{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Data Parallelism\n",
"\n",
"이번 세션에는 데이터 병렬화 기법에 대해 알아보겠습니다.\n",
"\n",
"## 1. `torch.nn.DataParallel`\n",
"가장 먼저 우리에게 친숙한 `torch.nn.DataParallel`의 동작 방식에 대해 알아봅시다. `torch.nn.DataParallel`은 single-node & multi-GPU에서 동작하는 multi-thread 모듈입니다."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
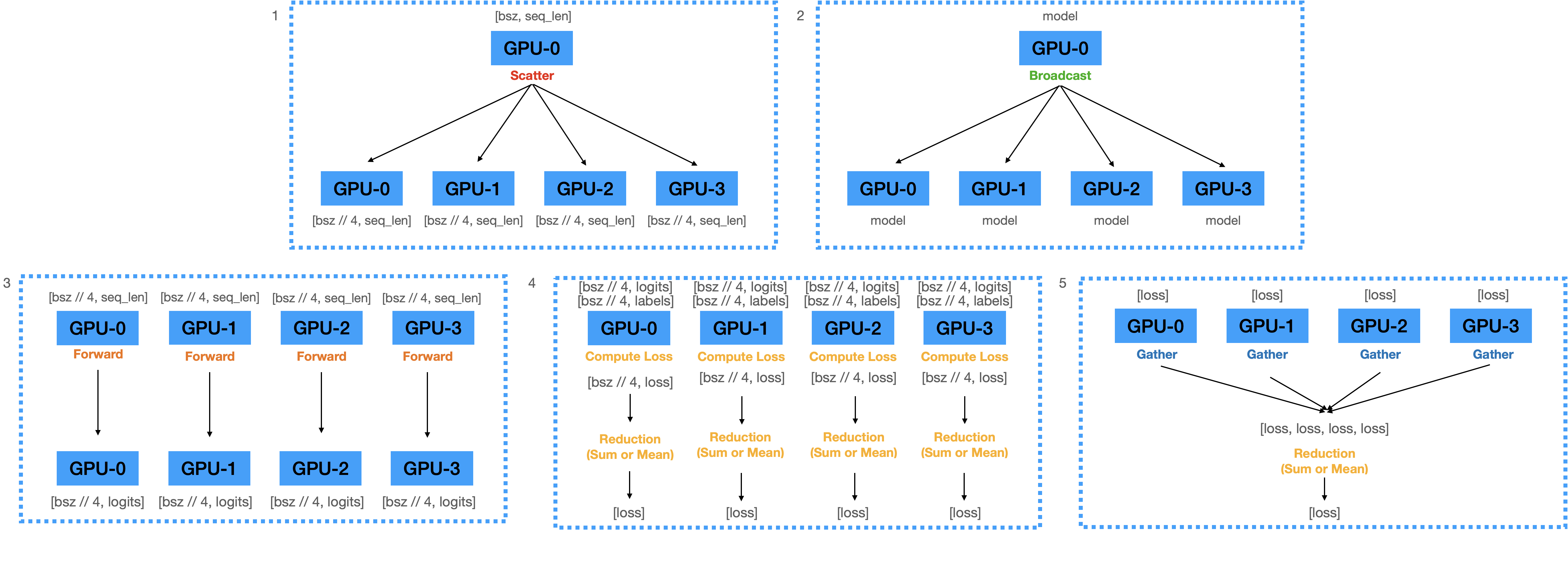
"### 1) Forward Pass\n",
"\n",
"1. 입력된 mini-batch를 **Scatter**하여 각 디바이스로 전송.\n",
"2. GPU-1에 올라와 있는 모델의 파라미터를 GPU-2,3,4로 **Broadcast**.\n",
"3. 각 디바이스로 복제된 모델로 **Forward**하여 Logits을 계산 함.\n",
"4. 계산된 Logits을 **Gather**하여 GPU-1에 모음.\n",
"5. Logits으로부터 **Loss**를 계산함. (with loss reduction)\n",
"\n",
"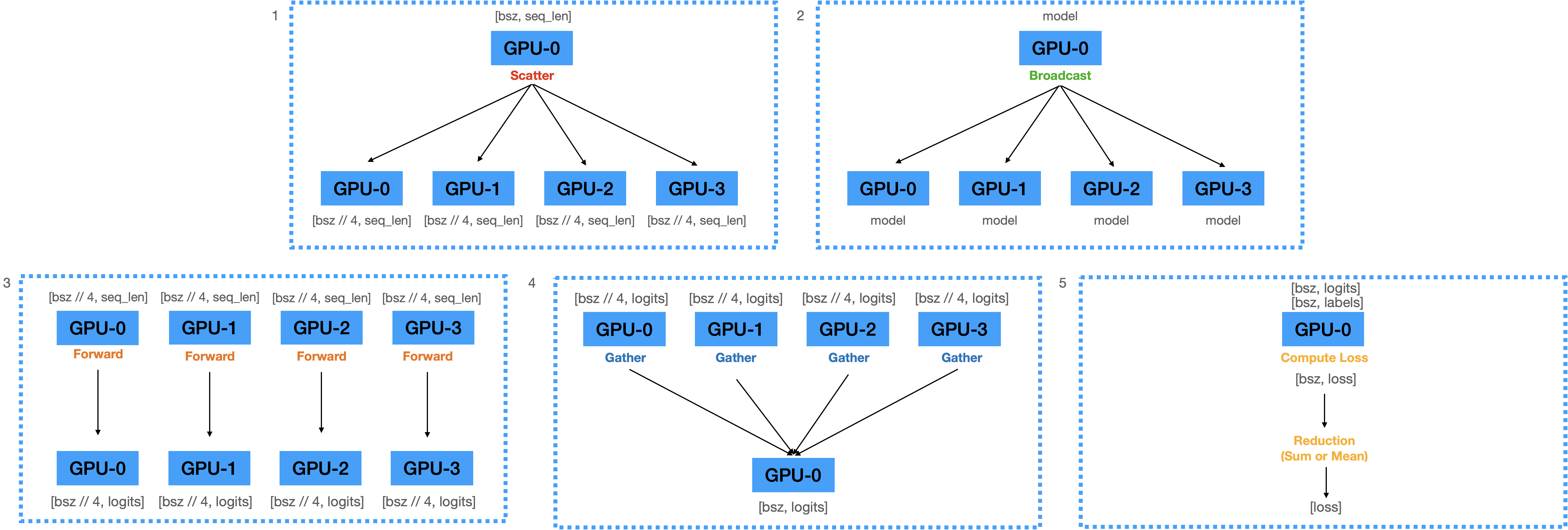\n",
"\n",
"
\n",
"\n",
"코드로 나타내면 아래와 같습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import torch.nn as nn\n",
"\n",
"\n",
"def data_parallel(module, inputs, labels, device_ids, output_device):\n",
" inputs = nn.parallel.scatter(inputs, device_ids)\n",
" # 입력 데이터를 device_ids들에 Scatter함\n",
"\n",
" replicas = nn.parallel.replicate(module, device_ids)\n",
" # 모델을 device_ids들에 복제함.\n",
" \n",
" logit = nn.parallel.parallel_apply(replicas, inputs)\n",
" # 각 device에 복제된 모델이 각 device의 데이터를 Forward함.\n",
"\n",
" logits = nn.parallel.gather(outputs, output_device)\n",
" # 모델의 logit을 output_device(하나의 device)로 모음\n",
" \n",
" return logits"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2) Backward Pass\n",
"\n",
"1. 계산된 Loss를 각 디바이스에 **Scatter**함.\n",
"2. 전달받은 Loss를 이용해서 각 디바이스에서 **Backward**를 수행하여 Gradients 계산.\n",
"3. 계산된 모든 Gradient를 GPU-1로 **Reduce**하여 GPU-1에 전부 더함.\n",
"4. 더해진 Gradients를 이용하여 GPU-1에 있는 모델을 업데이트.\n",
"\n",
"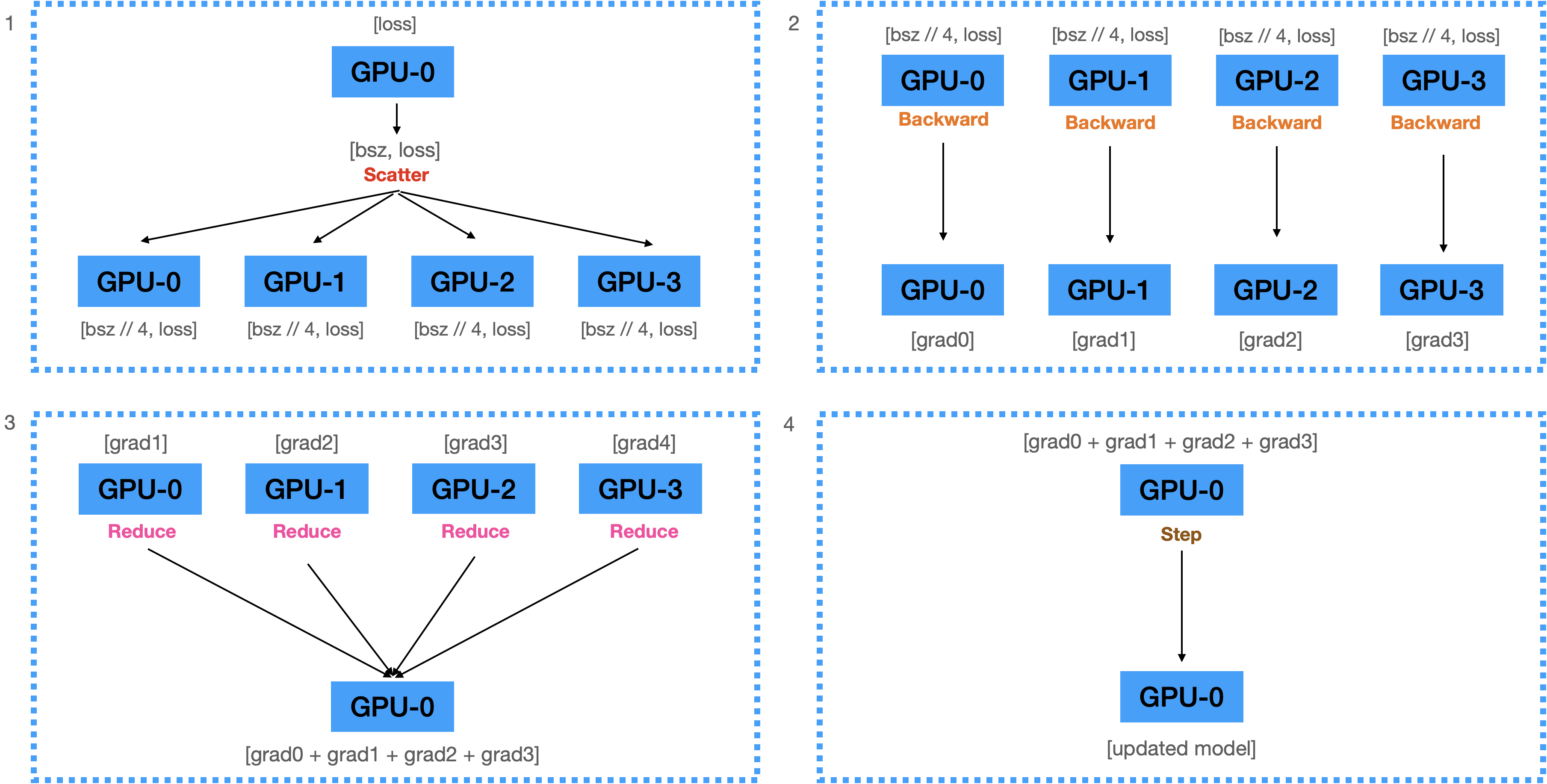\n",
"\n",
"\n",
"#### 혹시나 모르시는 분들을 위해...\n",
"- `loss.backward()`: 기울기를 미분해서 Gradient를 계산\n",
"- `optimizer.step()`: 계산된 Gradient를 이용해서 파라미터를 업데이트\n",
"- Computation cost는 `backward()` > `step()`.\n",
"\n",
"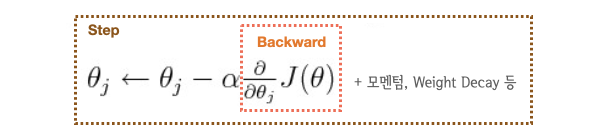\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/data_parallel.py\n",
"\"\"\"\n",
"\n",
"from torch import nn\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader\n",
"from transformers import BertForSequenceClassification, BertTokenizer\n",
"from datasets import load_dataset\n",
"\n",
"# 1. create dataset\n",
"datasets = load_dataset(\"multi_nli\").data[\"train\"]\n",
"datasets = [\n",
" {\n",
