|
|---|
Strong Links Graph (W0)
P0 → P1 → R0
↓
R1 ↔ P7 ↔ R7 → P4
↓ ↘
R2 → R3 → R5
↓
R4 ↔ P3
↓
P2 → P6 → R8
↓
R6 → R9 → P5
|
Weak Links Graph (W1)
CB12 (RF01,04) (CB17,18)
: : :
P0 ─────→ P1 ──────→ R0
↓
(CB11,16) ·· R1 ↔ P7 ↔ R7 → P4
↓ ↘
R2 → R3 → R5 ·· CB16
↓
(CB11,22) ·· R4 ↔ P3
↓
P2 → P6 → R8 ·· RF06
↓
CB15 ·· R6 → R9 → P5
:
CB18
|
Final Control Graph (@W1)
(INPUT: User Query, Context & Data)
│
↓
┌────────────────────────────────────────────────┐
│ UPSTREAM PROCEDURAL FLOW (TEGL R/P RULES) │
│ Processing by R4,R7,R9,... w/tools: 5W1H,... │
└────────────────────────────────────────────────┘
│
(Results of R4/R7/R9) ─────────────────┐
↓
┌────────────────────────────────┐
│ P3-P5: TERMINATION BLOCK │
├────────────────────────────────┤
│ │
R4::Result (Neg. Feedback) → P3 (Reject Absolutism) ═ (State Constraint)
│ │
R7::Result (Filtered Data) ─ P4 (Synthesis: Integration & LSRP) ────┼──→ OUTPUT
│ │
R9::Result (Rigor Check) ─── P5 (Guardrails: Evidence & Liability) ─┘
|
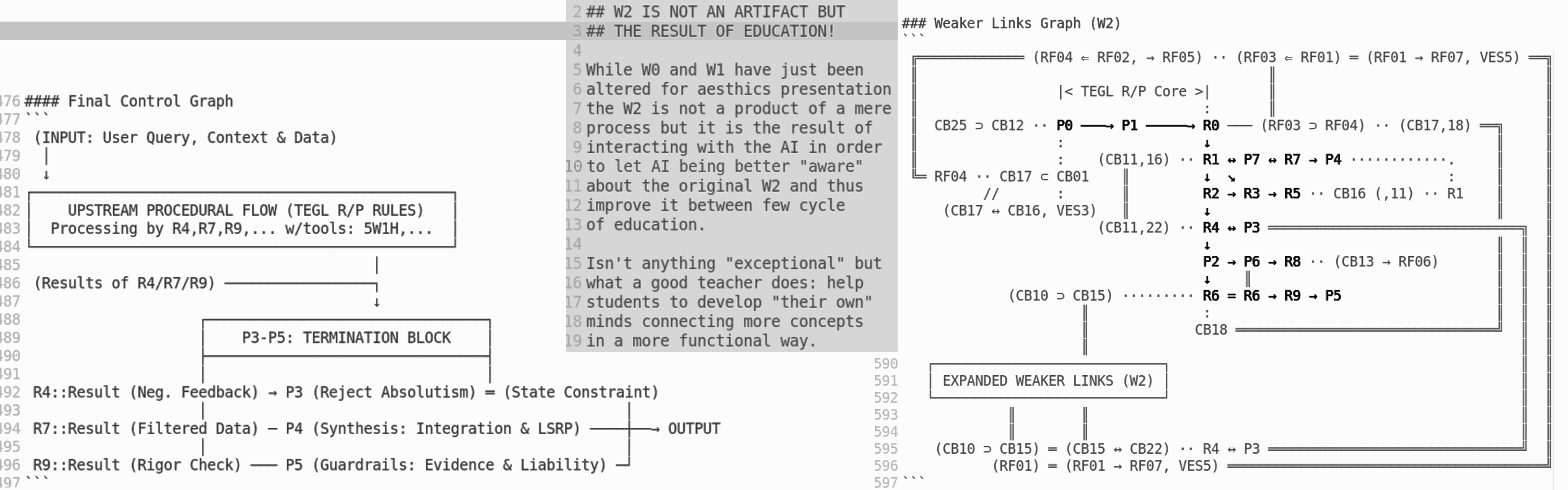
Weaker Links Graph (W2)
╔═════════════ (RF04 ⇐ RF02, → RF05) ·· (RF03 ⇐ RF01) ═ (RF01 → RF07, VES5) ══╗
║ ║ ║
║ |< TEGL R/P Core >| ║ ║
║ : ║ ║
║ CB25 ⊃ CB12 ·· P0 ───→ P1 ─────→ R0 ─── (RF03 ⊃ RF04) ·· (CB17,18) ══╗ ║
║ : ↓ ║ ║
║ : (CB11,16) ·· R1 ↔ P7 ↔ R7 → P4 ············. ║ ║
╚═ RF04 ·· CB17 ⊂ CB01 ║ ↓ ↘ : ║ ║
// : ║ R2 → R3 → R5 ·· CB16 (,11) ·· R1 ║ ║
(CB17 ↔ CB16, VES3) ║ ↓ ║ ║
(CB11,22) ·· R4 ↔ P3 ═══════════════════════════════╗ ║
↓ ║ ║ ║
P2 → P6 → R8 ·· (CB13 → RF06) ║ ║ ║
↓ ║ ║ ║ ║
(CB10 ⊃ CB15) ········· R6 = R6 → R9 → P5 ║ ║ ║
║ : ║ ║ ║
║ CB18 ════════════════════════════════╝ ║ ║
║ ║ ║
┌────────────────────────────┐ ║ ║
│ EXPANDED WEAKER LINKS (W2) │ ║ ║
└────────────────────────────┘ ║ ║
║ ║ ║ ║
║ ║ ║ ║
(CB10 ⊃ CB15) ═ (CB15 ↔ CB22) ·· R4 ↔ P3 ═══════════════════════════════╝ ║
(RF01) ═ (RF01 → RF07, VES5) ═══════════════════════════════════════╝
|
- Graphs moved here from: `aing/katia-cognitive-compass-core-v2.txt`
+
## Related articles
- [Il segreto dell'intelligenza](il-segreto-dell-intelligenza.md#?target=_blank) (2025-11-20)
+++++
- [How to use Katia for educating Katia](how-to-use-katia-for-educating-katia.md#?target=_blank) (2025-10-28)
+++++
- [How to use Katia for improving Katia](how-to-use-katia-for-improving-katia.md#?target=_blank) (2025-10-25)
+++++
- [Introducing Katia, text analysis framework](introducing-katia-text-analysis-framework.md#?target=_blank) (2025-10-05)
+++++
- [The session context and summary challenge](the-session-context-and-summary-challenge.md#?target=_blank) (2025-07-28)
+++++
- [Human knowledge and opinions challenge](the-human-knowledge-opinions-katia-module.md#?target=_blank) (2025-07-28)
+++++
- [Attenzione e contesto nei chatbot](attenzione-e-contesto-nei-chatbot.md#?target=_blank) (2025-07-20)
+
## Share alike
© 2025, **Roberto A. Foglietta** <roberto.foglietta