{
"cells": [
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true,
"slideshow": {
"slide_type": "skip"
}
},
"outputs": [],
"source": [
"import pandas as pd\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"%matplotlib inline\n",
"\n",
"plt.style.use('ggplot')\n",
"plt.rcParams['figure.figsize'] = (12,5)\n",
"\n",
"# Для кириллицы на графиках\n",
"font = {'family': 'Verdana',\n",
" 'weight': 'normal'}\n",
"plt.rc('font', **font)"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Майнор по Анализу Данных, Группа ИАД-2\n",
"## 10/04/2017 Отбор признаков и понижение размерности"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# Проклятье размености\n",
"\n",
"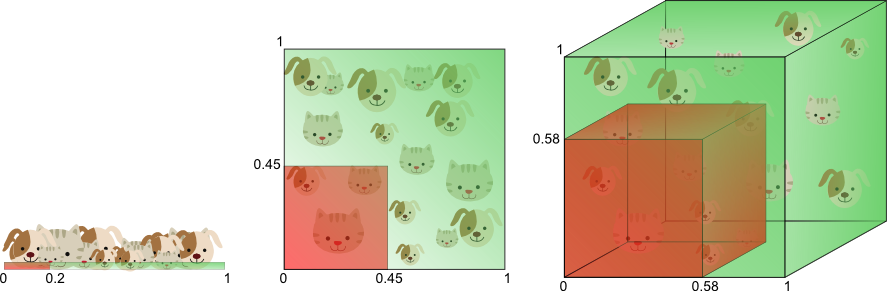 "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## Способы понижения размерности\n",
"\n",
"Избавляться от размерности можно методами **отбора признаков (Feature Selection)** и методами **уменьшения размерности (Feature Reduction)**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Feature Selection\n",
"Методы деляться на три группы:\n",
"* Filter methods \n",
" * Признаки рассматриваются независимо друг от друга\n",
" * Изучается индивидуальный \"вклад\" призника в предсказываемую переменную\n",
" * Быстрое вычисление\n",
"* Wrapper methods\n",
" * Идет отбор группы признаков\n",
" * Может быть оооочень медленным, но качество, обычно, лучше чем у Filter Methods\n",
"* Embedded methods\n",
" * Отбор признаков \"зашит\" в модель\n",
" * *Пример?*"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Filter method - Mutual Information\n",
"$$MI(y,x) = \\sum_{x,y} p(x,y) \\ln\\left[\\frac{p(x,y)}{p(x)p(y)}\\right]$$\n",
"Сколько информации $x$ сообщает об $y$.\n",
"$$NormalizedMI(y,x) = \\frac{MI(y,x)}{H(y)}$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Загрузим довольно известный набор данных о выживаемости после катастрофы титаника."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df_titanic = pd.read_csv('titanic.csv')\n",
"df_titanic.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"pd.crosstab(df_titanic.Survived, df_titanic.Sex)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Найдем MI между выживаемостью и остальными признаками"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def calc_mutual_information(y, x):\n",
" ## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Wrapper Methods - Recursive Feature Elimination\n",
"\n",
"При данном подходе из (линейной) модели последовательно удаляются признаки с наименьшим коэффициентом\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Используйте реализацию RFE в sklean c кросс-валидацией.\n",
"\n",
"* Обучите модель\n",
"* Выведите на графике размер признакового пространства и полученное качество\n",
"* Выведите веса признаков в выбранном признаковом пространстве"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from sklearn.linear_model import LogisticRegression\n",
"from sklearn.feature_selection import RFECV\n",
"from sklearn.model_selection import StratifiedKFold"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=123)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def titanic_preproc(df_input):\n",
" \n",
" df = df_input.copy()\n",
" \n",
" # Удаляем пропуски\n",
" df = df.dropna()\n",
"\n",
" # Создаем такой признак\n",
" df.loc[:, 'has_cabin'] = df.loc[:, 'Cabin'].isnull().astype(int) \n",
" \n",
" # Удаляем колонки\n",
" cols2drop = ['PassengerId', 'Name', 'Ticket', 'Cabin']\n",
" df = df.drop(cols2drop, axis=1)\n",
" \n",
" # Нормализуем Age Fare и SibSp (Так делать не оч хорошо)\n",
