhFwH2BkTKq3C9EfaY\nebq2+DwqUb7B+4gMM8x7Teb9ZEQMs5HGYL8PnXAJaZbgg0AesViEUGg3dXUpiMCuRprIUvbvr2LM\nmAKmTJnEVzGmTp1MZmYWP/2pCuk1NCT43e8+f3+D78po1Qj+D41P0yI+Twy0JZB4PEha2giqqzsT\nCATIyorSr9/Z/OUva3AtE18HBtHQ0MAvfnE5f/zjz6mqGsLw4X1paIgjh+8CJKnuNc9tpdGeKJmq\n1sy3G5k4ChAwlyIpsxwlMoVQSKeHgNXWuN9rzt+BQKYtkmiPRQRkm7HHEGglEDhtRmaXbshMcxYC\nqitxpRusCaQRV8VzvzkmgLPV23DSLuaxFBFTLZJsraN5L9IKQgg4q3EJcoORXdy2u7SRQrZHge25\n3N/MezGu+Z8dXcwxY8x5H3B4FM89Zq23mtdtD+GweZ6ETFQ7kEa1CpHXKnP/RyMtL9d8Nh0Rgdgu\nde+Z/emOAH0DIrqdiJTamHmsdmDNnTYKabuZe5B531Z0jeP7V9Hc3KPFec1AFzp2fIWGhhKeeSaJ\nRx55jq9ieJ7HypXvUF2doKBg6ieaZ1t9CBqtRPB/aHyVCS9LljxCOPwatbXHAOdxzz27mTPnPrKy\nwlRWfoB+8JsRKC1g9eoUPK8XF1/8J6qrB7Fo0eM0NeUjidcmOEXN7FZCno9L1lrb4vXdCMDDCDiq\nEJDsQNLqFnNMMQLX3UiK74bAJmbm24Sk/BQEKJm4mjYxLJA40LnTPLdN9TIR2B1r1r4A11DmeiS1\nJiGbfAIRzgcItE9BUS+ZZt12dMN18+qAzC9bcSarIIdX30wyx2UikNyDcgNykP18L9JaTjbzb0Lg\nbDOPc8z6uiPpOct8bo1Ie9iAQN5rcb2tZj6rFW1HpPY4rgjgTkRYb5jPb5mZL4FLnvNxLSpt7aL+\nZp9rcH4JgL1kZlo42YS0sGLzaIsA/g1pD1EkEDQD71JXt5bMzI7U18/9Skw41iz0l7+sBs4lEskh\nI+Ptj801aPUhaLQSwbdwqARFEeHwcOMQXs7Bg28yatQArrrqp4RC3QgG+yEbuXV0RvG8vqSm5gIX\nEw5bB2nL+jXt0I+5wFzJZjCfigBqIAKwPgicrGQdxpVmiCD7cBoCp5fR19A2lemIgLc9kohjyMyS\njJLFbDe0HmauVGTzLkEA9AIC8y3m/TpcfL2V0APIVn8mzrn8IjLtlCGzzZ+R7fx9FGFzEg5keyBp\neSsirAxcv+D5SANag9o+vmbu9XeIRGxoajGu/PN88/qr5v5tCe4wkrwvNntfaPYzw6w/YPY+hHIn\nupjrFSA7fx9cAbgKRMilZo9Gm3UOQ0Ddx6zl6BZ7NQDXfKg7jug8c0/vmnPXAN04cKAW2E0wGEEm\nLBtpNMDcQxIilX3AZWRl1TFixFDOPPNEQiH5GL5MZV47rL8tJaUHn5Rr0OpDOHy0EsG3cNgfQnOz\nnnve6wSD3TjttDFs317EtGkDCQaDJCfPNmeoppDvX86BAykEg8fQ1PQeAgDbyHwZAtfNhEKbgCjB\noA2lPIiLlvFQVE0nXIeul1EUzTYEMluQlP+cOcfmK0SRbTpm/joiEL8bRyZ9EOiVIEn2bHPeOkQc\nYxBovYgiXaoQYFkzSjLO13AQASwIBDshc1cARSkFcKUcuiIzWk8OD49tg8C4vdkrWwbCZhuPQmQ1\nzjwP4XwzNpTSgn5XRDA5CJD34aTzAJLiy5GkvwrXe7kfsre/iEw0RcifsRURgC2JsQdpbUfhHNd7\nEFGsN8dvReT4r8iHMQpHgO/jCud1xfUqCCOTYU/gFOLx3chhbH0/VksKIq2kA/n599Dc3I5rrvkx\n48ad9pVV5oUji9r7KkvDfxtGKxF8C4f90tfUNJOVdR6+35PTT89k27Y9zJw5hX37yonH15KRUcfg\nwaVccEE3XEZsM0uW3EwwaO3SgxDAZSOwOZ5YLAA8Rzxej0s22o5A7RoEgu8js0Ab9DU7CUmfhQgw\nas2cDQgQO6DsYytBZiPpda+ZZx+ubMWtyASVBPwFEYuVjicgUjoHgWVXBFaliGRKEVGVmTVb4tmL\nANyGuyajiCYL1AkEoBtxtfqTzHzVSELejEB1k5n3AQS4qQiAN5jjbR0m2zDmGnNfNh+g2cz5vtnf\neuTozkfElIII0prsbFJfFiKwc5Bpbi8iAtubwWpdLctTXGnWcZLZcxtKGzTnJ5vzisz9n4s0p32I\nmE9D5PQg0pwWmMcYrvtaKRIKSrDZ0qNHdz7kB/s6isF91pxfdWn4f/bh/TM4STzP8/8Z1vl/aZx3\n3uWsXr2ZaHQ4W7feTE7OlSQlvYvvNwM9KS7OokOHCrKyKggE4qxf34WkpFKam3Pp1m0zu3cHicVs\nyGEJAsLHUYjouwgUNiBb+iwkPWajKpfnYqtNClQ2IrCvQVLoPSiu3tqOCxCAHjDHjUVO5DMRQfzF\nHL/aXKM7atX4Q/Oaj8xS96IM2afMeo9DGbD1yCxTi4CtyLx3NzLT2FLToxHB/D9knx+HHMNFSDs5\nH0XJFCGz2hO4+j7tkdaTZ/bmRXON/0ZguRuR6lJzzbVIO+ppPrFSRCap5nEj0lbaIxLINe/tM/OO\nRwl8pWZPXkEazQvATKR9FZv9bURJeiuQFmEdxbao4PHI7m/3wpaxPsnMbyuRHmXO6WvW3IzItNi8\nNwCZ6X6CvjNPIo3C5owEEGmsIDNzGnl5u/nZzyZy+eUX802MW265k549Ox8WifdtK0TneR6+738m\nu7VqBN/S8cgjC5g16wYaGhS9Eo224eyzhxMMRigriwCzKS72ee+9baxfvxNYRnNzW+A8du6sIxaz\nJoMFSIJ8H2UHhxDIrkXSYy2uEmceKqWQi7SLHJwj0yarWfNRMgqvPBGZb7qb69h+tzaLNYKk/DCy\ngd+AM83Y2kJ/wkm5tpRCHQKw48x6Ykiitt22rDRtI6jDZr4XcKGStyDA3IBzmhaY+/6bueegmXM5\nIrIcZJaxGtWFuCJtdt2Y/9vjCKDG/J9r9qzC3Ic14dgqp2Gz/7aeUbJ5z15vBAL/3UhiTyCtaI/5\nDM40n91mc40UnKMbc33bv2A8Ip+4Wf9+M9d8s5+rzP70NvtgQ5JDqLlhAEglHC4CehII7DB763Hw\noM+ZZ474SkwxXzTyp7UaqRutRPAtHR+n+p5++klceOHpxOMuHHHQoF4IjCcjUByL7NM2Ksbar7OA\nOsLhZbguXntwQF0JlJGSsgnZm09HfgXbo3gjAvgQLoPX2o0zkenEOiltxE0c+RHamOPjyCzkIa3D\nxrMHcZVDbQhjAIGWLe28y6xrOSIsWwvHmpWykUQfRcD8Js4BbJvkvGCOtdFMb5njj0OS9knmmFJz\nry8gUH0VScLWpBRCoFlt1mHbVvYBvofA2FZ0tXkXNl8iydyr7S9ch6T6MHKS9+NwR28X8/90nD/H\nSvQdzT7awoVBM9ep5vlys7Z0VILDhuLahL7OuFaYpcgXtB7YjO9Xkp8/lUjkKFOAbrPpc9ETmIjv\nJ1i06AX69z/niBy0nwb2XybypzV8VKOVCL7FY+vW3dx11xmcfXZ77rprLNu27WHfvnIikSSys39E\nNJpEXV0DAoAnce0nbeJQBQKKZGAGKSndaWoahQB5FAKIV1GUT2dgHHV1+7DOSM8bjaRy6/SsRAB2\nLJJIr0ZAUoSk2GJkdrIF6UqRxLoGga8tG5HARRyVoeSkd3A1faIc3lg+CfkihqH8gwQyGb2AANy2\nycxCYGfr6PRAkv8AJP12RtJ3yMzXHdfboL257044R7Lt0nUyAvI9uPaP7RDQdkHgHEeAfwcCeEsW\ntk5QlTmvBJmBIri8CZsPMRRFbXlmzzsjAtyM2kVav0g5IrKuKCltM9ISluFKUC9HlUQj6HuwFFey\nY6K5/6C5vi1sGEZCxDJgEKWlb5NIvEAsNpSsLFvH6UwCgbZANzwvg5tums7OnUWfCcQfB/ZfReRP\na/ioxjdGBJ7n/cHzvI2e5631PO8hz/PafPZZrePzDJtpPH9+MZ7nMWPGTxkwoDfTpnWksTGL6dML\niMcDXH99F446qg3dum2msLCaaPR1oIpA4A3gfYLBdcBvqavLQolVo5AtGQRi1QiwD6/MKdNkEIHD\nJqR5KG9B0u5IBDhZCPyakEmiGecYHYmk5SQEfAcQiC7AJXztNdewVUIH4vonH49Atac5534Eks3m\n+AUIQJchkFyLNBBrLrGlK35v7mW3eU8akswiOQhcLcBnmz0JmOf/hYA3Dzly83ChlT6SqNPMXmxG\nvhPbunMVIkTbhexU5MtIRoDd2cxjScySkK0RFcA5x9PN/WbgynYca/bMkpUtCV6Ca1F6EiKSDET8\nGYi0bTbxVnPtbJKSnHM9Hm8kKelEVA23L55XQiRyC4kEFBS8g+93YuXKtcyb99FaQ1ZSX7Bg8RHX\n4Po8kT+t4aOHj29SI3gW6Of7/rHomzTzG1zLt2607F1gv+h5ecO4/fa/8vjjNdTUzOaxx6oJhQKs\nW/ceW7Y8xQ03XEZychKxWBdgLLm5x5KVlYzvDyAjwwKXBcdCZNe2cewBZF6y5p7zzUoCCFRORiTS\nFtcL17aFbESmoS4IpHMQkDYhsBuEpFJwUvmzyMRRj0B+kXleiTSDJATux+DCF5cic85QFBG0y8xp\ni731wZW6bsQVgPPM+W8hYDweOY3bIf/BDgSic80cNbjyGy2zaJ8313zBzHOBeW+PWUMUEWEWAu1i\nRISPIcLJQD6AXUgbsjH8GciklISIxkPZw0Xm+FxceK7VkHoi0tluXi9HhBdCFVZtqGlv5Eg+Fmk/\nIURMNrEvFRFPDRCnuTlgzm8gEMg9ZIasr49z3HGdufHGCxkypITjjsskI2Mtf/nLno8FYiup5+S0\nO+IaXJ8n8qc1fPTw8Y0Rge/7z/u+b8tW2m7jreMrGof3LtAXfe7cX/Ff/zXzsC//mWeO5LXXsoxE\n5lNcXEZzc3tgNmVlEWIxn5/+NJM775yGfl8WaMqQFL4QSeCvI//CbhzQleJ6EresM5SCkzxtOGhf\n9HWsQXbu3+Bq1SQjM8YK5LRegyT7hShT+D1U5C6BNJLRSAo+3hyTYtZiM6FTcT2CbekLSz7PmB20\n9ZO2IuK5xay5hsMJMW72wZqhEub/Hkij8XDO7lORJpCLAD6CtAB7j8ciM1fQHF9r/r8NaQSdkNZl\ntYDTEXF1Nevfixy6NebzSUME2TK7e7w5dwPyj3RHWt0WnNPb5hI048pf2AqoDcgn0t4cf9Ds4y5E\nCKu59tqh3H//uSQSe2ho8MnPn0JTk8+6dWEqKw+yaVNXJk8+l1mzbiAaVUirBWLwD5PUb7xxOdde\neyulpes/Fuy/aOhpa/jo4eP/StG5S9Evu3V8ybFw4RLmzr2f5uZjqK+/nYaGqYRCg9izpwE4kUAg\nwMGDDXTo8H2KivZy330jqa6ezbRpP+PAgZcJhWzrQY9YDIYO7c2CBbfw+9/fSbduW9mxw4J7Jw7v\nC2yBvQ4BUH8UFfRD5CAdhRK6OmD7I8j/YEsfgLSMtTgNwyaB5SGJ1ba6TMdFH4WQlhFFEm4A2f9t\n57DbkJYQQGAYNe83obDUSxGJ1SEg62rer26xlt1I0l+BS5y7wKyrFyKn9sh2Xo80mK1Ig2gy6x6I\nQPkanC1+JwL7NriEtHMQUYw311mGywfoiIuyGolI4yfIQbsOEWgQEfJqDs8biJt1PI1MPdZkdyfq\n3/ASLkPaZhLvNPc3AtdDIYqIdwlwiVnLBkRKy4EY1dWVXHbZTBKJXGA/e/duAzrh++czd+5bNDcX\nMW3abpKTy9i/P/2wIotTp15MVlYO1123DEsQo0YNZty40xg//oyPFFz8vMUdW44jKeT4XRlfq0bg\ned5znue92+JvnXk8p8UxvwCafd+/9+tcy3dlfFzvgrFjB+P7JzJ37uJDX/6ioke5+urx1NUpUic5\nOZWrrroI2y4yFJpMOBwkN7c9ixYt5dZb57Fjx1FI+nsYgauPANH2L3gAfaVsCKg1qYDMJ5sQqG1A\noBpGYJNAZofncTVsfmeO3YKAtsnMMwj4OQLJExAA5iPbt60Uus1co8L8/x4OcNNx1U+tJG7NWceY\n+0tDdv5ByKTVCWkQQxCx7UdAn2r2YQSynb+DNI4FSGqvwxGMJa5q897tZh39cfH8ncw9rzX7M99c\ns8HM+x4ipZY1oDBrT0NgXgzMQf6BKNIgfFxJj4DZtxycxlWKyKEa16pyO64qal+UZJeETE72XsIo\n3+MU834ECHHnnUuprfURWT2M7w/A998HoiQSAeBKkpOPYtSowSxZMv0waf7jJPXx409nwoSxX3mY\nZ2v4qBtfq0bg+/5pn/a+53k/QR7Akz/tOICbbrrp0P9jxoxhzJgxX25x39LR8ofUps0JlJdX8tRT\n6gOwcuUVvPnm7UyYcCLjx5/BCScM5M47S1tIZBnE42kUFOzn4MH2TJ3agbvu+htvv70RzxuGQOEy\nJLVaMDwZ1+mrBoHCFmSauQgBkJWa++Hi6X2cJDkbJTOtQNK9hysY56HqmNZRbGPoixGARTm873Bf\nM2/AzHG++f9VZOLphwghhMwq1lG93Zx7MwLFSpzv4Rfmmm+a9bZFhPIkAup5Zv2vIaC2mko3RHC2\n2c+5CMC3IfLoaM5JIHDuigghYO7Nmp86oyS8i5H034CrAZVm9vwZBPQFiACbUc7Ag+beTjGvH2PW\nFjT7OwinrUzFEdImHODnmLXtBO5CJDnBvB4w608x92Z9Dj7O4a4Q3Gj0UerrcygouIfKyg6MH3/m\nISm+pTTfKql/8fHyyy/z8ssvf+7zvsmoobGoIPz3fd9v/Kzjb7rppkN/rSTw6cP+kCoqVvC9740w\nUphHIhHgyisvYvHiuYcdZyWy9et3cu+909m16z7uuecs3nxzHQcP5rJrVxEHD9ofdQhJsP0RkDUj\ngAgiCXAh+uG/giTYjSi+fzACtzfMazEEtLZBDsiu/iqSTHciQDkRAXMJLq/hBSQVD0CmmBCujtDl\nZh3gWl3OR0Bom8l0MPNtQBqFXd9zyKHcBYFqDi4KpxA5Th8w1zsTgV8zjoSakUnFxuRvwzV1X4HM\nNcvNvi1AGlAdIpMFiEg/QGCfauZJwtUKsqUkwmZvc801HjWfiW0nGsbVaLKRSb1wTl1brfVn2BLR\njnSuNPN2xLXjbDD7mY18DyvNvh9A/p0kREAdEOE1m/WXm/M/ADoSi20jM3M1xx2XdUgD+HAcv+/7\nVFYeYNy40wFYteodbrjhMlrHkY0xY8YchpVHOr7JqKHb0Tf3Oc/z1nieN+8bXMu3aliVNxgM0qtX\nd3w/QDg8iXjcJxDwCAT0sc+Y8VNWrXoHkET29NOLGD/+DC6++ComTfo3Vq5MB/5Bba11gp6LwOIa\nZMLYjUAhHUXhWJ9BAQL5bCSBT0HgOQCBhQ3nvBwnKVsp1UrDIKl5gZnPOmjfxbWB/B4CvldwrTD3\n4LJpeyHAt0TTGUnE8xCot0eENgWBWT4qkWGzjG17ywoEhpVmvgOojEW7kHuPDgAAIABJREFUFuu3\n1VnHmbW9Yu7XFoVLIIBNwuUadEegaU00JWbPeiG/Ram53xiKxEky91tq7uV7uNLgVkt5HwHvblRy\no8gcfzsyOZ2Ai7D6PQL8EC4IYAauFMRKBOjLzTp34TK3fTNvN6Qp2SzpQrOnx6DQ19WI4Atpbh5M\nU1MzY8eecMgU8/e/P82sWc/z0ENy0reM6/+0GP/WRLCvdnyTUUM9fN/v4vv+IPM37Ztay7d5rF+/\ng+uv70J9/RKuv74r69a52vof/qHZH9df/zqH6dMvJBYDfUXSkMofw2Wy9jJ/Npb8XVy1ySQksTZx\neM36Ely2bBSBdpF5720ENuchiTwbSa82jv9mBF5NCDjTEIAfgyKGwgiIn8eZiirN2ibgSmH4yGRV\ngctItqGu65E28i6SwpchMHsRAaMt/bzGPLdmnzYonLMJkVQv81rLqKc2uLaTHnIGB3GZ0SPN2qLI\nFFZo9nqQueY2s46GFufeifNFVCKAth2+OpnzbAMZ66fYhRy9axFZfg+R+lZzDx3MOpPM57ENOfrL\nkcM8gTSIfzXzvYK0nvnm3E1mHxYiQkhDWl0ceJempihz5tzP5MlX0q/f2fzsZ/fR3NyXyy77A8nJ\nRzN9+pNUV89i0qR7mTTpP6iuHsTMma+QkzOMhQsXY8cnkUQrQXyx0ZpZ/C0Yn/blf+aZO7ntthkE\nAgFuu20GTz+96BOTaS6//EbmzdvHo48+j+cF8P0AoZC1Q5ejH34KAltbfsFD4PcycB6pqTl43jIE\n3qVImtyGACgPV2rCkkVH81iHon72IzOKNbXYTGdriy7AAbyVYm1m7RoEuLbC6H4zd5lZ325zjX24\n+jxbkSP7BZwmMByR0XlIys5EGsRtKDQ1A5lGTkA+g2iLc7eZvbJ5DzYzOIFMT8MQCD9o1hPD+SfW\n40gszVzbNpDPQ+atKnPuZrOX682xljh+iKuBdK25x0mIxA6Y69yFa/U5FZnAbHmRp8wxVbgyHbNx\n+RidzL7ayqwnmfu1a84w79tM5C7It1EHNBKLwa9/fSVlZQeorKw5VPeqtraQtLSIKZ3ukZ6eSZs2\nPYGLqaioo7a2C9nZ7T4zEaw1U/iLjVYi+BaMz/vld5FFsg2XlW2kqqqGl1/2Dv24Fi78G717byIS\n2YKk4yAu87YeScoJXLP2DsBY6upi+H5PBMrHIYn3bAS+tyMpsS2S9mchjaAtivkfgMwoJ5n3t5lr\nF6PolCACwJ64aKAyJOHuQaAzzpxzEEmqyxCwpyIgjCMwexSBcg0C8mwEbO3NunJw3btsf4GJyGTj\nIQl+PgK8ZbhM5fG44nrPIif3a0iSX4Izywwy648iQlmIwHw3IpsoLvnOkug45JxvNvcbQIQTQ+QI\nTrvZj6tAuhJnFpqPzDn7zLUmIkKIIUnehgCfZO7ZRoTZktWdzT7W4vIU2pu93m72sSvypYTN9a/F\nEnYolMNtty3i1VdzGDiwx6GEs0QiyPDhxxKLBenb91rq6mJUVjYQDv+AiooGGhou4cYblzN37v2M\nGNHvI4lgH84/+K5nCn/e0UoE/8Tji6bJ28iisrJaPG8S9fV5XHDBGYcqlTY0JLjnnt/x61//Gw0N\n3UhLGwj8ANnsbWP1o1GiWB7OsXgevh/C5QGkITBbhUBoJC4KJYIAep+Z904Efq+b54MQSTQhUIsh\nTaSHec+GOj6MHL3N5vixyDTTHhf14iNNohMiLKvJlCLTSa75y8I5Tn1EMu0Q4b2IyC0fkZLN0i0y\nj8OR9G4LtVn/yB/NXHZ94IC3LYf3N47gHNNnIcKtRSaoliGlQ3Emn9Fmrt1m71IQqe5DpFmOTD+d\ncT4cazYLIz/CXvPaTkTe7czn0cGsxzYgus3saTLOOW39RzbZLmHWZ4n0aBTRtA7Pqyc9vZhVq3Kp\nrT2Tl1+uABJ06HApyclBVq5cx113KXjh/PMjXHBBNxYvvpSsLPl+LOifdtqYjySCTZ16cWum8JcY\nrUTwTzy+aJr8woVLmDbtt2RkVOL7S2jbtpo77/w7paXV9O17LaWlVVxzzS388pcriMWOoqZmJbL9\nLiAQ6ALUmQzMRQhcW9bleQEB2IXI1l6MnKLzkTawHgHqswiA0nHgm2KOvRgBTntcJ68DCPifwEXp\nlJg72okLV/wBAqoyXIG0cgR6zQggw8is5Jvn+3CagQhN1xuBQmGrzBpG42oI2QJ93fkouXRCfRE6\nmHkbzfG9cc3cEzjzi622GkDSeBglfnU3c47GNeqxkVt7ESGOQNrOiSiCJxUBdi+US7CM1NSjETlZ\nf4iNFMo117SNaGzrT3DEtAWZz+qIRFJJS1uJC2mNorIiQVzXuSzksG7pmB4CHMD3mzlwwNZ8Wk5d\n3TZOOaWWoqL/Zvr0AqqqBh0SUpYu/SNLl95GIBCgqSmHvn3fOwT627bt+Ug2cWum8JcbrUTwTzy+\n6Jd/6tTJ/PnPvyQpKR8IkJSUzznnnMySJWezfv2fWLLkbNLTUykvrwUKSU7OIiVFxcTS09MZOXIA\nnTtvIRLJIytrJ8423AsBlk2ksg7cluWLE6jUQgoq7+AhkLW29AACcw9JzHEETlk4sN1vnhciE0Y/\nc24Pc/5qJKEuR8Rj/QE1SJI+H5HCfgTGNUhj+B4Cvc0IBG3Ej22eY80gP0NA14wLd/WQU9xH0rnV\nFDqY+z8OkWEhktwTZm/Wm2PTzXVTkNlnEJKohyGzUZ65r2HmXqPmvPuRKcaCul1HGFvYrrY2RjCY\nhkxCNrKpDc5J/S4inStwUUjjEaGlI0LJoqEhSE3NMPr370Io5KEQWuswTjb/t0Mk2rJPNIgE2+H7\ne8zzEsLh3nTv3okBA77P44/X0Nh4RwutdjEzZvyBrVt3fQT0PykR7OvodPZdGa1E8E8+vsiX/+MI\nZNy4Uw9lbz777DI2bSqgomI3sJHGxjTq66XCJxJBrr76R1x++WR+9KM2RKMVCATWIMk2Fc/LQsBl\nM3bBFVjLR7bkE5D5IYBr6vIariH8ZvOXhezrVWYuWytnH7LNd0QAOwIB2nsI8J5EJpKwmW8DAjQP\nlXrOQ+acY3GhkFORWSOdw3sJg2sNWYPIpwJJwUPMeSVIEi5C4P+4We+/42zsnjmvOy6Xsy2uDecy\nsz95wN/NfVgSjSDwzjF71B+RnTU3NaKsX0tum4FqPG8i4XCUjIw+wGA8L0h+/kO4+kttzJ8KDYqg\nXkYk8o7Zmx3Ai3heOrCIsrJexGIlwE2InHPMvjWbvU5HWpotghdBocJ9EGn2AQKkpOykpKTyY7Xa\nzMxsZs16nh49Oh9x9m9rpvAXH62tKr+j45Zb7qRHj06sWvUOQ4Ycw7Zte8jMjJg6RUezdevNBAKX\nkUiUEgqV0L59Mh988AqPPPIcd9zxV156aSkAkyZdzwMPrMT3f0EkcjOpqXGSkpI4+eQhVFVV88QT\n6xC49CMY3EA8fgwCoWXIifgCcuzmmJW9ATQSCERIJI7H897E94chsmhCEnoR0jhSkDO1FwLHcchO\nn40ycS9FEvgqJKluRJLpFkQuwxF4r0dN7w/i6v6PRgBWh4AxHZm8hiPNwGb5FiI/xU/MGo9FgLgJ\nl3nrm3VXIKDfYK5fbh7bINPO7UhL2okk9UozRzEil3HI3r4MWzE1EBhBIvEenhfC93sSCr1GLBZD\nJJIOtCU1dSUNDWlkZWVTXR1h8eJL+OUv57B5cw0C5i5mfvVeLizczoEDNVRWHk08Ph74LwKBIhKJ\nfOBpIpHLCQZfp7b2BPPZ7kJEuQWXy5CONJOdiJR+iMJSzwceIBBYy+DBXVm58hEeeugZLr30GTp1\n8ti+vZF27dYTi3U5rJ3qN9nS8p95tLaqbB2fOj6uV4H1OVRU1GEzkQsKUgkGu1Jc3J9HHnkOgDVr\n2vPww8/ieR4dO+bg+/1JTv4VDQ39ueSSc9m3bxlbt27iiSeWIQB+DdhBPJ4BLMLzahD4PIAk5YMI\nXPdjK26qOvkifH8wAv48BMwF5vhkXF397eZxFq6kwTnIjv4AitJZhMBqGTLdDDBzZpvjV6LyGeVm\nbhvVdBAXcdQDSe5WU8g0c04yz9PM+3kICPsjyb8NAuYsREbW1GWb53Q3n8pEsy9Bs444IjgbHfUi\nkvxtfsUwEokF5OUNJho9wKmn1vCb31zFiBGDCIeTgftJSztIYWFX7r//l5SUPMqSJZeybdseunQp\n4Jxz+hAMDiMl5QOglMzMWjxvE8cfP5Cf/ORcEglbwK4LZ501jEjkKFJTL6ShYQvBYG9kOgsBZQSD\n7+F5EcLhD/C8NHNvW5BZqwciuV1YYkxK6snPf34FnucdptX++MdtqKqqOxRWWlYWoaqqBt9PcMMN\ntzJjxq2tOQJfw2glgu/g+KRoo4svvoprr72FiopGlD28h+LiDQSD6cTjI7jool8yefJ9VFfPYtq0\nJ0hOPprbb78PWEtj49HAfObP30a/fmdzySUXcuaZI3BlmzMQyE3B9wMEAu8he7uNdLnOPE8DzsT3\nbdhiCIUt9kSA0hFJ1ykIHG25hjYI+N9DNutMlPSUjnOyhs06eiNALUYmnRjQEc+7BknoYQTWF5l5\nmpFt/nJEEuMQWJeiSJ4UREYJZEZ5F2kPWxCJFSBT1WZcJnGzubchyNa+E4H+S2at7VEfggJzbzYs\n9k0gxfQEljmlqQkSiV5cfvkPycpK4YMPdtPc3AG4ltraTHbs2ElZ2f5DJpPMzGRWr17Hpk05xOPz\niUZHUFBwgFtumcCDD95IUdHeQ53s8vOnAD7r1m1jyZJzuPvuHxMO96GqarP5NjUB4wkGk+nQoZZI\nxMf365DPwprX4uaeI9iIq9NPz2TbNvkLbIa77/u0bduWyy4771BYaTwe4MILzyA7ux1z565h7tw9\nrTkCX8NoJYLv4PikaKPFi+cyatRQsrIkDYdCYUIhj8bGZOBi4vFOxGKydScnpzJqVH8SiTACaNXl\naWyEESMGcMUVP6SkpAwB+OlAM6HQ26gU9kpSUmzDk4HIFLMa2Ifnhc3xQUKhcQhIZiOwrkBAewXS\nNNIQ4HpICi9EYGPbPp5pjgsgaduWaChCTtFZ2IiZU07J5sILzzLnZSOQbUClpNsi0N6D7PlTEIkE\nUd8EG3l0gllnAJl6ys2+2Kb2RchP8RNEYinmejapqxERVwecozWIyM5WEVWIq+93N/dzHuXl9Yfi\n7OfMuY9YrJnMzGrgT4RCb9HQ0JmcnHaHPv/MzGwOHux4SPNraoJZs25g6lSZXlavzuWll14nK+sd\nolE5l/fvb2bSpH/jyiufoqnpz4jABmCd4k1NPamqqqa2thdJST3N55LAlcZIQ8SoNT/33B7++Mf/\nZuHCxYfyYH7+81uZP7+YVas2EIkk0bfvNYRCcMcdf2XixOtoaOhOff1cJk26l44dR7XmCHyFo5UI\nvoPjk6KNAoEA48adSlNTDvn5lxOLdaRv3+7E4z4wGd/3CYUiZGf/iIMH6zn66P74fphAQCGSweAk\nkpIieJ5P//7nsG5dW2A+PXoMIRj8gFislt69VwOpJCd3AzwCgTDBYC55ebnADgKBPNq1mwe8SjS6\ni+TkbQjMi5FdfI/5sz2OP0CO6AZEFD4iphRcwbRdCNBXIsBu2YrSBwLs2LGTJ554AYHbk+a8nUyd\neipnn90HAfbjCKT/iLSbLgjstyNn6ShcE535KIa+HpFNEXJeL0LO6mPNNWxHsAPI/5CMSC0ZR15l\nuKiqShRR9D2gHM/bSSDwOrD7UKOhysrBVFXtJhQaRHPzscRijzN16mPk5Q2jY8dRXH31s8TjU6io\naCQUOp/q6kYWLlxK//7ncOONy6mpOYOSkmOor6+nvLwGGEtW1khGjRpAWVktNhdEJqAPUOG++dTV\nDSEe30lz89tm3eci4tqMiM1mGo+loaE9Bw505Le/vfNQWYm5c9+nunora9YUkZ39LlddNYh77z2P\n444bSCJxovnclXU8Z85Mduz47F7HrePIRisRfEfHJ0UbLVnyOBkZa4hGc4BM1qzZjn7si4EdJBKv\nUF1dweWX5/HCC28SDOYTCMTIytpJIJDB9OkFdO1ayE03TadDh46AR0VFHZ7Xm+uu+xG/+c0ZBIP5\nVFY2kp8/lUQizFlndWPo0CygHcOGpXHHHVcQDOYyYMBRpKXlISIIkZKSikB2FdDfRLH0QYC6EQF8\nLgKdMxF4NyIAOQWZfAoQeAdRmGoQ+CG1tYXU1AxFoOuRnZ1FYWEWDz+8nJde2oecnI0oXLQM5UH4\nKHxztJnzYgR0tsZQCPkQjjfn7sf1LF6EQkqXIVNSKrKn90F1l95GyV5vIzANIsCtQQQ4lVAoB89L\nIZHIJiNjMUVFz3HffSXU19+O73cxPaMrAI8DB+JkZKQQCMD+/doT3y8iFlsPHGDlyhKKinazffsz\nwAp8fx6JxHFUVr5Ghw7fZ//+DaxZs9VogJOBBnzfak7pgIfv27pOHZBTfCwihJlIE8o2e3IuECaR\nmEpxcVfKyl4Dlh7qVZCVdQKzZ8/E8+BXv7qDHTtyEbGqi1tl5RZuu+3O1lISX+FoJYLv6PhwqN0N\nN1zGjBl/4OGH72DWrBk0Nqo5TDTam/T0bqhOznCCwQ40NV3AnDkPs2lTBs3Np5GTk0n79s1cckkm\n2dk5zJw5Bc/zKC2tJhyeQEVFA7FYO+bMeY+JE6+jubmOROI1SksbgPN44omdPPbYW0Azr766hosu\nuoN4vDevv76e8vIIMuFk4/sHgVdITV0HvI7v9wf+jOvvu9M8FqKErGIkiQ9EfoS+iNQSyGH8AIrg\nWUxZWQiBcwdCoUHU1Gzn97+/gXnzfklWVj8Eah2Rqet4pHHsRlJ/d0RWA5EdX+YPPQZQ/R7b9yAV\nF0qaj0wmCVyYaAdktkpFUTeDURE6D5md0hChDCMWixMMRoBjiES60LZtwEjwHikpaQSDYWRymghE\nqawsoL6+kVgsgaqs7kQEOYWGhm4Eg1ECgSihkGoHNTX5XHPNeIqKHmXJkul06tSRcNhqaLb3Qg+z\n3vOBOJ73BEqms1VZPaRBBUlKqgTWkJrqKsWmpKQRDh9Fx46vEI/7pKT8mqKiZ/B9/1C2sG2elJ2d\nRufOqYRCu1i1KpeamrGtpSS+otFKBK0DcPWKHnnkuRZmo+tobi6lpmYl4fBDwHyam7sAD5KUlEp6\neiYwlaSkfH7zm6tYsODmw5J7liw5m8WLLyU19QNgH8FgiVHxryQzcwDhcCowFt/vipyIavaeSLQF\nbsf3B6L8hKV4nk9TUxPB4GhOPfVoevVqj6tkmornNZOU1I9evboQDpcg8mhCtXlswlcESbNHEYnY\n6px98LywkXRVOC07ux85OZUsXfr4oVIc0h6ScBm6FyIC2IBrktMZmYg2ANtp334dUEQgUIqArxQr\noQs4bSJbGwTwE3HhpN3N+q0JK9XsUX+U2b2Ptm3XEotFgdmUlpZy8GA1TU0h4BpqahI0NVWTkmKb\n259FfX0tffr0IBjcSDi8FxHXfGA5sdhq4vFarrpqLNFohIKCqcRiAU44YRCBQIAJE8by7/9+BZBi\nkgiPRQ70GDJ95dKt23bS0/OAPYTDJQQClWRl7SAQSOacczx+85tpXHfdBBoaGggE0vC8F6mvT3Dl\nlQOZPn0IZ5+doK4uCd8fyty5iw+ZMBOJEH37XktV1VZ27aolEhmFzU7eufNZRo7s31pK4kuOViL4\njo+PiyCaNu23XHRRlPXr/8QPfjCU4cN70r59Ni1DSuPxdtTVxT8xo3nmzCmUl5dx3XV/oKamPfAo\njY2dgD0Eg7MpL3+XpiZIS7OlFQJI2u6CizYJmOdv4fshfD9EPF7GY48l2Lx5v7mSpN309L4kJ++g\nsvIAnhcjFBqMMmPnI6nYFm/7BxAiHg+Sm3sJ0WiUa665gGDQOpRjxGIwe/ZM6utrDpXiECi/hutI\n9iLKFWiHczp/gOzh/Rk8uJBjjhnAlCmnEInsR1FCauWoc7ehePuzEAG+iaKGXjTHrjDHBxBp2P0I\nIWfxGRQW5mMT3Xy/Kz16dCESURhtNFrOyJEDufvu3xCNhsnNvZ9EohNduuRx//03snjxb0yIqUco\nVE4g0Jbq6uE8/fRy7rprLLt2LeTee889LEFx69bd3HvvdBYsuIJIpJLk5DeB/QSD24EF7N3bherq\nD+jQ4X+APK69dixlZc/w4IM/Y/jwIcyYMYXs7BwuvHAIDzxwLg8++CMuuCCdbdt2ceutf+aJJ1ah\n/IkFrFgRJBTqx3/+5xwuuiiK728mKysLOIWqKoXwBgL7CYW6c9ppY1pLSXzJ8X+leX3r+IbG1KmT\nycrKPqxZ+Lx5/37IbHTvvX/k739/mksvfYbc3Euork5l9uwJPPLICwAsWfKHT2wnOHXqZF555W2e\nfTZOebkLBc3Le4kuXXbz/vvr2L8/D0nKM5HNXP0N8vOnsHdvMr5/ACVsDSeRiKHksZuRD2AtCu+8\nhObmeTQ3Z1NX152rr+7Ck0++zObNNgQ1juvatZ7CwlrC4fdZv/5J/uVffsmCBQ+RnNyFurq/43nf\np7x8N4sWJVj5/9s78/Aoy3Nx389MJjtbwmYJCAgqIbig4gICPRXZke1SFPW0/CSsR5bQg8FWPR4L\nbhWNW4we8UiiaJDFtoIg1aK1CpXqAYoIBYWgQclCFrLNzPP745sZQsgyCRMmy3tfVy6Yybc873yT\n93nfZ/28E4MGufjLX/ZhlcW4iNMd1S7Ectw6K93DgWXHzmX//mJ69HBy6lQOp06VYWUjW9m+0JvY\n2BPk5XXC7Z6JFUK7B8sM9BMhIftwOqOx2b712M3DscJcf4cV+toOeIldu2aiup22ba+jouJqRKC0\ntBNxcbM4ebIbCxeO5ptvjrB69bgz2j5OnTqKtWs3IxJK+/bTKSiIom3bjuTnT+Trr99l0aIV5OSc\nOCuBy5t7smLFy6Snz2D//m/57LMv2L49jJMnhbKyEMaPH8iGDamsX7/VVwOochvKys3mAaZOHUVq\n6mp27NhNQUEspwvw2Rk+/Aq2bLF2BmvXbvZ8R4fhdq8nNvYuystjmDWrty8M1dBwzI6gleNPvSKv\nYzk7+1VWrx7PwYNZZGQ8QUbGE7Wm84sIkyePoLxc6NYtERDi4l7jp5+K2LfvIN9/P4Dy8h6EhWVj\nTYIHCAnJw27/hqefnsINNxQSEtKG+PjF2GxdsXYM3o5jFxIT0xZrcl9MSUkWTmc33O4hPPXU2+zf\nb8faWXiLvIUTElJMRMRAbrnlF2RlXcr69Vu58sp+dOgQRUmJFWYq0g2brZxPP82lsHAle/d2xOks\nReQ4pxvdezuSTcayj0/A28glPDwfmIHTGcGhQwf45JN9nK4z1A1LYfQhJ6fMY44ajqXQ+uB1Fjud\nkUABbncx1m7mB04X1fuQ0/4EO+PGDeHRR+cQG7uHI0fswC2Eh3ekXbt/kJ6+sda6PBkZE8jJWc3P\nf15MQcHXeJ3ELteVpKSsqdHu7r3msmWz6No1lsLCchyOO4Eodu4sZcCACZw48ZPfJR5mzbqTadNG\nez7bfLzRUldckYDNZjvjO9qp04uEh+eTmjqdVavGEBvb0ZSSCABmR2Cos1l45VVc5dVdfa69f/93\n5OXlcvDgd2zb9hnl5VehegPwNGVll2I5ahfhdn9M27Z5ZGS8y9ix/0b//of45JPdREX9jMLCScBG\nRG5BpAsjR17Gjh27OHRoMKofYk0k32MpACfWruE9rKicHFQrCA9388ILNkpLPyU5+bc4HF9xySVx\nHDsGsAhVYezYG/nyyxhOnRLy8w8SGWnn1KlvsZy0RZ7rF2PlNPzgGelkYB+lpT1p1+5R3O7Lueee\na0lL+5jiYu/EHcnp3gvbPeduw/JjeAvqKad9DdtxOL6goqIHVqRRsSe57zJCQ++gvLwtl17ai9mz\n7yY2thP33PMnYBRlZX9h5crkWp9V5Wc6a9ad/PWvq3A6c3A6rbyC//qv+X496169erFwYRvS0rKo\nqBhDSUma3+d6ERGys/MQyaFDBxfFxaH07p3Fnj1nL0Yqf0eNAggcRhEYzmmir8+1ATIzN7F5cw4O\nRwhwJzbbO7jdXhNOBG53D2bMuIYnn0z2OArdDBw4jpISF1YYaBGdO7eltHQH69YpZWVXYq2kJ3A6\n4cyBZbp5AWsCXYpIOm3a7CcmJpJDh+KBrZSUuIiP78bOnf8EOtGtm4OcHMjPDyE/P5LY2JspLb2U\nuDgX+/f3BCYSHZ3CqVNhuN1RWKvXrljO4eexzFZpdO58PyUln/LJJ+0pKcnB8lXc5jm2DfB7LHNP\nV6zdSnusVf40LEexEBHxPjCAOXOG8cwzOz25HG1wu08yfryyYUM6S5c+7ms9+uSTL1NY2IXo6Gnk\n53epVwnmgwezmDfvStLSjtOuXSI//hji9/nJyYkkJa2gqEiJi3uHkye7N6j8c0LCxWRm3lTjRN+Y\n31GDMQ0ZzhNep/T9939CaemvKCx0Y7dPRjUbmy2E003iHbzxxtckJIznpZfSWbduC/v3t8FmC8Nu\n/xD4kYKCLKKj29Ghw2VYk2kGlqP2AqxoEjtWoTjFMiVloWqnuDiPH34IRfV5QkPXkpX1Lhs3uvn+\n+3bAO5w6FUNsbDb79n1NYmIXiorCCA/fwfff9wBeJDT0HYqKvsNu30tU1E9YvZJ3YTmSy/A2wjlx\nooiVK+9j4sQxJCR0o3Pn/8MyIY3BcgSXY+0sQGSa59wPgaNERBzA4ThAz57R3HVXG156KROHoz2Q\nSvv2XWnbFux2fK1HJ00aSo8ew9i5swxwU1TUHofjb6Snb/T72SQnW07cVatG8913qYwZ4+bAgSN+\nP9P//d8vqGqSqi+mcmhwMYrAcF44s6xFFrGxxSxYcA12eye6d/+GhQsHEBb2T+BCSkqKGTIkgZSU\nNSxb9jGlpb8gMjIHl2s30JPycuW220ZRUaFYlUo3cjrcUrBW4IL+jYX/AAAVJ0lEQVRVSfRCrJwC\nB253FKdOXQTcj9O5C5ttIJZJKhYYT17eIVRLyMsT3nzzOGVlG3E4+lJcXAEIXbrEsnjxnUyZMpaY\nmIuB0TgcbbF8AD8HhLZtp+N0WiviZcsS+eqrDTz33ENEREQTEvI6cDFhYbFYOQXf0qGDnauuCsPK\nURhIZGQcb7zxJHv3/pErr4ynfftonE4ruqeoCNq0iWDkyCGANRGnpKyhoOBSrGxoAbJwOrvwzTdH\n6hVb752I163bwrZtEfTt2wOovR+295lGRvbFMkkpK1cms27d837f19A0MIrAcF6o7PDr2vUP5OXt\n4803f8TpfJfQ0Bt4/fU/UFYWTVzcUdzu7owYMbxSX+VICgoO0r79EOAlOne+gldeWUd+/r+IiPgM\nt3sflm/Aa14J89w1EivEswPwV1wub4ZqNm53OQ6Ht91kOFZo6Qmys/vjdj/MDz+cAmwUFJQSFhZN\nfPwi8vNLueGGgUyZcjM//riH0NCrqajog9W57RtEPmPatO6sWjXmDD/LwYNZzJ3bDbu9AJttG2Vl\nF2JN3JeQm/sZX3zxL6ywyRRycpSZM39LWloGs2bdyW23jcLlAliMy6Xceutovv32e0/ClTUROxze\ncFuA+YSE9K53m8aaChHOnp1cYwav6QrWcjCKwBAQals5evE6/I4d28DChVN8GaOHDx+nvLwb8Cci\nInrTrt2XZGSsr5TM9Sfs9p7Y7d649wjGjh3KmjUPUlj4CQkJP8Ny3h7FKsvgreGTTURENFbMvhur\nPIVV2dPhCKGsDCzbfbjndzbc7n/hjdmPjb0Lp7OMhIQsdu/2luI4wrPPvs7q1XM9sfhW57UOHdqz\nePFt9Ox50VmmDa/pJT19Hm+++Rihod6JO4rQ0F7YbL3whk22adOW0aOHkpg43edEDQvLpV8/JSws\njx079vDCC9m+MuAiQlFRBbGxdwFCTEwqRUUV9Z6QqxYiPHGikIKCAv78Z1ut/bBNV7CWgVEEhoDg\nzUyurfaL1/xgs9m4/vorPRmjiwgJCcXptEpFl5YqK1fex8iRQyolc2UQGVlCTs4punadQX5+CVOm\n3MzUqaOw2+2MGDEcq9RBF6yvdDesomhh9O9fQXR0PlaYZgFeX4Sqg0suOUJMTFcs270Tm82FVYbi\nISCXkBCIjv6BXbucrF+/lSlTRtKnT3f+8Y8ufPDBxyQlPUpFhZXJm5tbyltvbSYmJoLqSE6eydSp\no7DZ7Njt4Yjcgc2Wj6oNuz0cmy0fkTtwOm1MmXKzbxJPSLiY9PQZLFgwkI4dj/P11+3PmJjT09eT\nkTGBxYtvZPHiHkRFnSA9fbxfE3Jl5e29X3b2F/TrtwinU7j11tGeUiM198M2tv2WgVEEhnOiJpNC\nXfbp0yvJp7jpJielpfHExd3uMy/MmnXnGX2VIYKkpF4cO/bKWSvPvXsPM358Z0JCvKahHByOLlx0\nURhHjpwgOnoYlhP5AuAAkZG7sNm6MnbsMAoL9xEV9Tgix4mKsuL9RfoBhzl+/HPCwgbjcr3LnDkv\nExZ2madS5u/JzPySkydPERGxH3iKmJhihg4dVKc55sCBI/TseYC33rqLt96aSHx8FP36VTBhgvLW\nW3cxaVLEGWPzTrSJiXfy1FNLiYiwooq8E/P69amemH4rT+Po0QHs2PGVb0J2u91cd91k3G73WbJU\nVd7r139ASMglPPzwSFatGkN2dm61Zh9/dn+G5oVRBIZzoqbeBnVNiMnJMzlx4icSEsbzt785gFTC\nw3uh+iGrV79zlv3Z7e7uq3szefLN5Ofn+iai999/meuvv4Zbb40iM/OXZGZO5tZbezFjxnSee+43\nVFSA13nscPTktdf+mzfemMe2bZ8TEnIJr722hEWLpmKzeauGhtOtW2/Cwi6nvNw6NyysD/PnTyMs\nLArYQn7+hQwbNhCb7TLi45MoL49l8uSb6jTH9O3bg6ysfr76PV9+uZ7f/nY227ZFYLPZyMh4osbk\nvJrs8dOnz/c0CfoWeIFnnjlMWNhlTJ8+n1//+jE+/7wLS5c+7rtWVeXtVXLbtpVTUpLCsmUf88AD\nz1JcXFCt2cef3Z+hmaGqTf7HEtPQVMnM3KRt2izU+PhF2qbNAl27drNf57ndbn377fe0e/f7FFRj\nY6drRMR8zczcpKqqy5en6dq1m9XtduvatZt1xYqXffeLjl6gEyfOUrfbXadsYWFzNTb2ToVZOn58\nok6cmKjx8WO1b99lCm7t23eZxsUN07Cwcdq58y81ImKeZmZu0qSk5RoWNtc3rptuukNttqs0NPQe\nBbc6HHdrXNwwTU19/Qz5qo5x6dLH9MUXXz/rnl27XqsXXDBE+/RJVnhU+/RJ1vj4sZqaurrasdT0\nebhcLl206BG122crqNrts/XSS4draOgAdTgSPbImamjoAL3jjnlnfe5xcUt18eLfaffuSxVUu3e/\nTzMzN6nL5dKlSx/zfcapqavPGkNt8hqCj2furHOONTsCwzlz4MBRXn11JOPGdeHVV0f57TD0rmi9\nETi5uRG+FWn//uOIiYk4w/7coUO4byVbVDSSjRuFHj2G12qGSk9/l06d9tChQ3dgIp9+msP+/VkM\nHpxwxi7mxhuvIj193hllNGJjO5KRMcG3IrbZIli4cIqvAF9FRTi33WaZbWqyj3tXzx07duLBB+eS\nnZ3vu2dKyoM8/XQyeXlHgGzy8o7WupuqyR5vlWGw4XJBaOgduFzKmDEjmDfvNk+tIqtY4Pz5t7N6\ndcpZu4uTJ0s9r8vO2G2sW7fljJV/Q3d/hqaPUQSGc8ab9fnii9mISL0chla56nmsXv0wMTFWWema\nJpjExOkMHtyfw4e34G9dnPXrn6/UX2EUkZF9efjh/2DEiGFnmFm8zufK/RlOnsxj8uSbfe+9//4r\nFBYWcOxYnqe2TjgZGft8yW9eVJVRo+4mPn6sz/yybNnHzJnzMIWFh4iLSyQ/v4QPPthOUtLj5OZa\nbTNzc8NZtOhR0tIy6vcAgD17DrFkyYWUlKSzZElP9u799izlYLNZXei8n3tls8+ePYd8r2+/PZI5\nc/77LL9PWlqGCRdtoRhFYDgnGuos9nI6msZGebnUOsGICCNGDCckpFel5in4lIZW48SsybZ+8GBW\nrWGPNdnBrdo6PenSJQ5vjf+qSuudd97n009jGD16iG/1bIXIRgH3+jJwjx/P58Ybr/IpwJiYKIYO\nvZqZM++otzP2/fdf5okn7kNEsNttbNr00lnKwVuOwvu5V95dbN78su91aurveO65ZWfsXrxjNOGi\nLRR/7EfB/sH4CJosVe3NXvtyXbb7qtRk/67uuKSk5dqmzQKNi5upoaFzfD4Jr6+iqo/C32ur+mcH\nr8knUvXcCy5YoDbbVdq16ziNiPD6Kc78jKq7Vk3j8IdzObcyixcvV5itcXEz6+X3MTQt8NNHEPRJ\n3i8hjSJo0jTUWdxQqk7sEyfOabAT0+vM9SqumhSb13Hqcrl06NDbfRN5ZcVS9dx27eZrUtJydblc\nmpS0XENDJ5z1GVUeS2JisnbqNLhB4wiUI9d7ndjYyQqbtE+f+zQubqhOnDinXtcxNA2MIjCcN+qz\n4q4vLpdLr712krpcrhqP8XdXUnXSV61+BV3TKj06eoFec83EWpXd6XMXamjo7DojoBoyjnP5DPy9\nTmzsAk8k14IGXcfQNPBXEZgy1IZzpjFLBFeOg3/iifuqPaaqH+DoUXe1Pgav3f+aa7Zw4sRPpKSs\noaLico9v4zc88MCz3HvvNHJzS3y172fPXsbcuQ+jegFFRSfYubMPsJK5c+/1HV+5k5fXhu52u7n7\n7tfYsGEbU6eO8usz8nccgT63MmlpGTzySBq5uf3xZkzX1LHM0HIwzmJDk6S2JKnqqM2JWZ1DOyVl\nDYMH9682FLKyIzU1dTm33DKE3NxvsaqadgSE3NwSBg8ecFZkU0xMBA888Kyn3PYaduwI9TnPVf2v\nx9QQZ2wgHLmJidO58cZBxMQUUZ+MaUMzx59tQ7B/MKahVkd1SVKLFy+v1URUEzWZTd5++71afRtu\nt1v/8z8f1VtuSdSwsKlqs01UWKh2++2+pDN/71XZMdzUHa/n2+djaDxoLgllIpIkIm4RiQm2LIam\nQ3VJUpXj4OvDuYSQpqTs4o9/FLp3P0FIiIuYmMPYbO2YNy+u2qbp1d1r69a/kJAwvsEhtvVF/dh5\n1IYJEW2F+KMtGusHiMPqGnIYiKnluIBrSkPT5+ab79ElS1aoy+XSJUtW6MiRMxt8rfqGkHbpMkht\ntn4K9ym8pzBLIyMvq7WcRE33Wr48LSCOXH9pLjsPQ+ODnzsC0QauGgKBiGQCDwPvAlepam4Nx2kw\n5TS0LlSVpKTlrFz5HfA5MA54hK5dFxETc/AsB7E/rF27mRkz3qd7d+HoUTerVo0OuGPd27GsouJy\nDhx4hL59f4PD8VWD5DW0DDzVYuuMGAha1JCITACOqupuk6JuaCp4J9O8vD7AS8CvgE1APyoqrCzm\nhkzgXnNL5ebsgUJVSU5+guXLlxATE0tS0na8DvDlyxsmr6F10aiKQES2YnUL8b2F1YrpN8AyYESV\n39XIQw895Pv/8OHDGT58eKDENBh8JCZOJyYmlpkz38PqGBZJaelFhIe/R2Fhe79CMr0T84oVv/Yd\n25ghtqfDYrcGJITU0Hz56KOP+Oijj+p9XlBMQyKSAHwAnMJSAHHAMWCQqv5YzfHGNGQ4b1Q24xw8\nWMq99/bg8ceX+lbydRXV856/atWoRl2NV2cKys//iEmThpGa+ju/5TW0XPw1DQXVR+ATQuQwMFBV\n82r4vVEEhvPGihUvc/HFPc4w4/gzmZ5vG72qsnbtZpKStnP06Aq6d0/mqaeG+XIgDIYm7yOogtUY\n1WBoAjTUjOM1K50vG32gsokNhqDnEQCoau+aIoYMhuZC5Ym5X79FZGd/4Xu/sTAx/4ZA0CRMQ3Vh\nTEOG5oLXrOR2u/n3f3+PSZPCych4IthiGVop/pqGmsSOwGBoDPQcM2wbQuVaQyUlKezcGdqoWcQG\nQyAwisDQYqmpy1igqE7RmL6+huaIUQSGFse5ts/0l+oUTU11jYwD19CUMYrA0OJo7FV5XYrGOHAN\nzY2mEj5qMASMxg6rrCtMtDGziA2GxsDsCAwtksZclRvzj6GlYcJHDYYG0NDsY4PhfNKsSkzUhVEE\nBoPBUH9MHoHBYDAY/MIoAoPBYGjlGEVgMBgMrRyjCAwGg6GVYxSBwWAwtHKMImgCNKS1XHOiJY+v\nJY8NzPhaC0YRNAFa+pexJY+vJY8NzPhaC0YRGAwGQyvHKAKDwWBo5TSbzOJgy2AwGAzNkRZTYsJg\nMBgMjYcxDRkMBkMrxygCg8FgaOU0K0UgIv8hIvtEZLeIPBpseQKNiCSJiFtEYoItSyARkcc9z+1L\nEXlHRNoGW6ZAICKjRORrEflGRJYGW55AIiJxIvJnEdnr+Xu7N9gyBRoRsYnILhF5N9iyBBoRaSci\nmZ6/u70icm1txzcbRSAiw4HxwABVHQA8GVyJAouIxAEjgO+CLUsjsAXor6pXAAeA5CDLc86IiA14\nDhgJ9AduF5FLgytVQHECi1W1P3A9MK+FjQ9gAfDPYAvRSDwDvKeq/YDLgX21HdxsFAEwB3hUVZ0A\nqnoiyPIEmpXAr4MtRGOgqh+oqtvz8jMgLpjyBIhBwAFV/U5VK4A1wC1BlilgqGq2qn7p+X8R1kTS\nLbhSBQ7PwmsM8EqwZQk0nh33jaq6CkBVnapaUNs5zUkRXAwMFZHPRORDEbk62AIFChGZABxV1d3B\nluU8MAPYFGwhAkA3oHL/yyxa0ERZGRHpCVwBfB5cSQKKd+HVEsMmewEnRGSVx/SVJiIRtZ3QpJrX\ni8hWoEvlt7Ae1G+wZO2gqteJyDXA20Dv8y9lw6hjbMuwzEKVf9esqGV896vqHzzH3A9UqOobQRDR\n0ABEJBpYCyzw7AyaPSIyFjiuql96TM7N7u+tDkKAgcA8Vf27iDwN3Ac8WNsJTQZVHVHT70RkNrDO\nc9xOj1M1VlVzzpuA50BNYxORBKAn8JVY3c/jgC9EZJCq/ngeRTwnant2ACLyS6yt+L+dF4Ean2NA\nj0qv4zzvtRhEJARLCaxW1Y3BlieADAYmiMgYIAJoIyKvq+rdQZYrUGRhWRj+7nm9Fqg1mKE5mYY2\n4JlERORiwNFclEBtqOoeVe2qqr1VtRfWQ7yyOSmBuhCRUVjb8AmqWhZseQLETqCPiFwoIqHANKCl\nRZ+8CvxTVZ8JtiCBRFWXqWoPVe2N9dz+3IKUAKp6HDjqmScBfkEdTvEmtSOog1XAqyKyGygDWsyD\nq4LS8raqzwKhwFZr08Nnqjo3uCKdG6rqEpH5WBFRNuB/VLXWyIzmhIgMBqYDu0XkH1jfy2Wqujm4\nkhn85F4gQ0QcwCHgV7UdbEpMGAwGQyunOZmGDAaDwdAIGEVgMBgMrRyjCAwGg6GVYxSBwWAwtHKM\nIjAYDIZWjlEEBoPB0MoxisDQ6hCR+0Vkj4h85anFco3n/bTGqLApIoU1vP8/InJcRP4v0Pc0GOqD\nySMwtCpE5Drg98AwVXV6ej+Eqmp2I96zQFXP6sEgIkOAIuB1Vb2sse5vMNSF2REYWhsXACcqlTPP\n9SoBT1XbgZ7//z8R2e+pdpsmIime91eJyDMi8lcROSgikz3vR4nIByLyd89OY0JdgqjqJ0BeYw3U\nYPAXowgMrY0tQA9PZ7HnRWRo1QNE5AKsqrCDsAqUVTUXdVXVwViNkh7zvFcKTFTVq7FqYv2+sQZg\nMAQaowgMrQpVLcYq0ZsI/ASsEZGqdasGAR+p6klVdQGZVX6/wXOtfUBnz3sCrBCRr4APgJ+JSGcM\nhmZAcyo6ZzAEBLUcY9uB7Z4ihncDr1c5rLbCf5UrqHqPmw50xKoc6xaRw0B4gEQ2GBoVsyMwtCpE\n5GIR6VPprSs4u0/0TqxueO08Nfmn1HZJz7/tgB89SuDnwIXVHFPT+S2t2qyhmWF2BIbWRjTwrIi0\nw2rQfhDLTASetoWq+r2ILAd2ALnA18DJysdUwvs6A/iDxzT0d85sFl5taJ6IvAEMB2JF5AjwoLfP\nrMFwPjHhowZDNYhIlKoWi4gdWI/Vb6AldekyGHwY05DBUD0PeRqy7AYOGSVgaMmYHYHBYDC0csyO\nwGAwGFo5RhEYDAZDK8coAoPBYGjlGEVgMBgMrRyjCAwGg6GVYxSBwWAwtHL+P8lqdlEytmPoAAAA\nAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"%matplotlib inline\n",
"\"\"\"\n",
"Cocktail Party Problem solved via Independent Component Analysis.\n",
"The Fourth Order Blind Identification(FOBI) ICA is implemented here.\n",
"\"\"\"\n",
"# Import packages.\n",
"import matplotlib.pyplot as plt\n",
"from scipy import signal\n",
"import numpy as np\n",
"from scipy.io import wavfile\n",
"from scipy import linalg as LA\n",
"\n",
"# Input the data from the first receiver.\n",
"samplingRate, signal1 = wavfile.read('FOBI/Sounds/mix1.wav')\n",
"print \"Sampling rate = \", samplingRate\n",
"print \"Data type is \", signal1.dtype\n",
"\n",
"# Convert the signal so that amplitude lies between 0 and 1.\n",
"signal1 = signal1 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"# Output information about the sound samples.\n",
"a = signal1.shape\n",
"n = a[0]\n",
"print \"Number of samples: \", n\n",
"n = n * 1.0\n",
"\n",
"# Input data from the second receiver and standardise it's amplitude.\n",
"samplingRate, signal2 = wavfile.read('FOBI/Sounds/mix2.wav')\n",
"signal2 = signal2 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"# x is our initial data matrix.\n",
"x = [signal1, signal2]\n",
"\n",
"# Plot the signals from both sources to show correlations in the data.\n",
"plt.figure()\n",
"plt.plot(x[0], x[1], '*b')\n",
"plt.ylabel('Signal 2')\n",
"plt.xlabel('Signal 1')\n",
"plt.title(\"Original data\")\n",
"\n",
"# Calculate the covariance matrix of the initial data.\n",
"cov = np.cov(x)\n",
"# Calculate eigenvalues and eigenvectors of the covariance matrix.\n",
"d, E = LA.eigh(cov)\n",
"# Generate a diagonal matrix with the eigenvalues as diagonal elements.\n",
"D = np.diag(d)\n",
"\n",
"Di = LA.sqrtm(LA.inv(D))\n",
"# Perform whitening. xn is the whitened matrix.\n",
"xn = np.dot(Di, np.dot(np.transpose(E), x))\n",
"\n",
"# Plot whitened data to show new structure of the data.\n",
"plt.figure()\n",
"plt.plot(xn[0], xn[1], '*b')\n",
"plt.ylabel('Signal 2')\n",
"plt.xlabel('Signal 1')\n",
"plt.title(\"Whitened data\")\n"
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"collapsed": false
},
"outputs": [
{
"data": {
"text/plain": [
""
]
},
"execution_count": 27,
"metadata": {},
