{
"cells": [
{
"cell_type": "code",
"execution_count": 1,
"id": "5ae05502-f776-4489-ba3a-c0e822c395b0",
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
""
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"from IPython.display import display, HTML\n",
"display(HTML(''))"
]
},
{
"cell_type": "markdown",
"id": "d15870bc-87c8-4328-915b-ec3f02b4af7a",
"metadata": {},
"source": [
"### Import Packages"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "469b9d74-60af-4eb6-9dc5-fb0c06e04a02",
"metadata": {},
"outputs": [],
"source": [
"from langchain.document_loaders import PyPDFLoader\n",
"from langchain.text_splitter import RecursiveCharacterTextSplitter\n",
"from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings\n",
"\n",
"from langchain.retrievers import EnsembleRetriever, WeaviateHybridSearchRetriever\n",
"from langchain_community.retrievers import BM25Retriever\n",
"from langchain_chroma import Chroma\n",
"\n",
"from langchain_openai import ChatOpenAI\n",
"from langchain.chains import RetrievalQA\n",
"\n",
"from dotenv import load_dotenv\n",
"import weaviate\n",
"import os, torch"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "7b32bce7-64ff-4032-9f14-659be141d06b",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Device found: cpu\n"
]
}
],
"source": [
"DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n",
"print(f'Device found: {DEVICE}')\n",
"\n",
"_ = load_dotenv()\n",
"os.environ['OPENAI_API_KEY']=os.getenv('OPENAI_API_KEY')"
]
},
{
"cell_type": "markdown",
"id": "6737949d-8f88-4502-9f97-4d125732c549",
"metadata": {},
"source": [
"#### Constants"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "29d82f19-e521-4bf1-b782-034d40899a26",
"metadata": {},
"outputs": [],
"source": [
"# PDF file name\n",
"pdf_file = 'Llama3 paper.pdf'\n",
"\n",
"# Chunk size and chunk overlap for text splitter\n",
"chunk_size = 2500\n",
"chunk_overlap = 100\n",
"\n",
"# Ks to return from BM25, vector DB\n",
"return_k = 2\n",
"\n",
"# Constants for the Embedding model\n",
"DEVICE = 'cpu' # accepts 'cuda' or 'cpu'\n",
"HF_MODEL = './models/all-MiniLM-L6-v2' # Path where the embedding model is stored\n",
"HF_MODEL_PULL = 'sentence-transformers/all-MiniLM-L6-v2' # model to pull in case not found in local\n",
"HF_MODEL_KWARGS = {'device': DEVICE} # Model kwargs for the embedding model\n",
"HF_ENCODE_KWARGS = {'normalize_embeddings': True} # Encode kwargs for the embedding"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "cdfebda4-e0ef-4ef1-b8ad-365e4e555c87",
"metadata": {},
"outputs": [],
"source": [
"QUERY1 = \"What is the extended context length of Llama-3-8B-Instruct?\"\n",
"QUERY2 = \"What was the Zero-shot performance on MMLU?\""
]
},
{
"cell_type": "markdown",
"id": "90754a3e-97bf-4ec8-8f0f-9eb070f4fd61",
"metadata": {},
"source": [
"### Read data from the PDF"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "a5d7236b-d8c6-4821-8397-25b7988ecadb",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The total pages loaded as content: 6\n"
]
}
],
"source": [
"# Read data from the PDF\n",
"loader = PyPDFLoader(pdf_file)\n",
"docs = loader.load_and_split()\n",
"print(f'The total pages loaded as content: {len(docs)}')"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "514416c2-1932-4bea-941c-e8cb7b76f575",
