{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "nibpbUnTsxTd"
},
"source": [
"##### Copyright 2018 The TensorFlow Authors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "tXAbWHtqs1Y2"
},
"outputs": [],
"source": [
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HTgMAvQq-PU_"
},
"source": [
"# Ragged Tensors\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "HTgMAvQq-PU_"
},
"source": [
"> Note: This is an archived TF1 notebook. These are configured\n",
"to run in TF2's \n",
"[compatbility mode](https://www.tensorflow.org/guide/migrate)\n",
"but will run in TF1 as well. To use TF1 in Colab, use the\n",
"[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\n",
"magic."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cDIUjj07-rQg"
},
"source": [
"## Setup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "KKvdSorS-pDD"
},
"outputs": [],
"source": [
"import math\n",
"import tensorflow.compat.v1 as tf"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "pxi0m_yf-te5"
},
"source": [
"## Overview\n",
"\n",
"Your data comes in many shapes; your tensors should too.\n",
"*Ragged tensors* are the TensorFlow equivalent of nested variable-length\n",
"lists. They make it easy to store and process data with non-uniform shapes,\n",
"including:\n",
"\n",
"* Variable-length features, such as the set of actors in a movie.\n",
"* Batches of variable-length sequential inputs, such as sentences or video\n",
" clips.\n",
"* Hierarchical inputs, such as text documents that are subdivided into\n",
" sections, paragraphs, sentences, and words.\n",
"* Individual fields in structured inputs, such as protocol buffers.\n",
"\n",
"### What you can do with a ragged tensor\n",
"\n",
"Ragged tensors are supported by more than a hundred TensorFlow operations,\n",
"including math operations (such as `tf.add` and `tf.reduce_mean`), array operations\n",
"(such as `tf.concat` and `tf.tile`), string manipulation ops (such as\n",
"`tf.substr`), and many others:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "vGmJGSf_-PVB"
},
"outputs": [],
"source": [
"digits = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])\n",
"words = tf.ragged.constant([[\"So\", \"long\"], [\"thanks\", \"for\", \"all\", \"the\", \"fish\"]])\n",
"print(tf.add(digits, 3))\n",
"print(tf.reduce_mean(digits, axis=1))\n",
"print(tf.concat([digits, [[5, 3]]], axis=0))\n",
"print(tf.tile(digits, [1, 2]))\n",
"print(tf.strings.substr(words, 0, 2))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Pt-5OIc8-PVG"
},
"source": [
"There are also a number of methods and operations that are\n",
"specific to ragged tensors, including factory methods, conversion methods,\n",
"and value-mapping operations.\n",
"For a list of supported ops, see the `tf.ragged` package\n",
"documentation.\n",
"\n",
"As with normal tensors, you can use Python-style indexing to access specific\n",
"slices of a ragged tensor. For more information, see the section on\n",
"**Indexing** below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "n8YMKXpI-PVH"
},
"outputs": [],
"source": [
"print(digits[0]) # First row"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Awi8i9q5_DuX"
},
"outputs": [],
"source": [
"print(digits[:, :2]) # First two values in each row."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "sXgQtTcgHHMR"
},
"outputs": [],
"source": [
"print(digits[:, -2:]) # Last two values in each row."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6FU5T_-8-PVK"
},
"source": [
"And just like normal tensors, you can use Python arithmetic and comparison\n",
"operators to perform elementwise operations. For more information, see the section on\n",
"**Overloaded Operators** below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2tdUEtb7-PVL"
},
"outputs": [],
"source": [
"print(digits + 3)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "X-bxG0nc_Nmf"
},
"outputs": [],
"source": [
"print(digits + tf.ragged.constant([[1, 2, 3, 4], [], [5, 6, 7], [8], []]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2tsw8mN0ESIT"
},
"source": [
"If you need to perform an elementwise transformation to the values of a `RaggedTensor`, you can use `tf.ragged.map_flat_values`, which takes a function plus one or more arguments, and applies the function to transform the `RaggedTensor`'s values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "pvt5URbdEt-D"
},
"outputs": [],
"source": [
"times_two_plus_one = lambda x: x * 2 + 1\n",
"print(tf.ragged.map_flat_values(times_two_plus_one, digits))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7M5RHOgp-PVN"
},
"source": [
"### Constructing a ragged tensor\n",
"\n",
"The simplest way to construct a ragged tensor is using\n",