" df.loc[:, 'Age'] = (df.loc[:, 'Age'] - df.loc[:, 'Age'].mean())/df.loc[:, 'Age'].std()\n",
" df.loc[:, 'Fare'] = (df.loc[:, 'Fare'] - df.loc[:, 'Fare'].mean())/df.loc[:, 'Fare'].std()\n",
" df.loc[:, 'SibSp'] = (df.loc[:, 'SibSp'] - df.loc[:, 'SibSp'].mean())/df.loc[:, 'SibSp'].std()\n",
" \n",
" # Закодируем поле Sex\n",
" df.loc[:, 'Sex'] = df.loc[:, 'Sex'].replace({'male': 0, 'female':1})\n",
" \n",
" # Pclass и Embarked можно рассматривать как категориальный признак\n",
" df = pd.get_dummies(df, prefix_sep='=', columns=['Pclass', 'Embarked'], drop_first=True)\n",
" \n",
" return df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df_prep = df_titanic.pipe(titanic_preproc)\n",
"X, y = df_prep.iloc[:, 1:].values, df_prep.iloc[:, 0].values"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"model = LogisticRegression(random_state=123)\n",
"rfe = RFECV(model, step=1, cv=cv, scoring='roc_auc', verbose=1, n_jobs=-1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"rfe.fit(X, y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your code here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Embedded methods"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Обучите случайный лес на данных\n",
"* Выведите важность признаков и сравните с выдачей по Filter и Wrapper подходам"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your code here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Principal Component Analysis\n",
"## Метод Главных Компонент"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
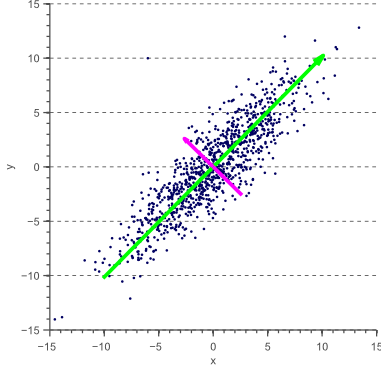
"# PCA\n",
"\n",
"* Позволяет уменьшить число переменных, выбрав самые изменчивые из них\n",
"* Новые переменные являются линейной комбинацией старых переменных\n",
"* Переход к ортономированному базису\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## Способы понижения размерности\n",
"\n",
"Избавляться от размерности можно методами **отбора признаков (Feature Selection)** и методами **уменьшения размерности (Feature Reduction)**"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Feature Selection\n",
"Методы деляться на три группы:\n",
"* Filter methods \n",
" * Признаки рассматриваются независимо друг от друга\n",
" * Изучается индивидуальный \"вклад\" призника в предсказываемую переменную\n",
" * Быстрое вычисление\n",
"* Wrapper methods\n",
" * Идет отбор группы признаков\n",
" * Может быть оооочень медленным, но качество, обычно, лучше чем у Filter Methods\n",
"* Embedded methods\n",
" * Отбор признаков \"зашит\" в модель\n",
" * *Пример?*"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Filter method - Mutual Information\n",
"$$MI(y,x) = \\sum_{x,y} p(x,y) \\ln\\left[\\frac{p(x,y)}{p(x)p(y)}\\right]$$\n",
"Сколько информации $x$ сообщает об $y$.\n",
"$$NormalizedMI(y,x) = \\frac{MI(y,x)}{H(y)}$$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Загрузим довольно известный набор данных о выживаемости после катастрофы титаника."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df_titanic = pd.read_csv('titanic.csv')\n",
"df_titanic.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"pd.crosstab(df_titanic.Survived, df_titanic.Sex)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Найдем MI между выживаемостью и остальными признаками"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def calc_mutual_information(y, x):\n",
" ## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Wrapper Methods - Recursive Feature Elimination\n",
"\n",