"metadata": {},
"outputs": [],
"source": [
"# # Split the content into chunks\n",
"# text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size,\n",
"# chunk_overlap=chunk_overlap)\n",
"\n",
"# docs = text_splitter.split_documents(content)\n",
"# print(f'Number of document chunks created: {len(docs)}')"
]
},
{
"cell_type": "markdown",
"id": "c5053432-224a-4a19-b37c-1cba62808eef",
"metadata": {},
"source": [
"### Sparse Retriever"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "035d972c-05ab-4025-aaa0-14434489c267",
"metadata": {},
"outputs": [],
"source": [
"# Initialize the BM25 retriever\n",
"bm25_retriever = BM25Retriever.from_documents(docs)\n",
"bm25_retriever.k = return_k"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "bbcc11bf-203d-4f27-8355-8a212ba1ffda",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU \n",
"\n",
"===========================\n",
"3K 6K 9K 11K 14K 16K 21K 26K 31K 36K\n",
"Context Length0.00.20.40.60.81.0Accuracy\n",
"Llama-3-8B-Instruct\n",
"Llama-3-8B-Instruct-262k\n",
"Llama-3-8B-Instruct-80K-QLoRAFigure 2: The accuracy of Topic Retrieval task.\n",
"Model Single-Doc Multi-Doc Summ. Few-Shot Synthetic Code Avg\n",
"Llama-3-8B-Instruct 37.33 36.04 26.83 69.56 37.75 53.24 43.20\n",
"Llama-3-8B-Instruct-262K 37.29 31.20 26.18 67.25 44.25 62.71 43.73\n",
"Llama-3-8B-Instruct-80K-QLoRA 43.57 43.07 28.93 69.15 48.50 51.95 47.19\n",
"Table 1: Evaluation results on LongBen \n",
"\n",
"===========================\n"
]
}
],
"source": [
"# Invoke the response\n",
"response = bm25_retriever.invoke(QUERY1)\n",
"for res in response:\n",
" print(res.page_content[0:500], '\\n\\n===========================')"
]
},
{
"cell_type": "markdown",
"id": "cc99ba6d-685d-40f7-9760-a1cb5dba8720",
"metadata": {},
"source": [
"### Dense Retriever"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "dc0f6f8f-ffb6-4c1a-b1f4-b7035715395d",
"metadata": {},
"outputs": [],
"source": [
"# Initialize HuggingFace SentenceTransformerEmbeddings with specified model and arguments\n",
"try:\n",
" embeddings = SentenceTransformerEmbeddings(\n",
" model_name=HF_MODEL, # The name of the saved HuggingFace model to use for embeddings\n",
" model_kwargs=HF_MODEL_KWARGS, # Additional keyword arguments for the model\n",
" encode_kwargs=HF_ENCODE_KWARGS # Keyword arguments for the encoding process\n",
" )\n",
"except:\n",
" # Fallback to a default model if the specified model fails to initialize\n",
" embeddings = SentenceTransformerEmbeddings(\n",
" model_name=HF_MODEL_PULL, # HuggingFace model to use for embeddings\n",
" model_kwargs=HF_MODEL_KWARGS, # Additional keyword arguments for the model\n",
" encode_kwargs=HF_ENCODE_KWARGS # Keyword arguments for the encoding process\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "cfa0f354-229a-4271-84f3-3420139a867c",
"metadata": {},
"outputs": [],
"source": [
"# Initialize a Chroma vector database\n",
"chroma_vectordb = Chroma.from_documents(\n",
" documents=docs, # The text chunks to be embedded and indexed\n",
" embedding=embeddings, # The embeddings generated by SentenceTransformerEmbeddings\n",
")\n",
