{
"cells": [
{
"cell_type": "markdown",
"id": "signed-syndication",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
" SoNAR (IDH) - HNA Curriculum \n",
"\n",
"Notebook 1: Jupyter and Python"
]
},
{
"cell_type": "markdown",
"id": "nervous-burning",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"This curriculum serves as a guide and introductory resource to using the SoNAR (IDH) network database with the help of Python and Jupyter notebooks.\n",
"\n",
"It uses [Jupyter](http://jupyter.org/) Notebooks to document and explain how to do historical network analysis with the SoNAR (IDH) data. \n",
"This first notebooks provides a high-level overview of the basic functionality of Jupyter notebooks as well as a quick introduction to basic Python. All the following notebooks will build up upon the fundamentals explained in this notebook.\n",
"\n",
"\n",
"If you are already familiar with Jupyter Notebooks and Python you can directly jump to [Notebook 2 - Historical Network Analysis](Notebook%202%20-%20Historical%20Network%20Analysis.ipynb)."
]
},
{
"cell_type": "markdown",
"id": "indoor-industry",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"source": [
"# Jupyter Notebooks"
]
},
{
"cell_type": "markdown",
"id": "nearby-patch",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Jupyter Notebooks are basically a kind of code editor you can use inside your web browser. This means you can write, edit and run code and from your browser, the code is immediately interpreted and the results are visible directly under the executed code. \n",
"\n",
"What makes Jupyter notebooks so versatile is that you can mix code blocks and text blocks within the same document and thus create interactive, transparent and reproducible documentations or guides. "
]
},
{
"cell_type": "markdown",
"id": "invalid-kentucky",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Project Jupyter"
]
},
{
"cell_type": "markdown",
"id": "floppy-hearts",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"[Project Jupyter](https://jupyter.org/) is the name of the non-profit and open-source project that develops the Jupyter notebook technology this curriculum is based on. \n",
"Project Jupyter is maintained and developed by a big community with a focus on making scientific computing accessible, easy and free. \n",
"The name Jupyter is derived from the names of the three programming languages **Ju**lia, **Pyt**hon and **R**. The main objective of Jupyter is supporting interactive data science and scientific computing across all programming languages. All notebooks in this curriculum use the Python programming language."
]
},
{
"cell_type": "markdown",
"id": "hired-electricity",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Operating Jupyter \n",
"\n",
"This curriculum consists of five Jupyter Notebooks. When you are new to Jupyter Notebooks you can take the \"User Interface Tour\" in the help menu on top of the screen. The screenshot below shows where to find the interactive tour:\n",
"\n",
"
\n",
"\n",
"  \n",
""
]
},
{
"cell_type": "markdown",
"id": "aquatic-visitor",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**Notebooks**\n",
"\n",
"Jupyter notebooks are documents that combine live runnable code with narrative text (*Markdown*), equations, images, interactive visualizations and other rich output.\n"
]
},
{
"cell_type": "markdown",
"id": "czech-necessity",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**The Toolbar**\n",
"\n",
"When you open up a notebook you can see the **toolbar** at the very top of the notebook. This is what the **toolbar** can do for you:\n",
"\n",
"\n",
"\n",
"
\n",
""
]
},
{
"cell_type": "markdown",
"id": "aquatic-visitor",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**Notebooks**\n",
"\n",
"Jupyter notebooks are documents that combine live runnable code with narrative text (*Markdown*), equations, images, interactive visualizations and other rich output.\n"
]
},
{
"cell_type": "markdown",
"id": "czech-necessity",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**The Toolbar**\n",
"\n",
"When you open up a notebook you can see the **toolbar** at the very top of the notebook. This is what the **toolbar** can do for you:\n",
"\n",
"\n",
"\n",
"  \n",
""
]
},
{
"cell_type": "markdown",
"id": "empirical-medicine",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"\n",
"Category | Data Types\n",
":-------------: | :----------------------\n",
" | Save the current state of the notebook\n",
" | Insert a new cell below the current selection\n",
" | Cut the selected cell\n",
" | Copy the selected cell\n",
" | Paste the copied or cut cell\n",
" | Move cell up or down\n",
" | Run the selected cell\n",
" | Stop the execution of the selected cell\n",
" | Restart the kernel of the notebook\n",
" | Restart the kernel and execute all code cells chronologically \n",
" | Select the cell type (Code, Markdown, Raw)\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "realistic-durham",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**The Cells**\n",
"\n",
"Jupyter Notebooks consist of cells that are arranged vertically. Every text you read so far is written inside a **cell**. When you double click any image or text in this notebook, the respective **cell** will jump into \"edit mode\" and you can change the contents to your liking. When you hit the **Run** button in the **toolbar** after you are done editing, the **cell** will be executed and it jumps back to what is called the \"command mode\" *(Double click this cell to try it)*.\n",
"\n",
"
\n",
""
]
},
{
"cell_type": "markdown",
"id": "empirical-medicine",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"\n",
"Category | Data Types\n",
":-------------: | :----------------------\n",
" | Save the current state of the notebook\n",
" | Insert a new cell below the current selection\n",
" | Cut the selected cell\n",
" | Copy the selected cell\n",
" | Paste the copied or cut cell\n",
" | Move cell up or down\n",
" | Run the selected cell\n",
" | Stop the execution of the selected cell\n",
" | Restart the kernel of the notebook\n",
" | Restart the kernel and execute all code cells chronologically \n",
" | Select the cell type (Code, Markdown, Raw)\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "realistic-durham",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**The Cells**\n",
"\n",
"Jupyter Notebooks consist of cells that are arranged vertically. Every text you read so far is written inside a **cell**. When you double click any image or text in this notebook, the respective **cell** will jump into \"edit mode\" and you can change the contents to your liking. When you hit the **Run** button in the **toolbar** after you are done editing, the **cell** will be executed and it jumps back to what is called the \"command mode\" *(Double click this cell to try it)*.\n",
"\n",
"\n",
"Hint:You can only edit cells when you are using the notebook in an interactive environment (either a local setup or on binder).