"При данном подходе из (линейной) модели последовательно удаляются признаки с наименьшим коэффициентом\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Используйте реализацию RFE в sklean c кросс-валидацией.\n",
"\n",
"* Обучите модель\n",
"* Выведите на графике размер признакового пространства и полученное качество\n",
"* Выведите веса признаков в выбранном признаковом пространстве"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from sklearn.linear_model import LogisticRegression\n",
"from sklearn.feature_selection import RFECV\n",
"from sklearn.model_selection import StratifiedKFold"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=123)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"def titanic_preproc(df_input):\n",
" \n",
" df = df_input.copy()\n",
" \n",
" # Удаляем пропуски\n",
" df = df.dropna()\n",
"\n",
" # Создаем такой признак\n",
" df.loc[:, 'has_cabin'] = df.loc[:, 'Cabin'].isnull().astype(int) \n",
" \n",
" # Удаляем колонки\n",
" cols2drop = ['PassengerId', 'Name', 'Ticket', 'Cabin']\n",
" df = df.drop(cols2drop, axis=1)\n",
" \n",
" # Нормализуем Age Fare и SibSp (Так делать не оч хорошо)\n",
" df.loc[:, 'Age'] = (df.loc[:, 'Age'] - df.loc[:, 'Age'].mean())/df.loc[:, 'Age'].std()\n",
" df.loc[:, 'Fare'] = (df.loc[:, 'Fare'] - df.loc[:, 'Fare'].mean())/df.loc[:, 'Fare'].std()\n",
" df.loc[:, 'SibSp'] = (df.loc[:, 'SibSp'] - df.loc[:, 'SibSp'].mean())/df.loc[:, 'SibSp'].std()\n",
" \n",
" # Закодируем поле Sex\n",
" df.loc[:, 'Sex'] = df.loc[:, 'Sex'].replace({'male': 0, 'female':1})\n",
" \n",
" # Pclass и Embarked можно рассматривать как категориальный признак\n",
" df = pd.get_dummies(df, prefix_sep='=', columns=['Pclass', 'Embarked'], drop_first=True)\n",
" \n",
" return df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df_prep = df_titanic.pipe(titanic_preproc)\n",
"X, y = df_prep.iloc[:, 1:].values, df_prep.iloc[:, 0].values"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"model = LogisticRegression(random_state=123)\n",
"rfe = RFECV(model, step=1, cv=cv, scoring='roc_auc', verbose=1, n_jobs=-1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"rfe.fit(X, y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your code here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Embedded methods"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Обучите случайный лес на данных\n",
"* Выведите важность признаков и сравните с выдачей по Filter и Wrapper подходам"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your code here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Principal Component Analysis\n",
"## Метод Главных Компонент"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"# PCA\n",
"\n",
"* Позволяет уменьшить число переменных, выбрав самые изменчивые из них\n",
"* Новые переменные являются линейной комбинацией старых переменных\n",
"* Переход к ортономированному базису\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {
"heading_collapsed": true
},
"source": [
"## FYI (Посмотрите дома, если интересно)"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Построение PCA\n",
"* Пусть $x \\in \\mathbb{R}^d$ - вектор признаков для какого-то объекта. Будем считать, что $x$ - центрировано и отшкалировано. $E[x_i] = 0, V[x_i] = 1, \\quad i=1 \\dots d$\n",
"* Требуется найти линейное преобразование, которое задается ортогональной матрицей $A$:\n",
"$$ pc = A^\\top x $$\n",
"\n",
"* $pc_i = a_i^\\top x = x^\\top a_i$\n",
"* $cov[x] = E[(x - E[x])(x - E[x])^\\top] = Exx^\\top = \\Sigma$ - ковариационная матрица"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"* $E[pc_i] = E[a_i^\\top x] = a_i^\\top E[x]$\n",