"output_type": "execute_result"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZUAAAEZCAYAAABfKbiYAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJztnXn8b0P9x18v++7StcZ1kaVQ+EXZoptsabNljVQiS0VR\ntmQpUpSKVChLKSo7aUHUlVISUtl3cV1cruXmvn9/nDn3zne+Z5lzzpz1+34+Ht/H55w5M3Pe5/Od\nz3nPvOc976GIQFEURVFCMEfbAiiKoijDQZWKoiiKEgxVKoqiKEowVKkoiqIowVCloiiKogRDlYqi\nKIoSDFUqCgCA5J4kbyxR7iqSe9Qhk3Ofc0geW/d9lOGhbbtZVKlkQHJnkjeTfIHkEyQnk9yvbbmS\nIHkdyb0rVlN40ZKIbCMi51W8byVILk3yUpKPkpxJckKb8vQBbdseBbrRtrcheSPJqSQfI/k9kgu2\nKVMeqlRSIHkIgFMBnARgKRFZGsC+ADYkOXfDsszZ5P16yEwAVwPYDiVeHmMNbdu9YhEAxwFYBsAb\nASwH4ORWJcpDRPTP+UP0j3wBwAdy8s0D4GsAHgTwOIDTAcxrrm0K4GEABwN4EsCjAPYqWPZQc+1H\nAMYBuBzAfwFMMcfLmvzHA/gfgOkAngdwmklfHcC1Jv8/Aexo3X9xAJcBeA7AzQCOBfD7lOecF8B5\nAJ4GMBXAnwAsYa5dB2BvczwHgK8DeArAvQD2R/TCn8PKeyyAm4yc1wBY3LrPz8zzTgVwPYA3WdfO\nAXBszv9jTnO/CW23oa7+advuZ9u28n4QwN/bbkdZfzpSSWYDRD+My3LynQTgDQDebD5fD+Bo6/rS\nABYGsCyAjwH4DslFC5QdB2ACgH0QNeqzASxv0qYD+A4AiMiRAG4EcICILCIiB5FcANGP7nwA4wHs\nDOB0kqub+k83dSwF4KMAsswLeyJ6Gb0e0Q92XwAvJeTbB8CW5pnWBfABjB457GLqWwLRD/qz1rWr\nAKwMYEkAfwVwQYZMSjm0bY+kb217UwB3lizbDG1rtS7+AdgNwGNO2h8Q9TKmA9jYpL0AYEUrzwYA\n7jPHmwJ4EaYnY9KeBLC+Z9mXAcydIePaAKZY57N6VeZ8JwA3OGW+C+AoRD/iVwGsYl07Aem9uY8g\n6oGtlXDN7s39FsDHrWvvAvAaRvbmDreu7wfgqpR7jkPUE1zYnOtIRdv2mG3bJt+7EY3MVm67HWX9\nzQUliSkAxpOcQ0RmAoCIbAQAJB8CMAfJJQAsAOBWknG5OQDQricub5gOYCHPsk+JyIz4hOT8AL6B\nqLc0zuRdiCTFtDiHFQC8neQzcRWIXrrnIupJzQXgESv/gwA2Sfk+zkVky73Q9EYvQPQDes3Jtywi\n00bMwxjNE9bxdAALmeebA8CXAeyAqPcp5m88gGkpcinF0bY9kl60bZJvN7JtLyL3+pRpCzV/JTMZ\nwCsA3p9wLf5xPI2o4awhIoubv3EismhCGRefsu6P6RAAqwBYT0TGAXiHI4+b/2EA11v1LyaR+eAA\nRHbhGYjMDTGpHlMi8pqIHCciawDYEMC2AD6ckPVxRD/Q3DoT2A3AewFMMs83EdGzMauQUhht27Yg\nPWjbJNcBcAmieavrC9y3FVSpJCAizyGadDud5PYkF2LE2oh6YTA9qO8D+IbpnYHk60lu4VF/mbIL\nI7L1Pk9ycQDHONefBLCSdX4FgFVJ7k5yLpJzk3wrydVMD/MXAI4hOT/JNyGyBSdCcjOSa5oe1wuI\nfrRuTw6IJiM/RXJZkuMQTcb6shCil91U4zL5FRTw5CI5L4D5zOl85lxx0LY9kq63bZJrIvJsPFBE\nripwz9ZQpZKCiJyMyLvlUETD2icAnGHO/2iyHQbgHgA3k3wW0eThqlnVWsefL1j2G4h+9E+b+7sN\n7JsAdiQ5heQ3ROQFAFsgmsR8zPydiGgCEQAORPRjfhzRJOnZGfdeGsDFiLxp7kRkPz4/4Zm+b57j\ndgC3ArgSwP8sM0nWD+lcAA8h8iS6A7O/Y19eQuR1IwDuRtRbVhLQtj2CrrftgxGZyc4iOc38/aNA\n+cZhsslSUapDcisAZ4jIim3Loigh0badjo5UlGCQnI/k1iTnJPl6AF9EZIpQlF6jbdsfHakowTBe\nPDcAWA2ROeoKAJ825gpF6S3atv1RpaIoiqIEQ81fiqIoSjBUqSiKoijBUKWiKIqiBEOViqIoihIM\nVSqKoihKMFSpKIqiKMFQpaIoCkiK2adEUSqhSkVReoZZ1V3Htr8ahLMEJH8aeltkkkeSzNtIrZOo\nUlGU/nEOgAfcRJKLk5xvdPZuQnIcyR+QXM9Jn4/kMiXr/DrJt4WR0JudAPyP5BsC1hmHy+8dqlQU\npX9sAmBZkus66VOQHZG3M5D8AqJo0h8FcItJ24CkADgVUeThMhyMaOvfNlg/PiD5GZLLmOcZU+jO\nj4rSI0huiWiTJyAKwU6S+yEKjw5EuyL61DMnou1PZuZmrofDYXZGtIj3mF+qYVlCcQHJS0XkRQCn\nIAr/HxSSbwFwe8qOmJ1ARyqK0i+uSUg7HtHGW0WYgmgfk7ZwFUovMRGLbcYnZgzHbQDeWfM9KqFK\nRVGGxUTPfIsC+L8a5ajCB9sWoADjnHN7wv7NvpWQXLSAqazTDhWqVBSl/9h7nS9bqGA9XmSdwmyX\n/KaaqndNdbZiOL5APYsXyOu1t31bqFJRlLHNqyTf07YQhsIeXyQPIvlgTrYNEG0VXAeb5WUg+V2P\nejo7R1IUVSoDh+RKJF/XthxKrYzouZJcumD5ieaz7XYywpuN5HdJLppT5p0AJpDcleQOJm1vJ8/8\noQQsySdILuKT0axPEeu8d+/o3glcNySPM7u8DYV7AVzUthBKozxOcq0C+WOldH0NslThEwCeyckT\nv4AvQLfb+XM51+PnOM5J77SpKwlVKqM5EsDabQsRGHcyURkWSUsDynhXjZgfML3m35UTqRgkF0u5\nlPeO6prZaEOS85QoV+Q5Oq1oVKlY9HGoWQSSN5M8s205YkjeTrJNt9beQ3IaqrvnpnlbHY7m3Ff/\nDGD7EuW6FkHgfACvBKgndlXu3TupdwLXzK7mc/XMXDVBcrGy3jgkF8lQinHP5m0AtihY7xIklygj\nkwdrAfhUTXWPFdIUSmLPl+R4yxNqYfM5yXy6I54mzcArp10g+Y6Mctt41N210cwISG4IwB3dxP+b\nTrsPJ6FKZSQbms+tylZgor1OLFn8GRRfxBbzHIA7SSaZQtYmuUleBSST1i38F8DDJWVqBePz/7W2\n5egCJOcn+W4r6XzM9oQqMu/SJrvmZxlJkrNCjW7FVfkDgNNSrvXuHd07gWvmo4HqGdXrKjBxOqHC\nfVcHcEbKtd+bz4kZ5f9iKyWSG5nD0r0lkhNMnKey5TcuUWwSgENKlh0Kx5mR60cAXGulZ3ohkexs\niBSS463jOUhunZH9ewlpnwwvFbyDV8a/J2NVcDt/afMwUxPSOm0yHvNKxURK/YA5jf+xQSfCSC4O\n4HbP7IX/JyRteT9WoNy9JJd3728pkxAhJ/YE8OUyBc3k7Y2mt+29OhnAL8znhpm5hs3miMxXblvO\nM2l10amDJD8D4CnLxLsugKuyyiSk1WHOK2JOvsl8PgfgK861tEWrSe+DkNGQgzPmlQqA/QH80klb\no2KdyznnRfZa2LnE/XayT1JMYEmshNEmkFcA3GTmdtLs8keQXNDzHgvnZ0kl/sEeCeDvJcqfVOHe\nQ+BJAN8GAJI7kFwOQN6cXRe/MyIK0AgAG1lpWWxrOnMAEI9oWn/fkYyDTK7jXHpjRplOe3u5tP4l\ndwD3nwsAVW2vPyxagGSqiYnkljkLGN0FYrkrk61NhQ4x515ukCTXRxR+4gCf/AA+55kviQvN5+EV\n6hjL2Ir/IgBHIb9tvJ/kkvWJVIqPW8dFvNHiecRVzGcX3nexafxdJB9tVZKa6MKX3DZl3BiLIgBQ\nYWX7NQCOSLpAcgMArpuwzw8vdsWMPX+2c64vB2ukQvKTZqXvn0zSgR738IbkxiTXDFmnqVe3d5iN\n7z4jb6lVimp8ieS3S5Yd8b4juTnJowPIVBbfOG1dCaPjhSqVEpB8F8ki8wTxy/m6jDy7p9wrHvp+\nmsm74R2akPYjD5nc4bY7xN7BOf+Oc+6G/M4kK9wGyXEAbgTwjyJ1enJMDXWOaUjO3fKarv0L5o/b\nqmuG/gKAL1UXp3YudxNIfqINQXxQpZJCTq/5IkQNsiijPMBIrmgOf5BSJh76E8CVCdfL9u5nbeFa\nV6RaknbIiYszPOCC7O/NaBtad91G4givjzRoW080hZK8jtGWua8AOLEhWULwVvO5i9MmW4cFdoYk\n+UXr1CdIZSuoUknnloxraSEl0rDNSG6I6/tIZg2DbZPZfKaOt1uKINETxOMFZDfmWxOuT0D1RWNH\nWsebI2U0BuDtFe8DE6/tJQDTqtbVYcqE/3DxCbF+tt1+rOPNEM1TEP0IZXRuwlzlkYyCT26Lji+K\nTOAY+8Ssx5qUkrc1VKmk4+V+aBY7FmmcJySkjWj4JG3TlG1mi3/ckwF8Nuc+eR5s9jaya2H0D+yA\nhLQRFPAAi9kjJX21gvUk0bXJ5T6zJAB7rmEmSTfyb9vvjqxOX8wiAC5JSL8AwLno0XbqxqXa5TAA\nvyXZqVA1bTeMThMPlY3iGGVGKWCOsF/O+5Jcw7FJuwrgrpR6VrVWxufN6eT9YEL00rz2Q7dI8zwq\nLAvJzTgymnTfep1lSFPKdfBu5/ws57y0yZLkIWXLliAtOgYBbFqlYpJbVilfkFMS0uL3z14NypGL\nKpVsbG+Z40ku4FyfZXoyimdfz3rvAHCQdX5uUiaSbgyyOeCxKVBc3DNfFnnPc2eBZwYAkNwuYZK3\nUEBEsyjyOoxc6Oku4rTzTyo4muwq32/wXmkdhliRu7+FInQhhE6IRZ4fClBHFWJ3/U69xzslTAdx\nTSov5kz0pYVISQpQeao1bE2bo0mqL9TL0a0naWOnDTzqSXvmNH4OYCWS9qLIoqFBYnu+HS/pvRn5\nv16wfmX0At6YeJ5s/aYE6TCFd6oMTDxa7NTiSFUqxTkyP8soj6q0nfjyekubJaSFmjvY0zk/NVC9\nvtgOCLNcRI0Twg9L1Dcz41ofJpX7Qtsv0i4xhNFvcFSpGNLmR0jOKFmlvS4jrfG9VqJe30WHeb0X\nn2CLRdwd16V/MMI1kW7G2w2jFV7evRdBdqDM3qOLODtJ3lbHYxJVKrO5KSU968ecZR6yX+ppL+c6\ng/elyk3/7ZKzev8utwJ4wjPvYkg3m2UtkozX1rzTStseUYC+XTzv3VdCBPdUwtKVgKVq/uooZRrI\nWzOu+SiV1I2JAnBwxjXfuF11Du/T6s7ycIpNZvb+GheHEUcpShfXSJTBONmEWAPUFtu2LYCNKpVq\nZL10fdwVU8sbk04VsuZeUiOiOnj1jjlynwvfSANFRkEx8WR8mbJ9p4umlt+2LUBA6uzg1U2Trs25\nqFKpRpZS+RkAkDwfQNLCJSB77mCVjGs+vJOkG78r5iOedfiuRTjHOvaNiVZ04SQw28V5LCqVzdoW\nYOCM5Q3dgqJKpRo+K1l3Q/oL4QMp6UCYvamTVu/XQZU9U4oQt9cVM3MNk83aFmDg1LEr5JiEImPb\nK67ORXEiwgr1X47stRdAtJbgkZL114aIEMj8bj+OnIV8ad9dle80lquPdHXxZtHv1Ljav1qTOFWZ\nICIP+2bu0v+kS21bRyrdxWfvFd/9GLpG6XZHcuheXkOnykr8unmobQGGwJhTKiayZx+CD/rMZ9xQ\nuxQlILluTpZtKlT/4wpllcCQPJRklqehS5m5tMYg6cY8UwoyJhZUmXAoK4jIvwBchch9uDPDxRR8\nlIrvepOmyeuN5v5wK+ySqTTLSQBAcgUAZ4jI3Tn5q3o11s216P67odOMlZHKYQDixr4hMOtH0GWy\n1sB0nbwfpY8J5IIQgiiNcRCAf3rk68w8RBpm3cqkhL2PFA8Gq1RIzmXiSO0FE7DQmVjziuFVUYZV\n675HR5kQoI7EzceUbkMydZtpku9Ax81fFr8FMKVtIfrIYL2/SB4L4KisPBW9s3w4CkCnti9tigDf\n7T0IrFi65CFTlC55Gnmwp4jM2s7BbOEQj2KmoTkX9MpktZku/U+61LYHpVSMHf5pANejG379U+Dn\nxTVEtgVwRdtC2HTph1eULr3APFkYwAdF5Lweyj6LpDZjQrq80oI4qXSpbQ/N/BV7FW3WphAWY1Wh\nAB1TKErjTEO0R3xvFQoAkPwwyWdIfsbazqJTCqVrDG2kcgi6sauc0kG61JsrQt9fzEOiAZN5KbrU\ntoemVIbzMEpwuvTDK4K2ayWPLrXtoZm/FEVRlBZRpaIoiuJPiECvg0aViqIoSj6PAlhQRLoaDLMz\nqFJR6iJrq2Vl+NxoPn/VqhTVGS8iFJHlRGS6SVu6VYk6zhCVykWIehU+XFmnIADWr7n+rvJtEbm5\nYh1rBZFEaQUReQeAtURkq7ZlqYKIjFpVLyJPwn8DuzHH4JSKiOwEYHkAb8rJepGI1Lq3s4j8uc76\nO8wxAep4IUAdSouIyB3mcC4A+7QpS0lSA5+KyFjcfdSLwbkUu651JCch2qFxbczeCfElAAuLyGsd\n3qSrzywkIi9WfPYVADwYSiCgW26XRehhG1pARF5KukDybgCrNSxPKfLaS5f+L11q24MPfS8ivwMA\nklcDuA/AT2U4mnQqgMXaFgLRnvGzRr0i8mKAOl8LUIfSAmkKxfAv9EOp+JrQFYfBmb/SkIgLe6RQ\nfMw/H69dCj9OLJjfZ/JWzQv94zgA/8vJc2YTglRgHKIo233eeqJVxoxS6SGXeOT5a+1S+PG7gvn/\n5ZEnbaTy3YL3GgIbAji5bSFyWFZEjhaRubMyichVTQlUkldF5GEReaJtQfqKKpX6+W/Jcrk2UhG5\nv2TdSVybkHZjQloS11nHX/XI7zNaTNzLQkT285JoQIjIZEQBGjuLiDzetgxVMa7DWaY7xQNVKvUz\nEdHOk0VpeuLtjoQ0rxGI8YT5P3P6eetS2n7yuaYtEdE5lZF01Wx7Qn4WZSyhSqVmTM+nzHqYqkpl\nGopFbK760rofiOaurLTnU/I+UvIeK5UsNwTua1uAJETkyC55HintMzSl4muuCcVkz3xp3lCnZJT5\nYTFRRrG8iHwu5dq5KemlEZGpCS+Xv6Rkf7jkPUKa+/rGWF3z1BQrti3AUBiaUqnCXiXKVHWd/XvG\ntUoThSLyXMble6rUXYBfp6Rr/KTidNH8NZiRo4g80LYMQ0GVymx+W6JM0uR2EmkvhCy34TpNCsRI\n2dOUo48MqauOATyWkl71BXlgxfJ9pHNKZYyPHJUUhqZUSr+IRaSMnf8PZe9nyOqx1zlRfTaAf1vn\nad9b3otsFRH5TdpFEUlbszATwNYp16Yhf+GZO4qbCuAXOWX6TteUyqZtCxAKnRMKy9CUSt/ImsC/\ns66bJijQyzBaQb4H+S+yZzxut0mSCEhfY7MaZnuS+bAjInt41166oenS890qIr9vWwhlFre2LYDN\n0JTKum0LkELiCyFrdX8DK///ZB1fAOCPzv2vQgATnIjcBOBUcxqvvJ8pIonrd0TkcRMFNoup1vEl\nZv6oSy/dOujS8+3StgCB2APDiCR+UtsC2AxNqSzQ8P3q/qF/ssa6b7KOry5Zh5ejgogcbBaWfcEk\n3e1kKWpGnLV+xjKxdemlO3QGERdLRM4fQiRxEbmobRlshqZUmsB+AWbFOToowL1c19+7AtT5NzfB\nLDR8xUraJr6UVolREq+kXc8p507wPlSwjiS5vldUlp6RtuanaW4F8HLbQijdRZVKNr9MSDvbOk5b\nhwGMXOCX14t+ICkxIdrve3Lq8eFPSYki8iyi51lGROKRS1MTmD4r9y9LSLMXdyaGdTF8F455r2+I\niM/8VROs15G9RKo6yYSIIecTw27MoUolBdOj3g6zG98zAMYDOMfKE8rk4q4pWTIl34MAvlXxXqnO\nASKynmcgvXkqyuDio1Q+4Jx/DukhQibZJyKyn4hsVEYwZQTbdijKd5W1TrcjjFv6EQHqGByqVPKJ\nJ8EOFZEp1o8qNrekBVD0Dc3yFBzvDRF5KimjuXfpHqtRlFeY07i3mbUj3y0p9cwoK0MCV2D2SO4/\naZncl5mIfM2MrpL4h1O/EoZ/5GdpjCqjpecz3N2bxjdq8w8AfDkhfb2AsgRBlUoO1kpbdz4jtnF/\nAQmIiN2TyurdLYtoX5QdPEW63jlP2gveZ5vkOFTK7Rl56p7EXAbA+61zV1kVMVnZUXJjs+GcIvLe\nMoIpo7hXRArNfdWMr3PJsrVKUR3fqBxfAnCemygiWSb4VlClksxZ9onp4SfG+XLsy4XDn4jI/0wd\nWS93G7eHdrZzPq+I2KOkuNGO2I/D9Py/VOC+MVPzs/ghIk+YZ4+Vrrvp2A4ADoCH04NltttPRF4y\n/7Mu2P5DUnYbhTK4+6JkzVkVJcRCVa/Fyikh+dOiZ7fBXp75umJ2zEWVCjB3woraMzzK3WsdH2U+\nPxFAnkuTEhNkjMPp243tg84ICYheyp8SkUMT6jwmZ/+I+NqPAWwG4OcotjCxECLirpV5XES+IyJe\n80hGkQx2Ey8RWarBe9nmoQ3gN/r15WMVy6+EFIcTDy4XEZ/ft1ddFctvKCLTPfM+htHepgtWvH8t\nDH6P+jxK2lbnh+WCKyLHkzzOSvu6exvr+CYAGyfUGZsWfEcC8XzCLJORiIzaLVJEfuhZ3yhE5AWM\n9AC7oWxdSn8RkSQTa5X6ppLlHQtF5H6SEwoUuQ7AO0vfMF2OV0mehpLLB9KsHyl5BcA99vdWQCE1\nio5UkkmcKI8RkZdTvGBiL64kV2Qg6m3slFJn0TUf8Ujp56Z8n+MX9WZo33OeRj9jpP0JoxdcFoni\nfbF1HLqttRKupsu/d1UqCZSckFxMRJJ2TwRmz4Nsb2y8hwFYPCXv0wlp9mKzPwLYQ0TiqMpD2CEx\nK1qzUp7fA7jGHI9H5KruMzEcwowbkp8CiF3C43m3Ih6I8Qv4ZTjzpT2g0hYYbaBKJRAZ7q3xZOEW\nsRlBRL4qIklmruUBHJmQPktxmIn986vK2yVEZArUFBscEdkURolY7vA+PfXOBosUkR+YT0H+/N7K\nzvlHRCRpEW0VbiuYPy2Qaow7ktwO0ZyWTdmwSo2gSqUeRu0jIiJpG1bZeR5JMYNlDXVfxez5ld4i\nuid9aPY1n27bcZ0eRrzEjLODG5utDkY5juQw6jcgIvYLekXnGkXE3YL5XgRGRIrU+WYRiRWhPQ8z\nGbO92VwPv/sT5rT2L3DPxlGlMpLD8rNkkxLbqjZE5DURWayp+yn9QETOTEn/i2OPb9JNuSy/ClGJ\nNBM8Ms2b8hQRSVw8KiIbAviJOW1CodeKKpWRnIXsLX7borOTckonKbJe6mAAy6VcezCALL6kuQg/\nIiJZgVTjiBCPA0gzC1+CkXHi6uRDKemu845rhozlu8ljEn5aYakaRO3YFsa2v3bbcjishWKTkoqy\npnV8IYD50jKadUqPprj4fhbN7VF0I4C3IWrr7sJLIP038AIwy3tyD5K7uxlE5FFEseKaIDGatET7\nCqUiIv/1cbPustdXjCqVjpPhUaYouUi010bSfhtLAZg3p+zFGOmOWyfxnNq2GGnuutXI8ijJVRqS\npQq+izIfSEl3vb16526vSkVR+s2WKDHnICk7b7bIlxGtUHdXic+KiScihcMgtYCPEpg3IfJFL0Yh\nPuiciqL0GBG5FsDnneQqYeFbQUSeF5E/ALjfSc+LeNGVaMM230LGuzVJoQwJVSqK0nNE5CREpqwD\nzHnvTCYxIvIfq8f+G48ivwSwaY0iFUZEDurz/6AqqlQUZQCY3q9vGPW+kPtiNouBu7pYs0oQzh8E\nk6JhhqZUGlsfoigt8QzS15ZkxqzrIWXc+7+Xn6UZnC0oivKZYII0zNAm6gdtq1QUAGuYz6R9QhJ3\n6uwo//bIkxQHL482JvM3QDRKLLo3USoi8kKVSM5tMrSRStX9DRSl05iNzWK30yedy1MRBV8sw0No\ncLGjiFwKYE5k7+75csa1NBrvWDphVMZ8x3ZoI5WyG/coSh8ZYR4ynlI7l6yr8UW/IjKTZFqE6reg\nXMiSM9HieyBhgv7PSF7MOViGplSCB4xTlI5yA9L37SlMStTsJvg3gC3cRBEpZUoSkZcBBN1UzJO0\n7y9pQ74idDokSxIcw55viqK0DMm5AMxndhntNSTn1GjbqlQURVGUgAxtol5RFEVpEVUqiqIoSjBU\nqSiKoijBUKWiKIqiBEOViqIoihIMVSqKoihKMFSpKIqiKMFQpaIoiqIEQ5WKoiiKEgxVKoqiKEow\nVKk0DMkvkPTaSKhIXo+6ZpJcqWCZXUleE+L+OffZlOTDdd9HqRdt24n3GXNtW2N/VYDkXgAOBrAy\ngOcAXALgCyLyXJtyJUHyNQCriMh9bcviQnJTAOeJyISU68cC+ACANwI4TkSObVK+sYi27TBktW2S\nSwD4JoBNASwA4A4Ah4hInzZbG4WOVEpC8hAAXwFwCIBFALwdwAoAfm0iryaVmbM5CUffvsV7V+U/\nAD4H4Iq2BRkLaNtujIUQ7da5DoDFAZwL4EqSC7QqVVVERP8K/gFYGNE+B9s76Qsi2j98L3P+RQAX\nATgPwLMA9jZp51llPgzgAUT7ix8J4H4Ak6zy55njFQDMNPkfNPc53KpnPUS76E0F8CiAbwGYy7o+\nE8BKKc+zF6K9aJ43n7uY9D0B3Gjl2wLRxklTAXwHwPUA9rbzAjgZ0T7q9wLYyrnHXeYe9wDYx7q2\nKYCHPL738wAc3fb/f8h/2rbbadtW/ucArNN2O6jypyOVcmwIYF44mySJyIsArgLwbiv5fQB+JiLj\nAPw4zgoAJN+EqAHvAmAZAIsCWNa5l2uf3AjAKgA2B3A0ydVM+msAPo2ox7MBgEkAPpn3IKZX9E0A\nW4rIIubZbnPvT3I8opfIYQBeB+Bf5j426wP4p7l+MoCzrGtPAtjG3OMjAE4l2fhug0ou2rZbatum\nzNyIFFPO6HjvAAAclUlEQVRvUaVSjvEAnhaRmQnXHjfXYyaLyOXArF3pbLYHcJmITJZoK9ijc+4r\nAI4RkVcl2hnv74i2XYWI/FVEbpGIhwB8D1EvyYfXAKxFcj4ReVJE/pmQZ2sAd4jIpSIyU0ROw+g9\n0h8UkbMl6nL9CMDSJJc08l0tIg+Y4xsBXAtgE0/5lObQtt1C2ya5CCLz1zEi0rvdHm1UqZTjaQDj\nSSZ9f8uY6zFZnh/L2tdF5CUAU3LubTf26YjssiC5CsnLST5O8lkAJ2DkCyAREZkO4EMA9gPwuKlj\ntYSsI2Q1POKcP+E8Cy35tiY5meQUklMR/ZBz5VMaR9t2RGNtm+R8AC4D8EcR+apvua6iSqUckwG8\nAmA7O5HkQoga1G+s5Cz3uscBLGeVnx/R8LoMZyAanq9szBFHwHMCU0R+LSJbAFga0dA/ydXzcQDL\nO2nLJeQbBcl5AFwM4KsAlhCRxQBc7Suf0ijatiMaadum/CWI5l329SnTdVSplEBEngdwLIBvkdyS\n5FwkJwL4KYCHAJzvWdXFAN5L8u0k5wZwTE7+rIa6MIDnRWQ6ydUR9c5yIbkkyfcZ+/MMAC8gmvh0\nuRLAmibvnCQPALCUzz0AzGP+nhaRmSS3RjQx6oX5fudD1F7nJjlvSk9aqYi27ebatvGk+zmiUdle\nnvfrPPrDLImInAzgcABfQ+SxMRmR58rmIjLDs467AByI6Af7GCLvkf8i6ikmFsk4/yyA3Ug+D+BM\nABfmlI2ZA9F6hEcRmTbegYQfrYhMAbAjoknKpwGsDuAvGbLOuqeIvADgIAAXkXwGwM4ALs0o5/J9\nRD+8nRF959MB7F6gvFIAbduNte0NAWyDSAk9R3IayedJbuRZvpPo4scOQXJBRO6ZbxCRB9uWJwuS\nRGR33lVEbmhbHqXbaNseO+hIpWVIbktyfvOj+zqA27v6oyO5BclFSc6LyK4NADe3KZPSXbRtj01U\nqbTP+xGZBx5BFBJj53bFyWQDRAu//gvgPQDeLyJZJgJlbKNtewyi5i9FURQlGDpSURRFUYKhSkVR\nFEUJhioVRek4JLdpWwZF8UXnVBSl45AUEdHoA0ov0JGKoiiKEgxVKoqiKEowVKkoiqIowVCloiiK\nogRDlYqiKIoSDFUqiqIoSjAGrVRIvq1tGUJAch0T6K7XkHw9SXczJEVRBsRglQrJxZAQZZTkPCTX\nLVnn3SS/XVm44vwVwP4J8ry9TGUkDyDZxgKl2wDcnSDPGiQXLloZyQVbeg5FUVIYrFKBebb4pWNe\nQL9GtEnPrSXrXA3ApmHEK8zXSb4eAEj+hOQKACaTLLPP+/+FFc2b8QAWIHk6AJD8JMndAdyBaIOk\noswXUjhFUaozSKVCcmNEO7jZTACwOXr0ImKE3RP/sPncGdGzAD3Z5915jnj3ve8A+JY5XqBZiRRF\nqYNBKhUANyakxS/fJXwrIbk6yfPCiFQKd/5hWeu4kDIheRPJeaqLVBtebZHkqX3fblVRhsxQlUoW\nhxTI+360uxe6+/9Z0zoetdd2DhsBWLSaOLWytWe+TwPYp05BhgjJhUku0rYcyvCZq20B2oImSp9v\nXmSMDEjOISIzgwnnR+xsUKRjQJKp+c018f1eAhHfq4hZMu85CEQPUkWwgXELgHkQ7cCoKLUxlkYq\nrlL4rpnsziJ+KZ0BIN5b2x4twLj6vlZdvNI8UcALbC1YssYvX4vXAOwSSrCCLEDS1wmCiGR9MwCQ\nXNK5fhmAyQFlGwKrAlipbSGKQPJzJC9vWw6lGGNJqbjsg8jrKItYqWwFYLmUPF0Y7fm+QJd1zpPW\n8axWUZaizGkdX09yKY8ysTKMX5IXOtc3Q/KzjWU691snKTnrlr4KYNum5FHC0LmGVgck18DIl1dM\nnsdRrFTyRjRNsRnJKkpsnPlc0Hwm/f8b8SaznqOMnT+W8dPmszcefX2F5FyxS3tgyrjEKx1mTCgV\nRCOSv9dUd9N2+xkVys5vPnc0nz6jgrqo8hwxsTfbBk66zqWE5zMAHnETzWLitc3xXEkLi42TgOvi\nPwqSR5E8Ioi0SmuMFaWSRt7zJ9r4PeZiOgXJuc3hSc6lfZuWxQMfhfAW8zmxRjkUACTHkZyE9BHF\n0wD+Zo73BHBrguv6kgBe59SbNCI+FsBxFcRVOsBYVyqpkHw30u25f0jI38k1IGYS351LidkiIW1i\nfdKUh+QEkqub0zXM5zzWddssWDjki5LK5wH8NuP6wgBA8mQA65i0D3jUOyElvReLeX0huTFJn+9j\nMIx5pUJyV/P5LqtHDwDXZhSzgzuuYj4/FFq2IpD8ofl8ozOSmgzg6AJV7RFSrhI8CQAkFyG5oZV+\nPYB/ZpRTk1c9+L7kPwsg/v24/4udM8otVFgiA8mVU0Y8XeInAH7ZthBNMuaVCoALSO4P4DcAPlii\nfGwW8F28V4SJBfLuSfJSAHcBuMG5tnpC/s5C8mEAx2DkiLD3UZqHQNb6IMxWQEs76cdnlPl9BXHu\nQXux+JQUVKlEnGA+k8xBSdj25bhXVsf6DtdVNo/3mU93zmdDN2NMzksiCCTnz881guVgTFxWTzTN\nhBezTFG5hoyZQN+pSE+e5PIJUZ83d7NlVPFx83laSv2lIjqQvDfj8oIZ17LqXJnkpiQ/RHK9NqJd\nk9yW5DiPfMuQfFcTMoVAlUpE3Ng/StLLPbWhkBelvbMKhJL/SNl7FKDMHEes4A/zfDE+XOIeQ+bd\nAH4Kx/SZ026T1mLF3lyLB5DJvves/6nH2qSVSP6dZNKIZ1GSC5E8paAslyAyqV6IeqwMMVlt93IA\nh3rUcTYiS0ovUKUympc88xVtxE3zvOealh/ULgmwWIWyXwFweihBxiDHOOepo1YbkluSvNJK+lh8\nyffGJN2FtGllfSay3wxglrux1dG4AMDPELk8x9fmIZkXPcAe4XzJlKujo5j4zCR/Zg6/4FHHVqZM\n1+ePAKhSqcJHsy6S3IDkNU0Jk0KQeQiSz5BMWjzqS57pKg8v12eSri1fGc1u8QHJL5I81c1AcgFE\nC0u3SSj/2QL3utvUFZO2er7qAkh3pHEogCyTGQCsmJD254pyAABIzknyHeY0re3vmJKexbtIftBE\nIhCSa+YXaR5VKgmQ9J1bAUYO4/cjOZHkWwC8F8CWwYUrRimff5JnkpybZPxSWQyW+24JSu20WYJV\n7ROS3zQL77atqBT7SFqvdndrBHsMZkclsElKi/lKQTns7/2mlDxZE/kjIPnm+DAj24h2T3IrzzmT\nVfOzeLE5RjvLhGB+AL9w7tM5VKkk8yufTGZtytpW0umIXJFvQ7tBJmM+k58FIOm6de6DqPdnmz+q\nvJSbGrZv7JwfBOBHiGzXugfLbGbkTBCPR7hN00b87621Rm66bxvxdl5hFOwVKLDTaaDORxxhYDOr\n3lIOBTmsV0OdlRmcUiE5scHb/RrA15y0eN1KJaXirJmpm2lWDzDGHWVVaSvvy88ShBNIvs5Ji93E\ne2GPbpBZHnkk7zE9+XivoT0BvCOxVHEmOucXmE/X/DNr/i/hf2jzxjibx71j01OR/33pdTMW8Ujv\nOivtTWmZSS5nHa9G8qqUrO90zncl+aYmPDiL0ClhAvHHBu+V9cOr+t0WMcGFwI2N9klgRM+tyvzM\nJhXKFuXnKekhXhZ9osiLNN5jZXvzWdnTy3rRuaPH2BSatQNrKDNUvOjQ3Rohi/Ek18nPNhKSk0je\nlZHFVQg29ohjb6R7o+2VkHYnZm8z3gmGqFS6sl4hyy7dJ440n7u2KoU/aYvhrmhUivYJZb4ahacp\nJzY3pr1j3J77iDkPj3v4KM04RtyBpk4x851Z3APgrx51w9Q5t1Gg78LsUVRiVs8qDzX1unH6shjl\nbNEmQ1QqXaFq/KmuhB15g/ns1ap8JfcllvdyrUr8bkmLOux6ltnyCkooRZI+ruu3Fa03h1cx2iGm\nqKk16bee5F2a9ny5CyibRJVKd/HxX2+C3c3nWmUKq5tvZyliEipDbC6t6/+f9OJO20ivbg7HyHUv\nSbLNUhyeTglZ80qdRpVKzZAsa592bdFtM9FzMaXLG/KzKDXQtmOClwelhTjHZeQves9KOG7Kn/LJ\nbzpZrlNMV6wSQVClUj9TPMJQ9IHXA/hy20IowajyImviJZhnykpSOsHmU51Fm0nXszpYSaPAo8zn\nyhjt9HJJyj02MsFue4UqlWYoGlCxq3yyRJm3BpdC8SGvp39ujXWHYKcG7pHFiySzRtkXFawv9j5M\nWwCaxE0Avl3wPq2jSqUZdmhbgECUWcBVJhyFUp3avL8aIu/dlBfbKwRZ+8DUGYSy16hSaYa2JhC7\ngFcAQyU4de71XmnVOcm0XR9jfOZU3uZ5r1GyWivt88gKc1Rl3Vbb8121okqlGXIn8RQlixJOEnWE\nBYmZUbF8GYePWZA8Df7vriSHl0KWA5LnkAwSbDKuMmBdnUOViqL0g9KLT0l69eoLIKbepEi/ZbFH\ntHkjlQMxcm+WLEI4FbwbNc8NFtj/qPOoUmkIkme1LUMISN5lAmkqzVLF3HJzMClGcl/AuuywLZMw\ne31UGr6jnaTw/d6Q/DAiz8e6aWKOqBFUqTTH3gBAcreeuxi/EcBXSb7V2jNCqZ+iv9W+/bb3so7f\nh/yXbKJ5L2Fh4WEJ2YosLP6EVXeomGSDNn9Vsm0qxXAWS/W5YX0Ks+eJ+vwcfWLo37MdQHWmR/7t\nUtJ9Qpas4ZEnxl6oeCMqbPGdw20kP5Gfrfv0rTeTCckmo+EqSpMU/a3WqYSq1p1X3mceZL6SdRfF\njm5dd2ibuuOxNcKglApmh/DuPJ470XWeoTxHD+iSUtmrhjrteTqfNpU2x9SHEV2ajIN4Hw/iISzO\naVuAIiR5fMT7T7chT1lIjgrz38fn6DhFf6t1bp+8bkWPsvVzrvsohokVynaVQbyPB/EQPeb5gXhS\nnUpyMN4rHaXob9XX5bYMvwVwfYXyeRGvq5ixvbcOrgPPCMRpCt/dbbWX6ER9+7xC8hoAD7YtSEXu\nJfkSqsWUUtJJVCpmUd7nEQX7PA/AT0RkSs2y7Iv0OQ0f8lbUV6EJ998sfJwM0takrBBSkLZQpdIN\nnkP4zYPaYH4M4zm6yASSq4nIv+IEktMRfee/MUnrA/gW6jcBVX1x7xZEimRqNbmSHC8iT1espmvb\nWgSFIsMxe/fUhr+wiLwQn/T0GQBgVxH5SXzSxecQkV7a20m+ALMuw36GtO9YRNjF738grA1gfwAf\nb1sQmy61bZ1TaZd5bYVi6GNP/2hboRhK7RSpJPKd+IDkwiQ3y1IaOr9VK6ehYwqlawzN/PVPRCu+\n+8B+IvKqmygi6wDd7OmnISKjormKyB2I5i178xwdxrbTP++R/966BFGgUSRyGJr5axIiz5TOkzdc\n7cvLuE/P0SUTQRG69B0q3aRLbXto5q+n2hbAk94s0sxhEGElFEUJx9CUyv/aFiCHZwHMLyIho7u2\nxSYi8r22hRgj7NK2AIriy9CUyjNtC5DDUiLycttCBGADESmy17ZSARG50Dr9WWuCKIoHg1IqIvJk\n2zKkISJMmpjvIauJSJH9Oar69CuzERH5EICf5+SrsjBRyeautgXoOoNSKkr9iMi/CxZ5sRZBxh7r\nmD+IyA6IFhB+OymjiLzSoFxjjUPaFqDrDMr7C+isp8xFIrJTkQIdfY7CXiYk70d68L9G6ZKHTCiS\n2okufqyVeURkRsXv91gARyekzwAwd5kKu9S2daTSDO4Cx7HEhflZlAocjv7HjQvJH9sWoAI+ccM6\njyqVZhi1OLCn7FOijC7EqxER+YqITDQ91cUb6rG+VrH8Z4JIkcx+NdYN5HuYXlmh7kHMP6pSqZ+5\nReT+toUIwMEi8v0S5dQM0xAiMrWhW52AaiHm6/SArLW9Sf58wUcrVP/TCmU7gyqVmhGRrq+d8eXi\ntgVQOsNMAP+oUP6hADLcnpLeqsu+pwdqmmIagnfo4GJ/dYouTZ5VYSjPoQRjppmsblWGpEQR+U/L\nclWht4Lb6EhFqZuumL8+27YAA6LqhHKINpE2UukDac+vSkVJZyi9+wDP0RWlcnnbAgyI82qu/0se\nefocWSDtN/X7RqWoCTV/KXUzvW0BDINQ8l1ARKrOiSStSn8FwLzm+E6POvr8/0ySfW4R+V+PTXez\n0JFKMl9pWwAA17ctQCBubFsApXM8kZBmKxKf0W3/374WA3LoUaWSwp8rlt8ugAxl1oSE5tiqFYjI\nYyEEqcj5AB5oWwglkxnW8UwA0zLyHgHgpXrFSeRfgerpikm4FlSpJPNAlcIi8ssAMrRuNhKRL7Yt\nQyA+rfGwauE9Aeuy9+bJdAQQkS8HvG8Rzm/pvr1iiEql6nqK9QD83TNvUqj9rSreP6ZqxOXpABb2\nzJu0CvioivcPyXIVyz8bRIp+YS+4fbyOG4jIVSWLJikNu713qSd/g3V8csP3vqbh+wVhiErlB1UK\ni8hf4N+od4BjIhKRX1W5v1VPVRvrZBHxjTm2H0YrkZDzSpViU4nIowWyn+Sc7ygiVcOK9BE7NNAW\nCdfPbkoQFxGZkZSccpxGlTmV/xbIe3h80PRoV0S2bvJ+oRicUgn1Uve813UALrOSqs7FuFQZbntP\nkIvIwyJyvJMW7EUsIhND1ZXDiSLyeSftFw3du7OIyB0JybWMXgKS136rKJVLCuRNUoBV8Vk5f6L5\n7MLcaiEGp1RC4BHfJ4kLAWweWJQT87OkkreRUxYTKpRtk0ud85VEZBCRX2tgGrobQVoAdGWr6th9\n+s2B6rsEwEUe+f4DACXj7bXKUJVK3YuzAOAe8xn3mKaIyPOB71Fll7nS4fZF5OEK9w1NbM7MVQ7u\njpQDCeRZFwLgN20LYdGk+cu70ygiT5pdW4vEOstaZ3MP/EY/ve0MDVWp+CyeipmC2TbWt6XkaWUI\nWnLEBAA3icgDHvm6uv3yf6zjA81nkglHKc+jmO3leAOAJdsTBcDIF72PG7qvUrk+Ia3o7qVFSYsW\nvTisOZocejsPOFSlUmQP9YNFZClzbK8UtkNFuCEh3otoO1ebpj1DXK6xQqrYE+PbIN0j7kQAeztp\nTYzyMhGRVQHcZo7jqLPvBHCqlc310PMJ7TGWSPJMtLkFwHXm+Hci8hSAIzPy++yLE7ed3wP4kzk+\nISXvr53zWUpFRP6K/H1LfJXKYQlpvnOVRULBnIPZLtZJ79XJIjLVOCn4yN7bucChKhUvzLD23JRr\nx1inrznXrhCRW8zpdJPW5u57x6V5iojI1ZhtO3dda+8XkXOctFbt7JZipJP+jIgcnFHuGOt0GoA/\nhJeuV9ySc32GmW96G4CvmbQpGfl9XoTTAEBENsXshYJpG9Sd7py7o/I8d1pf03CS84yPBeBzIvIh\nz3sAwGOWi3XSd3V3gbogIi96Zj0L9W56VpixolRcN9M03Mb2IwAwrrmJw1YRuQvA8uVFC4LrIuk+\nR2wO/BKAXTPqWR7A1aGEKkERj6S9AOyRcm0FhFsv1EtEJOu7XD02j4rILSKStND2TOfc5yV3DIBV\nnTR3/mAb85mmpB43cmWaf+ruxInI1/JzjSxiHSc9m/3/yFJqhUxzIvIxEflGkTJ1M1aUyq0ly81a\ngyIiqes2ROSRkvWH4oysiyIS95JmiMhPMvI9UmEeJwRv9Mz3sojcBuCKpIvGzFDaUWHoiEheuJHL\nRWRfM5IngNcByHXeEJGnRCSeD6NJm+nkSeu0CKK5iKDm1wbbs+2mnPRe9Y2QkTR3mBbAs4hrdGNo\nlOJssswBbfBlJIyYPNeUPI18k0iriMhzHtlORwdC2AyUeP3EU3aiiDzD4uFz8/K7q/FnIlJefeUe\n6zhJqfgqt6S2HcdBewDARCu91V0u0xgrI5WrAZySk+cQjP4xPdexfVGmAfhUTp4dkRBiRUSWEJHQ\nizOrsG3O9T0AjJonEpH9ReRz9Yg05olHCU8nXLsnIc1mI+c8c9W6szr9BhF5Vgw59wlBVrBKYLaJ\nzgszorM7RPE7I+07y3qnHAhgTSctXv92hJN+iJ+EzTImlIoxhRyGjHhWInJKDxbKvSgip2G0x9Ys\nRORiT3fiVhGRKwFsknH9HyLSy9hHfcUKn5I0XxEriURTsoj80Uk6AqPnGtNMaHU5VSR2oiyPwjSq\nrjeLlcZZ9m19ChrleqeT9oTp3F7ipHchAvgoxoRSAWbF0joBwEFty1KBewHAeGy5Ls1FqLKoMhgi\nchOiAJ5VJ12T9udQyrEIgO8mpMcvSq+V7iLycsJc45bOeTzq/nZKNb4BUdM4oGQ5n/VbqR0izH6v\n2orkRxn5fcy+bn2dZcwoFSCatBORb7UtRwVsX/4fV6jHJ0xEI0gUwNPt5foSr2XQSXl/Mtc/iMi0\nlBF7rFTcl6OPt1I8MnADMv7J3DPRUy3F2SLROcMhXn9TxEHnfdZ980x9QPa8XvxdCSLryFU5owrf\n9t/JORSXoSqVexD9A27LyFNmP+j3lhOnEs8BeEPKtbJRU4/PzxKccwCkzYUkrhXKQz28cjkLo0e0\nHw18jyK9Zzev71oMG3ddVRIPA6kOLD90E8ycyOUF5fib+Xwg4dqskYqIHC8iefvO+JrG7Hwr+ZRp\ng0EqFRF5VETmR/aq4rwVx0mEju2Vi4iME5F4NbM7TC7lKi0tbF0qIntn+P77Dv+VApg1DD920sru\nLZM2uezjyBLHzRrRu5coevIKRYQQEZ+V5lkyZSnVtPAqSXLEL/ikEYs9UknCHZn5rqOz79/ZuHaD\nVCoWacPKLZHvRZXEzYgW3bXF35zzDwOYVLKuPQA0tk2Ag9vb/AvKf68bwzJdKLURvyjLOLPsBUTB\nGd0LIpK2BqMKbgif2CoxPscZ53UAFip4r6RlB5lKxXYUMKOkMlaTzjL0dSqJixJF5NoylYnIq8ie\ncKsbdyHZvfCLyTQKEWlza1Q7YGTsdVTqexWRsR6OpVFk9AZbPiP+MmauMhxtPk/ByLAozwKAiGSu\nOzOjj6KyJimOpIl6l38AWKvgvaqUa4yhK5Xvo1hQuC7zOhnGPuuLIX+dgNI90kxK2wJYsMb7ngjA\n3XgtDQFmKQd7i+w9EUUITmLd8qLhdIzcbjgmz/wFRAFSi46KICKh9nWpjUGbv0Rkpoh420m7jIiU\nmQPqHMYPv7dhvccwiSNiEZlSkwkrJo6wfTdKutGbNnefk7wXgANExDUpF6l3fxFJ6rTGcdNSzcvm\ne2szCG1tDH2koihKGM5D+VH/IwBSI0zn8CQAiEhaXLhxiExWM1DAkUZE6jRjx3M6nZ1MrxO2Gz9Q\nUZQmIBmbhroUdqgS5pkWFJHpJKcC2FREbu+AXHMCmCQi7p4xYwJVKooyBiB5H4AVh6pU2pZFmY2a\nvxRlbLA7gLXbFqIGtFfcMXSkoihKLyG5L4AzG9wzRfFAlYqiKIoSjEG7FCuKoijNokpFURRFCYYq\nFUVRFCUYqlQURVGUYKhSURRFUYKhSkVRFEUJhioVRVEUJRiqVBRFUZRgqFJRFEVRgqFKRVEURQmG\nKhVFURQlGKpUFEVRlGCoUlEURVGCoUpFURRFCYYqFUVRFCUYqlQURVGUYKhSURRFUYKhSkVRFEUJ\nhioVRVEUJRiqVBRFUZRgqFJRFEVRgqFKRVEURQmGKhVFURQlGKpUFEVRlGCoUlEURVGCoUpFURRF\nCYYqFUVRFCUYqlQURVGUYKhSURRFUYKhSkVRFEUJhioVRVEUJRiqVBRFUZRgqFJRFEVRgqFKRVEU\nRQmGKhVFURQlGKpUFEVRlGCoUlEURVGCoUpFURRFCcb/Aw6dkT76fKfjAAAAAElFTkSuQmCC\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Perform FOBI.\n",
"norm_xn = LA.norm(xn, axis=0)\n",
"norm = [norm_xn, norm_xn]\n",
"\n",
"cov2 = np.cov(np.multiply(norm, xn))\n",
"\n",
"d_n, Y = LA.eigh(cov2)\n",
"\n",
"source = np.dot(np.transpose(Y), xn)\n",
"\n",
"# Plot the separated sources.\n",
"time = np.arange(0, n, 1)\n",
"time = time / samplingRate\n",
"time = time * 1000 # convert to milliseconds\n",
"\n",
"plt.figure()\n",
"plt.subplot(2, 2, 1).set_axis_off()\n",
"plt.plot(time, source[0], color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Generated signal 1\")\n",
"\n",
"plt.subplot(2, 2, 2).set_axis_off()\n",
"plt.plot(time, source[1], color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Generated signal 2\")\n",
"\n",
"# Plot the actual sources for comparison.\n",
"samplingRate, orig1 = wavfile.read('FOBI/Sounds/source1.wav')\n",
"orig1 = orig1 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"plt.subplot(2, 2, 3).set_axis_off()\n",
"plt.plot(time, orig1, color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Original signal 1\")\n",
"\n",
"samplingRate, orig2 = wavfile.read('FOBI/Sounds/source2.wav')\n",
"orig2 = orig2 / 255.0 - 0.5 # uint8 takes values from 0 to 255\n",
"\n",
"plt.subplot(2, 2, 4).set_axis_off()\n",
"plt.plot(time, orig2, color='k')\n",
"plt.ylabel('Amplitude')\n",
"plt.xlabel('Time (ms)')\n",
"plt.title(\"Original signal 2\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Again we plot the spectrograms"
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"collapsed": false,
"scrolled": false
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJztnXu8HVV1+L8LbtSLJsAtDdQASSAU0B+pxgpafKG0hiog\nVHlINShYShWtCKhFGvgpFakPFB8V4SdItUipEWgFkYpUUR4KSKQBE0wihBjAoLnIVXPD+v0xe9/Z\nZzJzzsycmXPm3LO+n8/5zD7z2LNnz2Ovtdfaa4uqYhiGYRhF2abfBTAMwzAGE2tADMMwjFJYA2IY\nhmGUwhoQwzAMoxTWgBiGYRilsAbEMAzDKIU1IIbRR0Tkj0XkLhH5tYi8o9/lMYwiWANiZCIiLxGR\nW0TkVyLymIh8V0ReUPM5V4vIK+s8R8M4A/i2qm6vqp9O20FEXisit4nIEyLyqIhcLiJz8p5ARG4S\nkbdWVeA8+YnI50XkPhHZIiJvrurcRrOwBsRIRURmAtcCnwR2BOYA5wC/63O5tm1yfiWYC9ybtVFE\nXg98Gfg48AfAc4HfA98Tke17UsJy3A2cDPyo3wUxakRV7We/rX7AC4CNbbYvAb4HXAj8Cvhf4JXB\n9lnAxcDDwIPABwEJtr/NHbMJ+AnwPOBLwBbgN279aUQf2KeAtwJrge+44w9zx20Evg3sE+S9CLgT\n+DVwJXAF8H/dtpe78pwBrAcuA3YgaiwfAX7p0nOC/G5y5b8FGAeuBsaAf3XnuA3YvU1dJcu6t1v/\n38AkMOGud0HKsWuA9yTWCbAcONv9XwpcHmz3dbYN8CF3jifdOT7l9nkKOAV4wF33+cHxhfNrc+3f\nBd7c7+fZfvX8+l4A+zXzB8wEHgUuBRYDOyS2LwE2A+8EtgWOcg3JDm77MuCzwDOAnYBbgbe5bW9w\nH/FF7v8ewG4uvRo4KDiP/3hdCowCTwf2Ap4AXunOfTqwEhgBZriP7jvctiOItKawAdkM/JPb9+mu\nMTjCpZ8JfBVYFpThJuCnwDxXL/cC9wEHuY/qZcAlGfX4x1llDfJ+a8axexM1qHNTtp0N3OLSS4Ev\nJepsC7BN1jlcnf43sD2wK3C/36dMfm2eI2tApvHPurCMVFR1HHgJ0YfmIuAREblaRP4w2G2Dqn5K\nVbeo6pVEH6HXiMhs4BDg3ar6W1V9DLgAOMYddwKRxHunO9fPVPXBIF9JFgdYqqoTqvo74GjgP1X1\n26q6BfgoUUP1Z8CLgG1V9dOuXMuA2xP5bXH5bVbV36nqRlVd5tK/AT4MvCxxzBdVdY2rl+uAB1T1\nJlV9Cvh34PkZVXlUSllHXVk7sZNbrk/Ztj7YXpbzVPXXqvoQ0f05tsv8jCFjpN8FMJqLqt5P1HWE\niPwxUV/8BcBxbpd1iUPWAs8mklhnAOtFBKIGQYCfu/12I+o6KcJDQfrZ7ly+nCoiDxHZaZ5KKdeD\nif+Pqupm/0dERomu69VE3VkCPEtERFV9tNENwfETKf+flVHutLI+6Mraicfc8o/CPIJ1j9EdYZ36\ne2cYuTENxMiFqv6UqBvp/wSrkx/B3YltHr8F/kBVx1R1R1XdQVUXuv0eBPbMOlWO9Q8TNVIhuxE1\nHOuJumSS29qd4z1E3WIvVNUdiLWPpCZUhqyyPpSybwuuAX+IqMtvCola5b8CbnSrfgNsF+zyR8ms\nMk4R1ou/d93kZwwZ1oAYqYjI3iJyqncXFZHdiLo4fhDsNltEThGRERF5A7AP8A1V/QVwA/AJEZkp\nEXuIiP8wXwycJiKLXN57uvwhkuz3SBYn8f9Koq6yg9y5TyNqsL7vyjcpIm8XkW1F5HBg/w6XOxNn\nyBaRMSL7QlVklfUHHY7znA58QESOEZGni8guwCWuzBe4fe4GXiYiuznPrPcl8kirU4DTRWQHV/fv\nInI26Ca/KURkhog8g+jePc2VvYoG2WgQ1oAYWYwDBwC3icg40cf5HiLPKM9tRJL7Y0ReSn+lqo+7\nbW8GnkbkabWRyE6wC4CqXgWcC3xFRDYRGdzH3HEfBs4SkY0icqpb1yLxOm3or4FPExn6XwMcqqqT\nrmvqSOBE4HHgjUReVe3cjy8gkrgfc9f5jcT20hJ3u7LmydvZlt4EnOrK9xMiY/+Bvq5V9UYiw/89\nwB1E1xvySeANIvJLEbkgWH81kZvtne6Y/9dlfiE3EHlqvRj4vEu/tN21GoOHxF28NZ1AZDHRC7oN\nkafKRxLbX070IP/Mrfqaqn6o1kIZXSMiS4ATVDVpbG4cInIr8DlVvazfZWkKIvIUkdvwzzrubBgZ\n1GpEF5FtiCSvVxH1r94hIler6n2JXf9HVQ+rsyzG8OC6yu4nktj/GtgPuL6vhTKMaUjdXlj7AytV\ndS2AiFwBHE7kQx9ifaNGlexNZHvYjkiz/StV3dD+kKHDDOFG19RtA5lDqwuld7VM8mIRuVtE/ktE\nnlNzmYwKUNXLmtp9papfUNVdVHWWqj5PVU37SKCq21r3ldEtTRgH8iOiMBBPisghwNeJRu8ahmEY\nDabuBmQdkX+5Z1cSg7xU9YkgfZ2IfFZExlR1Y7ifiJjKbRiGUQJVrcVMUHcDcgewQETmEg3wOoZE\nuAQR2dn3T4vI/kSeYRu3ygmo1j2/CsaIPFR7zc1EIZ2qYNQtJyrKzw+pgCjmXshstxwP1nV73puI\nQlJVyViQTru/Y0RxBGHrawzZxy3nEY/5myR+7WZQXb2PEIW2quq5aDq+DkdpfZ48NwF/7tJF67mu\n99qXud0zUwdn15ZzrQ2Iqm5xk+TcQOzGu0JEToo260XA60XkZKIAdxNEcY4ajq+2fjQeVTJCdR8w\nT9rL7PERUL5GqyLarxcri7T7Ooe4zBPAmS59TrDPCK3X4Afef43oI4bbPhmkq2KSKIrLdCYUdnx6\nHlFg4jQWuOWqnPl78+zmtnvFFH1um/J8V0ftNhBnwNw7se7zQfozwGfqLodhGIZRLU0wok9Tiko/\nRdironx6LRF9wi0XB+vWdlmOeQX2TWoIWYRdWF7SXUfcBbeRaH4nv91rcbNo1V68xnIqcH7BMpRh\nXk35NoVQW/Z1OCNtR6K6KPru+W7Jdlp0qHVMP42iKNaAlCLsjsjCf0jCD0xVPJvmdft4ZpL9AvpG\ndTnxxy4ZZLYo87s8Pg1/70ZobRAeCdb7eg/v7czE/ivcciVxOK5kZPkqqaMumkqnbqb5xO9p1vuX\nfFbbNRye8H3zgsYmqnsPm/pep2OxsAzDMIxSmAZSCi/RtPPWCDWQJlO1xBN6GSXz9HVyHJFheVCZ\nQ7rmlLzXXkJdRfzM1NmFNUz4Omz3Cev0eUtqHH7/rPsbUkfPAgzas2EaiGEYhlEK00BqJ69LYFGq\nklTy2HOKsLlNXr4ukraFXvX7Fs0/3D/UHNYR9Z9DqxSbNNqG15s2Nsa0kfL4Z2ZTm332dcssu1NW\n/efRLDZT/bszeJgGYhiGYZTCNJBS5JF+PE2XTqrWkEK3yuS1+213EtsH1qXs12/C1yLNk2eSdCk1\neR1eO1nA1gGo0/Y38uOfn3bawro222Dr+vd5PpLcMcDceEOsASmFN5bmcfurgyq7Pqp+Cdp1Yflu\nq9uJu4CaTjeG0o3B0o9y7vRRM/LhP/LtnFSKRvD373O79ys03ocj44ezMbEuLMMwDKMU1oCUYoJ6\nXPggn1LYZGknT9kOJZLKex1LLK/CPUn7LorRDtvT6Mf1Tmfmul8deea9r+P0rxeiGVgDYhiGYZTC\nbCClyCOhlI2FlSfvKm0gVbvQtgvn7sOb31jh+YpQ1Tnzap++j9wHmjaqw9uSsmJhhduy7nvyPfLv\nartwPJ52A2aHB9NADMMwjFKYBlIbdUTh9VQp8VQ9GKqdbWA7t8w7IdN0IRml12MDCcuTZ04VHz05\nKyxJ8tii87TYvbMGZKgZoZ6R8lmq/ZNu2XRX1vC16OYjMREs/ccsHGNgH6B6KRvpuZ/djYPVLWZd\nWIZhGEYpTAMZauqQcvIMJGy6QbmOehlud8/6mG7dgIMVX8s0EMMwDKMUpoEYPSRtRr9hoela13Sk\nrD2hrrk+8jBYz4lpIIZhGEYpTAMZaurQBNrlN1geJtUyzNdeJ1XWZxgc0ciDNSC14UNDF41/1O6j\n3svpZ8vSrvyhgbDJH1RfthlU9zEZLOPo9KBoXRe910XdvZv8zJfDurAMwzCMUpgGUht1qMF1SC69\nlIbCQYtNlsKKjkjOQ9bzMP2k0t5QZ3fTGPl6DrqZInl6YBqIYRiGUQrTQGqjrGQ0g8GTVJJ2jyyp\n2s/KtxYzWHoG7V43hSY8N6Y9WgPSOOqITVU3WUHpkoQxsAbxOo3pjf8c5n02izYc06/BsS4swzAM\noxTWgDSOIu6A/WaEYmWZ5X5QfErYXhJeV9FrNAYX/0wWjVtWdKrk6YM1IIZhGEYprAEZSJomxSQH\nVA261B5KilVJjYNeJ8NE0fvUtPexd1gDYhiGYZTCRKKBIm1Wu36SJnm1C2XSBNfLfjG8UurgYfcq\nL9aA1EYdLntF42r1g0myx3gMcwNiGNMP68IyDMMwSlF7AyIii0XkPhH5qYi8t81+LxSRzSJyZN1l\n6g3Tz2UvPxOkaxtmSDamC/YcQ80NiIhsA3waeDXwXOBYEdknY7/zgG/WWR7DMAyjOurWQPYHVqrq\nWlXdDFwBHJ6y3ynAVTTHOtxQBl2rGfTyG4YRUncDMgd4MPj/EHFEPQBE5NnA61T1c4DUXB7DMAyj\nIprQkXcBENpG2jQiNwXpecD8Wgpk5KGO6XANY1Bo8rO/GljTkzPV3YCsA3YP/u9Ka0hWgD8FrhAR\nAXYCDhGRzap6zdbZHVRTMQeNUfrvEjuD2F23aOygJpTfMLJognDUTRnm0ypc39x9cTKouwG5A1gg\nInOB9cAxwLHhDqq6h0+LyBeBa9MbD8MwDKNJ1NqAqOoWEXkHcAORveUSVV0hIidFm/Wi5CF1lmfw\nadIkTBOUf3wGcS6QJkilRjHKDuZtwn1uQhk6I6qD8c0WEYWz+12MPtOkBgTKv6CD+DEexDIPO9Nv\nAqdynI2q1uKg1AQjupGbmW7ZlAYkzzS2nY5rMjOJ63pQyjyd6LbRtntWNxbKxDAMwyiFaSADRZPH\nWRaZSXFQJMOi3mVFsW6x9ljdNB3TQIwKKDql52inHYcE+0Aag401IIZhGEYprAEZKEZoZkTbGUE6\nT9ma4gRQhKbVudGZJr4r0wtrQAzDMIxSWPPcGPKM8fB95k27beGgwunUrx/aagZRazKMejENxDAM\nwyhF00TZISOU2vNIuE0biZ5WnnauqX4gZN3usVXRlHo2yjGdtOFmYg1IX0l7wNt9gJt2u8IP7Jhb\nbsy5v2EYg451YRmGYRilaJpIawwsebqlBq1LwUaKG0Y7TAMxDMMwSmEaSONoJ/E22fg8newb/rWY\nAcxy6Xa2HaOZDJrTxuBhGohhGIZRCtNABopwPpCm9s2Hj1RTy9gJ7548C9jQz4IYXWGaR91YAzJQ\nhDGn/Me5m66juozEvpzt3JGb3LiMJ5ZJml5+w+gN1oVlGIZhlMI0kMaQZ5R5aMidmblXfrqRorOk\n8Bkp66o8by/wgyI3kW5EH4Y54A2jM6aBGIZhGKWwBqQxFJ27YJz+GgmzJOrNPS1FPcx2P4iuZzOw\nmEhLLDOb4iSRxliF1jgMlK3nJFbndWMNiGEYhlEKs4E0hjzaRNOi8WbRSQtpuk3gFW55NLDGpS8D\n9nPp5SXybPo9axL++ZlJXG9lnhdz460ba0AGikH4CE0SN3RZL32TGw+IGgvYur59wzEbeCRHPmGE\n4nAyMJ+eC6wtWcbpjK+fcewT1WysC8swDMMoRWbzLiKn5jj+N6r6+QrLY/ScOqaiHQRNqR3JCbKg\ntX4eIV93ot82RuwGPBrkZdpHZ5quraYxHad3TqedBnI68CxiV4a033vqLqBhGIbRTNp1MF6uqv+3\n3cEi8syKy2NMC6aTBJZmu4B8WpY3Bo+QPmNj050JjHIMzz3N1EBU9YxOB+fZxzAMw5iedDSii8gW\nETlPRCRYd2e9xTLSKTrYMA+TVC8x1ZFnL/E9tLNpHVQYDnDLcy98PYwTaSxea/H5jOXMxzCaSZ4n\n916ihuYGETlaVTcC0uEYoxYG+aMc0vSum6xovFndWXnwjcdIkB50ZwNj2MnjxjvpuqouBr4rIi8A\ntN5iGYZhGE0njwYiAKr6VRG5F/gKsHutpRpKppPh2ZMlqQ/6NeYtf9o9DdNzgXUF8zSM5pCnATnR\nJ1T1JyLyUuDw+opkGIZhDALtBhIeGaTnJjY/kfcEIrIYuICou+wSVf1IYvthwAeBp4j8Ht+tqrfk\nzd9oMsMuVXe6/rWYAd0YZNo9vYcm0tcG/xX4WqfMRWQb4NPAq4CHgTtE5GpVvS/Y7UZVvcbtvx9w\nJbBvvuIbhmEY/SKzAVHVt/i0iNwV/i/A/sBKVV3r8rmCqPtrqgFR1SeD/Z9FpIkMIf2S1qej7aUq\nRohnWDSPKcNIkjeYYlmvqznAg8H/h9y6FkTkdSKygkjLeWvJcxmlGPQxG3UTjt+omplY/RuDTCOi\n8arq11V1X+B1wIf6XR7DMAyjM+2M6NcSax57iMg14XZVPSxH/utodfndldhvcStU9XsisoeIjLkB\niwluCtLzgPk5imAYZalbMwjnuzAtZLBo8mDY1cQTodVLOyP6R4P0x0rmfwewwHlxrQeOAY4NdxCR\nPVX1AZdeBDwtvfEAOKhkMQzDMIaF+bQK1zfXdqZ2RvSuz6qqW0TkHcANxG68K0TkpGizXgT8lYi8\nGfg9UWfzUd2ed/BosjRj1Ie58BqDjaim28dF5CJV/Zu2B+fYpypEROHsXpyqD1gDMpyEDYjd/8Fi\nkN7Zs1HVWuIXthOBXiciv22zXbA+pYqYQb6H0frLpxeTmBYyqNg7CO2f3tNzHP/dqgoy3OR1E7WH\ntrf0Qsq0ezq4mEDXzgZyWS8LYhiGYQwWpj8bRia9kCxNih1c7J41YiChYRiGMXjkmdJ2v14UxAin\nS50umIJrGNOZPBrIZ0XkdhH5OxHZvvYSDRXhfNh1xlzqF0kV3+b/3hqLhWUMLh0bEFV9KXAcsBvw\nIxH5ioj8ee0lMwzDMBpNLnFQVVeKyAeAHwKfAp4vIgL8g6p2nBfEyMKHCg8l0CpdR5tmoG1KOTqR\n9loMStkNo3fksYEsFJFPACuAVwKHusi5rwQ+UXP5DMMwjIaSRwO5ELiYSNuY6qRX1YedVmKUJs3m\n0U7SLapRmNRcDqs3w8hDngbkNcCEqm6BqWlqn6GqT6rq5bWWzjAMw2gsebywbqTVv3Q7t84wBoyx\nfhcgBfNMMwaXPA3IM1T1Cf/Hpberr0jThTrGdQyKy2eTx7SU/WB3+5HPqpO0e1qm7qwhMnpPngbk\nN26iJwBE5AVMvwELhmEYRkHyiCx/D/y7iDxMFMJ9F+DoWks1LZjtlmsrzLOoEb0KN94ybsUz3bJp\ncsYokDHZZQu+3mbQOtCzm/rMqovRlO1Nq7dek1YnZSh7vwZpro/+0rEBUdU7RGQfYG+36n5V3Vxv\nsQzDMIymk7fT9IXAPLf/IhFBVb9UW6mmBY9krO9Gii16jN+/G4mqSmm73xS1LWx2P6hHIs16/UZp\nbh32An/tyRkbe+XG3kvto8yslM0ZINyxARGRy4E9gbuBLW61AtaAGIZhDDF5NJA/BZ6jWZOnGxlk\nSZBlpYYyWkS/vHKaKj2vyblf1ZJdlkaRdZ4y9dd/abR66grx04lenqsXPRH1kccL6ydEhnNjK5ru\nNjlJuptoN+RxF53lfmWOrZMZ9MfFeILIsWBmyrZBcc3uN72sI7sfecnzNu8E/K+I3A78zq9U1cNq\nK5VhGIbRePI0IGfXXYjqKWJkCtXVmcB4gfMUzd//z3ts0XP1grzXXPbYsuTpdpggn/bhNYXwWei2\nW6PIczXsNMdIbLQnjxvvzSIyF9hLVW8Uke2AbesvmmEYhtFk8oRzfxtwFfB5t2oO8PU6C9U9nfqV\nw3ZzRpBOSpxVEEq8Xor1Lon9tgnURT9mV8wrreYp2wz3C2dzrnqOFqMzVldNJ48R/e3AgcAmiCaX\nIh5mbRiGYQwpeZr436nq76MJCEFERojGgQwwoTRZl6ScFvm1zGCoKuh1aIZB7+/fmFiWJe1ep80T\nn7Z+mBk0d93hDX2SpwG5WUT+ARh1c6H/HXBtvcVqAt0+EOHHp98fiV6ft5fXW/e5qogcMEYsqDR1\njExTaPoYjDrzGTzydGG9D3gUWA6cBHwDsJkIDcMwhpw8XlhPAV9wP6MU3pA+TveRcekyj6J5VikR\nVhVlNaRu6c/