\n",
"\n",
"There are two relevant cell types Jupyter Notebooks provide. The first one being **Code** and the second one is **Markdown**. Here is how they differ from each other:"
]
},
{
"cell_type": "markdown",
"id": "virtual-comedy",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"***Code Cell***\n",
"\n",
"Code cells let you write and execute programming code. Make sure you select the **Code**cell type in the cell type drop down you find in the **toolbar**.\n",
"\n",
"When you type code in a code cell and hit on the **run** button in the toolbar, the code is executed and the output of the code is beneath the code cell: \n",
"\n",
"\n",
"  \n",
"\n",
"\n",
"Executed code will be held in memory of the *kernel*. That means that your running notebook will hold some kind of *state*, depending of which code blocks you already executed. This will come in handy when we'll discuss variables later on."
]
},
{
"cell_type": "markdown",
"id": "roman-application",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"***Markdown Cell***\n",
"\n",
"*Markdown* is a markup language you can use to format text. Markdown has a very simple syntax you can use for formatting text, tables or lists. You can also embed images, *HTML* blocks and other media formats with Markdown.\n",
"\n",
"
\n",
"\n",
"\n",
"Executed code will be held in memory of the *kernel*. That means that your running notebook will hold some kind of *state*, depending of which code blocks you already executed. This will come in handy when we'll discuss variables later on."
]
},
{
"cell_type": "markdown",
"id": "roman-application",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"***Markdown Cell***\n",
"\n",
"*Markdown* is a markup language you can use to format text. Markdown has a very simple syntax you can use for formatting text, tables or lists. You can also embed images, *HTML* blocks and other media formats with Markdown.\n",
"\n",
"\n",
"Hint: Double-click this cell to change it into edit mode and see the underlying markdown syntax.
\n",
"\n",
"\n",
"A quick example of how Markdown works can be found in the images beneath. The left hand side shows the markdown syntax during editing mode of a cell. The right hand side shows the executed Markdown cell after you hit the **run** button."
]
},
{
"cell_type": "markdown",
"id": "enabling-actor",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"|raw markdown | rendered markdown|\n",
"|:---:|:---:|\n",
"|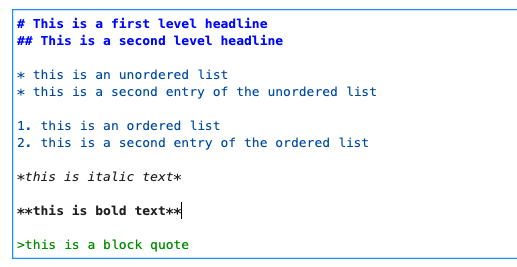 | |\n",
"\n",
"\n",
"A good overview of how Markdown in Jupyter notebooks works can be found [here](https://medium.com/analytics-vidhya/the-ultimate-markdown-guide-for-jupyter-notebook-d5e5abf728fd)."
]
},
{
"cell_type": "markdown",
"id": "mighty-wallpaper",
"metadata": {},
"source": [
"## 📝 Exercise\n",
"\n",
"Now, try to reproduce the example from above on your own following the steps below: \n",
"\n",
"1. Insert a new code cell below by selecting **Code** as the cell type and clicking on the **+** icon.\n",
"2. Type the code `print(\"Hello world!\")` inside this cell.\n",
"3. Execute the code cell (either by clicking on the run-button in the toolbar or by using the hotkey *command+shift+enter*)"
]
},
{
"cell_type": "markdown",
"id": "vital-gates",
"metadata": {},
"source": [
"Congratulations to your first line of code! 🎉"
]
},
{
"cell_type": "markdown",
"id": "accompanied-jersey",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"# Python "
]
},
{
"cell_type": "markdown",
"id": "satellite-discussion",
"metadata": {},
"source": [
"Jupyter Notebooks can be used with a multitude of programming languages. This curriculum uses *Python*, a language well known both for its friendliness towards beginners and its maturity as a professional tool. The following sections provide a quick introduction to Python. \n",
"\n",
"For a more in depth introduction you can check out these resources:\n",
"\n",
"* Structured, interactive beginner's guide to Python: [Learn Python](https://www.learnpython.org/)\n",
"* Big selection of free Python tutorials: [Real Python Tutorials](https://realpython.com/)\n",
"* Best practice guide for Python: [The Hitchhiker’s Guide to Python!](https://docs.python-guide.org/)"
]
},
{
"cell_type": "markdown",
"id": "fitting-geography",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Arithmetic & logical operators\n",
"\n",
"Some very basic commands you need to know when coding with Python are arithmetic operators. You can use these operators to execute basic calculations. See the table below for an overview about the base operators Python provides\n",
"\n",