"chroma_retriever = chroma_vectordb.as_retriever(search_kwargs={'k': return_k})"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "89eceed7-8cc8-4ae1-a2dd-67ab7c30a26d",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3K 6K 9K 11K 14K 16K 21K 26K 31K 36K\n",
"Context Length0.00.20.40.60.81.0Accuracy\n",
"Llama-3-8B-Instruct\n",
"Llama-3-8B-Instruct-262k\n",
"Llama-3-8B-Instruct-80K-QLoRAFigure 2: The accuracy of Topic Retrieval task.\n",
"Model Single-Doc Multi-Doc Summ. Few-Shot Synthetic Code Avg\n",
"Llama-3-8B-Instruct 37.33 36.04 26.83 69.56 37.75 53.24 43.20\n",
"Llama-3-8B-Instruct-262K 37.29 31.20 26.18 67.25 44.25 62.71 43.73\n",
"Llama-3-8B-Instruct-80K-QLoRA 43.57 43.07 28.93 69.15 48.50 51.95 47.19\n",
"Table 1: Evaluation results on LongBen\n",
"\n",
"===========================\n",
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU\n",
"\n",
"===========================\n"
]
}
],
"source": [
"# Get the similar texts based on a query provided - to check\n",
"results_with_scores = chroma_vectordb.similarity_search_with_score(QUERY1, k=return_k)\n",
"for doc, score in results_with_scores:\n",
" print(doc.page_content[0:500] + '\\n\\n===========================')"
]
},
{
"cell_type": "markdown",
"id": "13ddaf99-9935-4da4-b567-1af04051846f",
"metadata": {},
"source": [
"### Instantiate an Ensemble Retriever"
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "78aaedb9-091a-48fa-a53b-b8fa92bc090e",
"metadata": {},
"outputs": [],
"source": [
"# Initialize an ensemble retriever using BM25 and FAISS retriever defined above\n",
"ensemble_retriever = EnsembleRetriever(\n",
" retrievers=[bm25_retriever, chroma_retriever], weights=[0.6, 0.4]\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "95fb96c7-75a0-4bb7-966e-4ddbd4f308a8",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU \n",
"\n",
"===========================\n",
"3K 6K 9K 11K 14K 16K 21K 26K 31K 36K\n",
"Context Length0.00.20.40.60.81.0Accuracy\n",
"Llama-3-8B-Instruct\n",
"Llama-3-8B-Instruct-262k\n",
"Llama-3-8B-Instruct-80K-QLoRAFigure 2: The accuracy of Topic Retrieval task.\n",
"Model Single-Doc Multi-Doc Summ. Few-Shot Synthetic Code Avg\n",
"Llama-3-8B-Instruct 37.33 36.04 26.83 69.56 37.75 53.24 43.20\n",
"Llama-3-8B-Instruct-262K 37.29 31.20 26.18 67.25 44.25 62.71 43.73\n",
"Llama-3-8B-Instruct-80K-QLoRA 43.57 43.07 28.93 69.15 48.50 51.95 47.19\n",
"Table 1: Evaluation results on LongBen \n",
"\n",
"===========================\n"
]
}
],
"source": [
"# Get the retrieval for the QUERY1\n",
"response = ensemble_retriever.invoke(QUERY1)\n",
"for res in response:\n",
" print(res.page_content[0:500], '\\n\\n===========================')"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "9b827f28-8e55-4dca-b914-3dcb39459933",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"3K 6K 9K 11K 14K 16K 21K 26K 31K 36K\n",
"Context Length0.00.20.40.60.81.0Accuracy\n",
"Llama-3-8B-Instruct\n",
"Llama-3-8B-Instruct-262k\n",
"Llama-3-8B-Instruct-80K-QLoRAFigure 2: The accuracy of Topic Retrieval task.\n",
"Model Single-Doc Multi-Doc Summ. Few-Shot Synthetic Code Avg\n",
"Llama-3-8B-Instruct 37.33 36.04 26.83 69.56 37.75 53.24 43.20\n",
"Llama-3-8B-Instruct-262K 37.29 31.20 26.18 67.25 44.25 62.71 43.73\n",