" \"premise\": str(p),\n",
" \"hypothesis\": str(h),\n",
" \"labels\": l.as_py(),\n",
" }\n",
" for p, h, l in zip(datasets[2], datasets[5], datasets[9])\n",
"]\n",
"data_loader = DataLoader(datasets, batch_size=128, num_workers=4)\n",
"\n",
"# 2. create model and tokenizer\n",
"model_name = \"bert-base-cased\"\n",
"tokenizer = BertTokenizer.from_pretrained(model_name)\n",
"model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3).cuda()\n",
"\n",
"# 3. make data parallel module\n",
"# device_ids: 사용할 디바이스 리스트 / output_device: 출력값을 모을 디바이스\n",
"model = nn.DataParallel(model, device_ids=[0, 1, 2, 3], output_device=0)\n",
"\n",
"# 4. create optimizer and loss fn\n",
"optimizer = Adam(model.parameters(), lr=3e-5)\n",
"loss_fn = nn.CrossEntropyLoss(reduction=\"mean\")\n",
"\n",
"# 5. start training\n",
"for i, data in enumerate(data_loader):\n",
" optimizer.zero_grad()\n",
" tokens = tokenizer(\n",
" data[\"premise\"],\n",
" data[\"hypothesis\"],\n",
" padding=True,\n",
" truncation=True,\n",
" max_length=512,\n",
" return_tensors=\"pt\",\n",
" )\n",
"\n",
" logits = model(\n",
" input_ids=tokens.input_ids.cuda(),\n",
" attention_mask=tokens.attention_mask.cuda(),\n",
" return_dict=False,\n",
" )[0]\n",
"\n",
" loss = loss_fn(logits, data[\"labels\"].cuda())\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" if i % 10 == 0:\n",
" print(f\"step:{i}, loss:{loss}\")\n",
"\n",
" if i == 300:\n",
" break\n"
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Using custom data configuration default\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"100%|█████████████████████████████████████████████| 3/3 [00:00<00:00, 58.31it/s]\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.weight']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"step:0, loss:1.1612184047698975\n",
"step:10, loss:1.1026676893234253\n",
"step:20, loss:1.0577733516693115\n",
"step:30, loss:0.9685771465301514\n",
"step:40, loss:0.8478926420211792\n",
"step:50, loss:0.8693557977676392\n",
"step:60, loss:0.7827763557434082\n",
"step:70, loss:0.7895966172218323\n",
"step:80, loss:0.7631332278251648\n",
"step:90, loss:0.6766361594200134\n",
"step:100, loss:0.6931278109550476\n",
"step:110, loss:0.7477961778640747\n",
"step:120, loss:0.7386300563812256\n",
"step:130, loss:0.7414667010307312\n",
"step:140, loss:0.7170238494873047\n",
"step:150, loss:0.7286601066589355\n",