"`tf.ragged.constant`, which builds the\n",
"`RaggedTensor` corresponding to a given nested Python `list`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yhgKMozw-PVP"
},
"outputs": [],
"source": [
"sentences = tf.ragged.constant([\n",
" [\"Let's\", \"build\", \"some\", \"ragged\", \"tensors\", \"!\"],\n",
" [\"We\", \"can\", \"use\", \"tf.ragged.constant\", \".\"]])\n",
"print(sentences)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "TW1g7eE2ee8M"
},
"outputs": [],
"source": [
"paragraphs = tf.ragged.constant([\n",
" [['I', 'have', 'a', 'cat'], ['His', 'name', 'is', 'Mat']],\n",
" [['Do', 'you', 'want', 'to', 'come', 'visit'], [\"I'm\", 'free', 'tomorrow']],\n",
"])\n",
"print(paragraphs)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SPLn5xHn-PVR"
},
"source": [
"Ragged tensors can also be constructed by pairing flat *values* tensors with\n",
"*row-partitioning* tensors indicating how those values should be divided into\n",
"rows, using factory classmethods such as `tf.RaggedTensor.from_value_rowids`,\n",
"`tf.RaggedTensor.from_row_lengths`, and\n",
"`tf.RaggedTensor.from_row_splits`.\n",
"\n",
"#### `tf.RaggedTensor.from_value_rowids`\n",
"If you know which row each value belongs in, then you can build a `RaggedTensor` using a `value_rowids` row-partitioning tensor:\n",
"\n",
"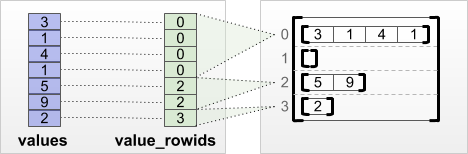"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SEvcPUcl-PVS"
},
"outputs": [],
"source": [
"print(tf.RaggedTensor.from_value_rowids(\n",
" values=[3, 1, 4, 1, 5, 9, 2, 6],\n",
" value_rowids=[0, 0, 0, 0, 2, 2, 2, 3]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "RBQh8sYc-PVV"
},
"source": [
"#### `tf.RaggedTensor.from_row_lengths`\n",
"\n",
"If you know how long each row is, then you can use a `row_lengths` row-partitioning tensor:\n",
"\n",
"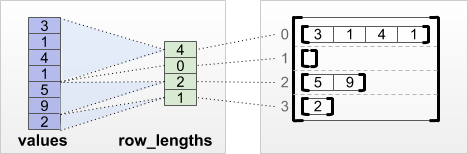"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "LBY81WXl-PVW"
},
"outputs": [],
"source": [
"print(tf.RaggedTensor.from_row_lengths(\n",
" values=[3, 1, 4, 1, 5, 9, 2, 6],\n",
" row_lengths=[4, 0, 3, 1]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8p5V8_Iu-PVa"
},
"source": [
"#### `tf.RaggedTensor.from_row_splits`\n",
"\n",
"If you know the index where each row starts and ends, then you can use a `row_splits` row-partitioning tensor:\n",
"\n",
"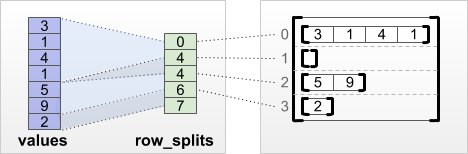"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "FwizuqZI-PVb"
},
"outputs": [],
"source": [
"print(tf.RaggedTensor.from_row_splits(\n",
" values=[3, 1, 4, 1, 5, 9, 2, 6],\n",
" row_splits=[0, 4, 4, 7, 8]))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E-9imo8DhwuA"
},
"source": [
"See the `tf.RaggedTensor` class documentation for a full list of factory methods."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YQAOsT1_-PVg"
},
"source": [
"### What you can store in a ragged tensor\n",
"\n",
"As with normal `Tensor`s, the values in a `RaggedTensor` must all have the same\n",
"type; and the values must all be at the same nesting depth (the *rank* of the\n",
"tensor):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "SqbPBd_w-PVi"
},
"outputs": [],
"source": [
"print(tf.ragged.constant([[\"Hi\"], [\"How\", \"are\", \"you\"]])) # ok: type=string, rank=2"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "83ZCSJnQAWAf"
},
"outputs": [],
"source": [
"print(tf.ragged.constant([[[1, 2], [3]], [[4, 5]]])) # ok: type=int32, rank=3"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ewA3cISdDfmP"
},
"outputs": [],
"source": [
"try:\n",
" tf.ragged.constant([[\"one\", \"two\"], [3, 4]]) # bad: multiple types\n",
"except ValueError as exception:\n",
" print(exception)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "EOWIlVidDl-n"
},
"outputs": [],
"source": [
"try:\n",
" tf.ragged.constant([\"A\", [\"B\", \"C\"]]) # bad: multiple nesting depths\n",
"except ValueError as exception:\n",
" print(exception)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nhHMFhSp-PVq"
},
"source": [
"### Example use case\n",
"\n",
"The following example demonstrates how `RaggedTensor`s can be used to construct\n",
"and combine unigram and bigram embeddings for a batch of variable-length\n",
"queries, using special markers for the beginning and end of each sentence.\n",
"For more details on the ops used in this example, see the `tf.ragged` package documentation."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ZBs_V7e--PVr"
},
"outputs": [],
"source": [
"queries = tf.ragged.constant([['Who', 'is', 'Dan', 'Smith'],\n",
" ['Pause'],\n",
" ['Will', 'it', 'rain', 'later', 'today']])\n",
"\n",
"# Create an embedding table.\n",
"num_buckets = 1024\n",
"embedding_size = 4\n",
"embedding_table = tf.Variable(\n",
" tf.truncated_normal([num_buckets, embedding_size],\n",
" stddev=1.0 / math.sqrt(embedding_size)))\n",
"\n",
"# Look up the embedding for each word.\n",
"word_buckets = tf.strings.to_hash_bucket_fast(queries, num_buckets)\n",
"word_embeddings = tf.ragged.map_flat_values(\n",
" tf.nn.embedding_lookup, embedding_table, word_buckets) # ①\n",
"\n",
"# Add markers to the beginning and end of each sentence.\n",
"marker = tf.fill([queries.nrows(), 1], '#')\n",
"padded = tf.concat([marker, queries, marker], axis=1) # ②\n",
"\n",
"# Build word bigrams & look up embeddings.\n",
"bigrams = tf.string_join([padded[:, :-1], padded[:, 1:]], separator='+') # ③\n",
"\n",
"bigram_buckets = tf.strings.to_hash_bucket_fast(bigrams, num_buckets)\n",
"bigram_embeddings = tf.ragged.map_flat_values(\n",
" tf.nn.embedding_lookup, embedding_table, bigram_buckets) # ④\n",
"\n",
"# Find the average embedding for each sentence\n",
"all_embeddings = tf.concat([word_embeddings, bigram_embeddings], axis=1) # ⑤\n",
"avg_embedding = tf.reduce_mean(all_embeddings, axis=1) # ⑥\n",
"print(avg_embedding)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Y_lE_LAVcWQH"
},
"source": [
"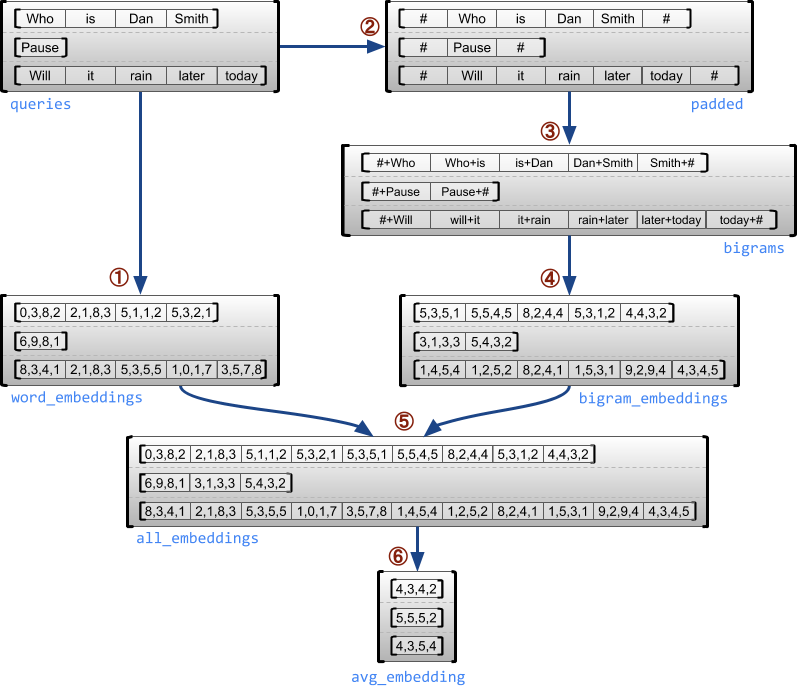"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "An_k0pX1-PVt"
},
"source": [
"## Ragged tensors: definitions\n",
"\n",
"### Ragged and uniform dimensions\n",
"\n",
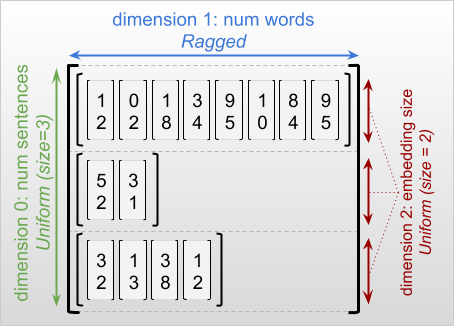
"A *ragged tensor* is a tensor with one or more *ragged dimensions*,\n",
"which are dimensions whose slices may have different lengths. For example, the\n",
"inner (column) dimension of `rt=[[3, 1, 4, 1], [], [5, 9, 2], [6], []]` is\n",
"ragged, since the column slices (`rt[0, :]`, ..., `rt[4, :]`) have different\n",
"lengths. Dimensions whose slices all have the same length are called *uniform\n",
"dimensions*.\n",
"\n",
"The outermost dimension of a ragged tensor is always uniform, since it consists\n",
"of a single slice (and so there is no possibility for differing slice lengths).\n",
"In addition to the uniform outermost dimension, ragged tensors may also have\n",
"uniform inner dimensions. For example, we might store the word embeddings for\n",
"each word in a batch of sentences using a ragged tensor with shape\n",
"`[num_sentences, (num_words), embedding_size]`, where the parentheses around\n",
"`(num_words)` indicate that the dimension is ragged.\n",
"\n",
"\n",
"\n",
"Ragged tensors may have multiple ragged dimensions. For example, we could store\n",
"a batch of structured text documents using a tensor with shape `[num_documents,\n",
"(num_paragraphs), (num_sentences), (num_words)]` (where again parentheses are\n",
"used to indicate ragged dimensions).\n",
"\n",
"#### Ragged tensor shape restrictions\n",
"\n",
"The shape of a ragged tensor is currently restricted to have the following form:\n",
"\n",
"* A single uniform dimension\n",
"* Followed by one or more ragged dimensions\n",
"* Followed by zero or more uniform dimensions.\n",
"\n",
"Note: These restrictions are a consequence of the current implementation, and we\n",
"may relax them in the future.\n",
"\n",
"### Rank and ragged rank\n",
"\n",
"The total number of dimensions in a ragged tensor is called its ***rank***, and\n",
"the number of ragged dimensions in a ragged tensor is called its ***ragged\n",
"rank***. In graph execution mode (i.e., non-eager mode), a tensor's ragged rank\n",
"is fixed at creation time: it can't depend\n",
"on runtime values, and can't vary dynamically for different session runs.\n",
"A ***potentially ragged tensor*** is a value that might be\n",
"either a `tf.Tensor` or a `tf.RaggedTensor`. The\n",
"ragged rank of a `tf.Tensor` is defined to be zero.\n",
"\n",
"### RaggedTensor shapes\n",
"\n",
"When describing the shape of a RaggedTensor, ragged dimensions are indicated by\n",
"enclosing them in parentheses. For example, as we saw above, the shape of a 3-D\n",
"RaggedTensor that stores word embeddings for each word in a batch of sentences\n",
"can be written as `[num_sentences, (num_words), embedding_size]`.\n",
"The `RaggedTensor.shape` attribute returns a `tf.TensorShape` for a\n",
"ragged tensor, where ragged dimensions have size `None`:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "M2Wzx4JEIvmb"
},
"outputs": [],
"source": [
"tf.ragged.constant([[\"Hi\"], [\"How\", \"are\", \"you\"]]).shape"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "G9tfJOeFlijE"
},
"source": [
"The method `tf.RaggedTensor.bounding_shape` can be used to find a tight\n",
"bounding shape for a given `RaggedTensor`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5DHaqXHxlWi0"
