| Agent | Support | Notes |
|---|---|---|
| Claude Code | ✅ | |
| OpenCode | ✅ | CLI v1.4.0+ required (structured output support) |
| OpenHands | ✅ | No native structured output; uses fallback JSON extraction |
| Goose | ✅ | CLI v1.25.0+ required (skill discovery via summon extension) |
| Codex CLI | ✅ | Skill discovery via .agents/skills/ symlink |
| Harbor | ✅ | Containerized task benchmarks with built-in verifiers |
| Capability | Status | Explanation |
|---|---|---|
| Evolution with a benchmark | ✅ | Skills can be effectively improved against your own or academic benchmarks. |
| Cross-agent transferability | ✅ | Skills are packaged as reusable folders with instructions, metadata, and helper scripts, compatible with many coding agents. |
| Cross-model transferability | ✅ | Demonstrated in EvoSkills, skills evolved with a fixed LLM can transfer their performance increase to other LLMs. |
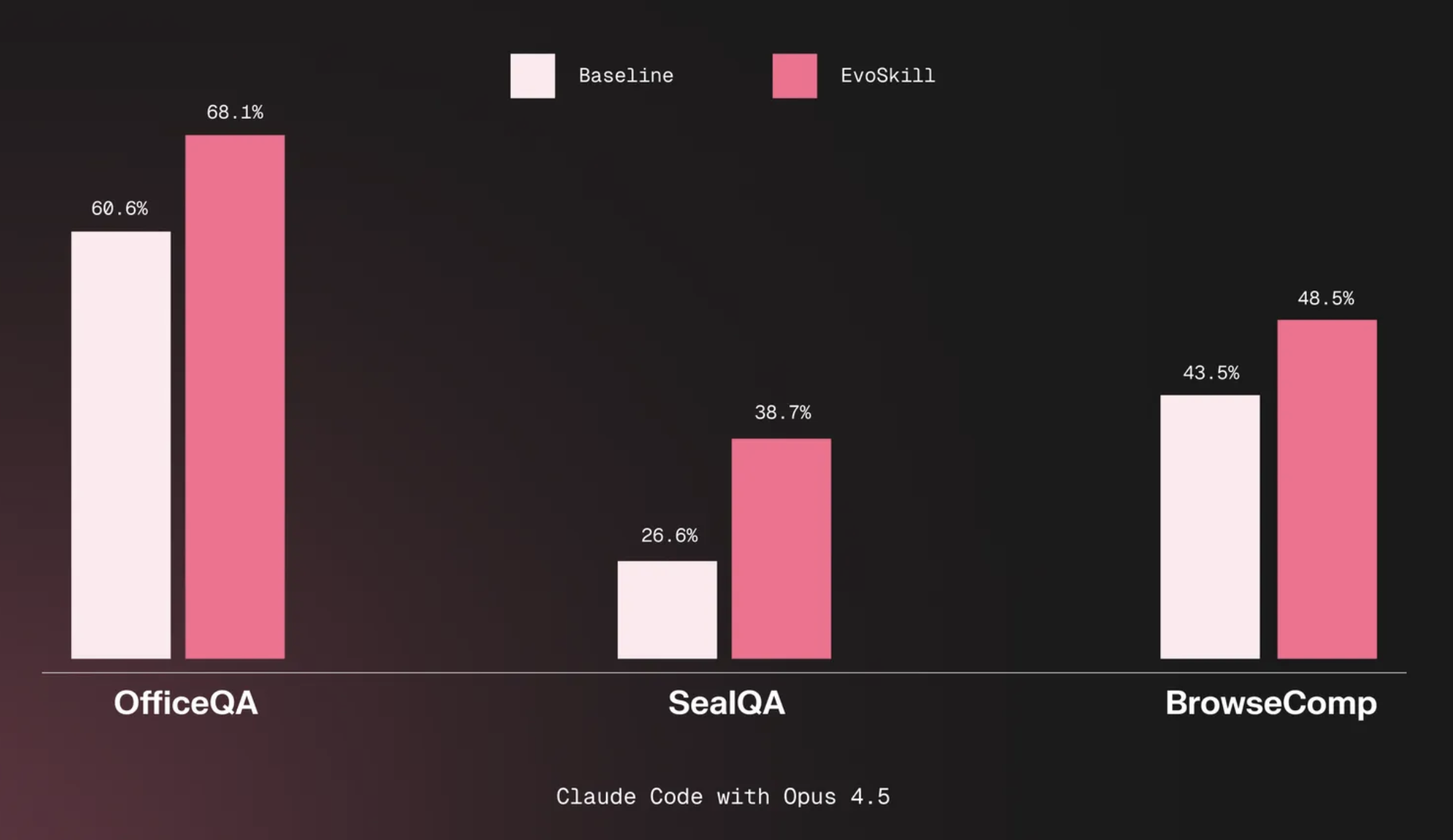
| Cross-task transferability | ✅ | Generated skills can be generic enough to transfer across tasks, for instance a SealQA skill improving BrowseComp performance (as shown in EvoSkill). |
| Evolution without a benchmark | 🛠️ | An open research direction where benchmarks are generated on the fly (ex. Hermes-Agent self-evolution). |
| Continuous evolution | 🛠️ | Integrating the ability to improve skills from regular usage. |