"Llama-3-8B-Instruct-80K-QLoRA 43.57 43.07 28.93 69.15 48.50 51.95 47.19\n",
"Table 1: Evaluation results on LongBen \n",
"\n",
"===========================\n",
"800014315 20631 26947 33263 39578 45894 52210 58526 64842 71157 77473 83789 90105 96421102736 109052 115368 121684 128000\n",
"Context Length0\n",
"11\n",
"22\n",
"33\n",
"44\n",
"55\n",
"66\n",
"77\n",
"88\n",
"100Depth Percent1.0Needle In A HayStack\n",
"12345678910\n",
"Accuracy Score from GPT3.5Figure 1: The accuracy score of Llama-3-8B-Instruct-80K-QLoRA on Needle-In-A-HayStack task.\n",
"The blue vertical line indicates the training length, i.e. 80K.\n",
"the same cluster to form each heterogeneous context. Therefore, the grouped texts share\n",
"some semantic si \n",
"\n",
"===========================\n",
"I. Molybog, Y . Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M.\n",
"Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan,\n",
"I. Zarov, Y . Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and\n",
"T. Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023.\n",
"[16] P. Zhang, Z. Liu, S. Xiao, N. Shao, Q. Ye, and Z. Dou. Soaring from 4k to 400k: Extending\n",
"llm’s context with activation beacon, 2024.\n",
"[1 \n",
"\n",
"===========================\n",
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU \n",
"\n",
"===========================\n"
]
}
],
"source": [
"# Get the retrieval for the QUERY2\n",
"response = ensemble_retriever.invoke(QUERY2)\n",
"for res in response:\n",
" print(res.page_content[:500], '\\n\\n===========================')"
]
},
{
"cell_type": "markdown",
"id": "9c5b8abf-8fc4-4c9c-911b-311a526846f0",
"metadata": {},
"source": [
"### Use LLM to ask question from the Ensemble Retriever"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "b6479945-9c36-436b-906c-74790a852b1e",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'query': 'What is the extended context length of Llama-3-8B-Instruct?',\n",
" 'result': 'The extended context length of Llama-3-8B-Instruct is 80K.'}"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"llm = ChatOpenAI(model=\"gpt-3.5-turbo\", temperature=0)\n",
"qa = RetrievalQA.from_chain_type(llm=llm, \n",
" chain_type='stuff', \n",
" retriever=ensemble_retriever)\n",
"qa.invoke(QUERY1)"
]
},
{
"cell_type": "markdown",
"id": "ec54b119-4b0b-403f-a953-8a409566b55d",
"metadata": {},
"source": [
"#### Response from the PDF:\n",
"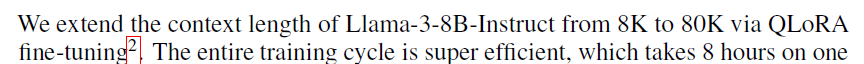"
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "390e6312-bc69-42f4-bdca-bfc7c1b9382b",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The extended context length of Llama-3-8B-Instruct is 4096 tokens.\n"
]
}
],
"source": [
"print(llm.invoke(QUERY1).content) ## Hallucinating"
]
},
{
"cell_type": "code",
"execution_count": 18,
"id": "3dc1f638-65f9-4623-ba0b-011e82a75a11",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'query': 'What was the Zero-shot performance on MMLU?',\n",
" 'result': 'The zero-shot performance on MMLU for the Llama-3-8B-Instruct model was as follows:\\n- STEM: 53.87%\\n- Social: 75.66%\\n- Humanities: 69.44%\\n- Others: 69.75%\\n- Average: 65.91%\\n\\nFor the Llama-3-8B-Instruct-262K model, the performance was:\\n- STEM: 52.10%\\n- Social: 73.26%\\n- Humanities: 67.15%\\n- Others: 69.80%\\n- Average: 64.34%\\n\\nAnd for the Llama-3-8B-Instruct-80K-QLoRA model, the performance was:\\n- STEM: 53.10%\\n- Social: 73.24%\\n- Humanities: 67.32%\\n- Others: 68.79%\\n- Average: 64.44%'}"