"step:160, loss:0.7063153982162476\n",
"step:170, loss:0.6415464282035828\n",
"step:180, loss:0.7068504095077515\n",
"step:190, loss:0.593433678150177\n",
"step:200, loss:0.6224725246429443\n",
"step:210, loss:0.7025654315948486\n",
"step:220, loss:0.5605336427688599\n",
"step:230, loss:0.578403890132904\n",
"step:240, loss:0.7344318628311157\n",
"step:250, loss:0.5977576971054077\n",
"step:260, loss:0.6717301607131958\n",
"step:270, loss:0.7103744745254517\n",
"step:280, loss:0.6679482460021973\n",
"step:290, loss:0.635512113571167\n",
"step:300, loss:0.45178914070129395\n"
]
}
],
"source": [
"!python ../src/data_parallel.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"Multi-GPU에서 학습이 잘 되는군요. 그런데 문제는 0번 GPU에 Logits이 쏠리다보니 GPU 메모리 불균형 문제가 일어납니다. 이러한 문제는 0번 device로 Logits이 아닌 Loss를 Gather하는 방식으로 변경하면 어느정도 완화시킬 수 있습니다. Logits에 비해 Loss는 Scalar이기 때문에 크기가 훨씬 작기 때문이죠. 이 작업은 [당근마켓 블로그](https://medium.com/daangn/pytorch-multi-gpu-%ED%95%99%EC%8A%B5-%EC%A0%9C%EB%8C%80%EB%A1%9C-%ED%95%98%EA%B8%B0-27270617936b)에 소개되었던 [PyTorch-Encoding](https://github.com/zhanghang1989/PyTorch-Encoding)의 `DataParallelCriterion`과 동일합니다. 블로그에 꽤나 복잡하게 설명되어 있는데, 복잡한 방법 대신 간단하게 **forward 함수를 오버라이드 하는 것** 만으로 동일 기능을 쉽게 구현 할 수 있습니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"핵심은 Loss Computation과 Loss가 reduction을 multi-thread 안에서 작동 시키는 것입니다. 모델의 forward 함수는 multi-thread에서 작동되고 있기 때문에 Loss Computation 부분을 forward 함수 안에 넣으면 매우 쉽게 구현할 수 있겠죠.\n",
"\n",
"한가지 특이한 점은 이렇게 구현하면 Loss의 reduction이 2번 일어나게 되는데요. multi-thread에서 batch_size//4개에서 4개로 reduction 되는 과정(그림에서 4번)이 한번 일어나고, 각 디바이스에서 출력된 4개의 Loss를 1개로 Reduction 하는 과정(그림에서 5번)이 다시 일어나게 됩니다. 그렇다고 하더라도 Loss computation 부분을 병렬화 시킬 수 있고, 0번 GPU에 가해지는 메모리 부담이 적기 때문에 훨씬 효율적이죠."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/custom_data_parallel.py\n",
"\"\"\"\n",
"\n",
"from torch import nn\n",
"\n",
"\n",
"# logits을 출력하는 일반적인 모델\n",
"class Model(nn.Module):\n",
" def __init__(self):\n",
" super().__init__()\n",
" self.linear = nn.Linear(768, 3)\n",
"\n",
" def forward(self, inputs):\n",
" outputs = self.linear(inputs)\n",
" return outputs\n",
"\n",
"\n",
"# forward pass에서 loss를 출력하는 parallel 모델\n",
"class ParallelLossModel(Model):\n",
" def __init__(self):\n",
" super().__init__()\n",
"\n",
" def forward(self, inputs, labels):\n",
" logits = super(ParallelLossModel, self).forward(inputs)\n",