"* $cov[pc_i, pc_j] = E[pc_i \\cdot pc_j^\\top] = a_i^\\top \\Sigma a_j $\n",
"* $\\Sigma$ - симметричная и положительно определенная матрица.\n",
" * Собственные числа $\\lambda_i \\in \\mathbb{R}, \\lambda_i \\geq 0$ (Будем считать, что $\\lambda_1 > \\lambda_2 > \\dots > \\lambda_d $\n",
" * Собственные вектора при $\\lambda_i \\neq \\lambda_j $ ортогональны: $v_i^\\top v_j = 0$\n",
" * У каждого $\\lambda_i$ есть единственный $v_i$"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Первая компонента\n",
"$$ pc_1 = a_1 ^\\top x $$\n",
"\n",
"\\begin{equation}\n",
"\\begin{cases}\n",
"V[pc_1] = a_1^\\top \\Sigma a_1 \\rightarrow \\max_a \\\\\n",
"a_1^\\top a_1 = 1\n",
"\\end{cases}\n",
"\\end{equation}\n",
"* Строим функцию лагранжа\n",
"$$ \\mathcal{L}(a_1, \\nu) = a_1^\\top \\Sigma a_1 - \\nu (a_1^\\top a_1 - 1) \\rightarrow max_{a_1, \\nu}$$\n",
"* Считаем производую по $a_1$\n",
"$$ \\frac{\\partial\\mathcal{L}}{\\partial a_1} = 2\\Sigma a_1 - 2\\nu a_1 = 0 $$\n",
"* Получается, что $a_1$ один из собственных векторов матрицы $\\Sigma$, причем при $\\lambda_1$\n",
"$$ V[pc_1] = a_1^\\top \\Sigma a_1 = \\lambda_i a_1^\\top a_1 = \\lambda_i $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Вторая компонента\n",
"$$ pc_2 = a_2 ^\\top x $$\n",
"\n",
"\\begin{equation}\n",
"\\begin{cases}\n",
"V[pc_1] = a_2^\\top \\Sigma a_2 \\rightarrow \\max_a \\\\\n",
"a_2^\\top a_2 = 1 \\\\\n",
"cov[pc_1, pc_2] = a_2^\\top \\Sigma a_1 = \\lambda_1 a_2^\\top a_1 = 0\n",
"\\end{cases}\n",
"\\end{equation}\n",
"* Строим функцию лагранжа\n",
"$$ \\mathcal{L}(a_2, \\nu, \\tau) = a_2^\\top \\Sigma a_2 - \\nu (a_2^\\top a_2 - 1) - \\tau a_2^\\top a_1 \\rightarrow max_{a_1, \\nu}$$\n",
"\n",
"Аналогичными выкладками приходим к тому, что $a_2$ - собственный вектор $\\Sigma$ при $\\lambda_2$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## Singular Value Decomposition\n",
"\n",
"Для любой матрицы $X$ размера $n \\times m$ можно найти разложение вида:\n",
"$$ X = U S V^\\top ,$$\n",
"где \n",
"* $U$ - унитарная матрица, состоящая из собственных векторов $XX^\\top$\n",
"* $V$ - унитарная матрица, состоящая из собственных векторов $X^\\top X$\n",
"* $S$ - диагональная матрица с сингулярными числами $s_i = \\sqrt{\\lambda_i}$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Матрицы $U$ и $V$ ортогональны и могут быть использованы для перехода к ортогональному базису:\n",
"$$ XV = US$$\n",
"\n",
"Сокращение размерности заключается в том, что вместо того, чтобы умножать $X$ на всю матрицу $V$, а лишь на первые $k
"
]
},
{
"cell_type": "markdown",
"metadata": {
"heading_collapsed": true
},
"source": [
"## FYI (Посмотрите дома, если интересно)"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Построение PCA\n",
"* Пусть $x \\in \\mathbb{R}^d$ - вектор признаков для какого-то объекта. Будем считать, что $x$ - центрировано и отшкалировано. $E[x_i] = 0, V[x_i] = 1, \\quad i=1 \\dots d$\n",
"* Требуется найти линейное преобразование, которое задается ортогональной матрицей $A$:\n",
"$$ pc = A^\\top x $$\n",
"\n",
"* $pc_i = a_i^\\top x = x^\\top a_i$\n",
"* $cov[x] = E[(x - E[x])(x - E[x])^\\top] = Exx^\\top = \\Sigma$ - ковариационная матрица"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"* $E[pc_i] = E[a_i^\\top x] = a_i^\\top E[x]$\n",
"* $cov[pc_i, pc_j] = E[pc_i \\cdot pc_j^\\top] = a_i^\\top \\Sigma a_j $\n",
"* $\\Sigma$ - симметричная и положительно определенная матрица.\n",
" * Собственные числа $\\lambda_i \\in \\mathbb{R}, \\lambda_i \\geq 0$ (Будем считать, что $\\lambda_1 > \\lambda_2 > \\dots > \\lambda_d $\n",