nfyBwW8lzbgqOScY+mhGkja27efutvRvtyBMLazUpNg9V3aOWEhmGYRgDQd5YWJ5n\nAG+gmXODNphQ4vYObFnRettRhxTmQ45kGYyrPGevZgHoVmvyj/c8Is0DorIf7NLnk0+LShuQSFC2\nfYifA7ONxCx0y32AW1y6zLw63g17ecb2XhvRp5821dEGoqq/DH7rVPUC4DU9KJthGIbRYPJ0YS0K\n/m5DpJHYCJ9ChP3fTZM0i8zQ1+08DIMiefk62QTcGaz39RB6VbUjDCjpr31f4qjAa+mdVlYVvfCS\n8nW+kthuVua8KzLWV60J1D0/SXPJ0xB8LEhPEj39R9VSmoGn04M5g+7GSJSZfKZbhtfHPfu683Y/\nrnPLg4k/hLcQd2POILt7pWn0o/tlnPh9mRmcO68QVndZp1+XVFHyeGEd1IuCGIZhGINFni6sU9tt\nV9WPdzh+MXABUffXJar6kcT2NwLvdX/HgZNVteFiWTfRfrvpwuqHpDNKMa2pCRpLXecvm++NQNgT\n7A3CafODNJV+3NPwWZqgNW5dHrzWt5l6jNzhQNFuoxYMJnm9sF4IXOP+HwrcTtRB2RYR2Qb4NPAq\n4GHgDhG5WlXvC3b7GfAyVf21a2y+ALwo/yUYhmEY/SBPA7IrsEhVxwFE5Gzgv1T1r3Mcuz+wUlXX\numOvAA4HphoQVb012P9Womi/04hQminjuttvitps+ql9hJGPq3JW8HnOJJaA12Xs2w5vGB4lfu2G\nU2rtTGg49/cxjLCdV8ud65braH2Oq3DyCMswaI4Q1ZEnlMnOwO+D/7936/IwB3gw+P8Q7RuIE4Hr\ncuZtGIZh9JE8GsiXgNtFZJn7/zrgsqoLIiIHAW8BXlJ13tXTjQTTNM+NOsKL9Is6JMEwCKK/d3OA\nDS5d9D6G/eVNeQby0MvnNnwW/aDOUFvLWwZva8r7XBTxcpwke6Do8JDHC+tcEbkOeKlb9RZVvStn\n/uuA3YP/u5Ki/4vIQuAiYLGqPp6d3U1Beh4wP2cx8lKXATj8SDftozEdGg5Pr+JibSxxLv8MbChx\nbBPoV5l9w1F0umko/mwXvcZ5btk0n5/VxGON6iXvgMDtgE2q+kUR+UMRma+qq3McdwewwE2Jux44\nBjg23EFEdgf+A3iTqj7QPjvzKDYMw2jPfFqF65trO1MeN96lRJ5YewNfJLIk/itxkKBMVHWLiLwD\nuIHYjXeFiJwUbdaLgLOI9NTPSjRr1WZV3b/sBXVHXVJWKAktcMtVNZ2rCKNMHw2kl+7DExTv+vPd\nKGHXRxM10jSa8JyMk96dVSVFB+rW8Q43rYu7PXk0kCOA5+PcSFT1YRHJ7cCuqtcTNT7hus8H6bcB\nb8ubn2EYhtEM8jQgv1dVFREFEJFn1lymacwIbmr5Lqlq4FJR42KT52eYQT1l8tc7g1Ytomz/+giD\nZ3QNr7WfA0Xrdnsucl1lbDJVl6H/5HHjvVJEPg/sICJvIxpWa5NLGYZhDDl5vLA+6uZC30TUFfWP\nqvqt2ks2LZlFdRJGFf3BRUM2hNJn1qC9fkmom6l+IGH4eoR2j3nEXi5lvLG85NpPaT7NhhOWJ7z2\nUPuqS9NLY4R48GbyfpbVhKuq83Gmlwt8Odo2ICKyLXCjC6jYgEajCXGW8pJmKB2jGsPbRmJjfC9H\nM4d1H740oTpf5v5U0S0WjlSeTTUvdbI8Ps81BfMJX7NxmtEN6MuQ7IoJ40f5Mb8TwT69/Fi2G31e\ntu4G5fsBgzDOpG0XlqpuAZ4Ske17VB7DMAxjQMhjRH8CWC4i3wJ+41eq6jtrK1UmTZceQoNrmtSw\npsJzlYnHlEYV0nDRKKlZzCG+rm7mPqk75ljRUcih84H/D/3VqH25x5ian2THk+PNj58T7Ftm4GTV\nNM2BYzb1P2deG2yuBpKnAfma+xmGYRjGFJkNiIjsrqo/V9XK415Nf5IDr+owtlWVVxXSXLeuyb4M\nhwL/Eqwr2wc8lzgOUlUktYUqohQ3wQayEVgSJR8/h/hZHSWWsCcpPrdGHTRB8/BUpXW3w9d/c+cb\naWcD+bpPiMh/9KAshmEYxgDRrgGRIL1H3QWZHoReI54RoqgvHSO/1MwIWymco0tzHjsa/Drl326f\nTmwm8i7zHmbhnNh5mON+u3ZRhpARWuvN10HeEHKDwAhwpftBpNlOEGklPj07+PVSC/B13cT67qVG\nUMXg43pod2c0I210JBl6ekPWjv1louOkkn5Htwxf5lm0dqNNZKwvwvXw/BOj5F0XU9xRwO9f1QuX\n/FimjZHohia4pWfFufoy8XXuBdzWsxLFNHF8ha+TcNxR3eXs9zOSTbs34U9EZBORJjLq0rj/qqqz\nai+dYRiG0VgyGxBV3baXBZl+hFXbhKid4X5ecrq+4DkniWJrAuwLI86QOHl+sE830thGuOselz4R\nuNil82oi/rp6NS9IU/Lp5twTxAbh5EC9Q1z6OporBZfR4qpyXW+ihtRb8sTCMgzDMIytGIIGpKwR\nrtt+7kXR72NnEvWX+lhCVRkF0wz2RSlqCPSunY8A6+B5RD/C6P7dSmWrot/7fV558/MG/FHqmdq2\nDppgHA6foYOJjOdLiOrxOvfrhctqWcqUrYp3p5f3rgnPSTpD0IAYhmEYdSCqg+FgFc1HcnaJI/sR\ntXMELjszSi65EbilgjyrpIoZ8QKtY+RUmDwne9fchC7Am4nnnM5rQ/ITWa6gyeEfmkc4S6a/B4to\n9bxqwnMXSOtXAAAe7klEQVSbRq/fqX5E4O32Gs9GVaXzfsVprm7Ud7p8KJecm7Kyl6Gwk4QPvlf7\ny3xkU+LztBjRuyEZ1beo88HtbjnWdi8DWuO2hfXsP4y9HvNRll6X0T9b62hWbK7+YF1YhmEYRimG\noAGpwmBW9pxZ80n0G2/Izzu1fWj4TzNsT9A6grwsG+k84j2LUJkuM0q4qSOe68I/n/tlbL+W4auT\nPGwgHhjcq29LczWcIWhADMMwjDoYIvGil8a25LkWueWdPTp/GqHWUHR2uTz1VsVgyTACb1EtYiFx\nCJM1FL/XvZTymtR3vor08oQReJtQzjoo800I66QpPQr9wzQQwzAMoxRDpIGUoaykmAwb0rRomt1I\nTm72OsYz8ulW0/NhS8aI661dfv4eHQwvddLhd6twKU7mH9KtRN5viT5pL/Ja3yLi+l9F/yTsorNR\nVvGeJvPL2uY1kLpnIxwMhqgBKfPSdvOi+wdtX6JxCU2h2w/8XtFiwcGw6jq37vZge1Uf143kezz9\n/hfCd/M6BZQpT0iXY4T63oDMABa79PVEEZQBbg726Wc5w6jHecYsVV3Oft+fwcG6sAzDMIxSDJEG\n0mucBjJ6CEz003juqcpw66LlrtoA7OzWhQMAuyGMY5XXRTKc9rZXMbDK1GE/RjBnsRlY5tKjFJ93\npVdMEj9Xo4n1/cK6rkJMAzEMwzBKYRpIbTg31IlzaUafalV9+X7/dcSuu7OpRgMpo0EsdMtb2u7V\nf5qgeXjy3PMmPLMhTao/aIYtq/+YBlI74UNWh5G3DH6EcZkXwI9EDz/2jxB5TXUbg2qSeF7zvLKN\nC5U/cymRcbiu0OPdzPWepEkjvJv2YW46PlLCJM26j1A+ikN5rAExDMMwStGk5nMImEU1XT3dqs/e\nbbNszKg0yuSVhjfozsqZp3MhHr+T4uHfO+EnqfJ4DavIRFdJRrs4tkpC5wNPeK39LKMvx2a6e87r\nGPEfRuMN3Y2b0J3V+3tmGohhGIZRCtNAekpV7pLdSDuz6c4V0Z97lOKG+TwSYdpAwnb7h9JqVZpH\nWJaqJqYK3XjD6+pXXKy062qCZgTVlaOOOm2qy3N/MA3EMAzDKIVpIENHtwOh5rjlZtIlxTzaRV4t\nJY8Eua9b3pNj337SFOneqIbQltUE+0d/qF0DEZHFInKfiPxURN6bsn1vEfm+iPxWRE6tuzy9w7vU\n7d9pxwFj5+g3/2TYbWn0KyyHtGs8vCtuTnfEkUOjX23uu1UzQjz51hj9mfDMKEfSyWAmzXHN7w+1\naiAisg3waeBVwMPAHSJytareF+z2S+AU4HV1lsUwDMOolrq7sPYHVqrqWgARuQI4HJhqQFT1MeAx\nEXltzWXpIaPEksmaPpajDlZGi9XnMuXSOHImTJ7rtncpTT//jGh514Xk6vaZOu8sWuNoVYV/RcL8\nyxjWfT4LiaMzL6A69+fpwghxt+QC4i7XJkQaSEZK8M9BU9x4e0/dXVhzgAeD/w8Rd6IbhmEYA8yA\nGdFvCtLzgPl9KkcnNhNLTgNWxR0JpW8nPU9+nGoksEmneQD7nQLL0+YbSTkmLEvlFJ2fJAsvNz1E\nLMlu6CK/6coMYLlLryKut3cDl7l0v7S2cMrl8cT6JrGaXvV81P11WwfsHvzfla4cqQ/qsjiGYRjT\nnfm0Ctc3Z+3YNXU3IHcAC0RkLrAeOAY4ts3+UnN5ekSZqTLrpo4Baz6vcVofpbLnGGVKulx+Dvk8\n2PLMWFcV3eS/Nkj7ujLX3vZMEA8O/RfgCJf+Sn+KA5jdo5VaGxBV3SIi7wBuILK3XKKqK0TkpGiz\nXiQiOwM/JPoSPCUi7wKeo6pP1Fm27sjzMQ6r1sfPOQWocr7uIqSVdZS4nHkNw50mRhqj/FiTxcCN\nQXnyTMTlr2uM+Brq+jBX1Qj7bplHgLkuvTZj37pp2ocw695NULzhqEKoacd+brmipvybT+0d9Kp6\nPbB3Yt3ng/QGYLe6y2EYhmFUy3Sz8PaIotLGiW55Y9u9eoe/7YuJJb7rC+aRnMbW14mfGwQKGzv3\nWwjLvQE1b5fUomhxxcFwjK/f23Iem4XvFjsKZu4aJcc3EhnAAa4tmH/4ms0grpcR+h9bqW7JeQ6x\ns0Dec812ywlan7EiGuBMwI9LPr/AudsRamujxMb+4cViYRmGYRilMA2kFlr7XmfrowA8Inn69HvI\nKQvhwnM779fC37rlGiJJHLaW7jaVK8/yL8NLj4vS3z2XzvYWmBpgdswtxEbWvHOJZOGv52YY9/fy\nEaa0nYPPhBs/F6zPwh87B3Y7Pko+eGNcZuZQXbTfouSp2yrYRDQgEILxw20YofXeeW1wlGL3dIzq\nBx9OAvsE/1cF64cT00AMwzCMUoiq9rsMuRARhbP7XYyczOEi/R8A/uaGL8Grz3fr++m2GfYfe8+f\ncFa1vCyOFgcfADd6ifA6qpmLYzaxlHkgsX2gXd51zq3RTkEvMqtjljdQU2YnbBLtvMK811Me20MZ\nD8MCXLIUTviy+7OGZmshZ6OqtQyRsAakFhYQjzZ+hPgj0S+XyTAq8C1BGcqUJ2260UXE4dTLXF8Y\nbyr8IPuuj3YNSJ2ulFXdr6x8muZCWyX+OZlJ91MIeIoICGEDUscYoZlwljPSf/Ba8rmc94v6GhDr\nwjIMwzBKYUb0UnSShDYSayB1dFGEcxDkVc99PKlJYjfJMpJhWsTbO4ldd0dK5LuzW55I60DLHN1i\nux0ZLR9cAVxZ8LxZeENpVVPkzkvk1YQpbeumm8jFWeSpo/CT5rsZk+9gN3UevHsf9A4oB5bIJw/N\nfzZMAzEMwzBKYRpIKTq5JW6kdfYyX83hrHndxMuaIJau8pDsDz7Ypb9CcW2kndYFXc3Qdg6wtOAx\nD3qNZSbdOQeEeOP9GK3Tlnqpeh5xtNN253Fa2X7HwfKL3boNbG1Ih9678xa1JxTVpP2z3o0G7meo\nhNa5OPKUeQ6tA1rDY7qwAb7e2T2uCgcntosWXYTBs5WZBmIYhmGUwrywStFJepsZbAslp3nwYjdQ\n7gcfpzWyp9dqDiAeoNftvAe+nIcQz4K3gakQDzsCj3/Vrc8zyAs6D0ALryVvnr6cVQVEHKP+OSNe\n7pZ5Q2WnzSORl6qDAhaVaMvc05LhbDqWA/IFMc0T1LMbL8SjAO/GmzePftk06vPCsi6srsh6ACdo\nfYFcd9P844IaD0OgTzL1Ys4/Glb7l7WoapwsT5TPIbqG68RPE7ozUzGdHr+S4h+0Th/24Fpy41/K\nsKsh70cz7aXM+mhV2RVQdJRz0XrO6n5JI+wuzdPwJvM71C0XBcdfSvwBnqS4Y4S/B1WOdclz78Ip\nBjzJ+142AvJM4mu5jNjZIpwEK0/Zpg/WhWUYhmGUwjSQrsiQKN5yJnzxO+7P7UxV8+pzYPVYsGPK\n8asvZCrmUiZZ0nkyv8h19DqZAac4d9cL1xC7u5aRDL12FBqD23VnFZG62l1LFt4FOE9U2yOJRs1D\n90brPOXzzgrJKMx5ujJ812ceCX6CWAvJU+ejQf4nEmtT1wZlO5i423MtrRGEPXk0w36NtA/Pmyyn\n18aLOlvsRVwnoabdheNIO/Z1HiUrziV/BGLopUOGaSCGYRhGKcyIXgrf97mOtNb+EN2P6+5xEv+f\nfI5i/cehBLmI9BAJhxJLje36+0Oqcg8Mo6N6diYeKFdG4vT1WdR2AvHsfmFolWSdhHVxhlv+U47y\nzCCOLDxBfG1hZNg29fdiJ0H+4FriUC8zyFdHrszvPxM+7Aes5T22E3Nh/vFRcnUYjTk5sNG7eI9R\n/N50YzBOc4GfpPO1h9raSJBPOAcLwBK33AQsK1CspfBbl9YyM4t67X0T+b4JzlZz2vHwUX+fwns0\ni6nYdMwj1nSTtlMLZWIYhmE0DNNAynCykyw/9zVSvS8+thTek2e+iCxCqSvFHfK8pfB+l95KEgqD\nHc5gayaC/GeQHpqkKCPAK1x6EfDxgnme4pYXU42EndSs0sJbdONeOkI+24vX1sIBicnnIcst2q0f\nPQN+4t7RPW8nfebIxRnrsxgj1txWJc4dPnu+bHOJNe11pGsXebTZbrzgQo0iTx9/csbMZF4QubMX\neVaPIJbuw9kkc17TqPtuTOQNvujf/VD7bcmQ2J5zT7A+WR6LxusakA/RBFe4q/X7ABwu3wQudGvD\nD1IYlrxo/J7wxZ0g3TC2CP7IuV6uP5/44ZoT5LWR2Ih7La0jev3H4w+IXRoLqPJt2Qc42qXDsS7t\ncC/WCDDpR2y3+zAXbQCDiZ2m7ku/JnIKCccLZcVrmkX8DBwPhF0Znv2Ju9rydDXNpPV5SKuLZDeS\n338e8dS+VUXZrYPk9LNh/foP8ya6C8tfxH06KcSE5wvLkxalICv/ZJddWLYQ68IyDMMwGoZpIIUJ\nVemDSZfc84yEDt15R4gliXFaNZCwS8oTGtJClsDVuwJw/mHv5PT/ibQjOUFh1deiXU4+Er7udl//\nVcoZrtsxGpQ5KVFl4ef0WEVsaJwgvubkgC+vNR1AawTeLMOtX38c4OphK6k7TavJ0nDydsWkzZ2S\nPFeW5OqvcZzWyLZZXV5eq0xqbml1MptY8h6BBUfHxZ3qkd0M/EuQDmOC1ekuWtVgz3buz76uNhK/\nh3ncwPchfhaLdrWG8ehCh4D9g32Sxm/vxBDWc9gFHXZxhyS/PaaBGIZhGA3DNJDChBLSAtLnjJhN\ndv+wlx4WwBFO8lt2HbEElCW1ZxhZW9YvIBrgB1u7+3kpfx5xrK1kZNg8ZIWBSNOI8sQjgljSyhO2\nw+cL/NEpsRfjFcCEH+R1W6J8rmynnQkXuFWTycFZUf1s84tX89SPnxmt+hDwQ7d5MzDp7Qyr6OxG\nDbFzwG3EA9D2Ipbg28XRclLyjifC40lX2zSytB1P+NweAS9eGCVPBE4I7U7+XhwPZ7k8P7gJ+IRb\nn9Sus7Q+f41h5OgsY3CynN4wHNoANhG/I3k0n/1hp0Oi5GM30hp65t1uuYG4ByGPRrEIeNKli2ru\nod1pjEgbhtb5bxJa06HONjgPuNBNi73fGfC8KLnNP/+Gp06PntWjvnQZP2VvAO6W+2jVqD5gGohh\nGIbRLAZMA/kI/QuN4MlyEU0GMVwTrPf7HAWje0XJ8+JD/uPUv+TID0YhNg4+6z/5b7nb7f8KIukV\n2odm8IRSzkZapcDJYJ8wUnBRDcT3H28I1iVtBUUHkXWakySrXzwMITFKq9vj2sQ2XBlPdukv0ypJ\nOw1txyPhca8tBIEnWzTNfWEnJyU/FnrBJVjgJMhVK4il6gzX761w1/b+U3nBP0XS84/kQFolVsfo\nUpjwkWE3sHUgQWitv0XwJufFd/k5pHv9Eedz2tL4cb7qUlqlW69dJDXnbiIIh+7P81x6lMjmBal1\nsBVLgO+49M602heOcss5xDaxPIEVjyK+jxAP3Hsox/Gj8FI3iPXtwDHee3NTsE+W7W4hrSGEfD3c\nAg+8KkruOUmsZSUDfdangQxYA/Ip6g/T3YkwjtAcWkc/uw/JwUvhRv+B3Qxs59LfIlZ9Q2NzMAHV\n6Bk878lbAbhr2YuRI3/s9rmd1hc3fNH9B2wGrUbBtAZkhNYuhZGUfbL5tD4IwPuePI8nrtjJrQTu\n8h+wVRSfpMobEpfT2S13hLgRC1/aZH1kNfKzg31Cw3C4r2+EZ9MaXj4ciR66T3bqVkqOvUk7NsvV\nNHg2djwDHvf1c36w73Hw5XkAXPrGo9mRXwHwPs5jhdzq9gnvRdgVk+yCTRtrMZep+GxnLYy/6b8i\nGroDsOLjkGpoDw3GRQ3kWW6s7QzkaQ1mu243/+zliXwdjucJI26PkW+CsbRuxiynk7CuQqeHVUxF\nSpCjQX13dDgOJIl1YRmGYRgNY8A0kC+Qz92uTkbhy04VfZHCKtewv/oeplTay06Nw+0Qusq2U+tH\ng2WkJt+p7+QXEnWn/CU34aWk2/Vy9l/oukGWQzy4bBaxRJWMAJuUyADmwLEuZte/5XTpPc91y7xv\nBVNS5sG7csi3oq6A5/C/fOzID0Trl11HPOI2R8yoJ4DloSbjCbW+GcRG0Itp1aZCd9dQQg2N9J1G\nM4/RKvmGAzPTNJB2EmealhgeOwdef3yUvOpi0jXMMB7XGK3X67XccGDaIuL5PTbD8502ddelxFrI\nBPFzMkHcpZaU+MeC9b5uQ0n+zKgrFuCbwE0++sI8WrVr3/3yCHGXbDsNc0aQ9oSaTB43+RFaNYTw\n2Q7ftSI9GsmpodPeqaz8km68YfRkP/D2q8HxoWayM61dxs4BgpnEWvjKYPskrW7/poEYhmEYDWPA\nNJB/JV9fY52MwOiZUfI02P4DvwDg1y/aBe7ymsAoxQ3VYR+5lz4XMiVZzDwexp2EJyeDOmnsrFHw\nNvcT4e8Oi2L7jDOTy297W7T+10TKG0Q2ZG8X/ntw3eWgSVfHTuUcTaz3Ev0iuMRJwCdA3FffzvnB\nubu+ZSzO5keufADvanVjfY9uC8BH15+FXOee39OAx70UNoPWOU+c6/GJx8PF/uIvSZTBSZC7nRLX\nyfgmYmn4IWIJfhOxpLiuzbV5TWANsXYxL16/H7D8lmCfQOs612llnwAeC43G3v6ziVaJ3D9jhxIb\nKTYR10MwGHD0VHCeyisf3Y0Fy6I6+cwRJ7CMIwB4Gr/jmxteDcBTuzxKNAMftGojY8QxwVaQrt0l\ntYhODhZvDK5rnFj72hikZ5HuPh+yTzS7J0Q2utcEmu29rm6fC/HzmeM9PWIpLPP36zsU00DmBukJ\neH3kzHHBv5/EcqdRXHLk24P8V8D9J0bJ/wTe4xw7dtu3tXPBufSyC/A+l76U+JsAMCGmgRiGYRjN\nYsA0kGuIvQ36OaDQ9x+HLpPt3PGKMpqSTnpopLlPhp4bM4mlww3E/aabaJ1VLQyFUKQ/OMueMxZs\nO4DYlbLd4K9wwGOat8wSYgl4kqk+9YOOgw+71VcTS12vBd5+qfuzlikbyE4nx9m8Zk1Qtgn4WCQR\n/uzUZ/My/geAh25YECu89wG/cOk5MHrW49GR2z+DVo+omDfqbgB85ftvjfP5HnGEED2fTK+z+ZGU\nrJcL9x64JwAf4b1cfqTTKpfdhreJXaR38LbbLgfgsgOO4qOcBsD6p57NL7f11xhoSv+1FP3XSCDd\n+ys/5qdTsuky4udtCZwWPT+n/PM/c+E9p0erv85U7Mvoovxzfwutnl6hF1Zov+rkhr8E3jQvSj5G\n/AjsDXv+870APPCN58Jrslx53QEnn8kJn/0MABcve0fgzbgMfhxdwAkLP8Ml//D2aPWH27hje25e\nytUvi7Syv+VfWH/6/Gj9boB3dvu3rNkDF7CrRu63T+d3PPDV50arjwm9184M9v8qo7/+CwC2e9aT\n/HJVpHn+xx//JUceHrn8n3MNLHUmTM6Aww6ItM1r//wNcGOotZsbr2tAfkSsv/VzPEinUb/dkmZs\nS4bc7nTepEE07YWuq+xhI5bH2NypWyN5vWGYcZ9/aOSepDU2lM8/NEaG9TNOaxdiSKe4WAeSr+sv\nJE8sqdAV2pf1QNj3wCg5B/iNWz0CvC5K7nnqvezJAwA8wJ488H33oXoX8EPXfbfTrvCYD2M+j7jR\n3kDraGmC9a7RHj3adf0ALwacJzfLgat8Y7ICdnNjFSaJulf85a76jvsTjsIv+swcRWsMtJBQsAmd\nAHwd3kdr/fvJw9bS+ZsSRp4Ixx3tDF923ZLHXUr6mJCkS3haqPYwijfEz/A46cZ1iBvwcP0Erc+W\nxcIyDMMwGkbtGoiILCaKQLQNcImqfiRln08BhxDJVMer6t0p+2g0+MmP4Oz3iPReUXRUd/K45LFV\nRTttAu0GlKURXnuWVlMmymrdz2Ka40LoRpow0LaUx0uiyVH7jwRpT+j6mdS4/H5hJINkl2cezTzt\nea6jDtvd304afp48Q3fjkKxrzzMoMk+UizIMqAYiItsQ+UC8mkjxPVZE9knscwiwp6ruBZxE3ENs\nZLK63wVoEFYXMVWH5h9kftbvAgwFaSFUq2R/YKWqrgUQkSuAw2l90g8HvgSgqreJyPYisrOqbtgq\nt5mjMF5WUhxU0qSPNcD8Ese1Wz+ITJCvLjyTGWmfV9ky1I0va1a4mXVu/a20agjJPMKBlp5k+Ucy\n1k9kpLP2ySKtbHXU4Wpg9+B/cj6dMudOlj1rrpg0JjK2ZZUr7X8aVWkp5ajbBjIHeDD4/xCxZShr\nn3Up+xiGYRgNo24NpFrGs1zk+kXd9oTpZK/IQz+vN3wVfN92sr88K92JrD7+PNcb7pNXq0yzf+UN\nRtipPGGdjFLPrIRV9DI8Revgviy7RNlzdKvhd3qWsuwtoQfXRlrndO80mLF66m5A1tGqR+7K1sGs\n1hF5Urfbx/GBCos26LSbjGjYsLqIsbqIsbqom7obkDuABSIyF1gPHAMcm9jnGqII+V8VkRcBv0qz\nf9TlRWAYhmGUo9YGRFW3iMg7gBuI3XhXiMhJ0Wa9SFW/ISJ/KSKriNx431JnmQzDMIxqGJiR6IZh\nGEazGIiR6CKyWETuE5Gfish7+12eKhCRS0Rkg4jcE6zbUURuEJH7ReSbIrJ9sO39IrJSRFaIyF8E\n6xeJyD2ubi4I1j9NRK5wx/xAREJbVKMQkV1F5Nsicq+ILBeRd7r1Q1cfIvJ0EblNRO5ydbHUrR+6\nuvCIyDYicqeIXOP+D2VdiMgaEfmxezZud+v6Wxeq2ugfUSO3imi47QyikHn79LtcFVzXS4iCMd8T\nrPsIcIZLvxc4z6WfA9xF1OU4z9WH1x5vA17o0t8AXu3SJwOfdemjgSv6fc1t6mIX4Hku/SzgfqIg\nRcNaH9u55bZEgzv2H9a6cGV8N9FcDte4/0NZF0SjI3dMrOtrXfS9UnJU2ouA64L/7wPe2+9yVXRt\nc2ltQO4DdnbpXYD70q4ZuI4o1O0uwP8G648BPufS1wMHuPS2wKP9vt4C9fJ14OBhrw9gO+CHwAuH\ntS6IvDK/BbyCuAEZ1rpYDfxBYl1f62IQurDyDEacLsxW54Gmqr8gDsmaNdhyDvH0UNBaN1PHqOoW\n4FciEoZYbSQiMo9IM7uV6MUYuvpwXTZ3EQWQ/5aq3sGQ1gXRlFqnA6GxdljrQoFvicgdIuJmm+pv\nXQzWQMLho0oPh8a7QYvIs4CrgHep6hMikrz+oagPVX0KeL6IzAKWichz2frap31diMhrgA2qereI\nvKLNrtO+LhwHqup6EflD4AYRuZ8+PxeDoIHkGYw4XdggIjsDiMguxCFTswZbthuEObVNRLYFZqlq\n74aoFkRERogaj8tV9Wq3emjrA0BVNxHNerWY4ayLA4HDRORnwL8BrxSRy4FfDGFdoKrr3fJRom7e\n/enzczEIDcjUYEQReRpRn901fS5TVQitrfw1wPEuvYRonj2//hjnJTGfaGab253K+msR2V9EBHhz\n4pglLv0G4Nu1XUU1/D+ivtlPBuuGrj5EZCfvSSMio8CfE00hOXR1oar/oKq7q+oeRO/9t1X1TcC1\nDFldiMh2TkNHRJ4J/AXRNF79fS76bRjKaTxaTOSZsxJ4X7/LU9E1fQV4GPgd8HOiAZQ7Ek25eD/R\n4Msdgv3fT+RJsQL4i2D9C9yDtBL4ZLD+6UTTtq0ksifM6/c1t6mLA4EtRB52dwF3uns+Nmz1Aezn\nrv9uovmbz3Trh64uEvXycmIj+tDVBVHIaf9+LPffwX7XhQ0kNAzDMEoxCF1YhmEYRgOxBsQwDMMo\nhTUghmEYRimsATEMwzBKYQ2IYRiGUQprQAzDMIxSWANiGIZhlMIaEGPaIiJjbu6EO0VkvYg85NJ3\nicj3ajjfEhF5REQuqjDPo9z8DNMl+oIxjbBgisa0RaM4Ps8HEJF/BJ5Q1Y/XfNorVPWdVWWmqleK\nyAbgPVXlaRhVYRqIMSy0RBYVkXG3fLmIfEdEvi4iq0TkwyLyRolmBfyxiyPkY1Rd5dbfJiJ/1vGE\nIs9x+94pIneLyJ5u/XHB+s+5mER+5s0fOQ3pW9VXgWFUi2kgxrASxvBZSDQD4q+IZn37gqoeINHU\nuqcApwKfBD6uqt8Xkd2AbxLN+taOvwUuUNV/c9GGtxWRfYhme/szVd0iIp8BjhOR64GLgJeo6s9F\nZIcKr9UwasEaEMOAO1T1EQAReYAoKB1EAede4dIHA/t6bQF4lohsp6pPtsn3B8CZrsH5mqquEpFX\nAYuAO1xezwA2EM28ebOq/hxAVX9V3eUZRj1YA2IYUURkz1PB/6eI3xEhmu5zc95MneZxK/Ba4L9E\n5CSXz2Wqema4r4i8lmZPZmQYW2E2EGNYKfqxvgF419TBIn/S8QQi81V1tapeSDTXwkLgv4HXu1nl\nEJEdRWR3ovDZLxWRuX59wfIZRs+xBsQYVrLmMcha/y7gT51h/SfASTnOcZSI/ESi+c2fC3xJVVcA\nHyCakvTHRA3TLqr6GPA3RFPY3gVcUeRiDKMf2HwghlERIrIE+FNVPaXifF8BnKqqh1WZr2F0i2kg\nhlEdE8DiqgcSAp8BGjlPtzHcmAZiGIZhlMI0EMMwDKMU1oAYhmEYpbAGxDAMwyiFNSCGYRhGKawB\nMQzDMErx/wG0iEZZP8ntsAAAAABJRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAZAAAAEZCAYAAAC5AHPcAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAALEgAACxIB0t1+/AAAIABJREFUeJzsvX2cnUV99/8eOHvjWnaVBbPSDWTRjbDVRIka9BdpQktv\nSb1RRCsq7Q0qPnArWmlFvdUfcFN84EcFxRYfsEItKFZBTWuspk0o5lZAE5tYN5poNk1iTAwb2VVX\n3QPz+2Pme+Z7zc51ztnNnt2zYT6v15XMzplrZq55/D7Nd4y1loyMjIyMjKniqLmuQEZGRkbG/ETe\nQDIyMjIypoW8gWRkZGRkTAt5A8nIyMjImBbyBpKRkZGRMS3kDSQjIyMjY1rIG0hGxhzCGPMUY8xm\nY8xDxpg3zXV9MjKmgryBZJTCGPM8Y8xGY8zPjTEHjTH3GmOe2eIydxpj/qCVZbQZrgD+zVr7OGvt\nR1IJjDH/wxhznzHmF8aYnxljPm2M6Wu2AGPMemPMq2eqwo3yM8YsNsZ80RhzwI+btcaYp8xU+Rnt\ng7yBZCRhjOkC1gAfAo4D+oCrgd/Mcb2Obuf8poFFwH+W/WiMeSlwO/BB4HjgqcBvgW8YYx43KzWc\nOh4PfAl4CtALPOD/zjjSYK3NT34mPcAzgZE6v18EfAO4Cfg58H3gD9Tv3cAtwE+A3cA1gFG/v9a/\nMwp8D3gG8PfAw8Avffxf4hbYR4BXA7uADf79F/r3RoB/A05TeS8DNgEPAZ8DPgv8H//bSl+fK4B9\nwG24BW8NcAB40If7VH7rff03AmO4xbAH+Adfxn3AyXXaKq7rqT7+X4EqMO6/dyDx7jDwF1GcAbYC\nV/m/rwQ+rX6XNjsK+Ctfxq98GR/2aR4BLgN+5L/7OvX+lPNrMJaO8+8fN9fjOj8z+8x5BfLTng/Q\nBfwMuBU4B3h89PtFwATwZuBo4GW4jeTx/ve7gb8FHgOcAHwLeK3/7U/8Ir7M//0k4CQf3gmcpcqR\nxetWoBM4BlgM/AL4A1/224DtQAXo8Ivum/xvL8ZxTXoDmQDe69Me4zeDF/vw7wB3AnerOqwHfgj0\n+3b5T2AbcJZfVG8DPlnSjk8pq6vK+9Ul756K21AXJX67Ctjow1cCfx+12cPAUWVl+Db9V+BxwELg\nB5JmOvk1GEvnAXvnekznZ+afLMLKSMJaOwY8D7fQfBw4YIz5kjHmCSrZfmvth621D1trP4dbhF5g\njFkArAbeaq39tbX2IHAj8HL/3mtwFO8mX9aPrbW7Vb4mrg5wpbV