CyberBattles: An Award Winning Educational Attack and Defence CTF Platform
What is a Cyber? What are Battles? Well in short, it's hundreds of hours worth of work that resulted in something that I don't think otherwise exists (commercially).
CyberBattles is the project that 5 classmates and myself have spent the last ~4 months banging our heads against. Completed as part of our capstone class for Computer Science, DECO3801, at the University of Queensland; DECO3801 or uninspiringly named "Design Computing Studio 3 - Build". The idea of the class, as much as many fellow students hate it, is to throw us in the deep-end and give us a taste of collaborative (i.e. real world) software engineering.
34 Boring Briefs and Something Interesting
At the beginning of the Semester we were given a list of 35 project briefs to choose from. Most (read: almost all) were incredibly boring, fun examples include "Geodatabase Tools for Load Modelling" and "Leveraging Digital Technologies to Influence Tourist Dispersal Behaviour", while these might be interesting to some strange people, they did not tickle my fancy. However, I was in luck as there was a category for "Cyber Security" and as an aspiring software-engineering-cyber-security-something this piqued my interest. The most interesting being "Red vs Blue Team Cybersecurity Simulation", or a boring description of what would become CyberBattles.
The brief was:
... design and develop a two-team “Capture the Flag” cybersecurity game platform as a learning tool ... implement an interactive system where two opposing teams, the Red Team (attackers) and Blue Team (defenders), compete in a scenario-based simulation to compromise or protect digital assets.
And it contained four success criteria: Team-Based Asymmetric Gameplay, Challenge-Based Capture the Flag Structure, Instructor Visibility and Game Balance, Post-Game Review and Learning Support.
This really piqued my interest, as an active member (and ex-executive) of UQ Cyber Squad I had a decent amount of exposure, if not experience, in capture the flag (CTF) challenges. And I kept hearing endlessly about Attack Defence competitions, which I am far from skilled enough to participate in. So, I got a group of friends together and we put in our bid for the project.
Explaining Words
If the words "Cybersecurity Simulation","Capture the Flag" or "Attack Defence" don't mean anything to you:
Cyber Security Simulation
This is a fancy way of saying gamified hacking competitions. The idea is that anyone with an interest in Cybersecurity can practice real world skills in a competitive, game-like, environment. While the skills learned in these types of simulations aren't always directly transferable to real-world use cases, they are an exercise in practising problem-solving and learning about the ever changing world of Cybersecurity.
Capture the Flag (CTF)
This is the most common form of "Cyber Security Simulation". The idea is a player is given a challenge, whether it be an image file, a website, or a program that contains a "flag" which normally resembles a string like this using leetspeak: cybrbtls{g00djobFORf1nd1ngm3}. The player then has to extract this flag through whatever means they can, usually via a form of "hacking".
Attack Defence (AD)
This is a type of "Cyber Security Simulation" normally of a CTF, where instead of the challenge being against a static or non-player controlled entity like a pre-made website or program. Players are given a matching environment with multiple vulnerable entities (programs, websites, etc.) to exploit. The challenge then becomes not only to try to capture the flags of other teams but also to defend against attacks against their own version of the programs. The way in which a team chooses to defend is entirely up to them, often the entity is accompanied by the code used to make it so players can read, rewrite, and patch it on-the-fly. An important and necessary caveat of this type of CTF challenge is that the service needs to be preserved so that a regular (usually automated) user can still use it for its intended purpose. This prevents a team trying to be smart and just shutting down their services to prevent being hacked.
Why the Brief was Interesting
As I've established above, CTFs, and AD CTFs specifically, have already been done; they aren't new. However, what didn't already exist was an easy to use, publicly accessible platform that did the hard parts of running an AD competition for you.
The Hard Parts
An AD competition is inherently not simple, it requires at the very least:
- Pre-made scenarios which well thought out and rewarding challenges
- An environment that replicates these services for every team in the competition
- A relatively anonymous bot that can mimic a real world user for every service
- A way to score the competition
- A secure way to interact with and access each environment
These might sound a little like the aforementioned success criteria given to us as part of the project brief, which they are indeed. At the end of the project, I can now appreciate that who (or what) ever wrote the brief had a good grasp on AD essentials.
A Storied Development
A Team Effort
For most of the team this was our first real team project and our first taste of dipping our toes in the deep-end of real world collaborative software engineering. Enthusiastically we said we'd do everything just like real developers. We set up a Github organisation, a nice looking repo (and domain), a Discord server with a bot that notifies us of each other's progress and most importantly (until we couldn't be bothered): Jira for story boarding. And importantly a timeline for when milestones should be done by.
What is story boarding? Great question, it seems to involve the words "epics" and "stories" quite often. But in short, it's just an extravagant way of breaking down a project into achievable sub-sections, but with a lot of "Silicon Valley"-esque lingo to make it seem cool and innovative. While initially it seemed like a great idea, we found that when nobody was enforcing the use of this story boarding it quickly fell apart. As it became just more work on top of the already large task we had ahead of us.
Divvying Up the Work
As a group of six, we sought to evenly distribute the work amongst ourselves, giving people tasks suited to their existing skill sets. We assigned three people to website/frontend development, as this would be the main way users interact with our project so it should look good. Then my friend Howie, someone with some real experience in playing and winning CTFs, was assigned to challenge development and to provide a template for the scenario networking. And unfortunately, another friend, Lachlan was given the job of code review and repo management. That left me to do the fun (hard) part, making the server that would orchestrate the whole shebang.
The Reality of Group Work
While we set out strong, as group projects are wont to do, the timeline quickly became a time-suggestion which ended up as a time-wish by the end of the semester. As my workload was relatively light for the semester, I had a majority of my side of the project done within a month. And unfortunately as the most experienced in web development on the team, much of my semester ended up being spent on that side of the project.