"Operator | Description | Example |\n",
"----------------- | :-----------------:|---------|\n",
"`+` | addition | 1 `+` 1 is 2 |\n",
"`-` | subtraction | 1 `-` 1 is 0 |\n",
"`*` | multiplication | 1 `*` 1 is 1 |\n",
"`/` | division | 2 `/` 2 is 1 |\n",
"`**` | exponentiation | 2 `**` 2 is 4 |\n",
"`%` | modulo operator (returns the remainder) | 5 `%` 2 is 1 |\n",
"`//` | integer division (drops the remainder) | 5 `//` 2 is 2 |\n",
"\n",
"Additionally Python also provides a set of logical and comparison operators. The evaluation of logical operators always result in *True* or *False*. See table below:\n",
"\n",
"Operator | Description |Example\n",
"----------------- | :----------------: |---------:|\n",
"`<` | less than | 2 `<` 3 is `True`|\n",
"`<=` | less than or equal to | 2 `<=` 3 is `True` |\n",
"`>` | greater than | 2 `>` 3 is `False`|\n",
"`>=` | greater than or equal to | 2 `>=` 3 is `False`\n",
"`==` | equal | 2 `==` 3 is `False`\n",
"`!=` | not equal | 2 `!=` 3 is `True`\n",
"`not` | not x; reverses result | `not` (2 `!=` 3) is `False`\n",
"`or` | x OR y must be true | 2 `==`3 `or` 2 `!=`3 is `True`\n",
"`and` | x AND y must be true | 2 `==`3 `or` 2 `!=`3 is `False`"
]
},
{
"cell_type": "markdown",
"id": "civilian-journalist",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's use these operators:\n",
"\n",
"\n",
"Hint: Remember that you execute code by selecting the cell and then either hitting the run button in the notebook toolbar or by using the keyboard shortcut Shift + Enter
"
]
},
{
"cell_type": "markdown",
"id": "informal-lodge",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Calculate `2*7`:"
]
},
{
"cell_type": "code",
"execution_count": 25,
"id": "moved-rocket",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"14"
]
},
"execution_count": 25,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"2*7"
]
},
{
"cell_type": "markdown",
"id": "asian-theology",
"metadata": {},
"source": [
"You also can use *variables* in Python to hold and manipulate values. The creation of a variable is very easy. All you need to do is coming up with a name for your variable and assign something to it. You can freely chose the name of the variable and you also can overwrite the data in a variable. Let's checkout what that means: "
]
},
{
"cell_type": "markdown",
"id": "shared-florence",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"In the code block below we create two *variables*. The first one we name `variable_1`and we assign the result of the calculation `1 + 1`to the variable. The second variable we name `variable_2` and we store the result off `2*7`in it.\n",
"\n",
"After that we can use the variables to manipulate them further or do some calculations with them. E.g. we can calculate `variable_1 - variable_2`."
]
},
{
"cell_type": "code",
"execution_count": 22,
"id": "sticky-flush",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"-12"
]
},
"execution_count": 22,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"variable_1 = 1+1\n",
"variable_2 = 2*7\n",
"\n",
"variable_1 - variable_2"
]
},
{
"cell_type": "markdown",
"id": "greater-panama",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"\n",
" Hint: Assigning values to a variable is done by using the = sign.\n",
"
Make sure not to confuse the single = (assignment operator) with the double == (logical operator)
\n"
]
},
{
"cell_type": "markdown",
"id": "naked-brain",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's check whether `variable2` is greater than `variable1`."
]
},
{
"cell_type": "code",
"execution_count": 23,
"id": "committed-invitation",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"True"
]
},
"execution_count": 23,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"variable_2 > variable_1"
]
},
{
"cell_type": "markdown",
"id": "patent-tiger",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Now let's check whether `variable2` is `14` and `variable1` is `3` (both conditions must be correct to be `True`, otherwise the condition is `False`)"
]
},
{
"cell_type": "code",
"execution_count": 24,
"id": "varied-parameter",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"False"
]
},
"execution_count": 24,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"variable_2 == 14 and variable_1 == 3"
]
},
{
"cell_type": "markdown",
"id": "rising-generator",
"metadata": {},
"source": [
"\n",
" Hint: Jupyter Notebooks follow a linear execution logic. This means you can use variables that were created in cells you already executed. However, when using variables of cells that you did not execute yet, Python will throw an error.