" * Собственные вектора при $\\lambda_i \\neq \\lambda_j $ ортогональны: $v_i^\\top v_j = 0$\n",
" * У каждого $\\lambda_i$ есть единственный $v_i$"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Первая компонента\n",
"$$ pc_1 = a_1 ^\\top x $$\n",
"\n",
"\\begin{equation}\n",
"\\begin{cases}\n",
"V[pc_1] = a_1^\\top \\Sigma a_1 \\rightarrow \\max_a \\\\\n",
"a_1^\\top a_1 = 1\n",
"\\end{cases}\n",
"\\end{equation}\n",
"* Строим функцию лагранжа\n",
"$$ \\mathcal{L}(a_1, \\nu) = a_1^\\top \\Sigma a_1 - \\nu (a_1^\\top a_1 - 1) \\rightarrow max_{a_1, \\nu}$$\n",
"* Считаем производую по $a_1$\n",
"$$ \\frac{\\partial\\mathcal{L}}{\\partial a_1} = 2\\Sigma a_1 - 2\\nu a_1 = 0 $$\n",
"* Получается, что $a_1$ один из собственных векторов матрицы $\\Sigma$, причем при $\\lambda_1$\n",
"$$ V[pc_1] = a_1^\\top \\Sigma a_1 = \\lambda_i a_1^\\top a_1 = \\lambda_i $$"
]
},
{
"cell_type": "markdown",
"metadata": {
"hidden": true,
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"### Вторая компонента\n",
"$$ pc_2 = a_2 ^\\top x $$\n",
"\n",
"\\begin{equation}\n",
"\\begin{cases}\n",
"V[pc_1] = a_2^\\top \\Sigma a_2 \\rightarrow \\max_a \\\\\n",
"a_2^\\top a_2 = 1 \\\\\n",
"cov[pc_1, pc_2] = a_2^\\top \\Sigma a_1 = \\lambda_1 a_2^\\top a_1 = 0\n",
"\\end{cases}\n",
"\\end{equation}\n",
"* Строим функцию лагранжа\n",
"$$ \\mathcal{L}(a_2, \\nu, \\tau) = a_2^\\top \\Sigma a_2 - \\nu (a_2^\\top a_2 - 1) - \\tau a_2^\\top a_1 \\rightarrow max_{a_1, \\nu}$$\n",
"\n",
"Аналогичными выкладками приходим к тому, что $a_2$ - собственный вектор $\\Sigma$ при $\\lambda_2$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## Singular Value Decomposition\n",
"\n",
"Для любой матрицы $X$ размера $n \\times m$ можно найти разложение вида:\n",
"$$ X = U S V^\\top ,$$\n",
"где \n",
"* $U$ - унитарная матрица, состоящая из собственных векторов $XX^\\top$\n",
"* $V$ - унитарная матрица, состоящая из собственных векторов $X^\\top X$\n",
"* $S$ - диагональная матрица с сингулярными числами $s_i = \\sqrt{\\lambda_i}$"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"Матрицы $U$ и $V$ ортогональны и могут быть использованы для перехода к ортогональному базису:\n",
"$$ XV = US$$\n",
"\n",
"Сокращение размерности заключается в том, что вместо того, чтобы умножать $X$ на всю матрицу $V$, а лишь на первые $k "
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## MNIST PCA\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"## MNIST PCA\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Игрушечный пример"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from sklearn.decomposition import PCA\n",
"from numpy.linalg import svd\n",
"from sklearn.datasets import load_digits"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"C = np.array([[0., -0.7], [1.5, 0.7]])\n",
"X = np.dot(np.random.randn(200, 2) + np.array([4, 2]), C)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"plt.scatter(X[:, 0], X[:, 1])\n",
"plt.axis('equal')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"pca = PCA(n_components=2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"PC = pca.fit_transform(X)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"coef = pca.components_\n",
"coef"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"m = np.mean(X,axis=0)\n",
"\n",
"fig, ax = plt.subplots(1,2)\n",
"\n",
"ax[0].plot([0, coef[0,0]*2]+m[0], [0, coef[0,1]*2]+m[1],'--k')\n",
"ax[0].plot([0, coef[1,0]*2]+m[0], [0, coef[1,1]*2]+m[1],'--k')\n",
"ax[0].scatter(X[:,0], X[:,1])\n",