My Half of the Whole Shebang
So I had the dead simple job of:
- Design the architecture and designate capabilities of the platform
- Create data types that would encapsulate all the information needed to run and manage the sessions
- Make it scalable for multiple teams
- Make it secure
It was not in fact simple nor straightforward. I started by finding out what kind of software solutions exist to connect all these things together. For the virtualising/encapsulation of the environment I picked Docker, as it is lightweight and I was already fairly experienced in using it. Fortunately, I found a very helpful Node.js module called Dockerode, which provides an easy to work with, programmatic interface for working with the Docker virtual environment. My plan of attack was to plan out each function I would need for the server to operate and work through them step-by-step until I reached a minimum viable product.
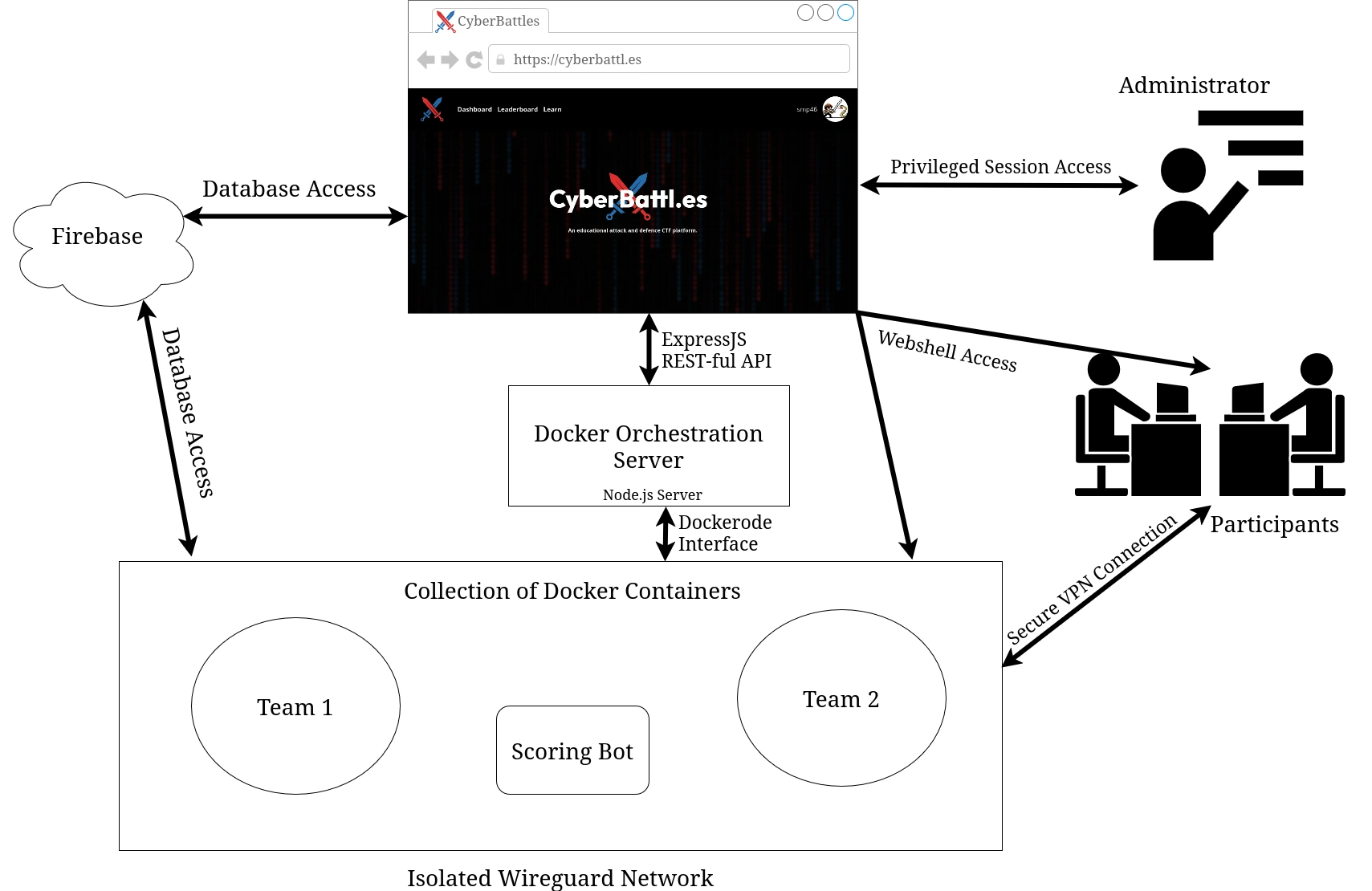
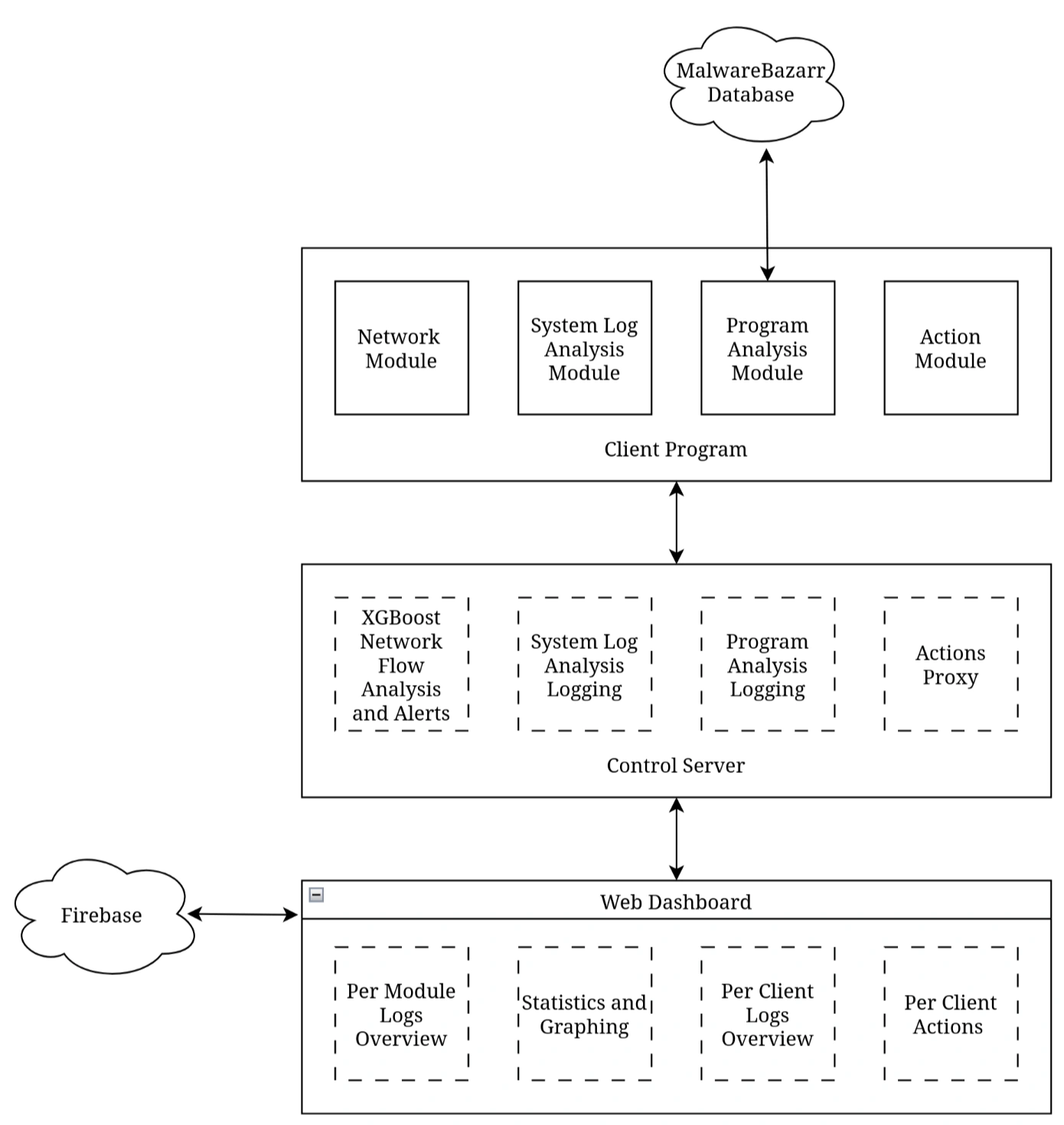
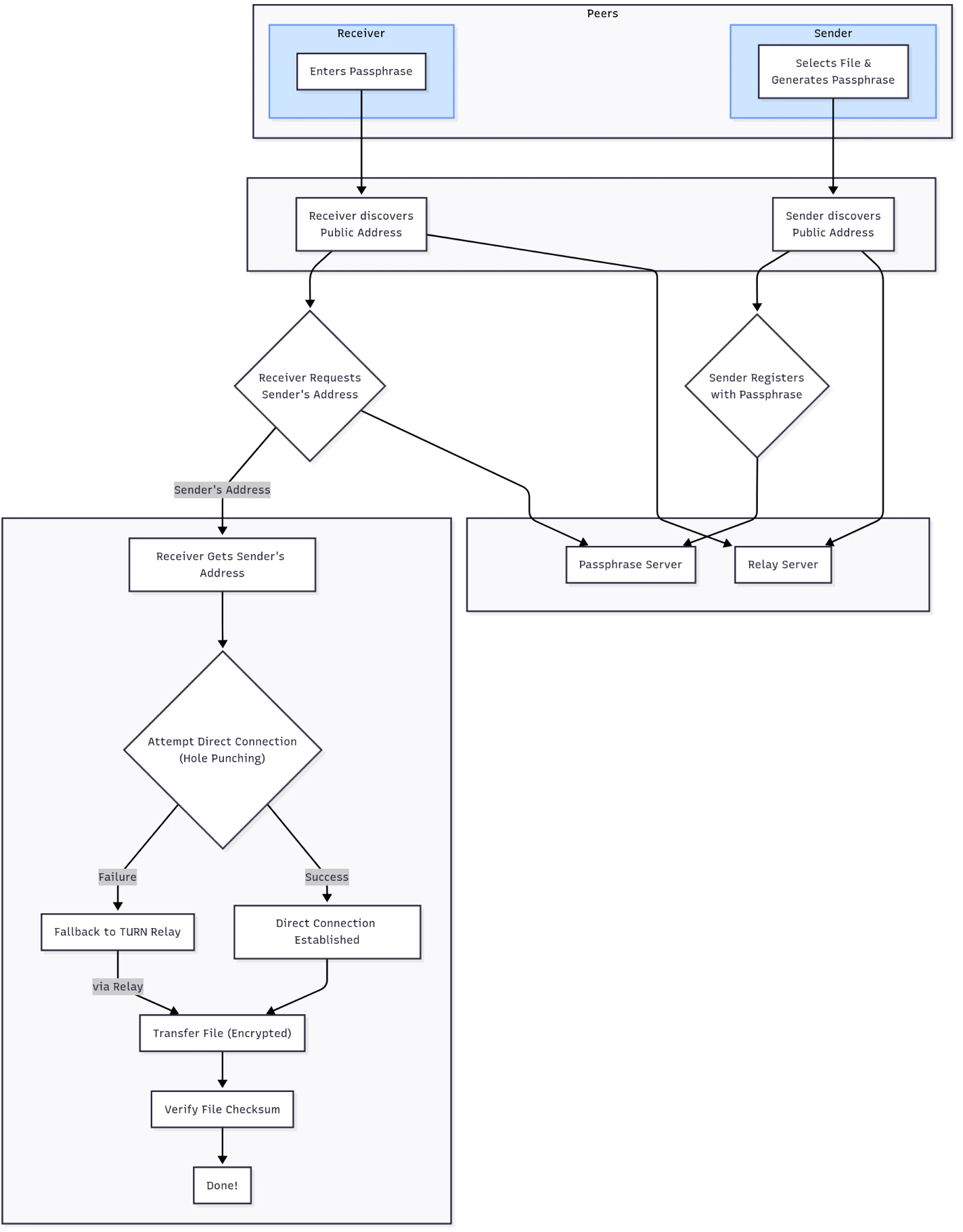
The flow of the Orchestration server looks roughly like this:
- On the website, a user creates a new session, selecting the number of teams, maximum members per team and one of the pre-made scenarios. This is then sent to the API listening on the server.