23Fr7G+AC4J+stf9mrX0YuB63\nUf0/wHOAo621H/H1uhu4P8rvYZ/fhLX2N9baEWvt3T78S+B9wO9H73zKWjvs22Ut8CNr7Xpr7SPA\nPwKnlzTlyxJ17fR1bYQT/P/7Er/tU79PF++31j5krd2D659XHGZ+k2CMWQh8BHjrTOedMfeozHUF\nMtoX1tof4ERHeCXo7biF5kKfZG/0yi7gd3EUawewzxgDbkMwwH/5dCfhRCdTwR4V/l1fltTTGmP2\n4PQ0jyTqtTv6+2fW2gn5wxjTifuu5+PEWQY41hhjrLXibXS/en888fexJfVO1XW3r2sjHPT/n6jz\nUHEHOTzoNpW+mzF4YuNfgI94AiPjCEPmQDKagrX2hzgx0tNUdLwInkzQefwaON5a22OtPc5a+3hr\n7VKfbjfw5LKimoj/CW6T0jgJt3Hsw4lk4t/qlfEXOLHYs621jydwHzEnNB2U1XVPIm0BfgPfgxP5\n1WDcrvwSYJ2P+iXwWJXkxDirkiJ0u0jfHU5+uo6Px20eX7TWvr9R+oz5ibyBZCRhjDnVGHO5mIsa\nY07CiTi+qZItMMZcZoypGGP+BDgN+Iq19qfA14AbjDFdxuFJxhhZmG8B/tIYs8zn/WSfPzjK/klx\ndaK/P4cTlZ3ly/5L3Ib1f339qsaYNxpjjjbGvAhY3uBzu/CKbGNMD06/MFMoq+s3G7wneBvwbmPM\ny40xxxhjngh80tf5Rp/mu8DvG2NO8pZZ74jySLUpwNuMMY/3bf8WnLHB4eQH1Cz4vgZ8w1r7ria/\nM2MeIm8gGWUYA84A7jPGjOEW5y04yyjBfTjK/SDOSukl1tpD/rf/Cfw3nKXVCE5P8EQAa+3ngWuB\nO4wxoziFe49/733Ae4wxI8aYy31cgeL13NCf4mTrPwNeAJxrra160dT5wCXAIeCVOKuqeubHN+Io\n7oP+O78S/T7tS3Pq1bWZvL3o58+Ay339vodT9q+QtrbWrsMp/rfgTGbXRNl8CPgTY8yDxpgbVfyX\ngO/gLNbWAH93mPkJXoyz4nuVMWbMP6NeH5JxBMEEEW+LCjDmHNwEPQpnqfKB6PeVuIH8Yx91l7X2\nr1paqYzDhjHmIuA11tpY2dx2MMZ8C7jZWnvbXNelXWCMeQRnNvzjhokzMkrQUiW6MeYoHOX1hzj5\n6gPGmC9Za7dFSf/dWvvCVtYl49EDLyr7AY5i/1NgCfDVOa1URsYRiFZbYS0HtltrdwEYYz4LvAhn\nQ68xE8rKjAzBqTjdw2NxnO1LrLX767/yqEO+yzrjsNFqHUgfRRNKMbWM8VxjzHeNMf9sjPm9Ftcp\nYwZgrb2tXcVX1tpPWGufaK3tttY+w1qbuY8I1tqjs/gq43DRDudAvoNzA/ErY8xq4Iu407sZGRkZ\nGW2MVm8ge3H25YKFRIe8rLW/UOG1xpi/Ncb0WGtHdDpjTGa5MzIyMqYBa21L1ASt3kAeAAaMMYtw\nB7xeTuQuwRjTK/JpY8xynGXYyKScgPrm+c4K9Bv2Np5nXuPjOgj71QCww4cX4CxL4XG/eQ0PveGJ\nLvpTN9XiHeT4wP04s3twfuQc3mMf4przr3V/3H0zziddMf/iOwvgpZe64OdHgRt8fCfwBh++wb+P\nz8+Fz7PH8UUjB7m/AvzRpPoUsQJ3tAHcOTaR4kwAgz68lTAEdD4rCd4/JtRvlTrlzSY63X8fugLe\ncgnOL+PGEE8H4dtHVfyF/m/gFYvhM3IObyNwrg9vIHxjp8qnAh/zVsWvHwLuUmkk/ThhnPQAF/vw\ndkL7dxEO8r83+iZ5dxAuWeWCt1yn6j+O6w98mbrvBoAv4Kxvb/HxYzj7AZjszUWXO+DDW0vStAMq\n2A+8GwDz9s8S5to44Rs3EazB/5FV9goANrz6HPjUzT6+SpibK/w74OZZyPMp9sUA/NAsxTlCBtee\nem7qfvHxx13qPMIB2GtVmstxzqzjshbAh/ya8JabqI3PSdDzbpn/fxTnKQfcWJLxsJqi5fVVJXke\nPlq6gVhrH/aX5HyNYMY7ZIx5vfvZfhx4qTHmUtzMGMf5OZoGVgDwPNNPWPg3EjxOjBA+t6P21kPP\neSJsvs7/dQUgYXGQin9PFpIe3ECCa+64tsSZxAHCYkAtPayAz9+p6rNAhcdVer35uIH2RdOr0h9D\nGFA9Kr1e8IZU/BbCQJ6guGBIW+gBeo8KdzJzm0Zqs5oO/CL6luugfyGccgasvwfnORzcd3Wq9L68\nP+uFdT7NZ24hjJMK7kgLhL6C4oYwztdedyYA//31V+CcDUsaDfk2cUYMjoj53z58HWExX0TwUFIh\n9NcQ3CKbPIRxWFXfpdtQ+r2KW0hOS3yLXrS61G8TpDeOdiEWAszbP+FDKygukNKeFUL7HM2GjnNc\nsHotIOcZr1PvTRA25F0E9ewoP3yld5rwA+BUvVFIG/ZQ7PvF7r9DawmbUh+BgN2u0o4Uw2+RcXIZ\nxc2qS4U1HlTxH1VlyVo3wWxpJ1peildgnhrFfUyF/wb4m1bXIyMjIyNjZtHyg4QzBacDuapxwq4r\nYUwogI0E6k2LNTR1tUSluYBAoei9VVNiFQKl20dgmeWqCJgsAupQ6Yd9+FyCKyNNYfREdRbqZ5RA\nId2v6qC5jhiSvpdAFck3gKOS5d12FFWVQb5rBPf9y3DtKpRdF0Xfg0KRDxIo1z5qVGOtH6BIWXYS\nuL4dOG/ugLkQ7E0qjZQ7TmjbTkBcf20J77KVohhEQzjDHYR+15TlGEUuLqb/fozzGi/YQRif0lZQ\n7GsoimJ0uJ2wiODirJMwj4YptptgO+4aFnBtIGnuILSbcG0x+nA3GIBzkiDpDyCSjiKHD0Vx9zKV\nRrej7nc9TvrVt8haoUVZZXNRxj1RXSD0O8Cb560OZBZxtvtvTLwygOscETUswS3y4Cb2Fh/eivMu\nDm6iyuK0F+eRAdwg0uykFm1p9lkPTBk4WnQwAnh5Jz0+Xx82l7mgvZYwiMYJA6GHwA73UZS7C/TC\nX1HvjlJceEQ8MkT54NTvpnQCc4UKof2X4RaKLRQXg0HCpjxKmFwbCd81qNIvw92PhI+ThUikqhLv\n37U3qzwHKC7MMn7GCJP7cpwHeHDjSNJfhLtKRL5Lyh0gEAhatyP1EEi8fOvJvo5aJCUimlgvpyFt\nspfJ4ykuc67QSajPRooiYiEE1CYPuPGNj1ul8pHxczZBN6WXwnHcRgNunGjxk+hbNlIUiUubXwRL\nfB22bgppjnsXHBLxlEYHYcx0ENalmGiVv8VtG75eQqTcp9IMEMZea5F9YWVkZGRkTAvzXISl2W2h\nBvooVxZWE/F6t9ZigV4C9aZZTk0Z9BGoAa2k7yZQOb0EzkEuzIvr00OgqLToRVMeyyla0qTq06zo\nKSWmiKmcWHE3kzgcEVksftTiHc+FsoYidajFgGJttQ5tTBH6q5Pw7Z2EMQDOR6PkL+IIxZkwRJGD\n1e2sy5I67CCIFvV3dUbvprg+PZb0+NeKdj3GNCdc1v4xBzvXnEdcHxENDav4CSaLgMH1Z78PjxC4\nrwpBKlGhKEbUbS4e+C8kWMvpftHWfZ0qHz1mdF8sIjjg0Mp+bdkFk8Wakj4lBSiTCGjDGoCrWibC\nyhxIRkZGRsa0cATpQISq0CaxEwRZ8ghpikq7SNI7fY/6TctfdR5a0aVl24MEU9hYsaopUclrlECF\naOpBl6UVorrcmKsRxGab0ibdKo2mXjT3VaZMbQeqtJui2bKEOygaCgjisxOid6pQ5EIlje4feUeg\nTUelbbXJZFXlWaVINWoqWfQh/RRl+am2jfOvRL/F0CbnUDQV1+U0UpzPdT/H6Kaob5T6rSDoKA5Q\n1FlJW41QNCbQCmbdLtKeFYIk4BaK806fq5E+1e2WMt+HooGO5ir1t2iuJjZ00HUs6zvNEc0OMgeS\nkZGRkTEtzHMOpKL+1zJOTbGJvPkWFT9WEtbQugtN6WmOonjQLOz896g08bup8CBFXYqmQroT8Vru\nHlsKCbQsVVNCZZY4UJTLxrqVOP/DweHko9tN64R0ntoUOtbtaOs1TaHqU+x6XIksXOs0dBtq6zhN\n/cecACpeuOL9hL7pomjpl+qnsvrXs47Teg8NTW2X1bOduJBRimNe66n0WNftv0ulifsMgpUWFLky\nzZ2OEdqqT70T68d0+Xq+iU7s2iid5hJSXiu01IDod60X0mmkPgVvUS3FPN9AUuyqDlcINv5aNNFB\nelHUA2Ijgf0fpXyC6sEi5rGxm4NqIn2sqE6JluIBkgpP5/xG2YZQpjhvp4WkTKRTJfSfPnuj0UH4\nxlh0oE0gJTwWpdcTXfpXixz1pNdtpvu6SnosxQtPCvFYqkb/p1A2xasNfm8HxCK71KY6QpGI0/2u\nRZeCCsFopo+iYjs1L2KxXqrvdJnx71rEmhIRpjahOI1G2fm0svStRRZhZWRkZGRMC/PcjDcFTe3F\nZoAawsYeiH4TaqISpUkdsNLQYoQqRXFEytxY0gn0NSnNsKBlXESj+A6KCuO5Phg4U4hNI8vMWlHx\n+l1tPJHiNOJ20u2ZUojqNGV9EZfViIKsR32WQVPn7cRJNouyvkvFx32hoQ0aUgYTsZl/Srqh89EH\nM8vSaGgjm7JjAWVoVrKg1xxdn3dnM96MjIyMjPbCEbKB6N1Wdl/ZtSXcTVBAVXFUQHxoR6hzoUaO\n94/GApWHpmC0/ForyCpMlq/KIweTdP1jE90ySB5laSTfMuVpnH+FoMitV24qz9mErqf8LabMWmfR\n7R/RI2m3MIIFhP6UvhiIypLxoM0zxUOxyMRT9dHp5R2tqO8gHIxrFmVUaE+Uv4a0Sfztus7tDOk7\n3eY6PqXzgDA/U7qwXsJB4T6CayDpu3q6QEkjxwLiPtHl6f6Q8Rf3QxnqcTRl81SbB3erp3U4QjaQ\njIyMjIzZRjubYEwBnVFYy5V7mYxYXp46bDhA4AZi010tw9YHEfWBPi1nTek6tJ5DO3jTabW3XEjr\nYcosMXpUWH+Xlqc2Y2ESY67l6PqwnpZn67rHBz+F0tYcZ0xpSpr4oGcqXqPeFEpxBMLVyO8pnUmZ\nbqqeLLyRriZGmZ6wlebb04E2txfucIf6vcxFCIR27qF48FP6dC9py64y1yL1XPwIZ6F/jyUPC314\nG8U21y5pUOnL0K3SaN2Ofr9ZTufwcARtIGU+ZKQhtYdSfZpZu8vW6CDYkccu1ssWZkHc+fryoZQI\nSSvalxDON2jb93jxS10EpReAuD1SHl17onR6MM71RlGG+ByFbluZQAMEe/34bIa0WxfFxUPESdoE\nu0LRc3Gj6aJFih0Ux4x2Qa/FlHpR1N+VKismRrRfJj0OJZ+9qtxu0ien41Py7bBppNBD0cNsiqDT\n8fqbtFI5NuWWfr9PxXcQ1gQRf8NkzxOaENPmurrO2redlLVBvasvnSrbzOO1JbVe6c0zNv9vHbII\nKyMjIyNjWjhCNpAzVFgr27pxu7VQdKJoFM+5Fdzuf4Z/qrjLh07z8ZJmhcp/GYHaXRbFCyoqn1j0\noSnlswkeZD26Vqt6dqv0S1QiEd3Eh5Bi6lSUxOAoXaF2U9+l48t8+0i+s+drZzKqFNtNFIp9FA0m\nRGGplak9hDbpxnEXg/6djf5ZrvIRLkIoT1FKrozKlbK6VFk6XMHdXf0yClzPWUtxVPWwj5C2rao8\nY+WxNsrQY0n3iw6LJ9reKL1WGOvvTSmG5wrCTfXi2lP6CxXWHHQ/wWigk9BHK1WaFRS9867wjzaG\nGKE4X5YTLoySttVm952k58UZxT9P6HTPJOV6Kp9qFI7FVXFfa5HVuKq/NgqZeRwhG0hGRkZGxmzj\nCNGBaHcG+pBRH0VKTNLElILcVKjljvp+D02FryNQH1tUXppLuJ/iNaeaSpR3dxBuUlNy0GOAMe2S\nQ/vC0tBGAPrbpaxY36JdnwhXtIPiEEi5X4llqfVcL8wWNvj/tR+qVSo8RPFmQFRY2nMH4SbKrSFd\nVy+M6W8X7qOPIM/uJ9xk10lQjuoDp7so6D0GfJvv6KPWlwvlfambvpNEKOuYsiw7QKfdduhxK9+v\n/X3FfVrmMmOuOZEq4bv2U37wVuu7+lRY2nCjele7JYp1C30qPJII6zEwQrEPpJ9iH3fqGtufo9Jo\nv3Y6PqXTiw82ah2OXls0hpkNZA4kIyMjI2NaOEI2kI2EHXtUhbtxd0TIPRGL/SOWG7KD60NV5/tH\nyR47FxPk2csJcvGqKms1jhISamiZf2KZtRxgrMKlne7RVhUXo8oS6kdzQwJNoeg4/S1abiqyZF3n\nFRQPN0l6bfocUzZlh7NmE3uZ7O5FzBjFIkbLifVhNG1aKfGqj56l86wS+lHri/ard+KyBOKmxFOq\nO/DWp4pq3QNBBi/lVf3fkv8ExTqndF/jFPtaxlg8PlYS9AGdiSeWuwvmUlCh9ZlaHyXfuEOlOZ6g\n85TvHyfoTcBJCaQ99TeKxZRwGFrPJroErW9ZRlrXBLU+OhcKh1sv9U/NTFvm67n+0QeZU22QOjis\n9X6SZ5Wwjp1PK3GEiLCWExbhMvPVMQJbF18nq83iZANQ5oF/BfyFvpinX6UX82B90Yt2h95D0c5b\niaK+K4EwkAf/v80MXS/dos8zLKZoEijQZobjBPZ2AUWzzYToqbMXxlPmh3rhiTeLuR4ysQJTvnE7\naVPl2CBAu/1PmDCvhyCK3KTeX0xRlKlNZbXIUaD9XImSXurj81w/SvGksNR/hUqvTbzj63n1ONEL\nmRZrSHg/4eIlqR9MNgtNiSjnWpQF7ntFIbyNdD23k974tPj3QDHNW/3/N2hx0ChBLFkhzHctMoXi\nvE6Mvar85rDww+78yp6b9BwSAwdJqz0aCPRYkhPtEpb89TzVa0JrcYRwIBkZGRkZs425JidnCEMU\nvegKHqRInWvPpLKjL1Lp9T0hatd/ny5rkEDJxZ5UhVU+QPEUu1ZsK06mRhAGZefQB04HvqO+RSjs\nYVVWfDBKK9g0FyTfto0i1S7V2a7id5Gmfia9VOe32YC+D0TMZaFoTDCClw9RvNp3L4GK7SB0gD5Q\nuQmnkJewULp3ESjXTcAlPnwt4WT0MsIh0BGKBhMyHs4HbvfhITjLm3qu16fqb6XIRWivBvruEX3w\nTaAp8OWEq5X3Ey5X+6rKp580VR2bhM9Vv+vri6Vu2hPuIkL7aw5tHGdGD66dZN5FV8J+WsrRXNwg\nk+ebxOu20oYLEl5GTWT+DcnXpd3z93rsSXw/wShEiw6rqs6x+bWMpQHCt8ccUOqw4cwjcyAZGRkZ\nGdPCPOdApPrdBApAuxvQikRt4qqp2GUEamaMoANR3MVBLVtdQ6AMNJX2IOmrLEcoHhRT1OIvU98E\ngZLepuqpFamiUIy/Rctx+6L6pOTYx1PkouRdLT/VLhLGSVOos4kqRV9IAk1BaoWybh8I37aX8C3a\nxHULYQz0EihOOagIrh1uVWVpbkHSjBI40nHSZpXD8HM5bKapzwMUONWazLvsOuJxgsJ3TUka4Lil\n7v9DdxO+N66XlLtX1WeuOBA99qoEfaMcMITiWJDDg+Dqu0ulT7n46YSD2nRaytqIM4qRch/04T0U\n56DM8W0UOQA/734BhblTq2o/gfsdpqhTFXSRNuXW5sbHE/yADRD0Ztr8v7WY5xuIDIq9BHGNtonX\n7L9WhmkfQRtJO0hTg+6ExXBQOkpbLW1S6ccJYhM9YOOTpsJaVtVPalP5DygqaGUA6oEfK+wFelHX\nrLbefHTdJiiyxjLoNPsbW3u1w5DRogxZJLQBQSdhg+1R8QMUiQVpw/i8hHZ4KWKQZYQ+0Bupblst\nSoWwOGvl/aWEhXAX7Ja0WsSq/SPFZxIEnarOE0y+3xvcBiYitXE4JP2q66w3Lt2Guqy5Ovujzzz0\nkBYZ6c2th7BKd0XvSvhB0mNen8PppTi35V2tgBdLL4H00T0UkWo7LZpeQOhrPQbqtb/0o56XwxS/\nazhR7swji7AyMjIyMqaFdiAnZwD65K420dWnTrViSVN1PRQ9kCY8kx6EsKNr3zKaShijSJHc5/8/\nQOBYtEdUXQdFSUxAYEX7SStN4ysrtZ8kLXaoqPQpsY8WU0Da43AsqmoHk05BLNJRp34LxhBaia5N\nccfVe6ptBy5wwR3XETiKrVF5l/v/P6jyWUagQHX7q/6NpUHf8e25CNKcIaRPJ8eGFJq7EGwl7Y0g\nNrzQZaUo5rk0nNAiwZSZvJ6vup6aw9SIDA5qNhhavNxHURQubaL7fzhKI/VRim2rTapRTMH9IW7S\nlQ0p0WtZ+yuvBpM40OFJqVuBzIFkZGRkZEwLRwgHEh+u0fGxrxkoyiCrFBXDKR819xF2+q0UvXsK\nhilyMgI5rQyTyU9Rzqm476ifC7qamIMo+y7tpVNTSCk5enyaO84PJlOk7eALS+u1BDH3KN8ZX3ma\nOmQ3SOE+hx3aBHvYh8VvmWCD/19zAjE1nGjz8do/DufoE+b6wKAeS6nLxmKqNcWRDlOEPsxYNvXn\n2ky7DPoeDyiObUFc99RBwmj8jgnlvle9r/UbFcI8qWdMIKzMsIr7FYU+q5kMa9PylIeJFPR4kDz1\nHUfxe9mMNyMjIyOjjXGEcCCQNnGM5fXjifiJ6O/Uzj0cpZedP+Z2NERunbLUEGxjEnbuUX/EVmQp\nXYdGbL6qOasUF6TLknTzASn5N6SpN92fWt6vv3VI/a3NRXWeMeel08i7Q1GaVHveWvxzaNgHtCm6\nfrfeFNXm1an0sQfbZqb7XJtpx0hxkmWIuZLUfNHcV5Wgq9Tx2sS77FBeLN1ItVdskXWX/1+vCfEa\nkJJilOWvof3lVZns0qk1OII2kBTihTZlrttMR5WJFOrlNRzVAyYvcClxUCwGSZn1lQ0m/b1xmolE\nfFwffaq7rKx2WVhS0AsqiTCk6x+PC23CKeljEaI2gx2P4srKTsVJvmVnPOq191T9VmlfamXpUnVu\nhz6vd3maQLdhhfIxX7YmSHx8zXXqKuD4iulGxIt+vx4xWG9ux783M99biyzCysjIyMiYFlq+gRhj\nzjHGbDPG/NAY8/Y66Z5tjJkwxsyg/+F4V0653W4GwxTFQ/HhOgjeUfVJVRFj6Xc1xPW0rtNaFZ4g\nuK1uBiluoRqFNZWsrzOtV8/5gjJX5/obm4H0b713pK3ii50albVQhSs4Q4oH1d8VmneXP9X+mmo7\ntBOa+U7d/lXS7ROPee0iHhWXmu89UbqU63uNcRw3ow1hdlD0S5fwUQdM7qfUt8R/p+Zya+dzSzcQ\nY8xRwEeA5wNPBV5hjDmtJN37gX9pZX0yMjIyMmYOreZAlgPbrbW7rLUTwGeBFyXSXQZ8npZrfsou\nZ2oETcXWM3/UO75QNs1QsTE3ozmlFFU9HWjKLFUHSHNW8wkpiquzJF4j7qMUZRm3i7RVSr5er6x6\n5pXybpmObaqIOZlmqNj5DHExM5ULz6RNUgdMY8TzsBFHJxyqNoSp4HxYCaaj+2oftHoD6UN5+8GZ\n/RR4NmPM7wLnWWtvBkyL65ORkZGRMUNoB4HojYDWjdTZRNarcD9wyjSLnAo12ii9QLv/aPbdMiua\nMlO+VmA2y5pNNHIDUQ8zxQE0QkqGnYqfLtphes82Uo4/yyyXyt5rtv1nop9SlqHThehcv8NsuTJp\n9QjbC5ys/l7I5OPPzwI+a4wxwAnAamPMhLX2y5OzO6vJYqcycOL3UqZ2zSA25ywz09OQeP3uOMGz\n8EwOLkF8mjbl1ffRhqmelYAg8tDniJp5NyYaHltSj5lAbH5+pCCeU/obU2dj4jTTbZPDnSNS3kya\n2Ka+5RR7ukXfAAAgAElEQVSKxHV8HmXmS28VHgAGjDGLgH3Ay4FX6ATW2idJ2BjzKWBNevPIyMjI\nyGgntHQDsdY+bIx5E/A1nL7lk9baIWPM693P9uPxKzNbgzJKRXsj1YipkzLKJoX44iJB2XWj8bsa\nomSLveXOBJo5WDcfUXYgS11NXIpYfJHyhxYjdW9GM+KyuC4PqvBMcwtxWe3gx2ymUGZ6ri+U0mh0\nWE9f0lbW/tojdlyXsndS6eNT44cD/b7091SlJ9NHy4Wk1tqvAqdGcR8rSfvqVtcnIyMjI2NmcIRq\n2VIyab0jxz74y96d7i6u34t9bRH9loK+t6TVOFKo0jKOsRmFeKyzmioOZxppLmGm+3v2KNHZRXwg\nVlDmUiSVTvIRjFI+91MGGWWuUmI0WmdmErOv78quTDIyMjIypoUjlAPRh/BS8WUy8XrOyVJpNOpZ\nfTRCnEao5pmkIMvyOVKssOKhLLLwRvoPKLZNB8VxU6b7qiTSTKcNNdUr+rJWHeacCe66HVBW/17K\n77gpezfl2qiR1SSU61HrlaXdp7QCs9+nR8gGEndUo0tZdLiRck2g2dVmNgftDnoqLporuIkA4eT8\n4aJMlBenmY+LSqO+mKopd8qXVgrx9anTqY/OZzo+2lJohggqO7PUjiibp6mNXfddWV/HcfKObpOy\nTaaMQGi2LPm7V8UdLuHWyLintcgirIyMjIyMaeEI4UDKTvTGv3Ukfm8GFYInzgOJ8qB4QE984Mi7\nU7mkp6rymUlzv3rltTL/mUbZIc24zw+HsmukTK0S+jTu9+m2Yw9B/NIsN5ga581wXPNp2k9F7Kav\nF54ql9VF+rKxsjpob81lZZXVuZ4H3zKUrQOpC+dmD5kDycjIyMiYFo7QDUQowViuLB5ytYfWMk+s\ncX7NQHsCrapnql5uewgcz1SoWu0xWH+DUMwpL6VdFD2RtjumorMS6kzas57+J5Vnb5RO94XkGXvg\nbeS1uSxe+xidKiUp4zg1llOYKX1Lq1FPd5f63nHCPTxl98Ck5nZqrUiVVZZmOqa6U10Tytarw+F6\nDx9H6AaSkZGRkdFqzCdhaAKNrIvK3Bk0a0mlofUnZRYXKYuIerLJsjqIV83Y8eFUUM8SrVkqvh1R\nTy9RNh60pdNU2rPMdLdKOOwZy78btWfZ7/rumGb7pFG5Zd86X0y2OwhzIbZGbOT0tKyvyw7OjhA4\n8bh9JP+pSibK6rAfWODDU70CqZ5lXbP1mjnM8w1EBtcE6UlR1pBaZDMSpWt0MjtWmgoqpO27621W\nHep/PdDEP1IXU2dzy1D2XdP1PjxX0ArI+OxNWf1lso6RPj1c9p6IqGCyR4GyMxuNvL7qRUi/+1jK\nF8tmkCqrTLnbSXOnqBvl32pM0JzHCFRYEwtT+cZ680zKKOuXeoSJPpMm9Rhhapde1avX3M7ZLMLK\nyMjIyJgW5jkHIqh3wEegKcKFwK98uEyZFVMVotSOrySNldX16lCP3dbUkrC1UxVfNUORlB1kmy9D\noYPQ3/VMenVYvnEBaSqyTPSlPSzHh9QaYTriR22SmapPjOlyBRNMzbR8OmXMFMq+MSUurpIW/zbz\nrp7HqYOh9TBRkqf8lqqDGE3sYGa4u3yQMCMjIyNjHmGebyCpC+t1uJe0+ep2HBeykKIZpijCU+Z6\nQ/7pUWmhyMGkzAabMeWLqQcxN14UxTcyES0z52wGPY2TtAU0J6D7K+47aYcqbhz04vpb0BmFU++K\nDiE20Y3bWYcbmYVq81LdTw9SHIeNzDMrTaSpp8+bqhnpXCE1f7vUE5uui/ufi0jPTeH24/t7xoCl\n/oHiuEqZ0OpwN8W1SKDXllhSscw/UMw/NX/LytWYG9Pseb6BZGRkZGTMFeaL4LsEKVk4KjxKmsrq\nANY1kWf8DkyWoUu62CJI/95Itll2Z0jsWbRRPvXKavTuTDhtnA00S3GnzHg3lKQtM9vU+hP5O/VO\nyqy4XnumZPPH09iTbKqO08VcWFVNFWWc3DhpHY5O/17SrmfqzdOhqAwot+bS4WbmjnZ9UgXuS6Rp\nZu6WhbMO5DDQQZr1G4vihR0eBQb8U08cpCEsag9FcUcjkYUWraRY05RIRNBPWrRShrjOZWKWFPrr\n/NZO0O1coSg6kFPIcfr9/tFiunjRLzvZrNOkRBllqJdGi2Wk3Kle7NXMieR6C1Ij8Ve7oMyDgoh5\nY4jYaiVpUXNqs8fHLyCYfOv8UmJt/a4WpdVLo+sjY3U6NHxqvGYRVkZGRkbGPMI8F2EJyii4ss/r\nAIZLfiszx6uq31OnR+ud7i0z5WvEmsYHDKdKMTZzWE4wFfHJXKKL8gt5UqIEbWJZduq3HqVedhiw\nzES0UZ5SJyiKHMvEMmVIcZvNlD3fIFxjfPVv2dyW+I2k+246Yt6UeCgWH6XerTf/Rkvim0HqnSzC\nysjIyMiYR5jnHIhQlktJK6UgLfPU7jBiqrVMFi3vxjJ2/ftMUH6xaWeKAqv37lTroI0A2hllClGN\nFPc4gDusJXlMxdBhlDRXUI/bnEr7Vwn9O1wnXTOUdDPllvl6amd0qv9T3LiYW+N/H/DhXTTmHOL2\nlLlfVtbhQJsNdxC+q4fm5/ZM1WXmkDmQjIyMjIxpYZ5zIEIxDJPemTspUltCVdS7G6LsLnOJ30Ga\nGijLT1NIjQ6GSZoFKjxSkiaF+HubgVDAY7Q3FyJtGLuS0UgN5zMIuo8y3UnsdFBzfak8yzgWTbk2\nK2sXSnSEQD3vKCZP5tNLud6qbJykym3nPu8h9Hc9p5X6uxar+GEV1u+V9Z3MtWbbpJEbI0p+71Nl\nNGs+r29EbR/M8w1EUNYJZW7VlwH3N/GO7nTZrKZ6VWazXjd1nvJOvOA1KreXqW8gkr6dFxKN2LBA\nI9U+E4TxUSYuqOf6vtlypCzBVMdJhakZMpRthqhy48VyoiTcrpjON/b7/zeSbv96fTLdOTDVtqxS\nnxBKYSa89848sggrIyMjI2NaKOVAjDGXN/H+L621H5vB+kwRZcpUQSyGkvAupm62Kt4zd03xvelQ\nNcIaT7WOU6Vq5hOaudshNZw3qfgyTrWMUj8cs+lmL/TS5sD1xKCHW5+p/NYuqMdtCmKx7Vr//1Q9\nK0xH/NvM3E71XTPekOtxj+2DehzI24BjKXoui5+/aHUFMzIyMjLaE/V0IJ+21v6fei8bY35nhusz\nRTRDAehb3mRH/1VJWo2YApgq5zEVxGaDw02+Q/ResxTR3PvQmTrKZN4a0iaaktxbJ30ZWmnmGutG\nRM4/1ftDplPH+cB1aDQ7v3Vb1NObCFJcQauU0ylOI74FNYWYI2ov5bmglAOx1l7R6OVm0mRkZGRk\nHJloqEQ3xjxsjHm/McaouE2trdZMIuWnf9s08mnkjHC2kfqu6VCY7fZdjdDIiiblgqadvjHVZ1Xq\nU9vzxfHhXCDWdRygXan1qWG6utPZdarYjBXWf/p0XzPGiDGyqZO+zTDdyRebzbVyEs+lguxIWpxS\nG4i+1Kcd0C71eDSjzMNvKzBThN50y2otmtlAql5UdQtwrzHmmYBtbbUyMjIyMtodzfD1BsBae6cx\n5j+BO4CTW1qrGcV0d+S5VC63kkrNFPBkzHabpEzLm6nDTPlbe7RjvhiOtD+a2UAukYC19nvGmDOB\nF7WuShkZGRkZ8wH1DhKer8KLop9/0WwBxphzgBtx4rJPWms/EP3+QuAa4BEcu/BWa+3GZvNvjPlA\nsc3UnQCPdsyXNpmqF93ppH204EjlJubHmlCPAzk3Cq9Rf1vgrkaZG2OOAj4C/CHwE+ABY8yXrLXa\nDGqdtfbLPv0S4HPAYHPVz8jIyMiYK5RuINbaV0nYGLNZ/z0FLAe2W2t3+Xw+ixN/1TYQa60+1Xcs\njhPJyMjIOAJwZHONzTpTnK7VVR+wW/29h+BUqgZjzHnGmCEcl/PqaZaVkZGRkTGLaAtvvNbaL1pr\nB4HzgL+a6/pkZGRkZDRGPSX6GgLn8SRjzJf179baFzaR/16KJr8LqeNi1lr7DWPMk4wxPdbahDvN\n9SrcD5zSRBUyMjIyHk3YSXP+9A4f9ZTo16vwX08z/weAAW/FtQ94OfAKncAY82Rr7Y98eBnw39Kb\nB8BZ06xGRkZGxqMFp1Akru9pWUn1lOiHXaq19mFjzJuArxHMeIeMMa93P9uPAy8xxvxP4Lc4m7yX\nHW65GRkZGRmth7E2rR83xnzcWvu6ui83kWamYIyxcNVsFJWRkZFxBOEqrLUt8V9YT4R1njHm13V+\nN2SZUkZGxrzAdG91zKiHehvI25p4/96Zqsj8RR6YGRntjzw/W4F6OpDbZrMiGRkZGRnzC21xDmRm\nMZ2LgzqZi8tYMmYS0+n36V401S6XUz1aMdX2P5z5nfu6Ho7ADSQjIyMjYzbQzJW2S2ajIjOHKlOn\nNlI32WUc+ZjuzXTtLE9/NFDMU+2zcebitr7WY+4lJs2Mtr81xhwD3Arcbq19qLVVmi70p5RtBmUK\n764G79VDuy4mcde2az2ng1Q/Tuf7prug5Iud5gbS71Odp4ezqba6n3Xdmi1Lt8PcGvE05ECstWcC\nFwInAd8xxtxhjPmjltcsIyMjI6Ot0ZQOxFq7HXg38HZgJfBhY8w2fenU3KNK2IX7SDj9jdJojPmn\nZxrlHo5yrhkl7nTz7yZ875FGLc/EN822qGcqCvvDGYdHWl8LhOur0nz7SJtPR6w9W5iOCFVEr0uY\n6/ndjA5kqTHmBmAI+APgXO859w+AG1pcv4yMjIyMNkUzHMhNwCbg6dbaN1prNwFYa3+C40raBJrC\nGPVPMxRHbOLXDKWi04gCvhnqsjMKN1PWCv8ALPLPgibKWq7yb5by7SLog+YDluDaYgHNfWOF4jdO\nVYmuKdqpQDgDoYQb5R+/q+tcxsks8Y9O00ybdE0h7VxigGI9mxmrIonQbd4M9xK3STPzVKeXcDPr\nTx9hHPbQ3JyVb+9grvuumZJfAIxbax+G2jW1j7HW/spa++mW1i4jIyMjo23RDAeyjuJW+lgf12a4\nwj8QqL3Yyia1W1+h4jsomvSW7e5n+weK1EkjaqCPQD300RT3MrjCPXQBI/4ZoyFVdO4ZBNPFmFIp\nq2e3f+Lvajf4ug2ej7sXRp5GfdEBXZe7h0soUntlFK3k82LSbVKPGxQKeInKpxnu4DIcB7kcNz5k\nPGs9QFTHrtXuAYq6r0bldRIo4HbmQi5Q4QWkuce4/qv80wks889olD7VNppLWUBxnjaaOxXgDP+M\n05h77CdIFvT466Yc5/tnP6Ed5uYwdDMbyGOstb+QP3z4sa2r0vTwPPt1nme/DpwPnVe4h6UUO3Dy\n5Huy/U9C51+o0tdb1Je5hwpF0UGKZda4kNDJC0mLNYrlLvr+NhZ9f5v7Ls71zziNzq4c+9mDuO9f\n6mP0glK2YLzMPz3qaQazvfD4ut0IXL3aPQzTuP27WDi6g4WjO4BewobcQTCkKMGZS4FB/+h2qWMy\n/txL3EMfof3rlOHxH/ZUYLV/OmlM1FSxHzbYDxuCuFPQQLk+cGkhn+YwB8TFq6A2Pi+9gNAOetGN\nNpTn9ruHPjhplXuAYpukNuSzCeN/sSqrt04FZYMaUA8l+Su8YgVuc7wAuJjQ1yVXIgGc2+uezktU\n3fSa0IyIe2bQzAbyS3/REwDGmGeST91lZGRkPOrRDOn458A/GmN+gnPh/kSK/GRb4Bt/5I+mdAFj\na3zsppLUQRH6o5OfCpWnuujq7TRDITIkorHVBGleleJtvakDPtuBAz68RcWLSApisdsZ3AfALlYC\nGxvXzeOtj72Ba5Zc6/7YOhT9KmXElJGwzRXq3DycQEcir1bCU3fnAePybR2EazyF04rRzZ6ThTLc\nqNJMkO4vqPXLN8AZIkJxjOiyone/uVbVrUH+jCPtfzwPAtepeF1WCgv4u4tf6YKv2h/9VvaOr8+D\nMPWDtHNwonsV8Ck/n2/eRqir7ouoXu/3/688F3bfon5o8J2DC2FIRNSfI3A2um1jY4rl/v9N/p24\nrM7J9QPefsfVfIAr3R+fuZZmDgau+vJXAdjw5XPgRfr75d063MsMo+EGYq19wBhzGnCqj/qBtfZI\n8wmQkZGRkTFFNOtM8dk4Yfoy4BX+Ctq2wuu+/iFe9/UPwbOgqFBKy4wFT/uvB+AZuKdZ09fTO9xT\nMyEVmWOJgrOGXjj9SvfUdBMCkV8WFd7H8FuO4bfssmdQVNTVx0/4XZ65ZSPP3LKRQGE3MEE1/jnu\n0vI0pZhNc8JV7nkDcMqge1hOsf1TfdHHsdsOcuy2g7g+Fh1RlXKTXh//Gghy8dQhVYG0Qzcct9o9\n8vckxajWbwR92gbzIEHftYjGbdvNbnMHu80dOC5Mp2/g5+3tMPXDaFPRj80QfgHvsVt4j90Sla3b\nJfqGr7rnyfaHBB2FVjiXl8Upi91DP8EYJdaZaKW6b+dzLwPO8Q/R75PH2Hl8Efshg/2QwfV3apwU\n8Qleyyd4LU954RaKer/ZPzjccMYbYz4NPBn4LvCwj7bA37ewXhkZGRkZbY5mSMZnAb9nyy5PbxN8\n3LzKh66Frne54FisA9HyZvfp3zv52bBbZNViWguOyhGTv2hH36zjhaJIyziL2Aqbt/vw8RT1Hh0q\nLKiw1Vt4Lfrj/QSdzl5VzzR1+S88nzfzYQC+w1KCXLQOhWL9dx3SltvNyMVnWaL5XP9/P7BTvmsF\nsMOHy/Q3q/jFjRL+F4Lcejvlui9vP3LLBOm2iOMUdXroThUnVPMIRS5Jy7ydlc+fnmSVzL4X2OXD\nwrHE6OUqvu/Dmwiy+nr6PD/e3nEdRQuvZqjXA42TzDTWwzVv/D3/xwBB96iXsKj+w+6/H/3uU3F9\nDMW5VvK9u7fjrK9SafSc1fH3u//WDFG0hJM0en0I/fjcOzer49gbCPNUl1usw+L/2gnAS06+kx/W\n1qh4KZ8daUAzpXwPpzjf1+K6HCZcwy+yL2GXud3HLaOoeNaTzw+i3UPwSW8//5qbCOKJskWoAvgN\n5/QLYLNsPvo8h5wn0e8A3Icz1QM3oLUiPZW+yneNmzSr7V2sNaLY08dwFhAmdBhoe8wEV9RsHeKj\nPAI9qKsE5V89c8UUypTWLcI397j/n7GQUP8dKoGecNGiW5uHywgLbL2FVrePtGE/qTYvhnsIC8lC\nwqKu6xmhMuj+fwdw/SUuvHOUQDjIuQIJS1nLocuLPX4xCNYbTziLkpLCelQa/S1T2Rya3XBmAJ9f\ny1OsI6Z++IReOOgVz1xHcUNW+IwzQOGSM+AWWZgvIozzMuJoK2EDGaNoFqsJMb35y1xercIrCH2n\niSwVfjksstsA2GVGqBEs7FdlRV53F7nN8AsMEAxH+mjKAGiG0cysPwH4vjHmfuA3EmmtfWHLapWR\nkZGR0fYwjSRTxpiVqXhr7T0tqVF5PSxcVfKr+IWB99kf8yt/zvEaI4f1wO36KZO3DviBP8H+a+Dp\nInbYRZFqSFFaL8MdLAO4ncC1VCilBro85fRVFKd7HYGyjClATym+/zL4pY+6ZgJ4b+JbdB01dfIu\nggnqXRTFU/odobT6CdSPFpfVQ2Pzw5mDb6tTLoed3tz1nitgpac4uYe0qfIAdF7oguO3wyk+vHMN\noX1i0YSY/a7AtR046nTYh0cIXOt+ipyPiMiAs1e5/9ftBz7qIyuEvhgDMec8Afi5j+4HdggXvY50\nO7+SwJWuxlHQAqGANQc6TvowpOZY4nZIYTY4EPneTth4OQDHP2cvDx79Kx//VcrFuae5/26/QE2F\ntdTETZPaX7AAOr0hyfgeXwa4uRC3Y1TPM98Fx/qotftVWUOJ+gGsgI1esnA2ML7Bx99Pubm9cClb\nCB4xdhDWn7jvrsJaaxKFHzaaMeO9xxizCFhsrV1njHkscHQrKpORkZGRMX/QjBXWa4HX4UiWJ+PI\nrY8Cf9jaqk0FYpoH7/zwDXCNxI8TDmRpakNM6nBxcuDoUxtwFBy4T0xRV4oC6RyEcaEOlxCo9hEC\nNa85ikogQv4SOMWHd2o5tJbZd1FT5O9HqT46qFFXbIvqqc03xRxwA0EG301RUaeh6yDUzGweEGwW\nXj79h8AtF7nwR8GR6+D0XkK9aSp5XBGBFwaqlHMIcmvd/lVCIm362Umg/DZQ9K8kiA4ACnNU6YWq\ncDU7KFK+N7n/Dl4GeE54xwvhTM+q3ruRNBW7ldB3Q4DXEXGu+q7Y0EErdGWsjlFO9aYwG2Mj6Dc6\nn3YIgAeP3kLQJcVuXnSd/DjfBlwjusqtBNdDW0lLCkZgfLtKI/NlOYGj6KOoJ/Xl3jsCJwl391EC\nd9pFGD/6oN92+Ac/llYBa0Ww82JgDWkI99Wr8r+H4sHY2XE108w5kDfi+PdRqF0uNXvOVjIyMjIy\n2hLNKNF/Y639rTFOhGaMqeDOgbQRxqlRTm8B3uOjr9mEo8LAyYLlcw9QoNSFsr9sFdy0wf+xnKL8\nWHMSvqzx7QQ590cJlEVXFBYqpwpVL2t/zCDsFFPN/ii9lul6TumL+nuHVZ5xFwrlsReO8zL1Q3sI\nFFsnReeSwolpynYXRSd1Wo9URnXOJqfi++V0cSwJPADB4q5K0F2MEbivEcX1EcyWC5SeeKf16Wtc\n3CCBw9lL0JnEOiuto5DDoj0w5utwei9s1royoVYPEDiZIXirt6C7YQ/c26vSp8yr91PsL0m/S8V1\nU+SsZPx0kKbCZ9HCqimMM/6441zwstU1Zg1uIXBNPYRxXqXWN9eMwulesrD5bOA2lV67/yj7XtE5\n6GMB+yn2hYT3wG7f10uuhK3DPl5bTmqMwc0S3gIf83P29fcRxt5IVJb06xXUOFVeSRi3H2W2Dno2\ns4HcY4z530Cnvwv9f1HOW80R1ER8J3C9jz53Bay51f+xl+LkFiZqHHb7iXvTVjhxlQvvE4UpFCeY\n3hzuJzTF5YCYT+qzFmMUm9mznOuvBt7q424hdH48mf27O9cRFsgXExabTsJA0wrvChwStn2IsJht\nUWk6iM+dOHSr/Hsp+gBqB/i+vh54ab8LLwa+6G9YHvogQbyg/YyNhz1g51p4p19U3reS0KfaBLsS\nwmYQrJ+sJ10Auz84uT6TfBBJuRvhHi+GWrmd0M7a2EJvDgNwg18hz7oM1ssK00PYsLSRRJWaWO+4\n1XBIxu4QBfFd8gzDKGHsdZEmKOYSqu9+4IOn7oFXLXThT50P3Op/2EXSpPrsbljn05x4MewTou8e\nCsRdcjncj/OEDZN9640nwv3UjC2qmujYT/H8iYZsAiPweonrJ4jLFjBJyQ+44wRCLOjjCvXMt2cW\nzYiw3gH8DCcMfD3wFdrqJsKMjIyMjLlAM1ZYjwCf8E+bopvajvu+W6hRA8dcRqAePkpg8+UOCPx7\ncrW7KEbBqX1ETNFHYBvHCFRFD4H6jw8KpU4eLyFQVEvgb/y7b1xGYL01awxFqsUrzk9cCvskfg2B\n2u4jcAsdBOpkL97tKo4T2ViSRouq9Ml4UdTtYnbNdcsgXBmw01N7154fum+og9BH2nzyNFgvSuWt\n8L5VLnjpQrhZX3OrD4v5b7fbcd4DcIdPa/lvpahEVxTwoO/Hoftgpdhs96t3uwljTBt2KMXw+rVw\npjcpvXcL6RPYI9Q+/tDtFEWg2tgipVjtpWh+nuJS5lKcJfWpBHeubIPnew7kpz2wVlP/iQPAG6Bm\nbt8H9Htu/JtrCH0xTPjGLsJBQi1a7KE4v3Sb+PGzpBu2+vo8FRgSZfwAYQ2JDhpXvLiyeh3FsSFH\nBDZFYclnMWH8QFqE3lo0Y4W1k4TOw1r7pJbUKCMjIyNjXqBZX1iCxwB/wqy74iyDUoCd5A8D7t5A\njUr4DQSFWR9F00UJa0XUKPxU8l5D0WxTN5VQOcME6nwHafcZOryVgtz6oOSnlWT67gj97qYQ3kf0\nLYtUPv2qPqKf0UZzGyl2n1BUmsqsqnIHCFTOLLorqQtPfZ4LrBl24ecBK7WiUuTVciUpwPFwuqc+\nN+8NHMLNd1J056G5SYnfpMJ9FCm/koOZQ2K7q81j11E0DZY21S5p9CGyUbj3Vh8eUd9ygNCPHdTc\n6xQOCY5S1JWlqNJYjp9yC9IG3CZ9hHm6jUUXuDGw6+UPEQwmDhD6oodaG1bXUhvnzz4Dbt6g0mjd\nl5ZKiDukUZW/1mPouimd59YRav34MIQ5uBTHBcq3SL+MQVWbnEv9byJ49N1C8OUVz2VUvB63U3VH\nND001IFYax9Uz15r7Y3AC2ahbhkZGRkZbYxmRFjL1J9H4TiSNiFFhTI6G3b73beyCqpud1/+5X/n\nfuPdVdSoF3AUhgjMhwF/myE98CYfvElzLLELA81peGqYUYry4xROI1CZVeWZpZcg215A0KsME2Sf\nE4Sr6LcTrKruJ3BEKwiWG1A0W9ZWGZoq1d+krYMEW2kPvYdA6XnWjMJbnXsLVg4RzC0HCJznGIFL\nnIDN/pDdbavhIhkTKwj9uI6iQ01po12EvlhDoET7CforTdFCoAJ7CO4w9H0i2yi2rZR1tkpzH8Hn\nzfE4iz1w1Kk4BdQydc1pxFyEPsAo5Y6qcAdTv52w1Vjl/18LyFxexq5ur6M4Cdgt7a+dQa4ktHk/\nDFzsgjePUuTcBOMULDNrfbqEQOlrU2ht1VZVed5FrQ0fA2GdWUORe9D9JXN/KVR8napvIOhmOwmH\nH5UkooAxQn9rHW9r0cxG8NcqLEdzX9aS2kwZUv1eeJZvsG/fiijA7je/7yxeAe7W9vo9hAV4P2GA\nrICb/OJ64mrYJ6aaemL1UvSSKe+ehhu04JpI2FUtLuqn0MniM2cs9k0kG0InQcR0Bl4biPvuxSqt\nKEoXEyZNhfRCeC7Bp9MYxUVFmx6nxDLtcDZgkFo7mG64QbHxz/IL/LfvI/TXGOEskLqe9CLtJ60X\n2OzD+hS+9i7QRzgB3Eno642EtooX434fHqcmgnjV5fApMffuoXh9gBaXiehDm/pq0esdhA1ziDB+\ndC+adKcAACAASURBVH8NqDSfoziuyk6cz951qM1BvmsFGL8hH90bLHdfMkLxjJMf85WlUF0X3pXh\nMNANO2Rx3a/yX05RhCWb9kbAe0ZmC6EN9Sa8gECUnYszDwa+DkViUxtJaCMVRZhUZTz0EcbGEkcY\nA1TvV3lqo5kJwmI3RFh/WotmrLDOmo2KZGRkZGTMLzQjwrq83u/W2g/W+90Ycw5wI0789Ulr7Qei\n31+Jv1gTt/Vfaq3dypTQo866Kf8wq4G7N/h4raDSFNgENd9BAz2ww5u77hsiTfktJlCW6wgK7KWE\nSmiTSSXaOuEMOCi+birUruu4RR9Q0n5sxnGcBziKVMoaICiJKwRq47EU2XBt0ihd3UWRo9AUsKY+\nJ1R6fYJ5rqFMjJ8MnOcpxetvgW9L+/RQ7DtpK6UQXY33lgqOytQeC1KihgkC17dN5bmawC3ovuuj\n6MnAk8DDEERbWhShjSe2EDwcbKLoqVko5oUELmiU0Nfa1FSLa7RBxhKVRiuetVhGY676Xc/ZxeEg\nZ7UfbvXz4sSe6KYi/41V7SX5dtgsVP4gnOjD+9RpdW0KzSKC0hoCx342Ne6iwD2OEfpiXcjz4AaK\nbafNpYUD6SGIIhcQ+uUcwri6P3iwoIswTrRSf5zghXmc2dIyNGuF9Wzgy/7vc3GC9u2lb3gYY44C\nPoJze/cT4AFjzJestZq/+jHw+9bah/xm8wngOc1/QkZGRkbGXKCZDWQhsMxaOwZgjLkK+Gdr7Z82\n8e5yYLu1dpd/97PAi1ACOmvtt1T6bxHIhuZR6fbXUALsgL/xLireqM1aNZWv3TdspUYlDAI7tFsQ\nwQSBItf3QmhKtZ9yL7eecj0I4fOG3S3zgDMlFq/B2k9RF4H6XBDyYQ3OdYqERY8xqtLo/X01QX+i\nZfbjUZ11vaUdUp5m5xKd1Oq/Yztcr5TTg14RPnQ8QRek3XP0UjOhXXsXoa1WETzYQsHQoUZlLiRQ\nhD1w3MUueGgDaT9mI3CK1z/sXEdt/FwMrBcOZDtFpazWyYgxxCLSepKx8C0Fn1qjBJn6XpWP5nY0\ng685k/jmvbnmOKvUxqEBrJ8X3zkDnimCj0HSiv8etE7jqJ8+DYBHnngj7FtKGsLta0X1RQTDhfso\n+s6S8FJVlnaTBBwnBzz1+qPbdSHBY/IgwTxcK8EXUNRP9qjwZT58E0Vd0Oz0XTOuTHqB36q/f0vz\nRsZ9wG719x7qbxCXEAzaMzIyMjLaGM1wIH8P3G+Mudv/fR7BRnLGYIw5C3gV7khYk/C7bHWCIJvs\nrHmccNSYWOmMEyj1kSDuXLeXGgXzkSqskV18D0UPp7LrTxAovw4401MA995J4FoGCVSePnTWQ8ES\n5ttCud5FoFq0S5GlBOr2AMGUbwi4OuRTy3OA4p0Dnoo5blA5Vuym2O1aL6R1Hdp1QtltiXNg3nvu\nGbBG+lqZ3K4+H9YKF9dHaM+F8M++s19wNQUnkWd7vce6qwnWSouotfnpl8FmaedNBL3EKjgkJsD6\nzmxNHR6AnfqOEZ9nBQK3003RokZbfEm/aBPjYUJfdBOsg6SOHhXvvqf6QfW9WvfVh7oMRUGPz7nm\nPsA1lq+/DXTlUX2/5JHaX3rc9lBr/+cC3wxU/CMbf8eHuimOeUGX43LA+93oVWmEG19MaJe9FKQJ\ntX7XVnMdQQBySB/IrRJ0bnq+7yUsXjep+h0gWFpeQOjvHopryyof3kjSpUsL0IwV1rXGmLXAmT7q\nVdbazfXeUdgLnKz+Xkjiy4wxS4GPA+dYaw+VZ7dehfsJvrm1Hfw4/3GBc5rz9Je/j+KZDJGcdcKJ\n1NJLM1x18ru5qrbJQNGTqeSvWctR+KbOWwbUVkLna0XXIoIobQBv5wcnXQK7b1b5S/rlhMG7UYUr\n8B7v9vmaa1U9h+AEv3gcHKK2IB3SLPkwRRGZLFrnUOyaYRXWynW9aWi2vdXw5a4ZJnxLcLm/5ysn\nsLDbH+0f+yAFL6sF158ipljHvq8/HoATe34Oh8S0Vi0qm/eHcumkJg46ZTXsXOXj11I0yNCXcmll\nuT9V/BEIorMt6l3tXXcp4Om15y72rurx55u0F119nkebbAvGVR1GCG2iNy7dd8cTxCAx5uIsUAcp\nl+aP/OB3CG2oMUbYbCG054IgwWWA4sVLagxbUWB3qnfXEgjPPoKApJ+iN2Rt9iubyToe960nA/DQ\nMXtVWR2hnmYpWBEzhvo87jd/wkPHfFLVx/fLEmCr9m8mpsrnqvp8A+f/tvVoVlX/WGDUWvspY8wT\njDGnWGt3NvHeA8CAvxJ3H/By4BU6gTHmZOALwJ9Za39UP7tsUZyRkZFRH6cQCCVwDtRbg2bMeK/E\nWWKdCnwKt0X+A2HLLYW19mFjzJuArxHMeIeMMa93P9uP465/6gH+1rhbqyastcvLc9WQnX4N+lKZ\nK2ssXnwoSj53pVJgT9Tir/r++wkUxghp3zKR59WqcBTLKF4upaF9Ycn7O6hRuxcA1+t7IST9EEWq\nRaiNi6MLphRLflBYWq34v48woMYJlKi+qyRmDIUa06dv44OEZSfuWwntgyoYBFzKzTB2bSL9QFFn\nXLtbdhHPwdtvHNLvaapdU/z7Q5KDUjYUPRRD6IsJQn+NU+Netp2h6hD7X5J+UXeG/BrlK0n7+qoQ\nKM4JCsp4kXId6lBl6X7TBx51fA/tIboSjBM49iq1+fwS4DIvArpJq0wnqPXTsPwNcABu8kYlX1gN\nL9E+pDRkoGix0g6ovMtXQSvpNafWSVg3VB1YwEMDT/ThEYrKfl8H20foix1wlivroWPiuvlxtXUN\nRb9tvp7HLYVDQyo+Fje3Bs1wIC8GTsf3pLX2J8aYrvqvBFhrv4pyxOzjPqbCrwVe22x+GRkZGRnt\ngWY2kN9aa60xxgIYY36n0QuzB9nHtB+qvXyx2+sH2EDgUu4mfO6Yoko7qFE2T4Wi+ao+cKcpdR0v\n5rKLCRShvhFMuzCQ38FRIZ4buR5Vz70UFerCsUwQqO/9sFWUvh0ESmsBwSRwjCL3ImkeJN3tsZ5D\nvlHrSeaSOpWyV1CkSl07v5I7WFPjPHVf74Bn+OC3tYJzjLu96fQy/oGi6xDhxrSxofIVdj3w+m4m\noyNKr7k631+H9GWemqJV5sncTe17j4UwWLWub4yiUlao3gocLXkOEsaD7lM9tuU3fB5luo656PtO\nisppPw4P3gknXKDS6LHq698H7NMGJb4Nty+m2G6CcYJQ5T4V3+m96kIw35dytRdd4Ui0T7lu2C1z\nZxHhHo9OlWaYgluTmpp3O2Etil0dyRjoprY+HILimtM+NxJ+zhjzMeDxxpjX4vjoT7S2WhkZGRkZ\n7Y5m3LlfD3wep+g+Ffh/rbU31X9rtlAleMJUllJjwzA2zHn2pzgqcG+Uftx58TwJAjVWBTbycfsx\nPm4/xmRPpiKjFupBKIhd7nnPMhwVsiN6dyLKR+TeEzgyqQ9394A+NCjopygb95Y3Z12Io8I3UaRM\nRnBU5yBBLu5dmrx1tXtq5r3agqoKSeszKN7S2CziQ4kziOO6CfUPFlN//PBXCGacQm17uflH8NZP\nVTSlv4UlbGEJro2k/dW3D4rJc0X9VnWOedjun3MojKvCt0v/gjPd3YPrs3f5R7fRMkJ/qXFwLzh5\n+UacD9NKeMwF7qm5/PDU+MEN3o3GBOEGRM0dxQfppP6il0u5M0mNz1ZjHI7rd0+BWzuA3Waw2wwF\n3RRjONn/Ae8CVuZOFUfpD/PTdxiK+kH5duC5ne5B9/s4j/v1T3ncr+WiIGkfcYgo4zAxTliBc+Dx\nZQI3IVjhnx2qPlV4K+7hnkIdausMWj2spAZnyt+z6wyz7iw3xhwNrPMOFb8+O1WaCrRYSbNsTqF1\nNTfyRV6ZeG8UdqfOK27htT/7NACv48kU2XkZwOtIsoePgbQJpDZ31ebAEBbnuyl2vCjANqTLejwU\nTQgFY4STx5HI4QZ94jnF3m5KxEE40Z1CmVijheKOgklywONu+w3hxHBU/v/Qf4R3L36znOW4nWSb\nDG1Xeanfh/REvaf4Tm2hGKMowtKecG9SYclXK/L1WLiTQCToMVsFe3MIF+ovfVkmrtGGCBrad1bc\nHrMjEpmEmshPlz/O1Xe83QU/E885378rRyiOE/f9v2//A2pH2iJ8U0RXxUX4oT5RhA9TbEfJv4u0\n0nqrqvcuFT9BEIdNFPP8rATi+gs2kvouvgHp9K1FXQ7EWvsw8Igx5nGzVJ+MjIyMjHmCZuQMvwC2\nGmO+DvxSIq21b25ZrZqGnNrcEsW7Xf/pf/wDAmWnKYd+iopYwQjm6XL9+7XRb9q7roZP8651pFGh\n/O6F21R8SnlZQlHcfXuUf2yimcKGkjo0KKttLhYSlHBKr9lE8UIs9Z0HN6TfuUmbYKe4x/tJ98td\nBNHULorQvsUSlCILSJ8S1n6udFm7CJzqWprj7rRSOZW+bIx0EwwHZscMtD46SftsneCq33u/D0en\n8GsGKHdF8W4O/vBt6pDmpLLuT8QDB7WHhhTKxEZ7KD+Eqw66auzb4ANl825/OtquSce3GM1sIHcx\nuTcyMjIyMh7lKN1AjDEnW2v/y1o7436vZg7iUyimDDzFv3YPaXcb+uBVhH1a6a0phn4fbujFniIF\nrE0v4zy1mwah/PZS3i3KPLCG2GSvTFatzDwLOplGaDdvvGWHF7dQ7OtGd1xAMNfUhgLxvSjaZFvC\nIwTfWcHFhqPay/pam9/Koc5OJh8OjMvVB9P6CONE30yXek/KEmifUTo+/q6y+s8FOkmPv6qyiNff\nBaF9Yo7Sf8P1eyjeGtlIjwHF67CF89wf8ixIEFRZhXG0hMB5jhC+K57rut76Vk1BGbczzFz0Vz0d\nSO2sszHmC7NQl4yMjIyMeYR6G4hR4Se1uiLTgzfZ06aNQM2M7uqFBFPKRQQTvBEVr00TO2DQP/QS\nTCArBBPRbp/XIorYTjB1vJy0OeSKULcCOuHqS9xTe6/Tl72MQO3Ku6MhTdfl6ts7VfrTVP6ayumg\n4LW00G5lJpzthAOkTUpHcA7lzqVo1l0hmMH2RO/48dO1GGfGPECRwhOPq31M1k1JWy2laGot7anv\n1tDoVGVpblZuBtQHTyFwv/24MbmfwJGINdiqqAz59k5fj7guFcIYjsdiYh7NKWSsRuNyfMQ9rMBR\n9+KpWtpwAenxfIBgQqvHQwfh2+MbJ+QowAKK40G3lZjP6/ZSeT7rfIIDTJECyDpTVY+Y9C6Azsvd\nA6qsHtJ9KuV14Ex94zWxNaiXuy0JtxFkEY/9EfnwlfgzE8D6Owns6mqCyadmf8dhyIvFnnsJfFN7\nyJVzEsOklaCyeMNkllfSx+IvWax6gmVnYVCPklbCDYeyngHcK4NWb4j6dL7YkeO/Q07camV8L8XL\njQRV0qx0q9CIDV9O5NzKYxx7izMWNJc8BNwQ8jnTT8J7r4vece3ztdEz+e9GlLJKhHDWFbD+g0xG\nJ5zl23B9bDwhY2CUtKK0V9X/hYSOX07oaz2+5GwBuH733pb5qCorroMmCAQLCGNAi9Ti9zpUuB02\nDy16RYX9HLvtUrhIjGj2Eq4hgPR43gD/4cfD03sJptG9FD3qJlC5VPnDkvMbUPQXpzFObY16MfBt\naVshIqTO+ttkDFwCb/TB6+UdgEsp+ljTZ8TkfM8ApQYBM4x6G8jTjTGjOE6k04fxf1trbcqXQ0ZG\nRkbGowSlG4i19uiy39oHQoGNMclLLgB3senf3u1Smu9TM+k9sxPuLTPNc+Zw+/7vOzmx++c++2uh\n4pVz1f2kqY1d8KGLXfCqM+BQTO3CZIWuUDB98Gc+eINWzlXUNw4RuJNd0LnaBc8B7tUXGmn/P9qL\nruB8iqaAkmc/acqrQlDaa8pViwdm8vRrSmmt0UP6CtOqOtO3EXcVKRQNCPWFSSDt/3sMEbSybwjv\nrIeiua669+PnkscmVdZaQtvGvpIEv6LG5ZxyLuyUvttEEEWNqncHcbcpAByAZ/lx+G2oHQg85UrY\nKd+5ldBfeqxeQOB29Al5TcWKeBQm38UxFwr1bgJHqEWWVUThbf/JYGqXno5CV78Ljt1G2qx7DHvQ\nSecNX1HxKwB9MFNz3T7NXwNv2eDjtTGHNqTQptPj1O79eBcUL6ASDuEcikYSfnye2Os5jyieW1Q+\nWiLQDcd5D8WHPshseQ1oxhdWRkZGRkbGJLRWw9JyiMmepgC0Sd1+Tn+up9L+DPi0pwwuAe5V1H9C\np/HE7z0Ush+rwhN8eN8Y6j5cCpTZY3zwWOCQUJZajnsxgcrpo3AITVQylXdBVQ4FDQdOY/x+AuWh\nqIt3DREo188R5KMXAZ8M6aR9ujphTFxZ9Kr6a79asRmrpJkI+RRMLFshL+8oyXOQye5DHMw+r6o7\ngcAhVMccUwFwrx4n47X8Fz7hoLuwAGAz1Mw5u4AxucVyAQUzz83ShufA6X6gbB4jmHv/itBfYugB\njqL27XwrsFJu1ttD6Nd+VdZegk5tufeTBFyoONmdVxOUyBD6b5zgOyk2IJAxX6bX0gdg4/jZ4kL6\nCIeEuykaKrjvH/pHCOOhD57vg5/XhiI7KCx1/4qK18p34bj6CQdW1XsLIVxNfDlUZdJOEK6o/STF\n2yEf9OG1cLXXx16pbszsOgPGZM6OUGvbfRPUdJSnXOL7GNxaIuNE98Wo98iLjzuH2UDmQDIyMjIy\npoV5zoGIzF67jdC78rgj+gHe8EFqn3uVzkNbQQQXAw887WmwQ3b9LtinLag2qLByG/E9H9x9LcUL\n7qVu2omxdoGxF8ZEhj2s4sdgXDvZ2xaC40Ihafm9mPlBuN9C6lgNSWryV50eyg/p6QNT+oCbdpkx\n0xZaZYcc11G89U/QDeuGXfCyfrjJh6koWbKG0lEc3Ai3eQucF6yjZiI5NkJonw6KcnFvvXPK5bBZ\nxkYPjvNI1T8+1AesHCVQwKMEx5ULKHJKMj6XwYXC9Z1N4DYXELjcSAZ/4ioX3Hdf+K6aGbugzGxX\nU/xzYZGlKPKClCDM08F/AZ4v37IJapdij1M8lBfq/3fXeger711G4HCGCW2u3eUoDvx6qHEp1Q0E\nTq+T4JaoQtFyTDjJEbhS5v8YtXFVuEVTc/vrqIlAdm4i9N0Ykw8SS1kyDgeZLeeX83wD0ZM0ZWo6\nxn+93jf8G5Qt+a91HlrZGfL8AO8I6enBeTZF/Q1FUc8YfEbCSwnK7wnCRtdNWuE8QU0c1Hk5jGuF\nqF6k9fcqj6on+Ss3d99O2Ew0Cz8a3j10M6GtLiFcv6vFUzFis1JILzSzgf2k23AUaWf7v07B3LTT\nx/d6sRQUF2Nd/+3YZz8PAIOleFWsXiQSRMqNwItkbOgri+MFT1AhtNcwgZDQi90uihuIYIJgAryf\nYLKq/YBBMMXtgn0SN6zK7aJscU3HzZU574PR37rvXPuYWy2c5aPXrwgSxM263Ypz/DWP9aKhAWCH\n38BP74bNMu+0ObMilL65lrDxLiO0/0cpNezQRgmnX+HrNkKQWceeD6Rc1T9dq2FM8r+DMPf1RXHg\nRNhSt/icWmuQRVgZGRkZGdPCPOdAdPXTVPCiHs9Ongnce6sLT0C5PyiX5xfMhfAsH/XtW+CEVS58\nsI7PnINyKOkcgvnoCwnUROoAotTd12d8I+GQ0RDlXl+H/f+DsFvKOpvAUXRE9dQUkvhi0iaB+mBU\nGWK/Q3OFMmW/r/8rINRTt3mkCK/hAD99gtxYsEG901unLE+V7oBwIHNYpY99lOl3tagkIdqqeUsQ\nyDi/n+I9MBLfQ+g7ZXZKD8HflzZD1miXPk1Bcz5xPX34M3fxNHsSAN8zx8Ld+iBhqu+AcWeUMLj9\nKQwZf1HUttU0FskOw6A3ahm6k8CBxCK+VLgDNuuDyam+iO4GqYlSr6PIUWh/XzIGdJ27cZxK65E5\nkIyMjIyMaWGecyCC2HeQoOJvsIMb//1j/LnxvgEe9r8B5RTY7bzvgW8D8E7zUnUnAJS79vDy6Xeu\nhvctrOUT0EPxoFYZ5acV4FqRqQ926e8Upd0tUZzmOnRZPSo+ZYrbDm4sytBBuc7Fxf/yW0fBY4Ty\n1vLvsgOP49zKq1QewpUp3VEZPoNKs5rAIcQHTlPtuQtqN2beoeoZuyARrmmC8O1aARxTtNLvIwSD\niQlCv2suqGz8x16p52I8dFI0IdeQ+BG27n4JAIa/pujKJOXJt4Jw89///MsxfMpFj29Qacq+dYxF\n33eGLLtMN2GeVilKClJ6tnMI69Qm9Vs3oX+DebLrk4t9+PYorx0qvcTrNWEJk93btAaZA8nIyMjI\nmBbmOQeiKbMySxJnmfOWd3ycP+dpLvrQLgLVFVvIyN/7eccnbwTgnTyJYNoXU7+a2nBU0jPe+y2+\n+749tXwC9OG4avTuSh8eIuhAYr2Evu1O8jkfdyINilZewdSxnIKM69OIymwHqrSMI6gg337siQ+r\n+DWkHcsVOa53mhtUtJhbbqTojkR/r6fyv70RZ80GjgMUqrdKkWPU78mY0DchaupTO7bUOptdhHGy\nQ9VHux2JuU0JD6iy4nswUhRzPD7nAsN1ylYH6P5C4pZR6ghx0nvw1