\n"
]
},
{
"cell_type": "markdown",
"id": "virtual-feature",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Data types\n",
"\n",
"In the previous section, numbers where used to calculate things. However, Python can handle a variety of other *data types* as well. \n",
"In this section we check out three of the most important categories of data types Python can handle. This list is not exhaustive though. You can find a complete overview of data types Python natively supports [here](https://www.w3schools.com/python/python_datatypes.asp).\n",
"\n",
"We will cover three categories of data types in this section, namely:\n",
"\n",
"Category | Data Types\n",
":-------------: | :----------------------:\n",
"`Text Type` | `str`\n",
"`Numeric Types` | `int`, `float`\n",
"`Sequence & Mapping Types` | `list`, `range`, `dict`"
]
},
{
"cell_type": "markdown",
"id": "victorian-mortality",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"### Text type"
]
},
{
"cell_type": "markdown",
"id": "swiss-institution",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"The text type is used for character input. Whenever you want to work with *character strings* (words & text) Python uses the text type for doing so. The differentiation between different types is crucial since there are operations that are meaningful for text but not for numbers (e.g. capitalizing letters, splitting at line breaks).\n",
"\n",
"In the following example we will assign a text to a variable. Afterwards we're gonna \"ask\" Python about the data type of this variable. \n",
"\n",
"We use the following sentence: \n",
">Ada Lovelace was an English mathematician and writer, chiefly known for her work on Charles Babbage's proposed mechanical general-purpose computer, the Analytical Engine.\n",
"\n",
"*Text taken from: https://en.wikipedia.org/wiki/Ada_Lovelace*\n",
"\n",
"\n",
"\n",
"Hint: When you want to assign text to a variable, make sure your text is wrapped inside quotation marks
\n"
]
},
{
"cell_type": "code",
"execution_count": 23,
"id": "perceived-territory",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [],
"source": [
"# We create a variable called 'ada_description'.\n",
"# By using the \"=\" sign, we assign the character string on the right side to the new variable\n",
"ada_description = \"Ada Lovelace was an English mathematician and writer, chiefly known for her work on Charles Babbage's proposed mechanical general-purpose computer, the Analytical Engine\""
]
},
{
"cell_type": "markdown",
"id": "entertaining-skating",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"There is no output of the cell above because we only assign something to a variable. This does not produce any output, we just created a new variable. \n",
"We can print the content of the variable by using the `print()` function mentioned earlier. We also can just type the variable name into a new cell and Jupyter will show us what's in the variable:"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "opposed-prediction",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"\"Ada Lovelace was an English mathematician and writer, chiefly known for her work on Charles Babbage's proposed mechanical general-purpose computer, the Analytical Engine\""
]
},
"execution_count": 8,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"ada_description"
]
},
{
"cell_type": "markdown",
"id": "heard-solomon",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's check the data type of `ada_description` by using a function called `type()`"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "underlying-bicycle",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"str"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"type(ada_description)"
]
},
{
"cell_type": "markdown",
"id": "hybrid-attachment",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Python returns `str` as the type of `ada_description`. This means that there is text (a `character string`) stored inside the `ada_description` object. \n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "identical-harris",
"metadata": {},
"source": [
"\n",
"Hint: Keep in mind that Python will only treat textual inputs as character strings when you put it into quotation marks (e.g. \"hello\"). If you do not wrap the textual input into quotation marks, Python will interpret the input as variable names (e.g. hello) - this can lead to errors or unwanted results.
\n"
]
},
{
"cell_type": "markdown",
"id": "extreme-compensation",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"### Numeric types"
]
},
{
"cell_type": "markdown",
"id": "constitutional-plaintiff",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**Integers**\n",
"\n",
"Integers are whole numbers."
]
},
{
"cell_type": "code",
"execution_count": 76,
"id": "isolated-nelson",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"-46\n"
]
},
{
"data": {
"text/plain": [
"int"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"age = -46\n",
"\n",
"print(age)\n",
"type(age)"
]
},
{
"cell_type": "markdown",
"id": "european-proportion",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"**Float**\n",
"\n",
"Floating point real values represent real numbers and are written with a decimal point."
]
},
{
"cell_type": "code",
"execution_count": 74,
"id": "different-novel",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"12.876\n"
]
},
{
"data": {
"text/plain": [
"float"
]
},
"execution_count": 12,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"temperature_celsius = 12.876\n",
"\n",
"print(temperature_celsius)\n",
"type(temperature_celsius)"
]
},
{
"cell_type": "markdown",
"id": "trained-method",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"### Sequence & mapping types"
]
},
{
"cell_type": "markdown",
"id": "laden-quarterly",
"metadata": {},
"source": [
"Python provides different built-in ways to store multiple values/items inside a single variable. These sequence and mapping types are ubiquitous when working with Python. "
]
},
{
"cell_type": "markdown",
"id": "waiting-catering",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"#### Lists\n",
"\n",
"Lists can be considered as the most basic form of item collections in Python. Items inside lists can be of different types; the items can be changed and lists can contain duplicate values. Lists are notated with square brackets `[]`. More about lists can be found [here](https://www.w3schools.com/python/python_lists.asp)."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "bizarre-union",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[1, '2', 3.5, '6']\n"
]
},
{
"data": {
"text/plain": [
"list"
]
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"sequence_1 = [1, \"2\", 3.5, \"6\"]\n",
"\n",
"print(sequence_1)\n",
"type(sequence_1)"
]
},
{
"cell_type": "markdown",
"id": "circular-gathering",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"#### Ranges\n",
"\n",
"\n",
"Ranges return a sequence of numbers. A range object itself only stores the information at which position the range starts (defaults to 0), where it ends and the step size of the range (defaults to 1).\n",
"\n",
"Ranges are very useful when creating iterations. See the [section about loops](#Loops) for more details an that. \n",
"General documentation about the usage of ranges can be found [here](https://www.w3schools.com/python/ref_func_range.asp).\n"
]
},
{
"cell_type": "code",
"execution_count": 77,
"id": "enclosed-performer",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"range(0, 100)\n"
]
},
{
"data": {
"text/plain": [
"range"
]
},
"execution_count": 77,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"sequence_2 = range(0, 100)\n",
"\n",
"print(sequence_2)\n",
"type(sequence_2)"
]
},
{
"cell_type": "markdown",
"id": "disturbed-biography",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"#### Dictionaries\n",
"\n",
"*Dictionaries* are used when *key-value* pairs are needed. Key-value pairs basically bind two values to each other, one being the *key* the other one being the *value*. The key usually represents something like a category or a class and the value is a form or characteristic the key can take. \n",
"\n",
"More details on dictionaries can be found [here](https://www.w3schools.com/python/python_dictionaries.asp)."