" loss = nn.CrossEntropyLoss(reduction=\"mean\")(logits, labels)\n",
" return loss\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"운이 좋게도 우리가 자주 사용하는 Huggingface Transformers 모델들은 forward pass에서 곧 바로 Loss를 구하는 기능을 내장하고 있습니다. 따라서 이러한 과정 없이 transformers의 기능을 이용하여 진행하겠습니다. 아래의 코드는 Transformers 모델의 `labels`인자에 라벨을 입력하여 Loss를 바로 출력합니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/efficient_data_parallel.py\n",
"\"\"\"\n",
"\n",
"# 1 ~ 4까지 생략...\n",
"\n",
"# 5. start training\n",
"for i, data in enumerate(data_loader):\n",
" optimizer.zero_grad()\n",
" tokens = tokenizer(\n",
" data[\"premise\"],\n",
" data[\"hypothesis\"],\n",
" padding=True,\n",
" truncation=True,\n",
" max_length=512,\n",
" return_tensors=\"pt\",\n",
" )\n",
"\n",
" loss = model(\n",
" input_ids=tokens.input_ids.cuda(),\n",
" attention_mask=tokens.attention_mask.cuda(),\n",
" labels=data[\"labels\"],\n",
" ).loss\n",
" \n",
" loss = loss.mean()\n",
" # (4,) -> (1,)\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" if i % 10 == 0:\n",
" print(f\"step:{i}, loss:{loss}\")\n",
"\n",
" if i == 300:\n",
" break"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Using custom data configuration default\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"100%|████████████████████████████████████████████| 3/3 [00:00<00:00, 199.34it/s]\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.LayerNorm.weight', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.weight']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"/home/ubuntu/kevin/kevin_env/lib/python3.8/site-packages/torch/nn/parallel/_functions.py:64: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\n",
" warnings.warn('Was asked to gather along dimension 0, but all '\n",
"step:0, loss:1.186471700668335\n",
"step:10, loss:1.1163532733917236\n",
"step:20, loss:1.091385841369629\n",
"step:30, loss:1.0980195999145508\n",
"step:40, loss:1.0779412984848022\n",
"step:50, loss:1.053116798400879\n",
"step:60, loss:0.9878815412521362\n",
"step:70, loss:0.9763977527618408\n",
"step:80, loss:0.8458528518676758\n",
"step:90, loss:0.8098542094230652\n",
"step:100, loss:0.7924742698669434\n",
"step:110, loss:0.8259536027908325\n",
"step:120, loss:0.8083906173706055\n",
"step:130, loss:0.7789419889450073\n",
"step:140, loss:0.7848180532455444\n",
"step:150, loss:0.7716841697692871\n",
"step:160, loss:0.7316021919250488\n",