ZeuongYWVCmCxxn15vFy/W3\nCP2lvTEXywjYqOInKDpG1WbpumzRqWqnqvE4TJm0b6TcG/TMYp5vILpRU2aPIA37l++/Bj4grP12\nlV4pX6MJZP5I4j+hyiq7cCiEv/uk5xDObFQJrtXVOY7CuxXCIjdKMBkeJH3VqsZdBAV7F2HgiHtw\nmNwmGxPxzYqw5nrI6LbX4he14B26lROtW2j3mU6Ki0pK/FhFzuj8t/0X8dvjU15Zy0xxN8ArfPrP\nvIxwKno7aUW4LvdBiq7YZQx0ku6LcYqLkJwh2Uqj8e/sW2X89RIMBepdXZu6jG02oc5LJH3duTRn\nf+6fXNBAMBroo3geY/I8Xb1pPUHsO0px7qQ2z4o6yqXPY3RTbiCjIePhIsLmoNs/bmeZ+yMEonJU\nvVNmqLEpEdcaZBFWRkZGxv/f3tnH2lFcB/x3wCZ9lI/gpjaSAZvGVTEkFAhgFKggTUqcNApV1RJS\nlNJKCTQKBDVVSxLSxBVqaSqVhkJKS0I/oG3cKKLBVb5MQkBFDeDENpjWULvx48OB5xBKbZKnyM+c\n/rEz3nPXu/fu3bd7d++75ydde97c2d2Zs7t3zpk5c8apRNvq5DyxMWeKtKREI/vzj3+MVKM8H/ij\ngvLmuPOieFaTaop/zEDTftfdHNQIV30Cdkb3vSLNfo5Ug7F7BZjFgj3ahj3HNnoj6saV0PvIX9wE\nqWZmJ/Xt8Fc/F9S2sG2xGnme5j3LEwcSq+9YbqTXVbloAj7R1G9dcjVXckbIW07+xHtGm40x0Ljb\nfLeP4hXelrgwcNq0JauV2vPEodHF9EYgKBriiDxizpONvlBE2+69RW7XvXxDXhNSq0ld1O0+LgVt\nfMP9pPurLOFgtO5DZGhlFZ1iVsOiEBNvzka/nSX/etaqWUnvanJbxl4z3tO4kVU2376n9qfcTuo3\ni1sgjuM4TiXG3ALJTupmMZrfDY/BmWGseku/48zY83PBYjn7Itgav7YukEXa214O7m72A0g1i+z8\nicXGtLFRRCNxe8ycevYwyLEgE8Hz4Di3HWNuW/PMI68tRaFX9nHs3/w4pO0eHVCsKSZtvvJP7iRd\nBGq1xD737u/tH3FeYobBcwjWolhFOnYdt+TNq2dkL+kE8G5zLRsl2Vo+9jxddtO22PtbEF4EODiy\n8KU1cHXI2mW+zn1vADZz1A8Tx5qXT8BEs7XHZK3H6eS/ay6HW+zvyFzm/zyCxcL99M7d5b1v9jyr\nSUco7DubdRO37Ry0KLgexrwDGeRnb3mA121OflQelxcy3xUNKyV+9hds+hEPih0iyE4+Z8+xB/4w\nTITf8E/kb7yUjW0V03YVu823HYv1tLHmqh3yss4Bdi2ErWdRbK5+smzbM8dif0gyE+ofmE6Sb3ob\nfNOuxRnwol//dTgxDGs8Y33ps2sKzKujcWb1cnqDYebJ367ZsPGsbFBLO2k6Ta+3T3SYWErawVlF\nY5Wpq5XJLL2bDNmhvFFuWTwM2egLec8wxDa+5+2f4a5dUYHKro3Ju9/7eHk6DH/975+RynMvxZ1t\nSN9y8B+Se2frWhQXyzrK2FXyNqJAPMY+24/Q+yzZ34SpnPJJ20aBD2E5juM4lRhzC2QYXuTx950T\n0vdTrumJNvOgvJ901al1sSwaFpiFG6L2mtU2rEYYsZqD3SzJbnZlyxesgO9Zrb6f3iGUomGQPPO+\nX3j2ti0P64KaHYKy1lGQyb+vJC/a8qHEcz2bjirlrmSGwrhMPfK0Q51k0vbY6fD/MnqtqdjGIisx\nmxfPv83UIdtW6wIcsS7JRXRhJfpgjfqu099H+p7aqM19hmRfFxPZEPrWUl2Uk7Yu3ieY+vWLXmCH\nFqPlmT+UeuhwVCyzxFwrO9R56Jq0pnELxHEcx6nEmHcgcQXoUpLeN/bANm347N7kw3YSDWB1pnyR\nVbKZRKOZIXUTjMcdTe8mPpHt4TMHU+9NPj3XWklqGWS1jfj5VXpXp64x15/i0EnkOZKVyheG9Iv0\njqfH69vyi8NnmanbvoLzt0msT9Tysx/otbSC/J9Uc+wU/e8zwB64keQDpPfX1iFvsd5+knv6VPic\nYvKjRZddsRwtxmNILJHl4TNL8kwvzVzLtjeuJp8l1URnw/HxntpjssS25LmrZmnT6rT3LZLn+DIH\n224jmUNcS+98Tzwmp3362eTDu0ju30rSleLx/bbPVUw/TOIocz7J5HiU/xzJ+7bKlM3Kb7k5dtZ8\nzjJlsvMuUQ4rTf4e0mcmS9G162XMOxDHcRynLURV265DKUREYV0mt8g9r4gYqmA1qUdEGZfVJaTW\nynaKXXEtUXtfZcqXCXdgjy3aF6KorXYOJHtcv2Mibc9v9KOq95cNaVHm2GgdQnK/8jx/iuS5afyF\niwAADfVJREFUnN5xbvtsFYUaie2yEaWzkZ/zxv+tW2t2HqOMV1WXvOmKKPIeLGIRvXHJhmnbpaTz\nJ2Xd2KPFME2534RIlfc0YudF4zEMOG4dqipDVLA0jXcgIrKWZOPPw4A7VPWTme9/Dvg7krvxUVW9\n6dCzFHUgw2Ld5QavcO2lYHOagdfKTsINQ5XJy7xrNTEJan/A2lw30tUfwiobNeX98Je5d9lrdVUm\nTTNfZWihyq25DqRRLywROQy4FXgz8D1gk4jco6o2quAPgGuAX2myLo7jOE69ND0Hci6wQ1WfUtX9\nwHrgEltAVV9Q1e8wkm4/TioNa31AOiE97LWy6WGoekz2uCZEG4dorPtgHQya5M6rR5OPzrD1iVRx\no8yGYodybcs7ZqFp0WWY78TxpMqtOk13IMuBZ8zfzzKqKF+O4zhOo4zZQsJvmvRK4OSW6uH0UqfW\nVhRCoi3mo82O6lqOY9lFb0id5mi6A9kNnGT+PoHyrkg5vGme1XEcx1nonEyvcv1AUcF50/QQ1iZg\nlYisEJEjgMuADX3KN+Ip4Iwjro07Ttdp1AJR1QMicjWwkdSNd7uIXJV8rbeLyDLg2yQ+jK+IyLXA\nqar6cpN1a4euDMs4juPMnzFfSDhueAfiOM6oaW4diIcyGSneefRnPgZxNvZRHQyKkeZ0G793TeMd\niOM4jlMJ70BGwhJ6d5zrClWi7Tap1cWwL1XO38QObEUL06rUz7Xh0eMLA5vGOxDHcRynEq4SNUaM\n/DvLcCFQRkmVIIh217wmgiiOg8boiwSdpp7/8cI7kMaoEm9rnPCXx5lkZikO0T85+BCW4ziOUwm3\nQJwOMZ/9T6hwrOPMh8m1PCJugTiO4ziV8A7E6RCLBxc5hPnuATEK3NBfOExRzf19YeIdiOM4jlMJ\nV41GThf2Xe7qvMFCHVPukoyd+RGfUY9rB26BjJgy/XUTfXp2FbwP+zh5eOyv8nT53Rkd3oE4juM4\nlRgzVWMF6QK9Lg93FK1SLaO1NKHZvEg68be/oWvUzWLgmJDu6kr+hYAdimnzuVge/n+Rbr/bo6T7\nCxXdAnEcx3EqMWYWyFNtV6AkU6SibSJKbBW6q8Xks5/xq3OWOjTIpmIudcGZw7J7hNeq2vZRO5/E\n+17mGWhnUt8tEMdxHKcSY2aBdIVBmuVsn+/quv7+kO6KBhmpSxPqWruqUMczsJ90t8U6rdmFIN+q\nxLYP+6zOV2ZVLZ8yz1E799M7kEpEt9iiCb+mh15m6e6ti5tCxXQZuroupQvMkXYcvvagXkYty4V3\n73wIy3Ecx6lEV9XYjhMn/NoUX542s4h0eM3G7Nltyo9i+GvY81atx6Rp5E21teg5niTZOlVwC8Rx\nHMephFsg82K+GlrdC4XseHnRhOu4u8ZmyXuEi+5LGevraJOeM+XLXsNSh6tsU1ZWrNti8p8Ja82O\ny+LTLF1zVbaUqZuN+jubk2fde4826dEtHXALxHEcx6mEWyAjx2p+kaWkmsU+PHRHWaq4Qw565GdL\nnNcGHBzW02zYOtuQLnsLjq9ipcTnr8gitcE2p0qU7yJl7mPVxYRVrJr4ji+inJVQ5OG5yKStR+jo\nLS3vQBqh38rRvLhDtuwi0odiCbCz3qrNm6Xh/+wP7bj8sAx6yeqMVzZXkB4Gu6aoX8cVf5yyQ3BF\nysgw98uWzW6m1NX1SGWoUuf5tLPOoWpInoV2lU0fwnIcx3Eq4RZIJawWlhfzqsoQR8RqjVPA60N6\nmymzHJjJHFOVYSfyYzuzWmm0mhYVlOnHJC8kHEb+RbKxw03ZYbq6HTWy1nIc2iqajHeao/13xS0Q\nx3EcpxJugVQijvtO0TvRWLcb3W56Fy3Ga81krotJxwlXG83WuqPayXsYXmssmtiz+XEcvuwkZd5k\n7X6KJ26XmvLW2hm03WiZ+mRfiapxk8peo0j+dbjQFu06aa+/LPOdrU98Zoqe567valkkw/h8lnGY\nsNRpKce6LSFxjojnLJpvss92Xr4t38/9vF7cAnEcx3Eq4RZIJaL2Mcq9Poo8eqwGso/BdRqFxlhV\nLlltvKiucVfKrDZmXaSLjh3kxWQ1wmzdouZqA0b2a6stby3AMp5LscwyUzcbvNNq1Ssy54r1X0y+\nl85i0h0AZ8hvg53fWEq+NTuoDVXJenpl6wODvY+mSOVvvRltfZeZ85SxxO1cn71+WW/EeKy9d3Yf\nlOzcqX2eY9qGKLIjIJDOiy4aUI/6EFUdyYXmi4gorGu7Gk7n6PJq4yawP672h3yx+T6vsyrbOQ/C\n6pzZ4VDbMU5afK0ubz+7DlWVJs7sQ1iO4zhOJRrvQERkrYg8ISL/LSLXFZT5SxHZISJbReSM4rP5\niJuTpesTuXUzaz5z5hPzXiQdyrTpucynKnnXzNYnW66O63adpjeR6yaNdiAichhwK/BW4DTg3SJy\nSqbM24DXqurPAlcBf91knRYGu9quQIdwWaS4LFJcFqOgaQvkXGCHqj6lqvuB9cAlmTKXAHcCqOrD\nwLEikvUtdHqYbrsCHWK67Qp0iOm2K9AhptuuwETQdAeyHHjG/P0sqftHUZndOWUcx3GcjjFmk+gL\neQzVcRxnvGh6Vno3cJL5+wR6HZ9jmRMHlAmsq69mY88DbVegQ7gsUlwWKS6Lpmm6A9kErBKRFcBz\nwGXAuzNlNgAfAP5FRM4DXlLVmUyZxvyYHcdxnGo02oGo6gERuRrYSDJcdoeqbheRq5Kv9XZV/bKI\nvF1EdgI/BH67yTo5juM49TA2K9Edx3GcbjEWk+hlFiOOGyJyh4jMiMhjJu84EdkoIk+KyNdE5Fjz\n3UfCYsvtInKxyT9LRB4LsvmUyT9CRNaHY74lInYuqlOIyAkicp+I/KeIbBORD4b8iZOHiLxKRB4W\nkS1BFp8I+RMni4iIHCYim0VkQ/h7ImUhItMi8mh4Nh4Jee3KQlU7/SHp5HaSRIxbDGwFTmm7XjW0\n6wLgDOAxk/dJ4A9C+jrgT0P6VGALyZDjyiCPaD0+DJwT0l8G3hrS7wf+KqTfBaxvu819ZHE8cEZI\nHwU8CZwywfI4Mvx/OPAQyXqqiZRFqOPvAv8IbAh/T6QsgO8Cx2XyWpVF60IpIbTzgK+Yvz8MXNd2\nvWpq2wp6O5AngGUhfTzwRF6bga8Aa0KZ/zL5lwG3hfRXgTUhfTjw/bbbO4Rcvgi8ZdLlARwJfBs4\nZ1JlQeKVeS9wEWkHMqmy2AX8VCavVVmMwxBWmcWIC4WlGjzQVPV50p2TihZbLieRR8TK5uAxqnoA\neElEltBxRGQliWX2EMmLMXHyCEM2W4DngXtVdRMTKgvgL4DfB+xk7aTKQoF7RWSTiLw35LUqC49O\n2G3q9HDovBu0iBwFfAG4VlVfFpFs+ydCHqr6CnCmiBwD/KuInMahbV/wshCRXwZmVHWriFzUp+iC\nl0XgfFV9TkR+GtgoIk/S8nMxDhZImcWIC4UZCXHAROR40p2TihZb9luEefA7ETkcOEZVB+3C0xoi\nsoik87hLVe8J2RMrDwBV3QvcD6xlMmVxPvBOEfku8DngF0XkLuD5CZQFqvpc+P/7JMO859LyczEO\nHcjBxYgicgTJmN2GlutUF0JvL78B+K2QvgK4x+RfFrwkTgZWAY8Ek/X/RORcERHgNzPHXBHSvw7c\n11gr6uFvScZmbzZ5EycPEXlN9KQRkSngl4DtTKAsVPWjqnqSqv4MyXt/n6q+B/g3JkwWInJksNAR\nkZ8ELga20fZz0fbEUMnJo7Uknjk7gA+3XZ+a2vTPwPeAHwNPkyygPA74emjrRuDVpvxHSDwptgMX\nm/w3hAdpB3CzyX8V8PmQ/xCwsu0295HF+cABEg+7LcDmcM+XTJo8gNeH9m8FHgOuD/kTJ4uMXC4k\nnUSfOFkAJ5v3Y1v8HWxbFr6Q0HEcx6nEOAxhOY7jOB3EOxDHcRynEt6BOI7jOJXwDsRxHMephHcg\njuM4TiW8A3Ecx3Eq4R2I4ziOUwnvQJwFi4gsCXsnbBaR50Tk2ZDeIiIPNnC9K0Rkj4jcXuM5Lw37\nMyyU6AvOAsKDKToLFk3i+JwJICIfB15W1Zsavux6Vf1gXSdT1c+LyAzwe3Wd03Hqwi0QZ1LoiSwq\nIvvC/xeKyP0i8kUR2SkiN4rIb0iyK+CjIY5QjFH1hZD/sIi8ceAFRU4NZTeLyFYReW3Iv9zk3xZi\nEsWdN78TLKR76xeB49SLWyDOpGJj+JxOsgPiSyS7vn1GVddIsrXuNcCHgJuBm1T1P0TkROBrJLu+\n9eN3gE+p6udCtOHDReQUkt3e3qiqB0Tk08DlIvJV4HbgAlV9WkReXWNbHacRvANxHNikqnsAROR/\nSILSQRJw7qKQfguwOloLwFEicqSq/qjPeb8FXB86nLtVdaeIvBk4C9gUzvUTwAzJzpsPqOrTAKr6\nUn3Nc5xm8A7EcZKIyJFXzN+vkL4jQrLd5/6yJw2Wx0PAO4AvichV4Tz/oKrX27Ii8g66vZmR4xyC\nz4E4k8qwP9YbgWsPHizy8wMvIHKyqu5S1VtI9lo4HfgG8GthVzlE5DgROYkkfPYviMiKmD9k/Rxn\n5HgH4kwqRfsYFOVfC5wdJtYfB64qcY1LReRxSfY3Pw24U1W3Ax8j2ZL0UZKO6XhVfQG4kmQL2y3A\n+mEa4zht4PuBOE5NiMgVwNmqek3N570I+JCqvrPO8zrOfHELxHHqYxZYW/dCQuDTQCf36XYmG7dA\nHMdxnEq4BeI4juNUwjsQx3EcpxLegTiO4ziV8A7EcRzHqYR3II7jOE4l/h/6g8X3uv9+VAAAAABJ\nRU5ErkJggg==\n",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"plt.figure()\n",
"f, t, S = signal.spectrogram(source[0])\n",
"plt.pcolormesh(t, f, S)\n",
"plt.ylabel('Frequency [Hz]')\n",
"plt.xlabel('Time [sec]')\n",
"plt.title('Spectrogram of Output 1')\n",
"\n",
"plt.figure()\n",
"f, t, S = signal.spectrogram(source[1])\n",
"plt.pcolormesh(t, f, S)\n",
"plt.ylabel('Frequency [Hz]')\n",
"plt.xlabel('Time [sec]')\n",
"plt.title('Spectrogram of Output 2')\n",
"\n",
"# Storing numpy array as audio\n",
"wavfile.write('FOBI/Sounds/out1.wav', samplingRate, np.transpose(source[0]))\n",
"wavfile.write('FOBI/Sounds/out2.wav', samplingRate, np.transpose(source[1]))"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Mixed Signal 1\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 29,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from IPython.display import Audio\n",
"print('Mixed Signal 1')\n",
"Audio(\"FOBI/Sounds/mix1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Mixed Signal 2\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 30,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Mixed Signal 2')\n",
"Audio(\"FOBI/Sounds/mix2.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 31,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Original separated sound 1\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 31,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Original separated sound 1')\n",
"Audio(\"FOBI/Sounds/source1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 35,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Original separated sound 2\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 35,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Original separated sound 2')\n",
"Audio(\"FOBI/Sounds/source2.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 36,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Separated signal 1 (output)\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 36,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Separated signal 1 (output)')\n",
"Audio(\"FOBI/Sounds/out1.wav\")"
]
},
{
"cell_type": "code",
"execution_count": 37,
"metadata": {
"collapsed": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Separated signal 1 (output)\n"
]
},
{
"data": {
"text/html": [
"\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 37,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"print('Separated signal 1 (output)')\n",
"Audio(\"FOBI/Sounds/out2.wav\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"### fastICA v/s FOBI\n",
"\n",
"The comparison of different implementations of ICA is very difficult as there are few parameters available to quantify and compare performance, and even then no one algorithm performs better unilaterally in all scenarios. Such metrics are usually thus compiled for data from highly specific domains. \n",
"\n",
"However, some broad conclusions have been drawn based on the asymptotic behaviour of algorithms.\n",
"\n",
"Alogrithms can be categorised on the basis of how of how Gaussianity is quantified. \n",
"\n",
"fastICA is based on negentropy. Maximum-likelihood and negenrtropy are considered optimal in their statistical properties. However, nengentropy is very computationally expensive to compute if the actual formula is used without any approximations. Hence, in practice, approximate formulae for negentropy are used. These approximations are a compromise between computational speed and statistical properties. \n",
"\n",
"FOBI does not explicitly use a cost function at all. It provides a purely algebraic method of implementing ICA. Yet, it's statistical properties are essentially that of Kurtosis and it implicitly uses fourth order moments. Kurtosis suffers from non-optimal dependence on outliers. FOBI in particular also involves a lot of matrix computations that might not scale well with the size of the data. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Limitations of ICA\n",
"\n",
"ICA generates the independent components upto a scaling factor. This means that the output can also be 'flipped' due to scaling by a negative number. This does not matter when it comes to sound signals but may be a problem to be rectified in other applications of ICA. \n",
"\n",
"ICA works very well when there is no noise. Noisy ICA methods have been developed that assume a Gaussian pdf for the noise. This is a reasonabel assumption to make in most cases but does not hold always hold.\n",
"\n",
"Feature extraction using ICA may not give the best results. This is true of face recognition in particular. Real images have a lot of variations in parameters that don't really matter in feature extraction. Like brightness. ICA is not 'smart' and will identify brightness also as an Independent component. Also, in higher dimensional data like faces, independent components may not form the best basis of understanding data. For face-recognition, due to the limitations of ICA, Fischer Linear Discriminant Analysis(LDA) is used instead. \n",
"\n",
"ICA works on linear models. Extending ICA to non-linear systems is much harder to do and is yet to have been solved for a general non-linear system. \n",
"\n",
"Often, the components estimated from data by an ICA algorithm are not independent. While the components are assumed to be independent in the model, the model does not have enough parameters to actually make the components independent for any given random vector **X**. This is because statistical independence is a very strong property with potentially an infinite number of degrees of freedom.\n",
"\n",
"Empirical results tend to show that ICA estimation seems to be rather robust against some violations of the independence assumption. Modelling dependencies of the estimated components is an important extension of the analysis provided by ICA. It can give useful information on the interactions between the components or sources recovered by ICA. Thus, the fact that the components are dependent can be a great opportunity for gaining further insights into the structure of the data."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Conclusion\n",
"\n",
"It is fair to say that ICA has become a standard tool in machine learning and signal processing. The generality and potential usefulness of the model were never in question, but in the early days of ICA, there was some doubt about the adequacy of the assumptions of non-Gaussianity and independence. \n",
"\n",
"It has been realized that non-Gaussianity is in fact quite widespread in any application dealing with scientific measurement devices (as opposed to, for example, data in the social and human sciences). On the other hand, independence is now being seen as a useful approximation that is hardly ever strictly true. Fortunately, it does not need to be strictly true because most ICA methods are relatively robust regarding some dependence of the components."
]
},
{
"cell_type": "markdown",
"metadata": {
"collapsed": true
},
"source": [
"## References\n",
"\n",
"A great tutorial on PCA:\n",
"\n",
"https://arxiv.org/pdf/1404.1100.pdf\n",
"\n",
"Quick explanation of ICA:\n",
"\n",
"http://research.ics.aalto.fi/ica/icademo/\n",
"\n",
"Comprehensive introductions to ICA: \n",
"\n",
"http://www.dsp.pub.ro/articles/spie/ICA_course.PDF\n",
"\n",
"http://www.bsp.brain.riken.jp/ICApub/NN00.pdf\n",
"\n",
"\n",
"ICA implemented using Neural Networks:\n",
"\n",
"https://www.cs.purdue.edu/homes/dgleich/projects/pca_neural_nets_website/\n",
"\n",
"http://shulgadim.blogspot.in/search/label/DSP\n",
"\n"
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.6"
}
},
"nbformat": 4,
"nbformat_minor": 0
}