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "recent-testimony",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'name': 'Ada Lovelace', 'birth_year': 1815}\n"
]
},
{
"data": {
"text/plain": [
"dict"
]
},
"execution_count": 1,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"mapping_ada_1 = {\"name\": \"Ada Lovelace\",\n",
" \"birth_year\": 1815}\n",
"\n",
"print(mapping_ada_1)\n",
"type(mapping_ada_1)"
]
},
{
"cell_type": "markdown",
"id": "blank-population",
"metadata": {},
"source": [
"#### Nested dictionaries\n",
"\n",
"Dictionaries can be *nested* arbitrarily. So the value of an key-value pair can itself be an dictionary. This is very useful for describing complex data structures."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "stone-damage",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"{'Ada Lovelace': {'birth_year': 1815, 'gender': 'female'}, 'Alan Turing': {'birth_year': 1912, 'gender': 'male', 'cause_of_death': 'homophobia'}}\n"
]
},
{
"data": {
"text/plain": [
"dict"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"mapping_2 = {\"Ada Lovelace\": { \"birth_year\": 1815,\n",
" \"gender\": \"female\" },\n",
" \"Alan Turing\": { \"birth_year\": 1912,\n",
" \"gender\": \"male\",\n",
" \"cause_of_death\": \"homophobia\" }\n",
" }\n",
"\n",
"print(mapping_2)\n",
"type(mapping_2)"
]
},
{
"cell_type": "markdown",
"id": "center-network",
"metadata": {},
"source": [
"\n",
"Hint: Nesting also applies to lists. So you can have a list in a list. Even a list in a dictionary and vice versa is possible! Feel free to try it out by editing the code cell above.
"
]
},
{
"cell_type": "markdown",
"id": "simple-jungle",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Loops & if/else statements\n",
"\n",
"For many computational tasks we need to define conditions and iterations, so the computer is able to do more than just executing a list of instructions from first to last."
]
},
{
"cell_type": "markdown",
"id": "objective-prague",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"### Loops \n",
"\n",
"Loops can be used to execute statements a desired number of times. This can be very helpful in reducing the amount of code needed for a specific task.\n",
"\n",
"#### For loops\n",
"\n",
"Let's start with a simple example. At first we create a list of five names. Afterwards we create a loop that outputs a personal greeting to each name:"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "exciting-bahrain",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hi Ada !\n",
"Hi Cornélie !\n",
"Hi Stanisław !\n",
"Hi Mathew !\n",
"Hi Liss !\n"
]
}
],
"source": [
"names = [\"Ada\", \"Cornélie\", \"Stanisław\", \"Mathew\", \"Liss\"]\n",
"\n",
"for name in names:\n",
" print(\"Hi\", name, \"!\")"
]
},
{
"cell_type": "markdown",
"id": "minute-spell",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's break that down:\n",
"\n",
"Part of Command | Meaning\n",
":-------------: | :----------------------:\n",
"`for name in names:` | We ask Python to do something for each element `name` in the variable `names`.
The singular `name` is an arbitrary choice to make this iteration more comprehensible. This is called an *iteration variable*.
You can use any term you like for the iteration variable.\n",
"`print(\"Hi\", name, \"!\")` | Here we tell Python to print the word `Hi` along with the respective
`name` element of the `names` list and a `!` afterwards."
]
},
{
"cell_type": "markdown",
"id": "invisible-intervention",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"We can also loop over `ranges`. Let's create a `range` from `0` to `5` and do some simple calculation and print meaningful outputs. This time we use the name `i` (short for *iteration*) as the name for the iteration variable:\n"
]
},
{
"cell_type": "code",
"execution_count": 26,
"id": "breathing-evaluation",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Current number is 0\n",
"Let's divide it by 3\n",
"0 divided by 3 is 0.0\n",
"\n",
"Current number is 1\n",
"Let's divide it by 3\n",
"1 divided by 3 is 0.3333333333333333\n",
"\n",
"Current number is 2\n",
"Let's divide it by 3\n",
"2 divided by 3 is 0.6666666666666666\n",
"\n",
"Current number is 3\n",
"Let's divide it by 3\n",
"3 divided by 3 is 1.0\n",
"\n",
"Current number is 4\n",
"Let's divide it by 3\n",
"4 divided by 3 is 1.3333333333333333\n",
"\n"
]
}
],
"source": [
"for i in range(0, 5):\n",
" print(\"Current number is\", i)\n",
" print(\"Let's divide it by 3\")\n",
" print(i, \"divided by 3 is\", i/3)\n",
" print(\"\") #this empty string results in a blank line after each iteration in the output below."
]
},
{
"cell_type": "markdown",
"id": "front-pearl",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"#### While loops\n",
"\n",
"Another kind of loop you can do is the *while loop*.\n",
"\n",
"The while loop works conditionally. This means you can define a condition and as long as this condition is true, the loop proceeds.\n",
"\n",
"Let's tell Python to count up from zero until it reaches `4`. "
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "smart-canadian",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"0\n",
"1\n",
"2\n",
"3\n"
]
}
],
"source": [
"count_variable = 0\n",
"\n",
"while count_variable < 4:\n",
" print(count_variable)\n",
" count_variable += 1 # This line raises the count variable by 1 after each iteration"
]
},
{
"cell_type": "markdown",
"id": "essential-papua",
"metadata": {},
"source": [
"After each iteration we use the `+=` operator which is equivalent to `count_variable = count_variable + 1`."