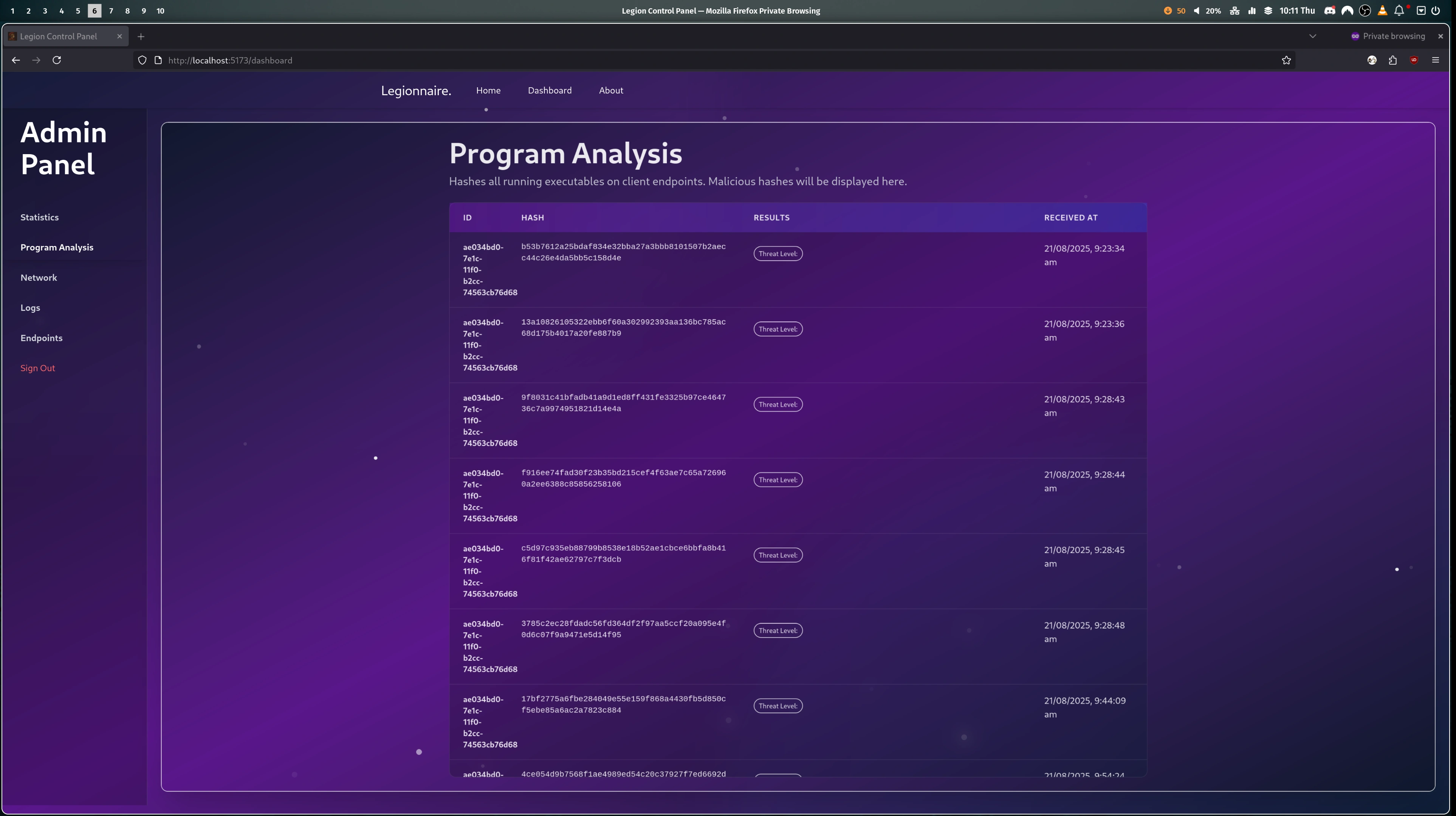
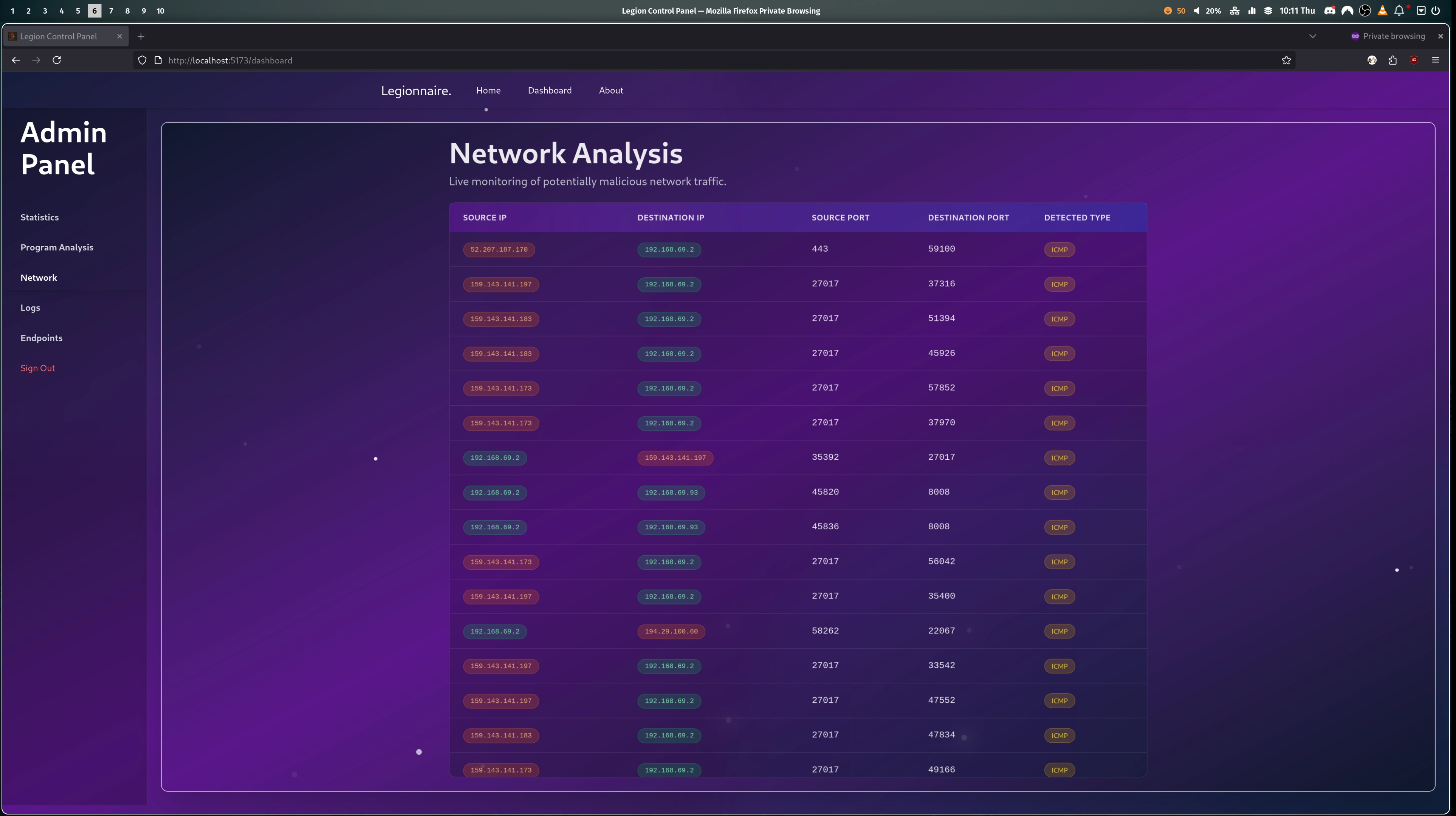
- The server creates a WireGuard VPN container which will act as the router. WireGuard then generates VPN configs: one for every team, one for every player, and one additional per team for the admin to use. Then one container is spun up for each team, using