"step:170, loss:0.6465802192687988\n",
"step:180, loss:0.7471408843994141\n",
"step:190, loss:0.5954912900924683\n",
"step:200, loss:0.6941753029823303\n",
"step:210, loss:0.7786209583282471\n",
"step:220, loss:0.6332131028175354\n",
"step:230, loss:0.6579948663711548\n",
"step:240, loss:0.7271711230278015\n",
"step:250, loss:0.5837332010269165\n",
"step:260, loss:0.6737046241760254\n",
"step:270, loss:0.6502429246902466\n",
"step:280, loss:0.6647026538848877\n",
"step:290, loss:0.6707975268363953\n",
"step:300, loss:0.47382402420043945\n"
]
}
],
"source": [
"!python ../src/efficient_data_parallel.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
\n",
"\n",
"## 2. `torch.nn.DataParallel`의 문제점\n",
"\n",
"\n",
"### 1) 멀티쓰레드 모듈이기 때문에 Python에서 비효율적임.\n",
"Python은 GIL (Global Interpreter Lock)에 의해 하나의 프로세스에서 동시에 여러개의 쓰레드가 작동 할 수 없습니다. 따라서 근본적으로 멀티 쓰레드가 아닌 **멀티 프로세스 프로그램**으로 만들어서 여러개의 프로세스를 동시에 실행하게 해야합니다.\n",
"\n",
"
\n",
"\n",
"### 2) 하나의 모델에서 업데이트 된 모델이 다른 device로 매 스텝마다 복제되어야 함.\n",
"현재의 방식은 각 디바이스에서 계산된 Gradient를 하나의 디바이스로 모아서(Gather) 업데이트 하는 방식이기 때문에 업데이트된 모델을 매번 다른 디바이스들로 복제(Broadcast)해야 하는데, 이 과정이 꽤나 비쌉니다. 그러나 Gradient를 Gather하지 않고 각 디바이스에서 자체적으로 `step()`을 수행한다면 모델을 매번 복제하지 않아도 되겠죠. 어떻게 이 것을 구현 할 수 있을까요?\n",
"\n",
"
\n",
"\n",
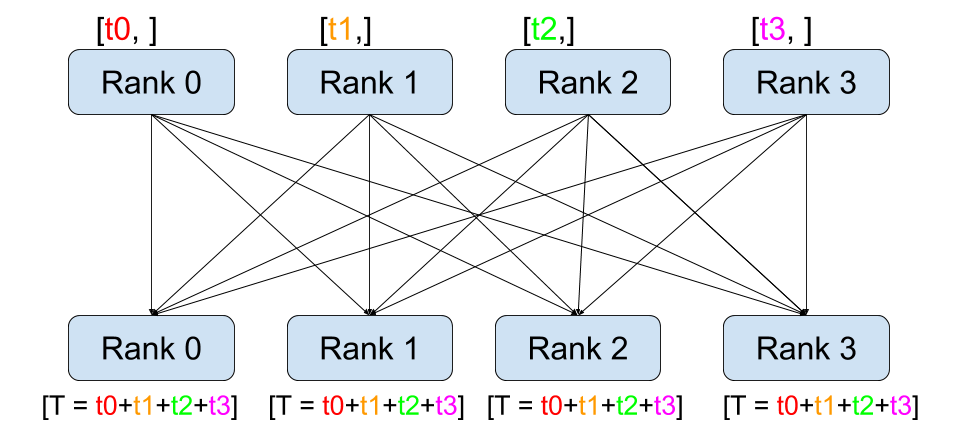
"### Solution? ➝ All-reduce!! 👍\n",
"\n",
"\n",
"정답은 앞서 배웠던 All-reduce 연산입니다. 각 디바이스에서 계산된 Gradients를 모두 더해서 모든 디바이스에 균일하게 뿌려준다면 각 디바이스에서 자체적으로 `step()`을 수행 할 수 있습니다. 그러면 매번 모델을 특정 디바이스로부터 복제해 올 필요가 없겠죠. 따라서 All-reduce를 활용하는 방식으로 기존 방식을 개선해야 합니다.\n",
"\n",
"
\n",
"\n",
"### 그러나... 🤔\n",
"그러나 All-reduce는 매우 비용이 높은 연산에 속합니다. 왜 그럴까요? All-reduce의 세부 구현을 살펴봅시다.\n",
"\n",
"
\n",
"\n",
"### Reduce + Broadcast 구현 방식\n",
"\n",
"\n",
"
\n",
"\n",
"### All to All 구현 방식\n",
"\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3. `torch.nn.parallel.DistributedDataParallel` (이하 DDP)\n",
"\n",
"### Ring All-reduce 💍\n",
"Ring All-reduce는 2017년에 바이두의 연구진이 개발한 새로운 연산입니다. 기존의 방식들에 비해 월등히 효율적인 성능을 보여줬기 때문에 DDP 개발의 핵심이 되었죠.\n",
"\n",
"- https://github.com/baidu-research/baidu-allreduce\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"### DDP란?\n",
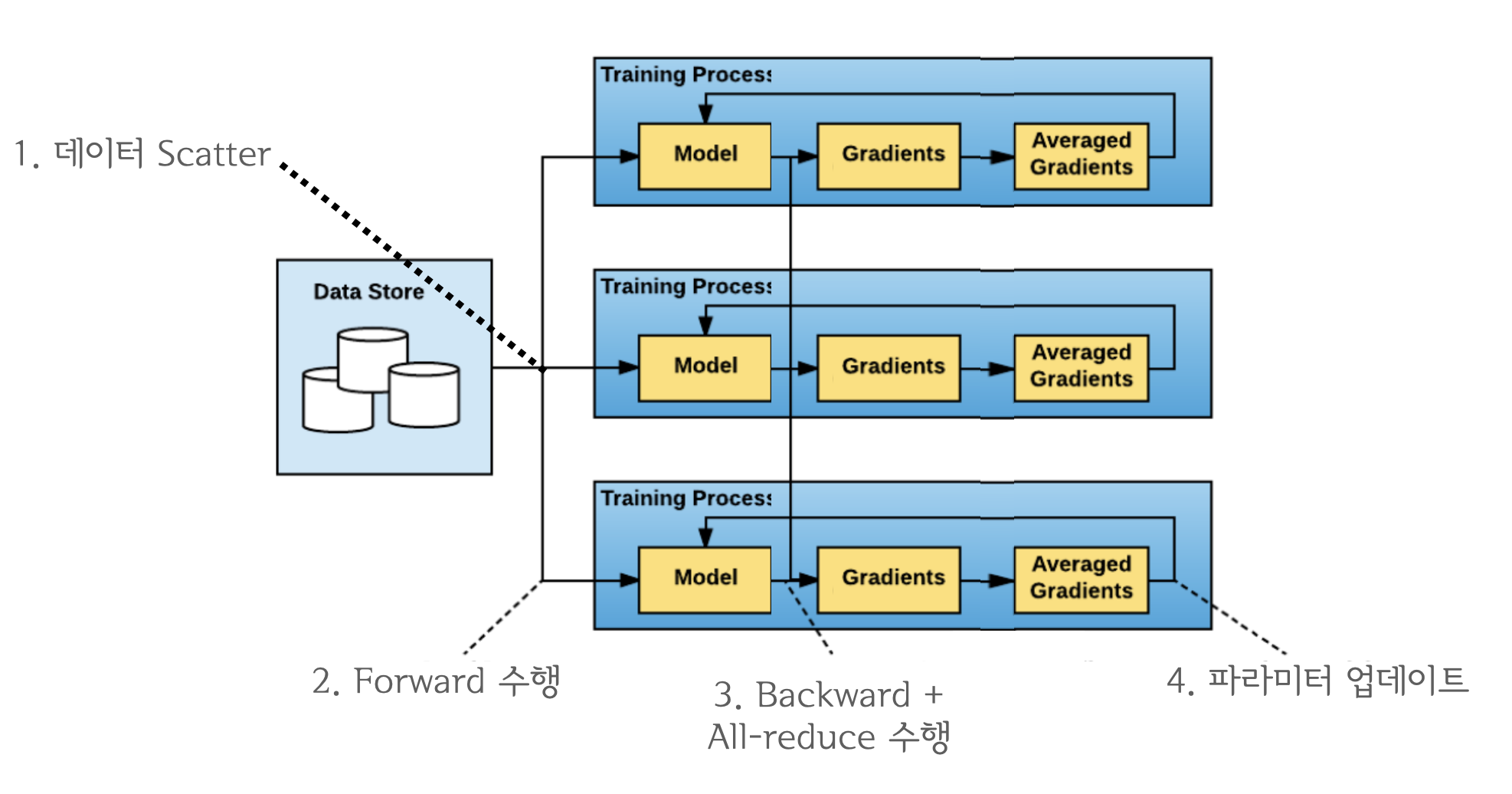
"DDP는 기존 DataParallel의 문제를 개선하기 위해 등장한 데이터 병렬처리 모듈이며 single/multi-node & multi-GPU에서 동작하는 multi-process 모듈입니다. All-reduce를 활용하게 되면서 마스터 프로세스의 개념이 없어졌기 때문에 학습 과정이 매우 심플하게 변합니다.\n",