"ax[0].set_xlabel('$x_1$')\n",
"ax[0].set_ylabel('$x_2$')\n",
"\n",
"ax[1].scatter(PC[:,0], PC[:,1])\n",
"ax[1].set_xlabel('$pc_1$')\n",
"ax[1].set_ylabel('$pc_2$')\n",
"\n",
"ax[0].axis('equal')\n",
"ax[1].axis('equal')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Сделаем все тоже самое через SVD"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Чиселки"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"digits = load_digits()\n",
"X = digits.images\n",
"y = digits.target"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"plt.imshow(X[2,:], cmap='Greys', interpolation='none')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Задание\n",
"* Переведите изображения к формату \"матрица объект-признак\" (reshape)\n",
"* Выполните PCA c двумя компонентами и изобратите полученные точки на плоскости, раскаживая каждую точку в отдельный цвет в соответствии с `y`\n",
"* Отнормируйте данные, запустите SVD, домножте `X` на нужную матрицу и убедитесь, что у вас получается тот же результат"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"### Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Пищевая ценность продуктов"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Загрузите набор данных о пищевом рационе в разных странах мира `diet.csv`\n",
"* Примените на данных PCA с 2 компонентами\n",
"* Изобразите объекты в сжатом пространстве"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = pd.read_csv('diet.csv', sep=';')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = df.dropna(axis=1)\n",
"df = df.drop('Energy (kcal/day)', axis=1)\n",
"df = df.set_index('Countries')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"X = df.values\n",
"X = (X - X.mean(axis=0))/X.std(axis=0)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Скорее всего вы обнаружите некоторые выбросы, с этим ничего не поделать - PCA чувствителен к выбросам\n",
"* Удалите объекты-выборосы и повторите процедуру\n",
"* Постарайтесь проинтерпретировать главные компоненты"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Bonus: T-distributed stochastic neighbor embedding"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"* [Вывод](http://jmlr.csail.mit.edu/papers/volume9/vandermaaten08a/vandermaaten08a.pdf)\n",
"* [Примеры](http://lvdmaaten.github.io/tsne/)\n",
"* [Демо](http://distill.pub/2016/misread-tsne/)"
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python [conda root]",
"language": "python",
"name": "conda-root-py"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.13"
},
"livereveal": {
"theme": "serif",
"transition": "concave",
"width": "1024px"
},
"nav_menu": {},
"toc": {
"navigate_menu": true,
"number_sections": false,
"sideBar": true,
"threshold": 6,
"toc_cell": false,
"toc_section_display": "none",
"toc_window_display": false
},
"toc_position": {
"height": "973px",
"left": "0px",
"right": "1708px",
"top": "109px",
"width": "212px"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Игрушечный пример"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"from sklearn.decomposition import PCA\n",
"from numpy.linalg import svd\n",
"from sklearn.datasets import load_digits"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"C = np.array([[0., -0.7], [1.5, 0.7]])\n",
"X = np.dot(np.random.randn(200, 2) + np.array([4, 2]), C)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"plt.scatter(X[:, 0], X[:, 1])\n",
"plt.axis('equal')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"pca = PCA(n_components=2)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"PC = pca.fit_transform(X)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"coef = pca.components_\n",