the Docker Image designated for the scenario. And finally the last container is added, this acts as the "Scoring Bot", pretending to be a real user to check the services work as expected and insert the flags the participants need to steal.
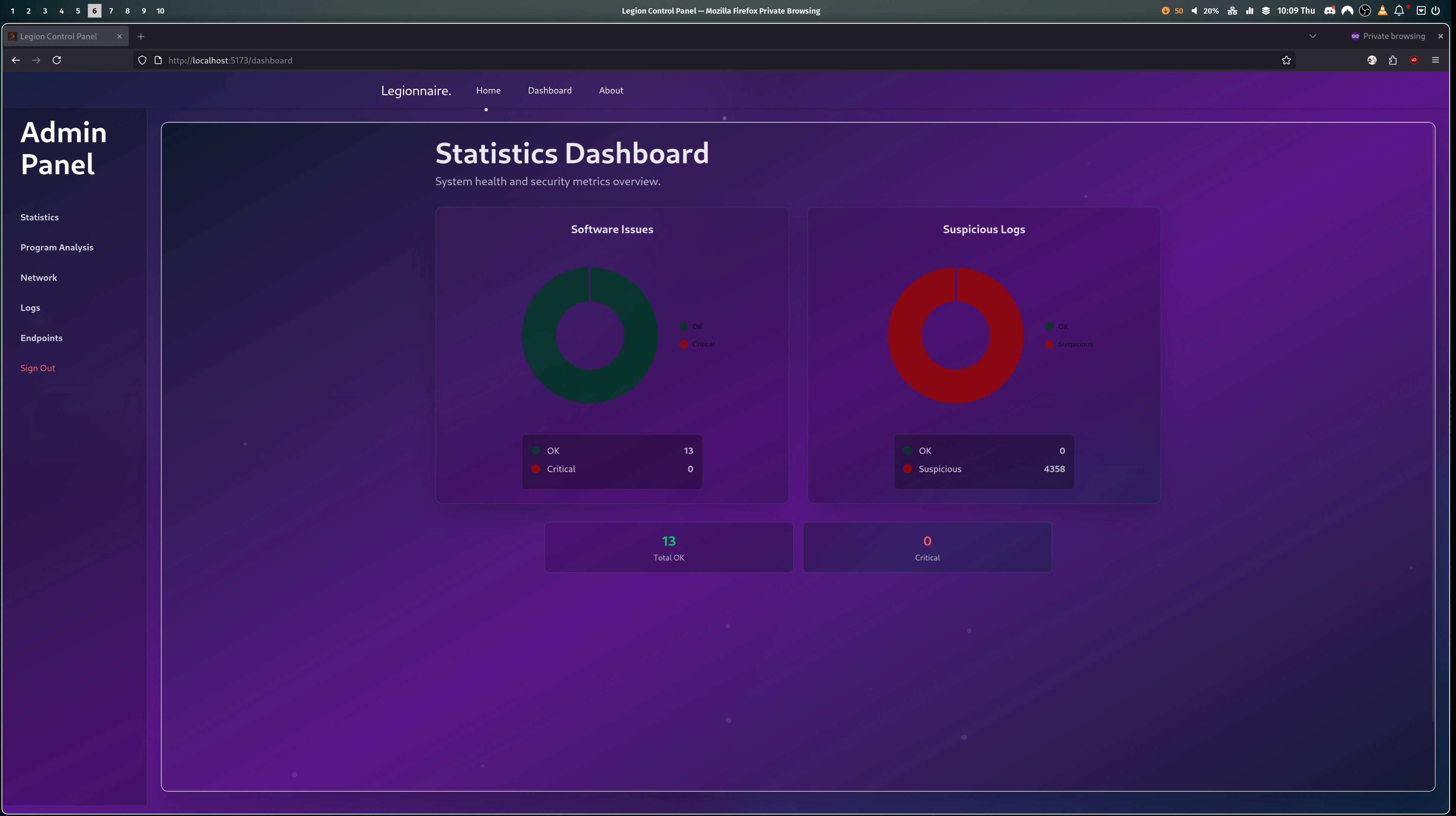
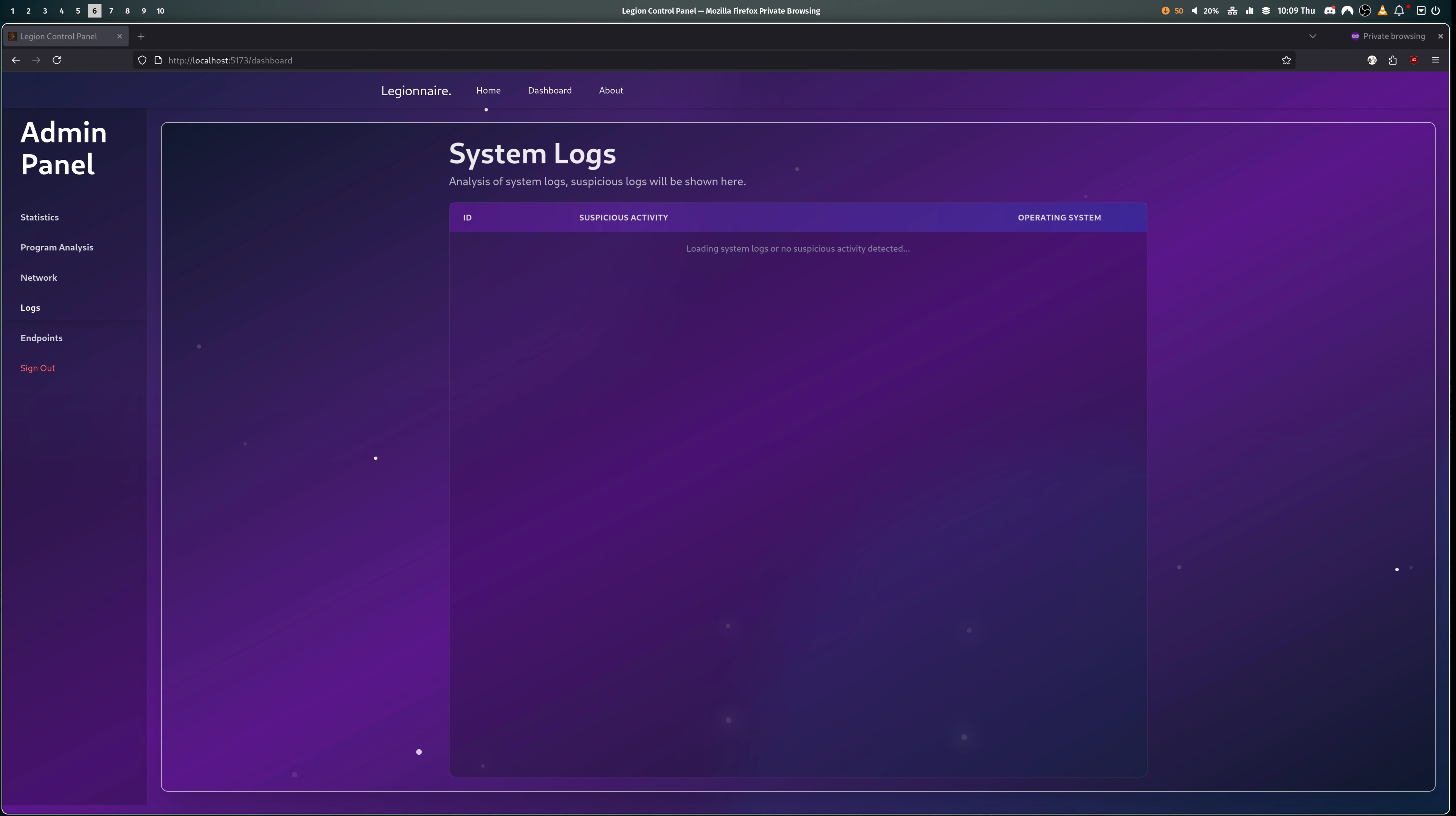