]
},
{
"cell_type": "markdown",
"id": "julian-resident",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"### If ... else statements\n",
"\n",
"There are many more scenarios in which you need to define other conditions for your code to run than while loops. In this case you can use *If/Else statements*.\n",
"If/Else statements let you run any code conditionally. With if/else statements you can define what code Python should run when a condition is true and what should happen when the condition is not true. \n",
"\n",
"Let's use the names list again from the for loop example above. \n",
"\n",
"This time we only want to greet every second person. This means we need to embed an If/Else statement within the for loop."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "danish-forum",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Hi Ada !\n",
"No greeting for Cornélie\n",
"Hi Stanisław !\n",
"No greeting for Mathew\n",
"Hi Liss !\n"
]
}
],
"source": [
"names = [\"Ada\", \"Cornélie\", \"Stanisław\", \"Mathew\", \"Liss\"]\n",
"greet = True\n",
"\n",
"for name in names:\n",
" if greet:\n",
" print(\"Hi\", name, \"!\")\n",
" else:\n",
" print(\"No greeting for\", name)\n",
" greet = not greet"
]
},
{
"cell_type": "markdown",
"id": "quantitative-bunny",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"source": [
"Let's break that down:\n",
"\n",
"Part of Command | Meaning\n",
":-------------: | :----------------------:\n",
"`greet` | The variable `greet` is set to the initial value `true` before we enter the if/else statement. \n",
"`if greet:` | Here we check whether `greet` is `True`. If it is, the line `print(\"Hi\", name, \"!\")` is executed. \n",
"`else:` | The `else` part of the code defines what happens, `greet` is not `True`. In this case the respective person is not greeted.\n",
"`greet = not greet`| After each iteration we use the `not` operator to reverse the current state of the `greet` variable. When `greet` is `True` it becomes `False` and the other way around. This way `greet` changes between `True` and `False` in every iteration."
]
},
{
"cell_type": "markdown",
"id": "careful-helicopter",
"metadata": {},
"source": [
"### 📝 Exercises"
]
},
{
"cell_type": "markdown",
"id": "chubby-rough",
"metadata": {},
"source": [
"1. Create a loop that counts from 100 to 115"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "closing-rates",
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"id": "adjusted-straight",
"metadata": {},
"source": [
"2. Use the following list of names and create a loop that adds the greeting \"Good Morning\" to every name:\n",
"\n",
"`names = [\"Ada\", \"Cornélie\", \"Stanisław\", \"Mathew\", \"Liss\"]`\n",
"\n",
"Desired output:\n",
"\n",
"`\n",
"\"Good Morning Ada\" \n",
"\"Good Morning Cornélie\" \n",
"\"Good Morning Stanisław\" \n",
"\"Good Morning Mathew\" \n",
"\"Good Morning Liss\"`"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "serial-shopping",
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"id": "sweet-uncertainty",
"metadata": {},
"source": [
"3. Use your for-loop from above and print \"Good Night\" instead of \"Good Morning\" for every list item on an even position (list entries: 0,2,4).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "charming-packet",
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "markdown",
"id": "documented-verification",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"source": [
"## Functions"
]
},
{
"cell_type": "markdown",
"id": "incomplete-humor",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"source": [
"Generally speaking, functions in Python are blocks of code that only run, when they are called. Functions always follow the pattern: \n",
">`function_name(arguments)`\n",
"\n",
"We already used some of the built-in functions of Python like `print()`, `list()` or `range()`. \n",
"\n",
"However, you can not only use function already existing in Python but you also can write your own functions.\n",
"\n",
"Let's write a small function and see how it works, afterwards."
]
},
{
"cell_type": "code",
"execution_count": 27,
"id": "employed-maria",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/plain": [
"'Hello Everyone, how are you?'"
]
},
"execution_count": 27,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# with >to=\"Everyone\"< we define a default value for the greeting. This way the function greets everyone by default.\n",
"def hello(to=\"Everyone\"): \n",
" return \"Hello {}, how are you?\".format(to)\n",
"\n",
"\n",
"hello()"
]
},
{
"cell_type": "code",
"execution_count": 28,
"id": "modular-census",
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"'Hello Ada, how are you?'"
]
},
"execution_count": 28,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"# Now we pass in a different argument to the function, so it greets \"Ada\" and not \"Everyone\"\n",
"\n",
"hello(to=\"Ada\")"
]
},
{
"cell_type": "markdown",
"id": "under-wisconsin",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"At first, let's quickly summarise what happened in the previous code blocks.
\n",
"We wrote a function called `hello()`. This function has one argument called `to`and the default value of this argument is `Everyone`. The function itself inserts this argument into a character string so the final return value of the function is \"`Hello Everyone, how are you?`\"\n",
"\n",
"Now, let's have a more detailed view at what happened:\n",
"\n",
"**1. `def`**\n",
"\n",
"When you want to create a new function you need to use `def` to let Python know you want to *define* a new function. \n",
"\n",
"**2. `hello(to='Everyone'):`**\n",
"\n",
"This part of the code defines the function name (`hello()`) as well as the argument it digests (`to=\"Everyone\"`).
\n",
"An argument is any kind of data or information you want to pass on from outside the function into the function. It is not mandatory to use any arguments, nor is it mandatory to define a default value for an argument.