},
"outputs": [],
"source": [
"print(tf.ragged.constant([[\"Hi\"], [\"How\", \"are\", \"you\"]]).bounding_shape())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "V8e7x95UcLS6"
},
"source": [
"## Ragged vs sparse tensors\n",
"\n",
"A ragged tensor should *not* be thought of as a type of sparse tensor, but\n",
"rather as a dense tensor with an irregular shape.\n",
"\n",
"As an illustrative example, consider how array operations such as `concat`,\n",
"`stack`, and `tile` are defined for ragged vs. sparse tensors. Concatenating\n",
"ragged tensors joins each row to form a single row with the combined length:\n",
"\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ush7IGUWLXIn"
},
"outputs": [],
"source": [
"ragged_x = tf.ragged.constant([[\"John\"], [\"a\", \"big\", \"dog\"], [\"my\", \"cat\"]])\n",
"ragged_y = tf.ragged.constant([[\"fell\", \"asleep\"], [\"barked\"], [\"is\", \"fuzzy\"]])\n",
"print(tf.concat([ragged_x, ragged_y], axis=1))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "pvQzZG8zMoWa"
},
"source": [
"But concatenating sparse tensors is equivalent to concatenating the corresponding dense tensors,\n",
"as illustrated by the following example (where Ø indicates missing values):\n",
"\n",
"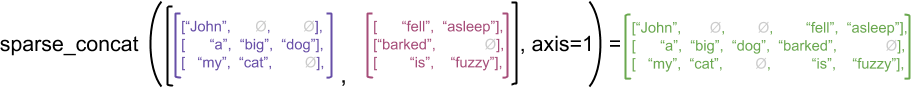\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eTIhGayQL0gI"
},
"outputs": [],
"source": [
"sparse_x = ragged_x.to_sparse()\n",
"sparse_y = ragged_y.to_sparse()\n",
"sparse_result = tf.sparse.concat(sp_inputs=[sparse_x, sparse_y], axis=1)\n",
"print(tf.sparse.to_dense(sparse_result, ''))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Vl8eQN8pMuYx"
},
"source": [
"For another example of why this distinction is important, consider the\n",
"definition of “the mean value of each row” for an op such as `tf.reduce_mean`.\n",
"For a ragged tensor, the mean value for a row is the sum of the\n",
"row’s values divided by the row’s width.\n",
"But for a sparse tensor, the mean value for a row is the sum of the\n",
"row’s values divided by the sparse tensor’s overall width (which is\n",
"greater than or equal to the width of the longest row).\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cRcHzS6pcHYC"
},
"source": [
"## Overloaded operators\n",
"\n",
"The `RaggedTensor` class overloads the standard Python arithmetic and comparison\n",
"operators, making it easy to perform basic elementwise math:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "skScd37P-PVu"
},
"outputs": [],
"source": [
"x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])\n",
"y = tf.ragged.constant([[1, 1], [2], [3, 3, 3]])\n",
"print(x + y)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XEGgbZHV-PVw"
},
"source": [
"Since the overloaded operators perform elementwise computations, the inputs to\n",
"all binary operations must have the same shape, or be broadcastable to the same\n",
"shape. In the simplest broadcasting case, a single scalar is combined\n",
"elementwise with each value in a ragged tensor:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "IYybEEWc-PVx"
},
"outputs": [],
"source": [
"x = tf.ragged.constant([[1, 2], [3], [4, 5, 6]])\n",
"print(x + 3)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "okGb9dIi-PVz"
},
"source": [
"For a discussion of more advanced cases, see the section on\n",
"**Broadcasting**.\n",
"\n",
"Ragged tensors overload the same set of operators as normal `Tensor`s: the unary\n",
"operators `-`, `~`, and `abs()`; and the binary operators `+`, `-`, `*`, `/`,\n",
"`//`, `%`, `**`, `&`, `|`, `^`, `<`, `<=`, `>`, and `>=`. Note that, as with\n",
"standard `Tensor`s, binary `==` is not overloaded; you can use\n",
"`tf.equal()` to check elementwise equality."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "f2anbs6ZnFtl"
},
"source": [
"## Indexing\n",
"\n",
"Ragged tensors support Python-style indexing, including multidimensional\n",
"indexing and slicing. The following examples demonstrate ragged tensor indexing\n",
"with a 2-D and a 3-D ragged tensor.\n",
"\n",
"### Indexing a 2-D ragged tensor with 1 ragged dimension"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MbSRZRDz-PV1"
},
"outputs": [],
"source": [
"queries = tf.ragged.constant(\n",
" [['Who', 'is', 'George', 'Washington'],\n",
" ['What', 'is', 'the', 'weather', 'tomorrow'],\n",
" ['Goodnight']])\n",
"print(queries[1])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "EFfjZV7YA3UH"
},
"outputs": [],
"source": [
"print(queries[1, 2]) # A single word"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "VISRPQSdA3xn"
},
"outputs": [],
"source": [