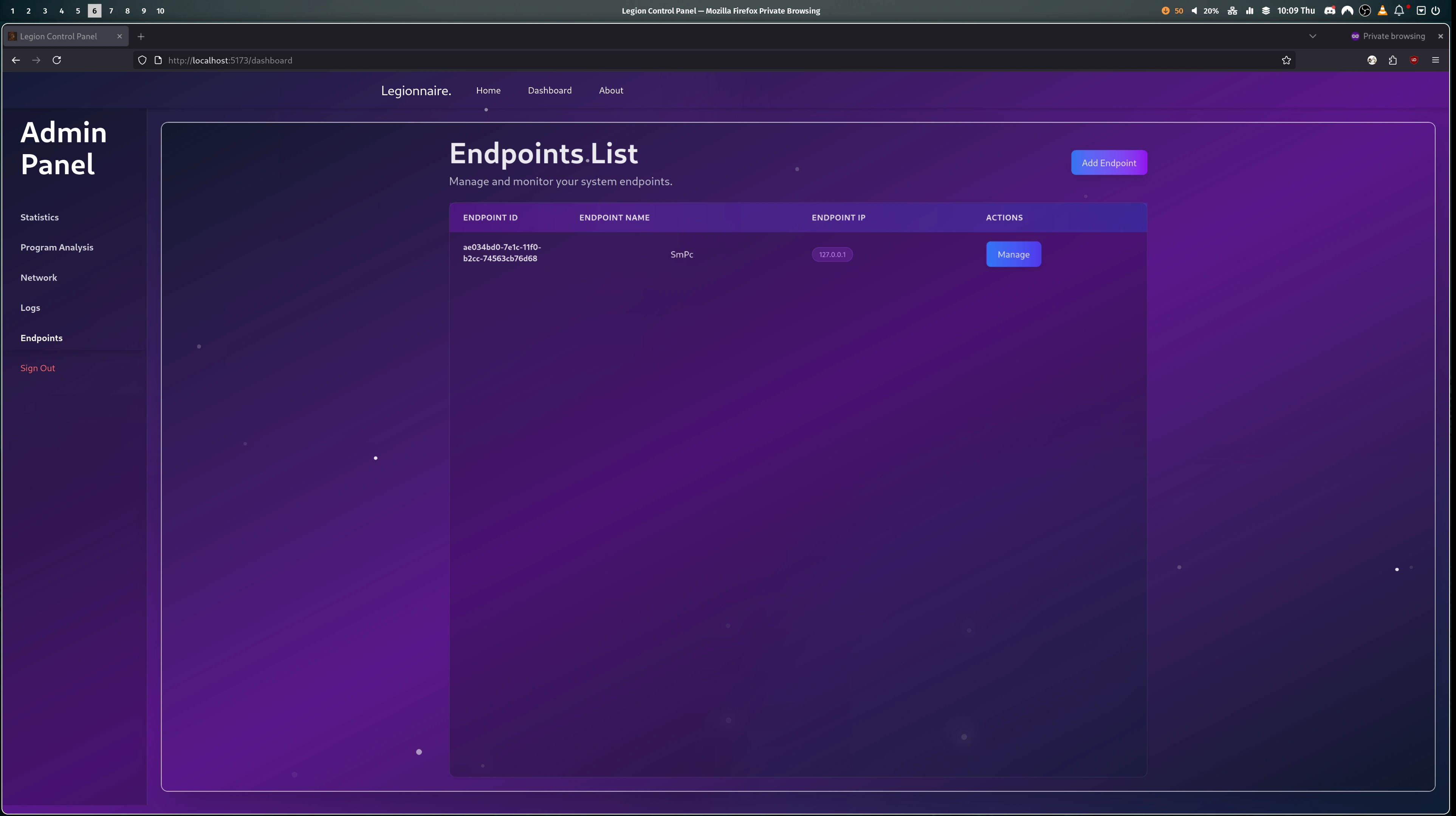
- The session is now in the "lobby" phase, the admin is presented with their dashboard on the website and they can invite users to join the teams.
- Once the admin starts the game on the website. The server gets to work and creates a user account on every team container, for each member of the team, as well as an additional account in every team for the admin. Then the "Scoring Bot" is instructed to start its scoring. The bot attempts to use the services as expected (e.g. inserts a flag into a notes app) and if it succeeds the flag is stored in Firebase. If it fails the attempt then a counter is increased and that team's score is affected.