"coef"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"m = np.mean(X,axis=0)\n",
"\n",
"fig, ax = plt.subplots(1,2)\n",
"\n",
"ax[0].plot([0, coef[0,0]*2]+m[0], [0, coef[0,1]*2]+m[1],'--k')\n",
"ax[0].plot([0, coef[1,0]*2]+m[0], [0, coef[1,1]*2]+m[1],'--k')\n",
"ax[0].scatter(X[:,0], X[:,1])\n",
"ax[0].set_xlabel('$x_1$')\n",
"ax[0].set_ylabel('$x_2$')\n",
"\n",
"ax[1].scatter(PC[:,0], PC[:,1])\n",
"ax[1].set_xlabel('$pc_1$')\n",
"ax[1].set_ylabel('$pc_2$')\n",
"\n",
"ax[0].axis('equal')\n",
"ax[1].axis('equal')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Сделаем все тоже самое через SVD"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Чиселки"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"digits = load_digits()\n",
"X = digits.images\n",
"y = digits.target"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"plt.imshow(X[2,:], cmap='Greys', interpolation='none')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Задание\n",
"* Переведите изображения к формату \"матрица объект-признак\" (reshape)\n",
"* Выполните PCA c двумя компонентами и изобратите полученные точки на плоскости, раскаживая каждую точку в отдельный цвет в соответствии с `y`\n",
"* Отнормируйте данные, запустите SVD, домножте `X` на нужную матрицу и убедитесь, что у вас получается тот же результат"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"### Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Пищевая ценность продуктов"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Загрузите набор данных о пищевом рационе в разных странах мира `diet.csv`\n",
"* Примените на данных PCA с 2 компонентами\n",
"* Изобразите объекты в сжатом пространстве"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = pd.read_csv('diet.csv', sep=';')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = df.dropna(axis=1)\n",
"df = df.drop('Energy (kcal/day)', axis=1)\n",
"df = df.set_index('Countries')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"X = df.values\n",
"X = (X - X.mean(axis=0))/X.std(axis=0)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"* Скорее всего вы обнаружите некоторые выбросы, с этим ничего не поделать - PCA чувствителен к выбросам\n",
"* Удалите объекты-выборосы и повторите процедуру\n",
"* Постарайтесь проинтерпретировать главные компоненты"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"collapsed": true
},
"outputs": [],
"source": [
"## Your Code Here"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "slide"
}
},
"source": [
"# Bonus: T-distributed stochastic neighbor embedding"
]
},
{
"cell_type": "markdown",
"metadata": {
"slideshow": {
"slide_type": "subslide"
}
},
"source": [
"* [Вывод](http://jmlr.csail.mit.edu/papers/volume9/vandermaaten08a/vandermaaten08a.pdf)\n",
"* [Примеры](http://lvdmaaten.github.io/tsne/)\n",
"* [Демо](http://distill.pub/2016/misread-tsne/)"
]
}
],
"metadata": {
"anaconda-cloud": {},
"kernelspec": {
"display_name": "Python [conda root]",
"language": "python",
"name": "conda-root-py"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.13"
},
"livereveal": {
"theme": "serif",
"transition": "concave",
"width": "1024px"
},
"nav_menu": {},
"toc": {
"navigate_menu": true,
"number_sections": false,
"sideBar": true,
"threshold": 6,
"toc_cell": false,
"toc_section_display": "none",
"toc_window_display": false
},
"toc_position": {
"height": "973px",
"left": "0px",
"right": "1708px",
"top": "109px",
"width": "212px"
}
},
"nbformat": 4,
"nbformat_minor": 2
}