"\n",
"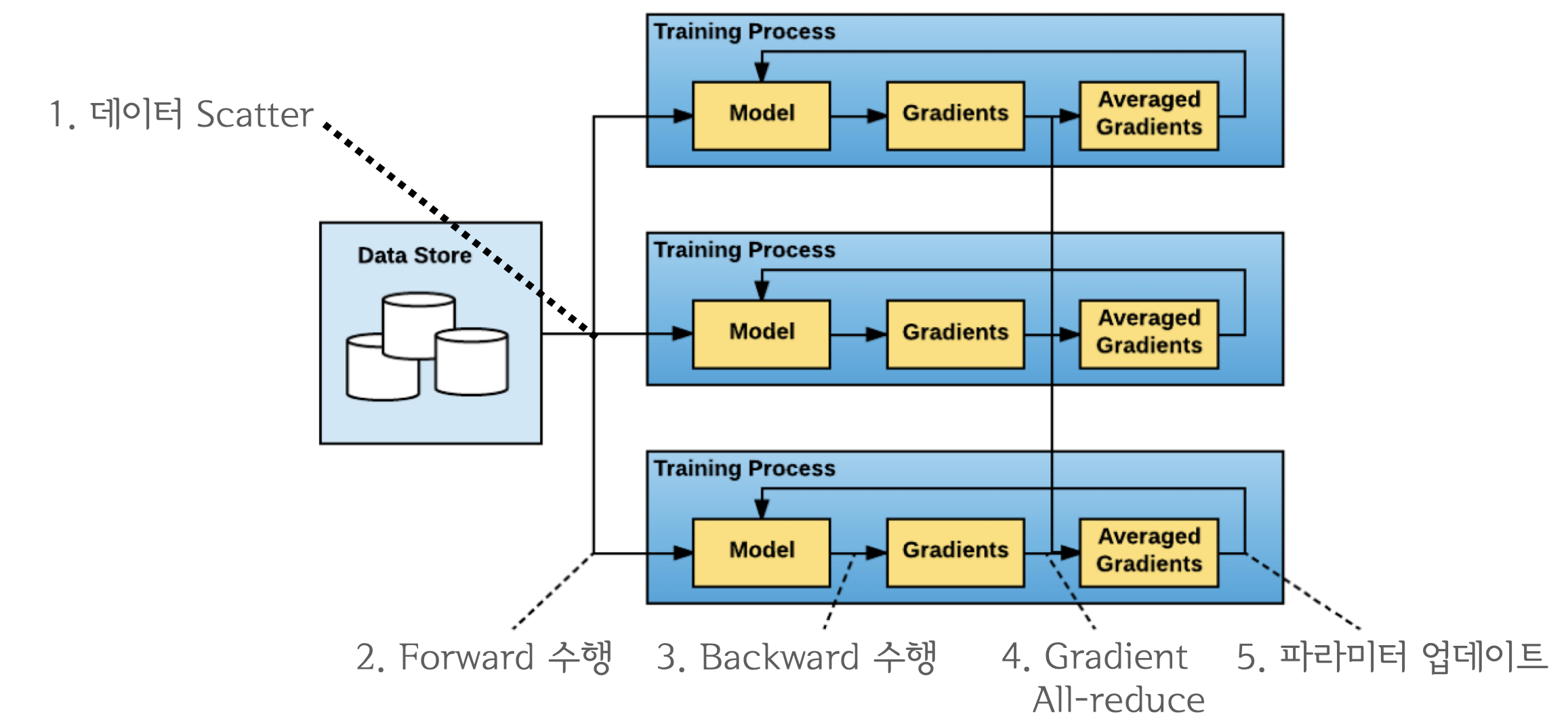\n",
"\n",
"
\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\"\n",
"src/ddp.py\n",
"\"\"\"\n",
"\n",
"import torch\n",
"import torch.distributed as dist\n",
"from torch.nn.parallel import DistributedDataParallel\n",
"from torch.optim import Adam\n",
"from torch.utils.data import DataLoader, DistributedSampler\n",
"from transformers import BertForSequenceClassification, BertTokenizer\n",
"from datasets import load_dataset\n",
"\n",
"# 1. initialize process group\n",
"dist.init_process_group(\"nccl\")\n",
"rank = dist.get_rank()\n",
"world_size = dist.get_world_size()\n",
"torch.cuda.set_device(rank)\n",
"device = torch.cuda.current_device()\n",
"\n",
"# 2. create dataset\n",
"datasets = load_dataset(\"multi_nli\").data[\"train\"]\n",
"datasets = [\n",
" {\n",
" \"premise\": str(p),\n",
" \"hypothesis\": str(h),\n",
" \"labels\": l.as_py(),\n",
" }\n",
" for p, h, l in zip(datasets[2], datasets[5], datasets[9])\n",
"]\n",
"\n",
"# 3. create DistributedSampler\n",
"# DistributedSampler는 데이터를 쪼개서 다른 프로세스로 전송하기 위한 모듈입니다.\n",
"sampler = DistributedSampler(\n",
" datasets,\n",
" num_replicas=world_size,\n",
" rank=rank,\n",
" shuffle=True,\n",
")\n",
"data_loader = DataLoader(\n",
" datasets,\n",
" batch_size=32,\n",
" num_workers=4,\n",
" sampler=sampler,\n",
" shuffle=False,\n",
" pin_memory=True,\n",
")\n",
"\n",
"\n",
"# 4. create model and tokenizer\n",
"model_name = \"bert-base-cased\"\n",
"tokenizer = BertTokenizer.from_pretrained(model_name)\n",
"model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3).cuda()\n",
"# 5. make distributed data parallel module\n",
"model = DistributedDataParallel(model, device_ids=[device], output_device=device)\n",
"\n",
"# 5. create optimizer\n",
"optimizer = Adam(model.parameters(), lr=3e-5)\n",
"\n",
"# 6. start training\n",
"for i, data in enumerate(data_loader):\n",
" optimizer.zero_grad()\n",
" tokens = tokenizer(\n",
" data[\"premise\"],\n",
" data[\"hypothesis\"],\n",
" padding=True,\n",
" truncation=True,\n",
" max_length=512,\n",
" return_tensors=\"pt\",\n",
" )\n",
"\n",
" loss = model(\n",
" input_ids=tokens.input_ids.cuda(),\n",
" attention_mask=tokens.attention_mask.cuda(),\n",
" labels=data[\"labels\"],\n",
" ).loss\n",
"\n",
" loss.backward()\n",
" optimizer.step()\n",
"\n",
" if i % 10 == 0 and rank == 0:\n",