"print(queries[1:]) # Everything but the first row"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "J1PpSyKQBMng"
},
"outputs": [],
"source": [
"print(queries[:, :3]) # The first 3 words of each query"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ixrhHmJBeidy"
},
"outputs": [],
"source": [
"print(queries[:, -2:]) # The last 2 words of each query"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "cnOP6Vza-PV4"
},
"source": [
"### Indexing a 3-D ragged tensor with 2 ragged dimensions"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8VbqbKcE-PV6"
},
"outputs": [],
"source": [
"rt = tf.ragged.constant([[[1, 2, 3], [4]],\n",
" [[5], [], [6]],\n",
" [[7]],\n",
" [[8, 9], [10]]])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "f9WPVWf4grVp"
},
"outputs": [],
"source": [
"print(rt[1]) # Second row (2-D RaggedTensor)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ad8FGJoABjQH"
},
"outputs": [],
"source": [
"print(rt[3, 0]) # First element of fourth row (1-D Tensor)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MPPr-a-bBjFE"
},
"outputs": [],
"source": [
"print(rt[:, 1:3]) # Items 1-3 of each row (3-D RaggedTensor)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6SIDeoIUBi4z"
},
"outputs": [],
"source": [
"print(rt[:, -1:]) # Last item of each row (3-D RaggedTensor)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_d3nBh1GnWvU"
},
"source": [
"`RaggedTensor`s supports multidimensional indexing and slicing, with one\n",
"restriction: indexing into a ragged dimension is not allowed. This case is\n",
"problematic because the indicated value may exist in some rows but not others.\n",
"In such cases, it's not obvious whether we should (1) raise an `IndexError`; (2)\n",
"use a default value; or (3) skip that value and return a tensor with fewer rows\n",
"than we started with. Following the\n",
"[guiding principles of Python](https://www.python.org/dev/peps/pep-0020/)\n",
"(\"In the face\n",
"of ambiguity, refuse the temptation to guess\" ), we currently disallow this\n",
"operation."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "IsWKETULAJbN"
},
"source": [
"## Tensor Type Conversion\n",
"\n",
"The `RaggedTensor` class defines methods that can be used to convert\n",
"between `RaggedTensor`s and `tf.Tensor`s or `tf.SparseTensors`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "INnfmZGcBoU_"
},
"outputs": [],
"source": [
"ragged_sentences = tf.ragged.constant([\n",
" ['Hi'], ['Welcome', 'to', 'the', 'fair'], ['Have', 'fun']])\n",
"print(ragged_sentences.to_tensor(default_value=''))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "41WAZLXNnbwH"
},
"outputs": [],
"source": [
"print(ragged_sentences.to_sparse())"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-rfiyYqne8QN"
},
"outputs": [],
"source": [
"x = [[1, 3, -1, -1], [2, -1, -1, -1], [4, 5, 8, 9]]\n",
"print(tf.RaggedTensor.from_tensor(x, padding=-1))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "S8MkYo2hfVhj"
},
"outputs": [],
"source": [
"st = tf.SparseTensor(indices=[[0, 0], [2, 0], [2, 1]],\n",
" values=['a', 'b', 'c'],\n",
" dense_shape=[3, 3])\n",
"print(tf.RaggedTensor.from_sparse(st))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qx025sNMkAHH"
},
"source": [
"## Evaluating ragged tensors\n",
"\n",
"### Eager execution\n",
"\n",
"In eager execution mode, ragged tensors are evaluated immediately. To access the\n",
"values they contain, you can:\n",
"\n",
"* Use the\n",
" `tf.RaggedTensor.to_list()`\n",
" method, which converts the ragged tensor to a Python `list`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "uMm1WMkc-PV_"
},
"outputs": [],
"source": [
"rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])\n",
"print(rt.to_list())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SrizmqTc-PWC"
},
"source": [
"* Use Python indexing. If the tensor piece you select contains no ragged\n",
" dimensions, then it will be returned as an `EagerTensor`. You can then use\n",
" the `numpy()` method to access the value directly."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "HpRHhfLe-PWD"
},
"outputs": [],
"source": [
"print(rt[1].numpy())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "sNlpI2fR-PWF"
},
"source": [
"* Decompose the ragged tensor into its components, using the\n",
" `tf.RaggedTensor.values`\n",
" and\n",
" `tf.RaggedTensor.row_splits`\n",
" properties, or row-paritioning methods such as `tf.RaggedTensor.row_lengths()`\n",
" and `tf.RaggedTensor.value_rowids()`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yTckrLdB-PWG"
},
"outputs": [],
"source": [
"print(rt.values)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "B8OnG9NzCEnv"
},
"outputs": [],
"source": [