]
},
"execution_count": 18,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"llm = ChatOpenAI(model=\"gpt-3.5-turbo\", temperature=0)\n",
"qa = RetrievalQA.from_chain_type(llm=llm, \n",
" chain_type='stuff', \n",
" retriever=ensemble_retriever)\n",
"qa.invoke(QUERY2)"
]
},
{
"cell_type": "markdown",
"id": "929c4265-7936-43bd-818c-fd2054d1ad98",
"metadata": {},
"source": [
"#### Response from the PDF:\n",
"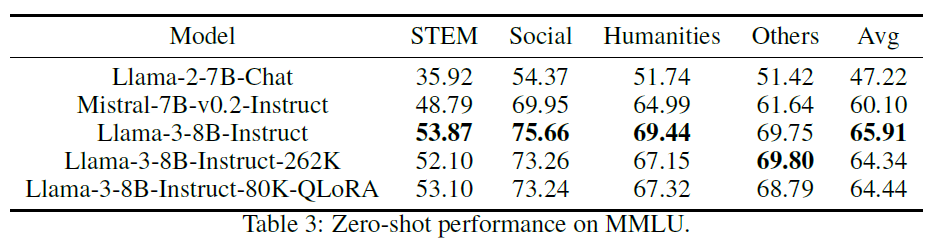"
]
},
{
"cell_type": "markdown",
"id": "a2808f9c-eef5-41a5-9168-b40296d84d2b",
"metadata": {},
"source": [
"### Using Weaviate to perform Hybrid Search"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "84c231ec-75d5-4c38-aa87-d3459e991336",
"metadata": {},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"D:\\Pratik Sharma\\Python Individual Envs\\Hybrid Search\\hs\\lib\\site-packages\\weaviate\\__init__.py:128: DeprecationWarning: Dep010: Importing AuthApiKey from weaviate is deprecated. Please import it from its specific module: weaviate.auth\n",
" _Warnings.root_module_import(name, map_[name])\n",
"D:\\Pratik Sharma\\Python Individual Envs\\Hybrid Search\\hs\\lib\\site-packages\\weaviate\\warnings.py:158: DeprecationWarning: Dep016: You are creating a Weaviate v3 client using `client = weaviate.Client(...)`, which is\n",
" deprecated. Consider creating a v4 (`weaviate.WeaviateClient`) client, using a `weaviate.connect_to_`\n",
" helper function.\n",
" See here for\n",
" - migrating from v3 to v4: https://weaviate.io/developers/weaviate/client-libraries/python/v3_v4_migration\n",
" - general v4 usage: https://weaviate.io/developers/weaviate/client-libraries/python\n",
" \n",
" warnings.warn(\n"
]
}
],
"source": [
"# Weaviate v4 connection - but langchain still uses v3 hence commented.\n",
"# https://github.com/langchain-ai/langchain/issues/18809\n",
"# client = weaviate.connect_to_wcs(\n",
"# cluster_url=os.getenv('WEAVIATE_URL'), # WCS URL\n",
"# auth_credentials=weaviate.auth.AuthApiKey(os.getenv('WEAVIATE_API_KEY')), # WCS key\n",
"# headers={'X-OpenAI-Api-key': os.getenv('OPENAI_API_KEY')} # OpenAI API key\n",
"# )\n",
"\n",
"# Get the Weaviate URL\n",
"WEAVIATE_URL = os.getenv('WEAVIATE_URL') \n",
"# Create an AuthApiKey object using the Weaviate API key\n",
"auth_client_secret = weaviate.AuthApiKey(api_key=os.getenv('WEAVIATE_API_KEY'))\n",
"\n",
"# Create a Weaviate client object\n",
"client = weaviate.Client(\n",
" url=WEAVIATE_URL, # Set the Weaviate URL\n",
" additional_headers={'X-OpenAI-Api-Key': os.getenv('OPENAI_API_KEY')}, # Add additional headers to the client\n",
" auth_client_secret=auth_client_secret # # Set the authentication method to use the API key\n",
")"
]
},
{
"cell_type": "code",
"execution_count": 20,
"id": "68600084-7dfb-4cbd-9376-852cd2f39599",
"metadata": {},
"outputs": [],
"source": [
"# Weaviate hybrid search retriever\n",
"weaviate_retriever = WeaviateHybridSearchRetriever(\n",
" alpha = 0.5, # defaults to 0.5, which is equal weighting between keyword and semantic search\n",