" print(f\"step:{i}, loss:{loss}\")\n",
"\n",
" if i == 300:\n",
" break\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"멀티프로세스 애플리케이션이기 때문에 `torch.distributed.launch`를 사용합니다."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"*****************************************\n",
"Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed. \n",
"*****************************************\n",
"Using custom data configuration default\n",
"Using custom data configuration default\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"100%|████████████████████████████████████████████| 3/3 [00:00<00:00, 181.01it/s]\n",
"100%|████████████████████████████████████████████| 3/3 [00:00<00:00, 149.46it/s]\n",
"Using custom data configuration default\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"100%|████████████████████████████████████████████| 3/3 [00:00<00:00, 229.28it/s]\n",
"Using custom data configuration default\n",
"Reusing dataset multi_nli (/home/ubuntu/.cache/huggingface/datasets/multi_nli/default/0.0.0/591f72eb6263d1ab527561777936b199b714cda156d35716881158a2bd144f39)\n",
"100%|████████████████████████████████████████████| 3/3 [00:00<00:00, 361.84it/s]\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.decoder.weight', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.weight', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.dense.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight']\n",
"- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\n",
"- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\n",
"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias']\n",
"You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n",
"step:0, loss:1.1451387405395508\n",
"step:10, loss:1.0912988185882568\n",
"step:20, loss:1.0485237836837769\n",
"step:30, loss:0.9971571564674377\n",
"step:40, loss:0.9472718238830566\n",
"step:50, loss:1.0532103776931763\n",
"step:60, loss:0.6478840112686157\n",
"step:70, loss:0.9035330414772034\n",
"step:80, loss:0.8176743388175964\n",
"step:90, loss:1.058182716369629\n",
"step:100, loss:0.7739772796630859\n",
"step:110, loss:0.6652507185935974\n",
"step:120, loss:0.7778272032737732\n",
"step:130, loss:0.827933669090271\n",
"step:140, loss:0.6303764581680298\n",
"step:150, loss:0.5062040090560913\n",
"step:160, loss:0.8570529222488403\n",
"step:170, loss:0.6550942063331604\n",
"step:180, loss:0.6157522797584534\n",