\n",
"\n",
"In the example above we defined a default value for the `to=` argument. This means that when calling the function it is not necessary to define the `to=` argument unless you want to use another value than the default `Everyone`.\n",
"\n",
"**3. `return \"Hello {}, how are you?\".format(to)`**\n",
"\n",
"This is the logic of the function. `return` defines what the function is supposed to return. In this case it is returning a character string called `Hello {}, how are you?`.
Right after the character string there is `.format(to)`. This is called a `method`. As discussed in [Section 2.2.1](#text-type) there are different things you can do with variables in dependance of the respective data type or class. Character strings in Python have plenty different methods (a kind of sub-function that only works for character strings). One of these methods is `format()`. `format()` can be used to replace a placeholder in a character string with a specified value.
\n",
"\n",
"Inside the return string `\"Hello {}, how are you?\"` there are curly brackets (`{}`) - this is the placeholder `format()` replaces with the specified value that is passed as an argument into `format()`. In the examle above we pass the argument `to` into `format()` - `to` has the deafult value `Everyone` und thus the resulting string that our function returns when calling `hello()` is `Hello Everyone, how are you?`\n",
"\n",
"\n",
"\n",
" Hint: What is the difference between a method and a function?
\n",
" A method is a function that is bound to an object. A function is not bound and might be applied to any object. Methods are called by attaching a . to the object name, followed by the method name: object_name.method_name(argument)
\n"
]
},
{
"cell_type": "markdown",
"id": "alpha-structure",
"metadata": {
"hideCode": false,
"hidePrompt": false,
"tags": []
},
"source": [
"## Libraries"
]
},
{
"cell_type": "markdown",
"id": "precise-catalog",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"So far we only used the base functionality of Python. But you also can extend Python by using additional packages/libraries. Throughout this curriculum we will use quite a variety of different libraries.\n",
"\n",
"Since Python is an open-source programming language, there are thousands of libraries written by the Python community. This means whenever you face an issue you want to solve with Python, the likelihood is rather high that there is a library that is exactly made for solving your specific problem. \n",
"\n",
"The installation of new libraries is very easy. You just need to run `pip install PACKAGE_NAME` from your command line. \n",
"\n",
"\n",
"Hint: When you want to install a new package from within a Jupyter notebook, you need to put a ! at the beginning of the code cell, to inform Jupyter about your intention to run the command as a terminal command and not as a Python command.
\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "comic-association",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's try that out by installing a package called `pandas` - `pandas` is the most popular Python library for working with tabular data."
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "different-classics",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Collecting pandas\n",
" Downloading pandas-1.2.3-cp38-cp38-manylinux1_x86_64.whl (9.7 MB)\n",
"\u001b[K |████████████████████████████████| 9.7 MB 2.2 MB/s eta 0:00:01\n",
"\u001b[?25hRequirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.8/site-packages (from pandas) (2.8.1)\n",
"Collecting numpy>=1.16.5\n",
" Downloading numpy-1.20.1-cp38-cp38-manylinux2010_x86_64.whl (15.4 MB)\n",
"\u001b[K |████████████████████████████████| 15.4 MB 22.6 MB/s eta 0:00:01\n",
"\u001b[?25hRequirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.8/site-packages (from pandas) (2021.1)\n",
"Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.8/site-packages (from python-dateutil>=2.7.3->pandas) (1.15.0)\n",
"Installing collected packages: numpy, pandas\n",
"Successfully installed numpy-1.20.1 pandas-1.2.3\n"
]
}
],
"source": [
"!pip install pandas"
]
},
{
"cell_type": "markdown",
"id": "permanent-emerald",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"After seccussfully installing `pandas`we can load the library in a code cell and use it in our code. \n",
"\n",
"You can import libraries to your project by using the `library` call. Additionally you have some option when loading libraries. You can define a new name under which the library should be available in your project. And you also can select just a subsection of the full library in case you do not need every functionality inside the library. \n",
"\n",
"Usually when using `pandas` there is a convention to abbreviate the library name to `pd`. So whenever you load the library and you want to stick to the convention you would load it as:"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "invalid-numbers",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [],
"source": [
"import pandas as pd"
]
},
{
"cell_type": "markdown",
"id": "attended-defensive",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"## Data Frames (with Pandas)"
]
},
{
"cell_type": "markdown",
"id": "common-infection",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Scientific computing often involves tabular data representation. The advantage of tabular data representation is the clear structure. This data structure is often referred to as *data frame* or *data table*. The terminology around data frames differs slightly, depending on the scientific field of the speaker/author.