" client = client, # keyword arguments to pass to the Weaviate client\n",
" index_name = \"LangChain\", # The name of the index to use\n",
" text_key = \"text\", # The name of the text key to use\n",
" attributes = [], # The attributes to return in the results\n",
" k=2 # Set the number of results to return to 2\n",
")\n",
"_ = weaviate_retriever.add_documents(docs)"
]
},
{
"cell_type": "code",
"execution_count": 21,
"id": "ae3b5858-2277-4fc0-a03e-62aa527a8e46",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU \n",
"\n",
"===========================\n",
"Extending Llama-3’s Context Ten-Fold Overnight\n",
"Peitian Zhang1,2, Ninglu Shao1,2, Zheng Liu1∗, Shitao Xiao1, Hongjin Qian1,2,\n",
"Qiwei Ye1, Zhicheng Dou2\n",
"1Beijing Academy of Artificial Intelligence\n",
"2Gaoling School of Artificial Intelligence, Renmin University of China\n",
"namespace.pt@gmail.com zhengliu1026@gmail.com\n",
"Abstract\n",
"We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA\n",
"fine-tuning2. The entire training cycle is super efficient, which takes 8 hours on one\n",
"8xA800 (80G) GPU \n",
"\n",
"===========================\n"
]
}
],
"source": [
"# Get the retrieval for the query using Weaviate\n",
"response = weaviate_retriever.invoke(QUERY1)\n",
"for res in response:\n",
" print(res.page_content[0:500], '\\n\\n===========================')"
]
},
{
"cell_type": "markdown",
"id": "bc2bede7-2d41-4ea0-9def-9b860760f906",
"metadata": {},
"source": [
"### Use LLM to ask question from the Weaviate Retriever"
]
},
{
"cell_type": "code",
"execution_count": 22,
"id": "9dc7dd4c-1d5e-4188-8a7f-1d2531020f78",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'query': 'What is the extended context length of Llama-3-8B-Instruct?',\n",
" 'result': 'The extended context length of Llama-3-8B-Instruct is 80K.'}"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"llm = ChatOpenAI(model=\"gpt-3.5-turbo\", temperature=0)\n",
"qa = RetrievalQA.from_chain_type(llm=llm, \n",
" chain_type='stuff', \n",
" retriever=weaviate_retriever)\n",
"qa.invoke(QUERY1)"
]
},
{
"cell_type": "markdown",
"id": "370d1f0a-4cc1-4a71-af35-d359c866e235",
"metadata": {},
"source": [
"#### Response from the PDF:\n",
"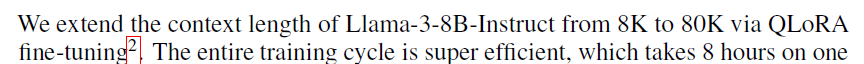"
]
},
{
"cell_type": "code",
"execution_count": 23,
"id": "6a4cd8e9-1b95-43a1-b28d-51a7ed657a08",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"{'query': 'What was the Zero-shot performance on MMLU?',\n",
" 'result': 'The zero-shot performance on MMLU for Llama-3-8B-Instruct was 65.91, for Llama-3-8B-Instruct-262K was 64.34, and for Llama-3-8B-Instruct-80K-QLoRA was 64.44.'}"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"llm = ChatOpenAI(model=\"gpt-3.5-turbo\", temperature=0)\n",
"qa = RetrievalQA.from_chain_type(llm=llm, \n",
" chain_type='stuff', \n",
" retriever=weaviate_retriever)\n",
"qa.invoke(QUERY2)"
]
},
{
"cell_type": "markdown",
"id": "f6977b73-bf05-447f-b195-412cfd1ff253",
"metadata": {},
"source": [
"#### Response from the PDF:\n",
""
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Hybrid Search",
"language": "python",
"name": "hs"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.2"
}
},
"nbformat": 4,
"nbformat_minor": 5
}