"print(rt.row_splits)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6tG3kBAo-PWI"
},
"source": [
"### Graph execution\n",
"\n",
"In graph execution mode, ragged tensors can be evaluated using `session.run()`,\n",
"just like standard tensors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "aDhVIrIs-PWJ"
},
"outputs": [],
"source": [
"with tf.Session() as session:\n",
" rt = tf.ragged.constant([[1, 2], [3, 4, 5], [6], [], [7]])\n",
" rt_value = session.run(rt)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "0-K5pqwJ-PWL"
},
"source": [
"The resulting value will be a\n",
"`tf.ragged.RaggedTensorValue`\n",
"instance. To access the values contained in a `RaggedTensorValue`, you can:\n",
"\n",
"* Use the\n",
" `tf.ragged.RaggedTensorValue.to_list()`\n",
" method, which converts the `RaggedTensorValue` to a Python `list`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "R2U3WZf8-PWM"
},
"outputs": [],
"source": [
"print(rt_value.to_list())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4x4b7DpY-PWO"
},
"source": [
"* Decompose the ragged tensor into its components, using the\n",
" `tf.ragged.RaggedTensorValue.values`\n",
" and\n",
" `tf.ragged.RaggedTensorValue.row_splits`\n",
" properties."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "RtREVSPB-PWO"
},
"outputs": [],
"source": [
"print(rt_value.values)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9BIpKNBnCmjV"
},
"outputs": [],
"source": [
"print(rt_value.row_splits)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qEmnOr01Cdl3"
},
"outputs": [],
"source": [
"tf.enable_eager_execution() # Resume eager execution mode."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EdljbNPq-PWS"
},
"source": [
"### Broadcasting\n",
"\n",
"Broadcasting is the process of making tensors with different shapes have\n",
"compatible shapes for elementwise operations. For more background on\n",
"broadcasting, see:\n",
"\n",
"* [Numpy: Broadcasting](https://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)\n",
"* `tf.broadcast_dynamic_shape`\n",
"* `tf.broadcast_to`\n",
"\n",
"The basic steps for broadcasting two inputs `x` and `y` to have compatible\n",
"shapes are:\n",
"\n",
"1. If `x` and `y` do not have the same number of dimensions, then add outer\n",
" dimensions (with size 1) until they do.\n",
"\n",
"2. For each dimension where `x` and `y` have different sizes:\n",
"\n",
" * If `x` or `y` have size `1` in dimension `d`, then repeat its values\n",
" across dimension `d` to match the other input's size.\n",
"\n",
" * Otherwise, raise an exception (`x` and `y` are not broadcast\n",
" compatible)."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-S2hOUWx-PWU"
},
"source": [
"Where the size of a tensor in a uniform dimension is a single number (the size\n",
"of slices across that dimension); and the size of a tensor in a ragged dimension\n",
"is a list of slice lengths (for all slices across that dimension).\n",
"\n",
"#### Broadcasting examples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "0n095XdR-PWU"
},
"outputs": [],
"source": [
"# x (2D ragged): 2 x (num_rows)\n",
"# y (scalar)\n",
"# result (2D ragged): 2 x (num_rows)\n",
"x = tf.ragged.constant([[1, 2], [3]])\n",
"y = 3\n",
"print(x + y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "0SVYk5AP-PWW"
},
"outputs": [],
"source": [
"# x (2d ragged): 3 x (num_rows)\n",
"# y (2d tensor): 3 x 1\n",
"# Result (2d ragged): 3 x (num_rows)\n",
"x = tf.ragged.constant(\n",
" [[10, 87, 12],\n",
" [19, 53],\n",
" [12, 32]])\n",
"y = [[1000], [2000], [3000]]\n",
"print(x + y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MsfBMD80s8Ux"
},
"outputs": [],
"source": [
"# x (3d ragged): 2 x (r1) x 2\n",
"# y (2d ragged): 1 x 1\n",
"# Result (3d ragged): 2 x (r1) x 2\n",
"x = tf.ragged.constant(\n",
" [[[1, 2], [3, 4], [5, 6]],\n",
" [[7, 8]]],\n",
" ragged_rank=1)\n",
"y = tf.constant([[10]])\n",
"print(x + y)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "rEj5QVfnva0t"
},
"outputs": [],
"source": [
"# x (3d ragged): 2 x (r1) x (r2) x 1\n",
"# y (1d tensor): 3\n",
"# Result (3d ragged): 2 x (r1) x (r2) x 3\n",
"x = tf.ragged.constant(\n",
" [\n",
" [\n",
" [[1], [2]],\n",
" [],\n",
" [[3]],\n",
" [[4]],\n",
" ],\n",
" [\n",
" [[5], [6]],\n",
" [[7]]\n",
" ]\n",
" ],\n",
" ragged_rank=2)\n",
"y = tf.constant([10, 20, 30])\n",
"print(x + y)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uennZ64Aqftb"
},
"source": [
"Here are some examples of shapes that do not broadcast:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "UpI0FlfL4Eim"
},
"outputs": [],
"source": [
"# x (2d ragged): 3 x (r1)\n",
"# y (2d tensor): 3 x 4 # trailing dimensions do not match\n",