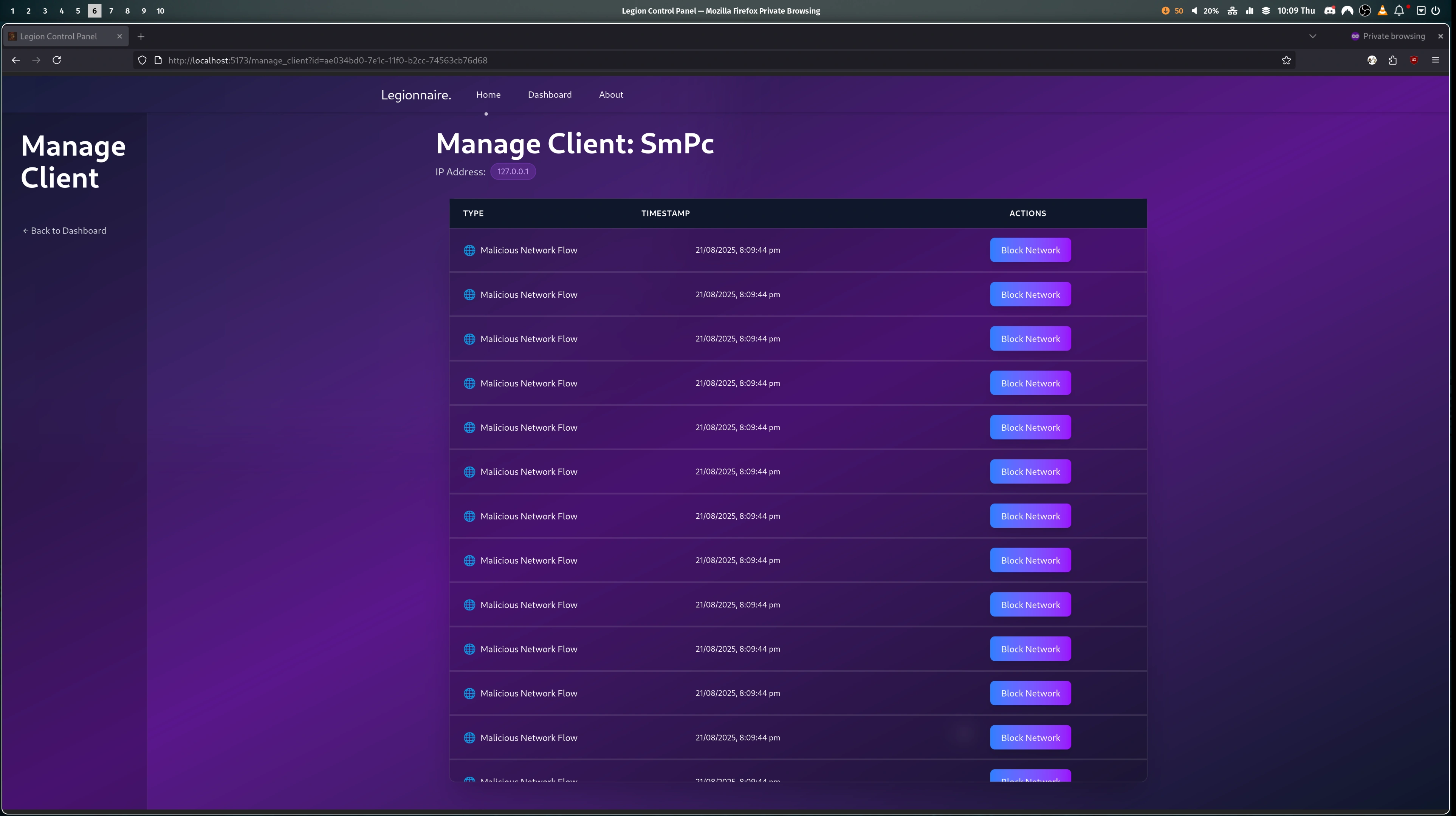
- Now the participants and the administrator can access their container via a web shell or via the VPN config provided to them. The web shell uses WebSockets to access a secure bash session directly on their team's container. Whereas the VPN gives the participant direct access to the isolated network, so they can SSH into their team container using their own preferred terminal.
- Once the game is finished the relevant session info is saved on the frontend and the Orchestration server goes through and removes every container, deleting all generated configs and finishing back on a clean slate.
The Architecture
Here is a rough diagram of how the whole platform comes together:
Challenges and Difficulties
Not Enough Hours in a Day nor Days in a Week
I would argue the hardest part of the project was the workload, as this was a group project it was a considerable task we were given. While the finished platform always felt achievable, it was hidden behind a mountain load of work, which wasn't always shared evenly, but c'est la vie.
Vibing Web Dev
Due to time constraints and lack-of-experience the frontend had a lot of vibe coding put into it. To each their own, sometimes it would be amusing to see PRs full of lengthy code comments, emojis and or my least favourite the AI glowing gradients on everything. But unfortunately, the end result is while the website is complete, the code quality is sub par and impossible to maintain. Especially with the Firebase integration, the website slurps up the user's resources even when it is just idle.
An Award Winning Result
While we can all complain endlessly about what should have been done differently. We did manage to produce a platform that meets, and arguably exceeds, the goals given to us. CyberBattles is now an easy to use and accessible Attack Defence platform. I think this is super important for lowering the bar to entry for this style of competition. Providing a gamified and educational way to learn essential skills in an ever growing industry.
An unexpected result was that the project was nominated by the course coordinator for UQ Illuminate, a showcase of the best projects produced by graduates (both under and post grads) in 2025. Specifically we were nominated for the category of "Best Cyber Security and Data Privacy Project". The event was a good chance for Lachlan and myself to show off what the team had put so much work into.
Here's a look at our booth for the night:

To our surprise, the judges picked CyberBattles as the best project for our category. This has been hugely encouraging and a really rewarding experience. Lachlan and I plan on continuing development of the platform and getting it into the hands of educators.
The Future of CyberBattles
We are excited and still surprised at what we managed to produce, but it's not done yet. There is a bit of a plan to carry out before we're ready to hand out the platform, however source code is now available on our repo (click the GitHub icon on this page). The main issue we want to address is that as an open-source platform, depending on Firebase as our database provider is limiting. Due to the nature of the platform, both in the hosting expense and the liability of providing relatively anonymous internet-connected virtual environments, due to that CyberBattles will be transitioned to a database solution that can be hosted alongside the rest of the platform (locally). I will also be personally taking this opportunity to rewrite the website to fit the new database solution, whatever we choose, and add a little more polish.
]]>






 I'm honestly not sure what the correct way to package something like this is, am
definitely open to feedback if anyone has any better ideas.
I'm honestly not sure what the correct way to package something like this is, am
definitely open to feedback if anyone has any better ideas.