\n",
"\n",
"This table provides a quick overview of different terms for the same concepts:\n",
"\n",
"Element | Term\n",
":-------------: | :----------------------:\n",
"Column | Feaure, Variable, Dimension\n",
"Row | Instance, Observation\n",
"Cell | Value, Data Point, Datum\n",
"\n",
"\n",
"Key advantages of *pandas data frames*:\n",
"* Manage and analyse data\n",
"* Well suited for working with relational and labeled data (e.g.: Excel, CSV, SQL Tables)"
]
},
{
"cell_type": "markdown",
"id": "judicial-champion",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"Let's create an example data frame with pandas. At first we create a dictionary that contains our data structure. Afterwards we transform the dictionary into a pandas data frame.\n",
"\n",
"This is the example table we want to create: \n",
"\n",
"name | birth_year | gender | \n",
":-------------: | :--------: | :------:\n",
"Ada | 1815 | female\n",
"Cornélie | 1965 | female\n",
"Stanisław | 1987 | male\n",
"Mathew | 1896 | male\n",
"Liss | 1976 | non-binary"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "changing-significance",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" birth_year | \n",
"
\n",
" \n",
" \n",
" \n",
" | count | \n",
" 5.000000 | \n",
"
\n",
" \n",
" | mean | \n",
" 1927.800000 | \n",
"
\n",
" \n",
" | std | \n",
" 72.365047 | \n",
"
\n",
" \n",
" | min | \n",
" 1815.000000 | \n",
"
\n",
" \n",
" | 25% | \n",
" 1896.000000 | \n",
"
\n",
" \n",
" | 50% | \n",
" 1965.000000 | \n",
"
\n",
" \n",
" | 75% | \n",
" 1976.000000 | \n",
"
\n",
" \n",
" | max | \n",
" 1987.000000 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
"
\n",
" \n",
" | gender | \n",
" | \n",
" | \n",
"
\n",
" \n",
" \n",
" \n",
" | female | \n",
" 2 | \n",
" 2 | \n",
"
\n",
" \n",
" | male | \n",
" 2 | \n",
" 2 | \n",
"
\n",
" \n",
" | non-binary | \n",
" 1 | \n",
" 1 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
" age | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
" 205 | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
" 55 | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
" 33 | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
" 124 | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
" 44 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" female | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" male | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
exchanging data between Python and R. [Click here](http://arrow.apache.org/docs/python/feather.html) for more details.\n",
"[`to_parquet()`](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_parquet.html) | Parquet is the data format of Apache Spark. To some extend it's
similar to Feather and extensively used in cloud computing environments.
[Click here](https://spark.apache.org/docs/latest/sql-data-sources-parquet.html) for more details.\n",
"\n",
"The example below shows how to save a dataset to a local file called \"example_exports.csv\"."
]
},
{
"cell_type": "code",
"execution_count": 45,
"id": "quarterly-accreditation",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [],
"source": [
"data_frame.to_csv(\"./example_export.csv\", index=False)"
]
},
{
"cell_type": "markdown",
"id": "celtic-disability",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"source": [
"#### Import\n",
"\n",
"Importing a dataset to the current Python session is as easy as exporting the data. For every export method in the table above, there is a complementary import method. \n",
"Every import method starts with a `read_`.\n",
"\n",
"The file that was exported in the cell above can be imported by using the `read_csv()` method as shown in the cell below."
]
},
{
"cell_type": "code",
"execution_count": 46,
"id": "atmospheric-omaha",
"metadata": {
"hideCode": false,
"hidePrompt": false
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" birth_year | \n",
" gender | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Ada | \n",
" 1815 | \n",
" female | \n",
"
\n",
" \n",
" | 1 | \n",
" Cornélie | \n",
" 1965 | \n",
" female | \n",
"
\n",
" \n",
" | 2 | \n",
" Stanisław | \n",
" 1987 | \n",
" male | \n",
"
\n",
" \n",
" | 3 | \n",
" Mathew | \n",
" 1896 | \n",
" male | \n",
"
\n",
" \n",
" | 4 | \n",
" Liss | \n",
" 1976 | \n",
" non-binary | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" City | \n",
" Country | \n",
" Inhabitants | \n",
" Wikipedia URL | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Trincomalee | \n",
" Sri Lanka | \n",
" 99135 | \n",
" https://en.wikipedia.org/wiki/Trincomalee | \n",
"
\n",
" \n",
" | 1 | \n",
" Kołobrzeg | \n",
" Poland | \n",
" 46830 | \n",
" https://en.wikipedia.org/wiki/Ko%C5%82obrzeg | \n",
"
\n",
" \n",
" | 2 | \n",
" Manali | \n",
" India | \n",
" 8096 | \n",
" https://en.wikipedia.org/wiki/Manali,_Himachal... | \n",
"
\n",
" \n",
" | 3 | \n",
" St. Paul's Bay | \n",
" Malta | \n",
" 29097 | \n",
" https://en.wikipedia.org/wiki/St._Paul%27s_Bay | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" City | \n",
" Country | \n",
" Inhabitants | \n",
" Wikipedia URL | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Trincomalee | \n",
" Sri Lanka | \n",
" 99135 | \n",
" https://en.wikipedia.org/wiki/Trincomalee | \n",
"
\n",
" \n",
" | 1 | \n",
" Kołobrzeg | \n",
" Poland | \n",
" 46830 | \n",
" https://en.wikipedia.org/wiki/Ko%C5%82obrzeg | \n",
"
\n",
" \n",
" | 3 | \n",
" St. Paul's Bay | \n",
" Malta | \n",
" 29097 | \n",
" https://en.wikipedia.org/wiki/St._Paul%27s_Bay | \n",
"
\n",
" \n",
" | 2 | \n",
" Manali | \n",
" India | \n",
" 8096 | \n",
" https://en.wikipedia.org/wiki/Manali,_Himachal... | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" City | \n",
" Country | \n",
" Inhabitants | \n",
" Wikipedia URL | \n",
"
\n",
" \n",
" \n",
" \n",
" | 3 | \n",
" St. Paul's Bay | \n",
" Malta | \n",
" 29097 | \n",
" https://en.wikipedia.org/wiki/St._Paul%27s_Bay | \n",
"
\n",
" \n",
" | 1 | \n",
" Kołobrzeg | \n",
" Poland | \n",
" 46830 | \n",
" https://en.wikipedia.org/wiki/Ko%C5%82obrzeg | \n",
"
\n",
" \n",
"
\n",
"