"x = tf.ragged.constant([[1, 2], [3, 4, 5, 6], [7]])\n",
"y = tf.constant([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])\n",
"try:\n",
" x + y\n",
"except tf.errors.InvalidArgumentError as exception:\n",
" print(exception)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qGq1zOT4zMoc"
},
"outputs": [],
"source": [
"# x (2d ragged): 3 x (r1)\n",
"# y (2d ragged): 3 x (r2) # ragged dimensions do not match.\n",
"x = tf.ragged.constant([[1, 2, 3], [4], [5, 6]])\n",
"y = tf.ragged.constant([[10, 20], [30, 40], [50]])\n",
"try:\n",
" x + y\n",
"except tf.errors.InvalidArgumentError as exception:\n",
" print(exception)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CvLae5vMqeji"
},
"outputs": [],
"source": [
"# x (3d ragged): 3 x (r1) x 2\n",
"# y (3d ragged): 3 x (r1) x 3 # trailing dimensions do not match\n",
"x = tf.ragged.constant([[[1, 2], [3, 4], [5, 6]],\n",
" [[7, 8], [9, 10]]])\n",
"y = tf.ragged.constant([[[1, 2, 0], [3, 4, 0], [5, 6, 0]],\n",
" [[7, 8, 0], [9, 10, 0]]])\n",
"try:\n",
" x + y\n",
"except tf.errors.InvalidArgumentError as exception:\n",
" print(exception)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "m0wQkLfV-PWa"
},
"source": [
"## RaggedTensor encoding\n",
"\n",
"Ragged tensors are encoded using the `RaggedTensor` class. Internally, each\n",
"`RaggedTensor` consists of:\n",
"\n",
"* A `values` tensor, which concatenates the variable-length rows into a\n",
" flattened list.\n",
"* A `row_splits` vector, which indicates how those flattened values are\n",
" divided into rows. In particular, the values for row `rt[i]` are stored in\n",
" the slice `rt.values[rt.row_splits[i]:rt.row_splits[i+1]]`.\n",
"\n",
"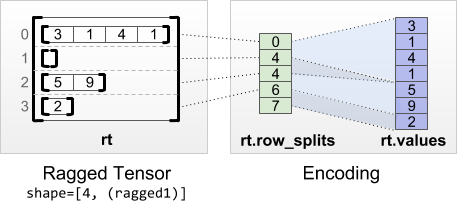\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MrLgMu0gPuo-"
},
"outputs": [],
"source": [
"rt = tf.RaggedTensor.from_row_splits(\n",
" values=[3, 1, 4, 1, 5, 9, 2],\n",
" row_splits=[0, 4, 4, 6, 7])\n",
"print(rt)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "bpB7xKoUPtU6"
},
"source": [
"### Multiple ragged dimensions\n",
"\n",
"A ragged tensor with multiple ragged dimensions is encoded by using a nested\n",
"`RaggedTensor` for the `values` tensor. Each nested `RaggedTensor` adds a single\n",
"ragged dimension.\n",
"\n",
"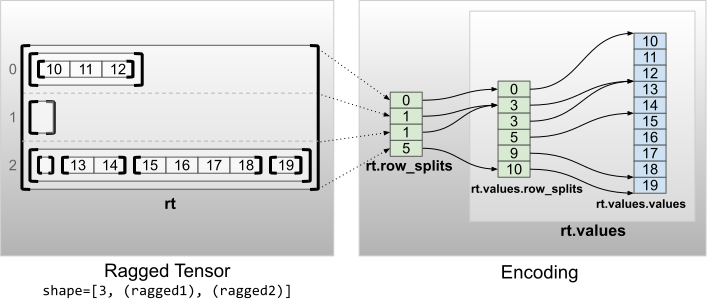"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yy3IGT2a-PWb"
},
"outputs": [],
"source": [
"rt = tf.RaggedTensor.from_row_splits(\n",
" values=tf.RaggedTensor.from_row_splits(\n",
" values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],\n",
" row_splits=[0, 3, 3, 5, 9, 10]),\n",
" row_splits=[0, 1, 1, 5])\n",
"print(rt)\n",
"print(\"Shape: {}\".format(rt.shape))\n",
"print(\"Number of ragged dimensions: {}\".format(rt.ragged_rank))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5HqEEDzk-PWc"
},
"source": [
"The factory function `tf.RaggedTensor.from_nested_row_splits` may be used to construct a\n",
"RaggedTensor with multiple ragged dimensions directly, by providing a list of\n",
"`row_splits` tensors:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "AKYhtFcT-PWd"
},
"outputs": [],
"source": [
"rt = tf.RaggedTensor.from_nested_row_splits(\n",
" flat_values=[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],\n",
" nested_row_splits=([0, 1, 1, 5], [0, 3, 3, 5, 9, 10]))\n",
"print(rt)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uba2EnAY-PWf"
},
"source": [
"### Uniform Inner Dimensions\n",
"\n",
"Ragged tensors with uniform inner dimensions are encoded by using a\n",
"multidimensional `tf.Tensor` for `values`.\n",
"\n",
"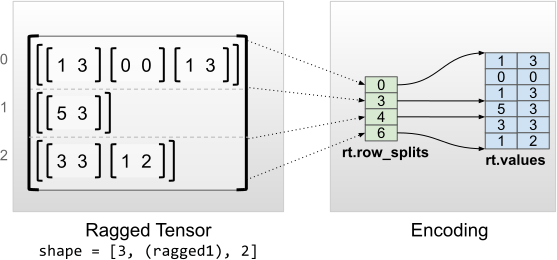"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "z2sHwHdy-PWg"
},
"outputs": [],
"source": [
"rt = tf.RaggedTensor.from_row_splits(\n",
" values=[[1, 3], [0, 0], [1, 3], [5, 3], [3, 3], [1, 2]],\n",
" row_splits=[0, 3, 4, 6])\n",
"print(rt)\n",
"print(\"Shape: {}\".format(rt.shape))\n",
"print(\"Number of ragged dimensions: {}\".format(rt.ragged_rank))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8yYaNrgX-PWh"
},
"source": [
"### Alternative row-partitioning schemes\n",
"\n",
"The `RaggedTensor` class uses `row_splits` as the primary mechanism to store\n",
"information about how the values are partitioned into rows. However,\n",
"`RaggedTensor` also provides support for four alternative row-partitioning\n",
"schemes, which can be more convenient to use depending on how your data is\n",
"formatted. Internally, `RaggedTensor` uses these additional schemes to improve\n",
"efficiency in some contexts.\n",
"\n",
"\n",
" - Row lengths
\n",
" - `row_lengths` is a vector with shape `[nrows]`, which specifies the\n",
" length of each row.