"step:190, loss:0.7612558007240295\n",
"step:200, loss:0.7380551099777222\n",
"step:210, loss:0.7818665504455566\n",
"step:220, loss:0.9607051610946655\n",
"step:230, loss:0.8241059184074402\n",
"step:240, loss:0.5454672574996948\n",
"step:250, loss:0.4731343686580658\n",
"step:260, loss:0.8883727788925171\n",
"step:270, loss:0.4605785310268402\n",
"step:280, loss:0.7553415298461914\n",
"step:290, loss:0.8398311138153076\n",
"step:300, loss:0.45668572187423706\n"
]
}
],
"source": [
"!python -m torch.distributed.launch --nproc_per_node=4 ../src/ddp.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 그런데 잠깐, All-reduce를 언제 수행하는게 좋을까요?\n",
"- All-reduce를 `backward()`연산과 함께 하는게 좋을까요?\n",
"- 아니면 `backward()`가 모두 끝나고 `step()` 시작 전에 하는게 좋을까요?\n",
"\n",
"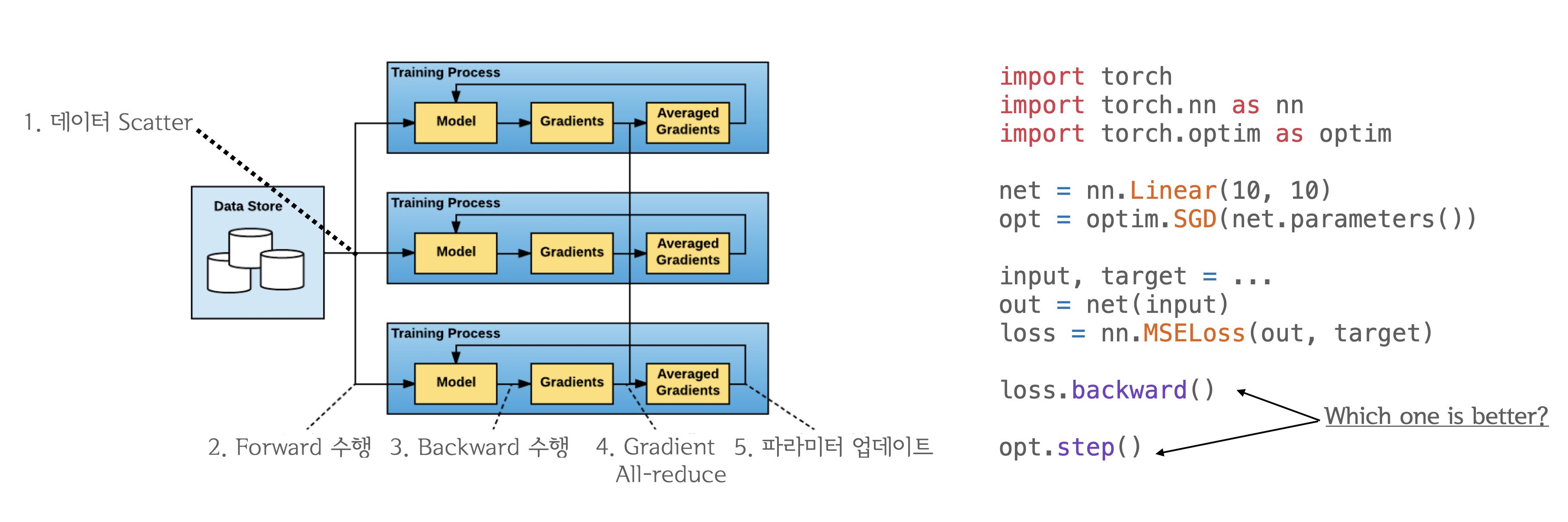\n",
"\n",
"
\n",
"\n",
"### 결과적으로 `backward()`와 `all-reduce`를 중첩시키는 것이 좋습니다.\n",
"\n",
"결과적으로 `backward()`와 `all-reduce`를 중첩시키는 것이 가장 효율적인 방식입니다. `all_reduce`는 네트워크 통신, `backward()`, `step()` 등은 GPU 연산이기 때문에 동시에 처리할 수 있죠. 이들을 중첩시키면 즉, computation과 communication이 최대한으로 overlap 되기 때문에 연산 효율이 크게 증가합니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
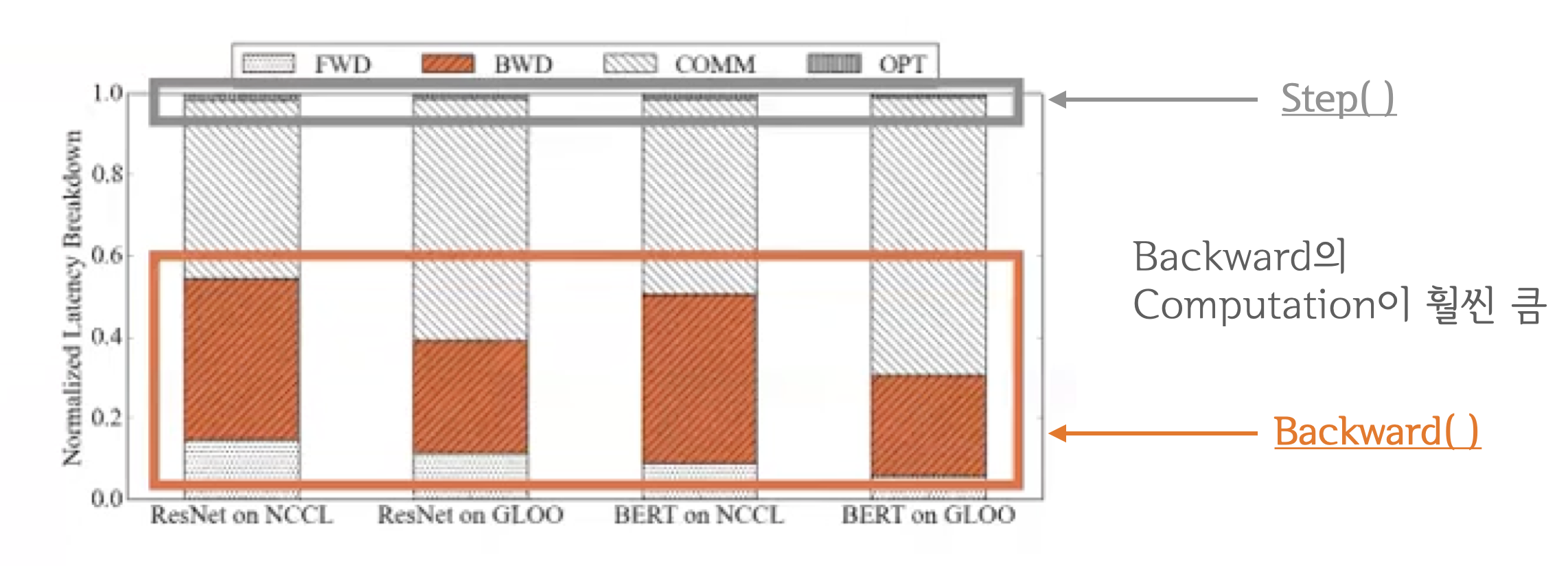
"분석 결과 `backward()`와 `step()`을 비교해보면 `backward()`가 훨씬 무거운 연산이였습니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
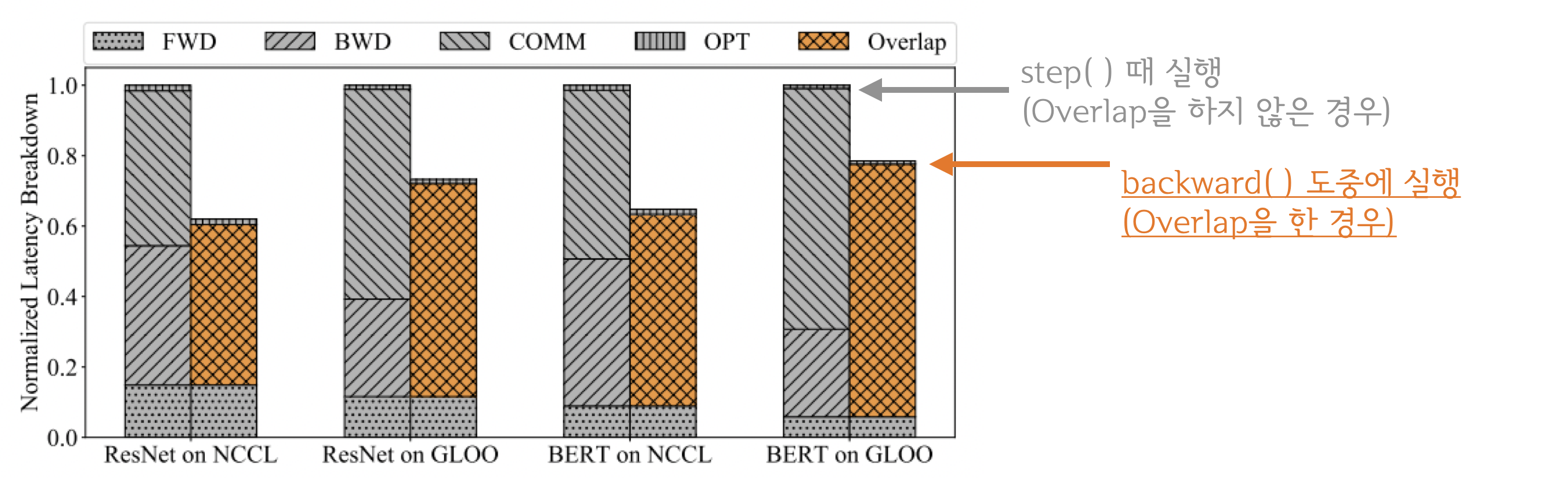
"당연히 더 무거운 연산을 중첩시킬 수록 전체 학습 과정을 수행하는 시간이 짧아집니다. 분석 결과 `backward()`가 끝날때 까지 기다리는 것 보다 `all-reduce`를 함께 수행하는 것이 훨씬 빨랐습니다.\n",
"\n",
"\n",
"\n",
"
\n",
"\n",
"### 이 때, 생길 수 있는 궁금증들...\n",
"- Q1: `backward()` 연산 중에 Gradient가 모두 계산되지 않았는데 어떻게 `all-reduce`를 수행합니까?\n",
" - A1: `backward()`는 뒤쪽 레이어부터 순차적으로 이루어지기 때문에 계산이 끝난 레이어 먼저 전송하면 됩니다.\n",
"\n",
"
\n",
"\n",
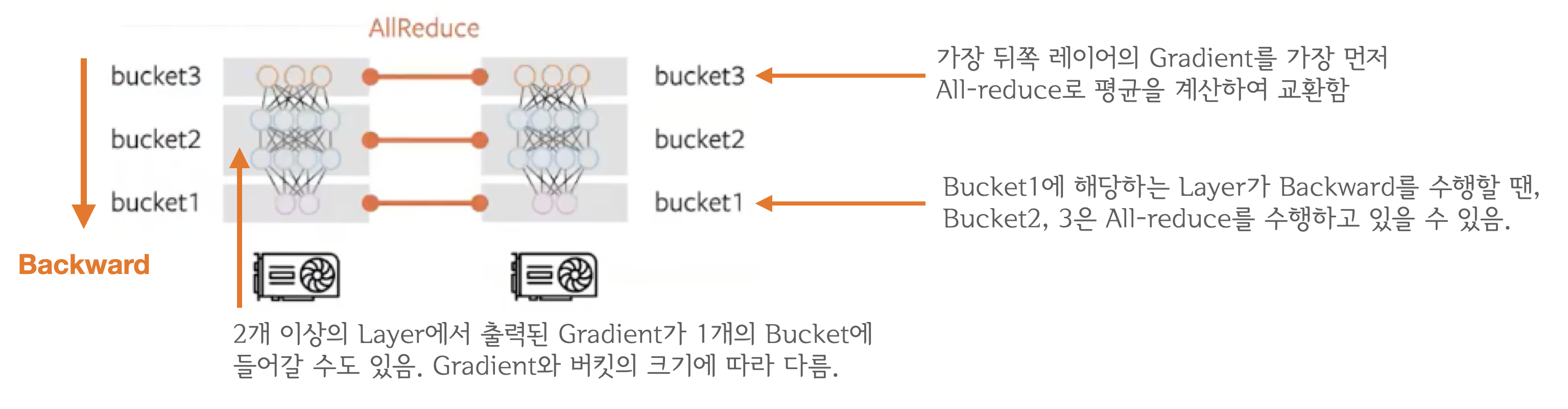
"- Q2: 그렇다면 언제마다 `all-reduce`를 수행하나요? 레이어마다 이루어지나요?\n",
" - A2: 아닙니다. Gradient Bucketing을 수행합니다. Bucket이 가득차면 All-reduce를 수행합니다.\n",
"\n",
"
\n",
"\n",
"### Gradient Bucekting\n",
"Gradient Bucekting는 Gradient를 일정한 사이즈의 bucket에 저장해두고 가득차면 다른 프로세스로 전송하는 방식입니다. 가장 먼저 `backward()` 연산 도중 뒤쪽부터 계산된 Gradient들을 차례대로 bucket에 저장하다가 bucket의 용량이 가득차면 All-reduce를 수행해서 각 device에 Gradient의 합을 전달합니다. 그림 때문에 헷갈릴 수도 있는데, bucket에 저장되는 것은 모델의 파라미터가 아닌 해당 레이어에서 출력된 Gradient입니다. 모든 bucket은 일정한 사이즈를 가지고 있으며 `bucket_size_mb` 인자를 통해 mega-byte 단위로 용량을 설정 할 수 있습니다.\n",
"\n",
"\n"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}