\n",
"\n",
" - Row starts
\n",
" - `row_starts` is a vector with shape `[nrows]`, which specifies the start\n",
" offset of each row. Equivalent to `row_splits[:-1]`.
\n",
"\n",
" - Row limits
\n",
" - `row_limits` is a vector with shape `[nrows]`, which specifies the stop\n",
" offset of each row. Equivalent to `row_splits[1:]`.
\n",
"\n",
" - Row indices and number of rows
\n",
" - `value_rowids` is a vector with shape `[nvals]`, corresponding\n",
" one-to-one with values, which specifies each value's row index. In\n",
" particular, the row `rt[row]` consists of the values `rt.values[j]` where\n",
" `value_rowids[j]==row`. \\\n",
" `nrows` is an integer that specifies the number of rows in the\n",
" `RaggedTensor`. In particular, `nrows` is used to indicate trailing empty\n",
" rows.
\n",
"
\n",
"\n",
"For example, the following ragged tensors are equivalent:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4TH6XoQ8-PWh"
},
"outputs": [],
"source": [
"values = [3, 1, 4, 1, 5, 9, 2, 6]\n",
"print(tf.RaggedTensor.from_row_splits(values, row_splits=[0, 4, 4, 7, 8, 8]))\n",
"print(tf.RaggedTensor.from_row_lengths(values, row_lengths=[4, 0, 3, 1, 0]))\n",
"print(tf.RaggedTensor.from_row_starts(values, row_starts=[0, 4, 4, 7, 8]))\n",
"print(tf.RaggedTensor.from_row_limits(values, row_limits=[4, 4, 7, 8, 8]))\n",
"print(tf.RaggedTensor.from_value_rowids(\n",
" values, value_rowids=[0, 0, 0, 0, 2, 2, 2, 3], nrows=5))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZGRrpwxjsOGr"
},
"source": [
"The RaggedTensor class defines methods which can be used to construct\n",
"each of these row-partitioning tensors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fIdn-hUBsoSj"
},
"outputs": [],
"source": [
"rt = tf.ragged.constant([[3, 1, 4, 1], [], [5, 9, 2], [6], []])\n",
"print(\" values: {}\".format(rt.values))\n",
"print(\" row_splits: {}\".format(rt.row_splits))\n",
"print(\" row_lengths: {}\".format(rt.row_lengths()))\n",
"print(\" row_starts: {}\".format(rt.row_starts()))\n",
"print(\" row_limits: {}\".format(rt.row_limits()))\n",
"print(\"value_rowids: {}\".format(rt.value_rowids()))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "2r9XUpLUsdOa"
},
"source": [
"(Note that `tf.RaggedTensor.values` and `tf.RaggedTensors.row_splits` are properties, while the remaining row-partitioning accessors are all methods. This reflects the fact that the `row_splits` are the primary underlying representation, and the other row-partitioning tensors must be computed.)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "NBX15kEr-PWi"
},
"source": [
"Some of the advantages and disadvantages of the different row-partitioning\n",
"schemes are:\n",
"\n",
"+ **Efficient indexing**:\n",
" The `row_splits`, `row_starts`, and `row_limits` schemes all enable\n",
" constant-time indexing into ragged tensors. The `value_rowids` and\n",
" `row_lengths` schemes do not.\n",
"\n",
"+ **Small encoding size**:\n",
" The `value_rowids` scheme is more efficient when storing ragged tensors that\n",
" have a large number of empty rows, since the size of the tensor depends only\n",
" on the total number of values. On the other hand, the other four encodings\n",
" are more efficient when storing ragged tensors with longer rows, since they\n",
" require only one scalar value for each row.\n",
"\n",
"+ **Efficient concatenation**:\n",
" The `row_lengths` scheme is more efficient when concatenating ragged\n",
" tensors, since row lengths do not change when two tensors are concatenated\n",
" together (but row splits and row indices do).\n",
"\n",
"+ **Compatibility**:\n",
" The `value_rowids` scheme matches the\n",
" [segmentation](../api_guides/python/math_ops.md#Segmentation)\n",
" format used by operations such as `tf.segment_sum`. The `row_limits` scheme\n",
" matches the format used by ops such as `tf.sequence_mask`."
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "ragged_tensors.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
 View source on GitHub\n",
"
View source on GitHub\n",
"